
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Установка, настройка и тестирование Fedora 21 Workstation на личном или игровом компьютере
 9-го декабря вышла новая Fedora 21 Workstation, которую по совокупности параметров можно назвать «самым свежим и стабильным» Линукс-десктопом.
За время использования и тестирования Fedora я проникся к этой платформе глубокой симпатией и хочу поделиться этим теплом и знаниями о ней с вами.
В течение года я наблюдал за её работой в качестве рабочего и игрового места в разных ситуациях — от станций с «умирающим» железом до нового игрового ноутбука Asus G750JM с Nvidia Optimus.
Собранные заметки получились несколько шершавыми, старающимися охватить одновременно и новичков в Линуксе, и опытных пользователей с разработчиками. Прошу простить. Хочу донести большой объем информации в одной статье: и по общей настройке и установке Федоры, и по технологии Nvidia Optimus на ноутбуках, wi-fi с проприетарными драйверами, о настройке симпатичных шрифтов в Java и IDE от JetBrains, запуску игр в Steam на дискретной видеокарте, о результатах сравнительного тестирования игр, графики и браузеров между Федорой и Windows 8.1, и даже об установлении одного «абсолютного» рекорда.
Хочу отметить, что свежие десктопные Линуксы также отличаются качественной поддержкой дисплеев высокого разрешения с хорошей отрисовкой шрифтов и оконных элементов, предоставляют высочайшую степень различных персональных настроек, «хаков» и возможностей оперирования с приложениями. Всё это позволяет не только значительно повысить эффективность своей работы, но и сделать это с комфортом для глаз.
Поскольку темы личной эффективности, комфортной для глаз темизации и различных «хаков» достаточно обширны и специфичны, в будущем я посвящу им две или три углубленных статьи. А в данном документе будет общая выжимка информации именно по настройке и общему использованию Fedora 21.
Содержание
----------
[О дистрибутиве Fedora](#about_fedora)
[Установка Fedora 21 Workstation](#install_fedora)
[Последовательная настройка](#overall_setup)
* [Чтобы заработал Wi-Fi на ноутбуке, если он не работает](#setup_wifi)
* [Первое — обновляем систему](#update_system)
* [Замедлить мышку](#slowdown_mouse)
* [Если ставите Fedora в виртуальную машину (VirtualBox)](#virt_fedora)
[Общие настройки системы](#main_setup)
* [Добавляем себе возможность использовать sudo](#add_sudo)
* [Установка Midnight Commander (mc)](#install_mc)
* [Шрифт в системной консоли](#sys_fonts)
[Gnome 3 — рабочая среда по-умолчанию](#gnome3)
* [Первым делом — утилита для настройки Gnome 3 и шрифтов](#gnome_tweak)
* [Сворачивание-разворачивание окон — шоткеи и кнопки](#gnome_shortkeys)
* [Удобные дополнения Gnome](#gnome_extensions)
* [Тонкости файлового менеджера Nautilus](#nautilus)
* [Добавить средства управления пакетами програм](#yumex)
* [Сетевые аккаунты — синхронизация с почтой, контактами и календарем Google](#gnome_online_accounts)
[Шрифты](#fonts)
* [Заменяем тонкие шрифты в IDE от JetBrains (IntelliJ, PyCharm и другие) и в Java](#fonts_jetbrains)
[Среды разработки и редакторы для языка программирования Python](#python_ide)
[Подключение к репозитариям RPMFUSION](#rpmfusion)
[Видео, аудио и книги](#video_audio_books)
* [Видеопроигрыватели](#video_players)
* [Аудиопрогрыватели + Вконтакте](#audio_players_vk)
* [Если вашим программам все ещё не хватает кодеков](#codecs)
* [Как слушать аудиокниги](#audiobook_players)
* [Как читать книги](#book_readers)
[Установка Дропбокса](#dropbox)
[Установка мессенджеров](#messenger)
* [Skype](#skype)
* [Viber](#viber)
* [Telegram](#telegram)
[Установка браузеров и flash](#browsers_and_flash)
* [Google Chrome](#chrome)
* [Установка Хромиума](#chromium)
* [Flash для браузеров и для системы](#flash)
[Проприетарные видеодрайверы](#videodrivers)
* [Nvidia «обычная»](#nvidia)
* [Проприетарные драйвера ATI](#ati)
* [Nvidia Optimus — установка Bumblebee](#nvidia_optimus)
* [Как запускать программы и игры в Steam на дискретной карте](#steam_optimus)
[Бенчмарки: Fedora 21 Optimus / Primus / Windows 8.1](#benchmarks)
* [Кроссплатформенный бенчмарк GPU — GPUTest](#gputest)
* [Кроссплатформенный бенчмарк Geekbench](#geekbench)
* [Решение проблемы с неработающим WebGL у Хрома](#chrome_webgl_optimus)
* [Бенчмарки для браузеров](#browser_benchmark)
* [Основная информация по моей системе для уточнения бенчмарков](#benchmark_base)
[Steam и игры](#steam)
[Запускаем Windows-игры и Windows-программы](#windows_play)
[Программы для рисования](#drawning_tools)
[KDE](#kde)
* [Офис Calligra](#calligra)
* [Настройка KDE](#setup_kde)
* [Синхронизация контактов, календаря и почты Google](#kde_sync_google)
* [Устранение проблемы многократного запуска некоторых QT-программ](#kde_qt_instances)
[Изучение иностранных языков](#foreign_languages)
* [Словарь с произношением — StarDict](#stardict)
* [Anki и карточки](#anki)
[Проблема с появившимся тихим шумом в наушниках](#noise_in_headset)
[Завершение](#ending)
О дистрибутиве Fedora
---------------------
Начиная с версии 21 установочный дистрибутив Федора разделен на 3 типа по предназначению: для рабочей станции, сервера и облака. Ознакомиться с ними можно на обновленном сайте Fedora, где это хорошо оформлено и описано: [getfedora.org](https://getfedora.org)
Официальная информация о релизе Fedora 21: [fedoramagazine.org/announcing-fedora-21](http://fedoramagazine.org/announcing-fedora-21)
Информация о релизе плюс много скриншотов: [www.webupd8.org/2014/12/fedora-21-available-for-download.html](http://www.webupd8.org/2014/12/fedora-21-available-for-download.html)
Краткий обзор возможностей Gnome 3.14, являющегося основной рабочей средой в Fedora 21 Workstation:
Fedora 21 Workstation сейчас позиционируется как отличная рабочая станция для разработчиков с минимальным отвлечением от работы. В систему включено большое количество необходимых инструментов, а также самый свежий софт для использования, тестов и исследований среды.
Среди заметных плюсов Федоры хочу отметить отсутствие необходимости подключать сторонние ненадежные репозитории для получения свежего программного обеспечения. Подавляющее большинство полезных программ уже находится в репозитарии rpmfusion и неплохо тестируется на совместимость с основным репозитарием Федоры. Это очень хорошо сказывается на стабильности и предсказуемости всей системы.
Конечно надо отметить, что самый свежий софт несет в себе не только новые возможности и плюсы в работе, но и иногда «болеет» проблемами роста (как, например, происходило некоторое время назад с Gnome 3). Однако в большинстве случаев такие проблемы решаются либо использованием альтернативы (в моем случае тогда это был KDE), или другими способами.
Возвращаясь к надежности Федоры: начав работать с ней после других дистрибутивов Линукса вы можете отметить снижение скорости обновления и установки пакетов, т.к. в системе по-умолчанию включены дополнительные шаги проверки до и после установки пакетов. До установки — выполнение тестовых транзакций без внесения изменений на диск, после — верификация выполненной транзакции.
Как я упоминал выше, Федора в целом на мой взгляд очень надежный дистрибутив, и даже в некоторых ситуациях работы на сбойном железе она неплохо на нем выживает.
Также отмечу, что все больше производителей софта в последнее время, в том числе и проприетарного, выпускают готовые пакеты и тестируют их именно для Fedora (а не только для Ubuntu). Среди них Viber, Dropbox и другие.
Установка Fedora 21 Workstation
-------------------------------
Скачать торрент со стандартным образом для живого тестирования и установки на рабочую станцию:
для 64-битных систем [torrent.fedoraproject.org/torrents/Fedora-Live-Workstation-x86\_64-21.torrent](http://torrent.fedoraproject.org/torrents/Fedora-Live-Workstation-x86_64-21.torrent)
для 32-битных [torrent.fedoraproject.org/torrents/Fedora-Live-Workstation-i686-21.torrent](http://torrent.fedoraproject.org/torrents/Fedora-Live-Workstation-i686-21.torrent)
Данный образ базируется на рабочей среде Gnome 3, как основной для Workstation.
Другие варианты скачивания образа Fedora 21 для рабочих станций: [getfedora.org/en/workstation/download](https://getfedora.org/en/workstation/download)
Торренты всех доступных вариантов образов Fedora 21, включая так называемые «спины», в которых вместо Gnome используются другие среды рабочего стола: KDE, Xfce, LXDE, Mate и т.д.: [torrent.fedoraproject.org](http://torrent.fedoraproject.org)
А более подробную информацию о «спинах» можно найти тут: [spins.fedoraproject.org](http://spins.fedoraproject.org)
Видео процесса установки Федоры на рабочую станцию и первого знакомства с ней:
Руководство по процессу установки: [docs.fedoraproject.org/install-guide](http://docs.fedoraproject.org/install-guide)
Как сделать загрузочную флешку: [docs.fedoraproject.org/en-US/Fedora/20/html/Burning\_ISO\_images\_to\_disc/Making\_USB\_Media.html](http://docs.fedoraproject.org/en-US/Fedora/20/html/Burning_ISO_images_to_disc/Making_USB_Media.html)
Во избежание проблем, которые иногда случаются при записи флешки, и препятствуют нормальному запуску системы с неё, рекомендую по-возможности пользоваться старой надежной dd (/dev/sdc — ваше устройство с флешкой):
```
sudo dd if=~/Download/Fedora-Live-Workstation-x86_64-21-5.iso of=/dev/sdc
```
Не забудьте перед запуском и установкой с флешки проверить в биосе переменную «Secure Boot Menu» в разделе «Security» — она должна быть выключена для нормальной установки новой системы. Также в биосе для удобной работы с подключенным монитором можете в разделе «Boot» включить опцию «Launch CSM» (Launch Compatibility Support Module). По-крайне мере так эти переменные выглядят на моем ноутбуке.
Если вы хотите проапгрейдить свою Fedora 20 до свежей версии 21 без переустановки:
[fedoramagazine.org/upgrading-to-fedora-21-workstation-from-fedora-20](http://fedoramagazine.org/upgrading-to-fedora-21-workstation-from-fedora-20)
Теперь переходим к последовательной настройке системы и программ в ней.
Последовательная настройка
==========================
Чтобы заработал Wi-Fi на ноутбуке, если он не работает
------------------------------------------------------
Если ваш чип Wi-Fi относится к сериям Broadcom's BCM4311-, BCM4312-, BCM4313-, BCM4321-, BCM4322-, BCM43224-, BCM43225-, BCM43227- или BCM43228, то вам потребуется установка проприетарных драйверов, чтобы он заработал корректно.
Посмотреть модель вашей карты в терминале можно командой lspci
У меня стоит Broadcom Corporation BCM4352 802.11ac Wireless Network Adapter (rev 03)
После того как мы убедились, что наша карта относится к вышеуказанным сериям, будем ставить для нее драйвера. Вам потребуется интернет через кабель Ethernet или придется вынимать пакеты вручную через другой компьютер. Ниже я описываю самый простой вариант, когда у вас работает интернет через кабель.
Сперва надо подключить репозиторий rpmfusion — информация об этом находится в статье ниже. После его подключения возвращайтесь обратно сюда.
Итак, рекомендуемый вариант установки драйвера для нашего wi-fi следующий:
```
su - -c "yum install kmod-wl"
```
Команда спросит пароль рута. На вопрос «установить-ли с зависимостями» отвечаете «y».
Подробнее о данной установке тут: [www.cyberciti.biz/faq/fedora-linux-install-broadcom-wl-sta-wireless-driver-for-bcm43228](http://www.cyberciti.biz/faq/fedora-linux-install-broadcom-wl-sta-wireless-driver-for-bcm43228)
У меня этого оказалось недостаточно в связи с багом, речь о котором идет тут:
[ask.fedoraproject.org/en/question/57806/broadcom-4321-wireless-not-working-in-fedora-21](https://ask.fedoraproject.org/en/question/57806/broadcom-4321-wireless-not-working-in-fedora-21)
И потребовалось сделать ещё несколько манипуляций:
```
su - -c "yum reinstall kmod-wl akmod-wl"
su - -c "yum install akmods kernel-devel"
su - -c "yum update"
```
Перезагружаемся.
```
su - -c "akmods"
```
(эта команда заново пересобирает модуль для wi-fi, здесь может потребоваться команда akmodsbuild от пользователя)
Перезагрузиться.
```
su - -c "modprobe wl"
```
(загружаем модуль для wi-fi)
После этого модуль wi-fi наконец заработал и я смог отсоединить провод Ethernet, почувствовав свободу.
Для информации оставлю здесь одну из свежих, но не проверенных рекомендаций по установке этого-же драйвера:
```
su - -c "yum install broadcom-wl kmod-wl akmod-wl rfkill"
su - -c "rfkill list"
su - -c "rfkill unblock all"
```
Дальнейшие действия выполняются после установки Федоры на жесткий диск и загрузки с него.
Первое — обновляем систему
--------------------------
Это важно! Без обновления системы могут получиться неприятности при установке следующих пакетов, необходимых для компиляции доп.модулей и другие нестыковочки.
Для этого нажимаем Win и пишем первый буквы «te» или «те» (Gnome ищет одновременно и по русскому и по английскому названию программ) дальше остаётся нажать Enter и запустить терминал. Это информация для новичков в Gnome 3.
Дальше в нем переходим в выполнение команд от рута:
```
su -
```
Вы можете ускорить загрузку пакетов из репозитория, если будут выбираться самые быстрые зеркала.
Для этого достаточно установить дополнение к yum, тестирующее сервера на скорость отклика, и переключающееся на самые быстрые из них:
```
yum install yum-plugin-fastestmirror
```
И, наконец, выполняем обновление всех установленных в системе пакетов:
```
yum update
```
Замедлить мышку
---------------
У некоторых из нас мышки поддерживают разное разрешение сенсора (1000...8000 dpi).
В Linux может оказаться, что ваша мышь слишком шустрая, и снизить её скорость обычными средствами настройки в графическом режиме невозможно.
Для этих случаев есть простое решение с замедлением указателя:
надо прописать конфиг для Иксов, в котором указать торможение как постоянную переменную.
В моем случае достаточно двухкратного торможения, отображаемого в значении ConstantDeceleration.
Выглядит вот так:
```
$ cat /etc/X11/xorg.conf
Section "InputClass"
Identifier "Logitech Gaming Mouse G600"
MatchIsPointer "on"
MatchProduct "Logitech Gaming Mouse G600"
Option "ConstantDeceleration" "2"
EndSection
```
Узнать название своей мышки можно вот так:
```
$ xinput list
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ Logitech Gaming Mouse G600 id=12 [slave pointer (2)]
...
```
Существует возможность установить замедление и через команду xinput, не прибегая к конфигу иксов, но такой вариант ограничен номерами указателя мыши в системе, которые меняются при перевтыкании мыши в другой порт или иногда при перезагрузке.
Если ставите Fedora в виртуальную машину (VirtualBox)
-----------------------------------------------------
От рута выполняем:
```
yum install binutils gcc make patch libgomp glibc-headers glibc-devel kernel-headers kernel-devel dkms
```
Больше информации по данной теме: [www.if-not-true-then-false.com/2010/install-virtualbox-with-yum-on-fedora-centos-red-hat-rhel](http://www.if-not-true-then-false.com/2010/install-virtualbox-with-yum-on-fedora-centos-red-hat-rhel)
Затем в самой виртуалке в меню выбираем Devices — Insert Guest Additional CD image
VirtualBox скачает нужный файл образа дополнений гостевой ОС.
Виртуальная Федора обнаружит «вставленный диск» и предложит автозапуск находящей на ней программы установки.
После запуска этой программы и предложения авторизоваться паролем рут не забудьте, что, возможно, надо переключиться обратно на английскую раскладку (Alt+Shift), т.к. в Федоре будет стоять русский ввод по-умолчанию (теперь при выбранной русской локали при инсталляции русский-же и является языком для ввода с клавиатуры по-умолчанию).
Результаты выполнения программы установки дополнений гостевой ОС выведутся в этом-же терминали.
При успешной установке модулей и после перезагрузки гостевая Федора будет удобная для использования в виртуальной машине — реагировать на изменений размеров её окна, корректно переходить в Fullscreen и т.д.
И можно будет переходить к дальнейшей настройке или экспериментам.
Напоминаю, что в виртуалке переключение по системным консолям производится не привычными Ctrl+Alt+F1..F7, а с помощью хост-клавиши: правый контрол + F1..F7
Общие настройки системы
-----------------------
### Добавляем себе возможность использовать sudo
Выполняем от рута
```
usermod sampleusername -a -G wheel
```
где sampleusername — логин вашего пользователя
Более подробная информация на эту тему: [fedoraproject.org/wiki/Configuring\_Sudo](http://fedoraproject.org/wiki/Configuring_Sudo)
После выполнения команды выходим из системы (logout) и входим снова.
Подсказка новичкам:
1. Чтобы выйти из рута в консоли набираем exit, затем или exit ещё раз, или закрываем окно (мышкой или хоткеем Alt+F4).
2. Чтобы выйти из Gnome щелкаем справа вверху по треугольнику или рядом с ним (тоже среагирует выпаданием этого меню), дальше щелкаем по имени нашего пользователя, под ним появляется «Завершить сеанс», кликаем по этому пункту.
3. Чтобы войти и правильно указать пароль, если он у вас в английской раскладке, не забудьте опять на неё переключить по Alt+Shift.
После этого все команды «от рута» можно выполнять через sudo.
### Установка Midnight Commander (mc)
Мне очень удобен и привычен MC, поэтому на любой новой системе я начинаю с его установки.
```
sudo yum install mc
```
Если пользуетесь MC и привыкли выходить из него по F10, то в терминале Гнома нужно отключить шоткей вызов меню гномовского терминала по F10:
«Правка» — «Параметры» — Включить быструю клавишу доступа к меню (по-умолчанию F10)
Или переназначить её.
### Шрифт в системной консоли
Если вы выбрали русский как основной язык системы при установке, значит системная консоль тоже будет с правильным русским.
Однако если вы ставили, выбрав английский, то русские символы в системной консоли будут отображаться квадратиками или кракозябриками.
Чтобы это «вылечить» надо в /etc/profile.local прописать строчку
```
setfont Cyr_a8x16
```
Gnome 3 — рабочая среда по-умолчанию
------------------------------------
Основной распространяемый вариант Fedora 21 Workstation по-умолчанию несет в своей основе рабочую среду Gnome 3.14
У этого решения есть свои плюсы и минусы.
Среди плюсов — интересная для некоторых динамика работы с окнами, рабочими столами, и информацией.
Возможность искать одновременно и программы, и сервисы, и свои контакты, и много другой информации.
Но здесь я опишу что с ней можно сделать для уютного обживания. :)
Если Вы не планируете работать с Gnome или воспользовались «спином» с другой рабочей средой, то можете пропустить этот раздел.
Обзоры возможностей последней версии Gnome с картинками и видео вы можете посмотреть тут:
[www.opennet.ru/opennews/art.shtml?num=40669](http://www.opennet.ru/opennews/art.shtml?num=40669)
[www.webupd8.org/2014/09/gnome-314-released-see-whats-new.html](http://www.webupd8.org/2014/09/gnome-314-released-see-whats-new.html)
### Первым делом — утилита для настройки Gnome 3 и шрифтов
Устанавливаем:
```
sudo yum install gnome-tweak-tool
```
Запускаем:
клавиша Win, затем набираем «tw» или «доп», Enter
Вкладка (кнопка) «Шрифты».
На ней мы можем увеличить все шрифты на 1-2 пункта для лучшей читабельности, а также выбрать вариант сглаживания (хинтинга), который лучше подходит для нашего монитора и личных предпочтений. Я предпочитаю вариант хинтинга «slight».
Скриншот окна найстроки шрифтов с указанными изменениями:
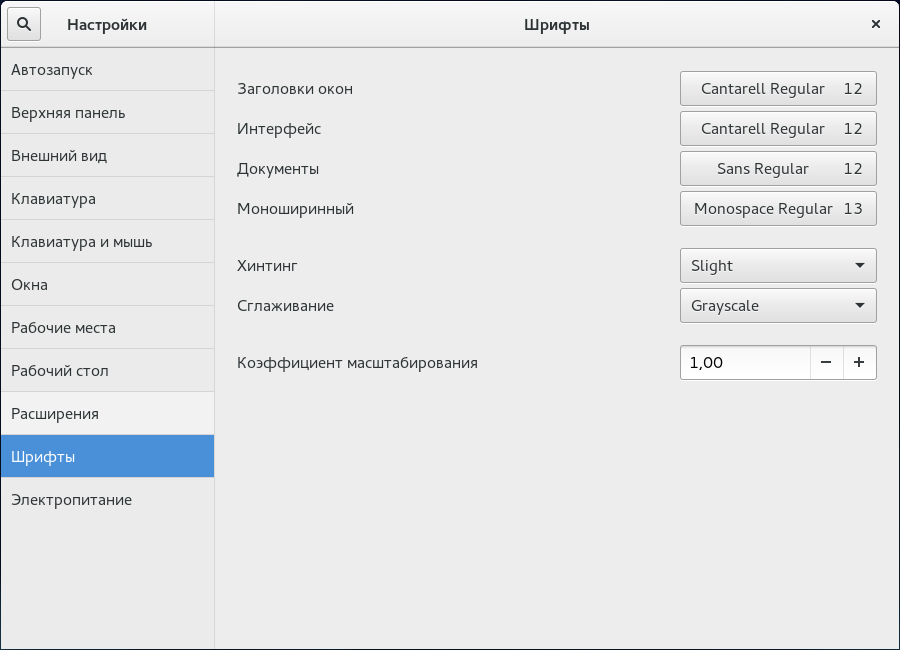
Окно терминала с открытым MC после применения изменений:

### Сворачивание-разворачивание окон — шоткеи и кнопки
Установив утилиту «тонкой» настройки Gnome мы можем управлять отображение кнопок в заголовках окон.
В Gnome Tweak Tool (она-же «Дополнительные параметры») в разделе «Окна» можно включить отображение привычных кнопок «Развернуть» и «Свернуть» в заголовке окон, возле кнопки «Закрыть».
Я этими кнопками не пользуюсь. В Гноме стандартный шоткей сворачивания окна: Win+H
У меня он также вызывается и нажатием на дополнительную кнопку мышки.
Также удобно использовать шоткеи Win + стрелка, они разворачивают-восстанавливают окна в разных направлениях.
### Удобные дополнения Gnome
Желающие использовать под полезный контент максимум места на экране, особенно владельцы ноутбуков и нетбуков, могут поставить 2 дополнения для Gnome:
1. Maximus Two [extensions.gnome.org/extension/844/maximus-two](https://extensions.gnome.org/extension/844/maximus-two)
2. Frippery Move Clock [extensions.gnome.org/extension/2/move-clock](https://extensions.gnome.org/extension/2/move-clock)
Скриншот Firefox в Gnome 3 без указанных дополнений:
И после установки дополнений, расширяющих полезное пространство:

Есть и другие варианты дополнений, аналогичные вышеуказанным.
Вообще, к Гному создано много полезных дополнений. Найти их можно на сайте [extensions.gnome.org](https://extensions.gnome.org)
Например, «Bumblebee» для владельцев ноутбуков с технологией Optimus, которое иконкой отображает использование дискретной карты в системе (установку, настройку и бенчмарки Nvidia Optimus и Bumblebee я буду рассматривать отдельно ниже). Или дополнение ускоряющее анимацию работы с окнами в Gnome.
Есть обзоры — что именно стоит поставить из дополнений на Gnome 3. Так что если вам симпатичная данная среда — не поленитесь ознакомиться с ними, выйдя на них через искомые для вас ключевые фразы.
Часто, люди используют восстановление привычного вида среды — нижней панели с запущенными программами, обычного трея с кучей иконок запущенных программ и расширенное меню для операций на окном через него.
Мне это не нужно, так как я стараюсь минимизировать любые отвлекающие факторы, и идея спрятать иконки меня вполне устраивает. При этом оповещения в системе сделаны ненавязчиво и доходчиво, их не так легко пропустить.
### Тонкости файлового менеджера Nautilus
По-умолчанию сортировка не выставляет папки до списка файлов, отображается всё в перемешку.
Исправляем:
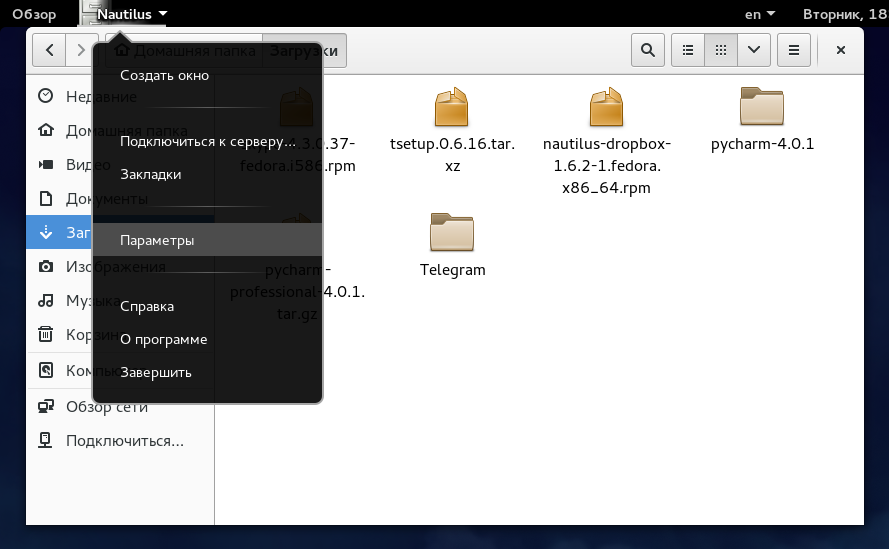
Nautilus — Параметры -> отмечаем чекбокс «Помещать папки перед файлами»
Также, я предпочитаю перемещаться по компьютеру без двойных щелчков мышки. Если вы согласны со мной, что действие в 1 клик приятней — в том-же окне переключитесь на вкладку «Поведение», и отметьте в «Поведение» — «Открывать объекты одним щелчком».
После этого можно закрыть окно настройки.
У файлового менеджера Nautilus есть неочевидная возможность добавлять свои «точки входа» — закладки на нужные вам адреса. Для этого, находясь по нужному адресу или в нужном каталоге, нажимаем Ctrl+D или выбираем мышкой иконку с горизонтальными черточками, и там в меню щелкаем по «Добавить закладку на этот адрес».
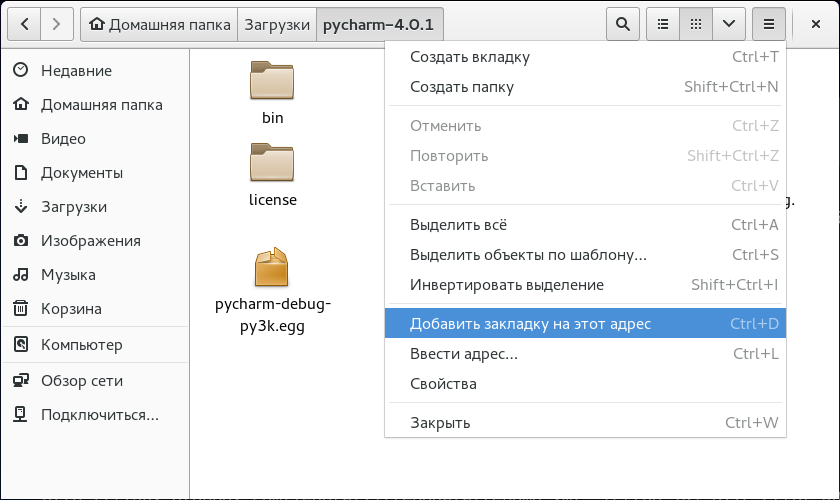
После этого слева внизу появится закладка с вашим адресом или папкой. Можете организовать их перетаскиванием мышкой, удалить вызвав контекстное меню, переименовать или производить другие требуемые операции.
### Добавить средства управления пакетами програм
Стандартное средство управления программами в Gnome ориентировно не на пакеты а на избранные программы. Чтобы получить возможность более полно изучать репозитарии доступного программного обеспечения и управлять ими, надо установить Yumex или использовать предустановленный Apper в KDE.
Устанавливаем Yumex:
```
sudo yum install yumex
```
### Сетевые учетные записи — синхронизация с почтой, контактами и календарем Google
В Гном встроена отличная интеграция с вашими основными данными из аккаунта Гугла, а также с множеством других сетевых сервисов.
Достаточно зайти в главное меню системы и написать «сете» — появится предложение выбрать настройку раздела «Сетевые учетные записи».
Указав свои параметры доступа к Гуглу и подтвердив их кодом (если у вас двухэтапная авторизация), вы получаете интеграцию календаря, задач, контактов и почты со своей системой.
Так, при клике по времени будет появляться информация о ваших ближайших событиях календаря. А при вбивании части имени одного из ваших контактов в главном меню системы его карточка будет появляться у вас прямо перед глазами. Далее вы сможете связаться с ним в 2 клика.
И удобство сетевых записей этим не ограничивается. Попробуйте!
Шрифты
------
У меня LCD мониторы и я предпочитаю шрифты с легким сглаживанием. Отсюда переменные в следующем конфиге.
Если вам нравится другое значение сглаживания (среднее, сильное или без него)- можете подставить соответствующее значение для переменной hintstyle вместо hintslight: hintmedium, hintfull или hintnone.
Также вам может потребоваться внести изменения и в переменную lcdfilter. Но подробнее об этом вы можете прочитать, например, тут [wiki.archlinux.org/index.php/font\_configuration](https://wiki.archlinux.org/index.php/font_configuration)
Приведенный ниже текст конфига улучшает шрифты во множестве программ, включая Firefox, KDE со штатной настройкой сглаживания «Как в системе» и в запущенных из-под него программах.
Вам необходимо создать файл /etc/fonts/local.conf со следующим содержимым:
```
xml version='1.0'?
rgb
true
hintslight
lcddefault
false
~/.fonts
```
После этого выходим из сеанса, и входим заново.
Система теперь полноценно узнала о том, какое сглаживание шрифтов вы хотите использовать.
В некоторых случаях требуется изменение стандартного dpi экрана, чтобы шрифты и графика после приведенных настроек действительно были отличными.
Этот момент я пока оставляю вам на самостоятельную проработку, если поймете, что вам надо его выполнить для обретения счастья на вашей системе.
### Заменяем тонкие шрифты в IDE от JetBrains (IntelliJ, PyCharm и другие) и в Java
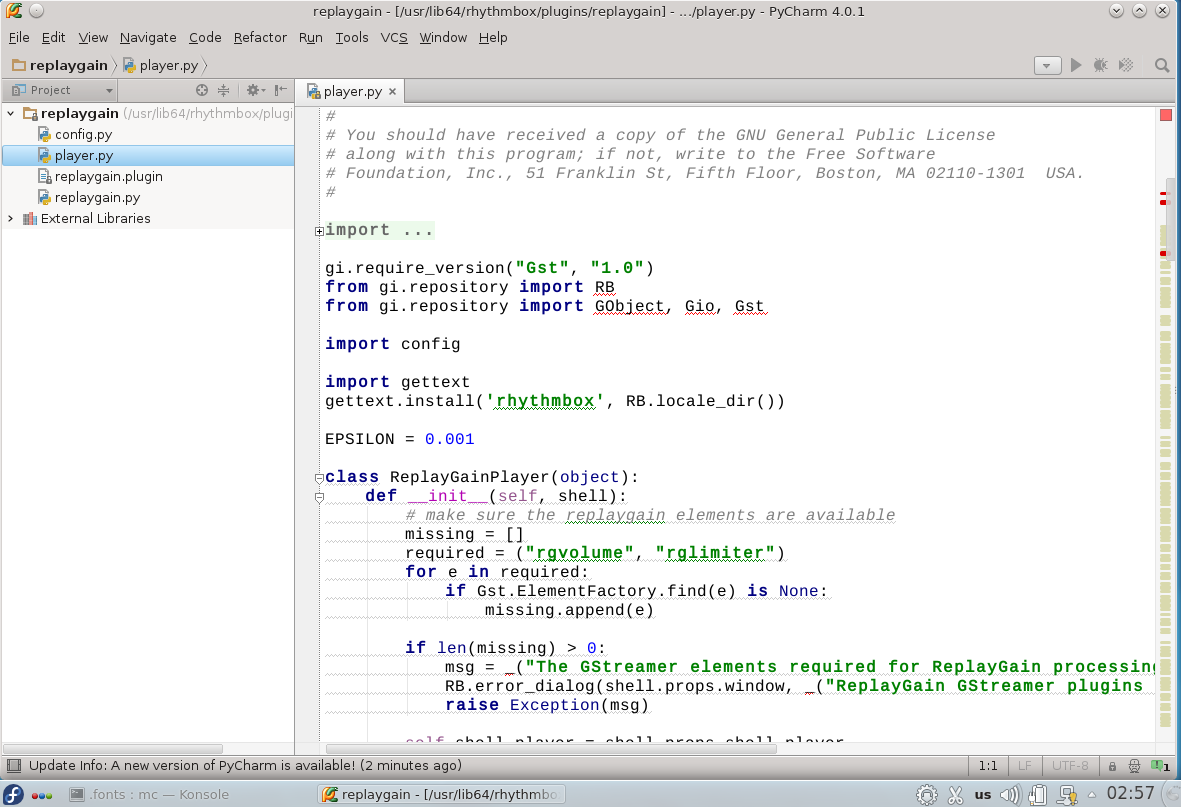
Хотя некоторым нравятся именно вариант тонких шрифтов, есть большая группа людей, которым нужна более «плотная», весомая отрисовка шрифтов. И если, например, в Eclipse с «плотными» шрифтами все в порядке, то вот популярные среды разработки от JetBrains несут на себе печать Явы и иногда вызывают отторжение своими шрифтами.
Pycharm с дефолтным шрифтом — Gnome 3
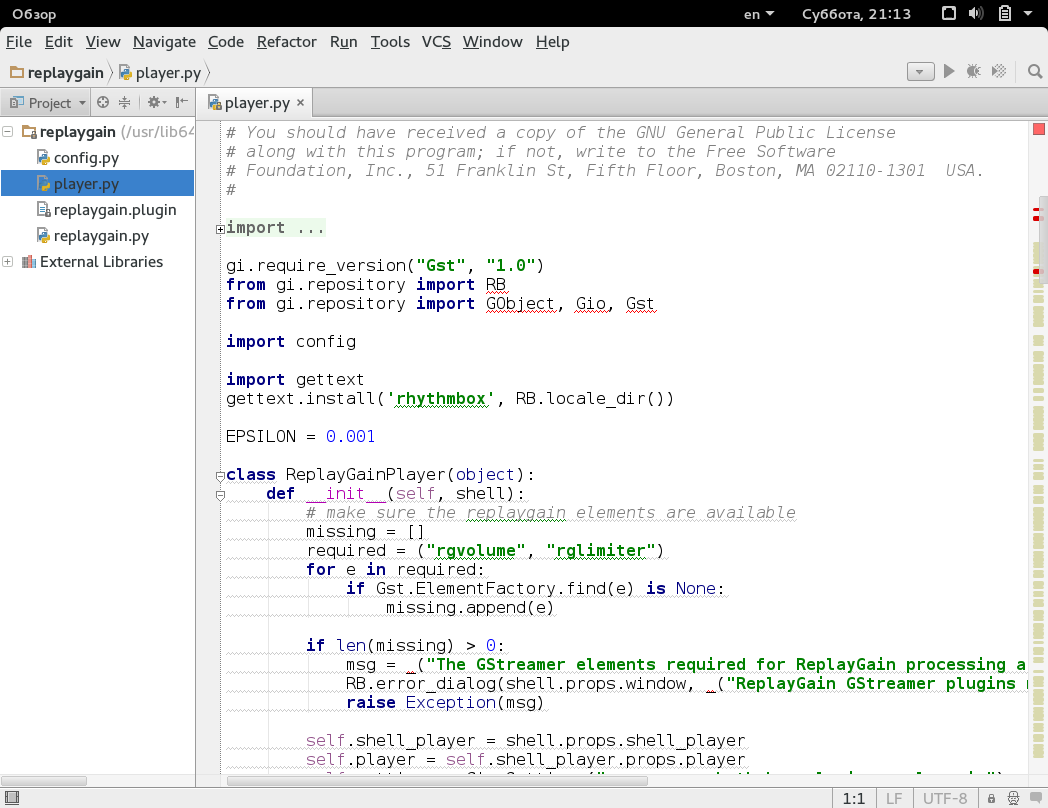
Pycharm с дефолтным шрифтом — KDE
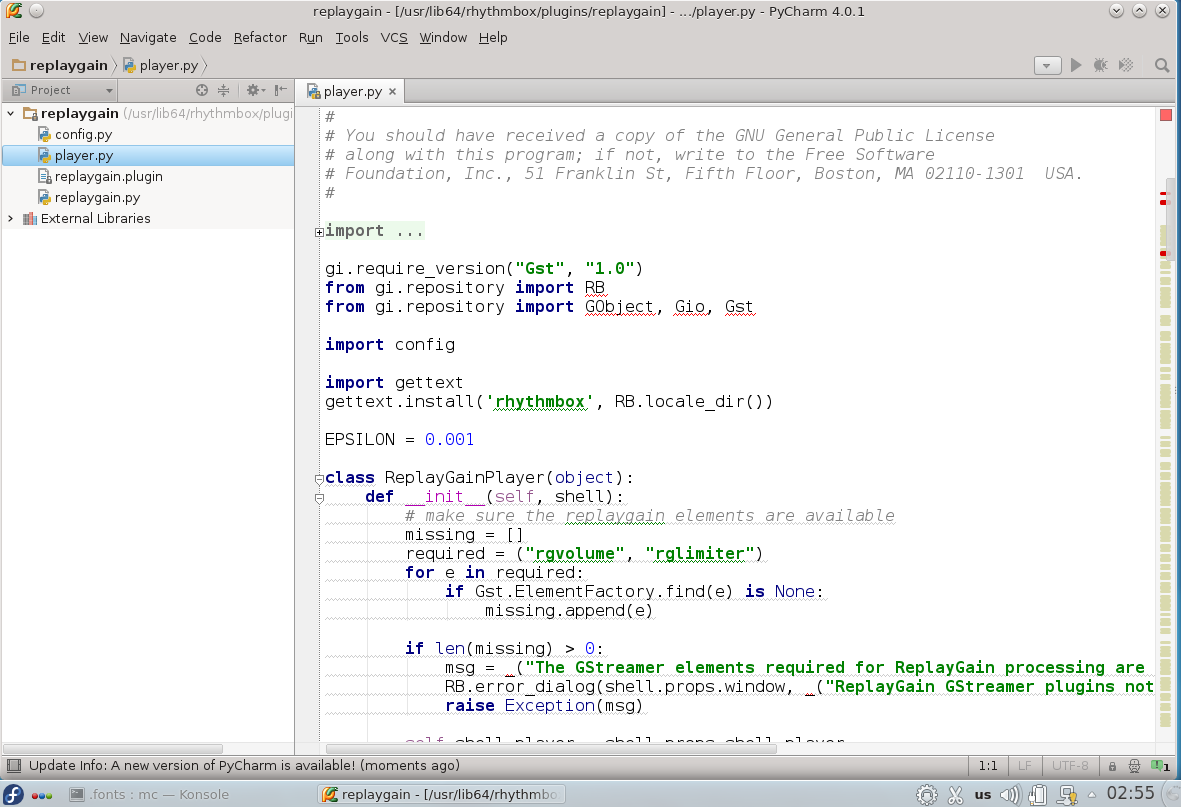
Pycharm с описанным ниже изменением шрифта — KDE
Ниже я опишу один из самых рабочих вариантов решения данной проблемы (подходящий и для Мака), в результате чего мы получим в нужных нам программах «плотные» шрифты, которые выглядят по мнению некоторых разработчиков куда лучше, чем в Windows.
Основная идея проста — если Java не обрабатывает инструкции хинтинга шрифта корректно, то надо эти инструкции из шрифта просто удалить.
Вот как это делается:
1. Выбираем любимые шрифты, которые хотим использовать в IntelliJ IDEA и других IDE этой линейки.
Например, Liberation Sans и Liberation Mono.
2. Устанавливаем программу редактирования шрифтов:
```
sudo yum install fontforge
```
3. Запускаем её и открываем нужный нам шрифт для изменения.
Например из каталога /usr/share/fonts/liberation/ следующие файлы:
LiberationSans-Regular.ttf
LiberationMono-Regular.ttf
4. Нажимаем Ctrl+A, чем выделяем все символы шрифта. В меню «Хинты» выбираем пункт «Очистить инструкции».
5. В меню «Элемент» — «Информация о шрифте» во все поля названий добавляем цифру «2», чтобы в поле «Название шрифта» стояло «LiberationSans2». Нажимаете Ок. Сразу-же программа сообщит что шрифт не имеет уникального идентификатора, а несет старый. Щелкаете на кнопку «Изменить», и нашему шрифту будет сгенерирован новый UID.
6. Меню «Файл» — «Создать шрифты». В появившемся окне справа щелкаем на иконку гаечного ключа и выбираем опцию «Показывать скрытые файлы». Затем переходим в домашний каталог и создаем в нем папку .fonts (если её там ещё нет). Сохраняем наш шрифт с новым именем (например LiberationSans2.ttf ). Я обычно выбираю тип сохраняемого файла TrueType. Если будут сообщения об ошибках типа самопересечения — жмите Ок. Пусть сохраняет.
Повторяем для другого выбранного шрифта. Затем закрываем оба окошка, отказавшись от сохранения шрифтов в формате sfd.
Теперь в нашей системе появились два наших новых шрифта, которые симпатично выглядят в нужных нам программах. Заходим в настройки IntelliJ и указываем использовать новый шрифт в редакторе.
Краткое сравнение результата с дефолтным шрифтом в Windows:

**Полноразмерные скриншоты с шрифтами под Gnome 3 и Windows 8.1**Полноразмерные скриншоты с шрифтами под Gnome 3 и Windows 8.1
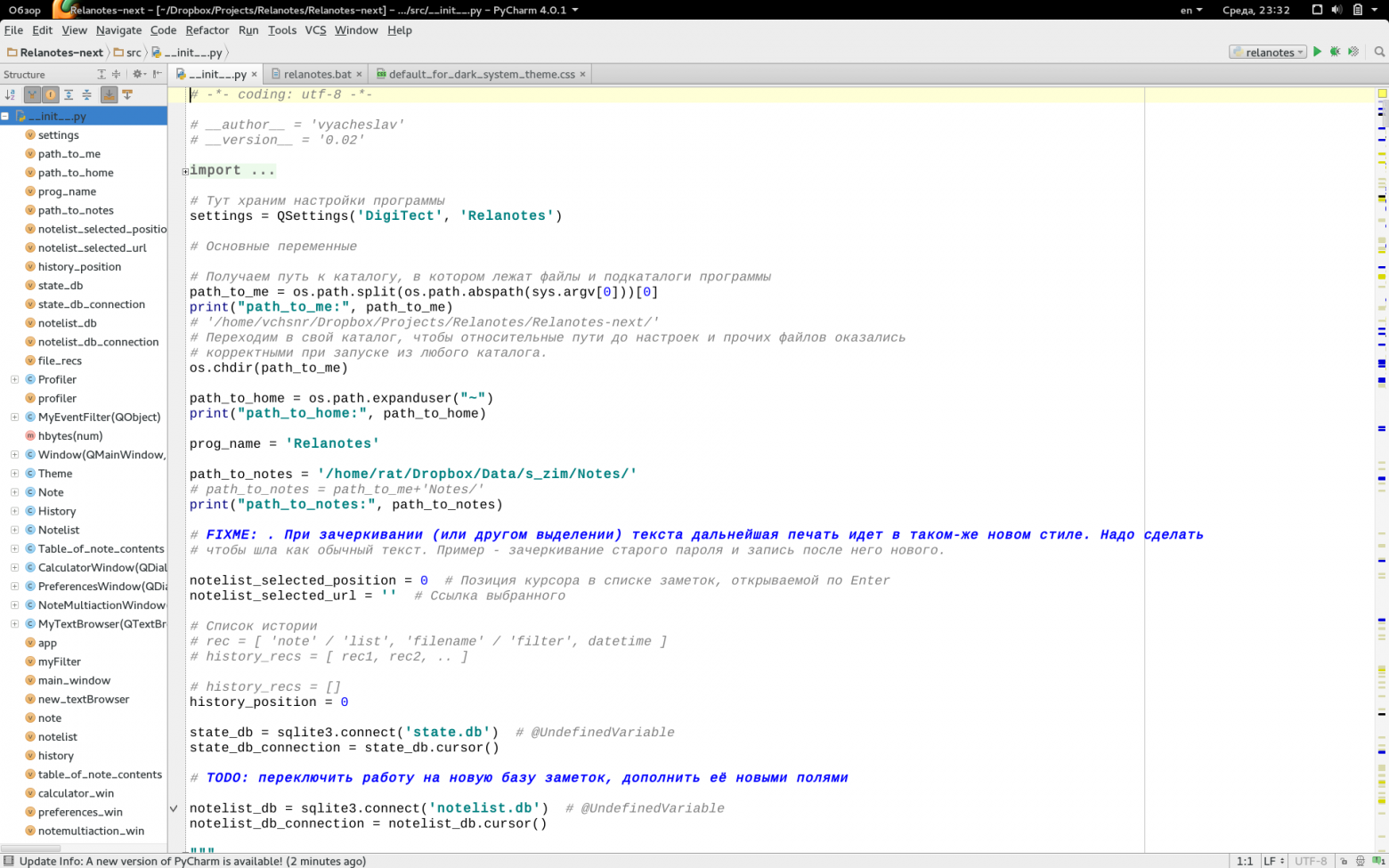
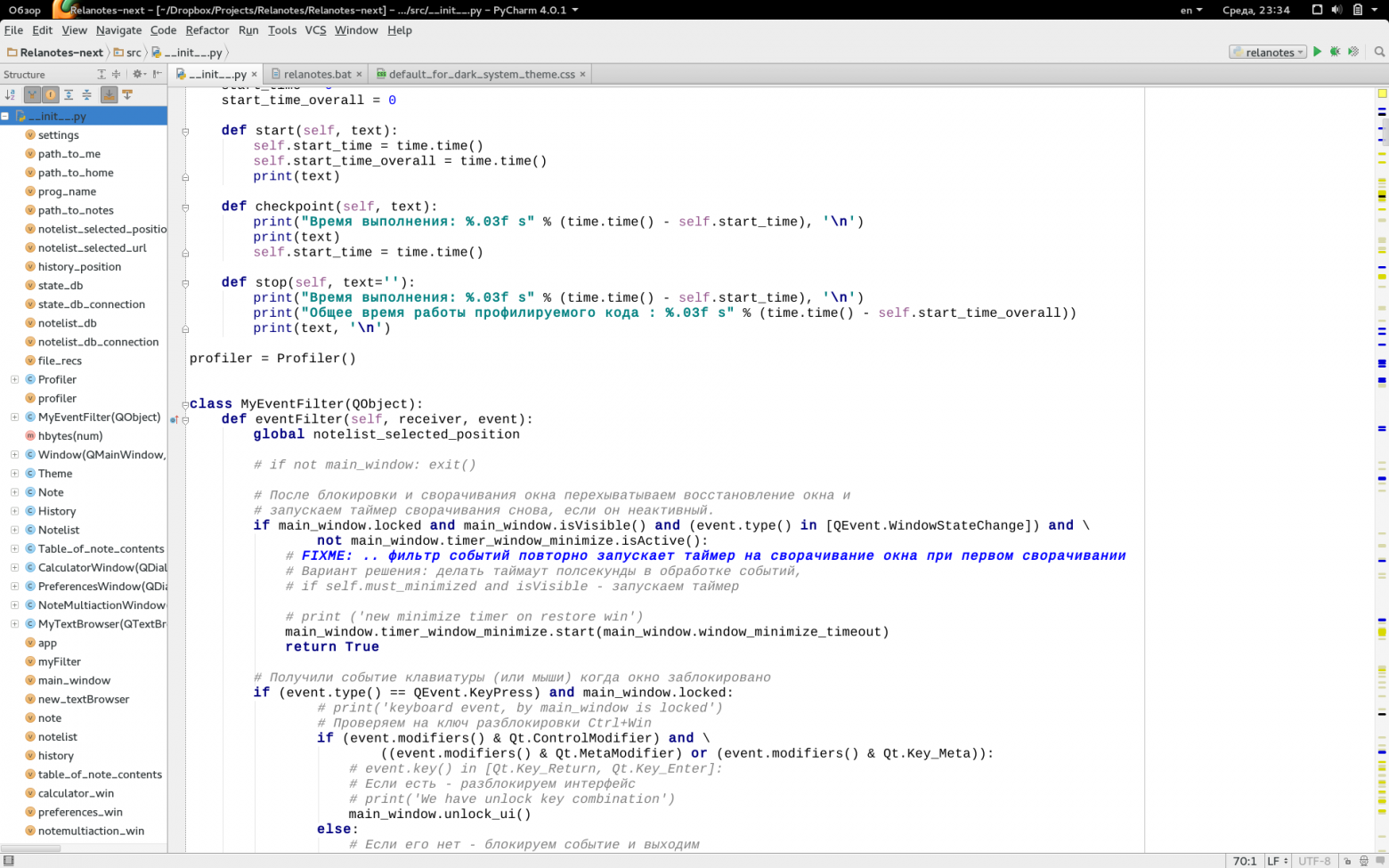
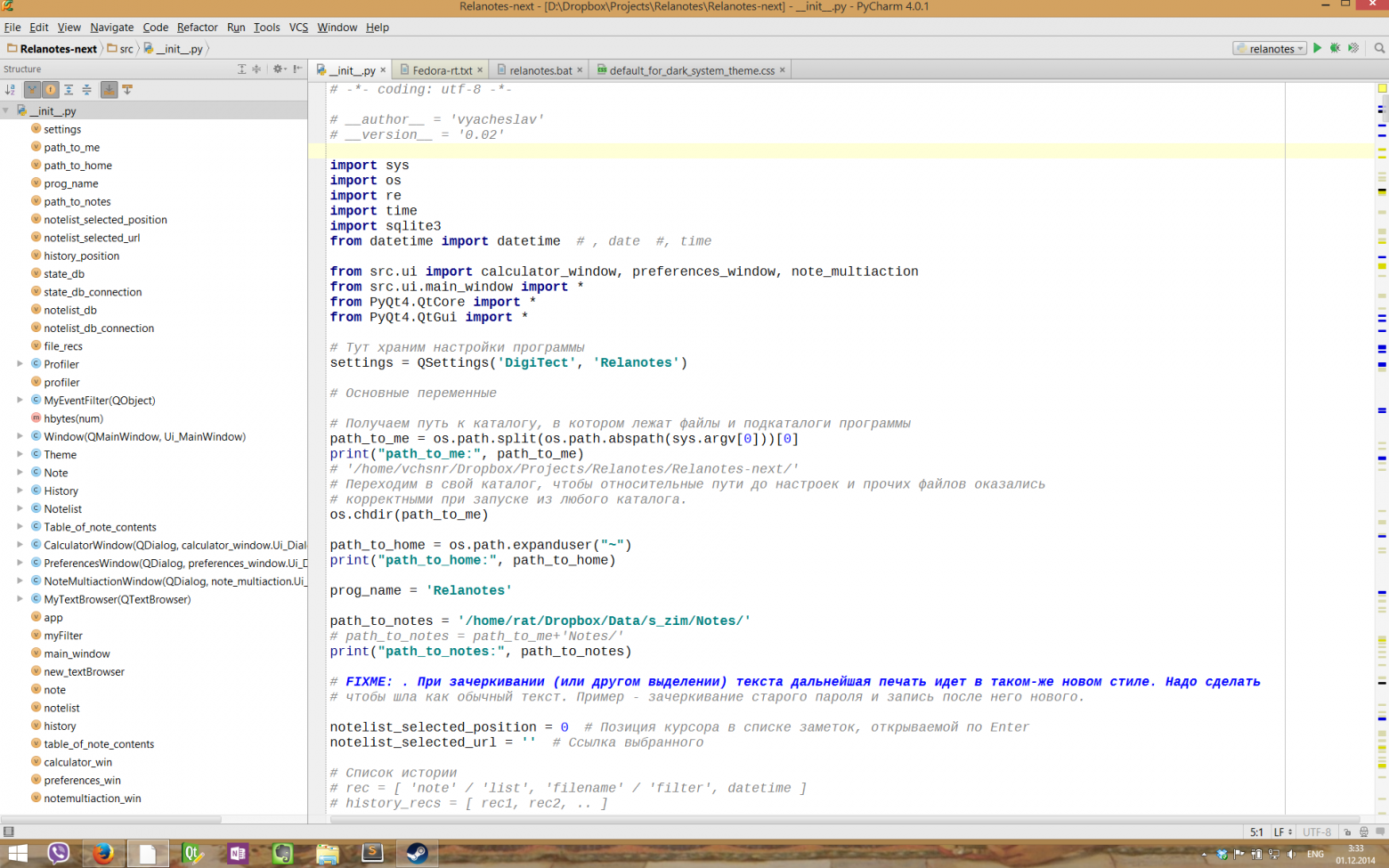
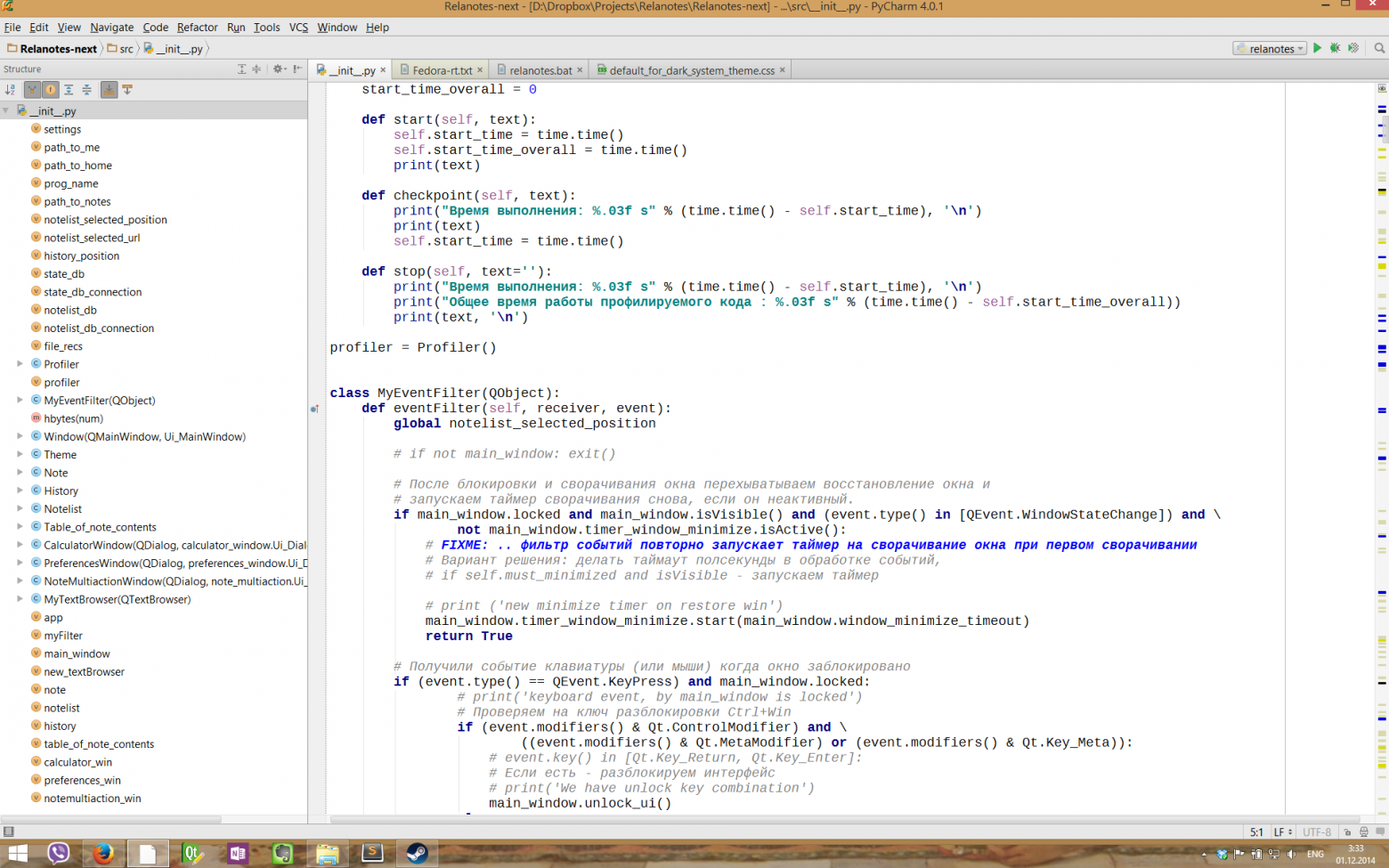
Подробнее о методах улучшения шрифтов в Яве тут:
[superuser.com/questions/614960/how-to-fix-font-anti-aliasing-in-intellij-idea-when-using-high-dpi/623596#623596](http://superuser.com/questions/614960/how-to-fix-font-anti-aliasing-in-intellij-idea-when-using-high-dpi/623596#623596)
К сожалению, подобная замена шрифтов не работает с популярной программой составления диаграм связи (mind map) — Freemind. Шрифты в ней всё-равно остаются тонкими.
Однако есть хорошая коммерческая альтернатива этой программе, у которой нет проблем со шрифтами — **XMind**, которой можно пользоваться как бесплатно, так и доплатив за некоторые продвинутые возможности. Ознакомиться с нею можно на сайте [www.xmind.net](http://www.xmind.net)
Если хотите её попробовать — скчайте для Федоры Portable версию программы отсюда [www.xmind.net/download/portable](http://www.xmind.net/download/portable)
Распакуйте архив, зайдите в созданную папку вида xmind-portable-3.5… затем в папку соответствующую архитектуре вашего дистрибутива (например, в XMind\_Linux\_64bit ) и запустите файл XMind
Вы можете самостоятельно создать ярлык для меню для этой программы в ~/.local/share/applications по аналогии с ярлыками из /usr/share/applications
Среды разработки и редакторы для языка программирования Python
--------------------------------------------------------------
Так как споры вокруг шрифтов в Linux лично я встречаю в основном в темах по разработке, то сразу привожу небольшую выжимку информации для работающих с Питоном, чтобы они могли проверить шрифты в своих рабочих инструментах. Все эти программы, кроме коммерческих, доступны из основных репозиториев. У всех из них после проведенной настройки с шрифтами все должно быть хорошо.
Те, кому это не актуально — переходите к следующему пункту. Там мы начинаем подготовку к просмотру видео, работе с flash и прочими «полезностями».
**Geany**
Отличный быстрый редактор / мини-IDE.
```
sudo yum install geany geany-plugins-common geany-themes
```
В yumex вы найдете к нему много полезных дополнений. Цветовые схемы и другое настраивается через «Правка» — «Настройки».
**Eclipse + pydev**
Широко известный, кроссплатформенный пакет с плагином, расширяющим его работу с Питоном.
```
sudo yum install eclipse-pydev
```
Будет предложено установить также и множество зависимостей. Соглашайтесь.
Настройки всего и вся в «Окно» — «Параметры». Шрифты работают нормально «из коробки».
Есть альтернативная коммерческая сборка от автора pydev — **LiClipse** [www.liclipse.com](http://www.liclipse.com)
**Kdevelop + kdev-python**
Среда разработки, реализованная под KDE. Отличается шустрой работой, неплохой реализацией работы с Питоном.
```
sudo yum install kdevelop kdevelop-python
```
Также в комплекте Федоры доступны для установки и **другие открытые редакторы и IDE**, в которых можно работать с Питоном: ninja-ide, spe, PyPE, spyder, anjuta, eric
Ознакомьтесь с ними, если приведенные выше и ниже решения вам не подходят или вам просто любопытно.
Из **коммерческих** хочу отметить 4 основных кроссплатформенных решения:
**Pycharm**
Широко известная IDE для Питона. Многие считают её лучшей. Не отличается высочайшей надежностью и устойчивостью, но зато славится хорошим автодополнением.
[www.jetbrains.com/pycharm/download](https://www.jetbrains.com/pycharm/download)
Есть платный и бесплатный (Community Edition) варианты.
Изменение настроек в «Файл» — «Настройки».
**Wing IDE**
Кто-то её любит и считает «номером 1», кому-то она совершенно не нравится. Многие обзоры признают её сильные стороны и сохраняют за ней как минимум «номер 2» из коммерческих IDE. Не зависит от Java.
[wingware.com/downloads](https://wingware.com/downloads)
Есть платный и бесплатный (Wing IDE 101) варианты.
Пару недель назад можно было приобрести коммерческую лицензию всего за 2100 рублей.
Шрифты настраиваются без проблем.
**Komodo IDE**
Считается более слабой IDE для Питона по сравнению с предыдущими, однако на неё тоже можно обратить внимание и протестировать в работе.
[komodoide.com](http://komodoide.com)
**Sublime Text**
Широко известный редактор с возможностью расширения для лучшей работы с Питоном.
[www.sublimetext.com/3](http://www.sublimetext.com/3)
Дальше возвращаемся обратно к настройке первоочередных потребностей в Fedora 21.
Подключение к репозитариям RPMFUSION
------------------------------------
Чтобы получить возможность ставить в Fedora дополнительные видеоплееры, видеокодеки, flash, несвободные программы и много чего ещё, надо подключиться к основным дополнительным репозиториям: Rpmfusion Free и NonFree
Самый простой вариант — выполнить команду в терминале:
```
su -c 'yum localinstall --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm http://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm'
```
Другие варианты подключения вы можете посмотреть на официальном сайте репозитория в разделе «Настройка» [rpmfusion.org/Configuration](http://rpmfusion.org/Configuration)
Видео, аудио и книги
--------------------
### Видеопроигрыватели
Из видеопроигрывателей я лично предпочитаю MPV — у него выше скорость отклика, меньше задержек при перемотке, визуальный минимализм и при этом достаточный функционал для постоянного использования.
Устанавливается MPV очень легко (должны быть подключены репозитарии rpmfusion):
```
sudo yum install mpv
```
Мой конфиг для mpv, который надо положить по адресу ~/.config/mpv/mpv.conf
```
# Сохранять позицию, на которой остановились при просмотре
save-position-on-quit=yes
# Запускать просмотр в fullscreen
fs=yes
# Отключить встроенное в программу управление звуком и использовать системный миксер, когда он доступен
softvol=no
# Прогресс-бар делаем тонким, полупрозрачным, и переносим его в низ экрана
osd-bar-align-y=1
osd-bar-h=1
osd-border-size=1
osd-color='#aaaaaaaa'
```
Подробнее о настройках MPV можно прочитать тут:
[wiki.archlinux.org/index.php/Mpv](https://wiki.archlinux.org/index.php/Mpv)
[github.com/mpv-player/mpv/blob/master/etc/example.conf](https://github.com/mpv-player/mpv/blob/master/etc/example.conf)
Шоткеи MPV в целом аналогичны mplayer. Отмечу несколько особо важных для меня:
**j** — переключение субтитров
**#** — переключение аудиодорожки
**D** — включение деинтерлейса (когда видео в горизонтальную полоску по типу ТВ)
Подробнее: [manpages.ubuntu.com/manpages/trusty/man1/mpv.1.html](http://manpages.ubuntu.com/manpages/trusty/man1/mpv.1.html)
Также можно установить проигрыватели с привычным графическим интерфейсом: smplayer и vlc
```
sudo yum install smplayer vlc
```
Дополнительно к этим проигрывателеям вы можете установить темы и прочие полезности, заглянув в список доступных пакетов.
Указанные выше проигрыватели в зависимостях несут с собой основные кодеки, которые требуются для воспроизведения видео.
Обращу ваше внимание, что иногда программы в процессе установки зависимостей подключают ответвление rpmfusion «rawhide», предназначенное для нестабильной Федоры. Рекомендую не соглашаться на подключение этого репозитория или отключать его в дальнейшем в Yumex, проверяя включены-ли rpmfusion для fedora 21. Вероятно, в ближайших обновлениях эта проблема будет исправлена, но всё-таки будьте внимательны.
### Аудиопрогрыватели + Вконтакте
**Rhythmbox**
Уже есть в установленных по-умолчанию программах в Гноме.
Эквалайзер к плееру ставится отдельно. Смотрите в списке пакетов в yumex или apper.
Плагин Rhytmbox для Вконтакта: [github.com/radistmorse/rhythmbox-vk](https://github.com/radistmorse/rhythmbox-vk)
Немного о нем и его установке на русском: [boutnew.ru/tehnika-i-tehnologii/muzyika-s-vk-com-cherez-rhythmbox-na-ubuntu-12-04-12-10-13-04-13-10.html](http://boutnew.ru/tehnika-i-tehnologii/muzyika-s-vk-com-cherez-rhythmbox-na-ubuntu-12-04-12-10-13-04-13-10.html)
Плагин простой, есть только общий поиск по всем композициям.
**Exaile**
[www.exaile.org](http://www.exaile.org)
Ставится из штатных репозитариев.
Есть плагин для Вконтакте. Методы установки плагина оставляю на ваши изыскания.
**Clementine**
[www.clementine-player.org/ru](https://www.clementine-player.org/ru)
Ставится из штатных репозитариев.
Вроде, есть плагин для Вконтакте. Методы установки плагина также оставляю на ваши изыскания.
Из плюсов — «легче» следующего Амарока.
**Amarok**
[amarok.kde.org](https://amarok.kde.org)
Имеет смысл ставить при установке KDE (об установке KDE будет ниже). Также идет в штатных репозитариях.
Установка плагина Вконтакте производится в несколько шагов:
1. В настройках Амарок в разделе «Скрипты» щелкаем по кнопке «Управление скриптами»
2. В поле поиска по доступным скриптам вбиваем «vk»
3. Появляется единственный скрипты, он-же нам и нужен. Кликаем по кнопке рядом с ним «Установить».
4. Перезагружаем Амарок
5. В настройках выбираем пукто «Авторизация vk», вбиваем нужные данные.
Можно слушать музыку Вконтакте — как свою так и своих друзей, или воспользоваться поиском по всей доступной.
### Если вашим программам все ещё не хватает кодеков
```
sudo yum install gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer-ffmpeg xine-lib-extras xine-lib-extras-freeworld k3b-extras-freeworld gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-bad-nonfree gstreamer-plugins-ugly gstreamer-ffmpeg
```
### Как слушать аудиокниги
С прослушиванием аудиокниг отлично справляется медиаплеер Banshee который входит в стандартный репозиторий Fedora 21:
```
sudo yum install banshee banshee-community-extensions
```
Программа по своим функциям является аналогом Rhythmbox. Подробнее о ней на [banshee.fm](http://banshee.fm)
Чтобы прослушать книги надо выполнить 2 шага:
1. Добавить папки с книгами в библиотеку Banshee (как обычную музыку)
2. Затем нужные «альбомы»-книги перетащить мышкой в раздел Аудиокниги.
После вам станет доступно запоминание позиции в книге и прочие приятности.
### Как читать книги
**fb2 / epub**
Calibre (для просмотра есть отдельная программка, идущая в комплекте) или fbreader
```
sudo yum install calibre fbreader
```
**pdf**
Отлично справляются штатные читалки pdf: evince (Gnome) или okular (KDE)
**djvu**
В Gnome нужно дополнение к evince
```
sudo yum install evince-djvu
```
а в KDE штатное средство просмотра документов уже умеет работать с этим форматом.
**Управление библиотекой и конвертация всего во все** — Calibre
Установка Дропбокса
-------------------
Заходим на [www.dropbox.com/install?os=lnx](https://www.dropbox.com/install?os=lnx)
Скачиваем пакет в подходящем формате.
Устанавливаем (двойной клик мышкой в файловом менеджере и нажатие кнопки «Установить»).
В главном меню запускаем свежеустановленный Dropbox. Даем ему возможность докачать свой установщик. Затем настраиваем привычные параметры своего аккаунта и синхронизации.
Примечание: пока репозитория дропбокса для Fedora 21 не существует, так что придется добавить ему опцию «пропускать, если недоступен»:
```
sudo yum-config-manager --save --setopt=Dropbox.skip_if_unavailable=true
```
Позднее он появится, и все будет работать ок.
Установка мессенджеров
----------------------
### Skype
Заходим на офф.сайт, скачиваем для федоры пакет со Скайпом:
[www.skype.com/ru/download-skype/skype-for-computer](http://www.skype.com/ru/download-skype/skype-for-computer)
Затем устанавливаем его двойным кликом и кнопкой «Установить» (или «Ок», если вы уже поставили yumex и он запускается вместо штатного установщика пакетов).
Все зависимости (которых множество, и все обязательно в 32-разрядной архитектуре) будут поставлены вместе со Скайпом, так что доставлять дополнительно, обычно, не нужно.
Для привычной работы со скайпом в Gnome 3 можно установить дополнение, которое добавит иконку скайпа в панель:
[extensions.gnome.org/extension/696/skype-integration](https://extensions.gnome.org/extension/696/skype-integration)
или
[extensions.gnome.org/extension/192/status-icon-fixer](https://extensions.gnome.org/extension/192/status-icon-fixer)
Если при работе скайпа будут проблемы со звуком, попробуйте запустить его следующей командой:
```
env PULSE_LATENCY_MSEC=30 skype %U
```
Также, можно попробовать использовать вместо цифры 30 цифру 60.
Если это решает проблему, можете переименовать /usr/bin/skype в /usr/bin/skype2, создать пустой файл /usr/bin/skype и прописать в нем следующие строчки:
```
#!/bin/sh
env PULSE_LATENCY_MSEC=30 skype2 %1 &
```
Сохранить и назначить права на выполнение:
```
sudo chmod +x /usr/bin/skype
```
Плюс такого варианта — любой запуск скайпа позволит ему нормально работать со звуком.
Или, если вам не нравится предыдущий вариант, можно сделать по-другому:
1.
```
sudo mcedit /usr/share/applications/skype.desktop
```
2. вместо строки Exec=skype %U записать вышеуказанную
```
Exec=env PULSE_LATENCY_MSEC=30 skype %U
```
Обычный запуск через иконку будет теперь работать со звуком нормально.
Однако запуск непосредственно команды «skype» так и будет шуметь и хрипеть.
### Viber
Скчиваем RPM-пакет с официального сайта [viber.com/products/linux](http://viber.com/products/linux)
Устанавливаем его (двойной клик мышкой, «Установить»)
Остается только запустить свежеустановленный Вайбер из главного меню.
### Telegram
С официального сайта [desktop.telegram.org](https://desktop.telegram.org) скачиваем пакет, который нам предлагают для Линукса. Распаковываем («Распаковать сюда», например). Заходим в свежесозданную папку «Telegram» и двойным кликом запускаем бинарник с аналогичным названием. Клиент запущен и работает.
Остается его при желании добавить в автозагрузку.
Подсказка:
Сначала создаете новый файл в ~/.local/share/applications по аналогии с файлами из /usr/share/applications
Затем добавляете его в «Дополнительные параметры» — «Автозапуск»
Установка браузеров и flash
---------------------------
Firefox стоит в системе по-умолчанию.
### Google Chrome
Для установки скачиваем с официального сайта нужную версию:
Stable [www.google.ru/chrome/browser/desktop](https://www.google.ru/chrome/browser/desktop)
Beta [www.google.com/chrome/browser/beta.html](https://www.google.com/chrome/browser/beta.html)
Выбираем свою 64- или 32-битный пакет для Fedora. Скачиваем. Устанавливаем двойным кликом.
Все необходимые зависимости подтянутся автоматически.
В комплекте самый свежий флеш, реакция внутри флеша на глобальные шоткеи и т.д.
Если вы, например, установили стабильный Хром, а затем хотите заменить его на бету, сделайте следующее:
1.
```
sudo yum remove google-chrome
```
2.
```
sudo yum install google-chrome-beta
```
### Установка Хромиума
Если вас не устраивает Хром от Гугла или хочется чего-то дополнительного в том-же духе.
В силу проблем с лицензиями Хромиума в основных репозиториях для Федоры нет. Однако он есть в неофициальном репозитарии Copr в «русской Федоре». Подробнее об этом [copr.fedoraproject.org/coprs/churchyard/chromium-russianfedora](http://copr.fedoraproject.org/coprs/churchyard/chromium-russianfedora)
Устанавливается Хромиум так:
1. Сохраняем файл [copr.fedoraproject.org/coprs/churchyard/chromium-russianfedora/repo/fedora-21/churchyard-chromium-russianfedora-fedora-21.repo](http://copr.fedoraproject.org/coprs/churchyard/chromium-russianfedora/repo/fedora-21/churchyard-chromium-russianfedora-fedora-21.repo) на диск
2. кладем его в каталог /etc/yum.repos.d
3.
```
sudo yum install chromium
```
### Flash для браузеров и для системы
Для 64bit системы:
```
sudo yum install http://linuxdownload.adobe.com/adobe-release/adobe-release-x86_64-1.0-1.noarch.rpm
```
Для 32bit:
```
sudo yum install http://linuxdownload.adobe.com/adobe-release/adobe-release-i386-1.0-1.noarch.rpm
```
Дальше для обоих систем:
```
sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-adobe-linux
sudo yum install flash-plugin
```
Остается только перезапустить браузер (в данном случае предполагается Firefox).
В Хроме свой собственный флеш.
А вот для Хромиума надо дополнительно установить симлинк на флеш руками.
Система 64bit:
```
sudo ln -s /usr/lib64/mozilla/plugins/libflashplayer.so /usr/lib64/chromium-browser/plugins/libflashplayer.so
```
Система 32bit:
```
sudo ln -s /usr/lib/mozilla/plugins/libflashplayer.so /usr/lib/chromium-browser/plugins/libflashplayer.so
```
Подробнее о об установке флеша под Федора: [ask.fedoraproject.org/en/question/10217/how-to-install-adobe-flash-on-fedora](https://ask.fedoraproject.org/en/question/10217/how-to-install-adobe-flash-on-fedora)
Проприетарные видеодрайверы
---------------------------
Указанные ниже драйвера надо ставить после подключения репозиториев rpmfusion (которое было описано раньше).
### Nvidia «обычная»
**Вариант 1 — совсем простой**
```
yum update
```
Перегружаемся если было обновлено что-то в системе
```
yum install akmod-nvidia xorg-x11-drv-nvidia-libs kernel-devel
```
Информация о способе: [jsn-techtips.blogspot.ru/2013/12/fedora-20-nvidia.html](http://jsn-techtips.blogspot.ru/2013/12/fedora-20-nvidia.html)
**Вариант 2 — немного другой**
```
sudo yum install akmod-nvidia
```
Чтобы работало ускорение в видеоплеере:
```
sudo yum install vdpauinfo libva-vdpau-driver libva-utils
```
При загрузке проверить, чтобы не грузился старый драйвер:
```
lsmod |grep nouveau
```
Если надо удалить старый драйвер Nvidia:
```
sudo yum remove xorg-x11-drv-nvidia\*
```
Если после установки драйвера Nvidia перестали грузиться иксы:
1. Проверяем ошибку
```
sudo akmod --force
```
2. Возможно надо установить исходники ядра:
```
sudo yum install kernel-devel
```
3. Снова запустить
```
sudo akmod --force
```
4. Если все ок — перезапускаем систему и должно работать.
Как резервный вариант отказа от попытки загрузки с новыми драйверами достаточно просто удалить (переименовать) файл /etc/X11/xorg.conf (сейчас он по-умолчанию в системах отсутствует, а создается инсталляторами типа Nvidia).
Подробнее об установке драйверов для Nvidia разных серий:
[blog.xenodesystems.com/2014/12/como-instalar-drivers-propietarios.html](http://blog.xenodesystems.com/2014/12/como-instalar-drivers-propietarios.html)
[rpmfusion.org/Howto/nVidia](http://rpmfusion.org/Howto/nVidia)
### Проприетарные драйвера ATI
Тут я с вашего позволения отделаюсь ссылкой на материалы.
На русском [Wiki Федоры](http://wiki.russianfedora.pro/index.php?title=%D0%A3%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0_%D0%B4%D1%80%D0%B0%D0%B9%D0%B2%D0%B5%D1%80%D0%BE%D0%B2_ATI) и актуальный опыт коллеги из Испании [blog.xenodesystems.com/2014/12/como-instalar-drivers-propietarios-ati.html](http://blog.xenodesystems.com/2014/12/como-instalar-drivers-propietarios-ati.html)
### Nvidia Optimus — установка Bumblebee
Nvidia Optimus это технология, которая позволяет на ноутбуке выбрать видеокарту для работы текущего приложения — интегрированную от Intel (экономичную) или мощную дискретную от NVIDIA.
Ссылка на понятно руководство как ставить и что делать: [fedoraproject.org/wiki/Bumblebee](http://fedoraproject.org/wiki/Bumblebee)
Не забывайте подставлять правильную цифру «21» там, где требуется указание номера Федоры, вместо «20».
Обращаю внимание, что мне пришлось снизить уровень внимательности системы безопасности Linux с «высокого» до «среднего», чтобы у меня заработала вторая (дискретная) видеокарта. Подробнее об этом в самом конце моих злоключений в данном разделе.
Вероятно, упомянутые дополнительные шаги 1..3 можно было и не проходить. Однако привожу эту информацию на случай, если кому-то понадобится сравнить это со своим опытом.
1. Если появляется ошибка при запуске приложения через optirun вида
```
[ERROR]Cannot access secondary GPU - error: [XORG] (EE) No devices detected.
[ERROR]Aborting because fallback start is disabled.
```
или
```
Cannot access secondary GPU - error: [XORG] (EE) systemd-logind: failed to get session
```
то вам нужно в настройках проверить правильный BusID вашей Nvidia-карты. Выполните в терминале:
```
lspci | egrep 'VGA|3D'
```
Пример вывода данной команды:
```
00:02.0 VGA compatible controller: Intel Corporation 3rd Gen Core processor Graphics Controller (rev 09)
01:00.0 VGA compatible controller: NVIDIA Corporation GF108M [GeForce GT 630M] (rev ff)
```
Заменив все точки на двоеточия — номера впереди будут обозначать BusID видеокарт, в примере получаем следующий BusID для карты nvidia:
BusID 01:00:0
Дальше правим конфигурационный файл xorg.conf.nvidia:
```
sudo gedit /etc/bumblebee/xorg.conf.nvidia
```
В этом файле приведен закомментированный пример указания BusID, по данному примеру указываем строчкой ниже правильный BusID (если номер BusID примера является правильным, то можно просто данную строчку раскомментировать, убрав '#'). В результате получится примерно следующее (в вашем случае номера могут быть другими):
```
# BusID "PCI:02:00:0"
BusID "PCI:01:00:0"
```
Дополнительная информация на [help.ubuntu.ru/wiki/bumblebee](http://help.ubuntu.ru/wiki/bumblebee)
2. В логах появляется следующая ошибка:
```
[ERROR]Cannot access secondary GPU - error: [XORG] (EE) [drm] failed to open device
```
Если в системе установлен драйвер nvidia и при этом присутствует загруженный модуль nouveau, тогда убедитесь в следующем:
в наличии строчки Driver=nvidia конфигурационного файла /etc/bumblebee/bumblebee.conf
в системе должен присутствовать один из файлов с содержимым blacklist nouveau:
```
$ grep -R nouveau /etc/modprobe.d/*
```
Больше информации на <https://ru.opensuse.org/SDB:Bumblebee>
3. Как добавить свободный драйвер в черный список:
[setiathome.berkeley.edu/forum\_thread.php?id=74094](http://setiathome.berkeley.edu/forum_thread.php?id=74094)
[kaischroed.wordpress.com/howto-install-nvidia-driver-on-fedora-replacing-nouveau](http://kaischroed.wordpress.com/howto-install-nvidia-driver-on-fedora-replacing-nouveau)
Открываем в редакторе файл
```
sudo mcedit /etc/modprobe.d/blacklist.conf
```
и добавить в конце файла строчку 'blacklist nouveau'
Если это не изменит ситуации можно удалить свободные драйвера полностью:
```
sudo yum remove xorg-x11-drv-nouveau.x86_64
```
Затем я оОбнаружил что в данный момент драйвер NVidia в черном списке:
```
cat /etc/modprobe.d/modprobe.conf
blacklist nvidia
```
Закомментировал эту строчку и перегрузился, но проблема осталась.
4. Шаг, решивший проблему. Указанные выше ошибки возникают в Fedora из-за SELinux при самом высоком уровне безопасности («enforcing»). Достаточно снизить его до уровня «permissive» и проблема уходит.
Узнать текущие настройки SELinux:
```
/usr/sbin/getenforce
/usr/sbin/sestatus
```
Редактируем конфиг:
```
sudo mcedit /etc/selinux/config
```
в нем находим переменную SELINUX= и выставляем ей следующее значение:
```
SELINUX=permissive
```
Перегружаемся.
После перезагрузки оказалось что проблема действительно была в строгой политике SELinux, и что теперь программы отлично запускаются и на второй (мощной) видеокарте.
Более подробная информация об [изменении настроек SELinux указана в документации к Федоре](http://docs.fedoraproject.org/ru-RU/Fedora/13/html/Security-Enhanced_Linux/sect-Security-Enhanced_Linux-Working_with_SELinux-Enabling_and_Disabling_SELinux.html).
### Как запускать программы и игры в Steam на дискретной карте
Обращаю ваше внимание, что установка Стима и исправление ошибок с его работоспособностью (если вы с такими столкнетесь) описана немного ниже. Для указания параметров запуска игр на дискретной карте из Стима он должен у вас нормально работать.
Заходим в Стим, в свою библиотеку («Library»). На игре кликаем правой кнопкой мышки и выбираем «Свойства» («Properties»). «Установить параметры запуска» («Set Launch Options ..») и указываем следующее:
```
optirun -b primus %command%
```
Сохраняем. Можно запускать эту игру.
Другие варианты команд запуска игр и сравнение их скорости можно посмотреть по ссылкам:
[forum.ubuntu.ru/index.php?topic=209722.0](http://forum.ubuntu.ru/index.php?topic=209722.0)
[support.steampowered.com/kb\_article.php?ref=6316-GJKC-7437](https://support.steampowered.com/kb_article.php?ref=6316-GJKC-7437)
### Бенчмарки: Fedora 21 Optimus / Primus / Windows 8.1
За несколько недель работа с бетой Федоры у меня было достаточно времени, чтобы потестить её в качестве основного рабочего и игрового места, а также сравнить её (условную) производительность с имеющимся на моем игровом ноутбуке Win8.1
Самое первое тестирование — по FPS в Serious Sam 3 на «ультра»-настройках.
В Windows 8.1 видим на выбранной карте средний FPS в районе 30-55. Иногда достигает «предельных» 60.
В Fedora 21 с вышеуказанной командой запуска практически стабильные 60 fps, иногда падающие до 55. В редких случаях удавалось отметить 48.
Верхний предел в 60 объясняется просто — это частота обновления моего монитора, и при обычных настройках большинство программ не генерируют больше этого значения.
Так, в Linux выкрутить FPS в программе на максимум часто позволяет команда запуска
```
vblank_mode=0 optirun -b primus %command%
```
Однако иногда она работает куда медленнее других вариантов ( optirun или optirun -b primus )
Пояснения по параметру vblank\_mode:
[askubuntu.com/questions/285342/why-does-vblank-mode-improve-framerate-drastically-in-benchmarks](http://askubuntu.com/questions/285342/why-does-vblank-mode-improve-framerate-drastically-in-benchmarks)
#### Кроссплатформенный бенчмарк GPU — GPUTest
Сайт программы: [www.geeks3d.com/gputest](http://www.geeks3d.com/gputest)
Windows, OpenGL 4.4.0
FurMark — 1186 points (FPS: 19)
TessMark X8 — 10306 points (FPS: 171)
TessMark X16 — 9006 points (FPS: 150)
TessMark X32 — 7499 points (FPS: 125)
TessMark x64 — 4460 points (FPS: 74)
GiMark — 1922 points (FPS: 32)
PixMark JuliaFP32 — 9079 points (FPS: 151)
PixMark JuliaFP64 — 765 points (FPS: 12)
PixMark Piano — 443 points (FPS: 7)
PixMark Volplosion — 1412 points (FPS: 23)
Plot3D — 11127 points (FPS: 186)
Итого **57205** очков.
Linux, OpenGL 4.4.0 (команда *optirun*)
FurMark — 1655 points (FPS: 27)
TessMark X8 — 8914 points (FPS: 148)
TessMark X16 — 8322 points (FPS: 138)
TessMark X32 — 6346 points (FPS: 105)
TessMark X64 — 3598 points (FPS: 59)
GiMark — 1633 points (FPS: 27)
PixMark JuliaFP32 — 5843 points (FPS: 97)
PixMark JuliaFP64 — 612 points (FPS: 10)
PixMark Piano — 355 points (FPS: 5)
PixMark Volplosion — 1065 points (FPS: 17)
Plot3D — 8914 points (FPS: 148)
Итого **47257** очков.
На общем фоне выделяется тест FurMark, в котором под Linux производительность радикально лучше чем в Win. В остальных идет проседание.
Linux, OpenGL 4.4.0 (команда *vblank\_mode=0 optirun -b primus*)
FurMark — 1868 points (FPS: 31)
TessMark X8 — 11448 points (FPS: 190)
TessMark X16 — 11521 points (FPS: 192)
TessMark X32 — 11072 points (FPS: 184)
TessMark X64 — 4831 points (FPS: 80)
GiMark — 1842 points (FPS: 30)
PixMark JuliaFP32 — 9831 points (FPS: 163)
PixMark JuliaFP64 — 625 points (FPS: 10)
PixMark Piano — 357 points (FPS: 5)
PixMark Volplosion — 1153 points (FPS: 19)
Plot3D — 11395 points (FPS: 189)
Итого **65943** очков.
А тут заметны очень забавные результаты на серии TessMark. Есть комментарии по этому поводу?
Особняком идет тест Triangle — в нем под Linux наблюдается провальное отставание:
Win Triangle — 21966 points (FPS: 366)
Lin *optirun* Triangle — 10179 points (FPS: 169)
Lin *vblank\_mode=0 optirun -b primus* Triangle — 11594 points (FPS: 193)
#### Кроссплатформенный бенчмарк Geekbench
Взят из магазина Steam. Ниже приведена только итоговая информация, т.к. результат у систем практически одинаковый.
Linux
Integer Score 3651 15278
Floating Point Score 3540 16041
Memory Score 3314 3631
Geekbench Score 3539 13253
Windows
Integer Score 3623 14898
Floating Point Score 3474 15923
Memory Score 3233 3578
Geekbench Score 3485 13044
В Win наблюдается несколько меньшая общая производительность.
Перед переходом к бенчмаркам браузеров мы временно решим проблему Хрома под Линуксом с работой на дискретной карте.
#### Решение проблемы с неработающим WebGL у Хрома
Чтобы работал WebGL под optirun в Google Chrome обычно советуют в его флагах включить возможность работать с WebGL ( Disable WebGL: Enable → Disable ) или запускать
```
optirun google-chrome --ignore-gpu-blacklist
```
Один из советов [askubuntu.com/questions/110132/problem-with-running-webgl-with-chrome](http://askubuntu.com/questions/110132/problem-with-running-webgl-with-chrome)
Однако у меня *optirun google-chrome-beta* отказывался запускаться со следующими ошибками:
```
'librrfaker.so' from LD_PRELOAD cannot be preloaded (cannot open shared object file)
```
Проблема проявлялась несмотря на то, что в системе уже установлены virtualgl обоих архитектур 32-bit и 64-bit (у меня 64-битная система).
Указания в переменной LD\_LIBRARY\_PATH где искать нужны библиотеки результата не дало.
Пробовал запускать через sudo, на случай если ругается на установленный бит защиты, но и это не возымело действия. Подробнее о ситуации с битом защиты [lists.fedoraproject.org/pipermail/scm-commits/Week-of-Mon-20130506/1014107.html](https://lists.fedoraproject.org/pipermail/scm-commits/Week-of-Mon-20130506/1014107.html)
Чтобы детализировать проблему запускал с параметром *LIBGL\_DEBUG=verbose primusrun…*
В результате гугления нашел временное решение проблемы на [code.google.com/p/chromium/issues/detail?id=351804](https://code.google.com/p/chromium/issues/detail?id=351804)
Рекомендуют отключать «песочницу» в Хроме, т.к. она в текущих его версиях с дискретной картой под Линукс работать не может. Для этого надо запускать Хром с флагом *--disable-gpu-sandbox*
Убеждаемся, что WebGL стал работать: переходим в Хроме по адресу *chrome://gpu*
WebGL заработал и теперь можно переходить к тестированию и сравнениям.
#### Бенчмарки для браузеров
По результатам проведенных тестов наблюдается интересная тенденция — браузеры в Linux серьёзно переигрывают своих собратьев, работающих в Widows. Более того Хрому под Линукс удалось показать абсолютно лучший результат в тесте [www.wirple.com/bmark](http://www.wirple.com/bmark) который когда-либо был измерен.
Напоминаю, что у меня присутствует Nvidia Optimus, и если не указано иное — браузеры запускались на обычной видеокарте. В противном случае я указываю основные модификаторы запуска, чтобы был понятен контекст замера. Также часто встречалась ситуация когда дискретная карта ничего не изменяла в результатах теста. В этом случае я просто не привожу значения запуска с ней.
**Тест 1** — [peacekeeper.futuremark.com](http://peacekeeper.futuremark.com)
Windows
Firefox 34 — 3661
Chrome 40 — 4313
Linux
Firefox 34 — 6433
*optirun* Firefox 34 — 6441
Chrome — 5837
Варианты запуска Хрома с optirun, vblank или nosandbox только немного ухудшали результат.
**Тест 2** — [browsermark.rightware.com](http://browsermark.rightware.com)
Windows
Firefox — 3306
Chrome — 5525
*на дискретной карте* Chrome — 6527
Linux
Firefox — 5167
*optirun* Firefox — 5468
*nosandbox* Chrome — 7138
*vblank + nosandbox* Chrome — 7223
На эти цифры Хрома тест сообщил мне:
*Desktop Linux with Google Chrome 40 is faster than 99% of all Desktops tested so far.*
**Тест 3** — [www.wirple.com/bmark](http://www.wirple.com/bmark)
Windows
Firefox: 1281 (Canvas score — Test 1: 77 — Test 2: 630, WebGL score — Test 1: 274 — Test 2: 300)
Chrome: 3172 (Canvas score — Test 1: 535 — Test 2: 1537, WebGL score — Test 1: 629 — Test 2: 471)
Linux
Firefox: 1116 (Canvas score — Test 1: 188 — Test 2: 354, WebGL score — Test 1: 306 — Test 2: 268)
*optirun* Firefox: 1546 (Canvas score — Test 1: 466 — Test 2: 372, WebGL score — Test 1: 361 — Test 2: 347)
А вот с параметром vblank произошло снижение производительности.
Chrome: 2506 (Canvas score — Test 1: 629 — Test 2: 614, WebGL score — Test 1: 677 — Test 2: 586)
И вот рекордная команда:
```
optirun -b primus google-chrome-beta --disable-gpu-sandbox --enable-webgl --ignore-gpu-blacklist
```
Chrome: **4240** (Canvas score — Test 1: 794 — Test 2: 2222, WebGL score — Test 1: 677 — Test 2: 547)
На этот результат тест мне сообщил о победе следующее:
*Your results compared to other users:
You score better than 100% of all users so far!
You score better than 100% of the people who use the same browser and OS!*
Это **лучший результат**, который отмечал данный тест за время своего существования.
Добавление к «рекордной» команде параметра vblank\_mode=0 сильно ухудшило результат
*+vblank\_mode* Chrome: 3363 (Canvas score — Test 1: 769 — Test 2: 1443, WebGL score — Test 1: 626 — Test 2: 525)
На этом я заканчиваю с информацией о результатах тестирования.
#### Основная информация о моей системе для уточнения бенчмарков
Ноутбук Asus G750JM
CPU: Intel I7-4710HQ/BGA
RAM: DDR3L 1600 8Gb\*2
Nvidia Optimus
Дискретная видеокарта Nvidia GeForce GTX 860M с 2 Гб видеопамяти
Windows 8.1
Nvidia: 344.48
Chrome Beta: 40.0.2214.10
Firefox: 34
Linux 3.17.4-300
Nvidia: 340.46
Firefox: 33.1
Chrome Beta: 40.0.2214.10
Теперь вернемся к настройке и использовании программ в Fedora 21.
Steam и игры
------------
Установка Steam
После включения ранее указанного репозитория RPMFusion выполняем
```
sudo yum install steam
```
После этого рекомендуют перегрузить систему.
Если у вас 64-разрядная система, то для корректной работы Стима придется доустановить 32-битные версии некоторых программ:
1. Чтобы корректно работал flash видео-плеер в магазине Стим:
```
sudo yum install http://linuxdownload.adobe.com/adobe-release/adobe-release-i386-1.0-1.noarch.rpm
sudo yum install flash-plugin.i386
```
2. Чтобы корректно работало 3D ускорение для Wine, который используют некоторые программы из Стима а также при получении ошибки:
```
OpenGL GLX context is not using direct rendering, which may cause performance problems.
```
Надо вернуться к установке драйверов для Nvidia и поставить 32-битную версию:
[rpmfusion.org/Howto/nVidia#x86\_64\_.2864bit.29\_users](http://rpmfusion.org/Howto/nVidia#x86_64_.2864bit.29_users)
Например, найти xorg-x11-drv-nvidia-libs для 32bit версии и установить её.
3. При возникновении ошибки
```
libGL error: Couldn't dlopen libudev.so.1 or libudev.so.0, driver detection may be broken.
Finished uploading minidump (out-of-process): success = no
error: libcurl.so: cannot open shared object file: No such file or directory
/home/vyacheslav/.local/share/Steam/steam.sh: line 730: 3585 Segmentation fault
```
Нужно поставить вот это:
```
sudo yum install systemd-libs.i686
```
Подробнее на [ask.fedoraproject.org/en/question/54746/steam-wont-run](https://ask.fedoraproject.org/en/question/54746/steam-wont-run)
Запускаем Windows-игры и Windows-программы
------------------------------------------
Для этого есть отличный пакет PlayOnLinux: [www.playonlinux.com/ru](https://www.playonlinux.com/ru)
Ставится легко прямо с сайта. Оставляю вам его на самостоятельную проработку.
Программы для рисования
-----------------------
Для редактирования растровых изображений отлично подходит известный GIMP [www.gimp.org](http://www.gimp.org)
```
sudo yum install gimp gimp-elsamuko gimp-data-extras
```
Также есть дополнительные плугины и расширения для GIMP. Посмотрите в yumex/apper.
Для редактирования векторных — Inkscape [inkscape.org](https://inkscape.org)
```
sudo yum install inkscape
```
В рассматриваемой ниже KDE есть также свои варианты программ для растровой и векторной графики:
Krita (растр) и Karbon (вектор). Они входят в офисный пакет KDE — Calligra. Его установка будет рассмотрена ниже.
KDE
---
Как установить KDE, если по-умолчанию у вас установлена другая рабочая среда:
```
sudo yum install @kde-desktop
```
Также устанавливаем KDE-программы для удобной работы с архивами и просмотра pdf:
```
sudo yum install ark okular
```
После установки KDE надо перегрузиться и на экране входа в систему под полем логина щелкнуть по иконке зубчатого колесика. В выпавшем меню выбрать «Рабочий стол Plasma» и выполнить вход.
Если хотите установить любимый многими аудио-плеер Amarok:
```
sudo yum install amarok
```
Если хотите не только установить KDE но и переключиться на использование менеджера дисплея KDM, то надо сделать следующее:
1. Устанавливаем KDM:
```
sudo yum install kdm
```
2. Устанавливаем программу переключения менеджеров дисплея:
```
sudo yum install system-switch-displaymanager-gnome
```
3. Запускаем программу system-switch-displaymanager и в открывшемся выбираем KDM.
### Офис Calligra
В Fedora по-умолчанию установлен LibreOffice. Если вам хочется попробовать чего-то ещё — обратите внимание на офис KDE — Calligra, включающий также программы для рисования в растре (Krita) и векторе (Karbon).
Поставить офис:
```
sudo yum install calligra
```
В Calligra входит очень много всего интересного, что не ставится по-умолчанию, так что рекомендую интересующимся поискать эти пакеты со словом «calligra» в Yumex/Apper.
Если вы хотите обойтись только программами для рисования, а не ставить все основные офисные программы Calligra то можно сделать так:
```
sudo yum install calligra-krita calligra-karbon
```
В определенном смысле они являются аналогами Gimp и Inkscape.
Подсказка по работе колесика мыши в Krita:
Чтобы вернуть в Krita привычный скроллинг колесиком мыши по вертикали надо зайти в настройки «Settings» — «Configure Krita ..» -> Canvas Input Settings — Zoom Canvas
Для обоих Mouse Wheel два раза щелкнуть по выбранному Input и указать модификатор, например, привычный Ctrl. Таким образом получим приближение и удаление при вращении колесика мыши при зажатом Ctrl. Простое вращение колесика будет скролить картинку вверх и вниз. Нажимаем «Ok» и закрываем окно настроек.
### Настройка KDE
Общий интерфейс KDE куда более привычен пользователям чем Gnome 3. Так что остановлюсь только на нескольких моментах, которые меняю у себя в первую очередь.
**Шрифты**
Главное меню -> Параметры системы -> Оформление приложений (находятся в середине второго раздела иконок). Открываем вкладку «Шрифты».
Для комфортной работы на мониторах с высоким разрешением необходимо увеличить размер всех шрифтов примерно на 1-2 единицы.
Примечание:
Иногда программы QT могут использовать в качестве одного из основных размер шрифта, записанного как «Панель инструментов». Обратите на это внимание при необходимости дополнительно увеличить их шрифт.
Затем надо откорректировать сглаживание шрифтов, чтобы оно распространялось и на Gnome-программы, запущенные из-под KDE: в том-же окне настройки шрифтов в пункте «Использовать сглаживание:» выбираем «включено» и щелкаем кнопку «настроить». Выставляем «использовать межтотечное сглаживание» — rgb и «стиль хинтинга» — легкий (напоминаю, что я предпочитаю легкое сглаживание, а вы можете указать другой).
### Синхронизация контактов, календаря и почты Google
Как настроить работу с контактами и календарем Google:
1. Запускаем Kontact, в нем добавляем новый календарь Гугла, там-же добавляем новую адресную книгу из Гугла (задачи Гугла тоже будут проимпортированы)
2. Чтобы можно было искать нужные контакты в строке быстрого поиска Krunner, запускаемого в системе по Alt+F2:
в левой части этой строки поиска нажимаем значок настройки, в появившемся окне отмечаем поиск по контактам и (если хотите) события календаря.
К сожалению, полной поддержки Gmail в Kontact и KMail этой версии KDE сделать пока не успели. Однако разработчики трудятся над этим и обещают скоро выпустить.
Сейчас есть возможность подключиться к Gmail как к обычному IMAP-ящику с периодичностью проверки в 5 минут.
### Устранение проблемы многократного запуска некоторых QT-программ
Рекомендую сразу в конце файла ~/.bash\_profile прописать следующие строчки:
```
TMPDIR=/var/tmp
export TMPDIR
```
После этого выйти из сеанса и зайти заново.
Таким образом решается проблема многократных запусков копий одной и той-же QT-программы.
Например, торрент-клиента qbittorrent при открытии торрентов из Firefox.
Изучение иностранных языков
---------------------------
### Словарь с произношением — StarDict
Отличная программа, которая может на лету сканировать все, что вы выделяете мышкой, и тут-же давать под курсором мыши небольшое всплывающее окно с переводом или ещё и воспроизводить произношение данного слова.
Устанавливаем программу:
```
sudo yum install stardict
```
Скачиваем словари для StarDict на любом известном вам крупном трекере торрентов. Там-же в раздачах есть пояснения — как и куда устанавливать скачиваемые словари.
Кратко об установке в Linux:
1. кладем словари в каталог /usr/share/stardict/dic или ~/.stardict/dic
2. звуковые файлы из архива распаковываются в любую папку на диске, затем открываем Stardict --> Настройки --> Звуки. В поле «RealPeopleTTS search path» прописать путь к каталогу со звуками, например, /home/your\_name/.stardict/en\_snd/
Перезапустить Stardict. После этого произнесение слов станет доступно.
### Anki и карточки
Также в Fedora доступна программа Anki для работы с карточками.
Однако эту тему я оставляю на вашу собственную проработку.
На мой взгляд практика с вышеописанными словарными статьями является более насыщенной, менее трудоемкой, лишенной сторонних ошибок и ограниченности смысловых переводов.
Проблема с появившимся тихим шумом в наушниках
----------------------------------------------
Эта проблема не зависит от Fedora, однако я приведу варианты борьбы с ней.
Среди вариантов решения проблемы появившегося под Linux шума в наушниках можно выделить следующие:
1. Отключение звуковой карты от DVD-привода
2. Отключение системного динамика в BIOS
3. Уменьшение разгона системы (как CPU так и видео)
4. Переназначение выхода на наушники программой hdajackretask
Устанавливаем пакет, содержащий эту программу:
```
sudo yum install alsa-utils
```
Запускаем *hdajackretask* и смотрим — что назначено выходу на наушники. Если назначение не верно — можно переназначить и получить звук получше. Подробнее о решении: [ubuntuforums.org/showthread.php?t=2249130](http://ubuntuforums.org/showthread.php?t=2249130)
5. Замена кабеля у наушников на кабель с высоким сопротивлением (у наушников с малым сопротивлением внутренний усилитель звука может вызывать постоянные тихие шумы, как в моей модели ноутбука)
6. Замена наушников на наушники с высоким сопротивлением
7. Использование внешней аудиокарты или предусилителя для наушников
Завершение
----------
На этом данную статью, составленную из «путевых» заметок моих приключений, я заканчиваю.
Надеюсь, вы отнесетесь с теплом к новой Федоре, попробуете её и напишете об этом пару строк в комментариях.
При желании, в дальнейшем можно будет собрать информацию и для следующей статьи о ней. | https://habr.com/ru/post/245651/ | null | ru | null |
# Централизованное управление CBPolicyD в мультисерверной инфраструктуре Zimbra OSE
CBPolicyD является универсальным инструментом для управления политиками в Postfix. Он входит в комплект поставки Zimbra OSE и ранее мы рассказывали о том, как настраивать CBPolicyD на своем почтовом сервере и создавать в нем различные политики, которые позволяют повысить уровень защищенности сервера от кибератак. Однако все данные ранее рекомендации были применимы к односерверной инфраструктуре Zimbra OSE, так как CBPolicyD по умолчанию использует автономную СУБД SQLite 3 для хранения и управления политиками, а это означает, что созданная на одном сервере политика не будет иметь силы на другом сервере и каждый раз для внедрения новой политики, администратору придется создавать ее на каждом сервере MTA. В случае с односерверной инфраструктурой это допустимо, однако когда речь идет о мультисерверной инфраструктуре Zimbra OSE, необходимо чтобы созданная политика применялась сразу на всех MTA. Это облегчает не только процесс создания политик, но и процесс управления ими. Для того, чтобы созданная политика автоматически применялась на всех MTA в инфраструктуре, необходимо подключить ее к глобальной СУБД MariaDB. Плюсом использования MariaDB является то, что эта СУБД более отказоустойчива, чем SQLite 3. То есть при больших нагрузках на MTA CBPolicyD гарантированно не будет пропускать письма, не соответствующие настроенным политикам. В данной статье мы расскажем о том, как это сделать.
Данная инструкция описывает настройку в инфраструктуре Zimbra OSE с несколькими серверами MTA. Для того, чтобы подключить CBPolicyD на всех MTA к единой СУБД MariaDB, мы добавим в инфраструктуру Zimbra OSE выделенный сервер, на котором установим копию MariaDB и настроим ее в качестве бэкенда ко всем CBPolicyD в инфраструктуре.
Для выделенного сервера сервера MariaDB, с учетом запущенной на нем Ubuntu Server, потребуются два ядра vCPU, 4 Гб оперативной памяти, а также около 20 Гб на диске. Для установки MariaDB выполните на сервере следующие команды:
**sudo apt install mariadb-server
sudo /usr/bin/mysql\_secure\_installation**
В файле /etc/mysql/mariadb.conf.d/50-server.cnf поменяйте значение строки port на 7306, а также закомментируйте строку bind-address
Изложенные ниже инструкции по подключению CBPolicyD к единой СУБД MariaDB необходимо выполнить на каждом сервере MTA. После того как все PolicyD в инфраструктуре будут подключены к единой СУБД, созданные на одном из серверов политики будут автоматически распространяться на всю инфраструктуру Zimbra OSE. Выделенный узел MariaDB в нашем случае имеет доменное имя [mysql.example.ru](http://mysql.example.ru) и IP-адрес 192.168.0.104, а сервер MTA - [mta.example.ru](http://mta.example.ru) и 192.168.0.105.
Для подключения CBPolicyD к серверу с MariaDB, в первую очередь необходимо на выделенном сервере MariaDB привязать порт 7306/TCP к IP-адресу 0.0.0.0. Для этого отредактируйте файл /opt/zimbra/conf/my.cnf на сервере MTA и приведите соответствующую строку к виду: bind-address=0.0.0.0.
После этого необходимо создать на сервере MariaDB базу данных под названием “policyd\_db” и пользователя “ad-policyd\_db”. Делается это при помощи следующих команд:
```
mysql
MariaDB [(none)]> create database policyd_db CHARACTER SET 'UTF8';
MariaDB [(none)]> create user 'ad-policyd_db'@'127.0.0.1' identified by 'P@ssw0rD';
MariaDB [(none)]> grant all privileges on policyd_db.* to 'ad-policyd_db'@'192.168.0.105' identified by 'P@ssw0rD' with grant option;
MariaDB [(none)]> flush privileges;
MariaDB [(none)]> quit;
```
Вместо адреса 192.168.0.105 подставьте адрес своего сервера MTA, на котором выполняется команда, а вместо P@ssw0rD укажите собственный пароль.
Настройка нового пользователя и базы данныхПосле этого сконвертируйте используемые CBPolicyD базы данных SQLite 3 в совместимый с MariaDB формат при помощи команд:
```
cd /opt/zimbra/common/share/database/
POLICYDTABLESSQL="$(mktemp /tmp/policyd-dbtables.XXXXXXXX.sql)"
for i in core.tsql access_control.tsql quotas.tsql amavis.tsql checkhelo.tsql checkspf.tsql greylisting.tsql accounting.tsql;
do
./convert-tsql mysql $i;
done > "${POLICYDTABLESSQL}"
```
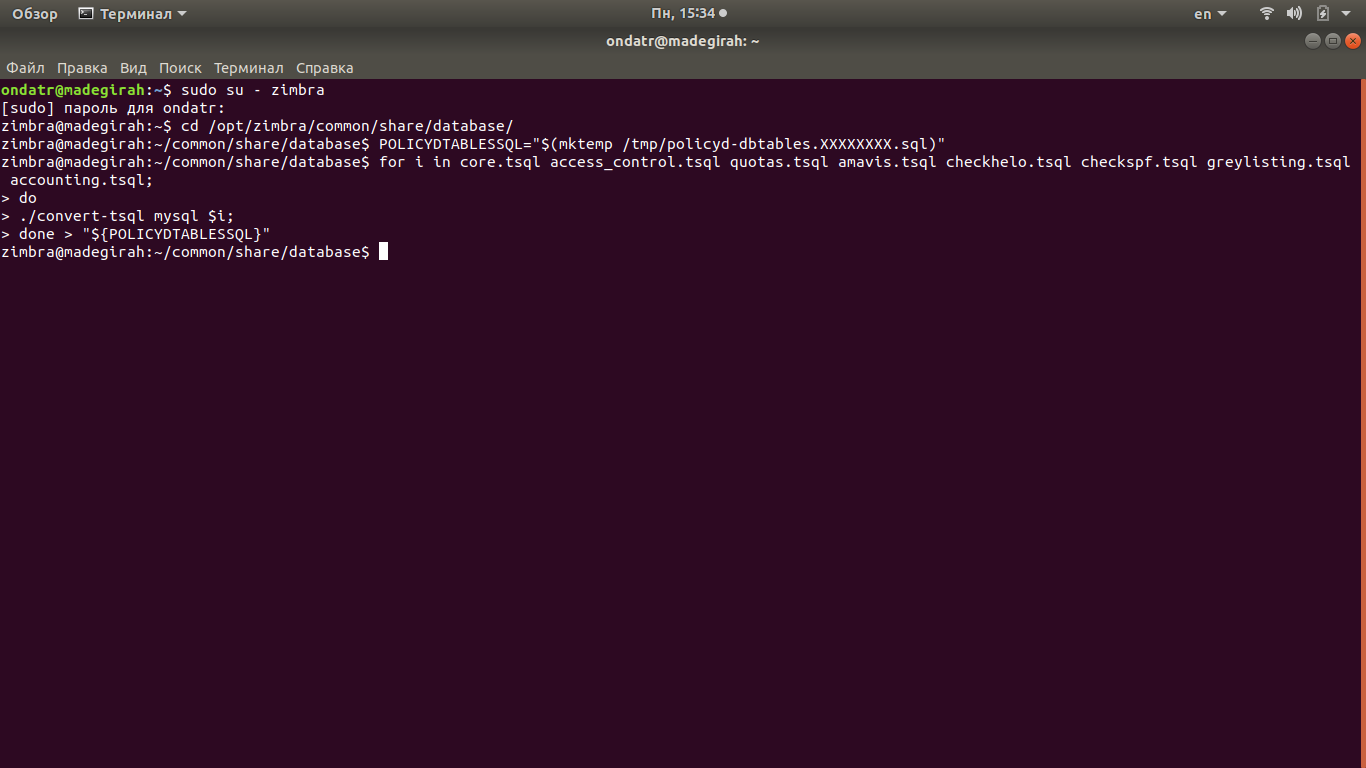В результате исполнения данного скрипта в папке /tmp появится файл с обфусцированным названием. В нашем случае это policyd-dbtables.QDyeA7WR.sql. Синхронизируйте полученный файл с почтовым сервером. Сделать это можно при помощи утилиты RSync: **rsync /tmp/policyd-dbtables.QDyeA7WR.sql [email protected]:/tmp/**.
После этого потребуется заполнить базу данных policy\_db на сервере с MariaDB. Для этого импортируем в нее данные из скопированного ранее файла:
```
mysql policyd_db < /tmp/policyd-dbtables.QDyeA7WR.sql
mysql
MariaDB [(none)]> show databases;
MariaDB [(none)]> use policyd_db;
MariaDB [(none)]> show tables;
MariaDB [(none)]> quit;
```
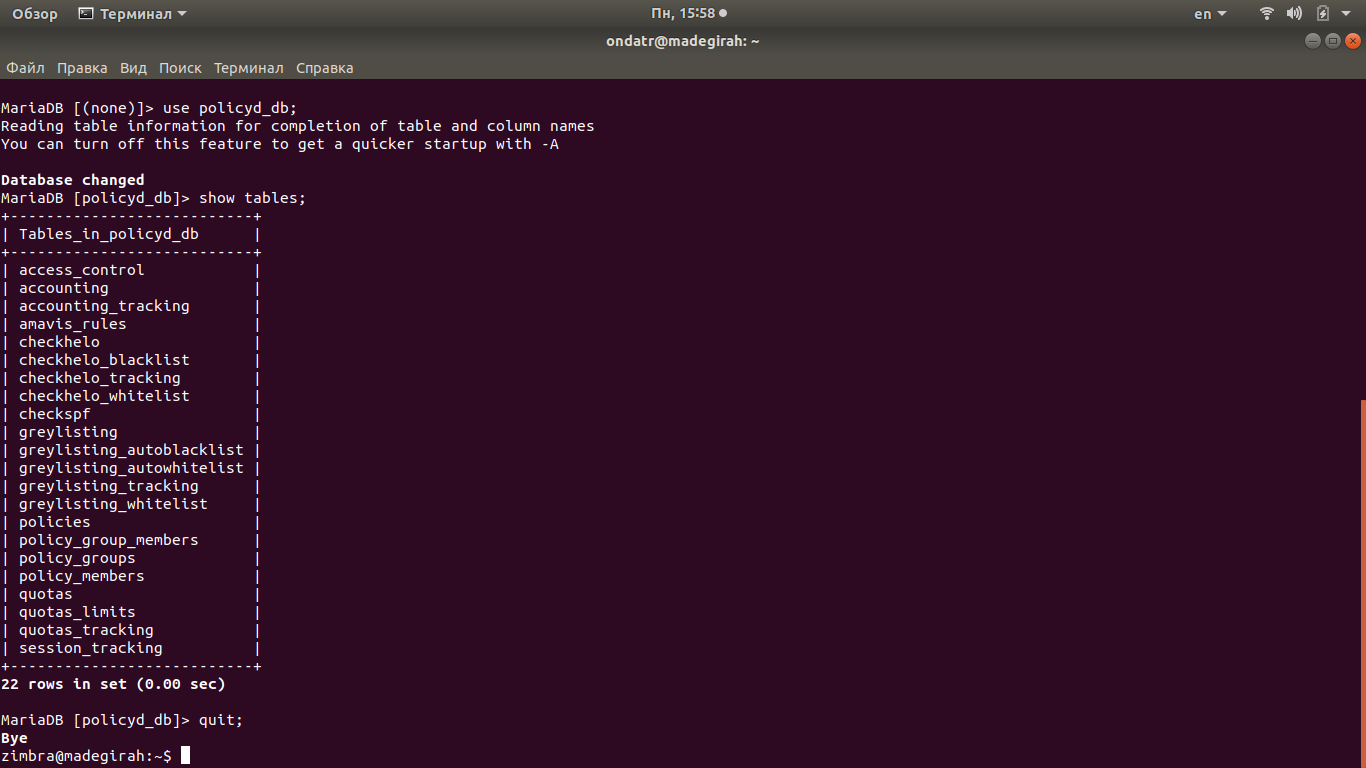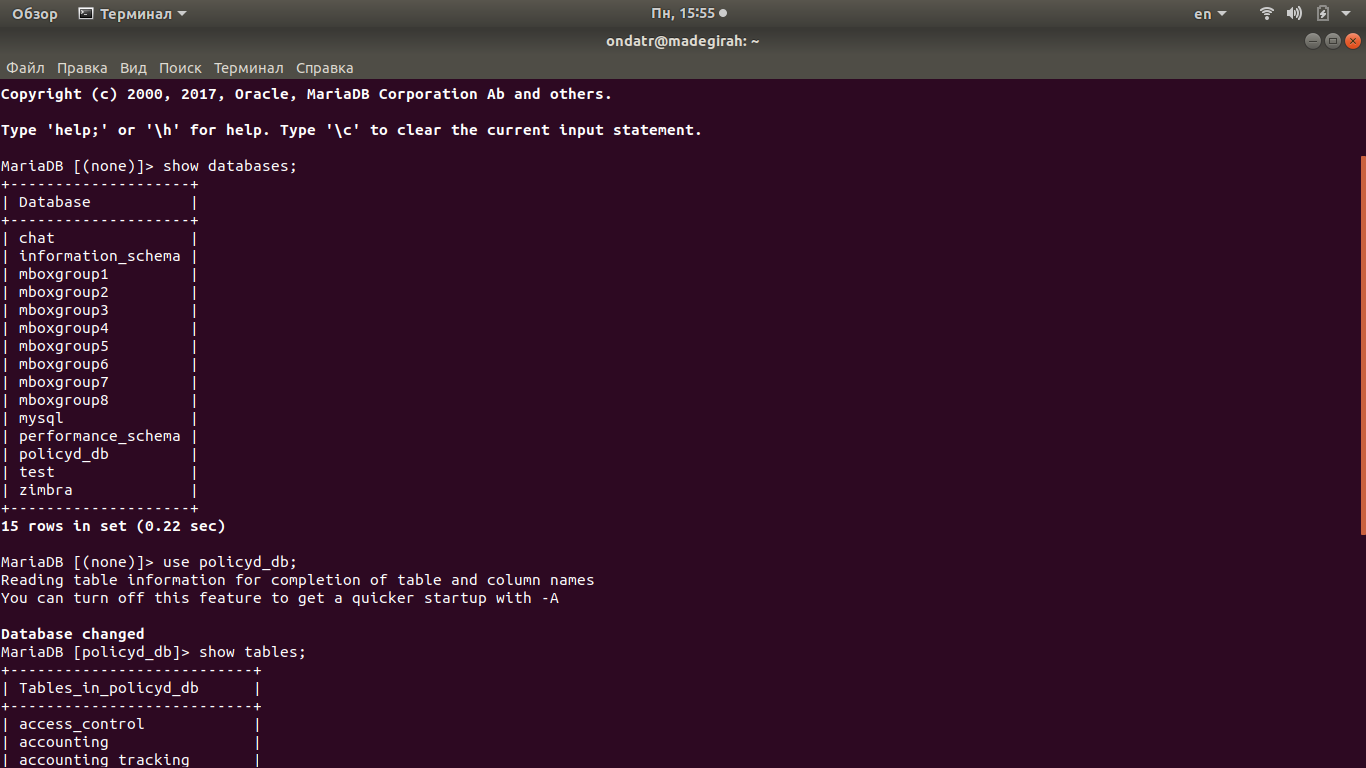Теперь настроим cbpolicyd так, чтобы он использовал Zimbra MySQL. Для этого введем на сервере MTA следующие команды:
```
echo "Setting username in /opt/zimbra/conf/cbpolicyd.conf.in"
grep -lZr -e ".*sername=.*$" "/opt/zimbra/conf/cbpolicyd.conf.in" | xargs -0 sed -i "s^.*sername=.*$^Username=ad-policyd_db^g"
echo "Setting password in /opt/zimbra/conf/cbpolicyd.conf.in"
grep -lZr -e ".*assword=.*$" "/opt/zimbra/conf/cbpolicyd.conf.in" | xargs -0 sed -i "s^.*assword=.*$^Password='P@ssw0rD^g"
echo "Setting database in /opt/zimbra/conf/cbpolicyd.conf.in"
grep -lZr -e "DSN=.*$" "/opt/zimbra/conf/cbpolicyd.conf.in" | xargs -0 sed -i "s^DSN=.*$^DSN=DBI:mysql:database=policyd_db;host=192.168.0.104;port=7306^g"
```
На сервере MariaDB настроим политики квотирования:
```
POLICYDPOLICYSQL="$(mktemp /tmp/policyd-dbtables.QDyeA7WR.sql)"
cat < "${POLICYDPOLICYSQL}"
INSERT INTO policies (ID, Name,Priority,Description) VALUES(6, 'Zimbra CBPolicyd Policies', 0, 'Zimbra CBPolicyd Policies');
INSERT INTO policy\_members (PolicyID,Source,Destination) VALUES(6, 'any', 'any');
INSERT INTO quotas (PolicyID,Name,Track,Period,Verdict,Data) VALUES (6, 'Sender:user@domain','Sender:user@domain', 60, 'DEFER', 'You are sending too many emails.');
INSERT INTO quotas (PolicyID,Name,Track,Period,Verdict) VALUES (6, 'Recipient:user@domain', 'Recipient:user@domain', 60, 'REJECT');
INSERT INTO quotas\_limits (QuotasID,Type,CounterLimit) VALUES(3, 'MessageCount', 100);
INSERT INTO quotas\_limits (QuotasID,Type,CounterLimit) VALUES(4, 'MessageCount', 125);
EOF
/opt/zimbra/bin/mysql policyd\_db < "${POLICYDPOLICYSQL}"
```
Убедитесь, что на сервере MTA включен и работает CBPolicyD. Сделать это можно с помощью следующих команд:
```
sudo su - zimbra
zmprov ms `zmhostname` +zimbraServiceEnabled cbpolicyd
zmprov ms `zmhostname` zimbraCBPolicydQuotasEnabled TRUE
zmcontrol restart
```
Просмотреть логи работы CBPolicyD можно с помощью команды **tail -f /opt/zimbra/log/cbpolicyd.log**.
Еще один нюанс, связанный с выносом базы данных на отдельный сервер, связан с возможностью его отказа. По умолчанию в Zimbra, если CBPolicyD не может провести проверку письма на соответствие заданным политикам, в том числе и из-за недоступной по тем или иным причинам базы данных. Для того, чтобы в случае отказа сервера MariaDB письма продолжали приходить и отправляться, измените настройку zimbraCBPolicydBypassMode при помощи команды **zmprov mcf zimbraCBPolicydBypassMode pass**. Чтобы вернуть значение этой настройки к изначальному, введите **zmprov mcf zimbraCBPolicydBypassMode tempfail**.
Также для создания единой базы данных CBPolicyD можно использовать СУБД MariaDB на одном из почтовых серверов. В таком случае в качестве адреса сервера MariaDB следует указывать адрес почтового сервера, а все связанные с настройкой СУБД команды выполнять от имени пользователя Zimbra. Однако мы не рекомендуем такой подход, так как это создает для системы риски несопоставимые с экономией на выделенном виртуальном сервере.
Еще одним актуальным вопросом при использовании CBPolicyD в мультисерверном режиме является защита входа в веб-консоль. Напомним, что в случае односерверной установки этот вопрос решался ограничением входа только с IP-адреса сервера, чтобы исключить несанкционированный доступ к CBPolicyD. В случае же мультисерверной инфраструктуры наиболее разумным будет открыть доступ к веб-интерфейсу CBPolicyD из всей локальной сети, а вход в него защитить с помощью пароля.
Для того, чтобы установить пароль на вход в CBPolicyD, необходимо от имени root-пользователя отредактировать файл **sudo nano /opt/zimbra/common/share/webui/.htaccess**, добавив в него строки:
```
AuthUserFile /opt/zimbra/common/share/webui/.htpasswd
AuthGroupFile /dev/null
AuthName "User and Password"
AuthType Basic
require valid-user
```
Затем создаем файл с именем пользователя и паролем при помощи команд:
```
sudo touch /opt/zimbra/common/share/webui/.htpasswd
sudo /opt/zimbra/common/bin/htpasswd -cb .htpasswd cbpolicyd-admin P@ssw0rD
```
И редактируем файл конфигурации **sudo nano /opt/zimbra/conf/httpd.conf**, добавляя в него следующие строки:
```
alias /webui /opt/zimbra/common/share/webui/
AllowOverride AuthConfig
Order Deny,Allow
Allow from all
```
После того как файл с изменениями будет сохранен, перезапустите сервер Apache, выполнив от имени пользователя zimbra команду **zmapachectl restart**. После этого при входе в веб-интерфейс управления CBPolicyD будет появляться окно ввода логина и пароля.
Эксклюзивный дистрибьютор Zextras [SVZcloud](https://svzcloud.ru/). По вопросам тестирования и приобретения Zextras Carbonio обращайтесь на электронную почту: [[email protected]](mailto:[email protected]) | https://habr.com/ru/post/572028/ | null | ru | null |
# Пишем живые обои с часами
Недавно я решил разобраться, как делать живые обои для андроида, а разбираться лучше всего на хорошем примере — таком, который потом пригодится. Я всегда хотел удобные часы. Для андроида уже существует достаточное количество подобных обоев, но обычно они рисуют большие часы в каком-нибудь фиксированном углу экрана и перекрываются виджетами, которых у меня немало. Мне хотелось, чтобы часы были разбросаны по всему экрану, тогда вероятность увидеть их будет выше.
Живые обои для андроида представляют собой сервис (фоновый процесс, в терминах платформы), причем в SDK уже существует [готовый класс](http://developer.android.com/reference/android/service/wallpaper/WallpaperService.Engine.html) для живых обоев, в котором нужно переопределить несколько методов, чтобы получить результат.
Для начала в манифесте описывается, что приложение будет предоставлять живые обои:
```
```
Самые важные строки здесь *android:permission* и *intent-filter*
Потом, собственно, кодирование. Мы создадим свой класс-наследник *WallpaperService* и переопределим его методы *onCreate, onDestroy, onVisibilityChanged, onSurfaceChanged, onSurfaceCreated, onSurfaceDestroyed*
Эти методы будут реагировать на системные события. Главное их назначение — включать и выключать отрисовку обоев, когда меняется их видимость, чтобы экономить батарею.
Фактически, нас интересуют только:
```
@Override
public void onVisibilityChanged(boolean visible) {
if (visible) {
painting.resumePainting();
} else {
// remove listeners and callbacks here
painting.pausePainting();
}
}
@Override
public void onDestroy() {
super.onDestroy();
// remove listeners and callbacks here
painting.stopPainting();
}
@Override
public void onSurfaceChanged(SurfaceHolder holder, int format, int width, int height) {
super.onSurfaceChanged(holder, format, width, height);
painting.setSurfaceSize(width, height);
Log.d("Clock", "Changed");
}
@Override
public void onSurfaceCreated(SurfaceHolder holder) {
super.onSurfaceCreated(holder);
painting.start();
}
@Override
public void onSurfaceDestroyed(SurfaceHolder holder) {
super.onSurfaceDestroyed(holder);
boolean retry = true;
painting.stopPainting();
while (retry) {
try {
painting.join();
retry = false;
} catch (InterruptedException e) {}
}
}
```
Саму отрисовку мы реализуем в отдельном потоке, чтобы реакции на пользовательские действия были своевременными и плавными. Для этого создадим еще одни класс-наследник *Thread*. Объект *painting* в примере выше и является этим потоком:
```
public ClockWallpaperPainting(SurfaceHolder surfaceHolder, Context context, int fontColor, int backgroundColor) {
this.surfaceHolder = surfaceHolder;
this.context_ = context;
clockFont_ = Typeface.createFromAsset(context.getAssets(), "digital_font.ttf");
textPainter_.setTypeface(clockFont_);
textPainter_.setTextSize(30);
setPreferences(fontColor, backgroundColor);
this.wait_ = true;
}
@Override
public void run() {
this.run_ = true;
Canvas c = null;
while (run_) {
try {
c = this.surfaceHolder.lockCanvas(null);
synchronized (this.surfaceHolder) {
doDraw( c );
}
} finally {
if (c != null) {
this.surfaceHolder.unlockCanvasAndPost( c );
}
}
// pause if no need to animate
synchronized (this) {
if (wait_) {
try {
wait();
} catch (Exception e) {}
}
}
}
}
public void pausePainting() {
this.wait_ = true;
synchronized(this) {
this.notify();
}
}
public void resumePainting() {
this.wait_ = false;
synchronized(this) {
this.notify();
}
}
public void stopPainting() {
this.run_ = false;
synchronized(this) {
this.notify();
}
}
```
Как видно, мы просто бесконечно выполняем метод *doDraw()*, периодически ставя его на паузу, когда рабочий стол не виден.
Сам метод выглядит примерно так:
```
private void doDraw(Canvas canvas) {
Date currentTime = new Date();
//Create text for clock
String clockText;
if (DateFormat.is24HourFormat(context_)) {
if (currentTime.getSeconds()%2 == 0)
clockText = DateFormat.format("kk:mm", currentTime).toString();
else
clockText = DateFormat.format("kk mm", currentTime).toString();
} else {
if (currentTime.getSeconds()%2 == 0)
clockText = DateFormat.format("h:mmaa", currentTime).toString();
else
clockText = DateFormat.format("h mmaa", currentTime).toString();
}
int textSize = (int)textPainter_.getTextSize();
//Erase Background
canvas.drawRect(0, 0, width_, height_, backgroundPainter_);
int stepX = (width_ - textSize) / (CLOCKS_COUNT + 1);
int stepY = (height_ - textSize*CLOCKS_COUNT) / (CLOCKS_COUNT + 1);
for (int i=1; i <= CLOCKS_COUNT; ++i)
canvas.drawText(clockText,
stepX/2 + stepX * (i-1) - absoluteOffset_,
height_/20 + stepY * i + textSize*(i-1),
textPainter_);
}
```
В сервисе мы переопределим еще один метод, чтобы обои реагировали на смену рабочих столов:
```
@Override
public void onOffsetsChanged(float xOffset, float yOffset, float xStep, float yStep, int xPixels, int yPixels) {
painting.setOffset(xOffset);
Log.d("Clock", String.format("off:%f-%f step:%f - %f px: %d - %d", xOffset, yOffset, xStep, yStep, xPixels, yPixels));
}
```
Как сделать отрисовку в отдельном потоке, отлично расписано в [этом примере](http://blog.androgames.net/58/android-live-wallpaper-tutorial/).
И, наконец, настройки. Делаются они несложно, так же как и настройки любых других андроид приложений. В xml файле нужно прописать настраиваемые параметры и диапазоны значений, которые они могут принимать. В нашем случае позволим пользователю выбирать цвет текста и фона.
```
```
Вот так это выглядит в итоге:
Скачать можно [тут](https://market.android.com/details?id=com.ruswizards.clockwallpaper).
Чтобы написать свои обои, начать можно [отсюда](http://www.vogella.com/tutorials/AndroidLiveWallpaper/article.html) | https://habr.com/ru/post/124322/ | null | ru | null |
# Сервер Игры на MS Orleans — часть 2: Делаем управляемую точку

Привет, Хабр! Я продолжаю изучать MS Orleans и делать простенькую онлайн игру с консольным клиентом и сервером работающим с Orleans грейнами. На этот раз я добавил в игру возможность управлять точкой. Ее можно двигать вверх, вниз, влево, вправо. За подробностями добро пожаловать под кат.
Содержание
----------
* [Сервер Игры на MS Orleans — часть 1: Что такое Акторы](https://habr.com/ru/post/498326/)
* Сервер Игры на MS Orleans — часть 2: Делаем управляемую точку
Исходники
---------
[MsOrleansOnlineGame](https://gitlab.com/VictorWinbringer/msorleansonlinegame)
Принцы работы сервера
---------------------
Клиент игры шлет серверу команды (нажатые игроком клавиши) и его принимает главный актор игры который обрабатывает эти команды. По таймеру обновляет свое состояние. По таймеру шлет клиенту свое состояние. Клиент при получении нового состояния его отображает. По хорошему надо бы сделать интерполяцию между новым состоянием и старым для большей плавности отображения. Состояние игры представляет собой просто набор координат различных игровых объектов. По сути мы через клиент смотрим стрим игры которая происходит на сервере и управляем своим персонажем отправляя на сервер нажатые нами клавиши.
Entities
--------
```
public enum Direction
{
None,
Left,
Right,
Top,
Bottom
}
```
```
public readonly struct Point
{
public int X { get; }
public int Y { get; }
public Point(int x, int y)
{
X = x;
Y = y;
}
public Point Move(Direction direction) => direction switch
{
Direction.Bottom => new Point(X, Y + 1),
Direction.Top => new Point(X, Y - 1),
Direction.Right => new Point(X + 1, Y),
Direction.Left => new Point(X - 1, Y),
_ => throw new ApplicationException("Неизвестное направление")
{
Data = { ["direction"] = direction }
}
};
}
```
```
public readonly struct GameState
{
public Point Point { get; }
public GameState(Point point)
{
Point = point;
}
}
```
Grains.Interfaces
-----------------
```
public interface IGame : IGrainWithIntegerKey
{
Task Handle(List commands);
}
```
Grains
------
```
public class GameGrain : Grain, IGame
{
private readonly ILogger \_logger;
private readonly IPersistentState \_store;
private IDisposable \_timer;
public GameGrain(
ILogger logger,
//Хранилище для нашего состояния
//В данном проекте у меня все в оперативной памяти лежит но можно в Базу сохранят
// game - Это что-то типо названия таблицы.
// gameState - Это то-то типо названия базы
[PersistentState("game", "gameState")] IPersistentState store
)
{
\_logger = logger;
\_store = store;
}
public override Task OnActivateAsync()
{
\_logger.LogWarning("ACTIVATED");
// Тут мы регистрируем стрим который будет раз в 100 миллисекунд
//Слать подключенным клиентам текущее состояние игры.
// Вообще хочу в будущем все это перенести на SignalR
var streamProvider = GetStreamProvider("SMSProvider");
var stream = streamProvider.GetStream(Guid.Empty, "GAME\_STATE");
\_timer = RegisterTimer(s =>
{
stream.OnNextAsync(new GameState(\_store.State)).Ignore();
\_logger.LogWarning("SEND TO STREAM");
return Task.CompletedTask;
}, null, TimeSpan.FromMilliseconds(1000), TimeSpan.FromMilliseconds(100));
return Task.CompletedTask;
}
public override Task OnDeactivateAsync()
{
\_logger.LogWarning("DEACTIVATED");
\_timer?.Dispose();
\_timer = null;
return Task.CompletedTask;
}
public async Task Handle(List commands)
{
var oldState = \_store.State;
foreach (var command in commands)
{
var direction = command switch
{
ConsoleKey.LeftArrow => Direction.Left,
ConsoleKey.A => Direction.Left,
ConsoleKey.RightArrow => Direction.Right,
ConsoleKey.D => Direction.Right,
ConsoleKey.UpArrow => Direction.Top,
ConsoleKey.W => Direction.Top,
ConsoleKey.DownArrow => Direction.Bottom,
ConsoleKey.S => Direction.Bottom,
\_ => throw new ApplicationException("Не валидная клавища")
{
Data = { ["key"] = command }
}
};
\_store.State = \_store.State.Move(direction);
}
\_logger.LogInformation("Player Moved!");
\_logger.LogInformation("{X}:{Y}", \_store.State.X, \_store.State.Y);
if (\_store.State.Y == oldState.Y && \_store.State.X == oldState.X)
return;
await \_store.WriteStateAsync();
}
}
```
Client
------
Следит за приходящим от сервера новым состоянием:
```
public class StreamObserver : IAsyncObserver
{
private const int MARGIN = 5;
private GameState \_old;
public Task OnNextAsync(GameState state, StreamSequenceToken token = null)
{
Console.SetCursorPosition(\_old.Point.X+MARGIN, \_old.Point.Y+ MARGIN);
Console.Write(' ');
Console.SetCursorPosition(0, 0);
Console.WriteLine("Для передвижения используйте клавиши W A S D или стрелочки на клавиатуре");
Console.SetCursorPosition(state.Point.X+ MARGIN, state.Point.Y+ MARGIN);
Console.Write('#');
\_old = state;
return Task.CompletedTask;
}
public Task OnCompletedAsync() => Task.CompletedTask;
public Task OnErrorAsync(Exception ex)
{
Console.WriteLine("ERROR");
Console.WriteLine(ex.Message);
return Task.CompletedTask;
}
}
```
```
class Program
{
static async Task Main(string[] args)
{
try
{
using (var client = await ConnectClient())
{
var id = Guid.Empty;
var streamProvider = client.GetStreamProvider("SMSProvider");
var stream = streamProvider.GetStream(id, "GAME\_STATE");
await stream.SubscribeAsync(new StreamObserver());
Console.CursorVisible = false;
Console.Clear();
var game = client.GetGrain(1);
await game.Handle(new List());
while (true)
{
var key = Console.ReadKey(true);
await game.Handle(new List() { key.Key });
}
}
}
catch (Exception e)
{
Console.WriteLine($"\nException while trying to run client: {e.Message}");
Console.WriteLine("Make sure the silo the client is trying to connect to is running.");
Console.WriteLine("\nPress any key to exit.");
}
Console.ReadLine();
}
private static async Task ConnectClient()
{
IClusterClient client;
client = new ClientBuilder()
.UseLocalhostClustering()
.Configure(options =>
{
options.ClusterId = "dev";
options.ServiceId = "OrleansBasics";
})
.ConfigureLogging(logging => logging.ClearProviders())
.AddSimpleMessageStreamProvider("SMSProvider")
.Build();
await client.Connect();
Console.WriteLine("Client successfully connected to silo host \n");
return client;
}
}
```
Server
------
```
public class Program
{
public static async Task Main(string[] args)
{
try
{
var host = await StartSilo();
Console.WriteLine("\n\n Press Enter to terminate...\n\n");
Console.ReadLine();
await host.StopAsync();
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
Console.ReadLine();
}
private static async Task StartSilo()
{
var builder = new SiloHostBuilder()
.UseLocalhostClustering()
.Configure(options =>
{
options.ClusterId = "dev";
options.ServiceId = "OrleansBasics";
})
.Configure(
options => options.AdvertisedIPAddress = IPAddress.Loopback
)
//Добавляем провайдера для стримов который работает по TCP
.AddSimpleMessageStreamProvider("SMSProvider")
//Добавляем хранилище в которому будут записывается подписчики и публикаторы событий
.AddMemoryGrainStorage("PubSubStore")
.ConfigureApplicationParts(
parts => parts
.AddApplicationPart(typeof(GameGrain).Assembly)
.WithReferences()
)
//Это хранилище в котором будет лежать состояние нашей игры
.AddMemoryGrainStorage("gameState")
.ConfigureLogging(logging => logging.AddConsole());
var host = builder.Build();
await host.StartAsync();
return host;
}
}
``` | https://habr.com/ru/post/499188/ | null | ru | null |
# Представления (VIEW) в MySQL
В комментариях Хабра упоминались вопросы по использованию представлений. Данный топик является обзором представлений, появившихся в MySQL версии 5.0. В нем рассмотрены вопросы создания, преимущества и ограничения представлений.
Что такое представление?
------------------------
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.
Представления могут основываться как на таблицах, так и на других представлениях, т.е. могут быть вложенными (до 32 уровней вложенности).
Преимущества использования представлений:
-----------------------------------------
1. Дает возможность гибкой настройки прав доступа к данным за счет того, что права даются не на таблицу, а на представление. Это очень удобно в случае если пользователю нужно дать права на отдельные строки таблицы или возможность получения не самих данных, а результата каких-то действий над ними.
2. Позволяет разделить логику хранения данных и программного обеспечения. Можно менять структуру данных, не затрагивая программный код, нужно лишь создать представления, аналогичные таблицам, к которым раньше обращались приложения. Это очень удобно когда нет возможности изменить программный код или к одной базе данных обращаются несколько приложений с различными требованиями к структуре данных.
3. Удобство в использовании за счет автоматического выполнения таких действий как доступ к определенной части строк и/или столбцов, получение данных из нескольких таблиц и их преобразование с помощью различных функций.
Ограничения представлений в MySQL
---------------------------------
В статье приведены ограничения для версии MySQL 5.1 (в дальнейшем их число может сократиться).
* нельзя повесить триггер на представление,
* нельзя сделать представление на основе временных таблиц; нельзя сделать временное представление;
* в определении представления нельзя использовать подзапрос в части FROM,
* в определении представления нельзя использовать системные и пользовательские переменные; внутри хранимых процедур нельзя в определении представления использовать локальные переменные или параметры процедуры,
* в определении представления нельзя использовать параметры подготовленных выражений (PREPARE),
* таблицы и представления, присутствующие в определении представления должны существовать.
* только представления, удовлетворяющие ряду требований, допускают запросы типа UPDATE, DELETE и INSERT.
Создание представлений
----------------------
Для создания представления используется оператор CREATE VIEW, имеющий следующий синтаксис:
> `CREATE [OR REPLACE]
>
> [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
>
> VIEW view\_name [(column\_list)]
>
> AS select\_statement
>
> [WITH [CASCADED | LOCAL] CHECK OPTION]
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
view\_name — имя создаваемого представления. select\_statement — оператор SELECT, выбирающий данные из таблиц и/или других представлений, которые будут содержаться в представлении
Оператор CREATE VIEW содержит 4 необязательные конструкции:
1. OR REPLACE — при использовании данной конструкции в случае существования представления с таким именем старое будет удалено, а новое создано. В противном случае возникнет ошибка, информирующая о сществовании представления с таким именем и новое представление создано не будет. Следует отметить одну особенность — имена таблиц и представлений в рамках одной базы данных должны быть уникальны, т.е. нельзя создать представление с именем уже существующей таблицы. Однако конструкция OR REPLACE действует только на представления и замещать таблицу не будет.
2. ALGORITM — определяет алгоритм, используемый при обращении к представлению (подробнее речь об этом пойдет ниже).
3. column\_list — задает имена полей представления.
4. WITH CHECK OPTION — при использовании данной конструкции все добавляемые или изменяемые строки будут проверяться на соответствие определению представления. В случае несоответствия данное изменение не будет выполнено. Обратите внимание, что при указании данной конструкции для необновляемого представления возникнет ошибка и представление не будет создано. (подробнее речь об этом пойдет ниже).
По умолчанию колонки представления имеют те же имена, что и поля возращаемые оператором SELECT в определении представления. При явном указании имен полей представления column\_list должен включать по одному имени для каждого поля разделенных запятой. Существует две причины по которым желательно использовать явное указание имен полей представления:
1. Имена полей представления должны быть уникальны в пределах данного представления. При создании представления основанного на нескольких таблицах возможна ситуация повторения имен полей представления. Например:
> `CREATE VIEW v AS SELECT a.id, b.id FROM a,b;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для избежания такой ситуации нужно явно указывать имена полей представления
> `CREATE VIEW v (a\_id, b\_id) AS SELECT a.id, b.id FROM a,b;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Того же результата можно добиться, используя синонимы (алиасы) для названий колонок:
> `CREATE VIEW v AS SELECT a.id a\_id, b.id b\_id FROM a,b;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
2. В случае если в определении представления получаемые данные преобразуются с помощью каких-то функций, то именем поля будет данное выражение, что не очень удобно для дальнейших ссылок на это поле. Напимер:
> `CREATE VIEW v AS SELECT group\_concat(DISTINCT column\_name oreder BY column\_name separator '+') FROM table\_name;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вряд ли удобно использовать в дальнейшем в качестве имени поля `group\_concat(DISTINCT username ORDER BY username separator '+')`
Для просмотра содержимого представления мы используем оператор SELECT (полностью аналогично как в случае простой таблицы), с другой строны, оператор SELECT есть в самом определении представления, т.е. получается вложенная конструкция — запрос в запросе. При этом, некоторые конструкции оператора SELECT могут присутствовать в обоих операторах. Возможны три варианта развития событий: они обе будут выполнены, одна из них будет проигнорированна и результат неопределен. Рассмотрим подробнее эти случаи:
1. Если в обоих операторах встречается условие WHERE, то оба этих условия будут выполнены как если бы они были объединены оператором AND.
2. Если в определении представления есть конструкция ORDER BY, то она будет работать только в случае отсутствия во внешнем операторе SELECT, обращающемся к представлению, собственного условия сортировки. При наличии конструкции ORDER BY во внешнем операторе сортировка, имеющаяся в определении представления, будет проигнорирована.
3. При наличии в обоих операторах модификаторов, влияющих на механизм блокировки, таких как HIGH\_PRIORITY, результат их совместного действия неопределен. Для избежания неопределенности рекомендуется в определении представления не использовать подобные модификаторы.
Алгоритмы представлений
-----------------------
Существует два алгоритма, используемых MySQL при обращении к представлению: MERGE и TEMPTABLE.
В случае алгоритма MERGE, MySQL при обращении к представлению добавляет в использующийся оператор соответствующие части из определения представления и выполняет получившийся оператор.
В случае алгоритма TEMPTABLE, MySQL заносит содержимое представления во временную таблицу, над которой затем выполняется оператор обращенный к представлению.
**Обратите внимание**: в случае использования этого алгоритма представление не может быть обновляемым (см. далее).
При создании представления есть возможность явно указать используемый алгоритм с помощью необязательной конструкции [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
UNDEFINED означает, что MySQL сам выбирает какой алгоритм использовать при обращении к представлению. Это значение по умолчанию, если данная конструкция отсутствует.
Использование алгоритма MERGE требует соответствия 1 к 1 между строками таблицы и основанного на ней представления.
Пусть наше представление выбирает отношение числа просмотров к числу ответов для тем форума:
> `CREATE VIEW v AS SELECT subject, num\_views/num\_replies AS param FROM topics WHERE num\_replies>0;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для данного представления каждая строка соответствует единственной строке из таблицы topics, т.е. может быть использован алгоритм MERGE. Рассмотрим следующее обращение к нашему представлению:
> `SELECT subject, param FROM v WHERE param>1000;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В случае MERGE алгоритма MySQL включает определение представления в использующийся оператор SELECT: заменяет имя представления на имя таблицы, заменяет список полей на определения полей представления и добавляет условие в части WHERE с помощью оператора AND. Итоговый оператор, выполняемый затем MySQL, выглядит следующим образом:
> `SELECT subject, num\_views/num\_replies AS param FROM topics WHERE num\_replies>0 AND num\_views/num\_replies>1000;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Если в определении представления используются групповые функции (count, max, avg, group\_concat и т.д.), подзапросы в части перечисления полей или конструкции DISTINCT, GROUP BY, то не выполняется требуемое алгоритмом MERGE соответствие 1 к 1 между строками таблицы и основанного на ней представления.
Пусть наше представление выбирает количество тем для каждого форума:
> `CREATE VIEW v AS SELECT forum\_id, count(\*) AS num FROM topics GROUP BY forum\_id;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Найдем максимальное количество тем в форуме:
> `SELECT MAX(num) FROM v;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Если бы использовался алгоритм MERGE, то этот запрос был бы преобразован следующим образом:
> `SELECT MAX(count(\*)) FROM topics GROUP BY forum\_id;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Выполнение этого запроса приводит к ошибке «ERROR 1111 (HY000): Invalid USE of GROUP function», так как используется вложенность групповых функций.
В этом случае MySQL использует алгоритм TEMPTABLE, т.е. заносит содержимое представления во временную таблицу (данный процесс иногда называют «материализацией представления»), а затем вычисляет MAX() используя данные временной таблицы:
> `CREATE TEMPORARY TABLE tmp\_table SELECT forum\_id, count(\*) AS num FROM topics GROUP BY forum\_id;
>
> SELECT MAX(num) FROM tmp\_table;
>
> DROP TABLE tpm\_table;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Подводя итог, следует отметить, что нет серьезных причин явно указывать алгоритм при создании представления, так как:1. В случае UNDEFINED MySQL пытается использовать MERGE везде где это возможно, так как он более эффективен чем TEMPTABLE и, в отличие от него, не делает представление не обновляемым.
2. Если вы явно указываете MERGE, а определение представления содержит конструкции запрещающие его использование, то MySQL выдаст предупреждение и установит значение UNDEFIND.
Обновляемость представлений
---------------------------
Представление называется обновляемым, если к нему могут быть применимы операторы UPDATE и DELETE для изменения данных в таблицах, на которых основано представление. Для того, чтобы представление было обновляемым должно быть выполнено 2 условия:
1. Соответствие 1 к 1 между строками представления и таблиц, на которых основано представление, т.е. каждой строке представления должно соответствовать по одной строке в таблицах-источниках.
2. Поля представления должны быть простым перечислением полей таблиц, а не выражениеями col1/col2 или col1+2.
**Обратите внимание**: встречающиеся в русско-язычной литературе требования, чтобы обновляемое представление было основано на единственной таблице и присутствие в числе полей представления первичного ключа физичекой таблицы не являются необходимыми. Скорее всего требование единственной таблицы является ошибкой перевода. Дело в том, что через представление, основанное на нескольких таблицах, может обновлять только одну таблицу за запрос, т.е. конструкция SET оператора UPDATE должна перечислять колонки только одной таблицы из определения представления. Кроме того, чтобы представление, основанное на нескольких таблицах, было обновляемым, таблицы в его определении должны быть объединены только с помощью INNER JOIN, а не OUTER JOIN или UNION.
Обновляемое представление может допускать добавление данных (INSERT), если все поля таблицы-источника, не присутствующие в представлении, имеют значения по умолчанию.
**Обратите внимание**: для представлений, основанных на нескольких таблицах, операция добавления данных (INSERT) работает только в случае если происходит добавление в единственную реальную таблицу. Удаление данных (DELETE) для таких представлений не поддерживается.
При использовании в определении представления конструкции WITH [CASCADED | LOCAL] CHECK OPTION все добавляемые или изменяемые строки будут проверяться на соответствие определению представления.
* Изменение данных (UPDATE) будет происходить только если строка с новыми значениями удовлетворяет условию WHERE в определении представления.
* Добавление данных (INSERT) будет происходить только если новая строка удовлетворяет условию WHERE в определении представления.
Иными словами, нельзя добавить или изменить данные в представлении таким образом, чтобы они не были доступны через представление.
Ключевые слова CASCADED и LOCAL определяют глубину проверки для представлений основанных на других представлениях:
* Для LOCAL происходит проверка условия WHERE только в собственном определении представления.
* Для CASCADED происходит проверка для всех представлений на которых основанно данное представление. Значением по умолчанию является CASCADED.
Рассмотрим пример обновляемого представления, основанного на двух таблицах. Пусть наше представление выбирает темы форума с числом просмотров более 2000.
> `punbb >CREATE OR REPLACE VIEW v AS
>
> -> SELECT forum\_name, `subject`, num\_views FROM topics,forums f
>
> -> WHERE forum\_id=f.id AND num\_views>2000 WITH CHECK OPTION;
>
> Query OK, 0 rows affected (0.03 sec)
>
>
>
> punbb >SELECT \* FROM v WHERE subject='test';
>
> +------------+---------+-----------+
>
> | forum\_name | subject | num\_views |
>
> +------------+---------+-----------+
>
> | Новости | test | 3000 |
>
> +------------+---------+-----------+
>
> 1 row IN SET (0.03 sec)
>
>
>
> punbb >UPDATE v SET num\_views=2003 WHERE subject='test';
>
> Query OK, 0 rows affected (0.03 sec)
>
> Rows matched: 1 Changed: 0 WARNINGS: 0
>
>
>
> punbb >SELECT \* FROM v WHERE subject='test';
>
> +------------+---------+-----------+
>
> | forum\_name | subject | num\_views |
>
> +------------+---------+-----------+
>
> | Новости | test | 2003 |
>
> +------------+---------+-----------+
>
> 1 row IN SET (0.01 sec)
>
>
>
> punbb >SELECT subject, num\_views FROM topics WHERE subject='test';
>
> +---------+-----------+
>
> | subject | num\_views |
>
> +---------+-----------+
>
> | test | 2003 |
>
> +---------+-----------+
>
> 1 rows IN SET (0.01 sec)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Однако, если мы попробуем установить значение num\_views меньше 2000, то новое значение не будет удовлетворять условию WHERE num\_views>2000 в определении представления и обновления не произойдет.
> `punbb >UPDATE v SET num\_views=1999 WHERE subject='test';
>
> ERROR 1369 (HY000): CHECK OPTION failed 'punbb.v'
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Не все обновляемые представления позволяют добавление данных:
> `punbb >INSERT INTO v (subject,num\_views) VALUES('test1',4000);
>
> ERROR 1369 (HY000): CHECK OPTION failed 'punbb.v'
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Причина в том, что значением по умолчанию колонки forum\_id является 0, поэтому добавляемая строка не удовлетворяет условию WHERE forum\_id=f.id в определении представления. Указать же явно значение forum\_id мы не можем, так как такого поля нет в определении представления:
> `punbb >INSERT INTO v (forum\_id,subject,num\_views) VALUES(1,'test1',4000);
>
> ERROR 1054 (42S22): Unknown COLUMN 'forum\_id' IN 'field list'
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
С другой строны:
> `punbb >INSERT INTO v (forum\_name) VALUES('TEST');
>
> Query OK, 1 row affected (0.00 sec)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Таким образом, наше представление, основанное на двух таблицах, позволяет обновлять обе таблицы и добавлять данные только в одну из них.
Удачи в работе с представлениями!
Кросспост [Представления (VIEW) в MySQL](http://sqlinfo.ru/articles/info/9.html) с SQLinfo. | https://habr.com/ru/post/47031/ | null | ru | null |
# Tower Defence на движке Unity — Часть 2
Всем привет! Это вторая часть урока для новичков о том, как создать маленькую игру жанра Tower Defence на движке Unity. Мы остановились на создании скрипта для спауна крипов. Если интересно, прошу под кат.

[Часть 1](https://habrahabr.ru/post/309378/) ⬝ Часть 2
#### Скрипт «Spawner»
Вот так выглядит шаблон кода при создании нового скрипта:
```
using UnityEngine;
public class Spawner : MonoBehaviour
{
void Start()
{
}
void Update()
{
}
}
```
Объявим публичную переменную хранящую образец объекта для клонирования.
```
public GameObject spawnObject;
```
Перейдём в редактор Unity, и перетащим скрипт на объект **Spawner**.

Этими действиями мы привязали скрипт к объекту. Так как переменная **spawnObject** с публичным модификатором, её мы сможем изменять прямо в редакторе Unity через окно инспектора.

Вернёмся к коду. Объявим ещё одну публичную переменную. Она будет отвечать за время в секундах, через которое произойдёт создание нового крипа. Также объявим приватную переменную **timer**.
```
public float spawnTime = 1f;
private float timer = 0;
```
С каждым кадром переменная **timer** будет уменьшать своё значение на дельту времени, пока не достигнет нуля или отрицательного значения. После чего, она примет значение переменной **spawnTime** и создаст нового крипа на сцене. И всё начнётся по новой.
Реализуем вышесказанное в методе **Update**:
```
timer -= Time.deltaTime;
if (timer <= 0)
{
Instantiate(spawnObject, transform.position, transform.rotation);
timer = spawnTime;
}
```
Функция **Instantiate** создаёт копию объекта и возвращает на него ссылку. В данной перегрузке принимает аргументы: ссылка на оригинальный объект, позиция и вращение для вставки нового объекта.
Весь код скрипта **Spawner** будет выглядеть так:
```
using UnityEngine;
public class Spawner : MonoBehaviour
{
public GameObject spawnObject;
public float spawnTime = 1f;
private float timer = 0;
void Start()
{
}
void Update()
{
timer -= Time.deltaTime;
if (timer <= 0)
{
Instantiate(spawnObject, transform.position, transform.rotation);
timer = spawnTime;
}
}
}
```
#### Крипы (противники)
Сохраним проект и перейдём в редактор Unity. Создадим новый объект сферу. Именно так будут выглядеть крипы в моём уроке. Занулим позицию. Немного уменьшим сферу по всем 3-м осям.
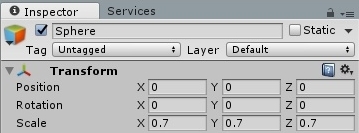
В папке материалов создадим новый материал. Назовём его **Enemy** — «Противник».
Я задам ему красный цвет. Переместим материал на сферу. Теперь создадим новый скрипт для того чтобы вдохнуть в крипа жизнь.

Переименуем сферу в **Enemy** и перетащим на неё одноимённый скрипт.
#### Любой уважающий себя крип должен двигаться к цели
Переходим к коду. Так как структура кода проекта была изменена в редакторе Unity, нам предлагают перезагрузить проект или выбрать другое действие.

Выберем перезагрузку и откроем скрипт **Enemy**. Объявим приватные переменные. Первая для хранения объекта содержащий вэйпоинты. Вторая для хранения трансформации текущего вэйпоинта (точки пути).
```
private Transform waypoints;
private Transform waypoint;
```
Именно к текущему вэйпоинту крип будет идти, пока собственно не дойдёт. После чего он выберет следующую точку и направится уже к ней. Объявим ещё одну переменную.
```
private int waypointIndex = -1;
```
Она будет хранить порядковый номер текущей точки пути. Зададим начальное значение -1. Почему так, узнаете дальше.
В методе **Start** напишем код для поиска объекта на сцене с именем **WayPoints** и установки первого вэйпоинта в качестве текущего:
```
waypoints = GameObject.Find("WayPoints").transform;
NextWaypoint();
```
Теперь опишем метод для выбора следующей точки пути:
```
void NextWaypoint()
{
// Тут был код…
}
```
В теле метода инкрементируем порядковый номер точки:
```
waypointIndex++;
```
Далее, проверяем, больше или равно ли значение индекса от кол-ва точек пути. Если условие верно, то уничтожаем объект на сцене и прерываем выполнение метода.
```
if (waypointIndex >= waypoints.childCount)
{
Destroy(gameObject);
return;
}
```
После блока **if**, переменной **waypoint** нужно присвоить точку пути по указанному порядковому номеру:
```
waypoint = waypoints.GetChild(waypointIndex);
```
Добавим публичную переменную скорости движения крипа:
```
public float speed = 2f;
```
В теле метода **Update**, напишем код движения крипа к текущей точке пути:
```
Vector3 dir = waypoint.transform.position - transform.position;
dir.y = 0;
```
Первой строчкой мы узнаём направление движения крипа. Второй строчкой обнуляем ось Y, что бы крип не смог стать кротом или бабочкой.
Объявим локальную переменную скорости для того чтобы не пересчитывать скорость по нескольку раз в методе. Перемещение крипа не должно зависеть от фреймрейта.
```
float _speed = Time.deltaTime * speed;
```
Смещаем позицию крипа в сторону точки пути, на шаг равный значению скорости. Для этого мы перемножили шаг на локальную переменную скорости:
```
transform.Translate(dir.normalized * _speed);
```
Теперь нужно поставить условие. Если длина вектора меньше или равна длине шага, то это сигнал к смене точки пути.
```
if (dir.magnitude <= _speed)
NextWaypoint();
```
В итоге весь код скрипта **Enemy** должен выглядеть так:
```
using UnityEngine;
public class Enemy : MonoBehaviour
{
public float speed = 2f;
private Transform waypoints;
private Transform waypoint;
private int waypointIndex = -1;
void Start()
{
waypoints = GameObject.Find("WayPoints").transform;
NextWaypoint();
}
void Update()
{
Vector3 dir = waypoint.transform.position - transform.position;
dir.y = 0;
float _speed = Time.deltaTime * speed;
transform.Translate(dir.normalized * _speed);
if (dir.magnitude <= _speed)
NextWaypoint();
}
void NextWaypoint()
{
waypointIndex++;
if (waypointIndex >= waypoints.childCount)
{
Destroy(gameObject);
return;
}
waypoint = waypoints.GetChild(waypointIndex);
}
}
```
#### Последние приготовления
Сохраняем код и возвращаемся к редактору Unity. Скрипту **Spawner**, который привязан к одноимённому объекту, нужно указать образец для клонирования. Образцом будет префаб **Enemy**, которого нет… Создадим его, перетащив объект **Enemy** из окна Иерархии в папку префабов. Оригинал удалим со сцены.

Теперь можно установить образец, присвоив переменной **spawnObject** префаб крипа.

Отключим коллизию у объекта **Spawner**.

Сохраняемся и смотрим что получилось.
Свеженькое мясо пошло по конвееру…
Для большей наглядности можно посмотреть видеоурок:
**P. S.:** Если у вас есть вопросы или пожелания, оставляйте свои комментарии на YouTube под видео.
На хабре я комментарии не читаю.
Многие заметили, что статья и видео похожи на уроки с [этого канала](https://www.youtube.com/channel/UCYbK_tjZ2OrIZFBvU6CCMiA). От части это так. Но я позаимствовал только лишь расстановку вэйпоинтов и построение уровня.
Спасибо за внимание! Конец второй части. | https://habr.com/ru/post/309544/ | null | ru | null |
# Строим Nested Set дерево без рекурсии
*Деревья в базах данных можно хранить тремя основными методами: Adjacency List, Matherialized Path & Nested Set. Когда мы хотим переехать с AL на NS, это можно сделать с помощью рекурсии (если БД расово верная). Но что делать в случае MySQL?*
#### Краткий обзор методов хранения деревьев в БД
Если кратко, то:1. AL — когда у нас родитель хранится в колонке типа parent\_id: ''1''
2. MP — полный путь до элемента хранится в колонке типа path: ''1.2.5''
3. NS [[2](#ref2), [3](#ref3)] — пара колонок lft и rgt, хранящие диапазон всех вложенных элементов, например, корень дерева из 9 элементов будет иметь левое значение ''1'', а правое — ''18''
Более подробно см. у тов. [Mikhus](http://habrahabr.ru/users/mikhus/) [[1](#ref1)]. Также существует ещё один метод Closure Table, на что указал тов. [resurection](http://habrahabr.ru/users/resurection/), но мы его пока в тренд не будем записывать.
#### MySQL и рекурсия
В случае MySQL мы имеем рекурсию, но только на уровне хранимых процедур да и то [до 255 уровней](http://dev.mysql.com/doc/refman/5.5/en/server-system-variables.html#sysvar_max_sp_recursion_depth). Также мы можем задействовать рекурсию в связке язык программирования + БД, но число запросов здесь может быть потрясающим. Лучше делать всё в базе.
Погуглив мы узнаём, что любую рекурсивную задачу можно решить без неё родимой [[4](#ref4)]. Задавшись подобным вопросом мы можем попробовать и… у нас получится! Ниже мы представляем вашему вниманию функцию rebuild\_nested\_set\_tree, которая заполняет lft и rgt, зная parent\_id.
#### Функция заполнения дерева без рекурсии
Для простоты представим, что у нас в табличке только одно дерево и в нём 8 элементов. На вход функция будет получать ничего. Естественно в production-версии мы будем на вход получать некие id вершин деревьев, которые будем учитывать в логике. Ниже мы приведём только тело функции для экономии места, а [полный текст и запросы](http://sqlfiddle.com/#!2/7e58b/3) смотрите на SQLFiddle (спасибо тов. [grokru](http://habrahabr.ru/users/grokru/) за открытие этого сервиса).
**Исходник тела функции rebuild\_nested\_set\_tree**
```
-- Изначально сбрасываем все границы в NULL
UPDATE tree t SET lft = NULL, rgt = NULL;
-- Устанавливаем границы корневым элементам
SET @i := 0;
UPDATE tree t SET lft = (@i := @i + 1), rgt = (@i := @i + 1)
WHERE t.parent_id IS NULL;
forever: LOOP
-- Находим элемент с минимальной правой границей -- самый левый в дереве
SET @parent_id := NULL;
SELECT t.id, t.rgt FROM tree t, tree tc
WHERE t.id = tc.parent_id AND tc.lft IS NULL AND t.rgt IS NOT NULL
ORDER BY t.rgt LIMIT 1 INTO @parent_id, @parent_right;
-- Выходим из бесконечности, когда у нас уже нет незаполненных элементов
IF @parent_id IS NULL THEN LEAVE forever; END IF;
-- Сохраняем левую границу текущего ряда
SET @current_left := @parent_right;
-- Вычисляем максимальную правую границу текущего ряда
SELECT @current_left + COUNT(*) * 2 FROM tree
WHERE parent_id = @parent_id INTO @parent_right;
-- Вычисляем длину текущего ряда
SET @current_length := @parent_right - @current_left;
-- Обновляем правые границы всех элементов, которые правее
UPDATE tree t SET rgt = rgt + @current_length
WHERE rgt >= @current_left ORDER BY rgt;
-- Обновляем левые границы всех элементов, которые правее
UPDATE tree t SET lft = lft + @current_length
WHERE lft > @current_left ORDER BY lft;
-- И только сейчас обновляем границы текущего ряда
SET @i := (@current_left - 1);
UPDATE tree t SET lft = (@i := @i + 1), rgt = (@i := @i + 1)
WHERE parent_id = @parent_id ORDER BY id;
END LOOP;
-- Возвращаем самый самую правую границу для дальнейшего использования
RETURN (SELECT MAX(rgt) FROM tree t);
```
#### Что мы здесь делаем?
В общем и целом мы находим крайний левый верхний элемент с заполненными границами и незаполненными детьми, вычисляем длину ряда его детей, обновляем границы элементов, которые справа от нас и затем уже обновляем границы его детей. Всё это делается без рекурсии в бесконечном цикле, пока у нас не кончатся элементы без границ.
Визуализировать процесс нам поможет несложная презенташка:
#### Ссылки
1. [Иерархические структуры данных и Doctrine](http://habrahabr.ru/post/46659/) by [Mikhus](http://habrahabr.ru/users/mikhus/), на Хабре, 10 декабря 2008 — хорошо описаны устройства каждого из основных методов
2. [Trees in SQL](http://www.ibase.ru/devinfo/DBMSTrees/sqltrees.html) by Joe Celko, at Intelligent Enterprise, October 20, 2000 (english) — что такое Nested Set, по сравнению с Adjacency List и как конвертнуть из второго в первый (Joe Celko — папа термина Nested Set)
3. [Storing Hierarchical Data in a Database](http://www.sitepoint.com/hierarchical-data-database/) by Gijs Van Tulder, at sitepoint.com, April 30, 2003 (english) — картинки для описания логики раздачи «левых» и «правых» индексов, а также описание конкретики работы с разными подходами
4. [Any recursive algorithm can be rewritten as an iterative algorithm ...](http://stackoverflow.com/a/1888735/388929) by community wiki & Kristopher Johnson, at stackoverflow.com, December 11, 2009 (english) — любой рекурсивный алгоритм может быть преобразован в итерационный со стэком
5. [Исходники функции rebuild\_nested\_set\_tree](http://sqlfiddle.com/#!2/7e58b/3) by [garex](http://habrahabr.ru/users/garex/), at sqlfiddle.com, 25 ноября 2012 — создание таблицы с деревом, заполнение тестовыми данными и создание функции для переезда
6. [Nested set без рекурсии: визуализация](http://www.slideshare.net/ustimenko-alexander/nested-set) by [garex](http://habrahabr.ru/users/garex/), at slideshare.net, 25 ноября 2012 — визуализация алгоритма в одном из циклов
#### Changelog
1. Добавлено упоминание об ещё одном методе — Closure Table
2. В исходных данных опечатка поправлена («Клёш» д.б. под «Брюками»)
3. Из тела функции убран изврат с having min и заменён на адекватный order by с limit 1 (но функция всё равно работала правильно, т.к. двигала все правые элементы — это я уже позже удивился) | https://habr.com/ru/post/153861/ | null | ru | null |
# Перевод часов в России 26 октября и Java
Всем привет!
Многие знакомые программисты считают, что для того, чтобы перевести часы в Java на новую Московскую таймзону (которая наступит уже 26 октября, таймзона Europe/Moscow станет равна GMT+3, а не GMT+4, как сейчас — и все остальные русские таймзоны тоже), достаточно поставить на Windows обновления, а на Unix — JDK версии 1.7.0\_72 (в статье речь про JDK7, однако информация актуальна для любой ветки, это касается и 5, и 6, и 8).
Так вот, это заблуждение — просто апгрейд JDK на Unix до 1.7.0\_72 не годится.
Внутри JDK пакетов есть файлики таймзон (пакет tzdata), вот здесь указано, какой пакет в какой дистрибутив входит и указан контент tzdata пакетов: [www.oracle.com/technetwork/java/javase/tzdata-versions-138805.html](http://www.oracle.com/technetwork/java/javase/tzdata-versions-138805.html)
Как видно, чтобы получить апдейт к русским таймзонам, нужен пакет как минимум **tzdata2014f**.
При этом в последних версиях JDK присутствует только **tzdata2014c**.
Как это решить?
Предположим, что у вас уже настроено:
```
user@host:/home/user$ echo $JAVA_HOME
/usr/lib/jvm/java-7-oracle
```
Тогда вам достаточно поставить отдельно пакет tzdata-java:
```
user@host:/home/host$ sudo apt-get install tzdata-java
```
Затем указать используемой Java (например, той, которая связана с переменной JAVA\_HOME) брать файлики таймзон из пакета tzdata-java. Для этого имеет смысл стереть или переименовать каталог с файликами таймзон внутри JDK и поставить символическую ссылку на /usr/share/javazi:
```
mv $JAVA_HOME/jre/lib/zi $JAVA_HOME/jre/lib/zi-default
ln –s /usr/share/javazi/ $JAVA_HOME/jre/lib/zi
```
Проверить можно следующим кодом на Java:
```
import java.util.*;
import java.text.DateFormat;
public class TestMSK {
public static void main(String[] args) {
Calendar c = Calendar.getInstance(TimeZone.getTimeZone("Europe/Moscow"));
DateFormat df = DateFormat.getDateTimeInstance(DateFormat.FULL, DateFormat.FULL, Locale.US);
df.setCalendar(c);
c.setTimeInMillis(1413769091L * 1000L);
if (!df.format(c.getTime()).equals("Monday, October 20, 2014 5:38:11 AM MSK")) {
System.out.println("FAIL1 - 20 Oct is not in sync ");
System.out.println(df.format(c.getTime()));
System.exit(1);
}
c.setTimeInMillis(1414633091L * 1000L);
if (!df.format(c.getTime()).equals("Thursday, October 30, 2014 4:38:11 AM MSK")) {
System.out.println("FAIL2 - 30 Oct is not in sync");
System.out.println(df.format(c.getTime()));
System.exit(2);
}
System.out.println("OK");
System.exit(0);
}
}
```
Проверка:
```
user@host:/home/user$ javac -cp . TestMSK.java
user@host:/home/user$
user@host:/home/user$ java -cp . TestMSK
OK
```
**Update**: спасибо всем за ценные комментарии. Для Windows тоже нужны ручные действия.
В данном случае апдейтом занимается tzupdater tool — качаем отсюда:
[www.oracle.com/technetwork/java/javase/downloads/tzupdater-download-513681.html](http://www.oracle.com/technetwork/java/javase/downloads/tzupdater-download-513681.html)
Запускаем из каждой версии JDK, которые хотим проапдейтить:
```
C:\jdk1.7.0_60\bin>.\java.exe -cp . -jar tzupdater.jar -u
```
Надеюсь, все вовремя обновятся и у нас не будет остановки половины софта в воскресенье/понедельник. | https://habr.com/ru/post/241411/ | null | ru | null |
# Самая короткая запись асинхронных вызовов в tornado v2, или патчим AST
Меня очень заинтересовала статья [Самая короткая запись асинхронных вызовов в tornado или патчим байткод в декораторе](http://habrahabr.ru/post/153595/), не столько с практической точки зрения, сколько с точки зрения реализации.
Всё-таки модификация байткода в рантайме это слишком опасная и ненадежная операция. И уж наверняка не поддерживаемая альтернативными интерпретаторами Python.
Попробуем исправить этот недостаток способом, который для этого предназначен куда больше и который применяется для схожих целей во многих других языках (я точно встречал в Lisp или Erlang). Этот способ — модификация Абстрактного синтаксического дерева (AST) программы.
Для начала — что такое AST? AST это промежуточное представление программного кода в процессе компиляции, которое получается на выходе из парсера.
Например, этот код
```
def func(who):
print "Hello, %s!" % who
func()
```
будет преобразован в следующее AST:
```
FunctionDef(
name='func', # имя функции
args=arguments( # дефолтные аргументы
args=[Name(id='who', ctx=Param())],
vararg=None,
kwarg=None,
defaults=[]),
body=[ # тело функции
Print(dest=None,
values=[
BinOp(left=Str(s='Hello %s!'),
op=Mod(),
right=Name(id='who', ctx=Load()))],
nl=True)],
decorator_list=[]), # декораторы
Expr(value=Call( # вызов функции
func=Name(id='func', ctx=Load()), # имя функции
args=[], # позиционные аргументы
keywords=[], # k-v аргументы
starargs=None, # *args аргументы
kwargs=None)) # **kwargs аргументы
```
На первый взгляд ничего не понятно, но если приглядеться — то можно угадать назначение любого элемента этого дерева. Полная документация по элементам и инструментам для работы с AST (имеются в стандартной библиотеке в модуле ast) есть [тут](http://docs.python.org/library/ast.html).
Так вот, вернёмся к Tornado. Попробуем использовать такие-же обозначения как в оригинальной статье, т.е. декоратор с именем `@shortgen` и оператор бинарного сдвига `<<`.
Будем использовать тот же пример кода, что и в оригинальной статье.
#### Подготовка
Установим tornado
```
mkdir tornado-shortgen
cd tornado-shortgen/
virtualenv .env
source .env/bin/activate
pip install tornado
```
Напишем Tornado — приложение
```
import tornado.ioloop
import tornado.web
import tornado.gen
import os
class Handler(web.RequestHandler):
@asynchronous
@gen.engine
@shortgen
def get_short(self):
(result, status) << self.db.posts.find_e({'name': 'post'})
@asynchronous
@gen.engine
def get(self):
(result, status) = yield gen.Task(self.db.posts.find_e, {'name': 'post'})
application = tornado.web.Application([
(r"/", Handler),
])
if __name__ == "__main__":
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
```
Сохраним в файл *shortgen\_test.py*
#### Реализация трансформации
Попробуем получить AST нашего модуля.
```
$ python
>>> import ast
>>> print ast.dump(ast.parse(open("shortgen_test.py").read()))
```
Увидим длинную неотформатированную портянку текста, из которой нас интересует только определения функций `get_short` и `get`
`get_short` — исходная функция с бинарным сдвигом и декоратором
```
FunctionDef(
name='get_short',
args=arguments(args=[Name(id='self', ctx=Param())],
vararg=None,
kwarg=None,
defaults=[]),
body=[
Expr(value=BinOp( # операция с 2-мя операндами
left=Tuple( # левый операнд - это кортеж
elts=[Name(id='result', ctx=Load()), Name(id='status', ctx=Load())],
ctx=Load()),
op=LShift(), # операция бинарного сдвига
right=Call( # правый операнд - вызов функции self.db.posts.find_e
func=Attribute(
value=Attribute(
value=Attribute(
value=Name(id='self', ctx=Load()),
attr='db',
ctx=Load()),
attr='posts',
ctx=Load()),
attr='find_e',
ctx=Load()),
args=[Dict(keys=[Str(s='name')], values=[Str(s='post')])], # функция вызывается с одним позиционным аргументом
keywords=[],
starargs=None,
kwargs=None)))],
decorator_list=[ # список декораторов
Attribute(value=Name(id='web', ctx=Load()), attr='asynchronous', ctx=Load()),
Attribute(value=Name(id='gen', ctx=Load()), attr='engine', ctx=Load()),
Name(id='shortgen', ctx=Load())]) # а вот и наш декоратор!
```
`get` — желаемый результат
```
FunctionDef(
name='get',
args=arguments(args=[Name(id='self', ctx=Param())],
vararg=None, kwarg=None, defaults=[]),
body=[
Assign( # операция присваивания
targets=[
Tuple(elts=[ # с левой стороны от = находится такой-же tuple, но ctx изменился на Store()
Name(id='result', ctx=Store()),
Name(id='status', ctx=Store())],
ctx=Store())],
value=Yield( # с правой - yield и вызов функции
value=Call( # вызов gen.Task
func=Attribute(
value=Name(id='gen', ctx=Load()),
attr='Task', ctx=Load()),
args=[Attribute( # первый аргумент - имя функции self.db.posts.find_e
value=Attribute(
value=Attribute(
value=Name(id='self', ctx=Load()),
attr='db', ctx=Load()),
attr='posts', ctx=Load()),
attr='find_e', ctx=Load()),
Dict(keys=[Str(s='name')], values=[Str(s='post')])],
keywords=[], # остальные аргументы не изменились
starargs=None,
kwargs=None)))],
decorator_list=[
Name(id='asynchronous', ctx=Load()),
Attribute(value=Name(id='gen', ctx=Load()), attr='engine', ctx=Load())]) # декоратора shortgen нет
```
Выглядит монструозно, но зато как гибко! На самом деле всё просто.
Давайте посмотрим на различия:
1. Полностью пропал `Expr`
2. Вместо `BinOp(left, op, right)` теперь `Assign(targets, value)`
3. У правого операнда значения `ctx` изменилось с `Load` на `Store`
4. Вызов `self.db.posts.find_e(...)` заменен на `gen.Task(self.db.posts.find_e, ...)`
5. Добавился `Yield` вокруг вызова функции
6. Пропал декоратор `@shortgen`
Соответственно, чтобы получить из первого второе, нам нужно
1. Найти функцию, у которой в `decorator_list` есть декоратор `@shortgen`
2. Удалить этот декоратор
3. Найти в теле функции оператор бинарного сдвига `BinOp`
4. Сохранить левый и правый операнды. В левом заменить `ctx` с `Load` на `Store`, из правого операнда извлечь название функции и её аргументы (позиционные, kw, и «звёздочные» — \*, \*\*)
5. Добавить название функции (`self.db.posts.find_e`) первым позиционным аргументом (т.е. в нашем примере получим позиционные аргументы `[self.db.posts.find_e, {'name': 'post'}]`, а все остальные пустые
6. Создать новый `Call`, но уже функции `gen.Task` с этими аргументами
7. Обернуть его в `Yield`
8. Создать `Assign(targets, value)` и в качестве targets взять сохраненный ранее левый операнд `BinOp` а в качестве value — только что созданный нами `Yield`
9. Заменить в исходном дереве `Expr` на наш свежесобранный `Assign`
Хоть звучит сложно, но в коде это заняло чуть больше 50 строк. Если что-то не понятно — смотрите сразу туда.
Как это реализовать? Можно написать решение в лоб каким-то while циклом или рекурсивной функцией. Но мы воспользуемся паттерном Visitor и его адаптацией [ast.NodeTransformer](http://docs.python.org/library/ast.html#ast.NodeTransformer)
Это класс, от которого можно отнаследоваться и насоздавать в нём методов типа `visit_[NodeType]` например `visit_FunctionDef` или `visit_Expr`. Значение, которое вернет метод станет новым значением элемента AST. А сам Visitor просто рекурсивно обходит дерево, вызывая наши методы тогда, когда в дереве встретился соответствующий элемент. Это поможет нам удобнее организовать наш код.
1. Создаем метод `visit_FunctionDef`, для отлова декорированной функции. В нём проверяем, что функция обернута в декоратор, если обернута — удаляем декоратор и ставим пометку `self.decorated`
2. Создаем метод `visit_Expression`, для отлова бинарного сдвига. В нем проверяем, что выставлен флаг `self.decorated` и что `Expr` — это именно бинарный сдвиг. Проводим остальные манипуляции (преобразование `Expr` в `Assign`) вручную. Благо, все нужные данные уже рядышком.
**Собственно код**
```
# -*- coding: utf-8 -*-
'''
Created on 2012-10-07
@author: Sergey
Альтернативный вариант решения из статьи http://habrahabr.ru/post/153595/
на базе модификации AST
'''
import ast
import marshal
import py\_compile
import time
import os.path
class RewriteGenTask(ast.NodeTransformer):
def \_\_init\_\_(self, \*args, \*\*kwargs):
self.on\_decorator = []
self.on\_assign = []
super(RewriteGenTask, self).\_\_init\_\_(\*args, \*\*kwargs)
def shortgen\_deco\_pos(self, decorator\_list):
# проверяет, что в списке декораторов имеется декоратор с именем
# shortgen и возвращает его позицию.
for pos, deco in enumerate(decorator\_list):
# Name(id='shortgen', ctx=Load())
if isinstance(deco, ast.Name) and deco.id == 'shortgen':
return pos
return -1
def visit\_FunctionDef(self, node):
"""
Проверяет, что функция обернута в декоратор shortgen.
Если обернута, удаляем декоратор и трансформируем содержимое.
FunctionDef(
name='get\_short',
args=arguments(...),
body=[...],
decorator\_list=[
Attribute(value=Name(id='web', ...), attr='asynchronous', ...),
Attribute(value=Name(id='gen', ...), attr='engine', ...),
Name(id='shortgen', ctx=Load())])
"""
deco\_pos = self.shortgen\_deco\_pos(node.decorator\_list)
if deco\_pos >= 0:
# если функция обернута в shortgen декоратор, удаляем его,
# делаем пометку в стеке и запускаем Visitor по содержимому
# функции
self.on\_decorator.append(True)
node.decorator\_list.pop(deco\_pos)
self.generic\_visit(node) # трансформируем содержимое функции
self.on\_decorator.pop()
return node
def visit\_Expr(self, expr):
"""
== Основная трансформация ==
Трансформируем
result2 << func(arg, k=v, \*args, \*\*kwargs)
в
result2 = gen.Task(func, arg, k=v, \*args, \*\*kwargs)
Пример AST представления "stmt << func(...)" (исходные данные):
Expr(value=BinOp(left=Name(id='result', ctx=Load()),
op=LShift(),
right=Call(
func=Name(id='fetch', ctx=Load()),
args=[Num(n=1)],
keywords=[keyword(arg='k', value=Num(n=2))],
starargs=Tuple(elts=[Num(n=3)], ctx=Load()),
kwargs=Dict(keys=[Str(s='k2')], values=[Num(n=4)])))))
---- vvvvvvvvvvv ----
Пример AST представления "stmt = yield func(...)" (результат):
Assign(targets=[Name(id='result', ctx=Store())],
value=Yield(value=Call(
func=Attribute(value=Name(id='gen', ctx=Load()),
attr='Task', ctx=Load()),
args=[Name(id='fetch', ctx=Load()), Num(n=1)],
keywords=[keyword(arg='k', value=Num(n=2))],
starargs=Tuple(elts=[Num(n=3)], ctx=Load()),
kwargs=Dict(keys=[Str(s='k2')], values=[Num(n=4)]))))
"""
node = expr.value # BinOp
if not (self.on\_decorator
and isinstance(expr.value, ast.BinOp)
and isinstance(node.op, ast.LShift)):
# если функция не обернута в декоратор (on\_decorator пуст), ничего
# не меняем
return expr
# если функция, содержащая LShift, обернута в декоратор,
# то заменяем на вызов gen.Task()
# для начала конвертируем изменение на месте (stmt <<) на
# присваивание (stmt =). Для этого заменяем ctx=Load на
# ctx=Store (см self.visit\_Load())
self.on\_assign.append(True)
assign\_target = self.visit(node.left)
self.on\_assign.pop()
# генерируем присваивание ... = ...
(new\_node, ) = ast.Assign(
targets = [assign\_target],
value = ast.Yield(
value=self.construct\_gen\_task\_call(node.right))),
# копируем номер линии оригинальной конструкции
new\_node = ast.fix\_missing\_locations(ast.copy\_location(new\_node, expr))
return new\_node
def construct\_gen\_task\_call(self, func\_call):
"""
Конвертируем вызов функции в вызов gen.Task с именем функции первым
параметром
func(arg, k=v, \*args, \*\*kwargs)
в
gen.Task(func, arg, k=v, \*args, \*\*kwargs)
Пример AST представления "func(...)":
Call(
func=Name(id='fetch', ctx=Load()),
args=[Num(n=1)],
keywords=[keyword(arg='k', value=Num(n=2))],
starargs=Tuple(elts=[Num(n=3)], ctx=Load()),
kwargs=Dict(keys=[Str(s='k2')], values=[Num(n=4)])))
---- vvvvvvvvv ----
Пример AST представления "gen.Task(func, ...)":
Call(
func=Attribute(value=Name(id='gen', ctx=Load()),
attr='Task', ctx=Load()),
args=[Name(id='fetch', ctx=Load()), Num(n=1)],
keywords=[keyword(arg='k', value=Num(n=2))],
starargs=Tuple(elts=[Num(n=3)], ctx=Load()),
kwargs=Dict(keys=[Str(s='k2')], values=[Num(n=4)]))
"""
# Генерируем gen.Task
gen\_task = ast.Attribute(
value=ast.Name(id='gen', ctx=ast.Load()),
attr='Task', ctx=ast.Load())
# Генерируем вызов gen.Task(func, ...)
call = ast.Call(
func=gen\_task,
# имя оригинальной ф-ции 1-м аргументом:
args=[func\_call.func] + func\_call.args,
keywords=func\_call.keywords,
starargs=func\_call.starargs,
kwargs=func\_call.kwargs)
return self.visit(call)
def visit\_Load(self, node):
# Заменяем Load() на Store()
if self.on\_assign:
return ast.copy\_location(ast.Store(), node)
return node
def shortgen(f):
raise RuntimeError("ERROR! file must be compiled with yield\_ast!")
def compile\_file(filepath):
path, filename = os.path.split(filepath)
with open(filepath) as src:
orig\_ast = ast.parse(src.read())
new\_ast = RewriteGenTask().visit(orig\_ast)
code = compile(new\_ast, filename, 'exec')
pyc\_filename = os.path.splitext(filename)[0] + '.pyc'
pyc\_filepath = os.path.join(path, pyc\_filename)
with open(pyc\_filepath, 'wb') as fc:
fc.write(py\_compile.MAGIC)
py\_compile.wr\_long(fc, long(time.time()))
marshal.dump(code, fc)
fc.flush()
if \_\_name\_\_ == '\_\_main\_\_':
import sys
if len(sys.argv) < 2:
print "Usage: %s file\_to\_compile1.py [file2.py] ..." % sys.argv[0]
for filename in sys.argv[1:]:
compile\_file(filename)
```
[Gist](https://gist.github.com/3849217)
Полученный AST можно либо исполнить:
```
with open(filepath) as src:
orig_ast = ast.parse(src.read())
new_ast = RewriteGenTask().visit(orig_ast)
code = compile(new_ast, filename, 'exec')
exec code
```
Либо сохранить в .pyo файл
[stackoverflow.com/questions/8627835/generate-pyc-from-python-ast](http://stackoverflow.com/questions/8627835/generate-pyc-from-python-ast)
[gist.github.com/3849217#L172](https://gist.github.com/3849217#L172)
И затем импортировать, либо вызывать `python my_module.pyo`
#### Заключение
Трансформация AST — более надежный и портируемый способ трансформации кода программы. Писать такие трансформации гораздо проще, чем модифицировать байткод. Этот способ широко применяется во многих языках, например Lisp или Erlang.
Второй плюс — нет необходимости ничего манкипатчить, трансформация работает и с нашим и с внешним кодом одинаково.
Остальные плюсы и минусы расписаны в моём [комментарии к оригинальной статье](http://habrahabr.ru/post/153595/#comment_5239485). Еще раз отмечу, что основной недостаток — проблематично применить трансформацию AST на лету. Она должна осуществляться на стадии компиляции в .pyc файл. (Ну и, конечно, если применяешь такие хаки, нужно это хорошо задокументировать).
Для маленьких проектов, в которых этот yield пишется в паре мест, такой сахар не имеет особого смысла, плюс усложняет разработку т.к. появляется отдельный этап компиляции файла. Но на больших Tornado проектах можно и попробовать.
#### Ссылки
[Весь код целиком на Gist](https://gist.github.com/3849217)
[Документация по AST](http://docs.python.org/library/ast.html)
[Документация по tornado.gen](http://www.tornadoweb.org/documentation/gen.html)
[Генерация .pyc файла из AST](http://stackoverflow.com/questions/8627835/generate-pyc-from-python-ast)
[Если всё это кажется страшными костылями, есть выход xD](http://erlang.org/)
#### Домашнее задание
* Правда ведь этот список из 3-х декораторов выглядит жутковато?
```
@asynchronous
@gen.engine
@shortgen
```
Как с помощью AST обойтись всего одним `@shortgen` а как без AST?
* Текущая реализация требует чтобы декоратор применялся именно как `@shortgen`, `@my_module.shortgen` уже не сработает. Плюс требуется, чтобы модуль tornado.gen был импортирован как `from tornado import gen`, `import tornado.gen` или `from tornado.gen import Task` уже не прокатит. Как это исправить?
* Попробуйте переписать сервер из статьи [Раздача больших файлов через сервер TornadoWEB](http://seriyps.ru/blog/2012/09/24/razdacha-bolshix-fajlov-cherez-server-tornadoweb/) с использованием shortgen, скомпилировать и запустить. | https://habr.com/ru/post/153949/ | null | ru | null |
# deb-пакет на коленке
Задача: создать пакет для Debian для выливки демона/сайта на сервер.
Я никогда ранее не работал с deb-пакетами — так что решение может быть не оптимальным. Но оно работает и достаточно просто в использовании.
###### Подготовка
В первую очередь для переодических выливок на сервер нам понадобится версионность кода. Если оспользуется svn — то, скорее всего, можно использовать номер ревизии. Так как я использую git — написал простенький скрипт для ведения версии проекта: [tag.sh](http://gist.github.com/212082)
Для увеличения версии проекта вызываем ./tag.sh build, ./tag minor или ./tag major. Скрипт создаёт метки вида v.. (к примеру v0.1.25)
Для получения версии вызываем git describe --match=v\* HEAD и получаем в результате версию в виде v0.2.1 (либо v0.2.1-59-g919ab19 если после тага были коммиты).
В сети много мануалов по созданию пакетов, которые используют dh\_make либо описывают все возможные варианты создания пакета с нуля. Но нам не требуется правильный пакет для внесения в репозиторий дебиана, а всего лишь пакет нашего проекта, который мы установим на сервере.
Из всех файлов конфигурации пакета важными показались лишь 2:
**control** — описание пакета
**conffiles** — описание конфигурационных файлов пакета (при установке новой версии apt спросит заменить ли файл или оставить старую версию).
###### control
Формат файла достаточно простой:
`Package: ИМЯ_ПАКЕТА
Version: ВЕРСИЯ - получаная git describe
Architecture: АРХИТЕКТУРА - amd64 если есть бинарники или all - если только скрипты
Depends: ЗАВИСИМОСТИ - можно упустить
Maintainer: ВАШЕ_ИМЯ
Description: ОПИСАНИЕ`
К примеру:
`Package: ggseductionserver
Version: v0.2.1-59-g919ab19
Architecture: amd64
Depends: libc6 (>= 2.4), libgcc1 (>= 1:4.1.1), libstdc++6 (>= 4.1.1), libboost-system1.38.0 (>=1.38.0),
libboost-thread1.38.0 (>=1.38.0), libboost-regex1.38.0 (>=1.38.0), libboost-serialization1.38.0 (>=1.38.0), libboost-program-options1.38.0 (>=1.38.0),
tokyotyrant, tokyocabinet, mysql-client (>=5.0), libssl0.9.8 (>=0.9.8), libreadline5 (>= 5.2), libmysql++3 (>= 3.0),
libpcre3 (>= 7.6), libpcrecpp0 (>= 7.6), libgd2-xpm (>= 2.0)
Maintainer: Alexander Fedora
Description: glagol games server
<ПРОБЕЛ>This is server`
Зависимости можно получить используя ldd и apt-file
`$ ldd ./build/server | grep libboost_thread
/usr/lib/libboost_thread-mt.so.1.38.0
$ apt-file search /usr/lib/libboost_thread-mt.so.1.38.0
libboost-thread1.38.0: /usr/lib/libboost_thread-mt.so.1.38.0
libboost1.38-dbg: /usr/lib/debug/usr/lib/libboost_thread-mt.so.1.38.0`
###### conffiles
В этом файле находится список конфигурационных файлов пакета. Пример:
`/etc/seduction/seductiond.conf
/etc/seduction/seductiond.log.properties`
###### Создание пакета
Я решил использовать простой шелл скрипт для создания пакета. Действия по порядку:
1. Создаём директорию deb
2. Создаём директорию deb/DEBIAN
3. Получаем текущую версию проекта version=`git describe --match=v\* HEAD`
4. Записываем в deb/DEBIAN/control описание пакета, а в качестве версии используем $version
5. Записываем в файл deb/DEBIAN/conffiles список конфигурационных файлов
6. В директорию deb/ записываем файлы прокета как будто deb/ — это рут диска (к примеру deb/usr/local/bin/exe\_name, deb/etc/config\_name и тд)
7. Создаём пакет при помощи комманды dpkg -b deb/ ИМЯПАКЕТА\_$version'.deb'
После имени пакета обязательно поставить подчеркивание (\_) перед версией.
Пример рабочего скрипта можно посмотреть [тут](http://gist.github.com/212115) (это пример для с++ демона, для сайта на php пример [тут](http://gist.github.com/212118))
###### Создание репозитория на сервере
Устанавливаем пакет dpkg-dev.
Создаем директорию /var/opt/repo/, а в ней 2 подддиректории binary и source.
Заливаем пакеты в binary и выполняем комманду для создания каталога архива:
`dpkg-scanpackages -m binary /dev/null | gzip -9c > binary/Packages.gz`
Записываем shell-скрипт для автоматизации апдейта сервера:
`rsync -av -e ssh $HOME/projects/repo/*.deb server_name:/var/opt/repo/ || exit 1
ssh server_name 'cd /var/opt/repo; dpkg-scanpackages -m binary /dev/null | gzip -9c > binary/Packages.gz' || exit 1`
###### Поднятие nginx для доступа к репозиторию
Устанавливаем nginx, добавляем новый сайт:
`$ cat /etc/nginx/sites-available/repo
server {
listen 9977;
server_name localhost;
access_log /var/log/nginx/repo.access.log;
location / {
autoindex on;
allow 127.0.0.1;
allow 192.168.0.2;
root /var/opt/repo;
}
}`
Поднимаем сайт и убеждаемся что он работает.
`$ ln -s /etc/nginx/sites-available/repo /etc/nginx/sites-enabled/repo
$ sudo /etc/init.d/nginx restart
$ wget 192.168.0.1:9977/binary/Packages.gz`
###### Установка пакетов из созданного репозитория
Добавляем в /etc/apt/sources.list наш сайт:
`deb 192.168.0.1:9977/ binary/`
И устанавливаем пакет:
`$ sudo apt-get update
$ sudo apt-get install package_name`
###### Заключение
При установке пакета apt-get будет вопить, что пакет не может быть аутентифицирован. В принципе можно добавить цифровую подпись к пакету, но мы то и так знаем что он устанавливается с нашего репозитория — поэтому можно добавить ключики -y --force-yes и устанавливать пакет в автоматическом режиме.
PS. сильно не пинайте — это мой первый пост. | https://habr.com/ru/post/72633/ | null | ru | null |
# Kohana-form: beta релиз. Изменения и новшества
Здравствуйте. Наконец то настал тот день, когда модуль приобрел те очертания к которым я стремился. В связи с этим вышел beta релиз, и я бы хотел рассказать вам, что нового появилось в функционале [kohana-form](https://github.com/NeZanyat/kohana-form).
Первая статья — [habrahabr.ru/post/216187](http://habrahabr.ru/post/216187/)
К имеющимся типам полей присоединились новые, которых так не хватало в первой версии.
Это поля с типом:
* File
* Choice
* MultiChoice
Думаю из названия поля File и так понятно для чего оно предназначено, поэтому не буду разжевывать.
Поля Choice и Multichoice по умолчанию генерируют select'ы с одиночным и множественным выбором. Инициализируются довольно просто.
```
"fields" => array(
"select" => Field::factory("Choice", array(
"choices" => array(1, 2, 3)
)),
"select" => Field::factory("MultiChoice", array(
"choices" => array(1, 2, 3)
)),
),
```
Но самое главное новшество — Relation fields.
Это поля с типом:
* One2Many
* Many2Many
Инициализируются так же просто как и поля типа Choice, но инициализировать их нужно в отдельном разделе 2m\_fields.
```
"fields" => array(),
"2m_fields" => array(
"owners" => Field::factory("One2Many", array(
"model" => ORM::factory("Owner")
))
"owners" => Field::factory("Many2Many", array(
"model" => ORM::factory("Owner")
))
),
```
Генерируются select'ы с подгружеными связями. Однако я не рекомендую использовать эти поля где то кроме админки, да и в админке нужно использовать с умом. Чаще всего можно обойтись просто полем BelongsTo которое тоже представлено в модуле и инициализируется таким образом:
```
"fields" => array(
"image" => Field::factory("Image"),
"owner" => Field::factory("BelongsTo", array(
"model" => ORM::factory("Owner")
)),
"body" => Field::factory("Text")->widget("CKEditor")
),
```
Плюс, из примера выше можно заметить что появился новый виджет, заменяющий стандартную textarea.
Также появилось несколько типов полей не очень отличающихся по функционалу от имеющихся, но нужных для генерации формы из ORM модели, и сейчас нет необходимости заострять на них внимание.
На этом всё, изменений не так много, но они довольно объемные и наконец то сделали kohana-form таким, каким я его видел, когда только садился за клавиатуру.
Однако рано расслабляться, проект только в стадии beta тестирования, и я как и в прошлый раз прошу помощи у сообщества с тестированием, развитием, написанием документации, что бы вместе мы смогли сделать лучший модуль форм из всех имеющихся.
Спасибо за внимание. | https://habr.com/ru/post/222649/ | null | ru | null |
# Format, Install, тюрьма

Много букв под хабракатом.
`Житель Екатеринбурга Александр Иванчиков-Нееловский 1972 года рождения предстанет перед судом за установку нелицензионных копий Microsoft Windows, Microsoft Office и других программ Microsoft на свой домашний компьютер, сообщает ИА REGNUM. Следственным отделом по Кировскому району Екатеринбурга по данному факту было возбуждено уголовное дело по части 2 статьи 146 Уголовного Кодекса РФ «Нарушение авторских и смежных прав». В ходе следствия ему также было предъявлено обвинение в совершении преступлений по статье 272 УК РФ «Неправомерный доступ к компьютерной информации». Предварительное следствие завершено, и дело направлено в Кировский районный суд Екатеринбурга для рассмотрения по существу.`
`Как сообщили в пресс-службе следственного управления Следственного комитета при прокуратуре РФ по Свердловской области, было установлено, что 12 марта 2009 г. мужчина установил на свой системный блок у себя дома программы «Microsoft Windows Professional SP3. Русская версия», «Microsoft Office 2007. Русская версия» и другие, правообладателем которых является корпорация Microsoft. Общая стоимость этих программ составила 125 142 руб.`
`Напомним, что часть 2 статьи 146 УК РФ, по которой обвиняется житель Екатеринбурга, гласит: «Незаконное использование объектов авторского права или смежных прав, а равно приобретение, хранение, перевозка контрафактных экземпляров произведений или фонограмм в целях сбыта, совершенные в крупном размере наказываются штрафом в размере до 200 тысяч рублей, либо обязательными работами на срок от 180 до 240 часов, либо лишением свободы на срок до 2 лет».`

Итак, то о чем так долго говорили большевики таки [началось воплощаться в жизнь](http://www.securitylab.ru/news/382975.php). В России опять сажают. В этот раз за Windows или Photoshop, поскольку как известно в России это самое страшное преступление. Отдел К по которому к примеру судя из заявлений господина Чичваркина (я почему то ему верю на 10000 процентов тут) плачет тюрьма посильнее любого «пирата» учит нерадивых своих граждан, чтить дух и букву закона.
Очередные пОносовы пошли под показательные процессы. В лучший советских традициях сажают за совершенно смешные мотивы. Какие то безработные сбившие себе 2-3к рублей за установку Windows и 1C. Браво господа! Виват правозащитная система! В нашем государстве все настолько ахуенно и честно что совершенно некого сажать? Даже так скажу.ВЫ А@#$И Б@#дЬ ЧТОЛИ? Давайте начнем с вас? Правоохранительной системы. Зайдем в любое отделение милиции пройдемся по it инфраструктуре? В домуправах? В собесах? В городских администрациях? Что мы там как вы думаете увидим? Потертые и старые желтые от времени системники с пиратской winxp или даже win98. Linux?.. !@#$й вам господа правоохранители, нет у вас линукса он вам @#$@уй не нужен. Так как перевод парка машин на свободное по всеже потянет денежные расходы на инсталяцию и поддержание парка машин в порядке. Хотя бы на первичном этапе миграции. Вместо этого нанимается вот такой студент Вася который за недорого «накатит» windows cкачанный из его домовой сети p2p сети. Притом чисто по советски все это выглядит так: Вась ну ты сделай там все чтобы как надо! Вась но денег нет! (с улыбкой). *Вот тебе пятак на водку и пошел отсюда вон (с) Филатов.*
Данный Вася в отличается выходит от других Васей индульгенцией на нарушение законодательства. В администрацию никогда не придут проверять, а если придут то посадят конечно Васю ) Так как начальник естественно не специалист и его естественно ввел в заблуждение этот самый Вася которому насчитают особо крупный ущерб и пойдет он таскать вонючий бушлат года на 3. Вот она Россия матушка, страшная и суровая. @#$здил вагон денег — ты почетный гражданин и уважаемый господин. Установил нелегальное по чтобы заработать на кусок хлеба — ты преступник. То есть с некоторой уверенностью можно говорить о избирательном действии закона в России. И начнет он действовать или нет зависит от того кому и зачем это нужно. Давайте посадим главу администрации какого нибудь города? Или проверим мерию Москвы на легальность по. Найдем миллион процентов. На 250 особо крупных размеров. Что из этого будет следовать? Ничего. В лучшем случае сядет Вася — админ который и рад был бы всадить какую нибудь Ubuntu на компы всех этих бухгалтеров, да не дадут: Ой Вась непонятно ничего сделай нам опять как было Вася идет к начальнику и просит профинансировать легализацию it инфраструктуры. Ответ — Вась ну ты сделай там все чтобы как надо! Вась но денег нет! (с улыбкой). И так практически везде. Проблема в том еще раз повторюсь что понятие толерантности к закону в России строго соотносится к финансовому статусу гражданина. Если ты нищервань то у тебя и за небольшой долг на мобильном или квартплату могут автомобиль прямо на дороге отобрать или не выпустить на отдых в какую нибудь сраную Турцию. Я не призываю всех использовать пиратское по и не говорю что это хорошо. На самом деле тут все гораздо сложнее.
Пиратское по несомненно приводит к падению дохода it компани -девелоперов. Но не линейно. Например компании производящей какой нибудь профессиональный продукт типа adobe карают за пиратство чисто показушно. Им просто необходимо взрастить на паленых копиях армию будущих покупателей продукта. А иначе он никому и нужен не будет за 33000 рублей на полке магазина )) Поэтому adobe скозь пальцы смотрит на пиратство как таковое и иногда выборочно наказывая. Другой случай -недорогой стартап пары человек с каким нибудь программным продуктом c узкой нишей назначения, может быть убит пиратскими копиями сразу. Проблему эту тюрьмами и законом я думаю уже не решить надо отказывать от концепции:
программный продукт = деньги и переходить к программный продукт > услуги с ним связанные = деньги.
Эта схема прекрасно работает в ряде отраслей связанных к примеру с операционными системами и играми и антивирусами, но плохо работает в ряде других областей. Ну к примеру за что брать деньги кроме стоимости в случае с Winrar?
Все это не отменяет здравой логики: Невозможно карать за использование и установку пиратского по и не карать за @#$зжевание городского или еще какого нибудь бюджета. Вот так и сидит Россия кто за мешок картошки украденный а кто за 2ух куриц. А коррупция все растет и растет.
`....Москвича Алексея Скворцова Головинский районный суд приговорил к 2 годам и 7 месяцам лишения свободы с испытательным сроком в течение трех лет по статье 146 части 2 УК РФ (нарушение авторских прав в крупном размере) и статье 273 часть 1 (создание, использование и распространение вредоносных программ). Как выяснило следствие, Скворцов, в частности, купил на Савеловском рынке диски с контрафатным ПО Microsoft и Adobe, затем разместил в интернете объявление, где предложил свои услуги по платной установке этих программ, чем впоследствии и занялся. Скворцов был ранее судим, правда, по статье, не связанной с авторским правом.`
`....Житель Астрахани Юрий Ли, генеральный директор компании «Линком-Строй», этим летом был приговорен к 10 годам лишения свободы в колонии общего режима и возмещению ущерба на сумму свыше 10 млн руб. за совершение ряда преступлений, в числе которых нарушение авторский прав в сфере ПО (по статье 146 части 3 УК РФ — в особо крупном размере). Приговор был вынесен по совокупности статей, при этом конкретно за пиратство присужден один год лишения свободы. Ли обвинялся, в частности, в том, что на компьютерах его компании были незаконно установлены и использовались различные программы Microsoft и «1C».` | https://habr.com/ru/post/84188/ | null | ru | null |
# SQL: задача на поиск последней цены
Здравствуйте! В эфире снова Радио SQL.
Давненько не выходили в эфир, но тут братья-гуманоиды из соседнего Малого МакГеланового облака подкинули задачку. Сходу в один присест задачка не решилась, пришлось подумать. Значит и в Западном рукаве Галактики тоже могут найтись желающие поломать мозг об задачку. Сейчас изложу условие, а ответ следующим посланием уйдёт.
Условие такое. Есть набор данных с ценами на товары (**prod\_id**) на складах (**stock\_id**). Причём цены бывают настоящие (**R**=Real), а бывают рекламные (**P**=Promo). Для каждой цены есть дата начала действия. Нужно к каждой строчке набора вытащить реальную цену, которая является последней по дате настоящей ценой (**price1**) с типом '**R**' на этот товар на соответствующем складе.
Вот начало запроса с тестовыми данными в виде CTE, на которых можно потренироваться:
```
with price(stock_id, prod_id, start_date, kind, price1, cost1, bonus1) as (
values (1,1,to_date('2000-01-01','YYYY-MM-DD'),'R',100.0,32.12,6.49),
(1,1,'2000-01-02','P', 80.0, 0, 0),
(1,1,'2000-01-03','P', 70.0, 0, 0),
(1,1,'2000-01-04','R',110.0,33.48,6.19),
(1,1,'2000-01-05','P', 90.0, 0, 0),
(1,1,'2000-01-06','R',120.0,41.22,6.19),
(1,1,'2000-01-07','P', 80.0, 0, 0),
(1,1,'2000-01-08','P', 90.0, 0, 0),
(1,1,'2000-01-09','R', 93.0,36.87,6.49),
(1,1,'2000-01-10','R', 94.0,36.85,6.99),
(1,2,'2000-01-01','R',101.0,52.06,9.00),
(1,2,'2000-01-02','P', 81.0, 0, 0),
(1,2,'2000-01-03','P', 71.0, 0, 0),
(1,3,'2000-01-04','R',111.0,64.96,4.50),
(1,3,'2000-01-05','P', 92.0, 0, 0),
(1,3,'2000-01-06','R',122.0,66.83,4.60),
(1,3,'2000-01-07','P', 82.0, 0, 0),
(1,3,'2000-01-08','P', 92.0, 0, 0))
select ...
```
Должно получиться что-то вида:
```
stock_id | prod_id | start_date | kind | price1 | cost1 | bonus1 | price1x
----------+---------+------------+------+--------+-------+--------+---------
1 | 1 | 2000-01-01 | R | 100.0 | 32.12 | 6.49 | 100.0
1 | 1 | 2000-01-02 | P | 80.0 | 0 | 0 | 100.0
1 | 1 | 2000-01-03 | P | 70.0 | 0 | 0 | 100.0
1 | 1 | 2000-01-04 | R | 110.0 | 33.48 | 6.19 | 110.0
1 | 1 | 2000-01-05 | P | 90.0 | 0 | 0 | 110.0
1 | 1 | 2000-01-06 | R | 120.0 | 41.22 | 6.19 | 120.0
1 | 1 | 2000-01-07 | P | 80.0 | 0 | 0 | 120.0
1 | 1 | 2000-01-08 | P | 90.0 | 0 | 0 | 120.0
...
```
Особенности же тут вот в чём. Я не зря радировал выше «*источник данных*», потому что не таблица тут у нас, а вьюха, собранная из самых разных и зачастую совершенно неожиданных источников, откуда всякие промо-цены и берутся. То есть primary key для строчек не только нету, но и даже суррогатный-то на лету не так сразу получишь, так как никаких CTID (или там ROWID) в помине нету... Второй нюанс — это тут я оставил только колонки **price1**, **cost1** и **bonus1**, а в настоящем источнике данных много всяких характеристик нужно было вытащить из последней 'R'-строки, так как на рекламных строках эти данные отсутствуют. И не спрашивайте, почему так — бизнесу виднее. Считайте расширенным условием задачи — выбрать все эти поля из последней R-записи.
Что ж, прошу в каменты с идеями и вариантами решений! Через мифический человеко-месяц будет подведение итогов и разбор решения. Решения в комментариях будут проверяться на PostgreSQL, так что можно пользоваться (но не злоупотреблять!) платформозависимыми особенностями. Большая просьба SQL-код убирать под спойлеры, чтобы не светить его тем, кто хотел бы попробовать свои силы в решении. Для не имеющих постгреса под руками, есть масса возможностей запустить запрос онлайн, так что за отмазку не засчитывается. Да и поставить работающий постгрес из штатных репозиториев ОС под любым не слишком экзотическим Linux можно буквально в одну команду.
P.S. Так как опубликовано в корпоративном блоге Постгрес Про, то будем пользоваться корпоративными привилегиями. Для стимуляции активности за самое интересное решение выдам какие-нибудь плюшки от лица компании, промокод на PGConf или на сдачу тестов по сертификации...
P.P.S. Разбор решения тут: <https://habr.com/ru/company/postgrespro/blog/557300/> | https://habr.com/ru/post/546768/ | null | ru | null |
# Опыт использования виртуализации на VirtualBox
*Уровень: начинающим*
Опыт использования виртуализации на VirtualBox
==============================================
Введение
--------
Несколько лет назад я начал разбираться с вируализацией, и у меня получились своего рода путевые заметки, которые я сейчас оформил и выкладываю сюда. Никаких откровений тут не будет, статья адресована начинающим админам. Задача которую я здесь решаю состоит в том, чтобы виртуализовать уже имеющиеся не виртуальные сервера на Linux и FreeBSD.
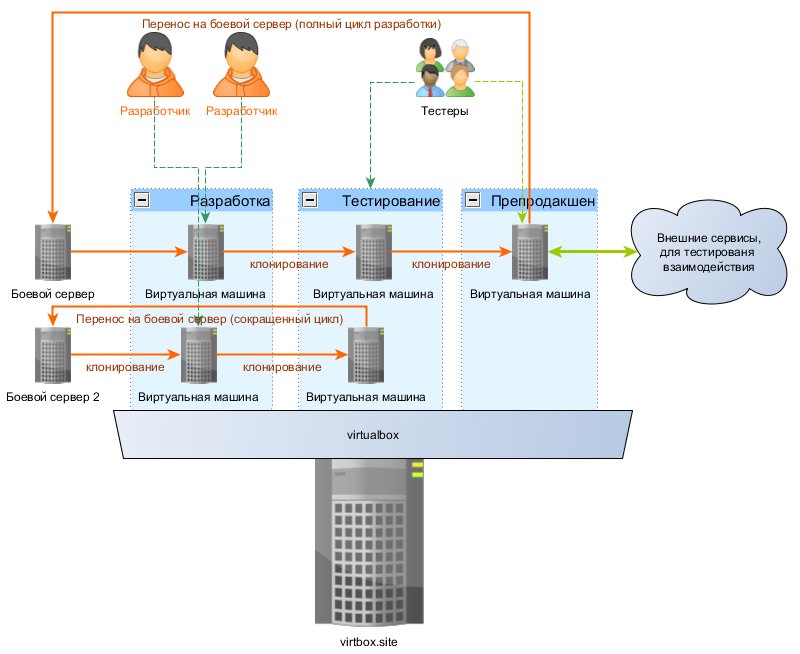
Причины, по которым я тогда выбрал VirtualBox
---------------------------------------------
Причины представлены ниже:* Простота использования
* Отличное руководство, подробно описывающее все аспекты работы VirtualBox
* Наличие отличных графического, консольного и web-интерфейса
* Возможность предоставления доступа к консоли гостевой ОС про протоколу RDP
* Удобство использования
[Полное руководство](http://download.virtualbox.org/virtualbox/UserManual.pdf) пользователя VirtualBox доступно на сайте производителя.
Причины, по которым я не выбрал бы его сейчас
---------------------------------------------
* Отсутствие хороших web-морд. Имеющийся web-интерфейс, несмотря на то, что он позволяет совершать с виртуальными машинами большинство требуемых действий (создание, снимки, удаление, создание виртуальных сетей), и реализован очень качественно, обладает следующими ограничениями:
+ Не позволяет назначать права на виртуальные машины (предоставления доступа разработчиками по списку только к своим машинам)
+ Не позволяет управлять несколькими физическими серверами из одной панели управления
+ Не отображает статистику по загрузке сервера
+ Пишется сторонними разработчиками, не имеющими отношения к VirtualBox, в их свободное время, из-за чего вызывает опасение возможность прекращения его развития
* [Более медленная работа](http://www.ilsistemista.net/index.php/virtualization/12-kvm-vs-virtualbox-40-on-rhel-6.html?start=4) при большом количестве запущенных виртуальных машин по сравнению с KVM.
* Оговорка в лицензии
Подготовка ОС для работы с виртуальными машинами
------------------------------------------------
VirtualBox можно установить практически на любую ОС, однако стабильная работа и все его возможности (например, RDP-подключение к консоли гостевой системы) доступны только на Линуксе, поэтому был выбран Debian Linux. Для самого VirtualBox специальной настройки ОС не требуется, достаточно выделить отдельный раздел для хранения образов дисков гостевых систем и образов установочных дисков для чистой установки гостевых систем.
Однако для управления VirtualBox через Веб-интерфейс (phpvirtualbox) требуется веб-сервер (выбран Apache 2) и PHP 5. В Debian конфигурация по умолчанию PHP 5 и Apache 2 удовлетворяет требованиям phpvirtualbox, специальным образом настраивать ничего не нужно.
Описание конфигурации сервера для виртуалок:
* cервер имеет имя virtbox.site и адрес 10.0.0.7 (кстати, поищите почему не нужно использовать .local)
* Раздел для хранения образов гостевых ос создан на отдельном жестком диске и примонтирован в /srv/vdi
* Установлены пакеты Apache 2 и PHP 5: virtbox# apt-get install apache2 php5
Установка phpvirtualbox
-----------------------
Для Virtualbox существует бесплатный web-интерфейс, реализованный на PHP и использующий встроенную в virtualbox службу удаленного управления virtualbox web service.
Устанавливаем phpvirtualbox:
1. На [сайте разработчика](http://code.google.com/p/phpvirtualbox/) смотрим последнюю версию и скачиваем ее на сервер:
`virtbox# cd /var/www && wget phpvirtualbox.googlecode.com/files/phpvirtualbox-4.1-7.zip`
2. Распаковываем:
`virtbox# unzip phpvirtualbox-4.1-7.zip`
3. Конфигурируем:
`virtbox# cd phpvirtualbox-4.1-7.zip && cp config.php-example config.php && vim config.php`
4. Прописываем адрес сервера, на котором работает VirtualBox, для удаленных подключений с помощью встроенного в VirtualBox RDP-plugin:
`var $consoleHost = '10.0.0.7';`
Внимание! Для успешных подключений на сервере должны быть открыты входящие порты, по умолчанию начиная с 3389 (TCP), по одному порту на гостевую систему.
5. Настраиваем virtualbox web service, для чего создаем файл /etc/vbox/vbox.cfg со следующим содержанием:
`VBOXWEB_USER='vbox'
VBOXWEB_HOST=127.0.0.1
VBOXWEB_LOGFILE=/srv/log/vboxwebservice`
6. Запускаем virtualbox web service, перед этим нужно убедиться в том, что файл /srv/log/vboxwebservice доступен для чтения и записи пользователю vbox:
`/etc/init.d/vboxweb-service start.`
phpvirtualbox теперь доступен по адресу [virtbox.site/phpvirtualbox](http://virtbox.site/phpvirtualbox/).
Создание виртуальных машин
--------------------------
Создание виртуальных машины через web-интерфейс достаточно очевидно, нужно нажать в phpvirtualbox кнопку New и следовать инструкциям мастера. Ниже приводится выработанный опытным путем список настроек гостевых систем, достаточный для нормальной работы гостевых Linux и FreeBSD.
1. System
1. Base Memory: 512 MB
2. Processor(s): 1
3. Enable PAE/NX: NO — эмуляция поддержки работы с более чем 4 ГБ памяти для 32-битных систем как правило не нужна
4. Chipset: PIIX3 — в руководстве ничего не сказано про зависимость быстродействия от типа эмулируемого чипсета, поэтому выбираем по умолчанию
5. Extended features
1. Enable IO APIC — без включенной эмуляции APIC некоторые клонированные сервера работать не будут
2. Hardware clock in UTC time — как правило гостевые системы ожидают системное время в формате UTC, и эта опция отвечает за передачу гостевой ОС времени в UTC, а не в Local time сервера.
3. Display: 2 MB — минимально возможное значение, при установке этого значения в 1 MB rdp-подключения работать не будут. При создании новых машин можно оставить значение по умолчанию, предлагаемое phpvirtualbox.
4. Storage: где нужно создать образ диска
2. Network
1. Debian: Virtio — Debian с помощью гостевых расширений умеет понимать, что она работает в виртуальной машине, и использовать виртуальную сетевую карту, что дает очень большой выигрыш в производительности
2. FreeBSD: Intep PRO/1000 MT Server network card — для FreeBSD гостевого драйвера сетевой карты нет, поэтому выбираем эмуляцию самой быстрой карты из доступных. Во FreeBSD устройство называется em0.
3. Serial ports: Disabled
4. USB: Disabled
5. Shared Folders: None — возможность VirtualBox предоставлять доступ гостевой системе к файлам хост-системы как правило не нужна, проще воспользоваться scp или sftp
Для создания виртуальных машин через консоль следуют воспользоваться [руководством](http://download.virtualbox.org/virtualbox/UserManual.pdf), раздел 8.6.
Управление виртуальными машинами
--------------------------------
### Управление через веб-интерфейс
Управление виртуальными машинами через web-интерфейс тривиально, достаточно выделить нужную машину в phpvirtualbox и выбрать в интерфейсе требуемое действие, например Start, Stop (безусловное выключение, отправка сигнала о нажатии кнопки выключения питания, перезагрузка, сохранение состояние гостевой системы с возможностью впоследствии откатить ее состояние и приостановка работы гостевой системы с сохранением ее памяти на диск и возможностью впоследствии загрузки памяти с диска и продолжения работы).
По щелчку на гостевой системе правой кнопкой машины доступны операции ее настроек, удаления, просмотра логов и т.д.
Также стоит отметить возможность подключения к консоли гостевой системы, что аналогично подключению к реальной машине мыши и клавиатуры. Для этого нужно выделить нужную гостевую систему, выбрать вкладку Console в phpvirtualbox, задать размер экрана (для текстовых режимов работы гостевых ОС достаточно 800х600), нажать Connect и щелкнуть мышью по клиенту удаленного подключения (в котором выводится содержимое консоли гостевой системы). Управлять гостевой системой можно с момента включения.
### Управление через консоль
Для управления гостевыми система в VirtualBox используются утилиты VBoxManage и VBoxHeadless, подробное описание которых доступно в [руководстве](http://download.virtualbox.org/virtualbox/UserManual.pdf).
Запускать команды нужно от пользователя vbox, под которым работает сам VrtualBox, в случае запуска от другого пользователя или root VirtualBox не сможет найти файлы конфигурации виртуальных машин, которые хранятся в домашней директории пользователя Vbox, и выдаст ошибку.
Для перехода под пользователя vbox нужно сказать:
`su -s /bin/bash vbox`
Оболочку нужно указывать явно, потому что по умолчанию у пользователя vbox стоит оболочка /bin/false.
Ниже для примера приведены команды для включения, выключения и работы с образами дисков.
1. Запуск группы гостевых систем (можно сделать автоматическим при включении и перезагрузке сервера):
`for M in test1 test2 test3 ; do VBoxManage startvm $M --type=headless ; sleep 30 ; done`
Если не указывать sleep 30 некоторые машины могут не запуститься из-за очень интенсивного чтения с жесткого диска сервера при запуске и некоторые гостевые системы решат, что у них ошибка чтения с жесткого диска.
2. Выключение группы гостевых систем (можно сделать автоматическим при включении и перезагрузке сервера):
`for M in test1 test2 test3 ; do VBoxManage controlvm $M acpipowerbutton ; sleep 30 ; done`
Практически все машины понимают нажатие на кнопку выключения питания и смогут корректно завершиться.
3. Создание диска фиксированного размера для гостевой системы:
`VBoxManage createhd --variant Fixed --size 20000 --format vdi --filename test`
4. Преобразование образа диска из формата VirtualBox в формат, понятный другим виртуальным машинам:
`VBoxManage internalcommands converttoraw test1.vdi test1.raw`
### Подключение через RDP
К консоли виртуальных машин можно подключиться через RDP. В Windows нужно открыть Пуск->Все программы->Стандартные->Подключение к удаленному рабочему столу и указать адрес virtbox.test и порт, сопоставленный конкретной гостевой системе, который можно посмотреть в phpvirtualbox. Для удобства использования в параметрах подключения можно указать разрешение экрана 1024х768, тогда окно с подключением не будет занимать весь экран и перехватывать системные сочетания клавиш, такие как Alt+Tab.
Важное замечание: возможно одновременное подключение к одной гостевой системе нескольких пользователей. При этом все видят одно и то же, и все совершенные кем-либо действия видны остальным подключившимся. Для включения этой настройки нужно в настройках виртуальной машины в phpvirtualbox в разделе Display на вкладке Remote Display установить галочку Allow Multiple Connections.
### Создание снимков гостевых систем
Снимки дают возможность сохранения состояния гостевых систем и возврата к этому состоянию по требованию. Что это означает на практике?
* Можно попробовать различные запросы к базе данных на гостевой системе с возможностью после каждого запроса восстанавливать начальное системы
* Можно попробовать различные конфигурации взаимодействия сервисов на гостевой системе без необходимости вручную откатывать изменения во многих конфигурационных файлах в случае получения нерабочей системы
* И наконец это иногда удобный инструмент создания резервных копий, который позволяет сделать полный снимок рабочей машины и восстановить ее полностью за минимальное количество административных действий. Внимание! Не делайте этого с продукционными машинами.
При создании снимка гостевой системы занимаемое ею место на диске фактически не увеличивается, дополнительный объем будут занимать только измененные по сравнению с уже существовавшим образом диска гостевой машины данные. Например, если будет изменен файл /etc/rc.conf, измененная копия будет записана отдельно.
Для создания снимка через phpvirtualbox нужно:* Выделить гостевую систему, с которой нужно сделать снимок
* Перейти на вкладку «Snapshots»
* Нажать кнопку «Take Snapshot» (с изображением фотоаппарата)
* Ввести название снимка и комментарий
Для восстановления снимка через phpvirtualbox нужно:* Выделить гостевую систему, с которой нужно сделать снимок
* Выключить гостевую систему, нажав «Stop»>«Power Off»
* Перейти на вкладку «Snapshots»
* Выделить снимок, который нужно восстановить
* Нажать кнопку «Restore Snapshot» (с изображением компьютера со стрелкой вверх)
### Создание дампа
#### Debian Linux
Процедуры клонирования и восстановления приведены на примере сервера test1 на котором установлена Debian Linux (любой версии, начиная с 5 Lenny точно). Предполжим, что у нас имеются три раздела с тремя файловыми системами: `/, /var, /usr`
Сначала нужно установить dump:
`aptitude install dump`
Далее, для создания дампа клонируемого сервера на Debian необходимо от суперпользователя (root) или с помощью sudo дать следующие команды (как сделать так, чтобы не сдампило дампы, думайте сами):
`dump 0af test1.root /
dump 0af test1.var /var
dump 0af test1.usr /usr`
Здесь:
`0 -- дамп уровня 0
a -- не делать предположений о размере носителя, на который осуществляется дамп
L -- делать дамп со смотрированной ФС, при этом сначало делается снимок фс, дапм, потом дамп еще раз, чтобы не было поврежденных файлов. Linux так не умеет.
f -- делать дамп в файл вместо ленточного накопителя.`
Полученные файлики нужно переложить на сервер с VirtualBox.
#### FreeBSD
Процедуры клонирования и восстановления приведены на примере сервера test1 на котором установлена FreeBSD (любой версии, начиная с 6 точно). Предполжим, что у нас имеются три раздела с тремя файловыми системами: `/, /var, /usr`
Для создания дампа клонируемого сервера на FreeBSD необходимо от суперпользователя (root) или с помощью sudo дать следующие команды (опять напоминаю про дампание дампов):
`dump 0aLf test1.root /
dump 0aLf test1.var /var
dump 0aLf test1.usr /usr`
Здесь:
`0 -- дамп уровня 0
a -- не делать предположений о размере носителя, на который осуществляется дамп
f -- делать дамп в файл вместо ленточного накопителя.`
Анаглогино, полученные файлики нужно переложить на сервер с VirtualBox.
### Развертывание дампа
#### Debian Linux
1. Нужно сделать виртуальную машину, прицепить к ней диск и загрузочный LiveCD Debian.
2. Затем нужно примонтировать получившийся раздел, зачать на него дампы, развернуть их:
`cd /mnt1 && restore -rf /mnt/test1.root && cd usr && restore -rf /mnt/test1.usr &&
cd ../var && restore -rf /mnt/test1.var`
3. Установить загрузчик:
`grub-install /dev/sda1`.
4. Поправить UUID в `/etc/fstab`
5. Проверить, чтобы в `/boot/grub/grub.cfg` были правильно указаны UUID разделов:
`search --no-floppy --fs-uuid --set df7f92ba-2877-4b39-8805-966cf9ab52f3
linux /boot/vmlinuz-2.6.32-5-amd64 root=UUID=df7f92ba-2877-4b39-8805-966cf9ab52f3 ro quiet`
6. Проверить `/var/spool/cron/crontabs, /etc/crontab` и отключить то, что ненужно.
7. Если на восстанавливаемом сервере была включена консоль, то убрать из `/etc/inittab` строчку похожую на следующую:
`T0:23:respawn:/sbin/getty -L ttyS0 9600 vt100`, а и из `/etc/default/grub` такую:
`GRUB_TERMINAL=console` (достаточно закомментировать).
#### FreeBSD
Созданные дампы нужно развернуть на образе диска, выделенного под гостевую систему. В настоящие время поддержка файловых систем UFS используемых во FreeBSD ограниченна, поэтому для развертывания дампов создается виртуальная машина FreeBSD, к ней подключается раздел для хранения дампов, на который с помощью scp и пересылаются дампы с клонируемых серверов. Потом к этой машине подключается образ диска выделенный под гостевую систему, на этом образе создается файловая система FreeBSD и разворачивается полученный дамп.
Далее предполагается, что раздел tmp примонтирован в /mnt, образ диска для гостевой ОС размечен под два слайса, первый из которых примонтирован в mnt1, а второй отдан под swap и не примонтирован. Тогда развернуть дамп можно следующим образом:
`cd /mnt1 && restore -rf /mnt/test1.root && cd usr && restore -rf /mnt/test1.usr &&
cd ../var && restore -rf /mnt/test1.var`
Здесь && нужно для того, что следующая команда выполнится только в случае успешного завершения предыдущий, и таким образом исключаются ситуации, когда например каталог var не будет создан, переход в него не осуществится и разворачивание дампа произойдет не туда, т.к. разворачивание дампа производится относительно текущей директории.
### Необходимые изменения в конфигурации гостевой ОС клонированного сервера
До загрузки гостевую ОС нужно перенастроить для работы в виртуальной машине. Количество требуемых действий как правило минимально и сводится к следующему:
1. Находясь в директории mnt1 (см. выше) удаляем файлы конфигурации загрузчика. Это особенно актуально, если виртуализуем какой-нибудь продукционный сервер, чтобы исключить использование COM-порта в качестве консоли по умолчанию, что приводит к зависанию загрузчика.
`rm /mnt1/boot.config
rm /mnt1/boot/device.hints`
2. Заменить содержимое файла `/mnt1/etc/fstab` следующим:
`/dev/ad0s1b none swap sw 0 0
/dev/ad0s1a / ufs rw 2 2`
При этом предполагается, что образ диска гостевой ОС разбит на 2 слайса, первый из которых отдан под хранение данных и второй под swap.
3. Если нужно, сказать клонированной системе о необходимости загрузки модуля ядра для работы с эмулированной сетевой картой, для чего нужно в файле `/boot/loader.conf добавить строчку if_em_load="YES"`
4. Указать клонированное системе выделенный для нее IP-адрес, для чего в `/etc/rc.conf` нужно закомментировать строчку текущих настроек сетевого адаптера и добавить новую строчку следующего вида:
`ifconfig_em0="inet 10.0.0.8/24"`
6. Если клонированному серверу выделяется видимый снаружи IP-адрес, то нужно удалить его настройки, отвечающие за его взаимодействие с другими серверами. Внимание! У клонированного сервера есть все настройки настоящего, поэтому теоретически возможно, что если настройки не удалить, то клонированный сервер будет мешать работе боевой системы. Главное место, которое нужно проверить на FreeBSD-based серверах, находится в `/var/cron/tabs/`.
7. Выключить FreeBSD, использованную для разворачивания дампа, и загрузить гостевую систему с клоном сервера. В случае проблем при загрузке возможно, что ядро на системе было пересобрано с измененной конфигурацией, это можно исправить сказав загрузчику загрузить ядро по умолчанию, которое я надеюсь вы сохранили в системе во время пересборки:
`unload
load boot/kernel.GENERIC/kernel
boot`
Для отдачи этих команд необходимо включить гостевую систему, подключиться к ней по RDP и дождаться появления на экране сообщений о том, что можно нажать Enter для указания опций загрузчику.
8. Добавить пользователя для доступа по ssh, зайдя через RDP на клонированный сервер:
`pw user add username -g wheel && passwd username`
Здесь опция `-g wheel` добавляет пользователя в группу wheel, члены которой во FreeBSD обладают правом делать sudo и su.
Создание виртуальных сетей
--------------------------
Внутри VirtualBox можно создавать полностью изолированные виртуальные сети. Какие возможности это дает?
Минимизация необходимости перенастройки клонированных серверов
Создание тестовой среды для отработки взаимодействия серверов между собой
### Создание виртуальной сети
Чтобы создать виртуальную сеть нужно в phpvirtualbox зайти в свойства гостевой системы, перейти в раздел Network, выбрать в поле «Attached to» опцию «Internal Network», а в выпадающем списке «Name» выбрать требуемую виртуальную сеть. Какие могут возникнуть сложности?
Нужно создать новую виртуальную сеть, а такой опции в интерфейсе нет. Есть два варианта решения:
Попробовать написать имя новой виртуальной сети прямо в выпадающем списке «Name». Однако в этом случае может возникнуть ошибка.
Тогда нужно привязать сетевой адаптер гостевой системы к виртуальной сети через CLI:
`sudo su -s /bin/bash vbox
VBoxManage modifyvm test1 --nic1 intnet`
Здесь
nic1 — сетевой адаптер гостевой системы, где 1 это его порядковый номер. Количество адаптеров в гостевой системе не ограничено
intnet — виртуальная сеть, название может быть любым. Особенность работы VirtualBox заключается в том, что специально создавать виртуальные сети не нужно, достаточно указать нескольким гостевым системам одну и ту же виртуальную сеть и они окажутся связанными на (эмулированном) физическом уровне автоматически, что аналогично подключению нескольких реальных компьютеров к одному свитчу (коммутатору).
Более подробная информация находится в разделе 8.7.2 Networking setting руководства пользователя.
Управление недоступными снаружи машинами в виртуальной сети
-----------------------------------------------------------
### Доступ по RDP
RDP-сервер работает на физическом сервере, поэтому для подключения к любой виртуальной машине справедливо написанное в разделе Управление через веб-интерфейс этой статьи.
### Проброс портов
Существует возможность создать в гостевой системе виртуальную сетевую карту с подключением через NAT (реализуемый автоматически средствами VirtualBox) и пробросить (отобразить) произвольный порт гостевой системы на порт сервера VirtualBox. Для того, чтобы сделать это через phpvirtualbox, нужно:
1. Зайти в свойства гостевой системы, перейти в раздел «Network», выбрать в поле «Attached to» опцию «NAT»
2. Раскрыть опции, скрывающиеся в разделе «Advanced» этого же раздела, и нажать там кнопку Port Forwarding
3. В открывшемся окне «Port Forwarding Rules» указать следующие параметры:
4. Нужный протокол, путем щелчка мышью по именованию «TCP» в поле «Protocol»
5. Указать свободный порт на сервере VirtualBox в поле «Host Port»
6. Указать порт гостевой системы в поле «Guest Port».
Больше ничего указывать не нужно. После применения настроек порт гостевой системы станет немедленно (без перезагрузки) доступен через соответствующий порт сервера VirtualBox. Как пример, в случае с пробросом порта ssh (22 TCP) гостевой системы на 2200 порт VirtualBox нужно указать следующие параметры:
`Параметр Значение
Name ssh (необязательный параметр)
Protocol TCP
Host IP Не указывать
Host Port 2200
Guest Port 22
Guest IP Не указывать`
Количество отображаемых портов не ограничено, можно отобразить столько, сколько нужно.
### Виртуальный маршрутизатор
В случае создание в VirtualBox группы взаимодействующих гостевых систем без внешних адресов имеет смысл установить еще одну гостевую систему, которая будет играть роль маршрутизатора. Какие цели при этом достигаются?
Конфигурацию сетевых адаптеров клонированных сервером можно не менять. При этом виртуальный маршрутизатор создает для остальных гостевых систем видимость того, что они настоящие и пользуются своими настоящими именами хостов и IP-адресами
К гостевым системам не имеющим ни внешних адресов, ни описанной выше возможности проброса портов, которая работает только в случае использования NAT опции VirtualBox, становится возможен прямой доступ по ssh.
Создание создание виртуального маршрутизатора состоит из следующих шагов:
* Создание гостевой системы
* Установка на гостевую систему любой ОС, которая может играть роль маршрутизатора, например Debian Linux или FreeBSD
* Ввод гостевой системы в виртуальную сеть как описано выше
* Настройка гостевой системы для выполнения функций маршрутизатора
* Подключение к гостевой системе второго виртуального сетевого адаптера в режиме моста с сетевым адаптером сервера VirtualBox
После этого можно пробрасывать порты с виртуального маршрутизатора на гостевые системы без внешних адресов. В случае Linux c iptables для проброса входящих соединений с 2200 порта протокола TCP виртуального маршрутизатора на 22 порт (TCP) гостевой системы без внешнего адреса c внутренним адресом 192.168.0.2 достаточно следующего правила:
`iptables -t nat -A ROUTING -p tcp -i eth0 --dport 2200 -j DNAT --to-destination 192.168.0.2:22`
При этом предполагается, что виртуальный маршрутизатор настроен правильно и имеет сетевой адаптер, настроенный на работу с виртуальной подсетью в которой находится гостевая система с адресом 192.168.0.2
### Доступ по SSH
В соответствии с вышеприведенным примером можно зайти по ssh на гостевую систему без внешнего адреса указав в ssh-клиенте адрес виртуального маршрутизатора и порт 2200. Аналогично можно зайти по scp для передачи файлов на гостевую систему. | https://habr.com/ru/post/142963/ | null | ru | null |
# Инжиниринг признаков в предварительной обработке данных
Привет, Хабр! На связи Рустем IBM Senior (помидор) DevOps Engineer и сегодня я хотел бы поговорить про Feature Engineering in Data Preprocessing.
Наши реквизиты: Python 3.6 и pandas.
Кодовая база: https://github.com/zetzo/Data-Preprocessing-Feature-Engineering.git
#### Что такое инженерия признаков/конструирование показателей?
*Инжиниринг признаков* — это создание новых признаков на основе существующих признаков, и он добавляет в ваш набор данных информацию, которая в некотором роде полезна: добавляет признаки, полезные для вашего прогноза или задачи кластеризации, или упускает понимание взаимосвязей между признаками. Реальные данные часто бывают нечеткими и аккуратными, и в дополнение к этапам предварительной обработки, таким как стандартизация, вам, вероятно, придется извлекать и расширять информацию, которая существует в столбцах вашего набора данных.
Feature engineering, более простыми словами — это техника решения задач машинного обучения, позволяющая увеличить качество разрабатываемых алгоритмов. Предусматривает превращение данных, специфических для предметной области, в понятные для модели векторы.
Разработка признаков сильно зависит от конкретного набора данных, который вы анализируете, поэтому очень важно иметь глубокое понимание набора данных, который вы хотите смоделировать.
Давайте рассмотрим несколько примеров, когда мы хотели бы заинжинирить наши показатели. Чрезвычайно распространенный — со строковыми данными.
Например, это ситуация, когда мы можем захотеть извлечь количество миль в качестве числового признака для моделирования из текста.
Еще один пример, связанный со строковыми данными: набор данных со столбцом, в котором записаны любимые цвета людей.
Чтобы ввести эту информацию в модель в scikit-learn, вам придется закодировать эту информацию численно.
Давайте посмотрим на набор данных добровольцев и определим некоторые возможности для разработки признаков:
Эти три столбца являются хорошими кандидатами для инжиниринга. `recurrence_type` — бинарная категориальная переменная:
`created_date` — это дата, и в этом наборе данных есть несколько других столбцов даты, которые необходимо преобразовать перед моделированием:
И, наконец, `category_desc` — это категориальная переменная с несколькими значениями:
#### Извлечение признаков с помощью регулярных выражений
Регулярные выражения — это шаблоны, которые можно использовать для извлечения паттернов из текстовых данных. Вот у нас есть строка, и мы хотим извлечь из нее цифру температуры — 45,6:
Обратите внимание, что это число является числом с плавающей запятой. Нам понадобится шаблон для извлечения этого числа с плавающей запятой, который мы можем создать с помощью библиотеки re Python.
Давайте разберем шаблон в re.compile. `\d` означает, что мы хотим захватить цифры, а `+` означает, что мы хотим захватить как можно больше, поэтому, если есть два рядом друг с другом, нам нужны оба (например, 45). `\.` означает, что мы хотим захватить десятичную точку, а затем еще один `\d+` в конце, чтобы захватить цифры в правой части десятичной дроби.
Чтобы вернуть соответствующий шаблон, мы можем использовать `findall()`:
Обратите внимание, что `findall()` возвращает список строк совпавшего паттерна. В этой ситуации мы хотели бы вернуть температуру в виде числа с плавающей запятой. Поскольку мы знаем, что в нашей строке есть только одна температура, мы можем сделать следующее:
Это было бы немного сложнее в обстоятельствах, когда у нас есть несколько числовых экземпляров в строке, но на данный момент этого достаточно.
Давайте попробуем это на наборе данных для пеших прогулок. Столбец «Length» в наборе данных для походов представляет собой столбец строк, но в столбце содержится километраж похода. Мы собираемся извлечь этот пробег с помощью регулярных выражений, а затем использовать лямбду в pandas, чтобы применить извлечение ко всему DataFrame.
Во-первых, давайте создадим функцию, которая будет находить и возвращать пробег в виде значения с плавающей запятой. Создание функции немного упрощает ее применение ко всему DataFrame. В этой функции мы будем использовать isinstance() Python, чтобы убедиться, что мы обрабатываем строку — в противном случае произойдет сбой при отсутствующих значениях. Проверяя длину нашего списка, созданного с помощью `findall()`, мы определяем, есть ли совпадения, и если да, то возвращаем их.
Затем давайте применим к столбцу «Length» и создадим новый столбец только с пешеходным километражем:
Наконец, давайте сравним наш новый столбец с исходным столбцом, чтобы убедиться, что он работает:
#### Бинарное кодирование категориальных переменных
Поскольку модели в scikit-learn требуют числового ввода, если ваш набор данных содержит категориальные переменные, вам придется их кодировать. Кодирование двоичных значений на самом деле довольно просто и может быть выполнено как в pandas, так и в scikit-learn. Вы можете захотеть закодировать переменные в pandas, если вы не закончили предварительную обработку или если вы заинтересованы в дальнейшей исследовательской работе после кодирования. С другой стороны, вы можете захотеть использовать scikit-learn, если, например, вы реализуете кодирование как часть функциональности конвейера scikit-learn, что позволяет вам объединять различные части процесса машинного обучения.
Давайте рассмотрим пример с использованием набора данных для пеших прогулок. Один столбец, который нуждается в кодировании, — это столбец Accessible, который имеет значения либо Y, либо N.
В pandas мы можем использовать `apply()` для кодирования 1 и 0 в столбце DataFrame, используя простое условие, которое возвращает 1, если значение в Accessible равно Y, и 0, если значение равно N.
Глядя на параллельное сравнение столбцов, вы можете видеть, что столбец теперь имеет числовое кодирование.
Вы также можете сделать это в scikit-learn, используя LabelEncoder. Создание объекта LabelEncoder также позволяет повторно использовать эту кодировку для других данных, таких как новые данные или тестовый набор. Вы можете использовать `fit_transform()` как для подгонки кодировщика к данным, так и для преобразования столбца.
Распечатав Accessible и его закодированные аналоги, мы видим, что значения Y и N были закодированы в 1 и 0 одинаковым образом как в pandas, так и в scikit-learn.
#### Кодирование категориальных переменных, One-Hot
One-hot кодирование кодирует категориальные переменные в 1 и 0, когда у вас есть более двух переменных для кодирования. Он работает, просматривая весь список уникальных значений в столбце, преобразуя каждое значение в массив и назначая 1 в соответствующей позиции для кодирования того, что конкретное значение встречается.
Давайте посмотрим на игрушечный пример, чтобы увидеть, как это работает, взяв небольшой набор данных цветов:
Здесь у нас есть три значения: `blue`, `green` и `red`. Чтобы сразу закодировать эти значения, мы можем использовать `get_dummies()` для создания столбцов для каждого.
Чтобы объединить эти столбцы с исходными данными, вы можете использовать pd.concat:
Если бы мы кодировали эти цвета с помощью 0 и 1 на основе этого списка, мы получили бы что-то вроде этого: `blue` будет иметь единицу в первой позиции, за которой следуют два нуля, `green` будет иметь единицу во второй позиции, а `red` будет иметь один в последней позиции. Таким образом, закодированный столбец будет выглядеть примерно так, где значение 1 указывает, что этот цвет появился в исходном столбце в этой конкретной строке.
Один из столбцов в наборе данных о волонтерах, `category_desc`, дает описания категорий для перечисленных вакансий волонтеров. Поскольку это категориальная переменная с более чем двумя категориями, давайте потренируемся использовать однократное кодирование для численного преобразования этого столбца:
Наконец, мы можем объединить их обратно в DataFrame и взглянуть на несколько строк и их кодировку:
#### Агрегация статистики
Если у вас есть, скажем, набор функций, связанных с одной функцией, такой как температура или время работы, вы можете вместо этого использовать среднее значение или медиану в качестве функции для моделирования.
Обычный метод разработки признаков состоит в том, чтобы взять совокупность набора чисел для использования вместо этих признаков. Это может быть полезно для уменьшения размерности вашего пространства признаков или, возможно, вам просто не нужны несколько одинаковых значений, которые находятся на близком расстоянии друг от друга.
Допустим, у нас есть DataFrame времени работы с именем `running_times_5k`:
Вместо того, чтобы использовать каждое отдельное время выполнения для построения нашей модели, давайте использовать среднее значение этих пяти запусков для каждого человека в наборе данных.
Давайте создадим список столбцов, которые мы хотим усреднить, просто чтобы упростить задачу:
И снова мы можем использовать `apply()` для применения функции к нашему набору данных. В этой ситуации мы применяем метод `mean()` только к тем столбцам, которые хотим усреднить, а `axis=1` будет возвращать значения по строкам:
И теперь у нас есть столбец агрегированного среднего.
#### Работа с datetimes
Даты и временные метки — это еще одна область, в которой вы можете уменьшить степень детализации набора данных. Если вы выполняете анализ временных рядов, это, вероятно, другая история, но если вы выполняете задачу прогнозирования, вам может понадобиться информация более высокого уровня, например месяц или год, или и то, и другое.
В наборе данных добровольцев есть несколько столбцов, состоящих из даты и времени.
Предположим, что полная дата слишком детализирована для задачи прогнозирования, которую мы хотим выполнить, поэтому давайте извлечем месяц из столбца `start_date_date`.
Первое, что нужно сделать, это преобразовать этот столбец в столбец даты и времени в pandas, используя метод `to_datetime()`. Это значительно упрощает задачу извлечения:
Поскольку этот столбец теперь является датой и временем, мы можем просто использовать атрибут `.month`, чтобы извлечь месяц из каждой строки, снова используя `apply()`:
Теперь у нас есть столбец только с номером месяца. Вы также можете использовать такие атрибуты, как «day», чтобы получить день:
И «year», чтобы получить год:
Для многих операций даты и времени, особенно связанных с анализом временных рядов, ваш столбец даты и времени должен быть индексом вашего DataFrame. Однако это все, что нам нужно знать, чтобы продолжить наше путешествие по разделу “Data Preprocessing in Data Engineering”.
---
> Всех желающих приглашаем на открытое занятие **«Greenplum Platform Extension Framework (PXF)»**. На этом занятии вместе с Вадимом Заигриным, Scala Big Data разработчиком рассмотрим фреймворк PXF (Platform Extension Framework): узнаем, что это и зачем он нужен, а также рассмотрим его архитектуру и принципы работы. Регистрация [по ссылке.](https://otus.pw/yMfL/)
>
> | https://habr.com/ru/post/679554/ | null | ru | null |
# Lexical Analysis in 11l
This article discusses the lexical analyzer, which is an integral part of any compiler.
The task of the lexical analyzer is to split the source code of the program into tokens.
So for example the code
```
print(1 + 2)
```
will be tokenized as
`print`, `(`, `1`, `+`, `2` and `)`
### Significance of indentation
Historically, compilers for most programming languages strip away all whitespace characters such as space, tab, and newline.
What does this mean? It means the compiler sees the source code like this:
```
if (foo)
if (bar)
m1();
else
m2();
```
↓
`if`, `(`, `foo`, `)`, `if`, `(`, `bar`, `)`, `m1`, `(`, `)`, `;`, `else`, `m2`, `(`, `)`, `;`
This code is taken from [the Nemerle programming language documentation](https://github.com/rsdn/nemerle/wiki/The-basics-(tutorial)#Rewriting_Line_Counter_without_the_loop). It contains a so-called dangling else bug: when looking at this code, you might think that the “else” branch refers to the condition “foo”, whereas in programming languages with C-like syntax (including C++, C#, Java and others) the “else” branch refers to the condition “bar”.
As a solution to this problem, the developers of the Nemerle language introduced a rule that an “if” statement must always have an “else” branch, and if the “else” branch is not required, then the “when” statement should be used instead of “if”.
In many new programming languages, such as Swift, Rust, and Go, the use of curly braces is mandatory even if the body of the “if” [or other control statement] is only one line. When curly braces are used, the problem disappears:
```
if (foo) {
if (bar) {
m1();
}
}
else {
m2();
}
```
Some coding standards, for example those [from Oracle](https://docs.oracle.com/cd/E12517_01/back_office/pdf/141/html/pos_impg2/developmentstandards.htm "<- google:‘oracle coding standard’"), [from Stanford University](https://stanford.edu/class/archive/cs/cs106b/cs106b.1158/styleguide.shtml "<- https://tproger.ru/translations/stanford-cpp-style-guide/ <- google:‘c++ code style’") or [Carnegie Mellon University](https://wiki.sei.cmu.edu/confluence/display/c/EXP19-C.+Use+braces+for+the+body+of+an+if,+for,+or+while+statement), require the bodies of “if” and “else” statements to be enclosed in curly braces, to avoid the possibility of this bug:
```
int login;
if (invalid_login())
login = 0;
else
printf("Login is valid\n");
login = 1;
```
Here the line `login = 1;` will be executed in any case, no matter what value is returned by the `invalid_login` function.
But in both of the above cases, the problem is not at all that “if” [allowing an “else” branch to be either absent or present] expresses the wrong logic, or even that the curly braces were forgotten: it is… the discrepancy between the way this code is perceived by the human programmer and by the compiler. A human being perceives block boundaries visually, using indentation as a guide; but the compiler makes use of symbols [which a human hardly notices]. What is more, the compiler [for C/C++, C#, Java, Nemerle, etc.] treats all whitespace characters in the same way, and, thus, completely ignores the indentation. This is where **the root of the problem lies: the compiler and the human see code like this differently**.
And to solve this problem, the compiler must somehow take indentation into account [so that the code examples given earlier either work as the programmer expects, or give an error at the compilation stage (or at least a [warning](https://developers.redhat.com/blog/2016/02/26/gcc-6-wmisleading-indentation-vs-goto-fail "<- google:‘Wmisleading-indentation’"))].
For this reason, it was decided to provide the new programming language 11l with a lexical analyzer that takes indentation into account.
Now let's look at the implementation process. A brief description of the algorithm for parsing indentation is given in the [Python programming language documentation](https://docs.python.org/reference/lexical_analysis.html#indentation). In short, the algorithm works like this: at the beginning of each line, the indentation level is compared to the value on the top of a special stack. If it is larger, then it is pushed onto the stack and the lexer generates an INDENT token. If it is smaller, then all values exceeding the current line indentation level are removed from the stack and a DEDENT token is generated for each value removed. Further, at the end of the source file, a DEDENT is generated for each value remaining on the stack.
In addition to the fact that the lexical analyzer of the 11l language takes indentation into account, like the lexical analyzer of the Python language, the new language adds support for curly braces, which makes it possible to write code on one line or without indentation:
| |
| --- |
| With indentation:
```
fn sum(a, b)
return a + b
```
On one line:
```
fn sum(a, b) {return a + b}
```
Without indentation:
```
fn sum(a, b)
{
return a + b
}
```
|
In addition, code can be written using both indention and curly braces.
**Here is how it works (in brief)**
The indentation levels stack (`indentation_levels`) in 11l, in contrast to the lexical analyzer of the Python language, stores not just the indentation level but also a flag that is set to true whenever a new block of code is formed by the symbol `{`, rather than by increasing the indentation level. The indentation level is then set to `-1`.
The `{` character is immediately followed by a new, arbitrary {i.e. lowering the indentation level is allowed} indentation level {its level is set instead of `-1`}, which remains in effect up to the matching `}` character.
Here is a [link](https://github.com/11l-lang/_11l_to_cpp/blob/529675344a73eac5cb313b5e22ab11191f2a1493/tokenizer.py#L212) to the corresponding source code.
This solution is the most versatile, and will suit both those who prefer using curly braces and those who prefer indentation.
All popular [indentation styles](https://en.wikipedia.org/wiki/Indentation_style) are supported:
| Allman | K&R | GNU |
| --- | --- | --- |
|
```
if x == y
{
something()
somethingelse()
}
```
|
```
if x == y {
something()
somethingelse()
}
```
|
```
if x == y
{
something ()
somethingelse ()
}
```
|
| Whitesmiths | Ratliff |
|
```
if x == y
{
something()
somethingelse()
}
```
|
```
if x == y {
something()
somethingelse()
}
```
|
### Automatic line joining
In addition to splitting the source code of a program into tokens, the lexical analyzer is also charged with determining statement boundaries. [Although in some programming languages (like [JavaScript or Kotlin](https://temperlang.dev/design-sketches/parsing-program-structure.html#syntactic-asi)) assistance from the parser is required.]
Traditionally, a semicolon is used in C-like programming languages (C++, C#, Java, D) as a statement terminator. However, most new programming languages (e.g. Swift, Go, Kotlin, CoffeeScript, Nim, Julia, Crystal, and others) allow the semicolon to be omitted, by using the newline character as the end of a statement. [[I am not the only one to have noticed this trend.](https://elizarov.medium.com/the-end-of-the-semicolon-era-60ab95e669ab)]
But the question then arises: when do two consecutive lines of source code represent parts of the single statement, and when are they two different statements? And different programming languages solve this problem in different ways.
Python [uses](https://docs.python.org/3/reference/lexical_analysis.html#implicit-line-joining) one simple rule for implicit line joining: if a line contains an unclosed parenthesis, square bracket, or curly brace, then it concatenates with following lines until all matching parentheses/brackets/braces are closed.
Go [uses](https://golang.org/doc/effective_go#semicolons) the rule: if the newline comes after a token that could end a statement, then the statement is ended. However, this rule imposes significant restrictions on coding style.
For example, in an “if” statement, the curly brace that opens a block must be on the same line — moving it down to the next line is not allowed. The “else” statement [must](https://stackoverflow.com/questions/26371645/unexpected-semicolon-or-newline-before-else-even-though-there-is-neither-before "<- google:‘go lang semicolons problem’") also appear on the same line as the closing curly brace.
| Right | Wrong |
| --- | --- |
|
```
if i < f() {
g()
}
```
|
```
if i < f()
{
g()
}
```
|
|
```
if x < 0 {
return -1
} else {
return 1
}
```
|
```
if x < 0 {
return -1
}
else {
return 1
}
```
|
JavaScript uses a rather complex [system of rules](http://www.ecma-international.org/ecma-262/6.0/index.html#sec-automatic-semicolon-insertion) to carry out automatic semicolon insertion.
```
a = 1
b = 2
```
In this example, a semicolon will be automatically inserted at the end of the first line, since `a = 1 b = 2` [is not a valid statement](https://slides.com/evanyou/semicolons/#/14).
However, in some cases a semicolon is not inserted, leading the code to function incorrectly.
For example, the following two lines of JavaScript code will be mistakenly joined into one.
```
a = b + c
[d, e] = [e, d]
```
And in this example, on the contrary, a semicolon will be erroneously inserted immediately after `return`.
```
return
"something";
```
That is, instead of returning a string `"something"`, the value `undefined` will be returned.
In most programming languages that allow semicolons to be omitted (for example, Python, Go, Kotlin, Ruby, Julia, and Nim), this code will not work:
```
r = 1
+ 2
```
Moreover, in Python, Go and Nim an error message will be displayed, while in Kotlin, Ruby and Julia the value of the variable `r` will be set to `1`.
To solve this problem, 11l uses the following 3 simple rules that are easily understood by both the programmer and the lexical analyzer:
1. If a line ends with a binary operator, then it is joined with the next line.
2. If a line begins with a binary operator, then it is joined with the previous line.
**(It is necessary to check that it is not a unary operator!)**
```
a = b
++i // the plus character at the beginning of this line should not be mistaken for the binary operator `+`
```
3. And also, just as in Python, a newline within expressions in parentheses or square brackets is ignored.
```
// 1.
if condition1 & // this line will be joined with the next one,
condition2 \\ since it ends with the binary operator `&`
some_func()
// 2.
some_variable = 2
+ 3 // this line will be joined with the previous one,
\\ since it starts with the binary operator `+`
// 3.
some_func( // since this line includes an unclosed parenthesis, all
argument1, \\ subsequent lines will be joined until
argument2) \\ the parenthesis is closed
```
### Semicolons
While it is not necessary to use a semicolon to mark the end of statements in 11l, semicolons can be used to place multiple statements on one line:
```
a = 1; b = 2; c = 3
```
But, for example, in Python it is not obvious what this line of code corresponds to:
```
if b: print(1); print(2)
```
| | |
| --- | --- |
| This code in Python: |
```
if b:
print(1)
print(2)
```
|
| Or this: |
```
if b:
print(1)
print(2)
```
|
| | |
| --- | --- |
| This code in 11l: |
```
if b {print(1); print(2)}
```
|
| Or this: |
```
if b {print(1)}; print(2)
```
|
Python's behavior in this case is logical in principle, but not obvious.
The behavior of 11l, by contrast, is both logical and obvious.
Furthermore, it is impossible to write a one-line function like this in Python:
```
def f(x): if x: print(x)
```
But in 11l, it is possible:
```
fn f(x) {if x {print(x)}}
```
### Always room for improvement
In my anything but humble opinion, 11l implements the most advanced lexical analyzer of all currently existing programming languages. However, it can still be improved.
For example, the third automatic line joining rule could be dropped, to support code like this:
```
set_timeout(
1.0,
fn ()
alert(‘!’)
,
0
)
```
In this case, the third rule must be replaced with the following two rules:
* If a line ends with an opening parenthesis (`(`) or square bracket (`[`), or a comma (`,`), then it is joined with the next line.
* If a line begins with a closing parenthesis (`)`) or square bracket (`]`), then it is joined with the previous line.
But since at the moment 11l parser does not support constructs of this kind {in particular, anonymous functions are not supported [instead, you can use "arrow" functions (for example, `(x, y) -> x + y`)]}, their implementation at the level of the lexical analyzer would make no practical sense.
In conclusion, I will provide links to the source code for the 11l lexical analyzer, which is available in three languages: [Python](https://github.com/11l-lang/_11l_to_cpp/blob/master/tests/python_to_cpp/_11l_to_cpp/tokenizer.py), [11l](https://github.com/11l-lang/_11l_to_cpp/blob/master/tests/python_to_cpp/_11l_to_cpp/tokenizer.11l) and [C++](https://github.com/11l-lang/_11l_to_cpp/blob/master/tests/python_to_cpp/_11l_to_cpp/tokenizer.hpp). | https://habr.com/ru/post/663872/ | null | en | null |
# ХабраГрамотность для всех
Привет хабрасообщество!
#### Оффтопик
Начну с наболевшего. Уже подготовил эту часть текста и захотел начать публиковать топик, как встретился с нововведением для меня — проверкой на то, что я читал правила Хабра. И вычитал там такие строки:
`**Хабр — для грамотных людей.** Мы любим русский язык и не любим тех, кто его коверкает. Ошибки и опечатки бывают у всех — старайтесь проверять текст перед отправкой. А постоянные орфографические ошибки и игнорирование правил пунктуации не приветствуются, а намеренное коверканье слов, «падонкоффский сленг» и мат очень скоро станут причиной бана.`
Это как раз то, что в последнее время все больше удручает на Хабре. И вот как-то в очередной раз читая топик, кишащий грамматическими ошибками, я понял — с этим надо что-то делать.
#### ХабраГрамотность
Сказано — сделано. За два дня разобрался в механизме экстеншенов в Chrome и написал на коленке первую версию помощника. Название пришло в голову сразу, основная функциональность тоже давно уже крутится в голове.
Итак, нам нужно уметь быстро, не мусоря в комментариях к топику, сообщить автору, что он не соблюдает правила уважаемого Хабра и ему стоит исправиться. Функцию эту я повесил на сочетание клавиш Alt+Enter. Кроме того, поместил кнопочку, напоминающую, что можно этой функцией пользоваться, в футер к каждой статье.

#### Последовательность действий
1. Выделяем ошибочное слово или выражение 
2. Нажимаем заветную кнопочку или сочетание клавиш Alt+Enter
3. Видим сообщение, говорящее нам о том, что все отправлено 
4. PROFIT!
#### Как получить и себе такую штуку
Скачать плагин можно с сайта [habraliteracy.appspot.com](http://habraliteracy.appspot.com). К сожалению, мне не удалось быстро разобраться почему то же самое не заработало под Greasemonkey, поэтому пока радуются «правильные» владельцы Google Chrome.
#### Планы развития
Самый главный план — понять насколько это интересует хабрасообщество и собрать пожелания. Уже сейчас я очень хочу сделать:
1. Добавить поддержку всех возможных браузеров.
2. Сделать возможность настраивать поведение. Например, изменить шаблон сообщения, поменять сочетание клавиш и т.д.
3. Объединение в ящике писем с ошибками по одному топику
4. Добавить возможность изменять и дополнять текст письма с ошибкой после нажатия сочетания клавиш
5. Поработать над дизайном сайта и встраиваемой кнопочки
6. Посылка кроме самой ошибки еще и текста, окружающего ее
ну и многое другое.
Welcome в комменты с замечаниями и предложениями!
**P.S.:** требуется помощь в разработке данного расширения. В основном дизайнерская. | https://habr.com/ru/post/115012/ | null | ru | null |
# Just backup btrfs
К btrfs приглядывался давно, даже на дисках с различными медиа-данными использовал около года, но расширенной функциональностью этой замечательной файловой системы не пользовался.
А вот появилось обновление — два новеньких SSD, было решено во время переноса системы заодно перейти на btrfs.
Всё отлично — RAID0 для данных RAID1 для метаданных средствами файловой системы, сжатие на лету, корень в одном суб-томе (subvolume), домашняя папка в другом, веб-сайты в третьем. Всё это грузится прямо с UEFI в Linux EFI stub без GRUB и других загрузчиков, работает быстро и удобно.
И вот дошло дело до снимков (snapshot), их я хотел использовать для резервных копий суб-томов средствами всё того же драйвера btrfs.
Поиск выдает несколько релевантных решений, но одни решения слишком громоздки (синхронизация резервных копий, через сеть, создание каких-то репозиториев, вложенных потоков и т.д.) и навязывают свою архитектуру, другие не имеют адекватной ротации резервных копий (можно указать только один интервал и количество копий в нём).
Решение принято — новому инструменту быть!
#### И что получилось?
Получился небольшой скрипт на PHP, который при запуске читает конфигурацию из простого JSON файла вида:
```
[
{
"source_mounted_volume" : "/",
"destination_within_partition" : "/backup/root",
"date_format" : "Y-m-d_H:i:s",
"keep_snapshots" : {
"hour" : 60,
"day" : 24,
"month" : 30,
"year" : 48
}
},
{
"source_mounted_volume" : "/home",
"destination_within_partition" : "/backup/home",
"date_format" : "Y-m-d_H:i:s",
"keep_snapshots" : {
"hour" : 120,
"day" : 48,
"month" : 60,
"year" : 96
}
}
]
```
И создает по указанному пути снимок, а так же при повторном запуске контролирует количество снимков, удаляя устаревшие.
В указанном примере конфигурации мы получим папку /backup, внутри которой будут отдельные папки для снимков корня и домашней папки. Снимки создаются только для чтения, таким образом мы имеем прямой доступ к любому снимку с сохранением прав доступа и без опасности повредить созданный снимок.
Так как btrfs поддерживает CoW (Copy on Write), то место занятое снимком определяется количеством и объемом измененных файлов с последнего снимка. При удалении снимка все файлы, которые есть только в нем, и больше нигде удаляются, освобождая свободное пространство.
Итого имеем мгновенный доступ к любому снимку и экономию занятого пространства (что вдвойне правда при наличии сжатия файловой системы).
#### Планы
Добавить сбрасывание последнего снимка (инкрементально) дополнительно на другой btrfs раздел, иначе получается не совсем резервное копирование, а просто машина времени.
Нужно будет добавить в readme настройку создания снимков перед установкой/удалением/обновлением пакетов (тут уже будет нужна помощь сообщества, так как пользуюсь Ubuntu, и не в курсе как сделать такое для систем с RPM или чем-то более экзотичным).
Хорошо было бы создать deb/rpm/? пакеты для популярных (и не очень) дистрибутивов, но раньше этого делать не приходилось, не в курсе что да как.
Возможно что-то ещё подскажете:)
#### Где взять
<https://github.com/nazar-pc/just-backup-btrfs>
Надеюсь, статья и решение будут полезными, делитесь рецептами использования btrfs в комментариях. | https://habr.com/ru/post/243727/ | null | ru | null |
# Создаем кэшируемую пагинацию, которая не боится неожиданного добавления данных в БД
Если на вашем сайте присутствует большое количество контента, то для отображения пользователю его приходится так или иначе делить.
Все известные мне способы имеют недостатки и я попытался создать систему, которая сможет решить некоторые из них и при этом не будет слишком сложна для реализации.
Существующие методы
-------------------
#### 1. Пагинация (разделение на отдельные страницы)
Пример с сайта habr.comПагинация или разделение на отдельные страницы — достаточно старый способ разделения контента, который, в том числе используется на Хабре. Основным преимуществом является его универсальность и простота реализации как со стороны сервера так и клиентской части.
Код запроса данных из бд чаще всего ограничивается парой строк.
Тут и далее примеры на языке arangodb aql, я скрыл код сервера т.к там пока ничего интересного.
```
// Возврат по 20 элементов для каждой страницы.
LET count = 20
LET offset = count * ${page}
FOR post IN posts
SORT post.date DESC // сортируем от новых к старым
LIMIT offset, count
RETURN post
```
На стороне клиента мы запрашиваем и выводим получившийся результат, я использую vuejs с nuxtjs для примера, но то же самое можно проделать на любом другом стеке, все специфичные для vue моменты я буду подписывать.
```
# https://example.com/posts?page=3
main.vue
{{ item.title }}
export default {
data() {
return {
posts: [], // инициализация массива с постами
}
},
computed: { // свойства объекта this, вычисляемые с помощью функции
currentPage(){
// получаем номер страницы из ссылки и приводим к числу с помощью +
return +this.$route.query.page || 0
},
},
async fetch() { // вызывается перед загрузкой страницы
const page = this.currentPage
// запрос к серверу, который выполнит запрос к базе данных
this.posts = await this.$axios.$get('posts', {params: {page}})
}
}
```
Теперь у нас выводятся все посты на странице, но погодите, как пользователи будут переключаться между страницами? Добавим пару кнопок для перелистывания страниц.
```
{{ item.title }}
Предыдущая страница
Следующая страница
export default {
//... тут код из прошлого примера
methods: {// добавим функций на страницу
prev(){
const page = this.currentPage()
if(page > 0)
// переходим на https://example.com/posts?page={page - 1}
this.$router.push({query: {page: page - 1}})
},
next(){
const page = this.currentPage()
if(page < 100) // для примера допустим что у нас всегда есть ровно 100 страниц
// переходим на https://example.com/posts?page={page + 1}
this.$router.push({query: {page: page + 1}})
},
},
}
```
**Минусы данного способа**
* При достижении конца страницы пользователю нужно переключаться на следующую страницу вручную.
* Не получится кешировать результаты, т.к посты находящиеся на странице 2, при добавлении новых, непременно сместятся на страницу 3, 4 и так далее, т.е одна и та же операция GET возвращает разные результаты в зависимости от количества постов.
* Если в момент перелистывания добавятся новые посты, то мы повторно увидим просмотренные элементы на следующей странице и напротив, пропустим если будем листать в обратную сторону.
#### 2. Бесконечный скроллинг
Этот способ решает первую проблему, теперь пользователю не нужно вручную переключаться между страницами.
Основная идея заключается в том, что мы получаем следующую страницу при достижении конца прошлой и добавляем новые элементы к существующим.
При таком подходе проблема №3 проявляются еще более явно, если раньше мы не могли увидеть 2 похожих элемента рядом, то теперь это станет обычной ситуацией, конечно можно воспользоваться грязным трюком и отфильтровывать элементы с совпадающим id прямо на клиенте, но что если добавится 40 новых элементов за раз? Мы потратим 3 запроса к серверу, чтобы достичь новых результатов, т.к прошлые сместятся на 2 страницы (при условии что на одной странице 20 элементов). Это не мой подход!
Как решают эту проблему люди из интернета:
* Используют описанный мной выше подход, я не искал подтверждение, но я практически уверен в этом, т.к это самое простое решение которое может прийти на ум, его можно использовать для быстрого прототипирования или создания mvp.
* Создают уникальный идентификатор при первом запросе, и сохраняют результаты запроса на сервере, а затем выдают порционно. Тут сразу напрашивается 2 минуса. Во-первых, это использование лишней памяти сервера для хранения результатов всех пользователей. Во-вторых, более сложная реализация, требующая и логики хранения результатов для каждого пользователя, и логики удаления устаревших запросов. Я уверен, что такие реализации существуют и возможно некоторым удалось решить проблему излишней памяти, но проще система от этого не стала, да и проблему кеширования это не решает, а лишь усугубляет ситуацию.
* Возможны и другие более или менее изобретательные решения, но то что я хочу вам предложить я пока не встречал. В свое время мне бы очень помогла подобная статья, поэтому я и решил её создать. Думаю что людям с похожей задачей она окажется полезной!
Моя реализация
--------------
Основная идея в том, что нам придется немного изменить логику запроса к базе, при этом не потребуется добавлять новые сущности или добавлять новые параметры в запрос.
#### Обновляем код на сервере
Для начала решим проблему кеширования, для этого просто всё перевернем.
Теперь последняя страница станет страницей номер 0, а предпоследняя страница номером 1, слово страница (page) сюда уже не вписывается, т.к мы с детства привыкли что в книжках страницы идут с начала, поэтому используем более нейтральное слово offset (смещение).
```
LET count = 20
LET offset = ${offset}
FOR post IN posts
SORT post.date ASC // для этого отсортируем всё в обратном порядке
LIMIT offset, count
RETURN post
```
Теперь сколько постов мы бы ни добавили, GET "/?offset=0" всегда будет возвращать один и тот же результат.
Получать первую страницу стало немного сложнее, поэтому совместим оба выше приведенных способа, для этого перейдем с уровня запроса к базе на уровень сервера (язык nodejs):
```
async getPosts({offset}) {
const isOffset = offset !== undefined
if (isOffset && isNaN(+offset)) throw new BadRequestException()
const count = 20
// Смещение должно быть кратно количеству элементов, чтобы результаты не пересекались
if (offset % count !== 0) throw new BadRequestException()
const sort = isOffset ? `
SORT post.date DESC
LIMIT ${+offset}, ${count}
` : `
SORT post.date ASC
LIMIT 0, ${count * 2} // Возвращаем больше чем нужно если это первая страница*
`
const q = {
query: `
FOR post IN posts
${sort}
RETURN post
`,
bindVars: {}
}
// получаем результат запроса вместе с общим количеством найденных элементов
const cursor = await this.db.query(q, {fullCount: true, count: isOffset})
const fullCount = cursor.extra.stats.fullCount
/*
*Если общее число элементов в базе не кратно count{20} то в начальном запросе приходит 2 страницы [21-39] элементов
В таком случае вторую страницу нужно пропустить т.к она уже входит в первую
Если общее число делится на 20 то в первом запросе приходит 1-я страница c count{20} элементов
*/
let data;
if (isOffset) {
// отсекаем попытку получить вторую страницу если она встроена в первую
const allow = offset <= fullCount - cursor.count - count
if (!allow) throw new NotFoundException()
// возвращаем нормальный порядок постам, т.к в запросе к базе мы всё перевернули
data = (await cursor.all()).reverse()
} else {
const all = await cursor.all()
if (fullCount % count === 0) {
// отрезаем лишние 20 элементов, это можно сделать как тут, так и в запросе к бд, вопрос лишь в оптимизации
data = all.slice(0, count)
} else {
/* Тут посложней, если ранее мы могли иметь на последней странице 0-20 элементов,
то теперь там нам всегда возвращается 20 элементов и недостачу нужно компенсировать,
для этого на первую страницу добавляются дополнительные 0-20 элементов к имеющимся,
в запросе к бд для первой страницы мы возвращаем с запасом 40 элементов
и затем здесь отрезаем лишние
*/
const pagesCountUp = Math.ceil(fullCount / count)
const resultCount = fullCount - pagesCountUp * count + count * 2
data = all.slice(0, resultCount)
}
}
if (!data.length) throw new NotFoundException()
return { fullCount, count: data.length, data }
}
```
**Чего мы этим добились:**
* Теперь перекрытия id после добавления новых элементов стали невозможны.
* Запросы теперь статичны и легко поддаются кешированию, единственным плавающим по количеству элементов и их id остался запрос без параметра offset.
* Наш код на клиенте теперь не работает(
Минусы моего способа:
* Вопрос что делать при удалении все ещё открыт, это не частая операция, поэтому можно каждый раз полностью сбрасывать кэш, либо возвращать null вместо отсутствующего элемента, это неплохое решение, т.к. зачастую реального удаления с сервера не происходит, элемент лишь помечается как удаленный, если таких "null-зомби" станет много, то можно удалить все null-зомби из выдачи и сбросить кэш для всех запросов.
* Если новый элемент оказывается не в начале после сортировки по выбранному полю (например по названию), то данный алгоритм не сработает. Поэтому подходит только сортировка по возрастающим или убывающим полям (например по дате или по id).
#### Обновляем код на клиенте
Заодно я покажу как сделать бесконечную прокрутку из пункта №2.
```
{{ item.title }}
Предыдущая страница
const count = 20
export default {
data() {
return {
posts: [],
fullCount: 0,
pagesCount: 0,
dataLoading: true,
offset: undefined,
}
},
async fetch() {
const offset = this.$route.query?.offset
this.offset = offset
this.posts = await this.loadData(offset)
setTimeout(() => this.dataLoading = false)
},
computed: {
currentPage() {
return this.offset === undefined ? 1 : this.pageFromOffset(this.offset)
}
},
methods: {
// используем код для преобразования смещения в страницы и обратно
pageFromOffset(offset) {
return offset === undefined ? 1 : this.pagesCount - offset / count
},
offsetFromPage(page) {
return page === 1 ? undefined : this.pagesCount \* count - count \* page
},
prev() {
const offset = this.offsetFromPage(this.currentPage - 1)
this.$router.push({query: {offset}})
},
async loadData(offset) {
try {
const data = await this.$axios.$get('posts', {params: {offset}})
this.fullCount = data.fullCount
this.pagesCount = Math.ceil(data.fullCount / count)
// Удаляем вторую страницу если она приходит вместе с первой
if (this.fullCount % count !== 0)
this.pagesCount -= 1
return data.data
} catch (e) {
//... обработка 404 и других ошибок сервера
return []
}
},
onScroll() {
// за 1000 пикселей до конца запрашиваем новые элементы
const load = this.$refs.posts.getBoundingClientRect().bottom - window.innerHeight < 1000
const nextPage = this.pageFromOffset(this.offset) + 1
const nextOffset = this.offsetFromPage(nextPage)
if (!this.dataLoading && load && nextPage <= this.pagesCount) {
this.dataLoading = true
this.offset = nextOffset
this.loadData(nextOffset).then(async (data) => {
const top = window.scrollY
// добавляем новые элементы и изменяем адресную строку
this.posts.push(...data)
await this.$router.replace({query: {offset: nextOffset}})
this.$nextTick(() => {
// Исключаем ситуации когда viewport браузера остается внизу страницы после подгрузки
window.scrollTo({top});
this.dataLoading = false
})
})
}
}
},
mounted() {
window.addEventListener('scroll', this.onScroll)
},
beforeDestroy() {
window.removeEventListener('scroll', this.onScroll)
},
}
```
Теперь у нас есть полностью лишенная обозначенных недостатков реализация. Несомненно присутствуют моменты которые можно сделать лучше, я хотел показать сам подход, реализация может быть у каждого разной.
Бонус: Добавляем гибкую систему перехода по страницам
-----------------------------------------------------
В данный момент мы можем перемещаться лишь на 1 страницу вперед или назад, добавим возможность перейти на любую страницу, элемент управления может выглядеть примерно так (в квадратных скобках текущая страница):
`< 1 ... 26 [27] 28 ... 255 >`
`< [1] 2 3 4 5 ... 255 >`
`< 1 ... 251 252 253 254 [255] >`
Основа метода для генерации пагинации взята из этого обсуждения: <https://gist.github.com/kottenator/9d936eb3e4e3c3e02598#gistcomment-3238804> и скрещена с моим решением.
Показать продолжение бонусаВ начале вам нужно добавить этот вспомогательный метод внутрь тега </p><pre><code class="javascript">const getRange = (start, end) => Array(end - start + 1).fill().map((v, i) => i + start)
const pagination = (currentPage, pagesCount, count = 4) => {
const isFirst = currentPage === 1
const isLast = currentPage === pagesCount
let delta
if (pagesCount <= 7 + count) {
// delta === 7: [1 2 3 4 5 6 7]
delta = 7 + count
} else {
// delta === 2: [1 ... 4 5 6 ... 10]
// delta === 4: [1 2 3 4 5 ... 10]
delta = currentPage > count + 1 && currentPage < pagesCount - (count - 1) ? 2 : 4
delta += count
delta -= (!isFirst + !isLast)
}
const range = {
start: Math.round(currentPage - delta / 2),
end: Math.round(currentPage + delta / 2)
}
if (range.start - 1 === 1 || range.end + 1 === pagesCount) {
range.start += 1
range.end += 1
}
let pages = currentPage > delta
? getRange(Math.min(range.start, pagesCount - delta), Math.min(range.end, pagesCount))
: getRange(1, Math.min(pagesCount, delta + 1))
const withDots = (value, pair) => (pages.length + 1 !== pagesCount ? pair : [value])
if (pages[0] !== 1) {
pages = withDots(1, [1, '...']).concat(pages)
}
if (pages[pages.length - 1] < pagesCount) {
pages = pages.concat(withDots(pagesCount, ['...', pagesCount]))
}
if (!isFirst) pages.unshift('<')
if (!isLast) pages.push('>')
return pages
}</code></pre><p>Добавляем недостающие методы</p><pre><code class="xml"><template>
<div ref='posts'>
<div>
<div v-for="post in posts" :key="item.id">{{ post.title }}</div>
</div>
<div style="position: fixed; bottom: 0;"> <!-- Прикрепим пагинацию к окну браузера -->
<template v-for="(i, key) in pagination">
<button v-if="i === '...'" :key="key + i" @click="selectPage()">{{ i }}</button>
<button :key="i" v-else :disabled="currentPage === i" @click="loadPage(pagePaginationOffset(i))">{{ i }}</button>
</template>
</div>
</div>
</template>
<script>
export default {
data() {
return {
posts: [],
fullCount: 0,
pagesCount: 0,
interval: null,
dataLoading: true,
offset: undefined,
}
},
async fetch() {/\* без изменений \*/},
computed: {
currentPage() {/\* без изменений \*/},
// генерирует пагинацию на основе текущей страницы и общего количества страниц
pagination() {
return this.pagesCount ? pagination(this.currentPage, this.pagesCount) : []
},
},
methods: {
pageFromOffset(offset) {/\* без изменений \*/},
offsetFromPage(page) {/\* без изменений \*/},
async loadData(offset) {/\* без изменений \*/},
onScroll() {/\* без изменений \*/},
// метод для перехода на нужную страницу
loadPage(offset) {
window.scrollTo({top: 0})
this.dataLoading = true
this.loadData(offset).then((data) => {
this.offset = offset
this.posts = data
this.$nextTick(() => {
this.dataLoading = false
})
})
},
// преобразуем элементы пагинации в смещения
pagePaginationOffset(item) {
if (item === '...') return undefined
let page = isNaN(item) ? this.currentPage + (item === '>') - (item === '<') : item
return page <= 1 ? undefined : this.offsetFromPage(page)
},
// Добавим простой метод для выбора любой страницы
selectPage() {
const page = +prompt("Введите номер существующей страницы");
this.loadPage(this.offsetFromPage(page))
},
},
mounted() {
window.addEventListener('scroll', this.onScroll)
},
beforeDestroy() {
window.removeEventListener('scroll', this.onScroll)
},
}
Теперь, при необходимости, можно перейти на нужную страницу. | https://habr.com/ru/post/554456/ | null | ru | null |
# Типограф для TinyMCE
Заметно, что на Хабре в последнее время всё чаще поднимается вопрос типографики, и это не может не радовать, ибо «оттипографленные» тексты и читать приятнее, и выглядят они куда аккуратнее обычных. Да и в целом создается ощущение, что автор заботился о своих читателях.
Примерно год–полтора назад я написал свой плагин для популярного редактора TinyMCE, который умел типографить тексты посредством [веб-интерфейса](http://www.artlebedev.ru/tools/typograf/webservice/) [типографа Студии Лебедева](http://www.artlebedev.ru/tools/typograf/). С того времени плагин успешно используется в проектах студий [Nimax](http://nimax.ru) и [Artilleria](http://artilleria.ru). После [недавнего поста](http://habrahabr.ru/blogs/typography/67387/) я решил таки его опубликовать, а также немного его усовершенствовал — добавил [Типограф](http://typograf.ru) тов. [spearance](https://habrahabr.ru/users/spearance/), а также [Типограф студии Муравьёва](http://habrahabr.ru/blogs/typography/67010/). Способ типографирования можно выбрать непосредственно перед «операцией».
Усовершенствованный типограф я сегодня и представляю на суд публики.
* Демка (UTF-8): [test.dis.dj/typograf](http://test.dis.dj/typograf/)
* Демка (CP1251): [test.dis.dj/typograf/cp1251.php](http://test.dis.dj/typograf/cp1251.php)
* Качаем по адресу: [test.dis.dj/typograf/typograf.zip](http://test.dis.dj/typograf/typograf.zip)
* Скрипты самих типографов: [test.dis.dj/typograf/typograf-engines.zip](http://test.dis.dj/typograf/typograf-engines.zip) (рекоммендую ознакомиться с инструкцией)
#### Возможности:
* Возможность выбора типографа
* Корректно обрабатывает выделенный текст
* Работает через веб-интерфейс, поэтому мгновенно воспринимает все багфиксы используемых движков (хотя, с другой стороны, это может стать минусом, если на хостинге PHP урезан в правах и не сможет установить соединение)
* Для случая, когда PHP урезан — можно использовать типограф студии Муравьёва, он локален
* Мультиязычный интерфейс (пока только русский и английский)
* Сразу видно результат, непосредственно в поле редактирования
* Если что-то пойдет не так — можно отказаться от результатов работы плагина
* Корректно работает с кодировками
#### Установка:
1. Скачиваем [PHP скрипт Студии Лебедева](http://www.artlebedev.ru/tools/typograf/webservice/) для работы с их типографом
2. Скачиваем [Типограф студии Муравьёва](http://emuravjev.ru/works/tg/)
3. Распаковываем оба скрипта куда-нибудь так, чтобы в каталоге оказались файл *remotetypograf.php* и каталог *Jare* (с файлом *Typograf.php*)
***Важное замечание!*** — в данный момент версия *2.0.0-rc2* типографа Студии Муравьёва имеет метку BOM во многих файлах, что может приводить к ошибкам вида *preg\_match() [function.preg-match]: Compilation failed: nothing to repeat at offset* на ряде серверов. Также из-за этого метка BOM попадает в выходной поток backend-скрипта, добавляя в контент пустой тег «P»«/P». Типограф обучен бороться с этой проблемой, вырезая метку из ответа сервера (спасибо юзеру [pixxxel](https://habrahabr.ru/users/pixxxel/)). Проблема с preg функциями решается банальным приведением файлов к обычному UTF-8 без метки (уж не знаю как это связано, но работает)
4. Для ленивых — в [этом архиве](http://test.dis.dj/typograf/typograf-engines.zip) есть оба скрипта, однако возможно это будут не самые свежие версии, но там устранена проблема с BOM
5. Распаковываем архив с плагином в папку плагинов TinyMCE (например */tinymce/plugins/*)
6. В файле */tinymce/plugins/typograf/typograf.php* правим константу *MCETYPOGRAF\_ENGINES*, чтобы указывала на папку с типографами
7. При инициализации прописать плагин в *plugins* и *theme\_advanced\_buttonsX*, например:
`tinyMCE.init({
…
"plugins": "…table,advimage,advlink,***typograf***",
"theme_advanced_buttons1": "…pagebreak,|,spellchecker,***typograf***,|,advcode…"`
8. Опционально, если пользуетесь *TinyMCE.Compressor*, то плагин надо также прописать и в конфиг-файл компрессора в *plugins*
#### Планируемые фичи:
* Расширение круга движков
* Поддержка типографирования текстов на разных языках. Пока что оба используемых плагина не позволяют задать язык или напрямую символы кавычек. Тов. [spearance](https://habrahabr.ru/users/spearance/) обещал сделать это в 3й версии своего типографа, от Лебедева пока ничего не известно
#### Известные баги:
* При слишком хитром выделении (через несколько ячеек таблицы, к примеру), может заглючить объект [Range](https://developer.mozilla.org/en/DOM/range), с этим я еще работаю…
P.S. Теоретически баг может сидеть в любой программе ;) Любой фидбэк ценится.
P.P.S. Комментарии к коду внутри плагина не по-русски… Писал так — еще не перевел. | https://habr.com/ru/post/67687/ | null | ru | null |
# Создание веб-приложения на Go в 2017 году. Часть 3
**Содержание**1. [Часть 1](https://habrahabr.ru/post/329582/)
2. [Часть 2](https://habrahabr.ru/post/329584/)
3. **Часть 3**
4. [Часть 4](https://habrahabr.ru/post/329622/)
В результате предыдущих статей у нас получилось приложение на Go, которое может обслуживать небольшой кусочек HTML. Эта статья расскажет о клиентской части, которая, увы, состоит в основном, из JavaScript, а не Go.
JavaScript в 2017 году
----------------------
Эта часть меня больше всего опечалила. Я действительно не знаю, ни как классифицировать тот беспорядок, который представляет собой сегодняшний JavaScript, ни чем его объяснить. Попытка во всем разобраться приведет к отличной, но совершенно другой статье. Так что давайте примем это как реальность, которую мы не можем изменить, и перейдем к тому, как лучше всего с этим работать.
Виды JS
-------
Наиболее распространенная в наши дни разновидность JS известна как ES2015 (он же ES6 или ECMAScript 6-е издание) и *в основном* поддерживается более-менее свежими браузерами. Последняя выпущенная спецификация JavaScript — ES7 (он же ES2016), но, поскольку браузеры все еще догоняют ES6, похоже, что ES7, как таковой, никогда не будет принят, потому что, скорее всего, в 2017 году выйдет следующий ES8, который заменит ES7 в плане ожидания готовности браузеров.
Это странно, но похоже, что нет простого способа создать среду, полностью соответствующую конкретной версии ECMAScript. Невозможно даже вернуться к старой полностью поддерживаемой версии ES5 или ES4, а следовательно нет возможности проверить ваш скрипт на соответствие. Максимум, что вы можете сделать, — это протестировать его во всех доступных браузерах и надеяться на лучшее.
Из-за постоянно изменяющейся и значительно различающейся поддержке языка среди платформ и браузеров, *транспиляция* возникла как общая идея решения этой проблемы. Транспиляция, в основном, сводится к преобразованию кода в такой, который соответствует конкретной версии ES или специфичной среде. Например, `import Bar from 'foo';` может стать `var Bar = require('foo');`. Поэтому, если какая-то конкретная особенность не поддерживается, ее можно сделать доступной с помощью подходящего плагина или транспилятора. Я подозреваю, что феномен распространенности транспиляции привел к дополнительным проблемам, таким, что ввод, ожидаемый транспилятором, предполагающим существование более не поддерживаемой особенности, совпадает с выводом. Часто это может быть исправлено дополнительными плагинами, и бывает очень трудно в этом разобраться. Неоднократно я проводил много времени пытаясь заставить что-то заработать, чтобы позднее выяснить, что весь мой подход устарел из-за нового и лучшего решения, встроенного теперь в какой-то другой инструмент.
JS фреймворки
-------------
Также есть много разногласий по поводу того, какой фреймворк JS — самый лучший. Этот вопрос еще более запутывает тот факт, что один и тот же фреймворк может радикально отличаться от версии к версии. Удивительно, почему бы при этом просто не сменить название.
Я понятия не имею, который из них самый лучший, а терпения у меня хватило только на парочку. Около года назад я потратил кучу времени, разбираясь с AngularJS, и на этот раз, разнообразия ради, я возился с React. Мне React показался более логичным, поэтому данный пример приложения его и использует, как бы там ни было.
React и JSX
-----------
Если вы не знаете, что собой представляет React, то вот вам мое (технически неверное) объяснение: это HTML, встроенный в JavaScript. У всех нас промыты мозги насчет того, что JavaScript является встраиваемым в HTML и это и есть естественный порядок вещей, так что инвертирование этой взаимосвязи не приходит никому в голову. Из-за фундаментальной простоты этого революционного (!) принципа я считаю React гениальным.
"Hello World!" в React выглядит примерно так:
```
class Hello extends React.Component {
render() {
let who = "World";
return (
Hello {who}!
=============
);
}
}
```
Обратите внимание — HTML-код начинается без всяких оберток или разделителей. Как ни странно, открывающая угловая скобка (”<”) работает достаточно надежно в качестве маркера, обозначающего начало HTML-кода. А внутри HTML открывающая фигурная скобка указывает, что мы временно возвращаемся в JavaScript, и таким образом значения переменных подставляются внутри HTML. Это почти все, что вам необходимо знать, чтобы “постичь” React.
Технически, вышеупомянутый формат файла известен как `JSX`, в то время как React — это библиотека, которая предоставляет классы для создания React-объектов, таких как `React.Component` выше. JSX транспилируется в обычный JavaScript с помощью инструмента, известного как Babel, и, фактически, JSX даже не требуется — React-компонент может быть написан на чистом JavaScript, и есть подход, в котором React используется без JSX. Лично я считаю, что способ "без JSX" несколько более шумный, и мне нравится, что Babel позволяет использовать более современный диалект JS (хотя, не иметь дела с транспиляторами — это, определенно, плюс).
Минимально работающий пример
----------------------------
Для начала, нам понадобятся три внешние библиотеки JavaScript. Это (1) React и ReactDOM, (2) браузерный транспилятор Babel и (3) небольшая библиотека под названием Axios, которая пригодится для выполнения JSON HTTP запросов. Я возьму их из Cloudflare CDN, но можно воспользоваться и каким-нибудь другим способом. Для подключения библиотек нужно расширить нашу переменную `indexHTML` до вот такого вида:
```
const (
cdnReact = "https://cdnjs.cloudflare.com/ajax/libs/react/15.5.4/react.min.js"
cdnReactDom = "https://cdnjs.cloudflare.com/ajax/libs/react/15.5.4/react-dom.min.js"
cdnBabelStandalone = "https://cdnjs.cloudflare.com/ajax/libs/babel-standalone/6.24.0/babel.min.js"
cdnAxios = "https://cdnjs.cloudflare.com/ajax/libs/axios/0.16.1/axios.min.js"
)
const indexHTML = `
Simple Go Web App
`
```
В самом конце теперь загружается `"/js/app.jsx"`, который нам еще предстоит создать. В предыдущей части с помощью `http.Dir()` мы заполнили поле в структуре настройки UI под названием `cfg.Assets`. Теперь нам нужно обернуть его в обработчик, который обслуживает файлы, и Go легко нам это обеспечит:
```
http.Handle("/js/", http.FileServer(cfg.Assets))
```
Таким образом, все файлы в каталоге `"assets/js"` будут доступны по пути `"/js/"`.
Теперь создадим сам файл `assets/js/app.jsx`:
```
class Hello extends React.Component {
render() {
let who = "World";
return (
Hello {who}!
=============
);
}
}
ReactDOM.render( , document.querySelector("#root"));
```
Единственное отличие от предыдущего листинга в самой последней строке, которая, фактически, и заставляет приложение отрисоваться.
Если мы сейчас зайдем на главную страницу браузером (JS-совместимым), то мы увидим “Hello World”.
Как это работает: браузер загрузил “app.jsx”, как ему было сказано, но, поскольку “jsx” — это незнакомый тип файла, браузер просто проигнорировал его. Когда Babel получил свой шанс поработать, он просмотрел наш документ на предмет наличия тэгов script с типом “text/babel” и повторно запросил эти страницы (поэтому они дважды появляются в инструментах разработчика, но второй запрос должен быть обслужен полностью из кэша браузера). Затем Babel трансформировал этот скрипт в корректный JavaScript и выполнил его, что, в свою очередь, заставило React фактически отобразить “Hello World”.
Список людей
------------
Сначала нам нужно вернуться к серверной части и создать URI, который будет выводить список людей. Для этого нам нужен http-обработчик, который может выглядеть так:
```
func peopleHandler(m *model.Model) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
people, err := m.People()
if err != nil {
http.Error(w, "This is an error", http.StatusBadRequest)
return
}
js, err := json.Marshal(people)
if err != nil {
http.Error(w, "This is an error", http.StatusBadRequest)
return
}
fmt.Fprintf(w, string(js))
})
}
```
И нам надо зарегистрировать его:
```
http.Handle("/people", peopleHandler(m))
```
Теперь, если мы зайдем на `"/people"`, мы должны получить в ответ `"[]"`. Если мы добавим запись в нашу таблицу людей с помощью:
```
INSERT INTO people (first, last) VALUES('John', 'Doe');
```
Ответ должен измениться на `[{"Id":1,"First":"John","Last":"Doe"}]`.
Наконец, нам нужно подключить наш React/JSX код, чтобы он все отобразил.
Для этого мы создадим компонент `PersonItem` и еще один, под названием `PeopleList`, который будет использовать `PersonItem`.
Компонент `PersonItem` должен только знать, как отобразить себя в виде строки таблицы:
```
class PersonItem extends React.Component {
render() {
return (
| {this.props.id} | {this.props.first} | {this.props.last} |
);
}
}
```
`PeopleList` немного сложнее:
```
class PeopleList extends React.Component {
constructor(props) {
super(props);
this.state = { people: [] };
}
componentDidMount() {
this.serverRequest =
axios
.get("/people")
.then((result) => {
this.setState({ people: result.data });
});
}
render() {
const people = this.state.people.map((person, i) => {
return (
);
});
return (
| Id | First | Last |
| --- | --- | --- |
{people}
);
}
}
```
У него есть конструктор, который инициализирует переменную `this.state`. Также в нем объявлен метод `componentDidMount()`, который будет вызван React'ом в тот момент, когда компонент должен приготовиться к отрисовке, т.е. это правильное место (одно из), чтобы получить данные с сервера. Метод получает данные через вызов Axios и сохраняет результат в `this.state.people`. Наконец, `render()` перебирает содержимое `this.state.people`, создавая для каждого элемента экземпляр `PersonItem`.
Вот и все, наше приложение отвечает таблицей (правда, довольно страшной) со списком людей из нашей базы данных.
Заключение
----------
По сути, это все, что вам нужно знать, чтобы создать полнофункциональное веб-приложение на Go. У этого приложения, конечно, есть ряд недостатков, которые, я, по возможности, рассмотрю позже. Например, транспиляция в браузере не идеальна, и хотя такой вариант подойдет для не очень ценного приложения, для которого не важно время загрузки страницы, вероятно, мы захотим найти способ предварительной транспиляции. Кроме того, наш JSX ограничен одним файлом, такой подход затруднит управление любым приложением серьезного размера с большим количеством компонентов. Приложение не имеет навигации. Нет стиля. Есть вещи, о которых я забываю…
Наслаждайтесь!
P.S. Весь код полностью находится [тут](https://github.com/grisha/gowebapp).
[Продолжение](https://habrahabr.ru/post/329622/) | https://habr.com/ru/post/329612/ | null | ru | null |
# Новый web-интерфейс статистики и прослушивания вызовов для IP АТС Asterisk
Идея написания web-интерфейса статистики и прослушивания вызовов для IP АТС Asterisk не покидала [меня](https://vistep.ru/) вот уже несколько лет. Решения, найденные в Интернет, не устраивали по тем или иным критериям — где-то не хватало функционала, какие-то из них совсем не радовали глаз.
И вот, вооружившись стеком технологий и оседлав боевого коня, предоставленного компанией [ServerClub](http://serverclub.ru), я отправился в путь.
Результатом моего путешествия стал новый [интерфейс](https://stat.vistep.ru), с диаграммами, графиками и возможностью скачивать и прослушивать вызовы. Не стану далее утомлять вас словесами, вот пара скриншотов:
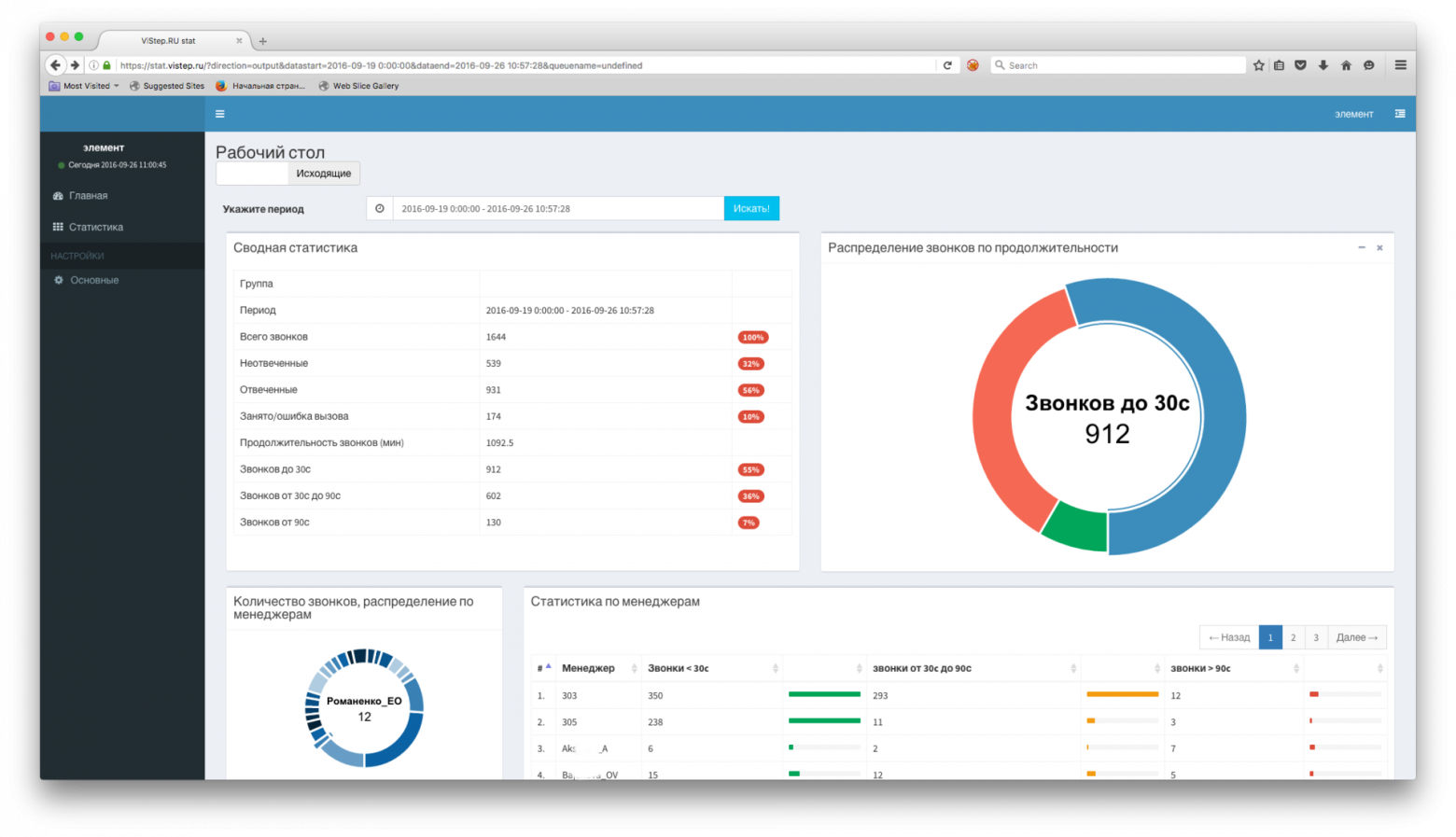
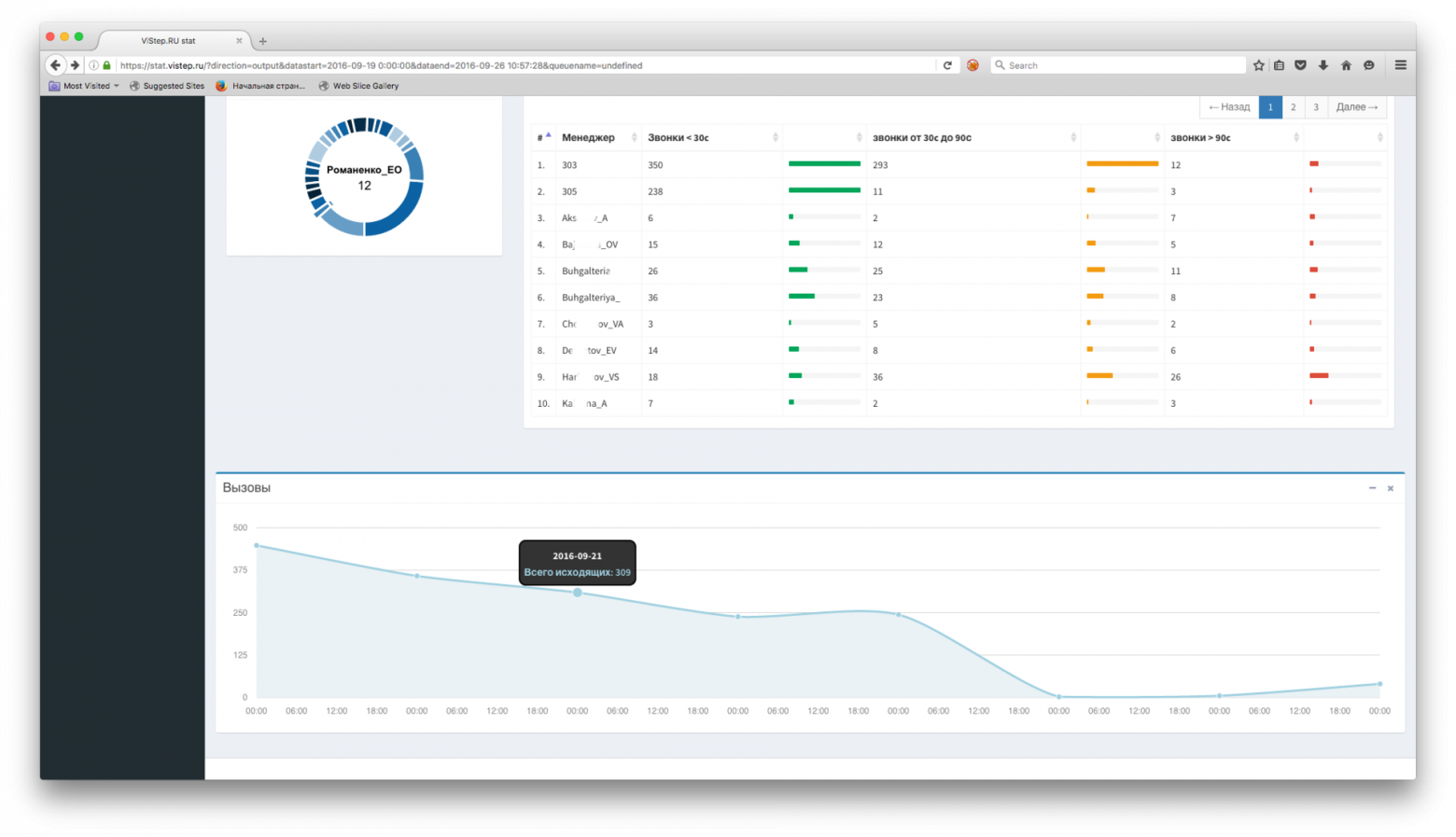
А под катом вас ждет видео-гайд по интерфейсу, необходимые настройки и подробное описание всего доступного функционала.
Интерфейс.
----------
Дабы пост не выглядел как простыня из скриншотов, я сделал небольшое слайдшоу, где вы можете ознакомиться с интерфейсом.
Описание. Что уже готово, планы.
--------------------------------
На текущий момент реализован следующий функционал:
Входящие вызовы:
* Отчет — Количество звонков в очереди за период (всего/непринятые/отвеченные/не дождались ответа)
* Диаграмма — Принятые/Непринятые
* Диаграмма — Принятые, распределение по операторам
* Диаграмма — Неотвеченные, распределение по операторам
* Отчет — Статистика по операторам. Кто и сколько принял/не принял вызовов
* Отчет — Причина разъединения (оператор/клиент)
* Отчет — Вызовы. Сколько на дату Поступило/Отвеченных/Неотвеченных
* Поиск записей в БД. Прослушивание и скачивание записей разговров
Исходящие вызовы:
* Отчет — Всего звонков, неотвеченные/отвеченные/занято(ошибка вызова), общая продолжительность и распределение вызовов по длительности (см. след. пункт).
* Диаграмма — Распределения вызовов по длительности: до 30с, от 30с до 90с, от 90с
* Диаграмма — Количество звонков, распределение по менеджерам
* Отчет — распределение звонков по длительности между менеджерами/операторами
* Отчет — Вызовы. Сколько было совершено вызовов на дату (считаем только отвеченные\*)
* Поиск записей в БД. Прослушивание и скачивание записей разговров
\*отчеты по исходящим строятся только по звонкам во мир, т.е. внутренние звонки между сотрудниками не учитываются
Так же доступны несколько настроек, где указывается использует ли Asterisk очереди\* и путь к файлам записей разговоров на сервере.
\*реализовано в настройках, но пока нет в интерфейсе
В ближайших планах добавить:
* возможность группировать менеджеров/операторов и строить отчеты по группам
* возможность создавать пользователей и разграничивать их права в просмотре отчетов по группам
* построение отчетов, если на Asterisk не используются очереди
* поиск, прослушивание и скачивание записей во всей БД, без фильтров «Входящие/Исходящие» (чтобы видеть и внутренние звонки)
Asterisk. Настройки
-------------------
Для работы с описываемым интерфейсом потребуется Asterisk версии 1.8 и выше. На АТС должно быть настроено ведение таблиц cdr, cel и queue\_log в БД MySQL. Если вы это еще не сделали, то я расскажу как.
Так же я приведу пример настройки диалплана Asterisk, для организации сохранения записей разговоров.
**Настраиваем Asterisk для работы с MySQL**
1. Устанавливаем необходимые пакеты (для примера в Debian/Ubuntu)
```
aptitude install unixodbc-dev libmyodbc
```
2. Asterisk должен быть собран со следующими опциями
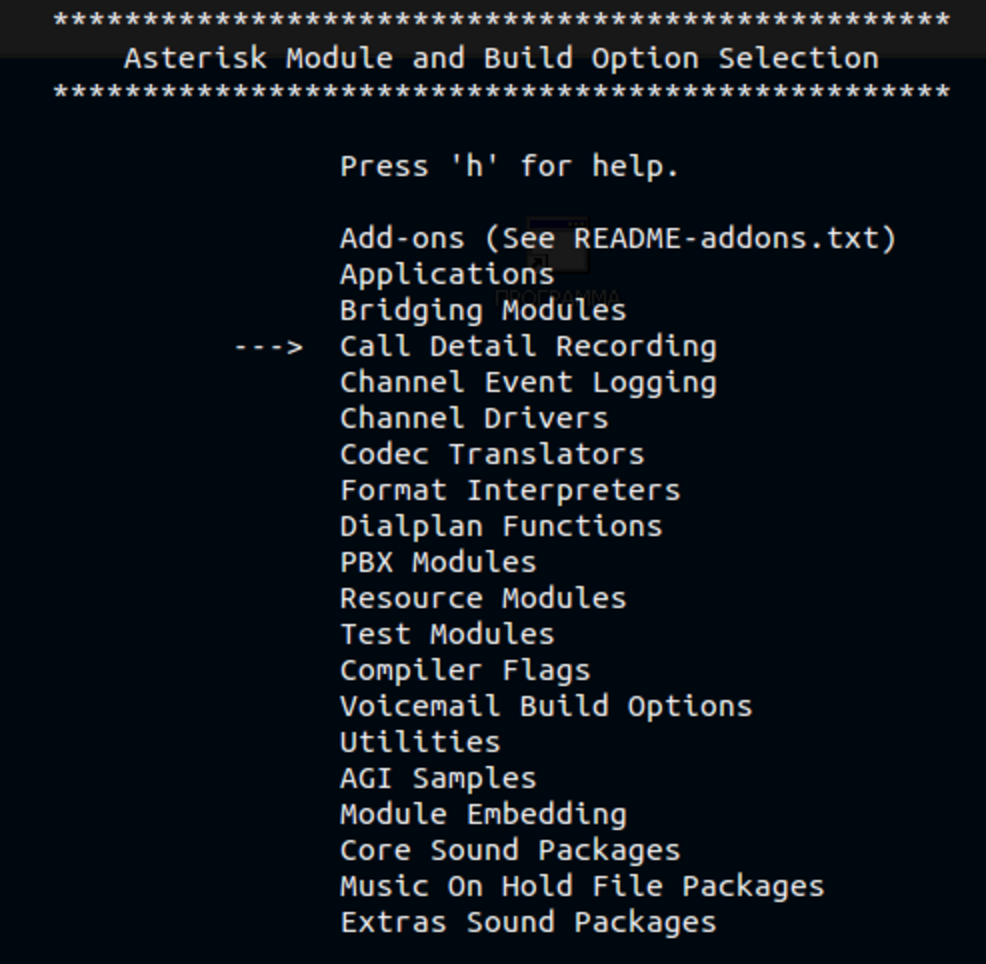
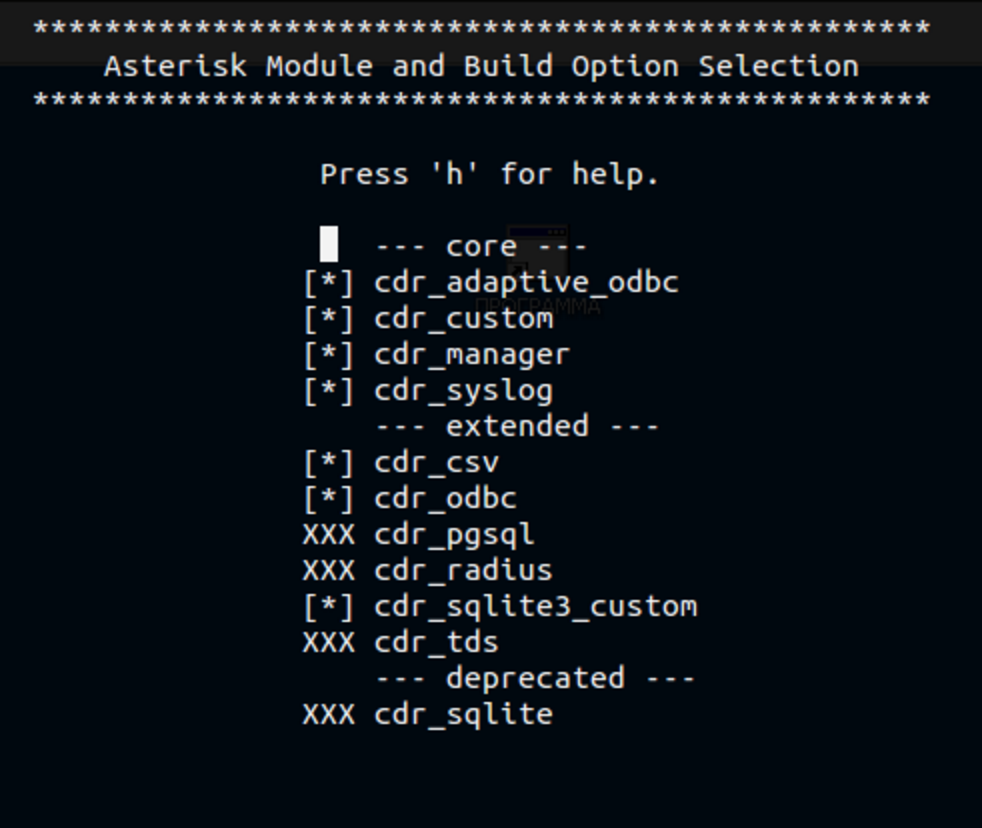
3. Далее редактируем несколько конфиг-файлов
**небольшой хинт, если odbc-коннектор не цепляется**
Поймал на одной из систем баг, при котором коннектор почему-то перестал цепляться и астер сваливался в корку:
Core was generated by `asterisk -cvvvvvvvgd'.
Program terminated with signal 8, Arithmetic exception.
#0 0x00007ff4cc77a61b in sqlchar\_as\_sqlwchar () from /usr/lib/x86\_64-linux-gnu/odbc/libmyodbc.so
решил тем, что скачал последнюю версию с сайта MySQL — [dev.mysql.com/downloads/file/?id=461779](http://dev.mysql.com/downloads/file/?id=461779)
распаковал либы в /usr/lib/x86\_64-linux-gnu/odbc/
и чуть подправил конфиг
`/etc/odbcinst.ini`
```
[MySQL] Descripti driver
Driver = /usr/lib/x86_64-linux-gnu/odbc/libmyodbc5w.so
Setup = /usr/lib/x86_64-linux-gnu/odbc/libodbcmy5S.so
CPTimeout =
CPReuse =
```
`/etc/asterisk/res_odbc.conf`
```
[asterisk]
enabled => yes
dsn => MySQL-asterisk
username => asterisk_user
password => 232d2edxse3e
```
`cdr_adaptive_odbc.conf`
```
[cdr_adaptive_connection]
connection=asterisk
table=cdr
alias start => calldate
# раскоментируй, если хочешь видеть реальный номер, накоторый пришел вызов, а не номер оператора очереди
#alias dst => does_not_exist
#alias realdst => dst
```
`/etc/odbc.ini`
```
[MySQL-asterisk]
Description = MySQL Asterisk database
;Trace = Off
;TraceFile = stderr
Driver = MySQL
Server = localhost
User = asterisk_user
Password = 232d2edxse3e
;Port = 3306
Socket = /var/run/mysqld/mysqld.sock
Database = asterisk
Charset = utf8
```
`/etc/odbcinst.ini`
```
[MySQL]
Description = MySQL driver
Driver = /usr/lib/odbc/libmyodbc.so
Setup = /usr/lib/odbc/libodbcmyS.so
CPTimeout =
CPReuse =
```
\*для x64
```
[MySQL]
Description = MySQL driver
Driver = /usr/lib/x86_64-linux-gnu/odbc/libmyodbc.so
Setup = /usr/lib/x86_64-linux-gnu/odbc/libodbcmyS.so
CPTimeout =
CPReuse =
```
в конец
`cdr_mysql.conf`
добавить
```
alias filename => filename
```
4. Создадим БД и таблицу cdr в MYSQL
```
mysql> create database asterisk;
mysql> use asterisk;
mysql> CREATE TABLE `cdr` ( `id` int(9) unsigned NOT NULL AUTO_INCREMENT,
`calldate` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
`clid` varchar(80) NOT NULL DEFAULT '',
`src` varchar(80) NOT NULL DEFAULT '',
`dst` varchar(80) NOT NULL DEFAULT '',
`dcontext` varchar(80) NOT NULL DEFAULT '',
`channel` varchar(80) NOT NULL DEFAULT '',
`dstchannel` varchar(80) NOT NULL DEFAULT '',
`lastapp` varchar(80) NOT NULL DEFAULT '',
`lastdata` varchar(80) NOT NULL DEFAULT '',
`duration` int(11) NOT NULL DEFAULT '0',
`billsec` int(11) NOT NULL DEFAULT '0',
`disposition` varchar(45) NOT NULL DEFAULT '',
`amaflags` int(11) NOT NULL DEFAULT '0',
`accountcode` varchar(20) NOT NULL DEFAULT '',
`uniqueid` varchar(32) NOT NULL DEFAULT '',
`userfield` varchar(255) NOT NULL DEFAULT '',
`filename` varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `calldate` (`calldate`),
KEY `accountcode` (`accountcode`),
KEY `uniqueid` (`uniqueid`),
KEY `dst` (`dst`),
KEY `src` (`src`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
mysql> grant all on asterisk.* to 'asterisk_user'@'localhost' identified by '232d2edxse3e';
```
5. Таблицу cel
```
mysql>CREATE TABLE `cel` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`eventtype` varchar(30) NOT NULL,
`eventtime` datetime NOT NULL,
`cid_name` varchar(80) NOT NULL,
`cid_num` varchar(80) NOT NULL,
`cid_ani` varchar(80) NOT NULL,
`cid_rdnis` varchar(80) NOT NULL,
`cid_dnid` varchar(80) NOT NULL,
`exten` varchar(80) NOT NULL,
`context` varchar(80) NOT NULL,
`channame` varchar(80) NOT NULL,
`src` varchar(80) DEFAULT NULL,
`dst` varchar(80) DEFAULT NULL,
`channel` varchar(80) DEFAULT NULL,
`dstchannel` varchar(80) DEFAULT NULL,
`appname` varchar(80) NOT NULL,
`appdata` varchar(80) NOT NULL,
`amaflags` int(11) NOT NULL,
`accountcode` varchar(20) NOT NULL,
`uniqueid` varchar(32) NOT NULL,
`linkedid` varchar(32) NOT NULL,
`peer` varchar(80) NOT NULL,
`userdeftype` varchar(255) NOT NULL,
`eventextra` varchar(255) DEFAULT NULL,
`userfield` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `uniqueid_index` (`uniqueid`),
KEY `linkedid_index` (`linkedid`),
KEY `eventtime` (`eventtime`),
KEY `exten` (`exten`),
KEY `eventtype` (`eventtype`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
```
6. Теперь создадим табличку queue\_log
```
mysql> CREATE TABLE IF NOT EXISTS `queue_log` (
id int(10) UNSIGNED NOT NULL AUTO_INCREMENT,
time timestamp NULL DEFAULT '0000-00-00 00:00:00',
callid varchar(32) NOT NULL default '',
queuename varchar(32) NOT NULL default '',
agent varchar(32) NOT NULL default '',
event varchar(32) NOT NULL default '',
data1 varchar(100) NOT NULL default '',
data2 varchar(100) NOT NULL default '',
data3 varchar(100) NOT NULL default '',
data4 varchar(100) NOT NULL default '',
data5 varchar(100) NOT NULL default '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> \q
Bye
```
6. Внесем в `/etc/asterisk/extconfig.conf`
строку
```
queue_log => odbc,asterisk
```
7. Перезагружаем Asterisk и проверяем подключение
```
*CLI> odbc show asterisk
ODBC DSN Settings
-----------------
Name: asterisk
DSN: MySQL-asterisk
Last connection attempt: 1970-01-01 07:00:00
Pooled: No
Connected: Yes
```
8. Так же стоит позвонить и проверить попадают ли данные в БД
**Диалплан Asterisk - выдержка из /etc/asterisk/extensions.ael**
```
globals {
WAV=/var/calls; //Временный каталог с WAV
MP3=/var/calls; //Куда выгружать mp3 файлы
RECORDING=1; // Запись, 1 - включена.
};
macro recording (calling,called) {
if ("${RECORDING}" = "1"){
Set(fname=${UNIQUEID}-${STRFTIME(${EPOCH},,%Y-%m-%d-%H_%M)}-${calling}-${called});
Set(datedir=${STRFTIME(${EPOCH},,%Y/%m/%d)});
System(mkdir -p ${MP3}/${datedir});
System(mkdir -p ${WAV}/${datedir});
Set(monopt=nice -n 19 /usr/bin/lame -b 32 --silent "${WAV}/${datedir}/${fname}.wav" "${MP3}/${datedir}/${fname}.mp3" && rm -f "${WAV}/${fname}.wav" && chmod o+r "${MP3}/${datedir}/${fname}.mp3");
Set(CDR(filename)=${fname}.mp3);
Set(CDR(recordingfile)=${fname}.wav);
Set(CDR(realdst)=${called});
MixMonitor(${WAV}/${datedir}/${fname}.wav,b,${monopt});
};
};
_XXXXXX => {
&recording(${CALLERID(number)},${EXTEN});
Dial(SIP/83843${EXTEN}@multifon,180,tT);
HangUP();
} // end of _XXXXXX
```
Файлы записей разговоров попадают прямиков в
`/var/calls`
где имеют следующую иерархию
```
ls /var/calls/2016/ -l
total 24
drwxr-xr-x 19 asterisk asterisk 4096 May 31 10:10 05
drwxr-xr-x 30 asterisk asterisk 4096 Jun 30 10:02 06
drwxr-xr-x 31 asterisk asterisk 4096 Jul 31 10:18 07
drwxr-xr-x 31 asterisk asterisk 4096 Aug 31 09:00 08
drwxr-xr-x 26 asterisk asterisk 4096 Sep 26 09:51 09
```
Asterisk. Подключение к интерфейсу статистики
---------------------------------------------
Настало время развеять некоторые сомнения, или же подтвердить некоторые догадки. Да — на текущий момент сервис предоставляется по модели SAAS, т.е. на вашу АТС устанавливается клиент для синхронизации БД и записей звонков.
После регистрации (не думаю, что стоит на ней подробно останавливаться — там все как обычно), нужно зайти в личный кабинет по адресу [stat.vistep.ru](https://stat.vistep.ru), перейти в настройки, указать путь к файлам записей и нажать «Сохранить». После чего будет доступна ссылка на скачивание скрипта-клиента.
Для установки скрипта нужно выполнить следующие шаги:
**1.** Установить на сервер `nodejs` и менеджер пакетов `npm`, если они еще не установлены (с помощью `yum` или `apt/aptitude/apt-get`)
**2.** Установить `pm2`
```
npm install -g pm2
```
**3.** Создать и перейти в папку `/opt/stat.vistep.ru`
```
mkdir /opt/stat.vistep.ru
cd /opt/stat.vistep.ru
```
**4.** Поместить архив со скриптом в папку, созданную шагом ранее, и распаковать его
```
unzip skript_name.zip
```
**5.** Отредактировать скрипт, внеся изменения в строки 393 — 397 (и 398 — опционально, если вам знакомы regexp), а именно
```
"dbhost":"localhost",
"dbuser":"asterisk_user",
"dbpassword":"232w2edxse3e",
"db":"asterisk",
"timezone":"Asia/Novokuznetsk", // <--- часовой пояс
"fileMask": /\.*/ //
```
**6.** Запустить скрипт на выполнение:
```
pm2 start stat.vistep.ru.js --name "ViStep.RU stat"
```
**7.** Настроить автозапуск/останов скрипта синхронизации вместе с ОС:
```
pm2 startup ubuntu #или centos, gentoo
pm2 save
```
С настройками на этом все. Осталось дождаться загрузки данных на сервер статистики и начать пользоваться!
Условия предоставления сервиса
------------------------------
На текущий момент мы предлагаем 2 варианта сотрудничества по продукту [Stat.ViStep.RU](https://stat.vistep.ru):
— **Локальная версия**, в постоянное пользование.
Все обновления будут доступны Вам без дополнительных оплат.
— **Облачная версия**.
Обновления включены в абонентскую плату.
Помощь в установке/настройке продукта бесплатна в обоих вариантах.
Все подробности вы можете узнать написав нам на [email protected]
Заключение
----------
Вот и завершился мой сказ о путешествии и его результатах. Но только сказ, не само путешествие — оно еще только начинается. Верю, что ждут меня еще многие свершения, увлекательные пути-дороги и интересные квесты.
За помощью в настройке Asterisk милости прошу писать нам на [email protected].
Ежели вопрос по сотрудничеству, условиям предоставления сервиса или еще какая оказия, то жду писем на [email protected]
Так же все мои контакты есть в профиле и, конечно, я с удовольствием отвечу на ваши вопросы в комментариях.
**Демо доступы:**
> [email protected]
>
> 0jnoiLJNFDr4-3r2f4
За сим позвольте закончить. **Благодарю за внимание!** | https://habr.com/ru/post/310988/ | null | ru | null |
# Накручиваем PollDaddy.com. Битва за iPad в 4-ех действиях

1. Предистория
--------------
Вот уже некоторое время я наблюдаю за развитием стартапа [friendsaround.me](http://friendsaround.me/). Идея стартапа это запустить социальную сеть для владельцев мобильных утройств с привязкой к местоположению. Сейчас как я понимаю они все еще в процессе разработки — ну не суть. Наблюдаю я достаточно пассивно и поэтому только 7 марта обнаружил, что они проводят конкурс на лучший слоган для их продукта с главным и единственным призом в виде iPad (а точнее iTunes gift карты на необходимую для его покупки сумму). Конкурс заканчивался сообственно 7 марта и я, предварительно посмотрев на текущие присланные варианты (и не найдя ни одного понравившегося), решил тоже попытать, так сказать, счастья. После нескольких минут креативного раздумья в голове вертелось несколько вариантов, из которых я остановился на слогане «Locate Friendship!» (А че — подумал я — коротко, ясно и по делу. Отличный слоган!). Его и послал на участие…
2. История
----------
На следующий день выяснилось что мой слоган меня не подвел и оказался в финале — вот это успех :)!
Финал представлял из себя голосование, в котором всем желающим предлагалось выбрать наиболее понравившийся слоган из 10 финалистов. Голосование было сделано через сервис [polldaddy.com](http://polldaddy.com/), главная задача, которого и заключалась собственно в проведении различного вида головалок. Поэтому я понадеясь (наивно) на честную борьбу стал активно рассылать агитационные сообщения друзьям типа «Чуваки, поддержите мой выдающийся слоган!». «Чуваки» поддерживали (спасибо вам, кстати, если читаете) и столбик голосов рядом с моим вариантом постепенно пополз вверх, а в голове уже стали появляться противоречивые мысли из серии «Хм, ну и зачем мне нужен еще один айфон?! Лучше добавлю денег и куплю тогда уж сразу макбук!!! Хм, хотя зачем мне макбук?!)». Но тут меня ожидало первое разочарование…
Совершенно без задней мысли решил в очередной раз посмотреть текуший результат госования. Посмотреть результаты тогда представлялось возможным только с помощью повторного голования (так как кнопочку «show results» я заметил не сразу), которое приводило на страницу с на где вежливо сообщалось, что повторное голосование невозможно, но при этом показывался текущий результат. Каково же было мое удивление, когда в очередной раз зайдя на эту страницу, я неожиданно увидел надпись «Thank you for voting!». «Ааа, наверное это из-за того, что браузер другой… Но неужели они не блокируют по IP» — мелькнуло в голове — «Ну как же так?!». Попробовал с третьего браузера — еще плюс голос — наверное значит блокируют от повторного голосования по cookie… Открыл хром в ингогнито режиме (вроде не должен сохранять cookie) — так и есть. При этом судя по характеру прибавления головов у другого участника стало понятно, что данное открытие принадлежит не только мне.
Сидеть и тупо накручивать голоса открыванием и закрыванием браузера абсолютно не хотелось, поэтому честно написав администрации конкурса о моем открытии, продолжил агитировать друзей. При этом моим главным аргументом для продолжения участия, была надежда то, что все таки организаторы, люди, которые занимаються веб/мобильной разработкой (и даже скоро собираются запускать стартап) должны понимать, что в таком виде как сейчас голосование теряет смысл еще не начавшись. «Наверное они все же записывают IP и хотят просто таким образом сразу узнать всех накрутчиков и пресечь их желание придумать более сложно отслеживаемый способ накрутки конкурса» — опять же наивно подумал я…
Тем временем к концу второго дня финала конкурса (9 марта) мой слоган вышел на второе место и потихоньку приближался к первому (который по моим ощущениям (как оказалось верным), как раз накручивал, причем накручивал вручную (у меня 120 голосов у него 140, через 3 часа у меня 139 у него все те же 140, но через 5 минут уже 160)). По условиям конкурса победителем объявлялся участник с наибольшим количеством голосов на «10 марта». Я подозревал, что «10 марта» это на самом деле 00 часов 00 минут 11 марта, но понимая, что это можно понять двояко и необычные движения возможны уже этой ночью, на всякий случай сделал скриншот:
[](http://picasaweb.google.com/lh/photo/Pre9dGkEOev4x4rtrhwGYA?authkey=Gv1sRgCPOb05DpxJHEvAE&feat=embedwebsite)
Проснувшись на следующее утро, я понял что нервы у ребят все таки не выдержали и картинка уже выглядела следующим образом:
[](http://picasaweb.google.com/lh/photo/y4RsKsa7cQf7GqacVztMug?authkey=Gv1sRgCPOb05DpxJHEvAE&feat=embedwebsite)
Как оказалось, порядка 3-ех с половиной тысяч человек (из 4100 всего проголосовавших на тот момент) никак не могли обрести покой той ночью не проголосовав за свой любимый слоган.
Самое забавное, что при всей абсурдности ситуации участники свято верили в свою «честную» победу и чтобы никто ничего не заподозрил(!) не отрывались друг от друга более чем на 50-100 голосов…
В этот момент я решил посмотреть, что же из себя представляет сервис PollDaddy.com «с той стороны» и зарегистрировался на нем (благо регистрация была бесплатна). А представлял он из себе платную и бесплатную версии. Платная позволяла различными способами отслеживать результаты конкурса, а бесплатная ничего не позволяла и показывала приблизительно ту же информацию, которую и так было видно всем участникам. А еще бесплатная версия добавляла небольшую ссылку на сайт самого PollDaddy.com. Именно ту ссылку которую можно наблюдать на приложенных мною скриншотах.
Администрация конкурса, от которой я ждал хоть какой то реакции на события произошедшие ночью развеяла всю мою в них веру сообщением в твиттере «Ребята! Голосуйте любимый за слоган! Сегодня последний шанс проголосовать!» (здесь немного вольный перевод с английского). Попробовал написать еще раз администации, чтобы они как то прояснили свою позицию на счет накруток и если они по прежнему собираються отдать приз участнику с «наибольшим» количеством голосов несмотря ни на что, я тоже могу попробовать написать свой скрипт. Подождал пару часов ответа не проследовало… Видимо им было все равно кто именно получит пресловутый iPad — слоганы то и так уже есть…
На самом деле в этот момент мне было больше всего было неудобно перед друзьями, которые откликнулись на мою просьбу и проголосовали (а в тот момент еще и писали мне, чтобы я не расстраивался, и, что скорее всего результаты подтасовали). Кроме этого начинал зарождаться спортивный интерес, так как голосования мне не никогда не приходилось накручивать, и как веб-разроботчику было интересно все-таки наконец попробовать (тем более что 2 человека из 10 это уже проделали. 3-ий мне кажется продолжал упорно накручивать голоса руками :) ).
Конечно был еще и альтернативный путь, а именно подождать когда конкурс завершится, приз найдет своего «законного» победителя, а потом вставать в ряды людей борящихся за правду и писать злобные и гневные сообщения в стиле «Нас обманули! Верните iPad законному владельцу!!! У меня было 190 честных голосов!!!!» Так, что под девизом «Может быть меня кто и осудит, но меня среди таких людей не будет», нажал заветную кнопку «View page source»…
3. Накрутка
-----------

Все оказалось еще проще, чем я думал. Кнопочка Vote! представляла из себя следующую разметку:
> `<input type="button" onclick="javascript:vote(2813361,0,1,0,10);" class="button-blue-big" value="Vote!" />
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Сама же функция vote() выглядела следующим образом:
> `function vote(id, poll\_other, rand, poll\_type, u) {
>
> var answerString = '';
>
> var otherText = '';
>
>
>
> for (i = 0; i < document.formPoll.elements.length; i++) {
>
> if (document.formPoll.elements[i].type == "checkbox" || document.formPoll.elements[i].type == "radio") {
>
> if (document.formPoll.elements[i].checked) {
>
> answerString += document.formPoll.elements[i].value + ',';
>
> }
>
> }
>
> }
>
>
>
> if (poll\_other == 1) {
>
> otherText = \_$('PDI\_OtherText').value;
>
> }
>
>
>
> if (answerString.length > 0 || otherText.length > 0) {
>
> location.href = '/vote.php?va=' + u + '&pt=' + poll\_type + '&r=' + rand + '&p=' + id + '&a=' + answerString + '&o=' + otherText;
>
> } else {
>
> alert( alert\_no\_answer );
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Ну вот, все вроде понятно — берем value(id) отмеченной радио кнопки и посылаем его по нужному адресу вместе с остальными параметрами. Смущала только переменная rand, которая видимо подразумевала какое то случайное значение, но при этом сколько я страницу не перезагружал всегда была равна 0.
После этого оставалось только написать небольшое консольное приложение (я использовал C#), которое генерирует HTTP GET request и посылает его по тому же адресу.
> `static void Main(string[] args)
>
> {
>
> int repeat = (args.Length > 0) ? int.Parse(args[0]) : 1;
>
> int sleepTime = 2000; //2 sec
>
> int rand = 0;
>
> string userAgent = "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.2 (KHTML, like Gecko) Chrome/5.0.342.3 Safari/533.2";
>
> int pollid = 2812840;
>
> int voting\_id = 13304535;
>
>
>
> for (int i = 0; i < repeat; i++)
>
> {
>
> Console.Write(i + " - ");
>
> string query = "http://polldaddy.com/vote.php?va=10&pt=0&r=" + rand + "&p=" + pollid + "&a=" + voting\_id + ",&o=";
>
> HttpWebRequest request = (HttpWebRequest)WebRequest.Create(query);
>
> request.UserAgent = userAgent;
>
> HttpWebResponse response;
>
> response = (HttpWebResponse)request.GetResponse();
>
> Console.Write(response.StatusCode);
>
> Console.WriteLine(". Waiting " + sleepTime/1000 + " seconds");
>
> Thread.Sleep(sleepTime);
>
> }
>
> Console.WriteLine("Done");
>
> Console.ReadKey();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Написал. На всякий случай поставил паузу между запросами 2 секунды. Запускаю: первый запрос — ОК, второй запрос — ОК, третий запрос — operation has timed out. Че за фигня?! Запускаю опять — то же самое — третий request не проходит. Увеличил паузу между запросами до 10 секунд. Не помогает. Решил попытаться посмотреть [Fiddler'ом](http://www.fiddler2.com/fiddler2/), в чем дело:
[](http://picasaweb.google.com/lh/photo/pOsyiw9b_6cPE_StVmULng?authkey=Gv1sRgCPOb05DpxJHEvAE&feat=embedwebsite)
Fiddler показал, что оказывается первая страница возвращает HTTP результат 302 и перенаправляет на другую, но никаких других различий между запросами я не заметил. Добавил в код request.AllowAutoRedirect = true, чтобы запрос автоматически редиректился (хотя в принципе это должно и так по умолчанию стоять) — опять тот же результат. Удача пришла неожиданно — случайно обнаружилось, что с включенным Fiddler'ом третий запрос проходит на ура (как видно на картинке), а также проходит и четвертый и пятый и т.д. Разбираться в чем разница между запросом который проходит через прокси Fiddler'а и обычным времени не было, главное, что в принципе накрутчик готов. Можно было запускать.
Тем не менее я не хотел останавливаться на таком простом решении, хотелось как то усложнить задачу, тем более, что когда я зарегистрировался на polldaddy.com и создал свое тестовое голование, я видел там все-таки опцию, «Блокировать по cookie и IP», которая по каким то непонятным соображениям была проигнорированна организаторами голосования. Понимая, что они в любой момент могут все таки «обнаружить» эту опцию и таким образом обрубить мой накрутчик, решил заблоговременно подготовиться… Естесвенно заставить запустить мое .NET приложение 10 тысяч человек не представлялось возможным, поэтому стал склоняться к javascript'у, который будет посылать ajax GET Request при загрузке какой нибудь страницы, а потом редиректить на другую с более интересным содержанием. Таким образом можно было бы дать подобную ссылку на каком нибудь популярном ресурсе и решить проблему блокировки по IP. Сделал такую страницу с помощью jQuery [здесь](http://mnarinsky.com/mnarinsky/pages/addVote.htm), но она так и не пригодилась в итоге.
4. Конец истории
----------------
Накрутчик у меня был готов, когда до конца конкурса оставалось еще приблизительно 7 часов. Играть в сложившуюся в конкурсе игру и выходить на первое место, с преимуществом в 10 голосов показалось глупым. Раз накручивать, так накручивать!!! — подумал я и включил его на максимальную скорость. Через некоторое время запустил накрутку с еще одной машины с другим IP. Приблизительно через полчаса догнал по результатам «лидеров». В этот момент администрация все же проснулась и сделала первое правильное решение в данной истории, а именно отключила возможность просмотра результатов. Еще через 3 часа, когда по моим подсчетам у меня должно было быть порядка 5-6 тысяч голосов, голосование было все же остановлено. Официальная причина, которую они потом озвучили через свой твиттер стало inconsistencies in voting practice.
На следующий день они объявили фактически новый конкурс, который теперь заключается в том, что надо просто тупо написать определенное сообщение в твиттере, а победитель будет выбран случайным образом из написавших. Я сообщение конечно написал, но интереса к этому конкурсу у меня уже практически нет. Можете тоже поучавствовать, кстати, если хотите — <http://friendsaround.me/contest> (если выиграете нужен будет адрес в США куда доставить приз — если что пишите, могу с этим помочь).
В конце концов один из организаторов на мой вопрос почему так было сложно продумать зашиту от накруток заранее, ответил в твиттере, что к подготовке конкурса они просто-напросто подошли не достаточно ответвенно… Ну будем надеяться, что хотя бы к запуску своего стартапа подойдут более серьезно…
UPD: Кстати, я так до сих пор так и не разобрался почему третий и последующий запросы в моем накрутчике проходили только при включенном Fiddler'е, буду признателен если кто-нибудь подскажет причину… | https://habr.com/ru/post/87365/ | null | ru | null |
# NHibernate: маленькая хитрость при работе с Oracle или PostgreSQL
В ADO.NET провайдерах для [Oracle](http://www.oracle.com/database), [PostgreSQL](http://www.postgresql.org/) и, возможно, других есть одна неприятная особенность, которая может сказаться на производительности вашего приложения, если вы запрашиваете у сервера большие объемы данных: они не кэшируют вызовы метода *[IDataReader.GetOrdinal](http://msdn.microsoft.com/en-us/library/system.data.idatarecord.getordinal.aspx)*. Как оказалось это очень критично для [NHibernate](http://nhforge.org/), но, к счастью, разработчики NHibernate (а точнее [Hibernate](http://www.hibernate.org/)) эту проблему заметили и уже решили.
Но эта фича осталась незамеченной и почти не задокументированной.
Для того, чтобы в NHibernate включить кэширование вызовов *IDataReader.GetOrdinal* необходимо в hibernate.cfg выставить опцию «adonet.wrap\_result\_sets» в значение «true»:
```
xml version="1.0" encoding="utf-8" ?
true
```
C помощью [FluentNHibernate](http://www.fluentnhibernate.org/) это делается так:
```
var config = Fluently.Configure()
.ExposeConfiguration(c => c.SetProperty(Environment.WrapResultSets, "true"))
.Database(db)
/* other configuration */
.BuildConfiguration();
```
Метод \_ExposeConfiguration\_ добавляет действия, которые будут вызваны над объектом *NHibernate.Cfg.Configuration* при вызове метода *BuildConfiguration*. Таким образом код выше будет аналогичен следующему:
```
var config = Fluently.Configure()
.Database(db)
/* other configuration */
.BuildConfiguration();
config.SetProperty(NHibernate.Cfg.Environment.WrapResultSets, "true");
```
##### Ссылки по теме
* [nhibernate.jira.com/browse/NH-3207](https://nhibernate.jira.com/browse/NH-3207)
* [ramblingabout.wordpress.com/2009/01/07/optimizing-oracle-and-hibernate-performance](http://ramblingabout.wordpress.com/2009/01/07/optimizing-oracle-and-hibernate-performance/)
* [martijndashorst.com/blog/2006/11/28/hibernate-31-something-performance-problems-contd](http://martijndashorst.com/blog/2006/11/28/hibernate-31-something-performance-problems-contd/) | https://habr.com/ru/post/147450/ | null | ru | null |
# То, чего вы не ждали от калькулятора. Пасьянс на bc
Невинные развлечения с bash больше не кажутся мне чем-то особенным. В качестве своей следующей цели для экспериментов я выбрала GNU bc — консольный калькулятор и скриптовый математический язык программирования в одной коробке. Эта статья наверняка будет полезна всем линуксоидам и юниксоидам, не очень тесно знакомым с bc.

Итак, короткое введение в программирование на bc, ~~кавай и нэки~~ пасьянс на чистом bc ~~и поэтессы~~.
Не помню, когда я впервые узнала про bc, но уже много лет в качестве калькулятора я использую только его. Простой и удобный консольный калькулятор, имеющийся по умолчанию в большинстве дистрибутивов Linux, пленяет своим удобством.
#### Девятый кю (белый пояс)
Запустить калькулятор можно очевидной командой *bc*. После этого можно вводить выражения для вычисления. Нажатие на *Enter* сразу выдаст результат.
```
c
carrot@ubuntu:~$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
>2*2
4
>3*(6+1)
21
>5||(1&&0)
1
>5/2
2
```
В выражениях можно использовать скобки, знаки сложения, вычитания, деления и умножения, а так же && (логическое «и»), || (логическое «или») и! (логическое «не»).
#### Шестой кю (зеленый пояс)
В калькуляторе bc можно и нужно использовать переменные. Чтобы определить переменную, нужно записать её имя, поставить знак «равно» и затем записать значение переменной. Всё как везде.
```
>raw=3116
>raw+1
3117
```
Самые внимательные успели обнаружить, что калькулятор округляет все числа до целых. Причина в следующем: специальная переменная scale, определяющая точность вычислений, по умолчанию равна нулю. Если вы хотите получить результат с точностью до десяти знаков, то присвойте переменной число 10.
```
>5/2
2
>scale=10
>5/2
2.5000000000
>7/191
.0366492146
```
В bc есть ещё три специальных переменных. Last хранит в себе прошлый результат вычислений, obase и ibase используются для работы с различными системами счисления.
```
>1
1
>last+10
11
>obase=16
>last
B
>255+1
100
>ibase=16
>FE+1
FF
```
#### Пятый кю (голубой пояс)
Пришло время научиться работать со стандартной библиотекой и подключать сторонние функции. Чтобы использовать стандартную библиотеку языка bc, нужно запускать его с параметром -l:
```
carrot@ubuntu:~$ bc -l
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
>s(3)
.14112000805986722210
```
В стандартной библиотеке определены следующие функции:
* s (x) — синус x
* c (x) — косинус x
* a (x) — арктангенс x
* l (x) — натуральный логарифм x
* e (x) — экспонента от x
* j (n,x) — функция Бесселя n-го порядка от x
Чтобы использовать сторонние библиотеки, стоит скачать их, например, с сайтов [phodd.net/gnu-bc](http://phodd.net/gnu-bc/) и <http://marcmmw.freeshell.org/esp/programacion/bc.html>. Вы найдете процедуры для работы с массивами, интегралами, производными, логикой, генераторы случайных чисел и многое другое. Моя любимая библиотека — для работы с изображениями в формате ppm. Это на bash можно что хочешь генерировать — хоть bmp, хоть jpeg, а здесь всё суровее. Не EГГОГология, конечно, но всё равно.
Запускать bc со сторонними библиотеками следует так:
```
carrot@ubuntu:~$ bc rand.bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
>rand(96)
21
```

*Фрактал Мандельброта, рассчитанный в bc и сохраненный в ppm.*
#### Четвертый кю (синий пояс)
Синтаксис bc очень похож на синтаксис Си. Поэтому можно смело использовать команды if, for, while, break, continue, return и расставлять фигурные скобки где ни попадя. Только после команд не нужно ставить точек с запятой, для вывода на экран использовать команду print, а для ввода — read. Функции определять командой define. Смотрите:
```
>define func () {
>for (i=0;i<10;i++) {
>a=a+i
>print a, «\n»
>}
>return 1}
>t=func ()
0
1
3
6
10
15
21
28
36
45
>print t
1
```
#### Третий кю (коричневый пояс)
В bc, к сожалению, нельзя работать с файловым вводом-выводом. Весь ввод через read, весь вывод через print. Еще в bc нельзя работать со строковыми переменными. Хотя, постойте! Можно использовать 36-ричную систему счисления, или же работать с массивами чисел как со строками.
Кроме того, в bc команда print не поддерживает полный набор escape-последовательностей.
```
The special characters recognized by bc are "a" (alert or bell), "b" (backspace), "f" (form feed), "n" (newline), "r" (carriage return), "q" (double quote), "t" (tab), and "\e" (backslash). Any other character following the backslash will be ignored.
```
Когда я узнала об этом печальном ограничении, я подумала, что меня ждет розовая птица обломинго, ведь для любой серьезной игрушки нужно точное позиционирование курсора, и желательно использование различных цветов. Однако, я взяла hex-редактор в руки и обошла ограничение следующим образом: вставила символ с кодом 1Bh (escape) в качестве аргумента команды print, и затем пользовалась всеми радостями Escape-последовательностей.
Ах, да, чтобы вызываемые функции не мусорили на экран, их return-значение следует присваивать какой-нибудь переменной так, как я делала это в прошлом примере.
И, наконец, самый унылый факт: в bc есть только один способ отлавливать нажатия клавиш — read. И он совершенно не подходит для интерактивных игр. А жаль, потому что на моём компьютере алгоритм рейкастинга, запущенный в bc, работает раз в десять быстрее, чем тот же алгоритм в bash, и выдает около 30-40 кадров в секунду.
#### Второй кю (всё еще коричневый пояс)
Теперь можно написать простой пасьянс на bc. Я выбрала пасьянс «Турецкий платок». Скачиваем [архив с исходными кодами](http://narod.ru/disk/31656937001/platok.tar.html), распаковываем, запускаем так:
```
bc rand.bc printcard.bc
```
После запуска нужно ввести seed — начальное значение генератора случайных чисел. После этого вы увидите перетасованную колоду карт, разложенную в десять столбцов. Вводите номера столбцов, и если последние карты столбцов имеют одинаковую картинку (например, двойка треф и двойка бубен), то они будут убраны. Как только все карты удастся разобрать, программа поздравит вас с победой и завершит bc. Если вы решили, что стоит прекратить распутывать платок, нажмите Ctrl+C дважды, и затем Enter.
#### Первый дан (черный пояс)
А не будет информации про него. Почему? *Потому что я еще не чувствую себя мастером...*
P.S. Ссылка на пасьянс ещё раз, специально для тех, кто всегда сначала скачивает все файлы, а потом читает статью: [narod.ru/disk/31656937001/platok.tar.html](http://narod.ru/disk/31656937001/platok.tar.html) | https://habr.com/ru/post/132840/ | null | ru | null |
# Лучшие подходы и решения для уменьшения кода на React. Часть 3
Привет! Это третья и заключительная часть серии статей “Лучшие подходы и решения для уменьшения кода на React” автора Rahul Sharma. Предыдущие статьи вы можете найти по ссылкам ниже:
* [Часть 1](https://habr.com/ru/post/657673/)
* [Часть 2](https://habr.com/ru/post/657879/)
* [Часть 3](https://habr.com/ru/post/658079/)
Храните токен в куки, вместо localStorage
-----------------------------------------
Плохой код:
```
const token = localStorage.getItem("token");
if (token) {
axios.defaults.headers.common["Authorization"] = token;
}
```
Хороший код:
```
import Cookies from "js-cookie"; // Вы можете использовать другую библиотеку
const token = Cookies.get("token");
if (token) {
axios.defaults.headers.common["Authorization"] = token;
}
```
Лучший код:
```
Без кода 😉
```
***Примечание:***
* *Куки распространяются на все сайты внутри одного домена. Так что нет необходимости прописывать токен в каждом запросе. Если же бэкенд находится не на том же домене, что и фронтенд, то вам нужно использовать решение из следующего пункта.*
* *Используйте HttpOnly атрибут для избегания получения доступа к куки через JavaScript.*
---
### Используйте перехватчики запросов (interceptors) для токена авторизации или других стандартных заголовков
Плохой код:
```
axios.get("/api", {
headers: {
ts: new Date().getTime(),
},
});
```
Хороший код:
```
axios.interceptors.request.use(
(config) => {
// Код, необходимый до отправки запроса
config.headers["ts"] = new Date().getTime();
return config;
},
(error) => {
// Обработка ошибки из запроса
return Promise.reject(error);
}
);
// Компонент
axios.get("/api");
```
---
### Используйте react context/redux для передачи пропов в дочерние элементы
Плохой код:
```
const auth = { name: "John", age: 30 };
return (
} />
} />
);
```
Хороший код:
```
return (
}
/>
}
/>
);
// Внутри дочернего компонента
const { auth } = useContext(AuthContext); // При использовании контекста
const { auth } = useSelector((state) => state.auth); // При использовании redux
```
---
### Используйте вспомогательные функции для styled-components
Не плохой код, но сложный для чтения, так как все привыкли думать в пикселях:
```
const Button = styled.button`
margin: 1.31rem 1.43rem;
padding: 1.25rem 1.5rem;
`;
```
Создайте вспомогательную функцию для перевода пикселей в rem:
```
const toRem = (value) => `${value / 16}rem`;
const Button = styled.button`
margin: ${toRem(21)} ${toRem(23)};
padding: ${toRem(20)} ${toRem(24)};
`;
```
---
### Используйте универсальные функции для изменения данных внутри полей ввода
Плохой код:
```
const onNameChange = (e) => setName(e.target.value);
const onEmailChange = (e) => setEmail(e.target.value);
return (
);
```
Хороший код:
```
const onInputChange = (e) => {
const { name, value } = e.target;
setFormData((prevState) => ({
...prevState,
[name]: value,
}));
};
return (
);
```
---
### Используйте intersection observer для реализации отложенной загрузки
Плохой код:
```
element.addEventListener("scroll", function (e) {
// do something
});
```
Хороший код:
```
const useScroll = (ele, options = {}): boolean => {
const [isIntersecting, setIsIntersecting] = useState(false);
useEffect(() => {
const cb = (entry) => setIsIntersecting(() => entry.isIntersecting);
const callback: IntersectionObserverCallback = (entries) => entries.forEach(cb);
const observer = new IntersectionObserver(callback, options);
if (ele) observer.observe(ele);
return (): void => ele && observer.unobserve(ele);
}, [ele]);
return isIntersecting;
};
// Компонент
const ref = useRef();
const isIntersecting = useScroll(ref?.current);
useEffect(() => {
if (isIntersecting) {
// вызов API
}
}, [isIntersecting]);
```
---
### Используйте HOC для авторизации и приватной навигации
Плохой код:
```
const Component = () => {
if (!isAuthenticated()) {
return ;
}
return ;
};
```
Хороший код:
```
const withAuth = (Component) => {
return (props) => {
if (!isAuthenticated()) {
return ;
}
return ;
};
};
// Навигация
;
// Компонент
const Component = (props) => ;
export default withAuth(Component);
```
---
### Используйте массив с объектами данных навигации при ее создании
Стандартное решение:
```
return (
} />
} />
} />
);
```
Хороший код:
```
const routes = [
{
path: "/",
role: ["ADMIN"],
element: React.lazy(() => import("../pages/App")),
children: [
{
path: "/child",
element: React.lazy(() => import("../pages/Child")),
},
],
},
{
path: "/about",
role: [],
element: React.lazy(() => import("../pages/About")),
},
{
path: "/topics",
role: ["User"],
element: React.lazy(() => import("../pages/Topics")),
},
];
const createRoute = ({ element, children, role, ...route }) => {
const Component = role.length > 0 ? withAuth(element) : element;
return (
}>
{children && children.map(createRoute)}
);
};
return {routes.map(createRoute)};
```
***Примечание:*** *это требует больше кода, но становится более настраиваемым. К примеру, если вы хотите использовать больше HOC, вам нужно всего лишь обновить createRoute.*
---
### Используйте Typescript
Ничего плохого, если вы не используете Typescript **😀**, попробуйте он поможет сделать ваш код лучше.
```
npx create-react-app my-app --template typescript
```
---
### Используйте eslint, prettier для форматирования
```
npm install -D eslint prettier
npx eslint --init
```
Ссылки для помощи в настройке: [Eslint](https://eslint.org/docs/user-guide/getting-started), [Prettier](https://prettier.io/docs/en/install.html)
---
### Используйте pre-commit хук для запуска eslint и prettier
Плохой код:
```
npx mrm@2 lint-staged // Установка и конфигурация pre-commit хука
// Скрипт будет создан в корне вашего проекта
.husky/pre-commit
// Package.json
"lint-staged": {
"src/**/*.{js,ts,jsx,tsx}": [
"npm run lint",
"npm run prettier",
"npm run unit-test",
"git add"
]
}
```
***Примечание:***
* *Вы можете обновить конфиг для запуска prettier и eslint при коммите. Вы также можете добавлять или удалять команды в package.json.*
* *Лучше, если в проекте настроен CI & CD для этого. Кто-то может закомментировать pre-commit хук и запушить его в гит.*
---
### Несколько VSCode расширений для более легкой разработки
[Auto Close Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-close-tag)**,**[Auto Rename Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag)**,**[CodeMetrics](https://marketplace.visualstudio.com/items?itemName=kisstkondoros.vscode-codemetrics)**,**[CSS Peek](https://marketplace.visualstudio.com/items?itemName=pranaygp.vscode-css-peek)**,**[ES7+ React/Redux/React-Native snippets](https://marketplace.visualstudio.com/items?itemName=dsznajder.es7-react-js-snippets)**,**[Eslint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)**,**[GitLens](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens)**,**[Import Cost](https://marketplace.visualstudio.com/items?itemName=wix.vscode-import-cost)**,**[Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
***Примечание:*** *попробуйте расширения для оценки сложности функций (CodeMetrics). Это поможет в написании более хорошего кода, так как вы будете видеть сложность выполнения кода.*

---
Спасибо за прочтение 😊 | https://habr.com/ru/post/658079/ | null | ru | null |
# Разбираем протокол новых датчиков Noolite

Привет!
На прошлой неделе компания Ноотехника [выпустила два первых датчика — движения и температуры и влажности](http://habrahabr.ru/post/228343/) для своей линейки дистанционного управления светом Noolite.
К сожалению, работа с датчиком температуры и влажности с помощью родного USB-приёмника от Ноотехники не поддерживается, только через их Ethernet-шлюз.
В нашем контроллере для домашней автоматизации [Wiren Board Smart Home](http://habrahabr.ru/company/contactless/blog/213243/) есть встроенный универсальный приёмопередатчик на частоту 433MHz, с помощью которого можно работать с многими устройствами. Это значит, что WB Smart Home может работать с устройствами Noolite напрямую, без использования USB-приёмников и передатчиков Ноотехники.
Впрочем, чтобы работать со сторонними устройствами, для начала обычно требуется реверс-инжиниринг (т.е. взлом) протокола радио-обмена.
Протокол Noolite, используемый в блоках управления освещением, мы вскрыли и разобрали [в одной из предыдущих статей](http://habrahabr.ru/company/contactless/blog/216023/).
В этой статье мы расскажем про реверс-инжиниринг протокола датчика PT111, обновлённую информацию об устройстве протокола Noolite вообще, а также покажем, как работа с датчиками выглядит в WB Smart Home.
#### Датчики

(как всегда, спасибо [dima117](https://habrahabr.ru/users/dima117/) и [thinking-home.ru](http://thinking-home.ru) за очень оперативно предоставленные устройства для экспериментов.)
Как уже было сказано, Ноотехника выпустила два датчика: движения PM111 и температуры/влажности PT111. По слухам, к выходу готовится ещё датчик температуры.
##### PM111
Датчик движения PM111 имеет PIR-сенсор и датчик освещённости. Датчик работает аналогично пультам Noolite.
После детектирования движения датчик отправляет команду на включение, через определённое время после отсутствия движения — команду на выключение.
Чувствительность датчика, длительность включения и порог освещённости регулируются.
Датчик движения со снятой задней крышкой и защитным колпачком (картинки кликабельны):
[](http://habrastorage.org/files/339/acf/17b/339acf17b5ac498d84dc99f66370f1bb.JPG)
Кстати, интересная трассировка платы.
##### Датчик температуры и влажности PT111
[](http://habrastorage.org/files/db1/578/63c/db157863c1844b1f8654caaff1f9ea03.JPG)
Внутри используется датчик [Sensirion SHT10](http://www.sensirion.com/en/products/humidity-temperature/humidity-sensor-sht10/).
Датчик SHT10 довольно дорогой: оптовая цена в России — [больше 400 рублей](http://www.efind.ru/icsearch/?search=SHT10), китайцы продают их по $6. Видимо этим частично и определяется довольно высокая цена итогового продукта.
PT111 умеет работать в трёх режимах: собственно в режиме передачи показаний, а также в режимах термостата и гигростата.
В двух последних режимах PT111 эмулирует обычный пульт Noolite, отправляя команды включения и выключения при переходе температуры или влажности через заданный порог.
В режимах термостата и гигростатата функциональность отправки показаний зачем-то отключается.
В отличие от распространённых погодных датчиков Oregon Scientific, PT111 отправляет пакет с данными только при изменении показаний температуры или влажности, но не чаще, чем примерно раз в минуту.
На задней панели датчика расположена кнопка, при нажатии на которую PT111 отправляет команды привязки или отвязки. При нажатии на кнопку в режиме датчика, PT111 также немедленно отправляет пакет с данными, если они изменились с прошлого раза.
#### Протокол PT111
Реверс-инжиниринг протокола как всегда начинается со сбора дампов пакетов.
Как сказано выше, у PT111 есть недокументированная особенность, очень полезная для отладки — датчик отправляет показания при нажатии на кнопку привязки.
Задача несколько усложнялась тем, что официального приёмника Noolite (ethernet-шлюза) под рукой у нас не было. Это значит, что не было правильных точных значений температуры и влажности для каждого пакета с данными.
В процесса сбора данных мы отправляли датчик в морозилку, грели его и т.д., чтобы собрать как можно больше данных.
Вот так выглядят приходящие с датчика данные, в том виде, как их принимает демон радио-модуля Wiren Board Smart Home:
```
$ mosquitto_sub -v -t /events/wb-homa-rcd/protocols/+
/events/wb-homa-rcd/protocols/raw raw=aaaaaaaaaaaaaaa85559aaa5569a66a6aaa6a960aab3554aad34cd4d554d52c055555555555555555550aaaaad34cd55554cb4a155555a699aaaaa99
/events/wb-homa-rcd/protocols/noo raw=1111110100000011111001001010001000000010000110 fmt=1 cmd=15 flip=1 addr=149f
```
Представленный здесь пакет — это пакет привязки пульта, отправленный при нажатии на кнопку на датчике.
Пакет с данными выглядит так (здесь уже приведена расшифровка):
```
/events/wb-homa-rcd/protocols/raw raw=aaaaaaaaaaaaaaa1999aaa9a9aa6a6569555555a699a95aa9a6a4333355535354d4cad2aaaaab4d3352b5534d480000000000000000000000101ffff
/events/wb-homa-rcd/protocols/noo addr=149f temp=27.2 lowbat=0 fmt=7 cmd=21 flip=0 humidity=58 raw=10101010000000100010000100010111001111111111111001001010001110000010010001
```
Исходный пакет
```
aaaaaaaaaaaaaaa1999aaa9a9aa6a6569555555a699a95aa9a6a4333355535354d4cad2aaaaab4d3352b5534d480000000000000000000000101ffff
```
после отрезания хвоста и преабмулы и преобразования из [манчестерского кода](http://en.wikipedia.org/wiki/Manchester_code) выглядит так:
```
10101010000000100010000100010111001111111111111001001010001110000010010001
```
##### «Расширенный» формат пакета
Разбиваем сообщение на октеты, начиная с конца — в пакетах Noolite формат и размер пакета кодируются в конце пакета.
```
10 10101000 00001000 10000100 01011100 11111111
( адрес, 16 bit ) 11111001 00101000
(формат) 11100000
(чексумма) 10010001
```
Значения последних 4 байт мы знаем: это 2 байта адреса блока, байт кода формата и байт контрольной суммы.
В отличие от ранее известных пакетов, этот имеет код формата fmt=7.
От пакетов с командами обычных пультов есть и другое отличие: количество первых бит.
Вот так выглядит пакет с обычной командой выключения:
```
#ch:2 off_ch 110000 10011111 10100100 00000000 10000100 # fmt=0
```
Здесь перед байтами идёт блок из 6 бит. Первый бит всегда единица, следующий бит (flip) инвертируется каждую передачу (чтобы отличить дубликаты команды от новой команды), затем идут 4 бита, задающие код команды.
В «расширенном» формате первый блок имеет 10 бит. Значение первого бита непонятно, для датчика PT111 он всегда равен единице. Следующий бит — это flip-бит. Под команду в этом формате отведено уже 8 бит, а не 4. Формат пакета (расширенный или обычный) определяется кодом формата из предпоследнего байта. «Расширенный» формат, кроме собственно датчика PT111 (fmt=7), замечен также в командах «switch mode» и «switch color» USB-передатчика Noolite с кодом формата fmt=4.
В «расширенном» формате не используются коды команды из обычного формата, т.е. 0-15 — влезающие в 4 бита; коды команд начинаются с 16.
В зависимости от формата пакета по-разному считается и контрольная сумма (последний байт). Функция подсчёта — crc8\_maxim — остаётся одинаковой в обоих случаях, однако по-разному обрабатывается первый блок, не кратный восьми битам:
```
if cmd < 16:
data = chr(((cmd << 1) | flip_bit) << 3)
else:
data = chr(flip_bit << 7) + chr(cmd)
```
Итоговый парсер пакета выглядит так (весь код есть в [репозитарии](https://github.com/contactless/rfm69-linux/blob/master/noolite.py)):
**парсер пакета**
```
def parsePacket(self, packet):
if len(packet) < 38:
return
remainder = (len(packet) - 6 ) % 4
if remainder != 0:
packet += '0'*(4-remainder)
crc = int(packet[-8:][::-1], 2)
fmt = int(packet[-16:-8][::-1], 2)
addr_lo = int(packet[-32:-24][::-1], 2)
addr_hi = int(packet[-24:-16][::-1], 2)
addr = (addr_hi << 8) + addr_lo
if fmt < 4:
sextet_1 = packet[:6]
flip_bit = int(sextet_1[1], 2)
cmd = int(sextet_1[2:][::-1], 2)
args_data = packet[6:-32]
else:
dectet_1 = packet[:10]
flip_bit = int(dectet_1[1], 2)
cmd = int(dectet_1[2:][::-1], 2)
args_data = packet[10:-32]
#~ print "fmt=", fmt, len(args_data)
#~ print args_data
if fmt == 0:
if len(args_data) != 0:
return
elif fmt == 1:
if len(args_data) != 8:
return
elif fmt == 3:
if len(args_data) != 32:
return
elif fmt == 4:
if len(args_data) != 0:
return
elif fmt == 7:
if len(args_data) != 32:
return
else:
return
if args_data:
args = [int(x[::-1], 2) for x in utils.batch_gen(args_data, 8, align_right=True)]
else:
args = []
return flip_bit, cmd, addr, fmt, crc, args
```
##### Извлекаем данные
```
(флип-бит, код команда) 10 10101000
(данные) 00001000 10000100 01011100 11111111
( адрес, 16 bit ) 11111001 00101000
(формат) 11100000
(чексумма) 10010001
```
Как видно выше, под данные в пакете PT111 отведено 4 байта.
Посмотрим, как меняются эти данные от посылки к посылке (4 байта данных выделены):
```
10 10101000 { 00101000 10000100 01010100 11111111 } 11111001 00101000 11100000 10000000
10 10101000 { 00001000 10000100 01001100 11111111 } 11111001 00101000 11100000 11101101
11 10101000 { 11000100 10000100 10000010 11111111 } 11111001 00101000 11100000 01010110
10 10101000 { 01011000 10000100 10111100 11111111 } 11111001 00101000 11100000 11001010
11 10101000 { 00011000 10000100 01011100 11111111 } 11111001 00101000 11100000 10101011
11 10101000 { 01101000 10000100 11110100 11111111 } 11111001 00101000 11100000 00100000
```
Видим, что четвёртый байт данных во всех посылках равен 0xFF (0b11111111). Видимо он является зарезервированным.
Что такое третий байт данных? С большой вероятностью это целое 8-битное значение влажности: раскодированные таким образом значения получаются адекватными. Более того, значение этого байта никогда не превышает 100 (0x64), что можно проверить выставив на датчике максимальную влажность (например подышать в сенсор пару минут).
При сильном локальном нагреве воздуха паяльником, значение байта падает до 5-10, что похоже на правду.
Первый байт постоянно меняется при различных манипуляциях с датчиком — видимо он каким-то образом отвечает за температуру.
Второй байт кажется не меняется. Проверим, не кодируется ли здесь статус разряженной батарейки (судя по описанию датчик передаёт предупреждение об этом по радио).
Замкнём контакты одной батарейки тонким проводом, чтобы понизить напряжение:
```
( было ) 10 10101000 11000000 { 10000100 } 00111100 11111111 11111001 00101000 11100000 10010101
( стало ) 10 10101000 11100000 { 10000101 } 00100110 11111111 11111001 00101000 11100000 00111000
```
Видим, что изменился младший бит этого байта. Он кодирует статус заряда батарейки.
Что может быть в оставшихся битах второго байта? Например там может отдельно храниться знак температуры, как в датчиках Oregon Scientific.
Охлаждаем сенсор:
```
11 10101000 00110000 { 10000100 } 00001100 11111111 11111001 00101000 11100000 1110011 # 12, 33
(первый бит поменялся)
10 10101000 10011000 { 00000100 } 01101100 11111111 11111001 00101000 11100000 1100101 (25)
10 10101000 00111000 { 00000100 } 11011100 11111111 11111001 00101000 11100000 0110111 (28)
11 10101000 10111000 { 00000100 } 11110100 11111111 11111001 00101000 11100000 10100001
(долго лежал при -18C, первые четыре бита стали 1111)
11 10101000 01111010 { 11110100 } 11000010 11111111 11111001 00101000 11100000 1000100 (3934 = -16.2C)
(достали из холодильника, датчик нагревается)
10 10101000 00101010 { 11110100 } 11011100 11111111 11111001 00101000 11100000 00100110 (-17.2C)
10 10101000 10110001 { 11110100 } 01111100 11111111 11111001 00101000 11100000 10001011 (-11.5C)
10 10101000 01000011 { 11110100 } 11100010 11111111 11111001 00101000 11100000 01010011 (-6.2C)
10 10101000 11000111 { 11110100 } 00101010 11111111 11111001 00101000 11100000 01010100 (-2.9C)
11 10101000 00001111 { 11110100 } 11011010 11111111 11111001 00101000 11100000 00101010 (-1.6C)
(переход через ноль? 1111 => 0000)
11 10101000 11100100 { 00000100 } 01111010 11111111 11111001 00101000 11100000 01011101 (3.9C)
10 10101000 11000010 { 00000100 } 10000110 11111111 11111001 00101000 11100000 00000100
```
Дополнительно греем сенсор:
```
10 10101000 11000101 { 01000100 } 11000000 11111111 11111001 00101000 11100000 1100011 # 67.5
10 10101000 00100110 { 01000100 } 01000000 11111111 11111001 00101000 11100000 1011001 #
```
Видим что первые 4 бита второго байта ведут себя следующим образом:
* При уменьшении температуры значение меняется сначала с 0b0001 на 0b0000 (порядок бит — обратный)
* После заморозки до -18, значение становится 0b1111
* При нагреве в какой-то момент значение меняется с 0b1111 на 0b0000
* При сильном нагреве выше комнатной температуры значение меняется с 0b0001 на 0b0002
Итого, самое простое объяснение, которое приходит в голову — это то, что в первых четырёх битах хранится кусок signed-значения температуры.
Склеиваем эти четыре бита с 8 битами из первого байта и получаем 12-бит signed значение. Результаты декодирования позволяют понять, что это 12-бит знаковое значение температуры в десяты долях градусов Цельсия.
Пример декодирования:
```
1)
bytes 1-2 = 11100100 00000100
0000 00100111 (bin) = 39 (dec) = 3.9C
2)
bytes 1-2 = 00101010 11110100
1111 01010100 (bin) = 3924 (dec).
3924 - 0x1000 = -172 = -17.2C
```
**Итоговый код декодирования температуры:**
```
temp = ((args[1] & 0x0F) << 8) + args[0]
if temp > 0x7ff:
temp = temp - 0x1000
temp = temp * 0.1
```
##### Итого, формат данных PT111
```
temp/hum:
flip, 2 bit --> 10 10101000 11100000 10000101 00100110 11111111 11111001 00101000 11100000 00111000
cmd 8 bit ---^ | | ^ ^ ^ ^ addr_lo addr_hi fmt crc
temperature, signed, 0.1C --> |-- 12 bit -| | | | |
unknown, 3bit, 0b010 ------->---------------- | | |
bat low, 1bit ------------->------------------ | |
humidity, 8 bit ------------->----------------------- |
unknown, 8 bit, always 0xFF so far -------->------------------
```
#### WB Smart Home
В нативном веб-интерфейсе [WB Smart Home](http://habrahabr.ru/company/contactless/blog/213243/) датчики выглядят как-то так:

Итоговый код работы с Noolite [в нашем репозитории](https://github.com/contactless/rfm69-linux/blob/master/noolite.py).
##### Реклама
Контроллер WB Smart Home доступен в продаже [у нас на сайте](http://contactless.ru/store/#!/~/category/id=8751035&inview=product27947443&offset=0&sort=normal).
**А ещё мы ищем программистов C/C++/Python (Linux)**(лучше сразу всё из списка), разрабатывать ПО для наших железок для домашней и промышленной автоматизации.
Работа включает в том числе добавление поддержки в WB Smart Home новых внешних проводных и беспроводных устройств, вроде описанных в этой статье.
География: Москва — Долгопрудный, удалённая работа и неполная занятость тоже рассматриваются.
Писать можно на [email protected]. | https://habr.com/ru/post/229469/ | null | ru | null |
# Конкурентность: Асинхронность
Мы всё-таки смогли дойти до третьей части и добрались до самого интересного — организации асинхронных вычислений.
В прошлых двух статьях мы посмотрели на абстракцию [параллельно выполняющегося кода](https://habrahabr.ru/post/318374/) и [кооперативного выполнения](https://habrahabr.ru/post/318786/) обработчиков задач.
Теперь посмотрим, как можно управлять потоком исполнения (control flow) в случае обработки асинхронных задач.
* [Параллелизм](https://habrahabr.ru/post/318374/) (часть 1)
+ [Потоки: scheduling, сон](https://habrahabr.ru/post/318374/#potoki)
+ [Синхронизация](https://habrahabr.ru/post/318374/#sinhronizaciya): [Spinlock, семафоры](https://habrahabr.ru/post/318374/#spinlock), [барьеры памяти](https://habrahabr.ru/post/318374/#barer-pamyati)
+ [Атомарность: TAS, CAS](https://habrahabr.ru/post/318374/#atomarnost)
* [Кооперативность](https://habrahabr.ru/post/318786/) (часть 2)
+ [Корутины (coroutines)](https://habrahabr.ru/post/318786/#korutiny)
+ [Акторы](https://habrahabr.ru/post/318786/#aktory)
* **Асинхронность** (часть 3, текущая)
+ [Event loop](#event-loop)
- [select](#select)
+ [Callbacks](#callbacks)
+ [Async Monad](#async-monad)
+ [Промисы (promises, обещания)](#promisy-promises-obeschaniya)
+ [async/await — промисы + корутины](#asyncawait--promisy--korutiny)
Асинхронность
=============
Синхронные операции — операции, при которых мы получаем результат в результате блокирования [потока](https://habrahabr.ru/post/318374/#potoki) выполнения. Для простых вычислительных операций (сложение/умножение чисел) — это единственный вариант их совершения, для операций ввода/вывода — один из, при этом мы говорим, к примеру, *«попытайся прочитать из файла что-нибудь за 100мс»*, и если для чтения ничего нет — поток выполнения будет заблокирован на эти 100мс.
В некоторых случаях это допустимо (например, если мы делаем простое консольное приложение, либо какую-либо утилиту, цель которой — отработать и всё), но в некоторых — нет. К примеру, если мы так застрянем в потоке, в котором обрабатывается UI — наше приложение зависнет. За примерами далеко ходить не нужно — если javascript на сайте сделает `while(true);`, то перестанут вызываться какие-либо другие обработчики событий страницы и её придётся закрыть. Те же дела, если начать что-нибудь вычислять под Android'ом в обработчиках UI-событий (код которых вызывается в UI-потоке), это приведёт к появлению окна «приложение не отвечает, закрыть?» (подобные окна вызываются по [watchdog-таймеру](https://en.wikipedia.org/wiki/Watchdog_timer), который сбрасывается, когда выполнение возвращается обратно к системе UI).
Асинхронные операции — операции, при которых мы **просим совершить** некоторую операцию и можем каким-либо образом отслеживать процесс/результат её выполнения. Когда она будет выполнена — неизвестно, но мы можем продолжить заниматься другими делами.
Event loop
----------
**Event loop** — это бесконечный цикл, который берёт **события** из очереди и как-то их обрабатывает. А в некоторых промежутках — смотрит, не произошло ли каких-нибудь **IO-событий**, либо не просрочились ли какие-либо **таймеры** — тогда добавляет в очередь событие об этом, чтобы потом обработать.
Вернёмся к примеру с браузером. Вся страница работает в одном **event loop'е**, загруженный страницей **javascript** добавляется в **очередь**, чтобы выполниться. Если на странице происходят какие-либо **UI-события** (клик по кнопке, перемещение мыши, прочее) — код их обработчиков добавляется в **очередь**. Обработчики выполняются последовательно, нет никакой параллельности, пока работает какой-либо код — все остальные ждут. Если какой-нибудь код вызовет какую-нибудь специальную функцию, вроде `setTimeout(function() { alert(42) }, 5000)` — то это создаст где-то вне цикла таймер, по истечению которого в **очередь** будет добавлен код функции с `alert(42)`.
**Фишка:** если кто-то в очереди перед выполнением обработчика будет что-то долго вычислять, то обработчик таймера, очевидно, выполнится позже, чем через пять секунд.
**Вторая фишка:** даже если мы попросим, например, 1 миллисекунду ожидания, может пройти куда больше, т.к. реализация **event loop'а** может посмотреть: «ага, очередь пуста, ближайший таймер через 1мс, будем ждать IO-событий 1мс», а когда мы вызовем select, реализация операционной системы может посмотреть: «ага, событий вроде нет, на твоё время мне всё равно, я делаю context switch, пока есть возможность», а там все остальные потоки заиспользовали всё доступное им время и мы пролетели.
### select
Асинхронные IO-события на низком уровне реализованы при помощи вариаций [select'а](https://en.wikipedia.org/wiki/Select_(Unix)). У нас есть некие файловые дескрипторы (которые могут быть либо файлами, либо сетевыми сокетами, либо чем-то ещё (по сути, в Linux что угодно может являться файлом (или наоборот, файл может являться чем угодно))).
И мы можем вызвать некоторую синхронную функцию, передав ей множество дескрипторов, от которых мы ожидаем ввода, либо же хотим что-то записать, которая заблокирует поток до тех пор пока:
1. Один или несколько переданных нами дескрипторов не станут готовы к совершению желаемой нами операции.
2. Не истекло время ожидания (если оно было задано).
В результате выполнения этой процедуры мы получим множества готовых к чтению/записи файлов.
Callbacks
---------
Самый простой способ получить результаты выполнения асинхронной операции — при её создании передать ссылки на функции, которые будут вызваны при каком-либо прогрессе выполнения/готовности результата.
Это довольно низкоуровневый подход, и часто неумение банально писать функции «в столбик» вместе со злоупотреблением анонимных функций приводит к «callback hell» (ситуация, когда мы имеем четыре-десять уровней вложенности функций, чтобы обработать последовательные операции):
```
// Вкладываем
function someAsync(a, callback) {
anotherAsync(a, function(b) {
asyncAgain(b, function(c) {
andAgain(b, c, function(d) {
lastAsync(d, callback);
});
});
});
}
// Линейно
function someAsync2(a, callback) {
var b;
anotherAsync(a, handleAnother);
function handleAnother(_b) {
b = _b;
asyncAgain(b, handleAgain);
}
function handleAgain(c) {
andAgain(b, c, handleAnd);
}
function handleAnd(d) {
lastAsync(d, callback);
}
}
```
Async Monad
-----------
Мы, программисты, любим абстрагировать и обобщать для сокрытия разных сложностей/рутины. Поэтому существует, в том числе, абстракция над асинхронными вычислениями.
Что такое **«вычисление»**? Это процесс **преобразования A в B**. Будем записывать синхронные вычисления как **A → B**.
Что такое **«асинхронное значение»**? Это обещание предоставить нам в будущем некоторое значение **T** (которое может быть успешным результатом, либо ошибкой). Будем обозначать это как **Async[T]**.
Тогда **«асинхронная операция»** будет выглядеть как `A → Async[T]`, где **A** — какие-то аргументы, необходимые для старта операции (например, это может быть URL, к которому мы хотим совершить GET-запрос).
Как работать с **Async[T]**? Пусть у него будет метод **run**, который примет **коллбэк**, который будет вызван тогда, когда данные станут доступны: `Async[T].run : (T → ()) → ()` (принимает функцию, принимающую **T**, ничего не возвращает).
Хорошо, а теперь добавим самое главное — возможность **продолжить** асинхронную операцию. Если у нас есть **Async[A]**, то, очевидно, когда **A** станет доступно, мы можем создать **Async[B]** и ждать уже его результата. Функция для такого продолжения будет выглядеть так:
`Async[A].then : (A → Async[B]) → Async[B]`
Т.е. если мы можем создать **Async[B]** из некого **A**, а так же имеем **Async[A]**, который когда-нибудь предоставит нам **A**, нет никаких проблем предоставить **Async[B]** сразу, ибо **B** мы сможем всё-таки получить через какое-то время и в итоге всё сойдётся.
**Реализация этого добра**
```
function Async(starter) {
this.run = function(callback) {
starter(callback);
};
var runParent = this.run;
this.then = function(f) {
return new Async(function(callback) {
runParent(function(x) {
f(x).run(callback);
});
});
};
}
```
И тогда тот наш синтетический пример выше становится:
```
function someAsync(a) {
return anotherAsync(a).then(function(b) {
return asyncAgain(b).then(function(c) {
return andAgain(b, c);
}).then(function(d) {
return lastAsync(d);
});
});
}
```
Но дальше интереснее. Явно разграничим тип асинхронного значения на ошибку/результат. Теперь у нас всегда **Async[E + R]** (плюс это тип-сумма, одно из двух). И тогда мы можем, к примеру, ввести метод `Async[E + R].success : (R → Async[E + N]) → Async[E + N]`. Обратите внимание, что **E** осталось нетронутым.
Мы можем реализовать этот метод только так, чтобы он выполнял переданную ему функцию только в случае получения успешного результата (т.е. получению **R**, а не **E**) и запускал следующую асинхронную операцию, иначе — результат асинхронной операции продолжает оставаться «ошибочным».
```
this.success = function(f) {
return new Async(function(callback) {
runParent(function(x) {
if (x.isError()) callback(x);
else f(x).run(callback);
});
});
};
```
Теперь если мы будем chain'ить асинхронные операции при помощи метода **success**, мы будем обрабатывать только успешную ветку развития событий, а любая ошибка проскочит все последующие обработчики и попадёт сразу в коллбэк, переданный в **run**.
Мы только что абстрагировали поток выполнения и ввели в нашу абстракцию **исключения**. Если поиграться ещё немного, можно будет придумать метод **failure**, который может преобразовать ошибку в другую ошибку, либо же вернуть **успешный результат**.
Промисы (promises, обещания)
----------------------------
Есть стандарт, описывающий интерфейс [Thenable](https://promisesaplus.com/). Он работает практически идентично тому, что было описано выше, но в **Promises/A+** нет понятия **старта** асинхронной операции. Если мы имеем на руках **Thenable**, то уже где-то что-то выполняется и всё что мы можем — подписаться на результат выполнения. И там один метод **then**, принимающий две опциональных функции для обработки успешной/провальной ветки, а не разные методы.
Здесь уж на вкус и цвет, у обоих подходов есть и плюсы и минусы.
async/await — промисы + корутины
--------------------------------
Чтобы использовать промисы, нам нужно использовать лямбда-функции в невероятных количествах. Что может быть довольно визуально шумно и неудобно. Нет ли возможности сделать это как-то лучше?
Есть.
У нас есть [корутины](https://habrahabr.ru/post/318786/#korutiny), у которых может быть множество точек входа. И это то, что нам нужно. Пусть у нас будет корутина, которая выдаёт наружу **Async[E + R]**, а внутрь неё подаётся получившееся **R**, либо возбуждается исключение **E**. И тогда начинается дзен:
```
function someAsync*(a) {
var b = yield anotherAsync(a),
c = yield asyncAgain(b),
d = yield andAgain(b, c);
yield lastAsync(d);
}
```
Затем нам нужен «executor» такого добра, который будет принимать эту корутину, доставать из неё выходы, если они являются **Async'ами** — выполнять их, если другими корутинами — рекурсивно execute'ить их, считая результатом последний **yield**.
А **async/await** — это когда мы **yield** переименовываем в **await**, а перед декларацией функции пишем **async**. Ну и иногда (в случае Python, например), можно увидеть **асинхронные генераторы**, в которых в наличии одновременно и **yield**, и **await**. Тогда они ведут себя как те же корутины, но операции с ней становятся асинхронными, ибо между возвратом/принятием она ждёт результатов своих внутренних асинхронных операций.
---
Что ж, на этом моя серия статей заканчивается, надеюсь, они кому-нибудь были полезны и не запутали ещё больше. | https://habr.com/ru/post/319350/ | null | ru | null |
# Java EE, JCA и jNode 2.X announce

Доброго времени суток, %username%.
Скажу сразу, на 99% данный пост про Java EE Connector Architecture, с примерами кода. Откуда взялся 1% про Fidonet вы поймете в самом конце.
**Резюме для ленивых**JMS и JCA — родственники, входящие принимает MessageDrivenBean, исходящие отправляются через ConnectionFactory.
Минимальный пакет для входящего соединения — 4 класса, для исходящего — 8 классов и настройка адаптера на стороне сервера приложений.
Дальше — только подробности и боль
Для начала — история вопроса и решение бизнес-задачи.
### Постановка задачи
Мне поставили задачу об интеграции существующей бизнес-системы («система А» ) с другой системой, которая была разработана много лет назад и понимает только собственный протокол передачи данных («система B»). Модифицировать чужие системы нельзя, соответственно задача свелась к написанию некой шины/прокси. Интеграция состоит в передаче туда-сюда сообщений с конвертацией их в процессе из одного формата в другой.
Система «А» имела много современных механизмов интеграции, самым простым для использования были признаны веб-сервисы. Под это дело был оперативно запилен стандартный интеграционный скелет для JEE — JAX-WS+EJB+JMS для гарантированной доставки сообщения.
А вот для работы с системой «B» стандартных средств не было. Робкие попытки поработать с сетью из контекста EJB успехом не увенчались, гугл подсказал два варианта решения проблемы: костылить сервлеты для работы с non-http или написать JCA-адаптер. Понятно, что был выбран второй путь — с JCA я до этого не работал, а узнать что-то новое всегда интересно.
### Исследование
Начав копать гугл, я достаточно сильно обломался. Везде писали, ЧТО именно нужно сделать ( коннектор, менеджер, адаптер итд ), но почти нигде не писали, КАК это сделать. Стандартный способ «посмотреть чужой код и понять процесс» дал сбой — чужого кода был такой мизер, что понять что-то мне не представлялось возможным.
Спасли меня две вещи: [JSR 322](https://jcp.org/en/jsr/detail?id=322) и единственный нагугленный адаптер на [google code](https://code.google.com/p/jca-sockets/). Собственно, это и стало отправной точкой — задеплоив примеры из jca-sockets и открыв pdf, я начал разбираться и путем научного тыка понимать, как оно собственно работает.
Потратив около 16 часов на исследование и эксперименты, я выяснил следующее:
JCA-модуль имеет внутри себя две независимых части: «Входящие» и «Исходящие». Эти части могут быть как вместе, так и по-отдельности. Более того, их может быть несколько. Сам модуль регистритуется классом, реализующим *javax.resource.spi.ResourceAdapter* и указанным в *META-INF/ra.xml*, при этом ResourceAdapter нужен в первую очередь для работы с Входящими; Для Исходящих адаптер ничего не делает и его скелет можно даже не заполнять.
### Входящие
Входящий канал биндится к *MessageEndpoint*'у ( обычно это *@MessageDrivenBean*; да-да, JCA это кишки JMS ) и активируется *ActivationSpec*'ом.
*META-INF/ra.xml* — описание ResourceAdapter'а и inbound потоков
**ra.xml**
```
xxx-services
FidoNet
2.5
in.fidonode.binkp.ra.BinkpServerResourceAdapter
version
java.lang.String
jnode-jee 2.5 binkp/1.1
in.fidonode.binkp.ra.BinkpMessageListener
in.fidonode.binkp.ra.BinkpActivationSpec
listenPort
listenPort
java.lang.Integer
24554
```
Интерфейс *BinkpMessageListener* — для клиентов и должен быть в classpath;
Приведу его тут:
```
public interface BinkpMessageListener {
public void onMessage(FidoMessage message);
}
```
Теперь рассмотрим простейшую реализацию *ResourceAdapter*
**BinkpServerResourceAdapter.java**
```
public class BinkpServerResourceAdapter implements ResourceAdapter, Serializable {
private static final long serialVersionUID = 1L;
private static Logger log = Logger.getLogger(BinkpServerResourceAdapter.class
.getName());
private ConcurrentHashMap activationMap =
new ConcurrentHashMap();
private BootstrapContext ctx;
private String version;
@Override
public void endpointActivation(MessageEndpointFactory endpointFactory,
ActivationSpec spec) throws ResourceException {
BinkpEndpoint activation = new BinkpEndpoint(ctx.getWorkManager(),
(BinkpActivationSpec) spec, endpointFactory);
activationMap.put((BinkpActivationSpec) spec, activation);
activation.start();
log.info("endpointActivation(" + activation + ")");
}
@Override
public void endpointDeactivation(MessageEndpointFactory endpointFactory,
ActivationSpec spec) {
BinkpEndpoint activation = activationMap.remove(spec);
if (activation != null)
activation.stop();
log.info("endpointDeactivation(" + activation + ")");
}
@Override
public void start(BootstrapContext ctx)
throws ResourceAdapterInternalException {
this.ctx = ctx;
log.info("start()");
}
@Override
public void stop() {
for (BinkpEndpoint act : activationMap.values()) {
act.stop();
}
activationMap.clear();
log.info("stop()");
}
@Override
public XAResource[] getXAResources(ActivationSpec[] arg0)
throws ResourceException {
return null;
}
public String getVersion() {
return version;
}
public void setVersion(String version) {
this.version = version;
}
}
```
Что тут происходит? При загрузке JCA-модуля создается экземпляр класса BinkpServerResourceAdapter, у него заполняются параметры ( в данном случае — поле version) и вызывается метод start().
На самом деле, внутри метода start() можно делать много всего, но в данном примере мы просто сохраняем контекст для получения из него в дальнейшем *WorkManager*'а.
Когда сервер приложений находит *@MessageDrivenBean*, он пытается найти адаптер, который отправляет сообщения на тот интерфейс, который реализует бин. Для JMS это *MessageListener*, у нас это *BinkpMessageListener*. Создается ActivationSpec ( у нас это BinkpActivationSpec, реализующий *javax.resource.spi.ActivationSpec*), поля в котором заполняются согласно данным в activationConfig, создается MessageEndpointFactory и вызывается ResourceAdapter.endpointActivation(). В этой функции необходимо создать тот «сервер», который будет принимать входящие соединения, будь то tcp/ip сервер или поток для работы с unix-socket, создать на основе того конфига который был в MDB. Класс *BinkpEndpoint* — это и есть тот самый «сервер».
**BinkpEndpoint.java**
```
public class BinkpEndpoint implements Work, FidoMessageListener {
private static final Logger logger = Logger.getLogger(BinkpEndpoint.class
.getName());
private BinkpServer server;
private final WorkManager workManager;
private final MessageEndpointFactory messageEndpointFactory;
public BinkpEndpoint(WorkManager workManager,
BinkpActivationSpec activationSpec,
MessageEndpointFactory messageEndpointFactory) {
this.workManager = workManager;
this.messageEndpointFactory = messageEndpointFactory;
server = new BinkpServer(activationSpec.getListenPort(), this);
}
public void start() throws ResourceException {
workManager.scheduleWork(this);
}
public void stop() {
if (server != null) {
server.stop();
}
}
/** из FidoMessageListener **/
@Override
public Message incomingMessage(FidoMessage message) {
String message = msg.encode();
BinkpMessageListener listener = (BinkpMessageListener) messageEndpointFactory
.createEndpoint(null);
listener.onMessage(message);
}
/** из Work **/
@Override
public void run() {
server.start();
}
/** из Work **/
@Override
public void release() {
stop();
}
}
```
Можно заметить, что везде фигурируют некие endpoint'ы. У меня был с этим некоторый затык, поэтому расшифрую:
*Endpoint* — это то, что слушает «входящий» поток. Именно к нему относятся функции endpointActication
*MessageEndpoint* — экземпляр MDB, который обрабатывает то или иное сообщение. Получается вызовом *MessageEndpointFactory.createEndpoint()* ( Эту функцию нельзя вызывать из основного треда ). Он легко кастится к интерфейсу MDB.
Собственно, все. Реализацию BinkpServer за ненадобностью опущу, но принцип должен быть понятен, минимальный «Входящий» JCA делается из четырех классов ( ResourceAdapter, MessageListener, ActivationSpec, Endpoint )
Создание Endpoint'а и обработка входящих:
```
@MessageDriven(messageListenerInterface = BinkpMessageListener.class,
activationConfig = { @ActivationConfigProperty(propertyName = "listenPort", propertyValue = "24554") })
public class ReceiveMessageBean implements BinkpMessageListener {
@Override
public void onMessage(FidoMessage msg) {
// do smth with mesaage
}
}
```
### Исходящие
А вот тут — все веселее, минимальный «Исходящий» JCA делается аж из 8 классов, что в 2 раза больше чем «Входящий». Но давайте по-порядку.
*META-INF/ra.xml* — описание ResourceAdapter'а и outbound потоков
**ra.xml**
```
xxx-services
FidoNet
2.5
in.fidonode.binkp.ra.BinkpServerResourceAdapter
version
java.lang.String
jnode-jee 2.5 binkp/1.1
in.fidonode.binkp.ra.ManagedConnectionFactory
in.fidonode.binkp.ra.ConnectionFactory
in.fidonode.binkp.ra.ConnectionFactoryImpl
in.fidonode.binkp.ra.Connection
in.fidonode.binkp.ra.ConnectionImpl
NoTransaction
false
```
Интерфейсы *Connection* и *ConnectionFactory* — для клиентов и должны быть в classpath. Сразу приведу их тут, там ничего интересного.
*BinkpClient* приводить не буду :-)
```
public interface Connection {
public BinkpClient connect(String hostname, int port);
}
public interface ConnectionFactory {
public Connection createConnection();
}
```
Соединения бывают Managed и Unmanaged. Первые — со свистелками, listener'ами и другим, вторые — без.
Класс, реализующий *ManagedConnectionFactory*, должен уметь создавать оба типа соединений.
**ManagedConnectionFactory.java**
```
public class ManagedConnectionFactory implements
javax.resource.spi.ManagedConnectionFactory {
private PrintWriter logwriter;
private static final long serialVersionUID = 1L;
/**
* Создание фабрики для unmanaged-соединений
*/
@Override
public Object createConnectionFactory() throws ResourceException {
return new ConnectionFactoryImpl();
}
/**
* Создание managed-фабрики для managed-connection
*/
@Override
public Object createConnectionFactory(ConnectionManager cxManager)
throws ResourceException {
return new ManagedConnectionFactoryImpl(this, cxManager);
}
/**
* Создание managed-соединения
*/
@Override
public ManagedConnection createManagedConnection(Subject subject,
ConnectionRequestInfo cxRequestInfo) throws ResourceException {
return new in.fidonode.binkp.ra.ManagedConnection();
}
@Override
public PrintWriter getLogWriter() throws ResourceException {
return logwriter;
}
@SuppressWarnings("rawtypes")
@Override
public ManagedConnection matchManagedConnections(Set connectionSet,
Subject subject, ConnectionRequestInfo cxRequestInfo)
throws ResourceException {
ManagedConnection result = null;
Iterator it = connectionSet.iterator();
while (result == null && it.hasNext()) {
ManagedConnection mc = (ManagedConnection) it.next();
if (mc instanceof in.fidonode.binkp.ra.ManagedConnection) {
result = mc;
}
}
return result;
}
@Override
public void setLogWriter(PrintWriter out) throws ResourceException {
logwriter = out;
}
}
```
Когда приложение запрашивает у JEE-сервера тот или иной коннектор, сервер приложений просит *ManagedConnectionFactory* создать *ConnectionFactory* и отдает его приложению.
Как можно заметить, *ConnectionFactory* тоже бывает Managed и Unmanaged. В принципе все это можно свести к одному классу, но это сильно зависит от того, что именно и как мы передаем, есть ли там транзакции итд.
*ConnectionFactoryIml* просто делает *new ConnectionImpl()*, а вот *ManagedConnectionFactoryImpl* чуть посложнее:
**ManagedConnectionFactoryImpl.java**
```
public class ManagedConnectionFactoryImpl implements ConnectionFactory {
private ManagedConnectionFactory factory;
private ConnectionManager manager;
public ManagedConnectionFactoryImpl(ManagedConnectionFactory factory,
ConnectionManager manager) {
super();
this.factory = factory;
this.manager = manager;
}
/** создает managed-соединение через родителя-ManagedConnectionFactory **/
@Override
public Connection createConnection() {
try {
return (Connection) manager.allocateConnection(factory, null);
} catch (ResourceException e) {
return null;
}
}
}
```
*ManagedConnection*, реализующий *javax.resource.spi.ManagedConnection* — это обертка для интерфейса Connection, которая как-раз добавляет свистелок и listener'ов. Именно этот класс возвращает *ManagedConnectionFactory.createManagedConnection()*, которую мы вызываем при создании соединения из *ManagedConnectionFactoryImpl.createConnection()* через *ConnectionManager.allocateConnection()*
**ManagedConnection.java**
```
public class ManagedConnection implements javax.resource.spi.ManagedConnection {
private PrintWriter logWriter;
private Connection connection;
private List listeners;
public ManagedConnection() {
listeners = Collections
.synchronizedList(new ArrayList());
}
@Override
public void associateConnection(Object connection) throws ResourceException {
if (connection != null && connection instanceof Connection) {
this.connection = (Connection) connection;
}
}
@Override
public Object getConnection(Subject subject,
ConnectionRequestInfo cxRequestInfo) throws ResourceException {
if (connection == null) {
connection = new ManagedConnectionImpl();
}
return connection;
}
@Override
public void cleanup() throws ResourceException {
}
@Override
public void destroy() throws ResourceException {
}
@Override
public PrintWriter getLogWriter() throws ResourceException {
return logWriter;
}
@Override
public ManagedConnectionMetaData getMetaData() throws ResourceException {
throw new NotSupportedException();
}
@Override
public XAResource getXAResource() throws ResourceException {
throw new NotSupportedException();
}
@Override
public LocalTransaction getLocalTransaction() throws ResourceException {
return null;
}
@Override
public void setLogWriter(PrintWriter out) throws ResourceException {
logWriter = out;
}
@Override
public void addConnectionEventListener(ConnectionEventListener listener) {
if (listener != null) {
listeners.add(listener);
}
}
@Override
public void removeConnectionEventListener(ConnectionEventListener listener) {
if (listener != null) {
listeners.remove(listener);
}
}
}
```
Ну вот, теперь мы подошли к самому простому — реализации соединения :-)
```
public class ConnectionImpl implements Connection {
@Override
public BinkpClient connect(String hostname, int port) {
return new BinkpClient(hostname, port);
}
}
```
**Итоговая цепочка вызовов для установления исходящего соединения**
*ManagedConnectionFactory.createConnectionFactory()*
->*ManagedConnectionFactoryImpl.createConnection()*
-->*СonnectionManager.allocateConnection()*
--->*ManagedConnectionFactory.createManagedConnection()*
---->*ManagedConnection.getConnection()*
----->*ManagedConnectionImpl.connect()*
Ну и не забудьте настроить сервер приложений для работы с этим адаптером, ну и jndi указать.
Код для вызова:
```
private BinkpClient createBinkpClient(String host, int port) {
ConnectionFactory cf = ((ConnectionFactory) new InitialContext().lookup("java:eis/BinkpConnectionFactory"));
Connection conn = cf.getConnection();
return conn.connect(host, port);
}
```
### А причем тут Фидо?
А почти непричем. Дело в том, что изначальная задача была вовсе не о binkp, но она была рабочей, а значит попадала под NDA. Поэтому, разобравшись с JCA и решив что нужно написать статью на Хабре ( кстати, оглядываясь назад я начинаю понимать, почему никто такую статью еще не написал. И это еще без транзакций! ), я разморозил старую идею — форк [jnode](http://habrahabr.ru/post/208414/) для JEE-серверов, для запуска ноды в виде одного ear. В свое время именно знаний JCA мне не хватило для того, чтобы запустить проект :-)
Под это все я написал вышеприведенные примеры, и они даже заработали. Так что если вы хотите потренироваться в java ee вообще и рефакторинге из java se в частности — пишите письма и коммитьте код. Да, пойнтов все еще беру.
Спасибо за внимание, оставайтесь с нами. Опечатки можно писать в комментариях, я даже не сомневаюсь что их тут десятки. | https://habr.com/ru/post/251131/ | null | ru | null |
# Внедрение DMARC для защиты корпоративного домена от спуфинга

[A Thief on the Run](http://manweri.deviantart.com/art/A-Thief-on-the-Run-577760957) by Manweri
Привет, Хабр! В этом посте мы снова поговорим о проблеме подделки отправителя (или так называемом спуфинге). В последнее время такие случаи очень участились: подделывается все: письма со счетами за ЖКХ, из налоговой инспекции, банков и так далее. Решить эту проблему помогает настройка строгой DMARC-политики. Мы как почтовая служба проверяем все приходящие к нам письма на DMARC начиная с февраля 2013 года. Мы были [первым в рунете почтовым сервисом](https://corp.mail.ru/ru/press/releases/8736/), поддержавшим стандарты DMARC. Однако чтобы минимизировать число поддельных писем, этого, к сожалению, недостаточно. Главное, чтобы строгий DMARC был поддержан на стороне отправителя. Вот почему мы не устаем качать эту тему, ведем активную разъяснительную работу и всячески призываем всех включать у себя строгий DMARC.
Позитивные сдвиги уже есть: с каждым месяцем мы видим прирост числа корпоративных отправителей, прописавших DMARC, на десятки процентов. Однако безусловно, еще есть над чем работать. Практика показывает, что IT-культура находится на очень разном уровне. Кто-то слышал краем уха про DMARC, но пока не собирается его внедрять. Есть и такие, для кого факт, что в транспортных протоколах электронной почты отсутствует какая-либо проверка и защита адреса отправителя, до сих пор является настоящим откровением. Кроме того, поддержка DMARC — задача непростая. Только на первый взгляд кажется, что достаточно опубликовать запись в DNS, и не требуется никакого дополнительного софта или технических средств (подробнее в нашей статье [DMARC: защитите вашу рассылку от подделок](https://habrahabr.ru/company/mailru/blog/170957/)). На практике в крупной компании с многочисленными потоками электронной почты и развесистой структурой почтовых доменов все гораздо сложнее. И есть моменты, которые следует предусмотреть и продумать заранее. Именно для таких сложных случаев мы написали эту статью, постаравшись собрать в ней все нюансы.
Мы хотим поделиться собственным опытом внедрения DMARC и всеми граблями, на которые мы наступили (зачеркнуто) теми рекомендациями, которые мы выработали при взаимодействии с крупными компаниями и государственными учреждениями. Мы рассмотрим только внедрение политики DMARC для защиты доменного имени. Внедрение серверной части DMARC для защиты пользователей корпоративного почтового сервера от поддельных писем — это отдельный, совершенно самостоятельный и независимый процесс.
DMARC — это политика действий с пришедшими письмами, у которых в поле From используется публикующий политику домен. DMARC позволяет не только указать, как поступать с такими письмами, но и собрать статистику от всех получателей, поддерживающих серверную часть DMARC.
Основной проблемой является то, что DMARC требует авторизации всех легитимных писем. А для этого необходимо не просто внедрить методы авторизации (в качестве базовых протоколов используются SPF и DKIM), но и добиться того, чтобы для всех без исключения легитимных писем с обратными адресами домена проходила авторизация. Поэтому внедрение DMARC стоит начинать с нижеследующего пункта.
1. Проведите ревизию легитимных писем от вашего домена и его поддоменов
-----------------------------------------------------------------------
Типичные упущения в этом процессе:
* коммерческие письма, отправляемые через внешних поставщиков услуг по рассылке;
* внутренние списки рассылки;
* перенаправления почты с ящиков пользователей;
* технологические письма, формируемые серверами и оборудованием;
* отчеты о доставке (DSN) или о невозможности доставки (NDR) писем.
Для каждой категории писем необходимо внедрить SPF и выяснить возможность или невозможность подписи писем с использованием DKIM.
2. Внедрите SPF для основного домена и его поддоменов
-----------------------------------------------------
Часто можно услышать, что SPF защищает адрес отправителя от подделки. Это не так. SPF контролирует только адрес SMTP-конверта, который не видит пользователь. При этом большое количество доменов до сих пор не внедрили его, и многие стороны не поддерживают переадресацию почты, совместимую с SPF. По этой причине чаще всего используется нейтральная политика SPF (neutral, `?`) или мягкое блокирование (soft reject, `~`). Для совместного использования с DMARC не имеет значения, какая именно дефолтная политика (neutral `?`, soft reject `~` или reject `-`) SPF будет использована. Мы не рекомендуем использовать политику reject (`-`) за исключением особо требовательных к безопасности доменов, так как это может негативно сказаться на доставке легитимных писем непрямыми способами, например через пересылки или списки рассылки. Хотя большая часть получателей не блокирует письма по SPF даже при публикации строгой политики, а использует SPF в рамках весовых классификаторов. Вопреки устоявшемуся мнению, именно такой режим SPF чаще всего применяется на практике, и он полностью соответствует рекомендациям стандарта.
Можно дать следующие рекомендации по внедрению SPF:
* Не забывайте, что SPF проверяется для домена из адреса envelope-from (он же MAIL FROM и Return-Path). Для того чтобы SPF можно было использовать для аутентификации отправителя сообщения, домен в envelope-from должен совпадать с доменом заголовка From с точностью до организационного домена (т. е. до домена второго уровня в .ru или .com). Использование неправильных адресов для envelope-from — одна из самых частых ошибок конфигурации сервера, CMS и серверных скриптов.
* В SMTP некоторые категории писем ([NDR](https://ru.wikipedia.org/wiki/%D0%92%D0%BE%D0%B7%D0%B2%D1%80%D0%B0%D1%89%D1%91%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D0%B8%D1%81%D1%8C%D0%BC%D0%BE), [DSN](https://tools.ietf.org/html/rfc1894)) имеют пустой адрес envelope-from. Для таких писем аутентификация производится по домену, который SMTP-сервер отправителя использует в команде HELO/EHLO и который, как правило, совпадает с каноническим именем сервера. Некорректные имена в команде HELO — это еще одна распространенная проблема. Убедитесь, что доменное имя в HELO правильное, и пропишите для него соответствующую SPF политику например, `mailserver.example.org. TXT "v=spf1 a -all"`. В сообщениях о невозможности доставки в адресе отправителя можно либо вообще не указывать домен (например `From: mailer-daemon:;`) или использовать домен, совпадающий с доменом HELO с точностью до домена организации (обычно это домен второго уровня, например `From: [email protected]`).
* Не забывайте, что SPF не действует на поддомены. Необходимо внедрять его для каждого поддомена или прибегать к [wildcards DNS](https://en.wikipedia.org/wiki/Wildcard_DNS_record).
* SPF имеет ограничение на 10 разрешений имен для одной записи. Поэтому следует минимизировать использование элементов, приводящих к дополнительным разрешениям, таких как `mx` и `include`. Например, для элемента `mx` требуется один дополнительный запрос на получение самой MX-записи и по одному запросу на каждый сервер в MX-записи для получения его IP-адреса по имени.
Подробней о практиках применения SPF можно прочитать в [этой статье](https://habr.com/en/company/vk/blog/338700/).
3. Опубликуйте DMARC-запись с политикой none для основного домена и поддоменов
------------------------------------------------------------------------------
Пример такой записи:
```
_dmarc.example.com. TXT "v=DMARC1;p=none;rua=mailto:[email protected];ruf=mailto:[email protected];fo=s"
```
Запись инструктирует получателя отправлять на адрес `[email protected]` ежедневные статистические отчеты. Из отчетов будут видны все IP-адреса, с которых производилась рассылка писем от имени вашего домена, и статус авторизации SPF, DKIM и DMARC для этих писем. Особенно внимательно следите за письмами с ваших IP-адресов. Проконтролируйте по отчетам, не упустили ли вы какие-то категории писем или их источники в своей ревизии. При необходимости скорректируйте SPF. Некоторые получатели могут слать отчеты по отдельным случаям проблем с SPF (`fo=s`) на адрес `ruf`, эти отчеты пригодятся для идентификации проблемных рассылок.
Типичные проблемы и рекомендации:
* Мы не советуем публиковать политику даже с тегом `none` до того, как для основных потоков писем будет внедрен хотя бы один из механизмов аутентификации SPF или DKIM.
* Запись должна начинаться именно с v=DMARC1, и регистр букв имеет значение.
* Некоторые клиенты DNS показывают обратные слеши перед точками с запятой `v=DMARC1\;p=none` — но в записях DNS-зоны обратный слеш добавлять, как правило, не требуется.
* Адреса rua/ruf должны принадлежать тому же организационному домену, для которого публикуется политика, либо принимающий домен должен опубликовать специальную политику, показывающую согласие на прием репортов. Не получится принимать репорты на адреса, например, публичных почт.
* Если вы еще не закончили внедрение DKIM, то вы будете получать достаточно много нарушений DMARC с IP-адресов публичных почт (Mail.Ru, Gmail, Hotmail/Outlook, Yahoo и т. п.). Это связано с тем, что пользователи данных сервисов часто используют перенаправления в другие ящики, и это приводит к нарушению аутентификации SPF. Устраняется проблема внедрением подписи DKIM.
* Есть неплохие инструменты для визуализации отчетов DMARC. [Dmarcian](https://dmarcian.com/) предоставляет платные и бесплатные (для небольших объемов почты) сервисы, и удобный удобный бесплатный инструмент [XML-To-Human Converter](https://dmarcian.com/dmarc-xml/) для просмотра DMARC-отчетов. [Agari](https://www.agari.com/) и [proofpoint](https://www.proofpoint.com/us/products/email-fraud-defense/) также предлагают коммерческие сервисы для внедрения и поддержки DMARC.
4. Внедрите DKIM
----------------
Рекомендации:
* Убедитесь, что генерируемые серверами письма соответствуют рекомендациям по структуре, кодировкам и количеству заголовков, иначе возможна ситуация, что при передаче почтовым релеем письмо будет изменено для приведения его в соответствие со стандартами (чаще всего происходит разбивка длинных строк), отчего нарушится DKIM-сигнатура.
* Используйте ключ длиной 1024 или 2048 бит.
* Убедитесь что ваш DNS-сервер поддерживает разрешение больших записей. Обычно для этого помимо доступа к серверу по порту UDP/53 необходимо дополнительно разрешить доступ по TCP/53. Убедитесь что TXT-запись с ключом DKIM корректно разрешается из внешних сетей.
* Используйте режим канонизации relaxed/relaxed, он реже приводит к проблемам, связанным с нормализацией письма при передаче.
* Не подписывайте заголовки, которые меняются при доставке письма (такие как Received: и Return-Path:), убедитесь, что обязательные заголовки (Date:, Message-ID:, From:) формируются до наложения DKIM-подписи
* Внедрите DKIM на всех источниках писем для всех поддоменов.
* Используйте отдельные селекторы с отдельными ключами для внешних источников (провайдеров услуг по рассылке почты), чтобы была возможность отозвать ключ при необходимости.
* Для DMARC необходимо, чтобы домен, используемый в DKIM-подписи, совпадал с точностью до организационного домена с доменом из заголовка From. При этом могут присутствовать и другие DKIM-подписи, но они будут игнорироваться.
* Контролируйте внедрение DKIM по статистическим отчетам от внешних сервисов.
* Используйте `fo=1` в политике DMARC, это позволит получать forensic-репорты по всем проблемам с SPF и DKIM, даже для писем, проходящих авторизацию DMARC.
5. Начните переключение на строгую политику
-------------------------------------------
Не используйте подолгу политику quarantine, так как она может маскировать имеющиеся проблемы. О наличии проблем вы гарантированно узнаете только из агрегированных отчетов, до получения которых может пройти более суток.
Можно начать с включения политики reject на 10% (`p=reject; pct=10`), чтобы отследить потенциальные проблемы по ошибкам доставки. Но долго держать такую политику не рекомендуется: на оставшиеся 90 % срабатываний будет применяться политика quarantine, и можно пропустить единичные проблемы.
Обязательно следите за журналами сервера и отчетами о невозможности доставки писем на предмет ошибок, связанных с DMARC. Стандарт рекомендует получателям, внедряющим серверную часть DMARC, обязательно указывать его как причину в сообщении об ошибке, поэтому для идентификации проблемы можно использовать «DMARC» как ключевое слово в сообщении об ошибке. По журналам сервера вы увидите проблему гораздо раньше, чем по отчетам и будете точно знать на какие адреса какие письма не были доставлены.
Можно внедрять политику, отличную от политики основного домена, на отдельные поддомены, публикуя для них отдельные политики или указав в политике основного домена (`p=none; sp=reject`): политика sp будет действовать на поддомены, которые не публикуют собственную политику.
Когда все поддомены будут переведены на строгую политику, можно убрать политики поддоменов — или же оставить, на ваше усмотрение. Влияет это только на генерацию репортов в соответствии со сложившейся практикой (в стандарте данный момент не обговорен). Если поддомен публикует свою политику, на нее станут приходить отдельные репорты; если отдельной политики нет, то отчеты по поддомену будут включаться в отчет родительского домена.
6. Тюнинг политики DMARC
------------------------
Ниже приведен разбор некоторых необязательных полей DMARC-записи, примеры и рекомендации по их использованию.
**p** (`p=reject`) — политика DMARC. Указывает получателю, как поступать с письмами, не проходящими аутентификацию. Может принимать значения `none` (доставлять письма получателю), `quarantine` (доставлять письма в папку «Спам») и `reject` (не принимать письма).
**sp** (`sp=quarantine`) — политика для поддоменов, не публикующих самостоятельной политики. Если поддомен имеет собственную политику DMARC, то `sp` на него не влияет. При отсутствии поля `sp` в записи DMARC для поддоменов, не имеющих собственной политики, применяется политика из поля `p`.
**pct** (`pct=20`) — процент писем, на которые действует данная политика. Например, при задании политики `reject` с `pct=20` к полученному письму с вероятностью 20 % будет применена политика `reject` и с вероятностью 80 % — политика `quarantine`.
**rua** (`rua=mailto:[email protected]`) — адрес, на который получатели будут отправлять аггрегированный (статистический) отчет. Адрес должен принадлежать тому же организационному домену. Мы рекомендуем обязательно публиковать адрес для аггрегированных отчетов и следить за ними как минимум на этапе внедрения политики DMARC.
**ruf** (`ruf=mailto:[email protected]`) — адрес, на который будут отправляться forensic-отчеты (т. е. исследовательские) по отдельным письмам. По умолчанию forensic-репорты отправляются только по нарушениям DMARC. Можно использовать опцию fo для регулирования поведения. В настоящее время относительно небольшое количество получателей отправляет forensic-отчеты.
**fo** (`fo=1`) — по каким нарушениям отправлять уведомления. `fo=0` (поведение по умолчанию) отправляет отчеты, только когда не прошли обе аутентификации: SPF и DKIM. `fo=1` — когда не проходит любая из аутентификация, даже если проходит альтернативный метод. `fo=s` шлет forensic-репорты на проблемы с SPF-аутентификаций. `fo=d` — на проблемы DKIM.
**adkim** (`adkim=r`) — режим проверки соответствия DKIM-домена. По умолчанию используется режим `r` (relaxed) и должен совпадать только организационный домен. В строгом (`s`) режиме требуется полное совпадение домена из адреса отправителя с доменом из DKIM-сигнатуры. Имеет смысл использовать строгое соответствие домена, если часть ваших поддоменов делегирована недоверенным сторонам.
**aspf** (`aspf=r`) — аналогично для домена из envelope-from, для которого проверяется SPF и From. При `aspf=s` эти домены должны полностью совпадать для прохождения аутентификации SPF.
**ri** (`ri=86400`) — желательный интервал получения аггрегированных отчетов (в секундах). По умолчанию отчеты отправляются раз в сутки, но некоторые получатели (не все, т.к. поддержка данного параметра сервером не является обязательной) поддерживают отправку отчетов с более короткими интервалами. На этапе внедрения политики можно попробовать использовать меньшие ri, например `ri=3600`.
Мы очень рады, что владельцы доменов начали задумываться о защите своего доменного имени в электронной переписке. Справку по настройке DMARC можно получить [здесь](https://help.mail.ru/mail-help/postmaster/dmarc). Если у вас есть вопросы или вам требуются советы либо помощь с настройкой SPF, DKIM, DMARC, обращайтесь по адресу [dmarc\[email protected]](mailto:[email protected]) или задайте вопрос здесь. Мы надеемся, что вместе сможем сделать электронную почту безопасней для всех пользователей. | https://habr.com/ru/post/315778/ | null | ru | null |
# Свой SVN на виртуальном (shared) хостинге

Решили мы как то с приятелем, запустить стартап не стартап, а так, сайт для души. Решили — значит будет запущен. Бюджет… А давай не купим ещё по 2 кружки пива, на это и запустим. В общем денег на домен да на виртуальный хостинг на валуехосте. Так люди мы «взрослые», и делать всё привыкли основательно, нам нужна система управления версиями и выкладыванием. Было решено поднять subversion репозиторий с возможностью раздачи доступа к нему нескольким разработчикам с разными логинами на valuehost. Но у нас виртуальный хостинг со всеми его ограничениями, что делать?
#### Необходимые условия:
Их всего два (в общем случае): наличие ssh-доступа к серверу хостера, и возможность ходить на этот SSH по ключу.
Кстати, хостер не обязательно должен быть valuehost.ru, смотрите в статье пример с valuehost и транслируйте на свою ситуацию, смысл везде одинаков.
#### Определяем установлен ли subversion:
`[megauser@megaserver ~]$ svn
-bash: svn: command not found
[megauser@megaserver ~]$ svnserve
-bash: svnserve: command not found`
Не установлен, значит установим его под своим аккаунтом.
Если в Вашем случае Subversion уже установлен, то пропускайте все действия
до пункта 4 «Настраиваем репозиторий и доступ к нему».
#### Устанавливаем Subversion
Первым делом смотрим, есть ли возможность собирать программы из исходников:
`[megauser@megaserver ~]$ make
-bash: make: command not found
[megauser@megaserver ~]$ gcc
-bash: gcc: command not found`
Возможности нет, значит придется собирать программы на другой машине
с такой же ОС, как и у хостера:
`[megauser@megaserver ~]$ uname -srm
FreeBSD 6.3-RELEASE i386`
Находим машину с такой же операционкой, куда у нас есть доступ, или, например,
ставим на домашний компьютер нужную операционку. Необходимо, чтобы на этой
машине у вас был доступ на запись в каталог, в который вы планируете установить
subversion на сервере хостера. В нашем случае это был каталог /pub/home/megauser/myroot
Собирали subversion мы без всяких хитростей, всё как в мануале для случая необходимости
только простого сервера svnserve, без интеграции svn в apache:
`wget subversion.tigris.org/downloads/subversion-1.5.1.tar.gz
wget subversion.tigris.org/downloads/subversion-deps-1.5.1.tar.gz
tar xvzf subversion-1.5.1.tar.gz
tar xvzf subversion-deps-1.5.1.tar.gz
cd subversion-1.5.1
./configure --prefix=/pub/home/megauser/myroot --enable-all-static --disable-mod-activation --without-apache --without-apxs --without-serf --without-berkeley-db --with-ssl
make
make install`
(Примечание: на данный момент последняя версия subversion — 1.5.4, но на момент наших
действий была только 1.5.1, поэтому пример основан на ней, думаем что можно брать 1.5.4
без каких либо изменений, но на всякий случай почитайте CHANGELOG)
Всё, SVN собран и установлен по нужному для нас пути, забираем его на сервер хостера:
`tar cvzf ~/builded-svn.tgz /pub/home/megauser/myroot/`
Потом переходим в SSH-консоль хостера:
`[megauser@megaserver ~]$ wget your.server/builded-svn.tgz
(или забираете файл любым другим возможным способом, хоть тем же scp)
[megauser@megaserver ~]$ tar xvzf builded-svn.tgz`
Всё, SVN установлен, осталось только добавить /pub/home/megauser/myroot/bin в
переменную окружения PATH, чтобы можно было запускать команду svn без указания полного
пути к ней. Пропишите в ~/.bashrc или ~/.profile или аналогичный по смыслу файл строку
`export PATH=~/myroot/bin:${PATH}`
Перелогиньтесь, и проверьте работоспособность свежеустановленного SVN:
`[megauser@megaserver ~]$ svn
Type 'svn help' for usage.
[megauser@megaserver ~]$ svnserve
You must specify exactly one of -d, -i, -t or -X.
Type 'svnserve --help' for usage.`
Если ответы будут другие — действуйте по ситуации, пока всё не наладится. На этом установка завершена.
#### Настраиваем репозиторий и доступ к нему
Первым делом создаём репозиторий:
`svnadmin create /pub/home/megauser/myrepo`
Описывать как залить в репозиторий начальную структуру проектов, как настроить нужные хуки и тому подобное я не буду,
для этого есть [svnbook.red-bean.com/nightly/ru/index.html](http://svnbook.red-bean.com/nightly/ru/index.html)
Затем настраиваем ключевой доступ по протоколу svn+ssh к нашему репозиторию:
(на сервере valuehost был SSH в варианте «ssh.com», а не «openssh», как бывает на linux-системах, соответственно наши примеры под вариант «ssh.com»,
но используя соответствующие мануалы вы легко сможете сделать тоже самое для linux).
На рабочих компьютерах будущих пользователей репозитория создаёте пары ключей, публичный сохраняете в формате «ssh.com», и заливаете его на сервер
хостера в ~/.ssh2/id\_rsa\_.pub, права файлу даёте 0600, чтобы ssh не пугался, и не отвергал пользователя с этим ключем по причине
большой доступности файла с ключем.
Затем создаёте файл ~/.ssh2/authorization с такими же правами доступа — 0600. В файле пишете следующее:
`Key id_rsa_user1.pub
Options command="/pub/home/megauser/myroot/bin/svnserve -t -r /pub/home/megauser/myrepo --tunnel-user=user1", no-port-forwarding, no-x11-forwarding, no-agent-forwarding, no-pty
Key id_rsa_user2.pub
Options command="/pub/home/megauser/myroot/bin/svnserve -t -r /pub/home/megauser/myrepo --tunnel-user=user2", no-port-forwarding, no-x11-forwarding, no-agent-forwarding, no-pty`
То есть на каждого svn-пользователя — две строки. В данном конкретном примере мы создали двух SVN-пользователей, user1 и user2.
Заметьте — именно user1 и user2, а не ваш оригинальный логин на сервер хостера будут использоваться как авторы коммитов в репозиторий,
что нам собственно и требовалось.
Всё, репозиторий и доступ к нему настроен, для проверки сделайте на рабочем компьютере в PuTTY (или другом ssh-клиенте) сессию с такими же параметрами как и обычная Ваша сессия доступа на сервер хостера,
но с приватным ключем, который Вы сгенерировали недавно для svn, и публичную часть от которого разместили в ~/.ssh2/id\_rsa\_.pub.
Запускайте эту сессию, если всё ок, то вы должны увидеть примерно такую строку
`( success ( 2 2 ( ) ( edit-pipeline svndiff1 absent-entries commit-revprops depth log-revprops partial-replay ) ) )`
Это означает что всё хорошо, вы можете брать Tortoise или любой другой SVN-клиент, и подключаться к svn+ssh://server.of.your.hoster.ru/
с использованием нужных приватных ключей.
Чтобы вам меньше мучаться — вот [архив с нашим каталогом](http://www.mirsisek.ru/myroot.tgz) /pub/home/megauser/myroot/
Помимо SVN в нём еще есть VIM, MC, rsync и простенький скрипт release, которым мы выкладываем закоммиченные изменения в боевую локацию сервера.
Вот такой подарок, пользуйтесь на здоровье :)
p.s.: вопросы «зачем вам это, есть же....» задавать не стоит. Хотелось сделать так | https://habr.com/ru/post/44742/ | null | ru | null |
# Хватит говорить, что PHP мертв
Это не так. PHP не умер. Он жив, и до “конца жизни” ему еще очень далеко. На этом все. Как бы некоторые ни хотели, чтобы он исчез, этого не произойдет. По крайней мере, в обозримом будущем уж точно.
---
Эта статья пролежала в моей папке для неопубликованных достаточно долго. Время от времени я вносил правки то тут, то там, но все никак не мог определиться со временем публикации. Но вот релиз PHP 8 наконец показался мне подходящим моментом.
Каждый месяц мне попадаются статьи, комментарии, или твиты, в которых говорится, что PHP умирает, и нам пора прекращать его использовать. Если кто-то задает вопрос на каком-либо форуме или на Stack Overflow касательно изучения PHP, с вероятностью почти в 100%, кто-то ответит что-то вроде: “Зачем вам изучать PHP? Потратьте время на что-нибудь стоящее, например <здесь-должен-быть-ваш-замечательный-язык-который-не-php>”.
На протяжении последних 20 лет, помимо других языков, я писал код на PHP (на самом деле, может быть и дольше. Я точно не помню, когда я начал это делать), и большую часть времени я просто игнорировал эти высказывания. И все эти годы PHP “умирал”, и я должен был бросить его использовать уже очень давно. Я отнюдь не претендую на звание эксперта ни в одном языке, которые я использую, и в PHP есть еще много вещей, в которых мне не мешало бы разобраться, но снова и снова я возвращаюсь к нему.
Я потратил много часов на изучение других языков, на что меня подтолкнули случайные, убедительно написанные статьи критикующие PHP. И я признаю, что эти приключения естественно были в высшей степени полезны для меня как для разработчика. Хотя я, вероятно, никогда не буду использовать многие из этих языков профессионально, я чувствую, что расту как программист, изучая другой язык.
Главная мысль, которую я хотел бы донести в этой статье: “выучить другой язык” — идея очень хорошая, но не потому, что “php умирает” — это просто неправда. Вы должны учить другие языки, потому что они будут полезны для вас как для программиста. Если бы PHP действительно умирал, то, конечно, у вас была бы еще одна (достаточно веская) причина двигаться дальше, но прямо сейчас, в данный момент, он не умирает.
Один из первых аргументов многих PHP-программистов, которым они будут парировать, отстаивая свой выбор, — это статистика, демонстрирующая, насколько PHP популярен в сети. Хотя эти цифры очень интересны, я склонен полагать, что они немного вводят в заблуждение. Было бы неправильно игнорировать тот факт, что львиной доле этой популярности PHP обязан WordPress. Любить его или ненавидеть, решать вам, но WordPress — причина, по которой мы все здесь. Но WordPress… такой… WordPress. У него много (действительно много) недостатков, но я знаю (и дружу с) множеством людей, которые создают много удивительных вещей — и зарабатывают большие деньги — с помощью WordPress.
PHP — это не WordPress. И, хотя WordPress увековечен в истории PHP, PHP лучше, чем WordPress — НАМНОГО лучше. В WordPress много чего не так, как и в PHP, но это не значит, что он не подходит для всех проектов. Я, вероятно, не стал бы писать свои веб-приложения на C++ (или, по крайней мере, он не стал бы ПЕРВЫМ среди языков, рассматриваемых для работы над этими проектами), но это не делает C++ плохим языком. Он просто не подходит для этой работы, точно так же, как я бы не стал использовать PHP для написания аппаратных драйверов или чего-то еще, связанного с ИИ. И дело просто в том, что это выходит далеко за пределы его специализации.
Выбор языка также во многом зависит от того, в чем вы разбираетесь. Как гласит старинная пословица: время — деньги, и в большинстве случаев использование нового языка для проекта — это серьезная затея, которое еще больше урезает временные рамки, которые обычно и без того очень сжаты. Я достаточно хорошо знаю PHP, поэтому в основном использую именно его. Я немного знаю Python, но лучше разбираюсь в PHP. Я, вероятно, мог бы сделать то же самое на Python, но это займет у меня вдвое больше времени (по крайней мере, в начале). Это не означает, что я вообще не буду использовать Python или что я имею что-то против Python, это просто означает, что PHP — это то, в чем я лучше.
Изучение языка на самом деле не так сложно, и опытный программист может понять суть языка, посвятив ему всего одни выходные. Но это не значит, что этого достаточно, чтобы в полной мере *знать* язык. Знание языка программирования — это не только знание того, какая встроенная функция что делает, но и наличие достаточного опыта, чтобы знать, КОГДА и какие фичи использовать или как экосистема сочетается друг с другом.
Я знаю PHP, и также знаю, как настроить Nginx на сервере и как конфигурировать FPM или opcache; У меня достаточно знаний, чтобы сделать разумный выбор в отношении зависимостей; Я знаю, как безопасно развертывать PHP-приложения в рабочей среде, и мне известно о проблемах безопасности, которые могут возникнуть, если я не буду внимательно следить за тем, как я использую определенные языковые фичи. Это больше, чем просто “знание” языка. Как программисты, мы тратим много времени на изучение подобных вещей, которые часто даже не связаны с языками, которые мы выбирали.
Вот почему меня очень разочаровывает, когда другой программист говорит мне, что мой выбор языка — “отстой”. Я потратил 20 с лишним лет, совершенствуя свои навыки, но теперь какой-то человек заявляет, что мой выбор был неправильным?
Что ж, они ошибаются. С помощью PHP я сделал свою карьеру, которой я очень доволен. Я живу в хорошем доме, езжу на отличной машине, потому что потратил 20 лет на то, чтобы стать по настоящему успешным в этом деле.
Но я немного отвлекся. Эта статья должна была быть о том, что PHP не отстой.
Многие из кружка “мы ненавидим PHP и думаем, что он скоро умрет” говорят о ряде вещей, которые, по их мнению, делают PHP плохим выбором во всех отношениях. Некоторые из них мы слышим годами и они имеют отношение к старым версиям PHP (я не понимаю, почему все до сих пор так зациклены на PHP 4, я серьезно). Остальные претензии просто безосновательны и не соответствуют действительности. Это не разглагольствования на тему “мой язык лучше твоего”, и я искренне верю, что у каждого языка программирования есть определенная цель. Люди, которые приносят эти инструменты в мир (которые намного умнее меня), обычно делают это не без оснований. Языки программирования обычно не появляются случайно.
### Итак, почему PHP?
Ответ очень прост: потому что тогда он был доступен. Я самоучка, и как-то обошел стороной формальное образование. За исключением, может быть, случайных онлайн-курсов, которые я проходил, у меня нет листка бумаги со штампом престижного университета, на котором написано, что я могу говорить компьютерам, что делать.
Я пришел в PHP из дизайна, и несмотря на то, что я возился с компьютерами и кодом лет с семи, я не последовал за этим увлечением и не поступил в университет на программиста. Я точно не смогу вам ответить, почему. Мне нравились компьютеры, и мне нравился интернет, но вместо этого я выбрал графический дизайн. Я не собираюсь особо углубляться в это, потому что моя ученая степень особо не играет большой роли в том, чем я занимаюсь сегодня.
Я пришел к PHP тем же путем, что и большинство PHP-программистов. Потому что мы хотели, чтобы сайт мог делать больше, чем просто отображать изображение и абзац текста. Я был невероятно взволнован, когда понял, как получить информацию из базы данных и отобразить ее на веб-странице. Это было потрясающе! Это было именно то, что мне было нужно, и я сразу нырнул в PHP с головой.
Затем я узнал о WordPress. И, как и для любого другого человека, сидящего перед экраном компьютера с некоторыми базовыми знаниями PHP, WordPress перевернул мой мир. Это было круто, правда?
WordPress обязан своим успехом таким людям, как мы - подросткам, которые хотели свой блог, но у них не было достаточно знаний для того, чтобы создать его самостоятельно.
Вы установили WordPress... Затем добавили плагин и изменили тему... Потом внесли небольшое изменение в тему, чтобы она работала по-другому или выглядела немного иначе. Затем вы модифицировали плагин. Затем вы создали свою собственную тему. После чего вы задумались... А что еще я могу сделать?
Так я познакомился с PHP. Я не выбирал PHP, он выбрал меня. 20 прошло, а я все еще пишу на PHP. Конечно, больше не через WordPress, и мне нравится то, что я уже достаточно вырос как PHP-программист, чтобы со знанием дела написать эту статью.
### “PHP слишком прост. Лучше выучи что-то посложнее”.
Одна из основных причин, по которой PHP так популярен, заключается в его повсеместном использовании. Его можно найти почти везде. Да даже самый обычный MacBook поставляется с предустановленным PHP (хотя похоже, что это изменится в будущей версии MacOS).
Писать на PHP с нуля не сложно. Обычно ничего особенного делать не нужно. Создайте index.php, поместите в него одну строку PHP-кода и загрузите практически на любую учетную запись общего хостинга:
```
php
echo 'Hello, World!';</code
```
Начало положено. Начать работу с PHP очень просто, потому что вам не нужно думать о том, как заставить PHP работать. Это почти всегда уже сделано за вас.
Однако, представьте себе, что именно эта “простота использования” на самом деле является одной из претензий к PHP. Теория гласит, что если PHP настолько прост, то на PHP очень легко написать действительно небезопасный код.
Меня всегда это немного настораживало. Значит ли это, что языки, которые труднее использовать, с меньшей вероятностью будут использоваться для написания плохого кода? Я где-то читал, что около 70% патчей, которые Microsoft выпускает для Windows, предназначены для решения проблем с памятью, возникших из-за C++ (но не цитируйте меня, это не официальное заявление). Я сомневаюсь, что люди, которые пишут на C++ для Microsoft, любители, и я почти уверен, что они знают, что делают. Да, Windows намного сложнее, чем ваш типовой сайт с корзины покупок, но я думаю, что аргумент остается в силе. Я не согласен с тем, что простота использования PHP делает его потенциально опасным. Python хорошо известен за то, как он удобен для начинающих, но не имеет такой “потенциально опасной” репутации. Легко написать небезопасный код на ЛЮБОМ языке. Не язык делает код небезопасным, а недостаток знаний.
“Простота” — это не причина отговаривать новичков от изучения PHP, а, скорее, причина дать этим новичкам лучшие инструменты для принятия более взвешенных решений относительно кода, который они пишут. Это повод помочь им найти нужные ресурсы для изучения PHP. Мне очень повезло; и хотя я написал свою долю “небезопасного” кода, в моей жизни были люди (не всегда PHP-программисты), которые помогли мне понять, что можно улучшить.
### PHP медленный
Что ж, это неправда. PHP работает настолько быстро или медленно, насколько написан ваш код. PHP — это скриптовый язык, поэтому сравнивать его с компилируемыми языками бессмысленно, но почему-то я даже видел, как люди сравнивают PHP с Rust или Go. Но это просто бессмысленно. Сравнение PHP с Python или Ruby, вероятно, понятнее, но “скорость” языка зависит от ряда различных факторов. Сам язык, да, но также его среда, какой код он выполняет, как настроен интерпретатор и т. д. Говорить, что PHP медленный без контекста, неправильно.
PHP определенно медленный в отношении определенных типов задач. Например, PHP, вероятно, не станет вашим первым выбором, если речь идет о машинном обучении (хотя есть несколько очень интересных проектов, которые имеют вполне реальные перспективы).
Можно встретить бенчмарки двух разных языков, выполняющих одно и то же, например, перебирающие миллион записей и выполняющие простые вычисления. Результаты часто отличаются миллисекундами. Иногда это используется, чтобы показать, что PHP работает медленно (или, в некоторых случаях, быстро). Если вы пишете программное обеспечение, в котором лишние несколько миллисекунд при циклическом просмотре миллиона записей были бы катастрофическими, то, возможно, вы задаете неправильные вопросы.
### WordPress плох
Да, я согласен. Я не самый большой поклонник WordPress, особенно в наши дни, но я также готов признать, что без WordPress у нас, вероятно, не было бы того PHP-сообщества, которое существует сегодня.
Однако судить о языке по одному программному обеспечению - это неправильно. Это все равно, что сказать, что C++ — плохой язык, потому что вам не нравится Microsoft Windows.
PHP — это не узкоспециальный язык, а WordPress — это только часть истории PHP. Существует множество фреймворков и пакетов на любой выбор, если уж на то пошло. Laravel пророчат “снова сделать PHP крутым”, и я должен признать, что этот фреймворк, безусловно, один из моих любимых и он удобен для большинства проектов.
Хулить PHP, презирая WordPress, действительно несправедливо. Можно утверждать, что WordPress был отражением ограничений PHP, но это было давно, и с тех пор язык сильно вырос.
### PHP не дотягивает до корпоративного уровня
Почему? Я действительно не понимаю, откуда это пошло. Но это серьезное заявление. Что делает язык “корпоративным” (enterprise ready)? Как определить, что один язык более корпоративный, чем другой? Java, вероятно, является одним из самых популярных языков в корпоративной среде, но это не потому, что Java сам по себе корпоративный. Причина в существовании платформы Java EE. Я не Java-разработчик, поэтому поправьте меня, если я неправ, но, насколько я понимаю, Java EE — это платформа, на которой создаются корпоративные приложения. Звучит как фреймворк, верно? Так что, возможно, вопрос должен звучать так: “Дотягивает ли <мой-любимый-php-фреймворк> до корпоративного уровня?”.
Для ответа на этот вопрос нужна целая отдельная статья. Я пытаюсь подчеркнуть, что PHP как язык настолько же “корпоративный”, как и любой другой язык. Это целиком и полностью зависит от того, как вы его используете.
*Примечание:* некоторое время назад я был частью небольшой команды, которая создала и развернула платформу управления событиями во внутренней сети одного из ведущих финансовых учреждений Южной Африки (я мог бы написать кое-что об опыте). Приложение было полностью написано на PHP и JavaScript. И в разгар пандемии Covid-19 система находилась под огромной нагрузкой, но справилась почти со всем. У нас было несколько заминок, но ничего такого, что нельзя было бы решить быстро.
### PHP не масштабируется
Это единственная претензия, в которой есть доля правды, но и тут все немного сложнее, чем вы думаете. По правде говоря, PHP прекрасно масштабируется, если вы пишете нормальный код. Когда люди говорят, что PHP не масштабируется, они обычно имеют в виду, что приложения, написанные на PHP, могут быть не в состоянии обрабатывать очень большое количество запросов (например, миллионы). Дело в том, что это все не так просто, и я думаю, что многие заблуждения уходят корнями в WordPress, который до недавнего времени был хорошо известен своими проблемами с масштабируемостью.
В качестве доказательства: Slack, платформа обмена сообщениями, которая нацелена заменить электронную почту, с миллионами пользователей, каждый из которых подключается каждый день к системе, имеет бэкенд написанный на PHP. Если это не пример того, как PHP может масштабироваться, то я не знаю, что вообще вас может переубедить. Многие люди приводят Facebook в качестве примера, и хотя я считаю, что Facebook, вероятно, все еще использует PHP в той или иной форме, я думаю, что они, скорее всего, перенесли большую часть своих приложений с PHP. Но, честно говоря, Facebook — это особый случай.
Нельзя говорить о масштабируемости, не говоря об инфраструктуре. Если вы размещаете блог WordPress на простом виртуальном хостинге и внезапно переживаете десятки тысяч посещений… ну, это может быть проблемой, и ваш хостинг отправит вам неприятное электронное письмо или, по крайней мере, выставит вам больший счет, чем вы ожидали.
Масштабирование приложения включает в себя гораздо больше, чем просто выбор языка. В этом деле очень много деталей, и меня расстраивает то, что все шишки достаются PHP. Более новые версии PHP, в правильной среде и правильно настроенные, более чем способны обрабатывать большое количество запросов. Laravel Vapor, первая бессерверная платформа для приложений Laravel, работающих на AWS, показывает действительно впечатляющие цифры.
Иногда я думаю, что вопрос масштабируемости также несколько преувеличен. За 20 лет написания вещей на PHP я никогда не сталкивался с “миллионами запросов” в секунду. Даже близко. Большинство из нас не будут создавать новый Facebook, как бы мы не мечтали. На самом деле мы создаем гораздо более узкоспециализированные приложения. Мы работаем с конкретными отраслями, часто в определенных странах, и нам не приходится беспокоиться об обработке более нескольких сотен запросов в секунду. Для многих проектов, в которых мы участвуем, это большие цифры. Это не значит, что то, что мы делаем, не важно, это просто означает, что нам не нужно беспокоиться о таком масштабе. Масштабирование приложений для обработки миллионов запросов просто не является частью нашей рутины.
### PHP уродлив
Вы, должно быть, шутите. Самую бесячую претензию я оставил напоследок. Если вы выбираете свой стек технологий, основываясь на том, как красиво что-либо выглядит, то вы серьезно заблуждаетесь, и вам нужно серьезно задуматься над своим выбором.
Но даже несмотря на это, я не думаю, что это правда. Вероятно, это происходит из-за давней практики использования PHP непосредственно в HTML (где он действительно выглядел не очень). Но дело в том, что мы больше этого не делаем, так как это не приветствуется.
Я не говорю, что так называемые “красивые языки” — неправильный выбор, но это определенно не должно быть определяющим фактором. Java совершенно некрасив, но при этом является одним из самых популярных языков в мире. Просто глупо возражать против использования PHP из-за того, что он некрасив.
PHP, вероятно, не самый красивый язык, но я нахожу его вполне читабельным, когда он хорошо написан. И в PHP 8 есть несколько действительно замечательных инструментов, которые помогут сделать ваш код еще более “красивым”.
### Я люблю PHP
Я действительно его люблю. Я люблю язык и экосистему. Мне нравится, какие улучшения произошли в нем за последние несколько лет. PHP 8 — это не просто еще одна версия того же языка. С каждым крупным релизом мы получаем более качественные и полезные инструменты.
Мне нравится, что с PHP легко начать работу, как и то, что он сложен и на самом деле нужно так много знать, чтобы считаться профессиональным PHP-программистом. Я люблю Symfony и Laravel и думаю, что люди, стоящие за ними, также ответственны за продвижение языка, как и основная команда PHP.
Но больше всего мне нравится быть программистом. Не только на PHP, но я люблю создавать вещи на любом языке, который мне приходится использовать. Мне нравится тот факт, что я могу указывать компьютерам, что делать, и что я сам этому научился. Я обязан этим PHP. Без PHP я не знаю, что бы я сейчас делал. Может быть, я был бы каким-то посредственным дизайнером, ненавидящим свою работу и свою жизнь (не в обиду дизайнерам, читающим это. У меня есть действительно талантливые друзья-дизайнеры, которым тоже нравится то, что они делают). Но вместо этого я делаю то, что люблю, используя язык, который мне нравится.
---
Перевод материал подготовлен в преддверии старта специализации ["PHP Developer".](https://otus.pw/Cb1O/) | https://habr.com/ru/post/661913/ | null | ru | null |
# Медленные и/или ресурсоёмкие задачи в коде: отложенные задания, очереди, задачи с ручной обработкой
Публикую по просьбе [eugenioz](https://habrahabr.ru/users/eugenioz/).
При работе больших Web проектов бывают такие задачи, выполнение которых не является необходимым прямо сейчас, однако действия критические и выполнить их обязательно. Такие действия можно проводить прямо в коде и при неудачной попытке повторять. Но, на мой взгляд, подобное лучше сразу выполнять вне основного кода задачи: этим разгружается код и достигается однообразие выполнения.
Общим подходом здесь является создание очередей выполнение и отложенных заданий. Основные примеры: пересылка/верификация данных у сторонних сайтов; передача данных от реселлерской панели на основной сайт; передача заданий, которые не могут быть выполнены автоматически, на ручную обработку.
В качестве средства распределения задач предлагаю вашему вниманию PHP-класс Tasks.
[Код класса](http://pastebin.com/mZy2RKWD "Tasks")
И теперь пояснения.
Задачи хранятся во временной директории в виде файлов. Скрипт, запускаемый по крону, получает список задач и выполняет у каждой задачи метод execute. После успешного исполнения файл задачи удаляется. Класс можно переработать для работы с MySQL-базой. Это имеет смысл, поскольку можно делать DELAYED INSERT, который не блокирует исполнение, однако сейчас используется файловая система в силу её большей надёжности.
Создаётся задача как обычный элемент алгоритма, не изменяя логики.
Например, было:
`$q_upd=update_order_data($params);`
стало
`$q_upd=tasks::create("update_order_data", 'api', 0, $params);`
У задач есть уровень приоритета, благодаря чему можно при каждом запуске cron-скрипта выполнять задачи в порядке «важности». Чем больше параметр priority, тем дальше отложится задача.
Вариант cron-скрипта: [код](http://pastebin.com/enC5iBFb).
Рядом с классом Tasks в коде есть класс task\_handlers — именно в task\_handlers вы можете создать обработчик.
Имя функции этого класса является именем обработчика, которое можно задать в момент создания задачи. В качестве примера приведены обработчики 'mysql' и 'mail' — их код мал, поэтому удобен для иллюстрации.
Автор кода — [eugenioz](https://habrahabr.ru/users/eugenioz/), разрешает использовать код под лицензией MIT.
Несмотря на простоту и легковесность этого класса, он позволяет очень эффективно распределить нагрузку, не изменяя при этом логику алгоритмов.
Ещё раз примеры применения:
* на странице настройки профиля одного из сервисов нужно взаимодействовать с другим сайтом, подтверждая у него данные. Сайт этот тоже мог ответить «не сразу». Вывод лаконичного «проверяется» в одном из блоков — гораздо лучше, чем генерация всей страницы в несколько секунд из-за задержки в одной строке;
* в данный момент для всех посетителей, которые зашли на wap-сайт с мобильного телефона, и чей IP не оказался в списке IP-гейтов операторов, создаётся задача проверки IP. В свободное время берётся whois-информация об IP и проверяется на наличие слов, которые могут указывать на принадлежность к оператору сотовой связи. При наличии таких слов IP добавляется в список «на проверку» и после «ручной» проверки этот IP может быть внесён в список IP-гейтов операторов;
* работа с удалённым API, который может быть недоступен, но действие может быть отложено и **должно** быть исполнено. Например, зачастую реселлерские панели не повторяют заказов, что приводит к большому количеству жалоб и упущенной выгоде.
***eugenioz**: Внимательно выслушаю конструктивную критику, вопросы и предложения по улучшению.* | https://habr.com/ru/post/95984/ | null | ru | null |
# О синглтонах и статических конструкторах
Изначально автор хотел назвать эту статью следующим образом: «О синглтонах, статических конструкторах и инициализаторах статических полей, о флаге beforeFieldInit и о его влиянии на deadlock-и статических конструкторов при старте сервисов релизных билдов в .Net Framework 3.5», однако в связи с тем, что многострочные названия по неведомой автору причине так и не прижились в современном компьютерном сообществе, он (автор) решил сократить это название, чудовищным образом исказив его исходный смысл.
-------------------------
Любая реализация паттерна Синглтон в общем случае преследует две цели: во-первых, реализация должна быть потокобезопасной, чтобы предотвратить создание более одного экземпляра в многопоточном мире .Net; а во-вторых, эта реализация должна быть «отложенной» (lazy), чтобы не создавать экземпляр (потенциально) дорого объекта раньше времени или в тех случаях, когда он вообще может не понадобиться. Но поскольку основное внимание при прочтении любой статьи про реализацию Синглтона отводится многопоточности, то на «ленивость» зачастую не хватает ни времени не желания.
Давайте рассмотрим одну из наиболее простых и популярных реализаций паттерна Синглтон (\*), основанную на инициализаторе статического поля:
> `public sealed class Singleton
>
> {
>
> private static readonly Singleton instance = new Singleton();
>
>
>
> // Explicit static constructor to tell C# compiler
>
> // not to mark type as beforefieldinit
>
> static Singleton()
>
> {}
>
>
>
> private Singleton()
>
> {}
>
>
>
> public static Singleton Instance { get { return instance; } }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Потокобезопасность этой реализации основывается на том, что статический конструктор (или, другими словами, инициализатор типа) в одном домене гарантировано вызывается не более одного раза. А раз так, то со стороны разработчика не нужно делать никакие финты ушами ради того, чтобы сделать потокобезопасность еще более безопасной. Большинство разработчиков (и до недавнего времени и я в том числе) на этом успокаиваются, поскольку основную проблему, которая может произойти с любым синглтоном, мы уже решили, так что на комментарий пустого статического конструктора мало кто обращает внимание. А поскольку этот комментарий вообще ~~нифига~~ не понятен, то пустой статический конструктор просто не доходит до многих реализаций в реальных приложениях.
#### **Статический конструктор и инициализаторы полей**
Статический конструктор – это штука, предназначенная для инициализации типа, которая должна быть вызвана перед доступом к любому статическому или не статическому члену, а также перед созданием экземпляра класса. Однако если класс в языке C# не содержит явного объявления статического конструктора, то компилятор помечает его атрибутом **beforeFieldInit**, что говорит среде времени выполнения о том, что тип можно инициализировать отложенным (“relaxed”) образом. Однако, как показывает практика, в .Net Framework до 4-й версии, это поведение можно назвать каким угодно, но не «отложенным».
Итак, давайте рассмотрим следующий код:
> `class Singleton
>
> {
>
> //static Singleton()
>
> //{
>
> // Console.WriteLine(".cctor");
>
> //}
>
>
>
> public static string S = Echo("Field initializer");
>
>
>
> public static string Echo(string s)
>
> {
>
> Console.WriteLine(s);
>
> return s;
>
> }
>
> }
>
>
>
> class Program
>
> {
>
>
>
> static void Main(string[] args)
>
> {
>
> Console.WriteLine("Starting Main...");
>
> if (args.Length == 1)
>
> {
>
> Console.WriteLine(Singleton.S);
>
> }
>
> Console.ReadLine();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Поскольку в данном случае явный статический конструктор класса **Singleton** отсутствует, то компилятор к этому типу добавляет атрибут **beforeFieldInit**. Согласно спецификации, в этом инициализация статического поля произойдет **до первого обращения** к этому полю, причем может она может произойти задолго до этого обращения. На практике при использовании .Net Framework 3.5 и ниже, это приводит к тому, что инициализация статического поля произойдет до вызова метода Main, даже если условие **args.****Legnth == 1** не будет выполнено. Все это приводит к тому, что при запуске указанного выше кода мы получим следующее:
Field initializer
Starting Main...
Как видно, что статическое поле будет проинициализировано, хотя сам тип в приложении не используется. Практика показывает, что в большинстве случаев при отсутствии явного конструктора, JIT-компилятор вызывает инициализатор статических переменных **непосредственно перед вызовом метода, в котором используется эта переменная**. Если раскомментировать статический конструктор класса **Singleton**, то поведение будет именно таким, которое ожидает большинство разработчиков – инициализатор поля вызван не будет и при запуске приложения на экране будет только одна строка: ***“******Starting*** ***Main…”***.
**ПРИМЕЧАНИЕ**Разработчик не может и не должен завязываться на время вызова статического конструктора. Если следовать «букве закона», то вполне возможна ситуация, когда в приведенном выше примере (без явного конструктора типа), переменная **Singleton.****S** не будет проинициализирована при создании экземпляра класса **Singleton** и при вызове статического метода, который **не использует поле** **S**, но будет проинициализирована при вызове статической функции, использующей поле **S**. И хотя именно такое поведение исходно заложено в определение флага **beforeFieldInit**, в спецификации языка C# специально говорится о том, что точное время вызова определяется реализацией. Так, например, при запуске приведенного выше исходного фрагмента (без явного статического конструктора) под .Net Framework 4, мы получим более ожидаемое поведение: **поле** **S проинициализировано** **не будет!** Более подробно об этом можно почитать в дополнительных ссылках, приведенных в конце статьи.
#### **Статические конструкторы и взаимоблокировка**
Поскольку статический конструктор указанного типа должен вызываться не более одного раза в домене приложения, то CLR вызывает его внутри некоторой блокировки. Тогда, если поток, исполняющий статический конструктор будет ожидать завершения другого потока, который в свою очередь попытается захватить ту же самую внутреннюю блокировку CLR, мы получим классический дедлок.
Воспроизвести подобную ситуацию в идеальных условиях весьма просто: для этого в статическом конструкторе достаточно создать новый поток и попытаться дождаться его выполнения:
> `class Program
>
> {
>
> static Program()
>
> {
>
> var thread = new Thread(o => { });
>
> thread.Start();
>
> thread.Join();
>
> }
>
>
>
> static void Main()
>
> {
>
> // Этот метод никогда не начнет выполняться,
>
> // поскольку дедлок произойдет в статическом
>
> // конструкторе класса Program
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Причем, если обратиться к спецификации CLI, то в ней сказано, что дедлок возможен при явном или не явном вызове блокирующей операции внутри статического конструктора. На практике это означает, что попытка блокировки потока внутри статического конструктора, например, из-за использования именованного мьютекса в некоторых случаях может приводить к дедлоку.
#### **Бага в реальном приложении**
Вся эта чепуха, связанная со временем вызова инициализаторов полей и дедлоками в статических конструкторах, может показаться высосанной из пальца и маловероятной в реальных приложениях. Если честно, я был такого же мнения еще неделю назад, до того, как провел целый день в отладке одного весьма неприятного бага.
Итак, вот симптомы реальной проблемы, с которой я столкнулся. У нас есть сервис, который прекрасно работает в консольном режиме, а также не менее прекрасно работает в виде сервиса, если собрать его в Debug-е. Однако если собрать его в релизе, то он запускается через раз: один раз запускается успешно, а во второй раз запуск падает по тайм-ауту (по умолчанию SCM прибивает процесс, если сервис не запустился за 30 секунд).
В результате отладки было найдено следующее. (1) У нас есть класс сервиса, в конструкторе которого происходит создание счетчиков производительности; (2) класс сервиса реализован в виде синглтона с помощью инициализации статического поля без явного статического конструктора, и (3) этот синглтон использовался напрямую в методе **Main** для запуска сервиса в консольном режиме:
> `// Класс сервиса
>
> partial class Service : ServiceBase
>
> {
>
> // "Кривоватая" реализаци Синглтона. Нет статического конструктора
>
> public static readonly Service instance = new Service();
>
> public static Service Instance { get { return instance; } }
>
>
>
> public Service()
>
> {
>
> InitializeComponent();
>
>
>
> // В конструкторе инициализирутся счетчики производительности
>
> var counters = new CounterCreationDataCollection();
>
>
>
> if (PerformanceCounterCategory.Exists(category))
>
> PerformanceCounterCategory.Delete(category);
>
>
>
> PerformanceCounterCategory.Create(category, description,
>
> PerformanceCounterCategoryType.SingleInstance, counters);
>
> }
>
>
>
> // Метод запуска сервиса
>
> public void Start()
>
> {}
>
>
>
> const string category = "Category";
>
> const string description = "Category description";
>
> }
>
> // А тем временем в классе Program
>
> static void Main(string[] args)
>
> {
>
> if (args[0] == "--console")
>
> Service.Instance.Start();
>
> else
>
> ServiceBase.Run(new Service());
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Поскольку класс **Server** не содержит явного статического конструктора и компилятор C# добавляет флаг **beforeFieldInit**, то вызов конструктора класса **Service** происходит до вызова метода **Main**. При этом для создания категории счетчиков производительности используется именованный мьютекс, что в определенных условиях приводит к дедлоку приложения: во время первого запуска указанной категории еще нет в системе, поэтому метод **Exists** возвращает **false** и метод **Create** завершается успешно; во время следующего запуска метод **Exists** возвращает **true**, метод **Delete** завершается успешно, но метод **Create** подвисает на веки. Понятное дело, что после того, как проблема была найдена, решение заняло ровно 13 секунд: добавить статический конструктор в класс **Service**.
#### **Заключение**
Пример с багом в реальном приложении говорит о том, что статьи о подводных камнях языка C# и о правильном применении известных паттернов и идиом не является бредом и выдумкой теоретиков (\*\*), многие подобные статьи основываются на шишках, набитых в реальном мире. Сегодня вы могли столкнуться с проблемами кривой реализации синглтона, завтра – с непонятным поведением изменяемых значимых типов, послезавтра вы прибиваете поток с помощью Thread.Abort и получаете рассогласованное состояние системы (\*\*\*). Все эти проблемы весьма реальны и понимание принципов, заложенных в их основу может сэкономить денек другой при поиске какого-нибудь особенно злого бага.
#### **Дополнительные ссылки**
* Bart de Smet. [Static constructor and Type initialization](http://bartdesmet.net/blogs/bart/archive/2006/10/30/Answers-to-C_2300_-Quiz-_2D00_-Static-constructors-and-type-initialization-.aspx)
* [Static constructor demystified](http://ondotnet.com/pub/a/dotnet/2003/07/07/staticxtor.html) (потрясная статья! рекомендую)
* Jon Skeet. [C# and befrefieldinit](http://csharpindepth.com/Articles/General/Beforefieldinit.aspx)
* Jon Skeet. [Implementing the Singleton Pattern in C#](http://csharpindepth.com/Articles/General/Singleton.aspx)
* Jon Skeet. [Type initialization changes in .Net 4.0](http://msmvps.com/blogs/jon_skeet/archive/2010/01/26/type-initialization-changes-in-net-4-0.aspx)
-------------------------
(\*) Двумя другими весьма популярными реализациями паттерна Синглтон являются: (1) блокировка с двойной проверкой (double checked locking), а также (2) с помощью типа **Lazy<****T>**, который появился в .Net Framework 4.
(\*\*) Один мой коллега свято верит в то, что книги и статьи читать не имеет смысла, поскольку их пишут те, кто ничего не смыслит в настоящей разработке ПО. Поэтому он считает, что существует только одна «настоящая» реализация синглтона, и что нужно добавлять пустой финализатор всем классам, реализующим интерфейс IDisposable.
(\*\*\*) Если интересно, какие такие проблемы таятся в изменяемых значимых типах, то вполне подойдет предыдущая заметка [«О вреде изменяемых значимых типов»](http://sergeyteplyakov.blogspot.com/2011/07/blog-post.html), ну а если интересно, что же такого плохого в вызове Thread.Abort, то тут есть даже две заметки: [«О вреде вызова Thread.Abort»](http://sergeyteplyakov.blogspot.com/2011/01/threadabort.html), а также перевод интересной статьи Криса Селлза [«Изучение ThreadAbortExcpetion с помощью Rotor»](http://sergeyteplyakov.blogspot.com/2009/07/threadabortexception-rotor.html). | https://habr.com/ru/post/125421/ | null | ru | null |
# Сотни тысяч платежей граждан в ГИБДД и ФССП находились в открытом доступе
Медицинские данные – [были](https://habr.com/ru/post/444114/), данные по кредитам – [были](https://habr.com/ru/post/445288/), на этот раз пришла очередь данных по платежам за штрафы ГИБДД и задолженности по исполнительным производствам службы судебных приставов.

Хорошая новость в том, что эти платежи не связаны с официальным сайтом Госуслуг. Плохая новость – данных много, и они более чем «персональные».
```
Дисклеймер: вся информация ниже публикуется исключительно в образовательных целях. Автор не получал доступа к персональным данным третьих лиц и компаний. Информация взята либо из открытых источников, либо была предоставлена автору анонимными доброжелателями.
```
12-го апреля (ночью) был обнаружен сервер Elasticsearch, не требующий аутентификации для подключения. Про то, [как обнаруживают открытые базы Elasticsearch](https://www.devicelock.com/ru/blog/obnaruzhenie-otkrytyh-baz-dannyh-mongodb-i-elasticsearch.html) я писал заметку в блоге.

В индексах Elasticsearch содержались логи некой информационной системы (ИС). Было сделано предположение о связи данного сервера с сайтами, принимающими оплату в пользу различных госсервисов: *оплатагибдд.рф*, *paygibdd.ru*, *gos-oplata.ru*, *штрафов.net* и *oplata-fssp.ru*.
Утром 13.04.2019 я отправил оповещение по адресам электронной почты: *[email protected]*, *[email protected]*, *[email protected]*, но ответа (как это часто бывает) не получил. Сервер был тихо «прикрыт» и исчез из открытого доступа 13.04.2019 около 15:20-15:45 (МСК).
На момент перед закрытием сервера, индексы Elasticsearch выглядели так:

Теперь перейдем к самому интересному – непосредственно к персональным данным. Как я написал выше, в индексах содержались какие-то логи какой-то ИС. И как это часто бывает логи оказались очень детальными, даже слишком.
Логи хранились, начиная с 28.02.2019, а не за все время работы ИС. В некоторых индексах данные были с 17.03.2019.
Например, по логам из индекса *gosoplata* можно было получить вот такое (всего 248365 исключая логирование ошибок):
```
{
"_index": "gosoplata",
"_type": "log",
"@timestamp": "2019-03-02T20:55:02+03:00",
"message": "Начисление найдено в ГИС",
"extra": "[\n 'gis_info' => unserialize('O:34:\"app\\\\models\\\\payment\\\\api\\\\PenaltyInfo\":10:{s:10:\"billNumber\";s:20:\"ХХХХХ021170025955001\";s:8:\"billDate\";s:10:\"2017-04-03\";s:10:\"validUntil\";s:10:\"2017-06-03\";s:6:\"amount\";s:9:\"146030.26\";s:7:\"addInfo\";s:1424:\"Оплата долга по ИП № ХХХХХ/17/ ХХХХХ -ИП от 03.04.2017 в отношении МИХХХ Х. Х., Задолженность по кредитным платежам (кроме ипотеки)///УИН32253021170025955001_ИП0;Подразделение: УФК ПО НОВГОРОДСКОЙ ОБЛАСТИ (ОСП НОВГОРОДСКОГО, БАТЕЦКОГО И КРЕСТЕЦКОГО РАЙОНОВ УФССП РОССИИ ПО НОВГОРОДСКОЙ ОБЛАСТИ Л/С 05501845860);Получатель: УФК ПО НОВГОРОДСКОЙ ОБЛАСТИ (ОСП НОВГОРОДСКОГО, БАТЕЦКОГО И КРЕСТЕЦКОГО РАЙОНОВ УФССП РОССИИ ПО НОВГОРОДСКОЙ ОБЛАСТИ Л/С 05501845860);Банк Получателя: ОТДЕЛЕНИЕ НОВГОРОД;Номер счёта Получателя: 40302810400001000005;ИНН: 5321100670;КПП: 532132002;БИК Банка Получателя: 044959001;ОКАТО: 49625000;КБК: 0;idDebtsum:146540.26;ipPaymentAmount:0.00;ipOperationAmount:0.00;dataUnloadDate:2018-12-04T11:26:19.000;dataIdDate:2017-01-27;dataIdNumber:2-53/2017;dataIpRiseDate:2017-04-03;dataIpNumber: ХХХХХ/17/ХХХХХ-ИП;dataIdDbtrFio:МИХХХ ХХХ ХХХ;dataIdDbtrBorn:ХХХ-09-03;dataIdDebtText:Задолженность по кредитным платежам (кроме ипотеки);\";s:7:\"docName\";s:3:\"inn\";s:9:\"docNumber\";s:12:\" ХХХХХ0819584\";s:9:\"payStatus\";s:1:\"0\";s:9:\"quittance\";s:1:\"3\";s:11:\"amountToPay\";s:9:\"146030.26\";}'),\n]",
"context": "[\n '_GET' => [],\n '_POST' => [],\n]"
}
}
```
*Я забил все чувствительные данные символом «Х». В реальности все хранилось в открытом виде.*
Из индекса *oplata-fssp* (всего 283958 исключая ошибки):
```
{
"_index": "oplata-fssp",
"_type": "log",
"@timestamp": "2019-02-28T22:17:24+03:00",
"extra": "[\n 'request_data' => [\n 'MNT_ID' => 'ХХХХХ3280',\n 'MNT_TRANSACTION_ID' => ''ХХХХХ0795c78337a5a308',\n 'MNT_OPERATION_ID' => ''ХХХХХ 3232',\n 'MNT_AMOUNT' => '544.00',\n 'MNT_CURRENCY_CODE' => 'RUB',\n 'MNT_TEST_MODE' => '0',\n 'MNT_SIGNATURE' => '6435224ccХХХХХХХ10bbc970f6479787',\n 'paymentSystem_unitId' => '1686945',\n 'MNT_CORRACCOUNT' => '303',\n 'MNT_PAY_SYSTEM' => 'payanyway',\n 'MNT_IS_REGULAR' => '',\n 'MNT_FORM_METHOD' => 'POST',\n 'cardnumber' => '639002********7417',\n ],\n 'model_attributes' => [\n 'id' => 482137,\n 'parent_id' => null,\n 'name' => 'ПОХХХ ГАЛИНА ГХХХ',\n 'ur' => 0,\n 'birthdate' => 'ХХХХ-06-06',\n 'doc_type' => null,\n 'doc_value' => null,\n 'hash' => ''ХХХХХ795c78337a5a308',\n 'created_at' => '2019-02-28 22:16:10',\n 'form_url' => 'https://service.moneta.ru/assistant.widget? 'ХХХХХ&MNT_CURRENCY_CODE=RUB&MNT_AMOUNT=544.00&MNT_DESCRIPTION=Оплата задолженности ФССП. Заказ N482137 УИН: 32223088190136500007 Делопроизводство: ХХХХХХ/19/ХХХХХ-ИП&MNT_TEST_MODE=0&'ХХХХХ &MNT_SUCCESS_URL=https://oplata-fssp.ru/payment/success&MNT_FAIL_URL=https://oplata-fssp.ru/payment/fail&MNT_PAY_SYSTEM=payanyway&MNT_IS_REGULAR=&MNT_FORM_METHOD=POST&followup=true',\n 'email' => ''ХХХХХ@bk.ru',\n 'payment_system_id' => 'moneta',\n 'transaction_id' => '338533232',\n 'updated_at' => '2019-02-28 22:16:16',\n 'a3_order_hash' => null,\n 'receipt_send' => null,\n 'receipt_status_id' => null,\n 'payment_status_id' => 'callback_received',\n 'lead_source' => 'fssp',\n ],\n]",
"context": "[\n '_GET' => [],\n '_POST' => [\n 'MNT_ID' => ''ХХХХХ280',\n 'MNT_TRANSACTION_ID' => ''ХХХХХ795c78337a5a308',\n 'MNT_OPERATION_ID' => ''ХХХХХ3232',\n 'MNT_AMOUNT' => '544.00',\n 'MNT_CURRENCY_CODE' => 'RUB',\n 'MNT_TEST_MODE' => '0',\n 'MNT_SIGNATURE' => '6435224cc'ХХХХХ10bbc970f6479787',\n 'paymentSystem_unitId' => ''ХХХХХ45',\n 'MNT_CORRACCOUNT' => '303',\n 'MNT_PAY_SYSTEM' => 'payanyway',\n 'MNT_IS_REGULAR' => '',\n 'MNT_FORM_METHOD' => 'POST',\n 'cardnumber' => '639002********7417',\n ],\n]"
}
}
```
Тут видно (значение *cardnumber*), что от утечки полных номеров кредитных карт, их владельцев уберегло только то, что шлюз оплаты (в данном случае *moneta.ru*) не отдавал данной ИС номера в открытом виде (только первые 6 и последние 4 цифры номера карты).
Также из логов было видно, что официальный сайт ФССП предлагает гражданам проводить платежи через данную ИС: *is.fssprus.ru/pay/?service=gosoplata&pay=ХХХХХХ/18/ХХХХХХ-IP*. Что косвенно подтверждается текстом в самом низу сайта *oplata-fssp.ru*:

Теперь посмотрим, что там с штрафами за ПДД. Явно за это ответчают индексы *shtrafov-net* (4528 записей исключая ошибки) и *paygibdd* (140666 записей исключая ошибки):
```
{
"_index": "shtrafov-net",
"_type": "log",
"@timestamp": "2019-03-17T17:16:51+03:00",
"message": "INSERT INTO customer (doc_type, doc_value, licence_plate, vehicle_model) VALUES ('ctc', '99026ХХХХХ', 'УХХХРМХХ', 'ЛЕНД РОВЕР РЕЙНДЖ РОВЕР')",
"context": "[\n '_GET' => [],\n '_POST' => [\n 'postdate' => '10/03/2019',\n 'postnum' => '18810018180002ХХХХХХ',\n 'postsum' => '1000',\n 'divid' => '1194040',\n 'uin' => '18810018180002ХХХХХХ',\n 'regnum' => 'УХХХРМ',\n 'regreg' => '1Х',\n 'reg' => 'ХХХХХ34084',\n 'discount' => '1',\n 'discountdate' => '01/04/2019 23:59:59',\n 'allfines' => '[{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2019-03-10 09:05:00\",\"KoAPcode\":\"12.6\",\"DateDiscount\":\"01/04/2019 23:59:59\",\"VehicleModel\":\"ЛЕНД РОВЕР РЕЙНДЖ РОВЕР\",\"KoAPtext\":\"УПРАВЛЕНИЕ ТРАНСПОРТНЫМ СРЕДСТВОМ ВОДИТЕЛЕМ, НЕ ПРИСТЕГНУТЫМ РЕМНЕМ БЕЗОПАСНОСТИ, ПЕРЕВОЗКА ПАССАЖИРОВ, НЕ ПРИСТЕГНУТЫХ РЕМНЯМИ БЕЗОПАСНОСТИ, ЕСЛИ КОНСТРУКЦИЕЙ ТРАНСПОРТНОГО СРЕДСТВА ПРЕДУСМОТРЕНЫ РЕМНИ БЕЗОПАСНОСТИ, А РАВНО УПРАВЛЕНИЕ МОТОЦИКЛОМ ЛИБО ПЕРЕВОЗКА НА МОТОЦИКЛЕ ПАССАЖИРОВ БЕЗ МОТОШЛЕМОВ ИЛИ В НЕЗАСТЕГНУТЫХ МОТОШЛЕМАХ\",\"NumPost\":\"18810018180002ХХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":1000,\"Division\":1194040,\"enablePics\":false,\"id\":\"18#FF474785255\",\"SupplierBillID\":\"18810018180002ХХХХХХ\",\"DatePost\":\"10/03/2019\"},{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2019-03-08 14:55:00\",\"KoAPcode\":\"12.9ч.2\",\"DateDiscount\":\"01/04/2019 23:59:59\",\"VehicleModel\":\"ЛЕНД РОВЕР РЕЙНДЖ РОВЕР\",\"KoAPtext\":\"ПРЕВЫШЕНИЕ УСТАНОВЛЕННОЙ СКОРОСТИ ДВИЖЕНИЯ ТРАНСПОРТНОГО СРЕДСТВА НА ВЕЛИЧИНУ БОЛЕЕ 20, НО НЕ БОЛЕЕ 40 КМ/Ч\",\"NumPost\":\"18810118190312ХХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":500,\"Division\":1194010,\"enablePics\":true,\"id\":\"18#18810118190312ХХХХХХ\",\"SupplierBillID\":\"18810118190312ХХХХХХ\",\"DatePost\":\"12/03/2019\"}]',\n ],\n]"
}
{
"_index": "paygibdd",
"_type": "log",
"@timestamp": "2019-02-28T17:30:57+03:00",
"message": "Входящий запрос на оплату",
"extra": "[\n 'request_data' => [\n 'postdate' => '02.10.2017',\n 'postnum' => '188101161710029ХХХХХ',\n 'postsum' => '500',\n 'divid' => '1192201',\n 'uin' => '188101161710029ХХХХХ',\n 'regnum' => 'XХХХCB',\n 'regreg' => '1ХХ',\n 'reg' => '16462ХХХХХ',\n 'discount' => '1',\n 'discountdate' => '2017-10-23 23:59:59',\n 'allfines' => '[{\"Discount\":\"0\",\"DateDecis\":\"2016-12-17 02:30:00\",\"KoAPcode\":\"12.26ч.1\",\"KoAPtext\":\"НЕВЫПОЛНЕНИЕ ВОДИТЕЛЕМ ЗАКОННОГО ТРЕБОВАНИЯ СОТРУДНИКА ПОЛИЦИИ О ПРОХОЖДЕНИИ МЕДИЦИНСКОГО ОСВИДЕТЕЛЬСТВОВАНИЯ НА СОСТОЯНИЕ ОПЬЯНЕНИЯ\",\"NumPost\":\"188104121603000ХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":\"30000\",\"Division\":1188030,\"enablePics\":false,\"id\":\"12#FF176064188\",\"SupplierBillID\":\"188104121603000ХХХХХ\",\"DatePost\":\"2017-03-06\",\"DateSSP\":null},{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2017-09-18 14:32:00\",\"KoAPcode\":\"12.9ч.2\",\"DateDiscount\":\"2017-10-23 23:59:59\",\"KoAPtext\":\"ПРЕВЫШЕНИЕ УСТАНОВЛЕННОЙ СКОРОСТИ ДВИЖЕНИЯ ТРАНСПОРТНОГО СРЕДСТВА НА ВЕЛИЧИНУ БОЛЕЕ 20, НО НЕ БОЛЕЕ 40 КМ/Ч\",\"NumPost\":\"188101161710029ХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":\"500\",\"Division\":1192201,\"enablePics\":true,\"id\":\"16#43522519023478911ХХХХХ\",\"SupplierBillID\":\"188101161710029ХХХХХ\",\"DatePost\":\"2017-10-02\",\"DateSSP\":null},{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2017-11-01 04:23:00\",\"KoAPcode\":\"12.9ч.2\",\"DateDiscount\":\"2017-11-24 23:59:59\",\"KoAPtext\":\"ПРЕВЫШЕНИЕ УСТАНОВЛЕННОЙ СКОРОСТИ ДВИЖЕНИЯ ТРАНСПОРТНОГО СРЕДСТВА НА ВЕЛИЧИНУ БОЛЕЕ 20, НО НЕ БОЛЕЕ 40 КМ/Ч\",\"NumPost\":\"18810116171104ХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":\"500\",\"Division\":1192201,\"enablePics\":true,\"id\":\"16#44211639030358281ХХХХХ\",\"SupplierBillID\":\"1881011617110ХХХХХ\",\"DatePost\":\"2017-11-04\",\"DateSSP\":null},{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2017-10-31 12:08:00\",\"KoAPcode\":\"12.9ч.2\",\"DateDiscount\":\"2017-11-27 23:59:59\",\"KoAPtext\":\"ПРЕВЫШЕНИЕ УСТАНОВЛЕННОЙ СКОРОСТИ ДВИЖЕНИЯ ТРАНСПОРТНОГО СРЕДСТВА НА ВЕЛИЧИНУ БОЛЕЕ 20, НО НЕ БОЛЕЕ 40 КМ/Ч\",\"NumPost\":\"188101161711056ХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":\"500\",\"Division\":1192201,\"enablePics\":true,\"id\":\"16#44236760030609331ХХХХХ\",\"SupplierBillID\":\"188101161711056ХХХХХ\",\"DatePost\":\"2017-11-05\",\"DateSSP\":null},{\"Discount\":\"1\",\"enableDiscount\":false,\"DateDecis\":\"2018-01-27 23:46:00\",\"KoAPcode\":\"12.37ч.2\",\"DateDiscount\":\"2018-02-16 23:59:59\",\"KoAPtext\":\"НЕИСПОЛНЕНИЕ ВЛАДЕЛЬЦЕМ ТРАНСПОРТНОГО СРЕДСТВА УСТАНОВЛЕННОЙ ФЕДЕРАЛЬНЫМ ЗАКОНОМ ОБЯЗАННОСТИ ОСАГО, А РАВНО УПРАВЛЕНИЕ ТРАНСПОРТНЫМ СРЕДСТВОМ, ЕСЛИ ТАКОЕ ОСАГО ЗАВЕДОМО ОТСУТСТВУЕТ\",\"NumPost\":\"188102161820027ХХХХХ\",\"kbk\":\"18811630020016000140\",\"Summa\":\"800\",\"Division\":1192200,\"enablePics\":false,\"id\":\"16#4516501003986993ХХХХХ\",\"SupplierBillID\":\"188102161820027ХХХХХ\",\"DatePost\":\"2018-01-27\",\"DateSSP\":null}]',\n ],\n]",
```
Суммируя написанное выше – в свободном доступе находились все подробности платежей: номер постановления о штрафе, государственный номерной знак автомобиля, номер исполнительного производства при платеже в пользу службы судебных приставов, первые и последние цифры банковских карт, через какой платёжный шлюз произведена оплата, ФИО и адрес электронной почты плательщика и многое другое.
За один выбранный день (12.04) в индексах находилось (записей):
```
shtrafov-net 251
paygibdd 3821
gosoplata 20676
oplata-fssp 15277
```
Поисковик Shodan впервые обнаружил этот сервер в открытом доступе 24.02.2019.
Новости про утечки информации и инсайдеров всегда можно найти на моем Telegram-канале «[Утечки информации](http://tele.click/dataleak)». | https://habr.com/ru/post/448440/ | null | ru | null |
# Расширения для Opera: Кнопки, бэджи и всплывающие окна
#### Вступление
Эта статья рассказывает о базовых шагах по созданию и управлению кнопками на панели браузера и различными их компонентами.
#### Кнопки на панели браузера
Расширение позволяет поместить одну кнопку на панель браузера Opera, справа от поля поиска. Кнопка может включать иконку размером 18х18 пикселей, подсказку (показывается при наведении), бэдж статуса и всплывающее окно.
#### Создание кнопок
Код создания кнопки должен быть добавлен в элемент script файла index.html. В этом примере мы выполняем код в момент срабатывания события load.
Первый шаг, это определение свойств кнопки. Сделать это можно с помощью объекта ToolbarUIItemProperties. Например:
```
var ToolbarUIItemProperties = {
disabled: false,
title: "Пример кнопки",
icon: "icons/button.png"
}
```
После того, как вы задали свойства кнопки в ToolbarUIItemProperties, вам необходимо создать собственно кнопку с помощью метода createItem:
```
var theButton = opera.contexts.toolbar.createItem(ToolbarUIItemProperties);
```
Всего, с помощью объекта ToolbarUIItemProperties вы можете определить 5 свойств:
###### disabled
Определяет, активна ли кнопка. Значение по умолчанию — true (неактивна), принимает булево значение. Вы можете сделать кнопку неактивной следующим образом:
```
theButton.disabled = true;
```
###### title
Свойство title устанавливает подсказку, которая показывает при наведении пользователем курсора на кнопку.
```
theButton.title = "Это подсказка";
```
###### icon
Свойство icon устанавливает иконку, которая используется кнопкой. Если вы укажете картинку размером отличную от 18х18 пикселей, то она будет автоматически отмасштабирована.
```
theButton.icon = "icons/beautiful-toobar-icon.png";
```
###### onclick
Эта функция вызывается, когда пользователь кликает по кнопке и возбуждается событие click.
```
theButton.onclick = function(){ /* делаем что-нибудь */ };
```
###### onremove
Эта функция вызывается, когда кнопка удаляется из ToolbarContext и возбуждается событие remove.
```
theButton.onremove = function(){ /* делаем что-нибудь */ };
```
#### Добавление кнопки на панель браузера
После создания кнопки нам необходимо поместить её на панель Opera. Сделаем это с помощью метода addItem:
```
opera.contexts.toolbar.addItem(theButton);
```
Пробуйте запустить [пример](http://dev.opera.com/articles/view/opera-extensions-buttons-badges-and-popups/example-button.oex). Он не делает ничего особенного, так как вы ещё не определили никаких действий для кнопки.
#### Удаление кнопки с панели браузера
Кнопка может быть удалена с панели браузера методом removeItem:
```
opera.contexts.toolbar.removeItem(theButton);
```
#### Создание всплывающего окна
Теперь у вас есть кнопка, вы хотите, чтобы она что-нибудь умела. При клике на кнопку может быть показано всплывающее окно. Всплывающее окно это окно с указанными шириной и высотой. Вы можете подгружать в него страницы, находящиеся в сети или поставляющиеся с вашим расширением.
Чтобы создать всплывающее окно, вам нужно определить свойства объекта Popup с помощью объекта ToolbarUIItemProperties:
```
var ToolbarUIItemProperties = {
disabled: false,
title: "Пример кнопки",
icon: "icons/button.png",
popup: {
href: "popup.html",
width: 300,
height: 300
}
}
```
#### Содержимое всплывающего окна
Для указания содержимого всплывающего окна используется свойство href. Вы можете указать на любую страницу в сети, используя её абсолютный URL:
```
theButton.popup.href = http://www.opera.com/";
```
Так же вы можете подгрузить страницу, поставляющуюся с расширением, указав её относительный адрес:
```
theButton.popup.href = "popup.html";
```
Эта страница может быть обычной HTML-страницей, никаких изменений вносить не нужно. Обратите внимание: если вы измените свойство href, в момент когда всплывающее окно открыто, то оно закроется.
#### Размеры всплывающего окна
Размеры всплывающего окна указываются в пикселях с помощью свойств width и height:
###### width
```
theButton.popup.width = 300;
```
###### height
```
theButton.popup.height = 300;
```
Всплывающее окно будет создано одновременно с кнопкой в момент вызова метода createItem.
Попробуйте пример [кнопки со всплывающим окном](http://dev.opera.com/articles/view/opera-extensions-buttons-badges-and-popups/example-button-popup.oex). Если вы пробовали пример из статьи «[Ваше первое расширение для Opera](http://habrahabr.ru/blogs/opera/106609/)», то он покажется вам очень знакомым.
#### Создание бэджа
Бэдж это наложение поверх иконки кнопки с текстовым содержимым. Чаще всего они используются для показа количества чего-либо, например непрочитанных писем или сообщений. Чтобы создать бэдж, вам нужно определить свойства объекта Badge через объект ToolbarUIItemProperties:
```
var ToolbarUIItemProperties = {
disabled: false,
title: "Пример кнопки",
icon: "icons/button.png",
badge: {
display: "block",
textContent: "12",
color: "white",
backgroundColor: "rgba(211, 0, 4, 1)"
}
}
```
Бэдж имеет 4 свойства, которые могут быть настроены:
###### display
Свойство display показывает и скрывает бэдж. Корректными значениями являются block и none. Значение по умолчанию — none. Сделать бэдж видимым можно так:
```
theButton.badge.display = "block";
```
###### textContent
Текст бэджа может быть выставлен через свойство textContent. Бэдж имеет ограниченное место для отображения текста, поэтому постарайтесь быть лаконичными.
```
theButton.badge.textContent = "12";
```
###### color и backgroundColor
Свойства color и backgroundColor устанавливают цвет текста и цвета фона бэджа. Они принимают значения в формате hexadecimal, RGBA и наименования цвета.
```
theButton.badge.color = "white";
theButton.badge.backgroundColor: = "rgba(211, 0, 4, 1)";
```
Вы можете попробовать пример [кнопки с бэджем](http://dev.opera.com/articles/view/opera-extensions-buttons-badges-and-popups/button-badge-popup.oex) и изучить различные пути создания и управления элементами пользовательского интерфейса расширений для Opera.
Вы можете обратиться к [API расширений для Opera](http://labs.opera.com/extensions-api/), чтобы получить полную информацию о различных объектах и методах.
#### Ссылки на API
объект [ToolbarContext](http://labs.opera.com/extensions-api/backgroundProcess/ToolbarContext.html)
объект [ToolbarUIItem](http://labs.opera.com/extensions-api/backgroundProcess/ToolbarUIItem.html)
объект [ToolbarUIItemProperties](http://labs.opera.com/extensions-api/backgroundProcess/ToolbarUIItemProperties.html)
объект [Popup](http://labs.opera.com/extensions-api/backgroundProcess/Popup.html)
объект [Badge](http://labs.opera.com/extensions-api/backgroundProcess/Badge.html) | https://habr.com/ru/post/107067/ | null | ru | null |
# Docker Remote API с аутентификацией по сертификату с проверкой отзыва
Описание проблемы
=================
Для нужд удаленного управления Docker'ом, Docker умеет предоставлять веб-API.
Это API может как вовсе не требовать аутентификации (что крайне не рекомендуется), так и использовать аутентификация по сертификату.
Проблема заключается в том, что родная аутентификация по сертификату не предусматривает проверку отзыва сертификата. И это может иметь серьезные последствия.
Я хочу рассказать как я решил эту проблему.
Решение проблемы
================
Для начала следует сказать что говорить я буду про Docker для Windows. Возможно в Linux все не так плохо, но сейчас не об этом.
Что мы имеем? У нас есть Docker, с вот таким конфигом:
```
{
"hosts": ["tcp://0.0.0.0:2376", "npipe://"],
"tlsverify": true,
"tlscacert": "C:\\ssl\\ca.cer",
"tlscert": "C:\\ssl\\server.cer",
"tlskey": "C:\\ssl\\server.key"
}
```
Клиенты могут подключаться со своими сертификатами, но эти сертификаты не проверяются на предмет отзыва.
Идея решения проблемы заключается в том, чтобы написать свой прокси-сервис, который выступал бы в качестве посредника. Наш сервис будет установлен на том же сервере что и Docker, заберет себе порт 2376, будет общаться с Docker по //./pipe/docker\_engine.
Недолго думая я создал ASP.NET Core проект и сделал простейшее проксирование:
**Код простейшего прокси**
```
app.Run(async (context) =>
{
var certificate = context.Connection.ClientCertificate;
if (certificate != null)
{
logger.LogInformation($"Certificate subject: {certificate.Subject}, serial: {certificate.SerialNumber}");
}
var handler = new ManagedHandler(async (host, port, cancellationToken) =>
{
var stream = new NamedPipeClientStream(".", "docker_engine", PipeDirection.InOut, PipeOptions.Asynchronous);
var dockerStream = new DockerPipeStream(stream);
await stream.ConnectAsync(NamedPipeConnectTimeout.Milliseconds, cancellationToken);
return dockerStream;
});
using (var client = new HttpClient(handler, true))
{
var method = new HttpMethod(context.Request.Method);
var builder = new UriBuilder("http://dockerengine")
{
Path = context.Request.Path,
Query = context.Request.QueryString.ToUriComponent()
};
using (var request = new HttpRequestMessage(method, builder.Uri))
{
request.Version = new Version(1, 11);
request.Headers.Add("User-Agent", "proxy");
if (method != HttpMethod.Get)
{
request.Content = new StreamContent(context.Request.Body);
request.Content.Headers.ContentType = new MediaTypeHeaderValue(context.Request.ContentType);
}
using (var response = await client.SendAsync(request, HttpCompletionOption.ResponseHeadersRead, context.RequestAborted))
{
context.Response.ContentType = response.Content.Headers.ContentType.ToString();
var output = await response.Content.ReadAsStreamAsync();
await output.CopyToAsync(context.Response.Body, 4096, context.RequestAborted);
}
}
}
});
```
Этого оказалось достаточно для простых запросов GET и POST из Docker API. Но этого мало, т.к. для более сложных операций (требующий пользовательской ввод) Docker использует что-то похожее на WebSocket. Засада была в том, что Kestrel наотрез отказывался принимать запросы, которые приходили от Docker Client, мотивируя это тем, что в запросе с заголовком Connection: Upgrade не может быть тела. А оно было.
Пришлось отказаться от Kestrel и написать чуть больше кода. По сути — свой web сервер. Самостоятельно открывать порт, создавать TLS соединение, парсить HTTP заголовки, устанавливать внутреннее соединение с Docker и обмениваться потоками ввода-вывода. И это сработало.
Исходники можно посмотреть [здесь](https://dev.azure.com/vitaliy-leschenko/docker-tls-proxy).
Итак, приложение написано и надо бы его как-то запускать. Идея заключается в том, чтобы создать контейнер с нашим приложением, прокинуть внутрь npine:// и опубликовать порт 2376
Сборка Docker образа
====================
Для сборки образа нам потребуется публичный сертификат центра сертификации (ca.cer), который будет выдавать сертификаты пользователям.
Этот сертификат будет установлен в доверенные корневые центры сертификации контейнера, в котором будет запущен наш прокси.
Установка его необходима для процедуры проверки сертификата.
Я не заморачивался написанием такого Docker-файла, который сам бы собирал приложение.
Поэтому его надо собрать самостоятельно. Из папки с dockerfile запускаем:
```
dotnet publish -c Release -o ..\publish .\DockerTLS\DockerTLS.csproj
```
Сейчас у нас должны быть: `Dockerfile`, `publish`, `ca.cer`. Собираем образ:
```
docker build -t vitaliyorg.azurecr.io/docker/proxy:1809 .
docker push vitaliyorg.azurecr.io/docker/proxy:1809
```
Разумеется, имя образа может быть любое.
Запуск
======
Для запуска контейнера нам понадобятся сертификат сервера `certificate.pfx` и файл с паролем `password.txt`. Все содержимое файла считается паролем. Поэтому лишних переводов строк быть не должно.
Пусть все это добро находится в папке: `c:\data` на сервере, где установлен Docker.
На этом же сервере запускаем:
```
docker run --name docker-proxy -d -v "c:/data:c:/data" -v \\.\pipe\docker_engine:\\.\pipe\docker_engine --restart always -p 2376:2376 vitaliyorg.azurecr.io/docker/proxy:1809
```
Логирование
===========
С помощью `docker logs` можно видеть кто что делал. Там же можно видеть попытки подключения, которые завершились неудачно. | https://habr.com/ru/post/433176/ | null | ru | null |
# CMake: the Case when the Project's Quality is Unforgivable

CMake is a cross-platform system for automating project builds. This system is much older than the PVS-Studio static code analyzer, but no one has tried to apply the analyzer on its code and review the errors. As it turned out, there are a lot of them. The CMake audience is huge. New projects start on it and old ones are ported. I shudder to think of how many developers could have had any given error.
Introduction
------------
[CMake](https://cmake.org/) is a cross-platform system for automating software building from source code. CMake isn't meant directly for building, it only generates files to control a build from CMakeLists.txt files. The first release of the program took place in 2000. For comparison, the PVS-Studio analyzer appeared only in 2008. At that time, it was aimed at searching for bugs resulted from porting 32-bit systems to 64-bit ones. In 2010, the first set of general purpose diagnostics appeared (V501-[V545](https://www.viva64.com/en/w/v501/)). By the way, the CMake code has a few warnings from this first set.
Unforgivable Errors
-------------------
[V1040](https://www.viva64.com/en/w/v1040/) Possible typo in the spelling of a pre-defined macro name. The '\_\_MINGW32\_' macro is similar to '\_\_MINGW32\_\_'. winapi.h 4112
```
/* from winternl.h */
#if !defined(__UNICODE_STRING_DEFINED) && defined(__MINGW32_)
#define __UNICODE_STRING_DEFINED
#endif
```
The [V1040](https://www.viva64.com/en/w/v1040/) diagnostic was implemented not so long ago. Most likely, at the time of posting the article, it won't be released yet, nevertheless, we already found a cool error with its help.
There's a typo made in the name *\_\_MINGW32\_*. At the end, one underline character is missing. If you search the code with this name, you can see that the version with two underline characters on both sides is used in the project:
[V531](https://www.viva64.com/en/w/v531/) It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 558
```
bool IsVisualStudioMacrosFileRegistered(const std::string& macrosFile,
const std::string& regKeyBase,
std::string& nextAvailableSubKeyName)
{
....
if (ERROR_SUCCESS == result) {
wchar_t subkeyname[256]; // <=
DWORD cch_subkeyname = sizeof(subkeyname) * sizeof(subkeyname[0]); // <=
wchar_t keyclass[256];
DWORD cch_keyclass = sizeof(keyclass) * sizeof(keyclass[0]);
FILETIME lastWriteTime;
lastWriteTime.dwHighDateTime = 0;
lastWriteTime.dwLowDateTime = 0;
while (ERROR_SUCCESS ==
RegEnumKeyExW(hkey, index, subkeyname, &cch_subkeyname, 0, keyclass,
&cch_keyclass, &lastWriteTime)) {
....
}
....
}
```
For a statically declared array, the *sizeof* operator will calculate size in bytes, taking into account the number of elements and their size. When evaluating the value of the *cch\_subkeyname* variable, a developer didn't take it into account and got a value 4 times greater than intended. Let's explain where «four times» come from.
The array and its wrong size is passed to the function [RegEnumKeyExW](https://docs.microsoft.com/en-us/windows/win32/api/winreg/nf-winreg-regenumkeyexw):
```
LSTATUS RegEnumKeyExW(
HKEY hKey,
DWORD dwIndex,
LPWSTR lpName, // <= subkeyname
LPDWORD lpcchName, // <= cch_subkeyname
LPDWORD lpReserved,
LPWSTR lpClass,
LPDWORD lpcchClass,
PFILETIME lpftLastWriteTime
);
```
The *lpcchName* pointer must point to the variable, containing the buffer size in characters: «A pointer to a variable that specifies the size of the buffer specified by the *lpClass* parameter, in characters». The *subkeyname* array size is 512 bytes and can store 256 characters of the *wchar\_t* type (in Windows, wchar\_t is 2 bytes). It is 256 that should be passed to the function. Instead, 512 is multiplied by 2 and we get 1024.
I think, it's clear now how to correct this error. You need to use division instead of multiplication:
```
DWORD cch_subkeyname = sizeof(subkeyname) / sizeof(subkeyname[0]);
```
By the way, the same error occurs when evaluating the value of the *cch\_keyclass* variable.
The error described can potentially lead to buffer overflow. All such fragments definitely have to be corrected:
* V531 It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 556
* V531 It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 572
* V531 It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 621
* V531 It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 622
* V531 It is odd that a sizeof() operator is multiplied by sizeof(). cmGlobalVisualStudioGenerator.cxx 649
[V595](https://www.viva64.com/en/w/v595/) The 'this->BuildFileStream' pointer was utilized before it was verified against nullptr. Check lines: 133, 134. cmMakefileTargetGenerator.cxx 133
```
void cmMakefileTargetGenerator::CreateRuleFile()
{
....
this->BuildFileStream->SetCopyIfDifferent(true);
if (!this->BuildFileStream) {
return;
}
....
}
```
The pointer *this->BuildFileStream* is dereferenced right before the check for its validity. Didn't that cause any problems for anyone? Below there is another example of such snippet. It's made just like a carbon copy. But in fact, there are a lot of [V595](https://www.viva64.com/en/w/v595/) warnings and most of them are not so obvious. From my experience, I can say that correcting warnings of this diagnostic takes the longest time.
* V595 The 'this->FlagFileStream' pointer was utilized before it was verified against nullptr. Check lines: 303, 304. cmMakefileTargetGenerator.cxx 303
[V614](https://www.viva64.com/en/w/v614/) Uninitialized pointer 'str' used. cmVSSetupHelper.h 80
```
class SmartBSTR
{
public:
SmartBSTR() { str = NULL; }
SmartBSTR(const SmartBSTR& src)
{
if (src.str != NULL) {
str = ::SysAllocStringByteLen((char*)str, ::SysStringByteLen(str));
} else {
str = ::SysAllocStringByteLen(NULL, 0);
}
}
....
private:
BSTR str;
};
```
The analyzer detected usage of the uninitialized *str* pointer. It appeared due to an ordinary typo. When calling the *SysAllocStringByteLen* function, one should have used the *src.str* pointer.
[V557](https://www.viva64.com/en/w/v557/) Array overrun is possible. The value of 'lensymbol' index could reach 28. archive\_read\_support\_format\_rar.c 2749
```
static int64_t
expand(struct archive_read *a, int64_t end)
{
....
if ((lensymbol = read_next_symbol(a, &rar->lengthcode)) < 0)
goto bad_data;
if (lensymbol > (int)(sizeof(lengthbases)/sizeof(lengthbases[0])))
goto bad_data;
if (lensymbol > (int)(sizeof(lengthbits)/sizeof(lengthbits[0])))
goto bad_data;
len = lengthbases[lensymbol] + 2;
if (lengthbits[lensymbol] > 0) {
if (!rar_br_read_ahead(a, br, lengthbits[lensymbol]))
goto truncated_data;
len += rar_br_bits(br, lengthbits[lensymbol]);
rar_br_consume(br, lengthbits[lensymbol]);
}
....
}
```
This piece of code hides several problems at once. When accessing *lengthbases* and *lengthbits* arrays, an array index might go out of bounds, as developers wrote the '>' operator instead of '>=' above. This check began to miss one unacceptable value. Here we have nothing but a classic error pattern called [Off-by-one Error](https://cwe.mitre.org/data/definitions/193.html).
Here's the entire list of array access operations by a non-valid index:
* V557 Array overrun is possible. The value of 'lensymbol' index could reach 28. archive\_read\_support\_format\_rar.c 2750
* V557 Array overrun is possible. The value of 'lensymbol' index could reach 28. archive\_read\_support\_format\_rar.c 2751
* V557 Array overrun is possible. The value of 'lensymbol' index could reach 28. archive\_read\_support\_format\_rar.c 2753
* V557 Array overrun is possible. The value of 'lensymbol' index could reach 28. archive\_read\_support\_format\_rar.c 2754
* V557 Array overrun is possible. The value of 'offssymbol' index could reach 60. archive\_read\_support\_format\_rar.c 2797
Memory Leak
-----------
[V773](https://www.viva64.com/en/w/v773/) The function was exited without releasing the 'testRun' pointer. A memory leak is possible. cmCTestMultiProcessHandler.cxx 193
```
void cmCTestMultiProcessHandler::FinishTestProcess(cmCTestRunTest* runner,
bool started)
{
....
delete runner;
if (started) {
this->StartNextTests();
}
}
bool cmCTestMultiProcessHandler::StartTestProcess(int test)
{
....
cmCTestRunTest* testRun = new cmCTestRunTest(*this); // <=
....
if (testRun->StartTest(this->Completed, this->Total)) {
return true; // <=
}
}
this->FinishTestProcess(testRun, false); // <=
return false;
}
```
The analyzer detected a memory leak. The memory by the *testRun* pointer isn't released, if the function *testRun->StartTest* returns *true*. When executing another code branch, this memory gets released in the function *this-> FinishTestProcess.*
Resource Leak
-------------
[V773](https://www.viva64.com/en/w/v773/) The function was exited without closing the file referenced by the 'fd' handle. A resource leak is possible. rhash.c 450
```
RHASH_API int rhash_file(....)
{
FILE* fd;
rhash ctx;
int res;
hash_id &= RHASH_ALL_HASHES;
if (hash_id == 0) {
errno = EINVAL;
return -1;
}
if ((fd = fopen(filepath, "rb")) == NULL) return -1;
if ((ctx = rhash_init(hash_id)) == NULL) return -1; // <= fclose(fd); ???
res = rhash_file_update(ctx, fd);
fclose(fd);
rhash_final(ctx, result);
rhash_free(ctx);
return res;
}
```
Strange Logic in Conditions
---------------------------
[V590](https://www.viva64.com/en/w/v590/) Consider inspecting the '\* s != '\0' && \* s == ' '' expression. The expression is excessive or contains a misprint. archive\_cmdline.c 76
```
static ssize_t
get_argument(struct archive_string *as, const char *p)
{
const char *s = p;
archive_string_empty(as);
/* Skip beginning space characters. */
while (*s != '\0' && *s == ' ')
s++;
....
}
```
*\*s* character comparison with null is redundant. The condition of the *while* loop depends only on whether the character is equal to a space or not. This is not an error, but an unnecessary complication of the code.
[V592](https://www.viva64.com/en/w/v592/) The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present. cmCTestTestHandler.cxx 899
```
void cmCTestTestHandler::ComputeTestListForRerunFailed()
{
this->ExpandTestsToRunInformationForRerunFailed();
ListOfTests finalList;
int cnt = 0;
for (cmCTestTestProperties& tp : this->TestList) {
cnt++;
// if this test is not in our list of tests to run, then skip it.
if ((!this->TestsToRun.empty() &&
std::find(this->TestsToRun.begin(), this->TestsToRun.end(), cnt) ==
this->TestsToRun.end())) {
continue;
}
tp.Index = cnt;
finalList.push_back(tp);
}
....
}
```
The analyzer warns that the negation operation probably should be taken out of brackets. It seems that there is no such a bug here — just unnecessary double brackets. But most likely, there is a logic error in the code.
The *continue* operator is executed only in the case if the list of tests *this->TestsToRun* isn't empty and *cnt* is absent in it. It is reasonable to assume that if the tests list is empty, the same action needs to take place. Most probably, the condition should be as follows:
```
if (this->TestsToRun.empty() ||
std::find(this->TestsToRun.begin(), this->TestsToRun.end(), cnt) ==
this->TestsToRun.end()) {
continue;
}
```
[V592](https://www.viva64.com/en/w/v592/) The expression was enclosed by parentheses twice: ((expression)). One pair of parentheses is unnecessary or misprint is present. cmMessageCommand.cxx 73
```
bool cmMessageCommand::InitialPass(std::vector const& args,
cmExecutionStatus&)
{
....
} else if (\*i == "DEPRECATION") {
if (this->Makefile->IsOn("CMAKE\_ERROR\_DEPRECATED")) {
fatal = true;
type = MessageType::DEPRECATION\_ERROR;
level = cmake::LogLevel::LOG\_ERROR;
} else if ((!this->Makefile->IsSet("CMAKE\_WARN\_DEPRECATED") ||
this->Makefile->IsOn("CMAKE\_WARN\_DEPRECATED"))) {
type = MessageType::DEPRECATION\_WARNING;
level = cmake::LogLevel::LOG\_WARNING;
} else {
return true;
}
++i;
}
....
}
```
It's a similar example, but this time I'm more confident that an error takes place. The function *IsSet(«CMAKE\_WARN\_DEPRECATED»)* checks that the value *CMAKE\_WARN\_DEPRECATED* is set globally, and the function *IsOn(«CMAKE\_WARN\_DEPRECATED»)* checks that the value is set in the project configuration. Most likely, the complementary operator is redundant, as in both cases, it's correct to set same values of *type* and *level.*
[V728](https://www.viva64.com/en/w/v728/) An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. cmCTestRunTest.cxx 151
```
bool cmCTestRunTest::EndTest(size_t completed, size_t total, bool started)
{
....
} else if ((success && !this->TestProperties->WillFail) ||
(!success && this->TestProperties->WillFail)) {
this->TestResult.Status = cmCTestTestHandler::COMPLETED;
outputStream << " Passed ";
}
....
}
```
This code can be simpler. One can rewrite the conditional expression in the following way:
```
} else if (success != this->TestProperties->WillFail)
{
this->TestResult.Status = cmCTestTestHandler::COMPLETED;
outputStream << " Passed ";
}
```
A few more places to simplify:
* V728 An excessive check can be simplified. The '(A && B) || (!A && !B)' expression is equivalent to the 'bool(A) == bool(B)' expression. cmCTestTestHandler.cxx 702
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. digest\_sspi.c 443
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. tcp.c 1295
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. testDynamicLoader.cxx 58
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. testDynamicLoader.cxx 65
* V728 An excessive check can be simplified. The '(A && !B) || (!A && B)' expression is equivalent to the 'bool(A) != bool(B)' expression. testDynamicLoader.cxx 72
Various Warnings
----------------
[V523](https://www.viva64.com/en/w/v523/) The 'then' statement is equivalent to the subsequent code fragment. archive\_read\_support\_format\_ar.c 415
```
static int
_ar_read_header(struct archive_read *a, struct archive_entry *entry,
struct ar *ar, const char *h, size_t *unconsumed)
{
....
/*
* "__.SYMDEF" is a BSD archive symbol table.
*/
if (strcmp(filename, "__.SYMDEF") == 0) {
archive_entry_copy_pathname(entry, filename);
/* Parse the time, owner, mode, size fields. */
return (ar_parse_common_header(ar, entry, h));
}
/*
* Otherwise, this is a standard entry. The filename
* has already been trimmed as much as possible, based
* on our current knowledge of the format.
*/
archive_entry_copy_pathname(entry, filename);
return (ar_parse_common_header(ar, entry, h));
}
```
The expression in the last condition is similar to the last two lines of the function. A developer can simplify this code by removing the condition, or there is an error in the code and it should be fixed.
[V535](https://www.viva64.com/en/w/v535/) The variable 'i' is being used for this loop and for the outer loop. Check lines: 2220, 2241. multi.c 2241
```
static CURLMcode singlesocket(struct Curl_multi *multi,
struct Curl_easy *data)
{
....
for(i = 0; (i< MAX_SOCKSPEREASYHANDLE) && // <=
(curraction & (GETSOCK_READSOCK(i) | GETSOCK_WRITESOCK(i)));
i++) {
unsigned int action = CURL_POLL_NONE;
unsigned int prevaction = 0;
unsigned int comboaction;
bool sincebefore = FALSE;
s = socks[i];
/* get it from the hash */
entry = sh_getentry(&multi->sockhash, s);
if(curraction & GETSOCK_READSOCK(i))
action |= CURL_POLL_IN;
if(curraction & GETSOCK_WRITESOCK(i))
action |= CURL_POLL_OUT;
actions[i] = action;
if(entry) {
/* check if new for this transfer */
for(i = 0; i< data->numsocks; i++) { // <=
if(s == data->sockets[i]) {
prevaction = data->actions[i];
sincebefore = TRUE;
break;
}
}
}
....
}
```
The *i* variable is used as a loop counter in the outer and inner loops. At the same time, the value of the counter again begins from zero in the inner loop. It might not be a bug here, but the code is suspicious.
[V519](https://www.viva64.com/en/w/v519/) The 'tagString' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 84, 86. cmCPackLog.cxx 86
```
void cmCPackLog::Log(int tag, const char* file, int line, const char* msg,
size_t length)
{
....
if (tag & LOG_OUTPUT) {
output = true;
display = true;
if (needTagString) {
if (!tagString.empty()) {
tagString += ",";
}
tagString = "VERBOSE";
}
}
if (tag & LOG_WARNING) {
warning = true;
display = true;
if (needTagString) {
if (!tagString.empty()) {
tagString += ",";
}
tagString = "WARNING";
}
}
....
}
```
The *tagString* variable is overwritten with a new value in all places. It's hard to say what's the issue or why they did it. Perhaps, the '=' and '+=' operators were muddled.
The entire list of such places:
* V519 The 'tagString' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 94, 96. cmCPackLog.cxx 96
* V519 The 'tagString' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 104, 106. cmCPackLog.cxx 106
* V519 The 'tagString' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 114, 116. cmCPackLog.cxx 116
* V519 The 'tagString' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 125, 127. cmCPackLog.cxx 127
[V519](https://www.viva64.com/en/w/v519/) The 'aes->aes\_set' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 4052, 4054. archive\_string.c 4054
```
int
archive_mstring_copy_utf8(struct archive_mstring *aes, const char *utf8)
{
if (utf8 == NULL) {
aes->aes_set = 0; // <=
}
aes->aes_set = AES_SET_UTF8; // <=
....
return (int)strlen(utf8);
}
```
Forced setting of the *AES\_SET\_UTF8* value looks suspicious. I think such code will confuse any developer, who comes to refining this fragment.
This code was copied to another place:
* V519 The 'aes->aes\_set' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 4066, 4068. archive\_string.c 4068
How to Find Bugs in a Project on CMake
--------------------------------------
In this section, I'll briefly tell you how to check CMake projects with PVS-Studio as easy as one-two-three.
**Windows/Visual Studio**
For Visual Studio, you can generate a project file using CMake GUI or the following command:
```
cmake -G "Visual Studio 15 2017 Win64" ..
```
Next, you can open the .sln file and check the project using the [plugin](https://marketplace.visualstudio.com/items?itemName=EvgeniyRyzhkov.PVS-Studio) for Visual Studio.
**Linux/macOS**
The file compile\_commands.json is used for checks on these systems. By the way, it can be generated in different build systems. This is how you do it in CMake:
```
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=On ..
```
The last thing to do is run the analyzer in the directory with the .json file:
```
pvs-studio-analyzer analyze -l /path/to/PVS-Studio.lic
-o /path/to/project.log -e /path/to/exclude-path -j
```
We have also developed a module for CMake projects. Some people like using it. CMake module and examples of its usage can be found in our repository on GitHub: [pvs-studio-cmake-examples](https://github.com/viva64/pvs-studio-cmake-examples).
Conclusion
----------
A huge audience of CMake users is great to test the project, but many issues could be prevented before the release by using static code analysis tools, such as [PVS-Studio](https://www.viva64.com/en/pvs-studio/).
If you liked the analyzer results, but your project isn't written in C and C++, I'd like to remind that the analyzer also supports analysis of projects in C# and Java. You can test the analyzer on your project by going to this [page](https://www.viva64.com/en/pvs-studio-download/). | https://habr.com/ru/post/464145/ | null | en | null |
# Как привести проект в чувство

> Представьте ситуацию, вы первый день на новом для вас проекте, с чего будете начинать? Опишите свои шаги.
Так звучит один из популярных вопросов на собеседовании для фронтенд-разработчиков. Я не знаю, что хочет услышать человек, задающий этот вопрос, но у меня есть ответ на его техническую составляющую и бэклог на несколько месяцев вперед.
Предисловие
-----------
В этой статье я буду опираться во многом на (осторожно, субъективное мнение, подтвержденное только внутренним чувством и количеством репозиториев на github) самый популярный сборщик статики — [webpack](https://webpack.js.org/). Если по какой-то причине в вашем проекте используется другой сборщик, то ничего страшного: аналоги инструментов, про которые пойдет речь, с большой вероятностью найдутся в поиске.
Но мой совет: если ваш проект не является npm-модулем, переведите сборку статики на webpack, так будет проще.
Метрики
-------
Первое, что нужно сделать, это собрать метрики. Они помогут понять, что ситуация стала лучше, а не хуже. Можно начать с веса статики (JS, CSS, HTML, картинки и т.д.). Делается это на удивление просто: собираем продовую версию проекта и получаем вес файлов. Второй важной для нас метрикой можно считать `web-performance`. Её можно получить с помощью [Lighthouse](https://developers.google.com/web/tools/lighthouse). Проводим замеры, сохраняем оценки. И мы готовы начать.
Неиспользуемые файлы
--------------------

Нам необходимо облегчить себе жизнь за счёт удаления неиспользуемых файлов. Они мешают воспринимать проект, и порой могут сильно путать. К примеру, один раз я удалил файлов на полпроекта, они просто нигде не использовались. Для решения этой задачи можно использовать плагин под webpack — [unused-files-webpack-plugin](https://github.com/tomchentw/unused-files-webpack-plugin). Подключаем плагин, запускаем сборку, получаем в консоль список мусорных файлов. У плагина есть параметр `failOnUnused`, значение по умолчанию — `false`. Если вы хотите сделать проверку строгой, то меняем значение на `true`, и сборка будет падать, если кто-то оставит в проекте лишний файл.
Статический анализ кода
-----------------------
Мы удалили лишние файлы, а значит не попадем в ситуацию, когда после исправлений в конкретном файле оказывается, что он не нужен, и мы впустую потратили время. Первое, что рекомендую установить на вашу IDE, это плагин [SonarLint](https://www.sonarlint.org/). Он умеет анализировать не только JavaScript, но и множество языков (полный список [тут](https://rules.sonarsource.com/javascript)). Устанавливаем, проверяем весь проект, видим ошибки, правим — профит.
Это, конечно же, не всё. Теперь нужно установить и настроить [ESLint](https://eslint.org/). Обратимся за помощью к довольно популярному конфигу от Airbnb: если у вас не React — [eslint-config-airbnb-base](https://www.npmjs.com/package/eslint-config-airbnb-base), а если React — [eslint-config-airbnb](https://www.npmjs.com/package/eslint-config-airbnb). Они различаются набором правил. Например, в пакете для React будут прописаны правила от ESLint-плагинов: `eslint-plugin-react`, `eslint-plugin-react-hooks`, `eslint-plugin-jsx-a11y`. Некоторые правила являются вкусовщиной, и если вам не по душе, например, [висящие запятые](https://eslint.org/docs/rules/comma-dangle), всегда можно поменять настройку правила.
Третьим шагом в нашем крестовом походе за стиль кода и качество кодовой базы будет подключение [eslint-plugin-sonarjs](https://github.com/SonarSource/eslint-plugin-sonarjs). Плагин для ESLint никак не заменяет плагин для IDE, а лишь приятно дополняет.
В первых трёх шагах мы делали упор на JS, но во фронтовых проектах немало стилей, давайте перейдем к ним. Для всего, что не является Stylus'ом, мы будем использовать [Stylelint](https://github.com/stylelint/stylelint), а для Stylus — [Stylint](https://github.com/SimenB/stylint).
Ожидаемо, что после внедрения SonarLint, ESlint и Stylelint или Stylint будет куча ошибок. Необязательно всё править за один раз, можно временно отключить правила и исправлять их по порядку, или перенастроить их до фикса на warning.
Зависимости
-----------
Львиную долю кода в проекте составляют зависимости. Во-первых, было бы неплохо знать инструменты, которыми мы пользуемся. Во-вторых, эти самые инструменты могут плохо повлиять на `web-performance` вашего приложения.
Идеальным инструментом для решения этой проблемы является плагин под webpack [bundle analyzer](https://github.com/webpack-contrib/webpack-bundle-analyzer). Он позволит посмотреть, что у приложения под капотом, найти самые тяжелые зависимости, а также зависимости, которые не должны были попасть в продовую сборку (например, prop-types, redux-devtools, hot-loader и т.д.).
Но у зависимостей есть еще одна проблема: они любят дублироваться. В большинстве своем из-за неправильно собранных npm-пакетов и разницы между мажорными версиями npm-пакетов.
Инструмент, который поможет нам найти дубли: [duplicate-package-checker-webpack-plugin](https://github.com/darrenscerri/duplicate-package-checker-webpack-plugin) (да, это очередной плагин под webpack). По аналогии с unused-files-webpack-plugin, его можно настроить на строгую проверку и завершать сборку при найденном дубле. Для этого нужно задать параметру `emitError` значение `true`.
Что мы будем делать с найденными дублями?
* В любом случае, стоит освежить версии всех зависимостей.
* Если это не помогло, можно поискать аналог пакета, который создает проблемы. Делать это можно через сервис [bundlephobia](https://bundlephobia.com/).
* Если аналога нет, попробуйте написать функциональность сами.
* Если писать самому не вариант, сделайте pull request.
Журналирование
--------------

После очистки кодовой базы от неиспользуемых файлов, правки стиля и разбирательства с зависимостями стоит прикрутить журналирование ошибок. Для этого прекрасно подходит [Sentry](https://sentry.io/welcome/). Она (он или оно) являлась де-факто стандартом везде, где я работал. Установить Sentry можно двумя способами:
* скриптом в HTML;
* как модуль через npm.
Я рекомендую устанавливать скриптом в HTML. Почему? Представим, что пользователь заходит на сайт, на котором используется модный и современный JavaScript. У пользователя старый браузер, и если тот не поймет синтаксис, пользователь получит неработающее приложение. Ведь если Sentry был установлен через пакет, он не сможет инициализироваться, чтобы отловить эту ошибку.
CI-пайплайн
-----------
Мы потратили немало времени, и чтобы проект не вернулся к изначальному состоянию, нам нужно автоматизировать все проверки, постаравшись исключить человеческий фактор хотя бы в этих частях.
Для этого напишем немного скриптов в package.json:
```
"scripts": {
"lint": "stylint src/ && eslint --ext .js,.jsx src/",
"prod": "BABEL_ENV=production webpack --env=prod --progress",
"build": "npm run lint && npm run prod"
}
```
Что мы получим:
* Запускается линтинг JS (из package.json).
* Запускается линтинг CSS (из package.json).
* Запускается webpack (из package.json).
* Запускается unused-webpack-plugin (из webpack).
* Запускается duplicate-package-checker-webpack-plugin (из webpack).
Web-performance
---------------
Стоит потратить время на исправление ошибок, найденных Lighthouse (о нем я упоминал в начале статьи). В Chrome вы можете всё проверять вручную: переключитесь в режим разработчика, и попадёте во вкладку Lighthouse. Целесообразно проверять в режиме mobile: если в нём получится добиться хорошего результата, то в desktop всё будет отлично. Также можно использовать [CLI](https://github.com/GoogleChrome/lighthouse).
Подведение итогов
-----------------

В самом начале я упомянул, что бэклога хватит на несколько месяцев вперед. Это не значит, что на всех проектах всё займет одинаковое количество времени. Это, скорее, в среднем по больнице, учитывая, что большую часть рабочего времени мы решаем проблемы бизнеса.
Чего мы добились:
1. Очистили проект от мусора.
2. Стандартизировали стиль кода внутри проекта.
3. Уменьшили вес кодовой базы.
4. Улучшили UX.
5. Настроили мониторинг.
6. Собрали CI.
Как минимум, это всё можно использовать как аргумент на вашем performance review.
P.S.
----
Пример проекта с настройками можно посмотреть на [github](https://github.com/domclick/web_app_sample). | https://habr.com/ru/post/524606/ | null | ru | null |
# Пасхалка в ionCube — попытка разработчиков замести мусор под ковер?
[](https://habr.com/ru/company/ruvds/blog/506890/)
Веб-разработчик знает, что скрипты, созданные в коммерческих целях, могут пойти гулять по сети с затёртыми копирайтами; не исключено, что скрипт начнут перепродавать от чужого имени. Чтобы скрыть исходный код скрипта и препятствовать его изменению, применяются обфускаторы, минификаторы и т.д. Один из самых давних и известных инструментов для шифрования скриптов на PHP — это ionCube. Появившийся в 2002, он продолжает следить за развитием PHP и заявляет о поддержке последних версий платформы. Как я покажу в этой статье, с поддержкой PHP 7 у ionCube далеко не всё в порядке...
Модель использования PHP-шифровщиков такая, что программист продаёт зашифрованный скрипт, а покупатель скрипта на своём сервере должен установить модуль расширения, который позволит выполнять зашифрованные скрипты. Скрипт, зашифрованный ionCube, выглядит примерно так:
```
php //0059b
// 10.2 72
//
// IONCUBE ONLINE ENCODER EVALUATION
// THIS FILE IS LICENSED TO BE USED FOR ENCODER TESTING
// PURPOSES ONLY AND SHOULD NOT BE DISTRIBUTED
//
if(!extension_loaded('ionCube Loader')){$__oc=strtolower(substr(php_uname(),//skipped
?
HR+cPn5yR+EksbFLjyZwm7EQh7Q0Y6YO6pLddgsuLRlBWUC5JWhAm3KcPBcRdP9D0zkMmdPNk5VG
rMP1GxIwsA5NinHkQjWqG2pHL5nIZUvatUW+XMas3Knjf4wz9+DJoq47N1qZLDXwVzpOOupqa+Y4
k8PPXt8WNYXL4gbJnVu6NrqBqqwOrtlHUE9Sc30fMfAAEDTAVfa7ADHT2egTb5xxy9RGlDCjGlma
RxoL1LvxvYcfe48f44x/H+GVTM7dPaYyy9DozcJjt3l8EDxcD73d67cWOtDgQGixQEmBlYJO7Cvh
IAfeCBywIrDMgWfCC80uEIX+WtSmt/PuI7OXMgsNG3yVZu2HXJvXFRmXvc6748uxr+Zh0uZnAqeL
pkJB5K9H5qbMr4YM/Aig+7MhwVG3KJ0kQCEhKxJe7+7Un/jSGcwQ8HKa/90ePzH2EXazm3T87pf2
hXL/exl4L7hutt/MfDGjculaEOCaoDLlUJjJqeXJL3kFDUsiPFfEL/BwAYUqe2pJAMjWXn7YIUt7
Y1DdTUD4ob/5fwE9wQwfG6PfDLPFkrGVKFpkBa95sRuA7qgtXATacXAVzsfYMxZgbwF3RcI5IxQo
HTgnCg57vWmM/u6swJrgkz+747DWZRS1TfJZnKbdbmWIHAW11HG2FloKdWWSIronfqnuXTI/j2/R
9hX1Uim6mQowBwjS5zHZY8WFU9xE1KgETkCTsaDZODg9NYTICKs5aAdujzAtzxLWSicHZCfmpgzd
FRhqYTYE1B9wktZsItkssDaq+xlyTZ+0LGnXAC6eaH7npS7w3NRBRj9ySVTRYPXBraVuJViMIX+U
4IzHJDFSNiT818GtS7erlLKcbGn4OZ40Ee3XEiicFzVrOfOvH0rJT3LZgVqY+KMtjqaQike2P4Dd
A0SOuqOlFgQitYoo
```
Пользователи [давно обратили внимание](https://forum.ioncube.com/viewtopic.php?p=806), что когда модуль ionCube Loader загружен, то в PHP появляются две глобальные функции с очень странными именами: `_dyuweyrj4` и `_dyuweyrj4r`. Если вызвать одну из этих функций, то PHP напечатает один из двух китайских афоризмов, и завершит выполнение:
`C:\php>**php -r "\_dyuweyrj4(); echo 'Hmm..';"**
A rat who gnaws at a cat's tail invites destruction.
C:\php>**php -r "\_dyuweyrj4(); echo 'Hmm..';"**
Do good, reap good; do evil, reap evil.
C:\php>**php -r "\_dyuweyrj4r(); echo 'Hmm..';"**
Do good, reap good; do evil, reap evil.`
Видно, что выводимая строка не зависит от вызванной функции, и выбирается случайно.
Напрашивается вопрос: зачем эти функции нужны, и что они делают?
Простые эксперименты
--------------------
Для начала посмотрим, какие параметры `_dyuweyrj4` принимает:
`C:\php>**php -r "\_dyuweyrj4(1,2,3);"**
PHP Warning: _dyuweyrj4() expects at most 2 parameters, 3 given in Standard input code on line 1
C:\php>**php -r "\_dyuweyrj4('foo', 'bar');"**
PHP Warning: _dyuweyrj4() expects parameter 1 to be int, string given in Standard input code on line 1
C:\php>**php -r "\_dyuweyrj4(1, 'bar');"**
PHP Warning: _dyuweyrj4() expects parameter 2 to be int, string given in Standard input code on line 1
C:\php>**php -r "\_dyuweyrj4(1, 2);"**
A rat who gnaws at a cat's tail invites destruction.`
Похоже, что принимает два числа, но какие бы числа ни были, печатает те же самые афоризмы.
Поиск использования
-------------------
На каком-то мутном индонезийском форуме удаётся найти запощенный в 2013 [пример](https://www.kaskus.co.id/show_post/5153cbd24f6ea1be3c000014/10097/-) — скорее всего, полученный каким-то дизассемблером байткода PHP:
```
function tconnect( )
{
$__tmp = _dyuweyrj4( 21711392, 920173696 );
return $__tmp[0];
return 1;
}
function tvariable( )
{
$__tmp = _dyuweyrj4( 21720496, 920165136 );
return $__tmp[0];
return 1;
}
```
Что интересного в парах чисел (21711392, 920173696) и (21720496, 920165136)? Внимательный исследователь заметит, что XOR чисел в каждой паре даёт 932443808. Попробуем сами вызвать `_dyuweyrj4` с парой чисел, дающих в результате XOR 932443808:
`C:\php>**php -r "\_dyuweyrj4(0, 932443808);"**`
Не напечаталось ничего!
`C:\php>**php -r "\_dyuweyrj4(932443808, 0);"**`

Погружаемся в отладчик
----------------------

Видим, что выполняется попытка чтения по адресу `[ecx+40h]`, причём `ecx` равен `0x3793f6a0` — переданному нами в функцию числу. Значит, функция ожидает получить в качестве параметра значение адреса в памяти процесса PHP, и к dword по адресу `[ecx+40h]` прибавит единицу (команда `inc dword ptr [eax]` видна чуть ниже точки крэша). Попробуем передать такой адрес: для этого обратим внимание, что адрес, по которому загружается основной модуль php.exe, не изменяется до перезагрузки Windows. В моём случае это `0x00980000`. Открыв php.exe в IDA, смотрим, какие данные доступны для перезаписи:
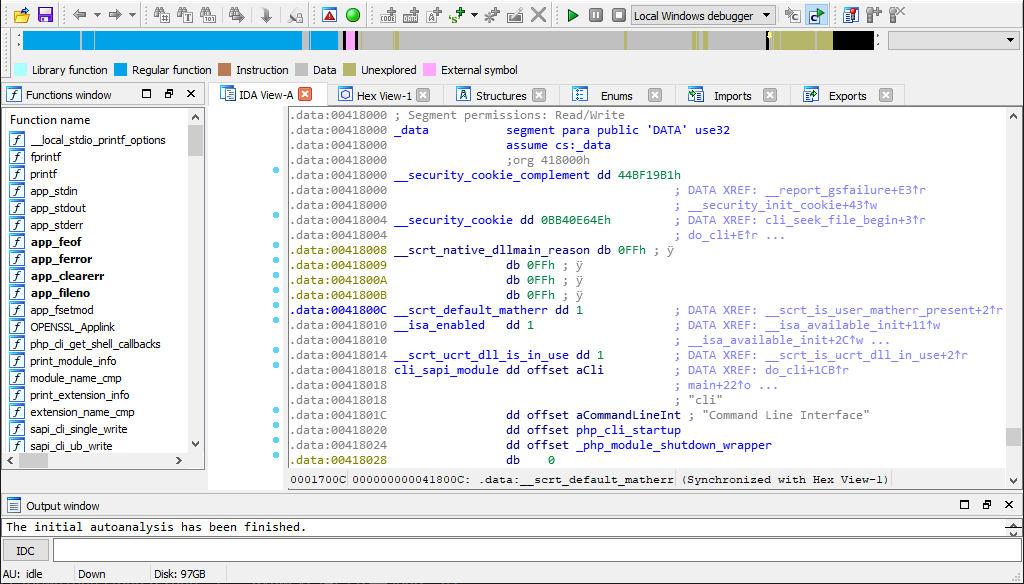
В качестве эксперимента попробуем перезаписать первый указатель в структуре `cli_sapi_module`. На него есть ссылка из `main+22`; при загрузке php.exe по адресу `0x00980000` эта ссылка будет находиться по адресу `0x00982d63`. Значит, в функцию `_dyuweyrj4` нам надо передать значение, меньшее на `0x40`, т.е. `0x00982d23`:
`C:\php>**php -r "\_dyuweyrj4(0x00982d23, 0x00982d23 ^ 0x3793f6a0);"**`

Опять крэш; но уже в другой функции внутри ioncube\_loader\_win\_7.3.dll. Что интереснее, адрес, по которому был прочитан нулевой указатель — `0x14c32820+0x78` — не имеет ничего общего с переданным в функцию значением. (Парадоксально, что проверка на нулевой указатель — `test ebx, ebx` — осуществляется сразу же **после** обращения по этому указателю.) Заглянув в память по адресу `0x14c32820`, находим там структуру `_zend_op_array`, т.е. определение функции. Заглянуть внутрь него удобнее всего через Immediate Window:
`**(\_zend\_op\_array\*)0x14c32820**
0x14c32820 {type=0x01 '\x1' arg_flags=0x14c32821 "" fn_flags=0x00000100 ...}
type: 0x01 '\x1'
arg_flags: 0x14c32821 ""
fn_flags: 0x00000100
function_name: 0x06f66850 {gc={refcount=0x00000001 u={type_info=0x000001c6 } } h=0xacaf1bdb len=0x0000000a ...}
scope: 0x00000000
prototype: 0x00000000
num\_args: 0x00000000
required\_num\_args: 0x00000000
arg\_info: 0x00000000
cache\_size: 0x131183d0
last\_var: 0x06ee0e98
T: 0x00000000
last: 0x00000000
opcodes: 0x00000000
run\_time\_cache: 0x00000000 {???}
static\_variables: 0x00000000
vars: 0x00000000 {???}
refcount: 0x600df45e {???}
last\_live\_range: 0x88008c00
last\_try\_catch: 0x00000001
live\_range: 0x00000100 {var=??? start=??? end=??? }
try\_catch\_array: 0x14c2d958 {try\_op=0x00000001 catch\_op=0x000001c6 finally\_op=0xddab5409 ...}
filename: 0x14c1a538 {gc={refcount=0x00000001 u={type\_info=0x14c00668 } } h=0x00000000 len=0x00000001 ...}
line\_start: 0x00000000
line\_end: 0x00000002
doc\_comment: 0x00000002 {gc={refcount=??? u={type\_info=??? } } h=??? len=??? ...}
last\_literal: 0x714beccc
literals: 0x71180110 {php7.dll!zif\_xmlwriter\_write\_pi(\_zend\_execute\_data \*, \_zval\_struct \*)} {value={lval=0x3314ec83 ...} ...}
reserved: 0x14c3288c {0x06ee0bc0, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000}
**((\_zend\_op\_array\*)0x14c32820)->function\_name**
0x06f66850 {gc={refcount=0x00000001 u={type\_info=0x000001c6 } } h=0xacaf1bdb len=0x0000000a ...}
gc: {refcount=0x00000001 u={type\_info=0x000001c6 } }
h: 0xacaf1bdb
len: 0x0000000a
val: 0x06f66860 "\_dyuweyrj4"
**&((\_zend\_op\_array\*)0)->reserved[3]**
0x00000078 {???}`
Как видим, нулевой указатель, вызвавший крэш — это поле `_zend_op_array.reserved[3]` в определении функции `_dyuweyrj4`. Видимо, это поле используется ionCube Loader в каких-то своих внутренних целях. Для проверки прогоним файл из одной строчки
```
php _dyuweyrj4(0x00982d23, 0x00982d23 ^ 0x3793f6a0);</code
```
— через их [Online PHP Encoder](https://www.ioncube.com/online_encoder.php). (Результат шифрования приведён в самом начале поста.) К сожалению, это не помогает: `_zend_op_array.reserved[3]` остаётся нулевым. Зато убеждаемся, что у выполняющейся (безымянной) функции `_zend_op_array.reserved[3]` теперь заполняется:
`**executor\_globals.current\_execute\_data->func->op\_array**
{type=0x02 '\x2' arg_flags=0x14a72141 "" fn_flags=0x08000000 ...}
type: 0x02 '\x2'
arg_flags: 0x14a72141 ""
fn_flags: 0x08000000
function_name: 0x00000000
scope: 0x00000000
prototype: 0x00000000
num\_args: 0x00000000
required\_num\_args: 0x00000000
arg\_info: 0x00000000
cache\_size: 0x00000004
last\_var: 0x00000000
T: 0x00000001
last: 0x00000005
opcodes: 0x14a72280 {handler=0x999fc7ce op1={constant=0x00000000 var=0x00000000 num=0x00000000 ...} op2={constant=...} ...}
run\_time\_cache: 0x14a74018 {0x14c27ba0}
static\_variables: 0x00000000
vars: 0x00000000 {???}
refcount: 0x14a74030 {0x00000002}
last\_live\_range: 0x00000000
last\_try\_catch: 0x00000000
live\_range: 0x00000000
try\_catch\_array: 0x00000000
filename: 0x14a66230 {gc={refcount=0x00000001 u={type\_info=0x00000006 } } h=0x00000000 len=0x00000032 ...}
line\_start: 0x00200001
line\_end: 0x00000001
doc\_comment: 0x00000000
last\_literal: 0x00000005
literals: 0x14a66280 {value={lval=0x0716a738 dval=5.875681226702e-316#DEN counted=0x0716a738 {gc={refcount=0x00000001 ...} } ...} ...}
reserved: 0x14a721ac {0x00000000, 0x00000000, 0x00000000, 0x14a6b200, 0x00000000, 0x00000000}`
Баг багом вышибают
------------------
Как мы видим, `_zend_op_array.reserved[3]` заполнен только у зашифрованных функций. (Это не единственная их отличительная черта: на распечатке выше можно заметить ещё и `line_start=0x00200001` вместо правдоподобного номера строки.) С другой стороны, указатель на `_zend_op_array`, который приходит в крэшащуюся функцию, берётся из `execute_data`, переданного в `_dyuweyrj4` [неявным первым параметром](http://www.phpinternalsbook.com/php7/extensions_design/php_functions.html) — так что этот `_zend_op_array` всегда соответствует вызываемой функции, а именно, самой `_dyuweyrj4`. Эта функция не зашифрована, и поэтому у неё `_zend_op_array.reserved[3]` всегда будет нулевым. Отсюда делаем вывод: вызов `_dyuweyrj4` с «правильными» параметрами **неизбежно ведёт к крэшу** (а с неправильными, как мы видели — к печати китайских афоризмов). Замечательно в этом то, что получающийся крэш не преднамерен, а вызывается использованием нулевого указателя перед его проверкой. Такой баг в коде поймал бы любой инструмент статического анализа; но видимо, в ionCube ничем подобным не пользуются.
Что получится, если пофиксить баг в ioncube\_loader\_win\_7.3.dll, поставив проверку указателя перед его использованием? Для этого удобнее всего использовать [x64dbg](https://x64dbg.com/):
Запускаем `php -r "_dyuweyrj4(0x00982d23, 0x00982d23 ^ 0x3793f6a0);"` с пропатченным ionCube Loader, и… получаем крэш уже в новом месте — опять при использовании нулевого указателя из `_zend_op_array.reserved[3]`:
Значит, от (некорректной) проверки на нулевой указатель толку всё равно не было: в следующей вызываемой функции этот же указатель используется уже без проверки. Делаем вывод, что потенциальная уязвимость, позволявшая бы нам изменять память процесса PHP по произвольному адресу, и посредством этого сбежать из сэндбокса — например, вызывать функции, запрещённые администратором сервера — в ionCube Loader «закрыта» последовательностью багов, приводящих к непреднамеренному крэшу php.exe.
Что имел в виду автор?
----------------------
Я полагаю, что изначально `_dyuweyrj4` появилась для того, чтобы привязать к зашифрованным функциям какой-то формально корректный массив "`zend_op`-ов прикрытия" — потому что ionCube Loader далеко не единственный модуль расширения, который залазит в эти массивы. (Один из распространённых случаев, когда расширения залазят в `zend_op`-ы функций — это кэширование этих `zend_op`-ов между запусками одного и того же скрипта; другой — PHP-дизассемблеры вроде того, вывод которого запощен на индонезийском форуме.) В качестве аргумента `_dyuweyrj4` получала указатель на `_zend_op_array` зашифрованной функции, и передавала управление расшифровщику, которым ionCube Loader заменяет стандартную функцию `zend_execute_ex`. Единственный сценарий, когда `_dyuweyrj4` могла бы вызываться — это если посторонний модуль расширения закэширует "`zend_op`-ы прикрытия" отдельно от зашифрованной функции, и потом попытается эти `zend_op`-ы выполнить. В этом случае вызов `_dyuweyrj4` с указателем на `_zend_op_array` зашифрованной функции превратится в расшифровку и запуск самой этой функции.
При переходе к PHP 7 [изменился](https://stackoverflow.com/q/34145752) ABI функций расширения: вместо четырёх неявных параметров `ht, return_value_ptr, this_ptr, return_value_used` стала использоваться структура `_zend_execute_data`. Тут программисты ionCube запутались, потому что `_dyuweyrj4` теперь получает два указателя на `_zend_op_array`: один — через поле `_zend_execute_data.func`, второй — явно переданным параметром. Первый соответствует самой `_dyuweyrj4`, второй — зашифрованной функции, которую требуется вызвать. И вот тут мы встречаем очередной баг: инкрементировав поле `refcount` зашифрованной функции, `_dyuweyrj4` **полностью о ней забывает**, и в дальнейшем работает только со своим собственным `_zend_op_array`. Естественно, что попытка вызвать функцию расширения, как если бы это была зашифрованная функция PHP, приводит ко крэшу — и хорошо ещё, что не к бесконечной рекурсии, потому что `_dyuweyrj4` пытается вызывать сама себя!
Напрашивается вопрос: как QA в ionCube пропустил в релиз функцию, которая в принципе никогда не способна работать как задумано? То, что в план тестирования она не попала, видно ещё и потому, что в 64-битной версии ionCube Loader параметры у `_dyuweyrj4` остаются 32-битными — это значит, что указатель на `_zend_op_array` зашифрованной функции обрезается до 32 бит ещё до инкремента `refcount`, и тот крэш, который мы поймали самым первым, гарантированно случается вообще при любом вызове `_dyuweyrj4`.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=art&utm_content=pashalka-ioncube)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=art&utm_content=pashalka-ioncube#order) | https://habr.com/ru/post/506890/ | null | ru | null |
# awless.io, могучий CLI для AWS

*Некоторые очень явно отдают предпочтение CLI (источник: Imgur)*
*Disclaimer*: это перевод статьи, оригинал можно найти [здесь](https://medium.com/@hbbio/awless-io-a-mighty-cli-for-aws-a0d48bdb59a4).
Пока облачные технологии набирали популярность, платформа Amazon Web Services (AWS), обеспечивающая сегодня работу многих интернет-гигантов и определяющая стандарты того, как должны быть организованы многие облачные сервисы, стала бесспорным лидером рынка облачных вычислений. Чтобы понимать как исползовать постоянно растущее число сервисов и предоставляемые ими возможности, DevOps инженер должен не отставать от темпа развития облачных технологий, который задает Amazon, и это становится настоящим испытанием.
DevOps'ы часто задаются вопросом о том, как лучше управлять быстро растущей инфраструктурой AWS. Они размышляют, лучше ли использовать для этого GUI ([AWS console](https://aws.amazon.com/ru/console/?nc1=h_ls)) или CLI ([AWS CLI](https://github.com/aws/aws-cli)). А может быть использовать и то, и другое?
Представляем вашему вниманию третий вариант, созданый для облегчения работы DevOps'ов: [awless.io](http://awless.io/) — новый open source CLI для AWS, написанный на Go. Проект получил одобрение Джеффа Барра (Jeff Barr), рок-звезды AWS, и всего за несколько месяцев собрал более 2.5K звезд на GitHub. В этой статье я объясню, почему компания Wallix, в которой я работаю, создала awless.io, и почему мы считаем, что этот инструмент может помочь DevOps'ам.
О чем, кстати, говорят эти твиты:
> <https://t.co/Hl0tdBJt11> : an alternative [#CLI](https://twitter.com/hashtag/CLI?src=hash) for [@awscloud](https://twitter.com/awscloud). Some good ideas in there, give it a try cc: [@jeffbarr](https://twitter.com/jeffbarr) [pic.twitter.com/tu0a8AGMEE](https://t.co/tu0a8AGMEE)
>
> — Julien Simon (@julsimon) [February 11, 2017](https://twitter.com/julsimon/status/830449554961072128)
> This looks really cool .. give it a try! <https://t.co/d38Bg3UhF9>
>
> — Jeff Barr (@jeffbarr) [February 13, 2017](https://twitter.com/jeffbarr/status/831224423944384512)
Любовь и ненавитсь к GUI
------------------------

*AWS предоставляет множество сервисов*
Сисадмины, как правило, ненавидят GUI. The Linux Foundation [считает их](https://training.linuxfoundation.org/images/lftc_evolution_sysadmin.jpg) уделом новичков. Является ли AWS Console исключением? Console предоставляет возможность управления всеми доступными сервисами и позволяет использовать мастеров настройки для решения разнообразных задач. Мы ценим возможности, предоставляемые Console, особенно при выполнении разовых задач, т.к. визуализация процесса в этом случае бывает очень полезна. А вот решение стандартных, повторяющихся задач с помощью GUI отнимает слишком много времени и может вывести из себя опытных пользователей.

*Мы на шестом шаге в AWS Console и мы все еще не создали инстанс*
С помощью GUI сложно автоматизировать действия, оставлять пометки для себя или взаимодействовать с коллегой для выполнения той или иной операции. Помните как вы в последний раз объясняли сослуживцу (или, например, маме) по телефону, как сделать что-то, с помощью веб-интерфейса, попутно копаясь в нем? Это действительно раздражает.
Трудности aws CLI
-----------------
CLI, с другой стороны, великолепен для решения рутинных задач. После пердварительной настройки с помощью CLI можно сделать что угодно, не вводя данные для входа в систему вручную и не прикасаясь к мыши.
Например, этой команды достаточно для запуска t1.micro инстанса:
```
find \
-name "sws"
> aws ec2 run-instances --image-id ami-xxxxxxxx --count 1 --instance-type t1.micro \
--key-name keypair-xxxxxxxx --security-groups sg-xxxxxxxx
```
Заметим, что запомнить идентификатор Amazon Machine Image (AMI) или имя ключевой пары может быть непросто, но эта проблема решается использованием команды оболочки *alias*. Например, для начала мы находим нужную security group:
```
> aws ec2 describe-security-groups --group-name "awless-secgroup"
```
и грепаем ID группы из вывода, который по умолчанию должен выглядеть как-то так:
```
{
"SecurityGroups": [
{
"IpPermissionsEgress": [
{
"PrefixListIds": [],
"FromPort": 80,
"IpRanges": [
{
"CidrIp": "0.0.0.0/0"
}
],
"ToPort": 80,
"IpProtocol": "tcp",
"UserIdGroupPairs": [],
"Ipv6Ranges": []
},
{
"PrefixListIds": [],
"FromPort": 443,
"IpRanges": [
{
"CidrIp": "0.0.0.0/0"
}
],
"ToPort": 443,
"IpProtocol": "tcp",
"UserIdGroupPairs": [],
"Ipv6Ranges": []
}
],
"Description": "awless-secgroup",
"IpPermissions": [
{
"PrefixListIds": [],
"FromPort": 22,
"IpRanges": [
{
"CidrIp": "0.0.0.0/0"
}
],
"ToPort": 22,
"IpProtocol": "tcp",
"UserIdGroupPairs": [],
"Ipv6Ranges": []
}
],
"GroupName": "awless-secgroup",
"VpcId": "vpc-00b68c65",
"OwnerId": "519101999238",
"GroupId": "sg-687a5d0e"
}
]
}
```
Хотя такой подход и кажется более «продвинутым» по сравнению с использованием AWS Console, он не всегда удобен и эффективен. При использовании aws CLI приходиться постоянно переключаться с ввода команд на выполнение других действий, таких как копирование вывода предыдущих команд или редактирования JSON сниппетов. Существующие open source альтернативы aws CLI только немного изменяют синтаксис операций, добавляют подсветку, автодополнение и прочие свистелки.
Такие инструменты как AWS CloudFormation удобны для создания стеков, но написание соответствующих шаблонов представляет собой отдельную задачу, а сами шаблоны не всегда могут заменить ручное выполнение нескольких команд. Однажды мы мучались, пытаясь с помощью aws CLI найти ресурсы, созданные с использование шаблонов CloudFormation. Угадать правильное место в килобайтах JSON, где нужно прописать Id — нелегкая задача. В конце концов мы сдались и использовали GUI.
Явление awless.io
-----------------
awless.io — альтернативный CLI для AWS, в котором простота использования ставится на первый план, перед исчерпывающей полнотой функционала. С помощью этого инструмента мы стремимся упростить 90 процентов возможных задач, путем изменения существующих команд.
awless.io не просто фронтэнд для AWS CLI: это новый консольный интерфейс, написанный на Go с использованием официального AWS Go SDK. Это полностью open-source проект, выпущенный под лицензией Apache. На данный момент awless.io поддерживает следующие AWS сервисы: IAM, EC2 (включая ELBv2), S3, Route53, RDS, SQS, SNS, Cloudfront, Cloudwatch, CloudFormation и Lambda. В ближайшем будущем планируется расширение этого списка.
Изначально awless.io разрабатывался отделом инноваций моей компании Wallix для решения ряда внутренних задач. Де-факто Wallix спонсировал разработку, но, по существу, awless.io — проект, который создается сообществом разработчиков, и ваше участие в нем строго приветствуется.
Преимущества awless.io
----------------------
При создании awless.io мы пытались следовать принципам, заложенным популярными инструментами, такими как git; большинство команд имеют вид:
```
awless [verb] [noun] [parameter=value ...]
```
Например, все это возможные команды:
```
# Показать существующих пользователей
awless list users
# Создать новый инстанс
awless create instance
# Добавить пользователя в группу
awless attach user name=my-user-name group=my-group
# Запустить шаблон
awless run https://example.com/create_vpc.aws
```
Основные принципы awless.io включают:
* использование «умных» настроек по умолчанию, которые позволят пользоваться интсрументом даже при минимальном знании облачных технологий
* вывод информации в формате, который одновременно и читаем, и удобен для парсинга
* локальное сохранение копии модели инфраструктуры в виде графа RDF (Resource Description Framework), что позволяет обращаться к ней и производить вычисления не удаленно
awless.io делает упор на использование одних и тех же глаголов (таких как *list*, *create*, *delete*) в синтаксисе разных операций, что в результате приводит к небольшому (и простому для запомнинания) множеству используемых команд. Синтаксис унифицирован для разных сервисов. К примеру, вы можете написать:
```
awless list [instances|users|buckets|records]
```
вместо:
```
aws ec2 describe-instances
aws iam list-users
aws s3api list-buckets
aws route53 list-resource-record-sets
```
Начинаем работу с awless.io
---------------------------
awless.io доступен на [GitHub](https://github.com/wallix/awless). Мы также распространяем его в качестве [скомпилированных пакетов](https://github.com/wallix/awless/releases/latest) и через Homebrew для macOS:
```
brew tap wallix/awless; brew install awless
```
Сборка из исходников очень проста, при условии что в системе установлен Go:
```
go get -u github.com/wallix/awless
```
При первом запуске, awless.io запросит идентификационные данные или, если в системе установлен и настроен aws-cli, подтнет их из его конфигурации автоматически. Помимо этого стоит установить автодополнение для [bash](https://github.com/wallix/awless/wiki/Setup-Autocomplete#bash) или [zsh](https://github.com/wallix/awless/wiki/Setup-Autocomplete#zsh).
Исследуем инфраструктуру AWS
----------------------------
awless.io предоставляет DevOps'ам широкий набор возможностей для навигации по развернутой AWS инфраструктуре. Две основные команды для этого — **list** и **show**. Для каждого типа ресурсов awless.io вначале выводит наиболее значимую информацию.
### Вывод списка объектов
awless.io позволяет выводить список всевозможных объектов AWS, таких как пользователи, группы безопасности или инстансы:
```
> awless list users
| ID ▲ | NAME | LASTUSED | CREATED |
|-----------------------|-----------|----------|-----------|
| AIDAI37GETCRRVNLDKFYQ | hbinsztok | 8 days | 10 months |
| AIDAI3FX74KAQQKIOM2XY | awless-ts | 13 weeks | 4 months |
[…]
```
Если ширина терминала не позволяет вывести данные полностью, то колонки обрезаются автоматически, и на экран выводится предупреждение о том, что такая-то информация была скрыта:
```
> awless list securitygroups
| ID ▲ | VPC | INBOUND |
|-------------|--------------|-------------------------------------|
| sg-1d578b64 | vpc-00b68c65 | [0.0.0.0/0](tcp:1433) |
| | | [0.0.0.0/0;::/0](tcp:443) |
| | | [::/0;0.0.0.0/0](tcp:80) |
| | | [::/0;0.0.0.0/0](tcp:2242) |
| | | [::/0;0.0.0.0/0](tcp:22) |
| | | [0.0.0.0/0](tcp:3389) |
| sg-30abc756 | vpc-00b68c65 | [0.0.0.0/0](tcp:443) |
| | | [0.0.0.0/0](tcp:80) |
[...]
Columns truncated to fit terminal: 'Outbound', 'Name', 'Description'
```
Вывод легко и непринужденно сортируется и фильтруется:
```
> awless list instance --sort uptime --filter zone=eu-west-1b
| ID | ZONE | NAME | STATE |
|---------------------|------------|---------------------|---------|
| i-03a1f22b36ddb0739 | eu-west-1b | blog-test | running |
| i-05adde5a930da5ed3 | eu-west-1b | authoringtest | stopped |
| i-06b8f07c1e4afb49a | eu-west-1b | AwlessWithScheduler | running |
[...]
Columns truncated to fit terminal: 'Type', 'Public IP', 'Private IP', 'Uptime', 'KeyPair'
```
Формат вывода может быть настроен. По умолчанию данные выводятся в удобочитаемую таблицу (результат выводится в markdown, который можно передать в качестве ввода в сторонний инструмент, например в [pandoc](http://pandoc.org/)). Данные можно также выводить в форматах csv, json или tsv:
```
> awless list subnets --format csv
ID,Name,CIDR,Zone,Default,Vpc,Public,State
subnet-0c41ad68,,172.31.0.0/20,eu-west-1a,true,vpc-00b68c65,true,available
subnet-2486b17c,demo-env-subnet,10.0.0.0/24,eu-west-1c,false,vpc-67b25c00,true,available
[...]
```
Одной из отличительных черт awless.io является возможность работы с инфраструктурой, представленной в виде [RDF](https://ru.wikipedia.org/wiki/Resource_Description_Framework) графа, и выполнения сложных запросов локально. Использование стандартизированного формата позволяет применять существующие инструменты, такие как [Protégé](http://protege.stanford.edu/), для выполнения запросов на графе. Сохраненный локально граф позволяет в определенной мере работать с инфраструктурой даже без выхода в интернет:
```
> ping amazon.com
ping: cannot resolve amazon.com: Unknown host
> awless list instances --local
| ID ▲ | ZONE | NAME | STATE |
|---------------------|------------|---------------------|---------|
| i-01b17116fed0a09bd | eu-west-1c | windows-demo-env | running |
| i-05c0a275adb5484fa | eu-west-1c | git.inno.wallix.com | running |
| i-06b8f07c1e4afb49a | eu-west-1b | AwlessWithScheduler | running |
[...]
```
### Получение информации о ресурсах
Команда **show** позволяет получить информацию о любом ресурсе:
```
> awless show i-03a1f22b36ddb0739
| PROPERTY ▲ | VALUE |
|-------------------|---------------------|
| Architecture | x86_64 |
| Hypervisor | xen |
| ID | i-03a1f22b36ddb0739 |
| Image | ami-70edb016 |
| KeyPair | keypair-blog |
| Name | blog-test |
| NetworkInterfaces | [eni-10e4352d] |
| Private IP | 10.0.20.245 |
| Public IP | 34.252.193.183 |
| RootDevice | /dev/xvda |
| RootDeviceType | ebs |
| SecurityGroups | [sg-a2a282c4] |
| State | running |
| Subnet | subnet-472a1731 |
| Type | t2.micro |
| Uptime | 46 hours |
| Vpc | vpc-96c7eef2 |
| Zone | eu-west-1b |
eu-west-1[region]
↳ @awless-test-vpc[vpc]
↳ @awless-public-subnet[subnet]
↳ @blog-test[instance]
Depending on: keypair-blog[keypair], @default[securitygroup], vol-0f82cd93824f456e5[volume]
Siblings: @AwlessWithScheduler[instance]
```
Эта команда выводит характеристики и зависимости облачного ресурса. Например, в случае инстанса, команда выведет его Virtual Private Cloud (VPC), подсеть, связаные с ним объекты и информацию о смонтированном томе, ключевой паре и гуппах безопасности инстанса. Список свойств будет различаться в зависимости от типа ресурса:
```
> awless show AIDAI3FX74KAQQKIOM2XY
| PROPERTY ▲ | VALUE |
|------------------|-----------------------------------------------|
| Arn | arn:aws:iam::519101999238:user/awless-test-usr|
| Created | 4 months |
| ID | AIDAI3FX74KAQQKIOM2XY |
| Name | awless-test-user |
| PasswordLastUsed | 2 weeks |
| Path | / |
Depending on: @PepsWallixS3Assume[policy], @PepsWallixS3[policy]
```
Однострочники и шаблоны
-----------------------
awless.io замечательный инструмент для просмотра и анализа облачных ресурсов. Но он также предоставляет мощный мехнизм шаблонов, поддерживающий операции с инфраструктурой (создание, редактирование и удаление ресурсов).
### Однострочники
Шаблоны awless.io можно применять путем ввода однострочных команд, или с помощью скриптов. Для создания инстанса, ключевой пары или ресурса любого другого типа достаточно двух простых команд:
```
> awless create instance
> awless create keypair
```
awless.io не требует ввода всей необходимой информации сразу. Вместо этого он запрашивает данные по ходу выполнения операции, предоставляя возможность автодополнения во время их ввода.
Давайте для начала создадим ключевую пару, которую мы используем для подключения по SSH к инстансам, которые мы создадим сразу после:
```
> awless create keypair
Please specify (Ctrl+C to quit, Tab for completion):
keypair.name? keypair-blog
create keypair name=keypair-blog
Confirm? (y/n): y
[info] Generating locally a RSA 4096 bits keypair…
[info] 4096 RSA keypair generated locally and stored in ‘/Users/henri/.awless/keys/keypair-blog.pem’
OK keypair = keypair-blog
[info] Revert this template with `awless revert 01BHAE1C0CPMNYQ0KFPRQQ7XYA`
```
Мы ввели только команду **awless create keypair**, имя ключевой пары **keypair-blog** и подтвредили ее создание.
awless.io использует одновременно данные, вводимые с помощью командной строки, и опции по-умолчанию, которые можно настроить (например, AMI и тип инстанса); перед внесением изменений в существующую инфраструктуру awless.io запрашивает подтверждение пользователя.
Теперь мы легко создаем инстанс, используя нашу новенькую пару ключей:
```
> awless create instance keypair=@keypair-blog
Please specify (Ctrl+C to quit, Tab for completion):
instance.name? instance-blog
instance.subnet?
@awless-private-subnet @awless-public-subnet @demo-env-subnet
instance.subnet? @demo-env-subnet
create instance count=1 image=ami-70edb016 keypair=keypair-blog name=instance-blog subnet=subnet-2486b17c type=t2.micro
Confirm? (y/n): y
[info] create tag ‘Name=instance-blog’ on ‘i-094ceffee40892f66’ done
[info] create instance ‘i-094ceffee40892f66’ done
OK instance = i-094ceffee40892f66
[info] Revert this template with `awless revert 01BHAGCXY80FPK5FR73GTWWSD2`
```
Для подключения к инстансу напрямую можно использовать команду **ssh**:
```
> awless ssh instance-blog
awless could not validate the authenticity of ‘34.252.193.183:22’ (unknown host)
ecdsa-sha2-nistp256 public key fingerprint is SHA256:Ay8ODMNQiEt1U6BoTsPyIajoaHZ047v7uNjTV1SSQmk.
Do you want to continue connecting and persist this key to ‘/Users/henri/.ssh/known_hosts’ (yes/no)? yes
[info] Login as ‘ec2-user’ on ‘34.252.193.183’, using keypair ‘/Users/henri/.awless/keys/keypair-blog.pem’ with ssh client ‘/usr/bin/ssh’
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2016.09-release-notes/
18 package(s) needed for security, out of 52 available
Run “sudo yum update” to apply all updates.
Amazon Linux version 2017.03 is available.
[ec2-user@ip-10–0–20–245 ~]$
```
Нет никакой необходимости в том, чтобы передавать ключи в качестве аргументов команды, т.к. они хранятся локально, нет никакой необходимости в том, чтобы указывать имя пользователя, т.к. awless.io угадывает его самостоятельно. Дьявол кроется в деталях, и awless.io делает все возможное для того, чтобы использование CLI было максимально удобным.
Помимо упрощенных коротких команд, к вашим услугам и другие новые и полезные функции. Если вы внимательно прочитали предыдущий вывод команды, вы могли обратить внимание на то, что с каждым успешно выполненым действием ассоциируется revert Id. Действительно, изменения в результате выполнения большинства шаблонов awless.io (однострочников и полноценных скриптов) можно очень просто отменить.
Как и git, awless.io ведет лог выполненных операций:
```
> awless log
[...]
ID: 01BHAE1C0CPMNYQ0KFPRQQ7XYA, Date: May 29 17:43:50, Author: user/hbinsztok, Region: eu-west-1
OK create keypair name=keypair-blog[keypair-blog]
ID: 01BHAGCXY80FPK5FR73GTWWSD2, Date: May 29 18:25:06, Author: user/hbinsztok, Region: eu-west-1
OK create instance count=1 image=ami-70edb016 keypair=keypair-blog name=instance-blog subnet=subnet-2486b17c type=t2.micro [i-094ceffee40892f66]
```
И как и коммиты, операции можно запросто откатить:
```
> awless revert 01BHAGCXY80FPK5FR73GTWWSD2
delete instance id=i-094ceffee40892f66
Confirm? (y/n): y
OK delete instance
```
### Шаблоны
Ранее мы использовали шаблоны, содержавшие только одну команду (однострочники). Вообще, шаблоны являются обобщением и представляют из себя последовательность команд awless.io.
```
# Создать новую группу безопасности для данного инстанса
securitygroup = create securitygroup vpc={instance.vpc} description={securitygroup.description} name=ssh-from-internet
# Открыть доступ через порт 22 к инстансам в данной группе безопасности
update securitygroup id=$securitygroup inbound=authorize protocol=tcp cidr=0.0.0.0/0 portrange=22
# Создать новую клучевую пару
keypair = create keypair name={keypair.name}
# Создать инстанс в группе безопасности, к которому можно подключиться, используя созданную ключевую пару
create instance subnet={instance.subnet} image={instance.image} type={instance.type} keypair=$keypair name={instance.name} count=1 securitygroup=$securitygroup
```
Мы добавили следующие возможности для выстраивания цепочек команд:
* результат выполнения операции может быть сохранен в переменную, соответствующий синтаксис: **value = command**. В дальнейшем к сохраненному значению можно обратиться так: **$value**;
* использование параметров шаблонов, т.е. отсутствующих аргументов команд, которые awless.io запросит во время исполнения. Они записываются в фигруных скобках, как **{instance.image}** в примере выше.
Шаблоны — крайне эффективная и полезная особенность awless.io. С помощью них, например, можно легко:
* развернуть высоконадежную инфраструктуру с балансировкой нагрузки для сайта на Wordpress при помощи короткого [шаблона](https://github.com/wallix/awless-templates#two-instances-bitnami-wordpress-behind-a-loadbalancer);
* создать [самомасштабирующуюся группу инстансов](https://github.com/wallix/awless-templates#group-of-instances-scaling-with-cpu-consumption) и отслеживать нагрузку на CPU каждого в отдельности, для динамического создания новых инстансов при необходимости.
Для выполнения шаблона в качестве аргумента можно передавать имя файла в официальном репозитории [awless-templates](https://github.com/wallix/awless-templates) (с префиксом **repo:**), URL или имя докального файла-шаблона:
```
> awless run repo:dynamic_autoscaling_watching_CPU
```
Попробуйте сами! Тем более после этого вы сможете использовать команду **awless revert**, которую мы обсудили выше, чтобы удалить все ресурсы созданные в результате выполнения шаблонов (инстансы, группы безопасности, группы целей (target groups), балансировщики нагрузки и т.д.).
Обратите внимание, что пока мы реализовали только черновой вариант мехнаизма шаблонов, и до выпуска awless.io 1.0 в него могут привноситься изменения и добавляться новые функции. После релиза 1.0 все новые версии будут сопровождаться утилитами для упрощения миграций.
Обзор команд
------------
Получить справку по функциям awless.io можно так:
```
> awless help
> awless [verb] -h
```
В [этих](https://airtable.com/shrtH7zFRzcxt7xYM/tblkmcYy5KIRmzC0q) [таблицах](https://airtable.com/shrgEQbnnVldi5hwL/tblMCCFbU94jqXsrb) собраны основные ключевые слова, использующиеся в командах и шаблонах.
И это только начало
-------------------
Сегодня, после более 20 альфа релизов, выпущенных с момента запуска проекта в январе 2017, мы представляем awless.io 0.1.0. Это проект все еще находится в стадии разработки. Мы планируем улучшить наш продукт во многих отношениях, в частности добавить поддержку еще большего числа AWS сервисов и функций. Пожалуйста, если ваш любимый сервис (все еще) не поддерживается, открывайте новые или плюcуйте существующие issues на GitHub. Вот план развития и функционал, который мы планируем добавить в течение следующего года:
* 0.2.0 — Работа с несколькими регионами. Использование локального графа для предложения выбора ресурсов в соответствие с их регионами; простое переключение между регионами;
* 0.3.0 — Усовершенстование языка скриптов. Мы хотим сделать формальное описание семантики и добавить проверку типов для шаблонов, для того чтобы диагностировать ошибки до выполнения запроса на стороне AWS (это относится в том числе и к dry-run'ам);
* 0.3.0 — Усовершенстование языка скриптов. Мы хотим сделать формальное описание семантики и добавить проверку типов для шаблонов, для того чтобы диагностировать ошибки до выполнения запроса на стороне AWS (это относится в том числе и к dry-run'ам);
* 0.4.0 — Добавление возможности выполнения сложных запросов к глобальной инфраструктуре с использованием локального графа.
Мы будем рады вашей помощи в реализации проекта, в том числе если вы расскажете о нем своим знакомым. А для того чтобы оставаться в курсе всех нововведений, следите за новосятми в официальном твиттере [@awlessCLI](https://twitter.com/awlesscli?lang=ru). | https://habr.com/ru/post/330502/ | null | ru | null |
# Настраиваем распределенную систему управления образами ISO с использованием BitTorrent
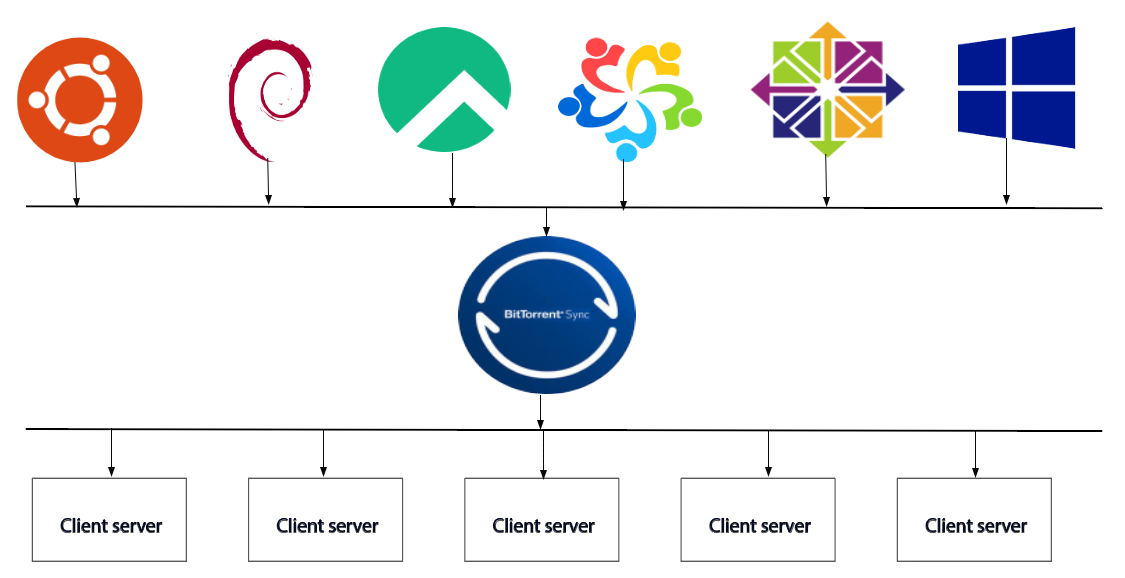Мы в [HOSTKEY](https://hostkey.ru/) [сдаем клиентам в аренду вычислительные мощности](https://hostkey.ru/dedicated-servers/) на площадках в Амстердаме, Нью-Йорке и Москве, при этом набор инструментов (в т. ч. список доступных образов ISO) должен быть одинаковым во всех локациях. Дистрибутивы могут потребоваться для ручной установки операционной системы на сервер, для выбора особой разметки и/или набора ПО, для восстановления системы, изменения разбивки загрузочного диска, либо если инсталляцию нужной системы мы [еще не автоматизировали](https://habr.com/ru/company/hostkey/blog/658087/). Рассказываем, как проблема решается в нашей распределенной инфраструктуре с помощью протокола BitTorrent.
### Проблема
В современных серверах есть модули IPMI, позволяющие загрузить файл ISO с компьютера клиента через веб-интерфейс или Java-апплет, но в случае значительной удаленности и/или медленного клиентского канала установка операционной системы может затянуться на часы. Для ускорения процесса логично держать пул наиболее популярных образов в непосредственной близости от сервера, а поскольку большинство модулей IPMI поддерживают монтирование ISO, на каждой из трех площадок у нас есть такое хранилище. Команда на IPMI для монтирования конкретного файла отправляется из клиентской панели управления.
**Пример списка образов:**

> Для поддерживаемых [нашей HTML5-консолью](https://habr.com/ru/company/hostkey/blog/661271/) серверов внутри контейнера доступен идентичный список файлов ISO.
>
>
Еще есть виртуальные серверы, где загрузочный образ монтируется с **ISO storage domain** соответствующего кластера **oVirt**, и в итоге мы получаем минимум три хранилища только на одной площадке. Необходимо, чтобы списки образов везде были одинаковыми (так проще поддерживать их актуальность), а также нам нужна уверенность, что выбранный в панели конкретный файл существует и будет смонтирован. Даже если пожертвовать отказоустойчивостью и попытаться повесить все функции по раздаче ISO в пределах датацентра на один сервер, все равно их потребуется не менее трех (по числу локаций).
### Решение
> Первой на ум приходит идея простого копирования образов по расписанию с некоего эталонного источника, например, через RSYNC. Мы пошли немного другим путем и стали передавать данные по протоколу BitTorrent, организовав между серверами-хранилищами сеть P2P.
>
>
Для использующегося в нашей инфраструктуре дистрибутива CentOS (да и под остальные популярные платформы) есть отличная программа [Resilio Sync](https://www.resilio.com/) (бывш. BTSync). Процесс ее развертывания довольно прост: ставим на каждый сервер по экземпляру из [пакета rpm](https://habr.com/ru/company/hostkey/blog/676848/) и генерируем конфигурационный файл, а также секретный ключ для шифрования трафика между хостами (это мы делаем уже с помощью Ansible).
**Также возможна установка бинарного файла из архива:**
```
wget https://download-cdn.resilio.com/stable/linux-x64/resilio-sync_x64.tar.gz
tar -xf resilio-sync_x64.tar.gz
cp rslsync /usr/local/bin
ln -s /usr/local/bin/rslsync /usr/local/bin/btsync
btsync --dump-sample-config > btsync.config
btsync --generate-secret
```
Правим конфигурационные файлы под наши нужды и раскладываем их по серверам. Для каждого сервера задаем **"device\_name"** и актуальный путь к директории с образами: веб-интерфейс для настройки общих директорий нам не нужен, ее можно сразу прописать в блоке **shared\_folders**.
**Пример конфигурации для нашего случая:**
```
# cat btsync.config
{
"device_name": "isoserver01.example.com", // уникальное имя для каждого сервера
"listening_port" : 58889,
"pid_file" : "/var/run/resilio.pid",
"use_upnp" : false,
"disk_low_priority" : true,
"lan_encrypt_data" : true,
"lan_use_tcp" : true,
"folder_rescan_interval" : 60,
"download_limit" : 0,
"upload_limit" : 0,
"shared_folders" :
[
{
"secret" : "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX", // сгенерированный нами ключ
"dir" : "/PATH/TO/ISO/", // путь к синхронизируемой директории
"use_relay_server" : false, // relay-сервера нам не нужны
"use_tracker" : false, // чтобы ничего не отправлялось в BitTorrent Inc
"use_dht" : false, // аналогично
"search_lan" : false, // тоже не нужно, ниже мы зададим хосты списком
"use_sync_trash" : true, // удалённые на другом сервер файлы будут попадать в «корзину»
"known_hosts" : // список хостов нашей сети P2P
[
"isoserver01.example.com:58889",
"isoserver02.example.com:58889",
"isoserver03.example.com:58889"
]
}
]
}
```
Также необходимо открыть порт в настройках межсетевого экрана (пример для firewalld):
```
firewall-cmd --zone=internal --add-port=58889/tcp --permanent
firewall-cmd --reload
```
Чтобы развернуть решение, остается только создать сервис, обеспечивающий автоматический запуск программы при старте ОС. Теперь достаточно добавить файл на любом из хостов (например, в локации, из которой поступил клиентский запрос на новый образ), и через короткое время он появится на остальных. Если файл удалить, на остальных хостах он попадет в поддиректорию **.sync/Archive/**, и при необходимости образ легко восстановить.
### Что в итоге?
В результате реализации этого решения мы получили надежную рабочую систему управления файлами образов ISO, а также их доставки до клиентских серверов. Resilio Sync работает по протоколу BitTorrent, что снимает ограничения на размер файлов и значительно сокращает время их передачи. Данные при этом передаются в зашифрованном виде и хранятся только на наших инфраструктурных серверах, что повышает защищенность системы.
\_\_\_\_\_\_\_\_\_\_\_
А еще в HOSTKEY можно пользоваться всеми возможностями технологичного API для [быстрого заказа и управления серверами](https://hostkey.ru/instant-servers/). Выберите сетевые настройки, операционную систему и получите любой сервер в течение 15 минут. Вы также можете собрать [сервер индивидуальной конфигурации](https://hostkey.ru/dedicated-servers/), в том числе с профессиональными [GPU-картами](https://hostkey.ru/gpu-dedicated-servers/).
[Еще у нас можно добавить NVIDIA А5500](https://habr.com/ru/company/hostkey/news/t/661273/), а специальный промокод для наших читателей «**Я С ХАБРА**» дает дополнительную скидку на любую покупку. При размещении заказа назовите промокод консультанту — и скидка ваша. | https://habr.com/ru/post/686336/ | null | ru | null |
# Как использовать все возможности мобильной ОС в React Native
На рынке есть несколько кроссплатформенных решений: Cordova, Xamarin, React Native и другие, менее известные. Многие мобильные разработчики считают, что кроссплатформенные решения никогда не позволят делать то, что могут нативные приложения.
В статье я развенчаю этот миф и расскажу о механизме в React Native, который позволяет сделать все, на что способно нативное приложение. Этот механизм – нативные модули. Под катом – подробное описание, как создавать нативные модули для Android и iOS.

Нативные модули в кроссплатформенной разработке под мобильники помогают сделать несколько вещей:
* Предоставить доступ к возможностям платформы, почитать из контент-провайдеров на Android или адресную книгу на iOS
* Обернуть стороннюю библиотеку для вызова в js
* Обернуть уже существующий код при добавлении в приложение частей на React Native
* Реализовать части, критические к производительности(н-р шифрование)
Примерная схема приложения на React Native
------------------------------------------
В операционной системе запущено нативное приложение. В нем на низком уровне работают рантайм React Native и код нативных модулей, созданных разработчиком приложения (или автором библиотек для React Native). Выше уровнем работает React Native Bridge – промежуточное звено между нативным кодом и js. Сам js исполняется внутри JS VM, чью роль исполняет JavaScriptCore. На iOS она предоставляется системой, на Android же приложение тащит ее в виде библиотеки.
Пишем нативный модуль
---------------------
### Под Android
План такой:
* Зарегистрировать пакет в ReactNativeHost
* Создать пакет
* Создать модуль
* Зарегистрировать модуль в пакете
* Создать метод в модуле
### Лирическое отступление 1 – Компоненты Android
Если ваш основной бэкграунд — Android, это отступление можно пропустить. Для разработчиков с основным опытом iOS или React JS нужно узнать, что приложение под Android может содержать следующие компоненты:
* Activity
* BroadcastReceiver
* Service
* ContentProvider
* Application
В этом контексте (кхе-кхе) нас, конечно, интересует только Application. Напомню, что этот компонент и есть обьект самого приложения. Вы можете (а для React Native приложения и должны) реализовать свой класс приложения и реализовать этим классом интерфейс ReactApplication:
```
package com.facebook.react;
public interface ReactApplication {
ReactNativeHost getReactNativeHost();
}
```
Нужно это, чтобы ReactNative узнал о тех нативных пакетах, которые вы хотите использовать. Для этого наш Application должен вернуть экземпляр ReactNativeHost, в котором перечислить список пакетов:
```
class MainApplication : Application(), ReactApplication {
private val mReactNativeHost = object : ReactNativeHost(this) {
override fun getPackages(): List {
return Arrays.asList(
MainReactPackage(),
NativeLoggerPackage()
)
}
override fun getReactNativeHost(): ReactNativeHost {
return mReactNativeHost
}
}
```
NativeLoggerPackage — тот пакет, который мы будем с вами писать. Он будет только логировать переданные в него значения, а мы сконцентрируемся на процессе создания нативного модуля вместо фактической функциональности.
Зачем нужно, чтобы Application реализовывал ReactApplication? Потому что внутри React Native есть вот такой веселый код:
```
public class ReactActivityDelegate {
protected ReactNativeHost getReactNativeHost() {
return ((ReactApplication) getPlainActivity().getApplication())
.getReactNativeHost();
}
}
```
Теперь реализуем NativeLoggerPackage:
```
class NativeLoggerPackage : ReactPackage {
override fun createNativeModules(reactContext: ReactApplicationContext): List
{
return Arrays.asList(NativeLoggerModule())
}
override fun createViewManagers(reactContext: ReactApplicationContext): List>
{
return emptyList>()
}
}
```
Метод createViewManagers мы опустим, нам он в этой статье неважен. А важен метод createNativeModules, который должен вернуть список созданных модулей. Модули – это классы, содержащие методы, которые можно вызвать из js. Давайте создадим NativeLoggerModule:
```
class NativeLoggerModule : BaseJavaModule() {
override fun getName(): String {
return "NativeLogger"
}
}
```
Модуль должен наследоваться как минимум от BaseJavaModule, если вам не нужен доступ к контексту Android. Если же в нем есть нужда, необходимо использовать другой базовый класс:
```
class NativeLoggerModule(context : ReactApplicationContext)
: ReactContextBaseJavaModule(context) {
override fun getName(): String {
return "NativeLogger"
}
}
```
В любом случае, необходимо определить метод getName(), который вернет имя, под которым ваш модуль будет доступен в js, мы увидим это чуть позже.
Теперь давайте наконец создадим метод для js. Делается это с помощью аннотации ReactMethod:
```
class NativeLoggerModule : BaseJavaModule() {
override fun getName(): String {
return "NativeLogger"
}
@ReactMethod
fun logTheObject() {
Log.d(name, “Method called”)
}
}
```
Здесь метод logTheObject становится доступен для вызова из js. Но вряд ли мы хотим просто вызывать методы без параметров, которые ничего не возвращают. Давайте разбираться с аргументами (слева java-типы, справа js):
Boolean -> Bool
Integer -> Number
Double -> Number
Float -> Number
String -> String
Callback -> function
ReadableMap -> Object
ReadableArray -> Array
Предположим, что в нативный метод мы хотим передать js-обьект. В java будет приходить ReadableMap:
```
@ReactMethod
fun logTheObject(map: ReadableMap) {
val value = map.getString("key1")
Log.d(name, "key1 = " + value)
}
```
В случае массива будет передаваться ReadableArray, итерация по которому не составляет проблем:
```
@ReactMethod
fun logTheArray(array: ReadableArray) {
val size = array.size()
for (index in 0 until size) {
val value = array.getInt(index)
Log.d(name, "array[$index] = $value")
}
}
```
Впрочем, если вы хотите передать первым аргументом обьект, а вторым массив, то тут тоже без сюрпризов:
```
@ReactMethod
fun logTheMapAndArray(map: ReadableMap, array: ReadableArray): Boolean {
logTheObject(map)
logTheArray(array)
return true
}
```
Как же это добро вызывать из javascript? Нет ничего проще. Первым делом нужно импортнуть NativeModules из корневой библиотеки react-native:
```
import { NativeModules } from 'react-native';
```
А затем заимпортить наш модуль(помните, мы назвали его NativeLogger ?):
```
import { NativeModules } from 'react-native';
const nativeModule = NativeModules.NativeLogger;
```
Теперь можно вызывать метод:
```
import { NativeModules } from 'react-native';
const nativeModule = NativeModules.NativeLogger;
export const log = () => {
nativeModule.logTheMapAndArray(
{ key1: 'value1' },
['1', '2', '3']
);
};
```
Работает! Но постойте, хочется же знать, все ли в порядке, удалось ли записать то, что мы хотели записать. Как насчет возвращаемых значений?

А вот возвращаемых значений у функций из нативных модулей и нет. Придется выкручиваться, передавая функцию:
```
@ReactMethod
fun logWithCallback(map: ReadableMap, array: ReadableArray, callback: Callback) {
logTheObject(map)
logTheArray(array)
callback.invoke("Logged")
}
```
В нативный код будет приходить интерфейс Callback с единственным методом invoke(Object… args). Со стороны js — это просто функция:
```
import { NativeModules } from 'react-native';
const nativeModule = NativeModules.NativeLogger;
export const log = () => {
const result = nativeModule.logWithCallback(
{ key1: 'value1' },
[1, 2, 3],
(message) => { console.log(`[NativeLogger] message = ${message}`) }
);
};
```
К сожалению, в compile-time нет инструментов сверить параметры коллбэка из нативного кода и функции в js, будьте внимательны.
К счастью, можно пользоваться механизмом промисов, которые в нативном коде поддерживаются интерфейсом Promise:
```
@ReactMethod
fun logAsync(value: String, promise: Promise) {
Log.d(name, "Logging value: " + value)
promise.resolve("Promise done")
}
```
Тогда вызывать этот код можно используя async/await:
```
import { NativeModules } from 'react-native';
const nativeModule = NativeModules.NativeLogger;
export const log = async () => {
const result = await nativeModule.logAsync('Logged value');
console.log(`[NativeModule] results = ${result}`);
};
```
На этом работа по выставлению нативного метода в js в Android завершена. Смотрим на iOS.

Создание нативного модуля в iOS
===============================
Первым делом создаем модуль NativeLogger.h :
```
#import
#import
@interface NativeLogger : NSObject
@end
```
и его реализацию NativeLogger.m:
```
#import
#import "NativeLogger.h"
@implementation NativeLogger {
}
RCT\_EXPORT\_MODULE();
```
RCT\_EXPORT\_MODULE — это макрос, который регистрирует наш модуль в ReactNative под именем файла, в котором обьявлен. Если это имя в js для вас не очень подходит, вы можете его поменять:
```
@implementation NativeLogger {
}
RCT_EXPORT_MODULE(NativeLogger);
```
Теперь давайте реализуем методы, которые делали для Android. Для этого нам понадобятся параметры.
```
string -> (NSString*)
number -> (NSInteger*, float, double, CGFloat*, NSNumber*)
boolean -> (BOOL, NSNumber*)
array -> (NSArray*)
object -> (NSDictionary*)
function -> (RCTResponseSenderBlock)
```
Для обьявления метода можно использовать макрос RCT\_EXPORT\_METHOD:
```
RCT_EXPORT_METHOD(logTheObject:(NSDictionary*) map)
{
NSString *value = map[@"key1"];
NSLog(@"[NativeModule] %@", value);
}
```
```
RCT_EXPORT_METHOD(logTheArray:(NSArray*) array)
{
for (id record in array) {
NSLog(@"[NativeModule] %@", record);
}
}
```
```
RCT_EXPORT_METHOD(log:(NSDictionary*) map
withArray:(NSArray*)array
andCallback:(RCTResponseSenderBlock)block)
{
NSLog(@"Got the log");
NSArray* events = @[@"Logged"];
block(@[[NSNull null], events]);
}
```
Самое интересное тут — поддержка промисов. Для этого придется воспользоваться другим макросом RCT\_REMAP\_METHOD, который первым аргументом принимает имя метода для js, а вторым и последующими — уже сигнатуру метода в objective-c.
Вместо интерфейса тут передаются два аргумента, RCTPromiseResolveBlock для резолва промиса и RCTPromiseRejectBlock для реджекта:
```
RCT_REMAP_METHOD(logAsync,
logAsyncWith:(NSString*)value
withResolver:(RCTPromiseResolveBlock)resolve
rejecter:(RCTPromiseRejectBlock)reject)
{
NSLog(@"[NativeModule] %@", value);
NSArray* events = @[@"Logged"];
resolve(events);
}
```
На этом все. Механизм передачи событий из нативных модулей в js мы рассмотрим в отдельной статье.
Нюансы
------
* Помните, что основная идея нативных модулей — абстракция операционной системы для кроссплатформенного кода. Это значит, что интерфейс модуля должен быть согласован между Android и iOS. Автоматических средств, как это контролировать я, к сожалению, не знаю.
* Помните, что по отдельности js и нативный код работают быстро. Бриджинг же между ними относительно медленный. Не стоит писать js циклы, в которых вызывать нативный модуль — перенесите цикл в натив.
Полезные ссылки
---------------
* [Официальный туториал по модулям](https://facebook.github.io/react-native/docs/native-modules-ios.html)
* [Тул для генерации бойлерплейта при создании модуля](https://github.com/peggyrayzis/react-native-create-bridge)
* [Задача в гитхабе про производительность React Native Bridge](https://github.com/facebook/react-native/issues/10504) | https://habr.com/ru/post/347346/ | null | ru | null |
# Как устроены массивы в PHP
В прошлой статье я рассказывал о переменных, теперь пойдет речь о массивах.
Что такое массивы на уровне PHP?
--------------------------------
На уровне PHP, массив — это упорядоченный список скрещенный с мэпом. Грубо говоря, PHP смешивает эти два понятия, в итоге получается, с одной стороны, очень гибкая структура данных, с другой стороны, возможно, не самая оптимальная, точнее, как выразился Anthony Ferrara:
> PHP arrays are a great one-size-fits-all data structure. But like all one-size-fits-all , [jack-of-all-trades usually means master of none.](http://en.wikipedia.org/wiki/Jack_of_all_trades,_master_of_none)
>
>
>
> [Ссылка на письмо](http://www.mail-archive.com/[email protected]/msg62370.html)
>
>

(на картине изображен HashTable с Bucket-ами, В. Васнецов)
А начнем вот с чего — попробуем замерить память и время, съедаемое на каждое вставляемое значение. Сделаем это с помощью таких скриптов:
```
// time.php
$ar = array();
$t = 0;
for ($i = 0; $i < 9000; ++$i) {
$t = microtime(1);
$ar[] = 1;
echo $i . ":" . (int)((microtime(1) - $t) * 100000000) . "\n";
}
// memory.php
$ar = array();
$m = 0;
for ($i = 0; $i < 9000; ++$i) {
$m = memory_get_usage();
$ar[] = 1;
echo $i . ":" . (memory_get_usage() - $m) . "\n";
}
```
Запускаем эти скрипты `php time.php > time` и `php memory.php > memory`, и нарисуем графики по ним, ибо данных много и смотреть на цифры долго (данные по времени были собраны много раз и выровнены, чтобы избежать лишних скачков на графике).

(по оси X — кол-во эл-тов в массиве)
Как видно, на обоих графиках есть скачки и по потребляемой памяти и по использованному времени, и эти скачки происходят в одни и те же моменты.
Дело в том, что на уровне C (да и вообще на системном уровне), не бывает массивов, с нефиксированным размером. Каждый раз, когда вы создаете массив в C, вы должны указать его размер, чтобы система знала, сколько нужно памяти на него выделить.
Тогда как это реализовано в PHP и как объянить те скачки на графике?
Когда вы создаете пустой массив, PHP создает его с определенным размером. Если вы заполняете массив и в какой-то момент достигаете и превышаете этот размер, то создается новый массив с вдвое большим размером, все элементы копируются в него и старый массив уничтожается. Вообще, это стандартный подход.
И как это реализовано?
----------------------
На самом деле, для реализации массивов в PHP, используется вполне себе стандартная структура данных [Hash Table](http://ru.wikipedia.org/wiki/Hash_table), о деталях реализации которой мы и поговорим.
Hash Table хранит в себе указатель на самое первое и последнее значения (нужно для упорядочивания массивов), указатель на текущее значение (используется для итерации по массиву, это то, что возвращает `current()`), кол-во элементов, представленых в массиве, массив указателей на Bucket-ы (о них далее), и еще кое-что.
Зачем
нам
ведра нужны
и куда
нам
их ложить
-----------------------------------------------------------------------
В Hash Table есть две главные сущности, первая — это собственно сам Hash Table, и вторая — это Bucket (далее ведро, чтобы не заскучали).
В ведрах хранятся сами значения, то есть на каждое значение — свое ведро. Но помимо этого в ведре хранится оригинал ключа, указатели на следующее и предыдущее ведра (они нужны для упорядочивания массива, ведь в PHP ключи могут идти в любом порядке, в каком вы захотите), и, опять же, еще кое-что.
Таким образом, когда вы добавляете новый элемент в массив, если такого ключа там еще нет, то под него создается новое ведро и добавляется в Hash Table.
Но что самое интересное — это как в Hash Table хранятся эти ведра.
Как было сказано выше, у HT есть некий массив указателей на ведра, при этом ведра доступны в этом массиве по некоему индексу, а этот индекс можно вычислить зная ключ ведра. Звучит немного сложно, но на самом деле, все гораздо проще чем кажется. Попробуем разобрать, как происходит получение элемента по ключу из HT:
* Если ключ строковый — то происходит хеширование строки до integer-a (используется алгоритм хеширования DJBX33A):
+ Первоначальное значение хеша взято за магические 5381
+ На каждый символ ключа умножаем хеш на 33 и прибавляем номер символа по ASCII
* На полученый числовой ключ накладывается маска (bitwise and), которая всегда равна размеру массива (который с ведрами) минус 1
* В итоге этот ключ можно использовать как индекс, чтобы вытащить нужный указатель на Bucket из массива
Про маску: допустим массив указателей содержит 4 элемента, таким образом маска равна трем, то есть 11 в двоичной системе.
Теперь если в качестве ключа у нас получится число вроде 123 (1111011), то после наложения маски мы получим 3 (3 & 123), это число уже можно будет использовать как индекс.
После этого попробуем добавить в Hash Table, с маской 3, элементы с ключами 54 и 90. А оба этих ключа после наложения маски будут равны двойки.
Что делать с коллизиями?
------------------------
У ведер оказывается есть еще пара карт в рукаве. Каждое ведро имеет также указатель на предыдущее и следующее ведро, у которых индексы (хеши от ключей) равны.
Таким образом, помимо основного двусвязного списка, который проходит между всеми ведрами, есть еще и мелкие двусвязные списки между теми ведрами, индексы которых равны. То есть получается примерно следующая картина:

Вернемся к нашему кейсу с ключами 54 и 90, и маской 3. После того, как вы добавите 54, структура HT будет выглядеть примерно так:
```
{
nTableSize: 4, // размер массива указателей на ведра
nTableMask: 3, // маска
nNumOfElements: 1, // число элементов в HT
nNextFreeElement: 55, // это будет использовано тогда, когда вы захотите добавить элемент в конец массива (без ключа)
...,
arBuckets: [
NULL,
NULL,
0xff0, // представим, что это указатель на Bucket, а сам он описан ниже
NULL
]
}
0xff0: {
h: 54, // числовой ключ
nKeyLength: 0, // это длина ключа, в случае когда он строковый
pData: 0xff1, // указатель на значение, в данном случае на структуру zval
...
}
```
Теперь добавим элемент с ключом 90, теперь все будет выглядеть примерно так:
```
{
nTableSize: 4,
nTableMask: 3,
nNumOfElements: 2,
nNextFreeElement: 91,
...,
arBuckets: [
NULL,
NULL,
0xff0, // здесь все так же всего один Bucket
NULL
]
}
0xff0: {
h: 54,
pListNext: 0xff2, // здесь хранится указатель на следующий Bucket по порядку (для итерирования)
pNext: 0xff2, // а сюда попал новый Bucket с таким же хешем
...
}
0xff2: {
h: 90,
pListLast: 0xff0, // это предыдущий элемент
pLast: 0xff0, // а это тот же предыдущий элемент
...
}
```
Теперь давайте добавим несколько элементов до переполнения nTableSize (напомню, что переполнение будет только тогда, когда nNumOfElements > nTableSize).
Добавим элементы с ключами 0, 1, 3 (такие, которых еще не было, и после наложения масок они останутся теми же), вот что будет:
```
{
nTableSize: 8, // теперь размер вдвое больше (прям как в той рекламе)
nTableMask: 7,
nNumOfElements: 5,
nNextFreeElement: 91, // это число осталось неизменным
...,
arBuckets: [ // теперь некоторые ведра переместились на новые места, с учетом новой маски и следовательного нового индекса
0xff3, // key = 0
0xff4, // key = 1
0xff2, // key = 90 - теперь здесь сидит ключ 90 (его индекс 90 & 7 = 2), а его бывший сосед съехал на 6-й индекс
0xff5, // key = 3
NULL,
NULL,
0xff0, // key = 54
NULL
]
}
0xff0: {
h: 54,
pListNext: 0xff2, // порядок остался тот же, поэтому это значение неизменно
pNext: NULL, // а здесь теперь ничего
...
}
0xff2: {
h: 90,
pListNext: 0xff3,
pListLast: 0xff0,
pLast: NULL,
...
}
0xff3: {
h: 0,
pListNext: 0xff4,
pListLast: 0xff2,
...
}
0xff4: {
h: 1,
pListNext: 0xff5,
pListLast: 0xff3,
...
}
0xff5: {
h: 3,
pListNext: NULL, // он был добавлен последним
pListLast: 0xff4,
...
}
```
То, что происходит после переполнения массива, называется rehash. По сути это итерирование по всем существующим ведрам (через pListNext), назначение их соседей (коллизий) и добавление ссылок на них в arBuckets.
А как же на самом деле происходит получение элемента по ключу? К предыдущему алгоритму добавится еще кое что:
* Если ключ строковый — то происходит хеширование строки до integer-a (используется алгоритм хеширования DJBX33A):
+ Первоначальное значение хеша взято за магические 5381
+ На каждый символ ключа умножаем хеш на 33 и прибавляем номер символа по ASCII
* На полученый числовой ключ накладывается маска (bitwise and), которая всегда равна размеру массива (который с ведрами) минус 1
* Вытаскиваем ведро по индексу
* Если ключ этого ведра равен искомому — поиск завершен, иначе:
* В цикле берем ведро из pNext (если существует) и смотрим равен ли ключ
Так до тех пор, пока либо не закончатся ведра в pNext (тогда будет выкинут Notice), либо пока не будет найдено совпадение.
Стоит отметить, что в PHP почти все посторено на одной этой структуре HashTable: все переменные, лежащие в каком-либо scope-е, на самом деле лежат в HT, все методы классов, все поля классов, даже сами дефинишины классов лежат в HT, это на самом деле очень гибкая структура. Помимо прочего, HT обеспечивает практически одинаковую скорость выборки/вставки/удаления и сложность всех троих является O(1), *но* с оговоркой на небольшой оверхед при коллизиях.
Кстати, [здесь](https://github.com/nikita2206/php-hash-table) я реализовал Hash Table в самом PHP. Ну, то есть, имплементировал PHP-шные массивы в PHP =) | https://habr.com/ru/post/162685/ | null | ru | null |
# Взламываем ТВ-приставку, чтобы получить плацдарм для хакерских атак
Привет, Хабр! Меня зовут Роман, я занимаюсь безопасностью IOT-устройств.
Мы в Бастион регулярно отрабатываем те или иные сценарии атак и устраиваем эксперименты. Об одном из них я расскажу прямо сейчас.
Представьте приемную крупной компании. Диван, низенький столик, подключенный к ТВ-приставке телевизор беззвучно крутит очередной выпуск новостей. Великолепный шанс для хакерской атаки. Нужно только получить доступ к устройству.
Мне предстояло найти способ отравить приставку и превратить ее в плацдарм для будущих атак на другие элементы сетевой инфраструктуры.
### Разведка
Для эксперимента мы кинули жребий и приобрели одну из приставок, которые продают многочисленные онлайн-кинотеатры и операторы IPTV.
В результате на мой рабочий стол попало устройство на платформе Amlogic S905X, очень похожее на Mecool M8S PRO+.
Блок-диаграмма Amlogic S905X. Это недорогой процессор с аппаратным видеодекодером, предназначенный для lzk-работы в потребительской медиаэлектронике: ТВ-приставках, умных колонкахБольшинство подобных приставок основано на референс-дизайне Droidlogic A95X. AliExpress завален такими устройствами. Они отличаются по внешнему виду, но почти идентичны в своей начинке. Варьируется разве что расположение элементов на плате.
Первым делом я решил взглянуть на плату поближе и вскрыл корпус. Как правило, я сразу демонтирую память, подключаю к программатору и снимаю дамп. Но на этот раз у меня не нашлось нужного трафарета, чтобы припаять чип назад. Так что пришлось отложить эту операцию и заказать трафарет. Появилось время погуглить.
Производители узкоспециализированных процессоров редко публикуют техническую документацию. Но на чип S905X утекло некоторое количество документации. К тому же, на этом чипе основаны Khadas VIM1 и одна из плат ODROID.
Одноплатник Khadas VIM1Это платформы типа Raspberry Pi, только ориентированные на медиафункционал. В сети по ним много информации.
Выяснилось, что на платы этого типа устанавливается либо eMMC, либо NAND-память. Причем пины eMMC подключаются к той же линии, что идет к посадочному месту для NAND-памяти. Поэтому удалять чип вовсе не обязательно. Вместо этого, я подпаялся программатором на место NAND-памяти и снял дамп с eMMC. Так что трафарет в итоге не пригодился.
С помощью документации Khadas мне удалось найти чип сброса контроллера на плате приставки. Параллельно я подпаял хардварную кнопку Reset. Затем нашел отладочный интерфейс JTAG.
*Плата нашей приставки. Желтым цветом подписаны штатные элементы, красным ― точки подключения отладочных интерфейсов и дополнительно установленные элементы*
В инструкциях нашлось описание процесса загрузки чипа. Оказалось, что, если eMMC по какой-то причине не работает, загрузчик ищет альтернативу ― SD-карточку или USB-флешку.
Чтобы эксплуатировать эту особенность загрузчика, я установил на одну из ножек чипа памяти кнопку, прерывающую считывание, и получил альтернативный вариант загрузки. Появилась возможность залить бекап и вернуть плату к заводскому состоянию. К тому же, теперь дамп eMMC можно было залить на внешнюю флешку и экспериментировать уже с ней, без перезаписи содержимого чипа.
Пришло время переходить к софту.
### Исследование загрузчика
В Amlogic S905X встроено расширение ARM Trust Zone. Оно нужно, чтобы выделить защищенную область памяти, которая доступна только для доверенного кода.
Описание работы референсной реализации ARM Trusted FirmwareTrust Zone работает следующим образом.
Производитель подписывает легитимный загрузчик закрытым ключом. Масочный загрузчик (RomBOOT) при каждом запуске считывает код из основной энергонезависимой загрузочной памяти и проверяет корректность подписи. Если подпись корректна ― код выполняется.
Открытые ключи прошиваются в eFUSE. Эта область памяти представляет собой набор перемычек, которые пережигаются еще во время производства. Такой подход защищает RomBOOT от подмены ключей.
Довольно надежная штука, так что столкнувшись с ней я решил сначала изучить загрузчик нулевого уровня.
Бинго! Оказалось, что в приставке использован U-Boot. Это проект с открытым исходным кодом, который используют повсюду от продуктов Cisco до безымянных китайских датчиков.
Вот только популярность U-Boot не означает, что все понимают, как правильно его сконфигурировать.
U-Boot не просто загрузчик, в него встроены инструменты для отладки. Они доступны через консоль на одном из портов UART сразу после прерывания загрузки. По-хорошему, перед выходом на прод разработчикам необходимо заблокировать доступ к прерыванию загрузки и перевести консоль в режим Read-Only, а также исключить большую часть команд, которые позволяют работать с памятью на низком уровне.
Это стоило проверить. Я нашел контакты UART-порта по надписям RX/TX на плате, подключил консольный кабель, подобрал скорость и увидел стандартное приглашение:
```
Hit Enter or space or Ctrl+C key to stop autoboot -- : 0
```
Разработчики выставили таймер на 0, и это должно было заблокировать перехват загрузки.
Тем не менее загрузка прерывалась, если сразу при старте слать в консоль большое количество .
Прервав загрузку, я получил доступ к командной строке. По запросу «?» она выдала длинный список доступных сервисных команд.
Среди них нашелся еще один способ создать полный дамп eMMC, но главное, там была команда efuse read. На проверку, область efuse оказалась пуста ― все значения skb равны 0x00.
Так я понял, что доверенная загрузка просто не работает. На приставке выполняется произвольный код, любые загрузчики. Хорошая новость для энтузиастов с XDA, и не очень хорошая для производителя. Оригинальный софт сносится по мановению руки.
Чтобы проверить гипотезу на практике, я взял образ Ubuntu, предназначенный для установки на Khadas и записал на SD-карту, как есть. Затем заблокировал работу eMMC кнопкой и вынудил RomBOOT загрузиться с SD-карты.
Вместо Android запустилась Ubuntu.
Еще, ради интереса, я собрал из исходников U-Boot и также загрузил с SD-карты. Он стартовал, но падал на этапе BL2=>BL3. Вероятно, мне попалась сборка с некорректными конфигами DDR-памяти.
Исправлять их я уже не стал. Для демонстрации уязвимости этого было достаточно, так что я решил поработать с оригинальной операционной системой и получить там привилегированные права.
### Получаем привилегии
На приставке крутился AOSP сборка Android 9 без сервисов Google. Вместо лаунчера запускается фирменное приложение, собранное таким образом, что оно выдает себя за лаунчер. Такой подход должен препятствовать установке сторонних приложений, но это было бессмысленно, так как на UART обнаружилась открытая консоль. Причем сразу c правами администратора и без аутентификации.
Кстати, SELinux работал в permissive-режиме, то есть, не обеспечивал защитуЧтобы не тратить время на ручную модификацию файлов, я получил Root с помощью Magisk, а затем настроил удаленную отладку. Производитель отключил ее вместе со всем меню разработчика, но ADB-интерфейс поднимается и руками:
```
setprop persist.sys.usb.config mtp,adb
/system/bin/mount -o rw,remount /
sed -i 's/ro.debuggable=0/ro.debuggable=1/g' /system/etc/prop.default
sed -i 's/ro.secure=1/ro.secure=0/g' /system/etc/prop.default
sed -i 's/ro.adb.secure=1/ro.adb.secure=0/g' /system/etc/prop.default
settings put global development_settings_enabled 1
/system/bin/mount -o ro,remount /
reboot
```
После выполнения этих команд, ADB-сессия без проблем открылась на удаленной машине. Дальше стало проще. Теперь я мог работать с ПК, а не набивать команды на клавиатуре, подключенной к приставке.
### Исследуем файловую систему
Пришло время посмотреть на файловую систему. Хорошая новость ― пользовательский раздел зашифрован. Плохая ― все остальное ― нет. Разделы, относящиеся к системным, полностью открыты и даже не подписаны, хотя для этого существует Android Verified Boot.
Из-за этого все изменения, которые я провел через консоль или ADB, без проблем проделываются через прямую модификацию файловой системы и заливаются снаружи через U-Boot. Это готовый вектор для атаки, однако здесь нужен физический доступ. Мне же хотелось найти вектор для удаленной атаки. Надо было посмотреть трафик.
Подслушиваем за приставкой
Приставка осуществляет обмен с инфраструктурой провайдера при помощи HTTP запросов поверх SSL. Для снятия SSL необходимо было направить трафик приставки на proxy-сервер и подменить корневые сертификаты.
В качестве инструмента для мониторинга HTTP я использовал Charles. Основной сценарий использования Charles ― мониторинг SSL трафика на локальной машине, но ничто не мешает перенаправить на нее трафик с удаленной машины, то есть, с приставки. В Android корневые сертификаты хранятся в папке /system/etc/security/cacerts/. Название файла должно соответствовать хэшу сертификата.
Подготовленный сертификат необходимо скопировать на флешку и далее записать в соответствующую директорию.
```
/system/bin/mount -o rw,remount /
cp /mnt/media_rw/6539-6535/9a5ba575.0 /system/etc/security/cacerts/
chmod 644 /system/etc/security/cacerts/9a5ba575.0
chown root:root /system/etc/security/cacerts/9a5ba575.0
/system/bin/mount -o ro,remount /
```
Проконтролировать корректность установки сертификата можно, вызвав системные настройки
```
am start -a android.settings.SETTINGS
```
и далее проверить наличие добавленного сертификата в меню «Security & location» => «Encryption & credentials» => Tap «Trusted credentials».
Перенаправить трафик можно либо на маршрутизаторе, либо задав системный прокси командой
```
settings put global http_proxy 10.2.100:8888
```
Выяснилось, что приставка регулярно запрашивает у производителя обновления операционной системы и приложений.
Обновление ОС запрашивается корректно, через SSL, а запросы на приложения отправляются без шифрования. Это возможность для MiTM-атаки.
### Векторы атак
В итоге найденные уязвимости сложились в два вектора атак:
#### 1. Установка отравленного системного обновления
Злоумышленнику нужно взять оригинальную прошивку, внести модификации в файловую систему, установить необходимый ему софт, собрать образ и сохранить на флешке.
Затем ему придется прийти в фойе, вставить флешку в приставку и зажать на 10 секунд стандартную кнопку перезагрузки.
Приставка уйдет в ребут и стянет с флешки новый образ. Системные разделы перезапишутся, и устройство получит новую, зловредную функциональность.
#### 2. MiTM атака через обновление приложения
Второй сценарий сложнее технически, но не требует физического доступа к устройству. На этот раз, злоумышленнику понадобится доступ к интернет-каналу, через который приставка общается с внешним миром. Он может взломать или подменить Wi-Fi или найти щиток и подключиться в разрыв интернет-кабеля.
Главное — перехватить запрос на обновление софта от приставки и залить на нее отравленное приложение. А оно уже выполнит работу по повышению привилегий в ОС, поднимет VPN и настроит удаленный доступ, даже если приставка находится за роутером или NAT.
В обоих случаях приставка превращается в настоящий зомбоящик ― полноценный плацдарм для атак на сетевую инфраструктуру компании.
### Вместо заключения: почему так вышло
Хочется найти конкретного виновника всех проблем, но, обычно уязвимость подобных устройств объясняется целым набором факторов. Этот случай ― не исключение.
Google уже давно предъявляет требования к железу, на котором выполняется Android. Например, среди них наличие многоуровневого безопасного загрузчика. Но Google не всемогущ, что бы ни говорили конспирологи. Компания не способна оценить реальную безопасность каждой железки.
В то же время, китайские вендоры довольно формально подходят к безопасности. Ведь если бы они дотошно все проверяли, их чипы уже не стоили так дешево.
Заказчики и разработчики софта, тоже не безгрешны. Первые порой и не вспоминают о безопасности и не закладывают ее в бюджет. Вторые не всегда подчеркивают, что безопасность стоит отдельных денег, допускают ошибки и остаются без времени и средств на их поиск и устранение.
В случае с приставкой, которую я тестировал, ошибки допустили по чуть-чуть на всех этапах разработки. В итоге, хотя чип и платформа имеют достаточно развитую функциональность для обеспечения безопасности, она не используется.
Производительных устройств, подключенных к сети, становится все больше, но их защищенность очень низкая. Это касается и потребительской электроники, и промышленной, автомобильной. Это общая проблема интернета вещей, который с каждым днем становится все больше, разнообразнее и умнее.
При этом средний уровень компьютерной грамотности был и остается достаточно невысоким, так что защита IoT ― задача и ответственность производителей. Причем для этого существуют готовые инструменты, просто ими необходимо правильно воспользоваться.
Хотелось бы, чтобы бизнес обращал на это больше внимания. Да, за защиту надо платить, но за ее отсутствие приходится расплачиваться. Зачастую, простым пользователям.
---
Что может изменить сложившуюся ситуацию? Какие технологии и подходы к разработке способны обеспечить безопасность IoT? Давайте обсудим это в комментариях. | https://habr.com/ru/post/587108/ | null | ru | null |
# Как сверстать тему для WordPress
#### Введение
В предыдущих статьях мы рассмотрели принципы верстки на чистом CSS и с помощью Bootstrap. Сегодняшней статьей мы начинаем рассматривать особенности верстки под популярные CMS. И начнем с WordPress, как самой популярной из них. Будем считать, что WordPress у вас уже установлен и перейдем непосредственно к созданию шаблона, в качестве которого у нас по-прежнему будет выступать [Corporate Blue](http://www.pcklab.com/templates/corporate-blue) от студии Pcklaboratory. Если вы не знаете как установить WordPress, то инструкцию можно найти [здесь](http://codex.wordpress.org/%D0%A3%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0_WordPress). В данном руководстве мы не будем подробно описывать CSS стили и HTML код – это было сделано уже в предыдущих статьях. Вместо этого рассмотрим детально особенности создания темы именно под WordPress.
#### Добавление темы
Для начала в папке themes создадим папку нашего шаблона «whitesquare». В ней будет находиться папка images и два необходимых пустых файла index.php и style.css.
Следующим шагом нужно добавить скриншот нашей темы. Сохраните изображение главной страницы из psd макета размером 880х660 в папку темы whitesquare с именем screenshot.png.
После этого мы уже можем использовать нашу тему. Зайдите в панель администратора по адресу http://{site-name}/wp-admin, а затем в управление темами (Appearance -> Themes). В списке уже должна появиться наша тема whitesquare. Наведитесь на тему и нажмите «Activate».
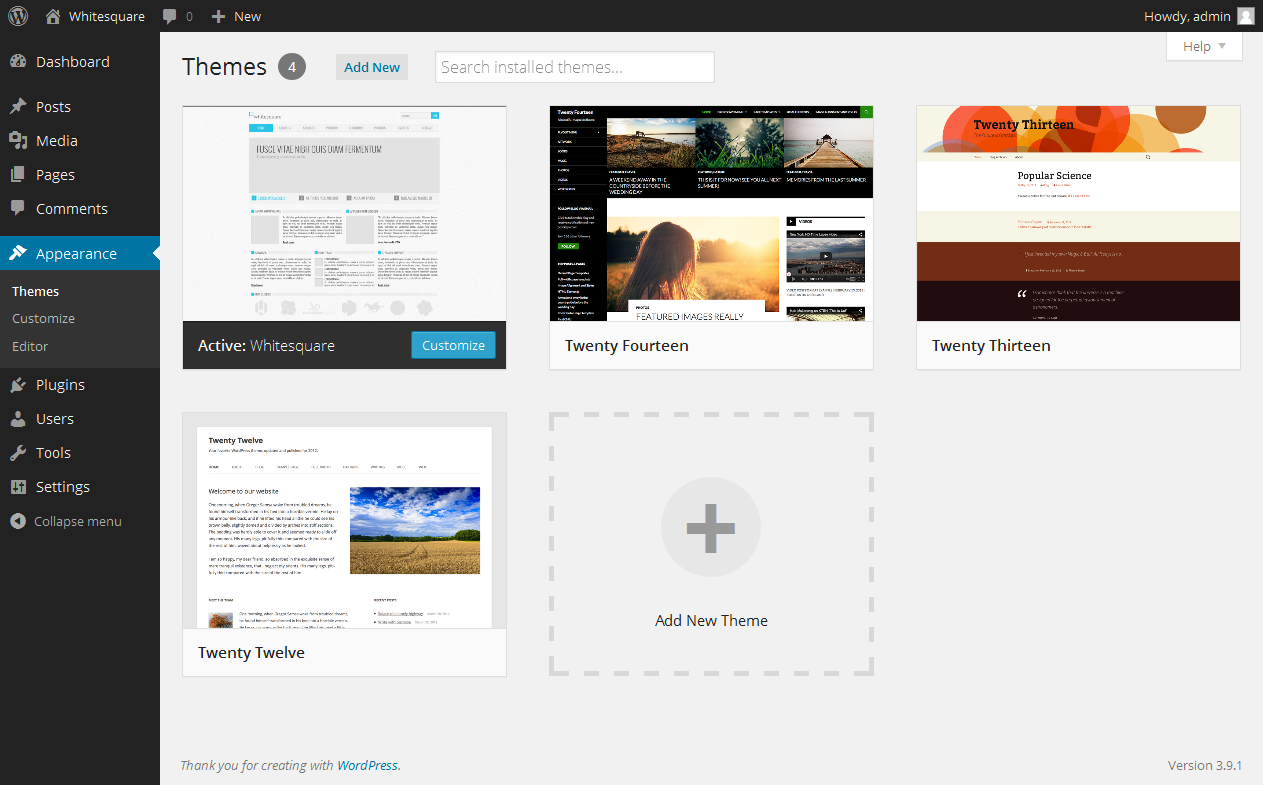
После того, как тема активируется, вы увидите сообщение со ссылкой на сайт. Уже сейчас можно зайти на него и увидеть пустую страницу.
#### Предварительный осмотр

Если посмотреть на макет, то можно увидеть, что наша страница состоит из шапки и футера, которые повторяются на всех страницах. Также на всех страницах, кроме главной, есть сайдбар слева. Для того чтобы руководство было более универсальным, давайте страницы главного меню оформим как «страницы WordPress» (page), а страницы подменю как «посты блога WordPress» (post) с комментариями. Главную же страницу сделаем как отдельную страницу (front-page) с собственной разметкой. Здесь надо отметить, что, несмотря на то, что страницы WordPress могут быть реализованы двумя способами (как страницы или как посты) в базе данных они различаются только типом, однако при создании шаблонов они обрабатываются немного по-разному. В этом вы сможете убедиться чуть ниже.
#### Структура страниц
Большинство руководств по созданию тем для WordPress ограничивается созданием макета и стилей для него. Мы же опишем весь порядок действий по созданию полноценного сайта на WordPress в рамках предоставленных макетов.
Давайте начнем со структуры страниц. Прежде чем добавлять страницы, нужно сначала зайти в настройки и указать стиль ссылок: Settings -> Permalink settings -> Post name. Это позволит сделать ссылки в виде «http://site\_name/page\_name».
Добавление страниц осуществляется через панель администратора: Pages -> Add new. Для каждой страницы в области Page Attributes в поле Order укажите цифрой порядок страницы в главном меню.
После добавления, список страниц должен выглядеть вот так:
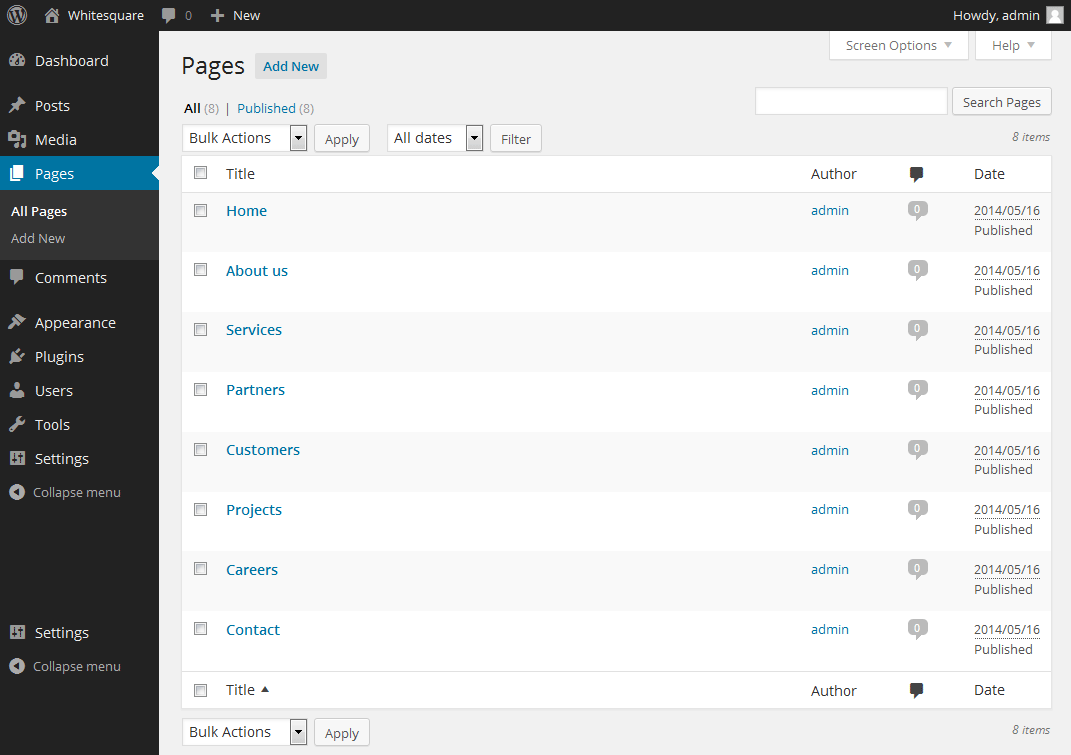
Когда все страницы будут добавлены, нужно указать, что страница Home будет главной. Для этого зайдите в меню Settings -> Reading и в поле Front page displays укажите: A static page -> Home.
#### Header.php и Footer.php
Шапка в терминологии WordPress, это не только визуальная шапка на макете сайта. По сути, она содержит весь общий код, который встречается в начале всех страниц сайта. Давайте создадим файл header.php в папке нашего шаблона и наполним его содержимым.
```
php wp\_title('«', true, 'right'); ? php bloginfo('name'); ?
php wp\_head(); ?
>
```
Внутри тега head мы установили кодировку, указанную в WordPress, заголовок страницы и pingback (для связи с другими сайтами). В последней строке вызываем команду wp\_head(), которая добавляет заголовки WordPress. Также открываем блок «wrapper».
Кроме этого, нам нужно подключить css и js файлы. В текущих версиях wordpress это делается не прямым текстом в header.php, а через подключение в специальных функциях. Для этого откройте файл functions.php внутри нашей темы и добавьте в него следующий код:
```
function enqueue_styles() {
wp_enqueue_style( 'whitesquare-style', get_stylesheet_uri());
wp_register_style('font-style', 'http://fonts.googleapis.com/css?family=Oswald:400,300');
wp_enqueue_style( 'font-style');
}
add_action('wp_enqueue_scripts', 'enqueue_styles');
function enqueue_scripts () {
wp_register_script('html5-shim', 'http://html5shim.googlecode.com/svn/trunk/html5.js');
wp_enqueue_script('html5-shim');
}
add_action('wp_enqueue_scripts', 'enqueue_scripts');
```
В функции enqueue\_styles мы зарегистрировали и подключили нужные стили, а затем указали вордпрессу, что эта функция является подключением стилей. Аналогично и для js файла, который требуется для отображения html5 тегов в старых браузерах.
Футер аналогично шапке — содержит общий код, который встречается в конце всех страниц сайта. Давайте запишем его содержимое в файл footer.php.
```
```
php wp\_footer(); ?
Здесь мы закрываем открытые блоки и вызываем wp\_footer(), чтобы добавить скрипты футера WordPress.
#### Шаблон страницы
Следующим шагом, нам нужно сделать шаблон обычной страницы WordPress.
Создайте в папке темы файл page.php и добавьте в него следующий код:
```
php get_header(); ?
php the\_title(); ?
===================
php if (have\_posts()): while (have\_posts()): the\_post(); ?
php the\_content(); ?
php endwhile; endif; ?
php get_footer(); ?
```
Здесь мы подключили наши файлы шапки и футера, создали блок названия страницы и в теге section вставили стандартный блок вывода контента страниц и постов.
Теперь нужно стилизовать получившуюся страницу. Сохраните фоны в файлы images/bg.png и images /h1-bg.png. Далее добавьте немного базовых стилей в файл style.css:
**Показать код**
```
body {
color: #8f8f8f;
font: 12px Tahoma, sans-serif;
background: #f8f8f8 url(images/bg.png);
border-top: 5px solid #7e7e7e;
margin: 0;
}
img {
border: 0;
}
p {
margin: 20px 0;
}
.alignleft {
float: left;
}
.alignright {
float: right;
}
.aligncenter {
display: block;
margin-left: auto;
margin-right: auto;
}
.input {
background-color: #f3f3f3;
border: 1px solid #e7e7e7;
height: 30px;
color: #b2b2b2;
padding: 0 10px;
vertical-align: top;
}
.button {
color: #fff;
background-color: #29c5e6;
border: none;
height: 32px;
font-family: 'Oswald', sans-serif;
}
.image {
border: 1px solid #fff;
outline: 1px solid #c9c9c9;
}
figure img {
display: block;
}
.wrapper {
max-width: 960px;
margin: auto;
}
header {
padding: 20px 0;
}
.main-heading {
background: transparent url(images/h1-bg.png);
margin: 30px 0;
padding-left: 20px;
}
.main-heading h1 {
display: inline-block;
color: #7e7e7e;
font: 40px/40px 'Oswald', sans-serif;
background: url(images/bg.png);
margin: 0;
padding: 0 10px;
text-transform: uppercase;
}
aside {
float: left;
width: 250px;
}
aside + section {
margin-left: 280px;
padding-bottom: 50px;
}
footer {
clear: both;
background: #7e7e7e;
color: #dbdbdb;
font-size: 11px;
}
```
В результате должна получиться вот такая картина:
#### Логотип

После того, как мы закончили с каркасом основной страницы, приступим к ее наполнению. Начнем с логотипа. Сохраните изображение логотипа в images/logo.png. В шаблон шапки, в файле header.php вставьте разметку для логотипа:
```
[; ?>/images/logo.png)](/)
```
#### Форма поиска
WordPress позволяет достаточно гибко сохранять блоки кода в отдельные файлы, а затем использовать их в нескольких разных местах. Рассмотрим пример на нашей форме поиска.
В папке темы создайте новый файл searchform.php и сохраните в него код формы поиска:
```
php echo \_\_('GO', 'whitesquare'); ?
```
А в файл стилей запишите стили для формы:
**Показать код**
```
.search-form {
float: right;
}
```
Всё, что осталось сделать – это подключить searchform.php внутри header.php.
```
…
php get\_search\_form(); ?
```
#### Навигация
Добавить навигацию на страницу можно разными способами, например через функцию wp\_list\_pages, но более современным способом будет добавление через админку. По умолчанию функционал добавления меню не активирован, для того, чтобы это сделать, добавьте в файл темы functions.php следующий код:
```
if (function_exists('add_theme_support')) {
add_theme_support('menus');
}
```
После этого, в панели администрирования в пукте меню Appearance появится подпункт Menus, в котором нужно нажать на ссылку Create new menu, ввести имя меню «top-menu», выделить страницы из левой колонки и добавить их в меню кнопкой Add to menu.
Теперь, когда меню создано, нужно его показать на страницах сайта. Для этого добавьте в конец header.php следующий код:
```
wp\_nav\_menu(array('menu' = 'top-menu', 'menu\_class' => 'top-menu')); ?>
```
Функция wp\_nav\_menu отобразит меню с именем «top-menu» и css классом «top-menu».
После этого меню уже появится на страницах но без стилей. Стилизуем его:
**Показать код**
```
.main-navigation {
background: #f3f3f3;
border: 1px solid #e7e7e7;
}
.top-menu {
margin: 0;
padding: 0;
}
.top-menu li {
display: inline-block;
padding: 10px 30px;
margin: 0;
text-transform: uppercase;
list-style-position: inside;
font: 14px 'Oswald', sans-serif;
}
.top-menu li.current_page_item {
background: #29c5e6;
}
.top-menu a {
color: #b2b2b2;
text-decoration: none;
}
.top-menu li.current_page_item a {
color: #fff;
}
```
#### Футер
Теперь приступаем к самой сложной части нашего шаблона. Давайте нарежем изображения и сохраним их в в папку images
images/footer-logo.png – логотип футера
images/social.png – спрайты больших иконок
images/social-small.png – спрайты маленьких иконок
Далее делаем вёрстку в файле footer.php:
```
### php echo \_\_('Twitter feed', 'whitesquare'); ?
[23 oct](#)
php echo \_\_('In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et nulla. In eget mi dui, sit amet scelerisque nunc. Aenean aug', 'whitesquare'); ?
### php echo \_\_('Sitemap', 'whitesquare'); ?
[php echo \_\_('Home', 'whitesquare'); ?](/home/)
[php echo \_\_('About', 'whitesquare'); ?](/about/)
[php echo \_\_('Services', 'whitesquare'); ?](/services/)
[php echo \_\_('Partners', 'whitesquare'); ?](/partners/)
[php echo \_\_('Support', 'whitesquare'); ?](/customers/)
[php echo \_\_('Contact', 'whitesquare'); ?](/contact/)
### php echo \_\_('Social networks', 'whitesquare'); ?
[; ?>/images/footer-logo.png)](/)
php echo \_\_('Copyright © 2012 Whitesquare. A <a href="http://pcklab.com"pcklab creation', 'whitesquare'); ?>
```
И прописываем стили в style.css:
**Показать код**
```
.footer-content {
max-width: 960px;
margin: auto;
padding: 10px 0;
height: 90px;
}
.footer-heading {
font: 14px 'Oswald', sans-serif;
color: #fff;
border-bottom: 1px solid #919191;
margin: 0 0 10px 0;
text-transform: uppercase;
}
footer a {
color: #dbdbdb;
}
footer p {
margin: 5px 0;
}
.twitter-time {
color: #b4aeae;
}
.twitter {
float: left;
width: 300px;
}
.twitter p {
padding-right: 15px;
}
.sitemap {
width: 150px;
float: left;
margin-left: 20px;
padding-right: 15px;
}
.sitemap .column {
display: inline-block;
margin-left: 40px;
}
.sitemap .column.first {
margin-left: 0;
}
.sitemap a {
display: block;
text-decoration: none;
font-size: 12px;
margin-bottom: 5px;
}
.sitemap a:hover {
text-decoration: underline;
}
.social {
float: left;
margin-left: 20px;
width: 130px;
}
.social-icon {
width: 30px;
height: 30px;
background: url(images/social.png) no-repeat;
display: inline-block;
margin-right: 10px;
}
.social-icon-small {
width: 16px;
height: 16px;
background: url(images/social-small.png) no-repeat;
display: inline-block;
margin: 5px 6px 0 0;
}
.twitter-icon {
background-position: 0 0;
}
.facebook-icon {
background-position: -30px 0;
}
.google-plus-icon {
background-position: -60px 0;
}
.vimeo-icon {
background-position: 0 0;
}
.youtube-icon {
background-position: -16px 0;
}
.flickr-icon {
background-position: -32px 0;
}
.instagram-icon {
background-position: -48px 0;
}
.rss-icon {
background-position: -64px 0;
}
.footer-logo {
float: right;
margin-top: 20px;
font-size: 10px;
text-align: right;
}
```
В итоге главная страница сайта должна выглядеть вот так:
#### Главная страница
Если вы посмотрите на psd макеты, то увидите, что разметка главной страницы отличается от внутренних. В частности, на главной странице нет сайдбара и заголовка страницы.
WordPress позволяет задавать разные шаблоны для разных страниц. Такой шаблон должен храниться в файле page-{название страницы}.php. Если шаблон не найден, то будет подключаться шаблон по умолчанию page.php.
Для главной страницы создайте новый файл front-page.php в папке темы. Добавьте в него следующий код:
```
php get_header(); ?
php if (have\_posts()): while (have\_posts()): the\_post(); ?
php the\_content(); ?
php endwhile; endif; ?
php get_footer(); ?
```
Он отличается от кода page.php только тем, что в нем нет заголовка страницы.
То, что мы будем делать дальше, уже выходит за рамки создания темы WordPress, однако мы попытаемся воссоздать полную картину из psd макета и наполним контентом главную страницу. Содержимым страница наполняется из панели администратора для того, чтобы владелец сайта мог зайти в эту панель и что-то изменить на странице, не изменяя код самой темы.
Прежде, чем добавить контент главной страницы – необходимо нарезать все изображения этой страницы и добавить их в библиотеку WordPress через меню Media -> Library. Назовём эти изображения так:
home-1.png
home-2.png
home-3.png
home-4.png
home-5.png
clients-1.png
clients-2.png
clients-3.png
clients-4.png
clients-5.png
clients-6.png
clients-7.png
Далее, перейдите в панели администратора к форме редактирования главной страницы Pages -> Home -> Edit Page и в поле text введите содержимое страницы:
**Показать код**
```
Fusce vitae nibn quis diam fermentum
Etiam adipscing ultricies commodo.
1. Lorem ipsum dolop
2. Ultricies pellentesque
3. Aliquam ipsum
4. Nullam sed mauris ut
### About whitesquare

In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et nulla. In eget mi dui, sit amet scelerisque nunc. Aenean augue arcu, convallis ac vulputate vitae, mollis non lectus. Donec hendrerit lacus ac massa ornare hendrerit sagittis lacus tempor. Vivamus et dui et neque accumsan varius et ut erat. Enean augue arcu, convallis ac ultrices.
[Read more](/about-us/)
### A word from our ceo

*In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et nulla. In eget mi dui, sit amet scelerisque nunc. Aenean augue arcu, convallis ac vulputate vitae, mollis non lectus. Donec hendrerit lacus ac massa ornare hendrerit sagittis lacus tempor. Vivamus et dui et neque accumsan varius et ut erat. Enean augue arcu, convallis ac ultrices.*
Yane Naumoski, CEO
### Services
In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et nulla. In eget mi dui, sit amet scelerisque nunc. Aenean augue arcu, convallis ac vulputate vitae, mollis non lectus. Donec hendrerit lacus ac massa ornare hendrerit sagittis lacus tempor. Vivamus et dui et neque accumsan varius et ut erat. Enean augue arcu, convallis ac ultrices.
[Read more](/services/)
### Our teams

#### Lorem ipsum
In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et

#### Lorem ipsum
In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et

#### Lorem ipsum
In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et
### 24/7/365 Support
In ultricies pellentesque massa a porta. Aliquam ipsum enim, hendrerit ut porta nec, ullamcorper et nulla. In eget mi dui, sit amet scelerisque nunc. Aenean augue arcu, convallis ac vulputate vitae, mollis non lectus. Donec hendrerit lacus ac massa ornare hendrerit sagittis lacus tempor. Vivamus et dui et neque accumsan varius et ut erat. Enean augue arcu, convallis ac ultrices.
[Read more](/contact/)
### Our clients







```
Не забудьте поправить пути до картинок. Они зависят от даты добавления.
Теперь осталось стилизовать данный код.
**Показать код**
```
.slider {
margin-top: 30px;
font-family: 'Oswald', sans-serif;
font-weight: 300;
text-transform: uppercase;
}
.slider .content {
height: 220px;
padding: 30px 40px;
background: #e2e2e2;
}
.slider .title {
color: #5a5a5a;
font-size: 42px;
}
.slider .subtitle {
color: #acacac;
font-size: 20px;
}
.slider .links {
display: block;
margin: 0;
padding: 10px;
background: #f3f3f3;
border-bottom: 1px solid #e7e7e7;
counter-reset: list 0;
color: #8f8f8f;
}
.slider .links li {
display: inline-block;
font-size: 18px;
line-height: 23px;
margin-right: 55px;
cursor: pointer;
}
.slider .links li.active {
color: #29c5e6;
}
.slider .links li:before {
display: inline-block;
counter-increment: list;
content: counter(list) " ";
background: #8f8f8f;
color: #fff;
width: 23px;
text-align: center;
margin-right: 10px;
font-size: 16px;
cursor: pointer;
}
.slider .links li.active:before {
background: #29c5e6;
}
.teaser {
display: inline-block;
padding: 0 10px;
box-sizing: border-box;
-moz-box-sizing: border-box;
vertical-align: top;
}
.teaser .heading {
background: transparent url(images/h1-bg.png);
margin: 40px 0 20px;
height: 16px;
}
.teaser .bullet {
display: inline-block;
width: 16px;
height: 16px;
background: #29c5e6;
vertical-align: top;
}
.teaser .heading-text {
display: inline-block;
text-transform: uppercase;
font: normal 14px/16px 'Oswald', sans-serif;
margin: 0;
padding: 0 10px;
background: url(images/bg.png);
}
.teaser .image {
float: left;
margin-right: 20px;
}
.teaser .small-block {
margin-bottom: 10px;
}
.teaser .small-block .image {
margin-right: 10px;
}
.teaser .more,
.teaser .more a {
color: #525252;
margin-bottom: 0;
}
.teaser-small-heading {
display: block;
color: #525252;
margin: 0;
font-weight: normal;
font-size: 11px;
text-transform: uppercase;
}
.teaser-small-paragraph {
margin: 4px 0;
font-size: 11px;
}
.clients img {
display: inline-block;
margin-right: 30px;
}
```
Если вы сейчас посмотрите на страницу, то увидите, что заголовки блоков разъехались. Это связано с тем, что редактор WordPress добавил пустые параграфы в наш код в местах перевода строк. Чтобы решить эту проблему, создайте в папке темы файл functions.php и поместите в него код:
```
php
remove_filter('the_content', 'wpautop');
</code
```
После этого, главная страница должна отобразиться правильно.
#### Сайдбар
Теперь, когда главная страница готова, давайте вернемся к шаблону внутренних страниц и добавим в него сайдбар.
Для этого создайте файл sidebar.php и поместите в него следующий код:
```
wp\_nav\_menu(array('menu' = 'aside-menu', 'menu\_class' => 'aside-menu')); ?>
php echo \_\_('Our offices', 'whitesquare'); ?
----------------------------------------------
; ?>/images/sample.png)
```
Здесь верстка состоит из двух частей: отображение навигации подменю и блок карты офисов. Для полноты картины в качестве подменю предлагаем показать список всех постов на сайте. Подменю создается аналогично тому, как мы создавали меню. При создании подменю в разделе админки Appearance -> Menus создадим новое меню с именем aside-menu. Чтобы добавить в него посты, кликните наверху в Screen options и отметьте галочкой Show on screen: Posts. Блок карты особых вопросов не вызывает.
После того, как блок сайдбара готов, нужно его подключить для всех подстраниц в файле page.php:
```
…
php get_sidebar(); ?
…
```
Далее нам нужно добавить стили для вёрстки:
**Показать код**
```
.aside-navigation {
background: #f3f3f3;
border: 1px solid #e7e7e7;
}
.aside-menu {
margin: 0;
padding: 0;
text-transform: uppercase;
}
.aside-menu li {
font-weight: 300;
list-style: square inside;
border-top: 1px solid #e7e7e7;
font: 14px 'Oswald', sans-serif;
padding: 10px;
font-weight: 300;
}
.aside-menu li:first-child {
border: none;
}
.aside-menu li.current-menu-item,
.aside-menu li.current-menu-item a {
color: #29c5e6;
}
.aside-menu a {
color: #8f8f8f;
text-decoration: none;
}
.sidebar-heading {
background: #29c5e6;
font: 14px 'Oswald', sans-serif;
color: #fff;
padding: 10px;
margin: 30px 0 0 0;
text-transform: uppercase;
}
.map {
background: #f3f3f3;
border: 1px solid #e7e7e7;
padding: 10px;
margin: 0 0 30px 0;
}
```
Ну и в заключение, добавьте несколько постов в наш блог. Делается это в панели администратора на вкладке Posts -> Add New. Мы добавили точно такие же названия, как были в psd макете.
#### Страница About us
Теперь, когда у нас готов шаблон для внутренних страниц, давайте наполним содержимым страницу About us. По той же схеме, как мы наполняли главную страницу – подготовьте изображения и добавьте их в в медиа библиотеку. Назовите изображения вот так:
about-1.png
about-2.png
team-Nobriga.jpg
team-Pittsley.jpg
team-Rousselle.jpg
team-Shoff.jpg
team-Simser.jpg
team-Tondrea.jpg
team-Venuti.jpg
team-Wollman.jpg
Далее перейдите в редактирование страницы в панели администратора и добавьте код:
**Показать код**
```
>
>
> “QUISQUE IN ENIM VELIT, AT DIGNISSIM EST. NULLA UL CORPER, DOLOR AC PELLENTESQUE PLACERAT, JUSTO TELLUS GRAVIDA ERAT, VEL PORTTITOR LIBERO ERAT.”
>
>
>
> John Doe, Lorem Ipsum
>
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean non neque ac sem accumsan rhoncus ut ut turpis. In hac habitasse platea dictumst. Proin eget nisi erat, et feugiat arcu. Duis semper porttitor lectus, ac pharetra erat imperdiet nec. Morbi interdum felis nulla. Aenean eros orci, pellentesque sed egestas vitae, auctor aliquam nisi. Nulla nec libero eget sem rutrum iaculis. Quisque in enim velit, at dignissim est. Nulla ullamcorper, dolor ac pellentesque placerat, justo tellus gravida erat, vel porttitor libero erat condimentum metus. Donec sodales aliquam orci id suscipit. Proin sed risus sit amet massa ultrices laoreet quis a erat. Aliquam et metus id erat vulputate egestas. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
Donec vel nisl nibh. Aenean quam tortor, tempus sit amet mattis dapibus, egestas tempor dui. Duis vestibulum imperdiet risus pretium pretium. Nunc vitae porta ligula. Vestibulum sit amet nulla quam. Aenean lacinia, ante vitae sodales sagittis, leo felis bibendum neque, mattis sagittis neque urna vel magna. Sed at sem vitae lorem blandit feugiat.
Donec vel orci purus, ut ornare orci. Aenean rutrum pellentesque quam. Quisque gravida adipiscing augue, eget commodo augue egestas varius. Integer volutpat, tellus porta tincidunt sodales, lacus est tempus odio, fringilla blandit tortor lectus ut sem. Pellentesque nec sem lacus, sit amet consequat neque. Etiam varius urna quis arcu cursus in consectetur dui tincidunt. Quisque arcu orci, lacinia eget pretium vel, iaculis pellentesque nibh. Etiam cursus lacus eget neque viverra vestibulum. Aliquam erat volutpat. Duis pulvinar tellus ut urna facilisis mollis. Maecenas ac pharetra dui. Pellentesque neque ante, luctus eget congue eget, rhoncus vel mauris. Duis nisi magna, aliquet a convallis non, venenatis at nisl. Nunc at quam eu magna malesuada dignissim. Duis bibendum iaculis felis, eu venenatis risus sodales non. In ligula mi, faucibus eu tristique sed, vulputate rutrum dolor.

```
И стили в style.css:
**Показать код**
```
.main-blockquote {
margin: 0;
background: #29c5e6;
padding: 10px 20px;
font-family: 'Oswald', sans-serif;
font-weight: 300;
}
.main-blockquote p {
color: #fff;
font-style: italic;
font-size: 33px;
margin: 0;
}
.main-blockquote cite {
display: block;
font-size: 20px;
font-style: normal;
color: #1d8ea6;
margin: 0;
text-align: right;
}
.content-heading {
background: #29c5e6;
font: 30px 'Oswald', sans-serif;
font-weight: 300;
color: #fff;
padding: 0 10px;
margin: 30px 0 0 0;
text-transform: uppercase;
}
.team-row figure {
display: inline-block;
margin: 20px 0 0;
font-family: 'Oswald', sans-serif;
font-weight: 300;
}
.team-row figure + figure {
margin-left: 43px;
}
.team-row figcaption {
font-size: 16px;
font-weight: 300;
margin-top: 5px;
}
.team-row .occupation {
display: block;
font-size: 14px;
color: #29c5e6;
}
```
#### Шаблон поста
После предыдущих действий, на нашем сайте уже доступны все страницы, кроме страниц с постами. За отображение одиночных постов отвечает шаблон single.php. Создайте его со следующим содержимым:
```
php get_header();?
php the\_title(); ?
===================
php get_sidebar();?
php while (have\_posts()): the\_post();?
php the\_content();?
php
if ( comments\_open() || get\_comments\_number() ) {
comments\_template();
}
?
php endwhile; ?
php get_footer(); ?
```
Этот шаблон аналогичен предыдущим шаблонам с той лишь разницей, что здесь мы сначала отображаем контент поста, а затем комментарии к нему.
#### Страница поиска
В самом начале, когда мы создавали шаблон шапки мы добавили в него поиск, однако страницы для отображения результатов поиска у нас еще нет. Создайте в папке темы файл search.php и добавьте в него содержимое:
```
php get_header(); ?
Search
======
php get_sidebar(); ?
php printf( \_\_('Search Results for: %s', 'default'), get\_search\_query() ); ?
--------------------------------------------------------------------------------
php if (have\_posts()): while (have\_posts()): the\_post(); ?
### [php the\_title(); ?](<?php the_permalink(); ?>)
php the\_excerpt(); ?
php endwhile; else:?
php echo \_\_('Sorry, no results found', 'whitesquare'); ?
php endif; ?
php get_footer(); ?
```
От других шаблонов этот отличается тем, что мы выводим заголовок с текстом поиска, а затем список результатов поиска.
#### Страница архива
В WordPress помимо одиночных постов существуют страницы, на которых отображаются списки постов. Это могут быть категории, сортировка по дате, автору или по ключевым словам. В нашем макете такого функционала нет, но добавить его обязательно нужно, так как мы создаем шаблон, который может использоваться с разным контентом. Для каждого из указанных списков, существуют свои шаблоны, однако если они не найдены, WordPress пытается найти общий файл archive.php. Мы этим воспользуемся и создадим его. Поскольку его содержимое ничем не будет отличаться от содержимого обычной страницы – просто скопируйте page.php в archive.php.
#### 404
Последний шаблон, который осталось добавить — это шаблон для 404 страницы, когда WordPress не смог найти запрошенную страницу. Он будет точно такой же, как page.php только вместо вывода постов будет написано сообщение об ошибке:
```
php get_header(); ?
php the\_title(); ?
===================
php get_sidebar(); ?
php echo \_\_('It looks like nothing was found at this location.', 'whitesquare'); ?
php get_footer(); ?
```
#### Заключение
На этом создание шаблона WordPress закончено. Готовый проект можно скачать [здесь](https://github.com/Mirantus/whitesquare-wordpress).
Ссылки на предыдущие статьи:
[Как сверстать веб-страницу. Часть 1](http://habrahabr.ru/post/202408/)
[Как сверстать веб-страницу. Часть 2 — Bootstrap](http://habrahabr.ru/post/211032/)
[Верстка для самых маленьких. Верстаем страницу по БЭМу](http://habrahabr.ru/post/203440/) ([xnim](https://habr.com/ru/users/xnim/))
[Создаём шаблон 1С-Битрикс на базе Bootstrap вёрстки](http://habrahabr.ru/post/212163/) ([lexnekr](https://habr.com/ru/users/lexnekr/))
**Update:**
Статья была существенно обновлена в соответствии с пожеланиями комментаторов.
* Создание меню теперь описано не на основе wp\_list\_pages, а с помощью wp\_nav\_menu.
* Все фразы, используемые в шаблоне вставляются через функцию локализации \_\_('')
* Стили и скрипты подключаются не в файле header.php, а через специальные функции в functions.php
* Код главной страницы в шаблоне перенесен из page-home.php во front-page.php | https://habr.com/ru/post/228523/ | null | ru | null |
# Вы все еще храните 404backup.zip на сервере? Я на 200ДА
Сумеречными зимними вечерами под песнь вьюги, укутавшись в овечий плед с бокальчиком «яблочной самогонки», я люблю почитывать логи на сервере. Авторизация по ключам упрощает сие, так что если в публичное помещение меня и не пустят, то сервер всегда рад приютить, старый чертяга.
В мире много чего происходит, у кого счастливое 200, кто-то недоуменно смотрит на 301, кто-то царапает похабщину на 403.
Но самый ценных мех — это исследователи. Это те, кто открывает новый для себя мир на основе своих знаний путем проб и 404.
Вот о 404 и пойдет речь. Это статья не то, чтобы не о чем. Она о безопасности.
С каждым днем все больше и больше людей разного возраста, религии, пола и установленной системы выбирают себе дорогу ИТ-опасника, чтобы потом стать ИТ-безопасником с хороших плохим послужным списком списком.
Такие креативные ребята и девчата денно и нощно посылают запросы об эксплоитах, которые отдаются им в виде 403 и 404, но это потом.
Все начинают с грубой аналитики поиска `backup.zip`, которые должен быть в корне сайта. Многие уходят за рамки `backup.zip`, и упираются в стенку `archive.zip`. Кто-то, поставив первую в своей жизни MySQL 3.0 ищет `dump.zip`, `mysql.zip` и, компьютерныхбоже алилуйя, `home.zip`. О `.7z` или `.tar.gz` даже мыслей нет!
Каждый раз, когда я вижу 404 в логе напротив очередного head, или того хуже get, мое сердце сжимается от боли, которую они чувствуют, читая ошибку с экрана, как вы читаете эту статью.
В один прекрасный день, я сказал себе — «Довольно, %username%! Ты жесток! Ты не даешь им шанса, так нельзя, это не по-человечески».
Я возразил, что жизнь вообще такая штука, нельзя им подать на блюде файл, да еще и с каемочкой. Третий голос молвил «моя преелесссть..», я не понял к чему, но рука потянулась в карман.
В итоге, после сделки с совестью и железным супергероем, которые есть почти в каждом из нас и из вас, я написал вот это:
```
location ~* "^/(archive|auth|backup|clients|com|dat|dump|engine|files|home|html|index|master|media|my|mysql|old|site|sql|website|wordpress)\.zip$" {
access_log /usr/local/nginx/logs/dummy.log;
default_type application/zip;
root /usr/local/nginx/html/dummy;
rewrite ^(.*)$ /mydummy break;
max_ranges 0;
limit_rate 4k;
include param/zone1rs;
}
```
`max_ranges 0;` — запрещает «докачку»
`limit_rate 4k;` — ограничивает скорость скачивания
`include param/zone1rs;` — Зона, где разрешен 1 коннект на 1 ип. В разных версиях nginx свой листинг. Главное — `limit_conn one 1;`, где `one` это имя вашей зоны.
`mydummy` получается очень просто:
```
dd bs=1024 count=1572864 mydummy
```
Затем нужно показать недоверчивым, что это zip архив:
```
echo -ne \\x50\\x4b\\x03\\x04\\x14\\x00\\x00\\x00\\x08\\x00 | dd conv=notrunc bs=1 count=10 of=mydummy
```
Теперь даже плохая погода мне нипочем! Ежели на дворе печальная осень, или мертвая зима, я бережно сдуваю хлебные крошки с консоли, вызываю:
```
tail -n 16 /usr/local/nginx/logs/dummy.log
```
… и на моем лице появляется улыбка! Я счастлив за будущее человечества, я горд за тех `adsl` или `cablenet`, кто целеустремленно, в течение пяти суток, бережно скачивает этот архив, этот маленький билетик в жизнь, весом в 1.5 гигабайта и ценой 5 дней этой же самой жизни. Я счастлив, что я могу сделать этот мир лучше и подарить неполную неделю счастья и практически рождественского ожидания подарка из моего правого носка.
 | https://habr.com/ru/post/272261/ | null | ru | null |
# Опыт автоматизации непростой переписки (Часть 2. Исходящий)
Хочу продолжить описание своего опыта усовершенствования процесса управления официальной корреспонденций в проектной организации, начатый в [предыдущей статье](https://habrahabr.ru/company/easla/blog/281839/). Напомню, что вместо elma была выбрана система easla.com и в ней уже было описано поведение входящего документа.

Следующим шагом к цели является описание поведения исходящего документа. То были цветочки… под катом еще больше текста и кода.
Требования к исходящему документу оказались в несколько раз серьезнее, чем к входящему. Если собрать только основные в отдельный сводный список, то получится:
* Регистрация исходящего документа любым сотрудником организации
* Совместная разработка сопроводительного письма (разумеется, не одновременно, но в одном файле)
* Сохранение промежуточных версий сопроводительного письма
* Хранение большого числа приложений в разных форматах
* Хранение архивных ([zip](https://ru.wikipedia.org/wiki/ZIP)) файлов с проектной документацией (с загрузкой из [TDMS](http://www.tdms.ru/) и хранением доп. информации о связи с объектами)
* Отправка исходящего документа различными способами (эл. почтой как есть, одним архивом, многотомным архивом, расшариванием, загрузкой на [ftp](https://ru.wikipedia.org/wiki/FTP) и т.п.)
Как видите, требования непростые. Именно поэтому я так внимательно отнесся к выбору новой системы и остановился на [easla.com](http://easla.com). Но, давайте расскажу по-порядку.
Начал я с того, что в процессе «Переписка» создал объект «Исходящий документ» и перешел к наполнению его атрибутами. Их еще больше, чем во входящем!
#### Атрибуты
##### Контрагент
Ссылка на объект «Контрагент» из процесса «Заказчики». Инициализация допустимых значений атрибута осуществляется в скрипте «После инициализации объекта»:
```
cobjectref()->attributeref('crs_management_outgoing_contragent')->values = prepareOutgoingContragents();
```
Вспомогательная функция prepareOutgoingContragents объявлена в скрипте «До инициализации объекта»:
```
function prepareOutgoingContragents()
{
$src_contragents = selectAll(
'crm_management',
'crm_management_contragent'
);
$end_contragents = array();
foreach ($src_contragents as $s)
$end_contragents += array($s['id'] => $s['description']);
asort($end_contragents);
return $end_contragents;
}
```
В зависимости от выбранного контрагента зависит список доступных контактов и рекомендуемое правило отправки письма. И если поведение с контактами понятно всем, то с правилом отправки — не каждому. Дело в том, что наши контрагенты, особенно заказчики, очень капризны в части приема эл. почты. Мне сложно объяснить причины такого поведения, но, например, одни заказчики принимают эл. письма максимальным объемом 3Мб и при этом требуют, чтобы всю документацию, которая может быть объемом и 100Мб, им присылали исключительно по эл. почте. Другие допускают передачу больших вложений в эл. письмах, скажем, порядка 10-15Мб, но требуют, чтобы все приложения поступали только в формате zip и ни в коем случае не многотомным архивом. Третьи настаивают на том, чтобы сопроводительное письмо было отправлено эл. почтой на их корпоративный адрес, а все приложения были переданы иным образом и другим адресатам. Четвертые просят выкладывать приложения к письмам на приватную «шару», чтобы они могли оттуда все скачать. Пару недель назад, один заказчик попросил при отправке письма все приложения перекладывать на защищенный [FTP](https://ru.wikipedia.org/wiki/FTP), а другой потребовал, чтобы все приложения и сопроводительное письмо закачивалось к ним на портал поднятый на FrontPage и раскладывалось по определенным папкам.
Было очевидно, что при интенсивной переписке, вручную удовлетворять требования всех заказчиков по отправке писем будет сложно. Возможно, но очень сложно. Придется и специалисту по делопроизводству, и ГИПам помнить, в каком именно виде отправлять письмо конкретному заказчику. Издевательство, а не работа!
Мне пришлось немного поломать себе голову, как бы сохранить все эти требования в [easla.com](http://easla.com), чтобы облегчить труд всех участников процесса. В итоге, я доработал объект «Контрагент» в процессе «Заказчики» путем добавления к нему двух атрибутов: один для хранения рекомендуемого правила отправки (о нем подробнее ниже), второй для списка дополнительных контактов (о нем тоже будет подробнее).
Короче, скрипт «При изменении» атрибута позволяет переопределить значения атрибутов в соответствии с выбранным контрагентом:
```
if (!empty(cattributeref()->value))
{
$contacts = cobjectref()->prepareOutgoingContacts(cattributeref()->value);
cobjectref()->attributeref('crs_management_outgoing_contact')->values = $contacts;
$contracts = cobjectref()->prepareContracts(cattributeref()->value);
if (empty($contracts))
$contracts = cobjectref()->prepareContracts();
cobjectref()->attributeref('crs_management_outgoing_contract')->values = $contracts;
$default_rule = cobjectref()->calcContragentOutgoingRule(cattributeref()->value);
if (!empty($default_rule))
cobjectref()->attributeref('crs_management_outgoing_rule')->value = $default_rule;
$default_notifiers = cobjectref()->calcContragentOutgoingNotifiers(cattributeref()->value);
if (!empty($default_notifiers))
cobjectref()->attributeref('crs_management_outgoing_notifiers')->value = $default_notifiers;
//if (cobjectref()->attributeref('crs_management_outgoing_contragent')->value == 45410)
}
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value = cobjectref()->updateDocumentCntNum();
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = cobjectref()->calcOutgoingCode();
```
Кстати, две последние строчки скрипта тоже добавлены недавно. Связано с тем, что один заказчик потребовал от нас использовать для идентификации исходящих документов свои обозначения, отличные от наших. Вот такие они – заказчики!
##### Контакт
Ссылка на объект «Контакт» в процессе «Заказчики». Как и список контрагентов, список контактов инициализируется в скрипте «После инициализации объекта»:
```
$contacts = prepareOutgoingContacts();
cobjectref()->attributeref('crs_management_outgoing_contact')->values = $contacts;
```
При этом вспомогательная функция prepareOutgoingContacts точно также объявлена в скрипте «До инициализации объекта»:
```
function prepareOutgoingContacts($contragent = null)
{
if (empty($contragent))
$src_contacts = selectAll(
'crm_management',
'crm_management_contact',
array('crm_management_contact_contragent.description'),
null
);
else
$src_contacts = selectAll(
'crm_management',
'crm_management_contact',
array('crm_management_contact_contragent.description'),
array('crm_management_contact_contragent'=>$contragent)
);
$end_contacts = array();
$processed_contact = array();
$processed_description = array();
foreach ($src_contacts as $s)
{
$e = array_search($s['description'], $processed_description);
if($e === false) {
$processed_contact += array($s['id'] => $s);
$processed_description += array($s['id'] => $s['description']);
$end_contacts += array($s['id'] => $s['description']);
} else {
$end_contacts[$e] = $processed_contact[$e]['description'].' ['.trim($processed_contact[$e]['crm_management_contact_contragent.description']).']';
$end_contacts += array($s['id'] => $s['description'].' ['.trim($s['crm_management_contact_contragent.description']).']');
}
}
unset($processed_contact,$processed_description);
asort($end_contacts);
return $end_contacts;
}
```
Функция, как и ее «сестра» в объекте «Входящий документ», ко всем полным тезкам дописывает название организации в которой они работают, чтобы их можно было отличить.
Ради дополнительного удобства, скрипт «При изменении» контакта и не указанном контрагенте, подставляет нужного контрагента и обновляет значения зависимых от него атрибутов:
```
if (empty(cobjectref()->attributeref('crs_management_outgoing_contact')->value))
return;
if (empty(cobjectref()->attributeref('crs_management_outgoing_contragent')->value))
{
$contact = select(cobjectref()->attributeref('crs_management_outgoing_contact')->value);
if (empty($contact))
return;
$contragent_id = $contact->attributeref('crm_management_contact_contragent')->value;
cobjectref()->attributeref('crs_management_outgoing_contragent')->value = $contragent_id;
$contracts = cobjectref()->prepareContracts($contragent_id);
if (empty($contracts))
$contracts = cobjectref()->prepareContracts();
cobjectref()->attributeref('crs_management_outgoing_contract')->values = $contracts;
$default_rule = cobjectref()->calcContragentOutgoingRule($contragent_id);
if (!empty($default_rule))
cobjectref()->attributeref('crs_management_outgoing_rule')->value = $default_rule;
$default_notifiers = cobjectref()->calcContragentOutgoingNotifiers($contragent_id);
if (!empty($default_notifiers))
cobjectref()->attributeref('crs_management_outgoing_notifiers')->value = $default_notifiers;
}
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value = cobjectref()->updateDocumentCntNum();
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = cobjectref()->calcOutgoingCode();
```
Выглядит результат примерно так:
##### Доп. контакты
Ссылка на объект «Контакт» в процессе «Заказчики». Представляет собой список дополнительных контактов, которые будут поставлены в копию при отправке письма основным адресатам. Как раз в этот атрибут записываются контакты, указанные в объекте «Контрагент», которым нужно отправить копии письма, если оно направлено определенному контрагенту.
Реализация получилась очень удобная, т.к. раньше, специалист по делопроизводству и ГИПы обклеивали свои мониторы липкими бумажками, на которых были написаны наименования заказчика и список лиц, которым отправлять копии писем. Вместо бумажек теперь используется [easla.com](http://easla.com) и никто не забывает указывать контакты в копии.
##### Доп. уведомлять по эл. почте
Ссылка на объект «Контакт» в процессе «Заказчики». Очередной список доп. контактов, которых надо отдельно оповещать копией письма. Зачастую это могут быть даже не сотрудники заказчика, а скажем, сотрудники головной организации или контролирующего органа.
##### Правило отправки
Классификатор, позволяющий определить способ отправки письма адресату. На сегодняшний день у нас используется 16 правил отправки. Некоторые отличаются только в цифрах, например:
* Все отправить всем (письмо не более 3Мб)
* Документ осн. контакту, все всем остальным (больше 5М, архивы по 4.5М)
* Всем отправить ссылку на архив с письмом и приложениями
* Документ осн. контакту, всем остальным ссылку на архив с письмом и приложениями
* Все отправить всем (больше 3М, архивы по 2.5М)
* Все переложить на ftp.sngp.ru для ООО «Заказчик»
* Все отправить как ссылки на портал pro.blablabla.ru
Список допустимых значений формируется в скрипте атрибута «При инициализации»:
```
$src_classificators = classificatorChilds('crs_outgoing_rule');
$end_classificators = array();
$default = 'crs_outgoing_rule_asis_max5';
$default_index = null;
foreach($src_classificators as $c) {
$end_classificators += array($c['id']=>$c['name']);
if ($c['code'] == $default)
$default_index = $c['id'];
}
if (count($end_classificators) > 0)
{
cattributeref()->values=$end_classificators;
cattributeref()->value = is_null($default_index) ? key($end_classificators) : $default_index;
}
```
Полезная функция classificatorChilds возвращает прямых потомков указанного классификатора. Остается только перебрать значения, сформировать массив и присвоить атрибуту.
Правило отправки использует в действии «Отправить по эл. почте», которое будет описано ниже.
##### Дата регистрации
Очевидно из названия, что хранит дату регистрации исходящего документа. Исходное значение соответствует текущей дате и инициализируется в скрипте атрибута «При инициализации»:
```
cobjectref()->attributeref('crs_management_outgoing_regdate')->value = currentDateTime();
```
##### Дата отправки
Также понятно из названия, что атрибут хранит дату отправки. Он только для чтения, т.е. сам пользователь не может его заполнить. В режим «только для чтения» атрибут переводится в скрипте «При инициализации»:
```
cattributeref()->readonly = true;
```
##### Исполнители
Пользователи (сотрудники) организации, участвующие в разработке письма. Атрибут множественный, так как в разработке письма может участвовать несколько сотрудников. Во время регистрации (создания) письма происходит идентификация текущего пользователя и, если он не относится к узкому кругу лиц, очерченному указанными в коде группами, то записывается в значение атрибута. Каждый последующий сотрудник должен сам добавить себя в список исполнителей, если хочет получить информацию об отправке письма. Кстати, исполнители указываются и в конце бланка исходящего письма с указанием их телефонов для обратной связи.
Инициализация допустимых значений атрибута происходит в скрипте «При инициализации»:
```
$src_users = corganization()->allUsers();
$end_users = array();
foreach($src_users as $u)
if ($u['islocked'] == 0)
$end_users += array($u['id']=>$u['description']);
asort($end_users);
cobjectref()->attributeref('crs_management_outgoing_performers')->values = $end_users;
if (!empty(cuser()))
{
$rsp_users = corganization()->allUsersByGroups(array(
'group_general_manager',
'group_general_engineer',
'group_general_manager_operations',
'group_general_manager_economics',
'group_gip',
'group_hr',
'group_dp'
), null);
$f = true;
foreach($rsp_users as $u)
if ($u['id'] == cuser()->id) {
$f = false;
break;
}
if ($f) {
cobjectref()->attributeref('crs_management_outgoing_performers')->value = cuser()->id;
cobjectref()->updateResponsibleGroup();
}
}
```
Вспомогательная функция updateResponsibleGroup предназначена для обновления значения атрибута «Отв. подразделение» и объявлена в скрипте «До инициализации объекта»:
```
function updateResponsibleGroup()
{
if (empty(cobjectref()->attributeref('crs_management_outgoing_performers')->value))
return;
if (empty(cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value))
{
$performers = cobjectref()->attributeref('crs_management_outgoing_performers')->value;
$user = corganization()->user($performers[0]);
if (empty($user))
return;
$groups = $user->groups();
foreach($groups as $group)
if (!empty($group['data_one']))
{
cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value = $group['id'];
break;
}
}
}
```
В случае изменения значения атрибута срабатывает скрипт «При изменении», который обновляет ответственное подразделение в форме исходящего документа:
```
if (!empty(cobjectref()->attributeref('crs_management_outgoing_performers')->value) && empty(cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value))
cobjectref()->updateResponsibleGroup();
```
##### Отв. сотрудник
Пользователи (сотрудники) организации, который будет подписывать исходящее письмо. В нашем случае, официальные письма подписывают только высшие руководители, начальник отдела кадров и ГИПы. Перечень допустимых сотрудников формируется в скрипте «При инициализации»:
```
$src_users = corganization()->allUsersByGroups(array(
'group_general_manager',
'group_general_engineer',
'group_general_manager_operations',
'group_general_manager_economics',
'group_gip_only',
'group_hr'
), null);
$end_users = array();
foreach($src_users as $u)
if ($u['islocked'] == 0)
$end_users += array($u['id']=>$u['description']);
asort($end_users);
cobjectref()->attributeref('crs_management_outgoing_responsibleuser')->values = $end_users;
```
Функция allUsersByGroups просто «палочка-выручалочка», когда нужно получить список пользователей входящих в определенные группы или наоборот.
При изменении атрибута происходит проверка наличия значения в атрибуте «Отв. подразделение». В том случае, если оно отсутствует, т.е. в письме не указан исполнитель, в него записывается подразделение, к которому относится отв. сотрудник:
```
if (!empty(cattributeref()->value) && empty(cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value))
{
$user = corganization()->user(cattributeref()->value);
$groups = $user->groups();
foreach ($groups as $group)
if (is_numeric($group->data_one))
{
cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value = $group->id;
break;
}
}
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = cobjectref()->calcOutgoingCode();
```
Очень радует возможность создавать такие динамические формы в easla.com. Изменяя значения одних атрибутов, могу изменять значения других в любой последовательности! Попробуйте сделать такое же, например, в Sharepoint.
##### Отв. подразделение
Группа пользователей, в нашем случае – подразделение организации, которое отвечает за разработку исходящего документа.
Все подразделения в нашей организации имеют свои числовые (дробные) идентификаторы присвоенные отделом кадров. Наверное, они применяются где-то еще, но в моем случае, они применяются для идентификации исходящего письма. Поэтому, когда я создавал группы для пользователей в easla.com, в так называемые «первые данные» вписал и эти идентификаторы.
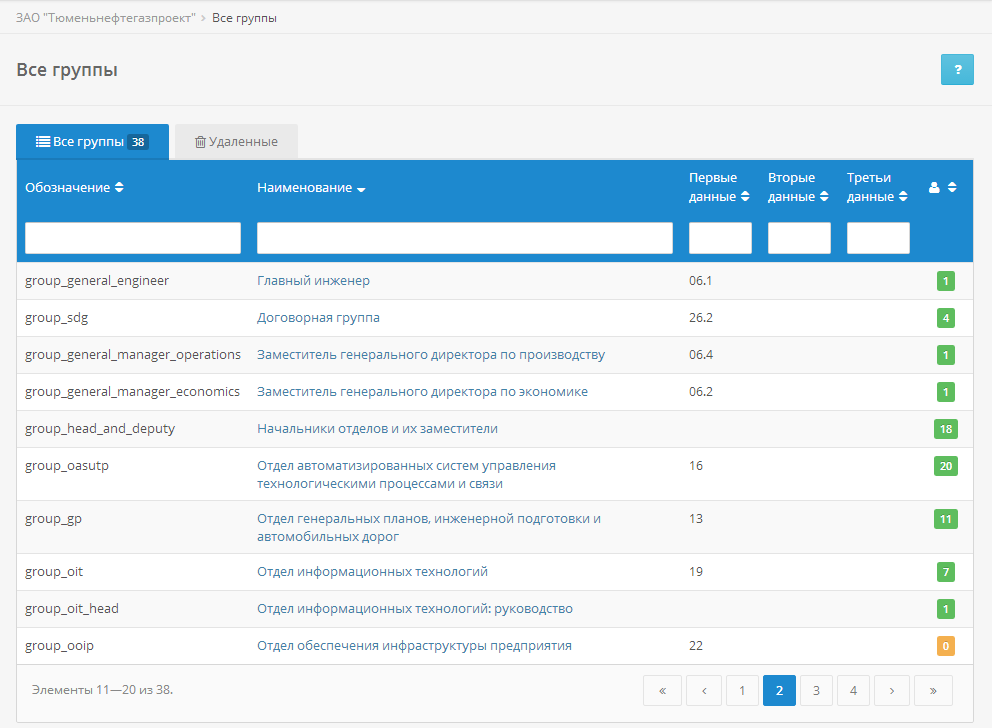
При формировании списка возможных отв. подразделений скрипт «При инициализации» проверяет наличие «первых данных» и включает группы в список только при их наличии:
```
$src_groups = corganization()->groups();
$end_groups = array();
foreach($src_groups as $g)
if (!empty($g['data_one']))
$end_groups += array($g['id']=>$g['name']);
asort($end_groups);
cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->values = $end_groups;
```
При изменении отв. подразделения изменяется обозначение регистрационного номера исходящего документа:
```
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = cobjectref()->calcOutgoingCode();
```
Вспомогательная функция calcOutgoingCode объявлена в скрипте «До инициализации объекта»:
```
function calcOutgoingCode()
{
if (empty(cobjectref()->attributeref('crs_management_outgoing_contragent')->value))
return;
if (empty(cobjectref()->attributeref('crs_management_outgoing_cntnum')->value))
return;
if (!empty(cobjectref()->attributeref('crs_management_outgoing_content')->value) &&
cobjectref()->attributeref('crs_management_outgoing_contragent')->value == 45410 &&
cobjectref()->attributeref('crs_management_outgoing_content')->value == 1192) {
//This is ZapSib-2 Project
if (empty(cobjectref()->attributeref('crs_management_outgoing_content')->value))
return;
$content = classificator(cobjectref()->attributeref('crs_management_outgoing_content')->value);
if (empty($content))
return;
$content_code = $content['data_one'];
if (empty($content_code))
return;
//TRANSMITTAL
return sprintf('TNGP-NPG-ZS2-0311-%s-%05d',
$content_code,
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value
);
}
if (empty(cobjectref()->attributeref('crs_management_outgoing_responsibleuser')->value))
return;
if (empty(cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value))
return;
$group_code = str_replace('.','-',corganization()->group(cobjectref()->attributeref('crs_management_outgoing_responsiblegroup')->value)->data_one);
$user_code = mb_substr(corganization()->allUser(cobjectref()->attributeref('crs_management_outgoing_responsibleuser')->value)->lastname, 0, 2);
return sprintf(
'%s/%s-%s',
$group_code,
$user_code,
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value
);
}
```
До недавнего времени функция была куда проще, но из-за последних требований, пришлось внести в нее изменение, которое учитывает идентификатор заказчика и тип письма. В соответствии с заполненными атрибутами функция формирует регистрационный номер документа.
##### Порядковый номер
Порядковый номер исходящего документа начинает свою нумерацию каждый год заново. Поэтому использовать встроенный в [easla.com](http://easla.com) нумератор оказалось невозможным. Пришлось написать свой.
Кроме этого, один из заказчиков потребовал использовать сквозную нумерацию для определенного типа своих писем, поэтому нумерация у нас как бы двойная. Обычная для писем с нашим регистрационным номером и необычная для писем с регистрационным номером затребованным заказчиком.
При создании исходящего документа происходит вычисление исходного порядкового номера:
```
cattributeref()->value = cobjectref()->updateDocumentCntNum();
```
Вспомогательная функция updateDocumentCntNum также объявлена в скрипте «До инициализации объекта»:
```
function updateDocumentCntNum()
{
if (cobjectref()->isNewRecord || empty(cobjectref()->attributeref('crs_management_outgoing_cntnum')->value))
{
if (!empty(cobjectref()->attributeref('crs_management_outgoing_contragent')->value) &&
!empty(cobjectref()->attributeref('crs_management_outgoing_content')->value) &&
cobjectref()->attributeref('crs_management_outgoing_contragent')->value == 45410 &&
cobjectref()->attributeref('crs_management_outgoing_content')->value == 1192)
{
$num = selectAggregateAll(
'max',
'crs_management',
'crs_management_outgoing',
'crs_management_outgoing_cntnum',
array(
'crs_management_outgoing_contragent'=>array('id',cobjectref()->attributeref('crs_management_outgoing_contragent')->value),
'crs_management_outgoing_content'=>array('id',cobjectref()->attributeref('crs_management_outgoing_content')->value)
)
);
return $num + 1;
}
$year = date_format(currentDateTime(), 'Y');
$condition = array(
'crs_management_outgoing_regdate'=>array('between', $year.'-01-01', $year.'-12-31'),
);
switch ($year) {
case '2016':
$condition['crs_management_outgoing_cntnum'] = '<4489';
$tmp = selectAggregateAll(
'max',
'crs_management',
'crs_management_outgoing',
'crs_management_outgoing_cntnum',
$condition
);
if ($tmp == 4488) {
unset($condition['crs_management_outgoing_cntnum']);
} else {
return $tmp + 1;
}
break;
}
$num = selectAggregateAll(
'max',
'crs_management',
'crs_management_outgoing',
'crs_management_outgoing_cntnum',
$condition
);
return $num + 1;
} else {
return cobjectref()->attributeref('crs_management_outgoing_cntnum')->value;
}
}
```
Если вы внимательно посмотрите на код, то увидите странное условие case '2016'. Это результат наших внутренних проблем. У нас тоже бывает регистрация документов «задним числом», поэтому в [easla.com](http://easla.com) я не стал делать «отсечку» на попытку обмана. Как бы, все на ответственности пользователя. Вот и создали в начале этого года письма с прошлогодними номерами. И даже успели их отправить! Пришлось ставить условие и отсекать такие письма, чтобы правильно нумеровать письма в нынешнем году.
Отдельно обращу внимание на функцию selectAggregateAll. Она возвращает агрегированное значение, в моем случае, максимальное числовое значение атрибута 'crs\_management\_outgoing\_cntnum' объекта 'crs\_management\_outgoing' в процессе 'crs\_management'. При этом использует условие поиска $condition, которое формируется немного выше.
В той же elma мне пришлось отказать от подобного метода в пользу обходного. Вот как было:
**Правильной, но тормозной код в elma**
```
var manager = EntityManager.Instance;
DateTime startdate = new DateTime(entity.RegDate.Value.Year, 1, 1);
DateTime enddate = new DateTime(entity.RegDate.Value.Year, 12, 31);
var allInYear = from d in manager.FindAll()
where d.RegDate.Value >= startdate && d.RegDate.Value <= enddate
orderby d.CntNum
select d;
if (allInYear.Count() == 0)
entity.CntNum = 1;
else
entity.CntNum = allInYear.Last().CntNum + 1;
```
Все работало до поры до времени, но потом начало так сильно тормозить, что пришлось искать узкие места. Выяснилось, что одним таким местом является вычисление порядкового номера. Пришлось создать доп. таблицы и заменить код, чтобы увеличить скорость работы объекта и системы в целом:
**Обходной маневр в elma**
```
string ConString = "Data Source=ss2;Initial Catalog=ELMA;User ID=sa;Password=password;";
using (SqlConnection connection = new SqlConnection(ConString))
{
using (SqlCommand command = connection.CreateCommand())
{
var year = entity.RegDate.Value.Year;
command.CommandText = "SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SELECT TOP 1 cntNum FROM [ELMA].[dbo].[OutgoingDoc] WHERE (RegDate >= CAST('" + year.ToString() + "-01-01 00:00:00' AS datetime)) AND (RegDate < CAST('" + year.ToString() + "-12-31 23:59:59' AS datetime)) ORDER BY cntNum DESC";
connection.Open();
SqlDataReader reader = command.ExecuteReader();
var cntNum = 0;
if (reader.Read())
cntNum = int.Parse(reader[0].ToString());
connection.Close();
command.CommandText = "SELECT TOP 1 reservedNum FROM [TNGP].[dbo].[ElmaReservedNums] WHERE docType = '" entity.TypeUid + "' ORDER BY reservedNum DESC";
connection.Open();
reader = command.ExecuteReader();
var reservedNum = 0;
if (reader.Read())
reservedNum = int.Parse(reader[0].ToString());
connection.Close();
if (cntNum < reservedNum)
cntNum = reservedNum;
if (cntNum == 0)
cntNum = 1;
else
cntNum++;
command.CommandText = "INSERT INTO [TNGP].[dbo].[ElmaReservedNums](reservedNum, docType) VALUES (" + cntNum.ToString() + ",'" + entity.TypeUid + "')";
connection.Open();
command.ExecuteNonQuery();
connection.Close();
entity.CntNum = cntNum;
}
}
```
Разве это дело?!
##### Регистрационный номер
Обязательный текстовый атрибут только для чтения. Хранит регистрационный номер исходящего документа. Вычисляется при инициализации:
```
cattributeref()->readonly = true;
cattributeref()->value = cobjectref()->calcOutgoingCode();
```
Обновляется при изменении других атрибутов, чьи значения влияют на регистрационный номер документа.
##### Тема
Обычный многострочный обязательный текстовый атрибут.
##### Тип содержания
Классификатор, позволяющий определить тип содержания письма. Точно такой же, как и у входящего документа. Список допустимых значений формируется «При инициализации»:
```
$src_classificators = classificatorChilds('crs_content');
$end_classificators = array();
foreach($src_classificators as $c) {
$end_classificators += array($c['id']=>$c['name']);
if ($c['code'] == 'crs_content_other')
$default = $c['id'];
}
if (count($end_classificators) > 0)
{
cattributeref()->values=$end_classificators;
cattributeref()->value = isset($default) ? $default : $c['id'];
}
```
Совсем недавно изменение значения атрибута потребовало обновления порядкового и, как следствие, регистрационного номера.
```
if (cobjectref()->attributeref('crs_management_outgoing_contragent')->value == 45410)
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value = cobjectref()->updateDocumentCntNum();
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = cobjectref()->calcOutgoingCode();
```
##### В ответ на входящие
Ссылка на «Входящий документ» этого же процесса. Такой же важный атрибут, как и "[В ответ на исходящее](https://habrahabr.ru/company/easla/blog/281839#incoming1)" для объекта «Входящий документ». Позволяет выстроить цепочку писем входящий-исходящий-входящий-исходящий и т.д.
В нашем случае, помимо цепочки писем, заполнение атрибута влияет еще и на появление соответствующих отметок в задачах, поставленных для подготовки ответа на входящее письмо. Но об этом надо рассказывать в отдельной статье про процесс «Задачи».
Инициализация списка доступных входящих писем осуществляется в скрипте атрибута «При инициализации»:
```
cattributeref()->values = cobjectref()->prepareIncomings();
```
Используется вспомогательная функция prepareIncomings объявленная в скрипте «До инициализации объекта»:
```
function prepareIncomings()
{
$src_documents = selectAll(
'crs_management',
'crs_management_incoming',
array('crs_management_incoming_contragent_regnum')
);
$end_documents = array();
foreach ($src_documents as $d)
$end_documents += array($d['id'] => $d['crs_management_incoming_contragent_regnum'].' ['.$d['description'].']');
asort($end_documents);
return $end_documents;
}
```
##### Договор
Ссылка на объект «Договор» в процессе «Договоры». Опять же, является полным аналогом атрибута "[Договор](https://habrahabr.ru/company/easla/blog/281839#incoming2)" в объекте «Входящий документ».
Инициализация списка доступных договоров происходит в скрипте «После инициализации объекта», сразу после инициализации списка контрагентов и контактов:
```
cobjectref()->attributeref('crs_management_outgoing_contract')->values = prepareContracts();
```
Изменение списка доступных договоров происходит при изменении других атрибутов, в частности, контрагента.
##### Регистрационный номер получателя
Практически всегда пустой атрибут, т.к. предназначен для хранения регистрационного номера присвоенного нашему письму на стороне получателя, т.е. на стороне заказчика. Но заказчики не торопятся его сообщать, поэтому, специалист по делопроизводству заполняет атрибут только тогда, когда этого потребует главный инженер и кто-то другой из высшего руководства.
##### Дата получения
Должен заполняться вместе с регистрационным номером получателя. Ну вы поняли…
##### Фамилия И.О. получателя
Должен заполняться вместе с регистрационным номером получателя и датой получения. Даже не знаю, что еще добавить. Именно поэтому эти три атрибута вынесены в конечном счете в отдельную форму.
##### Документ
Вот в этом атрибуте хранится собственно сам файл исходящего документа. Причем, следуя требованиям руководства, он настроен так, чтобы сохранять все версии файла.
Вся настройка атрибута осуществляется в скрипте «При инициализации»:
```
cattributeref()->revMode = true;
cattributeref()->canScan = true;
cattributeref()->fileLinks = 3;//1;//2;
```
Обалденно настраивается файловый атрибут. Включил revMode и вуаля, теперь при каждой загрузке/сохранении файла сохраняется его предыдущая версия (ревизия).
Включил canScan и вуаля, под атрибутом появилась кнопка для прямого сканирования файлов в объект.

Включил режим fileLinks=3 и вуаля, теперь при клике на файле он не скачивается, а сразу открывается в соответствующем приложении (при наличии установленного [Easla Agent](http://easla.com/ru/site/page/view/tools)). Нарочно не стал убирать комментарий в конце строки, он напоминает мне о том, как постепенно пользователи привыкали к изменению ссылки. Изначально был режим 0, т.е. обычный, когда клик по файлу приводил к его скачиванию. Потом включил режим 1 – файл стал открываться в приложении, а не скачиваться. Некоторых это не устроило, т.к. иногда файл надо именно скачать, а не открыть, поэтому включил режим 2 – при клике на файле происходит скачивание, но справа от файла доп. кнопка для открытия. И только потом включил режим 3 – при клике на файле он открывается в приложении, а рядом с файлом кнопка для скачивания (см. картинку выше).
Помимо этого, в [easla.com](http://easla.com) любой файловый атрибут может обладать шаблонами файлов. Пользователи могут выбрать шаблон на форме объекта и создать новый файл в атрибуте. Один из помощников ГИПа по поручению главного инженера разработал шаблоны исходящих писем с готовыми формулировками. Составлять текст письма стало проще.
Кстати, шаблон письма обладает специально созданными полями, в которые, с помощью макроса в Microsoft Word, вписываются нужные значения. Более того, они не просто вписываются, но еще и склоняются в нужном падеже. Таким образом, автор письма может не тратить время на нудное заполнение атрибутики письма, а сразу переходить к самому главному. Про интеграцию с Microsoft Word тоже можно написать отдельную статью.
При изменении атрибута, т.е. при загрузке файла, происходит выполнение скрипта, который обновляет имя файла:
```
cobjectref()->updateDocumentFileName();
```
Очень важно и полезно именовать файл документа в соответствии с заведенным правилом. Зачастую, при отсутствии такой технической возможности, пользователи или пишу галиматью, или пишут с ошибками, в итоге, когда файл оказывается вне системы, определить его назначение по имени не представляется возможным.
Обновлением имени файла занимается отдельная функция, объявленная в скрипте «До инициализации объекта»:
```
function calcOutgoingDesc()
{
$code = calcOutgoingCode();
if (empty($code))
return;
if (empty(cobjectref()->attributeref('crs_management_outgoing_sentdate')->value)) {
$d = date_create(cobjectref()->attributeref('crs_management_outgoing_regdate')->value);
} else {
$d = date_create(cobjectref()->attributeref('crs_management_outgoing_sentdate')->value);
}
return sprintf(
'%s от %s',
$code,
localeFormatDate($d)
);
}
function updateDocumentFileName()
{
$desc = calcOutgoingDesc();
if (empty($desc))
return;
$files = cobjectref()->attributeref('crs_management_outgoing_document')->availableFiles();
foreach ($files as $f)
{
$nowname = sprintf(
'%s.%s',
$desc,
pathinfo($f->nowname, PATHINFO_EXTENSION)
);
if (strcmp($nowname, $f->nowname) == 0)
continue;
$f->nowname = $nowname;
$f->save();
}
}
```
Вспомогательная функция calcOutgoingDesc применяется для вычисления описания объекта.
##### Приложения
А вот в этом атрибуте хранятся все приложения к сопроводительному письму. Количество прилагаемых файлов неограниченно, поэтому атрибут множественный. Исключительно для удобства в скрипте «При инициализации» настраивают колонки с информацией о файлах в зависимости от их количества:
```
if (cattributeref()->filesCount > 10)
cattributeref()->fileInfo = array('revcode','modifytime','count','total','header','filter');
else
cattributeref()->fileInfo = array('revcode','modifytime','count','total');
```
И все бы ничего, если б все приложения просто прикладывались и отправлялись по эл. почте.
Как я упоминал выше, в нашей организации используется система технического документооборота [TDMS](http://www.tdms.ru/), в которой хранится вся проектно-сметная документация. Ее регулярно необходимо отправлять на согласование с сопроводительным письмом. Причем зачастую, файлов много, их надо упаковывать в архив и загружать в письмо. Когда я представил, как пользователь будет выгружать файлы из [TDMS](http://www.tdms.ru/) и загружать в [easla.com](http://easla.com), наверное, побледнел.
Процедура выглядит так:
* Найти в TDMS нужный документ
* Выгрузить из него файлы в оригинальном формате или pdf на локальный диск (файлов может быть много и в чертежах могут присутствовать внешние ссылки)
* Найти их в том месте, куда выгрузили и упаковать в архив
* Имя архива должно в точности соответствовать обозначению документа
* Полученный архив закачать в письмо.
По скромным прикидкам, такая процедура займет у рядового пользователя в лучшем случае от 2 до 5 минут на один документ. Если к исходящему письму надо приложить 10 документов, то у пользователя на это уйдет уже час! Кошмар!
Но самое страшное, что о приложенных и отправленных таким образом файла ничего не знает [TDMS](http://www.tdms.ru/), а надо, чтобы знал!
В общем, стало понятно, что файлы в [easla.com](http://easla.com) надо перекладывать из [TDMS](http://www.tdms.ru/) только автоматическим способом. В результате, в [TDMS](http://www.tdms.ru/) была написана соответствующая команда, которая вызывается для каждого документа или пачки документов. После ее вызова появляется диалоговое окно, в котором нужно выбрать исходящий документ (список писем извлекается из [easla.com](http://easla.com) с помощью [SOAP](https://ru.wikipedia.org/wiki/SOAP)), а затем происходит магия программирования и через несколько секунд готовый архив уже загружен в исходящее письмо!
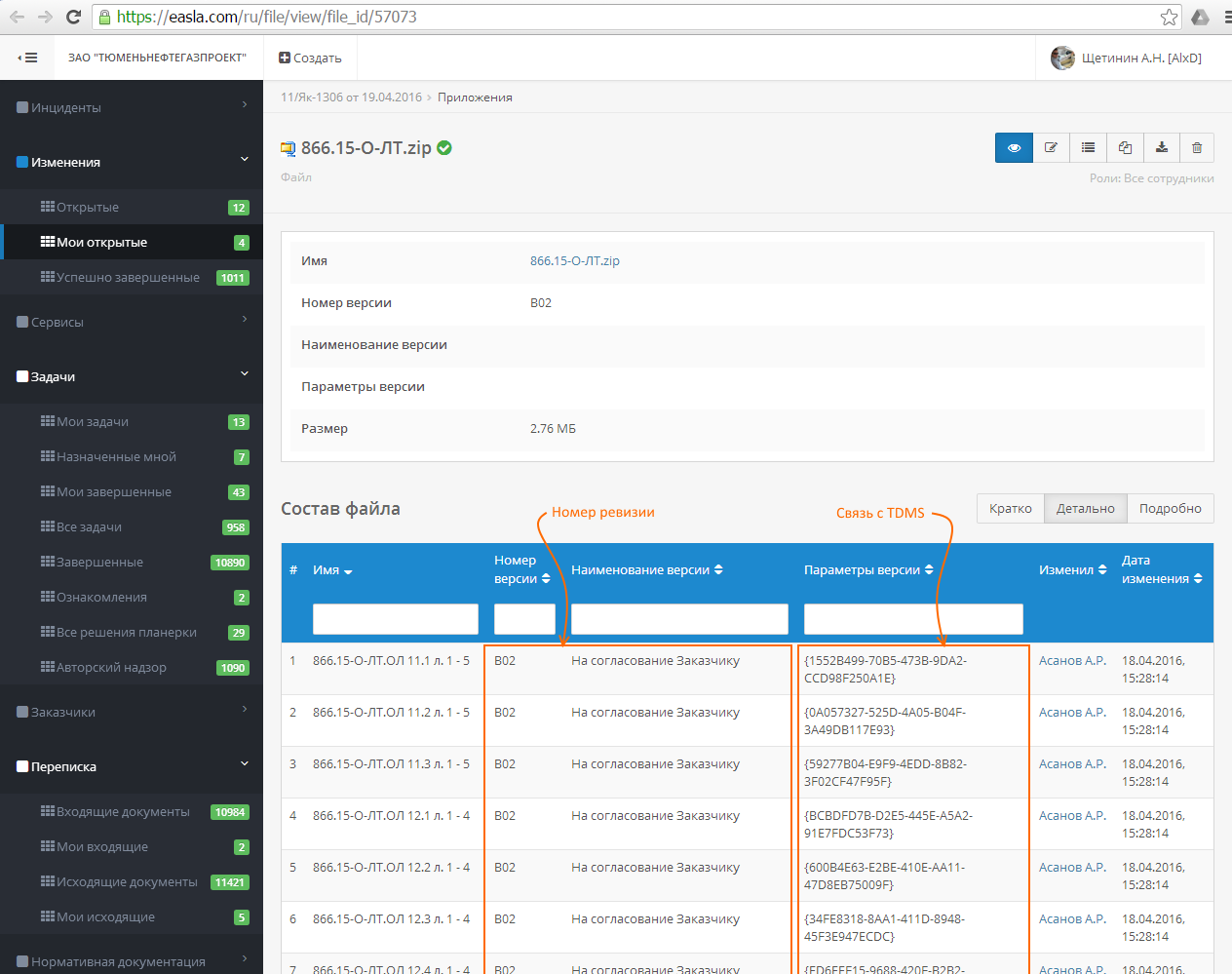
На эту тему можно отдельную статью написать, если кому будет интересно. Решение узкоспециализированное, но опыт очень полезный!
##### Ссылка на приложения в другом месте
Текстовый атрибут для хранения гиперссылки указывающий на хранение приложений где-нибудь в другом месте. Скажем, на публичном или корпоративном файлообменнике.
##### Текст письма
Недавно добавленный атрибут. Предназначен для написания текста письма, которое не предполагает наличие сопроводительного документа. Пока используется только для одного типа содержания – Transmittal.
#### Объект
Точно также, как и список входящих документов, список исходящих раскрашен в соответствии с их статусами. Достаточно было добавить код в скрипт «После инициализации объекта»:
```
switch (cobjectref()->status->code)
{
case 'crs_management_outgoing_created':
cobjectref()->status->state = 1;
break;
case 'crs_management_outgoing_fax':
case 'crs_management_outgoing_courier':
case 'crs_management_outgoing_narochnym':
case 'crs_management_outgoing_post':
cobjectref()->status->state = 2;
break;
case 'crs_management_outgoing_email':
cobjectref()->status->state = 4;
break;
}
```
Согласитесь, цвет добавляет наглядности.

Окончательную валидацию атрибуты объекта проходят в скрипте «До сохранения объекта»:
```
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = calcOutgoingCode();
cobjectref()->description = calcOutgoingDesc();
updateDocumentFileName();
if (!empty(cobjectref()->attributeref('crs_management_outgoing_cntnum')->value))
{
if (cobjectref()->attributeref('crs_management_outgoing_contragent')->value == 45410 &&
cobjectref()->attributeref('crs_management_outgoing_content')->value == 1192) {
$conditions = array(
'crs_management_outgoing_contragent'=>array('id',cobjectref()->attributeref('crs_management_outgoing_contragent')->value),
'crs_management_outgoing_content'=>array('id',cobjectref()->attributeref('crs_management_outgoing_content')->value),
'crs_management_outgoing_cntnum'=>cobjectref()->attributeref('crs_management_outgoing_cntnum')->value
);
if (!cobjectref()->isNewRecord)
$conditions['id'] = '<>'.cobjectref()->id;
$exist = selectCountAll('crs_management','crs_management_outgoing', $conditions);
if ($exist) {
$nownum = cobjectref()->attributeref('crs_management_outgoing_cntnum')->value;
$freenum = updateDocumentCntNum();
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value = $freenum;
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = calcOutgoingCode();
updateDocumentFileName();
throw new Exception('Невозможно сохранить документ, т.к. существует другой документ с рег. номером '.$nownum.'!Номер был изменен на '.$freenum.', попробуйте сохранить еще раз.');
}
} else {
$year = date_format(date_create(cobjectref()->attributeref('crs_management_outgoing_regdate')->value), 'Y');
$conditions = array(
'crs_management_outgoing_cntnum'=>cobjectref()->attributeref('crs_management_outgoing_cntnum')->value,
'crs_management_outgoing_regdate'=>array('between', $year.'-01-01', $year.'-12-31')
);
if (!cobjectref()->isNewRecord)
$conditions['id'] = '<>'.cobjectref()->id;
$exist = selectCountAll('crs_management','crs_management_outgoing', $conditions);
if ($exist) {
$nownum = cobjectref()->attributeref('crs_management_outgoing_cntnum')->value;
$freenum = updateDocumentCntNum();
cobjectref()->attributeref('crs_management_outgoing_cntnum')->value = $freenum;
cobjectref()->attributeref('crs_management_outgoing_regnum')->value = calcOutgoingCode();
updateDocumentFileName();
throw new Exception('Невозможно сохранить документ, т.к. существует другой документ с рег. номером '.$nownum.' созданный в '.$year.' году!Номер был изменен на '.$freenum.', попробуйте сохранить еще раз.');
}
}
}
if (cobjectref()->status->code == 'crs_management_outgoing_create') {
cobjectref()->status = 'crs_management_outgoing_created';
cobjectref()->flags = 1;
} else {
cobjectref()->flags = 0;
}
```
Здесь же происходит смена статуса объекта.
В скрипте «После сохранения объекта» происходит назначение прав на сохраненный объект:
```
if (empty(cobjectref()->crs_management_outgoing_responsibleuser))
return;
if (empty(cobjectref()->crs_management_outgoing_responsiblegroup))
return;
$ruser = corganization()->user(cobjectref()->crs_management_outgoing_responsibleuser);
if (empty($ruser))
return;
$rgroup = corganization()->group(cobjectref()->crs_management_outgoing_responsiblegroup);
if (empty($rgroup))
return;
$rugroups = $ruser->groups();
foreach ($rugroups as &$rug)
$rug = $rug['code'];
if ($rgroup->code == 'group_general_manager' && in_array($rgroup->code, $rugroups))
{
$c = classificator(cobjectref()->attributeref('crs_management_outgoing_content')->value);
//претензия
if ($c->code == 'crs_content_claim') {
cobjectref()->addRolesPermissions(array(
'crs_management_tops',
'crs_management_buh',
'crs_management_gip',
'crs_management_dp',
'crs_management_pmo',
));
} else {
cobjectref()->addRolesPermissions(array(
'crs_management_tops',
'crs_management_dp',
));
}
} elseif ($rgroup->code == 'group_pdg') {
cobjectref()->addRolesPermissions(array(
'crs_management_tops',
// 'crs_management_buh',
'crs_management_gip',
'crs_management_dp',
'crs_management_pmo',
));
} else
cobjectref()->resetRolesPermissions();
```
#### Формы
В [easla.com](http://easla.com) существует возможность создавать формы в объекте. Причем на каждой форме могут располагаться свои атрибуты. Особенно удобно использовать формы, когда атрибутов много. Первый раз использовал формы в объектах «Контрагент» и «Контакт», чтобы отделить основные атрибуты от юридического и почтового адресов.
В исходящем письме создал две формы: Основные и Получатель. В первую форму поместил все атрибуты, кроме: регистрационный номер получателя, дата получения и фамилия и.о. получателя. Соответственно, их поместил во вторую форму. Она нужна только специалисту по делопроизводству, остальным будут ее посещать крайней редко.

#### Статусы
К счастью, у исходящего документа, как конечного результата работы, изобретать статусы долго не пришлось. Все просто и очевидно:
* Регистрация – начальный статус
* Зарегистрирован — присваивается сразу после регистрации
Остальные статусы говорят сами за себя:
* Отправлен по факсу
* Отправлен курьером
* Отправлен нарочным
* Отправлен по эл. почте
* Отправлен почтой
Конечно, прежде, чем двигаться дальше, согласовал получившееся решение со специалистом по делопроизводству. Тем более, что именно на первом этапе только она активно регистрировала исходящие документы, т.к. остальные сотрудники пока не привыкли делать это самостоятельно. Получив полезную обратную связь, перешел к действиям.
#### Действия
Как было описано в предыдущей статье, действие – это кнопка под формой объекта или рядом с атрибутом, которая выполняет скрипт в контексте объекта. Сперва опишу простые действия, а самое «вкусненькое» и «здоровенькое» оставлю напоследок.
##### Оправлен […]
Действия, на самом деле не отправляющие исходящий документ, а только фиксирующие факт его выполнения специалистом по делопроизводству называются:
* Отправлен факсом
* Отправлен курьером
* Отправлен нарочным
* Отправлен почтой
Все действия имеют одинаковый скрипт, только отличаются кодом статуса:
```
if (empty(cobjectref()->attributeref('crs_management_outgoing_sentdate')->value)) {
cobjectref()->attributeref('crs_management_outgoing_sentdate')->value = currentDateTime();
}
cobjectref()->status = 'crs_management_outgoing_courier';
$msg = cobjectref()->commentTasks();
if (!empty($msg))
echo implode('',$msg);
```
В этом скрипте достаточно заменить 'crs\_management\_outgoing\_courier' на другой статус и получится другое действие.
##### Все доп. контакты
Сервисное действие, обновляет список значений атрибута «Доп. контакты» отображая в нем все доступные контакты. В атрибуте, после выбора контрагента, автоматически отображаются только контакты соответствующего контрагента. В большинстве случаев так и надо. В исключительно ситуации используется это действие. Скрипт простой:
```
$contacts = cobjectref()->prepareOutgoingContacts();
asort($contacts);
cobjectref()->attributeref('crs_management_outgoing_recipients')->values = $contacts;
```
##### Доп. контакты контрагента
Сервисное действие обратное выше описанному. После выполнения, в атрибуте отображаются только контакты указанного контрагента. Скрипт тоже простой:
```
if (!empty(cobjectref()->attributeref('crs_management_outgoing_contragent')->value))
{
$contacts = cobjectref()->prepareOutgoingContacts(cobjectref()->attributeref('crs_management_outgoing_contragent')->value);
cobjectref()->attributeref('crs_management_outgoing_recipients')->values = $contacts;
}
```
Обратите внимание, как изящно получилось решить формирование списка контактов с помощью объявленной в скрипте «До инициализации объекта» функции prepareOutgoingContacts. При отсутствии входного параметра – возвращает полный список контактов, при наличии идентификатора контрагента – возвращает отфильтрованный список. Очередное доказательство того, что «скриптованное» описание более гибкое, чем «накликиваемое».
##### Уведомить о доставке
Отправляет заинтересованным лицам уведомление о том, что письмо доставлено адресату и, главное, получен регистрационный номер получателя. Без заполненных специалистом по делопроизводству соответствующих полей, подтверждающих получение, уведомление отправлено не будет! Скрипт получился не очень сложный:
```
if (empty(cobjectref()->crs_management_outgoing_performers))
throw new Exception('Не указаны исполнители письма. Уведомлять некого!');
if (empty(cobjectref()->crs_management_outgoing_contragentdate))
throw new Exception('Не указана дата и время получения письма адресатом!');
if (cobjectref()->hasAttributeref('crs_management_outgoing_contragentperson') && empty(cobjectref()->crs_management_outgoing_contragentperson))
throw new Exception('Не указаны фамилия сотрудника получившего письмо!');
cobjectref()->description = cobjectref()->calcOutgoingDesc();
$to = corganization()->users(cobjectref()->crs_management_outgoing_performers);
$body = array(
'Добрый день!',
' ',
'Письмо: '.cobjectref()->viewLink(),
'Тема: '.cobjectref()->crs_management_outgoing_subj,
'Доставлено адресату успешно.',
'Получил: '.(cobjectref()->hasAttributeref('crs_management_outgoing_contragentperson') ? cobjectref()->crs_management_outgoing_contragentperson : ''),
'Дата и время получения: '.cobjectref()->crs_management_outgoing_contragentdate,
' ',
'С уважением,',
cuser()->description
);
$options = array(
'from'=>cuser(),
'to'=>$to,
'subj'=>'Уведомление о доставке '.cobjectref()->description,
'body'=>implode('',$body),
);
$options['bcc'] = cuser();
sendEmail($options);
$message = array();
foreach ($to as $u)
$message[] = $u->viewLink();
echo 'Уведомление отправлено следующим сотрудникам:'.implode('', $message);
//запись в историю
caction()->result = 'Уведомление отправлено: '.implode(',', $message);
```
Нравится, как изящно [easla.com](http://easla.com) умеет отправлять письма. Достаточно вызвать функцию sendMail с переданными параметрами и все! Никаких сложностей с подготовкой тела письма, вложения файлов и других сложных манипуляций. Все просто!
##### Расшарить
Некоторые заказчики просят не присылать им на эл. почту письма с вложениями, а присылать только ссылки для скачивания файлов. Нормальные такие заказчики, все бы такие были, но «не все коту масленица». Именно для таких нормальных заказчиков в [easla.com](http://easla.com) есть свой файлообменник или, как «айтишники» его называют, шара. Разместить на файлообменнике файлы можно на ограниченный срок, максимум полгода. После этого файлы удаляются и доступ к шаре уничтожается. Обратится к файлам можно по уникальной ссылке. Повторить ее случайно практически невозможно.
Иногда возникает необходимость расшарить переданные материалы повторно не отправляя письмо. Например, файл скачали и потеряли или по иным причинам хотят скачать, а он уже удален. Специалист по делопроизводству кликает на действие и выполняет скрипт:
```
$odt = date_create();
$cdt = date_add(date_create(), new DateInterval('P1D'));
$share = shareFiles(
cobjectref(),
array('crs_management_outgoing_document','crs_management_outgoing_attachments'),
$odt,
$cdt,
cuser(),
'CP866'
);
if (empty($share))
throw new Exception("Не удалось выложить архив в свободный доступ!");
echo 'Ссылка на архив файлов в свободном доступе: '.$share->link();
```
После выполнения появляется сообщение, из которого можно скопировать ссылку и отправить тому, кто просил.

##### В разработку
Сервисно-спасательное действие, доступно только специалисту по делопроизводству. Переводит письмо из конечного статуса, например «Отправлено по эл. почте» обратно в разработку. Бывает…
Это простейший пример действия, которое не проверяет конечный статус объекта, ради чего в нем снята соответствующая галочка. Скрипт только меняет статус:
```
cobjectref()->status = 'crs_management_outgoing_created';
```
##### Ознакомить
Создает ознакомительную задачу, в которой можно указать, кого ознакомить с указанным письмом. Но это относится скорее в процессу «Задачи» о котором надо писать отдельную статью. Скрипт создает объект в другом процессе:
```
$new_notification = new Objectref();
$new_notification->prepare(objectDef('tsk_management','tsk_notification'));
$new_notification->attributeref('tsk_notification_subj')->value = 'Прошу ознакомиться с '.cobjectref()->description;
$new_notification->attributeref('tsk_notification_base')->value = cobjectref()->id;
caction()->redirect = urlNewObjectref($new_notification);
```
##### Добавить задачу
Создает задачу со ссылкой на исходящий документ в основании для открытия. Но это тоже, скорее, про процесс «Задачи», хотя скрипт привести надо:
```
$subj = '';
if (!empty(cobjectref()->attributeref('crs_management_outgoing_subj')->value))
$subj = $subj.(strlen($subj) > 0 ? ' ' : '').cobjectref()->attributeref('crs_management_outgoing_subj')->value;
$new_task = new Objectref();
$new_task->prepare(objectDef('tsk_management','tsk_task'));
$new_task->attributeref('tsk_task_subj')->value = $subj;
$new_task->attributeref('tsk_task_base_open')->value = cobjectref()->id;
caction()->redirect = urlNewObjectref($new_task);
```
Если вы дочитали до этого места, верю, что последнее описанное действие вас не разочарует. Это не просто действие! Это монстр, который делает всю работу за человека! Это шедевр!
##### Отправить по эл. почте
Самое главное действие в исходящем документе! Оно отправляет исходящий документ в соответствии с указанным правилом отправки. При этом со стороны пользователя ничего не нужно делать! Действие само упакует файлы, разобьет на тома, сформирует одно или несколько писем и отправит адресатам.
На моей памяти, когда только запускал процесс, как всегда в пятницу ГИП готовил к отправке 3 письма, в каждом было примерно по 200Мб прилагаемых файлов. В то время ГИПам еще не разрешили отправлять письма самостоятельно, т.к. они «спустя рукава» относились к их оформлению. К концу рабочего дня, разумеется, он не успел подготовить письма, а в пятницу всем срочно-срочно надо домой/по делам/в паб, в общем, специалист по делопроизводству убежала домой, а он позвонил мне и начал умолять:
— Задержись, надо будет письма отправить! Пожалуйста!
— Так зачем задерживаться? Система же онлайн!
— И что?
— Ты пришли мне на почту номера писем или гиперссылки на письма, я из дома или с телефона отправлю.
— А так можно?
— Никаких проблем!
На том и порешили. Наверное в 9 вечера мне пришло письмо от ГИПа со ссылками на письма. Открыл каждое. Проверил оформление. Нажал на «Отправить по эл. почте». Все три письма ушли заказчику минут за 5! Да в былые времена, специалист по делопроизводству готовила бы эти письма к отправке еще часа 3 минимум!
Конечно, скрипт получился немаленький, но простой и понятный любому PHP программисту:
**Много-много кода для описания логики отправки исх. документа**
```
if (empty(cobjectref()->attributeref('crs_management_outgoing_regnum')->value))
throw new Exception('Невозможно отправить исходящее письмо без регистрационного номера!');
if (empty(cobjectref()->attributeref('crs_management_outgoing_subj')->value))
throw new Exception('Невозможно отправить исходящее письмо без темы!');
function contactEmail($contact)
{
if (empty($contact))
return false;
$emails = $contact->attributeref('crm_management_contact_email')->value;
if (empty($emails))
return false;
return $emails[0];
}
function contragentEmail($contagent)
{
if (empty($contagent))
return false;
$emails = $contagent->attributeref('crm_management_contragent_email')->value;
if (empty($emails))
return false;
return $emails[0];
}
function getEmail($contact)
{
$e = contactEmail($contact);
if ($e === false)
{
if (empty($contact->attributeref('crm_management_contact_contragent')->value))
throw new Exception("Не указан контрагент для контакта ".$contact->viewLink());
$contragent = select($contact->attributeref('crm_management_contact_contragent')->value);
$e = contragentEmail($contragent);
}
return $e === false ? false : array($e => $contact->description);
}
function getMainEmail($contact)
{
$e = contactEmail($contact);
if ($e === false)
$email_1 = false;
else
$email_1 = array($e => $contact->description);
$contragent = select($contact->attributeref('crm_management_contact_contragent')->value);
$e = contragentEmail($contragent);
if ($e === false)
$email_2 = false;
else
$email_2 = array($e => $contragent->description);
$emails = array();
if ($email_1)
$emails += $email_1;
if ($email_2)
$emails += $email_2;
unset($email_1, $email_2);
return $emails === array() ? false : $emails;
}
function sendEmailDocumentOnly(&$msg, $objref, $to, $cc, $user, $checkSize = 5120000, $maxSize = '4500k', $extra_msg = '')
{
$dfs = $objref->attributeref('crs_management_outgoing_document')->filesSize;
$body = array(
'Добрый день!',
' ',
'Сообщение сформировано автоматически из системы .', easla.com
'Во вложении исходящий документ '.$objref->description.'.',
$extra_msg,
'Пожалуйста, сообщите входящий номер полученного документа на Делопроизводитель@sngp.ru',
' ',
'С уважением,',
$user->description
);
if ($dfs < $checkSize)
$files = array('compress'=>'zip', 'codepage'=>'CP866');
else
$files = array('compress'=>array('maxSize'=>$maxSize));
$files['attributeCodes'] = 'crs_management_outgoing_document';
$options = array(
'from'=>$user,
'to'=>$to,
'subj'=>$objref->description.' '.$objref->attributeref('crs_management_outgoing_subj')->value,
'body'=>implode('',$body),
'objects'=>$objref,
'files'=>$files
);
if (!empty($cc))
$options['cc'] = $cc;
$options['bcc'] = $user;
sendEmail($options);
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
$msg = 'Документ отправлен следующим адресатам: '.implode(',', $rcvs).' Общий размер файлов: '.$dfs;
}
function sendEmailDocumentAndAttachments(&$msg, $objref, $to, $cc, $user, $checkSize = 5120000, $maxSize = '4500k', $extra_msg = '')
{
$dfs = $objref->attributeref('crs_management_outgoing_document')->filesSize;
$afs = $objref->attributeref('crs_management_outgoing_attachments')->filesSize;
$body = array(
'Добрый день!',
' ',
'Сообщение сформировано автоматически из системы .', easla.com
'Во вложении исходящий документ '.$objref->description.($afs > 0 ? ' и приложения' : '').'.',
$extra_msg,
'Пожалуйста, сообщите входящий номер полученного документа на Делопроизводитель@sngp.ru',
' ',
'С уважением,',
$user->description
);
if ($dfs +$afs < $checkSize)
$files = array('compress'=>'zip', 'codepage'=>'CP866');
else
$files = array('compress'=>array('maxSize'=>$maxSize));
$options = array(
'from'=>$user,
'to'=>$to,
'subj'=>$objref->description.' '.$objref->attributeref('crs_management_outgoing_subj')->value,
'body'=>implode('',$body),
'objects'=>$objref,
'files'=>$files
);
if (!empty($cc))
$options['cc'] = $cc;
$options['bcc'] = $user;
sendEmail($options);
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
$msg = 'Документ и приложения отправлен следующим адресатам: '.implode(',', $rcvs).' Общий размер файлов: '.($dfs+$afs);
}
function sendShareDocumentAndAttachments(&$msg, $objref, $to, $cc, $user, $extra_msg = '')
{
$odt = date_create();
$cdt = date_add(date_create(), new DateInterval('P14D'));
$share = shareFiles(
cobjectref(),
array('crs_management_outgoing_document','crs_management_outgoing_attachments'),
$odt,
$cdt,
$user,
'CP866'
);
$body = array(
'Добрый день!',
' ',
'Сообщение сформировано автоматически из системы .', easla.com
'Вы можете скачать письмо и приложения одним файлом по ссылке '.$share->link().'.',
$extra_msg,
'Пожалуйста, сообщите входящий номер полученного документа на Делопроизводитель@sngp.ru',
' ',
'С уважением,',
$user->description
);
$options = array(
'from'=>$user,
'to'=>$to,
'subj'=>$objref->description.' '.$objref->attributeref('crs_management_outgoing_subj')->value,
'body'=>implode('',$body),
);
if (!empty($cc))
$options['cc'] = $cc;
$options['bcc'] = $user;
sendEmail($options);
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
$msg = 'Ссылка на архив '.$share->link().' с документом и приложениями отправлен следующим адресатам: '.implode(',', $rcvs);
}
function shareAttachments(&$msg, $objref, $user)
{
$odt = date_create();
$cdt = date_add(date_create(), new DateInterval('P14D'));
$share = shareFiles(
cobjectref(),
array('crs_management_outgoing_attachments'),
$odt,
$cdt,
$user,
'CP866'
);
$msg = 'Вы можете скачать приложения одним файлом по ссылке '.$share->link();
}
function sendAsIsDocumentAndAttachments(&$msg, $objref, $to, $cc, $user, $maxSize = '4500k', $extra_msg = '')
{
$dfs = $objref->attributeref('crs_management_outgoing_document')->filesSize;
$afs = $objref->attributeref('crs_management_outgoing_attachments')->filesSize;
$body = array(
'Добрый день!',
' ',
'Сообщение сформировано автоматически из системы .', easla.com
'Во вложении исходящий документ '.$objref->description.($afs > 0 ? ' и приложения' : '').' общим объемом не более '. $maxSize.'.',
$extra_msg,
'Пожалуйста, сообщите входящий номер полученного документа на Делопроизводитель@sngp.ru',
' ',
'С уважением,',
$user->description
);
$options = array(
'from'=>$user,
'to'=>$to,
'subj'=>$objref->description.' '.$objref->attributeref('crs_management_outgoing_subj')->value,
'body'=>implode('',$body),
'objects'=>$objref,
'files'=>array('maxSize'=>$maxSize)
);
if (!empty($cc))
$options['cc'] = $cc;
$options['bcc'] = $user;
sendEmail($options);
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
$msg = 'Документ и приложения отправлен следующим адресатам: '.implode(',', $rcvs).' Общий размер файлов: '.($dfs+$afs);
}
function sendFtpSngpRuAttachments(&$msg, $objref, $to, $cc, $user, $login, $password)
{
$ftp_addr = 'ftp.sngp.ru';
$ftp_link = '';
$dfs = $objref->attributeref('crs_management_outgoing_document')->filesSize;
$afs = $objref->attributeref('crs_management_outgoing_attachments')->filesSize;
if (cobjectref()->attributeref('crs_management_outgoing_attachments')->filesCount > 0) {
$ftp = ftp_ssl_connect($ftp_addr);
if ($ftp == FALSE)
throw new Exception('Не удалось соединиться с FTPS сервером '.$ftp_addr.'!');
ftp_login($ftp,$login,$password);
ftp_pasv($ftp, true);
$dir = "files";
if (!@ftp_chdir($ftp, $dir)) {
ftp_mkdir($ftp, $dir);
ftp_chdir($ftp, $dir);
}
$zip = normalizeFilename($objref->description).' - приложения.zip';
$objref->attributeref('crs_management_outgoing_attachments')->ftp_put($ftp, $zip, FTP_BINARY);
ftp_close($ftp);
$ftp_link = ''; '.$zip.'
}
$files = array(
'attributeCodes'=>'crs_management_outgoing_document',
'compress'=>'zip',
'codepage'=>'CP866'
);
$body = array(
'Добрый день!',
' ',
'Сообщение сформировано автоматически из системы .', easla.com
'Во вложении исходящий документ '.$objref->description.' объемом '.formatSize($dfs).'.',
($ftp_link == '' ? '' : 'Приложения размещены на FTPS сервере ftps://'.$ftp_addr.' [логин: '.$login.'] файл '.$ftp_link.'.'),
'Пожалуйста, сообщите входящий номер полученного документа на Делопроизводитель@sngp.ru',
' ',
'С уважением,',
$user->description
);
$options = array(
'from'=>$user,
'to'=>$to,
'subj'=>$objref->description.' '.$objref->attributeref('crs_management_outgoing_subj')->value,
'body'=>implode('',$body),
'objects'=>$objref,
'files'=>$files
);
if (!empty($cc))
$options['cc'] = $cc;
$options['bcc'] = $user;
sendEmail($options);
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
$msg = 'Документ отправлен следующим адресатам: '.implode(',', $rcvs).' Объем документа: '.($dfs).' Приложения размещены на '.$ftp_addr.' [логин: '.$login.'].';
}
if (empty(cobjectref()->attributeref('crs_management_outgoing_contragent')->value))
throw new Exception('Не указан основной адресат (контрагент) в письме '.cobjectref()->viewLink());
if (empty(cobjectref()->attributeref('crs_management_outgoing_contact')->value))
throw new Exception('Не указан основной адресат (контакт) в письме '.cobjectref()->viewLink());
//define $to
$contragent = select(cobjectref()->attributeref('crs_management_outgoing_contragent')->value);
$to = contragentEmail($contragent);
if ($to === false)
throw new Exception('Не найден эл. адрес для '.$contragent->viewLink().' в письме '.cobjectref()->viewLink());
$to = array($to => $contragent->description);
//define $cc
$cc = array();
$contact = select(cobjectref()->attributeref('crs_management_outgoing_contact')->value);
$tmp = getEmail($contact);
if ($tmp === false)
throw new Exception('Не найден эл. адрес для '.$contact->viewLink().' в письме '.cobjectref()->viewLink());
$cc += $tmp;
if (!empty(cobjectref()->attributeref('crs_management_outgoing_recipients')->value))
{
$contacts = selects(cobjectref()->attributeref('crs_management_outgoing_recipients')->value);
foreach ($contacts as $contact)
{
$tmp = getEmail($contact);
if ($tmp === false)
throw new Exception('Не найден эл. адрес для '.$contact->viewLink().' в письме '.cobjectref()->viewLink());
$cc += $tmp;
}
}
if (!empty(cobjectref()->attributeref('crs_management_outgoing_notifiers')->value))
{
$contacts = selects(cobjectref()->attributeref('crs_management_outgoing_notifiers')->value);
foreach ($contacts as $contact)
{
$tmp = getEmail($contact);
if ($tmp === false)
throw new Exception('Не найден эл. адрес для '.$contact->viewLink().' в письме '.cobjectref()->viewLink());
$cc += $tmp;
}
}
if (empty($cc))
$cc = null;
$cuser = cuser();
$rule = '';
if (cobjectref()->hasAttributeref('crs_management_outgoing_rule'))
$rule = classificator(cobjectref()->crs_management_outgoing_rule)->code;
$link = '';
if (cobjectref()->hasAttributeref('crs_management_outgoing_attachments_link')) {
if (!empty(cobjectref()->attributeref('crs_management_outgoing_attachments_link')->value))
$link = 'Вы можете скачать доп. приложения по .'; ссылке
}
$msg = '';
switch ($rule)
{
case 'crs_outgoing_rule_all_max5':
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, 5120000, '4500k', $link);
break;
case 'crs_outgoing_rule_all_max4':
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, 4096000, '3500k', $link);
break;
case 'crs_outgoing_rule_all_max3':
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, 3072000, '2500k', $link);
break;
case 'crs_outgoing_rule_all_max10':
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, 10240000, '9500k', $link);
break;
case 'crs_outgoing_rule_all_max25':
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, 25600000, '20m', $link);
break;
case 'crs_outgoing_rule_doc_att_max5':
if (empty($cc))
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, null, $cuser, 5120000, '4500k', $link);
else {
$m1 = '';
$m2 = '';
sendEmailDocumentOnly($m1, cobjectref(), $to, null, $cuser, 5120000, '4500k', $link);
sendEmailDocumentAndAttachments($m2, cobjectref(), $cc, null, $cuser, 5120000, '4500k', $link);
$msg = $m1.' '.$m2;
unset($m1,$m2);
}
break;
case 'crs_outgoing_rule_doc_att_max25':
if (empty($cc))
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, null, $cuser, 25600000, '20m', $link);
else {
$m1 = '';
$m2 = '';
sendEmailDocumentOnly($m1, cobjectref(), $to, null, $cuser, 25600000, '20m', $link);
sendEmailDocumentAndAttachments($m2, cobjectref(), $cc, null, $cuser, 25600000, '20m', $link);
$msg = $m1.' '.$m2;
unset($m1,$m2);
}
break;
case 'crs_outgoing_rule_all_share':
sendShareDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, $link);
break;
case 'crs_outgoing_rule_doc_att_share':
if (empty($cc)) {
if (empty(cobjectref()->attributeref('crs_management_outgoing_attachments')->value))
sendEmailDocumentOnly($msg, cobjectref(), $to, null, $cuser, 25600000, '20m', $link);
else
sendShareDocumentAndAttachments($msg, cobjectref(), $to, null, $cuser, $link);
} else {
$m1 = '';
$m2 = '';
sendEmailDocumentOnly($m1, cobjectref(), $to, null, $cuser, 25600000, '20m', $link);
sendShareDocumentAndAttachments($m2, cobjectref(), $cc, null, $cuser, $link);
$msg = $m1.' '.$m2;
unset($m1,$m2);
}
break;
case 'crs_outgoing_rule_doc_att_share_max1':
$sum = cobjectref()->attributeref('crs_management_outgoing_document')->filesSize + cobjectref()->attributeref('crs_management_outgoing_attachments')->filesSize;
if ($sum < 1048576) {
sendAsIsDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, '1m', $link);
} else {
$m1 = '';
$m2 = '';
shareAttachments($m2, cobjectref(), $cuser);
sendEmailDocumentOnly($msg, cobjectref(), $to, $cc, $cuser, 25600000, '20m', $m2.''.$link);
}
break;
case 'crs_outgoing_rule_asis_max3':
sendAsIsDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, '3m', $link);
break;
case 'crs_outgoing_rule_asis_max5':
sendAsIsDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, '5m', $link);
break;
case 'crs_outgoing_rule_asis_max10':
sendAsIsDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, '10m', $link);
break;
case 'crs_outgoing_rule_asis_max20':
sendAsIsDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, '20m', $link);
break;
case 'crs_outgoing_rule_ftp_sngp_ru_tyungd':
sendFtpSngpRuAttachments($msg, cobjectref(), $to, $cc, $cuser, 'некий логин', 'некий пароль');
break;
default:
sendEmailDocumentAndAttachments($msg, cobjectref(), $to, $cc, $cuser, $link);
}
if (empty(cobjectref()->attributeref('crs_management_outgoing_sentdate')->value)) {
cobjectref()->attributeref('crs_management_outgoing_sentdate')->value = currentDateTime();
cobjectref()->description = cobjectref()->calcOutgoingDesc();
cobjectref()->updateDocumentFileName();
}
cobjectref()->status = 'crs_management_outgoing_email';
$rcvs = array();
foreach ($to as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
if (isset($cc))
foreach ($cc as $e=>$d)
$rcvs[] = corganization()->object($d)->viewLink().' ('.$e.')';
//отправка уведомления
$notices = array();
$ruser = corganization()->user(cobjectref()->crs_management_outgoing_responsibleuser);
$rgroups = $ruser->groups();
if (empty($rgroups))
$notices[] = $ruser;
else
{
$f = false;
foreach($rgroups as $rgroup)
if (strncmp($rgroup['data_one'],'09.',3) == 0)
{
$notices = $rgroup->users();
$f = true;
break;
}
if (!$f)
$notices[] = $ruser;
}
if (!empty(cobjectref()->crs_management_outgoing_performers))
{
$eusers = corganization()->users(cobjectref()->crs_management_outgoing_performers);
if (!empty($eusers))
$notices = array_merge($notices, $eusers);
}
$notices = array_unique($notices, SORT_REGULAR);
if (!empty(cobjectref()->crs_management_outgoing_contract)) {
$contracts = selects(cobjectref()->crs_management_outgoing_contract);
foreach($contracts as &$c) {
$c = $c->viewLink();
}
} else {
$contracts = array();
}
foreach($notices as $n) {
$rbody = array(
'Уважаемый '.$n->description.'!',
' ',
'Письмо: '.cobjectref()->viewLink(),
'Тема: '.cobjectref()->crs_management_outgoing_subj,
'Договор:'.implode(', ', $contracts),
'Отправлено следующим адресатам:',
implode('', $rcvs),
' ',
'С уважением,',
cuser()->description
);
sendEmail(array(
// 'from'=>cuser(),
'to'=>$n,
'subj'=>'Уведомление об отправке '.cobjectref()->description,
'body'=>implode('',$rbody),
));
}
$task_msg = cobjectref()->commentTasks();
if (!empty($task_msg))
$msg .= ''.implode('',$task_msg);
echo $msg;
//запись в историю
caction()->result = $msg;
```
Очередной раз обращу внимание на функцию sendMail. Она умеет отправлять письма с файлами, хранящихся в атрибутах указанных объектов без сжатия, со сжатием в [zip](https://ru.wikipedia.org/wiki/ZIP), со сжатием в многотомный [7zip](https://ru.wikipedia.org/wiki/7-Zip) и даже группируя по объему.
Все исполнители и отв. сотрудник указанные в исходящем документе получают вот такое уведомление после выполнения действия:
#### Роли
Распределение прав проще не придумаешь. Каждый может делать с исходящим документом все, что угодно, пока тот не отправлен, т.е. не переведен в конечный статус.

#### Пока все
Пока хватит и так много написал. Не осилить! Благодарю каждого, кто дочитал до конца, надеюсь, вы почерпнули для себя что-то полезное!
В следующей части расскажу про настройку видов. Писанины и кода будет меньше, но от этого не менее интересно. Все виды в [easla.com](http://easla.com) тоже настраиваются скриптами, отсюда невероятная гибкость в настройке!
P.S. Повторюсь. Описанный выше объект «Исходящий документ» полностью реализован в опубликованном для всех процессе [Переписка](https://easla.com/ru/process/infoAlone/process_id/159). Заимствуя процесс, вы можно не терять время на написание описанного выше кода. | https://habr.com/ru/post/281999/ | null | ru | null |
# Системы Линденмайера

Естественные паттерны
---------------------
Системы Линденмайера придумал венгерский биолог Аристид Линденмайер, изучая рост водорослей. Он разработал *L-системы* как способ описания процесса роста водорослей и простых растений. Результатом стал своего рода язык, на котором можно было выразить свойства рекурсивности и самоподобия роста организма. И в самом деле, L-системы можно использовать для генерирования естественных паттернов; кроме того, хорошо известные математические паттерны тоже можно записать в виде L-системы. В этой статье я расскажу о различных типах L-систем и продемонстрирую их с помощью отрисовки «черепашьей графикой» *двухмерных* и *трёхмерных систем Линденмейера*.
Язык очень прост, он состоит из символов (алфавита) и продукционных правил. Первое состояние предложения называется *аксиомой*. К этой аксиоме можно многократно применить продукционные правила для эволюции или роста системы. В качестве простого примера можно взять систему с аксиомой  и правилом . После первой итерации (первого случая применения правила) предложение сменится на . После второй итерации предложение будет иметь вид , и так далее. Можно увидеть, как саморасширяющееся предложение становится аналогом деления клеток в растениях и других биологических процессов.
| | |
| --- | --- |
| [A...Z] | Любая (не являющаяся константой) буква алфавита перемещает черепашку вперёд на фиксированное расстояние |
| + | Поворот черепашки вправо на фиксированное число градусов |
| - | Поворот черепашки влево на фиксированное количество градусов |
| [ | Запись текущего состояния черепашки в стек |
| ] | Извлечение последнего состояния черепашки из стека и присвоение этого состояния |
*Рисунок 1: Алфавит для рисования двухмерной системы Линденмайера*
Отрисовка предложений
---------------------
После того, как система задана и все итерации выполнены, у нас получается большое предложение с интересными свойствами. Для визуализации этих свойств нам необходимо создать способ их рендеринга. В этой статье я буду рендерить систему при помощи *«черепашьей графики»*.
Черепашья графика рендерится размещением на декартовой плоскости «черепашки» и передачей ей инструкций. Черепашка движется в соответствии с полученными ею инструкциями. Черепашка выполняет рисование, оставляя за собой след. В нашем случае черепашке отправляется каждый символ из предложения L-системы. В представленном выше коротком примере предложение достаточно просто, в нём содержатся только буквы. Сложно преобразовать строку букв в интересные инструкции для черепашки. Поэтому для кодирования команд черепашке задаются специальные символы. На Рисунке 1 показан ключ к моему черепашьему языку.
Ниже я реализовал интерактивный (в оригинале статьи) рендерер 2D-систем Линденмайера. В нём есть несколько примеров, а также можно задавать собственные системы из шести продукционных правил. Я добавил поле *constants*, в котором содержится строка символов. При рендеринге строки черепашкой она будет игнорировать все символы, являющиеся константами. Тем не менее, символы-константы всё равно подвержены действию правил. В поле *angle* указано количество градусов, на которые поворачивается черепашка при командах `+` и `-`. В полях правил можно использовать константу `AXIOM`. Она будет заменяться на исходную аксиому. Это используется в нескольких примерах.
**Примеры**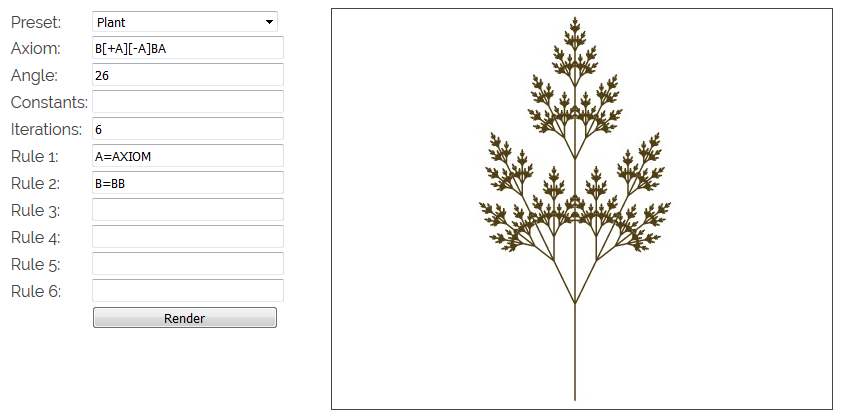

Исходный код этого примера на javascript находится в [репозитории](https://github.com/jobtalle/LindenmayerSystemsExample). Показанные примеры систем демонстрируют некоторые из возможностей систем Линденмайера, от шумных, похожих на случайные паттерны до строгих геометрических узоров. Все системы демонстрируют свойство самоподобия; когда количество итераций становится высоким, мелкие создаваемые детали уже неразличимы. Однако в теории мы можем неограниченно уменьшать масштаб, повышая при этом точность. Это хорошо известное свойство *фракталов*. При уменьшении масштаба фракталов часто видны те же паттерны, что и при большем масштабе.
Добавляем размерности
---------------------
Показанный выше пример может полностью демонстрировать свойства систем Линденмайера, но я хочу добавить ещё несколько характеристик, чтобы сделать алгоритм ещё мощнее. Лично меня очень интересует использование 3D-систем Линденмайера для генерирования растений и природных систем. Очень интересный источник информации по этой теме — [веб-сайт группы по исследованию биологического моделирования и визуализации](http://algorithmicbotany.org/) Университета Калгари. По этой тематике существует множество статей, которые представлены на этом веб-сайте.
Я хочу оставить мою систему как можно более простой, но мне не хватает некоторых особенностей, которые необходимы для создания более сложных систем. Я хотел бы по крайней мере моделировать следующее:
* Должна присутствовать возможность какой-нибудь рандомизации, потому что мы считаем, что в природе существует случайность форм
* Я хочу, чтобы символы могли отслеживать свой возраст, потому что в природе поведение клеток может зависеть от их возраста
* Продукционные правила должны учитывать контекст символов
* Я хочу отслеживать расстояние до корневой клетки
* Черепашка должна уметь двигаться в трёх измерениях, что позволит создавать более сложные формы
Реализовать движение в трёх измерениях не так сложно. Вместо перемещения на декартовой плоскости черепашка будет позицией в кватернионе. На каждом шаге я буду прибавлять единичный вектор (направленный вверх), повёрнутый этим кватернионом в положение черепашки, а сам кватернион будет поворачиваться при встрече символов поворота. Моделирование других особенностей как можно более простым способом будет немного более хитрой задачей.
| | |
| --- | --- |
| [A...Z] | Любая (не являющаяся константой) буква алфавита перемещает черепашку вперёд на фиксированное расстояние |
| + | Рыскание черепашки вправо на фиксированный угол |
| - | Рыскание черепашки влево на фиксированный угол |
| / | Крен черепашки вправо на фиксированный угол |
| \ | Крен черепашки влево на фиксированный угол |
| ^ | Тангаж черепашки вверх на фиксированный угол |
| \_ | Тангаж черепашки вниз на фиксированный угол |
| [ | Запись текущего состояния черепашки в стек |
| ] | Извлечение последнего состояния черепашки из стека и его присвоение |
*Рисунок 2: Алфавит для отрисовки трёхмерной системы Линденмайера*
Параметрическая грамматика
--------------------------
Чтобы упростить новые характеристики, мне нужно расширить алфавит и синтаксис. На Рисунке 2 показан ключ этой новой системы. Новые символы таблицы — это символы поворота, необходимые для перемещения черепашки в 3D-пространстве.
Случайность легко моделировать добавлением одному символу множества нечётких продукционных правил. Если у символа есть несколько правил, то случайным образом выбирается одно из них.
Для моделирования возраста клетки и расстояния до корня я *мог бы* добавить к каждому символу по две переменные. Если бы мне затем нужно было добавить другие свойства, то пришлось бы добавлять новые переменные. Такой подход оказался бы не особо гибким и очень специфичным. К счастью, есть более общее решение: *параметрические системы Линденмайера*. В параметрических L-системах за каждым символом следует список параметров (при их наличии). Продукционные правила могут быть применимы к символам с определённым набором параметров или для определённых условий этих параметров; кроме того, получаемые при использовании правила символы тоже могут иметь свои параметры.
Я продемонстрирую эту новую систему на примере символа с одним параметром (возрастом символа, измеряемым в количестве итераций). Пусть аксиомой является , а единственным продукционным правилом — . При каждой итерации параметр каждого символа  будет увеличиваться на единицу. Теперь я хочу изменять каждый символ  на , когда он достигает возраста восьми итераций. Продукционное правило будет иметь вид . Если я задам для этой системы продукционное правило , то оно никогда не применится: в системе не будет символа  с двумя параметрами. Стоит учесть, что  и  в этих примерах выбраны произвольно; они используются для работы со значениями параметров. У этих параметров нет конкретных имён,  и  — это просто переменные и могут быть любым символом.
Я добавил в язык два синтаксических правила: в скобках за символом указывается количество параметров, разделённых запятыми, а за первым операндом продукционного правила может идти символ , если оно должно выполняться только при соблюдении условия после этого символа. Параметрическая грамматика позволяет реализовать гораздо более обширные возможности, чем мне требовались изначально.
Контекстно-зависимая грамматика
-------------------------------
Система почти завершена. Последнее, что я хочу закодировать — это контекст. Контекст символа должен влиять на применяемые к нему правила. Теоретически, я мог бы закодировать контекст в параметрах символов, но в этом случае получится очень сложная система правил и списков параметров. Поэтому вместо этого я добавлю к продукционным методам одно последнее синтаксическое правило.
*Рисунок 3: Контекстно-зависимая система Линденмайера в действии*
Допустим, у меня есть аксиома, состоящая из нескольких  и одного  в начале, и я хочу, чтобы  перемещался на один шаг вправо на каждой итерации, не изменяя длину предложения. Это можно реализовать с помощью контекстно-зависимого правила. Во-первых, я добавлю правило . Его следует читать следующим образом: , если символу  *предшествует* . При каждой итерации, в которой применяется это правило, каждый символ , слева от которого находится , будет меняться на . Теперь мне просто нужно, чтобы  двигался, поэтому после каждой итерации  снова должен становиться , чтобы все  со временем не превратились в . Это реализуется простым правилом . На Рисунке 3 показана эта система, эволюционирующая в течение одиннадцати итераций, а начальная аксиома имеет вид .
Эта контекстно-зависимая грамматика совместима с описанной выше параметрической грамматикой. Допустим, у меня есть предложение из нескольких вхождений , где значение  для разных символов разное. Я хочу написать контекстно-зависимое продукционное правило, которое заменяет  на  только когда  окружён другими вхождениями , чьи параметры равны; иными словами, слева и справа должны быть  с одинаковыми значениями параметра. Продукционное правило выглядит следующим образом:

То есть последним дополнением грамматики становятся символы  и . Если левому операнду продукционного правила предшествует , то в качестве контекста ему требуется символ перед . Если за ним следует , то в качестве контекста ему требуется символ после . У продукционных правил также может не быть контекста, или быть только правый/левый контекст.
Трёхмерная контекстно-зависимая параметрическая система Линденмайера
--------------------------------------------------------------------
Теперь всё готово для создания рендерера трёхмерной контекстно-зависимой параметрической системы Линденмайера, которую я реализовал ниже (в оригинале статьи). В ней присутствуют все описанные в этой статье возможности. Большинство полей предыдущего 2D-рендерера скопировано, но в этой системе добавлена кнопка пошагового эволюционного изменения и функция печати конечного предложения. Парсер контекстно-зависимых параметрических систем Линденмайера находится в [этом репозитории](https://github.com/jobtalle/LSystem).
Реализовано несколько режимов рендеринга. Сгенерированное 3D-изображение можно поворачивать перетаскиванием мышью (или пальцем на сенсорном экране) и масштабировать колёсиком мыши. Исходный код этого рендерера находится [на GitHub](https://github.com/jobtalle/Lindenmayer3D). Нажмите на кнопку *Go*, чтобы сгенерировать текущую систему.
**Примеры**


Вывод
-----
Системы Линденмайера позволяют создавать очень интересные и естественные паттерны, которые могут быть полезными во многих областях. Помимо моделирования фракталов, их можно использовать для генерирования природного контента, например, деревьев и растений. Ещё одной областью применения является генерация процедурного окружения, в которой важную роль играют контекстно-зависимые правила. Я подозреваю, что системы Линденмайера можно изменять с помощью генетических алгоритмов, слегка изменяя продукционные правила. Это может оказаться очень интересным способом для эволюционного изменения растений, и я хочу поэкспериментировать с ним, если найдётся свободное время.
Похоже, что L-системы способны с определённой степенью точности моделировать природу. Любопытно, до какой степени они на самом деле могут моделировать процессы природного роста с помощью обнаруженных мною правил? | https://habr.com/ru/post/346388/ | null | ru | null |
# Как мы создаем микросервисные проекты с нуля
Считается, что запуск микросервисов изначально затратнее по времени, чем монолит, и наш опыт это подтверждает. Однако, если следовать проверенным процессам, эти затраты можно минимизировать. Делюсь лучшими практиками и составляю чек-лист запуска.
В red\_mad\_robot мы делаем полный цикл разработки ПО, в том числе полноценные бэкенды. Оставим за скобками холиварную тему «Монолит vs Микросервисы», и представим, что выбрана микросервисная архитектура. Отмечу, что многие пункты не содержат прямого совета делать только так и никак иначе, но призывают задуматься над выбранным решением. Также важно иметь в виду, что они могут быть очевидны или нерелевантны уже запущенным системам с налаженными процессами. Здесь речь пойдет именно про запуск новой системы, и советы как быстрее принять решение и ничего не забыть.
### 1. Монорепозиторий vs мультирепозиторий
Обычно старт проекта подразумевает несколько понятных микросервисов, которые, скорее всего, будут написаны на одном языке, и, возможно, реализованы одной командой. Удобнее всего держать все контракты в одном месте, а если они находятся в одном репозитории с кодом, мы избегаем проблем с синхронизацией или подменой локальных зависимостей.
В случае монорепозитория у нас появляется возможность унифицировать стадию сборки проекта (например, для Docker) и вести общий файл зависимостей для всех частей системы. Это ускоряет добавление новых микросервисов. По умолчанию мы выбираем монорепозиторий, если изначально не видим выгоды от мультирепозитория. С ростом количества микросервисов вопрос деления становится все более актуальным, но при общем их числе в 20–30 монорепозиторий весьма удобен.
### 2. Подумайте про архитектуру взаимодействия частей системы между собой
Микросервисная архитектура в самом простом виде предполагает набор бизнесовых сервисов (например, «Каталог книг» и «Продажи»), а также сервис Gateway, который предоставляет API клиенту и знает, как получить нужные ему данные. Конечно, Gateway лишь распространенный паттерн, но можно обходиться и без него; речь пойдет про взаимоотношения микросервисов между собой в целом. Представим, что клиенту необходим список книг, с указанием количества продаж каждой книги за месяц. Здесь можно использовать два варианта работы — оркестрацию и хореографию.
**Оркестрация** похожа на обход графа «в ширину»: сначала мы в сервисе Gateway получаем список книг из «Каталога», а затем по ID книг извлекаем нужные данные из «Продаж», объединяем их и отдаем клиенту. Если нам потребуются еще данные по пользователям, оформившим покупку, мы сделаем дополнительный вызов из Gateway.
**Хореография** похожа на обход графа «в глубину». В таком случае вся информация для Gateway целиком подготавливается в «Каталоге», где она обогащается нужными данными из «Продаж». В свою очередь «Продажи» предварительно также могут запросить что-то из смежного микросервиса для подготовки ответа, и так далее по цепочке.
Подход оркестрации уменьшает связность микросервисов, но быстро приводит к разрастанию Gateway, необходимости добавлять в него бизнес-логику и соблазнам. Самый простой пример — появление условий для сбора данных, когда в зависимости от параметров или состояния объекта мы выбираем, откуда и какие данные хотим получить. В итоге рискуем получить God-object и точку отказа всего приложения. Хореография позволяет держать Gateway максимально простым, но повышает связность внутренних сервисов. В своей работе мы балансируем между этими двумя подходами, но точка равновесия смещена вправо к хореографии.
**Удобство API важнее сложности внутренней реализации**. Ещё одно важное правило: API микросервиса нужно проектировать на основании потребностей в данных других микросервисов, которые его вызывают. Так мы везде сохраняем принцип «обхода в глубину», снижаем риск циклов или повторного запроса одних и тех же данных.
Для организации асинхронного взаимодействия обычно используется **шина сообщений**. Формально, общая шина — первый признак сервисной архитектуры, а не микросервисной, но это не мешает нам пользоваться ее преимуществами. Она хорошо подходит для поэтапной обработки информации, периодических задач и формирования логики реакций на неуспешные операции. Подумайте о бизнес-процессах и внедрении очередей с самого начала, тогда вам не понадобится сразу обновлять в базе некритичные сущности, и вы ускорите запросы. Но также подумайте, насколько для вас будет критично время ответа на старте.
### 3. Унифицируйте подходы
Стоит сделать шаблонный микросервис и заложить в нем:
* договоренности по именованию в коде;
* правила логирования;
* правила построения API;
* архитектуру и слои: модели, схемы, сервис, транспорт;
* формирование конфигурации;
* правила кодогенерации, если они предполагаются;
* артефакты развертывания, например, манифесты k8s, или пример контейнера в docker-compose;
* тесты, в идеале отдельно для бизнес-логики и отдельно для сообщений на уровне транспорта;
* некоторые базовые операции-утилиты, которые будут использоваться несколькими микросервисами, например, работа с пользователем и любимые таймзоны.
Всё вышеперечисленное полезно описать в документе вроде README, это всегда помогает при вгрузе новых людей в проект. На первом этапе важно выделять достаточное время на код-ревью и следить за соблюдением всех этих подходов. С развитием проекта они растиражируются, договоренности закрепятся и вы перестанете про них думать.
### 4. Подумайте над межсервисной авторизацией
Самое простое — сделать Gateway единой точкой входа, и делегировать ему все вопросы аутентификации и авторизации: доверять запросам от Gateway и сразу оттуда считывать информацию о юзере, по крайней мере его id.
Этого будет достаточно? По нашему опыту, лучше сразу делать проверку данных через JWT. Это вопрос больше не про безопасность, а про защиту от случайных ошибок в коде, когда один микросервис случайно заменяет user\_id инициатора. Такое, к примеру, встречается в запросах для админок, когда надо выполнить операцию для какого-то юзера от имени другого юзера.
Также для избежания ошибок при наличии ролевой модели — явно объявляйте для каждого метода необходимые права, и прокидывайте роль в JWT. Например, есть схожие методы для пользователя и администратора, и в спешке разработчик может случайно использовать вызов привилегированного метода от имени обычного посетителя.
### 5. Настройте процессы CI/CD
Сборка приложения не должна требовать от разработчика каких-либо усилий. Но когда микросервисов много, встаёт вопрос ускорения всех стадий. Мы используем подход liquid software, когда код выкатывается мелкими проверенными порциями сразу в master, а оттуда автоматически на dev контур.
Такой подход часто запускает стадии проверки линтерами, тестирование и сборку. Поэтому не забудьте при тестировании кешировать зависимости — можно использовать [мануал](https://docs.gitlab.com/ee/ci/caching/) для GitLab. Для сборки образа устанавливайте их слоем выше, чем вы копируете код. Также настройте правила, чтобы запускать пайплайн только для нужных микросервисов, для которых изменился код.
### 6. Подумайте над переменными окружения
Существуют специально предназначенные инструменты для работы с энвами, но далеко не всегда бывает время развернуть их на старте. Переменные окружения в файлах доступны с самого начала :). Подход «один файл на одну среду — dev, stage, prod» быстро приводит к огромному нечитабельному списку. Более удобное решение — один файл на один микросервис. Но оно приводит к дублированию переменных; логично вынести общие в еще один файл. В том числе в него же выносим внутренние адреса для общения между собой.
Поскольку обычно помимо конфигурации в окружение попадают и различные секреты, эти файлы не сохраняют в репозиторий, а помещают, например, в Gitlab CI Variables или Github Environment Secrets. Позаботьтесь о разработчиках, которые будут подключаться в будущем — сделайте шаблонный .env с необходимыми для запуска тестов переменными, и опишите в README весь процесс добавления новых энвов. Так вы избежите банальной проблемы — загрузили локально последние обновления и тесты перестали проходить, хотя у других все в порядке. Этот же .env можно использовать и в процессе CI.
### 7. Обратите внимание на методы API, возвращающие вложенные данные
Обычно фронтенд хочет получить максимальное количество данных в одном запросе. Если с бэкенда вы предоставляете вложенные модели или поля, которые формируются из нескольких микросервисов, это может привести к нежелательным эффектам.
Рассмотрим пример из пункта 2 с «Каталогом» и «Продажами».
Допустим, у нас GraphQL. Мы создаем `type Book { title: String! }`, у которого объявляем поле `sold_count` — количество проданных экземпляров. Фронтенд сам решает, какие поля ему нужны — он может запросить `sold_count`, а может и не запросить. Скорее всего, вы прокидываете выбранные поля как Only в sql-запрос в базу. Нужно отделить атрибут `sold_count` и явно обработать ситуацию его наличия или отсутствия, чтобы не ходить лишний раз в микросервис «Продажи» при вызове Book. А если помимо `sold_count` у нас появляется еще одно поле из «Продаж», скажем — выручка, то непонятно, обрабатывать поле также отдельно или писать сложную логику, чтобы делать первый эффективный запрос.
В случае с REST проблема аналогичная, только более явная. Мы понимаем маршрут сбора данных с микросевриса для каждого запроса. Но фронтендеру могут понадобиться Books в каких-то сценариях вместе с `sold_count`, а где-то без этого поля. Для оптимального выполнения нам нужно либо заводить схемы наподобие BookShort и BookFull, либо делать несколько похожих методов — здесь снова нет однозначного рецепта. Но точно стоит уделить внимание информированию фронтенда — в каком случае что использовать.
**Теперь поговорим про многовложенность**. Допустим, у продаж есть связь «покупатель», которая ведет в третий микросервис — «Пользователи». У книги есть список комментариев, каждый из которых, в свою очередь, также ведет к «Пользователям». Появилось желание в одном запросе получать список книг и вывести список комментариев к книге вместе с информацией о каждом покупателе. В случае использования REST здесь явно прослеживается пересечение двух вызовов к «Пользователям». Разумно их объединить в один, а затем смапить данные в нужных местах.
В случае предоставления GraphQL эта ситуация может произойти неявно. Например, если раньше был просто запрос со списком покупателей, а затем в схему ответа добавили список комментариев, не заметив, что схема комментария содержит в себе данные пользователя. Таким образом, это еще одно место для повышенного внимания. В конце концов, здесь точно стоит задуматься — а не будет ли удобнее разделить этот сценарий на два запроса на уровне API для фронтенда?
### 8. Создайте команду
Исторически микросервисы возникали как результат операции «распилить монолит», а типичным признаком её приближения служила нелинейно возрастающая сложность разработки. Тем не менее, микросервисы — удел не только крупных компаний с большими командами. Этот подход успешно применим и на старте проектов.
В этом тексте я затрагиваю много вопросов об архитектуре приложения, но технический успех проекта часто зависит еще и от организации работ. Взаимодействие разработчиков внутри команды между собой, а также с другими командами — тот «клей», который удерживает все аспекты вместе и приносит нужный результат.
Это отдельная большая тема, которую я не буду здесь затрагивать, но отмечу, что ежедневный комфорт в общении и доверие между участниками как внутри команды, так и с внешними заказчиками, дают значительный прирост в скорости работ. Поэтому, когда архитектура системы проработана, а правила работы с кодом в репозитории описаны — примените ваши лучшие наработки для создания сплоченной команды. Вместе вы сможете создать тот самый сервис, которым станут пользоваться миллионы и вам не придется думать, как справиться с неожиданной нагрузкой и что-то перепроектировать. | https://habr.com/ru/post/588546/ | null | ru | null |
# Реализация последовательностей жестов в Unity 3D с помощью библиотеки TouchScript
Для многих игровых приложений, особенно работающих на небольших экранах мобильных устройств, очень важно уменьшить область, занимаемую элементами управления, чтобы максимально расширить часть экрана, предназначенную для отображения основного контента. Для этого можно настроить цели касания (touch targets) так, чтобы они обрабатывали различные комбинации жестов. Таким образом, количество целей касания на экране сократится до минимума. Например, два элемента интерфейса, один из которых заставляет пушку стрелять, а второй — вращаться, можно заменить на один, позволяющий выполнять оба действия одним непрерывным касанием.
В этой статье я расскажу о том, как настроить сцену для управления контроллером от первого лица при помощи целей касания. Прежде всего необходимо настроить цели касания для базовой позиции контроллера и вращения, а затем расширить набор их функций. Последнего можно достичь за счет существующих элементов интерфейса, не добавляя новые объекты. Сцена, которая у нас получится, продемонстрирует широкие возможности Unity 3D в ОС Windows\* 8 как платформы для обработки различных последовательностей жестов.
#### Настройка сцены в Unity\* 3D
Для начала необходимо настроить сцену. Для этого импортируем в Unity\* 3D ресурс ландшафта в формате .fbx с горами и деревьями, экспортированный из Autodesk 3D Studio Max\*. Поместим контроллер в центре ландшафта.
Установим показатель глубины основной камеры (она входит в состав контроллера) на уровень -1. Создадим отдельный элемент интерфейса камеры с поддержкой ортогональной проекции, шириной 1 и высотой 0,5, а также флагами Don’t Clear. Затем создадим слой GUIWidget и сделаем его маской интерфейса камеры.
Расположим основные элементы интерфейса, управляющие контроллером, на сцене в поле обзора ортогональной камеры. Добавим сферу для каждого пальца левой руки. Сфера мизинца заставляет контроллер двигаться влево, сфера безымянного пальца — вперед, среднего пальца — вправо, а указательного пальца — назад. Сфера большого пальца позволяет прыгать и запускать сферические снаряды под углом 30 градусов по часовой стрелке.
Для элемента интерфейса правой руки создадим куб (квадрат в ортогональной проекции). Настроим для этого куба поддержку жеста сдвига и привяжем его к скрипту MouseLook.cs. Этот элемент интерфейса обеспечивает такие же возможности, как и сенсорная панель устройства Ultrabook.
Эти элементы интерфейса расположим вне поля обзора основной камеры, а в качестве слоя установим GUIWidget. На рис. 1 можно увидеть, как элементы интерфейса позволяют запускать снаряды и управлять позицией контроллера на сцене.

*Рисунок 1. Сцена контроллера от первого лица с ландшафтом и запущенными сферическими снарядами.*
На этой сцене снаряды, запущенные из контроллера, пролетают сквозь деревья. Чтобы это исправить, необходимо добавить сетку или коллайдер к каждому дереву. Другая проблема на этой сцене — низкая скорость движения вперед — возникает при попытке посмотреть вниз с помощью сенсорной панели одновременно с движением вперед с помощью сферы безымянного пальца. Чтобы устранить эту неполадку, можно ограничить угол обзора при взгляде вниз, когда удерживается кнопка движения вперед.
#### Множественные касания
На базовой сцене находится контроллер от первого лица, который запускает снаряды под определенным углом по направлению от центра (см. Рисунок 1). По умолчанию установлен угол в 30 градусов по часовой стрелке.
Настроим сцену для поддержки множественных касаний, выполняемых чаще, чем установленный период, изменим угол запуска снарядов и попробуем запустить снаряд. В этом случае можно настроить угол на возрастание в геометрической прогрессии в зависимости от числа касаний при помощи переменных типа float в скрипте для сферы большого пальца слева. Эти переменные регулируют угол и время с момента запуска последнего снаряда:
```
private float timeSinceFire = 0.0f;
private float firingAngle = 30.0f;
```
Далее настроим цикл Update в скрипте для сферы большого пальца так, чтобы угол запуска снарядов снижался, если касания сферы большого пальца выполняются чаще, чем раз в полсекунды. В том случае, если касания последуют реже, чем раз в полсекунды, или угол запуска снарядов снизится до 0 градусов, величина угла запуска снарядов вернется к показателю 30 градусов. Получится следующий код:
```
timeSinceFire += Time.deltaTime;
if(timeSinceFire <= 0.5f)
{
firingAngle += -l.0f;
}
else
{
firingAngle = 30.0f;
}
timeSinceFire = 0.0f;
if(firingAngle <= 0)
{
firingAngle = 30;
}
projectileSpawnRotation = Quaternion.AngleAxis(firingAngle,CH.transform.up);
```
Такой код произведет эффект обстрела, при котором непрерывные касания приведут к запуску снарядов под постоянно уменьшающимся углом (см. рис. 2). Этот эффект можно позволить настраивать пользователям либо сделать доступным при соблюдении определенных условий в игре или режиме симуляции.

*Рисунок 2. Непрерывные касания приводят к изменению направления запуска снарядов*
#### Масштабирование прокруткой
Мы настроили квадрат в правой нижней части экрана на рис. 1 на работу в режиме, аналогичном сенсорной панели на клавиатуре. При жесте сдвига квадрат не двигается, а поворачивает основную камеру сцены вверх, вниз, влево и вправо с помощью скрипта контроллера MouseLook. Аналогичным образом жест масштабирования (схожий со растягиванием/сжатием на других платформах) приводит не к масштабированию квадрата, а к изменению поля зрения основной камеры, благодаря которому пользователь может приблизить или отдалить объект на основной камере (см. Рисунок 3). Настроим контроллер таким образом, чтобы жест сдвига сразу после масштабирования возвращал поле зрения камеры к значению по умолчанию 60 градусов.
Для этого нужно запрограммировать логическую переменную (panned) и переменную типа float, чтобы они отмечали время, прошедшее от последнего жеста масштабирования:
```
private float timeSinceScale;
private float timeSincePan;
private bool panned;
```
Установим для переменной timeSinceScale значение 0.0f при выполнении жеста масштабирования, а для переменной panned — значение True при выполнении жеста сдвига. Поле зрения основной камеры сцены настраивается в цикле Update, как можно увидеть в скрипте для прямоугольника-сенсорной панели:
```
timeSinceScale += Time.deltaTime;
timeSincePan += Time.deltaTime;
if(panned && timeSinceScale >= 0.5f && timeSincePan >= 0.5f)
{
fieldOfView += 5.0f;
panned = false;
}
if(panned && timeSinceScale <= 0.5f)
{
fieldOfView = 60.0f;
panned = false;
}
Camera.main.fieldOfView = fieldOfView;
```
Рассмотрим функции onScale и onPan. Обратите внимание на то, что переменная float timeSincePan не позволяет полю зрения постоянно увеличиваться, когда для управления камерой используется сенсорная панель:
```
private void onPanStateChanged(object sender, GestureStateChangeEventArgs e)
{
switch (e.State)
{
case Gesture.GestureState.Began:
case Gesture.GestureState.Changed:
var target = sender as PanGesture;
Debug.DrawRay(transform.position, target.WorldTransformPlane.normal);
Debug.DrawRay(transform.position, target.WorldDeltaPosition.normalized);
var local = new Vector3(transform.InverseTransformDirection(target.WorldDeltaPosition).x, transform.InverseTransformDirection(target.WorldDeltaPosition).y, 0);
targetPan += transform.InverseTransformDirection(transform.TransformDirection(local));
//if (transform.InverseTransformDirection(transform.parent.TransformDirection(targetPan -startPos)).y < 0) targetPan = startPos;
timeSincePan = 0.0f;
panned = true;
break;
}
}
private void onScaleStateChanged(object sender, GestureStateChangeEventArgs e)
{
switch (e.State)
{
case Gesture.GestureState.Began:
case Gesture.GestureState.Changed:
var gesture = (ScaleGesture)sender;
if (Math.Abs(gesture.LocalDeltaScale) > 0.01 )
{
fieldOfView *= gesture.LocalDeltaScale;
if(fieldOfView >= 170){fieldOfView = 170;}
if(fieldOfView <= 1){fieldOfView = 1;}
timeSinceScale = O.Of;
}
break;
}
}
```

*Рисунок 3. Основная камера сцены с изображением, приближенным при помощи прямоугольника сенсорной панели справа.*
#### Нажатие, отпускание с щелчком
Если нажать и отпустить сферу мизинца, а затем в течение полусекунды провести по ней, можно увеличить горизонтальную скорость контроллера.
Для поддержки этой функции добавим переменную типа float и логическую переменную, которые позволят отмечать время с жестов отпускания сферы мизинца и жеста щелчка по ней:
```
private float timeSinceRelease;
private bool flicked;
```
При первоначальной установке сцены я предоставил скрипту сферы мизинца доступ к скрипту контроллера InputController, чтобы сфера мизинца слева могла заставлять контроллер двигаться влево. Переменная, управляющая горизонтальной скоростью контроллера, находится не в скрипте InputController, а в скрипте CharacterMotor. Передать скрипт сферы левого мизинца скрипту CharacterMotor можно аналогичным образом:
```
CH = GameObject.Find("First Person Controller");
CHFPSInputController =
(FPSInputController)CH.GetComponent("FPSInputController");
CHCharacterMotor = (CharacterMotor)CH.GetComponent ("CharacterMotor");
```
Функция onFlick в нашем скрипте лишь позволяет установить для логической переменной flicked значение, равное True.
Функция Update в скрипте вызывается один раз за кадр и изменяет движение контроллера по горизонтали следующим образом:
```
if(flicked && timeSinceRelease <= 0.5f)
{
CHCharacterMotor.movement.maxSidewaysSpeed += 2.0f;
flicked = false;
}
timeSinceRelease += Time.deltaTime;
}
```
Благодаря этому коду можно увеличивать скорость движения по горизонтали. Для этого нужно нажать и отпустить сферу мизинца, а затем провести по ней в течение полсекунды. Настроить замедление движения по горизонтали можно различными способами. Например, для этого можно использовать нажатие и отпускание сферы указательного пальца, а затем щелчок по ней. Обратите внимание на то, что способ CHCharacterMotor.movement содержит не только параметр maxSidewaysSpeed, но также gravity, maxForwardsSpeed, maxBackwardsSpeed, и другие. Использование разнообразных жестов библиотеки TouchScript и объектов, которые обрабатывают жесты, в сочетании с этими параметрами обеспечивает широкие возможности и различные стратегии разработки сенсорных интерфейсов в сценах Unity 3D. При создании сенсорных интерфейсов для таких приложений можно пробовать различные варианты и выбирать наиболее эффективные и эргономичные.
#### Проблемы с последовательностями жестов
Последовательности жестов, которые мы использовали в этой статье, существенно зависят от функции Time.deltaTime. Я применяю эту функцию в сочетании с разными жестами до и после того, как функция определит действие. Две основные проблемы, с которыми я столкнулся при настройке этих случаев, заключаются в величине временного интервала и характере жестов.
##### Временной интервал
При написании этой статьи я использовал интервал в полсекунды. Если я выбирал интервал равный одной десятой секунды, устройство не могло распознать последовательности жестов. Хотя мне казалось, что темп касаний был достаточно высок, это не приводило к нужным действиям на экране. Возможно, это связано с задержками в работе устройства и ПО, поэтому рекомендую при разработке последовательностей жестов учитывать производительность целевой платформы.
##### Жесты
При работе над этим примером я изначально собирался использовать жесты масштабирования и сдвига, а затем касания и щелчка. Масштабирование и сдвиг работали правильно, но перестали, как только я добавил жест касания. Хотя мне удалось настроить последовательности из жестов масштабирования и сдвига, она не очень удобна для пользователя. Более удачным вариантом будет настроить другую цель касания в элементе интерфейса на обработку жестов касания и проведения после масштабирования и сдвига.
В этом примере я использую интервал времени в полсекунды, чтобы определять, выполнено действие или нет. Также можно настроить несколько временных интервалов, хотя это и приведет к усложнению интерфейса. Например, последовательность жестов нажатия и отпускания и следующего в течение полсекунды за ними проведения может увеличивать скорость движения по горизонтали, а аналогичная последовательность с интервалом от полсекунды до секунды — снижать скорость. Используя временные интервалы таким образом, можно не только более гибко настроить пользовательский интерфейс, но и добавить на сцену скрытые секреты.
#### Заключение
В этой статье я настроил сцену с различными последовательностями жестов в Unity\* 3D с помощью библиотеки TouchScript на устройстве Ultrabook с ОС Windows 8. Цель реализации этих последовательностей — сократить область экрана, с помощью которой пользователь управляет приложением. В этом случае можно выделить большую площадь экрана для показа привлекательного контента.
В тех случаях, когда последовательности жестов не работали правильно, нам удавалось найти подходящее альтернативное решение. Одной из задач настройки было добиться правильной работы последовательности действий с помощью функции Time.deltaTime на имеющемся устройстве. Таким образом, сцена, которую мы создали в Unity 3D для этой статьи, подтверждает жизнеспособность ОС Windows 8 на устройствах Ultrabook как платформы для разработки приложений с использованием последовательностей жестов. | https://habr.com/ru/post/233773/ | null | ru | null |
# CEF, ES6, Angular 2, WebPack 2 .Net Core десктопное приложение без серверной части
Это продолжение статей:
→ [CEF, ES6, Angular 2, TypeScript использование классов .Net Core. Создание кроссплатформенного GUI для .Net с помощью CEF](https://habrahabr.ru/post/320960/)
→ [CEF, Angular 2 использование событий классов .Net Core](https://habrahabr.ru/post/321452/)
Основная идея этих статей — создание кроссплатформенных приложений на CEF с использованием Angular 2 и .Net Core. Чтобы отвязаться от сервера, используем свежий WebPack и настроим на локальное использование файлов.
Для начала создадим package.json.
**Содержимое package.json**
```
{
"name": "helloapp",
"version": "1.0.0",
"scripts": {
"start": "tsc && concurrently \"tsc -w\" \"lite-server\" ",
"lite": "lite-server",
"tsc": "tsc",
"tsc:w": "tsc -w"
},
"dependencies": {
"@angular/common": "~2.4.0",
"@angular/compiler": "~2.4.0",
"@angular/core": "~2.4.0",
"@angular/forms": "~2.4.0",
"@angular/http": "~2.4.0",
"@angular/platform-browser": "~2.4.0",
"@angular/platform-browser-dynamic": "~2.4.0",
"@angular/router": "~3.4.0",
"@angular/upgrade": "~2.4.0",
"angular-in-memory-web-api": "~0.2.4",
"babel-preset-es2015": "^6.22.0",
"babel-preset-es2016": "^6.22.0",
"babel-preset-react": "^6.23.0",
"bootstrap": "^3.3.7",
"core-js": "^2.4.1",
"css-loader": "^0.26.1",
"jquery": "^3.1.1",
"postcss-loader": "^1.3.0",
"raw-loader": "^0.5.1",
"reflect-metadata": "^0.1.9",
"rxjs": "^5.1.1",
"sass-loader": "^6.0.0",
"style-loader": "^0.13.1",
"systemjs": "^0.20.7",
"to-string-loader": "^1.1.5",
"ts-loader": "^2.0.0",
"typescript": "^2.1.6",
"webpack": "^2.2.0",
"webpack-fail-plugin": "^1.0.5",
"webpack-notifier": "^1.5.0",
"zone.js": "^0.7.7"
},
"devDependencies": {
"@types/core-js": "^0.9.35",
"@types/node": "^6.0.46",
"babel-core": "6.23.1",
"babel-eslint": "7.1.1",
"babel-loader": "6.3.0",
"babel-plugin-__coverage__": "^11.0.0",
"babel-polyfill": "^6.0.0",
"babel-preset-angular2": "^0.0.2",
"babel-preset-es2015": "^6.22.0",
"bootstrap-loader": "^2.0.0-beta.20",
"bootstrap-sass": "^3.3.7",
"chunk-manifest-webpack-plugin": "^1.0.0",
"concurrently": "^3.1.0",
"css-loader": "^0.26.1",
"css-to-string-loader": "^0.1.2",
"extract-text-webpack-plugin": "^2.0.0-rc.3",
"file-loader": "^0.10.0",
"html-webpack-plugin": "^2.28.0",
"jquery": "^3.1.1",
"lite-server": "^2.2.2",
"node-sass": "^4.5.0",
"resolve-url-loader": "^1.6.1",
"sass-loader": "^6.0.0",
"style-loader": "^0.13.1",
"typescript": "^2.1.5",
"url-loader": "^0.5.7"
}
}
```
Здесь собраны загрузчики, ссылки на необходимые файлы итд, которые были подобраны долгими исканиями.
Так же необходим tsconfig.json для компиляции TypeScript-файлов.
**Содержимое tsconfig.json**
```
{
"compilerOptions": {
"target": "es6",
"module": "commonjs",
"moduleResolution": "node",
"sourceMap": true,
"emitDecoratorMetadata": true,
"experimentalDecorators": true,
"removeComments": false,
"noImplicitAny": true,
"suppressImplicitAnyIndexErrors": true,
"lib": [ "es6", "dom" ],
"types": [ "node" ],
"typeRoots": [
"node_modules/@types"
]
},
"exclude": [
"node_modules",
"wwwroot",
"**/*.spec.ts"
],
"compileOnSave": true
}
```
Теперь мы можем создать на основании package.json директорию node\_modules с помощью команды npm install из директории приложения.
Прежде чем вызывать WebPack, нужно создать несколько файлов polyfills.ts.
**Содержимое polyfills.ts**
```
import 'core-js/es6';
import 'core-js/es7/reflect';
require('zone.js/dist/zone');
if (process.env.ENV === 'production') {
// Production
} else {
// Development and test
Error['stackTraceLimit'] = Infinity;
require('zone.js/dist/long-stack-trace-zone');
}
```
Добавить в main.ts ссылки на Bootstap и JQuery:
```
import 'jquery';
import 'bootstrap-loader';
import 'bootstrap/dist/css/bootstrap.css';
import 'bootstrap/dist/css/bootstrap-theme.css';
```
Теперь нам доступны стили, glyphicons и тд. Теперь перейдем к самому главному, а именно webpack.config.js, на основании которого и будут собираться нужные нам файлы.
```
var webpack = require('webpack');
var HtmlWebpackPlugin = require('html-webpack-plugin');
var ExtractTextPlugin = require("extract-text-webpack-plugin");
var helpers = require('./helpers');
var babelOptions = {
"presets": [
"react",
[
"es2015",
{
"modules": false
}
],
"es2016"
]
};
module.exports = {
cache: true,
entry: {
polyfills: './app/polyfills.ts',
main: './app/main.ts',
vendor: [
'babel-polyfill'
]
},
output: {
path: './wwwroot',
filename: './scripts/[name].js',
chunkFilename: './scripts/[chunkhash].js',
publicPath: './'
},
module: {
rules: [{
test: /\.ts(x?)$/,
exclude: /node_modules/,
include: /app/,
use: [
{
loader: 'babel-loader',
options: babelOptions
},
{
loader: 'ts-loader'
}
]
}, {
test: /\.js$/,
exclude: /node_modules/,
include: /app/,
use: [
{
loader: 'babel-loader',
options: babelOptions
}
]
},
{ test: /\.html$/, loader: 'raw-loader', exclude: [helpers.root('app/index.html')] },
{ test: /\.(png|jpg|jpeg|gif|svg)$/, loader: 'url-loader', query: { limit: 25000 } },
{ test: /\.css$/, loader: 'css-to-string-loader!css-loader' },
{ test: /\.scss$/, loaders: ['style', 'css', 'postcss', 'sass'] },
{ test: /\.(woff2?|ttf|eot|svg)$/, loader: 'url-loader?limit=10000' },
{ test: /bootstrap\/dist\/js\/umd\//, loader: 'imports?jQuery=jquery' }
]
},
resolve: {
extensions: ['.ts', '.tsx', '.js','.css']
},
plugins: [
// Workaround for angular/angular#11580
new webpack.optimize.CommonsChunkPlugin({
name: ['app', 'vendor', 'polyfills']
}),
new HtmlWebpackPlugin({
template: 'app/index.html'
}),
new ExtractTextPlugin(
{
filename: 'styles.css',
disable: false,
allChunks: true
}
),
new webpack.ProvidePlugin({
jQuery: 'jquery',
$: 'jquery',
jquery: 'jquery'
})
]
};
```
Здесь собрано всё, чтобы использовать es6 и всё собиралось в несколько файлов в директории
'./wwwroot'. Теперь можно запустить webpack --config webpack.config.js, который и создаст нужные нам файлы.
Но нам придется подправить выходной index.html. Почему-то для:
```
```
Добавляются лишние ./ — убрав ./, мы можем запустить index.html в любом браузере. Но нас интересует наш cefsimple.exe:
Укажем в адресе файла путь к index.html, например, d:\CEF\CefProgects\TestTypeScript\TestTypeScript\wwwroot\index.html
И Вуаля, мы работаем автономно, без Web-сервера. Если нужно подключиться к серверу, у нас есть все на .Net. Например, [.Net Core, WCF и ODATA-клиенты](https://habrahabr.ru/post/310152/).
Нужно добавить что я отказался от Routing в пользу NgSwitch
Так как в проект построен на использовании systemjs.config.js, то в нем нет поддержки require
который необходим для WebPack, что бы весь Html код интегрировался в js код.
Так как не нашел в TS условную компиляцию, для отладки необходимо закомментировать require
```
@Component({
selector: 'nav-menu',
template:require('./navmenu.component.html'),
styles: [require('./navmenu.component.css')]
// templateUrl: 'app/navmenu/navmenu.component.html',
// styleUrls: ['app/navmenu/navmenu.component.css']
})
```
И раскомментировать
```
// templateUrl: 'app/navmenu/navmenu.component.html',
// styleUrls: ['app/navmenu/navmenu.component.css']
```
исходники и программы и инструкцию использования можно найти в предыдущих статьях в самом низу. | https://habr.com/ru/post/321898/ | null | ru | null |
# Создаем Свой Sniffer/FireWall/Parental control/ SpyWare/Клиент для компьютерного Клуба. Технология LSP
#### Создаем Свой Sniffer/FireWall/Parental control/ SpyWare/Клиент для компьютерного Клуба. Технология LSP

Provider).
Недавно один знакомый выявил желание что ему для Электронного зала (библиотеки) нужна программа которая будет контролировать доступ к компьютерам и считать автоматически кто чего и почем.
Так как денег в бюджете за 2012 год не оказалось, знакомый дал отбой. Но идеей контроля доступа уже зажегся. Начал думать, как это можно сделать.
Больше всего меня беспокоил один вопрос. Как блокировать HTTP трафик если пользователь платит только за аренду компьютера, а не за аренду компьютера с интернетом?
На просторах интернета нашел интереснейшую статью о LSP и вот представляю ее перевод с некоторыми изменениями.
Кому интересно прошу под кат.
##### HTTP сниффер на базе LSP (Layered Service Provider)
Эта статья описывает, как создать простейший снифер для мониторинга HTTP трафика на ОС Windows. Эта программа основана на открытой технологии предоставленной Microsoft, имя ей — LSP (Layered Service Provider).
Эта технология используется различным ПО. В основном это Антивирусы, Фаерволлы и программы фильтрации трафика.
Для того чтобы создать этот пакет программ я использовал пример из Microsoft Platform SDK (Program Files\Microsoft Platform SDK\Samples\NetDS\WinSock\LSP\) и добавил дополнительную возможность для фильтрации HTTP трафика и сбора результатов в отдельное хранилище.
Концепция
Базовая Схема
Мы начинаем
Выводы и советы
Полезные Ссылки.
##### Концепция.
Главная идея LSP это создание провайдера который будет включен в цепочку существующих провайдеров. Чем то напоминает принцип Хуков в Windows.

Во время инсталяции провайдера, вы можете указать место в цепочке провайдеров. И цепочка будет перестроена согласно новым настройкам. В нашем случае провайдер устанавливается поверх [TCP/IP] провайдера. Будьте осторожны во время установки на реальную машину. Если при установки будет сбой, это добавит много проблем – потеря сети, интернета и сбоя некоторых сетевых приложений.
Для того чтобы обойти проблемы отладки и создания провайдера LSP тестируйте его на Виртуальной машине.
В LSP провайдере, вы должны заместить все методы библиотеки winsock. Вообще то в примере Platform SDK уже включена логика замещения, остается только добавить логику перехвата, блокировки УРЛа либо сохранения HTTP трафика.
LSP используют как легальные программы, так и SpyWare/AdWare.
Например:
**Легальные программы:**
* Sygate Firewall
* Mcafee Personal Firewall
* E-Safe
* Dr.Web Security Space 6 использует LSP в качестве модуля Родительского контроля.
**AdWare:**
* Webhancer
* New.net
* NewDotNet

##### LSP в действии.
##### Базовая Схема
Так выглядит базовая схема программного пакета.

После установки программного пакета, многие программы будут использовать наш провайдер (вообще наш провайдер это простой DLL файл, который загружается в каждое приложение которое использует библиотеку Winsock). Но нам нужно только определять HTTP трафик. Ниже представлена строка кода (нашего провайдера) с жестко привязанным портом, который и будет мониториться (HTTP протокол по умолчанию использует 80 порт ).
```
if((namelen >= sizeof(sockaddr_in)) && (((sockaddr_in*)name)->sin_port == htons(HTTPPort)))
{
SocketContext->intercept = TRUE;
}
```
Вы можете улучшить этот инструмент, и сделать более элегантную логику программы для сохранения своих настроек, а не жестко определенных констант как в примере.
Кроме того мы должны определить HTTP запросы. Запросы HTTP GET определяются простым сравнением со строкой “GET”. Определение запросов POST можно осуществить тем же путем.
Также у нас имеется Служба, которая собирает всю информацию которая фильтруется – служба была создана для того чтобы предотвратить повреждения данных, она может произойти если мы будем следить за несколькими приложениями, а не за одним. Все перехваченная информация из браузера будет передаваться этой службе. Эта служба представляет из себя Socket сервер (слушает на 4004 порту) так что никаких проблем с синхронизацией сбора данных не должно быть. В данном случае Хранилище данных это просто текстовый файл, но можно с легкостью заменить на более удобный и стабильный вариант (например использовать СУБД ).
##### Мы начинаем
Тестовый Пакет содержит следующие проекты.
1.Проект LSP (папка LSP)
Этот проект содержит перегрузку основных методов Winsock. Именно в этом месте, мы должны добавить свои изменения. В моем случае, этот проект содержит пример из Platform SDK, где я и добавил логику для определения соединения к 80-му порту и пометил его как перехватываемым в методе Connect:
```
if((namelen >= sizeof(sockaddr_in)) && (((sockaddr_in*)name)->sin_port == htons(HTTPPort)))
{
SocketContext->intercept = TRUE;
}
```
Таким образом, при будущих вызовах метода Send, мы обнаружим, что этот socket используется HTTP протоколом. Также мы установили соединение с Службой сбора трафика в методе Connect. В методе SEND, мы реализовали логику обнаружения запросов HTTP и перенаправления их на нашу службу(Service):
```
if (IsHTTPRequest(lpBuffers->buf) && SocketContext->intercept)
{
SetBlockingProvider(SocketContext->Provider);
ret = SocketContext->Provider->NextProcTable.lpWSPSend(
serviceConnection.GetSocket(),
lpBuffers,
dwBufferCount,
lpNumberOfBytesSent,
dwFlags,
lpOverlapped,
lpCompletionRoutine,
lpThreadId,
lpErrno
);
SetBlockingProvider(NULL);
}
```
Я создал специализированный класс который держит одно постоянное соединение для каждого загруженного DLL файла.
```
class ServiceConnectionKeeper;
```
Его роль сохранять Socket подключенным. Таким образом, только одно соединение установлено с службой хранилища.
2.Проект Common (папка Common)- этот проект содержит все утилиты предоставленные в примерах Platform SDK. И также были сделаны некоторые манипуляции с GUID от нашего LSP провайдера.
Проект Installer (папка Installer ) – это установщик LSP. Мы поменяли его главный метод – убрали парсинг командной строки и добавили поиск TCP провайдера. Теперь во время установки мы ищем ID TCP провайдера и перестраиваем цепочку провайдеров. Мы поместили наш провайдер поверх TCP.
```
if (IsHTTPRequest(lpBuffers->buf) && SocketContext->intercept)
{
SetBlockingProvider(SocketContext->Provider);
ret = SocketContext->Provider->NextProcTable.lpWSPSend(
serviceConnection.GetSocket(),
lpBuffers,
dwBufferCount,
lpNumberOfBytesSent,
dwFlags,
lpOverlapped,
lpCompletionRoutine,
lpThreadId,
lpErrno
);
SetBlockingProvider(NULL);
}
```
3.Проект Service (папка Service )– это сборщик трафика. Он представляет из себя простейшую службу Windows и методы установки и удаления службы. В функции MAIN нашей службы также реализован Socket сервер. Вся логика манипуляции со службой любезно позаимствована из MSDN. Сервер принимает все входящие подключения и запускает на каждое приложение отдельный поток. Запущенный поток принимает данные разделенные последовательною "\r\n\r\n" (по сути 2 пустые строки) и сохраняет их в хранилище.
```
do
{
result = recv(clientSocket, buffer, PACKSIZE, 0);
if (result > 0)
{
response += std::string(buffer, result);
do
{
position = response.find(messageTerminator);
if (std::string::npos != position)
{
if (!CollectorServer::Instance()->SaveData(std::string(response.begin(), response.begin() + position)))
{
return -1;
}
response = response.substr(position + messageTerminator.size());
}
} while (std::string::npos != position);
}
else
{
break;
}
} while (SOCKET_ERROR != result);
```
Для того чтобы начать работать с этим проектом вам понадобиться собрать весь проект Visual studio. После этого положите NSI скрипт в папку результата сборки и скомпилируете Nsi скрипт. У нас получиться установочный setup.exe файл
Во время установки setup.exe, все необходимые файлы будут распакованы в свои рабочие папки. LSP.DLL будет помещен в %SYSTEMROOT%\\system32\\LSP.dll. Служба и установщик провайдера будет помещен в папку Program Files. Также ярлык деинсталляции будет размещен на рабочий стол. Файл истории будет находиться в корне C://.
##### Выводы и советы.
В этой статье описывается, как создать свой собственный провайдер и мониторить весь сетевой трафик. Но это не единственный пример для использования данной технологии. Вы также можете легко реализовать логику для:
Блокирования HTTP запросов и ответов;
Изменять и удалять трафик;
Блокировать соединения (как это делает Firewall);
Перехватывать SLL зашифрованные данные (даже возможно сделать MITM перехват) (Man in the midle)
В разработке LSP было много граблей, чтобы не сожалеть, что интернет соединение было потеряно и были сбой, лучше для тестов использовать Виртуальную машину. Гораздо удобнее откатить образ ВМ на предыдущее состояние чем использовать каждый раз систему восстановления Windows.
Большая часть антивирусного ПО тоже использует данную технологию, так что вы можете найти их в цепочке установленных LSP провайдеров в вашей ОС. Также антивирусы могут стать для вас проблемой при тестирование своего LSP провайдера, потому что антивирусы тоже фильтруют трафик.
Вы можете добавить логику для игнорирования выбранных вами приложений. Чтобы Наш LSP-провайдер ничего не делал кроме передачи данных если приложение в списке игнорируемых.
Этот инструмент был разработан только для 32-битных приложений. Но оно может быть легко портировано на 64-разрядных приложений. Вы просто должны пересобрать проект в 64-битный и выставить флаг LspCatalog64Only во время установки провайдера.
Чтобы увидеть изменения в примере Platform SDK, которые были сделаны для создания этого инструмента, вы можете сравнить текст с оригинальным примером.
Также я отметил все блоки кода, которые были добавлены комментарием //ADDED
Также обратите внимание, что вы должны сгенерировать новый GUID для вашего LSP-провайдера, чтобы избежать коллизий с другими LSP-провайдерами.
##### Полезные ссылки
К сожалению ссылок не так много, но они все же есть.
0. [Оригинал статьи на английском](http://www.apriorit.com/dev-blog/238-lsp-based-http-sniffer)
1.[MSDN](http://www.microsoft.com/msj/0599/layeredservice/layeredservice.aspx) и документация Platform SDK.
2. [Также есть информация на вебсайте LSP разработчиков](http://www.komodia.com/lsp-sub).
Сам проект выложен [ТУТ](http://www.apriorit.com/downloads/HTTPSniffer.zip)
Также проект выложен на [ГИТХАБ](https://github.com/SOLON7/HTTPSniffer) | https://habr.com/ru/post/162401/ | null | ru | null |
# Разбор Java программы с помощью java программы
Разобрались с теорией в публикации [«Модификация программы и что лучше менять: исполняемый код или AST программы?»](http://habrahabr.ru/post/269037/). Перейдем к практике, используя Eclipse java compiler API.

Java программа, которая переваривает java программу, начинается с работы над абстрактным синтаксическим деревом (AST)…
Перед трансформацией программы, хорошо бы научиться работать с ее [промежуточным представлением](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) в памяти компьютера. С этого и начнем.
Повторюсь выводами из своей прошлой публикации, что для анализа исходных текстов на java нет публичного и универсального API для работы с абстрактным синтаксическим деревом программы. Придется работать либо с [com.sun.source.tree.\*](http://docs.oracle.com/javase/8/docs/jdk/api/javac/tree/index.html) либо org.eclipse.jdt.core.dom.\*
Выбор для примера в этой статье — Eclipse java compiler (ejc) и его AST модель [org.eclipse.jdt.core.dom.\*](http://help.eclipse.org/mars/index.jsp?topic=%2Forg.eclipse.jdt.doc.isv%2Freference%2Fapi%2Forg%2Feclipse%2Fjdt%2Fcore%2Fdom%2FExpression.html)
Приведу несколько доводов в пользу ejc:
* доступен в [maven репозитарии](http://central.maven.org/maven2/org/eclipse/tycho/org.eclipse.jdt.core/3.11.0.v20150602-1242/org.eclipse.jdt.core-3.11.0.v20150602-1242.pom) и не надо надеяться на наличие tools.jar
* реализует JavaCompiler API
* поддерживает java 8
* работает в Eclipse Java IDE и следовательно ejc достаточно популярный компилятор
Программа, которую я написал для примера работы с AST java программы, будет обходить все классы из jar файла и анализировать вызовы интересующих нас методов классов-логеров org.slf4j.Logger, org.apache.commons.logging.Log, org.springframework.boot.cli.util.Log
Задача с поиском исходного текста для класса легко решается, если проект публиковался в maven репозитарий вместе с артефактом типа source и в jar с классами есть файлы pom.properties или pom.xml. С извлечением этой информации, в момент выполнения программы, нам поможет класс MavenCoordHelper из артефакта io.fabric8.insight:insight-log4j и загрузчик классов из Maven репозитария MavenClassLoader из артефакта com.github.smreed:dropship.
MavenCoordHelper позволяет найти для заданного класса координаты groupId:artifactId:version из файла pom.properties в этом jar файле
```
public static String getMavenSourcesId(String className) {
String mavenCoordinates = io.fabric8.insight.log.log4j.MavenCoordHelper.getMavenCoordinates(className);
if(mavenCoordinates==null) return null;
DefaultArtifact artifact = new DefaultArtifact(mavenCoordinates);
return String.format("%s:%s:%s:sources:%s", artifact.getGroupId(), artifact.getArtifactId(),
artifact.getExtension(), artifact.getVersion());
}
```
MavenClassLoader позволяет загрузить исходный текст по этим координатам для анализа и составить classpath (включая транзитивные зависимости) для определения типов в программе. Загружаем из maven репозитария:
```
public static LoadingCache createMavenClassloaderCache() {
return CacheBuilder.newBuilder()
.maximumSize(MAX\_CACHE\_SIZE)
.build(new CacheLoader() {
@Override
public URLClassLoader load(String mavenId) throws Exception {
return com.github.smreed.dropship.MavenClassLoader.forMavenCoordinates(mavenId);
}
});
}
```
Сама инициализация компилятора EJC и работа с AST достаточно простая:
```
package com.github.igorsuhorukov.java.ast;
import com.google.common.cache.LoadingCache;
import org.eclipse.jdt.core.JavaCore;
import org.eclipse.jdt.core.dom.AST;
import org.eclipse.jdt.core.dom.ASTParser;
import org.eclipse.jdt.core.dom.CompilationUnit;
import java.net.URLClassLoader;
import java.util.Set;
import static com.github.igorsuhorukov.java.ast.ParserUtils.*;
public class Parser {
public static final String[] SOURCE_PATH = new String[]{System.getProperty("java.io.tmpdir")};
public static final String[] SOURCE_ENCODING = new String[]{"UTF-8"};
public static void main(String[] args) throws Exception {
if(args.length!=1) throw new IllegalArgumentException("Class name should be specified");
String file = getJarFileByClass(Class.forName(args[0]));
Set classes = getClasses(file);
LoadingCache classLoaderCache = createMavenClassloaderCache();
for (final String currentClassName : classes) {
String mavenSourcesId = getMavenSourcesId(currentClassName);
if (mavenSourcesId == null)
throw new IllegalArgumentException("Maven group:artifact:version not found for class " + currentClassName);
URLClassLoader urlClassLoader = classLoaderCache.get(mavenSourcesId);
ASTParser parser = ASTParser.newParser(AST.JLS8);
parser.setResolveBindings(true);
parser.setKind(ASTParser.K\_COMPILATION\_UNIT);
parser.setCompilerOptions(JavaCore.getOptions());
parser.setEnvironment(prepareClasspath(urlClassLoader), SOURCE\_PATH, SOURCE\_ENCODING, true);
parser.setUnitName(currentClassName + ".java");
String sourceText = getClassSourceCode(currentClassName, urlClassLoader);
if(sourceText == null) continue;
parser.setSource(sourceText.toCharArray());
CompilationUnit cu = (CompilationUnit) parser.createAST(null);
cu.accept(new LoggingVisitor(cu, currentClassName));
}
}
}
```
Создав парсер, указываем что исходный текст будет соответствовать Java 8 language specification
> ASTParser parser = ASTParser.newParser(AST.JLS8);
И что после разбора необходимо разрешать типы идентификаторов на основе classpath, что мы передали компилятору
> parser.setResolveBindings(true);
Исходный текст класса передаем парсеру с помощью вызова
> parser.setSource(sourceText.toCharArray());
Создаем AST дерево этого класса
> CompilationUnit cu = (CompilationUnit) parser.createAST(null);
И получаем события при обходе AST с помощью нашего класса Visitor
> cu.accept(new LoggingVisitor(cu, currentClassName));
Расширяя класс **ASTVisitor** и перегружая в нем метод **public boolean visit(MethodInvocation node)**, передаем его компилятору ejc. В этом обработчике анализируем что этот именно те методы именно тех классов, что нас интересуют и после этого анализируем аргументы, вызываемого метода.
При обходе AST дерева программы, которое содержит также дополнительную информацию о типах, будет вызываться наш метод visit. В нем же мы получаем информацию о расположении лексемы в исходном файле, параметрах, выражениях и т.п.
Основной «фарш» с разбором интересующих нас мест вызова методов логгеров в анализируемой программе инкапсулирован в LoggingVisitor:
**LoggingVisitor.java**
```
package com.github.igorsuhorukov.java.ast;
import org.eclipse.jdt.core.dom.*;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
class LoggingVisitor extends ASTVisitor {
final static Set LOGGER\_CLASS = new HashSet() {{
add("org.slf4j.Logger");
add("org.apache.commons.logging.Log");
add("org.springframework.boot.cli.util.Log");
}};
final static Set LOGGER\_METHOD = new HashSet() {{
add("fatal");
add("error");
add("warn");
add("info");
add("debug");
add("trace");
}};
public static final String LITERAL = "Literal";
public static final String FORMAT\_METHOD = "format";
private final CompilationUnit cu;
private final String currentClassName;
public LoggingVisitor(CompilationUnit cu, String currentClassName) {
this.cu = cu;
this.currentClassName = currentClassName;
}
@Override
public boolean visit(MethodInvocation node) {
if (LOGGER\_METHOD.contains(node.getName().getIdentifier())) {
ITypeBinding objType = node.getExpression() != null ? node.getExpression().resolveTypeBinding() : null;
if (objType != null && LOGGER\_CLASS.contains(objType.getBinaryName())) {
int lineNumber = cu.getLineNumber(node.getStartPosition());
boolean isFormat = false;
boolean isConcat = false;
boolean isLiteral1 = false;
boolean isLiteral2 = false;
boolean isMethod = false;
boolean withException = false;
for (int i = 0; i < node.arguments().size(); i++) {
ASTNode innerNode = (ASTNode) node.arguments().get(i);
if (i == node.arguments().size() - 1) {
if (innerNode instanceof SimpleName && ((SimpleName) innerNode).resolveTypeBinding() != null) {
ITypeBinding typeBinding = ((SimpleName) innerNode).resolveTypeBinding();
while (typeBinding != null && Object.class.getName().equals(typeBinding.getBinaryName())) {
if (Throwable.class.getName().equals(typeBinding.getBinaryName())) {
withException = true;
break;
}
typeBinding = typeBinding.getSuperclass();
}
if (withException) continue;
}
}
if (innerNode instanceof MethodInvocation) {
MethodInvocation methodInvocation = (MethodInvocation) innerNode;
if (FORMAT\_METHOD.equals(methodInvocation.getName().getIdentifier()) && methodInvocation.getExpression() != null
&& methodInvocation.getExpression().resolveTypeBinding() != null
&& String.class.getName().equals(methodInvocation.getExpression().resolveTypeBinding().getBinaryName())) {
isFormat = true;
} else {
isMethod = true;
}
} else if (innerNode instanceof InfixExpression) {
InfixExpression infixExpression = (InfixExpression) innerNode;
if (InfixExpression.Operator.PLUS.equals(infixExpression.getOperator())) {
List expressions = new ArrayList();
expressions.add(infixExpression.getLeftOperand());
expressions.add(infixExpression.getRightOperand());
expressions.addAll(infixExpression.extendedOperands());
long stringLiteralCount = expressions.stream().filter(item -> item instanceof StringLiteral).count();
long notLiteralCount = expressions.stream().filter(item -> item.getClass().getName().contains(LITERAL)).count();
if (notLiteralCount > 0 && stringLiteralCount > 0) {
isConcat = true;
}
}
} else if (innerNode instanceof Expression && innerNode.getClass().getName().contains(LITERAL)) {
isLiteral1 = true;
} else if (innerNode instanceof SimpleName || innerNode instanceof QualifiedName
|| innerNode instanceof ConditionalExpression || innerNode instanceof ThisExpression
|| innerNode instanceof ParenthesizedExpression
|| innerNode instanceof PrefixExpression || innerNode instanceof PostfixExpression
|| innerNode instanceof ArrayCreation || innerNode instanceof ArrayAccess
|| innerNode instanceof FieldAccess || innerNode instanceof ClassInstanceCreation) {
isLiteral2 = true;
}
}
String type = loggerInvocationType(node, isFormat, isConcat, isLiteral1 || isLiteral2, isMethod);
System.out.println(currentClassName + ":" + lineNumber + "\t\t\t" + node+"\t\ttype "+type); //node.getStartPosition()
}
}
return true;
}
private String loggerInvocationType(MethodInvocation node, boolean isFormat, boolean isConcat, boolean isLiteral, boolean isMethod) {
if (!isConcat && !isFormat && isLiteral) {
return "literal";
} else {
if (isFormat && isConcat) {
return "format concat";
} else if (isFormat && !isLiteral) {
return "format";
} else if (isConcat && !isLiteral) {
return "concat";
} else {
if (isConcat || isFormat || isLiteral) {
if (node.arguments().size() == 1) {
return "single argument";
} else {
return "mixed logging";
}
}
}
if(isMethod){
return "method";
}
}
return "unknown";
}
}
```
Зависимости программы-анализатора, необходимые для компиляции и работы описаны в
**pom.xml**
```
org.sonatype.oss
oss-parent
7
4.0.0
com.github.igor-suhorukov
java-ast
jar
1.0-SNAPSHOT
1.8
1.8
1.2.0.redhat-133
org.eclipse.tycho
org.eclipse.jdt.core
3.11.0.v20150602-1242
org.eclipse.core
runtime
3.9.100-v20131218-1515
org.eclipse.birt.runtime
org.eclipse.core.resources
3.8.101.v20130717-0806
io.fabric8.insight
insight-log4j
${insight.version}
\*
\*
io.fabric8.insight
insight-log-core
${insight.version}
io.fabric8
common-util
${insight.version}
com.github.igor-suhorukov
aspectj-scripting
1.0
agent
com.google.guava
guava
19.0-rc2
com.googlecode.log4jdbc
log4jdbc
1.2
```
Часть «уличной магии», что помогает при парсинге, скрыта в классе ParserUtils, реализована за счет сторонних библиотек и рассматривалась выше.
**ParserUtils.java**
```
package com.github.igorsuhorukov.java.ast;
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
import com.google.common.io.CharStreams;
import org.sonatype.aether.util.artifact.DefaultArtifact;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLClassLoader;
import java.security.CodeSource;
import java.util.Arrays;
import java.util.Collections;
import java.util.Set;
import java.util.function.Function;
import java.util.jar.JarEntry;
import java.util.jar.JarFile;
import java.util.stream.Collectors;
public class ParserUtils {
public static final int MAX_CACHE_SIZE = 1000;
public static Set getClasses(String file) throws IOException {
return Collections.list(new JarFile(file).entries()).stream()
.filter(jar -> jar.getName().endsWith("class") && !jar.getName().contains("$"))
.map(new Function() {
@Override
public String apply(JarEntry jarEntry) {
return jarEntry.getName().replace(".class", "").replace('/', '.');
}
}).collect(Collectors.toSet());
}
public static String getMavenSourcesId(String className) {
String mavenCoordinates = io.fabric8.insight.log.log4j.MavenCoordHelper.getMavenCoordinates(className);
if(mavenCoordinates==null) return null;
DefaultArtifact artifact = new DefaultArtifact(mavenCoordinates);
return String.format("%s:%s:%s:sources:%s", artifact.getGroupId(), artifact.getArtifactId(),
artifact.getExtension(), artifact.getVersion());
}
public static LoadingCache createMavenClassloaderCache() {
return CacheBuilder.newBuilder()
.maximumSize(MAX\_CACHE\_SIZE)
.build(new CacheLoader() {
@Override
public URLClassLoader load(String mavenId) throws Exception {
return com.github.smreed.dropship.MavenClassLoader.forMavenCoordinates(mavenId);
}
});
}
public static String[] prepareClasspath(URLClassLoader urlClassLoader) {
return Arrays.stream(urlClassLoader.getURLs()).map(new Function() {
@Override
public String apply(URL url) {
return url.getFile();
}
}).toArray(String[]::new);
}
public static String getJarFileByClass(Class clazz) {
CodeSource source = clazz.getProtectionDomain().getCodeSource();
String file = null;
if (source != null) {
URL locationURL = source.getLocation();
if ("file".equals(locationURL.getProtocol())) {
file = locationURL.getPath();
} else {
file = locationURL.toString();
}
}
return file;
}
static String getClassSourceCode(String className, URLClassLoader urlClassLoader) throws IOException {
String sourceText = null;
try (InputStream javaSource = urlClassLoader.getResourceAsStream(className.replace(".", "/") + ".java")) {
if (javaSource != null){
try (InputStreamReader sourceReader = new InputStreamReader(javaSource)){
sourceText = CharStreams.toString(sourceReader);
}
}
}
return sourceText;
}
}
```
Запустив com.github.igorsuhorukov.java.ast.Parser на исполнение и передав, как параметр для анализа, имя класса net.sf.log4jdbc.ConnectionSpy
Получим вывод в консоли, из которого можно понять, какие параметры передаются в методы: **Консоль приложения**
> [Dropship WARN] No dropship.properties found! Using .dropship-prefixed system properties (-D)
>
> [Dropship INFO] Collecting maven metadata.
>
> [Dropship INFO] Resolving dependencies.
>
> [Dropship INFO] Building classpath for com.googlecode.log4jdbc:log4jdbc:jar:sources:1.2 from 2 URLs.
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:104 jdbcLogger.error(header,e) type literal
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:105 sqlOnlyLogger.error(header,e) type literal
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:106 sqlTimingLogger.error(header,e) type literal
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:111 jdbcLogger.error(header + " " + sql,e) type mixed logging
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:116 sqlOnlyLogger.error(getDebugInfo() + nl + spyNo+ ". "+ sql,e) type mixed logging
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:120 sqlOnlyLogger.error(header + " " + sql,e) type mixed logging
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:126 sqlTimingLogger.error(getDebugInfo() + nl + spyNo+ ". "+ sql+ " {FAILED after "+ execTime+ " msec}",e) type mixed logging
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:130 sqlTimingLogger.error(header + " FAILED! " + sql+ " {FAILED after "+ execTime+ " msec}",e) type mixed logging
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:158 logger.debug(header + " " + getDebugInfo()) type concat
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:162 logger.info(header) type literal
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:221 sqlOnlyLogger.debug(getDebugInfo() + nl + spy.getConnectionNumber()+ ". "+ processSql(sql)) type concat
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:226 sqlOnlyLogger.info(processSql(sql)) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:352 sqlTimingLogger.error(buildSqlTimingDump(spy,execTime,methodCall,sql,sqlTimingLogger.isDebugEnabled())) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:360 sqlTimingLogger.warn(buildSqlTimingDump(spy,execTime,methodCall,sql,sqlTimingLogger.isDebugEnabled())) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:365 sqlTimingLogger.debug(buildSqlTimingDump(spy,execTime,methodCall,sql,true)) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:370 sqlTimingLogger.info(buildSqlTimingDump(spy,execTime,methodCall,sql,false)) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:519 debugLogger.debug(msg) type literal
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:531 connectionLogger.info(spy.getConnectionNumber() + ". Connection opened " + getDebugInfo()) type concat
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:533 connectionLogger.debug(ConnectionSpy.getOpenConnectionsDump()) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:537 connectionLogger.info(spy.getConnectionNumber() + ". Connection opened") type concat
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:550 connectionLogger.info(spy.getConnectionNumber() + ". Connection closed " + getDebugInfo()) type concat
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:552 connectionLogger.debug(ConnectionSpy.getOpenConnectionsDump()) type method
>
> net.sf.log4jdbc.Slf4jSpyLogDelegator:556 connectionLogger.info(spy.getConnectionNumber() + ". Connection closed") type concat
>
>
Например, если при вызове метода info, происходит конкатенация в строку результатов вызова метода spy.getConnectionNumber(), строки ". Connection opened " и вызова метода getDebugInfo(), мы получим сообщение что это **concat**
> net.sf.log4jdbc.Slf4jSpyLogDelegator:531 connectionLogger.info(spy.getConnectionNumber() + ". Connection opened " + getDebugInfo()) type concat
>
>
И после этого мы могли бы трансформировать исходный текст таким образом, чтобы заменить операцию конкатенации в параметрах этого метода, вызовом метода с шаблоном "{}. Connection opened {}" и параметрами spy.getConnectionNumber(), getDebugInfo(). А дальше этот более машиночитаемый вызов и информацию из него можно отправить сразу в Elasticsearch, о чем я уже рассказывал в статье [«Публикация логов в Elasticsearch — жизнь без регулярных выражений и без logstash»](http://habrahabr.ru/post/267009/).
Как видим, разбор и анализ java программы легко реализовать в java коде с помощью компилятора ejc и также легко программно получить из Maven репозитария исходные коды для интересующих нас классов. Пример из статьи доступен на [github](https://github.com/igor-suhorukov/java-ast-example)
Впереди нас ждет Java agent, модификация и компиляция в рантайм — задача **масштабнее и сложнее чем просто переваривание AST...**
До скорых встреч! | https://habr.com/ru/post/269129/ | null | ru | null |
# Полнодисковое шифрование Windows и Linux установленных систем. Зашифрованная мультизагрузка

**Обновленное свое же руководство по полнодисковому шифрованию в Рунете V0.2**
### Ковбойская стратегия:
[A] блочное системное шифрование Windows 7 установленной системы;
[B] блочное системное шифрование GNU/Linux *(Debian)* установленной системы *(включая /boot)*;
[C] настройка GRUB2, защита загрузчика цифровой подписью/аутентификацией/хэшированием;
[D] зачистка — уничтожение нешифрованных данных;
[E] универсальное резервное копирование зашифрованных ОС;
[F] атака <на п.[C6]> цель — загрузчик GRUB2;
[G] полезная документация.
**╭───Схема #комнаты 40# :**
├──╼ Windows 7 установленная — шифрование полное системное, не скрытое;
├──╼ GNU/Linux установленная *(Debian и производные дистрибутивы)* — шифрование полное системное не скрытое*(/, включая /boot; swap)*;
├──╼ независимые загрузчики: загрузчик VeraCrypt установлен в MBR, загрузчик GRUB2 установлен в расширенный раздел;
├──╼ установка/переустановка ОС не требуется;
└──╼ используемое криптографическое ПО: VeraCrypt; Cryptsetup; GnuPG; Seahorse; Hashdeep; GRUB2 – свободное/бесплатное.
Вышеописанная схема частично решает проблему «выносной boot на флэшку», позволяет наслаждаться зашифрованными OS Windows/Linux и обмениваться данными по «зашифрованному каналу» из одной ОС в другую.
**Порядок загрузки ПК (один из вариантов):**
* включение машины;
* загрузка загрузчика VeraCrypt *(верный ввод пароля продолжит загрузку Windows 7)*;
* нажатие клавиши «Esc» загрузит загрузчик GRUB2;
* загрузчик GRUB2 *(выбор дистрибутива/ GNU/Linux/CLI)*, затребует аутентификацию GRUB2-суперпользователя <логин/пароль>;
* после успешной аутентификации и выбора дистрибутива, потребуется ввод парольной фразы для разблокировки "/boot/initrd.img";
* после ввода безошибочных паролей в GRUB2 «потребуется» ввод пароля *(третьего по счету, пароль BIOS или пароль учётки пользователя GNU/Linux – not consider)* для разблокирования и загрузки ОС GNU/Linux, или автоматическая подстановка секретного ключа *(два пароля + ключ, либо пароль+ключ)*;
* внешнее вторжение в конфигурацию GRUB2 заморозит процесс загрузки GNU/Linux.
Хлопотно? Ок, идём автоматизировать процессы.
При разметке жесткого диска *(таблица MBR)* ПК может иметь не более 4-х главных разделов, или 3-х главных и одного расширенного, а также не размеченную область. Расширенный раздел в отличие от главного может содержать подразделы *(логические диски=расширенный раздел)*. Иными словами, «расширенный раздел» на HDD заменяет LVM для текущей задачи: полного системного шифрования. Если ваш диск размечен на 4 главные раздела, вам необходимо использовать lvm, либо трансформировать *(с форматированием)* раздел с главного на расширенный, либо грамотно воспользоваться всеми четырьмя разделами и оставить всё, как есть, получив желаемый результат. Даже если у вас на диске один раздел, Gparted поможет разбить HDD *(на дополнительные разделы)* без потери данных, но все же с небольшой расплатой за такие действия.
Схема разметки жесткого диска, относительно которой пойдет вербализация всей статьи, представлена в таблице ниже.

*Таблица (№1) разделов 1Тб.*
Что-то подобное должно быть и у вас.
sda1 — главный раздел №1 NTFS *(зашифрованный)*;
sda2 — расширенный раздел маркер;
sda6 — логический диск *(на него установлен загрузчик GRUB2);*
sda8 — swap (зашифрованный файл подкачки/не всегда);
sda9 — тестовый логический диск;
sda5 — логический диск для любопытных;
sda7 — ОС GNU/Linux (перенесенная ОС на зашифрованный логический диск);
sda3 — главный раздел №2 с ОС Windows 7 *(шифрованный)*;
sda4 — главный раздел №3 *(в нем располагалась незашифрованная GNU/Linux, используется под бэкап/не всегда)*.
[А] Блочное системное шифрование Windows 7
------------------------------------------
**А1. VeraCrypt**
Загрузка с [официального сайта](https://www.veracrypt.fr/en/Downloads.html), либо с зеркала [sourceforge](https://sourceforge.net/projects/veracrypt/) установочной версии криптографического ПО VeraCrypt *(на момент публикации статьи v1.24-Update3, портативная версия VeraCrypt не подойдет для системного шифрования)*. Чекните контрольную сумму загруженного софта
`$ Certutil -hashfile "C:\VeraCrypt Setup 1.24.exe" SHA256`
и сравните полученный результат с выложенной КС на сайте разработчика VeraCrypt.
Если установлено ПО HashTab, еще проще: ПКМ *(VeraCrypt Setup 1.24.exe)*-свойства-хэш суммы файлов.
Для проверки подписи программы в системе должны быть установлены ПО и публичный pgp ключ разработчика [gnuPG](https://www.gnupg.org/download/index.html); [gpg4win](https://www.gpg4win.org/get-gpg4win.html).
**А2. Установка/запуск ПО VeraCrypt с правами администратора**
**А3. Выбор параметров системного шифрования активного раздела**
VeraCrypt – Система – Зашифровать системный раздел/диск – Обычный – Зашифровать системный раздел Windows – Мультизагрузка – *(предупреждение: «Неопытным пользователям не рекомендуется использовать этот метод» и это правда, соглашаемся «Да»)* – Загрузочный диск *(«да», даже если не так, все равно «да»)* – Число системных дисков «2 и более» – Несколько систем на одном диске «Да» – Не Windows загрузчик «Нет» *(а по факту «Да»! Иначе загрузчики VeraCrypt/GRUB2 не поделят MBR между собой, точнее, в MBR/загрузочной дорожке хранится лишь наименьшая часть кода загрузчика, основная его часть располагается в пределах файловой системы)* – Мультизагрузка – Настройки параметров шифрования…
Если отклониться от вышеописанных шагов (*схемы блочного системного шифрования)*, то VeraCrypt выкатит предупреждение и не позволит шифровать раздел.
На следующем шаге, к целенаправленной защите данных, проведите «Тест» и выбирайте алгоритм шифрования. Если у вас несовременный CPU, то, возможно, самым быстрым окажется алгоритм шифрования Twofish, его и выбирайте. Если CPU современный, разницу заметите: AES — шифрование по результатам теста будет в несколько раз скоростнее своих криптоконкурентов. AES — самый популярный алгоритм шифрования, аппаратная часть современных CPU специально оптимизирована на «секрет» ~~так и на «взлом~~».
VeraCrypt поддерживает возможность криптовать диски каскадом AES*(Twofish)*/и другими комбинациями. На старо-ядерном CPU Intel десятилетней давности *(без аппаратной поддержки AES-NI, шифрование каскадом А/Т)* снижение производительности в сущности незаметное. *(у CPU AMD той же эпохи/~параметров —производительность немного снижена)*. ОС работает в динамике и потребление ресурсов на прозрачное шифрование – незаметное. В отличие, как например, заметное снижение производительности из-за установленного тестового нестабильного desktop environment Mate v1.20.1 *(или v1.20.2 точно не помню)* в GNU/Linux, или из-за работы подпрограммы сорняка телеметрии в Windows7. Обычно искушенные пользователи до шифрования проводят тесты на производительность железа. Например, в Aida64/Sysbench/systemd-analyze blame и сравнивают с результатами этих же тестов после криптования системы, тем самым, для себя опровергая миф, «системное шифрование — это вредно». Замедление машины и неудобство ощутимо при резервном копировании/восстановлении зашифрованных данных, потому что сама по себе операция «системного резервного копирования данных» измеряется не в мс, и добавляются те самые <расшифровать/зашифровать на лету>. В конечном итоге каждый пользователь, которому разрешено возиться с криптографией, устанавливает баланс алгоритма шифрования относительно удовлетворения поставленных задач, степени своей паранойи и удобством пользования.
Параметр PIM лучше оставить по умолчанию, чтобы при загрузке ОС каждый раз не вводить точные значения итераций. VeraCrypt применяет огромное кол-во итераций для создания действительно «медленного хэша». Атака на такую «криптоулитку» методом Brute force/радужных таблиц имеет смысл только при ~~короткой~~ «простой» парольной фразе и персонального charset-листа жертвы. Расплата за стойкость пароля – задержка при верном вводе пароля при загрузке ОС *(монтирование томов VeraCrypt в GNU/Linux — существенно быстрее).*
Свободный софт для реализации brute force атаки *(извлечение парольной фразы из заголовка диска VeraCrypt/LUKS)* Hashcat. John the Ripper не умеет «ломать Veracrypt», а при работе с LUKS не понимает криптографию Twofish. К слову, среди некоммерческого софта во всём остальном JtR лучше чем Hashcat.
По причине криптографической стойкости алгоритмов шифрования, неудержимые шифропанки и их антиподы разрабатывают софт с другим вектором атаки. Например, извлечения метаданных/ключей из ОЗУ *(атака холодным ботинком/прямым доступом к памяти),* кража заголовка LUKS с одновременным перехватом пароля и отправкой сетевых пакетов, возможно, что-то ещё, чего я не знаю. Существует специализированное свободное и несвободное ПО для этих целей.
По окончанию настройки/генерации «уникальных метаданных» шифруемого активного раздела, VeraCrypt предложит перезагрузить ПК и протестировать работоспособность своего загрузчика. После reboot-а/старта Windows, VeraCrypt подгрузится в режиме ожидания, останется лишь подтвердить процесс шифрования — Y.
На финальном шаге системного шифрования VeraCrypt предложит создать резервную копию заголовка активного зашифрованного раздела в виде «veracrypt rescue disk.iso» — сделать нужно обязательно — в этом софте такая операция является требованием *(в LUKS, как требование – это к сожалению, опущено, но подчеркнуто в документации)*. Rescue disk пригодится всем, а кому-то и не один раз. Не имея заголовка диска, перенос OS, утеря *(перезапись заголовка/MBR)* резервной копии заголовка навсегда лишит доступа к дешифрованному разделу с OS Windows.
**А4. Создание спасательного usb/диска VeraCrypt**
По умолчанию VeraCrypt предлагает прожечь «метаданные ~2-3мБ» на компакт-диск, но не у всех людей есть диски или приводы DWD-ROM-ы, а создание загрузочной флэшки «VeraCrypt Rescue disk» для кого-то окажется техническим сюрпризом: Rufus/GUIdd-ROSA ImageWriter и другой подобный софт — не смогут справиться с поставленной задачей, потому что помимо копирования смещенных метаданных на загрузочную флэшку, нужно из образа сделать copy/paste за пределами файловой системы usb-накопителя, короче, правильно скопировать MBR/дорожу на брелок. Из-под ОС GNU/Linux создать загрузочную флэшку, можно воспользовавшись утилитой «dd», глядя на эту табличку.
Создание спасательного диска в среде Windows — иначе. Разработчик VeraCrypt не включил решение этой задачки в официальную [документацию](https://www.veracrypt.fr/en/VeraCrypt%20Rescue%20Disk.html) по «rescue disk», но предложил решение другим путем: выложил дополнительное ПО по созданию «usb rescue disk» в свободный доступ, на своем форуме VeraCrypt. Update: 2020г разработчик сжалился над «горемыками» и включил решение по [usb rescue disk](https://sourceforge.net/projects/veracrypt/files/Contributions/VeraCryptUsbRescueDisk.zip) официально в своей документации.
После сохранения rescue disk.iso начнется процесс блочного системного шифрования активного раздела. Во время шифрования работа ОС не останавливается, перезагрузка ПК не требуется. По завершению операции криптования, активный раздел становится полностью зашифрованным, можно пользоваться. Если при запуске ПК не появляется загрузчик VeraCrypt, и не помогает операция восстановления заголовка, то проверьте флаг «boot», он должен быть установлен на раздел, где присутствует Windows *(независимо от шифрования и других ОС, см. таблица №1).*
После шифрования системного диска и логических дисков ntfs (одинаковый пароль) добавьте все шифрованные диски в «системное избранное». Далее «настройки» > «системные избранные тома» поставить галочку «монтировать системные избранные тома при старте Windows», при загрузке ОС — все ntfs-диски будут монтироваться автоматом.
***На этом описание блочного системного шифрования с ОС Windows закончено.***
[B] LUKS. Шифрование GNU/Linux *(~Debian)* установленной ОС. Алгоритм и Шаги
----------------------------------------------------------------------------
Для того чтобы зашифровать установленный Debian/производный дистрибутив, требуется сопоставить подготовленный раздел с виртуальным блочным устройством, перенести на сопоставленный диск GNU/Linux, и установить/настроить GRUB2. Если у вас не голый сервер, и вы дорожите своим временем, то пользоваться необходимо GUI, а большинство терминальных команд, описанных ниже, подразумевается водить в «режиме Чак-Норрис».
**B1. Загрузка ПК с live usb GNU/Linux**
«Провести криптотест на производительность железа»
```
lscpu && сryptsetup benchmark
```
Если вы счастливый владелец мощной тачки с аппаратной поддержкой AES-NI, то цифры будут похожи на правую часть терминала, если вы счастливый, но с античным железом — на левую часть.

Провести подобные тесты до и после шифрования ОС. Сравнить данные.
**B2. Разметка диска. монтирование/форматирование фс логического диска HDD в Ext4 (Gparted)**
**B2.1. Создание зашифрованного заголовка раздела sda7**
Описывать имена разделов, здесь и далее, буду согласно относительно своей таблицы разделов, выложенной выше. Согласно вашей разметке диска, вы должны подставлять свои имена разделов.
Сопоставление шифрования логического диска *(/dev/sda7 > /dev/mapper/sda7\_crypt).*
#Простое создание «LUKS-AES-XTS раздела»
```
cryptsetup -v -y luksFormat /dev/sda7
```
Опции:
\* luksFormat -инициализация LUKS заголовка;
\* -y -парольная фраза (не ключ/файл);
\* -v -вербализация (вывод информации в терминале);
\* /dev/sda7 -ваш логический диск из расширенного раздела *(туда, куда планируется перенос/шифрование GNU/Linux)*.
По умолчанию алгоритм шифрования UKS1: aes-xts-plain64, Key: 256 bits, LUKS header hashing: sha256, RNG: /dev/urandom> *(зависит от версии cryptsetup).*
```
#Проверка default-алгоритма шифрования
cryptsetup --help #самая последняя строка в выводе терминала.
```
При отсутствии аппаратной поддержки AES на CPU, лучшим выбором будет создание расширенного «LUKS-Twofish-XTS-раздела».
**B2.2. Расширенное создание «LUKS-Twofish-XTS-раздела»**
```
cryptsetup luksFormat /dev/sda7 -v -y -c twofish-xts-plain64 -s 512 -h sha512 -i 1500 --use-urandom
```
Опции:
\* luksFormat -инициализация LUKS заголовка;
\* /dev/sda7 ваш будущий зашифрованный логический диск;
\* -v вербализация;
\* -y запрос подтверждения парольной фразы;
\* -c выбор алгоритма шифрования данных;
\* -s размер ключа шифрования;
\* -h алгоритм хеширования/криптофункция, используется ГСЧ *(--use-urandom)* для генерации уникального ключа шифрования/дешифрирования заголовка логического диска, вторичного ключа заголовка (XTS); уникального мастер ключа хранящегося в зашифрованном заголовке диска, вторичного XTS ключа, все эти метаданные и подпрограмма шифрования, которая с помощью мастер ключа и вторичного XTS-ключа шифруют/дешифруют любые данные на разделе *(кроме заголовка раздела)* хранятся в ~3мБ на выбранном разделе жесткого диска.
\* -i Время итерации PBKDF для LUKS (в мс) *(задержка по времени при обработке парольной фразы, влияет на загрузку ОС и криптостойкость ключей).* Для сохранения баланса криптостойкости при простом пароле типа «russian» требуется увеличивать значение -(i), при сложном пароле типа «?8dƱob/øfh» значение можно уменьшать.
\* --use-urandom генератор случайных чисел, генерирует ключи и соль.
После сопоставления раздела sda7 > sda7\_crypt *(операция быстрая, так как создается зашифрованный заголовок с метаданными ~3 мБ и на этом всё)*, нужно отформатировать и смонтировать файловую систему sda7\_crypt.
**B2.3. Сопоставление**
```
cryptsetup open /dev/sda7 sda7_crypt
#выполнение данной команды запрашивает ввод секретной парольной фразы.
```
опции:
\* open -сопоставить раздел «с именем»;
\* /dev/sda7 -логический диск;
\* sda7\_crypt -сопоставление имени, которое используется для монтирования зашифрованного раздела или его инициализации при загрузке ОС.
**B2.4. Форматирование файловой системы sda7\_crypt в ext4. Монтирование диска в ОС**
*(Примечание: в Gparted работать с шифрованным разделом уже не получится)*
```
#форматирование блочного шифрованного устройства
mkfs.ext4 -v -L DebSHIFR /dev/mapper/sda7_crypt
```
опции:
\* -v -вербализация;
\* -L -метка диска (которая отображается в проводнике среди других дисков).
Далее, следует примонтировать виртуальное-шифрованное блочное устройство /dev/sda7\_crypt в систему
```
mount /dev/mapper/sda7_crypt /mnt
```
Работа с файлами в папке /mnt приведет к автоматическому шифрованию/дешифрированию данных на лету в sda7.
Удобнее сопоставлять и монтировать раздел в проводнике *(nautilus/caja GUI)*, раздел уже будет в списке выбора дисков, останется ввести только парольную фразу для открытия/расшифрования диска. Сопоставляемое имя при этом будет выбрано автоматически и не «sda7\_crypt», а что-то вроде /dev/mapper/Luks-xx-xx…
**B2.5. Резервное копирование заголовка диска (метаданные ~3мБ)**
Одна из самых **важных** операций, которую необходимо сделать, не откладывая — резервная копия заголовка «sda7\_crypt». Если перезаписать/повредить заголовок *(например, установкой GRUB2 в раздел sda7 и тд.)*, зашифрованные данные будут потеряны окончательно без какой-либо возможности их восстановить, потому что невозможно будет повторно сгенерировать одинаковые ключи, ключи создаются уникальные.
```
#Бэкап заголовка раздела
cryptsetup luksHeaderBackup --header-backup-file ~/Бэкап_DebSHIFR /dev/sda7
```
```
#Восстановление заголовка раздела
cryptsetup luksHeaderRestore --header-backup-file
```
опции:
\* luksHeaderBackup --header-backup-file -команда бэкап;
\* luksHeaderRestore --header-backup-file -команда восстановления;
\* ~/Бэкап\_DebSHIFR — файл резервной копии;
\* /dev/sda7 -раздел, чью резервную копию шифрованного заголовка диска требуется сохранить.
***Заметка**. Не пытайтесь восстановить заголовок LUKS-раздела от [sdaX] на [sdaY], большинство юзернэймов потерпит неудачу.*
***На этом шаге <создание и редактирование зашифрованного раздела> закончено.***
**B3. Перенос ОС GNU/Linux *(sda4)* на зашифрованный раздел *(sda7)***
***Заметка.** Перед переносом ОС на шифрованный раздел рекомендуется удалить лишний кэшированный хлам (подобный хлам можно найти с помощью ПО BleachBit), например, в моем случае это были несколько сотен тысяч мелких файлов /var/cache/fontconfig/\* и /home/user/.cache/fontconfig/\*
Если зачистили fontconfig-файлы, сделать $ fc-cache -fvr*
Создаем папку /mnt2 *(Примечание — мы все еще работаем с live usb, в точку /mnt смонтирован sda7\_crypt)*, и монтируем наш GNU/Linux в /mnt2, который необходимо зашифровать.
```
mkdir /mnt2
mount /dev/sda4 /mnt2
```
Осуществляем корректный перенос ОС с помощью ПО Rsync
```
rsync -avlxhHX --progress /mnt2/ /mnt
```
Опции Rsync описаны в п.E1.
Далее, **необходимо** провести дефрагментацию раздела логического диска
```
e4defrag -c /mnt/ #после проверки, e4defrag выдаст, что степень дефрагментации раздела ≈ 0, это заблуждение, которое может вам стоить существенной потери производительности!
e4defrag /mnt/ #проводим дефрагментацию шифрованной GNU/Linux
```
Возьмите за правило: делать e4defrag на зашифрованной GNU/Linux время от времени если у Вас HDD.
***Перенос и синхронизация [GNU/Linux > GNU/Linux-зашифрованная] на этом шаге закончены.***
**В4. Настройка GNU/Linux на зашифрованном разделе sda7**
После успешного переноса ОС /dev/sda4 > /dev/sda7 необходимо войти в GNU/Linux на зашифрованном разделе, и осуществить дальнейшую настройку *(без перезагрузки ПК)* относительно зашифрованной системы. То есть находиться в live usb, но команды выполнять «относительно корня шифрованной ОС». Симулировать подобную ситуацию будет «chroot». Чтобы оперативно получать информацию с какой ОС вы в данный момент времени работаете *(в шифрованной или нет, так как данные в sda4 и sda7 синхронизированы)*, рассинхронизируйте ОС-ы. Создайте в корневых каталогах *(sda4/sda7\_crypt)* пустые файлы-маркеры, например, /mnt/шифрованнаяОС и /mnt2/дешифрованнаяОС. Быстрая проверка в какой ОС вы находитесь *(в том числе и на будущее):*
```
ls /
```
**B4.1. «Симуляция входа в зашифрованную ОС»**
```
mount --bind /dev /mnt/dev
mount --bind /proc /mnt/proc
mount --bind /sys /mnt/sys
chroot /mnt
```
**B4.2. Проверка, что работа осуществляется относительно зашифрованной системы**
```
ls /mnt
#и видим файл "/шифрованнаяОС"
```
```
history
#в выводе терминала должна появиться история команд su рабочей ОС.
```
**B4.3. Создание/настройка зашифрованного swap**
Так как файл подкачки при каждом старте ОС форматируется, то не имеет смысла создавать и сопоставлять swap с логическим диском сейчас, и набивать команды, как в п.B2.2. Для Swap-а при каждом старте будут автоматически генерироваться свои временные шифровальные ключи. Жизненный цикл ключей swap-a: размонтирование/отключение swap-раздела *(+очистка ОЗУ)*; или перезапуск ОС. Настройка swap, открываем файл, отвечающий за конфигурацию блочных шифрованных устройств *(аналог fstab-файла, но отвечающий за крипто).*
```
nano /etc/crypttab
```
правим
> #«target name» «source device» «key file» «options»
>
> swap /dev/sda8 /dev/urandom swap,cipher=twofish-xts-plain64,size=512,hash=sha512
Опции
\* swap -сопоставленное имя при шифровании /dev/mapper/swap.
\* /dev/sda8 -используйте ваш логический раздел под swap.
\* /dev/urandom -генератор случайных ключей шифрования для swap (*с каждой новой загрузкой ОС — созданные новые ключи).* Генератор /dev/urandom менее случайный, чем /dev/random, как-никак /dev/random используется при работе в опасных параноидальных обстоятельствах. При загрузке ОС /dev/random тормозит загрузку на несколько ± минут *(см. systemd-analyze)*.
\* swap,cipher=twofish-xts-plain64,size=512,hash=sha512: -раздел знает, что он swap и форматируется «соответственно»; алгоритм шифрования.
```
#Открываем и правим fstab
nano /etc/fstab
```
правим
> # swap was on /dev/sda8 during installation
>
> /dev/mapper/swap none swap sw 0 0
>
>
/dev/mapper/swap -имя , которое задали в crypttab.
**Альтернативный зашифрованный swap**
Если по каким-то причинам вы не хотите отдавать целый раздел под файл подкачки, то можно пойти альтернативным и лучшим путём: создание файла подкачки в файле на зашифрованном разделе с ОС.
```
fallocate -l 3G /swap #создание файла размером 3Гб (почти мгновенная операция). На некоторых VPS может быть последующая ошибка, в таком случае
#dd if=/dev/zero of=/swap bs=1MiB count=3000
chmod 600 /swap #настройка прав
mkswap /swap #из файла создаём файл подкачки
swapon /swap #включаем наш swap
free -m #проверяем, что файл подкачки активирован и работает
printf "/swap none swap sw 0 0" >> /etc/fstab #при необходимости после перезагрузки swap будет постоянный
```
***Настройка раздела подкачки завершена.***
**B4.4. Настройка зашифрованной GNU/Linux (правка файлов crypttab/fstab)**
Файл /etc/crypttab, как написал выше, описывает зашифрованные блочные устройства, которые настраиваются во время загрузки системы.
```
#правим /etc/crypttab
nano /etc/crypttab
```
если сопоставляли раздел sda7>sda7\_crypt как в п.B2.1
> # «target name» «source device» «key file» «options»
>
> sda7\_crypt UUID=81048598-5bb9-4a53-af92-f3f9e709e2f2 none luks
>
>
если сопоставляли раздел sda7>sda7\_crypt как в п.B2.2
> # «target name» «source device» «key file» «options»
>
> sda7\_crypt UUID=81048598-5bb9-4a53-af92-f3f9e709e2f2 none cipher=twofish-xts-plain64,size=512,hash=sha512
если сопоставляли раздел sda7>sda7\_crypt как в п.B2.1 or B2.2, но не хотите повторно вводить пароль для разблокировки и загрузки ОС, то вместо пароля можно подставить секретный ключ/случайный файл
> # «target name» «source device» «key file» «options»
>
> sda7\_crypt UUID=81048598-5bb9-4a53-af92-f3f9e709e2f2 /etc/skey luks
Описание
\* none -сообщает, что при загрузке ОС, для разблокировки корня требуется ввод секретной парольной фразы.
\* UUID -идентификатор раздела. Чтобы узнать свой идентификатор набираете в терминале *(напоминание, что все это время и далее, вы работаете в терминале в среде chroot, а не в другом терминале live usb).*
```
fdisk -l #проверка всех разделов
blkid #должно быть что-то подобное
```
> /dev/sda7: UUID=«81048598-5bb9-4a53-af92-f3f9e709e2f2» TYPE=«crypto\_LUKS» PARTUUID=«0332d73c-07»
>
> /dev/mapper/sda7\_crypt: LABEL=«DebSHIFR» UUID=«382111a2-f993-403c-aa2e-292b5eac4780» TYPE=«ext4»
>
>
эту строчку видно при запросе blkid из терминала live usb при смонтированном sda7\_crypt).
UUID берете именно от вашего sdaX *(не sdaX\_crypt!, UUID sdaX\_crypt – автоматом уйдет при генерации конфига grub.cfg).*
\* cipher=twofish-xts-plain64,size=512,hash=sha512 -luks шифрование в расширенном режиме.
\* /etc/skey -секретный файл-ключ, который подставляется автоматически для разблокировки загрузки ОС *(вместо ввода 3-го пароля).* Файл можно указать любой до 8мБ, но считываться данные будут <1мБ.
```
#Создание "генерация" случайного файла <секретного ключа> размером 691б.
head -c 691 /dev/urandom > /etc/skey
```
```
#Добавление секретного ключа (691б) в 7-й слот заголовка luks
cryptsetup luksAddKey --key-slot 7 /dev/sda7 /etc/skey
```
```
#Проверка слотов "пароли/ключи luks-раздела"
cryptsetup luksDump /dev/sda7
```
Выглядеть будет примерно так:
> (Сделайте сами и сами увидите. Если шифруете в 2020г., то вывод будет в LUKS2, если ранее, вывод будет в LUKS1. Примечание автора — в LUKS1 информативнее и красивее вывод в CLI).
```
# Check "неизвестного раздела"
file -s /dev/sda7
/dev/sda7: LUKS encrypted file, ver 1 [twofish, xts-plain64, sha512] UUID: ХХХХ-- #в случае если LUKS
/dev/sda7: data #в случае если VeraCrypt
```
```
cryptsetup luksKillSlot /dev/sda7 7 #удаление ключа/пароля из 7 слота
```
/etc/fstab содержит описательную информацию о различных файловых системах.
```
#Правим /etc/fstab
nano /etc/fstab
```
> # «file system» «mount poin» «type» «options» «dump» «pass»
>
> # / was on /dev/sda7 during installation
>
> /dev/mapper/sda7\_crypt / ext4 errors=remount-ro 0 1
>
>
опция
\* /dev/mapper/sda7\_crypt -имя сопоставления sda7>sda7\_crypt, которое указано в файле /etc/crypttab.
**Настройка crypttab/fstab закончена.**
**B4.5. Редактирование файлов конфигурации. Ключевой момент**
**B4.5.1. Редактирование конфига /etc/initramfs-tools/conf.d/resume**
```
#Если у вас ранее был активирован swap раздел, отключите его.
nano /etc/initramfs-tools/conf.d/resume
```
и закомментируйте *(если существует)* "#" строчку «resume». Файл должен быть полностью пустой.
**B4.5.2. Редактирование конфига /etc/initramfs-tools/conf.d/cryptsetup**
```
nano /etc/initramfs-tools/conf.d/cryptsetup
```
должно соответствовать
> # /etc/initramfs-tools/conf.d/cryptsetup
>
> CRYPTSETUP=yes
>
> export CRYPTSETUP
>
>
**B4.5.3. Редактирование конфига /etc/default/grub *(именно этот конфиг отвечает за умение генерировать grub.cfg при работе с зашифрованным /boot)***
```
nano /etc/default/grub
```
добавляем строку «GRUB\_ENABLE\_CRYPTODISK=y»
значение 'y', grub-mkconfig и grub-install будут проверять наличие зашифрованных дисков и генерировать дополнительные команды, необходимые для их доступа во время загрузки *(insmod-ы )*.
должно быть подобие
> GRUB\_DEFAULT=0
>
> GRUB\_TIMEOUT=1
>
> GRUB\_DISTRIBUTOR=`lsb\_release -i -s 2> /dev/null || echo Debian`
>
> GRUB\_CMDLINE\_LINUX\_DEFAULT=«acpi\_backlight=vendor»
>
> GRUB\_CMDLINE\_LINUX=«quiet splash noautomount»
>
> GRUB\_ENABLE\_CRYPTODISK=y
>
>
**B4.5.4. Редактирование конфига /etc/cryptsetup-initramfs/conf-hook**
```
nano /etc/cryptsetup-initramfs/conf-hook
```
проверьте, что строка закомментирована <#>.
В будущем *(и даже уже сейчас, этот параметр не будет иметь никакого значения, но иногда он мешает обновлять образ initrd.img).*
В конец файла добавляем:
> KEYFILE\_PATTERN="/etc/skey"
>
> UMASK=0077
>
>
Это упакует секретный ключ «skey» в initrd.img, ключ необходим для разблокировки корня при загрузке ОС *(если нет желания при загрузке ОС дважды вводить свой пароль автоподставляется секретный ключ «skey» (пароль + ключ) см. п.B4.4).*
**B4.6. Обновление /boot/initrd.img [version]**
Чтобы упаковать секретный ключ в initrd.img и применить исправления cryptsetup, обновляем образ
```
update-initramfs -u -k all
```
при обновлении initrd.img *(как говорится «Возможно, но это не точно»)* появятся предупреждения, связанные с cryptsetup, или, например, уведомление о потере модулей Nvidia — это нормальное явление. После обновления файла, проверяйте, что он действительно обновился см. по времени *(относительно chroot среды./boot/initrd.img). **Внимание!** перед [update-initramfs -u -k all] обязательно проверить, что cryptsetup open /dev/sda7 **sda7\_crypt** — именно это имя должно быть, которое фигурирует в /etc/crypttab, иначе после reboot-a ошибка busybox)
***На этом шаге настройка файлов конфигурации завершена.****
[С] Установка и настройка GRUB2/Защита
--------------------------------------
**C1. При необходимости отформатируйте выделенный раздел для загрузчика (разделу достаточно не менее 20мБ)**
```
mkfs.ext4 -v -L GRUB2 /dev/sda6
```
**C2. Монтирование /dev/sda6 в /mnt**
Так мы работаем в chroot, то в корне не будет каталога /mnt2, а папка /mnt — будет пустой.
монтируем раздел GRUB2
```
mount /dev/sda6 /mnt
```
Если у вас установлена старая версия GRUB2, в каталоге /mnt/boot/grub/i-386-pc *(возможна другая платформа, например, не «i386-pc»)* отсутствуют криптомодули *(короче, в папке должны находиться модули, включая эти .mod: cryptodisk; luks; gcry\_twofish; gcry\_sha512; signature\_test.mod),* в таком случае GRUB2 необходимо встряхнуть.
```
apt-get update
apt-get install grub2
```
Важно! Во время обновления пакета GRUB2 из репозитория, на вопрос «о выборе» в какое место устанавливать загрузчик – необходимо отказаться от инсталляции *(причина — попытка установки GRUB2 — в «MBR» или на live usb)*. В противном случае вы повредите заголовок/загрузчик VeraCrypt. После обновления пакетов GRUB2, и отмены установки, загрузчик нужно инсталлировать вручную на логический диск, а не в «MBR». Если в вашем репозитории устаревшая версия GRUB2, попробуйте [апдейтить](https://www.gnu.org/software/grub/manual/grub/grub.html#Obtaining-and-Building-GRUB) его с официального сайта – не проверял *(работал со свежими загрузчиками GRUB 2.02 ~BetaX).*
**C3. Инсталляция GRUB2 в расширенный раздел [sda6]**
У вас должен быть смонтирован раздел [п.C.2]
```
grub-install --force --root-directory=/mnt /dev/sda6
```
опции
\* --force -установка загрузчика, минуя все предупреждения, которые практически всегда существуют и блокируют установку *(обязательный флаг).*
\* --root-directory -установка каталога в корень sda6.
\* /dev/sda6 -ваш sdaХ раздел *(не пропустите <пробел> между /mnt /dev/sda6).*
**C4. Создание файла конфигурации [grub.cfg]**
Забудьте о команде «update-grub2», и используйте полноценную команду генерации файла конфигурации
```
grub-mkconfig -o /mnt/boot/grub/grub.cfg
```
после завершения генерации/обновления файла grub.cfg, в терминале вывода должны быть строчки(а) с найденными ОС на диске *(«grub-mkconfig» возможно найдет и подхватит ОС с live usb, если у вас мультизагрузочная флэшка с Windows 10 и кучей живых дистрибутивов — это нормально).* Если в терминале «пусто», файл «grub.cfg» не сгенерирован, то это тот самый случай, когда в системе GRUBые баги *(и скорее всего загрузчик из тестовой ветки репозитория),* переустановите GRUB2 из надежных источников.
**Установка «простая конфигурация» и настройка GRUB2 завершена.**
**C5. Proof-test зашифрованной ОС GNU/Linux**
Корректно завершаем криптомиссию. Аккуратно покидаем зашифрованную GNU/Linux *(выход из среды chroot).*
```
umount -a #размонтирование всех смонтированных разделов шифрованной GNU/Linux
Ctrl+d #выход из среды chroot
umount /mnt/dev
umount /mnt/proc
umount /mnt/sys
umount -a #размонтирование всех смонтированных разделов на live usb
reboot
#извлекаем флэшку.
```
После перезагрузки ПК должен загрузиться загрузчик VeraCrypt.
\*Ввод пароля для активного раздела — начнется загрузка ОС Windows.
\*Нажатие клавиши «Esc» передаст управление GRUB2, при выборе зашифрованной GNU/Linux – потребуется пароль (sda7\_crypt) для разблокировки /boot/initrd.img (если grub2 пишет uuid «не найден» — это проблема загрузчика grub2, его следует переустановить, например, с тестовой ветки/стабильный и пд).
\*В зависимости от того, как вы настроили систему (см. п.B4.4/4.5) после верного ввода пароля для разблокировки образа /boot/initrd.img, потребуется пароль для загрузки ядра/корня ОС, либо автоматически подставится секретный ключ «skey», избавляя от повторного ввода парольной фразы.

(скрин «автоматическая подстановка секретного ключа»).
\*Далее понесется знакомый процесс загрузки GNU/Linux с аутентификацией учетки пользователя.

\*После авторизации пользователя и входа в ОС, нужно повторно обновить /boot/initrd.img *(см В4.6).*
```
update-initramfs -u -k all
```
А в случае лишних строк в меню GRUB2 *(из подхвата ОС-м с live usb)* избавиться от них
```
mount /dev/sda6 /mnt
grub-mkconfig -o /mnt/boot/grub/grub.cfg
```
**Краткий итог по системному шифрованию GNU/Linux:**
* GNU/Linux зашифрован полностью, включая /boot/kernel and initrd;
* секретный ключ упакован в initrd.img;
* текущая схема авторизации *(ввод пароля на разблокировку initrd; пароль/ключ на загрузку ОС; пароль авторизации учетки Linux)*.
**«Простая конфигурация GRUB2» системное шифрование блочного раздела закончено.**
**С6. Расширенная настройка GRUB2. Защита загрузчика цифровой подписью + защита аутентификацией**
GNU/Linux зашифрован полностью, но загрузчик шифровать нельзя – такое условие продиктовано BIOS. По этой причине цепочная зашифрованная загрузка GRUB2 невозможна, но возможна/доступна простая цепочная загрузка, с точки зрения защиты – не нужно [см. П. F].
Для «уязвимого» GRUB2 разработчики реализовали алгоритм защиты загрузчика «подписью/аутентификацией».
* При защите загрузчика «своей цифровой подписью» внешняя модификация файлов, либо попытка загрузить в данном загрузчике дополнительные модули – приведет процесс загрузки к блокировке.
* При защите загрузчика аутентификацией для выбора загрузки какого-либо дистрибутива, либо ввод дополнительных команд в CLI, потребуется ввести логин и пароль суперпользователя-GRUB2.
**С6.1. Защита загрузчика аутентификацией**
Проверьте, что вы работаете в терминале в зашифрованной ОС
```
ls / #обнаружить файл-маркер
```
создайте пароль суперпользователя для авторизации в GRUB2
```
grub-mkpasswd-pbkdf2 #введите/повторите пароль суперпользователя.
```
Получите хэш пароля. Что-то похоже на это
> grub.pbkdf2.sha512.10000.DE10E42B01BB6FEEE46250FC5F9C3756894A8476A7F7661A9FFE9D6CC4D0A168898B98C34EBA210F46FC10985CE28277D0563F74E108FCE3ACBD52B26F8BA04D.27625A4D30E4F1044962D3DD1C2E493EF511C01366909767C3AF9A005E81F4BFC33372B9C041BE9BA904D7C6BB141DE48722ED17D2DF9C560170821F033BCFD8
>
>
монтируем раздел GRUB
```
mount /dev/sda6 /mnt
```
редактируем конфиг
```
nano -$ /mnt/boot/grub/grub.cfg
```
проверьте поиск по файлу, что в «grub.cfg» отсутствуют где-либо флаги (" --unrestricted" "--user",
добавьте в самом конце *(перед строкой ### END /etc/grub.d/41\_custom ###)*
*«set superusers=»root"
password\_pbkdf2 root хэш".*
Должно быть примерно так
> # This file provides an easy way to add custom menu entries. Simply type the
>
> # menu entries you want to add after this comment. Be careful not to change
>
> # the 'exec tail' line above.
>
> ### END /etc/grub.d/40\_custom ###
>
>
>
> ### BEGIN /etc/grub.d/41\_custom ###
>
> if [ -f ${config\_directory}/custom.cfg ]; then
>
> source ${config\_directory}/custom.cfg
>
> elif [ -z "${config\_directory}" -a -f $prefix/custom.cfg ]; then
>
> source $prefix/custom.cfg;
>
> fi
>
> set superusers=«root»
>
> password\_pbkdf2 root grub.pbkdf2.sha512.10000.DE10E42B01BB6FEEE46250FC5F9C3756894A8476A7F7661A9FFE9D6CC4D0A168898B98C34EBA210F46FC10985CE28277D0563F74E108FCE3ACBD52B26F8BA04D.27625A4D30E4F1044962D3DD1C2E493EF511C01366909767C3AF9A005E81F4BFC33372B9C041BE9BA904D7C6BB141DE48722ED17D2DF9C560170821F033BCFD8
>
> ### END /etc/grub.d/41\_custom ###
>
> #
>
>
Если вы часто пользуетесь командой «grub-mkconfig -o /mnt/boot/grub/grub.cfg» и не хотите вносить каждый раз изменения в grub.cfg, занесите вышеописанные строки *(логин/пароль)* в пользовательский скрипт GRUB-а в самый низ
```
nano /etc/grub.d/41_custom
```
> cat << EOF
>
> set superusers=«root»
>
> password\_pbkdf2 root grub.pbkdf2.sha512.10000.DE10E42B01BB6FEEE46250FC5F9C3756894A8476A7F7661A9FFE9D6CC4D0A168898B98C34EBA210F46FC10985CE28277D0563F74E108FCE3ACBD52B26F8BA04D.27625A4D30E4F1044962D3DD1C2E493EF511C01366909767C3AF9A005E81F4BFC33372B9C041BE9BA904D7C6BB141DE48722ED17D2DF9C560170821F033BCFD8
>
> EOF
>
>
При генерации конфига «grub-mkconfig -o /mnt/boot/grub/grub.cfg», строки, отвечающие за аутентификацию, будут добавляться автоматически в grub.cfg.
**На этом шаге настройка аутентификации GRUB2 завершена.**
**С6.2. Защита загрузчика цифровой подписью**
Предполагается, что у вас уже есть ваш персональный pgp-ключ шифрования *(либо создайте такой ключ).* В системе должно быть установлено криптографическое ПО: gnuPG; kleopatra/GPA; Seahorse. Крипто-ПО существенно облегчит вам жизнь во всех подобных делах. Seahorse — стабильная версия пакета 3.14.0 *(версии выше, например, V3.20 – неполноценная и имеет существенные баги).*
PGP-ключ нужно генерировать/запускать/добавлять только в среде su!
Сгенерировать персональный шифровальный ключ
```
gpg - -gen-key
```
Экспортировать свой ключ
```
gpg --export -o ~/perskey
```
Смонтируйте логический диск в ОС если он еще не смонтирован
```
mount /dev/sda6 /mnt #sda6 – раздел GRUB2
```
очистите раздел GRUB2
```
rm -rf /mnt/
```
Инсталлируйте GRUB2 в sda6, положив ваш персональный ключ в основной образ GRUB «core.img»
```
grub-install --force --modules="gcry_sha256 gcry_sha512 signature_test gcry_dsa gcry_rsa" -k ~/perskey --root-directory=/mnt /dev/sda6
```
опции
\* --force -установка загрузчика, минуя все предупреждения, которые всегда существуют *(обязательный флаг).*
\* --modules=«gcry\_sha256 gcry\_sha512 signature\_test gcry\_dsa gcry\_rsa» -инструктирует GRUB2 на предварительную загрузку необходимых модулей при запуске ПК.
\* -k ~/perskey -путь до «PGP-ключа» *(после упаковывания ключа в образ, его можно удалить).*
\* --root-directory -установка каталога boot в корень sda6
/dev/sda6 -ваш sdaХ раздел.
Генерируем/обновляем grub.cfg
```
grub-mkconfig -o /mnt/boot/grub/grub.cfg
```
Добавляем в конец файла «grub.cfg» строку «trust /boot/grub/perskey» *(принудительно использовать pgp-ключ.)* Так как мы инсталлировали GRUB2 с набором модулей, в том числе и модулем подписи «signature\_test.mod», то это избавляет от добавления в конфиг команд типо «set check\_signatures=enforce».
Выглядеть должно примерно так *(концевые строки в файле grub.cfg)*
> ### BEGIN /etc/grub.d/41\_custom ###
>
> if [ -f ${config\_directory}/custom.cfg ]; then
>
> source ${config\_directory}/custom.cfg
>
> elif [ -z "${config\_directory}" -a -f $prefix/custom.cfg ]; then
>
> source $prefix/custom.cfg;
>
> fi
>
> trust /boot/grub/perskey
>
> set superusers=«root»
>
> password\_pbkdf2 root grub.pbkdf2.sha512.10000.DE10E42B01BB6FEEE46250FC5F9C3756894A8476A7F7661A9FFE9D6CC4D0A168898B98C34EBA210F46FC10985CE28277D0563F74E108FCE3ACBD52B26F8BA04D.27625A4D30E4F1044962D3DD1C2E493EF511C01366909767C3AF9A005E81F4BFC33372B9C041BE9BA904D7C6BB141DE48722ED17D2DF9C560170821F033BCFD8
>
> ### END /etc/grub.d/41\_custom ###
>
> #
Путь к "/boot/grub/perskey" не нужно указывать на конкретный раздел диска, например hd0,6, для себя загрузчика «корень» является дефолтным путем раздела, на который установлен GRUB2 *(см. set rot=..).*
Подписываем GRUB2 *(все файлы во всех директориях /GRUB)* своим ключом «perskey».
Простое решение, как подписать *(для проводника nautilus/caja):* устанавливаем из репозитория расширение «seahorse» для проводника. Ключ у вас должен быть добавлен в среду su.
Открываете проводник от sudo "/mnt/boot" – ПКМ – подписать. На скрине это выглядит это так
Сам ключ "/mnt/boot/grub/perskey" *(скопировать в каталог grub)* тоже должен быть подписан своей же подписью. Проверьте, что в каталоге/подкаталогах появились подписи файлов [\*.sig].
Вышеописанным способом подписываем "/boot" *(наши kernel, initrd).* Если ваше время чего-то стоит, то такой метод избавляет писать bash-скрипт для подписи «множества файлов».
Чтобы удалить все подписи загрузчика *(если что-то пошло не так)*
```
rm -f $(find /mnt/boot/grub -type f -name '*.sig')
```
Что бы не подписывать загрузчик после обновления системы, замораживаем все пакеты обновления, имеющие отношение к GRUB2.
```
apt-mark hold grub-common grub-pc grub-pc-bin grub2 grub2-common
```
**На этом шаге <защита загрузчика цифровой подписью> расширенная настройка GRUB2 завершена.**
**C6.3. Proof-test загрузчика GRUB2, защищенного цифровой подписью и аутентификацией**
GRUB2. При выборе какого-либо дистрибутива GNU/Linux или вход в CLI *(командную строку)* потребуется авторизация суперпользователя. После ввода верного логина/пароля потребуется пароль от initrd
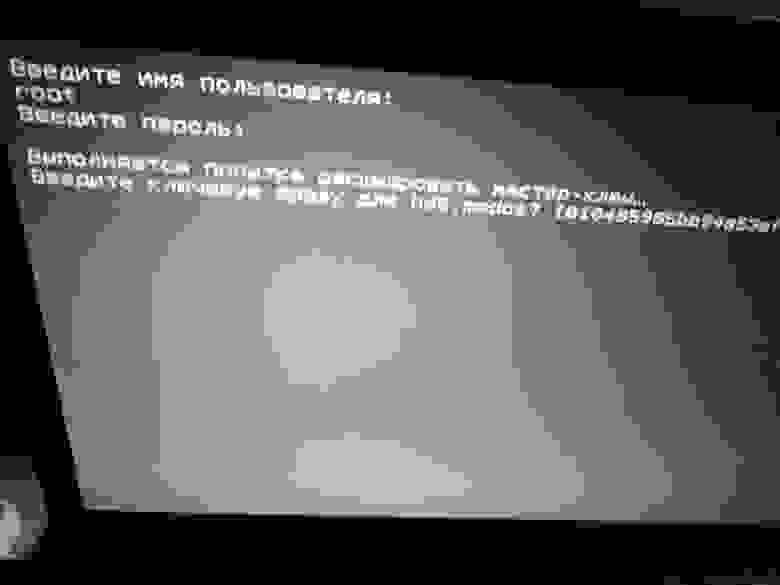
Скрин, успешная аутентификация GRUB2-суперпользователя.
Если подделать какой-либо из файлов GRUB2/внести изменения в grub.cfg, или удалить файл/подпись, подгрузить вредоносный модуль.mod, то появится соответствующее предупреждение. Загрузка GRUB2 приостановится.
Скрин, попытка вмешаться в GRUB2 «из вне».
При «нормальной» загрузке «без вторжения», системный статус кода выхода «0». Поэтому неизвестно работает ли защита или нет *(то есть «с защитой загрузчика подписью или без неё» при нормальной загрузке статус один и тот же «0» — это плохо).*
Как проверить защиту цифровой подписью?
Неудобный способ проверки: подделать/удалить используемый GRUB2 модуль, например, удалить подпись luks.mod.sig и получить ошибку.
Правильный способ: зайти в CLI загрузчика и набрать команду
```
trust_list
```
В ответ должны получить отпечаток «perskey», если статус «0», значит защита подписью не работает, перепроверяйте п.C6.2.
**На этом шаге расширенная настройка «Защита GRUB2 цифровой подписью и аутентификацией» окончена.**
**С7 Альтернативный метод защиты загрузчика GRUB2 с помощью хэширования**
Описанный выше способ «Защита загрузчика ЦП/Аутентификацией» — это классика. Из-за несовершенства GRUB2, в параноидальных условиях тот подвержен реальной атаке, которую я приведу ниже в п.[F]. Кроме того, после обновления ОС/ядра необходимо переподписывать загрузчик.
#### Защита загрузчика GRUB2 с помощью хэширования
**Преимущества перед классикой:**
* Более высокий уровень надежности/оповещения *(хэширование/проверка проходит только с зашифрованного локального ресурса. Контролируется весь выделенный раздел под GRUB2 на любые изменения, а все остальное зашифровано, в классической же схеме с защитой загрузчика ЦП/Аутентификацией контролируются лишь файлы, но не свободное пространство, в которое «что-то зловещее» можно дописать и контроль этот осуществляется с незашифрованного локального ресурса).*
* Зашифрованное логирование *(в схему добавляется удобочитаемый, персональный, шифрованный лог).*
* Скорость *(защита/проверка целого раздела выделенного под GRUB2 происходит практически мгновенно).*
* Автоматизация всех криптографических процессов.
**Недостатки перед классикой.**
* Подделка подписи *(теоретически, возможно нахождение заданной коллизии хэш функции).*
* The Worst Evil Script *(вектор атаки/условие: подмена загрузчика и загрузка не с GRUB контролируемого раздела, а с usb-брелка/другой микросхемы, система/хозяин не будут оповещены о вторжении в цитадель, а вредоносный модуль передаст перехваченные pass/заголовок\_LUKS по сети недоброжелателю).*
* Повышенный уровень сложности *(по сравнению с классикой требуется чуть больше навыков владения в ОС GNU/Linux).*
И общая проблема — [аппаратные кейлоггеры](http://bit.ly/2QrQk2O), которые открыто продаются не только с Поднебесной.
**Как работает идея с хэшированием GRUB2/раздела**
«Подписывается» раздел GRUB2, при загрузке ОС происходит проверка неизменности раздела загрузчика с последующим логированием в безопасной среде (зашифрованной). В случае компрометации загрузчика, либо его раздела во время работы ОС, в дополнение к логу вторжения запускается такая
**Штука.**

Те же действия вторжения, но во время загрузки ОС с раздела GRUB, save log, ПК выключается и не даёт зловреду передать перехваченный pas/заголовок\_LUKS по сети.
В случае атаки The Worst Evil Script хозяин обязан форматнуть ~~раздел~~ винт с обязательной перезаписью данных в один проход (либо перешифровать cryptsetup reencrypt), простое уничтожение заголовка LUKS не поможет.
Четыре раза в день происходит проверка хэширования раздела GRUB, которая не нагружает ресурсы системы.
С помощью команды "-$ проверка\_GRUB" происходит мгновенная проверка в любой момент времени без логирования, но с выводом информации в CLI.
С помощью команды "-$ sudo подпись\_GRUB" происходит мгновенное переподписание загрузчика GRUB2/раздела и его обновленное логирование *(необходимо после обновления ОС/boot), и жизнь продолжается дальше.*
**Реализация метода хэширования загрузчика и его раздела**
**0)** Подпишем загрузчик/раздел GRUB, предварительно смонтировав его в /media/username
```
-$ hashdeep -c md5 -r /media/username/GRUB > /podpis.txt
```
**1)** Создаем скрипт без расширения в корне зашифрованной ОС /podpis, применяем к нему нужные права 744 секьюрити и защита от «дурака».
**Наполняем его содержимое**
```
#!/bin/bash
#Проверка всего раздела выделенного под загрузчик GRUB2 на неизменность.
#Ведется лог "о вторжении/успешной проверке каталога", короче говоря ведется полный лог с тройной вербализацией. Внимание! обратить взор на пути: хранить ЦП GRUB2 только на зашифрованном разделе OS GNU/Linux.
echo -e "******************************************************************\n" >> '/var/log/podpis.txt' && date >> '/var/log/podpis.txt' && hashdeep -vvv -a -k '/podpis.txt' -r '/media/username/GRUB' >> '/var/log/podpis.txt'
a=`tail '/var/log/podpis.txt' | grep failed` #не использовать "cat"!!
b="hashdeep: Audit failed"
#Условие: в случае любых каких-либо изменений в разделе выделенном под GRUB2 к полному логу пишется второй отдельный краткий лог "только о вторжении" и выводится на монитор мигание gif-ки "warning".
if [[ "$a" = "$b" ]]
then
echo -e "****\n" >> '/var/log/vtorjenie.txt' && echo "vtorjenie" >> '/var/log/vtorjenie.txt' && date >> '/var/log/vtorjenie.txt' & sudo -u username DISPLAY=:0 eom '/warning.gif'
fi
```
Запускаем скрипт от *su*, произойдет проверка хэширования раздела GRUB и его загрузчика, save лог.
Создадим или скопируем, например, «вредоносный файл» [virus.mod] в раздел GRUB2 и запустим временную проверку/тестирования:
```
-$ hashdeep -vvv -a -k '/podpis.txt' -r '/media/username/GRUB
```
**В CLI должны увидеть вторжение в нашу -цитадель-**
#Урезанный лог в CLI
```
Ср янв 2 11::41 MSK 2020
/media/username/GRUB/boot/grub/virus.mod: Moved from /media/username/GRUB/1nononoshifr
/media/username/GRUB/boot/grub/i386-pc/mda_text.mod: Ok
/media/username/GRUB/boot/grub/grub.cfg: Ok
hashdeep: Audit failed
Input files examined: 0
Known files expecting: 0
Files matched: 325
Files partially matched: 0
Files moved: 1
New files found: 0
Known files not found: 0
```
#как видим появилось «Files moved: 1 и Audit failed» означает, что проверка не прошла.
Из-за особенностей тестируемого раздела вместо «New files found» > «Files moved»
**2)** Кладём гифку сюда > /warning.gif, задаем права 744.
**3)** Настраиваем fstab на автомонтирование раздела GRUB при загрузке
```
-$ sudo nano /etc/fstab
```
> LABEL=GRUB /media/username/GRUB ext4 defaults 0 0
**4)** Проводим ротацию лога
```
-$ sudo nano /etc/logrotate.d/podpis
```
> /var/log/podpis.txt {
>
> daily
>
> rotate 50
>
> size 5M
>
> dateext
>
> compress
>
> delaycompress
>
> olddir /var/log/old
>
> }
>
>
>
> /var/log/vtorjenie.txt {
>
> monthly
>
> rotate 5
>
> size 5M
>
> dateext
>
> olddir /var/log/old
>
> }
**5)** Добавляем задание в cron
```
-$ sudo crontab -e
```
> [reboot](https://habr.com/ru/users/reboot/) '/podpis' #проверка подписи при загрузке ОС
>
> 0 \*/6 \* \* \* '/podpis #проверка подписи в 0-00ч; 6ч; 12ч; 18ч.
>
>
**6)** Создаем постоянные алиасы
```
-$ sudo su
-$ echo "alias подпись_GRUB='hashdeep -c md5 -r /media/username/GRUB > /podpis.txt'" >> /root/.bashrc && bash
-$ echo "alias проверка_GRUB='hashdeep -vvv -a -k '/podpis.txt' -r /media/username/GRUB'" >> .bashrc && bash
```
После обновления ОС `-$ apt-get upgrade` переподписываем наш раздел GRUB
`-$ подпись_GRUB`
**На этом шаге защита хэшированием раздела GRUB завершена.**
[D] Зачистка — уничтожение нешифрованных данных
-----------------------------------------------
> Удалите свои личные файлы так полностью, что «даже Бог не может их прочитать», по словам представителя Южной Каролины Трей Гауди.
Как обычно существуют разные «мифы и [легенды](https://docs.bleachbit.org/doc/shred-files-and-wipe-disks.html)», о восстановлении данных после их удаления с жесткого диска. Если вы верите в киберколдоство, или являетесь прихожанином Dr web сообщества и никогда не пробовали восстановление данных после их удаления/перезаписи *(например, восстановление с помощью R-studio)*, тогда предложенный способ вряд ли вам подойдет, пользуйтесь тем, чем вам ближе.
После успешного переноса GNU/Linux на зашифрованный раздел, старую копию необходимо удалить без возможности восстановления данных. Универсальный способ очистки: софт для Windows/Linux свободное GUI ПО [BleachBit](https://www.bleachbit.org/).
Быстро **форматируем раздел**, данные на котором нужно уничтожить *(с помощью Gparted),* запускаем BleachBit, выбираем «Очистка свободного пространства» – выбираем раздел *(ваш sdaX с прошлой копией GNU/Linux)*, запустится процесс зачистки. BleachBit — протирает диск в один проход — это то, что «нам нужно», Но! так работает только в теории, если вы форматировали диск и чистили в ПО BB v2.0.
**Внимание**! BB протирает диск, оставляя метаданные: имена уничтоженных файлов при ликвидации данных сохраняются *(Ccleaner — не оставляет метаданных).*
**И миф о возможности восстановления данных является не совсем мифом.**
Bleachbit V2.0-2 бывший пакет unstable OS Debian *(и любой другой подобный софт: sfill; wipe-Nautilus -тоже были замечены в этом грязном деле )* на самом деле имел критическую ошибку: функция «свободная очистка пространства» **работает некорректно** на HDD/Флэшках *(ntfs/ext4)*. ПО подобного рода при очистке свободного места перезаписывают не весь диск, как многие пользователи думают. И некоторые *(много)* удаленные данные ОС/ПО считают эти данные неудаленными/пользовательскими и при очистке «ОСП» пропускают эти файлы. Проблема в том, что после такой, долгой по времени, очистки диска **«удаленные файлы» можно восстановить** даже через 3+ прохода протирания диска.
На GNU/Linux в Bleachbit **2.0-2** надежно работают функции безвозвратного удаления файлов и каталогов, но не очистка свободного пространства. Для сравнения: на Windows в ПО CCleaner функция «ОСП для ntfs» работает исправно, и Бог действительно не сможет прочитать удаленные данные.
И так, чтобы основательно удалить «компрометирующие» старые нешифрованные данные, **необходим прямой доступ Bleachbit к этим данным**, далее, воспользоваться функцией «удаление файлов/каталогов безвозвратно».
Для удаления «удаленных файлов штатными средствами ОС» в Windows используйте CCleaner/BB с функцией «ОСП». В GNU/Linux над этой проблемой *(удаление удаленных файлов)* вам необходимо получить практику самостоятельно *(удаление данных+самостоятельная попытка их восстановления и не стоит полагаться на версию ПО (если не закладка, то баг))*, только в таком случае вы сможете понять механизм этой проблемы и избавиться от удаленных данных окончательно.
Bleachbit v3.0 не проверял, возможно, проблему уже поправили.
Bleachbit v2.0 работает честно и для GNU/Linux и для Windows7.
**На этом шаге «зачистка диска» завершена.**
[E] Универсальное резервное копирование зашифрованных ОС
--------------------------------------------------------
У каждого пользователя свой метод резервного копирования данных, но зашифрованные данные «Системных ОС» требуют чуть иной подход к задаче. Унифицированное ПО, как например «Clonezilla» и подобный софт не могут работать напрямую с зашифрованными данными.
Постановка задачи резервного копирования зашифрованных блочных устройств:
1. универсальность — одинаковый алгоритм/ПО резервного копирования для Windows/Linux;
2. возможность работать в консоли с любой live usb GNU/Linux без необходимости дополнительного скачивания ПО *(но все же рекомендую GUI)*;
3. безопасность резервных копий — хранимые «образы» должны быть зашифрованы/запаролены;
4. размер зашифрованных данных должен соответствовать размеру реальных копируемых данных;
5. удобное извлечение нужных файлов из резервной копии *(отсутствие требования расшифровать сперва весь раздел).*
Например, резервная копия/восстановление через утилиту «dd»
```
dd if=/dev/sda7 of=/путь/sda7.img bs=7M conv=sync,noerror
dd if=/путь/sda7.img of=/dev/sda7 bs=7M conv=sync,noerror
```
Соответствует почти всем пунктам поставленной задачи, но по п.4 не выдерживает критики, так как копирует весь раздел диска целиком, в том числе и свободное пространство — не интересно.
Например, резервная копия GNU/Linux через архиватор [tar | gpg] «удобно», но для бэкапа Windows нужно искать другое решение — не интересно.
**E1. Универсальное резервное копирование Windows/Linux (связка rsync (Grsync)+VeraCrypt том) & Автомонтирование зашифрованных дисков**
**Алгоритм создания резервной копии:**
1. создание зашифрованного контейнера *(том/файл)* VeraCrypt для ОС;
2. перенос/синхронизация ОС с помощью ПО Rsync в криптоконтейнер VeraCrypt;
3. при необходимости загрузка тома VeraCrypt в www.
*Создание зашифрованного контейнера VeraCrypt имеет свои особенности:
1. создание динамического тома *(доступно создание ДТ только в ОС Windows, использовать можно и в GNU/Linux)*;
2. создание обычного тома, но присутствует требование «параноидального характера» *(со слов разработчика)* – форматирование контейнера.
Динамический том создается практически мгновенно в ОС Windows, но при копировании данных из ОС GNU/Linux > VeraCrypt ДТ, в целом производительность операции резервного копирования снижается существенно.
Обычный том Twofish в 70 Гб создается *(скажем так, на средней мощности ПК)* на HDD ~ за полчаса *(перезапись бывших данных контейнера в один проход, обусловлено требованием безопасности).* Из VeraCrypt Windows/Linux убрали функцию быстрого форматирования тома при его создании, поэтому создание контейнера возможно только через «перезапись в один проход», либо создание слабопроизводительного динамического тома.*
В 2017 году я обращался к разработчику VeraCrypt с просьбой ввести функцию «создание динамического тома и в ОС GNU/Linux». Получил ответ *Транслит en > ru*:
> Мой первый ответ был неверным, так как быстрое форматирование всегда
>
> отключено для файлового контейнера, чтобы избежать утечки данных на оригинальный диск.…
>
>
>
> В настоящее время динамические контейнеры не реализованы в Linux.
>
> Технически это должно быть возможно, но на него никогда не было запроса.
>
> Я посмотрю, легко ли это реализовать.
И так, динамический том VeraCrypt не перезатирает старые данные на HDD и создается мгновенно.
Обычный том перезаписывает старые данные, их невозможно в последующим восстановить, том создается небыстро *(предварительно «форматируется» область тома своего размера).*
В свежей версии ПО VeraCrypt 1.24-Update3 создание динамических томов можно реализовать и в GNU/Linux, но только для дисковых разделов (/dev/sdaX).
Для контейнеров/файлов — создание только обычных VeraCrypt-томов.
Создаём обычный том VeraCrypt *(нединамический/ntfs)*, никаких проблем возникнуть не должно.
Настраиваем/создаем/открываем контейнер в VeraCrypt GUI > GNU/Linux live usb *(том будет автомонтирован в /media/veracrypt2, том ОС Windows монтирован в /media/veracrypt1).* Создаем зашифрованную резервную копию ОС Windows с помощью GUI rsync *(grsync)*, расставив галочки.
Дождаться окончания процесса. По завершению резервного копирования, у нас будет один зашифрованный файл.
Аналогично создать резервную копию ОС GNU/Linux, скинув галочку в GUI rsync «совместимость с Windows».
**Внимание**! контейнер Veracrypt для «бэкапа GNU/Linux» создавать в файловой системе **ext4**. Если сделаете бэкап в контейнер ntfs, то при восстановлении такой копии потеряете все права/группы на все ваши данные.
Провести все операции можно и в терминале. Основные опции для rsync:
\* -g -сохранить группы;
\* -P --progress — статус времени работы над файлом;
\* -H -копировать хардлинки, как есть;
\* -а -режим архива *(несколько флагов rlptgoD)*;
\* -v -вербализация.
Если хочется монтировать «том Windows VeraCrypt» через консоль в ПО cryptsetup, можно создать alias (su)
```
echo "alias veramount='cryptsetup open --veracrypt --tcrypt-system --type tcrypt /dev/sdaX Windows_crypt && mount /dev/mapper/ Windows_crypt /media/veracrypt1'" >> .bashrc && bash
```
Теперь по команде «veramount ~~pictures~~» появится запрос на ввод парольной фразы, и в ОС-у подмонтируется, зашифрованный системный том Windows.
Сопоставить/смонтировать **системный том VeraCrypt** в cryptsetup команда
```
cryptsetup open --veracrypt --tcrypt-system --type tcrypt /dev/sdaX Windows_crypt
mount /dev/mapper/Windows_crypt /mnt
```
Сопоставить/смонтировать **раздел/контейнер VeraCrypt** в cryptsetup команда
```
cryptsetup open --veracrypt --type tcrypt /dev/sdaY test_crypt
mount /dev/mapper/test_crypt /mnt
```
**Вместо alias-а добавим (скрипт в автозагрузку) системный зашифрованный том с ОС Windows и логический криптованный диск ntfs в автозагрузку GNU/Linux с автоматическим монтированием/дешифрованием**
```
#создаем каталоги/точки монтирования для ntfs-дисков
mkdir /media/Winda7 && mkdir /media/КонтейнерНтфс
```
```
#кодируем наш пароль от шифрованных дисков VeraCrypt, чтобы "не валялся" в открытом виде
printf 'bob' | base64
Ym9i #вывод в cli закодированный пароль "bob"
```
Создаём скрипт и сохраняем его в /VeraOpen.sh
```
echo 'Ym9i' | base64 -d | cryptsetup open --veracrypt --tcrypt-system --type tcrypt /dev/sda3 Windows_crypt && mount /dev/mapper/Windows_crypt /media/Winda7 #декодируем пароль из base64 (bob) и отправляем его на запрос ввода пароля при монтировании системного диска ОС Windows.
echo 'Ym9i' | base64 -d | cryptsetup open --veracrypt --type tcrypt /dev/sda1 ntfscrypt && mount /dev/mapper/ntfscrypt /media/КонтейнерНтфс #аналогично, но монтируем логический диск ntfs.
```
Раздаем «верные» права:
```
sudo chmod 100 /VeraOpen.sh
```
Создаем два одинаковых файла (одинаковое имя!) в /etc/rc.local и /etc/init.d/rc.local
Наполняем файлы
```
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will «exit 0» on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
sh -c "sleep 1 && '/VeraOpen.sh'" #после загрузки ОС, ждём ~ 1с и только потом монтируем диски.
exit 0
```
Раздаем «верные» права:
```
sudo chmod 100 /etc/rc.local && sudo chmod 100 /etc/init.d/rc.local
```
Всё, теперь при загрузке GNU/Linux нам не требуется вводить пароли на монтирование зашифрованных дисков ntfs, диски монтируются автоматом.
После загрузки ОС, проверьте потерю темпа на расшифровку дисков:
```
systemd-analyze && systemd-analyze blame
```
***Заметка кратко о том, что описано выше в п.E1 по шагам (но теперь для резервного копирования/восстановления OS GNU/Linux)***
1) Создать том в фс ext4 > 4gb (для файла) Linux в Veracrypt [Криптоящик].
2) Reboot в live usb.
3) ~$ cryptsetup open /dev/sda7 Lunux #сопоставление шифрованного раздела.
4) ~$ mount /dev/mapper/Linux /mnt #монтирование шифрованного раздела в /mnt.
5) ~$ mkdir mnt2 #создание каталога для будущего бэкапа.
6) ~$ cryptsetup open --veracrypt --type tcrypt ~/Криптоящик Криптоящик && mount /dev/mapper/Криптоящик /mnt2 #Сопоставление тома Veracrypt с именем «Криптоящик» и монтирование Криптоящика в /mnt2.
7) ~$ rsync -avlxhHX --delete --progress /mnt/ /mnt2 #операция резервного копирования/восстановления шифрованного раздела в шифрованный том Veracrypt и обратно. Ключ "--delete" удаляет все лишне на приёмнике (если имеется), т.е. полная синхронизация данных между источником и приёмником.
(p/s/ **Внимание**! Если вы переносите шифрованную GNU/Linux с одной архитектуры/машины на другую, например, Intel > AMD *(то есть разворачиваете бэкап с одного шифрованного раздела на другой шифрованный раздел Intel > AMD)*, **не забывайте** после переноса шифрованной ОС править секретный подставляемый ключ вместо пароля, тк. предыдущий ключ /etc/skey — уже не подойдет к другому зашифрованному разделу, а новый ключ «cryptsetup luksAddKey» нежелательно создавать из под chroot — возможен глюк, просто в /etc/crypttab укажите вместо "/etc/skey" временно «none», после rebot-а и входа в ОС пересоздайте свой секретный подставляемый ключ заново.
Как ветераны IT незабываем отдельно делать бэкапы заголовков зашифрованных разделов ОС Windows/Linux, или шифрование обернется против Вас самих.
**На данном шаге резервное копирование/восстановление зашифрованных ОС закончено.**
[F] Атака на загрузчик GRUB2
----------------------------
**Подробности**
Если вы защитили свой загрузчик цифровой подписью и/или аутентификацией *(см п.C6.)*, то от физического доступа это никак не защитит. Зашифрованные данные будут по-прежнему недоступны, но обход защиты *(сброс защиты цифровой подписи)* GRUB2 позволяет киберзлодею внедрить свой код в загрузчик, не вызывая подозрений *(если только пользователь вручную не отслеживает состояние загрузчика, или не придумает свой прочный произвольный-скрипт-код для grub.cfg).*
Алгоритм атаки. Злоумышленник
\* Загружает ПК с live usb. Любое изменение *(нарушителем)* файлов приведет к оповещению реального хозяина ПК о вторжении в загрузчик. Но простая переустановка GRUB2 с сохранением grub.cfg *(и последующей возможностью его редактирования)* позволит злоумышленнику редактировать любые файлы *(при таком раскладе, при загрузке GRUB2, оповещение реальному пользователю не последует. Статус тот же <0>)*
\* Монтирует незашифрованный раздел, сохраняет у себя "/mnt/boot/grub/grub.cfg".
\* Переустанавливает загрузчик *(выбрасывая «perskey» из образа core.img)*
```
grub-install --force --root-directory=/mnt /dev/sda6
```
\* Возвращает «grub.cfg» > "/mnt/boot/grub/grub.cfg", при необходимости его редактирует, например, добавляя свой модуль «keylogger.mod» в папку с модулями загрузчика, в «grub.cfg» > строчку «insmod keylogger». Или, например, если враг коварен, то после переустановки GRUB2 *(все подписи остаются на месте)* он собирает основной образ GRUB2, используя «grub-mkimage с опцией (-с).» Опция «-с» позволит загружать свой конфиг до загрузки основного «grub.cfg». Конфиг может состоять всего лишь из одной строчки: перенаправление на любой «modern.cfg», смешанный, например, с ~400 файлами *(модули+подписи)* в папке "/boot/grub/i386-pc". При этом нарушитель может вносить произвольный код и подгружать модули, не затрагивая "/boot/grub/grub.cfg", даже если пользователь применил «hashsum» к файлу и временно выводил его на экран.
Взламывать логин/пароль суперпользователя GRUB2 атакующему не потребуется, нужно будет просто скопировать строки *(отвечающие за аутентификацию)* "/boot/grub/grub.cfg" в свой «modern.cfg»
> set superusers=«root»
>
> password\_pbkdf2 root grub.pbkdf2.sha512.10000.DE10E42B01BB6FEEE46250FC5F9C3756894A8476A7F7661A9FFE9D6CC4D0A168898B98C34EBA210F46FC10985CE28277D0563F74E108FCE3ACBD52B26F8BA04D.27625A4D30E4F1044962D3DD1C2E493EF511C01366909767C3AF9A005E81F4BFC33372B9C041BE9BA904D7C6BB141DE48722ED17D2DF9C560170821F033BCFD8
>
>
И для хозяина ПК по-прежнему будет действовать проверка подлинности суперпользователя GRUB2.
Цепочная загрузка *(загрузчик загружает другой загрузчик)*, как писал выше, не имеет смысла *(она предназначена для другой цели)*. Из-за BIOS нельзя загружать зашифрованный загрузчик *(при цепной загрузке происходит перезапуск GRUB2 > зашифрованный GRUB2, ошибка!)*. Однако если все-таки воспользоваться идеей от цепочной загрузки, то можно быть уверенным, что загружается именно зашифрованный *(не модернизированный)* «grub.cfg» с зашифрованного раздела. И это тоже ложное чувство безопасности, потому что, всё, что указано в зашифрованном «grub.cfg» *(подгрузка модулей ) складывается с модулями, которые подгружаются из незашифрованного GRUB2.*
Если вы хотите это проверить, то выделите/зашифруйте еще один раздел sdaY, скопируйте на него GRUB2 *(операция grub-install на зашифрованный раздел невозможна)* и в «grub.cfg» *(незашифрованного конфига)* измените строки подобные этим
> menuentry 'GRUBx2' --class parrot --class gnu-linux --class gnu --class os $menuentry\_id\_option 'gnulinux-simple-382111a2-f993-403c-aa2e-292b5eac4780' {
>
> load\_video
>
> insmod gzio
>
> if [ x$grub\_platform = xxen ]; then insmod xzio; insmod lzopio; fi
>
> insmod part\_msdos
>
> insmod cryptodisk
>
> insmod luks
>
> insmod gcry\_twofish
>
> insmod gcry\_twofish
>
> insmod gcry\_sha512
>
> insmod ext2
>
> cryptomount -u 15c47d1c4bd34e5289df77bcf60ee838
>
> set root='cryptouuid/15c47d1c4bd34e5289df77bcf60ee838'
>
> normal /boot/grub/grub.cfg
>
> }
>
>
строки
\* insmod -загрузка необходимых модулей для работы с зашифрованным диском;
\* GRUBx2 -название выводимой строки в меню загрузки GRUB2;
\* cryptomount -u 15c47d1c4bd34e5289df77bcf60ee838 -см. fdisk -l (sda9);
\* set root -установка корня;
\* normal /boot/grub/grub.cfg -исполняемый файл конфигурации на зашифрованном разделе.
Уверенность в том, что загружается именно зашифрованный «grub.cfg» — это положительный отклик на ввод пароля/разблокировка «sdaY» при выборе строчки «GRUBx2» в меню GRUB.
При работе в CLI, чтобы не запутаться *(и проверить сработало ли переменное окружение «set root»),* создайте пустые файлы маркеры, например, в зашифрованном разделе "/shifr\_grub", в незашифрованном разделе "/noshifr\_grub". Проверка в CLI
```
cat /Tab-Tab
```
Как было отмечено выше, это не поможет от загрузки вредоносных модулей, если такие модули окажутся на вашем ПК. Например, кейлоггер, который сможет сохранять нажатия клавиш в файл и смешиваться с другими файлами в "/boot/grub/i386-pc", пока его не скачает атакующий с физическим доступом к ПК.
Самый простой способ проверить, что защита цифровой подписи активно работает *(не сброшена)*, и никто не вторгся в загрузчик, в CLI набираем команду
```
list_trusted
```
в ответ получаем слепок нашего «perskey», или ничего не получаем, если нас атаковали *(также необходимо проверить «set check\_signatures=enforce»)*.
Существенный минус такого шага, набивать команды вручную. Если добавить эту команду в «grub.cfg» и защитить цифровой подписью конфиг, то предварительный вывод слепка ключа на экран слишком короткий по таймингу, и можно не успеть разглядеть вывод cli, получив загрузку GRUB2.
Предъявлять претензии особо не к кому: разработчик в своей [документации](https://www.gnu.org/software/grub/manual/grub/grub.html#Using-digital-signatures) п.18.2 официально заявляет
> «Note that even with GRUB password protection, GRUB itself cannot prevent someone with physical access to the machine from altering that machine’s firmware (e.g., Coreboot or BIOS) configuration to cause the machine to boot from a different (attacker-controlled) device. GRUB is at best only one link in a secure boot chain».
GRUB2 — слишком перегружен функциями, которые могут дать чувство ложной безопасности, а его развитие уже опередило по функциональности ОС MS-DOS, а ведь это всего лишь загрузчик. Забавно, что GRUB2 — «завтра» может стать ОС, а загружаемые GNU/Linux виртуальными машинами для него.
Небольшой ролик, о том, как я сбросил защиту цифровой подписью GRUB2, и заявил о своем вторжении реальному пользователю *(напугал, а вместо того, что показано на ролике – можно написать не безобидный произвольный код/.mod)*.
#### Выводы:
1) Блочное системное шифрование для Windows — реализовать проще, а защита одним паролем удобнее, чем защита несколькими паролями при блочном системном шифровании GNU/Linux, справедливости ради: последнее автоматизировано.
2) Статью написал, как релевантное, подробное и профессиональное руководство по полнодисковому шифрованию *'VeraCrypt/LUKS on one home the machine'*, которое, на сегодняшний день лучшее в Рунете (IMHO). В руководстве ~ 66.6k знаков поэтому в нём не рассматривались некоторые интересные главы: о [криптографах](https://github.com/dlitz/pycrypto/issues/173), которые [исчезают](https://en.wikipedia.org/wiki/Talk:FreeOTFE#Anyone_know_if_the_author_is_still_alive?)/[держатся](https://diskcryptor.net/forum/index.php?topic=5347.msg13975#msg13975) в [тени](https://www.schneier.com/blog/archives/2014/05/truecrypt_wtf.html); о том, что в разных книжках GNU/Linux мало/не пишут о криптографии; о ст.51 конституции РФ; о [лицензировании](http://www.consultant.ru/document/cons_doc_LAW_128739/1aad6fe079cd2555c9c329d872dfca33764f738f/)/запрете [шифрования в РФ](http://www.consultant.ru/document/cons_doc_LAW_128739/5b53393f08d12d297d683284d87338c801ed859b/), о том для чего нужно шифровать «корень/boot». Руководство получилось и без того немалое, но подробное *(описывающая даже простые шаги)*, в свою очередь, это сэкономит вам кучу времени, когда вы займетесь «настоящим шифрованием».
3) Полнодисковое шифрование проводил на Windows 7 64; GNU/Linux Parrot 4x; GNU/Debian 9.0/9.5.
4) Реализовал успешную атаку на загрузчик GRUB2.
5) Tutorial создан, чтобы помочь всем ~~параноикам СНГ~~, где работа с шифрованием разрешена на законодательном уровне. И в первую очередь для тех, кто желает накатить полнодисковое шифрование не снося свои настроенные системы.
6) Переработал и обновил своё руководство, которое актуально в 2020 году.
[G] Полезная документация
-------------------------
1. [Руководство пользователя TrueCrypt](https://www.dropbox.com/s/tg2etzeptae73xa/TrueCrypt%20%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%86%D0%B8%D1%8F%20%D0%BF%D0%BE%D0%B4%20%D1%81%D0%B2%D0%BE%D0%B1%D0%BE%D0%B4%D0%BD%D0%BE%D0%B9%20%D0%BB%D0%B8%D1%86%D0%B5%D0%BD%D0%B7%D0%B8%D0%B5%D0%B9.pdf?dl=0) *(февраль 2012 RU)*
2. [Документация VeraCrypt](https://www.veracrypt.fr/en/Documentation.html)
3. /usr/share/doc/cryptsetup(-run) [локальный ресурс] *(официальная подробная документация по настройке шифрования GNU/Linux с помощью cryptsetup)*
4. [Официальный FAQ cryptsetup](https://gitlab.com/cryptsetup/cryptsetup/-/wikis/FrequentlyAskedQuestions) *(краткая документация по настройке шифрования GNU/Linux с помощью cryptsetup)*
5. [Шифрование устройства LUKS](https://wiki.archlinux.org/index.php/Dm-crypt/Device_encryption#Encryption_options_with_dm-crypt) *(archlinux-документация)*
6. [Подробное описание синтаксиса cryptsetup](https://jlk.fjfi.cvut.cz/arch/manpages/man/cryptsetup.8.en) *(страница руководства arch)*
7. [Подробное описание crypttab](https://jlk.fjfi.cvut.cz/arch/manpages/man/core/systemd/crypttab.5.en) *(страница руководства arch)*
8. [Официальная документация GRUB2](https://www.gnu.org/software/grub/manual/grub/grub.html).
Метки: VeraCrypt, полное шифрование диска, шифрование раздела, полнодисковое шифрование Linux, полное системное шифрование LUKS1/LUKS2.
**Пасхалка**

© Данное, славное руководство защищено авторским правом.
[ne555](https://habr.com/ru/users/ne555/) 2018-2020 | https://habr.com/ru/post/482696/ | null | ru | null |
# Security Week 2240: новая уязвимость zero-day в Microsoft Exchange
На прошлой неделе стало известно о кибератаке, в которой используется новая уязвимость в почтовом сервере Microsoft Exchange. Через два дня после [публикации](https://www.gteltsc.vn/blog/warning-new-attack-campaign-utilized-a-new-0day-rce-vulnerability-on-microsoft-exchange-server-12715.html) вьетнамской компании GTSC корпорация Microsoft [признала](https://msrc-blog.microsoft.com/2022/09/29/customer-guidance-for-reported-zero-day-vulnerabilities-in-microsoft-exchange-server/) наличие проблемы. По факту в Exchange присутствует две уязвимости нулевого дня, которые пока не закрыты. Уязвимость CVE-2022-41040 относится к классу Server-Side Request Forgery и позволяет авторизованному пользователю выполнять на сервере команды PowerShell.

Вторая уязвимость, CVE-2022-41082, обеспечивает выполнение произвольного кода при наличии доступа к PowerShell. Соответственно, их комбинация позволяет получить полный контроль над почтовым сервером. В реальной атаке, проанализированной GTSC, на сервере устанавливался бэкдор для дальнейшего анализа корпоративной сети и кражи данных. Атака очень похожа на набор уязвимостей ProxyShell, [обнаруженный](https://habr.com/ru/company/kaspersky/blog/546082/) весной 2021 года. В том случае также использовалась уязвимость типа SSRF с последующим выполнением произвольного кода. Но есть и важное отличие: атака ProxyShell полностью обходила систему авторизации. Для новой атаки сначала потребуется получить доступ к любой учетной записи в Microsoft Exchange.
**Источники информации:**
* Обзорная [статья](https://www.bleepingcomputer.com/news/security/new-microsoft-exchange-zero-days-actively-exploited-in-attacks/) на Bleeping Computer.
* Изначальная [публикация](https://www.gteltsc.vn/blog/warning-new-attack-campaign-utilized-a-new-0day-rce-vulnerability-on-microsoft-exchange-server-12715.html) на сайте вьетнамской компании GTSC.
* Обновляемый [отчет](https://msrc-blog.microsoft.com/2022/09/29/customer-guidance-for-reported-zero-day-vulnerabilities-in-microsoft-exchange-server/) на сайте Microsoft с рекомендациями.
* [Статья](https://doublepulsar.com/proxynotshell-the-story-of-the-claimed-zero-day-in-microsoft-exchange-5c63d963a9e9) специалиста по безопасности Кевина Бьюмона.
Кевин Бьюмон, бывший сотрудник Microsoft, в свое время активно освещавший драму вокруг ProxyShell, предложил для нового набора уязвимостей название ProxyNotShell. Его авторству также принадлежит «логотип», показанный выше. Сходство с ProxyShell было настолько очевидным, что поначалу Кевин предположил, что именно эту уязвимость снова используют в атаках. Но буквально через день Microsoft сообщила, что речь идет о новом наборе проблем в почтовом сервере — отсюда и новое название.
Организация GTSC обнаружила не-ProxyShell еще в начале августа 2022 года во время рутинного анализа корпоративной сети клиента на безопасность. Тогда же о проблеме сообщили в Microsoft, а данные о двух уязвимостях были внесены в базу инициативы Zero Day Initiative. По оценке GTSC, уровень опасности двух дыр в Exchange составляет соответственно 8,8 балла из 10 для SSRF-уязвимости и 6,3 для RCE через оболочку PowerShell. Патча для Exchange пока нет, но есть временное решение: запретить обращения к PowerShell вовсе — путем добавления правила в веб-сервер Microsoft IIS:
`“.*autodiscover\.json.*\@.*Powershell.*`
Как это обычно происходит с «горячими уязвимостями», первоначальное решение (вариант правила, блокирующего запросы к Powershell), предложенное GTSC, можно было легко обойти. А способ, предложенный в публикации Microsoft (см. выше), считается рабочим. В отличие от ProxyShell, для проведения успешной атаки с помощью ProxyNotShell требуется взломать учетную запись пользователя на почтовом сервере. Если успешно украсть данные для доступа к серверу, то становится достаточно просто получить максимальные привилегии. Новая атака вряд ли приведет к масштабной эпидемии, как это случилось с ProxyShell, но может стать популярным инструментом для таргетированных атак. Именно такую атаку наблюдали представители GTSC во Вьетнаме. Кстати, Кевин Бьюмон в ходе подготовки публикации о новой уязвимости обнаружил, что серверов без патча для старой атаки ProxyShell по-прежнему находится довольно много.
### Что еще произошло
Эксперты «Лаборатории Касперского» опубликовали [подробный отчет](https://securelist.ru/the-secrets-of-schneider-electrics-umas-protocol/105911/) об уязвимостях в протоколе Schneider Electric UMAS, который используется в промышленных устройствах компании. Еще одна [публикация](https://securelist.com/prilex-atm-pos-malware-evolution/107551/) описывает деятельность группировки Prilex, атакующей банкоматы и платежные терминалы в Бразилии.
Издание Ars Technica [рассказывает](https://arstechnica.com/information-technology/2022/09/how-3-hours-of-inaction-from-amazon-cost-cryptocurrency-holders-235000/), как временный перехват контроля над IP-адресами Amazon Web Services (так называемая атака BGP hijack) привел к краже значительных средств в криптовалюте.
Разработчики открытой платформы Matrix [выпустили](https://www.bleepingcomputer.com/news/security/matrix-install-security-update-to-fix-end-to-end-encryption-flaws/) патчи, закрывающие критическую уязвимость в протоколе шифрования данных. Уязвимость теоретически позволяла получить доступ к данным, передаваемым с помощью шифрования end-to-end. | https://habr.com/ru/post/691270/ | null | ru | null |
# Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть III. Настройка puppet-db с помощью Puppet
→ [Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть I. Подготовительная](https://habrahabr.ru/post/316400/)
→ [Развертывание OpenSource Puppet 4 с несколькими Puppet masters. Часть II. Настройка Puppet Masters](https://habrahabr.ru/post/316482/)
Настройка puppet-db с помощью Puppet
====================================
Зададим настройки для ноды puppet-db в репозитории puppet-environments.git.
### В случае стандартного размещения datadir для postgresql
В репозитории puppet-environments.git в файл manifests/nodes.pp добавим настройки puppet-db:
```
node default {
}
node puppet-db {
class { 'puppetdb':
listen_addresses => '0.0.0.0',
}
}
```
### В случае нестандартного размещения datadir для postgresql
Хочу выразить благодарность Кену Барберу (Ken Barber) [за помощь в настройке](https://github.com/puppetlabs/puppetlabs-puppetdb/pull/245). Изначально я клонировал репозиторий модуля puppet-db, вносил в него изменения в части размещения данных postgresql, и устанавливал уже измененный модуль. Он подсказал, как сделать лучше.
```
node default {
}
node 'puppet-db.example.com' {
class { 'puppetdb':
listen_address => '0.0.0.0',
manage_dbserver => false,
}
class { '::postgresql::globals':
manage_package_repo => true,
version => '9.4',
}
class { '::postgresql::server':
datadir => '/media/data/postgresql/9.4/main',
}
postgresql::server::extension { 'pg_trgm':
database => 'puppetdb',
}
}
```
Не забудем создать каталог /media/data/postgresql/9.4/main если планируется использовать нестандартное размещение БД:
```
aspetrenko@puppet-db:~$ sudo mkdir -p /media/data/postgresql/9.4
```
### Фиксация изменений в репозитории
Зафиксируем изменения в репозитории, чтобы они попали на серверы puppet. Для любого размещения postgresql datadir выполним:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git add manifests/nodes.pp
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git commit manifests/nodes.pp -m "Add puppet-db config to nodes.pp"
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git push -u origin production
```
Применение настроек puppet-db
-----------------------------
Не забудьте задать настройки puppetmaster в /etc/puppetlabs/puppet/puppet.conf на сервере puppet-db.
Отправим запрос на добавление сертификата для сервера puppet-db на puppet-master01:
```
aspetrenko@puppet-db:~$ sudo -i puppet agent --enable
aspetrenko@puppet-db:~$ sudo -i puppet agent --test --waitforcert 60
```
Подтвердим сертификат на puppet-master01:
```
aspetrenko@puppet-master01:/etc/puppetlabs/code/environments/production$ sudo -i puppet cert list
"puppet-db.example.com" (SHA256) 9C:98:4C:D8:A9:B6:9D:27:5A:9D:A8:5F:15:E2:D8:99:6F:CF:0E:34:5B:B5:5C:BC:23:0D:6E:E0:84:BA:3F:05
aspetrenko@puppet-master01:/etc/puppetlabs/code/environments/production$ sudo -i puppet cert --sign puppet-db.example.com
Signing Certificate Request for:
"puppet-db.example.com" (SHA256) 9C:98:4C:D8:A9:B6:9D:27:5A:9D:A8:5F:15:E2:D8:99:6F:CF:0E:34:5B:B5:5C:BC:23:0D:6E:E0:84:BA:3F:05
```
После чего настройки сделанные в nodes.pp будут автоматически применены для puppet-db: будет установлен и настроен postgresql сервер и служба puppet-db.
Подключение puppet-master01 и puppet-master02 к puppet-db
---------------------------------------------------------
Добавим в файл manifests/nodes.pp следующие строки:
```
node 'puppet-master01.example.com' {
class { 'puppetdb::master::config':
puppetdb_server => 'puppet-db.example.com',
}
}
node 'puppet-master02.example.com' {
class { 'puppetdb::master::config':
puppetdb_server => 'puppet-db.example.com',
}
}
```
Или такие, если требуется настройка ntp (без использования hiera):
```
node 'puppet-master01.example.com' {
class {'::ntp':
servers => [ 'time.example.com', '0.pool.ntp.org' ],
}
class { 'puppetdb::master::config':
puppetdb_server => 'puppet-db.example.com',
}
}
node 'puppet-master02.example.com' {
class {'::ntp':
servers => [ 'time.example.com', '0.pool.ntp.org' ],
}
class { 'puppetdb::master::config':
puppetdb_server => 'puppet-db.example.com',
}
}
```
Зафиксируем изменения в репозитории:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git commit manifests/nodes.pp -m "Setup puppet-db server for puppet-master01 and puppet-master02"
```
И отправим изменения на сервер gitolite3:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git push -u origin production
```
Применим изменения на серверах puppet-master01 и puppet-master02:
```
sudo -i puppet agent --test
```
Проверим, применились ли настройки подключения к puppet-db на puppet-master01 и puppet-master02:
```
cat /etc/puppetlabs/puppet/puppetdb.conf
[main]
server_urls = https://puppet-db.example.com:8081/
soft_write_failure = false
```
Проверим, применились ли настройки ntp на puppet-master01 и puppet-master02:
```
cat /etc/ntp.conf | grep server
# Set up servers for ntpd with next options:
# server - IP address or DNS name of upstream NTP server
# prefer - select preferrable server
server time.example.com iburst
server 0.pool.ntp.org iburst
```
Настройка Hiera
===============
Для упрощения отладки hiera сделаем символическую ссылку на конфигурационный файл hiera на puppet-master01 и puppet-master02:
```
sudo ln -s /etc/puppetlabs/puppet/hiera.yaml /etc/hiera.yaml
```
Создадим файл manifests/site.pp, и подключим hiera с помощью hiera\_include('classes'). Содержимое site.pp:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ cat manifests/site.pp
hiera_include('classes')
```
На серверах puppet-master01 и puppet-master02 в файле /etc/puppetlabs/puppet/hiera.yaml по-умолчанию заданы настройки хиерархии:
```
:hierarchy:
- "nodes/%{::trusted.certname}"
- common
```
Создадим конфигурацию по умолчанию в файле common.yaml, которая будет применяться для всех нод, и зададим настройки ntp-клиента:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ cat hieradata/common.yaml
---
classes:
- ntp
ntp::servers:
- time.example.com
# - 1.pool.ntp.org
# - 2.pool.ntp.org
# - 3.pool.ntp.org
```
Создадим каталог для хранения конфигураций отдельных нод в hiera:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ mkdir hieradata/nodes
```
Имя конфигурационных файлов будет соответствовать именам сертификатов нод (%{::trusted.certname}).
Альтернативная реализация с помощью hiera, тех же настроек, что были заданы выше в manifests/nodes.pp
-----------------------------------------------------------------------------------------------------
### Конфигурация puppet-master
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ cat hieradata/nodes/puppet-master01.example.com.yaml
---
classes:
- puppetdb::master::config
puppetdb::master::config::puppetdb_server: 'puppet-db.example.com'
```
Аналогично в файле hieradata/nodes/puppet-master02.example.com.
### Конфигурация для puppet-db
#### Стандартное размещения datadir для postgresql
В случае стандартного размещения datadir для postgresql все просто:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ cat hieradata/nodes/puppet-db.example.com.yaml
---
classes:
- puppetdb
puppetdb::listen_address: '0.0.0.0'
```
#### Нестандартное размещения datadir для postgresql
А вот для этого случая простого решения не нашлось. Не знаю насколько критично наличие расширения pg\_trgm в postgresql для функционирования puppet-db. На всякий случай решил не убирать это расширение.
Дело в том, что в hiera нельзя просто так взять и объявить ресурсы (Defining resource types), как в Puppet language:
```
postgresql::server::extension { 'pg_trgm':
database => 'puppetdb',
}
```
Я перепробовал несколько не слишком удачных вариантов добавления ресурсов с помощью hiera:
→ [serverfault.com/questions/549720/hiera-include-equivalent-for-resource-types/549807](http://serverfault.com/questions/549720/hiera-include-equivalent-for-resource-types/549807)
→ [graviline.ru/index/show/41130](http://graviline.ru/index/show/41130)
Пока не нашел модуль [tedivm-hieratic](https://forge.puppet.com/tedivm/hieratic). Создатель модуля заявляет поддержку Puppet 3.x, но и в Puppet 4 все заработало. В Puppetfile нужно прописать еще один модуль:
```
mod 'tedivm-hieratic' # Hieratic allows Puppet Resources to be created directly in Hiera.
```
Включить hieratic в файле manifests/site.pp:
```
include hieratic
```
И тогда можно будет задать конфиг для нестандартного размещения datadir для postgresql hieradata/nodes/puppet-db.yaml:
```
---
classes:
- puppetdb
- postgresql::globals
- postgresql::server
puppetdb::listen_address: '0.0.0.0'
puppetdb::manage_dbserver: false
postgresql::globals::manage_package_repo: true
postgresql::globals::version: '9.4'
postgresql::server::datadir: '/media/data/postgresql/9.4/main'
postgresql_server_extension:
pg_trgm:
name: 'pg_trgm'
database: 'puppetdb'
```
### Применение конфигурации
Если настроили ноды через hiera, нужно не забыть удалить настройки нод из manifets/nodes.pp.
Фиксация изменений:
```
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git add --all
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git commit -a -m "Hiera config"
aspetrenko@aspetrenko-pc:~/sgl-git/puppet-environments$ git push -u origin production
```
Применение настроек на puppet-db:
```
aspetrenko@puppet-db:~$ sudo -i puppet agent --test
```
В результате получим инфраструктуру Puppet, которую можно расширять в дальнейшем, добавляя дополнительные ноды puppet-master по мере возрастания нагрузки на имеющиеся серверы. Теперь можно приступать к написанию манифестов для управляемых нод. Но об этом как-нибудь в другой раз. | https://habr.com/ru/post/316486/ | null | ru | null |
# Лучшие подходы переноса кода MATLAB в фиксированную точку
При конвертации проекта из плавающей точки в фиксированную точку инженеры должны определить оптимальные типы данных в фиксированной точке. Эти типы данных должны удовлетворять ограничениям встраиваемой аппаратуры, при этом удовлетворяя системным требованиям по точности вычислений. Fixed-Point Designer помогает разрабатывать алгоритмы в фиксированной точке и конвертировать алгоритмы из плавающей точки в фиксированную точку, автоматически предлагая типы данных и атрибуты арифметики в фиксированной точке. При этом предоставляется возможность сравнения результатов симуляции в фиксированной точке с точностью до бита с эталонными результатами в плавающей точке.
В этой статье приводятся оптимальные приемы подготовки кода MATLAB для конвертации, непосредственной конвертации кода MATLAB в фиксированную точку и оптимизации алгоритмов для эффективности и производительности. Если вы разрабатываете алгоритмы в фиксированной точке в MATLAB для последующего ручного написания кода или конвертируете в фиксированную точку для автоматической генерации кода, то описанные приемы помогут вам превратить ваш код MATLAB общего назначения в эффективный код в фиксированной точке.
**Подготовка кода к переводу в фиксированную точку**
Есть три шага, которые следует предпринять для обеспечения плавного процесса конвертации:
1. Отделить основной алгоритм от остального кода.
2. Подготовить код для инструментирования и ускорения.
3. Проверить используемые функции на поддержку фиксированной точки.
**Отделение основного алгоритма от остального кода MATLAB**
Обычно алгоритм сопровождается кодом, который подготавливает входные данные и кодом, который создает графики для верификации результатов. Поскольку в фиксированную точку нужно сконвертировать только ядро алгоритма, более эффективно будет структурировать код таким образом, чтобы отдельный тестовый файл создавал входы, вызывал основной алгоритм и строил графики результатов. При этом основной алгоритм также будет находиться в отдельном файле или файлах (Таблица 1).
| Оригинальный код | Модифицированный код |
| --- | --- |
|
```
% ТЕСТОВЫЕ ВХОДЫ
x = randn(100,1);
% АЛГОРИТМ
y = zeros(size(x));
y(1) = x(1);
for n=2:length(x)
y(n) = y(n-1) + x(n);
end
% ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ
yExpected = cumsum(x);
plot(y-yExpected)
title('Ошибка')
```
| Тестовый файл.
```
% ТЕСТОВЫЕ ВХОДЫ
x = randn(100,1);
% АЛГОРИТМ
y = cumulative_sum(x);
% ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ
yExpected = cumsum(x);
plot(y-yExpected)
title('Ошибка')
```
Файл с алгоритмом.
```
function y = cumulative_sum(x)
y = zeros(size(x));
y(1) = x(1);
for n=2:length(x)
y(n) = y(n-1) + x(n);
end
end
```
|
Таблица 1. Код до и после отделения основного алгоритма от тестовой обвязки.
**Подготовка алгоритмического кода к инструментированию и ускорению**
Инструментирование и ускорение позволяют упростить процесс конвертации. Fixed-Point Designer используется для инструментирования кода и записи минимальных и максимальных значений всех именованных и промежуточных переменных. Этот инструмент может использовать записанные значения, чтобы предложить типы данных для использования в коде в фиксированной точке.
С использованием Fixed-Point Designer можно также ускорять алгоритмы в фиксированной точке путем создания MEX файла, и ускорять симуляции, требуемые для верификации реализации в фиксированной точке относительно оригинальной версии.
Инструментирование и ускорение полагаются на технологию генерации кода, поэтому прежде чем их использовать, требуется подготовить алгоритм к генерации кода – даже если вы не планируете использовать MATLAB Coder или HDL Coder для генерации кода C или кода HDL.
Вначале требуется определить функции или конструкции в вашем коде MATLAB, не поддерживаемые для генерации кода (см. [Поддержка языка](http://www.mathworks.com/help/fixedpoint/language-and-functions-supported-for-code-acceleration.html) для получения списка поддерживаемых функций и объектов).
Есть два способа для автоматизации этого шага:
* Добавить директиву
```
%#codegen
```
в начале файла MATLAB, содержащего ядро вашего алгоритма. Эта директива сообщает [анализатору кода](http://www.mathworks.com/help/fixedpoint/ug/using-the-matlab-code-analyzer-to-check-code-interactively-at-design-time.html), что следует отмечать функции и конструкции, которые не содержатся в подмножестве языка MATLAB, поддерживаемого для генерации кода.
* Использовать [инструмент проверки готовности кода](http://www.mathworks.com/help/fixedpoint/ug/check-code-using-the-code-generation-readiness-tool.html) для создания отчета, который выявляет обращения к функциям и использование типов данных, не поддерживаемых для генерации кода.
После подготовки алгоритма к генерации кода, можно использовать Fixed-Point Designer для инструментирования и ускорения кода. Используйте
```
buildInstrumentedMex
```
для включения инструментирования с целью записи минимальных и максимальных значений всех именованных и промежуточных переменных. Также используйте
```
showInstrumentationResults
```
для просмотра отчета о генерации кода с предложенными типами данных в фиксированной точке. Запустите
```
fiaccel
```
для трансляции вашего алгоритма MATLAB в MEX файл и ускорения симуляций в фиксированной точке.
**Проверка поддержки фиксированной точки функциями, используемыми в алгоритмическом коде**
При выявлении функции, не поддерживаемой для генерации кода, у вас есть три возможности:
1. Заменить функцию на эквивалентную функцию в фиксированной точке.
2. Написать собственную эквивалентную функцию.
3. Изолировать неподдерживаемую функцию используя приведение типа к double на входе функции, и обратное приведение типа к фиксированной точке на выходе.
Затем можно продолжить конвертацию кода в фиксированную точку, и вернуться к неподдерживаемой функции, когда у вас будет подходящая замена (Таблица 2).
| Оригинальный код | Модифицированный код |
| --- | --- |
|
```
y = 1/exp(x);
```
|
```
y = 1/exp(double(x));
```
|
Таблица 2. Код до и после изоляции операции в плавающей точке при помощи приведения типа (обратное приведение типа к фиксированной точке на выходе не показано).
**Управление типами данных и ограничение роста разрядности**
В реализации с фиксированной точкой переменные в фиксированной точке должны оставаться в арифметике с ограниченной разрядностью, и не должны произвольно превращаться в плавающую точку. Также важно предотвратить [рост разрядности](http://www.mathworks.com/help/fixedpoint/gs/fixed-point-arithmetic_bt25flf-1.html#bt25flf-3).
Например, рассмотрим следующий код:
```
y = y + x(n)
```
Это выражение перезаписывает y значением
```
y + x(n)
```
Когда вы используете типы данных в фиксированной точке в коде (для y и x), то тип данных y может поменяться после перезаписи, потенциально приводя к росту разрядности.
Для сохранения типа данных y используйте синтаксис
```
(:) =
```
(Таблица 3). Такой синтаксис, известный как индексное присваивание, заставляет MATLAB сохранять существующий тип данных и размер массива перезаписываемой переменной. Выражение
```
y(:) = y + x(n)
```
приведет выражение справа к оригинальному типу данных y и предотвратит рост разрядности.
| Оригинальный код | Модифицированный код |
| --- | --- |
|
```
y = 0;
for n=1:length(x)
y = y + x(n);
end
```
|
```
y = 0;
for n=1:length(x)
y(:) = y + x(n);
end
```
|
Таблица 3. Код до и после использования индексного присваивания для предотвращения роста разрядности.
**Создание таблицы с типами для разделения определений типов данных и алгоритмического кода**
Разделение определений типов данных и алгоритмического кода упрощает сравнение реализаций в фиксированной точке и перенос алгоритма на другое целевое оборудование.
Для применения этой лучшей практики надо сделать следующее:
1. Использовать
```
cast(x,'like',y)
```
или
```
zeros(m,n,'like',y)
```
для приведения типа переменной к желаемому типы данных при первом определении переменной.
2. Создать таблицу определений типов, начиная с оригинальных типов данных, используемых в коде – обычно, в плавающей точке двойной точности – типа данных по умолчанию в MATLAB (Таблица 4а).
3. До конвертации в фиксированную точку, добавить тип данных single в таблицу типов для поиска несоответствий и других проблем (Таблица 4б).
4. Осуществить верификацию привязки, запустив код, привязанный к каждой таблице, с различными типами данных и сравнив результаты.
| Оригинальный код | Модифицированный код |
| --- | --- |
|
```
% Алгоритм
n = 128;
y = zeros(size(x));
```
|
```
% Алгоритм
T = mytypes('double');
n = cast(128,'like',T.n);
y = zeros(size(x),'like',T.y);
% Таблица типов
function T = mytypes(dt)
switch(dt)
case 'double'
T.n = double([]);
T.y = double([]);
end
end
```
|
Таблица 4a. Код до и после создания таблицы типов данных для отделения алгоритмического кода от определений типов.
| Оригинальный код | Модифицированный код |
| --- | --- |
|
```
% Таблица типов
function T = mytypes(dt)
switch(dt)
case 'double'
T.n = double([]);
T.y = double([]);
end
end
```
|
```
% Таблица типов
function T = mytypes(dt)
switch(dt)
case 'double'
T.n = double([]);
T.y = double([]);
case 'single'
T.n = single([]);
T.y = single([]);
end
end
```
|
Таблица 4б. Код до и после добавления типа данных единичной точности к таблице типов.
**Добавление типов данных в фиксированной точке в таблицу типов**
После создания таблицы с определениями типов данных, вы можете добавить типы данных в фиксированной точке на основании ваших целей конвертации в фиксированную точку. Например, если вы планируете реализовать алгоритм на языке C, размер слова типов данных в фиксированной точке будет ограничен числами, кратными 16. С другой стороны, если вы планируете реализовывать в HDL, размер слова не ограничен.
Чтобы получить набор предложенных типов данных для вашего кода, используйте команды Fixed-Point Designer
```
buildInstrumentedMex
```
и
```
showInstrumentationResults
```
(Таблица 5). Вам потребуется набор тестовых векторов, который задействует полный диапазон типов – поскольку типы, предложенные Fixed-Point Designer, хороши настолько, насколько хороши тестовые воздействия. Продолжительная симуляция с широким набором ожидаемых входных данных приведет к лучшим предложенным типам данных. Выберите первоначальный набор данных в фиксированной точке из предложенных в отчете по генерации кода (Рисунок 1).

Рисунок 1. Отчет по генерации кода, созданный showInstrumentationResults с предложенными типами данных для переменных в алгоритме фильтрации.
Затем вы можете подстроить предложенные типы при необходимости (Таблицы 5 и 6).
| Код алгоритма | Тестовый файл |
| --- | --- |
|
```
function [y,z] = myfilter(b,x,z)
y = zeros(size(x));
for n=1:length(x)
z(:) = [x(n); z(1:end-1)];
y(n) = b * z;
end
end
```
|
```
% Тестовые входы
b = fir1(11,0.25);
t = linspace(0,10*pi,256)';
x = sin((pi/16)*t.^2); % Линейный импульсный сигнал
z = zeros(size(b'));
% Построение
buildInstrumentedMex myfilter ...
-args {b,x,z} -histogram
% Запуск
[y,z] = myfilter_mex(b,x,z);
% Отображение
showInstrumentationResults myfilter_mex ...
-defaultDT numerictype(1,16) -proposeFL
```
|
Таблица 5. Алгоритм фильтрации и тестовый скрипт для инструментирования и выполнения кода и отображения предложенных типов данных в фиксированной точке для переменных.
| Код алгоритма | Тестовый файл | Таблица типов |
| --- | --- | --- |
|
```
function [y,z] = myfilter(b,x,z,T)
y = zeros(size(x),'like',T.y);
for n=1:length(x)
z(:) = [x(n); z(1:end-1)];
y(n) = b * z;
end
end
```
|
```
% Тестовые входы
b = fir1(11,0.25);
t = linspace(0,10*pi,256)';
x = sin((pi/16)*t.^2); % Линейный импульсный сигнал
% Приведение типов входов
T = mytypes('fixed16');
b = cast(b,'like',T.b);
x = cast(x,'like',T.x);
z = zeros(size(b'),'like',T.x);
% Запуск
[y,z] = myfilter(b,x,z,T);
```
|
```
function T = mytypes(dt)
switch dt
case 'double'
T.b = double([]);
T.x = double([]);
T.y = double([]);
case 'fixed16'
T.b = fi([],true,16,15);
T.x = fi([],true,16,15);
T.y = fi([],true,16,14);
end
end
```
|
Таблица 6. Тестовый скрипт и алгоритм фильтрации из Таблицы 4 с типами данных в фиксированной точке.
Запустите ваш алгоритм с новыми типами данных в фиксированной точке и сравните выход с результатами эталонного алгоритма в плавающей точке.
**Оптимизация типов данных**
Выбрали ли вы ваши собственные типы в фиксированной точке или использовали предложенные Fixed-Point Designer, всегда ищите возможности по оптимизации размеров слова, размеров дробной части, знаковости и, возможно, даже режимов арифметики ([fimath](http://www.mathworks.com/help/fixedpoint/ref/fimath.html)). Это можно сделать с использованием разрядных чисел двойной точности (scaled doubles), рассматривая гистограмму значений переменной или путем тестирования различных типов данных из вашей таблицы типов.
**Использование Scaled Doubles для выявления потенциальных переполнений**
[Scaled doubles](http://www.mathworks.com/help/fixedpoint/ug/fixed-point-numbers_bt3p32j-1.html#br4g2lj-2) являются гибридами чисел в плавающей точке и фиксированной точке. Fixed-Point Designer хранит scaled doubles в виде чисел двойной точности, но сохраняет информацию о разрядности, знаке и длине слова. Для использования scaled doubles требуется установить свойство перезаписи типа данных (data type override, DTO) (Таблица 7).
| Установка DTO | Пример |
| --- | --- |
| DTO установлен локально используя
```
numerictype
```
свойство 'DataType' |
```
>> T.a = fi([], 1, 16, 13, 'DataType', 'ScaledDouble');
>> a = cast(pi, 'like', T.a)
a =
3.1416
DataTypeMode: Scaled double: binary point scaling
Signedness: Signed
WordLength: 16
FractionLength: 13
```
|
| DTO установлен глобально используя
```
fipref
```
свойство 'DataTypeOverride' |
```
>> fipref('DataTypeOverride', 'ScaledDoubles');
>> T.a = fi([], 1, 16, 13);
>> a = cast(pi, 'like', T.a)
a =
3.1416
DataTypeMode: Scaled double: binary point scaling
Signedness: Signed
WordLength: 16
FractionLength: 13
```
|
Таблица 7. Методы установки свойства перезаписи типов данных – локально и глобально.
Не забудьте сбросить глобальный DTO, если в нем больше нет необходимости, при помощи команды
```
reset(fipref)
```
Используйте buildInstrumentedMex для запуска вашего кода и showInstrumentationResults для просмотра результатов. В отчете по генерации кода значения, которые бы переполнились, подсвечены красным цветом (Рисунок 2).
Рисунок 2. Отчет по генерации кода, показывающий переполнения при использовании типа Scaled Doubles (слева) и иконка гистограммы (справа).
**Проверка распределения значений переменной**
Вы можете использовать гистограмму для выявления типов данных со значениями, которые находятся в допустимом диапазоне, вне диапазона или ниже разрешения (точности). Щелкнув по иконке гистограммы, можно запустить [NumericTypeScope](http://www.mathworks.com/help/fixedpoint/ref/numerictypescope.html) и увидеть распределение значений, наблюдаемых во время симуляции для выбранной переменной (Рисунок 3).

Рисунок 3. Гистограмма, показывающая распределение значений переменной, которая переполнилась (“Outside range”), показанное красным цветом.
**Тестирование различных типов данных из таблицы типов**
Вы можете добавлять собственные вариации типов данных в фиксированной точке в таблицу типов (Таблица 8).
| Код алгоритма | Тестовый файл | Таблица типов |
| --- | --- | --- |
|
```
function [y,z] = myfilter(b,x,z,T)
y = zeros(size(x),'like',T.y);
for n=1:length(x)
z(:) = [x(n); z(1:end-1)];
y(n) = b * z;
end
end
```
|
```
function mytest
% Тестовые входы
b = fir1(11,0.25);
t = linspace(0,10*pi,256)';
x = sin((pi/16)*t.^2); % Линейный импульсный сигнал
% Запуск
y0 = entrypoint('double',b,x);
y8 = entrypoint('fixed8',b,x);
y16 = entrypoint('fixed16',b,x);
% Графики
subplot(3,1,1);plot(t,x,'c',t,y0,'k');
legend('Вход','Эталонный выход')
title('Эталонный запуск')
subplot(3,2,3);plot(t,y8,'k');
title('8-бит фикс. точка: Выход')
subplot(3,2,4);plot(t,y0-double(y8),'r');
title('8-бит фикс. точка: Ошибка')
subplot(3,2,5);plot(t,y16,'k');
title('16-бит фикс. точка: Выход')
xlabel('Время (с)')
subplot(3,2,6);plot(t,y0-double(y16),'r');
title('16-бит фикс. точка: Ошибка')
xlabel('Время (с)')
end
function [y,z] = entrypoint(dt,b,x)
T = mytypes(dt);
b = cast(b,'like',T.b);
x = cast(x,'like',T.x);
z = zeros(size(b'),'like',T.x);
[y,z] = myfilter(b,x,z,T);
end
```
|
```
function T = mytypes(dt)
switch dt
case 'double'
T.b = double([]);
T.x = double([]);
T.y = double([]);
case 'fixed8'
T.b = fi([],true,8,7);
T.x = fi([],true,8,7);
T.y = fi([],true,8,6);
case 'fixed16'
T.b = fi([],true,16,15);
T.x = fi([],true,16,15);
T.y = fi([],true,16,14);
end
end
```
|
Таблица 8. Тестовый скрипт для изучения эффектов использования различных типов данных в фиксированной точке из таблицы типов для функции фильтрации.
Сравнение результатов разных итераций для верификации точности алгоритма после каждого изменения (Рисунок 4).

Рисунок 4. Графики результатов тестового скрипта из Таблицы 8, показывающие выход и ошибку после конвертации в 8-битные и 16-битные типы данных в фиксированной точке.
**Оптимизация алгоритма**
Существуют три наиболее распространенных способа оптимизации вашего алгоритма для улучшения производительности и генерации более эффективного кода C.
Вы можете:
* Использовать свойства fimath для улучшения эффективности сгенерированного кода
* Заменять встроенные функции более эффективными реализациями в фиксированной точке
* Реализовывать операции деления иными методами
**Использование свойств fimath для улучшения эффективности сгенерированного кода**
При использовании настроек fimath по умолчанию, может генерироваться дополнительный код для реализации насыщения при переполнении, округления и арифметики с полной точностью (Таблица 9а).
| Код MATLAB | Сгенерированный код C |
| --- | --- |
|
```
Компилируемый код:
function y = adder(a,b)
y = a + b;
end
С типами, заданными с настройками
fimath по умолчанию:
T.a = fi([],1,16,0);
T.b = fi([],1,16,0);
a = cast(0,'like',T.a);
b = cast(0,'like',T.b);
```
|
```
int adder(short a, short b)
{
int y;
int i0;
int i1;
int i2;
int i3;
i0 = a;
i1 = b;
if ((i0 & 65536) != 0) {
i2 = i0 | -65536;
} else {
i2 = i0 & 65535;
}
if ((i1 & 65536) != 0) {
i3 = i1 | -65536;
} else {
i3 = i1 & 65535;
}
i0 = i2 + i3;
if ((i0 & 65536) != 0) {
y = i0 | -65536;
} else {
y = i0 & 65535;
}
return y;
}
```
|
Таблица 9а. Оригинальный код MATLAB и код C, сгенерированный с настройками fimath по умолчанию.
Чтобы сгенерированный код был более эффективным, требуется выбрать такие настройки арифметики с фиксированной точкой, которые подходят типам вашего процессора. Используйте свойства fimath для описания арифметики, способов округления и действий при переполнении, чтобы задать правила осуществления арифметических операций с вашими объектами fi (Таблица 9б).
| Код MATLAB | Сгенерированный код C |
| --- | --- |
|
```
Компилируемый код:
function y = adder(a,b)
y = a + b;
end
С типами, заданными с настройками
fimath по умолчанию:
T.a = fi([],1,16,0);
T.b = fi([],1,16,0);
a = cast(0,'like',T.a);
b = cast(0,'like',T.b);
```
|
```
int adder(short a, short b)
{
return a + b;
}
```
|
Таблица 9б. Оригинальный код MATLAB и код C, сгенерированный с настройками fimath, подходящими к типам процессора.
**Замена встроенных функций реализациями в фиксированной точке**
Некоторые функции MATLAB могут быть заменены для получения более эффективной реализации в фиксированной точке. Например, можно заменить встроенную функцию интерполяционной таблицей или реализацией CORDIC, которой требуются только итеративные операции сдвига и суммирования.
**Реализация операций деления другими способами**
Операции деления часто не поддерживаются полностью со стороны аппаратуры, и могут привести к медленным вычислениями. Когда в вашем алгоритме требуется операция деления, рассмотрите возможность замены её на более быструю альтернативу. Если знаменатель является степенью двойки, используйте битовый сдвиг; например, используйте bitsra(x,3) вместо x/8. Если знаменатель является константой, умножьте на обратную величину; например, используйте x\*0.2 вместо x/5.
**Что дальше?**
После конвертации вашего кода в плавающей точке в фиксированную точку с применением описанных лучших подходов с использованием Fixed-Point Designer, потратьте время на тщательное тестирование реализации в фиксированной точке с использованием реалистичных тестовых входов и сравните результаты симуляции с точностью до бита с вашим эталоном в плавающей точке. | https://habr.com/ru/post/255649/ | null | ru | null |
# Erlang. Рекомендации к оформлению кода
Не так давно, в команду пришлось приглашать нового программиста и знакомить его с Erlang. Для ускорения процесса обучения я решил перевести уже давно лежавший у меня материал [Erlang Programming Rules and Conventions](http://www.erlang.se/doc/programming_rules.shtml#HDR42). Чем в принципе и хочу поделиться с хабровчанами. Надеюсь что он будет полезен тем, кто собирается изучать или уже использует этот замечательный язык. Сразу скажу, что перевод вольный, так что не критикуйте сильно.
#### 1. Цели
В этой статье перечислены некоторые аспекты, которые должны быть учтены при разработке ПО с использованием Erlang.
##### 2. Структура и терминология Erlang
Все подсистемы Erlang разбиты на модули. модули в свою очередь состоят из функций и атрибутов.
Функции могут быть как внутренними, так и экспортированными для применения в сторонних модулях.
Атрибуты начинается с '-' и помещаются в начало модуля.
Все работы в архитектуре Erlang осуществляются потоками. Поток в свою очередь — это набор инструкций, который может использовать вызовы функций различных модулей. Потоки могут взаимодействовать между собой посредством посылки сообщений. Также, при получении, они могут определять какие сообщения необходимо обработать в первую очередь. Остальные же сообщения остаются в очереди до тех пор пока в них
не возникнет необходимость.
Потоки могут следить за работой друг друга посредством связывания (команда *link*). Когда поток заканчивает свое выполнение или падает автоматически посылается сигнал ко всем связанным потокам.
Реакцией по-умолчанию на этот сигнал для потока является немедленное прекращение выполнения операция.
Но это поведение может быть изменено установкой флага *trap\_exit*, при котором сигналы преобразуются в сообщения и могут быть обработаны программой.
Чистые функции — это функции значение которых зависит только от входных данных и не зависит от контекста вызова. Этим поведением они похожи на обычные математические. О тех же, которые не являются чистыми говорят, что это функции с побочными эффектами.
Побочный эффект обычно проявляется если функция:
* Отправляет сообщения
* Принимает сообщения
* Вызывает *exit*
* вызывает *BIF* который меняет окружение потока (такие как *get/1*, *put/2*, *erase/1*, *process\_flag/2*)
#### 3 Принципы проектирования
##### 3.1 Экспортируйте как можно меньше функций из модуля
Модули являются базовой структурной единицей в Erlang. Они могут содержать огромное количество функций, но только те, что включены в список экспорта будут доступны сторонним модулям.
Сложность модуля напрямую зависит от количества экспортируемых функций. Согласитесь, ведь легче разобраться с модулем который экспортирует пару функций, чем тот, который экспортирует дюжину.
Ведь пользователю требуется разобраться только теми, что экспортированны.
Кроме того, тому, кто сопровождает код модуля можно не опасаясь менять внутренние функции, ведь интерфейс обращения к модулю остается неизменным.
##### 3.2 Пытайтесь уменьшить зависимости между модулями
Модуль, который обращается ко множеству других, намного труднее поддерживать, потому что, если меняется
интерфейс, то необходимо менять код везде, где использовался этот модуль.
Запомните, что в идеале вызовы модулей должны представлять собой дерево а не граф с циклами. (от себя. Для этого в инструменте для рефакторинга [Wrangler](https://github.com/RefactoringTools/wrangler) есть удобный механизм, основанный на GraphViz, который может отрисовать граф вызова функций)
В итоге код вызова должен быть представлен примерно так:

А не:
##### 3.3 Помещайте в библиотеки только часто используемый код.
В библиотеке (модуле) должен быть набор только связанных функций.
Задача разработчика состоит в том, чтобы создаваемые библиотеки содержали функции одного и того же типа.
Таким образом к примеру библиотека *lists*, которая содержит код по работе со списками — пример хорошей архитектуры, а *lists\_and\_method*, которая содержит как код работы со списками, так и по математическим алгоритмам — плохой.
Лучше всего, когда все функции в библиотеке не содержат побочных эффектов. Тогда ее можно с легкостью использовать повторно.
##### 3.4 Изолируйте «хаки» и «грязный код» в отдельные модули
Часто решение проблемы требует совместного использования «чистого» и «грязного» кода.
Разделяйте такие участки в разные модули.
К примеру «грязный код»:* использует словарь процесса
* использует *erlang:process\_info/1* для не совсем адекватных целей :)
* делает что-то, что вы изначально не предполагали делать, но пришлось
Старайтесь писать как можно больше чистого кода, а «грязный», во-первых используйте как можно меньше, во-вторых документируйте все возможные побочные эффекты и проблемы использования.
##### 3.5 Не думайте о том как вызывающая функция будет использовать результат
Не думайте о том как вызывающая функция будет использовать результат выполнения вашей.
К примеру, предположим, вы вызываете функцию *route*, передавая ей аргументы, которые могут быть не корректными. Создатель функции route не должен думать о том, что мы будем делать, когда аргументы не корректны.
Не нужно писать подобный код:
```
do_something(Args) ->
case check_args(Args) of
ok ->
{ok, do_it(Args)};
{error, What} ->
String = format_the_error(What),
io:format("* error:~s\n", [String]), %% Don’t do this
error
end.
```
Лучше сделать так:
```
do_something(Args) ->
case check_args(Args) of
ok ->
{ok, do_it(Args)};
{error, What} ->
{error, What}
end.
error_report({error, What}) ->
format_the_error(What).
```
В первом случае ошибка всегда выводится на консоль, во втором же — просто возвращается описание ошибки. Разработчик приложения может сам решить что делать с ней — проигнорировать или привести к печатному виду с помощью *error\_report/1*. В любом случае за ним остается право выбора, что делать при возникновении ошибки.
##### 3.6 Выделяйте общие шаблоны и поведения из логики кода
Если в коде какое-то поведение начинает повторяться, попытайтесь выделить его в отдельную функцию или модуль. Так его будет намного легче поддерживать, чем несколько копий разбросанных по программе.
Не используйте «Copy & Paste», используйте функции!
##### 3.7 Проектирование «сверху вниз»
Разрабатывайте программу по принципу сверху вниз. Это позволит постепенно детализировать код, до тех пор пока вы не дойдете примитивных функций. Код, написанный таким образом не зависит от представления данных, т. к. представление еще не известно когда вы ведете разработку на более высоком уровне.
##### 3.8 Не надо оптимизировать код
Не оптимизируйте код на начальной стадии разработки. Сначала заставьте его правильно работать, а уже потом, если появится необходимость, займитесь оптимизацией.
##### 3.9 Пишите предсказуемый код
Результат выполнения функций не должен стать сюрпризом для пользователя. Функции, которые выполняют сходные действия должны выглядеть одинаково или хотя бы быть похожи. Пользователь должен иметь возможность предугадать что может вернуть функция. Если результат выполнения не оправдывает ожиданий, то значит либо название функции не соответствует ее назначению, либо сам код функции работает не верно.
##### 3.10 Пытайтесь избежать побочных эффектов
В Erlang есть несколько примитивов с побочными эффектами. Функции, которые их используют не так просто повторно использовать, т. к. они они зависят от окружения и программисту необходимо контролировать состояние потока перед вызовом.
Пишите как можно больше кода без побочных эффектов.
Четко документируйте все возможные проблемы при использовании не чистых функций. Это сильно облегачает написание тестов и поддержку.
##### 3.11 Не разрешайте внутренним данным покидать модуль
Легче всего продемонстрировать на примере. Предположим есть функция управления очередью:
```
-module(queue).
-export([add/2, fetch/1]).
add(Item, Q) ->
lists:append(Q, [Item]).
fetch([H|T]) ->
{ok, H, T};
fetch([]) ->
empty.
```
Она описывает очередь как список. И используется примерно так:
```
NewQ = [], % Не делайте так
Queue1 = queue:add(joe, NewQ),
Queue2 = queue:add(mike, Queue1), ....
```
Из этого вытекает несколько проблем:
* необходимо знать, что очередь это список
* в дальнейшем мы не сможем изменить представление на другое ( когда понадобится, к примеру, оптимизация)
Намного лучше писать так:
```
-module(queue).
-export([new/0, add/2, fetch/1]).
new() ->
[].
add(Item, Q) ->
lists:append(Q, [Item]).
fetch([H|T]) ->
{ok, H, T};
fetch([]) ->
empty.
```
Теперь использование будет выглядеть так:
```
NewQ = queue:new(),
Queue1 = queue:add(joe, NewQ),
Queue2 = queue:add(mike, Queue1), …
```
Этот код лишен недостатков описанных выше.
Теперь предположим, что необходимо узнать длину очереди. Если пользователь знает, что очередь это список он напишет:
```
Len = length(Queue) % не пишите так
```
Снова проблемы, так как пользователь опять жестко связывает реализацию с представлением, такой код тяжело поддерживать и читать. Для этого случая лучше предусмотреть отдельную функцию и добавить в модуль:
```
-module(queue).
-export([new/0, add/2, fetch/1, len/1]).
new() -> [].
add(Item, Q) ->
lists:append(Q, [Item]).
fetch([H|T]) ->
{ok, H, T};
fetch([]) ->
empty.
len(Q) ->
length(Q).
```
Теперь пользователь сможет взамен своему коду вызывать *queue:len(Queue)*.
В данном коде мы «абстрагировались» от деталей реализации типа данных очередь. Т.е. другими словами очередь теперь — «абстрактный тип данных».
К чему вся эта морока? На практике, получился легкий механизм для замены внутреннего представления, и теперь можно поменять реализацию своего модуля не боясь нарушить обратную совместимость с пользовательским кодом. Например для лучшей реализации код переписан так:
```
-module(queue).
-export([new/0, add/2, fetch/1, len/1]).
new() ->
{[],[]}.
add(Item, {X,Y}) -> % Вставка ускорена
{[Item|X], Y}.
fetch({X, [H|T]}) ->
{ok, H, {X,T}};
fetch({[], []) ->
empty;
fetch({X, []) ->
% Выполняем эти тяжелые вычисления только иногда
fetch({[],lists:reverse(X)}).
len({X,Y}) ->
length(X) + length(Y).
```
##### 3.12 Делайте код детерминированным настолько, на сколько это возможно
Детерминированные программы всегда ведут себя одинаково не зависимо от того сколько раз их запускали. Не детерминированные могут вести себя по разному при каждом запуске. Первый вариант намного легче для отладки и позволяет отследить и избежать множество ошибок, так что старайтесь придерживаться его.
Например, программа должна запустить 5 разных потоков, а затем проверить, что они запустились, притом порядок запуска не важен.
Можно запустить все 5 сразу, а потом проверить, но лучше запускать их по очереди, каждый раз проверяя запустился ли поток и только после этого запускать следующий.
##### 3.13 Не надо постоянно проверять корректность входных данных
Часто программисты не доверяют входным данным для части системы, которую они разрабатывают. Большая часть кода не должна заботиться о корректности передаваемых ей данных. Проверка должна происходить только тогда, когда данные передаются извне.
Например:
```
%% Args: Option is all|normal
get_server_usage_info(Option, AsciiPid) ->
Pid = list_to_pid(AsciiPid),
case Option of
all -> get_all_info(Pid);
normal -> get_normal_info(Pid)
end.
```
Функция завершит выполнение ошибкой, если *Option* это не *normall* или *all*. Так и должно быть! Тот кто вызывает эту функцию должен контролировать то, что ей передать.
##### 3.14 Изолируйте логику работы с аппаратным средствами в драйвер
Оборудование должно быть изолировано от системы с помощью драйвера. Задача драйвера представить аппаратуру в системе так, как будто это просто Erlang поток, который так же как и простой поток принимает и отсылает сообщения и реагирует на ошибки.
##### 3.15 Отменяйте действия в той же функции, что и делаете
Предположим, что есть код, который открывает файл, что-от с ним делает и потом закрывает.
```
do_something_with(File) ->
case file:open(File, read) of,
{ok, Stream} ->
doit(Stream),
file:close(Stream) % Правильное решение
Error -> Error
end.
```
Обратите внимание, что открытие и закрытие файла происходит в той же функции. Код легко читаем и понятен. А вот, к примеру, такой код тяжелее понять и сразу не понятно, когда закрывается файл:
```
do_something_with(File) ->
case file:open(File, read) of,
{ok, Stream} ->
doit(Stream)
Error -> Error
end.
doit(Stream) ->
....,
func234(...,Stream,...).
...
func234(..., Stream, ...) ->
...,
file:close(Stream) %% Не делайте так
```
#### 4 Обработка ошибок
##### 4.1 Отделяйте обработку от нормального кода
Не смешивыйте нормальный код с кодом обработки ошибок. Вы должны программировать нормальное поведение. Если что-то пойдет не так, процесс должен тут же завершиться с ошибкой. Не пытайтесь исправить ошибку и продолжить. Обработкой ошибок должен занимать другой процесс.
##### 4.2 Выделяйте «ядро ошибок»
Одним их этапов разработки является определение того какая часть системы всегда должна функционировать без ошибок, а в какой ошибки допустимы.
К примеру, в операционных системах ядро должно функционировать без ошибок, в то время как обычные приложения могут упасть с ошибкой, но это не отразится на функционировании системы в целом.
Та часть которая должна всегда работать корректно мы называем «ядро ошибок». Эта часть, как правило, потсоянно сохраняет свое промежуточное состояние в БД или на диск.
#### 5 Потоки, серверы и сообщения
###### 5.1 Реализуйте весь код потока в одном модуле
Конечно надо понимать, что поток вызывает функции из других модулей, но здесь речь идет о том, что главный цикл потока должен быть в одном модуле, а не разбит на несколько. Иначе будет тяжело контролировать ход выполнения. Это так же не означает, что не стоит использовать *generic* библиотеки. Они как раз и предназначены для помощи в организации потока.
Также не стоит забывать, что код, общий для нескольких потоков, должен быть реализован в своем совершенно отдельном модуле.
##### 5.2 Используйте потоки для построения системы
Потоки — это базовые структурные элементы системы. Но не используйте их и отправку сообщения, когда возможно просто вызвать функцию.
##### 5.3 Зарегистрированные потоки
Потоки должны быть зарегистрированы под тем же именем, что название модуля, который содержит их код. Это значительно облегчит поддержку. Регистрируйте только те потоки, который планируется использовать длительное время.
##### 5.4 Создавайте только один поток в системе для каждого физически параллельного действия
Использовать потоки или решать задачу последовательно зависит напрямую от проблемы, которую мы стараемся решить. Но желательно руководствоваться одним главным правилом:
«Используйте один поток для каждого параллельного процесса в реальном мире».
Если соблюдать это правило, то логику программы будет легко понять.
##### 5.5 У каждого потока должна быть только одна «роль»
Потоки могут выполнять разные роли в системе. Например, в архитектуре клиент-сервер поток может быть и клиентом и сервером, но лучше разделить две роли на два потока.
Другие роли:
* **супервизор (*supervisor*)** — наблюдает за потоками и перезапускает их после падения;
* **рабочий (*worker*)** — обычный исполнительный поток, в котором могут возникать ошибки;
* **доверенный поток (или системный, *trusted worker*)** — поток, в котором не должно возникать ошибок.
##### 5.6 Используйте *generic* функции для создания серверов и работы с протоколами всегда, когда это возможно
В большинстве случаев использовать *gen\_server* для создания серверов является самым лучшим решением, т. к. это сильно облегчит структуру системы. Это верно и для обработки протоколов передачи данных.
##### 5.7 Добавляйте тэги к сообщениям
У всех сообщений должны быть тэги. Тэгированными сообщениями легче управлять, т. к. не важен их порядок в блоке *receive*, и легче добавлять поддержку новых сообщений.
Не стоит писать такой код:
```
loop(State) ->
receive
...
{Mod, Funcs, Args} -> % Не делайте так
apply(Mod, Funcs, Args},
loop(State);
...
end.
```
Если возникнет необходимость добавить обработку сообщения *{get\_status\_info, From, Option}* и его обработку разместить под первым блоком, то возникнет конфликт и новый код не выполнится никогда.
Если сообщения синхронные, то результат тоже должен быть помечен тэгом, но отличным от запроса. Например: при запросе с тэгом *get\_status\_info*, должен придти ответ *status\_info*. Соблюдение этого правила существенно облегчает отладку.
Вот пример правильного кода:
```
loop(State) ->
receive
...
{execute, Mod, Funcs, Args} -> % Используются тэгированные сообщени
apply(Mod, Funcs, Args},
loop(State);
{get_status_info, From, Option} ->
From ! {status_info, get_status_info(Option, State)}, % Тэгированный ответ
loop(State);
...
end.
```
##### 5.8 Очищайте очередь от неизвестных вашему коду сообщений
Каждый сервер воизбежание переполнения очереди должен обрабатывать все приходящие к нему сообщения к примеру так:
```
main_loop() ->
receive
{msg1, Msg1} ->
...,
main_loop();
{msg2, Msg2} ->
...,
main_loop();
Other -> % Очистка очереди
error_logger:error_msg(
"Error: Process ~w got unknown msg ~w~n.",[self(), Other]),
main_loop()
end.
```
##### 5.9 Используйте хвостовую рекурсию при написании серверов
Все сервера обязаны быть реализованы с использованием хвостовой рекурсии, дабы избежать переполнения памяти.
Не стоит писать так:
```
loop() ->
receive
{msg1, Msg1} ->
...,
loop();
stop ->
true;
Other ->
error_logger:log({error, {process_got_other, self(), Other}}),
loop()
end,
io:format("Server going down"). % не делайте так
% Это не хвостовая рекурсия!
```
Лучше так:
```
loop() ->
receive
{msg1, Msg1} ->
...,
loop();
stop ->
io:format("Server going down");
Other ->
error_logger:log({error, {process_got_other, self(), Other}}),
loop()
end. % А вот это хвостовая рекурсия
```
##### 5.10 Создавайте интерфейс доступа к своему серверу
Используйте функции для доступа к серверу взамен прямой отправки сообщений всегда, когда это возможно.
Протокол обмена сообщениями это внутренняя информация и она не должна быть доступна другим модулям.
Пример:
```
-module(fileserver).
-export([start/0, stop/0, open_file/1, ...]).
open_file(FileName) ->
fileserver ! {open_file_request, FileName},
receive
{open_file_response, Result} -> Result
end.
...`...`
```
##### 5.11 Таймауты
Будьте предельно осторожны при использовании *after* при получении сообщений. Убедитесь, что вы предусмотрели ситуацию когда сообщение придет уже после таймаута. (см. п. 5.8).
##### 5.12 Перехват сигнала выхода
Как можно меньше потоков должны выставлять *trap\_exit* флаг. Но использовать его или нет, это все же зависит от назначения модуля.
#### 6 Рекомендации к коду Erlang
##### 6.1 Используйте *record* для хранения структур
Тип данных *record* это тэгированный кортеж во внутреннем представлении Erlang. Впервые он появился в Erlang 4.3. Record очень похож на *struct* в C или *record* в Pascal.
Если *record* планируется использовать в нескольких модулях, то его определение следует поместить в заголовочный файл.
*Record* лучше всего использовать для обеспечения совместимости модулей при передаче данных между ними.
##### 6.2 Используйте селекторы и конструкторы
Используйте селекторы и конструкторы для управления *record*. Никогда не используйте *record* как кортэж.
Пример:
```
demo() ->
P = #person{name = "Joe", age = 29},
#person{name = Name1} = P,% matching или...
Name2 = P#person.name. % селектор
```
Не стоит использовать *record* так:
```
demo() ->
P = #person{name = "Joe", age = 29},
{person, Name, _Age, _Phone, _Misc} = P. % Не стоит так делать
```
##### 6.3 Возвращайте тэгированный результат функции
Не стоит писать так:
```
keysearch(Key, [{Key, Value}|_Tail]) ->
Value; %% Не возвращайте нетэгированное значение!
keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) ->
keysearch(Key, Tail);
keysearch(Key, []) ->
false.
```
При таком решении *{Key, Value}* не может содержать *false* в качестве значения. Вот правильный код:
```
keysearch(Key, [{Key, Value}|_Tail]) ->
{value, Value}; %% Все исправлено.
keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) ->
keysearch(Key, Tail);
keysearch(Key, []) ->
false.
```
##### 6.4 Используйте с осторожностью catch и throw
Не используйте *catch* и *throw* в случае если вы не уверены в том, что вы делаете.
*Catch* и *throw* могут быть полезны при обработке внешних входных данных, или данных которые требуют сложной обработки (например обработка текста компилятором).
##### 6.5 Используйте словарь процесса с предельной осторожностью
Не используйте *get* и *put* в случае если вы не уверены в том, что вы делаете.
Функции которые используют *put* и *get* могут быть достаточно просто переписаны добавлением еще одного аргумента.
Не стоит писать так:
```
tokenize([H|T]) ->
...;
tokenize([]) ->
case get_characters_from_device(get(device)) of % Не используйте get/1!
eof -> [];
{value, Chars} ->
tokenize(Chars)
end.
```
Лучше переписать:
```
tokenize(_Device, [H|T]) ->
...;
tokenize(Device, []) ->
case get_characters_from_device(Device) of % Так лучше
eof -> [];
{value, Chars} ->
tokenize(Device, Chars)
end.
```
Использование *put* и *get* делает функцию не детерминированной. В этом случае значительно осложняется отладка, т.к. результат выполнения функции зависит не только от входных данных но и от словаря процесса. Тем более Erlang при ошибке (к примеру *bad\_match*) выводит в описании только аргументы вызовов функции, а не состояние словаря потока на тот момент.
##### 6.6 Не используйте *import*
Код с импорт тяжелее читать. Лучше чтобы все определения функций модуля были в одном файле.
##### 6.7 Экспортирование функций
Следует различать то, зачем экспортируются функции:
1. Для предоставления возможности внешнего обращения к ним
2. Для предоставления интерфейса пользователю
3. Для вызовов через spawn или apply изнутри самого модуля.
Группируйте *-export* и комментируйте причину экспорта.
```
%% интерфейса пользователю
-export([help/0, start/0, stop/0, info/1]).
%% для внешнего обращения
-export([make_pid/1, make_pid/3]).
-export([process_abbrevs/0, print_info/5]).
%% для внутреннего использования
-export([init/1, info_log_impl/1]).
```
#### 7. Рекомендации для стилистического и лексического оформления кода
##### 7.1 Не пишите сильно вложенный код
Под сильно вложенным понимается код, в котором много блоков *case* / *if* / *receive* вложено в другие блоки *case* / *if* / *receive*. Считается плохим тоном наличие более двух уровней вложенности. Такой код тяжело читается. Лучше разбивать такой код на мелкие функции.
##### 7.2 Не пишите слишком большие модули
Модуль не должен содержать более 400 строк кода. Лучше разбивать такие модули на несколько маленьких.
##### 7.3 Не пишите слишком длинные функции
Функция не должна быть длиннее 15-20 строк. Не пытайтесь решить проблему написанием всего в одну строчку.
##### 7.4 Не стоит писать много символов в одной строке
Число символов в строке должно быть не больше 80 ( чтобы поместиться на A4 ).
В Erlang строки, объявленные после переноса, автоматически склеиваются.
Например:
```
io:format("Name: ~s, Age: ~w, Phone: ~w ~n"
"Dictionary: ~w.~n", [Name, Age, Phone, Dict])
```
##### 7.5 Именовение переменных
Выбрать правильное(значимое) имя для переменной — достаточно трудная задача.
Если имя переменной состоит из нескольких слов лучше их разделять либо через *'\_'* либо использовать [CamelCase](http://ru.wikipedia.org/wiki/CamelCase)
Не используйте *'\_'* для игнорирования переменной в функции, лучше пишите название переменнной, начинающееся с *'\_'*, например *\_Name*.
##### 7.6 Именование функций
Название функции должно четко отражать её назначение. Результат выполнения должен быть предсказуем исходя из названия. Следует использовать стандартные имена для стандартных функций (такие как *start*,*stop*,*init*,*main\_loop* …).
Функции из разных модулей, но с одинаковым назначением должны называться одинаково (например, *Module:module\_info()*).
Неправильный выбор имени функции — самая распространенная ошибка.
Некоторые соглашения в именах функций намного облегчают этот выбор. К примеру префикс *'is\_'* говорит от том, что результатом выполнения будет *true* или *false*.
```
is_...() -> true | false
check_...() -> {ok, ...} | {error, ...}
```
##### 7.7 Именование модулей
В Erlang плоская модель именования модулей, т.е. нет пакетов как, например, в Java (но, если быть точным, есть, но их применение на практике пока приносит больше проблем, чем пользы).
Обычно для обозначения того, что модули как-то связаны используют одинаковые префиксы. Например ISDN реализован так:
isdn\_init
isdn\_partb
isdn\_…
##### 7.8 Оформляйте код единообразно
Единообразный стиль позволяет разработчикам легче понимать код друг друга.
Все люди привыкли писать код по разному.
К примеру кто-то определяет элементы кортежа через пробел
```
{12, 23, 45}
```
кто-то без
```
{12,23,45}
```
Как только вы выработаете для себя единый стиль — придерживайтесь его.
#### 8 Документирование кода
##### 8.1 Атрибуты кода
Необходимо всегда правильно задавать атрибуты модуля в заголовке. Описывать откуда возникла идея этого модуля, если код появился в результате работы на другим модулем, описать это.
Никогда не воруйте код. Воровство — это копирование кода без указания первоисточника.
Примеры атрибутов:
> -revision('Revision: 1.14 ').
>
> -created('Date: 1995/01/01 11:21:11 ').
>
> -created\_by('eklas@erlang’).
>
> -modified('Date: 1995/01/05 13:04:07 ').
>
> -modified\_by('mbj@erlang').
>
>
##### 8.2 Оставляйте ссылки на спецификацию
Если код реализует какой-то стандарт, обязательно оставляйте ссылку на документацию (к примеру RFC).
##### 8.3 Документируйте все ошибки
Все ошибки должны быть понятно описаны в отдельном документе.
В коде в местах где возможна логическая вызывайте *error\_logger*:
> **error\_logger**:error\_msg(Format, {Descriptor, Arg1, Arg2, ....})
>
>
И убедитесь, что {Descriptor, Arg1, Arg2, ....} описаны в документе «Описание ошибок».
##### 8.4 Документируйте все типы данных, которые передаются в сообщениях
Используйте тэгированные кортежи в качестве сообщений пересылаемых потоками.
Использование *record* в сообщениях гарантирует совместимость между различными модулями.
Документируйте все эти типы данных документе «Описание сообщений».
##### 8.5 Комментируйте код
Комментарии не должны быть многословны, но должны быть достаточны для понимания вашего кода. Всегда поддерживайте их в актуальном состоянии.
Комментарии касательно модулей должны быть без отступов и начинаться с *%%%*.
Комментарии касательно функций должны быть без отступов и начинаться с *%%*.
Комментарии к коду должны быть выровнены также как и он, и начинаться с *%*. Такие комментарии должны находится над кодом или на одной линии с ним. На одной линии более предпочтительно (если помещается).
> *%% Comment about function*some\_useful\_functions(UsefulArgugument) ->
>
> another\_functions(UsefulArgugument), *% Comment at end of line* *% Comment about complicated\_stmnt at the same level of indentation* complicated\_stmnt,
>
> …
>
>
##### 8.6 Комментируйте каждую функцию
Важно документировать:
* цели этой функции
* допустимую область входных данных
* область выходных данных
* Если функция реализует какой-то алгоритм-опишите его
* Возможные падения этой функции, наличие вызовов *exit/1* и *throw/1*, возможные ошибки.
* Побочные эфекты
Пример:
> *%%----------------------------------------------------------------------
>
> %% Function: get\_server\_statistics/2
>
> %% Purpose: Get various information from a process.
>
> %% Args: Option is normal|all.
>
> %% Returns: A list of {Key, Value}
>
> %% or {error, Reason} (if the process is dead)
>
> %%----------------------------------------------------------------------*get\_server\_statistics(Option, Pid) **when** pid(Pid) ->
>
> …
>
>
##### 8.7 Структуры данных
*Record* должен быть определен вместе с описанием. Например:
> *%% File: my\_data\_structures.h
>
> %%---------------------------------------------------------------------
>
> %% Data Type: person
>
> %% where:
>
> %% name: A string (default is undefined).
>
> %% age: An integer (default is undefined).
>
> %% phone: A list of integers (default is []).
>
> %% dict: A dictionary containing various information about the person.
>
> %% A {Key, Value} list (default is the empty list).
>
> %%----------------------------------------------------------------------*-**record**(person, {name, age, phone = [], dict = []}).
>
>
##### 8.8 Заголовок файла, копирайт
Каждый файл должен начинаться информации о копирайте. Например:
> *%%%---------------------------------------------------------------------
>
> %%% Copyright Ericsson Telecom AB 1996
>
> %%%
>
> %%% All rights reserved. No part of this computer programs(s) may be
>
> %%% used, reproduced,stored in any retrieval system, or transmitted,
>
> %%% in any form or by any means, electronic, mechanical, photocopying,
>
> %%% recording, or otherwise without prior written permission of
>
> %%% Ericsson Telecom AB.
>
> %%%---------------------------------------------------------------------*
>
>
##### 8.9 Заголовок файла, история версий
В каждом файле должна быть история версий, в которой показано кто сделал какие изменения и с какой целью.
> *%%%---------------------------------------------------------------------
>
> %%% Revision History
>
> %%%---------------------------------------------------------------------
>
> %%% Rev PA1 Date 960230 Author Fred Bloggs (ETXXXXX)
>
> %%% Intitial pre release. Functions for adding and deleting foobars
>
> %%% are incomplete
>
> %%%---------------------------------------------------------------------
>
> %%% Rev A Date 960230 Author Johanna Johansson (ETXYYY)
>
> %%% Added functions for adding and deleting foobars and changed
>
> %%% data structures of foobars to allow for the needs of the Baz
>
> %%% signalling system
>
> %%%---------------------------------------------------------------------*
>
>
##### 8.10 Заголовок файла, описание
Каждый файл должен начинаться с короткого описания назначения модуля и списка экспортируемых функций.
> *%%%---------------------------------------------------------------------
>
> %%% Description module foobar\_data\_manipulation
>
> %%%---------------------------------------------------------------------
>
> %%% Foobars are the basic elements in the Baz signalling system. The
>
> %%% functions below are for manipulating that data of foobars and for
>
> %%% etc etc etc
>
> %%%---------------------------------------------------------------------
>
> %%% Exports
>
> %%%---------------------------------------------------------------------
>
> %%% create\_foobar(Parent, Type)
>
> %%% returns a new foobar object
>
> %%% etc etc etc
>
> %%%---------------------------------------------------------------------*
Если вам известны какие-либо проблемы с использование кода или что-то не завершено, описывайте их здесь. Это поможет в дальнейшем поддержке вашего кода.
##### 8.11 Не комментируйте старый код — удаляйте его
Удаляйте старый код и оставляйте описание в системе контроля версий. CSV поможет вам.
##### 8.12 Используйте системы контроля версий
Все более менее сложные проекты должны использовать контроль версий (Git, SVN и т.п.)
#### 9 Частые ошибки
Написание функций на несколько страниц
Написание функций с множеством вложенных *case* / *if* / *receive*
Написание нетэгированных функций
Имена функций не соответствуют и функциональному назначению
Плохие имена переменных
использование потоков, когда в это нет необходимости
Неправильный выбор структур данных (плохое представление)
Плохое комментирование или отсутствие комментариев
Код без отступов
Использование *put* / *get*
Плохой контроль очереди сообщений
#### 10 Документация
В этом блоке описана документация которая необходима для проекта для го поддержки и администрирования.
##### 10.1 Описание модулей
Одна глава на модуль. Она должна содержать описание каждого модуля и описание всех экспортируемых им функций:
* назначение
* описание входных данных
* описание выходных данных
* возможные проблемы использования и вызовы *exit/1*.
##### 10.2 Описание сообщени
Описание сообщений, используемых в системе, кроме тех, которые используются только внутри модулей
##### 10.3 Описание потоков
Описание всех зарегистрированных потоков и интерфейсов к ним.
Описание всех динамически создаваемых потоков и интерфейсов к ним.
##### 10.4 Описание ошибок
Описание всех возможных ошибок системы. | https://habr.com/ru/post/142594/ | null | ru | null |
# uWSGI включает полноценную поддержку PHP

Сегодня [появилась](http://projects.unbit.it/uwsgi/wiki/PHP) приятная новость о том, что отныне uWSGI сервер поддерживает PHP. Нет, на уровне GGI он поддерживал и раньше, но это не идёт ни в какое сравнение с поддержкой на уровне ядра самого uWSGI.
##### uWSGI
Для тех, кто по какой-то причине еще не использует этот удобный и стабильный сервер — краткая справка.
uWSGI — быстрый, удобный и, при этом, надежный WSGI-сервер.* *Быстрый*, потому что написан на C.
* *Удобный*, потому что легко конфигурируется всеми мыслимыми и немыслимыми видами: `.ini, yaml, json, XML` или через переменные окружения.
* *Надежный* (в оригинале это звучит `self-healing`), потому что имеет функцию самоуправления: если запрос длится дольше отведенного времени, то master-процесс завершит исполнение текущего worker'a, чтобы не забивать память (функционал носит говорящее название `Harakiri mode`).
##### Сборка PHP-плагина
Скачать исходники php, «связать» uwsgi исходники с ними и сконфигурировать среду окружения PHP:
```
ln -s /usr/src/uwsgi/plugins/php /usr/src/php/sapi/uwsgi
./buildconf --force
./configure --prefix=/opt/php --with-mysql --with-uwsgi=/usr/src/uwsgi
```
Затем собрать PHP традиционным `make, make install`.
##### Использование вместе с Nginx
В энджинксе обработка php-запросов описывается привычной (для связки с WSGI-приложениями через uWSGI) секцией:
```
location ~ .php$ {
include uwsgi_params;
uwsgi_modifier1 14;
uwsgi_pass 127.0.0.1:3030;
}
```
##### Запуск uWSGI
Пока поддержка PHP (в виде плагина) находится в состоянии альфы, никакой конфигурации плагина не требуется. А запустить сервер в режиме его использования можно так:
```
uwsgi --plugins php --master --socket :3030 --processes 4
```
Такими темпами можно будет скоро отказаться не только от Apache, но и ото всех FastCGI-php-fpm вместе взятыми.
##### Ссылки по теме
Запуск PHP-скриптов в uWSGI: [projects.unbit.it/uwsgi/wiki/PHP](http://projects.unbit.it/uwsgi/wiki/PHP)
Подробнее о «Harakiri mode» в WiKi: [projects.unbit.it/uwsgi/wiki](http://projects.unbit.it/uwsgi/wiki) | https://habr.com/ru/post/134987/ | null | ru | null |
# Яндекс выложил в опенсорс YDB
Сегодня мы выложили в опенсорс систему управления базами данных YDB — плод многолетнего опыта Яндекса в разработке систем хранения и обработки данных. Исходный код, документация, SDK и все инструменты для работы с базой [опубликованы на GitHub](https://github.com/ydb-platform/ydb) под лицензией Apache 2.0. Развернуть базу можно как на собственных, так и на сторонних серверах — в том числе в любых облачных сервисах.

YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.
В нашей компании YDB используется уже больше пяти лет. На мультитенантных кластерах развёрнуты базы с очень разными нагрузками и паттернами доступа к данным. На практике мы встречаемся с многократным ростом баз данных, ростом объёмов данных с единиц гигабайт до сотен терабайт и ростом нагрузок с тысяч до миллионов RPS. При этом решение задач масштабируемости и отказоустойчивости автоматически осуществляет база, снимая их с разработчиков прикладного кода. Но YDB распространена не только в проектах с высокой нагрузкой. Команды разработки Яндекса сами определяют свой стек в зависимости от задач, аудитории и другой специфики, и многие выбирают YDB за отказоустойчивость, даже если текущие нагрузки невелики. Одна из причин в том, что в случае внезапного роста нагрузок разработчикам будет достаточно добавить ресурсы, не внося изменения в код приложения и не прикладывая усилия к ручному перешардированию базы. Проекты в YDB размещают команды Алисы, Такси, Метрики и других сервисов — сейчас в системе почти 500 проектов.
Широкое распространение YDB внутри Яндекса, популярность в качестве сервиса Яндекс Облака и запросы пользователей cтали для нас хорошим стимулом раскрыть исходный код и сделать базу доступной для свободного использования.
Немного истории
---------------
За два последних десятилетия непрерывно растёт использование интернета, в последние годы он начал прочно входить в бытовую сферу. Часы, очки, лампочки, пылесосы — практически все устройства подключены к интернету или подключатся в скором времени. Всё это ведёт к непрерывному росту объёмов хранимых данных и нагрузок, которые БД обрабатывают.
С начала 2000-х вместе с бурным ростом интернета выросла популярность опенсорсных СУБД для OLTP-нагрузок — например, MySQL и PostgreSQL.
Без них или их аналогов сложно представить себе нынешние темпы развития интернета. Даже небольшие стартапы получили возможность работать с возрастающими нагрузками на бесплатных БД. Конечно, существовали тяжёлые коммерческие решения, которые позволяли масштабироваться вертикально, но они были доступны только большим компаниям с соответствующими бюджетами.
К середине 2000-х стали популярны разные виды логического шардирования БД — когда базу шардируют на несколько узлов, исходя из бизнес-логики приложения и его сущностей. Промежуточный слой между приложением и базой или само приложение принимает решение, на каком из узлов БД находятся данные. Но этот распространённый подход приводит к усложнению логики пользовательского приложения и значительно усложняет поддержку множества кластеров. Дополнительные сложности возникают при необходимости выполнить запрос, результат которого выдаёт консистентный результат объединения данных из разных шардов. Эту проблему можно решить за счёт отгрузки данных в отдельную систему или дополнительного усложнения логики приложения, но каждый такой дополнительный шаг только усложняет обслуживаемость системы и делает её менее технологичной. В то же время остаются открытыми такие вопросы, как перешардирование данных при росте нагрузки на конкретный шард. Сложно развить изначально выбранный подход к шардированию при изменившихся бизнес-требованиях к приложению. Нагрузки продолжают расти, а критичность отказов возрастает.
В конце 2000-х набирают популярность NoSQL-решения. Во главе угла становятся проблемы масштабируемости и отказоустойчивовости, в жертву приносится диалект SQL и функциональность join. Приемлемой считается eventual consistency, то есть консистентность в конечном итоге: рано или поздно все реплики во всех зонах доступности или регионах получат консистентный набор данных. Растёт популярность key-value-хранилищ (Redis, AWS DynamoDB), column-family (Cassandra, Hbase) и документных БД (MongoDB, Couchbase).
Мы шли тем же путем, и история развития OLTP СУБД в Яндексе повторяет историю развития операционных БД. Предшественником YDB была СУБД NoSQL (KV), которую мы разрабатывали с 2008 года.
Отсутствие поддержки ACID-транзакций приводит к необходимости самостоятельно их эмулировать. Возрастает сложность прикладного кода, и каждый разработчик фактически вынужден дорабатывать на стороне этого кода функциональность базы — что, во-первых очень сложно, а во-вторых, на большом количестве проектов требует множества костылей и велосипедов в каждом проекте.
Проблема оставалась актуальной. В начале 2010-х появляется новый термин — NewSQL. Про него рассказывают [Майкл Стоунбрейкер](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%BE%D1%83%D0%BD%D0%B1%D1%80%D0%B5%D0%B9%D0%BA%D0%B5%D1%80,_%D0%9C%D0%B0%D0%B9%D0%BA%D0%BB) и [Энди Павло](http://www.cs.cmu.edu/~pavlo/), описывая новые требования к OLTP СУБД (точнее, ожидания от такой базы).
NewSQL-базы должны обладать масштабируемостью и отказоустойчивовостью, свойственной NoSQL-системам, но при этом предоставлять ACID-гарантии транзакций и SQL-диалект. Чуть позже термин NewSQL трансформировался — масштабируемые, отказоустойчивые БД с поддержкой SQL и строгой консистентностью стали называть Distributed SQL Databases. Вдохновившись идеей NewSQL, в 2012 году мы сделали первый коммит в YDB.
Зачем использовать YDB
----------------------
Рынок СУБД развивается давно, на нём представлено много известных и зрелых продуктов. Давайте разберём, какие преимущества может дать YDB в сравнении с другими базами.
#### Традиционные (нераспределённые) реляционные СУБД
Один из вариантов масштабирования в реляционных базах — ручное шардирование. То есть при разворачивании нужно настроить несколько экземпляров базы и решить, к какому экземпляру обращаться в вашем приложении. Если вам нужен одновременный доступ к данным из нескольких экземпляров БД, вам придется самостоятельно заниматься организацией распределённых транзакций. YDB масштабируется на чтение и запись «из коробки», для этого достаточно добавить больше оборудования в кластер. На практике мы работаем с базами размером в сотни терабайт под нагрузкой в миллионы RPS.
#### NoSQL-базы
NoSQL-базы очень хорошо масштабируются, но их функциональность ограничена по сравнению с реляционными БД. Например, транзакционное обновление нескольких таблиц с высокой скоростью при помощи SQL-запросов — реальная проблема для NoSQL.
#### Опенсорсные базы Distributed SQL
Некоторые из таких систем имеют очень похожие возможности по сравнению с YDB. У YDB, на наш взгляд, следующие плюсы:
* Яндекс как пользователь даёт YDB возможность на практике доказывать все свои свойства — поверх СУБД работает множество сервисов с высокими нагрузками и большими объёмами данных.
* Поверх YDB как платформы мы реализовали системы хранения и обработки данных: хранилище временных рядов, на базе которого построены мониторинги в Яндексе; персистентные очереди, на которых построена шина передачи данных Logbroker; Network Block Store — виртуальные диски для Yandex Cloud.
* YDB может стать экосистемой управления данными, поскольку она даёт возможность использовать механизм федеративных запросов и механизм потоковых запросов на базе [YQL](https://habr.com/ru/company/yandex/blog/312430/).
#### Проприетарные базы Distributed SQL
Код большинства систем ведущих мировых облачных провайдеров закрыт. Некоторые из этих систем также завязаны на специализированное оборудование. Это лишает клиентов возможности локального развертывания системы и разворачивания в различных облаках. YDB, в свою очередь, работает на стандартном железе, её можно развернуть везде с помощью оператора Kubernetes или вручную.
Опыт наших пользователей
------------------------
#### Yandex Cloud
YDB — ключевой компонент Yandex Cloud. Напомню, что вся облачная платформа [построена](https://habr.com/ru/company/yandex/blog/432042/) на гиперконвергентной архитектуре. Это означает, что на одном и том же оборудовании работает слой storage и слой compute, они отделены и независимы друг от друга. На том же оборудовании работает и control plane. YDB обеспечивает уровень хранения данных в Yandex Cloud. Это и слой хранения данных для сетевых дисков, и слой хранения данных и метаданных инфраструктурных и платформенных сервисов. Также есть сервисы, которые сами предоставляют средства для работы с данными и реализованы поверх YDB: Monitoring — сервис для сбора и визуализации метрик приложений; Message Queue — очереди для обмена сообщениями между приложениями; Data Streams — масштабируемый сервис для управления потоками данных в реалтайме; Cloud Logging — предназначен для агрегации и чтения логов.
#### Алиса
Команда Алисы решила переехать на YDB, когда готовилась к существенному росту нагрузки и объёмов данных. До переезда использовали другую базу и замечали нежелательные эффекты при переключении мастера между дата-центрами. После длительных регламентных работ отставшие на много часов реплики приходилось бережно возвращать в строй, тратить на них ресурсы девопс-команды. Переехав, команда смогла отказаться от ручного шардирования, получить из коробки строгую консистентность в кластере на три дата-центра и снизить девопс-нагрузку. Сейчас Алиса использует YDB в разных сценариях. Например, хранит в базе контекст для поддержания естественного диалога с пользователем, необходимую информацию для привязки активационных фраз устройств умного дома к их идентификаторам и расположению в доме. Оперативные логи инфраструктурной платформы разработчиков тоже хранятся в YDB.
#### Авто.ру
У Авто.ру микросервисная архитектура. Коллеги пришли в YDB, когда столкнулись с тем, что существующие бэкенды базы для трейсов Jaeger стали очень дорогостоящими с точки зрения обработки количества трейсов на ядро сервера. Для команды YDB это был вызов, и мы реализовали специальный API (BulkUpsert) для записи логов и трейсов и оптимизировали базу для трейсов. Производительность YDB позволила в три раза сэкономить вычислительные ресурсы и писать все трейсы без сэмплинга (нагрузка трейсами на YDB сейчас составляет 500 000 спанов в секунду). Когда YDB зарекомендовала себя как экономичная, эффективная, отказоустойчивая база для хранения трейсов в Авто.ру и Яндекс Недвижимости, её также начали использовать как реляционную базу.
#### Метрика
В Метрике анализируются визиты пользователей на сайты. Для этого необходимо хранить историю всех событий и «склеивать» их на лету. Раньше использовалась конвейерная распределённая система — со своим самописным локальным хранилищем и своей логикой репликации и шардирования. По мере роста нагрузки команда Метрики споткнулась о производительность шардов самописного хранилища, а продолжать наращивать количество шардов без принципиального изменения архитектуры было крайне болезненно.
Новым хранилищем визитов (после экспериментов и нагрузочного тестирования) стала YDB: база обеспечивает прозрачную масштабируемость по месту и по нагрузке. Это позволило продолжить наращивать трафик — сейчас база визитов содержит больше 100 терабайт данных и при этом держит нагрузку больше миллиона RPS. Подробнее про этот проект можно будет узнать из [доклада](https://www.highload.ru/foundation/2022/abstracts/8149) Александра Прудаева на ближайшем HighLoad++.
Почему мы пошли в опенсорс
--------------------------
Мы уверены, что бурное развитие технологий, которое мы наблюдаем в последние десятилетия, было бы невозможно без культуры опенсорс. Например, сейчас уже нельзя представить себе интернет без таких БД, как MySQL, PostgreSQL и ClickHouse, веб-серверов Apache и nginx — примеров можно привести множество.
Открытие проекта создаёт интереснейшую для всех win-win-ситуацию. У сообщества, с одной стороны, появляется возможность пользоваться уникальными наработками, в которые Яндекс инвестировал сотни человеко-лет, познакомиться с кодом, свободно запускать и разрабатывать у себя решения на базе YDB. Технологии, позволяющие Яндексу развиваться быстрее, оперативно реагировать на рост нагрузок и масштабироваться, теперь доступны каждому. С другой стороны, сильно увеличится вариативность пользователей, мы сможем получить обратную связь от мирового сообщества и сделать базу ещё лучше. Важно сломать барьер для пользователей, которые заинтересованы в технологии, но останавливаются, опасаясь закрытости и/или невозможности использовать её на своем оборудовании или в своих облаках.
Как попробовать YDB
-------------------
Давайте попробуем самый простой вариант, который можно использовать для локального тестирования или отладки — [Docker-контейнер](https://ydb.tech/ru/docs/getting_started/self_hosted/ydb_docker).
#### Работа с Docker-образом YDB
По умолчанию в Docker-образе запускается база данных с именем `/local` и используются следующие порты:
* Для взаимодействия с YDB API по gRPC без TLS — 2136.
* Для взаимодействия с YDB API по gRPC с поддержкой TLS — 2135. Сертификаты генерируются автоматически. Для использования сертификатов необходимо смонтировать на хост-системе директорию /ydb\_cert Docker-контейнера.
* Встроенные средства мониторинга и интроспекции — 8765.
Загрузите актуальную версию Docker-образа:
```
docker pull cr.yandex/yc/yandex-docker-local-ydb:latest
```
Docker-контейнер YDB хранит данные в файловой системе контейнера, разделы которой отражаются на директории в хост-системе. Приведенная ниже команда запуска контейнера создаст файлы в текущей директории, поэтому перед запуском создайте рабочую директорию, и выполняйте запуск из неё.
Запустите YDB Docker-контейнер со следующими параметрами:
```
docker run -d \
--rm \
--name ydb-local \
-h localhost \
-p 2135:2135 \
-p 8765:8765 \
-p 2136:2136 \
-v $(pwd)/ydb_certs:/ydb_certs -v $(pwd)/ydb_data:/ydb_data \
-e YDB_DEFAULT_LOG_LEVEL=NOTICE \
-e GRPC_TLS_PORT=2135 \
-e GRPC_PORT=2136 \
-e MON_PORT=8765 \
cr.yandex/yc/yandex-docker-local-ydb:latest
```
Параметры запуска:
* -d — запустить Docker-контейнер в фоновом режиме.
* --rm — удалить контейнер после завершения его работы.
* --name — имя контейнера.
* -h — имя хоста контейнера.
* -p — опубликовать порты контейнера на хост-системе.
* -v — монтировать директории хост-системы в контейнер.
* -e — задать переменные окружения.
С описанием дополнительных параметров запуска Docker-образа YDB можно ознакомиться в [документации](https://ydb.tech/ru/docs/getting_started/self_hosted/ydb_docker#start-pars).
#### Консольный клиент YDB CLI
Для выполнения запросов и запуска тестовой нагрузки мы будем использовать консольный клиент YDB.
Установите YDB CLI по [инструкции](https://ydb.tech/ru/docs/reference/ydb-cli/install). Для проверки успешности соединения с базой данных выполните запрос к базе в Docker-контейнере:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local table query execute -q 'select 1;'
```
Параметры запуска:
* -e — эндпоинт базы данных.
* --ca-file — путь к TLS-сертификату.
* -d — имя базы данных и параметры запроса.
В результате вы должны увидеть сообщение:
```
┌─────────┐
| column0 |
├─────────┤
| 1 |
└─────────┘
```
Это значит, что соединение с базой прошло и запрос выполнен успешно.
#### Использование языка запросов YQL
Ниже — краткая инструкция по использованию синтаксиса YQL. Подробнее с синтаксисом и примерами использования можно познакомиться в [документации](https://ydb.tech/docs/yql/reference/) к YQL.
Создайте таблицу с помощью инструкции CREATE TABLE:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'CREATE TABLE series (series_id Uint64, title Utf8, PRIMARY KEY (series_id));'
```
Убедитесь что таблица создалась, с помощью команды получения списка объектов базы `scheme ls`:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme ls
```

Чтобы посмотреть свойства созданной таблицы, воспользуйтесь командой `describe`:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme describe series
```

Добавьте данные в таблицу с помощью инструкции INSERT INTO:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'INSERT INTO series (series_id, title) VALUES (1, "IT Crowd"), (2, "Silicon Valley"), (3, "Fake Series");'
```
Прочитайте данные из таблицы с помощью инструкции SELECT:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'SELECT * FROM series;'
```
Обновите данные в таблице с помощью инструкции UPDATE:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'UPDATE series SET title="Fake Series Updated" WHERE series_id = 3;'
```
Удалите данные в таблице с помощью инструкции DELETE:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DELETE FROM series WHERE series_id = 3;'
```
Удалите таблицу с помощью инструкции DROP TABLE:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DROP TABLE series;'
```
#### YDB UI — ограничимся скриншотом
Встроенный YDB UI доступен на порту 8765. Перейдите по ссылке <http://localhost:8765>, чтобы познакомиться с его возможностями.
#### Запуск тестовой нагрузки YDB Workload
Для демонстрации работы и нагрузочного тестирования мы интегрировали в функциональность консольного клиента YDB симулятор склада интернет-магазина — создание заказов из нескольких товаров, получение списка заказов по клиенту.
**Cимулятор склада позволяет запускать пять видов нагрузки**
* getCustomerHistory — чтение заданного количества заказов покупателя с id = 10 000. Создаётся нагрузка на чтение одних и тех же строк из разных потоков.
* getRandomCustomerHistory — чтение заданного количества заказов случайно выбранного покупателя. Создаётся нагрузка на чтение из разных потоков.
* insertRandomOrder — создание случайно сгенерированного заказа. Например, клиент создал заказ из двух товаров, но ещё не оплатил его, поэтому остатки товаров не снижаются. В БД записывается информация о заказе и товарах. Создаётся нагрузка на запись и чтение.
* submitRandomOrder — создание и обработка случайно сгенерированного заказа. Например, покупатель создал и оплатил заказ из двух товаров. В БД записывается информация о заказе, товарах, проверяется их наличие и уменьшаются остатки. Создаётся смешанная нагрузка.
* submitSameOrder — создание заказов с одним и тем же набором товаров. Например, все покупатели покупают один и тот же набор (только что вышедший телефон и зарядное устройство). Создаётся нагрузка в виде конкурентного обновления одних и тех же строк в таблице.
Для начала работы нужно проинициализировать базу данных — создать таблицы и заполнить их данными. Для этого нужно выполнить команду:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock init -p 100 -q 1000 -o 1000
```
Здесь:
* -p — количество видов товаров,
* -q — количество каждого вида товара на складе,
* -o — первоначальное количество заказов в базе.
Будут созданы таблицы со следующей структурой и настройками:
Остатки:
```
CREATE TABLE `stock`(
product Utf8,
quantity Int64,
PRIMARY KEY(product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT =
);
```
Заказы:
```
CREATE TABLE `orders`(
id Uint64,
customer Utf8,
created Datetime,
processed Datetime,
PRIMARY KEY(id),
INDEX ix_cust GLOBAL ON (customer, created)
) WITH (
READ_REPLICAS_SETTINGS = "per_az:1",
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = ,
UNIFORM\_PARTITIONS = ,
AUTO\_PARTITIONING\_MAX\_PARTITIONS\_COUNT = 1000
);
```
Позиции:
```
CREATE TABLE `orderLines`(
id_order Uint64,
product Utf8,
quantity Int64,
PRIMARY KEY(id_order, product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = ,
UNIFORM\_PARTITIONS = ,
AUTO\_PARTITIONING\_MAX\_PARTITIONS\_COUNT = 1000
);
```
**Справка по свойствам таблиц YDB, которые используются в примере**
В таблице YDB всегда есть один или несколько столбцов, составляющих первичный ключ (primary key), и она всегда упорядочена по первичному ключу.
Таблица может быть шардирована по диапазонам значений первичного ключа. Разные шарды таблицы могут обслуживаться разными серверами распределённой БД (в том числе расположенными в разных локациях), а также могут независимо друг от друга перемещаться между серверами для перебалансировки или поддержания работоспособности шарда при отказах серверов или сетевого оборудования.
При росте объёма данных, обслуживаемых шардом (как и при росте нагрузки на шард), YDB автоматически разбивает его на два. Разбиение происходит по медианному значению первичного ключа.
Помимо автоматического разделения вы можете создать пустую таблицу с предопределённым количеством шардов. При этом можно вручную задать точные границы разделения ключей по шардам или указать равномерное разделение на предопределённое количество шардов. Тогда границы создадутся по первой компоненте первичного ключа.
Можно определить следующие параметры партиционирования таблицы:
* AUTO\_PARTITIONING\_BY\_SIZE — режим автоматического партиционирования по размеру партиции. Если размер партиции превысил значение, заданное параметром AUTO\_PARTITIONING\_PARTITION\_SIZE\_MB, то она встаёт в очередь на разделение (split). Если суммарный размер двух соседних партиций меньше 50% от значения параметра AUTO\_PARTITIONING\_PARTITION\_SIZE\_MB, то они встают в очередь на объединение (merge).
* AUTO\_PARTITIONING\_PARTITION\_SIZE\_MB — предпочитаемый размер каждой партиции в мегабайтах.
* AUTO\_PARTITIONING\_BY\_LOAD — режим автоматического партиционирования по нагрузке. Если в течение нескольких десятков секунд шард потребляет более 50% CPU, то он ставится в очередь на разделение (split). Если в течение часа суммарная нагрузка на два соседних шарда утилизировала менее 35% CPU, то они ставятся в очередь на объединение (merge). Выполнение операций разделения или объединения само по себе утилизирует CPU — и занимает время. Поэтому при работе с плавающей нагрузкой рекомендуется вместе с включением этого режима устанавливать отличное от 1 значение параметра минимального количество партиций AUTO\_PARTITIONING\_MIN\_PARTITIONS\_COUNT. Тогда спады нагрузки не приведут к снижению количества партиций ниже необходимого, и не будет потребности их заново делить при появлении нагрузки.
* AUTO\_PARTITIONING\_MIN\_PARTITIONS\_COUNT — объединение партиций (merge) производится, только если их фактическое количество превышает заданное этим параметром значение.
* AUTO\_PARTITIONING\_MAX\_PARTITIONS\_COUNT — разделение партиций (split) производится, только если их количество не превышает заданное этим параметром значение.
* UNIFORM\_PARTITIONS — количество партиций для равномерного начального разделения таблицы. Первая колонка первичного ключа должна иметь тип Uint64 или Uint32. Созданная таблица сразу будет разделена на указанное количество партиций.
**Чтение из реплик**
При выполнении запросов в YDB фактическое выполнение запроса к каждому шарду осуществляется в единой точке, обслуживающей протокол распределённых транзакций. Но благодаря хранению данных на разделяемом хранилище возможен запуск одного или нескольких фолловеров шарда без выделения дополнительного места в хранилище — данные уже хранятся реплицированно и возможно обслуживание более одного читателя (но писатель при этом всё ещё в каждый момент строго один).
Применение чтения из фолловеров позволяет:
* Обслуживать клиентов, критичных к минимальным задержкам, недостижимым иными способами в мульти-ДЦ-кластере.
* Обслуживать читающие запросы из фолловеров без влияния на модифицирующие запросы, выполняющиеся на шарде.
* Продолжать обслуживание при переездах лидера партиции (как штатной, при балансировке, так и при сбоях).
* В целом повышать предел производительности чтения шарда, если множество читающих запросов попадают на одни и те же ключи. Можно указать необходимость запуска реплик для чтения для каждого шарда таблицы. Обращения к репликам для чтения (то есть к фолловерам) обычно происходят в пределах сети дата-центра, что позволяет обеспечить время ответа в единицы миллисекунд.
* READ\_REPLICAS\_SETTINGS — PER\_AZ означает использование указанного количества реплик в каждой AZ.
#### Примеры запуска нагрузки
Запуск нагрузки insertRandomOrder на 10 секунд в 10 потоков с 1000 видов товаров:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run insertRandomOrder -s 120 -t 10 -p 1000
```
Запуск нагрузки submitRandomOrder на 10 секунд в 5 потоков с 1000 видов товаров в заказе:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run submitRandomOrder -s 10 -t 5 -p 1000
```
Запуск нагрузки getRandomCustomerHistory на 5 секунд в 10 потоков:
```
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run getRandomCustomerHistory -s 5 -t 10
```
Пример результатов нагрузки:
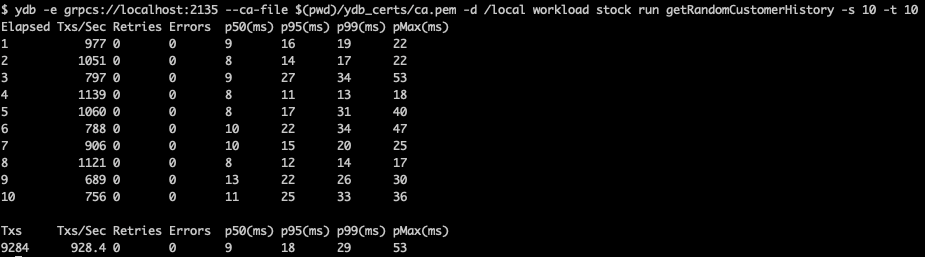
Что означают результаты вывода:
* Elapsed — номер временного окна. По умолчанию временное окно равно 1 секунде.
* Txs/sec — количество успешных транзакций нагрузки во временном окне.
* Retries — количество повторных попыток исполнения транзакции клиентом во временном окне.
* Errors — количество ошибок, случившихся во временном окне.
* p50(ms) — 50-й перцентиль latency запросов в мс.
* p95(ms) — 95-й перцентиль latency запросов в мс.
* p99(ms) — 99-й перцентиль latency запросов в мс.
* pMax(ms) — 100-й перцентиль latency запросов в мс.
* Timestamp — временная метка конца временного окна.
#### Завершение работы с Docker-контейнером
После завершения работы с YDB остановите Docker-контейнер:
```
docker kill ydb-local
```
#### Какие еще есть варианты использования?
Мы постарались предоставить максимальную гибкость при использовании YDB. Для локального тестирования или отладки можно использовать [Docker-контейнер](https://ydb.tech/ru/docs/getting_started/self_hosted/ydb_docker) или запустить кластер в Kubernetes (например, локально при помощи [Minikube](https://ydb.tech/ru/docs/getting_started/self_hosted/ydb_minikube)). Можно самостоятельно сконфигурировать и запустить кластер YDB с помощью подготовленной нами [сборки](https://ydb.tech/ru/docs/getting_started/self_hosted/ydb_local).
Для промышленной эксплуатации мы рекомендуем развернуть YDB [с помощью Kubernetes](https://ydb.tech/ru/docs/deploy/orchestrated/concepts) либо воспользоваться полностью управляемым [сервисом](https://cloud.yandex.ru/docs/ydb/) в Yandex Cloud. И, конечно, вы всегда можете [собрать](https://github.com/ydb-platform/ydb#how-to-build-from-source-code) YDB из исходников.
Что дальше?
-----------
Выход в опенсорс — ни в коем случае не финальная остановка. Для нас это скорее начало пути к тому, чтобы стать одной из лучших баз в мире в своём сегменте. Предстоит серьёзная работа: прямо сейчас мы активно трудимся над расширением аналитических способностей YDB.
В разработке возможность «охлаждения» данных в таблицах YDB для удешевления их хранения. Также мы планируем подготовить драйверы для популярных бенчмарков (таких как TPC-C и YCSB), чтобы предоставить возможность тестировать YDB привычным способом и сравнивать базу с аналогами. Планируем продолжать работу над инструментами экспорта и импорта данных. Будем развивать CDC — генерацию потоков событий об изменениях в БД и механизм записи этих событий в поддерживаемые системы передачи (чтобы получить консистентное состояние при их обработке на «приёмнике»). И, конечно, одним из безусловных приоритетов для нас всегда остаётся повышение эффективности системы и улучшение производительности.
Если у вас возникли вопросы — спрашивайте в комментариях и задавайте их на Stack Overflow с тегом YDB. Узнать больше о возможностях и вариантах использования, познакомиться с документацией, а также загрузить необходимые файлы и инструменты можно на странице [ydb.tech](https://ydb.tech). | https://habr.com/ru/post/660271/ | null | ru | null |
# Валидация элементов формы textInputLayout в Android с помощью связывания данных
> Прямо сейчас в OTUS открыт набор на [новый поток курса "Android Developer. Basic"](https://otus.pw/Plc2/). В преддверии старта курса традиционно подготовили для вас интересный перевод, а так же предлагаем посмотреть [день открытых дверей по курсу, в рамках которого вы подробно узнаете о процессе обучение и получите ответы на интересующие вопросы](https://otus.pw/Plc2/).
>
>

---
### Удобный способ валидации форм
*«Чтобы научиться чему-то хорошо, нужно научиться делать это несколькими способами».*
Несколько дней назад я работал над проектом, где мне нужно было реализовать валидацию элементов формы `textInputLayout` и `textInputEditText` с помощью связывания данных. К сожалению, доступно не так много документации на эту тему.
В конце концов я добился желаемого результата, изучив кое-какие материалы и проведя ряд экспериментов. Вот что я хотел получить:
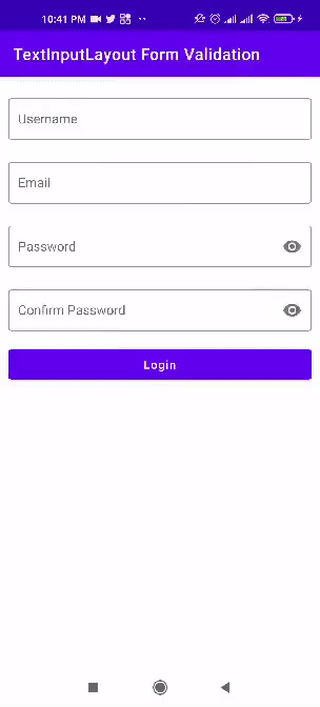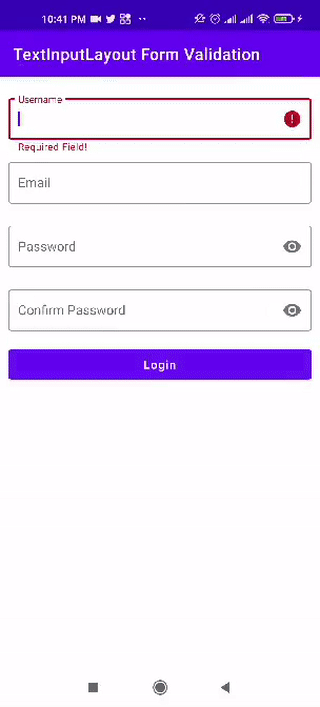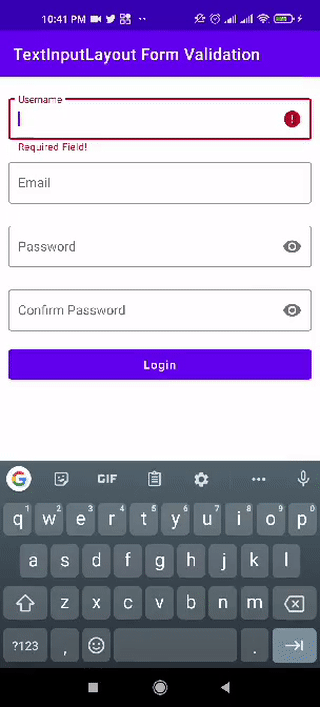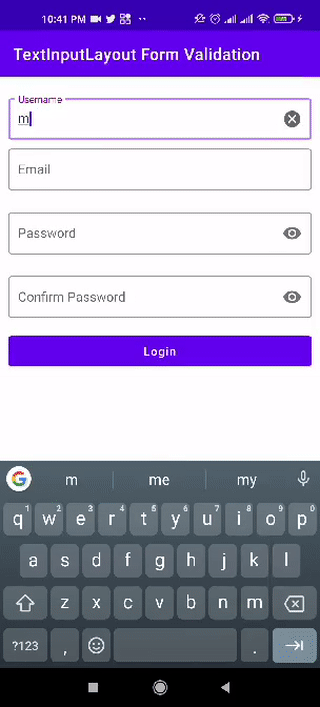Финальный вид приложенияУверен, что многие разработчики хотели бы реализовать такой же функционал и удобное взаимодействие с формами. Итак, давайте начнем.
Что нам потребуется?
--------------------
1. [Kotlin](https://developer.android.com/kotlin)
2. Статья [Связывание данных](https://medium.com/better-programming/android-data-binding-139686b65aec)
3. [Библиотека Material](https://material.io/)
Я разобью проект на этапы, чтобы легче было понять, что мы делаем.
**1.** Настроим исходный проект и включим связывание данных в файле `build.gradle(:app)`, добавив под тег `android{}` следующую строку:
```
dataBinding{
enabled true
}
```
Для использования элементов `textInputLayout` и `textInputEditText` необходимо включить поддержку Material для Android, добавив в файл `build.gradle(:app)` следующую зависимость:
```
implementation 'com.google.android.material:material:1.2.1'
```
Создадим макет нашей формы. Я сделаю простой макет, потому что моя цель — определить его основной функционал, а не создать хороший дизайн.
Я создал вот такой простой макет:
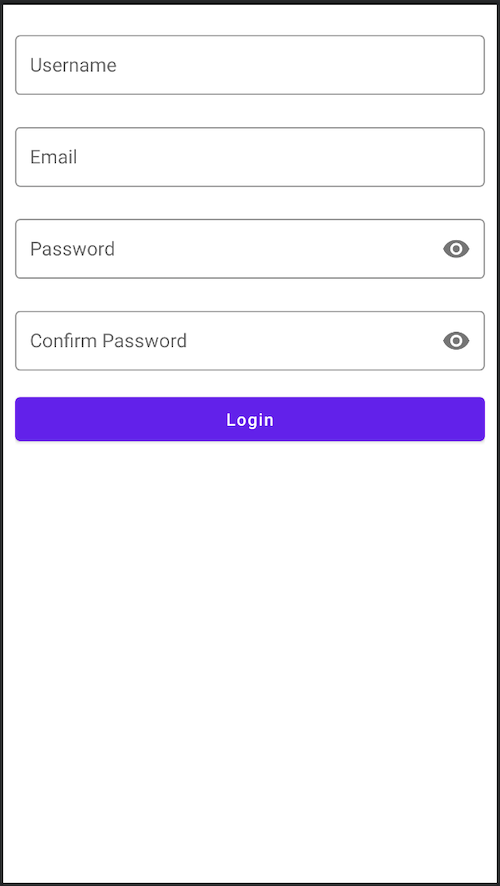Вот содержимое файла `activity_main.xml`:
```
xml version="1.0" encoding="utf-8"?
```
*Если вас смущают теги* *, не переживайте — о них я написал в своей* [*предыдущей статье*](https://medium.com/better-programming/android-data-binding-139686b65aec)*.*
Наш макет готов. Теперь займемся кодом.
**2.** На GIF-анимации, показывающей поведение финального варианта приложения (см. выше), видно, как появляются и исчезают сообщения об ошибках, когда заданные условия принимают значение **true**. Это происходит потому, что я связал каждое текстовое поле с объектом **TextWatcher**, к которому постоянно происходит обращение по мере ввода текста пользователем.
В файле `MainActivity.kt` я создал класс, который унаследован от класса `TextWatcher`:
```
/**
* applying text watcher on each text field
*/
inner class TextFieldValidation(private val view: View) : TextWatcher {
override fun afterTextChanged(s: Editable?) {}
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {
// checking ids of each text field and applying functions accordingly.
}
}
```
Параметр `view`, который передается в конструктор класса, я опишу позже.
**3.** Это основная часть. У каждого текстового поля имеется ряд условий, которые должны иметь значение true перед отправкой данных формы. Код, задающий условия для каждого текстового поля, представлен ниже:
```
/**
* field must not be empy
*/
private fun validateUserName(): Boolean {
if (binding.userName.text.toString().trim().isEmpty()) {
binding.userNameTextInputLayout.error = "Required Field!"
binding.userName.requestFocus()
return false
} else {
binding.userNameTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) text should matches email address format
*/
private fun validateEmail(): Boolean {
if (binding.email.text.toString().trim().isEmpty()) {
binding.emailTextInputLayout.error = "Required Field!"
binding.email.requestFocus()
return false
} else if (!isValidEmail(binding.email.text.toString())) {
binding.emailTextInputLayout.error = "Invalid Email!"
binding.email.requestFocus()
return false
} else {
binding.emailTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) password lenght must not be less than 6
* 3) password must contain at least one digit
* 4) password must contain atleast one upper and one lower case letter
* 5) password must contain atleast one special character.
*/
private fun validatePassword(): Boolean {
if (binding.password.text.toString().trim().isEmpty()) {
binding.passwordTextInputLayout.error = "Required Field!"
binding.password.requestFocus()
return false
} else if (binding.password.text.toString().length < 6) {
binding.passwordTextInputLayout.error = "password can't be less than 6"
binding.password.requestFocus()
return false
} else if (!isStringContainNumber(binding.password.text.toString())) {
binding.passwordTextInputLayout.error = "Required at least 1 digit"
binding.password.requestFocus()
return false
} else if (!isStringLowerAndUpperCase(binding.password.text.toString())) {
binding.passwordTextInputLayout.error =
"Password must contain upper and lower case letters"
binding.password.requestFocus()
return false
} else if (!isStringContainSpecialCharacter(binding.password.text.toString())) {
binding.passwordTextInputLayout.error = "1 special character required"
binding.password.requestFocus()
return false
} else {
binding.passwordTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) password and confirm password should be same
*/
private fun validateConfirmPassword(): Boolean {
when {
binding.confirmPassword.text.toString().trim().isEmpty() -> {
binding.confirmPasswordTextInputLayout.error = "Required Field!"
binding.confirmPassword.requestFocus()
return false
}
binding.confirmPassword.text.toString() != binding.password.text.toString() -> {
binding.confirmPasswordTextInputLayout.error = "Passwords don't match"
binding.confirmPassword.requestFocus()
return false
}
else -> {
binding.confirmPasswordTextInputLayout.isErrorEnabled = false
}
}
return true
}
```
**4.** Теперь необходимо связать каждое текстовое поле с классом `textWatcher`, который был создан ранее:
```
private fun setupListeners() {
binding.userName.addTextChangedListener(TextFieldValidation(binding.userName))
binding.email.addTextChangedListener(TextFieldValidation(binding.email))
binding.password.addTextChangedListener(TextFieldValidation(binding.password))
binding.confirmPassword.addTextChangedListener(TextFieldValidation(binding.confirmPassword))
}
```
Но как класс `TextFieldValidation` узнает, с каким текстовым полем нужно связываться? Прокрутив статью выше, вы увидите, что я добавил следующий комментарий в один из методов класса `TextFieldValidation`:
```
// проверка идентификаторов текстовых полей и применение соответствующих функций
```
Обратите внимание, что я передаю параметр view в конструктор класса `TextFieldValidation`, который отвечает за разделение каждого текстового поля и применение каждого из указанных выше методов следующим образом:
```
/**
* applying text watcher on each text field
*/
inner class TextFieldValidation(private val view: View) : TextWatcher {
override fun afterTextChanged(s: Editable?) {}
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {
// checking ids of each text field and applying functions accordingly.
when (view.id) {
R.id.userName -> {
validateUserName()
}
R.id.email -> {
validateEmail()
}
R.id.password -> {
validatePassword()
}
R.id.confirmPassword -> {
validateConfirmPassword()
}
}
}
}
```
Финальный вариант файла `MainActivity.kt` выглядит так:
```
package com.example.textinputlayoutformvalidation
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import android.text.Editable
import android.text.TextWatcher
import android.util.Patterns
import android.view.View
import android.widget.Toast
import androidx.databinding.DataBindingUtil
import com.example.textinputlayoutformvalidation.FieldValidators.isStringContainNumber
import com.example.textinputlayoutformvalidation.FieldValidators.isStringContainSpecialCharacter
import com.example.textinputlayoutformvalidation.FieldValidators.isStringLowerAndUpperCase
import com.example.textinputlayoutformvalidation.FieldValidators.isValidEmail
import com.example.textinputlayoutformvalidation.databinding.ActivityMainBinding
/**
* created by : Mustufa Ansari
* Email : [email protected]
*/
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.activity_main)
setupListeners()
binding.loginButton.setOnClickListener {
if (isValidate()) {
Toast.makeText(this, "validated", Toast.LENGTH_SHORT).show()
}
}
}
private fun isValidate(): Boolean =
validateUserName() && validateEmail() && validatePassword() && validateConfirmPassword()
private fun setupListeners() {
binding.userName.addTextChangedListener(TextFieldValidation(binding.userName))
binding.email.addTextChangedListener(TextFieldValidation(binding.email))
binding.password.addTextChangedListener(TextFieldValidation(binding.password))
binding.confirmPassword.addTextChangedListener(TextFieldValidation(binding.confirmPassword))
}
/**
* field must not be empy
*/
private fun validateUserName(): Boolean {
if (binding.userName.text.toString().trim().isEmpty()) {
binding.userNameTextInputLayout.error = "Required Field!"
binding.userName.requestFocus()
return false
} else {
binding.userNameTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) text should matches email address format
*/
private fun validateEmail(): Boolean {
if (binding.email.text.toString().trim().isEmpty()) {
binding.emailTextInputLayout.error = "Required Field!"
binding.email.requestFocus()
return false
} else if (!isValidEmail(binding.email.text.toString())) {
binding.emailTextInputLayout.error = "Invalid Email!"
binding.email.requestFocus()
return false
} else {
binding.emailTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) password lenght must not be less than 6
* 3) password must contain at least one digit
* 4) password must contain atleast one upper and one lower case letter
* 5) password must contain atleast one special character.
*/
private fun validatePassword(): Boolean {
if (binding.password.text.toString().trim().isEmpty()) {
binding.passwordTextInputLayout.error = "Required Field!"
binding.password.requestFocus()
return false
} else if (binding.password.text.toString().length < 6) {
binding.passwordTextInputLayout.error = "password can't be less than 6"
binding.password.requestFocus()
return false
} else if (!isStringContainNumber(binding.password.text.toString())) {
binding.passwordTextInputLayout.error = "Required at least 1 digit"
binding.password.requestFocus()
return false
} else if (!isStringLowerAndUpperCase(binding.password.text.toString())) {
binding.passwordTextInputLayout.error =
"Password must contain upper and lower case letters"
binding.password.requestFocus()
return false
} else if (!isStringContainSpecialCharacter(binding.password.text.toString())) {
binding.passwordTextInputLayout.error = "1 special character required"
binding.password.requestFocus()
return false
} else {
binding.passwordTextInputLayout.isErrorEnabled = false
}
return true
}
/**
* 1) field must not be empty
* 2) password and confirm password should be same
*/
private fun validateConfirmPassword(): Boolean {
when {
binding.confirmPassword.text.toString().trim().isEmpty() -> {
binding.confirmPasswordTextInputLayout.error = "Required Field!"
binding.confirmPassword.requestFocus()
return false
}
binding.confirmPassword.text.toString() != binding.password.text.toString() -> {
binding.confirmPasswordTextInputLayout.error = "Passwords don't match"
binding.confirmPassword.requestFocus()
return false
}
else -> {
binding.confirmPasswordTextInputLayout.isErrorEnabled = false
}
}
return true
}
/**
* applying text watcher on each text field
*/
inner class TextFieldValidation(private val view: View) : TextWatcher {
override fun afterTextChanged(s: Editable?) {}
override fun beforeTextChanged(s: CharSequence?, start: Int, count: Int, after: Int) {}
override fun onTextChanged(s: CharSequence?, start: Int, before: Int, count: Int) {
// checking ids of each text field and applying functions accordingly.
when (view.id) {
R.id.userName -> {
validateUserName()
}
R.id.email -> {
validateEmail()
}
R.id.password -> {
validatePassword()
}
R.id.confirmPassword -> {
validateConfirmPassword()
}
}
}
}
}
```
Запустим приложение и полюбуемся поведением формы ввода:
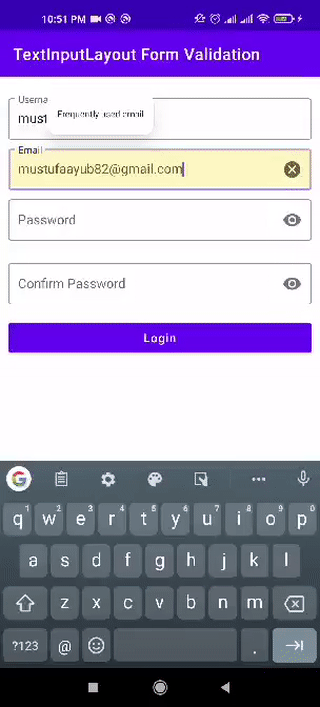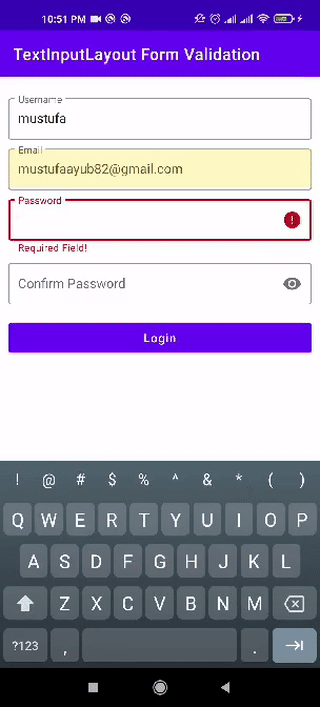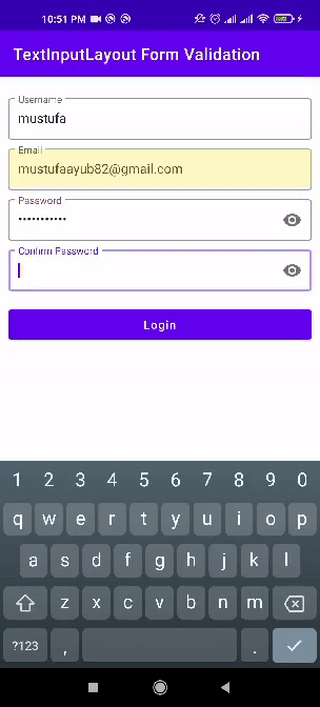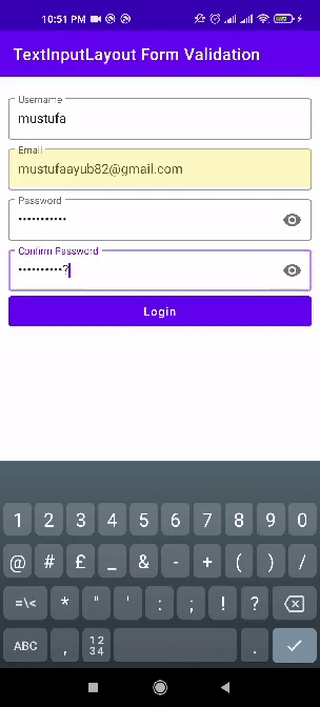Полный исходный код этого проекта можно скачать по ссылке ниже:
### https://github.com/Mustufa786/TextInputLayout-FormValidation
Надеюсь, вы узнали из этой статьи что-то новое для себя. Следите за появлением новых статей! Успехов в разработке!
> [Узнать подробнее о курсе.](https://otus.pw/Plc2/)
>
> | https://habr.com/ru/post/529886/ | null | ru | null |
# Создание приложения для Windows Phone 7 от начала до конца. Часть 8. Создание согласованного внешнего вида
[Предыдущая часть](http://habrahabr.ru/blogs/windows_mobile/118242/)
Существуют различные способы создания согласованного внешнего вида. Например, вы можете использовать встроенные стили и ресурсы, вы можете создать свой собственный стиль, а также вы можете использовать шаблоны данных для настройки элементов в списке.
В этой части вы узнаете:
* Как использовать стили, встроенные в Windows Phone.
* Как создать свой собственный стиль.
* Что такое шаблоны данных.
#### Цвета и темы
Согласованный внешний вид и соблюдение рекомендаций дизайна Metro крайне важны для Windows Phone приложений. На следующем изображении показаны примеры различных основных цветов (accent colors), а также светлая и тёмная темы.

#### Использование встроенных стилей
Также, как и каскадные таблицы стилей (CSS) совместно с HTML, XAML позволяет вам применять те же настройки для свойств элементов управления, используя специальный синтаксис, называемый расширением разметки. С помощью стилей и ресурсов вы можете повторно использовать настройки и создать для вашего приложения согласованный внешний вид.
Существует множество встроенных стилей и ресурсов для использования в Windows Phone проектах, которые соответствуют требованиям дизайна Metro и подходят как для светлой, так и для тёмной темы. Эти ресурсы включают кисти, цвета, шрифты, стили текста и темы.
В следующем примере показано, как привязать к фону (background) элемента управления Button кисть, являющуюся встроенным в Windows Phone ресурсом, с помощью расширения разметки.
> `1. <Button Content="Button" Height="72" Background="{StaticResource PhoneAccentBrush}" Width="160" />
> \* This source code was highlighted with Source Code Highlighter.`
На следующем изображении показано, как привязать к фону (background) элемента управления Button кисть, являющуюся встроенным в Windows Phone ресурсом, с помощью окна Properties.
Поскольку фон предыдущего примера имеет значение PhoneAccentBrush, цвет кнопки будет основываться на текущем основном цвете (accent color), выбранном пользователем. На следующем изображении показано, как кнопка выглядит, когда пользователь выбирает в качестве основного цвета синий или зеленый.

**Рекомендация по проектированию интерфейса:**
Если основной или фоновый цвет элемента управления задан явно, убедитесь, что его содержание одинаково хорошо видно как при темной, так и при светлой теме оформления. Если указанного цвета не видно, также явно задайте фон или основной цвет, чтобы он был достаточно контрастным или выберите более подходящий цвет.
В следующем примере показан TextBlock со страницы со сводной информацией приложения Fuel Tracker, где свойство Style имеет значение стиля, являющегося встроенным в Windows Phone ресурсом, с помощью расширения разметки.
> `1. <TextBlock Grid.Row="0" Grid.Column="0"
> 2. Style="{StaticResource PhoneTextLargeStyle}"
> 3. Text="CURRENT MPG:"
> 4. HorizontalAlignment="Right" VerticalAlignment="Center"/>
> \* This source code was highlighted with Source Code Highlighter.`
**Рекомендация по проектированию интерфейса:**
Придерживайтесь единого стиля использования заглавных букв.
Список доступных встроенных стилей и ресурсов для Windows Phone вы можете увидеть здесь: [Theme Resources for Windows Phone](http://msdn.microsoft.com/en-us/library/ff769552(VS.92).aspx). Дополнительные сведения о расширениях разметки вы можете получить здесь: [XAML Overview](http://msdn.microsoft.com/en-us/library/cc189036(VS.95).aspx).
#### Создание собственных стилей
Если вы хотите создать свой собственный стиль, как правило, вы должны объявить стиль как ресурс страницы или панели и применить его в качестве статического ресурса с помощью расширения разметки. Каждый стиль, как правило, имеет ключ (key), который используется для ссылки на него в дальнейшем, и целевой тип (target type), который указывает, к какому типу элементов управления он может быть применен. Основная часть стиля — это коллекция объектов Setter, которые содержат параметры Property (свойство) и Value (значение). Вы можете создавать стили в Visual Studio, указывая их прямо в коде XAML или вы можете использовать Expression Blend, который позволяет создавать стили более визуализированным способом. При создании ресурсов, которые устанавливают цвета, вы должны убедиться, что ваш выбор цветов одинаково хорошо выглядит как в светлой, так и в тёмной темах.
Приложение Fuel Tracker использует стили во многих местах. Например, страница со сводной информацией содержит стили **LabelStyle** и **ValueStyle** в первом элементе Pivot, который определен в разделе ресурсов Grid. В файле страницы со сводной информацией эти стили применяются к объектам TextBlock. Следующий фрагмент XAML-кода показывает пример того, как определяются стили и как они применяются.
> `1. <Grid.Resources>
> 2. <Style x:Key="LabelStyle" TargetType="TextBlock">
> 3. <Setter Property="HorizontalAlignment" Value="Right"/>
> 4. <Setter Property="Margin" Value="15,5" />
> 5. Style>
> 6. <Style x:Key="ValueStyle" TargetType="TextBlock">
> 7. <Setter Property="Margin" Value="15,5" />
> 8. Style>
> 9. Grid.Resources>
> 10.
> 11. . . .
> 12.
> 13. <TextBlock Grid.Row="2" Grid.Column="0"
> 14. Style="{StaticResource LabelStyle}"
> 15. Text="date:">TextBlock>
> 16.
> 17. <TextBlock Grid.Row="2" Grid.Column="1"
> 18. Style="{StaticResource ValueStyle}"
> 19. Text="{Binding FillupHistory[0].Date, Converter={StaticResource StringFormatter}, ConverterParameter=\{0:d\} }" >TextBlock>
> \* This source code was highlighted with Source Code Highlighter.`
#### Шаблоны данных
Когда вы привязываете коллекцию объектов к элементу управления ListBox или любому другому списку, ListBox отображает строковое представление объектов в коллекции. Для того, чтобы настроить внешний вида объектов в коллекции вам следует установить свойство ItemTemplate элемента управления ListBox в значение DataTemplate, который определяет внешний вид объектов. Дополнительную информации о том, как вы можете использовать шаблоны данных для настройки внешнего вида вы узнаете в следующей части под названием «Отображение данных».
[Следующая часть](http://habrahabr.ru/blogs/windows_mobile/118287/) | https://habr.com/ru/post/118281/ | null | ru | null |
# Мой второй день с Haiku: восхищен, но пока не готов перейти

**TL;DR: я восхищен Haiku, но доработать есть что**
[Вчера я изучал Haiku](https://habr.com/ru/company/southbridge/blog/461141/) — операционную систему, которая меня приятно удивила. День второй. Поймите правильно: я все еще восхищен тем, насколько легко она делает то, что тяжело дается на рабочих окружениях для Linux. Горю желанием узнать, как она работает, а также полон энтузиазма использовать ее ежедневно. Правда, день для полного перехода еще не наступил: страдать не хочется.
[](https://habrastorage.org/webt/f3/3i/cz/f33icz_otuexckcgwaagoidrqa0.png)
*Растровый графический редактор WonderBrush — если вы знаете, где его найти*
В принципе, ожидаемо для версии ниже 1.0. Однако не стоит преуменьшать удивительные достижения, помня Mac OS X в ее предрелизные дни, и с учетом размера команды Haiku.
Я обычно высказываю свои мысли о #LinuxUsability ([часть 1](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-1-5fa0fb369b42?source=post_page---------------------------), [часть 2](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-2-d34b86fd9b79?source=post_page---------------------------), [часть 3](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-3-780f127f5794?source=post_page---------------------------), [часть 4](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-4-13be6486b358?source=post_page---------------------------), [часть 5](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-5-d810a0d2f368?source=post_page---------------------------), [часть 6](https://medium.com/@probonopd/make-it-simple-linux-desktop-usability-part-6-1c03de7c00a9?source=post_page---------------------------)), так что не стоит удивляться придиркам к Haiku в плане удобства использования. Большинство из них, к счастью, относятся к различным усовершенствованиям.
Это было предисловие, а теперь обратим внимание на некоторые неприятности.
### Неприятность №1: неполадки с браузером
Есть 3 браузера, основанные на [WebKit](https://webkit.org/?source=post_page---------------------------): основной ([WebPositive](https://en.wikipedia.org/wiki/WebPositive?source=post_page---------------------------)) и два дополнительных на Qt (QupZilla, устаревшее название [Falkon](https://www.falkon.org/?source=post_page---------------------------), и [OtterBrowser](https://otter-browser.org/?source=post_page---------------------------)), которые могут быть установлены из репозитория. Ни один не работает корректно. У основного браузера есть проблемы с функциональностью и отрисовкой (к примеру, невозможно решить captcha при входе в [Haiku bugtracker](https://dev.haiku-os.org/query?source=post_page---------------------------)), а у дополнительных — большие проблемы с производительностью на Haiku.

*Так выглядит Twitter в WebPositive, основном браузере Haiku*
QupZilla и OtterBrowser сильно лагают на ненадежных соединениях с Интернетом (например, в поезде). Переключение между вкладками становится невозможным, если данные не влетают бесперебойно. Нереально открыть новую вкладку до тех пор, пока текущая загружает данные по сети. Все тупит, несмотря на малую загрузку. Вероятно браузеры не полностью оптимизированы под многопоточность Haiku, или имеют другие проблемы с Haiku [на Linux у меня тоже так иногда бывает — *прим. переводчика*].
С QupZilla мне не удалось написать что-либо на Medium...
[Компания Apple сделала много для обеспечения стабильной работы браузера с отличной производительностью](https://www.youtube.com/watch?v=xImAMe32Itg&source=post_page---------------------------). Мне кажется, эти вложения окупятся и на Haiku. Особенно с учетом возросшей важности веб-приложений, а тем более с учетом того, что родные приложения пока еще не доступны для всех вариантов использования.
*Рассказ Kenneth Kocienda и Richard Williamson: как появились Safari и Webkit*
### Неприятность №2: Launcher и Dock
В правом верхнем углу экрана расположен [Deskbar](https://www.haiku-os.org/docs/userguide/en/deskbar.html?source=post_page---------------------------), причудливая смесь, приготовленная из меню "Пуск" от Windows с вкраплениями функций Dock и некоторыми другими возможностями.
[](https://habrastorage.org/webt/wu/8c/dk/wu8cdkedsejj0ijyvqdnmj1oazm.png)
*Deskbar*
Поскольку это был, возможно, ключевой элемент пользовательского опыта для BeOS, ему не хватает возможностей современного рабочего окружения: мне нужно средство запуска программ, вроде [Spotlight](https://en.wikipedia.org/wiki/Spotlight_(software)?source=post_page---------------------------), запускаемое через Alt+пробел. Запуск приложений по щелчку медленный. Есть инструмент "Найти", выглядящий как [Штирлиц](https://en.wikipedia.org/wiki/Sherlock_(software)?source=post_page---------------------------) под прикрытием, но он не рассчитан на удобный запуск приложений, даже если ему придать ускорения.
[](https://habrastorage.org/webt/4v/d9/qe/4vd9qeznecf3fceeygfukkx4z74.png)
*Spotlight на Mac OS X Leopard, запущенный по Command + пробел*
Есть [LnLauncher](https://www.eiman.tv/LnLauncher/?source=post_page---------------------------), устанавливаемый в [HaikuDepot](https://depot.haiku-os.org/?source=post_page---------------------------). При первом запуске он полностью пустой, и не совсем понятно, как в него что-либо добавить. К тому же он появляется не в совсем удобном месте экрана без очевидного способа изменения позиции. Ну как мне поставить его слева или внизу экрана, как Dock в Mac OS X? Считаю, что UX в данном случае непознаваем.
[DockBert](https://github.com/HaikuArchives/DockBert?source=post_page---------------------------), также устанавливаемый из [HaikuDepot](https://depot.haiku-os.org/?source=post_page---------------------------). Уже лучше. Показывается внизу экрана. Немного не ожидал, что порядок иконок будет обратный: корзина в начале, но в целом выглядит многообещающе.
Как выставить его по-умолчанию вместо Deskbar? Если щелкнуть по иконке Deskbar в DockBert и выбрать "закрыть" — он, конечно, закроется… и появится обратно через полсекунды. (Разработчики сказали, что это, в принципе, bug в DockBert). Было бы неплохо, если бы DockBert был достаточно умным, понимая, что нужно пользователю и делая это. По-умолчанию, в DockBert нет иконок приложений, но он показывает "тяни сюда", так что известно, как все добавить. Однако у меня не получилось удалить приложения — ни щелкая правой кнопкой мыши, ни перетаскиванием иконки из DockBert.
Пробую [HiQDock](https://discuss.haiku-os.org/t/hiqdock-new-dock-coming-soon/3691?source=post_page---------------------------). Я его случайно нашел [в стороннем репозитории](https://www.software.besly.de/?source=post_page---------------------------). Выглядит так, как мне хочется. С упором на "выглядит". Потому что он пока что не работает: все еще Beta-версия. Он написан на Qt4, так что сомневаюсь, что его заберут в установочный образ.

*HiQDock.*
В принципе, не только я считаю, что ситуация с Dock и Launcher сложная. По этой теме я даже нашел [целую статью](https://www.haiku-os.org/blog/moochris/2017-01-22_which_launcher/).
*QuickLaunch*
Потом я узнал о [QuickLaunch](https://github.com/humdingerb/quicklaunch?source=post_page---------------------------), который рекомендуется запускать, добавив сочетание кнопок в настройках Shortcuts.
*Настройки Shortcuts в Haiku*
Было бы неплохо, если бы такие вещи были настроены, чтобы "просто работать" по-умолчанию. Я сказал Alt+пробел? Ну, в принципе, QuickLaunch может при первом запуске спросить, нужно ли настроить сочетание клавиш. Делать это в настройках Shortcuts громоздко.

*Окно, в котором предлагается ввести "приложение" в настройках Shortcuts. Без шуток*
Готов спорить, что большинство пользователей не знают, что надо ввести в качестве "приложения", а именно: `/boot/system/apps/QuickLaunch` (просто `QuickLaunch` не работает).
> Быстрое решение: поставить QuickLaunch по умолчанию и назначить ему ярлык alt+пробел по умолчанию.
К счастью, у меня есть информация от разработчиков, что в какой-то момент они, возможно, включат его в качестве улучшения или замены старого доброго Deskbar. Может быть… когда-нибудь… Скрестим пальцы! (Оставьте заявку, или его так и не будет. [Вот здесь](https://dev.haiku-os.org/ticket/14841)). Еще один разработчик сказал, цитата: "по моему мнению, следовать путем Windows, то есть включить поле поиска в начальное меню, это достаточно просто для Beta-версии, я бы сказал, это будет иметь огромное значение для многих". Согласен! (опять же: заявка или не будет).
А почему QuickLaunch находит программу для создания снимков экрана дважды, в `/boot/system/apps` и в `/boot/system/bin`? Разработчики в курсе, поскольку в файле /boot/system/apps/QuickLaunch/ReadMe.html.
> /system/bin ранее не обрабатывался, портированные программы часто попадают в каталог /bin, а это — плохая затея. Можно убрать нежелательные CLI приложения, к примеру с помощью кнопки "Добавить в список игнорирования" в контекстном меню
>
>
>
> быстрое решение: фильтровать приложения с /system/bin, существующие также в /system/apps
### Неприятность №3: нет аппаратного ускорения
BeOS была обвешана демонстрационными программами. Ни одно видео с BeOS не обходилось без множества окон с воспроизводящимися разными видеороликами. Удивительное достижение на то время. Haiku поставляется с 3D демонстрационными программами, показывающими 3d-шрифты, движущиеся в космосе. (Эй, Haiku ведь не готовят к IPO, а?)
*BeOS в 1995, на идеях которой основана Haiku. В то время работала на двух процессорах PowerPC 603 с тактовой частотой 66 МГц*
> Мы хотим стать Linux в мире звука и видео.
>
>
>
> —[Жан-Луи Гессе](https://de.wikipedia.org/wiki/Jean-Louis_Gassée?source=post_page---------------------------), генеральный директор
Что удивительно, видео и 3D на самом деле не ускоряются аппаратно в Haiku. Я полагаю, что игры тоже.
У разработчиков [mr. waddlesplash](https://medium.com/u/f103a52f4b96?source=post_page---------------------------) и [Alex von Gluck](https://medium.com/u/b7c6faaf2877?source=post_page---------------------------) есть документация для аппаратного ускорения («нужно порядка двух человеко-месяцев»). 3D ускорение будет через Mesa (Haiku, как уже говорилось, использует Mesa и LLVMPipe в качестве базы для OpenGL), для видео можно опереться на [FFmpeg](https://ffmpeg.org/?source=post_page---------------------------) или сделать собственное решение (мне известно, что Haiku уже использует FFMpeg внутри, просто без ускоренных драйверов невозможно использовать VDPAU или другой подобный API).
Скрестим пальцы!
### Неприятность №4: не ищутся программы
Я знаю, что уже достаточно много CLI программ портировано для Haiku, но я не вижу их в HaikuDepot. Нет даже намеков. В командной строке нет команд "haiku..." или "port..."
```
~/testing> haikuports
bash: haikuports: command not found
```
Погуглив, я [нашел](https://eu.hpkg.haiku-os.org/haikuports/master/x86_64/current/packages/), откуда скачал avrdude. При запуске по двойному щелчку показалось окно с неудовлетворенными зависимостями. Было бы неплохо, чтобы такое не случалось. (Одна из причин, почему мне так нравятся [пакеты](https://developer.apple.com/documentation/foundation/bundle?source=post_page---------------------------) .app для Mac и [AppImage](https://appimage.org/?source=post_page---------------------------) для Linux).
От разработчиков я узнал, что "теоретически" есть [система](https://eu.hpkg.haiku-os.org/haikuports/master/x86_64/current/repo_consistency.txt?source=post_page---------------------------), предотвращающая это. Видимо ей нужно больше любви.
Что же надо сделать? [Здесь](https://github.com/haikuports/haikuports/wiki) есть инструкции для тех, кто желает портировать программы для Haiku, но нет инструкций тем, кто просто желает пользоваться портированными программами. Тут-то я и встрял.
Разработчик сказал мне: "Мы не упоминаем о HaikuPorts, потому что 99.9% пользователей не обязаны знать или заботиться о том, как именно эти пакеты создаются и появляются в HaikuDepot". Согласен. Разговор о HaikuDepot, и о том, как получить что-то оттуда, потому что интерфейс HaikuDepot это не показывает (к примеру, `avrdude` cli). По всей видимости, должен быть флажок, отображающий приложения CLI в интерфейсе HaikuDepot, но я его не нашел, а может, его и не существует. ("Рекомендуемые" или "Все пакеты»… оно вам надо? Нет, не хочу смотреть "все" пакеты, предполагаю, что будет показано множество библиотек. Что-то вроде старого доброго [Synaptic](https://en.wikipedia.org/wiki/Synaptic_(software)?source=post_page---------------------------)).
Вместо этого я [нашел](https://haikuarchives.github.io/software.html). Также не в курсе, как его поставить (Говорят, что HaikuArchives это "хранилище поддерживаемого программного обеспечения", а также, что "все стоящие программы уже есть в HaikuPorts" — нужны интеграторы).
Еще чуток погуглив, я нашел:
```
/> pkgman search avrdudeStatus Name Description
-------------------------------
avrdude A tool to up/download to AVR microcontrollers
```
Ух ты! Было бы неплохо сделать эту команду более заметной. Один из разработчиков подтвердил, что "pkgman — cli аналог для HaikuDepot". Почему же ее тогда не назвали `haikudepot`?
Первым делом я поставил command\_not\_found-0.0.1~git-3-any.hpkg. Теперь могу делать так:
```
/> file /bin/bash
DEBUG:main:Entered CNF: file
This application is aviaiblible via pkgman install file
```
> быстрое решение: добавить `command_not_found-*-any.hpkg` в установку по умолчанию.
Разработчик Haiku считает, что "в Haiku, в отличие от Linux, нет реальной нужды в command-not-found", потому что "можно просто запустить pkgman install cmd:commandname". Ну откуда мне, "простому смертному", знать об этом?!
Пакеты, менеджеры пакетов, зависимости. Тот, что в Haiku, конечно намного умнее, чем большинство, но все же это менеджер пакетов:
```
/> pkgman install avrdude100% repochecksum-1 [65 bytes]
Validating checksum for Haiku…done.
100% repochecksum-1 [64 bytes]
Validating checksum for HaikuPorts... done.
100% repocache-2 [951.69 KiB]
Validating checksum for HaikuPorts... done.
Encountered problems:
problem 1: nothing provides lib:libconfuse>=2.7 needed by libftdi-1.4–7
solution 1:
- do not install “providing avrdude”
Please select a solution, skip the problem for now or quit.
select [1/s/q]:
```
Менеджеры пакетов делают то, что всегда, так или иначе, делают менеджеры пакетов независимо от операционной системы. Есть причина, по которой меня тянет — я уже говорил, нет? — к [пакетам](https://developer.apple.com/documentation/foundation/bundle?source=post_page---------------------------) .app и [AppImages](https://appimage.org/?source=post_page---------------------------).
Помимо этого здесь отсутствуют некоторые весьма популярные приложения с открытым исходным кодом:
```
/> pkgman install inkscape
100% repochecksum-1 [65 bytes]
Validating checksum for Haiku…done.
100% repochecksum-1 [64 bytes]
Validating checksum for HaikuPorts…done.
*** Failed to find a match for “inkscape”: Name not found
```
Ответ разработчиков: "Поскольку нету Gtk — не будет Inkscape". Понял. Еще один разработчик добавил: "Зато у нас есть удивительный WonderBrush". Не знал о таком, но его ведь не видно в HaikuDepot, да и откуда бы? (поправка: надо было переключиться на вкладку "Все пакеты»! Совершенно упустил этот момент!)
```
/> pkgman install gimp
100% repochecksum-1 [65 bytes]
Validating checksum for Haiku... done.
100% repochecksum-1 [64 bytes]
Validating checksum for HaikuPorts... done.
*** Failed to find a match for “gimp”: Name not found/> pkgman install arduino
100% repochecksum-1 [65 bytes]
Validating checksum for Haiku... done.
100% repochecksum-1 [64 bytes]
Validating checksum for HaikuPorts... done.
*** Failed to find a match for “arduino”: Name not found
```
Мне известно, что "arduino был там раньше"… куда все подевалось?
Кроме прочего, меня удивил факт «техноговорливости": столько строчек выводится просто так, чтобы в конце выдать: "это программное обеспечение недоступно".
### Неприятность №5: различные шероховатости, которые стоит подправить
**Переключение между приложениями**
Скучно без alt+tab для переключения приложений. Сtrl+tab работает, но как-то кривенько.
Подсказка от разработчиков: если я включу раскладку от Windows, Cmd и Ctrl поменяются местами, и alt+Tab станет привычным. Но я хочу чувствовать Mac, работая за клавиатурой от PC!
Замечание от разработчиков: "Переключение ctrl+tab на alt+tab удивит некоторых пользователей". Простое решение: включить оба! (я, как пользователь Mac, Windows и Linux с Gnome, KDE, Xfce все равно не знаю, чего ожидать).

*Переключение приложений через ctrl+tab используя Twitcher. Местами он появляется, иногда не с первого раза*
Что еще хуже: ctrl+tab иногда показывает окно с иконками приложений, а иногда — нет. Кроме прочего, порядок переключения приложений выглядит случайным: StyledEdit-WebPositive-обратно StyledEdit-WebPositive-StyledEdit-окно с иконками приложений… Программная ошибка? (Может, кто знает, есть ли инструмент записи Gif-изображеинй для Haiku?) **Поправка**: это такая особенность, а не ошибка.
Короткое нажатие сочетания ctrl+tab переключает непосредственно на предыдущее приложение без отображения окна Twitcher. Если удерживать сочетания дольше, получается то, к чему я уже привык.
**Shortcuts**
Если говорить о сочетаниях клавиш, то как только вы сообразили, что все схоже с Mac — автоматически попробуете использовать привычные сочетания… К примеру, в диалоговых окнах "Открыть..." и "Сохранить как..." мне хочется нажать alt+d для каталога "рабочий стол", ну и так далее.
У разработчиков "есть возможность добавить это", "в заявку на улучшение о файловых диалогах". Я бы создал такую заявку, будь местный issue tracker на GitHub или GitLab, где у меня есть учетные записи.
Но, как я уже пояснил ранее, я не могу зарегистрироваться в их системе. (Как вы уже наверное догадались, я хочу подчеркнуть легкость при работе с подобными вещами при использовании общедоступных сервисов типа GitHub или GitLab). Поправка: <https://dev.haiku-os.org/ticket/15148>
**Несоответствия**
Приложения на Qt и "родные" приложения различаются поведением. К примеру, можно удалить последнее слово с помощью alt+backspace в приложениях на Qt, но невозможно в родных. Возможно, есть и другие различия при редактировании текста. Хотелось бы, чтобы такие несоответствия убрали.
Поправка: я еще не окончил писать эту статью (я показал ее сначала на канале разработчиков Haiku для сбора комментариев), как выяснилось, что это несоответствие исправили! Невероятно! Как же я люблю проекты с открытым исходным кодом! Спасибо, [Kacper Kasper](https://github.com/KapiX?source=post_page---------------------------)!
### Примечания
Я все еще в процессе изучения Haiku, а она продолжает меня впечатлять. Несмотря на то, что сегодня я сосредоточился на описании неприятностей, не могу не напомнить, почему эта операционная система настолько интригующая. Ниже — несколько примеров. Просто напоминание, чтобы увидеть как в Haiku делаются концептуально правильные вещи.
Если дважды щелкнуть по исполняемому файлу, у которого нет нужных библиотек, в Linux ничего не видно. В Haiku появится приятный графический диалог с информацией о проблеме. Давно мечтал о подобных вещах в Linux, и до сих пор в восторге от того, что это сделано правильно в Haiku. Этим примером показано, что операционная система является согласованной на всех уровнях. Результат — элегантность, красота и простота, даже в таких случаях, как обработка ошибок.
### Увлекательное заглядывание под капот.
Документация по QuickLaunch гласит:
> Может быть 2 причины, по которым QuickLaunch не найдет приложение:
>
> * Приложение находится не на разделе с BeFS, или раздел BeFS не отформатирован для поддержки запросов.
> * Приложение не имеет надлежащего атрибута BEOS:APP\_SIG. В этом случае попросите разработчика приложения добавить его, или попробуйте последовать
>
> такому совету: если используете приложение или скрипт, которые не отображаются в QuickLaunch (и находятся в доступном для записи месте) — попробуйте добавить эти атрибуты в терминале.
>
>
>
> addattr BEOS:TYPE application/x-vnd.Be-elfexecutable /path/to/your/app-or-script
>
>
>
> addattr BEOS:APP\_SIG application/x-vnd.anything-unique /path/to/your/app-or-script
>
>
>
>
Это дает некоторое представление о том, как на самом деле работает магия, подобная Launch Services, которой я продолжаю восхищаться ([и которая напрочь отсутствует в рабочих окружениях на Linux](https://github.com/AppImage/appimaged/issues/30?source=post_page---------------------------)).
### Не менее увлекательно "Открыть с помощью..."
Выберите файл, нажмите alt+I, после чего на информационном экране можно выбрать, какое приложение может открывать определенный файл.

*В Haiku я могу переопределить приложение для открытия одного конкретного файла. Круто?*
Все это работает, даже при отсутствующем расширении имени файла, и я могу, наконец-то, указать для разных файлов одного типа, что они должны открываться в разных приложениях, что очень сложно, если не почти невозможно, в рабочих окружениях Linux.
### Заключение
Как я уже писал вчера, Haiku открыла мне глаза, показала, как рабочее окружение может "просто работать". На второй день я также нашел несколько моментов, явно нуждающихся в доработке.
Ни один из них не остановит работу. Я реально взволнован будущим этой личной операционной системы для настольных компьютеров. Это долгожданное развитие за пределами "рабочих окружений Linux", продолжающих показывать серьезные, нерешаемые в ближайшее время, [архитектурные проблемы](https://media.ccc.de/v/ASG2018-174-2018_desktop_linux_platform_issues?source=post_page---------------------------).
Надеюсь на Haiku.
Попробуйте сами! Ведь проект Haiku предоставляет образы для загрузки с DVD или USB, формируемые [ежедневно](https://download.haiku-os.org/?source=post_page---------------------------). Для установки достаточно скачать образ и записать его на флешку с помощью [Etcher](https://www.balena.io/etcher/?source=post_page---------------------------)
Появились вопросы? Приглашаем вас в русскоязычный [telegram-канал](https://t.me/HaikuOS_RU_chat).
Обзор ошибок: [Как выстрелить себе в ногу в C и C++. Сборник рецептов Haiku OS](https://habr.com/ru/company/pvs-studio/blog/461255/)
От автора перевода: это вторая статья из цикла про Haiku.
Список статей: [Первая](https://habr.com/ru/company/southbridge/blog/461141/) Вторая [Третья](https://habr.com/ru/company/southbridge/blog/462815/) [Четвертая](https://habr.com/ru/company/southbridge/blog/463105/) [Пятая](https://habr.com/ru/company/southbridge/blog/463803/) [Шестая](https://habr.com/ru/company/southbridge/blog/464819/) [Седьмая](https://habr.com/ru/company/southbridge/blog/465241/) [Восьмая](https://habr.com/ru/company/southbridge/blog/466301/) [Девятая](https://habr.com/company/southbridge/blog/468059/) | https://habr.com/ru/post/461451/ | null | ru | null |
# «constexpr» функции не имеют спецификатор «const»
Просто хотел Вас предупредить: С++14 не будет обратно совместим с C++11 в одном аспекте `constexpr` функций.
В С++11, если Вы определите `constexpr` функцию-член, то она неявно получит спецификатор `const`:
```
// C++11
struct NonNegative
{
int i;
constexpr int const& get() /*const*/ { return i; }
int& get() { return i; }
};
```
Первое объявление функции `get` получит спецификатор `const`, даже если мы не укажем это явно. Следовательно, эти две функции являются перегруженными: `const` и не-`const` версии.
В С++14 это будет уже не так: оба объявления будут определять одиннаковую, не-`const` версию функции-члена с различающимися возвращаемыми значениями — это приведет к ошибке компиляции. Если Вы уже начали использовать `constexpr` функции и надеетесь на неявный спецификатор `const`, то я советую Вам начать добавлять его явно, чтобы Ваш код продолжал компилироваться, если Вы решите перейти на компиляторы С++14.
#### Что не так с неявным `const`?
Проблемы начнутся, если Вы попытаетесь использовать наш тип следующим образом:
```
// C++11
constexpr int i = NonNegative{2}.get(); // ERROR
```
Согласно (несколько необычным) правилам С++, при выборе функции-члена для временного объекта, не-`const` версия предпочтительней `const` версии. Наша не-`const` функция-член `get` не является `constexpr`, поэтому она не может быть использована для инициализации `constexpr` переменной и мы получим ошибку на этапе компиляции. Мы не можем сделать эту функцию `constexpr`, потому что это автоматически добавит спецификатор `const`…
Я сказал, что правила подбора лучшей функции — необычны, потому что они немного противоречат тому, как мы выбираем лучшую функцию-нечлен для временных объектов. В этом случае мы предпочитаем `const` lvalue ссылки к не-`const` версии:
```
// C++11
constexpr int const& get(NonNegative const& n) { return n.i; }
constexpr int& get(NonNegative& n) { return n.i; }
NonNegative N = readValue();
constexpr int * P = &get(N);
int main()
{
*P = 1;
}
```
Смотрите, что получается: глобальная переменная `N` не является константой. Поэтому вторая, не-`const` перегруженная функция выбирается для вызова при инициализации указателя `P`. Но не-`const` функция при этом все равно имеет спецификатор `constexpr`! А все потому, что правило "`constexpr` означает `const`" применяется только для неявного `this` аргумента нестатической функции-члена. `constexpr` функция может получить ссылку на не-`const` объект и вернуть ссылку на не-`const` подобъект. Здесь нету никаких проблем: адрес глобального объекта постоянен и известен во время компиляции. Однако значение по адресу `P` не постоянно и может быть изменено позже.
Если предыдущий пример выглядит несколько надуманным, рассмотрим следующий, более реалистичный пример:
```
// C++11
constexpr NonNegative* address(NonNegative& n) { return &n }
NonNegative n{0}; // non-const
constexpr NonNegative* p = address(n);
```
Здесь все работает отлично, но если Вы попытаетесь сделать `address` функцией членом, она перестанет работать:
```
// C++11
struct NonNegative
{
// ...
constexpr NonNegative* maddress() { return this; } // ERROR
};
NonNegative n{0}; // non-const
constexpr NonNegative* p = n.maddress();
```
Это потому, что `maddress` неявно определен со спецификатором `const`, `this` имеет тип `NonNegative const*` и не может быть конвертировано к `NonNegative*`.
Следует отметить, что это не сама функция-член является `const`, а *неявный* (`this`) аргумент функции. Объявление функции-члена может быть переписано в псевдо-коде как:
```
// PSEUDO CODE
struct NonNegative
{
// ...
constexpr NonNegative* maddress(NonNegative const& (*this));
};
```
И этот неявный аргумент функции, в отличие от других аргументов функций, получает (иногда нежелательный) спецификатор `const`.
Эта асимметричность будет удалена в С++14. Если Вы хотите спецификатор `const` для неявного аргумента (`this`), Вам следует добавить его самим. Следующий код будет действительным в C++14:
```
// C++14
struct NonNegative
{
int i;
constexpr int const& get() const { return i; }
constexpr int& get() { return i; }
};
``` | https://habr.com/ru/post/184250/ | null | ru | null |
# Нормальные алгоритмы Маркова как основание языка программирования
В этой статье хотелось бы поделиться мыслями о применении Нормальных Алгоритмов Маркова (далее по тексту: НАМ) в качестве основания для языка программирования.
Заранее скажу, что представленный концепт ЯП не претендует на решение каких-либо «мировых» проблем программирования, не представляет собой замену существующим инструментам, это результат моих скромных исследований в области проектирования ЯП.
К истории вопроса
-----------------
20 век ознаменовался становлением и бурным развитием компьютерной индустрии. Пока практики — инженеры и программисты совершенствовали компьютеры и программы для них, теоретики — математики, а позже и специалисты в области компьютерных наук, совершенствовали формальное основание всего этого.
На заре вычислительной эры, когда объёмы памяти измерялись не гигабайтами, а за клавиатурами сидели не любители булочек, а электрики и учёные, одной из важнейших задач теоретической информатики была формализация понятия «алгоритм». Решения этой задачи были найдены, и как следует из моих слов, этих решений было несколько.
Первой, и самой очевидной для нас сейчас, формализацией алгоритма была машина Тьюринга (а также её собратья: машина Поста и машина Минского). Машина представляла собой устройство, последовательно читающее ленту с командами и выполняющее их. Всё просто и понятно: алгоритм в данном случае являлся последовательностью шагов, которые приводят к какому-либо результату.
Иной, «более математический» вариант предложил Алонзо Чёрч: разработанная им теория лямбда-исчисления представляла алгоритм как совокупность аппликации — применения функции к аргументу и абстракции — создания новой функции.
Наконец, третью составляющую важность для нас теорию предложил советский математик Андрей Андреевич Марков. Нормальный алгоритм, введённый Марковым состоял из трёх частей:
1. Алфавита, с которым работает алгоритм.
2. Правил подстановки.
3. Начального состояния.
Алфавит представляет собой множество символов которые алгоритм будет распознавать. К алфавиту применяются *правила подстановки*. Правила подстановки есть правила вида: `A → B`*,* означающее, что всякое `A` мы заменяем на `B`. Для наглядности рассмотрим пример:
```
Алфавит = A, B, C
Правила = A → B,
B → CC,
C → ø
Исходное состояние = ABC
Шаг 0. ABC
Шаг 1. BBC
Шаг 2. CCBC
Шаг 3. øCBC
Шаг 4. øøBC
Шаг 5. øøCCC
Шаг 6. øøøCC
Шаг 7. øøøøC
Шаг 8. øøøøø
```
В кратце, именно в этом и состоит суть НАМ.
Так что же с языками программирования? — спросит читатель, порядком уставший от заунывных теоретических выкладок, — Доколе бюрократией мы будем заниматься?
Не унывать! — отвечу я, — переходим ближе к делу.
Итак, мы имеем три основных формализации алгоритмов — в основу каких парадигм и языков программирования они легли? Машина Тьюринга стала базой для императивного программирования, в лоне лямбда-исчисления сформировался функциональный подход. Что же с НАМ? А они стали основой для продукционной парадигмы, о которой ни то, что статьи в Википедии, но и в обозримой части Интернета материалов нет (соглашусь, если Вы скажете, что есть, но они очень низкого качества). Да, из всё той же Википедии вы узнаете, что нормальные алгоритмы воплотились в языке РЕФАЛ, но я спешу сообщить следующее: (1) к сожалению, он не обрёл должной популярности, не смог распространить идеи продукционного программирования среди широких масс, (2) концепт языка, который я хотел представить сильно отличается от РЕФАЛа, (3) кроме нормальных алгоритмов РЕФАЛ содержит множество других средств, моей же задачей было исследовать язык содержащий только НАМ. (Про Thue и MarkovJunior я молчу, позже вы поймёте, почему).
Перейдём же теперь от теории к практике.
---
LN — язык, основанный на нормальных алгоритмах
----------------------------------------------
LN (**L**anguage of **N**ormal Markov algorithms, знаю, сокращение необычное) — это язык, основанный на НАМ, который навязывает их так же, как C — императивный подход, а Haskell — доску, мел и учебник по теории категорий.
В отличие от других «Марковских» ЯП — Thue и MarkovJunior, LN работает не с отдельными символами, а со *словами* и *последовательностями*, то бишь, в нём возможно создать правило типа `python → shit`, `c_coding → Segmentation fault`, `best language → lisp` или `maybe vim? → no, emacs better`.
*Словом* будем называть любую совокупность символов, ограниченную пробелами, *последовательностью* — слова ограниченные специальными словами `[` и `]`. Таким образом `JS` — слово, `JS is evil` — 3 разных слова, `[ JS is evil ]` — последовательность слов.
Основу языка составляет единственное ключевое слово: `rule`, посредством которого создаются новые правила подстановки, имеет оно следующий синтаксис:
```
rule .word .word (выполняем подстановку типа слово → слово)
rule .word .seq (выполняем подстановку типа слово → последовательность)
rule .seq .word (выполняем подстановку типа последовательность → слово)
rule .seq .seq (выполняем подставноку типа последовательность → последовательность)
```
Учитывая это, приведённые выше холиварные примеры можно переписать так:
```
rule python shit
rule c_coding [ Segmentation fault ]
rule [ Best language ] Lisp
rule [ maybe vim? ] [ no, Emacs better ]
```
Теперь, имея правила, неплохо было бы их применять. Условимся всё, что не является вызовом ключевого слова, считать исходным состоянием. Тогда нашу одиозную программу выше можно дополнить так:
```
python
c_coding
[ Best language ] [ maybe vim? ]
```
После ряда подстановок мы получим следующий код:
```
shit
[ Segmentation fault ]
Lisp no, emacs better
```
После этого интерпретатор попытается вычислить этот код, у него ничего не получится, и мы получим ошибку. Но так как пока это лишь концепт, и интерпретатор не ограничивает нашу фантазию, то мы можем побаловаться, не обращая внимания на работоспособность программ.
Важно отметить тот факт, что представленный выше результат работы программы весьма условен: на самом деле сначала интерпретатор прочтёт слово `python`, обнаружит, что для него существует правило, выполнит подстановку и придёт к ошибке.
Создание простейших программ
----------------------------
Как можно использовать такой необычный язык программирования? Ну, например, он может решать задачи по готовым формулам, т.е. выполнять роль мощного калькулятора. Приведём пример:
> Задача. Воде, массой 5 кг и теплоёмкостью 4200 Дж/кг×°C, сообщили теплоту. В результате её температура изменилась на 20°C. Какую теплоту сообщили воде? Теплообменом с сосудом и окружающей средой пренебречь.
>
>
Для решения этой задачи достаточно написать простейшую программу:
```
rule Q [ * C m dT ]
rule C 4200
rule m 5
rule dT 20
print Q
```
Из приведённого выше примера можно сделать следующие выводы:
1. В языке используется префиксная нотация для записи выражений.
2. Функция `print` реализует вывод на экран.
3. Программа написана в декларативном стиле, т.е. мы лишь описали саму задачу, решение же её возложено на компьютер.
Кроме того, такой язык «из коробки» может решать системы уравнений методом подстановки, достаточно лишь задать саму систему и выразить одну из переменных.
Ну а что же с реальными задачами? — спросит неутомимый практик, — Уравнения решать и энергию расчитывать это одно, а скажем ветвления, циклы? Как их реализовать в таком ЯП?
Создаём управляющие конструкции: начало
---------------------------------------
Ну что же, давайте смотреть. Начнём с ветвлений. Для начала добавим в язык новое ключевое слово — `atom`, оно сообщит интерпретатору, что, то или иное слово атомарно, пытаться вычислять его не нужно. Зная это, можно реализовать ветвление следующим образом:
```
atom simple-if
rule [ simple-if 1 ] [ print "True" ]
rule [ simple-if 0 ] [ print "False" ]
[ simple-if some-condition ]
```
`some-condition` в данном случае, это некоторое условие, результатом которого становится `1` — истина, и `0` — ложь. Так же можно заметить, что каждый раз, когда требуется ввести условие, потребуется вводить два правила (при условии, что атом `simple-if` уже введён, ибо его можно использовать повторно). Исправить это можно, но мы сделаем это чуть позже, сейчас же заострим внимание на другой детали: зачем нам `simple-if`?
Сначала может показаться что это вещь совсем ненужная, результат работы твердолобого теоретика, который спит и видит, как бы ввести новую бесполезную абстракцию, насолить бравым программистам. На самом же деле `simple-if` выполняет очень важную роль: он позволяет отделить выражения ветвлений от всего остального, это в некотором смысле маяк, увидев который интерпретатор понимает, что перед не очередное баловство программиста, а самое обыкновенное ветвление. Впредь такие, с виду бесполезные атомы, мы и будем называть *маяками*.
Переходим к циклам. Здесь, уже набившего оскомину инструментария `atom` и `rule` будет не достаточно, нам потребуются некоторые абстракции — введём их. Пусть слово `.word` обозначает любое корректное слово, а `.seq` — любую корректную последовательность. Внимательный читатель подметит мою забывчивость, и действительно, мы уже встречались с этими word и seq, однако тогда, я так и не дал им объяснения, да и использовал в другом контексте. Условимся `.word` и `.seq` называть *заполнителями*. Теперь с их помощью мы можем реализовать цикл while:
```
atom simple-while
rule [ simple-while 1 .seq ]
[ simple-while
cond [ some data ]
print "Hello, world" ]
[ simple-while
cond
print "Hello, world!" ]
```
Как видно, заполнитель `.seq` в данном случае мы используем, чтобы сократить первую часть правила.
С виду может показаться, что наш язык совершенно не пригоден для использования на практике. И действительно, представленные реализации `if` и `while` крайне ограничены и просты. Однако, позже мы дополним их, сделаем их мощь сопоставимой с таковой в императивных ЯП. Сейчас же отойдём в сторону, поговорим о переменных и функциях.
Переменные и функции
--------------------
Что же, перейдём к... переменным? Сначала значит, мы рассуждаем о циклах и ветвлениях, а тут вдруг о переменных вспомнили. Странно, не правда ли? В свою защиту могу сказать, что переменные в LN вещь более сложная, чем простейшие управляющие конструкции. Почему? — Спросите вы. Потому что их нет! — Отвечу я.
Действительно, при детальном рассмотрении окажется, что реализовать переменные при помощи `rule` нельзя. Наоборот, переменные в LN, в том смысле, в котором они есть например в C, не существуют. В языках императивных переменная — как мы помним из детского сада — это некоторая именованная область памяти, контейнер куда мы можем что-то положить. В LN же, мы можем лишь создать правило, согласно которому `the-best-coder` будет заменяться на `"you, my dear ❤️"`. Да, это будет похоже на переменные, но ими являться не будет. Не возможны потому и указатели.
С точки зрения типов наш язык будет очень близок к Common Lisp — переменные, которых нет, типов иметь не будут, типизированы будут данные. Как и CL, концептуальный язык обладает сильной динамической типизацией. Судить о том, хорошо это или плохо не берусь, ибо совсем не являюсь экспертом в данной теме. Сами основные типы таковы:
* `seq` — последовательности (например: `[ a b c ]`)
* `word` — слова (например: `peace`)
* `numeric` — необычный тип, описывающий «что-то числовое» (*необязательно* число), представляет собой слово, состоящее из *числовых символов* — цифр, `.` (точки), `/` (косой черты, деления), `-` (минуса), `:` (двоеточия), `|` (вертикальной черты), `e` (сокращение для 10^). Данный тип позволяет описывать как числа, так и различные совокупности чисел: коды, номера, даты, время и т.п. Пример: `7`, `3.14`, `2/3`, `12.45.6`, `--34/56.89:1||15`.
* `complex` — комплексные числа (например: `89|12`)
* `rational` — рациональные числа (например: `6.626e-34`)
* `integer` — целые числа (например: `9`)
* `fraction` — обыкновенные дроби (например: `8/9`)
* `symbolic` — тип, сходный `numeric`, описывает «что-то символьное».
* `character` — UTF-8 символ
* `string` — UTF-8 строка
Представленные типы имеют следующую иерархию:
```
seq
└── word
├── numeric
│ └── complex
│ ├── rational
│ │ └── integer
│ └── fraction
└── symbolic
├── character
└── string
```
Теперь, введём для наших типов пару простых правил:
1. Типы, находящиеся в иерархии на одном уровне будем называть *равноправными*. Например, `numeric` и `symbolic` — равноправны, `rational` и `fraction` — равноправны, `complex` и `character` — равноправны, а вот `string` и `rational` уже не равноправны.
2. Равноправные типы не заменяемы. Это означает, что в следующее правило: `rule [ + .integer .integer ]` ... передать `character` или `string нельзя.`
3. Типы, могут иметь *подтипы*, т.е. такие типы, которые находятся в иерархии на более низком уровне. Например, `word` — подтип `seq`, `numeric` — подтип `word`, `complex` — подтип `numeric`.
4. Типы заменяемы подтипами, но не наоборот. Другими словами, типу `numeric` можно передать значение любого его подтипа: `complex`, `rational`, `integer`, `fraction` — это не вызовет ошибок. Например, в следующее правило: `rule [ example .word .word ] ...` можно передать не только слова, но и любые числа, символы и строки.
Всем типам соответствуют заполнители, имена которых, это имя типа с точкой в начале (типу `seq` соответствует `.seq`, `word` — `.word` и т.д.).
Учитывая природу переменных в LN (а природа их исходит из `rule`), они будут глобальными и независящими от контекста создания: объявите переменную хоть в глобальной области видимости, хоть в теле функции — она будет видна везде.
А будут ли переменные, которых нет, *переменными*? Что с иммутабельностью? Чёткого ответа у меня нет. Вполне допустима как переписываемость правил:
```
rule best-poet Homer
rule best-poet John-Milton
print best-poet
(John-Milton)
```
так и константность их:
```
rule best-poet Homer
rule best-poet John-Milton
(ошибка)
```
На данный момент моё мнение состоит в следующем: правила должны быть мутабельны, обратное сделает язык менее гибким.
Хорошо, с переменными мы разобрались, перейдём к функциям.
Здесь читатель догадливо заметит, что и их нет в таком ЯП, и он окажется прав. Функций в LN нет, есть лишь правила, используемые в качестве таковых, несмотря на это, далее по тексту, слово «функция» будет повсеместно использоваться, сделано так для большей простоты и лёгкости материала.
Однако, для введения функций нам нужны параметры, а текущая версия `rule` позволяет определить лишь подстановки без параметризации. Что же, давайте изменим это. Условимся следующую запись заполнителя: `.placeholder:name` называть *именованным заполнителем*, где `placeholder` — тип заполнителя (`.seq`, `.word` и др.), а `name` — имя заполнителя. Учитывая это мы можем написать две классические функции — сумму аргументов, и приветствие:
```
rule [ sum .rational:a .rational:b ]
[ + a b ]
rule [ greeting .string:name ]
[ print [ "Hello, " name "!" ] ]
[ sum 6 9 ] → 15
[ greeting "Sasha" ] → "Hello, Sasha!"
```
В последний раз обратим своё внимание на типизацию. Ранее было сказано, что она динамическая и сильная, однако, не вооружённым глазом видно, что в объявлении «функции» чётко заданы типы аргументов. Поэтому, правильнее наверное будет сказать, что наш язык имеет типизацию *близкую* к динамической сильной.
Не трудно заметить, что в силу своей природы «функции» могут использовать собственный синтаксис. Например, математические операции в LN работают в префиксной форме, но это легко исправить (другой вопрос надо ли, ибо префикс совершенней инфикса, как мне кажется):
```
rule [ .rational:a my+ .rational:b ]
[ + a b ]
[ 4 my+ 5 ] → 9
```
В этом примере мы пользуемся тем фактом, что функции — это правила, а потому, порядок следования элементов правила мы можем задать любой. Здесь, однако, следует сделать оговорку: правила не должны выглядеть одинаково, создание двух одинаковых правил означает создание одного, которое мы просто переписываем (или вообще получаем ошибку, если правила иммутабельны).
Так же правила могут порождать другие правила (или, если вам будет понятнее: «функции» могут порождать «функции»). Такие правила (функции) мы будем называть *конструкторами*. Например, ниже представлен простейший конструктор — синтаксический сахар для «переменных».
```
rule [ var .word:name .word:value ]
[ rule name value ]
var pastille "very tasty stuff"
```
Заметьте, что здесь мы используем 4-е правило типизации: «функция» определена для двух слов, но мы спокойно можем передавать и строки и числа, а вот передача последовательности в качестве аргумента вызовет ошибку.
### Создаём управляющие конструкции: продолжение
Итак, после того, как мы изучили лжепеременные, лжефункции и типизацию, можно возвратиться к конструированию ветвлений и циклов.
Начнём с ветвлений. Используя именованные заполнители, мы можем написать следующее:
```
atom if
rule [ if 1 .seq:true-body .seq:false-body ]
true-body
rule [ if 0 .seq:true-body .seq:false-body ]
false-body
[ if [ - 1 0 ]
[ print "- 1 0 == 1" ]
[ print "- 1 0 == 0" ] ] → [ print "- 1 0 == 1" ] → "- 1 0 == 1"
[ if [ - 1 1 ]
[ print "- 1 1 == 1" ]
[ print "- 1 1 == 0" ] ] → [ print "- 1 1 == 0" ] → "- 1 1 == 0"
```
С виду, этот код может показаться лёгким и понятным. Однако, эта простота обманчива, и потому советую вам сделать попытку самостоятельно решить поставленную задачу.
Поясняя же работу этой реализации ветвлений скажу, что устроены они так: мы определили маяк `if`. Далее задали два правила, пока не обращайте на них внимания. Далее написали 2 ветвления. Как они будут вычисляться? `if` является атомом, он будет пропущен, а вот выражение стоящее за ним будет вычислено и заменено своим результатом — нулём или единицей. Тут-то правила и выходят на сцену: последовательность `if 1 .seq` будет заменена на код if-ветки, соответственно `if 0 .seq` — на else-ветку.
Здесь некоторые вспомнят известную шутку про троллейбус из буханки хлеба и спросят: зачем вообще нужен ЯП на котором простые, базовые конструкции реализуются так сложно, в котором программист, будто человек эпохи первобытности, должен всё делать сам, бегать за мамонтом ногами, а не послать за ним робота. На этот сложный, и действительно важный вопрос я отвечу позже. Сейчас же вернёмся к делу.
И так, нашей задачей было улучшить цикл `while`, как же это сделать? Прежде всего, надо указать, что в языке, построенном на НАМ, цикл (а равно и рекурсия, ибо ни того, ни другого в чистом виде в нашем ЯП нет) есть правило, которое вычисляется в само себя с некоторыми отличиями (или без них). Легко понять, что под каждый цикл придётся писать отдельное правило, это не удобно, потому, как и в прошлый раз воспользуемся конструктором.
```
atom while
rule [ while .seq:cond .seq:body ]
[ rule [ while 1 .seq ]
[ while cond body ] ]
[ while [ some-condition ] [ print "Hi" ] ]
```
Устроен этот листинг достаточно просто: конструктор создаёт правило, согласно которому, истина условия в цикле порождает этот же цикл.
---
Зачем? Кому?
------------
Этими вопросами любой здравомыслящий читатель задумался при прочтении статьи уже не единожды, пришло время ответить на них.
Для начала повторяя себя скажу, что изначально никакой практической цели перед ЯП не ставилось, а потому вопрос "Зачем?" не очень уместен. Однако, спрашивающий прав в некоторой степени, ибо любая технология имеет какое-то применение и цель. Зачем же может понадобиться LN? Приведу список своих мыслей по этому поводу:
1. LN интересен с точки зрения фундаментальной информатики. С одной стороны, он сочетает в себе простоту и минимализм возможностей и синтаксиса, а с другой — чрезвычайную мощь и выразительность. Может в будущем продукционное программирование приобретёт популярность, а LN будет известен как один из языков, где данная парадигма получила своё воплощение.
2. Обработка текстов и данных. Вы возможно заметили, что весь LN построен на идее анализа последовательностей. Это свойство можно применять и для обработки текстов (например для расстановки знаков препинания) где имеет место некоторая шаблонность и структурируемость. То же самое и с данными, хотя честно скажу, с Data Science я не знаком, и моя оценка может быть неверна.
3. LN так же может применяться для автоматического решения математических, физических и логических задач различного типа. Достаточно лишь задать условия и начальное состояние — далее система будет действовать сама.
В завершение этого скромного раздела скажу одно: пока судить о том, где такой ЯП можно применять сложно. Сейчас мы имеем лишь формальное описание, фантазию скрупулёзного теоретика, В перспективе, когда я таки сделаю интерпретатор (есть у меня таковое намерение) можно будет говорить более конкретно.
---
Заключение
----------
Наконец, подводя итог нужно сказать, что я прошёлся по верхам своих мыслей, бегло рассказал о своей задумке. Однако, этого ознакомления, по моему мнению, достаточно для первого знакомства с языком. В будущем я намерен развивать эту тему, надеюсь, что читателям будет интересно.
Не относитесь к представленному слишком строго или снисходительно, это лишь скромное исследование не претендующие на оригинальность или новизну. Я лишь хотел исследовать ещё одну грань информатики.
Исследуйте новые технологии, учите новые языки, и конечно, «Sapere aude»! До встречи, читатель.
---
Спасибо моему другу Александру, без него этой статьи не было бы.
**Полезные ссылки**
Нормальные алгоритмы Маркова: [Википедия](https://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%80%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC)
Язык программирования РЕФАЛ: [Википедия](https://ru.wikipedia.org/wiki/%D0%A0%D0%95%D0%A4%D0%90%D0%9B), [Содружество РЕФАЛ/Суперкомпиляция](http://www.refal.net/)
Язык программирования Thue: [Википедия](https://ru.wikipedia.org/wiki/Thue), [Github](https://github.com/jcolag/Thue)
Язык программирования MarkovJunior: [Github](https://github.com/mxgmn/MarkovJunior) | https://habr.com/ru/post/682972/ | null | ru | null |
# Python в металлургической промышленности
Когда речь заходит о тяжелой промышленности и технологиях в ней, в большинстве случаев мы ожидаем услышать Java, а может быть и Java EE, или наоборот что-то очень низкоуровневое. Именно такие предположения я чаще всего слышу от друзей, когда рассказываю, где работаю.
Однако, в реальности всё немного иначе и на практике мои коллеги используют множество технологий. Это может быть C++ для низкоуровневой обработки данных или скрипты синхронизации, написанные на Bash, различные десктопные приложения, написанные на C# или PyQt, часто можно встретить серверы на NodeJS, но редко - приложения на R. Весь фронт мы стараемся писать на TypeScript (JavaScript), но иногда это реализовано через серверный рендеринг шаблонов и простой HTML. Это еще раз подтверждает очевидный факт - для каждой задачи свой инструмент.
Но что же с Python? В действительности мы часто используем Python. В этой статье я расскажу о том, зачем на металлургическом комбинате Python и с какими проблемами я столкнулся при работе над задачами.
Меня зовут Лев и я - Python разработчик в группе компаний НЛМК. Так вышло, что в зону моей ответственности попадает много различных проектов, а также в нее входит помощь коллегам с реализацией их задач. Поэтому моя работа сильно отличается от классической разработки по готовому техническому заданию. В этом есть свои плюсы и минусы, но в любом случае это интересно и, безусловно, это огромный опыт для меня.
Я мог бы рассказать про какой-то интересный случай использования Python для решения конкретной проблемы производства с применением Deep Learning. Но решил посвятить эту статью иным проблемам, а именно проблемам унификации подходов при разработке и внутреннего роста компетенций разработчиков.
Если сегментировать нашу разработку на Python, то ее можно разделить на три основные группы: оптимизация производства, внутренние продукты и интеграции.
### Оптимизация производства
Больше нескольких десятков разработчиков в дюжине команд, которые ежедневно работают над конкретными продуктами, цель которых - улучшить производство. Достичь этого можно различными методами - ускорить процессы, повысить безопасность участка, снизить количество брака, снизить количество вредных выбросов или уменьшить количество ручного труда. В данной группе значительно преобладает количество Python разработчиков и данное направление очень важное по многим причинам.
### Внутренние продукты
Кроме оптимизации производства, существуют различные проекты, связанные с внутренними продуктами. Над этими задачами работают несколько команд.
Ежедневно появляются новые запросы на перенос данных из одного хранилища в другое, на получение доступа из одной подсистемы к другой, на потоковую обработку тех или иных данных. Большинство таких запросов выливаются либо в отдельные микросервисы, либо в полноценные внутренние продукты. Как правило, далеко не все потребности производства мы можем закрыть готовыми продуктами. Причин на это множество: от невозможности использовать готовое решение из-за огромного объема обрабатываемых данных до банального отсутствия таких решений на рынке.
### Интеграции
В данную группу попадают разработчики, которые привлекаются для интеграции с различными системами. Например, для взаимодействия с SAP. Из-за того, что в данных направлениях используются специфические технологии, такие как IronPython и другие, это заслуживает отдельной статьи, поэтому оставим на будущее.
Анализ
------
Работу над своими задачами я начал с анализа технологического ландшафта и проектов.
Концептуально все подсистемы комбината делятся на 2 части - технологический и бизнес сегменты. Возможен только односторонний доступ из технологического сегмента в бизнес-сегмент, обратное невозможно из соображений информационной безопасности.
### Ландшафт
Технологический сегмент - это всё, что связано с тем или иным агрегатом и его подсистемами управления.
Бизнес-сегмент - зона, в которой мы можем строить связи между различными подсистемами. Именно об этой части и пойдет дальнейшее повествование.
Изначально, компоненты бизнес-сегмента представляли из себя набор виртуальных машин, выделяемых под тот или иной проект/команду с дальнейшей эксплуатацией систем. Если проектов немного, тогда никаких проблем в данной схеме не возникает. Однако, ранее я говорил, что у нас несколько десятков команд. Если каждой команде под каждый продукт будет выделяться отдельная виртуальная машина, то очень быстро это превратится в нечто не поддерживаемое. Для решения данной проблемы в НЛМК была создана **Единая Цифровая Платформа**, которая предоставляет большинство систем как сервисы.
Если коротко, то произошло примерно следующее:
* код приложений переехал в GitLab репозитории;
* bash скрипты запуска приложений превратились в Docker образы с хранением в jFrog Artifactory;
* виртуальные машины превратились в OpenShift кластера;
* файлы с логами переехали в ELK/Sentry/Jaeger;
* файловые хранилища переехали в S3 на базе Minio и HDFS;
* Basic Auth авторизация мутировала в SSO + ADFS на базе KeyCloak.
Также как сервис стали доступны следующие системы:
* Kafka
* NiFi
* SonarQube
* Matomo, аналог “Яндекс.Метрики”
* Prometheus/VictoriaMetrics
* Grafana
### Проекты
По результатам анализа нескольких десятков различных продуктов стало понятно, что значительная часть Python продуктов, которые посвящены улучшению производства, имеют общую структуру:
Общая схема проектов* API - отвечает за авторизацию и общую полезную нагрузку
* Consumer - часть, которая потребляет данные из очередей, чаще всего из Kafka
* Model - математическая модель, которая позволяет решить ту или иную проблему
Описанную структуру имеют не все проекты, некоторые имеют более сложную структуру и иные механики или, наоборот, более простую. В части проектов используется Machine Learning модель, а где-то используется Deep Learning.
Проблематика
------------
После анализа проектов и сбора информации, я смог сегментировать технические проблемы по следующим группам:
* всё, что связанно с выбором библиотек и подходов;
* качество кода - нарушение принципов программирования и общепринятых практик;
* безопасность - авторизация, уязвимости - Cmd-Injection, SQL-Injection, etc …
* сопровождение - тесты, миграции, метрики, логи;
Выявить технические проблемы - это только часть решения. Другой проблемой стало то обстоятельство, что команд много, у каждой свои подходы, а уровень компетенций команд сильно отличался друг от друга. Простое требование использовать ту или иную технологию не привело бы к решению действительных проблем.
За время анализа я встретил значительное количество странного кода. Один раз я встретил Python код, который был полностью написан в стилистике Java. Иной раз это был файл на несколько тысяч строк с несколькими десятками функций, которые использовали глобальные переменные в качестве аргументов. В некоторых проектах разом использовались все парадигмы параллелизма и конкуренции - многопоточность, многопроцессорность и асинхронность. И многое-многое другое.
Все мы когда-то писали что-то странное и сложно объяснимое, однако, в рамках рабочих проектов такой подход вызывает много сложностей и болей. Сказать, что данный код не является поддерживаемым, это ничего не сказать. Как мне кажется, один из важнейших критериев любого проекта - его сопровождаемость. Поддерживать и как-либо модифицировать проект без документации, тестов и понятной структуры крайне сложно, а что более важно - дорого. Мы тратим время разработчика не на написание кода, а на понимание как этот код работает и зачем здесь тот или иной атрибут.
Пути решения
------------
Потратив значительное время на размышления и попытки как-то всё систематизировать, я пришел к двум мыслям: что наилучшим решением будет двигаться поступательно и что быстрого решения нет.
Самым первым и простым действом было создать пространство в Confluence и заполнить его базовой информацией. Затем создать проекты, которые показывают как работать с той или иной технологией правильно. После был сформирован план - определить стек технологий, разработать стандарты и начать развивать Python-сообщество.
### Стандартизация
Стало очевидно, для снижения временных издержек необходимо прийти к некоторым стандартным практикам. Начал с простого, со списка принципов разработки - DRY/DIE, KISS, YAGNI, SOLID и Дзен Python. Следующими шагами стали введение общего Style Guide и написание различных внутренних статей о повышении качества кода.
С каждой неделей статей становилось всё больше и на данный момент в нашем пространстве содержится около 100 статей, посвященных разработке на Python. Кроме Python, конечно же, есть мир и вокруг, поэтому мы уделяем время и другим вопросам:
* Как правильно писать Dockerfile?
* Зачем использовать [git|github|gitlab…] flow?
* Чем отличается Pod в OpenShift от виртуальной машины?
* Что такое идемпотентный метод в RESTful приложениях?
Статьи - это прекрасно, но нужны инструменты, которые помогут разработчикам избежать рутинных задач. Для решения данной проблемы мы создали типовой pyproject.toml, в котором описали настройки для различных линтеров и форматтеров. Для запуска всех необходимых проверок у нас рекомендуется использовать pre-commit. Примерный список плагинов, которые мы используем в pre-commit:
* trailing-whitespace
* end-of-file-fixer
* check-yaml
* check-added-large-files
* check-ast
* mypy
* black
* isort
* pylint
* darglint
* bandit
* vulture
### Пример pyproject.toml
```
# …
[tool.black]
multi-line-output = 3 # Многострочный вывод (3 - вертикально висячий) для совместимости с isort.
[tool.isort]
multi_line_output = 3 # Многострочный вывод (3 - вертикально висячий).
include_trailing_comma = true # Включает конечную запятую перед скобками в многострочных импортах.
force_grid_wrap = 0 # Принудительное оборачивание импортов в таблицу.
use_parentheses = true # Использует скобки вместо слеша для продолжения линии, превысившей лимит.
ensure_newline_before_comments = true # вставляет пустую строку перед комментарием после импорта.
line_length = 88 # Максимальная длина линии импорта.
[tool.pylint.messages_control]
disable = "C0330, C0326" # Отключить некоторые проверки для совместимости с SonarQube
[tool.pylint.format]
max-line-length = "88" # Максимальное количество символов в одной строке.
[tool.pytest.ini_options]
minversion = "6.2.5" # Версия pytest, начиная с которой будет работать этот файл (лучше указывать версию, которая установлена у вас).
testpaths = ["tests"] # Путь до папки с тестами (в данном примере папка лежит в корне).
[tool.coverage.run]
branch = true # Включает анализ покрытия по веткам, а не по стокам кода.
omit = [".venv/*", "tests/*"] # Файлы, которые не должны быть в отчетности или изменяться.
[tool.coverage.report]
omit = [".venv/*", "tests/*"] # Файлы, которые не должны быть в отчетности.
[tool.mypy]
ignore_missing_imports = true
# …
```
Кроме написания статей и ответов на конкретные вопросы, весь функционал, который может быть использован в других проектах, выделяется в отдельные библиотеки. Это в значительной степени снижает дублирование кода. Создаваемые библиотеки развиваются по модели OpenSource внутри компании, что позволяет привлекать значительное количество разработчиков для повышения качества кода.
### Рекомендуемый стек
| | |
| --- | --- |
| **Разработка** | **Дополнительное** |
| **Web server**: aiohttp, fastapi, flask**Web client**: aiohttp, requests**DB**: aiopg, asyncpg**ORM**: SQLAlchemy, alembic**(De-)Serialization**: marshmallow, pydantic**Configuration**: dynaconf, pydantic**Template**: jinja2**Redis**: aioredis, redis-py**RabbitMQ**: pika, aio-pika**Avro**: avro, fastavro**Kafka**: aiokafka, confluent-kafka**MinIO**: aiobotocore, minio, boto3**SOAP Client**: zeep**SOAP Server**: spyne**JSON**: orjson, ujson | **Test libs**: pytest, unittest**Mock**: unittest.mock**Fake data**: faker, factory\_boy**Coverage**: coverage, pytest-cov**Exceptions**: sentry-sdk**Metrics**: prometheus-client, aioprometheus**Trace**: jaeger-client, opentelemetry-python**Docs**: pydoc3, sphinx |
Мы стараемся придерживаться использования отдельных библиотек, а не “комбайнов”. Это одна из причин, почему в рекомендуемом стеке технологий нет Django. Django - великолепный фреймворк. Но, к сожалению, данный фреймворк не подходит под наши цели и задачи.
Приложения, которые мы пишем, делятся на два типа:
Простые приложения, реализующие API интерфейсБолее сложные приложенияДля разрабатываемых приложений важна отказоустойчивость и возможность горизонтального масштабирования, к тому же почти все приложения запускаются в OpenShift. Чтобы реализовать подобные решения желательно придерживаться stateless концепции, а для оптимальной утилизации ресурсов наилучшим решением будет использовать асинхронные возможности Python, которые появились с 3.7 версии.
Проведя исследование и сравнив различные библиотеки и фреймворки, я остановился на двух представителях - AIOHTTP и FastAPI. Однако, в рамках наших проектов приоритет отдается именно AIOHTTP.
FastAPI. Всё же это фреймворк, хоть и легковесный. С другой стороны, как только заходит речь про асинхронную сторону вопроса, например, получать события из Kafka и отправлять пользователю по WS/SSE - с FastAPI появляются сложности.
В подавляющем большинстве случаев в качестве WEB сервера и клиента мы используем AIOHTTP. На текущем этапе развития данный пакет закрывает большую часть потребностей. Кроме того, большинство пакетов из aio-libs регулярно используются в нашей повседневной работе. Для работы с базами данных и миграциями применяются SQLAlchemy и Alembic соответственно.
После того, как был сформирован рекомендуемый стек и заполнены основные разделы, коллеги стали выражать б**о**льшую заинтересованность и задавать вопросы. Таким образом стало формироваться внутреннее Python-сообщество.
### Внутреннее сообщество
На данный момент, наше Python-сообщество состоит из трех частей:
* пространство в Confluence - много статей и ссылок, книги
* тематические чаты - у кого-то есть вопрос или смешной мем
* регулярные еженедельные миты - в неформальной обстановке каждый участник может рассказать про свой продукт или послушать про использование конкретной технологии
Для поддержания интереса к технологиям и развития команд проводятся отдельные тематические сессии, доклады и презентации.
Заключение
----------
От момента первых шагов прошло немногим меньше года и я могу с уверенностью сказать - описанный подход работает! Компетенции команд значительно выросли за этот период, а разработчики стали более вовлеченными в сообщество - пишут статьи, готовят доклады, спорят и вместе обсуждают технические решения. Систематизировались подходы и продолжают унифицироваться решения, как следствие, код становится чище, функциональнее и безопаснее.
Количество просмотров страниц Confluence в течение годаОднако у данного подхода есть и минусы - это сложно, отнимает много сил и требует достаточного количества знаний, и, к сожалению, все процессы проходят медленнее, чем хотелось бы.
### P.S.:
Выражаю благодарность коллегам из ЕЦП и ЦТ за помощь и участие. | https://habr.com/ru/post/645943/ | null | ru | null |
# BottomSheetDialogFragment с анимацией при смене состояния и sticky button
Почти каждый андройд разработчик сталкивался с BottomSheetBehavior, но гораздо реже требуется не просто показать BottomSheet, а ещё и добавить анимации, либо пригвоздить какой-то из элементов при раскрытии.
Недавно я столкнулся с такой задачей, реализовал её и решил составить небольшой туториал, который может помочь сэкономить время.
На данной гифке показано, что мы увидим в конце туториала:
Что нужно знать:
----------------
* Как создать проект и запустить его
* Kotlin
* Поверхностное понимание что такое BottomSheetDialogFragment и BottomSheetBehavior
* Поверхностное понимание что такое LayoutParams
* ViewBinding(можно обойтись без него и использовать обычные findViewById)
Первый этап
-----------
На первом этапе мы сделаем смену контента в BottomSheetDialogFragment, визуализировав это fading эффектом.
Создадим в папке drawable файл под именем *bottom\_sheet\_background.xml*, в котором опишем background для нашего фрагмента, выставив цвет фона и закруглённые углы
```
xml version="1.0" encoding="UTF-8"?
```
Далее опишем стиль для нашего фрагмента в файле *styles.xml* в папке values
```
xml version="1.0" encoding="utf-8"?
<item name="bottomSheetStyle">@style/AppModalStyle</item>
<item name="android:background">@drawable/bottom\_sheet\_background</item>
```
Создадим файл *bottom\_sheet\_layout.xml* с разметкой для нашего фрагмента, в комментариях в xml расписано назначение каждого элемента.
bottom\_sheet\_layout.xml
```
xml version="1.0" encoding="utf-8"?
```
В разметке мы имеем одну ViewGroup, которая будет в обоих стейтах и не будет изменяться, и две отдельных ViewGroup для состояний collapsed и expanded.
При вытягивании фрагмента первая будет исчезать и в определённый момент будет заменена второй.
Мы можем перейти к созданию самого фрагмента.
Создадим класс BottomFragment, унаследовав его от BottomSheetDialogFragment
Полный код BottomFragment
```
private const val COLLAPSED_HEIGHT = 228
class BottomFragment : BottomSheetDialogFragment() {
// Можно обойтись без биндинга и использовать findViewById
lateinit var binding: BottomSheetLayoutBinding
// Переопределим тему, чтобы использовать нашу с закруглёнными углами
override fun getTheme() = R.style.AppBottomSheetDialogTheme
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View {
binding = BottomSheetLayoutBinding.bind(inflater.inflate(R.layout.bottom_sheet_layout, container))
return binding.root
}
// Я выбрал этот метод ЖЦ, и считаю, что это удачное место
// Вы можете попробовать производить эти действия не в этом методе ЖЦ, а например в onCreateDialog()
override fun onStart() {
super.onStart()
// Плотность понадобится нам в дальнейшем
val density = requireContext().resources.displayMetrics.density
dialog?.let {
// Находим сам bottomSheet и достаём из него Behaviour
val bottomSheet = it.findViewById(com.google.android.material.R.id.design\_bottom\_sheet) as FrameLayout
val behavior = BottomSheetBehavior.from(bottomSheet)
// Выставляем высоту для состояния collapsed и выставляем состояние collapsed
behavior.peekHeight = (COLLAPSED\_HEIGHT \* density).toInt()
behavior.state = BottomSheetBehavior.STATE\_COLLAPSED
behavior.addBottomSheetCallback(object : BottomSheetBehavior.BottomSheetCallback() {
override fun onStateChanged(bottomSheet: View, newState: Int) {
// Нам не нужны действия по этому колбеку
}
override fun onSlide(bottomSheet: View, slideOffset: Float) {
with(binding) {
// Нас интересует только положительный оффсет, тк при отрицательном нас устроит стандартное поведение - скрытие фрагмента
if (slideOffset > 0) {
// Делаем "свёрнутый" layout более прозрачным
layoutCollapsed.alpha = 1 - 2 \* slideOffset
// И в то же время делаем "расширенный layout" менее прозрачным
layoutExpanded.alpha = slideOffset \* slideOffset
// Когда оффсет превышает половину, мы скрываем collapsed layout и делаем видимым expanded
if (slideOffset > 0.5) {
layoutCollapsed.visibility = View.GONE
layoutExpanded.visibility = View.VISIBLE
}
// Если же оффсет меньше половины, а expanded layout всё ещё виден, то нужно скрывать его и показывать collapsed
if (slideOffset < 0.5 && binding.layoutExpanded.visibility == View.VISIBLE) {
layoutCollapsed.visibility = View.VISIBLE
layoutExpanded.visibility = View.INVISIBLE
}
}
}
}
})
}
}
}
```
Обратим внимание на ключевые моменты
* Мы получаем BottomSheetBehavior, выставляем ему peekHeight и вешаем на него слушателя
* В методе onSlide() в зависимости от оффсета мы меняем прозрачность наших двух layout и в определённый момент меняем их видимость
* Коэффициент 0.5 можно заменить на какой-либо другой и тогда исчезание и появление будет происходить раньше или позже
Вызовем наш фрагмент. Чтобы сделать это быстрее и не добавлять новые кнопки и слушатели, сделаем это прямо из метода onCreate() в MainActivity
```
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
BottomFragment().show(supportFragmentManager, "tag")
}
}
```
Можем запускать наш проект. Мы увидим вот такое поведение:
Второй этап
-----------
На данном этапе мы добавим sticky кнопку внизу нашего фрагмента. Для этого мы программно добавим view к нашему экрану.
Сперва создадим layout файл *button.xml* с кнопкой
```
```
Далее программно добавим кнопку к нашему фрагменту, вставив этот код между установкой *behavior.state* и добавлением коллбека behavior.addBottomSheetCallback
```
// Достаём корневые лэйауты
val coordinator = (it as BottomSheetDialog).findViewById(com.google.android.material.R.id.coordinator)
val containerLayout = it.findViewById(com.google.android.material.R.id.container)
// Надуваем наш лэйаут с кнопкой
val buttons = it.layoutInflater.inflate(R.layout.button, null)
// Выставляем параметры для нашей кнопки
buttons.layoutParams = FrameLayout.LayoutParams(
FrameLayout.LayoutParams.MATCH\_PARENT,
FrameLayout.LayoutParams.WRAP\_CONTENT
).apply {
height = (60 \* density).toInt()
gravity = Gravity.BOTTOM
}
// Добавляем кнопку в контейнер
containerLayout?.addView(buttons)
// Перерисовываем лэйаут
buttons.post {
(coordinator?.layoutParams as ViewGroup.MarginLayoutParams).apply {
buttons.measure(
View.MeasureSpec.makeMeasureSpec(0, View.MeasureSpec.UNSPECIFIED),
View.MeasureSpec.makeMeasureSpec(0, View.MeasureSpec.UNSPECIFIED)
)
// Устраняем разрыв между кнопкой и скролящейся частью
this.bottomMargin = (buttons.measuredHeight - 8 \* density).toInt()
containerLayout?.requestLayout()
}
}
```
Ключевые моменты:
* Мы программно надуваем и добавляем наш layout с кнопкой к родительскому layout
* Вместо кнопки мы можем начинить наш layout любыми другими view
Запустив проект мы увидим следующее:
Полный финальный код
```
private const val COLLAPSED_HEIGHT = 228
class BottomFragment : BottomSheetDialogFragment() {
// Можно обойтись без биндинга и использовать findViewById
lateinit var binding: BottomSheetLayoutBinding
// Переопределим тему, чтобы использовать нашу с закруглёнными углами
override fun getTheme() = R.style.AppBottomSheetDialogTheme
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View {
binding = BottomSheetLayoutBinding.bind(inflater.inflate(R.layout.bottom_sheet_layout, container))
return binding.root
}
// Я выбрал этот метод ЖЦ, и считаю, что это удачное место
// Вы можете попробовать производить эти действия не в этом методе ЖЦ, а например в onCreateDialog()
override fun onStart() {
super.onStart()
// Плотность понадобится нам в дальнейшем
val density = requireContext().resources.displayMetrics.density
dialog?.let {
// Находим сам bottomSheet и достаём из него Behaviour
val bottomSheet = it.findViewById(com.google.android.material.R.id.design\_bottom\_sheet) as FrameLayout
val behavior = BottomSheetBehavior.from(bottomSheet)
// Выставляем высоту для состояния collapsed и выставляем состояние collapsed
behavior.peekHeight = (COLLAPSED\_HEIGHT \* density).toInt()
behavior.state = BottomSheetBehavior.STATE\_COLLAPSED
// Достаём корневые лэйауты
val coordinator = (it as BottomSheetDialog).findViewById(com.google.android.material.R.id.coordinator)
val containerLayout = it.findViewById(com.google.android.material.R.id.container)
// Надуваем наш лэйаут с кнопкой
val buttons = it.layoutInflater.inflate(R.layout.button, null)
// Выставояем параметры для нашей кнопки
buttons.layoutParams = FrameLayout.LayoutParams(
FrameLayout.LayoutParams.MATCH\_PARENT,
FrameLayout.LayoutParams.WRAP\_CONTENT
).apply {
height = (60 \* density).toInt()
gravity = Gravity.BOTTOM
}
// Добавляем кнопку в контейнер
containerLayout?.addView(buttons)
// Перерисовываем лэйаут
buttons.post {
(coordinator?.layoutParams as ViewGroup.MarginLayoutParams).apply {
buttons.measure(
View.MeasureSpec.makeMeasureSpec(0, View.MeasureSpec.UNSPECIFIED),
View.MeasureSpec.makeMeasureSpec(0, View.MeasureSpec.UNSPECIFIED)
)
// Устраняем разрыв между кнопкой и скролящейся частью
this.bottomMargin = (buttons.measuredHeight - 8 \* density).toInt()
containerLayout?.requestLayout()
}
}
behavior.addBottomSheetCallback(object : BottomSheetBehavior.BottomSheetCallback() {
override fun onStateChanged(bottomSheet: View, newState: Int) {
// Нам не нужны действия по этому колбеку
}
override fun onSlide(bottomSheet: View, slideOffset: Float) {
with(binding) {
// Нас интересует только положительный оффсет, тк при отрицательном нас устроит стандартное поведение - скрытие фрагмента
if (slideOffset > 0) {
// Делаем "свёрнутый" layout более прозрачным
layoutCollapsed.alpha = 1 - 2 \* slideOffset
// И в то же время делаем "расширенный layout" менее прозрачным
layoutExpanded.alpha = slideOffset \* slideOffset
// Когда оффсет превышает половину, мы скрываем collapsed layout и делаем видимым expanded
if (slideOffset > 0.5) {
layoutCollapsed.visibility = View.GONE
layoutExpanded.visibility = View.VISIBLE
}
// Если же оффсет меньше половины, а expanded layout всё ещё виден, то нужно скрывать его и показывать collapsed
if (slideOffset < 0.5 && binding.layoutExpanded.visibility == View.VISIBLE) {
layoutCollapsed.visibility = View.VISIBLE
layoutExpanded.visibility = View.INVISIBLE
}
}
}
}
})
}
}
}
```
Заключение
----------
[Полный код вот здес](https://github.com/goldenluk/AnimatedBottomSheet)ь
Данное решение не претендует на истинно верное.
Вероятно, есть более красивые способы сделать это, я буду рад узнать о таких!
Вы можете экспериментировать с размерами, константами и тд, чтобы подгонять этот подход под вашу ситуацию.
Спасибо за внимание! Буду рад замечаниям и предложениями. | https://habr.com/ru/post/567828/ | null | ru | null |
# Как подключить сторонний браузер в приложении на C#

В определенный момент мне стало некомфортно использовать стандартный контрол WebBrowser, предлагаемый Visual Studio.
Причин было несколько:
1. Использовался IE-движок, что само по себе уже сильный аргумент.
2. Кривая работа с JS.
3. Отсутствие масштабирования.
4. Если запустить на машине, где стоит IE6, то все его «достоинства» переносятся на приложение.
В итоге был начат поиск альтернативных решений.
Было рассмотрено 2 SDK. xulrunner(Mozilla) и Awesomium(Chrome)
Подключение обоих происходит примерно одинаково, но на всякий случай опишу оба.
**1. xulrunner**
шаг 1
Идем на офицальный сайт <http://ftp.mozilla.org/pub/mozilla.org/xulrunner/releases/>
Выбираем подходящую нам версию.
Тут хотелось бы сделать маленькое отступление. Чем позднее версия, тем она тяжелее: к примеру, 1.9v весит 21Мб., а уже 19v весит 32Мб. Помимо этого каждая следующая версия требует все больше ресурсов. Забегая вперед скажу, что это и стало основной причиной отказа от этой SDK.
По данной ссылке заходим в папку с выбранной версией, далее sdk/xulrunner-X.X.en-US.win32.sdk.zip
шаг 2
Скачиваем и распаковываем содержимое. Нас интересует из архива только папочка bin. Копируем ее в папку с приложением и переименовываем в xulrunner. Имя можно и другое, но чтобы не было различий с моим описанием, лучше имя сделать такое.
шаг 3
Для работы с этой SDK нам потребуется библиотека Skybound.GeckoFX.bin.v1.9.1.0 Ее можно скачать тут <http://code.google.com/p/geckofx/>
Данная библиотека работает xulrunner версии 1.9.
Если вы решили использовать более позднюю версию, то нужно искать Skybound.GeckoFX 2.0, она подходит для версий 2.0 и выше.
шаг 4
В нашем приложении добавляем в References Skybound.Gecko.dll из скачанного архива
шаг 5
Правим класс Program:
```
static class Program
{
[STAThread]
static void Main()
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form2());
}
}
```
Инициализируем контрол браузера:
```
string path = "C:\\Program Files (x86)\\xulrunner\\"; //Путь к распакованной и переименованной папке bin из архива SDK
Skybound.Gecko.Xpcom.Initialize(path);
webBrowser1 = new Skybound.Gecko.GeckoWebBrowser();
webBrowser1.Parent = this.panel1;
webBrowser1.Dock = DockStyle.Fill;
string u = "http://www.ya.ru";
//Загрузка выбранной страницы
webBrowser1.Navigate(u);
```
По данному коду родительской панелью будет panel1
шаг 6
Чтобы выполнить программно какой-либо JavaScript пришлось идти на ухищрения, т.к. то ли функции, которые для этого по идее предназначены не дописаны в этой версии, то ли что-то еще. Но выход я нашел только такой:
```
webBrowser1.Navigate("javascript:ImGecko()");
```
Минусом является то, что нельзя получить результат обработки, только в виде alert();
Данная проблема также стала причиной того, что я начал искать замену и пришел к Awesomium
**2. Awesomium**
шаг 1
Скачиваем SDK по ссылке <http://awesomium.com/>
На сайте имеется две версии — стабильная(1.6.5) и тестовая(1.7). Тестовая в целом работает лучше.
Для работы нам понадобятся файлы
Awesomium.Core.dll
Awesomium.dll
Awesomium.Windows.Controls.Design.dll
Awesomium.Windows.Controls.dll
Awesomium.Windows.Forms.dll
шаг 2
Подключаем к проекту библиотеки
Awesomium.Core.dll
Awesomium.Windows.Forms.dll
шаг 3
В Toolbox кликаем правой кнопкой и выбираем Choose Items. Далее жмем browse и подключаем Awesomium.Windows.Forms.dll, после этого у нас появится новые контролы WebControl, AddressBox и т.д. Нам в первую очередь важен WebControl
шаг 4
Размещаем контрол в дизайне
шаг 5
Примеры использования различных функций.
Открытие страниц
```
webControl1.LoadURL("http://ya.ru");
```
Загрузка Cookies
```
string cookie; // Строка с cookie которые нужно подключить
string domen; // Домен
string[] mascook;
mascook = cookie.Split(';');
Awesomium.Core.WebCore.ClearCookies();
foreach (string cook in mascook)
Awesomium.Core.WebCore.SetCookie("http://" + domen, cook + "; domain=" + domen, true, true);
```
Получение значений переменных mx и my
```
Awesomium.Core.JSValue x = webControl1.ExecuteJavascriptWithResult("mx", 500);
Awesomium.Core.JSValue y = webControl1.ExecuteJavascriptWithResult("my", 500);
```
500 — это таймаут.
Вызов JS функции
```
webControl1.CallJavascriptFunction("", "al", new Awesomium.Core.JSValue[] {});
```
al — это имя функции
второй параметр передает значения в фунцию. В данном случае он пустой.
Приведенные примеры работают на Awesomium 1.6.5, в версии 1.7 немного изменена архитектура и некоторые методы могут отсутствовать или вызываться по другому.
**Выводы**
На текущий момент во всех проектах, где нужен браузер, использую Awesomium: он и работает стабильнее и функционал побогаче. Нагрузка от него небольшая. Единственный минус — это то, что не отрабатывает клик правой кнопкой по флешу, потому нельзя поменять необходимые параметры(возможно я просто не разобрался как). В остальном данная SDK меня во всем устроила. | https://habr.com/ru/post/170015/ | null | ru | null |
# Убираем радиальное искажение с фото и видео при помощи библиотеки openCV и языка python
В данной статье будет рассказываться о применении библиотеки машинного зрения (openCV) для удаления эффекта радиального искажения (дисторсии) с фото и видео. Данный эффект также известен как эффект рыбьего глаза (fisheye) или distortion. Решение написать данную статью было принято после нескольких дней поиска информации в интернете. Не смотря на то, что есть гайды на английском языке, они не объясняют как правильно установить openCV, чтобы все работало. В статье присутствует готовый код.
Сразу привожу фото итогового результата. Слева оригинальное фото, справа — обработанное:
 
#### Сборка и установка openCV
Первое, что нужно сделать, это грамотно установить библиотеку openCV. Для этого скачиваем из официального репозитория два проекта — [openCV](https://github.com/opencv/opencv) и [opencv\_contrib](https://github.com/opencv/opencv_contrib).
```
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
```
Пока загружается openCV, устанавливаем видеокодек ffmpeg:
```
sudo apt-get install ffmpeg
```
Заходим в папку openCV, создаем подпапку buid и заходим в нее. Вся работа по сборке и установке библиотеки openCV будет производиться из этой директории.
```
cd opencv
mkdir build
cd build/
```
Для сборки библиотеки выполняем следующие команды:
```
cmake .. -DOPENCV_EXTRA_MODULES_PATH=/путь к папке opencv_contrib/modules/ /путь к папке opencv/
make -j5
sudo make install
```
У меня сборка заняла около полутора часов, установка — несколько минут. Обратите внимание: если у вас возникла ошибка при сборке(выполнение команды cmake), для нового запуска необходимо удалить файл **CMakeCache.txt**. После установки можем проверить все ли правильно получилось. Для этого можно вызвать рабочую среду python и импортировать библиотеку openCV. Если никаких ошибок не произошло, то вы все сделали правильно. Вторая строчка покажет, какая версия у вас установлена. На момент написания статьи я пользовался 3 версией библиотеки.
```
import cv2
print ("OpenCV version : {0}".format(cv2.__version__))
```
#### Калибровка камеры
Для того, чтобы убрать искажения, нам необходимо определить калибровочные коэффициенты для нашей камеры. Для этого необходимо скачать картинку с [шахматной доской](https://habrastorage.org/webt/bo/jt/j9/bojtj9sk5wjjtbwi9hi8fuezmt0.png), сделать 5-6 снимков на камеру, изображения с которой мы хотим обработать. Все изображения необходимо конвертировать в **формат png**. Далее выполняем следующий код:
**Определение поправочных коэффициентов**
```
from __future__ import print_function
import numpy as np
import cv2
from common import splitfn
import os
if __name__ == '__main__':
import sys
import getopt
from glob import glob
args, img_mask = getopt.getopt(sys.argv[1:], '', ['debug=', 'square_size='])
args = dict(args)
args.setdefault('--debug', '/рабочая директория/')
args.setdefault('--square_size', 1.0)
if not img_mask:
img_mask = '/папка с изображениями/*.png'
else:
img_mask = img_mask[0]
img_names = glob(img_mask)
debug_dir = args.get('--debug')
if not os.path.isdir(debug_dir):
os.mkdir(debug_dir)
square_size = float(args.get('--square_size'))
pattern_size = (9, 6)
pattern_points = np.zeros((np.prod(pattern_size), 3), np.float32)
pattern_points[:, :2] = np.indices(pattern_size).T.reshape(-1, 2)
pattern_points *= square_size
obj_points = []
img_points = []
h, w = 0, 0
img_names_undistort = []
for fn in img_names:
print('processing %s... ' % fn, end='')
img = cv2.imread(fn, 0)
if img is None:
print("Failed to load", fn)
continue
h, w = img.shape[:2]
found, corners = cv2.findChessboardCorners(img, pattern_size)
if found:
term = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)
cv2.cornerSubPix(img, corners, (5, 5), (-1, -1), term)
if not found:
print('chessboard not found')
continue
img_points.append(corners.reshape(-1, 2))
obj_points.append(pattern_points)
print('ok')
rms, camera_matrix, dist_coefs, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, (w, h), None, None)
print("\nRMS:", rms)
print("camera matrix:\n", camera_matrix)
print("distortion coefficients: ", dist_coefs.ravel())
cv2.destroyAllWindows()
```
В результате выполнения данного скрипта в консоли появится сообщение об обработанных фото и отобразятся два важных параметра — camera matrix и distortion coefficients. Это и есть те калибровочные коэффициенты, которые нам нужны.

#### Обработка фото и видео
Для обработки фото и/или видио необходимо выполнить скрипты, приведенные ниже. В скриптах нужно указать свои калибровочные параметры и рабочие папки.
**Скрипт для обработки фото**
```
from __future__ import print_function
import numpy as np
import cv2
import glob
from matplotlib import pyplot as plt
from common import splitfn
import os
img_names_undistort = [img for img in glob.glob("/путь до папки с фотографиями/*.png")]
new_path = "/путь для сохранения обработанных изображений/"
camera_matrix = np.array([[1.26125746e+03, 0.00000000e+00, 9.40592038e+02],
[0.00000000e+00, 1.21705719e+03, 5.96848905e+02],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00]]);
dist_coefs = np.array([-0.49181345, 0.25848255, -0.01067125, -0.00127517, -0.01900726]);
i = 0
#for img_found in img_names_undistort:
while i < len(img_names_undistort):
img = cv2.imread(img_names_undistort[i])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w = img.shape[:2]
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(camera_matrix, dist_coefs, (w, h), 1, (w, h))
dst = cv2.undistort(img, camera_matrix, dist_coefs, None, newcameramtx)
dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
# crop and save the image
x, y, w, h = roi
dst = dst[y:y+h-50, x+70:x+w-20]
name = img_names_undistort[i].split("/")
name = name[6].split(".")
name = name[0]
full_name = new_path + name + '.jpg'
#outfile = img_names_undistort + '_undistorte.png'
print('Undistorted image written to: %s' % full_name)
cv2.imwrite(full_name, dst)
i = i + 1
```
**Скрипт для обработки видео**
```
from __future__ import print_function
import numpy as np
import cv2
import glob
from matplotlib import pyplot as plt
from common import splitfn
import os
FILENAME_IN = "videoin.mp4"
FILENAME_OUT = "videoout.mp4"
CODEC = 'mp4v'
camera_matrix = np.array([[1.26125746e+03, 0.00000000e+00, 9.40592038e+02],
[0.00000000e+00, 1.21705719e+03, 5.96848905e+02],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00]]);
dist_coefs = np.array([-3.18345478e+01, 7.26874187e+02, -1.20480816e-01, 9.43789095e-02, 5.28916586e-01]);
print ("OpenCV version : {0}".format(cv2.__version__))
print((cv2.__version__).split('.'))
# Load video
video = cv2.VideoCapture(FILENAME_IN)
fourcc = cv2.VideoWriter_fourcc(*list(CODEC))
fps = video.get(cv2.CAP_PROP_FPS)
frame_count = video.get(cv2.CAP_PROP_FRAME_COUNT)
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))
sizew = (1676, 846)
writer = cv2.VideoWriter(FILENAME_OUT, fourcc, 25, sizew)
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(camera_matrix, dist_coefs, (size[0], size[1]), 1, (size[0], size[1]))
x, y, w, h = roi
M = cv2.getRotationMatrix2D((size[0]/2,size[1]/2),5,1)
while video.grab() is True:
print("On frame %i of %i."%(video.get(cv2.CAP_PROP_POS_FRAMES), frame_count))
frame = video.retrieve()[1]
frame = cv2.undistort(frame, camera_matrix, dist_coefs, None, newcameramtx)
frame = frame[y:y+h-50, x+70:x+w-20]
writer.write(frame)
video.release()
writer.release()
``` | https://habr.com/ru/post/341160/ | null | ru | null |
# Как заставить дженкинс сделать вашу жизнь проще и стать счастливым
Когда разработка мобильных приложений в компании переходит на промышленные рельсы, неизменно всплывает вопрос об автоматической сборке. Continuous Integration — это то, что является неотъемлемой частью процесса. Итог этого процесса — сборки для тестирования на устройствах компании для OTA распространения заказчикам и удаленным тестировщикам.
При публикации под аккаунтом своей компании или под аккаунтом заказчика приходится иметь дело с большим количеством профилей и сертификатов, ключей, свойств и настроек. Не всегда удобно заменять конкретный ключ на устройстве. Поэтому в нашей компании мы придумали решение, автоматизирующее этот процесс. Автоматизация распространения артефактов на всех устройствах, используемых для сборки, и будет описана в этой статье.
Итак, эта статья о том, как реализовать копирование сертификатов и профилей для iOS сборок и свойств, и ключей для Android сборок на все слейвы дженкинса в рамках Continuous Integration. Такая автоматизация экономит время и помогает избежать ошибок. Статья будет интересна разработчикам мобильных приложений и тем, кто администрирует Jenkins.
Поехали!

#### Проблема
Несколько лет назад, когда мы только настроили Jenkins (сервер непрерывной интеграции), у нас была всего одна машинка (мак-мини), на которой выполнялись все сборки. Со временем дженкинс переехал на виртуалку, а миник превратился в слейва (вспомогательный узел дженкинса, использующийся для сборки проектов). iOS-проекты можно собирать только на Mac OS, а Android — везде, поэтому iOS-ные проекты собирались на слейве, а Androidные — на мастере (где установлен сам дженкинс). Всё, что необходимо для сборки проектов, устанавливалось и раскладывалось на двух машинах руками, и всё было ок! О том, как настроить Jenkins, мы рассказали в одной из предыдущих статей — [«Автоматическая сборка iOS-приложений на разных версиях Xcode с помощью Jenkins»](http://habrahabr.ru/company/eastbanctech/blog/192784/).
Количество проектов росло, и мы подключили сначала по одному сборщику для iOS и Android проектов, а позже — больше. Чтобы собирать приложения на свежеподключенных слейвах, необходимо иметь установленные инструменты, SDK, и для каждого проекта — ключи и файлы, которыми приложение подписывается.
Мы решили оптимизировать настройку слейвов дженкинса, а именно сделать автоматическое копирование и установку необходимых файлов для подписывания iOS и Android приложений.
#### Начнем с iOS
Есть несколько слейвов дженкинса для сборки iOS проектов. Все слейвы помечены лейблами, позволяющими определить версию Xcode, установленную на них. Для распределения нагрузки все сборки помечены лейблами, и могут быть выполнены на любом слейве с соответствующим Xcode.
Для того, чтобы собрать iOS приложение, необходимо иметь:
* Xcode
* Developer/Distribution certificate + Private key
* Provisioning profile
Обычно на jenkins мы собираем Distribution сборки — AdHoc, Enterprise и AppStore. Вот только собирать приходится для большого числа аккаунтов разработчика, соответственно, и сертификатов с ключами у нас довольно много.
Чтобы положить сертификат с ключом на удаленную машинку, нужно:
1. экспортировать сертификат с ключом на машине, на которой они установлены
2. скопировать файл .p12 на удаленную машину
3. зайти на удаленную машину и открыть файл .p12, ввести пароль для установки сертификата и ключа в кейчейн,
4. после установки сертификата и ключа открыть информацию о ключе и во вкладке Access Control выбрать «Allow all applications to access this item»
Чтобы сделать то же самое через ssh, нужно использовать команду security.
Для установки профилей достаточно скопировать их в нужную директорию: ~/Library/MobileDevice/Provisioning\ Profiles/
При этом старый профиль желательно удалить, т.к. при сборке Xcode может использовать старый профиль вместо обновленного.
Обычно для обновления списка профилей достаточно зайти в настройки Xcode и, выбрав нужный аккаунт, нажать кнопку Reload. Xcode сам заменит старые профили на новые, если они были отредактированы на портале. Но проделывать это на нескольких машинах под всеми аккаунтами — не эффективно и вообще уныло.
Можно настроить синхронизацию папок, например, rsync'ом, и обновлять профили руками только на одной машине. Мы выбрали немного другой подход, потому что доступ к редактированию и созданию сертификатов и профилей есть у нескольких человек, и каждый может работать как на виртуалке, так и на своей машине: мы сделали гит-репозиторий для сертификатов, ключей и профилей.
Дальше осталось немного — по обновлению в гите запускать скрипт, который разложит файлы по нодам дженкинса и установит сертификаты и ключи. Первая мысль была — написать git-hook, но у гитовой машины нет доступа к нодам дженкинса. А вот у дженкинса он есть. И дженкинс отлично выполняет job'ы, которые стартуют, когда происходит пуш в гит — для этого в проекте в гите добавляется web hook.
В результате мы сделали:
* гит-репозиторий, в котором в папках profiles и certificates лежат \*.mobileprovision и \*.p12
* job в дженкинсе, который берет файлы из гита и выполняет скрипт:
```
#!/bin/bash
slaves=( "192.168.2.10" "192.168.2.20" "192.168.2.30" )
for i in "${slaves[@]}"
do
ssh jenkins@"$i" rm -f "~/Library/MobileDevice/Provisioning\ Profiles/*"
scp ${WORKSPACE}/profiles/* "jenkins@$i:/Users/jenkins/Library/MobileDevice/Provisioning\ Profiles/"
ssh jenkins@"$i" mkdir -p "~/pp_cc"
scp ${WORKSPACE}/certificates/* "jenkins@$i:/Users/jenkins/pp_cc/"
ssh jenkins@"$i" 'security unlock-keychain -p jenkins /Users/jenkins/Library/Keychains/login.keychain; cd /Users/jenkins/pp_cc/; for a in *; do security import $a -k /Users/jenkins/Library/Keychains/login.keychain -P xxxXXXxxx -A; done'
done
```
*slaves* — это массив слейвов дженкинса, а точнее их ip-адресов. *xxxXXXxxx* — пароль от p12. Да, мы для всех сертификатов, которые кладем в гит, используем одинаковый пароль.
#### И такая же магия для Android
С Android-проектами ситуация в целом похожая. Только вместо профилей и сертификатов для подписывания сборок используются файлы keystore. Для использования файла keystore необходимо знать пароль и алиас. Для сборок Android-приложений мы используем Gradle и в файле настроек gradle.properties указываем следующую информацию:
```
releaseStoreFile=/home/jenkins/gradle_keys/customer/project_name.keystore
releaseStorePassword=project_pass
releaseKeyAlias=project_alias
releaseKeyPassword=project_pass
```
В простой ситуации можно положить файл keystore на машине-сборщике и залить в гит .properties проекта. Сложности начинаются, когда разработчики и сборщики работают на разных операционных системах: сложно положить ключи на всех машинках по одинаковому пути. Наше решение для Android-сборок:
* гит-репозиторий для keystore и properties
* сборка на дженкинсе, которая выполняет скрипт:
```
# slaves
cp -r keys keys_for_ubuntu
cd keys_for_ubuntu
PATHREPL='\/home\/jenkins\/gradle_keys'
find . -name "*\.properties" | while read line; do sed -i -e 's/'PATH_TO_KEYS'/'"$PATHREPL"'/g' "$line"; done
slaves=( "192.168.2.10" "192.168.2.20" "192.168.2.30" )
for i in "${slaves[@]}"
do
scp -r ./ jenkins@"$i":/home/jenkins/gradle_keys/
done
#master
cd ../keys
PATHREPL='\/var\/lib\/jenkins\/gradle_keys'
find . -name "*\.properties" | while read line; do sed -i -e 's/'PATH_TO_KEYS'/'"$PATHREPL"'/g' "$line"; done
cp -r ./ /var/lib/jenkins/gradle_keys/
```
Сборка, которая раскладывает файлы по слейвам, выполняется всегда на мастере, т.к. у мастера есть доступ ко всем сборщикам. Для того, чтобы указать правильные пути для различных операционных систем, в гит файлы кладутся с плейсхолдером «PATH\_TO\_KEYS», т.е. в нашем случае файл выглядит так:
```
releaseStoreFile=PATH_TO_KEYS/customer/project_name.keystore
releaseStorePassword=project_pass
releaseKeyAlias=project_alias
releaseKeyPassword=project_pass
```
Нужные пути в файлах подставляются во время исполнения сборки с помощью команды sed. Чтобы использовать файлы, скачанные из репозитория, несколько раз, перед изменением путей, они копируются в отдельную папку. В нашем примере на слейвах home directory совпадает, но отличается от home directory мастера.
В настройках проекта для релизной сборки путь к gradle.properties указан относительно директории проекта, поэтому файл properties нужно скопировать из общей директории сборщика ~/gradle\_keys в рабочую директорию, для этого в сборке проекта перед Invoke Gradle script выставляем Build step Execute shell:
```
cp ~/gradle_keys/customer/project_name.properties ${WORKSPACE}/
```
#### Как сделать еще лучше
Чтобы не выписывать адреса всех слейвов, можно использовать плагин [Elastic+Axis](https://wiki.jenkins-ci.org/display/JENKINS/Elastic+Axis), который позволяет настроить сборку для выполнения на нескольких узлах. Скрипт для настройки сборщиков iOS будет выглядеть так:
```
rm -f ~/Library/MobileDevice/Provisioning\ Profiles/*
cp ${WORKSPACE}/profiles/* ~/Library/MobileDevice/Provisioning\ Profiles/
security unlock-keychain -p jenkins $HOME/Library/Keychains/login.keychain; cd ${WORKSPACE}/certificates/; for a in *; do security import $a -k $HOME/Library/Keychains/login.keychain -P xxxXXXxxx -A; done
```
Скрипт для настройки сборщиков Android будет выглядеть так:
```
cd keys
KEYS_PATH="$HOME/gradle_keys"
REPL_PATH=$(echo "$KEYS_PATH" | sed -e 's/[\/&]/\\&/g')
find . -name "*\.properties" | while read line; do sed -i -e "s/PATH_TO_KEYS/$REPL_PATH/g" "$line"; done
cp -r ./ $KEYS_PATH
```
#### Выводы
Говорят, если хочешь написать хорошую статью, нужно написать выводы о сильных и слабых сторонах своего решения. С сильными сторонами тут все просто:
* это решение экономит время при изменении и добавлении файлов для сборок
* это решение экономит время на добавление слейвов при расширении инфраструктуры
* это решение позволяет ограничить доступ к важным файлам (ключи и сертификаты не лежат в репозитории проекта) — у нас они и раньше не лежали, но говорят, что некоторые так делают
* это решение — прикольное, потому что дженкинс «настраивает» сам себя
Слабые стороны:
* это решение рассчитано на то, что один репозиторий используется для ключей от всех Android-проектов и аналогично с iOS. Соответственно, настройка доступа к нему негибкая — у человека либо есть доступ ко всему, либо нет доступа ни к чему. В случае, если доступ к подобным файлам должен иметь не главный технический специалист по направлению, а, например, менеджер проекта, это решение не подойдет.
* безопасность этого подхода во многом зависит от безопасности реализации идеи релизных сборок на дженкинсе вообще, т.е., если вы их используете, вам все равно нужно где-то хранить ключи, прописывать пути к ним и т.п., и безопасность зависит от настройки доступа к задачам дженкинса, к машинам, на которых установлены дженкинс и его сборщики, от способа распространения собранных приложений.
#### Заключение
Предложенный подход позволил в нашей компании упростить процедуру управления многочисленными артефактами, необходимыми для сборки приложений. Теперь изменение и добавление ключей происходит быстро, стабильно и на всех нужных машинах. При расширении инфраструктуры из-за увеличения числа проектов добавление новых узлов для дженкинса происходит так же быстро и легко. Мы рады поделиться опытом и будем рады, если эта статья поможет решить подобную проблему в тех компаниях, где накопилось большое количество разрабатываемых и поддерживаемых приложений. | https://habr.com/ru/post/262527/ | null | ru | null |
# Algorithms in Go: Sliding Window Pattern (Part II)
This is the second part of the article covering the Sliding Window Pattern and its implementation in Go, the first part can be found [here](https://habr.com/en/post/531444/).
Let's have a look at the following problem: we have an array of words, and we want to check whether a concatenation of these words is present in the given string. The length of all words is the same, and the concatenation must include all the words without any overlapping. Would it be possible to solve the problem with **linear time complexity**?
Let's start with string `catdogcat` and target words `cat` and `dog`.
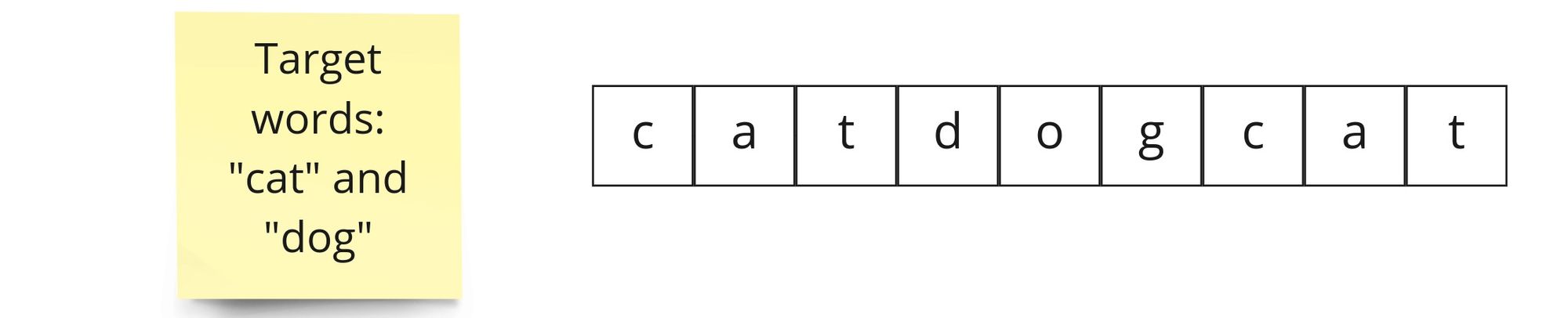
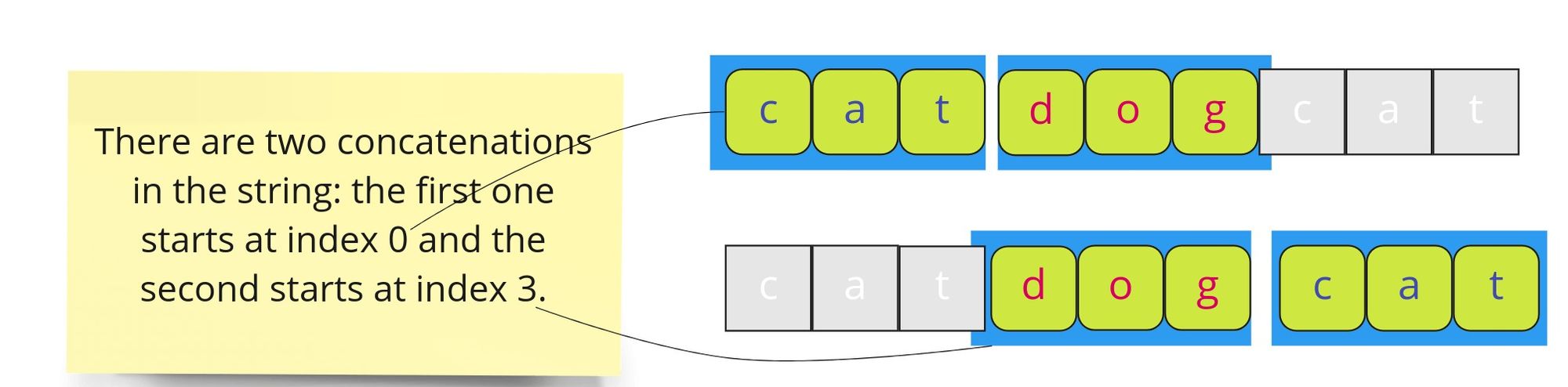
How can we handle this problem? Unfortunately, the article name spoils all the intrigue — we can indeed apply the [Sliding Window Pattern](https://habr.com/en/post/531444/). Let's recap it base form:
1. Iterate through items in the array till you fill the sliding window.
2. Process the remaining items in the array in a step-wise fashion, and on each step check whether we fulfill the required condition. If the condition is fulfilled try to shrink the window from the left, and see whether the condition is still satisfied.
3. To prepare for a new iteration, drop the leftmost item, and update the stats of the window if necessary.
4. Repeat the loop till the array exhaustion.
Ok, how can we apply this algorithm to the problem at hand? Well, the array, in this case, is just our string, i.e. `catdogcat`.
Now, what is the window size in our case? As we need to find a substring that includes all the targeted words, its length must be at least equal to the combined length of the targeted words. What condition do we need to check at each step? A concatenation of all words is basically a permutation of all words. Therefore, by item in the array, we mean a substring of size equal to the size of a single word.
We iterate through each symbol in the string and constitute a new item with the last character equal to the symbol. At each step, we check whether the current item is equal to any of the target words. If we have matched all the words, we have found a required concatenation in the string. To track the number of matches we will have a running counter of matches with the initial value equal to the number of the target words. If the current item matches any of the required words we decrease the counter. Consequently, if the leftmost item that we are going to drop matches the target word, we increase the counter. When the counter goes down to zero, we have all the required matches.
However, a single match counter is not enough: if we have two occurrences of a word in the window, and we only need one, then we would (erroneously) decrease the counter twice. We need to check not only whether an item equals one of the target words, but also whether we already matched the word earlier. To do so, we calculate a frequency map of the targeted words, where words will be used as keys, and counts of needed occurrences as values. When an item matches a word, we decrease the frequency of the word. When the frequency goes down to zero, we have matched the word the required number of items. If we found one more occurrence of the word after that, we have too many "instances" of the word in the window, and the match wasn't useful. Therefore, we decrease the match counter, only when the item is present in the frequency map and still have a positive count in the frequency map.
We can visually represent the above algorithm in the following way:
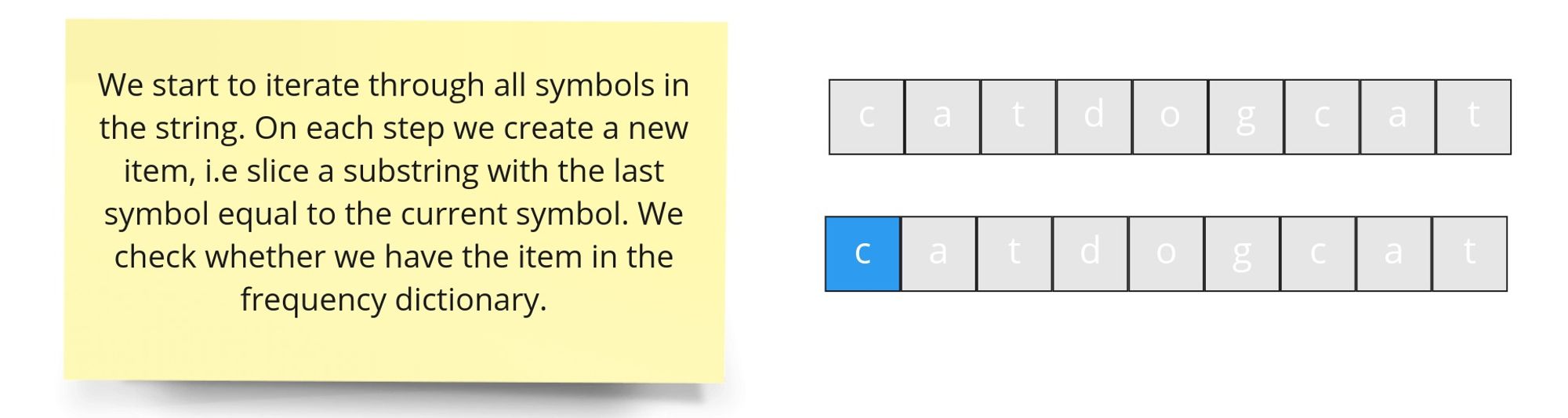
.jpg?table=block&id=7fa8b33f-810f-40f2-b433-e921998230a4&width=1900&userId=&cache=v2)
.jpg?table=block&id=05a477c1-e261-4685-8f54-78b1beb9ff35&width=3430&userId=&cache=v2)
.jpg?table=block&id=faee29af-a39d-49af-8ccf-15d1f00e10d1&width=2960&userId=&cache=v2)
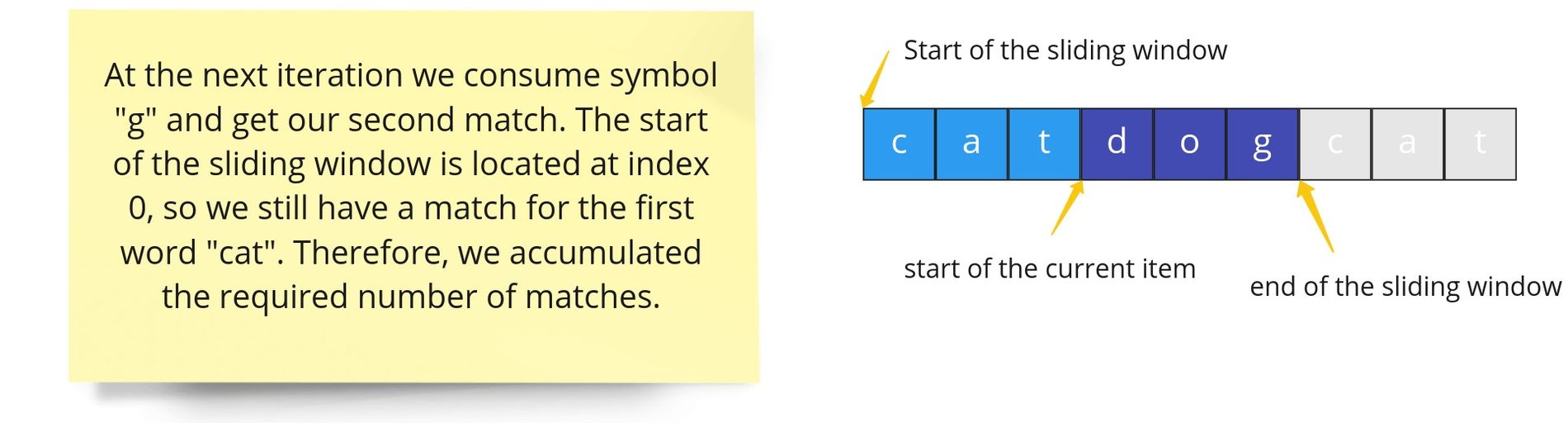
We continue the iteration in the same manner and find the second concatenation starting at index 3.
How can we represent the algorithm in the code?
We have two input arguments:
* string `str` representing the string in which we search the concatenations.
* slice of strings `words` that represents the target words.
We have slice of integers `res` that collects the starting indices of the concatenations as a single output.
We start with the initialization of the variables.
```
// the remaining number of matches
matches := len(words)
// start of the sliding window,
// not the start of the current item
var start int
freqs := make(map[string]int)
for _, word := range words {
freqs[word]++
}
wordSize := len(words[0])
var res []int
```
We iterate through all symbols in `str` and check whether the condition is satisfied.
```
for stop := wordSize - 1; stop < len(str); stop++ {
itemStart := stop + 1 - wordSize
item := str[itemStart : stop+1]
if freq, exists := freqs[item]; exists {
if freq > 0 {
matches--
}
freqs[item]--
}
if matches == 0 {
// shrink from the left
start = stop - len(words)*wordSize + 1
res = append(res, start)
}
// have not yet filled the window,
// no need to drop the leftmost item
if stop < len(words)*wordSize-1 {
continue
}
// prepare for the next iteration,
// i.e. accommodate space for the next item.
left := str[start : start+wordSize]
start++
if freq, exists := freqs[left]; exists {
if freq >= 0 {
matches++
}
freqs[left]++
}
}
```
Let's zoom some parts of the code.
```
if freq, exists := freqs[item]; exists {
if freq > 0 {
matches--
}
freqs[item]--
}
```
What is the purpose of this `if` condition? If the current frequency is zero we already filled all positions for the word in the window. If the frequency is less than zero we have more occurrences of the word in the current window than needed. In both such cases, we don't need any more occurrences of the word, therefore, the match wasn't useful and it shouldn't be counted.
```
left := str[start : start+wordSize]
start++
if freq, exists := freqs[left]; exists {
if freq >= 0 {
matches++
}
freqs[left]++
}
```
In the code snippet above, we do the reverse operation. If by dropping the leftmost item we losing a useful match, we increase the number of remaining matches.
After the iteration slice `res` contains starting positions of all possible concatenations of the words in the string. If there are no concatenations then `res` remains as an uninitialized slice.
What time complexity do we have? We iterate all the symbols in the string and on each iteration we slice a substring of size equal to the word size: `O (N * M)`, where `N` is the length of the string, and `M` is the size of a word.
Here you can find the [code](https://gist.github.com/ayzu/c57ed8a660580d66e71fbeec07d90185) and the [tests](https://gist.github.com/ayzu/cf5e6df48a95a83147757559696412d6).
In this post, we implemented a solution for the Sliding Window problem. This is one of the most popular algorithmic patterns that solve an entire class of problems. More algorithmic patterns such as [Merge Intervals](https://habr.com/en/post/538888/) or [Dutch National Flag](https://habr.com/en/post/541130/) can be found in the series [Algorithms in Go](https://habr.com/en/post/545986/). | https://habr.com/ru/post/532504/ | null | en | null |
# Пишем квайн-полиглот-палиндромы в честь дня 2^2^3
[](https://habrahabr.ru/post/309702/)
Поздравляю всех трансляторов человеческого языка в машинный с их профессиональным днем, желаю вам меньше багов и больше-либо-равно классных идей! А в качестве идейного подарка со своей стороны предлагаю решение одной красивой задачи — написание кода, который на выходе выдаёт свой собственный текст, является валидным для интерпретаторов и компиляторов разных языков, и при этом правильно исполняется при реверсе исходников.
Не так давно я узнал о коде, который может одновременно интерпретироваться в PHP и компилироваться в Java: [PhpJava.java](https://gist.github.com/forairan/b1143f42883b3b0ee1237bc9bd0b7b2c). Как оказалось, эта идея не нова: код, валидный сразу для нескольких компиляторов или интерпретаторов, называется [полиглотом (polyglot)](https://en.wikipedia.org/wiki/Polyglot_(computing)). Такой код возможно писать из-за особенностей обработки строк и комментариев в различных интерпретаторах или компиляторах.
Например, в Java можно описывать символы как в обычном виде, например символ '/', так и в виде юникод-записи: 'u002F'. В компиляторе C# такие записи не будут валидными. Однако если их "спрятать" в комментарий, то, с одной стороны, они не будут мешать при компиляции C# кода, с другой — будут валидными в Java-коде. Например, если нужно, чтобы код **A** компилировался только в языке C#, но не компилировался в Java, а код **B** компилировался только в Java, но не компилировался в C#, нужно использовать следующий фрагмент:
```
//\u000A\u002F\u002A
A//\u002A\u002FB
```
C#-компилятор будет "воспринимать" этот код обычным образом, комментарии останутся комментариями:
```
//\u000A\u002F\u002A
A//\u002A\u002FB
```
А вот с Java все интересней, т.к. юникод-запись трасформируется и получится следующее:
```
//
/*
A//*/B
```
Комбинируя общие для обоих языков инструкции, а также разделяя различные, можно написать любую программу.
Однако такими юникод-записями трюки не ограничиваются. Например, в C-подобных языках существуют директивы препроцессора, которые могут определять, какой код должен компилироваться, а какой нет. В некомпилируемый код можно помещать код совсем другого языка. Например, ниже приведен код-полиглот на C++ и Python ([отсюда](https://gist.github.com/LionZXY/5916ce355d08d6d43a8b6acd71951c25)), в котором в секции `#if false` как раз и помещен код Python. А последовательности `'''` начинают и заканчивают комментарий в коде Python.
```
#include
#if false
print "Hello world"
'''
#endif
int main() {
printf("Hello world");
return 0;
}
#if false
'''
#endif
```
В HTML, например, комментарии начинаются с последовательности символов `I'm a HTML page
I'm a horrible HTML page
========================
<!--: # \
setTimeout( // \
function () { // \
document.body.innerHTML = "<h1>I'm a javascript-generated HTML page</h1>"; // \
}, 10000); // \
//-->
~`
Квайн-полиглот
--------------
Для того чтобы написать квайн-полиглот на языках C# и Java, необходимо совместить принципы разработки квайна и полиглота. Как оказалось, и такая тема не нова: на сайте codegolf пользователи соревнуются, у кого квайн-полиглот или поликвайн получится короче: [Write a Polyquine](http://codegolf.stackexchange.com/questions/37464/write-a-polyquine). Однако в этом вопросе не было вариантов с более многословными языками C# и Java, что мне и захотелось исправить.
Для написания такого квайна-полиглота нужно экранировать символы, запрещенные в строках обоих языков и встречающиеся в строках самой программы. Такими символами являются кавычки ", перенос строки \n и обратный слеш \. А чтобы еще уменьшить размер кода, повторяющиеся последовательности символов, такие как \u000A, \u002F и \u002A, также были заменены на одиночные символы в самой кодирующей строке. Вот пример получившегося квайна-полиглота, валидного для компиляторов C# и Java:
### PolyglotQuine.cs.java, 757 символов:
```
//\u000A\u002F\u002A
using System;//\u002A\u002F
class Program{public static void//\u000A\u002F\u002A
Main//\u002A\u002Fmain
(String[]z){String s="//@#'^using System;//'#^class Program{public static void//@#'^Main//'#main^(String[]z){String s=!$!,t=s;int[]a=new int[]{33,94,38,64,35,39,36};String[]b=new String[]{!&!!,!&n!,!&&!,!&@!,!&#!,!&'!,s};for(int i=0;i<7;i++)t=t.//@#'^Replace//'#replace^(!!+(char)a[i],b[i]);//@#'^Console.Write//'#System.out.printf^(t);}}",t=s;int[]a=new int[]{33,94,38,64,35,39,36};String[]b=new String[]{"\"","\n","\\","\\u000A","\\u002F","\\u002A",s};for(int i=0;i<7;i++)t=t.//\u000A\u002F\u002A
Replace//\u002A\u002Freplace
(""+(char)a[i],b[i]);//\u000A\u002F\u002A
Console.Write//\u002A\u002FSystem.out.printf
(t);}}
```
Квайн-полиглот-палиндром
------------------------
Еще больше усложним задачу: попробуем написать квайн-полиглот-палиндром. Напомню, что палиндром — это число или текст, одинаково читающиеся в обоих направлениях. Принцип разработки квайнов-палиндромов я [описывал в статье](https://habrahabr.ru/post/189192/) 3 года назад, тоже в день программиста. Принцип кода-палиндрома заключается в том, что зеркальная часть программы помещается в однострочный или многострочный комментарий, что не мешает при компиляции. Простейший код-палиндром в C# выглядит следующим образом:
```
/**/class P{static void Main(){}};/*/;}}{)(niaM diov citats{P ssalc/**/
```
Как видим, многострочный комментарий `/*` начинается с середины и продолжается до конца, где и закрывается последовательностью `*/`. Пустой комментарий в начале нужен для того, чтобы строка полностью стала симметричной.
Итак, объединяя принципы создания палиндрома, полиглота и квайна, я написал следующий код:
### PalidromePolyglotQuine.cs.java, 1747 символов:
```
/**///\u000A\u002F\u002A
using System;//\u002A\u002F
class Program{public static void//\u000A\u002F\u002A
Main//\u002A\u002Fmain
(String[]z){String s="`**?`@#_^using System;?_#^class Program{public static void?@#_^Main?_#main^(String[]z){String s=!$!,t=s;int i;int[]a=new int[]{33,94,38,64,35,95,96,63,36};String[]b=new String[]{!&!!,!&n!,!&&!,!&@!,!&#!,!&_!,!`!,!?!,s};for(i=0;i<9;i++)t=t.?@#_^Replace?_#replace^(!!+(char)a[i],b[i]);t+='*';for(i=872;i>=0;i--)t=t+t?@#_^[i];Console.Write?_#.charAt(i);System.out.printf^(t);}}/",t=s;int i;int[]a=new int[]{33,94,38,64,35,95,96,63,36};String[]b=new String[]{"\"","\n","\\","\\u000A","\\u002F","\\u002A","/","//",s};for(i=0;i<9;i++)t=t.//\u000A\u002F\u002A
Replace//\u002A\u002Freplace
(""+(char)a[i],b[i]);t+='*';for(i=872;i>=0;i--)t=t+t//\u000A\u002F\u002A
[i];Console.Write//\u002A\u002F.charAt(i);System.out.printf
(t);}}/*/}};)t(
ftnirp.tuo.metsyS;)i(tArahc.F200u\A200u\//etirW.elosnoC;]i[
A200u\F200u\A000u\//t+t=t)--i;0=>i;278=i(rof;'*'=+t;)]i[b,]i[a)rahc(+""(
ecalperF200u\A200u\//ecalpeR
A200u\F200u\A000u\//.t=t)++i;9<i;0=i(rof;}s,"//","/","A200u\\","F200u\\","A000u\\","\\","n\",""\"{][gnirtS wen=b][gnirtS;}63,36,69,59,53,46,83,49,33{][tni wen=a][tni;i tni;s=t,"/}};)t(^ftnirp.tuo.metsyS;)i(tArahc.#_?etirW.elosnoC;]i[^_#@?t+t=t)--i;0=>i;278=i(rof;'*'=+t;)]i[b,]i[a)rahc(+!!(^ecalper#_?ecalpeR^_#@?.t=t)++i;9<i;0=i(rof;}s,!?!,!`!,!_&!,!#&!,!@&!,!&&!,!n&!,!!&!{][gnirtS wen=b][gnirtS;}63,36,69,59,53,46,83,49,33{][tni wen=a][tni;i tni;s=t,!$!=s gnirtS{)z][gnirtS(^niam#_?niaM^_#@?diov citats cilbup{margorP ssalc^#_?;metsyS gnisu^_#@`?**`"=s gnirtS{)z][gnirtS(
niamF200u\A200u\//niaM
A200u\F200u\A000u\//diov citats cilbup{margorP ssalc
F200u\A200u\//;metsyS gnisu
A200u\F200u\A000u\///**/</code></pre><br/>
<p>К сожалению, монстр получился слишком большим (1747 символов), однако это объясняется длинными цепочками юникод-символов и многословностью языков C# и Java. Уверен, что на других языках можно будет написать квайн-палиндром-полиглот гораздо меньшего размера.</p><br/>
<p>Теперь проверим, как эта программа исполняется. Для начала избавимся от всех комментариев и правильно отформатируем код:</p><br/>
<div class="spoiler"><b class="spoiler_title">Отформатированный и очищенный код PalidromePolyglotQuine.cs.java под C#</b><div class="spoiler_text"><pre><code>using System;
class Program
{
public static void Main(String[] z)
{
String s = "`**?`@#_^using System;?_#^class Program{public static void?@#_^Main?_#main^(String[]z){String s=!$!,t=s;int i;int[]a=new int[]{33,94,38,64,35,95,96,63,36};String[]b=new String[]{!&!!,!&n!,!&&!,!&@!,!&#!,!&_!,!`!,!?!,s};for(i=0;i<9;i++)t=t.?@#_^Replace?_#replace^(!!+(char)a[i],b[i]);t+='*';for(i=872;i>=0;i--)t=t+t?@#_^[i];Console.Write?_#.charAt(i);System.out.printf^(t);}}/",
t = s;
int i;
int[] a = new int[] { 33, 94, 38, 64, 35, 95, 96, 63, 36 };
String[] b = new String[] { "\"", "\n", "\\", "\\u000A", "\\u002F", "\\u002A", "/", "//", s };
for (i = 0; i < 9; i++)
t = t.Replace("" + (char)a[i], b[i]);
t += '*';
for (i = 872; i >= 0; i--)
t = t + t[i];
Console.Write(t);
}
}</code></pre></div></div><br/>
<p>Из листинга становится понятно, что переменная <code>s</code> содержит код программы, в котором экранированы запрещенные в строках символы и сжаты повторяющиеся последовательности. Ниже представлена таблица символов в формате код — символ — замена, которая используется для формирования выводимой строки <code>t</code>.</p><br/>
<table>
<thead>
<tr>
<th>код</th>
<th>символ</th>
<th>замена</th>
</tr>
</thead>
<tbody>
<tr>
<td>33</td>
<td>!</td>
<td>"</td>
</tr>
<tr>
<td>94</td>
<td>^</td>
<td>\n</td>
</tr>
<tr>
<td>38</td>
<td>&</td>
<td>\</td>
</tr>
<tr>
<td>64</td>
<td>@</td>
<td>\u000A</td>
</tr>
<tr>
<td>35</td>
<td>#</td>
<td>\u002F</td>
</tr>
<tr>
<td>95</td>
<td>_</td>
<td>\u002A</td>
</tr>
<tr>
<td>96</td>
<td>`</td>
<td>/</td>
</tr>
<tr>
<td>63</td>
<td>?</td>
<td>//</td>
</tr>
<tr>
<td>36</td>
<td>$</td>
<td>s</td>
</tr>
</tbody>
</table><br/>
<p>На следующем этапе происходит конкатенация строки <code>t</code> с ней же, инвертированной для того, чтобы на выходе получился палиндром. Стоит отметить, что число 872 (длина строки <code>t</code>) необходимо просчитывать после того, как квайн уже был написан. А для этого необходимо запускать уже написанный код, что также представляет определенные сложности.</p><br/>
<p>Главным критерием при написании такого кода было достижение наименьшего размера в текстовом виде, а не его чистота. Поэтому, понятное дело, выглядит он несколько странно. </p><br/>
<p>Как видим, ничего сложного в написании таких квайнов нет. Для тех, кто не верит, что это все действительно работает, были написаны тесты в репозитории <a href="https://github.com/KvanTTT/Freaky-Sources/blob/master/FreakySources.Tests/QuineTests.cs">Freaky-Sources</a> (для запуска требуется, чтобы Java была установлена).</p><br/>
<p>Кидайте в комментарии ваши квайнды-палиндромы-полиглоты на других языках и другие интересные кодофричные вещи, с удовольствием их изучу.</p><br/>
<p>Еще раз поздравляю всех программистов и сочувствующих!</p></div>
``` | https://habr.com/ru/post/309702/ | null | ru | null |
# Понимаем implicit'ы в Scala

В последнее время у меня было несколько разговоров с друзьями из Java мира об их опыте использования Scala. Большинство использовали Scala, как улучшенную Java и, в итоге, были разочарованы. Основная критика была направлена но то, что Scala слишком мощный язык с высоким уровнем свободы, где одно и тоже можно реализовать различными способами. Ну и вишенкой на торте недовольства являются, конечно же, implicit'ы. Я соглашусь, что implicit'ы одна из самых спорных фич языка, особенно для новичков. Само название «неявные», как бы намекает. В неопытных руках implicit'ы могут стать причиной плохого дизайна приложения и множества ошибок. Я думаю каждый, работающий со Scala, хотя бы раз сталкивался с ошибками разрешения ипмлиситных зависимостей и первые мысли были что делать? куда смотреть? как решить проблему? В результате приходилось гуглить или даже читать документацию к библиотеке, если она есть, конечно же. Обычно решение находится импортом необходимых зависимостей и проблема забывается до следующего раза.
В этом посте я бы хотел рассказать о некоторых распространенных практиках использования имплиситов и помочь их сделать более «явными» и понятными. Наиболее распространенные варианты их использования:
* Неявные параметры (implicit parameters)
* Неявные преобразования (implicit conversions)
* Неявные классы (implicit classes — «Pimp My Library» паттерн)
* Тайп-классы (type classes)
В сети много статей, документации и докладов, посвященных этой теме. Я, однако, хотел бы остановиться на их практическом применении на примере создания Scala-friendly API для замечательной Java библиотеки ~~Typesafe~~ [Lightbend Config](https://github.com/lightbend/config). Для начала нужно ответить на вопрос, а что, собственно, не так с родным API? Давайте взглянем на пример из документации.
```
import com.typesafe.config.ConfigFactory
val conf = ConfigFactory.load();
val foo = config.getString("simple-lib.foo")
val bar = config.getInt("simple-lib.bar")
```
Я вижу здесь, как минимум, две проблемы:
1. Обработка ошибок. Например, если метод `getInt` не сможет вернуть значение нужного типа, то будет брошено исключение. А мы хотим писать «чистый» код, без исключений.
2. Расширяемость. Этот API поддерживает некоторые Java типы, но что, если мы захотим расширить поддержку типов?
Давайте начнем со второй проблемы. Стандартное Java решение — наследование. Мы можем расширить функциональность базового класса путем добавления новых методов. Обычно это не является проблемой, если вы владеете кодом, но что делать если это сторонняя библиотека? «Наивный» путь решения в Scala будет через использование неявных классов или «Pimp My Library» паттерна.
```
implicit class RichConfig(val config: Config) extends AnyVal {
def getLocalDate(path: String): LocalDate = LocalDate.parse(config.getString(path), DateTimeFormatter.ISO_DATE)
}
```
Теперь мы можем использовать метод `getLocalDate`, как если бы он был определен в исходном классе. Неплохо. Но мы решили проблему только локально и мы должны поддерживать всю новую функциональность в одном `RichConfig` классе или потенциально иметь ошибку «Ambiguous implicit values», если одинаковые методы будут определены в разных неявных классах.
Можно ли как-то это улучшить? Здесь давайте вспомним, что обычно в Java, наследование используется для реализации полиморфизма. На самом деле, полиморфизм бывает разных видов:
1. Ad hoc полиморфизм.
2. Параметрический полиморфизм.
3. Полиморфизм подтипов.
Наследование используется для реализации полиморфизма подтипов. Нас же интересует ad hoc полиморфизм. Он означает, что мы будем использовать другую реализацию в зависимости от типа параметра. В Java это реализуется при помощи перегрузки методов. В Scala его можно дополнительно реализовать при помощи тайп классов. Эта концепция пришла из Haskel, где является встроенной в язык, а в Scala это паттерн, который требует implicit'ов для реализации. Если описать вкратце, то тайп класс — это некоторый контракт, например трейт `Foo[T]`, параметризованный типом `T`, который используется в разрешении неявных зависимостей и нужная имплементация контракта выбирается по типу. Звучит запутано, но на самом деле это просто.
Давайте рассмотрим на примере. Для нашего случая, определим контракт для чтения значения из конфига:
```
trait Reader[A] {
def read(config: Config, path: String): Either[Throwable, A]
}
```
Как мы видим, трейт `Reader` параметризирован типом `A`. Для решения первой проблемы мы возвращаем `Either`. Больше никаких исключений. Для упрощения кода можем написать тайп алиас.
```
trait Reader[A] {
def read(config: Config, path: String): Reader.Result[A]
}
object Reader {
type Result[A] = Either[Throwable, A]
def apply[A](read: (Config, String) => A): Reader[A] = new Reader[A] {
def read[A](config: Config, path: String): Result[A] = Try(read(config, path)).toEither
}
implicit val intReader = Reader[Int]((config: Config, path: String) => config.getInt(path))
implicit val stringReader = Reader[String]((config: Config, path: String) => config.getString(path))
implicit val localDateReader = Reader[LocalDate]((config: Config, path: String) => LocalDate.parse(config.getString(path), DateTimeFormatter.ISO_DATE);)
}
```
Мы определили тайп класс Reader и добавили несколько реализаций для типов `Int`, `String`, `LocalDate`. Теперь нужно научить `Config` работать с нашим тайп классом. И здесь уже пригодится «Pimp My Library» паттерн и неявные аргументы:
```
implicit class ConfigSyntax(config: Config) extends AnyVal {
def as[A](path: String)(implicit reader: Reader[A]): Reader.Result[A] = reader.read(config, path)
}
```
Мы можем переписать более кратко при помощи ограничения контекста(context bounds):
```
implicit class ConfigSyntax(config: Config) extends AnyVal {
def as[A : Reader](path: String): Reader.Result[A] = implicitly[Reader[A]].read(config, path)
}
```
И теперь, пример использования:
```
val foo = config.as[String]("simple-lib.foo")
val bar = config.as[Int]("simple-lib.bar")
```
Тайп классы — очень мощный механизм, который позволяет писать легко расширяемый код. Если требуется поддержка новых типов, то можно просто написать реализацию нужного тайп класса и поместить её в контекст. Также, используя [приоритет](https://www.scala-lang.org/files/archive/spec/2.12/06-expressions.html#overloading-resolution) в разрешении неявных зависимостей, можно переопределять стандартную реализацию. Например, можно определить другой вариант `LocalDate` ридера:
```
implicit val localDateReader2 = Reader[LocalDate]((config: Config, path: String) =>
Instant
.ofEpochMilli(config.getLong(path))
.atZone(ZoneId.systemDefault())
.toLocalDate()
)
```
Как мы видим, implicit'ы, при правильном использовании, позволяют писать чистый и расширяемый код. Они позволяют расширить функциональность сторонних библиотек, без изменения исходного кода. Позволяют писать обобщённый код и использовать ad hoc полиморфизм при помощи тайп классов. Нет необходимости беспокоиться о сложной иерархии классов, можно просто разделить функциональность на части и реализовывать их отдельно. Принцип разделяй и властвуй в действии.
[Github](https://github.com/andr83/scalaconfig) проект с примерами. | https://habr.com/ru/post/354028/ | null | ru | null |
# Кастомные переменные Google Analytics, или новые возможности для сегментирования вашего трафика
Как Вы, вероятно, уже знаете не так давно произошло обновление Google Analytics. Данное обновление было освещено и здесь, на хабре, — [Грандиозное обновление Google Analytics](http://habrahabr.ru/linker/go/74221/)
В частности изменения коснулись:
* Увеличено количество целей до 20 (4 набора по 5 целей в каждом)
* Появились цели новых типов (время проведенное на сайте и кол-во просмотренных страниц)
* Веб-аналитика мобильных сайтов. Статистика с приложений на платформах Android и IPhone также как для веб-сайтав
* Адаптация кода Analytics под выбранную платформу
* Появление Pivot таблиц в отчетах — то чего очень не хватало многим, и из-за чего приходилось использовать Excel
* Фильтрация данных в отчетах на лету
* Добавлена новая метрика — уникальные посетители
* Расширена возможность работы с событиями
* **Полностью изменены принципы работы с пользовательскими переменными**
На последнем я бы и хотел остановить свое внимание.
Долгое время единственным предоставляемым GA способом сегментировать свой трафик в статистике была ф-ия **\_setVar()**. С помощью этой ф-ии можно было установить пользовательскую переменную (только одну!) и таким образом, причислить пользователя к определенной категории. Выглядело это как-то так:
`pageTracker._setVar(”registered”);
pageTracker._trackPageview();`
Скажем, код выше мог стоять на странице thankyou\_for\_registration.html и здесь мы устанавливаем, что пользователь зарегистировался на сайте, чтобы в дальнейшем отслеживать отдельно исключительно поведение зарегистрированных пользователей на сайте.
Сделать можно это в разделе Visitors->User-Defined
Как это работало:
При установки переменной выставлялась дополнительная кука для пользователя **\_\_utmv**, значение которой присваивалось название переменной из ф-ии \_setVar, т.е. в нашем случае: ”registered”. Эта кука ставилась продолжительность на 2 года.
В дальнейшем получая эту куку Analytics считал, что пользователь относится к сегменту зарегистрированных пользователей на сайте.
В некоторых случаях этого было достаточно, например, если хотелось сигментировать по гендорному признаку, по тому зарегистрирован пользователь или нет, сделал ли уже покупку. Но если хотелось добавить несколько таких фильтров, то все шло наперекосяк, т.к. если у пользователя была уже установлена эта кука, скажем, в значение ”registered”, и после этого он заполнял о себе в профайле инфо и указывал свой пол, и мы вызывали повторно ф-ию pageTracker.\_setVar(”male”); то вызов этой ф-ии перезатирал предыдущее установленное значение (”registered”).
Таким образом GA сохранял только последнее значение переменно, записанной в \_\_utmv куки.
Было и частичное решение этой проблемы, о котором можно прочитать перейдя по этой [ссылке](http://www.lunametrics.com/blog/2008/04/17/stuff-more-than-one-value-in-gas-user-defined-segment/)
Основная идея этого решения: не перезаписывать переменные в \_\_utmv куки, а дополнять к текущему значению переменной — новое (конкатенировать новый лейбл к уже установленному)
Например, после последовательных вызовов:
pageTracker.\_setVar(”male”);
pageTracker.\_setVar(”registered”);
Реально мы будем иметь данные только о том, что пользователь ”registered”
Используя метод конкатенации:
superSetVar('/male');
superSetVar('/registered');
Мы создадим переменную /male/registered которая будет отражать композитный смысл нашей сегментации.
Но все еще оставалось проблема подсчета таких важных критериев как bounce rate и time on site, а именно они очень сильно изменялись bounce rate — рос, time on site — падал. Это происходило потому, что после установки переменной \_setVar — визит считался новым.
Все это вместе привело к тому, что после обновления GA метод \_setVar стал [deprecated](http://code.google.com/apis/analytics/docs/gaJS/gaJSApiBasicConfiguration.html#_gat.GA_Tracker_._setVar)
#### А что появилось вместо него?
А появился, собственно метод [\_\_setCustomVar](http://code.google.com/apis/analytics/docs/gaJS/gaJSApiBasicConfiguration.html#_gat.GA_Tracker_._setCustomVar)
Сигнатура данного метода выглядит следующим образом:
\_setCustomVar(index, name, value, opt\_scope)
Помимо имени переменной (name) и значения (value) тут появились еще 2 интересных параметра
**opt\_scope**: существует 3 контекста переменных: 1 (visitor-level), 2 (session-level), 3 (page-level).
* **visitor-level** — Время жизни — вечная. Полезно когда ставится для пользователя раз и навсегда (например, пол, зарегистрирован или нет, совершил ли покупку, является ли вип пользователем(клиентом)).
* **session-level** — Время жизни сессия. Полезна, например, для треккинка залогиненых пользователей и анонимов
* **page-level** — Применяется для отслеживания событий или определенных просмотров страниц.
**index** — слот. существует 5 слотов (от 1 до 5). Переменная должна быть помещена в один из слотов.
Не буду вдаваться дальше в детали, т.к. есть очень неплохой [мануал от Google по кастомным переменным](http://code.google.com/apis/analytics/docs/tracking/gaTrackingCustomVariables.html) . Правда на английском. Там приведены примеры и описано подробно что, как и зачем.
Приведу пример только как использую это я.
Например, для сегментации по полу и по тому зарегистрирован ли пользователь, на первой странице после регистрации (та самая thankyou\_for\_registration.html ) я добавляю
`pageTracker._setCustomVar(
1, // This custom var is set to slot #1
"Users", // The name of the custom variable
"Registered", // Sets the value of "Users" var
1 // Sets the scope to visitor-level
);
pageTracker._setCustomVar(
2, // This custom var is set to slot #2
"Gender", // The name of the custom variable
"$Gender", // Sets the value of "Gender" to "Male" or "Female" depending on field in registration form
1 // Sets the scope to visitor-level
);
pageTracker._trackPageview();`
При использовании различных скопов нужно быть предельно внимательным, чтобы переменные не перезаписали друг друга. Об этом также можно почитать [здесь](http://code.google.com/apis/analytics/docs/tracking/gaTrackingCustomVariables.html#usage)
В данной статье только рассказал какими инструментами пользуюсь я для сегментации трафика, буду рад услышать чем пользуетесь Вы :-) | https://habr.com/ru/post/74730/ | null | ru | null |
# Cоздаем игровую приставку Pong-типа с помощью блочного языка и Arduino
Игровые приставки Pong (или как их еще называют Pong-типа) стали одним из первых видов домашних развлечений для детей и взрослых. Еще до появления Atari 2600, NES и других приставок, можно было подключить к телевизору «коробочку» с джойстиками и поиграть с другом или одному в простую, но достаточно увлекательную игру.
На экране было видно поле, движущиеся по краям «биты» и летающий по экрану квадратик-мячик. Для управления нужно было крутить ручку на джойстике, а кнопка предназначалась для «вброса» мяча в игру.
На игровых автоматах разработка от Atari появилась еще в 1972 году, а в 1975 году была выпущена домашняя версия Pong. Успех игровой приставки привел к массовому появлению её клонов: та же Nintendo выпускала аналог под именем Color TV Game 6.
В СССР не отставали (копировать), и уже в 1978 году на прилавках магазинов появилась приставка Турнир, которая стоила 150 рублей, не в последнюю очередь из-за применения импортной микросхемы AY-3-8500. Клонировав ее как К145ИК17, в том же году в СССР наладили выпуск множества других приставок Pong-типа. В 1989 году в 10 номере журнала "Юный техник" вышла публикация «Сквош по пятому каналу», в которой было рассказано, как сделать самому теле-игровую приставку на микросхеме К145ИК17.
Что-то подобное мы решили воплотить в жизнь вместе с детьми младшего школьного возраста. Для этого нужно было использовать что-то привычное по среде и языку программирования, и выбор пал на Scratch и что-то недорогое по элементной базе. Поэтому использовался вариант с Arduino Nano, цена которой «у китайцев», на момент написания статьи, была в районе 150 рублей.
Из дополнительных элементов нам понадобилась кнопка, переменный резистор-крутилка (для аутентичности) на 100Ком (у меня это B100K), мини макетная плата, резистор на 4.7 КОм для устранения дребезга контактов кнопки (подтяжки на землю) и пара перемычек для макетной платы. Переменный резистор лучше вынести отдельно, как сделали мы, так как если его воткнуть напрямую в макетную плату, то работать ничего не будет (а у нас даже начал выходить «синий дым», без которого платы обычно не работают). Один из возможных вариантов – это прикрепить вторую макетную плату ниже (они есть с разъемами для объединения нескольких плат в одну) и разместить кнопку и «крутилку» на ней.
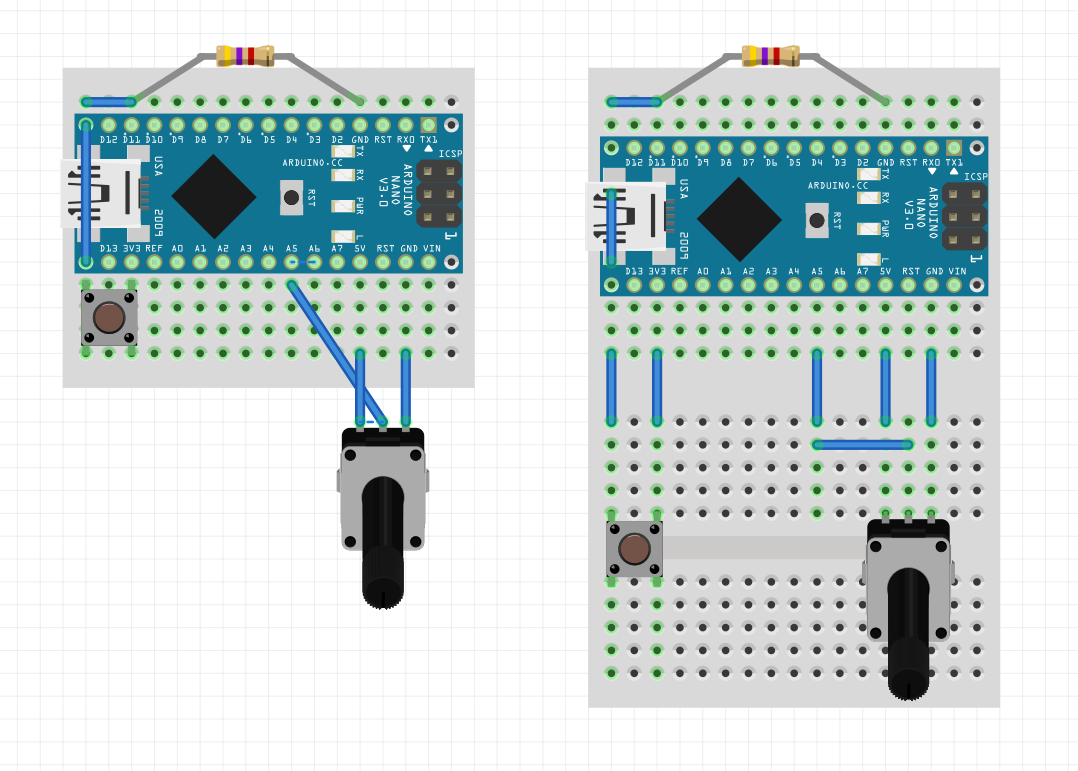А вот как выглядит готовый «джойстик»:
Теперь все это надо подключить к Scratch и запрограммировать саму игру. Для первого приближения решено было делать «сквош» для одного игрока, когда нужно отбивать битой мяч с одной стороны экрана, а от трех остальных он должен отскакивать. В Scratch версий 1.4 и 2 простым способом подключения необходимых нам кнопки и переменного резистора была эмуляция платой Arduino другой платы PicoBoard, поддержка которой была «встроена» внутрь ПО.
Но в Scratch 3.0 поддержку этой платы «выпилили» и необходимо было найти варианты решения данной проблемы. Забегая вперед, скажем, что решение для «оригинального» Scratch найдено не было, и во всех вариантах нам пришлось использовать его модифицированные версии.
### mBlock
Первым делом в голову пришла мысль посмотреть в сторону [mBlock](https://mblock.makeblock.com/en-us/). Эта среда программирования заслуживает отдельной статьи, так как ее возможности работы с аппаратным обеспечением и наличие плагинов превосходят Scratch. Плюс этой среды –есть русский язык, онлайн и оффлайн редактор, поддержка огромного числа плат и роботов и простота настройки работы с ними. Вам достаточно поставить на компьютер ПО mLink2 и настроить аппаратуру, затем можно начинать программировать те же платы Arduino в режиме «прямого» подключения, не требующего заливки на плату кода. А можно создать код для платы и залить его для автономной работы.
Минусы (относительные) – работа оффлайн только под Windows и Mac (на ПК, есть и мобильные версии, а для Linux есть пакеты mLink и предлагается программировать в веб-редакторе) и разделение кода на «аппаратный» и «программный», то есть в нашем случае необходимо обязательно использовать переменные и сигналы для передачи данных между двумя составляющими кода.
Код самой игры (Персонажи + Фон) будут в этом случае аналогичны, вам нужно будет только переделать его на необходимые переменные. Причем mBlock понимает как свой формат файлов, так и формат файлов Scratch 3.
### Scratch 3 OneGPIO Extensions
На [это расширение](https://mryslab.github.io/s3-extend/) мы возлагали большие надежды, так как думали, что сможем обойтись «старой» прошивкой эмуляции PicoBoard. Увы, что-то пошло не так, и в этом клоне Scratch нам тоже пришлось использовать работу с платой Arduino на уровне аналоговых и цифровых выходов.
Расширение работает на уровне сервера, считывая информацию с платы и передавая ее в веб-версию Scratch (онлайн или запускаемую оффлайн). Порядок настройки сервера описан пошагово в инструкции. Вам нужно установить Python 3.7, затем через **pip** установить само расширение **s3-extend**. Все это можно проделать как в Windows, так и в OSX или Linux.
Если все сделано правильно, то командой s3a для Arduino можно запустить сервер, а затем можно зайти [в модифицированный веб-редактор](https://mryslab.github.io/s3onegpio/), добавить нужные блоки и написать программу, взаимодействующую с вашей платой. Для работы в оффлайн режиме авторы предлагают [скачать с Github исходный код](https://github.com/MrYsLab/s3onegpio/tree/gh-pages) и запускать редактор из него.
Саму плату Arduino тоже необходимо предварительно подготовить. В Arduino IDE вам нужно добавить библиотеку **FirmataExpress**, выбрав и установив ее через *Tools/Manage Libraries*.
После этого нужно в библиотеке примеров (меню *File/Example*) найти код **FirmataExpress** и залить его в нашу Arduino Nano.
В итоге плату будет видно в среде программирования, и с ней можно будет работать.
### Программируем Сквош
У нас есть две вводные: кнопка подключена к цифровому входу D11, а резистор подключен к аналоговому входу A5. Запускаем из терминала Командной строки сервер расширения командой s3a, затем сам редактор кода. Перед нами откроется привычный Scratch 3. Добавляем необходимые нам блоки Arduino через меню (в левом нижнем углу) *Добавить расширения* и выбрав **OneGpio Arduino**. У нас будут два спрайта: биты и шарика.
В спрайте биты-ракетки мы реализуем код работы с платой. Одним блоком кода мы считываем с цифрового пина 11 статус нажатия кнопки (0 или 1) и передаем Сообщение в код игры, чтобы перезапустить шарик из центра экрана.
Вторым блоком мы выводим на экран Биту в местоположении, определяемым значением переменного резистора, подключенного к аналоговому пину 5. Это значение меняется от 0 до 1023, поэтому нам нужно перевести его в систему координат Scratch.
«Экранчик» в Scrarch имеет размер 480x360 точек и координаты от -240 до 240 и от -180 до 180 (координата 0,0 находится в центре экрана). Поэтому мы переводим значение с резистора в текущие координаты по формуле: `Значение _с_A5 / 2.85 – 180`
Сам код игры простой. Мы имеем две переменные **xpong** и **ypong**, которые содержат приращение координат для мяча на экране. При старте игры мы задаем их случайно от 5 до 15, чтобы у нас мяч всегда летел под разными углами. При достижении мячиком краев экрана мы просто меняем знак у этих приращений, симулируя упругий удар. В случае биты-ракетки мы определяем соударение через касание спрайтов мяча и биты, также меняя значение **xpong** на противоположное. И если координата мяча по оси X оказывается меньше координаты края биты, засчитываем игроку гол.
Нажатие кнопки вызывает передачу Сообщения и перезапуск кода игры. Код игры для Scratch 3 OneGPIO можно скачать [по этой ссылке](https://disk.yandex.ru/d/P-YnTeY9xNjlCg).
Получившуюся игру есть куда дорабатывать и модифицировать, и эту задачу уже можно дать и детям. Например, на другой аналоговый порт можно добавить еще один резистор-крутилку, добавить кнопки выбора сложности (скорости) игры и выбора ее типа, как в оригинальном Pong, где были еще хоккей и футбол. Можно даже собрать световой пистолет. Можно нарисовать оригинальные цифры счета и добавить возможность игры до определенного числа очков. Можно изменять скорость полета мяча, размеры бит, сделать отскоки более непредсказуемыми. Все в ваших руках.
---
Мы в [RoboUniver будем рады узнать и даже увидеть ваши проекты](https://robounivermsk.obraz.pro/?utm_source=habr&utm_medium=article&utm_campaign=pong), созданные по типу нашего, а также прочитать ваши отзывы. Если вам будет интересно узнать побольше о том же MBlock, подключении разных датчиков, или как работать в Scratch-подобных средах с другими платами, такими как Raspberry Pi или Micro:bit, то напишите об этом в комментариях. | https://habr.com/ru/post/702064/ | null | ru | null |
# Добавляем Web API для программы на C++ с помощью библиотеки POCO
В жизни любой достаточно большой программы наступает момент, когда нужно вывести наружу какой-нибудь API — для плагинов, для интеграции с другими системами, для автоматизации и т.д. Для этого есть много разных технологий, но как-то так исторически сложилось, что сейчас принято делать API в виде REST-сервисов. В принципе, если не гнаться за экономией каждого байта и микросекунды, то в этом есть смысл: HTTP-запрос сделать легко из любого языка, это хорошо работает и локально, и по сети, не нужно сильно глубоко погружаться в недры сетевых протоколов.
Давайте посмотрим, как к уже существующей программе на C++ можно быстренько прикрутить Web API, используя для этого библиотеку [POCO](http://pocoproject.org/).
#### Задача
Пусть у нас есть вот такая программа:
```
#include
#include
int main(int argc, char\*\* argv)
{
for(;;)
{
std::cout << "Hello world!" << std::endl;
\_getch();
}
return 0;
}
```
Мы хотим дать возможность извне менять выводимый текст. Для этого клиенту будет достаточно сделать запрос вида:
```
http://host:port/setText?text=NewText
```
#### Собираем POCO
1. Идём [вот сюда](http://pocoproject.org/download/index.html) и скачиваем последнюю версию Basic Edition for Windows (1.4.6p1 на момент написания этой статьи).
2. Разархивируем куда-нибудь.
3. Идём туда, куда разархивировали и видим там батники с именами **build\_vs90.cmd**, **build\_vs100.cmd**, **build\_vs110.cmd**. Они собирают библиотеку POCO с помощью разных версий Visual Studio. Просто запустите нужный (студия, само-собой, к этому моменту должна быть уже установлена). Я лично компилировал POCO под VS2008, VS2010 и VS2012 — проблем не возникло ни разу.
#### Подключаем POCO к своему проекту
1. Сделайте в папке своего проекта папку POCO
2. В этой папке сделайте три подпапки: include, lib, bin.
3. В папку include скопируйте все заголовочные файлы POCO (из папок %POCO%\XML\include, %POCO%\Util\include, %POCO%\Net\include и %POCO%\Foundation\include)
4. В папку lib скопируйте lib-файлы из %POCO%\lib. Для удобства можно разнести их по подпапкам Debug и Release.
5. В папку bin скопируйте dll-файлы из %POCO%\bin. Их аналогично можно разнести по подпапкам Debug и Release.
6. Добавьте путь к папке include в **Additional Include Directories**, а путь к папке lib — в **Additional Library Directories** своего проекта. Удобно использовать переменную **$(SolutionDir)** и относительные пути.
7. Добавьте файлы PocoFoundationd.lib, PocoNetd.lib, PocoUtild.lib в **Additional Dependencies** проекта для Debug-конфигурации, а их версии без буквы «d» в конце — для Release-конфигурации.
8. Не забудьте, что dll-файлы из папки bin нужно будет деплоить вместе с вашим приложением. Можете просто их скопировать в папки Debug\Release или сделать шаг в процессе компиляции, где они будут туда копироваться.
В конце топика есть ссылка на настроенный проект на GitHub — можете использовать его как базу.
#### Используем POCO для создания Web API
Код получается очень простой и понятный. В главном файле создаём объект класса, унаследованного от ServerApplication. Это позволит нам сохранить в главном потоке вывод наших сообщений, одновременно запустив в другом потоке веб-сервер с помощью класса HTTPServer. Для того, чтобы объяснить веб-серверу, как обрабатывать входящие запросы мы сделаем свою фабрику, унаследованную от HTTPRequestHandlerFactory. На каждый запрос она будет создавать новый объект обработчика (класса, унаследованного от HTTPRequestHandler), который уже и будет заниматься разбором входящего запроса, его обработкой и выдачей клиенту результата.
В коде всё выглядит даже проще, чем в описании выше.
**PocoHelloWorld.cpp**
```
#include "MyRequestHandler.h"
int main(int argc, char** argv)
{
MyServerApp app;
return app.run(argc, argv);
}
```
**MyRequestHandler.h**
```
#pragma once
#include
#include
using namespace Poco;
using namespace Poco::Util;
using namespace std;
class MyServerApp : public ServerApplication
{
public:
static string getText();
static void setText(string newText);
protected:
int main(const vector &);
static string text;
static Mutex textLock;
};
```
**MyRequestHandler.cpp**
```
#include
#include
#include
#include "MyRequestHandler.h"
#include
#include
#include
#include
#include
#include
#include
#include
using namespace Poco::Net;
string MyServerApp::text = "Hello world!";
Mutex MyServerApp::textLock;
class CMyRequestHandler : public HTTPRequestHandler
{
public:
void handleRequest(HTTPServerRequest &req, HTTPServerResponse &resp)
{
resp.setStatus(HTTPResponse::HTTP\_OK);
resp.setContentType("text/html");
ostream& out = resp.send();
URI uri(req.getURI());
if (uri.toString().find("/setText") == 0)
{
StringTokenizer str(uri.getQuery(), "=");
if (str.count() == 2 && str[0] == "text")
{
MyServerApp::setText(str[1]);
out << "ok";
out.flush();
return;
}
}
out << "error";
out.flush();
}
};
class MyRequestHandlerFactory : public HTTPRequestHandlerFactory
{
public:
virtual HTTPRequestHandler\* createRequestHandler(const HTTPServerRequest &)
{
return new CMyRequestHandler;
}
};
void MyServerApp::setText(string newText)
{
ScopedLock lock(textLock);
text = newText;
}
string MyServerApp::getText()
{
ScopedLock lock(textLock);
return text;
}
int MyServerApp::main(const vector &)
{
HTTPServer s(new MyRequestHandlerFactory, ServerSocket(8000), new HTTPServerParams);
s.start();
for(;;)
{
cout << MyServerApp::getText() << endl;
\_getch();
}
s.stop();
return Application::EXIT\_OK;
}
```
#### Дополнительные материалы
* [Исходники проекта на GitHub](https://github.com/ezhikus/PocoHelloWorld)
* [Сайт библиотеки POCO](http://pocoproject.org)
* [Хорошая обзорная статья о POCO на Хабре](http://habrahabr.ru/post/148173/)
Всем спасибо, удачи в использовании POCO. | https://habr.com/ru/post/178403/ | null | ru | null |
# OTRS на прокачку в стиле REG.RU

Наверное, нет необходимости рассказывать, что такое [OTRS](https://www.otrs.com/). Многие компании используют его как средство управления услугами и для осуществления поддержки своих клиентов. История этого проекта берет своё начало аж в 2001 году. И в этом есть свои плюсы и свои минусы. Очень мощный инструмент с огромным количеством функционала практически под любые нужды малого и среднего бизнеса. Причём бесплатно. Платная поддержка только для тех, кому недостаточно базового функционала или нужна помощь в настройке.
Об этом инструменте, который активно используется в нашей компании с 2008 года, и пойдёт речь. А точнее, о том, что с ним стало в руках нетерпеливых Perl-программистов компании REG.RU.
Для чего мы используем OTRS?
----------------------------
Да для того же, что и все остальные:
* приёма заявок и писем (тикетов) от клиентов;
* решения задач на основе полученных тикетов;
* передачи сведений о багах и задач для программистов, если в тикете указали на ошибку на нашем сайте;
* сбора статистики о количестве обращений и других метриках, позволяющих анализировать качество работы нашей техподдержки и многого другого.
OTRS — основной инструмент всех наших клиентских служб. И поэтому для нас важна его стабильная, быстрая и бесперебойная работа.
Немного статистики и интересных фактов
--------------------------------------

Уже давно прошли те времена, когда мы большую часть клиентов узнавали по голосу в телефонной трубке. Да-да, было такое время на заре становления, когда, услышав знакомый голос в трубке, говоришь: «Здравствуйте, Иван Иванович! Рад Вас слышать», а не дежурную фразу, и параллельно уже открываешь карточку нужного клиента, готовый выслушать новую просьбу или описание проблемы. Сейчас по многим показателям среди [регистраторов](http://statonline.ru/registrar?tld=ru) и [хостинг-провайдеров](http://statonline.ru/metrics/hosting?tld=ru) в России мы уже первые (ну не буду я считать Hetzner российской компанией, уж простите), а значит и количество обращений в день давно превысило объёмы, которые может удержать в голове рядовой сотрудник клиентской службы.
### За 2014–2015 годы
* Всего создано тикетов (включая спам и системные уведомления): 2 287 701.
* Тикетов, на которые хотя бы раз отвечали: 769 344.
* Всего ответов по тикетам: 1 008 714.
* В среднем ответов клиентам в день: 1 867.
* Среднее количество ответов для решения проблемы по тикету: 1.3.
* В среднем обрабатываемых тикетов в день: 1 424.
* В среднем за месяц новых тикетов: 42 741.
### Количество активных тикетов по годам
*Активными считаются тикеты, созданные реальными клиентами, — не спам и не служебные автоматические уведомления.*
* **2014 г.** — 799 476
* **2013 г.** — 386 604
* **2012 г.** — 118 704
* **2011 г.** — 13 886
* **до 2011 г.** — 1 602
### На данный момент
* В среднем на сотрудника приходится 8-10 ответов в час.
* Минимальное время ответа на новый тикет — 1 минута.
* Среднее время решения проблемы по тикету — 5-7 минут.
* Максимальное время реакции на тикет (2015 год) — 24 часа.
### Графики за август 2015 г. по максимальному времени реакции
#### Техническая поддержка хостинга
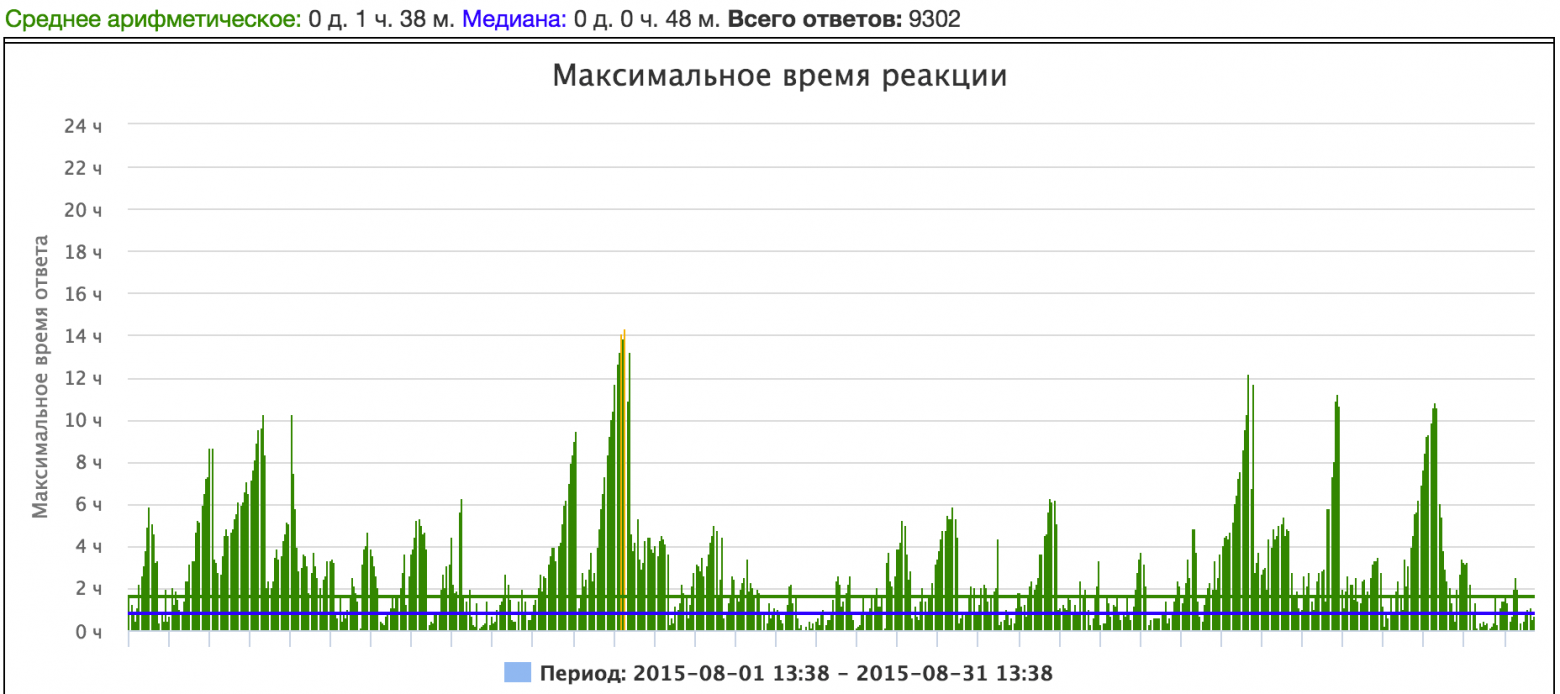
#### Техническая поддержка по доменам
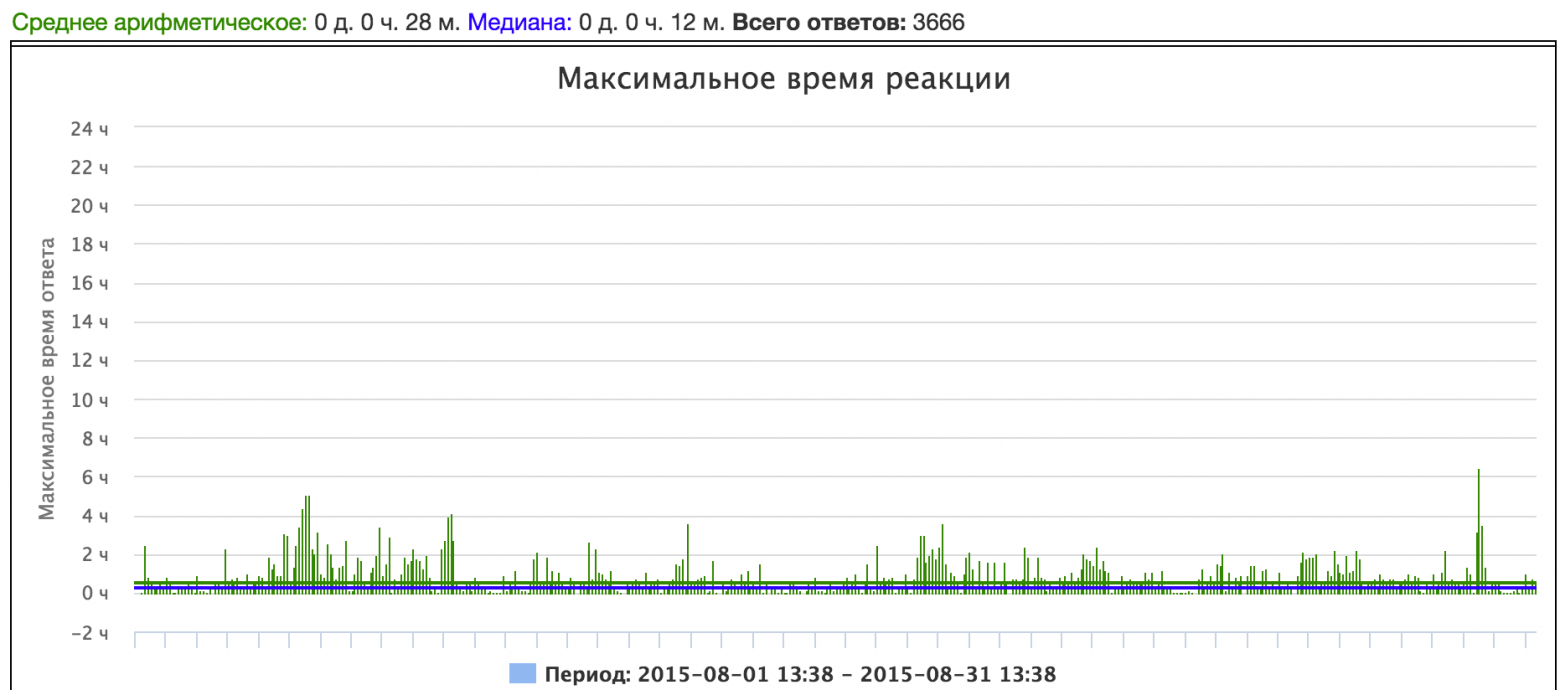
#### Техническая поддержка облачных услуг
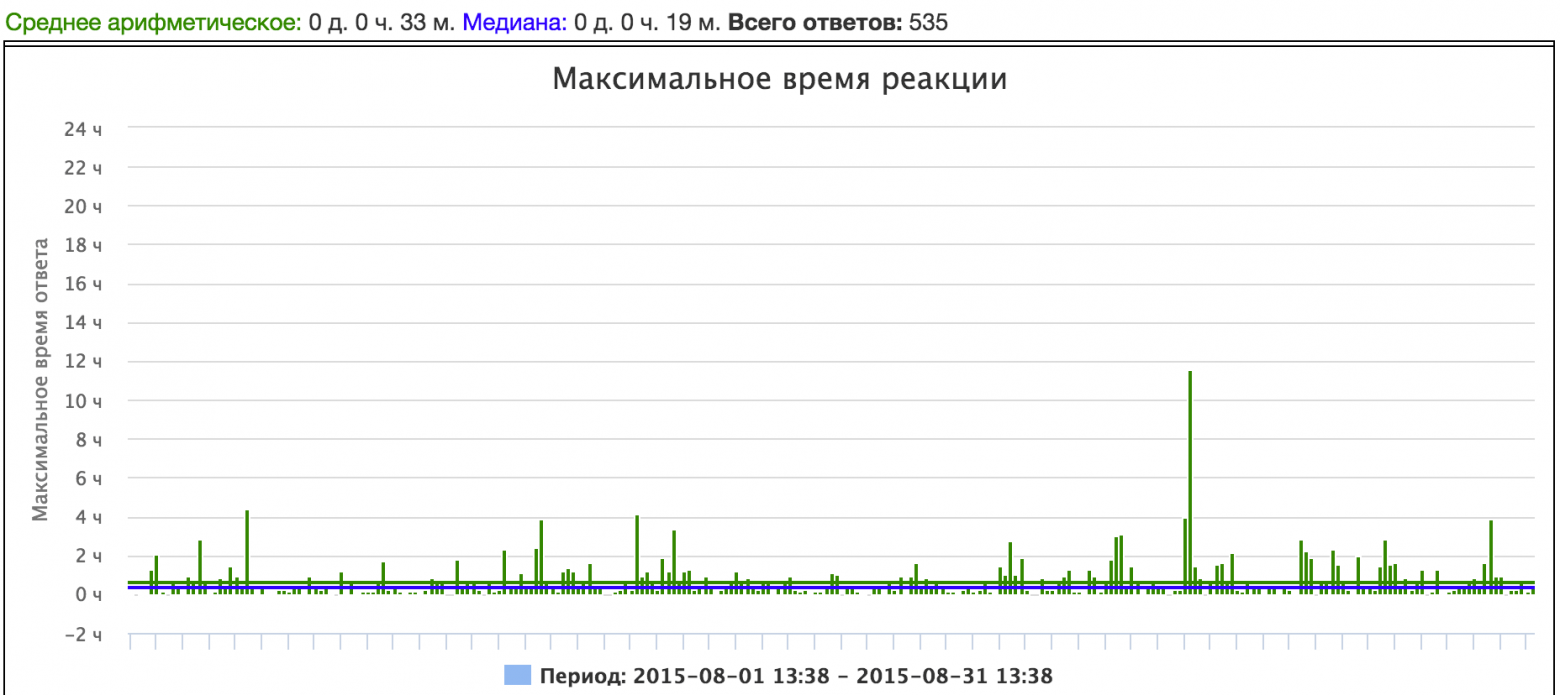
#### Техническая поддержка по биллингу
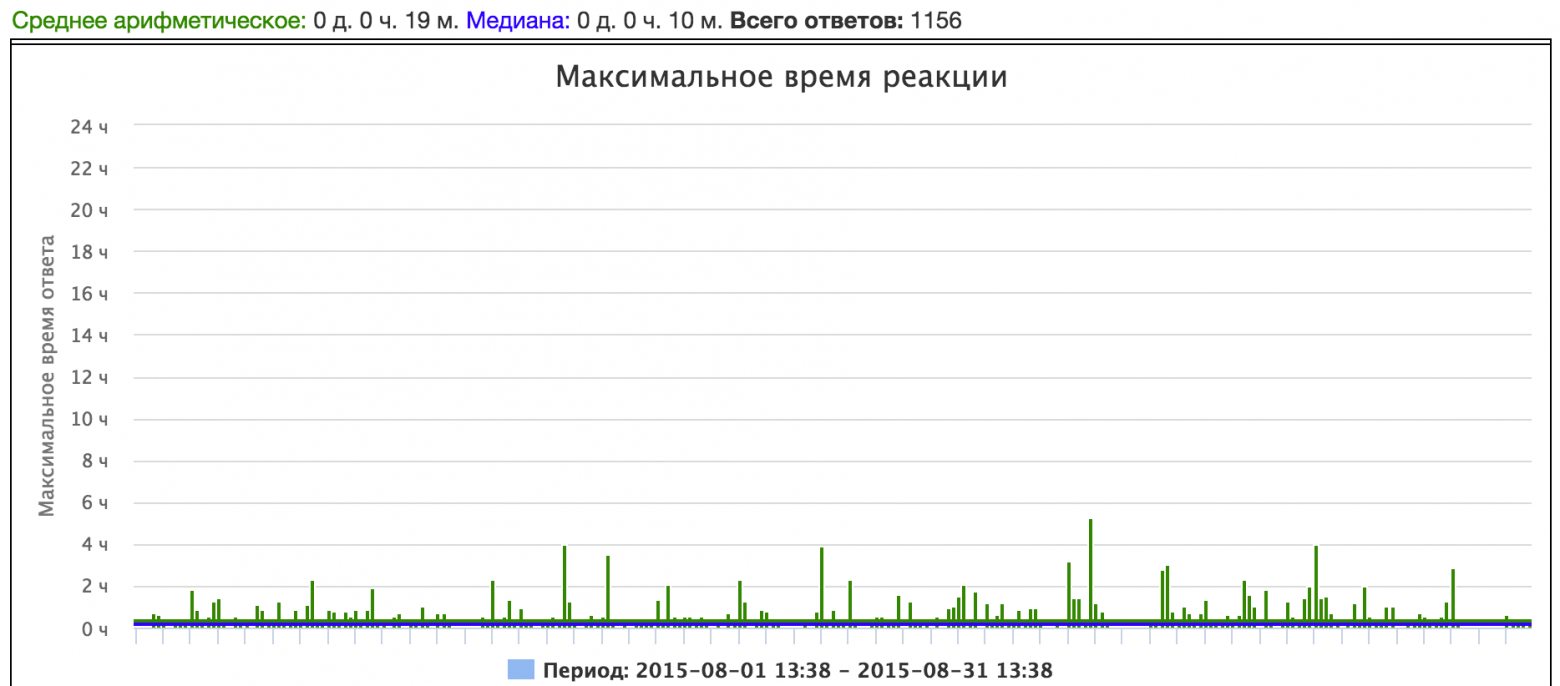
Кому-то эти объёмы покажутся большими, кому-то — мизерными. Но мы и не поддержка World of Warcraft ;-)
Теперь давайте посмотрим, что позволило нам добиться этих результатов, как мы улучшили и модернизировали OTRS.
Начнём с того, что в начале прошлого года мы отказались от обратной совместимости с основной веткой OTRS, поддерживаемой разработчиками. На это было много причин. В OTRS есть механизмы для расширения функционала, но используя лишь предоставленный инструментарий, мы были скованы в возможностях. Кроме того, не скроем и тот факт, что раньше (несколько лет назад) все доработки делались на живую в коде, и выполняли их зачастую программисты, которые не вели проект OTRS полноценно, а просто их просили срочно что-то поправить в смежном проекте. Им было выделено небольшое время, чтобы разобраться в вопросе и быстро пофиксить или внедрить какую-то фичу. Естественно, при таком подходе страдала и совместимость, и общее качество кода OTRS.
Два года назад была произведена попытка мигрировать тогда ещё на новый OTRS 3.3, при этом сохранив все собственные наработки. Операция проходила тяжело, длилась несколько месяцев и в итоге её результат не стоил тех усилий, которые мы на это потратили. Горький опыт, но со своими плюсами. Благодаря этому опыту мы покопались практически в каждом файле OTRS, поняли, как работают многие механизмы, наметили несколько десятков мест, которые стоит отрефакторить или переписать полностью. Не обошлось и без откровенно плачевных конструкций (не наших), которые ввергали в ужас не только новичков в языке Perl и веб-программировании, но и опытных ведущих программистов. Хотя всё это вполне ожидаемо, ведь мощный продукт, который живёт уже 14 лет, не мог полностью избавиться от некоторых частей в коде, тянущихся с самого зарождения продукта.
К этому моменту мы уже окончательно поняли несколько вещей:
* у нас собралась команда, готовая улучшать и развивать OTRS всё своё рабочее время (2-3 человека);
* у нас есть понимание, как должны работать такие вещи как кэш, поиск, роли etc в контексте данного инструмента;
* нужна интеграция с другими ресурсами REG.RU для упрощения и автоматизации работы клиентских служб;
* нам проще вручную вытаскивать полезные фишки из основной ветки OTRS и внедрять их, не поддерживая полную совместимость.
Большие переработки
-------------------
### Поиск
Самой большой проблемой на протяжении длительного времени был, конечно же, поиск по тикетам. Вы же помните цифры из предыдущей главы? А теперь представьте, что сотрудник в поле полнотекстового поиска вводит слово «reg.ru» (или любой другой домен) для поиска по всей базе без указания диапазона дат. Вполне, кстати, обычная задачка для сотрудника. А что при этом делает OTRS на базе mysql? Она делает запрос примерно такого вида:
```
SELECT * FROM ticket, article WHERE from LIKE ‘%reg.ru%’ OR to LIKE ‘%reg.ru%’ OR title LIKE ‘%reg.ru%’ OR body LIKE ‘%reg.ru%’ — и ещё несколько менее значимых полей с таким LIKE.
```
Стоит ли говорить, как висла наша база от таких запросов и, если даже запрос выполнялся удачно, то сколько времени это занимало. А если таких «искателей» было несколько одновременно? Мягко говоря, было тяжело. В рабочее время чуть ли не постоянно был включен mytop и отслеживание долгих запросов, которые мы вручную убивали.
Поэтому первой и важной доработкой стал поиск через Sphinx. Писали его мы достаточно долго, но результат был отличным. Итогом стал модуль на CPAN [OTRS::SphinxSearch](https://metacpan.org/pod/OTRS::SphinxSearch), который поможет таким же энтузиастам развернуть у себя поиск через Sphinx. Автор модуля, я уверен, обязательно ответит на ваши вопросы или отреагирует на найденные баги.
База индексов Sphinx, как известно, хранится в оперативной памяти. На наши тикеты со всеми сообщениями, кроме очереди SPAM и Raw, потребовалось около 4,5 гигабайт ОЗУ. Достаточно низкая цена за моментальный поиск.
Кроме того, сначала Sphinx работал с дельта-индексами, создаваемыми по крону: пятиминутки, пятнадцатиминутки, часовые, шестичасовые и, наконец, суточные. «Сложно и запутанно», — скажете вы и будете абсолютно правы. Кроме того, это имело несколько неприятных следствий. Во-первых, от момента появления сообщения до возможности поиска по нему проходило до 5 минут. Во-вторых, в моменты индексации сильно нагружался CPU, из-за чего весь OTRS стабильно подтормаживал, что сказывалось на производительности всех сотрудников службы поддержки.
В какой-то момент мы вернулись к тому, от чего уходили: запросы переиндексации Sphinx вешали намертво mysql. Это нужно было срочно исправлять.
Вторая реинкарнация поиска была уже на RealTime индексах. Она работала уже гораздо шустрее, не нагружала CPU, лишь добавляла один sql-запрос к интерфейсу Sphinx в виде INSERT или REPLACE, в зависимости от ситуации.
Такой поиск работает у нас до сих пор. Было несколько незначительных правок в коде и только. С нетерпением ждём [Sphinx 3.0](http://habrahabr.ru/post/257789/), чтобы воспользоваться всеми его крутыми фишками.
### Мотивация «Решай всё подряд»
Вторая проблема, которая волновала уже не только сотрудников, но и клиентов — это время ответа на тикет. Особенно, если вопрос был сложный.
Раньше оценка качества работы сотрудника технической поддержки базировалась на количестве обработанных им тикетов в месяц. Это имело свои недостатки, ведь если в очереди 10 тикетов, из них 2 сложных, а 8 остальных лёгкие, то в первую очередь в работу шли самые лёгкие и зачастую не самые старые тикеты. В статистике у сотрудника красовались 8 выполненных тикетов. А пока он на них отвечал, появлялись новые лёгкие тикеты и он продолжал решать только самые несложные вопросы. В то время как сложные тикеты могли висеть часами и даже днями, пока суровый руководитель не приходил и лично не тыкал в этот, наводящий так много страха, тикет.
Для того чтобы сотрудник имел мотивацию взять самый верхний тикет в очереди (верхний — это самый старый), невзирая на его сложность, была разработана система баллов. Честно скажу: как она используется в мотивации я не очень представляю, это всё хитрости руководителей клиентских служб. Но с программистской точки зрения было сделано следующее:
1. Каждому тикету назначается определённое количество баллов, в зависимости от позиции в очереди. Все просчёты баллов тикета происходят в режиме реального времени для каждого сотрудника отдельно, базируясь на ролях. Чем старше тикет, тем выше он в очереди, тем больше за него баллов.
2. За каждый взятый тикет сотруднику начисляются баллы на его счет. Если сотрудник ответил на тикет, эти баллы закрепляются за ним. Если сотрудник разблокировал тикет и не дал ответ клиенту, то начисляется штраф, в несколько раз превышающий количество баллов. Таким образом можно уйти даже в минус.
3. В конце месяца по собранной статистике руководители определяют, кто работал хорошо, а кто не очень. И, наверное, даже дают денежные премии или выписывают штрафы.
Данная задача, на самом деле, очень обширная и затрагивает множество небольших нововведений.
К примеру, был добавлен так называемый пул тикетов. Приходя на рабочее место, сотрудник заходит в этот пул и сразу же (или почти сразу) для него открывается тикет, на который он должен ответить. Как только сотрудник отправил ответ на тикет, тут же открывается новый тикет из его очереди. Вот такой конвейер придумали для тикетов.
**Забавная история про то, как мы пришли к пулу**Сразу после ввода баллов за тикеты была некоторая неразбериха. Оно и понятно: никто не знал, зачем они нужны и на что они влияют. Скажу по секрету: сами руководители ещё толком не знали, зачем они придумали эти баллы и как мы будем их использовать. Что и говорить про рядовых сотрудников технической поддержки, которым не рассказывали всё до последнего момента.
Увидев в интерфейсе какие-то непонятные «баллы», сотрудники начали поддаваться вполне естественной панике, а потом уже на помощь пришла смекалка: «Если за каждый тикет назначают баллы, значит, чем больше баллов у сотрудника, тем лучше». Ещё хочу заметить, что система баллов была внедрена в летний период, когда по естественным причинам нагрузка на техническую поддержку снижается (клиенты в отпуске и им не до сайтов и доменов). В свете нововведения у всех сотрудников открылось второе дыхание, и они с утроенной силой стали решать задачи по тикетам и брать новые. Произошло невиданное для нас событие: очередь тикетов хостинга, в которой всегда крутилось не менее ста тикетов, опустела за два дня! Были в шоке все, включая клиентов. Скорость ответа на обращения повысилась в разы.
Теперь перед сотрудниками встала новая проблема: тикетов нет, а баллы нужны. Что же делать? Сначала все лихорадочно нажимали F5 в ожидании нового тикета, чтобы скорее забрать его. Ведь вы помните про баллы, да? Они всё еще начисляются за успешный ответ, а выгода от баллов всё так же неизвестна.
Особо рукастые сотрудники техподдержки решили упростить себе жизнь и не заниматься обезьяньим трудом: «Зачем мне самому нажимать F5, когда я могу заставить скрипт автоматически делать это за меня». Стали появляться первые боты, написанные на различных языках и работающие по разным принципам. В коллективе была здоровая (а временами и не очень :) ) конкуренция. Практически никто не делился своими ботами и каждый писал своего.
Боты поражали своим разнообразием и функциональностью. Были плагины для Chrome и Firefox, были скрипты, работающие в фоновом режиме на компьютере сотрудника, были даже демоны, которые крутятся постоянно на собственной VPS сотрудника. Разнообразие языков тоже радовало: Javascript, PHP, Python.
Теперь уже появилась проблема у ботов — конкуренция. Ведь в один поток многого не нахватаешь, надо распараллеливать процесс. Так наши новоиспеченные программисты в лице сотрудников техподдержки изучили и применили на практике многопоточные процессы и асинхронные запросы. Неплохая, кстати, практика.
Всё это продолжалось какое-то время, но с ситуацией явно нужно было что-то делать. 5-6 ботов, каждый от 10 до 100 потоков, долбятся на наш бедный сервер OTRS. Я до сих пор не понимаю, каким образом он не падал, а кряхтел, тужился, но обрабатывал такое количество запросов.
В итоге руководители запретили использовать подобные боты, а ситуацию с баллами прояснили. Но данная история будет ещё долго храниться в нашей памяти. Весёлое было время.
Другими словами, это уже не очередь тикетов, а очередь сотрудников. Где каждый получает ровно по одному тикету и встаёт в конец очереди в ожидании новой порции. Саму очередь с тикетами он при этом не видит, а получает только то, что выдала ему бездушная машина, не разбирая, насколько сложный или лёгкий тикет.
Примерно таким образом мы добились равноправия и все тикеты выполняются в строгой очередности. Надеюсь, наши клиенты заметили это, ведь для хостинговых вопросов максимальное время реакции 8 часов.
### Свой API к интерфейсу OTRS
В процессе развития инструмента нам очень хотелось сократить время получения заявок. Стандартный способ получения тикетов в OTRS — почта. ОТRS может принимать почту по-разному. Может ходить по крону на почтовый сервер и забирать почту оттуда. Может, опять же по крону, читать почту из каталога sendmail и формировать тикеты. В любом случае время между проверками почты составляет не менее одной минуты. А по большому счёту две и более. Стандартный скрипт обработки почты достаточно тяжеловесный и на больших письмах может тратить десятки секунд на парсинг и запись в базу.
А хотелось чего-то лёгкого, современного, молодёжного. Поэтому написали свой API, который принимает JSON, а также адекватно обрабатывает заявки с вложениями файлов.
И тут опытный OTRS-программист меня подловит: зачем писать свой API, ведь у них есть rpc.pl? И будет в чём-то прав. API действительно есть, но мы им не воспользовались и сделали это сознательно. Одна из причин — rpc.pl работает в формате xml-rpc, а я говорил о том, что хочется чего-то современного и лёгкого. Да и по факту его разработка заняла всего несколько дней. Кроме того, наше решение позволило не только получать информацию о тикетах, но и создавать новые, вести переписку, открывать/закрывать тикеты и многое другое. Теперь для создания тикетов с сайта REG.RU мы используем этот API и времени на создание заявок тратится гораздо меньше.
А что делать, если OTRS по каким-то причинам недоступен? Проблемы с сетью или профилактика? Тикеты клиентов не создадутся и вы потеряете все с такой любовью написанные строчки?
На это у нас есть решение в виде очереди заданий на базе Redis. Более подробно про очередь можно почитать в [презентации Ивана Соколова про FastQueue](http://www.slideshare.net/ivsokolov/fast-queue-perl-redis). В случае не 200-го ответа от сервера OTRS мы создаём задание в очереди и складываем в него всё содержимое письма и даже чуточку больше, а также файлы вложения в бинарном виде. В течение нескольких часов происходят попытки отправить информацию о новом тикете. Даже если были кратковременные сбои в работе серверов, за несколько часов уже всё налаживается и новые задачи приходят сотрудникам.
Но некоторым сотрудникам и этого мало. В головах бродят идеи, как через API передавать пакеты задач.
### Теги
Ещё одним достаточно глобальным дополнением стали теги. Они помогают руководителям клиентских служб собирать метрику и анализировать трафик входящих сообщений.
Теги изначально базировались на динамических полях (стандартный механизм OTRS). Но в итоге мы не стали нагружать и без того не быстрые таблицы динамических полей и создали свой механизм с отдельными таблицами для хранения тегов. Также по тегам доступен поиск и фильтрация. Существует несколько видов тегов, которые прикрепляются к тикету.
Во-первых, это тег источника, т. е. откуда поступила заявка. Источников может быть несколько: с авторизованной части сайта REG.RU (пользователь залогинен в REG.RU), с неавторизованной части, через почту и ещё несколько более редких источников. Это помогает определять популярность того или иного способа.
Во-вторых, теги участников. Каждый раз, когда сотрудник отвечает на тикет, к тикету прикрепляется именной тег участника. Это также помогает контролировать, как ведётся работа над запросами наших клиентов.
В-третьих, есть теги уведомлений. Они позволяют быстро производить фильтрацию по письмам, которые были отправлены в автоматическом режиме. В основном к таким уведомлениям относятся предупреждения о превышении лимитов на хостинге или возросших нагрузках.
### Подтверждение e-mail
Одной из первых доработок в OTRS стал механизм подтверждения своей электронной почты. Он используется всегда, если клиент пишет из неавторизованной части сайта. Очевидно, что создано это для того, чтобы мы могли быть уверенными в том, что заявка от клиента действительно создана им, а не злоумышленником, который узнал почтовый ящик клиента.
Этот механизм не раз спасал нас от дерзких запросов «Переустановите мою VPS» от посетителей, которые пытаются выдать себя за одного из наших клиентов.
Сейчас это уже доработанный инструмент, встроенный в клиентскую часть.
### Своя статистика с метриками и фильтрами
Серьезная техническая поддержка требует использования серьезных инструментов. Чтобы можно было уследить за каждым ответом и убедиться, что он был качественным и полным, а также для того, чтобы следить за средними показателями скорости ответов, нагрузки на сотрудников, мы разработали свою статистику по тикетам в OTRS.
Опять же, знатоки скажут, что внутри OTRS есть немало своих отчётов и можно создавать новые. Но и от этого встроенного инструмента мы отказались по множеству причин.
Встроенные отчёты работают долго, используют всё те же LIKE при выборке, нет возможности вывести их все на одной странице. При изменении параметров фильтрации нужно ждать, пока система всё заново перестроит.
А хотелось лёгкого инструмента с фильтрами, таблицами, графиками, гистаграммами, пирогами и другими плюшками. И чтобы они заполнялись в риалтайм и не нагружали основную базу. И чтобы был контроль доступа к ним. Да много чего хотелось. Взваливать всю эту красоту на плечи OTRS не хотелось ну никак. Вспомните к тому же, что у OTRS только с версией 4.0 (которая вышла совсем недавно) появился адекватный шаблонизатор Template::Toolkit. Предыдущий был самописный и даже не поддерживал циклов (ну ладно, поддерживал, но их предварительно нужно было написать в контроллере).
Так и родился ещё один проект по сбору и отображению различных метрик. Среди них собираются такие данные:
1. производительность сотрудников:
* уникальные тикеты по сотрудникам;
* оценка качества ответов;
* количество ответов, переносов, заметок и т. д.;
2. производительность отдела:
* история загруженности очередей;
* время и количество блокировок тикетов;
* время реакции отделов;
3. отчёты:
* количество тикетов по очередям;
* почасовое распределение нагрузки.
И многое другое. Статистика постоянно дорабатывается и добавляются всё новые срезы и фильтры. Надеюсь, это помогает руководителям наших клиентских служб анализировать качество работы отделов в целом и отдельных сотрудников в частности.
### Jabber и SMS-оповещения
Одно из недавних нововведений, которое наконец-то приняло приличный вид и реализацию. Идея оповещать сотрудников о срочных или важных тикетах была давно, но только недавно (в течение последнего года) мы реализовали её в форме, которая всех устраивает.
Началось всё с введения услуги «Обратный звонок». Какое-то время нас устраивало, что заявка на обратный звонок сразу появлялась вверху списка, и сотрудник брал её в работу. Но это продолжалось недолго. Хотелось сократить время между появлением заявки и фактическим звонком.
Для начала было реализовано оповещение в Jabber через модуль [Net::XMPP](https://metacpan.org/pod/Net::XMPP) на рабочие аккаунты ответственных сотрудников. Но мы столкнулись с неразрешимыми (по крайней мере пока) проблемами реализации XMPP для нашего провайдера jabber-протокола. Такие частые «бродкасты» на десяток адресатов быстро уводили нас во временный бан и уведомлений не получал никто. Было пролито немало крови, прежде чем решили от этого отказаться в пользу PUSH-уведомлений прямо в браузер.
Теперь сотрудники, которые уполномочены позвонить клиенту и решить его проблему, в случае, если они на рабочем месте, получают уведомление прямо на экран своего компьютера и могут оперативно среагировать (перейти на страницу с тикетом, узнать подробности, нажать кнопку «Позвонить клиенту»).
Но, помимо обратных звонков, есть ещё ряд заявок, которые должны быть обработаны незамедлительно, желательно прямо сейчас. К примеру, к таким заявкам относятся просьбы и задачи по услугам Colocation. Не всегда сотрудник, который может решить задачу клиента, находится на своем рабочем месте. Банальный пример: сегодня выходной. Для таких случаев реализовали уведомления на мобильный телефон в виде SMS, в котором указаны номер тикета, идентификатор клиента и тема сообщения.
Такие SMS-уведомления позволили моментально реагировать на входящие срочные задачи от клиента в нерабочие время и праздничные дни. Кстати, учёт рабочего времени ведётся по календарю специально для отдела, а учёт праздничных дней — с помощью [Date::Holidays::RU](https://metacpan.org/pod/Date::Holidays::RU). Так что мы (да и вы тоже) можем быть уверены, что ни одно срочное сообщение не пробудет без внимания дольше 2-3 минут.
Небольшие нововведения
----------------------
Мы рассказали о наиболее масштабных изменениях, но помимо них есть ещё и куча небольших доработок, которые делают работу в ОТRS удобнее и быстрее.
**Быстрый поиск ответов из корпоративной wiki**
Небольшое, но очень полезное изменение. Как вы уже заметили, очень многие инструменты, которые были доступны изначально в OTRS, мы отмели по тем или иным причинам. Не избежало этой участи и FAQ OTRS. Мы используем свою наработку для поиска и вставки быстрых ответов в нашем внутреннем FAQ на базе Mediawiki.
**Возможность смены очереди при добавлении заметки**
Совсем крохотное изменение — добавили возможность сразу поменять очередь, когда ввели заметку. Позволяет не открывать тикет два раза, а сделать всё за один подход.
**Поиск по базе клиентов REG.RU**
В карточке о клиенте в OTRS отображаем ссылку на его аккаунт в REG.RU с возможностью быстро открыть перечень его услуг. Привязка клиента и обращения идёт по нескольким параметрам, таким как e-mail, логин в REG.RU и некоторым другим.
**Разграничение доступа к очередям**
Здесь вообще вряд ли можно указать на работу программиста. Всего лишь грамотно работаем с ролями и группами, функционал которых идёт в базовой конфигурации OTRS.
**Быстрое перекидывание тикета в предыдущую очередь**
При решении сложных задач тикеты иногда по цепочке передаются специалистам дольше обычного. Чаще всего тикеты передаются администраторам хостинга, чтобы они помогли клиенту решить его проблему. После решения проблемы администраторам нужно быстро вернуть тикет в предыдущий отдел для уведомления клиента о результате выполненных работ.
**Двуязычные подписи, ФИО и другие параметры сотрудника**
Нам пишут не только русскоязычные пользователи, но иностранцы, которые заказывают услуги у нас или просто интересуются какими-либо вопросами. Чтобы стать ближе к клиентам, мы доработали карточки сотрудников, введя вторые поля для ФИО, подписей и некоторых других текстов, и теперь можем отправлять подписи и уведомления на более понятном для клиента языке.
**Дополнительные уведомления о состоянии работы над тикетом**
Помимо стандартных триггеров в OTRS для уведомления клиентов о состоянии тикета, добавили ещё несколько механизмов, отслеживающих состояние тикетов и отсылки почтового уведомления. Клиенты должны знать, что мы о них не забыли и занимаемся их вопросом.
**Дополнительная роль «тим-лид» — администратор с ограниченными правами в рамках своего отдела**
С ростом компании росла и техническая поддержка. И не только в профессиональном, но и в количественном аспекте. Когда сотрудников стало достаточно много, стало ясно, что придётся менять иерархию внутри отдела. Будут те, кто отвечает клиентам, а будут руководители и лидеры, которые помогают новичкам в решении тех или иных задач. Для таких лидеров мы создали урезанную версию администраторских прав на OTRS, которые позволяют только управлять ролями внутри своего отдела.
**Оценка ответов сотрудника клиентами**
Клиент может дать краткую характеристику каждому ответу сотрудника. Для этого вместе с ответом приходит ссылка для голосования, пройдя по которой, пользователь может по пятибалльной шкале оценить полноту и качество ответа, а также добавить комментарий. Вся информация сохраняется в статистике и изучается бдительными руководителями и аналитиками. Так что можно с уверенность сказать, что все баллы, которые ставят клиенты, и все их комментарии действительно читаются и не остаются без внимания.
**Звонки из ОТRS клиентам (как мы работаем с SIP-телефонией)**
Одна из моих любимых фишек. В OTRS работают не только сотрудники хостинга, но и все остальные клиентские службы. К примеру, они занимаются консультацией новых и старых партнёров. Для оперативной связи с клиентом у определенной роли есть специальная кнопка «Позвонить клиенту». Нажав на эту кнопку, сотрудник сразу же соединяется с клиентом по номеру телефона, указанному в карточке клиента. Здесь используется Asterisk Restful Interface (ARI) для соединения внутреннего номера сотрудника с номером клиента.
Помните, что говорит милый робот в трубку? «В целях улучшениях качества обслуживания все разговоры с оператором записываются». Так вот, это не шутка. Мы действительно записываем звонки, а бдительные руководители периодически прослушивают нужные разговоры, оценивают качество и полноту ответа, и принимают меры, если сотрудник где-то ошибся или повёл себя некорректно. Данные о звонках также идут в статистику, про которую я писал выше.
**Кэш на Redis**
Стандартный кэш в OTRS подразумевает хранение его в файлах. А если очень долго не чистить кэш на файлах (есть специальный крон-скрипт), то очень быстро на сервере закончатся все inode и работа сервера встанет. Кроме того, в некоторых случаях с лёгкой руки крон-скрипта мы не можем очищать папку с кэшем.
Поэтому мы перевели хранение кэша на Redis. Это, во-первых, ещё немного ускорило работу всей системы в целом. А во-вторых, позволило нам более гибко и тонко настраивать механизм кэширования. К слову сказать, реализация заняла всего один рабочий день. Базовый механизм кэша OTRS на Redis был найден в Интернете (готовый модуль), оставалось только протестировать его и сделать несколько корректировок в коде под наши реалии.
**Сворачивание цитированной части сообщения**
Одна из недавних доработок, которая позволила убрать лишний мусор в агентской части. При затяжных переписках с клиентами зачастую формируется большой кусок цитируемых сообщений в каждом письме. Чтобы они не мешали чтению и не захламляли страницу, мы добавили скрытие цитируемой части. Почти как у Google в веб-интерфейсе почты. Сложности в реализации были только с определением цитируемой части для писем, сформированных в формате HTML, но и с этой проблемой мы справились.
**LDAP-синхронизация агентов**
Также подключили LDAP-синхронизацию с нашим внутренним сервисом авторизации. Опять же, есть готовый модуль в OTRS, но его функционал не позволял нам сделать всё задуманное. К тому же теперь сотрудникам не приходится вводить свои реквизиты для доступа к OTRS.
**Настраиваемая сортировка очередей для перемещения тикета**
В каждом отделе технической поддержки у нас достаточно строгое распределение должностных обязанностей и периодически тикеты попадали не в ту очередь. Нашим сотрудникам приходилось переносить тикеты из одной очереди в другую, используя при этом стандартный select с более чем 80 очередями, отсортированными только в алфавитном порядке. Например, одна из самых популярных очередей «Техподдержка по доменам» находилась аж на 55 месте. Нами была реализована сортировки очередей в зависимости от ролей пользователя, чтобы каждый отдел мог самостоятельно вывести наверх самые популярные у него очереди.
**Мелочи SQL-жизни**
Тут сложно выделить что-то конкретное, но в целом за весь период активного развития платформы было оптимизировано немало таблиц. Добавлены недостающие индексы, удалены лишние поля (остатки после обновления версии), оптимизированы многие запросы.
Результаты
----------
Очень сложно мне написать о результатах, но всё же попробую. За пару лет активной разработки и поддержки платформы было оптимизировано немало внутреннего кода, написаны десятки новых контроллеров, оптимизированы многие страницы. Список задач в нашем баг-трекере с запланированными изменениями и ещё не взятыми в работу никогда не пустеет. В работе параллельно находится от 2 до 5 задач по улучшению, автоматизации, интеграции с другими ресурсами. Кроме того, не стоит забывать про технический долг и тикеты-рефакторинги, которых у нас уже тоже порядочно накопилось, но мы не можем за них взяться по причине нехватки времени. Воистину неисчерпаемы идеи в головах руководителей наших клиентских служб! На каждую реализованную задачу приходят две новые. Спасибо им за это.
Благодаря нововведениям удалось существенно ускорить время реакции на тикеты. До них клиент мог ждать ответ на свой вопрос сутками и не факт, что он ещё оставался нашим клиентом, когда получал запоздалый ответ. Теперь же в большинстве случаев клиент получает ответ в тот же день.
Кратко о планах
---------------
 Многие части нашего кода достаточно грубо вторгаются в экосистему OTRS. Хотя мы и отказались от перехода на новые релизы проекта, использовать новые нужные фичи мы всё же хотим. Для этого мы в обозримом будущем собираемся переводить весь наш код из ядра OTRS на EventHandler, который дал бы нам более модульную структуру наших изменений.
Также в планах продолжить автоматизацию работы нашей службы технической поддержки для сокращения времени ожидания ответа и оптимизации процессов сотрудника.
Если когда-нибудь мы ~~увидим свет в конце тоннеля~~ решим почти все задачи от клиентских служб по нововведениям, то обязательно уделим внимание нашему старому коду, написанного несколько лет назад и что-нибудь отрефакторим.
Где самое важное?
-----------------
Уверен, многих наших клиентов последние несколько месяцев волнует вопрос: «Куда вы спрятали клиентскую часть ОТRS и где мне посмотреть все свои тикеты?». Действительно, было очень много жалоб на то, что мы скрыли такой важный раздел от всех клиентов, и мы этого не могли не заметить.
На самом деле мы осознанно пошли на такой шаг, и всё это время активно разрабатывали новую, современную, быструю, безопасную клиентскую часть. Немало времени ушло на её тестирование и «допиливание напильником». Это один из наших самых больших «долгостроев» для OTRS. Ни одна другая фича не занимала у нас так много человеко-часов во всех задействованных отделах. Где-то мы просчитались по срокам, где-то было переосмысление концепции и, следовательно, переписывание отдельных частей кода с нуля. Но я надеюсь, всё это мы делали не зря.
Сегодня уже доступна новая клиентская часть для OTRS, которая позволяет следить за всеми тикетами, писать ответы, прикладывать файлы и уведомлять о сообщениях. Сейчас она вшита в интерфейс REG.RU и доступна в Личном кабинете. Теперь всё общение клиентов и техподдержки происходит именно через неё, а на почту приходит только ссылка для перехода в тред.
Зачем это сделано? По многим причинам. Одна из них — исключение возможности злоумышленникам под видом клиента отправлять вопросы и задачи для техподдержки.
Кроме того, новая клиентская часть позволяет поддерживать её всегда в актуальном состоянии — как по дизайну, так и по функционалу. Процесс поддержки и развития сильно упрощается, т. к. находится на одной кодовой базе с основным проектом.
Весь процесс общения между клиентской частью и OTRS происходит через то самое внутреннее API, про которое я уже рассказывал, что снова даёт нам прирост в производительности и удобстве обслуживания.
Благодарности
-------------
Спасибо всем за потраченное на чтение статьи время. Не думал, что будет так много текста.
Спасибо всем клиентам, что остаются с нами.
Спасибо всем, кто терпеливо ждёт исправления ошибок и с пониманием относится к косякам, которые случаются у всех.
Статья является коллективным творением [Chips](http://habrahabr.ru/users/chips/), [banaking](http://habrahabr.ru/users/banaking/), [shikin](http://habrahabr.ru/users/shikin/), [imir](http://habrahabr.ru/users/imir/). Спасибо всем, кто принимал участие в подготовке и сборе материала, вычитке и контроле фактической точности. А также всем тем, кто реализовывал все эти нововведения. | https://habr.com/ru/post/267925/ | null | ru | null |
# Используем Google Cloud Print без Google Chrome

В этой статье я хочу рассказать, как можно использовать Google Cloud Print без установки Google Chrome. Целью статьи будет настройка машины под управлением Ubuntu Server в качестве сервера печати, а также настройка клиентов под управлением Windows, Mac OS и Linux (на примере Ubuntu). В общем случае в качестве сервера может выступать любая машина под управлением ОС семейства GNU/Linux, в том числе маршрутизатор с функцией принт-сервера.
#### 1. Настройка сервера печати
Предположим, что у нас есть машина с установленной ОС Ubuntu Server (в примере используется версия 12.04) и корректно настроенным принтером. Воспользуемся руководством [[1]](http://ubuntuforums.org/showthread.php?t=1794179).
Установим Git для того, чтобы клонировать репозиторий проекта [CloudPrint](https://github.com/armooo/cloudprint). Проект написан на *python* и используем модуль *python-cups*, установим и их. Для сборки проекта нам также понадобиться модуль *python-setuptools*.
```
sudo apt-get install git-core python python-cups python-setuptools
```
Клонируем репозиторий, перейдем в папку с проектом и сделаем скрипт сборки выполняемым.
```
git clone git://github.com/armooo/cloudprint.git
cd ~/cloudprint
chmod +x setup.py
```
Соберем и установим проект.
```
python setup.py build
sudo python setup.py install
```
Выполним первый запуск приложения.
```
/usr/local/lib/python2.7/dist-packages/cloudprint-0.5-py2.7.egg/cloudprint/cloudprint.py
```
Укажем имя пользователя и пароль аккаунта Google, к которому необходимо привязать принтер. Стоит обратить внимание, что в случае, если включена двухэтапная аутентификация, в качестве пароля необходимо указать пароль приложения, сгенерированный на странице настройки аккаунта. Если все настроено верно, на экране отобразится что-то вроде: "*Updated Printer HP\_LaserJet\_1018*". Можно завершить приложение (Ctrl + C).
Теперь добавим скрипт автоматического запуска с помощью upstart. Для этого создадим файл cloudprint.conf.
```
sudo nano /etc/init/cloudprint.conf
```
Ниже представлено содержимое этого файла. $RUN\_AS\_USER необходимо заменить на имя пользователя, под которым будет запускаться программа.
```
start on (started cups and local-filesystems and t-device-up IFACE=eth0)
stop on runlevel [345]
respawn
console none
script
chdir /usr/local/lib/python2.7/dist-packages/cloudprint-0.5-py2.7.egg/cloudprint/
exec su -c /usr/local/lib/python2.7/dist-packages/cloudprint-0.5-py2.7.egg/cloudprint/cloudprint.py - $RUN_AS_USER
end script
```
Запустим программу.
```
sudo start cloudprint
```
На [странице](https://www.google.com/cloudprint?user=0#printers) управления принтерами должен появиться наш принтер.
#### 2. Настройка «облачного» принтера в Windows
Для работы с принтером в ОС Windows воспользуемся программой [Paperless Printer](http://www.rarefind.com/paperlessprinter/index.html), которая бесплатна для домашнего использования.
После установки программы в списке принтеров появится *Paperless Printer*, одной из возможностей которого является *Find a Cloud Printer* — печать произвольного документа на «облачный» принтер Google.
#### 3. Настройка «облачного» принтера в Mac OS X
Для печати в Mac OS X воспользуемся программой [Cloud Printer](http://itunes.apple.com/ru/app/cloud-printer/id463448876?mt=12). Настройка программы не отличается простотой, однако она подробно описана в руководстве [[2]](http://www.webabode.com/software/cloudprint.html), а также представлена на видео.
К сожалению, *Cloud Printer* не дает таких же широких возможностей для пользователей, как *Paperless Printer*, однако эта программа позволяет печатать некоторые документы без использования Google Chrome.
#### 4. Настройка «облачного» принтера в Ubuntu
Для печати в Ubuntu установим драйвер для CUPS по инструкции [[3]](http://www.niftiestsoftware.com/cups-cloud-print/).
```
sudo add-apt-repository ppa:simon-cadman/cups-cloud-print
sudo apt-get update
sudo apt-get install cupscloudprint
sudo /usr/lib/cloudprint-cups/setupcloudprint.py
```
В процессе настройки на вопрос *Add all Google Cloud Print printers to local CUPS install?* необходимо ответить "*yes*".
Работа с «облачным» принтером в Ubuntu не должна вызвать затруднения.
#### 5. Вместо заключения
Цель статьи можно считать достигнутой: у нас появился сервер с настроенным принтером, а также клиенты с возможностью печати на него не из Google Chrome. Однако не стоит понимать эту статью как призыв к отказу от этого браузера. У нас всегда остается возможность распечатать открытую страничку или письмо Gmail напрямую из браузера на домашний принтер где бы мы не находились.
#### 6. Ссылки на источники информации
[[1]](http://ubuntuforums.org/showthread.php?t=1794179) HOWTO: Use Google Cloud Print for Linux (print from Andriod device)
[[2]](http://www.webabode.com/software/cloudprint.html) Cloud Printer (formerly, Cloud Print) for Mac OS X By Somasundaram M (2011)
[[3]](http://www.niftiestsoftware.com/cups-cloud-print/) CUPS Cloud Print (Installation)
P.S. К сожалению, я не обладаю достаточным опытым создания скриптов для upstart. Буду благодарен, если вы поможете мне оптимизировать предложенный выше скрипт. | https://habr.com/ru/post/149520/ | null | ru | null |
# Создание игр на Python 3 и Pygame: Часть 4

Это четвёртая из пяти частей туториала, посвящённого созданию игр с помощью Python 3 и Pygame. В третьей части мы углубились в сердце Breakout и узнали, как обрабатывать события, познакомились с основным классом Breakout и увидели, как перемещать разные игровые объекты.
(Остальные части туториала: [первая](https://habrahabr.ru/post/347138/), [вторая](https://habrahabr.ru/post/347170/), [третья](https://habrahabr.ru/post/347256/), [пятая](https://habrahabr.ru/post/347286/).)
В этой части мы узнаем, как распознавать коллизии и что случается, когда мяч ударяется об разные объекты: ракетку, кирпичи, стены, потолок и пол. Наконец, мы рассмотрим важную тему пользовательского интерфейса и в частности то, как создать меню из собственных кнопок.
Распознавание коллизий
----------------------
В играх объекты сталкиваются друг с другом, и Breakout не является исключением. В основном с объектами сталкивается мяч. В методе `handle_ball_collisions()` есть встроенная функция под названием `intersect()`, которая используется для проверки того, ударился ли мяч об объект, и того, где он столкнулся с объектом. Она возвращает 'left', 'right', 'top', 'bottom' или None, если мяч не столкнулся с объектом.
```
def handle_ball_collisions(self):
def intersect(obj, ball):
edges = dict(
left=Rect(obj.left, obj.top, 1, obj.height),
right=Rect(obj.right, obj.top, 1, obj.height),
top=Rect(obj.left, obj.top, obj.width, 1),
bottom=Rect(obj.left, obj.bottom, obj.width, 1))
collisions = set(edge for edge, rect in edges.items() if
ball.bounds.colliderect(rect))
if not collisions:
return None
if len(collisions) == 1:
return list(collisions)[0]
if 'top' in collisions:
if ball.centery >= obj.top:
return 'top'
if ball.centerx < obj.left:
return 'left'
else:
return 'right'
if 'bottom' in collisions:
if ball.centery >= obj.bottom:
return 'bottom'
if ball.centerx < obj.left:
return 'left'
else:
return 'right'
```
### Столкновение мяча с ракеткой
Когда мяч стукается об ракетку, он отскакивает. Если он ударяется о верхнюю часть ракетки, то отражается обратно вверх, но сохраняет тот же компонент горизонтальной скорости.
Но если он ударяется о боковую часть ракетки, то отскакивает в противоположную сторону (влево или вправо) и продолжает движение вниз, пока не столкнётся с полом. В коде используется функция `intersect()`.
```
# Удар об ракетку
s = self.ball.speed
edge = intersect(self.paddle, self.ball)
if edge is not None:
self.sound_effects['paddle_hit'].play()
if edge == 'top':
speed_x = s[0]
speed_y = -s[1]
if self.paddle.moving_left:
speed_x -= 1
elif self.paddle.moving_left:
speed_x += 1
self.ball.speed = speed_x, speed_y
elif edge in ('left', 'right'):
self.ball.speed = (-s[0], s[1])
```
### Столкновение с полом
Когда ракетка пропускает мяч на пути вниз (или мяч ударяется об ракетку сбоку), то мяч продолжает падать и затем ударяется об пол. В этот момент игрок теряет жизнь и мяч создаётся заново, чтобы игра могла продолжаться. Игра завершается, когда у игрока заканчиваются жизни.
```
# Удар об пол
if self.ball.top > c.screen_height:
self.lives -= 1
if self.lives == 0:
self.game_over = True
else:
self.create_ball()
```
### Столкновение с потолком и стенами
Когда мяч ударяется об стены или потолок, он просто отскакивает от них.
```
# Удар об потолок
if self.ball.top < 0:
self.ball.speed = (s[0], -s[1])
# Удар об стену
if self.ball.left < 0 or self.ball.right > c.screen_width:
self.ball.speed = (-s[0], s[1])
```
### Столкновение с кирпичами
Когда мяч ударяется об кирпич, это является основным событием игры Breakout — кирпич исчезает, игрок получает очко, мяч отражается назад и происходят ещё несколько событий (звуковой эффект, а иногда и спецэффект), которые я рассмотрю позже.
Чтобы определить, что мяч ударился об кирпич, код проверят, пересекается ли какой-нибудь из кирпичей с мячом:
```
# Удар об кирпич
for brick in self.bricks:
edge = intersect(brick, self.ball)
if not edge:
continue
self.bricks.remove(brick)
self.objects.remove(brick)
self.score += self.points_per_brick
if edge in ('top', 'bottom'):
self.ball.speed = (s[0], -s[1])
else:
self.ball.speed = (-s[0], s[1])
```
Программирование игрового меню
------------------------------
В большинстве игр есть какой-нибудь UI. В Breakout есть простое меню с двумя кнопками, 'PLAY' и 'QUIT'. Меню отображается в начале игры и пропадает, когда игрок нажимает на 'PLAY'. Давайте посмотрим, как реализуются кнопки и меню, а также как они интегрируются в игру.
### Создание кнопок
В Pygame нет встроенной библиотеки UI. Есть сторонние расширения, но для меню я решил создать свои кнопки. Кнопка — это игровой объект, имеющий три состояния: нормальное, выделенное и нажатое. Нормальное состояние — это когда мышь не находится над кнопкой, а выделенное состояние — когда мышь находится над кнопкой, но левая кнопка мыши ещё не нажата. Нажатое состояние — это когда мышь находится над кнопкой и игрок нажал на левую кнопку мыши.
Кнопка реализуется как прямоугольник с фоновым цветом и текст, отображаемый поверх него. Также кнопка получает функцию on\_click (по умолчанию являющуюся пустой лямбда-функцией), которая вызывается при нажатии кнопки.
```
import pygame
from game_object import GameObject
from text_object import TextObject
import config as c
class Button(GameObject):
def __init__(self,
x,
y,
w,
h,
text,
on_click=lambda x: None,
padding=0):
super().__init__(x, y, w, h)
self.state = 'normal'
self.on_click = on_click
self.text = TextObject(x + padding,
y + padding, lambda: text,
c.button_text_color,
c.font_name,
c.font_size)
def draw(self, surface):
pygame.draw.rect(surface,
self.back_color,
self.bounds)
self.text.draw(surface)
```
Кнопка обрабатывает собственные события мыши и изменяет своё внутреннее состояние на основании этих событий. Когда кнопка находится в нажатом состоянии и получает событие `MOUSEBUTTONUP`, это означает, что игрок нажал на кнопку, и вызывается функция `on_click()`.
```
def handle_mouse_event(self, type, pos):
if type == pygame.MOUSEMOTION:
self.handle_mouse_move(pos)
elif type == pygame.MOUSEBUTTONDOWN:
self.handle_mouse_down(pos)
elif type == pygame.MOUSEBUTTONUP:
self.handle_mouse_up(pos)
def handle_mouse_move(self, pos):
if self.bounds.collidepoint(pos):
if self.state != 'pressed':
self.state = 'hover'
else:
self.state = 'normal'
def handle_mouse_down(self, pos):
if self.bounds.collidepoint(pos):
self.state = 'pressed'
def handle_mouse_up(self, pos):
if self.state == 'pressed':
self.on_click(self)
self.state = 'hover'
```
Свойство `back_color`, используемое для отрисовки фонового прямоугольника, всегда возвращает цвет, соответствующий текущему состоянию кнопки, чтобы игроку было ясно, что кнопка активна:
```
@property
def back_color(self):
return dict(normal=c.button_normal_back_color,
hover=c.button_hover_back_color,
pressed=c.button_pressed_back_color)[self.state]
```
### Создание меню
Функция `create_menu()` создаёт меню с двумя кнопками с текстом 'PLAY' и 'QUIT'. Она имеет две встроенные функции, `on_play()` и `on_quit()`, которые она передаёт соответствующей кнопке. Каждая кнопка добавляется в список `objects` (для отрисовки), а также в поле `menu_buttons`.
```
def create_menu(self):
for i, (text, handler) in enumerate((('PLAY', on_play),
('QUIT', on_quit))):
b = Button(c.menu_offset_x,
c.menu_offset_y + (c.menu_button_h + 5) * i,
c.menu_button_w,
c.menu_button_h,
text,
handler,
padding=5)
self.objects.append(b)
self.menu_buttons.append(b)
self.mouse_handlers.append(b.handle_mouse_event)
```
При нажатии кнопки PLAY вызывается функция `on_play()`, удаляющая кнопки из списка `objects`, чтобы они больше не отрисовывались. Кроме того, значения булевых полей, которые запускают начало игры — `is_game_running` и `start_level` — становятся равными True.
При нажатии кнопки QUIT `is_game_running` принимает значение `False` (фактически ставя игру на паузу), а `game_over` присваивается значение True, что приводит к срабатыванию последовательности завершения игры.
```
def on_play(button):
for b in self.menu_buttons:
self.objects.remove(b)
self.is_game_running = True
self.start_level = True
def on_quit(button):
self.game_over = True
self.is_game_running = False
```
### Отображение и сокрытие игрового меню
Отображение и сокрытие меню выполняются неявным образом. Когда кнопки находятся в списке `objects`, меню видимо; когда они удаляются, оно скрывается. Всё очень просто.
Можно создать встроенное меню с собственной поверхностью, которое рендерит свои подкомпоненты (кнопки и другие объекты), а затем просто добавлять/удалять эти компоненты меню, но для такого простого меню это не требуется.
Подводим итог
-------------
В этой части мы рассмотрели распознавание коллизий и то, что происходит, когда мяч сталкивается с разными объектами: ракеткой, кирпичами, стенами, полом и потолком. Также мы создали меню с собственными кнопками, которое можно скрывать и отображать по команде.
В последней части серии мы рассмотрим завершение игры, отслеживание очков и жизней, звуковые эффекты и музыку.
Затем мы разработаем сложную систему спецэффектов, добавляющих в игру немного специй. Наконец, мы обсудим дальнейшее развитие и возможные улучшения. | https://habr.com/ru/post/347266/ | null | ru | null |
# Концепты и модули cpp. Взгляд сo стороны undefined разработчика
В 2002 году Алекс А. Степанов проводит лекцию в адоби: STL and Its Design Principles - где упоминает кейворд concept (там прям целый слайд про концепты). В 2009 году в свет выходит книга Elements of programming (Stepanov, McJones) и где по-моему нет ни одного алгоритма без концептов. В 2011 новый стандарт языка с++11, где в отложенных (прям очень жаль) фичах фигурируют концепты. В 2014 мир видит творенье Страуструпа - Tour of C++, где глава 5.4 названа Concepts and Generic Programming, хотя язык не поддерживает кейворд concept. Годом ранее, в 2013, Андрю Саттон публикует бумагу Concepts Lite. В стандарте с++14 появляется новая фича digit separators, но нет концептов. В 2017 на реддите обсуждают c++17 и предлагают отдохнуть еще три года.
Через три года сочувствующий html разработчик захочет попробовать язык с чистого листа, заюзав и концепты, и модули. Модули привносят важное свойство - уменьшение времени компиляции. Идея в шаг за шагом написании небольших компонентов и комбинировании их после в нечто осознаное, например, линтер.
Первым делом добавим функцию print:
```
// guard for non-printable types
template
void print(const T& x, const Ts&...) {
auto msg = "\n[error] not supported print operation for type ";
std::cout << msg << typeid(x).name() << "\n";
}
// print first arg and continue with rest
template
void print(const T& x, const Ts&... rest) { ... }
```
Компонент для матчинга строки нашего линтера (javascript кода) будет выглядить как-то так:
```
// checking for pair of quotes, while skipping whats inside them
template
constexpr result\_t lint(...) {
auto pred = [](char ch){ return ch == '\'' || ch == '"'; };
...
}
```
Так как алгоритм выше constexpr, запускаем тесты на каждую! компиляцию модуля:
```
constexpr auto test(const std::string_view str) {
auto p = std::make_pair(std::begin(str), std::end(str));
return !lint(..., p) && p.first == p.second;
}
static_assert(test("'foo'"), "single quoted string test");
static_assert(test("'\\' quoted'"), "string with escaped single quote test");
```
У линтера, кажется, вырисовывается интерфейс:
```
result_t lint(..., /* pairs of iterators */) { }
```
Тут идея вполне очевидная: много компонентов с одинаковым интерфейсом. Можем решить ее с помощью наследования, а можем позаимствовать идею из видео Better Code: Runtime Polymorphism (Sean Parent) -- в двух словах, тот же самый полиморфизм, но удобнее (e.g. extension of built-in types). Продолжим:
```
struct keyword_t { std::size_t id; };
template
constexpr result\_t lint(const keyword\_t& x, matcher*& m) { ... }
// models forall relation
// if at least one fails -> all fail
template
constexpr result\_t lint(const std::vector& xs, matcher*& m) { ... }**
```
Первый аргумент отвечает за тип компонента, второй -- обертка над парой итераторов. Обертка исключительно для читаемости:
```
template
struct matcher {
I first;
I last;
constexpr matcher(I first, I last) : first{first}, last{last} {}
// advance 'first' while predicate is hold
template Op>
constexpr void skip(Op pred) {
first = std::find\_if\_not(first, last, std::move(pred));
}
...
```
Есть несколько вариантов для типа возвращаемого значения result\_t. У линтера на самом деле простая задача и, следовательно, простой результат действия: или мы нашли несоответствие, или все ок. По идее, выбор падает на bool, но на практике интересен линтер чуть-чуть поумнее, например std::optional\. Если все ок, возвращаем пустой опшионал, в противном случае - количество проделанных шагов до несоответствия.
Если линтер нашел недействительный токен или не нашел искомый, кидаем эксепшн:
```
struct panic_t { };
template
constexpr result\_t lint(const panic\_t&, matcher*& m) {
return 0
? result\_t{}
: throw std::domain\_error("\n err near \n-> " + m.debug\_info());
}
struct iff\_t { linter a; linter b; };
// models relation between pair of linters
// if linter 'a' not fails, linter 'b' must not fail
template
constexpr result\_t lint(const iff\_t& x, matcher*& m) {
auto lhs = lint(x.a, m);
if (lhs.has\_value()) return lhs;
auto rhs = lint(x.b, m);
return rhs.has\_value() ? lint(panic\_t{}, m) : result\_t{};
}**
```
Компоненты нашего линтера захочется композировать (или компоновать), поэтому пару/тройку связующих:
```
struct or_t { linter a; linter b; };
template
constexpr result\_t lint(const or\_t& x, matcher*& m) {
return lint(x.a, m) ? lint(x.b, m) : result\_t{};
}
struct optional\_t { linter a; };
template
constexpr result\_t lint(const optional\_t& x, matcher*& m) {
lint(x.a, m);
return {};
}
// models forall relation
// if at least one fails -> all fail
template
constexpr result\_t lint(const std::vector& xs, matcher*& m) {
for (const auto& x : xs) {
auto r = lint(x, m);
if (r.has\_value()) return r;
}
return {};
}***
```
Теперь собственно к разборке ("линтингу") javascript кода. Хедеры (или импорты) javascript файлов выглядят примерно так:
```
import * as foo from "../foo"
import bar, { boo, kung as fu, mu } from "../bar";
```
Грамматика хедеров тут: <https://262.ecma-international.org/6.0/#sec-imports> .
Компонент для хедеров import\_t сигнатурой будет очень похож на все предыдушие компоненты:
```
struct import_t{};
template
result\_t lint(const import\_t&, matcher*& m) { ... }*
```
Внутри хотя будет интереснее, так как грамматику можно описать композицией компонентов (тут прям нужно добавить, что описание декларативное без всяких while и for-loop :)
```
// match: * as foo
auto namespace_import = iff_t{
char_t{context::Chars::Star},
std::vector{
keyword\_t{context::Keywords::As},
identifier\_t{}
}
};
// match: { foo, bar as boo, ... }
auto named\_import = iff\_t{
char\_t{context::Chars::LeftCurlyBracket},
std::vector{
optional\_t{import\_var\_list\_t{}},
char\_t{context::Chars::RightCurlyBracket},
}
};
// match: foo | foo, \* as bar | foo, { bar... }
auto imported\_default\_binding = std::vector{
identifier\_t{},
optional\_t {
iff\_t {
char\_t{context::Chars::Comma},
or\_t{
namespace\_import,
named\_import
}
}
}
};
// and combining all togather
auto rule = iff\_t{
keyword\_t{ context::Keywords::Import },
or\_t{
std::vector{
string\_t{},
optional\_t{char\_t{context::Chars::Semicolon}},
},
std::vector{
or3\_t {
namespace\_import,
named\_import,
imported\_default\_binding,
},
keyword\_t{context::Keywords::From},
string\_t{},
optional\_t{char\_t{context::Chars::Semicolon}},
}
}
};
```
Описание import\_t моделирует граф. Если в графах грамматики встречается цикл, уносим его в алгоритм, другими словами, для удобства добиваемся direct acyclic graph. Примером цикла есть токен import\_var\_list\_t выше, который матчит { foo, bar, ...}, алгоритм которого будет петля, которую тоже можно тестировать на каждую компиляцию.
Как-то не хочется заключение писать, так как линтер еще ой как далек от завершения. Хочется вспомнить книгу JavaScript: The Good Parts (Douglas Crockford, 8 May 2008), которая, как видно из названия, предлагает юзать только "хороший" сабсет грамматики из "яваскрипта". На сегодняшний день хороший сабсет будет еще меньше (например, for-loop, while -- нежелательны; var, let запрещены), то есть задача создания хорошего и быстрого линтера кажется не такая уж непосильная. | https://habr.com/ru/post/673388/ | null | ru | null |
# Децентрализованный поиск для свободного веба
Возможно ли создать поисковую систему, которую на практике нельзя подвергнуть цензуре, влиянию и блокировке?
Говоря техническим языком, возможно ли выполнять полнотекстовый поиск не имея удаленного сервера, удобным для пользователя способом, одновременно храня поисковый индекс в peer-to-peer системе и имея возможность быстро обновлять поисковый индекс?
Да, это возможно!
Существует редкий класс баз данных - peer-to-peer БД. Такие базы проигрывают по большинству параметров обычным БД и используются скорее для экспериментов.
В качестве примера p2p базы данных можно привести Orbit DB. Orbit DB действительно закрывает часть потребностей пользователей обычных БД: в нем реализованы счетчики, append log и KV-хранилище. И все же этого недостаточно для создания полноценных dWeb приложений.
По запросу Distributed Serverless Search найти в Интернете мне ничего не удалось. И раз полнотекстового поиска для dWeb нет, то мы его создадим.
Статья состоит из нескольких частей. В первых частях описаны необходимые для создания децентрализованного поиска и доступные в 2022 году библиотеки и технологии. В последней части техники соединяются в единую поисковую систему и описано как запустить такой поиск самостоятельно.
Я постарался избавить статью от ненужных подробностей и рефлексии, однако за ней стоят долгие месяцы экспериментов и разработки.
Поисковый движок
----------------
В 2017 году бывший сотрудник Google опубликовал первую версию [Tantivy](https://github.com/quickwit-oss/tantivy), поискового движка написанного на Rust. Архитектурно Tantivy похож на Lucene, однако работает быстрее и имеет меньшую кодовую базу.
Рядом с Tantivy чуть больше года назад я начал пилить сервер [Summa](https://github.com/izihawa/summa). Изначально Summa добавляла в Tantivy GRPC API для поиска и индексации, возможность индексации из топиков Kafka, язык [fasteval2](https://crates.io/crates/fasteval2) для описания функций ранжирования и некоторые дополнительные функции поиска.
Подробное описание устройства поиска есть в моей более ранней [статье](https://habr.com/ru/post/545634/), здесь же приведу лишь самые важные для распределенного поиска свойства Tantivy/Summa:
* Производительность: уже на тот момент связка работала [сильно быстрее](https://tantivy-search.github.io/bench/) Lucene/ES
* Иммутабельность данных: после выполнения коммита данные сохраняются в набор файлов, называемых сегментом и далее они не изменяются.
Следующий commit сохраняет новую порцию данных в новые файлы, а факт удаления строки сохранится как бит в битовой маске рядом с уже существующим сегментом. Обновление данных реализуется как DELETE + INSERT, и потому сам сегмент остается неизменным при любых операциях с данными кроме выполнения компакшена (merge в терминах Tantivy).
* Локальность запросов: поиск по всей базе данных требует считывания малого количества данных с диска.
Высокая локальность ведет к меньшему количеству чтений с диска. Плохая локальность - основная проблема, не позволяющая просто взять и запустить произвольную БД поверх p2p-системы или сетевой файловой системы. Произвольные чтения перегружают сеть и просто добивают её при сколько-нибудь значимой нагрузке. Комбинируя определенные подходы, в Tantivy получилось достичь высокой локальности для всех компонент поискового индекса.
Поисковый сегмент состоит из нескольких частей: постинг-листов, хранилища документов, словаря термов. На каждый поисковый запрос необходимо найти n постинг-листов, где n - количество слов в запросе, затем считать постинг-листы, выбрать из них необходимые документы и в конце концов вычитать с диска сами документы из хранилища документов.
**Локальность словаря термов**
Словарь термов - это простой KV-storage, где ключ - слово, а значение - указатель на список документов с этим словом (постинг-лист). KVs для поиска термов должен быть относительно быстрым и сериализуемым на диск. В Tantivy в качестве KVs использовались Finite State Transducers из библиотеки [fst](https://docs.rs/fst/latest/fst/).
FST - очень крутая штука, быстрая и компактная за счет иммутабельности. Но она оказалась плохо приспособленной для распределенного поиска, так как имела плохую локальность. Поиск терма в fst требует обращений к разрозненным блокам памяти и исправить это никак не возможно, так как свойство заложено в дизайн алгоритма.
Как почетный велосипедостроитель я быстро закостылил это сам заменой KVs на более локальную структуру данных для экспериментов, а спустя несколько месяцев в Tantivy была добавлена реализация KVs на Sorted String Tables (ssTable).
ssTable обладают меньшей производительностью в некоторых ситуациях, что некритично и отличной локальностью, что позволило использовать их в дальнейшем.
**Локальность постинг-листа и хранилища документов**
С этими двумя структурами все проще, так как они изначально являются сортированными сущностями, снабженными индексом для быстрой навигации по ним. В Tantivy для индексации используются скип-листы, плотность которых можно регулировать, запустив грязные руки в исходники. Смысл регулировки в подборе размера скип-листа и количества хопов по скип-листу таким способом, чтобы считываний из памяти было минимум. Впрочем, сильно улучшить локальность здесь мне не удалось.
Достаточно прогрузить в память скип-листы (1 хоп по памяти) и дальше за log(n) от размера мы прыгаем по листам и хранилищу в поисках нужных нам документов. Tantivy из коробки дает еще и поблочное сжатие постинг-листов, что положительно влияет на локальность.
Но и это не все, локальность удалось увеличить еще сильнее агрессивным использованием кеша.
**HotCache**
Создатель Tantivy спустя пару лет разработки нащупал бизнес-модель и создал Quickwit - поисковик, хранящий поисковые сегменты на Amazon S3. Для меня это оказалось хорошей новостью, так как сеть и хранение индекса в удаленном хранилище теперь стали фичами первого класса в Tantivy.
Довольно скоро после этого в Tantivy появился HotCache - структура данных для быстрого открытия удаленного поискового индекса на чтение.
HotCache - это кеш наиболее часто используемых частей индекса. Tantivy один раз открывает индекс на чтение, прогревает его, а все запросы к файлам кеширует и компактно сохраняет в один файл. Затем этот файл сохраняется и передается репликам, а реплики открывают его и в течении десятков миллисекунд становятся готовыми обслуживать поисковые запросы. Еще одна монетка в копилку локальности.
Последующие тесты показали, что на ~10GB индексе HotCache занимает порядка 10MB, а запросы по высокочастотным термам потребляют по 400-500KB. Пагинация по запросу далее подъедает по 100-150KB на SERP из 10 документов. Это замечательный результат, означающий, что за среднюю поисковую сессию в 6 запросов пользователь совершит чтений на 3-4MB без учета HotCache, заранее загружаемого в память.
IPFS
----
Поисковый индекс необходимо положить на p2p-систему. Не могу сказать, что я сильно изучал альтернативы, скорее просто выбрал сердцем уже знакомый мне IPFS.
IPFS - это BitTorrent, но с человеческим лицом. В основе IPFS лежит Kademlia, реализован неплохой десктопный клиент, плагины для Chrome/Firefox, а внутри системы уже много узлов.
У системы есть некоторые проблемы, например плохая работа внутри одной ноды с большим количеством файлов и довольно всратая поддержка сидирования лежащих вне хранилища IPFS файлов. Тем не менее, IPFS можно пользоваться, IPFS работает и работает относительно шустро. Из всех существующих P2P-систем IPFS выглядит наиболее функциональной и перспективной.
IPFS обладает важными для нас особенностями:
* IPFS режет файлы на кусочки по N байт и хранит в IPFS уже отдельные кусочки, соединенные DAGом. Обращаться к кусочкам можно по отдельности, таким образом если вам нужны лишь определенные байты из файла то достаточно скачать лишь кусочки, содержащие эти байты
* IPFS из коробки имеет удобную концепцию директорий и клиент IPFS напрямую поддерживает публикацию локальных директорий в IPFS. Что не менее важно, если две директории имеют общие файлы, то скачивая обе директории, вы не будете скачивать все по два раза. Общие файлы будут скачаны только один раз.
* Рядом с IPFS идет IPNS - DNS для IPFS. Любой узел сети IPFS может опубликовать любой файл или директорию под неизменным именем на основе пары ключей и впоследствии выполнять перепубликацию с тем же именем. Это имя может быть разрезолвлено на любом другом узле IPFS.
* Пользователи сами становятся сидерами при получение куска данных. Хотя, как и в BitTorrent, здесь можно отключить раздачу, на практике в IPFS пользователи этого не делают и продолжают раздавать скачанные блоки
Все особенности вместе позволяют провернуть следующее: вы можете опубликовать директорию в IPFS, дать ей имя в IPNS и отдать ссылку пользователям. Затем вы обновляете файлы в директории и публикуете их заново под тем же самым IPNS именем. Пользователи, периодически проверяющие IPNS-имя, видят обновление и выкачивают его, по факту скачивая лишь измененные файлы.
Получается, мы теперь можем под постоянным именем выкладывать поисковый индекс в IPFS. Остается избавиться от центрального поискового сервера. Сделал я это в лоб, просто унеся поиск прямо к пользователю под нос.
### WASM
Можно было бы сказать, что WASM является одним из многих форматов байт-кода, таким же как LLVM, JVM и десятки других. Но есть у него одна особенность - программу на WASM можно выполнить в браузере.
Разработка WASM началась в 2015 году и спустя несколько лет появились первые рабочие прототипы в популярных браузерах. Уязвимости Meltdown и Spectre притормозили на несколько лет развитие WASM, но последнее время вокруг него опять наблюдается все больше и больше активности.
Нормальный байт-код - это ровно то, что нужно для запуска *нормальных* программ в браузере. Простите мне мою нелюбовь к JavaScript и давайте спишем ее в личные недостатки.
Звезды и здесь сошлись: в мире Rust существует проект wasm-bindgen. Этот тулинг позволяет собрать программу на Rust в WASM, снабдить ее JavaScript-биндингами и получить на выходе модуль, который можно импортировать и использовать в внутри браузера.
Первые попытки запустить поисковый движок Summa внутри браузера в начале лета 2022 года не увенчались успехом. Браузерный JS исполняется Event Loop'ом по одной таске за раз в один поток, поэтому наивная попытка скомпилировать движок и запустить его в Chrome провалилась же на первом растовом Mutex'e.
Wasm-bindgen был все же еще относительно сырым, а гигантские стектрейсы и чёрти где разыменованные указатели на некоторое время выбили почву у меня из под ног, и идея была отложена в стол. Тем более опыта на Rust на тот момент было с гулькин нос, а JavaScript я всеми силами старался избегать, как вы уже поняли.
Однако иногда упоротая одержимость идеями может брать верх. В сентябре я провел десяток дней за красноглазым курением мануалов wasm-bindgen и его флагов. Я читал треды на GitHub Issues перед сном и выяснял почему флаги компиляции работают через жопу. В приступах помутнения я пытался обмануть компилятор, расставляя unsafe и создавая тут и там примитивы синхронизации в надежде, что хоть в этот раз компилятор расслабится, отвлечется и пропустит мой код. Каждый раз все кончалось ошибками памяти.
В приступах прокрастинации я натыкался на треды в Интернете, где мои предшественники пытались запустить что-то сложное на Rust внутри браузера. Эти треды были усеяны черепами и предупреждающими надписями.
В конце концов я распилил зависимости Summa и переложил вагоны JSONов. Слой похода за файлами на диск был заменен на слой, делающий HTTP-Range запросы за файлами.
Ежеминутные проклятия в адрес JavaScript по поводу отсутствующей типизации и семиэтажный мат на жуткий мультитрединг браузера, смехотворно названный Web Worker API, распугали всех моих домашних. Но неделю назад мне таки удалось запихнуть поисковый движок в этот чертов браузер. В тот вечер в голове опрокинулся маленький бочонок с эндорфинами.
Результат страданий - NPM модуль summa-wasm, содержащий tantivy и модуль summa-core (парсер запросов, токензайзеры и рутины для работы с индексом). Библиотека принимает описание того, как ей достучаться до файлов поискового индекса по сети. В ответ она даст вам функцию search, способную выполнить полнотекстовый поиск.
Соединяем все вместе
--------------------
Возможно, вы уже догадались как все должно работать. Исходный код веб-интерфейса, summa и summa-wasm опубликован на [GitHub](https://github.com/izihawa/summa), здесь же я разберу ключевые моменты. Более полноценная документация живет на [https://izihawa.github.io](https://izihawa.github.io/summa/), но так как проект я пилю в одно жало и в свободное время, то скорее всего что-нибудь да пропустил. Пишите мне в личку, если будут баги сборки или дыры в документации.
**Сборка поискового индекса**
Для сборки индекса я буду использовать сервер Summa, но summa-wasm также способен открыть и обычный индекс Tantivy. В Summa реализованы функции, снижающие объемы сетевых обновлений через управление политикой слияния сегментов. Я послал соответствующие патчи в апстрим Tantivy, но гарантий что их примут нет, так что лучше сразу берите в руки Summa.
Кроме Summa я запилил на Python асинхронный клиент aiosumma, который будет использован в примерах дальше. Поехали!
```
# Установим клиент `aiosumma` на Python для выполнения запросов к summa
pip3 install -U aiosumma
# Создадим директорию для индекса
mkdir data
# Сгенерируем конфиг для Summa
docker run izihawa/summa-server:testing generate-config -d /data \
-g 0.0.0.0:8082 -m 0.0.0.0:8084 -i host.docker.internal:5001 > summa.yaml
# И запустим Summa
docker run -v $(pwd)/summa.yaml:/summa.yaml -v $(pwd)/data:/data \
-p 8082:8082 -p 8084:8084 \
izihawa/summa-server:testing serve /summa.yaml
```
Дальше берем публично доступный дамп базы данных Wiki Books. Можете зарядить туда свои данные, предварительно нарисовав схему данных по аналогии.
Создание схемы
```
# Download sample dataset
CURRENT_DUMP=$(curl -s -L "https://dumps.wikimedia.org/other/cirrussearch/current" | grep -oh '\"enwikibooks.*\content.json\.gz\"' | tr -d '"')
wget "https://dumps.wikimedia.org/other/cirrussearch/current/$CURRENT_DUMP" -O enwikibooks.json.gz
gunzip enwikibooks.json.gz
# Create index schema in file
cat << EOF > schema.yaml
---
# yamllint disable rule:key-ordering
index_name: page
compression: Zstd
multi_fields: ["category"]
default_fields: ["opening_text", "title", "text"]
writer_heap_size_bytes: 1073741824
writer_threads: 4
schema: >
- name: category
type: text
options:
indexing:
fieldnorms: true
record: position
tokenizer: default
stored: true
- name: content_model
type: text
options:
indexing:
fieldnorms: true
record: basic
tokenizer: default
stored: true
- name: opening_text
type: text
options:
indexing:
fieldnorms: true
record: position
tokenizer: default
stored: true
- name: auxiliary_text
type: text
options:
indexing:
fieldnorms: true
record: position
tokenizer: default
stored: true
- name: language
type: text
options:
indexing:
fieldnorms: true
record: basic
tokenizer: default
stored: true
- name: title
type: text
options:
indexing:
fieldnorms: true
record: position
tokenizer: default
stored: true
- name: text
type: text
options:
indexing:
fieldnorms: true
record: position
tokenizer: default
stored: true
- name: timestamp
type: date
options:
fast: single
fieldnorms: false
indexed: true
stored: true
- name: create_timestamp
type: date
options:
fast: single
fieldnorms: false
indexed: true
stored: true
- name: popularity_score
type: f64
options:
fast: single
fieldnorms: false
indexed: true
stored: true
- name: incoming_links
type: u64
options:
fast: single
fieldnorms: false
indexed: true
stored: true
- name: namespace
type: u64
options:
fast: single
fieldnorms: false
indexed: true
stored: true
EOF
```
И наконец-то - наливка данных. Я взял половину строк, чтобы после начальной публикации можно было долить вторую половину и протестировать инкрементальное обновление данных
```
# Создаем индекс из схемы
summa-cli localhost:8082 - create-index-from-file schema.yaml
# Грузим каждую 4-ую строку. В исходном дампе половина строк технические, их нужно выкинуть
# Наливка индекса займет некоторое время
awk 'NR%4==0' enwikibooks.json | summa-cli localhost:8082 - index-document-stream page
# Коммит
summa-cli localhost:8082 - commit-index page --commit-mode Sync
```
Проверим работает ли обычный поиск:
```
summa-cli localhost:8082 - search page '{"match": {"value": "astronomy"}}' '[{"top_docs": {"limit": 10}}, {"count": {}}]'
```
**Публикация индекса в IPFS**
Для публикации индекса в [IPFS](http://docs.ipfs.tech.ipns.localhost:8080/install/ipfs-desktop/) необходимо установить [IPFS](http://docs.ipfs.tech.ipns.localhost:8080/install/ipfs-desktop/).
После запуска демона IPFS выполним публикацию с копированием файлов внутрь IPFS. Summa также поддерживает --no-copy режим, но из-за ограничений IPFS нужны некоторые приседания, которые здесь хотелось бы опустить.
```
summa-cli localhost:8082 - publish-index page --copy
```
В ответ должно вернуться что-то типа
```
{
"key": {
"name": "page",
"id": "k51qzi5uqu5dg9kaxpau2an7ae09yl4yrgna5x8uunvwn5wy27tr7r8uddxn72"
}
}
```
Для индекса с именем page сервер создал в IPFS пару ключей с именем page и опубликовал индекс в IPNS. Готово, в IPFS выложен поисковый индекс, который может скачать кто угодно.
**Сборка веб-интерфейса для поискового индекса**
Репозиторий Summa имеет демонстрационный веб-интерфейс. Интерфейс не претендует на функциональность и служит лишь иллюстрацией того, как использовать модуль summa-wasm. Но лучше все-таки посмотреть на него одним глазом - подводных камней я собрал немеренно.
Для использования локального демона IPFS из веб-интерфейса необходимо настроить CORS-заголовки в IPFS. От этого шага возможно будет избавиться после патчей в IPFS, которые добавят в HTTP интерфейс демона нужную функциональность и позволят браузеру ходить в Same Domain, а не в отдельное API на другом порту.
Но пока нужные функции IPFS существуют только в выделенном IPFS API приходится выполнять эти приседания с настройкой демона.
```
# Патчим CORS
# Данные разрешения слишком широкие и возможно вам необходимо будет их настроить под себя
ipfs config --json API.HTTPHeaders.Access-Control-Allow-Origin '["*"]'
ipfs config --json API.HTTPHeaders.Access-Control-Allow-Methods '["GET", "POST"]'
```
Затем собираем и запускаем веб-интерфейс. Если захотите собрать интерфейс со своим индексом, то [поменяйте](https://github.com/izihawa/summa/blob/8a25a5daa23fd32fe91fb202b9cfba611d4c2549/summa-web/src/App.vue#L29) IPNS имя на то, которое вы получили в предыдущем пункте
```
git clone https://github.com/izihawa/summa
cd summa/summa-web
npm i && npm run dev
```
Все готово, можно выполнять поиск. Первые разы все будет подтормаживать, так как IPFS необходимо найти пиры и прогрузить первоначальные данные.
**Обновление данных**
Мы можем долить данные в индекс
```
awk 'NR%4==2' enwikibooks.json | summa-cli localhost:8082 - index-document-stream page
summa-cli localhost:8082 - commit-index page --commit-mode Sync
```
и после этого заново опубликовать индекс
```
summa-cli localhost:8082 - publish-index page --copy
```
Веб-интерфейс в браузере пользователя заново разрезолвит это имя в локальном IPFS, после чего сможет обращаться к уже обновленной базе данных. Приказов сверху от центрального сервера для этого не требуется и интерфейс, собранный единожды, далее может постоянно подтягивать новые данные из IPFS. Да что уж там, сам интерфейс может быть собран и опубликован внутри IPFS.
Для примера я собрал и выложил подобную страницу, можете проверить как это работает [тут](http://k51qzi5uqu5dj3e0a29e54zhjtl28iulvd40xcxvmhvie93vavz5etavco1jb4.ipns.localhost:8080/#/?q=&p=1), предварительно установив IPFS Companion.
Зачем все это?
--------------
Реализация поиска поверх IPFS обладает несомненными плюсами.
* Высокая локальность обеспечивает вменяемое время поиска, а внутреннее устройство IPFS помогает разносить горячие блоки поискового индекса по пользователям. Чем чаще пользователи выполняют запрос, тем больше сидеров будет у блоков c запрошенными документами. Система обладает способностью самостоятельно увеличивать свою пропускную способность в ответ на нагрузку.
* Репликация индекса между его пользователями не дает отцензурировать поисковую выдачу. В эру государств-левиафанов, пожирающих свободу информации, такое качество оказывается полезным. Да, все еще можно уничтожить источник обновлений, но теперь его можно спрятать далеко и надежно, а за доставку будет отвечать IPFS
* Индекс надежно сохраняется на неопределенное время до тех пор, пока есть его пользователи. В мире существуют наборы данных, которые стоило бы сохранять получше - образовательные видео, научные публикации, книги, исходные коды открытого ПО. IPFS и до существования Summa решал эту задачу, однако теперь стало возможно организовать поиск по сохраненному точно таким же децентрализованным способом.
Возможно, это ещё одна разработка в стол. Возможно, нет. Но если вам есть что сохранить или есть что-то, что нужно спрятать от Левиафана, то теперь вы знаете как сделать поиск для этого. | https://habr.com/ru/post/690252/ | null | ru | null |
# SparrowHub — репозиторий готовых утилит для системного администрирования
[SparrowHub](https://sparrowhub.org/) — проект, целью которого является распространение различных готовых решений для задач системного администрирования и не только.
Несмотря на то, что существует масса решений по автоматизации задач системного администрирования, определенная ниша в этой области все же остается незанятой. Что мы делаем, когда хотим решить какую-то специфическую задачу? Например, проверить логи нашего ssh сервиса на наличие неудачных попыток логинов с целью позаботиться о секьюрности наших серверов? — Берем и пишем однострочник, состоящий из bash команд вида grep, sed, awk и так далее, ну, или можем написать скрипт на [Perl](https://www.perl.org/). Отлично, все работает. Eсть решение, которое устраивает нас. И мы пользуемся им. Вопрос в том, *как* мы хотим сохранить результаты наших трудов, что бы поделиться ими с другими или же когда пройдет время снова воспользоваться придуманным решением. Вот тут и возникает проблема.
Кастомные скрипты, написанные "на коленке" хороши, когда нужно что-то сделать прямо здесь и сейчас, но с ними есть проблемы:
* они плохо переносимы
* они легко забываются ( у них зачастую невнятный интерфейс и "захардкоженная" конфигурация )
Тут и возникает идея репозитария переносимых утилит. В принципе, это может быть все что угодно — проверки оставшегося места на диске, поиск определенной группы процессов в списке, учет времени работы отдельных программ, анализ логов на наличие определенных событий и так далее. Вы пишите утилиту, точнее, в терминах SparrowHub — плагин, загружаете его в репозиторий, и, вуаля — он становится доступным для других!
Достаточно установить на своем сервере утилиту sparrow которая предоставляет интерфейс к репозитарию SparrowHub и начать пользоваться готовыми плагинами.
Вот как это выглядит в моей случае, приведу несколько примеров. И хотя кому-то они могут показаться тривиальными с точки зрения замены их своими кастомными решениями, все же вспоминаем то, с чего я начал свой топик — почему кастомные скрипты могут быть проблематичны в использовании. И потом, т.к. SparrowHub проект достаточно молодой, на нем еще не успело накопится достаточное количество плагинов, собственно данный пост и нацелен на то, что бы привлечь в коммьюнити новых разработчиков!
Итак, ставим сначала sparrow, это — [CPAN](https://de.wikipedia.org/wiki/CPAN) модуль:
```
$ cpanm Sparrow
```
Из не Perl зависимостей нам еще понадобится curl:
```
$ yum install curl
```
Проверяем, что sparrow клиент установлен:
```
$ sparrow
```
Далее создаем проект. Проект — это просто контейнер для плагинов, которые мы будет устанавливать и использовать. Можно иметь несколько проектов, для разбиения используемых плагины на логические группы. Например, проект *system* — для системных проверок, например места на диске или отслеживания долго работающих процессов, проект *nginx* — для различных проверок nginx сервера, и так далее.
```
$ sparrow project create system
```
Далее мы можем поискать различные плагины. Альтернативным способом будет являться посещение ресурса <https://sparrowhub.org> и поиском через web интерфейс.
```
$ sparrow index update # получим обновления индекса из SpаrrowHub
$ sparrow plg search
```
Последняя приведенная команда выдаст нам список всех доступных плагинов. Выбираем *df-check* — плагин для проверки оставшегося места на диске. Устанавливаем плагин:
```
$ sparrow plg install df-check
```
Ок. В принципе уже можно запустить плагин как есть командой:
```
$ sparrow plg run df-check
```
И убедится, что места на диске на сервере достаточно. Но добавим еще один шаг, сделав наш плагин *настраиваемым*. Для это воспользуемся концепцией чекпоинтов или контрольных точек, извиняюсь за невольную тафтологию :) Чекпоинт в sparrow — это абстракция позволяющая связывать отдельный плагин с конкретной конфигурацией. Таким образом, вы можете использовать один и тот же плагин с разными конфигурациями, не трудно догадаться, что в этом случае мы будем иметь несколько чекппоинтов. Чекпоинты добавляются в проекты, связываются с *установленными* плагинами ( здесь и происходит разбивка плагинов по логическим группам ) и затем настраиваются.
Создадим чекпоинт:
```
$ sparrow check add system disk
```
Свяжем чекпоинт с плагином:
```
$ sparrow check set system disk df-check
```
И теперь самое интересное… настоим чекпоинт или плагин, что в данном случае одно и тоже ...
```
$ export EDITOR=nano
$ sparrow check ini system disk
[disk]
# установить в процентном соотношении допустимый размер занятого места на диске
threshold = 70
```
Отлично. Теперь запустим чекпоинт, точнее плагин с настройками, определенными для данного чекпоинта:
```
$ sparrow check run system disk
```
На моей машине результат будет выглядеть так:
```
vagrant@Debian-jessie-amd64-netboot:~/my/outthentic$ sparrow check run system disk
# running cd /home/vagrant/sparrow/plugins/public/df-check && carton exec 'strun --root ./ --ini /home/vagrant/sparrow/proj$
/tmp/.outthentic/13248/home/vagrant/sparrow/plugins/public/df-check/disk-shortage/story.t ..
ok 1 - perl /home/vagrant/sparrow/plugins/public/df-check/disk-shortage/story.pl succeeded
ok 2 - stdout saved to /tmp/.outthentic/13248/KopZcyueYX
# threshhold: 70
# verify ... /dev/sda1
# verify ... udev
# verify ... tmpfs
# verify ... tmpfs
# verify ... tmpfs
# verify ... tmpfs
# verify ... none
# verify ... none
ok 3 - output match /(\S+)\s+(\S+)\s+(\S+)\s+(\S+)\s+(\S+)/
ok 4 - enough disk space (84%) on /dev/sda1
ok 5 - enough disk space (0%) on udev
ok 6 - enough disk space (1%) on tmpfs
ok 7 - enough disk space (1%) on tmpfs
ok 8 - enough disk space (0%) on tmpfs
ok 9 - enough disk space (0%) on tmpfs
ok 10 - enough disk space (92%) on none
ok 11 - enough disk space (92%) on none
1..11
ok
All tests successful.
Files=1, Tests=11, 1 wallclock secs ( 0.02 usr 0.00 sys + 0.05 cusr 0.00 csys = 0.07 CPU)
Result: PASS
```
Собственно на этом ознакомление co SparrowHub в его практическом применении можно закончить. Существует, конечно же ряд других интересных утилит, разработанных и выложенных мной на SparrowHub — среди них например — [stale-proc-check](https://sparrowhub.org/info/stale-proc-check) — плагин по поиску долгоиграющих ( устаревших — stale ) процессов или [logdog](https://sparrowhub.org/info/logdog) — утилиты по поиску записей в логах за заданный период времени с возможностью группировки и фильтрации. Статьи по практическому применению данных плагинов были недавно написаны мной на английском и размещены на сайтe blogs.perl.org :
* [find "stale" processes on linux / unix servers](http://blogs.perl.org/users/melezhik/2016/04/find-stale-processes-on-linux-unix-servers.html)
* [Monitoring bad ssh logins with sparrow and logdog](http://blogs.perl.org/users/melezhik/2016/04/monitoring-bad-ssh-logins-with-sparrow-and-logdog.html)
Заключение.
В этой статье я коснулся только основных возможностей, предоставляемых репозитарием SparrowHub, всего конечно не расскажешь, да и не в этом цель. Задавайте вопросы, пишите комменты, загружайте свои плагины, используйте существующие или кидайте реквесты на разработку новых — было бы очень интересно узнать что именно требуются другим людям и реализовать это в виде плагинов. В конце концов выиграют все!
PS> для мердж реквестов и issues на утилиту sparrow используйте [<https://github.com/melezhik/sparrow>](https://github.com/melezhik/sparrow), туда же можно постить запросы на новые плагины.
PS2> первая статья про sparrow была написано мной какое-то время назад и с ее текстом можно ознакомиться [здесь](https://habrahabr.ru/post/272245/), предупреждение — за это время многое изменилось.
---
Алексей Мележик, автор sparrow и SparrowHub. | https://habr.com/ru/post/281583/ | null | ru | null |
# Метапрограммирование в JavaScript
> Метапрограммирование — вид программирования, связанный с созданием программ, которые порождают другие программы как результат своей работы, либо программ, которые меняют себя во время выполнения. (Википедия)
Говоря более простым языком, метапрограммированием в рамках JavaScript можно считать механизмы, позволяющие анализировать и менять программу в режиме реального времени в зависимости от каких-либо действий. И, скорее всего, вы так или иначе используете их при написании скриптов каждый день.
JavaScript по своей природе является очень мощным динамическим языком и позволяет приятно писать гибкий код:
```
/**
* Динамическое создание save-метода для каждого свойства
*/
const comment = { authorId: 1, comment: 'Комментарий' };
for (let name in comment) {
const pascalCasedName = name.slice(0, 1).toUpperCase() + name.slice(1);
comment[`save${pascalCasedName}`] = function() {
// Сохраняем поле
}
}
comment.saveAuthorId(); // Сохраняем authorId
comment.saveComment(); // Сохраняем comment
```
Аналогичный код для динамического создания методов в других языках очень часто может потребовать специальный синтаксис или API для этого. Например, PHP тоже является динамическим языком, но в нём это потребует больше усилий:
```
php
class Comment {
public $authorId;
public $comment;
public function __construct($authorId, $comment) {
$this-authorId = $authorId;
$this->comment = $comment;
}
// Перехватываем все вызовы методов в классе
public function __call($methodName, $arguments) {
foreach (get_object_vars($this) as $fieldName => $fieldValue) {
$saveMethodName = "save" . strtoupper($fieldName[0]) . substr($fieldName, 1);
if ($methodName == $saveMethodName) {
// Сохраняем поле
}
}
}
}
$comment = new Comment(1, 'Комментарий');
$comment->saveAuthorId(); // Сохраняем authorId
$comment->saveComment(); // Сохраняем comment
```
В дополнение к гибкому синтаксису, у нас есть ещё и куча полезных функций для написания динамического кода: Object.create, Object.defineProperty, Function.apply и многие другие.
Рассмотрим же их поподробнее.
1. [Генерация кода](#1-generaciya-koda)
2. [Работа с функциями](#2-rabota-s-funkciyami)
3. [Работа с объектами](#3-rabota-s-obektami)
4. [Reflect API](#4-reflect-api)
5. [Символы (Symbols)](#5-simvoly-symbols)
6. [Прокси (Proxy)](#6-proksi-proxy)
7. [Заключение](#7-zaklyuchenie)
1. Генерация кода
-----------------
Стандартным средством для динамического выполнения кода является функция [eval](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/eval), позволяющая выполнить код из переданной строки:
```
eval('alert("Hello, world")');
```
К сожалению, eval имеет много нюансов:
* если наш код написан в строгом режиме ('use strict'), то переменные, объявленные внутри eval, не будут видны в вызывающем eval коде. При этом сам код внутри eval всегда может менять внешние переменные.
* код внутри eval может выполняться как в глобальном контексте (если его вызвать через window.eval), так и в контексте функции, внутри которой произошёл вызов (если просто eval, без window).
* могут возникнуть проблемы из-за минификации JS, когда названия переменных заменяются на более короткие для уменьшения размера. Код, переданный в виде строки в eval, минификатор обычно не трогает, из-за этого мы можем начать обращаться к внешним переменным по старым неминифицированными названиям, что приведёт к трудноуловимым ошибкам.
Для решения этих проблем есть прекрасная альтернатива — [new Function](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function).
```
const hello = new Function('name', 'alert("Hello, " + name)');
hello('Андрей') // alert("Hello, Андрей");
```
В отличие от eval, мы всегда можем явно передавать параметры через аргументы функции и динамически указывать ей контекст this (через [Function.apply](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/apply) или [Function.call](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/call)). К тому же создаваемая функция всегда вызывается в глобальной области видимости.
В старые времена, eval часто использовался для динамического изменения кода, т.к. JavaScript имел очень мало механизмов для рефлексии и без eval обойтись было нельзя. Но в современном стандарте языка появилось намного больше высокоуровневого функционала и eval теперь применяется намного реже.
2. Работа с функциями
---------------------
JavaScript предоставляет нам множество прекрасных средств для динамической работы с функциями, позволяя как получать в рантайме различную информацию о функции, так и менять её:
* [Function.length](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/length) — позволяет узнать количество аргументов у функции:
```
const func = function(name, surname) {
console.log(`Hello, ${surname} ${name}`)
};
console.log(func.length) // 2
```
* [Function.apply](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/apply) и [Function.call](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/call) — позволяют динамически менять контекст this у функции:
```
const person = {
name: 'Иван',
introduce: function() {
return `Я ${this.name}`;
}
}
person.introduce(); // Я Иван
person.introduce.call({ name: 'Егор' }); // Я Егор
```
Отличаются они друг друга только тем, что в Function.apply аргументы функции подаются в виде массива, а в Function.call — через запятую. Эту особенность раньше часто использовали, чтобы передавать в функцию список аргументов в виде массива. Распространённый пример — это функция [Math.max](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/max) (по умолчанию она не умеет работать с массивами):
```
Math.max.apply(null, [1, 2, 4, 3]); // 4
```
С появлением нового [spread-оператора](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Spread_syntax) можно просто писать так:
```
Math.max(...[1, 2, 4, 3]); // 4
```
* [Function.bind](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/bind) — позволяет создать копию функцию из существующей, но с другим контекстом:
```
const person = {
name: 'Иван',
introduce: function() {
return `Я ${this.name}`;
}
}
person.introduce(); // Я Иван
const introduceEgor = person.introduce.bind({ name: 'Егор' });
introduceEgor(); // Я Егор
```
* [Function.caller](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/caller) — позволяет получить вызывающую функцию. **Использовать её не рекомендуется**, так как она отсутствует в стандарте языка и не будет работать в строгом режиме. Это было сделано из-за того, что если различные движки JavaScript реализуют описанную в спецификации языка оптимизацию [tail call](http://2ality.com/2015/06/tail-call-optimization.html), то вызов Function.caller может начать приводить к неправильным результатам. Пример использования:
```
const a = function() {
console.log(a.caller == b);
}
const b = function() {
a();
}
b(); // true
```
* [Function.toString](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/toString) — возвращает строковое представление функции. Это очень мощная возможность, позволяющая исследовать как содержимое функции, так и её аргументы:
```
const getFullName = (name, surname, middlename) => {
console.log(`${surname} ${name} ${middlename}`);
}
getFullName.toString()
/*
* "(name, surname, middlename) => {
* console.log(`${surname} ${name} ${middlename}`);
* }"
*/
```
Получив строковое представление функции, мы можем его распарсить и проанализировать. Это можно использовать, чтобы, например, вытащить названия аргументов функции и, в зависимости от названия, автоматически подставлять нужный параметр. В целом, парсить можно двумя способами:
+ Парсим кучей регулярок и получаем приемлимый уровень надёжности (может не работать, если мы не покроем все возможные виды записей функции).
+ Получаем строковое представление функции и суём в готовый парсер JavaScript (например [esprima](http://esprima.org/) или [acorn](https://github.com/acornjs/acorn)), а затем работаем уже со структурированным AST. [Пример разбора в AST через esprima.](https://is.gd/u0jVJk) Также могу посоветовать [хороший доклад про парсеры](https://www.youtube.com/watch?v=au9_j2NjNaI) от Алексея Охрименко.
Простые примеры с парсингом функций регулярками:
**Получение списка аргументов функции**
```
/**
* Получить список параметром функции.
* @param fn Функция
*/
const getFunctionParams = fn => {
const COMMENTS = /(\/\/.*$)|(\/\*[\s\S]*?\*\/)|(\s*=[^,\)]*(('(?:\\'|[^'\r\n])*')|("(?:\\"|[^"\r\n])*"))|(\s*=[^,\)]*))/gm;
const DEFAULT_PARAMS = /=[^,]+/gm;
const FAT_ARROW = /=>.*$/gm;
const ARGUMENT_NAMES = /([^\s,]+)/g;
const formattedFn = fn
.toString()
.replace(COMMENTS, "")
.replace(FAT_ARROW, "")
.replace(DEFAULT_PARAMS, "");
const params = formattedFn
.slice(formattedFn.indexOf("(") + 1, formattedFn.indexOf(")"))
.match(ARGUMENT_NAMES);
return params || [];
};
const getFullName = (name, surname, middlename) => {
console.log(surname + ' ' + name + ' ' + middlename);
};
console.log(getFunctionParams(getFullName)); // ["name", "surname", "middlename"]
```
**Получение тела функции**
```
/**
* Получить строковое представление тела функции.
* @param fn Функция
*/
const getFunctionBody = fn => {
const restoreIndent = body => {
const lines = body.split("\n");
const bodyLine = lines.find(line => line.trim() !== "");
let indent = typeof bodyLine !== "undefined" ? (/[ \t]*/.exec(bodyLine) || [])[0] : "";
indent = indent || "";
return lines.map(line => line.replace(indent, "")).join("\n");
};
const fnStr = fn.toString();
const rawBody = fnStr.substring(
fnStr.indexOf("{") + 1,
fnStr.lastIndexOf("}")
);
const indentedBody = restoreIndent(rawBody);
const trimmedBody = indentedBody.replace(/^\s+|\s+$/g, "");
return trimmedBody;
};
// Получим список параметров и тело функции getFullName
const getFullName = (name, surname, middlename) => {
console.log(surname + ' ' + name + ' ' + middlename);
};
console.log(getFunctionBody(getFullName));
```
Важно заметить, что при использовании минификатора как сам код внутри парсируемой функции, так и её аргументы могут оптимизироваться и, поэтому, измениться.
3. Работа с объектами
---------------------
В JavaScript имеется глобальный объект Object, содержащий множество методов для динамической работы с объектами.
Большинство таких методов оттуда уже давно существуют в языке и повсеместно используются.
### Свойства объекта
* [Object.assign](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign) — для удобного копирования свойств одного или нескольких объектов в объект, указанный первым параметром:
```
Object.assign({}, { a: 1 }, { b: 2 }, { c: 3 }) // {a: 1, b: 2, c: 3}
```
* [Object.keys](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/keys) и [Object.values](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/values) — возвращает либо список ключей, либо список значений объекта:
```
const obj = { a: 1, b: 2, c: 3 };
console.log(Object.keys(obj)); // ["a", "b", "c"]
console.log(Object.values(obj)); // [1, 2, 3]
```
* [Object.entries](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/entries) — возвращает список своих свойств в формате *[[ключ1, значение1], [ключ2, значение2]]*:
```
const obj = { a: 1, b: 2, c: 3 };
console.log(Object.entries(obj)); // [["a", 1], ["b", 2], ["c", 3]]
```
* [Object.prototype.hasOwnProperty](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/hasOwnProperty) — проверяет, содержится ли свойство в объекте (не в его прототипной цепочке):
```
const obj = { a: 1 };
obj.__proto__ = { b: 2 };
console.log(obj.hasOwnProperty('a')); // true
console.log(obj.hasOwnProperty('b')) // false
```
* [Object.getOwnPropertyNames](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getOwnPropertyNames) — возвращает список собственных свойств, включая как перечисляемые, так и неперечисляемые:
```
const obj = { a: 1, b: 2 };
Object.defineProperty(obj, 'c', { value: 3, enumerable: false }); // Создаём неперечисляемое свойство
for (let key in obj) {
console.log(key);
}
// "a", "b"
console.log(Object.getOwnPropertyNames(obj)); // [ "a", "b", "c" ]
```
* [Object.getOwnPropertySymbols](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getOwnPropertySymbols) — возвращает список собственных (содержащихся именно в объекте, а не в его прототипной цепочке) символов:
```
const obj = {};
const a = Symbol('a');
obj[a] = 1;
console.log(Object.getOwnPropertySymbols(obj)); // [ Symbol(a) ]
```
* [Object.prototype.propertyIsEnumerable](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/propertyIsEnumerable) — проверяет, является ли свойство перечисляемым (к примеру, доступно ли в циклах for-in, for-of):
```
const arr = [ 'Первый элемент' ];
console.log(arr.propertyIsEnumerable(0)); // true — элемент 'Первый элемент' является перечисляемым
console.log(arr.propertyIsEnumerable('length')); // false — свойство length не является перечисляемым
```
### Дескрипторы свойств объекта
Дескрипторы позволяют тонко настраивать параметры свойств. С помощью них мы можем удобно делать собственные перехватчики во время чтения/записи какого-либо свойства (геттеры и сеттеры — get/set), делать свойства неизменяемыми или неперечисляемыми и ряд других вещей.
* [Object.defineProperty](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/defineProperty) и [Object.defineProperties](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/defineProperties) — создаёт один или несколько дескрипторов свойств. Создадим свой собственный дескриптор с геттером и сеттером:
```
const obj = { name: 'Михаил', surname: 'Горшенёв' };
Object.defineProperty(obj, 'fullname', {
// Вызывается при чтении свойства fullname
get: function() {
return `${this.name} ${this.surname}`;
},
// Вызывается при изменении свойства fullname (но не умеет перехватывать удаление delete obj.fullname)
set: function(value) {
const [name, surname] = value.split(' ');
this.name = name;
this.surname = surname;
},
});
console.log(obj.fullname); // Михаил Горшенёв
obj.fullname = 'Егор Летов';
console.log(obj.name); // Егор
console.log(obj.surname); // Летов
```
В примере выше, свойство fullname не имело своего собственного значения, а динамически работало со свойствами name и surname. Необязательно определять одновременно геттер и сеттер — мы можем оставить только геттер и получить свойство, доступное только для чтения. Или можем в сеттере вместе с установкой значения добавить дополнительное действие, например, логгирование.
Кроме свойств get/set, дескрипторы имеют ещё несколько свойств для настройки:
```
const obj = {};
// Если не нужны свои обработчики get/set, то можно просто указать значение через value. Нельзя одновременно использовать get/set и value. По умолчанию — undefined.
Object.defineProperty(obj, 'name', { value: 'Егор' });
// Указываем, что созданное свойство видно при итерации свойств объекта (for-in, for-of, Object.keys). По умолчанию — false.
Object.defineProperty(obj, 'a', { enumerable: true });
// Можно ли в дальнейшем поменять созданное свойство через defineProperty или удалить его через delete. По умолчанию — false.
Object.defineProperty(obj, 'b', { configurable: false });
// Можно ли будет менять значение свойства. По умолчанию — false.
Object.defineProperty(obj, 'c', { writable: true });
```
* [Object.getOwnPropertyDescriptor](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getOwnPropertyDescriptor) и [Object.getOwnPropertyDescriptors](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getOwnPropertyDescriptors) — позволяют получить нужный дескриптор объекта или их полный список:
```
const obj = { a: 1, b: 2 };
console.log(Object.getOwnPropertyDescriptor(obj, "a")); // { configurable: true, enumerable: true, value: 1, writable: true }
/**
* {
* a: { configurable: true, enumerable: true, value: 1, writable: true },
* b: { configurable: true, enumerable: true, value: 2, writable: true }
* }
*/
console.log(Object.getOwnPropertyDescriptors(obj));
```
### Создание ограничений при работе с объектами
* [Object.freeze](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/freeze) — "замораживает" свойства объекта. Следствием такой "заморозки" является полная неизменяемость свойств объекта — их нельзя изменять и удалять, добавлять новые, менять дескрипторы:
```
const obj = Object.freeze({ a: 1 });
// В строгом режиме следующие строчки кидают исключения, а в обычном просто ничего не происходит.
obj.a = 2;
obj.b = 3;
console.log(obj); // { a: 1 }
console.log(Object.isFrozen(obj)) // true
```
* [Object.seal](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/seal) — "запечатывает" свойства объекта. "Запечатывание" похоже на Object.freeze, но имеет ряд отличий. Мы также, как и в Object.freeze запрещаем добавлять новые свойства, удалять существующие, менять их дескрипторы, но в то же время можем менять значения свойств:
```
const obj = Object.seal({ a: 1 });
obj.a = 2; // Свойство a теперь равно 2
// В строгом режиме кинет исключение, а в обычном просто ничего не происходит.
obj.b = 3;
console.log(obj); // { a: 2 }
console.log(Object.isSealed(obj)) // true
```
* [Object.preventExtensions](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/preventExtensions) — запрещает добавление новых свойств/дескрипторов:
```
const obj = Object.preventExtensions({ a: 1 });
obj.a = 2;
// В строгом режиме следующие строчки кидают исключения, а в обычном просто ничего не происходит.
obj.b = 3;
console.log(obj); // { a: 2 }
console.log(Object.isExtensible(obj)) // false
```
### Прототипы объектов
* [Object.create](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/create) — для создания объекта с указанным в параметре прототипом. Эту возможность можно использовать как для [прототипного наследования](https://learn.javascript.ru/class-inheritance), так и для создания "чистых" объектов, без свойств из [Object.prototype](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/prototype):
```
const pureObj = Object.create(null);
```
* [Object.getPrototypeOf](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getPrototypeOf) и [Object.setPrototypeOf](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/setPrototypeOf) — для получения/изменения прототипа объекта:
```
const duck = {};
const bird = {};
Object.setPrototypeOf(duck, bird);
console.log(Object.getPrototypeOf(duck) === bird); // true
console.log(duck.__proto__ === bird); // true
```
* [Object.prototype.isPrototypeOf](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/isPrototypeOf) — проверяет, содержится ли текущий объект в прототипной цепочке другого:
```
const duck = {};
const bird = {};
duck.__proto__ = bird;
console.log(bird.isPrototypeOf(duck)); // true
```
4. Reflect API
--------------
С появлением ES6, в JavaScript добавили глобальный объект [Reflect](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect), предназначенный для хранения различных методов, связанных с рефлексией и интроспекцией.
Большая часть его методов — это результат переноса существующих методов из таких глобальных объектов, как [Object](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object) и [Function](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function) в отдельное пространство имён с небольшим рефакторингом для более комфортного использования.
Перенос функций в объект Reflect не только облегчил поиск нужных методов для рефлексии и дал большую семантичность, но также позволил избежать неприятных ситуаций, когда наш объект не содержит в своём прототипе [Object.prototype](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/prototype), но мы хотим использовать методы оттуда:
```
let obj = Object.create(null);
obj.qwerty = 'qwerty';
console.log(obj.__proto__) // null
console.log(obj.hasOwnProperty('qwerty')) // Uncaught TypeError: obj.hasOwnProperty is not a function
console.log(obj.hasOwnProperty === undefined); // true
console.log(Object.prototype.hasOwnProperty.call(obj, 'qwerty')); // true
```
Рефакторинг сделал поведение методов более явным и однообразным. К примеру, если раньше при вызове [Object.defineProperty](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/defineProperty) на некорректном значении (как число или строка) кидалось исключение, но в то же время вызов [Object.getOwnPropertyDescriptor](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/getOwnPropertyDescriptor) на несуществующем дескрипторе объекта молча возвращал undefined, то аналогичные методы из Reflect при некорректных данных всегда кидают исключения.
Также добавилось несколько новых методов:
* [Reflect.construct](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/construct) — более удобная альтернатива [Object.create](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/create), позволяющая не просто создать объект с указанным прототипом, но и сразу проинициализировать его:
```
function Person(name, surname) {
this.name = this.formatParam(name);
this.surname = this.formatParam(surname);
}
Person.prototype.formatParam = function(param) {
return param.slice(0, 1).toUpperCase() + param.slice(1).toLowerCase();
}
const oldPerson = Object.create(Person.prototype); // {}
Person.call(oldPerson, 'Иван', 'Иванов'); // {name: "Иван", surname: "Иванов"}
const newPerson = Reflect.construct(Person, ['Андрей', 'Смирнов']); // {name: "Андрей", surname: "Смирнов"}
```
* [Reflect.ownKeys](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/ownKeys) — возвращает массив свойств, принадлежащих именно указанному объекту (а не объектам в цепочке прототипов):
```
let person = { name: 'Иван', surname: 'Иванов' };
person.__proto__ = { age: 30 };
console.log(Reflect.ownKeys(person)); // ["name", "surname"]
```
* [Reflect.deleteProperty](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/deleteProperty) — альтернатива оператору *delete*, выполненная в виде метода:
```
let person = { name: 'Иван', surname: 'Иванов' };
delete person.name; // person = {surname: "Иванов"}
Reflect.deleteProperty(person, 'surname'); // person = {}
```
* [Reflect.has](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/has) — альтернатива оператору *in*, выполненная в виде метода:
```
let person = { name: 'Иван', surname: 'Иванов' };
console.log('name' in person); // true
console.log(Reflect.has(person, 'name')); // true
```
* [Reflect.get](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/get) и [Reflect.set](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect/set) — для чтения/изменения свойств объекта:
```
let person = { name: 'Иван', surname: 'Иванов' };
console.log(Reflect.get(person, 'name')); // Иван
Reflect.set(person, 'surname', 'Петров') // person = {name: "Иван", surname: "Петров"}
```
Более подробно с изменениями можно ознакомиться [здесь](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Reflect).
### Reflect metadata
Кроме перечисленных выше методов объекта Reflect, существует экспериментальный proposal для удобного привязывания различных метаданных к объектам.
Метаданными может быть любая полезная информация не относящаяся к объекту напрямую, например:
* TypeScript при включенном флаге [emitDecoratorMetadata](http://www.typescriptlang.org/docs/handbook/decorators.html) записывает в метаданные информацию о типах, позволяя получить к ним доступ в рантайме. Далее, эта информация может быть получена по ключу design:type:
```
const typeData = Reflect.getMetadata("design:type", object, propertyName);
```
* Популярная библиотека [InversifyJS](https://github.com/inversify/InversifyJS) для инверсии контроля хранит в метаданных различную информацию об описанных связях.
В данный момент для его работы в браузерах используется этот [полифилл](https://github.com/rbuckton/reflect-metadata)
5. Символы (Symbols)
--------------------
Символы являются новым неизменяемым типом данным, в основном использующийся для создания уникальных названий идентификаторов свойств объектов. У нас имеется возможность создавать символы двумя способами:
1. Локальные символы — текст в параметрах функции Symbol не влияет на уникальность и нужен лишь для отладки:
```
const sym1 = Symbol('name');
const sym2 = Symbol('name');
console.log(sym1 == sym2); // false
```
2. Глобальные символы — символы хранятся в глобальном реестре, поэтому символы с одинаковым ключом равны:
```
const sym3 = Symbol.for('name');
const sym4 = Symbol.for('name');
const sym5 = Symbol.for('other name');
console.log(sym3 == sym4); // true, символы имеют один и тот же ключ 'name'
console.log(sym3 == sym5); // false, символы имеют разные ключи
```
Возможность создавать такие идентификаторы позволяет не бояться того, что мы можем затереть какое-то свойство в неизвестном нам объекте. Это качество позволяет создателям стандарта легко добавлять новые стандартные свойства в объекты, при этом не сломав совместимость с различными существующими библиотеками (которые уже могли определить такое же свойство) и пользовательским кодом. Поэтому существует ряд стандартных символов и часть из них даёт новые возможности для рефлексии:
* [Symbol.iterator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/iterator) — позволяет создавать собственные правила итерации объектов с помощью *for-of* или *...spread operator*:
```
let arr = [1, 2, 3];
// Выводим элементы массива в обратном порядке
arr[Symbol.iterator] = function() {
const self = this;
let pos = this.length - 1;
return {
next() {
if (pos >= 0) {
return {
done: false,
value: self[pos--]
};
} else {
return {
done: true
};
}
}
}
};
console.log([...arr]); // [3, 2, 1]
```
* [Symbol.hasInstance](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/hasInstance) — метод, определяющий, распознает ли конструктор некоторый объект как свой экземпляр. Используется оператором instanceof:
```
class MyArray {
static [Symbol.hasInstance](instance) {
return Array.isArray(instance);
}
}
console.log([] instanceof MyArray); // true
```
* [Symbol.isConcatSpreadable](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/isConcatSpreadable) — указывает, должен ли массив сплющиваться при конкатенации в Array.concat:
```
let firstArr = [1, 2, 3];
let secondArr = [4, 5, 6];
firstArr.concat(secondArr); // [1, 2, 3, 4, 5, 6]
secondArr[Symbol.isConcatSpreadable] = false;
console.log(firstArr.concat(secondArr)); // [1, 2, 3, [4, 5, 6]]
```
* [Symbol.species](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/species) — позволяет указать какой конструктор будет использоваться для создания производных объектов внутри класса.
Например, у нас есть стандартный класс Array для работы с массивами и в нём есть метод .map, создающий новый массив на основе текущего. Для того, чтобы узнать какой класс нужно использовать для создания этого нового массива, Array обращается к *this.constructor[Symbol.species]* примерно так:
```
Array.prototype.map = function(cb) {
const ArrayClass = this.constructor[Symbol.species];
const result = new ArrayClass(this.length);
this.forEach((value, index, arr) => {
result[index] = cb(value, index, arr);
});
return result;
}
```
Тем самым, переопределяя Symbol.species мы можем создать собственный класс для работы с массивами и сказать, чтобы все стандартные методы вроде .map, .reduce и др. возвращали не экземпляр класса Array, а экземпляр нашего класса:
```
class MyArray extends Array {
static get [Symbol.species]() { return this; }
}
const arr = new MyArray(1, 2, 3); // [1, 2, 3]
console.log(arr instanceof MyArray); // true
console.log(arr instanceof Array); // true
// Обычная реализация Array.map вернула бы экземпляр класса Array, но мы переопределили Symbol.species на this и теперь возвращается экземпляр класса MyArray
const doubledArr = arr.map(x => x * 2);
console.log(doubledArr instanceof MyArray); // true
console.log(doubledArr instanceof Array); // true
```
Само собой, это работает не только с массивами, но и с другими стандартными классами. Более того, даже если мы просто создаём свой класс с методами, возвращающими новые экземпляры этого же класса, то мы по-хорошему должны использовать this.constructor[Symbol.species] для получения ссылки на констуктор.
* [Symbol.toPrimitive](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/toPrimitive) — позволяет указать каким образом нужно конвертировать наш объект в примитивное значение. Если ранее для приведения к примитиву нам нужно было использовали toString вместе с valueOf, то теперь всё можно сделать в одном удобном методе:
```
const figure = {
id: 1,
name: 'Прямоугольник',
[Symbol.toPrimitive](hint) {
if (hint === 'string') {
return this.name;
} else if (hint === 'number') {
return this.id;
} else { // default
return this.name;
}
}
}
console.log(`${figure}`); // hint = string
console.log(+figure); // hint = number
console.log(figure + ''); // hint = default
```
* [Symbol.match](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/match) — позволяет создавать свои собственные классы-обработчики для метода для функции [String.prototype.match](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match):
```
class StartAndEndsWithMatcher {
constructor(value) {
this.value = value;
}
[Symbol.match](str) {
const startsWith = str.startsWith(this.value);
const endsWith = str.endsWith(this.value);
if (startsWith && endsWith) {
return [this.value];
}
return null;
}
}
const testMatchResult = '|тест|'.match(new StartAndEndsWithMatcher('|'));
console.log(testMatchResult); // ["|"]
const catMatchResult = 'кот|'.match(new StartAndEndsWithMatcher('|'));
console.log(catMatchResult) // null
```
Также существуют похожие символы — [Symbol.replace](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/replace), [Symbol.search](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/search) и [Symbol.split](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol/split) для аналогичных методов из [String.prototype](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/prototype).
Важно заметить, что символы (как и reflect-metadata из прошлой секции) можно использовать для присоединения своих метаданных к любому объекту. Ведь из-за уникальности создаваемых символов, мы можем не бояться, что случайно перезапишем имеющееся свойство в объекте. Для примера присоединим метаданные для валидации к объекту:
```
const validationRules = Symbol('validationRules');
const person = { name: 'Иван', surname: 'Иванов' };
person[validationRules] = {
name: ['max-length-256', 'required'],
surname: ['max-length-256']
};
```
6. Прокси (Proxy)
-----------------
[Proxy](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) является принципиально новым функционалом, появившимся вместе с Reflect API и Symbols в ES6, предназначающийся для перехвата в любом объекте чтения/записи/удаления любых свойств, вызова функций, переопределения правил итерирования и других полезных вещей. Важно заметить, что *прокси нормально не полифилятся*.
С помощью проксей мы можем сильно расширить удобство использования кучи библиотек, например библиотек для data-binding вроде MobX из React, Vue и других. Рассмотрим пример до использования прокси и после.
С прокси:
```
const formData = {
login: 'User',
password: 'pass'
};
const proxyFormData = new Proxy(formData, {
set(target, name, value) {
target[name] = value;
this.forceUpdate(); // Перерисовываем наш React-компонент
}
});
// При изменении любого свойства также вызывается forceUpdate() для перерисовки в React
proxyFormData.login = 'User2';
// Такого свойства ещё не существует, но прокси всё-равно перехватит присваивание и корректно обработает
proxyFormData.age = 20;
```
Без прокси мы можем попробовать сделать нечно похожее, используя геттеры/сеттеры:
```
const formData = {
login: 'User',
password: 'pass'
};
const proxyFormData = {};
for (let param in formData) {
Reflect.defineProperty(proxyFormData, `__private__${param}`, {
value: formData[param],
enumerable: false,
configurable: true
});
Reflect.defineProperty(proxyFormData, param, {
get: function() {
return this[`__private__${param}`];
},
set: function(value) {
this[`__private__${param}`] = value;
this.forceUpdate(); // Перерисовываем наш React-компонент
},
enumerable: true,
configurable: true
});
}
// При изменении любого свойства также вызывается forceUpdate() для перерисовки в React
proxyFormData.login = 'User2';
// Такого свойства не существует и мы не сможем его обработать пока явно не зададим ещё одну пара геттеров-сеттеров через Reflect.defineProperty
proxyFormData.age = 20;
```
При использовании геттеров и сеттеров мы получаем кучу неудобного бойлерплейт-кода, а самый главный минус — при использовании Proxy мы создаём проксируемый объект один раз и он перехватывает все свойства (независимо от того, существуют они в объекте или ещё нет), а с использованием геттеров/сеттеров нам приходится для каждого нового свойства вручную создавать пару из геттера и сеттера, к тому же сеттером мы не можем отслеживать работу оператора *delete obj[name]*.
7. Заключение
-------------
JavaScript является мощным и гибким языком и очень радует, что он больше не находится в застое как во времена ECMAScript 4, а постоянно улучшается и добавляет в себя всё больше новых и удобных возможностей. Благодаря этому мы можем писать всё более хорошие программы как с точки зрения пользовательского опыта, так и разработческого.
Для более детального погружения в тему рекомендую прочитать находящийся в свободном доступе [раздел про метапрограммирование](https://github.com/getify/You-Dont-Know-JS/blob/master/es6%20%26%20beyond/ch7.md) замечательной книги [You Don't Know JS](https://github.com/getify/You-Dont-Know-JS). | https://habr.com/ru/post/417097/ | null | ru | null |
# DevOps приходит к нам домой? Домашний Minecraft server в Azure с применением современных DevOps практик
Эта статья НЕ про майнкрафт. Эта статья про **Azure** и про современные подходы к деливери ПО.
Если вы просто хотите развернуть себе сервер майнкрафт — спросите гугл «minecraft server hosting» — будет и проще и дешевле.
А вот если вы хотите посмотреть на реальный кейс использования подходов *Infrastructure as Code*, *Configuration as Code* применительно к неадаптированному к Azure ПО на примере майнкрафта — то добро пожаловать
### Roadmap
Azure Stack огромен и хочется потыкать в разные его части, поэтому эта статья будет всяко не одна.
План статей пока видится такой:
* Автоматизированный деплой и настройка сервера с применением Azure CLI 2 и Powershell DSC
* Поддержка конфигурации сервера в консистентном состоянии с применением Azure Automation
* Автоматизированное обновление сервера на новую версию
* Получение логов майнкрафта, анализ и отображение с применением Azure Stream Analytics и Power BI
* Организация active/passive кластера с управлением через Azure Automation
* ...
Но конечно процесс появления новых статей может быть остановлен отсутствием вашего интереса )
### Disclaimer
* Я не it инженер, не devops инженер, не игрок в майнкрафт. Поэтому если вы шарите и вам кажется, что я всё делаю не правильно — то скорее всего так оно и есть — напишите в коментах как надо.
* Все примеры к статье 100% рабочие, но поставляются «как есть». Если у вас что-то не работает — почините это самостоятельно или забейте.
Итак.
Автоматизированный деплой и настройка сервера с применением Azure CLI 2 и Powershell DSC
----------------------------------------------------------------------------------------
#### О задаче
Задача не синтетическая. Сервер попросили развернуть дети и он реально будет использоваться. Меньше всего я хочу его постоянно чинить и поднимать. Ещё меньше я хочу терять данные при обновлениях. Поэтому требования к нему вполне себе prod-like )
#### Общий подход
* 100% автоматизация.
* Относимся к скриптам как к коду
* Соблюдаем базовые требования конфигурационного управления к деливери процессу на prod окружения
Все пункты буду пояснять по ходу дела
#### О ПО
В качестве сервера я взял официальный сервер [minecraft.net/en-us/download/server](https://minecraft.net/en-us/download/server). Беглое изучение выявило, что:
* Сервер представляет из себя jar файл и требует для запуска java
* Для запуска ему требуется рядом с собой файл eula.txt с определённым содержимым
* Сервер конфигурируется с помощью файла server.properties который тоже должен лежать рядом
* Сервер слушает 25565 порт по протоколу TCP
* Данные (карту) сервер хранит в папочке World рядом с собой (и это будет слегка проблемой)
* Сервер умеет данные апгрейдить, если они созданы предыдущей версией (и это сильно упростит жизнь при апгрейде)
* Логи хранятся в папочке Logs рядом
#### Инфраструктура
Применим самую базовую схему:
одна **Resource Group** c:
* **Network Security Group** (будут открыты порты 25565 (minecraft) и 3389 (rdp)
* **VNET** c 1 subnet
* **NIC** и статический **public IP** c DNS именем
* 1 **VM** под Windows Server 2016 core + 2 **Managed Disk** (OS + Data)
* **Storage account** и 1 container для **Blob storage**
Данные будем хранить отдельно от виртуальной машины на отдельном **managed disk** и линковать в папочку World рядом с jar'кой с помощью Symlink (я писал выше, что расположение папочки world не настраивается и должно быть всегда рядом с jar).
Это даст возможность запускать сервер как с прилинкованным диском, так и без (для тестов) — в этом случае папка world будет создана с пустой картой.
Сервер будем конфигурировать на основании:
* Дистрибутива (jar с сервером + jre + начальные данные), который будет предварительно загружаться в Blob storage
* Конфигурации (Powershell DSC), которая также будет предварительно загружаться в Blob storage
Я там выше обещал следования некоторым требованиям конфигурационного управления — вот первое:
> *все артефакты, которые требуются для разворачивания приложения, должны быть опубликованы в подконтрольный сторадж с высокой доступностью.*
Именно поэтому мы и дистрибутив и конфигурацию будем предварительно собирать из артефактов в интернетах и перепубликовывать в Blob Storage.
Таким образом, алгоритм процедуры развертывания следующий:
* Создать новую Resource Group, Storage Account и Storage Container
* Сформировать дистрибутив (jar с сервером + jre + начальные данные) и загрузить его в Blob Storage
* Создать всю остальную инфраструктуру в Resource Group
* Сформировать DSC конфигурацию и загрузить её в Blob Storage
* Сконфигурировать сервер на основании конфигурации и дистрибутива
#### Исходники
* Храним на [github](https://github.com/AndreyPoturaev/minecraft-in-azure/tree/v1.0.0)
* Соблюдаем какую-нибудь внятную стратегию бранчевания и релизного цикла (ну например [gitflow](https://datasift.github.io/gitflow/IntroducingGitFlow.html) и релиз каждую статью :))
* Используем azure cli 2 и bash там, где это возможно (к слову, в этой статье удалось совсем избежать использования powershell api. А вот в следующей это уже не получится)
Реализация шагов процедуры развертывания
----------------------------------------
#### 1. Создать новую Resource Group, Storage Account и Storage Container
реализация тривиальная, просто вызовы cli
**initial\_preparation.sh**
```
az configure --defaults location=$LOCATION group=$GROUP
echo "create new group"
az group create -n $GROUP
echo "create storage account"
az storage account create -n $STORAGE_ACCOUNT --sku Standard_LRS
STORAGE_CS=$(az storage account show-connection-string -n $STORAGE_ACCOUNT)
export AZURE_STORAGE_CONNECTION_STRING="$STORAGE_CS"
echo "create storage container"
az storage container create -n $STORAGE_CONTAINER --public-access blob
```
#### 2. Сформировать дистрибутив (jar с сервером + jre + начальные данные) и загрузить его в Blob Storage
Скачиваем сервер и карту, jre берём с текущего компьютера и всё пакуем в zip
структура дистрибутива:
* .jar
* jre
* initial\_world — папка с начальной картой
**prepare\_distr.sh**
```
mkdir $DISTR_DIR
cd $DISTR_DIR
echo "download minecraft server from official site"
curl -Os https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.$MVERSION.jar
echo "copy jre from this machine"
cp -r "$JRE" ./jre
echo "create ititial world folder"
mkdir initial_world
cd initial_world
echo "download initial map"
curl -Os https://dl01.mcworldmap.com/user/1821/world2.zip
unzip -q world2.zip
cp -r StarWars/* .
rm -r -f StarWars
rm world2.zip
cd ../
echo "create archive (zip utility -> https://ranxing.wordpress.com/2016/12/13/add-zip-into-git-bash-on-windows/)"
cd ../
zip -r -q $DISTR_ZIP $DISTR_DIR
rm -r -f $DISTR_DIR
```
#### 3. Сформировать DSC конфигурацию и загрузить её в Blob Storage
DSC конфигурация представляет собой один ps1 файл (о структуре его — позже), который будет запускаться на сервере и его конфигурировать.
Но скрипты в ps1 файле имеют депенды на внешние модули, которые не будут установлены на сервер автоматически.
Поэтому конфигурацию надо передать на сервер не просто как ps1 файл, а как архив с:
* ps1 файлом
* Всеми зависимыми модулями, сложенными в одноименных папочках рядом с ps1 файлом
Зависимые модули можно просто скачать curl'ом как nuget пакет с репозитория powershell gallery и разархивировать в нужное место.
Также можно использовать и команду powershell Save-Module — которая включает эти два шага
Обратите внимание, что версии зависимых модулей и в ps1 файле и в скриптах формирования архива с конфигурацией указаны и совпадают.
И тут мы опять следуем требованиям очередного правила конфигурационного управления:
> *Все зависимости должны быть точно определены и ресолвиться всегда однозначно*
**prepare\_config.sh**
```
echo "prepare server configuration"
curl -s -L -o configuration/xPSDesiredStateConfiguration.zip "https://www.powershellgallery.com/api/v2/package/xPSDesiredStateConfiguration/7.0.0.0"
curl -s -L -o configuration/xNetworking.zip "https://www.powershellgallery.com/api/v2/package/xNetworking/5.1.0.0"
curl -s -L -o configuration/xStorage.zip "https://www.powershellgallery.com/api/v2/package/xStorage/3.2.0.0"
cd configuration
unzip -q xPSDesiredStateConfiguration.zip -d xPSDesiredStateConfiguration
rm -r xPSDesiredStateConfiguration.zip
unzip -q xNetworking.zip -d xNetworking
rm -r xNetworking.zip
unzip -q xStorage.zip -d xStorage
rm -r xStorage.zip
zip -r -q ../$CONFIG_ZIP . *
rm -r -f xPSDesiredStateConfiguration
rm -r -f xNetworking
rm -r -f xStorage
cd ../
```
#### 4. Создать всю остальную инфраструктуру в Resource Group
реализация тривиальная, просто вызовы cli:
**iaas\_preparation.sh**
```
echo "create network security group and rules"
az network nsg create -n $NSG
az network nsg rule create --nsg-name $NSG -n AllowMinecraft --destination-port-ranges 25556 --protocol Tcp --priority 100
az network nsg rule create --nsg-name $NSG -n AllowRDP --destination-port-ranges 3389 --protocol Tcp --priority 110
echo "create vnet, nic and pip"
NIC_NAME=minesrvnic
PIP_NAME=minepip
SUBNET_NAME=servers
az network vnet create -n $VNET --subnet-name $SUBNET_NAME
az network public-ip create -n $PIP_NAME --dns-name $DNS --allocation-method Static
az network nic create --vnet-name $VNET --subnet $SUBNET_NAME --public-ip-address $PIP_NAME -n $NIC_NAME
echo "create data disk"
DISK_NAME=minedata
az disk create -n $DISK_NAME --size-gb 10 --sku Standard_LRS
echo "create server vm"
az vm create -n $VM_NAME --size $VM_SIZE --image $VM_IMAGE \
--nics $NIC_NAME \
--admin-username $VM_ADMIN_LOGIN --admin-password $VM_ADMIN_PASSWORD \
--os-disk-name ${VM_NAME}disk --attach-data-disk $DISK_NAME
```
#### 5. Сконфигурировать сервер на основании конфигурации и дистрибутива
Вот тут, наверное самое интересное место. Конфигурирование сервера происходит на основании DSC конфигурации, загруженной ранее с помощью DSC расширения для vm.
DSC extension кормится конфигом в котором указан URL до архива с конфигурацией и значения параметров
**server\_configuration.sh**
```
echo "prepare dsc extension settings"
cat MinecraftServerDSCSettings.json | envsubst > ThisMinecraftServerDSCSettings.json
echo "configure vm"
az vm extension set \
--name DSC \
--publisher Microsoft.Powershell \
--version 2.7 \
--vm-name $VM_NAME \
--resource-group $GROUP \
--settings ThisMinecraftServerDSCSettings.json
rm -f ThisMinecraftServerDSCSettings.json
```
#### О Powershell DSC
Ну это некоторая надстройка над powershell, которая позволяет декларативно описывать требуемое состояние компьютера.
DSC конфигурация анализируется на целевой машине, строится диф относительно текущей конфигурации этой машины, а затем происходит приведение конфигурации к нужной. Ближайший аналог powershell DSC в «opensource» мире — **Ansible**.
Реализация DSC конфигурации MinecraftServer
-------------------------------------------
Структурно конфигурация состоит из набора шагов, которые выполняются в определенном порядке (с учётом зависимостей). Пробежимся по всем:
```
xRemoteFile DistrCopy
{
Uri = "https://$accountName.blob.core.windows.net/$containerName/mineserver.$minecraftVersion.zip"
DestinationPath = "$mineHome.zip"
MatchSource = $true
}
```
Декларирует, что на компьютере должен лежать zip с дистрибутивом сервера по пути DestinationPath, если его там не лежит — он будет скачен по адресу Uri:
```
Archive UnzipServer
{
Ensure = "Present"
Path = "$mineHome.zip"
Destination = $mineHomeRoot
DependsOn = "[xRemoteFile]DistrCopy"
Validate = $true
Force = $true
}
```
Декларирует, что на компьютере в папке Destination должен лежить разархивированный архив с дистрибутивом сервера если его там не лежит (или если состав файлов отличается от того что в архиве) — они будут добавлены:
```
File CheckProperties
{
DestinationPath = "$mineHome\server.properties"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "....."
}
File CheckEULA
{
DestinationPath = "$mineHome\eula.txt"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "..."
DependsOn = "[File]CheckProperties"
}
```
Декларирует, что по пути DestinationPath должны лежать файлы с конфигом сервера и с лицензией. Если их нет — они создаются с содержимым Contents:
```
xWaitForDisk WaitWorldDisk
{
DiskIdType = "Number"
DiskId = "2"
RetryIntervalSec = 60
RetryCount = 5
DependsOn = "[File]CheckEULA"
}
xDisk PrepareWorldDisk
{
DependsOn = "[xWaitForDisk]WaitWorldDisk"
DiskIdType = "Number"
DiskId = "2"
DriveLetter = "F"
AllowDestructive = $false
}
xWaitForVolume WaitForF
{
DriveLetter = 'F'
RetryIntervalSec = 5
RetryCount = 10
DependsOn = "[xDisk]PrepareWorldDisk"
}
```
Тут мы декларируем о том, что managed disk с данными должен быть инициализирован в OS и ему должна быть присвоена буква F:
```
File WorldDirectoryExists
{
Ensure = "Present"
Type = "Directory"
Recurse = $true
DestinationPath = "F:\world"
SourcePath = "$mineHome\initial_world"
MatchSource = $false
DependsOn = "[xWaitForVolume]WaitForF"
}
```
Декларируем о том, что на диске F должна присутствовать директори world (с миром). Если её там нет — мы считаем что происходит деплой впервые и нам надо эту папку создать, взяв за основу карту из initial\_world дистрибутива:
```
Script LinkWorldDirectory
{
DependsOn="[File]WorldDirectoryExists"
GetScript=
{
@{ Result = (Test-Path "$using:mineHome\World") }
}
SetScript=
{
New-Item -ItemType SymbolicLink -Path "$using:mineHome\World" -Confirm -Force -Value "F:\world"
}
TestScript=
{
return (Test-Path "$using:mineHome\World")
}
}
```
Это кастомный шаг — проверяем, что у нас в папке с сервером есть папка World. Если её нету — линкуем её с диска F. Script работает следующим образом — если TestScript вернул false — вызывается SetScript. Иначе не вызывается:
```
Script EnsureServerStart
{
DependsOn="[Script]LinkWorldDirectory"
GetScript=
{
@{ Result = (Get-Process -Name java -ErrorAction SilentlyContinue) }
}
SetScript=
{
Start-Process -FilePath "$using:mineHome\jre\bin\java" -WorkingDirectory "$using:mineHome" -ArgumentList "-Xms512M -Xmx512M -jar `"$using:mineHome\minecraft_server.$using:minecraftVersion.jar`" nogui"
}
TestScript=
{
return (Get-Process -Name java -ErrorAction SilentlyContinue) -ne $null
}
}
```
Ещё один кастомный шаг. Проверяем, что запущен java процесс с сервером ). Если не запущен — запускаем:
```
xFirewall FirewallIn
{
Name = "Minecraft-in"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Inbound'
}
xFirewall FirewallOut
{
Name = "Minecraft-out"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Outbound'
}
```
И последние шаги — открываем 25565 порт.
Эпилог
------
Статья получилась и так длинная, надо закругляться. Остались за бортом вопросы дебага этого DSC (очень интересные сами по себе) — освещу их в следующей.
Всем спасибо за внимание.
**Как всё это запустить из Windows**Нам нужен будет
* [Git и (обязательно) Git Bash](https://git-scm.com/downloads)
* [zip utility (прописать в PATH)](https://ranxing.wordpress.com/2016/12/13/add-zip-into-git-bash-on-windows/)
* [Azure CLI 2](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest)
Запуск процедуры ролаута
```
git clone https://github.com/AndreyPoturaev/minecraft-in-azure
cd minecraft-in-azure
git checkout v1.0.0
export MINESERVER_PASSWORD=
export MINESERVER\_DNS=
export MINESERVER\_STORAGE\_ACCOUNT=
az login
. rollout.sh
```
Результат:
 | https://habr.com/ru/post/339034/ | null | ru | null |
# Lua, ООП и ничего лишнего
*Однажды судьба свела меня с ней. С первого взгляда я был ослеплен и долгое время не мог отвести от нее взгляд. Шло время, но она не переставала меня удивлять, иногда казалось, что я изучил ее вдоль и поперек, но она снова переворачивала все мои представления. Ее гибкости не было предела, а потом я узнал, что она умеет еще и… ООП!*
Как-то я всерьез занялся покорением ООП в lua. И все, что я находил в интернете по этой теме, было вырвиглазными нагромождениями кода с обилием нижних подчеркиваний, которые никак не вписывались в элегантность этого языка. Поэтому я решил искать простое решение.
После прочтения множества умных книжек и разбора нескольких ужасных реализаций ООП, я, крупица за крупицей, собирал все самое полезное и простое, пока не выработал свой стиль объектно ориентированного программирования на lua.
#### **Создание класса и экземпляра**
**class Person**
```
--класс
Person= {}
--тело класса
function Person:new(fName, lName)
-- свойства
local obj= {}
obj.firstName = fName
obj.lastName = lName
-- метод
function obj:getName()
return self.firstName
end
--чистая магия!
setmetatable(obj, self)
self.__index = self; return obj
end
--создаем экземпляр класса
vasya = Person:new("Вася", "Пупкин")
--обращаемся к свойству
print(vasya.firstName) --> результат: Вася
--обращаемся к методу
print(vasya:getName()) --> результат: Вася
```
Как видите, все очень просто. Если кто-то путается где ставить точку, а где двоеточие, правило следующее: если обращаемся к свойству — ставим точку (object.name), если к методу — ставим двоеточие (object:getName()).
Дальше интереснее.
Как известно, ООП держится на трех китах: наследование, инкапсуляция и полиморфизм. Проведем «разбор полетов» в этом же порядке.
#### **Наследование**
Допустим, нам нужно создать класс унаследованный от предыдущего (Person).
**class Woman**
```
Woman = {}
--наследуемся
setmetatable(Woman ,{__index = Person})
--проверяем
masha = Woman:new("Марья","Ивановна")
print(masha:getName()) --->результат: Марья
```
Все работает, но лично мне не нравится такой вариант наследования, некрасиво. Поэтому я просто создаю глобальную функцию extended():
**extended()**
```
function extended (child, parent)
setmetatable(child,{__index = parent})
end
```
Теперь наследование классов выглядит куда красивее:
**class Woman**
```
Woman = {};
--наследуемся
extended(Woman, Person)
--проверяем
masha = Woman:new("Марья","Ивановна")
print(masha:getName()) --->результат: Марья
```
#### **Инкапсуляция**
Все свойства и методы до этого момента в наших классах были публичные, но мы так же легко можем создавать и приватные:
**class Person**
```
Person = {}
function Person:new(name)
local private = {}
--приватное свойство
private.age = 18
local public = {}
--публичное свойство
public.name = name or "Вася" -- "Вася" - это значение по умолчанию
--публичный метод
function public:getAge()
return private.age
end
setmetatable(public,self)
self.__index = self; return public
end
vasya = Person:new()
print(vasya.name) --> результат: Вася
print(vasya.age) --> результат: nil
print(vasya:getAge()) --> результат: 18
```
Видите? Все почти так же как вы и привыкли.
#### **Полиморфизм**
Тут все еще проще.
**полиморфизм**
```
Person = {}
function Person:new(name)
local private = {}
private.age = 18
local public = {}
public.name = name or "Вася"
--это защищенный метод, его нельзя переопределить
function public:getName()
return "Person protected "..self.name
end
--это открытый метод, его можно переопределить
function Person:getName2()
return "Person "..self.name
end
setmetatable(public,self)
self.__index = self; return public
end
--создадим класс, унаследованный от Person
Woman = {}
extended(Woman, Person) --не забываем про эту функцию
--переопределим защищенный метод
function Woman:getName()
return "Woman protected "..self.name
end
--переопределим метод getName2()
function Woman:getName2()
return "Woman "..self.name
end
--проверим
masha = Woman:new()
print(masha:getName()) --> Person protected Вася
print(masha:getName2()) --> Woman Вася
```
Итак, что мы тут сделали?
— создали класс Person, с двумя методами: getName() и getName2(), первый из них защищен от переопределения;
— создали класс Woman и унаследовали его от класса Person;
— переопределили оба метода в классе Woman. Первый не переопределился;
— получили профит!
Кстати, открытые методы можно определять так же и вне тела класса:
**полиморфизм**
```
Person = {}
function Person:new(name)
local private = {}
private.age = 18
local public = {}
public.name = name or "Вася"
--это защищенный метод, его нельзя переопределить
function public:getName()
return "Person protected "..self.name
end
setmetatable(public,self)
self.__index = self; return public
end
--это открытый метод, его можно
function Person:getName2()
return "Person "..self.name
end
```
А что делать, если нужно вызвать метод базового класса, который у нас переопределен? Это тоже делается легко!
Синтаксис таков: РодительскийКласс.Метод(сам\_объект, параметры (если есть)).
**class Woman**
```
--создадим класс, унаследованный от Person
Woman = {}
extended(Woman, Person) --не забываем про эту функцию
--переопределим метод setName
function Woman:getName2()
return "Woman "..self.name
end
print(masha:getName2()) --> Woman Вася
--вызываем метод родительского класса
print(Person.getName2(masha)) --> Person Вася
```
#### **Постскриптум**
На этом все, искренне надеюсь, что хоть кому-нибудь эта статья окажется полезной.
Напоследок приведу полный код, можете его скопипастить в IDE и убедиться в работоспособности.
**Полный код**
```
function extended (child, parent)
setmetatable(child,{__index = parent})
end
Person = {}
function Person:new(name)
local private = {}
private.age = 18
local public = {}
public.name = name or "Вася"
--это защищенный метод, его нельзя переопределить
function public:getName()
return "Person protected "..self.name
end
--этот метод можно переопределить
function Person:getName2()
return "Person "..self.name
end
setmetatable(public,self)
self.__index = self;
return public
end
--создадим класс, унаследованный от Person
Woman = {}
extended(Woman, Person) --не забываем про эту функцию
--переопределим метод setName
function Woman:getName2()
return "Woman "..self.name
end
masha = Woman:new()
print(masha:getName2()) --> Woman Вася
--вызываем метод родительского класса
print(Person.getName2(masha)) --> Person Вася
``` | https://habr.com/ru/post/259265/ | null | ru | null |
# Защита Linux-сервера. Что сделать в первую очередь

*[Habib M’henni / Wikimedia Commons](https://commons.wikimedia.org/wiki/File:GNU_and_Stallman_2012.JPG), CC BY-SA*
В наше время поднять сервер на хостинге — дело пары минут и нескольких щелчков мыши. Но сразу после запуска он попадает во враждебную среду, потому что открыт для всего интернета как невинная девушка на рокерской дискотеке. Его быстро нащупают сканеры и обнаружат тысячи автоматически скриптовых ботов, которые рыскают по сети в поисках уязвимостей и неправильных конфигураций. Есть несколько вещей, которые следует сделать сразу после запуска, чтобы обеспечить базовую защиту.
Содержание
==========
* [Нерутовый юзер](#1)
* [Ключи вместо паролей SSH](#2)
* [Файрвол](#3)
* [Fail2Ban](#4)
* [Автоматические обновления безопасности](#5)
* [Смена портов по умолчанию](#6)
Нерутовый юзер
==============
Первым делом нужно завести для себя нерутового юзера. Дело в том, что у пользователя `root` абсолютные привилегии в системе, а если разрешить ему удалённое администрирование, то вы сделаете половину работы для хакера, оставив для него валидный username.
Поэтому нужно завести другого юзера, а для рута отключить удалённое администрирование по SSH.
Новый пользователь заводится командой `useradd`:
```
useradd [options]
```
Затем для него добавляется пароль командой `passwd`:
```
passwd
```
Наконец, этого пользователя нужно добавить в группу, которая имеет право выполнять команды с повышением привилегий `sudo`. В зависимости от дитрибутива Linux, это могут быть разные группы. Например, в CentOS и Red Hat юзера добавляют в группу `wheel`:
```
usermod -aG wheel
```
В Ubuntu он добавляется в группу `sudo`:
```
usermod -aG sudo
```
Ключи вместо паролей SSH
========================
Брутфорс или утечка паролей — стандартный вектор атаки, так что аутентификацию по паролям в SSH (Secure Shell) лучше отключить, а вместо неё использовать аутентификацию по ключам.
Есть разные программы для реализации протокола SSH, такие как [lsh](http://www.lysator.liu.se/~nisse/lsh/) и [Dropbear](https://matt.ucc.asn.au/dropbear/dropbear.html), но самой популярной является OpenSSH. Установка клиента OpenSSH на Ubuntu:
```
sudo apt install openssh-client
```
Установка на сервере:
```
sudo apt install openssh-server
```
Запуск демона SSH (sshd) на сервере под Ubuntu:
```
sudo systemctl start sshd
```
Автоматический запуск демона при каждой загрузке:
```
sudo systemctl enable sshd
```
Нужно заметить, что серверная часть OpenSSH включает в себя клиентскую. То есть через `openssh-server` можно подключаться к другим серверам. Более того, со своей клиентской машины вы можете запустить SSH-туннель с удалённого сервера на сторонний хост, и тогда сторонний хост будет считать удалённый сервер источником запросов. Очень удобная функция для маскировки своей системы. Подробнее см. статью [«Практические советы, примеры и туннели SSH»](https://hackertarget.com/ssh-examples-tunnels/).
На клиентской машине обычно нет смысла ставить полноценный сервер, чтобы не допускать возможность удалённого подключения к компьютеру (в целях безопасности).
Итак, для своего нового юзера сначала нужно сгенерировать ключи SSH на компьютере, с которого вы будете заходить на сервер:
```
ssh-keygen -t rsa
```
Публичный ключ хранится в файле `.pub` и выглядит как строка случайных символов, которые начинаются с `ssh-rsa`.
`ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQ3GIJzTX7J6zsCrywcjAM/7Kq3O9ZIvDw2OFOSXAFVqilSFNkHlefm1iMtPeqsIBp2t9cbGUf55xNDULz/bD/4BCV43yZ5lh0cUYuXALg9NI29ui7PEGReXjSpNwUD6ceN/78YOK41KAcecq+SS0bJ4b4amKZIJG3JWm49NWvoo0hdM71sblF956IXY3cRLcTjPlQ84mChKL1X7+D645c7O4Z1N3KtL7l5nVKSG81ejkeZsGFzJFNqvr5DuHdDL5FAudW23me3BDmrM9ifUmt1a00mWci/1qUlaVFft085yvVq7KZbF2OP2NQACUkwfwh+iSTP username@hostname`
Затем из-под рута создать на сервере директорию SSH в домашнем каталоге пользователя и добавить публичный ключ SSH в файл `authorized_keys`, используя текстовый редактор вроде Vim:
```
mkdir -p /home/user_name/.ssh && touch /home/user_name/.ssh/authorized_keys
```
```
vim /home/user_name/.ssh/authorized_keys
```
Наконец, установить корректные разрешения для файла:
```
chmod 700 /home/user_name/.ssh && chmod 600 /home/user_name/.ssh/authorized_keys
```
и изменить владение на этого юзера:
```
chown -R username:username /home/username/.ssh
```
На стороне клиента нужно указать местоположение секретного ключа для аутентификации:
```
ssh-add DIR_PATH/keylocation
```
Теперь можно залогиниться на сервер под именем юзера по этому ключу:
```
ssh [username]@hostname
```
После авторизации можно использовать команду scp для копирования файлов, утилиту [sshfs](https://github.com/libfuse/sshfs) для удалённого примонтирования файловой системы или директорий.
Желательно сделать несколько резервных копий приватного ключа, потому что если отключить аутентификацию по паролю и потерять его, то у вас не останется вообще никакой возможности зайти на собственный сервер.
Как упоминалось выше, в SSH нужно отключить аутентификацию для рута (по этой причине мы и заводили нового юзера).
На CentOS/Red Hat находим строку `PermitRootLogin yes` в конфигурационном файле `/etc/ssh/sshd_config` и изменяем её:
```
PermitRootLogin no
```
На Ubuntu добавляем строку `PermitRootLogin no` в конфигурационный файл `10-my-sshd-settings.conf`:
```
sudo echo "PermitRootLogin no" >> /etc/ssh/sshd_config.d/10-my-sshd-settings.conf
```
После проверки, что новый юзер проходит аутентификацию по своему ключу, можно отключить аутентификацию по паролю, чтобы исключить риск его утечки или брутфорса. Теперь для доступа на сервер злоумышленнику необходимо будет достать приватный ключ.
На CentOS/Red Hat находим строку `PasswordAuthentication yes` в конфигурационном файле `/etc/ssh/sshd_config` и изменяем её следующим образом:
```
PasswordAuthentication no
```
На Ubuntu добавляем строку `PasswordAuthentication no` в файл `10-my-sshd-settings.conf`:
```
sudo echo "PasswordAuthentication no" >> /etc/ssh/sshd_config.d/10-my-sshd-settings.conf
```
Инструкцию по подключению двухфакторной аутентификации по SSH см. [здесь](https://www.linode.com/docs/security/authentication/use-one-time-passwords-for-two-factor-authentication-with-ssh-on-ubuntu-16-04-and-debian-8/).
Файрвол
=======
Файрвол гарантирует, что на сервер пойдёт только тот трафик по тем портам, которые вы напрямую разрешили. Это защищает от эксплуатации портов, которые случайно включились с другими сервисами, то есть сильно уменьшает поверхность атаки.
Перед установкой файрвола нужно убедиться, что SSH внесён в список исключений и не будет блокироваться. Иначе после запуска файрвола мы не сможем подключиться к серверу.
С дистрибутивом Ubuntu идёт Uncomplicated Firewall ([ufw](https://wiki.ubuntu.com/UncomplicatedFirewall)), а с CentOS/Red Hat — [firewalld](https://firewalld.org/).
Разрешение SSH в файрволе на Ubuntu:
```
sudo ufw allow ssh
```
На CentOS/Red Hat используем команду `firewall-cmd`:
```
sudo firewall-cmd --zone=public --add-service=ssh --permanent
```
После этой процедуры можно запустить файрвол.
На CentOS/Red Hat запускаем сервис systemd для firewalld:
```
sudo systemctl start firewalld
sudo systemctl enable firewalld
```
На Ubuntu используем такую команду:
```
sudo ufw enable
```
Fail2Ban
========
Сервис [Fail2Ban](https://www.fail2ban.org/wiki/index.php/Main_Page) анализирует логи на сервере и подсчитывает количество попыток доступа с каждого IP-адреса. В настройках указаны правила, сколько попыток доступа разрешено за определённый интервал — после чего данный IP-адрес блокируется на заданный отрезок времени. Например, разрешаем 5 неудачных попыток аутентификации по SSH в промежуток 2 часа, после чего блокируем данный IP-адрес на 12 часов.
Установка Fail2Ban на CentOS и Red Hat:
```
sudo yum install fail2ban
```
Установка на Ubuntu и Debian:
```
sudo apt install fail2ban
```
Запуск:
```
systemctl start fail2ban
systemctl enable fail2ban
```
В программе два конфигурационных файла: `/etc/fail2ban/fail2ban.conf` и `/etc/fail2ban/jail.conf`. Ограничения для бана указываются во втором файле.
Джейл для SSH включён по умолчанию с дефолтными настройками (5 попыток, интервал 10 минут, бан на 10 минут).
```
[DEFAULT]
ignorecommand =
bantime = 10m
findtime = 10m
maxretry = 5
```
Кроме SSH, Fail2Ban может защищать и другие сервисы на веб-сервере nginx или Apache.
Автоматические обновления безопасности
======================================
Как известно, во всех программах постоянно находят новые уязвимости. После публикации информации эксплоиты добавляются в популярные эксплоит-паки, которые массово используются хакерами и подростками при сканировании всех серверов подряд. Поэтому очень важно устанавливать обновления безопасности как только они появляются.
На сервере Ubuntu в конфигурации по умолчанию включены автоматические обновления безопасности, так что дополнительных действий не требуется.
На CentOS/Red Hat нужно установить приложение [dnf-automatic](https://fedoraproject.org/wiki/AutoUpdates) и включить таймер:
```
sudo dnf upgrade
sudo dnf install dnf-automatic -y
sudo systemctl enable --now dnf-automatic.timer
```
Проверка таймера:
```
sudo systemctl status dnf-automatic.timer
```
Смена портов по умолчанию
=========================
SSH был разработан в 1995 году для замены telnet (порт 23) и ftp (порт 21), поэтому автор программы Тату Илтонен [выбрал порт 22 по умолчанию](https://www.ssh.com/ssh/port), и его утвердили в IANA.
Естественно, все злоумышленники в курсе, на каком порту работает SSH — и сканируют его вместе с остальными стандартными портами, чтобы узнать версию программного обеспечения, для проверки стандартных паролей рута и так далее.
Смена стандартных портов — обфускация — в несколько раз сокращает объём мусорного трафика, размер логов и нагрузку на сервер, а также сокращает поверхность атаки. Хотя некоторые [критикуют такой метод «защиты через неясность»](https://en.wikipedia.org/wiki/Security_through_obscurity#Criticism) (security through obscurity). Причина в том, что эта техника противопоставляется фундаментальной [архитектурной защите](https://en.wikipedia.org/wiki/Secure_by_design). Поэтому, например, Национальный институт стандартов и технологий США в [«Руководстве по безопасности сервера»](http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-123.pdf) указывает необходимость открытой серверной архитектуры: «Безопасность системы не должна полагаться на скрытность реализации её компонентов», — сказано в документе.
Теоретически, смена портов по умолчанию противоречит практике открытой архитектуры. Но на практике объём вредоносного трафика действительно сокращается, так что это простая и эффективная мера.
Номер порта можно настроить, изменив директиву `Port 22` в файле конфигурации [/etc/ssh/sshd\_config](https://www.ssh.com/ssh/sshd_config/). Он также указывается параметром `-p` в [sshd](https://www.ssh.com/ssh/sshd/). Клиент SSH и программы [sftp](https://www.ssh.com/ssh/sftp/) тоже поддерживают параметр `-p` .
Параметр `-p` можно использовать для указания номера порта при подключении с помощью команды `ssh` в Linux. В [sftp](https://www.ssh.com/ssh/sftp/) и `scp` используется параметр `-P` (заглавная P). Указание из командной строки переопределяет любое значение в файлах конфигурации.
Если серверов много, почти все эти действия по защите Linux-сервера можно автоматизировать в скрипте. Но если сервер только один, то лучше вручную контролировать процесс.
---
#### На правах рекламы
Закажи и сразу работай! [Создание VDS](https://vdsina.ru/cloud-servers?partner=habr135) любой конфигурации и с любой операционной системой в течение минуты. Максимальная конфигурация позволит оторваться на полную — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe. Эпичненько :)
[](https://vdsina.ru/cloud-servers?partner=habr135) | https://habr.com/ru/post/521388/ | null | ru | null |
# Скрипт для удобного просмотра Wikipedia 10 июля 2012
Доброго времени суток, Хабрасообщество.
Хочу рассказать о способе чтения Wikipedia, который нашел мой друг — хабраюзер [porqz](https://habrahabr.ru/users/porqz/), но так как он очень занят, то не смог опубликовать его самостоятельно.
Итак, есть интересующая нас статья в Википедии:
Досадно, но содержимое скрыто.
Теперь скопируем этот небольшой скриптик (оригинал лежит на https://gist.github.com/3082958):
`javascript:(function() { $("#blackout").remove(); $("head").append(''); })();`
и вставим его в строку браузера (не забудьте про «javascript:» в начале):
Жмем Enter и вуаля — читаем статью:
Не забываем поблагодарить [porqz](https://habrahabr.ru/users/porqz/) за этот небольшой, но полезный хак! | https://habr.com/ru/post/147510/ | null | ru | null |
# Zabbix-мониторинг данных в БД Oracle без unixODBC
Была поставлена задача: реализовать мониторинг БД Oracle средствами Zabbix, а именно — отслеживать параметры табличных пространств на определенном инстансе. Раз задача поставлена, значит делаем. Как известно, Zabbix предоставляет возможность через предопределенный тип данных осуществлять запросы к базам данным и получать результат запроса. На официальном сайте разработчиков Zabbix есть очень хорошая [документация по настройке ODBC-мониторинга](https://www.zabbix.com/documentation/3.0/ru/manual/config/items/itemtypes/odbc_checks).
[](https://habrahabr.ru/company/at_consulting/blog/321894/)
У нас сервер Zabbix 3.0.4 под управлением Centos 7. Ранее ODBC мониторинг не был настроен, а следовательно, нужно открывать инструкции и начинать установку и настройку.
Согласно инструкции с официального сайта Zabbix был установлен пакет [unixODBC](http://www.unixodbc.org/download.html). Так как UnixODBC-драйвер для Oracle триальный, а бюджет под эту задачу не выделяли, было принято решение — искать другой способ. Перелопатив кучу сайтов с инструкциями установки клиента Oracle, были скачаны с сайта [oracle.com](http://www.oracle.com/technetwork/topics/linuxx86-64soft-092277.html) пакеты:
> oracle-instantclient11.2-basic-11.2.0.3.0-1.x86\_64.rpm
>
> oracle-instantclient11.2-sqlplus-11.2.0.3.0-1.x86\_64.rpm
>
> oracle-instantclient11.2-devel-11.2.0.3.0-1.x86\_64.rpm
>
> oracle-instantclient11.2-odbc-11.2.0.3.0-1.x86\_64.rpm
После того, как все эти пакеты были установлены, осталось только произвести настройки клиента и unixODBC. В результате все настройки были произведены и осталось только протестировать, что все работает.
Перелогиниваемся под пользователем zabbix и выполняем команду isql, согласно инструкции.
```
[user@serverZabbix]$ isql -v CMSAHI username/password
```
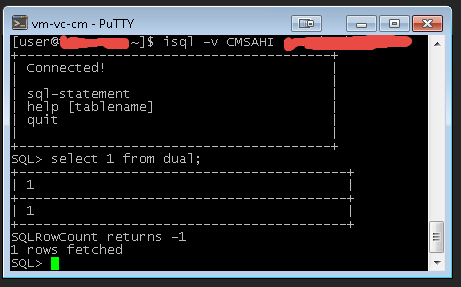
Все ок. Пробуем получить тот же результат из веб Zabbix. После настройки элемента данных «Мониторинг БД» ждем результата. Но не тут-то было. Элемент данных перешел в статус «Не поддерживается». Получаем ошибку: **Cannot connect to ODBC DSN:[SQL\_ERROR]:[01000][0][[unixODBC][Driver Manager]Can't open lib '/usr/lib/oracle/11.2/client64/lib/libsqora.so.11.1': file not found]|**.
Странная ошибка, тем более, что указанный файл по указанному пути есть.

Начался процесс поиска причины и попытки исправить ошибку. После нескольких дней поиска, перепробовав кучу советов, найденных в интернете, набрёл на [тикет](https://support.zabbix.com/browse/ZBX-11356) в баг-трекере Zabbix. По описанию проблемы – это как раз наша проблема. Что же делать? Тикет открыт, баг найден и в последующих версиях Zabbix, а следовательно, если причина нашей ошибки именно этот баг, настроить мониторинг не получится. Ну не ставить же свежевышедшую версию Zabbix ради решения одной задачи.
В голову пришла мысль: а что, если для подключения к БД использовать не unixODBC а SqlPlus, который был установлен вместе с пакетом oracle-instantclient11.2-sqlplus-11.2.0.3.0-1.x86\_64.rpm. Исходя из этой идеи, необходимо настроить клиент oracle для подключения.
Клиент Oracle был установлен в **/usr/lib/oracle/11.2/client64**. Первое, что нужно сделать – это создать файл [**tnsnames.ora**](http://www.orafaq.com/wiki/Tnsnames.ora) и заполнить его данными для подключения к БД oracle. Для этого нужно создать папку для хранения этого файла:
```
sudo mkdir /usr/lib/oracle/11.2/client64/network/admin –p
```
В созданной директории нужно создать файл с именем tnsnames.ora и заполнить его. Обязательно нужно проверить, чтобы у всех созданных директорий и самого файла были права доступа на чтение для пользователя zabbix.
Далее, нужно создать скрипт для подключения к БД и выполнения запросов. Ниже пример скрипта для выполнения простых селектов:
```
#!/bin/sh
## Для корректной работы нужно задать переменные окружения ниже
export ORACLE_HOME=/usr/lib/oracle/11.2/client64
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:/usr/lib:$ORACLE_HOME/bin
export TNS_ADMIN=$ORACLE_HOME/network/admin
## Директория для хранения sql – файлов. Созданная предварительно.
## Обязательно убедиться, что пользователю zabbix выданы права доступа на запись и чтение
scriptLocation=/etc/zabbix/SqlScripts
## Тут задается абсолютный путь и название создаваемого файла с выполняемым запросом
## в качестве первого параметра скрипта предполагается передавать какую-то уникальную ## строку, для идентификации файла с запросом
sqlFile=$scriptLocation/sqlScript_"$1".sql
## Записываем выполняемый запрос в файл
echo "$2" > sqlFile;
## Собственно, ниже подключаемся к БД и выполняем запрос из ранее сохраненного файла.
## Логин и пароль открытые, не хорошо.
username="$3"
password="$4"
tnsname="$5"
var=$($ORACLE_HOME/bin/sqlplus -s $username/$password@$tnsname < $sqlFile)
## Получаем результат запроса из полученной выше строки и возвращаем результат.
echo $var | cut -f3 -d " "
```
Скрипт необходимо поместить в папку **/etc/zabbix/externalscripts –** папка для хранения скриптов внешних проверок (см настройки zabbix\_server.conf строка ExternalScripts=/etc/zabbix/externalscripts). Также скрипту необходимо выдать права доступа на чтение и выполнение пользователю zabbix. Скрипт готов. Настраиваем элемент данных «Внешняя проверка» в веб-интерфейсе Zabbix как на скрине ниже.

Созданный ранее скрипт принимает сл. параметры:
1. Идентификатор файла с запросом (строка)
2. Простой запрос (строка)
3. логин для подключения к БД (строка)
4. Пароль, для подключения к БД (строка)
5. TNS БД, к которой хотим подключиться (строка)
На скрине выше поле «Ключ» заполнено следующим образом:
```
getOracleSelect.sh["TestSelect","select count(*) from testTable;","username","password","CMSAHI"]
```
*где «TestSelect» – строковый идентификатор, для формирования sql-файла;
«select count(\*) from testTable;» – сам запрос.
«username» и «password» – данные подключения к базе
«tnsname» – название базы (см tnsnames.ora)*
**! ВАЖНО!** Запрос должен возвращать значение только одной колонки результирующей таблицы, если ожидается получить численное или текстовое значение результата выборки.
После того, как элемент создан, если все настроено верно, веб-интерфейс Zabbix отобразит результат выполнения запроса.
Данный метод, конечно же, имеет ряд недостатков, но, в качестве временного решения он работает. Таким недостатком, например, является то, что большой и сложный запрос вписывать в качестве параметра очень неудобно.
Для получения параметров занятого табличного пространства использован скрипт ниже:
```
SELECT round((totalspace — freespace) * 100 / decode(maxspace, 0, totalspace, maxspace), 2) "%USED"
FROM (SELECT tablespace_name, SUM (bytes) / (1024*1024*1024) totalspace, Sum(maxbytes)/ 1024/1024/1024 maxspace
FROM dba_data_files
GROUP BY tablespace_name) a,
(SELECT tablespace_name, SUM (Bytes) / (1024*1024*1024) freespace
FROM dba_free_space
GROUP BY tablespace_name) b
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME (+)
AND A.TABLESPACE_NAME = 'TAB_SPACE1';
```
Так как требуется мониторить всего несколько табличных пространств, под каждое был создан свой sql-файл. Для решения поставленной задачи, скрипт получения данных из бд был изменен. Ниже сам скрипт:
```
#!/bin/sh
export ORACLE_HOME=/usr/lib/oracle/11.2/client64
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:/usr/lib:$ORACLE_HOME/bin
export TNS_ADMIN=$ORACLE_HOME/network/admin
scriptLocation=/etc/zabbix/SqlScripts
sqlFile=$scriptLocation/getPUsedTableSpace_"$1".sql
username="$2"
password="$3"
tnsname="$4"
var=$($ORACLE_HOME/bin/sqlplus -s $username/$password@$tnsname < $sqlFile)
echo $var | cut -f3 -d " "
```
Ключ для элемента данных, соответственно, выглядит так:
```
getOracleSelect.sh["TAB_SPACE1","username","password","CMSAHI"]
```
где 'TAB\_SPACE1' — наименование табличного пространства.

Как видно из скрина выше, веб-интерфейс Zabbix получает результаты выполнения запроса и отображает процентное значение использованного табличного пространства.
Остается только настроить триггеры и действия оповещений.
Если кому-то поможет данный способ, буду рад. Если у кого-то будут идеи по модернизации скриптов и самого подхода, минуя unixODBC, пишите. | https://habr.com/ru/post/321894/ | null | ru | null |
# Сенсоры от Yoctopuce — погода дома
Некоторое время назад я занимался поисками датчика давления для [одного сайта](http://yartemp.com/). Требования были простыми — подключение по USB и минимум паяльника, т.к. опыт использования данного инструмента у меня только в криптоанализе. Оказывается, что в отличие от температуры и влажности, китайцы ещё не освоили этот рынок, и наиболее простой и дешёвый вариант: купить любой барометр, направить на него веб-камеру и анализировать показания.
Несмотря на бредовость данной затеи, она серьёзно рассматривалась, но в конце-концов была отметена по банальной причине — ночью нужна подсветка. Т.е. работать система ночью не будет, а если будет, то потребует дополнительных усилий по настройке.
Из других вариантов, наиболее подходящим была [USB Meteo Board](http://www.sparkfun.com/products/10586) от Sparkfun на основе Arduino, или самодельная система на основе того же Arduino или Netduino.
Но совершенно случайно я наткнулся на [Yoctopuce](http://www.yoctopuce.com/), и понял, что это оно. Их сенсоры и датчики настолько меня поразили в мелочах, что я не могу молчать и хочу поделиться с хабра-сообществом про эти замечательные датчики.
[](http://habrastorage.org/storage2/d00/acd/ca9/d00acdca94144203c830c4dd26c2bc42.jpg)
##### О yoctopuce
Это швейцарская фирма, с симпатичным осьминогом на логотипе. Название как раз и образовано от осьминога (octopuce) и приставки йокто- (10-24). Все свои устройства и API они начинают с приставки Yocto. Тем не менее, для удобства я их называю ёктопуками, и мне этот вариант весьма нравится. :)
Как я понял там трудится совсем немного людей, которые занимаются всякими умными штуками, и бонусом решили организовать производство и магазин всяких сенсоров. При этом, они ориентируются на 2 важных критерия: качество изготовления и простота использования.
##### Датчики
Доступных датчиков не так уж и много:
* Сенсор, читающий показания 5 кнопок
* Датчик освещённости
* Температурный датчик
* Метео-устройство (давление, температура, влажность)
* Устройство с двумя трёхцветными диодами
* Реле
* Контроллер для сервомоторов
* micro-USB хаб для удобства работы с множеством устройств
* Коннекторы, проводки, крепёж
* Демо-устройство с зелёным диодом
У меня сейчас в наличии 4 из них: Yocto-Meteo, Yocto-Temperature и Yocto-Light и Yocto-Demo.
##### Общее

Все датчики имеют общие свойства и построены на одной базе:
* Упакованы в антистатичные пакеты с названием и датой производства (!!!)
* Все датчики цифровые. Не требуют калибровки и специальных алгоритмов обработки результатов
* Подключаются по micro-USB (драйверов не требуют, COM-порт не эмулируют)
* Имеют ёкто-кнопку и ёкто-диод. Они нужны для обнаружения устройства на компьютере или наоборот. Т.е. если у вас много одинаковых устройств, то нажатием кнопки на устройстве можно увидеть как оно называется в компьютере, а вызовом соответствующей функции в API можно включить маяк на устройстве.
* Дружно живут вместе с другими устройствами
* Бескорпусные
* Имеют крепёжные отверстия
* Вместо micro-USB можно припаять провода напрямую
* Во многих случаях плату можно разломать на 2 части
* Прошивка устройств и API постоянно обновляется
Вообще, в устройствах поражает именно внимание к мелочам. Сделана очень хорошая база и удобная, на которую теперь навешиваются различные датчики.
##### API
У ёктопуков отличное API (помните я говорил про простоту): оно делится на высокоуровневое и низкоуровневое. Высокоуровневое: поднимается http-сервер на 4444-ом порту, и к нему можно обращаться через JavaScript или PHP. Низкоуровневое: тут всё классически: Objective-C, Delphi, C++, C#.
Есть версии под Windows, Mac и Linux.
У всех устройств есть стандартные функции (имя модуля, потребляемый ток, время работы, версия прошивки) и специфичные (узнать температуру, включить лампочку и прочее).
Можно подписываться на события подключения нового устройства или отключения. Собственно рассказывать про код как-то неправильно, лучше показать:
```
static void Main()
{
string errmsg = "";
//подключаемся к хабу
if (yAPI.RegisterHub("usb", ref errmsg) != yAPI.SUCCESS)
{
Console.WriteLine(errmsg);
return;
}
yAPI.DisableExceptions();
//берём первые попавшиеся устройства нужных типов
YPressure ypr = YPressure.FirstPressure();
YHumidity yhu = YHumidity.FirstHumidity();
YTemperature yte = YTemperature.FirstTemperature();
while(true)
{
//забираем текущие значения и логгируем
double pres = ypr.get_currentValue();
double hum = yhu.get_currentValue();
double temp = yte.get_currentValue();
Console.WriteLine("{0:0}\t{1:00}\t{2:0.0}", pres, hum, temp);
Thread.Sleep(5000);
}
}
```
Данный код берёт температуру, влажность и давление с первых попавшихся датчиков. Как видите, более банального кода написать сложно. Естественно, при желании можно определить и названия устройства и выбрать нужное, в общем отсылаю на [сайт](http://www.yoctopuce.com/EN/libraries.php), там для каждого из устройств есть шикарная документация по всем функциям.
##### VirtualHub
Кроме API, всегда можно обратиться на <http://127.0.0.1:4444/> и посмотреть список подключённых устройств, перепрошить их, посмотреть текущие данные, и возможные функции. Т.е. даже без программирования всё можно вполне удобно использовать.
[](http://habrastorage.org/storage2/23c/b7c/95d/23cb7c95d401a9e66e836abd612189b4.png)
##### Бонусы
Большинство устройств могут при отсутствии подключения к компьютеру самостоятельно логгировать данные. Естественно, чудес тут нет, и питание им надо выдать, но тем не менее, такая дополнительная симпатичная возможность. При этом, по утверждению разработчиков, в случае переполнения памяти (~500,000 показаний), логгирование не остановится, не будет всё переписываться по кругу, вместо этого старые данные постепенно будут проряжаться (раз в минуту, раз в час, раз в день). Так что возможностей хватит надолго.
##### Сами устройства (те, что у меня в наличии)
###### Yocto-Meteo
[](http://habrastorage.org/storage2/79b/8ee/0d6/79b8ee0d6825c46952e0e32800fafa77.jpg)
Меряет влажность, давление и температуру. Влажность от 0 до 100%, температуру от -40° до 125° (точность сенсора ±0.2°, показания с точность до 1/16 градуса, API округляет до 0.1), давление в миллибарах, в мм рт.ст. можно привести самостоятельно при желании.
Плату можно разломать на 2 части — база и отдельно датчики, соединив их 4-мя проводами для передачи информации. Ломать можно в двух местах — под коннекторы или прямую пайку.
Датчик влажности можно закрыть специальной крышкой (продаётся отдельно), чтобы защитить его от пыли. Т.к. датчик влажности не имеет смысла упаковывать герметично, в отличие от температуры и давления.
###### Yocto-Temperature
[](http://habrastorage.org/storage2/150/0b1/ab6/1500b1ab6c65cbfaf2fa733087a773f3.jpg)[](http://habrastorage.org/storage2/67f/c89/119/67fc891194a3b1d5cb41944b64d5be95.jpg)
Упрощённая и более дешёвая версия Yocto-Meteo, меряет только температуру.
Температурные датчики от метео-платы и этой, положенные вместе, показывают почти идентичную температуру ±0.2-0.4° (в пределах декларируемой погрешности).
Плата была разрезана, припаяны проводки, получилось как-то так:
[](http://habrastorage.org/storage2/364/b11/d5c/364b11d5c0c8394109c63b591c9900a7.jpg)
В дальнейшем, термоусадочная трубка на датчике была обработана феном и изолентой. Сама плата была упакована с целью изоляции, а датчик упакован в свой же антистатичный пакет. Финальный результат:
[](http://habrastorage.org/storage2/289/892/c52/289892c52fbbfa960db4097416ebb9d5.jpg)
###### Yocto-Light
[](http://habrastorage.org/storage2/e44/a7d/9ed/e44a7d9eda55450715d435508d096d29.jpg)
Меряет освещённость в люксах, ломается только в одном месте (под коннекторы нет отверстий). Разработчики использовали для создания умного почтового ящика (светили лазером и по прерыванию сигнала определяли наличие письма).
###### Yocto-Demo
[](http://habrastorage.org/storage2/f48/33a/8d9/f4833a8d973873e1a097f467d68ef03f.jpg)
Самое бестолковое устройство для тестирования размером 2 на 2 см. Можно управлять одним зелёным диодом, менять ему яркость, включать/выключать, различным образом мигать. Цель устройства — демонстрация возможностей и функционала. Можно разобраться с API и решить, как использовать другие, более функциональные и полезные устройства.
##### Покупка
Тут всё просто. Оплата карточкой (PayPal не поддерживается), в долларах, евро или швейцарских франках. Доставка обычной почтой (трекинг предоставляют), заняла месяц (за сутки ушла из Швейцарии посылка, дальше всё на совести нашей почты). От 100 франков доставка бесплатна.
Стоят датчики не очень дешёво, например, Yocto-Meteo ~$67, но в принципе, удобство работы и простота того стоит.
##### Аналоги
Их не так уж и много:
* Arduino и аналоги. Позволяет сделать более дешёвые и функциональные устройства, но нужно потратить больше времени на изготовление и настройку. Как вариант, готовый комплект [USB Meteo Board](http://www.sparkfun.com/products/10586), уже собранный профессиональными людьми за вас.
* [Phidgets](http://www.phidgets.com/) — гораздо больший выбор сенсоров, есть наборы для развлечения с кучей сенсоров, коробки для устройств и многое другое, но чуть больше возни с подключением, если не нужно много сенсоров получается не очень приятно по цене.
* [USBTenki](http://www.raphnet-tech.com/products.php?cmd=list&category=Sensors) — на некоторых фотографиях не очень весёлое качество сборки, ограниченное API (хотя кому-то может понравится тем что OpenSource).
* Демо-наборы от Freescale и прочих — фирмы, производящие сенсоры, предоставляют наборы для оценки сенсоров. Возможно, подобные наборы кому-то будут интересны. Проблемы — наборы в общем-то совершенно не предназначены для конечного потребителя и необходимо повозиться с настройкой и программированием. | https://habr.com/ru/post/138502/ | null | ru | null |
# Ленивая подгрузка библиотек из CDN в Angular
Когда я интегрировал свое [Angular-караоке](https://jamigo.app/custom/LZdhtPriojIoY0X38M3w) с YouTube, мне попался [официальный YouTube-компонент](https://github.com/angular/components/tree/master/src/youtube-player#readme) из Angular Material. В README прилагалась инструкция для подключения:
```
let apiLoaded = false;
@Component({
template: '',
selector: 'youtube-player-example',
})
class YoutubePlayerExample implements OnInit {
ngOnInit() {
if (!apiLoaded) {
const tag = document.createElement('script');
tag.src = 'https://www.youtube.com/iframe_api';
document.body.appendChild(tag);
apiLoaded = true;
}
}
}
```
Почти каждая строка в этом примере сомнительна — от отсутствия раннего выхода до глобальных переменных и прямой манипуляции с DOM. Это работает, конечно, но в Angular мы можем лучше! Давайте разберемся, как можно применить имеющиеся инструменты для ленивой подгрузки библиотеки.
Dependency Injection снова выручает
-----------------------------------
Есть неплохой трюк для ленивой загрузки блока кода через токен, про который писал [Reactive Fox](https://twitter.com/thekiba_io):
У этого подхода есть один недостаток — он работает только с локальными файлами. Так не получится загрузить библиотеку с CDN. Но мы всё равно можем применить токен для похожего эффекта.
DI-токен отлично подходит для того, что нужно загрузить один раз во время первого запроса. Это хорошая альтернатива грязному подходу с глобальной переменной из примера выше. С помощью токена `DOCUMENT` мы также можем абстрагироваться от прямой манипуляции DOM, и наш код не упадет при серверном рендеринге ([об этом я уже писал](https://habr.com/ru/company/tinkoff/blog/548510/)). Но сначала давайте добавим вспомогательный токен на CDN URL:
```
export const API_URL = new InjectionToken('CDN URL of Youtube API', {
factory: () => 'https://www.youtube.com/iframe\_api'
});
```
Библиотеки часто регистрируют себя на глобальном объекте `window`. Вот так будет выглядеть типовой токен на библиотеку:
```
export const API$ = new InjectionToken>(
'A stream with third party library object',
{
factory: () => {
const documentRef = inject(DOCUMENT);
const script = documentRef.createElement('script');
script.src = inject(API\_URL);
documentRef.body.appendChild(script);
return fromEvent(script, 'load').pipe(
map(() => documentRef.defaultView.libraryObject),
);
}
}
);
```
В случае YouTube API недостаточно просто дождаться загрузки скрипта. [В документации](https://developers.google.com/youtube/iframe_api_reference) написано, что нужно добавить колбэк `onYouTubeIframeAPIReady` на `window` и скрипт вызовет его, когда будет готов. Стоит заметить, что это произойдет в обход zone.js. То есть, даже если мы правильно отреагируем на вызов, Angular его не заметит и не запустит проверку изменений. Поэтому нужно обернуть вызов в `NgZone.run`:
```
export const API$ = new InjectionToken>(
'A stream with YT object',
{
factory: () => {
const documentRef = inject(DOCUMENT);
const zone = inject(NgZone);
const windowRef = documentRef.defaultView;
const script = documentRef.createElement('script');
const loaded$ = new ReplaySubject(1);
script.src = inject(API\_URL);
documentRef.body.appendChild(script);
windowRef.onYouTubeIframeAPIReady = () => {
zone.run(() => loaded$.next(windowRef.YT));
};
return loaded$;
}
}
);
```
Это токен — `Observable`. В большинстве случаев удобнее работать с непосредственным значением. Поэтому давайте добавим последний токен на сам объект `YT`:
```
export const API = new InjectionToken('Youtube API object');
```
Работаем с написанным
---------------------
Первый способ превратить `Observable` в значение и работать с ним дальше — [Resolver.](https://angular.io/api/router/Resolve) Возьмем lazy-роут, который использует YouTube, и добавим специальный ресолвер, который возьмет наш токен и дождется загрузки. Так объект `YT` станет доступным в `data` нашего роута. Затем можно положить его в токен. Что-то подобное [Hien Pham](https://twitter.com/HienHuuPham) описывал в своей статье [про уменьшение дублирования через DI.](https://indepth.dev/posts/1471/leveraging-dependency-injection-to-reduce-duplicated-code-in-angular)
Второй способ — создать [структурную директиву](https://angular.io/guide/structural-directives), которая будет ждать загрузки API, прежде чем инстанцировать шаблон. Сама директива будет простой:
```
export class WithYTDirective implements OnChanges {
@Input()
withYT: YT | null = null;
constructor(
private readonly templateRef: TemplateRef<{}>,
private readonly vcr: ViewContainerRef
) {}
ngOnChanges() {
if (this.withYT) {
this.vcr.createEmbeddedView(this.templateRef);
}
}
}
```
Поскольку шаблон создается только когда в `withYT` уже будет объект `YT`, мы можем добавить следующий провайдер:
```
export function extractAPI({ withYT }: WithYTDirective): YT {
return withYT;
}
@Directive({
selector: '[withYT]',
providers: [
{
provide: API,
deps: [WithYTDirective],
useFactory: extractAPI
}
]
})
export class WithYTDirective implements OnChanges {
// ...
}
```
> *Напомню, фабрика провайдера вызовется, только когда его запросят.*
>
>
Теперь мы можем создать компонент YouTube, который просто берет API из DI. Описывать подробно такой компонент я не буду. Предположим, что он у нас есть. Вот так мы могли бы использовать его с нашей директивой:
```
@Component(
selector: 'my-component',
template: ``
)
export class MyComponent {
constructor(@Inject(API$) readonly api$: Observable) {}
}
```
Итоговый вариант можно посмотреть [на StackBlitz.](https://stackblitz.com/edit/angular-di-youtube)
Вместо заключения
-----------------
DI, токены и фабрики дают мощные инструменты абстракции. Мы можем вынести в них трансформацию данных или логику инициализации. Это особенно полезно для авторов библиотек, но может пригодиться и при создании приложений.
Уделите побольше времени, чтобы ближе познакомиться с Dependency Injection, и он станет вашим верным союзником в написании надежного гибкого кода. | https://habr.com/ru/post/585534/ | null | ru | null |
# Инструменты разработчика на языке Elm
С момента публикации статьи [Основы разработки на языке Elm (руководство по инструментарию для начинающих)](https://habrahabr.ru/post/302154/) прошло полтора года. За это время в инструментарии для языка разработки веб-интерфейсов [Elm](http://elm-lang.org/) произошли многочисленные изменения: появилась более удобная система сборки с возможностью генерации нового проекта; для редактора Atom набор дополнений в некоторых отношениях теперь лучше, чем для популярного тогда среди разработчиков на Elm редактора LightTable; заработал инспектор состояния приложения. Давайте пройдёмся по этому набору на простом примере.

Базовые средства Elm
--------------------
Elm можно установить как пакет NPM:
```
npm install -g elm
```
Есть и другие способы установить Elm. Они описываются в [официальном руководстве](https://guide.elm-lang.org/install.html).
Проверим версию только что установленного Elm:
```
elm --version
```
```
0.18.0
```
`elm` является обёрткой для вызова отдельных утилит:
* `elm-make`: сборка кода на Elm;
* `elm-package`: управление пакетами на Elm;
* `elm-reactor`: утилита слежения за кодом на Elm для перекомпиляции и перезагрузки его в браузере;
* `elm-repl`: REPL для Elm.
Управление кодом на Elm с помощью Brunch
----------------------------------------
Одним из удобнейших средств управления кодом на Elm представляется [Brunch](http://brunch.io/). Устанавливается Brunch как пакет NPM:
```
npm install -g brunch
```
Проверим версию только что установленного Brunch:
```
brunch --version
```
```
2.10.12
```
Вызовем Brunch для генерации кода нашего примера проекта на Elm:
```
brunch new --skeleton MattCheely/elm-brunch-skeleton demo-application
```
После генерации кода Brunch также сразу загрузит все необходимые NPM- и Elm-пакеты.
Рассмотрим сгенерированное дерево каталогов:
* `app\`: исходные тексты приложения
+ `assets\`:
+ `index.html`: минимальный документ HTML5, который будет контейнером для нашего приложения
+ `css\`:
+ `style.css`: стили для примера приложения
+ `elm\`: исходные тексты на Elm
+ `Main.elm`: главный модуль приложения на Elm
+ `js\`: код на JavaScript
+ `app.js`: пример кода, работающего отдельно от кода на Elm
* `elm-stuff\`: загруженные пакеты на Elm
* `node_modules\`: загруженные NPM-пакеты
* `.gitignore`
* `README.md`
* `brunch-config.js`: настройки для Brunch с учётом поддержки Elm
* `elm-packages.json`: настройки для Elm, в том числе список используемых пакетов
* `package-lock.json`: список зависимостей NPM (сгенерирован NPM автоматически)
* `package.json`: настройки для NPM
Уже сейчас мы можем собрать наш проект:
```
cd demo-application
npm build
```
После сборки проекта появится также папка `public`, в которой разместятся все части нашего веб-приложения.
Давайте запустим приложение в режиме отладки:
```
npm start
```
Откроем в браузере ссылку `http://localhost:3333/` и полюбуемся на прекрасное веб-приложение:
В правом нижнем углу находится интерфейс инспектора состояния приложения. Щёлкнем на нём. Сейчас счётчик `value` имеет значение `0`:

Пощёлкаем на кнопках `+1` и `-1` и понаблюдаем как меняется состояние:
Мы можем вернуться к любому предыдущему состоянию:

И даже вернуться к последнему, просто нажав на кнопку `Resume`.
Неискушённому ~~зрителю~~ читателю наверное будет интересно также узнать, как устроено приложение на Elm, но сначала давайте настроим редактор, чтобы изучать исходный код приложения было приятней и удобней.
Настройка Atom для работы с Elm
-------------------------------
Поддержка разработки на Elm есть для многих редакторов, однако здесь мы рассмотрим только один, [Atom](https://atom.io/), так как на взгляд автора для него существует самый функциональный набор дополнений, облегчающий работу с Elm. Будем исходить из того, что Atom у вас уже установлен (хотя, подскажу [откуда его можно загрузить](https://github.com/atom/atom/releases)).
Перво наперво установим дополнение [language-elm](https://atom.io/packages/language-elm):
```
apm install language-elm
```
Это дополнение предоставит базовую поддержку Elm, такую как синтаксическая подсветка кода.
Для поддержки переходов к определениям и всплывающим подсказкам с типами выражений установим пакет [atom-ide-ui](https://atom.io/packages/atom-ide-ui).
```
apm install atom-ide-ui
```
Для поддержки автодополнения поставим [autocomplete-plus](https://atom.io/packages/autocomplete-plus):
```
apm install autocomplete-plus
```
Если используете сокращённый набор кода, поставьте [snippets](https://atom.io/packages/snippets):
```
apm install snippets
```
Наконец мы готовы установить [Elmjutsu](https://github.com/halohalospecial/atom-elmjutsu):
```
apm install elmjutsu
```
Теперь мы можем открыть наш проект в Atom:
Для руководства по настройке и функциям Elmjutsu обязательно зайдите на страничку этого дополнения, и не забудьте задать все необходимые параметры в Atom.
Дополнительный, но важный инструментарий
----------------------------------------
Пожалуй самый важный инструмент из дополнительных это [elm-format](https://github.com/avh4/elm-format). С помощью этой утилиты можно приводить внешний вид программы к стандартному (общепринятому) виду. Установим его:
```
npm install -g elm-format
```
Также установим соответствующее дополнение для Atom [elm-format](https://atom.io/packages/elm-format):
```
apm install elm-format
```
Благодаря этому дополнению, каждый раз, как мы будем сохранять наш код, elm-format будет его форматировать. Если в коде будет синтаксическая ошибка, то утилита её обнаружит, и мы об этом узнаем, хотя, для выяснения наличия ошибок всё же лучше использовать компилятор. А в этом нам будет помогать дополнение для Atom [linter-elm-make](https://atom.io/packages/linter-elm-make).
Поставим его:
```
apm install linter
apm install linter-elm-make
```
Не забудьте также зайти в настройки этих дополнений и задать все необходимые параметры.
Дополнение [elm-lens](https://atom.io/packages/elm-lens) показывает прямо в коде для функций и типов экспонируются ли они или являются локальными, а также сколько раз на них ссылаются. Для установки дополнения просто вызовите:
```
apm install elm-lens
```
Для поддержки REPL в Atom можно установить дополнение [elm-instant](https://atom.io/packages/elm-instant):
```
apm install elm-instant
```
Если вы хотите работать с терминалом прямо в Atom, рекомендую установить дополнение [platformio-ide-terminal](https://atom.io/packages/platformio-ide-terminal):
```
apm install platformio-ide-terminal
```
Поэкспериментируем
------------------
Для начала откроем окно терминала в Atom, нажав кнопку `+` в нижней части окна, и запустим слежение за нашим кодом на Elm:
```
npm start
```
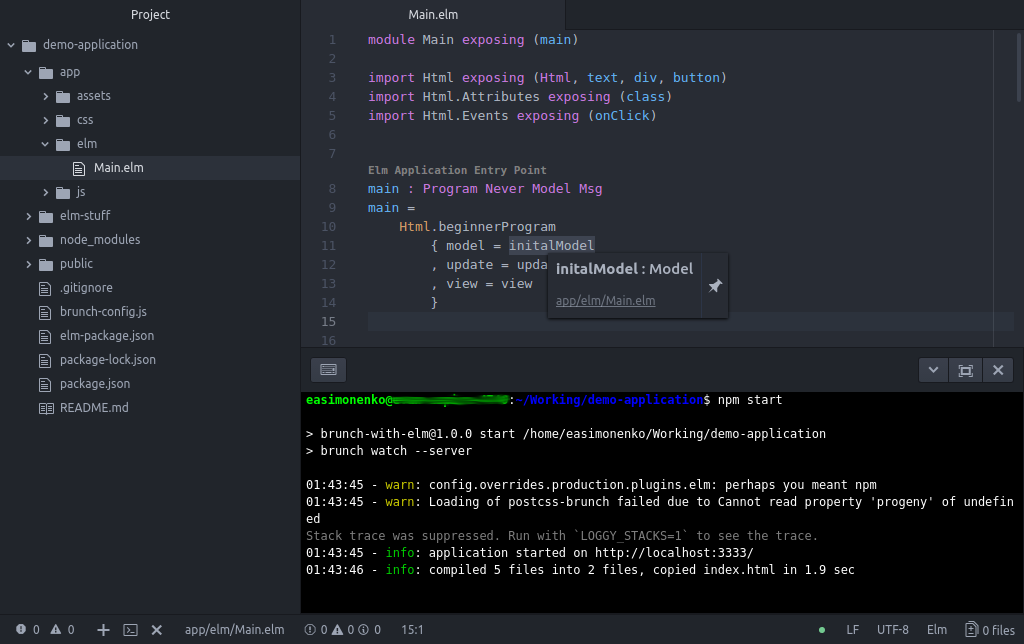
Давайте внесём ошибку в код:
Можно заметить, что во-первых ошибка была обнаружена без ручного запуска компиляции, во-вторых были предложены варианты для исправления ошибки.
Для непосвящённых
-----------------
Как и обещал, немного расскажу, как устроен код приложения на Elm. Давайте взглянем на тот исходный код, который нам сгенерировал Brunch:
```
module Main exposing (main)
import Html exposing (Html, text, div, button)
import Html.Attributes exposing (class)
import Html.Events exposing (onClick)
main : Program Never Model Msg
main =
Html.beginnerProgram
{ model = initalModel
, update = update
, view = view
}
-- Model
type alias Model =
{ value : Int
}
initalModel : Model
initalModel =
{ value = 0
}
-- Update
type Msg
= Increment
| Decrement
update : Msg -> Model -> Model
update msg model =
case msg of
Increment ->
{ model | value = model.value + 1 }
Decrement ->
{ model | value = model.value - 1 }
-- View
view : Model -> Html Msg
view model =
div []
[ div [ class "counter" ]
[ text (toString model.value) ]
, div [ class "controls" ]
[ button [ onClick Increment ] [ text "+1" ]
, button [ onClick Decrement ] [ text "-1" ]
]
]
```
Приложение на Elm оформляется как модуль `Main`, экспонирующий функцию `main`. Это мы видим в первой строке кода. Далее идёт импорт модулей. Некоторые модули импортируются по умолчанию, но модули `Html`, `Html.Attributes` и `Html.Events` нужно импортировать. Здесь они импортируются с экспонированием отдельных функций и типов. Это делается, чтобы не квалифицировать имя модуля, например, вместо `Html.Attributes.class` будем писать просто `class`.
Ниже объявляется и определяется функция `main`. В объявлении задаётся её тип. Тип функции указывается после символа `:`, определение происходит после знака `=`. Как увидим ниже, указание имён параметров и их типов осуществляется раздельно. Elm поддерживает вывод типов, однако для функций верхнего уровня хорошим тоном считается ручное указание типа.
В нашем случае функция `main` вызывает функцию `Html.beginnerProgram`, которая получает на вход структуру с тремя полями: `model`, `update`, `view`. Эта функция запустит цикл обработки сообщений. Параметр `model` получает начальное состояние приложения, которое задано в функции `initialModel`. Функция `update` вызывается всякий раз, когда происходит какое-то событие и передаётся соответствующее сообщение. После обработки сообщения вызывается функция `view`, занимающаяся формированием нового дерева DOM.
Далее определяется тип `Model`, точнее синоним типа структуры, состоящей из поля `value` типа `Int`. Тип `Int`, как нетрудно догадаться, представляет целые числа.
Как уже было сказано, функция `initialModel` возвращает начальное значение состояния, которое содержит одно поле `value` со значением `0`. Типом состояния может быть любой тип, не только структура.
Далее определяется тип сообщения `Msg`. Это тип-перечисление с двумя возможными значениями: `Increment` и `Decrement`.
Функция `update` получает на вход сообщение и состояние приложения. Обычно код этой функции включает в себя оператор сопоставления с образцом `case .. of ..`. Здесь происходит изменение состояния в зависимости от пришедшего сообщения: значение поля `value` либо увеличивается на `1`, либо уменьшается на `1`.
Наконец, функция `view` принимает состояние приложения и формирует с помощью функций модулей `Html`, `Html.Attributes` и `Html.Events` требуемое дерево DOM.
Установка дополнительных пакетов Elm
------------------------------------
И последнее, но не менее важное: чтобы установить дополнительные пакеты Elm, нужно вызвать команду `elm-package`. Например, установим пакет `elm-community/list-extra`:
```
elm package install elm-community/list-extra
```
Обратите внимание, что идентификатор пакета состоит из двух частей, то есть не просто `list-extra`, а `elm-community/list-extra`.
С этой командой связан файл проекта `elm-package.json`. В него записываются названия и версии устанавливаемых пакетов в разделе `dependencies`. Например, сгенерированный Brunch файл `elm-package.json` выглядит так:
```
{
"version": "1.0.0",
"summary": "helpful summary of your project, less than 80 characters",
"repository": "https://github.com/user/project.git",
"license": "BSD3",
"source-directories": ["app/elm"],
"exposed-modules": [],
"dependencies": {
"elm-lang/core": "5.0.0 <= v < 6.0.0",
"elm-lang/dom": "1.1.1 <= v < 2.0.0",
"elm-lang/html": "2.0.0 <= v < 3.0.0"
},
"elm-version": "0.18.0 <= v < 0.19.0"
}
```
Репозиторий пакетов можно просматривать [здесь](http://package.elm-lang.org/).
Что дальше
----------
Пожалуй лучший источник информации об Elm это его родной сайт:
* [руководство](https://guide.elm-lang.org/)
* [примеры](http://elm-lang.org/examples/)
* [пакеты](http://package.elm-lang.org/)
Вероятно стоит также перечитать статью [Основы разработки на языке Elm (руководство по инструментарию для начинающих)](https://habrahabr.ru/post/302154/).
Опрос
-----
Как и в прошлый раз проведу опрос, но немного его переориентирую, если можно так сказать. Ведь в прошлый раз автор приглашал к опросу только тех, кто уже программирует на функциональных языках, теперь же аудитория расширяется до всех, кто разрабатывает веб-приложения.
Подведу также итоги прошлого опроса. Итак, на вопрос "Если Вы программируете на функциональных языках, то каково Ваше мнение об Elm" расклад был получен такой:
* 28.2%: первый раз слышу, но выглядит годным
* 21.1%: не нужен
* 20.5%: годный, я на нём уже программирую
* 15.8%: сыроват для продакшн
* 14.1%: годный, но писать на нём не собираюсь
Проголосовало 170, воздержалось 147. Прочитало статью 13,9k, добавило в закладки 51.
Интересно, наверное, будет сравнить с результатами голосования, зафиксированными автором через неделю после публикации той статьи:
* 31%: не нужен
* 18%: первый раз слышу, но выглядит годным
* 18%: сыроват для продакшн
* 18%: годный, но писать на нём не собираюсь
* 15%: годный, я на нём уже программирую
Проголосовало 99, воздержалось 76. Прочитало статью 5,5k, добавило в закладки 41.
Заметен рост благосклонности к Elm, существенно уменьшилось число тех, кто считал, что Elm не нужен, также заметно выросло число тех, кто на нём уже программирует. При этом также увеличилось число тех, кто считает язык годным, но писать на нём не собирается.
Сообщество
----------
С момента публикации прошлой версии статьи (30 мая 2016) существует рускоязычное сообщество во [Вконтакте](https://vk.com/elm_lang_ru). Число участников сообщества на момент написания этой статьи 179. Присоединяйтесь!
Ссылки
------
* [Elm](http://elm-lang.org/)
* [Brunch](http://brunch.io/)
* [Atom](https://atom.io/)
* [Elmjutsu](https://github.com/halohalospecial/atom-elmjutsu)
* [elm-format](https://github.com/avh4/elm-format)
---
© Симоненко Евгений, 2018 | https://habr.com/ru/post/347730/ | null | ru | null |
# Установка SMS Linux (Slackware) на eBox-2300SX
Уже достаточно давно поглядываю на eBox-2300SX и примеряю его в качестве простенького домашнего сервера. Тем более, что читал на Хабре тему [Идеальный NAS? Другая точка зрения, eBox-2300SX](http://habrahabr.ru/blogs/hardware/62902/). Железка выглядит довольно интересной, но подходит ли она в качестве HTTP-сервера и Jabber? Думаю, что каждый это может решить самостоятельно. А я же просто опишу свой опыт установки на неё Linux.
#### О самом eBox-2300SX
Временно утянул с работы домой один eBox для экспериментов. У пациента есть следующие разъёмы: 3 USB, 1 Ethernet, 1 PS/2 для клавиатуры, 1 VGA, 1 CompactFlash и 1 питание. В зависимости от конфигурации могут присутствовать и другие интерфейсы. Мне досталась моделька с двумя COM-портами (которые лично мне вообще не нужны).
Первым делом я его вскрыл. Внутри, как уже можно было узнать из обзоров есть и cPCI, и E-IDE разъёмы. Но не стоит раскатывать губу, т.к. разъём стандартного E-IDE шлейфа не лезет в корпус по высоте. Но это меня не расстроило, т.к. IDE дисков у меня нет, зато есть SATA диск с переходником на USB.
Отдельно хочу отметить, что eBox потянул USB CD-ROM. Правда, пришлось занять для этого два разъёма из трёх доступных.
#### Первая попытка установить Linux
Обладая знаниями того, что eBox-2300SX не имеет математического сопроцессора, я подбирал дистрибутив с учётом этого параметра. Помимо этого хотелось выбрать уже знакомый дистрибутив или его клон — для меня это Slackware и Arch. Немного погуглив, я выбрал [SMS](http://sms.it-ccs.com/about.html). Во-первых, это Slackware для слабеньких машин. Во-вторых, это Slackware c небольшим количеством пакетов. Ну и в-третьих, это Slackware, с которым я немного знаком, начиная с 4.0 и до 13.0.
Скачал SMS 1.6.0 (это была последняя версия на тот момент) и записал на RW болванку. Загрузился с USB CD-ROM и понял, что установка не пойдёт — eBox просто зависал на этапе загрузки. И ещё не хватало одного USB разъёмов, т.к. у меня не было PS/2 клавиатуры.
#### Вторая (и более правильная попытка) установить Linux
Тут мне подумалось, что устанавливать Linux на сам eBox вовсе не обязательно, можно воспользоваться возможностями виртуализации. Если быть точнее, то VMWare. Создаём новую виртуальную машину со стандартными настройками и удаляем всё лишнее — звук, флопик и диск. В качестве диска добавляем подключенный к хост-машине USB винчестер. Установка в виртуальной машине проходит вполне легко и знакомо (для тех, кто знаком со Slackware, конечно). К сожалению, грузиться с USB диска как с USB устройства VMWare не умеет (я не нашёл таких опций в её BIOS). Так что переходим к полевым испытаниям на eBox.
Ничего удивительного нет в том, что eBox опять завис с ядром от SMS. По крайней мере я не удивился. Чтобы не мучить почтенную публику, я дальше не буду лить столько воды, а покороче расскажу, с какими трудностями я столкнулся, и как их решил.
#### Подготовка ядра
Если ядро от SMS не идёт на eBox, то на eBox можно затянуть ядро от [X-Linux](http://www.dmp.com.tw/tech/os-xlinux/). Это такой специальный Linux для eBox, в котором ничего толкового нет. Зато он работает на eBox. Просто так взять готовое ядро 2.6.29 не интересно. Лучше всего на основе его .config подготовить ядро 2.6.37.6 (родное для SMS). Для этого делаем следующее:
* Скачиваем и распаковываем исходники [ядра 2.6.37.6](http://www.kernel.org/pub/linux/kernel/v2.6/linux-2.6.37.6.tar.bz2)
* Скачиваем архив [xlinux-5.7-src-sx.zip](ftp://[email protected]/os-xlinux/xlinux-5.7-src-sx.zip) (Пароль: download)
* Находим конфиг ядра в каталоге etc/kernel-config под именем kernel-2.6.29.6-vortex86sx.config и копируем его в каталог с исходниками ядра 2.6.37.6 как .config.
* Переходим в каталог с исходниками и делаем `make oldconfig`. Отвечаем на несколько простых вопросов. Я отказался от всего нового.
* Потом делаем, например, `make menuconfig` и включаем поддержку Ext4 и JFS
* После этого уже `make -j12 bzImage`
* Ядро готово
#### Подготовка ядра на хосте x86\_64
На моём ноуте установлен Arch x86\_64 и после сборки я получил ядро, которому нужен 64-битный процессор. Как-то сильно для eBox, подумал я. Чтобы ядро нормально собралось в системе с архитектурой x86\_64 (amd64) надо делать всё также как написано в предыдущем разделе, но добавить [префикс ARCH=i386](http://kernelnewbies.org/FAQ/KernelCrossCompilation) команде make:
* `make ARCH=i386 oldconfig`
* `make ARCH=i386 menuconfig`
* `make ARCH=i386 -j12 bzImage`
Всё это будет работать, если на хосте поддерживается multilib.
#### Особенность Ext4
При установке SMS Linux я, конечно, отформатировал корневой раздел в Ext4, а при подготовки ядра отключил поддержку больших файлов. Да и откуда на eBox будут файлы по 2ТБ? Оказалось, что я заблуждался. Для корректной работы Ext4 должна быть установлена опция CONFIG\_LBDAF (поддержка больших файлов). Понятное дело, что eBox в моём случае не загружался. Похоже, что есть два способа решить проблему, подумал я. Первый — переустановить SMS на раздел Ext3. Второй — пересобрать ядро с поддержкой больших файлов. И третий — [отключить поддержку больших файлов в разделе Ext4](http://www.nicolaskuttler.com/post/filesystem-with-huge-files-cannot-be-mounted-read-write-without-config_lbdaf/). Да, третий способ нашёлся в гугле и он мне понравился больше первых двух. Подключаем USB диск к хост системе и выполняем следующие команды:
`# tune2fs -O ^huge_file /dev/раздел
# fsck /dev/раздел`
#### Установка нового ядра на USB диск
Пока USB диск подключен к хост-машине, скопируем в корневой раздел (у меня это /dev/sdb2) новое ядро. Я назвал его vmlinuz-xlinux-5.7-2.6.37.6. Для этого переходим в каталог с исходниками ядра и выполняем команды:
`# mkdir /mnt/tmp
# mount /dev/sdb2 /mnt/tmp
# cp arch/i386/boot/bzImage /mnt/tmp/boot/vmlinuz-xlinux-5.7-2.6.37.6
# umount /mnt/tmp`
Не забудем подправить конфиг LILO. Я добавил такую секцию:
`image = /boot/vmlinuz-xlinux-5.7-2.6.37.6
root = /dev/sda2
append = "rootdelay=10"
label = X-Linux-5.7
# initrd = /boot/initrd.splash
read-only`
Понятно, что на eBox у меня только один диск, поэтому не /dev/sdb2, а /dev/sdba2. И обратите внимание на опцию rootdelay=10. Эта опция задаёт задержку перед монтированием корневой файловой системы, что бывает полезно при использовании USB устройства в качестве носителя корневой файловой системы.
После этого вновь надо загрузиться в VMWare с установочного диска SMS и выполнить следующие магические команды (чтобы LILO узнал о новом ядре):
`# mount /dev/sda2 /mnt
# chroot /mnt
# lilo
# exit
# halt`
#### В результате
А в результате eBox таки загрузился с SMS Linux. Первая загрузка заняла довольно много времени, на мой взгляд, большую часть из которого (времени, а не взгляда) заняла генерация ключей OpenSSH. Это поубавило мне оптимизма в дальнейшей настройке сервера на eBox.
Для себя я сделал следующие выводы. Преимущества eBox это его малые габариты и бесшумность, т.к. используется пассивное охлаждение. Но поскольку эти преимущества для меня не имеют значения, то я подумываю собрать сервер на VIA PV530. Если добавить туда память и корпус, то можно вполне уложиться в цену eBox (~130$). А это уже будет более шустрое железо и памяти получится 2Гб а не 128Мб (на eBox).
Пока готовил материал, вышла новая версия SMS 1.6.1. Переделывать топик не стал, т.к. принцип установки SMS тот же. | https://habr.com/ru/post/124082/ | null | ru | null |
# Основные возможности CUBRID 8.4.0
Приветствую всех!
Этот блог будет очень занимательным! Сегодня я расскажу об очень интересных особенностях последней версии CUBRID 8.4.0, о том, чего обычно не найдешь в мануале. Приведу очень важные рекоммендации по оптимизации запросов и индексов, приведу результаты тестов, а также примеры использования в реальных Веб сервисах.
Ранее я уже поверхностно [рассказывал](http://habrahabr.ru/company/cubrid/blog/119342/) об изменениях в новой версии, о вдвое ускоренном движке базы данных, о расширенной поддержке MySQL синтаксиса, и т.д. А сегодня расскажу о них и других вещах более подробно, акцентируя на том, как мы смогли увеличить производительность CUBRID в два раза.
Основные направления, повлиявшие на производительность CUBRID, являются:
* Уменьшение размера тома базы данных
* Улучшенные параллельные вычисления в Windows версии
* Оптимизации индексов
* Оптимизации обработки условий в LIMIT
* Оптимизации обработки условий в GROUP BY
#### Уменьшение размера тома базы данных
В CUBRID 8.4.0 размер тома базы данных уменьшился аж на целых 218%. Причиной этому является полностью измененнная структура для хранения индексов, что параллельно повлияло на производительность всей системы.
В следующем рисунке можно увидеть сравнение размера томов базы данных в предыдущей версии 8.3.1 и новой 8.4.0. В этом случае обе базы данных хранили по 64,000,000 записей с первичным ключем. Данные указаны в гигабайтах.

#### Улучшенные параллельные вычисления в Windows версии
В CUBRID 8.4.0 улучшены параллельные вычисления в версии для Windows платформы с помощью усовершенствованных Мьютексов. В следующем графике указаны сравнительные результаты производительности предыдущей и новой версий.

#### Оптимизации индексов
Вот тут-то я расскажу Вам все очень подробно.
CUBRID 8.4.0 отличается от предыдущей версии вдвое ускоренным движком базы данных. Мы реализовали несколько очень важных оптимизаций индексов, как:
* Покрывающий индекс
* Оптимизация обработки условий в LIMIT
— Ограничение по ключям (Key Limit)
— Многодиапазонное сканирование (Multi Range)
* Оптимизация обработки условий в GROUP BY
* Сканирование индекса по убыванию
* Поддержка сканирования индекса в операторах LIKE
Теперь давайте посмотрим как организована структура индексов в CUBRID 8.4.0. В CUBRID *индекс* реализован в виде [B+ дерева](http://ru.wikipedia.org/wiki/B%2B_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) [ссылка на статью в Википедии], в котором значения ключей индекса хранятся в листьях дерева.
Для практического примера предлагаю посмотреть на следующую структуру таблицы (STRING = VARCHAR(1,073,741,823)):
`CREATE TABLE tbl (a INT, b STRING, c BIGINT);`
Введем данные:
`INSERT INTO tbl VALUES (1, ‘AAA, 123), (2, ‘AAA’, 12), …;`
И создадим многоколоночный индекс. Кстати, заметьте, что индекс я создаю после того, как ввел данные. Это — рекоммендуемый способ, если Вы хотите вводить данные на начальном этапе или при их востановлении. Таким образом, вы можем избежать затраты времени и ресурсов на индексирования при каждом вводе. Более подробно о рекоммендациях при вводе больших данных вы можете прочитать [здесь](http://www.cubrid.org/import_large_file).
`CREATE INDEX idx ON tbl (a, b);`
На рисунке ниже показана структура этого индекса, в *листьях* которого есть указатели (**OID**) на сами данные, находящиеся в куче-файле (heap file) на диске.
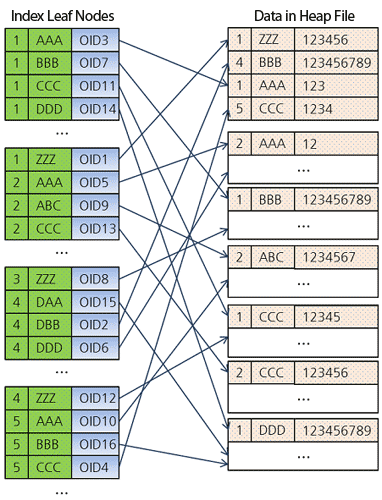
1. Таким образом, значения ключей индекса (**a** и **b**) отсортированы по увеличению (по умолчанию).
2. Каждый лист имеет указатель (указанный стрелкой) на соответсвующие данные (запись в таблице), находящиеся в куче на диске.
3. Данные в куче расположены в случайном порядке, как указано на рисунке.
##### Сканирование индекса
Теперь посмотрим, как обычно происходит поиск с использованием индексов. Учитывая выше созданную таблицу, мы запустим следующий запрос.
`SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
AND c > 10000
ORDER BY b;`
1. Сначала CUBRID найдет все листья, в которых **a >1 и a < 5**.
2. Затем среди этого результата, он отберет листья, в которых **b < 'K'**.
3. Так как колонка **c** не индексирована, для получения ее значений необходимо обратиться в кучу, который находится на диске.
4. Каждый лист в дереве индекса содержит значение OID (Идентификатор Объекта), который указывает, где именно на диске хранятся данные определенной записи таблицы.
5. Исходя из этих OID, сервер обратится в кучу для получения значений колонки **c**.
6. Затем CUBRID найдет все те записи, в которых **c > 10000**.
7. В результате все эти записи будут отсортированы по колонке **b**, как требуется в запросе.
8. Затем полученные результаты отправляется к клиенту.

##### Покрывающий индекс
Теперь посмотрим, каким образом покрывающий индекс может значительно увеличить производительность CUBRID. В кратце, покрывающий индекс позволяет получить результаты запроса без необходимости обращения к куче на диске, что снижает количество операций ввода/вывода, что в свою очередь является самой дорогой операцией в плане затраченного времени.
Однако магия Покрывающего индекса можно применить только, **когда все колонки, значения которых запрашиваются в запросе, находятся в одном составном индексе**. Иначе говоря, их значения должны находиться в одном листе дерева индекса. Например, посмотрим на следующий запрос.
`SELECT a, b FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
ORDER BY b;`
* Как Вы можете заметить, все колонки, используемые в данном запросе, находятся в одном многоколоночном индексе, который мы создали в самом начале.
* В условии оператора WHERE указаны только те колоки, которые находятся в одном многоколоночном индексе.
* Также в условии оператора ORDER BY указана только та колонка, которая находятся в том же многоколоночном индексе.
И так, если мы запустим этот запрос:
1. Как часть обычного процесса сканирования индекса, CUBRID сначала найдет все листья в дереве индекса, в которых **a >1 и a < 5**.
2. Затем среди этого результата, он отберет листья, в которых **b < 'K'**.
3. Так как значения колонок **a** и **b** уже получены в процессе сканирования индекса, уже нет необходимости идти и смотреть в кучу на диске, чтобы получить эти значения. Таким образом, после второго шага сервер сразу приступает в сортированию результатов по колонке **b**.
4. Затем возвращает значения.

Давайте теперь посмотрим, насколько покрывающий индекс может улучшить производительность сервера. Для того же вышеуказаного примера мы предположим, что в базе хранится очень большое количество данных.
**Q1.** Ниже приведен запрос, который использует колонки, указанные в одном составном индексе.
`SELECT a, b FROM tbl WHERE a BETWEEN ? AND ?`
**Q2.** А теперь запрос, где колонка **a** индексирована, а колонка **c** — нет.
`SELECT a, c FROM tbl WHERE a BETWEEN ? AND ?`
Следующая график показывает, насколько быстро могут быть обработаны запросы, если они используют покрывающий индекс.

#### Оптимизации обработки условий в LIMIT
##### Ограничение по ключям (Key Limit)
У CUBRID 8.4.0 — очень «умный» анализатор операторов LIMIT. Данный анализатор был очень оптимизирован, что позволяет обрабатывать только то количество записей, которое требуется в условии оператора LIMIT, при достижении которого сервер сразу возвращает результаты. К примеру, посмотрим на следующий запрос.
`SELECT * FROM tbl
WHERE a = 2
AND b < ‘K’
ORDER BY b
LIMIT 3;`
1. CUBRID сначала находит первый лист в дереве индекса, в котором **a = 2**.
2. Так как индекс включает значения колонки **b**, которые уже отсортированы, нет необходимости отдельно отсортировывать результаты.
3. Сервер проходит только по первым 3-м ключам индекса и на этом останавливается, так как нет необходимости возвращать больше 3 результатов.
4. Затем сервер уже обрщается в кучу, чтобы получить значения всех остальных колонок. Таким образом только 3 записи будет затронуты на диске.

##### Многодиапазонное сканирование (Multi Range)
Оптимизация многодиапазонного сканирования является еще одним главным усовершенствованием в новом CUBRID 8.4.0. Когда пользователи заправшивают данные, которые лежат в определенном диапазоне, например, между **a > 0 AND a < 5**, задача является довольно легкой для большинства СУБД. Однако все становится намного сложнее, когда в условия включаются разбросанные диапазоны, например, **a > 0 AND a < 5 AND a = 7 AND a > 10 AND a < 15**. Здесь то CUBRID и отличается. Новая функция оптимизации **in-place sorting** (сортировка на лету) позволяет решить сразу две задачи:
1. Ограничение по ключям (Key Limit)
2. А также сортировка записей на лету
К примеру, рассмотрим следующий запрос.
`SELECT * FROM tbl
WHERE a IN (2, 4, 5)
AND b < ‘K’
ORDER BY b
LIMIT 3;`
1. Так как все ключи в дереве индекса отсортированы, сервер начнет сканирование, начиная с первого листа, где a = 2 (см. рисунок ниже).
2. Так как необходимо получить только 3 строки таблицы, отсортированные по колонке **b**, сервер будет отсортировывать результаты, удовлетворяющие условию **a IN (2, 4, 5) AND b < 'K'**, на лету.
1. В самом начале сервер найдет запись (2, AAA), что дает 1-й результат.
2. Затем находит запись (2, ABC), что дает 2-й результат.
3. Затем находит запись (2, CCC), что дает 3-й результат.
4. Так как сервер нашел уже 3 записи, он прыгает на следующий диапазон, в целях поиска записей, где значения колонки **b** будут меньше уже найденных значений.
1. Сначала сервер найдет запись (4, DAA), который больше, чем последнее значение колонки **b** уже найденных записей. Поэтому этот диапазон сразу отпадает, и сервер прыгает на следующий диапазон.
2. Находит запись (5, AAA), который меньше, чем ABC и CCC. Поэтому убирает последнюю запись и вставляет эту запись в подходящее место.
3. Следующая запись (5, BBB) уже больше, чем последняя запись предварительных результатов. Поэтому на этом сканирование этого диапазона завершается. Также завершается и весь поиск, так как больше нет других диапазонов необходимые для сканирования.
3. Так как все результаты уже отсортированы, остается только заглянуть в кучу и получить значения остальных колонок.
Благодаря этой возможности многодиапазонного сканирования с сортированием на лету, CUBRID может производить очень быстрый поиск среди большого количества данных.

##### Результаты тестов
В Корее есть очень популярный Веб сервис Me2Day, аналог Твиттера. Следующие результаты тестов были получены на основе реальных данных этого сервиса.
Как и в Твиттере, в Me2Day есть таблица **posts**, где хранятся все «твиты». Статистика пользователей и их отношений показывает, что:
* 50% пользователей следят за 1-50 пользователями.
* 40% пользователей следят за 51-2000 пользователями.
* 10% пользователей следят за 2001+ пользователями.
Для этой таблицы создан следующий индекс.
`INDEX (author_id, registered DESC)`
Самый главный запрос, который чаще всего запрашивается и в сервисе Twitter, и в сервисе Me2Day — это "**показать последние 20 случайных постов всех пользователей, за которыми я слежу**". Ниже приведен этот самый запрос.
`SELECT * FROM posts
WHERE author_id IN (?, ?, ..., ?) AND registered < :from ORDER BY reg_date DESC
LIMIT 20;`
Тест был запущен на 10 минут, в период которых продолжительно обрабатывался этот запрос. Ниже приведет график результатов тестирования, в котором сравнивается оператор **UNION в MySQL**, который в среднем в 4 раза быстрее, чем IN оператор в MySQL, с оператором **IN в CUBRID**. За одно, сравнив с предыдущей версие, Вы можете посмотреть, насколько увеличилась производительность CUBRID 8.4.0 после реализации многодеапазонного сканирования.

После таких положительных результатов мы заменили MySQL сервера Me2Day, отвечающие за ежедневную работу сервиса, на сервера CUBRID. В следующий раз расскажу об этом тесте более подробно. А пока Вы можете также прочитать о нем на английском [на главном сайте](http://www.cubrid.org/cubrid_mysql_sns_benchmark_test).
#### Оптимизации обработки условий в GROUP BY
Новая версия CUBRID 8.4.0 значительно ускорила обработку запросов, содержащие ORDER BY и GROUP BY операторы. Когда в условиях ORDER BY и GROUP BY используются колонки, включенные в многоколоночный индекс, отпадает необходимость отсортировывать значения, так как они уже отсортированы в дереве индекса. Такая оптимизация позволяет значительно увеличить производительность обработки всего запроса. Можем посмотреть на работу следующего запроса.
`SELECT COUNT(*) FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’ AND c > 10000
GROUP BY a;`
1. Как часть обычного процесса сканирования индекса, CUBRID сначала найдет все листья в дереве индекса, в которых **a >1 и a < 5**.
2. Используя значения OID, сервер обратится в кучу для получения значений колонки **c**.
3. Затем CUBRID найдет все те записи, в которых **c > 10000**.
4. Так как все необходимые значения уже отсортированы, операция GROUP BY будет производиться сразу же без предварительной сортировки.
5. Затем сервер возвращает полученные результаты.

#### Увеличение Продуктивности Разработчиков
Помимо улучшения производительности всей системы, новая версия CUBRID 8.4.0 поддерживает более 90% SQL синтаксиса СУБД MySQL. Мы также реализовали расширенную поддержку неявного преобразования типов, чтобы разработчики концентрировались на улучшение функциональности своих приложений, в то время как CUBRID будет делать все внутренние преобразования. Ниже приведу несколько примеров нового синтаксиса.
* Неявное преобразование типов
`CREATE TABLE x (a INT);
INSERT INTO x VALUES (‘1’);`
* Запросы SHOW
`SHOW TABLES; SHOW COLUMNS; SHOW INDEX; …`
* ALTER TABLE… CHANGE/MODIFY COLUMN…
`CREATE TABLE t1 (a INTEGER);
ALTER TABLE t1 CHANGE a b DOUBLE;
ALTER TABLE t2 MODIFY col1 BIGINT DEFAULT 1;`
* UPDATE… ORDER BY
`UPDATE t
SET i = i + 1
WHERE 1 = 1
ORDER BY i
LIMIT 10;`
* DROP TABLE IF EXISTS…
`DROP TABLE IF EXISTS history;`
Всего в новой версии 23 новых DATE/TIME синтаксиса, 5 — связанных со строками, и 5 новых функций аггрегирования. Весь список нового синтаксиса можете найти в [блоге](http://blog.cubrid.org/cubrid-life/roadmap-what-to-expect-in-cubrid-3-2/) на офф. сайте.
#### Улучшение недёжности Высокой Доступности
##### Улучшение блокировки следующего ключа
Также в версии CUBRID 8.4.0 значительно улучшили механизм блокировки, чтобы минимизировать появления застоев. Например, в среде Высокой Доступности застои не будут образовываться между транзакциями, которые вводят данные в одну и ту же таблицу в одно и то же время.
#### Заключение
Как Вы, наверное, уже поняли, новая версия CUBRID 8.4.0 явно превосходит все предыдущие версии и в производительности, и в надёжности, и в удобстве разработки. CUBRID разрабатывается с целью использования в Веб приложениях и сервисах, посему все основные разработки, улучшения и оптимизации ведутся в сфере функций, часто используемых в Веб приложениях (например, как операторы IN, ограничения LIMIT, группировки и сортирование, а также Высокая Доступность), превосходство в производительности которых доказывается результатами сравнительных тестов.
Если у Вас есть определенные вопросы, пишите в комментариях. Буду очень рад все разъяснить! | https://habr.com/ru/post/117684/ | null | ru | null |
# Если у вас не работает Spring BootJar
### Решаем проблемы с загрузкой Spring Boot Jar

Сталкивались ли вы с проблемой запуска нового загрузочного архива Spring Boot?
Вообще, новация в этом направлении уже не первая, стандартов особых нет. Поэтому многие огребают проблемы и решают их на форумах и стек-оверфлоу.
Если вы также столкнулись с проблемой, я помогу её решить. В таком случае читаем дальше.
Итак, проблем с BootJar на самом деле хватает. Особенно учитывая, что уже минимум три версии формата поменялось.
Здесь я расскажу о часто встречающемся случае с потерей ресурсов. Конкретнее в моём случае — с потерей JSP шаблонов. Почему JSP? Мне так привычнее, проект я по-быстрому начал с них, и не думал, что будут *такие* проблемы.
Итак структура проекта (стандартный веб):
```
/src/main/
java/
resources/
static/
some.html
public/
webapp/
WEB-INF/jsp
index.jsp
```
По заявлению создателей BootJar / BootWar, jsp не поддерживается толком в новом BootJar формате. Но совместимость должна быть в BootWar. На это я и надеялся, когда ваял код. Пока ваял, никаких проблем — всё запускается, всё работает, как обычно, в общем. BootRun отрабатывает, только опции успевай подставлять.
Проблема пришла, откуда не ждали: когда пришло время разворачиваться на Амазоне, тогда и вылезла.
Итак, дубль раз. Чуть ли не в первый раз запускаю задачу BootJar. Ярхив готов, деплоим… Готово! Сигнала нет, сыпет ошибки 302 + 404 (это авторизация не находит вью). Но это пока не понятно.
Отключаем Секурити — всё равно ничего не находит, кроме голимой статики, и то не всей, а только из webjars. ???
Дубль два. Догадываясь о несовместимости jsp и BootJar, пакуем BootWar. Деплоим… Не работает. Не помню точно, но примерно то же самое в результате.
Хм, странно. Запускаем BootJar локально — всё работает. Чудеса.
Выяснилось: Spring Boot слишком умный, он при запуске из каталога разработки даже релизного ярника всё равно все тащит из каталога разработки. Из другого запускаем — перестаёт работать. Фух! Ну хоть отлаживать можно.
Что и делаем. Выясняется — ресурсы BootJar запакованные не из библиотек (webjars), а из проекта, не включаются в перечисление, и это, оказывается, по дизайну! Подробности [здесь](https://github.com/spring-projects/spring-boot/issues/9525), точнее [вот здесь](https://github.com/spring-projects/spring-boot/issues/8324).
Вернее не так — есть спец-ресурсы в каталогах типа static/, public/. И они вроде находятся, если объявить. Но jsp не видит в упор хоть тресни. И дело не в том, что не там лежат. Оказалось, что Томкат (в нашем плохом случае), грузит jsp особым механизмом после редиректа. И сами jsp можно загрузить без рендеринга, если правильно задать их положение в настройках
`spring.resources.static-locations`
Но это нас не устраивает.
Оказалось, что при использования встроенного томката, ресурсы вью он грузит отдельно и в первую очередь своей старой встроенной логикой, которую Спрингисты настраивать не научились. А этой логике нужен либо архив Вар, либо он же распакованный (почему кстати при разработке нормально отрабатывает расположение webapp/), либо ресурсы из библиотек, которые прекрасно видны, если правильно упакованы в изначальных либах — нужно чтоб лежали в META-INF/resources, как в стандарте сервлетов. Последнее работает даже внутри BootJar. Удивительно.
Почему не сработал распакованный архив? Ё-маё, на амазоне он распакуется черти-куда, и приложение про это место ничего не знает, если не сказать. Но хардкодить пути — плохая привычка. Сам ярник запускается затем безо всякой распаковки, хотя вроде права позволяют распаковать прям на месте. Ну да ладно, способ пролетел.
Почему не работает способ с Вар-архивом? Ё-маё, Амазон решил, что лучше меня знает, что я буду грузить именно в яр-формате, хотя интерфейс заявлет о готовности съесть варник. Он этот варник переименовывает в ярник, умник такой. А Томкат не умничает, он смотрит расширение: не Вар — ну тогда, извините, это не мой случай.
В итоге корень деплоя не находится. И ресурсы оттуда тоже. Ресурсы из статики не грузятся, потому что ищутся в корне и ресурсных либах, а не в classpath.
Ладно, проблема понятна. Решение?
Было три варианта.
1. Сделать свой spring-загрузчик ресурсов. Вариант отпал, поскольку, как я уже сказал, Томкат отрабатывает jsp до их запуска.
2. Прокинуть загрузку в Томкат. Стал прикидывать: надо расширить контекст spring-а, прокинуть пути в контекст Томката, там ещё раза два переложить — непонятно, насколько сложно, и можно ли без изменения самого томката. Спрингисты не осилили, и я не хочу.
3. Вариант попроще — пакуем ресурсы в ресурсную либу в BootJar.
Вот о нём подробнее. Пихать всё в отдельный модуль, как предлагали [здесь](https://github.com/spring-projects/spring-boot/issues/8324), не хотелось.
Делаем отдельной задачей в Gradle.
Создаём конфигурацию.
```
sourceSets {
jsp {
resources.source(sourceSets.main.resources);
resources.srcDirs += ['src/main/webapp'];
}
jmh {
.. ..
}
}
```
Сама задача
```
task jsp(type: Jar, description: 'JSP Packaging') {
archiveBaseName = 'jsp'
group = "build"
def art = sourceSets.jsp.output
from(art) {
exclude('META-INF')
into('META-INF/resources/')
}
from(art) {
include('META-INF/*')
into('/')
}
dependsOn(processJspResources)
}
```
Задача processJspResources уже создана, её не надо делать. Ставим всё в зависимость и пакуем:
```
bootJar {
dependsOn(jsp)
bootInf.with {
from(jsp.archiveFile) {
include('**/*.jar')
}
into('lib/')
}
}
```
Как добавить другим способом (прямым), не нашёл — подключить в зависимости конфиг jspImplementation самого же проекта — нельзя, а хотелось бы. Но если все же из другого модуля забирать, то вот так ещё делаем:
```
artifacts {
jspImplementation jsp
}
```
Всё, теперь имеем ресурсную либу, которую по всем стандартам томкат должен грузить, и он грузит. Запускаем, как BootJar. | https://habr.com/ru/post/535246/ | null | ru | null |
# Пишем игру «Карточки памяти» на Swift

В этой статье описывается процесс создания простой игры для тренировки памяти, которая мне очень нравится. Кроме того, что она сама по себе хороша, во время работы вы немного больше узнаете о классах и протоколах Swift. Но прежде чем начать, давайте разберемся в самой игре.
> **Напоминаем:** *для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».*
>
>
>
> **Skillbox рекомендует:** Образовательный онлайн-курс [«Профессия Java-разработчик»](https://skillbox.ru/java/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=JAVDEV&utm_content=articles&utm_term=swiftcardgame).
### Как играть в Memory Card
Игра начинается с демонстрации набора карточек. Они лежат «рубашкой» вверх (соответственно, изображением вниз). Когда вы кликаете по любой, на несколько секунд открывается изображение.
Задача игрока — найти все карточки с одинаковыми картинками. Если после открытия первой карты вы переворачиваете вторую и картинки совпадают, обе карточки остаются открытыми. Если не совпадают, карточки снова закрываются. Задача — открыть все.
### Структура проекта
Для того, чтобы создать простую версию этой игры нужны следующие компоненты:
* Один контроллер (One Controller): GameController.swift.
* Один просмотр (One View): CardCell.swift.
* Две модели (Two Models): MemoryGame.swift and Card.swift.
* Main.storyboard для того, чтобы весь набор компонентов был в наличии.
Начинаем с самого простого компонента игры, карточки.
**Card.swift**
У модели карточки будет три свойства: id для идентификации каждой, логическая переменная shown для уточнения статуса карты (скрыта или открыта) и artworkURL для картинок на карточках.
```
class Card {
var id: String
var shown: Bool = false
var artworkURL: UIImage!
}
```
Также будут нужны эти методы для управления взаимодействием пользователя с картами:
**Метод для вывода изображения на карту.** Здесь мы сбрасываем все свойства на дефолтные. Для id генерируем случайный id путем вызова NSUUIS().uuidString.
```
init(image: UIImage) {
self.id = NSUUID().uuidString
self.shown = false
self.artworkURL = image
}
```
**Метод для сравнения id карт.**
```
func equals(_ card: Card) -> Bool {
return (card.id == id)
}
```
**Метод для создания копии каждой карточки** — для того, чтобы получить большее число одинаковых. Этот метод будет возвращать card с аналогичными значениями.
```
func copy() -> Card {
return Card(card: self)
}
init(card: Card) {
self.id = card.id
self.shown = card.shown
self.artworkURL = card.artworkURL
}
```
**И еще один метод нужен для перемешивания карточек на старте.** Мы сделаем его расширением класса Array.
```
extension Array {
mutating func shuffle() {
for _ in 0...self.count {
sort { (_,_) in arc4random() < arc4random() }
}
}
}
```
А вот реализация кода для модели Card со всеми свойствами и методами.
```
class Card {
var id: String
var shown: Bool = false
var artworkURL: UIImage!
static var allCards = [Card]()
init(card: Card) {
self.id = card.id
self.shown = card.shown
self.artworkURL = card.artworkURL
}
init(image: UIImage) {
self.id = NSUUID().uuidString
self.shown = false
self.artworkURL = image
}
func equals(_ card: Card) -> Bool {
return (card.id == id)
}
func copy() -> Card {
return Card(card: self)
}
}
extension Array {
mutating func shuffle() {
for _ in 0...self.count {
sort { (_,_) in arc4random() < arc4random() }
}
}
}
```
Идем дальше.
Вторая модель — MemoryGame, здесь задаем сетку 4\*4. У модели будут такие свойства, как cards (массив карточек на сетке), массив cardsShown с уже открытыми карточками и логическая переменная isPlaying для отслеживания статуса игры.
```
class MemoryGame {
var cards:[Card] = [Card]()
var cardsShown:[Card] = [Card]()
var isPlaying: Bool = false
}
```
Нам также нужно разработать методы для управления взаимодействия пользователя с сеткой.
**Метод, который перемешивает карточки в сетке.**
```
func shuffleCards(cards:[Card]) -> [Card] {
var randomCards = cards
randomCards.shuffle()
return randomCards
}
```
**Метод для создания новой игры.** Здесь мы вызываем первый метод для старта начальной раскладки и инициализируем переменную isPlaying как true.
```
func newGame(cardsArray:[Card]) -> [Card] {
cards = shuffleCards(cards: cardsArray)
isPlaying = true
return cards
}
```
**Если мы хотим перезапустить игру,** то устанавливаем переменную isPlaying как false и убираем первоначальную раскладку карточек.
```
func restartGame() {
isPlaying = false
cards.removeAll()
cardsShown.removeAll()
}
```
**Метод для верификации нажатых карточек.** Подробнее о нем позже.
```
func cardAtIndex(_ index: Int) -> Card? {
if cards.count > index {
return cards[index]
} else {
return nil
}
}
```
**Метод, возвращающий позицию определенной карточки.**
```
func indexForCard(_ card: Card) -> Int? {
for index in 0...cards.count-1 {
if card === cards[index] {
return index
}
}
return nil
}
```
Проверка соответствия выбранной карточке эталону.
```
func unmatchedCardShown() -> Bool {
return cardsShown.count % 2 != 0
}
```
Этот метод читает последний элемент в массиве \*\*cardsShown\*\* и возвращает несоответствующую карточку.
```
func didSelectCard(_ card: Card?) {
guard let card = card else { return }
if unmatchedCardShown() {
let unmatched = unmatchedCard()!
if card.equals(unmatched) {
cardsShown.append(card)
} else {
let secondCard = cardsShown.removeLast()
}
} else {
cardsShown.append(card)
}
if cardsShown.count == cards.count {
endGame()
}
}
```
### Main.storyboard и GameController.swift
Main.storyboard выглядит примерно так:

Изначально в контроллере нужно установить новую игру как viewDidLoad, включая изображения для сетки. В игре все это будет представлено 4\*4 collectionView. Если вы еще не знакомы с collectionView, вот здесь [можно получить нужную информацию](https://www.raywenderlich.com/9334-uicollectionview-tutorial-getting-started).
Мы настроим GameController в качестве корневого контроллера приложения. В GameController будет collectionView, на который мы будем ссылаться в качестве IBOutlet. Еще одна ссылка — на кнопку IBAction onStartGame (), это UIButton, ее вы можете увидеть в раскадровке под названием PLAY.
Немного о реализации контроллеров:
* Сначала инициализируем два главных объекта — сетку (the grid): game = MemoryGame(), и на набор карточек: cards = [Card]().
* Устанавливаем начальные переменные как viewDidLoad, это первый метод, который вызывается в процессе работы игры.
* collectionView устанавливаем как hidden, поскольку все карты скрыты до того момента, пока пользователь не нажмет PLAY.
* Как только нажимаем PLAY, стартует раздел onStartGame IBAction, и мы выставляем свойство collectionView isHidden как false, чтобы карточки могли стать видимыми.
* Каждый раз, когда пользователь выбирает карточку, вызывается метод didSelectItemAt. В методе мы вызываем didSelectCard для реализации основной логики игры.
Вот финальная реализация GameController:
```
class GameController: UIViewController {
@IBOutlet weak var collectionView: UICollectionView!
let game = MemoryGame()
var cards = [Card]()
override func viewDidLoad() {
super.viewDidLoad()
game.delegate = self
collectionView.dataSource = self
collectionView.delegate = self
collectionView.isHidden = true
APIClient.shared.getCardImages { (cardsArray, error) in
if let _ = error {
// show alert
}
self.cards = cardsArray!
self.setupNewGame()
}
}
override func viewDidDisappear(_ animated: Bool) {
super.viewDidDisappear(animated)
if game.isPlaying {
resetGame()
}
}
func setupNewGame() {
cards = game.newGame(cardsArray: self.cards)
collectionView.reloadData()
}
func resetGame() {
game.restartGame()
setupNewGame()
}
@IBAction func onStartGame(_ sender: Any) {
collectionView.isHidden = false
}
}
// MARK: - CollectionView Delegate Methods
extension GameController: UICollectionViewDelegate, UICollectionViewDataSource {
func numberOfSections(in collectionView: UICollectionView) -> Int {
return 1
}
func collectionView(_ collectionView: UICollectionView, numberOfItemsInSection section: Int) -> Int {
return cards.count
}
func collectionView(_ collectionView: UICollectionView, cellForItemAt indexPath: IndexPath) -> UICollectionViewCell {
let cell = collectionView.dequeueReusableCell(withReuseIdentifier: "CardCell", for: indexPath) as! CardCell
cell.showCard(false, animted: false)
guard let card = game.cardAtIndex(indexPath.item) else { return cell }
cell.card = card
return cell
}
func collectionView(_ collectionView: UICollectionView, didSelectItemAt indexPath: IndexPath) {
let cell = collectionView.cellForItem(at: indexPath) as! CardCell
if cell.shown { return }
game.didSelectCard(cell.card)
collectionView.deselectItem(at: indexPath, animated:true)
}
}
```
Теперь давайте немного остановимся на важных протоколах.
### Протоколы
Работа с протоколами — основа основ программирования на Swift. Протоколы дают возможность задать правила для класса, структуры или перечисления. Этот принцип позволяет писать модульный и расширяемый код. Фактически это шаблон, который мы уже реализуем для collectionView в GameController. Теперь сделаем собственный вариант. Синтаксис будет выглядеть так:
```
protocol MemoryGameProtocol {
//protocol definition goes here
}
```
Мы знаем, что протокол позволяет определить правила или инструкции для реализации класса, поэтому давайте подумаем, какими они должны быть. Всего нужно четыре.
* Начало игры: memoryGameDidStart.
* Нужно перевернуть карточку рубашкой вниз: memoryGameShowCards.
* Нужно перевернуть карточку рубашкой вверх: memoryGameHideCards.
* Завершение игры: memoryGameDidEnd.
Все четыре метода реализуем для основного класса, а это GameController.
### memoryGameDidStart
Когда этот метод запущен, игра должна начаться (пользователь нажимает PLAY). Здесь просто перезагрузим контент, вызвав collectionView.reloadData (), что приведет к перемешиванию карт.
```
func memoryGameDidStart(_ game: MemoryGame) {
collectionView.reloadData()
}
```
### memoryGameShowCards
Вызываем этот метод из collectionSDViewSelectItemAt. Сначала он показывает выбранную карту. Затем проверяет, есть ли в массиве cardsShown несопоставленная карта (если число cardsShown нечетное). Если такая есть, выбранная карта сравнивается с ней. Если картинки одинаковые, обе карты добавляются к cardsShown и остаются открытыми. Если разные, карта уходит из cardsShown, и обе переворачиваются рубашкой вверх.
### memoryGameHideCards
Если карты не соответствуют друг другу, вызывается этот метод, и картинки карточек скрываются.
shown = false.
### memoryGameDidEnd
Когда вызывается этот метод, означает, что все карты уже открыты и находятся в списке cardsShown: cardsShown.count = cards.count, так что игра окончена. Метод вызывается специально после того, как мы вызвали endGame (), чтобы установить isPlaying var в false, после чего показывается сообщение о завершении игры. Также alertController используется в качестве индикатора для контроллера. Вызывается viewDidDisappear и игра сбрасывается.
Вот как все это выглядит в GameController:
```
extension GameController: MemoryGameProtocol {
func memoryGameDidStart(_ game: MemoryGame) {
collectionView.reloadData()
}
func memoryGame(_ game: MemoryGame, showCards cards: [Card]) {
for card in cards {
guard let index = game.indexForCard(card)
else { continue
}
let cell = collectionView.cellForItem(
at: IndexPath(item: index, section:0)
) as! CardCell
cell.showCard(true, animted: true)
}
}
func memoryGame(_ game: MemoryGame, hideCards cards: [Card]) {
for card in cards {
guard let index = game.indexForCard(card)
else { continue
}
let cell = collectionView.cellForItem(
at: IndexPath(item: index, section:0)
) as! CardCell
cell.showCard(false, animted: true)
}
}
func memoryGameDidEnd(_ game: MemoryGame) {
let alertController = UIAlertController(
title: defaultAlertTitle,
message: defaultAlertMessage,
preferredStyle: .alert
)
let cancelAction = UIAlertAction(
title: "Nah", style: .cancel) {
[weak self] (action) in
self?.collectionView.isHidden = true
}
let playAgainAction = UIAlertAction(
title: "Dale!", style: .default) {
[weak self] (action) in
self?.collectionView.isHidden = true
self?.resetGame()
}
alertController.addAction(cancelAction)
alertController.addAction(playAgainAction)
self.present(alertController, animated: true) { }
resetGame()
}
}
```

Собственно, вот и все. Вы можете использовать этот проект для создания собственного варианта игры.
Удачного кодинга!
> **Skillbox рекомендует:**
>
>
>
> * Практический курс [«Мобильный разработчик PRO»](https://skillbox.ru/agima/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=AGIMA&utm_content=articles&utm_term=swiftcardgame).
> * Прикладной онлайн-курс [«Аналитик данных Python»](https://skillbox.ru/python-data/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=PTNANA&utm_content=articles&utm_term=swiftcardgame).
> * Двухлетний практический курс [«Я — веб-разработчик PRO»](https://iamwebdev.skillbox.ru/?utm_source=skillbox.media&utm_medium=habr.com&utm_campaign=WEBDEVPRO&utm_content=articles&utm_term=swiftcardgame).
> | https://habr.com/ru/post/447598/ | null | ru | null |
# Museria — децентрализованное хранилище музыки

Собрался я однажды написать приложение, чтобы отбирать музыку для себя и слушать дома/на улице/тренировках и.т.д. И чтобы все это работало в потоке, с минимальным моим участием. Придумал архитектуру, набросал прототип и в итоге столкнулся с одной “небольшой проблемой”.
А непонятно откуда брать сами файлы песен. К этому моменту вконтакте уже закрыла api, на крупных музыкальных порталах тоже все глухо, даже песни отдаются кусками, чтобы не парсили. Оставались только какие-то отдельные сайты-однодневки с тонной рекламы и всякого мусора, всякие сомнительные программы-грабберы и прочие “грязные” варианты. В общем, ни одного действительного хорошего решения. Можно, конечно, купить подписку на какую-нибудь яндекс музыку или подобное. Но опять же, там нигде нет открытого публичного api и у тебя нет доступа к музыке программно. Несколько крупных компаний, по сути, ограничили остальным доступ к музыке. Почему так произошло вообще? Копнув глубже, стало понятно, что основная проблема в авторских правах. Текущее решение в виде подписок устраивает многих коммерческих авторов музыкальных произведений и эти самые компании. При этом некоммерческая и условно-коммерческая музыка тоже попадают в общий список. Ты либо платишь за все, либо не слушаешь вообще ничего.
И я начал думать что с этим всем делать. Как можно организовать свободное распространение музыки? Что бы я делал, если бы сам занимался созданием музыки и хотел бы зарабатывать на этом? Понравилось бы мне, если бы мои песни начали распространять пиратским образом? Какое вообще есть альтернативное решение?
В итоге сложились две основные проблемы, которые нужно решать:
* Организация свободного распространения музыки удобными для большинства людей методами, в том числе программными.
* Предложение альтернатив создателям музыки для заработка
### Глобальное децентрализованное хранилище музыки
Изначально я попробовал найти уже существующие решения и создать все на базе этого. После некоторого времени поисков, первым приглянулся [ipfs](https://github.com/ipfs/ipfs). Я начал реализацию своей идеи, но через некоторое время обнаружил несколько критичных проблем в этом решении:
* Ipfs — хранилище для всего и вся. Тут и изображения и музыка и видео и все что угодно. В общем-то большая такая планетарная «помойка». Поэтому когда ты запускаешь свой узел, то сразу получаешь огромную нагрузку. Машина просто корчится от боли.
* Какой-то недоделанный механизм сборки «мусора». Не знаю как с этим сейчас, но в тот момент, если ты в конфиге прописывал, что хочешь ограничить хранилище десятью гигабайтами данных, то это не значило ничего. Хранилище разрасталось, игнорируя многие параметры конфигурации. В итоге, нужно было иметь огромный запас жесткого диска, пока ipfs сообразит как сбросить ненужное.
* На момент использования библиотеки (не знаю как с этим сейчас), у клиента не были реализованы таймауты. Посылаешь запрос на получение файла, и если его нет, то просто висишь. Конечно, люди придумали всякие обходные пути, которые отчасти решали проблему, но это было костыли. Такие вещи должны быть из коробки.
Еще было много мелких проблем, впечатление сложилось тогда однозначное: это нельзя использовать для проекта. Я продолжил поиски хранилища, изучал разные варианты, но так и не нашел ничего подходящего.
В итоге, решил, что стоит попробовать написать децентрализованное хранилище самому. Пускай оно не будет претендовать на роль межпланетного, но будет решать конкретно поставленную задачу.
Так и получились [spreadable](https://github.com/ortexx/spreadable), [storacle](https://github.com/ortexx/storacle/), [metastocle](https://github.com/ortexx/metastocle), [museria](https://github.com/ortexx/museria), [museria-global](https://github.com/ortexx/museria-global).
**spreadable** — это основной, самый нижний слой, который позволяет объединять узлы в сеть. В нем заложен алгоритм, который я пока реализовал частично из расчета где-то на 10000 серверов. Полная версия алгоритма намного сложнее в реализации и потребовала бы еще несколько дополнительных месяцев (может и больше).
Подробно я spreadable в этой статье не буду описывать, лучше напишу отдельную как-нибудь. Тут лишь отмечу некоторые особенности:
* Работает через http/https.
* Можно создавать отдельную сеть под конкретную задачу, что существенно снизит нагрузку на каждый отдельный проект, чем если бы они все были в одной сети.
* Изначально продуман механизм с таймаутами и другими мелочами. И это работает для всех методов и в клиенте и в узле. Можно гибко управлять параметрами из своего приложения.
* Библиотека написана на nodejs. Проблемы с производительностью стека компенсируются децентрализованной природой. Нагрузку можно «размазать», увеличением количества узлов. Взамен много плюсов: огромное сообщество, простота и удобство работы, изоморфный клиент, отсутствие внешних зависимостей и.т.д.
**storacle** — это слой, наследующийся от spreadable, который позволяет хранить в сети файлы. Каждый файл имеет свой хэш по содержимому, по которому его позже и можно получить. Файлы не делятся на блоки, а хранятся целиком.
**metastocle** — слой, наследующийся от spreadable, который позволяет хранить в сети данные, но не файлы. Интерфейс похож на nosql базы данных. Можно, например, добавить файл в storacle, получить его хэш и записать в metastocle с привязкой к чему-либо.
**museria** — наследуется от storacle и metastocle. Этот слой непосредственно отвечает за хранение музыки. Хранилище работает только с mp3 файлами и id3 тэгами.
В качестве «ключа» к песне используется ее полное название в виде **Исполнитель (TPE1) — Название (TIT2)**. Например:
* Brimstone — The Burden
* Hi-rez — Lost My Way (feat. Emilio Rojas, Dani Devinci)
Максимально подробно узнать как формируются названия песен можно [тут](https://github.com/ortexx/museria/blob/master/src/utils.js). Надо смотреть функцию **utils.beautifySongTitle()**.
Совпадением по ключам считается определенный в настройках узла процент. Например, значение 0.85 означает, что если функция сравнения ключей(названий песен) обнаружила схожесть более 85%, то это одна и та же песня.
Алгоритм определения схожести там же, в функции **utils.getSongSimilarity()**.
Cover к песне, для последующего получения, также прикрепляться через тэги (**APIC**). В утилитах(utils) есть все необходимые методы для получения и обработки тэгов.
Пример работы с хранилищем через клиент можно посмотреть в [readme](https://github.com/ortexx/museria).
> Все вышеперечисленные слои являются самодостаточными и могут быть использованы отдельно как более низкие слои для других проектов. Например, уже сейчас есть мысль сделать слой для хранения книг.
**museria-global** — это уже сконфигурированный гит-репозиторий для запуска собственного узла в глобальной сети музыки. Клонируете, **npm i && npm** start и по сути все. Можно настроить более детально, запустить в докере и.т.д. Подробная информация есть на [гитхабе](https://github.com/ortexx/museria-global#museria-global-storage-alpha-).
Когда репозиторий обновляется, нужно обновить и свой узел. Если меняется мажорный или минорный номер версии, то это действие обязательно, иначе старые узлы будут игнорироваться сетью.
Работать с песнями можно вручную и программно. Каждый узел запускает сервер для различных задач. В том числе, при посещении дефолтного эндпоинта, вы получите интерфейс для работы с музыкой. Например, можно зайти на [корневой узел](http://storage.museria.com) (ссылка может быть не актуальна позже, входные узлы можно получить также в [телеграмме](https://t.me/museria), либо посмотреть обновления на гитхабе).
Так вы можете искать и загружать песни в хранилище. Загрузка песен может проходить в двух режимах: обычный и модерируемый. Второй режим означает, что работу ведет человек, а не программа. И если вы ставите эту галочку при добавлении, то нужно будет решить капчу. Песни можно добавлять с приоритетами -1, 0 или 1. Приоритет 1 можно ставить только в модерируемом режиме. Приоритеты нужны, чтобы хранилище эффективнее принимало решение, что делать когда вы пытаетесь заменить уже существующую песню новой. Чем больше приоритет, тем больше шансов, что вы перезапишете существующий файл. Это помогает бороться со спамом и увеличивает качество загружаемых песен.
Если вы начнете добавлять песни в хранилище, старайтесь прикреплять и изображения (cover), хоть это поле и не обязательное. В 99% случаев первые же картинки в гугле по названиям песен это каверы альбомов.
Как технически происходит добавление файлов, в двух словах:
* Клиент получает адрес свободного узла, который на некоторое время станет координатором.
* Триггерится функция добавления песни (человеком или кодом), происходит запрос на добавление на эндпоинт координатора.
* Координатор вычисляет, сколько дубликатов нужно сохранить (конфигурируемый параметр).
* Ищутся наиболее подходящие узлы для сохранения.
* Файл, непосредственно, уходит на эти узлы.
Как технически происходит получение файлов:
* Клиент получает адрес свободного узла, который на некоторое время станет координатором.
* Триггерится функция получения песни (человеком или кодом), происходит запрос на получение на эндпоинт координатора.
* Координатор проверяет наличие ссылки в кэше. Если такая есть и она рабочая, то сразу возвращается клиенту, иначе опрашиваются узлы на предмет наличия.
* Происходит получение файла по ссылке, если таковая нашлась.
### Альтернативы для создателей музыки
Меня всегда интересовал вопрос, как вообще можно оценить объективно стоимость многих творческих произведений? Почему, например, человек выставляет свой музыкальной альбом за 10$? Или за 20$ или за 100$. Где алгоритм? Когда, например, мы говорим о каком-то физическом продукте, или даже многих видах услуг, то мы можем как минимум посчитать себестоимость и исходить из этого.
Окей, допустим 10$ поставили. Очень уж ли это эффективно? Допустим я послушал альбом где-нибудь или песню оттуда и решил отблагодарить. Но по моим ощущениям и собственным возможностям 3$ — мой потолок. И как тут быть? Скорее всего я просто не сделаю ничего, как и большинство людей.
Выставляя какую-то фиксированную цену за творческий труд, ты просто ограничиваешь себя, не даешь бОльшому числу людей отправить тебе меньшие деньги, которые в сумме могут быть внушительнее, чем у тех кто купят по установленной тобой цене. Мне кажется творчество — это именно та сфера, где в первую очередь должны рулить донаты. Для этого нужно:
* Научить людей благодарить именно таким образом. Творцы сами должны это четко показывать, что хотели бы получать донаты, добавлять везде ссылки на разные способы оплаты и.т.д.
* Нужно больше механизмов для упрощения и усиления этих процессов. Например, создать некий глобальный сайт, куда можно донатить за творчество с помощью авторских ссылок.
Допустим, ссылка примерно такая:
**`http://someartistsdonationsite.site/category/artist?external-info`**
Если сузить до музыкантов, то:
**`http://someartistsdonationsite.com/music/miyagi?song=blabla`**
Исполнителю нужно верифицировать свой никнейм и прикрепиться за ним.
В клиент museria добавляем функцию генерации подобной ссылки, и все проекты использующие хранилище, могут расположить на своих сайты/приложениях кнопки для донатов с этими ссылками рядом с песнями. Пользователи имеют возможность очень быстро и просто сделать донат. Естественно, этот подход можно использовать в любом проекте и категории творчества, не только через хранилище.
### Зачем, именно тебе, музыкальное хранилище, и как в этом можно участвовать
* Если ты работаешь над проектом, связанным с музыкой, либо планируешь такой создать, то ради этого все и было задумано. Ты можешь использовать museria для хранения и получения песен, увеличивая поток песен в сети. Если, при этом, у тебя есть возможности поднять и удерживать хотя бы один собственный узел, то это будет наилучшим вкладом в развитие сети.
* Возможно ты готов взять какую-то иную роль на себя: помочь с кодом, или заполнять и модерировать базу, распространять информацию о проекте своим знакомым и.т.д.
* Может быть тебе понравилась идея и ты готов помочь материально, чтобы это все жило и развивалось. Чем больше узлов, тем больше песен.
* Или тебе просто в какой-то момент понадобится найти и скачать песню. Ты сможешь сделать это очень просто, например, через [телеграмм бота](https://t.me/MuseriaBot).
Проект сейчас на самой начальной стадии. Запущена тестовая сеть, узлы могут часто перезагружаться, требовать обновлений и.т.д. В случаи отсутствия критических проблем в течение оценочного периода, эта же сеть и трансформируется в основную.
Посмотреть информацию об узле извне: количество песен, свободного места и.т.д., можно по ссылке вида **`http://node-address/status`** или **`http://node-address/status?pretty`**
Мои контакты:
* [@ortex](https://t.me/ortex)
* [[email protected]](mailto:[email protected])
* [Группа в телеграм на английском.](https://t.me/museria)
* [Ну и сайт, благодаря которому все эта идея зародилась.](https://museria.com/) | https://habr.com/ru/post/495058/ | null | ru | null |
# Generating HTML reports for dynamic table-structures
В относительно недавнем прошлом, возникла задача автоматизировать процесс генерации и рассылки *HTML* отчетов руководству по продажам за текущий месяц. Так уж вышло, что для каждого руководящего лица создавались отдельные таблицы с необходимой только им информацией.
Поскольку, для каждого отчета, все делалось вручную, что, мягко говоря, было нерациональным.
Было решено генерировать *HTML* со стороны сервера базы данных и через *Database Mail* формировать рассылку путем выполнения команды *sp\_send\_dbmail*.
Большинство примеров, приведенный в Сети, создавали разметку вручную — это было не слишком эффективным подходом. При этом я не нашел универсального решения, позволяющего работать с таблицой имеющей произвольную структуру.
Чтобы заполнить этот пробел предлагаю на рассмотрение мой вариант решения.
Из системного представления получаем список столбцов для требуемой таблицы:
```
DECLARE @object_name SYSNAME
, @object_id INT
, @SQL NVARCHAR(MAX)
SELECT @object_name = '[dbo].[Products]'
, @object_id = OBJECT_ID(@object_name)
SELECT @SQL = 'SELECT
[header/style/@type] = ''text/css''
, [header/style] = ''
table {border-collapse:collapse;}
td, table {
border:1px solid silver;
padding:3px;
}
th, td {
vertical-align: top;
font-family: Tahoma;
font-size: 8pt;
text-align: left;
}''
, body = (
SELECT * FROM (
SELECT tr = (
SELECT * FROM (
VALUES ' +
STUFF(CAST((
SELECT ', (''' + c.name + ''')'
FROM sys.columns c WITH(NOLOCK)
WHERE c.[object_id] = @object_id
AND c.system_type_id NOT IN (34, 36, 98, 128, 129, 130, 165, 173, 189, 241)
ORDER BY c.column_id
FOR XML PATH(''), TYPE) AS NVARCHAR(MAX)), 1, 2, '') + '
) t (th)
FOR XML PATH('''')
)
UNION ALL
SELECT (
SELECT * FROM (
VALUES' + STUFF(CAST((
SELECT ', ' +
CASE WHEN c.is_nullable = 1
THEN '(ISNULL(' ELSE '(' END +
CASE WHEN TYPE_NAME(c.system_type_id) NOT IN ('nvarchar', 'nchar', 'varchar', 'char')
THEN 'CAST(' + '[' + c.name + '] AS NVARCHAR(MAX))' ELSE '[' + c.name + ']' END +
CASE WHEN c.is_nullable = 1
THEN ',''''))' ELSE ')' END
FROM sys.columns c WITH(NOLOCK)
WHERE c.[object_id] = @object_id
AND c.system_type_id NOT IN (34, 36, 98, 128, 129, 130, 165, 173, 189, 241)
ORDER BY c.column_id
FOR XML PATH(''), TYPE) AS NVARCHAR(MAX)), 1, 2, ' ') + '
) t (td)
FOR XML PATH(''''), TYPE)
FROM ' + @object_name + '
) t
FOR XML PATH(''''), ROOT(''table''), TYPE
)
FOR XML PATH(''''), ROOT(''html''), TYPE'
PRINT @SQL
EXEC sys.sp_executesql @SQL
```
Далее динамическим *SQL* создаем запрос, который генерирует *XML*:
```
SELECT
[header/style/@type] = 'text/css'
, [header/style] = 'css style ...'
, body = (
SELECT *
FROM (
SELECT tr = (
SELECT *
FROM (
VALUES ('column_name1', 'column_name2', ...)
) t (th)
FOR XML PATH('')
)
UNION ALL
SELECT (
SELECT *
FROM (
VALUES ([column_value1], [column_value2], ...)
)t (td)
FOR XML PATH(''), TYPE
)
FROM [table]
) t
FOR XML PATH(''), ROOT('table'), TYPE
)
FOR XML PATH(''), ROOT('html'), TYPE
```
При этом столбцы, содержащие специфичные типы данных (например, *UNIQUEIDENTIFIER*) в генерируемый отчет не включаются:
```
SELECT name
FROM sys.types
WHERE user_type_id IN (
34, 36, 98,
128, 129, 130,
165, 173, 189, 241
)
```
При выполнении запроса мы получаем следующую *HTML* разметку, которая прикреплялась к письму:
```
...
| column\_name1 | column\_name2 |
...
| --- | --- |
| column\_value1 | column\_value2 |
...
```
Чтобы вручную не выполнять этот скрипт каждую неделю, в *SQL Agent* был добавлен *Job*, который автоматически генерировал и отправлял отчеты.
Надеюсь, что приведенное здесь решение будет полезно при решении подобных задач.
**PS:** Многострочная конструкция *VALUES* появилась только в *SQL Server 2008*, поэтому, для экономии времени, привожу пример того же скрипта, но для 2005 сервера:
```
DECLARE @object_name SYSNAME
, @object_id INT
, @SQL NVARCHAR(MAX)
SELECT @object_name = '[dbo].[Products]'
, @object_id = OBJECT_ID(@object_name)
SELECT @SQL = 'SELECT
[header/style/@type] = ''text/css''
, [header/style] = ''
table {border-collapse:collapse;}
td, table {
border:1px solid silver;
padding:3px;
}
th, td {
vertical-align: top;
font-family: Tahoma;
font-size: 8pt;
text-align: left;
}''
, body = (
SELECT * FROM (
SELECT tr = (
SELECT * FROM (
' +
STUFF(CAST((
SELECT ' UNION ALL SELECT ''' + c.name + ''''
FROM sys.columns c WITH(NOLOCK)
WHERE c.[object_id] = @object_id
AND c.system_type_id NOT IN (34, 36, 98, 128, 129, 130, 165, 173, 189, 241)
ORDER BY c.column_id
FOR XML PATH(''), TYPE) AS NVARCHAR(MAX)), 1, 17, 'SELECT th =') + '
) t
FOR XML PATH('''')
)
UNION ALL
SELECT (
SELECT * FROM (
' + STUFF(CAST((
SELECT ' UNION ALL SELECT ' +
CASE WHEN c.is_nullable = 1
THEN 'ISNULL(' ELSE '' END +
CASE WHEN TYPE_NAME(c.system_type_id) NOT IN ('nvarchar', 'nchar', 'varchar', 'char')
THEN 'CAST(' + '[' + c.name + '] AS NVARCHAR(MAX))' ELSE '[' + c.name + ']' END +
CASE WHEN c.is_nullable = 1
THEN ','''')' ELSE '' END
FROM sys.columns c WITH(NOLOCK)
WHERE c.[object_id] = @object_id
AND c.system_type_id NOT IN (34, 36, 98, 128, 129, 130, 165, 173, 189, 241)
ORDER BY c.column_id
FOR XML PATH(''), TYPE) AS NVARCHAR(MAX)), 1, 17, 'SELECT td =') + '
) t
FOR XML PATH(''''), TYPE)
FROM ' + @object_name + '
) t
FOR XML PATH(''''), ROOT(''table''), TYPE
)
FOR XML PATH(''''), ROOT(''html''), TYPE'
PRINT @SQL
EXEC sys.sp_executesql @SQL
``` | https://habr.com/ru/post/203076/ | null | ru | null |
# Пытаемся автоматизировать процессы с помощью Powershell
[](https://habr.com/ru/company/ultravds/blog/483416/)
В этой статье рассмотрим почему мы все любим Powershell на паре рабочих примеров. Все это будет полезно при инвентаризации, поиске конкретного компьютера и прочих делах. Powershell оборудован удобными и запоминающимися командлетами, автодополнение всего и интуитивные названия делают его наверное самым простым в освоении языком.
В этом руководстве рассмотрим несколько крутых по мнению автора команд и расскажем почему это круто. Начнем со снипетов.
Полезные снипеты:
-----------------
**Заносим компьютер в TrustedHosts**
Пригодится при подключении к серверу по WinRm. Команда перезапишет предыдущее значение, будьте осторожны, добавляйте ip или имена хостов через запятую. Если все ваши хосты находятся в AD, трогать этот файл не нужно.
```
Set-Item WSMan:\localhost\Client\TrustedHosts -Value '192.168.0.1'
```
Wildcard тоже работает, если не хотите каждый раз добавлять новый хост в TrustedHosts.
```
Set-Item WSMan:\localhost\Client\TrustedHosts -Value '*'
```
**Храним пароль в зашифрованном виде в файле:**
Пригодится для автоматизации, сильно облегчает жизнь при выполнении скриптов из планировщика, но при этом пароль хранится в безопасном виде.
Если выполнять скрипты из под зашедшего пользователя, будут использоваться креды этого пользователя.
```
Read-Host -AsSecureString | ConvertTo-SecureString -AsPlainText -Force | ConvertFrom-SecureString | Out-File -FilePath .\Password.txt
```
Забираем зашифрованный пароль из файла:
```
$Password = Get-Content C:\Password.txt | ConvertTo-SecureString
```
Тоже самое можно проделать и с Credentials, заменим Read-Host на Get-Credential.
```
Get-Credential | ConvertTo-SecureString -AsPlainText -Force | ConvertFrom-SecureString | Out-File -FilePath .\Credential.txt
```
**Получаем дату последней загрузки ОС.**
```
(gcim win32_operatingsystem).LastBootUpTime
```
Тем же самым способом получаем еще и аптайм.
```
Get-CimInstance Win32_operatingsystem -ComputerName $computers |
Select-Object LastBootUpTime,
@{Name="Uptime";Expression = {(Get-Date) - $_.LastBootUptime}}
```
**Получаем список установленных программ:**
Именно программ, а не компонентов:
```
Get-ItemProperty HKLM:\Software\Microsoft\Windows\CurrentVersion\Uninstall\* | Select-Object DisplayName, DisplayVersion, Publisher, InstallDate |
Format-Table –AutoSize
```
**Получаем список дисков, в том числе сетевых и свободное место на них**
```
Get-PSDrive -PSProvider filesystem | where-object {$_.used -gt 0} |
Select-Object -property Root,@{name="Size";expression={($_.used+$_.free)/1GB -as [int]}},
@{name="Used";expression={($_.used/1GB) -as [int]}},
@{name="Free";expression={($_.free/1GB) -as [int]}}
```
**Останавливаем процесс по его имени.**
В этом примере останавливаем Chrome. Wildcard тоже подойдет, если хотите завершить всё.
```
Get-Process -Name "chrome" | Stop-Process
```
**Копируем настройки доступа к папкам на дочерние папки**
Пригодится, если вам захочется отобрать или дать права на пользование к папке и всем подпапкам у группы пользователей или у пользователя. Команда рекурсивно, снизу вверх копирует права на чтение и запись.
Копируем ACL у папки:
```
$Acl = Get-Acl -Path C:\folder\
```
Вставляем ACL на все файлы и подпапки:
```
Get-ChildItem -Path C:\Folder\ -Recurse | Set-Acl $Acl
```
Полезные скрипты:
-----------------
Вот тут начинается самое страшное веселье. Если вам нужно провести инвентаризацию, будет очень полезно глянуть. Если ваши компьютеры не в AD, то скрипт станет немного сложнее, итерировать придется по заранее составленному файлу, а пароли нужно будет брать из файла или через Get-Credential. Вся разница:
C AD:
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
```
Без AD:
```
$Credentials = Get-Credential
$Computers = Get-Content -Path C:\servers.txt
```
**Получаем аптайм дату последней загрузки каждого из компьютеров в AD:**
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
foreach ($i in $ADComputers) {
Invoke-Command $i {
Get-CimInstance Win32_operatingsystem |
Select-Object LastBootUpTime,
@{Name="Uptime";Expression = {(Get-Date) - $_.LastBootUptime}}
}
}
```
**Получаем все установленные программы на всех компьютерах AD:**
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
foreach ($i in $ADComputers) {
Invoke-Command -computername $i {
gcim win32_product -computername $env:computername | Sort-Object -property Vendor,Name | Select-Object -property Vendor,Name, Caption
}
}
```
Тоже самое можно будет получить и для компонентов, подставив в Invoke-Command:
```
Get-WindowsFeature | Where-Object -Property "Installed" -EQ "Installed"
```
**Получаем компьютеры, где запущен нужный нам процесс:**
Если вы забыли на каком компьютере запущена та или иная программа, можно получить её таким способом. Рассмотрим на примере браузера:
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
foreach ($i in $ADComputers) {
Invoke-Command -computername $i {
Get-Process -Name "Chrome" -ErrorAction SilentlyContinue
}
}
```
Убить браузер можно будет так же легко, как и получить процесс:
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
foreach ($i in $ADComputers) {
Invoke-Command -computername $i {
Get-Process -Name "Chrome" | Stop-Process -ErrorAction SilentlyContinue
}
}
```
**Получаем компьютеры, где установлена конкретная программа:**
Кокретно в этом случае Java. Поможет при проведении инвентаризации можно будет посмотреть имена компьютеров где она была установлена.
```
$ADComputers = (Get-ADComputer -filter *).DNSHostName
foreach ($i in $ADComputers) {
Invoke-Command -computername $i {
gcim win32_product -computername $env:computername | Select-String -Pattern "Java" -AllMatches | Sort-Object -property Vendor,Name | Format-Table -ErrorAction SilentlyContinue
}
}
```
Если у вас возникнут предложения, будем рады добавить их в эту статью. Надеемся, эти примеры были для вас полезны.
Предлагаем обновлённый тариф UltraLite [Windows VDS](https://ultravds.com/) за 99 рублей с установленной Windows Server 2019 Core.
[](https://ultravds.com/) | https://habr.com/ru/post/483416/ | null | ru | null |
# К вопросу о TI
**«Сейчас я покажу вам портрет… Хм… Я предупреждаю вас, что это именно портрет… Во всяком случае, прошу отнестись к нему, как к портрету...**
В данном посте пойдет речь о разработке и отладке программ для МК СС1350 в рекомендованной производителем среде разработки CCS. Будут затронуты достоинства (а они есть) и недостатки (а как же без них) вышеупомянутых продуктов. В тексте не будет скриншотов, призванных показать (обведенное кружочком) расположение иконки компиляции в интегрированной среде программирования или выбора файла в директории. Признавая принципиальную возможность статей в подобном стиле, я постараюсь сосредоточиться на концептуальных моментах в надежде, что мой читатель сам сможет разобраться в деталях.
Целью данного опуса, помимо передачи полученного опыта, является попытка возбудить здоровую зависть у отечественных производителей МК, являющихся прямыми конкурентами TI (»на территории страны, где мы с Вами и процветаем") — задача откровенно неблагодарная, но говорят, что капля камень точит.
Сразу подчеркну — речь будет идти только о Windows (более того, только) 7 версии, хотя на сайте TI есть вариант и под Мак и под Линух, я их не пробовал, вполне готов поверить, что там все не так здорово, но зачем думать о плохом (или наоборот, там все великолепно, но тогда зачем завидовать).
Итак, чему нас учит сайт TI — для начала работы с оценочными модулями следует выполнить три необходимых шага:
1. Купить оценочные модули — выполнено.
Примечание на полях(Пнп): Вам тоже придется это сделать, поскольку в рассматриваемой среде программирования лично мне (к глубокому сожалению) не удалось найти возможность эмуляции аппаратных средств для отладки, по крайней мере там, где я искал.
2. Установить среду разработки — скачиваем, запускаем инсталлятор, все получилось. Подключаем оценочный модуль к USB — дрова поднимаются сами и все опять получилось — выполнено. При попытке запрограммировать устройство получаем сообщение о необходимости обновить прошивку, соглашаемся и опять все получилось. В общем писать-то и не о чем, если бы так было всегда и везде ...
3. Пойти и изучить курс TI SimpleLink Academy 3.10.01 for SimpleLink CC13x0 SDK 3.10 — странное предложение, вроде как меня учить — только портить, но так уж и быть, открываю соответствующую ссылку и тихо обалдеваю — сколько тут всего понапихано.
Здесь мы видим обучающие материалы по работе с драйверами аппаратуры SYS/BIOS и с операционной системой TI-RTOS и по использованию сетевого стека NDK, включая USB, и по использованию беспроводных протоколов и по еще множеству аспектов работы с представителями разнообразных семейств МК, выпускаемых фирмой. И сопровождается все это богатство готовыми к применению примерами, а если еще учесть наличие руководств пользователя и описания модулей, то, пожалуй, больше и пожелать нечего. А ведь еще есть и утилиты, облегчающие работу по подготовке и конфигурированию программного кода, прошивке и отладке различными способами, и это богатство тоже достаточно документировано.
Пнп: если кто-либо склонен рассматривать данный материал как рекламный в отношении фирмы, ее продукции и системы программирования, то он будет, скорее всего, прав и я действительно очень впечатлен объемом обнаруженного софта. О его качестве речь пойдет дальше и, надеюсь, подозрения в предвзятости будут развеяны, меня совершенно не ослепило чувство и я продолжаю прекрасно видеть и недочеты объекта описания, так что это не влюбленность юности, а серьезное чувство взрослого специалиста. Мне страшно представить объем материальных затрат, необходимый для создания и поддержания такого объема софта и документации к нему, но это было сделано явно не за один месяц, ну и фирма наверняка понимает, что делает.
Ладно, пока отложим изучение материалов на потом, будем все постигать «по ходу дела нутром самородка» и смело открываем CCS. Здесь реализована концепция рабочих пространств, полученная от родителя — Eclipse. Лично мне ближе концепция проекта, но нам никто не мешает держать в пространстве ровно один проект, так что идем дальше.
А вот дальше дела становятся несколько хуже — открываем рабочее пространство (РП) для нашей отладочной платы и видим множество проектов (как правило, в двух вариантах — под РТОС и для «голого железа»). Как я сказал ранее, это не криминал, но вот то, что многие проекты содержат одинаковые файлы с идентичными программными модулями — это совсем не здорово. Код многократно дублируется и поддержка изменений становится весьма нетривиальной задачей. Да, при таком решении намного проще переносить проект, просто скопировав директорию, но для подобных вещей есть экспорт проекта, и он вполне себе неплохо реализован. Ссылки на файлы в дереве проекта поддерживаются адекватно, так что решение с включением самих файлов в предоставляемых примерах нельзя считать удовлетворительным.
Продолжаем исследования — начнем работу с готовым проектом, но не мигание светодиодом, хотя их на отладочной плате целых два, а работу с последовательным портом, готовый пример uartecho. Создаем новое РП, включаем в него интересующий нас проект и… ничего не получается, из сообщения ясно, что требуется включить в РП связанный проект. Не очень понятно, зачем это делать, но выполнить требования среды нетрудно, после чего проект начинает собираться.
Пнп: на домашней машине я воспользовался командой «Импорт проекта» и все необходимые включения произошли сами по себе. Где именно указываются связанные проекты, я не знаю, оставим разбор данного аспекта на будущее.
Компилируем, прошиваем и начинаем отладку. Обнаруживаем интересное явление — исполнение по шагам не вполне адекватно отображается при рассмотрении библиотеки работы с последовательным портом — издержки оптимизации. Отключаем оптимизацию в настройках компилятора (каких только настроек там нет, неужели есть люди, которые все их знают и, более того, всеми ими пользуются), собираем проект заново — и ничего не меняется. Оказывается, перекомпилируются только те файлы, которые включены в дерево проекта, хотя бы в виде ссылок. Добавляем ссылки на исходники библиотеки и после пересборки все отлаживается правильно (при условии, что у нас включена опция генерации отладочной информации).
Пнп: зато я нашел опции включения проверки на соответствие MISRA-C.
Пнп: другой способ — воспользоваться командой «Clean...» с последующей сборкой, команда «Build All» почему-то на связанный проект не влияет.
Далее обнаруживаем, что не всегда и не все отлаживается нормально, иногда мы оказываемся в таких областях машинного кода, для которых компилятор не находит исходников. Поскольку среда программирования предоставляет нам все необходимые для работы файлы — результат работы препроцессора, ассемблерный код и карту линкера (надо только не забыть включить соответствующие опции), обращаемся к последней. Обнаруживаем две области кода программы — начиная с 0х0000. и начиная с 0х1000. (всем хороши 32- разрядные архитектуры, но запись адресов — не их сильное место). Обращаемся к документации на микросхему и выясняем, что внутри имеется область ПЗУ, картированная именно на 0х1000., и в ней расположена встроенная часть библиотек. Утверждается, что использование подпрограмм из нее повышает быстродействие и снижает потребление по сравнению с адресным пространством 0х000. Пока мы осваиваем МК, нас не столь интересуют последние параметры, а вот удобство отладки является определяющим. Отключить использование ПЗУ можно (а для наших целей нужно), задав компилятору опцию NO\_ROM, что мы делаем и пересобираем проект.
Пнп: весьма забавно выглядит переход на подпрограмму в ПЗУ — в системе команд нет длинного перехода, поэтому сначала выполняется переход с возвратом на промежуточную точку в области малых адресов (0х0000), а уже там лежит команда загрузки PC, параметры которой дизассемблером не распознаются. Что-то мне не верится, будто бы при таких накладных расходах можно выиграть в быстродействии, хотя для длинных подпрограмм — почему бы и нет.
Кстати, интересный вопрос — а чем вообще гарантируется, что содержимое ПЗУ соответствует исходным кодам, любезно представленным фирмой. Я сразу могу предложить механизм встраивания в ПЗУ дополнительных (конечно же, отладочных и сервисных) функций, которые для пользователя — программиста МК будут совершенно не заметны. И лично я не сомневаюсь, что разработчики микросхемы знают и множество других механизмов, реализующих подобный функционал, но закончим приступ паранойи.
С другой стороны, я могу только приветствовать появление подобного аналога BIOS, ведь в перспективе это позволит сделать реальностью мечту разработчиков о настоящей переносимости кода между разными семейства МК с одним ядром. Отметим также особенность реализации взаимодействия со «вшитыми» программными модулями. Если в ранних попытках создать подобный механизм, реализованных в моделях TivaC, имел место супервизор вызовов, к которому обращались с номером группы и номером точки входа в подпрограмму, что вызывало значительный оверхед, то здесь разрешение связей идет на уровне линкера за счет двойных наименований функций и вставлены прямые длинные переходы на подпрограммы в ПЗУ. Это намного быстрее в исполнении, но требует перекомпиляции проекта при изменении модели использования.
Теперь, когда мы полностью готовы к удобной отладке, возвращаемся к нашему проекту и начинаем спокойно отлаживать программу с доступом к исходным кодам модулей (ну это я так думал ...), что позволит нам составить свое мнение о качестве этих текстов. Исследуемый проект осуществляет зеркало последовательного канала связи и исключительно удобен для целей обучения. Разумеется, мы взяли вариант с применением РТОС, я не вижу ни малейших оснований не использовать ее в нашей конфигурации (много памяти и памяти программ).
Сразу отметим, что исходные коды представлены на языке С, часто это не слишком удобно, многие языковые конструкции выглядят громоздко, по сравнению с аналогами на плюсах, но создателей больше волновала совместимость кода, нежели синтаксический сахар. Хотя, можно было бы создать и С++ версию библиотек, условная компиляция известна давно и используется повсеместно, но это влечет за собой дополнительные материальные издержки. Наверняка, руководство фирмы знает, что делает, а мои замечания являются некоей «диванной аналитикой», но мне кажется, что я тоже имею право на свое мнение.
Мне известен и обратный подход, когда библиотека проектируется с использованием новейших средств языка С++, а на вопрос, что делать тем разработчикам, у кого в инструментах используются компиляторы, не отвечающие новейшим спецификациям, следует прекрасный ответ — переходить на новые версии либо не юзать данную библиотеку (я настоятельно рекомендую в таких случаях второй вариант). Мое личное мнение — если мы действительно хотим, чтобы наш продукт использовали (а фирма TI этого явно желает, а не делает библиотеку по принципу «от… валите на фиг от меня, вот вам новый барабан»), то ее подход является безусловно верным.
Исходный текст программы выглядит классически — инициализация железа и программного окружения, создание задач и запуск шедулера в основном модуле, текст задачи в отдельном модуле компиляции. В рассматриваемом примере задача ровно одна — mainThread, назначение не вполне понятно из названия, и еще, что меня несколько смущает — имя файла, содержащего исходный текст, не совпадает с именем функции (uartecho.c — хотя как раз тут имя говорящее) ну да поиск в среде программирования реализован стандартным образом (контекстное меню либо F3 на имени сущности) и с этим проблем нет.
Процесс настройки параметров задачи перед запуском довольно-таки ожидаем:
1. создаем структуру параметров (локальную, конечно),
2. присваиваем ей значения по умолчанию,
3. задаем параметры, отличные от стандартных, и
4. используем структуру при создании задачи.
Несмотря на вроде как естественность этих операций, не для всех авторов библиотек она очевидна, и я видел разные реализации, в которых не было, например, стадии 2, что приводило к забавному (для постороннего наблюдателя, не для программиста) поведению программы. В рассматриваемом случае все хорошо, единственный возникший вопрос — почему значения по умолчанию не константны, наверное, это наследие проклятого прошлого.
Пнп: в широко известной FREE-RTOS принят несколько иной подход с указанием параметров задачи непосредственно в теле вызова АПИ функции создании задачи. Плюсы и минусы данных подходов следующие:
1. +позволяет не указывать явно параметры, совпадающие со значениями по умолчанию, +не требует запоминания порядка параметров, -более многословен, -бОльшие затраты памяти, -надо знать параметры по умолчанию, -создает именованный промежуточный объект
2. — требует указания всех параметров, -требует запоминания порядка параметров, +более компактен, +требует меньше памяти, +не требует именованных промежуточных объектов.
Есть третий способ, пропагандируемый автором данного поста (в стиле ТУРБО), у которого свой набор
3. +позволяет не указывать явно параметры, совпадающие со стандартным, +не требует запоминания порядка параметров, -многословен, -бОльшие затраты памяти, -надо знать параметры по умолчанию, +работает в стиля «лямбда», +делает труднореализуемыми стандартные ошибки, -выглядит несколько странновато из за множества правых скобок.
Ну и есть еще четвертый вариант, лишенный каких либо недостатков, но требующий С++ не ниже 14 – облизываемся и проходим мимо.
Начинаем отладку, запускаем программу и открываем один из двух последовательных портов, предоставляемых отладочной платой, в терминальном окне, предоставляемой средой программирования. Какой именно из двух портов (один — отладочный, наверное, второй — пользовательский, номера их можно посмотреть в системе) заранее сказать трудно, иногда младший, иногда старший, хорошо хоть, он не меняется при переподключении платы, поэтому его можно на плате написать. Ну и еще одно неудобство — открытые терминалы не сохраняются вместе с проектом и не восстанавливаются при открытии отладочной сессии, хотя и не закрываются при выходе из нее. Проверяем работу программы и сразу обнаруживаем еще один недостаток — терминал невозможно настроить, он, например, принципиально работает в Unix стиле с закрывающим /r, отвык я от подобного минимализма, хотя никто не мешает нам пользоваться внешней терминальной программой.
Пнп: Отметим еще одну особенность отладки, ну это верно для любой среды разработки — при переключении задачи шедулером мы теряем фокус трассировки, точки останова нам помогут решить эту проблему.
Для начала рассмотрим процесс создания экземпляра последовательного порта — тут вроде все стандартно, используется структура, полям которой присваиваем требуемые параметры объекта. Отметим, что на плюсах у нас есть возможность, полностью отсутствующая на С, всю инициализацию очень красиво спрятать «под капот», но возможные аргументы в пользу второго решения я уже озвучил. Есть функция инициализация настроечной структуры, и это хорошо (как это ни парадоксально прозвучит, данная функция не представляется обязательной для авторов некоторых библиотек). В этой точке повествования медовый месяц заканчивается и начинается обыкновенная (супружеская) жизнь.
Внимательное изучение исходников показывает, что не все уж настолько хорошо. В чем проблема — функция инициализации копирует в нашу управляющую структуру значения по умолчанию из объекта, который лежит в области констант, и это замечательно, но почему-то:
1. объект глобальный, хотя используется единственной функцией инициализации параметров (в свое время похожая практика обошлась Тойоте в приличную сумму) — ладно, добавить директиву static несложно;
2. управляющий объект именован, в С красивого решения этой проблемы нет, вернее, решение с анонимным экземпляром есть и я его давал в давнем посте, но множество правых скобок не дает назвать этот вариант по-настоящему красивым, в плюсах есть решение обалденной красоты, но что мечтать о несбыточном;
3. все поля объекта явно избыточны по разрядности, даже битовые поля (перечисления из двух возможных значений) хранятся в 32-разрядных словах;
4. перечислимые константы режимов заданы в виде дефайнов, что делает невозможной проверку на этапе компиляции и необходимой — в ран-тайме;
5. повтор секции бесконечного цикла в разных местах возможных отказов, намного правильнее было бы сделать один (в данном случае пустой) обработчик;
6. ну и все операции по настройке и запуску задачи можно (и нужно) спрятать в одну функцию или даже макрос.
Зато хорошо сделана инициализация буфера приема — используем заранее зарезервированную память, никаких манипуляций с хипом, цепочка вызовов несколько сложна, но все вполне читаемо.
Пнп: в окне отладки у нас перед глазами стек вызова, все сделано как положено и добротно — респект и уважуха. Единственное, что несколько удивляет — попытка скрыть это окно приводит к завершению сеанса отладки.
Ну и еще одно несколько неожиданное решение — задание возможного количества объектов в перечислении, для последовательных портов и для данной отладочной платы равного 1, в стиле
```
typedef enum CC1310_LAUNCHXL_UARTName {
CC1310_LAUNCHXL_UART0 = 0,
CC1310_LAUNCHXL_UARTCOUNT
} CC1310_LAUNCHXL_UARTName;
```
Такие решения стандартны для настоящих перечислений, но для описания аппаратных объектов — а я и не знал, что так можно, хотя вполне себе работает. С инициализацией железа покончили, идем дальше.
Мы наблюдаем в запущенной задаче классический бесконечный цикл, в котором читаются данные из последовательного порта функцией
```
UART_read(uart, &input, 1);
```
и тут же отправляются обратно функцией
```
UART_write(uart, &input, 1);
```
. Войдем в первую из них и видим попытку чтения символов из приемного буфера
```
return (handle->fxnTablePtr->readPollingFxn(handle, buffer, size))
```
(как же я ненавижу такие вещи, но в С иначе просто нельзя), проходим глубже и оказываемся в UARTCC26XX\_read, а из нее попадаем в реализации кольцевого буфера — функция
```
RingBuf_get(&object->ringBuffer, &readIn)
```
. Здесь обычная жизнь переходит в острую фазу.
Сказать, что данный конкретный модуль (файл ringbuf.c) мне не понравился — это не сказать ничего, написано просто ужасно и лично я бы на месте такой уважаемой компании авторов данной части выгнал с позором (можно еще взять меня на их место, но боюсь что уровень зарплат наших индийских коллег меня не устроит), но, наверное, я чего то не знаю. Следите за руками:
1) ре-ролл указателей чтения/записи реализован через остаток от деления
```
object->tail = (object->tail + 1) % object->length;
```
и никаких оптимизаций компилятора при выполнении этой операции вроде наложения битовой маски тут нет и быть не может, поскольку длина буфера не есть константа. Да, в данном МК есть аппаратная операция деления и она довольно-таки быстрая (я об этом писал), но все равно она никогда не займет 2 такта, как в правильной реализации с честным ре-роллом (и об этом я тоже писал),
Пнп: недавно видел описание новой архитектуры М7 в реализации уж и не помню кого, так там почему-то деление 32 на 32 стало выполняться за 2-12 тактов вместо 2-7. Или это ошибка перевода, или… даже и не знаю, что придумать.
2) мало того, этот фрагмент кода повторен более чем в одном месте — макросы и инлайны для слабаков, ctrl+C и ctrl+V рулят, принцип DRY идет лесом,
3) реализован совершенно излишний счетчик заполненных мест в буфере, что повлекло за собой следующий недостаток,
4) критические секции как в чтении, так и в записи. Ну ладно, я еще могу поверить, что авторы данного модуля не читают мои посты на Хабре (хотя для профессионалов в области прошивки такое поведение недопустимо), но с «Книгой мустанга» они должны быть знакомы, там этот вопрос рассмотрен подробно,
5) как вишенка на торте, введен еще индикатор максимального размера буфера, причем с весьма невнятным именем и полностью отсутствующим описанием (последнее относится вообще ко всему модулю). Я не исключаю, что данный параметр может быть полезен при отладке, но зачем тащить его в релиз — нам что, такты процессора вообще девать некуда вместе с оперативкой?
6) при этом полностью отсутствует обработка переполнения буфера (есть возврат -1, сигнализирующей о данной ситуации)- даже в Ардуино она есть, оставим в стороне качество этой обработки, но ее отсутствие еще хуже. Или же авторов вдохновлял известный факт о том, что относительно пустого множества справедливы любые предположения, в том числе и то, что оно не пусто?
В общем, мои замечания полностью соответствуют первой строчке демотиватора на тему ревью кода «10 строк кода — 10 замечаний».
Кстати, предпоследний из отмеченных недостатков заставляет задуматься о более глобальных вещах — а как нам вообще реализовывать базовый класс, чтобы иметь возможность проводить его глубокую модификацию. Делать все поля защищенными — сомнительная идея (хотя, наверное, единственно правильная), вставлять вызов дружественных функций в наследников — очень сильно похоже на костыли. Если в данном конкретном случае есть простой ответ на вопрос о введении индикатора наполненности буфера — порожденный класс с перекрытыми записью и чтением и дополнительный счетчик, то для реализации чтения без продвижения буфера (как в данном случае) или замены последнего помещенного символа (видел я и такие реализации кольцевого буфера) без доступа к внутренним данным родительского класса не обойтись.
При этом к реализации собственно чтения из последовательного интерфейса претензий нет — ввод блокирующий, при отсутствии в приемном буфере достаточного количества символов взводится семафор и управление передается шедулеру — все реализовано аккуратно и правильно. Лично мне не очень нравится управление аппаратурой в процедуре общего назначения, но это позволяет снизить вложенность процедур и уменьшает индекс цикломатической сложности, что бы это ни значило.
Обратим теперь внимание на передачу принятых данных в последовательный канал, поскольку при создании объекта ему предоставили только один кольцевой буфер — приемный. И действительно, для передачи символов используется внутренний буфер аппаратной части и при его заполнении вводится ожидание готовности (по крайней мере в блокирующем режиме работы). Не могу не удержаться, чтобы не покритиковать стиль соответствующих функций: 1) в объекте почему-то имеется обобщенный указатель, который внутри функции постоянно превращается в указатель на символы
```
*(unsigned char *)object->writeBuf);
```
2) логика работы совершенно непрозрачна и слегка запутана. Но все это не столь важно, поскольку остается спрятанным от пользователя и «на максимальную скорость не влияет».
В процессе исследований наталкиваемся еще на одну особенность — мы не видим исходного кода некоторых внутренних функций в режиме отладки — это связано с изменением имен для разных вариантов компиляции (ROM/NO\_ROM). Подменить требуемый файл исходного текста (C:\Jenkins\jobs\FWGroup-DriverLib\workspace\modules\output\cc13xx\_cha\_2\_0\_ext\driverlib\bin\ccs/./../../../driverlib/uart.c--) мне не удалось (но я не очень то и старался), хотя исходник я нашел (естественно, в файле в файле uart.c, спасибо, капитан), по счастью, этот фрагмент несложен и однозначно отождествить ассемблерный код с исходным текстом на С несложно (особенно если знать особенности команды ITxxx). Как решать эту проблему для библиотек со сложными функциями пока не знаю, будем думать, когда возникнет необходимость.
Ну и напоследок небольшое замечание — я готов поверить, что аппаратная часть реализации последовательного канала для моделей МК СС13х0 совпадает с таковой для СС26х0, и дублирование содержимого файла с названием UARTCC26XX.c--- нельзя назвать правильным решением, но создание промежуточного файла определений с включением исходного файла, переопределением функций и соответствующим комментарием приветствовал бы, поскольку это сделало бы программу более понятной, а это всегда должно приветствоваться, воут.
Итак, тестовый пример работает, мы узнали многое о внутреннем устройстве стандартных библиотек, отметили их сильные и не очень стороны, в заключение обзора попробуем найти ответ на вопрос, который обычно волнует программиста в дилемме «ОС или не ОС» — время переключения контекста. Здесь возможны два пути: 1) рассмотрение исходного кода — это скорее теоретический путь, он требует такого уровня погружения в предмет, который я продемонстрировать не готов, и 2) практический эксперимент. Конечно, второй метод, в отличие от первого, не дает абсолютно верных результатов, но «истина всегда конкретна» и полученные данные вполне можно рассматривать как адекватные, если измерения организованы правильно.
Для начала, чтобы оценить время переключения, нам необходимо научиться оценивать вообще время исполнения различных фрагментов программы. В рассматриваемой архитектуре имеется модуль отладки, частью которого является системный счетчик. Информация о данном модуле вполне доступна, но дьявол, как всегда, прячется в деталях. Для начала попробуем настроить необходимый режим ручками напрямую через доступ к регистрам. Быстро находим блок регистров CPU\_DWT и в нем обнаруживаем как собственно счетчик CYCCNT, так и управляющий регистр к нему CTRL с битом CYCCNTENA. Естественно, или, как еще говорят, разумеется, ничего не получилось и на сайте ARM есть ответ на вопрос, почему — необходимо разрешить работу модуля отладки битом TRCENA в регистре DEMCR. А вот с последним регистром не все так просто — в блоке DWT его нет, в других блоках искать лениво — они достаточно длинные, а никакого поиска по имени в окне регистров я не нашел (а было бы неплохо его иметь). Идем в окно памяти, вводим адрес регистра (он нам известен из дата) (кстати, почему-то шестнадцатеричный формат адреса не является дефолтным, надо ручками добавлять префикс 0х) и, внезапно, видим именованную ячейку памяти с именем CPU\_CSC\_DEMCR. Забавно, если не сказать больше, зачем фирма переименовала регистры по сравнению с предлагаемой лицензиатором архитектуры названиями, наверное, так надо было. И точно, в блоке регистров CPU\_CSC находим наш регистр, ставим в нем нужный бит, возвращаемся к счетчику, разрешаем его и все заработало.
Пнп: поиск по имени все-таки есть, вызывается (естественно) комбинацией Ctrl-F, просто он есть только в контекстном меню, а в обычном погашен, приношу извинения разработчикам.
Сразу отмечу еще недостаток окна памяти — печать содержимого прерывается указанием именованных ячеек, что делает выдачу рваной и ни фига не сегментированной по 16 (8,32,64, нужное подставить) слов. Более того, формат выдачи меняется при изменении размера окна. Может быть, все это можно настроить так, как пользователю нужно, но, исходя из собственного опыта (а из чего еще мне исходить) заявляю, что к интуитивно-очевидным решениям настройка формата выдачи окна просмотра памяти не относится. Я полностью за то, чтобы такая удобная фича, как показ именованных областей памяти в окне просмотра, была включена по умолчанию, иначе о ней многие пользователи и не узнали бы никогда, но надо позаботиться и о тех, кто сознательно ее хочет отключить.
Кстати, я бы совсем не отказался от возможности создания макросов (или скриптов) по работе со средой, ведь такую настройку регистров (для включения измерения времени) приходилось делать всякий раз после сброса МК, поскольку корректировать код путем вставления манипуляций с регистрами для целей отладки считаю не очень правильным. Но, хотя макросов я так и не нашел, работу с регистрами можно сильно упростить за счет того, что отдельные (необходимые) регистры можно включить в окно выражений, и тем самым существенно облегчить и ускорить работу с ними.
Чтобы подчеркнуть, что чувство инженера к семейству МК не охладело (а то я все ругаю разные аспекты среды разработки), отмечу, что счетчик работает прекрасно — никаких лишних тактов ни в одном из режимов отладки я обнаружить не смог, а раньше такое явление имело место быть, по крайней мере в серии МК разработки LuminaryMicro.
Итак, намечаем план эксперимента по определению времени переключения контекста — создаем вторую задачу, которая будет инкрементировать некий внутренний счетчик (в бесконечном цикле), запускаем МК на определенное время, находим соотношение между системным счетчиком и счетчиком задачи. Далее запускаем МК на аналогичное время (не обязательно точно такое же) и вводим 10 символов в темпе приблизительно раз в секунду. Можно ожидать, что при этом произойдет 10 переключений на задачу эха и 10 переключений обратно на задачу счетчика. Да, эти переключения контекста будут производится не по таймеру шедулера, а по событию, но на общее время исполнения исследуемой функции это не должно повлиять, так что начинаем претворять план в жизнь, создаем задачу счетчика и запускаем ее.
Тут же обнаруживаем одну особенность РТОС, по крайней мере в стандартной конфигурации — она не является вытесняющей «по настоящему»: если более приоритетная задача постоянно готова к выполнению (а задача счетчика такова) и не отдает управление шедулеру (не ожидает сигналов, не засыпает, не блокируется по флагам и т.д.) то ни одна задача более низкого приоритета не будет исполняться от слова совсем. Это не Линукс, в котором применяются различные методы для гарантии получения кванта всеми, «и чтобы никто не ушел обиженным». Данное поведение вполне ожидаемо, многие легкие ОСРВ ведут себя так, но проблема оказывается глубже, поскольку управление не получают и задачи равного с постоянно готовой приоритета. Именно поэтому в рассматриваемом примере я ставлю задаче эха, которая входит в ожидание, приоритет выше, чем постоянно готовой задаче счетчика, иначе последняя захватит все ресурсы процессора по времени.
Начинаем эксперимент, первая часть (просто ожидание времени исполнения) дала данные отношения счетчиков 406181к/58015к = 7 — вполне ожидаемо. Вторая часть (с 10 последовательными символами в течении ~10 секунд) дает результаты 351234к-50167к\*7 = 63к/20=3160 тактов, последняя цифра и есть время, связанное с процедурой переключения контекста в тактах МК. Лично мне данная величина кажется несколько большей, чем ожидалось, продолжаем исследования, похоже, что есть еще какие-то действия, которые портят статистику.
Пнп: частая ошибка экспериментатора — не оценить предварительно ожидаемые результаты и поверить в полученный мусор (привет разработчикам 737).
Очевидно («ну да, совершенно очевидно»), что в полученном результате, помимо времени собственно переключения контекста, содержится еще и время, необходимое для выполнения операций чтения символа из буфера и вывода его в последовательный порт. Менее очевидно, что в нем есть еще и время, необходимое для обработки прерывания при приеме и помещения символа в приемный буфер). Как нам отделить кошку от мяса — для этого у нас есть хитрый трюк — останавливаем программу, вводим 10 символов и запускаем ее. Можно ожидать (надо бы посмотреть исходники), что прерывание по приему произойдет только 1 раз и сразу все символы будут пересланы из приемного буфера в кольцевой, значит и мы увидим меньшие накладные расходы. Определить время выдачи в последовательный порт также несложно — будем выводить каждый второй символ и решим получившиеся 2 линейных уравнения с 2 неизвестны. А можно и еще проще – ничего не выводить, что я и сделал.
И вот результаты подобных хитрых манипуляций: делаем ввод пакетом и пропавших тактов становится меньше – 2282, отключаем вывод и затраты падают до 1222 тактов – уже лучше, хотя я надеялся тактов на 300.
А вот со временем выполнения считывания ничего подобного придумать не удастся, оно масштабируется одновременно с искомым временем переключения контекста. Единственное, что я могу предложить — это отключать внутренний таймер при начале ввода принятого символа и снова включать его перед входом в ожидание очередного. Тогда два счетчика будут работать синхронно (за исключением переключения) и его легко можно определить. Но такой подход требует глубокого внедрения в тексты системных программ и все равно составляющая обработки прерываний останется. Поэтому я предлагаю ограничиться уже полученными данными, которые позволяют твердо утверждать, что время переключения задач в рассматриваемой TI-RTOS не превосходит 1222 тактов, что при заданной тактовой частоте составляет 30 мксек.
Пнп: все равно очень много – я рассчитывал тактов на 100: 30 на сохранение контекста, 40 на определение готовой задачи и 30 на восстановление контекста, а у нас получается на порядок больше. Хотя сейчас отключена оптимизация, включим –o2 и посмотрим результат: почти не изменился – стало 2894 вместо 3160.
Есть еще одна идея — если бы в ОС поддерживалось переключение равноранговых задач, то можно было бы запустить две задачи со счетчиками, некоторым волшебным образом получить данные о количестве переключений за некое время и рассчитать убыль системного счетчика, но в силу особенностей шедулера, о которой я уже говорил, данный подход не приведет к успеху. Хотя возможен другой вариант — делать пинг-понг между двумя одноранговыми (или даже разноранговыми) задачами через семафор, здесь легко посчитать число переключений контекста — надо будет попробовать, но это уже завтра.
Традиционный опрос в конце поста на этот раз будет посвящен не уровню изложения (любому непредвзятому читателю ясно, что он вне всяких похвал и превосходит любые ожидания), а теме очередного поста. | https://habr.com/ru/post/451918/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.